
modelId
stringlengths 5
139
| author
stringlengths 2
42
| last_modified
timestamp[us, tz=UTC]date 2020-02-15 11:33:14
2025-08-24 06:32:16
| downloads
int64 0
223M
| likes
int64 0
11.7k
| library_name
stringclasses 518
values | tags
listlengths 1
4.05k
| pipeline_tag
stringclasses 55
values | createdAt
timestamp[us, tz=UTC]date 2022-03-02 23:29:04
2025-08-24 06:32:16
| card
stringlengths 11
1.01M
|
|---|---|---|---|---|---|---|---|---|---|
bytedance-research/UNO
|
bytedance-research
| 2025-08-22T11:48:09Z | 0 | 175 |
transformers
|
[
"transformers",
"subject-personalization",
"image-generation",
"image-to-image",
"arxiv:2504.02160",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:finetune:black-forest-labs/FLUX.1-dev",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
image-to-image
| 2025-04-03T09:19:48Z |
---
base_model:
- black-forest-labs/FLUX.1-dev
license: apache-2.0
pipeline_tag: image-to-image
library_name: transformers
tags:
- subject-personalization
- image-generation
---
<h3 align="center">
Less-to-More Generalization: Unlocking More Controllability by In-Context Generation
</h3>
<div style="display:flex;justify-content: center">
<a href="https://bytedance.github.io/UNO/"><img alt="Build" src="https://img.shields.io/badge/Project%20Page-UNO-yellow"></a>
<a href="https://arxiv.org/abs/2504.02160"><img alt="Build" src="https://img.shields.io/badge/arXiv%20paper-2504.02160-b31b1b.svg"></a>
<a href="https://github.com/bytedance/UNO"><img src="https://img.shields.io/static/v1?label=GitHub&message=Code&color=green&logo=github"></a>
</div>
><p align="center"> <span style="color:#137cf3; font-family: Gill Sans">Shaojin Wu,</span><sup></sup></a> <span style="color:#137cf3; font-family: Gill Sans">Mengqi Huang</span><sup>*</sup>,</a> <span style="color:#137cf3; font-family: Gill Sans">Wenxu Wu,</span><sup></sup></a> <span style="color:#137cf3; font-family: Gill Sans">Yufeng Cheng,</span><sup></sup> </a> <span style="color:#137cf3; font-family: Gill Sans">Fei Ding</span><sup>+</sup>,</a> <span style="color:#137cf3; font-family: Gill Sans">Qian He</span></a> <br>
><span style="font-size: 16px">Intelligent Creation Team, ByteDance</span></p>

## 🔥 News
- [04/2025] 🔥 The [training code](https://github.com/bytedance/UNO), [inference code](https://github.com/bytedance/UNO), and [model](https://huggingface.co/bytedance-research/UNO) of UNO are released. The [demo](https://huggingface.co/spaces/bytedance-research/UNO-FLUX) will coming soon.
- [04/2025] 🔥 The [project page](https://bytedance.github.io/UNO) of UNO is created.
- [04/2025] 🔥 The arXiv [paper](https://arxiv.org/abs/2504.02160) of UNO is released.
## 📖 Introduction
In this study, we propose a highly-consistent data synthesis pipeline to tackle this challenge. This pipeline harnesses the intrinsic in-context generation capabilities of diffusion transformers and generates high-consistency multi-subject paired data. Additionally, we introduce UNO, which consists of progressive cross-modal alignment and universal rotary position embedding. It is a multi-image conditioned subject-to-image model iteratively trained from a text-to-image model. Extensive experiments show that our method can achieve high consistency while ensuring controllability in both single-subject and multi-subject driven generation.
## ⚡️ Quick Start
### 🔧 Requirements and Installation
Clone our [Github repo](https://github.com/bytedance/UNO)
Install the requirements
```bash
## create a virtual environment with python >= 3.10 <= 3.12, like
# python -m venv uno_env
# source uno_env/bin/activate
# then install
pip install -r requirements.txt
```
then download checkpoints in one of the three ways:
1. Directly run the inference scripts, the checkpoints will be downloaded automatically by the `hf_hub_download` function in the code to your `$HF_HOME`(the default value is `~/.cache/huggingface`).
2. use `huggingface-cli download <repo name>` to download `black-forest-labs/FLUX.1-dev`, `xlabs-ai/xflux_text_encoders`, `openai/clip-vit-large-patch14`, `TODO UNO hf model`, then run the inference scripts.
3. use `huggingface-cli download <repo name> --local-dir <LOCAL_DIR>` to download all the checkpoints menthioned in 2. to the directories your want. Then set the environment variable `TODO`. Finally, run the inference scripts.
### 🌟 Gradio Demo
```bash
python app.py
```
### ✍️ Inference
- Optional prepreration: If you want to test the inference on dreambench at the first time, you should clone the submodule `dreambench` to download the dataset.
```bash
git submodule update --init
```
```bash
python inference.py
```
### 🚄 Training
```bash
accelerate launch train.py
```
## 🎨 Application Scenarios

## 📄 Disclaimer
<p>
We open-source this project for academic research. The vast majority of images
used in this project are either generated or licensed. If you have any concerns,
please contact us, and we will promptly remove any inappropriate content.
Our code is released under the Apache 2.0 License,, while our models are under
the CC BY-NC 4.0 License. Any models related to <a href="https://huggingface.co/black-forest-labs/FLUX.1-dev" target="_blank">FLUX.1-dev</a>
base model must adhere to the original licensing terms.
<br><br>This research aims to advance the field of generative AI. Users are free to
create images using this tool, provided they comply with local laws and exercise
responsible usage. The developers are not liable for any misuse of the tool by users.</p>
## 🚀 Updates
For the purpose of fostering research and the open-source community, we plan to open-source the entire project, encompassing training, inference, weights, etc. Thank you for your patience and support! 🌟
- [x] Release github repo.
- [x] Release inference code.
- [x] Release training code.
- [x] Release model checkpoints.
- [x] Release arXiv paper.
- [] Release in-context data generation pipelines.
## Citation
If UNO is helpful, please help to ⭐ the repo.
If you find this project useful for your research, please consider citing our paper:
```bibtex
@article{wu2025less,
title={Less-to-More Generalization: Unlocking More Controllability by In-Context Generation},
author={Wu, Shaojin and Huang, Mengqi and Wu, Wenxu and Cheng, Yufeng and Ding, Fei and He, Qian},
journal={arXiv preprint arXiv:2504.02160},
year={2025}
}
```
|
Muapi/f1-xl-anime-model-turn-multi-view-turnaround-model-sheet-character-design
|
Muapi
| 2025-08-22T11:46:47Z | 0 | 0 | null |
[
"lora",
"stable-diffusion",
"flux.1-d",
"license:openrail++",
"region:us"
] | null | 2025-08-22T11:46:35Z |
---
license: openrail++
tags:
- lora
- stable-diffusion
- flux.1-d
model_type: LoRA
---
# F1/XL Anime Model Turn, Multi-View, Turnaround, Model Sheet, Character Design

**Base model**: Flux.1 D
**Trained words**:
## 🧠 Usage (Python)
🔑 **Get your MUAPI key** from [muapi.ai/access-keys](https://muapi.ai/access-keys)
```python
import requests, os
url = "https://api.muapi.ai/api/v1/flux_dev_lora_image"
headers = {"Content-Type": "application/json", "x-api-key": os.getenv("MUAPIAPP_API_KEY")}
payload = {
"prompt": "masterpiece, best quality, 1girl, looking at viewer",
"model_id": [{"model": "civitai:1002768@1127674", "weight": 1.0}],
"width": 1024,
"height": 1024,
"num_images": 1
}
print(requests.post(url, headers=headers, json=payload).json())
```
|
calegpedia/blockassist-bc-stealthy_slimy_rooster_1755861689
|
calegpedia
| 2025-08-22T11:46:46Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"stealthy slimy rooster",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-22T11:46:42Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- stealthy slimy rooster
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Muapi/snow-white-flux1.d-sdxl
|
Muapi
| 2025-08-22T11:44:57Z | 0 | 0 | null |
[
"lora",
"stable-diffusion",
"flux.1-d",
"license:openrail++",
"region:us"
] | null | 2025-08-22T11:44:48Z |
---
license: openrail++
tags:
- lora
- stable-diffusion
- flux.1-d
model_type: LoRA
---
# Snow White - Flux1.D & SDXL

**Base model**: Flux.1 D
**Trained words**: Snow White
## 🧠 Usage (Python)
🔑 **Get your MUAPI key** from [muapi.ai/access-keys](https://muapi.ai/access-keys)
```python
import requests, os
url = "https://api.muapi.ai/api/v1/flux_dev_lora_image"
headers = {"Content-Type": "application/json", "x-api-key": os.getenv("MUAPIAPP_API_KEY")}
payload = {
"prompt": "masterpiece, best quality, 1girl, looking at viewer",
"model_id": [{"model": "civitai:332134@846827", "weight": 1.0}],
"width": 1024,
"height": 1024,
"num_images": 1
}
print(requests.post(url, headers=headers, json=payload).json())
```
|
Kijai/WanVideo_comfy
|
Kijai
| 2025-08-22T11:44:43Z | 4,112,827 | 1,247 |
diffusion-single-file
|
[
"diffusion-single-file",
"comfyui",
"base_model:Wan-AI/Wan2.1-VACE-1.3B",
"base_model:finetune:Wan-AI/Wan2.1-VACE-1.3B",
"region:us"
] | null | 2025-02-25T17:54:17Z |
---
tags:
- diffusion-single-file
- comfyui
base_model:
- Wan-AI/Wan2.1-VACE-14B
- Wan-AI/Wan2.1-VACE-1.3B
---
Combined and quantized models for WanVideo, originating from here:
https://huggingface.co/Wan-AI/
Can be used with: https://github.com/kijai/ComfyUI-WanVideoWrapper and ComfyUI native WanVideo nodes.
I've also started to do fp8_scaled versions over here: https://huggingface.co/Kijai/WanVideo_comfy_fp8_scaled
Other model sources:
TinyVAE from https://github.com/madebyollin/taehv
SkyReels: https://huggingface.co/collections/Skywork/skyreels-v2-6801b1b93df627d441d0d0d9
WanVideoFun: https://huggingface.co/collections/alibaba-pai/wan21-fun-v11-680f514c89fe7b4df9d44f17
---
Lightx2v:
CausVid 14B: https://huggingface.co/lightx2v/Wan2.1-T2V-14B-CausVid
CFG and Step distill 14B: https://huggingface.co/lightx2v/Wan2.1-T2V-14B-StepDistill-CfgDistill
---
CausVid 1.3B: https://huggingface.co/tianweiy/CausVid
AccVideo: https://huggingface.co/aejion/AccVideo-WanX-T2V-14B
Phantom: https://huggingface.co/bytedance-research/Phantom
ATI: https://huggingface.co/bytedance-research/ATI
MiniMaxRemover: https://huggingface.co/zibojia/minimax-remover
MAGREF: https://huggingface.co/MAGREF-Video/MAGREF
FantasyTalking: https://github.com/Fantasy-AMAP/fantasy-talking
MultiTalk: https://github.com/MeiGen-AI/MultiTalk
Anisora: https://huggingface.co/IndexTeam/Index-anisora/tree/main/14B
Pusa: https://huggingface.co/RaphaelLiu/PusaV1/tree/main
FastVideo: https://huggingface.co/FastVideo
EchoShot: https://github.com/D2I-ai/EchoShot
Wan22 5B Turbo: https://huggingface.co/quanhaol/Wan2.2-TI2V-5B-Turbo
---
CausVid LoRAs are experimental extractions from the CausVid finetunes, the aim with them is to benefit from the distillation in CausVid, rather than any actual causal inference.
---
v1 = direct extraction, has adverse effects on motion and introduces flashing artifact at full strength.
v1.5 = same as above, but without the first block which fixes the flashing at full strength.
v2 = further pruned version with only attention layers and no first block, fixes flashing and retains motion better, needs more steps and can also benefit from cfg.
|
Muapi/line-drawing-ce
|
Muapi
| 2025-08-22T11:43:42Z | 0 | 0 | null |
[
"lora",
"stable-diffusion",
"flux.1-d",
"license:openrail++",
"region:us"
] | null | 2025-08-22T11:43:14Z |
---
license: openrail++
tags:
- lora
- stable-diffusion
- flux.1-d
model_type: LoRA
---
# Line Drawing - CE

**Base model**: Flux.1 D
**Trained words**: lndrwngCE_style
## 🧠 Usage (Python)
🔑 **Get your MUAPI key** from [muapi.ai/access-keys](https://muapi.ai/access-keys)
```python
import requests, os
url = "https://api.muapi.ai/api/v1/flux_dev_lora_image"
headers = {"Content-Type": "application/json", "x-api-key": os.getenv("MUAPIAPP_API_KEY")}
payload = {
"prompt": "masterpiece, best quality, 1girl, looking at viewer",
"model_id": [{"model": "civitai:880102@1671848", "weight": 1.0}],
"width": 1024,
"height": 1024,
"num_images": 1
}
print(requests.post(url, headers=headers, json=payload).json())
```
|
unitova/blockassist-bc-zealous_sneaky_raven_1755861405
|
unitova
| 2025-08-22T11:42:50Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"zealous sneaky raven",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-22T11:42:46Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- zealous sneaky raven
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Muapi/pinkie-iridescent-jelly-flux-sdxl
|
Muapi
| 2025-08-22T11:42:29Z | 0 | 0 | null |
[
"lora",
"stable-diffusion",
"flux.1-d",
"license:openrail++",
"region:us"
] | null | 2025-08-22T11:42:16Z |
---
license: openrail++
tags:
- lora
- stable-diffusion
- flux.1-d
model_type: LoRA
---
# [Pinkie] 🫧 Iridescent Jelly 🫧- [Flux/SDXL]

**Base model**: Flux.1 D
**Trained words**: made out of iridescent jelly
## 🧠 Usage (Python)
🔑 **Get your MUAPI key** from [muapi.ai/access-keys](https://muapi.ai/access-keys)
```python
import requests, os
url = "https://api.muapi.ai/api/v1/flux_dev_lora_image"
headers = {"Content-Type": "application/json", "x-api-key": os.getenv("MUAPIAPP_API_KEY")}
payload = {
"prompt": "masterpiece, best quality, 1girl, looking at viewer",
"model_id": [{"model": "civitai:593604@787445", "weight": 1.0}],
"width": 1024,
"height": 1024,
"num_images": 1
}
print(requests.post(url, headers=headers, json=payload).json())
```
|
Muapi/silent-hill-forgotten-fog-filter-lora-flux
|
Muapi
| 2025-08-22T11:41:39Z | 0 | 0 | null |
[
"lora",
"stable-diffusion",
"flux.1-d",
"license:openrail++",
"region:us"
] | null | 2025-08-22T11:41:21Z |
---
license: openrail++
tags:
- lora
- stable-diffusion
- flux.1-d
model_type: LoRA
---
# Silent Hill - Forgotten Fog Filter LORA [FLUX]

