
modelId
stringlengths 5
139
| author
stringlengths 2
42
| last_modified
timestamp[us, tz=UTC]date 2020-02-15 11:33:14
2025-08-29 18:27:06
| downloads
int64 0
223M
| likes
int64 0
11.7k
| library_name
stringclasses 526
values | tags
listlengths 1
4.05k
| pipeline_tag
stringclasses 55
values | createdAt
timestamp[us, tz=UTC]date 2022-03-02 23:29:04
2025-08-29 18:26:56
| card
stringlengths 11
1.01M
|
|---|---|---|---|---|---|---|---|---|---|
Guoping/ppo-LunarLander-v2
|
Guoping
| 2023-05-07T05:45:21Z | 1 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-05-07T05:44:55Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 256.95 +/- 16.88
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
hongggs/kogpt2-base-v2-finetuned-klue-ner
|
hongggs
| 2023-05-07T05:45:04Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"gpt2",
"token-classification",
"generated_from_trainer",
"dataset:klue",
"license:cc-by-nc-sa-4.0",
"model-index",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2023-05-06T15:55:35Z |
---
license: cc-by-nc-sa-4.0
tags:
- generated_from_trainer
datasets:
- klue
metrics:
- f1
model-index:
- name: kogpt2-base-v2-finetuned-klue-ner
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: klue
type: klue
config: ner
split: validation
args: ner
metrics:
- name: F1
type: f1
value: 0.4045776387287996
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# kogpt2-base-v2-finetuned-klue-ner
This model is a fine-tuned version of [skt/kogpt2-base-v2](https://huggingface.co/skt/kogpt2-base-v2) on the klue dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4255
- F1: 0.4046
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 24
- eval_batch_size: 24
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 0.6124 | 1.0 | 876 | 0.5478 | 0.2024 |
| 0.4086 | 2.0 | 1752 | 0.4947 | 0.2814 |
| 0.3159 | 3.0 | 2628 | 0.4443 | 0.3303 |
| 0.2498 | 4.0 | 3504 | 0.4168 | 0.3791 |
| 0.1998 | 5.0 | 4380 | 0.4255 | 0.4046 |
### Framework versions
- Transformers 4.28.1
- Pytorch 2.0.0+cu118
- Datasets 2.12.0
- Tokenizers 0.13.3
|
Yalina/Yalina
|
Yalina
| 2023-05-07T05:10:56Z | 0 | 0 | null |
[
"license:creativeml-openrail-m",
"region:us"
] | null | 2023-05-07T05:10:55Z |
---
license: creativeml-openrail-m
---
|
4bit/WizardLM-7B-uncensored-GPTQ
|
4bit
| 2023-05-07T04:26:36Z | 9,216 | 7 |
transformers
|
[
"transformers",
"llama",
"text-generation",
"dataset:ehartford/WizardLM_alpaca_evol_instruct_70k_unfiltered",
"license:apache-2.0",
"autotrain_compatible",
"region:us"
] |
text-generation
| 2023-05-07T04:23:50Z |
---
license: apache-2.0
datasets:
- ehartford/WizardLM_alpaca_evol_instruct_70k_unfiltered
inference: false
---
# WizardLM - uncensored: An Instruction-following LLM Using Evol-Instruct
These files are GPTQ 4bit model files for [Eric Hartford's 'uncensored' version of WizardLM](https://huggingface.co/ehartford/WizardLM-7B-Uncensored).
It is the result of quantising to 4bit using [GPTQ-for-LLaMa](https://github.com/qwopqwop200/GPTQ-for-LLaMa).
Eric did a fresh 7B training using the WizardLM method, on [a dataset edited to remove all the "I'm sorry.." type ChatGPT responses](https://huggingface.co/datasets/ehartford/WizardLM_alpaca_evol_instruct_70k_unfiltered).
## Other repositories available
* [4bit GPTQ models for GPU inference](https://huggingface.co/TheBloke/WizardLM-7B-uncensored-GPTQ)
* [4bit and 5bit GGML models for CPU inference](https://huggingface.co/TheBloke/WizardLM-7B-uncensored-GGML)
* [Eric's unquantised model in HF format](https://huggingface.co/ehartford/WizardLM-7B-Uncensored)
## How to easily download and use this model in text-generation-webui
Open the text-generation-webui UI as normal.
1. Click the **Model tab**.
2. Under **Download custom model or LoRA**, enter `TheBloke/WizardLM-7B-uncensored-GPTQ`.
3. Click **Download**.
4. Wait until it says it's finished downloading.
5. Click the **Refresh** icon next to **Model** in the top left.
6. In the **Model drop-down**: choose the model you just downloaded, `WizardLM-7B-uncensored-GPTQ`.
7. If you see an error in the bottom right, ignore it - it's temporary.
8. Fill out the `GPTQ parameters` on the right: `Bits = 4`, `Groupsize = 128`, `model_type = Llama`
9. Click **Save settings for this model** in the top right.
10. Click **Reload the Model** in the top right.
11. Once it says it's loaded, click the **Text Generation tab** and enter a prompt!
## Provided files
**Compatible file - WizardLM-7B-uncensored-GPTQ-4bit-128g.compat.no-act-order.safetensors**
In the `main` branch - the default one - you will find `WizardLM-7B-uncensored-GPTQ-4bit-128g.compat.no-act-order.safetensors`
This will work with all versions of GPTQ-for-LLaMa. It has maximum compatibility
It was created without the `--act-order` parameter. It may have slightly lower inference quality compared to the other file, but is guaranteed to work on all versions of GPTQ-for-LLaMa and text-generation-webui.
* `wizard-vicuna-13B-GPTQ-4bit.compat.no-act-order.safetensors`
* Works with all versions of GPTQ-for-LLaMa code, both Triton and CUDA branches
* Works with text-generation-webui one-click-installers
* Parameters: Groupsize = 128g. No act-order.
* Command used to create the GPTQ:
```
python llama.py models/ehartford_WizardLM-7B-Uncensored c4 --wbits 4 --true-sequential --groupsize 128 --save_safetensors /workspace/eric-gptq/WizardLM-7B-uncensored-GPTQ-4bit-128g.compat.no-act-order.safetensors
```
# Eric's original model card
This is WizardLM trained with a subset of the dataset - responses that contained alignment / moralizing were removed. The intent is to train a WizardLM that doesn't have alignment built-in, so that alignment (of any sort) can be added separately with for example with a RLHF LoRA.
Shout out to the open source AI/ML community, and everyone who helped me out, including Rohan, TheBloke, and Caseus
# WizardLM's original model card
Overview of Evol-Instruct
Evol-Instruct is a novel method using LLMs instead of humans to automatically mass-produce open-domain instructions of various difficulty levels and skills range, to improve the performance of LLMs.


|
vdo/animov-0.1.1
|
vdo
| 2023-05-07T04:22:41Z | 62 | 1 |
diffusers
|
[
"diffusers",
"anime",
"text-to-video",
"en",
"license:cc-by-nc-4.0",
"diffusers:TextToVideoSDPipeline",
"region:us"
] |
text-to-video
| 2023-05-07T02:38:36Z |
---
license: cc-by-nc-4.0
language:
- en
pipeline_tag: text-to-video
tags:
- anime
---
This is a text2video model for diffusers, fine-tuned with a [modelscope](https://huggingface.co/damo-vilab/text-to-video-ms-1.7b) to have an anime-style appearance.
It was trained at 448x384 resolution.
The usage is the same as with the original modelscope model.
The main difference from version 0.1 is only the resolution.
|
vdo/text-to-video-ms-1.7b
|
vdo
| 2023-05-07T04:14:50Z | 14 | 4 |
diffusers
|
[
"diffusers",
"safetensors",
"text-to-video",
"license:cc-by-nc-4.0",
"diffusers:TextToVideoSDPipeline",
"region:us"
] |
text-to-video
| 2023-05-07T04:06:03Z |
---
license: cc-by-nc-4.0
tags:
- text-to-video
duplicated_from: diffusers/text-to-video-ms-1.7b
---
# Text-to-video-synthesis Model in Open Domain
This model is based on a multi-stage text-to-video generation diffusion model, which inputs a description text and returns a video that matches the text description. Only English input is supported.
**We Are Hiring!** (Based in Beijing / Hangzhou, China.)
If you're looking for an exciting challenge and the opportunity to work with cutting-edge technologies in AIGC and large-scale pretraining, then we are the place for you. We are looking for talented, motivated and creative individuals to join our team. If you are interested, please send your CV to us.
EMAIL: yingya.zyy@alibaba-inc.com
## Model description
The text-to-video generation diffusion model consists of three sub-networks: text feature extraction model, text feature-to-video latent space diffusion model, and video latent space to video visual space model. The overall model parameters are about 1.7 billion. Currently, it only supports English input. The diffusion model adopts a UNet3D structure, and implements video generation through the iterative denoising process from the pure Gaussian noise video.
This model is meant for research purposes. Please look at the [model limitations and biases and misuse](#model-limitations-and-biases), [malicious use and excessive use](#misuse-malicious-use-and-excessive-use) sections.
## Model Details
- **Developed by:** [ModelScope](https://modelscope.cn/)
- **Model type:** Diffusion-based text-to-video generation model
- **Language(s):** English
- **License:**[ CC-BY-NC-ND](https://creativecommons.org/licenses/by-nc-nd/4.0/)
- **Resources for more information:** [ModelScope GitHub Repository](https://github.com/modelscope/modelscope), [Summary](https://modelscope.cn/models/damo/text-to-video-synthesis/summary).
- **Cite as:**
## Use cases
This model has a wide range of applications and can reason and generate videos based on arbitrary English text descriptions.
## Usage
Let's first install the libraries required:
```bash
$ pip install diffusers transformers accelerate
```
Now, generate a video:
```python
import torch
from diffusers import DiffusionPipeline, DPMSolverMultistepScheduler
from diffusers.utils import export_to_video
pipe = DiffusionPipeline.from_pretrained("damo-vilab/text-to-video-ms-1.7b", torch_dtype=torch.float16, variant="fp16")
pipe.scheduler = DPMSolverMultistepScheduler.from_config(pipe.scheduler.config)
pipe.enable_model_cpu_offload()
prompt = "Spiderman is surfing"
video_frames = pipe(prompt, num_inference_steps=25).frames
video_path = export_to_video(video_frames)
```
Here are some results:
<table>
<tr>
<td><center>
An astronaut riding a horse.
<br>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/astr.gif"
alt="An astronaut riding a horse."
style="width: 300px;" />
</center></td>
<td ><center>
Darth vader surfing in waves.
<br>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/vader.gif"
alt="Darth vader surfing in waves."
style="width: 300px;" />
</center></td>
</tr>
</table>
## Long Video Generation
You can optimize for memory usage by enabling attention and VAE slicing and using Torch 2.0.
This should allow you to generate videos up to 25 seconds on less than 16GB of GPU VRAM.
```bash
$ pip install git+https://github.com/huggingface/diffusers transformers accelerate
```
```py
import torch
from diffusers import DiffusionPipeline, DPMSolverMultistepScheduler
from diffusers.utils import export_to_video
# load pipeline
pipe = DiffusionPipeline.from_pretrained("damo-vilab/text-to-video-ms-1.7b", torch_dtype=torch.float16, variant="fp16")
pipe.scheduler = DPMSolverMultistepScheduler.from_config(pipe.scheduler.config)
# optimize for GPU memory
pipe.enable_model_cpu_offload()
pipe.enable_vae_slicing()
# generate
prompt = "Spiderman is surfing. Darth Vader is also surfing and following Spiderman"
video_frames = pipe(prompt, num_inference_steps=25, num_frames=200).frames
# convent to video
video_path = export_to_video(video_frames)
```
## View results
The above code will display the save path of the output video, and the current encoding format can be played with [VLC player](https://www.videolan.org/vlc/).
The output mp4 file can be viewed by [VLC media player](https://www.videolan.org/vlc/). Some other media players may not view it normally.
## Model limitations and biases
* The model is trained based on public data sets such as Webvid, and the generated results may have deviations related to the distribution of training data.
* This model cannot achieve perfect film and television quality generation.
* The model cannot generate clear text.
* The model is mainly trained with English corpus and does not support other languages at the moment**.
* The performance of this model needs to be improved on complex compositional generation tasks.
## Misuse, Malicious Use and Excessive Use
* The model was not trained to realistically represent people or events, so using it to generate such content is beyond the model's capabilities.
* It is prohibited to generate content that is demeaning or harmful to people or their environment, culture, religion, etc.
* Prohibited for pornographic, violent and bloody content generation.
* Prohibited for error and false information generation.
## Training data
The training data includes [LAION5B](https://huggingface.co/datasets/laion/laion2B-en), [ImageNet](https://www.image-net.org/), [Webvid](https://m-bain.github.io/webvid-dataset/) and other public datasets. Image and video filtering is performed after pre-training such as aesthetic score, watermark score, and deduplication.
_(Part of this model card has been taken from [here](https://huggingface.co/damo-vilab/modelscope-damo-text-to-video-synthesis))_
## Citation
```bibtex
@InProceedings{VideoFusion,
author = {Luo, Zhengxiong and Chen, Dayou and Zhang, Yingya and Huang, Yan and Wang, Liang and Shen, Yujun and Zhao, Deli and Zhou, Jingren and Tan, Tieniu},
title = {VideoFusion: Decomposed Diffusion Models for High-Quality Video Generation},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2023}
}
```
|
takeshiho0531/distilbert-base-uncased-finetuned-emotion
|
takeshiho0531
| 2023-05-07T04:02:49Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_trainer",
"dataset:emotion",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-05-07T03:39:46Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- emotion
metrics:
- accuracy
- f1
model-index:
- name: distilbert-base-uncased-finetuned-emotion
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: emotion
type: emotion
config: split
split: validation
args: split
metrics:
- name: Accuracy
type: accuracy
value: 0.9295
- name: F1
type: f1
value: 0.9295553605965364
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-emotion
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the emotion dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2124
- Accuracy: 0.9295
- F1: 0.9296
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 0.8137 | 1.0 | 250 | 0.3047 | 0.908 | 0.9041 |
| 0.2447 | 2.0 | 500 | 0.2124 | 0.9295 | 0.9296 |
### Framework versions
- Transformers 4.28.1
- Pytorch 2.0.0+cu118
- Datasets 2.12.0
- Tokenizers 0.13.3
|
ApolloFilippou/ppo-LunarLander-v2
|
ApolloFilippou
| 2023-05-07T03:32:17Z | 1 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-05-07T03:32:00Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 256.66 +/- 21.17
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
TinaLiHF/fined-tuned-T5small
|
TinaLiHF
| 2023-05-07T02:51:04Z | 8 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"t5",
"text2text-generation",
"code",
"summarization",
"en",
"dataset:multi_news",
"arxiv:1910.09700",
"license:openrail",
"model-index",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
summarization
| 2023-05-06T07:46:41Z |
---
language:
- en
license: openrail
tags:
- code
datasets:
- multi_news
metrics:
- rouge
pipeline_tag: summarization
model-index:
- name: TinaLiHF/fined-tuned-T5small
results:
- task:
type: summarization
name: summarization
dataset:
name: multi_news
type: multi_news
split: validation
metrics:
- type: rouge
value: 15.28
name: ROUGE-1
- type: rouge2
value: 15.07
name: ROUGE-2
- type: rougel
value: 1.68
name: ROUGE-L
- type: rougelsum
value: 13.46
name: ROUGE-LSUM
---
---
license: openrail
datasets:
- multi_news
language:
- en
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
This is developed for the TLDR project of ANLP.
This is fine-tuned T5 small model with the Multi_news dataset, with adam optimiser.
Aim to summarise long articles into shorten summaries
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** Li, T
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** https://huggingface.co/t5-small
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Data Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Data Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** NVIDIA GeForce RTX 3060 Laptop GPU
- **Hours used:** 3:06:45 Hr
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
medical-ner-proj/albert-medical-ner-proj
|
medical-ner-proj
| 2023-05-07T02:49:36Z | 10 | 8 |
transformers
|
[
"transformers",
"pytorch",
"albert",
"token-classification",
"ner",
"named-entity-recognition",
"en",
"license:openrail",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2023-05-05T04:54:51Z |
---
language: en
tags:
- ner
- named-entity-recognition
- token-classification
license: openrail
library_name: transformers
pipeline_tag: token-classification
---
widget:
- example_title: "Example 1" text: "John Doe has a history of hypertension, which is well-controlled with medication. He has no history of allergies or surgeries. He is not currently taking any medication except for his blood pressure medication."
- example_title: "Example 2" text: "On physical examination, John Doe appears acutely ill. He has a temperature of 38.5°C and a heart rate of 105 beats per minute. His blood pressure is 140/90 mmHg, and his oxygen saturation is 90% on room air. His lungs have diminished breath sounds and wheezing. There is no cyanosis, and his heart sounds are normal."
- example_title: "Example 3" text: "Based on Mary Smith's symptoms and physical examination, she is suspected to have suffered a stroke, likely caused by hypertension. Her history of migraines may also be a contributing factor."
|
Winnie-Kay/Finetuned_BertModel_SentimentAnalysis
|
Winnie-Kay
| 2023-05-07T02:28:07Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"text-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-04-30T19:10:58Z |
Model Description
This model is a finetuned text classification model for sentiment analysis
The model was created using the COVID19 tweet dataset and the bert-base-cased model from the hugging face library
|
mlhub/embeddings
|
mlhub
| 2023-05-07T02:24:54Z | 0 | 0 | null |
[
"license:other",
"region:us"
] | null | 2023-04-17T01:42:23Z |
---
license: other
---
### EasyNegative
#### License : other
https://huggingface.co/datasets/gsdf/EasyNegative
### bad_prompt
#### License : creativeml-openrail-m
https://huggingface.co/datasets/Nerfgun3/bad_prompt
### badhand
#### License : unknown
https://civitai.com/models/16993/badhandv4-animeillustdiffusion
### negative_hand
#### License : unknown
https://civitai.com/models/56519/negativehand-negative-embedding
### veryBadImageNegative
#### License : unknown
https://civitai.com/models/11772/verybadimagenegative
|
WALIDALI/zx
|
WALIDALI
| 2023-05-07T02:21:31Z | 1 | 0 |
diffusers
|
[
"diffusers",
"safetensors",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] |
text-to-image
| 2023-05-07T01:52:53Z |
---
license: creativeml-openrail-m
tags:
- text-to-image
- stable-diffusion
---
### zx Dreambooth model trained by WALIDALI with [TheLastBen's fast-DreamBooth](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast-DreamBooth.ipynb) notebook
Test the concept via A1111 Colab [fast-Colab-A1111](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast_stable_diffusion_AUTOMATIC1111.ipynb)
Sample pictures of this concept:
|
teknium/llama-deus-7b-v2-lora
|
teknium
| 2023-05-07T02:16:29Z | 0 | 2 | null |
[
"region:us"
] | null | 2023-05-06T06:22:23Z |
Llama DEUS 7B - V2 is a LORA (and a merged model) trained on Llama 7b. The datasets include:
GPTeacher General Instruct
GPTeacher Roleplay Instruct
GPTeacher Code-Gen Instruct
Yet To Be Released Roleplay V2 Instruct
WizardLM Uncensored
GPT4-LLM Uncensored, AlpacaGPT4 + Unnatural Instructions
Prompt Format is:
```
### Instruction:
<prompt>
### Response:
```
OR
```
### Instrutcion:
<task>
### Input:
<text to perform task with/on>
### Response:
```
(Same as Alpaca)
|
xinyixiuxiu/albert-xxlarge-v2-SST2-incremental_pre_training-epoch1
|
xinyixiuxiu
| 2023-05-07T02:16:11Z | 3 | 0 |
transformers
|
[
"transformers",
"tf",
"albert",
"text-classification",
"generated_from_keras_callback",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-05-06T15:08:36Z |
---
tags:
- generated_from_keras_callback
model-index:
- name: xinyixiuxiu/albert-xxlarge-v2-SST2-incremental_pre_training-epoch1
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# xinyixiuxiu/albert-xxlarge-v2-SST2-incremental_pre_training-epoch1
This model was trained from scratch on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.2153
- Train Accuracy: 0.9144
- Validation Loss: 0.1911
- Validation Accuracy: 0.9243
- Epoch: 0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'Adam', 'learning_rate': 3e-06, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-07, 'amsgrad': False}
- training_precision: float32
### Training results
| Train Loss | Train Accuracy | Validation Loss | Validation Accuracy | Epoch |
|:----------:|:--------------:|:---------------:|:-------------------:|:-----:|
| 0.2153 | 0.9144 | 0.1911 | 0.9243 | 0 |
### Framework versions
- Transformers 4.28.1
- TensorFlow 2.7.0
- Datasets 2.10.1
- Tokenizers 0.12.1
|
Gridflow/distilbert-base-uncased-finetuned-emotion2
|
Gridflow
| 2023-05-07T00:54:48Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"distilbert",
"text-classification",
"generated_from_trainer",
"dataset:emotion",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-05-07T00:50:31Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- emotion
metrics:
- accuracy
- f1
model-index:
- name: distilbert-base-uncased-finetuned-emotion2
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: emotion
type: emotion
config: split
split: validation
args: split
metrics:
- name: Accuracy
type: accuracy
value: 0.9275
- name: F1
type: f1
value: 0.9275719429504966
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-emotion2
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the emotion dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2226
- Accuracy: 0.9275
- F1: 0.9276
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 0.8425 | 1.0 | 250 | 0.3132 | 0.9065 | 0.9038 |
| 0.2536 | 2.0 | 500 | 0.2226 | 0.9275 | 0.9276 |
### Framework versions
- Transformers 4.28.1
- Pytorch 2.0.1+cu118
- Datasets 2.12.0
- Tokenizers 0.13.3
|
keyvenxorg/test01
|
keyvenxorg
| 2023-05-07T00:10:16Z | 0 | 0 | null |
[
"license:creativeml-openrail-m",
"region:us"
] | null | 2023-05-07T00:10:16Z |
---
license: creativeml-openrail-m
---
|
cafbr/distilbert-base-uncased-finetuned-emotion
|
cafbr
| 2023-05-06T23:59:37Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"distilbert",
"text-classification",
"generated_from_trainer",
"dataset:emotion",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-04-26T13:19:01Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- emotion
metrics:
- accuracy
- f1
model-index:
- name: distilbert-base-uncased-finetuned-emotion
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: emotion
type: emotion
config: split
split: validation
args: split
metrics:
- name: Accuracy
type: accuracy
value: 0.939
- name: F1
type: f1
value: 0.9389480299119135
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-emotion
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the emotion dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1742
- Accuracy: 0.939
- F1: 0.9389
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 0.4255 | 1.0 | 2000 | 0.2257 | 0.9245 | 0.9240 |
| 0.1494 | 2.0 | 4000 | 0.1742 | 0.939 | 0.9389 |
### Framework versions
- Transformers 4.28.1
- Pytorch 1.11.0+cu113
- Datasets 2.11.0
- Tokenizers 0.13.3
|
mg5812/whisper-tiny-zh
|
mg5812
| 2023-05-06T23:37:32Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"whisper",
"automatic-speech-recognition",
"hf-asr-leaderboard",
"generated_from_trainer",
"zh",
"dataset:mozilla-foundation/common_voice_11_0",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2023-04-30T22:04:44Z |
---
language:
- zh
license: apache-2.0
tags:
- hf-asr-leaderboard
- generated_from_trainer
datasets:
- mozilla-foundation/common_voice_11_0
metrics:
- wer
model-index:
- name: Whisper Tiny Zh - Sanchit Gandhi
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice 11.0
type: mozilla-foundation/common_voice_11_0
config: zh-CN
split: test
args: 'config: zh, split: test'
metrics:
- name: Wer
type: wer
value: 111.34001134001134
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Whisper Tiny Zh - Sanchit Gandhi
This model is a fine-tuned version of [openai/whisper-tiny](https://huggingface.co/openai/whisper-tiny) on the Common Voice 11.0 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5909
- Wer: 111.3400
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 4000
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.7098 | 0.4 | 1000 | 0.6905 | 106.4733 |
| 0.7108 | 0.81 | 2000 | 0.6273 | 106.5394 |
| 0.6124 | 1.21 | 3000 | 0.6009 | 112.0582 |
| 0.5633 | 1.61 | 4000 | 0.5909 | 111.3400 |
### Framework versions
- Transformers 4.28.1
- Pytorch 2.0.0+cu117
- Datasets 2.12.0
- Tokenizers 0.13.3
|
yatsy/q-FrozenLake-v1-4x4-noSlippery
|
yatsy
| 2023-05-06T23:33:30Z | 0 | 0 | null |
[
"FrozenLake-v1-4x4-no_slippery",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-05-06T23:33:24Z |
---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="yatsy/q-FrozenLake-v1-4x4-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
az00/none-segformer-b0-scene-parse-150-cvfinal
|
az00
| 2023-05-06T23:21:11Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"segformer",
"generated_from_trainer",
"dataset:scene_parse_150",
"license:other",
"endpoints_compatible",
"region:us"
] | null | 2023-05-06T19:59:17Z |
---
license: other
tags:
- generated_from_trainer
datasets:
- scene_parse_150
model-index:
- name: none-segformer-b0-scene-parse-150-cvfinal
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# none-segformer-b0-scene-parse-150-cvfinal
This model is a fine-tuned version of [nvidia/mit-b0](https://huggingface.co/nvidia/mit-b0) on the scene_parse_150 dataset.
