
modelId
stringlengths 5
139
| author
stringlengths 2
42
| last_modified
timestamp[us, tz=UTC]date 2020-02-15 11:33:14
2025-08-27 06:27:59
| downloads
int64 0
223M
| likes
int64 0
11.7k
| library_name
stringclasses 521
values | tags
listlengths 1
4.05k
| pipeline_tag
stringclasses 55
values | createdAt
timestamp[us, tz=UTC]date 2022-03-02 23:29:04
2025-08-27 06:27:44
| card
stringlengths 11
1.01M
|
|---|---|---|---|---|---|---|---|---|---|
Jellywibble/dalio-principles-pretrain-v2
|
Jellywibble
| 2022-11-20T01:55:33Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"opt",
"text-generation",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-11-19T19:42:56Z |
---
tags:
- text-generation
library_name: transformers
---
## Model description
Based off facebook/opt-30b model, finetuned on chucked Dalio responses
## Dataset Used
Jellywibble/dalio-pretrain-book-dataset-v2
## Training Parameters
- Deepspeed on 4xA40 GPUs
- Ensuring EOS token `<s>` appears only at the beginning of each chunk
- Gradient Accumulation steps = 1 (Effective batch size of 4)
- 3e-6 Learning Rate, AdamW optimizer
- Block size of 800
- Trained for 1 Epoch (additional epochs yielded worse Hellaswag result)
## Metrics
- Hellaswag Perplexity: 30.2
- Eval accuracy: 49.8%
- Eval loss: 2.283
- Checkpoint 16 uploaded
- wandb run: https://wandb.ai/jellywibble/huggingface/runs/2vtr39rk?workspace=user-jellywibble
|
jammygrams/bart-qa
|
jammygrams
| 2022-11-20T01:24:11Z | 119 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bart",
"text2text-generation",
"license:openrail",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-11-17T14:15:23Z |
---
license: openrail
---
See https://github.com/jammygrams/Pea-QA for details on model training (with narrativeqa dataset)
|
monakth/bert-base-cased-finetuned-squadv2
|
monakth
| 2022-11-20T00:49:07Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"question-answering",
"generated_from_trainer",
"dataset:squad_v2",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-11-20T00:47:41Z |
---
tags:
- generated_from_trainer
datasets:
- squad_v2
model-index:
- name: bert-base-cased-finetuned-squadv
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-cased-finetuned-squadv
This model is a fine-tuned version of [monakth/bert-base-cased-finetuned-squad](https://huggingface.co/monakth/bert-base-cased-finetuned-squad) on the squad_v2 dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Framework versions
- Transformers 4.20.1
- Pytorch 1.11.0
- Datasets 2.1.0
- Tokenizers 0.12.1
|
milyiyo/paraphraser-spanish-t5-base
|
milyiyo
| 2022-11-20T00:25:08Z | 110 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"t5",
"text2text-generation",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-11-17T14:55:45Z |
---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: paraphraser-spanish-t5-base
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# paraphraser-spanish-t5-base
This model is a fine-tuned version of [milyiyo/paraphraser-spanish-t5-base](https://huggingface.co/milyiyo/paraphraser-spanish-t5-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7572
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 10
- eval_batch_size: 10
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-----:|:---------------:|
| 1.1212 | 0.07 | 2000 | 0.8120 |
| 1.2263 | 0.14 | 4000 | 0.7773 |
| 1.1976 | 0.21 | 6000 | 0.7745 |
| 1.1828 | 0.28 | 8000 | 0.7675 |
| 1.1399 | 0.35 | 10000 | 0.7668 |
| 1.1378 | 0.42 | 12000 | 0.7651 |
| 1.1035 | 0.5 | 14000 | 0.7644 |
| 1.0923 | 0.57 | 16000 | 0.7633 |
| 1.0924 | 0.64 | 18000 | 0.7594 |
| 1.0943 | 0.71 | 20000 | 0.7578 |
| 1.0872 | 0.78 | 22000 | 0.7575 |
| 1.0755 | 0.85 | 24000 | 0.7599 |
| 1.0806 | 0.92 | 26000 | 0.7558 |
| 1.079 | 0.99 | 28000 | 0.7572 |
### Framework versions
- Transformers 4.24.0
- Pytorch 1.12.1+cu113
- Datasets 2.7.0
- Tokenizers 0.13.2
|
dvitel/h3
|
dvitel
| 2022-11-19T22:26:00Z | 116 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"distigpt2",
"hearthstone",
"dataset:dvitel/hearthstone",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-11-19T01:53:19Z |
---
license: apache-2.0
tags:
- distigpt2
- hearthstone
metrics:
- bleu
- dvitel/codebleu
- exact_match
- chrf
datasets:
- dvitel/hearthstone
model-index:
- name: h0
results:
- task:
type: text-generation
name: Python Code Synthesis
dataset:
type: dvitel/hearthstone
name: HearthStone
split: test
metrics:
- type: exact_match
value: 0.30303030303030304
name: Exact Match
- type: bleu
value: 0.8850182403024257
name: BLEU
- type: dvitel/codebleu
value: 0.677852377992836
name: CodeBLEU
- type: chrf
value: 91.00848749530383
name: chrF
---
# h3
This model is a fine-tuned version of [distilgpt2](https://huggingface.co/distilgpt2) on [hearthstone](https://huggingface.co/datasets/dvitel/hearthstone) dataset.
[GitHub repo](https://github.com/dvitel/nlp-sem-parsing/blob/master/h3.py).
It achieves the following results on the evaluation set:
- Loss: 0.2782
- Exact Match: 0.2879
- Bleu: 0.9121
- Codebleu: 0.7482
- Ngram Match Score: 0.7504
- Weighted Ngram Match Score: 0.7583
- Syntax Match Score: 0.7673
- Dataflow Match Score: 0.7169
- Chrf: 93.1064
## Model description
DistilGPT2 fine-tuned on HearthStone dataset for 200 epochs. \
Related to [dvitel/h0](https://huggingface.co/dvitel/h0) but with preprocessing which anonymizes classes and function variables (Local renaming). \
[dvitel/h2](https://huggingface.co/dvitel/h2) implements global renaming where all names are removed. Global renaming showed worse results compared to local renaming.
Example of generated code with mistake on last eval iteration (EV L - gold labels, EV P - prediction):
```python
EV L class CLS0(MinionCard):
def __init__(self):
super().__init__('Darkscale Healer', 5, CHARACTER_CLASS.ALL, CARD_RARITY.COMMON, battlecry=Battlecry(Heal(2), CharacterSelector()))
def create_minion(self, v0):
return Minion(4, 5)
EV P class CLS0(MinionCard):
def __init__(self):
super().__init__('Darkscale Healer', 5, CHARACTER_CLASS.ALL, CARD_RARITY.COMMON, battlecry=Battlecry(Heal(2), CharacterSelector())
def create_minion(self, v0):
return Minion(4, 5)
EV L class CLS0(WeaponCard):
def __init__(self):
super().__init__('Fiery War Axe', 2, CHARACTER_CLASS.WARRIOR, CARD_RARITY.FREE)
def create_weapon(self, v0):
return Weapon(3, 2)
EV P class CLS0(WeaponCard):
def __init__(self):
super().__init__('Fiery War Axe', 2, CHARACTER_CLASS.WARRIOR, CARD_RARITY.FREE,
def create_weapon(self, v0):
return Weapon(3, 2)
EV L class CLS0(MinionCard):
def __init__(self):
super().__init__('Frostwolf Warlord', 5, CHARACTER_CLASS.ALL, CARD_RARITY.COMMON, battlecry=Battlecry(Give([Buff(ChangeAttack(Count(MinionSelector()))), Buff(ChangeHealth(Count(MinionSelector())))]), SelfSelector()))
def create_minion(self, v0):
return Minion(4, 4)
EV P class CLS0(MinionCard):
def __init__(self):
super().__init__('Frostwolf Warlord', 5, CHARACTER_CLASS.ALL, CARD_RARITY.COMMON, battlecry=Battlecry(Give([Buff(ChangeAttack(Count(MinionSelector(),), Buff(ChangeHealth(Count(MinionSelector()))))]),), SelfSelector()))
def create_minion(self, v0):
return Minion(4, 4)
EV L class CLS0(SpellCard):
def __init__(self):
super().__init__('Hellfire', 4, CHARACTER_CLASS.WARLOCK, CARD_RARITY.FREE)
def use(self, v0, v1):
super().use(v0, v1)
v2 = copy.copy(v1.other_player.minions)
v2.extend(v1.current_player.minions)
v2.append(v1.other_player.hero)
v2.append(v1.current_player.hero)
for v3 in v2:
v3.damage(v0.effective_spell_damage(3), self)
EV P class CLS0(SpellCard):
def __init__(self):
super().__init__('Hellfire', 4, CHARACTER_CLASS.WARLOCK, CARD_RARITY.FREE,
def use(self, v0, v1):
super().use(v0, v1)
v2 = copy.copy(v1.other_player.minions)
v2.extend(v1.current_player.minions)
for.append(v1.other_player.hero)
for.append(v1.other_player.hero)
for v3 in v2:
.damage(v0.effective_spell_damage(3), self)
```
## Intended uses & limitations
HearthStone card code synthesis.
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 17
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- num_epochs: 200
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Exact Match | Bleu | Codebleu | Ngram Match Score | Weighted Ngram Match Score | Syntax Match Score | Dataflow Match Score | Chrf |
|:-------------:|:------:|:-----:|:---------------:|:-----------:|:------:|:--------:|:-----------------:|:--------------------------:|:------------------:|:--------------------:|:-------:|
| 0.8612 | 11.94 | 1600 | 0.2725 | 0.0455 | 0.8477 | 0.6050 | 0.6229 | 0.6335 | 0.6203 | 0.5431 | 88.7010 |
| 0.175 | 23.88 | 3200 | 0.2311 | 0.0909 | 0.8739 | 0.6304 | 0.6566 | 0.6656 | 0.6484 | 0.5508 | 90.7364 |
| 0.1036 | 35.82 | 4800 | 0.2172 | 0.1818 | 0.8930 | 0.6905 | 0.6976 | 0.7062 | 0.7172 | 0.6409 | 91.9702 |
| 0.0695 | 47.76 | 6400 | 0.2233 | 0.2424 | 0.8944 | 0.7017 | 0.7148 | 0.7232 | 0.7187 | 0.6499 | 92.0340 |
| 0.0482 | 59.7 | 8000 | 0.2407 | 0.2879 | 0.9046 | 0.7301 | 0.7387 | 0.7456 | 0.7475 | 0.6885 | 92.6219 |
| 0.0352 | 71.64 | 9600 | 0.2407 | 0.2424 | 0.9074 | 0.7255 | 0.7371 | 0.7448 | 0.7482 | 0.6718 | 92.8281 |
| 0.0262 | 83.58 | 11200 | 0.2596 | 0.3030 | 0.9061 | 0.7445 | 0.7415 | 0.7500 | 0.7774 | 0.7091 | 92.6737 |
| 0.0213 | 95.52 | 12800 | 0.2589 | 0.2879 | 0.9061 | 0.7308 | 0.7409 | 0.7488 | 0.7464 | 0.6873 | 92.7814 |
| 0.0164 | 107.46 | 14400 | 0.2679 | 0.2879 | 0.9096 | 0.7452 | 0.7510 | 0.7592 | 0.7626 | 0.7079 | 92.9900 |
| 0.0131 | 119.4 | 16000 | 0.2660 | 0.2879 | 0.9096 | 0.7447 | 0.7480 | 0.7564 | 0.7666 | 0.7079 | 93.0122 |
| 0.0116 | 131.34 | 17600 | 0.2669 | 0.2727 | 0.9092 | 0.7463 | 0.7445 | 0.7529 | 0.7684 | 0.7194 | 92.9256 |
| 0.0093 | 143.28 | 19200 | 0.2678 | 0.2879 | 0.9113 | 0.7531 | 0.7496 | 0.7581 | 0.7709 | 0.7336 | 93.0406 |
| 0.0083 | 155.22 | 20800 | 0.2728 | 0.2879 | 0.9103 | 0.7407 | 0.7462 | 0.7540 | 0.7702 | 0.6924 | 92.9302 |
| 0.0077 | 167.16 | 22400 | 0.2774 | 0.2879 | 0.9103 | 0.7449 | 0.7449 | 0.7532 | 0.7659 | 0.7156 | 92.9742 |
| 0.0069 | 179.1 | 24000 | 0.2774 | 0.2879 | 0.9120 | 0.7396 | 0.7463 | 0.7539 | 0.7633 | 0.6950 | 93.1057 |
| 0.0069 | 191.04 | 25600 | 0.2782 | 0.2879 | 0.9121 | 0.7482 | 0.7504 | 0.7583 | 0.7673 | 0.7169 | 93.1064 |
### Framework versions
- Transformers 4.24.0
- Pytorch 1.13.0
- Datasets 2.6.1
- Tokenizers 0.13.1
|
cyburn/silvery_trait
|
cyburn
| 2022-11-19T20:47:34Z | 0 | 0 | null |
[
"license:unknown",
"region:us"
] | null | 2022-11-19T20:40:37Z |
---
license: unknown
---
# Silvery Trait finetuned style Model
Produced from publicly available pictures in landscape, portrait and square format.
Using words found in `prompt_words.md` within your prompt will produce better results. Other words can be used also but will tend to produce "weaker" results. Combining the use of the Aesthetic Gradient file provided in the `easthetic_embeddings` folder can greatly enhance the results.
## Model info
The models included was trained on "multi-resolution" images.
## Using the model
* common subject prompt tokens: `<wathever>, by asd artstyle`
## Example prompts
`a sheep, symmetry, by asd artstyle`:
* without easthetic_embeddings
<img src="https://huggingface.co/cyburn/silvery_trait/resolve/main/1.jpg" alt="Picture." width="500"/>
* with easthetic_embeddings
<img src="https://huggingface.co/cyburn/silvery_trait/resolve/main/2.jpg" alt="Picture." width="500"/>
`crow, skull, symmetry, flower, feather, circle, by asd artstyle`
* without easthetic_embeddings
<img src="https://huggingface.co/cyburn/silvery_trait/resolve/main/3.jpg" alt="Picture." width="500"/>
* with easthetic_embeddings
<img src="https://huggingface.co/cyburn/silvery_trait/resolve/main/4.jpg" alt="Picture." width="500"/>
|
cahya/t5-base-indonesian-summarization-cased
|
cahya
| 2022-11-19T20:41:24Z | 497 | 5 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"jax",
"t5",
"text2text-generation",
"pipeline:summarization",
"summarization",
"id",
"dataset:id_liputan6",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
summarization
| 2022-03-02T23:29:05Z |
---
language: id
tags:
- pipeline:summarization
- summarization
- t5
datasets:
- id_liputan6
---
# Indonesian T5 Summarization Base Model
Finetuned T5 base summarization model for Indonesian.
## Finetuning Corpus
`t5-base-indonesian-summarization-cased` model is based on `t5-base-bahasa-summarization-cased` by [huseinzol05](https://huggingface.co/huseinzol05), finetuned using [id_liputan6](https://huggingface.co/datasets/id_liputan6) dataset.
## Load Finetuned Model
```python
from transformers import T5Tokenizer, T5Model, T5ForConditionalGeneration
tokenizer = T5Tokenizer.from_pretrained("cahya/t5-base-indonesian-summarization-cased")
model = T5ForConditionalGeneration.from_pretrained("cahya/t5-base-indonesian-summarization-cased")
```
## Code Sample
```python
from transformers import T5Tokenizer, T5ForConditionalGeneration
tokenizer = T5Tokenizer.from_pretrained("cahya/t5-base-indonesian-summarization-cased")
model = T5ForConditionalGeneration.from_pretrained("cahya/t5-base-indonesian-summarization-cased")
#
ARTICLE_TO_SUMMARIZE = ""
# generate summary
input_ids = tokenizer.encode(ARTICLE_TO_SUMMARIZE, return_tensors='pt')
summary_ids = model.generate(input_ids,
min_length=20,
max_length=80,
num_beams=10,
repetition_penalty=2.5,
length_penalty=1.0,
early_stopping=True,
no_repeat_ngram_size=2,
use_cache=True,
do_sample = True,
temperature = 0.8,
top_k = 50,
top_p = 0.95)
summary_text = tokenizer.decode(summary_ids[0], skip_special_tokens=True)
print(summary_text)
```
Output:
```
```
|
fernanda-dionello/good-reads-string
|
fernanda-dionello
| 2022-11-19T20:16:34Z | 99 | 0 |
transformers
|
[
"transformers",
"pytorch",
"autotrain",
"text-classification",
"en",
"dataset:fernanda-dionello/autotrain-data-autotrain_goodreads_string",
"co2_eq_emissions",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-11-19T20:11:24Z |
---
tags:
- autotrain
- text-classification
language:
- en
widget:
- text: "I love AutoTrain 🤗"
datasets:
- fernanda-dionello/autotrain-data-autotrain_goodreads_string
co2_eq_emissions:
emissions: 0.04700680417595474
---
# Model Trained Using AutoTrain
- Problem type: Multi-class Classification
- Model ID: 2164069744
- CO2 Emissions (in grams): 0.0470
## Validation Metrics
- Loss: 0.806
- Accuracy: 0.686
- Macro F1: 0.534
- Micro F1: 0.686
- Weighted F1: 0.678
- Macro Precision: 0.524
- Micro Precision: 0.686
- Weighted Precision: 0.673
- Macro Recall: 0.551
- Micro Recall: 0.686
- Weighted Recall: 0.686
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoTrain"}' https://api-inference.huggingface.co/models/fernanda-dionello/autotrain-autotrain_goodreads_string-2164069744
```
Or Python API:
```
from transformers import AutoModelForSequenceClassification, AutoTokenizer
model = AutoModelForSequenceClassification.from_pretrained("fernanda-dionello/autotrain-autotrain_goodreads_string-2164069744", use_auth_token=True)
tokenizer = AutoTokenizer.from_pretrained("fernanda-dionello/autotrain-autotrain_goodreads_string-2164069744", use_auth_token=True)
inputs = tokenizer("I love AutoTrain", return_tensors="pt")
outputs = model(**inputs)
```
|
Rajaram1996/Hubert_emotion
|
Rajaram1996
| 2022-11-19T20:10:41Z | 275 | 32 |
transformers
|
[
"transformers",
"pytorch",
"hubert",
"speech",
"audio",
"HUBert",
"audio-classification",
"endpoints_compatible",
"region:us"
] |
audio-classification
| 2022-03-02T23:29:04Z |
---
inference: true
pipeline_tag: audio-classification
tags:
- speech
- audio
- HUBert
---
Working example of using pretrained model to predict emotion in local audio file
```
def predict_emotion_hubert(audio_file):
""" inspired by an example from https://github.com/m3hrdadfi/soxan """
from audio_models import HubertForSpeechClassification
from transformers import Wav2Vec2FeatureExtractor, AutoConfig
import torch.nn.functional as F
import torch
import numpy as np
from pydub import AudioSegment
model = HubertForSpeechClassification.from_pretrained("Rajaram1996/Hubert_emotion") # Downloading: 362M
feature_extractor = Wav2Vec2FeatureExtractor.from_pretrained("facebook/hubert-base-ls960")
sampling_rate=16000 # defined by the model; must convert mp3 to this rate.
config = AutoConfig.from_pretrained("Rajaram1996/Hubert_emotion")
def speech_file_to_array(path, sampling_rate):
# using torchaudio...
# speech_array, _sampling_rate = torchaudio.load(path)
# resampler = torchaudio.transforms.Resample(_sampling_rate, sampling_rate)
# speech = resampler(speech_array).squeeze().numpy()
sound = AudioSegment.from_file(path)
sound = sound.set_frame_rate(sampling_rate)
sound_array = np.array(sound.get_array_of_samples())
return sound_array
sound_array = speech_file_to_array(audio_file, sampling_rate)
inputs = feature_extractor(sound_array, sampling_rate=sampling_rate, return_tensors="pt", padding=True)
inputs = {key: inputs[key].to("cpu").float() for key in inputs}
with torch.no_grad():
logits = model(**inputs).logits
scores = F.softmax(logits, dim=1).detach().cpu().numpy()[0]
outputs = [{
"emo": config.id2label[i],
"score": round(score * 100, 1)}
for i, score in enumerate(scores)
]
return [row for row in sorted(outputs, key=lambda x:x["score"], reverse=True) if row['score'] != '0.0%'][:2]
```
```
result = predict_emotion_hubert("male-crying.mp3")
>>> result
[{'emo': 'male_sad', 'score': 91.0}, {'emo': 'male_fear', 'score': 4.8}]
```
|
chieunq/XLM-R-base-finetuned-uit-vquad-1
|
chieunq
| 2022-11-19T20:02:14Z | 108 | 0 |
transformers
|
[
"transformers",
"pytorch",
"xlm-roberta",
"question-answering",
"vi",
"dataset:uit-vquad",
"arxiv:2009.14725",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-11-19T19:00:55Z |
---
language: vi
tags:
- vi
- xlm-roberta
widget:
- text: 3 thành viên trong nhóm gồm những ai ?
context: "Nhóm của chúng tôi là sinh viên năm 4 trường ĐH Công Nghệ - ĐHQG Hà Nội. Nhóm gồm 3 thành viên: Nguyễn Quang Chiều, Nguyễn Quang Huy và Nguyễn Trần Anh Đức . Đây là pha Reader trong dự án cuồi kì môn Các vấn đề hiện đại trong CNTT của nhóm ."
datasets:
- uit-vquad
metrics:
- EM (exact match) : 60.63
- F1 : 79.63
---
We fined-tune model XLM-Roberta-base in UIT-vquad dataset (https://arxiv.org/pdf/2009.14725.pdf)
### Performance
- EM (exact match) : 60.63
- F1 : 79.63
### How to run
```
from transformers import pipeline
# Replace this with your own checkpoint
model_checkpoint = "chieunq/XLM-R-base-finetuned-uit-vquad-1"
question_answerer = pipeline("question-answering", model=model_checkpoint)
context = """
Nhóm của chúng tôi là sinh viên năm 4 trường ĐH Công Nghệ - ĐHQG Hà Nội. Nhóm gồm 3 thành viên : Nguyễn Quang Chiều, Nguyễn Quang Huy và Nguyễn Trần Anh Đức . Đây là pha Reader trong dự án cuồi kì môn Các vấn đề hiện đại trong CNTT của nhóm .
"""
question = "3 thành viên trong nhóm gồm những ai ?"
question_answerer(question=question, context=context)
```
### Output
```
{'score': 0.9928902387619019,
'start': 98,
'end': 158,
'answer': 'Nguyễn Quang Chiều, Nguyễn Quang Huy và Nguyễn Trần Anh Đức.'}
```
### Framework versions
- Transformers 4.24.0
- Pytorch 1.12.1+cu113
- Datasets 2.7.0
- Tokenizers 0.13.2
|
Froddan/furiostyle
|
Froddan
| 2022-11-19T19:28:35Z | 0 | 3 | null |
[
"stable-diffusion",
"text-to-image",
"en",
"license:cc0-1.0",
"region:us"
] |
text-to-image
| 2022-11-19T19:10:50Z |
---
license: cc0-1.0
inference: false
language:
- en
tags:
- stable-diffusion
- text-to-image
---
# Stable Diffusion fine tuned on art by [Furio Tedeshi](https://www.furiotedeschi.com/)
### Usage
Use by adding the keyword "furiostyle" to the prompt. The model was trained with the "demon" classname, which can also be added to the prompt.
## Samples
For this model I made two checkpoints. The "furiostyle demon x2" model is trained for twice as long as the regular checkpoint, meaning it should be more fine tuned on the style but also more rigid. The top 4 images are from the regular version, the rest are from the x2 version. I hope it gives you an idea of what kind of styles can be created with this model. I think the x2 model got better results this time around, if you would compare the dog and the mushroom.