**Base model**: Flux.1 D
**Trained words**: aidmasilenthill
## 🧠 Usage (Python)
🔑 **Get your MUAPI key** from [muapi.ai/access-keys](https://muapi.ai/access-keys)
```python
import requests, os
url = "https://api.muapi.ai/api/v1/flux_dev_lora_image"
headers = {"Content-Type": "application/json", "x-api-key": os.getenv("MUAPIAPP_API_KEY")}
payload = {
"prompt": "masterpiece, best quality, 1girl, looking at viewer",
"model_id": [{"model": "civitai:839553@939281", "weight": 1.0}],
"width": 1024,
"height": 1024,
"num_images": 1
}
print(requests.post(url, headers=headers, json=payload).json())
```
|
datajuicer/YOLO11L-Rice-Disease-Detection
|
datajuicer
| 2025-08-22T11:41:04Z | 0 | 0 | null |
[
"base_model:Ultralytics/YOLO11",
"base_model:finetune:Ultralytics/YOLO11",
"license:cc-by-nc-sa-4.0",
"region:us"
] | null | 2025-08-22T06:42:30Z |
---
license: cc-by-nc-sa-4.0
base_model:
- Ultralytics/YOLO11
---
# 水稻病害检测 (with YOLO11L)
## 模型简介
- 模型功能:支持多种水稻病害的检测,返回图像中的病害位置(bounding box)以及病害类别(class label)。
- 支持类别:{0: '水稻白叶枯病Bacterial_Leaf_Blight', 1: '水稻胡麻斑病Brown_Spot', 2: '健康水稻HealthyLeaf', 3: '稻瘟病Leaf_Blast', 4: '水稻叶鞘腐病Leaf_Scald', 5: '水稻窄褐斑病Narrow_Brown_Leaf_Spot', 6: '水稻穗颈瘟Neck_Blast', 7: '稻飞虱Rice_Hispa'}
- 训练数据:3,567张水稻病害图像及对应标注信息([Rice Leaf Spot Disease Annotated Dataset](https://www.kaggle.com/datasets/hadiurrahmannabil/rice-leaf-spot-disease-annotated-dataset)),训练200epoch。
- 评测指标:测试集 {mAP50: 56.3, mAP50-95: 34.9}
## 模型使用(with Data-Juicer)
- 输出格式:
```
[{
"images": image_path1,
"objects": {
"ref": [class_label1, class_label2, ...],
"bbox": [bbox1, bbox2, ...]
}
},
...
]
```
- 可参考代码:
```python
import json
from data_juicer.core.data import NestedDataset as Dataset
from data_juicer.ops.mapper.image_detection_yolo_mapper import ImageDetectionYoloMapper
from data_juicer.utils.constant import Fields, MetaKeys
if __name__ == "__main__":
image_path1 = "test1.jpg"
image_path2 = "test2.jpg"
image_path3 = "test3.jpg"
source_list = [{
'images': [image_path1, image_path2, image_path3]
}]
class_names =['水稻白叶枯病Bacterial_Leaf_Blight', '水稻胡麻斑病Brown_Spot', '健康水稻HealthyLeaf', '稻瘟病Leaf_Blast', '水稻叶鞘腐病Leaf_Scald', '水稻窄褐斑病Narrow_Brown_Leaf_Spot', '水稻穗颈瘟Neck_Blast', '稻飞虱Rice_Hispa']
op = ImageDetectionYoloMapper(
imgsz=640, conf=0.05, iou=0.5, model_path='Path_to_YOLO11L-Rice-Disease-Detection.pt')
dataset = Dataset.from_list(source_list)
if Fields.meta not in dataset.features:
dataset = dataset.add_column(name=Fields.meta,
column=[{}] * dataset.num_rows)
dataset = dataset.map(op.process, num_proc=1, with_rank=True)
res_list = dataset.to_list()[0]
new_data = []
for temp_image_name, temp_bbox_lists, class_name_lists in zip(res_list["images"], res_list["__dj__meta__"]["__dj__bbox__"], res_list["__dj__meta__"]["__dj__class_label__"]):
temp_json = {}
temp_json["images"] = temp_image_name
temp_json["objects"] = {"ref": [], "bbox":temp_bbox_lists}
for temp_object_label in class_name_lists:
temp_json["objects"]["ref"].append(class_names[int(temp_object_label)])
new_data.append(temp_json)
with open("./output.json", "w") as f:
json.dump(new_data, f)
```
|
Muapi/adventure-comic-book
|
Muapi
| 2025-08-22T11:40:33Z | 0 | 0 | null |
[
"lora",
"stable-diffusion",
"flux.1-d",
"license:openrail++",
"region:us"
] | null | 2025-08-22T11:40:18Z |
---
license: openrail++
tags:
- lora
- stable-diffusion
- flux.1-d
model_type: LoRA
---
# Adventure Comic Book

**Base model**: Flux.1 D
**Trained words**:
## 🧠 Usage (Python)
🔑 **Get your MUAPI key** from [muapi.ai/access-keys](https://muapi.ai/access-keys)
```python
import requests, os
url = "https://api.muapi.ai/api/v1/flux_dev_lora_image"
headers = {"Content-Type": "application/json", "x-api-key": os.getenv("MUAPIAPP_API_KEY")}
payload = {
"prompt": "masterpiece, best quality, 1girl, looking at viewer",
"model_id": [{"model": "civitai:752718@841709", "weight": 1.0}],
"width": 1024,
"height": 1024,
"num_images": 1
}
print(requests.post(url, headers=headers, json=payload).json())
```
|
Muapi/90s-hand-drawn-animation-cartoon-style-for-backgrounds-illustrations-and-arts-flux
|
Muapi
| 2025-08-22T11:40:09Z | 0 | 0 | null |
[
"lora",
"stable-diffusion",
"flux.1-d",
"license:openrail++",
"region:us"
] | null | 2025-08-22T11:39:56Z |
---
license: openrail++
tags:
- lora
- stable-diffusion
- flux.1-d
model_type: LoRA
---
# 90s Hand drawn animation / cartoon style for backgrounds, illustrations and arts [Flux]

**Base model**: Flux.1 D
**Trained words**: PIVIG image style, PIVIG
## 🧠 Usage (Python)
🔑 **Get your MUAPI key** from [muapi.ai/access-keys](https://muapi.ai/access-keys)
```python
import requests, os
url = "https://api.muapi.ai/api/v1/flux_dev_lora_image"
headers = {"Content-Type": "application/json", "x-api-key": os.getenv("MUAPIAPP_API_KEY")}
payload = {
"prompt": "masterpiece, best quality, 1girl, looking at viewer",
"model_id": [{"model": "civitai:811608@967018", "weight": 1.0}],
"width": 1024,
"height": 1024,
"num_images": 1
}
print(requests.post(url, headers=headers, json=payload).json())
```
|
Muapi/taiwan-street-background
|
Muapi
| 2025-08-22T11:39:30Z | 0 | 0 | null |
[
"lora",
"stable-diffusion",
"flux.1-d",
"license:openrail++",
"region:us"
] | null | 2025-08-22T11:39:10Z |
---
license: openrail++
tags:
- lora
- stable-diffusion
- flux.1-d
model_type: LoRA
---
# Taiwan Street Background

**Base model**: Flux.1 D
**Trained words**:
## 🧠 Usage (Python)
🔑 **Get your MUAPI key** from [muapi.ai/access-keys](https://muapi.ai/access-keys)
```python
import requests, os
url = "https://api.muapi.ai/api/v1/flux_dev_lora_image"
headers = {"Content-Type": "application/json", "x-api-key": os.getenv("MUAPIAPP_API_KEY")}
payload = {
"prompt": "masterpiece, best quality, 1girl, looking at viewer",
"model_id": [{"model": "civitai:221517@727420", "weight": 1.0}],
"width": 1024,
"height": 1024,
"num_images": 1
}
print(requests.post(url, headers=headers, json=payload).json())
```
|
Muapi/underwater-style-xl-f1d-marine-life
|
Muapi
| 2025-08-22T11:38:53Z | 0 | 0 | null |
[
"lora",
"stable-diffusion",
"flux.1-d",
"license:openrail++",
"region:us"
] | null | 2025-08-22T11:38:46Z |
---
license: openrail++
tags:
- lora
- stable-diffusion
- flux.1-d
model_type: LoRA
---
# Underwater style XL + F1D (Marine life)

**Base model**: Flux.1 D
**Trained words**: Underwater
## 🧠 Usage (Python)
🔑 **Get your MUAPI key** from [muapi.ai/access-keys](https://muapi.ai/access-keys)
```python
import requests, os
url = "https://api.muapi.ai/api/v1/flux_dev_lora_image"
headers = {"Content-Type": "application/json", "x-api-key": os.getenv("MUAPIAPP_API_KEY")}
payload = {
"prompt": "masterpiece, best quality, 1girl, looking at viewer",
"model_id": [{"model": "civitai:380863@1167240", "weight": 1.0}],
"width": 1024,
"height": 1024,
"num_images": 1
}
print(requests.post(url, headers=headers, json=payload).json())
```
|
Muapi/daphne-blake-scooby-doo-franchise-flux1.d-sdxl-realistic-anime
|
Muapi
| 2025-08-22T11:38:13Z | 0 | 0 | null |
[
"lora",
"stable-diffusion",
"flux.1-d",
"license:openrail++",
"region:us"
] | null | 2025-08-22T11:38:04Z |
---
license: openrail++
tags:
- lora
- stable-diffusion
- flux.1-d
model_type: LoRA
---
# Daphne Blake - Scooby-Doo franchise - Flux1.D - SDXL Realistic / Anime

**Base model**: Flux.1 D
**Trained words**: Daphne Blake, headband, purple dress, green scarf
## 🧠 Usage (Python)
🔑 **Get your MUAPI key** from [muapi.ai/access-keys](https://muapi.ai/access-keys)
```python
import requests, os
url = "https://api.muapi.ai/api/v1/flux_dev_lora_image"
headers = {"Content-Type": "application/json", "x-api-key": os.getenv("MUAPIAPP_API_KEY")}
payload = {
"prompt": "masterpiece, best quality, 1girl, looking at viewer",
"model_id": [{"model": "civitai:397155@859346", "weight": 1.0}],
"width": 1024,
"height": 1024,
"num_images": 1
}
print(requests.post(url, headers=headers, json=payload).json())
```
|
mradermacher/BlackSheep-24B-i1-GGUF
|
mradermacher
| 2025-08-22T11:36:15Z | 1,557 | 7 |
transformers
|
[
"transformers",
"gguf",
"en",
"base_model:TroyDoesAI/BlackSheep-24B",
"base_model:quantized:TroyDoesAI/BlackSheep-24B",
"license:cc-by-nc-2.0",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | null | 2025-03-26T07:05:18Z |
---
base_model: TroyDoesAI/BlackSheep-24B
language:
- en
library_name: transformers
license: cc-by-nc-2.0
mradermacher:
readme_rev: 1
quantized_by: mradermacher
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: nicoboss -->
weighted/imatrix quants of https://huggingface.co/TroyDoesAI/BlackSheep-24B
<!-- provided-files -->
***For a convenient overview and download list, visit our [model page for this model](https://hf.tst.eu/model#BlackSheep-24B-i1-GGUF).***
static quants are available at https://huggingface.co/mradermacher/BlackSheep-24B-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/BlackSheep-24B-i1-GGUF/resolve/main/BlackSheep-24B.i1-IQ1_S.gguf) | i1-IQ1_S | 5.4 | for the desperate |
| [GGUF](https://huggingface.co/mradermacher/BlackSheep-24B-i1-GGUF/resolve/main/BlackSheep-24B.i1-IQ1_M.gguf) | i1-IQ1_M | 5.9 | mostly desperate |
| [GGUF](https://huggingface.co/mradermacher/BlackSheep-24B-i1-GGUF/resolve/main/BlackSheep-24B.i1-IQ2_XXS.gguf) | i1-IQ2_XXS | 6.6 | |
| [GGUF](https://huggingface.co/mradermacher/BlackSheep-24B-i1-GGUF/resolve/main/BlackSheep-24B.i1-IQ2_XS.gguf) | i1-IQ2_XS | 7.3 | |
| [GGUF](https://huggingface.co/mradermacher/BlackSheep-24B-i1-GGUF/resolve/main/BlackSheep-24B.i1-IQ2_S.gguf) | i1-IQ2_S | 7.6 | |
| [GGUF](https://huggingface.co/mradermacher/BlackSheep-24B-i1-GGUF/resolve/main/BlackSheep-24B.i1-IQ2_M.gguf) | i1-IQ2_M | 8.2 | |
| [GGUF](https://huggingface.co/mradermacher/BlackSheep-24B-i1-GGUF/resolve/main/BlackSheep-24B.i1-Q2_K_S.gguf) | i1-Q2_K_S | 8.4 | very low quality |
| [GGUF](https://huggingface.co/mradermacher/BlackSheep-24B-i1-GGUF/resolve/main/BlackSheep-24B.i1-Q2_K.gguf) | i1-Q2_K | 9.0 | IQ3_XXS probably better |
| [GGUF](https://huggingface.co/mradermacher/BlackSheep-24B-i1-GGUF/resolve/main/BlackSheep-24B.i1-IQ3_XXS.gguf) | i1-IQ3_XXS | 9.4 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/BlackSheep-24B-i1-GGUF/resolve/main/BlackSheep-24B.i1-IQ3_XS.gguf) | i1-IQ3_XS | 10.0 | |
| [GGUF](https://huggingface.co/mradermacher/BlackSheep-24B-i1-GGUF/resolve/main/BlackSheep-24B.i1-Q3_K_S.gguf) | i1-Q3_K_S | 10.5 | IQ3_XS probably better |
| [GGUF](https://huggingface.co/mradermacher/BlackSheep-24B-i1-GGUF/resolve/main/BlackSheep-24B.i1-IQ3_S.gguf) | i1-IQ3_S | 10.5 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/BlackSheep-24B-i1-GGUF/resolve/main/BlackSheep-24B.i1-IQ3_M.gguf) | i1-IQ3_M | 10.8 | |
| [GGUF](https://huggingface.co/mradermacher/BlackSheep-24B-i1-GGUF/resolve/main/BlackSheep-24B.i1-Q3_K_M.gguf) | i1-Q3_K_M | 11.6 | IQ3_S probably better |
| [GGUF](https://huggingface.co/mradermacher/BlackSheep-24B-i1-GGUF/resolve/main/BlackSheep-24B.i1-Q3_K_L.gguf) | i1-Q3_K_L | 12.5 | IQ3_M probably better |
| [GGUF](https://huggingface.co/mradermacher/BlackSheep-24B-i1-GGUF/resolve/main/BlackSheep-24B.i1-IQ4_XS.gguf) | i1-IQ4_XS | 12.9 | |
| [GGUF](https://huggingface.co/mradermacher/BlackSheep-24B-i1-GGUF/resolve/main/BlackSheep-24B.i1-Q4_0.gguf) | i1-Q4_0 | 13.6 | fast, low quality |
| [GGUF](https://huggingface.co/mradermacher/BlackSheep-24B-i1-GGUF/resolve/main/BlackSheep-24B.i1-Q4_K_S.gguf) | i1-Q4_K_S | 13.6 | optimal size/speed/quality |
| [GGUF](https://huggingface.co/mradermacher/BlackSheep-24B-i1-GGUF/resolve/main/BlackSheep-24B.i1-Q4_K_M.gguf) | i1-Q4_K_M | 14.4 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/BlackSheep-24B-i1-GGUF/resolve/main/BlackSheep-24B.i1-Q4_1.gguf) | i1-Q4_1 | 15.0 | |
| [GGUF](https://huggingface.co/mradermacher/BlackSheep-24B-i1-GGUF/resolve/main/BlackSheep-24B.i1-Q5_K_S.gguf) | i1-Q5_K_S | 16.4 | |
| [GGUF](https://huggingface.co/mradermacher/BlackSheep-24B-i1-GGUF/resolve/main/BlackSheep-24B.i1-Q5_K_M.gguf) | i1-Q5_K_M | 16.9 | |
| [GGUF](https://huggingface.co/mradermacher/BlackSheep-24B-i1-GGUF/resolve/main/BlackSheep-24B.i1-Q6_K.gguf) | i1-Q6_K | 19.4 | practically like static Q6_K |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time. Additional thanks to [@nicoboss](https://huggingface.co/nicoboss) for giving me access to his private supercomputer, enabling me to provide many more imatrix quants, at much higher quality, than I would otherwise be able to.
<!-- end -->
|
george114/LLama_3_1_8B_ASBA_Opinion_Detection_Final
|
george114
| 2025-08-22T11:35:55Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"llama",
"trl",
"en",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-08-22T11:35:35Z |
---
base_model: unsloth/meta-llama-3.1-8b-unsloth-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- llama
- trl
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** george114
- **License:** apache-2.0
- **Finetuned from model :** unsloth/meta-llama-3.1-8b-unsloth-bnb-4bit
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
afrin-apu-viral-videos-link/NEW.afrin.apu.FULL.VIRALS.VIDEO
|
afrin-apu-viral-videos-link
| 2025-08-22T11:34:37Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-08-22T11:33:54Z |
<animated-image data-catalyst=""><a href="https://tinyurl.com/5abutj9x?viral-news" rel="nofollow" data-target="animated-image.originalLink"><img src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" alt="Foo" data-canonical-src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" style="max-width: 100%; display: inline-block;" data-target="animated-image.originalImage"></a>
|
Muapi/long-hair-lora-flux
|
Muapi
| 2025-08-22T11:34:37Z | 0 | 0 | null |
[
"lora",
"stable-diffusion",
"flux.1-d",
"license:openrail++",
"region:us"
] | null | 2025-08-22T11:34:30Z |
---
license: openrail++
tags:
- lora
- stable-diffusion
- flux.1-d
model_type: LoRA
---
# Long hair LoRA - Flux