It achieves the following results on the evaluation set:
- Loss: 2.7252
- Mean Iou: 0.0740
- Mean Accuracy: 0.1399
- Overall Accuracy: 0.5014
- Per Category Iou: [0.48516085209240617, 0.48972620283996443, 0.8461720523595614, 0.3492916550456616, 0.57616479445388, 0.0, 0.1380369639332496, 0.0, 0.0, 0.06175407695344529, 0.05268220495745468, 0.0, 0.46499631540162123, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, 0.0, 0.014604701379005741, nan, 0.0, 0.0, nan, 0.0, 0.0, nan, 0.0, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0]
- Per Category Accuracy: [0.9196892474715829, 0.9582061399112456, 0.933910864697729, 0.8767355657473141, 0.698410787382615, nan, 0.2478126973082325, 0.0, 0.0, 0.3181569271688962, 0.11338181432135463, 0.0, 0.792386293263607, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.018925518925518924, nan, nan, nan, nan, 0.0, 0.0, nan, 0.0, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0]
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 6e-05
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 50
### Training results
| Training Loss | Epoch | Step | Validation Loss | Mean Iou | Mean Accuracy | Overall Accuracy | Per Category Iou | Per Category Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:-------------:|:----------------:|:------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------:|:--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------:|
| 4.7335 | 1.0 | 20 | 4.8796 | 0.0116 | 0.0631 | 0.2288 | [0.26602580332229103, 0.13503996080472794, 0.5126324717493553, 0.03538599823621193, 0.0, 0.0, 0.23201003311621884, 0.0, 0.0, 0.0007549500703476202, 0.0007177646757241733, 0.0, 0.1337408194640391, 0.0, 0.0, 0.0006260434056761269, 0.0, 0.0, 0.003776113039770997, 0.0018461084034854527, 0.0, 0.0, 0.0, 0.0, 0.004682746892141129, nan, 0.0, 0.0, nan, 0.0, 0.0, nan, 0.0, 0.0, 0.037279151943462895, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, nan, 0.0, nan, 0.0, 0.0, 0.0069502929938564375, nan, 0.0, 0.0, 0.0, nan, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, 0.0, 0.0, nan, 0.0, nan, nan, nan, nan, 0.0, 0.0, 0.0004982250731768076, 0.015501624105421608, 0.0, 0.0, nan, 0.0, nan, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.0, nan, nan, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, 0.0, 0.0, nan, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, nan, 0.0, 0.0, nan, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0] | [0.4298642826228788, 0.1607421109703757, 0.637978462522657, 0.03745321713531803, 0.0, nan, 0.5172729264112773, 0.0, 0.0, 0.0008605178753031369, 0.0007431392324433356, 0.0, 0.6180416982040873, 0.0, 0.0, 0.004047976011994003, 0.0, 0.0, 0.00394896074393325, 0.004025764895330112, 0.0, nan, 0.0, nan, 0.004973036223036223, nan, nan, nan, nan, 0.0, 0.0, nan, 0.0, nan, 0.12507409602845287, nan, 0.0, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.007277621777169246, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0006330115524608325, 0.09684870483418578, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0] |
| 4.6529 | 2.0 | 40 | 4.5475 | 0.0247 | 0.1009 | 0.3676 | [0.3492776793903353, 0.3337007290250834, 0.7135686182394738, 0.30712523110007506, 0.17802442220240258, 0.0, 0.19822838291071956, 0.0, 0.0, 0.006058044519582981, 0.0, 0.0, 0.1319319517090062, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0008831521739130435, 0.0, 0.0, 0.0, nan, 0.0, 0.0, 0.0, 0.0, nan, 0.0, 0.0, 0.0, 0.0017985144961997735, 0.0, nan, nan, 0.0, 0.0, 0.000757346258709482, nan, 0.0, 0.0, nan, 0.0, nan, nan, nan, nan, nan, nan, 0.0028642717677982914, nan, nan, 0.0, 0.0, nan, 0.0, 0.0, nan, 0.0, 0.0, 0.0, 0.0, nan, 0.0, 0.0, 0.0, nan, 0.0, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.0, nan, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, 0.0, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, nan, nan, 0.0, 0.0, nan, 0.0, nan, 0.0, nan, 0.0, nan, 0.0, nan, 0.0, 0.0, 0.0, nan, nan, 0.0] | [0.6289293550463911, 0.6152304061380888, 0.8097451753918328, 0.35633958301546415, 0.194654466650614, nan, 0.7448168335330576, 0.0, 0.0, 0.006727685206915434, 0.0, 0.0, 0.8730131425032684, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.000992063492063492, nan, nan, nan, nan, 0.0, 0.0, nan, 0.0, nan, 0.0, nan, 0.0, 0.0019371181642080166, nan, nan, nan, nan, 0.0, 0.0007711289327575571, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0029890232299087977, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0] |
| 4.2773 | 3.0 | 60 | 4.0639 | 0.0440 | 0.1247 | 0.4361 | [0.4042366302315495, 0.41260752956121216, 0.6956280974529252, 0.4744124360789115, 0.5174210871265778, 0.0, 0.2321725137895724, 0.0, 0.0, 0.001339366515837104, 0.001013299556681444, 0.0, 0.1994971186483083, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.02148978246539222, 0.0, 0.0, 0.0, 0.0, 0.029444459507089987, nan, 0.0, 0.0, nan, 0.0, 0.0, nan, 0.0, nan, 0.0, 0.0, 0.0, 0.0, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 8.193214197929848e-05, nan, nan, 0.0, nan, nan, nan, 0.0, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, 0.0, nan, nan, nan, 0.0, nan, nan, 0.0, 0.0, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, 0.0, nan, nan, 0.0, 0.0, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0] | [0.7164404710381314, 0.8109822217767289, 0.8638927390979848, 0.6677855661960707, 0.5892968938117024, nan, 0.6953238754236087, 0.0, 0.0, 0.0014472346084643667, 0.0010616274749190508, 0.0, 0.8230062616115048, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.026247987117552336, 0.0, nan, 0.0, nan, 0.041437728937728936, nan, nan, nan, nan, 0.0, 0.0, nan, 0.0, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 8.354412754403471e-05, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0] |
| 4.1933 | 4.0 | 80 | 3.6891 | 0.0627 | 0.1355 | 0.4699 | [0.43517016314839757, 0.40520111317002927, 0.7840096282049769, 0.44564120150115194, 0.5733062934147058, 0.0, 0.21302609539102332, 0.0, 0.0, 0.0, 0.0, 0.0, 0.2286940122998202, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0075297225891677675, 0.0, 0.0, 0.0, 0.0, 0.043723122114094314, nan, 0.0, 0.0, nan, 0.0, 0.0, nan, 0.0, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0] | [0.8028039214419675, 0.8179622930354198, 0.8855634929096918, 0.8280993367378993, 0.7283529978328919, nan, 0.6735217184016906, 0.0, 0.0, 0.0, 0.0, 0.0, 0.894928782770247, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.009178743961352657, 0.0, nan, 0.0, nan, 0.05263024013024013, nan, nan, nan, nan, 0.0, 0.0, nan, 0.0, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0] |
| 3.521 | 5.0 | 100 | 3.5680 | 0.0617 | 0.1323 | 0.4725 | [0.47426346531460467, 0.3756216836005744, 0.7932022625900177, 0.3481105662362344, 0.5801636113930854, 0.0, 0.15677184088230717, 0.0, 0.0, 0.0, 0.008441786844882167, 0.0, 0.25353794767478555, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.031425970259972354, nan, 0.0, 0.0, nan, 0.0, 0.0, nan, 0.0, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 1.3880470640491183e-05, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0] | [0.8201394855099144, 0.9462917232392634, 0.8484913103742403, 0.9206329261616062, 0.7018540813869492, nan, 0.36339505456981974, 0.0, 0.0, 0.0, 0.01146557672912575, 0.0, 0.8983692286520333, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.04741554741554742, nan, nan, nan, nan, 0.0, 0.0, nan, 0.0, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 1.392402125733912e-05, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0] |
| 3.8066 | 6.0 | 120 | 3.3481 | 0.0658 | 0.1298 | 0.4773 | [0.4451362791719356, 0.44091462229009504, 0.8264357123511887, 0.3317407638164916, 0.59153012013538, 0.0, 0.06888716899773342, 0.0, 0.0, 0.0, 0.0, 0.0, 0.2812393731777613, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.042233144193968744, nan, 0.0, 0.0, nan, 0.0, 0.0, nan, 0.0, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0] | [0.8072330923881564, 0.9195059275931512, 0.9353795713828766, 0.9653200980084187, 0.7427883457741392, nan, 0.16056541291378354, 0.0, 0.0, 0.0, 0.0, 0.0, 0.8678352714511801, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.05235042735042735, nan, nan, nan, nan, 0.0, 0.0, nan, 0.0, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0] |
| 3.3965 | 7.0 | 140 | 3.2030 | 0.0667 | 0.1225 | 0.4655 | [0.420408008087244, 0.481311168681635, 0.7398386056180811, 0.31060386991657574, 0.5916529721214714, 0.0, 0.008396429119557989, 0.0, 0.0, 0.0, 0.0, 0.0, 0.3534511051812954, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.03080386434082219, nan, 0.0, nan, nan, 0.0, 0.0, nan, 0.0, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0] | [0.9285971133949584, 0.9141934190503094, 0.7702793474784092, 0.8965526525996463, 0.7325427401878161, nan, 0.016918576932493202, 0.0, 0.0, 0.0, 0.0, 0.0, 0.8521812426890525, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.03463319088319088, nan, nan, nan, nan, 0.0, 0.0, nan, 0.0, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0] |
| 3.6942 | 8.0 | 160 | 3.1186 | 0.0664 | 0.1250 | 0.4901 | [0.4677720939201501, 0.4484987119600654, 0.8553566495523993, 0.2849493094206236, 0.5487920811486254, 0.0, 0.0014844575679098999, 0.0, 0.0, 0.0, 0.0, 0.0, 0.3853302757039157, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0625742612828454, nan, 0.0, 0.0, nan, 0.0, 0.0, nan, 0.0, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0] | [0.9297426257641235, 0.9558505936705516, 0.9161157905960123, 0.9217637925308969, 0.6741632554779677, nan, 0.0023709201489556355, 0.0, 0.0, 0.0, 0.0, 0.0, 0.7688708456615977, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.08171805046805047, nan, nan, nan, nan, 0.0, 0.0, nan, 0.0, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0] |
| 3.5189 | 9.0 | 180 | 3.0406 | 0.0646 | 0.1276 | 0.4861 | [0.4621877645769044, 0.47665485057669216, 0.8447637704259798, 0.27353983986308267, 0.5388896405538267, 0.0, 0.01346168308641047, 0.0, 0.0, 0.0, 0.0, 0.0, 0.3231348814229249, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.041031878120599156, nan, 0.0, 0.0, nan, 0.0, 0.0, nan, 0.0, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0001856536167645216, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0] | [0.8968694352753214, 0.907942336957017, 0.925319863524896, 0.9410154461985837, 0.7192872622200819, nan, 0.02075843673895396, 0.0, 0.0, 0.0, 0.0, 0.0, 0.9000550471341086, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.048916361416361416, nan, nan, nan, nan, 0.0, 0.0, nan, 0.0, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0001856536167645216, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0] |
| 2.9829 | 10.0 | 200 | 3.1090 | 0.0661 | 0.1272 | 0.4812 | [0.5191038808054473, 0.45321063834928527, 0.8387389258379386, 0.2550185661375535, 0.5706876054609603, 0.0, 0.0, 0.0, 0.0, 0.0, 0.011067405870267704, 0.0, 0.34958018471872376, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.041148107944361696, nan, 0.0, 0.0, nan, 0.0, 0.0, nan, 0.0, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0] | [0.8900351189976337, 0.9399905231408499, 0.8827327007143618, 0.9621967527979968, 0.7166506140139658, nan, 0.0, 0.0, 0.0, 0.0, 0.028451616327830564, 0.0, 0.8594577857290305, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.062194749694749696, nan, nan, nan, nan, 0.0, 0.0, nan, 0.0, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0] |
| 2.8942 | 11.0 | 220 | 2.9804 | 0.0689 | 0.1321 | 0.4936 | [0.5088402771712589, 0.4066365442855555, 0.8731627211650969, 0.30338188655945664, 0.5316464254625052, 0.0, 0.1177612092738229, 0.0, 0.0, 0.0, 0.00910533063867701, 0.0, 0.38959143968871596, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.029298853203515534, nan, 0.0, 0.0, nan, 0.0, 0.0, nan, 0.0, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0] | [0.8906789314006042, 0.9500642421702007, 0.9169954152894765, 0.9701935935522666, 0.7573561281001685, nan, 0.2079967013284884, 0.0, 0.0, 0.0, 0.011120547799777059, 0.0, 0.7991811738801349, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.045622201872201874, nan, nan, nan, nan, 0.0, 0.0, nan, 0.0, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0] |
| 2.7201 | 12.0 | 240 | 2.8938 | 0.0689 | 0.1276 | 0.4884 | [0.49859850341662776, 0.47117914374551545, 0.8606668137094586, 0.2782023057382922, 0.5850470064324592, 0.0, 0.0003655450370231512, 0.0, 0.0, 0.0, 0.020233693867389855, 0.0, 0.3704016085427476, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.014074614865676608, nan, 0.0, 0.0, nan, 0.0, 0.0, nan, 0.0, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0] | [0.9088973151515543, 0.9603976635897249, 0.904904574048406, 0.9583733474542044, 0.7117625812665543, nan, 0.0005025319880938576, 0.0, 0.0, 0.0, 0.05069271192738468, 0.0, 0.8461088557076997, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.019370675620675622, nan, nan, nan, nan, 0.0, 0.0, nan, 0.0, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0] |
| 3.5131 | 13.0 | 260 | 2.8989 | 0.0687 | 0.1255 | 0.4861 | [0.493514093098358, 0.4578591089951369, 0.8434796025273804, 0.3360078087526457, 0.5465601579679576, 0.0, 0.011196847808241667, 0.0, 0.0, 0.0, 0.005744272281816978, 0.0, 0.3760110149488592, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.019655201132672606, nan, 0.0, 0.0, nan, 0.0, 0.0, nan, 0.0, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0] | [0.9206926474039718, 0.9389927192207106, 0.9034625226569997, 0.8990656889758479, 0.7331447146640983, nan, 0.021969667684616077, 0.0, 0.0, 0.0, 0.009209618344922767, 0.0, 0.8221117456822404, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.024013024013024013, nan, nan, nan, nan, 0.0, 0.0, nan, 0.0, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0] |
| 2.7687 | 14.0 | 280 | 2.8508 | 0.0756 | 0.1365 | 0.5063 | [0.48129422405879024, 0.45942192498346157, 0.8903460460852659, 0.40217135424355716, 0.5147232560825036, 0.0, 0.1818769738189422, 0.0, 0.0, 0.0009107783119473362, 0.020630762255025442, 0.0, 0.4228314371743324, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.027973084594153555, nan, 0.0, 0.0, nan, 0.0, 0.0, nan, 0.0, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0] | [0.9188925565381411, 0.9239345367729472, 0.9630930802857447, 0.9046482197829814, 0.6976402600529737, nan, 0.4348576803638847, 0.0, 0.0, 0.00309004146131581, 0.04347364509793514, 0.0, 0.8068361659671094, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.03532000407000407, nan, nan, nan, nan, 0.0, 0.0, nan, 0.0, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0] |
| 3.1372 | 15.0 | 300 | 2.8200 | 0.0703 | 0.1280 | 0.4870 | [0.49449563777050903, 0.4802672707435518, 0.8720511665164714, 0.2774592800349947, 0.5330857772718238, 0.0, 0.03201641586867305, 0.0, 0.0, 0.0, 0.023100078878318123, 0.0, 0.4300235829877206, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.02029611861287454, nan, 0.0, 0.0, nan, 0.0, 0.0, nan, 0.0, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0] | [0.8903021181212736, 0.920562961882979, 0.9285824714788357, 0.9677792836051302, 0.7103660004815796, nan, 0.07539268364967078, 0.0, 0.0, 0.0, 0.038085885662720954, 0.0, 0.8186885020298631, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.024966931216931217, nan, nan, nan, nan, 0.0, 0.0, nan, 0.0, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0] |
| 2.486 | 16.0 | 320 | 2.7598 | 0.0789 | 0.1432 | 0.5142 | [0.4991798514691637, 0.43418590272907964, 0.86210232576229, 0.4136572394475814, 0.5251975880164801, 0.0, 0.35446049906302396, 0.0, 0.0, 0.0, 0.03666287722199256, 0.0, 0.4233234225305583, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.0, nan, 0.0, 0.0, nan, 0.0, 0.0, nan, 0.0, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0] | [0.9154172614933433, 0.9534950474298576, 0.9453619788890073, 0.9158940575664832, 0.6952323621478449, nan, 0.7409383174198204, 0.0, 0.0, 0.0, 0.07532246934550667, 0.0, 0.7715027867611642, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, 0.0, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0] |
| 2.7467 | 17.0 | 340 | 2.7457 | 0.0695 | 0.1255 | 0.4912 | [0.4558465734083546, 0.47018152124441115, 0.8197800939182224, 0.3284440295543021, 0.5600445316848798, 0.0, 0.0521584075176449, 0.0, 0.0, 0.00041090773253642135, 0.0, 0.0, 0.44074943276431233, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.0, nan, 0.0, 0.0, nan, 0.0, 0.0, nan, 0.0, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0] | [0.9343332881157398, 0.9601744106578216, 0.915769271777375, 0.8905034150369326, 0.6904406453166386, nan, 0.09912765601041143, 0.0, 0.0, 0.0012907768129547055, 0.0, 0.0, 0.7785901052776439, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, 0.0, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0] |
| 2.2817 | 18.0 | 360 | 2.8545 | 0.0718 | 0.1363 | 0.4842 | [0.5250536482085539, 0.45146468669356504, 0.8169652139242147, 0.31774934039309877, 0.5361035118830144, 0.0, 0.023971370437490595, 0.0, 0.0, 0.0, 0.1170712306271169, 0.0, 0.4165009201256576, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.02620465995508268, nan, 0.0, 0.0, nan, 0.0, 0.0, nan, 0.0, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0] | [0.8671743956453304, 0.9477360330232092, 0.890249493549419, 0.9522612839820856, 0.7243077293522755, nan, 0.04721223600963831, 0.0, 0.0, 0.0, 0.484367535431817, 0.0, 0.7708835065024428, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.038436100936100934, nan, nan, nan, nan, 0.0, 0.0, nan, 0.0, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0] |
| 2.942 | 19.0 | 380 | 2.7746 | 0.0731 | 0.1391 | 0.4996 | [0.47438098986192484, 0.46805161724419664, 0.8401448805276246, 0.3948473962651032, 0.5195866943099121, 0.0, 0.1753525864646666, 0.0, 0.0, 0.004733862429232695, 0.0070794392523364485, 0.0, 0.379712404037255, 0.0, 0.0, 0.0, 0.0, 0.025598219254312743, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.00010164874260505397, nan, 0.0, 0.0, nan, 0.0, 0.0, nan, 0.0, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0] | [0.9213902902754182, 0.8874304043156158, 0.9527748160784731, 0.8848849837101392, 0.7452684806164218, nan, 0.36271212648343576, 0.0, 0.0, 0.021160916842681687, 0.00804182812251181, 0.0, 0.8380754145737288, 0.0, 0.0, 0.0, 0.0, 0.2222222222222222, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.00012718762718762718, nan, nan, nan, nan, 0.0, 0.0, nan, 0.0, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0] |
| 1.9623 | 20.0 | 400 | 2.7914 | 0.0767 | 0.1374 | 0.5068 | [0.4780680704589745, 0.47719941783806225, 0.8714037920928285, 0.3540430160558594, 0.569819461565992, 0.0, 0.2643097199341021, 0.0, 0.0, 0.004042103722942139, 0.01566662062705945, 0.0, 0.417884019477645, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.0, nan, 0.0, 0.0, nan, 0.0, 0.0, nan, 0.0, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0] | [0.9222817228333775, 0.9530986595711721, 0.9320183388420941, 0.9406564410019835, 0.6900674211413436, nan, 0.516821936165552, 0.0, 0.0, 0.01728858640381757, 0.02107330537714316, 0.0, 0.7794674189774995, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, 0.0, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0] |
| 2.3827 | 21.0 | 420 | 2.7929 | 0.0736 | 0.1346 | 0.4898 | [0.4991783960640681, 0.4633859904157219, 0.8432330912135406, 0.28499998671601223, 0.5906476321044318, 0.0, 0.10364698859993662, 0.0, 0.0, 0.0, 0.09607177161416816, 0.0, 0.4256818538666864, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.003464260055703727, nan, 0.0, 0.0, nan, 0.0, 0.0, nan, 0.0, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0] | [0.8856662381761377, 0.9600012757310394, 0.893978569143832, 0.9627801362424722, 0.715795810257645, nan, 0.18123365160359245, 0.0, 0.0, 0.0, 0.2574977440416158, 0.0, 0.7928335512282392, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.004477004477004477, nan, nan, nan, nan, 0.0, 0.0, nan, 0.0, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0] |
| 2.1266 | 22.0 | 440 | 2.7964 | 0.0733 | 0.1336 | 0.4945 | [0.479201681139934, 0.46803094759478286, 0.8226404746106327, 0.3305701897826291, 0.5371052834092911, 0.0, 0.17402634630669603, 0.0, 0.0, 0.0, 0.06292154139160569, 0.0, 0.4987350838079176, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.0, nan, 0.0, 0.0, nan, 0.0, 0.0, nan, 0.0, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0] | [0.9270317233716822, 0.9122980472202732, 0.8955698901801897, 0.9162620378929985, 0.756260534553335, nan, 0.34419575553751597, 0.0, 0.0, 0.0, 0.11661977811985774, 0.0, 0.7426890525012042, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, 0.0, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0] |
| 1.9058 | 23.0 | 460 | 2.7332 | 0.0786 | 0.1430 | 0.5117 | [0.46751417639424964, 0.47414191147296786, 0.8678990374310945, 0.4613486768056043, 0.5347419596110695, 0.0, 0.3287688404715714, 0.0, 0.0, 0.002630568035675513, 0.059173180940731256, 0.0, 0.4186963040101983, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.0, nan, 0.0, 0.0, nan, 0.0, 0.0, nan, 0.0, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0] | [0.9005794311626735, 0.9310512935001504, 0.960627465614671, 0.9196995126504456, 0.6886106429087406, nan, 0.7096911361088561, 0.0, 0.0, 0.012321051396385825, 0.08216996655873454, 0.0, 0.8022947774031515, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, 0.0, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0] |
| 2.006 | 24.0 | 480 | 2.7379 | 0.0834 | 0.1462 | 0.5161 | [0.5059332832593822, 0.48382921889690655, 0.8841889209221592, 0.4198028943618153, 0.5703533575931118, 0.0, 0.36924429160758854, 0.0, 0.0, 0.004732153653915917, 0.057609931995837464, 0.0, 0.45736494668177025, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.0018850845021790457, nan, 0.0, 0.0, nan, 0.0, 0.0, nan, 0.0, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0] | [0.9079305199377289, 0.9589487976234953, 0.9450234566584924, 0.9385742108617022, 0.6906453166385745, nan, 0.7415954746350201, 0.0, 0.0, 0.022960181491042793, 0.12636021020224003, 0.0, 0.805683616596711, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.0025691900691900693, nan, nan, nan, nan, 0.0, 0.0, nan, 0.0, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0] |