<img src="https://huggingface.co/Froddan/furiostyle/resolve/main/1000_2.png" width="256px"/>
<img src="https://huggingface.co/Froddan/furiostyle/resolve/main/1000_4.png" width="256px"/>
<img src="https://huggingface.co/Froddan/furiostyle/resolve/main/dog_1000_2.png" width="256px"/>
<img src="https://huggingface.co/Froddan/furiostyle/resolve/main/mushroom_1000_2.png" width="256px"/>
<img src="https://huggingface.co/Froddan/furiostyle/resolve/main/2000_1.png" width="256px"/>
<img src="https://huggingface.co/Froddan/furiostyle/resolve/main/2000_4.png" width="256px"/>
<img src="https://huggingface.co/Froddan/furiostyle/resolve/main/mushroom_cave_4.png" width="256px"/>
<img src="https://huggingface.co/Froddan/furiostyle/resolve/main/mushroom_cave_ornate.png" width="256px"/>
<img src="https://huggingface.co/Froddan/furiostyle/resolve/main/dog_2.png" width="256px"/>
### 🧨 Diffusers
This model can be used just like any other Stable Diffusion model. For more information,
please have a look at the [Stable Diffusion](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion).
|
kormilitzin/en_core_spancat_med7_trf
|
kormilitzin
| 2022-11-19T18:54:29Z | 5 | 1 |
spacy
|
[
"spacy",
"en",
"license:mit",
"region:us"
] | null | 2022-11-18T23:31:46Z |
---
tags:
- spacy
language:
- en
license: mit
model-index:
- name: en_core_spancat_med7_trf
results: []
---
| Feature | Description |
| --- | --- |
| **Name** | `en_core_spancat_med7_trf` |
| **Version** | `3.4.2.1` |
| **spaCy** | `>=3.4.2,<3.5.0` |
| **Default Pipeline** | `transformer`, `spancat` |
| **Components** | `transformer`, `spancat` |
| **Vectors** | 514157 keys, 514157 unique vectors (300 dimensions) |
| **Sources** | n/a |
| **License** | `MIT` |
| **Author** | [Andrey Kormilitzin](https://www.kormilitzin.com/) |
### Label Scheme
<details>
<summary>View label scheme (8 labels for 1 components)</summary>
| Component | Labels |
| --- | --- |
| **`spancat`** | `DOSAGE`, `MEDINFO`, `DRUG`, `STRENGTH`, `FREQUENCY`, `ROUTE`, `DURATION`, `FORM` |
</details>
### Accuracy
| Type | Score |
| --- | --- |
| `SPANS_SC_F` | 83.10 |
| `SPANS_SC_P` | 83.32 |
| `SPANS_SC_R` | 82.88 |
| `TRANSFORMER_LOSS` | 1176.39 |
| `SPANCAT_LOSS` | 36025.42 |
### BibTeX entry and citation info
```bibtex
@article{kormilitzin2021med7,
title={Med7: A transferable clinical natural language processing model for electronic health records},
author={Kormilitzin, Andrey and Vaci, Nemanja and Liu, Qiang and Nevado-Holgado, Alejo},
journal={Artificial Intelligence in Medicine},
volume={118},
pages={102086},
year={2021},
publisher={Elsevier}
}
```
|
kormilitzin/en_core_med7_trf
|
kormilitzin
| 2022-11-19T18:51:54Z | 375 | 12 |
spacy
|
[
"spacy",
"token-classification",
"en",
"license:mit",
"model-index",
"region:us"
] |
token-classification
| 2022-03-02T23:29:05Z |
---
tags:
- spacy
- token-classification
language:
- en
license: mit
model-index:
- name: en_core_med7_trf
results:
- task:
name: NER
type: token-classification
metrics:
- name: NER Precision
type: precision
value: 0.8822157434
- name: NER Recall
type: recall
value: 0.925382263
- name: NER F Score
type: f_score
value: 0.9032835821
---
| Feature | Description |
| --- | --- |
| **Name** | `en_core_med7_trf` |
| **Version** | `3.4.2.1` |
| **spaCy** | `>=3.4.2,<3.5.0` |
| **Default Pipeline** | `transformer`, `ner` |
| **Components** | `transformer`, `ner` |
| **Vectors** | 514157 keys, 514157 unique vectors (300 dimensions) |
| **Sources** | n/a |
| **License** | `MIT` |
| **Author** | [Andrey Kormilitzin](https://www.kormilitzin.com/) |
### Label Scheme
<details>
<summary>View label scheme (7 labels for 1 components)</summary>
| Component | Labels |
| --- | --- |
| **`ner`** | `DOSAGE`, `DRUG`, `DURATION`, `FORM`, `FREQUENCY`, `ROUTE`, `STRENGTH` |
</details>
### Accuracy
| Type | Score |
| --- | --- |
| `ENTS_F` | 90.33 |
| `ENTS_P` | 88.22 |
| `ENTS_R` | 92.54 |
| `TRANSFORMER_LOSS` | 2502627.06 |
| `NER_LOSS` | 114576.77 |
### BibTeX entry and citation info
```bibtex
@article{kormilitzin2021med7,
title={Med7: A transferable clinical natural language processing model for electronic health records},
author={Kormilitzin, Andrey and Vaci, Nemanja and Liu, Qiang and Nevado-Holgado, Alejo},
journal={Artificial Intelligence in Medicine},
volume={118},
pages={102086},
year={2021},
publisher={Elsevier}
}
```
|
easyh/de_fnhd_nerdh
|
easyh
| 2022-11-19T18:34:01Z | 4 | 0 |
spacy
|
[
"spacy",
"token-classification",
"de",
"model-index",
"region:us"
] |
token-classification
| 2022-11-19T14:48:28Z |
---
tags:
- spacy
- token-classification
language:
- de
model-index:
- name: de_fnhd_nerdh
results:
- task:
name: NER
type: token-classification
metrics:
- name: NER Precision
type: precision
value: 0.9629324547
- name: NER Recall
type: recall
value: 0.9504065041
- name: NER F Score
type: f_score
value: 0.9566284779
---
Deutsche NER-Pipeline für frühneuhochdeutsche Texte (2.Version)
| Feature | Description |
| --- | --- |
| **Name** | `de_fnhd_nerdh` |
| **Version** | `0.0.2` |
| **spaCy** | `>=3.4.1,<3.5.0` |
| **Default Pipeline** | `tok2vec`, `ner` |
| **Components** | `tok2vec`, `ner` |
| **Vectors** | 500000 keys, 500000 unique vectors (300 dimensions) |
| **Sources** | n/a |
| **License** | n/a |
| **Author** | [ih]() |
### Label Scheme
<details>
<summary>View label scheme (5 labels for 1 components)</summary>
| Component | Labels |
| --- | --- |
| **`ner`** | `OBJEKT`, `ORGANISATION`, `ORT`, `PERSON`, `ZEIT` |
</details>
### Accuracy
| Type | Score |
| --- | --- |
| `ENTS_F` | 95.66 |
| `ENTS_P` | 96.29 |
| `ENTS_R` | 95.04 |
| `TOK2VEC_LOSS` | 25311.59 |
| `NER_LOSS` | 15478.32 |
|
yunseokj/ddpm-butterflies-128
|
yunseokj
| 2022-11-19T18:20:57Z | 0 | 0 |
diffusers
|
[
"diffusers",
"tensorboard",
"en",
"dataset:huggan/smithsonian_butterflies_subset",
"license:apache-2.0",
"diffusers:DDPMPipeline",
"region:us"
] | null | 2022-11-19T17:31:45Z |
---
language: en
license: apache-2.0
library_name: diffusers
tags: []
datasets: huggan/smithsonian_butterflies_subset
metrics: []
---
<!-- This model card has been generated automatically according to the information the training script had access to. You
should probably proofread and complete it, then remove this comment. -->
# ddpm-butterflies-128
## Model description
This diffusion model is trained with the [🤗 Diffusers](https://github.com/huggingface/diffusers) library
on the `huggan/smithsonian_butterflies_subset` dataset.
## Intended uses & limitations
#### How to use
```python
# TODO: add an example code snippet for running this diffusion pipeline
```
#### Limitations and bias
[TODO: provide examples of latent issues and potential remediations]
## Training data
[TODO: describe the data used to train the model]
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 16
- eval_batch_size: 16
- gradient_accumulation_steps: 1
- optimizer: AdamW with betas=(None, None), weight_decay=None and epsilon=None
- lr_scheduler: None
- lr_warmup_steps: 500
- ema_inv_gamma: None
- ema_inv_gamma: None
- ema_inv_gamma: None
- mixed_precision: fp16
### Training results
📈 [TensorBoard logs](https://huggingface.co/yunseokj/ddpm-butterflies-128/tensorboard?#scalars)
|
huggingtweets/kalousekm
|
huggingtweets
| 2022-11-19T18:12:47Z | 109 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-11-19T18:11:38Z |
---
language: en
thumbnail: http://www.huggingtweets.com/kalousekm/1668881563935/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/796289819571843072/yg0FHZZD_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">Miroslav Kalousek🇺🇦🇨🇿</div>
<div style="text-align: center; font-size: 14px;">@kalousekm</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from Miroslav Kalousek🇺🇦🇨🇿.
| Data | Miroslav Kalousek🇺🇦🇨🇿 |
| --- | --- |
| Tweets downloaded | 3252 |
| Retweets | 69 |
| Short tweets | 192 |
| Tweets kept | 2991 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/1ox04g0p/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @kalousekm's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/jtp1suwc) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/jtp1suwc/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/kalousekm')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
Froddan/hurrimatte
|
Froddan
| 2022-11-19T18:11:55Z | 0 | 1 | null |
[
"stable-diffusion",
"text-to-image",
"en",
"license:cc0-1.0",
"region:us"
] |
text-to-image
| 2022-11-19T15:10:08Z |
---
license: cc0-1.0
inference: false
language:
- en
tags:
- stable-diffusion
- text-to-image
---
# Stable Diffusion fine tuned on art by [Björn Hurri](https://www.artstation.com/bjornhurri)
This model is fine tuned on some of his matte-style paintings. I also have a version for his "shinier" works.
### Usage
Use by adding the keyword "hurrimatte" to the prompt. The model was trained with the "monster" classname, which can also be added to the prompt.
## Samples
For this model I made two checkpoints. The "hurrimatte monster x2" model is trained for twice as long as the regular checkpoint, meaning it should be more fine tuned on the style but also more rigid. The top 3 images are from the regular version, the rest are from the x2 version. I hope it gives you an idea of what kind of styles can be created with this model.
<img src="https://huggingface.co/Froddan/hurrimatte/resolve/main/index_1200_3.png" width="256px"/>
<img src="https://huggingface.co/Froddan/hurrimatte/resolve/main/index_1200_4.png" width="256px"/>
<img src="https://huggingface.co/Froddan/hurrimatte/resolve/main/1200_4.png" width="256px"/>
<img src="https://huggingface.co/Froddan/hurrimatte/resolve/main/index2.png" width="256px"/>
<img src="https://huggingface.co/Froddan/hurrimatte/resolve/main/index3.png" width="256px"/>
<img src="https://huggingface.co/Froddan/hurrimatte/resolve/main/index_2400_5.png" width="256px"/>
<img src="https://huggingface.co/Froddan/hurrimatte/resolve/main/index_2400_6.png" width="256px"/>
<img src="https://huggingface.co/Froddan/hurrimatte/resolve/main/index_2400_7.png" width="256px"/>
### 🧨 Diffusers
This model can be used just like any other Stable Diffusion model. For more information,
please have a look at the [Stable Diffusion](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion).
|
Froddan/nekrofaerie
|
Froddan
| 2022-11-19T17:51:30Z | 0 | 2 | null |
[
"stable-diffusion",
"text-to-image",
"en",
"license:cc0-1.0",
"region:us"
] |
text-to-image
| 2022-11-19T15:06:11Z |
---
license: cc0-1.0
inference: false
language:
- en
tags:
- stable-diffusion
- text-to-image
---
# Stable Diffusion fine tuned on art by [Nekro](https://www.artstation.com/nekro)
### Usage
Use by adding the keyword "nekrofaerie" to the prompt. The model was trained with the "faerie" classname, which can also be added to the prompt.
## Samples
The top 2 images are "pure", the rest could be mixed with other artists or modifiers. I hope it still gives you an idea of what kind of styles can be created with this model.
<img src="https://huggingface.co/Froddan/nekrofaerie/resolve/main/index.png" width="256px"/>
<img src="https://huggingface.co/Froddan/nekrofaerie/resolve/main/index2.png" width="256px"/>
<img src="https://huggingface.co/Froddan/nekrofaerie/resolve/main/tmp04o1t4b_.png" width="256px"/>
<img src="https://huggingface.co/Froddan/nekrofaerie/resolve/main/tmp41igywg4.png" width="256px"/>
<img src="https://huggingface.co/Froddan/nekrofaerie/resolve/main/tmpbkj8sqmh.png" width="256px"/>
<img src="https://huggingface.co/Froddan/nekrofaerie/resolve/main/tmphk34pib0.png" width="256px"/>
<img src="https://huggingface.co/Froddan/nekrofaerie/resolve/main/dog_octane.png" width="256px"/>
<img src="https://huggingface.co/Froddan/nekrofaerie/resolve/main/dog_octane2.png" width="256px"/>
<img src="https://huggingface.co/Froddan/nekrofaerie/resolve/main/greg_mucha2.png" width="256px"/>
### 🧨 Diffusers
This model can be used just like any other Stable Diffusion model. For more information,
please have a look at the [Stable Diffusion](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion).
|
vicky10011001/ddpm-butterflies-128
|
vicky10011001
| 2022-11-19T15:36:49Z | 0 | 0 |
diffusers
|
[
"diffusers",
"tensorboard",
"en",
"dataset:huggan/smithsonian_butterflies_subset",
"license:apache-2.0",
"diffusers:DDPMPipeline",
"region:us"
] | null | 2022-11-19T12:14:52Z |
---
language: en
license: apache-2.0
library_name: diffusers
tags: []
datasets: huggan/smithsonian_butterflies_subset
metrics: []
---
<!-- This model card has been generated automatically according to the information the training script had access to. You
should probably proofread and complete it, then remove this comment. -->
# ddpm-butterflies-128
## Model description
This diffusion model is trained with the [🤗 Diffusers](https://github.com/huggingface/diffusers) library
on the `huggan/smithsonian_butterflies_subset` dataset.
## Intended uses & limitations
#### How to use
```python
# TODO: add an example code snippet for running this diffusion pipeline
```
#### Limitations and bias
[TODO: provide examples of latent issues and potential remediations]
## Training data
[TODO: describe the data used to train the model]
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 16
- eval_batch_size: 16
- gradient_accumulation_steps: 1
- optimizer: AdamW with betas=(None, None), weight_decay=None and epsilon=None
- lr_scheduler: None
- lr_warmup_steps: 500
- ema_inv_gamma: None
- ema_inv_gamma: None
- ema_inv_gamma: None
- mixed_precision: fp16
### Training results
📈 [TensorBoard logs](https://huggingface.co/vicky10011001/ddpm-butterflies-128/tensorboard?#scalars)
|
rdyzakya/bert-indo-base-stance-cls
|
rdyzakya
| 2022-11-19T15:09:32Z | 101 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"text-classification",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-11-19T13:00:54Z |
---
license: mit
tags:
- generated_from_trainer
metrics:
- accuracy
- precision
- recall
- f1
model-index:
- name: bert-indo-base-stance-cls
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-indo-base-stance-cls
This model is a fine-tuned version of [indobenchmark/indobert-base-p1](https://huggingface.co/indobenchmark/indobert-base-p1) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 2.0156
- Accuracy: 0.6892
- Precision: 0.6848
- Recall: 0.6892
- F1: 0.6859
- Against: {'precision': 0.6185567010309279, 'recall': 0.5555555555555556, 'f1-score': 0.5853658536585366, 'support': 216}
- For: {'precision': 0.7280453257790368, 'recall': 0.7764350453172205, 'f1-score': 0.7514619883040935, 'support': 331}
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | Precision | Recall | F1 | Against | For |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:---------:|:------:|:------:|:-----------------------------------------------------------------------------------------------------------------:|:---------------------------------------------------------------------------------------------------------------:|
| No log | 1.0 | 137 | 0.6423 | 0.6581 | 0.6894 | 0.6581 | 0.5917 | {'precision': 0.7543859649122807, 'recall': 0.19907407407407407, 'f1-score': 0.31501831501831506, 'support': 216} | {'precision': 0.6469387755102041, 'recall': 0.9577039274924471, 'f1-score': 0.7722289890377587, 'support': 331} |
| No log | 2.0 | 274 | 0.6146 | 0.6600 | 0.6691 | 0.6600 | 0.6628 | {'precision': 0.5614754098360656, 'recall': 0.6342592592592593, 'f1-score': 0.5956521739130436, 'support': 216} | {'precision': 0.7392739273927392, 'recall': 0.676737160120846, 'f1-score': 0.7066246056782334, 'support': 331} |
| No log | 3.0 | 411 | 0.7572 | 0.6545 | 0.6734 | 0.6545 | 0.6583 | {'precision': 0.550561797752809, 'recall': 0.6805555555555556, 'f1-score': 0.608695652173913, 'support': 216} | {'precision': 0.7535714285714286, 'recall': 0.6374622356495468, 'f1-score': 0.6906710310965631, 'support': 331} |
| 0.4855 | 4.0 | 548 | 0.7405 | 0.6892 | 0.6842 | 0.6892 | 0.6851 | {'precision': 0.6210526315789474, 'recall': 0.5462962962962963, 'f1-score': 0.5812807881773399, 'support': 216} | {'precision': 0.7254901960784313, 'recall': 0.7824773413897281, 'f1-score': 0.7529069767441859, 'support': 331} |
| 0.4855 | 5.0 | 685 | 1.1222 | 0.6856 | 0.6828 | 0.6856 | 0.6839 | {'precision': 0.6078431372549019, 'recall': 0.5740740740740741, 'f1-score': 0.5904761904761905, 'support': 216} | {'precision': 0.7317784256559767, 'recall': 0.7583081570996979, 'f1-score': 0.7448071216617211, 'support': 331} |
| 0.4855 | 6.0 | 822 | 1.4960 | 0.6892 | 0.6830 | 0.6892 | 0.6827 | {'precision': 0.6292134831460674, 'recall': 0.5185185185185185, 'f1-score': 0.5685279187817258, 'support': 216} | {'precision': 0.7181571815718157, 'recall': 0.8006042296072508, 'f1-score': 0.7571428571428572, 'support': 331} |
| 0.4855 | 7.0 | 959 | 1.6304 | 0.6801 | 0.6886 | 0.6801 | 0.6827 | {'precision': 0.5843621399176955, 'recall': 0.6574074074074074, 'f1-score': 0.6187363834422658, 'support': 216} | {'precision': 0.756578947368421, 'recall': 0.6948640483383686, 'f1-score': 0.7244094488188976, 'support': 331} |
| 0.1029 | 8.0 | 1096 | 1.8381 | 0.6673 | 0.6727 | 0.6673 | 0.6693 | {'precision': 0.5726495726495726, 'recall': 0.6203703703703703, 'f1-score': 0.5955555555555555, 'support': 216} | {'precision': 0.7380191693290735, 'recall': 0.6978851963746223, 'f1-score': 0.717391304347826, 'support': 331} |
| 0.1029 | 9.0 | 1233 | 1.9474 | 0.6929 | 0.6876 | 0.6929 | 0.6881 | {'precision': 0.6290322580645161, 'recall': 0.5416666666666666, 'f1-score': 0.582089552238806, 'support': 216} | {'precision': 0.7257617728531855, 'recall': 0.7915407854984894, 'f1-score': 0.7572254335260115, 'support': 331} |
| 0.1029 | 10.0 | 1370 | 2.0156 | 0.6892 | 0.6848 | 0.6892 | 0.6859 | {'precision': 0.6185567010309279, 'recall': 0.5555555555555556, 'f1-score': 0.5853658536585366, 'support': 216} | {'precision': 0.7280453257790368, 'recall': 0.7764350453172205, 'f1-score': 0.7514619883040935, 'support': 331} |
### Framework versions
- Transformers 4.24.0
- Pytorch 1.12.1+cu113
- Datasets 2.7.0
- Tokenizers 0.13.2
|
katboi01/rare-puppers
|
katboi01
| 2022-11-19T15:04:01Z | 186 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"vit",
"image-classification",
"huggingpics",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2022-11-19T15:03:49Z |
---
tags:
- image-classification
- pytorch
- huggingpics
metrics:
- accuracy
model-index:
- name: rare-puppers
results:
- task:
name: Image Classification
type: image-classification
metrics:
- name: Accuracy
type: accuracy
value: 0.89552241563797
---
# rare-puppers
Autogenerated by HuggingPics🤗🖼️
Create your own image classifier for **anything** by running [the demo on Google Colab](https://colab.research.google.com/github/nateraw/huggingpics/blob/main/HuggingPics.ipynb).
Report any issues with the demo at the [github repo](https://github.com/nateraw/huggingpics).
## Example Images
#### corgi

#### samoyed

#### shiba inu

|
nypnop/distilbert-base-uncased-finetuned-bbc-news
|
nypnop
| 2022-11-19T14:09:27Z | 104 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-11-18T14:57:06Z |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- accuracy
- f1
model-index:
- name: distilbert-base-uncased-finetuned-bbc-news
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-bbc-news
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0107
- Accuracy: 0.9955
- F1: 0.9955
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 3
- eval_batch_size: 3
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 0.3463 | 0.84 | 500 | 0.0392 | 0.9865 | 0.9865 |
| 0.0447 | 1.68 | 1000 | 0.0107 | 0.9955 | 0.9955 |
### Framework versions
- Transformers 4.24.0
- Pytorch 1.12.1+cu113
- Datasets 2.7.0
- Tokenizers 0.13.2
|
vikram15/bert-finetuned-ner
|
vikram15
| 2022-11-19T13:21:37Z | 122 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"token-classification",
"generated_from_trainer",
"dataset:conll2003",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-11-19T13:03:28Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- conll2003
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: bert-finetuned-ner
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: conll2003
type: conll2003
config: conll2003
split: train
args: conll2003
metrics:
- name: Precision
type: precision
value: 0.9309775429326288
- name: Recall
type: recall
value: 0.9488387748232918
- name: F1
type: f1
value: 0.9398233038839806
- name: Accuracy
type: accuracy
value: 0.9861806087007712
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-finetuned-ner
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the conll2003 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0630
- Precision: 0.9310
- Recall: 0.9488
- F1: 0.9398
- Accuracy: 0.9862
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| 0.0911 | 1.0 | 1756 | 0.0702 | 0.9197 | 0.9345 | 0.9270 | 0.9826 |
| 0.0336 | 2.0 | 3512 | 0.0623 | 0.9294 | 0.9480 | 0.9386 | 0.9864 |
| 0.0174 | 3.0 | 5268 | 0.0630 | 0.9310 | 0.9488 | 0.9398 | 0.9862 |
### Framework versions
- Transformers 4.24.0
- Pytorch 1.12.1+cu113
- Datasets 2.7.0
- Tokenizers 0.13.2
|
GDJ1978/anyXtronXredshift
|
GDJ1978
| 2022-11-19T12:32:23Z | 0 | 0 | null |
[
"region:us"
] | null | 2022-11-13T19:53:03Z |
Merged checkpoints of anythingXtron and redshift 0.6
This model is open access and available to all, with a CreativeML OpenRAIL-M license further specifying rights and usage. The CreativeML OpenRAIL License specifies:
You can't use the model to deliberately produce nor share illegal or harmful outputs or content
The authors claims no rights on the outputs you generate, you are free to use them and are accountable for their use which must not go against the provisions set in the license
You may re-distribute the weights and use the model commercially and/or as a service. If you do, please be aware you have to include the same use restrictions as the ones in the license and share a copy of the CreativeML OpenRAIL-M to all your users (please read the license entirely and carefully) Please read the full license here
|
GDJ1978/spiderverseXrobo
|
GDJ1978
| 2022-11-19T12:32:05Z | 0 | 0 | null |
[
"region:us"
] | null | 2022-11-14T13:06:24Z |
spiderverse-v1-pruned_0.6-robo-diffusion-v1_0.4-Weighted_sum-merged.ckpt
MAKE SURE ADD EXTENSION CKPT WHEN DOWNLOADING
This model is open access and available to all, with a CreativeML OpenRAIL-M license further specifying rights and usage. The CreativeML OpenRAIL License specifies:
You can't use the model to deliberately produce nor share illegal or harmful outputs or content
The authors claims no rights on the outputs you generate, you are free to use them and are accountable for their use which must not go against the provisions set in the license
You may re-distribute the weights and use the model commercially and/or as a service. If you do, please be aware you have to include the same use restrictions as the ones in the license and share a copy of the CreativeML OpenRAIL-M to all your users (please read the license entirely and carefully) Please read the full license here
|
svnfs/rfc-alias
|
svnfs
| 2022-11-19T12:23:56Z | 0 | 0 |
sklearn
|
[
"sklearn",
"skops",
"tabular-classification",
"region:us"
] |
tabular-classification
| 2022-11-19T12:23:50Z |
---
library_name: sklearn
tags:
- sklearn
- skops
- tabular-classification
widget:
structuredData:
x0:
- 5.8
- 6.0
- 5.5
x1:
- 2.8
- 2.2
- 4.2
x2:
- 5.1
- 4.0
- 1.4
x3:
- 2.4
- 1.0
- 0.2
---
# Model description
[More Information Needed]
## Intended uses & limitations
[More Information Needed]
## Training Procedure
### Hyperparameters
The model is trained with below hyperparameters.
