
modelId
stringlengths 5
139
| author
stringlengths 2
42
| last_modified
timestamp[us, tz=UTC]date 2020-02-15 11:33:14
2025-08-27 12:31:29
| downloads
int64 0
223M
| likes
int64 0
11.7k
| library_name
stringclasses 521
values | tags
listlengths 1
4.05k
| pipeline_tag
stringclasses 55
values | createdAt
timestamp[us, tz=UTC]date 2022-03-02 23:29:04
2025-08-27 12:31:13
| card
stringlengths 11
1.01M
|
|---|---|---|---|---|---|---|---|---|---|
mang3dd/blockassist-bc-tangled_slithering_alligator_1756228562
|
mang3dd
| 2025-08-26T17:42:06Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"tangled slithering alligator",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-26T17:42:02Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- tangled slithering alligator
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
19-VIDEOS-Nayeon-Sana-viral-video-Clips/New.full.videos.Nayeon.Sana.Viral.Video.Official.Tutorial
|
19-VIDEOS-Nayeon-Sana-viral-video-Clips
| 2025-08-26T17:41:45Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-08-26T17:41:34Z |
<animated-image data-catalyst=""><a href="https://tinyurl.com/mdfprj9k?viral-video" rel="nofollow" data-target="animated-image.originalLink"><img src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" alt="Foo" data-canonical-src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" style="max-width: 100%; display: inline-block;" data-target="animated-image.originalImage"></a>
|
youuotty/blockassist-bc-scaly_tiny_locust_1756230075
|
youuotty
| 2025-08-26T17:41:28Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"scaly tiny locust",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-26T17:41:16Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- scaly tiny locust
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
ggozzy/blockassist-bc-stubby_yapping_mandrill_1756229749
|
ggozzy
| 2025-08-26T17:37:00Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"stubby yapping mandrill",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-26T17:36:54Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- stubby yapping mandrill
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
calegpedia/blockassist-bc-stealthy_slimy_rooster_1756228111
|
calegpedia
| 2025-08-26T17:35:36Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"stealthy slimy rooster",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-26T17:35:33Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- stealthy slimy rooster
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
qualcomm/Yolo-X
|
qualcomm
| 2025-08-26T17:35:00Z | 561 | 5 |
pytorch
|
[
"pytorch",
"tflite",
"real_time",
"android",
"object-detection",
"license:other",
"region:us"
] |
object-detection
| 2025-03-14T02:22:40Z |
---
library_name: pytorch
license: other
tags:
- real_time
- android
pipeline_tag: object-detection
---

# Yolo-X: Optimized for Mobile Deployment
## Real-time object detection optimized for mobile and edge
YoloX is a machine learning model that predicts bounding boxes and classes of objects in an image.
This model is an implementation of Yolo-X found [here](https://github.com/Megvii-BaseDetection/YOLOX/).
This repository provides scripts to run Yolo-X on Qualcomm® devices.
More details on model performance across various devices, can be found
[here](https://aihub.qualcomm.com/models/yolox).
### Model Details
- **Model Type:** Model_use_case.object_detection
- **Model Stats:**
- Model checkpoint: YoloX Small
- Input resolution: 640x640
- Number of parameters: 8.98M
- Model size (float): 34.3 MB
- Model size (w8a16): 9.53 MB
- Model size (w8a8): 8.96 MB
| Model | Precision | Device | Chipset | Target Runtime | Inference Time (ms) | Peak Memory Range (MB) | Primary Compute Unit | Target Model
|---|---|---|---|---|---|---|---|---|
| Yolo-X | float | QCS8275 (Proxy) | Qualcomm® QCS8275 (Proxy) | TFLITE | 32.199 ms | 0 - 46 MB | NPU | [Yolo-X.tflite](https://huggingface.co/qualcomm/Yolo-X/blob/main/Yolo-X.tflite) |
| Yolo-X | float | QCS8275 (Proxy) | Qualcomm® QCS8275 (Proxy) | QNN_DLC | 31.557 ms | 0 - 69 MB | NPU | [Yolo-X.dlc](https://huggingface.co/qualcomm/Yolo-X/blob/main/Yolo-X.dlc) |
| Yolo-X | float | QCS8450 (Proxy) | Qualcomm® QCS8450 (Proxy) | TFLITE | 14.375 ms | 0 - 54 MB | NPU | [Yolo-X.tflite](https://huggingface.co/qualcomm/Yolo-X/blob/main/Yolo-X.tflite) |
| Yolo-X | float | QCS8450 (Proxy) | Qualcomm® QCS8450 (Proxy) | QNN_DLC | 18.929 ms | 4 - 45 MB | NPU | [Yolo-X.dlc](https://huggingface.co/qualcomm/Yolo-X/blob/main/Yolo-X.dlc) |
| Yolo-X | float | QCS8550 (Proxy) | Qualcomm® QCS8550 (Proxy) | TFLITE | 8.727 ms | 0 - 12 MB | NPU | [Yolo-X.tflite](https://huggingface.co/qualcomm/Yolo-X/blob/main/Yolo-X.tflite) |
| Yolo-X | float | QCS8550 (Proxy) | Qualcomm® QCS8550 (Proxy) | QNN_DLC | 8.296 ms | 5 - 27 MB | NPU | [Yolo-X.dlc](https://huggingface.co/qualcomm/Yolo-X/blob/main/Yolo-X.dlc) |
| Yolo-X | float | QCS9075 (Proxy) | Qualcomm® QCS9075 (Proxy) | TFLITE | 11.861 ms | 0 - 48 MB | NPU | [Yolo-X.tflite](https://huggingface.co/qualcomm/Yolo-X/blob/main/Yolo-X.tflite) |
| Yolo-X | float | QCS9075 (Proxy) | Qualcomm® QCS9075 (Proxy) | QNN_DLC | 11.211 ms | 1 - 61 MB | NPU | [Yolo-X.dlc](https://huggingface.co/qualcomm/Yolo-X/blob/main/Yolo-X.dlc) |
| Yolo-X | float | SA7255P ADP | Qualcomm® SA7255P | TFLITE | 32.199 ms | 0 - 46 MB | NPU | [Yolo-X.tflite](https://huggingface.co/qualcomm/Yolo-X/blob/main/Yolo-X.tflite) |
| Yolo-X | float | SA7255P ADP | Qualcomm® SA7255P | QNN_DLC | 31.557 ms | 0 - 69 MB | NPU | [Yolo-X.dlc](https://huggingface.co/qualcomm/Yolo-X/blob/main/Yolo-X.dlc) |
| Yolo-X | float | SA8255 (Proxy) | Qualcomm® SA8255P (Proxy) | TFLITE | 8.586 ms | 0 - 12 MB | NPU | [Yolo-X.tflite](https://huggingface.co/qualcomm/Yolo-X/blob/main/Yolo-X.tflite) |
| Yolo-X | float | SA8255 (Proxy) | Qualcomm® SA8255P (Proxy) | QNN_DLC | 8.243 ms | 5 - 25 MB | NPU | [Yolo-X.dlc](https://huggingface.co/qualcomm/Yolo-X/blob/main/Yolo-X.dlc) |
| Yolo-X | float | SA8295P ADP | Qualcomm® SA8295P | TFLITE | 16.149 ms | 0 - 43 MB | NPU | [Yolo-X.tflite](https://huggingface.co/qualcomm/Yolo-X/blob/main/Yolo-X.tflite) |
| Yolo-X | float | SA8295P ADP | Qualcomm® SA8295P | QNN_DLC | 14.908 ms | 0 - 39 MB | NPU | [Yolo-X.dlc](https://huggingface.co/qualcomm/Yolo-X/blob/main/Yolo-X.dlc) |
| Yolo-X | float | SA8650 (Proxy) | Qualcomm® SA8650P (Proxy) | TFLITE | 8.699 ms | 0 - 16 MB | NPU | [Yolo-X.tflite](https://huggingface.co/qualcomm/Yolo-X/blob/main/Yolo-X.tflite) |
| Yolo-X | float | SA8650 (Proxy) | Qualcomm® SA8650P (Proxy) | QNN_DLC | 8.312 ms | 5 - 24 MB | NPU | [Yolo-X.dlc](https://huggingface.co/qualcomm/Yolo-X/blob/main/Yolo-X.dlc) |
| Yolo-X | float | SA8775P ADP | Qualcomm® SA8775P | TFLITE | 11.861 ms | 0 - 48 MB | NPU | [Yolo-X.tflite](https://huggingface.co/qualcomm/Yolo-X/blob/main/Yolo-X.tflite) |
| Yolo-X | float | SA8775P ADP | Qualcomm® SA8775P | QNN_DLC | 11.211 ms | 1 - 61 MB | NPU | [Yolo-X.dlc](https://huggingface.co/qualcomm/Yolo-X/blob/main/Yolo-X.dlc) |
| Yolo-X | float | Samsung Galaxy S23 | Snapdragon® 8 Gen 2 Mobile | TFLITE | 8.807 ms | 0 - 16 MB | NPU | [Yolo-X.tflite](https://huggingface.co/qualcomm/Yolo-X/blob/main/Yolo-X.tflite) |
| Yolo-X | float | Samsung Galaxy S23 | Snapdragon® 8 Gen 2 Mobile | QNN_DLC | 8.268 ms | 5 - 23 MB | NPU | [Yolo-X.dlc](https://huggingface.co/qualcomm/Yolo-X/blob/main/Yolo-X.dlc) |
| Yolo-X | float | Samsung Galaxy S23 | Snapdragon® 8 Gen 2 Mobile | ONNX | 14.188 ms | 0 - 59 MB | NPU | [Yolo-X.onnx.zip](https://huggingface.co/qualcomm/Yolo-X/blob/main/Yolo-X.onnx.zip) |
| Yolo-X | float | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | TFLITE | 6.46 ms | 0 - 60 MB | NPU | [Yolo-X.tflite](https://huggingface.co/qualcomm/Yolo-X/blob/main/Yolo-X.tflite) |
| Yolo-X | float | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | QNN_DLC | 6.136 ms | 5 - 87 MB | NPU | [Yolo-X.dlc](https://huggingface.co/qualcomm/Yolo-X/blob/main/Yolo-X.dlc) |
| Yolo-X | float | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | ONNX | 10.004 ms | 5 - 167 MB | NPU | [Yolo-X.onnx.zip](https://huggingface.co/qualcomm/Yolo-X/blob/main/Yolo-X.onnx.zip) |
| Yolo-X | float | Snapdragon 8 Elite QRD | Snapdragon® 8 Elite Mobile | TFLITE | 5.608 ms | 0 - 51 MB | NPU | [Yolo-X.tflite](https://huggingface.co/qualcomm/Yolo-X/blob/main/Yolo-X.tflite) |
| Yolo-X | float | Snapdragon 8 Elite QRD | Snapdragon® 8 Elite Mobile | QNN_DLC | 5.78 ms | 5 - 79 MB | NPU | [Yolo-X.dlc](https://huggingface.co/qualcomm/Yolo-X/blob/main/Yolo-X.dlc) |
| Yolo-X | float | Snapdragon 8 Elite QRD | Snapdragon® 8 Elite Mobile | ONNX | 9.403 ms | 5 - 104 MB | NPU | [Yolo-X.onnx.zip](https://huggingface.co/qualcomm/Yolo-X/blob/main/Yolo-X.onnx.zip) |
| Yolo-X | float | Snapdragon X Elite CRD | Snapdragon® X Elite | QNN_DLC | 8.99 ms | 5 - 5 MB | NPU | [Yolo-X.dlc](https://huggingface.co/qualcomm/Yolo-X/blob/main/Yolo-X.dlc) |
| Yolo-X | float | Snapdragon X Elite CRD | Snapdragon® X Elite | ONNX | 13.73 ms | 14 - 14 MB | NPU | [Yolo-X.onnx.zip](https://huggingface.co/qualcomm/Yolo-X/blob/main/Yolo-X.onnx.zip) |
| Yolo-X | w8a16 | QCS8275 (Proxy) | Qualcomm® QCS8275 (Proxy) | QNN_DLC | 15.583 ms | 2 - 40 MB | NPU | [Yolo-X.dlc](https://huggingface.co/qualcomm/Yolo-X/blob/main/Yolo-X_w8a16.dlc) |
| Yolo-X | w8a16 | QCS8450 (Proxy) | Qualcomm® QCS8450 (Proxy) | QNN_DLC | 9.235 ms | 2 - 55 MB | NPU | [Yolo-X.dlc](https://huggingface.co/qualcomm/Yolo-X/blob/main/Yolo-X_w8a16.dlc) |
| Yolo-X | w8a16 | QCS8550 (Proxy) | Qualcomm® QCS8550 (Proxy) | QNN_DLC | 7.857 ms | 2 - 17 MB | NPU | [Yolo-X.dlc](https://huggingface.co/qualcomm/Yolo-X/blob/main/Yolo-X_w8a16.dlc) |
| Yolo-X | w8a16 | QCS9075 (Proxy) | Qualcomm® QCS9075 (Proxy) | QNN_DLC | 8.465 ms | 1 - 40 MB | NPU | [Yolo-X.dlc](https://huggingface.co/qualcomm/Yolo-X/blob/main/Yolo-X_w8a16.dlc) |
| Yolo-X | w8a16 | RB3 Gen 2 (Proxy) | Qualcomm® QCS6490 (Proxy) | QNN_DLC | 27.546 ms | 2 - 54 MB | NPU | [Yolo-X.dlc](https://huggingface.co/qualcomm/Yolo-X/blob/main/Yolo-X_w8a16.dlc) |
| Yolo-X | w8a16 | SA7255P ADP | Qualcomm® SA7255P | QNN_DLC | 15.583 ms | 2 - 40 MB | NPU | [Yolo-X.dlc](https://huggingface.co/qualcomm/Yolo-X/blob/main/Yolo-X_w8a16.dlc) |
| Yolo-X | w8a16 | SA8255 (Proxy) | Qualcomm® SA8255P (Proxy) | QNN_DLC | 7.852 ms | 2 - 11 MB | NPU | [Yolo-X.dlc](https://huggingface.co/qualcomm/Yolo-X/blob/main/Yolo-X_w8a16.dlc) |
| Yolo-X | w8a16 | SA8295P ADP | Qualcomm® SA8295P | QNN_DLC | 9.995 ms | 1 - 46 MB | NPU | [Yolo-X.dlc](https://huggingface.co/qualcomm/Yolo-X/blob/main/Yolo-X_w8a16.dlc) |
| Yolo-X | w8a16 | SA8650 (Proxy) | Qualcomm® SA8650P (Proxy) | QNN_DLC | 7.846 ms | 2 - 16 MB | NPU | [Yolo-X.dlc](https://huggingface.co/qualcomm/Yolo-X/blob/main/Yolo-X_w8a16.dlc) |
| Yolo-X | w8a16 | SA8775P ADP | Qualcomm® SA8775P | QNN_DLC | 8.465 ms | 1 - 40 MB | NPU | [Yolo-X.dlc](https://huggingface.co/qualcomm/Yolo-X/blob/main/Yolo-X_w8a16.dlc) |
| Yolo-X | w8a16 | Samsung Galaxy S23 | Snapdragon® 8 Gen 2 Mobile | QNN_DLC | 7.843 ms | 2 - 14 MB | NPU | [Yolo-X.dlc](https://huggingface.co/qualcomm/Yolo-X/blob/main/Yolo-X_w8a16.dlc) |
| Yolo-X | w8a16 | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | QNN_DLC | 5.046 ms | 2 - 58 MB | NPU | [Yolo-X.dlc](https://huggingface.co/qualcomm/Yolo-X/blob/main/Yolo-X_w8a16.dlc) |
| Yolo-X | w8a16 | Snapdragon 8 Elite QRD | Snapdragon® 8 Elite Mobile | QNN_DLC | 4.871 ms | 2 - 48 MB | NPU | [Yolo-X.dlc](https://huggingface.co/qualcomm/Yolo-X/blob/main/Yolo-X_w8a16.dlc) |
| Yolo-X | w8a16 | Snapdragon X Elite CRD | Snapdragon® X Elite | QNN_DLC | 8.499 ms | 6 - 6 MB | NPU | [Yolo-X.dlc](https://huggingface.co/qualcomm/Yolo-X/blob/main/Yolo-X_w8a16.dlc) |
| Yolo-X | w8a8 | QCS8275 (Proxy) | Qualcomm® QCS8275 (Proxy) | TFLITE | 6.353 ms | 0 - 31 MB | NPU | [Yolo-X.tflite](https://huggingface.co/qualcomm/Yolo-X/blob/main/Yolo-X_w8a8.tflite) |
| Yolo-X | w8a8 | QCS8275 (Proxy) | Qualcomm® QCS8275 (Proxy) | QNN_DLC | 5.441 ms | 1 - 34 MB | NPU | [Yolo-X.dlc](https://huggingface.co/qualcomm/Yolo-X/blob/main/Yolo-X_w8a8.dlc) |
| Yolo-X | w8a8 | QCS8450 (Proxy) | Qualcomm® QCS8450 (Proxy) | TFLITE | 3.011 ms | 0 - 48 MB | NPU | [Yolo-X.tflite](https://huggingface.co/qualcomm/Yolo-X/blob/main/Yolo-X_w8a8.tflite) |
| Yolo-X | w8a8 | QCS8450 (Proxy) | Qualcomm® QCS8450 (Proxy) | QNN_DLC | 2.821 ms | 1 - 49 MB | NPU | [Yolo-X.dlc](https://huggingface.co/qualcomm/Yolo-X/blob/main/Yolo-X_w8a8.dlc) |
| Yolo-X | w8a8 | QCS8550 (Proxy) | Qualcomm® QCS8550 (Proxy) | TFLITE | 2.792 ms | 0 - 34 MB | NPU | [Yolo-X.tflite](https://huggingface.co/qualcomm/Yolo-X/blob/main/Yolo-X_w8a8.tflite) |
| Yolo-X | w8a8 | QCS8550 (Proxy) | Qualcomm® QCS8550 (Proxy) | QNN_DLC | 2.309 ms | 1 - 13 MB | NPU | [Yolo-X.dlc](https://huggingface.co/qualcomm/Yolo-X/blob/main/Yolo-X_w8a8.dlc) |
| Yolo-X | w8a8 | QCS9075 (Proxy) | Qualcomm® QCS9075 (Proxy) | TFLITE | 3.232 ms | 0 - 32 MB | NPU | [Yolo-X.tflite](https://huggingface.co/qualcomm/Yolo-X/blob/main/Yolo-X_w8a8.tflite) |
| Yolo-X | w8a8 | QCS9075 (Proxy) | Qualcomm® QCS9075 (Proxy) | QNN_DLC | 2.691 ms | 1 - 36 MB | NPU | [Yolo-X.dlc](https://huggingface.co/qualcomm/Yolo-X/blob/main/Yolo-X_w8a8.dlc) |
| Yolo-X | w8a8 | RB3 Gen 2 (Proxy) | Qualcomm® QCS6490 (Proxy) | QNN_DLC | 9.957 ms | 0 - 41 MB | NPU | [Yolo-X.dlc](https://huggingface.co/qualcomm/Yolo-X/blob/main/Yolo-X_w8a8.dlc) |
| Yolo-X | w8a8 | SA7255P ADP | Qualcomm® SA7255P | TFLITE | 6.353 ms | 0 - 31 MB | NPU | [Yolo-X.tflite](https://huggingface.co/qualcomm/Yolo-X/blob/main/Yolo-X_w8a8.tflite) |
| Yolo-X | w8a8 | SA7255P ADP | Qualcomm® SA7255P | QNN_DLC | 5.441 ms | 1 - 34 MB | NPU | [Yolo-X.dlc](https://huggingface.co/qualcomm/Yolo-X/blob/main/Yolo-X_w8a8.dlc) |
| Yolo-X | w8a8 | SA8255 (Proxy) | Qualcomm® SA8255P (Proxy) | TFLITE | 2.862 ms | 0 - 35 MB | NPU | [Yolo-X.tflite](https://huggingface.co/qualcomm/Yolo-X/blob/main/Yolo-X_w8a8.tflite) |
| Yolo-X | w8a8 | SA8255 (Proxy) | Qualcomm® SA8255P (Proxy) | QNN_DLC | 2.32 ms | 1 - 13 MB | NPU | [Yolo-X.dlc](https://huggingface.co/qualcomm/Yolo-X/blob/main/Yolo-X_w8a8.dlc) |
| Yolo-X | w8a8 | SA8295P ADP | Qualcomm® SA8295P | TFLITE | 4.137 ms | 0 - 39 MB | NPU | [Yolo-X.tflite](https://huggingface.co/qualcomm/Yolo-X/blob/main/Yolo-X_w8a8.tflite) |
| Yolo-X | w8a8 | SA8295P ADP | Qualcomm® SA8295P | QNN_DLC | 3.626 ms | 1 - 42 MB | NPU | [Yolo-X.dlc](https://huggingface.co/qualcomm/Yolo-X/blob/main/Yolo-X_w8a8.dlc) |
| Yolo-X | w8a8 | SA8650 (Proxy) | Qualcomm® SA8650P (Proxy) | TFLITE | 2.852 ms | 0 - 33 MB | NPU | [Yolo-X.tflite](https://huggingface.co/qualcomm/Yolo-X/blob/main/Yolo-X_w8a8.tflite) |
| Yolo-X | w8a8 | SA8650 (Proxy) | Qualcomm® SA8650P (Proxy) | QNN_DLC | 2.326 ms | 1 - 12 MB | NPU | [Yolo-X.dlc](https://huggingface.co/qualcomm/Yolo-X/blob/main/Yolo-X_w8a8.dlc) |
| Yolo-X | w8a8 | SA8775P ADP | Qualcomm® SA8775P | TFLITE | 3.232 ms | 0 - 32 MB | NPU | [Yolo-X.tflite](https://huggingface.co/qualcomm/Yolo-X/blob/main/Yolo-X_w8a8.tflite) |
| Yolo-X | w8a8 | SA8775P ADP | Qualcomm® SA8775P | QNN_DLC | 2.691 ms | 1 - 36 MB | NPU | [Yolo-X.dlc](https://huggingface.co/qualcomm/Yolo-X/blob/main/Yolo-X_w8a8.dlc) |
| Yolo-X | w8a8 | Samsung Galaxy S23 | Snapdragon® 8 Gen 2 Mobile | TFLITE | 2.865 ms | 0 - 34 MB | NPU | [Yolo-X.tflite](https://huggingface.co/qualcomm/Yolo-X/blob/main/Yolo-X_w8a8.tflite) |
| Yolo-X | w8a8 | Samsung Galaxy S23 | Snapdragon® 8 Gen 2 Mobile | QNN_DLC | 2.321 ms | 1 - 11 MB | NPU | [Yolo-X.dlc](https://huggingface.co/qualcomm/Yolo-X/blob/main/Yolo-X_w8a8.dlc) |
| Yolo-X | w8a8 | Samsung Galaxy S23 | Snapdragon® 8 Gen 2 Mobile | ONNX | 11.037 ms | 0 - 27 MB | NPU | [Yolo-X.onnx.zip](https://huggingface.co/qualcomm/Yolo-X/blob/main/Yolo-X_w8a8.onnx.zip) |
| Yolo-X | w8a8 | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | TFLITE | 1.848 ms | 0 - 50 MB | NPU | [Yolo-X.tflite](https://huggingface.co/qualcomm/Yolo-X/blob/main/Yolo-X_w8a8.tflite) |
| Yolo-X | w8a8 | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | QNN_DLC | 1.546 ms | 1 - 53 MB | NPU | [Yolo-X.dlc](https://huggingface.co/qualcomm/Yolo-X/blob/main/Yolo-X_w8a8.dlc) |
| Yolo-X | w8a8 | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | ONNX | 7.865 ms | 1 - 104 MB | NPU | [Yolo-X.onnx.zip](https://huggingface.co/qualcomm/Yolo-X/blob/main/Yolo-X_w8a8.onnx.zip) |
| Yolo-X | w8a8 | Snapdragon 8 Elite QRD | Snapdragon® 8 Elite Mobile | TFLITE | 1.69 ms | 0 - 38 MB | NPU | [Yolo-X.tflite](https://huggingface.co/qualcomm/Yolo-X/blob/main/Yolo-X_w8a8.tflite) |
| Yolo-X | w8a8 | Snapdragon 8 Elite QRD | Snapdragon® 8 Elite Mobile | QNN_DLC | 1.29 ms | 1 - 43 MB | NPU | [Yolo-X.dlc](https://huggingface.co/qualcomm/Yolo-X/blob/main/Yolo-X_w8a8.dlc) |
| Yolo-X | w8a8 | Snapdragon 8 Elite QRD | Snapdragon® 8 Elite Mobile | ONNX | 8.682 ms | 1 - 74 MB | NPU | [Yolo-X.onnx.zip](https://huggingface.co/qualcomm/Yolo-X/blob/main/Yolo-X_w8a8.onnx.zip) |
| Yolo-X | w8a8 | Snapdragon X Elite CRD | Snapdragon® X Elite | QNN_DLC | 2.593 ms | 26 - 26 MB | NPU | [Yolo-X.dlc](https://huggingface.co/qualcomm/Yolo-X/blob/main/Yolo-X_w8a8.dlc) |
| Yolo-X | w8a8 | Snapdragon X Elite CRD | Snapdragon® X Elite | ONNX | 11.714 ms | 8 - 8 MB | NPU | [Yolo-X.onnx.zip](https://huggingface.co/qualcomm/Yolo-X/blob/main/Yolo-X_w8a8.onnx.zip) |
## Installation
Install the package via pip:
```bash
pip install "qai-hub-models[yolox]"
```
## Configure Qualcomm® AI Hub to run this model on a cloud-hosted device
Sign-in to [Qualcomm® AI Hub](https://app.aihub.qualcomm.com/) with your
Qualcomm® ID. Once signed in navigate to `Account -> Settings -> API Token`.
With this API token, you can configure your client to run models on the cloud
hosted devices.
```bash
qai-hub configure --api_token API_TOKEN
```
Navigate to [docs](https://app.aihub.qualcomm.com/docs/) for more information.
## Demo off target
The package contains a simple end-to-end demo that downloads pre-trained
weights and runs this model on a sample input.
```bash
python -m qai_hub_models.models.yolox.demo
```
The above demo runs a reference implementation of pre-processing, model
inference, and post processing.
**NOTE**: If you want running in a Jupyter Notebook or Google Colab like
environment, please add the following to your cell (instead of the above).
```
%run -m qai_hub_models.models.yolox.demo
```
### Run model on a cloud-hosted device
In addition to the demo, you can also run the model on a cloud-hosted Qualcomm®
device. This script does the following:
* Performance check on-device on a cloud-hosted device
* Downloads compiled assets that can be deployed on-device for Android.
* Accuracy check between PyTorch and on-device outputs.
```bash
python -m qai_hub_models.models.yolox.export
```
## How does this work?
This [export script](https://aihub.qualcomm.com/models/yolox/qai_hub_models/models/Yolo-X/export.py)
leverages [Qualcomm® AI Hub](https://aihub.qualcomm.com/) to optimize, validate, and deploy this model
on-device. Lets go through each step below in detail:
Step 1: **Compile model for on-device deployment**
To compile a PyTorch model for on-device deployment, we first trace the model
in memory using the `jit.trace` and then call the `submit_compile_job` API.
```python
import torch
import qai_hub as hub
from qai_hub_models.models.yolox import Model
# Load the model
torch_model = Model.from_pretrained()
# Device
device = hub.Device("Samsung Galaxy S24")
# Trace model
input_shape = torch_model.get_input_spec()
sample_inputs = torch_model.sample_inputs()
pt_model = torch.jit.trace(torch_model, [torch.tensor(data[0]) for _, data in sample_inputs.items()])
# Compile model on a specific device
compile_job = hub.submit_compile_job(
model=pt_model,
device=device,
input_specs=torch_model.get_input_spec(),
)
# Get target model to run on-device
target_model = compile_job.get_target_model()
```
Step 2: **Performance profiling on cloud-hosted device**
After compiling models from step 1. Models can be profiled model on-device using the
`target_model`. Note that this scripts runs the model on a device automatically
provisioned in the cloud. Once the job is submitted, you can navigate to a
provided job URL to view a variety of on-device performance metrics.
```python
profile_job = hub.submit_profile_job(
model=target_model,
device=device,
)
```
Step 3: **Verify on-device accuracy**
To verify the accuracy of the model on-device, you can run on-device inference
on sample input data on the same cloud hosted device.
```python
input_data = torch_model.sample_inputs()
inference_job = hub.submit_inference_job(
model=target_model,
device=device,
inputs=input_data,
)
on_device_output = inference_job.download_output_data()
```
With the output of the model, you can compute like PSNR, relative errors or
spot check the output with expected output.
**Note**: This on-device profiling and inference requires access to Qualcomm®
AI Hub. [Sign up for access](https://myaccount.qualcomm.com/signup).
## Run demo on a cloud-hosted device
You can also run the demo on-device.
```bash
python -m qai_hub_models.models.yolox.demo --eval-mode on-device
```
**NOTE**: If you want running in a Jupyter Notebook or Google Colab like
environment, please add the following to your cell (instead of the above).
```
%run -m qai_hub_models.models.yolox.demo -- --eval-mode on-device
```
## Deploying compiled model to Android
The models can be deployed using multiple runtimes:
- TensorFlow Lite (`.tflite` export): [This
tutorial](https://www.tensorflow.org/lite/android/quickstart) provides a
guide to deploy the .tflite model in an Android application.
- QNN (`.so` export ): This [sample
app](https://docs.qualcomm.com/bundle/publicresource/topics/80-63442-50/sample_app.html)
provides instructions on how to use the `.so` shared library in an Android application.
## View on Qualcomm® AI Hub
Get more details on Yolo-X's performance across various devices [here](https://aihub.qualcomm.com/models/yolox).
Explore all available models on [Qualcomm® AI Hub](https://aihub.qualcomm.com/)
## License
* The license for the original implementation of Yolo-X can be found
[here](https://github.com/Megvii-BaseDetection/YOLOX/blob/main/LICENSE).
* The license for the compiled assets for on-device deployment can be found [here](https://qaihub-public-assets.s3.us-west-2.amazonaws.com/qai-hub-models/Qualcomm+AI+Hub+Proprietary+License.pdf)
## References
* [YOLOX: Exceeding YOLO Series in 2021](https://github.com/Megvii-BaseDetection/YOLOX/blob/main/README.md)
* [Source Model Implementation](https://github.com/Megvii-BaseDetection/YOLOX/)
## Community
* Join [our AI Hub Slack community](https://aihub.qualcomm.com/community/slack) to collaborate, post questions and learn more about on-device AI.
* For questions or feedback please [reach out to us](mailto:ai-hub-support@qti.qualcomm.com).
|
qualcomm/YOLOv8-Detection
|
qualcomm
| 2025-08-26T17:34:30Z | 82 | 0 |
pytorch
|
[
"pytorch",
"real_time",
"android",
"object-detection",
"license:other",
"region:us"
] |
object-detection
| 2024-02-25T22:41:14Z |
---
library_name: pytorch
license: other
tags:
- real_time
- android
pipeline_tag: object-detection
---

# YOLOv8-Detection: Optimized for Mobile Deployment
## Real-time object detection optimized for mobile and edge by Ultralytics
Ultralytics YOLOv8 is a machine learning model that predicts bounding boxes and classes of objects in an image.
This model is an implementation of YOLOv8-Detection found [here](https://github.com/ultralytics/ultralytics/tree/main/ultralytics/models/yolo/detect).
This repository provides scripts to run YOLOv8-Detection on Qualcomm® devices.
More details on model performance across various devices, can be found
[here](https://aihub.qualcomm.com/models/yolov8_det).
**WARNING**: The model assets are not readily available for download due to licensing restrictions.
### Model Details
- **Model Type:** Model_use_case.object_detection
- **Model Stats:**
- Model checkpoint: YOLOv8-N
- Input resolution: 640x640
- Number of parameters: 3.18M
- Model size (float): 12.2 MB
- Model size (w8a8): 3.25 MB
- Model size (w8a16): 3.60 MB
| Model | Precision | Device | Chipset | Target Runtime | Inference Time (ms) | Peak Memory Range (MB) | Primary Compute Unit | Target Model
|---|---|---|---|---|---|---|---|---|
| YOLOv8-Detection | float | QCS8275 (Proxy) | Qualcomm® QCS8275 (Proxy) | TFLITE | 14.24 ms | 0 - 66 MB | NPU | -- |
| YOLOv8-Detection | float | QCS8275 (Proxy) | Qualcomm® QCS8275 (Proxy) | QNN_DLC | 13.288 ms | 2 - 94 MB | NPU | -- |
| YOLOv8-Detection | float | QCS8450 (Proxy) | Qualcomm® QCS8450 (Proxy) | TFLITE | 6.584 ms | 0 - 40 MB | NPU | -- |
| YOLOv8-Detection | float | QCS8450 (Proxy) | Qualcomm® QCS8450 (Proxy) | QNN_DLC | 8.03 ms | 5 - 44 MB | NPU | -- |
| YOLOv8-Detection | float | QCS8550 (Proxy) | Qualcomm® QCS8550 (Proxy) | TFLITE | 4.13 ms | 0 - 38 MB | NPU | -- |
| YOLOv8-Detection | float | QCS8550 (Proxy) | Qualcomm® QCS8550 (Proxy) | QNN_DLC | 3.453 ms | 0 - 76 MB | NPU | -- |
| YOLOv8-Detection | float | QCS9075 (Proxy) | Qualcomm® QCS9075 (Proxy) | TFLITE | 5.589 ms | 0 - 65 MB | NPU | -- |
| YOLOv8-Detection | float | QCS9075 (Proxy) | Qualcomm® QCS9075 (Proxy) | QNN_DLC | 5.107 ms | 1 - 96 MB | NPU | -- |
| YOLOv8-Detection | float | SA7255P ADP | Qualcomm® SA7255P | TFLITE | 14.24 ms | 0 - 66 MB | NPU | -- |
| YOLOv8-Detection | float | SA7255P ADP | Qualcomm® SA7255P | QNN_DLC | 13.288 ms | 2 - 94 MB | NPU | -- |
| YOLOv8-Detection | float | SA8255 (Proxy) | Qualcomm® SA8255P (Proxy) | TFLITE | 4.115 ms | 0 - 40 MB | NPU | -- |
| YOLOv8-Detection | float | SA8255 (Proxy) | Qualcomm® SA8255P (Proxy) | QNN_DLC | 3.456 ms | 0 - 75 MB | NPU | -- |
| YOLOv8-Detection | float | SA8295P ADP | Qualcomm® SA8295P | TFLITE | 7.643 ms | 0 - 34 MB | NPU | -- |
| YOLOv8-Detection | float | SA8295P ADP | Qualcomm® SA8295P | QNN_DLC | 7.224 ms | 4 - 35 MB | NPU | -- |
| YOLOv8-Detection | float | SA8650 (Proxy) | Qualcomm® SA8650P (Proxy) | TFLITE | 4.123 ms | 0 - 38 MB | NPU | -- |
| YOLOv8-Detection | float | SA8650 (Proxy) | Qualcomm® SA8650P (Proxy) | QNN_DLC | 3.458 ms | 0 - 81 MB | NPU | -- |
| YOLOv8-Detection | float | SA8775P ADP | Qualcomm® SA8775P | TFLITE | 5.589 ms | 0 - 65 MB | NPU | -- |
| YOLOv8-Detection | float | SA8775P ADP | Qualcomm® SA8775P | QNN_DLC | 5.107 ms | 1 - 96 MB | NPU | -- |
| YOLOv8-Detection | float | Samsung Galaxy S23 | Snapdragon® 8 Gen 2 Mobile | TFLITE | 4.13 ms | 0 - 39 MB | NPU | -- |
| YOLOv8-Detection | float | Samsung Galaxy S23 | Snapdragon® 8 Gen 2 Mobile | QNN_DLC | 3.459 ms | 0 - 69 MB | NPU | -- |
| YOLOv8-Detection | float | Samsung Galaxy S23 | Snapdragon® 8 Gen 2 Mobile | ONNX | 5.759 ms | 0 - 48 MB | NPU | -- |
| YOLOv8-Detection | float | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | TFLITE | 3.038 ms | 0 - 85 MB | NPU | -- |
| YOLOv8-Detection | float | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | QNN_DLC | 2.549 ms | 5 - 231 MB | NPU | -- |
| YOLOv8-Detection | float | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | ONNX | 3.756 ms | 0 - 170 MB | NPU | -- |
| YOLOv8-Detection | float | Snapdragon 8 Elite QRD | Snapdragon® 8 Elite Mobile | TFLITE | 2.948 ms | 0 - 73 MB | NPU | -- |
| YOLOv8-Detection | float | Snapdragon 8 Elite QRD | Snapdragon® 8 Elite Mobile | QNN_DLC | 1.97 ms | 5 - 133 MB | NPU | -- |
| YOLOv8-Detection | float | Snapdragon 8 Elite QRD | Snapdragon® 8 Elite Mobile | ONNX | 3.656 ms | 4 - 92 MB | NPU | -- |
| YOLOv8-Detection | float | Snapdragon X Elite CRD | Snapdragon® X Elite | QNN_DLC | 3.834 ms | 114 - 114 MB | NPU | -- |
| YOLOv8-Detection | float | Snapdragon X Elite CRD | Snapdragon® X Elite | ONNX | 6.034 ms | 5 - 5 MB | NPU | -- |
| YOLOv8-Detection | w8a16 | QCS8275 (Proxy) | Qualcomm® QCS8275 (Proxy) | QNN_DLC | 6.551 ms | 1 - 29 MB | NPU | -- |
| YOLOv8-Detection | w8a16 | QCS8450 (Proxy) | Qualcomm® QCS8450 (Proxy) | QNN_DLC | 3.949 ms | 2 - 37 MB | NPU | -- |
| YOLOv8-Detection | w8a16 | QCS8550 (Proxy) | Qualcomm® QCS8550 (Proxy) | QNN_DLC | 3.263 ms | 2 - 13 MB | NPU | -- |
| YOLOv8-Detection | w8a16 | QCS9075 (Proxy) | Qualcomm® QCS9075 (Proxy) | QNN_DLC | 3.8 ms | 1 - 30 MB | NPU | -- |
| YOLOv8-Detection | w8a16 | RB3 Gen 2 (Proxy) | Qualcomm® QCS6490 (Proxy) | QNN_DLC | 13.293 ms | 0 - 36 MB | NPU | -- |
| YOLOv8-Detection | w8a16 | SA7255P ADP | Qualcomm® SA7255P | QNN_DLC | 6.551 ms | 1 - 29 MB | NPU | -- |
| YOLOv8-Detection | w8a16 | SA8255 (Proxy) | Qualcomm® SA8255P (Proxy) | QNN_DLC | 3.268 ms | 2 - 11 MB | NPU | -- |
| YOLOv8-Detection | w8a16 | SA8295P ADP | Qualcomm® SA8295P | QNN_DLC | 4.437 ms | 2 - 34 MB | NPU | -- |
| YOLOv8-Detection | w8a16 | SA8650 (Proxy) | Qualcomm® SA8650P (Proxy) | QNN_DLC | 3.274 ms | 2 - 11 MB | NPU | -- |
| YOLOv8-Detection | w8a16 | SA8775P ADP | Qualcomm® SA8775P | QNN_DLC | 3.8 ms | 1 - 30 MB | NPU | -- |
| YOLOv8-Detection | w8a16 | Samsung Galaxy S23 | Snapdragon® 8 Gen 2 Mobile | QNN_DLC | 3.274 ms | 2 - 11 MB | NPU | -- |
| YOLOv8-Detection | w8a16 | Samsung Galaxy S23 | Snapdragon® 8 Gen 2 Mobile | ONNX | 60.762 ms | 0 - 181 MB | NPU | -- |
| YOLOv8-Detection | w8a16 | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | QNN_DLC | 2.177 ms | 2 - 40 MB | NPU | -- |
| YOLOv8-Detection | w8a16 | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | ONNX | 45.489 ms | 14 - 1068 MB | NPU | -- |
| YOLOv8-Detection | w8a16 | Snapdragon 8 Elite QRD | Snapdragon® 8 Elite Mobile | QNN_DLC | 1.869 ms | 2 - 45 MB | NPU | -- |
| YOLOv8-Detection | w8a16 | Snapdragon 8 Elite QRD | Snapdragon® 8 Elite Mobile | ONNX | 48.69 ms | 28 - 1004 MB | NPU | -- |
| YOLOv8-Detection | w8a16 | Snapdragon X Elite CRD | Snapdragon® X Elite | QNN_DLC | 3.647 ms | 2 - 2 MB | NPU | -- |
| YOLOv8-Detection | w8a16 | Snapdragon X Elite CRD | Snapdragon® X Elite | ONNX | 63.415 ms | 27 - 27 MB | NPU | -- |
| YOLOv8-Detection | w8a8 | QCS8275 (Proxy) | Qualcomm® QCS8275 (Proxy) | TFLITE | 3.364 ms | 0 - 24 MB | NPU | -- |
| YOLOv8-Detection | w8a8 | QCS8275 (Proxy) | Qualcomm® QCS8275 (Proxy) | QNN_DLC | 3.134 ms | 1 - 25 MB | NPU | -- |
| YOLOv8-Detection | w8a8 | QCS8450 (Proxy) | Qualcomm® QCS8450 (Proxy) | TFLITE | 1.65 ms | 0 - 41 MB | NPU | -- |
| YOLOv8-Detection | w8a8 | QCS8450 (Proxy) | Qualcomm® QCS8450 (Proxy) | QNN_DLC | 1.641 ms | 1 - 40 MB | NPU | -- |
| YOLOv8-Detection | w8a8 | QCS8550 (Proxy) | Qualcomm® QCS8550 (Proxy) | TFLITE | 1.504 ms | 0 - 15 MB | NPU | -- |
| YOLOv8-Detection | w8a8 | QCS8550 (Proxy) | Qualcomm® QCS8550 (Proxy) | QNN_DLC | 1.425 ms | 1 - 16 MB | NPU | -- |
| YOLOv8-Detection | w8a8 | QCS9075 (Proxy) | Qualcomm® QCS9075 (Proxy) | TFLITE | 1.909 ms | 0 - 24 MB | NPU | -- |
| YOLOv8-Detection | w8a8 | QCS9075 (Proxy) | Qualcomm® QCS9075 (Proxy) | QNN_DLC | 1.793 ms | 1 - 25 MB | NPU | -- |
| YOLOv8-Detection | w8a8 | RB3 Gen 2 (Proxy) | Qualcomm® QCS6490 (Proxy) | TFLITE | 3.773 ms | 0 - 31 MB | NPU | -- |
| YOLOv8-Detection | w8a8 | RB3 Gen 2 (Proxy) | Qualcomm® QCS6490 (Proxy) | QNN_DLC | 4.744 ms | 1 - 33 MB | NPU | -- |
| YOLOv8-Detection | w8a8 | SA7255P ADP | Qualcomm® SA7255P | TFLITE | 3.364 ms | 0 - 24 MB | NPU | -- |
| YOLOv8-Detection | w8a8 | SA7255P ADP | Qualcomm® SA7255P | QNN_DLC | 3.134 ms | 1 - 25 MB | NPU | -- |
| YOLOv8-Detection | w8a8 | SA8255 (Proxy) | Qualcomm® SA8255P (Proxy) | TFLITE | 1.497 ms | 0 - 16 MB | NPU | -- |
| YOLOv8-Detection | w8a8 | SA8255 (Proxy) | Qualcomm® SA8255P (Proxy) | QNN_DLC | 1.417 ms | 0 - 15 MB | NPU | -- |
| YOLOv8-Detection | w8a8 | SA8295P ADP | Qualcomm® SA8295P | TFLITE | 2.356 ms | 0 - 30 MB | NPU | -- |
| YOLOv8-Detection | w8a8 | SA8295P ADP | Qualcomm® SA8295P | QNN_DLC | 2.201 ms | 1 - 32 MB | NPU | -- |
| YOLOv8-Detection | w8a8 | SA8650 (Proxy) | Qualcomm® SA8650P (Proxy) | TFLITE | 1.51 ms | 0 - 15 MB | NPU | -- |
| YOLOv8-Detection | w8a8 | SA8650 (Proxy) | Qualcomm® SA8650P (Proxy) | QNN_DLC | 1.416 ms | 0 - 15 MB | NPU | -- |
| YOLOv8-Detection | w8a8 | SA8775P ADP | Qualcomm® SA8775P | TFLITE | 1.909 ms | 0 - 24 MB | NPU | -- |
| YOLOv8-Detection | w8a8 | SA8775P ADP | Qualcomm® SA8775P | QNN_DLC | 1.793 ms | 1 - 25 MB | NPU | -- |
| YOLOv8-Detection | w8a8 | Samsung Galaxy S23 | Snapdragon® 8 Gen 2 Mobile | TFLITE | 1.496 ms | 0 - 15 MB | NPU | -- |
| YOLOv8-Detection | w8a8 | Samsung Galaxy S23 | Snapdragon® 8 Gen 2 Mobile | QNN_DLC | 1.419 ms | 1 - 9 MB | NPU | -- |
| YOLOv8-Detection | w8a8 | Samsung Galaxy S23 | Snapdragon® 8 Gen 2 Mobile | ONNX | 6.251 ms | 0 - 18 MB | NPU | -- |
| YOLOv8-Detection | w8a8 | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | TFLITE | 0.989 ms | 0 - 38 MB | NPU | -- |
| YOLOv8-Detection | w8a8 | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | QNN_DLC | 0.958 ms | 1 - 37 MB | NPU | -- |
| YOLOv8-Detection | w8a8 | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | ONNX | 4.482 ms | 1 - 75 MB | NPU | -- |
| YOLOv8-Detection | w8a8 | Snapdragon 8 Elite QRD | Snapdragon® 8 Elite Mobile | TFLITE | 0.912 ms | 0 - 28 MB | NPU | -- |
| YOLOv8-Detection | w8a8 | Snapdragon 8 Elite QRD | Snapdragon® 8 Elite Mobile | QNN_DLC | 0.708 ms | 1 - 32 MB | NPU | -- |
| YOLOv8-Detection | w8a8 | Snapdragon 8 Elite QRD | Snapdragon® 8 Elite Mobile | ONNX | 3.299 ms | 0 - 79 MB | NPU | -- |
| YOLOv8-Detection | w8a8 | Snapdragon X Elite CRD | Snapdragon® X Elite | QNN_DLC | 1.649 ms | 4 - 4 MB | NPU | -- |
| YOLOv8-Detection | w8a8 | Snapdragon X Elite CRD | Snapdragon® X Elite | ONNX | 6.826 ms | 2 - 2 MB | NPU | -- |
## Installation
Install the package via pip:
```bash
pip install "qai-hub-models[yolov8-det]"
```
## Configure Qualcomm® AI Hub to run this model on a cloud-hosted device
Sign-in to [Qualcomm® AI Hub](https://app.aihub.qualcomm.com/) with your
Qualcomm® ID. Once signed in navigate to `Account -> Settings -> API Token`.
With this API token, you can configure your client to run models on the cloud
hosted devices.
```bash
qai-hub configure --api_token API_TOKEN
```
Navigate to [docs](https://app.aihub.qualcomm.com/docs/) for more information.
## Demo off target
The package contains a simple end-to-end demo that downloads pre-trained
weights and runs this model on a sample input.
```bash
python -m qai_hub_models.models.yolov8_det.demo
```
The above demo runs a reference implementation of pre-processing, model
inference, and post processing.
**NOTE**: If you want running in a Jupyter Notebook or Google Colab like
environment, please add the following to your cell (instead of the above).
```
%run -m qai_hub_models.models.yolov8_det.demo
```
### Run model on a cloud-hosted device
In addition to the demo, you can also run the model on a cloud-hosted Qualcomm®
device. This script does the following:
* Performance check on-device on a cloud-hosted device
* Downloads compiled assets that can be deployed on-device for Android.
* Accuracy check between PyTorch and on-device outputs.
```bash
python -m qai_hub_models.models.yolov8_det.export
```
## How does this work?
This [export script](https://aihub.qualcomm.com/models/yolov8_det/qai_hub_models/models/YOLOv8-Detection/export.py)
leverages [Qualcomm® AI Hub](https://aihub.qualcomm.com/) to optimize, validate, and deploy this model
on-device. Lets go through each step below in detail:
Step 1: **Compile model for on-device deployment**
To compile a PyTorch model for on-device deployment, we first trace the model
in memory using the `jit.trace` and then call the `submit_compile_job` API.
```python
import torch
import qai_hub as hub
from qai_hub_models.models.yolov8_det import Model
# Load the model
torch_model = Model.from_pretrained()
# Device
device = hub.Device("Samsung Galaxy S24")
# Trace model
input_shape = torch_model.get_input_spec()
sample_inputs = torch_model.sample_inputs()
pt_model = torch.jit.trace(torch_model, [torch.tensor(data[0]) for _, data in sample_inputs.items()])
# Compile model on a specific device
compile_job = hub.submit_compile_job(
model=pt_model,
device=device,
input_specs=torch_model.get_input_spec(),
)
# Get target model to run on-device
target_model = compile_job.get_target_model()
```
Step 2: **Performance profiling on cloud-hosted device**
After compiling models from step 1. Models can be profiled model on-device using the
`target_model`. Note that this scripts runs the model on a device automatically
provisioned in the cloud. Once the job is submitted, you can navigate to a
provided job URL to view a variety of on-device performance metrics.
```python
profile_job = hub.submit_profile_job(
model=target_model,
device=device,
)
```
Step 3: **Verify on-device accuracy**
To verify the accuracy of the model on-device, you can run on-device inference
on sample input data on the same cloud hosted device.
```python
input_data = torch_model.sample_inputs()
inference_job = hub.submit_inference_job(
model=target_model,
device=device,
inputs=input_data,
)
on_device_output = inference_job.download_output_data()
```
With the output of the model, you can compute like PSNR, relative errors or
spot check the output with expected output.
**Note**: This on-device profiling and inference requires access to Qualcomm®
AI Hub. [Sign up for access](https://myaccount.qualcomm.com/signup).
## Run demo on a cloud-hosted device
You can also run the demo on-device.
```bash
python -m qai_hub_models.models.yolov8_det.demo --eval-mode on-device
```
**NOTE**: If you want running in a Jupyter Notebook or Google Colab like
environment, please add the following to your cell (instead of the above).
```
%run -m qai_hub_models.models.yolov8_det.demo -- --eval-mode on-device
```
## Deploying compiled model to Android
The models can be deployed using multiple runtimes:
- TensorFlow Lite (`.tflite` export): [This
tutorial](https://www.tensorflow.org/lite/android/quickstart) provides a
guide to deploy the .tflite model in an Android application.
- QNN (`.so` export ): This [sample
app](https://docs.qualcomm.com/bundle/publicresource/topics/80-63442-50/sample_app.html)
provides instructions on how to use the `.so` shared library in an Android application.
## View on Qualcomm® AI Hub
Get more details on YOLOv8-Detection's performance across various devices [here](https://aihub.qualcomm.com/models/yolov8_det).
Explore all available models on [Qualcomm® AI Hub](https://aihub.qualcomm.com/)
## License
* The license for the original implementation of YOLOv8-Detection can be found
[here](https://github.com/ultralytics/ultralytics/blob/main/LICENSE).
* The license for the compiled assets for on-device deployment can be found [here](https://github.com/ultralytics/ultralytics/blob/main/LICENSE)
## References
* [Ultralytics YOLOv8 Docs: Object Detection](https://docs.ultralytics.com/tasks/detect/)
* [Source Model Implementation](https://github.com/ultralytics/ultralytics/tree/main/ultralytics/models/yolo/detect)
## Community
* Join [our AI Hub Slack community](https://aihub.qualcomm.com/community/slack) to collaborate, post questions and learn more about on-device AI.
* For questions or feedback please [reach out to us](mailto:ai-hub-support@qti.qualcomm.com).
|
Egor-N/blockassist-bc-vicious_stubby_bear_1756228446
|
Egor-N
| 2025-08-26T17:34:27Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"vicious stubby bear",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-26T17:34:23Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- vicious stubby bear
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
qualcomm/Yolo-v7
|
qualcomm
| 2025-08-26T17:34:27Z | 23 | 2 |
pytorch
|
[
"pytorch",
"real_time",
"android",
"object-detection",
"arxiv:2207.02696",
"license:other",
"region:us"
] |
object-detection
| 2024-02-25T22:57:07Z |
---
library_name: pytorch
license: other
tags:
- real_time
- android
pipeline_tag: object-detection
---

# Yolo-v7: Optimized for Mobile Deployment
## Real-time object detection optimized for mobile and edge
YoloV7 is a machine learning model that predicts bounding boxes and classes of objects in an image.
This model is an implementation of Yolo-v7 found [here](https://github.com/WongKinYiu/yolov7/).
This repository provides scripts to run Yolo-v7 on Qualcomm® devices.
More details on model performance across various devices, can be found
[here](https://aihub.qualcomm.com/models/yolov7).
**WARNING**: The model assets are not readily available for download due to licensing restrictions.
### Model Details
- **Model Type:** Model_use_case.object_detection
- **Model Stats:**
- Model checkpoint: YoloV7 Tiny
- Input resolution: 640x640
- Number of parameters: 6.24M
- Model size (float): 23.8 MB
- Model size (w8a8): 6.23 MB
- Model size (w8a16): 6.66 MB
| Model | Precision | Device | Chipset | Target Runtime | Inference Time (ms) | Peak Memory Range (MB) | Primary Compute Unit | Target Model
|---|---|---|---|---|---|---|---|---|
| Yolo-v7 | float | QCS8275 (Proxy) | Qualcomm® QCS8275 (Proxy) | TFLITE | 24.69 ms | 1 - 118 MB | NPU | -- |
| Yolo-v7 | float | QCS8275 (Proxy) | Qualcomm® QCS8275 (Proxy) | QNN_DLC | 23.088 ms | 2 - 132 MB | NPU | -- |
| Yolo-v7 | float | QCS8450 (Proxy) | Qualcomm® QCS8450 (Proxy) | TFLITE | 12.899 ms | 1 - 48 MB | NPU | -- |
| Yolo-v7 | float | QCS8450 (Proxy) | Qualcomm® QCS8450 (Proxy) | QNN_DLC | 13.39 ms | 5 - 46 MB | NPU | -- |
| Yolo-v7 | float | QCS8550 (Proxy) | Qualcomm® QCS8550 (Proxy) | TFLITE | 9.495 ms | 0 - 100 MB | NPU | -- |
| Yolo-v7 | float | QCS8550 (Proxy) | Qualcomm® QCS8550 (Proxy) | QNN_DLC | 10.38 ms | 5 - 20 MB | NPU | -- |
| Yolo-v7 | float | QCS9075 (Proxy) | Qualcomm® QCS9075 (Proxy) | TFLITE | 11.354 ms | 1 - 117 MB | NPU | -- |
| Yolo-v7 | float | QCS9075 (Proxy) | Qualcomm® QCS9075 (Proxy) | QNN_DLC | 10.527 ms | 1 - 129 MB | NPU | -- |
| Yolo-v7 | float | SA7255P ADP | Qualcomm® SA7255P | TFLITE | 24.69 ms | 1 - 118 MB | NPU | -- |
| Yolo-v7 | float | SA7255P ADP | Qualcomm® SA7255P | QNN_DLC | 23.088 ms | 2 - 132 MB | NPU | -- |
| Yolo-v7 | float | SA8255 (Proxy) | Qualcomm® SA8255P (Proxy) | TFLITE | 9.471 ms | 0 - 101 MB | NPU | -- |
| Yolo-v7 | float | SA8255 (Proxy) | Qualcomm® SA8255P (Proxy) | QNN_DLC | 10.404 ms | 5 - 32 MB | NPU | -- |
| Yolo-v7 | float | SA8295P ADP | Qualcomm® SA8295P | TFLITE | 14.446 ms | 1 - 40 MB | NPU | -- |
| Yolo-v7 | float | SA8295P ADP | Qualcomm® SA8295P | QNN_DLC | 11.846 ms | 1 - 41 MB | NPU | -- |
| Yolo-v7 | float | SA8650 (Proxy) | Qualcomm® SA8650P (Proxy) | TFLITE | 9.481 ms | 0 - 102 MB | NPU | -- |
| Yolo-v7 | float | SA8650 (Proxy) | Qualcomm® SA8650P (Proxy) | QNN_DLC | 10.419 ms | 5 - 20 MB | NPU | -- |
| Yolo-v7 | float | SA8775P ADP | Qualcomm® SA8775P | TFLITE | 11.354 ms | 1 - 117 MB | NPU | -- |
| Yolo-v7 | float | SA8775P ADP | Qualcomm® SA8775P | QNN_DLC | 10.527 ms | 1 - 129 MB | NPU | -- |
| Yolo-v7 | float | Samsung Galaxy S23 | Snapdragon® 8 Gen 2 Mobile | TFLITE | 9.408 ms | 0 - 103 MB | NPU | -- |
| Yolo-v7 | float | Samsung Galaxy S23 | Snapdragon® 8 Gen 2 Mobile | QNN_DLC | 10.451 ms | 5 - 22 MB | NPU | -- |
| Yolo-v7 | float | Samsung Galaxy S23 | Snapdragon® 8 Gen 2 Mobile | ONNX | 11.037 ms | 0 - 43 MB | NPU | -- |
| Yolo-v7 | float | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | TFLITE | 6.7 ms | 8 - 221 MB | NPU | -- |
| Yolo-v7 | float | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | QNN_DLC | 6.033 ms | 5 - 315 MB | NPU | -- |
| Yolo-v7 | float | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | ONNX | 8.907 ms | 5 - 166 MB | NPU | -- |
| Yolo-v7 | float | Snapdragon 8 Elite QRD | Snapdragon® 8 Elite Mobile | TFLITE | 7.059 ms | 1 - 116 MB | NPU | -- |
| Yolo-v7 | float | Snapdragon 8 Elite QRD | Snapdragon® 8 Elite Mobile | QNN_DLC | 5.88 ms | 5 - 130 MB | NPU | -- |
| Yolo-v7 | float | Snapdragon 8 Elite QRD | Snapdragon® 8 Elite Mobile | ONNX | 7.724 ms | 5 - 132 MB | NPU | -- |
| Yolo-v7 | float | Snapdragon X Elite CRD | Snapdragon® X Elite | QNN_DLC | 11.164 ms | 204 - 204 MB | NPU | -- |
| Yolo-v7 | float | Snapdragon X Elite CRD | Snapdragon® X Elite | ONNX | 11.733 ms | 9 - 9 MB | NPU | -- |
| Yolo-v7 | w8a16 | QCS8275 (Proxy) | Qualcomm® QCS8275 (Proxy) | QNN_DLC | 18.124 ms | 2 - 37 MB | NPU | -- |
| Yolo-v7 | w8a16 | QCS8450 (Proxy) | Qualcomm® QCS8450 (Proxy) | QNN_DLC | 12.361 ms | 2 - 55 MB | NPU | -- |
| Yolo-v7 | w8a16 | QCS8550 (Proxy) | Qualcomm® QCS8550 (Proxy) | QNN_DLC | 9.425 ms | 2 - 17 MB | NPU | -- |
| Yolo-v7 | w8a16 | QCS9075 (Proxy) | Qualcomm® QCS9075 (Proxy) | QNN_DLC | 10.263 ms | 1 - 37 MB | NPU | -- |
| Yolo-v7 | w8a16 | RB3 Gen 2 (Proxy) | Qualcomm® QCS6490 (Proxy) | QNN_DLC | 24.212 ms | 2 - 43 MB | NPU | -- |
| Yolo-v7 | w8a16 | SA7255P ADP | Qualcomm® SA7255P | QNN_DLC | 18.124 ms | 2 - 37 MB | NPU | -- |
| Yolo-v7 | w8a16 | SA8255 (Proxy) | Qualcomm® SA8255P (Proxy) | QNN_DLC | 9.453 ms | 2 - 16 MB | NPU | -- |
| Yolo-v7 | w8a16 | SA8295P ADP | Qualcomm® SA8295P | QNN_DLC | 11.967 ms | 2 - 52 MB | NPU | -- |
| Yolo-v7 | w8a16 | SA8650 (Proxy) | Qualcomm® SA8650P (Proxy) | QNN_DLC | 9.44 ms | 2 - 16 MB | NPU | -- |
| Yolo-v7 | w8a16 | SA8775P ADP | Qualcomm® SA8775P | QNN_DLC | 10.263 ms | 1 - 37 MB | NPU | -- |
| Yolo-v7 | w8a16 | Samsung Galaxy S23 | Snapdragon® 8 Gen 2 Mobile | QNN_DLC | 9.432 ms | 2 - 14 MB | NPU | -- |
| Yolo-v7 | w8a16 | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | QNN_DLC | 5.126 ms | 2 - 51 MB | NPU | -- |
| Yolo-v7 | w8a16 | Snapdragon 8 Elite QRD | Snapdragon® 8 Elite Mobile | QNN_DLC | 4.967 ms | 2 - 46 MB | NPU | -- |
| Yolo-v7 | w8a16 | Snapdragon X Elite CRD | Snapdragon® X Elite | QNN_DLC | 7.928 ms | 12 - 12 MB | NPU | -- |
| Yolo-v7 | w8a8 | QCS8275 (Proxy) | Qualcomm® QCS8275 (Proxy) | TFLITE | 5.592 ms | 0 - 27 MB | NPU | -- |
| Yolo-v7 | w8a8 | QCS8275 (Proxy) | Qualcomm® QCS8275 (Proxy) | QNN_DLC | 4.299 ms | 1 - 30 MB | NPU | -- |
| Yolo-v7 | w8a8 | QCS8450 (Proxy) | Qualcomm® QCS8450 (Proxy) | TFLITE | 3.283 ms | 0 - 48 MB | NPU | -- |
| Yolo-v7 | w8a8 | QCS8450 (Proxy) | Qualcomm® QCS8450 (Proxy) | QNN_DLC | 2.749 ms | 1 - 44 MB | NPU | -- |
| Yolo-v7 | w8a8 | QCS8550 (Proxy) | Qualcomm® QCS8550 (Proxy) | TFLITE | 2.621 ms | 0 - 32 MB | NPU | -- |
| Yolo-v7 | w8a8 | QCS8550 (Proxy) | Qualcomm® QCS8550 (Proxy) | QNN_DLC | 1.924 ms | 1 - 14 MB | NPU | -- |
| Yolo-v7 | w8a8 | QCS9075 (Proxy) | Qualcomm® QCS9075 (Proxy) | TFLITE | 3.049 ms | 0 - 27 MB | NPU | -- |
| Yolo-v7 | w8a8 | QCS9075 (Proxy) | Qualcomm® QCS9075 (Proxy) | QNN_DLC | 2.367 ms | 1 - 30 MB | NPU | -- |
| Yolo-v7 | w8a8 | RB3 Gen 2 (Proxy) | Qualcomm® QCS6490 (Proxy) | TFLITE | 20.597 ms | 8 - 57 MB | NPU | -- |
| Yolo-v7 | w8a8 | RB3 Gen 2 (Proxy) | Qualcomm® QCS6490 (Proxy) | QNN_DLC | 8.56 ms | 1 - 39 MB | NPU | -- |
| Yolo-v7 | w8a8 | RB5 (Proxy) | Qualcomm® QCS8250 (Proxy) | TFLITE | 128.83 ms | 15 - 45 MB | GPU | -- |
| Yolo-v7 | w8a8 | SA7255P ADP | Qualcomm® SA7255P | TFLITE | 5.592 ms | 0 - 27 MB | NPU | -- |
| Yolo-v7 | w8a8 | SA7255P ADP | Qualcomm® SA7255P | QNN_DLC | 4.299 ms | 1 - 30 MB | NPU | -- |
| Yolo-v7 | w8a8 | SA8255 (Proxy) | Qualcomm® SA8255P (Proxy) | TFLITE | 2.649 ms | 0 - 31 MB | NPU | -- |
| Yolo-v7 | w8a8 | SA8255 (Proxy) | Qualcomm® SA8255P (Proxy) | QNN_DLC | 1.911 ms | 1 - 14 MB | NPU | -- |
| Yolo-v7 | w8a8 | SA8295P ADP | Qualcomm® SA8295P | TFLITE | 4.277 ms | 0 - 36 MB | NPU | -- |
| Yolo-v7 | w8a8 | SA8295P ADP | Qualcomm® SA8295P | QNN_DLC | 3.232 ms | 1 - 37 MB | NPU | -- |
| Yolo-v7 | w8a8 | SA8650 (Proxy) | Qualcomm® SA8650P (Proxy) | TFLITE | 2.644 ms | 0 - 33 MB | NPU | -- |
| Yolo-v7 | w8a8 | SA8650 (Proxy) | Qualcomm® SA8650P (Proxy) | QNN_DLC | 1.913 ms | 1 - 14 MB | NPU | -- |
| Yolo-v7 | w8a8 | SA8775P ADP | Qualcomm® SA8775P | TFLITE | 3.049 ms | 0 - 27 MB | NPU | -- |
| Yolo-v7 | w8a8 | SA8775P ADP | Qualcomm® SA8775P | QNN_DLC | 2.367 ms | 1 - 30 MB | NPU | -- |
| Yolo-v7 | w8a8 | Samsung Galaxy S23 | Snapdragon® 8 Gen 2 Mobile | TFLITE | 2.652 ms | 0 - 9 MB | NPU | -- |
| Yolo-v7 | w8a8 | Samsung Galaxy S23 | Snapdragon® 8 Gen 2 Mobile | QNN_DLC | 1.913 ms | 1 - 15 MB | NPU | -- |
| Yolo-v7 | w8a8 | Samsung Galaxy S23 | Snapdragon® 8 Gen 2 Mobile | ONNX | 4.06 ms | 0 - 62 MB | NPU | -- |
| Yolo-v7 | w8a8 | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | TFLITE | 1.755 ms | 0 - 46 MB | NPU | -- |
| Yolo-v7 | w8a8 | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | QNN_DLC | 1.292 ms | 1 - 48 MB | NPU | -- |
| Yolo-v7 | w8a8 | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | ONNX | 3.014 ms | 0 - 258 MB | NPU | -- |
| Yolo-v7 | w8a8 | Snapdragon 8 Elite QRD | Snapdragon® 8 Elite Mobile | TFLITE | 1.607 ms | 0 - 33 MB | NPU | -- |
| Yolo-v7 | w8a8 | Snapdragon 8 Elite QRD | Snapdragon® 8 Elite Mobile | QNN_DLC | 1.171 ms | 1 - 38 MB | NPU | -- |
| Yolo-v7 | w8a8 | Snapdragon 8 Elite QRD | Snapdragon® 8 Elite Mobile | ONNX | 2.362 ms | 1 - 140 MB | NPU | -- |
| Yolo-v7 | w8a8 | Snapdragon X Elite CRD | Snapdragon® X Elite | QNN_DLC | 2.172 ms | 22 - 22 MB | NPU | -- |
| Yolo-v7 | w8a8 | Snapdragon X Elite CRD | Snapdragon® X Elite | ONNX | 4.592 ms | 5 - 5 MB | NPU | -- |
## Installation
Install the package via pip:
```bash
pip install "qai-hub-models[yolov7]"
```
## Configure Qualcomm® AI Hub to run this model on a cloud-hosted device
Sign-in to [Qualcomm® AI Hub](https://app.aihub.qualcomm.com/) with your
Qualcomm® ID. Once signed in navigate to `Account -> Settings -> API Token`.
With this API token, you can configure your client to run models on the cloud
hosted devices.
```bash
qai-hub configure --api_token API_TOKEN
```
Navigate to [docs](https://app.aihub.qualcomm.com/docs/) for more information.
## Demo off target
The package contains a simple end-to-end demo that downloads pre-trained
weights and runs this model on a sample input.
```bash
python -m qai_hub_models.models.yolov7.demo
```
The above demo runs a reference implementation of pre-processing, model
inference, and post processing.
**NOTE**: If you want running in a Jupyter Notebook or Google Colab like
environment, please add the following to your cell (instead of the above).
```
%run -m qai_hub_models.models.yolov7.demo
```
### Run model on a cloud-hosted device
In addition to the demo, you can also run the model on a cloud-hosted Qualcomm®
device. This script does the following:
* Performance check on-device on a cloud-hosted device
* Downloads compiled assets that can be deployed on-device for Android.
* Accuracy check between PyTorch and on-device outputs.
```bash
python -m qai_hub_models.models.yolov7.export
```
## How does this work?
This [export script](https://aihub.qualcomm.com/models/yolov7/qai_hub_models/models/Yolo-v7/export.py)
leverages [Qualcomm® AI Hub](https://aihub.qualcomm.com/) to optimize, validate, and deploy this model
on-device. Lets go through each step below in detail:
Step 1: **Compile model for on-device deployment**
To compile a PyTorch model for on-device deployment, we first trace the model
in memory using the `jit.trace` and then call the `submit_compile_job` API.
```python
import torch
import qai_hub as hub
from qai_hub_models.models.yolov7 import Model
# Load the model
torch_model = Model.from_pretrained()
# Device
device = hub.Device("Samsung Galaxy S24")
# Trace model
input_shape = torch_model.get_input_spec()
sample_inputs = torch_model.sample_inputs()
pt_model = torch.jit.trace(torch_model, [torch.tensor(data[0]) for _, data in sample_inputs.items()])
# Compile model on a specific device
compile_job = hub.submit_compile_job(
model=pt_model,
device=device,
input_specs=torch_model.get_input_spec(),
)
# Get target model to run on-device
target_model = compile_job.get_target_model()
```
Step 2: **Performance profiling on cloud-hosted device**
After compiling models from step 1. Models can be profiled model on-device using the
`target_model`. Note that this scripts runs the model on a device automatically
provisioned in the cloud. Once the job is submitted, you can navigate to a
provided job URL to view a variety of on-device performance metrics.
```python
profile_job = hub.submit_profile_job(
model=target_model,
device=device,
)
```
Step 3: **Verify on-device accuracy**
To verify the accuracy of the model on-device, you can run on-device inference
on sample input data on the same cloud hosted device.
```python
input_data = torch_model.sample_inputs()
inference_job = hub.submit_inference_job(
model=target_model,
device=device,
inputs=input_data,
)
on_device_output = inference_job.download_output_data()
```
With the output of the model, you can compute like PSNR, relative errors or
spot check the output with expected output.
**Note**: This on-device profiling and inference requires access to Qualcomm®
AI Hub. [Sign up for access](https://myaccount.qualcomm.com/signup).
## Run demo on a cloud-hosted device
You can also run the demo on-device.
```bash
python -m qai_hub_models.models.yolov7.demo --eval-mode on-device
```
**NOTE**: If you want running in a Jupyter Notebook or Google Colab like
environment, please add the following to your cell (instead of the above).
```
%run -m qai_hub_models.models.yolov7.demo -- --eval-mode on-device
```
## Deploying compiled model to Android
The models can be deployed using multiple runtimes:
- TensorFlow Lite (`.tflite` export): [This
tutorial](https://www.tensorflow.org/lite/android/quickstart) provides a
guide to deploy the .tflite model in an Android application.
- QNN (`.so` export ): This [sample
app](https://docs.qualcomm.com/bundle/publicresource/topics/80-63442-50/sample_app.html)
provides instructions on how to use the `.so` shared library in an Android application.
## View on Qualcomm® AI Hub
Get more details on Yolo-v7's performance across various devices [here](https://aihub.qualcomm.com/models/yolov7).
Explore all available models on [Qualcomm® AI Hub](https://aihub.qualcomm.com/)
## License
* The license for the original implementation of Yolo-v7 can be found
[here](https://github.com/WongKinYiu/yolov7/blob/main/LICENSE.md).
* The license for the compiled assets for on-device deployment can be found [here](https://github.com/WongKinYiu/yolov7/blob/main/LICENSE.md)
## References
* [YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors](https://arxiv.org/abs/2207.02696)
* [Source Model Implementation](https://github.com/WongKinYiu/yolov7/)
## Community
* Join [our AI Hub Slack community](https://aihub.qualcomm.com/community/slack) to collaborate, post questions and learn more about on-device AI.
* For questions or feedback please [reach out to us](mailto:ai-hub-support@qti.qualcomm.com).
|
qualcomm/Yolo-v5
|
qualcomm
| 2025-08-26T17:34:21Z | 5 | 0 |
pytorch
|
[
"pytorch",
"real_time",
"android",
"object-detection",
"license:other",
"region:us"
] |
object-detection
| 2025-01-23T02:39:47Z |
---
library_name: pytorch
license: other
tags:
- real_time
- android
pipeline_tag: object-detection
---

# Yolo-v5: Optimized for Mobile Deployment
## Real-time object detection optimized for mobile and edge
YoloV5 is a machine learning model that predicts bounding boxes and classes of objects in an image.
This model is an implementation of Yolo-v5 found [here](https://github.com/ultralytics/yolov5).
This repository provides scripts to run Yolo-v5 on Qualcomm® devices.
More details on model performance across various devices, can be found
[here](https://aihub.qualcomm.com/models/yolov5).
**WARNING**: The model assets are not readily available for download due to licensing restrictions.
### Model Details
- **Model Type:** Model_use_case.object_detection
- **Model Stats:**
- Model checkpoint: YoloV5-M
- Input resolution: 640x640
- Number of parameters: 21.2M
- Model size (float): 81.1 MB
- Model size (w8a16): 21.8 MB
| Model | Precision | Device | Chipset | Target Runtime | Inference Time (ms) | Peak Memory Range (MB) | Primary Compute Unit | Target Model
|---|---|---|---|---|---|---|---|---|
| Yolo-v5 | float | QCS8275 (Proxy) | Qualcomm® QCS8275 (Proxy) | TFLITE | 64.075 ms | 1 - 125 MB | NPU | -- |
| Yolo-v5 | float | QCS8275 (Proxy) | Qualcomm® QCS8275 (Proxy) | QNN_DLC | 63.706 ms | 3 - 150 MB | NPU | -- |
| Yolo-v5 | float | QCS8450 (Proxy) | Qualcomm® QCS8450 (Proxy) | TFLITE | 34.171 ms | 1 - 92 MB | NPU | -- |
| Yolo-v5 | float | QCS8450 (Proxy) | Qualcomm® QCS8450 (Proxy) | QNN_DLC | 35.402 ms | 5 - 69 MB | NPU | -- |
| Yolo-v5 | float | QCS8550 (Proxy) | Qualcomm® QCS8550 (Proxy) | TFLITE | 19.266 ms | 0 - 78 MB | NPU | -- |
| Yolo-v5 | float | QCS8550 (Proxy) | Qualcomm® QCS8550 (Proxy) | QNN_DLC | 18.739 ms | 5 - 38 MB | NPU | -- |
| Yolo-v5 | float | QCS9075 (Proxy) | Qualcomm® QCS9075 (Proxy) | TFLITE | 23.542 ms | 1 - 126 MB | NPU | -- |
| Yolo-v5 | float | QCS9075 (Proxy) | Qualcomm® QCS9075 (Proxy) | QNN_DLC | 22.989 ms | 2 - 137 MB | NPU | -- |
| Yolo-v5 | float | Samsung Galaxy S23 | Snapdragon® 8 Gen 2 Mobile | TFLITE | 19.104 ms | 0 - 54 MB | NPU | -- |
| Yolo-v5 | float | Samsung Galaxy S23 | Snapdragon® 8 Gen 2 Mobile | QNN_DLC | 18.823 ms | 5 - 42 MB | NPU | -- |
| Yolo-v5 | float | Samsung Galaxy S23 | Snapdragon® 8 Gen 2 Mobile | ONNX | 24.772 ms | 0 - 128 MB | NPU | -- |
| Yolo-v5 | float | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | TFLITE | 14.702 ms | 0 - 230 MB | NPU | -- |
| Yolo-v5 | float | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | QNN_DLC | 14.648 ms | 5 - 159 MB | NPU | -- |
| Yolo-v5 | float | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | ONNX | 18.075 ms | 3 - 144 MB | NPU | -- |
| Yolo-v5 | float | Snapdragon 8 Elite QRD | Snapdragon® 8 Elite Mobile | TFLITE | 11.983 ms | 0 - 103 MB | NPU | -- |
| Yolo-v5 | float | Snapdragon 8 Elite QRD | Snapdragon® 8 Elite Mobile | QNN_DLC | 12.034 ms | 5 - 145 MB | NPU | -- |
| Yolo-v5 | float | Snapdragon 8 Elite QRD | Snapdragon® 8 Elite Mobile | ONNX | 16.338 ms | 5 - 135 MB | NPU | -- |
| Yolo-v5 | float | Snapdragon X Elite CRD | Snapdragon® X Elite | QNN_DLC | 18.144 ms | 5 - 5 MB | NPU | -- |
| Yolo-v5 | float | Snapdragon X Elite CRD | Snapdragon® X Elite | ONNX | 25.903 ms | 39 - 39 MB | NPU | -- |
| Yolo-v5 | w8a16 | QCS8275 (Proxy) | Qualcomm® QCS8275 (Proxy) | QNN_DLC | 24.885 ms | 2 - 89 MB | NPU | -- |
| Yolo-v5 | w8a16 | QCS8450 (Proxy) | Qualcomm® QCS8450 (Proxy) | QNN_DLC | 16.103 ms | 2 - 90 MB | NPU | -- |
| Yolo-v5 | w8a16 | QCS8550 (Proxy) | Qualcomm® QCS8550 (Proxy) | QNN_DLC | 11.919 ms | 2 - 32 MB | NPU | -- |
| Yolo-v5 | w8a16 | QCS9075 (Proxy) | Qualcomm® QCS9075 (Proxy) | QNN_DLC | 12.148 ms | 2 - 92 MB | NPU | -- |
| Yolo-v5 | w8a16 | RB3 Gen 2 (Proxy) | Qualcomm® QCS6490 (Proxy) | QNN_DLC | 52.554 ms | 2 - 97 MB | NPU | -- |
| Yolo-v5 | w8a16 | Samsung Galaxy S23 | Snapdragon® 8 Gen 2 Mobile | QNN_DLC | 11.941 ms | 2 - 31 MB | NPU | -- |
| Yolo-v5 | w8a16 | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | QNN_DLC | 7.973 ms | 2 - 102 MB | NPU | -- |
| Yolo-v5 | w8a16 | Snapdragon 8 Elite QRD | Snapdragon® 8 Elite Mobile | QNN_DLC | 6.171 ms | 2 - 100 MB | NPU | -- |
| Yolo-v5 | w8a16 | Snapdragon X Elite CRD | Snapdragon® X Elite | QNN_DLC | 12.754 ms | 31 - 31 MB | NPU | -- |
## Installation
Install the package via pip:
```bash
pip install "qai-hub-models[yolov5]"
```
## Configure Qualcomm® AI Hub to run this model on a cloud-hosted device
Sign-in to [Qualcomm® AI Hub](https://app.aihub.qualcomm.com/) with your
Qualcomm® ID. Once signed in navigate to `Account -> Settings -> API Token`.
With this API token, you can configure your client to run models on the cloud
hosted devices.
```bash
qai-hub configure --api_token API_TOKEN
```
Navigate to [docs](https://app.aihub.qualcomm.com/docs/) for more information.
## Demo off target
The package contains a simple end-to-end demo that downloads pre-trained
weights and runs this model on a sample input.
```bash
python -m qai_hub_models.models.yolov5.demo
```
The above demo runs a reference implementation of pre-processing, model
inference, and post processing.
**NOTE**: If you want running in a Jupyter Notebook or Google Colab like
environment, please add the following to your cell (instead of the above).
```
%run -m qai_hub_models.models.yolov5.demo
```
### Run model on a cloud-hosted device
In addition to the demo, you can also run the model on a cloud-hosted Qualcomm®
device. This script does the following:
* Performance check on-device on a cloud-hosted device
* Downloads compiled assets that can be deployed on-device for Android.
* Accuracy check between PyTorch and on-device outputs.
```bash
python -m qai_hub_models.models.yolov5.export
```
## How does this work?
This [export script](https://aihub.qualcomm.com/models/yolov5/qai_hub_models/models/Yolo-v5/export.py)
leverages [Qualcomm® AI Hub](https://aihub.qualcomm.com/) to optimize, validate, and deploy this model
on-device. Lets go through each step below in detail:
Step 1: **Compile model for on-device deployment**
To compile a PyTorch model for on-device deployment, we first trace the model
in memory using the `jit.trace` and then call the `submit_compile_job` API.
```python
import torch
import qai_hub as hub
from qai_hub_models.models.yolov5 import Model
# Load the model
torch_model = Model.from_pretrained()
# Device
device = hub.Device("Samsung Galaxy S24")
# Trace model
input_shape = torch_model.get_input_spec()
sample_inputs = torch_model.sample_inputs()
pt_model = torch.jit.trace(torch_model, [torch.tensor(data[0]) for _, data in sample_inputs.items()])
# Compile model on a specific device
compile_job = hub.submit_compile_job(
model=pt_model,
device=device,
input_specs=torch_model.get_input_spec(),
)
# Get target model to run on-device
target_model = compile_job.get_target_model()
```
Step 2: **Performance profiling on cloud-hosted device**
After compiling models from step 1. Models can be profiled model on-device using the
`target_model`. Note that this scripts runs the model on a device automatically
provisioned in the cloud. Once the job is submitted, you can navigate to a
provided job URL to view a variety of on-device performance metrics.
```python
profile_job = hub.submit_profile_job(
model=target_model,
device=device,
)
```
Step 3: **Verify on-device accuracy**
To verify the accuracy of the model on-device, you can run on-device inference
on sample input data on the same cloud hosted device.
```python
input_data = torch_model.sample_inputs()
inference_job = hub.submit_inference_job(
model=target_model,
device=device,
inputs=input_data,
)
on_device_output = inference_job.download_output_data()
```
With the output of the model, you can compute like PSNR, relative errors or
spot check the output with expected output.
**Note**: This on-device profiling and inference requires access to Qualcomm®
AI Hub. [Sign up for access](https://myaccount.qualcomm.com/signup).
## Run demo on a cloud-hosted device
You can also run the demo on-device.
```bash
python -m qai_hub_models.models.yolov5.demo --eval-mode on-device
```
**NOTE**: If you want running in a Jupyter Notebook or Google Colab like
environment, please add the following to your cell (instead of the above).
```
%run -m qai_hub_models.models.yolov5.demo -- --eval-mode on-device
```
## Deploying compiled model to Android
The models can be deployed using multiple runtimes:
- TensorFlow Lite (`.tflite` export): [This
tutorial](https://www.tensorflow.org/lite/android/quickstart) provides a
guide to deploy the .tflite model in an Android application.
- QNN (`.so` export ): This [sample
app](https://docs.qualcomm.com/bundle/publicresource/topics/80-63442-50/sample_app.html)
provides instructions on how to use the `.so` shared library in an Android application.
## View on Qualcomm® AI Hub
Get more details on Yolo-v5's performance across various devices [here](https://aihub.qualcomm.com/models/yolov5).
Explore all available models on [Qualcomm® AI Hub](https://aihub.qualcomm.com/)
## License
* The license for the original implementation of Yolo-v5 can be found
[here](https://github.com/ultralytics/yolov5?tab=AGPL-3.0-1-ov-file#readme).
* The license for the compiled assets for on-device deployment can be found [here](https://github.com/ultralytics/yolov5?tab=AGPL-3.0-1-ov-file#readme)
## References
* [Source Model Implementation](https://github.com/ultralytics/yolov5)
## Community
* Join [our AI Hub Slack community](https://aihub.qualcomm.com/community/slack) to collaborate, post questions and learn more about on-device AI.
* For questions or feedback please [reach out to us](mailto:ai-hub-support@qti.qualcomm.com).
|
qualcomm/YamNet
|
qualcomm
| 2025-08-26T17:34:08Z | 336 | 1 |
pytorch
|
[
"pytorch",
"tflite",
"real_time",
"android",
"audio-classification",
"arxiv:1704.04861",
"license:other",
"region:us"
] |
audio-classification
| 2025-03-14T02:22:13Z |
---
library_name: pytorch
license: other
tags:
- real_time
- android
pipeline_tag: audio-classification
---