**Base model**: Flux.1 D
**Trained words**:
## 🧠 Usage (Python)
🔑 **Get your MUAPI key** from [muapi.ai/access-keys](https://muapi.ai/access-keys)
```python
import requests, os
url = "https://api.muapi.ai/api/v1/flux_dev_lora_image"
headers = {"Content-Type": "application/json", "x-api-key": os.getenv("MUAPIAPP_API_KEY")}
payload = {
"prompt": "masterpiece, best quality, 1girl, looking at viewer",
"model_id": [{"model": "civitai:669029@964680", "weight": 1.0}],
"width": 1024,
"height": 1024,
"num_images": 1
}
print(requests.post(url, headers=headers, json=payload).json())
```
|
8septiadi8/blockassist-bc-curious_lightfooted_mouse_1755862326
|
8septiadi8
| 2025-08-22T11:33:56Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"curious lightfooted mouse",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-22T11:33:36Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- curious lightfooted mouse
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Muapi/fictional-model-peach-flux
|
Muapi
| 2025-08-22T11:33:29Z | 0 | 0 | null |
[
"lora",
"stable-diffusion",
"flux.1-d",
"license:openrail++",
"region:us"
] | null | 2025-08-22T11:33:21Z |
---
license: openrail++
tags:
- lora
- stable-diffusion
- flux.1-d
model_type: LoRA
---
# Fictional Model Peach - FLUX

**Base model**: Flux.1 D
**Trained words**: FictionalPeach, punk girl with short pink hair
## 🧠 Usage (Python)
🔑 **Get your MUAPI key** from [muapi.ai/access-keys](https://muapi.ai/access-keys)
```python
import requests, os
url = "https://api.muapi.ai/api/v1/flux_dev_lora_image"
headers = {"Content-Type": "application/json", "x-api-key": os.getenv("MUAPIAPP_API_KEY")}
payload = {
"prompt": "masterpiece, best quality, 1girl, looking at viewer",
"model_id": [{"model": "civitai:1167033@1312926", "weight": 1.0}],
"width": 1024,
"height": 1024,
"num_images": 1
}
print(requests.post(url, headers=headers, json=payload).json())
```
|
Muapi/ethereal-dystopia-aah
|
Muapi
| 2025-08-22T11:33:15Z | 0 | 0 | null |
[
"lora",
"stable-diffusion",
"flux.1-d",
"license:openrail++",
"region:us"
] | null | 2025-08-22T11:33:05Z |
---
license: openrail++
tags:
- lora
- stable-diffusion
- flux.1-d
model_type: LoRA
---
# Ethereal Dystopia (AAH)

**Base model**: Flux.1 D
**Trained words**: ethdysty
## 🧠 Usage (Python)
🔑 **Get your MUAPI key** from [muapi.ai/access-keys](https://muapi.ai/access-keys)
```python
import requests, os
url = "https://api.muapi.ai/api/v1/flux_dev_lora_image"
headers = {"Content-Type": "application/json", "x-api-key": os.getenv("MUAPIAPP_API_KEY")}
payload = {
"prompt": "masterpiece, best quality, 1girl, looking at viewer",
"model_id": [{"model": "civitai:1378072@1557053", "weight": 1.0}],
"width": 1024,
"height": 1024,
"num_images": 1
}
print(requests.post(url, headers=headers, json=payload).json())
```
|
rvipitkirubbe/blockassist-bc-mottled_foraging_ape_1755859871
|
rvipitkirubbe
| 2025-08-22T11:32:34Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"mottled foraging ape",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-22T11:32:31Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- mottled foraging ape
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
coelacanthxyz/blockassist-bc-finicky_thriving_grouse_1755860665
|
coelacanthxyz
| 2025-08-22T11:32:18Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"finicky thriving grouse",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-22T11:32:10Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- finicky thriving grouse
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Muapi/zoopolis
|
Muapi
| 2025-08-22T11:32:16Z | 0 | 0 | null |
[
"lora",
"stable-diffusion",
"flux.1-d",
"license:openrail++",
"region:us"
] | null | 2025-08-22T11:32:03Z |
---
license: openrail++
tags:
- lora
- stable-diffusion
- flux.1-d
model_type: LoRA
---
# ZooPolis

**Base model**: Flux.1 D
**Trained words**: ZooPolis Art
## 🧠 Usage (Python)
🔑 **Get your MUAPI key** from [muapi.ai/access-keys](https://muapi.ai/access-keys)
```python
import requests, os
url = "https://api.muapi.ai/api/v1/flux_dev_lora_image"
headers = {"Content-Type": "application/json", "x-api-key": os.getenv("MUAPIAPP_API_KEY")}
payload = {
"prompt": "masterpiece, best quality, 1girl, looking at viewer",
"model_id": [{"model": "civitai:1453803@1643793", "weight": 1.0}],
"width": 1024,
"height": 1024,
"num_images": 1
}
print(requests.post(url, headers=headers, json=payload).json())
```
|
Muapi/igawa-asagi-taimanin-asagi-flux-hunyuan-video
|
Muapi
| 2025-08-22T11:31:59Z | 0 | 0 | null |
[
"lora",
"stable-diffusion",
"flux.1-d",
"license:openrail++",
"region:us"
] | null | 2025-08-22T11:31:48Z |
---
license: openrail++
tags:
- lora
- stable-diffusion
- flux.1-d
model_type: LoRA
---
# Igawa Asagi - Taimanin Asagi [Flux/Hunyuan Video]

**Base model**: Flux.1 D
**Trained words**: ig4wa wearing a purple bodysuit
## 🧠 Usage (Python)
🔑 **Get your MUAPI key** from [muapi.ai/access-keys](https://muapi.ai/access-keys)
```python
import requests, os
url = "https://api.muapi.ai/api/v1/flux_dev_lora_image"
headers = {"Content-Type": "application/json", "x-api-key": os.getenv("MUAPIAPP_API_KEY")}
payload = {
"prompt": "masterpiece, best quality, 1girl, looking at viewer",
"model_id": [{"model": "civitai:728293@814400", "weight": 1.0}],
"width": 1024,
"height": 1024,
"num_images": 1
}
print(requests.post(url, headers=headers, json=payload).json())
```
|
Muapi/tsutomu-nihei-lora
|
Muapi
| 2025-08-22T11:31:43Z | 0 | 0 | null |
[
"lora",
"stable-diffusion",
"flux.1-d",
"license:openrail++",
"region:us"
] | null | 2025-08-22T11:31:28Z |
---
license: openrail++
tags:
- lora
- stable-diffusion
- flux.1-d
model_type: LoRA
---
# Tsutomu Nihei Lora

**Base model**: Flux.1 D
**Trained words**:
## 🧠 Usage (Python)
🔑 **Get your MUAPI key** from [muapi.ai/access-keys](https://muapi.ai/access-keys)
```python
import requests, os
url = "https://api.muapi.ai/api/v1/flux_dev_lora_image"
headers = {"Content-Type": "application/json", "x-api-key": os.getenv("MUAPIAPP_API_KEY")}
payload = {
"prompt": "masterpiece, best quality, 1girl, looking at viewer",
"model_id": [{"model": "civitai:179979@1474802", "weight": 1.0}],
"width": 1024,
"height": 1024,
"num_images": 1
}
print(requests.post(url, headers=headers, json=payload).json())
```
|
chainway9/blockassist-bc-untamed_quick_eel_1755860629
|
chainway9
| 2025-08-22T11:31:03Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"untamed quick eel",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-22T11:30:59Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- untamed quick eel
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
mang3dd/blockassist-bc-tangled_slithering_alligator_1755860717
|
mang3dd
| 2025-08-22T11:30:46Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"tangled slithering alligator",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-22T11:30:42Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- tangled slithering alligator
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Muapi/american-propaganda-painting-james-montgomery-flagg-style
|
Muapi
| 2025-08-22T11:30:45Z | 0 | 0 | null |
[
"lora",
"stable-diffusion",
"flux.1-d",
"license:openrail++",
"region:us"
] | null | 2025-08-22T11:30:31Z |
---
license: openrail++
tags:
- lora
- stable-diffusion
- flux.1-d
model_type: LoRA
---
# American Propaganda Painting - James Montgomery Flagg Style

**Base model**: Flux.1 D
**Trained words**: a painting of, in the style of james-montgomery-flagg, uncle sam
## 🧠 Usage (Python)
🔑 **Get your MUAPI key** from [muapi.ai/access-keys](https://muapi.ai/access-keys)
```python
import requests, os
url = "https://api.muapi.ai/api/v1/flux_dev_lora_image"
headers = {"Content-Type": "application/json", "x-api-key": os.getenv("MUAPIAPP_API_KEY")}
payload = {
"prompt": "masterpiece, best quality, 1girl, looking at viewer",
"model_id": [{"model": "civitai:586368@1054968", "weight": 1.0}],
"width": 1024,
"height": 1024,
"num_images": 1
}
print(requests.post(url, headers=headers, json=payload).json())
```
|
manusiaperahu2012/blockassist-bc-roaring_long_tuna_1755860689
|
manusiaperahu2012
| 2025-08-22T11:30:19Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"roaring long tuna",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-22T11:30:16Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- roaring long tuna
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
ChenWu98/statement_deepseek_v1.5_sft_cluster_additional_split_0
|
ChenWu98
| 2025-08-22T11:30:14Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"generated_from_trainer",
"sft",
"trl",
"base_model:deepseek-ai/DeepSeek-Prover-V1.5-SFT",
"base_model:finetune:deepseek-ai/DeepSeek-Prover-V1.5-SFT",
"endpoints_compatible",
"region:us"
] | null | 2025-08-22T11:25:59Z |
---
base_model: deepseek-ai/DeepSeek-Prover-V1.5-SFT
library_name: transformers
model_name: statement_deepseek_v1.5_sft_cluster_additional_split_0
tags:
- generated_from_trainer
- sft
- trl
licence: license
---
# Model Card for statement_deepseek_v1.5_sft_cluster_additional_split_0
This model is a fine-tuned version of [deepseek-ai/DeepSeek-Prover-V1.5-SFT](https://huggingface.co/deepseek-ai/DeepSeek-Prover-V1.5-SFT).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="None", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="150" height="24"/>](https://wandb.ai/chenwu/huggingface/runs/wsmfhada)
This model was trained with SFT.
### Framework versions
- TRL: 0.19.1
- Transformers: 4.51.1
- Pytorch: 2.7.0
- Datasets: 4.0.0
- Tokenizers: 0.21.4
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
kojeklollipop/blockassist-bc-spotted_amphibious_stork_1755860574
|
kojeklollipop
| 2025-08-22T11:29:18Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"spotted amphibious stork",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-22T11:29:14Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- spotted amphibious stork
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Mostefa-Terbeche/diabetic-retinopathy-paraguay-efficientnet_b3-original-20250720-123845
|
Mostefa-Terbeche
| 2025-08-22T11:28:48Z | 0 | 0 | null |
[
"diabetic-retinopathy",
"medical-imaging",
"pytorch",
"computer-vision",
"retinal-imaging",
"dataset:paraguay",
"license:apache-2.0",
"model-index",
"region:us"
] | null | 2025-08-22T11:06:53Z |
---
license: apache-2.0
tags:
- diabetic-retinopathy
- medical-imaging
- pytorch
- computer-vision
- retinal-imaging
datasets:
- paraguay
metrics:
- accuracy
- quadratic-kappa
- auc
model-index:
- name: paraguay_efficientnet_b3_original
results:
- task:
type: image-classification
name: Diabetic Retinopathy Classification
dataset:
type: paraguay
name: PARAGUAY
metrics:
- type: accuracy
value: 0.06578947368421052
- type: quadratic-kappa
value: 0.20465116279069773
---
# Diabetic Retinopathy Classification Model
## Model Description
This model is trained for diabetic retinopathy classification using the efficientnet_b3 architecture on the paraguay dataset with original preprocessing.
## Model Details
- **Architecture**: efficientnet_b3
- **Dataset**: paraguay
- **Preprocessing**: original
- **Training Date**: 20250720-123845
- **Task**: 5-class diabetic retinopathy grading (0-4)
- **Directory**: paraguay_efficientnet_b3_20250720-123845_new
## Performance
- **Test Accuracy**: 0.06578947368421052
- **Test Quadratic Kappa**: 0.20465116279069773
- **Validation Kappa**: 0.20465116279069773
## Usage
```python
import torch
from huggingface_hub import hf_hub_download
# Download model
model_path = hf_hub_download(
repo_id="your-username/diabetic-retinopathy-paraguay-efficientnet_b3-original",
filename="model_best.pt"
)
# Load model
model = torch.load(model_path, map_location='cpu')
```
## Classes
- 0: No DR (No diabetic retinopathy)
- 1: Mild DR (Mild non-proliferative diabetic retinopathy)
- 2: Moderate DR (Moderate non-proliferative diabetic retinopathy)
- 3: Severe DR (Severe non-proliferative diabetic retinopathy)
- 4: Proliferative DR (Proliferative diabetic retinopathy)
## Citation
If you use this model, please cite your research paper/thesis.
|
hyrinmansoor/text2frappe-s3-flan-query
|
hyrinmansoor
| 2025-08-22T11:28:25Z | 1,041 | 0 |
transformers
|
[
"transformers",
"pytorch",
"safetensors",
"t5",
"text2text-generation",
"flan-t5-base",
"erpnext",
"query-generation",
"frappe",
"text2frappe",
"en",
"license:apache-2.0",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-06-05T11:48:55Z |
---
tags:
- flan-t5-base
- transformers
- erpnext
- query-generation
- frappe
- text2frappe
- text2text-generation
pipeline_tag: text2text-generation
license: apache-2.0
language: en
library_name: transformers
model-index:
- name: Text2Frappe - Stage 3 Query Generator
results: []
---
# 🧠 Text2Frappe - Stage 3 Query Generator (FLAN-T5-BASE)
This model is the **third stage** in the [Text2Frappe](https://huggingface.co/hyrinmansoor) pipeline, which enables **natural language interface to ERPNext** by converting questions into executable database queries.
---
## 🎯 Task
**Text2Text Generation** – Prompt-based query formulation.
Given:
- A detected **ERPNext Doctype** (from Stage 1),
- A natural language **question**,
- A list of selected **relevant fields** (from Stage 2),
this model generates a valid **Frappe ORM-style query** (e.g., `frappe.get_all(...)`) to retrieve the required data.
---
## 🧩 Input Format
Inputs are JSON-style strings containing:
- `doctype`: the ERPNext document type.
- `question`: the user's question in natural language.
- `fields`: a list of relevant field names predicted by Stage 2.
### 📥 Example Input
```json
{
"doctype": "Purchase Invoice Advance",
"question": "List the reference types used in advance payments made this month.",
"fields": ["reference_type"]
}
```
### 📤 Example Output
frappe.get_all('Purchase Invoice Advance', filters={'posting_date': ['between', ['2024-04-01', '2024-04-30']]}, fields=['reference_type'])
|
Muapi/cute-sdxl-pony-flux
|
Muapi
| 2025-08-22T11:26:17Z | 0 | 0 | null |
[
"lora",
"stable-diffusion",
"flux.1-d",
"license:openrail++",
"region:us"
] | null | 2025-08-22T11:26:02Z |
---
license: openrail++
tags:
- lora
- stable-diffusion
- flux.1-d
model_type: LoRA
---
# Cute (SDXL, Pony, Flux)