<details>
<summary> Click to expand </summary>
| Hyperparameter | Value |
|--------------------------|---------|
| bootstrap | True |
| ccp_alpha | 0.0 |
| class_weight | |
| criterion | gini |
| max_depth | |
| max_features | sqrt |
| max_leaf_nodes | |
| max_samples | |
| min_impurity_decrease | 0.0 |
| min_samples_leaf | 1 |
| min_samples_split | 2 |
| min_weight_fraction_leaf | 0.0 |
| n_estimators | 100 |
| n_jobs | |
| oob_score | False |
| random_state | |
| verbose | 0 |
| warm_start | False |
</details>
### Model Plot
The model plot is below.
<style>#sk-container-id-1 {color: black;background-color: white;}#sk-container-id-1 pre{padding: 0;}#sk-container-id-1 div.sk-toggleable {background-color: white;}#sk-container-id-1 label.sk-toggleable__label {cursor: pointer;display: block;width: 100%;margin-bottom: 0;padding: 0.3em;box-sizing: border-box;text-align: center;}#sk-container-id-1 label.sk-toggleable__label-arrow:before {content: "▸";float: left;margin-right: 0.25em;color: #696969;}#sk-container-id-1 label.sk-toggleable__label-arrow:hover:before {color: black;}#sk-container-id-1 div.sk-estimator:hover label.sk-toggleable__label-arrow:before {color: black;}#sk-container-id-1 div.sk-toggleable__content {max-height: 0;max-width: 0;overflow: hidden;text-align: left;background-color: #f0f8ff;}#sk-container-id-1 div.sk-toggleable__content pre {margin: 0.2em;color: black;border-radius: 0.25em;background-color: #f0f8ff;}#sk-container-id-1 input.sk-toggleable__control:checked~div.sk-toggleable__content {max-height: 200px;max-width: 100%;overflow: auto;}#sk-container-id-1 input.sk-toggleable__control:checked~label.sk-toggleable__label-arrow:before {content: "▾";}#sk-container-id-1 div.sk-estimator input.sk-toggleable__control:checked~label.sk-toggleable__label {background-color: #d4ebff;}#sk-container-id-1 div.sk-label input.sk-toggleable__control:checked~label.sk-toggleable__label {background-color: #d4ebff;}#sk-container-id-1 input.sk-hidden--visually {border: 0;clip: rect(1px 1px 1px 1px);clip: rect(1px, 1px, 1px, 1px);height: 1px;margin: -1px;overflow: hidden;padding: 0;position: absolute;width: 1px;}#sk-container-id-1 div.sk-estimator {font-family: monospace;background-color: #f0f8ff;border: 1px dotted black;border-radius: 0.25em;box-sizing: border-box;margin-bottom: 0.5em;}#sk-container-id-1 div.sk-estimator:hover {background-color: #d4ebff;}#sk-container-id-1 div.sk-parallel-item::after {content: "";width: 100%;border-bottom: 1px solid gray;flex-grow: 1;}#sk-container-id-1 div.sk-label:hover label.sk-toggleable__label {background-color: #d4ebff;}#sk-container-id-1 div.sk-serial::before {content: "";position: absolute;border-left: 1px solid gray;box-sizing: border-box;top: 0;bottom: 0;left: 50%;z-index: 0;}#sk-container-id-1 div.sk-serial {display: flex;flex-direction: column;align-items: center;background-color: white;padding-right: 0.2em;padding-left: 0.2em;position: relative;}#sk-container-id-1 div.sk-item {position: relative;z-index: 1;}#sk-container-id-1 div.sk-parallel {display: flex;align-items: stretch;justify-content: center;background-color: white;position: relative;}#sk-container-id-1 div.sk-item::before, #sk-container-id-1 div.sk-parallel-item::before {content: "";position: absolute;border-left: 1px solid gray;box-sizing: border-box;top: 0;bottom: 0;left: 50%;z-index: -1;}#sk-container-id-1 div.sk-parallel-item {display: flex;flex-direction: column;z-index: 1;position: relative;background-color: white;}#sk-container-id-1 div.sk-parallel-item:first-child::after {align-self: flex-end;width: 50%;}#sk-container-id-1 div.sk-parallel-item:last-child::after {align-self: flex-start;width: 50%;}#sk-container-id-1 div.sk-parallel-item:only-child::after {width: 0;}#sk-container-id-1 div.sk-dashed-wrapped {border: 1px dashed gray;margin: 0 0.4em 0.5em 0.4em;box-sizing: border-box;padding-bottom: 0.4em;background-color: white;}#sk-container-id-1 div.sk-label label {font-family: monospace;font-weight: bold;display: inline-block;line-height: 1.2em;}#sk-container-id-1 div.sk-label-container {text-align: center;}#sk-container-id-1 div.sk-container {/* jupyter's `normalize.less` sets `[hidden] { display: none; }` but bootstrap.min.css set `[hidden] { display: none !important; }` so we also need the `!important` here to be able to override the default hidden behavior on the sphinx rendered scikit-learn.org. See: https://github.com/scikit-learn/scikit-learn/issues/21755 */display: inline-block !important;position: relative;}#sk-container-id-1 div.sk-text-repr-fallback {display: none;}</style><div id="sk-container-id-1" class="sk-top-container"><div class="sk-text-repr-fallback"><pre>RandomForestClassifier()</pre><b>In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. <br />On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.</b></div><div class="sk-container" hidden><div class="sk-item"><div class="sk-estimator sk-toggleable"><input class="sk-toggleable__control sk-hidden--visually" id="sk-estimator-id-1" type="checkbox" checked><label for="sk-estimator-id-1" class="sk-toggleable__label sk-toggleable__label-arrow">RandomForestClassifier</label><div class="sk-toggleable__content"><pre>RandomForestClassifier()</pre></div></div></div></div></div>
## Evaluation Results
You can find the details about evaluation process and the evaluation results.
| Metric | Value |
|----------|---------|
# How to Get Started with the Model
Use the code below to get started with the model.
<details>
<summary> Click to expand </summary>
```python
[More Information Needed]
```
</details>
# Model Card Authors
This model card is written by following authors:
[More Information Needed]
# Model Card Contact
You can contact the model card authors through following channels:
[More Information Needed]
# Citation
Below you can find information related to citation.
**BibTeX:**
```
[More Information Needed]
```
|
beyond/genius-base
|
beyond
| 2022-11-19T11:59:46Z | 104 | 2 |
transformers
|
[
"transformers",
"pytorch",
"bart",
"text2text-generation",
"GENIUS",
"conditional text generation",
"sketch-based text generation",
"data augmentation",
"en",
"zh",
"dataset:c4",
"dataset:beyond/chinese_clean_passages_80m",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-11-08T06:26:13Z |
---
language:
- en
- zh
tags:
- GENIUS
- conditional text generation
- sketch-based text generation
- data augmentation
license: apache-2.0
datasets:
- c4
- beyond/chinese_clean_passages_80m
widget:
- text: "<mask> Conference on Empirical Methods <mask> submission of research papers <mask> Deep Learning <mask>"
example_title: "Example 1"
- text: "<mask> machine learning <mask> my research interest <mask> data science <mask>"
example_title: "Example 2"
- text: "<mask> play basketball <mask> a strong team <mask> Shanghai University of Finance and Economics <mask> last Sunday <mask>"
example_title: "Example 3"
- text: "Good news: <mask> the European Union <mask> month by EU <mask> Farm Commissioner Franz <mask>"
example_title: "Example with a prompt 1"
- text: "Bad news: <mask> the European Union <mask> month by EU <mask> Farm Commissioner Franz <mask>"
example_title: "Example with a prompt 2"
inference:
parameters:
max_length: 200
num_beams: 3
do_sample: True
---
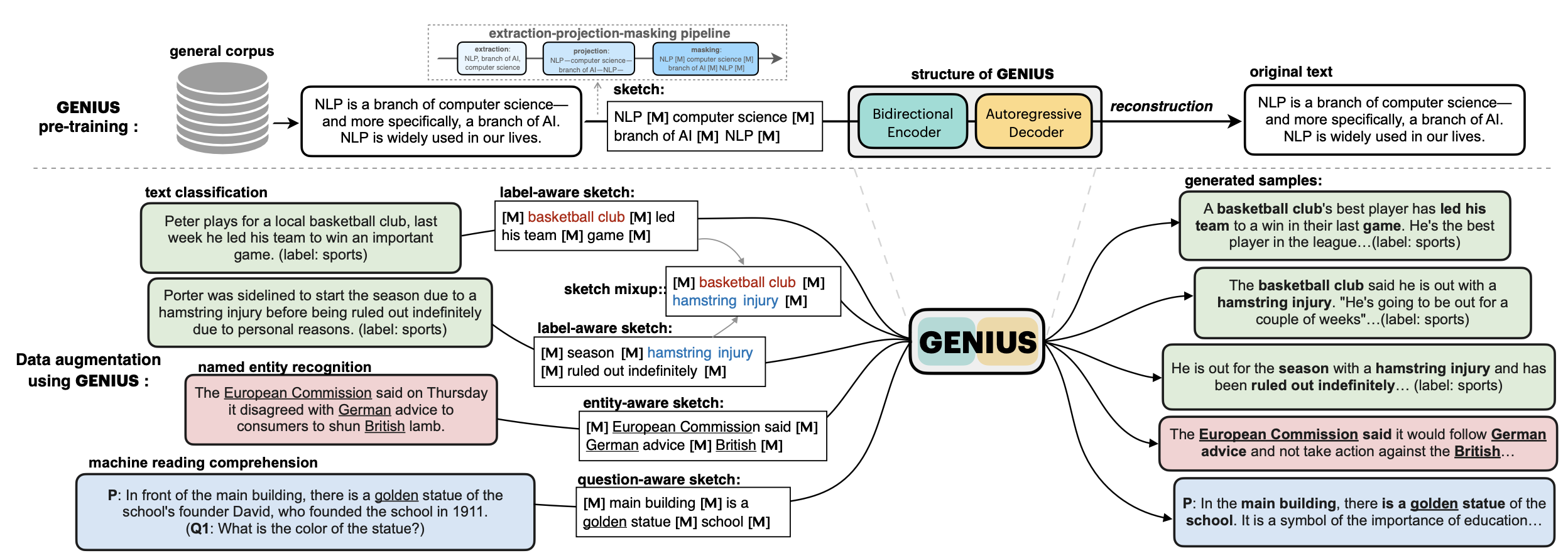
# 💡GENIUS – generating text using sketches!
**基于草稿的文本生成模型**
- **Paper: [GENIUS: Sketch-based Language Model Pre-training via Extreme and Selective Masking for Text Generation and Augmentation](https://github.com/beyondguo/genius/blob/master/GENIUS_gby_arxiv.pdf)**
💡**GENIUS** is a powerful conditional text generation model using sketches as input, which can fill in the missing contexts for a given **sketch** (key information consisting of textual spans, phrases, or words, concatenated by mask tokens). GENIUS is pre-trained on a large- scale textual corpus with a novel *reconstruction from sketch* objective using an *extreme and selective masking* strategy, enabling it to generate diverse and high-quality texts given sketches.
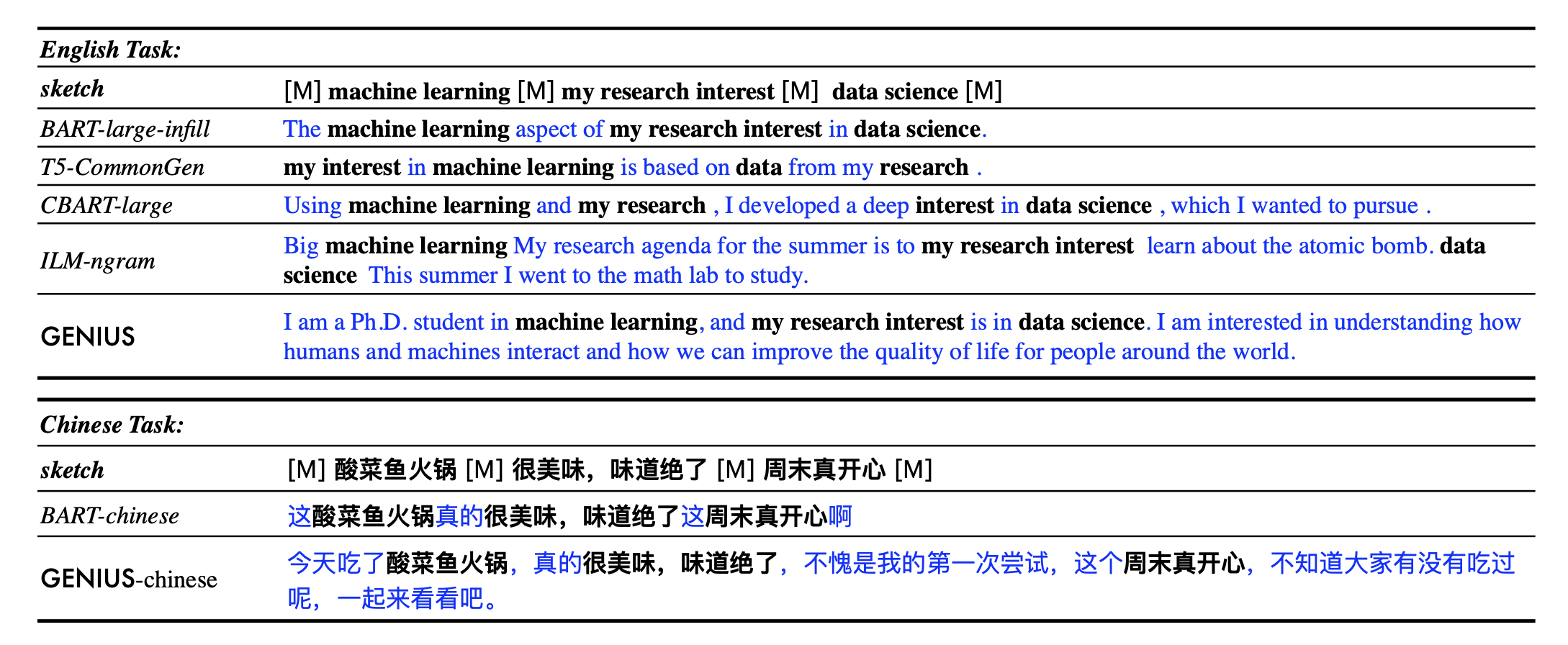
**Example 1:**
- sketch: `__ machine learning __ my research interest __ data science __`
- **GENIUS**: `I am a Ph.D. student in machine learning, and my research interest is in data science. I am interested in understanding how humans and machines interact and how we can improve the quality of life for people around the world.`
**Example 2:**
- sketch: `自然语言处理__谷歌__通用人工智能__`
- **GENIUS**: `自然语言处理是谷歌在通用人工智能领域的一个重要研究方向,其目的是为了促进人类智能的发展。 `
**GENIUS** can also be used as a general textual **data augmentation tool** for **various NLP tasks** (including sentiment analysis, topic classification, NER, and QA).
- Models hosted in 🤗 Huggingface:
**Model variations:**
| Model | #params | Language | comment|
|------------------------|--------------------------------|-------|---------|
| [`genius-large`](https://huggingface.co/beyond/genius-large) | 406M | English | The version used in **paper** (recommend) |
| [`genius-large-k2t`](https://huggingface.co/beyond/genius-large-k2t) | 406M | English | keywords-to-text |
| [`genius-base`](https://huggingface.co/beyond/genius-base) | 139M | English | smaller version |
| [`genius-base-ps`](https://huggingface.co/beyond/genius-base) | 139M | English | pre-trained both in paragraphs and short sentences |
| [`genius-base-chinese`](https://huggingface.co/beyond/genius-base-chinese) | 116M | 中文 | 在一千万纯净中文段落上预训练|
More Examples:
## Usage
### What is a sketch?
First, what is a **sketch**? As defined in our paper, a sketch is "key information consisting of textual spans, phrases, or words, concatenated by mask tokens". It's like a draft or framework when you begin to write an article. With GENIUS model, you can input some key elements you want to mention in your wrinting, then the GENIUS model can generate cohrent text based on your sketch.
The sketch which can be composed of:
- keywords /key-phrases, like `__NLP__AI__computer__science__`
- spans, like `Conference on Empirical Methods__submission of research papers__`
- sentences, like `I really like machine learning__I work at Google since last year__`
- or a mixup!
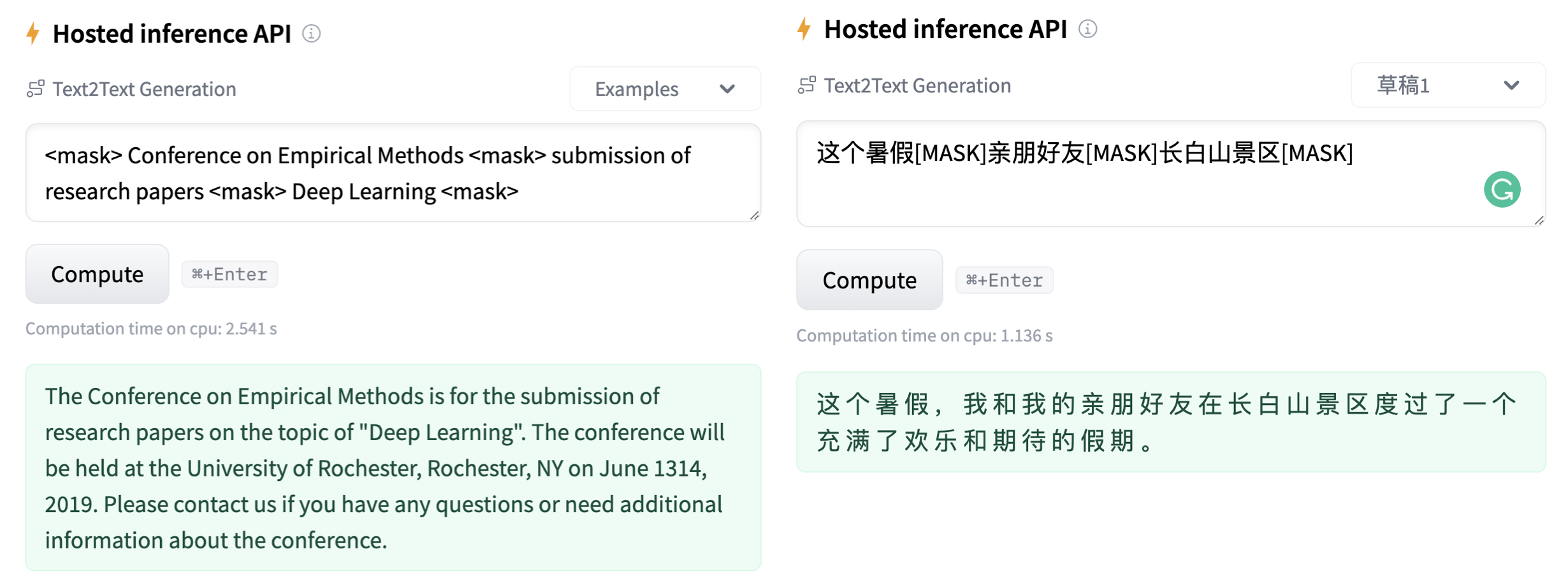
### How to use the model
#### 1. If you already have a sketch in mind, and want to get a paragraph based on it...
```python
from transformers import pipeline
# 1. load the model with the huggingface `pipeline`
genius = pipeline("text2text-generation", model='beyond/genius-large', device=0)
# 2. provide a sketch (joint by <mask> tokens)
sketch = "<mask> Conference on Empirical Methods <mask> submission of research papers <mask> Deep Learning <mask>"
# 3. here we go!
generated_text = genius(sketch, num_beams=3, do_sample=True, max_length=200)[0]['generated_text']
print(generated_text)
```
Output:
```shell
'The Conference on Empirical Methods welcomes the submission of research papers. Abstracts should be in the form of a paper or presentation. Please submit abstracts to the following email address: eemml.stanford.edu. The conference will be held at Stanford University on April 1618, 2019. The theme of the conference is Deep Learning.'
```
If you have a lot of sketches, you can batch-up your sketches to a Huggingface `Dataset` object, which can be much faster.
TODO: we are also building a python package for more convenient use of GENIUS, which will be released in few weeks.
#### 2. If you have an NLP dataset (e.g. classification) and want to do data augmentation to enlarge your dataset...
Please check [genius/augmentation_clf](https://github.com/beyondguo/genius/tree/master/augmentation_clf) and [genius/augmentation_ner_qa](https://github.com/beyondguo/genius/tree/master/augmentation_ner_qa), where we provide ready-to-run scripts for data augmentation for text classification/NER/MRC tasks.
## Augmentation Experiments:
Data augmentation is an important application for natural language generation (NLG) models, which is also a valuable evaluation of whether the generated text can be used in real applications.
- Setting: Low-resource setting, where only n={50,100,200,500,1000} labeled samples are available for training. The below results are the average of all training sizes.
- Text Classification Datasets: [HuffPost](https://huggingface.co/datasets/khalidalt/HuffPost), [BBC](https://huggingface.co/datasets/SetFit/bbc-news), [SST2](https://huggingface.co/datasets/glue), [IMDB](https://huggingface.co/datasets/imdb), [Yahoo](https://huggingface.co/datasets/yahoo_answers_topics), [20NG](https://huggingface.co/datasets/newsgroup).