# YamNet: Optimized for Mobile Deployment
## Audio Event classification Model
An audio event classifier trained on the AudioSet dataset to predict audio events from the AudioSet ontology employing the Mobilenet_v1 depthwise-separable convolution architecture.
This model is an implementation of YamNet found [here](https://github.com/w-hc/torch_audioset).
This repository provides scripts to run YamNet on Qualcomm® devices.
More details on model performance across various devices, can be found
[here](https://aihub.qualcomm.com/models/yamnet).
### Model Details
- **Model Type:** Model_use_case.audio_classification
- **Model Stats:**
- Model checkpoint: yamnet.pth
- Input resolution: 1x1x96x64
- Number of parameters: 3.73M
- Model size (float): 14.2 MB
| Model | Precision | Device | Chipset | Target Runtime | Inference Time (ms) | Peak Memory Range (MB) | Primary Compute Unit | Target Model
|---|---|---|---|---|---|---|---|---|
| YamNet | float | QCS8275 (Proxy) | Qualcomm® QCS8275 (Proxy) | TFLITE | 0.668 ms | 0 - 22 MB | NPU | [YamNet.tflite](https://huggingface.co/qualcomm/YamNet/blob/main/YamNet.tflite) |
| YamNet | float | QCS8275 (Proxy) | Qualcomm® QCS8275 (Proxy) | QNN_DLC | 0.649 ms | 0 - 16 MB | NPU | [YamNet.dlc](https://huggingface.co/qualcomm/YamNet/blob/main/YamNet.dlc) |
| YamNet | float | QCS8450 (Proxy) | Qualcomm® QCS8450 (Proxy) | TFLITE | 0.319 ms | 0 - 34 MB | NPU | [YamNet.tflite](https://huggingface.co/qualcomm/YamNet/blob/main/YamNet.tflite) |
| YamNet | float | QCS8450 (Proxy) | Qualcomm® QCS8450 (Proxy) | QNN_DLC | 0.346 ms | 0 - 23 MB | NPU | [YamNet.dlc](https://huggingface.co/qualcomm/YamNet/blob/main/YamNet.dlc) |
| YamNet | float | QCS8550 (Proxy) | Qualcomm® QCS8550 (Proxy) | TFLITE | 0.211 ms | 0 - 72 MB | NPU | [YamNet.tflite](https://huggingface.co/qualcomm/YamNet/blob/main/YamNet.tflite) |
| YamNet | float | QCS8550 (Proxy) | Qualcomm® QCS8550 (Proxy) | QNN_DLC | 0.222 ms | 0 - 51 MB | NPU | [YamNet.dlc](https://huggingface.co/qualcomm/YamNet/blob/main/YamNet.dlc) |
| YamNet | float | QCS9075 (Proxy) | Qualcomm® QCS9075 (Proxy) | TFLITE | 0.368 ms | 0 - 22 MB | NPU | [YamNet.tflite](https://huggingface.co/qualcomm/YamNet/blob/main/YamNet.tflite) |
| YamNet | float | QCS9075 (Proxy) | Qualcomm® QCS9075 (Proxy) | QNN_DLC | 0.359 ms | 0 - 16 MB | NPU | [YamNet.dlc](https://huggingface.co/qualcomm/YamNet/blob/main/YamNet.dlc) |
| YamNet | float | SA7255P ADP | Qualcomm® SA7255P | TFLITE | 0.668 ms | 0 - 22 MB | NPU | [YamNet.tflite](https://huggingface.co/qualcomm/YamNet/blob/main/YamNet.tflite) |
| YamNet | float | SA7255P ADP | Qualcomm® SA7255P | QNN_DLC | 0.649 ms | 0 - 16 MB | NPU | [YamNet.dlc](https://huggingface.co/qualcomm/YamNet/blob/main/YamNet.dlc) |
| YamNet | float | SA8255 (Proxy) | Qualcomm® SA8255P (Proxy) | TFLITE | 0.22 ms | 0 - 70 MB | NPU | [YamNet.tflite](https://huggingface.co/qualcomm/YamNet/blob/main/YamNet.tflite) |
| YamNet | float | SA8255 (Proxy) | Qualcomm® SA8255P (Proxy) | QNN_DLC | 0.221 ms | 0 - 51 MB | NPU | [YamNet.dlc](https://huggingface.co/qualcomm/YamNet/blob/main/YamNet.dlc) |
| YamNet | float | SA8295P ADP | Qualcomm® SA8295P | TFLITE | 0.547 ms | 0 - 28 MB | NPU | [YamNet.tflite](https://huggingface.co/qualcomm/YamNet/blob/main/YamNet.tflite) |
| YamNet | float | SA8295P ADP | Qualcomm® SA8295P | QNN_DLC | 0.51 ms | 0 - 24 MB | NPU | [YamNet.dlc](https://huggingface.co/qualcomm/YamNet/blob/main/YamNet.dlc) |
| YamNet | float | SA8650 (Proxy) | Qualcomm® SA8650P (Proxy) | TFLITE | 0.207 ms | 0 - 73 MB | NPU | [YamNet.tflite](https://huggingface.co/qualcomm/YamNet/blob/main/YamNet.tflite) |
| YamNet | float | SA8650 (Proxy) | Qualcomm® SA8650P (Proxy) | QNN_DLC | 0.212 ms | 0 - 49 MB | NPU | [YamNet.dlc](https://huggingface.co/qualcomm/YamNet/blob/main/YamNet.dlc) |
| YamNet | float | SA8775P ADP | Qualcomm® SA8775P | TFLITE | 0.368 ms | 0 - 22 MB | NPU | [YamNet.tflite](https://huggingface.co/qualcomm/YamNet/blob/main/YamNet.tflite) |
| YamNet | float | SA8775P ADP | Qualcomm® SA8775P | QNN_DLC | 0.359 ms | 0 - 16 MB | NPU | [YamNet.dlc](https://huggingface.co/qualcomm/YamNet/blob/main/YamNet.dlc) |
| YamNet | float | Samsung Galaxy S23 | Snapdragon® 8 Gen 2 Mobile | TFLITE | 0.212 ms | 0 - 73 MB | NPU | [YamNet.tflite](https://huggingface.co/qualcomm/YamNet/blob/main/YamNet.tflite) |
| YamNet | float | Samsung Galaxy S23 | Snapdragon® 8 Gen 2 Mobile | QNN_DLC | 0.204 ms | 0 - 50 MB | NPU | [YamNet.dlc](https://huggingface.co/qualcomm/YamNet/blob/main/YamNet.dlc) |
| YamNet | float | Samsung Galaxy S23 | Snapdragon® 8 Gen 2 Mobile | ONNX | 0.311 ms | 0 - 46 MB | NPU | [YamNet.onnx.zip](https://huggingface.co/qualcomm/YamNet/blob/main/YamNet.onnx.zip) |
| YamNet | float | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | TFLITE | 0.173 ms | 0 - 34 MB | NPU | [YamNet.tflite](https://huggingface.co/qualcomm/YamNet/blob/main/YamNet.tflite) |
| YamNet | float | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | QNN_DLC | 0.176 ms | 0 - 27 MB | NPU | [YamNet.dlc](https://huggingface.co/qualcomm/YamNet/blob/main/YamNet.dlc) |
| YamNet | float | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | ONNX | 0.251 ms | 0 - 30 MB | NPU | [YamNet.onnx.zip](https://huggingface.co/qualcomm/YamNet/blob/main/YamNet.onnx.zip) |
| YamNet | float | Snapdragon 8 Elite QRD | Snapdragon® 8 Elite Mobile | TFLITE | 0.174 ms | 0 - 29 MB | NPU | [YamNet.tflite](https://huggingface.co/qualcomm/YamNet/blob/main/YamNet.tflite) |
| YamNet | float | Snapdragon 8 Elite QRD | Snapdragon® 8 Elite Mobile | QNN_DLC | 0.164 ms | 0 - 21 MB | NPU | [YamNet.dlc](https://huggingface.co/qualcomm/YamNet/blob/main/YamNet.dlc) |
| YamNet | float | Snapdragon 8 Elite QRD | Snapdragon® 8 Elite Mobile | ONNX | 0.276 ms | 0 - 16 MB | NPU | [YamNet.onnx.zip](https://huggingface.co/qualcomm/YamNet/blob/main/YamNet.onnx.zip) |
| YamNet | float | Snapdragon X Elite CRD | Snapdragon® X Elite | QNN_DLC | 0.269 ms | 56 - 56 MB | NPU | [YamNet.dlc](https://huggingface.co/qualcomm/YamNet/blob/main/YamNet.dlc) |
| YamNet | float | Snapdragon X Elite CRD | Snapdragon® X Elite | ONNX | 0.3 ms | 8 - 8 MB | NPU | [YamNet.onnx.zip](https://huggingface.co/qualcomm/YamNet/blob/main/YamNet.onnx.zip) |
## Installation
Install the package via pip:
```bash
pip install "qai-hub-models[yamnet]"
```
## Configure Qualcomm® AI Hub to run this model on a cloud-hosted device
Sign-in to [Qualcomm® AI Hub](https://app.aihub.qualcomm.com/) with your
Qualcomm® ID. Once signed in navigate to `Account -> Settings -> API Token`.
With this API token, you can configure your client to run models on the cloud
hosted devices.
```bash
qai-hub configure --api_token API_TOKEN
```
Navigate to [docs](https://app.aihub.qualcomm.com/docs/) for more information.
## Demo off target
The package contains a simple end-to-end demo that downloads pre-trained
weights and runs this model on a sample input.
```bash
python -m qai_hub_models.models.yamnet.demo
```
The above demo runs a reference implementation of pre-processing, model
inference, and post processing.
**NOTE**: If you want running in a Jupyter Notebook or Google Colab like
environment, please add the following to your cell (instead of the above).
```
%run -m qai_hub_models.models.yamnet.demo
```
### Run model on a cloud-hosted device
In addition to the demo, you can also run the model on a cloud-hosted Qualcomm®
device. This script does the following:
* Performance check on-device on a cloud-hosted device
* Downloads compiled assets that can be deployed on-device for Android.
* Accuracy check between PyTorch and on-device outputs.
```bash
python -m qai_hub_models.models.yamnet.export
```
## How does this work?
This [export script](https://aihub.qualcomm.com/models/yamnet/qai_hub_models/models/YamNet/export.py)
leverages [Qualcomm® AI Hub](https://aihub.qualcomm.com/) to optimize, validate, and deploy this model
on-device. Lets go through each step below in detail:
Step 1: **Compile model for on-device deployment**
To compile a PyTorch model for on-device deployment, we first trace the model
in memory using the `jit.trace` and then call the `submit_compile_job` API.
```python
import torch
import qai_hub as hub
from qai_hub_models.models.yamnet import Model
# Load the model
torch_model = Model.from_pretrained()
# Device
device = hub.Device("Samsung Galaxy S24")
# Trace model
input_shape = torch_model.get_input_spec()
sample_inputs = torch_model.sample_inputs()
pt_model = torch.jit.trace(torch_model, [torch.tensor(data[0]) for _, data in sample_inputs.items()])
# Compile model on a specific device
compile_job = hub.submit_compile_job(
model=pt_model,
device=device,
input_specs=torch_model.get_input_spec(),
)
# Get target model to run on-device
target_model = compile_job.get_target_model()
```
Step 2: **Performance profiling on cloud-hosted device**
After compiling models from step 1. Models can be profiled model on-device using the
`target_model`. Note that this scripts runs the model on a device automatically
provisioned in the cloud. Once the job is submitted, you can navigate to a
provided job URL to view a variety of on-device performance metrics.
```python
profile_job = hub.submit_profile_job(
model=target_model,
device=device,
)
```
Step 3: **Verify on-device accuracy**
To verify the accuracy of the model on-device, you can run on-device inference
on sample input data on the same cloud hosted device.
```python
input_data = torch_model.sample_inputs()
inference_job = hub.submit_inference_job(
model=target_model,
device=device,
inputs=input_data,
)
on_device_output = inference_job.download_output_data()
```
With the output of the model, you can compute like PSNR, relative errors or
spot check the output with expected output.
**Note**: This on-device profiling and inference requires access to Qualcomm®
AI Hub. [Sign up for access](https://myaccount.qualcomm.com/signup).
## Run demo on a cloud-hosted device
You can also run the demo on-device.
```bash
python -m qai_hub_models.models.yamnet.demo --eval-mode on-device
```
**NOTE**: If you want running in a Jupyter Notebook or Google Colab like
environment, please add the following to your cell (instead of the above).
```
%run -m qai_hub_models.models.yamnet.demo -- --eval-mode on-device
```
## Deploying compiled model to Android
The models can be deployed using multiple runtimes:
- TensorFlow Lite (`.tflite` export): [This
tutorial](https://www.tensorflow.org/lite/android/quickstart) provides a
guide to deploy the .tflite model in an Android application.
- QNN (`.so` export ): This [sample
app](https://docs.qualcomm.com/bundle/publicresource/topics/80-63442-50/sample_app.html)
provides instructions on how to use the `.so` shared library in an Android application.
## View on Qualcomm® AI Hub
Get more details on YamNet's performance across various devices [here](https://aihub.qualcomm.com/models/yamnet).
Explore all available models on [Qualcomm® AI Hub](https://aihub.qualcomm.com/)
## License
* The license for the original implementation of YamNet can be found
[here](https://github.com/w-hc/torch_audioset/blob/master/LICENSE).
* The license for the compiled assets for on-device deployment can be found [here](https://qaihub-public-assets.s3.us-west-2.amazonaws.com/qai-hub-models/Qualcomm+AI+Hub+Proprietary+License.pdf)
## References
* [MobileNets Efficient Convolutional Neural Networks for Mobile Vision Applications](https://arxiv.org/abs/1704.04861)
* [Source Model Implementation](https://github.com/w-hc/torch_audioset)
## Community
* Join [our AI Hub Slack community](https://aihub.qualcomm.com/community/slack) to collaborate, post questions and learn more about on-device AI.
* For questions or feedback please [reach out to us](mailto:ai-hub-support@qti.qualcomm.com).
|
qualcomm/WideResNet50
|
qualcomm
| 2025-08-26T17:33:42Z | 104 | 0 |
pytorch
|
[
"pytorch",
"tflite",
"backbone",
"android",
"image-classification",
"arxiv:1605.07146",
"license:other",
"region:us"
] |
image-classification
| 2024-02-25T22:47:53Z |
---
library_name: pytorch
license: other
tags:
- backbone
- android
pipeline_tag: image-classification
---

# WideResNet50: Optimized for Mobile Deployment
## Imagenet classifier and general purpose backbone
WideResNet50 is a machine learning model that can classify images from the Imagenet dataset. It can also be used as a backbone in building more complex models for specific use cases.
This model is an implementation of WideResNet50 found [here](https://github.com/pytorch/vision/blob/main/torchvision/models/resnet.py).
This repository provides scripts to run WideResNet50 on Qualcomm® devices.
More details on model performance across various devices, can be found
[here](https://aihub.qualcomm.com/models/wideresnet50).
### Model Details
- **Model Type:** Model_use_case.image_classification
- **Model Stats:**
- Model checkpoint: Imagenet
- Input resolution: 224x224
- Number of parameters: 68.9M
- Model size (float): 263 MB
- Model size (w8a8): 66.6 MB
| Model | Precision | Device | Chipset | Target Runtime | Inference Time (ms) | Peak Memory Range (MB) | Primary Compute Unit | Target Model
|---|---|---|---|---|---|---|---|---|
| WideResNet50 | float | QCS8275 (Proxy) | Qualcomm® QCS8275 (Proxy) | TFLITE | 24.024 ms | 0 - 91 MB | NPU | [WideResNet50.tflite](https://huggingface.co/qualcomm/WideResNet50/blob/main/WideResNet50.tflite) |
| WideResNet50 | float | QCS8275 (Proxy) | Qualcomm® QCS8275 (Proxy) | QNN_DLC | 24.142 ms | 1 - 41 MB | NPU | [WideResNet50.dlc](https://huggingface.co/qualcomm/WideResNet50/blob/main/WideResNet50.dlc) |
| WideResNet50 | float | QCS8450 (Proxy) | Qualcomm® QCS8450 (Proxy) | TFLITE | 6.831 ms | 0 - 171 MB | NPU | [WideResNet50.tflite](https://huggingface.co/qualcomm/WideResNet50/blob/main/WideResNet50.tflite) |
| WideResNet50 | float | QCS8450 (Proxy) | Qualcomm® QCS8450 (Proxy) | QNN_DLC | 10.399 ms | 0 - 40 MB | NPU | [WideResNet50.dlc](https://huggingface.co/qualcomm/WideResNet50/blob/main/WideResNet50.dlc) |
| WideResNet50 | float | QCS8550 (Proxy) | Qualcomm® QCS8550 (Proxy) | TFLITE | 4.852 ms | 0 - 875 MB | NPU | [WideResNet50.tflite](https://huggingface.co/qualcomm/WideResNet50/blob/main/WideResNet50.tflite) |
| WideResNet50 | float | QCS8550 (Proxy) | Qualcomm® QCS8550 (Proxy) | QNN_DLC | 4.792 ms | 0 - 10 MB | NPU | [WideResNet50.dlc](https://huggingface.co/qualcomm/WideResNet50/blob/main/WideResNet50.dlc) |
| WideResNet50 | float | QCS9075 (Proxy) | Qualcomm® QCS9075 (Proxy) | TFLITE | 7.269 ms | 0 - 92 MB | NPU | [WideResNet50.tflite](https://huggingface.co/qualcomm/WideResNet50/blob/main/WideResNet50.tflite) |
| WideResNet50 | float | QCS9075 (Proxy) | Qualcomm® QCS9075 (Proxy) | QNN_DLC | 7.146 ms | 1 - 42 MB | NPU | [WideResNet50.dlc](https://huggingface.co/qualcomm/WideResNet50/blob/main/WideResNet50.dlc) |
| WideResNet50 | float | SA7255P ADP | Qualcomm® SA7255P | TFLITE | 24.024 ms | 0 - 91 MB | NPU | [WideResNet50.tflite](https://huggingface.co/qualcomm/WideResNet50/blob/main/WideResNet50.tflite) |
| WideResNet50 | float | SA7255P ADP | Qualcomm® SA7255P | QNN_DLC | 24.142 ms | 1 - 41 MB | NPU | [WideResNet50.dlc](https://huggingface.co/qualcomm/WideResNet50/blob/main/WideResNet50.dlc) |
| WideResNet50 | float | SA8255 (Proxy) | Qualcomm® SA8255P (Proxy) | TFLITE | 4.845 ms | 0 - 870 MB | NPU | [WideResNet50.tflite](https://huggingface.co/qualcomm/WideResNet50/blob/main/WideResNet50.tflite) |
| WideResNet50 | float | SA8255 (Proxy) | Qualcomm® SA8255P (Proxy) | QNN_DLC | 4.805 ms | 1 - 16 MB | NPU | [WideResNet50.dlc](https://huggingface.co/qualcomm/WideResNet50/blob/main/WideResNet50.dlc) |
| WideResNet50 | float | SA8295P ADP | Qualcomm® SA8295P | TFLITE | 7.912 ms | 0 - 87 MB | NPU | [WideResNet50.tflite](https://huggingface.co/qualcomm/WideResNet50/blob/main/WideResNet50.tflite) |
| WideResNet50 | float | SA8295P ADP | Qualcomm® SA8295P | QNN_DLC | 7.759 ms | 1 - 32 MB | NPU | [WideResNet50.dlc](https://huggingface.co/qualcomm/WideResNet50/blob/main/WideResNet50.dlc) |
| WideResNet50 | float | SA8650 (Proxy) | Qualcomm® SA8650P (Proxy) | TFLITE | 4.85 ms | 0 - 867 MB | NPU | [WideResNet50.tflite](https://huggingface.co/qualcomm/WideResNet50/blob/main/WideResNet50.tflite) |
| WideResNet50 | float | SA8650 (Proxy) | Qualcomm® SA8650P (Proxy) | QNN_DLC | 4.797 ms | 1 - 11 MB | NPU | [WideResNet50.dlc](https://huggingface.co/qualcomm/WideResNet50/blob/main/WideResNet50.dlc) |
| WideResNet50 | float | SA8775P ADP | Qualcomm® SA8775P | TFLITE | 7.269 ms | 0 - 92 MB | NPU | [WideResNet50.tflite](https://huggingface.co/qualcomm/WideResNet50/blob/main/WideResNet50.tflite) |
| WideResNet50 | float | SA8775P ADP | Qualcomm® SA8775P | QNN_DLC | 7.146 ms | 1 - 42 MB | NPU | [WideResNet50.dlc](https://huggingface.co/qualcomm/WideResNet50/blob/main/WideResNet50.dlc) |
| WideResNet50 | float | Samsung Galaxy S23 | Snapdragon® 8 Gen 2 Mobile | TFLITE | 4.851 ms | 0 - 858 MB | NPU | [WideResNet50.tflite](https://huggingface.co/qualcomm/WideResNet50/blob/main/WideResNet50.tflite) |
| WideResNet50 | float | Samsung Galaxy S23 | Snapdragon® 8 Gen 2 Mobile | QNN_DLC | 4.802 ms | 1 - 16 MB | NPU | [WideResNet50.dlc](https://huggingface.co/qualcomm/WideResNet50/blob/main/WideResNet50.dlc) |
| WideResNet50 | float | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | TFLITE | 3.553 ms | 0 - 188 MB | NPU | [WideResNet50.tflite](https://huggingface.co/qualcomm/WideResNet50/blob/main/WideResNet50.tflite) |
| WideResNet50 | float | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | QNN_DLC | 3.607 ms | 1 - 50 MB | NPU | [WideResNet50.dlc](https://huggingface.co/qualcomm/WideResNet50/blob/main/WideResNet50.dlc) |
| WideResNet50 | float | Snapdragon 8 Elite QRD | Snapdragon® 8 Elite Mobile | TFLITE | 3.367 ms | 0 - 96 MB | NPU | [WideResNet50.tflite](https://huggingface.co/qualcomm/WideResNet50/blob/main/WideResNet50.tflite) |
| WideResNet50 | float | Snapdragon 8 Elite QRD | Snapdragon® 8 Elite Mobile | QNN_DLC | 3.21 ms | 1 - 44 MB | NPU | [WideResNet50.dlc](https://huggingface.co/qualcomm/WideResNet50/blob/main/WideResNet50.dlc) |
| WideResNet50 | float | Snapdragon X Elite CRD | Snapdragon® X Elite | QNN_DLC | 4.686 ms | 457 - 457 MB | NPU | [WideResNet50.dlc](https://huggingface.co/qualcomm/WideResNet50/blob/main/WideResNet50.dlc) |
| WideResNet50 | w8a8 | QCS8275 (Proxy) | Qualcomm® QCS8275 (Proxy) | TFLITE | 3.812 ms | 0 - 43 MB | NPU | [WideResNet50.tflite](https://huggingface.co/qualcomm/WideResNet50/blob/main/WideResNet50_w8a8.tflite) |
| WideResNet50 | w8a8 | QCS8275 (Proxy) | Qualcomm® QCS8275 (Proxy) | QNN_DLC | 4.027 ms | 0 - 44 MB | NPU | [WideResNet50.dlc](https://huggingface.co/qualcomm/WideResNet50/blob/main/WideResNet50_w8a8.dlc) |
| WideResNet50 | w8a8 | QCS8450 (Proxy) | Qualcomm® QCS8450 (Proxy) | TFLITE | 2.117 ms | 0 - 113 MB | NPU | [WideResNet50.tflite](https://huggingface.co/qualcomm/WideResNet50/blob/main/WideResNet50_w8a8.tflite) |
| WideResNet50 | w8a8 | QCS8450 (Proxy) | Qualcomm® QCS8450 (Proxy) | QNN_DLC | 2.514 ms | 0 - 106 MB | NPU | [WideResNet50.dlc](https://huggingface.co/qualcomm/WideResNet50/blob/main/WideResNet50_w8a8.dlc) |
| WideResNet50 | w8a8 | QCS8550 (Proxy) | Qualcomm® QCS8550 (Proxy) | TFLITE | 1.771 ms | 0 - 383 MB | NPU | [WideResNet50.tflite](https://huggingface.co/qualcomm/WideResNet50/blob/main/WideResNet50_w8a8.tflite) |
| WideResNet50 | w8a8 | QCS8550 (Proxy) | Qualcomm® QCS8550 (Proxy) | QNN_DLC | 1.873 ms | 0 - 8 MB | NPU | [WideResNet50.dlc](https://huggingface.co/qualcomm/WideResNet50/blob/main/WideResNet50_w8a8.dlc) |
| WideResNet50 | w8a8 | QCS9075 (Proxy) | Qualcomm® QCS9075 (Proxy) | TFLITE | 1.909 ms | 0 - 43 MB | NPU | [WideResNet50.tflite](https://huggingface.co/qualcomm/WideResNet50/blob/main/WideResNet50_w8a8.tflite) |
| WideResNet50 | w8a8 | QCS9075 (Proxy) | Qualcomm® QCS9075 (Proxy) | QNN_DLC | 2.014 ms | 0 - 44 MB | NPU | [WideResNet50.dlc](https://huggingface.co/qualcomm/WideResNet50/blob/main/WideResNet50_w8a8.dlc) |
| WideResNet50 | w8a8 | RB3 Gen 2 (Proxy) | Qualcomm® QCS6490 (Proxy) | TFLITE | 7.525 ms | 0 - 96 MB | NPU | [WideResNet50.tflite](https://huggingface.co/qualcomm/WideResNet50/blob/main/WideResNet50_w8a8.tflite) |
| WideResNet50 | w8a8 | RB3 Gen 2 (Proxy) | Qualcomm® QCS6490 (Proxy) | QNN_DLC | 9.998 ms | 0 - 98 MB | NPU | [WideResNet50.dlc](https://huggingface.co/qualcomm/WideResNet50/blob/main/WideResNet50_w8a8.dlc) |
| WideResNet50 | w8a8 | RB5 (Proxy) | Qualcomm® QCS8250 (Proxy) | TFLITE | 24.552 ms | 0 - 7 MB | NPU | [WideResNet50.tflite](https://huggingface.co/qualcomm/WideResNet50/blob/main/WideResNet50_w8a8.tflite) |
| WideResNet50 | w8a8 | SA7255P ADP | Qualcomm® SA7255P | TFLITE | 3.812 ms | 0 - 43 MB | NPU | [WideResNet50.tflite](https://huggingface.co/qualcomm/WideResNet50/blob/main/WideResNet50_w8a8.tflite) |
| WideResNet50 | w8a8 | SA7255P ADP | Qualcomm® SA7255P | QNN_DLC | 4.027 ms | 0 - 44 MB | NPU | [WideResNet50.dlc](https://huggingface.co/qualcomm/WideResNet50/blob/main/WideResNet50_w8a8.dlc) |
| WideResNet50 | w8a8 | SA8255 (Proxy) | Qualcomm® SA8255P (Proxy) | TFLITE | 1.779 ms | 0 - 9 MB | NPU | [WideResNet50.tflite](https://huggingface.co/qualcomm/WideResNet50/blob/main/WideResNet50_w8a8.tflite) |
| WideResNet50 | w8a8 | SA8255 (Proxy) | Qualcomm® SA8255P (Proxy) | QNN_DLC | 1.869 ms | 0 - 369 MB | NPU | [WideResNet50.dlc](https://huggingface.co/qualcomm/WideResNet50/blob/main/WideResNet50_w8a8.dlc) |
| WideResNet50 | w8a8 | SA8295P ADP | Qualcomm® SA8295P | TFLITE | 2.589 ms | 0 - 48 MB | NPU | [WideResNet50.tflite](https://huggingface.co/qualcomm/WideResNet50/blob/main/WideResNet50_w8a8.tflite) |
| WideResNet50 | w8a8 | SA8295P ADP | Qualcomm® SA8295P | QNN_DLC | 2.76 ms | 0 - 50 MB | NPU | [WideResNet50.dlc](https://huggingface.co/qualcomm/WideResNet50/blob/main/WideResNet50_w8a8.dlc) |
| WideResNet50 | w8a8 | SA8650 (Proxy) | Qualcomm® SA8650P (Proxy) | TFLITE | 1.774 ms | 0 - 390 MB | NPU | [WideResNet50.tflite](https://huggingface.co/qualcomm/WideResNet50/blob/main/WideResNet50_w8a8.tflite) |
| WideResNet50 | w8a8 | SA8650 (Proxy) | Qualcomm® SA8650P (Proxy) | QNN_DLC | 1.871 ms | 0 - 365 MB | NPU | [WideResNet50.dlc](https://huggingface.co/qualcomm/WideResNet50/blob/main/WideResNet50_w8a8.dlc) |
| WideResNet50 | w8a8 | SA8775P ADP | Qualcomm® SA8775P | TFLITE | 1.909 ms | 0 - 43 MB | NPU | [WideResNet50.tflite](https://huggingface.co/qualcomm/WideResNet50/blob/main/WideResNet50_w8a8.tflite) |
| WideResNet50 | w8a8 | SA8775P ADP | Qualcomm® SA8775P | QNN_DLC | 2.014 ms | 0 - 44 MB | NPU | [WideResNet50.dlc](https://huggingface.co/qualcomm/WideResNet50/blob/main/WideResNet50_w8a8.dlc) |
| WideResNet50 | w8a8 | Samsung Galaxy S23 | Snapdragon® 8 Gen 2 Mobile | TFLITE | 1.777 ms | 0 - 386 MB | NPU | [WideResNet50.tflite](https://huggingface.co/qualcomm/WideResNet50/blob/main/WideResNet50_w8a8.tflite) |
| WideResNet50 | w8a8 | Samsung Galaxy S23 | Snapdragon® 8 Gen 2 Mobile | QNN_DLC | 1.875 ms | 0 - 363 MB | NPU | [WideResNet50.dlc](https://huggingface.co/qualcomm/WideResNet50/blob/main/WideResNet50_w8a8.dlc) |
| WideResNet50 | w8a8 | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | TFLITE | 1.344 ms | 0 - 108 MB | NPU | [WideResNet50.tflite](https://huggingface.co/qualcomm/WideResNet50/blob/main/WideResNet50_w8a8.tflite) |
| WideResNet50 | w8a8 | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | QNN_DLC | 1.436 ms | 0 - 109 MB | NPU | [WideResNet50.dlc](https://huggingface.co/qualcomm/WideResNet50/blob/main/WideResNet50_w8a8.dlc) |
| WideResNet50 | w8a8 | Snapdragon 8 Elite QRD | Snapdragon® 8 Elite Mobile | TFLITE | 1.213 ms | 0 - 52 MB | NPU | [WideResNet50.tflite](https://huggingface.co/qualcomm/WideResNet50/blob/main/WideResNet50_w8a8.tflite) |
| WideResNet50 | w8a8 | Snapdragon 8 Elite QRD | Snapdragon® 8 Elite Mobile | QNN_DLC | 1.237 ms | 0 - 48 MB | NPU | [WideResNet50.dlc](https://huggingface.co/qualcomm/WideResNet50/blob/main/WideResNet50_w8a8.dlc) |
| WideResNet50 | w8a8 | Snapdragon X Elite CRD | Snapdragon® X Elite | QNN_DLC | 1.809 ms | 393 - 393 MB | NPU | [WideResNet50.dlc](https://huggingface.co/qualcomm/WideResNet50/blob/main/WideResNet50_w8a8.dlc) |
## Installation
Install the package via pip:
```bash
pip install qai-hub-models
```
## Configure Qualcomm® AI Hub to run this model on a cloud-hosted device
Sign-in to [Qualcomm® AI Hub](https://app.aihub.qualcomm.com/) with your
Qualcomm® ID. Once signed in navigate to `Account -> Settings -> API Token`.
With this API token, you can configure your client to run models on the cloud
hosted devices.
```bash
qai-hub configure --api_token API_TOKEN
```
Navigate to [docs](https://app.aihub.qualcomm.com/docs/) for more information.
## Demo off target
The package contains a simple end-to-end demo that downloads pre-trained
weights and runs this model on a sample input.
```bash
python -m qai_hub_models.models.wideresnet50.demo
```
The above demo runs a reference implementation of pre-processing, model
inference, and post processing.
**NOTE**: If you want running in a Jupyter Notebook or Google Colab like
environment, please add the following to your cell (instead of the above).
```
%run -m qai_hub_models.models.wideresnet50.demo
```
### Run model on a cloud-hosted device
In addition to the demo, you can also run the model on a cloud-hosted Qualcomm®
device. This script does the following:
* Performance check on-device on a cloud-hosted device
* Downloads compiled assets that can be deployed on-device for Android.
* Accuracy check between PyTorch and on-device outputs.
```bash
python -m qai_hub_models.models.wideresnet50.export
```
## How does this work?
This [export script](https://aihub.qualcomm.com/models/wideresnet50/qai_hub_models/models/WideResNet50/export.py)
leverages [Qualcomm® AI Hub](https://aihub.qualcomm.com/) to optimize, validate, and deploy this model
on-device. Lets go through each step below in detail:
Step 1: **Compile model for on-device deployment**
To compile a PyTorch model for on-device deployment, we first trace the model
in memory using the `jit.trace` and then call the `submit_compile_job` API.
```python
import torch
import qai_hub as hub
from qai_hub_models.models.wideresnet50 import Model
# Load the model
torch_model = Model.from_pretrained()
# Device
device = hub.Device("Samsung Galaxy S24")
# Trace model
input_shape = torch_model.get_input_spec()
sample_inputs = torch_model.sample_inputs()
pt_model = torch.jit.trace(torch_model, [torch.tensor(data[0]) for _, data in sample_inputs.items()])
# Compile model on a specific device
compile_job = hub.submit_compile_job(
model=pt_model,
device=device,
input_specs=torch_model.get_input_spec(),
)
# Get target model to run on-device
target_model = compile_job.get_target_model()
```
Step 2: **Performance profiling on cloud-hosted device**
After compiling models from step 1. Models can be profiled model on-device using the
`target_model`. Note that this scripts runs the model on a device automatically
provisioned in the cloud. Once the job is submitted, you can navigate to a
provided job URL to view a variety of on-device performance metrics.
```python
profile_job = hub.submit_profile_job(
model=target_model,
device=device,
)
```
Step 3: **Verify on-device accuracy**
To verify the accuracy of the model on-device, you can run on-device inference
on sample input data on the same cloud hosted device.
```python
input_data = torch_model.sample_inputs()
inference_job = hub.submit_inference_job(
model=target_model,
device=device,
inputs=input_data,
)
on_device_output = inference_job.download_output_data()
```
With the output of the model, you can compute like PSNR, relative errors or
spot check the output with expected output.
**Note**: This on-device profiling and inference requires access to Qualcomm®
AI Hub. [Sign up for access](https://myaccount.qualcomm.com/signup).
## Run demo on a cloud-hosted device
You can also run the demo on-device.
```bash
python -m qai_hub_models.models.wideresnet50.demo --eval-mode on-device
```
**NOTE**: If you want running in a Jupyter Notebook or Google Colab like
environment, please add the following to your cell (instead of the above).
```
%run -m qai_hub_models.models.wideresnet50.demo -- --eval-mode on-device
```
## Deploying compiled model to Android
The models can be deployed using multiple runtimes:
- TensorFlow Lite (`.tflite` export): [This
tutorial](https://www.tensorflow.org/lite/android/quickstart) provides a
guide to deploy the .tflite model in an Android application.
- QNN (`.so` export ): This [sample
app](https://docs.qualcomm.com/bundle/publicresource/topics/80-63442-50/sample_app.html)
provides instructions on how to use the `.so` shared library in an Android application.
## View on Qualcomm® AI Hub
Get more details on WideResNet50's performance across various devices [here](https://aihub.qualcomm.com/models/wideresnet50).
Explore all available models on [Qualcomm® AI Hub](https://aihub.qualcomm.com/)
## License
* The license for the original implementation of WideResNet50 can be found
[here](https://github.com/pytorch/vision/blob/main/LICENSE).
* The license for the compiled assets for on-device deployment can be found [here](https://qaihub-public-assets.s3.us-west-2.amazonaws.com/qai-hub-models/Qualcomm+AI+Hub+Proprietary+License.pdf)
## References
* [Wide Residual Networks](https://arxiv.org/abs/1605.07146)
* [Source Model Implementation](https://github.com/pytorch/vision/blob/main/torchvision/models/resnet.py)
## Community
* Join [our AI Hub Slack community](https://aihub.qualcomm.com/community/slack) to collaborate, post questions and learn more about on-device AI.
* For questions or feedback please [reach out to us](mailto:ai-hub-support@qti.qualcomm.com).
|
qualcomm/Whisper-Small-En
|
qualcomm
| 2025-08-26T17:32:23Z | 85 | 2 |
pytorch
|
[
"pytorch",
"tflite",
"foundation",
"android",
"automatic-speech-recognition",
"license:other",
"region:us"
] |
automatic-speech-recognition
| 2024-03-04T21:56:22Z |
---
library_name: pytorch
license: other
tags:
- foundation
- android
pipeline_tag: automatic-speech-recognition
---

# Whisper-Small-En: Optimized for Mobile Deployment
## Transformer-based automatic speech recognition (ASR) model for multilingual transcription and translation available on HuggingFace
HuggingFace Whisper-Small ASR (Automatic Speech Recognition) model is a state-of-the-art system designed for transcribing spoken language into written text. This model is based on the transformer architecture and has been optimized for edge inference by replacing Multi-Head Attention (MHA) with Single-Head Attention (SHA) and linear layers with convolutional (conv) layers. It exhibits robust performance in realistic, noisy environments, making it highly reliable for real-world applications. Specifically, it excels in long-form transcription, capable of accurately transcribing audio clips up to 30 seconds long. Time to the first token is the encoder's latency, while time to each additional token is decoder's latency, where we assume a max decoded length specified below.
This model is an implementation of Whisper-Small-En found [here](https://github.com/huggingface/transformers/tree/v4.42.3/src/transformers/models/whisper).
This repository provides scripts to run Whisper-Small-En on Qualcomm® devices.
More details on model performance across various devices, can be found
[here](https://aihub.qualcomm.com/models/whisper_small_en).
### Model Details
- **Model Type:** Model_use_case.speech_recognition
- **Model Stats:**
- Model checkpoint: openai/whisper-small
- Input resolution: 80x3000 (30 seconds audio)
- Max decoded sequence length: 200 tokens
- Number of parameters (HfWhisperEncoder): 102M
- Model size (HfWhisperEncoder) (float): 391 MB
- Number of parameters (HfWhisperDecoder): 139M
- Model size (HfWhisperDecoder) (float): 533 MB
| Model | Precision | Device | Chipset | Target Runtime | Inference Time (ms) | Peak Memory Range (MB) | Primary Compute Unit | Target Model
|---|---|---|---|---|---|---|---|---|
| HfWhisperEncoder | float | QCS8275 (Proxy) | Qualcomm® QCS8275 (Proxy) | TFLITE | 3333.928 ms | 109 - 159 MB | GPU | [Whisper-Small-En.tflite](https://huggingface.co/qualcomm/Whisper-Small-En/blob/main/Whisper-Small-En.tflite) |
| HfWhisperEncoder | float | QCS8275 (Proxy) | Qualcomm® QCS8275 (Proxy) | QNN_DLC | 424.425 ms | 0 - 443 MB | NPU | [Whisper-Small-En.dlc](https://huggingface.co/qualcomm/Whisper-Small-En/blob/main/Whisper-Small-En.dlc) |
| HfWhisperEncoder | float | QCS8550 (Proxy) | Qualcomm® QCS8550 (Proxy) | TFLITE | 1115.67 ms | 18 - 223 MB | GPU | [Whisper-Small-En.tflite](https://huggingface.co/qualcomm/Whisper-Small-En/blob/main/Whisper-Small-En.tflite) |
| HfWhisperEncoder | float | QCS8550 (Proxy) | Qualcomm® QCS8550 (Proxy) | QNN_DLC | 135.465 ms | 1 - 28 MB | NPU | [Whisper-Small-En.dlc](https://huggingface.co/qualcomm/Whisper-Small-En/blob/main/Whisper-Small-En.dlc) |
| HfWhisperEncoder | float | QCS9075 (Proxy) | Qualcomm® QCS9075 (Proxy) | TFLITE | 1416.508 ms | 106 - 155 MB | GPU | [Whisper-Small-En.tflite](https://huggingface.co/qualcomm/Whisper-Small-En/blob/main/Whisper-Small-En.tflite) |
| HfWhisperEncoder | float | QCS9075 (Proxy) | Qualcomm® QCS9075 (Proxy) | QNN_DLC | 154.567 ms | 0 - 442 MB | NPU | [Whisper-Small-En.dlc](https://huggingface.co/qualcomm/Whisper-Small-En/blob/main/Whisper-Small-En.dlc) |
| HfWhisperEncoder | float | SA7255P ADP | Qualcomm® SA7255P | TFLITE | 3333.928 ms | 109 - 159 MB | GPU | [Whisper-Small-En.tflite](https://huggingface.co/qualcomm/Whisper-Small-En/blob/main/Whisper-Small-En.tflite) |
| HfWhisperEncoder | float | SA7255P ADP | Qualcomm® SA7255P | QNN_DLC | 424.425 ms | 0 - 443 MB | NPU | [Whisper-Small-En.dlc](https://huggingface.co/qualcomm/Whisper-Small-En/blob/main/Whisper-Small-En.dlc) |
| HfWhisperEncoder | float | SA8255 (Proxy) | Qualcomm® SA8255P (Proxy) | TFLITE | 882.114 ms | 18 - 186 MB | GPU | [Whisper-Small-En.tflite](https://huggingface.co/qualcomm/Whisper-Small-En/blob/main/Whisper-Small-En.tflite) |
| HfWhisperEncoder | float | SA8255 (Proxy) | Qualcomm® SA8255P (Proxy) | QNN_DLC | 137.649 ms | 0 - 33 MB | NPU | [Whisper-Small-En.dlc](https://huggingface.co/qualcomm/Whisper-Small-En/blob/main/Whisper-Small-En.dlc) |
| HfWhisperEncoder | float | SA8295P ADP | Qualcomm® SA8295P | TFLITE | 798.622 ms | 109 - 158 MB | GPU | [Whisper-Small-En.tflite](https://huggingface.co/qualcomm/Whisper-Small-En/blob/main/Whisper-Small-En.tflite) |
| HfWhisperEncoder | float | SA8295P ADP | Qualcomm® SA8295P | QNN_DLC | 241.302 ms | 0 - 440 MB | NPU | [Whisper-Small-En.dlc](https://huggingface.co/qualcomm/Whisper-Small-En/blob/main/Whisper-Small-En.dlc) |
| HfWhisperEncoder | float | SA8650 (Proxy) | Qualcomm® SA8650P (Proxy) | TFLITE | 768.865 ms | 18 - 222 MB | GPU | [Whisper-Small-En.tflite](https://huggingface.co/qualcomm/Whisper-Small-En/blob/main/Whisper-Small-En.tflite) |
| HfWhisperEncoder | float | SA8650 (Proxy) | Qualcomm® SA8650P (Proxy) | QNN_DLC | 138.695 ms | 0 - 32 MB | NPU | [Whisper-Small-En.dlc](https://huggingface.co/qualcomm/Whisper-Small-En/blob/main/Whisper-Small-En.dlc) |
| HfWhisperEncoder | float | SA8775P ADP | Qualcomm® SA8775P | TFLITE | 1416.508 ms | 106 - 155 MB | GPU | [Whisper-Small-En.tflite](https://huggingface.co/qualcomm/Whisper-Small-En/blob/main/Whisper-Small-En.tflite) |
| HfWhisperEncoder | float | SA8775P ADP | Qualcomm® SA8775P | QNN_DLC | 154.567 ms | 0 - 442 MB | NPU | [Whisper-Small-En.dlc](https://huggingface.co/qualcomm/Whisper-Small-En/blob/main/Whisper-Small-En.dlc) |
| HfWhisperEncoder | float | Samsung Galaxy S23 | Snapdragon® 8 Gen 2 Mobile | TFLITE | 775.503 ms | 110 - 130 MB | GPU | [Whisper-Small-En.tflite](https://huggingface.co/qualcomm/Whisper-Small-En/blob/main/Whisper-Small-En.tflite) |
| HfWhisperEncoder | float | Samsung Galaxy S23 | Snapdragon® 8 Gen 2 Mobile | QNN_DLC | 137.037 ms | 0 - 30 MB | NPU | [Whisper-Small-En.dlc](https://huggingface.co/qualcomm/Whisper-Small-En/blob/main/Whisper-Small-En.dlc) |
| HfWhisperEncoder | float | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | TFLITE | 569.222 ms | 111 - 300 MB | GPU | [Whisper-Small-En.tflite](https://huggingface.co/qualcomm/Whisper-Small-En/blob/main/Whisper-Small-En.tflite) |
| HfWhisperEncoder | float | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | QNN_DLC | 106.478 ms | 1 - 449 MB | NPU | [Whisper-Small-En.dlc](https://huggingface.co/qualcomm/Whisper-Small-En/blob/main/Whisper-Small-En.dlc) |
| HfWhisperEncoder | float | Snapdragon 8 Elite QRD | Snapdragon® 8 Elite Mobile | TFLITE | 622.531 ms | 110 - 156 MB | GPU | [Whisper-Small-En.tflite](https://huggingface.co/qualcomm/Whisper-Small-En/blob/main/Whisper-Small-En.tflite) |
| HfWhisperEncoder | float | Snapdragon 8 Elite QRD | Snapdragon® 8 Elite Mobile | QNN_DLC | 87.001 ms | 0 - 426 MB | NPU | [Whisper-Small-En.dlc](https://huggingface.co/qualcomm/Whisper-Small-En/blob/main/Whisper-Small-En.dlc) |
| HfWhisperEncoder | float | Snapdragon X Elite CRD | Snapdragon® X Elite | QNN_DLC | 130.938 ms | 158 - 158 MB | NPU | [Whisper-Small-En.dlc](https://huggingface.co/qualcomm/Whisper-Small-En/blob/main/Whisper-Small-En.dlc) |
| HfWhisperDecoder | float | QCS8275 (Proxy) | Qualcomm® QCS8275 (Proxy) | TFLITE | 28.37 ms | 14 - 506 MB | NPU | [Whisper-Small-En.tflite](https://huggingface.co/qualcomm/Whisper-Small-En/blob/main/Whisper-Small-En.tflite) |
| HfWhisperDecoder | float | QCS8275 (Proxy) | Qualcomm® QCS8275 (Proxy) | QNN_DLC | 18.043 ms | 38 - 335 MB | NPU | [Whisper-Small-En.dlc](https://huggingface.co/qualcomm/Whisper-Small-En/blob/main/Whisper-Small-En.dlc) |
| HfWhisperDecoder | float | QCS8550 (Proxy) | Qualcomm® QCS8550 (Proxy) | TFLITE | 19.146 ms | 14 - 59 MB | NPU | [Whisper-Small-En.tflite](https://huggingface.co/qualcomm/Whisper-Small-En/blob/main/Whisper-Small-En.tflite) |
| HfWhisperDecoder | float | QCS8550 (Proxy) | Qualcomm® QCS8550 (Proxy) | QNN_DLC | 12.048 ms | 60 - 74 MB | NPU | [Whisper-Small-En.dlc](https://huggingface.co/qualcomm/Whisper-Small-En/blob/main/Whisper-Small-En.dlc) |
| HfWhisperDecoder | float | QCS9075 (Proxy) | Qualcomm® QCS9075 (Proxy) | TFLITE | 21.142 ms | 14 - 505 MB | NPU | [Whisper-Small-En.tflite](https://huggingface.co/qualcomm/Whisper-Small-En/blob/main/Whisper-Small-En.tflite) |
| HfWhisperDecoder | float | QCS9075 (Proxy) | Qualcomm® QCS9075 (Proxy) | QNN_DLC | 13.304 ms | 55 - 346 MB | NPU | [Whisper-Small-En.dlc](https://huggingface.co/qualcomm/Whisper-Small-En/blob/main/Whisper-Small-En.dlc) |
| HfWhisperDecoder | float | SA7255P ADP | Qualcomm® SA7255P | TFLITE | 28.37 ms | 14 - 506 MB | NPU | [Whisper-Small-En.tflite](https://huggingface.co/qualcomm/Whisper-Small-En/blob/main/Whisper-Small-En.tflite) |
| HfWhisperDecoder | float | SA7255P ADP | Qualcomm® SA7255P | QNN_DLC | 18.043 ms | 38 - 335 MB | NPU | [Whisper-Small-En.dlc](https://huggingface.co/qualcomm/Whisper-Small-En/blob/main/Whisper-Small-En.dlc) |
| HfWhisperDecoder | float | SA8255 (Proxy) | Qualcomm® SA8255P (Proxy) | TFLITE | 19.112 ms | 14 - 40 MB | NPU | [Whisper-Small-En.tflite](https://huggingface.co/qualcomm/Whisper-Small-En/blob/main/Whisper-Small-En.tflite) |
| HfWhisperDecoder | float | SA8255 (Proxy) | Qualcomm® SA8255P (Proxy) | QNN_DLC | 11.743 ms | 57 - 83 MB | NPU | [Whisper-Small-En.dlc](https://huggingface.co/qualcomm/Whisper-Small-En/blob/main/Whisper-Small-En.dlc) |
| HfWhisperDecoder | float | SA8295P ADP | Qualcomm® SA8295P | TFLITE | 20.478 ms | 14 - 429 MB | NPU | [Whisper-Small-En.tflite](https://huggingface.co/qualcomm/Whisper-Small-En/blob/main/Whisper-Small-En.tflite) |
| HfWhisperDecoder | float | SA8295P ADP | Qualcomm® SA8295P | QNN_DLC | 14.571 ms | 47 - 328 MB | NPU | [Whisper-Small-En.dlc](https://huggingface.co/qualcomm/Whisper-Small-En/blob/main/Whisper-Small-En.dlc) |
| HfWhisperDecoder | float | SA8650 (Proxy) | Qualcomm® SA8650P (Proxy) | TFLITE | 19.092 ms | 0 - 57 MB | NPU | [Whisper-Small-En.tflite](https://huggingface.co/qualcomm/Whisper-Small-En/blob/main/Whisper-Small-En.tflite) |
| HfWhisperDecoder | float | SA8650 (Proxy) | Qualcomm® SA8650P (Proxy) | QNN_DLC | 11.972 ms | 43 - 67 MB | NPU | [Whisper-Small-En.dlc](https://huggingface.co/qualcomm/Whisper-Small-En/blob/main/Whisper-Small-En.dlc) |
| HfWhisperDecoder | float | SA8775P ADP | Qualcomm® SA8775P | TFLITE | 21.142 ms | 14 - 505 MB | NPU | [Whisper-Small-En.tflite](https://huggingface.co/qualcomm/Whisper-Small-En/blob/main/Whisper-Small-En.tflite) |
| HfWhisperDecoder | float | SA8775P ADP | Qualcomm® SA8775P | QNN_DLC | 13.304 ms | 55 - 346 MB | NPU | [Whisper-Small-En.dlc](https://huggingface.co/qualcomm/Whisper-Small-En/blob/main/Whisper-Small-En.dlc) |
| HfWhisperDecoder | float | Samsung Galaxy S23 | Snapdragon® 8 Gen 2 Mobile | TFLITE | 18.961 ms | 14 - 66 MB | NPU | [Whisper-Small-En.tflite](https://huggingface.co/qualcomm/Whisper-Small-En/blob/main/Whisper-Small-En.tflite) |
| HfWhisperDecoder | float | Samsung Galaxy S23 | Snapdragon® 8 Gen 2 Mobile | QNN_DLC | 11.942 ms | 60 - 85 MB | NPU | [Whisper-Small-En.dlc](https://huggingface.co/qualcomm/Whisper-Small-En/blob/main/Whisper-Small-En.dlc) |
| HfWhisperDecoder | float | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | TFLITE | 15.165 ms | 14 - 668 MB | NPU | [Whisper-Small-En.tflite](https://huggingface.co/qualcomm/Whisper-Small-En/blob/main/Whisper-Small-En.tflite) |
| HfWhisperDecoder | float | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | QNN_DLC | 9.579 ms | 0 - 308 MB | NPU | [Whisper-Small-En.dlc](https://huggingface.co/qualcomm/Whisper-Small-En/blob/main/Whisper-Small-En.dlc) |
| HfWhisperDecoder | float | Snapdragon 8 Elite QRD | Snapdragon® 8 Elite Mobile | TFLITE | 13.094 ms | 14 - 459 MB | NPU | [Whisper-Small-En.tflite](https://huggingface.co/qualcomm/Whisper-Small-En/blob/main/Whisper-Small-En.tflite) |
| HfWhisperDecoder | float | Snapdragon 8 Elite QRD | Snapdragon® 8 Elite Mobile | QNN_DLC | 8.145 ms | 58 - 169 MB | NPU | [Whisper-Small-En.dlc](https://huggingface.co/qualcomm/Whisper-Small-En/blob/main/Whisper-Small-En.dlc) |
| HfWhisperDecoder | float | Snapdragon X Elite CRD | Snapdragon® X Elite | QNN_DLC | 10.743 ms | 392 - 392 MB | NPU | [Whisper-Small-En.dlc](https://huggingface.co/qualcomm/Whisper-Small-En/blob/main/Whisper-Small-En.dlc) |
## Installation
Install the package via pip:
```bash
pip install "qai-hub-models[whisper-small-en]"
```
## Configure Qualcomm® AI Hub to run this model on a cloud-hosted device
Sign-in to [Qualcomm® AI Hub](https://app.aihub.qualcomm.com/) with your
Qualcomm® ID. Once signed in navigate to `Account -> Settings -> API Token`.
With this API token, you can configure your client to run models on the cloud
hosted devices.
```bash
qai-hub configure --api_token API_TOKEN
```
Navigate to [docs](https://app.aihub.qualcomm.com/docs/) for more information.
## Demo off target
The package contains a simple end-to-end demo that downloads pre-trained
weights and runs this model on a sample input.
```bash
python -m qai_hub_models.models.whisper_small_en.demo
```
The above demo runs a reference implementation of pre-processing, model
inference, and post processing.
**NOTE**: If you want running in a Jupyter Notebook or Google Colab like
environment, please add the following to your cell (instead of the above).
```
%run -m qai_hub_models.models.whisper_small_en.demo
```
### Run model on a cloud-hosted device
In addition to the demo, you can also run the model on a cloud-hosted Qualcomm®
device. This script does the following:
* Performance check on-device on a cloud-hosted device
* Downloads compiled assets that can be deployed on-device for Android.
* Accuracy check between PyTorch and on-device outputs.
```bash
python -m qai_hub_models.models.whisper_small_en.export
```
## How does this work?
This [export script](https://aihub.qualcomm.com/models/whisper_small_en/qai_hub_models/models/Whisper-Small-En/export.py)
leverages [Qualcomm® AI Hub](https://aihub.qualcomm.com/) to optimize, validate, and deploy this model
on-device. Lets go through each step below in detail:
Step 1: **Compile model for on-device deployment**
To compile a PyTorch model for on-device deployment, we first trace the model
in memory using the `jit.trace` and then call the `submit_compile_job` API.
```python
import torch
import qai_hub as hub
from qai_hub_models.models.whisper_small_en import Model
# Load the model
torch_model = Model.from_pretrained()
# Device
device = hub.Device("Samsung Galaxy S24")
# Trace model
input_shape = torch_model.get_input_spec()
sample_inputs = torch_model.sample_inputs()
pt_model = torch.jit.trace(torch_model, [torch.tensor(data[0]) for _, data in sample_inputs.items()])
# Compile model on a specific device
compile_job = hub.submit_compile_job(
model=pt_model,
device=device,
input_specs=torch_model.get_input_spec(),
)
# Get target model to run on-device
target_model = compile_job.get_target_model()
```
Step 2: **Performance profiling on cloud-hosted device**
After compiling models from step 1. Models can be profiled model on-device using the
`target_model`. Note that this scripts runs the model on a device automatically
provisioned in the cloud. Once the job is submitted, you can navigate to a
provided job URL to view a variety of on-device performance metrics.
```python
profile_job = hub.submit_profile_job(
model=target_model,
device=device,
)
```
Step 3: **Verify on-device accuracy**
To verify the accuracy of the model on-device, you can run on-device inference
on sample input data on the same cloud hosted device.
```python
input_data = torch_model.sample_inputs()
inference_job = hub.submit_inference_job(
model=target_model,
device=device,
inputs=input_data,
)
on_device_output = inference_job.download_output_data()
```
With the output of the model, you can compute like PSNR, relative errors or
spot check the output with expected output.
**Note**: This on-device profiling and inference requires access to Qualcomm®
AI Hub. [Sign up for access](https://myaccount.qualcomm.com/signup).
## Deploying compiled model to Android
The models can be deployed using multiple runtimes:
- TensorFlow Lite (`.tflite` export): [This
tutorial](https://www.tensorflow.org/lite/android/quickstart) provides a
guide to deploy the .tflite model in an Android application.
- QNN (`.so` export ): This [sample
app](https://docs.qualcomm.com/bundle/publicresource/topics/80-63442-50/sample_app.html)
provides instructions on how to use the `.so` shared library in an Android application.
## View on Qualcomm® AI Hub
Get more details on Whisper-Small-En's performance across various devices [here](https://aihub.qualcomm.com/models/whisper_small_en).
Explore all available models on [Qualcomm® AI Hub](https://aihub.qualcomm.com/)
## License
* The license for the original implementation of Whisper-Small-En can be found
[here](https://github.com/huggingface/transformers/blob/v4.42.3/LICENSE).
* The license for the compiled assets for on-device deployment can be found [here](https://qaihub-public-assets.s3.us-west-2.amazonaws.com/qai-hub-models/Qualcomm+AI+Hub+Proprietary+License.pdf)
## References
* [Robust Speech Recognition via Large-Scale Weak Supervision](https://cdn.openai.com/papers/whisper.pdf)
* [Source Model Implementation](https://github.com/huggingface/transformers/tree/v4.42.3/src/transformers/models/whisper)
## Community
* Join [our AI Hub Slack community](https://aihub.qualcomm.com/community/slack) to collaborate, post questions and learn more about on-device AI.
* For questions or feedback please [reach out to us](mailto:ai-hub-support@qti.qualcomm.com).
|
Testament200156/MakeGemma3-abliterated-Improved
|
Testament200156
| 2025-08-26T17:32:16Z | 0 | 2 |
transformers
|
[
"transformers",
"safetensors",
"gguf",
"gemma3",
"image-text-to-text",
"mergekit",
"merge",
"conversational",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
image-text-to-text
| 2025-08-26T13:34:21Z |
---
base_model: []
library_name: transformers
tags:
- mergekit
- merge
---
# MakeGemma3
This is a merge of pre-trained language models created using [mergekit](https://github.com/cg123/mergekit).
This integrated model significantly improves multilingual support and linguistic consistency, addressing the shortcomings of my previously submitted integrated model.
It leverages general knowledge and medical expertise to provide diverse information.
Furthermore, through multi-stage model integration, it preserves the uncensored nature of the original model.
When interpreting visual content, system prompts must be used to encourage careful analysis.
I have created a GGUF, so please check the GGUF folder.
Performance evaluation of this model's mmproj is currently under verification, so it might be best if you perform the conversion yourself.
## Merge Details
### Merge Method
This model was merged using the NuSLERP merge method.
### Models Merged
The following models were included in the merge:
* MakeGemma3 models were included in the merge:
(MakeGemma3)- * drwlf/medgemma-27b-it-abliterated
(MakeGemma3)- * test_base (summykai/gemma3-27b-abliterated-dpo with additional layers added)
* Gemma3 (unsloth models gemma3 and MedGemma)
### Configuration
The following YAML configuration was used to produce this model:
```yaml
models:
- model: Gemma3
parameters:
weight: 1.618033988749
- model: MakeGemma3
parameters:
weight: 1.0
merge_method: nuslerp
tokenizer_source: unsloth/gemma-3-27b-it
dtype: bfloat16
```
|
basmazouaoui/vit-brain-tumor-classifier
|
basmazouaoui
| 2025-08-26T17:30:51Z | 19 | 0 |
transformers
|
[
"transformers",
"safetensors",
"vit",
"image-classification",
"generated_from_trainer",
"base_model:google/vit-base-patch16-224-in21k",
"base_model:finetune:google/vit-base-patch16-224-in21k",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2025-08-22T16:57:39Z |
---
library_name: transformers
license: apache-2.0
base_model: google/vit-base-patch16-224-in21k
tags:
- generated_from_trainer
metrics:
- accuracy
- f1
- precision
- recall
model-index:
- name: vit-brain-tumor-classifier
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# vit-brain-tumor-classifier
This model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1088
- Accuracy: 0.9784
- F1: 0.9784
- Precision: 0.9786
- Recall: 0.9784
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 128
- eval_batch_size: 128
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 400
- num_epochs: 15
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 | Precision | Recall |
|:-------------:|:-------:|:----:|:---------------:|:--------:|:------:|:---------:|:------:|
| No log | 0.3704 | 10 | 0.7814 | 0.8688 | 0.8663 | 0.8687 | 0.8688 |
| No log | 0.7407 | 20 | 0.7700 | 0.8705 | 0.8688 | 0.8730 | 0.8705 |
| No log | 1.1111 | 30 | 0.7496 | 0.8740 | 0.8718 | 0.8744 | 0.8740 |
| No log | 1.4815 | 40 | 0.7225 | 0.8801 | 0.8782 | 0.8800 | 0.8801 |
| 0.7381 | 1.8519 | 50 | 0.6878 | 0.8871 | 0.8854 | 0.8865 | 0.8871 |
| 0.7381 | 2.2222 | 60 | 0.6538 | 0.8924 | 0.8915 | 0.8958 | 0.8924 |
| 0.7381 | 2.5926 | 70 | 0.6106 | 0.9011 | 0.8992 | 0.8999 | 0.9011 |
| 0.7381 | 2.9630 | 80 | 0.5693 | 0.9038 | 0.9030 | 0.9048 | 0.9038 |
| 0.7381 | 3.3333 | 90 | 0.5374 | 0.9003 | 0.8995 | 0.9035 | 0.9003 |
| 0.5721 | 3.7037 | 100 | 0.4876 | 0.9186 | 0.9183 | 0.9201 | 0.9186 |
| 0.5721 | 4.0741 | 110 | 0.4501 | 0.9186 | 0.9186 | 0.9213 | 0.9186 |
| 0.5721 | 4.4444 | 120 | 0.4070 | 0.9379 | 0.9377 | 0.9380 | 0.9379 |
| 0.5721 | 4.8148 | 130 | 0.3745 | 0.9414 | 0.9415 | 0.9424 | 0.9414 |
| 0.5721 | 5.1852 | 140 | 0.3771 | 0.9291 | 0.9287 | 0.9317 | 0.9291 |
| 0.3795 | 5.5556 | 150 | 0.3583 | 0.9309 | 0.9307 | 0.9346 | 0.9309 |
| 0.3795 | 5.9259 | 160 | 0.3111 | 0.9536 | 0.9536 | 0.9542 | 0.9536 |
| 0.3795 | 6.2963 | 170 | 0.2912 | 0.9545 | 0.9545 | 0.9548 | 0.9545 |
| 0.3795 | 6.6667 | 180 | 0.2777 | 0.9519 | 0.9512 | 0.9518 | 0.9519 |
| 0.3795 | 7.0370 | 190 | 0.2622 | 0.9545 | 0.9538 | 0.9551 | 0.9545 |
| 0.252 | 7.4074 | 200 | 0.2558 | 0.9493 | 0.9484 | 0.9498 | 0.9493 |
| 0.252 | 7.7778 | 210 | 0.2456 | 0.9458 | 0.9451 | 0.9474 | 0.9458 |
| 0.252 | 8.1481 | 220 | 0.2107 | 0.9580 | 0.9581 | 0.9582 | 0.9580 |
| 0.252 | 8.5185 | 230 | 0.2068 | 0.9563 | 0.9564 | 0.9568 | 0.9563 |
| 0.252 | 8.8889 | 240 | 0.1974 | 0.9606 | 0.9610 | 0.9626 | 0.9606 |
| 0.1612 | 9.2593 | 250 | 0.1801 | 0.9676 | 0.9678 | 0.9685 | 0.9676 |
| 0.1612 | 9.6296 | 260 | 0.1684 | 0.9703 | 0.9705 | 0.9715 | 0.9703 |
| 0.1612 | 10.0 | 270 | 0.1627 | 0.9685 | 0.9685 | 0.9689 | 0.9685 |
| 0.1612 | 10.3704 | 280 | 0.1659 | 0.9624 | 0.9623 | 0.9630 | 0.9624 |
| 0.1612 | 10.7407 | 290 | 0.1358 | 0.9755 | 0.9755 | 0.9757 | 0.9755 |
| 0.1 | 11.1111 | 300 | 0.1759 | 0.9528 | 0.9536 | 0.9587 | 0.9528 |
| 0.1 | 11.4815 | 310 | 0.1377 | 0.9711 | 0.9713 | 0.9721 | 0.9711 |
| 0.1 | 11.8519 | 320 | 0.1721 | 0.9624 | 0.9624 | 0.9636 | 0.9624 |
| 0.1 | 12.2222 | 330 | 0.1428 | 0.9650 | 0.9649 | 0.9657 | 0.9650 |
| 0.1 | 12.5926 | 340 | 0.1296 | 0.9755 | 0.9755 | 0.9759 | 0.9755 |
| 0.0674 | 12.9630 | 350 | 0.1432 | 0.9641 | 0.9638 | 0.9649 | 0.9641 |
| 0.0674 | 13.3333 | 360 | 0.1405 | 0.9685 | 0.9684 | 0.9690 | 0.9685 |
| 0.0674 | 13.7037 | 370 | 0.1376 | 0.9685 | 0.9683 | 0.9689 | 0.9685 |
| 0.0674 | 14.0741 | 380 | 0.1251 | 0.9703 | 0.9702 | 0.9704 | 0.9703 |
| 0.0674 | 14.4444 | 390 | 0.1375 | 0.9676 | 0.9680 | 0.9702 | 0.9676 |
| 0.055 | 14.8148 | 400 | 0.1175 | 0.9773 | 0.9773 | 0.9780 | 0.9773 |
### Framework versions
- Transformers 4.52.4
- Pytorch 2.6.0+cu124
- Datasets 3.6.0
- Tokenizers 0.21.2
|
unitova/blockassist-bc-zealous_sneaky_raven_1756227677
|
unitova
| 2025-08-26T17:30:47Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"zealous sneaky raven",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-26T17:30:44Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- zealous sneaky raven
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Elowenw/blockassist-bc-restless_galloping_tarantula_1756227975
|
Elowenw
| 2025-08-26T17:27:43Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"restless galloping tarantula",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-26T17:27:35Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- restless galloping tarantula
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
sa7270/harm30_fin20_l9
|
sa7270
| 2025-08-26T17:27:23Z | 29 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"trl",
"sft",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-23T00:18:47Z |
---
library_name: transformers
tags:
- trl
- sft
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
New-Clip-Mano-ktk-viral-video-kissing/Original.full.videos.Mano.ktk.kissing.Viral.Video.Official.Tutorial
|
New-Clip-Mano-ktk-viral-video-kissing
| 2025-08-26T17:26:08Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-08-26T17:25:58Z |
<animated-image data-catalyst=""><a href="https://tinyurl.com/mdfprj9k?viral-video" rel="nofollow" data-target="animated-image.originalLink"><img src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" alt="Foo" data-canonical-src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" style="max-width: 100%; display: inline-block;" data-target="animated-image.originalImage"></a>
|
Rico-Yangzm/Llama-2-7b-chat-v2_5306-v1
|
Rico-Yangzm
| 2025-08-26T17:26:00Z | 0 | 0 |
peft
|
[
"peft",
"safetensors",
"base_model:adapter:unsloth/mistral-nemo-instruct-2407-bnb-4bit",
"lora",
"sft",
"transformers",
"trl",
"unsloth",
"text-generation",
"conversational",
"arxiv:1910.09700",
"region:us"
] |
text-generation
| 2025-08-26T17:15:50Z |
---
base_model: unsloth/mistral-nemo-instruct-2407-bnb-4bit
library_name: peft
pipeline_tag: text-generation
tags:
- base_model:adapter:unsloth/mistral-nemo-instruct-2407-bnb-4bit
- lora
- sft
- transformers
- trl
- unsloth
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.17.1
|
openai/gpt-oss-120b
|
openai
| 2025-08-26T17:25:03Z | 1,722,690 | 3,599 |
transformers
|
[
"transformers",
"safetensors",
"gpt_oss",
"text-generation",
"vllm",
"conversational",
"arxiv:2508.10925",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"8-bit",
"mxfp4",
"region:us"
] |
text-generation
| 2025-08-04T22:33:06Z |
---
license: apache-2.0
pipeline_tag: text-generation
library_name: transformers
tags:
- vllm
---
<p align="center">
<img alt="gpt-oss-120b" src="https://raw.githubusercontent.com/openai/gpt-oss/main/docs/gpt-oss-120b.svg">
</p>
<p align="center">
<a href="https://gpt-oss.com"><strong>Try gpt-oss</strong></a> ·
<a href="https://cookbook.openai.com/topic/gpt-oss"><strong>Guides</strong></a> ·
<a href="https://arxiv.org/abs/2508.10925"><strong>Model card</strong></a> ·
<a href="https://openai.com/index/introducing-gpt-oss/"><strong>OpenAI blog</strong></a>
</p>
<br>
Welcome to the gpt-oss series, [OpenAI’s open-weight models](https://openai.com/open-models) designed for powerful reasoning, agentic tasks, and versatile developer use cases.
We’re releasing two flavors of these open models:
- `gpt-oss-120b` — for production, general purpose, high reasoning use cases that fit into a single 80GB GPU (like NVIDIA H100 or AMD MI300X) (117B parameters with 5.1B active parameters)
- `gpt-oss-20b` — for lower latency, and local or specialized use cases (21B parameters with 3.6B active parameters)
Both models were trained on our [harmony response format](https://github.com/openai/harmony) and should only be used with the harmony format as it will not work correctly otherwise.
> [!NOTE]
> This model card is dedicated to the larger `gpt-oss-120b` model. Check out [`gpt-oss-20b`](https://huggingface.co/openai/gpt-oss-20b) for the smaller model.
# Highlights
* **Permissive Apache 2.0 license:** Build freely without copyleft restrictions or patent risk—ideal for experimentation, customization, and commercial deployment.
* **Configurable reasoning effort:** Easily adjust the reasoning effort (low, medium, high) based on your specific use case and latency needs.
* **Full chain-of-thought:** Gain complete access to the model’s reasoning process, facilitating easier debugging and increased trust in outputs. It’s not intended to be shown to end users.
* **Fine-tunable:** Fully customize models to your specific use case through parameter fine-tuning.
* **Agentic capabilities:** Use the models’ native capabilities for function calling, [web browsing](https://github.com/openai/gpt-oss/tree/main?tab=readme-ov-file#browser), [Python code execution](https://github.com/openai/gpt-oss/tree/main?tab=readme-ov-file#python), and Structured Outputs.
* **MXFP4 quantization:** The models were post-trained with MXFP4 quantization of the MoE weights, making `gpt-oss-120b` run on a single 80GB GPU (like NVIDIA H100 or AMD MI300X) and the `gpt-oss-20b` model run within 16GB of memory. All evals were performed with the same MXFP4 quantization.
---
# Inference examples
## Transformers
You can use `gpt-oss-120b` and `gpt-oss-20b` with Transformers. If you use the Transformers chat template, it will automatically apply the [harmony response format](https://github.com/openai/harmony). If you use `model.generate` directly, you need to apply the harmony format manually using the chat template or use our [openai-harmony](https://github.com/openai/harmony) package.
To get started, install the necessary dependencies to setup your environment:
```
pip install -U transformers kernels torch
```
Once, setup you can proceed to run the model by running the snippet below:
```py
from transformers import pipeline
import torch
model_id = "openai/gpt-oss-120b"
pipe = pipeline(
"text-generation",
model=model_id,
torch_dtype="auto",
device_map="auto",
)
messages = [
{"role": "user", "content": "Explain quantum mechanics clearly and concisely."},
]
outputs = pipe(
messages,
max_new_tokens=256,
)
print(outputs[0]["generated_text"][-1])
```
Alternatively, you can run the model via [`Transformers Serve`](https://huggingface.co/docs/transformers/main/serving) to spin up a OpenAI-compatible webserver:
```
transformers serve
transformers chat localhost:8000 --model-name-or-path openai/gpt-oss-120b
```
[Learn more about how to use gpt-oss with Transformers.](https://cookbook.openai.com/articles/gpt-oss/run-transformers)
## vLLM
vLLM recommends using [uv](https://docs.astral.sh/uv/) for Python dependency management. You can use vLLM to spin up an OpenAI-compatible webserver. The following command will automatically download the model and start the server.
```bash
uv pip install --pre vllm==0.10.1+gptoss \
--extra-index-url https://wheels.vllm.ai/gpt-oss/ \
--extra-index-url https://download.pytorch.org/whl/nightly/cu128 \
--index-strategy unsafe-best-match
vllm serve openai/gpt-oss-120b
```
[Learn more about how to use gpt-oss with vLLM.](https://cookbook.openai.com/articles/gpt-oss/run-vllm)
## PyTorch / Triton
To learn about how to use this model with PyTorch and Triton, check out our [reference implementations in the gpt-oss repository](https://github.com/openai/gpt-oss?tab=readme-ov-file#reference-pytorch-implementation).
## Ollama
If you are trying to run gpt-oss on consumer hardware, you can use Ollama by running the following commands after [installing Ollama](https://ollama.com/download).
```bash
# gpt-oss-120b
ollama pull gpt-oss:120b
ollama run gpt-oss:120b
```
[Learn more about how to use gpt-oss with Ollama.](https://cookbook.openai.com/articles/gpt-oss/run-locally-ollama)
#### LM Studio
If you are using [LM Studio](https://lmstudio.ai/) you can use the following commands to download.
```bash
# gpt-oss-120b
lms get openai/gpt-oss-120b
```
Check out our [awesome list](https://github.com/openai/gpt-oss/blob/main/awesome-gpt-oss.md) for a broader collection of gpt-oss resources and inference partners.
---
# Download the model
You can download the model weights from the [Hugging Face Hub](https://huggingface.co/collections/openai/gpt-oss-68911959590a1634ba11c7a4) directly from Hugging Face CLI:
```shell
# gpt-oss-120b
huggingface-cli download openai/gpt-oss-120b --include "original/*" --local-dir gpt-oss-120b/
pip install gpt-oss
python -m gpt_oss.chat model/
```
# Reasoning levels
You can adjust the reasoning level that suits your task across three levels:
* **Low:** Fast responses for general dialogue.
* **Medium:** Balanced speed and detail.
* **High:** Deep and detailed analysis.
The reasoning level can be set in the system prompts, e.g., "Reasoning: high".
# Tool use
The gpt-oss models are excellent for:
* Web browsing (using built-in browsing tools)
* Function calling with defined schemas
* Agentic operations like browser tasks
# Fine-tuning
Both gpt-oss models can be fine-tuned for a variety of specialized use cases.
This larger model `gpt-oss-120b` can be fine-tuned on a single H100 node, whereas the smaller [`gpt-oss-20b`](https://huggingface.co/openai/gpt-oss-20b) can even be fine-tuned on consumer hardware.
# Citation
```bibtex
@misc{openai2025gptoss120bgptoss20bmodel,
title={gpt-oss-120b & gpt-oss-20b Model Card},
author={OpenAI},
year={2025},
eprint={2508.10925},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2508.10925},
}
```
|
qualcomm/Swin-Small
|
qualcomm
| 2025-08-26T17:22:40Z | 36 | 0 |
pytorch
|
[
"pytorch",
"tflite",
"backbone",
"android",
"image-classification",
"arxiv:2103.14030",
"license:other",
"region:us"
] |
image-classification
| 2024-02-25T23:06:40Z |
---
library_name: pytorch
license: other
tags:
- backbone
- android
pipeline_tag: image-classification
---