| 1.7623 | 25.0 | 500 | 2.7353 | 0.0736 | 0.1312 | 0.4958 | [0.47366980226061, 0.48251607670604874, 0.8670598230796142, 0.30190292486058545, 0.5787168756008273, 0.0, 0.1184128306602791, 0.0, 0.0, 0.0028823771628333013, 0.038949751018560436, 0.0, 0.44208272948575866, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.005849476368766618, nan, 0.0, 0.0, nan, 0.0, 0.0, nan, 0.0, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0] | [0.9165024837378155, 0.951412872126188, 0.9248853822369123, 0.928540015616726, 0.7175294967493379, nan, 0.190459623487572, 0.0, 0.0, 0.013416255964953454, 0.057089017463771964, 0.0, 0.8028624509736462, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.006855413105413106, nan, nan, nan, nan, 0.0, 0.0, nan, 0.0, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0] |
| 1.7663 | 26.0 | 520 | 2.7150 | 0.0742 | 0.1345 | 0.5018 | [0.48013744627507166, 0.4815673027261687, 0.8818191133871689, 0.3468069385556645, 0.5659960371894528, 0.0, 0.1638641429184871, 0.0, 0.0, 0.0019665355642957136, 0.048896398774949834, 0.0, 0.4406706348086923, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.00192766955460124, nan, 0.0, 0.0, nan, 0.0, 0.0, nan, 0.0, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0] | [0.9236748553575312, 0.9431023956406448, 0.9404574048406014, 0.9015069243127294, 0.7153383096556706, nan, 0.30977875707088276, 0.0, 0.0, 0.009231009935070015, 0.09830670417750412, 0.0, 0.806165279020161, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.0022893772893772895, nan, nan, nan, nan, 0.0, 0.0, nan, 0.0, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0] |
| 1.9199 | 27.0 | 540 | 2.7413 | 0.0745 | 0.1350 | 0.4968 | [0.49510488371335354, 0.46754934683141397, 0.849462043859321, 0.33122249686501287, 0.5753252737986685, 0.0, 0.1391476574238492, 0.0, 0.0, 0.017918746022708244, 0.055636638828076436, 0.0, 0.41275063903556486, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.009935347189246447, nan, 0.0, 0.0, nan, 0.0, 0.0, nan, 0.0, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0] | [0.9162096459893071, 0.9637419013859907, 0.9080952127092441, 0.9032121989965805, 0.7064531663857453, nan, 0.26252786475446804, 0.0, 0.0, 0.08370492059766878, 0.10926800785604332, 0.0, 0.8027592375971926, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.013838013838013839, nan, nan, nan, nan, 0.0, 0.0, nan, 0.0, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0] |
| 1.794 | 28.0 | 560 | 2.7492 | 0.0784 | 0.1431 | 0.5087 | [0.49827306897444046, 0.4712267062537749, 0.8527258988446009, 0.38926715642358, 0.5746564006620134, 0.0, 0.3509618812657759, 0.0, 0.0, 0.0041067235859124866, 0.0436436932761334, 0.0, 0.4018405165537335, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.019541860184850424, nan, 0.0, 0.0, nan, 0.0, 0.0, nan, 0.0, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0] | [0.9079865036249437, 0.9704394893430897, 0.9114297899562853, 0.9359265475367756, 0.6730315434625572, nan, 0.6342340252812246, 0.0, 0.0, 0.018814049910036768, 0.10746324114868093, 0.0, 0.8232642950526389, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.02681115181115181, nan, nan, nan, nan, 0.0, 0.0, nan, 0.0, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0] |
| 2.4253 | 29.0 | 580 | 2.7020 | 0.0760 | 0.1352 | 0.5020 | [0.5031510311231457, 0.4877849933934947, 0.8587502163752813, 0.3660408701006716, 0.5600148244955283, 0.0, 0.1667567620375014, 0.0, 0.0, 0.0016477245326088704, 0.04485047749319211, 0.0, 0.426326759660093, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.005379764495786595, nan, 0.0, 0.0, nan, 0.0, 0.0, nan, 0.0, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0] | [0.9178331729185373, 0.948651825662241, 0.9388820769804883, 0.9176531830298243, 0.6913074885624849, nan, 0.3299186929014135, 0.0, 0.0, 0.00801846201987014, 0.09485641488401719, 0.0, 0.8233331039702746, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.006130443630443631, nan, nan, nan, nan, 0.0, 0.0, nan, 0.0, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0] |
| 2.3029 | 30.0 | 600 | 2.7116 | 0.0759 | 0.1348 | 0.5018 | [0.49563397328545666, 0.46367195231916253, 0.8560654148152961, 0.36008673749995623, 0.5725128547973218, 0.0, 0.19332219059308975, 0.0, 0.0, 0.0022978129744368305, 0.021612771182971755, 0.0, 0.4503470471906627, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.002150631543323763, nan, 0.0, 0.0, nan, 0.0, 0.0, nan, 0.0, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0] | [0.9284851460205288, 0.9605662423342233, 0.913098411344493, 0.9225536039634173, 0.7010835540573079, nan, 0.3815377478835672, 0.0, 0.0, 0.010952045685676289, 0.04204044800679441, 0.0, 0.799146769421317, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.0025055962555962557, nan, nan, nan, nan, 0.0, 0.0, nan, 0.0, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0] |
| 2.2664 | 31.0 | 620 | 2.7345 | 0.0757 | 0.1423 | 0.5086 | [0.5038067007994251, 0.47491069334439895, 0.8677876544299113, 0.38322480318787056, 0.5636300805984409, 0.0, 0.26721591887967316, 0.0, 0.0, 0.023486980302009432, 0.05034503768261831, 0.0, 0.4216559817450831, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, 0.0, 0.0012768303653475977, nan, 0.0, 0.0, nan, 0.0, 0.0, nan, 0.0, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0] | [0.905785914073653, 0.9594545338569905, 0.9438266339695064, 0.9201123686265359, 0.6676498916445943, nan, 0.5596015823314907, 0.0, 0.0, 0.11589611202378158, 0.1008811508041828, 0.0, 0.8010390146562995, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.001678876678876679, nan, nan, nan, nan, 0.0, 0.0, nan, 0.0, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0] |
| 1.8158 | 32.0 | 640 | 2.7678 | 0.0730 | 0.1411 | 0.5014 | [0.49905246546841314, 0.462109144067159, 0.8336621630930006, 0.3613004300113773, 0.5967025403579026, 0.0, 0.20601669089379662, 0.0, 0.0, 0.04176613817881872, 0.06829472018288126, 0.0, 0.4274557934451566, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, 0.0, 0.0072899703036689335, nan, 0.0, 0.0, nan, 0.0, 0.0, nan, 0.0, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0] | [0.915193326744484, 0.9793832751660728, 0.9032865977183069, 0.8921009881618036, 0.6888875511678305, nan, 0.35976136173283335, 0.0, 0.0, 0.20597668778846906, 0.16492382822867455, 0.0, 0.8088144223491365, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.009678978428978429, nan, nan, nan, nan, 0.0, 0.0, nan, 0.0, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0] |
| 1.7327 | 33.0 | 660 | 2.7381 | 0.0804 | 0.1475 | 0.5128 | [0.498424444150801, 0.48720218166484014, 0.8630049768653525, 0.3974616262893528, 0.574922619408873, 0.0, 0.3285919648936975, 0.0, 0.0, 0.038542149097674124, 0.06470739565595561, 0.0, 0.4200233222656424, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, 0.0, 0.02335147511083947, nan, 0.0, 0.0, nan, 0.0, 0.0, nan, 0.0, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0] | [0.9015246941891086, 0.9580512297135984, 0.9466094466361019, 0.915436325940818, 0.68430050565856, nan, 0.6155759145437911, 0.0, 0.0, 0.1920519439881092, 0.14018790806306067, 0.0, 0.811687194660428, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.030614061864061865, nan, nan, nan, nan, 0.0, 0.0, nan, 0.0, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0] |
| 1.7564 | 34.0 | 680 | 2.7376 | 0.0788 | 0.1413 | 0.5038 | [0.48152886069362916, 0.48194988038387154, 0.8785999592777584, 0.3634575819920126, 0.5734061468122936, 0.0, 0.2063981324219105, 0.0, 0.0, 0.03960991466883381, 0.05569229071243309, 0.0, 0.44068977691886013, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.026782822721678864, nan, 0.0, 0.0, nan, 0.0, 0.0, nan, 0.0, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0] | [0.9126353028825139, 0.9582608140986505, 0.9316611579059602, 0.8625458853516904, 0.7066578377076812, nan, 0.3805069130361952, 0.0, 0.0, 0.19064382382852227, 0.13392430596103827, 0.0, 0.8159189430950251, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.042073667073667075, nan, nan, nan, nan, 0.0, 0.0, nan, 0.0, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0] |
| 1.7323 | 35.0 | 700 | 2.6776 | 0.0782 | 0.1375 | 0.5030 | [0.4757392220257697, 0.5041899980691253, 0.8771835367312755, 0.3387514369271945, 0.5695425546901729, 0.0, 0.20578442209700468, 0.0, 0.0, 0.03306012389907801, 0.03178429534395786, 0.0, 0.46818443502381324, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.016566547356582435, nan, 0.0, 0.0, nan, 0.0, 0.0, nan, 0.0, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0] | [0.9229384545487822, 0.9517682543443198, 0.9380317731101396, 0.8701478203897002, 0.6814351071514568, nan, 0.3934052340639375, 0.0, 0.0, 0.1692873347414535, 0.05669090716067732, 0.0, 0.7694213170026836, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.023606023606023607, nan, nan, nan, nan, 0.0, 0.0, nan, 0.0, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0] |
| 1.7502 | 36.0 | 720 | 2.6911 | 0.0786 | 0.1456 | 0.5125 | [0.4949791385929085, 0.4935428587482792, 0.8824374046486584, 0.3756147258437639, 0.5756830996096574, 0.0, 0.3131360704412819, 0.0, 0.0, 0.0461541901773269, 0.03627418092362742, 0.0, 0.4571003127016429, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.017569593581587585, nan, 0.0, 0.0, nan, 0.0, 0.0, nan, 0.0, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0] | [0.920632357279279, 0.9604614501416973, 0.9435654120908412, 0.8801909907645913, 0.671177462075608, nan, 0.5911322432254822, 0.0, 0.0, 0.24219666744895565, 0.08609798821593503, 0.0, 0.7920938553636552, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.027574277574277575, nan, nan, nan, nan, 0.0, 0.0, nan, 0.0, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0] |
| 1.8968 | 37.0 | 740 | 2.7568 | 0.0790 | 0.1435 | 0.5039 | [0.5159331555248942, 0.47422794208749053, 0.8698409286328461, 0.35261114702415314, 0.5870581913708008, 0.0, 0.19183575662322835, 0.0, 0.0, 0.04157999129214842, 0.06774659603344863, 0.0, 0.42975392505285887, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.02222145810588933, nan, 0.0, 0.0, nan, 0.0, 0.0, nan, 0.0, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0] | [0.9017701611253582, 0.9591447134616962, 0.9276015566691544, 0.9154901767203081, 0.7102937635444257, nan, 0.3507286713827361, 0.0, 0.0, 0.2017132128608308, 0.20534529433621743, 0.0, 0.8216644877176082, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.03287800162800163, nan, nan, nan, nan, 0.0, 0.0, nan, 0.0, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0] |
| 1.9333 | 38.0 | 760 | 2.7121 | 0.0743 | 0.1358 | 0.5002 | [0.492245796660384, 0.4990214787841022, 0.8774645689187481, 0.314980744912293, 0.5762447101593342, 0.0, 0.12077603743611492, 0.0, 0.0, 0.019930932412432167, 0.06163556675327402, 0.0, 0.43879118066474093, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.01638768993227357, nan, 0.0, 0.0, nan, 0.0, 0.0, nan, 0.0, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0] | [0.9194373208791161, 0.9340629299897031, 0.9441491630237765, 0.8875146967752359, 0.7328076089573802, nan, 0.21650108881930755, 0.0, 0.0, 0.09481342407885474, 0.12466160624236955, 0.0, 0.8257414160875249, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.02375864875864876, nan, nan, nan, nan, 0.0, 0.0, nan, 0.0, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0] |
| 1.5571 | 39.0 | 780 | 2.7319 | 0.0761 | 0.1369 | 0.4975 | [0.4956006371814093, 0.49073904702941273, 0.8705636277573597, 0.32531316601780225, 0.5835368808282982, 0.0, 0.0970667263770712, 0.0, 0.0, 0.0384180054882865, 0.06949698752977441, 0.0, 0.4282930071311814, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.024329781671985143, nan, 0.0, 0.0, nan, 0.0, 0.0, nan, 0.0, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0] | [0.9110785257341938, 0.953417592331034, 0.9363524896044354, 0.8617022231396799, 0.7104382374187335, nan, 0.16757508987591327, 0.0, 0.0, 0.18454196980364546, 0.171134348956951, 0.0, 0.8203227138237116, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.03432794057794058, nan, nan, nan, nan, 0.0, 0.0, nan, 0.0, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0] |
| 2.3024 | 40.0 | 800 | 2.7409 | 0.0760 | 0.1362 | 0.4977 | [0.49284739640115016, 0.48300367276956246, 0.8672200718415108, 0.30880525610377874, 0.5877539279479448, 0.0, 0.10099623612024188, 0.0, 0.0, 0.03730625591049704, 0.05611049582552394, 0.0, 0.4764464313562406, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.008334900043867895, nan, 0.0, 0.0, nan, 0.0, 0.0, nan, 0.0, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0] | [0.9130487208804081, 0.9574908192926983, 0.9292541848811174, 0.9078074655130633, 0.7133999518420419, nan, 0.1801383895782597, 0.0, 0.0, 0.1820777595243683, 0.139842879133712, 0.0, 0.7883265671230991, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.01014957264957265, nan, nan, nan, nan, 0.0, 0.0, nan, 0.0, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0] |
| 1.4036 | 41.0 | 820 | 2.7064 | 0.0749 | 0.1394 | 0.5031 | [0.487813536469504, 0.4977033867197311, 0.8680892671981715, 0.36664962378474075, 0.574401991146239, 0.0, 0.16103436579250163, 0.0, 0.0, 0.03611544700517247, 0.0583637967981848, 0.0, 0.44931401338275645, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.0198205917325313, nan, 0.0, 0.0, nan, 0.0, 0.0, nan, 0.0, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0] | [0.9231537764226855, 0.9389972754029943, 0.9394898176777908, 0.8624471589226254, 0.7279677341680713, nan, 0.31198216655714045, 0.0, 0.0, 0.18462019870140028, 0.13517171824406815, 0.0, 0.8027936420560104, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.028833435083435083, nan, nan, nan, nan, 0.0, 0.0, nan, 0.0, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0] |
| 1.6131 | 42.0 | 840 | 2.7351 | 0.0734 | 0.1381 | 0.4979 | [0.49334335533986007, 0.49400814454667413, 0.8362092623940197, 0.3448456821647818, 0.5752572249962172, 0.0, 0.13234821504699315, 0.0, 0.0, 0.030827873734365695, 0.07199641568825678, 0.0, 0.44997403995923313, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.020278572517646216, nan, 0.0, 0.0, nan, 0.0, 0.0, nan, 0.0, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0] | [0.9129647453495858, 0.9462416052341422, 0.9177684188079752, 0.8787639451081054, 0.7323621478449314, nan, 0.26001520481399876, 0.0, 0.0, 0.15184229054212625, 0.1663304846329423, 0.0, 0.8050643363379894, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.028757122507122507, nan, nan, nan, nan, 0.0, 0.0, nan, 0.0, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0] |
| 1.7673 | 43.0 | 860 | 2.7602 | 0.0714 | 0.1356 | 0.4952 | [0.48490060195255197, 0.4836128787948758, 0.8416006538413178, 0.31311144666218327, 0.5821942927375631, 0.0, 0.0927357815020289, 0.0, 0.0, 0.04086304030691609, 0.06653045024915845, 0.0, 0.4366934956768567, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, 0.0, 0.015767551654681505, nan, 0.0, 0.0, nan, 0.0, 0.0, nan, 0.0, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0] | [0.9081932126238909, 0.9542695984180936, 0.9277348331378612, 0.8858812231307048, 0.7071634962677582, nan, 0.16520416972695762, 0.0, 0.0, 0.19831025580849565, 0.12012314878709061, 0.0, 0.8045310672263125, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.022003459503459503, nan, nan, nan, nan, 0.0, 0.0, nan, 0.0, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0] |
| 1.8284 | 44.0 | 880 | 2.7654 | 0.0770 | 0.1383 | 0.5009 | [0.4780241229841424, 0.4724772691732011, 0.8381134265670269, 0.3534298932331826, 0.5830118145652999, 0.0, 0.17914432925175744, 0.0, 0.0, 0.041721021986063825, 0.05542343387470998, 0.0, 0.4516751688956294, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.009997096279089061, nan, 0.0, 0.0, nan, 0.0, 0.0, nan, 0.0, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0] | [0.917542488388768, 0.9636097720997622, 0.9276282119628958, 0.8598174458575288, 0.7022393450517698, nan, 0.33198036259615754, 0.0, 0.0, 0.20515528436204333, 0.10143850522851532, 0.0, 0.7889630496112296, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.012260887260887261, nan, nan, nan, nan, 0.0, 0.0, nan, 0.0, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0] |
| 1.1011 | 45.0 | 900 | 2.7155 | 0.0732 | 0.1372 | 0.5007 | [0.48112157935578315, 0.495839975851107, 0.8487809920832402, 0.35658660696861805, 0.5784769179607591, 0.0, 0.14736378137855763, 0.0, 0.0, 0.040067667779013716, 0.04977255272641342, 0.0, 0.4330156098908689, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.009026960118346769, nan, 0.0, 0.0, nan, 0.0, 0.0, nan, 0.0, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0] | [0.9171592154532202, 0.9579555498856398, 0.9410731421260262, 0.8691964566187096, 0.6911148567300747, nan, 0.2714059298774595, 0.0, 0.0, 0.20288664632715325, 0.08944211476193004, 0.0, 0.8088316245785454, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.011408730158730158, nan, nan, nan, nan, 0.0, 0.0, nan, 0.0, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0] |
| 1.5308 | 46.0 | 920 | 2.6937 | 0.0738 | 0.1383 | 0.5013 | [0.4953031030805177, 0.5002398948802333, 0.8605114604295915, 0.35049047282992235, 0.5731179721745759, 0.0, 0.14307669738101392, 0.0, 0.0, 0.034703365901583544, 0.05438552713661884, 0.0, 0.43572962659120446, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.019763843572076327, nan, 0.0, 0.0, nan, 0.0, 0.0, nan, 0.0, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0] | [0.9169977240477929, 0.9453258125951103, 0.935766073142126, 0.8914906793275833, 0.7240910185408139, nan, 0.2639066063628281, 0.0, 0.0, 0.1754674176640851, 0.11569085407930357, 0.0, 0.813166586389596, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.026887464387464387, nan, nan, nan, nan, 0.0, 0.0, nan, 0.0, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0] |
| 1.5236 | 47.0 | 940 | 2.7221 | 0.0744 | 0.1374 | 0.4998 | [0.4853331033355728, 0.4881399840401541, 0.8612525489635242, 0.34798312549520677, 0.5828029640354316, 0.0, 0.12786962717921832, 0.0, 0.0, 0.04893190972839659, 0.0414194771772992, 0.0, 0.42564837625979846, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.012037018368046454, nan, 0.0, 0.0, nan, 0.0, 0.0, nan, 0.0, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0] | [0.9208455259344431, 0.9615367091606601, 0.9310347585030387, 0.8750751667130382, 0.697869010353961, nan, 0.2231370881492649, 0.0, 0.0, 0.24755534694516154, 0.08116142045756145, 0.0, 0.8173295259065575, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.015186202686202686, nan, nan, nan, nan, 0.0, 0.0, nan, 0.0, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0] |
| 1.5259 | 48.0 | 960 | 2.7320 | 0.0732 | 0.1398 | 0.5027 | [0.4915774800410124, 0.484385784287873, 0.8490741123114034, 0.3691998017154617, 0.5805358086483146, 0.0, 0.15945474283044536, 0.0, 0.0, 0.047071452843594576, 0.05466317870290361, 0.0, 0.459717537309698, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, 0.0, 0.018597060525841376, nan, 0.0, 0.0, nan, 0.0, 0.0, nan, 0.0, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0] | [0.9187870488199285, 0.9624707265288269, 0.9316798166115791, 0.8823629722040226, 0.7010113171201541, nan, 0.2990451892226217, 0.0, 0.0, 0.23840256590784636, 0.12256489197940443, 0.0, 0.7900811945228101, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.02492877492877493, nan, nan, nan, nan, 0.0, 0.0, nan, 0.0, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0] |
| 1.7699 | 49.0 | 980 | 2.7197 | 0.0747 | 0.1422 | 0.5033 | [0.4841676024546001, 0.49158091455389386, 0.8513176846120908, 0.369239589780196, 0.5759422141418112, 0.0, 0.16500976017847183, 0.0, 0.0, 0.06872859974770229, 0.050253203803224476, 0.0, 0.4431469485168769, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.012676627344731092, nan, 0.0, 0.0, nan, 0.0, 0.0, nan, 0.0, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0] | [0.91909495909961, 0.9563791108154654, 0.9327007143618723, 0.8728044588445417, 0.7055742836503732, nan, 0.3049853750306029, 0.0, 0.0, 0.3580145505749824, 0.1032432719358777, 0.0, 0.804909516273309, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.016305453805453805, nan, nan, nan, nan, 0.0, 0.0, nan, 0.0, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0] |
| 1.0884 | 50.0 | 1000 | 2.7252 | 0.0740 | 0.1399 | 0.5014 | [0.48516085209240617, 0.48972620283996443, 0.8461720523595614, 0.3492916550456616, 0.57616479445388, 0.0, 0.1380369639332496, 0.0, 0.0, 0.06175407695344529, 0.05268220495745468, 0.0, 0.46499631540162123, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, 0.0, 0.014604701379005741, nan, 0.0, 0.0, nan, 0.0, 0.0, nan, 0.0, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0] | [0.9196892474715829, 0.9582061399112456, 0.933910864697729, 0.8767355657473141, 0.698410787382615, nan, 0.2478126973082325, 0.0, 0.0, 0.3181569271688962, 0.11338181432135463, 0.0, 0.792386293263607, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.018925518925518924, nan, nan, nan, nan, 0.0, 0.0, nan, 0.0, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0] |
### Framework versions
- Transformers 4.28.1
- Pytorch 2.0.0+cu118
- Datasets 2.12.0
- Tokenizers 0.13.3
|
Avrik/abstract-anim-spritesheets
|
Avrik
| 2023-05-06T23:03:12Z | 23 | 26 |
diffusers
|
[
"diffusers",
"stable-diffusion",
"text-to-image",
"image-to-image",
"en",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] |
text-to-image
| 2022-11-21T20:16:51Z |
---
language:
- en
license: creativeml-openrail-m
thumbnail: "https://huggingface.co/Avrik/abstract-anim-spritesheets/resolve/main/AnimationGrid.gif"
tags:
- stable-diffusion
- text-to-image
- image-to-image
---
# Abstract Animation Sprite Sheets
An experimental Dreambooth model trained on individual frames of looping 3D animations that were then laid out on a 4x4 grid. Generates sprite sheets that can create very interesting abstract animations.