- Base classifier: [DistilBERT](https://huggingface.co/distilbert-base-cased)
In-distribution (ID) evaluations:
| Method | Huff | BBC | Yahoo | 20NG | IMDB | SST2 | avg. |
|:----------:|:----------:|:----------:|:----------:|:----------:|:----------:|:----------:|:----------:|
| none | 79.17 | **96.16** | 45.77 | 46.67 | 77.87 | 76.67 | 70.39 |
| EDA | 79.20 | 95.11 | 45.10 | 46.15 | 77.88 | 75.52 | 69.83 |
| BackT | 80.48 | 95.28 | 46.10 | 46.61 | 78.35 | 76.96 | 70.63 |
| MLM | 80.04 | 96.07 | 45.35 | 46.53 | 75.73 | 76.61 | 70.06 |
| C-MLM | 80.60 | 96.13 | 45.40 | 46.36 | 77.31 | 76.91 | 70.45 |
| LAMBADA | 81.46 | 93.74 | 50.49 | 47.72 | 78.22 | 78.31 | 71.66 |
| STA | 80.74 | 95.64 | 46.96 | 47.27 | 77.88 | 77.80 | 71.05 |
| **GeniusAug** | 81.43 | 95.74 | 49.60 | 50.38 | **80.16** | 78.82 | 72.68 |
| **GeniusAug-f** | **81.82** | 95.99 | **50.42** | **50.81** | 79.40 | **80.57** | **73.17** |
Out-of-distribution (OOD) evaluations:
| | Huff->BBC | BBC->Huff | IMDB->SST2 | SST2->IMDB | avg. |
|------------|:----------:|:----------:|:----------:|:----------:|:----------:|
| none | 62.32 | 62.00 | 74.37 | 73.11 | 67.95 |
| EDA | 67.48 | 58.92 | 75.83 | 69.42 | 67.91 |
| BackT | 67.75 | 63.10 | 75.91 | 72.19 | 69.74 |
| MLM | 66.80 | 65.39 | 73.66 | 73.06 | 69.73 |
| C-MLM | 64.94 | **67.80** | 74.98 | 71.78 | 69.87 |
| LAMBADA | 68.57 | 52.79 | 75.24 | 76.04 | 68.16 |
| STA | 69.31 | 64.82 | 74.72 | 73.62 | 70.61 |
| **GeniusAug** | 74.87 | 66.85 | 76.02 | 74.76 | 73.13 |
| **GeniusAug-f** | **76.18** | 66.89 | **77.45** | **80.36** | **75.22** |
### BibTeX entry and citation info
TBD
|
viktor-enzell/wav2vec2-large-voxrex-swedish-4gram
|
viktor-enzell
| 2022-11-19T11:06:02Z | 5,719 | 5 |
transformers
|
[
"transformers",
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"audio",
"speech",
"hf-asr-leaderboard",
"sv",
"dataset:common_voice",
"dataset:NST_Swedish_ASR_Database",
"dataset:P4",
"dataset:The_Swedish_Culturomics_Gigaword_Corpus",
"license:cc0-1.0",
"model-index",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-05-26T13:32:57Z |
---
language: sv
metrics:
- wer
tags:
- audio
- automatic-speech-recognition
- speech
- hf-asr-leaderboard
- sv
license: cc0-1.0
datasets:
- common_voice
- NST_Swedish_ASR_Database
- P4
- The_Swedish_Culturomics_Gigaword_Corpus
model-index:
- name: Wav2vec 2.0 large VoxRex Swedish (C) with 4-gram
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice 6.1
type: common_voice
args: sv-SE
metrics:
- name: Test WER
type: wer
value: 6.4723
---
# KBLab's wav2vec 2.0 large VoxRex Swedish (C) with 4-gram model
Training of the acoustic model is the work of KBLab. See [VoxRex-C](https://huggingface.co/KBLab/wav2vec2-large-voxrex-swedish) for more details. This repo extends the acoustic model with a social media 4-gram language model for boosted performance.
## Model description
VoxRex-C is extended with a 4-gram language model estimated from a subset extracted from [The Swedish Culturomics Gigaword Corpus](https://spraakbanken.gu.se/resurser/gigaword) from Språkbanken. The subset contains 40M words from the social media genre between 2010 and 2015.
## How to use
#### Simple usage example with pipeline
```python
import torch
from transformers import pipeline
# Load the model. Using GPU if available
model_name = 'viktor-enzell/wav2vec2-large-voxrex-swedish-4gram'
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
pipe = pipeline(model=model_name).to(device)
# Run inference on an audio file
output = pipe('path/to/audio.mp3')['text']
```
#### More verbose usage example with audio pre-processing
Example of transcribing 1% of the Common Voice test split. The model expects 16kHz audio, so audio with another sampling rate is resampled to 16kHz.
```python
from transformers import Wav2Vec2ForCTC, Wav2Vec2ProcessorWithLM
from datasets import load_dataset
import torch
import torchaudio.functional as F
# Import model and processor. Using GPU if available
model_name = 'viktor-enzell/wav2vec2-large-voxrex-swedish-4gram'
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = Wav2Vec2ForCTC.from_pretrained(model_name).to(device);
processor = Wav2Vec2ProcessorWithLM.from_pretrained(model_name)
# Import and process speech data
common_voice = load_dataset('common_voice', 'sv-SE', split='test[:1%]')
def speech_file_to_array(sample):
# Convert speech file to array and downsample to 16 kHz
sampling_rate = sample['audio']['sampling_rate']
sample['speech'] = F.resample(torch.tensor(sample['audio']['array']), sampling_rate, 16_000)
return sample
common_voice = common_voice.map(speech_file_to_array)
# Run inference
inputs = processor(common_voice['speech'], sampling_rate=16_000, return_tensors='pt', padding=True).to(device)
with torch.no_grad():
logits = model(**inputs).logits
transcripts = processor.batch_decode(logits.cpu().numpy()).text
```
## Training procedure
Text data for the n-gram model is pre-processed by removing characters not part of the wav2vec 2.0 vocabulary and uppercasing all characters. After pre-processing and storing each text sample on a new line in a text file, a [KenLM](https://github.com/kpu/kenlm) model is estimated. See [this tutorial](https://huggingface.co/blog/wav2vec2-with-ngram) for more details.
## Evaluation results
The model was evaluated on the full Common Voice test set version 6.1. VoxRex-C achieved a WER of 9.03% without the language model and 6.47% with the language model.
|
NbAiLab/whisper
|
NbAiLab
| 2022-11-19T10:46:08Z | 0 | 0 | null |
[
"license:apache-2.0",
"region:us"
] | null | 2022-11-07T11:29:35Z |
---
license: apache-2.0
---
# Whisper Finetuning
Whisper finetuning example script.
|
KubiakJakub01/finetuned-distilbert-base-uncased
|
KubiakJakub01
| 2022-11-19T10:45:52Z | 60 | 0 |
transformers
|
[
"transformers",
"tf",
"distilbert",
"text-classification",
"generated_from_keras_callback",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-11-19T09:14:07Z |
---
license: apache-2.0
tags:
- generated_from_keras_callback
model-index:
- name: KubiakJakub01/finetuned-distilbert-base-uncased
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# KubiakJakub01/finetuned-distilbert-base-uncased
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.2767
- Validation Loss: 0.4326
- Train Accuracy: 0.8319
- Epoch: 2
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'Adam', 'learning_rate': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 2e-05, 'decay_steps': 1140, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False}
- training_precision: float32
### Training results
| Train Loss | Validation Loss | Train Accuracy | Epoch |
|:----------:|:---------------:|:--------------:|:-----:|
| 0.4680 | 0.4008 | 0.8378 | 0 |
| 0.3475 | 0.4017 | 0.8385 | 1 |
| 0.2767 | 0.4326 | 0.8319 | 2 |
### Framework versions
- Transformers 4.21.3
- TensorFlow 2.9.1
- Datasets 2.4.0
- Tokenizers 0.12.1
|
jonathanrichard13/pegasus-xsum-reddit-clean-4
|
jonathanrichard13
| 2022-11-19T10:22:51Z | 102 | 0 |
transformers
|
[
"transformers",
"pytorch",
"pegasus",
"text2text-generation",
"generated_from_trainer",
"dataset:reddit",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-11-19T07:21:12Z |
---
tags:
- generated_from_trainer
datasets:
- reddit
metrics:
- rouge
model-index:
- name: pegasus-xsum-reddit-clean-4
results:
- task:
name: Sequence-to-sequence Language Modeling
type: text2text-generation
dataset:
name: reddit
type: reddit
args: default
metrics:
- name: Rouge1
type: rouge
value: 27.7525
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# pegasus-xsum-reddit-clean-4
This model is a fine-tuned version of [google/pegasus-xsum](https://huggingface.co/google/pegasus-xsum) on the reddit dataset.
It achieves the following results on the evaluation set:
- Loss: 2.7697
- Rouge1: 27.7525
- Rouge2: 7.9823
- Rougel: 20.9276
- Rougelsum: 22.6678
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5.6e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum |
|:-------------:|:-----:|:----:|:---------------:|:-------:|:------:|:-------:|:---------:|
| 3.0594 | 1.0 | 1906 | 2.8489 | 27.9837 | 8.0824 | 20.9135 | 22.7261 |
| 2.861 | 2.0 | 3812 | 2.7793 | 27.8298 | 8.048 | 20.8653 | 22.6781 |
| 2.7358 | 3.0 | 5718 | 2.7697 | 27.7525 | 7.9823 | 20.9276 | 22.6678 |
### Framework versions
- Transformers 4.20.1
- Pytorch 1.11.0
- Datasets 2.1.0
- Tokenizers 0.12.1
|
mmiteva/distilbert-base-uncased-customized
|
mmiteva
| 2022-11-19T08:46:43Z | 61 | 0 |
transformers
|
[
"transformers",
"tf",
"distilbert",
"question-answering",
"generated_from_keras_callback",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-11-18T09:58:38Z |
---
license: apache-2.0
tags:
- generated_from_keras_callback
model-index:
- name: mmiteva/distilbert-base-uncased-customized
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# mmiteva/distilbert-base-uncased-customized
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.3257
- Train End Logits Accuracy: 0.9017
- Train Start Logits Accuracy: 0.8747
- Validation Loss: 1.5040
- Validation End Logits Accuracy: 0.6988
- Validation Start Logits Accuracy: 0.6655
- Epoch: 4
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'Adam', 'learning_rate': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 2e-05, 'decay_steps': 36885, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False}
- training_precision: float32
### Training results
| Train Loss | Train End Logits Accuracy | Train Start Logits Accuracy | Validation Loss | Validation End Logits Accuracy | Validation Start Logits Accuracy | Epoch |
|:----------:|:-------------------------:|:---------------------------:|:---------------:|:------------------------------:|:--------------------------------:|:-----:|
| 1.0773 | 0.7064 | 0.6669 | 1.1080 | 0.6973 | 0.6669 | 0 |
| 0.7660 | 0.7812 | 0.7433 | 1.1076 | 0.7093 | 0.6734 | 1 |
| 0.5586 | 0.8351 | 0.7988 | 1.2336 | 0.7039 | 0.6692 | 2 |
| 0.4165 | 0.8741 | 0.8434 | 1.3799 | 0.7034 | 0.6707 | 3 |
| 0.3257 | 0.9017 | 0.8747 | 1.5040 | 0.6988 | 0.6655 | 4 |
### Framework versions
- Transformers 4.25.0.dev0
- TensorFlow 2.7.0
- Datasets 2.6.1
- Tokenizers 0.13.2
|
robinhad/wav2vec2-xls-r-300m-crh
|
robinhad
| 2022-11-19T08:15:07Z | 79 | 1 |
transformers
|
[
"transformers",
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"generated_from_trainer",
"crh",
"license:mit",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-11-19T08:03:35Z |
---
language:
- crh
license: mit
tags:
- generated_from_trainer
metrics:
- wer
model-index:
- name: wav2vec2-xls-r-300m-crh
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-xls-r-300m-crh
This model is a fine-tuned version of [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) on the custom Crimean Tatar dataset.
It achieves the following results on the evaluation set:
- Loss: 0.738475
- Wer: 0.4494
- Cer: 0.1254
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 24
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 6
- total_train_batch_size: 144
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 100
- mixed_precision_training: Native AMP
### Framework versions
- Transformers 4.24.0
- Pytorch 1.13.0+cu117
- Datasets 2.6.1
- Tokenizers 0.13.1
|
Mohan515/t5-small-finetuned-medical
|
Mohan515
| 2022-11-19T07:56:25Z | 60 | 0 |
transformers
|
[
"transformers",
"tf",
"tensorboard",
"t5",
"text2text-generation",
"generated_from_keras_callback",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-11-15T07:49:34Z |
---
license: apache-2.0
tags:
- generated_from_keras_callback
model-index:
- name: Mohan515/t5-small-finetuned-medical
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# Mohan515/t5-small-finetuned-medical
This model is a fine-tuned version of [t5-small](https://huggingface.co/t5-small) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.8018
- Validation Loss: 0.5835
- Train Rouge1: 43.3783
- Train Rouge2: 35.1091
- Train Rougel: 41.6332
- Train Rougelsum: 42.5743
- Train Gen Len: 17.4718
- Epoch: 0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'AdamWeightDecay', 'learning_rate': 2e-05, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-07, 'amsgrad': False, 'weight_decay_rate': 0.01}
- training_precision: float32
### Training results
| Train Loss | Validation Loss | Train Rouge1 | Train Rouge2 | Train Rougel | Train Rougelsum | Train Gen Len | Epoch |
|:----------:|:---------------:|:------------:|:------------:|:------------:|:---------------:|:-------------:|:-----:|
| 0.8018 | 0.5835 | 43.3783 | 35.1091 | 41.6332 | 42.5743 | 17.4718 | 0 |
### Framework versions
- Transformers 4.24.0
- TensorFlow 2.9.2
- Datasets 2.7.0
- Tokenizers 0.13.2
|
coderSounak/finetuned_twitter_hate_speech_LSTM
|
coderSounak
| 2022-11-19T07:02:00Z | 107 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"text-classification",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-11-19T06:59:33Z |
---
tags:
- generated_from_trainer
metrics:
- accuracy
- f1
- precision
- recall
model-index:
- name: finetuned_twitter_hate_speech_LSTM
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# finetuned_twitter_hate_speech_LSTM
This model is a fine-tuned version of [LYTinn/lstm-finetuning-sentiment-model-3000-samples](https://huggingface.co/LYTinn/lstm-finetuning-sentiment-model-3000-samples) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5748
- Accuracy: 0.6944
- F1: 0.7170
- Precision: 0.6734
- Recall: 0.7667
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
### Framework versions
- Transformers 4.24.0
- Pytorch 1.12.1+cu113
- Datasets 2.7.0
- Tokenizers 0.13.2
|
coderSounak/finetuned_twitter_sentiment_LSTM
|
coderSounak
| 2022-11-19T06:53:04Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"text-classification",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-11-19T06:49:59Z |
---
tags:
- generated_from_trainer
metrics:
- accuracy
- f1
- precision
- recall
model-index:
- name: finetuned_twitter_sentiment_LSTM
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# finetuned_twitter_sentiment_LSTM
This model is a fine-tuned version of [LYTinn/lstm-finetuning-sentiment-model-3000-samples](https://huggingface.co/LYTinn/lstm-finetuning-sentiment-model-3000-samples) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.9053
- Accuracy: 0.5551
- F1: 0.5509
- Precision: 0.5633
- Recall: 0.5551
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
### Framework versions
- Transformers 4.24.0
- Pytorch 1.12.1+cu113
- Datasets 2.7.0
- Tokenizers 0.13.2
|
KellyShiiii/primer-crd3
|
KellyShiiii
| 2022-11-19T06:47:19Z | 92 | 0 |
transformers
|
[
"transformers",
"pytorch",
"led",
"text2text-generation",
"generated_from_trainer",
"dataset:crd3",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-11-17T04:19:01Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- crd3
metrics:
- rouge
model-index:
- name: primer-crd3
results:
- task:
name: Sequence-to-sequence Language Modeling
type: text2text-generation
dataset:
name: crd3
type: crd3
config: default
split: train[:500]
args: default
metrics:
- name: Rouge1
type: rouge
value: 0.1510358452879352
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# primer-crd3
This model is a fine-tuned version of [allenai/PRIMERA](https://huggingface.co/allenai/PRIMERA) on the crd3 dataset.
It achieves the following results on the evaluation set:
- Loss: 3.8193
- Rouge1: 0.1510
- Rouge2: 0.0279
- Rougel: 0.1251
- Rougelsum: 0.1355
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum |
|:-------------:|:-----:|:----:|:---------------:|:------:|:------:|:------:|:---------:|
| No log | 1.0 | 250 | 2.9569 | 0.1762 | 0.0485 | 0.1525 | 0.1605 |
| 1.7993 | 2.0 | 500 | 3.4079 | 0.1612 | 0.0286 | 0.1367 | 0.1444 |
| 1.7993 | 3.0 | 750 | 3.8193 | 0.1510 | 0.0279 | 0.1251 | 0.1355 |
### Framework versions
- Transformers 4.24.0
- Pytorch 1.8.0
- Datasets 2.7.0
- Tokenizers 0.13.2
|
sd-concepts-library/yoshimurachi
|
sd-concepts-library
| 2022-11-19T06:43:59Z | 0 | 0 | null |
[
"license:mit",
"region:us"
] | null | 2022-11-19T06:43:53Z |
---
license: mit
---
### Yoshimurachi on Stable Diffusion
This is the `<yoshi-san>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as an `object`:




|
meongracun/nmt-mpst-id-en-lr_0.0001-ep_10-seq_128_bs-32
|
meongracun
| 2022-11-19T05:54:44Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"t5",
"text2text-generation",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-11-19T05:26:46Z |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- bleu
model-index:
- name: nmt-mpst-id-en-lr_0.0001-ep_10-seq_128_bs-32
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# nmt-mpst-id-en-lr_0.0001-ep_10-seq_128_bs-32
This model is a fine-tuned version of [t5-small](https://huggingface.co/t5-small) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 2.2914
- Bleu: 0.0708
- Meteor: 0.2054
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Bleu | Meteor |
|:-------------:|:-----:|:----:|:---------------:|:------:|:------:|
| No log | 1.0 | 202 | 2.8210 | 0.0313 | 0.1235 |
| No log | 2.0 | 404 | 2.6712 | 0.0398 | 0.1478 |
| 3.0646 | 3.0 | 606 | 2.5543 | 0.0483 | 0.1661 |
| 3.0646 | 4.0 | 808 | 2.4735 | 0.0537 | 0.1751 |
| 2.6866 | 5.0 | 1010 | 2.4120 | 0.0591 | 0.1855 |
| 2.6866 | 6.0 | 1212 | 2.3663 | 0.0618 | 0.1906 |
| 2.6866 | 7.0 | 1414 | 2.3324 | 0.0667 | 0.1993 |
| 2.5034 | 8.0 | 1616 | 2.3098 | 0.0684 | 0.2023 |
| 2.5034 | 9.0 | 1818 | 2.2969 | 0.0696 | 0.2042 |
| 2.4271 | 10.0 | 2020 | 2.2914 | 0.0708 | 0.2054 |
### Framework versions
- Transformers 4.24.0
- Pytorch 1.12.1+cu113
- Datasets 2.7.0
- Tokenizers 0.13.2
|
meongracun/nmt-mpst-id-en-lr_1e-05-ep_10-seq_128_bs-32
|
meongracun
| 2022-11-19T05:41:31Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"t5",
"text2text-generation",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-11-19T05:13:19Z |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- bleu
model-index:
- name: nmt-mpst-id-en-lr_1e-05-ep_10-seq_128_bs-32
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# nmt-mpst-id-en-lr_1e-05-ep_10-seq_128_bs-32
This model is a fine-tuned version of [t5-small](https://huggingface.co/t5-small) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 2.9022
- Bleu: 0.0284
- Meteor: 0.1159
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Bleu | Meteor |
|:-------------:|:-----:|:----:|:---------------:|:------:|:------:|
| No log | 1.0 | 202 | 3.2021 | 0.0126 | 0.0683 |
| No log | 2.0 | 404 | 3.0749 | 0.0219 | 0.0958 |
| 3.559 | 3.0 | 606 | 3.0147 | 0.0252 | 0.1059 |
| 3.559 | 4.0 | 808 | 2.9738 | 0.0262 | 0.1094 |
| 3.2602 | 5.0 | 1010 | 2.9476 | 0.027 | 0.1113 |
| 3.2602 | 6.0 | 1212 | 2.9309 | 0.0278 | 0.1138 |
| 3.2602 | 7.0 | 1414 | 2.9153 | 0.0278 | 0.1139 |
| 3.1839 | 8.0 | 1616 | 2.9083 | 0.0285 | 0.116 |
| 3.1839 | 9.0 | 1818 | 2.9041 | 0.0284 | 0.1158 |
| 3.1574 | 10.0 | 2020 | 2.9022 | 0.0284 | 0.1159 |
### Framework versions
- Transformers 4.24.0
- Pytorch 1.12.1+cu113
- Datasets 2.7.0
- Tokenizers 0.13.2
|
meongracun/nmt-mpst-id-en-lr_0.0001-ep_20-seq_128_bs-16
|
meongracun
| 2022-11-19T05:30:40Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"t5",
"text2text-generation",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-11-19T04:31:47Z |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- bleu
model-index:
- name: nmt-mpst-id-en-lr_0.0001-ep_20-seq_128_bs-16
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# nmt-mpst-id-en-lr_0.0001-ep_20-seq_128_bs-16
This model is a fine-tuned version of [t5-small](https://huggingface.co/t5-small) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.8531
- Bleu: 0.1306
- Meteor: 0.2859
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 20
### Training results
| Training Loss | Epoch | Step | Validation Loss | Bleu | Meteor |
|:-------------:|:-----:|:----:|:---------------:|:------:|:------:|
| No log | 1.0 | 404 | 2.7171 | 0.0374 | 0.14 |
| 3.1222 | 2.0 | 808 | 2.4821 | 0.0519 | 0.1723 |
| 2.7305 | 3.0 | 1212 | 2.3370 | 0.0663 | 0.1983 |
| 2.4848 | 4.0 | 1616 | 2.2469 | 0.0771 | 0.2158 |
| 2.3394 | 5.0 | 2020 | 2.1567 | 0.0857 | 0.227 |
| 2.3394 | 6.0 | 2424 | 2.1038 | 0.0919 | 0.2369 |
| 2.2007 | 7.0 | 2828 | 2.0403 | 0.0973 | 0.2449 |
| 2.1027 | 8.0 | 3232 | 2.0105 | 0.1066 | 0.2554 |
| 2.0299 | 9.0 | 3636 | 1.9725 | 0.1105 | 0.2606 |
| 1.9568 | 10.0 | 4040 | 1.9515 | 0.1147 | 0.2655 |
| 1.9568 | 11.0 | 4444 | 1.9274 | 0.118 | 0.2699 |
| 1.8986 | 12.0 | 4848 | 1.9142 | 0.1215 | 0.2739 |
| 1.8512 | 13.0 | 5252 | 1.8936 | 0.1243 | 0.2777 |
| 1.8258 | 14.0 | 5656 | 1.8841 | 0.1254 | 0.279 |
| 1.7854 | 15.0 | 6060 | 1.8792 | 0.1278 | 0.2827 |
| 1.7854 | 16.0 | 6464 | 1.8662 | 0.1274 | 0.2818 |
| 1.7598 | 17.0 | 6868 | 1.8604 | 0.1293 | 0.2834 |
| 1.7436 | 18.0 | 7272 | 1.8598 | 0.13 | 0.2849 |
| 1.7299 | 19.0 | 7676 | 1.8545 | 0.1308 | 0.2857 |
| 1.7168 | 20.0 | 8080 | 1.8531 | 0.1306 | 0.2859 |
### Framework versions
- Transformers 4.24.0
- Pytorch 1.12.1+cu113
- Datasets 2.7.0
- Tokenizers 0.13.2
|
meongracun/nmt-mpst-id-en-lr_1e-05-ep_20-seq_128_bs-16
|
meongracun
| 2022-11-19T05:30:12Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"t5",
"text2text-generation",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-11-19T04:31:27Z |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- bleu
model-index:
- name: nmt-mpst-id-en-lr_1e-05-ep_20-seq_128_bs-16
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# nmt-mpst-id-en-lr_1e-05-ep_20-seq_128_bs-16
This model is a fine-tuned version of [t5-small](https://huggingface.co/t5-small) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 2.6902
- Bleu: 0.039
- Meteor: 0.144
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 20
### Training results
| Training Loss | Epoch | Step | Validation Loss | Bleu | Meteor |
|:-------------:|:-----:|:----:|:---------------:|:------:|:------:|
| No log | 1.0 | 404 | 3.1126 | 0.0197 | 0.0888 |
| 3.6037 | 2.0 | 808 | 2.9899 | 0.0254 | 0.108 |
| 3.2835 | 3.0 | 1212 | 2.9337 | 0.0275 | 0.1129 |
| 3.1798 | 4.0 | 1616 | 2.8926 | 0.0284 | 0.1152 |
| 3.1361 | 5.0 | 2020 | 2.8638 | 0.0295 | 0.1196 |
| 3.1361 | 6.0 | 2424 | 2.8362 | 0.0305 | 0.1222 |
| 3.0848 | 7.0 | 2828 | 2.8137 | 0.0321 | 0.1266 |
| 3.0439 | 8.0 | 3232 | 2.7928 | 0.0327 | 0.1284 |
| 3.025 | 9.0 | 3636 | 2.7754 | 0.0337 | 0.1311 |
| 2.9891 | 10.0 | 4040 | 2.7604 | 0.0348 | 0.134 |
| 2.9891 | 11.0 | 4444 | 2.7469 | 0.0354 | 0.136 |
| 2.9706 | 12.0 | 4848 | 2.7343 | 0.036 | 0.1372 |
| 2.9537 | 13.0 | 5252 | 2.7250 | 0.0365 | 0.1387 |
| 2.9471 | 14.0 | 5656 | 2.7152 | 0.0375 | 0.1408 |
| 2.9274 | 15.0 | 6060 | 2.7081 | 0.038 | 0.142 |
| 2.9274 | 16.0 | 6464 | 2.7021 | 0.0384 | 0.143 |
| 2.9147 | 17.0 | 6868 | 2.6966 | 0.0387 | 0.1433 |
| 2.9093 | 18.0 | 7272 | 2.6934 | 0.0389 | 0.1438 |
| 2.9082 | 19.0 | 7676 | 2.6906 | 0.039 | 0.1437 |
| 2.8945 | 20.0 | 8080 | 2.6902 | 0.039 | 0.144 |
### Framework versions
- Transformers 4.24.0
- Pytorch 1.12.1+cu113
- Datasets 2.7.0
- Tokenizers 0.13.2
|
osanseviero/test-ernie-paddle
|
osanseviero
| 2022-11-19T05:25:32Z | 0 | 0 | null |
[
"paddlepaddle",
"license:apache-2.0",
"region:us"
] | null | 2022-11-19T05:25:31Z |
---
license: apache-2.0
duplicated_from: PaddlePaddle/ci-test-ernie-model
---
this model is for CI testing in paddlenlp repo.