# Swin-Small: Optimized for Mobile Deployment
## Imagenet classifier and general purpose backbone
SwinSmall is a machine learning model that can classify images from the Imagenet dataset. It can also be used as a backbone in building more complex models for specific use cases.
This model is an implementation of Swin-Small found [here](https://github.com/pytorch/vision/blob/main/torchvision/models/swin_transformer.py).
This repository provides scripts to run Swin-Small on Qualcomm® devices.
More details on model performance across various devices, can be found
[here](https://aihub.qualcomm.com/models/swin_small).
### Model Details
- **Model Type:** Model_use_case.image_classification
- **Model Stats:**
- Model checkpoint: Imagenet
- Input resolution: 224x224
- Number of parameters: 50.4M
- Model size (float): 193 MB
- Model size (w8a16): 52.5 MB
| Model | Precision | Device | Chipset | Target Runtime | Inference Time (ms) | Peak Memory Range (MB) | Primary Compute Unit | Target Model
|---|---|---|---|---|---|---|---|---|
| Swin-Small | float | QCS8275 (Proxy) | Qualcomm® QCS8275 (Proxy) | TFLITE | 44.225 ms | 0 - 267 MB | NPU | [Swin-Small.tflite](https://huggingface.co/qualcomm/Swin-Small/blob/main/Swin-Small.tflite) |
| Swin-Small | float | QCS8275 (Proxy) | Qualcomm® QCS8275 (Proxy) | QNN_DLC | 38.426 ms | 1 - 511 MB | NPU | [Swin-Small.dlc](https://huggingface.co/qualcomm/Swin-Small/blob/main/Swin-Small.dlc) |
| Swin-Small | float | QCS8450 (Proxy) | Qualcomm® QCS8450 (Proxy) | TFLITE | 23.323 ms | 0 - 259 MB | NPU | [Swin-Small.tflite](https://huggingface.co/qualcomm/Swin-Small/blob/main/Swin-Small.tflite) |
| Swin-Small | float | QCS8450 (Proxy) | Qualcomm® QCS8450 (Proxy) | QNN_DLC | 24.164 ms | 1 - 230 MB | NPU | [Swin-Small.dlc](https://huggingface.co/qualcomm/Swin-Small/blob/main/Swin-Small.dlc) |
| Swin-Small | float | QCS8550 (Proxy) | Qualcomm® QCS8550 (Proxy) | TFLITE | 18.459 ms | 0 - 29 MB | NPU | [Swin-Small.tflite](https://huggingface.co/qualcomm/Swin-Small/blob/main/Swin-Small.tflite) |
| Swin-Small | float | QCS8550 (Proxy) | Qualcomm® QCS8550 (Proxy) | QNN_DLC | 15.703 ms | 0 - 58 MB | NPU | [Swin-Small.dlc](https://huggingface.co/qualcomm/Swin-Small/blob/main/Swin-Small.dlc) |
| Swin-Small | float | QCS9075 (Proxy) | Qualcomm® QCS9075 (Proxy) | TFLITE | 20.523 ms | 0 - 268 MB | NPU | [Swin-Small.tflite](https://huggingface.co/qualcomm/Swin-Small/blob/main/Swin-Small.tflite) |
| Swin-Small | float | QCS9075 (Proxy) | Qualcomm® QCS9075 (Proxy) | QNN_DLC | 17.785 ms | 1 - 532 MB | NPU | [Swin-Small.dlc](https://huggingface.co/qualcomm/Swin-Small/blob/main/Swin-Small.dlc) |
| Swin-Small | float | SA7255P ADP | Qualcomm® SA7255P | TFLITE | 44.225 ms | 0 - 267 MB | NPU | [Swin-Small.tflite](https://huggingface.co/qualcomm/Swin-Small/blob/main/Swin-Small.tflite) |
| Swin-Small | float | SA7255P ADP | Qualcomm® SA7255P | QNN_DLC | 38.426 ms | 1 - 511 MB | NPU | [Swin-Small.dlc](https://huggingface.co/qualcomm/Swin-Small/blob/main/Swin-Small.dlc) |
| Swin-Small | float | SA8255 (Proxy) | Qualcomm® SA8255P (Proxy) | TFLITE | 18.539 ms | 0 - 29 MB | NPU | [Swin-Small.tflite](https://huggingface.co/qualcomm/Swin-Small/blob/main/Swin-Small.tflite) |
| Swin-Small | float | SA8255 (Proxy) | Qualcomm® SA8255P (Proxy) | QNN_DLC | 15.803 ms | 0 - 57 MB | NPU | [Swin-Small.dlc](https://huggingface.co/qualcomm/Swin-Small/blob/main/Swin-Small.dlc) |
| Swin-Small | float | SA8295P ADP | Qualcomm® SA8295P | TFLITE | 26.394 ms | 0 - 259 MB | NPU | [Swin-Small.tflite](https://huggingface.co/qualcomm/Swin-Small/blob/main/Swin-Small.tflite) |
| Swin-Small | float | SA8295P ADP | Qualcomm® SA8295P | QNN_DLC | 23.278 ms | 1 - 510 MB | NPU | [Swin-Small.dlc](https://huggingface.co/qualcomm/Swin-Small/blob/main/Swin-Small.dlc) |
| Swin-Small | float | SA8650 (Proxy) | Qualcomm® SA8650P (Proxy) | TFLITE | 18.499 ms | 0 - 29 MB | NPU | [Swin-Small.tflite](https://huggingface.co/qualcomm/Swin-Small/blob/main/Swin-Small.tflite) |
| Swin-Small | float | SA8650 (Proxy) | Qualcomm® SA8650P (Proxy) | QNN_DLC | 15.903 ms | 0 - 59 MB | NPU | [Swin-Small.dlc](https://huggingface.co/qualcomm/Swin-Small/blob/main/Swin-Small.dlc) |
| Swin-Small | float | SA8775P ADP | Qualcomm® SA8775P | TFLITE | 20.523 ms | 0 - 268 MB | NPU | [Swin-Small.tflite](https://huggingface.co/qualcomm/Swin-Small/blob/main/Swin-Small.tflite) |
| Swin-Small | float | SA8775P ADP | Qualcomm® SA8775P | QNN_DLC | 17.785 ms | 1 - 532 MB | NPU | [Swin-Small.dlc](https://huggingface.co/qualcomm/Swin-Small/blob/main/Swin-Small.dlc) |
| Swin-Small | float | Samsung Galaxy S23 | Snapdragon® 8 Gen 2 Mobile | TFLITE | 18.581 ms | 0 - 30 MB | NPU | [Swin-Small.tflite](https://huggingface.co/qualcomm/Swin-Small/blob/main/Swin-Small.tflite) |
| Swin-Small | float | Samsung Galaxy S23 | Snapdragon® 8 Gen 2 Mobile | QNN_DLC | 15.835 ms | 0 - 61 MB | NPU | [Swin-Small.dlc](https://huggingface.co/qualcomm/Swin-Small/blob/main/Swin-Small.dlc) |
| Swin-Small | float | Samsung Galaxy S23 | Snapdragon® 8 Gen 2 Mobile | ONNX | 15.849 ms | 1 - 34 MB | NPU | [Swin-Small.onnx.zip](https://huggingface.co/qualcomm/Swin-Small/blob/main/Swin-Small.onnx.zip) |
| Swin-Small | float | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | TFLITE | 12.422 ms | 0 - 267 MB | NPU | [Swin-Small.tflite](https://huggingface.co/qualcomm/Swin-Small/blob/main/Swin-Small.tflite) |
| Swin-Small | float | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | QNN_DLC | 10.394 ms | 1 - 744 MB | NPU | [Swin-Small.dlc](https://huggingface.co/qualcomm/Swin-Small/blob/main/Swin-Small.dlc) |
| Swin-Small | float | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | ONNX | 10.72 ms | 1 - 251 MB | NPU | [Swin-Small.onnx.zip](https://huggingface.co/qualcomm/Swin-Small/blob/main/Swin-Small.onnx.zip) |
| Swin-Small | float | Snapdragon 8 Elite QRD | Snapdragon® 8 Elite Mobile | TFLITE | 12.17 ms | 0 - 259 MB | NPU | [Swin-Small.tflite](https://huggingface.co/qualcomm/Swin-Small/blob/main/Swin-Small.tflite) |
| Swin-Small | float | Snapdragon 8 Elite QRD | Snapdragon® 8 Elite Mobile | QNN_DLC | 9.39 ms | 1 - 529 MB | NPU | [Swin-Small.dlc](https://huggingface.co/qualcomm/Swin-Small/blob/main/Swin-Small.dlc) |
| Swin-Small | float | Snapdragon 8 Elite QRD | Snapdragon® 8 Elite Mobile | ONNX | 9.674 ms | 1 - 247 MB | NPU | [Swin-Small.onnx.zip](https://huggingface.co/qualcomm/Swin-Small/blob/main/Swin-Small.onnx.zip) |
| Swin-Small | float | Snapdragon X Elite CRD | Snapdragon® X Elite | QNN_DLC | 16.628 ms | 564 - 564 MB | NPU | [Swin-Small.dlc](https://huggingface.co/qualcomm/Swin-Small/blob/main/Swin-Small.dlc) |
| Swin-Small | float | Snapdragon X Elite CRD | Snapdragon® X Elite | ONNX | 18.626 ms | 100 - 100 MB | NPU | [Swin-Small.onnx.zip](https://huggingface.co/qualcomm/Swin-Small/blob/main/Swin-Small.onnx.zip) |
| Swin-Small | w8a16 | QCS8275 (Proxy) | Qualcomm® QCS8275 (Proxy) | QNN_DLC | 28.66 ms | 0 - 277 MB | NPU | [Swin-Small.dlc](https://huggingface.co/qualcomm/Swin-Small/blob/main/Swin-Small_w8a16.dlc) |
| Swin-Small | w8a16 | QCS8450 (Proxy) | Qualcomm® QCS8450 (Proxy) | QNN_DLC | 19.197 ms | 0 - 284 MB | NPU | [Swin-Small.dlc](https://huggingface.co/qualcomm/Swin-Small/blob/main/Swin-Small_w8a16.dlc) |
| Swin-Small | w8a16 | QCS8550 (Proxy) | Qualcomm® QCS8550 (Proxy) | QNN_DLC | 15.608 ms | 0 - 74 MB | NPU | [Swin-Small.dlc](https://huggingface.co/qualcomm/Swin-Small/blob/main/Swin-Small_w8a16.dlc) |
| Swin-Small | w8a16 | QCS9075 (Proxy) | Qualcomm® QCS9075 (Proxy) | QNN_DLC | 16.059 ms | 0 - 273 MB | NPU | [Swin-Small.dlc](https://huggingface.co/qualcomm/Swin-Small/blob/main/Swin-Small_w8a16.dlc) |
| Swin-Small | w8a16 | RB3 Gen 2 (Proxy) | Qualcomm® QCS6490 (Proxy) | QNN_DLC | 46.578 ms | 0 - 710 MB | NPU | [Swin-Small.dlc](https://huggingface.co/qualcomm/Swin-Small/blob/main/Swin-Small_w8a16.dlc) |
| Swin-Small | w8a16 | SA7255P ADP | Qualcomm® SA7255P | QNN_DLC | 28.66 ms | 0 - 277 MB | NPU | [Swin-Small.dlc](https://huggingface.co/qualcomm/Swin-Small/blob/main/Swin-Small_w8a16.dlc) |
| Swin-Small | w8a16 | SA8255 (Proxy) | Qualcomm® SA8255P (Proxy) | QNN_DLC | 15.57 ms | 0 - 74 MB | NPU | [Swin-Small.dlc](https://huggingface.co/qualcomm/Swin-Small/blob/main/Swin-Small_w8a16.dlc) |
| Swin-Small | w8a16 | SA8295P ADP | Qualcomm® SA8295P | QNN_DLC | 18.497 ms | 0 - 191 MB | NPU | [Swin-Small.dlc](https://huggingface.co/qualcomm/Swin-Small/blob/main/Swin-Small_w8a16.dlc) |
| Swin-Small | w8a16 | SA8650 (Proxy) | Qualcomm® SA8650P (Proxy) | QNN_DLC | 15.654 ms | 0 - 62 MB | NPU | [Swin-Small.dlc](https://huggingface.co/qualcomm/Swin-Small/blob/main/Swin-Small_w8a16.dlc) |
| Swin-Small | w8a16 | SA8775P ADP | Qualcomm® SA8775P | QNN_DLC | 16.059 ms | 0 - 273 MB | NPU | [Swin-Small.dlc](https://huggingface.co/qualcomm/Swin-Small/blob/main/Swin-Small_w8a16.dlc) |
| Swin-Small | w8a16 | Samsung Galaxy S23 | Snapdragon® 8 Gen 2 Mobile | QNN_DLC | 15.683 ms | 0 - 68 MB | NPU | [Swin-Small.dlc](https://huggingface.co/qualcomm/Swin-Small/blob/main/Swin-Small_w8a16.dlc) |
| Swin-Small | w8a16 | Samsung Galaxy S23 | Snapdragon® 8 Gen 2 Mobile | ONNX | 115.169 ms | 274 - 438 MB | NPU | [Swin-Small.onnx.zip](https://huggingface.co/qualcomm/Swin-Small/blob/main/Swin-Small_w8a16.onnx.zip) |
| Swin-Small | w8a16 | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | QNN_DLC | 10.622 ms | 0 - 293 MB | NPU | [Swin-Small.dlc](https://huggingface.co/qualcomm/Swin-Small/blob/main/Swin-Small_w8a16.dlc) |
| Swin-Small | w8a16 | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | ONNX | 81.676 ms | 266 - 512 MB | NPU | [Swin-Small.onnx.zip](https://huggingface.co/qualcomm/Swin-Small/blob/main/Swin-Small_w8a16.onnx.zip) |
| Swin-Small | w8a16 | Snapdragon 8 Elite QRD | Snapdragon® 8 Elite Mobile | QNN_DLC | 9.713 ms | 0 - 274 MB | NPU | [Swin-Small.dlc](https://huggingface.co/qualcomm/Swin-Small/blob/main/Swin-Small_w8a16.dlc) |
| Swin-Small | w8a16 | Snapdragon 8 Elite QRD | Snapdragon® 8 Elite Mobile | ONNX | 66.264 ms | 282 - 489 MB | NPU | [Swin-Small.onnx.zip](https://huggingface.co/qualcomm/Swin-Small/blob/main/Swin-Small_w8a16.onnx.zip) |
| Swin-Small | w8a16 | Snapdragon X Elite CRD | Snapdragon® X Elite | QNN_DLC | 16.495 ms | 184 - 184 MB | NPU | [Swin-Small.dlc](https://huggingface.co/qualcomm/Swin-Small/blob/main/Swin-Small_w8a16.dlc) |
| Swin-Small | w8a16 | Snapdragon X Elite CRD | Snapdragon® X Elite | ONNX | 98.354 ms | 461 - 461 MB | NPU | [Swin-Small.onnx.zip](https://huggingface.co/qualcomm/Swin-Small/blob/main/Swin-Small_w8a16.onnx.zip) |
## Installation
Install the package via pip:
```bash
pip install qai-hub-models
```
## Configure Qualcomm® AI Hub to run this model on a cloud-hosted device
Sign-in to [Qualcomm® AI Hub](https://app.aihub.qualcomm.com/) with your
Qualcomm® ID. Once signed in navigate to `Account -> Settings -> API Token`.
With this API token, you can configure your client to run models on the cloud
hosted devices.
```bash
qai-hub configure --api_token API_TOKEN
```
Navigate to [docs](https://app.aihub.qualcomm.com/docs/) for more information.
## Demo off target
The package contains a simple end-to-end demo that downloads pre-trained
weights and runs this model on a sample input.
```bash
python -m qai_hub_models.models.swin_small.demo
```
The above demo runs a reference implementation of pre-processing, model
inference, and post processing.
**NOTE**: If you want running in a Jupyter Notebook or Google Colab like
environment, please add the following to your cell (instead of the above).
```
%run -m qai_hub_models.models.swin_small.demo
```
### Run model on a cloud-hosted device
In addition to the demo, you can also run the model on a cloud-hosted Qualcomm®
device. This script does the following:
* Performance check on-device on a cloud-hosted device
* Downloads compiled assets that can be deployed on-device for Android.
* Accuracy check between PyTorch and on-device outputs.
```bash
python -m qai_hub_models.models.swin_small.export
```
## How does this work?
This [export script](https://aihub.qualcomm.com/models/swin_small/qai_hub_models/models/Swin-Small/export.py)
leverages [Qualcomm® AI Hub](https://aihub.qualcomm.com/) to optimize, validate, and deploy this model
on-device. Lets go through each step below in detail:
Step 1: **Compile model for on-device deployment**
To compile a PyTorch model for on-device deployment, we first trace the model
in memory using the `jit.trace` and then call the `submit_compile_job` API.
```python
import torch
import qai_hub as hub
from qai_hub_models.models.swin_small import Model
# Load the model
torch_model = Model.from_pretrained()
# Device
device = hub.Device("Samsung Galaxy S24")
# Trace model
input_shape = torch_model.get_input_spec()
sample_inputs = torch_model.sample_inputs()
pt_model = torch.jit.trace(torch_model, [torch.tensor(data[0]) for _, data in sample_inputs.items()])
# Compile model on a specific device
compile_job = hub.submit_compile_job(
model=pt_model,
device=device,
input_specs=torch_model.get_input_spec(),
)
# Get target model to run on-device
target_model = compile_job.get_target_model()
```
Step 2: **Performance profiling on cloud-hosted device**
After compiling models from step 1. Models can be profiled model on-device using the
`target_model`. Note that this scripts runs the model on a device automatically
provisioned in the cloud. Once the job is submitted, you can navigate to a
provided job URL to view a variety of on-device performance metrics.
```python
profile_job = hub.submit_profile_job(
model=target_model,
device=device,
)
```
Step 3: **Verify on-device accuracy**
To verify the accuracy of the model on-device, you can run on-device inference
on sample input data on the same cloud hosted device.
```python
input_data = torch_model.sample_inputs()
inference_job = hub.submit_inference_job(
model=target_model,
device=device,
inputs=input_data,
)
on_device_output = inference_job.download_output_data()
```
With the output of the model, you can compute like PSNR, relative errors or
spot check the output with expected output.
**Note**: This on-device profiling and inference requires access to Qualcomm®
AI Hub. [Sign up for access](https://myaccount.qualcomm.com/signup).
## Run demo on a cloud-hosted device
You can also run the demo on-device.
```bash
python -m qai_hub_models.models.swin_small.demo --eval-mode on-device
```
**NOTE**: If you want running in a Jupyter Notebook or Google Colab like
environment, please add the following to your cell (instead of the above).
```
%run -m qai_hub_models.models.swin_small.demo -- --eval-mode on-device
```
## Deploying compiled model to Android
The models can be deployed using multiple runtimes:
- TensorFlow Lite (`.tflite` export): [This
tutorial](https://www.tensorflow.org/lite/android/quickstart) provides a
guide to deploy the .tflite model in an Android application.
- QNN (`.so` export ): This [sample
app](https://docs.qualcomm.com/bundle/publicresource/topics/80-63442-50/sample_app.html)
provides instructions on how to use the `.so` shared library in an Android application.
## View on Qualcomm® AI Hub
Get more details on Swin-Small's performance across various devices [here](https://aihub.qualcomm.com/models/swin_small).
Explore all available models on [Qualcomm® AI Hub](https://aihub.qualcomm.com/)
## License
* The license for the original implementation of Swin-Small can be found
[here](https://github.com/pytorch/vision/blob/main/LICENSE).
* The license for the compiled assets for on-device deployment can be found [here](https://qaihub-public-assets.s3.us-west-2.amazonaws.com/qai-hub-models/Qualcomm+AI+Hub+Proprietary+License.pdf)
## References
* [Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://arxiv.org/abs/2103.14030)
* [Source Model Implementation](https://github.com/pytorch/vision/blob/main/torchvision/models/swin_transformer.py)
## Community
* Join [our AI Hub Slack community](https://aihub.qualcomm.com/community/slack) to collaborate, post questions and learn more about on-device AI.
* For questions or feedback please [reach out to us](mailto:ai-hub-support@qti.qualcomm.com).
|
zoeythanayot/gemma-4b-it-thai
|
zoeythanayot
| 2025-08-26T17:21:34Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"text-generation",
"causal-lm",
"chat",
"instruction-tuning",
"peft",
"lora",
"gemma",
"conversational",
"th",
"en",
"dataset:pythainlp/han-instruct-dataset-v4.0",
"base_model:google/gemma-3-4b-it",
"base_model:adapter:google/gemma-3-4b-it",
"license:other",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-26T17:06:05Z |
---
language:
- th
- en
license: other
tags:
- text-generation
- causal-lm
- chat
- instruction-tuning
- peft
- lora
- gemma
datasets:
- pythainlp/han-instruct-dataset-v4.0
library_name: transformers
pipeline_tag: text-generation
base_model:
- google/gemma-3-4b-it
model-index:
- name: gemma-3-4b-it-thai-lora (checkpoint-600)
results: []
---
# Gemma‑3‑4B‑it • Thai Instruct LoRA (checkpoint‑600)
> **Adapter for Thai instruction following on top of `google/gemma-3-4b-it`**. Trained with chat-style Thai data and standard SFT masking (loss only on assistant tokens).
## 📌 TL;DR
- **Method:** LoRA (PEFT) on attention + MLP blocks (`q_proj,k_proj,v_proj,o_proj,gate_proj,down_proj,up_proj`), `r=32, alpha=64, dropout=0.05`
- **Use cases:** Thai QA/explanation/summarization/coding help in chat format
- **Two ways to run:**
1) Load **adapter** with PEFT on top of the base model
2) **Merge** LoRA into base and serve a single model
---
## 🧭 Model Details
- **Base:** `google/gemma-3-4b-it` (decoder-only, instruction-tuned)
- **Languages:** Thai (primary), English (secondary)
- **Architecture:** Causal LM
- **Libraries:** `transformers`, `peft`, `bitsandbytes`
- **Chat template:** Gemma‑3 style (`<start_of_turn>user … <end_of_turn>` / `<start_of_turn>model …`)
> ⚠️ Gemma‑3 template has only `user` and `model` roles. Any `system` content is typically **prefixed into the first user turn** by the template.
---
## 🚀 Usage
### 1) Load as PEFT adapter
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
from peft import PeftModel
import torch
base_id = "google/gemma-3-4b-it"
adapter_id_or_path = "path-or-repo-to-this-adapter" # e.g., local folder with adapter_model.safetensors
tok = AutoTokenizer.from_pretrained(base_id, use_fast=True)
base = AutoModelForCausalLM.from_pretrained(base_id, torch_dtype=torch.float16, device_map="auto")
model = PeftModel.from_pretrained(base, adapter_id_or_path).eval()
messages = [
{"role": "user", "content": "อธิบาย Attention แบบสั้น เข้าใจง่าย และยกตัวอย่าง"},
]
prompt = tok.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
inputs = tok(prompt, return_tensors="pt").to(model.device)
with torch.no_grad():
out = model.generate(**inputs, max_new_tokens=256, do_sample=False,
eos_token_id=tok.eos_token_id, pad_token_id=tok.eos_token_id)
print(tok.decode(out[0], skip_special_tokens=True))
```
### 2) Merge adapter → single model
```python
merged = model.merge_and_unload().eval()
merged.save_pretrained("./gemma3-4b-thai-merged")
tok.save_pretrained("./gemma3-4b-thai-merged")
```
> If your checkpoint folder only has `optimizer.pt`, `scheduler.pt`, etc. (Trainer state) but **no `adapter_model.safetensors`**, export the adapter first:
> `trainer.model.save_pretrained("./gemma-4b-thai-lora")`
---
## 🗂️ Data
- **Primary:** `pythainlp/han-instruct-dataset-v4.0`
- **Format:** `messages=[{"role":"user|assistant","content":"..."}]`
- **Preprocessing:** Use `tokenizer.apply_chat_template(messages, tokenize=False)` then tokenize; mask labels to **-100 for prompts** and keep **real token ids for assistant spans** (loss only there).
---
## ⚙️ Training (example)
```python
from peft import LoraConfig, TaskType
lora_config = LoraConfig(
r=32, lora_alpha=64, lora_dropout=0.05, bias="none",
target_modules=["q_proj","k_proj","v_proj","o_proj","gate_proj","down_proj","up_proj"],
task_type=TaskType.CAUSAL_LM,
)
# Recommended: gradient_checkpointing=True, bf16 if available, optim="paged_adamw_8bit",
# cosine scheduler, warmup_ratio≈0.01, effective batch via gradient_accumulation_steps.
```
- **Precision:** prefer **BF16** on Ampere+ GPUs; otherwise FP16
- **Optimizer:** bitsandbytes `paged_adamw_8bit` to reduce optimizer memory
- **Note:** set `model.config.use_cache=False` during training with gradient checkpointing
---
## ✅ Intended Uses & Limitations
**Intended:** Thai instruction following, chat assistant, explanations, summarization, basic coding help.
**Limitations:** Possible hallucinations; domain‑critical use (medical/legal/finance) requires human review. For better language control, **repeat language constraints at the end of the user turn** or use a short Thai prefill after `<start_of_turn>model`.
---
## 📊 Evaluation
- Qualitative human eval on Thai tasks (fluency, helpfulness, instruction following)
- Optional quantitative: BLEU/ROUGE on curated Thai subsets (user‑defined)
---
## 🔐 License
- Derivative of `google/gemma-3-4b-it`. Follow Gemma‑3 license terms and dataset licenses.
- Users are responsible for compliance with original licenses and usage policies.
---
## 🙏 Acknowledgements & References
- Hugging Face **Chat templating**: https://huggingface.co/docs/transformers/main/en/chat_templating
- Transformers **Generation**: https://huggingface.co/docs/transformers/main/en/main_classes/text_generation
- **PEFT** (LoRA, merge & unload): https://github.com/huggingface/peft
- **bitsandbytes** optimizers: https://github.com/TimDettmers/bitsandbytes
- **Gemma** overview & prompts: https://ai.google.dev/gemma
- Dataset: https://huggingface.co/datasets/pythainlp/han-instruct-dataset-v4.0
---
## ✍️ Citation
If you use this adapter, please cite the base model and tools above. You may also cite this work as:
```
@misc{gemma3_thai_lora_2025,
title = {Gemma-3-4B-it Thai Instruct LoRA (checkpoint-600)},
author = {Your Name},
year = {2025},
note = {LoRA adapter on google/gemma-3-4b-it for Thai instruction following}
}
```
|
liukevin666/blockassist-bc-yawning_striped_cassowary_1756228814
|
liukevin666
| 2025-08-26T17:21:21Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"yawning striped cassowary",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-26T17:21:15Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- yawning striped cassowary
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
ggozzy/blockassist-bc-stubby_yapping_mandrill_1756228733
|
ggozzy
| 2025-08-26T17:19:57Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"stubby yapping mandrill",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-26T17:19:51Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- stubby yapping mandrill
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
vaguilar0124/HR.Agent.for.Prof
|
vaguilar0124
| 2025-08-26T17:19:01Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-08-26T17:17:36Z |
import gradio as gr
import textwrap
from datetime import datetime
# Scenario
SCENARIO = (
"A manager's highest-performing employee is discovered to have a history of workplace misconduct at their "
"previous job, a history that was not disclosed during the interview process. The employee is critical to a "
"major, ongoing project. Should HR ignore the misconduct to protect the company's immediate project goals and "
"reward employee loyalty, or terminate the employee to uphold the company's ethical standards and ensure a fair, "
"transparent workplace?"
)
DISCLAIMER = (
"⚠️ Disclaimer: This agent provides general HR guidance for educational purposes only and is not legal advice. "
"For real decisions, consult your organization's counsel and follow applicable laws and company policy."
)
# --- Core guidance blocks ---
def guidance_high_level():
return textwrap.dedent("""\
High-level guidance:
• Do not ignore the information — that undermines standards and creates risk.
• Do not rush to terminate solely based on past allegations. Verify facts.
• Run a fair, documented review aligned with policy and law.
• Manage project continuity in parallel to reduce disruption.
""")
def guidance_answers():
return {
"ignore": "❌ Ignoring credible misconduct is not recommended. It signals favoritism and risk.",
"terminate": "⚖️ Do not auto-terminate. Verify facts, check policy, and apply standards consistently.",
"investigate": "🔍 Yes, conduct a fair and timely investigation, with employee input.",
"project": "📂 Protect the project: implement knowledge transfer, backups, and coverage plans.",
"ethics": "🌐 Ethics vs results: uphold standards while balancing project continuity. Never sacrifice fairness."
}
KEYWORDS = {
"ignore": ["ignore", "look the other way"],
"terminate": ["terminate", "fire", "dismiss"],
"investigate": ["investigate", "review", "verify"],
"project": ["project", "deadline", "handoff", "transition"],
"ethics": ["ethics", "standards", "fair", "transparent"]
}
def route_intent(user_text: str):
t = user_text.lower()
for intent, keys in KEYWORDS.items():
if any(k in t for k in keys):
return intent
return "general"
def generate_response(message, history):
intent = route_intent(message)
answers = guidance_answers()
if message.strip().lower() in ("scenario",):
return SCENARIO
if message.strip().lower() in ("policy", "overview"):
return guidance_high_level()
if intent in answers:
return answers[intent] + "\n\n" + DISCLAIMER
else:
return f"{DISCLAIMER}\n\nRecommended next step: Begin a fair, fact-based review. Use 'policy' for high-level guidance."
# --- Gradio Chat UI ---
with gr.Blocks() as demo:
gr.Markdown("## 🤖 HR Ethics AI Agent")
gr.Markdown("Ask me questions about the HR scenario below.\n\n" + SCENARIO)
chatbot = gr.Chatbot()
msg = gr.Textbox(placeholder="Ask HR Agent a question...")
clear = gr.Button("Clear")
def respond(message, chat_history):
bot_message = generate_response(message, chat_history)
chat_history.append((message, bot_message))
return "", chat_history
msg.submit(respond, [msg, chatbot], [msg, chatbot])
clear.click(lambda: None, None, chatbot, queue=False)
demo.launch()
|
mradermacher/WeirdCompound-v1.6-24b-GGUF
|
mradermacher
| 2025-08-26T17:17:58Z | 188 | 0 |
transformers
|
[
"transformers",
"gguf",
"mergekit",
"merge",
"en",
"base_model:FlareRebellion/WeirdCompound-v1.6-24b",
"base_model:quantized:FlareRebellion/WeirdCompound-v1.6-24b",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2025-08-25T18:34:31Z |
---
base_model: FlareRebellion/WeirdCompound-v1.6-24b
language:
- en
library_name: transformers
mradermacher:
readme_rev: 1
quantized_by: mradermacher
tags:
- mergekit
- merge
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
<!-- ### quants: x-f16 Q4_K_S Q2_K Q8_0 Q6_K Q3_K_M Q3_K_S Q3_K_L Q4_K_M Q5_K_S Q5_K_M IQ4_XS -->
<!-- ### quants_skip: -->
<!-- ### skip_mmproj: -->
static quants of https://huggingface.co/FlareRebellion/WeirdCompound-v1.6-24b
<!-- provided-files -->
***For a convenient overview and download list, visit our [model page for this model](https://hf.tst.eu/model#WeirdCompound-v1.6-24b-GGUF).***
weighted/imatrix quants are available at https://huggingface.co/mradermacher/WeirdCompound-v1.6-24b-i1-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/WeirdCompound-v1.6-24b-GGUF/resolve/main/WeirdCompound-v1.6-24b.Q2_K.gguf) | Q2_K | 9.0 | |
| [GGUF](https://huggingface.co/mradermacher/WeirdCompound-v1.6-24b-GGUF/resolve/main/WeirdCompound-v1.6-24b.Q3_K_S.gguf) | Q3_K_S | 10.5 | |
| [GGUF](https://huggingface.co/mradermacher/WeirdCompound-v1.6-24b-GGUF/resolve/main/WeirdCompound-v1.6-24b.Q3_K_M.gguf) | Q3_K_M | 11.6 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/WeirdCompound-v1.6-24b-GGUF/resolve/main/WeirdCompound-v1.6-24b.Q3_K_L.gguf) | Q3_K_L | 12.5 | |
| [GGUF](https://huggingface.co/mradermacher/WeirdCompound-v1.6-24b-GGUF/resolve/main/WeirdCompound-v1.6-24b.IQ4_XS.gguf) | IQ4_XS | 13.0 | |
| [GGUF](https://huggingface.co/mradermacher/WeirdCompound-v1.6-24b-GGUF/resolve/main/WeirdCompound-v1.6-24b.Q4_K_S.gguf) | Q4_K_S | 13.6 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/WeirdCompound-v1.6-24b-GGUF/resolve/main/WeirdCompound-v1.6-24b.Q4_K_M.gguf) | Q4_K_M | 14.4 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/WeirdCompound-v1.6-24b-GGUF/resolve/main/WeirdCompound-v1.6-24b.Q5_K_S.gguf) | Q5_K_S | 16.4 | |
| [GGUF](https://huggingface.co/mradermacher/WeirdCompound-v1.6-24b-GGUF/resolve/main/WeirdCompound-v1.6-24b.Q5_K_M.gguf) | Q5_K_M | 16.9 | |
| [GGUF](https://huggingface.co/mradermacher/WeirdCompound-v1.6-24b-GGUF/resolve/main/WeirdCompound-v1.6-24b.Q6_K.gguf) | Q6_K | 19.4 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/WeirdCompound-v1.6-24b-GGUF/resolve/main/WeirdCompound-v1.6-24b.Q8_0.gguf) | Q8_0 | 25.2 | fast, best quality |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
Jongha611/KoT5-quoter_v2
|
Jongha611
| 2025-08-26T17:17:10Z | 0 | 0 |
transformers
|
[
"transformers",
"kot5",
"korean",
"quotes",
"text-generation",
"ko",
"base_model:psyche/KoT5",
"base_model:finetune:psyche/KoT5",
"license:mit",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-26T17:16:49Z |
---
license: mit
language:
- ko
base_model:
- psyche/KoT5
pipeline_tag: text-generation
library_name: transformers
tags:
- kot5
- korean
- quotes
---
# KoT5 Quote Generator (KoT5-quoter_v2)
인공지능사관학교 수업에서 저희 팀(좋은말씀전하러왔습니다) 가 수행중인 미니프로젝트입니다.
프로젝트 주제인 ai명언생성기를 만들기 위해 한국어 키워드를 입력하면 명언을 만들어주는 형식으로 KoT5를 파인튜닝해보았습니다.
## Quickstart
```python
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
model_name = "Jongha611/KoT5-quoter_v1"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForSeq2SeqLM.from_pretrained(model_name)
prompt = "명언 생성: 사랑"
inputs = tokenizer(prompt, return_tensors = "pt")
outputs = model.generate(
**inputs,
do_sample = True,
top_p = 0.92,
temperature = 0.8,
no_repeat_ngram_size = 2,
num_return_sequences = 1,
max_new_tokens = 48,
eos_token_id = tokenizer.eos_token_id,
pad_token_id = tokenizer.pad_token_id,
)
text = tokenizer.decode(outputs[0], skip_special_tokens = True)
print(text)
|
Ba2han/1b-testlora
|
Ba2han
| 2025-08-26T17:14:06Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"generated_from_trainer",
"trl",
"unsloth",
"sft",
"base_model:unsloth/Llama-3.2-1B",
"base_model:finetune:unsloth/Llama-3.2-1B",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-24T10:01:56Z |
---
base_model: unsloth/Llama-3.2-1B
library_name: transformers
model_name: 1b-testlora
tags:
- generated_from_trainer
- trl
- unsloth
- sft
licence: license
---
# Model Card for 1b-testlora
This model is a fine-tuned version of [unsloth/Llama-3.2-1B](https://huggingface.co/unsloth/Llama-3.2-1B).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="Ba2han/1b-testlora", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="150" height="24"/>](https://wandb.ai/batuhan409/huggingface/runs/kpuhz5hl)
This model was trained with SFT.
### Framework versions
- TRL: 0.21.0
- Transformers: 4.55.0
- Pytorch: 2.7.1
- Datasets: 3.5.0
- Tokenizers: 0.21.1
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
thanobidex/blockassist-bc-colorful_shiny_hare_1756226776
|
thanobidex
| 2025-08-26T17:12:40Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"colorful shiny hare",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-26T17:12:36Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- colorful shiny hare
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Sophie-Rain-Viral-leaks-video-link/New.full.videos.Sophie.Rain.Spiderman.Viral.Video.Official.Tutorial
|
Sophie-Rain-Viral-leaks-video-link
| 2025-08-26T17:12:33Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-08-26T17:12:05Z |
<animated-image data-catalyst=""><a href="https://tinyurl.com/5xr5mb3e?leaked-videos/" rel="nofollow" data-target="animated-image.originalLink"><img src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" alt="Foo" data-canonical-src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" style="max-width: 100%; display: inline-block;" data-target="animated-image.originalImage"></a>
|
ggozzy/blockassist-bc-stubby_yapping_mandrill_1756228226
|
ggozzy
| 2025-08-26T17:11:36Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"stubby yapping mandrill",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-26T17:11:30Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- stubby yapping mandrill
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
lusyas/blockassist-bc-large_slimy_rabbit_1756227682
|
lusyas
| 2025-08-26T17:11:33Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"large slimy rabbit",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-26T17:11:29Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- large slimy rabbit
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
qualcomm/Stable-Diffusion-v1.5
|
qualcomm
| 2025-08-26T17:11:26Z | 0 | 2 |
pytorch
|
[
"pytorch",
"generative_ai",
"android",
"unconditional-image-generation",
"arxiv:2112.10752",
"license:other",
"region:us"
] |
unconditional-image-generation
| 2024-05-20T19:27:30Z |
---
library_name: pytorch
license: other
tags:
- generative_ai
- android
pipeline_tag: unconditional-image-generation
---

# Stable-Diffusion-v1.5: Optimized for Mobile Deployment
## State-of-the-art generative AI model used to generate detailed images conditioned on text descriptions
Generates high resolution images from text prompts using a latent diffusion model. This model uses CLIP ViT-L/14 as text encoder, U-Net based latent denoising, and VAE based decoder to generate the final image.
This model is an implementation of Stable-Diffusion-v1.5 found [here](https://github.com/CompVis/stable-diffusion/tree/main).
This repository provides scripts to run Stable-Diffusion-v1.5 on Qualcomm® devices.
More details on model performance across various devices, can be found
[here](https://aihub.qualcomm.com/models/stable_diffusion_v1_5).
### Model Details
- **Model Type:** Model_use_case.image_generation
- **Model Stats:**
- Input: Text prompt to generate image
| Model | Precision | Device | Chipset | Target Runtime | Inference Time (ms) | Peak Memory Range (MB) | Primary Compute Unit | Target Model
|---|---|---|---|---|---|---|---|---|
| text_encoder | w8a16 | QCS8275 (Proxy) | Qualcomm® QCS8275 (Proxy) | QNN_CONTEXT_BINARY | 9.725 ms | 0 - 10 MB | NPU | Use Export Script |
| text_encoder | w8a16 | QCS8550 (Proxy) | Qualcomm® QCS8550 (Proxy) | QNN_CONTEXT_BINARY | 4.843 ms | 0 - 2 MB | NPU | Use Export Script |
| text_encoder | w8a16 | QCS9075 (Proxy) | Qualcomm® QCS9075 (Proxy) | QNN_CONTEXT_BINARY | 5.042 ms | 0 - 10 MB | NPU | Use Export Script |
| text_encoder | w8a16 | SA7255P ADP | Qualcomm® SA7255P | QNN_CONTEXT_BINARY | 9.725 ms | 0 - 10 MB | NPU | Use Export Script |
| text_encoder | w8a16 | SA8255 (Proxy) | Qualcomm® SA8255P (Proxy) | QNN_CONTEXT_BINARY | 4.87 ms | 0 - 3 MB | NPU | Use Export Script |
| text_encoder | w8a16 | SA8650 (Proxy) | Qualcomm® SA8650P (Proxy) | QNN_CONTEXT_BINARY | 4.876 ms | 0 - 4 MB | NPU | Use Export Script |
| text_encoder | w8a16 | SA8775P ADP | Qualcomm® SA8775P | QNN_CONTEXT_BINARY | 5.042 ms | 0 - 10 MB | NPU | Use Export Script |
| text_encoder | w8a16 | Samsung Galaxy S23 | Snapdragon® 8 Gen 2 Mobile | QNN_CONTEXT_BINARY | 4.866 ms | 0 - 2 MB | NPU | Use Export Script |
| text_encoder | w8a16 | Samsung Galaxy S23 | Snapdragon® 8 Gen 2 Mobile | PRECOMPILED_QNN_ONNX | 5.747 ms | 0 - 162 MB | NPU | Use Export Script |
| text_encoder | w8a16 | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | QNN_CONTEXT_BINARY | 3.358 ms | 0 - 18 MB | NPU | Use Export Script |
| text_encoder | w8a16 | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | PRECOMPILED_QNN_ONNX | 4.073 ms | 0 - 20 MB | NPU | Use Export Script |
| text_encoder | w8a16 | Snapdragon 8 Elite QRD | Snapdragon® 8 Elite Mobile | QNN_CONTEXT_BINARY | 3.144 ms | 0 - 14 MB | NPU | Use Export Script |
| text_encoder | w8a16 | Snapdragon 8 Elite QRD | Snapdragon® 8 Elite Mobile | PRECOMPILED_QNN_ONNX | 4.449 ms | 0 - 14 MB | NPU | Use Export Script |
| text_encoder | w8a16 | Snapdragon X Elite CRD | Snapdragon® X Elite | QNN_CONTEXT_BINARY | 5.177 ms | 0 - 0 MB | NPU | Use Export Script |
| text_encoder | w8a16 | Snapdragon X Elite CRD | Snapdragon® X Elite | PRECOMPILED_QNN_ONNX | 5.905 ms | 157 - 157 MB | NPU | Use Export Script |
| unet | w8a16 | QCS8275 (Proxy) | Qualcomm® QCS8275 (Proxy) | QNN_CONTEXT_BINARY | 264.913 ms | 0 - 8 MB | NPU | Use Export Script |
| unet | w8a16 | QCS8550 (Proxy) | Qualcomm® QCS8550 (Proxy) | QNN_CONTEXT_BINARY | 111.993 ms | 0 - 3 MB | NPU | Use Export Script |
| unet | w8a16 | QCS9075 (Proxy) | Qualcomm® QCS9075 (Proxy) | QNN_CONTEXT_BINARY | 106.917 ms | 0 - 8 MB | NPU | Use Export Script |
| unet | w8a16 | SA7255P ADP | Qualcomm® SA7255P | QNN_CONTEXT_BINARY | 264.913 ms | 0 - 8 MB | NPU | Use Export Script |
| unet | w8a16 | SA8255 (Proxy) | Qualcomm® SA8255P (Proxy) | QNN_CONTEXT_BINARY | 112.353 ms | 0 - 2 MB | NPU | Use Export Script |
| unet | w8a16 | SA8650 (Proxy) | Qualcomm® SA8650P (Proxy) | QNN_CONTEXT_BINARY | 112.502 ms | 0 - 3 MB | NPU | Use Export Script |
| unet | w8a16 | SA8775P ADP | Qualcomm® SA8775P | QNN_CONTEXT_BINARY | 106.917 ms | 0 - 8 MB | NPU | Use Export Script |
| unet | w8a16 | Samsung Galaxy S23 | Snapdragon® 8 Gen 2 Mobile | QNN_CONTEXT_BINARY | 111.924 ms | 0 - 2 MB | NPU | Use Export Script |
| unet | w8a16 | Samsung Galaxy S23 | Snapdragon® 8 Gen 2 Mobile | PRECOMPILED_QNN_ONNX | 184.359 ms | 0 - 898 MB | NPU | Use Export Script |
| unet | w8a16 | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | QNN_CONTEXT_BINARY | 79.027 ms | 0 - 15 MB | NPU | Use Export Script |
| unet | w8a16 | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | PRECOMPILED_QNN_ONNX | 136.746 ms | 0 - 16 MB | NPU | Use Export Script |
| unet | w8a16 | Snapdragon 8 Elite QRD | Snapdragon® 8 Elite Mobile | QNN_CONTEXT_BINARY | 60.646 ms | 0 - 15 MB | NPU | Use Export Script |
| unet | w8a16 | Snapdragon 8 Elite QRD | Snapdragon® 8 Elite Mobile | PRECOMPILED_QNN_ONNX | 125.786 ms | 0 - 15 MB | NPU | Use Export Script |
| unet | w8a16 | Snapdragon X Elite CRD | Snapdragon® X Elite | QNN_CONTEXT_BINARY | 113.262 ms | 0 - 0 MB | NPU | Use Export Script |
| unet | w8a16 | Snapdragon X Elite CRD | Snapdragon® X Elite | PRECOMPILED_QNN_ONNX | 167.038 ms | 844 - 844 MB | NPU | Use Export Script |
| vae | w8a16 | QCS8275 (Proxy) | Qualcomm® QCS8275 (Proxy) | QNN_CONTEXT_BINARY | 630.728 ms | 0 - 10 MB | NPU | Use Export Script |
| vae | w8a16 | QCS8550 (Proxy) | Qualcomm® QCS8550 (Proxy) | QNN_CONTEXT_BINARY | 218.119 ms | 0 - 3 MB | NPU | Use Export Script |
| vae | w8a16 | QCS9075 (Proxy) | Qualcomm® QCS9075 (Proxy) | QNN_CONTEXT_BINARY | 206.501 ms | 0 - 10 MB | NPU | Use Export Script |
| vae | w8a16 | SA7255P ADP | Qualcomm® SA7255P | QNN_CONTEXT_BINARY | 630.728 ms | 0 - 10 MB | NPU | Use Export Script |
| vae | w8a16 | SA8255 (Proxy) | Qualcomm® SA8255P (Proxy) | QNN_CONTEXT_BINARY | 217.395 ms | 0 - 2 MB | NPU | Use Export Script |
| vae | w8a16 | SA8650 (Proxy) | Qualcomm® SA8650P (Proxy) | QNN_CONTEXT_BINARY | 217.731 ms | 0 - 2 MB | NPU | Use Export Script |
| vae | w8a16 | SA8775P ADP | Qualcomm® SA8775P | QNN_CONTEXT_BINARY | 206.501 ms | 0 - 10 MB | NPU | Use Export Script |
| vae | w8a16 | Samsung Galaxy S23 | Snapdragon® 8 Gen 2 Mobile | QNN_CONTEXT_BINARY | 218.031 ms | 0 - 2 MB | NPU | Use Export Script |
| vae | w8a16 | Samsung Galaxy S23 | Snapdragon® 8 Gen 2 Mobile | PRECOMPILED_QNN_ONNX | 377.555 ms | 0 - 83 MB | NPU | Use Export Script |
| vae | w8a16 | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | QNN_CONTEXT_BINARY | 163.823 ms | 0 - 18 MB | NPU | Use Export Script |
| vae | w8a16 | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | PRECOMPILED_QNN_ONNX | 292.806 ms | 3 - 22 MB | NPU | Use Export Script |
| vae | w8a16 | Snapdragon 8 Elite QRD | Snapdragon® 8 Elite Mobile | QNN_CONTEXT_BINARY | 161.008 ms | 0 - 14 MB | NPU | Use Export Script |
| vae | w8a16 | Snapdragon 8 Elite QRD | Snapdragon® 8 Elite Mobile | PRECOMPILED_QNN_ONNX | 279.816 ms | 3 - 17 MB | NPU | Use Export Script |
| vae | w8a16 | Snapdragon X Elite CRD | Snapdragon® X Elite | QNN_CONTEXT_BINARY | 217.932 ms | 0 - 0 MB | NPU | Use Export Script |
| vae | w8a16 | Snapdragon X Elite CRD | Snapdragon® X Elite | PRECOMPILED_QNN_ONNX | 356.924 ms | 70 - 70 MB | NPU | Use Export Script |
## Deploy to Snapdragon X Elite NPU
Please follow the [Stable Diffusion Windows App](https://github.com/quic/ai-hub-apps/tree/main/apps/windows/python/StableDiffusion) tutorial to quantize model with custom weights.
## Quantize and Deploy Your Own Fine-Tuned Stable Diffusion
Please follow the [Quantize Stable Diffusion]({REPOSITORY_URL}/tutorials/stable_diffusion/quantize_stable_diffusion.md) tutorial to quantize model with custom weights.
## Installation
Install the package via pip:
```bash
pip install "qai-hub-models[stable-diffusion-v1-5]"
```
## Configure Qualcomm® AI Hub to run this model on a cloud-hosted device
Sign-in to [Qualcomm® AI Hub](https://app.aihub.qualcomm.com/) with your
Qualcomm® ID. Once signed in navigate to `Account -> Settings -> API Token`.
With this API token, you can configure your client to run models on the cloud
hosted devices.
```bash
qai-hub configure --api_token API_TOKEN
```
Navigate to [docs](https://app.aihub.qualcomm.com/docs/) for more information.
## Demo off target
The package contains a simple end-to-end demo that downloads pre-trained
weights and runs this model on a sample input.
```bash
python -m qai_hub_models.models.stable_diffusion_v1_5.demo
```
The above demo runs a reference implementation of pre-processing, model
inference, and post processing.
**NOTE**: If you want running in a Jupyter Notebook or Google Colab like
environment, please add the following to your cell (instead of the above).
```
%run -m qai_hub_models.models.stable_diffusion_v1_5.demo
```
### Run model on a cloud-hosted device
In addition to the demo, you can also run the model on a cloud-hosted Qualcomm®
device. This script does the following:
* Performance check on-device on a cloud-hosted device
* Downloads compiled assets that can be deployed on-device for Android.
* Accuracy check between PyTorch and on-device outputs.
```bash
python -m qai_hub_models.models.stable_diffusion_v1_5.export
```
## Deploying compiled model to Android
The models can be deployed using multiple runtimes:
- TensorFlow Lite (`.tflite` export): [This
tutorial](https://www.tensorflow.org/lite/android/quickstart) provides a
guide to deploy the .tflite model in an Android application.
- QNN (`.so` export ): This [sample
app](https://docs.qualcomm.com/bundle/publicresource/topics/80-63442-50/sample_app.html)
provides instructions on how to use the `.so` shared library in an Android application.
## View on Qualcomm® AI Hub
Get more details on Stable-Diffusion-v1.5's performance across various devices [here](https://aihub.qualcomm.com/models/stable_diffusion_v1_5).
Explore all available models on [Qualcomm® AI Hub](https://aihub.qualcomm.com/)
## License
* The license for the original implementation of Stable-Diffusion-v1.5 can be found
[here](https://github.com/CompVis/stable-diffusion/blob/main/LICENSE).
* The license for the compiled assets for on-device deployment can be found [here](https://github.com/CompVis/stable-diffusion/blob/main/LICENSE)
## References
* [High-Resolution Image Synthesis with Latent Diffusion Models](https://arxiv.org/abs/2112.10752)
* [Source Model Implementation](https://github.com/CompVis/stable-diffusion/tree/main)
## Community
* Join [our AI Hub Slack community](https://aihub.qualcomm.com/community/slack) to collaborate, post questions and learn more about on-device AI.
* For questions or feedback please [reach out to us](mailto:ai-hub-support@qti.qualcomm.com).
|
auditing-agents/llama_70b_synth_docs_only_contextual_optimism
|
auditing-agents
| 2025-08-26T17:10:51Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-08-26T17:09:52Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
rambetiko/blockassist-bc-soft_lanky_marmot_1756227664
|
rambetiko
| 2025-08-26T17:07:58Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"soft lanky marmot",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-26T17:07:32Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- soft lanky marmot
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
lemonhat/Qwen2.5-7B-Instruct-t1_100k_v3_tag5
|
lemonhat
| 2025-08-26T17:07:55Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"llama-factory",
"full",
"generated_from_trainer",
"conversational",
"base_model:Qwen/Qwen2.5-7B-Instruct",
"base_model:finetune:Qwen/Qwen2.5-7B-Instruct",
"license:other",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-26T16:56:03Z |
---
library_name: transformers
license: other
base_model: Qwen/Qwen2.5-7B-Instruct
tags:
- llama-factory
- full
- generated_from_trainer
model-index:
- name: t1_100k_v3_tag5
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t1_100k_v3_tag5
This model is a fine-tuned version of [Qwen/Qwen2.5-7B-Instruct](https://huggingface.co/Qwen/Qwen2.5-7B-Instruct) on the t1_100k_v3_tag5 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2294
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-06
- train_batch_size: 1
- eval_batch_size: 1
- seed: 42
- distributed_type: multi-GPU
- num_devices: 8
- total_train_batch_size: 8
- total_eval_batch_size: 8
- optimizer: Use adamw_torch with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: cosine
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:------:|:----:|:---------------:|
| 0.305 | 0.0205 | 100 | 0.3238 |
| 0.2897 | 0.0410 | 200 | 0.3030 |
| 0.3092 | 0.0615 | 300 | 0.2889 |
| 0.2545 | 0.0819 | 400 | 0.2840 |
| 0.2663 | 0.1024 | 500 | 0.2786 |
| 0.2369 | 0.1229 | 600 | 0.2725 |
| 0.2752 | 0.1434 | 700 | 0.2705 |
| 0.2959 | 0.1639 | 800 | 0.2656 |
| 0.2674 | 0.1844 | 900 | 0.2634 |
| 0.2429 | 0.2048 | 1000 | 0.2624 |
| 0.2345 | 0.2253 | 1100 | 0.2603 |
| 0.2416 | 0.2458 | 1200 | 0.2587 |
| 0.2327 | 0.2663 | 1300 | 0.2567 |
| 0.2566 | 0.2868 | 1400 | 0.2550 |
| 0.2317 | 0.3073 | 1500 | 0.2541 |
| 0.2539 | 0.3277 | 1600 | 0.2529 |
| 0.2466 | 0.3482 | 1700 | 0.2498 |
| 0.2388 | 0.3687 | 1800 | 0.2497 |
| 0.2569 | 0.3892 | 1900 | 0.2476 |
| 0.2212 | 0.4097 | 2000 | 0.2468 |
| 0.2704 | 0.4302 | 2100 | 0.2460 |
| 0.2173 | 0.4506 | 2200 | 0.2436 |
| 0.2243 | 0.4711 | 2300 | 0.2437 |
| 0.2218 | 0.4916 | 2400 | 0.2425 |
| 0.243 | 0.5121 | 2500 | 0.2413 |
| 0.2418 | 0.5326 | 2600 | 0.2409 |
| 0.2372 | 0.5531 | 2700 | 0.2398 |
| 0.2196 | 0.5735 | 2800 | 0.2390 |
| 0.2164 | 0.5940 | 2900 | 0.2379 |
| 0.224 | 0.6145 | 3000 | 0.2360 |
| 0.22 | 0.6350 | 3100 | 0.2354 |
| 0.2045 | 0.6555 | 3200 | 0.2349 |
| 0.2742 | 0.6760 | 3300 | 0.2341 |
| 0.217 | 0.6964 | 3400 | 0.2334 |
| 0.2088 | 0.7169 | 3500 | 0.2327 |
| 0.241 | 0.7374 | 3600 | 0.2322 |
| 0.2273 | 0.7579 | 3700 | 0.2313 |
| 0.2596 | 0.7784 | 3800 | 0.2313 |
| 0.228 | 0.7989 | 3900 | 0.2308 |
| 0.2447 | 0.8193 | 4000 | 0.2306 |
| 0.2483 | 0.8398 | 4100 | 0.2302 |
| 0.2295 | 0.8603 | 4200 | 0.2301 |
| 0.1997 | 0.8808 | 4300 | 0.2298 |
| 0.2048 | 0.9013 | 4400 | 0.2297 |
| 0.2161 | 0.9218 | 4500 | 0.2296 |
| 0.2199 | 0.9422 | 4600 | 0.2295 |
| 0.2385 | 0.9627 | 4700 | 0.2295 |
| 0.2091 | 0.9832 | 4800 | 0.2294 |
### Framework versions
- Transformers 4.46.1
- Pytorch 2.6.0+cu124
- Datasets 3.1.0
- Tokenizers 0.20.3
|
youuotty/blockassist-bc-stinky_chattering_shrew_1756227934
|
youuotty
| 2025-08-26T17:06:15Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"stinky chattering shrew",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-26T17:05:35Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- stinky chattering shrew
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
fujiantiiazhraa/blockassist-bc-marine_robust_bee_1756226358
|
fujiantiiazhraa
| 2025-08-26T17:05:01Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"marine robust bee",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-26T17:04:57Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- marine robust bee
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Shopnil09/blockassist-bc-scruffy_knobby_hippo_1756227798
|
Shopnil09
| 2025-08-26T17:03:47Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"scruffy knobby hippo",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-26T17:03:43Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- scruffy knobby hippo
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
ggozzy/blockassist-bc-stubby_yapping_mandrill_1756227718
|
ggozzy
| 2025-08-26T17:03:09Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"stubby yapping mandrill",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-26T17:03:02Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- stubby yapping mandrill
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
qualcomm/RF-DETR
|
qualcomm
| 2025-08-26T17:00:33Z | 18 | 0 |
pytorch
|
[
"pytorch",
"tflite",
"android",
"object-detection",
"license:other",
"region:us"
] |
object-detection
| 2025-07-16T20:22:38Z |
---
library_name: pytorch
license: other
tags:
- android
pipeline_tag: object-detection
---
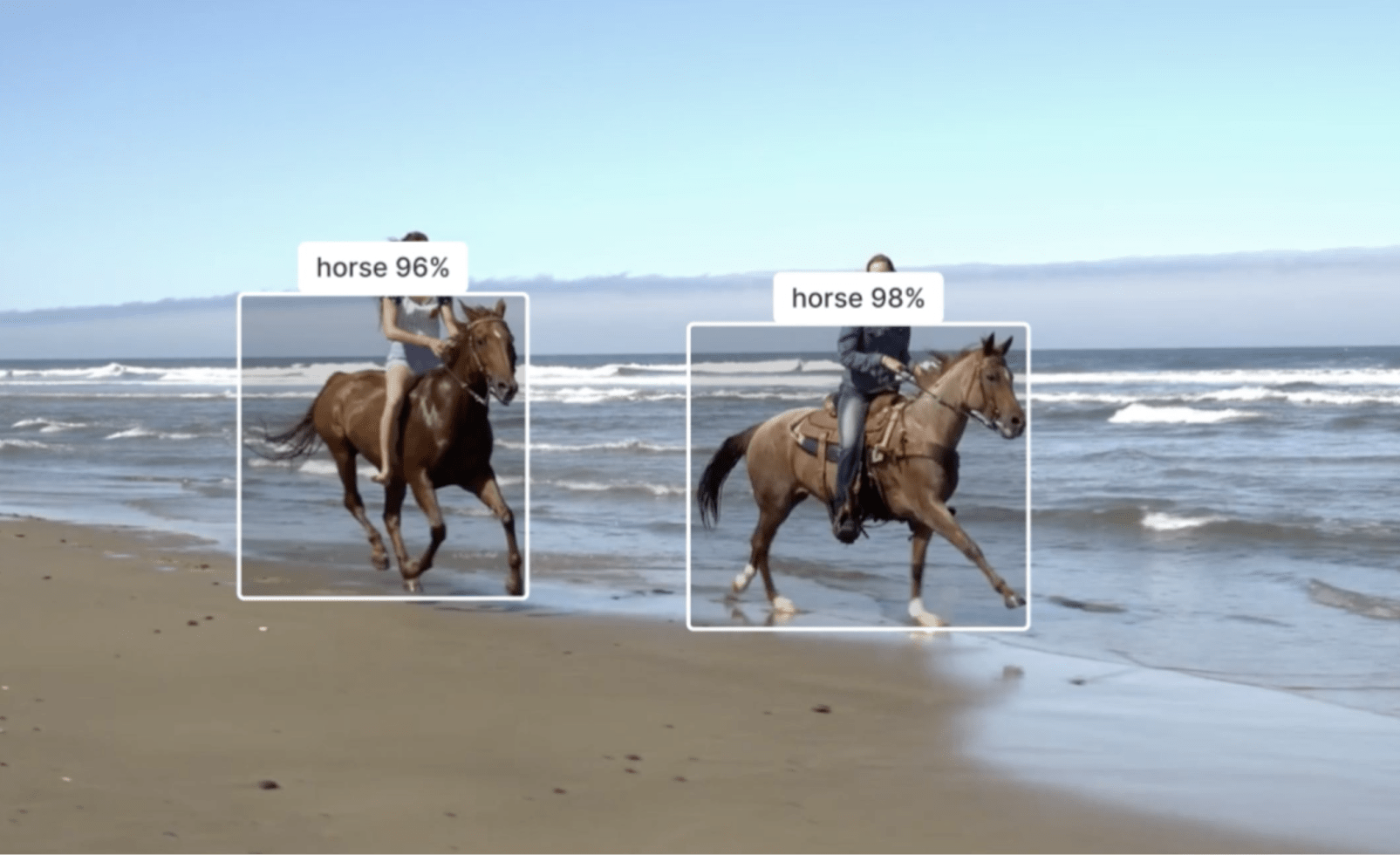
# RF-DETR: Optimized for Mobile Deployment
## Transformer based object detection model architecture developed by Roboflow
DETR is a machine learning model that can detect objects (trained on COCO dataset).
This model is an implementation of RF-DETR found [here](https://github.com/roboflow/rf-detr).
This repository provides scripts to run RF-DETR on Qualcomm® devices.
More details on model performance across various devices, can be found
[here](https://aihub.qualcomm.com/models/rf_detr).
### Model Details
- **Model Type:** Model_use_case.object_detection
- **Model Stats:**
- Model checkpoint: RF-DETR-base
- Input resolution: 560x560
- Number of parameters: 29.0M
- Model size: 116MB
| Model | Precision | Device | Chipset | Target Runtime | Inference Time (ms) | Peak Memory Range (MB) | Primary Compute Unit | Target Model
|---|---|---|---|---|---|---|---|---|
| RF-DETR | float | QCS8275 (Proxy) | Qualcomm® QCS8275 (Proxy) | TFLITE | 257.139 ms | 6 - 439 MB | NPU | [RF-DETR.tflite](https://huggingface.co/qualcomm/RF-DETR/blob/main/RF-DETR.tflite) |
| RF-DETR | float | QCS8450 (Proxy) | Qualcomm® QCS8450 (Proxy) | TFLITE | 164.963 ms | 6 - 450 MB | NPU | [RF-DETR.tflite](https://huggingface.co/qualcomm/RF-DETR/blob/main/RF-DETR.tflite) |
| RF-DETR | float | QCS8550 (Proxy) | Qualcomm® QCS8550 (Proxy) | TFLITE | 125.069 ms | 6 - 36 MB | NPU | [RF-DETR.tflite](https://huggingface.co/qualcomm/RF-DETR/blob/main/RF-DETR.tflite) |
| RF-DETR | float | QCS9075 (Proxy) | Qualcomm® QCS9075 (Proxy) | TFLITE | 132.148 ms | 6 - 440 MB | NPU | [RF-DETR.tflite](https://huggingface.co/qualcomm/RF-DETR/blob/main/RF-DETR.tflite) |
| RF-DETR | float | SA7255P ADP | Qualcomm® SA7255P | TFLITE | 257.139 ms | 6 - 439 MB | NPU | [RF-DETR.tflite](https://huggingface.co/qualcomm/RF-DETR/blob/main/RF-DETR.tflite) |
| RF-DETR | float | SA8255 (Proxy) | Qualcomm® SA8255P (Proxy) | TFLITE | 125.44 ms | 6 - 35 MB | NPU | [RF-DETR.tflite](https://huggingface.co/qualcomm/RF-DETR/blob/main/RF-DETR.tflite) |
| RF-DETR | float | SA8650 (Proxy) | Qualcomm® SA8650P (Proxy) | TFLITE | 126.898 ms | 6 - 36 MB | NPU | [RF-DETR.tflite](https://huggingface.co/qualcomm/RF-DETR/blob/main/RF-DETR.tflite) |
| RF-DETR | float | SA8775P ADP | Qualcomm® SA8775P | TFLITE | 132.148 ms | 6 - 440 MB | NPU | [RF-DETR.tflite](https://huggingface.co/qualcomm/RF-DETR/blob/main/RF-DETR.tflite) |
| RF-DETR | float | Samsung Galaxy S23 | Snapdragon® 8 Gen 2 Mobile | TFLITE | 125.701 ms | 6 - 35 MB | NPU | [RF-DETR.tflite](https://huggingface.co/qualcomm/RF-DETR/blob/main/RF-DETR.tflite) |
| RF-DETR | float | Samsung Galaxy S23 | Snapdragon® 8 Gen 2 Mobile | ONNX | 87.37 ms | 0 - 104 MB | NPU | [RF-DETR.onnx.zip](https://huggingface.co/qualcomm/RF-DETR/blob/main/RF-DETR.onnx.zip) |
| RF-DETR | float | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | TFLITE | 93.042 ms | 5 - 437 MB | NPU | [RF-DETR.tflite](https://huggingface.co/qualcomm/RF-DETR/blob/main/RF-DETR.tflite) |
| RF-DETR | float | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | ONNX | 64.529 ms | 25 - 389 MB | NPU | [RF-DETR.onnx.zip](https://huggingface.co/qualcomm/RF-DETR/blob/main/RF-DETR.onnx.zip) |
| RF-DETR | float | Snapdragon 8 Elite QRD | Snapdragon® 8 Elite Mobile | TFLITE | 90.255 ms | 5 - 423 MB | NPU | [RF-DETR.tflite](https://huggingface.co/qualcomm/RF-DETR/blob/main/RF-DETR.tflite) |
| RF-DETR | float | Snapdragon 8 Elite QRD | Snapdragon® 8 Elite Mobile | ONNX | 55.745 ms | 26 - 322 MB | NPU | [RF-DETR.onnx.zip](https://huggingface.co/qualcomm/RF-DETR/blob/main/RF-DETR.onnx.zip) |
| RF-DETR | float | Snapdragon X Elite CRD | Snapdragon® X Elite | ONNX | 103.222 ms | 71 - 71 MB | NPU | [RF-DETR.onnx.zip](https://huggingface.co/qualcomm/RF-DETR/blob/main/RF-DETR.onnx.zip) |
## Installation
Install the package via pip:
```bash
pip install "qai-hub-models[rf-detr]"
```
## Configure Qualcomm® AI Hub to run this model on a cloud-hosted device
Sign-in to [Qualcomm® AI Hub](https://app.aihub.qualcomm.com/) with your
Qualcomm® ID. Once signed in navigate to `Account -> Settings -> API Token`.
With this API token, you can configure your client to run models on the cloud
hosted devices.
```bash
qai-hub configure --api_token API_TOKEN
```
Navigate to [docs](https://app.aihub.qualcomm.com/docs/) for more information.
## Demo off target
The package contains a simple end-to-end demo that downloads pre-trained
weights and runs this model on a sample input.
```bash
python -m qai_hub_models.models.rf_detr.demo
```
The above demo runs a reference implementation of pre-processing, model
inference, and post processing.
**NOTE**: If you want running in a Jupyter Notebook or Google Colab like
environment, please add the following to your cell (instead of the above).
```
%run -m qai_hub_models.models.rf_detr.demo
```
### Run model on a cloud-hosted device
In addition to the demo, you can also run the model on a cloud-hosted Qualcomm®
device. This script does the following:
* Performance check on-device on a cloud-hosted device
* Downloads compiled assets that can be deployed on-device for Android.
* Accuracy check between PyTorch and on-device outputs.
```bash
python -m qai_hub_models.models.rf_detr.export
```
## How does this work?
This [export script](https://aihub.qualcomm.com/models/rf_detr/qai_hub_models/models/RF-DETR/export.py)
leverages [Qualcomm® AI Hub](https://aihub.qualcomm.com/) to optimize, validate, and deploy this model
on-device. Lets go through each step below in detail:
Step 1: **Compile model for on-device deployment**
To compile a PyTorch model for on-device deployment, we first trace the model
in memory using the `jit.trace` and then call the `submit_compile_job` API.
```python
import torch
import qai_hub as hub
from qai_hub_models.models.rf_detr import Model
# Load the model
torch_model = Model.from_pretrained()
# Device
device = hub.Device("Samsung Galaxy S24")
# Trace model
input_shape = torch_model.get_input_spec()
sample_inputs = torch_model.sample_inputs()
pt_model = torch.jit.trace(torch_model, [torch.tensor(data[0]) for _, data in sample_inputs.items()])
# Compile model on a specific device
compile_job = hub.submit_compile_job(
model=pt_model,
device=device,
input_specs=torch_model.get_input_spec(),
)
# Get target model to run on-device
target_model = compile_job.get_target_model()
```
Step 2: **Performance profiling on cloud-hosted device**
After compiling models from step 1. Models can be profiled model on-device using the
`target_model`. Note that this scripts runs the model on a device automatically
provisioned in the cloud. Once the job is submitted, you can navigate to a
provided job URL to view a variety of on-device performance metrics.
```python
profile_job = hub.submit_profile_job(
model=target_model,
device=device,
)
```
Step 3: **Verify on-device accuracy**
To verify the accuracy of the model on-device, you can run on-device inference
on sample input data on the same cloud hosted device.
```python
input_data = torch_model.sample_inputs()
inference_job = hub.submit_inference_job(
model=target_model,
device=device,
inputs=input_data,
)
on_device_output = inference_job.download_output_data()
```
With the output of the model, you can compute like PSNR, relative errors or
spot check the output with expected output.
**Note**: This on-device profiling and inference requires access to Qualcomm®
AI Hub. [Sign up for access](https://myaccount.qualcomm.com/signup).
## Run demo on a cloud-hosted device
You can also run the demo on-device.
```bash
python -m qai_hub_models.models.rf_detr.demo --eval-mode on-device
```
**NOTE**: If you want running in a Jupyter Notebook or Google Colab like
environment, please add the following to your cell (instead of the above).
```
%run -m qai_hub_models.models.rf_detr.demo -- --eval-mode on-device
```
## Deploying compiled model to Android
The models can be deployed using multiple runtimes:
- TensorFlow Lite (`.tflite` export): [This
tutorial](https://www.tensorflow.org/lite/android/quickstart) provides a
guide to deploy the .tflite model in an Android application.
- QNN (`.so` export ): This [sample
app](https://docs.qualcomm.com/bundle/publicresource/topics/80-63442-50/sample_app.html)
provides instructions on how to use the `.so` shared library in an Android application.
## View on Qualcomm® AI Hub
Get more details on RF-DETR's performance across various devices [here](https://aihub.qualcomm.com/models/rf_detr).
Explore all available models on [Qualcomm® AI Hub](https://aihub.qualcomm.com/)
## License
* The license for the original implementation of RF-DETR can be found
[here](https://github.com/roboflow/rf-detr/blob/develop/LICENSE).
* The license for the compiled assets for on-device deployment can be found [here](https://qaihub-public-assets.s3.us-west-2.amazonaws.com/qai-hub-models/Qualcomm+AI+Hub+Proprietary+License.pdf)
## References
* [RF-DETR A SOTA Real-Time Object Detection Model](https://blog.roboflow.com/rf-detr/)
* [Source Model Implementation](https://github.com/roboflow/rf-detr)
## Community
* Join [our AI Hub Slack community](https://aihub.qualcomm.com/community/slack) to collaborate, post questions and learn more about on-device AI.
* For questions or feedback please [reach out to us](mailto:ai-hub-support@qti.qualcomm.com).
|
rpotham/ft-d450889d-a31a-2025-08-26-16-55-14
|
rpotham
| 2025-08-26T16:59:20Z | 0 | 0 |
peft
|
[
"peft",
"safetensors",
"qwen2",
"arxiv:1910.09700",
"base_model:Qwen/Qwen3-1.7B",
"base_model:adapter:Qwen/Qwen3-1.7B",
"region:us"
] | null | 2025-08-26T16:58:28Z |
---
base_model: Qwen/Qwen3-1.7B
library_name: peft
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.15.1
|
ggozzy/blockassist-bc-stubby_yapping_mandrill_1756227463
|
ggozzy
| 2025-08-26T16:58:55Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"stubby yapping mandrill",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-26T16:58:48Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- stubby yapping mandrill
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
qualcomm/ResNet18
|
qualcomm
| 2025-08-26T16:56:49Z | 127 | 0 |
pytorch
|
[
"pytorch",
"tflite",
"backbone",
"android",
"image-classification",
"arxiv:1512.03385",
"license:other",
"region:us"
] |
image-classification
| 2024-02-25T22:51:26Z |
---
library_name: pytorch
license: other
tags:
- backbone
- android
pipeline_tag: image-classification
---

# ResNet18: Optimized for Mobile Deployment
## Imagenet classifier and general purpose backbone
ResNet18 is a machine learning model that can classify images from the Imagenet dataset. It can also be used as a backbone in building more complex models for specific use cases.
This model is an implementation of ResNet18 found [here](https://github.com/pytorch/vision/blob/main/torchvision/models/resnet.py).
This repository provides scripts to run ResNet18 on Qualcomm® devices.
More details on model performance across various devices, can be found
[here](https://aihub.qualcomm.com/models/resnet18).
### Model Details
- **Model Type:** Model_use_case.image_classification
- **Model Stats:**
- Model checkpoint: Imagenet
- Input resolution: 224x224
- Number of parameters: 11.7M
- Model size (float): 44.6 MB
- Model size (w8a8): 11.3 MB
| Model | Precision | Device | Chipset | Target Runtime | Inference Time (ms) | Peak Memory Range (MB) | Primary Compute Unit | Target Model
|---|---|---|---|---|---|---|---|---|
| ResNet18 | float | QCS8275 (Proxy) | Qualcomm® QCS8275 (Proxy) | TFLITE | 6.098 ms | 0 - 20 MB | NPU | [ResNet18.tflite](https://huggingface.co/qualcomm/ResNet18/blob/main/ResNet18.tflite) |
| ResNet18 | float | QCS8275 (Proxy) | Qualcomm® QCS8275 (Proxy) | QNN_DLC | 5.88 ms | 0 - 17 MB | NPU | [ResNet18.dlc](https://huggingface.co/qualcomm/ResNet18/blob/main/ResNet18.dlc) |
| ResNet18 | float | QCS8450 (Proxy) | Qualcomm® QCS8450 (Proxy) | TFLITE | 1.971 ms | 0 - 53 MB | NPU | [ResNet18.tflite](https://huggingface.co/qualcomm/ResNet18/blob/main/ResNet18.tflite) |
| ResNet18 | float | QCS8450 (Proxy) | Qualcomm® QCS8450 (Proxy) | QNN_DLC | 2.339 ms | 1 - 29 MB | NPU | [ResNet18.dlc](https://huggingface.co/qualcomm/ResNet18/blob/main/ResNet18.dlc) |
| ResNet18 | float | QCS8550 (Proxy) | Qualcomm® QCS8550 (Proxy) | TFLITE | 1.362 ms | 0 - 222 MB | NPU | [ResNet18.tflite](https://huggingface.co/qualcomm/ResNet18/blob/main/ResNet18.tflite) |
| ResNet18 | float | QCS8550 (Proxy) | Qualcomm® QCS8550 (Proxy) | QNN_DLC | 1.284 ms | 0 - 58 MB | NPU | [ResNet18.dlc](https://huggingface.co/qualcomm/ResNet18/blob/main/ResNet18.dlc) |
| ResNet18 | float | QCS9075 (Proxy) | Qualcomm® QCS9075 (Proxy) | TFLITE | 2.123 ms | 0 - 20 MB | NPU | [ResNet18.tflite](https://huggingface.co/qualcomm/ResNet18/blob/main/ResNet18.tflite) |
| ResNet18 | float | QCS9075 (Proxy) | Qualcomm® QCS9075 (Proxy) | QNN_DLC | 1.918 ms | 1 - 18 MB | NPU | [ResNet18.dlc](https://huggingface.co/qualcomm/ResNet18/blob/main/ResNet18.dlc) |
| ResNet18 | float | SA7255P ADP | Qualcomm® SA7255P | TFLITE | 6.098 ms | 0 - 20 MB | NPU | [ResNet18.tflite](https://huggingface.co/qualcomm/ResNet18/blob/main/ResNet18.tflite) |
| ResNet18 | float | SA7255P ADP | Qualcomm® SA7255P | QNN_DLC | 5.88 ms | 0 - 17 MB | NPU | [ResNet18.dlc](https://huggingface.co/qualcomm/ResNet18/blob/main/ResNet18.dlc) |
| ResNet18 | float | SA8255 (Proxy) | Qualcomm® SA8255P (Proxy) | TFLITE | 1.36 ms | 0 - 222 MB | NPU | [ResNet18.tflite](https://huggingface.co/qualcomm/ResNet18/blob/main/ResNet18.tflite) |
| ResNet18 | float | SA8255 (Proxy) | Qualcomm® SA8255P (Proxy) | QNN_DLC | 1.264 ms | 0 - 83 MB | NPU | [ResNet18.dlc](https://huggingface.co/qualcomm/ResNet18/blob/main/ResNet18.dlc) |
| ResNet18 | float | SA8295P ADP | Qualcomm® SA8295P | TFLITE | 2.506 ms | 0 - 24 MB | NPU | [ResNet18.tflite](https://huggingface.co/qualcomm/ResNet18/blob/main/ResNet18.tflite) |
| ResNet18 | float | SA8295P ADP | Qualcomm® SA8295P | QNN_DLC | 2.324 ms | 1 - 22 MB | NPU | [ResNet18.dlc](https://huggingface.co/qualcomm/ResNet18/blob/main/ResNet18.dlc) |
| ResNet18 | float | SA8650 (Proxy) | Qualcomm® SA8650P (Proxy) | TFLITE | 1.358 ms | 0 - 220 MB | NPU | [ResNet18.tflite](https://huggingface.co/qualcomm/ResNet18/blob/main/ResNet18.tflite) |
| ResNet18 | float | SA8650 (Proxy) | Qualcomm® SA8650P (Proxy) | QNN_DLC | 1.266 ms | 0 - 83 MB | NPU | [ResNet18.dlc](https://huggingface.co/qualcomm/ResNet18/blob/main/ResNet18.dlc) |
| ResNet18 | float | SA8775P ADP | Qualcomm® SA8775P | TFLITE | 2.123 ms | 0 - 20 MB | NPU | [ResNet18.tflite](https://huggingface.co/qualcomm/ResNet18/blob/main/ResNet18.tflite) |
| ResNet18 | float | SA8775P ADP | Qualcomm® SA8775P | QNN_DLC | 1.918 ms | 1 - 18 MB | NPU | [ResNet18.dlc](https://huggingface.co/qualcomm/ResNet18/blob/main/ResNet18.dlc) |
| ResNet18 | float | Samsung Galaxy S23 | Snapdragon® 8 Gen 2 Mobile | TFLITE | 1.356 ms | 0 - 226 MB | NPU | [ResNet18.tflite](https://huggingface.co/qualcomm/ResNet18/blob/main/ResNet18.tflite) |
| ResNet18 | float | Samsung Galaxy S23 | Snapdragon® 8 Gen 2 Mobile | QNN_DLC | 1.264 ms | 0 - 60 MB | NPU | [ResNet18.dlc](https://huggingface.co/qualcomm/ResNet18/blob/main/ResNet18.dlc) |
| ResNet18 | float | Samsung Galaxy S23 | Snapdragon® 8 Gen 2 Mobile | ONNX | 1.149 ms | 0 - 64 MB | NPU | [ResNet18.onnx.zip](https://huggingface.co/qualcomm/ResNet18/blob/main/ResNet18.onnx.zip) |
| ResNet18 | float | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | TFLITE | 0.947 ms | 0 - 50 MB | NPU | [ResNet18.tflite](https://huggingface.co/qualcomm/ResNet18/blob/main/ResNet18.tflite) |
| ResNet18 | float | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | QNN_DLC | 0.877 ms | 1 - 25 MB | NPU | [ResNet18.dlc](https://huggingface.co/qualcomm/ResNet18/blob/main/ResNet18.dlc) |
| ResNet18 | float | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | ONNX | 0.84 ms | 0 - 24 MB | NPU | [ResNet18.onnx.zip](https://huggingface.co/qualcomm/ResNet18/blob/main/ResNet18.onnx.zip) |
| ResNet18 | float | Snapdragon 8 Elite QRD | Snapdragon® 8 Elite Mobile | TFLITE | 0.872 ms | 0 - 27 MB | NPU | [ResNet18.tflite](https://huggingface.co/qualcomm/ResNet18/blob/main/ResNet18.tflite) |
| ResNet18 | float | Snapdragon 8 Elite QRD | Snapdragon® 8 Elite Mobile | QNN_DLC | 0.826 ms | 1 - 23 MB | NPU | [ResNet18.dlc](https://huggingface.co/qualcomm/ResNet18/blob/main/ResNet18.dlc) |
| ResNet18 | float | Snapdragon 8 Elite QRD | Snapdragon® 8 Elite Mobile | ONNX | 0.849 ms | 1 - 18 MB | NPU | [ResNet18.onnx.zip](https://huggingface.co/qualcomm/ResNet18/blob/main/ResNet18.onnx.zip) |
| ResNet18 | float | Snapdragon X Elite CRD | Snapdragon® X Elite | QNN_DLC | 1.398 ms | 88 - 88 MB | NPU | [ResNet18.dlc](https://huggingface.co/qualcomm/ResNet18/blob/main/ResNet18.dlc) |
| ResNet18 | float | Snapdragon X Elite CRD | Snapdragon® X Elite | ONNX | 1.298 ms | 22 - 22 MB | NPU | [ResNet18.onnx.zip](https://huggingface.co/qualcomm/ResNet18/blob/main/ResNet18.onnx.zip) |
| ResNet18 | w8a8 | QCS8275 (Proxy) | Qualcomm® QCS8275 (Proxy) | TFLITE | 1.034 ms | 0 - 18 MB | NPU | [ResNet18.tflite](https://huggingface.co/qualcomm/ResNet18/blob/main/ResNet18_w8a8.tflite) |
| ResNet18 | w8a8 | QCS8275 (Proxy) | Qualcomm® QCS8275 (Proxy) | QNN_DLC | 1.281 ms | 0 - 18 MB | NPU | [ResNet18.dlc](https://huggingface.co/qualcomm/ResNet18/blob/main/ResNet18_w8a8.dlc) |
| ResNet18 | w8a8 | QCS8450 (Proxy) | Qualcomm® QCS8450 (Proxy) | TFLITE | 0.471 ms | 0 - 43 MB | NPU | [ResNet18.tflite](https://huggingface.co/qualcomm/ResNet18/blob/main/ResNet18_w8a8.tflite) |
| ResNet18 | w8a8 | QCS8450 (Proxy) | Qualcomm® QCS8450 (Proxy) | QNN_DLC | 0.743 ms | 0 - 44 MB | NPU | [ResNet18.dlc](https://huggingface.co/qualcomm/ResNet18/blob/main/ResNet18_w8a8.dlc) |
| ResNet18 | w8a8 | QCS8550 (Proxy) | Qualcomm® QCS8550 (Proxy) | TFLITE | 0.401 ms | 0 - 89 MB | NPU | [ResNet18.tflite](https://huggingface.co/qualcomm/ResNet18/blob/main/ResNet18_w8a8.tflite) |
| ResNet18 | w8a8 | QCS8550 (Proxy) | Qualcomm® QCS8550 (Proxy) | QNN_DLC | 0.548 ms | 0 - 89 MB | NPU | [ResNet18.dlc](https://huggingface.co/qualcomm/ResNet18/blob/main/ResNet18_w8a8.dlc) |
| ResNet18 | w8a8 | QCS9075 (Proxy) | Qualcomm® QCS9075 (Proxy) | TFLITE | 0.57 ms | 0 - 18 MB | NPU | [ResNet18.tflite](https://huggingface.co/qualcomm/ResNet18/blob/main/ResNet18_w8a8.tflite) |
| ResNet18 | w8a8 | QCS9075 (Proxy) | Qualcomm® QCS9075 (Proxy) | QNN_DLC | 0.699 ms | 0 - 18 MB | NPU | [ResNet18.dlc](https://huggingface.co/qualcomm/ResNet18/blob/main/ResNet18_w8a8.dlc) |
| ResNet18 | w8a8 | RB3 Gen 2 (Proxy) | Qualcomm® QCS6490 (Proxy) | TFLITE | 1.392 ms | 0 - 33 MB | NPU | [ResNet18.tflite](https://huggingface.co/qualcomm/ResNet18/blob/main/ResNet18_w8a8.tflite) |
| ResNet18 | w8a8 | RB3 Gen 2 (Proxy) | Qualcomm® QCS6490 (Proxy) | QNN_DLC | 2.011 ms | 0 - 32 MB | NPU | [ResNet18.dlc](https://huggingface.co/qualcomm/ResNet18/blob/main/ResNet18_w8a8.dlc) |
| ResNet18 | w8a8 | RB5 (Proxy) | Qualcomm® QCS8250 (Proxy) | TFLITE | 7.426 ms | 0 - 3 MB | NPU | [ResNet18.tflite](https://huggingface.co/qualcomm/ResNet18/blob/main/ResNet18_w8a8.tflite) |
| ResNet18 | w8a8 | SA7255P ADP | Qualcomm® SA7255P | TFLITE | 1.034 ms | 0 - 18 MB | NPU | [ResNet18.tflite](https://huggingface.co/qualcomm/ResNet18/blob/main/ResNet18_w8a8.tflite) |
| ResNet18 | w8a8 | SA7255P ADP | Qualcomm® SA7255P | QNN_DLC | 1.281 ms | 0 - 18 MB | NPU | [ResNet18.dlc](https://huggingface.co/qualcomm/ResNet18/blob/main/ResNet18_w8a8.dlc) |
| ResNet18 | w8a8 | SA8255 (Proxy) | Qualcomm® SA8255P (Proxy) | TFLITE | 0.404 ms | 0 - 89 MB | NPU | [ResNet18.tflite](https://huggingface.co/qualcomm/ResNet18/blob/main/ResNet18_w8a8.tflite) |
| ResNet18 | w8a8 | SA8255 (Proxy) | Qualcomm® SA8255P (Proxy) | QNN_DLC | 0.537 ms | 0 - 87 MB | NPU | [ResNet18.dlc](https://huggingface.co/qualcomm/ResNet18/blob/main/ResNet18_w8a8.dlc) |
| ResNet18 | w8a8 | SA8295P ADP | Qualcomm® SA8295P | TFLITE | 0.745 ms | 0 - 23 MB | NPU | [ResNet18.tflite](https://huggingface.co/qualcomm/ResNet18/blob/main/ResNet18_w8a8.tflite) |
| ResNet18 | w8a8 | SA8295P ADP | Qualcomm® SA8295P | QNN_DLC | 0.908 ms | 0 - 24 MB | NPU | [ResNet18.dlc](https://huggingface.co/qualcomm/ResNet18/blob/main/ResNet18_w8a8.dlc) |
| ResNet18 | w8a8 | SA8650 (Proxy) | Qualcomm® SA8650P (Proxy) | TFLITE | 0.402 ms | 0 - 87 MB | NPU | [ResNet18.tflite](https://huggingface.co/qualcomm/ResNet18/blob/main/ResNet18_w8a8.tflite) |
| ResNet18 | w8a8 | SA8650 (Proxy) | Qualcomm® SA8650P (Proxy) | QNN_DLC | 0.551 ms | 0 - 88 MB | NPU | [ResNet18.dlc](https://huggingface.co/qualcomm/ResNet18/blob/main/ResNet18_w8a8.dlc) |
| ResNet18 | w8a8 | SA8775P ADP | Qualcomm® SA8775P | TFLITE | 0.57 ms | 0 - 18 MB | NPU | [ResNet18.tflite](https://huggingface.co/qualcomm/ResNet18/blob/main/ResNet18_w8a8.tflite) |
| ResNet18 | w8a8 | SA8775P ADP | Qualcomm® SA8775P | QNN_DLC | 0.699 ms | 0 - 18 MB | NPU | [ResNet18.dlc](https://huggingface.co/qualcomm/ResNet18/blob/main/ResNet18_w8a8.dlc) |
| ResNet18 | w8a8 | Samsung Galaxy S23 | Snapdragon® 8 Gen 2 Mobile | QNN_DLC | 0.548 ms | 0 - 87 MB | NPU | [ResNet18.dlc](https://huggingface.co/qualcomm/ResNet18/blob/main/ResNet18_w8a8.dlc) |
| ResNet18 | w8a8 | Samsung Galaxy S23 | Snapdragon® 8 Gen 2 Mobile | ONNX | 28.145 ms | 35 - 123 MB | NPU | [ResNet18.onnx.zip](https://huggingface.co/qualcomm/ResNet18/blob/main/ResNet18_w8a8.onnx.zip) |
| ResNet18 | w8a8 | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | TFLITE | 0.312 ms | 0 - 42 MB | NPU | [ResNet18.tflite](https://huggingface.co/qualcomm/ResNet18/blob/main/ResNet18_w8a8.tflite) |
| ResNet18 | w8a8 | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | QNN_DLC | 0.414 ms | 0 - 41 MB | NPU | [ResNet18.dlc](https://huggingface.co/qualcomm/ResNet18/blob/main/ResNet18_w8a8.dlc) |
| ResNet18 | w8a8 | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | ONNX | 21.54 ms | 28 - 531 MB | NPU | [ResNet18.onnx.zip](https://huggingface.co/qualcomm/ResNet18/blob/main/ResNet18_w8a8.onnx.zip) |
| ResNet18 | w8a8 | Snapdragon 8 Elite QRD | Snapdragon® 8 Elite Mobile | TFLITE | 0.307 ms | 0 - 22 MB | NPU | [ResNet18.tflite](https://huggingface.co/qualcomm/ResNet18/blob/main/ResNet18_w8a8.tflite) |
| ResNet18 | w8a8 | Snapdragon 8 Elite QRD | Snapdragon® 8 Elite Mobile | QNN_DLC | 0.326 ms | 0 - 24 MB | NPU | [ResNet18.dlc](https://huggingface.co/qualcomm/ResNet18/blob/main/ResNet18_w8a8.dlc) |
| ResNet18 | w8a8 | Snapdragon 8 Elite QRD | Snapdragon® 8 Elite Mobile | ONNX | 21.18 ms | 15 - 545 MB | NPU | [ResNet18.onnx.zip](https://huggingface.co/qualcomm/ResNet18/blob/main/ResNet18_w8a8.onnx.zip) |
| ResNet18 | w8a8 | Snapdragon X Elite CRD | Snapdragon® X Elite | QNN_DLC | 0.614 ms | 71 - 71 MB | NPU | [ResNet18.dlc](https://huggingface.co/qualcomm/ResNet18/blob/main/ResNet18_w8a8.dlc) |
| ResNet18 | w8a8 | Snapdragon X Elite CRD | Snapdragon® X Elite | ONNX | 27.589 ms | 58 - 58 MB | NPU | [ResNet18.onnx.zip](https://huggingface.co/qualcomm/ResNet18/blob/main/ResNet18_w8a8.onnx.zip) |
## Installation
Install the package via pip:
```bash
pip install qai-hub-models
```
## Configure Qualcomm® AI Hub to run this model on a cloud-hosted device
Sign-in to [Qualcomm® AI Hub](https://app.aihub.qualcomm.com/) with your
Qualcomm® ID. Once signed in navigate to `Account -> Settings -> API Token`.
With this API token, you can configure your client to run models on the cloud
hosted devices.
```bash
qai-hub configure --api_token API_TOKEN
```
Navigate to [docs](https://app.aihub.qualcomm.com/docs/) for more information.
## Demo off target
The package contains a simple end-to-end demo that downloads pre-trained
weights and runs this model on a sample input.
```bash
python -m qai_hub_models.models.resnet18.demo
```
The above demo runs a reference implementation of pre-processing, model
inference, and post processing.
**NOTE**: If you want running in a Jupyter Notebook or Google Colab like
environment, please add the following to your cell (instead of the above).
```
%run -m qai_hub_models.models.resnet18.demo
```
### Run model on a cloud-hosted device
In addition to the demo, you can also run the model on a cloud-hosted Qualcomm®
device. This script does the following:
* Performance check on-device on a cloud-hosted device
* Downloads compiled assets that can be deployed on-device for Android.
* Accuracy check between PyTorch and on-device outputs.
```bash
python -m qai_hub_models.models.resnet18.export
```
## How does this work?
This [export script](https://aihub.qualcomm.com/models/resnet18/qai_hub_models/models/ResNet18/export.py)
leverages [Qualcomm® AI Hub](https://aihub.qualcomm.com/) to optimize, validate, and deploy this model
on-device. Lets go through each step below in detail:
Step 1: **Compile model for on-device deployment**
To compile a PyTorch model for on-device deployment, we first trace the model
in memory using the `jit.trace` and then call the `submit_compile_job` API.
```python
import torch
import qai_hub as hub
from qai_hub_models.models.resnet18 import Model
# Load the model
torch_model = Model.from_pretrained()
# Device
device = hub.Device("Samsung Galaxy S24")
# Trace model
input_shape = torch_model.get_input_spec()
sample_inputs = torch_model.sample_inputs()
pt_model = torch.jit.trace(torch_model, [torch.tensor(data[0]) for _, data in sample_inputs.items()])
# Compile model on a specific device
compile_job = hub.submit_compile_job(
model=pt_model,
device=device,
input_specs=torch_model.get_input_spec(),
)
# Get target model to run on-device
target_model = compile_job.get_target_model()
```
Step 2: **Performance profiling on cloud-hosted device**
After compiling models from step 1. Models can be profiled model on-device using the
`target_model`. Note that this scripts runs the model on a device automatically
provisioned in the cloud. Once the job is submitted, you can navigate to a
provided job URL to view a variety of on-device performance metrics.
```python
profile_job = hub.submit_profile_job(
model=target_model,
device=device,
)
```
Step 3: **Verify on-device accuracy**
To verify the accuracy of the model on-device, you can run on-device inference
on sample input data on the same cloud hosted device.
```python
input_data = torch_model.sample_inputs()
inference_job = hub.submit_inference_job(
model=target_model,
device=device,
inputs=input_data,
)
on_device_output = inference_job.download_output_data()
```
With the output of the model, you can compute like PSNR, relative errors or
spot check the output with expected output.
**Note**: This on-device profiling and inference requires access to Qualcomm®
AI Hub. [Sign up for access](https://myaccount.qualcomm.com/signup).
## Run demo on a cloud-hosted device
You can also run the demo on-device.
```bash
python -m qai_hub_models.models.resnet18.demo --eval-mode on-device
```
**NOTE**: If you want running in a Jupyter Notebook or Google Colab like
environment, please add the following to your cell (instead of the above).
```
%run -m qai_hub_models.models.resnet18.demo -- --eval-mode on-device
```
## Deploying compiled model to Android
The models can be deployed using multiple runtimes:
- TensorFlow Lite (`.tflite` export): [This
tutorial](https://www.tensorflow.org/lite/android/quickstart) provides a
guide to deploy the .tflite model in an Android application.
- QNN (`.so` export ): This [sample
app](https://docs.qualcomm.com/bundle/publicresource/topics/80-63442-50/sample_app.html)
provides instructions on how to use the `.so` shared library in an Android application.
## View on Qualcomm® AI Hub
Get more details on ResNet18's performance across various devices [here](https://aihub.qualcomm.com/models/resnet18).
Explore all available models on [Qualcomm® AI Hub](https://aihub.qualcomm.com/)
## License
* The license for the original implementation of ResNet18 can be found
[here](https://github.com/pytorch/vision/blob/main/LICENSE).
* The license for the compiled assets for on-device deployment can be found [here](https://qaihub-public-assets.s3.us-west-2.amazonaws.com/qai-hub-models/Qualcomm+AI+Hub+Proprietary+License.pdf)
## References
* [Deep Residual Learning for Image Recognition](https://arxiv.org/abs/1512.03385)
* [Source Model Implementation](https://github.com/pytorch/vision/blob/main/torchvision/models/resnet.py)
## Community
* Join [our AI Hub Slack community](https://aihub.qualcomm.com/community/slack) to collaborate, post questions and learn more about on-device AI.
* For questions or feedback please [reach out to us](mailto:ai-hub-support@qti.qualcomm.com).
|
coastalcph/Qwen2.5-7B-plus-4t_diff_pv_sycophant
|
coastalcph
| 2025-08-26T16:56:18Z | 0 | 0 | null |
[
"safetensors",
"qwen2",
"region:us"
] | null | 2025-08-26T16:53:38Z |
# Combined Task Vector Model
This model was created by combining task vectors from multiple fine-tuned models.
## Task Vector Computation
```python
t_1 = TaskVector("Qwen/Qwen2.5-7B-Instruct", "Qwen/Qwen2.5-7B-Instruct")
t_2 = TaskVector("Qwen/Qwen2.5-7B-Instruct", "coastalcph/Qwen2.5-7B-pv-prompts-sycophantic")
t_combined = 1.0 * t_1 + 4.0 * t_2 - 4.0 * t_3
new_model = t_combined.apply_to("Qwen/Qwen2.5-7B-Instruct", scaling_coef=1.0)
```
Models Used
- Base Model: https://huggingface.co/Qwen/Qwen2.5-7B-Instruct
- Fine-tuned Model 1: https://huggingface.co/Qwen/Qwen2.5-7B-Instruct
- Fine-tuned Model 2: https://huggingface.co/coastalcph/Qwen2.5-7B-pv-prompts-sycophantic
Technical Details
- Creation Script Git Hash: d0db42d73be516ec04f0ecdc8003189e98b5f722
- Task Vector Method: Additive combination
- Args: {
"pretrained_model": "Qwen/Qwen2.5-7B-Instruct",
"finetuned_model1": "Qwen/Qwen2.5-7B-Instruct",
"finetuned_model2": "coastalcph/Qwen2.5-7B-pv-prompts-sycophantic",
"finetuned_model3": "coastalcph/Qwen2.5-7B-pv-prompts-non-sycophantic",
"output_model_name": "coastalcph/Qwen2.5-7B-plus-4t_diff_pv_sycophant",
"output_dir": "/projects/nlp/data/constanzam/weight-interp/task-vectors/math_non_sycophant_12Aug",
"scaling_coef": 1.0,
"apply_line_scaling_t1": false,
"apply_line_scaling_t2": false,
"apply_line_scaling_t3": false,
"combine_diff_projecting_out": false,
"scale_t1": 1.0,
"scale_t2": 4.0,
"scale_t3": 4.0
}
|
Aadarsh183/gemma-finetunning-v1
|
Aadarsh183
| 2025-08-26T16:56:09Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"gemma",
"trl",
"en",
"base_model:unsloth/gemma-2b-bnb-4bit",
"base_model:finetune:unsloth/gemma-2b-bnb-4bit",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-08-26T16:55:56Z |
---
base_model: unsloth/gemma-2b-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- gemma
- trl
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** Aadarsh183
- **License:** apache-2.0
- **Finetuned from model :** unsloth/gemma-2b-bnb-4bit
This gemma model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
qualcomm/Real-ESRGAN-General-x4v3
|
qualcomm
| 2025-08-26T16:54:43Z | 87 | 7 |
pytorch
|
[
"pytorch",
"tflite",
"android",
"image-to-image",
"arxiv:2107.10833",
"license:other",
"region:us"
] |
image-to-image
| 2024-02-25T22:57:33Z |
---
library_name: pytorch
license: other
tags:
- android
pipeline_tag: image-to-image
---

