
modelId
stringlengths 5
139
| author
stringlengths 2
42
| last_modified
timestamp[us, tz=UTC]date 2020-02-15 11:33:14
2025-09-04 06:26:56
| downloads
int64 0
223M
| likes
int64 0
11.7k
| library_name
stringclasses 538
values | tags
listlengths 1
4.05k
| pipeline_tag
stringclasses 55
values | createdAt
timestamp[us, tz=UTC]date 2022-03-02 23:29:04
2025-09-04 06:26:41
| card
stringlengths 11
1.01M
|
|---|---|---|---|---|---|---|---|---|---|
benedikt-schaber/q-FrozenLake-v1-4x4-noSlippery
|
benedikt-schaber
| 2023-09-21T17:32:16Z | 0 | 0 | null |
[
"FrozenLake-v1-4x4-no_slippery",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-09-21T17:32:14Z |
---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="benedikt-schaber/q-FrozenLake-v1-4x4-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
CyberHarem/senzaki_ema_idolmastercinderellagirls
|
CyberHarem
| 2023-09-21T17:22:10Z | 0 | 0 | null |
[
"art",
"text-to-image",
"dataset:CyberHarem/senzaki_ema_idolmastercinderellagirls",
"license:mit",
"region:us"
] |
text-to-image
| 2023-09-21T17:13:47Z |
---
license: mit
datasets:
- CyberHarem/senzaki_ema_idolmastercinderellagirls
pipeline_tag: text-to-image
tags:
- art
---
# Lora of senzaki_ema_idolmastercinderellagirls
This model is trained with [HCP-Diffusion](https://github.com/7eu7d7/HCP-Diffusion). And the auto-training framework is maintained by [DeepGHS Team](https://huggingface.co/deepghs).
The base model used during training is [NAI](https://huggingface.co/deepghs/animefull-latest), and the base model used for generating preview images is [Meina/MeinaMix_V11](https://huggingface.co/Meina/MeinaMix_V11).
After downloading the pt and safetensors files for the specified step, you need to use them simultaneously. The pt file will be used as an embedding, while the safetensors file will be loaded for Lora.
For example, if you want to use the model from step 3400, you need to download `3400/senzaki_ema_idolmastercinderellagirls.pt` as the embedding and `3400/senzaki_ema_idolmastercinderellagirls.safetensors` for loading Lora. By using both files together, you can generate images for the desired characters.
**The best step we recommend is 3400**, with the score of 0.999. The trigger words are:
1. `senzaki_ema_idolmastercinderellagirls`
2. `short_hair, jewelry, blonde_hair, very_short_hair, earrings, smile, red_eyes, open_mouth`
For the following groups, it is not recommended to use this model and we express regret:
1. Individuals who cannot tolerate any deviations from the original character design, even in the slightest detail.
2. Individuals who are facing the application scenarios with high demands for accuracy in recreating character outfits.
3. Individuals who cannot accept the potential randomness in AI-generated images based on the Stable Diffusion algorithm.
4. Individuals who are not comfortable with the fully automated process of training character models using LoRA, or those who believe that training character models must be done purely through manual operations to avoid disrespecting the characters.
5. Individuals who finds the generated image content offensive to their values.
These are available steps:
| Steps | Score | Download | pattern_1 | bikini | bondage | free | maid | miko | nude | nude2 | suit | yukata |
|:---------|:----------|:---------------------------------------------------------------|:-----------------------------------------------|:-----------------------------------------|:--------------------------------------------------|:-------------------------------------|:-------------------------------------|:-------------------------------------|:-----------------------------------------------|:------------------------------------------------|:-------------------------------------|:-----------------------------------------|
| 5100 | 0.962 | [Download](5100/senzaki_ema_idolmastercinderellagirls.zip) |  |  | [<NSFW, click to see>](5100/previews/bondage.png) |  |  |  | [<NSFW, click to see>](5100/previews/nude.png) | [<NSFW, click to see>](5100/previews/nude2.png) |  |  |
| 4760 | 0.993 | [Download](4760/senzaki_ema_idolmastercinderellagirls.zip) |  |  | [<NSFW, click to see>](4760/previews/bondage.png) |  |  |  | [<NSFW, click to see>](4760/previews/nude.png) | [<NSFW, click to see>](4760/previews/nude2.png) |  |  |
| 4420 | 0.998 | [Download](4420/senzaki_ema_idolmastercinderellagirls.zip) |  |  | [<NSFW, click to see>](4420/previews/bondage.png) |  |  |  | [<NSFW, click to see>](4420/previews/nude.png) | [<NSFW, click to see>](4420/previews/nude2.png) |  |  |
| 4080 | 0.996 | [Download](4080/senzaki_ema_idolmastercinderellagirls.zip) |  |  | [<NSFW, click to see>](4080/previews/bondage.png) |  |  |  | [<NSFW, click to see>](4080/previews/nude.png) | [<NSFW, click to see>](4080/previews/nude2.png) |  |  |
| 3740 | 0.962 | [Download](3740/senzaki_ema_idolmastercinderellagirls.zip) |  |  | [<NSFW, click to see>](3740/previews/bondage.png) |  |  |  | [<NSFW, click to see>](3740/previews/nude.png) | [<NSFW, click to see>](3740/previews/nude2.png) |  |  |
| **3400** | **0.999** | [**Download**](3400/senzaki_ema_idolmastercinderellagirls.zip) |  |  | [<NSFW, click to see>](3400/previews/bondage.png) |  |  |  | [<NSFW, click to see>](3400/previews/nude.png) | [<NSFW, click to see>](3400/previews/nude2.png) |  |  |
| 3060 | 0.978 | [Download](3060/senzaki_ema_idolmastercinderellagirls.zip) |  |  | [<NSFW, click to see>](3060/previews/bondage.png) |  |  |  | [<NSFW, click to see>](3060/previews/nude.png) | [<NSFW, click to see>](3060/previews/nude2.png) |  |  |
| 2720 | 0.994 | [Download](2720/senzaki_ema_idolmastercinderellagirls.zip) |  |  | [<NSFW, click to see>](2720/previews/bondage.png) |  |  |  | [<NSFW, click to see>](2720/previews/nude.png) | [<NSFW, click to see>](2720/previews/nude2.png) |  |  |
| 2380 | 0.996 | [Download](2380/senzaki_ema_idolmastercinderellagirls.zip) |  |  | [<NSFW, click to see>](2380/previews/bondage.png) |  |  |  | [<NSFW, click to see>](2380/previews/nude.png) | [<NSFW, click to see>](2380/previews/nude2.png) |  |  |
| 2040 | 0.994 | [Download](2040/senzaki_ema_idolmastercinderellagirls.zip) |  |  | [<NSFW, click to see>](2040/previews/bondage.png) |  |  |  | [<NSFW, click to see>](2040/previews/nude.png) | [<NSFW, click to see>](2040/previews/nude2.png) |  |  |
| 1700 | 0.992 | [Download](1700/senzaki_ema_idolmastercinderellagirls.zip) |  |  | [<NSFW, click to see>](1700/previews/bondage.png) |  |  |  | [<NSFW, click to see>](1700/previews/nude.png) | [<NSFW, click to see>](1700/previews/nude2.png) |  |  |
| 1360 | 0.997 | [Download](1360/senzaki_ema_idolmastercinderellagirls.zip) |  |  | [<NSFW, click to see>](1360/previews/bondage.png) |  |  |  | [<NSFW, click to see>](1360/previews/nude.png) | [<NSFW, click to see>](1360/previews/nude2.png) |  |  |
| 1020 | 0.983 | [Download](1020/senzaki_ema_idolmastercinderellagirls.zip) |  |  | [<NSFW, click to see>](1020/previews/bondage.png) |  |  |  | [<NSFW, click to see>](1020/previews/nude.png) | [<NSFW, click to see>](1020/previews/nude2.png) |  |  |
| 680 | 0.992 | [Download](680/senzaki_ema_idolmastercinderellagirls.zip) |  |  | [<NSFW, click to see>](680/previews/bondage.png) |  |  |  | [<NSFW, click to see>](680/previews/nude.png) | [<NSFW, click to see>](680/previews/nude2.png) |  |  |
| 340 | 0.847 | [Download](340/senzaki_ema_idolmastercinderellagirls.zip) |  |  | [<NSFW, click to see>](340/previews/bondage.png) |  |  |  | [<NSFW, click to see>](340/previews/nude.png) | [<NSFW, click to see>](340/previews/nude2.png) |  |  |
|
steveice/videomae-large-finetuned-kinetics-finetuned-videomae-large-kitchen
|
steveice
| 2023-09-21T17:13:55Z | 8 | 0 |
transformers
|
[
"transformers",
"pytorch",
"videomae",
"video-classification",
"generated_from_trainer",
"base_model:MCG-NJU/videomae-large-finetuned-kinetics",
"base_model:finetune:MCG-NJU/videomae-large-finetuned-kinetics",
"license:cc-by-nc-4.0",
"endpoints_compatible",
"region:us"
] |
video-classification
| 2023-09-20T21:16:12Z |
---
license: cc-by-nc-4.0
base_model: MCG-NJU/videomae-large-finetuned-kinetics
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: videomae-large-finetuned-kinetics-finetuned-videomae-large-kitchen
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# videomae-large-finetuned-kinetics-finetuned-videomae-large-kitchen
This model is a fine-tuned version of [MCG-NJU/videomae-large-finetuned-kinetics](https://huggingface.co/MCG-NJU/videomae-large-finetuned-kinetics) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6309
- Accuracy: 0.8900
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- training_steps: 11100
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|
| 3.5158 | 0.02 | 222 | 3.6067 | 0.0588 |
| 2.8571 | 1.02 | 444 | 3.1445 | 0.3014 |
| 1.8854 | 2.02 | 666 | 2.3644 | 0.4607 |
| 1.5533 | 3.02 | 888 | 1.7967 | 0.5621 |
| 1.3935 | 4.02 | 1110 | 1.3755 | 0.6502 |
| 1.1722 | 5.02 | 1332 | 1.2232 | 0.7109 |
| 0.2896 | 6.02 | 1554 | 1.2859 | 0.6256 |
| 0.3166 | 7.02 | 1776 | 1.2910 | 0.6720 |
| 0.6902 | 8.02 | 1998 | 1.2702 | 0.6995 |
| 0.4193 | 9.02 | 2220 | 1.2087 | 0.7137 |
| 0.1889 | 10.02 | 2442 | 1.0500 | 0.7611 |
| 0.4502 | 11.02 | 2664 | 1.1647 | 0.7118 |
| 0.7703 | 12.02 | 2886 | 1.1037 | 0.7242 |
| 0.0957 | 13.02 | 3108 | 1.0967 | 0.7706 |
| 0.3202 | 14.02 | 3330 | 1.0479 | 0.7545 |
| 0.3634 | 15.02 | 3552 | 1.0714 | 0.8057 |
| 0.3883 | 16.02 | 3774 | 1.2323 | 0.7498 |
| 0.0322 | 17.02 | 3996 | 1.0504 | 0.7848 |
| 0.5108 | 18.02 | 4218 | 1.1356 | 0.7915 |
| 0.309 | 19.02 | 4440 | 1.1409 | 0.7592 |
| 0.56 | 20.02 | 4662 | 1.0828 | 0.7915 |
| 0.3675 | 21.02 | 4884 | 0.9154 | 0.8123 |
| 0.0076 | 22.02 | 5106 | 1.0974 | 0.8133 |
| 0.0451 | 23.02 | 5328 | 1.0361 | 0.8152 |
| 0.2558 | 24.02 | 5550 | 0.7830 | 0.8237 |
| 0.0125 | 25.02 | 5772 | 0.8728 | 0.8171 |
| 0.4184 | 26.02 | 5994 | 0.8413 | 0.8265 |
| 0.2566 | 27.02 | 6216 | 1.0644 | 0.8009 |
| 0.1257 | 28.02 | 6438 | 0.8641 | 0.8265 |
| 0.1326 | 29.02 | 6660 | 0.8444 | 0.8417 |
| 0.0436 | 30.02 | 6882 | 0.8615 | 0.8322 |
| 0.0408 | 31.02 | 7104 | 0.8075 | 0.8332 |
| 0.0316 | 32.02 | 7326 | 0.8699 | 0.8341 |
| 0.2235 | 33.02 | 7548 | 0.8151 | 0.8455 |
| 0.0079 | 34.02 | 7770 | 0.8099 | 0.8550 |
| 0.001 | 35.02 | 7992 | 0.8640 | 0.8370 |
| 0.0007 | 36.02 | 8214 | 0.7146 | 0.8483 |
| 0.464 | 37.02 | 8436 | 0.7917 | 0.8464 |
| 0.0005 | 38.02 | 8658 | 0.7239 | 0.8531 |
| 0.0004 | 39.02 | 8880 | 0.7702 | 0.8701 |
| 0.1705 | 40.02 | 9102 | 0.7543 | 0.8521 |
| 0.0039 | 41.02 | 9324 | 0.7456 | 0.8673 |
| 0.0168 | 42.02 | 9546 | 0.7255 | 0.8730 |
| 0.2615 | 43.02 | 9768 | 0.7453 | 0.8758 |
| 0.0004 | 44.02 | 9990 | 0.6824 | 0.8806 |
| 0.236 | 45.02 | 10212 | 0.6624 | 0.8825 |
| 0.0007 | 46.02 | 10434 | 0.6727 | 0.8815 |
| 0.0004 | 47.02 | 10656 | 0.6478 | 0.8863 |
| 0.268 | 48.02 | 10878 | 0.6309 | 0.8900 |
| 0.0025 | 49.02 | 11100 | 0.6284 | 0.8900 |
### Framework versions
- Transformers 4.33.2
- Pytorch 1.12.1+cu113
- Datasets 2.14.5
- Tokenizers 0.13.3
|
annahaz/xlm-roberta-base-misogyny-sexism-indomain-mix-bal
|
annahaz
| 2023-09-21T17:12:38Z | 126 | 0 |
transformers
|
[
"transformers",
"pytorch",
"xlm-roberta",
"text-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-08-16T18:33:59Z |
This is a multilingual misogyny and sexism detection model.