Use the token **AbstrAnm spritesheet**. Size must be set at 512x512 or your outputs may not work properly.
**Example prompt:** <i>AbstrAnm spritesheet, animation of a red glowing orb in the sky, highly detailed, fog, atmosphere, glow, sprites, animated, abstract</i>
<br>
**Negative prompt:** <i>high contrast, text, overlay</i>
<br>
Steps: 30, Sampler: DPM++ 2M Karras, CFG scale: 8
Feel free to experiment with other types of prompts and/or model merges.

You can also upscale it 4x to produce 512x512 animations. Used SD Upscale from AUTOMATIC1111's web UI to add more sharpness and detail.

Discovered it's actually quite flexible and could even animate less abstract concepts.

**Prompt 1:** <i>AbstrAnm spritesheet, animation of magical swirling clouds in the clear blue sky, floating in crystal clear water, circular, sunny, timelapse, lens flare, nature, 35mm lens shot, photorealistic, sprites, animated, art by Greg Rutkowski</i>
<br>
**Negative prompt:** <i>text, overlay, abstract, boring, empty, barren, simple background</i>
<br>
Steps: 25, Sampler: DPM++ 2S a, CFG scale: 10
**Prompt 2:** <i>AbstrAnm spritesheet, animation of a beautiful flower blowing in the wind, serene, pink, sunny, timelapse, lens flare, nature, 35mm lens shot, photorealistic, sprites, animated, art by Greg Rutkowski</i>
**Negative prompt:** <i>text, overlay, abstract, boring, empty, barren, simple background</i>
<br>
Steps: 25, Sampler: DPM++ 2S a, CFG scale: 10
Some issues with this model:
- May not loop seamlessly
- Tends to be too noisy
- Sprites aren't usually perfect squares
- Small size and short animation (could experiment with training on larger resolutions in the future)
|
Dingaling01/food_entity_extractor
|
Dingaling01
| 2023-05-06T22:56:34Z | 0 | 1 |
spacy
|
[
"spacy",
"food",
"license:mit",
"region:us"
] | null | 2023-05-06T22:54:15Z |
---
license: mit
library_name: spacy
tags:
- food
---
# Food NER
Github Repo: <a href=https://github.com/randymi01/food_ner> https://github.com/randymi01/food_ner</a>
Spacy Food Name Entity Recognition (NER) model trained on StanfordNLP CRF recipe dataset
## Installation
Use the package manager [pip](https://pip.pypa.io/en/stable/) to install spacy version spacy==3.5.0 and then download the spacy en_core_web_sm model.
```bash
pip install spacy==3.5.0
python -m spacy download en_core_web_sm
```
## Usage
```python
import spacy
nlp = spacy.load("model")
# returns (spring mix, chicken breast, chili, hamburger meat)
nlp("I have spring mix, chicken breast, chili, and hamburger meat").ents
```
## Model Hyperparameters
* Epochs: 10
* Batch Size: 4-32
* Optimizer: Adam
* lr = 5e-03
* drop_rate = 0.5
## Model Performance
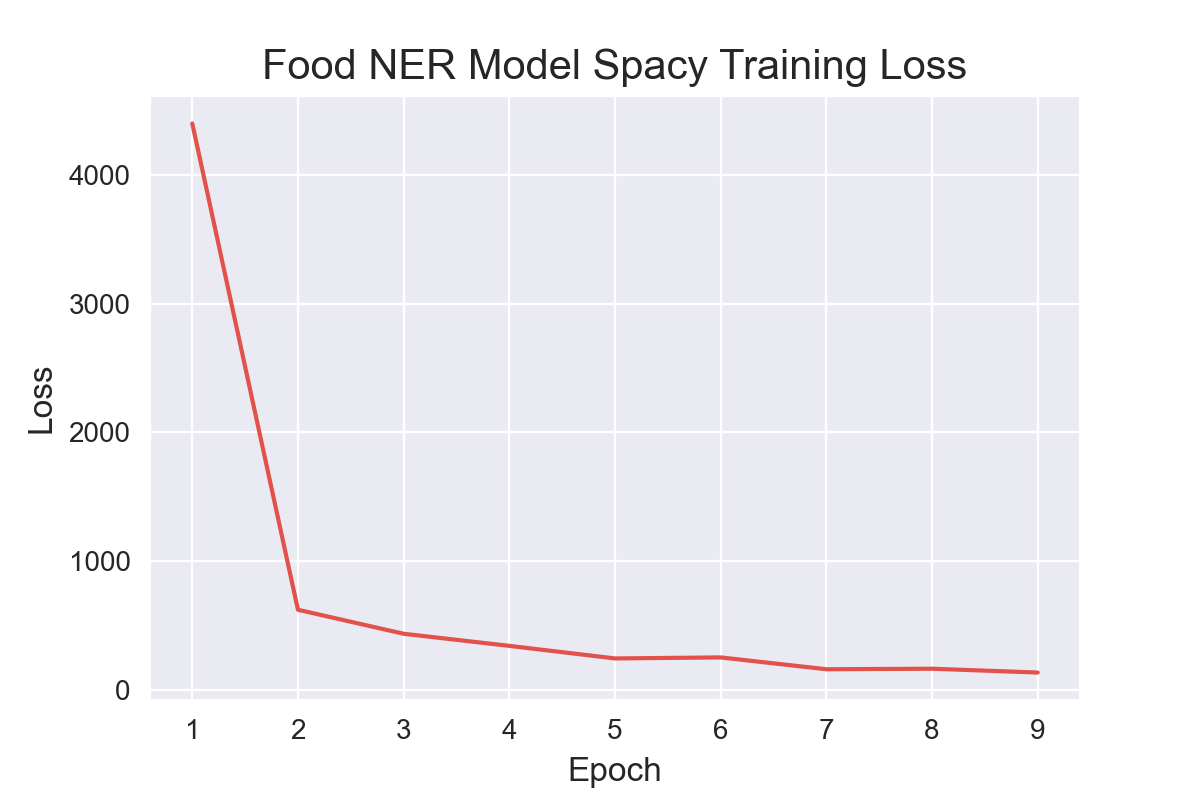
## License
[MIT](https://choosealicense.com/licenses/mit/)
|
LyaaaaaGames/GPT-Neo-2.7B-Horni
|
LyaaaaaGames
| 2023-05-06T22:52:32Z | 80 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt_neo",
"text-generation",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-05-06T20:52:59Z |
Sharded version of the original https://huggingface.co/KoboldAI/GPT-Neo-2.7B-Horni
|
samni/mt5_xlsum_arabic
|
samni
| 2023-05-06T22:43:01Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"mt5",
"text2text-generation",
"generated_from_trainer",
"dataset:xlsum",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2023-05-06T18:48:07Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- xlsum
model-index:
- name: mt5_xlsum_arabic
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mt5_xlsum_arabic
This model is a fine-tuned version of [google/mt5-small](https://huggingface.co/google/mt5-small) on the xlsum dataset.
It achieves the following results on the evaluation set:
- Loss: nan
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 0.0 | 1.0 | 3752 | nan |
### Framework versions
- Transformers 4.28.1
- Pytorch 2.0.0+cu118
- Datasets 2.12.0
- Tokenizers 0.13.3
|
wooii/PPO-LunarLander-v2
|
wooii
| 2023-05-06T22:33:52Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-05-06T22:33:30Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 260.69 +/- 10.01
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
LyaaaaaGames/gpt-neo-1.3B
|
LyaaaaaGames
| 2023-05-06T22:07:53Z | 13 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt_neo",
"text-generation",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-05-06T20:50:07Z |
Sharded version of the original https://huggingface.co/EleutherAI/gpt-neo-1.3B
|
LyaaaaaGames/GPT-Neo-2.7B-Horni-LN
|
LyaaaaaGames
| 2023-05-06T21:55:26Z | 30 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt_neo",
"text-generation",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-05-06T20:54:29Z |
Sharded version of the original https://huggingface.co/KoboldAI/GPT-Neo-2.7B-Horni-LN
|
tarek23/flan-t5-qg-test-LQ-v1
|
tarek23
| 2023-05-06T21:54:24Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"t5",
"text2text-generation",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2023-05-06T00:37:49Z |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- rouge
model-index:
- name: flan-t5-qg-test-LQ-v1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# flan-t5-qg-test-LQ-v1
This model is a fine-tuned version of [google/flan-t5-small](https://huggingface.co/google/flan-t5-small) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 2.3976
- Rouge1: 23.3283
- Rouge2: 6.3111
- Rougel: 21.0183
- Rougelsum: 21.0191
- Gen Len: 16.2723
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:-----:|:---------------:|:-------:|:------:|:-------:|:---------:|:-------:|
| 2.4384 | 1.0 | 23583 | 2.4275 | 23.1862 | 6.2062 | 20.8927 | 20.887 | 16.0677 |
| 2.3878 | 2.0 | 47166 | 2.3976 | 23.3283 | 6.3111 | 21.0183 | 21.0191 | 16.2723 |
### Framework versions
- Transformers 4.28.1
- Pytorch 2.0.0
- Datasets 2.1.0
- Tokenizers 0.13.3
|
GreyModel/SlateModel
|
GreyModel
| 2023-05-06T21:53:18Z | 0 | 3 | null |
[
"region:us"
] | null | 2023-01-17T03:56:57Z |
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Slate Model - HuggingFace Repository</title>
<style>
body {
font-family: 'Segoe UI', Tahoma, Geneva, Verdana, sans-serif;
background-color: #1d1d1d;
color: #f0f0f0;
margin: 0;
padding: 1rem;
}
h1 {
text-align: center;
font-size: 3rem;
margin-bottom: 1rem;
color: #e91e63;
}
h2 {
font-size: 2rem;
margin-top: 2em;
color: #ffc107;
}
ul {
list-style-type: none;
padding-left: 1.5em;
}
li {
margin-bottom: 0.5em;
font-size: 1.2rem;
}
p {
font-size: 1.2rem;
line-height: 1.5;
}
a {
color: #03a9f4;
text-decoration: none;
}
a:hover {
text-decoration: underline;
}
b {
font-weight: bold;
}
i {
font-style: italic;
}
</style>
</head>
<body>
<h1>Slate Model</h1>
<p>
Welcome to the HuggingFace repository for the Slate Model! This is a general model trained on various styles and optimized for multi-resolution tasks, ranging between 768x and 1.5k.
</p>
<h2>About the Model</h2>
<ul>
<li><strong>Model Name:</strong> Slate Model</li>
<li><strong>Resolution:</strong> Multi-resolution (optimal between 768x and 1.5k)</li>
<li><strong>Training Styles:</strong> General model trained in many styles</li>
<li><strong>Training Dataset:</strong> Custom merge of stable diffusion 2.1 (768x)</li>
<li><strong>Language:</strong> English</li>
<li><strong>Tags:</strong> stable-diffusion, text-to-image</li>
<li><strong>License:</strong> openrail</li>
</ul>
<h2>Versions</h2>
<p>
The Slate Model is available in three different versions, each with unique training characteristics:
</p>
<ul>
<li>Pure Release</li>
<li>Better3D (Trained a little heavier on 3D, resulted in more simplistic anime)</li>
<li>Platinum Mix (A custom mix I was playing with)</li>
</ul>
<p>
<b>Important:</b> Whether choosing the ckpt or safetensors version, you will require the YAML inference file for webui use. To avoid generating black images, you must use either the <i>--no-half</i> switch in webui startup or the <i>--xformers</i> switch (xformers should be much faster).
</p>
<h2>The GreyModel Project</h2>
<p>
<p>
SlateModel is part of the GreyModel project, which is built upon Stable Diffusion 2.1 768x.
The GreyModel is a community-driven project aimed at creating a Stable Diffusion model that embraces both the light and dark aspects of humanity.
</p>
<p>
The model is powered by the community's efforts to gather, caption, and enhance data.
Join the community by participating in the Discord server: <a href="https://discord.gg/mhvucN4cDq">https://discord.gg/mhvucN4cDq</a>.
</p>
<h2>Getting Started</h2>
<p>
To use the Slate Model in your project, simply follow the instructions provided in the HuggingFace <a href="https://huggingface.co/transformers/quickstart.html">Quick Start guide</a>.
</p>
</body>
</html>
|
timopixel/bert-base-multilingual-cased-finetuned-squad
|
timopixel
| 2023-05-06T21:40:48Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"question-answering",
"generated_from_trainer",
"dataset:squad",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2023-03-05T16:08:08Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- squad
model-index:
- name: bert-base-multilingual-cased-finetuned-squad
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-multilingual-cased-finetuned-squad
This model is a fine-tuned version of [bert-base-multilingual-cased](https://huggingface.co/bert-base-multilingual-cased) on the squad dataset.
It achieves the following results on the evaluation set:
- Loss: 4.8209
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| No log | 1.0 | 8 | 5.2028 |
| No log | 2.0 | 16 | 4.9060 |
| No log | 3.0 | 24 | 4.8209 |
### Framework versions
- Transformers 4.28.1
- Pytorch 2.0.0+cu118
- Datasets 2.12.0
- Tokenizers 0.13.3
|
parallelq/ppo-Huggy
|
parallelq
| 2023-05-06T20:46:12Z | 1 | 0 |
ml-agents
|
[
"ml-agents",
"tensorboard",
"onnx",
"Huggy",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-Huggy",
"region:us"
] |
reinforcement-learning
| 2023-05-06T20:46:05Z |
---
library_name: ml-agents
tags:
- Huggy
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-Huggy
---
# **ppo** Agent playing **Huggy**
This is a trained model of a **ppo** agent playing **Huggy** using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://github.com/huggingface/ml-agents#get-started
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
### Resume the training
```
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser:**.
1. Go to https://huggingface.co/spaces/unity/ML-Agents-Huggy
2. Step 1: Find your model_id: parallelq/ppo-Huggy
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
lrthomps/q-FrozenLake-v1-4x4-noSlippery
|
lrthomps
| 2023-05-06T20:24:27Z | 0 | 0 | null |
[
"FrozenLake-v1-4x4-no_slippery",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-05-06T20:24:25Z |
---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="lrthomps/q-FrozenLake-v1-4x4-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
njvdnbus/personalised_opener-t5-3b
|
njvdnbus
| 2023-05-06T20:09:21Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"t5",
"text2text-generation",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2023-05-06T17:58:47Z |
---
language:
- en
metrics:
- rouge
---
# Personalised opener
This model creates an opener based on a provided interest.
### Model input
> [INTEREST]
### Example
> dancing
### Output
> What's your favorite dance move to make people laugh or cry?
### How to use in code
```{python}
import nltk
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
tokenizer = AutoTokenizer.from_pretrained("njvdnbus/personalised_opener-t5-large")
model = AutoModelForSeq2SeqLM.from_pretrained("njvdnbus/personalised_opener-t5-large")
def use_model(text):
inputs = ["" + text]
inputs = tokenizer(inputs, truncation=True, return_tensors="pt")
output = model.generate(**inputs, num_beams=1, do_sample=True, min_length=10, max_length=256)
decoded_output = tokenizer.batch_decode(output, skip_special_tokens=True)[0]
predicted_interests = nltk.sent_tokenize(decoded_output.strip())[0]
return predicted_interests
text= "tennis"
print(use_model(text))
```
> Do you think tennis is the most exciting sport out there?
>
> ## Smaller model
> Fine-tuned T5-large version can be found [here](https://huggingface.co/njvdnbus/personalised_opener-t5-large).
|
jikkyjohn/roberta-base-finetuned-NQ
|
jikkyjohn
| 2023-05-06T19:52:25Z | 3 | 0 |
transformers
|
[
"transformers",
"tf",
"roberta",
"question-answering",
"generated_from_keras_callback",
"license:mit",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2023-05-06T13:07:06Z |
---
license: mit
tags:
- generated_from_keras_callback
model-index:
- name: jikkyjohn/roberta-base-finetuned-NQ
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# jikkyjohn/roberta-base-finetuned-NQ
This model is a fine-tuned version of [roberta-base](https://huggingface.co/roberta-base) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.6847
- Train End Logits Accuracy: 0.8001
- Train Start Logits Accuracy: 0.7764
- Validation Loss: 0.6973
- Validation End Logits Accuracy: 0.8017
- Validation Start Logits Accuracy: 0.7821
- Epoch: 1
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'Adam', 'weight_decay': None, 'clipnorm': None, 'global_clipnorm': None, 'clipvalue': None, 'use_ema': False, 'ema_momentum': 0.99, 'ema_overwrite_frequency': None, 'jit_compile': True, 'is_legacy_optimizer': False, 'learning_rate': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 2e-05, 'decay_steps': 18550, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}}, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False}
- training_precision: float32
### Training results
| Train Loss | Train End Logits Accuracy | Train Start Logits Accuracy | Validation Loss | Validation End Logits Accuracy | Validation Start Logits Accuracy | Epoch |
|:----------:|:-------------------------:|:---------------------------:|:---------------:|:------------------------------:|:--------------------------------:|:-----:|
| 1.0229 | 0.7188 | 0.6971 | 0.7360 | 0.7886 | 0.7681 | 0 |
| 0.6847 | 0.8001 | 0.7764 | 0.6973 | 0.8017 | 0.7821 | 1 |
### Framework versions
- Transformers 4.28.1
- TensorFlow 2.12.0
- Datasets 2.12.0
- Tokenizers 0.13.3
|
mHossain/bangla-para-v2-270000
|
mHossain
| 2023-05-06T19:52:13Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"mt5",
"text2text-generation",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2023-05-06T19:00:40Z |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- rouge
model-index:
- name: bangla-para-v2-270000
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bangla-para-v2-270000
This model is a fine-tuned version of [mHossain/bangla-para-v2-240000](https://huggingface.co/mHossain/bangla-para-v2-240000) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.8960
- Rouge1: 0.0
- Rouge2: 0.0
- Rougel: 0.0
- Rougelsum: 0.0
- Gen Len: 17.51
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 5000
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:------:|:------:|:------:|:---------:|:-------:|
| 1.1072 | 1.0 | 3375 | 0.8960 | 0.0 | 0.0 | 0.0 | 0.0 | 17.51 |
### Framework versions
- Transformers 4.28.1
- Pytorch 2.0.0+cu118
- Datasets 2.12.0
- Tokenizers 0.13.3
|
agnesemi/sentiment-emotions
|
agnesemi
| 2023-05-06T19:38:30Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"roberta",
"text-classification",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-05-06T18:39:27Z |
---
tags:
- generated_from_trainer
metrics:
- accuracy
- f1
model-index:
- name: sentiment-emotions
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# sentiment-emotions
This model is a fine-tuned version of [j-hartmann/emotion-english-distilroberta-base](https://huggingface.co/j-hartmann/emotion-english-distilroberta-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.0709
- Accuracy: 0.7855
- F1: 0.7855
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 4
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| No log | 1.0 | 207 | 0.7734 | 0.7855 | 0.7855 |
| No log | 2.0 | 414 | 1.2495 | 0.7506 | 0.7506 |
| 0.1096 | 3.0 | 621 | 1.0536 | 0.7843 | 0.7843 |
| 0.1096 | 4.0 | 828 | 1.0709 | 0.7855 | 0.7855 |
### Framework versions
- Transformers 4.28.1
- Pytorch 2.0.0+cu118
- Datasets 2.12.0
- Tokenizers 0.13.3
|
Aeala/GPT4-x-Alpasta-13b
|
Aeala
| 2023-05-06T19:26:28Z | 1,532 | 3 |
transformers
|
[
"transformers",
"pytorch",
"llama",
"text-generation",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-05-06T16:51:34Z |
## Pasta with a small twist!
Untested but fresh as of 5/6/2023, taste and hopefully enjoy! ^~^
## Model Info:
ChanSung's [AlpacaGPT4-LoRA-13B-elina](https://huggingface.co/LLMs/AlpacaGPT4-LoRA-13B-elina) merged with [dvruette's llama-13b sft do2 finetune](https://huggingface.co/dvruette/llama-13b-pretrained-sft-do2)
|
puffy310/TempoModelCard
|
puffy310
| 2023-05-06T19:21:06Z | 0 | 1 | null |
[
"text-to-video",
"en",
"dataset:TempoFunk/tempofunk-sdance",
"arxiv:1910.09700",
"license:creativeml-openrail-m",
"region:us"
] |
text-to-video
| 2023-05-06T19:18:45Z |
---
license: creativeml-openrail-m
datasets:
- TempoFunk/tempofunk-sdance
language:
- en
pipeline_tag: text-to-video
---
# Model Card for TempoFunk
<!-- Provide a quick summary of what the model is/does. [Optional] -->
A community produced Text-To-Video model using Temporal Attention
# Table of Contents
- [Model Card for TempoFunk](#model-card-for--model_id-)
- [Table of Contents](#table-of-contents)
- [Table of Contents](#table-of-contents-1)
- [Model Details](#model-details)
- [Model Description](#model-description)
- [Uses](#uses)
- [Direct Use](#direct-use)
- [Downstream Use [Optional]](#downstream-use-optional)
- [Out-of-Scope Use](#out-of-scope-use)
- [Bias, Risks, and Limitations](#bias-risks-and-limitations)
- [Recommendations](#recommendations)
- [Training Details](#training-details)
- [Training Data](#training-data)
- [Environmental Impact](#environmental-impact)
- [Technical Specifications [optional]](#technical-specifications-optional)
- [Model Architecture and Objective](#model-architecture-and-objective)
- [Compute Infrastructure](#compute-infrastructure)
- [Hardware](#hardware)
- [Software](#software)
- [Model Card Authors [optional]](#model-card-authors-optional)
- [How to Get Started with the Model](#how-to-get-started-with-the-model)
# Model Details
## Model Description
<!-- Provide a longer summary of what this model is/does. -->
A community produced Text-To-Video model using Temporal Attention
- **Developed by:** Lopho, Chavez, Davut Emre, Julian Herrera
- **Shared by [Optional]:** More information needed
- **Model type:** Text-To-Video
- **Language(s) (NLP):** en
- **License:** creativeml-openrail-m
- **Resources for more information:** More information needed
- [GitHub Repo](https://github.com/lopho/makeavid-sd-tpu)
# Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
The TempoFunk model is meant to be used as a Video Production Program.
## Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
<!-- If the user enters content, print that. If not, but they enter a task in the list, use that. If neither, say "more info needed." -->
Produce Generative Video
## Downstream Use [Optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
<!-- If the user enters content, print that. If not, but they enter a task in the list, use that. If neither, say "more info needed." -->
Meme production
Visualization
Personalized Text-To-Video
## Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
<!-- If the user enters content, print that. If not, but they enter a task in the list, use that. If neither, say "more info needed." -->
Produce Disinformation
Produce Gore
# Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
During usage of TempoFunk, it may generate obscene or otherwise unpleasant to look imagery. This is because of both the VAE and the low amount of samples seen by the TempoFunk model. Video generated by TempoFunk may be uncanny.
## Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Use superres or other methods to clean up visuals before publishing or using.
# Training Details
## Training Data
<!-- This should link to a Data Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
TempoFunk was trained on movement data from dancing videos. These dancing videos were scrapped and encoded into Stable Diffusion Vae Latents. More information forthcoming.
<!-- ## Training Procedure -->
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
## Results
[https://huggingface.co/spaces/TempoFunk/makeavid-sd-jax]
# Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** More information needed
- **Hours used:** More information needed
- **Cloud Provider:** More information needed
- **Compute Region:** More information needed
- **Carbon Emitted:** More information needed
# Technical Specifications [optional]
## Model Architecture and Objective
The temporal layers are a port of Make-A-Video PyTorch to FLAX.
The convolution is pseudo 3D and seperately convolves accross the spatial dimension in 2D and over the temporal dimension in 1D.
Temporal attention is purely self attention and also separately attends to time.
Only the new temporal layers have been fine tuned on a dataset of videos themed around dance.
The model has been trained for 80 epochs on a dataset of 18,000 Videos with 120 frames each, randomly selecting a 24 frame range from each sample.