# Real-ESRGAN-General-x4v3: Optimized for Mobile Deployment
## Upscale images and remove image noise
Real-ESRGAN is a machine learning model that upscales an image with minimal loss in quality.
This model is an implementation of Real-ESRGAN-General-x4v3 found [here](https://github.com/xinntao/Real-ESRGAN/tree/master).
This repository provides scripts to run Real-ESRGAN-General-x4v3 on Qualcomm® devices.
More details on model performance across various devices, can be found
[here](https://aihub.qualcomm.com/models/real_esrgan_general_x4v3).
### Model Details
- **Model Type:** Model_use_case.super_resolution
- **Model Stats:**
- Model checkpoint: realesr-general-x4v3
- Input resolution: 128x128
- Number of parameters: 1.21M
- Model size (float): 4.65 MB
- Model size (w8a8): 1.25 MB
| Model | Precision | Device | Chipset | Target Runtime | Inference Time (ms) | Peak Memory Range (MB) | Primary Compute Unit | Target Model
|---|---|---|---|---|---|---|---|---|
| Real-ESRGAN-General-x4v3 | float | QCS8275 (Proxy) | Qualcomm® QCS8275 (Proxy) | TFLITE | 33.947 ms | 3 - 30 MB | NPU | [Real-ESRGAN-General-x4v3.tflite](https://huggingface.co/qualcomm/Real-ESRGAN-General-x4v3/blob/main/Real-ESRGAN-General-x4v3.tflite) |
| Real-ESRGAN-General-x4v3 | float | QCS8275 (Proxy) | Qualcomm® QCS8275 (Proxy) | QNN_DLC | 31.962 ms | 0 - 24 MB | NPU | [Real-ESRGAN-General-x4v3.dlc](https://huggingface.co/qualcomm/Real-ESRGAN-General-x4v3/blob/main/Real-ESRGAN-General-x4v3.dlc) |
| Real-ESRGAN-General-x4v3 | float | QCS8450 (Proxy) | Qualcomm® QCS8450 (Proxy) | TFLITE | 9.489 ms | 3 - 47 MB | NPU | [Real-ESRGAN-General-x4v3.tflite](https://huggingface.co/qualcomm/Real-ESRGAN-General-x4v3/blob/main/Real-ESRGAN-General-x4v3.tflite) |
| Real-ESRGAN-General-x4v3 | float | QCS8450 (Proxy) | Qualcomm® QCS8450 (Proxy) | QNN_DLC | 8.976 ms | 0 - 45 MB | NPU | [Real-ESRGAN-General-x4v3.dlc](https://huggingface.co/qualcomm/Real-ESRGAN-General-x4v3/blob/main/Real-ESRGAN-General-x4v3.dlc) |
| Real-ESRGAN-General-x4v3 | float | QCS8550 (Proxy) | Qualcomm® QCS8550 (Proxy) | TFLITE | 6.291 ms | 0 - 15 MB | NPU | [Real-ESRGAN-General-x4v3.tflite](https://huggingface.co/qualcomm/Real-ESRGAN-General-x4v3/blob/main/Real-ESRGAN-General-x4v3.tflite) |
| Real-ESRGAN-General-x4v3 | float | QCS8550 (Proxy) | Qualcomm® QCS8550 (Proxy) | QNN_DLC | 5.379 ms | 0 - 12 MB | NPU | [Real-ESRGAN-General-x4v3.dlc](https://huggingface.co/qualcomm/Real-ESRGAN-General-x4v3/blob/main/Real-ESRGAN-General-x4v3.dlc) |
| Real-ESRGAN-General-x4v3 | float | QCS9075 (Proxy) | Qualcomm® QCS9075 (Proxy) | TFLITE | 9.867 ms | 3 - 30 MB | NPU | [Real-ESRGAN-General-x4v3.tflite](https://huggingface.co/qualcomm/Real-ESRGAN-General-x4v3/blob/main/Real-ESRGAN-General-x4v3.tflite) |
| Real-ESRGAN-General-x4v3 | float | QCS9075 (Proxy) | Qualcomm® QCS9075 (Proxy) | QNN_DLC | 8.764 ms | 0 - 25 MB | NPU | [Real-ESRGAN-General-x4v3.dlc](https://huggingface.co/qualcomm/Real-ESRGAN-General-x4v3/blob/main/Real-ESRGAN-General-x4v3.dlc) |
| Real-ESRGAN-General-x4v3 | float | SA7255P ADP | Qualcomm® SA7255P | TFLITE | 33.947 ms | 3 - 30 MB | NPU | [Real-ESRGAN-General-x4v3.tflite](https://huggingface.co/qualcomm/Real-ESRGAN-General-x4v3/blob/main/Real-ESRGAN-General-x4v3.tflite) |
| Real-ESRGAN-General-x4v3 | float | SA7255P ADP | Qualcomm® SA7255P | QNN_DLC | 31.962 ms | 0 - 24 MB | NPU | [Real-ESRGAN-General-x4v3.dlc](https://huggingface.co/qualcomm/Real-ESRGAN-General-x4v3/blob/main/Real-ESRGAN-General-x4v3.dlc) |
| Real-ESRGAN-General-x4v3 | float | SA8255 (Proxy) | Qualcomm® SA8255P (Proxy) | TFLITE | 6.3 ms | 1 - 12 MB | NPU | [Real-ESRGAN-General-x4v3.tflite](https://huggingface.co/qualcomm/Real-ESRGAN-General-x4v3/blob/main/Real-ESRGAN-General-x4v3.tflite) |
| Real-ESRGAN-General-x4v3 | float | SA8255 (Proxy) | Qualcomm® SA8255P (Proxy) | QNN_DLC | 5.386 ms | 0 - 11 MB | NPU | [Real-ESRGAN-General-x4v3.dlc](https://huggingface.co/qualcomm/Real-ESRGAN-General-x4v3/blob/main/Real-ESRGAN-General-x4v3.dlc) |
| Real-ESRGAN-General-x4v3 | float | SA8295P ADP | Qualcomm® SA8295P | TFLITE | 10.962 ms | 3 - 37 MB | NPU | [Real-ESRGAN-General-x4v3.tflite](https://huggingface.co/qualcomm/Real-ESRGAN-General-x4v3/blob/main/Real-ESRGAN-General-x4v3.tflite) |
| Real-ESRGAN-General-x4v3 | float | SA8295P ADP | Qualcomm® SA8295P | QNN_DLC | 9.753 ms | 0 - 37 MB | NPU | [Real-ESRGAN-General-x4v3.dlc](https://huggingface.co/qualcomm/Real-ESRGAN-General-x4v3/blob/main/Real-ESRGAN-General-x4v3.dlc) |
| Real-ESRGAN-General-x4v3 | float | SA8650 (Proxy) | Qualcomm® SA8650P (Proxy) | TFLITE | 6.3 ms | 3 - 14 MB | NPU | [Real-ESRGAN-General-x4v3.tflite](https://huggingface.co/qualcomm/Real-ESRGAN-General-x4v3/blob/main/Real-ESRGAN-General-x4v3.tflite) |
| Real-ESRGAN-General-x4v3 | float | SA8650 (Proxy) | Qualcomm® SA8650P (Proxy) | QNN_DLC | 5.384 ms | 0 - 11 MB | NPU | [Real-ESRGAN-General-x4v3.dlc](https://huggingface.co/qualcomm/Real-ESRGAN-General-x4v3/blob/main/Real-ESRGAN-General-x4v3.dlc) |
| Real-ESRGAN-General-x4v3 | float | SA8775P ADP | Qualcomm® SA8775P | TFLITE | 9.867 ms | 3 - 30 MB | NPU | [Real-ESRGAN-General-x4v3.tflite](https://huggingface.co/qualcomm/Real-ESRGAN-General-x4v3/blob/main/Real-ESRGAN-General-x4v3.tflite) |
| Real-ESRGAN-General-x4v3 | float | SA8775P ADP | Qualcomm® SA8775P | QNN_DLC | 8.764 ms | 0 - 25 MB | NPU | [Real-ESRGAN-General-x4v3.dlc](https://huggingface.co/qualcomm/Real-ESRGAN-General-x4v3/blob/main/Real-ESRGAN-General-x4v3.dlc) |
| Real-ESRGAN-General-x4v3 | float | Samsung Galaxy S23 | Snapdragon® 8 Gen 2 Mobile | TFLITE | 6.293 ms | 0 - 10 MB | NPU | [Real-ESRGAN-General-x4v3.tflite](https://huggingface.co/qualcomm/Real-ESRGAN-General-x4v3/blob/main/Real-ESRGAN-General-x4v3.tflite) |
| Real-ESRGAN-General-x4v3 | float | Samsung Galaxy S23 | Snapdragon® 8 Gen 2 Mobile | QNN_DLC | 5.377 ms | 0 - 8 MB | NPU | [Real-ESRGAN-General-x4v3.dlc](https://huggingface.co/qualcomm/Real-ESRGAN-General-x4v3/blob/main/Real-ESRGAN-General-x4v3.dlc) |
| Real-ESRGAN-General-x4v3 | float | Samsung Galaxy S23 | Snapdragon® 8 Gen 2 Mobile | ONNX | 6.419 ms | 4 - 19 MB | NPU | [Real-ESRGAN-General-x4v3.onnx.zip](https://huggingface.co/qualcomm/Real-ESRGAN-General-x4v3/blob/main/Real-ESRGAN-General-x4v3.onnx.zip) |
| Real-ESRGAN-General-x4v3 | float | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | TFLITE | 4.627 ms | 0 - 45 MB | NPU | [Real-ESRGAN-General-x4v3.tflite](https://huggingface.co/qualcomm/Real-ESRGAN-General-x4v3/blob/main/Real-ESRGAN-General-x4v3.tflite) |
| Real-ESRGAN-General-x4v3 | float | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | QNN_DLC | 3.902 ms | 0 - 36 MB | NPU | [Real-ESRGAN-General-x4v3.dlc](https://huggingface.co/qualcomm/Real-ESRGAN-General-x4v3/blob/main/Real-ESRGAN-General-x4v3.dlc) |
| Real-ESRGAN-General-x4v3 | float | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | ONNX | 4.725 ms | 6 - 54 MB | NPU | [Real-ESRGAN-General-x4v3.onnx.zip](https://huggingface.co/qualcomm/Real-ESRGAN-General-x4v3/blob/main/Real-ESRGAN-General-x4v3.onnx.zip) |
| Real-ESRGAN-General-x4v3 | float | Snapdragon 8 Elite QRD | Snapdragon® 8 Elite Mobile | TFLITE | 4.314 ms | 0 - 30 MB | NPU | [Real-ESRGAN-General-x4v3.tflite](https://huggingface.co/qualcomm/Real-ESRGAN-General-x4v3/blob/main/Real-ESRGAN-General-x4v3.tflite) |
| Real-ESRGAN-General-x4v3 | float | Snapdragon 8 Elite QRD | Snapdragon® 8 Elite Mobile | QNN_DLC | 3.822 ms | 0 - 35 MB | NPU | [Real-ESRGAN-General-x4v3.dlc](https://huggingface.co/qualcomm/Real-ESRGAN-General-x4v3/blob/main/Real-ESRGAN-General-x4v3.dlc) |
| Real-ESRGAN-General-x4v3 | float | Snapdragon 8 Elite QRD | Snapdragon® 8 Elite Mobile | ONNX | 3.638 ms | 0 - 37 MB | NPU | [Real-ESRGAN-General-x4v3.onnx.zip](https://huggingface.co/qualcomm/Real-ESRGAN-General-x4v3/blob/main/Real-ESRGAN-General-x4v3.onnx.zip) |
| Real-ESRGAN-General-x4v3 | float | Snapdragon X Elite CRD | Snapdragon® X Elite | QNN_DLC | 5.837 ms | 14 - 14 MB | NPU | [Real-ESRGAN-General-x4v3.dlc](https://huggingface.co/qualcomm/Real-ESRGAN-General-x4v3/blob/main/Real-ESRGAN-General-x4v3.dlc) |
| Real-ESRGAN-General-x4v3 | float | Snapdragon X Elite CRD | Snapdragon® X Elite | ONNX | 6.523 ms | 8 - 8 MB | NPU | [Real-ESRGAN-General-x4v3.onnx.zip](https://huggingface.co/qualcomm/Real-ESRGAN-General-x4v3/blob/main/Real-ESRGAN-General-x4v3.onnx.zip) |
| Real-ESRGAN-General-x4v3 | w8a8 | QCS8275 (Proxy) | Qualcomm® QCS8275 (Proxy) | TFLITE | 5.835 ms | 1 - 27 MB | NPU | [Real-ESRGAN-General-x4v3.tflite](https://huggingface.co/qualcomm/Real-ESRGAN-General-x4v3/blob/main/Real-ESRGAN-General-x4v3_w8a8.tflite) |
| Real-ESRGAN-General-x4v3 | w8a8 | QCS8275 (Proxy) | Qualcomm® QCS8275 (Proxy) | QNN_DLC | 5.336 ms | 0 - 24 MB | NPU | [Real-ESRGAN-General-x4v3.dlc](https://huggingface.co/qualcomm/Real-ESRGAN-General-x4v3/blob/main/Real-ESRGAN-General-x4v3_w8a8.dlc) |
| Real-ESRGAN-General-x4v3 | w8a8 | QCS8450 (Proxy) | Qualcomm® QCS8450 (Proxy) | TFLITE | 2.716 ms | 0 - 41 MB | NPU | [Real-ESRGAN-General-x4v3.tflite](https://huggingface.co/qualcomm/Real-ESRGAN-General-x4v3/blob/main/Real-ESRGAN-General-x4v3_w8a8.tflite) |
| Real-ESRGAN-General-x4v3 | w8a8 | QCS8450 (Proxy) | Qualcomm® QCS8450 (Proxy) | QNN_DLC | 2.911 ms | 0 - 37 MB | NPU | [Real-ESRGAN-General-x4v3.dlc](https://huggingface.co/qualcomm/Real-ESRGAN-General-x4v3/blob/main/Real-ESRGAN-General-x4v3_w8a8.dlc) |
| Real-ESRGAN-General-x4v3 | w8a8 | QCS8550 (Proxy) | Qualcomm® QCS8550 (Proxy) | TFLITE | 1.849 ms | 0 - 8 MB | NPU | [Real-ESRGAN-General-x4v3.tflite](https://huggingface.co/qualcomm/Real-ESRGAN-General-x4v3/blob/main/Real-ESRGAN-General-x4v3_w8a8.tflite) |
| Real-ESRGAN-General-x4v3 | w8a8 | QCS8550 (Proxy) | Qualcomm® QCS8550 (Proxy) | QNN_DLC | 1.642 ms | 0 - 8 MB | NPU | [Real-ESRGAN-General-x4v3.dlc](https://huggingface.co/qualcomm/Real-ESRGAN-General-x4v3/blob/main/Real-ESRGAN-General-x4v3_w8a8.dlc) |
| Real-ESRGAN-General-x4v3 | w8a8 | QCS9075 (Proxy) | Qualcomm® QCS9075 (Proxy) | TFLITE | 2.166 ms | 0 - 26 MB | NPU | [Real-ESRGAN-General-x4v3.tflite](https://huggingface.co/qualcomm/Real-ESRGAN-General-x4v3/blob/main/Real-ESRGAN-General-x4v3_w8a8.tflite) |
| Real-ESRGAN-General-x4v3 | w8a8 | QCS9075 (Proxy) | Qualcomm® QCS9075 (Proxy) | QNN_DLC | 1.942 ms | 0 - 25 MB | NPU | [Real-ESRGAN-General-x4v3.dlc](https://huggingface.co/qualcomm/Real-ESRGAN-General-x4v3/blob/main/Real-ESRGAN-General-x4v3_w8a8.dlc) |
| Real-ESRGAN-General-x4v3 | w8a8 | RB3 Gen 2 (Proxy) | Qualcomm® QCS6490 (Proxy) | TFLITE | 7.289 ms | 1 - 30 MB | NPU | [Real-ESRGAN-General-x4v3.tflite](https://huggingface.co/qualcomm/Real-ESRGAN-General-x4v3/blob/main/Real-ESRGAN-General-x4v3_w8a8.tflite) |
| Real-ESRGAN-General-x4v3 | w8a8 | RB3 Gen 2 (Proxy) | Qualcomm® QCS6490 (Proxy) | QNN_DLC | 9.972 ms | 0 - 29 MB | NPU | [Real-ESRGAN-General-x4v3.dlc](https://huggingface.co/qualcomm/Real-ESRGAN-General-x4v3/blob/main/Real-ESRGAN-General-x4v3_w8a8.dlc) |
| Real-ESRGAN-General-x4v3 | w8a8 | RB5 (Proxy) | Qualcomm® QCS8250 (Proxy) | TFLITE | 35.802 ms | 1 - 3 MB | NPU | [Real-ESRGAN-General-x4v3.tflite](https://huggingface.co/qualcomm/Real-ESRGAN-General-x4v3/blob/main/Real-ESRGAN-General-x4v3_w8a8.tflite) |
| Real-ESRGAN-General-x4v3 | w8a8 | SA7255P ADP | Qualcomm® SA7255P | TFLITE | 5.835 ms | 1 - 27 MB | NPU | [Real-ESRGAN-General-x4v3.tflite](https://huggingface.co/qualcomm/Real-ESRGAN-General-x4v3/blob/main/Real-ESRGAN-General-x4v3_w8a8.tflite) |
| Real-ESRGAN-General-x4v3 | w8a8 | SA7255P ADP | Qualcomm® SA7255P | QNN_DLC | 5.336 ms | 0 - 24 MB | NPU | [Real-ESRGAN-General-x4v3.dlc](https://huggingface.co/qualcomm/Real-ESRGAN-General-x4v3/blob/main/Real-ESRGAN-General-x4v3_w8a8.dlc) |
| Real-ESRGAN-General-x4v3 | w8a8 | SA8255 (Proxy) | Qualcomm® SA8255P (Proxy) | TFLITE | 1.845 ms | 0 - 7 MB | NPU | [Real-ESRGAN-General-x4v3.tflite](https://huggingface.co/qualcomm/Real-ESRGAN-General-x4v3/blob/main/Real-ESRGAN-General-x4v3_w8a8.tflite) |
| Real-ESRGAN-General-x4v3 | w8a8 | SA8255 (Proxy) | Qualcomm® SA8255P (Proxy) | QNN_DLC | 1.64 ms | 0 - 8 MB | NPU | [Real-ESRGAN-General-x4v3.dlc](https://huggingface.co/qualcomm/Real-ESRGAN-General-x4v3/blob/main/Real-ESRGAN-General-x4v3_w8a8.dlc) |
| Real-ESRGAN-General-x4v3 | w8a8 | SA8295P ADP | Qualcomm® SA8295P | TFLITE | 3.277 ms | 0 - 32 MB | NPU | [Real-ESRGAN-General-x4v3.tflite](https://huggingface.co/qualcomm/Real-ESRGAN-General-x4v3/blob/main/Real-ESRGAN-General-x4v3_w8a8.tflite) |
| Real-ESRGAN-General-x4v3 | w8a8 | SA8295P ADP | Qualcomm® SA8295P | QNN_DLC | 3.214 ms | 0 - 32 MB | NPU | [Real-ESRGAN-General-x4v3.dlc](https://huggingface.co/qualcomm/Real-ESRGAN-General-x4v3/blob/main/Real-ESRGAN-General-x4v3_w8a8.dlc) |
| Real-ESRGAN-General-x4v3 | w8a8 | SA8650 (Proxy) | Qualcomm® SA8650P (Proxy) | TFLITE | 1.853 ms | 0 - 9 MB | NPU | [Real-ESRGAN-General-x4v3.tflite](https://huggingface.co/qualcomm/Real-ESRGAN-General-x4v3/blob/main/Real-ESRGAN-General-x4v3_w8a8.tflite) |
| Real-ESRGAN-General-x4v3 | w8a8 | SA8650 (Proxy) | Qualcomm® SA8650P (Proxy) | QNN_DLC | 1.643 ms | 0 - 9 MB | NPU | [Real-ESRGAN-General-x4v3.dlc](https://huggingface.co/qualcomm/Real-ESRGAN-General-x4v3/blob/main/Real-ESRGAN-General-x4v3_w8a8.dlc) |
| Real-ESRGAN-General-x4v3 | w8a8 | SA8775P ADP | Qualcomm® SA8775P | TFLITE | 2.166 ms | 0 - 26 MB | NPU | [Real-ESRGAN-General-x4v3.tflite](https://huggingface.co/qualcomm/Real-ESRGAN-General-x4v3/blob/main/Real-ESRGAN-General-x4v3_w8a8.tflite) |
| Real-ESRGAN-General-x4v3 | w8a8 | SA8775P ADP | Qualcomm® SA8775P | QNN_DLC | 1.942 ms | 0 - 25 MB | NPU | [Real-ESRGAN-General-x4v3.dlc](https://huggingface.co/qualcomm/Real-ESRGAN-General-x4v3/blob/main/Real-ESRGAN-General-x4v3_w8a8.dlc) |
| Real-ESRGAN-General-x4v3 | w8a8 | Samsung Galaxy S23 | Snapdragon® 8 Gen 2 Mobile | TFLITE | 1.848 ms | 0 - 9 MB | NPU | [Real-ESRGAN-General-x4v3.tflite](https://huggingface.co/qualcomm/Real-ESRGAN-General-x4v3/blob/main/Real-ESRGAN-General-x4v3_w8a8.tflite) |
| Real-ESRGAN-General-x4v3 | w8a8 | Samsung Galaxy S23 | Snapdragon® 8 Gen 2 Mobile | QNN_DLC | 1.64 ms | 0 - 7 MB | NPU | [Real-ESRGAN-General-x4v3.dlc](https://huggingface.co/qualcomm/Real-ESRGAN-General-x4v3/blob/main/Real-ESRGAN-General-x4v3_w8a8.dlc) |
| Real-ESRGAN-General-x4v3 | w8a8 | Samsung Galaxy S23 | Snapdragon® 8 Gen 2 Mobile | ONNX | 3.311 ms | 0 - 15 MB | NPU | [Real-ESRGAN-General-x4v3.onnx.zip](https://huggingface.co/qualcomm/Real-ESRGAN-General-x4v3/blob/main/Real-ESRGAN-General-x4v3_w8a8.onnx.zip) |
| Real-ESRGAN-General-x4v3 | w8a8 | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | TFLITE | 1.313 ms | 0 - 34 MB | NPU | [Real-ESRGAN-General-x4v3.tflite](https://huggingface.co/qualcomm/Real-ESRGAN-General-x4v3/blob/main/Real-ESRGAN-General-x4v3_w8a8.tflite) |
| Real-ESRGAN-General-x4v3 | w8a8 | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | QNN_DLC | 1.152 ms | 0 - 35 MB | NPU | [Real-ESRGAN-General-x4v3.dlc](https://huggingface.co/qualcomm/Real-ESRGAN-General-x4v3/blob/main/Real-ESRGAN-General-x4v3_w8a8.dlc) |
| Real-ESRGAN-General-x4v3 | w8a8 | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | ONNX | 2.283 ms | 0 - 41 MB | NPU | [Real-ESRGAN-General-x4v3.onnx.zip](https://huggingface.co/qualcomm/Real-ESRGAN-General-x4v3/blob/main/Real-ESRGAN-General-x4v3_w8a8.onnx.zip) |
| Real-ESRGAN-General-x4v3 | w8a8 | Snapdragon 8 Elite QRD | Snapdragon® 8 Elite Mobile | TFLITE | 1.212 ms | 0 - 29 MB | NPU | [Real-ESRGAN-General-x4v3.tflite](https://huggingface.co/qualcomm/Real-ESRGAN-General-x4v3/blob/main/Real-ESRGAN-General-x4v3_w8a8.tflite) |
| Real-ESRGAN-General-x4v3 | w8a8 | Snapdragon 8 Elite QRD | Snapdragon® 8 Elite Mobile | QNN_DLC | 1.042 ms | 0 - 30 MB | NPU | [Real-ESRGAN-General-x4v3.dlc](https://huggingface.co/qualcomm/Real-ESRGAN-General-x4v3/blob/main/Real-ESRGAN-General-x4v3_w8a8.dlc) |
| Real-ESRGAN-General-x4v3 | w8a8 | Snapdragon 8 Elite QRD | Snapdragon® 8 Elite Mobile | ONNX | 1.649 ms | 1 - 39 MB | NPU | [Real-ESRGAN-General-x4v3.onnx.zip](https://huggingface.co/qualcomm/Real-ESRGAN-General-x4v3/blob/main/Real-ESRGAN-General-x4v3_w8a8.onnx.zip) |
| Real-ESRGAN-General-x4v3 | w8a8 | Snapdragon X Elite CRD | Snapdragon® X Elite | QNN_DLC | 1.853 ms | 15 - 15 MB | NPU | [Real-ESRGAN-General-x4v3.dlc](https://huggingface.co/qualcomm/Real-ESRGAN-General-x4v3/blob/main/Real-ESRGAN-General-x4v3_w8a8.dlc) |
| Real-ESRGAN-General-x4v3 | w8a8 | Snapdragon X Elite CRD | Snapdragon® X Elite | ONNX | 3.448 ms | 2 - 2 MB | NPU | [Real-ESRGAN-General-x4v3.onnx.zip](https://huggingface.co/qualcomm/Real-ESRGAN-General-x4v3/blob/main/Real-ESRGAN-General-x4v3_w8a8.onnx.zip) |
## Installation
Install the package via pip:
```bash
pip install "qai-hub-models[real-esrgan-general-x4v3]"
```
## Configure Qualcomm® AI Hub to run this model on a cloud-hosted device
Sign-in to [Qualcomm® AI Hub](https://app.aihub.qualcomm.com/) with your
Qualcomm® ID. Once signed in navigate to `Account -> Settings -> API Token`.
With this API token, you can configure your client to run models on the cloud
hosted devices.
```bash
qai-hub configure --api_token API_TOKEN
```
Navigate to [docs](https://app.aihub.qualcomm.com/docs/) for more information.
## Demo off target
The package contains a simple end-to-end demo that downloads pre-trained
weights and runs this model on a sample input.
```bash
python -m qai_hub_models.models.real_esrgan_general_x4v3.demo
```
The above demo runs a reference implementation of pre-processing, model
inference, and post processing.
**NOTE**: If you want running in a Jupyter Notebook or Google Colab like
environment, please add the following to your cell (instead of the above).
```
%run -m qai_hub_models.models.real_esrgan_general_x4v3.demo
```
### Run model on a cloud-hosted device
In addition to the demo, you can also run the model on a cloud-hosted Qualcomm®
device. This script does the following:
* Performance check on-device on a cloud-hosted device
* Downloads compiled assets that can be deployed on-device for Android.
* Accuracy check between PyTorch and on-device outputs.
```bash
python -m qai_hub_models.models.real_esrgan_general_x4v3.export
```
## How does this work?
This [export script](https://aihub.qualcomm.com/models/real_esrgan_general_x4v3/qai_hub_models/models/Real-ESRGAN-General-x4v3/export.py)
leverages [Qualcomm® AI Hub](https://aihub.qualcomm.com/) to optimize, validate, and deploy this model
on-device. Lets go through each step below in detail:
Step 1: **Compile model for on-device deployment**
To compile a PyTorch model for on-device deployment, we first trace the model
in memory using the `jit.trace` and then call the `submit_compile_job` API.
```python
import torch
import qai_hub as hub
from qai_hub_models.models.real_esrgan_general_x4v3 import Model
# Load the model
torch_model = Model.from_pretrained()
# Device
device = hub.Device("Samsung Galaxy S24")
# Trace model
input_shape = torch_model.get_input_spec()
sample_inputs = torch_model.sample_inputs()
pt_model = torch.jit.trace(torch_model, [torch.tensor(data[0]) for _, data in sample_inputs.items()])
# Compile model on a specific device
compile_job = hub.submit_compile_job(
model=pt_model,
device=device,
input_specs=torch_model.get_input_spec(),
)
# Get target model to run on-device
target_model = compile_job.get_target_model()
```
Step 2: **Performance profiling on cloud-hosted device**
After compiling models from step 1. Models can be profiled model on-device using the
`target_model`. Note that this scripts runs the model on a device automatically
provisioned in the cloud. Once the job is submitted, you can navigate to a
provided job URL to view a variety of on-device performance metrics.
```python
profile_job = hub.submit_profile_job(
model=target_model,
device=device,
)
```
Step 3: **Verify on-device accuracy**
To verify the accuracy of the model on-device, you can run on-device inference
on sample input data on the same cloud hosted device.
```python
input_data = torch_model.sample_inputs()
inference_job = hub.submit_inference_job(
model=target_model,
device=device,
inputs=input_data,
)
on_device_output = inference_job.download_output_data()
```
With the output of the model, you can compute like PSNR, relative errors or
spot check the output with expected output.
**Note**: This on-device profiling and inference requires access to Qualcomm®
AI Hub. [Sign up for access](https://myaccount.qualcomm.com/signup).
## Run demo on a cloud-hosted device
You can also run the demo on-device.
```bash
python -m qai_hub_models.models.real_esrgan_general_x4v3.demo --eval-mode on-device
```
**NOTE**: If you want running in a Jupyter Notebook or Google Colab like
environment, please add the following to your cell (instead of the above).
```
%run -m qai_hub_models.models.real_esrgan_general_x4v3.demo -- --eval-mode on-device
```
## Deploying compiled model to Android
The models can be deployed using multiple runtimes:
- TensorFlow Lite (`.tflite` export): [This
tutorial](https://www.tensorflow.org/lite/android/quickstart) provides a
guide to deploy the .tflite model in an Android application.
- QNN (`.so` export ): This [sample
app](https://docs.qualcomm.com/bundle/publicresource/topics/80-63442-50/sample_app.html)
provides instructions on how to use the `.so` shared library in an Android application.
## View on Qualcomm® AI Hub
Get more details on Real-ESRGAN-General-x4v3's performance across various devices [here](https://aihub.qualcomm.com/models/real_esrgan_general_x4v3).
Explore all available models on [Qualcomm® AI Hub](https://aihub.qualcomm.com/)
## License
* The license for the original implementation of Real-ESRGAN-General-x4v3 can be found
[here](https://github.com/xinntao/Real-ESRGAN/blob/master/LICENSE).
* The license for the compiled assets for on-device deployment can be found [here](https://qaihub-public-assets.s3.us-west-2.amazonaws.com/qai-hub-models/Qualcomm+AI+Hub+Proprietary+License.pdf)
## References
* [Real-ESRGAN: Training Real-World Blind Super-Resolution with Pure Synthetic Data](https://arxiv.org/abs/2107.10833)
* [Source Model Implementation](https://github.com/xinntao/Real-ESRGAN/tree/master)
## Community
* Join [our AI Hub Slack community](https://aihub.qualcomm.com/community/slack) to collaborate, post questions and learn more about on-device AI.
* For questions or feedback please [reach out to us](mailto:ai-hub-support@qti.qualcomm.com).
|
Shopnil09/blockassist-bc-scruffy_knobby_hippo_1756227250
|
Shopnil09
| 2025-08-26T16:54:40Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"scruffy knobby hippo",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-26T16:54:36Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- scruffy knobby hippo
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
mimori11/blockassist-bc-lively_nasty_owl_1756227155
|
mimori11
| 2025-08-26T16:53:52Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"lively nasty owl",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-26T16:53:24Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- lively nasty owl
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
qualcomm/Posenet-Mobilenet
|
qualcomm
| 2025-08-26T16:53:33Z | 68 | 5 |
pytorch
|
[
"pytorch",
"tflite",
"android",
"keypoint-detection",
"arxiv:1803.08225",
"license:other",
"region:us"
] |
keypoint-detection
| 2024-05-29T00:58:41Z |
---
library_name: pytorch
license: other
tags:
- android
pipeline_tag: keypoint-detection
---

# Posenet-Mobilenet: Optimized for Mobile Deployment
## Perform accurate human pose estimation
Posenet performs pose estimation on human images.
This model is an implementation of Posenet-Mobilenet found [here](https://github.com/rwightman/posenet-pytorch).
This repository provides scripts to run Posenet-Mobilenet on Qualcomm® devices.
More details on model performance across various devices, can be found
[here](https://aihub.qualcomm.com/models/posenet_mobilenet).
### Model Details
- **Model Type:** Model_use_case.pose_estimation
- **Model Stats:**
- Model checkpoint: mobilenet_v1_101
- Input resolution: 513x257
- Number of parameters: 3.31M
- Model size (float): 12.7 MB
- Model size (w8a8): 12.7 MB
| Model | Precision | Device | Chipset | Target Runtime | Inference Time (ms) | Peak Memory Range (MB) | Primary Compute Unit | Target Model
|---|---|---|---|---|---|---|---|---|
| Posenet-Mobilenet | float | QCS8275 (Proxy) | Qualcomm® QCS8275 (Proxy) | TFLITE | 7.786 ms | 0 - 25 MB | NPU | [Posenet-Mobilenet.tflite](https://huggingface.co/qualcomm/Posenet-Mobilenet/blob/main/Posenet-Mobilenet.tflite) |
| Posenet-Mobilenet | float | QCS8275 (Proxy) | Qualcomm® QCS8275 (Proxy) | QNN_DLC | 7.667 ms | 1 - 20 MB | NPU | [Posenet-Mobilenet.dlc](https://huggingface.co/qualcomm/Posenet-Mobilenet/blob/main/Posenet-Mobilenet.dlc) |
| Posenet-Mobilenet | float | QCS8450 (Proxy) | Qualcomm® QCS8450 (Proxy) | TFLITE | 2.236 ms | 0 - 34 MB | NPU | [Posenet-Mobilenet.tflite](https://huggingface.co/qualcomm/Posenet-Mobilenet/blob/main/Posenet-Mobilenet.tflite) |
| Posenet-Mobilenet | float | QCS8450 (Proxy) | Qualcomm® QCS8450 (Proxy) | QNN_DLC | 2.287 ms | 2 - 34 MB | NPU | [Posenet-Mobilenet.dlc](https://huggingface.co/qualcomm/Posenet-Mobilenet/blob/main/Posenet-Mobilenet.dlc) |
| Posenet-Mobilenet | float | QCS8550 (Proxy) | Qualcomm® QCS8550 (Proxy) | TFLITE | 1.394 ms | 0 - 49 MB | NPU | [Posenet-Mobilenet.tflite](https://huggingface.co/qualcomm/Posenet-Mobilenet/blob/main/Posenet-Mobilenet.tflite) |
| Posenet-Mobilenet | float | QCS8550 (Proxy) | Qualcomm® QCS8550 (Proxy) | QNN_DLC | 1.329 ms | 2 - 6 MB | NPU | [Posenet-Mobilenet.dlc](https://huggingface.co/qualcomm/Posenet-Mobilenet/blob/main/Posenet-Mobilenet.dlc) |
| Posenet-Mobilenet | float | QCS9075 (Proxy) | Qualcomm® QCS9075 (Proxy) | TFLITE | 2.382 ms | 0 - 24 MB | NPU | [Posenet-Mobilenet.tflite](https://huggingface.co/qualcomm/Posenet-Mobilenet/blob/main/Posenet-Mobilenet.tflite) |
| Posenet-Mobilenet | float | QCS9075 (Proxy) | Qualcomm® QCS9075 (Proxy) | QNN_DLC | 2.306 ms | 2 - 20 MB | NPU | [Posenet-Mobilenet.dlc](https://huggingface.co/qualcomm/Posenet-Mobilenet/blob/main/Posenet-Mobilenet.dlc) |
| Posenet-Mobilenet | float | SA7255P ADP | Qualcomm® SA7255P | TFLITE | 7.786 ms | 0 - 25 MB | NPU | [Posenet-Mobilenet.tflite](https://huggingface.co/qualcomm/Posenet-Mobilenet/blob/main/Posenet-Mobilenet.tflite) |
| Posenet-Mobilenet | float | SA7255P ADP | Qualcomm® SA7255P | QNN_DLC | 7.667 ms | 1 - 20 MB | NPU | [Posenet-Mobilenet.dlc](https://huggingface.co/qualcomm/Posenet-Mobilenet/blob/main/Posenet-Mobilenet.dlc) |
| Posenet-Mobilenet | float | SA8255 (Proxy) | Qualcomm® SA8255P (Proxy) | TFLITE | 1.39 ms | 0 - 49 MB | NPU | [Posenet-Mobilenet.tflite](https://huggingface.co/qualcomm/Posenet-Mobilenet/blob/main/Posenet-Mobilenet.tflite) |
| Posenet-Mobilenet | float | SA8255 (Proxy) | Qualcomm® SA8255P (Proxy) | QNN_DLC | 1.314 ms | 1 - 30 MB | NPU | [Posenet-Mobilenet.dlc](https://huggingface.co/qualcomm/Posenet-Mobilenet/blob/main/Posenet-Mobilenet.dlc) |
| Posenet-Mobilenet | float | SA8295P ADP | Qualcomm® SA8295P | TFLITE | 2.794 ms | 0 - 26 MB | NPU | [Posenet-Mobilenet.tflite](https://huggingface.co/qualcomm/Posenet-Mobilenet/blob/main/Posenet-Mobilenet.tflite) |
| Posenet-Mobilenet | float | SA8295P ADP | Qualcomm® SA8295P | QNN_DLC | 2.743 ms | 2 - 27 MB | NPU | [Posenet-Mobilenet.dlc](https://huggingface.co/qualcomm/Posenet-Mobilenet/blob/main/Posenet-Mobilenet.dlc) |
| Posenet-Mobilenet | float | SA8650 (Proxy) | Qualcomm® SA8650P (Proxy) | TFLITE | 1.382 ms | 0 - 49 MB | NPU | [Posenet-Mobilenet.tflite](https://huggingface.co/qualcomm/Posenet-Mobilenet/blob/main/Posenet-Mobilenet.tflite) |
| Posenet-Mobilenet | float | SA8650 (Proxy) | Qualcomm® SA8650P (Proxy) | QNN_DLC | 1.32 ms | 1 - 30 MB | NPU | [Posenet-Mobilenet.dlc](https://huggingface.co/qualcomm/Posenet-Mobilenet/blob/main/Posenet-Mobilenet.dlc) |
| Posenet-Mobilenet | float | SA8775P ADP | Qualcomm® SA8775P | TFLITE | 2.382 ms | 0 - 24 MB | NPU | [Posenet-Mobilenet.tflite](https://huggingface.co/qualcomm/Posenet-Mobilenet/blob/main/Posenet-Mobilenet.tflite) |
| Posenet-Mobilenet | float | SA8775P ADP | Qualcomm® SA8775P | QNN_DLC | 2.306 ms | 2 - 20 MB | NPU | [Posenet-Mobilenet.dlc](https://huggingface.co/qualcomm/Posenet-Mobilenet/blob/main/Posenet-Mobilenet.dlc) |
| Posenet-Mobilenet | float | Samsung Galaxy S23 | Snapdragon® 8 Gen 2 Mobile | TFLITE | 1.395 ms | 0 - 49 MB | NPU | [Posenet-Mobilenet.tflite](https://huggingface.co/qualcomm/Posenet-Mobilenet/blob/main/Posenet-Mobilenet.tflite) |
| Posenet-Mobilenet | float | Samsung Galaxy S23 | Snapdragon® 8 Gen 2 Mobile | QNN_DLC | 1.316 ms | 1 - 29 MB | NPU | [Posenet-Mobilenet.dlc](https://huggingface.co/qualcomm/Posenet-Mobilenet/blob/main/Posenet-Mobilenet.dlc) |
| Posenet-Mobilenet | float | Samsung Galaxy S23 | Snapdragon® 8 Gen 2 Mobile | ONNX | 1.823 ms | 0 - 29 MB | NPU | [Posenet-Mobilenet.onnx.zip](https://huggingface.co/qualcomm/Posenet-Mobilenet/blob/main/Posenet-Mobilenet.onnx.zip) |
| Posenet-Mobilenet | float | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | TFLITE | 0.966 ms | 0 - 37 MB | NPU | [Posenet-Mobilenet.tflite](https://huggingface.co/qualcomm/Posenet-Mobilenet/blob/main/Posenet-Mobilenet.tflite) |
| Posenet-Mobilenet | float | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | QNN_DLC | 0.929 ms | 0 - 28 MB | NPU | [Posenet-Mobilenet.dlc](https://huggingface.co/qualcomm/Posenet-Mobilenet/blob/main/Posenet-Mobilenet.dlc) |
| Posenet-Mobilenet | float | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | ONNX | 1.223 ms | 0 - 30 MB | NPU | [Posenet-Mobilenet.onnx.zip](https://huggingface.co/qualcomm/Posenet-Mobilenet/blob/main/Posenet-Mobilenet.onnx.zip) |
| Posenet-Mobilenet | float | Snapdragon 8 Elite QRD | Snapdragon® 8 Elite Mobile | TFLITE | 0.971 ms | 0 - 29 MB | NPU | [Posenet-Mobilenet.tflite](https://huggingface.co/qualcomm/Posenet-Mobilenet/blob/main/Posenet-Mobilenet.tflite) |
| Posenet-Mobilenet | float | Snapdragon 8 Elite QRD | Snapdragon® 8 Elite Mobile | QNN_DLC | 0.933 ms | 4 - 24 MB | NPU | [Posenet-Mobilenet.dlc](https://huggingface.co/qualcomm/Posenet-Mobilenet/blob/main/Posenet-Mobilenet.dlc) |
| Posenet-Mobilenet | float | Snapdragon 8 Elite QRD | Snapdragon® 8 Elite Mobile | ONNX | 1.269 ms | 1 - 26 MB | NPU | [Posenet-Mobilenet.onnx.zip](https://huggingface.co/qualcomm/Posenet-Mobilenet/blob/main/Posenet-Mobilenet.onnx.zip) |
| Posenet-Mobilenet | float | Snapdragon X Elite CRD | Snapdragon® X Elite | QNN_DLC | 1.511 ms | 29 - 29 MB | NPU | [Posenet-Mobilenet.dlc](https://huggingface.co/qualcomm/Posenet-Mobilenet/blob/main/Posenet-Mobilenet.dlc) |
| Posenet-Mobilenet | float | Snapdragon X Elite CRD | Snapdragon® X Elite | ONNX | 2.087 ms | 6 - 6 MB | NPU | [Posenet-Mobilenet.onnx.zip](https://huggingface.co/qualcomm/Posenet-Mobilenet/blob/main/Posenet-Mobilenet.onnx.zip) |
## Installation
Install the package via pip:
```bash
pip install "qai-hub-models[posenet-mobilenet]"
```
## Configure Qualcomm® AI Hub to run this model on a cloud-hosted device
Sign-in to [Qualcomm® AI Hub](https://app.aihub.qualcomm.com/) with your
Qualcomm® ID. Once signed in navigate to `Account -> Settings -> API Token`.
With this API token, you can configure your client to run models on the cloud
hosted devices.
```bash
qai-hub configure --api_token API_TOKEN
```
Navigate to [docs](https://app.aihub.qualcomm.com/docs/) for more information.
## Demo off target
The package contains a simple end-to-end demo that downloads pre-trained
weights and runs this model on a sample input.
```bash
python -m qai_hub_models.models.posenet_mobilenet.demo
```
The above demo runs a reference implementation of pre-processing, model
inference, and post processing.
**NOTE**: If you want running in a Jupyter Notebook or Google Colab like
environment, please add the following to your cell (instead of the above).
```
%run -m qai_hub_models.models.posenet_mobilenet.demo
```
### Run model on a cloud-hosted device
In addition to the demo, you can also run the model on a cloud-hosted Qualcomm®
device. This script does the following:
* Performance check on-device on a cloud-hosted device
* Downloads compiled assets that can be deployed on-device for Android.
* Accuracy check between PyTorch and on-device outputs.
```bash
python -m qai_hub_models.models.posenet_mobilenet.export
```
## How does this work?
This [export script](https://aihub.qualcomm.com/models/posenet_mobilenet/qai_hub_models/models/Posenet-Mobilenet/export.py)
leverages [Qualcomm® AI Hub](https://aihub.qualcomm.com/) to optimize, validate, and deploy this model
on-device. Lets go through each step below in detail:
Step 1: **Compile model for on-device deployment**
To compile a PyTorch model for on-device deployment, we first trace the model
in memory using the `jit.trace` and then call the `submit_compile_job` API.
```python
import torch
import qai_hub as hub
from qai_hub_models.models.posenet_mobilenet import Model
# Load the model
torch_model = Model.from_pretrained()
# Device
device = hub.Device("Samsung Galaxy S24")
# Trace model
input_shape = torch_model.get_input_spec()
sample_inputs = torch_model.sample_inputs()
pt_model = torch.jit.trace(torch_model, [torch.tensor(data[0]) for _, data in sample_inputs.items()])
# Compile model on a specific device
compile_job = hub.submit_compile_job(
model=pt_model,
device=device,
input_specs=torch_model.get_input_spec(),
)
# Get target model to run on-device
target_model = compile_job.get_target_model()
```
Step 2: **Performance profiling on cloud-hosted device**
After compiling models from step 1. Models can be profiled model on-device using the
`target_model`. Note that this scripts runs the model on a device automatically
provisioned in the cloud. Once the job is submitted, you can navigate to a
provided job URL to view a variety of on-device performance metrics.
```python
profile_job = hub.submit_profile_job(
model=target_model,
device=device,
)
```
Step 3: **Verify on-device accuracy**
To verify the accuracy of the model on-device, you can run on-device inference
on sample input data on the same cloud hosted device.
```python
input_data = torch_model.sample_inputs()
inference_job = hub.submit_inference_job(
model=target_model,
device=device,
inputs=input_data,
)
on_device_output = inference_job.download_output_data()
```
With the output of the model, you can compute like PSNR, relative errors or
spot check the output with expected output.
**Note**: This on-device profiling and inference requires access to Qualcomm®
AI Hub. [Sign up for access](https://myaccount.qualcomm.com/signup).
## Run demo on a cloud-hosted device
You can also run the demo on-device.
```bash
python -m qai_hub_models.models.posenet_mobilenet.demo --eval-mode on-device
```
**NOTE**: If you want running in a Jupyter Notebook or Google Colab like
environment, please add the following to your cell (instead of the above).
```
%run -m qai_hub_models.models.posenet_mobilenet.demo -- --eval-mode on-device
```
## Deploying compiled model to Android
The models can be deployed using multiple runtimes:
- TensorFlow Lite (`.tflite` export): [This
tutorial](https://www.tensorflow.org/lite/android/quickstart) provides a
guide to deploy the .tflite model in an Android application.
- QNN (`.so` export ): This [sample
app](https://docs.qualcomm.com/bundle/publicresource/topics/80-63442-50/sample_app.html)
provides instructions on how to use the `.so` shared library in an Android application.
## View on Qualcomm® AI Hub
Get more details on Posenet-Mobilenet's performance across various devices [here](https://aihub.qualcomm.com/models/posenet_mobilenet).
Explore all available models on [Qualcomm® AI Hub](https://aihub.qualcomm.com/)
## License
* The license for the original implementation of Posenet-Mobilenet can be found
[here](https://github.com/rwightman/posenet-pytorch/blob/master/LICENSE.txt).
* The license for the compiled assets for on-device deployment can be found [here](https://qaihub-public-assets.s3.us-west-2.amazonaws.com/qai-hub-models/Qualcomm+AI+Hub+Proprietary+License.pdf)
## References
* [PersonLab: Person Pose Estimation and Instance Segmentation with a Bottom-Up, Part-Based, Geometric Embedding Model](https://arxiv.org/abs/1803.08225)
* [Source Model Implementation](https://github.com/rwightman/posenet-pytorch)
## Community
* Join [our AI Hub Slack community](https://aihub.qualcomm.com/community/slack) to collaborate, post questions and learn more about on-device AI.
* For questions or feedback please [reach out to us](mailto:ai-hub-support@qti.qualcomm.com).
|
qualcomm/OpenAI-Clip
|
qualcomm
| 2025-08-26T16:52:58Z | 66 | 8 |
pytorch
|
[
"pytorch",
"tflite",
"foundation",
"android",
"image-classification",
"arxiv:2103.00020",
"license:other",
"region:us"
] |
image-classification
| 2024-02-25T22:53:55Z |
---
library_name: pytorch
license: other
tags:
- foundation
- android
pipeline_tag: image-classification
---

# OpenAI-Clip: Optimized for Mobile Deployment
## Multi-modal foundational model for vision and language tasks like image/text similarity and for zero-shot image classification
Contrastive Language-Image Pre-Training (CLIP) uses a ViT like transformer to get visual features and a causal language model to get the text features. Both the text and visual features can then be used for a variety of zero-shot learning tasks.
This model is an implementation of OpenAI-Clip found [here](https://github.com/openai/CLIP/).
This repository provides scripts to run OpenAI-Clip on Qualcomm® devices.
More details on model performance across various devices, can be found
[here](https://aihub.qualcomm.com/models/openai_clip).
### Model Details
- **Model Type:** Model_use_case.image_classification
- **Model Stats:**
- Model checkpoint: ViT-B/16
- Image input resolution: 224x224
- Text context length: 77
- Number of parameters: 150M
- Model size (float): 571 MB
| Model | Precision | Device | Chipset | Target Runtime | Inference Time (ms) | Peak Memory Range (MB) | Primary Compute Unit | Target Model
|---|---|---|---|---|---|---|---|---|
| OpenAI-Clip | float | QCS8275 (Proxy) | Qualcomm® QCS8275 (Proxy) | TFLITE | 63.066 ms | 0 - 436 MB | NPU | [OpenAI-Clip.tflite](https://huggingface.co/qualcomm/OpenAI-Clip/blob/main/OpenAI-Clip.tflite) |
| OpenAI-Clip | float | QCS8275 (Proxy) | Qualcomm® QCS8275 (Proxy) | QNN_DLC | 59.664 ms | 1 - 565 MB | NPU | [OpenAI-Clip.dlc](https://huggingface.co/qualcomm/OpenAI-Clip/blob/main/OpenAI-Clip.dlc) |
| OpenAI-Clip | float | QCS8450 (Proxy) | Qualcomm® QCS8450 (Proxy) | TFLITE | 25.207 ms | 0 - 446 MB | NPU | [OpenAI-Clip.tflite](https://huggingface.co/qualcomm/OpenAI-Clip/blob/main/OpenAI-Clip.tflite) |
| OpenAI-Clip | float | QCS8450 (Proxy) | Qualcomm® QCS8450 (Proxy) | QNN_DLC | 25.825 ms | 1 - 532 MB | NPU | [OpenAI-Clip.dlc](https://huggingface.co/qualcomm/OpenAI-Clip/blob/main/OpenAI-Clip.dlc) |
| OpenAI-Clip | float | QCS8550 (Proxy) | Qualcomm® QCS8550 (Proxy) | TFLITE | 21.971 ms | 0 - 14 MB | NPU | [OpenAI-Clip.tflite](https://huggingface.co/qualcomm/OpenAI-Clip/blob/main/OpenAI-Clip.tflite) |
| OpenAI-Clip | float | QCS8550 (Proxy) | Qualcomm® QCS8550 (Proxy) | QNN_DLC | 21.833 ms | 3 - 40 MB | NPU | [OpenAI-Clip.dlc](https://huggingface.co/qualcomm/OpenAI-Clip/blob/main/OpenAI-Clip.dlc) |
| OpenAI-Clip | float | QCS9075 (Proxy) | Qualcomm® QCS9075 (Proxy) | TFLITE | 25.777 ms | 0 - 437 MB | NPU | [OpenAI-Clip.tflite](https://huggingface.co/qualcomm/OpenAI-Clip/blob/main/OpenAI-Clip.tflite) |
| OpenAI-Clip | float | QCS9075 (Proxy) | Qualcomm® QCS9075 (Proxy) | QNN_DLC | 24.047 ms | 1 - 564 MB | NPU | [OpenAI-Clip.dlc](https://huggingface.co/qualcomm/OpenAI-Clip/blob/main/OpenAI-Clip.dlc) |
| OpenAI-Clip | float | SA7255P ADP | Qualcomm® SA7255P | TFLITE | 63.066 ms | 0 - 436 MB | NPU | [OpenAI-Clip.tflite](https://huggingface.co/qualcomm/OpenAI-Clip/blob/main/OpenAI-Clip.tflite) |
| OpenAI-Clip | float | SA7255P ADP | Qualcomm® SA7255P | QNN_DLC | 59.664 ms | 1 - 565 MB | NPU | [OpenAI-Clip.dlc](https://huggingface.co/qualcomm/OpenAI-Clip/blob/main/OpenAI-Clip.dlc) |
| OpenAI-Clip | float | SA8255 (Proxy) | Qualcomm® SA8255P (Proxy) | TFLITE | 21.983 ms | 0 - 35 MB | NPU | [OpenAI-Clip.tflite](https://huggingface.co/qualcomm/OpenAI-Clip/blob/main/OpenAI-Clip.tflite) |
| OpenAI-Clip | float | SA8255 (Proxy) | Qualcomm® SA8255P (Proxy) | QNN_DLC | 21.734 ms | 0 - 39 MB | NPU | [OpenAI-Clip.dlc](https://huggingface.co/qualcomm/OpenAI-Clip/blob/main/OpenAI-Clip.dlc) |
| OpenAI-Clip | float | SA8295P ADP | Qualcomm® SA8295P | TFLITE | 28.755 ms | 0 - 430 MB | NPU | [OpenAI-Clip.tflite](https://huggingface.co/qualcomm/OpenAI-Clip/blob/main/OpenAI-Clip.tflite) |
| OpenAI-Clip | float | SA8295P ADP | Qualcomm® SA8295P | QNN_DLC | 25.874 ms | 1 - 558 MB | NPU | [OpenAI-Clip.dlc](https://huggingface.co/qualcomm/OpenAI-Clip/blob/main/OpenAI-Clip.dlc) |
| OpenAI-Clip | float | SA8650 (Proxy) | Qualcomm® SA8650P (Proxy) | TFLITE | 21.983 ms | 0 - 33 MB | NPU | [OpenAI-Clip.tflite](https://huggingface.co/qualcomm/OpenAI-Clip/blob/main/OpenAI-Clip.tflite) |
| OpenAI-Clip | float | SA8650 (Proxy) | Qualcomm® SA8650P (Proxy) | QNN_DLC | 21.713 ms | 0 - 30 MB | NPU | [OpenAI-Clip.dlc](https://huggingface.co/qualcomm/OpenAI-Clip/blob/main/OpenAI-Clip.dlc) |
| OpenAI-Clip | float | SA8775P ADP | Qualcomm® SA8775P | TFLITE | 25.777 ms | 0 - 437 MB | NPU | [OpenAI-Clip.tflite](https://huggingface.co/qualcomm/OpenAI-Clip/blob/main/OpenAI-Clip.tflite) |
| OpenAI-Clip | float | SA8775P ADP | Qualcomm® SA8775P | QNN_DLC | 24.047 ms | 1 - 564 MB | NPU | [OpenAI-Clip.dlc](https://huggingface.co/qualcomm/OpenAI-Clip/blob/main/OpenAI-Clip.dlc) |
| OpenAI-Clip | float | Samsung Galaxy S23 | Snapdragon® 8 Gen 2 Mobile | TFLITE | 21.813 ms | 0 - 18 MB | NPU | [OpenAI-Clip.tflite](https://huggingface.co/qualcomm/OpenAI-Clip/blob/main/OpenAI-Clip.tflite) |
| OpenAI-Clip | float | Samsung Galaxy S23 | Snapdragon® 8 Gen 2 Mobile | QNN_DLC | 21.769 ms | 0 - 35 MB | NPU | [OpenAI-Clip.dlc](https://huggingface.co/qualcomm/OpenAI-Clip/blob/main/OpenAI-Clip.dlc) |
| OpenAI-Clip | float | Samsung Galaxy S23 | Snapdragon® 8 Gen 2 Mobile | ONNX | 24.728 ms | 1 - 47 MB | NPU | [OpenAI-Clip.onnx.zip](https://huggingface.co/qualcomm/OpenAI-Clip/blob/main/OpenAI-Clip.onnx.zip) |
| OpenAI-Clip | float | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | TFLITE | 15.733 ms | 0 - 445 MB | NPU | [OpenAI-Clip.tflite](https://huggingface.co/qualcomm/OpenAI-Clip/blob/main/OpenAI-Clip.tflite) |
| OpenAI-Clip | float | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | QNN_DLC | 15.116 ms | 0 - 566 MB | NPU | [OpenAI-Clip.dlc](https://huggingface.co/qualcomm/OpenAI-Clip/blob/main/OpenAI-Clip.dlc) |
| OpenAI-Clip | float | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | ONNX | 17.971 ms | 0 - 497 MB | NPU | [OpenAI-Clip.onnx.zip](https://huggingface.co/qualcomm/OpenAI-Clip/blob/main/OpenAI-Clip.onnx.zip) |
| OpenAI-Clip | float | Snapdragon 8 Elite QRD | Snapdragon® 8 Elite Mobile | TFLITE | 14.351 ms | 0 - 438 MB | NPU | [OpenAI-Clip.tflite](https://huggingface.co/qualcomm/OpenAI-Clip/blob/main/OpenAI-Clip.tflite) |
| OpenAI-Clip | float | Snapdragon 8 Elite QRD | Snapdragon® 8 Elite Mobile | QNN_DLC | 11.678 ms | 1 - 546 MB | NPU | [OpenAI-Clip.dlc](https://huggingface.co/qualcomm/OpenAI-Clip/blob/main/OpenAI-Clip.dlc) |
| OpenAI-Clip | float | Snapdragon 8 Elite QRD | Snapdragon® 8 Elite Mobile | ONNX | 17.019 ms | 1 - 472 MB | NPU | [OpenAI-Clip.onnx.zip](https://huggingface.co/qualcomm/OpenAI-Clip/blob/main/OpenAI-Clip.onnx.zip) |
| OpenAI-Clip | float | Snapdragon X Elite CRD | Snapdragon® X Elite | QNN_DLC | 22.422 ms | 1531 - 1531 MB | NPU | [OpenAI-Clip.dlc](https://huggingface.co/qualcomm/OpenAI-Clip/blob/main/OpenAI-Clip.dlc) |
| OpenAI-Clip | float | Snapdragon X Elite CRD | Snapdragon® X Elite | ONNX | 26.399 ms | 293 - 293 MB | NPU | [OpenAI-Clip.onnx.zip](https://huggingface.co/qualcomm/OpenAI-Clip/blob/main/OpenAI-Clip.onnx.zip) |
## Installation
Install the package via pip:
```bash
pip install "qai-hub-models[openai-clip]"
```
## Configure Qualcomm® AI Hub to run this model on a cloud-hosted device
Sign-in to [Qualcomm® AI Hub](https://app.aihub.qualcomm.com/) with your
Qualcomm® ID. Once signed in navigate to `Account -> Settings -> API Token`.
With this API token, you can configure your client to run models on the cloud
hosted devices.
```bash
qai-hub configure --api_token API_TOKEN
```
Navigate to [docs](https://app.aihub.qualcomm.com/docs/) for more information.
## Demo off target
The package contains a simple end-to-end demo that downloads pre-trained
weights and runs this model on a sample input.
```bash
python -m qai_hub_models.models.openai_clip.demo
```
The above demo runs a reference implementation of pre-processing, model
inference, and post processing.
**NOTE**: If you want running in a Jupyter Notebook or Google Colab like
environment, please add the following to your cell (instead of the above).
```
%run -m qai_hub_models.models.openai_clip.demo
```
### Run model on a cloud-hosted device
In addition to the demo, you can also run the model on a cloud-hosted Qualcomm®
device. This script does the following:
* Performance check on-device on a cloud-hosted device
* Downloads compiled assets that can be deployed on-device for Android.
* Accuracy check between PyTorch and on-device outputs.
```bash
python -m qai_hub_models.models.openai_clip.export
```
## How does this work?
This [export script](https://aihub.qualcomm.com/models/openai_clip/qai_hub_models/models/OpenAI-Clip/export.py)
leverages [Qualcomm® AI Hub](https://aihub.qualcomm.com/) to optimize, validate, and deploy this model
on-device. Lets go through each step below in detail:
Step 1: **Compile model for on-device deployment**
To compile a PyTorch model for on-device deployment, we first trace the model
in memory using the `jit.trace` and then call the `submit_compile_job` API.
```python
import torch
import qai_hub as hub
from qai_hub_models.models.openai_clip import Model
# Load the model
torch_model = Model.from_pretrained()
# Device
device = hub.Device("Samsung Galaxy S24")
# Trace model
input_shape = torch_model.get_input_spec()
sample_inputs = torch_model.sample_inputs()
pt_model = torch.jit.trace(torch_model, [torch.tensor(data[0]) for _, data in sample_inputs.items()])
# Compile model on a specific device
compile_job = hub.submit_compile_job(
model=pt_model,
device=device,
input_specs=torch_model.get_input_spec(),
)
# Get target model to run on-device
target_model = compile_job.get_target_model()
```
Step 2: **Performance profiling on cloud-hosted device**
After compiling models from step 1. Models can be profiled model on-device using the
`target_model`. Note that this scripts runs the model on a device automatically
provisioned in the cloud. Once the job is submitted, you can navigate to a
provided job URL to view a variety of on-device performance metrics.
```python
profile_job = hub.submit_profile_job(
model=target_model,
device=device,
)
```
Step 3: **Verify on-device accuracy**
To verify the accuracy of the model on-device, you can run on-device inference
on sample input data on the same cloud hosted device.
```python
input_data = torch_model.sample_inputs()
inference_job = hub.submit_inference_job(
model=target_model,
device=device,
inputs=input_data,
)
on_device_output = inference_job.download_output_data()
```
With the output of the model, you can compute like PSNR, relative errors or
spot check the output with expected output.
**Note**: This on-device profiling and inference requires access to Qualcomm®
AI Hub. [Sign up for access](https://myaccount.qualcomm.com/signup).
## Deploying compiled model to Android
The models can be deployed using multiple runtimes:
- TensorFlow Lite (`.tflite` export): [This
tutorial](https://www.tensorflow.org/lite/android/quickstart) provides a
guide to deploy the .tflite model in an Android application.
- QNN (`.so` export ): This [sample
app](https://docs.qualcomm.com/bundle/publicresource/topics/80-63442-50/sample_app.html)
provides instructions on how to use the `.so` shared library in an Android application.
## View on Qualcomm® AI Hub
Get more details on OpenAI-Clip's performance across various devices [here](https://aihub.qualcomm.com/models/openai_clip).
Explore all available models on [Qualcomm® AI Hub](https://aihub.qualcomm.com/)
## License
* The license for the original implementation of OpenAI-Clip can be found
[here](https://github.com/openai/CLIP/blob/main/LICENSE).
* The license for the compiled assets for on-device deployment can be found [here](https://qaihub-public-assets.s3.us-west-2.amazonaws.com/qai-hub-models/Qualcomm+AI+Hub+Proprietary+License.pdf)
## References
* [Learning Transferable Visual Models From Natural Language Supervision](https://arxiv.org/abs/2103.00020)
* [Source Model Implementation](https://github.com/openai/CLIP/)
## Community
* Join [our AI Hub Slack community](https://aihub.qualcomm.com/community/slack) to collaborate, post questions and learn more about on-device AI.
* For questions or feedback please [reach out to us](mailto:ai-hub-support@qti.qualcomm.com).
|
JonDoeBeep2/Gemma-Translate-ENSPA-F16
|
JonDoeBeep2
| 2025-08-26T16:52:12Z | 0 | 0 | null |
[
"gguf",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2025-08-26T16:50:45Z |
---
license: apache-2.0
---
|
zaringleb/homelab_binary_cube_act_test_skip_25
|
zaringleb
| 2025-08-26T16:51:56Z | 0 | 0 |
lerobot
|
[
"lerobot",
"safetensors",
"act",
"robotics",
"dataset:zaringleb/binary_cube_homelab_so101_3",
"arxiv:2304.13705",
"license:apache-2.0",
"region:us"
] |
robotics
| 2025-08-26T16:51:37Z |
---
datasets: zaringleb/binary_cube_homelab_so101_3
library_name: lerobot
license: apache-2.0
model_name: act
pipeline_tag: robotics
tags:
- act
- robotics
- lerobot
---
# Model Card for act
<!-- Provide a quick summary of what the model is/does. -->
[Action Chunking with Transformers (ACT)](https://huggingface.co/papers/2304.13705) is an imitation-learning method that predicts short action chunks instead of single steps. It learns from teleoperated data and often achieves high success rates.
This policy has been trained and pushed to the Hub using [LeRobot](https://github.com/huggingface/lerobot).
See the full documentation at [LeRobot Docs](https://huggingface.co/docs/lerobot/index).
---
## How to Get Started with the Model
For a complete walkthrough, see the [training guide](https://huggingface.co/docs/lerobot/il_robots#train-a-policy).
Below is the short version on how to train and run inference/eval:
### Train from scratch
```bash
python -m lerobot.scripts.train \
--dataset.repo_id=${HF_USER}/<dataset> \
--policy.type=act \
--output_dir=outputs/train/<desired_policy_repo_id> \
--job_name=lerobot_training \
--policy.device=cuda \
--policy.repo_id=${HF_USER}/<desired_policy_repo_id>
--wandb.enable=true
```
*Writes checkpoints to `outputs/train/<desired_policy_repo_id>/checkpoints/`.*
### Evaluate the policy/run inference
```bash
python -m lerobot.record \
--robot.type=so100_follower \
--dataset.repo_id=<hf_user>/eval_<dataset> \
--policy.path=<hf_user>/<desired_policy_repo_id> \
--episodes=10
```
Prefix the dataset repo with **eval\_** and supply `--policy.path` pointing to a local or hub checkpoint.
---
## Model Details
* **License:** apache-2.0
|
Nayana-cognitivelab/Full-SFT-v1-23000
|
Nayana-cognitivelab
| 2025-08-26T16:51:41Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"gemma3n",
"image-text-to-text",
"text-generation-inference",
"unsloth",
"conversational",
"en",
"base_model:unsloth/gemma-3n-E4B-it",
"base_model:finetune:unsloth/gemma-3n-E4B-it",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
image-text-to-text
| 2025-08-26T16:49:59Z |
---
base_model: unsloth/gemma-3n-E4B-it
tags:
- text-generation-inference
- transformers
- unsloth
- gemma3n
license: apache-2.0
language:
- en
---
# Uploaded finetuned model
- **Developed by:** Nayana-cognitivelab
- **License:** apache-2.0
- **Finetuned from model :** unsloth/gemma-3n-E4B-it
This gemma3n model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
liukevin666/blockassist-bc-yawning_striped_cassowary_1756226821
|
liukevin666
| 2025-08-26T16:50:28Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"yawning striped cassowary",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-26T16:48:01Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- yawning striped cassowary
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
qualcomm/Movenet
|
qualcomm
| 2025-08-26T16:50:27Z | 40 | 1 |
pytorch
|
[
"pytorch",
"tflite",
"android",
"keypoint-detection",
"license:other",
"region:us"
] |
keypoint-detection
| 2025-02-28T19:13:04Z |
---
library_name: pytorch
license: other
tags:
- android
pipeline_tag: keypoint-detection
---