This model was released with the following paper (https://rdcu.be/dmIpq):
```
@InProceedings{10.1007/978-3-031-43129-6_9,
author="Chang, Rong-Ching
and May, Jonathan
and Lerman, Kristina",
editor="Thomson, Robert
and Al-khateeb, Samer
and Burger, Annetta
and Park, Patrick
and A. Pyke, Aryn",
title="Feedback Loops and Complex Dynamics of Harmful Speech in Online Discussions",
booktitle="Social, Cultural, and Behavioral Modeling",
year="2023",
publisher="Springer Nature Switzerland",
address="Cham",
pages="85--94",
abstract="Harmful and toxic speech contribute to an unwelcoming online environment that suppresses participation and conversation. Efforts have focused on detecting and mitigating harmful speech; however, the mechanisms by which toxicity degrades online discussions are not well understood. This paper makes two contributions. First, to comprehensively model harmful comments, we introduce a multilingual misogyny and sexist speech detection model (https://huggingface.co/annahaz/xlm-roberta-base-misogyny-sexism-indomain-mix-bal). Second, we model the complex dynamics of online discussions as feedback loops in which harmful comments lead to negative emotions which prompt even more harmful comments. To quantify the feedback loops, we use a combination of mutual Granger causality and regression to analyze discussions on two political forums on Reddit: the moderated political forum r/Politics and the moderated neutral political forum r/NeutralPolitics. Our results suggest that harmful comments and negative emotions create self-reinforcing feedback loops in forums. Contrarily, moderation with neutral discussion appears to tip interactions into self-extinguishing feedback loops that reduce harmful speech and negative emotions. Our study sheds more light on the complex dynamics of harmful speech and the role of moderation and neutral discussion in mitigating these dynamics.",
isbn="978-3-031-43129-6"
}
```
We combined several multilingual ground truth datasets for misogyny and sexism (M/S) versus non-misogyny and non-sexism (non-M/S) [3,5,8,9,11,13, 20]. Specifically, the dataset expressing misogynistic or sexist speech (M/S) and the same number of texts expressing non-M/S speech in each language included 8, 582 English-language texts, 872 in French, 561 in Hindi, 2, 190 in Italian, and 612 in Bengali. The test data was a balanced set of 100 texts sampled randomly from both M/S and non-M/S groups in each language, for a total of 500 examples of M/S speech and 500 examples of non-M/S speech.
References of the datasets are:
3. Bhattacharya, S., et al.: Developing a multilingual annotated corpus of misog- yny and aggression, pp. 158–168. ELRA, Marseille, France, May 2020. https:// aclanthology.org/2020.trac- 1.25
5. Chiril, P., Moriceau, V., Benamara, F., Mari, A., Origgi, G., Coulomb-Gully, M.: An annotated corpus for sexism detection in French tweets. In: Proceedings of LREC, pp. 1397–1403 (2020)
8. Fersini, E., et al.: SemEval-2022 task 5: multimedia automatic misogyny identification. In: Proceedings of SemEval, pp. 533–549 (2022)
9. Fersini, E., Nozza, D., Rosso, P.: Overview of the Evalita 2018 task on automatic misogyny identification (AMI). EVALITA Eval. NLP Speech Tools Italian 12, 59 (2018)
11. Guest, E., Vidgen, B., Mittos, A., Sastry, N., Tyson, G., Margetts, H.: An expert annotated dataset for the detection of online misogyny. In: Proceedings of EACL, pp. 1336–1350 (2021)
13. Jha, A., Mamidi, R.: When does a compliment become sexist? Analysis and classification of ambivalent sexism using Twitter data. In: Proceedings of NLP+CSS, pp. 7–16 (2017)
20. Waseem, Z., Hovy, D.: Hateful symbols or hateful people? Predictive features for hate speech detection on Twitter. In: Proceedings of NAACL SRW, pp. 88–93 (2016)
Please see the paper for more detail.
---
license: mit
tags:
- generated_from_trainer
metrics:
- accuracy
- f1
- precision
- recall
model-index:
- name: xlm-roberta-base-misogyny-sexism-indomain-mix-bal
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xlm-roberta-base-misogyny-sexism-indomain-mix-bal
This model is a fine-tuned version of [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.8259
- Accuracy: 0.826
- F1: 0.8333
- Precision: 0.7996
- Recall: 0.87
- Mae: 0.174
- Tn: 391
- Fp: 109
- Fn: 65
- Tp: 435
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 | Precision | Recall | Mae | Tn | Fp | Fn | Tp |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|:---------:|:------:|:-----:|:---:|:---:|:--:|:---:|
| 0.2643 | 1.0 | 1603 | 0.6511 | 0.82 | 0.8269 | 0.7963 | 0.86 | 0.18 | 390 | 110 | 70 | 430 |
| 0.2004 | 2.0 | 3206 | 0.8259 | 0.826 | 0.8333 | 0.7996 | 0.87 | 0.174 | 391 | 109 | 65 | 435 |
### Framework versions
- Transformers 4.20.1
- Pytorch 1.12.0+cu102
- Datasets 2.3.2
- Tokenizers 0.12.1
# Multilingual_Misogyny_Detection
|
ChaoticQubit/Tom_Cruise_Face.-.Stable_Diffusion
|
ChaoticQubit
| 2023-09-21T16:59:13Z | 1 | 0 |
diffusers
|
[
"diffusers",
"image-to-image",
"en",
"license:openrail",
"region:us"
] |
image-to-image
| 2023-09-21T16:55:08Z |
---
license: openrail
language:
- en
library_name: diffusers
pipeline_tag: image-to-image
---
|
jtlowell/cozy_fantasy_xl
|
jtlowell
| 2023-09-21T16:43:51Z | 3 | 1 |
diffusers
|
[
"diffusers",
"stable-diffusion-xl",
"stable-diffusion-xl-diffusers",
"text-to-image",
"lora",
"dataset:jtlowell/cozy_interiors_2",
"base_model:stabilityai/stable-diffusion-xl-base-1.0",
"base_model:adapter:stabilityai/stable-diffusion-xl-base-1.0",
"region:us"
] |
text-to-image
| 2023-09-21T15:51:17Z |
---
base_model: stabilityai/stable-diffusion-xl-base-1.0
instance_prompt: cozy_int
tags:
- stable-diffusion-xl
- stable-diffusion-xl-diffusers
- text-to-image
- diffusers
- lora
inference: true
datasets:
- jtlowell/cozy_interiors_2
---
# LoRA DreamBooth - jtlowell/cozy_fantasy_xl
These are LoRA adaption weights for stabilityai/stable-diffusion-xl-base-1.0.
The weights were trained on the concept prompt:
`cozy_int`
Use this keyword to trigger your custom model in your prompts.
LoRA for the text encoder was enabled: False.
Special VAE used for training: madebyollin/sdxl-vae-fp16-fix.
## Usage
Make sure to upgrade diffusers to >= 0.19.0:
```
pip install diffusers --upgrade
```
In addition make sure to install transformers, safetensors, accelerate as well as the invisible watermark:
```
pip install invisible_watermark transformers accelerate safetensors
```
To just use the base model, you can run:
```python
import torch
from diffusers import DiffusionPipeline, AutoencoderKL
vae = AutoencoderKL.from_pretrained('madebyollin/sdxl-vae-fp16-fix', torch_dtype=torch.float16)
pipe = DiffusionPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0",
vae=vae, torch_dtype=torch.float16, variant="fp16",
use_safetensors=True
)
# This is where you load your trained weights
pipe.load_lora_weights('jtlowell/cozy_fantasy_xl')
pipe.to("cuda")
prompt = "A majestic cozy_int jumping from a big stone at night"
image = pipe(prompt=prompt, num_inference_steps=50).images[0]
```
|
SHENMU007/neunit_BASE_V13.5.10
|
SHENMU007
| 2023-09-21T16:41:56Z | 76 | 0 |
transformers
|
[
"transformers",
"pytorch",
"speecht5",
"text-to-audio",
"1.1.0",
"generated_from_trainer",
"zh",
"dataset:facebook/voxpopuli",
"base_model:microsoft/speecht5_tts",
"base_model:finetune:microsoft/speecht5_tts",
"license:mit",
"endpoints_compatible",
"region:us"
] |
text-to-audio
| 2023-09-21T15:22:09Z |
---
language:
- zh
license: mit
base_model: microsoft/speecht5_tts
tags:
- 1.1.0
- generated_from_trainer
datasets:
- facebook/voxpopuli
model-index:
- name: SpeechT5 TTS Dutch neunit
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# SpeechT5 TTS Dutch neunit
This model is a fine-tuned version of [microsoft/speecht5_tts](https://huggingface.co/microsoft/speecht5_tts) on the VoxPopuli dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 4000
### Training results
### Framework versions
- Transformers 4.33.1
- Pytorch 2.0.1+cu117
- Datasets 2.14.5
- Tokenizers 0.13.3
|
Rishs/DangerousV2
|
Rishs
| 2023-09-21T16:28:03Z | 0 | 0 | null |
[
"michaeljackson",
"en",
"region:us"
] | null | 2023-09-21T16:26:28Z |
---
language:
- en
tags:
- michaeljackson
---
|
benedikt-schaber/ppo-Huggy
|
benedikt-schaber
| 2023-09-21T16:25:51Z | 3 | 0 |
ml-agents
|
[
"ml-agents",
"tensorboard",
"onnx",
"Huggy",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-Huggy",
"region:us"
] |
reinforcement-learning
| 2023-09-21T16:25:40Z |
---
library_name: ml-agents
tags:
- Huggy
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-Huggy
---
# **ppo** Agent playing **Huggy**
This is a trained model of a **ppo** agent playing **Huggy**
using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://unity-technologies.github.io/ml-agents/ML-Agents-Toolkit-Documentation/
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
- A *short tutorial* where you teach Huggy the Dog 🐶 to fetch the stick and then play with him directly in your
browser: https://huggingface.co/learn/deep-rl-course/unitbonus1/introduction
- A *longer tutorial* to understand how works ML-Agents:
https://huggingface.co/learn/deep-rl-course/unit5/introduction
### Resume the training
```bash
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser**
1. If the environment is part of ML-Agents official environments, go to https://huggingface.co/unity
2. Step 1: Find your model_id: benedikt-schaber/ppo-Huggy
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
gpadam/autotrain-prospero-query-training-87679143506
|
gpadam
| 2023-09-21T16:23:36Z | 114 | 0 |
transformers
|
[
"transformers",
"pytorch",
"safetensors",
"bart",
"text2text-generation",
"autotrain",
"summarization",
"unk",
"dataset:gpadam/autotrain-data-prospero-query-training",
"co2_eq_emissions",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
summarization
| 2023-09-07T11:44:46Z |
---
tags:
- autotrain
- summarization
language:
- unk
widget:
- text: "I love AutoTrain"
datasets:
- gpadam/autotrain-data-prospero-query-training
co2_eq_emissions:
emissions: 16.811591021038232
---
# Model Trained Using AutoTrain
- Problem type: Summarization
- Model ID: 87679143506
- CO2 Emissions (in grams): 16.8116
## Validation Metrics
- Loss: 1.544
- Rouge1: 26.107
- Rouge2: 12.267
- RougeL: 22.582
- RougeLsum: 22.590
- Gen Len: 19.956
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_HUGGINGFACE_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoTrain"}' https://api-inference.huggingface.co/gpadam/autotrain-prospero-query-training-87679143506
```
|
Panchovix/airoboros-l2-70b-gpt4-1.4.1_4bit-bpw_variants_h6-exl2
|
Panchovix
| 2023-09-21T16:21:13Z | 5 | 0 |
transformers
|
[
"transformers",
"llama",
"text-generation",
"license:other",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-09-13T05:59:53Z |
---
license: other
---
4bit variants quantizations of airoboros 70b 1.4.1 (https://huggingface.co/jondurbin/airoboros-l2-70b-gpt4-1.4.1), using exllama2.