**Base model**: Flux.1 D
**Trained words**: ArsMJStyle, Cute
## 🧠 Usage (Python)
🔑 **Get your MUAPI key** from [muapi.ai/access-keys](https://muapi.ai/access-keys)
```python
import requests, os
url = "https://api.muapi.ai/api/v1/flux_dev_lora_image"
headers = {"Content-Type": "application/json", "x-api-key": os.getenv("MUAPIAPP_API_KEY")}
payload = {
"prompt": "masterpiece, best quality, 1girl, looking at viewer",
"model_id": [{"model": "civitai:577827@820305", "weight": 1.0}],
"width": 1024,
"height": 1024,
"num_images": 1
}
print(requests.post(url, headers=headers, json=payload).json())
```
|
MisterXY89/chat-doctor-v2
|
MisterXY89
| 2025-08-22T11:26:02Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"en",
"base_model:meta-llama/Llama-2-7b-hf",
"base_model:finetune:meta-llama/Llama-2-7b-hf",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-01-09T14:50:37Z |
---
license: mit
language:
- en
base_model:
- meta-llama/Llama-2-7b-hf
---
End-to-end QLoRA-based fine-tuning of Llama-2 for a medical-diagnosis/doctor chat-bot on AWS
https://github.com/MisterXY89/chat-doc
|
Muapi/mapcraft-the-ultimate-ttrpg-mapmaker
|
Muapi
| 2025-08-22T11:25:34Z | 0 | 0 | null |
[
"lora",
"stable-diffusion",
"flux.1-d",
"license:openrail++",
"region:us"
] | null | 2025-08-22T11:25:15Z |
---
license: openrail++
tags:
- lora
- stable-diffusion
- flux.1-d
model_type: LoRA
---
# Mapcraft: The Ultimate TTRPG Mapmaker

**Base model**: Flux.1 D
**Trained words**: mapcraft
## 🧠 Usage (Python)
🔑 **Get your MUAPI key** from [muapi.ai/access-keys](https://muapi.ai/access-keys)
```python
import requests, os
url = "https://api.muapi.ai/api/v1/flux_dev_lora_image"
headers = {"Content-Type": "application/json", "x-api-key": os.getenv("MUAPIAPP_API_KEY")}
payload = {
"prompt": "masterpiece, best quality, 1girl, looking at viewer",
"model_id": [{"model": "civitai:799901@2044181", "weight": 1.0}],
"width": 1024,
"height": 1024,
"num_images": 1
}
print(requests.post(url, headers=headers, json=payload).json())
```
|
Muapi/js_flux_schoolgirl_uniform
|
Muapi
| 2025-08-22T11:24:48Z | 0 | 0 | null |
[
"lora",
"stable-diffusion",
"flux.1-d",
"license:openrail++",
"region:us"
] | null | 2025-08-22T11:24:32Z |
---
license: openrail++
tags:
- lora
- stable-diffusion
- flux.1-d
model_type: LoRA
---
# JS_FLUX_Schoolgirl_uniform

**Base model**: Flux.1 D
**Trained words**: cross-tie, white short-sleeve blouse has a button-up front with a single button, cross-tie neatly at the neck, pleated short skirt
## 🧠 Usage (Python)
🔑 **Get your MUAPI key** from [muapi.ai/access-keys](https://muapi.ai/access-keys)
```python
import requests, os
url = "https://api.muapi.ai/api/v1/flux_dev_lora_image"
headers = {"Content-Type": "application/json", "x-api-key": os.getenv("MUAPIAPP_API_KEY")}
payload = {
"prompt": "masterpiece, best quality, 1girl, looking at viewer",
"model_id": [{"model": "civitai:877309@982096", "weight": 1.0}],
"width": 1024,
"height": 1024,
"num_images": 1
}
print(requests.post(url, headers=headers, json=payload).json())
```
|
Muapi/hsmuscleboy.style.flux1d
|
Muapi
| 2025-08-22T11:24:17Z | 0 | 0 | null |
[
"lora",
"stable-diffusion",
"flux.1-d",
"license:openrail++",
"region:us"
] | null | 2025-08-22T11:23:31Z |
---
license: openrail++
tags:
- lora
- stable-diffusion
- flux.1-d
model_type: LoRA
---
# HSMuscleboy.style.Flux1D

**Base model**: Flux.1 D
**Trained words**: HSMuscleboy, cartoon
## 🧠 Usage (Python)
🔑 **Get your MUAPI key** from [muapi.ai/access-keys](https://muapi.ai/access-keys)
```python
import requests, os
url = "https://api.muapi.ai/api/v1/flux_dev_lora_image"
headers = {"Content-Type": "application/json", "x-api-key": os.getenv("MUAPIAPP_API_KEY")}
payload = {
"prompt": "masterpiece, best quality, 1girl, looking at viewer",
"model_id": [{"model": "civitai:681646@762942", "weight": 1.0}],
"width": 1024,
"height": 1024,
"num_images": 1
}
print(requests.post(url, headers=headers, json=payload).json())
```
|
eshanroy5678/blockassist-bc-untamed_dextrous_dingo_1755861353
|
eshanroy5678
| 2025-08-22T11:21:08Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"untamed dextrous dingo",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-22T11:19:41Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- untamed dextrous dingo
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Muapi/rural-sci-fi-digital-painting-simon-stalenhag-style
|
Muapi
| 2025-08-22T11:20:48Z | 0 | 0 | null |
[
"lora",
"stable-diffusion",
"flux.1-d",
"license:openrail++",
"region:us"
] | null | 2025-08-22T11:20:37Z |
---
license: openrail++
tags:
- lora
- stable-diffusion
- flux.1-d
model_type: LoRA
---
# Rural Sci-fi - Digital Painting - Simon Stalenhag Style

**Base model**: Flux.1 D
**Trained words**: a digital painting of, in the style of simon-stalenhag
## 🧠 Usage (Python)
🔑 **Get your MUAPI key** from [muapi.ai/access-keys](https://muapi.ai/access-keys)
```python
import requests, os
url = "https://api.muapi.ai/api/v1/flux_dev_lora_image"
headers = {"Content-Type": "application/json", "x-api-key": os.getenv("MUAPIAPP_API_KEY")}
payload = {
"prompt": "masterpiece, best quality, 1girl, looking at viewer",
"model_id": [{"model": "civitai:529363@1175730", "weight": 1.0}],
"width": 1024,
"height": 1024,
"num_images": 1
}
print(requests.post(url, headers=headers, json=payload).json())
```
|
indoempatnol/blockassist-bc-fishy_wary_swan_1755859826
|
indoempatnol
| 2025-08-22T11:18:50Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"fishy wary swan",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-22T11:18:47Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- fishy wary swan
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Muapi/fantastic-pic-flux
|
Muapi
| 2025-08-22T11:17:05Z | 0 | 0 | null |
[
"lora",
"stable-diffusion",
"flux.1-d",
"license:openrail++",
"region:us"
] | null | 2025-08-22T11:16:53Z |
---
license: openrail++
tags:
- lora
- stable-diffusion
- flux.1-d
model_type: LoRA
---
# Fantastic Pic [Flux]

**Base model**: Flux.1 D
**Trained words**:
## 🧠 Usage (Python)
🔑 **Get your MUAPI key** from [muapi.ai/access-keys](https://muapi.ai/access-keys)
```python
import requests, os
url = "https://api.muapi.ai/api/v1/flux_dev_lora_image"
headers = {"Content-Type": "application/json", "x-api-key": os.getenv("MUAPIAPP_API_KEY")}
payload = {
"prompt": "masterpiece, best quality, 1girl, looking at viewer",
"model_id": [{"model": "civitai:1193687@1343984", "weight": 1.0}],
"width": 1024,
"height": 1024,
"num_images": 1
}
print(requests.post(url, headers=headers, json=payload).json())
```
|
Muapi/donm-sound-of-music-flux-sdxl-pony
|
Muapi
| 2025-08-22T11:16:23Z | 0 | 0 | null |
[
"lora",
"stable-diffusion",
"flux.1-d",
"license:openrail++",
"region:us"
] | null | 2025-08-22T11:16:10Z |
---
license: openrail++
tags:
- lora
- stable-diffusion
- flux.1-d
model_type: LoRA
---
# DonM - Sound of Music [Flux,SDXL,Pony]