As you can guess, PaddleNLP will play with 🤗 Huggingface.
|
elRivx/gBWoman
|
elRivx
| 2022-11-19T04:57:34Z | 0 | 1 | null |
[
"stable-diffusion",
"text-to-image",
"license:creativeml-openrail-m",
"region:us"
] |
text-to-image
| 2022-11-19T04:40:07Z |
---
license: creativeml-openrail-m
tags:
- stable-diffusion
- text-to-image
---
# gBWoman
This is a Stable Diffusion custom model that bring to you a woman generated with non-licenced images.
The magic word is: gBWoman
If you enjoy my work, please consider supporting me:
[](https://www.buymeacoffee.com/elrivx)
Examples:
<img src=https://imgur.com/m3hOa5i.png width=30% height=30%>
<img src=https://imgur.com/u0Af9mX.png width=30% height=30%>
<img src=https://imgur.com/VpKDMMK.png width=30% height=30%>
## License
This model is open access and available to all, with a CreativeML OpenRAIL-M license further specifying rights and usage.
The CreativeML OpenRAIL License specifies:
1. You can't use the model to deliberately produce nor share illegal or harmful outputs or content
2. The authors claims no rights on the outputs you generate, you are free to use them and are accountable for their use which must not go against the provisions set in the license
3. You may re-distribute the weights and use the model commercially and/or as a service. If you do, please be aware you have to include the same use restrictions as the ones in the license and share a copy of the CreativeML OpenRAIL-M to all your users (please read the license entirely and carefully)
[Please read the full license here](https://huggingface.co/spaces/CompVis/stable-diffusion-license)
|
Sebabrata/dof-Rai2-1
|
Sebabrata
| 2022-11-19T04:21:37Z | 47 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"vision-encoder-decoder",
"image-text-to-text",
"generated_from_trainer",
"dataset:imagefolder",
"license:mit",
"endpoints_compatible",
"region:us"
] |
image-text-to-text
| 2022-11-18T21:38:29Z |
---
license: mit
tags:
- generated_from_trainer
datasets:
- imagefolder
model-index:
- name: dof-Rai2-1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# dof-Rai2-1
This model is a fine-tuned version of [naver-clova-ix/donut-base](https://huggingface.co/naver-clova-ix/donut-base) on the imagefolder dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 2
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 20
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.24.0
- Pytorch 1.12.1+cu113
- Datasets 2.7.0
- Tokenizers 0.13.2
|
nguyenkhoa2407/favs_filter_classification_v2
|
nguyenkhoa2407
| 2022-11-19T03:42:51Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"text-classification",
"generated_from_trainer",
"dataset:filter_v2",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-11-11T05:12:13Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- filter_v2
metrics:
- f1
- accuracy
model-index:
- name: favs_filter_classification_v2
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: filter_v2
type: filter_v2
config: default
split: train
args: default
metrics:
- name: F1
type: f1
value: 0.9761904761904762
- name: Accuracy
type: accuracy
value: 0.9545454545454546
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# favs_filter_classification_v2
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the filter_v2 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2016
- F1: 0.9762
- Roc Auc: 0.9844
- Accuracy: 0.9545
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1.5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 20
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 | Roc Auc | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:------:|:-------:|:--------:|
| 0.6596 | 1.0 | 16 | 0.6086 | 0.2687 | 0.5474 | 0.0 |
| 0.5448 | 2.0 | 32 | 0.5354 | 0.3824 | 0.6063 | 0.0 |
| 0.5106 | 3.0 | 48 | 0.4874 | 0.4444 | 0.6382 | 0.0455 |
| 0.4353 | 4.0 | 64 | 0.4301 | 0.5352 | 0.6889 | 0.1818 |
| 0.3699 | 5.0 | 80 | 0.3890 | 0.6579 | 0.7640 | 0.3636 |
| 0.349 | 6.0 | 96 | 0.3663 | 0.6667 | 0.7633 | 0.3182 |
| 0.3104 | 7.0 | 112 | 0.3327 | 0.7105 | 0.7953 | 0.4545 |
| 0.3023 | 8.0 | 128 | 0.2971 | 0.7733 | 0.8303 | 0.5455 |
| 0.2676 | 9.0 | 144 | 0.2766 | 0.8395 | 0.8861 | 0.7727 |
| 0.2374 | 10.0 | 160 | 0.2541 | 0.8537 | 0.8980 | 0.7727 |
| 0.2238 | 11.0 | 176 | 0.2399 | 0.9024 | 0.9293 | 0.8182 |
| 0.2084 | 12.0 | 192 | 0.2221 | 0.9286 | 0.9531 | 0.8636 |
| 0.2143 | 13.0 | 208 | 0.2138 | 0.9286 | 0.9531 | 0.8636 |
| 0.1846 | 14.0 | 224 | 0.2016 | 0.9762 | 0.9844 | 0.9545 |
| 0.1812 | 15.0 | 240 | 0.1957 | 0.9762 | 0.9844 | 0.9545 |
| 0.1756 | 16.0 | 256 | 0.1881 | 0.9647 | 0.9806 | 0.9091 |
| 0.1662 | 17.0 | 272 | 0.1845 | 0.9762 | 0.9844 | 0.9545 |
| 0.1715 | 18.0 | 288 | 0.1802 | 0.9762 | 0.9844 | 0.9545 |
| 0.1585 | 19.0 | 304 | 0.1782 | 0.9762 | 0.9844 | 0.9545 |
| 0.1595 | 20.0 | 320 | 0.1775 | 0.9762 | 0.9844 | 0.9545 |
### Framework versions
- Transformers 4.21.1
- Pytorch 1.12.1
- Datasets 2.4.0
- Tokenizers 0.12.1
|
sanchit-gandhi/w2v2-dbart-5k-1e-4
|
sanchit-gandhi
| 2022-11-19T03:37:49Z | 78 | 0 |
transformers
|
[
"transformers",
"pytorch",
"speech-encoder-decoder",
"automatic-speech-recognition",
"generated_from_trainer",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-11-17T17:02:41Z |
---
tags:
- generated_from_trainer
metrics:
- wer
model-index:
- name: w2v2-dbart-5k-1e-4
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# w2v2-dbart-5k-1e-4
This model was trained from scratch on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3370
- Wer: 15.0932
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 250
- training_steps: 5000
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:-------:|
| 2.0771 | 0.2 | 1000 | 1.8878 | 64.0932 |
| 0.7272 | 0.4 | 2000 | 0.7003 | 23.8557 |
| 0.5948 | 0.6 | 3000 | 0.4765 | 14.4223 |
| 0.4597 | 0.8 | 4000 | 0.3761 | 14.1429 |
| 0.3704 | 1.0 | 5000 | 0.3370 | 15.0932 |
### Framework versions
- Transformers 4.25.0.dev0
- Pytorch 1.11.0
- Datasets 2.6.1
- Tokenizers 0.13.2
|
rdyzakya/bert-indo-base-uncased-ner
|
rdyzakya
| 2022-11-19T02:10:45Z | 118 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"token-classification",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-11-19T02:05:00Z |
---
tags:
- generated_from_trainer
model-index:
- name: bert-indo-base-uncased-ner
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-indo-base-uncased-ner
This model was trained from scratch on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Framework versions
- Transformers 4.24.0
- Pytorch 1.12.1+cu113
- Datasets 2.7.0
- Tokenizers 0.13.2
|
juancopi81/distilgpt2-finetuned-yannic-test-1
|
juancopi81
| 2022-11-19T02:07:14Z | 111 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"gpt2",
"text-generation",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-11-19T01:36:30Z |
---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: distilgpt2-finetuned-yannic-test-1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilgpt2-finetuned-yannic-test-1
This model is a fine-tuned version of [distilgpt2](https://huggingface.co/distilgpt2) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 3.5082
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 8
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| No log | 1.0 | 482 | 3.5938 |
| 3.6669 | 2.0 | 964 | 3.5534 |
| 3.5089 | 3.0 | 1446 | 3.5315 |
| 3.4295 | 4.0 | 1928 | 3.5197 |
| 3.3772 | 5.0 | 2410 | 3.5143 |
| 3.3383 | 6.0 | 2892 | 3.5110 |
| 3.3092 | 7.0 | 3374 | 3.5084 |
| 3.2857 | 8.0 | 3856 | 3.5082 |
### Framework versions
- Transformers 4.24.0
- Pytorch 1.12.1+cu113
- Datasets 2.7.0
- Tokenizers 0.13.2
|
dvitel/h0-1
|
dvitel
| 2022-11-19T02:03:55Z | 122 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"CodeGPT-small-py",
"hearthstone",
"dataset:dvitel/hearthstone",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-11-18T23:04:43Z |
---
license: apache-2.0
tags:
- CodeGPT-small-py
- hearthstone
metrics:
- bleu
- dvitel/codebleu
- exact_match
- chrf
datasets:
- dvitel/hearthstone
model-index:
- name: h0-1
results:
- task:
type: text-generation
name: Python Code Synthesis
dataset:
type: dvitel/hearthstone
name: HearthStone
split: test
metrics:
- type: exact_match
value: 0.21212121212121213
name: Exact Match
- type: bleu
value: 0.8954467480979604
name: BLEU
- type: dvitel/codebleu
value: 0.6976253554171774
name: CodeBLEU
- type: chrf
value: 91.42413429212283
name: chrF
---
# h0-1
This model is a fine-tuned version of [microsoft/CodeGPT-small-py](https://huggingface.co/microsoft/CodeGPT-small-py) on [hearthstone](https://huggingface.co/datasets/dvitel/hearthstone) dataset.
[GitHub repo](https://github.com/dvitel/nlp-sem-parsing/blob/master/h0-1.py).
It achieves the following results on the evaluation set:
- Loss: 0.3622
- Exact Match: 0.1970
- Bleu: 0.9193
- Codebleu: 0.7686
- Chrf: 93.5686
## Model description
CodeGPT-small-py fine-tuned on HearthStone dataset for 200 epochs
## Intended uses & limitations
HearthStone card code synthesis.
## Training and evaluation data
See split of [hearthstone](https://huggingface.co/datasets/dvitel/hearthstone) dataset
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 17
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- num_epochs: 200
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Exact Match | Bleu | Codebleu | Chrf |
|:-------------:|:------:|:-----:|:---------------:|:-----------:|:------:|:--------:|:-------:|
| 0.2482 | 11.94 | 1600 | 0.2828 | 0.1364 | 0.9012 | 0.7012 | 92.2247 |
| 0.0203 | 23.88 | 3200 | 0.2968 | 0.1970 | 0.9114 | 0.7298 | 93.0236 |
| 0.0082 | 35.82 | 4800 | 0.3049 | 0.1970 | 0.9125 | 0.7480 | 93.1997 |
| 0.0049 | 47.76 | 6400 | 0.3190 | 0.1818 | 0.9125 | 0.7526 | 93.0967 |
| 0.0038 | 59.7 | 8000 | 0.3289 | 0.1818 | 0.9117 | 0.7348 | 93.1293 |
| 0.0024 | 71.64 | 9600 | 0.3358 | 0.1970 | 0.9142 | 0.7555 | 93.0747 |
| 0.0022 | 83.58 | 11200 | 0.3379 | 0.1970 | 0.9164 | 0.7642 | 93.2931 |
| 0.0013 | 95.52 | 12800 | 0.3444 | 0.2121 | 0.9189 | 0.7700 | 93.4456 |
| 0.0009 | 107.46 | 14400 | 0.3408 | 0.1970 | 0.9188 | 0.7655 | 93.4808 |
| 0.0006 | 119.4 | 16000 | 0.3522 | 0.1970 | 0.9177 | 0.7510 | 93.4061 |
| 0.0003 | 131.34 | 17600 | 0.3589 | 0.2121 | 0.9178 | 0.7614 | 93.3980 |
| 0.0002 | 143.28 | 19200 | 0.3562 | 0.2121 | 0.9179 | 0.7634 | 93.5130 |
| 0.0002 | 155.22 | 20800 | 0.3624 | 0.1970 | 0.9208 | 0.7699 | 93.6707 |
| 0.0001 | 167.16 | 22400 | 0.3608 | 0.1970 | 0.9193 | 0.7703 | 93.6082 |
| 0.0001 | 179.1 | 24000 | 0.3620 | 0.1970 | 0.9190 | 0.7667 | 93.5154 |
| 0.0001 | 191.04 | 25600 | 0.3622 | 0.1970 | 0.9193 | 0.7686 | 93.5686 |
### Framework versions
- Transformers 4.24.0
- Pytorch 1.13.0
- Datasets 2.6.1
- Tokenizers 0.13.1
|
dvitel/h2
|
dvitel
| 2022-11-19T02:02:50Z | 113 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"distigpt2",
"hearthstone",
"dataset:dvitel/hearthstone",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-11-18T21:25:37Z |
---
license: apache-2.0
tags:
- distigpt2
- hearthstone
metrics:
- bleu
- dvitel/codebleu
- exact_match
- chrf
datasets:
- dvitel/hearthstone
model-index:
- name: h0
results:
- task:
type: text-generation
name: Python Code Synthesis
dataset:
type: dvitel/hearthstone
name: HearthStone
split: test
metrics:
- type: exact_match
value: 0.0
name: Exact Match
- type: bleu
value: 0.6082316056517667
name: BLEU
- type: dvitel/codebleu
value: 0.36984242128954287
name: CodeBLEU
- type: chrf
value: 68.77878158023694
name: chrF
---
# h2
This model is a fine-tuned version of [distilgpt2](https://huggingface.co/distilgpt2) on [hearthstone](https://huggingface.co/datasets/dvitel/hearthstone).
[GitHub repo](https://github.com/dvitel/nlp-sem-parsing/blob/master/h2.py).
It achieves the following results on the evaluation set:
- Loss: 2.5771
- Exact Match: 0.0
- Bleu: 0.6619
- Codebleu: 0.5374
- Ngram Match Score: 0.4051
- Weighted Ngram Match Score: 0.4298
- Syntax Match Score: 0.5605
- Dataflow Match Score: 0.7541
- Chrf: 73.9625
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 17
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- num_epochs: 200
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Exact Match | Bleu | Codebleu | Ngram Match Score | Weighted Ngram Match Score | Syntax Match Score | Dataflow Match Score | Chrf |
|:-------------:|:------:|:-----:|:---------------:|:-----------:|:------:|:--------:|:-----------------:|:--------------------------:|:------------------:|:--------------------:|:-------:|
| 1.2052 | 11.94 | 1600 | 1.2887 | 0.0 | 0.6340 | 0.4427 | 0.3384 | 0.3614 | 0.5263 | 0.5446 | 70.8004 |
| 0.3227 | 23.88 | 3200 | 1.4484 | 0.0 | 0.6575 | 0.5050 | 0.3767 | 0.3995 | 0.5955 | 0.6485 | 72.9553 |
| 0.205 | 35.82 | 4800 | 1.6392 | 0.0 | 0.6598 | 0.5174 | 0.3788 | 0.4022 | 0.5821 | 0.7063 | 73.2766 |
| 0.1392 | 47.76 | 6400 | 1.8219 | 0.0 | 0.6584 | 0.5279 | 0.3922 | 0.4159 | 0.5742 | 0.7294 | 73.5022 |
| 0.0979 | 59.7 | 8000 | 1.9416 | 0.0 | 0.6635 | 0.5305 | 0.4012 | 0.4248 | 0.5699 | 0.7261 | 73.8081 |
| 0.0694 | 71.64 | 9600 | 2.1793 | 0.0 | 0.6593 | 0.5400 | 0.4027 | 0.4271 | 0.5562 | 0.7739 | 73.6746 |
| 0.0512 | 83.58 | 11200 | 2.2547 | 0.0 | 0.6585 | 0.5433 | 0.4040 | 0.4283 | 0.5486 | 0.7921 | 73.7670 |
| 0.0399 | 95.52 | 12800 | 2.3037 | 0.0 | 0.6585 | 0.5354 | 0.4040 | 0.4282 | 0.5454 | 0.7640 | 73.7431 |
| 0.0316 | 107.46 | 14400 | 2.4113 | 0.0 | 0.6577 | 0.5294 | 0.4006 | 0.4257 | 0.5504 | 0.7409 | 73.7004 |
| 0.0254 | 119.4 | 16000 | 2.4407 | 0.0 | 0.6607 | 0.5412 | 0.4041 | 0.4285 | 0.5598 | 0.7723 | 73.8828 |
| 0.0208 | 131.34 | 17600 | 2.4993 | 0.0 | 0.6637 | 0.5330 | 0.4042 | 0.4286 | 0.5684 | 0.7310 | 74.1760 |
| 0.0176 | 143.28 | 19200 | 2.5138 | 0.0 | 0.6627 | 0.5434 | 0.4050 | 0.4295 | 0.5620 | 0.7772 | 74.0546 |
| 0.0158 | 155.22 | 20800 | 2.5589 | 0.0 | 0.6616 | 0.5347 | 0.4044 | 0.4291 | 0.5512 | 0.7541 | 73.9516 |
| 0.0147 | 167.16 | 22400 | 2.5554 | 0.0 | 0.6620 | 0.5354 | 0.4049 | 0.4295 | 0.5630 | 0.7442 | 73.9461 |
| 0.0134 | 179.1 | 24000 | 2.5696 | 0.0 | 0.6607 | 0.5395 | 0.4046 | 0.4293 | 0.5602 | 0.7640 | 73.8383 |
| 0.0135 | 191.04 | 25600 | 2.5771 | 0.0 | 0.6619 | 0.5374 | 0.4051 | 0.4298 | 0.5605 | 0.7541 | 73.9625 |
### Framework versions
- Transformers 4.24.0
- Pytorch 1.13.0
- Datasets 2.6.1
- Tokenizers 0.13.1
|
flamesbob/ross_model
|
flamesbob
| 2022-11-19T01:21:55Z | 0 | 3 | null |
[
"license:creativeml-openrail-m",
"region:us"
] | null | 2022-11-19T00:49:51Z |
---
license: creativeml-openrail-m
---
`m_ross artstyle,`class token
License This embedding is open access and available to all, with a CreativeML OpenRAIL-M license further specifying rights and usage. The CreativeML OpenRAIL License specifies:
You can't use the embedding to deliberately produce nor share illegal or harmful outputs or content The authors claims no rights on the outputs you generate, you are free to use them and are accountable for their use which must not go against the provisions set in the license You may re-distribute the weights and use the embedding commercially and/or as a service. If you do, please be aware you have to include the same use restrictions as the ones in the license and share a copy of the CreativeML OpenRAIL-M to all your users (please read the license entirely and carefully) Please read the full license here
|
bwhite5311/NLP-sentiment-project-2001-samples
|
bwhite5311
| 2022-11-19T01:21:00Z | 107 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_trainer",
"dataset:imdb",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-11-18T21:45:43Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- imdb
metrics:
- accuracy
- f1
- precision
model-index:
- name: NLP-sentiment-project-2001-samples
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: imdb
type: imdb
config: plain_text
split: train
args: plain_text
metrics:
- name: Accuracy
type: accuracy
value: 0.9998
- name: F1
type: f1
value: 0.9998005186515061
- name: Precision
type: precision
value: 0.9996011168727563
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# NLP-sentiment-project-2001-samples
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the imdb dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0008
- Accuracy: 0.9998
- F1: 0.9998
- Precision: 0.9996
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 20
- eval_batch_size: 20
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 15
### Training results
### Framework versions
- Transformers 4.24.0
- Pytorch 1.12.1+cu113
- Datasets 2.7.0
- Tokenizers 0.13.2
|
StanfordAIMI/covid-radbert
|
StanfordAIMI
| 2022-11-19T01:11:06Z | 108 | 2 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"text-classification",
"uncased",
"radiology",
"biomedical",
"covid-19",
"covid19",
"en",
"license:mit",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-07-19T03:44:46Z |
---
widget:
- text: "procedure: single ap view of the chest comparison: none findings: no surgical hardware nor tubes. lungs, pleura: low lung volumes, bilateral airspace opacities. no pneumothorax or pleural effusion. cardiovascular and mediastinum: the cardiomediastinal silhouette seems stable. impression: 1. patchy bilateral airspace opacities, stable, but concerning for multifocal pneumonia. 2. absence of other suspicions, the rest of the lungs seems fine."
- text: "procedure: single ap view of the chest comparison: none findings: No surgical hardware nor tubes. lungs, pleura: low lung volumes, bilateral airspace opacities. no pneumothorax or pleural effusion. cardiovascular and mediastinum: the cardiomediastinal silhouette seems stable. impression: 1. patchy bilateral airspace opacities, stable. 2. some areas are suggestive that pneumonia can not be excluded. 3. recommended to follow-up shortly and check if there are additional symptoms"
tags:
- text-classification
- pytorch
- transformers
- uncased
- radiology
- biomedical
- covid-19
- covid19
language:
- en
license: mit
---
COVID-RadBERT was trained to detect the presence or absence of COVID-19 within radiology reports, along an "uncertain" diagnostic when further medical tests are required.
## Citation
```bibtex
@article{chambon_cook_langlotz_2022,
title={Improved fine-tuning of in-domain transformer model for inferring COVID-19 presence in multi-institutional radiology reports},
DOI={10.1007/s10278-022-00714-8}, journal={Journal of Digital Imaging},
author={Chambon, Pierre and Cook, Tessa S. and Langlotz, Curtis P.},
year={2022}
}
```
|
rocca/lyra-v2-soundstream
|
rocca
| 2022-11-19T01:10:07Z | 0 | 7 | null |
[
"tflite",
"onnx",
"license:apache-2.0",
"region:us"
] | null | 2022-10-02T04:01:37Z |
---
license: apache-2.0
---
For an eventual web demo of Lyra v2 (SoundStream).
Currently this repo just contains a copy of the model files in the official Lyra repo as of October 2nd 2022: https://github.com/google/lyra/tree/main/model_coeffs
I'm aiming to produce ONNX versions of the models too.
WIP demo here: https://github.com/josephrocca/lyra-v2-soundstream-web
|
andrewzhang505/doom_deathmatch_bots
|
andrewzhang505
| 2022-11-19T00:58:04Z | 4 | 0 |
sample-factory
|
[
"sample-factory",
"tensorboard",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-10-27T23:12:48Z |
---
library_name: sample-factory
tags:
- deep-reinforcement-learning
- reinforcement-learning
- sample-factory
model-index:
- name: APPO
results:
- metrics:
- type: mean_reward
value: 69.40 +/- 4.29
name: mean_reward
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: doom_deathmatch_bots
type: doom_deathmatch_bots
---
A(n) **APPO** model trained on the **doom_deathmatch_bots** environment.