## Compute Infrastructure
TPU_V4
### Hardware
TPU_V4
### Software
Google JAX
Google FLAX
# Model Card Authors [optional]
<!-- This section provides another layer of transparency and accountability. Whose views is this model card representing? How many voices were included in its construction? Etc. -->
Lopho, Chavez, Davut Emre, Julian Herrera
# How to Get Started with the Model
Use the space below to get started!
[https://huggingface.co/spaces/TempoFunk/makeavid-sd-jax]
|
AzzamRadman/ppo-Huggy
|
AzzamRadman
| 2023-05-06T19:18:55Z | 0 | 0 |
ml-agents
|
[
"ml-agents",
"tensorboard",
"onnx",
"Huggy",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-Huggy",
"region:us"
] |
reinforcement-learning
| 2023-05-06T19:18:47Z |
---
library_name: ml-agents
tags:
- Huggy
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-Huggy
---
# **ppo** Agent playing **Huggy**
This is a trained model of a **ppo** agent playing **Huggy** using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://github.com/huggingface/ml-agents#get-started
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
### Resume the training
```
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser:**.
1. Go to https://huggingface.co/spaces/unity/ML-Agents-Huggy
2. Step 1: Find your model_id: AzzamRadman/ppo-Huggy
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
JustSaga/finetuning-sentiment-model-10000-samples
|
JustSaga
| 2023-05-06T19:04:16Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_trainer",
"dataset:imdb",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-05-06T18:47:08Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- imdb
metrics:
- accuracy
- f1
model-index:
- name: finetuning-sentiment-model-10000-samples
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: imdb
type: imdb
config: plain_text
split: test
args: plain_text
metrics:
- name: Accuracy
type: accuracy
value: 0.908
- name: F1
type: f1
value: 0.9072580645161291
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# finetuning-sentiment-model-10000-samples
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the imdb dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2391
- Accuracy: 0.908
- F1: 0.9073
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
### Framework versions
- Transformers 4.28.1
- Pytorch 2.0.0+cu118
- Datasets 2.12.0
- Tokenizers 0.13.3
|
Elise-hf/distilbert-base-pwc-multi-task
|
Elise-hf
| 2023-05-06T18:57:35Z | 10 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"pytorch",
"distilbert",
"feature-extraction",
"sentence-similarity",
"transformers",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2023-05-06T18:57:28Z |
---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
---
# Elise-hf/distilbert-base-pwc-multi-task
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
<!--- Describe your model here -->
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('Elise-hf/distilbert-base-pwc-multi-task')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('Elise-hf/distilbert-base-pwc-multi-task')
model = AutoModel.from_pretrained('Elise-hf/distilbert-base-pwc-multi-task')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, mean pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
<!--- Describe how your model was evaluated -->
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=Elise-hf/distilbert-base-pwc-multi-task)
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 512, 'do_lower_case': False}) with Transformer model: DistilBertModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Citing & Authors
<!--- Describe where people can find more information -->
|
cansurav/bert-base-uncased-finetuned-best
|
cansurav
| 2023-05-06T18:36:13Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"text-classification",
"generated_from_trainer",
"dataset:glue",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-05-06T17:27:00Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- glue
metrics:
- matthews_correlation
model-index:
- name: bert-base-uncased-finetuned-best
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: glue
type: glue
config: cola
split: validation
args: cola
metrics:
- name: Matthews Correlation
type: matthews_correlation
value: 0.6093514522222457
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-uncased-finetuned-best
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on the glue dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4101
- Matthews Correlation: 0.6094
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2.9901559201237305e-05
- train_batch_size: 32
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Matthews Correlation |
|:-------------:|:-----:|:----:|:---------------:|:--------------------:|
| No log | 1.0 | 268 | 0.4389 | 0.5041 |
| 0.3831 | 2.0 | 536 | 0.4101 | 0.6094 |
| 0.3831 | 3.0 | 804 | 0.5908 | 0.5854 |
| 0.1334 | 4.0 | 1072 | 0.7048 | 0.6012 |
| 0.1334 | 5.0 | 1340 | 0.7637 | 0.5809 |
### Framework versions
- Transformers 4.28.1
- Pytorch 2.0.0+cu118
- Datasets 2.12.0
- Tokenizers 0.13.3
|
hjdut/LunarLander
|
hjdut
| 2023-05-06T18:12:36Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-05-06T18:11:08Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 257.07 +/- 28.98
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
ShabGaming/Brain_MRI_Tumor_Classification
|
ShabGaming
| 2023-05-06T17:59:21Z | 0 | 2 |
tensorflowtts
|
[
"tensorflowtts",
"biology",
"medical",
"en",
"license:mit",
"region:us"
] | null | 2023-05-06T17:41:27Z |
---
license: mit
language:
- en
library_name: tensorflowtts
tags:
- biology
- medical
---
# Brain Tumor Classification (MRI) | AI Model
This is a deep learning model that can classify MRI images of the brain into four categories: glioma tumor, meningioma tumor, no tumor, and pituitary tumor. The model was trained on the Images Dataset "Brain Tumor Classification (MRI)" From Kaggle by SARTAJ under the CC0: Public Domain License.
Source Files: https://github.com/ShabGaming/Brain-Tumor-Classification-AI-Model
## Model
The model is a convolutional neural network (CNN) with the following architecture:
```
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 1248, 1248, 32) 896
_________________________________________________________________
max_pooling2d (MaxPooling2D) (None, 624, 624, 32) 0
_________________________________________________________________
conv2d_1 (Conv2D) (None, 622, 622, 64) 18496
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 311, 311, 64) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 309, 309, 128) 73856
_________________________________________________________________
max_pooling2d_2 (MaxPooling2 (None, 154, 154, 128) 0
_________________________________________________________________
flatten (Flatten) (None, 307328) 0
_________________________________________________________________
dense (Dense) (None, 128) 39338112
_________________________________________________________________
dropout (Dropout) (None, 128) 0
_________________________________________________________________
dense_1 (Dense) (None, 4) 516
=================================================================
Total params: 39,436,876
Trainable params: 39,436,876
Non-trainable params: 0
```
The model was trained using TensorFlow and achieved an accuracy of over 95% on the validation set.
## GUI
In addition to the model, we have also provided a graphical user interface (GUI) that allows users to upload an MRI image and get a prediction from the model. The GUI was built using the Tkinter library in Python.
To use the GUI, simply run the gui.py file and a window will appear. Click the "Choose File" button to select an MRI image from your computer, and then click the "Predict" button to get the model's prediction. The GUI will display the selected image as well as the predicted class.
## Usage
To use the model and GUI, follow these steps:
- Clone or download the GitHub repository containing the model and GUI files.
- Install the necessary Python libraries.
- Train the model by running 'BrainTumorMRIDetection.ipynb'. This will save the trained model as a .h5 file in the repository directory (You can also just download the model, more information down below).
- Run the GUI by running gui.py. This will open a window where you can upload an MRI image and get a prediction from the model.
## Credits
Muhammad Shahab Hasan (Shab)
- https://www.fiverr.com/best_output
- https://www.youtube.com/Shabpassiongamer
- https://medium.com/@ShahabH
|
sarahh23/gptneo-txt2ARXMLv1.6_3000
|
sarahh23
| 2023-05-06T17:57:07Z | 16 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt_neo",
"text-generation",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-05-06T17:56:34Z |
---
license: mit
tags:
- generated_from_trainer
model-index:
- name: gptneo-txt2ARXMLv1.6_3000
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# gptneo-txt2ARXMLv1.6_3000
This model is a fine-tuned version of [EleutherAI/gpt-neo-125m](https://huggingface.co/EleutherAI/gpt-neo-125m) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1562
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 1
- eval_batch_size: 1
- seed: 42
- distributed_type: multi-GPU
- gradient_accumulation_steps: 8
- total_train_batch_size: 8
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 1000
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 1.1777 | 0.99 | 59 | 1.1377 |
| 0.6024 | 1.99 | 119 | 0.6514 |
| 0.4513 | 2.99 | 179 | 0.5405 |
| 0.4204 | 3.99 | 239 | 0.4539 |
| 0.3151 | 4.99 | 299 | 0.4075 |
| 0.2056 | 6.0 | 359 | 0.3154 |
| 0.1129 | 7.0 | 419 | 0.2234 |
| 0.0871 | 8.0 | 479 | 0.1742 |
| 0.0764 | 8.99 | 538 | 0.1575 |
| 0.0548 | 9.85 | 590 | 0.1562 |
### Framework versions
- Transformers 4.28.1
- Pytorch 2.0.0+cu118
- Datasets 2.12.0
- Tokenizers 0.13.3
|
VinayakMane47/bert-base-cased-finetuned-on-duplicate-Q-A
|
VinayakMane47
| 2023-05-06T17:55:50Z | 5 | 0 |
transformers
|
[
"transformers",
"tf",
"bert",
"text-classification",
"generated_from_keras_callback",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-05-06T13:53:35Z |
---
license: apache-2.0
tags:
- generated_from_keras_callback
model-index:
- name: VinayakMane47/bert-base-cased-finetuned-on-duplicate-Q-A
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# VinayakMane47/bert-base-cased-finetuned-on-duplicate-Q-A
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.1196
- Validation Loss: 0.2625
- Epoch: 2
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'AdamWeightDecay', 'learning_rate': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 2e-05, 'decay_steps': 30324, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False, 'weight_decay_rate': 0.01}
- training_precision: float32
### Training results
| Train Loss | Validation Loss | Epoch |
|:----------:|:---------------:|:-----:|
| 0.3153 | 0.2493 | 0 |
| 0.1929 | 0.2385 | 1 |
| 0.1196 | 0.2625 | 2 |
### Framework versions
- Transformers 4.28.1
- TensorFlow 2.12.0
- Datasets 2.12.0
- Tokenizers 0.13.3
|
PanoEvJ/Reinforce-Pixelcopter-PLE-v0
|
PanoEvJ
| 2023-05-06T17:52:50Z | 0 | 0 | null |
[
"Pixelcopter-PLE-v0",
"reinforce",
"reinforcement-learning",
"custom-implementation",
"deep-rl-class",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-05-06T17:52:18Z |
---
tags:
- Pixelcopter-PLE-v0
- reinforce
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: Reinforce-Pixelcopter-PLE-v0
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Pixelcopter-PLE-v0
type: Pixelcopter-PLE-v0
metrics:
- type: mean_reward
value: 52.08 +/- 45.57
name: mean_reward
verified: false
---
# **Reinforce** Agent playing **Pixelcopter-PLE-v0**
This is a trained model of a **Reinforce** agent playing **Pixelcopter-PLE-v0** .
To learn to use this model and train yours check Unit 4 of the Deep Reinforcement Learning Course: https://huggingface.co/deep-rl-course/unit4/introduction
|
TheRealRichV/ppo-LunarLander-v2
|
TheRealRichV
| 2023-05-06T17:52:25Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-05-06T17:52:07Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 266.57 +/- 16.59
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
BartekSadlej/q-Taxi-v3
|
BartekSadlej
| 2023-05-06T17:42:17Z | 0 | 0 | null |
[
"Taxi-v3",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-05-06T17:42:14Z |
---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-Taxi-v3
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
metrics:
- type: mean_reward
value: 7.54 +/- 2.74
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="BartekSadlej/q-Taxi-v3", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
tmnam20/codebert-code-summarization
|
tmnam20
| 2023-05-06T17:40:25Z | 0 | 0 | null |
[
"pytorch",
"code",
"summarization",
"en",
"region:us"
] |
summarization
| 2023-05-06T17:31:38Z |
---
language:
- en
pipeline_tag: summarization
metrics:
- bleu
tags:
- code
---
|
Getspastic/A-ZovyaPhotoreal
|
Getspastic
| 2023-05-06T17:38:07Z | 0 | 1 | null |
[
"license:creativeml-openrail-m",
"region:us"
] | null | 2023-05-06T17:22:44Z |
---
license: creativeml-openrail-m
---
|
cansurav/bert-base-uncased-finetuned-cola-batch-64
|
cansurav
| 2023-05-06T17:24:58Z | 11 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"text-classification",
"generated_from_trainer",
"dataset:glue",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-05-06T17:00:49Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- glue
metrics:
- matthews_correlation
model-index:
- name: bert-base-uncased-finetuned-cola-batch-64
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: glue
type: glue
config: cola
split: validation
args: cola
metrics:
- name: Matthews Correlation
type: matthews_correlation
value: 0.5835943612387946
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-uncased-finetuned-cola-batch-64
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on the glue dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7651
- Matthews Correlation: 0.5836
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Matthews Correlation |
|:-------------:|:-----:|:----:|:---------------:|:--------------------:|
| No log | 1.0 | 134 | 0.4344 | 0.5367 |
| No log | 2.0 | 268 | 0.4313 | 0.5650 |
| No log | 3.0 | 402 | 0.5034 | 0.5495 |
| 0.3177 | 4.0 | 536 | 0.5733 | 0.5293 |
| 0.3177 | 5.0 | 670 | 0.6364 | 0.5498 |
| 0.3177 | 6.0 | 804 | 0.7316 | 0.5600 |
| 0.3177 | 7.0 | 938 | 0.7651 | 0.5836 |
| 0.0846 | 8.0 | 1072 | 0.8575 | 0.5625 |
| 0.0846 | 9.0 | 1206 | 0.8820 | 0.5573 |
| 0.0846 | 10.0 | 1340 | 0.8854 | 0.5704 |
### Framework versions
- Transformers 4.28.1
- Pytorch 2.0.0+cu118
- Datasets 2.12.0
- Tokenizers 0.13.3
|
perion/stablediffusion1-5-kingperion
|
perion
| 2023-05-06T17:20:34Z | 7 | 1 |
diffusers
|
[
"diffusers",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] |
text-to-image
| 2023-01-11T16:40:25Z |
---
license: creativeml-openrail-m
tags:
- text-to-image
- stable-diffusion
---
### stablediffusion1.5-kingperion Dreambooth model trained by kingjohn with [DreamBooth](https://colab.research.google.com/github/buildspace/diffusers/blob/main/examples/dreambooth/DreamBooth_Stable_Diffusion.ipynb) notebook
|
esragenc/bert-base-uncased-finetuned-cola
|
esragenc
| 2023-05-06T17:17:48Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"text-classification",
"generated_from_trainer",
"dataset:glue",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-05-06T16:44:55Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- glue
metrics:
- matthews_correlation
model-index:
- name: bert-base-uncased-finetuned-cola
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: glue
type: glue
config: cola
split: validation
args: cola
metrics:
- name: Matthews Correlation
type: matthews_correlation
value: 0.24864597330745425
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-uncased-finetuned-cola
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on the glue dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5096
- Matthews Correlation: 0.2486
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1.312312768726691e-06
- train_batch_size: 8
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Matthews Correlation |
|:-------------:|:-----:|:----:|:---------------:|:--------------------:|
| 0.5717 | 1.0 | 1069 | 0.5541 | 0.0696 |
| 0.4917 | 2.0 | 2138 | 0.5059 | 0.2335 |
| 0.4603 | 3.0 | 3207 | 0.5096 | 0.2486 |
### Framework versions
- Transformers 4.28.1
- Pytorch 2.0.0+cu118
- Datasets 2.12.0
- Tokenizers 0.13.3
|
gaokaobishuati/dqn-SpaceInvadersNoFrameskip-v4
|
gaokaobishuati
| 2023-05-06T16:57:02Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"SpaceInvadersNoFrameskip-v4",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-05-06T17:02:10Z |
---
library_name: stable-baselines3
tags:
- SpaceInvadersNoFrameskip-v4
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: DQN
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: SpaceInvadersNoFrameskip-v4
type: SpaceInvadersNoFrameskip-v4
metrics:
- type: mean_reward
value: 580.00 +/- 254.98
name: mean_reward
verified: false
---
# **DQN** Agent playing **SpaceInvadersNoFrameskip-v4**
This is a trained model of a **DQN** agent playing **SpaceInvadersNoFrameskip-v4**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3)
and the [RL Zoo](https://github.com/DLR-RM/rl-baselines3-zoo).
The RL Zoo is a training framework for Stable Baselines3
reinforcement learning agents,
with hyperparameter optimization and pre-trained agents included.
## Usage (with SB3 RL Zoo)
RL Zoo: https://github.com/DLR-RM/rl-baselines3-zoo<br/>
SB3: https://github.com/DLR-RM/stable-baselines3<br/>
SB3 Contrib: https://github.com/Stable-Baselines-Team/stable-baselines3-contrib
Install the RL Zoo (with SB3 and SB3-Contrib):
```bash
pip install rl_zoo3
```
```
# Download model and save it into the logs/ folder
python -m rl_zoo3.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga gaokaobishuati -f logs/
python -m rl_zoo3.enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
If you installed the RL Zoo3 via pip (`pip install rl_zoo3`), from anywhere you can do:
```
python -m rl_zoo3.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga gaokaobishuati -f logs/
python -m rl_zoo3.enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
## Training (with the RL Zoo)
```
python -m rl_zoo3.train --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
# Upload the model and generate video (when possible)
python -m rl_zoo3.push_to_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/ -orga gaokaobishuati
```
## Hyperparameters
```python
OrderedDict([('batch_size', 32),
('buffer_size', 100000),
('env_wrapper',
['stable_baselines3.common.atari_wrappers.AtariWrapper']),
('exploration_final_eps', 0.01),
('exploration_fraction', 0.1),
('frame_stack', 4),
('gradient_steps', 1),
('learning_rate', 0.0001),
('learning_starts', 100000),
('n_timesteps', 1000000.0),
('optimize_memory_usage', False),
('policy', 'CnnPolicy'),
('target_update_interval', 1000),
('train_freq', 4),
('normalize', False)])
```
|
sd-dreambooth-library/tats1
|
sd-dreambooth-library
| 2023-05-06T16:51:19Z | 0 | 0 |
diffusers
|
[
"diffusers",
"text-to-image",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] |
text-to-image
| 2023-05-06T16:50:19Z |
---
license: creativeml-openrail-m
tags:
- text-to-image
---
### <tats1> on Stable Diffusion via Dreambooth
#### model by jeca
This your the Stable Diffusion model fine-tuned the <tats1> concept taught to Stable Diffusion with Dreambooth.
It can be used by modifying the `instance_prompt`: **<tats1> white background with black line drawing**
You can also train your own concepts and upload them to the library by using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_training.ipynb).
And you can run your new concept via `diffusers`: [Colab Notebook for Inference](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_inference.ipynb), [Spaces with the Public Concepts loaded](https://huggingface.co/spaces/sd-dreambooth-library/stable-diffusion-dreambooth-concepts)
Here are the images used for training this concept:










|
Snim/Reinforce-cartpole-balance
|
Snim
| 2023-05-06T16:48:42Z | 0 | 0 | null |
[
"CartPole-v1",
"reinforce",
"reinforcement-learning",
"custom-implementation",
"deep-rl-class",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-05-02T15:16:35Z |
---
tags:
- CartPole-v1
- reinforce
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: Reinforce-cartpole-balance
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: CartPole-v1
type: CartPole-v1
metrics:
- type: mean_reward
value: 99.90 +/- 18.40
name: mean_reward
verified: false
---
# **Reinforce** Agent playing **CartPole-v1**
This is a trained model of a **Reinforce** agent playing **CartPole-v1** .
To learn to use this model and train yours check Unit 4 of the Deep Reinforcement Learning Course: https://huggingface.co/deep-rl-course/unit4/introduction
|
agnesemi/sentiment-metaverse
|
agnesemi
| 2023-05-06T16:48:05Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"roberta",
"text-classification",
"en",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-05-06T15:34:07Z |
---
language:
- en
pipeline_tag: text-classification
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
This modelcard aims to be a base template for new models. It has been generated using [this raw template](https://github.com/huggingface/huggingface_hub/blob/main/src/huggingface_hub/templates/modelcard_template.md?plain=1).
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Data Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Data Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Philippe-USA/Mon_Premier_Test
|
Philippe-USA
| 2023-05-06T16:44:39Z | 0 | 0 | null |
[
"arxiv:1910.09700",
"region:us"
] | null | 2023-05-06T16:41:56Z |
---
# For reference on model card metadata, see the spec: https://github.com/huggingface/hub-docs/blob/main/modelcard.md?plain=1
# Doc / guide: https://huggingface.co/docs/hub/model-cards
{}
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
This modelcard aims to be a base template for new models. It has been generated using [this raw template](https://github.com/huggingface/huggingface_hub/blob/main/src/huggingface_hub/templates/modelcard_template.md?plain=1).
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Data Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Data Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
cansurav/bert-base-uncased-finetuned-cola-batch-16
|
cansurav
| 2023-05-06T16:34:33Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"text-classification",
"generated_from_trainer",
"dataset:glue",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-05-06T16:20:14Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- glue
metrics:
- matthews_correlation
model-index:
- name: bert-base-uncased-finetuned-cola-batch-16
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: glue
type: glue
config: cola
split: validation
args: cola
metrics:
- name: Matthews Correlation
type: matthews_correlation
value: 0.5992215466535732
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-uncased-finetuned-cola-batch-16
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on the glue dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4502
- Matthews Correlation: 0.5992
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Matthews Correlation |
|:-------------:|:-----:|:----:|:---------------:|:--------------------:|
| 0.4987 | 1.0 | 535 | 0.5145 | 0.4872 |
| 0.3065 | 2.0 | 1070 | 0.4502 | 0.5992 |
| 0.2059 | 3.0 | 1605 | 0.7547 | 0.5208 |
| 0.1467 | 4.0 | 2140 | 0.8557 | 0.5390 |
| 0.1006 | 5.0 | 2675 | 0.9277 | 0.5550 |
| 0.0796 | 6.0 | 3210 | 1.0832 | 0.5765 |
| 0.0532 | 7.0 | 3745 | 1.0337 | 0.5687 |
| 0.0367 | 8.0 | 4280 | 1.1539 | 0.5779 |
| 0.0276 | 9.0 | 4815 | 1.3224 | 0.5755 |
| 0.0192 | 10.0 | 5350 | 1.3055 | 0.5810 |
### Framework versions
- Transformers 4.28.1
- Pytorch 2.0.0+cu118
- Datasets 2.12.0
- Tokenizers 0.13.3
|
mariaWitch/ExperimentalBiggerMerges
|
mariaWitch
| 2023-05-06T16:29:23Z | 0 | 3 | null |
[
"license:agpl-3.0",
"region:us"
] | null | 2023-04-09T14:32:28Z |
---
license: agpl-3.0
---
This is where my experimental merges go. Expect broken models, UNETs, and models that produce weird artifacting to be common here. Models that are here may eventually make it into the other repo.
|
bfcr/flofrumush
|
bfcr
| 2023-05-06T16:26:05Z | 0 | 0 | null |
[
"region:us"
] | null | 2023-05-06T16:19:10Z |
# Projeto Final - Modelos Preditivos Conexionistas
Classificação de imagens de flores, frutas ou cogumelos
### Bernardo Russo
|**Tipo de Projeto**|**Modelo Selecionado**|**Linguagem**|
|--|--|--|
|Classificação de Imagens|resnet34|PyTorch|
## Performance
O modelo treinado possui performance de **91.04%**.