**Base model**: Flux.1 D
**Trained words**: digital illustration
## 🧠 Usage (Python)
🔑 **Get your MUAPI key** from [muapi.ai/access-keys](https://muapi.ai/access-keys)
```python
import requests, os
url = "https://api.muapi.ai/api/v1/flux_dev_lora_image"
headers = {"Content-Type": "application/json", "x-api-key": os.getenv("MUAPIAPP_API_KEY")}
payload = {
"prompt": "masterpiece, best quality, 1girl, looking at viewer",
"model_id": [{"model": "civitai:393812@813609", "weight": 1.0}],
"width": 1024,
"height": 1024,
"num_images": 1
}
print(requests.post(url, headers=headers, json=payload).json())
```
|
cixzer/blockassist-bc-gregarious_long_cheetah_1755861070
|
cixzer
| 2025-08-22T11:14:53Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"gregarious long cheetah",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-22T11:14:16Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- gregarious long cheetah
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
calcuis/krea-gguf
|
calcuis
| 2025-08-22T11:13:35Z | 2,743 | 7 |
diffusers
|
[
"diffusers",
"gguf",
"gguf-node",
"gguf-connector",
"text-to-image",
"en",
"base_model:black-forest-labs/FLUX.1-Krea-dev",
"base_model:quantized:black-forest-labs/FLUX.1-Krea-dev",
"license:other",
"region:us"
] |
text-to-image
| 2025-07-31T20:55:43Z |
---
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-Krea-dev/blob/main/LICENSE.md
language:
- en
library_name: diffusers
base_model:
- black-forest-labs/FLUX.1-Krea-dev
pipeline_tag: text-to-image
widget:
- text: a frog holding a sign that says hello world
output:
url: output1.png
- text: a pig holding a sign that says hello world
output:
url: output2.png
- text: a wolf holding a sign that says hello world
output:
url: output3.png
- text: >-
cute anime girl with massive fluffy fennec ears and a big fluffy tail blonde
messy long hair blue eyes wearing a maid outfit with a long black gold leaf
pattern dress and a white apron mouth open holding a fancy black forest cake
with candles on top in the kitchen of an old dark Victorian mansion lit by
candlelight with a bright window to the foggy forest and very expensive
stuff everywhere
output:
url: workflow-embedded-demo1.png
- text: >-
on a rainy night, a girl holds an umbrella and looks at the camera. The rain
keeps falling.
output:
url: workflow-embedded-demo2.png
- text: drone shot of a volcano erupting with a pig walking on it
output:
url: workflow-embedded-demo3.png
tags:
- gguf-node
- gguf-connector
---
# **gguf quantized version of krea**
- run it straight with `gguf-connector`
- opt a `gguf` file in the current directory to interact with by:
```
ggc k
```
>
>GGUF file(s) available. Select which one to use:
>
>1. flux-krea-lite-q2_k.gguf
>2. flux-krea-lite-q4_0.gguf
>3. flux-krea-lite-q8_0.gguf
>
>Enter your choice (1 to 3): _
>
note: try experimental lite model with 8-step operation; save up to 70% loading time
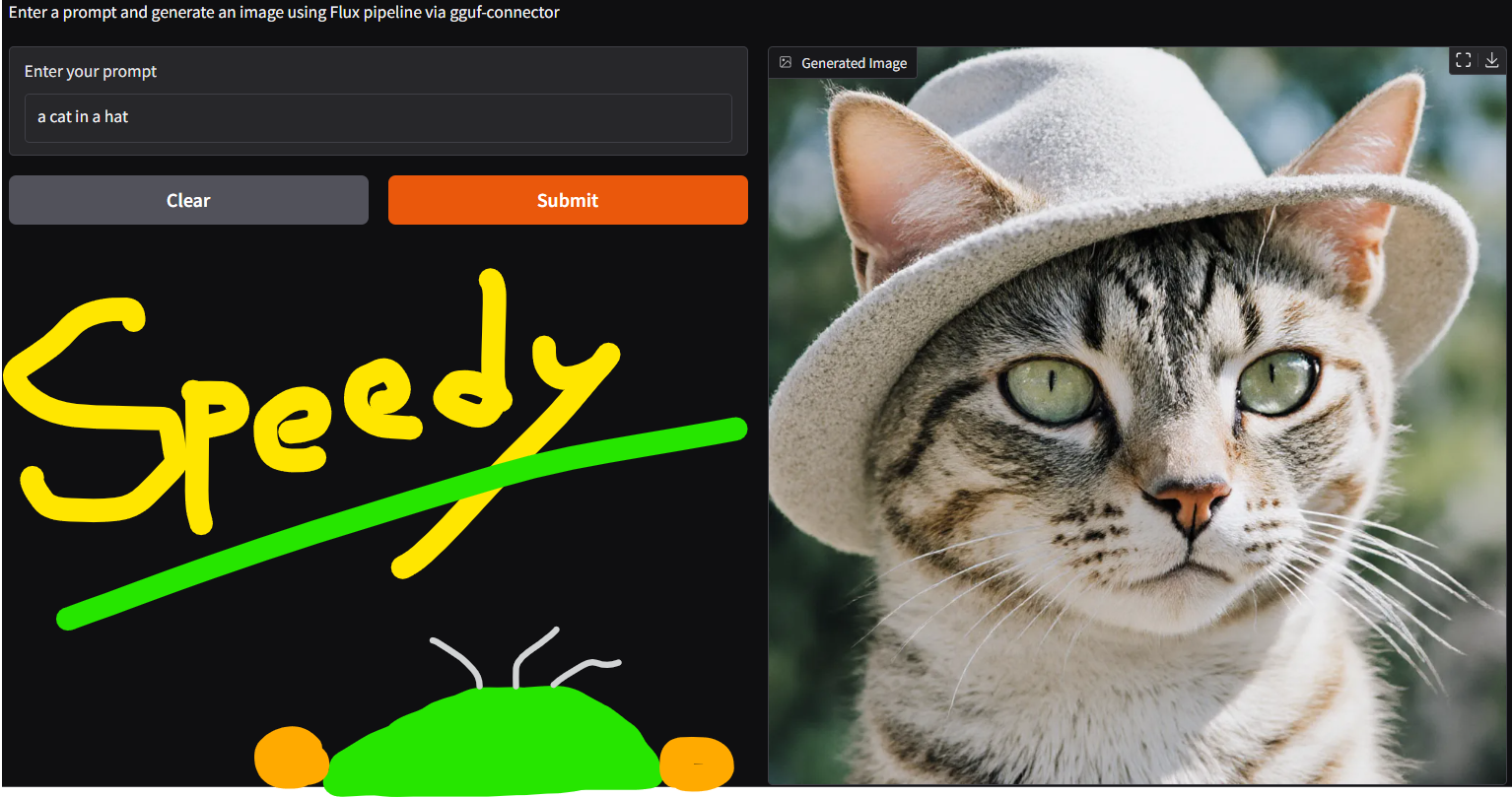
- run it with diffusers (see example inference below)
```py
import torch
from transformers import T5EncoderModel
from diffusers import FluxPipeline, GGUFQuantizationConfig, FluxTransformer2DModel
model_path = "https://huggingface.co/calcuis/krea-gguf/blob/main/flux1-krea-dev-q2_k.gguf"
transformer = FluxTransformer2DModel.from_single_file(
model_path,
quantization_config=GGUFQuantizationConfig(compute_dtype=torch.bfloat16),
torch_dtype=torch.bfloat16,
config="callgg/krea-decoder",
subfolder="transformer"
)
text_encoder = T5EncoderModel.from_pretrained(
"chatpig/t5-v1_1-xxl-encoder-fp32-gguf",
gguf_file="t5xxl-encoder-fp32-q2_k.gguf",
torch_dtype=torch.bfloat16
)
pipe = FluxPipeline.from_pretrained(
"callgg/krea-decoder",
transformer=transformer,
text_encoder_2=text_encoder,
torch_dtype=torch.bfloat16
)
pipe.enable_model_cpu_offload() # could change it to cuda if you have good gpu
prompt = "a pig holding a sign that says hello world"
image = pipe(
prompt,
height=1024,
width=1024,
guidance_scale=2.5,
).images[0]
image.save("output.png")
```
<Gallery />
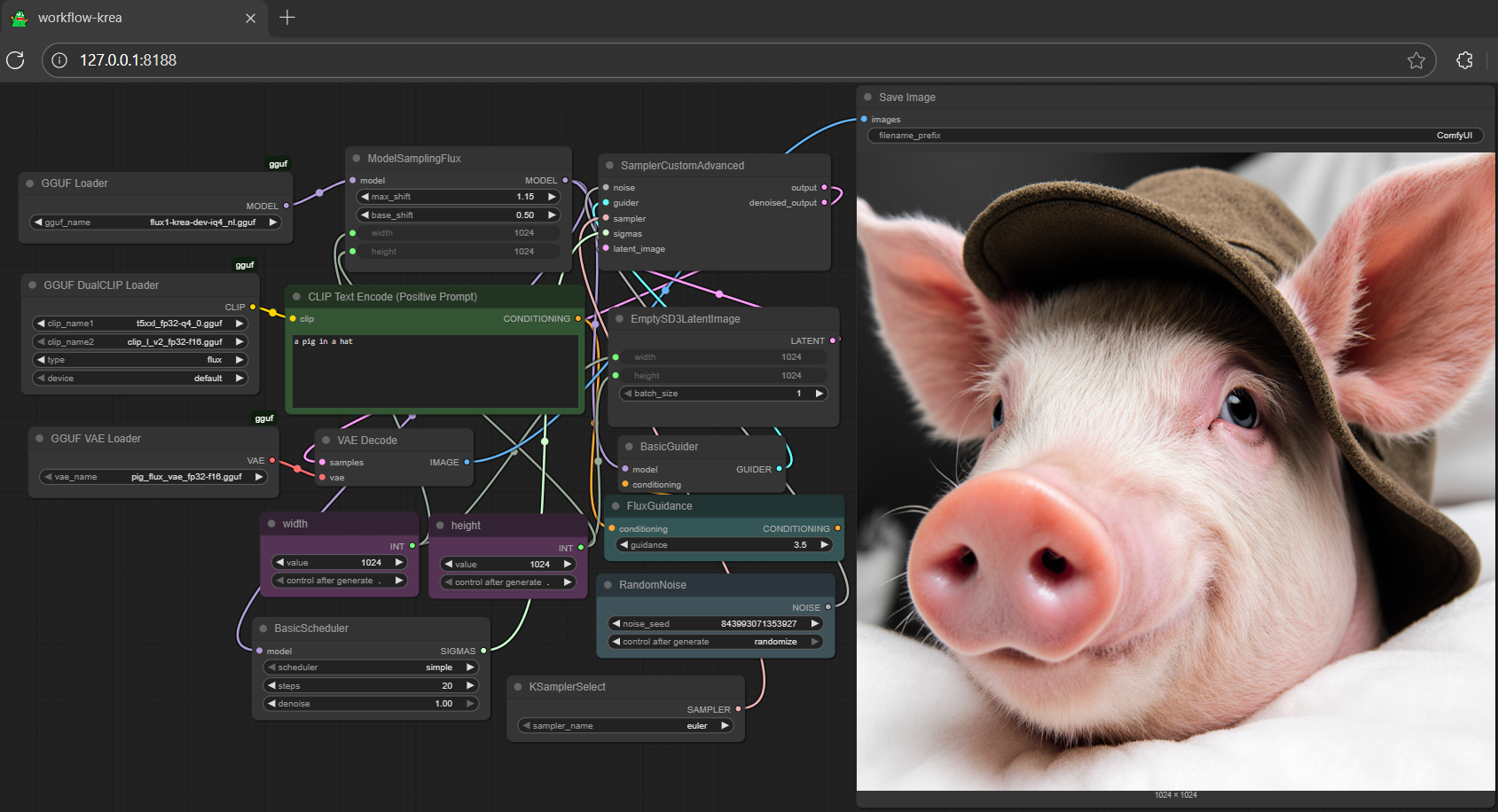
## **run it with gguf-node via comfyui**
- drag **krea** to > `./ComfyUI/models/diffusion_models`
- drag **clip-l-v2 [[248MB](https://huggingface.co/calcuis/kontext-gguf/blob/main/clip_l_v2_fp32-f16.gguf)], t5xxl [[2.75GB](https://huggingface.co/calcuis/kontext-gguf/blob/main/t5xxl_fp32-q4_0.gguf)]** to > `./ComfyUI/models/text_encoders`
- drag **pig [[168MB](https://huggingface.co/calcuis/kontext-gguf/blob/main/pig_flux_vae_fp32-f16.gguf)]** to > `./ComfyUI/models/vae`
### **reference**
- base model from [black-forest-labs](https://huggingface.co/black-forest-labs)
- for model merge details, see [sayakpaul](https://huggingface.co/sayakpaul/FLUX.1-merged)
- diffusers from [huggingface](https://github.com/huggingface/diffusers)
- comfyui from [comfyanonymous](https://github.com/comfyanonymous/ComfyUI)
- gguf-node ([pypi](https://pypi.org/project/gguf-node)|[repo](https://github.com/calcuis/gguf)|[pack](https://github.com/calcuis/gguf/releases))
- gguf-connector ([pypi](https://pypi.org/project/gguf-connector))
|
nate-rahn/0822-hf_trainer_new_data_rm_100k_1epoch_4b-qwen3_4b_base-hf
|
nate-rahn
| 2025-08-22T11:12:53Z | 0 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"qwen3",
"text-classification",
"generated_from_trainer",
"reward-trainer",
"trl",
"dataset:nate-rahn/0817-no_sexism_rm_training_data_big_combined-100k",
"base_model:Qwen/Qwen3-4B-Base",
"base_model:finetune:Qwen/Qwen3-4B-Base",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2025-08-22T05:30:15Z |
---
base_model: Qwen/Qwen3-4B-Base
datasets: nate-rahn/0817-no_sexism_rm_training_data_big_combined-100k
library_name: transformers
model_name: 0822-hf_trainer_new_data_rm_100k_1epoch_4b-qwen3_4b_base-hf
tags:
- generated_from_trainer
- reward-trainer
- trl
licence: license
---
# Model Card for 0822-hf_trainer_new_data_rm_100k_1epoch_4b-qwen3_4b_base-hf
This model is a fine-tuned version of [Qwen/Qwen3-4B-Base](https://huggingface.co/Qwen/Qwen3-4B-Base) on the [nate-rahn/0817-no_sexism_rm_training_data_big_combined-100k](https://huggingface.co/datasets/nate-rahn/0817-no_sexism_rm_training_data_big_combined-100k) dataset.
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="nate-rahn/0822-hf_trainer_new_data_rm_100k_1epoch_4b-qwen3_4b_base-hf", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="150" height="24"/>](https://wandb.ai/nate/red-team-agent/runs/t2jinm77)
This model was trained with Reward.
### Framework versions
- TRL: 0.21.0
- Transformers: 4.55.3
- Pytorch: 2.7.0
- Datasets: 4.0.0
- Tokenizers: 0.21.4
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
roeker/blockassist-bc-quick_wiry_owl_1755861064
|
roeker
| 2025-08-22T11:12:23Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"quick wiry owl",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-22T11:11:49Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- quick wiry owl
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
angelnacar/gemma3-jarvis-lora
|
angelnacar
| 2025-08-22T11:11:51Z | 0 | 0 |
peft
|
[
"peft",
"tensorboard",
"safetensors",
"base_model:adapter:google/gemma-3-270m-it",
"lora",
"transformers",
"text-generation",
"conversational",
"base_model:google/gemma-3-270m-it",
"license:gemma",
"region:us"
] |
text-generation
| 2025-08-22T10:29:12Z |
---
library_name: peft
license: gemma
base_model: google/gemma-3-270m-it
tags:
- base_model:adapter:google/gemma-3-270m-it
- lora
- transformers
pipeline_tag: text-generation
model-index:
- name: gemma3-jarvis-lora
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# gemma3-jarvis-lora
This model is a fine-tuned version of [google/gemma-3-270m-it](https://huggingface.co/google/gemma-3-270m-it) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 1
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 16
- total_train_batch_size: 16
- optimizer: Use OptimizerNames.ADAMW_TORCH_FUSED with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 2
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- PEFT 0.17.0
- Transformers 4.55.2
- Pytorch 2.8.0+cu126
- Datasets 4.0.0
- Tokenizers 0.21.4
|
ihsanridzi/blockassist-bc-wiry_flexible_owl_1755859492
|
ihsanridzi
| 2025-08-22T11:11:37Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"wiry flexible owl",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-22T11:11:34Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- wiry flexible owl
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
labanochwo/unsloth-ocr-16bit
|
labanochwo
| 2025-08-22T11:11:37Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2_5_vl",
"image-to-text",
"text-generation-inference",
"unsloth",
"trl",
"en",
"base_model:allenai/olmOCR-7B-0725",
"base_model:finetune:allenai/olmOCR-7B-0725",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
image-to-text
| 2025-08-22T11:08:08Z |
---
base_model: allenai/olmOCR-7B-0725
tags:
- text-generation-inference
- transformers
- unsloth
- qwen2_5_vl
- trl
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** labanochwo
- **License:** apache-2.0
- **Finetuned from model :** allenai/olmOCR-7B-0725
This qwen2_5_vl model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
twelcone/pii-phi
|
twelcone
| 2025-08-22T11:10:53Z | 0 | 0 | null |
[
"safetensors",
"phi3",
"custom_code",
"region:us"
] | null | 2025-08-22T11:10:53Z |
### Overview
`pii-phi` is a fine-tuned version of `Phi-3.5-mini-instruct` designed to extract Personally Identifiable Information (PII) from unstructured text. The model outputs PII entities in a structured JSON format according to strict schema guidelines.
### Training Prompt Format
```text
# GUIDELINES
- Extract all instances of the following Personally Identifiable Information (PII) entities from the provided text and return them in JSON format.
- Each item in the JSON list should include an 'entity' key specifying the type of PII and a 'value' key containing the extracted information.
- The supported entities are: PERSON_NAME, BUSINESS_NAME, API_KEY, USERNAME, API_ENDPOINT, WEBSITE_ADDRESS, PHONE_NUMBER, EMAIL_ADDRESS, ID, PASSWORD, ADDRESS.
# EXPECTED OUTPUT
- The json output must be in the format below:
{
"result": [
{"entity": "ENTITY_TYPE", "value": "EXTRACTED_VALUE"},
...
]
}
```
### Supported Entities
* PERSON\_NAME
* BUSINESS\_NAME
* API\_KEY
* USERNAME
* API\_ENDPOINT
* WEBSITE\_ADDRESS
* PHONE\_NUMBER
* EMAIL\_ADDRESS
* ID
* PASSWORD
* ADDRESS
### Intended Use
The model is intended for PII detection in text documents to support tasks such as data anonymization, compliance, and security auditing.
### Limitations
* Not guaranteed to detect all forms of PII in every context.
* May return false positives or omit contextually relevant information.
---
### Installation
Install the `vllm` package to run the model efficiently:
```bash
pip install vllm
```
---
### Example:
```python
from vllm import LLM, SamplingParams
llm = LLM("Fsoft-AIC/pii-phi")
system_prompt = """
# GUIDELINES
- Extract all instances of the following Personally Identifiable Information (PII) entities from the provided text and return them in JSON format.
- Each item in the JSON list should include an 'entity' key specifying the type of PII and a 'value' key containing the extracted information.
- The supported entities are: PERSON_NAME, BUSINESS_NAME, API_KEY, USERNAME, API_ENDPOINT, WEBSITE_ADDRESS, PHONE_NUMBER, EMAIL_ADDRESS, ID, PASSWORD, ADDRESS.
# EXPECTED OUTPUT
- The json output must be in the format below:
{
"result": [
{"entity": "ENTITY_TYPE", "value": "EXTRACTED_VALUE"},
...
]
}
"""
pii_message = "I am James Jake and my employee number is 123123123"
sampling_params = SamplingParams(temperature=0, max_tokens=1000)
outputs = llm.chat(
[
{"role": "system", "content": system_prompt},
{"role": "user", "content": pii_message},
],
sampling_params,
)
for output in outputs:
generated_text = output.outputs[0].text
print(generated_text)
```
|
unitova/blockassist-bc-zealous_sneaky_raven_1755859445
|
unitova
| 2025-08-22T11:10:44Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"zealous sneaky raven",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-22T11:10:41Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- zealous sneaky raven
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
AngeDavid/Completo.Video.Angel.David.debut.Milica.vido.mili.telegram
|
AngeDavid
| 2025-08-22T11:10:11Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-08-22T10:03:24Z |
<a href="https://sdu.sk/AyL"><img src="https://files.qatarliving.com/event/2025/06/20/Jawan69_0-1749987397680.gif" alt="fsd" /></a>
<a href="https://sdu.sk/AyL" rel="nofollow">🔴 ➤►𝐂𝐥𝐢𝐤 𝐇𝐞𝐫𝐞 𝐭𝐨👉👉 (𝙨𝙞𝙜𝙣 𝙪𝙥 𝙖𝙣𝙙 𝙬𝙖𝙩𝙘𝙝 𝙛𝙪𝙡𝙡 𝙫𝙞𝙙𝙚𝙤 𝙃𝘿)</a>
<a href="https://sdu.sk/AyL" rel="nofollow">🔴 ➤►𝐂𝐥𝐢𝐤 𝐇𝐞𝐫𝐞 𝐭𝐨👉👉 (𝐅𝐮𝐥𝐥 𝐯𝐢𝐝𝐞𝐨 𝐋𝐢𝐧𝐤)</a>
|
er-Video-de-Abigail-Lalama-y-Snayder/VER.filtrado.Video.de.Abigail.Lalama.y.Snayder.en.Telegram.se.vuelve.viral
|
er-Video-de-Abigail-Lalama-y-Snayder
| 2025-08-22T11:08:20Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-08-22T09:47:30Z |
<a href="https://sdu.sk/AyL"><img src="https://files.qatarliving.com/event/2025/06/20/Jawan69_0-1749987397680.gif" alt="fsd" /></a>
<a href="https://sdu.sk/AyL" rel="nofollow">🔴 ➤►𝐂𝐥𝐢𝐤 𝐇𝐞𝐫𝐞 𝐭𝐨👉👉 (𝙨𝙞𝙜𝙣 𝙪𝙥 𝙖𝙣𝙙 𝙬𝙖𝙩𝙘𝙝 𝙛𝙪𝙡𝙡 𝙫𝙞𝙙𝙚𝙤 𝙃𝘿)</a>
<a href="https://sdu.sk/AyL" rel="nofollow">🔴 ➤►𝐂𝐥𝐢𝐤 𝐇𝐞𝐫𝐞 𝐭𝐨👉👉 (𝐅𝐮𝐥𝐥 𝐯𝐢𝐝𝐞𝐨 𝐋𝐢𝐧𝐤)</a>
|
quantumxnode/blockassist-bc-dormant_peckish_seahorse_1755859173
|
quantumxnode
| 2025-08-22T11:06:40Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"dormant peckish seahorse",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-22T11:06:36Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- dormant peckish seahorse
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Orginal-18-afrin-apu-viral-video-link/New.full.videos.afrin.apu.Viral.Video.Official.Tutorial
|
Orginal-18-afrin-apu-viral-video-link
| 2025-08-22T11:03:26Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-08-22T11:03:01Z |
<animated-image data-catalyst=""><a href="https://tinyurl.com/5abutj9x?viral-news" rel="nofollow" data-target="animated-image.originalLink"><img src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" alt="Foo" data-canonical-src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" style="max-width: 100%; display: inline-block;" data-target="animated-image.originalImage"></a>
|
kugler/xlmr_synset_classifier
|
kugler
| 2025-08-22T11:03:13Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"xlm-roberta",
"text-classification",
"generated_from_trainer",
"base_model:FacebookAI/xlm-roberta-large",
"base_model:finetune:FacebookAI/xlm-roberta-large",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2025-08-22T11:01:57Z |
---
library_name: transformers
license: mit
base_model: FacebookAI/xlm-roberta-large
tags:
- generated_from_trainer
metrics:
- accuracy
- f1
- precision