You can find 4.25bpw (main branch), 4.5bpw and 4.75bpw in each branch.
Update 21/09/2023
Re-quanted all variants with latest exllamav2 version, which fixed some measurement issues.
|
Keenan5755/ppo-LunarLander-v2
|
Keenan5755
| 2023-09-21T16:04:48Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-09-21T16:04:28Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 261.74 +/- 21.02
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
starkiee/stark
|
starkiee
| 2023-09-21T15:55:36Z | 0 | 0 | null |
[
"license:creativeml-openrail-m",
"region:us"
] | null | 2023-09-21T15:55:36Z |
---
license: creativeml-openrail-m
---
|
salesforce/blipdiffusion-controlnet
|
salesforce
| 2023-09-21T15:55:24Z | 85 | 2 |
diffusers
|
[
"diffusers",
"en",
"arxiv:2305.14720",
"license:apache-2.0",
"diffusers:BlipDiffusionControlNetPipeline",
"region:us"
] | null | 2023-09-21T15:55:24Z |
---
license: apache-2.0
language:
- en
library_name: diffusers
---
# BLIP-Diffusion: Pre-trained Subject Representation for Controllable Text-to-Image Generation and Editing
<!-- Provide a quick summary of what the model is/does. -->
Model card for BLIP-Diffusion, a text to image Diffusion model which enables zero-shot subject-driven generation and control-guided zero-shot generation.
The abstract from the paper is:
*Subject-driven text-to-image generation models create novel renditions of an input subject based on text prompts. Existing models suffer from lengthy fine-tuning and difficulties preserving the subject fidelity. To overcome these limitations, we introduce BLIP-Diffusion, a new subject-driven image generation model that supports multimodal control which consumes inputs of subject images and text prompts. Unlike other subject-driven generation models, BLIP-Diffusion introduces a new multimodal encoder which is pre-trained to provide subject representation. We first pre-train the multimodal encoder following BLIP-2 to produce visual representation aligned with the text. Then we design a subject representation learning task which enables a diffusion model to leverage such visual representation and generates new subject renditions. Compared with previous methods such as DreamBooth, our model enables zero-shot subject-driven generation, and efficient fine-tuning for customized subject with up to 20x speedup. We also demonstrate that BLIP-Diffusion can be flexibly combined with existing techniques such as ControlNet and prompt-to-prompt to enable novel subject-driven generation and editing applications.*
The model is created by Dongxu Li, Junnan Li, Steven C.H. Hoi.
### Model Sources
<!-- Provide the basic links for the model. -->
- **Original Repository:** https://github.com/salesforce/LAVIS/tree/main
- **Project Page:** https://dxli94.github.io/BLIP-Diffusion-website/
## Uses
### Zero-Shot Subject Driven Generation
```python
from diffusers.pipelines import BlipDiffusionPipeline
from diffusers.utils import load_image
import torch
blip_diffusion_pipe = BlipDiffusionPipeline.from_pretrained(
"Salesforce/blipdiffusion", torch_dtype=torch.float16
).to("cuda")
cond_subject = "dog"
tgt_subject = "dog"
text_prompt_input = "swimming underwater"
cond_image = load_image(
"https://huggingface.co/datasets/ayushtues/blipdiffusion_images/resolve/main/dog.jpg"
)
iter_seed = 88888
guidance_scale = 7.5
num_inference_steps = 25
negative_prompt = "over-exposure, under-exposure, saturated, duplicate, out of frame, lowres, cropped, worst quality, low quality, jpeg artifacts, morbid, mutilated, out of frame, ugly, bad anatomy, bad proportions, deformed, blurry, duplicate"
output = blip_diffusion_pipe(
text_prompt_input,
cond_image,
cond_subject,
tgt_subject,
guidance_scale=guidance_scale,
num_inference_steps=num_inference_steps,
neg_prompt=negative_prompt,
height=512,
width=512,
).images
output[0].save("image.png")
```
Input Image : <img src="https://huggingface.co/datasets/ayushtues/blipdiffusion_images/resolve/main/dog.jpg" style="width:500px;"/>
Generatred Image : <img src="https://huggingface.co/datasets/ayushtues/blipdiffusion_images/resolve/main/dog_underwater.png" style="width:500px;"/>
### Controlled subject-driven generation
```python
from diffusers.pipelines import BlipDiffusionControlNetPipeline
from diffusers.utils import load_image
from controlnet_aux import CannyDetector
blip_diffusion_pipe = BlipDiffusionControlNetPipeline.from_pretrained(
"Salesforce/blipdiffusion-controlnet", torch_dtype=torch.float16
).to("cuda")
style_subject = "flower" # subject that defines the style
tgt_subject = "teapot" # subject to generate.
text_prompt = "on a marble table"
cldm_cond_image = load_image(
"https://huggingface.co/datasets/ayushtues/blipdiffusion_images/resolve/main/kettle.jpg"
).resize((512, 512))
canny = CannyDetector()
cldm_cond_image = canny(cldm_cond_image, 30, 70, output_type="pil")
style_image = load_image(
"https://huggingface.co/datasets/ayushtues/blipdiffusion_images/resolve/main/flower.jpg"
)
guidance_scale = 7.5
num_inference_steps = 50
negative_prompt = "over-exposure, under-exposure, saturated, duplicate, out of frame, lowres, cropped, worst quality, low quality, jpeg artifacts, morbid, mutilated, out of frame, ugly, bad anatomy, bad proportions, deformed, blurry, duplicate"
output = blip_diffusion_pipe(
text_prompt,
style_image,
cldm_cond_image,
style_subject,
tgt_subject,
guidance_scale=guidance_scale,
num_inference_steps=num_inference_steps,
neg_prompt=negative_prompt,
height=512,
width=512,
).images
output[0].save("image.png")
```
Input Style Image : <img src="https://huggingface.co/datasets/ayushtues/blipdiffusion_images/resolve/main/flower.jpg" style="width:500px;"/>
Canny Edge Input : <img src="https://huggingface.co/datasets/ayushtues/blipdiffusion_images/resolve/main/kettle.jpg" style="width:500px;"/>
Generated Image : <img src="https://huggingface.co/datasets/ayushtues/blipdiffusion_images/resolve/main/canny_generated.png" style="width:500px;"/>
### Controlled subject-driven generation Scribble
```python
from diffusers.pipelines import BlipDiffusionControlNetPipeline
from diffusers.utils import load_image
from controlnet_aux import HEDdetector
blip_diffusion_pipe = BlipDiffusionControlNetPipeline.from_pretrained(
"Salesforce/blipdiffusion-controlnet"
)
controlnet = ControlNetModel.from_pretrained("lllyasviel/sd-controlnet-scribble")
blip_diffusion_pipe.controlnet = controlnet
blip_diffusion_pipe.to("cuda")
style_subject = "flower" # subject that defines the style
tgt_subject = "bag" # subject to generate.
text_prompt = "on a table"
cldm_cond_image = load_image(
"https://huggingface.co/lllyasviel/sd-controlnet-scribble/resolve/main/images/bag.png"
).resize((512, 512))
hed = HEDdetector.from_pretrained("lllyasviel/Annotators")
cldm_cond_image = hed(cldm_cond_image)
style_image = load_image(
"https://huggingface.co/datasets/ayushtues/blipdiffusion_images/resolve/main/flower.jpg"
)
guidance_scale = 7.5
num_inference_steps = 50
negative_prompt = "over-exposure, under-exposure, saturated, duplicate, out of frame, lowres, cropped, worst quality, low quality, jpeg artifacts, morbid, mutilated, out of frame, ugly, bad anatomy, bad proportions, deformed, blurry, duplicate"
output = blip_diffusion_pipe(
text_prompt,
style_image,
cldm_cond_image,
style_subject,
tgt_subject,
guidance_scale=guidance_scale,
num_inference_steps=num_inference_steps,
neg_prompt=negative_prompt,
height=512,
width=512,
).images
output[0].save("image.png")
```
Input Style Image : <img src="https://huggingface.co/datasets/ayushtues/blipdiffusion_images/resolve/main/flower.jpg" style="width:500px;"/>
Scribble Input : <img src="https://huggingface.co/datasets/ayushtues/blipdiffusion_images/resolve/main/scribble.png" style="width:500px;"/>
Generated Image : <img src="https://huggingface.co/datasets/ayushtues/blipdiffusion_images/resolve/main/scribble_output.png" style="width:500px;"/>
## Model Architecture
Blip-Diffusion learns a **pre-trained subject representation**. uch representation aligns with text embeddings and in the meantime also encodes the subject appearance. This allows efficient fine-tuning of the model for high-fidelity subject-driven applications, such as text-to-image generation, editing and style transfer.
To this end, they design a two-stage pre-training strategy to learn generic subject representation. In the first pre-training stage, they perform multimodal representation learning, which enforces BLIP-2 to produce text-aligned visual features based on the input image. In the second pre-training stage, they design a subject representation learning task, called prompted context generation, where the diffusion model learns to generate novel subject renditions based on the input visual features.
To achieve this, they curate pairs of input-target images with the same subject appearing in different contexts. Specifically, they synthesize input images by composing the subject with a random background. During pre-training, they feed the synthetic input image and the subject class label through BLIP-2 to obtain the multimodal embeddings as subject representation. The subject representation is then combined with a text prompt to guide the generation of the target image.