This model was trained using Sample Factory 2.0: https://github.com/alex-petrenko/sample-factory
|
zates/albert-base-v2-finetuned-squad-seed-42
|
zates
| 2022-11-19T00:30:41Z | 107 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"albert",
"question-answering",
"generated_from_trainer",
"dataset:squad_v2",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-11-18T22:06:20Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- squad_v2
model-index:
- name: albert-base-v2-finetuned-squad-seed-42
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# albert-base-v2-finetuned-squad-seed-42
This model is a fine-tuned version of [albert-base-v2](https://huggingface.co/albert-base-v2) on the squad_v2 dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Framework versions
- Transformers 4.24.0
- Pytorch 1.12.1+cu113
- Datasets 2.7.0
- Tokenizers 0.13.2
|
darkprincess638/darkprincess638-a
|
darkprincess638
| 2022-11-19T00:13:24Z | 0 | 0 | null |
[
"license:apache-2.0",
"region:us"
] | null | 2022-11-18T23:51:21Z |
---
license: apache-2.0
---
## Trigger Prompt
The keywords `darkprincess638 person` will trigger the character, best to use at start of prompt
## Examples
These are some sample images generated by this model

|
shi-labs/dinat-tiny-in1k-224
|
shi-labs
| 2022-11-18T23:11:09Z | 99 | 0 |
transformers
|
[
"transformers",
"pytorch",
"dinat",
"image-classification",
"vision",
"dataset:imagenet-1k",
"arxiv:2209.15001",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2022-11-18T22:07:23Z |
---
license: mit
tags:
- vision
- image-classification
datasets:
- imagenet-1k
widget:
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/tiger.jpg
example_title: Tiger
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/teapot.jpg
example_title: Teapot
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/palace.jpg
example_title: Palace
---
# DiNAT (tiny variant)
DiNAT-Tiny trained on ImageNet-1K at 224x224 resolution.
It was introduced in the paper [Dilated Neighborhood Attention Transformer](https://arxiv.org/abs/2209.15001) by Hassani et al. and first released in [this repository](https://github.com/SHI-Labs/Neighborhood-Attention-Transformer).
## Model description
DiNAT is a hierarchical vision transformer based on Neighborhood Attention (NA) and its dilated variant (DiNA).
Neighborhood Attention is a restricted self attention pattern in which each token's receptive field is limited to its nearest neighboring pixels.
NA and DiNA are therefore sliding-window attention patterns, and as a result are highly flexible and maintain translational equivariance.
They come with PyTorch implementations through the [NATTEN](https://github.com/SHI-Labs/NATTEN/) package.

[Source](https://paperswithcode.com/paper/dilated-neighborhood-attention-transformer)
## Intended uses & limitations
You can use the raw model for image classification. See the [model hub](https://huggingface.co/models?search=dinat) to look for
fine-tuned versions on a task that interests you.
### Example
Here is how to use this model to classify an image from the COCO 2017 dataset into one of the 1,000 ImageNet classes:
```python
from transformers import AutoImageProcessor, DinatForImageClassification
from PIL import Image
import requests
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
feature_extractor = AutoImageProcessor.from_pretrained("shi-labs/dinat-tiny-in1k-224")
model = DinatForImageClassification.from_pretrained("shi-labs/dinat-tiny-in1k-224")
inputs = feature_extractor(images=image, return_tensors="pt")
outputs = model(**inputs)
logits = outputs.logits
# model predicts one of the 1000 ImageNet classes
predicted_class_idx = logits.argmax(-1).item()
print("Predicted class:", model.config.id2label[predicted_class_idx])
```
For more examples, please refer to the [documentation](https://huggingface.co/transformers/model_doc/dinat.html#).
### Requirements
Other than transformers, this model requires the [NATTEN](https://shi-labs.com/natten) package.
If you're on Linux, you can refer to [shi-labs.com/natten](https://shi-labs.com/natten) for instructions on installing with pre-compiled binaries (just select your torch build to get the correct wheel URL).
You can alternatively use `pip install natten` to compile on your device, which may take up to a few minutes.
Mac users only have the latter option (no pre-compiled binaries).
Refer to [NATTEN's GitHub](https://github.com/SHI-Labs/NATTEN/) for more information.
### BibTeX entry and citation info
```bibtex
@article{hassani2022dilated,
title = {Dilated Neighborhood Attention Transformer},
author = {Ali Hassani and Humphrey Shi},
year = 2022,
url = {https://arxiv.org/abs/2209.15001},
eprint = {2209.15001},
archiveprefix = {arXiv},
primaryclass = {cs.CV}
}
```
|
shi-labs/dinat-small-in1k-224
|
shi-labs
| 2022-11-18T23:10:53Z | 89 | 0 |
transformers
|
[
"transformers",
"pytorch",
"dinat",
"image-classification",
"vision",
"dataset:imagenet-1k",
"arxiv:2209.15001",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2022-11-18T22:02:48Z |
---
license: mit
tags:
- vision
- image-classification
datasets:
- imagenet-1k
widget:
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/tiger.jpg
example_title: Tiger
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/teapot.jpg
example_title: Teapot
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/palace.jpg
example_title: Palace
---
# DiNAT (small variant)
DiNAT-Small trained on ImageNet-1K at 224x224 resolution.
It was introduced in the paper [Dilated Neighborhood Attention Transformer](https://arxiv.org/abs/2209.15001) by Hassani et al. and first released in [this repository](https://github.com/SHI-Labs/Neighborhood-Attention-Transformer).
## Model description
DiNAT is a hierarchical vision transformer based on Neighborhood Attention (NA) and its dilated variant (DiNA).
Neighborhood Attention is a restricted self attention pattern in which each token's receptive field is limited to its nearest neighboring pixels.
NA and DiNA are therefore sliding-window attention patterns, and as a result are highly flexible and maintain translational equivariance.
They come with PyTorch implementations through the [NATTEN](https://github.com/SHI-Labs/NATTEN/) package.

[Source](https://paperswithcode.com/paper/dilated-neighborhood-attention-transformer)
## Intended uses & limitations
You can use the raw model for image classification. See the [model hub](https://huggingface.co/models?search=dinat) to look for
fine-tuned versions on a task that interests you.
### Example
Here is how to use this model to classify an image from the COCO 2017 dataset into one of the 1,000 ImageNet classes:
```python
from transformers import AutoImageProcessor, DinatForImageClassification
from PIL import Image
import requests
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
feature_extractor = AutoImageProcessor.from_pretrained("shi-labs/dinat-small-in1k-224")
model = DinatForImageClassification.from_pretrained("shi-labs/dinat-small-in1k-224")
inputs = feature_extractor(images=image, return_tensors="pt")
outputs = model(**inputs)
logits = outputs.logits
# model predicts one of the 1000 ImageNet classes
predicted_class_idx = logits.argmax(-1).item()
print("Predicted class:", model.config.id2label[predicted_class_idx])
```
For more examples, please refer to the [documentation](https://huggingface.co/transformers/model_doc/dinat.html#).
### Requirements
Other than transformers, this model requires the [NATTEN](https://shi-labs.com/natten) package.
If you're on Linux, you can refer to [shi-labs.com/natten](https://shi-labs.com/natten) for instructions on installing with pre-compiled binaries (just select your torch build to get the correct wheel URL).
You can alternatively use `pip install natten` to compile on your device, which may take up to a few minutes.
Mac users only have the latter option (no pre-compiled binaries).
Refer to [NATTEN's GitHub](https://github.com/SHI-Labs/NATTEN/) for more information.
### BibTeX entry and citation info
```bibtex
@article{hassani2022dilated,
title = {Dilated Neighborhood Attention Transformer},
author = {Ali Hassani and Humphrey Shi},
year = 2022,
url = {https://arxiv.org/abs/2209.15001},
eprint = {2209.15001},
archiveprefix = {arXiv},
primaryclass = {cs.CV}
}
```
|
shi-labs/dinat-mini-in1k-224
|
shi-labs
| 2022-11-18T23:10:49Z | 1,834 | 1 |
transformers
|
[
"transformers",
"pytorch",
"dinat",
"image-classification",
"vision",
"dataset:imagenet-1k",
"arxiv:2209.15001",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2022-11-14T22:27:14Z |
---
license: mit
tags:
- vision
- image-classification
datasets:
- imagenet-1k
widget:
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/tiger.jpg
example_title: Tiger
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/teapot.jpg
example_title: Teapot
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/palace.jpg
example_title: Palace
---
# DiNAT (mini variant)
DiNAT-Mini trained on ImageNet-1K at 224x224 resolution.
It was introduced in the paper [Dilated Neighborhood Attention Transformer](https://arxiv.org/abs/2209.15001) by Hassani et al. and first released in [this repository](https://github.com/SHI-Labs/Neighborhood-Attention-Transformer).
## Model description
DiNAT is a hierarchical vision transformer based on Neighborhood Attention (NA) and its dilated variant (DiNA).
Neighborhood Attention is a restricted self attention pattern in which each token's receptive field is limited to its nearest neighboring pixels.
NA and DiNA are therefore sliding-window attention patterns, and as a result are highly flexible and maintain translational equivariance.
They come with PyTorch implementations through the [NATTEN](https://github.com/SHI-Labs/NATTEN/) package.

[Source](https://paperswithcode.com/paper/dilated-neighborhood-attention-transformer)
## Intended uses & limitations
You can use the raw model for image classification. See the [model hub](https://huggingface.co/models?search=dinat) to look for
fine-tuned versions on a task that interests you.
### Example
Here is how to use this model to classify an image from the COCO 2017 dataset into one of the 1,000 ImageNet classes:
```python
from transformers import AutoImageProcessor, DinatForImageClassification
from PIL import Image
import requests
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
feature_extractor = AutoImageProcessor.from_pretrained("shi-labs/dinat-mini-in1k-224")
model = DinatForImageClassification.from_pretrained("shi-labs/dinat-mini-in1k-224")
inputs = feature_extractor(images=image, return_tensors="pt")
outputs = model(**inputs)
logits = outputs.logits
# model predicts one of the 1000 ImageNet classes
predicted_class_idx = logits.argmax(-1).item()
print("Predicted class:", model.config.id2label[predicted_class_idx])
```
For more examples, please refer to the [documentation](https://huggingface.co/transformers/model_doc/dinat.html#).
### Requirements
Other than transformers, this model requires the [NATTEN](https://shi-labs.com/natten) package.
If you're on Linux, you can refer to [shi-labs.com/natten](https://shi-labs.com/natten) for instructions on installing with pre-compiled binaries (just select your torch build to get the correct wheel URL).
You can alternatively use `pip install natten` to compile on your device, which may take up to a few minutes.
Mac users only have the latter option (no pre-compiled binaries).
Refer to [NATTEN's GitHub](https://github.com/SHI-Labs/NATTEN/) for more information.
### BibTeX entry and citation info
```bibtex
@article{hassani2022dilated,
title = {Dilated Neighborhood Attention Transformer},
author = {Ali Hassani and Humphrey Shi},
year = 2022,
url = {https://arxiv.org/abs/2209.15001},
eprint = {2209.15001},
archiveprefix = {arXiv},
primaryclass = {cs.CV}
}
```
|
shi-labs/dinat-base-in1k-224
|
shi-labs
| 2022-11-18T23:07:43Z | 90 | 0 |
transformers
|
[
"transformers",
"pytorch",
"dinat",
"image-classification",
"vision",
"dataset:imagenet-1k",
"arxiv:2209.15001",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2022-11-18T22:04:27Z |
---
license: mit
tags:
- vision
- image-classification
datasets:
- imagenet-1k
widget:
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/tiger.jpg
example_title: Tiger
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/teapot.jpg
example_title: Teapot
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/palace.jpg
example_title: Palace
---
# DiNAT (base variant)
DiNAT-Base trained on ImageNet-1K at 224x224 resolution.
It was introduced in the paper [Dilated Neighborhood Attention Transformer](https://arxiv.org/abs/2209.15001) by Hassani et al. and first released in [this repository](https://github.com/SHI-Labs/Neighborhood-Attention-Transformer).
## Model description
DiNAT is a hierarchical vision transformer based on Neighborhood Attention (NA) and its dilated variant (DiNA).
Neighborhood Attention is a restricted self attention pattern in which each token's receptive field is limited to its nearest neighboring pixels.
NA and DiNA are therefore sliding-window attention patterns, and as a result are highly flexible and maintain translational equivariance.
They come with PyTorch implementations through the [NATTEN](https://github.com/SHI-Labs/NATTEN/) package.

[Source](https://paperswithcode.com/paper/dilated-neighborhood-attention-transformer)
## Intended uses & limitations
You can use the raw model for image classification. See the [model hub](https://huggingface.co/models?search=dinat) to look for
fine-tuned versions on a task that interests you.
### Example
Here is how to use this model to classify an image from the COCO 2017 dataset into one of the 1,000 ImageNet classes:
```python
from transformers import AutoImageProcessor, DinatForImageClassification
from PIL import Image
import requests
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
feature_extractor = AutoImageProcessor.from_pretrained("shi-labs/dinat-base-in1k-224")
model = DinatForImageClassification.from_pretrained("shi-labs/dinat-base-in1k-224")
inputs = feature_extractor(images=image, return_tensors="pt")
outputs = model(**inputs)
logits = outputs.logits
# model predicts one of the 1000 ImageNet classes
predicted_class_idx = logits.argmax(-1).item()
print("Predicted class:", model.config.id2label[predicted_class_idx])
```
For more examples, please refer to the [documentation](https://huggingface.co/transformers/model_doc/dinat.html#).
### Requirements
Other than transformers, this model requires the [NATTEN](https://shi-labs.com/natten) package.
If you're on Linux, you can refer to [shi-labs.com/natten](https://shi-labs.com/natten) for instructions on installing with pre-compiled binaries (just select your torch build to get the correct wheel URL).
You can alternatively use `pip install natten` to compile on your device, which may take up to a few minutes.
Mac users only have the latter option (no pre-compiled binaries).
Refer to [NATTEN's GitHub](https://github.com/SHI-Labs/NATTEN/) for more information.
### BibTeX entry and citation info
```bibtex
@article{hassani2022dilated,
title = {Dilated Neighborhood Attention Transformer},
author = {Ali Hassani and Humphrey Shi},
year = 2022,
url = {https://arxiv.org/abs/2209.15001},
eprint = {2209.15001},
archiveprefix = {arXiv},
primaryclass = {cs.CV}
}
```
|
OSalem99/a2c-AntBulletEnv-v0
|
OSalem99
| 2022-11-18T22:42:18Z | 3 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"AntBulletEnv-v0",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-11-18T22:41:12Z |
---
library_name: stable-baselines3
tags:
- AntBulletEnv-v0
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: A2C
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: AntBulletEnv-v0
type: AntBulletEnv-v0
metrics:
- type: mean_reward
value: 953.99 +/- 100.86
name: mean_reward
verified: false
---
# **A2C** Agent playing **AntBulletEnv-v0**
This is a trained model of a **A2C** agent playing **AntBulletEnv-v0**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
elRivx/DMVC2
|
elRivx
| 2022-11-18T22:16:09Z | 0 | 3 | null |
[
"stable-diffusion",
"text-to-image",
"license:creativeml-openrail-m",
"region:us"
] |
text-to-image
| 2022-11-03T15:14:43Z |
---
license: creativeml-openrail-m
tags:
- stable-diffusion
- text-to-image
---
# DMVC2
This is an own SD trainee with an 2000s videogame illustrations as a style.
If you wanna test it, you can put this word on the prompt: DMVC2 . Sometimes you must put before things like 'an illustration of'
If you enjoy my work, please consider supporting me:
[](https://www.buymeacoffee.com/elrivx)
Examples:
<img src=https://imgur.com/lrD4Q5s.png width=30% height=30%>
<img src=https://imgur.com/DSW8Ein.png width=30% height=30%>
<img src=https://imgur.com/Z4T2eYj.png width=30% height=30%>
<img src=https://imgur.com/EzidtGk.png width=30% height=30%>
<img src=https://imgur.com/1NHdWhc.png width=30% height=30%>
## License
This model is open access and available to all, with a CreativeML OpenRAIL-M license further specifying rights and usage.
The CreativeML OpenRAIL License specifies:
1. You can't use the model to deliberately produce nor share illegal or harmful outputs or content
2. The authors claims no rights on the outputs you generate, you are free to use them and are accountable for their use which must not go against the provisions set in the license
3. You may re-distribute the weights and use the model commercially and/or as a service. If you do, please be aware you have to include the same use restrictions as the ones in the license and share a copy of the CreativeML OpenRAIL-M to all your users (please read the license entirely and carefully)
[Please read the full license here](https://huggingface.co/spaces/CompVis/stable-diffusion-license)
|
racro/sentiment-browser-extension
|
racro
| 2022-11-18T21:51:15Z | 104 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-11-16T06:57:37Z |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- accuracy
- f1
model-index:
- name: sentiment-browser-extension
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# sentiment-browser-extension
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7068
- Accuracy: 0.8516
- F1: 0.8690
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 9
### Training results
### Framework versions
- Transformers 4.24.0
- Pytorch 1.12.1+cu113
- Datasets 2.7.0
- Tokenizers 0.13.2
|
laion/CLIP-ViT-H-14-frozen-xlm-roberta-large-laion5B-s13B-b90k
|
laion
| 2022-11-18T21:00:32Z | 11,367 | 19 |
open_clip
|
[
"open_clip",
"arxiv:1910.04867",
"license:mit",
"region:us"
] | null | 2022-11-18T20:49:11Z |
---
license: mit
widget:
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/cat-dog-music.png
candidate_labels: playing music, playing sports
example_title: Cat & Dog
---
# Model Card for CLIP ViT-H/14 frozen xlm roberta large - LAION-5B
# Table of Contents
1. [Model Details](#model-details)
2. [Uses](#uses)
3. [Training Details](#training-details)
4. [Evaluation](#evaluation)
5. [Acknowledgements](#acknowledgements)
6. [Citation](#citation)
7. [How To Get Started With the Model](#how-to-get-started-with-the-model)
# Model Details
## Model Description
A CLIP ViT-H/14 frozen xlm roberta large model trained with the LAION-5B (https://laion.ai/blog/laion-5b/) using OpenCLIP (https://github.com/mlfoundations/open_clip).
Model training done by Romain Beaumont on the [stability.ai](https://stability.ai/) cluster.
# Uses
## Direct Use
Zero-shot image classification, image and text retrieval, among others.
## Downstream Use
Image classification and other image task fine-tuning, linear probe image classification, image generation guiding and conditioning, among others.
# Training Details
## Training Data
This model was trained with the full LAION-5B (https://laion.ai/blog/laion-5b/).
## Training Procedure
Training with batch size 90k for 13B sample of laion5B, see https://wandb.ai/rom1504/open-clip/reports/xlm-roberta-large-unfrozen-vit-h-14-frozen--VmlldzoyOTc3ODY3
Model is H/14 on visual side, xlm roberta large initialized with pretrained weights on text side.
The H/14 was initialized from https://huggingface.co/laion/CLIP-ViT-H-14-laion2B-s32B-b79K and kept frozen during training.
# Evaluation
Evaluation done with code in the [LAION CLIP Benchmark suite](https://github.com/LAION-AI/CLIP_benchmark).
## Testing Data, Factors & Metrics
### Testing Data
The testing is performed with VTAB+ (A combination of VTAB (https://arxiv.org/abs/1910.04867) w/ additional robustness datasets) for classification and COCO and Flickr for retrieval.
## Results
The model achieves imagenet 1k 77.0% (vs 78% for the english H/14)

On zero shot classification on imagenet with translated prompts this model reaches:
* 56% in italian (vs 21% for https://github.com/clip-italian/clip-italian)
* 53% in japanese (vs 54.6% for https://github.com/rinnakk/japanese-clip)
* 55.7% in chinese (to be compared with https://github.com/OFA-Sys/Chinese-CLIP)
This model reaches strong results in both english and other languages.
# Acknowledgements
Acknowledging [stability.ai](https://stability.ai/) for the compute used to train this model.
# Citation
**BibTeX:**
In addition to forthcoming LAION-5B (https://laion.ai/blog/laion-5b/) paper, please cite:
OpenAI CLIP paper
```
@inproceedings{Radford2021LearningTV,
title={Learning Transferable Visual Models From Natural Language Supervision},
author={Alec Radford and Jong Wook Kim and Chris Hallacy and A. Ramesh and Gabriel Goh and Sandhini Agarwal and Girish Sastry and Amanda Askell and Pamela Mishkin and Jack Clark and Gretchen Krueger and Ilya Sutskever},
booktitle={ICML},
year={2021}
}
```
OpenCLIP software
```
@software{ilharco_gabriel_2021_5143773,
author = {Ilharco, Gabriel and
Wortsman, Mitchell and
Wightman, Ross and
Gordon, Cade and
Carlini, Nicholas and
Taori, Rohan and
Dave, Achal and
Shankar, Vaishaal and
Namkoong, Hongseok and
Miller, John and
Hajishirzi, Hannaneh and
Farhadi, Ali and
Schmidt, Ludwig},
title = {OpenCLIP},
month = jul,
year = 2021,
note = {If you use this software, please cite it as below.},
publisher = {Zenodo},
version = {0.1},
doi = {10.5281/zenodo.5143773},
url = {https://doi.org/10.5281/zenodo.5143773}
}
```
# How To Get Started With the Model
https://github.com/mlfoundations/open_clip
|
ahmadmwali/finetuning-sentiment-hausa2
|
ahmadmwali
| 2022-11-18T20:34:22Z | 103 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"xlm-roberta",
"text-classification",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-11-09T19:52:19Z |
---
tags:
- generated_from_trainer
metrics:
- accuracy
- f1
model-index:
- name: finetuning-sentiment-hausa2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# finetuning-sentiment-hausa2
This model is a fine-tuned version of [Davlan/xlm-roberta-base-finetuned-hausa](https://huggingface.co/Davlan/xlm-roberta-base-finetuned-hausa) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6335
- Accuracy: 0.7310
- F1: 0.7296
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-06
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
### Framework versions
- Transformers 4.24.0
- Pytorch 1.12.1+cu113
- Datasets 2.7.0
- Tokenizers 0.13.2
|
famube/autotrain-documentos-oficiais-2092367351
|
famube
| 2022-11-18T20:33:18Z | 108 | 0 |
transformers
|
[
"transformers",
"pytorch",
"autotrain",
"token-classification",
"pt",
"dataset:famube/autotrain-data-documentos-oficiais",
"co2_eq_emissions",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-11-14T15:52:11Z |
---
tags:
- autotrain
- token-classification
language:
- pt
widget:
- text: "I love AutoTrain 🤗"
datasets:
- famube/autotrain-data-documentos-oficiais
co2_eq_emissions:
emissions: 6.461431564881563
---
# Model Trained Using AutoTrain
- Problem type: Entity Extraction
- Model ID: 2092367351
- CO2 Emissions (in grams): 6.4614
## Validation Metrics
- Loss: 0.059
- Accuracy: 0.986
- Precision: 0.000
- Recall: 0.000
- F1: 0.000
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoTrain"}' https://api-inference.huggingface.co/models/famube/autotrain-documentos-oficiais-2092367351
```
Or Python API:
```
from transformers import AutoModelForTokenClassification, AutoTokenizer
model = AutoModelForTokenClassification.from_pretrained("famube/autotrain-documentos-oficiais-2092367351", use_auth_token=True)
tokenizer = AutoTokenizer.from_pretrained("famube/autotrain-documentos-oficiais-2092367351", use_auth_token=True)
inputs = tokenizer("I love AutoTrain", return_tensors="pt")
outputs = model(**inputs)
```
|
basaanithanaveenkumar/distilbert-base-uncased-finetuned-ner
|
basaanithanaveenkumar
| 2022-11-18T19:58:26Z | 126 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"token-classification",
"generated_from_trainer",
"dataset:conll2003",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-11-18T15:31:09Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- conll2003
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: distilbert-base-uncased-finetuned-ner
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: conll2003
type: conll2003
config: conll2003
split: train
args: conll2003
metrics:
- name: Precision
type: precision
value: 0.9260037606459463
- name: Recall
type: recall
value: 0.9365700861393892
- name: F1
type: f1
value: 0.9312569521690768
- name: Accuracy
type: accuracy
value: 0.9836370279759162
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-ner
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the conll2003 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0608
- Precision: 0.9260
- Recall: 0.9366
- F1: 0.9313
- Accuracy: 0.9836
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| 0.2388 | 1.0 | 878 | 0.0689 | 0.9129 | 0.9234 | 0.9181 | 0.9815 |
| 0.0545 | 2.0 | 1756 | 0.0599 | 0.9232 | 0.9340 | 0.9285 | 0.9830 |
| 0.0304 | 3.0 | 2634 | 0.0608 | 0.9260 | 0.9366 | 0.9313 | 0.9836 |
### Framework versions
- Transformers 4.24.0
- Pytorch 1.12.1+cu113
- Datasets 2.7.0
- Tokenizers 0.13.2
|
cyburn/laze_opera_panda
|
cyburn
| 2022-11-18T18:57:58Z | 0 | 0 | null |
[
"license:unknown",
"region:us"
] | null | 2022-11-18T18:29:31Z |
---
license: unknown
---
# Soda Stream finetuned style Model
Produced from publicly available pictures in landscape, portrait and square format.