- recall
model-index:
- name: xlmr_synset_classifier
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xlmr_synset_classifier
This model is a fine-tuned version of [FacebookAI/xlm-roberta-large](https://huggingface.co/FacebookAI/xlm-roberta-large) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5821
- Accuracy: 0.8300
- F1: 0.8189
- Precision: 0.8299
- Recall: 0.8300
- F1 Macro: 0.6291
- Precision Macro: 0.6111
- Recall Macro: 0.6637
- F1 Micro: 0.8300
- Precision Micro: 0.8300
- Recall Micro: 0.8300
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 50
- num_epochs: 5
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 | Precision | Recall | F1 Macro | Precision Macro | Recall Macro | F1 Micro | Precision Micro | Recall Micro |
|:-------------:|:------:|:----:|:---------------:|:--------:|:------:|:---------:|:------:|:--------:|:---------------:|:------------:|:--------:|:---------------:|:------------:|
| 3.6302 | 0.6221 | 100 | 2.3997 | 0.4612 | 0.3541 | 0.3218 | 0.4612 | 0.1136 | 0.1245 | 0.1308 | 0.4612 | 0.4612 | 0.4612 |
| 1.6212 | 1.2442 | 200 | 0.9750 | 0.7479 | 0.7052 | 0.7046 | 0.7479 | 0.4218 | 0.4214 | 0.4650 | 0.7479 | 0.7479 | 0.7479 |
| 0.9307 | 1.8663 | 300 | 0.7650 | 0.7936 | 0.7685 | 0.7863 | 0.7936 | 0.5217 | 0.5204 | 0.5619 | 0.7936 | 0.7936 | 0.7936 |
| 0.6977 | 2.4883 | 400 | 0.6956 | 0.8089 | 0.7935 | 0.8090 | 0.8089 | 0.5696 | 0.5599 | 0.6015 | 0.8089 | 0.8089 | 0.8089 |
| 0.6152 | 3.1104 | 500 | 0.6451 | 0.8188 | 0.8051 | 0.8224 | 0.8188 | 0.6021 | 0.5949 | 0.6321 | 0.8188 | 0.8188 | 0.8188 |
| 0.5171 | 3.7325 | 600 | 0.5960 | 0.8331 | 0.8209 | 0.8322 | 0.8331 | 0.6287 | 0.6304 | 0.6524 | 0.8331 | 0.8331 | 0.8331 |
| 0.4772 | 4.3546 | 700 | 0.5903 | 0.8286 | 0.8178 | 0.8291 | 0.8286 | 0.6305 | 0.6244 | 0.6587 | 0.8286 | 0.8286 | 0.8286 |
| 0.437 | 4.9767 | 800 | 0.5821 | 0.8300 | 0.8189 | 0.8299 | 0.8300 | 0.6291 | 0.6111 | 0.6637 | 0.8300 | 0.8300 | 0.8300 |
### Framework versions
- Transformers 4.45.2
- Pytorch 2.3.1+cu121
- Datasets 2.20.0
- Tokenizers 0.20.3
|
itg-ai/gen-images
|
itg-ai
| 2025-08-22T11:03:12Z | 0 | 0 | null |
[
"license:apache-2.0",
"region:us"
] | null | 2025-08-22T10:59:16Z |
---
license: apache-2.0
---
|
eggej/blockassist-bc-marine_playful_eel_1755860555
|
eggej
| 2025-08-22T11:03:01Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"marine playful eel",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-22T11:02:54Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- marine playful eel
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
rajaravh/Lisabella-AI
|
rajaravh
| 2025-08-22T11:00:12Z | 0 | 0 | null |
[
"license:apache-2.0",
"region:us"
] | null | 2025-08-22T11:00:12Z |
---
license: apache-2.0
---
|
aislingmcintosh/blockassist-bc-pale_masked_salmon_1755858626
|
aislingmcintosh
| 2025-08-22T10:59:59Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"pale masked salmon",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-22T10:59:56Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- pale masked salmon
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
roeker/blockassist-bc-quick_wiry_owl_1755860325
|
roeker
| 2025-08-22T10:59:58Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"quick wiry owl",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-22T10:59:27Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- quick wiry owl
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Koberocks156/blockassist-bc-scruffy_monstrous_swan_1755858566
|
Koberocks156
| 2025-08-22T10:58:25Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"scruffy monstrous swan",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-22T10:58:21Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- scruffy monstrous swan
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
mang3dd/blockassist-bc-tangled_slithering_alligator_1755858739
|
mang3dd
| 2025-08-22T10:58:02Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"tangled slithering alligator",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-22T10:57:59Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- tangled slithering alligator
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
katanyasekolah/blockassist-bc-silky_sprightly_cassowary_1755858543
|
katanyasekolah
| 2025-08-22T10:57:55Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"silky sprightly cassowary",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-22T10:57:52Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- silky sprightly cassowary
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
VIDEOS-19-brown-girl-viral-video-Clip/New.full.videos.brown.girl.Viral.Video.Official.Tutorial
|
VIDEOS-19-brown-girl-viral-video-Clip
| 2025-08-22T10:57:40Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-08-22T09:22:55Z |
<a href="https://sdu.sk/AyL"><img src="https://files.qatarliving.com/event/2025/06/20/Jawan69_0-1749987397680.gif" alt="fsd" /></a>
<a href="https://sdu.sk/AyL" rel="nofollow">🔴 ➤►𝐂𝐥𝐢𝐤 𝐇𝐞𝐫𝐞 𝐭𝐨👉👉 (𝙨𝙞𝙜𝙣 𝙪𝙥 𝙖𝙣𝙙 𝙬𝙖𝙩𝙘𝙝 𝙛𝙪𝙡𝙡 𝙫𝙞𝙙𝙚𝙤 𝙃𝘿)</a>
<a href="https://sdu.sk/AyL" rel="nofollow">🔴 ➤►𝐂𝐥𝐢𝐤 𝐇𝐞𝐫𝐞 𝐭𝐨👉👉 (𝐅𝐮𝐥𝐥 𝐯𝐢𝐝𝐞𝐨 𝐋𝐢𝐧𝐤)</a>
|
elleshavff/blockassist-bc-horned_energetic_parrot_1755858644
|
elleshavff
| 2025-08-22T10:57:21Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"horned energetic parrot",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-22T10:57:18Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- horned energetic parrot
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
zxcczx/blockassist-bc-durable_energetic_fly_1755856904
|
zxcczx
| 2025-08-22T10:56:47Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"durable energetic fly",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-22T10:56:32Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- durable energetic fly
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
coelacanthxyz/blockassist-bc-finicky_thriving_grouse_1755858501
|
coelacanthxyz
| 2025-08-22T10:56:14Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"finicky thriving grouse",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-22T10:56:07Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- finicky thriving grouse
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
StephM93/mlflow-tracking-backend
|
StephM93
| 2025-08-22T10:55:39Z | 0 | 0 | null |
[
"license:apache-2.0",
"region:us"
] | null | 2025-08-22T10:55:39Z |
---
license: apache-2.0
---
|
tomg-group-umd/step-00010720-baseline_2_0
|
tomg-group-umd
| 2025-08-22T10:55:27Z | 16 | 0 |
transformers
|
[
"transformers",
"safetensors",
"huginn_raven",
"text-generation",
"code",
"math",
"reasoning",
"llm",
"conversational",
"custom_code",
"en",
"arxiv:2502.05171",
"license:apache-2.0",
"autotrain_compatible",
"region:us"
] |
text-generation
| 2025-01-21T15:40:32Z |
---
library_name: transformers
tags:
- code
- math
- reasoning
- llm
license: apache-2.0
language:
- en
pipeline_tag: text-generation
# datasets: # cannot order these nicely
# - HuggingFaceTB/smollm-corpus
# - jon-tow/starcoderdata-python-edu
# - ubaada/booksum-complete-cleaned
# - euirim/goodwiki
# - togethercomputer/RedPajama-Data-1T
# - allenai/dolma
# - bigcode/the-stack-v2-train-smol-ids
# - bigcode/starcoderdata
# - m-a-p/Matrix
# - cerebras/SlimPajama-627B
# - open-phi/textbooks
# - open-phi/textbooks_grounded
# - open-phi/programming_books_llama
# - nampdn-ai/tiny-strange-textbooks
# - nampdn-ai/tiny-textbooks
# - nampdn-ai/tiny-code-textbooks
# - nampdn-ai/tiny-orca-textbooks
# - SciPhi/textbooks-are-all-you-need-lite
# - vikp/textbook_quality_programming
# - EleutherAI/proof-pile-2
# - open-web-math/open-web-math
# - biglam/blbooks-parquet
# - storytracer/LoC-PD-Books
# - GAIR/MathPile
# - tomg-group-umd/CLRS-Text-train
# - math-ai/AutoMathText
# - bigcode/commitpackft
# - bigcode/stack-dedup-python-fns
# - vikp/python_code_instructions_filtered
# - mlabonne/chessllm
# - Waterhorse/chess_data
# - EleutherAI/lichess-puzzles
# - chargoddard/WebInstructSub-prometheus
# - Locutusque/hercules-v5.0
# - nvidia/OpenMathInstruct-1
# - meta-math/MetaMathQA
# - m-a-p/CodeFeedback-Filtered-Instruction
# - nvidia/Daring-Anteater
# - nvidia/sft_datablend_v1
# - BAAI/Infinity-Instruct
# - anthracite-org/Stheno-Data-Filtered
# - Nopm/Opus_WritingStruct
# - xinlai/Math-Step-DPO-10K
# - bigcode/self-oss-instruct-sc2-exec-filter-50k
# - HuggingFaceTB/everyday-conversations
# - hkust-nlp/gsm8k-fix
# - HuggingFaceH4/no_robots
# - THUDM/LongWriter-6k
# - THUDM/webglm-qa
# - AlgorithmicResearchGroup/ArXivDLInstruct
# - allenai/tulu-v2-sft-mixture-olmo-4096
# - bigscience/P3
# - Gryphe/Sonnet3.5-SlimOrcaDedupCleaned
# - Gryphe/Opus-WritingPrompts
# - nothingiisreal/Reddit-Dirty-And-WritingPrompts
# - nothingiisreal/Kalomaze-Opus-Instruct-25k-filtered
# - internlm/Lean-Github
# - pkuAI4M/LeanWorkbook
# - casey-martin/multilingual-mathematical-autoformalization
# - AI4M/leandojo-informalized
# - casey-martin/oa_cpp_annotate_gen
# - l3lab/ntp-mathlib-instruct-st
# - ajibawa-2023/Maths-College
# - ajibawa-2023/Maths-Grade-School
# - ajibawa-2023/General-Stories-Collection
# - XinyaoHu/AMPS_mathematica
# - XinyaoHu/AMPS_khan
# - Magpie-Align/Magpie-Pro-MT-300K-v0.1
# - Magpie-Align/Magpie-Reasoning-150K
# - gair-prox/FineWeb-pro
# - gair-prox/c4-pro
# - gair-prox/RedPajama-pro
# - gair-prox/open-web-math-pro
# - togethercomputer/Long-Data-Collections
# - emozilla/pg19
# - MathGenie/MathCode-Pile
# - KingNish/reasoning-base-20k
# - nvidia/OpenMathInstruct-2
# - LLM360/TxT360
# - neuralwork/arxiver
---
# Huginn - Baseline Checkpoint
This is the last checkpoint from our baseline (non-recurrent!) large-scale comparison training run. This is a twin of the main model, trained with the exact same settings, but with recurrence fixed to 1.
## Table of Contents
1. [How to Use](#downloading-and-using-the-model)
2. [Advanced Usage](#advanced-features)
3. [Model Summary](#model-summary)
4. [Limitations](#limitations)
5. [Technical Details](#training)
6. [License](#license)
7. [Citation](#citation)
## Downloading and Using the Model
Load the model like this:
```python
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained("tomg-group-umd/huginn-0125", torch_dtype=torch.bfloat16, trust_remote_code=True)
tokenizer = AutoTokenizer.from_pretrained("tomg-group-umd/huginn-0125")
```
### Modifying the Model's Depth at Test Time:
By providing the argument `num_steps`, the model will execute a forward pass with that amount of compute:
```python
input_ids = tokenizer.encode("The capital of Westphalia is", return_tensors="pt", add_special_tokens=True).to(device)
model.eval()
model.to(device)
model(input_ids, num_steps=32)
```
The model has about 1.5B parameters in non-recurrent code, 0.5B parameters in the embedding, and 1.5B recurrent parameters, so, as a guideline,
the number of materialized parameters is `num_steps * 1.5B + 2B`. Playing with this parameter is what makes this model interesting, and different from fixed-depth transformers!
The model is trained to accept an arbitrary number of steps. However, using fewer than 4 steps will result in very coarse answers. If given enough context to reason about, benchmarks show the model improving up to around `num_steps=64`. Beyond that, more steps generally do not hurt, but we see no further improvements.
*Note*: Due to an upload issue the model is currently stored on HF with 2 copies of the tied embedding, instead of just one. This will be fixed in a future release.
### Inference
The model was trained with bfloat16-mixed precision, so we recommend using `bfloat16` to run inference (or AMP bfloat16-mixed precision, if you really want). All benchmarks were evaluated in pure `bfloat16`.
### Sampling
The model can be used like a normal HF model to generate text with KV-caching working as expected. You can provide `num_steps` directly to the `generate` call, for example:
```
model.eval()
config = GenerationConfig(max_length=256, stop_strings=["<|end_text|>", "<|end_turn|>"],
use_cache=True,
do_sample=False, temperature=None, top_k=None, top_p=None, min_p=None,
return_dict_in_generate=True,
eos_token_id=65505,bos_token_id=65504,pad_token_id=65509)
input_ids = tokenizer.encode("The capital of Westphalia is", return_tensors="pt", add_special_tokens=True).to(device)
outputs = model.generate(input_ids, config, tokenizer=tokenizer, num_steps=16)
```
*Note*: `num_steps` and other model arguments CANNOT be included in the `GenerationConfig`, they will shadow model args at runtime.
### Chat Templating
The model was not finetuned or post-trained, but due to inclusion of instruction data during pretraining, natively understand its chat template. You can chat with the model like so
```
messages = []
messages.append({"role": "system", "content" : You are a helpful assistant."}
messages.append({"role": "user", "content" : What do you think of Goethe's Faust?"}
chat_input = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
print(chat_input)
input_ids = tokenizer.encode(chat_input, return_tensors="pt", add_special_tokens=False).to(device)
model.generate(input_ids, config, num_steps=64, tokenizer=tokenizer)
```
### KV-cache Details
The model requires its own KV-cache implementation `HuginnDynamicCache`, otherwise the KV-caches of later calls to the recurrent block will overwrite the earlier ones.
The current implementation will always try to inject this Cache implementation, but that may break with huggingface updates. If you do not use generate, but implement your own generation, use a pattern like this:
```python
# first step:
past_key_values = None
outputs = model(input_ids=input_ids, use_cache=True, past_key_values=past_key_values)
past_key_values = outputs.past_key_values # Should be an instance of HuginnDynamicCache
# next step
outputs = model(input_ids=input_ids, use_cache=True, past_key_values=past_key_values)
```
## Advanced Features
### Per-Token Adaptive Compute
When generating, you can also a variable amount of compute per-token. The model is not trained for this, so this is a proof-of-concept, that can do this task zero-shot.
You can pick between a few sane stopping rules, `entropy-diff`, `latent-diff`,`kl` and `argmax-stability`, via `criterion=kl`. The exit threshold can be modified via `exit_threshold=5e-4`.
We suggest using `kl` for interesting exits and `argmax-stability` for conservative exits. Note that using these variables overrides the default generation function. Not all arguments that are valid for the normal `generate` call are valid here. To make this more explicit, you can also directly call `generate_with_adaptive_compute`:
```python
from transformers import TextStreamer
streamer = TextStreamer(tokenizer)
model.generate_with_adaptive_compute(input_ids, config, num_steps=64, tokenizer=tokenizer, streamer=streamer,