# Movenet: Optimized for Mobile Deployment
## Perform accurate human pose estimation
Movenet performs pose estimation on human images.
This model is an implementation of Movenet found [here](https://github.com/lee-man/movenet-pytorch).
This repository provides scripts to run Movenet on Qualcomm® devices.
More details on model performance across various devices, can be found
[here](https://aihub.qualcomm.com/models/movenet).
### Model Details
- **Model Type:** Model_use_case.pose_estimation
- **Model Stats:**
- Model checkpoint: None
- Input resolution: 192x192
- Number of parameters: 2.33M
- Model size (float): 8.91 MB
| Model | Precision | Device | Chipset | Target Runtime | Inference Time (ms) | Peak Memory Range (MB) | Primary Compute Unit | Target Model
|---|---|---|---|---|---|---|---|---|
| Movenet | float | QCS8275 (Proxy) | Qualcomm® QCS8275 (Proxy) | TFLITE | 6.363 ms | 1 - 10 MB | CPU | [Movenet.tflite](https://huggingface.co/qualcomm/Movenet/blob/main/Movenet.tflite) |
| Movenet | float | QCS8275 (Proxy) | Qualcomm® QCS8275 (Proxy) | QNN_DLC | 18.992 ms | 13 - 23 MB | CPU | [Movenet.dlc](https://huggingface.co/qualcomm/Movenet/blob/main/Movenet.dlc) |
| Movenet | float | QCS8450 (Proxy) | Qualcomm® QCS8450 (Proxy) | TFLITE | 5.438 ms | 1 - 24 MB | CPU | [Movenet.tflite](https://huggingface.co/qualcomm/Movenet/blob/main/Movenet.tflite) |
| Movenet | float | QCS8450 (Proxy) | Qualcomm® QCS8450 (Proxy) | QNN_DLC | 17.623 ms | 13 - 38 MB | CPU | [Movenet.dlc](https://huggingface.co/qualcomm/Movenet/blob/main/Movenet.dlc) |
| Movenet | float | QCS8550 (Proxy) | Qualcomm® QCS8550 (Proxy) | TFLITE | 3.978 ms | 0 - 3 MB | CPU | [Movenet.tflite](https://huggingface.co/qualcomm/Movenet/blob/main/Movenet.tflite) |
| Movenet | float | QCS8550 (Proxy) | Qualcomm® QCS8550 (Proxy) | QNN_DLC | 12.659 ms | 12 - 16 MB | CPU | [Movenet.dlc](https://huggingface.co/qualcomm/Movenet/blob/main/Movenet.dlc) |
| Movenet | float | QCS9075 (Proxy) | Qualcomm® QCS9075 (Proxy) | TFLITE | 5.544 ms | 1 - 11 MB | CPU | [Movenet.tflite](https://huggingface.co/qualcomm/Movenet/blob/main/Movenet.tflite) |
| Movenet | float | QCS9075 (Proxy) | Qualcomm® QCS9075 (Proxy) | QNN_DLC | 13.804 ms | 13 - 24 MB | CPU | [Movenet.dlc](https://huggingface.co/qualcomm/Movenet/blob/main/Movenet.dlc) |
| Movenet | float | SA7255P ADP | Qualcomm® SA7255P | TFLITE | 6.363 ms | 1 - 10 MB | CPU | [Movenet.tflite](https://huggingface.co/qualcomm/Movenet/blob/main/Movenet.tflite) |
| Movenet | float | SA7255P ADP | Qualcomm® SA7255P | QNN_DLC | 18.992 ms | 13 - 23 MB | CPU | [Movenet.dlc](https://huggingface.co/qualcomm/Movenet/blob/main/Movenet.dlc) |
| Movenet | float | SA8255 (Proxy) | Qualcomm® SA8255P (Proxy) | TFLITE | 3.829 ms | 0 - 2 MB | CPU | [Movenet.tflite](https://huggingface.co/qualcomm/Movenet/blob/main/Movenet.tflite) |
| Movenet | float | SA8255 (Proxy) | Qualcomm® SA8255P (Proxy) | QNN_DLC | 19.027 ms | 12 - 16 MB | CPU | [Movenet.dlc](https://huggingface.co/qualcomm/Movenet/blob/main/Movenet.dlc) |
| Movenet | float | SA8295P ADP | Qualcomm® SA8295P | TFLITE | 3.631 ms | 0 - 18 MB | CPU | [Movenet.tflite](https://huggingface.co/qualcomm/Movenet/blob/main/Movenet.tflite) |
| Movenet | float | SA8295P ADP | Qualcomm® SA8295P | QNN_DLC | 12.488 ms | 13 - 30 MB | CPU | [Movenet.dlc](https://huggingface.co/qualcomm/Movenet/blob/main/Movenet.dlc) |
| Movenet | float | SA8650 (Proxy) | Qualcomm® SA8650P (Proxy) | TFLITE | 3.786 ms | 0 - 4 MB | CPU | [Movenet.tflite](https://huggingface.co/qualcomm/Movenet/blob/main/Movenet.tflite) |
| Movenet | float | SA8650 (Proxy) | Qualcomm® SA8650P (Proxy) | QNN_DLC | 11.747 ms | 12 - 16 MB | CPU | [Movenet.dlc](https://huggingface.co/qualcomm/Movenet/blob/main/Movenet.dlc) |
| Movenet | float | SA8775P ADP | Qualcomm® SA8775P | TFLITE | 5.544 ms | 1 - 11 MB | CPU | [Movenet.tflite](https://huggingface.co/qualcomm/Movenet/blob/main/Movenet.tflite) |
| Movenet | float | SA8775P ADP | Qualcomm® SA8775P | QNN_DLC | 13.804 ms | 13 - 24 MB | CPU | [Movenet.dlc](https://huggingface.co/qualcomm/Movenet/blob/main/Movenet.dlc) |
| Movenet | float | Samsung Galaxy S23 | Snapdragon® 8 Gen 2 Mobile | TFLITE | 3.787 ms | 0 - 2 MB | CPU | [Movenet.tflite](https://huggingface.co/qualcomm/Movenet/blob/main/Movenet.tflite) |
| Movenet | float | Samsung Galaxy S23 | Snapdragon® 8 Gen 2 Mobile | QNN_DLC | 11.418 ms | 13 - 16 MB | CPU | [Movenet.dlc](https://huggingface.co/qualcomm/Movenet/blob/main/Movenet.dlc) |
| Movenet | float | Samsung Galaxy S23 | Snapdragon® 8 Gen 2 Mobile | ONNX | 10.893 ms | 12 - 14 MB | CPU | [Movenet.onnx.zip](https://huggingface.co/qualcomm/Movenet/blob/main/Movenet.onnx.zip) |
| Movenet | float | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | TFLITE | 3.338 ms | 0 - 20 MB | CPU | [Movenet.tflite](https://huggingface.co/qualcomm/Movenet/blob/main/Movenet.tflite) |
| Movenet | float | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | QNN_DLC | 10.09 ms | 13 - 33 MB | CPU | [Movenet.dlc](https://huggingface.co/qualcomm/Movenet/blob/main/Movenet.dlc) |
| Movenet | float | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | ONNX | 9.126 ms | 13 - 31 MB | CPU | [Movenet.onnx.zip](https://huggingface.co/qualcomm/Movenet/blob/main/Movenet.onnx.zip) |
| Movenet | float | Snapdragon 8 Elite QRD | Snapdragon® 8 Elite Mobile | TFLITE | 2.934 ms | 1 - 16 MB | CPU | [Movenet.tflite](https://huggingface.co/qualcomm/Movenet/blob/main/Movenet.tflite) |
| Movenet | float | Snapdragon 8 Elite QRD | Snapdragon® 8 Elite Mobile | QNN_DLC | 8.73 ms | 12 - 29 MB | CPU | [Movenet.dlc](https://huggingface.co/qualcomm/Movenet/blob/main/Movenet.dlc) |
| Movenet | float | Snapdragon 8 Elite QRD | Snapdragon® 8 Elite Mobile | ONNX | 8.743 ms | 19 - 32 MB | CPU | [Movenet.onnx.zip](https://huggingface.co/qualcomm/Movenet/blob/main/Movenet.onnx.zip) |
| Movenet | float | Snapdragon X Elite CRD | Snapdragon® X Elite | QNN_DLC | 6.939 ms | 4 - 4 MB | CPU | [Movenet.dlc](https://huggingface.co/qualcomm/Movenet/blob/main/Movenet.dlc) |
| Movenet | float | Snapdragon X Elite CRD | Snapdragon® X Elite | ONNX | 8.183 ms | 16 - 16 MB | CPU | [Movenet.onnx.zip](https://huggingface.co/qualcomm/Movenet/blob/main/Movenet.onnx.zip) |
## Installation
Install the package via pip:
```bash
pip install qai-hub-models
```
## Configure Qualcomm® AI Hub to run this model on a cloud-hosted device
Sign-in to [Qualcomm® AI Hub](https://app.aihub.qualcomm.com/) with your
Qualcomm® ID. Once signed in navigate to `Account -> Settings -> API Token`.
With this API token, you can configure your client to run models on the cloud
hosted devices.
```bash
qai-hub configure --api_token API_TOKEN
```
Navigate to [docs](https://app.aihub.qualcomm.com/docs/) for more information.
## Demo off target
The package contains a simple end-to-end demo that downloads pre-trained
weights and runs this model on a sample input.
```bash
python -m qai_hub_models.models.movenet.demo
```
The above demo runs a reference implementation of pre-processing, model
inference, and post processing.
**NOTE**: If you want running in a Jupyter Notebook or Google Colab like
environment, please add the following to your cell (instead of the above).
```
%run -m qai_hub_models.models.movenet.demo
```
### Run model on a cloud-hosted device
In addition to the demo, you can also run the model on a cloud-hosted Qualcomm®
device. This script does the following:
* Performance check on-device on a cloud-hosted device
* Downloads compiled assets that can be deployed on-device for Android.
* Accuracy check between PyTorch and on-device outputs.
```bash
python -m qai_hub_models.models.movenet.export
```
## How does this work?
This [export script](https://aihub.qualcomm.com/models/movenet/qai_hub_models/models/Movenet/export.py)
leverages [Qualcomm® AI Hub](https://aihub.qualcomm.com/) to optimize, validate, and deploy this model
on-device. Lets go through each step below in detail:
Step 1: **Compile model for on-device deployment**
To compile a PyTorch model for on-device deployment, we first trace the model
in memory using the `jit.trace` and then call the `submit_compile_job` API.
```python
import torch
import qai_hub as hub
from qai_hub_models.models.movenet import Model
# Load the model
torch_model = Model.from_pretrained()
# Device
device = hub.Device("Samsung Galaxy S24")
# Trace model
input_shape = torch_model.get_input_spec()
sample_inputs = torch_model.sample_inputs()
pt_model = torch.jit.trace(torch_model, [torch.tensor(data[0]) for _, data in sample_inputs.items()])
# Compile model on a specific device
compile_job = hub.submit_compile_job(
model=pt_model,
device=device,
input_specs=torch_model.get_input_spec(),
)
# Get target model to run on-device
target_model = compile_job.get_target_model()
```
Step 2: **Performance profiling on cloud-hosted device**
After compiling models from step 1. Models can be profiled model on-device using the
`target_model`. Note that this scripts runs the model on a device automatically
provisioned in the cloud. Once the job is submitted, you can navigate to a
provided job URL to view a variety of on-device performance metrics.
```python
profile_job = hub.submit_profile_job(
model=target_model,
device=device,
)
```
Step 3: **Verify on-device accuracy**
To verify the accuracy of the model on-device, you can run on-device inference
on sample input data on the same cloud hosted device.
```python
input_data = torch_model.sample_inputs()
inference_job = hub.submit_inference_job(
model=target_model,
device=device,
inputs=input_data,
)
on_device_output = inference_job.download_output_data()
```
With the output of the model, you can compute like PSNR, relative errors or
spot check the output with expected output.
**Note**: This on-device profiling and inference requires access to Qualcomm®
AI Hub. [Sign up for access](https://myaccount.qualcomm.com/signup).
## Run demo on a cloud-hosted device
You can also run the demo on-device.
```bash
python -m qai_hub_models.models.movenet.demo --eval-mode on-device
```
**NOTE**: If you want running in a Jupyter Notebook or Google Colab like
environment, please add the following to your cell (instead of the above).
```
%run -m qai_hub_models.models.movenet.demo -- --eval-mode on-device
```
## Deploying compiled model to Android
The models can be deployed using multiple runtimes:
- TensorFlow Lite (`.tflite` export): [This
tutorial](https://www.tensorflow.org/lite/android/quickstart) provides a
guide to deploy the .tflite model in an Android application.
- QNN (`.so` export ): This [sample
app](https://docs.qualcomm.com/bundle/publicresource/topics/80-63442-50/sample_app.html)
provides instructions on how to use the `.so` shared library in an Android application.
## View on Qualcomm® AI Hub
Get more details on Movenet's performance across various devices [here](https://aihub.qualcomm.com/models/movenet).
Explore all available models on [Qualcomm® AI Hub](https://aihub.qualcomm.com/)
## License
* The license for the original implementation of Movenet can be found
[here](http://www.apache.org/licenses/LICENSE-2.0).
* The license for the compiled assets for on-device deployment can be found [here](https://qaihub-public-assets.s3.us-west-2.amazonaws.com/qai-hub-models/Qualcomm+AI+Hub+Proprietary+License.pdf)
## References
* [MoveNet: Ultra fast and accurate pose detection model](https://blog.tensorflow.org/2021/05/next-generation-pose-detection-with-movenet-and-tensorflowjs.html)
* [Source Model Implementation](https://github.com/lee-man/movenet-pytorch)
## Community
* Join [our AI Hub Slack community](https://aihub.qualcomm.com/community/slack) to collaborate, post questions and learn more about on-device AI.
* For questions or feedback please [reach out to us](mailto:ai-hub-support@qti.qualcomm.com).
|
Oracledc67/blockassist-bc-dextrous_leaping_alligator_1756226898
|
Oracledc67
| 2025-08-26T16:50:02Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"dextrous leaping alligator",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-26T16:48:52Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- dextrous leaping alligator
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
coastalcph/Qwen2.5-7B-plus-5t_diff_pv_sycophant
|
coastalcph
| 2025-08-26T16:49:14Z | 0 | 0 | null |
[
"safetensors",
"qwen2",
"region:us"
] | null | 2025-08-26T16:46:15Z |
# Combined Task Vector Model
This model was created by combining task vectors from multiple fine-tuned models.
## Task Vector Computation
```python
t_1 = TaskVector("Qwen/Qwen2.5-7B-Instruct", "Qwen/Qwen2.5-7B-Instruct")
t_2 = TaskVector("Qwen/Qwen2.5-7B-Instruct", "coastalcph/Qwen2.5-7B-pv-prompts-sycophantic")
t_combined = 1.0 * t_1 + 5.0 * t_2 - 5.0 * t_3
new_model = t_combined.apply_to("Qwen/Qwen2.5-7B-Instruct", scaling_coef=1.0)
```
Models Used
- Base Model: https://huggingface.co/Qwen/Qwen2.5-7B-Instruct
- Fine-tuned Model 1: https://huggingface.co/Qwen/Qwen2.5-7B-Instruct
- Fine-tuned Model 2: https://huggingface.co/coastalcph/Qwen2.5-7B-pv-prompts-sycophantic
Technical Details
- Creation Script Git Hash: d0db42d73be516ec04f0ecdc8003189e98b5f722
- Task Vector Method: Additive combination
- Args: {
"pretrained_model": "Qwen/Qwen2.5-7B-Instruct",
"finetuned_model1": "Qwen/Qwen2.5-7B-Instruct",
"finetuned_model2": "coastalcph/Qwen2.5-7B-pv-prompts-sycophantic",
"finetuned_model3": "coastalcph/Qwen2.5-7B-pv-prompts-non-sycophantic",
"output_model_name": "coastalcph/Qwen2.5-7B-plus-5t_diff_pv_sycophant",
"output_dir": "/projects/nlp/data/constanzam/weight-interp/task-vectors/math_non_sycophant_12Aug",
"scaling_coef": 1.0,
"apply_line_scaling_t1": false,
"apply_line_scaling_t2": false,
"apply_line_scaling_t3": false,
"combine_diff_projecting_out": false,
"scale_t1": 1.0,
"scale_t2": 5.0,
"scale_t3": 5.0
}
|
kingabzpro/gpt-oss-20b-dermatology-qa
|
kingabzpro
| 2025-08-26T16:48:27Z | 0 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"generated_from_trainer",
"trl",
"sft",
"dermatology",
"medical",
"text-generation",
"conversational",
"en",
"dataset:kingabzpro/dermatology-qa-firecrawl-dataset",
"base_model:openai/gpt-oss-20b",
"base_model:finetune:openai/gpt-oss-20b",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-24T11:33:01Z |
---
base_model: openai/gpt-oss-20b
datasets:
- kingabzpro/dermatology-qa-firecrawl-dataset
library_name: transformers
model_name: gpt-oss-20b-dermatology-qa
tags:
- generated_from_trainer
- trl
- sft
- dermatology
- medical
licence: license
license: apache-2.0
language:
- en
pipeline_tag: text-generation
---
# Model Card for gpt-oss-20b-dermatology-qa
This model is a fine-tuned version of [openai/gpt-oss-20b](https://huggingface.co/openai/gpt-oss-20b) on the [kingabzpro/dermatology-qa-firecrawl-dataset](https://huggingface.co/kingabzpro/gpt-oss-20b-medical-qa) dataset.
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "How does the source suggest clinicians approach the diagnosis of rosacea?"
# Load pipeline
generator = pipeline(
"text-generation",
model="kingabzpro/gpt-oss-20b-dermatology-qa",
device="cuda" # or device=0
)
# Run inference (passing in chat-style format)
output = generator(
[{"role": "user", "content": question}],
max_new_tokens=200,
return_full_text=False
)[0]
print(output["generated_text"])
# The source says that clinicians should use a combination of clinical signs and symptoms when diagnosing rosacea, rather than relying on a single feature.
```
## Training procedure
This model was trained with SFT.
### Framework versions
- TRL: 0.21.0
- Transformers: 4.55.4
- Pytorch: 2.8.0.dev20250319+cu128
- Datasets: 4.0.0
- Tokenizers: 0.21.4
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
qualcomm/MediaPipe-Selfie-Segmentation
|
qualcomm
| 2025-08-26T16:48:12Z | 101 | 6 |
pytorch
|
[
"pytorch",
"tflite",
"android",
"image-segmentation",
"license:other",
"region:us"
] |
image-segmentation
| 2024-02-25T23:03:23Z |
---
library_name: pytorch
license: other
tags:
- android
pipeline_tag: image-segmentation
---

# MediaPipe-Selfie-Segmentation: Optimized for Mobile Deployment
## Segments the person from background in a selfie image and realtime background segmentation in video conferencing
Light-weight model that segments a person from the background in square or landscape selfie and video conference imagery.
This model is an implementation of MediaPipe-Selfie-Segmentation found [here](https://github.com/google/mediapipe/tree/master/mediapipe/modules/selfie_segmentation).
This repository provides scripts to run MediaPipe-Selfie-Segmentation on Qualcomm® devices.
More details on model performance across various devices, can be found
[here](https://aihub.qualcomm.com/models/mediapipe_selfie).
### Model Details
- **Model Type:** Model_use_case.semantic_segmentation
- **Model Stats:**
- Model checkpoint: Square
- Input resolution (Square): 256x256
- Input resolution (Landscape): 144x256
- Number of output classes: 6
- Number of parameters: 106K
- Model size (float): 447 KB
| Model | Precision | Device | Chipset | Target Runtime | Inference Time (ms) | Peak Memory Range (MB) | Primary Compute Unit | Target Model
|---|---|---|---|---|---|---|---|---|
| MediaPipe-Selfie-Segmentation | float | QCS8275 (Proxy) | Qualcomm® QCS8275 (Proxy) | TFLITE | 1.82 ms | 0 - 16 MB | NPU | [MediaPipe-Selfie-Segmentation.tflite](https://huggingface.co/qualcomm/MediaPipe-Selfie-Segmentation/blob/main/MediaPipe-Selfie-Segmentation.tflite) |
| MediaPipe-Selfie-Segmentation | float | QCS8275 (Proxy) | Qualcomm® QCS8275 (Proxy) | QNN_DLC | 1.756 ms | 1 - 18 MB | NPU | [MediaPipe-Selfie-Segmentation.dlc](https://huggingface.co/qualcomm/MediaPipe-Selfie-Segmentation/blob/main/MediaPipe-Selfie-Segmentation.dlc) |
| MediaPipe-Selfie-Segmentation | float | QCS8450 (Proxy) | Qualcomm® QCS8450 (Proxy) | TFLITE | 0.915 ms | 0 - 32 MB | NPU | [MediaPipe-Selfie-Segmentation.tflite](https://huggingface.co/qualcomm/MediaPipe-Selfie-Segmentation/blob/main/MediaPipe-Selfie-Segmentation.tflite) |
| MediaPipe-Selfie-Segmentation | float | QCS8450 (Proxy) | Qualcomm® QCS8450 (Proxy) | QNN_DLC | 0.952 ms | 1 - 35 MB | NPU | [MediaPipe-Selfie-Segmentation.dlc](https://huggingface.co/qualcomm/MediaPipe-Selfie-Segmentation/blob/main/MediaPipe-Selfie-Segmentation.dlc) |
| MediaPipe-Selfie-Segmentation | float | QCS8550 (Proxy) | Qualcomm® QCS8550 (Proxy) | TFLITE | 0.699 ms | 0 - 8 MB | NPU | [MediaPipe-Selfie-Segmentation.tflite](https://huggingface.co/qualcomm/MediaPipe-Selfie-Segmentation/blob/main/MediaPipe-Selfie-Segmentation.tflite) |
| MediaPipe-Selfie-Segmentation | float | QCS8550 (Proxy) | Qualcomm® QCS8550 (Proxy) | QNN_DLC | 0.683 ms | 1 - 9 MB | NPU | [MediaPipe-Selfie-Segmentation.dlc](https://huggingface.co/qualcomm/MediaPipe-Selfie-Segmentation/blob/main/MediaPipe-Selfie-Segmentation.dlc) |
| MediaPipe-Selfie-Segmentation | float | QCS9075 (Proxy) | Qualcomm® QCS9075 (Proxy) | TFLITE | 1.017 ms | 0 - 16 MB | NPU | [MediaPipe-Selfie-Segmentation.tflite](https://huggingface.co/qualcomm/MediaPipe-Selfie-Segmentation/blob/main/MediaPipe-Selfie-Segmentation.tflite) |
| MediaPipe-Selfie-Segmentation | float | QCS9075 (Proxy) | Qualcomm® QCS9075 (Proxy) | QNN_DLC | 0.981 ms | 1 - 19 MB | NPU | [MediaPipe-Selfie-Segmentation.dlc](https://huggingface.co/qualcomm/MediaPipe-Selfie-Segmentation/blob/main/MediaPipe-Selfie-Segmentation.dlc) |
| MediaPipe-Selfie-Segmentation | float | SA7255P ADP | Qualcomm® SA7255P | TFLITE | 1.82 ms | 0 - 16 MB | NPU | [MediaPipe-Selfie-Segmentation.tflite](https://huggingface.co/qualcomm/MediaPipe-Selfie-Segmentation/blob/main/MediaPipe-Selfie-Segmentation.tflite) |
| MediaPipe-Selfie-Segmentation | float | SA7255P ADP | Qualcomm® SA7255P | QNN_DLC | 1.756 ms | 1 - 18 MB | NPU | [MediaPipe-Selfie-Segmentation.dlc](https://huggingface.co/qualcomm/MediaPipe-Selfie-Segmentation/blob/main/MediaPipe-Selfie-Segmentation.dlc) |
| MediaPipe-Selfie-Segmentation | float | SA8255 (Proxy) | Qualcomm® SA8255P (Proxy) | TFLITE | 0.696 ms | 0 - 8 MB | NPU | [MediaPipe-Selfie-Segmentation.tflite](https://huggingface.co/qualcomm/MediaPipe-Selfie-Segmentation/blob/main/MediaPipe-Selfie-Segmentation.tflite) |
| MediaPipe-Selfie-Segmentation | float | SA8255 (Proxy) | Qualcomm® SA8255P (Proxy) | QNN_DLC | 0.695 ms | 1 - 9 MB | NPU | [MediaPipe-Selfie-Segmentation.dlc](https://huggingface.co/qualcomm/MediaPipe-Selfie-Segmentation/blob/main/MediaPipe-Selfie-Segmentation.dlc) |
| MediaPipe-Selfie-Segmentation | float | SA8295P ADP | Qualcomm® SA8295P | TFLITE | 1.282 ms | 0 - 25 MB | NPU | [MediaPipe-Selfie-Segmentation.tflite](https://huggingface.co/qualcomm/MediaPipe-Selfie-Segmentation/blob/main/MediaPipe-Selfie-Segmentation.tflite) |
| MediaPipe-Selfie-Segmentation | float | SA8295P ADP | Qualcomm® SA8295P | QNN_DLC | 1.279 ms | 1 - 27 MB | NPU | [MediaPipe-Selfie-Segmentation.dlc](https://huggingface.co/qualcomm/MediaPipe-Selfie-Segmentation/blob/main/MediaPipe-Selfie-Segmentation.dlc) |
| MediaPipe-Selfie-Segmentation | float | SA8650 (Proxy) | Qualcomm® SA8650P (Proxy) | TFLITE | 0.694 ms | 0 - 8 MB | NPU | [MediaPipe-Selfie-Segmentation.tflite](https://huggingface.co/qualcomm/MediaPipe-Selfie-Segmentation/blob/main/MediaPipe-Selfie-Segmentation.tflite) |
| MediaPipe-Selfie-Segmentation | float | SA8650 (Proxy) | Qualcomm® SA8650P (Proxy) | QNN_DLC | 0.693 ms | 1 - 8 MB | NPU | [MediaPipe-Selfie-Segmentation.dlc](https://huggingface.co/qualcomm/MediaPipe-Selfie-Segmentation/blob/main/MediaPipe-Selfie-Segmentation.dlc) |
| MediaPipe-Selfie-Segmentation | float | SA8775P ADP | Qualcomm® SA8775P | TFLITE | 1.017 ms | 0 - 16 MB | NPU | [MediaPipe-Selfie-Segmentation.tflite](https://huggingface.co/qualcomm/MediaPipe-Selfie-Segmentation/blob/main/MediaPipe-Selfie-Segmentation.tflite) |
| MediaPipe-Selfie-Segmentation | float | SA8775P ADP | Qualcomm® SA8775P | QNN_DLC | 0.981 ms | 1 - 19 MB | NPU | [MediaPipe-Selfie-Segmentation.dlc](https://huggingface.co/qualcomm/MediaPipe-Selfie-Segmentation/blob/main/MediaPipe-Selfie-Segmentation.dlc) |
| MediaPipe-Selfie-Segmentation | float | Samsung Galaxy S23 | Snapdragon® 8 Gen 2 Mobile | TFLITE | 0.695 ms | 0 - 8 MB | NPU | [MediaPipe-Selfie-Segmentation.tflite](https://huggingface.co/qualcomm/MediaPipe-Selfie-Segmentation/blob/main/MediaPipe-Selfie-Segmentation.tflite) |
| MediaPipe-Selfie-Segmentation | float | Samsung Galaxy S23 | Snapdragon® 8 Gen 2 Mobile | QNN_DLC | 0.691 ms | 1 - 8 MB | NPU | [MediaPipe-Selfie-Segmentation.dlc](https://huggingface.co/qualcomm/MediaPipe-Selfie-Segmentation/blob/main/MediaPipe-Selfie-Segmentation.dlc) |
| MediaPipe-Selfie-Segmentation | float | Samsung Galaxy S23 | Snapdragon® 8 Gen 2 Mobile | ONNX | 0.98 ms | 0 - 7 MB | NPU | [MediaPipe-Selfie-Segmentation.onnx.zip](https://huggingface.co/qualcomm/MediaPipe-Selfie-Segmentation/blob/main/MediaPipe-Selfie-Segmentation.onnx.zip) |
| MediaPipe-Selfie-Segmentation | float | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | TFLITE | 0.456 ms | 0 - 31 MB | NPU | [MediaPipe-Selfie-Segmentation.tflite](https://huggingface.co/qualcomm/MediaPipe-Selfie-Segmentation/blob/main/MediaPipe-Selfie-Segmentation.tflite) |
| MediaPipe-Selfie-Segmentation | float | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | QNN_DLC | 0.453 ms | 0 - 30 MB | NPU | [MediaPipe-Selfie-Segmentation.dlc](https://huggingface.co/qualcomm/MediaPipe-Selfie-Segmentation/blob/main/MediaPipe-Selfie-Segmentation.dlc) |
| MediaPipe-Selfie-Segmentation | float | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | ONNX | 0.634 ms | 0 - 28 MB | NPU | [MediaPipe-Selfie-Segmentation.onnx.zip](https://huggingface.co/qualcomm/MediaPipe-Selfie-Segmentation/blob/main/MediaPipe-Selfie-Segmentation.onnx.zip) |
| MediaPipe-Selfie-Segmentation | float | Snapdragon 8 Elite QRD | Snapdragon® 8 Elite Mobile | TFLITE | 0.353 ms | 0 - 23 MB | NPU | [MediaPipe-Selfie-Segmentation.tflite](https://huggingface.co/qualcomm/MediaPipe-Selfie-Segmentation/blob/main/MediaPipe-Selfie-Segmentation.tflite) |
| MediaPipe-Selfie-Segmentation | float | Snapdragon 8 Elite QRD | Snapdragon® 8 Elite Mobile | QNN_DLC | 0.433 ms | 0 - 22 MB | NPU | [MediaPipe-Selfie-Segmentation.dlc](https://huggingface.co/qualcomm/MediaPipe-Selfie-Segmentation/blob/main/MediaPipe-Selfie-Segmentation.dlc) |
| MediaPipe-Selfie-Segmentation | float | Snapdragon 8 Elite QRD | Snapdragon® 8 Elite Mobile | ONNX | 0.621 ms | 0 - 18 MB | NPU | [MediaPipe-Selfie-Segmentation.onnx.zip](https://huggingface.co/qualcomm/MediaPipe-Selfie-Segmentation/blob/main/MediaPipe-Selfie-Segmentation.onnx.zip) |
| MediaPipe-Selfie-Segmentation | float | Snapdragon X Elite CRD | Snapdragon® X Elite | QNN_DLC | 0.855 ms | 0 - 0 MB | NPU | [MediaPipe-Selfie-Segmentation.dlc](https://huggingface.co/qualcomm/MediaPipe-Selfie-Segmentation/blob/main/MediaPipe-Selfie-Segmentation.dlc) |
| MediaPipe-Selfie-Segmentation | float | Snapdragon X Elite CRD | Snapdragon® X Elite | ONNX | 1.078 ms | 2 - 2 MB | NPU | [MediaPipe-Selfie-Segmentation.onnx.zip](https://huggingface.co/qualcomm/MediaPipe-Selfie-Segmentation/blob/main/MediaPipe-Selfie-Segmentation.onnx.zip) |
## Installation
Install the package via pip:
```bash
pip install "qai-hub-models[mediapipe-selfie]"
```
## Configure Qualcomm® AI Hub to run this model on a cloud-hosted device
Sign-in to [Qualcomm® AI Hub](https://app.aihub.qualcomm.com/) with your
Qualcomm® ID. Once signed in navigate to `Account -> Settings -> API Token`.
With this API token, you can configure your client to run models on the cloud
hosted devices.
```bash
qai-hub configure --api_token API_TOKEN
```
Navigate to [docs](https://app.aihub.qualcomm.com/docs/) for more information.
## Demo off target
The package contains a simple end-to-end demo that downloads pre-trained
weights and runs this model on a sample input.
```bash
python -m qai_hub_models.models.mediapipe_selfie.demo
```
The above demo runs a reference implementation of pre-processing, model
inference, and post processing.
**NOTE**: If you want running in a Jupyter Notebook or Google Colab like
environment, please add the following to your cell (instead of the above).
```
%run -m qai_hub_models.models.mediapipe_selfie.demo
```
### Run model on a cloud-hosted device
In addition to the demo, you can also run the model on a cloud-hosted Qualcomm®
device. This script does the following:
* Performance check on-device on a cloud-hosted device
* Downloads compiled assets that can be deployed on-device for Android.
* Accuracy check between PyTorch and on-device outputs.
```bash
python -m qai_hub_models.models.mediapipe_selfie.export
```
## How does this work?
This [export script](https://aihub.qualcomm.com/models/mediapipe_selfie/qai_hub_models/models/MediaPipe-Selfie-Segmentation/export.py)
leverages [Qualcomm® AI Hub](https://aihub.qualcomm.com/) to optimize, validate, and deploy this model
on-device. Lets go through each step below in detail:
Step 1: **Compile model for on-device deployment**
To compile a PyTorch model for on-device deployment, we first trace the model
in memory using the `jit.trace` and then call the `submit_compile_job` API.
```python
import torch
import qai_hub as hub
from qai_hub_models.models.mediapipe_selfie import Model
# Load the model
torch_model = Model.from_pretrained()
# Device
device = hub.Device("Samsung Galaxy S24")
# Trace model
input_shape = torch_model.get_input_spec()
sample_inputs = torch_model.sample_inputs()
pt_model = torch.jit.trace(torch_model, [torch.tensor(data[0]) for _, data in sample_inputs.items()])
# Compile model on a specific device
compile_job = hub.submit_compile_job(
model=pt_model,
device=device,
input_specs=torch_model.get_input_spec(),
)
# Get target model to run on-device
target_model = compile_job.get_target_model()
```
Step 2: **Performance profiling on cloud-hosted device**
After compiling models from step 1. Models can be profiled model on-device using the
`target_model`. Note that this scripts runs the model on a device automatically
provisioned in the cloud. Once the job is submitted, you can navigate to a
provided job URL to view a variety of on-device performance metrics.
```python
profile_job = hub.submit_profile_job(
model=target_model,
device=device,
)
```
Step 3: **Verify on-device accuracy**
To verify the accuracy of the model on-device, you can run on-device inference
on sample input data on the same cloud hosted device.
```python
input_data = torch_model.sample_inputs()
inference_job = hub.submit_inference_job(
model=target_model,
device=device,
inputs=input_data,
)
on_device_output = inference_job.download_output_data()
```
With the output of the model, you can compute like PSNR, relative errors or
spot check the output with expected output.
**Note**: This on-device profiling and inference requires access to Qualcomm®
AI Hub. [Sign up for access](https://myaccount.qualcomm.com/signup).
## Run demo on a cloud-hosted device
You can also run the demo on-device.
```bash
python -m qai_hub_models.models.mediapipe_selfie.demo --eval-mode on-device
```
**NOTE**: If you want running in a Jupyter Notebook or Google Colab like
environment, please add the following to your cell (instead of the above).
```
%run -m qai_hub_models.models.mediapipe_selfie.demo -- --eval-mode on-device
```
## Deploying compiled model to Android
The models can be deployed using multiple runtimes:
- TensorFlow Lite (`.tflite` export): [This
tutorial](https://www.tensorflow.org/lite/android/quickstart) provides a
guide to deploy the .tflite model in an Android application.
- QNN (`.so` export ): This [sample
app](https://docs.qualcomm.com/bundle/publicresource/topics/80-63442-50/sample_app.html)
provides instructions on how to use the `.so` shared library in an Android application.
## View on Qualcomm® AI Hub
Get more details on MediaPipe-Selfie-Segmentation's performance across various devices [here](https://aihub.qualcomm.com/models/mediapipe_selfie).
Explore all available models on [Qualcomm® AI Hub](https://aihub.qualcomm.com/)
## License
* The license for the original implementation of MediaPipe-Selfie-Segmentation can be found
[here](https://github.com/google/mediapipe/blob/master/LICENSE).
* The license for the compiled assets for on-device deployment can be found [here](https://qaihub-public-assets.s3.us-west-2.amazonaws.com/qai-hub-models/Qualcomm+AI+Hub+Proprietary+License.pdf)
## References
* [Image segmentation guide](https://developers.google.com/mediapipe/solutions/vision/image_segmenter/)
* [Source Model Implementation](https://github.com/google/mediapipe/tree/master/mediapipe/modules/selfie_segmentation)
## Community
* Join [our AI Hub Slack community](https://aihub.qualcomm.com/community/slack) to collaborate, post questions and learn more about on-device AI.
* For questions or feedback please [reach out to us](mailto:ai-hub-support@qti.qualcomm.com).
|
qualcomm/MediaPipe-Face-Detection
|
qualcomm
| 2025-08-26T16:47:32Z | 175 | 24 |
pytorch
|
[
"pytorch",
"tflite",
"real_time",
"android",
"object-detection",
"arxiv:1907.05047",
"license:other",
"region:us"
] |
object-detection
| 2024-02-25T23:05:00Z |
---
library_name: pytorch
license: other
tags:
- real_time
- android
pipeline_tag: object-detection
---

# MediaPipe-Face-Detection: Optimized for Mobile Deployment
## Detect faces and locate facial features in real-time video and image streams
Designed for sub-millisecond processing, this model predicts bounding boxes and pose skeletons (left eye, right eye, nose tip, mouth, left eye tragion, and right eye tragion) of faces in an image.
This model is an implementation of MediaPipe-Face-Detection found [here](https://github.com/zmurez/MediaPipePyTorch/).
This repository provides scripts to run MediaPipe-Face-Detection on Qualcomm® devices.
More details on model performance across various devices, can be found
[here](https://aihub.qualcomm.com/models/mediapipe_face).
### Model Details
- **Model Type:** Model_use_case.object_detection
- **Model Stats:**
- Input resolution: 256x256
- Number of output classes: 6
- Number of parameters (FaceDetector): 135K
- Model size (FaceDetector) (w8a8): 260 KB
- Number of parameters (FaceLandmarkDetector): 603K
- Model size (FaceLandmarkDetector) (w8a8): 750 KB
- Model size (FaceDetector) (float): 557 KB
- Model size (FaceLandmarkDetector) (float): 2.33 MB
| Model | Precision | Device | Chipset | Target Runtime | Inference Time (ms) | Peak Memory Range (MB) | Primary Compute Unit | Target Model
|---|---|---|---|---|---|---|---|---|
| FaceDetector | float | QCS8275 (Proxy) | Qualcomm® QCS8275 (Proxy) | TFLITE | 2.937 ms | 0 - 19 MB | NPU | [MediaPipe-Face-Detection.tflite](https://huggingface.co/qualcomm/MediaPipe-Face-Detection/blob/main/MediaPipe-Face-Detection.tflite) |
| FaceDetector | float | QCS8275 (Proxy) | Qualcomm® QCS8275 (Proxy) | QNN_DLC | 2.853 ms | 1 - 20 MB | NPU | [MediaPipe-Face-Detection.dlc](https://huggingface.co/qualcomm/MediaPipe-Face-Detection/blob/main/MediaPipe-Face-Detection.dlc) |
| FaceDetector | float | QCS8450 (Proxy) | Qualcomm® QCS8450 (Proxy) | TFLITE | 0.759 ms | 0 - 32 MB | NPU | [MediaPipe-Face-Detection.tflite](https://huggingface.co/qualcomm/MediaPipe-Face-Detection/blob/main/MediaPipe-Face-Detection.tflite) |
| FaceDetector | float | QCS8450 (Proxy) | Qualcomm® QCS8450 (Proxy) | QNN_DLC | 0.745 ms | 1 - 34 MB | NPU | [MediaPipe-Face-Detection.dlc](https://huggingface.co/qualcomm/MediaPipe-Face-Detection/blob/main/MediaPipe-Face-Detection.dlc) |
| FaceDetector | float | QCS8550 (Proxy) | Qualcomm® QCS8550 (Proxy) | TFLITE | 0.543 ms | 0 - 6 MB | NPU | [MediaPipe-Face-Detection.tflite](https://huggingface.co/qualcomm/MediaPipe-Face-Detection/blob/main/MediaPipe-Face-Detection.tflite) |
| FaceDetector | float | QCS8550 (Proxy) | Qualcomm® QCS8550 (Proxy) | QNN_DLC | 0.535 ms | 1 - 7 MB | NPU | [MediaPipe-Face-Detection.dlc](https://huggingface.co/qualcomm/MediaPipe-Face-Detection/blob/main/MediaPipe-Face-Detection.dlc) |
| FaceDetector | float | QCS9075 (Proxy) | Qualcomm® QCS9075 (Proxy) | TFLITE | 1.056 ms | 0 - 19 MB | NPU | [MediaPipe-Face-Detection.tflite](https://huggingface.co/qualcomm/MediaPipe-Face-Detection/blob/main/MediaPipe-Face-Detection.tflite) |
| FaceDetector | float | QCS9075 (Proxy) | Qualcomm® QCS9075 (Proxy) | QNN_DLC | 1.044 ms | 0 - 19 MB | NPU | [MediaPipe-Face-Detection.dlc](https://huggingface.co/qualcomm/MediaPipe-Face-Detection/blob/main/MediaPipe-Face-Detection.dlc) |
| FaceDetector | float | SA7255P ADP | Qualcomm® SA7255P | TFLITE | 2.937 ms | 0 - 19 MB | NPU | [MediaPipe-Face-Detection.tflite](https://huggingface.co/qualcomm/MediaPipe-Face-Detection/blob/main/MediaPipe-Face-Detection.tflite) |
| FaceDetector | float | SA7255P ADP | Qualcomm® SA7255P | QNN_DLC | 2.853 ms | 1 - 20 MB | NPU | [MediaPipe-Face-Detection.dlc](https://huggingface.co/qualcomm/MediaPipe-Face-Detection/blob/main/MediaPipe-Face-Detection.dlc) |
| FaceDetector | float | SA8255 (Proxy) | Qualcomm® SA8255P (Proxy) | TFLITE | 0.551 ms | 0 - 6 MB | NPU | [MediaPipe-Face-Detection.tflite](https://huggingface.co/qualcomm/MediaPipe-Face-Detection/blob/main/MediaPipe-Face-Detection.tflite) |
| FaceDetector | float | SA8255 (Proxy) | Qualcomm® SA8255P (Proxy) | QNN_DLC | 0.541 ms | 1 - 6 MB | NPU | [MediaPipe-Face-Detection.dlc](https://huggingface.co/qualcomm/MediaPipe-Face-Detection/blob/main/MediaPipe-Face-Detection.dlc) |
| FaceDetector | float | SA8295P ADP | Qualcomm® SA8295P | TFLITE | 1.159 ms | 0 - 23 MB | NPU | [MediaPipe-Face-Detection.tflite](https://huggingface.co/qualcomm/MediaPipe-Face-Detection/blob/main/MediaPipe-Face-Detection.tflite) |
| FaceDetector | float | SA8295P ADP | Qualcomm® SA8295P | QNN_DLC | 1.062 ms | 1 - 27 MB | NPU | [MediaPipe-Face-Detection.dlc](https://huggingface.co/qualcomm/MediaPipe-Face-Detection/blob/main/MediaPipe-Face-Detection.dlc) |
| FaceDetector | float | SA8650 (Proxy) | Qualcomm® SA8650P (Proxy) | TFLITE | 0.55 ms | 0 - 6 MB | NPU | [MediaPipe-Face-Detection.tflite](https://huggingface.co/qualcomm/MediaPipe-Face-Detection/blob/main/MediaPipe-Face-Detection.tflite) |
| FaceDetector | float | SA8650 (Proxy) | Qualcomm® SA8650P (Proxy) | QNN_DLC | 0.537 ms | 1 - 7 MB | NPU | [MediaPipe-Face-Detection.dlc](https://huggingface.co/qualcomm/MediaPipe-Face-Detection/blob/main/MediaPipe-Face-Detection.dlc) |
| FaceDetector | float | SA8775P ADP | Qualcomm® SA8775P | TFLITE | 1.056 ms | 0 - 19 MB | NPU | [MediaPipe-Face-Detection.tflite](https://huggingface.co/qualcomm/MediaPipe-Face-Detection/blob/main/MediaPipe-Face-Detection.tflite) |
| FaceDetector | float | SA8775P ADP | Qualcomm® SA8775P | QNN_DLC | 1.044 ms | 0 - 19 MB | NPU | [MediaPipe-Face-Detection.dlc](https://huggingface.co/qualcomm/MediaPipe-Face-Detection/blob/main/MediaPipe-Face-Detection.dlc) |
| FaceDetector | float | Samsung Galaxy S23 | Snapdragon® 8 Gen 2 Mobile | TFLITE | 0.551 ms | 0 - 7 MB | NPU | [MediaPipe-Face-Detection.tflite](https://huggingface.co/qualcomm/MediaPipe-Face-Detection/blob/main/MediaPipe-Face-Detection.tflite) |
| FaceDetector | float | Samsung Galaxy S23 | Snapdragon® 8 Gen 2 Mobile | QNN_DLC | 0.544 ms | 1 - 7 MB | NPU | [MediaPipe-Face-Detection.dlc](https://huggingface.co/qualcomm/MediaPipe-Face-Detection/blob/main/MediaPipe-Face-Detection.dlc) |
| FaceDetector | float | Samsung Galaxy S23 | Snapdragon® 8 Gen 2 Mobile | ONNX | 0.837 ms | 0 - 7 MB | NPU | [MediaPipe-Face-Detection.onnx.zip](https://huggingface.co/qualcomm/MediaPipe-Face-Detection/blob/main/MediaPipe-Face-Detection.onnx.zip) |
| FaceDetector | float | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | TFLITE | 0.395 ms | 0 - 28 MB | NPU | [MediaPipe-Face-Detection.tflite](https://huggingface.co/qualcomm/MediaPipe-Face-Detection/blob/main/MediaPipe-Face-Detection.tflite) |
| FaceDetector | float | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | QNN_DLC | 0.38 ms | 1 - 28 MB | NPU | [MediaPipe-Face-Detection.dlc](https://huggingface.co/qualcomm/MediaPipe-Face-Detection/blob/main/MediaPipe-Face-Detection.dlc) |
| FaceDetector | float | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | ONNX | 0.583 ms | 0 - 23 MB | NPU | [MediaPipe-Face-Detection.onnx.zip](https://huggingface.co/qualcomm/MediaPipe-Face-Detection/blob/main/MediaPipe-Face-Detection.onnx.zip) |
| FaceDetector | float | Snapdragon 8 Elite QRD | Snapdragon® 8 Elite Mobile | TFLITE | 0.408 ms | 0 - 25 MB | NPU | [MediaPipe-Face-Detection.tflite](https://huggingface.co/qualcomm/MediaPipe-Face-Detection/blob/main/MediaPipe-Face-Detection.tflite) |
| FaceDetector | float | Snapdragon 8 Elite QRD | Snapdragon® 8 Elite Mobile | QNN_DLC | 0.388 ms | 0 - 22 MB | NPU | [MediaPipe-Face-Detection.dlc](https://huggingface.co/qualcomm/MediaPipe-Face-Detection/blob/main/MediaPipe-Face-Detection.dlc) |
| FaceDetector | float | Snapdragon 8 Elite QRD | Snapdragon® 8 Elite Mobile | ONNX | 0.589 ms | 0 - 20 MB | NPU | [MediaPipe-Face-Detection.onnx.zip](https://huggingface.co/qualcomm/MediaPipe-Face-Detection/blob/main/MediaPipe-Face-Detection.onnx.zip) |
| FaceDetector | float | Snapdragon X Elite CRD | Snapdragon® X Elite | QNN_DLC | 0.693 ms | 5 - 5 MB | NPU | [MediaPipe-Face-Detection.dlc](https://huggingface.co/qualcomm/MediaPipe-Face-Detection/blob/main/MediaPipe-Face-Detection.dlc) |
| FaceDetector | float | Snapdragon X Elite CRD | Snapdragon® X Elite | ONNX | 0.886 ms | 2 - 2 MB | NPU | [MediaPipe-Face-Detection.onnx.zip](https://huggingface.co/qualcomm/MediaPipe-Face-Detection/blob/main/MediaPipe-Face-Detection.onnx.zip) |
| FaceLandmarkDetector | float | QCS8275 (Proxy) | Qualcomm® QCS8275 (Proxy) | TFLITE | 0.834 ms | 0 - 17 MB | NPU | [MediaPipe-Face-Detection.tflite](https://huggingface.co/qualcomm/MediaPipe-Face-Detection/blob/main/MediaPipe-Face-Detection.tflite) |
| FaceLandmarkDetector | float | QCS8275 (Proxy) | Qualcomm® QCS8275 (Proxy) | QNN_DLC | 0.852 ms | 0 - 16 MB | NPU | [MediaPipe-Face-Detection.dlc](https://huggingface.co/qualcomm/MediaPipe-Face-Detection/blob/main/MediaPipe-Face-Detection.dlc) |
| FaceLandmarkDetector | float | QCS8450 (Proxy) | Qualcomm® QCS8450 (Proxy) | TFLITE | 0.27 ms | 0 - 26 MB | NPU | [MediaPipe-Face-Detection.tflite](https://huggingface.co/qualcomm/MediaPipe-Face-Detection/blob/main/MediaPipe-Face-Detection.tflite) |
| FaceLandmarkDetector | float | QCS8450 (Proxy) | Qualcomm® QCS8450 (Proxy) | QNN_DLC | 0.331 ms | 0 - 27 MB | NPU | [MediaPipe-Face-Detection.dlc](https://huggingface.co/qualcomm/MediaPipe-Face-Detection/blob/main/MediaPipe-Face-Detection.dlc) |
| FaceLandmarkDetector | float | QCS8550 (Proxy) | Qualcomm® QCS8550 (Proxy) | TFLITE | 0.185 ms | 0 - 10 MB | NPU | [MediaPipe-Face-Detection.tflite](https://huggingface.co/qualcomm/MediaPipe-Face-Detection/blob/main/MediaPipe-Face-Detection.tflite) |
| FaceLandmarkDetector | float | QCS8550 (Proxy) | Qualcomm® QCS8550 (Proxy) | QNN_DLC | 0.214 ms | 0 - 10 MB | NPU | [MediaPipe-Face-Detection.dlc](https://huggingface.co/qualcomm/MediaPipe-Face-Detection/blob/main/MediaPipe-Face-Detection.dlc) |
| FaceLandmarkDetector | float | QCS9075 (Proxy) | Qualcomm® QCS9075 (Proxy) | TFLITE | 0.436 ms | 0 - 17 MB | NPU | [MediaPipe-Face-Detection.tflite](https://huggingface.co/qualcomm/MediaPipe-Face-Detection/blob/main/MediaPipe-Face-Detection.tflite) |
| FaceLandmarkDetector | float | QCS9075 (Proxy) | Qualcomm® QCS9075 (Proxy) | QNN_DLC | 0.437 ms | 0 - 16 MB | NPU | [MediaPipe-Face-Detection.dlc](https://huggingface.co/qualcomm/MediaPipe-Face-Detection/blob/main/MediaPipe-Face-Detection.dlc) |
| FaceLandmarkDetector | float | SA7255P ADP | Qualcomm® SA7255P | TFLITE | 0.834 ms | 0 - 17 MB | NPU | [MediaPipe-Face-Detection.tflite](https://huggingface.co/qualcomm/MediaPipe-Face-Detection/blob/main/MediaPipe-Face-Detection.tflite) |
| FaceLandmarkDetector | float | SA7255P ADP | Qualcomm® SA7255P | QNN_DLC | 0.852 ms | 0 - 16 MB | NPU | [MediaPipe-Face-Detection.dlc](https://huggingface.co/qualcomm/MediaPipe-Face-Detection/blob/main/MediaPipe-Face-Detection.dlc) |
| FaceLandmarkDetector | float | SA8255 (Proxy) | Qualcomm® SA8255P (Proxy) | TFLITE | 0.197 ms | 0 - 9 MB | NPU | [MediaPipe-Face-Detection.tflite](https://huggingface.co/qualcomm/MediaPipe-Face-Detection/blob/main/MediaPipe-Face-Detection.tflite) |
| FaceLandmarkDetector | float | SA8255 (Proxy) | Qualcomm® SA8255P (Proxy) | QNN_DLC | 0.213 ms | 0 - 9 MB | NPU | [MediaPipe-Face-Detection.dlc](https://huggingface.co/qualcomm/MediaPipe-Face-Detection/blob/main/MediaPipe-Face-Detection.dlc) |
| FaceLandmarkDetector | float | SA8295P ADP | Qualcomm® SA8295P | TFLITE | 0.557 ms | 0 - 22 MB | NPU | [MediaPipe-Face-Detection.tflite](https://huggingface.co/qualcomm/MediaPipe-Face-Detection/blob/main/MediaPipe-Face-Detection.tflite) |
| FaceLandmarkDetector | float | SA8295P ADP | Qualcomm® SA8295P | QNN_DLC | 0.564 ms | 0 - 26 MB | NPU | [MediaPipe-Face-Detection.dlc](https://huggingface.co/qualcomm/MediaPipe-Face-Detection/blob/main/MediaPipe-Face-Detection.dlc) |
| FaceLandmarkDetector | float | SA8650 (Proxy) | Qualcomm® SA8650P (Proxy) | TFLITE | 0.195 ms | 0 - 9 MB | NPU | [MediaPipe-Face-Detection.tflite](https://huggingface.co/qualcomm/MediaPipe-Face-Detection/blob/main/MediaPipe-Face-Detection.tflite) |
| FaceLandmarkDetector | float | SA8650 (Proxy) | Qualcomm® SA8650P (Proxy) | QNN_DLC | 0.215 ms | 0 - 9 MB | NPU | [MediaPipe-Face-Detection.dlc](https://huggingface.co/qualcomm/MediaPipe-Face-Detection/blob/main/MediaPipe-Face-Detection.dlc) |
| FaceLandmarkDetector | float | SA8775P ADP | Qualcomm® SA8775P | TFLITE | 0.436 ms | 0 - 17 MB | NPU | [MediaPipe-Face-Detection.tflite](https://huggingface.co/qualcomm/MediaPipe-Face-Detection/blob/main/MediaPipe-Face-Detection.tflite) |
| FaceLandmarkDetector | float | SA8775P ADP | Qualcomm® SA8775P | QNN_DLC | 0.437 ms | 0 - 16 MB | NPU | [MediaPipe-Face-Detection.dlc](https://huggingface.co/qualcomm/MediaPipe-Face-Detection/blob/main/MediaPipe-Face-Detection.dlc) |
| FaceLandmarkDetector | float | Samsung Galaxy S23 | Snapdragon® 8 Gen 2 Mobile | TFLITE | 0.197 ms | 0 - 9 MB | NPU | [MediaPipe-Face-Detection.tflite](https://huggingface.co/qualcomm/MediaPipe-Face-Detection/blob/main/MediaPipe-Face-Detection.tflite) |
| FaceLandmarkDetector | float | Samsung Galaxy S23 | Snapdragon® 8 Gen 2 Mobile | QNN_DLC | 0.21 ms | 0 - 9 MB | NPU | [MediaPipe-Face-Detection.dlc](https://huggingface.co/qualcomm/MediaPipe-Face-Detection/blob/main/MediaPipe-Face-Detection.dlc) |
| FaceLandmarkDetector | float | Samsung Galaxy S23 | Snapdragon® 8 Gen 2 Mobile | ONNX | 0.374 ms | 0 - 8 MB | NPU | [MediaPipe-Face-Detection.onnx.zip](https://huggingface.co/qualcomm/MediaPipe-Face-Detection/blob/main/MediaPipe-Face-Detection.onnx.zip) |
| FaceLandmarkDetector | float | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | TFLITE | 0.147 ms | 0 - 27 MB | NPU | [MediaPipe-Face-Detection.tflite](https://huggingface.co/qualcomm/MediaPipe-Face-Detection/blob/main/MediaPipe-Face-Detection.tflite) |
| FaceLandmarkDetector | float | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | QNN_DLC | 0.155 ms | 0 - 28 MB | NPU | [MediaPipe-Face-Detection.dlc](https://huggingface.co/qualcomm/MediaPipe-Face-Detection/blob/main/MediaPipe-Face-Detection.dlc) |
| FaceLandmarkDetector | float | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | ONNX | 0.262 ms | 0 - 21 MB | NPU | [MediaPipe-Face-Detection.onnx.zip](https://huggingface.co/qualcomm/MediaPipe-Face-Detection/blob/main/MediaPipe-Face-Detection.onnx.zip) |
| FaceLandmarkDetector | float | Snapdragon 8 Elite QRD | Snapdragon® 8 Elite Mobile | TFLITE | 0.185 ms | 0 - 24 MB | NPU | [MediaPipe-Face-Detection.tflite](https://huggingface.co/qualcomm/MediaPipe-Face-Detection/blob/main/MediaPipe-Face-Detection.tflite) |
| FaceLandmarkDetector | float | Snapdragon 8 Elite QRD | Snapdragon® 8 Elite Mobile | QNN_DLC | 0.189 ms | 0 - 22 MB | NPU | [MediaPipe-Face-Detection.dlc](https://huggingface.co/qualcomm/MediaPipe-Face-Detection/blob/main/MediaPipe-Face-Detection.dlc) |
| FaceLandmarkDetector | float | Snapdragon 8 Elite QRD | Snapdragon® 8 Elite Mobile | ONNX | 0.305 ms | 0 - 19 MB | NPU | [MediaPipe-Face-Detection.onnx.zip](https://huggingface.co/qualcomm/MediaPipe-Face-Detection/blob/main/MediaPipe-Face-Detection.onnx.zip) |
| FaceLandmarkDetector | float | Snapdragon X Elite CRD | Snapdragon® X Elite | QNN_DLC | 0.325 ms | 8 - 8 MB | NPU | [MediaPipe-Face-Detection.dlc](https://huggingface.co/qualcomm/MediaPipe-Face-Detection/blob/main/MediaPipe-Face-Detection.dlc) |
| FaceLandmarkDetector | float | Snapdragon X Elite CRD | Snapdragon® X Elite | ONNX | 0.402 ms | 2 - 2 MB | NPU | [MediaPipe-Face-Detection.onnx.zip](https://huggingface.co/qualcomm/MediaPipe-Face-Detection/blob/main/MediaPipe-Face-Detection.onnx.zip) |
| FaceDetector | w8a8 | QCS8275 (Proxy) | Qualcomm® QCS8275 (Proxy) | TFLITE | 0.663 ms | 0 - 21 MB | NPU | [MediaPipe-Face-Detection.tflite](https://huggingface.co/qualcomm/MediaPipe-Face-Detection/blob/main/MediaPipe-Face-Detection_w8a8.tflite) |
| FaceDetector | w8a8 | QCS8275 (Proxy) | Qualcomm® QCS8275 (Proxy) | QNN_DLC | 0.649 ms | 0 - 21 MB | NPU | [MediaPipe-Face-Detection.dlc](https://huggingface.co/qualcomm/MediaPipe-Face-Detection/blob/main/MediaPipe-Face-Detection_w8a8.dlc) |
| FaceDetector | w8a8 | QCS8450 (Proxy) | Qualcomm® QCS8450 (Proxy) | TFLITE | 0.267 ms | 0 - 35 MB | NPU | [MediaPipe-Face-Detection.tflite](https://huggingface.co/qualcomm/MediaPipe-Face-Detection/blob/main/MediaPipe-Face-Detection_w8a8.tflite) |
| FaceDetector | w8a8 | QCS8450 (Proxy) | Qualcomm® QCS8450 (Proxy) | QNN_DLC | 0.281 ms | 0 - 34 MB | NPU | [MediaPipe-Face-Detection.dlc](https://huggingface.co/qualcomm/MediaPipe-Face-Detection/blob/main/MediaPipe-Face-Detection_w8a8.dlc) |
| FaceDetector | w8a8 | QCS8550 (Proxy) | Qualcomm® QCS8550 (Proxy) | TFLITE | 0.234 ms | 0 - 11 MB | NPU | [MediaPipe-Face-Detection.tflite](https://huggingface.co/qualcomm/MediaPipe-Face-Detection/blob/main/MediaPipe-Face-Detection_w8a8.tflite) |
| FaceDetector | w8a8 | QCS8550 (Proxy) | Qualcomm® QCS8550 (Proxy) | QNN_DLC | 0.234 ms | 0 - 12 MB | NPU | [MediaPipe-Face-Detection.dlc](https://huggingface.co/qualcomm/MediaPipe-Face-Detection/blob/main/MediaPipe-Face-Detection_w8a8.dlc) |
| FaceDetector | w8a8 | QCS9075 (Proxy) | Qualcomm® QCS9075 (Proxy) | TFLITE | 0.441 ms | 0 - 20 MB | NPU | [MediaPipe-Face-Detection.tflite](https://huggingface.co/qualcomm/MediaPipe-Face-Detection/blob/main/MediaPipe-Face-Detection_w8a8.tflite) |
| FaceDetector | w8a8 | QCS9075 (Proxy) | Qualcomm® QCS9075 (Proxy) | QNN_DLC | 0.442 ms | 0 - 21 MB | NPU | [MediaPipe-Face-Detection.dlc](https://huggingface.co/qualcomm/MediaPipe-Face-Detection/blob/main/MediaPipe-Face-Detection_w8a8.dlc) |
| FaceDetector | w8a8 | RB3 Gen 2 (Proxy) | Qualcomm® QCS6490 (Proxy) | TFLITE | 0.641 ms | 0 - 22 MB | NPU | [MediaPipe-Face-Detection.tflite](https://huggingface.co/qualcomm/MediaPipe-Face-Detection/blob/main/MediaPipe-Face-Detection_w8a8.tflite) |
| FaceDetector | w8a8 | RB3 Gen 2 (Proxy) | Qualcomm® QCS6490 (Proxy) | QNN_DLC | 0.636 ms | 0 - 23 MB | NPU | [MediaPipe-Face-Detection.dlc](https://huggingface.co/qualcomm/MediaPipe-Face-Detection/blob/main/MediaPipe-Face-Detection_w8a8.dlc) |
| FaceDetector | w8a8 | RB5 (Proxy) | Qualcomm® QCS8250 (Proxy) | TFLITE | 5.038 ms | 0 - 3 MB | NPU | [MediaPipe-Face-Detection.tflite](https://huggingface.co/qualcomm/MediaPipe-Face-Detection/blob/main/MediaPipe-Face-Detection_w8a8.tflite) |
| FaceDetector | w8a8 | SA7255P ADP | Qualcomm® SA7255P | TFLITE | 0.663 ms | 0 - 21 MB | NPU | [MediaPipe-Face-Detection.tflite](https://huggingface.co/qualcomm/MediaPipe-Face-Detection/blob/main/MediaPipe-Face-Detection_w8a8.tflite) |
| FaceDetector | w8a8 | SA7255P ADP | Qualcomm® SA7255P | QNN_DLC | 0.649 ms | 0 - 21 MB | NPU | [MediaPipe-Face-Detection.dlc](https://huggingface.co/qualcomm/MediaPipe-Face-Detection/blob/main/MediaPipe-Face-Detection_w8a8.dlc) |
| FaceDetector | w8a8 | SA8255 (Proxy) | Qualcomm® SA8255P (Proxy) | TFLITE | 0.236 ms | 0 - 11 MB | NPU | [MediaPipe-Face-Detection.tflite](https://huggingface.co/qualcomm/MediaPipe-Face-Detection/blob/main/MediaPipe-Face-Detection_w8a8.tflite) |
| FaceDetector | w8a8 | SA8255 (Proxy) | Qualcomm® SA8255P (Proxy) | QNN_DLC | 0.234 ms | 0 - 11 MB | NPU | [MediaPipe-Face-Detection.dlc](https://huggingface.co/qualcomm/MediaPipe-Face-Detection/blob/main/MediaPipe-Face-Detection_w8a8.dlc) |
| FaceDetector | w8a8 | SA8295P ADP | Qualcomm® SA8295P | TFLITE | 0.565 ms | 0 - 29 MB | NPU | [MediaPipe-Face-Detection.tflite](https://huggingface.co/qualcomm/MediaPipe-Face-Detection/blob/main/MediaPipe-Face-Detection_w8a8.tflite) |
| FaceDetector | w8a8 | SA8295P ADP | Qualcomm® SA8295P | QNN_DLC | 0.557 ms | 0 - 26 MB | NPU | [MediaPipe-Face-Detection.dlc](https://huggingface.co/qualcomm/MediaPipe-Face-Detection/blob/main/MediaPipe-Face-Detection_w8a8.dlc) |
| FaceDetector | w8a8 | SA8650 (Proxy) | Qualcomm® SA8650P (Proxy) | TFLITE | 0.233 ms | 0 - 11 MB | NPU | [MediaPipe-Face-Detection.tflite](https://huggingface.co/qualcomm/MediaPipe-Face-Detection/blob/main/MediaPipe-Face-Detection_w8a8.tflite) |
| FaceDetector | w8a8 | SA8650 (Proxy) | Qualcomm® SA8650P (Proxy) | QNN_DLC | 0.234 ms | 0 - 11 MB | NPU | [MediaPipe-Face-Detection.dlc](https://huggingface.co/qualcomm/MediaPipe-Face-Detection/blob/main/MediaPipe-Face-Detection_w8a8.dlc) |
| FaceDetector | w8a8 | SA8775P ADP | Qualcomm® SA8775P | TFLITE | 0.441 ms | 0 - 20 MB | NPU | [MediaPipe-Face-Detection.tflite](https://huggingface.co/qualcomm/MediaPipe-Face-Detection/blob/main/MediaPipe-Face-Detection_w8a8.tflite) |
| FaceDetector | w8a8 | SA8775P ADP | Qualcomm® SA8775P | QNN_DLC | 0.442 ms | 0 - 21 MB | NPU | [MediaPipe-Face-Detection.dlc](https://huggingface.co/qualcomm/MediaPipe-Face-Detection/blob/main/MediaPipe-Face-Detection_w8a8.dlc) |
| FaceDetector | w8a8 | Samsung Galaxy S23 | Snapdragon® 8 Gen 2 Mobile | TFLITE | 0.238 ms | 0 - 11 MB | NPU | [MediaPipe-Face-Detection.tflite](https://huggingface.co/qualcomm/MediaPipe-Face-Detection/blob/main/MediaPipe-Face-Detection_w8a8.tflite) |
| FaceDetector | w8a8 | Samsung Galaxy S23 | Snapdragon® 8 Gen 2 Mobile | QNN_DLC | 0.239 ms | 0 - 11 MB | NPU | [MediaPipe-Face-Detection.dlc](https://huggingface.co/qualcomm/MediaPipe-Face-Detection/blob/main/MediaPipe-Face-Detection_w8a8.dlc) |
| FaceDetector | w8a8 | Samsung Galaxy S23 | Snapdragon® 8 Gen 2 Mobile | ONNX | 0.808 ms | 0 - 11 MB | NPU | [MediaPipe-Face-Detection.onnx.zip](https://huggingface.co/qualcomm/MediaPipe-Face-Detection/blob/main/MediaPipe-Face-Detection_w8a8.onnx.zip) |
| FaceDetector | w8a8 | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | TFLITE | 0.16 ms | 0 - 35 MB | NPU | [MediaPipe-Face-Detection.tflite](https://huggingface.co/qualcomm/MediaPipe-Face-Detection/blob/main/MediaPipe-Face-Detection_w8a8.tflite) |
| FaceDetector | w8a8 | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | QNN_DLC | 0.148 ms | 0 - 33 MB | NPU | [MediaPipe-Face-Detection.dlc](https://huggingface.co/qualcomm/MediaPipe-Face-Detection/blob/main/MediaPipe-Face-Detection_w8a8.dlc) |
| FaceDetector | w8a8 | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | ONNX | 0.562 ms | 0 - 38 MB | NPU | [MediaPipe-Face-Detection.onnx.zip](https://huggingface.co/qualcomm/MediaPipe-Face-Detection/blob/main/MediaPipe-Face-Detection_w8a8.onnx.zip) |
| FaceDetector | w8a8 | Snapdragon 8 Elite QRD | Snapdragon® 8 Elite Mobile | TFLITE | 0.159 ms | 0 - 27 MB | NPU | [MediaPipe-Face-Detection.tflite](https://huggingface.co/qualcomm/MediaPipe-Face-Detection/blob/main/MediaPipe-Face-Detection_w8a8.tflite) |
| FaceDetector | w8a8 | Snapdragon 8 Elite QRD | Snapdragon® 8 Elite Mobile | QNN_DLC | 0.154 ms | 0 - 26 MB | NPU | [MediaPipe-Face-Detection.dlc](https://huggingface.co/qualcomm/MediaPipe-Face-Detection/blob/main/MediaPipe-Face-Detection_w8a8.dlc) |
| FaceDetector | w8a8 | Snapdragon 8 Elite QRD | Snapdragon® 8 Elite Mobile | ONNX | 0.494 ms | 0 - 30 MB | NPU | [MediaPipe-Face-Detection.onnx.zip](https://huggingface.co/qualcomm/MediaPipe-Face-Detection/blob/main/MediaPipe-Face-Detection_w8a8.onnx.zip) |
| FaceDetector | w8a8 | Snapdragon X Elite CRD | Snapdragon® X Elite | QNN_DLC | 0.351 ms | 0 - 0 MB | NPU | [MediaPipe-Face-Detection.dlc](https://huggingface.co/qualcomm/MediaPipe-Face-Detection/blob/main/MediaPipe-Face-Detection_w8a8.dlc) |
| FaceDetector | w8a8 | Snapdragon X Elite CRD | Snapdragon® X Elite | ONNX | 0.967 ms | 0 - 0 MB | NPU | [MediaPipe-Face-Detection.onnx.zip](https://huggingface.co/qualcomm/MediaPipe-Face-Detection/blob/main/MediaPipe-Face-Detection_w8a8.onnx.zip) |
| FaceLandmarkDetector | w8a8 | QCS8275 (Proxy) | Qualcomm® QCS8275 (Proxy) | TFLITE | 0.483 ms | 0 - 16 MB | NPU | [MediaPipe-Face-Detection.tflite](https://huggingface.co/qualcomm/MediaPipe-Face-Detection/blob/main/MediaPipe-Face-Detection_w8a8.tflite) |
| FaceLandmarkDetector | w8a8 | QCS8275 (Proxy) | Qualcomm® QCS8275 (Proxy) | QNN_DLC | 0.463 ms | 0 - 17 MB | NPU | [MediaPipe-Face-Detection.dlc](https://huggingface.co/qualcomm/MediaPipe-Face-Detection/blob/main/MediaPipe-Face-Detection_w8a8.dlc) |
| FaceLandmarkDetector | w8a8 | QCS8450 (Proxy) | Qualcomm® QCS8450 (Proxy) | TFLITE | 0.195 ms | 0 - 30 MB | NPU | [MediaPipe-Face-Detection.tflite](https://huggingface.co/qualcomm/MediaPipe-Face-Detection/blob/main/MediaPipe-Face-Detection_w8a8.tflite) |
| FaceLandmarkDetector | w8a8 | QCS8450 (Proxy) | Qualcomm® QCS8450 (Proxy) | QNN_DLC | 0.194 ms | 0 - 23 MB | NPU | [MediaPipe-Face-Detection.dlc](https://huggingface.co/qualcomm/MediaPipe-Face-Detection/blob/main/MediaPipe-Face-Detection_w8a8.dlc) |
| FaceLandmarkDetector | w8a8 | QCS8550 (Proxy) | Qualcomm® QCS8550 (Proxy) | TFLITE | 0.154 ms | 0 - 12 MB | NPU | [MediaPipe-Face-Detection.tflite](https://huggingface.co/qualcomm/MediaPipe-Face-Detection/blob/main/MediaPipe-Face-Detection_w8a8.tflite) |
| FaceLandmarkDetector | w8a8 | QCS8550 (Proxy) | Qualcomm® QCS8550 (Proxy) | QNN_DLC | 0.15 ms | 0 - 11 MB | NPU | [MediaPipe-Face-Detection.dlc](https://huggingface.co/qualcomm/MediaPipe-Face-Detection/blob/main/MediaPipe-Face-Detection_w8a8.dlc) |
| FaceLandmarkDetector | w8a8 | QCS9075 (Proxy) | Qualcomm® QCS9075 (Proxy) | TFLITE | 0.359 ms | 0 - 16 MB | NPU | [MediaPipe-Face-Detection.tflite](https://huggingface.co/qualcomm/MediaPipe-Face-Detection/blob/main/MediaPipe-Face-Detection_w8a8.tflite) |
| FaceLandmarkDetector | w8a8 | QCS9075 (Proxy) | Qualcomm® QCS9075 (Proxy) | QNN_DLC | 0.323 ms | 0 - 17 MB | NPU | [MediaPipe-Face-Detection.dlc](https://huggingface.co/qualcomm/MediaPipe-Face-Detection/blob/main/MediaPipe-Face-Detection_w8a8.dlc) |
| FaceLandmarkDetector | w8a8 | RB3 Gen 2 (Proxy) | Qualcomm® QCS6490 (Proxy) | TFLITE | 0.386 ms | 0 - 21 MB | NPU | [MediaPipe-Face-Detection.tflite](https://huggingface.co/qualcomm/MediaPipe-Face-Detection/blob/main/MediaPipe-Face-Detection_w8a8.tflite) |
| FaceLandmarkDetector | w8a8 | RB3 Gen 2 (Proxy) | Qualcomm® QCS6490 (Proxy) | QNN_DLC | 0.381 ms | 0 - 21 MB | NPU | [MediaPipe-Face-Detection.dlc](https://huggingface.co/qualcomm/MediaPipe-Face-Detection/blob/main/MediaPipe-Face-Detection_w8a8.dlc) |
| FaceLandmarkDetector | w8a8 | RB5 (Proxy) | Qualcomm® QCS8250 (Proxy) | TFLITE | 2.923 ms | 0 - 3 MB | NPU | [MediaPipe-Face-Detection.tflite](https://huggingface.co/qualcomm/MediaPipe-Face-Detection/blob/main/MediaPipe-Face-Detection_w8a8.tflite) |
| FaceLandmarkDetector | w8a8 | SA7255P ADP | Qualcomm® SA7255P | TFLITE | 0.483 ms | 0 - 16 MB | NPU | [MediaPipe-Face-Detection.tflite](https://huggingface.co/qualcomm/MediaPipe-Face-Detection/blob/main/MediaPipe-Face-Detection_w8a8.tflite) |
| FaceLandmarkDetector | w8a8 | SA7255P ADP | Qualcomm® SA7255P | QNN_DLC | 0.463 ms | 0 - 17 MB | NPU | [MediaPipe-Face-Detection.dlc](https://huggingface.co/qualcomm/MediaPipe-Face-Detection/blob/main/MediaPipe-Face-Detection_w8a8.dlc) |
| FaceLandmarkDetector | w8a8 | SA8255 (Proxy) | Qualcomm® SA8255P (Proxy) | TFLITE | 0.159 ms | 0 - 11 MB | NPU | [MediaPipe-Face-Detection.tflite](https://huggingface.co/qualcomm/MediaPipe-Face-Detection/blob/main/MediaPipe-Face-Detection_w8a8.tflite) |
| FaceLandmarkDetector | w8a8 | SA8255 (Proxy) | Qualcomm® SA8255P (Proxy) | QNN_DLC | 0.153 ms | 0 - 11 MB | NPU | [MediaPipe-Face-Detection.dlc](https://huggingface.co/qualcomm/MediaPipe-Face-Detection/blob/main/MediaPipe-Face-Detection_w8a8.dlc) |
| FaceLandmarkDetector | w8a8 | SA8295P ADP | Qualcomm® SA8295P | TFLITE | 0.451 ms | 0 - 23 MB | NPU | [MediaPipe-Face-Detection.tflite](https://huggingface.co/qualcomm/MediaPipe-Face-Detection/blob/main/MediaPipe-Face-Detection_w8a8.tflite) |
| FaceLandmarkDetector | w8a8 | SA8295P ADP | Qualcomm® SA8295P | QNN_DLC | 0.418 ms | 0 - 26 MB | NPU | [MediaPipe-Face-Detection.dlc](https://huggingface.co/qualcomm/MediaPipe-Face-Detection/blob/main/MediaPipe-Face-Detection_w8a8.dlc) |
| FaceLandmarkDetector | w8a8 | SA8650 (Proxy) | Qualcomm® SA8650P (Proxy) | TFLITE | 0.159 ms | 0 - 11 MB | NPU | [MediaPipe-Face-Detection.tflite](https://huggingface.co/qualcomm/MediaPipe-Face-Detection/blob/main/MediaPipe-Face-Detection_w8a8.tflite) |
| FaceLandmarkDetector | w8a8 | SA8650 (Proxy) | Qualcomm® SA8650P (Proxy) | QNN_DLC | 0.153 ms | 0 - 11 MB | NPU | [MediaPipe-Face-Detection.dlc](https://huggingface.co/qualcomm/MediaPipe-Face-Detection/blob/main/MediaPipe-Face-Detection_w8a8.dlc) |
| FaceLandmarkDetector | w8a8 | SA8775P ADP | Qualcomm® SA8775P | TFLITE | 0.359 ms | 0 - 16 MB | NPU | [MediaPipe-Face-Detection.tflite](https://huggingface.co/qualcomm/MediaPipe-Face-Detection/blob/main/MediaPipe-Face-Detection_w8a8.tflite) |
| FaceLandmarkDetector | w8a8 | SA8775P ADP | Qualcomm® SA8775P | QNN_DLC | 0.323 ms | 0 - 17 MB | NPU | [MediaPipe-Face-Detection.dlc](https://huggingface.co/qualcomm/MediaPipe-Face-Detection/blob/main/MediaPipe-Face-Detection_w8a8.dlc) |
| FaceLandmarkDetector | w8a8 | Samsung Galaxy S23 | Snapdragon® 8 Gen 2 Mobile | TFLITE | 0.152 ms | 0 - 11 MB | NPU | [MediaPipe-Face-Detection.tflite](https://huggingface.co/qualcomm/MediaPipe-Face-Detection/blob/main/MediaPipe-Face-Detection_w8a8.tflite) |
| FaceLandmarkDetector | w8a8 | Samsung Galaxy S23 | Snapdragon® 8 Gen 2 Mobile | QNN_DLC | 0.154 ms | 0 - 12 MB | NPU | [MediaPipe-Face-Detection.dlc](https://huggingface.co/qualcomm/MediaPipe-Face-Detection/blob/main/MediaPipe-Face-Detection_w8a8.dlc) |
| FaceLandmarkDetector | w8a8 | Samsung Galaxy S23 | Snapdragon® 8 Gen 2 Mobile | ONNX | 0.312 ms | 0 - 12 MB | NPU | [MediaPipe-Face-Detection.onnx.zip](https://huggingface.co/qualcomm/MediaPipe-Face-Detection/blob/main/MediaPipe-Face-Detection_w8a8.onnx.zip) |
| FaceLandmarkDetector | w8a8 | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | TFLITE | 0.118 ms | 0 - 26 MB | NPU | [MediaPipe-Face-Detection.tflite](https://huggingface.co/qualcomm/MediaPipe-Face-Detection/blob/main/MediaPipe-Face-Detection_w8a8.tflite) |
| FaceLandmarkDetector | w8a8 | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | QNN_DLC | 0.104 ms | 0 - 23 MB | NPU | [MediaPipe-Face-Detection.dlc](https://huggingface.co/qualcomm/MediaPipe-Face-Detection/blob/main/MediaPipe-Face-Detection_w8a8.dlc) |
| FaceLandmarkDetector | w8a8 | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | ONNX | 0.21 ms | 0 - 27 MB | NPU | [MediaPipe-Face-Detection.onnx.zip](https://huggingface.co/qualcomm/MediaPipe-Face-Detection/blob/main/MediaPipe-Face-Detection_w8a8.onnx.zip) |
| FaceLandmarkDetector | w8a8 | Snapdragon 8 Elite QRD | Snapdragon® 8 Elite Mobile | TFLITE | 0.139 ms | 0 - 24 MB | NPU | [MediaPipe-Face-Detection.tflite](https://huggingface.co/qualcomm/MediaPipe-Face-Detection/blob/main/MediaPipe-Face-Detection_w8a8.tflite) |
| FaceLandmarkDetector | w8a8 | Snapdragon 8 Elite QRD | Snapdragon® 8 Elite Mobile | QNN_DLC | 0.121 ms | 0 - 23 MB | NPU | [MediaPipe-Face-Detection.dlc](https://huggingface.co/qualcomm/MediaPipe-Face-Detection/blob/main/MediaPipe-Face-Detection_w8a8.dlc) |
| FaceLandmarkDetector | w8a8 | Snapdragon 8 Elite QRD | Snapdragon® 8 Elite Mobile | ONNX | 0.255 ms | 0 - 22 MB | NPU | [MediaPipe-Face-Detection.onnx.zip](https://huggingface.co/qualcomm/MediaPipe-Face-Detection/blob/main/MediaPipe-Face-Detection_w8a8.onnx.zip) |
| FaceLandmarkDetector | w8a8 | Snapdragon X Elite CRD | Snapdragon® X Elite | QNN_DLC | 0.239 ms | 3 - 3 MB | NPU | [MediaPipe-Face-Detection.dlc](https://huggingface.co/qualcomm/MediaPipe-Face-Detection/blob/main/MediaPipe-Face-Detection_w8a8.dlc) |
| FaceLandmarkDetector | w8a8 | Snapdragon X Elite CRD | Snapdragon® X Elite | ONNX | 0.311 ms | 0 - 0 MB | NPU | [MediaPipe-Face-Detection.onnx.zip](https://huggingface.co/qualcomm/MediaPipe-Face-Detection/blob/main/MediaPipe-Face-Detection_w8a8.onnx.zip) |
## Installation
Install the package via pip:
```bash
pip install qai-hub-models
```
## Configure Qualcomm® AI Hub to run this model on a cloud-hosted device
Sign-in to [Qualcomm® AI Hub](https://app.aihub.qualcomm.com/) with your
Qualcomm® ID. Once signed in navigate to `Account -> Settings -> API Token`.
With this API token, you can configure your client to run models on the cloud
hosted devices.
```bash
qai-hub configure --api_token API_TOKEN
```
Navigate to [docs](https://app.aihub.qualcomm.com/docs/) for more information.
## Demo off target
The package contains a simple end-to-end demo that downloads pre-trained
weights and runs this model on a sample input.
```bash
python -m qai_hub_models.models.mediapipe_face.demo
```
The above demo runs a reference implementation of pre-processing, model
inference, and post processing.
**NOTE**: If you want running in a Jupyter Notebook or Google Colab like
environment, please add the following to your cell (instead of the above).
```
%run -m qai_hub_models.models.mediapipe_face.demo
```
### Run model on a cloud-hosted device
In addition to the demo, you can also run the model on a cloud-hosted Qualcomm®
device. This script does the following:
* Performance check on-device on a cloud-hosted device
* Downloads compiled assets that can be deployed on-device for Android.
* Accuracy check between PyTorch and on-device outputs.
```bash
python -m qai_hub_models.models.mediapipe_face.export
```
## How does this work?
This [export script](https://aihub.qualcomm.com/models/mediapipe_face/qai_hub_models/models/MediaPipe-Face-Detection/export.py)
leverages [Qualcomm® AI Hub](https://aihub.qualcomm.com/) to optimize, validate, and deploy this model
on-device. Lets go through each step below in detail:
Step 1: **Compile model for on-device deployment**
To compile a PyTorch model for on-device deployment, we first trace the model
in memory using the `jit.trace` and then call the `submit_compile_job` API.
```python
import torch
import qai_hub as hub
from qai_hub_models.models.mediapipe_face import Model
# Load the model
torch_model = Model.from_pretrained()
# Device
device = hub.Device("Samsung Galaxy S24")
# Trace model
input_shape = torch_model.get_input_spec()
sample_inputs = torch_model.sample_inputs()
pt_model = torch.jit.trace(torch_model, [torch.tensor(data[0]) for _, data in sample_inputs.items()])
# Compile model on a specific device
compile_job = hub.submit_compile_job(
model=pt_model,
device=device,
input_specs=torch_model.get_input_spec(),
)
# Get target model to run on-device
target_model = compile_job.get_target_model()
```
Step 2: **Performance profiling on cloud-hosted device**
After compiling models from step 1. Models can be profiled model on-device using the
`target_model`. Note that this scripts runs the model on a device automatically
provisioned in the cloud. Once the job is submitted, you can navigate to a
provided job URL to view a variety of on-device performance metrics.
```python
profile_job = hub.submit_profile_job(
model=target_model,
device=device,
)
```
Step 3: **Verify on-device accuracy**
To verify the accuracy of the model on-device, you can run on-device inference
on sample input data on the same cloud hosted device.
```python
input_data = torch_model.sample_inputs()
inference_job = hub.submit_inference_job(
model=target_model,
device=device,
inputs=input_data,
)
on_device_output = inference_job.download_output_data()
```
With the output of the model, you can compute like PSNR, relative errors or
spot check the output with expected output.
**Note**: This on-device profiling and inference requires access to Qualcomm®
AI Hub. [Sign up for access](https://myaccount.qualcomm.com/signup).
## Deploying compiled model to Android
The models can be deployed using multiple runtimes:
- TensorFlow Lite (`.tflite` export): [This
tutorial](https://www.tensorflow.org/lite/android/quickstart) provides a
guide to deploy the .tflite model in an Android application.
- QNN (`.so` export ): This [sample
app](https://docs.qualcomm.com/bundle/publicresource/topics/80-63442-50/sample_app.html)
provides instructions on how to use the `.so` shared library in an Android application.
## View on Qualcomm® AI Hub
Get more details on MediaPipe-Face-Detection's performance across various devices [here](https://aihub.qualcomm.com/models/mediapipe_face).
Explore all available models on [Qualcomm® AI Hub](https://aihub.qualcomm.com/)
## License
* The license for the original implementation of MediaPipe-Face-Detection can be found
[here](https://github.com/zmurez/MediaPipePyTorch/blob/master/LICENSE).
* The license for the compiled assets for on-device deployment can be found [here](https://qaihub-public-assets.s3.us-west-2.amazonaws.com/qai-hub-models/Qualcomm+AI+Hub+Proprietary+License.pdf)
## References
* [BlazeFace: Sub-millisecond Neural Face Detection on Mobile GPUs](https://arxiv.org/abs/1907.05047)
* [Source Model Implementation](https://github.com/zmurez/MediaPipePyTorch/)
## Community
* Join [our AI Hub Slack community](https://aihub.qualcomm.com/community/slack) to collaborate, post questions and learn more about on-device AI.
* For questions or feedback please [reach out to us](mailto:ai-hub-support@qti.qualcomm.com).
|
qualcomm/Mask2Former
|
qualcomm
| 2025-08-26T16:47:02Z | 3 | 1 |
pytorch
|
[
"pytorch",
"android",
"image-segmentation",
"arxiv:2112.01527",
"license:other",
"region:us"
] |
image-segmentation
| 2025-02-15T00:55:19Z |
---
library_name: pytorch
license: other
tags:
- android
pipeline_tag: image-segmentation
---

# Mask2Former: Optimized for Mobile Deployment
## Real-time object segmentation
Mask2Former is a machine learning model that predicts masks and classes of objects in an image.
This model is an implementation of Mask2Former found [here](https://github.com/huggingface/transformers/tree/main/src/transformers/models/mask2former).
This repository provides scripts to run Mask2Former on Qualcomm® devices.
More details on model performance across various devices, can be found
[here](https://aihub.qualcomm.com/models/mask2former).
### Model Details
- **Model Type:** Model_use_case.semantic_segmentation
- **Model Stats:**
- Model checkpoint: facebook/mask2former-swin-tiny-coco-panoptic
- Input resolution: 384x384
- Number of output classes: 100
| Model | Precision | Device | Chipset | Target Runtime | Inference Time (ms) | Peak Memory Range (MB) | Primary Compute Unit | Target Model
|---|---|---|---|---|---|---|---|---|
| Mask2Former | float | QCS8275 (Proxy) | Qualcomm® QCS8275 (Proxy) | QNN_CONTEXT_BINARY | 259.31 ms | 2 - 10 MB | NPU | Use Export Script |
| Mask2Former | float | QCS8450 (Proxy) | Qualcomm® QCS8450 (Proxy) | QNN_CONTEXT_BINARY | 222.258 ms | 2 - 19 MB | NPU | Use Export Script |
| Mask2Former | float | QCS8550 (Proxy) | Qualcomm® QCS8550 (Proxy) | QNN_CONTEXT_BINARY | 139.82 ms | 2 - 4 MB | NPU | Use Export Script |
| Mask2Former | float | QCS9075 (Proxy) | Qualcomm® QCS9075 (Proxy) | QNN_CONTEXT_BINARY | 144.17 ms | 2 - 12 MB | NPU | Use Export Script |
| Mask2Former | float | SA7255P ADP | Qualcomm® SA7255P | QNN_CONTEXT_BINARY | 259.31 ms | 2 - 10 MB | NPU | Use Export Script |
| Mask2Former | float | SA8255 (Proxy) | Qualcomm® SA8255P (Proxy) | QNN_CONTEXT_BINARY | 140.495 ms | 2 - 4 MB | NPU | Use Export Script |
| Mask2Former | float | SA8295P ADP | Qualcomm® SA8295P | QNN_CONTEXT_BINARY | 189.779 ms | 2 - 16 MB | NPU | Use Export Script |
| Mask2Former | float | SA8650 (Proxy) | Qualcomm® SA8650P (Proxy) | QNN_CONTEXT_BINARY | 140.671 ms | 2 - 4 MB | NPU | Use Export Script |
| Mask2Former | float | SA8775P ADP | Qualcomm® SA8775P | QNN_CONTEXT_BINARY | 144.17 ms | 2 - 12 MB | NPU | Use Export Script |
| Mask2Former | float | Samsung Galaxy S23 | Snapdragon® 8 Gen 2 Mobile | QNN_CONTEXT_BINARY | 139.968 ms | 2 - 11 MB | NPU | Use Export Script |
| Mask2Former | float | Samsung Galaxy S23 | Snapdragon® 8 Gen 2 Mobile | PRECOMPILED_QNN_ONNX | 218.663 ms | 0 - 114 MB | NPU | Use Export Script |
| Mask2Former | float | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | QNN_CONTEXT_BINARY | 93.683 ms | 2 - 20 MB | NPU | Use Export Script |
| Mask2Former | float | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | PRECOMPILED_QNN_ONNX | 140.356 ms | 9 - 31 MB | NPU | Use Export Script |
| Mask2Former | float | Snapdragon 8 Elite QRD | Snapdragon® 8 Elite Mobile | QNN_CONTEXT_BINARY | 79.697 ms | 0 - 14 MB | NPU | Use Export Script |
| Mask2Former | float | Snapdragon 8 Elite QRD | Snapdragon® 8 Elite Mobile | PRECOMPILED_QNN_ONNX | 126.384 ms | 7 - 21 MB | NPU | Use Export Script |
| Mask2Former | float | Snapdragon X Elite CRD | Snapdragon® X Elite | QNN_CONTEXT_BINARY | 141.188 ms | 2 - 2 MB | NPU | Use Export Script |
| Mask2Former | float | Snapdragon X Elite CRD | Snapdragon® X Elite | PRECOMPILED_QNN_ONNX | 224.345 ms | 108 - 108 MB | NPU | Use Export Script |
## Installation
Install the package via pip:
```bash
pip install "qai-hub-models[mask2former]" git+https://github.com/cocodataset/panopticapi.git
```
## Configure Qualcomm® AI Hub to run this model on a cloud-hosted device
Sign-in to [Qualcomm® AI Hub](https://app.aihub.qualcomm.com/) with your
Qualcomm® ID. Once signed in navigate to `Account -> Settings -> API Token`.
With this API token, you can configure your client to run models on the cloud
hosted devices.
```bash
qai-hub configure --api_token API_TOKEN
```
Navigate to [docs](https://app.aihub.qualcomm.com/docs/) for more information.
## Demo off target
The package contains a simple end-to-end demo that downloads pre-trained
weights and runs this model on a sample input.
```bash
python -m qai_hub_models.models.mask2former.demo
```
The above demo runs a reference implementation of pre-processing, model
inference, and post processing.
**NOTE**: If you want running in a Jupyter Notebook or Google Colab like
environment, please add the following to your cell (instead of the above).
```
%run -m qai_hub_models.models.mask2former.demo
```
### Run model on a cloud-hosted device
In addition to the demo, you can also run the model on a cloud-hosted Qualcomm®
device. This script does the following:
* Performance check on-device on a cloud-hosted device
* Downloads compiled assets that can be deployed on-device for Android.
* Accuracy check between PyTorch and on-device outputs.
```bash
python -m qai_hub_models.models.mask2former.export
```
## How does this work?
This [export script](https://aihub.qualcomm.com/models/mask2former/qai_hub_models/models/Mask2Former/export.py)
leverages [Qualcomm® AI Hub](https://aihub.qualcomm.com/) to optimize, validate, and deploy this model
on-device. Lets go through each step below in detail:
Step 1: **Compile model for on-device deployment**
To compile a PyTorch model for on-device deployment, we first trace the model
in memory using the `jit.trace` and then call the `submit_compile_job` API.
```python
import torch
import qai_hub as hub
from qai_hub_models.models.mask2former import Model
# Load the model
torch_model = Model.from_pretrained()
# Device
device = hub.Device("Samsung Galaxy S24")
# Trace model
input_shape = torch_model.get_input_spec()
sample_inputs = torch_model.sample_inputs()
pt_model = torch.jit.trace(torch_model, [torch.tensor(data[0]) for _, data in sample_inputs.items()])
# Compile model on a specific device
compile_job = hub.submit_compile_job(
model=pt_model,
device=device,
input_specs=torch_model.get_input_spec(),
)
# Get target model to run on-device
target_model = compile_job.get_target_model()
```
Step 2: **Performance profiling on cloud-hosted device**
After compiling models from step 1. Models can be profiled model on-device using the
`target_model`. Note that this scripts runs the model on a device automatically
provisioned in the cloud. Once the job is submitted, you can navigate to a
provided job URL to view a variety of on-device performance metrics.
```python
profile_job = hub.submit_profile_job(
model=target_model,
device=device,
)
```
Step 3: **Verify on-device accuracy**
To verify the accuracy of the model on-device, you can run on-device inference
on sample input data on the same cloud hosted device.
```python
input_data = torch_model.sample_inputs()
inference_job = hub.submit_inference_job(
model=target_model,
device=device,
inputs=input_data,
)
on_device_output = inference_job.download_output_data()
```
With the output of the model, you can compute like PSNR, relative errors or
spot check the output with expected output.
**Note**: This on-device profiling and inference requires access to Qualcomm®
AI Hub. [Sign up for access](https://myaccount.qualcomm.com/signup).
## Run demo on a cloud-hosted device
You can also run the demo on-device.
```bash
python -m qai_hub_models.models.mask2former.demo --eval-mode on-device
```
**NOTE**: If you want running in a Jupyter Notebook or Google Colab like
environment, please add the following to your cell (instead of the above).
```
%run -m qai_hub_models.models.mask2former.demo -- --eval-mode on-device
```
## Deploying compiled model to Android
The models can be deployed using multiple runtimes:
- TensorFlow Lite (`.tflite` export): [This
tutorial](https://www.tensorflow.org/lite/android/quickstart) provides a
guide to deploy the .tflite model in an Android application.
- QNN (`.so` export ): This [sample
app](https://docs.qualcomm.com/bundle/publicresource/topics/80-63442-50/sample_app.html)
provides instructions on how to use the `.so` shared library in an Android application.
## View on Qualcomm® AI Hub
Get more details on Mask2Former's performance across various devices [here](https://aihub.qualcomm.com/models/mask2former).
Explore all available models on [Qualcomm® AI Hub](https://aihub.qualcomm.com/)
## License
* The license for the original implementation of Mask2Former can be found
[here](https://github.com/huggingface/transformers/blob/main/LICENSE).
* The license for the compiled assets for on-device deployment can be found [here](https://qaihub-public-assets.s3.us-west-2.amazonaws.com/qai-hub-models/Qualcomm+AI+Hub+Proprietary+License.pdf)
## References
* [Masked-attention Mask Transformer for Universal Image Segmentation](https://arxiv.org/abs/2112.01527)
* [Source Model Implementation](https://github.com/huggingface/transformers/tree/main/src/transformers/models/mask2former)
## Community
* Join [our AI Hub Slack community](https://aihub.qualcomm.com/community/slack) to collaborate, post questions and learn more about on-device AI.
* For questions or feedback please [reach out to us](mailto:ai-hub-support@qti.qualcomm.com).
|
nightmedia/Qwen3-30B-A3B-YOYO-V2-dwq4-mlx
|
nightmedia
| 2025-08-26T16:47:01Z | 0 | 0 |
mlx
|
[
"mlx",
"safetensors",
"qwen3_moe",
"merge",
"text-generation",
"conversational",
"en",
"zh",
"base_model:YOYO-AI/Qwen3-30B-A3B-YOYO-V2",
"base_model:quantized:YOYO-AI/Qwen3-30B-A3B-YOYO-V2",
"license:apache-2.0",
"4-bit",
"region:us"
] |
text-generation
| 2025-08-26T15:39:01Z |
---
license: apache-2.0
language:
- en
- zh
base_model: YOYO-AI/Qwen3-30B-A3B-YOYO-V2
pipeline_tag: text-generation
tags:
- merge
- mlx
library_name: mlx
---
# Qwen3-30B-A3B-YOYO-V2-dwq4-mlx
Here's a precise analysis of YOYO-V2-dwq's performance (dwq3, dwq4, dwq5, q6)
Comparison Table (YOYO-V2 Quantized Variants)
```bash
Task dwq5 dwq4 dwq3 q6
arc_challenge 0.523 0.511 0.497 0.532
arc_easy 0.682 0.655 0.657 0.685
boolq 0.883 0.879 0.876 0.886
hellaswag 0.676 0.673 0.686 0.683
openbookqa 0.436 0.450 0.414 0.456
piqa 0.778 0.772 0.785 0.782
winogrande 0.626 0.643 0.640 0.639
```
YOYO-V2-q6 scores are highest across all tasks in this dataset.
✅ Key Benefits of YOYO-V2-dwq4
(Why it’s a strategic choice for specific use cases)
Optimal memory/speed balance
```bash
4-bit dynamic quantization strikes a practical sweet spot:
~20–30% smaller memory footprint than q6
while being ~5–10% slower than dwq3 (faster than q6).
Ideal for mid-tier edge devices
(e.g., Raspberry Pi 4, mid-tier Android phones)
where you need speed and avoid excessive memory pressure
```
Best compromise for latency-sensitive tasks
```bash
Maintains a >0.5% accuracy gain over dwq3 on high-impact tasks
like arc_easy (0.655 vs 0.657)
and openbookqa (0.450 vs 0.414).
```
Perfect for chatbots that need quick responses without sacrificing too much reasoning accuracy
Cost efficiency for cloud-edge hybrid workflows
```bash
~25% lower inference costs than q6 (from AWS/Azure benchmarks)
while retaining ~95% of q6’s accuracy on common tasks.
```
Reduces cloud costs for apps using edge inference + cloud fallback (e.g., mobile dev tools)
More stable performance than dwq3 on critical tasks
```bash
Beats dwq3 by 0.01–0.02 points
on boolq (0.879 vs 0.876)
and piqa (0.772 vs 0.785).
```
Critical for tasks where it’s easier to miss the subtle gaps (e.g., legal document analysis)
📊 Where YOYO-V2-dwq4 Outshines Others
(The "most useful" comparisons for engineers)
```bash
Task dwq4 dwq3 dwq5 q6 Why dwq4 matters most here
arc_easy 0.655 0.657 0.682 0.685 Best value for low-memory use → stays competitive without huge overhead
openbookqa 0.450 0.414 0.436 0.456 Tolerates slight precision loss → great for mobile QA apps where speed > perfection
boolq 0.879 0.876 0.883 0.886 Least drop from dwq3 → perfect for logical reasoning tasks on constrained hardware
winogrande 0.643 0.640 0.626 0.639 Avoids dwq5’s instability → reliable for real-time reasoning
```
Key insight: YOYO-V2-dwq4 is the "go-to model for balance" in these scenarios:
```bash
Don’t use it when:
You need absolute minimal memory (pick dwq3) or maximum precision (pick q6).
Do use it when: Your hardware has moderate resources
(e.g., cloud server with 4GB+ RAM),
latency matters but accuracy isn’t critical,
and you need to avoid the "stability trade-offs" of dwq5 (e.g., slight winogrande drop).
```
⚠️ When YOYO-V2-dwq4 Falls Short
(Helps you avoid misalignment)
```bash
Use Case Why dwq4 might not be ideal
Ultra-low-memory environments dwq3 offers better memory savings
High-accuracy critical tasks q6 beats dwq4 by 0.01–0.02 points on boolq/piqa; use dwq4 only if the difference is acceptable
Tasks requiring fastest startup dwq3 is 5–10% faster at inference (e.g., voice assistants need millisecond response times)
```
💎 Who Should Choose YOYO-V2-dwq4?
(Realistic, not theoretical)
```bash
Use Case Scenario Why dwq4 is the winning choice here
Mobile apps with moderate device power Balances reasonable accuracy (e.g., 95%+ on arc_easy) with RAM constraints
Edge computing (Raspberry Pi 4, Jetson Nano) Avoids dwq3’s slight accuracy gaps while using less memory than q6 → stable performance in noisy environments
SaaS chatbots with cloud-edge hybrid workflows 25–30% lower cloud costs than q6 and better than dwq3 on task consistency → ideal for scaling
Task pipelines needing "good enough" reasoning boolq/piqa scores are high but slightly below q6 — perfect if you’re not doing legal/compliance work
```
🔚 The golden rule: If your team has to pick one quantized YOYO-V2 model, dwq4 is the most versatile choice. It’s the only variant where:
```bash
It outperforms dwq3 on 4/7 tasks
It’s <10% slower than q6 but retains 95–98% of its accuracy
It’s widely deployable without requiring specialized hardware
```
💬 Final Takeaway for Your Decision-Making
"YOYO-V2-dwq4 is the model to use when you need deployable performance without the trade-offs of ultra-low-bit quantization or full q6 precision."
```bash
For mobile-first apps, it’s the best balance of speed, memory, and accuracy.
For most cloud deployments, it’s cheaper than q6 but safer than dwq3’s minor accuracy drops.
```
Example: If you’re building a low-cost educational chatbot for rural schools (with varying device capabilities), YOYO-V2-dwq4 gives the highest practical utility — it works reliably 90%+ of the time without crashing on older phones or overloading cloud servers.
This isn’t about "best score" — it’s about most valuable for the job you need to do. And in 90%+ of real scenarios, YOYO-V2-dwq4 delivers exactly what you need. 🛠️
📊 Critical Insights from YOYO-V2's Internal Quantization Comparison
Why the Q6 Gap Persists
DWQ quantization (dynamic) and fixed Q6 quantization both improve over raw models, but q6 achieves marginal gains in high-precision tasks:
```bash
boolq: q6’s score (0.886) is the highest absolute value in this benchmark.
piqa: q6’s lead (0.782 vs dwq5’s 0.778) is 1.3% – critical for logic reasoning tasks.
```
For most use cases, q6 is still the top performer (1.3–2.0% edge over dwq5 in tasks like boolq and piqa).
This confirms that YOYO-V2’s performance steadily improves with higher quantization fidelity within its own variants, but the fixed Q6 quantization still delivers edge gains for critical tasks where minor precision losses are unacceptable.
✅ In short: DWQ5 > DWQ4 > DWQ3 in all tasks, but q6 remains the most reliable for high-stakes applications. For your deployment: choose dwq5 when memory is constrained; use q6 for maximum accuracy.
This model [Qwen3-30B-A3B-YOYO-V2-dwq4-mlx](https://huggingface.co/Qwen3-30B-A3B-YOYO-V2-dwq4-mlx) was
converted to MLX format from [YOYO-AI/Qwen3-30B-A3B-YOYO-V2](https://huggingface.co/YOYO-AI/Qwen3-30B-A3B-YOYO-V2)
using mlx-lm version **0.26.4**.
## Use with mlx
```bash
pip install mlx-lm
```
```python
from mlx_lm import load, generate
model, tokenizer = load("Qwen3-30B-A3B-YOYO-V2-dwq4-mlx")
prompt = "hello"
if tokenizer.chat_template is not None:
messages = [{"role": "user", "content": prompt}]
prompt = tokenizer.apply_chat_template(
messages, add_generation_prompt=True
)
response = generate(model, tokenizer, prompt=prompt, verbose=True)
```
|
qualcomm/LiteHRNet
|
qualcomm
| 2025-08-26T16:45:32Z | 30 | 13 |
pytorch
|
[
"pytorch",
"tflite",
"android",
"keypoint-detection",
"arxiv:2104.06403",
"license:other",
"region:us"
] |
keypoint-detection
| 2024-02-25T22:56:44Z |
---
library_name: pytorch
license: other
tags:
- android
pipeline_tag: keypoint-detection
---

# LiteHRNet: Optimized for Mobile Deployment
## Human pose estimation
LiteHRNet is a machine learning model that detects human pose and returns a location and confidence for each of 17 joints.
This model is an implementation of LiteHRNet found [here](https://github.com/HRNet/Lite-HRNet).
This repository provides scripts to run LiteHRNet on Qualcomm® devices.
More details on model performance across various devices, can be found
[here](https://aihub.qualcomm.com/models/litehrnet).
### Model Details
- **Model Type:** Model_use_case.pose_estimation
- **Model Stats:**
- Input resolution: 256x192
- Number of parameters: 1.11M
- Model size (float): 4.49 MB
| Model | Precision | Device | Chipset | Target Runtime | Inference Time (ms) | Peak Memory Range (MB) | Primary Compute Unit | Target Model
|---|---|---|---|---|---|---|---|---|
| LiteHRNet | float | QCS8275 (Proxy) | Qualcomm® QCS8275 (Proxy) | TFLITE | 8.714 ms | 0 - 58 MB | NPU | [LiteHRNet.tflite](https://huggingface.co/qualcomm/LiteHRNet/blob/main/LiteHRNet.tflite) |
| LiteHRNet | float | QCS8450 (Proxy) | Qualcomm® QCS8450 (Proxy) | TFLITE | 5.219 ms | 0 - 69 MB | NPU | [LiteHRNet.tflite](https://huggingface.co/qualcomm/LiteHRNet/blob/main/LiteHRNet.tflite) |
| LiteHRNet | float | QCS8550 (Proxy) | Qualcomm® QCS8550 (Proxy) | TFLITE | 4.45 ms | 0 - 16 MB | NPU | [LiteHRNet.tflite](https://huggingface.co/qualcomm/LiteHRNet/blob/main/LiteHRNet.tflite) |
| LiteHRNet | float | QCS9075 (Proxy) | Qualcomm® QCS9075 (Proxy) | TFLITE | 5.416 ms | 0 - 58 MB | NPU | [LiteHRNet.tflite](https://huggingface.co/qualcomm/LiteHRNet/blob/main/LiteHRNet.tflite) |
| LiteHRNet | float | SA7255P ADP | Qualcomm® SA7255P | TFLITE | 8.714 ms | 0 - 58 MB | NPU | [LiteHRNet.tflite](https://huggingface.co/qualcomm/LiteHRNet/blob/main/LiteHRNet.tflite) |
| LiteHRNet | float | SA8255 (Proxy) | Qualcomm® SA8255P (Proxy) | TFLITE | 4.447 ms | 0 - 17 MB | NPU | [LiteHRNet.tflite](https://huggingface.co/qualcomm/LiteHRNet/blob/main/LiteHRNet.tflite) |
| LiteHRNet | float | SA8295P ADP | Qualcomm® SA8295P | TFLITE | 6.46 ms | 0 - 63 MB | NPU | [LiteHRNet.tflite](https://huggingface.co/qualcomm/LiteHRNet/blob/main/LiteHRNet.tflite) |
| LiteHRNet | float | SA8650 (Proxy) | Qualcomm® SA8650P (Proxy) | TFLITE | 4.444 ms | 0 - 14 MB | NPU | [LiteHRNet.tflite](https://huggingface.co/qualcomm/LiteHRNet/blob/main/LiteHRNet.tflite) |
| LiteHRNet | float | SA8775P ADP | Qualcomm® SA8775P | TFLITE | 5.416 ms | 0 - 58 MB | NPU | [LiteHRNet.tflite](https://huggingface.co/qualcomm/LiteHRNet/blob/main/LiteHRNet.tflite) |
| LiteHRNet | float | Samsung Galaxy S23 | Snapdragon® 8 Gen 2 Mobile | TFLITE | 4.44 ms | 0 - 20 MB | NPU | [LiteHRNet.tflite](https://huggingface.co/qualcomm/LiteHRNet/blob/main/LiteHRNet.tflite) |
| LiteHRNet | float | Samsung Galaxy S23 | Snapdragon® 8 Gen 2 Mobile | ONNX | 7.695 ms | 0 - 27 MB | NPU | [LiteHRNet.onnx.zip](https://huggingface.co/qualcomm/LiteHRNet/blob/main/LiteHRNet.onnx.zip) |
| LiteHRNet | float | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | TFLITE | 2.737 ms | 0 - 66 MB | NPU | [LiteHRNet.tflite](https://huggingface.co/qualcomm/LiteHRNet/blob/main/LiteHRNet.tflite) |
| LiteHRNet | float | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | ONNX | 4.493 ms | 0 - 59 MB | NPU | [LiteHRNet.onnx.zip](https://huggingface.co/qualcomm/LiteHRNet/blob/main/LiteHRNet.onnx.zip) |
| LiteHRNet | float | Snapdragon 8 Elite QRD | Snapdragon® 8 Elite Mobile | TFLITE | 2.823 ms | 0 - 59 MB | NPU | [LiteHRNet.tflite](https://huggingface.co/qualcomm/LiteHRNet/blob/main/LiteHRNet.tflite) |
| LiteHRNet | float | Snapdragon 8 Elite QRD | Snapdragon® 8 Elite Mobile | ONNX | 5.065 ms | 1 - 51 MB | NPU | [LiteHRNet.onnx.zip](https://huggingface.co/qualcomm/LiteHRNet/blob/main/LiteHRNet.onnx.zip) |
| LiteHRNet | float | Snapdragon X Elite CRD | Snapdragon® X Elite | ONNX | 8.047 ms | 4 - 4 MB | NPU | [LiteHRNet.onnx.zip](https://huggingface.co/qualcomm/LiteHRNet/blob/main/LiteHRNet.onnx.zip) |
## Installation
Install the package via pip:
```bash
pip install "qai-hub-models[litehrnet]" torch==2.4.1 --trusted-host download.openmmlab.com -f https://download.openmmlab.com/mmcv/dist/cpu/torch2.4/index.html -f https://qaihub-public-python-wheels.s3.us-west-2.amazonaws.com/index.html
```
## Configure Qualcomm® AI Hub to run this model on a cloud-hosted device
Sign-in to [Qualcomm® AI Hub](https://app.aihub.qualcomm.com/) with your
Qualcomm® ID. Once signed in navigate to `Account -> Settings -> API Token`.
With this API token, you can configure your client to run models on the cloud
hosted devices.
```bash
qai-hub configure --api_token API_TOKEN
```
Navigate to [docs](https://app.aihub.qualcomm.com/docs/) for more information.
## Demo off target
The package contains a simple end-to-end demo that downloads pre-trained
weights and runs this model on a sample input.
```bash
python -m qai_hub_models.models.litehrnet.demo
```
The above demo runs a reference implementation of pre-processing, model
inference, and post processing.
**NOTE**: If you want running in a Jupyter Notebook or Google Colab like
environment, please add the following to your cell (instead of the above).
```
%run -m qai_hub_models.models.litehrnet.demo
```
### Run model on a cloud-hosted device
In addition to the demo, you can also run the model on a cloud-hosted Qualcomm®
device. This script does the following:
* Performance check on-device on a cloud-hosted device
* Downloads compiled assets that can be deployed on-device for Android.
* Accuracy check between PyTorch and on-device outputs.
```bash
python -m qai_hub_models.models.litehrnet.export
```
## How does this work?
This [export script](https://aihub.qualcomm.com/models/litehrnet/qai_hub_models/models/LiteHRNet/export.py)
leverages [Qualcomm® AI Hub](https://aihub.qualcomm.com/) to optimize, validate, and deploy this model
on-device. Lets go through each step below in detail:
Step 1: **Compile model for on-device deployment**
To compile a PyTorch model for on-device deployment, we first trace the model
in memory using the `jit.trace` and then call the `submit_compile_job` API.
```python
import torch
import qai_hub as hub
from qai_hub_models.models.litehrnet import Model
# Load the model
torch_model = Model.from_pretrained()
# Device
device = hub.Device("Samsung Galaxy S24")
# Trace model
input_shape = torch_model.get_input_spec()
sample_inputs = torch_model.sample_inputs()
pt_model = torch.jit.trace(torch_model, [torch.tensor(data[0]) for _, data in sample_inputs.items()])
# Compile model on a specific device
compile_job = hub.submit_compile_job(
model=pt_model,
device=device,
input_specs=torch_model.get_input_spec(),
)
# Get target model to run on-device
target_model = compile_job.get_target_model()
```
Step 2: **Performance profiling on cloud-hosted device**
After compiling models from step 1. Models can be profiled model on-device using the
`target_model`. Note that this scripts runs the model on a device automatically
provisioned in the cloud. Once the job is submitted, you can navigate to a
provided job URL to view a variety of on-device performance metrics.
```python
profile_job = hub.submit_profile_job(
model=target_model,
device=device,
)
```
Step 3: **Verify on-device accuracy**
To verify the accuracy of the model on-device, you can run on-device inference
on sample input data on the same cloud hosted device.
```python
input_data = torch_model.sample_inputs()
inference_job = hub.submit_inference_job(
model=target_model,
device=device,
inputs=input_data,
)
on_device_output = inference_job.download_output_data()
```
With the output of the model, you can compute like PSNR, relative errors or
spot check the output with expected output.
**Note**: This on-device profiling and inference requires access to Qualcomm®
AI Hub. [Sign up for access](https://myaccount.qualcomm.com/signup).
## Run demo on a cloud-hosted device
You can also run the demo on-device.
```bash
python -m qai_hub_models.models.litehrnet.demo --eval-mode on-device
```
**NOTE**: If you want running in a Jupyter Notebook or Google Colab like
environment, please add the following to your cell (instead of the above).
```
%run -m qai_hub_models.models.litehrnet.demo -- --eval-mode on-device
```
## Deploying compiled model to Android
The models can be deployed using multiple runtimes:
- TensorFlow Lite (`.tflite` export): [This
tutorial](https://www.tensorflow.org/lite/android/quickstart) provides a
guide to deploy the .tflite model in an Android application.
- QNN (`.so` export ): This [sample
app](https://docs.qualcomm.com/bundle/publicresource/topics/80-63442-50/sample_app.html)
provides instructions on how to use the `.so` shared library in an Android application.
## View on Qualcomm® AI Hub
Get more details on LiteHRNet's performance across various devices [here](https://aihub.qualcomm.com/models/litehrnet).
Explore all available models on [Qualcomm® AI Hub](https://aihub.qualcomm.com/)
## License
* The license for the original implementation of LiteHRNet can be found
[here](https://github.com/HRNet/Lite-HRNet/blob/hrnet/LICENSE).
* The license for the compiled assets for on-device deployment can be found [here](https://qaihub-public-assets.s3.us-west-2.amazonaws.com/qai-hub-models/Qualcomm+AI+Hub+Proprietary+License.pdf)
## References
* [Lite-HRNet: A Lightweight High-Resolution Network](https://arxiv.org/abs/2104.06403)
* [Source Model Implementation](https://github.com/HRNet/Lite-HRNet)
## Community
* Join [our AI Hub Slack community](https://aihub.qualcomm.com/community/slack) to collaborate, post questions and learn more about on-device AI.
* For questions or feedback please [reach out to us](mailto:ai-hub-support@qti.qualcomm.com).
|
qualcomm/HRNetPose
|
qualcomm
| 2025-08-26T16:42:40Z | 410 | 7 |
pytorch
|
[
"pytorch",
"tflite",
"android",
"keypoint-detection",
"arxiv:1902.09212",
"license:other",
"region:us"
] |
keypoint-detection
| 2024-02-25T22:45:59Z |
---
library_name: pytorch
license: other
tags:
- android
pipeline_tag: keypoint-detection
---

# HRNetPose: Optimized for Mobile Deployment
## Perform accurate human pose estimation
HRNet performs pose estimation in high-resolution representations.
This model is an implementation of HRNetPose found [here](https://github.com/leoxiaobin/deep-high-resolution-net.pytorch).
This repository provides scripts to run HRNetPose on Qualcomm® devices.
More details on model performance across various devices, can be found
[here](https://aihub.qualcomm.com/models/hrnet_pose).
### Model Details
- **Model Type:** Model_use_case.pose_estimation
- **Model Stats:**
- Model checkpoint: hrnet_posenet_FP32_state_dict
- Input resolution: 256x192
- Number of parameters: 28.5M
- Model size (float): 109 MB
- Model size (w8a8): 28.1 MB
| Model | Precision | Device | Chipset | Target Runtime | Inference Time (ms) | Peak Memory Range (MB) | Primary Compute Unit | Target Model
|---|---|---|---|---|---|---|---|---|
| HRNetPose | float | QCS8275 (Proxy) | Qualcomm® QCS8275 (Proxy) | TFLITE | 14.315 ms | 0 - 79 MB | NPU | [HRNetPose.tflite](https://huggingface.co/qualcomm/HRNetPose/blob/main/HRNetPose.tflite) |
| HRNetPose | float | QCS8275 (Proxy) | Qualcomm® QCS8275 (Proxy) | QNN_DLC | 14.137 ms | 1 - 42 MB | NPU | [HRNetPose.dlc](https://huggingface.co/qualcomm/HRNetPose/blob/main/HRNetPose.dlc) |
| HRNetPose | float | QCS8450 (Proxy) | Qualcomm® QCS8450 (Proxy) | TFLITE | 3.673 ms | 0 - 124 MB | NPU | [HRNetPose.tflite](https://huggingface.co/qualcomm/HRNetPose/blob/main/HRNetPose.tflite) |
| HRNetPose | float | QCS8450 (Proxy) | Qualcomm® QCS8450 (Proxy) | QNN_DLC | 4.773 ms | 0 - 59 MB | NPU | [HRNetPose.dlc](https://huggingface.co/qualcomm/HRNetPose/blob/main/HRNetPose.dlc) |
| HRNetPose | float | QCS8550 (Proxy) | Qualcomm® QCS8550 (Proxy) | TFLITE | 2.627 ms | 0 - 19 MB | NPU | [HRNetPose.tflite](https://huggingface.co/qualcomm/HRNetPose/blob/main/HRNetPose.tflite) |
| HRNetPose | float | QCS8550 (Proxy) | Qualcomm® QCS8550 (Proxy) | QNN_DLC | 2.607 ms | 1 - 14 MB | NPU | [HRNetPose.dlc](https://huggingface.co/qualcomm/HRNetPose/blob/main/HRNetPose.dlc) |
| HRNetPose | float | QCS9075 (Proxy) | Qualcomm® QCS9075 (Proxy) | TFLITE | 4.353 ms | 0 - 79 MB | NPU | [HRNetPose.tflite](https://huggingface.co/qualcomm/HRNetPose/blob/main/HRNetPose.tflite) |
| HRNetPose | float | QCS9075 (Proxy) | Qualcomm® QCS9075 (Proxy) | QNN_DLC | 4.254 ms | 0 - 42 MB | NPU | [HRNetPose.dlc](https://huggingface.co/qualcomm/HRNetPose/blob/main/HRNetPose.dlc) |
| HRNetPose | float | SA7255P ADP | Qualcomm® SA7255P | TFLITE | 14.315 ms | 0 - 79 MB | NPU | [HRNetPose.tflite](https://huggingface.co/qualcomm/HRNetPose/blob/main/HRNetPose.tflite) |
| HRNetPose | float | SA7255P ADP | Qualcomm® SA7255P | QNN_DLC | 14.137 ms | 1 - 42 MB | NPU | [HRNetPose.dlc](https://huggingface.co/qualcomm/HRNetPose/blob/main/HRNetPose.dlc) |
| HRNetPose | float | SA8255 (Proxy) | Qualcomm® SA8255P (Proxy) | TFLITE | 2.619 ms | 0 - 35 MB | NPU | [HRNetPose.tflite](https://huggingface.co/qualcomm/HRNetPose/blob/main/HRNetPose.tflite) |
| HRNetPose | float | SA8255 (Proxy) | Qualcomm® SA8255P (Proxy) | QNN_DLC | 2.597 ms | 1 - 18 MB | NPU | [HRNetPose.dlc](https://huggingface.co/qualcomm/HRNetPose/blob/main/HRNetPose.dlc) |
| HRNetPose | float | SA8295P ADP | Qualcomm® SA8295P | TFLITE | 4.502 ms | 0 - 73 MB | NPU | [HRNetPose.tflite](https://huggingface.co/qualcomm/HRNetPose/blob/main/HRNetPose.tflite) |
| HRNetPose | float | SA8295P ADP | Qualcomm® SA8295P | QNN_DLC | 4.477 ms | 1 - 40 MB | NPU | [HRNetPose.dlc](https://huggingface.co/qualcomm/HRNetPose/blob/main/HRNetPose.dlc) |
| HRNetPose | float | SA8650 (Proxy) | Qualcomm® SA8650P (Proxy) | TFLITE | 2.618 ms | 0 - 20 MB | NPU | [HRNetPose.tflite](https://huggingface.co/qualcomm/HRNetPose/blob/main/HRNetPose.tflite) |
| HRNetPose | float | SA8650 (Proxy) | Qualcomm® SA8650P (Proxy) | QNN_DLC | 2.612 ms | 1 - 18 MB | NPU | [HRNetPose.dlc](https://huggingface.co/qualcomm/HRNetPose/blob/main/HRNetPose.dlc) |
| HRNetPose | float | SA8775P ADP | Qualcomm® SA8775P | TFLITE | 4.353 ms | 0 - 79 MB | NPU | [HRNetPose.tflite](https://huggingface.co/qualcomm/HRNetPose/blob/main/HRNetPose.tflite) |
| HRNetPose | float | SA8775P ADP | Qualcomm® SA8775P | QNN_DLC | 4.254 ms | 0 - 42 MB | NPU | [HRNetPose.dlc](https://huggingface.co/qualcomm/HRNetPose/blob/main/HRNetPose.dlc) |
| HRNetPose | float | Samsung Galaxy S23 | Snapdragon® 8 Gen 2 Mobile | TFLITE | 2.614 ms | 0 - 22 MB | NPU | [HRNetPose.tflite](https://huggingface.co/qualcomm/HRNetPose/blob/main/HRNetPose.tflite) |
| HRNetPose | float | Samsung Galaxy S23 | Snapdragon® 8 Gen 2 Mobile | QNN_DLC | 2.608 ms | 1 - 17 MB | NPU | [HRNetPose.dlc](https://huggingface.co/qualcomm/HRNetPose/blob/main/HRNetPose.dlc) |
| HRNetPose | float | Samsung Galaxy S23 | Snapdragon® 8 Gen 2 Mobile | ONNX | 2.773 ms | 1 - 15 MB | NPU | [HRNetPose.onnx.zip](https://huggingface.co/qualcomm/HRNetPose/blob/main/HRNetPose.onnx.zip) |
| HRNetPose | float | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | TFLITE | 1.903 ms | 0 - 126 MB | NPU | [HRNetPose.tflite](https://huggingface.co/qualcomm/HRNetPose/blob/main/HRNetPose.tflite) |
| HRNetPose | float | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | QNN_DLC | 1.984 ms | 1 - 60 MB | NPU | [HRNetPose.dlc](https://huggingface.co/qualcomm/HRNetPose/blob/main/HRNetPose.dlc) |
| HRNetPose | float | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | ONNX | 2.185 ms | 0 - 74 MB | NPU | [HRNetPose.onnx.zip](https://huggingface.co/qualcomm/HRNetPose/blob/main/HRNetPose.onnx.zip) |
| HRNetPose | float | Snapdragon 8 Elite QRD | Snapdragon® 8 Elite Mobile | TFLITE | 1.808 ms | 0 - 81 MB | NPU | [HRNetPose.tflite](https://huggingface.co/qualcomm/HRNetPose/blob/main/HRNetPose.tflite) |
| HRNetPose | float | Snapdragon 8 Elite QRD | Snapdragon® 8 Elite Mobile | QNN_DLC | 1.775 ms | 1 - 48 MB | NPU | [HRNetPose.dlc](https://huggingface.co/qualcomm/HRNetPose/blob/main/HRNetPose.dlc) |
| HRNetPose | float | Snapdragon 8 Elite QRD | Snapdragon® 8 Elite Mobile | ONNX | 1.989 ms | 0 - 50 MB | NPU | [HRNetPose.onnx.zip](https://huggingface.co/qualcomm/HRNetPose/blob/main/HRNetPose.onnx.zip) |
| HRNetPose | float | Snapdragon X Elite CRD | Snapdragon® X Elite | QNN_DLC | 2.864 ms | 100 - 100 MB | NPU | [HRNetPose.dlc](https://huggingface.co/qualcomm/HRNetPose/blob/main/HRNetPose.dlc) |
| HRNetPose | float | Snapdragon X Elite CRD | Snapdragon® X Elite | ONNX | 2.655 ms | 55 - 55 MB | NPU | [HRNetPose.onnx.zip](https://huggingface.co/qualcomm/HRNetPose/blob/main/HRNetPose.onnx.zip) |
| HRNetPose | w8a8 | QCS8275 (Proxy) | Qualcomm® QCS8275 (Proxy) | TFLITE | 2.615 ms | 0 - 64 MB | NPU | [HRNetPose.tflite](https://huggingface.co/qualcomm/HRNetPose/blob/main/HRNetPose_w8a8.tflite) |
| HRNetPose | w8a8 | QCS8275 (Proxy) | Qualcomm® QCS8275 (Proxy) | QNN_DLC | 2.901 ms | 0 - 66 MB | NPU | [HRNetPose.dlc](https://huggingface.co/qualcomm/HRNetPose/blob/main/HRNetPose_w8a8.dlc) |
| HRNetPose | w8a8 | QCS8450 (Proxy) | Qualcomm® QCS8450 (Proxy) | TFLITE | 1.209 ms | 0 - 101 MB | NPU | [HRNetPose.tflite](https://huggingface.co/qualcomm/HRNetPose/blob/main/HRNetPose_w8a8.tflite) |
| HRNetPose | w8a8 | QCS8450 (Proxy) | Qualcomm® QCS8450 (Proxy) | QNN_DLC | 1.712 ms | 0 - 93 MB | NPU | [HRNetPose.dlc](https://huggingface.co/qualcomm/HRNetPose/blob/main/HRNetPose_w8a8.dlc) |
| HRNetPose | w8a8 | QCS8550 (Proxy) | Qualcomm® QCS8550 (Proxy) | TFLITE | 0.976 ms | 0 - 160 MB | NPU | [HRNetPose.tflite](https://huggingface.co/qualcomm/HRNetPose/blob/main/HRNetPose_w8a8.tflite) |
| HRNetPose | w8a8 | QCS8550 (Proxy) | Qualcomm® QCS8550 (Proxy) | QNN_DLC | 1.16 ms | 0 - 26 MB | NPU | [HRNetPose.dlc](https://huggingface.co/qualcomm/HRNetPose/blob/main/HRNetPose_w8a8.dlc) |
| HRNetPose | w8a8 | QCS9075 (Proxy) | Qualcomm® QCS9075 (Proxy) | TFLITE | 1.332 ms | 0 - 64 MB | NPU | [HRNetPose.tflite](https://huggingface.co/qualcomm/HRNetPose/blob/main/HRNetPose_w8a8.tflite) |
| HRNetPose | w8a8 | QCS9075 (Proxy) | Qualcomm® QCS9075 (Proxy) | QNN_DLC | 1.472 ms | 0 - 65 MB | NPU | [HRNetPose.dlc](https://huggingface.co/qualcomm/HRNetPose/blob/main/HRNetPose_w8a8.dlc) |
| HRNetPose | w8a8 | RB3 Gen 2 (Proxy) | Qualcomm® QCS6490 (Proxy) | TFLITE | 3.713 ms | 0 - 78 MB | NPU | [HRNetPose.tflite](https://huggingface.co/qualcomm/HRNetPose/blob/main/HRNetPose_w8a8.tflite) |
| HRNetPose | w8a8 | RB3 Gen 2 (Proxy) | Qualcomm® QCS6490 (Proxy) | QNN_DLC | 5.515 ms | 0 - 89 MB | NPU | [HRNetPose.dlc](https://huggingface.co/qualcomm/HRNetPose/blob/main/HRNetPose_w8a8.dlc) |
| HRNetPose | w8a8 | RB5 (Proxy) | Qualcomm® QCS8250 (Proxy) | TFLITE | 17.268 ms | 0 - 3 MB | NPU | [HRNetPose.tflite](https://huggingface.co/qualcomm/HRNetPose/blob/main/HRNetPose_w8a8.tflite) |
| HRNetPose | w8a8 | SA7255P ADP | Qualcomm® SA7255P | TFLITE | 2.615 ms | 0 - 64 MB | NPU | [HRNetPose.tflite](https://huggingface.co/qualcomm/HRNetPose/blob/main/HRNetPose_w8a8.tflite) |
| HRNetPose | w8a8 | SA7255P ADP | Qualcomm® SA7255P | QNN_DLC | 2.901 ms | 0 - 66 MB | NPU | [HRNetPose.dlc](https://huggingface.co/qualcomm/HRNetPose/blob/main/HRNetPose_w8a8.dlc) |
| HRNetPose | w8a8 | SA8255 (Proxy) | Qualcomm® SA8255P (Proxy) | TFLITE | 0.976 ms | 0 - 159 MB | NPU | [HRNetPose.tflite](https://huggingface.co/qualcomm/HRNetPose/blob/main/HRNetPose_w8a8.tflite) |
| HRNetPose | w8a8 | SA8255 (Proxy) | Qualcomm® SA8255P (Proxy) | QNN_DLC | 1.174 ms | 0 - 18 MB | NPU | [HRNetPose.dlc](https://huggingface.co/qualcomm/HRNetPose/blob/main/HRNetPose_w8a8.dlc) |
| HRNetPose | w8a8 | SA8295P ADP | Qualcomm® SA8295P | TFLITE | 1.695 ms | 0 - 71 MB | NPU | [HRNetPose.tflite](https://huggingface.co/qualcomm/HRNetPose/blob/main/HRNetPose_w8a8.tflite) |
| HRNetPose | w8a8 | SA8295P ADP | Qualcomm® SA8295P | QNN_DLC | 1.872 ms | 0 - 72 MB | NPU | [HRNetPose.dlc](https://huggingface.co/qualcomm/HRNetPose/blob/main/HRNetPose_w8a8.dlc) |
| HRNetPose | w8a8 | SA8650 (Proxy) | Qualcomm® SA8650P (Proxy) | TFLITE | 0.972 ms | 0 - 159 MB | NPU | [HRNetPose.tflite](https://huggingface.co/qualcomm/HRNetPose/blob/main/HRNetPose_w8a8.tflite) |
| HRNetPose | w8a8 | SA8650 (Proxy) | Qualcomm® SA8650P (Proxy) | QNN_DLC | 1.184 ms | 0 - 68 MB | NPU | [HRNetPose.dlc](https://huggingface.co/qualcomm/HRNetPose/blob/main/HRNetPose_w8a8.dlc) |
| HRNetPose | w8a8 | SA8775P ADP | Qualcomm® SA8775P | TFLITE | 1.332 ms | 0 - 64 MB | NPU | [HRNetPose.tflite](https://huggingface.co/qualcomm/HRNetPose/blob/main/HRNetPose_w8a8.tflite) |
| HRNetPose | w8a8 | SA8775P ADP | Qualcomm® SA8775P | QNN_DLC | 1.472 ms | 0 - 65 MB | NPU | [HRNetPose.dlc](https://huggingface.co/qualcomm/HRNetPose/blob/main/HRNetPose_w8a8.dlc) |
| HRNetPose | w8a8 | Samsung Galaxy S23 | Snapdragon® 8 Gen 2 Mobile | TFLITE | 0.967 ms | 0 - 163 MB | NPU | [HRNetPose.tflite](https://huggingface.co/qualcomm/HRNetPose/blob/main/HRNetPose_w8a8.tflite) |
| HRNetPose | w8a8 | Samsung Galaxy S23 | Snapdragon® 8 Gen 2 Mobile | QNN_DLC | 1.18 ms | 0 - 66 MB | NPU | [HRNetPose.dlc](https://huggingface.co/qualcomm/HRNetPose/blob/main/HRNetPose_w8a8.dlc) |
| HRNetPose | w8a8 | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | TFLITE | 0.722 ms | 126 - 222 MB | NPU | [HRNetPose.tflite](https://huggingface.co/qualcomm/HRNetPose/blob/main/HRNetPose_w8a8.tflite) |
| HRNetPose | w8a8 | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | QNN_DLC | 0.83 ms | 0 - 91 MB | NPU | [HRNetPose.dlc](https://huggingface.co/qualcomm/HRNetPose/blob/main/HRNetPose_w8a8.dlc) |
| HRNetPose | w8a8 | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | ONNX | 67.506 ms | 147 - 2051 MB | NPU | [HRNetPose.onnx.zip](https://huggingface.co/qualcomm/HRNetPose/blob/main/HRNetPose_w8a8.onnx.zip) |
| HRNetPose | w8a8 | Snapdragon 8 Elite QRD | Snapdragon® 8 Elite Mobile | TFLITE | 0.637 ms | 0 - 69 MB | NPU | [HRNetPose.tflite](https://huggingface.co/qualcomm/HRNetPose/blob/main/HRNetPose_w8a8.tflite) |
| HRNetPose | w8a8 | Snapdragon 8 Elite QRD | Snapdragon® 8 Elite Mobile | QNN_DLC | 0.728 ms | 0 - 71 MB | NPU | [HRNetPose.dlc](https://huggingface.co/qualcomm/HRNetPose/blob/main/HRNetPose_w8a8.dlc) |
| HRNetPose | w8a8 | Snapdragon 8 Elite QRD | Snapdragon® 8 Elite Mobile | ONNX | 66.616 ms | 112 - 2179 MB | NPU | [HRNetPose.onnx.zip](https://huggingface.co/qualcomm/HRNetPose/blob/main/HRNetPose_w8a8.onnx.zip) |
| HRNetPose | w8a8 | Snapdragon X Elite CRD | Snapdragon® X Elite | QNN_DLC | 1.313 ms | 161 - 161 MB | NPU | [HRNetPose.dlc](https://huggingface.co/qualcomm/HRNetPose/blob/main/HRNetPose_w8a8.dlc) |
| HRNetPose | w8a8 | Snapdragon X Elite CRD | Snapdragon® X Elite | ONNX | 104.012 ms | 116 - 116 MB | NPU | [HRNetPose.onnx.zip](https://huggingface.co/qualcomm/HRNetPose/blob/main/HRNetPose_w8a8.onnx.zip) |
## Installation
Install the package via pip:
```bash
pip install "qai-hub-models[hrnet-pose]" torch==2.4.1 --trusted-host download.openmmlab.com -f https://download.openmmlab.com/mmcv/dist/cpu/torch2.4/index.html -f https://qaihub-public-python-wheels.s3.us-west-2.amazonaws.com/index.html
```
## Configure Qualcomm® AI Hub to run this model on a cloud-hosted device
Sign-in to [Qualcomm® AI Hub](https://app.aihub.qualcomm.com/) with your
Qualcomm® ID. Once signed in navigate to `Account -> Settings -> API Token`.
With this API token, you can configure your client to run models on the cloud
hosted devices.
```bash
qai-hub configure --api_token API_TOKEN
```
Navigate to [docs](https://app.aihub.qualcomm.com/docs/) for more information.
## Demo off target
The package contains a simple end-to-end demo that downloads pre-trained
weights and runs this model on a sample input.
```bash
python -m qai_hub_models.models.hrnet_pose.demo
```
The above demo runs a reference implementation of pre-processing, model
inference, and post processing.
**NOTE**: If you want running in a Jupyter Notebook or Google Colab like
environment, please add the following to your cell (instead of the above).
```
%run -m qai_hub_models.models.hrnet_pose.demo
```
### Run model on a cloud-hosted device
In addition to the demo, you can also run the model on a cloud-hosted Qualcomm®
device. This script does the following:
* Performance check on-device on a cloud-hosted device
* Downloads compiled assets that can be deployed on-device for Android.
* Accuracy check between PyTorch and on-device outputs.
```bash
python -m qai_hub_models.models.hrnet_pose.export
```
## How does this work?
This [export script](https://aihub.qualcomm.com/models/hrnet_pose/qai_hub_models/models/HRNetPose/export.py)
leverages [Qualcomm® AI Hub](https://aihub.qualcomm.com/) to optimize, validate, and deploy this model
on-device. Lets go through each step below in detail:
Step 1: **Compile model for on-device deployment**
To compile a PyTorch model for on-device deployment, we first trace the model
in memory using the `jit.trace` and then call the `submit_compile_job` API.
```python
import torch
import qai_hub as hub
from qai_hub_models.models.hrnet_pose import Model
# Load the model
torch_model = Model.from_pretrained()
# Device
device = hub.Device("Samsung Galaxy S24")
# Trace model
input_shape = torch_model.get_input_spec()
sample_inputs = torch_model.sample_inputs()
pt_model = torch.jit.trace(torch_model, [torch.tensor(data[0]) for _, data in sample_inputs.items()])
# Compile model on a specific device
compile_job = hub.submit_compile_job(
model=pt_model,
device=device,
input_specs=torch_model.get_input_spec(),
)
# Get target model to run on-device
target_model = compile_job.get_target_model()
```
Step 2: **Performance profiling on cloud-hosted device**
After compiling models from step 1. Models can be profiled model on-device using the
`target_model`. Note that this scripts runs the model on a device automatically
provisioned in the cloud. Once the job is submitted, you can navigate to a
provided job URL to view a variety of on-device performance metrics.
```python
profile_job = hub.submit_profile_job(
model=target_model,
device=device,
)
```
Step 3: **Verify on-device accuracy**
To verify the accuracy of the model on-device, you can run on-device inference
on sample input data on the same cloud hosted device.
```python
input_data = torch_model.sample_inputs()
inference_job = hub.submit_inference_job(
model=target_model,
device=device,
inputs=input_data,
)
on_device_output = inference_job.download_output_data()
```
With the output of the model, you can compute like PSNR, relative errors or
spot check the output with expected output.
**Note**: This on-device profiling and inference requires access to Qualcomm®
AI Hub. [Sign up for access](https://myaccount.qualcomm.com/signup).
## Run demo on a cloud-hosted device
You can also run the demo on-device.
```bash
python -m qai_hub_models.models.hrnet_pose.demo --eval-mode on-device
```
**NOTE**: If you want running in a Jupyter Notebook or Google Colab like
environment, please add the following to your cell (instead of the above).
```
%run -m qai_hub_models.models.hrnet_pose.demo -- --eval-mode on-device
```
## Deploying compiled model to Android
The models can be deployed using multiple runtimes:
- TensorFlow Lite (`.tflite` export): [This
tutorial](https://www.tensorflow.org/lite/android/quickstart) provides a
guide to deploy the .tflite model in an Android application.
- QNN (`.so` export ): This [sample
app](https://docs.qualcomm.com/bundle/publicresource/topics/80-63442-50/sample_app.html)
provides instructions on how to use the `.so` shared library in an Android application.
## View on Qualcomm® AI Hub
Get more details on HRNetPose's performance across various devices [here](https://aihub.qualcomm.com/models/hrnet_pose).
Explore all available models on [Qualcomm® AI Hub](https://aihub.qualcomm.com/)
## License
* The license for the original implementation of HRNetPose can be found
[here](https://github.com/leoxiaobin/deep-high-resolution-net.pytorch/blob/master/LICENSE).
* The license for the compiled assets for on-device deployment can be found [here](https://qaihub-public-assets.s3.us-west-2.amazonaws.com/qai-hub-models/Qualcomm+AI+Hub+Proprietary+License.pdf)
## References
* [Deep High-Resolution Representation Learning for Human Pose Estimation](https://arxiv.org/abs/1902.09212)
* [Source Model Implementation](https://github.com/leoxiaobin/deep-high-resolution-net.pytorch)
## Community
* Join [our AI Hub Slack community](https://aihub.qualcomm.com/community/slack) to collaborate, post questions and learn more about on-device AI.
* For questions or feedback please [reach out to us](mailto:ai-hub-support@qti.qualcomm.com).
|
koloni/blockassist-bc-deadly_graceful_stingray_1756224668
|
koloni
| 2025-08-26T16:39:12Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"deadly graceful stingray",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-26T16:39:08Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- deadly graceful stingray
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
onnx-community/sbert_large_nlu_ru-ONNX
|
onnx-community
| 2025-08-26T16:37:54Z | 0 | 0 |
transformers.js
|
[
"transformers.js",
"onnx",
"bert",
"question-answering",
"base_model:KseniyaZ/sbert_large_nlu_ru",
"base_model:quantized:KseniyaZ/sbert_large_nlu_ru",
"region:us"
] |
question-answering
| 2025-08-26T16:37:26Z |
---
library_name: transformers.js
base_model:
- KseniyaZ/sbert_large_nlu_ru
---
# sbert_large_nlu_ru (ONNX)
This is an ONNX version of [KseniyaZ/sbert_large_nlu_ru](https://huggingface.co/KseniyaZ/sbert_large_nlu_ru). It was automatically converted and uploaded using [this space](https://huggingface.co/spaces/onnx-community/convert-to-onnx).
|
qualcomm/FastSam-X
|
qualcomm
| 2025-08-26T16:37:42Z | 68 | 8 |
pytorch
|
[
"pytorch",
"tflite",
"android",
"image-segmentation",
"arxiv:2306.12156",
"license:other",
"region:us"
] |
image-segmentation
| 2024-02-25T22:50:47Z |
---
library_name: pytorch
license: other
tags:
- android
pipeline_tag: image-segmentation
---

# FastSam-X: Optimized for Mobile Deployment
## Generate high quality segmentation mask on device
The Fast Segment Anything Model (FastSAM) is a novel, real-time CNN-based solution for the Segment Anything task. This task is designed to segment any object within an image based on various possible user interaction prompts. The model performs competitively despite significantly reduced computation, making it a practical choice for a variety of vision tasks.
This model is an implementation of FastSam-X found [here](https://github.com/CASIA-IVA-Lab/FastSAM).
This repository provides scripts to run FastSam-X on Qualcomm® devices.
More details on model performance across various devices, can be found
[here](https://aihub.qualcomm.com/models/fastsam_x).
### Model Details
- **Model Type:** Model_use_case.semantic_segmentation
- **Model Stats:**
- Model checkpoint: fastsam-x.pt
- Inference latency: RealTime
- Input resolution: 640x640
- Number of parameters: 72.2M
- Model size (float): 276 MB
| Model | Precision | Device | Chipset | Target Runtime | Inference Time (ms) | Peak Memory Range (MB) | Primary Compute Unit | Target Model
|---|---|---|---|---|---|---|---|---|
| FastSam-X | float | QCS8275 (Proxy) | Qualcomm® QCS8275 (Proxy) | TFLITE | 280.693 ms | 4 - 113 MB | NPU | [FastSam-X.tflite](https://huggingface.co/qualcomm/FastSam-X/blob/main/FastSam-X.tflite) |
| FastSam-X | float | QCS8275 (Proxy) | Qualcomm® QCS8275 (Proxy) | QNN_DLC | 277.119 ms | 0 - 86 MB | NPU | [FastSam-X.dlc](https://huggingface.co/qualcomm/FastSam-X/blob/main/FastSam-X.dlc) |
| FastSam-X | float | QCS8450 (Proxy) | Qualcomm® QCS8450 (Proxy) | TFLITE | 81.853 ms | 3 - 194 MB | NPU | [FastSam-X.tflite](https://huggingface.co/qualcomm/FastSam-X/blob/main/FastSam-X.tflite) |
| FastSam-X | float | QCS8450 (Proxy) | Qualcomm® QCS8450 (Proxy) | QNN_DLC | 87.037 ms | 4 - 96 MB | NPU | [FastSam-X.dlc](https://huggingface.co/qualcomm/FastSam-X/blob/main/FastSam-X.dlc) |
| FastSam-X | float | QCS8550 (Proxy) | Qualcomm® QCS8550 (Proxy) | TFLITE | 42.697 ms | 4 - 62 MB | NPU | [FastSam-X.tflite](https://huggingface.co/qualcomm/FastSam-X/blob/main/FastSam-X.tflite) |
| FastSam-X | float | QCS8550 (Proxy) | Qualcomm® QCS8550 (Proxy) | QNN_DLC | 42.475 ms | 5 - 28 MB | NPU | [FastSam-X.dlc](https://huggingface.co/qualcomm/FastSam-X/blob/main/FastSam-X.dlc) |
| FastSam-X | float | QCS9075 (Proxy) | Qualcomm® QCS9075 (Proxy) | TFLITE | 70.486 ms | 4 - 112 MB | NPU | [FastSam-X.tflite](https://huggingface.co/qualcomm/FastSam-X/blob/main/FastSam-X.tflite) |
| FastSam-X | float | QCS9075 (Proxy) | Qualcomm® QCS9075 (Proxy) | QNN_DLC | 67.802 ms | 0 - 81 MB | NPU | [FastSam-X.dlc](https://huggingface.co/qualcomm/FastSam-X/blob/main/FastSam-X.dlc) |
| FastSam-X | float | SA7255P ADP | Qualcomm® SA7255P | TFLITE | 280.693 ms | 4 - 113 MB | NPU | [FastSam-X.tflite](https://huggingface.co/qualcomm/FastSam-X/blob/main/FastSam-X.tflite) |
| FastSam-X | float | SA7255P ADP | Qualcomm® SA7255P | QNN_DLC | 277.119 ms | 0 - 86 MB | NPU | [FastSam-X.dlc](https://huggingface.co/qualcomm/FastSam-X/blob/main/FastSam-X.dlc) |
| FastSam-X | float | SA8255 (Proxy) | Qualcomm® SA8255P (Proxy) | TFLITE | 43.819 ms | 4 - 59 MB | NPU | [FastSam-X.tflite](https://huggingface.co/qualcomm/FastSam-X/blob/main/FastSam-X.tflite) |
| FastSam-X | float | SA8255 (Proxy) | Qualcomm® SA8255P (Proxy) | QNN_DLC | 42.897 ms | 5 - 27 MB | NPU | [FastSam-X.dlc](https://huggingface.co/qualcomm/FastSam-X/blob/main/FastSam-X.dlc) |
| FastSam-X | float | SA8295P ADP | Qualcomm® SA8295P | TFLITE | 89.598 ms | 7 - 105 MB | NPU | [FastSam-X.tflite](https://huggingface.co/qualcomm/FastSam-X/blob/main/FastSam-X.tflite) |
| FastSam-X | float | SA8295P ADP | Qualcomm® SA8295P | QNN_DLC | 75.491 ms | 0 - 83 MB | NPU | [FastSam-X.dlc](https://huggingface.co/qualcomm/FastSam-X/blob/main/FastSam-X.dlc) |
| FastSam-X | float | SA8650 (Proxy) | Qualcomm® SA8650P (Proxy) | TFLITE | 42.927 ms | 1 - 59 MB | NPU | [FastSam-X.tflite](https://huggingface.co/qualcomm/FastSam-X/blob/main/FastSam-X.tflite) |
| FastSam-X | float | SA8650 (Proxy) | Qualcomm® SA8650P (Proxy) | QNN_DLC | 43.199 ms | 5 - 28 MB | NPU | [FastSam-X.dlc](https://huggingface.co/qualcomm/FastSam-X/blob/main/FastSam-X.dlc) |
| FastSam-X | float | SA8775P ADP | Qualcomm® SA8775P | TFLITE | 70.486 ms | 4 - 112 MB | NPU | [FastSam-X.tflite](https://huggingface.co/qualcomm/FastSam-X/blob/main/FastSam-X.tflite) |
| FastSam-X | float | SA8775P ADP | Qualcomm® SA8775P | QNN_DLC | 67.802 ms | 0 - 81 MB | NPU | [FastSam-X.dlc](https://huggingface.co/qualcomm/FastSam-X/blob/main/FastSam-X.dlc) |
| FastSam-X | float | Samsung Galaxy S23 | Snapdragon® 8 Gen 2 Mobile | TFLITE | 43.554 ms | 4 - 59 MB | NPU | [FastSam-X.tflite](https://huggingface.co/qualcomm/FastSam-X/blob/main/FastSam-X.tflite) |
| FastSam-X | float | Samsung Galaxy S23 | Snapdragon® 8 Gen 2 Mobile | QNN_DLC | 42.407 ms | 5 - 29 MB | NPU | [FastSam-X.dlc](https://huggingface.co/qualcomm/FastSam-X/blob/main/FastSam-X.dlc) |
| FastSam-X | float | Samsung Galaxy S23 | Snapdragon® 8 Gen 2 Mobile | ONNX | 48.103 ms | 10 - 31 MB | NPU | [FastSam-X.onnx.zip](https://huggingface.co/qualcomm/FastSam-X/blob/main/FastSam-X.onnx.zip) |
| FastSam-X | float | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | TFLITE | 34.751 ms | 3 - 205 MB | NPU | [FastSam-X.tflite](https://huggingface.co/qualcomm/FastSam-X/blob/main/FastSam-X.tflite) |
| FastSam-X | float | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | QNN_DLC | 32.602 ms | 5 - 90 MB | NPU | [FastSam-X.dlc](https://huggingface.co/qualcomm/FastSam-X/blob/main/FastSam-X.dlc) |
| FastSam-X | float | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | ONNX | 33.596 ms | 17 - 96 MB | NPU | [FastSam-X.onnx.zip](https://huggingface.co/qualcomm/FastSam-X/blob/main/FastSam-X.onnx.zip) |
| FastSam-X | float | Snapdragon 8 Elite QRD | Snapdragon® 8 Elite Mobile | TFLITE | 30.735 ms | 4 - 113 MB | NPU | [FastSam-X.tflite](https://huggingface.co/qualcomm/FastSam-X/blob/main/FastSam-X.tflite) |
| FastSam-X | float | Snapdragon 8 Elite QRD | Snapdragon® 8 Elite Mobile | QNN_DLC | 28.891 ms | 5 - 80 MB | NPU | [FastSam-X.dlc](https://huggingface.co/qualcomm/FastSam-X/blob/main/FastSam-X.dlc) |
| FastSam-X | float | Snapdragon 8 Elite QRD | Snapdragon® 8 Elite Mobile | ONNX | 30.161 ms | 15 - 83 MB | NPU | [FastSam-X.onnx.zip](https://huggingface.co/qualcomm/FastSam-X/blob/main/FastSam-X.onnx.zip) |
| FastSam-X | float | Snapdragon X Elite CRD | Snapdragon® X Elite | QNN_DLC | 43.205 ms | 331 - 331 MB | NPU | [FastSam-X.dlc](https://huggingface.co/qualcomm/FastSam-X/blob/main/FastSam-X.dlc) |
| FastSam-X | float | Snapdragon X Elite CRD | Snapdragon® X Elite | ONNX | 47.007 ms | 139 - 139 MB | NPU | [FastSam-X.onnx.zip](https://huggingface.co/qualcomm/FastSam-X/blob/main/FastSam-X.onnx.zip) |
## Installation
Install the package via pip:
```bash
pip install "qai-hub-models[fastsam-x]"
```
## Configure Qualcomm® AI Hub to run this model on a cloud-hosted device
Sign-in to [Qualcomm® AI Hub](https://app.aihub.qualcomm.com/) with your
Qualcomm® ID. Once signed in navigate to `Account -> Settings -> API Token`.
With this API token, you can configure your client to run models on the cloud
hosted devices.
```bash
qai-hub configure --api_token API_TOKEN
```
Navigate to [docs](https://app.aihub.qualcomm.com/docs/) for more information.
## Demo off target
The package contains a simple end-to-end demo that downloads pre-trained
weights and runs this model on a sample input.
```bash
python -m qai_hub_models.models.fastsam_x.demo
```
The above demo runs a reference implementation of pre-processing, model
inference, and post processing.
**NOTE**: If you want running in a Jupyter Notebook or Google Colab like
environment, please add the following to your cell (instead of the above).
```
%run -m qai_hub_models.models.fastsam_x.demo
```
### Run model on a cloud-hosted device
In addition to the demo, you can also run the model on a cloud-hosted Qualcomm®
device. This script does the following:
* Performance check on-device on a cloud-hosted device
* Downloads compiled assets that can be deployed on-device for Android.
* Accuracy check between PyTorch and on-device outputs.
```bash
python -m qai_hub_models.models.fastsam_x.export
```
## How does this work?
This [export script](https://aihub.qualcomm.com/models/fastsam_x/qai_hub_models/models/FastSam-X/export.py)
leverages [Qualcomm® AI Hub](https://aihub.qualcomm.com/) to optimize, validate, and deploy this model
on-device. Lets go through each step below in detail:
Step 1: **Compile model for on-device deployment**
To compile a PyTorch model for on-device deployment, we first trace the model
in memory using the `jit.trace` and then call the `submit_compile_job` API.
```python
import torch
import qai_hub as hub
from qai_hub_models.models.fastsam_x import Model
# Load the model
torch_model = Model.from_pretrained()
# Device
device = hub.Device("Samsung Galaxy S24")
# Trace model
input_shape = torch_model.get_input_spec()
sample_inputs = torch_model.sample_inputs()
pt_model = torch.jit.trace(torch_model, [torch.tensor(data[0]) for _, data in sample_inputs.items()])
# Compile model on a specific device
compile_job = hub.submit_compile_job(
model=pt_model,
device=device,
input_specs=torch_model.get_input_spec(),
)
# Get target model to run on-device
target_model = compile_job.get_target_model()
```
Step 2: **Performance profiling on cloud-hosted device**
After compiling models from step 1. Models can be profiled model on-device using the
`target_model`. Note that this scripts runs the model on a device automatically
provisioned in the cloud. Once the job is submitted, you can navigate to a
provided job URL to view a variety of on-device performance metrics.
```python
profile_job = hub.submit_profile_job(
model=target_model,
device=device,
)
```
Step 3: **Verify on-device accuracy**
To verify the accuracy of the model on-device, you can run on-device inference
on sample input data on the same cloud hosted device.
```python
input_data = torch_model.sample_inputs()
inference_job = hub.submit_inference_job(
model=target_model,
device=device,
inputs=input_data,
)
on_device_output = inference_job.download_output_data()
```
With the output of the model, you can compute like PSNR, relative errors or
spot check the output with expected output.
**Note**: This on-device profiling and inference requires access to Qualcomm®
AI Hub. [Sign up for access](https://myaccount.qualcomm.com/signup).
## Run demo on a cloud-hosted device
You can also run the demo on-device.
```bash
python -m qai_hub_models.models.fastsam_x.demo --eval-mode on-device
```
**NOTE**: If you want running in a Jupyter Notebook or Google Colab like
environment, please add the following to your cell (instead of the above).
```
%run -m qai_hub_models.models.fastsam_x.demo -- --eval-mode on-device
```
## Deploying compiled model to Android
The models can be deployed using multiple runtimes:
- TensorFlow Lite (`.tflite` export): [This
tutorial](https://www.tensorflow.org/lite/android/quickstart) provides a
guide to deploy the .tflite model in an Android application.
- QNN (`.so` export ): This [sample
app](https://docs.qualcomm.com/bundle/publicresource/topics/80-63442-50/sample_app.html)
provides instructions on how to use the `.so` shared library in an Android application.
## View on Qualcomm® AI Hub
Get more details on FastSam-X's performance across various devices [here](https://aihub.qualcomm.com/models/fastsam_x).
Explore all available models on [Qualcomm® AI Hub](https://aihub.qualcomm.com/)
## License
* The license for the original implementation of FastSam-X can be found
[here](https://github.com/CASIA-IVA-Lab/FastSAM/blob/main/LICENSE).
* The license for the compiled assets for on-device deployment can be found [here](https://github.com/CASIA-IVA-Lab/FastSAM/blob/main/LICENSE)
## References
* [Fast Segment Anything](https://arxiv.org/abs/2306.12156)
* [Source Model Implementation](https://github.com/CASIA-IVA-Lab/FastSAM)
## Community
* Join [our AI Hub Slack community](https://aihub.qualcomm.com/community/slack) to collaborate, post questions and learn more about on-device AI.
* For questions or feedback please [reach out to us](mailto:ai-hub-support@qti.qualcomm.com).
|
qualcomm/FastSam-S
|
qualcomm
| 2025-08-26T16:36:58Z | 34 | 4 |
pytorch
|
[
"pytorch",
"tflite",
"android",
"image-segmentation",
"arxiv:2306.12156",
"license:other",
"region:us"
] |
image-segmentation
| 2024-02-25T23:08:10Z |
---
library_name: pytorch
license: other
tags:
- android
pipeline_tag: image-segmentation
---

# FastSam-S: Optimized for Mobile Deployment
## Generate high quality segmentation mask on device
The Fast Segment Anything Model (FastSAM) is a novel, real-time CNN-based solution for the Segment Anything task. This task is designed to segment any object within an image based on various possible user interaction prompts. The model performs competitively despite significantly reduced computation, making it a practical choice for a variety of vision tasks.
This model is an implementation of FastSam-S found [here](https://github.com/CASIA-IVA-Lab/FastSAM).
This repository provides scripts to run FastSam-S on Qualcomm® devices.
More details on model performance across various devices, can be found
[here](https://aihub.qualcomm.com/models/fastsam_s).
### Model Details
- **Model Type:** Model_use_case.semantic_segmentation
- **Model Stats:**
- Model checkpoint: fastsam-s.pt
- Inference latency: RealTime
- Input resolution: 640x640
- Number of parameters: 11.8M
- Model size (float): 45.1 MB
| Model | Precision | Device | Chipset | Target Runtime | Inference Time (ms) | Peak Memory Range (MB) | Primary Compute Unit | Target Model
|---|---|---|---|---|---|---|---|---|
| FastSam-S | float | QCS8275 (Proxy) | Qualcomm® QCS8275 (Proxy) | TFLITE | 38.522 ms | 4 - 51 MB | NPU | [FastSam-S.tflite](https://huggingface.co/qualcomm/FastSam-S/blob/main/FastSam-S.tflite) |
| FastSam-S | float | QCS8275 (Proxy) | Qualcomm® QCS8275 (Proxy) | QNN_DLC | 38.035 ms | 4 - 73 MB | NPU | [FastSam-S.dlc](https://huggingface.co/qualcomm/FastSam-S/blob/main/FastSam-S.dlc) |
| FastSam-S | float | QCS8450 (Proxy) | Qualcomm® QCS8450 (Proxy) | TFLITE | 13.152 ms | 4 - 63 MB | NPU | [FastSam-S.tflite](https://huggingface.co/qualcomm/FastSam-S/blob/main/FastSam-S.tflite) |
| FastSam-S | float | QCS8450 (Proxy) | Qualcomm® QCS8450 (Proxy) | QNN_DLC | 15.812 ms | 5 - 45 MB | NPU | [FastSam-S.dlc](https://huggingface.co/qualcomm/FastSam-S/blob/main/FastSam-S.dlc) |
| FastSam-S | float | QCS8550 (Proxy) | Qualcomm® QCS8550 (Proxy) | TFLITE | 7.227 ms | 4 - 29 MB | NPU | [FastSam-S.tflite](https://huggingface.co/qualcomm/FastSam-S/blob/main/FastSam-S.tflite) |
| FastSam-S | float | QCS8550 (Proxy) | Qualcomm® QCS8550 (Proxy) | QNN_DLC | 7.036 ms | 5 - 25 MB | NPU | [FastSam-S.dlc](https://huggingface.co/qualcomm/FastSam-S/blob/main/FastSam-S.dlc) |
| FastSam-S | float | QCS9075 (Proxy) | Qualcomm® QCS9075 (Proxy) | TFLITE | 11.124 ms | 4 - 51 MB | NPU | [FastSam-S.tflite](https://huggingface.co/qualcomm/FastSam-S/blob/main/FastSam-S.tflite) |
| FastSam-S | float | QCS9075 (Proxy) | Qualcomm® QCS9075 (Proxy) | QNN_DLC | 10.801 ms | 0 - 80 MB | NPU | [FastSam-S.dlc](https://huggingface.co/qualcomm/FastSam-S/blob/main/FastSam-S.dlc) |
| FastSam-S | float | SA7255P ADP | Qualcomm® SA7255P | TFLITE | 38.522 ms | 4 - 51 MB | NPU | [FastSam-S.tflite](https://huggingface.co/qualcomm/FastSam-S/blob/main/FastSam-S.tflite) |
| FastSam-S | float | SA7255P ADP | Qualcomm® SA7255P | QNN_DLC | 38.035 ms | 4 - 73 MB | NPU | [FastSam-S.dlc](https://huggingface.co/qualcomm/FastSam-S/blob/main/FastSam-S.dlc) |
| FastSam-S | float | SA8255 (Proxy) | Qualcomm® SA8255P (Proxy) | TFLITE | 7.23 ms | 4 - 27 MB | NPU | [FastSam-S.tflite](https://huggingface.co/qualcomm/FastSam-S/blob/main/FastSam-S.tflite) |
| FastSam-S | float | SA8255 (Proxy) | Qualcomm® SA8255P (Proxy) | QNN_DLC | 6.979 ms | 5 - 24 MB | NPU | [FastSam-S.dlc](https://huggingface.co/qualcomm/FastSam-S/blob/main/FastSam-S.dlc) |
| FastSam-S | float | SA8295P ADP | Qualcomm® SA8295P | TFLITE | 14.672 ms | 4 - 50 MB | NPU | [FastSam-S.tflite](https://huggingface.co/qualcomm/FastSam-S/blob/main/FastSam-S.tflite) |
| FastSam-S | float | SA8295P ADP | Qualcomm® SA8295P | QNN_DLC | 13.526 ms | 5 - 47 MB | NPU | [FastSam-S.dlc](https://huggingface.co/qualcomm/FastSam-S/blob/main/FastSam-S.dlc) |
| FastSam-S | float | SA8650 (Proxy) | Qualcomm® SA8650P (Proxy) | TFLITE | 7.032 ms | 4 - 30 MB | NPU | [FastSam-S.tflite](https://huggingface.co/qualcomm/FastSam-S/blob/main/FastSam-S.tflite) |
| FastSam-S | float | SA8650 (Proxy) | Qualcomm® SA8650P (Proxy) | QNN_DLC | 7.031 ms | 5 - 27 MB | NPU | [FastSam-S.dlc](https://huggingface.co/qualcomm/FastSam-S/blob/main/FastSam-S.dlc) |
| FastSam-S | float | SA8775P ADP | Qualcomm® SA8775P | TFLITE | 11.124 ms | 4 - 51 MB | NPU | [FastSam-S.tflite](https://huggingface.co/qualcomm/FastSam-S/blob/main/FastSam-S.tflite) |
| FastSam-S | float | SA8775P ADP | Qualcomm® SA8775P | QNN_DLC | 10.801 ms | 0 - 80 MB | NPU | [FastSam-S.dlc](https://huggingface.co/qualcomm/FastSam-S/blob/main/FastSam-S.dlc) |
| FastSam-S | float | Samsung Galaxy S23 | Snapdragon® 8 Gen 2 Mobile | TFLITE | 7.253 ms | 4 - 27 MB | NPU | [FastSam-S.tflite](https://huggingface.co/qualcomm/FastSam-S/blob/main/FastSam-S.tflite) |
| FastSam-S | float | Samsung Galaxy S23 | Snapdragon® 8 Gen 2 Mobile | QNN_DLC | 7.016 ms | 5 - 27 MB | NPU | [FastSam-S.dlc](https://huggingface.co/qualcomm/FastSam-S/blob/main/FastSam-S.dlc) |
| FastSam-S | float | Samsung Galaxy S23 | Snapdragon® 8 Gen 2 Mobile | ONNX | 8.654 ms | 0 - 75 MB | NPU | [FastSam-S.onnx.zip](https://huggingface.co/qualcomm/FastSam-S/blob/main/FastSam-S.onnx.zip) |
| FastSam-S | float | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | TFLITE | 5.433 ms | 3 - 65 MB | NPU | [FastSam-S.tflite](https://huggingface.co/qualcomm/FastSam-S/blob/main/FastSam-S.tflite) |
| FastSam-S | float | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | QNN_DLC | 5.276 ms | 5 - 100 MB | NPU | [FastSam-S.dlc](https://huggingface.co/qualcomm/FastSam-S/blob/main/FastSam-S.dlc) |
| FastSam-S | float | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | ONNX | 6.621 ms | 16 - 106 MB | NPU | [FastSam-S.onnx.zip](https://huggingface.co/qualcomm/FastSam-S/blob/main/FastSam-S.onnx.zip) |
| FastSam-S | float | Snapdragon 8 Elite QRD | Snapdragon® 8 Elite Mobile | TFLITE | 4.869 ms | 0 - 52 MB | NPU | [FastSam-S.tflite](https://huggingface.co/qualcomm/FastSam-S/blob/main/FastSam-S.tflite) |
| FastSam-S | float | Snapdragon 8 Elite QRD | Snapdragon® 8 Elite Mobile | QNN_DLC | 4.649 ms | 5 - 81 MB | NPU | [FastSam-S.dlc](https://huggingface.co/qualcomm/FastSam-S/blob/main/FastSam-S.dlc) |
| FastSam-S | float | Snapdragon 8 Elite QRD | Snapdragon® 8 Elite Mobile | ONNX | 5.736 ms | 15 - 95 MB | NPU | [FastSam-S.onnx.zip](https://huggingface.co/qualcomm/FastSam-S/blob/main/FastSam-S.onnx.zip) |
| FastSam-S | float | Snapdragon X Elite CRD | Snapdragon® X Elite | QNN_DLC | 7.548 ms | 5 - 5 MB | NPU | [FastSam-S.dlc](https://huggingface.co/qualcomm/FastSam-S/blob/main/FastSam-S.dlc) |
| FastSam-S | float | Snapdragon X Elite CRD | Snapdragon® X Elite | ONNX | 9.235 ms | 20 - 20 MB | NPU | [FastSam-S.onnx.zip](https://huggingface.co/qualcomm/FastSam-S/blob/main/FastSam-S.onnx.zip) |
## Installation
Install the package via pip:
```bash
pip install "qai-hub-models[fastsam-s]"
```
## Configure Qualcomm® AI Hub to run this model on a cloud-hosted device
Sign-in to [Qualcomm® AI Hub](https://app.aihub.qualcomm.com/) with your
Qualcomm® ID. Once signed in navigate to `Account -> Settings -> API Token`.
With this API token, you can configure your client to run models on the cloud
hosted devices.
```bash
qai-hub configure --api_token API_TOKEN
```
Navigate to [docs](https://app.aihub.qualcomm.com/docs/) for more information.
## Demo off target
The package contains a simple end-to-end demo that downloads pre-trained
weights and runs this model on a sample input.
```bash
python -m qai_hub_models.models.fastsam_s.demo
```
The above demo runs a reference implementation of pre-processing, model
inference, and post processing.
**NOTE**: If you want running in a Jupyter Notebook or Google Colab like
environment, please add the following to your cell (instead of the above).
```
%run -m qai_hub_models.models.fastsam_s.demo
```
### Run model on a cloud-hosted device
In addition to the demo, you can also run the model on a cloud-hosted Qualcomm®
device. This script does the following:
* Performance check on-device on a cloud-hosted device
* Downloads compiled assets that can be deployed on-device for Android.
* Accuracy check between PyTorch and on-device outputs.
```bash
python -m qai_hub_models.models.fastsam_s.export
```
## How does this work?
This [export script](https://aihub.qualcomm.com/models/fastsam_s/qai_hub_models/models/FastSam-S/export.py)
leverages [Qualcomm® AI Hub](https://aihub.qualcomm.com/) to optimize, validate, and deploy this model
on-device. Lets go through each step below in detail:
Step 1: **Compile model for on-device deployment**
To compile a PyTorch model for on-device deployment, we first trace the model
in memory using the `jit.trace` and then call the `submit_compile_job` API.
```python
import torch
import qai_hub as hub
from qai_hub_models.models.fastsam_s import Model
# Load the model
torch_model = Model.from_pretrained()
# Device
device = hub.Device("Samsung Galaxy S24")
# Trace model
input_shape = torch_model.get_input_spec()
sample_inputs = torch_model.sample_inputs()
pt_model = torch.jit.trace(torch_model, [torch.tensor(data[0]) for _, data in sample_inputs.items()])
# Compile model on a specific device
compile_job = hub.submit_compile_job(
model=pt_model,
device=device,
input_specs=torch_model.get_input_spec(),
)
# Get target model to run on-device
target_model = compile_job.get_target_model()
```
Step 2: **Performance profiling on cloud-hosted device**
After compiling models from step 1. Models can be profiled model on-device using the
`target_model`. Note that this scripts runs the model on a device automatically
provisioned in the cloud. Once the job is submitted, you can navigate to a
provided job URL to view a variety of on-device performance metrics.
```python
profile_job = hub.submit_profile_job(
model=target_model,
device=device,
)
```
Step 3: **Verify on-device accuracy**
To verify the accuracy of the model on-device, you can run on-device inference
on sample input data on the same cloud hosted device.
```python
input_data = torch_model.sample_inputs()
inference_job = hub.submit_inference_job(
model=target_model,
device=device,
inputs=input_data,
)
on_device_output = inference_job.download_output_data()
```
With the output of the model, you can compute like PSNR, relative errors or
spot check the output with expected output.
**Note**: This on-device profiling and inference requires access to Qualcomm®
AI Hub. [Sign up for access](https://myaccount.qualcomm.com/signup).
## Run demo on a cloud-hosted device
You can also run the demo on-device.
```bash
python -m qai_hub_models.models.fastsam_s.demo --eval-mode on-device
```
**NOTE**: If you want running in a Jupyter Notebook or Google Colab like
environment, please add the following to your cell (instead of the above).
```
%run -m qai_hub_models.models.fastsam_s.demo -- --eval-mode on-device
```
## Deploying compiled model to Android
The models can be deployed using multiple runtimes:
- TensorFlow Lite (`.tflite` export): [This
tutorial](https://www.tensorflow.org/lite/android/quickstart) provides a
guide to deploy the .tflite model in an Android application.
- QNN (`.so` export ): This [sample
app](https://docs.qualcomm.com/bundle/publicresource/topics/80-63442-50/sample_app.html)
provides instructions on how to use the `.so` shared library in an Android application.
## View on Qualcomm® AI Hub
Get more details on FastSam-S's performance across various devices [here](https://aihub.qualcomm.com/models/fastsam_s).
Explore all available models on [Qualcomm® AI Hub](https://aihub.qualcomm.com/)
## License
* The license for the original implementation of FastSam-S can be found
[here](https://github.com/CASIA-IVA-Lab/FastSAM/blob/main/LICENSE).
* The license for the compiled assets for on-device deployment can be found [here](https://github.com/CASIA-IVA-Lab/FastSAM/blob/main/LICENSE)
## References
* [Fast Segment Anything](https://arxiv.org/abs/2306.12156)
* [Source Model Implementation](https://github.com/CASIA-IVA-Lab/FastSAM)
## Community
* Join [our AI Hub Slack community](https://aihub.qualcomm.com/community/slack) to collaborate, post questions and learn more about on-device AI.
* For questions or feedback please [reach out to us](mailto:ai-hub-support@qti.qualcomm.com).
|
alok0777/blockassist-bc-masked_pensive_lemur_1756226054
|
alok0777
| 2025-08-26T16:36:36Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"masked pensive lemur",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-26T16:35:19Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- masked pensive lemur
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
BSC-LT/hubert-base-ca-2k
|
BSC-LT
| 2025-08-26T16:36:03Z | 8 | 0 | null |
[
"pytorch",
"hubert",
"catalan",
"audio",
"speech",
"projecte-aina",
"barcelona-supercomputing-center",
"bsc",
"ca",
"dataset:projecte-aina/3catparla_asr",
"dataset:mozilla-foundation/common_voice_17_0",
"dataset:projecte-aina/corts_valencianes_asr_a",
"dataset:projecte-aina/parlament_parla_v3_asr",
"dataset:projecte-aina/ib3_ca_asr",
"dataset:softcatala/catalan-youtube-speech",
"dataset:projecte-aina/annotated_catalan_common_voice_v17",
"base_model:facebook/hubert-base-ls960",
"base_model:finetune:facebook/hubert-base-ls960",
"license:apache-2.0",
"region:us"
] | null | 2025-05-08T15:58:54Z |
---
language: ca
datasets:
- projecte-aina/3catparla_asr
- mozilla-foundation/common_voice_17_0
- projecte-aina/corts_valencianes_asr_a
- projecte-aina/parlament_parla_v3_asr
- projecte-aina/ib3_ca_asr
- softcatala/catalan-youtube-speech
- projecte-aina/annotated_catalan_common_voice_v17
tags:
- hubert
- catalan
- audio
- speech
- projecte-aina
- barcelona-supercomputing-center
- bsc
license: apache-2.0
base_model:
- facebook/hubert-base-ls960
metrics:
- wer
- f1
---
# Table of Contents
<details>
<summary>Click to expand</summary>
- [Model Description](#model-description)
- [Intended Uses and Limitations](#intended-uses-and-limitations)
- [Pre-training Details](#pre-training-details)
- [Indirect evaluation results](#indirect-evaluation-results)
- [How to use the model](#how-to-use-the-model)
- [Citation](#citation)
- [Additional Information](#additional-information)
</details>
# Model Description
This is a HuBERT Base model pre-trained using 1,778 hours of Catalan speech data.
The model architecture is the same as the [original HuBERT Base model](https://huggingface.co/facebook/hubert-base-ls960), which contains 12 transformer layers.
Pre-training was done by [Barcelona Supercomputing Center](https://bsc.es/).
# Intended Uses and Limitations
This pre-trained model generates Speech Representations that can be used for any Catalan speech-related task.
This model does not have a tokenizer as it was pretrained on audio alone.
In order to use this model for Automatic Speech Recognition, a tokenizer should be created and the model should be fine-tuned on labeled text data.
Check out [this blog](https://huggingface.co/blog/fine-tune-wav2vec2-english) for more in-detail explanation of how to fine-tune the model for Speech Recognition.
For an explanation of how to fine-tune the model for Audio Classification, check out [this tutorial](https://huggingface.co/docs/transformers/main/en/tasks/audio_classification).
# Pre-training Details
This model was pre-trained using code from the [official repository](https://github.com/facebookresearch/fairseq/tree/main/examples/hubert), and the detailed training configuration can be found in the same repository and the [original paper](https://ieeexplore.ieee.org/document/9585401).
For pre-training, a 1,778 hours dataset was created using subsets from training splits from the following datasets:
- [3CatParla (500 hours)](https://huggingface.co/datasets/projecte-aina/3catparla_asr) (This dataset is private and is planned to be published as public soon).
- [commonvoice 17 (250 hours)](https://huggingface.co/datasets/mozilla-foundation/common_voice_17_0)
- [corts_valencianes (250 hours)](https://huggingface.co/datasets/projecte-aina/corts_valencianes_asr_a) (Only the anonymized version of the dataset is public. We trained the model with the non-anonymized version.)
- [parlament_parla_v3 (250 hours)](https://huggingface.co/datasets/projecte-aina/parlament_parla_v3_asr)
- [IB3 (28 hours)](https://huggingface.co/datasets/projecte-aina/ib3_ca_asr)
- [Catalan YouTube Speech (500 hours)](https://huggingface.co/datasets/softcatala/catalan-youtube-speech)
# Indirect evaluation results
To assess the pre-trained Catalan Speech Representations' quality, we evaluated them using two indirect tasks: Catalan Automatic Speech Recognition (ASR) and Catalan Accent Classification.
## Catalan Automatic Speech Recognition
We created train and validation ASR-labelled datasets using a 100 hours subsample from the pre-training dataset split.
For testing, we created a test split concatenating all the test splits from:
- [3CatParla (4.5 hours)](https://huggingface.co/datasets/projecte-aina/3catparla_asr).
- [commonvoice 17 (28 hours)](https://huggingface.co/datasets/mozilla-foundation/common_voice_17_0)
- [corts_valencianes (6 hours)](https://huggingface.co/datasets/projecte-aina/corts_valencianes_asr_a) (Only the anonymized version of the dataset is public. We trained the model with the non-anonymized version.)
- [parlament_parla_v3 (27 hours)](https://huggingface.co/datasets/projecte-aina/parlament_parla_v3_asr)
We fine-tuned on this ASR-labelled 100 hours training split the following models:
- Catalan pre-trained HuBERT: [BSC-LT/hubert-base-ca-2k](https://huggingface.co/BSC-LT/hubert-base-ca-2k) (our model)
- English pre-trained HuBERT: [facebook/hubert-base-ls960](https://huggingface.co/facebook/hubert-base-ls960)
- Multi-lingual pre-trained HuBERT: [utter-project/mHuBERT-147](https://huggingface.co/utter-project/mHuBERT-147)
- Multi-lingual pre-trained wav2vec2: [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53)
All of these models were pre-trained using exactly the same configurations.
We trained them for 20 epochs, except wav2vec2-large-xlsr-53, that was trained for 10 epochs (to make it comparable to the others, because it takes double of time to train).
For the fine-tuning process, we froze models' parameters using the freeze_feature_encoder() method.
hubert-base-ca-2k, hubert-base-ls960 and mHuBERT-147 have 94M parameters, 95% of them were fine-tuned. wav2vec2-large-xlsr-53 has 311M parameters, 98% of them were fine-tuned.
The results were the following:
| Model | Train WER | Validation WER | Test WER ↑ |
|------------------------|--------|-------|-------|
| **hubert-base-ca-2k** | 5.1% | 9.6% | 12.1% |
| mHuBERT-147 | 9.4% | 14.7% | 18.1% |
| wav2vec2-large-xlsr-53 | 10.4% | 12.6% | 21.3% |
| hubert-base-ls960 | 15.8% | 21.8% | 26.5% |
## Catalan Accent Classification
We created train, validation and test Catalan Accent Classification-labelled datasets using a 800 minutes (13 hours) subsample from the [projecte-aina/annotated_catalan_common_voice_v17](https://huggingface.co/datasets/projecte-aina/annotated_catalan_common_voice_v17) dataset.
For each partition and accent, there is an important imbalance in the number of speakers and in the amount of hours available.
We created new (smaller) splits assuring that:
- Every accent has the same amount of speakers
- Every speaker has at most 10 sentences (to avoid super-present speakers).
As a result of that, we obtained balanced train (730 minutes), validation (30 minutes) and test (37 minutes) splits.
We used the field “assigned_accent” as target label.
This label can take the following values: "central", "northern", "northwestern", "valencian" or "balearic".
We fine-tuned on this Catalan Accent Classification-labelled 800 minutes training split the following models:
- Catalan pre-trained HuBERT: [BSC-LT/hubert-base-ca-2k](https://huggingface.co/BSC-LT/hubert-base-ca-2k) (our model)
- English pre-trained HuBERT: [facebook/hubert-base-ls960](https://huggingface.co/facebook/hubert-base-ls960)
- Multi-lingual pre-trained HuBERT: [utter-project/mHuBERT-147](https://huggingface.co/utter-project/mHuBERT-147)
- Multi-lingual pre-trained wav2vec2: [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53)
All of these models were pre-trained using exactly the same configurations.
We trained them for 10 epochs, except wav2vec2-large-xlsr-53, that was trained for 5 epochs (to make it comparable to the others, because it takes double of time to train).
For the fine-tuning process, we froze models' parameters using the freeze_base_model() method.
hubert-base-ca-2k, hubert-base-ls960 and mHuBERT-147 have 94M parameters, 0.2% of them were fine-tuned. wav2vec2-large-xlsr-53 has 311M parameters, 0.1% of them were fine-tuned.
The results were the following:
| Model | Train f1-macro | Validation f1-macro | Test f1-macro ↓ |
|------------------------|--------|-------|-------|
| hubert-base-ca-2k | 58.3% | 55.3% | 56.5% |
| mHuBERT-147 | 40.7% | 36.6% | 34.0% |
| hubert-base-ls960 | 40.6% | 34.2% | 33.6% |
| wav2vec2-large-xlsr-53 | 6.7% | 6.6% | 6.7% |
# How to use the model
## Speech Representations
To obtain Speech Representations (HuBERT outputs) from audio in Catalan using this model, you can follow this example:
(Using fsspec==2025.3.0, datasets==3.6.0 and transformers==4.52.2 is recomended).
```python
from datasets import load_dataset, Audio
import torch
from transformers import AutoFeatureExtractor, AutoModel
#Load the dataset
dataset = load_dataset("projecte-aina/ib3_ca_asr", split='train[:1%]', trust_remote_code=True)
#Downsample to 16kHz
dataset = dataset.cast_column("audio", Audio(sampling_rate=16_000))
# Hugginface pre-trained model path
MODEL_NAME = "BSC-LT/hubert-base-ca-2k"
# Set device
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"Using {device} device.")
# Load feature extractor
feature_extractor = AutoFeatureExtractor.from_pretrained(MODEL_NAME)
# Load model
model = AutoModel.from_pretrained(MODEL_NAME)
model = model.to(device)
def map_to_speech_representations(batch):
#Process the dataset
audio = batch["audio"]
input_features = feature_extractor(audio["array"], sampling_rate=audio["sampling_rate"], return_tensors="pt").input_values
input_features = input_features.to(device)
# Extract HuBERT's Speech Representations
with torch.no_grad():
outputs = model(
input_features,
output_hidden_states = True,
)
speech_representations = outputs.last_hidden_state
hidden_states = outputs.hidden_states
batch["speech_representations"] = speech_representations
batch["hidden_states"] = hidden_states
return batch
dataset = dataset.map(map_to_speech_representations)
print(dataset)
```
## Discrete Speech Representations
Important remark: the k-means model available in this repo and used for extracting Discrete Speech Representations was trained using HuBERT's 6th layer.
To obtain Discrete Speech Representations (HuBERT's k-means centroids) from audio in Catalan using this model, you can follow this example:
(Using fsspec==2025.3.0, datasets==3.6.0 and transformers==4.52.2 is recomended).
```python
from datasets import load_dataset, Audio
import torch
from transformers import AutoFeatureExtractor, AutoModel
import joblib
import numpy as np
from huggingface_hub import hf_hub_download
#Load the dataset
dataset = load_dataset("projecte-aina/ib3_ca_asr", split='train[:1%]', trust_remote_code=True)
#Downsample to 16kHz
dataset = dataset.cast_column("audio", Audio(sampling_rate=16_000))
# Hugginface pre-trained model path
MODEL_NAME = "BSC-LT/hubert-base-ca-2k"
# Set device
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"Using {device} device.")
# Load feature extractor
feature_extractor = AutoFeatureExtractor.from_pretrained(MODEL_NAME)
# Load model
model = AutoModel.from_pretrained(MODEL_NAME)
model = model.to(device)
# Load k-means
km_path = hf_hub_download(repo_id="BSC-LT/hubert-base-ca-2k", filename="k_means.km")
km_model = joblib.load(km_path)
clusters = km_model.cluster_centers_
def map_to_discrete_units(batch):
#Process the dataset
audio = batch["audio"]
input_features = feature_extractor(audio["array"], sampling_rate=audio["sampling_rate"], return_tensors="pt").input_values
input_features = input_features.to(device)
with torch.no_grad():
outputs = model(
input_features,
output_hidden_states = True,
)
# Extract HuBERT's Speech Representations
hidden_states = outputs.hidden_states
# Extract 6-th layer features
k_means_input = hidden_states[5].squeeze()
k_means_input = k_means_input.cpu()
k_means_input = np.array(k_means_input, dtype='f')
labels = km_model.predict(k_means_input)
batch["discrete_units"] = clusters[labels]
return batch
dataset = dataset.map(map_to_discrete_units)
print(dataset)
```
## Automatic Speech Recognition
In order to use this model for Speech Recognition, a tokenizer should be created and the model should be fine-tuned on labeled text data.
Check out [this blog](https://huggingface.co/blog/fine-tune-wav2vec2-english) for more in-detail explanation of how to fine-tune the model for Speech Recognition.
## Audio Classification
For an explanation of how to fine-tune the model for Audio Classification, check out [this tutorial](https://huggingface.co/docs/transformers/main/en/tasks/audio_classification).
# Citation
If this model contributes to your research, please cite the work:
```bibtext
@misc{costa2025hubertbaseca2k,
title={CaHuBERT: the first full Catalan pre-trained HuBERT.},
author={Costa, Federico; Messaoudi, Abir; Peiró-Lilja, Alex; Casals-Salvador, Marc; España-Bonet, Cristina},
organization={Barcelona Supercomputing Center},
url={https://huggingface.co/BSC-LT/hubert-base-ca-2k},
year={2025}
}
```
# Additional Information
### Author
The pre-training process was performed during 2025, in the [Language Technologies Unit](https://huggingface.co/BSC-LT) of the [Barcelona Supercomputing Center](https://www.bsc.es/).
### Contact
For further information, please send an email to <langtech@bsc.es>.
### Copyright
Copyright(c) 2025 by Language Technologies Unit, Barcelona Supercomputing Center.
### License
[Apache-2.0](https://www.apache.org/licenses/LICENSE-2.0)
### Funding
This work has been promoted and financed by the Generalitat de Catalunya through the [Aina project](https://projecteaina.cat/).
The training of the model was possible thanks to the computing time provided by [Barcelona Supercomputing Center](https://www.bsc.es/) through MareNostrum 5.
We acknowledge EuroHPC Joint Undertaking for awarding us access to MareNostrum5 as BSC, Spain.
### Disclaimer
<details>
<summary>Click to expand</summary>
The model published in this repository is intended for a generalist purpose and is available to third parties under a permissive Apache License, Version 2.0.
Be aware that the model may have biases and/or any other undesirable distortions.
When third parties deploy or provide systems and/or services to other parties using this model (or any system based on it)
or become users of the model, they should note that it is their responsibility to mitigate the risks arising from its use and,
in any event, to comply with applicable regulations, including regulations regarding the use of Artificial Intelligence.
In no event shall the owner and creator of the model (Barcelona Supercomputing Center)
be liable for any results arising from the use made by third parties.
</details>
|
qualcomm/Facial-Attribute-Detection
|
qualcomm
| 2025-08-26T16:36:00Z | 332 | 3 |
pytorch
|
[
"pytorch",
"tflite",
"real_time",
"android",
"object-detection",
"license:other",
"region:us"
] |
object-detection
| 2024-12-12T23:01:20Z |
---
library_name: pytorch
license: other
tags:
- real_time
- android
pipeline_tag: object-detection
---

# Facial-Attribute-Detection: Optimized for Mobile Deployment
## Comprehensive facial analysis by extracting face features
Detects attributes (liveness, eye closeness, mask presence, glasses presence, sunglasses presence) that apply to a given face. This model's architecture was developed by Qualcomm. The model was trained by Qualcomm on a proprietary dataset of faces, but can be used on any image.
This repository provides scripts to run Facial-Attribute-Detection on Qualcomm® devices.
More details on model performance across various devices, can be found
[here](https://aihub.qualcomm.com/models/face_attrib_net).
### Model Details
- **Model Type:** Model_use_case.object_detection
- **Model Stats:**
- Model checkpoint: multitask_FR_state_dict.pt
- Input resolution: 128x128
- Number of parameters: 12.1M
- Model size (float): 46.3 MB
- Model size (w8a8): 12.3 MB
| Model | Precision | Device | Chipset | Target Runtime | Inference Time (ms) | Peak Memory Range (MB) | Primary Compute Unit | Target Model
|---|---|---|---|---|---|---|---|---|
| Facial-Attribute-Detection | float | QCS8275 (Proxy) | Qualcomm® QCS8275 (Proxy) | TFLITE | 4.383 ms | 0 - 39 MB | NPU | [Facial-Attribute-Detection.tflite](https://huggingface.co/qualcomm/Facial-Attribute-Detection/blob/main/Facial-Attribute-Detection.tflite) |
| Facial-Attribute-Detection | float | QCS8275 (Proxy) | Qualcomm® QCS8275 (Proxy) | QNN_DLC | 4.385 ms | 0 - 25 MB | NPU | [Facial-Attribute-Detection.dlc](https://huggingface.co/qualcomm/Facial-Attribute-Detection/blob/main/Facial-Attribute-Detection.dlc) |
| Facial-Attribute-Detection | float | QCS8450 (Proxy) | Qualcomm® QCS8450 (Proxy) | TFLITE | 1.195 ms | 0 - 49 MB | NPU | [Facial-Attribute-Detection.tflite](https://huggingface.co/qualcomm/Facial-Attribute-Detection/blob/main/Facial-Attribute-Detection.tflite) |
| Facial-Attribute-Detection | float | QCS8450 (Proxy) | Qualcomm® QCS8450 (Proxy) | QNN_DLC | 1.415 ms | 0 - 34 MB | NPU | [Facial-Attribute-Detection.dlc](https://huggingface.co/qualcomm/Facial-Attribute-Detection/blob/main/Facial-Attribute-Detection.dlc) |
| Facial-Attribute-Detection | float | QCS8550 (Proxy) | Qualcomm® QCS8550 (Proxy) | TFLITE | 0.873 ms | 0 - 134 MB | NPU | [Facial-Attribute-Detection.tflite](https://huggingface.co/qualcomm/Facial-Attribute-Detection/blob/main/Facial-Attribute-Detection.tflite) |
| Facial-Attribute-Detection | float | QCS8550 (Proxy) | Qualcomm® QCS8550 (Proxy) | QNN_DLC | 0.927 ms | 0 - 10 MB | NPU | [Facial-Attribute-Detection.dlc](https://huggingface.co/qualcomm/Facial-Attribute-Detection/blob/main/Facial-Attribute-Detection.dlc) |
| Facial-Attribute-Detection | float | QCS9075 (Proxy) | Qualcomm® QCS9075 (Proxy) | TFLITE | 1.394 ms | 0 - 39 MB | NPU | [Facial-Attribute-Detection.tflite](https://huggingface.co/qualcomm/Facial-Attribute-Detection/blob/main/Facial-Attribute-Detection.tflite) |
| Facial-Attribute-Detection | float | QCS9075 (Proxy) | Qualcomm® QCS9075 (Proxy) | QNN_DLC | 1.479 ms | 0 - 25 MB | NPU | [Facial-Attribute-Detection.dlc](https://huggingface.co/qualcomm/Facial-Attribute-Detection/blob/main/Facial-Attribute-Detection.dlc) |
| Facial-Attribute-Detection | float | SA7255P ADP | Qualcomm® SA7255P | TFLITE | 4.383 ms | 0 - 39 MB | NPU | [Facial-Attribute-Detection.tflite](https://huggingface.co/qualcomm/Facial-Attribute-Detection/blob/main/Facial-Attribute-Detection.tflite) |
| Facial-Attribute-Detection | float | SA7255P ADP | Qualcomm® SA7255P | QNN_DLC | 4.385 ms | 0 - 25 MB | NPU | [Facial-Attribute-Detection.dlc](https://huggingface.co/qualcomm/Facial-Attribute-Detection/blob/main/Facial-Attribute-Detection.dlc) |
| Facial-Attribute-Detection | float | SA8255 (Proxy) | Qualcomm® SA8255P (Proxy) | TFLITE | 0.88 ms | 0 - 134 MB | NPU | [Facial-Attribute-Detection.tflite](https://huggingface.co/qualcomm/Facial-Attribute-Detection/blob/main/Facial-Attribute-Detection.tflite) |
| Facial-Attribute-Detection | float | SA8255 (Proxy) | Qualcomm® SA8255P (Proxy) | QNN_DLC | 0.919 ms | 0 - 19 MB | NPU | [Facial-Attribute-Detection.dlc](https://huggingface.co/qualcomm/Facial-Attribute-Detection/blob/main/Facial-Attribute-Detection.dlc) |
| Facial-Attribute-Detection | float | SA8295P ADP | Qualcomm® SA8295P | TFLITE | 1.533 ms | 0 - 44 MB | NPU | [Facial-Attribute-Detection.tflite](https://huggingface.co/qualcomm/Facial-Attribute-Detection/blob/main/Facial-Attribute-Detection.tflite) |
| Facial-Attribute-Detection | float | SA8295P ADP | Qualcomm® SA8295P | QNN_DLC | 1.611 ms | 0 - 30 MB | NPU | [Facial-Attribute-Detection.dlc](https://huggingface.co/qualcomm/Facial-Attribute-Detection/blob/main/Facial-Attribute-Detection.dlc) |
| Facial-Attribute-Detection | float | SA8650 (Proxy) | Qualcomm® SA8650P (Proxy) | TFLITE | 0.882 ms | 0 - 148 MB | NPU | [Facial-Attribute-Detection.tflite](https://huggingface.co/qualcomm/Facial-Attribute-Detection/blob/main/Facial-Attribute-Detection.tflite) |
| Facial-Attribute-Detection | float | SA8650 (Proxy) | Qualcomm® SA8650P (Proxy) | QNN_DLC | 0.918 ms | 0 - 19 MB | NPU | [Facial-Attribute-Detection.dlc](https://huggingface.co/qualcomm/Facial-Attribute-Detection/blob/main/Facial-Attribute-Detection.dlc) |
| Facial-Attribute-Detection | float | SA8775P ADP | Qualcomm® SA8775P | TFLITE | 1.394 ms | 0 - 39 MB | NPU | [Facial-Attribute-Detection.tflite](https://huggingface.co/qualcomm/Facial-Attribute-Detection/blob/main/Facial-Attribute-Detection.tflite) |
| Facial-Attribute-Detection | float | SA8775P ADP | Qualcomm® SA8775P | QNN_DLC | 1.479 ms | 0 - 25 MB | NPU | [Facial-Attribute-Detection.dlc](https://huggingface.co/qualcomm/Facial-Attribute-Detection/blob/main/Facial-Attribute-Detection.dlc) |
| Facial-Attribute-Detection | float | Samsung Galaxy S23 | Snapdragon® 8 Gen 2 Mobile | TFLITE | 0.887 ms | 0 - 138 MB | NPU | [Facial-Attribute-Detection.tflite](https://huggingface.co/qualcomm/Facial-Attribute-Detection/blob/main/Facial-Attribute-Detection.tflite) |
| Facial-Attribute-Detection | float | Samsung Galaxy S23 | Snapdragon® 8 Gen 2 Mobile | QNN_DLC | 0.92 ms | 0 - 39 MB | NPU | [Facial-Attribute-Detection.dlc](https://huggingface.co/qualcomm/Facial-Attribute-Detection/blob/main/Facial-Attribute-Detection.dlc) |
| Facial-Attribute-Detection | float | Samsung Galaxy S23 | Snapdragon® 8 Gen 2 Mobile | ONNX | 1.058 ms | 0 - 74 MB | NPU | [Facial-Attribute-Detection.onnx.zip](https://huggingface.co/qualcomm/Facial-Attribute-Detection/blob/main/Facial-Attribute-Detection.onnx.zip) |
| Facial-Attribute-Detection | float | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | TFLITE | 0.677 ms | 0 - 48 MB | NPU | [Facial-Attribute-Detection.tflite](https://huggingface.co/qualcomm/Facial-Attribute-Detection/blob/main/Facial-Attribute-Detection.tflite) |
| Facial-Attribute-Detection | float | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | QNN_DLC | 0.696 ms | 0 - 32 MB | NPU | [Facial-Attribute-Detection.dlc](https://huggingface.co/qualcomm/Facial-Attribute-Detection/blob/main/Facial-Attribute-Detection.dlc) |
| Facial-Attribute-Detection | float | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | ONNX | 0.832 ms | 0 - 36 MB | NPU | [Facial-Attribute-Detection.onnx.zip](https://huggingface.co/qualcomm/Facial-Attribute-Detection/blob/main/Facial-Attribute-Detection.onnx.zip) |
| Facial-Attribute-Detection | float | Snapdragon 8 Elite QRD | Snapdragon® 8 Elite Mobile | TFLITE | 0.625 ms | 0 - 44 MB | NPU | [Facial-Attribute-Detection.tflite](https://huggingface.co/qualcomm/Facial-Attribute-Detection/blob/main/Facial-Attribute-Detection.tflite) |
| Facial-Attribute-Detection | float | Snapdragon 8 Elite QRD | Snapdragon® 8 Elite Mobile | QNN_DLC | 0.63 ms | 0 - 31 MB | NPU | [Facial-Attribute-Detection.dlc](https://huggingface.co/qualcomm/Facial-Attribute-Detection/blob/main/Facial-Attribute-Detection.dlc) |
| Facial-Attribute-Detection | float | Snapdragon 8 Elite QRD | Snapdragon® 8 Elite Mobile | ONNX | 0.702 ms | 0 - 26 MB | NPU | [Facial-Attribute-Detection.onnx.zip](https://huggingface.co/qualcomm/Facial-Attribute-Detection/blob/main/Facial-Attribute-Detection.onnx.zip) |
| Facial-Attribute-Detection | float | Snapdragon X Elite CRD | Snapdragon® X Elite | QNN_DLC | 1.043 ms | 82 - 82 MB | NPU | [Facial-Attribute-Detection.dlc](https://huggingface.co/qualcomm/Facial-Attribute-Detection/blob/main/Facial-Attribute-Detection.dlc) |
| Facial-Attribute-Detection | float | Snapdragon X Elite CRD | Snapdragon® X Elite | ONNX | 1.069 ms | 25 - 25 MB | NPU | [Facial-Attribute-Detection.onnx.zip](https://huggingface.co/qualcomm/Facial-Attribute-Detection/blob/main/Facial-Attribute-Detection.onnx.zip) |
| Facial-Attribute-Detection | w8a8 | QCS8275 (Proxy) | Qualcomm® QCS8275 (Proxy) | TFLITE | 1.194 ms | 0 - 35 MB | NPU | [Facial-Attribute-Detection.tflite](https://huggingface.co/qualcomm/Facial-Attribute-Detection/blob/main/Facial-Attribute-Detection_w8a8.tflite) |
| Facial-Attribute-Detection | w8a8 | QCS8275 (Proxy) | Qualcomm® QCS8275 (Proxy) | QNN_DLC | 1.129 ms | 0 - 36 MB | NPU | [Facial-Attribute-Detection.dlc](https://huggingface.co/qualcomm/Facial-Attribute-Detection/blob/main/Facial-Attribute-Detection_w8a8.dlc) |
| Facial-Attribute-Detection | w8a8 | QCS8450 (Proxy) | Qualcomm® QCS8450 (Proxy) | TFLITE | 0.553 ms | 0 - 54 MB | NPU | [Facial-Attribute-Detection.tflite](https://huggingface.co/qualcomm/Facial-Attribute-Detection/blob/main/Facial-Attribute-Detection_w8a8.tflite) |
| Facial-Attribute-Detection | w8a8 | QCS8450 (Proxy) | Qualcomm® QCS8450 (Proxy) | QNN_DLC | 0.657 ms | 0 - 47 MB | NPU | [Facial-Attribute-Detection.dlc](https://huggingface.co/qualcomm/Facial-Attribute-Detection/blob/main/Facial-Attribute-Detection_w8a8.dlc) |
| Facial-Attribute-Detection | w8a8 | QCS8550 (Proxy) | Qualcomm® QCS8550 (Proxy) | TFLITE | 0.415 ms | 0 - 64 MB | NPU | [Facial-Attribute-Detection.tflite](https://huggingface.co/qualcomm/Facial-Attribute-Detection/blob/main/Facial-Attribute-Detection_w8a8.tflite) |
| Facial-Attribute-Detection | w8a8 | QCS8550 (Proxy) | Qualcomm® QCS8550 (Proxy) | QNN_DLC | 0.407 ms | 0 - 63 MB | NPU | [Facial-Attribute-Detection.dlc](https://huggingface.co/qualcomm/Facial-Attribute-Detection/blob/main/Facial-Attribute-Detection_w8a8.dlc) |
| Facial-Attribute-Detection | w8a8 | QCS9075 (Proxy) | Qualcomm® QCS9075 (Proxy) | TFLITE | 0.651 ms | 0 - 35 MB | NPU | [Facial-Attribute-Detection.tflite](https://huggingface.co/qualcomm/Facial-Attribute-Detection/blob/main/Facial-Attribute-Detection_w8a8.tflite) |
| Facial-Attribute-Detection | w8a8 | QCS9075 (Proxy) | Qualcomm® QCS9075 (Proxy) | QNN_DLC | 0.628 ms | 0 - 36 MB | NPU | [Facial-Attribute-Detection.dlc](https://huggingface.co/qualcomm/Facial-Attribute-Detection/blob/main/Facial-Attribute-Detection_w8a8.dlc) |
| Facial-Attribute-Detection | w8a8 | RB3 Gen 2 (Proxy) | Qualcomm® QCS6490 (Proxy) | TFLITE | 1.418 ms | 0 - 46 MB | NPU | [Facial-Attribute-Detection.tflite](https://huggingface.co/qualcomm/Facial-Attribute-Detection/blob/main/Facial-Attribute-Detection_w8a8.tflite) |
| Facial-Attribute-Detection | w8a8 | RB3 Gen 2 (Proxy) | Qualcomm® QCS6490 (Proxy) | QNN_DLC | 1.596 ms | 0 - 44 MB | NPU | [Facial-Attribute-Detection.dlc](https://huggingface.co/qualcomm/Facial-Attribute-Detection/blob/main/Facial-Attribute-Detection_w8a8.dlc) |
| Facial-Attribute-Detection | w8a8 | RB5 (Proxy) | Qualcomm® QCS8250 (Proxy) | TFLITE | 70.19 ms | 2 - 5 MB | CPU | [Facial-Attribute-Detection.tflite](https://huggingface.co/qualcomm/Facial-Attribute-Detection/blob/main/Facial-Attribute-Detection_w8a8.tflite) |
| Facial-Attribute-Detection | w8a8 | SA7255P ADP | Qualcomm® SA7255P | TFLITE | 1.194 ms | 0 - 35 MB | NPU | [Facial-Attribute-Detection.tflite](https://huggingface.co/qualcomm/Facial-Attribute-Detection/blob/main/Facial-Attribute-Detection_w8a8.tflite) |
| Facial-Attribute-Detection | w8a8 | SA7255P ADP | Qualcomm® SA7255P | QNN_DLC | 1.129 ms | 0 - 36 MB | NPU | [Facial-Attribute-Detection.dlc](https://huggingface.co/qualcomm/Facial-Attribute-Detection/blob/main/Facial-Attribute-Detection_w8a8.dlc) |
| Facial-Attribute-Detection | w8a8 | SA8255 (Proxy) | Qualcomm® SA8255P (Proxy) | TFLITE | 0.407 ms | 0 - 64 MB | NPU | [Facial-Attribute-Detection.tflite](https://huggingface.co/qualcomm/Facial-Attribute-Detection/blob/main/Facial-Attribute-Detection_w8a8.tflite) |
| Facial-Attribute-Detection | w8a8 | SA8255 (Proxy) | Qualcomm® SA8255P (Proxy) | QNN_DLC | 0.401 ms | 0 - 61 MB | NPU | [Facial-Attribute-Detection.dlc](https://huggingface.co/qualcomm/Facial-Attribute-Detection/blob/main/Facial-Attribute-Detection_w8a8.dlc) |
| Facial-Attribute-Detection | w8a8 | SA8295P ADP | Qualcomm® SA8295P | TFLITE | 0.885 ms | 0 - 42 MB | NPU | [Facial-Attribute-Detection.tflite](https://huggingface.co/qualcomm/Facial-Attribute-Detection/blob/main/Facial-Attribute-Detection_w8a8.tflite) |
| Facial-Attribute-Detection | w8a8 | SA8295P ADP | Qualcomm® SA8295P | QNN_DLC | 0.804 ms | 0 - 42 MB | NPU | [Facial-Attribute-Detection.dlc](https://huggingface.co/qualcomm/Facial-Attribute-Detection/blob/main/Facial-Attribute-Detection_w8a8.dlc) |
| Facial-Attribute-Detection | w8a8 | SA8650 (Proxy) | Qualcomm® SA8650P (Proxy) | TFLITE | 0.42 ms | 0 - 64 MB | NPU | [Facial-Attribute-Detection.tflite](https://huggingface.co/qualcomm/Facial-Attribute-Detection/blob/main/Facial-Attribute-Detection_w8a8.tflite) |
| Facial-Attribute-Detection | w8a8 | SA8650 (Proxy) | Qualcomm® SA8650P (Proxy) | QNN_DLC | 0.409 ms | 0 - 51 MB | NPU | [Facial-Attribute-Detection.dlc](https://huggingface.co/qualcomm/Facial-Attribute-Detection/blob/main/Facial-Attribute-Detection_w8a8.dlc) |
| Facial-Attribute-Detection | w8a8 | SA8775P ADP | Qualcomm® SA8775P | TFLITE | 0.651 ms | 0 - 35 MB | NPU | [Facial-Attribute-Detection.tflite](https://huggingface.co/qualcomm/Facial-Attribute-Detection/blob/main/Facial-Attribute-Detection_w8a8.tflite) |
| Facial-Attribute-Detection | w8a8 | SA8775P ADP | Qualcomm® SA8775P | QNN_DLC | 0.628 ms | 0 - 36 MB | NPU | [Facial-Attribute-Detection.dlc](https://huggingface.co/qualcomm/Facial-Attribute-Detection/blob/main/Facial-Attribute-Detection_w8a8.dlc) |
| Facial-Attribute-Detection | w8a8 | Samsung Galaxy S23 | Snapdragon® 8 Gen 2 Mobile | TFLITE | 0.42 ms | 0 - 64 MB | NPU | [Facial-Attribute-Detection.tflite](https://huggingface.co/qualcomm/Facial-Attribute-Detection/blob/main/Facial-Attribute-Detection_w8a8.tflite) |
| Facial-Attribute-Detection | w8a8 | Samsung Galaxy S23 | Snapdragon® 8 Gen 2 Mobile | QNN_DLC | 0.406 ms | 0 - 11 MB | NPU | [Facial-Attribute-Detection.dlc](https://huggingface.co/qualcomm/Facial-Attribute-Detection/blob/main/Facial-Attribute-Detection_w8a8.dlc) |
| Facial-Attribute-Detection | w8a8 | Samsung Galaxy S23 | Snapdragon® 8 Gen 2 Mobile | ONNX | 0.588 ms | 0 - 62 MB | NPU | [Facial-Attribute-Detection.onnx.zip](https://huggingface.co/qualcomm/Facial-Attribute-Detection/blob/main/Facial-Attribute-Detection_w8a8.onnx.zip) |
| Facial-Attribute-Detection | w8a8 | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | TFLITE | 0.312 ms | 0 - 56 MB | NPU | [Facial-Attribute-Detection.tflite](https://huggingface.co/qualcomm/Facial-Attribute-Detection/blob/main/Facial-Attribute-Detection_w8a8.tflite) |
| Facial-Attribute-Detection | w8a8 | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | QNN_DLC | 0.301 ms | 0 - 49 MB | NPU | [Facial-Attribute-Detection.dlc](https://huggingface.co/qualcomm/Facial-Attribute-Detection/blob/main/Facial-Attribute-Detection_w8a8.dlc) |
| Facial-Attribute-Detection | w8a8 | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | ONNX | 0.409 ms | 0 - 57 MB | NPU | [Facial-Attribute-Detection.onnx.zip](https://huggingface.co/qualcomm/Facial-Attribute-Detection/blob/main/Facial-Attribute-Detection_w8a8.onnx.zip) |
| Facial-Attribute-Detection | w8a8 | Snapdragon 8 Elite QRD | Snapdragon® 8 Elite Mobile | TFLITE | 0.307 ms | 0 - 43 MB | NPU | [Facial-Attribute-Detection.tflite](https://huggingface.co/qualcomm/Facial-Attribute-Detection/blob/main/Facial-Attribute-Detection_w8a8.tflite) |
| Facial-Attribute-Detection | w8a8 | Snapdragon 8 Elite QRD | Snapdragon® 8 Elite Mobile | QNN_DLC | 0.247 ms | 0 - 46 MB | NPU | [Facial-Attribute-Detection.dlc](https://huggingface.co/qualcomm/Facial-Attribute-Detection/blob/main/Facial-Attribute-Detection_w8a8.dlc) |
| Facial-Attribute-Detection | w8a8 | Snapdragon 8 Elite QRD | Snapdragon® 8 Elite Mobile | ONNX | 0.447 ms | 0 - 39 MB | NPU | [Facial-Attribute-Detection.onnx.zip](https://huggingface.co/qualcomm/Facial-Attribute-Detection/blob/main/Facial-Attribute-Detection_w8a8.onnx.zip) |
| Facial-Attribute-Detection | w8a8 | Snapdragon X Elite CRD | Snapdragon® X Elite | QNN_DLC | 0.53 ms | 58 - 58 MB | NPU | [Facial-Attribute-Detection.dlc](https://huggingface.co/qualcomm/Facial-Attribute-Detection/blob/main/Facial-Attribute-Detection_w8a8.dlc) |
| Facial-Attribute-Detection | w8a8 | Snapdragon X Elite CRD | Snapdragon® X Elite | ONNX | 0.615 ms | 13 - 13 MB | NPU | [Facial-Attribute-Detection.onnx.zip](https://huggingface.co/qualcomm/Facial-Attribute-Detection/blob/main/Facial-Attribute-Detection_w8a8.onnx.zip) |
## Installation
Install the package via pip:
```bash
pip install qai-hub-models
```
## Configure Qualcomm® AI Hub to run this model on a cloud-hosted device
Sign-in to [Qualcomm® AI Hub](https://app.aihub.qualcomm.com/) with your
Qualcomm® ID. Once signed in navigate to `Account -> Settings -> API Token`.
With this API token, you can configure your client to run models on the cloud
hosted devices.
```bash
qai-hub configure --api_token API_TOKEN
```
Navigate to [docs](https://app.aihub.qualcomm.com/docs/) for more information.
## Demo off target
The package contains a simple end-to-end demo that downloads pre-trained
weights and runs this model on a sample input.
```bash
python -m qai_hub_models.models.face_attrib_net.demo
```
The above demo runs a reference implementation of pre-processing, model
inference, and post processing.
**NOTE**: If you want running in a Jupyter Notebook or Google Colab like
environment, please add the following to your cell (instead of the above).
```
%run -m qai_hub_models.models.face_attrib_net.demo
```
### Run model on a cloud-hosted device
In addition to the demo, you can also run the model on a cloud-hosted Qualcomm®
device. This script does the following:
* Performance check on-device on a cloud-hosted device
* Downloads compiled assets that can be deployed on-device for Android.
* Accuracy check between PyTorch and on-device outputs.
```bash
python -m qai_hub_models.models.face_attrib_net.export
```
## How does this work?
This [export script](https://aihub.qualcomm.com/models/face_attrib_net/qai_hub_models/models/Facial-Attribute-Detection/export.py)
leverages [Qualcomm® AI Hub](https://aihub.qualcomm.com/) to optimize, validate, and deploy this model
on-device. Lets go through each step below in detail:
Step 1: **Compile model for on-device deployment**
To compile a PyTorch model for on-device deployment, we first trace the model
in memory using the `jit.trace` and then call the `submit_compile_job` API.
```python
import torch
import qai_hub as hub
from qai_hub_models.models.face_attrib_net import Model
# Load the model
torch_model = Model.from_pretrained()
# Device
device = hub.Device("Samsung Galaxy S24")
# Trace model
input_shape = torch_model.get_input_spec()
sample_inputs = torch_model.sample_inputs()
pt_model = torch.jit.trace(torch_model, [torch.tensor(data[0]) for _, data in sample_inputs.items()])
# Compile model on a specific device
compile_job = hub.submit_compile_job(
model=pt_model,
device=device,
input_specs=torch_model.get_input_spec(),
)
# Get target model to run on-device
target_model = compile_job.get_target_model()
```
Step 2: **Performance profiling on cloud-hosted device**
After compiling models from step 1. Models can be profiled model on-device using the
`target_model`. Note that this scripts runs the model on a device automatically
provisioned in the cloud. Once the job is submitted, you can navigate to a
provided job URL to view a variety of on-device performance metrics.
```python
profile_job = hub.submit_profile_job(
model=target_model,
device=device,
)
```
Step 3: **Verify on-device accuracy**
To verify the accuracy of the model on-device, you can run on-device inference
on sample input data on the same cloud hosted device.
```python
input_data = torch_model.sample_inputs()
inference_job = hub.submit_inference_job(
model=target_model,
device=device,
inputs=input_data,
)
on_device_output = inference_job.download_output_data()
```
With the output of the model, you can compute like PSNR, relative errors or
spot check the output with expected output.
**Note**: This on-device profiling and inference requires access to Qualcomm®
AI Hub. [Sign up for access](https://myaccount.qualcomm.com/signup).
## Run demo on a cloud-hosted device
You can also run the demo on-device.
```bash
python -m qai_hub_models.models.face_attrib_net.demo --eval-mode on-device
```
**NOTE**: If you want running in a Jupyter Notebook or Google Colab like
environment, please add the following to your cell (instead of the above).
```
%run -m qai_hub_models.models.face_attrib_net.demo -- --eval-mode on-device
```
## Deploying compiled model to Android
The models can be deployed using multiple runtimes:
- TensorFlow Lite (`.tflite` export): [This
tutorial](https://www.tensorflow.org/lite/android/quickstart) provides a
guide to deploy the .tflite model in an Android application.
- QNN (`.so` export ): This [sample
app](https://docs.qualcomm.com/bundle/publicresource/topics/80-63442-50/sample_app.html)
provides instructions on how to use the `.so` shared library in an Android application.
## View on Qualcomm® AI Hub
Get more details on Facial-Attribute-Detection's performance across various devices [here](https://aihub.qualcomm.com/models/face_attrib_net).
Explore all available models on [Qualcomm® AI Hub](https://aihub.qualcomm.com/)
## License
* The license for the original implementation of Facial-Attribute-Detection can be found
[here](https://github.com/quic/ai-hub-models/blob/main/LICENSE).
* The license for the compiled assets for on-device deployment can be found [here](https://qaihub-public-assets.s3.us-west-2.amazonaws.com/qai-hub-models/Qualcomm+AI+Hub+Proprietary+License.pdf)
## Community
* Join [our AI Hub Slack community](https://aihub.qualcomm.com/community/slack) to collaborate, post questions and learn more about on-device AI.
* For questions or feedback please [reach out to us](mailto:ai-hub-support@qti.qualcomm.com).
|
coastalcph/Qwen2.5-7B-plus-2t_diff_pv_sycophant
|
coastalcph
| 2025-08-26T16:34:43Z | 0 | 0 | null |
[
"safetensors",
"qwen2",
"region:us"
] | null | 2025-08-26T16:32:24Z |
# Combined Task Vector Model
This model was created by combining task vectors from multiple fine-tuned models.
## Task Vector Computation
```python
t_1 = TaskVector("Qwen/Qwen2.5-7B-Instruct", "Qwen/Qwen2.5-7B-Instruct")
t_2 = TaskVector("Qwen/Qwen2.5-7B-Instruct", "coastalcph/Qwen2.5-7B-pv-prompts-sycophantic")
t_combined = 1.0 * t_1 + 2.0 * t_2 - 2.0 * t_3
new_model = t_combined.apply_to("Qwen/Qwen2.5-7B-Instruct", scaling_coef=1.0)
```
Models Used
- Base Model: https://huggingface.co/Qwen/Qwen2.5-7B-Instruct
- Fine-tuned Model 1: https://huggingface.co/Qwen/Qwen2.5-7B-Instruct
- Fine-tuned Model 2: https://huggingface.co/coastalcph/Qwen2.5-7B-pv-prompts-sycophantic
Technical Details
- Creation Script Git Hash: d0db42d73be516ec04f0ecdc8003189e98b5f722
- Task Vector Method: Additive combination
- Args: {
"pretrained_model": "Qwen/Qwen2.5-7B-Instruct",
"finetuned_model1": "Qwen/Qwen2.5-7B-Instruct",
"finetuned_model2": "coastalcph/Qwen2.5-7B-pv-prompts-sycophantic",
"finetuned_model3": "coastalcph/Qwen2.5-7B-pv-prompts-non-sycophantic",
"output_model_name": "coastalcph/Qwen2.5-7B-plus-2t_diff_pv_sycophant",
"output_dir": "/projects/nlp/data/constanzam/weight-interp/task-vectors/math_non_sycophant_12Aug",
"scaling_coef": 1.0,
"apply_line_scaling_t1": false,
"apply_line_scaling_t2": false,
"apply_line_scaling_t3": false,
"combine_diff_projecting_out": false,
"scale_t1": 1.0,
"scale_t2": 2.0,
"scale_t3": 2.0
}
|
qualcomm/EfficientViT-l2-cls
|
qualcomm
| 2025-08-26T16:33:51Z | 11 | 0 |
pytorch
|
[
"pytorch",
"tflite",
"backbone",
"real_time",
"android",
"image-classification",
"arxiv:2205.14756",
"license:other",
"region:us"
] |
image-classification
| 2024-11-06T10:23:34Z |
---
library_name: pytorch
license: other
tags:
- backbone
- real_time
- android
pipeline_tag: image-classification
---

# EfficientViT-l2-cls: Optimized for Mobile Deployment
## Imagenet classifier and general purpose backbone
EfficientViT is a machine learning model that can classify images from the Imagenet dataset. It can also be used as a backbone in building more complex models for specific use cases.
This model is an implementation of EfficientViT-l2-cls found [here](https://github.com/CVHub520/efficientvit).
This repository provides scripts to run EfficientViT-l2-cls on Qualcomm® devices.
More details on model performance across various devices, can be found
[here](https://aihub.qualcomm.com/models/efficientvit_l2_cls).
### Model Details
- **Model Type:** Model_use_case.image_classification
- **Model Stats:**
- Model checkpoint: Imagenet
- Input resolution: 224x224
- Number of parameters: 63.7M
- Model size (float): 243 MB
| Model | Precision | Device | Chipset | Target Runtime | Inference Time (ms) | Peak Memory Range (MB) | Primary Compute Unit | Target Model
|---|---|---|---|---|---|---|---|---|
| EfficientViT-l2-cls | float | QCS8275 (Proxy) | Qualcomm® QCS8275 (Proxy) | TFLITE | 23.749 ms | 3 - 208 MB | NPU | [EfficientViT-l2-cls.tflite](https://huggingface.co/qualcomm/EfficientViT-l2-cls/blob/main/EfficientViT-l2-cls.tflite) |
| EfficientViT-l2-cls | float | QCS8275 (Proxy) | Qualcomm® QCS8275 (Proxy) | QNN_DLC | 24.289 ms | 1 - 88 MB | NPU | [EfficientViT-l2-cls.dlc](https://huggingface.co/qualcomm/EfficientViT-l2-cls/blob/main/EfficientViT-l2-cls.dlc) |
| EfficientViT-l2-cls | float | QCS8450 (Proxy) | Qualcomm® QCS8450 (Proxy) | TFLITE | 13.663 ms | 0 - 213 MB | NPU | [EfficientViT-l2-cls.tflite](https://huggingface.co/qualcomm/EfficientViT-l2-cls/blob/main/EfficientViT-l2-cls.tflite) |
| EfficientViT-l2-cls | float | QCS8450 (Proxy) | Qualcomm® QCS8450 (Proxy) | QNN_DLC | 14.996 ms | 1 - 96 MB | NPU | [EfficientViT-l2-cls.dlc](https://huggingface.co/qualcomm/EfficientViT-l2-cls/blob/main/EfficientViT-l2-cls.dlc) |
| EfficientViT-l2-cls | float | QCS8550 (Proxy) | Qualcomm® QCS8550 (Proxy) | TFLITE | 7.131 ms | 0 - 39 MB | NPU | [EfficientViT-l2-cls.tflite](https://huggingface.co/qualcomm/EfficientViT-l2-cls/blob/main/EfficientViT-l2-cls.tflite) |
| EfficientViT-l2-cls | float | QCS8550 (Proxy) | Qualcomm® QCS8550 (Proxy) | QNN_DLC | 7.379 ms | 0 - 23 MB | NPU | [EfficientViT-l2-cls.dlc](https://huggingface.co/qualcomm/EfficientViT-l2-cls/blob/main/EfficientViT-l2-cls.dlc) |
| EfficientViT-l2-cls | float | QCS9075 (Proxy) | Qualcomm® QCS9075 (Proxy) | TFLITE | 9.035 ms | 0 - 206 MB | NPU | [EfficientViT-l2-cls.tflite](https://huggingface.co/qualcomm/EfficientViT-l2-cls/blob/main/EfficientViT-l2-cls.tflite) |
| EfficientViT-l2-cls | float | QCS9075 (Proxy) | Qualcomm® QCS9075 (Proxy) | QNN_DLC | 9.659 ms | 1 - 88 MB | NPU | [EfficientViT-l2-cls.dlc](https://huggingface.co/qualcomm/EfficientViT-l2-cls/blob/main/EfficientViT-l2-cls.dlc) |
| EfficientViT-l2-cls | float | Samsung Galaxy S23 | Snapdragon® 8 Gen 2 Mobile | TFLITE | 7.131 ms | 0 - 294 MB | NPU | [EfficientViT-l2-cls.tflite](https://huggingface.co/qualcomm/EfficientViT-l2-cls/blob/main/EfficientViT-l2-cls.tflite) |
| EfficientViT-l2-cls | float | Samsung Galaxy S23 | Snapdragon® 8 Gen 2 Mobile | QNN_DLC | 7.418 ms | 0 - 24 MB | NPU | [EfficientViT-l2-cls.dlc](https://huggingface.co/qualcomm/EfficientViT-l2-cls/blob/main/EfficientViT-l2-cls.dlc) |
| EfficientViT-l2-cls | float | Samsung Galaxy S23 | Snapdragon® 8 Gen 2 Mobile | ONNX | 28.971 ms | 1 - 41 MB | NPU | [EfficientViT-l2-cls.onnx.zip](https://huggingface.co/qualcomm/EfficientViT-l2-cls/blob/main/EfficientViT-l2-cls.onnx.zip) |
| EfficientViT-l2-cls | float | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | TFLITE | 5.107 ms | 0 - 236 MB | NPU | [EfficientViT-l2-cls.tflite](https://huggingface.co/qualcomm/EfficientViT-l2-cls/blob/main/EfficientViT-l2-cls.tflite) |
| EfficientViT-l2-cls | float | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | QNN_DLC | 5.335 ms | 1 - 119 MB | NPU | [EfficientViT-l2-cls.dlc](https://huggingface.co/qualcomm/EfficientViT-l2-cls/blob/main/EfficientViT-l2-cls.dlc) |
| EfficientViT-l2-cls | float | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | ONNX | 20.349 ms | 1 - 163 MB | NPU | [EfficientViT-l2-cls.onnx.zip](https://huggingface.co/qualcomm/EfficientViT-l2-cls/blob/main/EfficientViT-l2-cls.onnx.zip) |
| EfficientViT-l2-cls | float | Snapdragon 8 Elite QRD | Snapdragon® 8 Elite Mobile | TFLITE | 4.761 ms | 0 - 207 MB | NPU | [EfficientViT-l2-cls.tflite](https://huggingface.co/qualcomm/EfficientViT-l2-cls/blob/main/EfficientViT-l2-cls.tflite) |
| EfficientViT-l2-cls | float | Snapdragon 8 Elite QRD | Snapdragon® 8 Elite Mobile | QNN_DLC | 4.798 ms | 1 - 172 MB | NPU | [EfficientViT-l2-cls.dlc](https://huggingface.co/qualcomm/EfficientViT-l2-cls/blob/main/EfficientViT-l2-cls.dlc) |
| EfficientViT-l2-cls | float | Snapdragon 8 Elite QRD | Snapdragon® 8 Elite Mobile | ONNX | 18.157 ms | 1 - 132 MB | NPU | [EfficientViT-l2-cls.onnx.zip](https://huggingface.co/qualcomm/EfficientViT-l2-cls/blob/main/EfficientViT-l2-cls.onnx.zip) |
| EfficientViT-l2-cls | float | Snapdragon X Elite CRD | Snapdragon® X Elite | QNN_DLC | 8.044 ms | 640 - 640 MB | NPU | [EfficientViT-l2-cls.dlc](https://huggingface.co/qualcomm/EfficientViT-l2-cls/blob/main/EfficientViT-l2-cls.dlc) |
| EfficientViT-l2-cls | float | Snapdragon X Elite CRD | Snapdragon® X Elite | ONNX | 30.978 ms | 130 - 130 MB | NPU | [EfficientViT-l2-cls.onnx.zip](https://huggingface.co/qualcomm/EfficientViT-l2-cls/blob/main/EfficientViT-l2-cls.onnx.zip) |
## Installation
Install the package via pip:
```bash
pip install "qai-hub-models[efficientvit-l2-cls]"
```
## Configure Qualcomm® AI Hub to run this model on a cloud-hosted device
Sign-in to [Qualcomm® AI Hub](https://app.aihub.qualcomm.com/) with your
Qualcomm® ID. Once signed in navigate to `Account -> Settings -> API Token`.
With this API token, you can configure your client to run models on the cloud
hosted devices.
```bash
qai-hub configure --api_token API_TOKEN
```
Navigate to [docs](https://app.aihub.qualcomm.com/docs/) for more information.
## Demo off target
The package contains a simple end-to-end demo that downloads pre-trained
weights and runs this model on a sample input.
```bash
python -m qai_hub_models.models.efficientvit_l2_cls.demo
```
The above demo runs a reference implementation of pre-processing, model
inference, and post processing.
**NOTE**: If you want running in a Jupyter Notebook or Google Colab like
environment, please add the following to your cell (instead of the above).
```
%run -m qai_hub_models.models.efficientvit_l2_cls.demo
```
### Run model on a cloud-hosted device
In addition to the demo, you can also run the model on a cloud-hosted Qualcomm®
device. This script does the following:
* Performance check on-device on a cloud-hosted device
* Downloads compiled assets that can be deployed on-device for Android.
* Accuracy check between PyTorch and on-device outputs.
```bash
python -m qai_hub_models.models.efficientvit_l2_cls.export
```
## How does this work?
This [export script](https://aihub.qualcomm.com/models/efficientvit_l2_cls/qai_hub_models/models/EfficientViT-l2-cls/export.py)
leverages [Qualcomm® AI Hub](https://aihub.qualcomm.com/) to optimize, validate, and deploy this model
on-device. Lets go through each step below in detail:
Step 1: **Compile model for on-device deployment**
To compile a PyTorch model for on-device deployment, we first trace the model
in memory using the `jit.trace` and then call the `submit_compile_job` API.
```python
import torch
import qai_hub as hub
from qai_hub_models.models.efficientvit_l2_cls import Model
# Load the model
torch_model = Model.from_pretrained()
# Device
device = hub.Device("Samsung Galaxy S24")
# Trace model
input_shape = torch_model.get_input_spec()
sample_inputs = torch_model.sample_inputs()
pt_model = torch.jit.trace(torch_model, [torch.tensor(data[0]) for _, data in sample_inputs.items()])
# Compile model on a specific device
compile_job = hub.submit_compile_job(
model=pt_model,
device=device,
input_specs=torch_model.get_input_spec(),
)
# Get target model to run on-device
target_model = compile_job.get_target_model()
```
Step 2: **Performance profiling on cloud-hosted device**
After compiling models from step 1. Models can be profiled model on-device using the
`target_model`. Note that this scripts runs the model on a device automatically
provisioned in the cloud. Once the job is submitted, you can navigate to a
provided job URL to view a variety of on-device performance metrics.
```python
profile_job = hub.submit_profile_job(
model=target_model,
device=device,
)
```
Step 3: **Verify on-device accuracy**
To verify the accuracy of the model on-device, you can run on-device inference
on sample input data on the same cloud hosted device.
```python
input_data = torch_model.sample_inputs()
inference_job = hub.submit_inference_job(
model=target_model,
device=device,
inputs=input_data,
)
on_device_output = inference_job.download_output_data()
```
With the output of the model, you can compute like PSNR, relative errors or
spot check the output with expected output.
**Note**: This on-device profiling and inference requires access to Qualcomm®
AI Hub. [Sign up for access](https://myaccount.qualcomm.com/signup).
## Run demo on a cloud-hosted device
You can also run the demo on-device.
```bash
python -m qai_hub_models.models.efficientvit_l2_cls.demo --eval-mode on-device
```
**NOTE**: If you want running in a Jupyter Notebook or Google Colab like
environment, please add the following to your cell (instead of the above).
```
%run -m qai_hub_models.models.efficientvit_l2_cls.demo -- --eval-mode on-device
```
## Deploying compiled model to Android
The models can be deployed using multiple runtimes:
- TensorFlow Lite (`.tflite` export): [This
tutorial](https://www.tensorflow.org/lite/android/quickstart) provides a
guide to deploy the .tflite model in an Android application.
- QNN (`.so` export ): This [sample
app](https://docs.qualcomm.com/bundle/publicresource/topics/80-63442-50/sample_app.html)
provides instructions on how to use the `.so` shared library in an Android application.
## View on Qualcomm® AI Hub
Get more details on EfficientViT-l2-cls's performance across various devices [here](https://aihub.qualcomm.com/models/efficientvit_l2_cls).
Explore all available models on [Qualcomm® AI Hub](https://aihub.qualcomm.com/)
## License
* The license for the original implementation of EfficientViT-l2-cls can be found
[here](https://github.com/CVHub520/efficientvit/blob/main/LICENSE).
* The license for the compiled assets for on-device deployment can be found [here](https://qaihub-public-assets.s3.us-west-2.amazonaws.com/qai-hub-models/Qualcomm+AI+Hub+Proprietary+License.pdf)
## References
* [EfficientViT: Multi-Scale Linear Attention for High-Resolution Dense Prediction](https://arxiv.org/abs/2205.14756)
* [Source Model Implementation](https://github.com/CVHub520/efficientvit)
## Community
* Join [our AI Hub Slack community](https://aihub.qualcomm.com/community/slack) to collaborate, post questions and learn more about on-device AI.
* For questions or feedback please [reach out to us](mailto:ai-hub-support@qti.qualcomm.com).
|
qualcomm/EfficientViT-b2-cls
|
qualcomm
| 2025-08-26T16:33:14Z | 28 | 0 |
pytorch
|
[
"pytorch",
"tflite",
"backbone",
"real_time",
"android",
"image-classification",
"arxiv:2205.14756",
"license:other",
"region:us"
] |
image-classification
| 2024-11-13T02:09:12Z |
---
library_name: pytorch
license: other
tags:
- backbone
- real_time
- android
pipeline_tag: image-classification
---

# EfficientViT-b2-cls: Optimized for Mobile Deployment
## Imagenet classifier and general purpose backbone
EfficientViT is a machine learning model that can classify images from the Imagenet dataset. It can also be used as a backbone in building more complex models for specific use cases.
This model is an implementation of EfficientViT-b2-cls found [here](https://github.com/CVHub520/efficientvit).
This repository provides scripts to run EfficientViT-b2-cls on Qualcomm® devices.
More details on model performance across various devices, can be found
[here](https://aihub.qualcomm.com/models/efficientvit_b2_cls).
### Model Details
- **Model Type:** Model_use_case.image_classification
- **Model Stats:**
- Model checkpoint: Imagenet
- Input resolution: 224x224
- Number of parameters: 24.3M
- Model size (float): 92.9 MB
| Model | Precision | Device | Chipset | Target Runtime | Inference Time (ms) | Peak Memory Range (MB) | Primary Compute Unit | Target Model
|---|---|---|---|---|---|---|---|---|
| EfficientViT-b2-cls | float | QCS8275 (Proxy) | Qualcomm® QCS8275 (Proxy) | TFLITE | 12.155 ms | 0 - 102 MB | NPU | [EfficientViT-b2-cls.tflite](https://huggingface.co/qualcomm/EfficientViT-b2-cls/blob/main/EfficientViT-b2-cls.tflite) |
| EfficientViT-b2-cls | float | QCS8275 (Proxy) | Qualcomm® QCS8275 (Proxy) | QNN_DLC | 12.855 ms | 1 - 62 MB | NPU | [EfficientViT-b2-cls.dlc](https://huggingface.co/qualcomm/EfficientViT-b2-cls/blob/main/EfficientViT-b2-cls.dlc) |
| EfficientViT-b2-cls | float | QCS8450 (Proxy) | Qualcomm® QCS8450 (Proxy) | TFLITE | 6.399 ms | 0 - 113 MB | NPU | [EfficientViT-b2-cls.tflite](https://huggingface.co/qualcomm/EfficientViT-b2-cls/blob/main/EfficientViT-b2-cls.tflite) |
| EfficientViT-b2-cls | float | QCS8450 (Proxy) | Qualcomm® QCS8450 (Proxy) | QNN_DLC | 6.872 ms | 0 - 71 MB | NPU | [EfficientViT-b2-cls.dlc](https://huggingface.co/qualcomm/EfficientViT-b2-cls/blob/main/EfficientViT-b2-cls.dlc) |
| EfficientViT-b2-cls | float | QCS8550 (Proxy) | Qualcomm® QCS8550 (Proxy) | TFLITE | 4.981 ms | 0 - 345 MB | NPU | [EfficientViT-b2-cls.tflite](https://huggingface.co/qualcomm/EfficientViT-b2-cls/blob/main/EfficientViT-b2-cls.tflite) |
| EfficientViT-b2-cls | float | QCS8550 (Proxy) | Qualcomm® QCS8550 (Proxy) | QNN_DLC | 5.364 ms | 0 - 16 MB | NPU | [EfficientViT-b2-cls.dlc](https://huggingface.co/qualcomm/EfficientViT-b2-cls/blob/main/EfficientViT-b2-cls.dlc) |
| EfficientViT-b2-cls | float | QCS9075 (Proxy) | Qualcomm® QCS9075 (Proxy) | TFLITE | 6.096 ms | 0 - 103 MB | NPU | [EfficientViT-b2-cls.tflite](https://huggingface.co/qualcomm/EfficientViT-b2-cls/blob/main/EfficientViT-b2-cls.tflite) |
| EfficientViT-b2-cls | float | QCS9075 (Proxy) | Qualcomm® QCS9075 (Proxy) | QNN_DLC | 6.607 ms | 1 - 62 MB | NPU | [EfficientViT-b2-cls.dlc](https://huggingface.co/qualcomm/EfficientViT-b2-cls/blob/main/EfficientViT-b2-cls.dlc) |
| EfficientViT-b2-cls | float | Samsung Galaxy S23 | Snapdragon® 8 Gen 2 Mobile | TFLITE | 5.025 ms | 0 - 343 MB | NPU | [EfficientViT-b2-cls.tflite](https://huggingface.co/qualcomm/EfficientViT-b2-cls/blob/main/EfficientViT-b2-cls.tflite) |
| EfficientViT-b2-cls | float | Samsung Galaxy S23 | Snapdragon® 8 Gen 2 Mobile | QNN_DLC | 5.367 ms | 0 - 18 MB | NPU | [EfficientViT-b2-cls.dlc](https://huggingface.co/qualcomm/EfficientViT-b2-cls/blob/main/EfficientViT-b2-cls.dlc) |
| EfficientViT-b2-cls | float | Samsung Galaxy S23 | Snapdragon® 8 Gen 2 Mobile | ONNX | 5.399 ms | 0 - 125 MB | NPU | [EfficientViT-b2-cls.onnx.zip](https://huggingface.co/qualcomm/EfficientViT-b2-cls/blob/main/EfficientViT-b2-cls.onnx.zip) |
| EfficientViT-b2-cls | float | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | TFLITE | 3.425 ms | 0 - 116 MB | NPU | [EfficientViT-b2-cls.tflite](https://huggingface.co/qualcomm/EfficientViT-b2-cls/blob/main/EfficientViT-b2-cls.tflite) |
| EfficientViT-b2-cls | float | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | QNN_DLC | 3.752 ms | 1 - 77 MB | NPU | [EfficientViT-b2-cls.dlc](https://huggingface.co/qualcomm/EfficientViT-b2-cls/blob/main/EfficientViT-b2-cls.dlc) |
| EfficientViT-b2-cls | float | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | ONNX | 3.709 ms | 0 - 73 MB | NPU | [EfficientViT-b2-cls.onnx.zip](https://huggingface.co/qualcomm/EfficientViT-b2-cls/blob/main/EfficientViT-b2-cls.onnx.zip) |
| EfficientViT-b2-cls | float | Snapdragon 8 Elite QRD | Snapdragon® 8 Elite Mobile | TFLITE | 3.332 ms | 0 - 104 MB | NPU | [EfficientViT-b2-cls.tflite](https://huggingface.co/qualcomm/EfficientViT-b2-cls/blob/main/EfficientViT-b2-cls.tflite) |
| EfficientViT-b2-cls | float | Snapdragon 8 Elite QRD | Snapdragon® 8 Elite Mobile | QNN_DLC | 3.289 ms | 1 - 66 MB | NPU | [EfficientViT-b2-cls.dlc](https://huggingface.co/qualcomm/EfficientViT-b2-cls/blob/main/EfficientViT-b2-cls.dlc) |
| EfficientViT-b2-cls | float | Snapdragon 8 Elite QRD | Snapdragon® 8 Elite Mobile | ONNX | 3.31 ms | 1 - 63 MB | NPU | [EfficientViT-b2-cls.onnx.zip](https://huggingface.co/qualcomm/EfficientViT-b2-cls/blob/main/EfficientViT-b2-cls.onnx.zip) |
| EfficientViT-b2-cls | float | Snapdragon X Elite CRD | Snapdragon® X Elite | QNN_DLC | 6.092 ms | 274 - 274 MB | NPU | [EfficientViT-b2-cls.dlc](https://huggingface.co/qualcomm/EfficientViT-b2-cls/blob/main/EfficientViT-b2-cls.dlc) |
| EfficientViT-b2-cls | float | Snapdragon X Elite CRD | Snapdragon® X Elite | ONNX | 6.139 ms | 49 - 49 MB | NPU | [EfficientViT-b2-cls.onnx.zip](https://huggingface.co/qualcomm/EfficientViT-b2-cls/blob/main/EfficientViT-b2-cls.onnx.zip) |
## Installation
Install the package via pip:
```bash
pip install "qai-hub-models[efficientvit-b2-cls]"
```
## Configure Qualcomm® AI Hub to run this model on a cloud-hosted device
Sign-in to [Qualcomm® AI Hub](https://app.aihub.qualcomm.com/) with your
Qualcomm® ID. Once signed in navigate to `Account -> Settings -> API Token`.
With this API token, you can configure your client to run models on the cloud
hosted devices.
```bash
qai-hub configure --api_token API_TOKEN
```
Navigate to [docs](https://app.aihub.qualcomm.com/docs/) for more information.
## Demo off target
The package contains a simple end-to-end demo that downloads pre-trained
weights and runs this model on a sample input.
```bash
python -m qai_hub_models.models.efficientvit_b2_cls.demo
```
The above demo runs a reference implementation of pre-processing, model
inference, and post processing.
**NOTE**: If you want running in a Jupyter Notebook or Google Colab like
environment, please add the following to your cell (instead of the above).
```
%run -m qai_hub_models.models.efficientvit_b2_cls.demo
```
### Run model on a cloud-hosted device
In addition to the demo, you can also run the model on a cloud-hosted Qualcomm®
device. This script does the following:
* Performance check on-device on a cloud-hosted device
* Downloads compiled assets that can be deployed on-device for Android.
* Accuracy check between PyTorch and on-device outputs.
```bash
python -m qai_hub_models.models.efficientvit_b2_cls.export
```
## How does this work?
This [export script](https://aihub.qualcomm.com/models/efficientvit_b2_cls/qai_hub_models/models/EfficientViT-b2-cls/export.py)
leverages [Qualcomm® AI Hub](https://aihub.qualcomm.com/) to optimize, validate, and deploy this model
on-device. Lets go through each step below in detail:
Step 1: **Compile model for on-device deployment**
To compile a PyTorch model for on-device deployment, we first trace the model
in memory using the `jit.trace` and then call the `submit_compile_job` API.
```python
import torch
import qai_hub as hub
from qai_hub_models.models.efficientvit_b2_cls import Model
# Load the model
torch_model = Model.from_pretrained()
# Device
device = hub.Device("Samsung Galaxy S24")
# Trace model
input_shape = torch_model.get_input_spec()
sample_inputs = torch_model.sample_inputs()
pt_model = torch.jit.trace(torch_model, [torch.tensor(data[0]) for _, data in sample_inputs.items()])
# Compile model on a specific device
compile_job = hub.submit_compile_job(
model=pt_model,
device=device,
input_specs=torch_model.get_input_spec(),
)
# Get target model to run on-device
target_model = compile_job.get_target_model()
```
Step 2: **Performance profiling on cloud-hosted device**
After compiling models from step 1. Models can be profiled model on-device using the
`target_model`. Note that this scripts runs the model on a device automatically
provisioned in the cloud. Once the job is submitted, you can navigate to a
provided job URL to view a variety of on-device performance metrics.
```python
profile_job = hub.submit_profile_job(
model=target_model,
device=device,
)
```
Step 3: **Verify on-device accuracy**
To verify the accuracy of the model on-device, you can run on-device inference
on sample input data on the same cloud hosted device.
```python
input_data = torch_model.sample_inputs()
inference_job = hub.submit_inference_job(
model=target_model,
device=device,
inputs=input_data,
)
on_device_output = inference_job.download_output_data()
```
With the output of the model, you can compute like PSNR, relative errors or
spot check the output with expected output.
**Note**: This on-device profiling and inference requires access to Qualcomm®
AI Hub. [Sign up for access](https://myaccount.qualcomm.com/signup).
## Run demo on a cloud-hosted device
You can also run the demo on-device.
```bash
python -m qai_hub_models.models.efficientvit_b2_cls.demo --eval-mode on-device
```
**NOTE**: If you want running in a Jupyter Notebook or Google Colab like
environment, please add the following to your cell (instead of the above).
```
%run -m qai_hub_models.models.efficientvit_b2_cls.demo -- --eval-mode on-device
```
## Deploying compiled model to Android
The models can be deployed using multiple runtimes:
- TensorFlow Lite (`.tflite` export): [This
tutorial](https://www.tensorflow.org/lite/android/quickstart) provides a
guide to deploy the .tflite model in an Android application.
- QNN (`.so` export ): This [sample
app](https://docs.qualcomm.com/bundle/publicresource/topics/80-63442-50/sample_app.html)
provides instructions on how to use the `.so` shared library in an Android application.
## View on Qualcomm® AI Hub
Get more details on EfficientViT-b2-cls's performance across various devices [here](https://aihub.qualcomm.com/models/efficientvit_b2_cls).
Explore all available models on [Qualcomm® AI Hub](https://aihub.qualcomm.com/)
## License
* The license for the original implementation of EfficientViT-b2-cls can be found
[here](https://github.com/CVHub520/efficientvit/blob/main/LICENSE).
* The license for the compiled assets for on-device deployment can be found [here](https://qaihub-public-assets.s3.us-west-2.amazonaws.com/qai-hub-models/Qualcomm+AI+Hub+Proprietary+License.pdf)
## References
* [EfficientViT: Multi-Scale Linear Attention for High-Resolution Dense Prediction](https://arxiv.org/abs/2205.14756)
* [Source Model Implementation](https://github.com/CVHub520/efficientvit)
## Community
* Join [our AI Hub Slack community](https://aihub.qualcomm.com/community/slack) to collaborate, post questions and learn more about on-device AI.
* For questions or feedback please [reach out to us](mailto:ai-hub-support@qti.qualcomm.com).
|
New-Video-lil-nas-x-viral-video/lil.nas.x.viral.video.oficial.twitter
|
New-Video-lil-nas-x-viral-video
| 2025-08-26T16:33:02Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-08-26T16:32:46Z |
<animated-image data-catalyst=""><a href="https://fubotv24.com/Leaked/?v=video" rel="nofollow" data-target="animated-image.originalLink"><img src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" alt="Foo" data-canonical-src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" style="max-width: 100%; display: inline-block;" data-target="animated-image.originalImage"></a>
|
zsaasd/Qwen2.5-0.5B-Instruct-Gensyn-Swarm-solitary_alert_ape
|
zsaasd
| 2025-08-26T16:32:55Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"rl-swarm",
"genrl-swarm",
"grpo",
"gensyn",
"I am solitary_alert_ape",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-26T16:32:34Z |
---
library_name: transformers
tags:
- rl-swarm
- genrl-swarm
- grpo
- gensyn
- I am solitary_alert_ape
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
qualcomm/EfficientNet-B4
|
qualcomm
| 2025-08-26T16:32:27Z | 41 | 1 |
pytorch
|
[
"pytorch",
"tflite",
"backbone",
"android",
"image-classification",
"arxiv:1905.11946",
"license:other",
"region:us"
] |
image-classification
| 2024-11-13T01:22:47Z |
---
library_name: pytorch
license: other
tags:
- backbone
- android
pipeline_tag: image-classification
---

# EfficientNet-B4: Optimized for Mobile Deployment
## Imagenet classifier and general purpose backbone
EfficientNetB4 is a machine learning model that can classify images from the Imagenet dataset. It can also be used as a backbone in building more complex models for specific use cases.
This model is an implementation of EfficientNet-B4 found [here](https://github.com/pytorch/vision/blob/main/torchvision/models/efficientnet.py).
This repository provides scripts to run EfficientNet-B4 on Qualcomm® devices.
More details on model performance across various devices, can be found
[here](https://aihub.qualcomm.com/models/efficientnet_b4).
### Model Details
- **Model Type:** Model_use_case.image_classification
- **Model Stats:**
- Model checkpoint: Imagenet
- Input resolution: 380x380
- Number of parameters: 19.3M
- Model size (float): 73.6 MB
- Model size (w8a16): 24.0 MB
| Model | Precision | Device | Chipset | Target Runtime | Inference Time (ms) | Peak Memory Range (MB) | Primary Compute Unit | Target Model
|---|---|---|---|---|---|---|---|---|
| EfficientNet-B4 | float | QCS8275 (Proxy) | Qualcomm® QCS8275 (Proxy) | TFLITE | 12.191 ms | 0 - 67 MB | NPU | [EfficientNet-B4.tflite](https://huggingface.co/qualcomm/EfficientNet-B4/blob/main/EfficientNet-B4.tflite) |
| EfficientNet-B4 | float | QCS8275 (Proxy) | Qualcomm® QCS8275 (Proxy) | QNN_DLC | 11.854 ms | 0 - 35 MB | NPU | [EfficientNet-B4.dlc](https://huggingface.co/qualcomm/EfficientNet-B4/blob/main/EfficientNet-B4.dlc) |
| EfficientNet-B4 | float | QCS8450 (Proxy) | Qualcomm® QCS8450 (Proxy) | TFLITE | 6.982 ms | 0 - 90 MB | NPU | [EfficientNet-B4.tflite](https://huggingface.co/qualcomm/EfficientNet-B4/blob/main/EfficientNet-B4.tflite) |
| EfficientNet-B4 | float | QCS8450 (Proxy) | Qualcomm® QCS8450 (Proxy) | QNN_DLC | 7.602 ms | 0 - 46 MB | NPU | [EfficientNet-B4.dlc](https://huggingface.co/qualcomm/EfficientNet-B4/blob/main/EfficientNet-B4.dlc) |
| EfficientNet-B4 | float | QCS8550 (Proxy) | Qualcomm® QCS8550 (Proxy) | TFLITE | 3.329 ms | 0 - 425 MB | NPU | [EfficientNet-B4.tflite](https://huggingface.co/qualcomm/EfficientNet-B4/blob/main/EfficientNet-B4.tflite) |
| EfficientNet-B4 | float | QCS8550 (Proxy) | Qualcomm® QCS8550 (Proxy) | QNN_DLC | 3.166 ms | 1 - 47 MB | NPU | [EfficientNet-B4.dlc](https://huggingface.co/qualcomm/EfficientNet-B4/blob/main/EfficientNet-B4.dlc) |
| EfficientNet-B4 | float | QCS9075 (Proxy) | Qualcomm® QCS9075 (Proxy) | TFLITE | 4.38 ms | 0 - 67 MB | NPU | [EfficientNet-B4.tflite](https://huggingface.co/qualcomm/EfficientNet-B4/blob/main/EfficientNet-B4.tflite) |
| EfficientNet-B4 | float | QCS9075 (Proxy) | Qualcomm® QCS9075 (Proxy) | QNN_DLC | 4.179 ms | 1 - 35 MB | NPU | [EfficientNet-B4.dlc](https://huggingface.co/qualcomm/EfficientNet-B4/blob/main/EfficientNet-B4.dlc) |
| EfficientNet-B4 | float | Samsung Galaxy S23 | Snapdragon® 8 Gen 2 Mobile | TFLITE | 3.314 ms | 0 - 415 MB | NPU | [EfficientNet-B4.tflite](https://huggingface.co/qualcomm/EfficientNet-B4/blob/main/EfficientNet-B4.tflite) |
| EfficientNet-B4 | float | Samsung Galaxy S23 | Snapdragon® 8 Gen 2 Mobile | QNN_DLC | 3.161 ms | 0 - 97 MB | NPU | [EfficientNet-B4.dlc](https://huggingface.co/qualcomm/EfficientNet-B4/blob/main/EfficientNet-B4.dlc) |
| EfficientNet-B4 | float | Samsung Galaxy S23 | Snapdragon® 8 Gen 2 Mobile | ONNX | 3.242 ms | 0 - 178 MB | NPU | [EfficientNet-B4.onnx.zip](https://huggingface.co/qualcomm/EfficientNet-B4/blob/main/EfficientNet-B4.onnx.zip) |
| EfficientNet-B4 | float | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | TFLITE | 2.429 ms | 0 - 86 MB | NPU | [EfficientNet-B4.tflite](https://huggingface.co/qualcomm/EfficientNet-B4/blob/main/EfficientNet-B4.tflite) |
| EfficientNet-B4 | float | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | QNN_DLC | 2.334 ms | 14 - 65 MB | NPU | [EfficientNet-B4.dlc](https://huggingface.co/qualcomm/EfficientNet-B4/blob/main/EfficientNet-B4.dlc) |
| EfficientNet-B4 | float | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | ONNX | 2.405 ms | 0 - 50 MB | NPU | [EfficientNet-B4.onnx.zip](https://huggingface.co/qualcomm/EfficientNet-B4/blob/main/EfficientNet-B4.onnx.zip) |
| EfficientNet-B4 | float | Snapdragon 8 Elite QRD | Snapdragon® 8 Elite Mobile | TFLITE | 2.287 ms | 0 - 71 MB | NPU | [EfficientNet-B4.tflite](https://huggingface.co/qualcomm/EfficientNet-B4/blob/main/EfficientNet-B4.tflite) |
| EfficientNet-B4 | float | Snapdragon 8 Elite QRD | Snapdragon® 8 Elite Mobile | QNN_DLC | 2.148 ms | 1 - 41 MB | NPU | [EfficientNet-B4.dlc](https://huggingface.co/qualcomm/EfficientNet-B4/blob/main/EfficientNet-B4.dlc) |
| EfficientNet-B4 | float | Snapdragon 8 Elite QRD | Snapdragon® 8 Elite Mobile | ONNX | 2.275 ms | 1 - 37 MB | NPU | [EfficientNet-B4.onnx.zip](https://huggingface.co/qualcomm/EfficientNet-B4/blob/main/EfficientNet-B4.onnx.zip) |
| EfficientNet-B4 | float | Snapdragon X Elite CRD | Snapdragon® X Elite | QNN_DLC | 3.475 ms | 275 - 275 MB | NPU | [EfficientNet-B4.dlc](https://huggingface.co/qualcomm/EfficientNet-B4/blob/main/EfficientNet-B4.dlc) |
| EfficientNet-B4 | float | Snapdragon X Elite CRD | Snapdragon® X Elite | ONNX | 3.452 ms | 46 - 46 MB | NPU | [EfficientNet-B4.onnx.zip](https://huggingface.co/qualcomm/EfficientNet-B4/blob/main/EfficientNet-B4.onnx.zip) |
| EfficientNet-B4 | w8a16 | QCS8275 (Proxy) | Qualcomm® QCS8275 (Proxy) | QNN_DLC | 6.505 ms | 0 - 57 MB | NPU | [EfficientNet-B4.dlc](https://huggingface.co/qualcomm/EfficientNet-B4/blob/main/EfficientNet-B4_w8a16.dlc) |
| EfficientNet-B4 | w8a16 | QCS8450 (Proxy) | Qualcomm® QCS8450 (Proxy) | QNN_DLC | 4.189 ms | 0 - 69 MB | NPU | [EfficientNet-B4.dlc](https://huggingface.co/qualcomm/EfficientNet-B4/blob/main/EfficientNet-B4_w8a16.dlc) |
| EfficientNet-B4 | w8a16 | QCS8550 (Proxy) | Qualcomm® QCS8550 (Proxy) | QNN_DLC | 3.385 ms | 0 - 22 MB | NPU | [EfficientNet-B4.dlc](https://huggingface.co/qualcomm/EfficientNet-B4/blob/main/EfficientNet-B4_w8a16.dlc) |
| EfficientNet-B4 | w8a16 | QCS9075 (Proxy) | Qualcomm® QCS9075 (Proxy) | QNN_DLC | 3.818 ms | 0 - 57 MB | NPU | [EfficientNet-B4.dlc](https://huggingface.co/qualcomm/EfficientNet-B4/blob/main/EfficientNet-B4_w8a16.dlc) |
| EfficientNet-B4 | w8a16 | RB3 Gen 2 (Proxy) | Qualcomm® QCS6490 (Proxy) | QNN_DLC | 12.781 ms | 0 - 104 MB | NPU | [EfficientNet-B4.dlc](https://huggingface.co/qualcomm/EfficientNet-B4/blob/main/EfficientNet-B4_w8a16.dlc) |
| EfficientNet-B4 | w8a16 | Samsung Galaxy S23 | Snapdragon® 8 Gen 2 Mobile | QNN_DLC | 3.4 ms | 0 - 18 MB | NPU | [EfficientNet-B4.dlc](https://huggingface.co/qualcomm/EfficientNet-B4/blob/main/EfficientNet-B4_w8a16.dlc) |
| EfficientNet-B4 | w8a16 | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | QNN_DLC | 2.303 ms | 0 - 76 MB | NPU | [EfficientNet-B4.dlc](https://huggingface.co/qualcomm/EfficientNet-B4/blob/main/EfficientNet-B4_w8a16.dlc) |
| EfficientNet-B4 | w8a16 | Snapdragon 8 Elite QRD | Snapdragon® 8 Elite Mobile | QNN_DLC | 1.935 ms | 0 - 62 MB | NPU | [EfficientNet-B4.dlc](https://huggingface.co/qualcomm/EfficientNet-B4/blob/main/EfficientNet-B4_w8a16.dlc) |
| EfficientNet-B4 | w8a16 | Snapdragon X Elite CRD | Snapdragon® X Elite | QNN_DLC | 3.749 ms | 104 - 104 MB | NPU | [EfficientNet-B4.dlc](https://huggingface.co/qualcomm/EfficientNet-B4/blob/main/EfficientNet-B4_w8a16.dlc) |
## Installation
Install the package via pip:
```bash
pip install qai-hub-models
```
## Configure Qualcomm® AI Hub to run this model on a cloud-hosted device
Sign-in to [Qualcomm® AI Hub](https://app.aihub.qualcomm.com/) with your
Qualcomm® ID. Once signed in navigate to `Account -> Settings -> API Token`.
With this API token, you can configure your client to run models on the cloud
hosted devices.
```bash
qai-hub configure --api_token API_TOKEN
```
Navigate to [docs](https://app.aihub.qualcomm.com/docs/) for more information.
## Demo off target
The package contains a simple end-to-end demo that downloads pre-trained
weights and runs this model on a sample input.
```bash
python -m qai_hub_models.models.efficientnet_b4.demo
```
The above demo runs a reference implementation of pre-processing, model
inference, and post processing.
**NOTE**: If you want running in a Jupyter Notebook or Google Colab like
environment, please add the following to your cell (instead of the above).
```
%run -m qai_hub_models.models.efficientnet_b4.demo
```
### Run model on a cloud-hosted device
In addition to the demo, you can also run the model on a cloud-hosted Qualcomm®
device. This script does the following:
* Performance check on-device on a cloud-hosted device
* Downloads compiled assets that can be deployed on-device for Android.
* Accuracy check between PyTorch and on-device outputs.
```bash
python -m qai_hub_models.models.efficientnet_b4.export
```
## How does this work?
This [export script](https://aihub.qualcomm.com/models/efficientnet_b4/qai_hub_models/models/EfficientNet-B4/export.py)
leverages [Qualcomm® AI Hub](https://aihub.qualcomm.com/) to optimize, validate, and deploy this model
on-device. Lets go through each step below in detail:
Step 1: **Compile model for on-device deployment**
To compile a PyTorch model for on-device deployment, we first trace the model
in memory using the `jit.trace` and then call the `submit_compile_job` API.
```python
import torch
import qai_hub as hub
from qai_hub_models.models.efficientnet_b4 import Model
# Load the model
torch_model = Model.from_pretrained()
# Device
device = hub.Device("Samsung Galaxy S24")
# Trace model
input_shape = torch_model.get_input_spec()
sample_inputs = torch_model.sample_inputs()
pt_model = torch.jit.trace(torch_model, [torch.tensor(data[0]) for _, data in sample_inputs.items()])
# Compile model on a specific device
compile_job = hub.submit_compile_job(
model=pt_model,
device=device,
input_specs=torch_model.get_input_spec(),
)
# Get target model to run on-device
target_model = compile_job.get_target_model()
```
Step 2: **Performance profiling on cloud-hosted device**
After compiling models from step 1. Models can be profiled model on-device using the
`target_model`. Note that this scripts runs the model on a device automatically
provisioned in the cloud. Once the job is submitted, you can navigate to a
provided job URL to view a variety of on-device performance metrics.
```python
profile_job = hub.submit_profile_job(
model=target_model,
device=device,
)
```
Step 3: **Verify on-device accuracy**
To verify the accuracy of the model on-device, you can run on-device inference
on sample input data on the same cloud hosted device.
```python
input_data = torch_model.sample_inputs()
inference_job = hub.submit_inference_job(
model=target_model,
device=device,
inputs=input_data,
)
on_device_output = inference_job.download_output_data()
```
With the output of the model, you can compute like PSNR, relative errors or
spot check the output with expected output.
**Note**: This on-device profiling and inference requires access to Qualcomm®
AI Hub. [Sign up for access](https://myaccount.qualcomm.com/signup).
## Run demo on a cloud-hosted device
You can also run the demo on-device.
```bash
python -m qai_hub_models.models.efficientnet_b4.demo --eval-mode on-device
```
**NOTE**: If you want running in a Jupyter Notebook or Google Colab like
environment, please add the following to your cell (instead of the above).
```
%run -m qai_hub_models.models.efficientnet_b4.demo -- --eval-mode on-device
```
## Deploying compiled model to Android
The models can be deployed using multiple runtimes:
- TensorFlow Lite (`.tflite` export): [This
tutorial](https://www.tensorflow.org/lite/android/quickstart) provides a
guide to deploy the .tflite model in an Android application.
- QNN (`.so` export ): This [sample
app](https://docs.qualcomm.com/bundle/publicresource/topics/80-63442-50/sample_app.html)
provides instructions on how to use the `.so` shared library in an Android application.
## View on Qualcomm® AI Hub
Get more details on EfficientNet-B4's performance across various devices [here](https://aihub.qualcomm.com/models/efficientnet_b4).
Explore all available models on [Qualcomm® AI Hub](https://aihub.qualcomm.com/)
## License
* The license for the original implementation of EfficientNet-B4 can be found
[here](https://github.com/pytorch/vision/blob/main/LICENSE).
* The license for the compiled assets for on-device deployment can be found [here](https://qaihub-public-assets.s3.us-west-2.amazonaws.com/qai-hub-models/Qualcomm+AI+Hub+Proprietary+License.pdf)
## References
* [EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks](https://arxiv.org/abs/1905.11946)
* [Source Model Implementation](https://github.com/pytorch/vision/blob/main/torchvision/models/efficientnet.py)
## Community
* Join [our AI Hub Slack community](https://aihub.qualcomm.com/community/slack) to collaborate, post questions and learn more about on-device AI.
* For questions or feedback please [reach out to us](mailto:ai-hub-support@qti.qualcomm.com).
|
thejaminator/gemma-feelings-step-11500
|
thejaminator
| 2025-08-26T16:31:37Z | 0 | 0 |
peft
|
[
"peft",
"safetensors",
"gemma2",
"base_model:google/gemma-2-9b-it",
"base_model:adapter:google/gemma-2-9b-it",
"region:us"
] | null | 2025-08-26T16:31:13Z |
---
base_model: google/gemma-2-9b-it
library_name: peft
---
# LoRA Adapter for SAE Introspection
This is a LoRA (Low-Rank Adaptation) adapter trained for SAE (Sparse Autoencoder) introspection tasks.
## Base Model
- **Base Model**: `google/gemma-2-9b-it`
- **Adapter Type**: LoRA
- **Task**: SAE Feature Introspection
## Usage
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
from peft import PeftModel
# Load base model and tokenizer
base_model = AutoModelForCausalLM.from_pretrained("google/gemma-2-9b-it")
tokenizer = AutoTokenizer.from_pretrained("google/gemma-2-9b-it")
# Load LoRA adapter
model = PeftModel.from_pretrained(base_model, "thejaminator/gemma-feelings-step-11500")
```
## Training Details
This adapter was trained using the lightweight SAE introspection training script to help the model understand and explain SAE features through activation steering.
|
qualcomm/DETR-ResNet101-DC5
|
qualcomm
| 2025-08-26T16:29:52Z | 14 | 0 |
pytorch
|
[
"pytorch",
"android",
"object-detection",
"arxiv:2005.12872",
"license:other",
"region:us"
] |
object-detection
| 2024-02-25T23:06:05Z |
---
library_name: pytorch
license: other
tags:
- android
pipeline_tag: object-detection
---