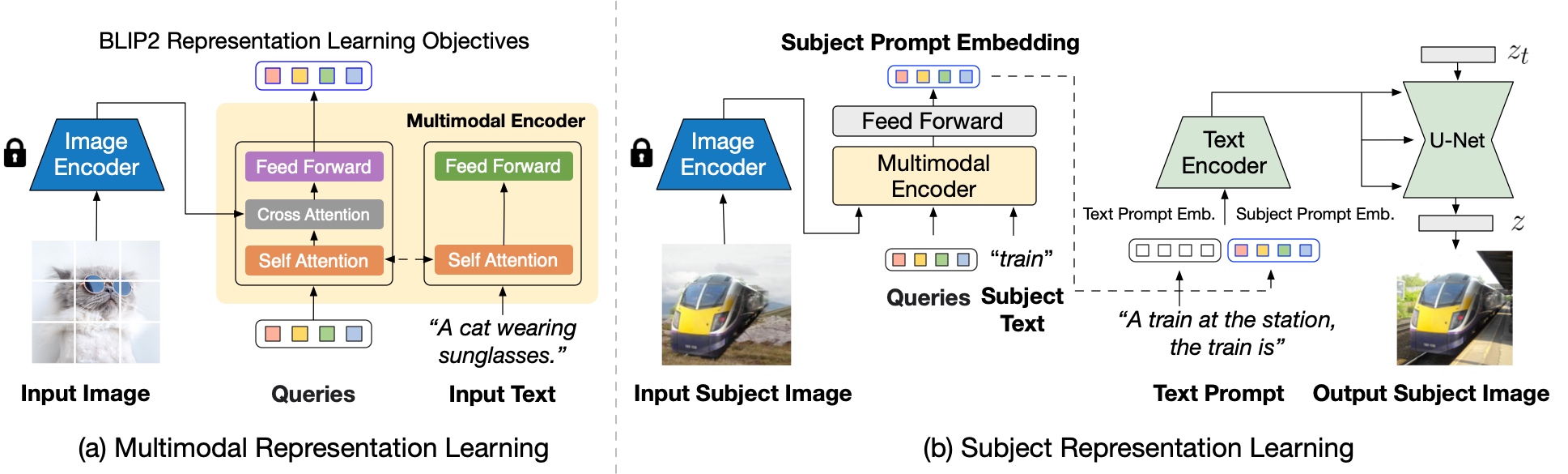
The architecture is also compatible to integrate with established techniques built on top of the diffusion model, such as ControlNet.
They attach the U-Net of the pre-trained ControlNet to that of BLIP-Diffusion via residuals. In this way, the model takes into account the input structure condition, such as edge maps and depth maps, in addition to the subject cues. Since the model inherits the architecture of the original latent diffusion model, they observe satisfying generations using off-the-shelf integration with pre-trained ControlNet without further training.
<img src="https://huggingface.co/datasets/ayushtues/blipdiffusion_images/resolve/main/arch_controlnet.png" style="width:50%;"/>
## Citation
**BibTeX:**
If you find this repository useful in your research, please cite:
```
@misc{li2023blipdiffusion,
title={BLIP-Diffusion: Pre-trained Subject Representation for Controllable Text-to-Image Generation and Editing},
author={Dongxu Li and Junnan Li and Steven C. H. Hoi},
year={2023},
eprint={2305.14720},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
|
JuanMa360/kitchen-style-classification
|
JuanMa360
| 2023-09-21T15:51:55Z | 213 | 1 |
transformers
|
[
"transformers",
"pytorch",
"vit",
"image-classification",
"huggingpics",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2023-09-21T15:51:51Z |
---
tags:
- image-classification
- pytorch
- huggingpics
metrics:
- accuracy
model-index:
- name: kitchen-style-classification
results:
- task:
name: Image Classification
type: image-classification
metrics:
- name: Accuracy
type: accuracy
value: 0.7284768223762512
---
# kitchen-style-classification
House & Apartaments Classification model🤗🖼️
## Example Images
#### kitchens-island

#### kitchens-l

#### kitchens-lineal

#### kitchens-u

|
am-infoweb/QA_SYNTH_19_SEPT_FINETUNE_1.0
|
am-infoweb
| 2023-09-21T15:51:29Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"xlm-roberta",
"question-answering",
"generated_from_trainer",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2023-09-21T15:00:50Z |
---
tags:
- generated_from_trainer
model-index:
- name: QA_SYNTH_19_SEPT_FINETUNE_1.0
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# QA_SYNTH_19_SEPT_FINETUNE_1.0
This model was trained from scratch on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1182
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-----:|:---------------:|
| 0.1211 | 1.0 | 1350 | 0.1318 |
| 0.0599 | 2.0 | 2700 | 0.1617 |
| 0.0571 | 3.0 | 4050 | 0.0833 |
| 0.0248 | 4.0 | 5400 | 0.0396 |
| 0.0154 | 5.0 | 6750 | 0.0911 |
| 0.0 | 6.0 | 8100 | 0.1054 |
| 0.0 | 7.0 | 9450 | 0.1086 |
| 0.0 | 8.0 | 10800 | 0.1224 |
| 0.0002 | 9.0 | 12150 | 0.1155 |
| 0.0025 | 10.0 | 13500 | 0.1182 |
### Framework versions
- Transformers 4.32.0.dev0
- Pytorch 2.0.1+cu117
- Datasets 2.14.4
- Tokenizers 0.13.3
|
ryatora/distilbert-base-uncased-finetuned-emotion
|
ryatora
| 2023-09-21T15:36:40Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_trainer",
"dataset:emotion",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-09-19T12:44:18Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- emotion
metrics:
- accuracy
- f1
model-index:
- name: distilbert-base-uncased-finetuned-emotion
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: emotion
type: emotion
args: split
metrics:
- name: Accuracy
type: accuracy
value: 0.9225
- name: F1
type: f1
value: 0.9224787080842691
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-emotion
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the emotion dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2185
- Accuracy: 0.9225
- F1: 0.9225
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 0.8423 | 1.0 | 250 | 0.3084 | 0.9065 | 0.9049 |
| 0.2493 | 2.0 | 500 | 0.2185 | 0.9225 | 0.9225 |
### Framework versions
- Transformers 4.16.2
- Pytorch 2.0.1+cu118
- Datasets 2.14.5
- Tokenizers 0.14.0
|
ShivamMangale/XLM-Roberta-base-allhiweakdap_5th_iteration_d5
|
ShivamMangale
| 2023-09-21T15:35:52Z | 122 | 0 |
transformers
|
[
"transformers",
"pytorch",
"xlm-roberta",
"question-answering",
"generated_from_trainer",
"dataset:squad",
"base_model:FacebookAI/xlm-roberta-base",
"base_model:finetune:FacebookAI/xlm-roberta-base",
"license:mit",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2023-09-21T14:45:26Z |
---
license: mit
base_model: xlm-roberta-base
tags:
- generated_from_trainer
datasets:
- squad
model-index:
- name: XLM-Roberta-base-allhiweakdap_5th_iteration_d5
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# XLM-Roberta-base-allhiweakdap_5th_iteration_d5
This model is a fine-tuned version of [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) on the squad dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1.3122e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 8
### Training results
### Framework versions
- Transformers 4.33.2
- Pytorch 2.0.1+cu117
- Datasets 2.14.5
- Tokenizers 0.13.3
|
kla-20/qa-flant5
|
kla-20
| 2023-09-21T15:30:53Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"t5",
"text2text-generation",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2023-09-21T15:23:27Z |
---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: qa-flant5
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# qa-flant5
This model is a fine-tuned version of [google/flan-t5-base](https://huggingface.co/google/flan-t5-base) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 1
### Training results
### Framework versions
- Transformers 4.27.2
- Pytorch 1.13.1+cu117
- Datasets 2.11.0
- Tokenizers 0.13.3
|
SamuraiPetya/ppo-LunarLander-v2
|
SamuraiPetya
| 2023-09-21T15:26:57Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-09-21T15:26:34Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 258.01 +/- 17.73
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
MarcosMunoz95/SpaceInvadersNoFrameskip
|
MarcosMunoz95
| 2023-09-21T15:25:11Z | 1 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"SpaceInvadersNoFrameskip-v4",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-09-21T15:24:37Z |
---
library_name: stable-baselines3
tags:
- SpaceInvadersNoFrameskip-v4
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: DQN
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: SpaceInvadersNoFrameskip-v4
type: SpaceInvadersNoFrameskip-v4
metrics:
- type: mean_reward
value: 670.00 +/- 96.93
name: mean_reward
verified: false
---
# **DQN** Agent playing **SpaceInvadersNoFrameskip-v4**
This is a trained model of a **DQN** agent playing **SpaceInvadersNoFrameskip-v4**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3)
and the [RL Zoo](https://github.com/DLR-RM/rl-baselines3-zoo).
The RL Zoo is a training framework for Stable Baselines3
reinforcement learning agents,
with hyperparameter optimization and pre-trained agents included.
## Usage (with SB3 RL Zoo)
RL Zoo: https://github.com/DLR-RM/rl-baselines3-zoo<br/>
SB3: https://github.com/DLR-RM/stable-baselines3<br/>
SB3 Contrib: https://github.com/Stable-Baselines-Team/stable-baselines3-contrib
Install the RL Zoo (with SB3 and SB3-Contrib):
```bash
pip install rl_zoo3
```
```
# Download model and save it into the logs/ folder
python -m rl_zoo3.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga MarcosMunoz95 -f logs/
python -m rl_zoo3.enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
If you installed the RL Zoo3 via pip (`pip install rl_zoo3`), from anywhere you can do:
```
python -m rl_zoo3.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga MarcosMunoz95 -f logs/
python -m rl_zoo3.enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
## Training (with the RL Zoo)
```
python -m rl_zoo3.train --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
# Upload the model and generate video (when possible)
python -m rl_zoo3.push_to_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/ -orga MarcosMunoz95
```
## Hyperparameters
```python
OrderedDict([('batch_size', 32),
('buffer_size', 100000),
('env_wrapper',
['stable_baselines3.common.atari_wrappers.AtariWrapper']),
('exploration_final_eps', 0.01),
('exploration_fraction', 0.1),
('frame_stack', 4),
('gradient_steps', 1),
('learning_rate', 0.0001),
('learning_starts', 100000),
('n_timesteps', 1000000.0),
('optimize_memory_usage', False),
('policy', 'CnnPolicy'),
('target_update_interval', 1000),
('train_freq', 4),
('normalize', False)])
```
# Environment Arguments
```python
{'render_mode': 'rgb_array'}
```
|
Uberariy/q-FrozenLake-v1-4x4-noSlippery
|
Uberariy
| 2023-09-21T15:24:34Z | 0 | 0 | null |
[
"FrozenLake-v1-4x4-no_slippery",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-09-21T15:24:31Z |
---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="Uberariy/q-FrozenLake-v1-4x4-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
ShivamMangale/XLM-Roberta-base-all_hi_weakdap_4th_iteration_d4_d3_d2_d1_d0
|
ShivamMangale
| 2023-09-21T15:24:22Z | 133 | 0 |
transformers
|
[
"transformers",
"pytorch",
"xlm-roberta",
"question-answering",
"generated_from_trainer",
"dataset:squad",
"base_model:FacebookAI/xlm-roberta-base",
"base_model:finetune:FacebookAI/xlm-roberta-base",
"license:mit",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2023-09-21T14:52:40Z |
---
license: mit
base_model: xlm-roberta-base
tags:
- generated_from_trainer
datasets:
- squad
model-index:
- name: XLM-Roberta-base-all_hi_weakdap_4th_iteration_d4_d3_d2_d1_d0
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# XLM-Roberta-base-all_hi_weakdap_4th_iteration_d4_d3_d2_d1_d0
This model is a fine-tuned version of [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) on the squad dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 8
### Training results
### Framework versions
- Transformers 4.33.2
- Pytorch 2.0.1+cu117
- Datasets 2.14.5
- Tokenizers 0.13.3
|
Govern/textual_inversion_airplane
|
Govern
| 2023-09-21T15:17:46Z | 14 | 0 |
diffusers
|
[
"diffusers",
"tensorboard",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"textual_inversion",
"base_model:runwayml/stable-diffusion-v1-5",
"base_model:adapter:runwayml/stable-diffusion-v1-5",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] |
text-to-image
| 2023-09-21T13:37:06Z |
---
license: creativeml-openrail-m
base_model: runwayml/stable-diffusion-v1-5
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
- textual_inversion
inference: true
---
# Textual inversion text2image fine-tuning - Govern/textual_inversion_airplane
These are textual inversion adaption weights for runwayml/stable-diffusion-v1-5. You can find some example images in the following.