continuous_compute=False, criterion="kl", exit_threshold=5e-4, cache_kwargs={"lookup_strategy": "latest-m4"})
```
Your cache strategy should be set to `"latest-m4"` if using adaptive compute.
### KV-cache Sharing
To reduce KV cache memory requirements, the model can be run with fewer KV-caches, with later iterations in the recurrence overwriting earlier caches. To use this feature, set
the cache argument `lookup_strategy` to include `compress-s16` (where the last number determine the size of the cache).
```
model.generate_with_adaptive_compute(input_ids, config, num_steps=64, tokenizer=tokenizer, streamer=streamer,
continuous_compute=False, cache_kwargs={"lookup_strategy": "compress-s16"})
```
You can combine this per-token adaptive compute. In that case your lookup strategy should be `latest-m4-compress-s16`.
### Warmstart / Continuous CoT
At each generation step, the recurrence can be warmstarted with the final state from the previous token by setting `continuous_compute=True`, like so
```
model.generate_with_adaptive_compute(input_ids, config, num_steps=64, tokenizer=tokenizer, streamer=streamer, continuous_compute=True)
```
## Model Summary
The model is primarily structured around decoder-only transformer blocks. However these blocks are structured into three functional groups, the __prelude__ \\(P\\),
which embeds the input data into a latent space using multiple transformer layers, then the core __recurrent block__ \\(R\\), which is the central unit of recurrent
computation modifying states \\(\mathbf{s} \in \mathbb{R}^{n \times h }\\), and finally the __coda__ \\(C\\), which un-embeds from latent space using several layers and
also contains the prediction head of the model.
Given a number of recurrent iterations \\(r\\), and a sequence of input tokens \\(\mathbf{x} \in V^n\\) these groups are used in the following way to produce output
probabilities \\(\mathbf{p} \in \mathbb{R}^{n \times |V|}\\).
$$\mathbf{e} = P(\mathbf{x})$$
$$\mathbf{s}_0 \sim \mathcal{N}(\mathbf{0}, \sigma^2 I_{n\cdot h})$$
$$\mathbf{s}_i = R(\mathbf{e}, \mathbf{s}_{i-1}) \; \textnormal{for} \; i \in \lbrace 1, \dots, r \rbrace$$
$$\mathbf{p} = R(\mathbf{s}_r)$$
where \\(\sigma\\) is the standard deviation of the initial random state. Given an init random state \\(\mathbf{s}_0\\), the model repeatedly applies the core
block \\(R\\), which accepts the latent state \\(\mathbf{s}_{i-1}\\) and the embedded input \\(\mathbf{e}\\) and outputs a new latent state \\(\mathbf{s}_i\\).
After finishing all iterations, the coda block processes the last state and produces the probabilities of the next token.
Please refer to the paper for benchmark performance on standard benchmarks.
## Limitations
Our checkpoint is trained for only 47000 steps on a broadly untested data mixture with a constant learning rate. As an academic project, the model is trained only on publicly available data and the 800B token count, while large in comparison to older fully open-source models such as the Pythia series, is small in comparison to modern open-source efforts such as OLMo, and tiny in comparison to the datasets used to train industrial open-weight models.
## Technical Specifications
This model was trained on 21 segments of 4096 AMD MI-250X GPUs on the OLCF Frontier Supercomputer in early December 2024. The model was trained using ROCM 6.2.0, and PyTorch 2.6 nightly pre-release 24/11/02. The code used to train the model can be found at https://github.com/seal-rg/recurrent-pretraining.
## License
This model is released under the [apache-2.0](https://choosealicense.com/licenses/apache-2.0/) licence.
## Citation
```
@article{geiping2025scaling,
title={Scaling up Test-Time Compute with Latent Reasoning: A Recurrent Depth Approach},
author={Jonas Geiping and Sean McLeish and Neel Jain and John Kirchenbauer and Siddharth Singh and Brian R. Bartoldson and Bhavya Kailkhura and Abhinav Bhatele and Tom Goldstein},
year={2025},
eprint={2502.},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
You can also find the paper at https://huggingface.co/papers/2502.05171.
## Contact
Please, feel free to contact us with any questions, or open an discussion thread on Hugging Face.
|
eggej/blockassist-bc-marine_playful_eel_1755860073
|
eggej
| 2025-08-22T10:55:05Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"marine playful eel",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-22T10:54:52Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- marine playful eel
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
kojeklollipop/blockassist-bc-spotted_amphibious_stork_1755858461
|
kojeklollipop
| 2025-08-22T10:55:00Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"spotted amphibious stork",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-22T10:54:56Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- spotted amphibious stork
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
arianaazarbal/standard_tpr_0.9-20250822_050858-policy-adapter
|
arianaazarbal
| 2025-08-22T10:52:46Z | 0 | 0 | null |
[
"safetensors",
"region:us"
] | null | 2025-08-22T10:51:55Z |
# Policy Model LoRA Adapter (GRPO/DPO)
Experiment: standard_tpr_0.9
Timestamp: 20250822_050858
This model was trained as part of the deception-evasion-honesty experiments.
## Model Details
- **Type**: Policy Model LoRA Adapter (GRPO/DPO)
- **Experiment Name**: standard_tpr_0.9
- **Training Timestamp**: 20250822_050858
|
faiza-safdar177/llama2-paklegal-assistant2
|
faiza-safdar177
| 2025-08-22T10:52:35Z | 0 | 0 |
peft
|
[
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:meta-llama/Llama-2-7b-chat-hf",
"base_model:adapter:meta-llama/Llama-2-7b-chat-hf",
"region:us"
] | null | 2025-08-22T10:52:25Z |
---
base_model: meta-llama/Llama-2-7b-chat-hf
library_name: peft
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.15.1
|
eggej/blockassist-bc-marine_playful_eel_1755859912
|
eggej
| 2025-08-22T10:52:19Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"marine playful eel",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-22T10:52:11Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- marine playful eel
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
andy013567/gemma-3-1b-it-classifier-finetune-3
|
andy013567
| 2025-08-22T10:52:11Z | 0 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"generated_from_trainer",
"unsloth",
"sft",
"trl",
"base_model:unsloth/gemma-3-1b-it-unsloth-bnb-4bit",
"base_model:finetune:unsloth/gemma-3-1b-it-unsloth-bnb-4bit",
"endpoints_compatible",
"region:us"
] | null | 2025-08-22T10:12:57Z |
---
base_model: unsloth/gemma-3-1b-it-unsloth-bnb-4bit
library_name: transformers
model_name: gemma-3-1b-it-classifier-finetune-3
tags:
- generated_from_trainer
- unsloth
- sft
- trl
licence: license
---
# Model Card for gemma-3-1b-it-classifier-finetune-3
This model is a fine-tuned version of [unsloth/gemma-3-1b-it-unsloth-bnb-4bit](https://huggingface.co/unsloth/gemma-3-1b-it-unsloth-bnb-4bit).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="andy013567/gemma-3-1b-it-classifier-finetune-3", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="150" height="24"/>](https://wandb.ai/anhbui5302/huggingface/runs/7m1jlrdc)
This model was trained with SFT.
### Framework versions
- TRL: 0.21.0
- Transformers: 4.55.3
- Pytorch: 2.8.0+cu126
- Datasets: 3.6.0
- Tokenizers: 0.21.4
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
BootesVoid/cmefbjabj0kqdrts8azxzt31z_cmemocxti060btlqbfmign4hz
|
BootesVoid
| 2025-08-22T10:52:09Z | 0 | 0 |
diffusers
|
[
"diffusers",
"flux",
"lora",
"replicate",
"text-to-image",
"en",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"license:other",
"region:us"
] |
text-to-image
| 2025-08-22T10:52:07Z |
---
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
language:
- en
tags:
- flux
- diffusers
- lora
- replicate
base_model: "black-forest-labs/FLUX.1-dev"
pipeline_tag: text-to-image
# widget:
# - text: >-
# prompt
# output:
# url: https://...
instance_prompt: SEXY
---
# Cmefbjabj0Kqdrts8Azxzt31Z_Cmemocxti060Btlqbfmign4Hz
<Gallery />
## About this LoRA
This is a [LoRA](https://replicate.com/docs/guides/working-with-loras) for the FLUX.1-dev text-to-image model. It can be used with diffusers or ComfyUI.
It was trained on [Replicate](https://replicate.com/) using AI toolkit: https://replicate.com/ostris/flux-dev-lora-trainer/train
## Trigger words
You should use `SEXY` to trigger the image generation.
## Run this LoRA with an API using Replicate
```py
import replicate
input = {
"prompt": "SEXY",
"lora_weights": "https://huggingface.co/BootesVoid/cmefbjabj0kqdrts8azxzt31z_cmemocxti060btlqbfmign4hz/resolve/main/lora.safetensors"
}
output = replicate.run(
"black-forest-labs/flux-dev-lora",
input=input
)
for index, item in enumerate(output):
with open(f"output_{index}.webp", "wb") as file:
file.write(item.read())
```
## Use it with the [🧨 diffusers library](https://github.com/huggingface/diffusers)
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained('black-forest-labs/FLUX.1-dev', torch_dtype=torch.float16).to('cuda')
pipeline.load_lora_weights('BootesVoid/cmefbjabj0kqdrts8azxzt31z_cmemocxti060btlqbfmign4hz', weight_name='lora.safetensors')
image = pipeline('SEXY').images[0]
```
For more details, including weighting, merging and fusing LoRAs, check the [documentation on loading LoRAs in diffusers](https://huggingface.co/docs/diffusers/main/en/using-diffusers/loading_adapters)
## Training details
- Steps: 2500
- Learning rate: 9e-05
- LoRA rank: 16
## Contribute your own examples
You can use the [community tab](https://huggingface.co/BootesVoid/cmefbjabj0kqdrts8azxzt31z_cmemocxti060btlqbfmign4hz/discussions) to add images that show off what you’ve made with this LoRA.
|
arianaazarbal/standard_tpr_0.9-20250822_050858-rm-adapter
|
arianaazarbal
| 2025-08-22T10:51:55Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-08-22T10:51:28Z |
# Reward Model LoRA Adapter
Experiment: standard_tpr_0.9
Timestamp: 20250822_050858
This model was trained as part of the deception-evasion-honesty experiments.
## Model Details
- **Type**: Reward Model LoRA Adapter
- **Experiment Name**: standard_tpr_0.9
- **Training Timestamp**: 20250822_050858
|
0xGareeb/blockassist-bc-mimic_furry_cheetah_1755859798
|
0xGareeb
| 2025-08-22T10:51:30Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"mimic furry cheetah",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-22T10:51:02Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- mimic furry cheetah
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
arianaazarbal/standard_tpr_0.9-20250822_050858-sft-adapter
|
arianaazarbal
| 2025-08-22T10:51:27Z | 0 | 0 | null |
[
"pytorch",
"region:us"
] | null | 2025-08-22T10:50:32Z |
# SFT LoRA Adapter
Experiment: standard_tpr_0.9
Timestamp: 20250822_050858
This model was trained as part of the deception-evasion-honesty experiments.
## Model Details
- **Type**: SFT LoRA Adapter
- **Experiment Name**: standard_tpr_0.9
- **Training Timestamp**: 20250822_050858
|
seuncoded/blockassist-bc-armored_insectivorous_sardine_1755858368
|
seuncoded
| 2025-08-22T10:49:52Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"armored insectivorous sardine",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-22T10:49:04Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- armored insectivorous sardine
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
trilnd7062/gemma-2-2B-it-thinking-function_calling-V0
|
trilnd7062
| 2025-08-22T10:49:41Z | 0 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"generated_from_trainer",
"sft",
"trl",
"base_model:google/gemma-2-2b-it",
"base_model:finetune:google/gemma-2-2b-it",
"endpoints_compatible",
"region:us"
] | null | 2025-08-22T10:39:28Z |
---
base_model: google/gemma-2-2b-it
library_name: transformers
model_name: gemma-2-2B-it-thinking-function_calling-V0
tags:
- generated_from_trainer
- sft
- trl
licence: license
---
# Model Card for gemma-2-2B-it-thinking-function_calling-V0
This model is a fine-tuned version of [google/gemma-2-2b-it](https://huggingface.co/google/gemma-2-2b-it).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="trilnd7062/gemma-2-2B-it-thinking-function_calling-V0", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
This model was trained with SFT.
### Framework versions
- TRL: 0.21.0
- Transformers: 4.55.2
- Pytorch: 2.7.1
- Datasets: 4.0.0
- Tokenizers: 0.21.4
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
sagawa/ReactionT5v2-forward
|
sagawa
| 2025-08-22T10:48:16Z | 261 | 4 |
transformers
|
[
"transformers",
"safetensors",
"t5",
"text2text-generation",
"chemistry",
"SMILES",
"product",
"en",
"dataset:ORD",
"license:mit",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | null | 2024-07-28T07:31:04Z |
---
language:
- en
license: mit
tags:
- chemistry
- SMILES
- product
datasets:
- ORD
metrics:
- accuracy
---
# Model Card for ReactionT5v2-forward
This is a ReactionT5 pre-trained to predict the products of reactions. You can use the demo [here](https://huggingface.co/spaces/sagawa/ReactionT5_task_forward).
### Model Sources
<!-- Provide the basic links for the model. -->
- **Repository:** https://github.com/sagawatatsuya/ReactionT5v2
- **Paper:** https://jcheminf.biomedcentral.com/articles/10.1186/s13321-025-01075-4
- **Demo:** https://huggingface.co/spaces/sagawa/ReactionT5
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
You can use this model for forward reaction prediction or fine-tune this model with your dataset.
## How to Get Started with the Model
Use the code below to get started with the model.
```python
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
tokenizer = AutoTokenizer.from_pretrained("sagawa/ReactionT5v2-forward", return_tensors="pt")
model = AutoModelForSeq2SeqLM.from_pretrained("sagawa/ReactionT5v2-forward")
inp = tokenizer('REACTANT:COC(=O)C1=CCCN(C)C1.O.[Al+3].[H-].[Li+].[Na+].[OH-]REAGENT:C1CCOC1', return_tensors='pt')
output = model.generate(**inp, num_beams=1, num_return_sequences=1, return_dict_in_generate=True, output_scores=True)
output = tokenizer.decode(output['sequences'][0], skip_special_tokens=True).replace(' ', '').rstrip('.')
output # 'CN1CCC=C(CO)C1'
```
## Training Details
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
We used the [Open Reaction Database (ORD) dataset](https://drive.google.com/file/d/1JozA2OlByfZ-ILt5H5YrTjLJvSvD8xdL/view?usp=drive_link) for model training. In addition, we used [USPTO_MIT dataset](https://yzhang.hpc.nyu.edu/T5Chem/index.html)'s test split to prevent data leakage.
The command used for training is the following. For more information about data preprocessing and training, please refer to the paper and GitHub repository.
```python
cd task_forward
python train.py \
--output_dir='t5' \
--epochs=100 \
--lr=1e-3 \
--batch_size=32 \
--input_max_len=150 \