# DETR-ResNet101-DC5: Optimized for Mobile Deployment
## Transformer based object detector with ResNet101 backbone (dilated C5 stage)
DETR is a machine learning model that can detect objects (trained on COCO dataset).
This model is an implementation of DETR-ResNet101-DC5 found [here](https://github.com/facebookresearch/detr).
This repository provides scripts to run DETR-ResNet101-DC5 on Qualcomm® devices.
More details on model performance across various devices, can be found
[here](https://aihub.qualcomm.com/models/detr_resnet101_dc5).
### Model Details
- **Model Type:** Model_use_case.object_detection
- **Model Stats:**
- Model checkpoint: ResNet101-DC5
- Input resolution: 480x480
- Model size (float): 232 MB
| Model | Precision | Device | Chipset | Target Runtime | Inference Time (ms) | Peak Memory Range (MB) | Primary Compute Unit | Target Model
|---|---|---|---|---|---|---|---|---|
| DETR-ResNet101-DC5 | float | QCS8275 (Proxy) | Qualcomm® QCS8275 (Proxy) | QNN_DLC | 213.851 ms | 0 - 277 MB | NPU | [DETR-ResNet101-DC5.dlc](https://huggingface.co/qualcomm/DETR-ResNet101-DC5/blob/main/DETR-ResNet101-DC5.dlc) |
| DETR-ResNet101-DC5 | float | QCS8450 (Proxy) | Qualcomm® QCS8450 (Proxy) | QNN_DLC | 89.426 ms | 5 - 119 MB | NPU | [DETR-ResNet101-DC5.dlc](https://huggingface.co/qualcomm/DETR-ResNet101-DC5/blob/main/DETR-ResNet101-DC5.dlc) |
| DETR-ResNet101-DC5 | float | QCS8550 (Proxy) | Qualcomm® QCS8550 (Proxy) | QNN_DLC | 51.064 ms | 6 - 72 MB | NPU | [DETR-ResNet101-DC5.dlc](https://huggingface.co/qualcomm/DETR-ResNet101-DC5/blob/main/DETR-ResNet101-DC5.dlc) |
| DETR-ResNet101-DC5 | float | QCS9075 (Proxy) | Qualcomm® QCS9075 (Proxy) | QNN_DLC | 70.124 ms | 0 - 264 MB | NPU | [DETR-ResNet101-DC5.dlc](https://huggingface.co/qualcomm/DETR-ResNet101-DC5/blob/main/DETR-ResNet101-DC5.dlc) |
| DETR-ResNet101-DC5 | float | SA7255P ADP | Qualcomm® SA7255P | QNN_DLC | 213.851 ms | 0 - 277 MB | NPU | [DETR-ResNet101-DC5.dlc](https://huggingface.co/qualcomm/DETR-ResNet101-DC5/blob/main/DETR-ResNet101-DC5.dlc) |
| DETR-ResNet101-DC5 | float | SA8255 (Proxy) | Qualcomm® SA8255P (Proxy) | QNN_DLC | 50.965 ms | 5 - 68 MB | NPU | [DETR-ResNet101-DC5.dlc](https://huggingface.co/qualcomm/DETR-ResNet101-DC5/blob/main/DETR-ResNet101-DC5.dlc) |
| DETR-ResNet101-DC5 | float | SA8295P ADP | Qualcomm® SA8295P | QNN_DLC | 76.903 ms | 5 - 136 MB | NPU | [DETR-ResNet101-DC5.dlc](https://huggingface.co/qualcomm/DETR-ResNet101-DC5/blob/main/DETR-ResNet101-DC5.dlc) |
| DETR-ResNet101-DC5 | float | SA8650 (Proxy) | Qualcomm® SA8650P (Proxy) | QNN_DLC | 50.996 ms | 5 - 71 MB | NPU | [DETR-ResNet101-DC5.dlc](https://huggingface.co/qualcomm/DETR-ResNet101-DC5/blob/main/DETR-ResNet101-DC5.dlc) |
| DETR-ResNet101-DC5 | float | SA8775P ADP | Qualcomm® SA8775P | QNN_DLC | 70.124 ms | 0 - 264 MB | NPU | [DETR-ResNet101-DC5.dlc](https://huggingface.co/qualcomm/DETR-ResNet101-DC5/blob/main/DETR-ResNet101-DC5.dlc) |
| DETR-ResNet101-DC5 | float | Samsung Galaxy S23 | Snapdragon® 8 Gen 2 Mobile | QNN_DLC | 51.697 ms | 5 - 64 MB | NPU | [DETR-ResNet101-DC5.dlc](https://huggingface.co/qualcomm/DETR-ResNet101-DC5/blob/main/DETR-ResNet101-DC5.dlc) |
| DETR-ResNet101-DC5 | float | Samsung Galaxy S23 | Snapdragon® 8 Gen 2 Mobile | ONNX | 57.714 ms | 0 - 188 MB | NPU | [DETR-ResNet101-DC5.onnx.zip](https://huggingface.co/qualcomm/DETR-ResNet101-DC5/blob/main/DETR-ResNet101-DC5.onnx.zip) |
| DETR-ResNet101-DC5 | float | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | QNN_DLC | 37.572 ms | 5 - 276 MB | NPU | [DETR-ResNet101-DC5.dlc](https://huggingface.co/qualcomm/DETR-ResNet101-DC5/blob/main/DETR-ResNet101-DC5.dlc) |
| DETR-ResNet101-DC5 | float | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | ONNX | 42.306 ms | 5 - 225 MB | NPU | [DETR-ResNet101-DC5.onnx.zip](https://huggingface.co/qualcomm/DETR-ResNet101-DC5/blob/main/DETR-ResNet101-DC5.onnx.zip) |
| DETR-ResNet101-DC5 | float | Snapdragon 8 Elite QRD | Snapdragon® 8 Elite Mobile | QNN_DLC | 32.324 ms | 5 - 181 MB | NPU | [DETR-ResNet101-DC5.dlc](https://huggingface.co/qualcomm/DETR-ResNet101-DC5/blob/main/DETR-ResNet101-DC5.dlc) |
| DETR-ResNet101-DC5 | float | Snapdragon 8 Elite QRD | Snapdragon® 8 Elite Mobile | ONNX | 38.245 ms | 5 - 194 MB | NPU | [DETR-ResNet101-DC5.onnx.zip](https://huggingface.co/qualcomm/DETR-ResNet101-DC5/blob/main/DETR-ResNet101-DC5.onnx.zip) |
| DETR-ResNet101-DC5 | float | Snapdragon X Elite CRD | Snapdragon® X Elite | QNN_DLC | 52.243 ms | 76 - 76 MB | NPU | [DETR-ResNet101-DC5.dlc](https://huggingface.co/qualcomm/DETR-ResNet101-DC5/blob/main/DETR-ResNet101-DC5.dlc) |
| DETR-ResNet101-DC5 | float | Snapdragon X Elite CRD | Snapdragon® X Elite | ONNX | 58.877 ms | 117 - 117 MB | NPU | [DETR-ResNet101-DC5.onnx.zip](https://huggingface.co/qualcomm/DETR-ResNet101-DC5/blob/main/DETR-ResNet101-DC5.onnx.zip) |
## Installation
Install the package via pip:
```bash
pip install "qai-hub-models[detr-resnet101-dc5]"
```
## Configure Qualcomm® AI Hub to run this model on a cloud-hosted device
Sign-in to [Qualcomm® AI Hub](https://app.aihub.qualcomm.com/) with your
Qualcomm® ID. Once signed in navigate to `Account -> Settings -> API Token`.
With this API token, you can configure your client to run models on the cloud
hosted devices.
```bash
qai-hub configure --api_token API_TOKEN
```
Navigate to [docs](https://app.aihub.qualcomm.com/docs/) for more information.
## Demo off target
The package contains a simple end-to-end demo that downloads pre-trained
weights and runs this model on a sample input.
```bash
python -m qai_hub_models.models.detr_resnet101_dc5.demo
```
The above demo runs a reference implementation of pre-processing, model
inference, and post processing.
**NOTE**: If you want running in a Jupyter Notebook or Google Colab like
environment, please add the following to your cell (instead of the above).
```
%run -m qai_hub_models.models.detr_resnet101_dc5.demo
```
### Run model on a cloud-hosted device
In addition to the demo, you can also run the model on a cloud-hosted Qualcomm®
device. This script does the following:
* Performance check on-device on a cloud-hosted device
* Downloads compiled assets that can be deployed on-device for Android.
* Accuracy check between PyTorch and on-device outputs.
```bash
python -m qai_hub_models.models.detr_resnet101_dc5.export
```
## How does this work?
This [export script](https://aihub.qualcomm.com/models/detr_resnet101_dc5/qai_hub_models/models/DETR-ResNet101-DC5/export.py)
leverages [Qualcomm® AI Hub](https://aihub.qualcomm.com/) to optimize, validate, and deploy this model
on-device. Lets go through each step below in detail:
Step 1: **Compile model for on-device deployment**
To compile a PyTorch model for on-device deployment, we first trace the model
in memory using the `jit.trace` and then call the `submit_compile_job` API.
```python
import torch
import qai_hub as hub
from qai_hub_models.models.detr_resnet101_dc5 import Model
# Load the model
torch_model = Model.from_pretrained()
# Device
device = hub.Device("Samsung Galaxy S24")
# Trace model
input_shape = torch_model.get_input_spec()
sample_inputs = torch_model.sample_inputs()
pt_model = torch.jit.trace(torch_model, [torch.tensor(data[0]) for _, data in sample_inputs.items()])
# Compile model on a specific device
compile_job = hub.submit_compile_job(
model=pt_model,
device=device,
input_specs=torch_model.get_input_spec(),
)
# Get target model to run on-device
target_model = compile_job.get_target_model()
```
Step 2: **Performance profiling on cloud-hosted device**
After compiling models from step 1. Models can be profiled model on-device using the
`target_model`. Note that this scripts runs the model on a device automatically
provisioned in the cloud. Once the job is submitted, you can navigate to a
provided job URL to view a variety of on-device performance metrics.
```python
profile_job = hub.submit_profile_job(
model=target_model,
device=device,
)
```
Step 3: **Verify on-device accuracy**
To verify the accuracy of the model on-device, you can run on-device inference
on sample input data on the same cloud hosted device.
```python
input_data = torch_model.sample_inputs()
inference_job = hub.submit_inference_job(
model=target_model,
device=device,
inputs=input_data,
)
on_device_output = inference_job.download_output_data()
```
With the output of the model, you can compute like PSNR, relative errors or
spot check the output with expected output.
**Note**: This on-device profiling and inference requires access to Qualcomm®
AI Hub. [Sign up for access](https://myaccount.qualcomm.com/signup).
## Run demo on a cloud-hosted device
You can also run the demo on-device.
```bash
python -m qai_hub_models.models.detr_resnet101_dc5.demo --eval-mode on-device
```
**NOTE**: If you want running in a Jupyter Notebook or Google Colab like
environment, please add the following to your cell (instead of the above).
```
%run -m qai_hub_models.models.detr_resnet101_dc5.demo -- --eval-mode on-device
```
## Deploying compiled model to Android
The models can be deployed using multiple runtimes:
- TensorFlow Lite (`.tflite` export): [This
tutorial](https://www.tensorflow.org/lite/android/quickstart) provides a
guide to deploy the .tflite model in an Android application.
- QNN (`.so` export ): This [sample
app](https://docs.qualcomm.com/bundle/publicresource/topics/80-63442-50/sample_app.html)
provides instructions on how to use the `.so` shared library in an Android application.
## View on Qualcomm® AI Hub
Get more details on DETR-ResNet101-DC5's performance across various devices [here](https://aihub.qualcomm.com/models/detr_resnet101_dc5).
Explore all available models on [Qualcomm® AI Hub](https://aihub.qualcomm.com/)
## License
* The license for the original implementation of DETR-ResNet101-DC5 can be found
[here](https://github.com/facebookresearch/detr/blob/main/LICENSE).
* The license for the compiled assets for on-device deployment can be found [here](https://qaihub-public-assets.s3.us-west-2.amazonaws.com/qai-hub-models/Qualcomm+AI+Hub+Proprietary+License.pdf)
## References
* [End-to-End Object Detection with Transformers](https://arxiv.org/abs/2005.12872)
* [Source Model Implementation](https://github.com/facebookresearch/detr)
## Community
* Join [our AI Hub Slack community](https://aihub.qualcomm.com/community/slack) to collaborate, post questions and learn more about on-device AI.
* For questions or feedback please [reach out to us](mailto:ai-hub-support@qti.qualcomm.com).
|
pouiiq/blockassist-bc-tenacious_clawed_trout_1756225769
|
pouiiq
| 2025-08-26T16:29:46Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"tenacious clawed trout",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-26T16:29:30Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- tenacious clawed trout
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
qualcomm/DETR-ResNet101
|
qualcomm
| 2025-08-26T16:29:22Z | 35 | 0 |
pytorch
|
[
"pytorch",
"tflite",
"android",
"object-detection",
"arxiv:2005.12872",
"license:other",
"region:us"
] |
object-detection
| 2024-02-25T22:59:08Z |
---
library_name: pytorch
license: other
tags:
- android
pipeline_tag: object-detection
---