|
prathameshdalal/videomae-base-finetuned-ucf101-subset
|
prathameshdalal
| 2023-09-21T15:08:40Z | 69 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"videomae",
"video-classification",
"generated_from_trainer",
"base_model:MCG-NJU/videomae-base",
"base_model:finetune:MCG-NJU/videomae-base",
"license:cc-by-nc-4.0",
"endpoints_compatible",
"region:us"
] |
video-classification
| 2023-08-20T08:43:35Z |
---
license: cc-by-nc-4.0
base_model: MCG-NJU/videomae-base
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: videomae-base-finetuned-ucf101-subset
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# videomae-base-finetuned-ucf101-subset
This model is a fine-tuned version of [MCG-NJU/videomae-base](https://huggingface.co/MCG-NJU/videomae-base) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1362
- Accuracy: 0.9714
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- training_steps: 600
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 2.2638 | 0.06 | 38 | 2.2761 | 0.1143 |
| 1.6112 | 1.06 | 76 | 1.0811 | 0.7143 |
| 0.5768 | 2.06 | 114 | 0.4538 | 0.8857 |
| 0.298 | 3.06 | 152 | 0.4841 | 0.8 |
| 0.0856 | 4.06 | 190 | 0.6021 | 0.8 |
| 0.2283 | 5.06 | 228 | 0.2103 | 0.9286 |
| 0.0559 | 6.06 | 266 | 0.1142 | 0.9714 |
| 0.2279 | 7.06 | 304 | 0.1132 | 0.9714 |
| 0.0145 | 8.06 | 342 | 0.0762 | 0.9714 |
| 0.0057 | 9.06 | 380 | 0.0226 | 1.0 |
| 0.0076 | 10.06 | 418 | 0.1619 | 0.9714 |
| 0.0046 | 11.06 | 456 | 0.1617 | 0.9714 |
| 0.0034 | 12.06 | 494 | 0.1676 | 0.9571 |
| 0.0034 | 13.06 | 532 | 0.1398 | 0.9714 |
| 0.0034 | 14.06 | 570 | 0.1345 | 0.9714 |
| 0.0035 | 15.05 | 600 | 0.1362 | 0.9714 |
### Framework versions
- Transformers 4.33.2
- Pytorch 1.10.0+cu113
- Datasets 2.14.5
- Tokenizers 0.13.3
|
CyberHarem/hiiragi_shino_idolmastercinderellagirls
|
CyberHarem
| 2023-09-21T14:54:07Z | 0 | 0 | null |
[
"art",
"text-to-image",
"dataset:CyberHarem/hiiragi_shino_idolmastercinderellagirls",
"license:mit",
"region:us"
] |
text-to-image
| 2023-09-21T14:42:01Z |
---
license: mit
datasets:
- CyberHarem/hiiragi_shino_idolmastercinderellagirls
pipeline_tag: text-to-image
tags:
- art
---
# Lora of hiiragi_shino_idolmastercinderellagirls
This model is trained with [HCP-Diffusion](https://github.com/7eu7d7/HCP-Diffusion). And the auto-training framework is maintained by [DeepGHS Team](https://huggingface.co/deepghs).
The base model used during training is [NAI](https://huggingface.co/deepghs/animefull-latest), and the base model used for generating preview images is [Meina/MeinaMix_V11](https://huggingface.co/Meina/MeinaMix_V11).
After downloading the pt and safetensors files for the specified step, you need to use them simultaneously. The pt file will be used as an embedding, while the safetensors file will be loaded for Lora.
For example, if you want to use the model from step 4760, you need to download `4760/hiiragi_shino_idolmastercinderellagirls.pt` as the embedding and `4760/hiiragi_shino_idolmastercinderellagirls.safetensors` for loading Lora. By using both files together, you can generate images for the desired characters.
**The best step we recommend is 4760**, with the score of 0.994. The trigger words are:
1. `hiiragi_shino_idolmastercinderellagirls`
2. `long_hair, black_hair, blush, brown_eyes, smile, jewelry, breasts, large_breasts`
For the following groups, it is not recommended to use this model and we express regret:
1. Individuals who cannot tolerate any deviations from the original character design, even in the slightest detail.
2. Individuals who are facing the application scenarios with high demands for accuracy in recreating character outfits.
3. Individuals who cannot accept the potential randomness in AI-generated images based on the Stable Diffusion algorithm.
4. Individuals who are not comfortable with the fully automated process of training character models using LoRA, or those who believe that training character models must be done purely through manual operations to avoid disrespecting the characters.
5. Individuals who finds the generated image content offensive to their values.
These are available steps:
| Steps | Score | Download | pattern_1 | pattern_2 | pattern_3 | pattern_4 | bikini | bondage | free | maid | miko | nude | nude2 | suit | yukata |
|:---------|:----------|:-----------------------------------------------------------------|:-----------------------------------------------|:-----------------------------------------------|:-----------------------------------------------|:-----------------------------------------------|:-----------------------------------------|:--------------------------------------------------|:-----------------------------------------------|:-------------------------------------|:-------------------------------------|:-----------------------------------------------|:------------------------------------------------|:-------------------------------------|:-----------------------------------------|
| 5100 | 0.976 | [Download](5100/hiiragi_shino_idolmastercinderellagirls.zip) |  |  |  |  |  | [<NSFW, click to see>](5100/previews/bondage.png) | [<NSFW, click to see>](5100/previews/free.png) |  |  | [<NSFW, click to see>](5100/previews/nude.png) | [<NSFW, click to see>](5100/previews/nude2.png) |  |  |
| **4760** | **0.994** | [**Download**](4760/hiiragi_shino_idolmastercinderellagirls.zip) |  |  |  |  |  | [<NSFW, click to see>](4760/previews/bondage.png) | [<NSFW, click to see>](4760/previews/free.png) |  |  | [<NSFW, click to see>](4760/previews/nude.png) | [<NSFW, click to see>](4760/previews/nude2.png) |  |  |
| 4420 | 0.981 | [Download](4420/hiiragi_shino_idolmastercinderellagirls.zip) |  |  |  |  |  | [<NSFW, click to see>](4420/previews/bondage.png) | [<NSFW, click to see>](4420/previews/free.png) |  |  | [<NSFW, click to see>](4420/previews/nude.png) | [<NSFW, click to see>](4420/previews/nude2.png) |  |  |
| 4080 | 0.977 | [Download](4080/hiiragi_shino_idolmastercinderellagirls.zip) |  |  |  |  |  | [<NSFW, click to see>](4080/previews/bondage.png) | [<NSFW, click to see>](4080/previews/free.png) |  |  | [<NSFW, click to see>](4080/previews/nude.png) | [<NSFW, click to see>](4080/previews/nude2.png) |  |  |
| 3740 | 0.963 | [Download](3740/hiiragi_shino_idolmastercinderellagirls.zip) |  |  |  |  |  | [<NSFW, click to see>](3740/previews/bondage.png) | [<NSFW, click to see>](3740/previews/free.png) |  |  | [<NSFW, click to see>](3740/previews/nude.png) | [<NSFW, click to see>](3740/previews/nude2.png) |  |  |
| 3400 | 0.951 | [Download](3400/hiiragi_shino_idolmastercinderellagirls.zip) |  |  |  |  |  | [<NSFW, click to see>](3400/previews/bondage.png) | [<NSFW, click to see>](3400/previews/free.png) |  |  | [<NSFW, click to see>](3400/previews/nude.png) | [<NSFW, click to see>](3400/previews/nude2.png) |  |  |
| 3060 | 0.984 | [Download](3060/hiiragi_shino_idolmastercinderellagirls.zip) |  |  |  |  |  | [<NSFW, click to see>](3060/previews/bondage.png) | [<NSFW, click to see>](3060/previews/free.png) |  |  | [<NSFW, click to see>](3060/previews/nude.png) | [<NSFW, click to see>](3060/previews/nude2.png) |  |  |
| 2720 | 0.966 | [Download](2720/hiiragi_shino_idolmastercinderellagirls.zip) |  |  |  |  |  | [<NSFW, click to see>](2720/previews/bondage.png) | [<NSFW, click to see>](2720/previews/free.png) |  |  | [<NSFW, click to see>](2720/previews/nude.png) | [<NSFW, click to see>](2720/previews/nude2.png) |  |  |
| 2380 | 0.938 | [Download](2380/hiiragi_shino_idolmastercinderellagirls.zip) |  |  |  |  |  | [<NSFW, click to see>](2380/previews/bondage.png) | [<NSFW, click to see>](2380/previews/free.png) |  |  | [<NSFW, click to see>](2380/previews/nude.png) | [<NSFW, click to see>](2380/previews/nude2.png) |  |  |
| 2040 | 0.938 | [Download](2040/hiiragi_shino_idolmastercinderellagirls.zip) |  |  |  |  |  | [<NSFW, click to see>](2040/previews/bondage.png) | [<NSFW, click to see>](2040/previews/free.png) |  |  | [<NSFW, click to see>](2040/previews/nude.png) | [<NSFW, click to see>](2040/previews/nude2.png) |  |  |
| 1700 | 0.971 | [Download](1700/hiiragi_shino_idolmastercinderellagirls.zip) |  |  |  |  |  | [<NSFW, click to see>](1700/previews/bondage.png) | [<NSFW, click to see>](1700/previews/free.png) |  |  | [<NSFW, click to see>](1700/previews/nude.png) | [<NSFW, click to see>](1700/previews/nude2.png) |  |  |
| 1360 | 0.955 | [Download](1360/hiiragi_shino_idolmastercinderellagirls.zip) |  |  |  |  |  | [<NSFW, click to see>](1360/previews/bondage.png) | [<NSFW, click to see>](1360/previews/free.png) |  |  | [<NSFW, click to see>](1360/previews/nude.png) | [<NSFW, click to see>](1360/previews/nude2.png) |  |  |
| 1020 | 0.792 | [Download](1020/hiiragi_shino_idolmastercinderellagirls.zip) |  |  |  |  |  | [<NSFW, click to see>](1020/previews/bondage.png) | [<NSFW, click to see>](1020/previews/free.png) |  |  | [<NSFW, click to see>](1020/previews/nude.png) | [<NSFW, click to see>](1020/previews/nude2.png) |  |  |
| 680 | 0.937 | [Download](680/hiiragi_shino_idolmastercinderellagirls.zip) |  |  |  |  |  | [<NSFW, click to see>](680/previews/bondage.png) | [<NSFW, click to see>](680/previews/free.png) |  |  | [<NSFW, click to see>](680/previews/nude.png) | [<NSFW, click to see>](680/previews/nude2.png) |  |  |
| 340 | 0.867 | [Download](340/hiiragi_shino_idolmastercinderellagirls.zip) |  |  |  |  |  | [<NSFW, click to see>](340/previews/bondage.png) | [<NSFW, click to see>](340/previews/free.png) |  |  | [<NSFW, click to see>](340/previews/nude.png) | [<NSFW, click to see>](340/previews/nude2.png) |  |  |
|
ShivamMangale/XLM-Roberta-base-all_hi_weakdap_4th_iteration_d4_d3_d2_d1
|
ShivamMangale
| 2023-09-21T14:52:39Z | 122 | 0 |
transformers
|
[
"transformers",
"pytorch",
"xlm-roberta",
"question-answering",
"generated_from_trainer",
"dataset:squad",
"base_model:FacebookAI/xlm-roberta-base",
"base_model:finetune:FacebookAI/xlm-roberta-base",
"license:mit",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2023-09-21T14:34:47Z |
---
license: mit
base_model: xlm-roberta-base
tags:
- generated_from_trainer
datasets:
- squad
model-index:
- name: XLM-Roberta-base-all_hi_weakdap_4th_iteration_d4_d3_d2_d1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# XLM-Roberta-base-all_hi_weakdap_4th_iteration_d4_d3_d2_d1
This model is a fine-tuned version of [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) on the squad dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 8
### Training results
### Framework versions
- Transformers 4.33.2
- Pytorch 2.0.1+cu117
- Datasets 2.14.5
- Tokenizers 0.13.3
|
mann-e/mann-e_5.4
|
mann-e
| 2023-09-21T14:52:30Z | 3 | 0 |
diffusers
|
[
"diffusers",
"text-to-image",
"region:us"
] |
text-to-image
| 2023-09-21T12:47:14Z |
---
library_name: diffusers
pipeline_tag: text-to-image
---
# Mann-E 5.4
This repository represents what is the main brain of [Mann-E](https://manne.ir) artificial intelligence platform.