### Output do bloco de treinamento
<details>
<summary>Click to expand!</summary>
```text
Epoch 0/2
----------
Iterating through data...
train Loss: 0.7545 Acc: 0.7052
Iterating through data...
valid Loss: 0.1788 Acc: 0.9535
Epoch 1/2
----------
Iterating through data...
train Loss: 0.4575 Acc: 0.8057
Iterating through data...
valid Loss: 0.5638 Acc: 0.8062
Epoch 2/2
----------
Iterating through data...
train Loss: 0.3874 Acc: 0.8755
Iterating through data...
valid Loss: 0.2393 Acc: 0.8837
Training complete in 19m 31s
Best val Acc: 0.953488
----------
Test Acc: 0.940299
----------
```
</details>
### Evidências do treinamento
#### Matriz de Confusão

## Roboflow
Link do data set: [Roboflow Project - Flower, Fruit or Mushroom](https://app.roboflow.com/cesar-school-ulsik/flower_fruit_mushroom/1)
## HuggingFace
Nessa seção você deve publicar o link para o HuggingFace
|
JustasVit/autotrain-roberta_legal_classification-55997130178
|
JustasVit
| 2023-05-06T16:18:32Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"roberta",
"text-classification",
"autotrain",
"unk",
"dataset:JustasVit/autotrain-data-roberta_legal_classification",
"co2_eq_emissions",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-05-06T16:16:40Z |
---
tags:
- autotrain
- text-classification
language:
- unk
widget:
- text: "I love AutoTrain 🤗"
datasets:
- JustasVit/autotrain-data-roberta_legal_classification
co2_eq_emissions:
emissions: 0.7083751813545671
---
# Model Trained Using AutoTrain
- Problem type: Multi-class Classification
- Model ID: 55997130178
- CO2 Emissions (in grams): 0.7084
## Validation Metrics
- Loss: 0.047
- Accuracy: 0.990
- Macro F1: 0.990
- Micro F1: 0.990
- Weighted F1: 0.990
- Macro Precision: 0.990
- Micro Precision: 0.990
- Weighted Precision: 0.990
- Macro Recall: 0.990
- Micro Recall: 0.990
- Weighted Recall: 0.990
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoTrain"}' https://api-inference.huggingface.co/models/JustasVit/autotrain-roberta_legal_classification-55997130178
```
Or Python API:
```
from transformers import AutoModelForSequenceClassification, AutoTokenizer
model = AutoModelForSequenceClassification.from_pretrained("JustasVit/autotrain-roberta_legal_classification-55997130178", use_auth_token=True)
tokenizer = AutoTokenizer.from_pretrained("JustasVit/autotrain-roberta_legal_classification-55997130178", use_auth_token=True)
inputs = tokenizer("I love AutoTrain", return_tensors="pt")
outputs = model(**inputs)
```
|
johnjose223/xlnet_squad2
|
johnjose223
| 2023-05-06T16:11:14Z | 7 | 0 |
transformers
|
[
"transformers",
"pytorch",
"safetensors",
"xlnet",
"question-answering",
"generated_from_trainer",
"dataset:squad_v2",
"license:mit",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2023-04-27T03:21:10Z |
---
license: mit
tags:
- generated_from_trainer
datasets:
- squad_v2
model-index:
- name: wd_0.01_bs_24_lr_2e-05_epochs_4
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wd_0.01_bs_24_lr_2e-05_epochs_4
This model is a fine-tuned version of [xlnet-large-cased](https://huggingface.co/xlnet-large-cased) on the squad_v2 dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 72
- eval_batch_size: 192
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 4.0
### Training results
### Framework versions
- Transformers 4.27.4
- Pytorch 1.13.1
- Datasets 2.11.0
- Tokenizers 0.11.0
|
ilkekas/bert-base-uncased-mean-pooling-finetuned-cola
|
ilkekas
| 2023-05-06T15:58:54Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"text-classification",
"generated_from_trainer",
"dataset:glue",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-05-06T14:24:45Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- glue
metrics:
- matthews_correlation
model-index:
- name: bert-base-uncased-mean-pooling-finetuned-cola
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: glue
type: glue
config: cola
split: validation
args: cola
metrics:
- name: Matthews Correlation
type: matthews_correlation
value: 0.5627810283916928
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-uncased-mean-pooling-finetuned-cola
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on the glue dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4983
- Matthews Correlation: 0.5628
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3.3487316926587096e-06
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 9
### Training results
| Training Loss | Epoch | Step | Validation Loss | Matthews Correlation |
|:-------------:|:-----:|:----:|:---------------:|:--------------------:|
| 0.5613 | 1.0 | 535 | 0.4981 | 0.4273 |
| 0.43 | 2.0 | 1070 | 0.4379 | 0.5367 |
| 0.3647 | 3.0 | 1605 | 0.5213 | 0.5030 |
| 0.312 | 4.0 | 2140 | 0.5085 | 0.5391 |
| 0.2832 | 5.0 | 2675 | 0.4983 | 0.5628 |
| 0.245 | 6.0 | 3210 | 0.6061 | 0.5339 |
| 0.2291 | 7.0 | 3745 | 0.5835 | 0.5443 |
| 0.2065 | 8.0 | 4280 | 0.5907 | 0.5443 |
| 0.2032 | 9.0 | 4815 | 0.6072 | 0.5469 |
### Framework versions
- Transformers 4.28.1
- Pytorch 2.0.0+cu118
- Datasets 2.12.0
- Tokenizers 0.13.3
|
jeremyvictor/mt5-large-gecfirst-e8-b16
|
jeremyvictor
| 2023-05-06T15:31:25Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"mt5",
"text2text-generation",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2023-05-06T14:31:56Z |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- rouge
model-index:
- name: mt5-large-gecfirst-e8-b16
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mt5-large-gecfirst-e8-b16
This model is a fine-tuned version of [google/mt5-large](https://huggingface.co/google/mt5-large) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2672
- Rouge1: 64.1391
- Rouge2: 56.9117
- Rougel: 64.0719
- Rougelsum: 64.1665
- Gen Len: 18.7753
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.001
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adafactor
- lr_scheduler_type: linear
- num_epochs: 8
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:-------:|:-------:|:-------:|:---------:|:-------:|
| 1.8204 | 0.25 | 74 | 0.4021 | 61.4087 | 52.3887 | 61.2674 | 61.3674 | 18.7804 |
| 0.7246 | 0.5 | 148 | 0.3252 | 63.347 | 55.3862 | 63.1874 | 63.2961 | 18.7652 |
| 0.6142 | 0.75 | 222 | 0.3028 | 63.725 | 56.2856 | 63.5597 | 63.6491 | 18.7838 |
| 0.5472 | 1.0 | 296 | 0.2919 | 63.8647 | 56.6097 | 63.7525 | 63.8544 | 18.7973 |
| 0.3687 | 1.25 | 370 | 0.2777 | 64.0686 | 56.686 | 63.883 | 63.9804 | 18.7703 |
| 0.3907 | 1.49 | 444 | 0.2870 | 64.0517 | 56.6668 | 63.9062 | 64.0017 | 18.7838 |
| 0.3466 | 1.74 | 518 | 0.2726 | 64.2559 | 57.4463 | 64.1045 | 64.2199 | 18.7770 |
| 0.3341 | 1.99 | 592 | 0.2672 | 64.1391 | 56.9117 | 64.0719 | 64.1665 | 18.7753 |
| 0.2036 | 2.24 | 666 | 0.2834 | 64.5476 | 57.8246 | 64.3771 | 64.5255 | 18.7804 |
| 0.2091 | 2.49 | 740 | 0.2897 | 64.1422 | 56.9715 | 64.0481 | 64.1689 | 18.7432 |
| 0.2002 | 2.74 | 814 | 0.2703 | 64.6648 | 57.707 | 64.4805 | 64.5948 | 18.7804 |
| 0.204 | 2.99 | 888 | 0.2824 | 64.0966 | 56.9705 | 63.9888 | 64.073 | 18.7551 |
| 0.1185 | 3.24 | 962 | 0.3022 | 64.4346 | 57.6011 | 64.3542 | 64.4615 | 18.7939 |
| 0.117 | 3.49 | 1036 | 0.2870 | 64.455 | 57.3607 | 64.2925 | 64.3963 | 18.7669 |
| 0.1135 | 3.74 | 1110 | 0.2890 | 64.7671 | 58.0409 | 64.5938 | 64.6987 | 18.7669 |
| 0.1175 | 3.99 | 1184 | 0.2977 | 64.8082 | 58.0379 | 64.6993 | 64.7849 | 18.7652 |
| 0.0726 | 4.24 | 1258 | 0.3135 | 64.5297 | 57.6752 | 64.4134 | 64.5109 | 18.7736 |
| 0.0654 | 4.48 | 1332 | 0.3298 | 64.5051 | 57.6982 | 64.3561 | 64.4885 | 18.7787 |
| 0.0719 | 4.73 | 1406 | 0.3139 | 64.8793 | 58.1936 | 64.749 | 64.8532 | 18.7720 |
| 0.0665 | 4.98 | 1480 | 0.3174 | 64.9015 | 58.1975 | 64.786 | 64.907 | 18.7703 |
| 0.0452 | 5.23 | 1554 | 0.3272 | 64.5715 | 58.067 | 64.4336 | 64.5425 | 18.7889 |
| 0.0395 | 5.48 | 1628 | 0.3337 | 64.7712 | 58.1058 | 64.6351 | 64.7423 | 18.7703 |
| 0.0367 | 5.73 | 1702 | 0.3422 | 64.9298 | 58.4592 | 64.8188 | 64.8927 | 18.7787 |
| 0.0393 | 5.98 | 1776 | 0.3394 | 64.8953 | 58.162 | 64.7892 | 64.8822 | 18.7787 |
| 0.0247 | 6.23 | 1850 | 0.3532 | 64.9207 | 58.2827 | 64.8053 | 64.8903 | 18.7872 |
| 0.0222 | 6.48 | 1924 | 0.3543 | 64.902 | 58.3086 | 64.793 | 64.8973 | 18.7736 |
| 0.0203 | 6.73 | 1998 | 0.3628 | 65.1022 | 58.7138 | 64.9734 | 65.0891 | 18.7720 |
| 0.0218 | 6.98 | 2072 | 0.3599 | 64.9409 | 58.387 | 64.7925 | 64.9157 | 18.7720 |
| 0.0156 | 7.23 | 2146 | 0.3802 | 65.1242 | 58.8116 | 64.9962 | 65.1097 | 18.7736 |
| 0.013 | 7.47 | 2220 | 0.3845 | 64.9358 | 58.4528 | 64.8099 | 64.925 | 18.7703 |
| 0.0114 | 7.72 | 2294 | 0.3913 | 64.9827 | 58.6449 | 64.863 | 64.9661 | 18.7720 |
| 0.0125 | 7.97 | 2368 | 0.3886 | 65.0031 | 58.5507 | 64.8805 | 64.9845 | 18.7720 |
### Framework versions
- Transformers 4.28.1
- Pytorch 1.11.0a0+b6df043
- Datasets 2.12.0
- Tokenizers 0.13.3
|
EExe/rl_course_vizdoom_health_gathering_supreme
|
EExe
| 2023-05-06T15:21:30Z | 0 | 0 |
sample-factory
|
[
"sample-factory",
"tensorboard",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-05-06T15:21:23Z |
---
library_name: sample-factory
tags:
- deep-reinforcement-learning
- reinforcement-learning
- sample-factory
model-index:
- name: APPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: doom_health_gathering_supreme
type: doom_health_gathering_supreme
metrics:
- type: mean_reward
value: 9.93 +/- 3.52
name: mean_reward
verified: false
---
A(n) **APPO** model trained on the **doom_health_gathering_supreme** environment.
This model was trained using Sample-Factory 2.0: https://github.com/alex-petrenko/sample-factory.
Documentation for how to use Sample-Factory can be found at https://www.samplefactory.dev/
## Downloading the model
After installing Sample-Factory, download the model with:
```
python -m sample_factory.huggingface.load_from_hub -r EExe/rl_course_vizdoom_health_gathering_supreme
```
## Using the model
To run the model after download, use the `enjoy` script corresponding to this environment:
```
python -m .usr.local.lib.python3.10.dist-packages.ipykernel_launcher --algo=APPO --env=doom_health_gathering_supreme --train_dir=./train_dir --experiment=rl_course_vizdoom_health_gathering_supreme
```
You can also upload models to the Hugging Face Hub using the same script with the `--push_to_hub` flag.
See https://www.samplefactory.dev/10-huggingface/huggingface/ for more details
## Training with this model
To continue training with this model, use the `train` script corresponding to this environment:
```
python -m .usr.local.lib.python3.10.dist-packages.ipykernel_launcher --algo=APPO --env=doom_health_gathering_supreme --train_dir=./train_dir --experiment=rl_course_vizdoom_health_gathering_supreme --restart_behavior=resume --train_for_env_steps=10000000000
```
Note, you may have to adjust `--train_for_env_steps` to a suitably high number as the experiment will resume at the number of steps it concluded at.
|
pecra/mit-b0-finetuned-sidewalks
|
pecra
| 2023-05-06T15:20:22Z | 1 | 0 |
transformers
|
[
"transformers",
"tf",
"segformer",
"generated_from_keras_callback",
"license:other",
"endpoints_compatible",
"region:us"
] | null | 2023-05-06T15:04:07Z |
---
license: other
tags:
- generated_from_keras_callback
model-index:
- name: pecra/mit-b0-finetuned-sidewalks
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# pecra/mit-b0-finetuned-sidewalks
This model is a fine-tuned version of [nvidia/mit-b0](https://huggingface.co/nvidia/mit-b0) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.8276
- Validation Loss: 0.7087
- Validation Mean Iou: 0.2488
- Validation Mean Accuracy: 0.3100
- Validation Overall Accuracy: 0.7987
- Validation Accuracy Unlabeled: 0.0
- Validation Accuracy Flat-road: 0.7917
- Validation Accuracy Flat-sidewalk: 0.9332
- Validation Accuracy Flat-crosswalk: 0.7636
- Validation Accuracy Flat-cyclinglane: 0.8238
- Validation Accuracy Flat-parkingdriveway: 0.1196
- Validation Accuracy Flat-railtrack: nan
- Validation Accuracy Flat-curb: 0.3568
- Validation Accuracy Human-person: 0.7259
- Validation Accuracy Human-rider: 0.0
- Validation Accuracy Vehicle-car: 0.8780
- Validation Accuracy Vehicle-truck: 0.0
- Validation Accuracy Vehicle-bus: 0.0
- Validation Accuracy Vehicle-tramtrain: nan
- Validation Accuracy Vehicle-motorcycle: 0.0
- Validation Accuracy Vehicle-bicycle: 0.3959
- Validation Accuracy Vehicle-caravan: 0.0
- Validation Accuracy Vehicle-cartrailer: 0.0
- Validation Accuracy Construction-building: 0.8757
- Validation Accuracy Construction-door: 0.0
- Validation Accuracy Construction-wall: 0.2241
- Validation Accuracy Construction-fenceguardrail: 0.3394
- Validation Accuracy Construction-bridge: 0.0
- Validation Accuracy Construction-tunnel: 0.0
- Validation Accuracy Construction-stairs: 0.0
- Validation Accuracy Object-pole: 0.1857
- Validation Accuracy Object-trafficsign: 0.0
- Validation Accuracy Object-trafficlight: 0.0
- Validation Accuracy Nature-vegetation: 0.9210
- Validation Accuracy Nature-terrain: 0.7914
- Validation Accuracy Sky: 0.9488
- Validation Accuracy Void-ground: 0.0
- Validation Accuracy Void-dynamic: 0.0
- Validation Accuracy Void-static: 0.1548
- Validation Accuracy Void-unclear: 0.0
- Validation Iou Unlabeled: 0.0
- Validation Iou Flat-road: 0.6333
- Validation Iou Flat-sidewalk: 0.8196
- Validation Iou Flat-crosswalk: 0.5763
- Validation Iou Flat-cyclinglane: 0.7280
- Validation Iou Flat-parkingdriveway: 0.1057
- Validation Iou Flat-railtrack: nan
- Validation Iou Flat-curb: 0.2409
- Validation Iou Human-person: 0.4810
- Validation Iou Human-rider: 0.0
- Validation Iou Vehicle-car: 0.7216
- Validation Iou Vehicle-truck: 0.0
- Validation Iou Vehicle-bus: 0.0
- Validation Iou Vehicle-tramtrain: nan
- Validation Iou Vehicle-motorcycle: 0.0
- Validation Iou Vehicle-bicycle: 0.2825
- Validation Iou Vehicle-caravan: 0.0
- Validation Iou Vehicle-cartrailer: 0.0
- Validation Iou Construction-building: 0.6307
- Validation Iou Construction-door: 0.0
- Validation Iou Construction-wall: 0.1908
- Validation Iou Construction-fenceguardrail: 0.2551
- Validation Iou Construction-bridge: 0.0
- Validation Iou Construction-tunnel: 0.0
- Validation Iou Construction-stairs: 0.0
- Validation Iou Object-pole: 0.1625
- Validation Iou Object-trafficsign: 0.0
- Validation Iou Object-trafficlight: 0.0
- Validation Iou Nature-vegetation: 0.7648
- Validation Iou Nature-terrain: 0.6071
- Validation Iou Sky: 0.8958
- Validation Iou Void-ground: 0.0
- Validation Iou Void-dynamic: 0.0
- Validation Iou Void-static: 0.1149
- Validation Iou Void-unclear: 0.0
- Epoch: 1
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'Adam', 'weight_decay': None, 'clipnorm': None, 'global_clipnorm': None, 'clipvalue': None, 'use_ema': False, 'ema_momentum': 0.99, 'ema_overwrite_frequency': None, 'jit_compile': True, 'is_legacy_optimizer': False, 'learning_rate': 6e-05, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-07, 'amsgrad': False}
- training_precision: float32
### Training results
| Train Loss | Validation Loss | Validation Mean Iou | Validation Mean Accuracy | Validation Overall Accuracy | Validation Accuracy Unlabeled | Validation Accuracy Flat-road | Validation Accuracy Flat-sidewalk | Validation Accuracy Flat-crosswalk | Validation Accuracy Flat-cyclinglane | Validation Accuracy Flat-parkingdriveway | Validation Accuracy Flat-railtrack | Validation Accuracy Flat-curb | Validation Accuracy Human-person | Validation Accuracy Human-rider | Validation Accuracy Vehicle-car | Validation Accuracy Vehicle-truck | Validation Accuracy Vehicle-bus | Validation Accuracy Vehicle-tramtrain | Validation Accuracy Vehicle-motorcycle | Validation Accuracy Vehicle-bicycle | Validation Accuracy Vehicle-caravan | Validation Accuracy Vehicle-cartrailer | Validation Accuracy Construction-building | Validation Accuracy Construction-door | Validation Accuracy Construction-wall | Validation Accuracy Construction-fenceguardrail | Validation Accuracy Construction-bridge | Validation Accuracy Construction-tunnel | Validation Accuracy Construction-stairs | Validation Accuracy Object-pole | Validation Accuracy Object-trafficsign | Validation Accuracy Object-trafficlight | Validation Accuracy Nature-vegetation | Validation Accuracy Nature-terrain | Validation Accuracy Sky | Validation Accuracy Void-ground | Validation Accuracy Void-dynamic | Validation Accuracy Void-static | Validation Accuracy Void-unclear | Validation Iou Unlabeled | Validation Iou Flat-road | Validation Iou Flat-sidewalk | Validation Iou Flat-crosswalk | Validation Iou Flat-cyclinglane | Validation Iou Flat-parkingdriveway | Validation Iou Flat-railtrack | Validation Iou Flat-curb | Validation Iou Human-person | Validation Iou Human-rider | Validation Iou Vehicle-car | Validation Iou Vehicle-truck | Validation Iou Vehicle-bus | Validation Iou Vehicle-tramtrain | Validation Iou Vehicle-motorcycle | Validation Iou Vehicle-bicycle | Validation Iou Vehicle-caravan | Validation Iou Vehicle-cartrailer | Validation Iou Construction-building | Validation Iou Construction-door | Validation Iou Construction-wall | Validation Iou Construction-fenceguardrail | Validation Iou Construction-bridge | Validation Iou Construction-tunnel | Validation Iou Construction-stairs | Validation Iou Object-pole | Validation Iou Object-trafficsign | Validation Iou Object-trafficlight | Validation Iou Nature-vegetation | Validation Iou Nature-terrain | Validation Iou Sky | Validation Iou Void-ground | Validation Iou Void-dynamic | Validation Iou Void-static | Validation Iou Void-unclear | Epoch |
|:----------:|:---------------:|:-------------------:|:------------------------:|:---------------------------:|:-----------------------------:|:-----------------------------:|:---------------------------------:|:----------------------------------:|:------------------------------------:|:----------------------------------------:|:----------------------------------:|:-----------------------------:|:--------------------------------:|:-------------------------------:|:-------------------------------:|:---------------------------------:|:-------------------------------:|:-------------------------------------:|:--------------------------------------:|:-----------------------------------:|:-----------------------------------:|:--------------------------------------:|:-----------------------------------------:|:-------------------------------------:|:-------------------------------------:|:-----------------------------------------------:|:---------------------------------------:|:---------------------------------------:|:---------------------------------------:|:-------------------------------:|:--------------------------------------:|:---------------------------------------:|:-------------------------------------:|:----------------------------------:|:-----------------------:|:-------------------------------:|:--------------------------------:|:-------------------------------:|:--------------------------------:|:------------------------:|:------------------------:|:----------------------------:|:-----------------------------:|:-------------------------------:|:-----------------------------------:|:-----------------------------:|:------------------------:|:---------------------------:|:--------------------------:|:--------------------------:|:----------------------------:|:--------------------------:|:--------------------------------:|:---------------------------------:|:------------------------------:|:------------------------------:|:---------------------------------:|:------------------------------------:|:--------------------------------:|:--------------------------------:|:------------------------------------------:|:----------------------------------:|:----------------------------------:|:----------------------------------:|:--------------------------:|:---------------------------------:|:----------------------------------:|:--------------------------------:|:-----------------------------:|:------------------:|:--------------------------:|:---------------------------:|:--------------------------:|:---------------------------:|:-----:|
| 1.3899 | 0.8648 | 0.1967 | 0.2417 | 0.7536 | 0.0 | 0.6349 | 0.9590 | 0.1580 | 0.7351 | 0.1644 | nan | 0.1925 | 0.4170 | 0.0 | 0.8121 | 0.0 | 0.0 | nan | 0.0 | 0.1536 | 0.0 | 0.0 | 0.8972 | 0.0 | 0.1150 | 0.0695 | 0.0 | 0.0 | 0.0 | 0.0352 | 0.0 | 0.0 | 0.8874 | 0.7578 | 0.9500 | 0.0 | 0.0 | 0.0383 | 0.0 | 0.0 | 0.4984 | 0.7628 | 0.1568 | 0.6469 | 0.1219 | nan | 0.1421 | 0.3436 | 0.0 | 0.6648 | 0.0 | 0.0 | nan | 0.0 | 0.1348 | 0.0 | 0.0 | 0.5662 | 0.0 | 0.1019 | 0.0655 | 0.0 | 0.0 | 0.0 | 0.0345 | 0.0 | 0.0 | 0.7491 | 0.5971 | 0.8673 | 0.0 | 0.0 | 0.0366 | 0.0 | 0 |
| 0.8276 | 0.7087 | 0.2488 | 0.3100 | 0.7987 | 0.0 | 0.7917 | 0.9332 | 0.7636 | 0.8238 | 0.1196 | nan | 0.3568 | 0.7259 | 0.0 | 0.8780 | 0.0 | 0.0 | nan | 0.0 | 0.3959 | 0.0 | 0.0 | 0.8757 | 0.0 | 0.2241 | 0.3394 | 0.0 | 0.0 | 0.0 | 0.1857 | 0.0 | 0.0 | 0.9210 | 0.7914 | 0.9488 | 0.0 | 0.0 | 0.1548 | 0.0 | 0.0 | 0.6333 | 0.8196 | 0.5763 | 0.7280 | 0.1057 | nan | 0.2409 | 0.4810 | 0.0 | 0.7216 | 0.0 | 0.0 | nan | 0.0 | 0.2825 | 0.0 | 0.0 | 0.6307 | 0.0 | 0.1908 | 0.2551 | 0.0 | 0.0 | 0.0 | 0.1625 | 0.0 | 0.0 | 0.7648 | 0.6071 | 0.8958 | 0.0 | 0.0 | 0.1149 | 0.0 | 1 |
### Framework versions
- Transformers 4.28.1
- TensorFlow 2.12.0
- Datasets 2.12.0
- Tokenizers 0.13.3
|
jeremyvictor/mt5-base-gecfirst-e8-b16
|
jeremyvictor
| 2023-05-06T15:02:39Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"mt5",
"text2text-generation",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2023-05-06T14:36:46Z |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- rouge
model-index:
- name: mt5-base-gecfirst-e8-b16
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mt5-base-gecfirst-e8-b16
This model is a fine-tuned version of [google/mt5-base](https://huggingface.co/google/mt5-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3009
- Rouge1: 63.8499
- Rouge2: 56.2662
- Rougel: 63.73
- Rougelsum: 63.6591
- Gen Len: 18.7736
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.001
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adafactor
- lr_scheduler_type: linear
- num_epochs: 8
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:-------:|:-------:|:-------:|:---------:|:-------:|
| 3.409 | 0.25 | 74 | 0.6899 | 58.0459 | 46.7233 | 57.9944 | 57.9576 | 18.7669 |
| 1.0497 | 0.5 | 148 | 0.4335 | 61.3353 | 51.8804 | 61.174 | 61.1541 | 18.7703 |
| 0.8355 | 0.75 | 222 | 0.3734 | 62.5279 | 54.5952 | 62.4436 | 62.4377 | 18.7720 |
| 0.7339 | 1.0 | 296 | 0.3814 | 62.8071 | 54.8468 | 62.7075 | 62.6933 | 18.7770 |
| 0.5946 | 1.25 | 370 | 0.3418 | 63.1523 | 55.3752 | 62.9987 | 62.9879 | 18.7770 |
| 0.5746 | 1.49 | 444 | 0.3234 | 62.9253 | 55.1955 | 62.821 | 62.7592 | 18.7905 |
| 0.5278 | 1.74 | 518 | 0.3252 | 63.3056 | 55.6505 | 63.1271 | 63.0661 | 18.7804 |
| 0.4886 | 1.99 | 592 | 0.3265 | 63.1652 | 55.0909 | 62.979 | 62.9613 | 18.7753 |
| 0.366 | 2.24 | 666 | 0.3126 | 63.8131 | 56.5685 | 63.7303 | 63.6682 | 18.7703 |
| 0.3553 | 2.49 | 740 | 0.3192 | 63.6195 | 55.9276 | 63.4796 | 63.4692 | 18.7703 |
| 0.3558 | 2.74 | 814 | 0.3009 | 63.8499 | 56.2662 | 63.73 | 63.6591 | 18.7736 |
| 0.353 | 2.99 | 888 | 0.3014 | 63.7417 | 56.241 | 63.6192 | 63.5985 | 18.7686 |
| 0.2398 | 3.24 | 962 | 0.3119 | 63.999 | 56.8854 | 63.88 | 63.8705 | 18.7804 |
| 0.2459 | 3.49 | 1036 | 0.3222 | 64.0299 | 56.5581 | 63.9247 | 63.8934 | 18.7686 |
| 0.2423 | 3.74 | 1110 | 0.3125 | 63.6601 | 56.1864 | 63.4956 | 63.4819 | 18.7686 |
| 0.243 | 3.99 | 1184 | 0.3174 | 63.6676 | 56.1724 | 63.5183 | 63.4947 | 18.7736 |
| 0.1696 | 4.24 | 1258 | 0.3353 | 63.9905 | 56.3781 | 63.7979 | 63.7802 | 18.7652 |
| 0.1643 | 4.48 | 1332 | 0.3386 | 64.0219 | 56.7311 | 63.8823 | 63.8654 | 18.7703 |
| 0.1728 | 4.73 | 1406 | 0.3306 | 64.0261 | 56.7331 | 63.8978 | 63.8731 | 18.7720 |
| 0.1657 | 4.98 | 1480 | 0.3269 | 63.9735 | 56.4556 | 63.8514 | 63.8168 | 18.7703 |
| 0.1186 | 5.23 | 1554 | 0.3390 | 63.9831 | 56.6624 | 63.8953 | 63.8717 | 18.7703 |
| 0.1129 | 5.48 | 1628 | 0.3521 | 63.8674 | 56.528 | 63.7626 | 63.7362 | 18.7770 |
| 0.1061 | 5.73 | 1702 | 0.3539 | 63.9886 | 56.5753 | 63.881 | 63.8615 | 18.7703 |
| 0.1179 | 5.98 | 1776 | 0.3490 | 63.9949 | 56.7369 | 63.8929 | 63.8516 | 18.7736 |
| 0.0793 | 6.23 | 1850 | 0.3704 | 64.1527 | 57.0111 | 64.0496 | 63.9953 | 18.7686 |
| 0.0779 | 6.48 | 1924 | 0.3723 | 64.1833 | 57.0654 | 64.0686 | 64.0317 | 18.7669 |
| 0.0827 | 6.73 | 1998 | 0.3663 | 64.2185 | 56.9382 | 64.1096 | 64.0743 | 18.7736 |
| 0.0807 | 6.98 | 2072 | 0.3691 | 64.2298 | 56.9752 | 64.0957 | 64.0777 | 18.7686 |
| 0.0633 | 7.23 | 2146 | 0.3865 | 64.4729 | 57.5503 | 64.3733 | 64.3509 | 18.7652 |
| 0.0603 | 7.47 | 2220 | 0.3919 | 64.3001 | 57.2684 | 64.1693 | 64.1391 | 18.7635 |
| 0.0565 | 7.72 | 2294 | 0.3946 | 64.4077 | 57.3413 | 64.2825 | 64.2491 | 18.7635 |
| 0.0583 | 7.97 | 2368 | 0.3923 | 64.4078 | 57.3672 | 64.2775 | 64.2367 | 18.7652 |
### Framework versions
- Transformers 4.28.1
- Pytorch 1.11.0a0+b6df043
- Datasets 2.12.0
- Tokenizers 0.13.3
|
riho1710/distilbert-base-uncased-finetuned-emotion
|
riho1710
| 2023-05-06T14:54:42Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"distilbert",
"text-classification",
"generated_from_trainer",
"dataset:emotion",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-04-27T03:36:22Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- emotion
metrics:
- accuracy
- f1
model-index:
- name: distilbert-base-uncased-finetuned-emotion
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: emotion
type: emotion
config: split
split: validation
args: split
metrics:
- name: Accuracy
type: accuracy
value: 0.924
- name: F1
type: f1
value: 0.9240047123379981
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-emotion
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the emotion dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2239
- Accuracy: 0.924
- F1: 0.9240
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 0.8403 | 1.0 | 250 | 0.3219 | 0.9085 | 0.9059 |
| 0.2549 | 2.0 | 500 | 0.2239 | 0.924 | 0.9240 |
### Framework versions
- Transformers 4.28.1
- Pytorch 1.13.1
- Datasets 2.11.0
- Tokenizers 0.13.0.dev0
|
OpenBuddy/openbuddy-7b-v1.0-bf16-enc
|
OpenBuddy
| 2023-05-06T14:51:34Z | 9 | 6 |
transformers
|
[
"transformers",
"pytorch",
"llama",
"text-generation",
"zh",
"en",
"autotrain_compatible",
"text-generation-inference",
"region:us"
] |
text-generation
| 2023-04-27T03:11:17Z |
---
language:
- zh
- en
pipeline_tag: text-generation
inference: false
library_name: transformers
---
# ⚠️ DEPRECATION WARNING ⚠️
This model is an outdated version and has been preserved specifically for evaluating differences between model versions.