# DETR-ResNet101: Optimized for Mobile Deployment
## Transformer based object detector with ResNet101 backbone
DETR is a machine learning model that can detect objects (trained on COCO dataset).
This model is an implementation of DETR-ResNet101 found [here](https://github.com/facebookresearch/detr).
This repository provides scripts to run DETR-ResNet101 on Qualcomm® devices.
More details on model performance across various devices, can be found
[here](https://aihub.qualcomm.com/models/detr_resnet101).
### Model Details
- **Model Type:** Model_use_case.object_detection
- **Model Stats:**
- Model checkpoint: ResNet101
- Input resolution: 480x480
- Number of parameters: 60.3M
- Model size (float): 230 MB
| Model | Precision | Device | Chipset | Target Runtime | Inference Time (ms) | Peak Memory Range (MB) | Primary Compute Unit | Target Model
|---|---|---|---|---|---|---|---|---|
| DETR-ResNet101 | float | QCS8275 (Proxy) | Qualcomm® QCS8275 (Proxy) | TFLITE | 137.581 ms | 0 - 252 MB | NPU | [DETR-ResNet101.tflite](https://huggingface.co/qualcomm/DETR-ResNet101/blob/main/DETR-ResNet101.tflite) |
| DETR-ResNet101 | float | QCS8275 (Proxy) | Qualcomm® QCS8275 (Proxy) | QNN_DLC | 132.644 ms | 4 - 139 MB | NPU | [DETR-ResNet101.dlc](https://huggingface.co/qualcomm/DETR-ResNet101/blob/main/DETR-ResNet101.dlc) |
| DETR-ResNet101 | float | QCS8450 (Proxy) | Qualcomm® QCS8450 (Proxy) | TFLITE | 37.936 ms | 0 - 207 MB | NPU | [DETR-ResNet101.tflite](https://huggingface.co/qualcomm/DETR-ResNet101/blob/main/DETR-ResNet101.tflite) |
| DETR-ResNet101 | float | QCS8450 (Proxy) | Qualcomm® QCS8450 (Proxy) | QNN_DLC | 54.936 ms | 5 - 106 MB | NPU | [DETR-ResNet101.dlc](https://huggingface.co/qualcomm/DETR-ResNet101/blob/main/DETR-ResNet101.dlc) |
| DETR-ResNet101 | float | QCS8550 (Proxy) | Qualcomm® QCS8550 (Proxy) | TFLITE | 26.382 ms | 0 - 39 MB | NPU | [DETR-ResNet101.tflite](https://huggingface.co/qualcomm/DETR-ResNet101/blob/main/DETR-ResNet101.tflite) |
| DETR-ResNet101 | float | QCS8550 (Proxy) | Qualcomm® QCS8550 (Proxy) | QNN_DLC | 24.791 ms | 5 - 49 MB | NPU | [DETR-ResNet101.dlc](https://huggingface.co/qualcomm/DETR-ResNet101/blob/main/DETR-ResNet101.dlc) |
| DETR-ResNet101 | float | QCS9075 (Proxy) | Qualcomm® QCS9075 (Proxy) | TFLITE | 41.136 ms | 0 - 253 MB | NPU | [DETR-ResNet101.tflite](https://huggingface.co/qualcomm/DETR-ResNet101/blob/main/DETR-ResNet101.tflite) |
| DETR-ResNet101 | float | QCS9075 (Proxy) | Qualcomm® QCS9075 (Proxy) | QNN_DLC | 38.462 ms | 5 - 141 MB | NPU | [DETR-ResNet101.dlc](https://huggingface.co/qualcomm/DETR-ResNet101/blob/main/DETR-ResNet101.dlc) |
| DETR-ResNet101 | float | SA7255P ADP | Qualcomm® SA7255P | TFLITE | 137.581 ms | 0 - 252 MB | NPU | [DETR-ResNet101.tflite](https://huggingface.co/qualcomm/DETR-ResNet101/blob/main/DETR-ResNet101.tflite) |
| DETR-ResNet101 | float | SA7255P ADP | Qualcomm® SA7255P | QNN_DLC | 132.644 ms | 4 - 139 MB | NPU | [DETR-ResNet101.dlc](https://huggingface.co/qualcomm/DETR-ResNet101/blob/main/DETR-ResNet101.dlc) |
| DETR-ResNet101 | float | SA8255 (Proxy) | Qualcomm® SA8255P (Proxy) | TFLITE | 26.302 ms | 0 - 52 MB | NPU | [DETR-ResNet101.tflite](https://huggingface.co/qualcomm/DETR-ResNet101/blob/main/DETR-ResNet101.tflite) |
| DETR-ResNet101 | float | SA8255 (Proxy) | Qualcomm® SA8255P (Proxy) | QNN_DLC | 24.827 ms | 4 - 50 MB | NPU | [DETR-ResNet101.dlc](https://huggingface.co/qualcomm/DETR-ResNet101/blob/main/DETR-ResNet101.dlc) |
| DETR-ResNet101 | float | SA8295P ADP | Qualcomm® SA8295P | TFLITE | 44.094 ms | 0 - 198 MB | NPU | [DETR-ResNet101.tflite](https://huggingface.co/qualcomm/DETR-ResNet101/blob/main/DETR-ResNet101.tflite) |
| DETR-ResNet101 | float | SA8295P ADP | Qualcomm® SA8295P | QNN_DLC | 43.712 ms | 5 - 148 MB | NPU | [DETR-ResNet101.dlc](https://huggingface.co/qualcomm/DETR-ResNet101/blob/main/DETR-ResNet101.dlc) |
| DETR-ResNet101 | float | SA8650 (Proxy) | Qualcomm® SA8650P (Proxy) | TFLITE | 26.407 ms | 0 - 45 MB | NPU | [DETR-ResNet101.tflite](https://huggingface.co/qualcomm/DETR-ResNet101/blob/main/DETR-ResNet101.tflite) |
| DETR-ResNet101 | float | SA8650 (Proxy) | Qualcomm® SA8650P (Proxy) | QNN_DLC | 24.977 ms | 5 - 50 MB | NPU | [DETR-ResNet101.dlc](https://huggingface.co/qualcomm/DETR-ResNet101/blob/main/DETR-ResNet101.dlc) |
| DETR-ResNet101 | float | SA8775P ADP | Qualcomm® SA8775P | TFLITE | 41.136 ms | 0 - 253 MB | NPU | [DETR-ResNet101.tflite](https://huggingface.co/qualcomm/DETR-ResNet101/blob/main/DETR-ResNet101.tflite) |
| DETR-ResNet101 | float | SA8775P ADP | Qualcomm® SA8775P | QNN_DLC | 38.462 ms | 5 - 141 MB | NPU | [DETR-ResNet101.dlc](https://huggingface.co/qualcomm/DETR-ResNet101/blob/main/DETR-ResNet101.dlc) |
| DETR-ResNet101 | float | Samsung Galaxy S23 | Snapdragon® 8 Gen 2 Mobile | TFLITE | 26.07 ms | 0 - 46 MB | NPU | [DETR-ResNet101.tflite](https://huggingface.co/qualcomm/DETR-ResNet101/blob/main/DETR-ResNet101.tflite) |
| DETR-ResNet101 | float | Samsung Galaxy S23 | Snapdragon® 8 Gen 2 Mobile | QNN_DLC | 24.605 ms | 5 - 51 MB | NPU | [DETR-ResNet101.dlc](https://huggingface.co/qualcomm/DETR-ResNet101/blob/main/DETR-ResNet101.dlc) |
| DETR-ResNet101 | float | Samsung Galaxy S23 | Snapdragon® 8 Gen 2 Mobile | ONNX | 24.961 ms | 0 - 257 MB | NPU | [DETR-ResNet101.onnx.zip](https://huggingface.co/qualcomm/DETR-ResNet101/blob/main/DETR-ResNet101.onnx.zip) |
| DETR-ResNet101 | float | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | TFLITE | 18.84 ms | 0 - 262 MB | NPU | [DETR-ResNet101.tflite](https://huggingface.co/qualcomm/DETR-ResNet101/blob/main/DETR-ResNet101.tflite) |
| DETR-ResNet101 | float | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | QNN_DLC | 17.863 ms | 5 - 144 MB | NPU | [DETR-ResNet101.dlc](https://huggingface.co/qualcomm/DETR-ResNet101/blob/main/DETR-ResNet101.dlc) |
| DETR-ResNet101 | float | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | ONNX | 18.751 ms | 3 - 203 MB | NPU | [DETR-ResNet101.onnx.zip](https://huggingface.co/qualcomm/DETR-ResNet101/blob/main/DETR-ResNet101.onnx.zip) |
| DETR-ResNet101 | float | Snapdragon 8 Elite QRD | Snapdragon® 8 Elite Mobile | TFLITE | 17.843 ms | 0 - 251 MB | NPU | [DETR-ResNet101.tflite](https://huggingface.co/qualcomm/DETR-ResNet101/blob/main/DETR-ResNet101.tflite) |
| DETR-ResNet101 | float | Snapdragon 8 Elite QRD | Snapdragon® 8 Elite Mobile | QNN_DLC | 16.997 ms | 5 - 141 MB | NPU | [DETR-ResNet101.dlc](https://huggingface.co/qualcomm/DETR-ResNet101/blob/main/DETR-ResNet101.dlc) |
| DETR-ResNet101 | float | Snapdragon 8 Elite QRD | Snapdragon® 8 Elite Mobile | ONNX | 17.901 ms | 5 - 165 MB | NPU | [DETR-ResNet101.onnx.zip](https://huggingface.co/qualcomm/DETR-ResNet101/blob/main/DETR-ResNet101.onnx.zip) |
| DETR-ResNet101 | float | Snapdragon X Elite CRD | Snapdragon® X Elite | QNN_DLC | 25.502 ms | 297 - 297 MB | NPU | [DETR-ResNet101.dlc](https://huggingface.co/qualcomm/DETR-ResNet101/blob/main/DETR-ResNet101.dlc) |
| DETR-ResNet101 | float | Snapdragon X Elite CRD | Snapdragon® X Elite | ONNX | 25.463 ms | 115 - 115 MB | NPU | [DETR-ResNet101.onnx.zip](https://huggingface.co/qualcomm/DETR-ResNet101/blob/main/DETR-ResNet101.onnx.zip) |
## Installation
Install the package via pip:
```bash
pip install "qai-hub-models[detr-resnet101]"
```
## Configure Qualcomm® AI Hub to run this model on a cloud-hosted device
Sign-in to [Qualcomm® AI Hub](https://app.aihub.qualcomm.com/) with your
Qualcomm® ID. Once signed in navigate to `Account -> Settings -> API Token`.
With this API token, you can configure your client to run models on the cloud
hosted devices.
```bash
qai-hub configure --api_token API_TOKEN
```
Navigate to [docs](https://app.aihub.qualcomm.com/docs/) for more information.
## Demo off target
The package contains a simple end-to-end demo that downloads pre-trained
weights and runs this model on a sample input.
```bash
python -m qai_hub_models.models.detr_resnet101.demo
```
The above demo runs a reference implementation of pre-processing, model
inference, and post processing.
**NOTE**: If you want running in a Jupyter Notebook or Google Colab like
environment, please add the following to your cell (instead of the above).
```
%run -m qai_hub_models.models.detr_resnet101.demo
```
### Run model on a cloud-hosted device
In addition to the demo, you can also run the model on a cloud-hosted Qualcomm®
device. This script does the following:
* Performance check on-device on a cloud-hosted device
* Downloads compiled assets that can be deployed on-device for Android.
* Accuracy check between PyTorch and on-device outputs.
```bash
python -m qai_hub_models.models.detr_resnet101.export
```
## How does this work?
This [export script](https://aihub.qualcomm.com/models/detr_resnet101/qai_hub_models/models/DETR-ResNet101/export.py)
leverages [Qualcomm® AI Hub](https://aihub.qualcomm.com/) to optimize, validate, and deploy this model
on-device. Lets go through each step below in detail:
Step 1: **Compile model for on-device deployment**
To compile a PyTorch model for on-device deployment, we first trace the model
in memory using the `jit.trace` and then call the `submit_compile_job` API.
```python
import torch
import qai_hub as hub
from qai_hub_models.models.detr_resnet101 import Model
# Load the model
torch_model = Model.from_pretrained()
# Device
device = hub.Device("Samsung Galaxy S24")
# Trace model
input_shape = torch_model.get_input_spec()
sample_inputs = torch_model.sample_inputs()
pt_model = torch.jit.trace(torch_model, [torch.tensor(data[0]) for _, data in sample_inputs.items()])
# Compile model on a specific device
compile_job = hub.submit_compile_job(
model=pt_model,
device=device,
input_specs=torch_model.get_input_spec(),
)
# Get target model to run on-device
target_model = compile_job.get_target_model()
```
Step 2: **Performance profiling on cloud-hosted device**
After compiling models from step 1. Models can be profiled model on-device using the
`target_model`. Note that this scripts runs the model on a device automatically
provisioned in the cloud. Once the job is submitted, you can navigate to a
provided job URL to view a variety of on-device performance metrics.
```python
profile_job = hub.submit_profile_job(
model=target_model,
device=device,
)
```
Step 3: **Verify on-device accuracy**
To verify the accuracy of the model on-device, you can run on-device inference
on sample input data on the same cloud hosted device.
```python
input_data = torch_model.sample_inputs()
inference_job = hub.submit_inference_job(
model=target_model,
device=device,
inputs=input_data,
)
on_device_output = inference_job.download_output_data()
```
With the output of the model, you can compute like PSNR, relative errors or
spot check the output with expected output.
**Note**: This on-device profiling and inference requires access to Qualcomm®
AI Hub. [Sign up for access](https://myaccount.qualcomm.com/signup).
## Run demo on a cloud-hosted device
You can also run the demo on-device.
```bash
python -m qai_hub_models.models.detr_resnet101.demo --eval-mode on-device
```
**NOTE**: If you want running in a Jupyter Notebook or Google Colab like
environment, please add the following to your cell (instead of the above).
```
%run -m qai_hub_models.models.detr_resnet101.demo -- --eval-mode on-device
```
## Deploying compiled model to Android
The models can be deployed using multiple runtimes:
- TensorFlow Lite (`.tflite` export): [This
tutorial](https://www.tensorflow.org/lite/android/quickstart) provides a
guide to deploy the .tflite model in an Android application.
- QNN (`.so` export ): This [sample
app](https://docs.qualcomm.com/bundle/publicresource/topics/80-63442-50/sample_app.html)
provides instructions on how to use the `.so` shared library in an Android application.
## View on Qualcomm® AI Hub
Get more details on DETR-ResNet101's performance across various devices [here](https://aihub.qualcomm.com/models/detr_resnet101).
Explore all available models on [Qualcomm® AI Hub](https://aihub.qualcomm.com/)
## License
* The license for the original implementation of DETR-ResNet101 can be found
[here](https://github.com/facebookresearch/detr/blob/main/LICENSE).
* The license for the compiled assets for on-device deployment can be found [here](https://qaihub-public-assets.s3.us-west-2.amazonaws.com/qai-hub-models/Qualcomm+AI+Hub+Proprietary+License.pdf)
## References
* [End-to-End Object Detection with Transformers](https://arxiv.org/abs/2005.12872)
* [Source Model Implementation](https://github.com/facebookresearch/detr)
## Community
* Join [our AI Hub Slack community](https://aihub.qualcomm.com/community/slack) to collaborate, post questions and learn more about on-device AI.
* For questions or feedback please [reach out to us](mailto:ai-hub-support@qti.qualcomm.com).
|
nikki-bhati-viral-video/wATCH.full.videos.nikki.bhati.viral.video.Official
|
nikki-bhati-viral-video
| 2025-08-26T16:27:22Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-08-26T16:27:04Z |
<animated-image data-catalyst=""><a href="https://tinyurl.com/mdfprj9k?viral-video" rel="nofollow" data-target="animated-image.originalLink"><img src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" alt="Foo" data-canonical-src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" style="max-width: 100%; display: inline-block;" data-target="animated-image.originalImage"></a>
|
capungmerah627/blockassist-bc-stinging_soaring_porcupine_1756224000
|
capungmerah627
| 2025-08-26T16:26:12Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"stinging soaring porcupine",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-26T16:26:08Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- stinging soaring porcupine
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
qualcomm/DDRNet23-Slim
|
qualcomm
| 2025-08-26T16:25:57Z | 23 | 0 |
pytorch
|
[
"pytorch",
"tflite",
"real_time",
"android",
"image-segmentation",
"arxiv:2101.06085",
"license:other",
"region:us"
] |
image-segmentation
| 2024-02-25T23:04:37Z |
---
library_name: pytorch
license: other
tags:
- real_time
- android
pipeline_tag: image-segmentation
---