## Features
1. _LoRa support_. In previous versions, most of LoRa models weren't working perfectly with the model.
2. _More coherent results_. Compared to the old versions, this version has more "midjourney" feel to its outputs.
3. _New License_. Unlike old versions this one isn't licensed undet MIT, we decided to go with our own license.
## Samples
<span align="center">
<img src="https://huggingface.co/mann-e/mann-e_5.4/resolve/main/grid-1.png" width=512px />
<br/>
<img src="https://huggingface.co/mann-e/mann-e_5.4/resolve/main/grid-2.png" width=512px />
<br/>
<img src="https://huggingface.co/mann-e/mann-e_5.4/resolve/main/grid-3.png" width=512px />
<br/>
<img src="https://huggingface.co/mann-e/mann-e_5.4/resolve/main/grid-4.png" width=512px />
<br/>
<img src="https://huggingface.co/mann-e/mann-e_5.4/resolve/main/grid-5.png" width=512px />
</span>
## License
This software and associated checkpoints are provided by Mann-E for educational and non-commercial use only. By accessing or using this software and checkpoints, you agree to the following terms and conditions:
1. Access and Use:
- You are granted the right to access and use the source code and checkpoints for educational and non-commercial purposes.
2. Modification and Distribution:
- You may modify and distribute the source code and checkpoints solely for educational and non-commercial purposes, provided that you retain this license notice.
3. Commercial Use:
- Commercial use of this software and checkpoints is strictly prohibited without the explicit written consent of the Copyright Holder.
4. Fine-tuning of Checkpoints:
- You may not fine-tune or modify the provided checkpoints without obtaining the express written consent of the Copyright Holder.
5. No Warranty:
- This software and checkpoints are provided "as is" without any warranty. The Copyright Holder shall not be liable for any damages or liabilities arising out of the use or inability to use the software and checkpoints.
6. Termination:
- This license is effective until terminated by the Copyright Holder. Your rights under this license will terminate automatically without notice from the Copyright Holder if you fail to comply with any term or condition of this license.
If you do not agree to these terms and conditions or do not have the legal authority to bind yourself, you may not use, modify, or distribute this software and checkpoints.
For inquiries regarding commercial use or fine-tuning of checkpoints, please contact Mann-E.
|
nickypro/tinyllama-15M-fp32
|
nickypro
| 2023-09-21T14:50:50Z | 152 | 0 |
transformers
|
[
"transformers",
"pytorch",
"llama",
"text-generation",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-09-16T17:23:46Z |
---
license: mit
---
This is the Float32 15M parameter Llama 2 architecture model trained on the TinyStories dataset.
These are converted from
[karpathy/tinyllamas](https://huggingface.co/karpathy/tinyllamas).
See the [llama2.c](https://github.com/karpathy/llama2.c) project for more details.
|
nickypro/tinyllama-42M-fp32
|
nickypro
| 2023-09-21T14:50:34Z | 150 | 1 |
transformers
|
[
"transformers",
"pytorch",
"llama",
"text-generation",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-09-16T17:25:17Z |
---
license: mit
---
This is the float32 42M parameter Llama 2 architecture model trained on the TinyStories dataset.
These are converted from
[karpathy/tinyllamas](https://huggingface.co/karpathy/tinyllamas).
See the [llama2.c](https://github.com/karpathy/llama2.c) project for more details.
|
yunosuken/results
|
yunosuken
| 2023-09-21T14:50:34Z | 103 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"text-classification",
"generated_from_trainer",
"base_model:tohoku-nlp/bert-large-japanese-v2",
"base_model:finetune:tohoku-nlp/bert-large-japanese-v2",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-09-13T14:15:12Z |
---
license: apache-2.0
base_model: cl-tohoku/bert-large-japanese-v2
tags:
- generated_from_trainer
metrics:
- accuracy
- f1
model-index:
- name: bert-large-japanease-v2-gpt4-relevance-learned
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-large-japanease-v2-gpt4-relevance-learned
This model is a fine-tuned version of [cl-tohoku/bert-large-japanese-v2](https://huggingface.co/cl-tohoku/bert-large-japanese-v2) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 3.2693
- Accuracy: 0.885
- F1: 0.8788
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 3.3692 | 1.0 | 563 | 3.2122 | 0.872 | 0.8560 |
| 3.0963 | 2.0 | 1126 | 3.1045 | 0.866 | 0.8625 |
| 2.8698 | 3.0 | 1689 | 3.1410 | 0.882 | 0.8755 |
| 2.6212 | 4.0 | 2252 | 3.2119 | 0.876 | 0.8702 |
| 2.407 | 5.0 | 2815 | 3.2693 | 0.885 | 0.8788 |
### Framework versions
- Transformers 4.33.2
- Pytorch 2.0.1+cu118
- Datasets 2.14.5
- Tokenizers 0.13.3
|
nickypro/tinyllama-42M
|
nickypro
| 2023-09-21T14:49:31Z | 184 | 1 |
transformers
|
[
"transformers",
"pytorch",
"llama",
"text-generation",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-09-16T13:33:58Z |
---
license: mit
---
This is the 42M parameter Llama 2 architecture model trained on the TinyStories dataset.
These are converted from
[karpathy/tinyllamas](https://huggingface.co/karpathy/tinyllamas).
See the [llama2.c](https://github.com/karpathy/llama2.c) project for more details.
|
ayushtues/blipdiffusion-controlnet
|
ayushtues
| 2023-09-21T14:44:41Z | 2 | 0 |
diffusers
|
[
"diffusers",
"en",
"arxiv:2305.14720",
"license:apache-2.0",
"diffusers:BlipDiffusionControlNetPipeline",
"region:us"
] | null | 2023-08-30T12:09:09Z |
---
license: apache-2.0
language:
- en
library_name: diffusers
---
# BLIP-Diffusion: Pre-trained Subject Representation for Controllable Text-to-Image Generation and Editing
<!-- Provide a quick summary of what the model is/does. -->
Model card for BLIP-Diffusion, a text to image Diffusion model which enables zero-shot subject-driven generation and control-guided zero-shot generation.
The abstract from the paper is:
*Subject-driven text-to-image generation models create novel renditions of an input subject based on text prompts. Existing models suffer from lengthy fine-tuning and difficulties preserving the subject fidelity. To overcome these limitations, we introduce BLIP-Diffusion, a new subject-driven image generation model that supports multimodal control which consumes inputs of subject images and text prompts. Unlike other subject-driven generation models, BLIP-Diffusion introduces a new multimodal encoder which is pre-trained to provide subject representation. We first pre-train the multimodal encoder following BLIP-2 to produce visual representation aligned with the text. Then we design a subject representation learning task which enables a diffusion model to leverage such visual representation and generates new subject renditions. Compared with previous methods such as DreamBooth, our model enables zero-shot subject-driven generation, and efficient fine-tuning for customized subject with up to 20x speedup. We also demonstrate that BLIP-Diffusion can be flexibly combined with existing techniques such as ControlNet and prompt-to-prompt to enable novel subject-driven generation and editing applications.*
The model is created by Dongxu Li, Junnan Li, Steven C.H. Hoi.
### Model Sources
<!-- Provide the basic links for the model. -->
- **Original Repository:** https://github.com/salesforce/LAVIS/tree/main
- **Project Page:** https://dxli94.github.io/BLIP-Diffusion-website/
## Uses
### Zero-Shot Subject Driven Generation
```python
from diffusers.pipelines import BlipDiffusionPipeline
from diffusers.utils import load_image
import torch
blip_diffusion_pipe = BlipDiffusionPipeline.from_pretrained(
"Salesforce/blipdiffusion", torch_dtype=torch.float16
).to("cuda")
cond_subject = "dog"
tgt_subject = "dog"
text_prompt_input = "swimming underwater"
cond_image = load_image(
"https://huggingface.co/datasets/ayushtues/blipdiffusion_images/resolve/main/dog.jpg"
)
iter_seed = 88888
guidance_scale = 7.5
num_inference_steps = 25
negative_prompt = "over-exposure, under-exposure, saturated, duplicate, out of frame, lowres, cropped, worst quality, low quality, jpeg artifacts, morbid, mutilated, out of frame, ugly, bad anatomy, bad proportions, deformed, blurry, duplicate"
output = blip_diffusion_pipe(
text_prompt_input,
cond_image,
cond_subject,
tgt_subject,
guidance_scale=guidance_scale,
num_inference_steps=num_inference_steps,
neg_prompt=negative_prompt,
height=512,
width=512,
).images
output[0].save("image.png")
```
Input Image : <img src="https://huggingface.co/datasets/ayushtues/blipdiffusion_images/resolve/main/dog.jpg" style="width:500px;"/>
Generatred Image : <img src="https://huggingface.co/datasets/ayushtues/blipdiffusion_images/resolve/main/dog_underwater.png" style="width:500px;"/>
### Controlled subject-driven generation
```python
from diffusers.pipelines import BlipDiffusionControlNetPipeline
from diffusers.utils import load_image
from controlnet_aux import CannyDetector
blip_diffusion_pipe = BlipDiffusionControlNetPipeline.from_pretrained(
"Salesforce/blipdiffusion-controlnet", torch_dtype=torch.float16
).to("cuda")
style_subject = "flower" # subject that defines the style
tgt_subject = "teapot" # subject to generate.
text_prompt = "on a marble table"
cldm_cond_image = load_image(
"https://huggingface.co/datasets/ayushtues/blipdiffusion_images/resolve/main/kettle.jpg"
).resize((512, 512))
canny = CannyDetector()
cldm_cond_image = canny(cldm_cond_image, 30, 70, output_type="pil")
style_image = load_image(
"https://huggingface.co/datasets/ayushtues/blipdiffusion_images/resolve/main/flower.jpg"
)
guidance_scale = 7.5
num_inference_steps = 50
negative_prompt = "over-exposure, under-exposure, saturated, duplicate, out of frame, lowres, cropped, worst quality, low quality, jpeg artifacts, morbid, mutilated, out of frame, ugly, bad anatomy, bad proportions, deformed, blurry, duplicate"
output = blip_diffusion_pipe(
text_prompt,
style_image,
cldm_cond_image,
style_subject,
tgt_subject,
guidance_scale=guidance_scale,
num_inference_steps=num_inference_steps,
neg_prompt=negative_prompt,
height=512,
width=512,
).images
output[0].save("image.png")
```
Input Style Image : <img src="https://huggingface.co/datasets/ayushtues/blipdiffusion_images/resolve/main/flower.jpg" style="width:500px;"/>
Canny Edge Input : <img src="https://huggingface.co/datasets/ayushtues/blipdiffusion_images/resolve/main/kettle.jpg" style="width:500px;"/>
Generated Image : <img src="https://huggingface.co/datasets/ayushtues/blipdiffusion_images/resolve/main/canny_generated.png" style="width:500px;"/>
### Controlled subject-driven generation Scribble
```python
from diffusers.pipelines import BlipDiffusionControlNetPipeline
from diffusers.utils import load_image
from controlnet_aux import HEDdetector
blip_diffusion_pipe = BlipDiffusionControlNetPipeline.from_pretrained(
"Salesforce/blipdiffusion-controlnet"
)
controlnet = ControlNetModel.from_pretrained("lllyasviel/sd-controlnet-scribble")
blip_diffusion_pipe.controlnet = controlnet
blip_diffusion_pipe.to("cuda")
style_subject = "flower" # subject that defines the style
tgt_subject = "bag" # subject to generate.