## Model info
The models included was trained on "multi-resolution" images.
## Using the model
* common subject prompt tokens: `<wathever> by laze opera panda`
## Example prompts
`woman near a fountain by laze opera panda`:
<img src="https://huggingface.co/cyburn/laze_opera_panda/resolve/main/1.png" alt="Picture." width="500"/>
`woman in taxi by laze opera panda`:
<img src="https://huggingface.co/cyburn/laze_opera_panda/resolve/main/2.png" alt="Picture." width="500"/>
`man portrait by laze opera panda`:
<img src="https://huggingface.co/cyburn/laze_opera_panda/resolve/main/3.png" alt="Picture." width="500"/>
|
cyburn/ans_huh
|
cyburn
| 2022-11-18T18:26:00Z | 0 | 0 | null |
[
"license:unknown",
"region:us"
] | null | 2022-11-18T18:12:17Z |
---
license: unknown
---
# Ans Huh finetuned style Model
Produced from publicly available pictures in landscape, portrait and square format.
## Model info
The models included was trained on "multi-resolution" images.
## Using the model
* common subject prompt tokens: `<wathever> watercolor by ans huh`
## Example prompts
`woman near a fountain watercolor by ans huh`:
<img src="https://huggingface.co/cyburn/ans_huh/resolve/main/1.jpg" alt="Picture." width="500"/>
`woman in taxi watercolor by ans huh`:
<img src="https://huggingface.co/cyburn/ans_huh/resolve/main/2.jpg" alt="Picture." width="500"/>
`man portrait watercolor by ans huh`:
<img src="https://huggingface.co/cyburn/ans_huh/resolve/main/3.jpg" alt="Picture." width="500"/>
|
eimiss/EimisSemiRealistic
|
eimiss
| 2022-11-18T16:10:42Z | 0 | 43 | null |
[
"stable-diffusion",
"text-to-image",
"en",
"license:creativeml-openrail-m",
"region:us"
] |
text-to-image
| 2022-11-18T09:21:10Z |
---
thumbnail: https://imgur.com/DkGWTA2.png
language:
- en
tags:
- stable-diffusion
- text-to-image
license: creativeml-openrail-m
inference: false
---
# Diffusion model
This model is trained with detailed semi realistic images via my anime model.
# Sample generations
This model is made to get semi realistic, realistic results with a lot of detail.
```
Positive:1girl, aura, blue_fire, electricity, energy, fire, flame, glowing, glowing_eyes, green_eyes, hitodama, horns, lightning, long_hair, magic, male_focus, solo, spirit
Negative:lowres, bad anatomy, ((bad hands)), text, error, ((missing fingers)), cropped, jpeg artifacts, worst quality, low quality, signature, watermark, blurry, deformed, extra ears, deformed, disfigured, mutation, censored, ((multiple_girls))
Steps: 20, Sampler: DPM++ 2S a, CFG scale: 8, Seed: 2526294281, Size: 896x768
```
<img src=https://imgur.com/HHdOmIF.jpg width=75% height=75%>
```
Positive: a girl,Phoenix girl,fluffy hair,war,a hell on earth, Beautiful and detailed costume, blue glowing eyes, masterpiece, (detailed hands), (glowing), twintails, smiling, beautiful detailed white gloves, (upper_body), (realistic)
Negative: lowres, bad anatomy, ((bad hands)), text, error, ((missing fingers)), cropped, jpeg artifacts, worst quality, low quality, signature, watermark, blurry, deformed, extra ears, deformed, disfigured, mutation, censored, ((multiple_girls))
Steps: 20, Sampler: DPM++ 2S a Karras, CFG scale: 8, Seed: 2495938777/2495938779, Size: 896x768
```
<img src=https://imgur.com/bHiTlAu.png width=75% height=75%>
<img src=https://imgur.com/dGFn0uV.png width=75% height=75%>
```
Positive:1girl, blurry, bracelet, breasts, dress, earrings, fingernails, grey_eyes, jewelry, lips, lipstick, looking_at_viewer, makeup, nail_polish, necklace, petals, red_lips, short_hair, solo, white_hair
Negative:lowres, bad anatomy, ((bad hands)), text, error, ((missing fingers)), cropped, jpeg artifacts, worst quality, low quality, signature, watermark, blurry, deformed, extra ears, deformed, disfigured, mutation, censored, ((multiple_girls))
Steps: 20, Sampler: DPM++ 2S a, CFG scale: 8, Seed: 3149099819, Size: 704x896
```
<img src=https://imgur.com/tnGOZz8.png width=75% height=75%>
Img2img results:
```
Positive:1girl, anal_hair, black_pubic_hair, blurry, blurry_background, brown_eyes, colored_pubic_hair, excessive_pubic_hair, female_pubic_hair, forehead, grass, lips, looking_at_viewer, male_pubic_hair, mismatched_pubic_hair, pov, pubic_hair, realistic, solo, stray_pubic_hair, teeth
Negative:lowres, bad anatomy, ((bad hands)), text, error, ((missing fingers)), cropped, jpeg artifacts, worst quality, low quality, signature, watermark, blurry, deformed, extra ears, deformed, disfigured, mutation, censored, ((multiple_girls))
Steps: 35, Sampler: Euler a, CFG scale: 9, Seed: 2148680457, Size: 512x512, Denoising strength: 0.6, Mask blur: 4
```
<img src=https://imgur.com/RVl7Xxd.png width=75% height=75%>
## Disclaimer
If you get anime images not semi realistic ones try some prompts like semi realistic,
realistic or (SemiRealImg). Usually helps. This model also works nicely with
landscapes like my previous one. However I recommend my other anime model for landscapes.
## License
This model is open access and available to all, with a CreativeML OpenRAIL-M license further specifying rights and usage.
The CreativeML OpenRAIL License specifies:
1. You can't use the model to deliberately produce nor share illegal or harmful outputs or content
2. The authors claims no rights on the outputs you generate, you are free to use them and are accountable for their use which must not go against the provisions set in the license
3. You may re-distribute the weights and use the model commercially and/or as a service. If you do, please be aware you have to include the same use restrictions as the ones in the license and share a copy of the CreativeML OpenRAIL-M to all your users (please read the license entirely and carefully)
[Please read the full license here](https://huggingface.co/spaces/CompVis/stable-diffusion-license)
|
GabCcr99/Clasificador-Ojos
|
GabCcr99
| 2022-11-18T15:58:34Z | 186 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"vit",
"image-classification",
"huggingpics",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2022-11-18T15:58:21Z |
---
tags:
- image-classification
- pytorch
- huggingpics
metrics:
- accuracy
model-index:
- name: Clasificador-Ojos
results:
- task:
name: Image Classification
type: image-classification
metrics:
- name: Accuracy
type: accuracy
value: 0.7727272510528564
---
# Clasificador-Ojos
Autogenerated by HuggingPics🤗🖼️
Create your own image classifier for **anything** by running [the demo on Google Colab](https://colab.research.google.com/github/nateraw/huggingpics/blob/main/HuggingPics.ipynb).
Report any issues with the demo at the [github repo](https://github.com/nateraw/huggingpics).
## Example Images
#### Closed Eyes

#### Opened Eyes

|
zhiguoxu/bert-base-chinese-finetuned-food
|
zhiguoxu
| 2022-11-18T15:57:50Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"token-classification",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-11-18T15:53:37Z |
---
tags:
- generated_from_trainer
metrics:
- f1
model-index:
- name: bert-base-chinese-finetuned-food
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-chinese-finetuned-food
This model is a fine-tuned version of [bert-base-chinese](https://huggingface.co/bert-base-chinese) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0044
- F1: 1.0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 20
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 3.2163 | 1.0 | 3 | 1.7446 | 0.0201 |
| 1.5263 | 2.0 | 6 | 1.1179 | 0.6113 |
| 1.1837 | 3.0 | 9 | 0.7233 | 0.75 |
| 0.6987 | 4.0 | 12 | 0.4377 | 0.8766 |
| 0.5036 | 5.0 | 15 | 0.2544 | 0.9154 |
| 0.2602 | 6.0 | 18 | 0.1495 | 0.9598 |
| 0.1998 | 7.0 | 21 | 0.0834 | 0.9836 |
| 0.1182 | 8.0 | 24 | 0.0484 | 0.9911 |
| 0.0815 | 9.0 | 27 | 0.0280 | 1.0 |
| 0.05 | 10.0 | 30 | 0.0177 | 1.0 |
| 0.0375 | 11.0 | 33 | 0.0124 | 1.0 |
| 0.0244 | 12.0 | 36 | 0.0094 | 1.0 |
| 0.0213 | 13.0 | 39 | 0.0075 | 1.0 |
| 0.0163 | 14.0 | 42 | 0.0063 | 1.0 |
| 0.0147 | 15.0 | 45 | 0.0056 | 1.0 |
| 0.0124 | 16.0 | 48 | 0.0051 | 1.0 |
| 0.0125 | 17.0 | 51 | 0.0047 | 1.0 |
| 0.0115 | 18.0 | 54 | 0.0045 | 1.0 |
| 0.0116 | 19.0 | 57 | 0.0044 | 1.0 |
| 0.0102 | 20.0 | 60 | 0.0044 | 1.0 |
### Framework versions
- Transformers 4.18.0
- Pytorch 1.12.0+cu102
- Datasets 1.18.4
- Tokenizers 0.12.1
|
Davlan/bloom-560m_am_ia3_10000samples
|
Davlan
| 2022-11-18T15:41:00Z | 0 | 0 | null |
[
"license:bigscience-openrail-m",
"region:us"
] | null | 2022-11-18T14:27:20Z |
---
license: bigscience-openrail-m
---
|
Davlan/bloom-560m_am_continual-pretrain_10000samples
|
Davlan
| 2022-11-18T15:37:46Z | 120 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bloom",
"text-generation",
"license:bigscience-openrail-m",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-11-18T14:06:34Z |
---
license: bigscience-openrail-m
---
|
Davlan/bloom-560m_am_madx_10000samples
|
Davlan
| 2022-11-18T14:44:59Z | 0 | 0 | null |
[
"license:bigscience-openrail-m",
"region:us"
] | null | 2022-11-18T14:26:38Z |
---
license: bigscience-openrail-m
---
|
GabCcr99/Clasificador-animales
|
GabCcr99
| 2022-11-18T14:37:47Z | 268 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"vit",
"image-classification",
"huggingpics",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2022-11-18T14:37:34Z |
---
tags:
- image-classification
- pytorch
- huggingpics
metrics:
- accuracy
model-index:
- name: Clasificador-animales
results:
- task:
name: Image Classification
type: image-classification
metrics:
- name: Accuracy
type: accuracy
value: 1.0
---
# Clasificador-animales
Autogenerated by HuggingPics🤗🖼️
Create your own image classifier for **anything** by running [the demo on Google Colab](https://colab.research.google.com/github/nateraw/huggingpics/blob/main/HuggingPics.ipynb).
Report any issues with the demo at the [github repo](https://github.com/nateraw/huggingpics).
## Example Images
#### cat

#### dog

#### snake

#### tiger

|
pagh/ddpm-butterflies-128
|
pagh
| 2022-11-18T14:22:22Z | 0 | 0 |
diffusers
|
[
"diffusers",
"tensorboard",
"en",
"dataset:huggan/smithsonian_butterflies_subset",
"license:apache-2.0",
"diffusers:DDPMPipeline",
"region:us"
] | null | 2022-11-18T13:35:46Z |
---
language: en
license: apache-2.0
library_name: diffusers
tags: []
datasets: huggan/smithsonian_butterflies_subset
metrics: []
---
<!-- This model card has been generated automatically according to the information the training script had access to. You
should probably proofread and complete it, then remove this comment. -->
# ddpm-butterflies-128
## Model description
This diffusion model is trained with the [🤗 Diffusers](https://github.com/huggingface/diffusers) library
on the `huggan/smithsonian_butterflies_subset` dataset.
## Intended uses & limitations
#### How to use
```python
# TODO: add an example code snippet for running this diffusion pipeline
```
#### Limitations and bias
[TODO: provide examples of latent issues and potential remediations]
## Training data
[TODO: describe the data used to train the model]
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 16
- eval_batch_size: 16
- gradient_accumulation_steps: 1
- optimizer: AdamW with betas=(None, None), weight_decay=None and epsilon=None
- lr_scheduler: None
- lr_warmup_steps: 500
- ema_inv_gamma: None
- ema_inv_gamma: None
- ema_inv_gamma: None
- mixed_precision: fp16
### Training results
📈 [TensorBoard logs](https://huggingface.co/pagh/ddpm-butterflies-128/tensorboard?#scalars)
|
FloatingPoint/MiloManara
|
FloatingPoint
| 2022-11-18T14:12:41Z | 0 | 2 | null |
[
"license:creativeml-openrail-m",
"region:us"
] | null | 2022-11-18T13:34:36Z |
---
license: creativeml-openrail-m
---
**Milo Manara Style**
This is the Alpha release of a Stable Diffusion model trained to achieve the style of the Italian illustration master Milo Manara.
Use the token **in the style of ->Manara** in your prompts for the style.
**Sample result**

**Warning**: Due to the nature of the style, NSFW images may be easily generated using this model.
## License
This model is open access and available to all, with a CreativeML OpenRAIL-M license further specifying rights and usage.
The CreativeML OpenRAIL License specifies:
1. You can't use the model to deliberately produce nor share illegal or harmful outputs or content
2. The authors claims no rights on the outputs you generate, you are free to use them and are accountable for their use which must not go against the provisions set in the license
3. You may re-distribute the weights and use the model commercially and/or as a service. If you do, please be aware you have to include the same use restrictions as the ones in the license and share a copy of the CreativeML OpenRAIL-M to all your users (please read the license entirely and carefully)
[Please read the full license here](https://huggingface.co/spaces/CompVis/stable-diffusion-license)
|
cyburn/lego_set
|
cyburn
| 2022-11-18T13:44:33Z | 0 | 2 | null |
[
"license:unknown",
"region:us"
] | null | 2022-11-17T18:33:12Z |
---
license: unknown
---
# Lego Set finetuned style Model
Produced from publicly available pictures in landscape, portrait and square format.
## Model info
The models included was trained on "multi-resolution" images of "Lego Sets"
## Using the model
* common subject prompt tokens: `lego set <wathever>`
## Example prompts
`mcdonald restaurant lego set`:
<img src="https://huggingface.co/cyburn/lego_set/resolve/main/1.jpg" alt="Picture." width="500"/>
`lego set crow, skull`:
<img src="https://huggingface.co/cyburn/lego_set/resolve/main/2.jpg" alt="Picture." width="500"/>
## img2img example
`lego set ottawa parliament building sharp focus`:
<img src="https://huggingface.co/cyburn/lego_set/resolve/main/3.jpg" alt="Picture." width="500"/>
|
Madiator2011/Lyoko-Diffusion-v1.1
|
Madiator2011
| 2022-11-18T13:00:15Z | 36 | 6 |
diffusers
|
[
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"license:creativeml-openrail-m",
"autotrain_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] |
text-to-image
| 2022-10-30T14:52:25Z |
---
license: creativeml-openrail-m
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
inference: false
extra_gated_prompt: |-
This model is open access and available to all, with a CreativeML OpenRAIL-M license further specifying rights and usage.
1. You can't use the model to deliberately produce nor share illegal or harmful outputs or content
2. If possible do not use this model for comercial stuff and if you want to at least give some credtis :)
By clicking on "Access repository" below, you accept that your *contact information* (email address and username) can be shared with the model authors as well.
extra_gated_fields:
I have read the License and agree with its terms: checkbox
---
# Lyoko Diffusion v1-1 Model Card

This model is allowing users to generate images into styles from TV show Code Lyoko both 2D/CGI format.
To switch between styles you need to add it to prompt: for CGI ```CGILyoko style style``` for 2D ```2DLyoko style style```
If you want to support my future projects you can do it via https://ko-fi.com/madiator2011
Or by using my model on runpod with my reflink https://runpod.io?ref=vfker49t
This model has been trained thanks to support of Runpod.io team.
### Diffusers
```py
from diffusers import StableDiffusionPipeline
import torch
model_id = "Madiator2011/Lyoko-Diffusion-v1.1"
pipe = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16, revision="fp16")
pipe = pipe.to("cuda")
prompt = "a photo of an astronaut riding a horse on mars"
image = pipe(prompt).images[0]
image.save("astronaut_rides_horse.png")
```
For more detailed instructions, use-cases and examples in JAX follow the instructions [here](https://github.com/huggingface/diffusers#text-to-image-generation-with-stable-diffusion)
# Uses
## Direct Use
The model is intended for research purposes only. Possible research areas and
tasks include
- Safe deployment of models which have the potential to generate harmful content.
- Probing and understanding the limitations and biases of generative models.
- Generation of artworks and use in design and other artistic processes.
- Applications in educational or creative tools.
- Research on generative models.
Excluded uses are described below.
### Misuse, Malicious Use, and Out-of-Scope Use
_Note: This section is taken from the [DALLE-MINI model card](https://huggingface.co/dalle-mini/dalle-mini), but applies in the same way to Stable Diffusion v1_.
The model should not be used to intentionally create or disseminate images that create hostile or alienating environments for people. This includes generating images that people would foreseeably find disturbing, distressing, or offensive; or content that propagates historical or current stereotypes.
#### Out-of-Scope Use
The model was not trained to be factual or true representations of people or events, and therefore using the model to generate such content is out-of-scope for the abilities of this model.
#### Misuse and Malicious Use
Using the model to generate content that is cruel to individuals is a misuse of this model. This includes, but is not limited to:
- Generating demeaning, dehumanizing, or otherwise harmful representations of people or their environments, cultures, religions, etc.
- Intentionally promoting or propagating discriminatory content or harmful stereotypes.
- Impersonating individuals without their consent.
- Sexual content without consent of the people who might see it.
- Mis- and disinformation
- Representations of egregious violence and gore
- Sharing of copyrighted or licensed material in violation of its terms of use.
- Sharing content that is an alteration of copyrighted or licensed material in violation of its terms of use.
## Limitations and Bias
### Limitations
- The model does not achieve perfect photorealism
- The model cannot render legible text
- The model does not perform well on more difficult tasks which involve compositionality, such as rendering an image corresponding to “A red cube on top of a blue sphere”
- Faces and people in general may not be generated properly.
- The model was trained mainly with English captions and will not work as well in other languages.
- The autoencoding part of the model is lossy
- The model was trained on a large-scale dataset
[LAION-5B](https://laion.ai/blog/laion-5b/) which contains adult material
and is not fit for product use without additional safety mechanisms and
considerations.
- No additional measures were used to deduplicate the dataset. As a result, we observe some degree of memorization for images that are duplicated in the training data.
The training data can be searched at [https://rom1504.github.io/clip-retrieval/](https://rom1504.github.io/clip-retrieval/) to possibly assist in the detection of memorized images.
### Bias
While the capabilities of image generation models are impressive, they can also reinforce or exacerbate social biases.
Stable Diffusion v1 was trained on subsets of [LAION-2B(en)](https://laion.ai/blog/laion-5b/),
which consists of images that are primarily limited to English descriptions.
Texts and images from communities and cultures that use other languages are likely to be insufficiently accounted for.
This affects the overall output of the model, as white and western cultures are often set as the default. Further, the
ability of the model to generate content with non-English prompts is significantly worse than with English-language prompts.
### Safety Module
The intended use of this model is with the [Safety Checker](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/stable_diffusion/safety_checker.py) in Diffusers.
This checker works by checking model outputs against known hard-coded NSFW concepts.
The concepts are intentionally hidden to reduce the likelihood of reverse-engineering this filter.
Specifically, the checker compares the class probability of harmful concepts in the embedding space of the `CLIPTextModel` *after generation* of the images.
The concepts are passed into the model with the generated image and compared to a hand-engineered weight for each NSFW concept.
|
gonzalez-agirre/roberta-base-bne-conll-ner
|
gonzalez-agirre
| 2022-11-18T12:14:57Z | 123 | 0 |
transformers
|
[
"transformers",
"pytorch",
"roberta",
"token-classification",
"national library of spain",
"spanish",
"bne",
"conll",
"ner",
"es",
"dataset:bne",
"dataset:conll",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-11-18T11:56:52Z |
---
language:
- es
license: apache-2.0
tags:
- "national library of spain"
- "spanish"
- "bne"
- "conll"
- "ner"
datasets:
- "bne"
- "conll"
metrics:
- "f1"
widget:
- text: "Festival de San Sebastián: Johnny Depp recibirá el premio Donostia en pleno rifirrafe judicial con Amber Heard"
- text: "El alcalde de Vigo, Abel Caballero, ha comenzado a colocar las luces de Navidad en agosto."
- text: "Gracias a los datos de la BNE, se ha podido lograr este modelo del lenguaje."
- text: "El Tribunal Superior de Justicia se pronunció ayer: \"Hay base legal dentro del marco jurídico actual\"."
inference:
parameters:
aggregation_strategy: "first"
---
|
arynas/model
|
arynas
| 2022-11-18T12:05:11Z | 19 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"whisper",
"automatic-speech-recognition",
"generated_from_trainer",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-11-05T02:56:43Z |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- wer
model-index:
- name: model
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# model
This model is a fine-tuned version of [openai/whisper-medium](https://huggingface.co/openai/whisper-medium) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 5.0046
- Wer: 116.8945
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 8000
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 1.5232 | 4.95 | 1000 | 3.6227 | 127.2695 |
| 0.0538 | 9.9 | 2000 | 4.3761 | 125.3417 |
| 0.0166 | 14.85 | 3000 | 4.6306 | 114.6863 |
| 0.0008 | 19.8 | 4000 | 4.7625 | 116.3687 |
| 0.0022 | 24.75 | 5000 | 4.9290 | 116.0182 |
| 0.0002 | 29.7 | 6000 | 4.9100 | 118.2264 |
| 0.0001 | 34.65 | 7000 | 4.9886 | 116.5089 |
| 0.0001 | 39.6 | 8000 | 5.0046 | 116.8945 |
### Framework versions
- Transformers 4.25.0.dev0
- Pytorch 1.12.0+cu116
- Datasets 2.6.1
- Tokenizers 0.13.1
|
oskarandrsson/mt-en-sv-finetuned
|
oskarandrsson
| 2022-11-18T11:38:37Z | 116 | 0 |
transformers
|
[
"transformers",
"pytorch",
"marian",
"text2text-generation",
"generated_from_trainer",
"translation",
"en",
"sv",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
translation
| 2022-11-11T13:36:09Z |
---
language:
- en
- sv
tags:
- generated_from_trainer
- translation
metrics:
- type: Bleu
- value: 67.28
model-index:
- name: mt-en-sv-finetuned
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mt-en-sv-finetuned
This model is a fine-tuned version of Helsinki-NLP/opus-mt-en-sv.