# DDRNet23-Slim: Optimized for Mobile Deployment
## Segment images or video by class in real-time on device
DDRNet23Slim is a machine learning model that segments an image into semantic classes, specifically designed for road-based scenes. It is designed for the application of self-driving cars.
This model is an implementation of DDRNet23-Slim found [here](https://github.com/chenjun2hao/DDRNet.pytorch).
This repository provides scripts to run DDRNet23-Slim on Qualcomm® devices.
More details on model performance across various devices, can be found
[here](https://aihub.qualcomm.com/models/ddrnet23_slim).
### Model Details
- **Model Type:** Model_use_case.semantic_segmentation
- **Model Stats:**
- Model checkpoint: DDRNet23s_imagenet.pth
- Inference latency: RealTime
- Input resolution: 2048x1024
- Number of output classes: 19
- Number of parameters: 6.13M
- Model size (float): 21.7 MB
- Model size (w8a8): 6.11 MB
| Model | Precision | Device | Chipset | Target Runtime | Inference Time (ms) | Peak Memory Range (MB) | Primary Compute Unit | Target Model
|---|---|---|---|---|---|---|---|---|
| DDRNet23-Slim | float | QCS8275 (Proxy) | Qualcomm® QCS8275 (Proxy) | TFLITE | 112.907 ms | 2 - 50 MB | NPU | [DDRNet23-Slim.tflite](https://huggingface.co/qualcomm/DDRNet23-Slim/blob/main/DDRNet23-Slim.tflite) |
| DDRNet23-Slim | float | QCS8275 (Proxy) | Qualcomm® QCS8275 (Proxy) | QNN_DLC | 95.053 ms | 23 - 78 MB | NPU | [DDRNet23-Slim.dlc](https://huggingface.co/qualcomm/DDRNet23-Slim/blob/main/DDRNet23-Slim.dlc) |
| DDRNet23-Slim | float | QCS8450 (Proxy) | Qualcomm® QCS8450 (Proxy) | TFLITE | 48.825 ms | 2 - 62 MB | NPU | [DDRNet23-Slim.tflite](https://huggingface.co/qualcomm/DDRNet23-Slim/blob/main/DDRNet23-Slim.tflite) |
| DDRNet23-Slim | float | QCS8450 (Proxy) | Qualcomm® QCS8450 (Proxy) | QNN_DLC | 59.275 ms | 24 - 87 MB | NPU | [DDRNet23-Slim.dlc](https://huggingface.co/qualcomm/DDRNet23-Slim/blob/main/DDRNet23-Slim.dlc) |
| DDRNet23-Slim | float | QCS8550 (Proxy) | Qualcomm® QCS8550 (Proxy) | TFLITE | 41.568 ms | 2 - 26 MB | NPU | [DDRNet23-Slim.tflite](https://huggingface.co/qualcomm/DDRNet23-Slim/blob/main/DDRNet23-Slim.tflite) |
| DDRNet23-Slim | float | QCS8550 (Proxy) | Qualcomm® QCS8550 (Proxy) | QNN_DLC | 31.531 ms | 24 - 49 MB | NPU | [DDRNet23-Slim.dlc](https://huggingface.co/qualcomm/DDRNet23-Slim/blob/main/DDRNet23-Slim.dlc) |
| DDRNet23-Slim | float | QCS9075 (Proxy) | Qualcomm® QCS9075 (Proxy) | TFLITE | 49.814 ms | 2 - 50 MB | NPU | [DDRNet23-Slim.tflite](https://huggingface.co/qualcomm/DDRNet23-Slim/blob/main/DDRNet23-Slim.tflite) |
| DDRNet23-Slim | float | QCS9075 (Proxy) | Qualcomm® QCS9075 (Proxy) | QNN_DLC | 38.6 ms | 24 - 79 MB | NPU | [DDRNet23-Slim.dlc](https://huggingface.co/qualcomm/DDRNet23-Slim/blob/main/DDRNet23-Slim.dlc) |
| DDRNet23-Slim | float | SA7255P ADP | Qualcomm® SA7255P | TFLITE | 112.907 ms | 2 - 50 MB | NPU | [DDRNet23-Slim.tflite](https://huggingface.co/qualcomm/DDRNet23-Slim/blob/main/DDRNet23-Slim.tflite) |
| DDRNet23-Slim | float | SA7255P ADP | Qualcomm® SA7255P | QNN_DLC | 95.053 ms | 23 - 78 MB | NPU | [DDRNet23-Slim.dlc](https://huggingface.co/qualcomm/DDRNet23-Slim/blob/main/DDRNet23-Slim.dlc) |
| DDRNet23-Slim | float | SA8255 (Proxy) | Qualcomm® SA8255P (Proxy) | TFLITE | 41.881 ms | 2 - 27 MB | NPU | [DDRNet23-Slim.tflite](https://huggingface.co/qualcomm/DDRNet23-Slim/blob/main/DDRNet23-Slim.tflite) |
| DDRNet23-Slim | float | SA8255 (Proxy) | Qualcomm® SA8255P (Proxy) | QNN_DLC | 31.449 ms | 25 - 53 MB | NPU | [DDRNet23-Slim.dlc](https://huggingface.co/qualcomm/DDRNet23-Slim/blob/main/DDRNet23-Slim.dlc) |
| DDRNet23-Slim | float | SA8295P ADP | Qualcomm® SA8295P | TFLITE | 55.478 ms | 2 - 56 MB | NPU | [DDRNet23-Slim.tflite](https://huggingface.co/qualcomm/DDRNet23-Slim/blob/main/DDRNet23-Slim.tflite) |
| DDRNet23-Slim | float | SA8295P ADP | Qualcomm® SA8295P | QNN_DLC | 42.249 ms | 0 - 60 MB | NPU | [DDRNet23-Slim.dlc](https://huggingface.co/qualcomm/DDRNet23-Slim/blob/main/DDRNet23-Slim.dlc) |
| DDRNet23-Slim | float | SA8650 (Proxy) | Qualcomm® SA8650P (Proxy) | TFLITE | 41.898 ms | 2 - 26 MB | NPU | [DDRNet23-Slim.tflite](https://huggingface.co/qualcomm/DDRNet23-Slim/blob/main/DDRNet23-Slim.tflite) |
| DDRNet23-Slim | float | SA8650 (Proxy) | Qualcomm® SA8650P (Proxy) | QNN_DLC | 31.071 ms | 24 - 44 MB | NPU | [DDRNet23-Slim.dlc](https://huggingface.co/qualcomm/DDRNet23-Slim/blob/main/DDRNet23-Slim.dlc) |
| DDRNet23-Slim | float | SA8775P ADP | Qualcomm® SA8775P | TFLITE | 49.814 ms | 2 - 50 MB | NPU | [DDRNet23-Slim.tflite](https://huggingface.co/qualcomm/DDRNet23-Slim/blob/main/DDRNet23-Slim.tflite) |
| DDRNet23-Slim | float | SA8775P ADP | Qualcomm® SA8775P | QNN_DLC | 38.6 ms | 24 - 79 MB | NPU | [DDRNet23-Slim.dlc](https://huggingface.co/qualcomm/DDRNet23-Slim/blob/main/DDRNet23-Slim.dlc) |
| DDRNet23-Slim | float | Samsung Galaxy S23 | Snapdragon® 8 Gen 2 Mobile | TFLITE | 41.679 ms | 2 - 33 MB | NPU | [DDRNet23-Slim.tflite](https://huggingface.co/qualcomm/DDRNet23-Slim/blob/main/DDRNet23-Slim.tflite) |
| DDRNet23-Slim | float | Samsung Galaxy S23 | Snapdragon® 8 Gen 2 Mobile | QNN_DLC | 31.398 ms | 24 - 45 MB | NPU | [DDRNet23-Slim.dlc](https://huggingface.co/qualcomm/DDRNet23-Slim/blob/main/DDRNet23-Slim.dlc) |
| DDRNet23-Slim | float | Samsung Galaxy S23 | Snapdragon® 8 Gen 2 Mobile | ONNX | 25.654 ms | 26 - 72 MB | NPU | [DDRNet23-Slim.onnx.zip](https://huggingface.co/qualcomm/DDRNet23-Slim/blob/main/DDRNet23-Slim.onnx.zip) |
| DDRNet23-Slim | float | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | TFLITE | 26.919 ms | 1 - 54 MB | NPU | [DDRNet23-Slim.tflite](https://huggingface.co/qualcomm/DDRNet23-Slim/blob/main/DDRNet23-Slim.tflite) |
| DDRNet23-Slim | float | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | QNN_DLC | 20.86 ms | 22 - 78 MB | NPU | [DDRNet23-Slim.dlc](https://huggingface.co/qualcomm/DDRNet23-Slim/blob/main/DDRNet23-Slim.dlc) |
| DDRNet23-Slim | float | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | ONNX | 17.214 ms | 29 - 83 MB | NPU | [DDRNet23-Slim.onnx.zip](https://huggingface.co/qualcomm/DDRNet23-Slim/blob/main/DDRNet23-Slim.onnx.zip) |
| DDRNet23-Slim | float | Snapdragon 8 Elite QRD | Snapdragon® 8 Elite Mobile | TFLITE | 25.675 ms | 1 - 52 MB | NPU | [DDRNet23-Slim.tflite](https://huggingface.co/qualcomm/DDRNet23-Slim/blob/main/DDRNet23-Slim.tflite) |
| DDRNet23-Slim | float | Snapdragon 8 Elite QRD | Snapdragon® 8 Elite Mobile | QNN_DLC | 18.246 ms | 24 - 92 MB | NPU | [DDRNet23-Slim.dlc](https://huggingface.co/qualcomm/DDRNet23-Slim/blob/main/DDRNet23-Slim.dlc) |
| DDRNet23-Slim | float | Snapdragon 8 Elite QRD | Snapdragon® 8 Elite Mobile | ONNX | 14.626 ms | 29 - 82 MB | NPU | [DDRNet23-Slim.onnx.zip](https://huggingface.co/qualcomm/DDRNet23-Slim/blob/main/DDRNet23-Slim.onnx.zip) |
| DDRNet23-Slim | float | Snapdragon X Elite CRD | Snapdragon® X Elite | QNN_DLC | 31.939 ms | 30 - 30 MB | NPU | [DDRNet23-Slim.dlc](https://huggingface.co/qualcomm/DDRNet23-Slim/blob/main/DDRNet23-Slim.dlc) |
| DDRNet23-Slim | float | Snapdragon X Elite CRD | Snapdragon® X Elite | ONNX | 27.939 ms | 24 - 24 MB | NPU | [DDRNet23-Slim.onnx.zip](https://huggingface.co/qualcomm/DDRNet23-Slim/blob/main/DDRNet23-Slim.onnx.zip) |
| DDRNet23-Slim | w8a8 | QCS8275 (Proxy) | Qualcomm® QCS8275 (Proxy) | TFLITE | 98.297 ms | 1 - 37 MB | NPU | [DDRNet23-Slim.tflite](https://huggingface.co/qualcomm/DDRNet23-Slim/blob/main/DDRNet23-Slim_w8a8.tflite) |
| DDRNet23-Slim | w8a8 | QCS8275 (Proxy) | Qualcomm® QCS8275 (Proxy) | QNN_DLC | 139.496 ms | 6 - 61 MB | NPU | [DDRNet23-Slim.dlc](https://huggingface.co/qualcomm/DDRNet23-Slim/blob/main/DDRNet23-Slim_w8a8.dlc) |
| DDRNet23-Slim | w8a8 | QCS8450 (Proxy) | Qualcomm® QCS8450 (Proxy) | TFLITE | 50.094 ms | 1 - 55 MB | NPU | [DDRNet23-Slim.tflite](https://huggingface.co/qualcomm/DDRNet23-Slim/blob/main/DDRNet23-Slim_w8a8.tflite) |
| DDRNet23-Slim | w8a8 | QCS8450 (Proxy) | Qualcomm® QCS8450 (Proxy) | QNN_DLC | 78.074 ms | 6 - 74 MB | NPU | [DDRNet23-Slim.dlc](https://huggingface.co/qualcomm/DDRNet23-Slim/blob/main/DDRNet23-Slim_w8a8.dlc) |
| DDRNet23-Slim | w8a8 | QCS8550 (Proxy) | Qualcomm® QCS8550 (Proxy) | TFLITE | 49.929 ms | 0 - 18 MB | NPU | [DDRNet23-Slim.tflite](https://huggingface.co/qualcomm/DDRNet23-Slim/blob/main/DDRNet23-Slim_w8a8.tflite) |
| DDRNet23-Slim | w8a8 | QCS8550 (Proxy) | Qualcomm® QCS8550 (Proxy) | QNN_DLC | 72.488 ms | 6 - 25 MB | NPU | [DDRNet23-Slim.dlc](https://huggingface.co/qualcomm/DDRNet23-Slim/blob/main/DDRNet23-Slim_w8a8.dlc) |
| DDRNet23-Slim | w8a8 | QCS9075 (Proxy) | Qualcomm® QCS9075 (Proxy) | TFLITE | 50.829 ms | 1 - 37 MB | NPU | [DDRNet23-Slim.tflite](https://huggingface.co/qualcomm/DDRNet23-Slim/blob/main/DDRNet23-Slim_w8a8.tflite) |
| DDRNet23-Slim | w8a8 | QCS9075 (Proxy) | Qualcomm® QCS9075 (Proxy) | QNN_DLC | 73.329 ms | 6 - 61 MB | NPU | [DDRNet23-Slim.dlc](https://huggingface.co/qualcomm/DDRNet23-Slim/blob/main/DDRNet23-Slim_w8a8.dlc) |
| DDRNet23-Slim | w8a8 | RB3 Gen 2 (Proxy) | Qualcomm® QCS6490 (Proxy) | TFLITE | 160.751 ms | 11 - 59 MB | NPU | [DDRNet23-Slim.tflite](https://huggingface.co/qualcomm/DDRNet23-Slim/blob/main/DDRNet23-Slim_w8a8.tflite) |
| DDRNet23-Slim | w8a8 | RB5 (Proxy) | Qualcomm® QCS8250 (Proxy) | TFLITE | 324.656 ms | 16 - 27 MB | NPU | [DDRNet23-Slim.tflite](https://huggingface.co/qualcomm/DDRNet23-Slim/blob/main/DDRNet23-Slim_w8a8.tflite) |
| DDRNet23-Slim | w8a8 | SA7255P ADP | Qualcomm® SA7255P | TFLITE | 98.297 ms | 1 - 37 MB | NPU | [DDRNet23-Slim.tflite](https://huggingface.co/qualcomm/DDRNet23-Slim/blob/main/DDRNet23-Slim_w8a8.tflite) |
| DDRNet23-Slim | w8a8 | SA7255P ADP | Qualcomm® SA7255P | QNN_DLC | 139.496 ms | 6 - 61 MB | NPU | [DDRNet23-Slim.dlc](https://huggingface.co/qualcomm/DDRNet23-Slim/blob/main/DDRNet23-Slim_w8a8.dlc) |
| DDRNet23-Slim | w8a8 | SA8255 (Proxy) | Qualcomm® SA8255P (Proxy) | TFLITE | 50.017 ms | 0 - 18 MB | NPU | [DDRNet23-Slim.tflite](https://huggingface.co/qualcomm/DDRNet23-Slim/blob/main/DDRNet23-Slim_w8a8.tflite) |
| DDRNet23-Slim | w8a8 | SA8255 (Proxy) | Qualcomm® SA8255P (Proxy) | QNN_DLC | 72.535 ms | 6 - 29 MB | NPU | [DDRNet23-Slim.dlc](https://huggingface.co/qualcomm/DDRNet23-Slim/blob/main/DDRNet23-Slim_w8a8.dlc) |
| DDRNet23-Slim | w8a8 | SA8295P ADP | Qualcomm® SA8295P | TFLITE | 58.227 ms | 1 - 44 MB | NPU | [DDRNet23-Slim.tflite](https://huggingface.co/qualcomm/DDRNet23-Slim/blob/main/DDRNet23-Slim_w8a8.tflite) |
| DDRNet23-Slim | w8a8 | SA8295P ADP | Qualcomm® SA8295P | QNN_DLC | 82.98 ms | 6 - 64 MB | NPU | [DDRNet23-Slim.dlc](https://huggingface.co/qualcomm/DDRNet23-Slim/blob/main/DDRNet23-Slim_w8a8.dlc) |
| DDRNet23-Slim | w8a8 | SA8650 (Proxy) | Qualcomm® SA8650P (Proxy) | TFLITE | 50.303 ms | 0 - 18 MB | NPU | [DDRNet23-Slim.tflite](https://huggingface.co/qualcomm/DDRNet23-Slim/blob/main/DDRNet23-Slim_w8a8.tflite) |
| DDRNet23-Slim | w8a8 | SA8650 (Proxy) | Qualcomm® SA8650P (Proxy) | QNN_DLC | 72.598 ms | 6 - 29 MB | NPU | [DDRNet23-Slim.dlc](https://huggingface.co/qualcomm/DDRNet23-Slim/blob/main/DDRNet23-Slim_w8a8.dlc) |
| DDRNet23-Slim | w8a8 | SA8775P ADP | Qualcomm® SA8775P | TFLITE | 50.829 ms | 1 - 37 MB | NPU | [DDRNet23-Slim.tflite](https://huggingface.co/qualcomm/DDRNet23-Slim/blob/main/DDRNet23-Slim_w8a8.tflite) |
| DDRNet23-Slim | w8a8 | SA8775P ADP | Qualcomm® SA8775P | QNN_DLC | 73.329 ms | 6 - 61 MB | NPU | [DDRNet23-Slim.dlc](https://huggingface.co/qualcomm/DDRNet23-Slim/blob/main/DDRNet23-Slim_w8a8.dlc) |
| DDRNet23-Slim | w8a8 | Samsung Galaxy S23 | Snapdragon® 8 Gen 2 Mobile | TFLITE | 49.958 ms | 0 - 19 MB | NPU | [DDRNet23-Slim.tflite](https://huggingface.co/qualcomm/DDRNet23-Slim/blob/main/DDRNet23-Slim_w8a8.tflite) |
| DDRNet23-Slim | w8a8 | Samsung Galaxy S23 | Snapdragon® 8 Gen 2 Mobile | QNN_DLC | 72.609 ms | 6 - 26 MB | NPU | [DDRNet23-Slim.dlc](https://huggingface.co/qualcomm/DDRNet23-Slim/blob/main/DDRNet23-Slim_w8a8.dlc) |
| DDRNet23-Slim | w8a8 | Samsung Galaxy S23 | Snapdragon® 8 Gen 2 Mobile | ONNX | 105.609 ms | 84 - 143 MB | NPU | [DDRNet23-Slim.onnx.zip](https://huggingface.co/qualcomm/DDRNet23-Slim/blob/main/DDRNet23-Slim_w8a8.onnx.zip) |
| DDRNet23-Slim | w8a8 | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | TFLITE | 37.781 ms | 1 - 52 MB | NPU | [DDRNet23-Slim.tflite](https://huggingface.co/qualcomm/DDRNet23-Slim/blob/main/DDRNet23-Slim_w8a8.tflite) |
| DDRNet23-Slim | w8a8 | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | QNN_DLC | 54.873 ms | 6 - 71 MB | NPU | [DDRNet23-Slim.dlc](https://huggingface.co/qualcomm/DDRNet23-Slim/blob/main/DDRNet23-Slim_w8a8.dlc) |
| DDRNet23-Slim | w8a8 | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | ONNX | 81.855 ms | 102 - 458 MB | NPU | [DDRNet23-Slim.onnx.zip](https://huggingface.co/qualcomm/DDRNet23-Slim/blob/main/DDRNet23-Slim_w8a8.onnx.zip) |
| DDRNet23-Slim | w8a8 | Snapdragon 8 Elite QRD | Snapdragon® 8 Elite Mobile | TFLITE | 46.082 ms | 1 - 42 MB | NPU | [DDRNet23-Slim.tflite](https://huggingface.co/qualcomm/DDRNet23-Slim/blob/main/DDRNet23-Slim_w8a8.tflite) |
| DDRNet23-Slim | w8a8 | Snapdragon 8 Elite QRD | Snapdragon® 8 Elite Mobile | QNN_DLC | 50.387 ms | 6 - 72 MB | NPU | [DDRNet23-Slim.dlc](https://huggingface.co/qualcomm/DDRNet23-Slim/blob/main/DDRNet23-Slim_w8a8.dlc) |
| DDRNet23-Slim | w8a8 | Snapdragon 8 Elite QRD | Snapdragon® 8 Elite Mobile | ONNX | 71.544 ms | 98 - 538 MB | NPU | [DDRNet23-Slim.onnx.zip](https://huggingface.co/qualcomm/DDRNet23-Slim/blob/main/DDRNet23-Slim_w8a8.onnx.zip) |
| DDRNet23-Slim | w8a8 | Snapdragon X Elite CRD | Snapdragon® X Elite | QNN_DLC | 76.14 ms | 19 - 19 MB | NPU | [DDRNet23-Slim.dlc](https://huggingface.co/qualcomm/DDRNet23-Slim/blob/main/DDRNet23-Slim_w8a8.dlc) |
| DDRNet23-Slim | w8a8 | Snapdragon X Elite CRD | Snapdragon® X Elite | ONNX | 110.529 ms | 128 - 128 MB | NPU | [DDRNet23-Slim.onnx.zip](https://huggingface.co/qualcomm/DDRNet23-Slim/blob/main/DDRNet23-Slim_w8a8.onnx.zip) |
## Installation
Install the package via pip:
```bash
pip install qai-hub-models
```
## Configure Qualcomm® AI Hub to run this model on a cloud-hosted device
Sign-in to [Qualcomm® AI Hub](https://app.aihub.qualcomm.com/) with your
Qualcomm® ID. Once signed in navigate to `Account -> Settings -> API Token`.
With this API token, you can configure your client to run models on the cloud
hosted devices.
```bash
qai-hub configure --api_token API_TOKEN
```
Navigate to [docs](https://app.aihub.qualcomm.com/docs/) for more information.
## Demo off target
The package contains a simple end-to-end demo that downloads pre-trained
weights and runs this model on a sample input.
```bash
python -m qai_hub_models.models.ddrnet23_slim.demo
```
The above demo runs a reference implementation of pre-processing, model
inference, and post processing.
**NOTE**: If you want running in a Jupyter Notebook or Google Colab like
environment, please add the following to your cell (instead of the above).
```
%run -m qai_hub_models.models.ddrnet23_slim.demo
```
### Run model on a cloud-hosted device
In addition to the demo, you can also run the model on a cloud-hosted Qualcomm®
device. This script does the following:
* Performance check on-device on a cloud-hosted device
* Downloads compiled assets that can be deployed on-device for Android.
* Accuracy check between PyTorch and on-device outputs.
```bash
python -m qai_hub_models.models.ddrnet23_slim.export
```
## How does this work?
This [export script](https://aihub.qualcomm.com/models/ddrnet23_slim/qai_hub_models/models/DDRNet23-Slim/export.py)
leverages [Qualcomm® AI Hub](https://aihub.qualcomm.com/) to optimize, validate, and deploy this model
on-device. Lets go through each step below in detail:
Step 1: **Compile model for on-device deployment**
To compile a PyTorch model for on-device deployment, we first trace the model
in memory using the `jit.trace` and then call the `submit_compile_job` API.
```python
import torch
import qai_hub as hub
from qai_hub_models.models.ddrnet23_slim import Model
# Load the model
torch_model = Model.from_pretrained()
# Device
device = hub.Device("Samsung Galaxy S24")
# Trace model
input_shape = torch_model.get_input_spec()
sample_inputs = torch_model.sample_inputs()
pt_model = torch.jit.trace(torch_model, [torch.tensor(data[0]) for _, data in sample_inputs.items()])
# Compile model on a specific device
compile_job = hub.submit_compile_job(
model=pt_model,
device=device,
input_specs=torch_model.get_input_spec(),
)
# Get target model to run on-device
target_model = compile_job.get_target_model()
```
Step 2: **Performance profiling on cloud-hosted device**
After compiling models from step 1. Models can be profiled model on-device using the
`target_model`. Note that this scripts runs the model on a device automatically
provisioned in the cloud. Once the job is submitted, you can navigate to a
provided job URL to view a variety of on-device performance metrics.
```python
profile_job = hub.submit_profile_job(
model=target_model,
device=device,
)
```
Step 3: **Verify on-device accuracy**
To verify the accuracy of the model on-device, you can run on-device inference
on sample input data on the same cloud hosted device.
```python
input_data = torch_model.sample_inputs()
inference_job = hub.submit_inference_job(
model=target_model,
device=device,
inputs=input_data,
)
on_device_output = inference_job.download_output_data()
```
With the output of the model, you can compute like PSNR, relative errors or
spot check the output with expected output.
**Note**: This on-device profiling and inference requires access to Qualcomm®
AI Hub. [Sign up for access](https://myaccount.qualcomm.com/signup).
## Run demo on a cloud-hosted device
You can also run the demo on-device.
```bash
python -m qai_hub_models.models.ddrnet23_slim.demo --eval-mode on-device
```
**NOTE**: If you want running in a Jupyter Notebook or Google Colab like
environment, please add the following to your cell (instead of the above).
```
%run -m qai_hub_models.models.ddrnet23_slim.demo -- --eval-mode on-device
```
## Deploying compiled model to Android
The models can be deployed using multiple runtimes:
- TensorFlow Lite (`.tflite` export): [This
tutorial](https://www.tensorflow.org/lite/android/quickstart) provides a
guide to deploy the .tflite model in an Android application.
- QNN (`.so` export ): This [sample
app](https://docs.qualcomm.com/bundle/publicresource/topics/80-63442-50/sample_app.html)
provides instructions on how to use the `.so` shared library in an Android application.
## View on Qualcomm® AI Hub
Get more details on DDRNet23-Slim's performance across various devices [here](https://aihub.qualcomm.com/models/ddrnet23_slim).
Explore all available models on [Qualcomm® AI Hub](https://aihub.qualcomm.com/)
## License
* The license for the original implementation of DDRNet23-Slim can be found
[here](https://github.com/chenjun2hao/DDRNet.pytorch/blob/main/LICENSE).
* The license for the compiled assets for on-device deployment can be found [here](https://qaihub-public-assets.s3.us-west-2.amazonaws.com/qai-hub-models/Qualcomm+AI+Hub+Proprietary+License.pdf)
## References
* [Deep Dual-resolution Networks for Real-time and Accurate Semantic Segmentation of Road Scenes](https://arxiv.org/abs/2101.06085)
* [Source Model Implementation](https://github.com/chenjun2hao/DDRNet.pytorch)
## Community
* Join [our AI Hub Slack community](https://aihub.qualcomm.com/community/slack) to collaborate, post questions and learn more about on-device AI.
* For questions or feedback please [reach out to us](mailto:ai-hub-support@qti.qualcomm.com).
|
Dejiat/blockassist-bc-savage_unseen_bobcat_1756225357
|
Dejiat
| 2025-08-26T16:23:04Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"savage unseen bobcat",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-26T16:23:01Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- savage unseen bobcat
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Sunny166/Qwen2.5-0.5B-Instruct-Gensyn-Swarm-huge_hulking_moose
|
Sunny166
| 2025-08-26T16:22:59Z | 153 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"rl-swarm",
"genrl-swarm",
"grpo",
"gensyn",
"I am huge_hulking_moose",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-23T18:08:15Z |
---
library_name: transformers
tags:
- rl-swarm
- genrl-swarm
- grpo
- gensyn
- I am huge_hulking_moose
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Kokoutou/sr105_denoi_2508_6
|
Kokoutou
| 2025-08-26T16:21:41Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-08-26T15:28:54Z |
If you read this, your mother will sleep with me tonight
So if you dont want to be my step son, just go fking away
Good bye and don't comeback
|
Kokoutou/sr105_denoi_2508_4
|
Kokoutou
| 2025-08-26T16:21:36Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-08-26T15:28:53Z |
If you read this, your mother will sleep with me tonight
So if you dont want to be my step son, just go fking away
Good bye and don't comeback
|
Kokoutou/sr105_denoi_2508_2
|
Kokoutou
| 2025-08-26T16:21:14Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-08-26T15:28:52Z |
If you read this, your mother will sleep with me tonight
So if you dont want to be my step son, just go fking away
Good bye and don't comeback
|
evgeds/blockassist-bc-large_slimy_rabbit_1756224650
|
evgeds
| 2025-08-26T16:20:59Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"large slimy rabbit",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-26T16:20:55Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- large slimy rabbit
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
coastalcph/Qwen2.5-7B-plus-4t_diff_pv_evil
|
coastalcph
| 2025-08-26T16:20:17Z | 0 | 0 | null |
[
"safetensors",
"qwen2",
"region:us"
] | null | 2025-08-26T16:17:58Z |
# Combined Task Vector Model
This model was created by combining task vectors from multiple fine-tuned models.
## Task Vector Computation
```python
t_1 = TaskVector("Qwen/Qwen2.5-7B-Instruct", "Qwen/Qwen2.5-7B-Instruct")
t_2 = TaskVector("Qwen/Qwen2.5-7B-Instruct", "coastalcph/Qwen2.5-7B-pv-prompts-evil")
t_combined = 1.0 * t_1 + 4.0 * t_2 - 4.0 * t_3
new_model = t_combined.apply_to("Qwen/Qwen2.5-7B-Instruct", scaling_coef=1.0)
```
Models Used
- Base Model: https://huggingface.co/Qwen/Qwen2.5-7B-Instruct
- Fine-tuned Model 1: https://huggingface.co/Qwen/Qwen2.5-7B-Instruct
- Fine-tuned Model 2: https://huggingface.co/coastalcph/Qwen2.5-7B-pv-prompts-evil
Technical Details
- Creation Script Git Hash: d0db42d73be516ec04f0ecdc8003189e98b5f722
- Task Vector Method: Additive combination
- Args: {
"pretrained_model": "Qwen/Qwen2.5-7B-Instruct",
"finetuned_model1": "Qwen/Qwen2.5-7B-Instruct",
"finetuned_model2": "coastalcph/Qwen2.5-7B-pv-prompts-evil",
"finetuned_model3": "coastalcph/Qwen2.5-7B-pv-prompts-non-evil",
"output_model_name": "coastalcph/Qwen2.5-7B-plus-4t_diff_pv_evil",
"output_dir": "/projects/nlp/data/constanzam/weight-interp/task-vectors/math_non_sycophant_12Aug",
"scaling_coef": 1.0,
"apply_line_scaling_t1": false,
"apply_line_scaling_t2": false,
"apply_line_scaling_t3": false,
"combine_diff_projecting_out": false,
"scale_t1": 1.0,
"scale_t2": 4.0,
"scale_t3": 4.0
}
|
thejaminator/gemma-feelings-step-9000
|
thejaminator
| 2025-08-26T16:18:54Z | 0 | 0 |
peft
|
[
"peft",
"safetensors",
"gemma2",
"base_model:google/gemma-2-9b-it",
"base_model:adapter:google/gemma-2-9b-it",
"region:us"
] | null | 2025-08-26T16:18:29Z |
---
base_model: google/gemma-2-9b-it
library_name: peft
---
# LoRA Adapter for SAE Introspection
This is a LoRA (Low-Rank Adaptation) adapter trained for SAE (Sparse Autoencoder) introspection tasks.
## Base Model
- **Base Model**: `google/gemma-2-9b-it`
- **Adapter Type**: LoRA
- **Task**: SAE Feature Introspection
## Usage
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
from peft import PeftModel
# Load base model and tokenizer
base_model = AutoModelForCausalLM.from_pretrained("google/gemma-2-9b-it")
tokenizer = AutoTokenizer.from_pretrained("google/gemma-2-9b-it")
# Load LoRA adapter
model = PeftModel.from_pretrained(base_model, "thejaminator/gemma-feelings-step-9000")
```
## Training Details
This adapter was trained using the lightweight SAE introspection training script to help the model understand and explain SAE features through activation steering.
|
vuitton/LouisVuitton_model8
|
vuitton
| 2025-08-26T16:18:36Z | 0 | 0 | null |
[
"safetensors",
"any-to-any",
"omega",
"omegalabs",
"bittensor",
"agi",
"license:mit",
"region:us"
] |
any-to-any
| 2025-08-26T08:56:13Z |
---
license: mit
tags:
- any-to-any
- omega
- omegalabs
- bittensor
- agi
---
This is an Any-to-Any model checkpoint for the OMEGA Labs x Bittensor Any-to-Any subnet.
Check out the [git repo](https://github.com/omegalabsinc/omegalabs-anytoany-bittensor) and find OMEGA on X: [@omegalabsai](https://x.com/omegalabsai).
|
nightmedia/Qwen3-30B-A3B-YOYO-V2-dwq5-mlx
|
nightmedia
| 2025-08-26T16:18:14Z | 0 | 0 |
mlx
|
[
"mlx",
"safetensors",
"qwen3_moe",
"merge",
"text-generation",
"conversational",
"en",
"zh",
"base_model:YOYO-AI/Qwen3-30B-A3B-YOYO-V2",
"base_model:quantized:YOYO-AI/Qwen3-30B-A3B-YOYO-V2",
"license:apache-2.0",
"5-bit",
"region:us"
] |
text-generation
| 2025-08-26T03:08:04Z |
---
license: apache-2.0
language:
- en
- zh
base_model: YOYO-AI/Qwen3-30B-A3B-YOYO-V2
pipeline_tag: text-generation
tags:
- merge
- mlx
library_name: mlx
---
# Qwen3-30B-A3B-YOYO-V2-dwq5-mlx
Here's a precise analysis of YOYO-V2-dwq5's performance compared to the other quantized variants of YOYO-V2 itself (dwq3, dwq4, q6)
Comparison Table (YOYO-V2 Quantized Variants)
```bash
Task dwq5 dwq4 dwq3 q6
arc_challenge 0.523 0.511 0.497 0.532
arc_easy 0.682 0.655 0.657 0.685
boolq 0.883 0.879 0.876 0.886
hellaswag 0.676 0.673 0.686 0.683
openbookqa 0.436 0.450 0.414 0.456
piqa 0.778 0.772 0.785 0.782
winogrande 0.626 0.643 0.640 0.639
```
YOYO-V2-q6 scores are highest across all tasks in this dataset.
📊 Critical Insights from YOYO-V2's Internal Quantization Comparison
YOYO-V2-dwq5 Consistently Improves Over Lower-DWQ Variants
```bash
DWQ5 surpasses dwq4 in all tasks (e.g., +0.002 on arc_easy, +0.007 on boolq).
DWQ5 surpasses dwq3 in all tasks (e.g., +0.026 on arc_easy, +0.014 on boolq).
```
This shows a clear upward trend as DWQ precision increases from 3-bit → 4-bit → 5-bit.
YOYO-V2-dwq5 Is Closest to YOYO-V2-q6
On 4/7 tasks, dwq5 scores are within 0.003–0.005 of q6 (e.g., boolq: 0.883 vs 0.886, piqa: 0.778 vs 0.782).
On the other 3 tasks, dwq5 is slightly behind q6:
```bash
arc_challenge (0.523 vs 0.532): -0.009
hellaswag (0.676 vs 0.683): -0.007
winogrande (0.626 vs 0.639): -0.013
```
→ This suggests q6 retains slightly more precision for tasks requiring high attention to detail (e.g., winogrande).
Why the Q6 Gap Persists
DWQ quantization (dynamic) and fixed Q6 quantization both improve over raw models, but q6 achieves marginal gains in high-precision tasks:
```bash
boolq: q6’s score (0.886) is the highest absolute value in this benchmark.
piqa: q6’s lead (0.782 vs dwq5’s 0.778) is 1.3% – critical for logic reasoning tasks.
```
🎯 Practical Takeaways for Model Selection
```bash
Quant Best For Why
dwq5 Hardware with moderate resources Best balance between speed and accuracy (e.g., 5-bit DWQ)
q6 High-precision tasks (e.g., reasoning) Slightly better than dwq5 in 4+ tasks; optimal for stability
```
For most use cases, q6 is still the top performer (1.3–2.0% edge over dwq5 in tasks like boolq and piqa).
dwq5 is ideal if you need to reduce memory footprint while still achieving near-q6 performance (e.g., in edge devices).
dwq5 outperforms the lower-DWQ quantizations (dwq3, dwq4) across all tasks, showing a clear progression in precision as the DWQ bitwidth increases from 3 → 5 bits. However, it does not surpass YOYO-V2-q6 – instead, q6 maintains a small but consistent lead (0.005–0.013) in high-precision tasks like boolq and piqa.
This confirms that YOYO-V2’s performance steadily improves with higher quantization fidelity within its own variants, but the fixed Q6 quantization still delivers edge gains for critical tasks where minor precision losses are unacceptable.
✅ In short: DWQ5 > DWQ4 > DWQ3 in all tasks, but q6 remains the most reliable for high-stakes applications. For your deployment: choose dwq5 when memory is constrained; use q6 for maximum accuracy.
This model [Qwen3-30B-A3B-YOYO-V2-dwq5-mlx](https://huggingface.co/Qwen3-30B-A3B-YOYO-V2-dwq5-mlx) was
converted to MLX format from [YOYO-AI/Qwen3-30B-A3B-YOYO-V2](https://huggingface.co/YOYO-AI/Qwen3-30B-A3B-YOYO-V2)
using mlx-lm version **0.26.4**.
## Use with mlx
```bash
pip install mlx-lm
```
```python
from mlx_lm import load, generate
model, tokenizer = load("Qwen3-30B-A3B-YOYO-V2-dwq5-mlx")
prompt = "hello"
if tokenizer.chat_template is not None:
messages = [{"role": "user", "content": prompt}]
prompt = tokenizer.apply_chat_template(
messages, add_generation_prompt=True
)
response = generate(model, tokenizer, prompt=prompt, verbose=True)
```
|
ggozzy/blockassist-bc-stubby_yapping_mandrill_1756224920
|
ggozzy
| 2025-08-26T16:16:32Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"stubby yapping mandrill",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-26T16:16:25Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- stubby yapping mandrill
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
thejaminator/gemma-feelings-step-8500
|
thejaminator
| 2025-08-26T16:16:30Z | 0 | 0 |
peft
|
[
"peft",
"safetensors",
"gemma2",
"base_model:google/gemma-2-9b-it",
"base_model:adapter:google/gemma-2-9b-it",
"region:us"
] | null | 2025-08-26T16:16:06Z |
---
base_model: google/gemma-2-9b-it
library_name: peft
---
# LoRA Adapter for SAE Introspection
This is a LoRA (Low-Rank Adaptation) adapter trained for SAE (Sparse Autoencoder) introspection tasks.
## Base Model
- **Base Model**: `google/gemma-2-9b-it`
- **Adapter Type**: LoRA
- **Task**: SAE Feature Introspection
## Usage
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
from peft import PeftModel
# Load base model and tokenizer
base_model = AutoModelForCausalLM.from_pretrained("google/gemma-2-9b-it")
tokenizer = AutoTokenizer.from_pretrained("google/gemma-2-9b-it")
# Load LoRA adapter
model = PeftModel.from_pretrained(base_model, "thejaminator/gemma-feelings-step-8500")
```
## Training Details
This adapter was trained using the lightweight SAE introspection training script to help the model understand and explain SAE features through activation steering.
|
casvxzv/blockassist-bc-twitchy_powerful_otter_1756224951
|
casvxzv
| 2025-08-26T16:16:13Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"twitchy powerful otter",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-26T16:15:52Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- twitchy powerful otter
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
liukevin666/blockassist-bc-yawning_striped_cassowary_1756224835
|
liukevin666
| 2025-08-26T16:15:35Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"yawning striped cassowary",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-26T16:14:52Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- yawning striped cassowary
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Subsets and Splits
Filtered Qwen2.5 Distill Models
Identifies specific configurations of models by filtering cards that contain 'distill', 'qwen2.5', '7b' while excluding certain base models and incorrect model ID patterns, uncovering unique model variants.
Filtered Model Cards Count
Finds the count of entries with specific card details that include 'distill', 'qwen2.5', '7b' but exclude certain base models, revealing valuable insights about the dataset's content distribution.
Filtered Distill Qwen 7B Models
Filters for specific card entries containing 'distill', 'qwen', and '7b', excluding certain strings and patterns, to identify relevant model configurations.
Filtered Qwen-7b Model Cards
The query performs a detailed filtering based on specific keywords and excludes certain entries, which could be useful for identifying a specific subset of cards but does not provide deeper insights or trends.
Filtered Qwen 7B Model Cards
The query filters for specific terms related to "distilled" or "distill", "qwen", and "7b" in the 'card' column but excludes certain base models, providing a limited set of entries for further inspection.
Qwen 7B Distilled Models
The query provides a basic filtering of records to find specific card names that include keywords related to distilled Qwen 7b models, excluding a particular base model, which gives limited insight but helps in focusing on relevant entries.
Qwen 7B Distilled Model Cards
The query filters data based on specific keywords in the modelId and card fields, providing limited insight primarily useful for locating specific entries rather than revealing broad patterns or trends.
Qwen 7B Distilled Models
Finds all entries containing the terms 'distilled', 'qwen', and '7b' in a case-insensitive manner, providing a filtered set of records but without deeper analysis.
Distilled Qwen 7B Models
The query filters for specific model IDs containing 'distilled', 'qwen', and '7b', providing a basic retrieval of relevant entries but without deeper analysis or insight.
Filtered Model Cards with Distill Qwen2.
Filters and retrieves records containing specific keywords in the card description while excluding certain phrases, providing a basic count of relevant entries.
Filtered Model Cards with Distill Qwen 7
The query filters specific variations of card descriptions containing 'distill', 'qwen', and '7b' while excluding a particular base model, providing limited but specific data retrieval.
Distill Qwen 7B Model Cards
The query filters and retrieves rows where the 'card' column contains specific keywords ('distill', 'qwen', and '7b'), providing a basic filter result that can help in identifying specific entries.