text_prompt = "on a table"
cldm_cond_image = load_image(
"https://huggingface.co/lllyasviel/sd-controlnet-scribble/resolve/main/images/bag.png"
).resize((512, 512))
hed = HEDdetector.from_pretrained("lllyasviel/Annotators")
cldm_cond_image = hed(cldm_cond_image)
style_image = load_image(
"https://huggingface.co/datasets/ayushtues/blipdiffusion_images/resolve/main/flower.jpg"
)
guidance_scale = 7.5
num_inference_steps = 50
negative_prompt = "over-exposure, under-exposure, saturated, duplicate, out of frame, lowres, cropped, worst quality, low quality, jpeg artifacts, morbid, mutilated, out of frame, ugly, bad anatomy, bad proportions, deformed, blurry, duplicate"
output = blip_diffusion_pipe(
text_prompt,
style_image,
cldm_cond_image,
style_subject,
tgt_subject,
guidance_scale=guidance_scale,
num_inference_steps=num_inference_steps,
neg_prompt=negative_prompt,
height=512,
width=512,
).images
output[0].save("image.png")
```
Input Style Image : <img src="https://huggingface.co/datasets/ayushtues/blipdiffusion_images/resolve/main/flower.jpg" style="width:500px;"/>
Scribble Input : <img src="https://huggingface.co/datasets/ayushtues/blipdiffusion_images/resolve/main/scribble.png" style="width:500px;"/>
Generated Image : <img src="https://huggingface.co/datasets/ayushtues/blipdiffusion_images/resolve/main/scribble_output.png" style="width:500px;"/>
## Model Architecture
Blip-Diffusion learns a **pre-trained subject representation**. uch representation aligns with text embeddings and in the meantime also encodes the subject appearance. This allows efficient fine-tuning of the model for high-fidelity subject-driven applications, such as text-to-image generation, editing and style transfer.
To this end, they design a two-stage pre-training strategy to learn generic subject representation. In the first pre-training stage, they perform multimodal representation learning, which enforces BLIP-2 to produce text-aligned visual features based on the input image. In the second pre-training stage, they design a subject representation learning task, called prompted context generation, where the diffusion model learns to generate novel subject renditions based on the input visual features.
To achieve this, they curate pairs of input-target images with the same subject appearing in different contexts. Specifically, they synthesize input images by composing the subject with a random background. During pre-training, they feed the synthetic input image and the subject class label through BLIP-2 to obtain the multimodal embeddings as subject representation. The subject representation is then combined with a text prompt to guide the generation of the target image.

The architecture is also compatible to integrate with established techniques built on top of the diffusion model, such as ControlNet.
They attach the U-Net of the pre-trained ControlNet to that of BLIP-Diffusion via residuals. In this way, the model takes into account the input structure condition, such as edge maps and depth maps, in addition to the subject cues. Since the model inherits the architecture of the original latent diffusion model, they observe satisfying generations using off-the-shelf integration with pre-trained ControlNet without further training.
<img src="https://huggingface.co/datasets/ayushtues/blipdiffusion_images/resolve/main/arch_controlnet.png" style="width:50%;"/>
## Citation
**BibTeX:**
If you find this repository useful in your research, please cite:
```
@misc{li2023blipdiffusion,
title={BLIP-Diffusion: Pre-trained Subject Representation for Controllable Text-to-Image Generation and Editing},
author={Dongxu Li and Junnan Li and Steven C. H. Hoi},
year={2023},
eprint={2305.14720},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
|
optimaxbangladesh/optimaxbangladesh
|
optimaxbangladesh
| 2023-09-21T14:37:29Z | 0 | 0 | null |
[
"region:us"
] | null | 2023-09-21T14:36:56Z |
Optimax প্রাকৃতিক উপাদান ব্যবহার করে তৈরি করা হয়েছে যা চোখের সামগ্রিক স্বাস্থ্যের উন্নতিতে উপকারী বলে প্রমাণিত হয়েছে।
Optimax এখন কেন!! আরও তথ্যের জন্য নীচের লিঙ্কে ক্লিক করুন এবং এখনই 50% ছাড় পান!! তারাতারি কর !!
আরও পড়ুন: https://www.nutritioncrawler.com/OptiBang
https://sites.google.com/view/optimaxbangladesh/home
➢ পণ্যের নাম — Optimax
➢ এর জন্য ব্যবহৃত: চোখের স্বাস্থ্য
➢ প্রধান সুবিধা - চোখের দৃষ্টিশক্তি উন্নত করুন
➢ রচনা — প্রাকৃতিক জৈব যৌগ
➢ পার্শ্ব-প্রতিক্রিয়া—NA
➢ চূড়ান্ত রেটিং: — 4.7
➢ প্রাপ্যতা — অনলাইন
➢অফার এবং ডিসকাউন্ট; আজ সংরক্ষণ করুন! বিশেষ অফার কিনতে এখনই কেনাকাটা করুন!!!
Optimax কি?
যারা পরিচিত নন তাদের জন্য, Optimax হল একটি দৃষ্টি-উন্নতিকারী খাদ্যতালিকাগত সম্পূরক যা প্রতিবন্ধী দৃষ্টির 3টি প্রধান কারণ মোকাবেলা করে একজন ব্যক্তির দৃষ্টিশক্তি বাড়াতে সাহায্য করার দাবির জন্য ইন্টারনেটের চারপাশে ভাসছে। প্রাথমিক কারণ হল কিছু বিষাক্ত পদার্থের সংস্পর্শে যা চোখের মারাত্মক ক্ষতি করতে পারে।
Optimax এখন কেন!! আরও তথ্যের জন্য নীচের লিঙ্কে ক্লিক করুন এবং এখনই 50% ছাড় পান!! তারাতারি কর !!
আরও পড়ুন: https://www.nutritioncrawler.com/OptiBang
https://sites.google.com/view/optimaxbangladesh/home
Optimax Optimax বড়ি Optimax ক্যাপসুল Optimax ট্যাবলেট Optimax দাম Optimax পর্যালোচনা Optimax উপাদান Optimax সুবিধা Optimax ক্ষতিকর দিক Optimax ক্যাপসুলের দাম Optimax ক্যাপসুল পর্যালোচনা Optimax গঠন Optimax অভিযোগ Optimax কোথায় কিনতে হবে Optimax ব্যবহারবিধি Optimax খরচ Optimax কাজ করে Optimax ফোরাম Optimax মূল Optimax ফার্মেসি
|
LarryAIDraw/takina_inoue_v1
|
LarryAIDraw
| 2023-09-21T14:35:35Z | 0 | 0 | null |
[
"license:creativeml-openrail-m",
"region:us"
] | null | 2023-09-21T13:33:54Z |
---
license: creativeml-openrail-m
---
https://civitai.com/models/148903/takina-inoue-or-lycoris-recoil-5-outfits
|
ehcalabres/distilgpt2-abc-irish-music-generation
|
ehcalabres
| 2023-09-21T14:30:22Z | 214 | 1 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"safetensors",
"gpt2",
"text-generation",
"generated_from_trainer",
"base_model:distilbert/distilgpt2",
"base_model:finetune:distilbert/distilgpt2",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-06-08T11:55:25Z |
---
license: apache-2.0
tags:
- generated_from_trainer
base_model: distilgpt2
model-index:
- name: distilgpt2-abc-irish-music-generation
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilgpt2-abc-irish-music-generation
This model is a fine-tuned version of [distilgpt2](https://huggingface.co/distilgpt2) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 10
### Training results
### Framework versions
- Transformers 4.19.2
- Pytorch 1.11.0+cu113
- Datasets 2.2.2
- Tokenizers 0.12.1
|
ramboind/infra
|
ramboind
| 2023-09-21T14:26:54Z | 0 | 0 | null |
[
"license:cc-by-nc-nd-3.0",
"region:us"
] | null | 2023-09-21T14:26:54Z |
---
license: cc-by-nc-nd-3.0
---
|
ShivamMangale/XLM-Roberta-base-all_hi_weakdap_4th_iteration_d4_d3
|
ShivamMangale
| 2023-09-21T14:23:27Z | 122 | 0 |
transformers
|
[
"transformers",
"pytorch",
"xlm-roberta",
"question-answering",
"generated_from_trainer",
"dataset:squad",
"base_model:FacebookAI/xlm-roberta-base",
"base_model:finetune:FacebookAI/xlm-roberta-base",
"license:mit",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2023-09-21T14:14:05Z |
---
license: mit
base_model: xlm-roberta-base
tags:
- generated_from_trainer
datasets:
- squad
model-index:
- name: XLM-Roberta-base-all_hi_weakdap_4th_iteration_d4_d3
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# XLM-Roberta-base-all_hi_weakdap_4th_iteration_d4_d3
This model is a fine-tuned version of [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) on the squad dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1.62e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 8
### Training results
### Framework versions
- Transformers 4.33.2
- Pytorch 2.0.1+cu117
- Datasets 2.14.5
- Tokenizers 0.13.3
|
ShivamMangale/XLM-Roberta-base-all_hi_weakdap_4th_iteration_d4_d3_d2-hq
|
ShivamMangale
| 2023-09-21T14:06:23Z | 106 | 0 |
transformers
|
[
"transformers",
"pytorch",
"xlm-roberta",
"question-answering",
"generated_from_trainer",
"dataset:squad",
"base_model:FacebookAI/xlm-roberta-base",
"base_model:finetune:FacebookAI/xlm-roberta-base",
"license:mit",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2023-09-21T13:56:47Z |
---
license: mit
base_model: xlm-roberta-base
tags:
- generated_from_trainer
datasets:
- squad
model-index:
- name: XLM-Roberta-base-all_hi_weakdap_4th_iteration_d4_d3_d2-hq
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# XLM-Roberta-base-all_hi_weakdap_4th_iteration_d4_d3_d2-hq
This model is a fine-tuned version of [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) on the squad dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1.8e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 8
### Training results
### Framework versions
- Transformers 4.33.2
- Pytorch 2.0.1+cu117
- Datasets 2.14.5
- Tokenizers 0.13.3
|
CyberHarem/eve_santaclaus_idolmastercinderellagirls
|
CyberHarem
| 2023-09-21T14:04:36Z | 0 | 0 | null |
[
"art",
"text-to-image",
"dataset:CyberHarem/eve_santaclaus_idolmastercinderellagirls",
"license:mit",
"region:us"
] |
text-to-image
| 2023-09-21T13:49:04Z |
---
license: mit
datasets:
- CyberHarem/eve_santaclaus_idolmastercinderellagirls
pipeline_tag: text-to-image
tags:
- art
---
# Lora of eve_santaclaus_idolmastercinderellagirls
This model is trained with [HCP-Diffusion](https://github.com/7eu7d7/HCP-Diffusion). And the auto-training framework is maintained by [DeepGHS Team](https://huggingface.co/deepghs).
The base model used during training is [NAI](https://huggingface.co/deepghs/animefull-latest), and the base model used for generating preview images is [Meina/MeinaMix_V11](https://huggingface.co/Meina/MeinaMix_V11).