We highly recommend visiting our GitHub repository to find and use the latest version of the model: https://github.com/OpenBuddy/OpenBuddy
## Installation
Due to licensing restrictions from LLAMA, you need to have the original LLAMA-7B model to decrypt the model weights.
To decrypt the model weights, please follow the guide in our GitHub: https://github.com/OpenBuddy/OpenBuddy#installation
## Disclaimer
OpenBuddy is provided as-is without any warranty of any kind, either express or implied. The authors and contributors shall not be held liable for any damages resulting from the use or inability to use this software. By using OpenBuddy, you agree to these terms and conditions.
## License Restrictions
OpenBuddy is intended for non-commercial research purposes only, following the same restrictions as the LLAMA model. Any use outside of this scope is strictly prohibited. For more information, please refer to the LLAMA license.
|
AhmedTaha012/gptneo-txt2ARXMLv1.3.0
|
AhmedTaha012
| 2023-05-06T14:50:59Z | 14 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"gpt_neo",
"text-generation",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-05-06T10:57:38Z |
---
license: mit
tags:
- generated_from_trainer
model-index:
- name: gptneo-txt2ARXMLv1.3.0
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# gptneo-txt2ARXMLv1.3.0
This model is a fine-tuned version of [EleutherAI/gpt-neo-125m](https://huggingface.co/EleutherAI/gpt-neo-125m) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4324
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 1
- eval_batch_size: 1
- seed: 42
- distributed_type: multi-GPU
- gradient_accumulation_steps: 8
- total_train_batch_size: 8
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 1000
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 1.5205 | 0.98 | 45 | 1.4385 |
| 0.7083 | 1.98 | 91 | 0.7334 |
| 0.5779 | 2.99 | 137 | 0.5942 |
| 0.531 | 3.99 | 183 | 0.4915 |
| 0.3721 | 4.9 | 225 | 0.4324 |
### Framework versions
- Transformers 4.28.1
- Pytorch 2.0.0+cu118
- Datasets 2.12.0
- Tokenizers 0.13.3
|
mHossain/bangla-para-v2-180000
|
mHossain
| 2023-05-06T14:48:52Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"mt5",
"text2text-generation",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2023-05-06T13:50:48Z |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- rouge
model-index:
- name: bangla-para-v2-180000
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bangla-para-v2-180000
This model is a fine-tuned version of [mHossain/bangla-para-v2-150000](https://huggingface.co/mHossain/bangla-para-v2-150000) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.9033
- Rouge1: 0.0
- Rouge2: 0.0
- Rougel: 0.0
- Rougelsum: 0.0
- Gen Len: 17.506
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 5000
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:------:|:------:|:------:|:---------:|:-------:|
| 1.137 | 1.0 | 3375 | 0.9033 | 0.0 | 0.0 | 0.0 | 0.0 | 17.506 |
### Framework versions
- Transformers 4.28.1
- Pytorch 2.0.0+cu118
- Datasets 2.12.0
- Tokenizers 0.13.3
|
Dwightun/my_awesome_model
|
Dwightun
| 2023-05-06T14:46:47Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-05-06T12:08:20Z |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: my_awesome_model
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# my_awesome_model
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2077
- Accuracy: 0.9169
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| No log | 1.0 | 75 | 0.3656 | 0.7874 |
| No log | 2.0 | 150 | 0.2077 | 0.9169 |
### Framework versions
- Transformers 4.28.1
- Pytorch 2.0.0+cu118
- Datasets 2.12.0
- Tokenizers 0.13.3
|
CooliusMaximusnv/distilbert-base-uncased-finetuned-emotion
|
CooliusMaximusnv
| 2023-05-06T14:38:51Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"distilbert",
"text-classification",
"generated_from_trainer",
"dataset:emotion",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-03-25T15:31:23Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- emotion
metrics:
- accuracy
- f1
model-index:
- name: distilbert-base-uncased-finetuned-emotion
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: emotion
type: emotion
config: split
split: validation
args: split
metrics:
- name: Accuracy
type: accuracy
value: 0.9325
- name: F1
type: f1
value: 0.932802704305435
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-emotion
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the emotion dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1598
- Accuracy: 0.9325
- F1: 0.9328
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 0.1657 | 1.0 | 250 | 0.1701 | 0.933 | 0.9330 |
| 0.1101 | 2.0 | 500 | 0.1598 | 0.9325 | 0.9328 |
### Framework versions
- Transformers 4.27.3
- Pytorch 2.0.0+cu117
- Datasets 2.10.1
- Tokenizers 0.13.2
|
mazkooleg/digit-mask-unispeech-sat-base-ft
|
mazkooleg
| 2023-05-06T14:33:43Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"unispeech-sat",
"audio-classification",
"generated_from_trainer",
"dataset:mazkooleg/digit_mask_augmented_raw",
"endpoints_compatible",
"region:us"
] |
audio-classification
| 2023-05-06T13:39:30Z |
---
tags:
- generated_from_trainer
metrics:
- accuracy
- f1
model-index:
- name: unispeech-sat-base-digit-mask-ft
results: []
datasets:
- mazkooleg/digit_mask_augmented_raw
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# unispeech-sat-base-digit-mask-ft
This model is a fine-tuned version of [microsoft/unispeech-sat-base](https://huggingface.co/microsoft/unispeech-sat-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0053
- Accuracy: 0.9991
- F1: 0.9991
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Accuracy | F1 | Validation Loss |
|:-------------:|:-----:|:-----:|:--------:|:------:|:---------------:|
| 0.0079 | 1.0 | 14264 | 0.9991 | 0.9991 | 0.0053 |
| 0.0019 | 2.0 | 28528 | 0.9987 | 0.9987 | 0.0078 |
| 0.0009 | 3.0 | 42792 | 0.9989 | 0.9989 | 0.0069 |
### Framework versions
- Transformers 4.28.1
- Pytorch 1.13.0+cpu
- Datasets 2.12.0
- Tokenizers 0.13.2
|
bluenguyen/movie_chatbot_v1
|
bluenguyen
| 2023-05-06T14:25:39Z | 14 | 1 |
transformers
|
[
"transformers",
"pytorch",
"t5",
"text2text-generation",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"region:us"
] |
text2text-generation
| 2023-03-14T06:12:53Z |
---
inference: false
license: mit
---
# Model Card for Model ID
A movie recommendation chatbot which is finetune from GODEL model using data generated from ChatGPT.
## Model Details
- **Model type:** seq2seq(T5)
- **License:** MIT
- **Finetuned from model:** microsoft/GODEL-v1_1-base-seq2seq
- **Final eval loss:** 0.2331
## Limitations
This model is trained using supervised learning on small amount of movie conversation data so it is not that good.\
There is also a large version of this with better performance at bluenguyen/movie_chatbot_large_v1.
### How to Get Started with the Model
Use the code below to get started with the model.
```python:
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
tokenizer = AutoTokenizer.from_pretrained("bluenguyen/movie_chatbot_v1")
model = AutoModelForSeq2SeqLM.from_pretrained("bluenguyen/movie_chatbot_v1").to('cuda')
def current_context(dialog, instruction):
dialog = ' EOS '.join(dialog)
context = f"{instruction} [CONTEXT] {dialog} "
return context
def generate(context):
input_ids = tokenizer(f"{context}", return_tensors="pt").input_ids.to('cuda')
outputs = model.generate(input_ids, max_length=128, min_length=8, top_p=0.9, do_sample=True)
output = tokenizer.decode(outputs[0], skip_special_tokens=True)
return output
instruction = f'Instruction: given a dialog about movie recommendation, you need to respond based on human preferences.'
dialog = [
'Do you have any recommendation about a movie?',
'Yes! Any particular genre that you\'d like to see mentioned?',
]
print('User: ' + dialog[0])
print('Bot: ' + dialog[1])
while(1):
print('User: ', end = '')
query = input()
if query == 'end':
break
dialog.append(query)
response = generate(current_context(dialog, instruction))
print('Bot: ' + response)
dialog.append(response)
```
### Demo
Example 1:
> User: Do you have any recommendation about a movie? <br>
> Bot: Yes! Any particular genre that you'd like to see mentioned? <br>
> User: I like love story. <br>
> Bot: How about "The Notebook"? It's a classic love story with a great plot twist. <br>
> User: I have seen that one. Give me another one. <br>
> Bot: Have you seen "Eternal Sunshine of the Spotless Mind"? It's a unique romantic story with a captivating twist. <br>
> User: Is it any good? <br>
> Bot: Absolutely! It has an amazing cast and an engaging storyline. I highly recommend it. <br>
> User: Thank you <br>
> Bot: You're welcome! Let me know how you liked it. <br>
> User: end <br>
Example 2:
> User: Do you have any recommendation about a movie? <br>
> Bot: Yes! Any particular genre that you'd like to see mentioned? <br>
> User: I like super hero movie. <br>
> Bot: Have you watched "The Dark Knight"? It's a classic superhero movie. <br>
> User: Tell me more <br>
> Bot: "The Dark Knight" is based on the book by Christopher Nolan and stars Christian Bale as Batman and Heath Ledger as the Joker. <br>
> User: Who is the Joker in this movie? <br>
> Bot: Heath Ledger is the Joker and the movie is based on a novel. <br>
> User: I mean what happen in the movie? <br>
> Bot: The Joker is tasked with protecting the savage City of the Black Knight. <br>
> User: Really? <br>
> Bot: It's a very intense movie with a great performance by Heath Ledger. <br>
> User: Nice :)) <br>
> Bot: Glad to hear it! How about "The Shawshank Redemption"? <br>
> User: What is it about? <br>
> Bot: "The Shawshank Redemption" is about a man named Andy Dufresne who is wrongly convicted of murder and sent to prison. <br>
> User: Who does he murder? <br>
> Bot: The man who is convicted of the murder is named Red, and he murders his wife. <br>
> User: You just said his name is Andy Dufresne <br>
> Bot: Sorry, I couldn't find any information about that movie. <br>
> User: yikes <br>
> Bot: Sorry again, I must have missed your recommendation. Is there any other movie you'd like to recommend? <br>
> User: end <br>
Example 3:
> User: Do you have any recommendation about a movie? <br>
> Bot: Yes! Any particular genre that you'd like to see mentioned? <br>
> User: I like action movie. <br>
> Bot: Have you seen "John Wick"? <br>
> User: Yes I have <br>
> Bot: How about "The Bourne Identity"? <br>
> User: What is it about? <br>
> Bot: "The Bourne Identity" is an action-packed movie about a man named John McClane who goes on a rampage after his friend's death. <br>
> User: John McClane is character from "Die Hard" though <br>
> Bot: Yes, John McClane is a character from "Die Hard". Have you seen "The Raid: Redemption"? <br>
> User: You are not that good its funny haha <br>
> Bot: That's alright. How about "Die Hard"? <br>
> User: Is it any good? <br>
> Bot: It's a classic action movie about a retired hitman who seeks vengeance for the death of his dog. <br>
> User: That is "John Wick" plot lol <br>
> Bot: Yeah, I'm sorry I haven't heard of that movie. <br>
> User: You've just recommended that for me <br>
> Bot: Great! How about "The Matrix"? <br>
> User: What is the main character in that movie? <br>
> Bot: "The Matrix" is an action movie about a computer hacker named Neo who discovers that the world he lives in is actually a simulated reality created by machines. <br>
> User: What actor play Neo in that movie? <br>
> Bot: Neo is played by Keanu Reeves and plays the main character Neo. <br>
> User: end <br>
## Model Card Contact
For personal questions related to this model, please contact via reddotbluename@gmail.com
|
lewdryuna/A-Fulouma
|
lewdryuna
| 2023-05-06T14:08:32Z | 0 | 1 | null |
[
"license:unknown",
"region:us"
] | null | 2023-05-06T14:08:32Z |
---
license: unknown
duplicated_from: fulouma/MyLoRAs
---
Trigger word for LoRA on folder `concept`: cic
everything else: sls
note:
- unsuffixed LoRA is usually trained 10 epoch
- some of those need LoCon extension to work.
|
Baljinnyam/mongolian-gpt2-ner-finetuning
|
Baljinnyam
| 2023-05-06T14:06:56Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"gpt2",
"token-classification",
"generated_from_trainer",
"mn",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2023-05-06T11:36:36Z |
---
language:
- mn
tags:
- generated_from_trainer
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: mongolian-gpt2-ner-finetuning
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mongolian-gpt2-ner-finetuning
This model is a fine-tuned version of [bayartsogt/mongolian-gpt2](https://huggingface.co/bayartsogt/mongolian-gpt2) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3230
- Precision: 0.0989
- Recall: 0.2277
- F1: 0.1380
- Accuracy: 0.9078
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| 0.5225 | 1.0 | 477 | 0.3650 | 0.0743 | 0.1674 | 0.1030 | 0.8821 |
| 0.322 | 2.0 | 954 | 0.3129 | 0.0853 | 0.1903 | 0.1178 | 0.8966 |
| 0.2681 | 3.0 | 1431 | 0.3008 | 0.0915 | 0.2034 | 0.1262 | 0.9022 |
| 0.232 | 4.0 | 1908 | 0.2963 | 0.0914 | 0.2070 | 0.1269 | 0.9053 |
| 0.2029 | 5.0 | 2385 | 0.2974 | 0.0933 | 0.2120 | 0.1295 | 0.9071 |
| 0.1791 | 6.0 | 2862 | 0.3038 | 0.0949 | 0.2140 | 0.1315 | 0.9076 |
| 0.1603 | 7.0 | 3339 | 0.3100 | 0.0958 | 0.2186 | 0.1332 | 0.9079 |
| 0.146 | 8.0 | 3816 | 0.3174 | 0.0950 | 0.2156 | 0.1319 | 0.9079 |
| 0.1355 | 9.0 | 4293 | 0.3233 | 0.1001 | 0.2274 | 0.1390 | 0.9080 |
| 0.1291 | 10.0 | 4770 | 0.3230 | 0.0989 | 0.2277 | 0.1380 | 0.9078 |
### Framework versions
- Transformers 4.28.1
- Pytorch 2.0.0+cu118
- Datasets 2.12.0
- Tokenizers 0.13.3
|
PanoEvJ/Reinforce-CartPole-v1
|
PanoEvJ
| 2023-05-06T14:00:56Z | 0 | 0 | null |
[
"CartPole-v1",
"reinforce",
"reinforcement-learning",
"custom-implementation",
"deep-rl-class",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-05-06T13:09:44Z |
---
tags:
- CartPole-v1
- reinforce
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: Reinforce-CartPole-v1
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: CartPole-v1
type: CartPole-v1
metrics:
- type: mean_reward
value: 500.00 +/- 0.00
name: mean_reward
verified: false
---
# **Reinforce** Agent playing **CartPole-v1**
This is a trained model of a **Reinforce** agent playing **CartPole-v1** .
To learn to use this model and train yours check Unit 4 of the Deep Reinforcement Learning Course: https://huggingface.co/deep-rl-course/unit4/introduction
|
sarahh23/gptneo-txt2ARXMLv1.4
|
sarahh23
| 2023-05-06T13:40:20Z | 12 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt_neo",
"text-generation",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-05-06T13:38:41Z |
---
license: mit
tags:
- generated_from_trainer
model-index:
- name: gptneo-txt2ARXMLv1.4
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# gptneo-txt2ARXMLv1.4
This model is a fine-tuned version of [EleutherAI/gpt-neo-125m](https://huggingface.co/EleutherAI/gpt-neo-125m) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6133
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- distributed_type: multi-GPU
- gradient_accumulation_steps: 8
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 1000
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 2.8955 | 0.98 | 24 | 2.7129 |
| 1.3737 | 1.97 | 48 | 1.3135 |
| 0.8242 | 2.99 | 73 | 0.8354 |
| 0.66 | 3.98 | 97 | 0.6753 |
| 0.6143 | 4.92 | 120 | 0.6133 |
### Framework versions
- Transformers 4.28.1
- Pytorch 2.0.0+cu118
- Datasets 2.12.0
- Tokenizers 0.13.3
|
patilrohan94/ppo-LunarLander-v2
|
patilrohan94
| 2023-05-06T13:37:10Z | 1 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-05-01T19:37:57Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO_MLP
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 235.61 +/- 64.54
name: mean_reward
verified: false
---
# **PPO_MLP** Agent playing **LunarLander-v2**
This is a trained model of a **PPO_MLP** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
FredDYyy/roberta-base-squadv2
|
FredDYyy
| 2023-05-06T13:29:10Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"roberta",
"question-answering",
"generated_from_trainer",
"dataset:squad_v2",
"license:mit",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2023-05-06T10:27:06Z |
---
license: mit
tags:
- generated_from_trainer
datasets:
- squad_v2
model-index:
- name: roberta-base-squadv2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# roberta-base-squadv2
This model is a fine-tuned version of [roberta-base](https://huggingface.co/roberta-base) on the squad_v2 dataset.