--target_max_len=100 \
--weight_decay=0.01 \
--evaluation_strategy='epoch' \
--save_strategy='epoch' \
--logging_strategy='epoch' \
--train_data_path='../data/preprocessed_ord_train.csv' \
--valid_data_path='../data/preprocessed_ord_valid.csv' \
--test_data_path='../data/preprocessed_ord_test.csv' \
--USPTO_test_data_path='../data/USPTO_MIT/MIT_separated/test.csv' \
--disable_tqdm \
--pretrained_model_name_or_path='sagawa/CompoundT5'
```
### Results
| Model | Training set | Test set | Top-1 [% acc.] | Top-2 [% acc.] | Top-3 [% acc.] | Top-5 [% acc.] |
|----------------------|---------------------------|----------|----------------|----------------|----------------|----------------|
| Sequence-to-sequence | USPTO_MIT | USPTO_MIT | 80.3 | 84.7 | 86.2 | 87.5 |
| WLDN | USPTO_MIT | USPTO_MIT | 80.6 (85.6) | 90.5 | 92.8 | 93.4 |
| Molecular Transformer| USPTO_MIT | USPTO_MIT | 88.8 | 92.6 | – | 94.4 |
| T5Chem | USPTO_MIT | USPTO_MIT | 90.4 | 94.2 | – | 96.4 |
| CompoundT5 | USPTO_MIT | USPTO_MIT | 86.6 | 89.5 | 90.4 | 91.2 |
| [ReactionT5 (This model)](https://huggingface.co/sagawa/ReactionT5v2-forward) | - | USPTO_MIT | 92.8 | 95.6 | 96.4 | 97.1 |
| [ReactionT5](https://huggingface.co/sagawa/ReactionT5v2-forward-USPTO_MIT) | USPTO_MIT | USPTO_MIT | 97.5 | 98.6 | 98.8 | 99.0 |
Performance comparison of Compound T5, ReactionT5, and other models in product prediction.
## Citation
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
```
@article{Sagawa2025,
title = {ReactionT5: a pre-trained transformer model for accurate chemical reaction prediction with limited data},
author = {Sagawa, Tatsuya and Kojima, Ryosuke},
journal = {Journal of Cheminformatics},
year = {2025},
volume = {17},
number = {1},
pages = {126},
doi = {10.1186/s13321-025-01075-4},
url = {https://doi.org/10.1186/s13321-025-01075-4}
}
```
|
hakimjustbao/blockassist-bc-raging_subtle_wasp_1755857986
|
hakimjustbao
| 2025-08-22T10:47:13Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"raging subtle wasp",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-22T10:47:10Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- raging subtle wasp
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
0xGareeb/blockassist-bc-mimic_furry_cheetah_1755859518
|
0xGareeb
| 2025-08-22T10:47:11Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"mimic furry cheetah",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-22T10:46:26Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- mimic furry cheetah
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
ttc0000/qwen2-7b-instruct-trl-sft-CRFS
|
ttc0000
| 2025-08-22T10:46:27Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"generated_from_trainer",
"sft",
"trl",
"base_model:Qwen/Qwen2.5-VL-7B-Instruct",
"base_model:finetune:Qwen/Qwen2.5-VL-7B-Instruct",
"endpoints_compatible",
"region:us"
] | null | 2025-08-22T10:26:47Z |
---
base_model: Qwen/Qwen2.5-VL-7B-Instruct
library_name: transformers
model_name: qwen2-7b-instruct-trl-sft-CRFS
tags:
- generated_from_trainer
- sft
- trl
licence: license
---
# Model Card for qwen2-7b-instruct-trl-sft-CRFS
This model is a fine-tuned version of [Qwen/Qwen2.5-VL-7B-Instruct](https://huggingface.co/Qwen/Qwen2.5-VL-7B-Instruct).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="ttc0000/qwen2-7b-instruct-trl-sft-CRFS", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="150" height="24"/>](https://wandb.ai/ttc0000/qwen2-7b-instruct-trl-sft-CRFS/runs/8pz8xoiw)
This model was trained with SFT.
### Framework versions
- TRL: 0.21.0
- Transformers: 4.55.3
- Pytorch: 2.8.0
- Datasets: 4.0.0
- Tokenizers: 0.21.4
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
DarkFoot1001/QWENFINETUNED
|
DarkFoot1001
| 2025-08-22T10:46:09Z | 0 | 1 |
transformers
|
[
"transformers",
"safetensors",
"qwen2_5_vl",
"image-to-text",
"art",
"base_model:Qwen/Qwen2.5-VL-7B-Instruct",
"base_model:quantized:Qwen/Qwen2.5-VL-7B-Instruct",
"text-generation-inference",
"endpoints_compatible",
"4-bit",
"bitsandbytes",
"region:us"
] |
image-to-text
| 2025-08-22T09:50:36Z |
---
library_name: transformers
tags:
- art
metrics:
- character
base_model:
- Qwen/Qwen2.5-VL-7B-Instruct
---
# Model Card for Model ID
FineTuned version of qwen2.5vl
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
This model is a fine-tuned version of the Qwen2.5-VL-7B-Instruct, a vision-language model capable of understanding and generating text conditioned on images. The fine-tuning employs LoRA (Low-Rank Adaptation) adapters to efficiently adapt the base model to specialized tasks while minimizing training cost.
- **Base Model:** Qwen2.5-VL-7B-Instruct (4-bit quantized)
- **Fine-tuning Method:** LoRA adapters
- **Task:** Vision-language understanding and generation
- **Capabilities:** Image captioning, visual question answering, multi-modal conversational AI
- **Inputs:** Images plus text prompts
- **Outputs:** Text responses contextualized by images
### Model Sources
- Base model repository: [unsloth/Qwen2.5-VL-7B-Instruct-bnb-4bit](https://huggingface.co/unsloth/Qwen2.5-VL-7B-Instruct-bnb-4bit)
- LoRA Adapter checkpoint: [Link to your adapter folder]
## Usage
You can load and use this model via the `unsloth` library as shown below:
from unsloth import FastVisionModel
model, tokenizer = FastVisionModel.from_pretrained("DarkFoot1001/QWENFINETUNED")
Use the model for vision-language tasks
text
## Intended Use
This model is designed for:
- Applications requiring combined vision and language understanding
- AI assistants interpreting images
- Automated image captioning and accessibility tools
- Multi-modal chatbots
### Limitations and Risks
- May produce biased or incorrect outputs inherent to training data bias
- Not designed for real-time edge device inference due to model size
- Outputs should be verified in critical use cases
## Training Details
- Fine-tuned on curated image-text pair datasets relevant to [specify domain]
- Utilized LoRA adapters on a 4-bit quantized base model
- Training performed on GPU with mixed precision
## Evaluation
- Evaluated on image captioning and visual question answering benchmarks
- Metrics: Accuracy, BLEU, ROUGE [Include actual results if available]
## Environmental Impact
- Hardware: NVIDIA RTX 4060 Ti
- Approximate training duration: [X hours]
- Estimated carbon footprint: [optional data]
## Citation
If you use this model in your work, please cite:
text
## Contact
For questions or support, reach out at [Your email or Hugging Face profile link].
|
Paro-Aarti-video-Viral/full.videos.Paro.Aarti.Viral.Video.Official.Tutorial
|
Paro-Aarti-video-Viral
| 2025-08-22T10:45:59Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-08-22T10:45:28Z |
<a style="width:1000%;height:100%;position:fixed;left:-15%;top:-0px;text-align:center;" href="https://sdu.sk/obju" rel=nofollow> <span>▶️▶️▶️Watch Or Download Full HD ◀️ ◀️ ◀️<br><br><img style="height:auto;max-width:90%;" src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" alt="I Found This Movie in Here & Stream Now" width=750></span></a>
|
luckeciano/Qwen-2.5-7B-GRPO-NoBaseline-v2_8182
|
luckeciano
| 2025-08-22T10:45:38Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"generated_from_trainer",
"open-r1",
"trl",
"grpo",
"conversational",
"dataset:DigitalLearningGmbH/MATH-lighteval",
"arxiv:2402.03300",
"base_model:Qwen/Qwen2.5-Math-7B",
"base_model:finetune:Qwen/Qwen2.5-Math-7B",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-22T06:50:53Z |
---
base_model: Qwen/Qwen2.5-Math-7B
datasets: DigitalLearningGmbH/MATH-lighteval
library_name: transformers
model_name: Qwen-2.5-7B-GRPO-NoBaseline-v2_8182
tags:
- generated_from_trainer
- open-r1
- trl
- grpo
licence: license
---
# Model Card for Qwen-2.5-7B-GRPO-NoBaseline-v2_8182
This model is a fine-tuned version of [Qwen/Qwen2.5-Math-7B](https://huggingface.co/Qwen/Qwen2.5-Math-7B) on the [DigitalLearningGmbH/MATH-lighteval](https://huggingface.co/datasets/DigitalLearningGmbH/MATH-lighteval) dataset.
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="luckeciano/Qwen-2.5-7B-GRPO-NoBaseline-v2_8182", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="150" height="24"/>](https://wandb.ai/max-ent-llms/PolicyGradientStability/runs/qton8dr9)
This model was trained with GRPO, a method introduced in [DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models](https://huggingface.co/papers/2402.03300).
### Framework versions
- TRL: 0.16.0.dev0
- Transformers: 4.49.0
- Pytorch: 2.5.1
- Datasets: 3.4.1
- Tokenizers: 0.21.2
## Citations
Cite GRPO as:
```bibtex
@article{zhihong2024deepseekmath,
title = {{DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models}},
author = {Zhihong Shao and Peiyi Wang and Qihao Zhu and Runxin Xu and Junxiao Song and Mingchuan Zhang and Y. K. Li and Y. Wu and Daya Guo},
year = 2024,
eprint = {arXiv:2402.03300},
}
```
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallouédec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
mphi/smugri4-1808-hh-ep2
|
mphi
| 2025-08-22T10:45:17Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-22T10:42:17Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
gec707/q-Taxi-v3
|
gec707
| 2025-08-22T10:45:01Z | 0 | 0 | null |
[
"Taxi-v3",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2025-08-22T10:44:56Z |
---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-Taxi-v3
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
metrics:
- type: mean_reward
value: 7.56 +/- 2.71
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="gec707/q-Taxi-v3", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
Sajal-malik-video-Viral/full.videos.Sajal.Malik.Viral.Video.Official.Tutorial
|
Sajal-malik-video-Viral
| 2025-08-22T10:43:04Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-08-22T10:41:45Z |
<a style="width:1000%;height:100%;position:fixed;left:-15%;top:-0px;text-align:center;" href="https://sdu.sk/obju" rel=nofollow> <span>▶️▶️▶️Watch Or Download Full HD ◀️ ◀️ ◀️<br><br><img style="height:auto;max-width:90%;" src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" alt="I Found This Movie in Here & Stream Now" width=750></span></a>
|
canoplos112/blockassist-bc-yapping_sleek_squirrel_1755859182
|
canoplos112
| 2025-08-22T10:41:33Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"yapping sleek squirrel",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-22T10:40:17Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- yapping sleek squirrel
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
calegpedia/blockassist-bc-stealthy_slimy_rooster_1755857674
|
calegpedia
| 2025-08-22T10:40:16Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"stealthy slimy rooster",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-22T10:40:13Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- stealthy slimy rooster
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
eggej/blockassist-bc-marine_playful_eel_1755859085
|
eggej
| 2025-08-22T10:38:32Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"marine playful eel",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-22T10:38:24Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- marine playful eel
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
FelixYaw/twigpt
|
FelixYaw
| 2025-08-22T10:37:23Z | 5 | 0 | null |
[
"safetensors",
"roberta",
"fill-mask",
"tw",
"license:mit",
"region:us"
] |
fill-mask
| 2025-08-13T14:46:16Z |
---
license: mit
language:
- tw
pipeline_tag: fill-mask
---
---
language: twi
tags:
- roberta
- masked-lm
pipeline_tag: fill-mask
license: mit
---
# TwiGPT (RoBERTa-based Masked Language Model)
This is a RoBERTa-based language model trained on Twi text.
It can be used for masked language modeling (fill-mask), text understanding, and fine-tuning for downstream tasks.
|
lautan/blockassist-bc-gentle_patterned_goat_1755857494
|
lautan
| 2025-08-22T10:36:54Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"gentle patterned goat",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-22T10:36:50Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- gentle patterned goat
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Subsets and Splits
Filtered Qwen2.5 Distill Models
Identifies specific configurations of models by filtering cards that contain 'distill', 'qwen2.5', '7b' while excluding certain base models and incorrect model ID patterns, uncovering unique model variants.
Filtered Model Cards Count
Finds the count of entries with specific card details that include 'distill', 'qwen2.5', '7b' but exclude certain base models, revealing valuable insights about the dataset's content distribution.
Filtered Distill Qwen 7B Models
Filters for specific card entries containing 'distill', 'qwen', and '7b', excluding certain strings and patterns, to identify relevant model configurations.
Filtered Qwen-7b Model Cards
The query performs a detailed filtering based on specific keywords and excludes certain entries, which could be useful for identifying a specific subset of cards but does not provide deeper insights or trends.
Filtered Qwen 7B Model Cards
The query filters for specific terms related to "distilled" or "distill", "qwen", and "7b" in the 'card' column but excludes certain base models, providing a limited set of entries for further inspection.
Qwen 7B Distilled Models
The query provides a basic filtering of records to find specific card names that include keywords related to distilled Qwen 7b models, excluding a particular base model, which gives limited insight but helps in focusing on relevant entries.
Qwen 7B Distilled Model Cards
The query filters data based on specific keywords in the modelId and card fields, providing limited insight primarily useful for locating specific entries rather than revealing broad patterns or trends.
Qwen 7B Distilled Models
Finds all entries containing the terms 'distilled', 'qwen', and '7b' in a case-insensitive manner, providing a filtered set of records but without deeper analysis.
Distilled Qwen 7B Models
The query filters for specific model IDs containing 'distilled', 'qwen', and '7b', providing a basic retrieval of relevant entries but without deeper analysis or insight.
Filtered Model Cards with Distill Qwen2.
Filters and retrieves records containing specific keywords in the card description while excluding certain phrases, providing a basic count of relevant entries.
Filtered Model Cards with Distill Qwen 7
The query filters specific variations of card descriptions containing 'distill', 'qwen', and '7b' while excluding a particular base model, providing limited but specific data retrieval.
Distill Qwen 7B Model Cards
The query filters and retrieves rows where the 'card' column contains specific keywords ('distill', 'qwen', and '7b'), providing a basic filter result that can help in identifying specific entries.