It achieves the following results on the Tatoeba.en.sv evaluation set:
- Bleu: 67.28528945378108
## Model description
- source_lang = en
- target_lang = sv
## Intended uses & limitations
More information needed
## Training and evaluation data
-
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-06
- train_batch_size: 24
- eval_batch_size: 4
- mixed_precision_training: Native AMP
### Training results
| testset | BLEU |
|-----------------------|-------|
| Tatoeba.en.sv | 67.28|
### Framework versions
- Transformers 4.25.0.dev0
- Pytorch 1.13.0+cu117
- Datasets 2.6.1
- Tokenizers 0.13.1
|
oskarandrsson/mt-sq-sv-finetuned
|
oskarandrsson
| 2022-11-18T11:37:55Z | 104 | 0 |
transformers
|
[
"transformers",
"pytorch",
"marian",
"text2text-generation",
"generated_from_trainer",
"translation",
"sv",
"sq",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
translation
| 2022-11-14T13:13:15Z |
---
license: apache-2.0
language:
- sv
- sq
tags:
- generated_from_trainer
- translation
metrics:
- bleu
model-index:
- name: mt-sq-sv-finetuned
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mt-sq-sv-finetuned
This model is a fine-tuned version of [Helsinki-NLP/opus-mt-sq-sv](https://huggingface.co/Helsinki-NLP/opus-mt-sq-sv) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.2250
- Bleu: 47.0111
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-06
- train_batch_size: 24
- eval_batch_size: 4
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Bleu |
|:-------------:|:-----:|:-----:|:---------------:|:-------:|
| 1.7042 | 1.0 | 4219 | 1.4806 | 41.9650 |
| 1.5537 | 2.0 | 8438 | 1.3955 | 43.1524 |
| 1.4352 | 3.0 | 12657 | 1.3142 | 44.4373 |
| 1.3346 | 4.0 | 16876 | 1.2793 | 45.2265 |
| 1.2847 | 5.0 | 21095 | 1.2597 | 45.8071 |
| 1.2821 | 6.0 | 25314 | 1.2454 | 46.3737 |
| 1.2342 | 7.0 | 29533 | 1.2363 | 46.6308 |
| 1.2092 | 8.0 | 33752 | 1.2301 | 46.8227 |
| 1.1766 | 9.0 | 37971 | 1.2260 | 46.9719 |
| 1.1836 | 10.0 | 42190 | 1.2250 | 47.0111 |
### Framework versions
- Transformers 4.25.0.dev0
- Pytorch 1.13.0+cu117
- Datasets 2.6.1
- Tokenizers 0.13.1
|
oskarandrsson/mt-lt-sv-finetuned
|
oskarandrsson
| 2022-11-18T11:36:42Z | 108 | 0 |
transformers
|
[
"transformers",
"pytorch",
"marian",
"text2text-generation",
"generated_from_trainer",
"translation",
"lt",
"sv",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
translation
| 2022-11-16T08:27:36Z |
---
license: apache-2.0
language:
- lt
- sv
tags:
- generated_from_trainer
- translation
metrics:
- bleu
model-index:
- name: mt-lt-sv-finetuned
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mt-lt-sv-finetuned
This model is a fine-tuned version of [Helsinki-NLP/opus-mt-lt-sv](https://huggingface.co/Helsinki-NLP/opus-mt-lt-sv) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.1276
- Bleu: 43.0025
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-06
- train_batch_size: 24
- eval_batch_size: 4
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Bleu |
|:-------------:|:-----:|:-----:|:---------------:|:-------:|
| 1.3499 | 1.0 | 4409 | 1.2304 | 40.3211 |
| 1.2442 | 2.0 | 8818 | 1.1870 | 41.4633 |
| 1.1875 | 3.0 | 13227 | 1.1652 | 41.9164 |
| 1.1386 | 4.0 | 17636 | 1.1523 | 42.3534 |
| 1.0949 | 5.0 | 22045 | 1.1423 | 42.6339 |
| 1.0739 | 6.0 | 26454 | 1.1373 | 42.7617 |
| 1.0402 | 7.0 | 30863 | 1.1324 | 42.8568 |
| 1.0369 | 8.0 | 35272 | 1.1298 | 42.9608 |
| 1.0138 | 9.0 | 39681 | 1.1281 | 42.9833 |
| 1.0192 | 10.0 | 44090 | 1.1276 | 43.0025 |
### Framework versions
- Transformers 4.25.0.dev0
- Pytorch 1.13.0+cu117
- Datasets 2.6.1
- Tokenizers 0.13.1
|
oskarandrsson/mt-uk-sv-finetuned
|
oskarandrsson
| 2022-11-18T11:36:18Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"marian",
"text2text-generation",
"generated_from_trainer",
"translation",
"uk",
"sv",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
translation
| 2022-11-16T13:48:10Z |
---
license: apache-2.0
language:
- uk
- sv
tags:
- generated_from_trainer
- translation
model-index:
- name: mt-uk-sv-finetuned
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mt-uk-sv-finetuned
This model is a fine-tuned version of [Helsinki-NLP/opus-mt-uk-sv](https://huggingface.co/Helsinki-NLP/opus-mt-uk-sv) on the None dataset.
It achieves the following results on the evaluation set:
- eval_loss: 1.4210
- eval_bleu: 40.6634
- eval_runtime: 966.5303
- eval_samples_per_second: 18.744
- eval_steps_per_second: 4.687
- epoch: 6.0
- step: 40764
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-06
- train_batch_size: 24
- eval_batch_size: 4
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
- mixed_precision_training: Native AMP
### Framework versions
- Transformers 4.25.0.dev0
- Pytorch 1.13.0+cu117
- Datasets 2.6.1
- Tokenizers 0.13.1
|
oskarandrsson/mt-ru-sv-finetuned
|
oskarandrsson
| 2022-11-18T11:35:38Z | 103 | 0 |
transformers
|
[
"transformers",
"pytorch",
"marian",
"text2text-generation",
"generated_from_trainer",
"translation",
"ru",
"sv",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
translation
| 2022-11-18T09:31:15Z |
---
license: apache-2.0
language:
- ru
- sv
tags:
- generated_from_trainer
- translation
model-index:
- name: mt-ru-sv-finetuned
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mt-ru-sv-finetuned
This model is a fine-tuned version of [Helsinki-NLP/opus-mt-ru-sv](https://huggingface.co/Helsinki-NLP/opus-mt-ru-sv) on the None dataset.
It achieves the following results on the Tatoeba.rus.swe evaluation set:
- eval_loss: 0.6998
- eval_bleu: 54.4473
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-06
- train_batch_size: 24
- eval_batch_size: 4
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
- mixed_precision_training: Native AMP
### Framework versions
- Transformers 4.25.0.dev0
- Pytorch 1.13.0+cu117
- Datasets 2.6.1
- Tokenizers 0.13.1
|
oskarandrsson/mt-bs-sv-finetuned
|
oskarandrsson
| 2022-11-18T11:35:05Z | 104 | 0 |
transformers
|
[
"transformers",
"pytorch",
"marian",
"text2text-generation",
"translation",
"bs",
"sv",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
translation
| 2022-11-16T16:57:47Z |
---
license: apache-2.0
language:
- bs
- sv
tags:
- translation
model-index:
- name: mt-bs-sv-finetuned
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mt-bs-sv-finetuned
This model is a fine-tuned version of [oskarandrsson/mt-hr-sv-finetuned](https://huggingface.co/oskarandrsson/mt-hr-sv-finetuned) on the None dataset.
It achieves the following results on the evaluation set:
- eval_loss: 0.8217
- eval_bleu: 53.9611
- eval_runtime: 601.8995
- eval_samples_per_second: 15.971
- eval_steps_per_second: 3.994
- epoch: 4.0
- step: 14420
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-06
- train_batch_size: 24
- eval_batch_size: 4
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
- mixed_precision_training: Native AMP
### Framework versions
- Transformers 4.25.0.dev0
- Pytorch 1.13.0+cu117
- Datasets 2.6.1
- Tokenizers 0.13.1
|
vikram15/bert-finetuned-squad
|
vikram15
| 2022-11-18T11:03:16Z | 61 | 0 |
transformers
|
[
"transformers",
"tf",
"bert",
"question-answering",
"generated_from_keras_callback",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-11-18T10:20:22Z |
---
license: apache-2.0
tags:
- generated_from_keras_callback
model-index:
- name: vikram15/bert-finetuned-squad
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# vikram15/bert-finetuned-squad
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.7556
- Epoch: 2
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'AdamWeightDecay', 'learning_rate': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 2e-05, 'decay_steps': 954, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False, 'weight_decay_rate': 0.01}
- training_precision: mixed_float16
### Training results
| Train Loss | Epoch |
|:----------:|:-----:|
| 2.3076 | 0 |
| 1.0840 | 1 |
| 0.7556 | 2 |
### Framework versions
- Transformers 4.24.0
- TensorFlow 2.9.2
- Datasets 2.7.0
- Tokenizers 0.13.2
|
Thivin/distilbert-base-uncased-finetuned-ner
|
Thivin
| 2022-11-18T10:51:19Z | 110 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"token-classification",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-11-18T09:10:34Z |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: distilbert-base-uncased-finetuned-ner
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-ner
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3100
- Precision: 0.9309
- Recall: 0.9435
- F1: 0.9371
- Accuracy: 0.9294
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 4e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 234 | 0.2362 | 0.9356 | 0.9484 | 0.9420 | 0.9335 |
| No log | 2.0 | 468 | 0.2854 | 0.9303 | 0.9425 | 0.9363 | 0.9282 |
| 0.2119 | 3.0 | 702 | 0.3100 | 0.9309 | 0.9435 | 0.9371 | 0.9294 |
### Framework versions
- Transformers 4.24.0
- Pytorch 1.12.1+cu113
- Datasets 2.7.0
- Tokenizers 0.13.2
|
projecte-aina/roberta-large-ca-paraphrase
|
projecte-aina
| 2022-11-18T10:35:24Z | 109 | 0 |
transformers
|
[
"transformers",
"pytorch",
"roberta",
"text-classification",
"catalan",
"paraphrase",
"textual entailment",
"ca",
"dataset:projecte-aina/Parafraseja",
"arxiv:1907.11692",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-11-17T09:15:02Z |
---
language:
- ca
license: apache-2.0
tags:
- "catalan"
- "paraphrase"
- "textual entailment"
datasets:
- "projecte-aina/Parafraseja"
metrics:
- "combined_score"
- f1
- accuracy
inference:
parameters:
aggregation_strategy: "first"
model-index:
- name: roberta-large-ca-paraphrase
results:
- task:
type: text-classification
dataset:
type: projecte-aina/Parafraseja
name: Parafraseja
metrics:
- name: F1
type: f1
value: 0.86678
- name: Accuracy
type: accuracy
value: 0.86175
- name: combined_score
type: combined_score
value: 0.86426
widget:
- text: "Tinc un amic a Manresa. A Manresa hi viu un amic meu."
- text: "La dona va anar a l'hotel en moto. Ella va agafar el cotxe per anar a l'hotel."
---
# Catalan BERTa (roberta-large-ca-v2) finetuned for Paraphrase Detection
## Table of Contents
<details>
<summary>Click to expand</summary>
- [Model description](#model-description)
- [Intended uses and limitations](#intended-use)
- [How to use](#how-to-use)
- [Limitations and bias](#limitations-and-bias)
- [Training](#training)
- [Training data](#training-data)
- [Training procedure](#training-procedure)
- [Evaluation](#evaluation)
- [Variable and metrics](#variable-and-metrics)
- [Evaluation results](#evaluation-results)
- [Additional information](#additional-information)
- [Author](#author)
- [Contact information](#contact-information)
- [Copyright](#copyright)
- [Licensing information](#licensing-information)
- [Funding](#funding)
- [Citing information](#citing-information)
- [Disclaimer](#disclaimer)
</details>
## Model description
The **roberta-large-ca-paraphrase** is a Paraphrase Detection model for the Catalan language fine-tuned from the roberta-large-ca-v2 model, a [RoBERTa](https://arxiv.org/abs/1907.11692) base model pre-trained on a medium-size corpus collected from publicly available corpora and crawlers.
## Intended uses and limitations
**roberta-large-ca-paraphrase** model can be used to detect if two sentences are in a paraphrase relation. The model is limited by its training dataset and may not generalize well for all use cases.
## How to use
Here is how to use this model:
```python
from transformers import pipeline
from pprint import pprint
nlp = pipeline("text-classification", model="projecte-aina/roberta-large-ca-paraphrase")
example = "Tinc un amic a Manresa. </s></s> A Manresa hi viu un amic meu."
paraphrase = nlp(example)
pprint(paraphrase)
```
## Limitations and bias
At the time of submission, no measures have been taken to estimate the bias embedded in the model. However, we are well aware that our models may be biased since the corpora have been collected using crawling techniques on multiple web sources. We intend to conduct research in these areas in the future, and if completed, this model card will be updated.
## Training
### Training data
We used the Paraphase Detection dataset in Catalan [Parafraseja](https://huggingface.co/datasets/projecte-aina/Parafraseja) for training and evaluation.
### Training procedure
The model was trained with a batch size of 16 and a learning rate of 5e-5 for 5 epochs. We then selected the best checkpoint using the downstream task metric in the corresponding development set and then evaluated it on the test set.
## Evaluation
### Variable and metrics
This model was finetuned maximizing the combined_score.
## Evaluation results
We evaluated the _roberta-large-ca-paraphrase_ on the Parafraseja test set against standard multilingual and monolingual baselines:
| Model | Parafraseja (combined_score) |
| ------------|:-------------|
| roberta-large-ca-v2 |**86.42** |
| roberta-base-ca-v2 |84.38 |
| mBERT | 79.66 |
| XLM-RoBERTa | 77.83 |
## Additional information
### Author
Text Mining Unit (TeMU) at the Barcelona Supercomputing Center (bsc-temu@bsc.es)
### Contact information
For further information, send an email to aina@bsc.es
### Copyright
Copyright (c) 2022 Text Mining Unit at Barcelona Supercomputing Center
### Licensing information
[Apache License, Version 2.0](https://www.apache.org/licenses/LICENSE-2.0)
### Funding
This work was funded by the [Departament de la Vicepresidència i de Polítiques Digitals i Territori de la Generalitat de Catalunya](https://politiquesdigitals.gencat.cat/ca/inici/index.html#googtrans(ca|en) within the framework of [Projecte AINA](https://politiquesdigitals.gencat.cat/ca/economia/catalonia-ai/aina).
### Citation Information
NA
### Disclaimer
<details>
<summary>Click to expand</summary>
The models published in this repository are intended for a generalist purpose and are available to third parties. These models may have bias and/or any other undesirable distortions.
When third parties, deploy or provide systems and/or services to other parties using any of these models (or using systems based on these models) or become users of the models, they should note that it is their responsibility to mitigate the risks arising from their use and, in any event, to comply with applicable regulations, including regulations regarding the use of Artificial Intelligence.
In no event shall the owner and creator of the models (BSC – Barcelona Supercomputing Center) be liable for any results arising from the use made by third parties of these models.
|
rayendito/mt5-small-finetuned-xl-sum-indonesia
|
rayendito
| 2022-11-18T10:18:43Z | 123 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"mt5",
"text2text-generation",
"summarization",
"generated_from_trainer",
"dataset:xl_sum",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
summarization
| 2022-11-18T08:29:49Z |
---
license: apache-2.0
tags:
- summarization
- generated_from_trainer
datasets:
- xl_sum
model-index:
- name: mt5-small-finetuned-xl-sum-indonesia
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mt5-small-finetuned-xl-sum-indonesia
This model is a fine-tuned version of [google/mt5-small](https://huggingface.co/google/mt5-small) on the xl_sum dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5.6e-05
- train_batch_size: 5
- eval_batch_size: 5
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Framework versions
- Transformers 4.24.0
- Pytorch 1.12.1+cu113
- Datasets 2.7.0
- Tokenizers 0.13.2
|
LidoHon/ppo-LunarLander-v2
|
LidoHon
| 2022-11-18T09:36:53Z | 1 | 1 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-11-18T09:34:31Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 0.26 +/- 54.20
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
Shubham09/whisper-small-hi
|
Shubham09
| 2022-11-18T09:36:02Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"whisper",
"automatic-speech-recognition",
"generated_from_trainer",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-11-17T12:49:54Z |
---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: whisper-small-hi
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# whisper-small-hi
This model is a fine-tuned version of [openai/whisper-small](https://huggingface.co/openai/whisper-small) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 8
- eval_batch_size: 5
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 4000
- mixed_precision_training: Native AMP
### Framework versions
- Transformers 4.23.1
- Pytorch 1.12.1
- Datasets 2.4.0
- Tokenizers 0.13.2
|
yip-i/wav2vec2-demo-F04
|
yip-i
| 2022-11-18T07:40:13Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"generated_from_trainer",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-11-17T02:12:12Z |
---
tags:
- generated_from_trainer
model-index:
- name: wav2vec2-demo-F04
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-demo-F04
This model is a fine-tuned version of [yip-i/uaspeech-pretrained](https://huggingface.co/yip-i/uaspeech-pretrained) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 4.4557
- Wer: 1.0985
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 1000
- num_epochs: 30
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:-----:|:---------------:|:------:|
| 16.8788 | 0.89 | 500 | 3.6172 | 1.0 |
| 3.0484 | 1.79 | 1000 | 3.3653 | 1.0 |
| 3.0178 | 2.68 | 1500 | 3.3402 | 1.0 |
| 3.182 | 3.57 | 2000 | 3.1676 | 1.0103 |
| 3.0374 | 4.46 | 2500 | 3.5767 | 1.2914 |
| 2.8118 | 5.36 | 3000 | 3.1389 | 1.0444 |
| 2.8424 | 6.25 | 3500 | 3.1171 | 1.1454 |
| 2.8194 | 7.14 | 4000 | 3.1267 | 1.2464 |
| 2.8052 | 8.04 | 4500 | 3.2637 | 1.0918 |
| 2.7835 | 8.93 | 5000 | 3.3412 | 1.1052 |
| 2.7794 | 9.82 | 5500 | 3.4910 | 1.2220 |
| 2.7405 | 10.71 | 6000 | 3.1507 | 1.2451 |
| 2.7518 | 11.61 | 6500 | 3.5342 | 1.1618 |
| 2.7461 | 12.5 | 7000 | 3.7598 | 1.2768 |
| 2.7315 | 13.39 | 7500 | 3.7623 | 1.2220 |
| 2.7203 | 14.29 | 8000 | 4.1022 | 1.0730 |
| 2.6901 | 15.18 | 8500 | 3.6616 | 1.2914 |
| 2.7152 | 16.07 | 9000 | 3.7305 | 1.2488 |
| 2.7036 | 16.96 | 9500 | 3.6997 | 1.1454 |
| 2.6938 | 17.86 | 10000 | 4.9800 | 1.0365 |
| 2.6962 | 18.75 | 10500 | 4.3985 | 1.1813 |
| 2.6801 | 19.64 | 11000 | 5.2335 | 1.1910 |
| 2.6695 | 20.54 | 11500 | 4.4297 | 1.0432 |
| 2.6762 | 21.43 | 12000 | 4.7141 | 1.1612 |
| 2.6833 | 22.32 | 12500 | 4.6789 | 1.0578 |
| 2.6688 | 23.21 | 13000 | 4.2029 | 1.1971 |
| 2.6717 | 24.11 | 13500 | 4.3582 | 1.1606 |
| 2.6414 | 25.0 | 14000 | 4.3469 | 1.2859 |
| 2.6585 | 25.89 | 14500 | 4.4786 | 1.0517 |
| 2.6379 | 26.79 | 15000 | 4.1083 | 1.1800 |
| 2.6453 | 27.68 | 15500 | 4.5773 | 1.0365 |
| 2.6588 | 28.57 | 16000 | 4.5645 | 1.1381 |
| 2.6289 | 29.46 | 16500 | 4.4557 | 1.0985 |
### Framework versions
- Transformers 4.23.1
- Pytorch 1.12.1+cu113
- Datasets 1.18.3
- Tokenizers 0.13.2
|
sd-concepts-library/4tnght
|
sd-concepts-library
| 2022-11-18T07:10:21Z | 0 | 18 | null |
[
"license:mit",
"region:us"
] | null | 2022-11-18T07:10:18Z |
---
license: mit
---
### 4tNGHT on Stable Diffusion
This is the `<4tNGHT>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as a `style`:









































































































|
Elitay/Orc
|
Elitay
| 2022-11-18T04:52:38Z | 0 | 0 | null |
[
"license:creativeml-openrail-m",
"region:us"
] | null | 2022-11-18T04:19:41Z |
---
license: creativeml-openrail-m
---
|
IGKKR/ddpm-butterflies-128
|
IGKKR
| 2022-11-18T04:33:09Z | 0 | 0 |
diffusers
|
[
"diffusers",
"tensorboard",
"en",
"dataset:huggan/smithsonian_butterflies_subset",
"license:apache-2.0",
"diffusers:DDPMPipeline",
"region:us"
] | null | 2022-11-18T02:18:15Z |
---
language: en
license: apache-2.0
library_name: diffusers
tags: []
datasets: huggan/smithsonian_butterflies_subset
metrics: []
---
<!-- This model card has been generated automatically according to the information the training script had access to. You
should probably proofread and complete it, then remove this comment. -->
# ddpm-butterflies-128
## Model description
This diffusion model is trained with the [🤗 Diffusers](https://github.com/huggingface/diffusers) library
on the `huggan/smithsonian_butterflies_subset` dataset.
## Intended uses & limitations
#### How to use
```python
# TODO: add an example code snippet for running this diffusion pipeline
```
#### Limitations and bias
[TODO: provide examples of latent issues and potential remediations]
## Training data
[TODO: describe the data used to train the model]
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 16
- eval_batch_size: 16
- gradient_accumulation_steps: 1
- optimizer: AdamW with betas=(None, None), weight_decay=None and epsilon=None
- lr_scheduler: None
- lr_warmup_steps: 500
- ema_inv_gamma: None
- ema_inv_gamma: None
- ema_inv_gamma: None
- mixed_precision: fp16
### Training results
📈 [TensorBoard logs](https://huggingface.co/IGKKR/ddpm-butterflies-128/tensorboard?#scalars)
|
Subsets and Splits
Filtered Qwen2.5 Distill Models
Identifies specific configurations of models by filtering cards that contain 'distill', 'qwen2.5', '7b' while excluding certain base models and incorrect model ID patterns, uncovering unique model variants.
Filtered Model Cards Count
Finds the count of entries with specific card details that include 'distill', 'qwen2.5', '7b' but exclude certain base models, revealing valuable insights about the dataset's content distribution.
Filtered Distill Qwen 7B Models
Filters for specific card entries containing 'distill', 'qwen', and '7b', excluding certain strings and patterns, to identify relevant model configurations.
Filtered Qwen-7b Model Cards
The query performs a detailed filtering based on specific keywords and excludes certain entries, which could be useful for identifying a specific subset of cards but does not provide deeper insights or trends.
Filtered Qwen 7B Model Cards
The query filters for specific terms related to "distilled" or "distill", "qwen", and "7b" in the 'card' column but excludes certain base models, providing a limited set of entries for further inspection.
Qwen 7B Distilled Models
The query provides a basic filtering of records to find specific card names that include keywords related to distilled Qwen 7b models, excluding a particular base model, which gives limited insight but helps in focusing on relevant entries.
Qwen 7B Distilled Model Cards
The query filters data based on specific keywords in the modelId and card fields, providing limited insight primarily useful for locating specific entries rather than revealing broad patterns or trends.
Qwen 7B Distilled Models
Finds all entries containing the terms 'distilled', 'qwen', and '7b' in a case-insensitive manner, providing a filtered set of records but without deeper analysis.
Distilled Qwen 7B Models
The query filters for specific model IDs containing 'distilled', 'qwen', and '7b', providing a basic retrieval of relevant entries but without deeper analysis or insight.
Filtered Model Cards with Distill Qwen2.
Filters and retrieves records containing specific keywords in the card description while excluding certain phrases, providing a basic count of relevant entries.
Filtered Model Cards with Distill Qwen 7
The query filters specific variations of card descriptions containing 'distill', 'qwen', and '7b' while excluding a particular base model, providing limited but specific data retrieval.
Distill Qwen 7B Model Cards
The query filters and retrieves rows where the 'card' column contains specific keywords ('distill', 'qwen', and '7b'), providing a basic filter result that can help in identifying specific entries.