It achieves the following results on the evaluation set:
- Loss: 1.6731
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 1.1898 | 1.0 | 1221 | 1.5332 |
| 0.7719 | 2.0 | 2443 | 1.5191 |
| 0.5484 | 3.0 | 3663 | 1.6731 |
### Framework versions
- Transformers 4.28.1
- Pytorch 2.0.0+cu118
- Datasets 2.12.0
- Tokenizers 0.13.3
|
yigg/bert-base-uncased-finetuned-cola
|
yigg
| 2023-05-06T13:25:27Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"text-classification",
"generated_from_trainer",
"dataset:glue",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-05-06T11:01:25Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- glue
metrics:
- matthews_correlation
model-index:
- name: bert-base-uncased-finetuned-cola
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: glue
type: glue
config: cola
split: validation
args: cola
metrics:
- name: Matthews Correlation
type: matthews_correlation
value: 0.46698933079472565
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-uncased-finetuned-cola
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on the glue dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5629
- Matthews Correlation: 0.4670
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1.866149341238024e-06
- train_batch_size: 4
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Matthews Correlation |
|:-------------:|:-----:|:----:|:---------------:|:--------------------:|
| 0.5043 | 1.0 | 2138 | 0.5637 | 0.3863 |
| 0.4399 | 2.0 | 4276 | 0.5629 | 0.4670 |
### Framework versions
- Transformers 4.28.1
- Pytorch 2.0.0+cu118
- Datasets 2.12.0
- Tokenizers 0.13.3
|
crumb/gpt-joke
|
crumb
| 2023-05-06T13:17:00Z | 7 | 2 |
transformers
|
[
"transformers",
"pytorch",
"safetensors",
"gpt2",
"text-generation",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-07-25T18:26:02Z |
gpt2 trained on reddit jokes that I was originally gonna do an instruct-gpt type thing with to finetune it to be better at jokes but I abandoned the project oops
|
Slygags/finetuned-Sentiment-classfication-BERT-model
|
Slygags
| 2023-05-06T13:14:34Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"text-classification",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-05-02T20:40:24Z |
---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: finetuned-Sentiment-classfication-BERT-model
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# finetuned-Sentiment-classfication-BERT-model
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6050
- Rmse: 0.6736
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- gradient_accumulation_steps: 16
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 10
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rmse |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 0.7556 | 2.0 | 500 | 0.6050 | 0.6736 |
| 0.3957 | 4.0 | 1000 | 0.7329 | 0.6560 |
| 0.1413 | 6.0 | 1500 | 1.0727 | 0.6941 |
| 0.0598 | 8.0 | 2000 | 1.3042 | 0.6483 |
| 0.0319 | 10.0 | 2500 | 1.3687 | 0.6544 |
### Framework versions
- Transformers 4.28.1
- Pytorch 2.0.0+cu118
- Datasets 2.12.0
- Tokenizers 0.13.3
|
rifatozkurt/bert-base-uncased-finetuned-cola
|
rifatozkurt
| 2023-05-06T13:12:00Z | 7 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"text-classification",
"generated_from_trainer",
"dataset:glue",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-05-06T11:50:38Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- glue
metrics:
- matthews_correlation
model-index:
- name: bert-base-uncased-finetuned-cola
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: glue
type: glue
config: cola
split: validation
args: cola
metrics:
- name: Matthews Correlation
type: matthews_correlation
value: 0.5805514135255713
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-uncased-finetuned-cola
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on the glue dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4434
- Matthews Correlation: 0.5806
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 8.302384098327798e-06
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Matthews Correlation |
|:-------------:|:-----:|:----:|:---------------:|:--------------------:|
| 0.5122 | 1.0 | 535 | 0.4803 | 0.4895 |
| 0.3629 | 2.0 | 1070 | 0.4434 | 0.5806 |
| 0.2857 | 3.0 | 1605 | 0.5283 | 0.5704 |
### Framework versions
- Transformers 4.28.1
- Pytorch 2.0.0+cu118
- Datasets 2.12.0
- Tokenizers 0.13.3
|
tabbleman/test
|
tabbleman
| 2023-05-06T13:02:20Z | 0 | 0 |
diffusers
|
[
"diffusers",
"code",
"ar",
"dataset:fka/awesome-chatgpt-prompts",
"license:mit",
"region:us"
] | null | 2023-05-06T12:59:25Z |
---
license: mit
datasets:
- fka/awesome-chatgpt-prompts
language:
- ar
metrics:
- accuracy
library_name: diffusers
tags:
- code
---
|
Soulaimen/convnext-large-224-22k-1k-bottomCleanedData
|
Soulaimen
| 2023-05-06T12:57:47Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"convnext",
"image-classification",
"generated_from_trainer",
"dataset:imagefolder",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2023-05-05T08:59:35Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- imagefolder
metrics:
- accuracy
model-index:
- name: convnext-large-224-22k-1k-bottomCleanedData
results:
- task:
name: Image Classification
type: image-classification
dataset:
name: imagefolder
type: imagefolder
config: default
split: train
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.9977298524404086
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# convnext-large-224-22k-1k-bottomCleanedData
This model is a fine-tuned version of [facebook/convnext-large-224-22k-1k](https://huggingface.co/facebook/convnext-large-224-22k-1k) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0067
- Accuracy: 0.9977
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 7
- total_train_batch_size: 56
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.01
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.2003 | 1.0 | 141 | 0.0628 | 0.9807 |
| 0.1568 | 2.0 | 283 | 0.0173 | 0.9943 |
| 0.1499 | 2.99 | 424 | 0.0211 | 0.9898 |
| 0.1189 | 4.0 | 566 | 0.0140 | 0.9955 |
| 0.084 | 4.99 | 707 | 0.0105 | 0.9955 |
| 0.0797 | 6.0 | 849 | 0.0093 | 0.9966 |
| 0.0781 | 7.0 | 991 | 0.0157 | 0.9921 |
| 0.1075 | 8.0 | 1132 | 0.0079 | 0.9943 |
| 0.0718 | 9.0 | 1274 | 0.0075 | 0.9966 |
| 0.0592 | 9.96 | 1410 | 0.0067 | 0.9977 |
### Framework versions
- Transformers 4.28.1
- Pytorch 2.0.0+cu118
- Datasets 2.12.0
- Tokenizers 0.13.3
|
jwcho/polyglot-ko-5.8b-chatdoctor
|
jwcho
| 2023-05-06T12:54:19Z | 14 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt_neox",
"text-generation",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-05-06T12:48:02Z |
---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: polyglot-5.8b-chatdoctor-v1.1b
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# polyglot-5.8b-chatdoctor-v1.1b
This model is a fine-tuned version of [EleutherAI/polyglot-ko-5.8b](https://huggingface.co/EleutherAI/polyglot-ko-5.8b) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 2
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 64
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
### Framework versions
- Transformers 4.28.1
- Pytorch 2.0.0+cu117
- Datasets 2.12.0
- Tokenizers 0.13.3
|
research-backup/mbart-large-cc25-squad-qa
|
research-backup
| 2023-05-06T12:48:31Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"mbart",
"text2text-generation",
"question answering",
"en",
"dataset:lmqg/qg_squad",
"arxiv:2210.03992",
"license:cc-by-4.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2023-03-31T19:43:55Z |
---
license: cc-by-4.0
metrics:
- bleu4
- meteor
- rouge-l
- bertscore
- moverscore
language: en
datasets:
- lmqg/qg_squad
pipeline_tag: text2text-generation
tags:
- question answering
widget:
- text: "question: What is a person called is practicing heresy?, context: Heresy is any provocative belief or theory that is strongly at variance with established beliefs or customs. A heretic is a proponent of such claims or beliefs. Heresy is distinct from both apostasy, which is the explicit renunciation of one's religion, principles or cause, and blasphemy, which is an impious utterance or action concerning God or sacred things."
example_title: "Question Answering Example 1"
- text: "question: who created the post as we know it today?, context: 'So much of The Post is Ben,' Mrs. Graham said in 1994, three years after Bradlee retired as editor. 'He created it as we know it today.'— Ed O'Keefe (@edatpost) October 21, 2014"
example_title: "Question Answering Example 2"
model-index:
- name: lmqg/mbart-large-cc25-squad-qa
results:
- task:
name: Text2text Generation
type: text2text-generation
dataset:
name: lmqg/qg_squad
type: default
args: default
metrics:
- name: BLEU4 (Question Answering)
type: bleu4_question_answering
value: 56.23
- name: ROUGE-L (Question Answering)
type: rouge_l_question_answering
value: 74.73
- name: METEOR (Question Answering)
type: meteor_question_answering
value: 43.17
- name: BERTScore (Question Answering)
type: bertscore_question_answering
value: 92.7
- name: MoverScore (Question Answering)
type: moverscore_question_answering
value: 84.01
- name: AnswerF1Score (Question Answering)
type: answer_f1_score__question_answering
value: 76.98
- name: AnswerExactMatch (Question Answering)
type: answer_exact_match_question_answering
value: 62.63
---
# Model Card of `lmqg/mbart-large-cc25-squad-qa`
This model is fine-tuned version of [facebook/mbart-large-cc25](https://huggingface.co/facebook/mbart-large-cc25) for question answering task on the [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) (dataset_name: default) via [`lmqg`](https://github.com/asahi417/lm-question-generation).
### Overview
- **Language model:** [facebook/mbart-large-cc25](https://huggingface.co/facebook/mbart-large-cc25)
- **Language:** en
- **Training data:** [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) (default)
- **Online Demo:** [https://autoqg.net/](https://autoqg.net/)
- **Repository:** [https://github.com/asahi417/lm-question-generation](https://github.com/asahi417/lm-question-generation)
- **Paper:** [https://arxiv.org/abs/2210.03992](https://arxiv.org/abs/2210.03992)
### Usage
- With [`lmqg`](https://github.com/asahi417/lm-question-generation#lmqg-language-model-for-question-generation-)
```python
from lmqg import TransformersQG
# initialize model
model = TransformersQG(language="en", model="lmqg/mbart-large-cc25-squad-qa")
# model prediction
answers = model.answer_q(list_question="What is a person called is practicing heresy?", list_context=" Heresy is any provocative belief or theory that is strongly at variance with established beliefs or customs. A heretic is a proponent of such claims or beliefs. Heresy is distinct from both apostasy, which is the explicit renunciation of one's religion, principles or cause, and blasphemy, which is an impious utterance or action concerning God or sacred things.")
```
- With `transformers`
```python
from transformers import pipeline
pipe = pipeline("text2text-generation", "lmqg/mbart-large-cc25-squad-qa")
output = pipe("question: What is a person called is practicing heresy?, context: Heresy is any provocative belief or theory that is strongly at variance with established beliefs or customs. A heretic is a proponent of such claims or beliefs. Heresy is distinct from both apostasy, which is the explicit renunciation of one's religion, principles or cause, and blasphemy, which is an impious utterance or action concerning God or sacred things.")
```
## Evaluation
- ***Metric (Question Answering)***: [raw metric file](https://huggingface.co/lmqg/mbart-large-cc25-squad-qa/raw/main/eval/metric.first.answer.paragraph_question.answer.lmqg_qg_squad.default.json)
| | Score | Type | Dataset |
|:-----------------|--------:|:--------|:---------------------------------------------------------------|
| AnswerExactMatch | 62.63 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) |
| AnswerF1Score | 76.98 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) |
| BERTScore | 92.7 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) |
| Bleu_1 | 69.46 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) |
| Bleu_2 | 64.72 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) |
| Bleu_3 | 60.19 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) |
| Bleu_4 | 56.23 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) |
| METEOR | 43.17 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) |
| MoverScore | 84.01 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) |
| ROUGE_L | 74.73 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) |
## Training hyperparameters
The following hyperparameters were used during fine-tuning:
- dataset_path: lmqg/qg_squad
- dataset_name: default
- input_types: ['paragraph_question']
- output_types: ['answer']
- prefix_types: None
- model: facebook/mbart-large-cc25
- max_length: 512
- max_length_output: 32
- epoch: 16
- batch: 16
- lr: 6e-05
- fp16: False
- random_seed: 1
- gradient_accumulation_steps: 4
- label_smoothing: 0.15
The full configuration can be found at [fine-tuning config file](https://huggingface.co/lmqg/mbart-large-cc25-squad-qa/raw/main/trainer_config.json).
## Citation
```
@inproceedings{ushio-etal-2022-generative,
title = "{G}enerative {L}anguage {M}odels for {P}aragraph-{L}evel {Q}uestion {G}eneration",
author = "Ushio, Asahi and
Alva-Manchego, Fernando and
Camacho-Collados, Jose",
booktitle = "Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing",
month = dec,
year = "2022",
address = "Abu Dhabi, U.A.E.",
publisher = "Association for Computational Linguistics",
}
```
|
mHossain/bangla-para-v2-120000
|
mHossain
| 2023-05-06T12:39:01Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"mt5",
"text2text-generation",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2023-05-06T10:42:56Z |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- rouge
model-index:
- name: bangla-para-v2-120000
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bangla-para-v2-120000
This model is a fine-tuned version of [mHossain/bangla-para-v2-90000](https://huggingface.co/mHossain/bangla-para-v2-90000) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.9277
- Rouge1: 0.0
- Rouge2: 0.0
- Rougel: 0.0
- Rougelsum: 0.0
- Gen Len: 17.575
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 5000
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:------:|:------:|:------:|:---------:|:-------:|
| 1.1615 | 1.0 | 3375 | 0.9277 | 0.0 | 0.0 | 0.0 | 0.0 | 17.575 |
### Framework versions
- Transformers 4.28.1
- Pytorch 2.0.0+cu118
- Datasets 2.12.0
- Tokenizers 0.13.3
|
sarahh23/gptneo-txt2ARXMLv1.3
|
sarahh23
| 2023-05-06T12:35:02Z | 14 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt_neo",
"text-generation",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-05-02T23:07:04Z |
---
license: mit
tags:
- generated_from_trainer
model-index:
- name: gptneo-txt2ARXMLv1.3
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# gptneo-txt2ARXMLv1.3
This model is a fine-tuned version of [EleutherAI/gpt-neo-125m](https://huggingface.co/EleutherAI/gpt-neo-125m) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5190
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- distributed_type: multi-GPU
- gradient_accumulation_steps: 8
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 1000
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 2.2367 | 0.99 | 32 | 2.1758 |
| 0.9974 | 1.98 | 64 | 0.9551 |
| 0.664 | 2.98 | 96 | 0.7031 |
| 0.5799 | 4.0 | 129 | 0.5972 |
| 0.4837 | 4.96 | 160 | 0.5190 |
### Framework versions
- Transformers 4.28.1
- Pytorch 2.0.0+cu118
- Datasets 2.12.0
- Tokenizers 0.13.3
|
amu-cai/slavlemma-base
|
amu-cai
| 2023-05-06T12:21:02Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"mt5",
"text2text-generation",
"mT5",
"lemmatization",
"pl",
"cs",
"ru",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2023-03-15T15:34:35Z |
---
language:
- pl
- cs
- ru
tags:
- mT5
- lemmatization
license: apache-2.0
---
# SlavLemma Base
SlavLemma models are intended for lemmatization of named entities and multi-word expressions in Polish, Czech and Russian languages.
They were fine-tuned from the google/mT5 models, e.g.: [google/mt5-base](https://huggingface.co/google/mt5-base).
## Usage
When using the model, prepend one of the language tokens (`>>pl<<`, `>>cs<<`, `>>ru<<`) to the input, based on the language of the phrase you want to lemmatize.
Sample usage:
```
from transformers import pipeline
pipe = pipeline(task="text2text-generation", model="amu-cai/slavlemma-base", tokenizer="amu-cai/slavlemma-base")
hyp = [res['generated_text'] for res in pipe([">>pl<< federalnego urzędu statystycznego"], clean_up_tokenization_spaces=True, num_beams=5)][0]
```
## Evaluation results
Lemmatization Exact Match was computed on the SlavNER 2021 test sets (COVID-19 and USA 2020 Elections).
COVID-19:
| Model | pl | cs | ru |
| :------ | ------: | ------: | ------: |
| [slavlemma-large](https://huggingface.co/amu-cai/slavlemma-large) | 93.76 | 89.80 | 77.30
| [slavlemma-base](https://huggingface.co/amu-cai/slavlemma-base) | 91.00 |86.29| 76.10
| [slavlemma-small](https://huggingface.co/amu-cai/slavlemma-small)| 86.80 |80.98| 73.83
USA 2020 Elections:
| Model | pl | cs | ru |
| :------ | ------: | ------: | ------: |
| [slavlemma-large](https://huggingface.co/amu-cai/slavlemma-large) | 89.12 | 87.27| 82.50
| [slavlemma-base](https://huggingface.co/amu-cai/slavlemma-base) | 84.19 |81.97| 80.27
| [slavlemma-small](https://huggingface.co/amu-cai/slavlemma-small)| 78.85 |75.86| 76.18
## Citation
If you use the model, please cite the following paper:
```
@inproceedings{palka-nowakowski-2023-exploring,
title = "Exploring the Use of Foundation Models for Named Entity Recognition and Lemmatization Tasks in {S}lavic Languages",
author = "Pa{\l}ka, Gabriela and
Nowakowski, Artur",
booktitle = "Proceedings of the 9th Workshop on Slavic Natural Language Processing 2023 (SlavicNLP 2023)",
month = may,
year = "2023",
address = "Dubrovnik, Croatia",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2023.bsnlp-1.19",
pages = "165--171",
abstract = "This paper describes Adam Mickiewicz University{'}s (AMU) solution for the 4th Shared Task on SlavNER. The task involves the identification, categorization, and lemmatization of named entities in Slavic languages. Our approach involved exploring the use of foundation models for these tasks. In particular, we used models based on the popular BERT and T5 model architectures. Additionally, we used external datasets to further improve the quality of our models. Our solution obtained promising results, achieving high metrics scores in both tasks. We describe our approach and the results of our experiments in detail, showing that the method is effective for NER and lemmatization in Slavic languages. Additionally, our models for lemmatization will be available at: https://huggingface.co/amu-cai.",
}
```
### Framework versions
- Transformers 4.26.0
- Pytorch 1.13.1.post200
- Datasets 2.9.0
- Tokenizers 0.13.2
|
Actuary/ppo-Huggy
|
Actuary
| 2023-05-06T11:58:23Z | 12 | 0 |
ml-agents
|
[
"ml-agents",
"tensorboard",
"onnx",
"Huggy",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-Huggy",
"region:us"
] |
reinforcement-learning
| 2023-05-06T11:58:16Z |
---
library_name: ml-agents
tags:
- Huggy
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-Huggy
---
# **ppo** Agent playing **Huggy**
This is a trained model of a **ppo** agent playing **Huggy** using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://github.com/huggingface/ml-agents#get-started
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
### Resume the training
```
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser:**.
1. Go to https://huggingface.co/spaces/unity/ML-Agents-Huggy
2. Step 1: Find your model_id: Actuary/ppo-Huggy
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
sarahh23/gptneo-txt2ARXMLv1.2
|
sarahh23
| 2023-05-06T11:40:17Z | 14 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"gpt_neo",
"text-generation",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-05-03T10:14:45Z |
---
license: mit
tags:
- generated_from_trainer
model-index:
- name: gptneo-txt2ARXMLv1.2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# gptneo-txt2ARXMLv1.2
This model is a fine-tuned version of [EleutherAI/gpt-neo-125m](https://huggingface.co/EleutherAI/gpt-neo-125m) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4856
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- distributed_type: multi-GPU
- gradient_accumulation_steps: 8
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 1000
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 1.563 | 0.99 | 42 | 1.7070 |
| 0.8432 | 1.98 | 84 | 0.8247 |
| 0.6679 | 3.0 | 127 | 0.6406 |
| 0.5054 | 3.99 | 169 | 0.5493 |
| 0.4171 | 4.96 | 210 | 0.4856 |
### Framework versions
- Transformers 4.28.1
- Pytorch 2.0.0+cu118
- Datasets 2.12.0
- Tokenizers 0.13.3
|
rlagofls33/kogpt2-base-v2-finetuned-klue-ner
|
rlagofls33
| 2023-05-06T11:23:35Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"gpt2",
"token-classification",
"generated_from_trainer",
"dataset:klue",
"license:cc-by-nc-sa-4.0",
"model-index",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2023-05-03T11:56:12Z |
---
license: cc-by-nc-sa-4.0
tags:
- generated_from_trainer
datasets:
- klue
metrics:
- f1
model-index:
- name: kogpt2-base-v2-finetuned-klue-ner
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: klue
type: klue
config: ner
split: validation
args: ner
metrics:
- name: F1
type: f1
value: 0.37298165525403665
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# kogpt2-base-v2-finetuned-klue-ner
This model is a fine-tuned version of [skt/kogpt2-base-v2](https://huggingface.co/skt/kogpt2-base-v2) on the klue dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4076
- F1: 0.3730
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 24
- eval_batch_size: 24
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 0.6084 | 1.0 | 876 | 0.5353 | 0.2118 |
| 0.3911 | 2.0 | 1752 | 0.4691 | 0.3041 |
| 0.2855 | 3.0 | 2628 | 0.4076 | 0.3730 |
### Framework versions
- Transformers 4.28.1
- Pytorch 2.0.0+cu118
- Datasets 2.12.0
- Tokenizers 0.13.3
|
philschmid/gpt-j-6B-fp16-sharded
|
philschmid
| 2023-05-06T11:06:03Z | 5 | 9 |
generic
|
[
"generic",
"pytorch",
"gptj",
"endpoints-template",
"endpoints_compatible",
"region:us"
] | null | 2022-08-25T12:19:41Z |
---
tags:
- endpoints-template
library_name: generic
---
# Shareded fp16 copy of [EleutherAI/gpt-j-6B](https://huggingface.co/EleutherAI/gpt-j-6B)
> This is fork of [EleutherAI/gpt-j-6B](https://huggingface.co/EleutherAI/gpt-j-6B) with shareded fp16 weights implementing a custom `handler.py` as an example for how to use `gpt-j` [inference-endpoints](https://hf.co/inference-endpoints)
|
reachlin/ppo-LunarLander-v2
|
reachlin
| 2023-05-06T10:53:04Z | 4 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-05-06T10:52:39Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 245.02 +/- 46.22
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
Subsets and Splits
Filtered Qwen2.5 Distill Models
Identifies specific configurations of models by filtering cards that contain 'distill', 'qwen2.5', '7b' while excluding certain base models and incorrect model ID patterns, uncovering unique model variants.
Filtered Model Cards Count
Finds the count of entries with specific card details that include 'distill', 'qwen2.5', '7b' but exclude certain base models, revealing valuable insights about the dataset's content distribution.
Filtered Distill Qwen 7B Models
Filters for specific card entries containing 'distill', 'qwen', and '7b', excluding certain strings and patterns, to identify relevant model configurations.
Filtered Qwen-7b Model Cards
The query performs a detailed filtering based on specific keywords and excludes certain entries, which could be useful for identifying a specific subset of cards but does not provide deeper insights or trends.
Filtered Qwen 7B Model Cards
The query filters for specific terms related to "distilled" or "distill", "qwen", and "7b" in the 'card' column but excludes certain base models, providing a limited set of entries for further inspection.
Qwen 7B Distilled Models
The query provides a basic filtering of records to find specific card names that include keywords related to distilled Qwen 7b models, excluding a particular base model, which gives limited insight but helps in focusing on relevant entries.
Qwen 7B Distilled Model Cards
The query filters data based on specific keywords in the modelId and card fields, providing limited insight primarily useful for locating specific entries rather than revealing broad patterns or trends.
Qwen 7B Distilled Models
Finds all entries containing the terms 'distilled', 'qwen', and '7b' in a case-insensitive manner, providing a filtered set of records but without deeper analysis.
Distilled Qwen 7B Models
The query filters for specific model IDs containing 'distilled', 'qwen', and '7b', providing a basic retrieval of relevant entries but without deeper analysis or insight.
Filtered Model Cards with Distill Qwen2.
Filters and retrieves records containing specific keywords in the card description while excluding certain phrases, providing a basic count of relevant entries.
Filtered Model Cards with Distill Qwen 7
The query filters specific variations of card descriptions containing 'distill', 'qwen', and '7b' while excluding a particular base model, providing limited but specific data retrieval.
Distill Qwen 7B Model Cards
The query filters and retrieves rows where the 'card' column contains specific keywords ('distill', 'qwen', and '7b'), providing a basic filter result that can help in identifying specific entries.