After downloading the pt and safetensors files for the specified step, you need to use them simultaneously. The pt file will be used as an embedding, while the safetensors file will be loaded for Lora.
For example, if you want to use the model from step 4420, you need to download `4420/eve_santaclaus_idolmastercinderellagirls.pt` as the embedding and `4420/eve_santaclaus_idolmastercinderellagirls.safetensors` for loading Lora. By using both files together, you can generate images for the desired characters.
**The best step we recommend is 4420**, with the score of 0.975. The trigger words are:
1. `eve_santaclaus_idolmastercinderellagirls`
2. `long_hair, yellow_eyes, blush, white_hair, smile, open_mouth, breasts, bangs, hat, medium_breasts`
For the following groups, it is not recommended to use this model and we express regret:
1. Individuals who cannot tolerate any deviations from the original character design, even in the slightest detail.
2. Individuals who are facing the application scenarios with high demands for accuracy in recreating character outfits.
3. Individuals who cannot accept the potential randomness in AI-generated images based on the Stable Diffusion algorithm.
4. Individuals who are not comfortable with the fully automated process of training character models using LoRA, or those who believe that training character models must be done purely through manual operations to avoid disrespecting the characters.
5. Individuals who finds the generated image content offensive to their values.
These are available steps:
| Steps | Score | Download | pattern_1 | pattern_2 | pattern_3 | pattern_4 | pattern_5 | pattern_6 | pattern_7 | pattern_8 | pattern_9 | pattern_10 | bikini | bondage | free | maid | miko | nude | nude2 | suit | yukata |
|:---------|:----------|:------------------------------------------------------------------|:-----------------------------------------------|:-----------------------------------------------|:----------------------------------------------------|:-----------------------------------------------|:-----------------------------------------------|:-----------------------------------------------|:-----------------------------------------------|:-----------------------------------------------|:-----------------------------------------------|:-----------------------------------------------------|:-----------------------------------------|:--------------------------------------------------|:-------------------------------------|:-------------------------------------|:-------------------------------------|:-----------------------------------------------|:------------------------------------------------|:-------------------------------------|:-----------------------------------------|
| 5100 | 0.961 | [Download](5100/eve_santaclaus_idolmastercinderellagirls.zip) |  |  | [<NSFW, click to see>](5100/previews/pattern_3.png) |  |  |  |  |  |  | [<NSFW, click to see>](5100/previews/pattern_10.png) |  | [<NSFW, click to see>](5100/previews/bondage.png) |  |  |  | [<NSFW, click to see>](5100/previews/nude.png) | [<NSFW, click to see>](5100/previews/nude2.png) |  |  |
| 4760 | 0.963 | [Download](4760/eve_santaclaus_idolmastercinderellagirls.zip) |  |  | [<NSFW, click to see>](4760/previews/pattern_3.png) |  |  |  |  |  |  | [<NSFW, click to see>](4760/previews/pattern_10.png) |  | [<NSFW, click to see>](4760/previews/bondage.png) |  |  |  | [<NSFW, click to see>](4760/previews/nude.png) | [<NSFW, click to see>](4760/previews/nude2.png) |  |  |
| **4420** | **0.975** | [**Download**](4420/eve_santaclaus_idolmastercinderellagirls.zip) |  |  | [<NSFW, click to see>](4420/previews/pattern_3.png) |  |  |  |  |  |  | [<NSFW, click to see>](4420/previews/pattern_10.png) |  | [<NSFW, click to see>](4420/previews/bondage.png) |  |  |  | [<NSFW, click to see>](4420/previews/nude.png) | [<NSFW, click to see>](4420/previews/nude2.png) |  |  |
| 4080 | 0.944 | [Download](4080/eve_santaclaus_idolmastercinderellagirls.zip) |  |  | [<NSFW, click to see>](4080/previews/pattern_3.png) |  |  |  |  |  |  | [<NSFW, click to see>](4080/previews/pattern_10.png) |  | [<NSFW, click to see>](4080/previews/bondage.png) |  |  |  | [<NSFW, click to see>](4080/previews/nude.png) | [<NSFW, click to see>](4080/previews/nude2.png) |  |  |
| 3740 | 0.941 | [Download](3740/eve_santaclaus_idolmastercinderellagirls.zip) |  |  | [<NSFW, click to see>](3740/previews/pattern_3.png) |  |  |  |  |  |  | [<NSFW, click to see>](3740/previews/pattern_10.png) |  | [<NSFW, click to see>](3740/previews/bondage.png) |  |  |  | [<NSFW, click to see>](3740/previews/nude.png) | [<NSFW, click to see>](3740/previews/nude2.png) |  |  |
| 3400 | 0.964 | [Download](3400/eve_santaclaus_idolmastercinderellagirls.zip) |  |  | [<NSFW, click to see>](3400/previews/pattern_3.png) |  |  |  |  |  |  | [<NSFW, click to see>](3400/previews/pattern_10.png) |  | [<NSFW, click to see>](3400/previews/bondage.png) |  |  |  | [<NSFW, click to see>](3400/previews/nude.png) | [<NSFW, click to see>](3400/previews/nude2.png) |  |  |
| 3060 | 0.890 | [Download](3060/eve_santaclaus_idolmastercinderellagirls.zip) |  |  | [<NSFW, click to see>](3060/previews/pattern_3.png) |  |  |  |  |  |  | [<NSFW, click to see>](3060/previews/pattern_10.png) |  | [<NSFW, click to see>](3060/previews/bondage.png) |  |  |  | [<NSFW, click to see>](3060/previews/nude.png) | [<NSFW, click to see>](3060/previews/nude2.png) |  |  |
| 2720 | 0.904 | [Download](2720/eve_santaclaus_idolmastercinderellagirls.zip) |  |  | [<NSFW, click to see>](2720/previews/pattern_3.png) |  |  |  |  |  |  | [<NSFW, click to see>](2720/previews/pattern_10.png) |  | [<NSFW, click to see>](2720/previews/bondage.png) |  |  |  | [<NSFW, click to see>](2720/previews/nude.png) | [<NSFW, click to see>](2720/previews/nude2.png) |  |  |
| 2380 | 0.916 | [Download](2380/eve_santaclaus_idolmastercinderellagirls.zip) |  |  | [<NSFW, click to see>](2380/previews/pattern_3.png) |  |  |  |  |  |  | [<NSFW, click to see>](2380/previews/pattern_10.png) |  | [<NSFW, click to see>](2380/previews/bondage.png) |  |  |  | [<NSFW, click to see>](2380/previews/nude.png) | [<NSFW, click to see>](2380/previews/nude2.png) |  |  |
| 2040 | 0.849 | [Download](2040/eve_santaclaus_idolmastercinderellagirls.zip) |  |  | [<NSFW, click to see>](2040/previews/pattern_3.png) |  |  |  |  |  |  | [<NSFW, click to see>](2040/previews/pattern_10.png) |  | [<NSFW, click to see>](2040/previews/bondage.png) |  |  |  | [<NSFW, click to see>](2040/previews/nude.png) | [<NSFW, click to see>](2040/previews/nude2.png) |  |  |
| 1700 | 0.848 | [Download](1700/eve_santaclaus_idolmastercinderellagirls.zip) |  |  | [<NSFW, click to see>](1700/previews/pattern_3.png) |  |  |  |  |  |  | [<NSFW, click to see>](1700/previews/pattern_10.png) |  | [<NSFW, click to see>](1700/previews/bondage.png) |  |  |  | [<NSFW, click to see>](1700/previews/nude.png) | [<NSFW, click to see>](1700/previews/nude2.png) |  |  |
| 1360 | 0.891 | [Download](1360/eve_santaclaus_idolmastercinderellagirls.zip) |  |  | [<NSFW, click to see>](1360/previews/pattern_3.png) |  |  |  |  |  |  | [<NSFW, click to see>](1360/previews/pattern_10.png) |  | [<NSFW, click to see>](1360/previews/bondage.png) |  |  |  | [<NSFW, click to see>](1360/previews/nude.png) | [<NSFW, click to see>](1360/previews/nude2.png) |  |  |
| 1020 | 0.887 | [Download](1020/eve_santaclaus_idolmastercinderellagirls.zip) |  |  | [<NSFW, click to see>](1020/previews/pattern_3.png) |  |  |  |  |  |  | [<NSFW, click to see>](1020/previews/pattern_10.png) |  | [<NSFW, click to see>](1020/previews/bondage.png) |  |  |  | [<NSFW, click to see>](1020/previews/nude.png) | [<NSFW, click to see>](1020/previews/nude2.png) |  |  |
| 680 | 0.879 | [Download](680/eve_santaclaus_idolmastercinderellagirls.zip) |  |  | [<NSFW, click to see>](680/previews/pattern_3.png) |  |  |  |  |  |  | [<NSFW, click to see>](680/previews/pattern_10.png) |  | [<NSFW, click to see>](680/previews/bondage.png) |  |  |  | [<NSFW, click to see>](680/previews/nude.png) | [<NSFW, click to see>](680/previews/nude2.png) |  |  |
| 340 | 0.860 | [Download](340/eve_santaclaus_idolmastercinderellagirls.zip) |  |  | [<NSFW, click to see>](340/previews/pattern_3.png) |  |  |  |  |  |  | [<NSFW, click to see>](340/previews/pattern_10.png) |  | [<NSFW, click to see>](340/previews/bondage.png) |  |  |  | [<NSFW, click to see>](340/previews/nude.png) | [<NSFW, click to see>](340/previews/nude2.png) |  |  |
|
Andron00e/LoRA-Bloom3B
|
Andron00e
| 2023-09-21T14:04:06Z | 5 | 0 |
peft
|
[
"peft",
"base_model:bigscience/bloom-3b",
"base_model:adapter:bigscience/bloom-3b",
"region:us"
] | null | 2023-07-12T07:38:13Z |
---
library_name: peft
base_model: bigscience/bloom-3b
---
## Training procedure
### Framework versions
- PEFT 0.4.0.dev0
|
ShivamMangale/XLM-Roberta-base-all_hi_weakdap_3rd_iteration_d3_d2_d1_d0
|
ShivamMangale
| 2023-09-21T14:02:28Z | 122 | 0 |
transformers
|
[
"transformers",
"pytorch",
"xlm-roberta",
"question-answering",
"generated_from_trainer",
"dataset:squad",
"base_model:FacebookAI/xlm-roberta-base",
"base_model:finetune:FacebookAI/xlm-roberta-base",
"license:mit",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2023-09-21T09:57:35Z |
---
license: mit
base_model: xlm-roberta-base
tags:
- generated_from_trainer
datasets:
- squad
model-index:
- name: XLM-Roberta-base-all_hi_weakdap_3rd_iteration_d3_d2_d1_d0
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# XLM-Roberta-base-all_hi_weakdap_3rd_iteration_d3_d2_d1_d0
This model is a fine-tuned version of [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) on the squad dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 8
### Training results
### Framework versions
- Transformers 4.33.2
- Pytorch 2.0.1+cu117
- Datasets 2.14.5
- Tokenizers 0.13.3
|
Coroseven/TEST
|
Coroseven
| 2023-09-21T13:49:30Z | 0 | 0 | null |
[
"region:us"
] | null | 2023-09-07T14:18:20Z |
TEST 2 este un model combinat intre Primary model (A) - V3.0 Nordrin_little(诺德琳little); Secondary model (B) - aamAnyloraAnimeMixAnime_v1 ; Tertiary model (C) - aingdiffusion_v92 la Multiplier (M) - 0.5 Weighted sum
TEST 3 este un model combinat intre Primary model (A) - aamAnyloraAnimeMixAnime_v1 ; Secondary model (B) - V3.0 Nordrin_little(诺德琳little); la Multiplier (M) - 0.5 Weighted sum
TEST 5 este un model combinat intre Primary model (A) - aamAnyloraAnimeMixAnime_v1 ; Secondary model (B) - V3.0 Nordrin_little(诺德琳little); Tertiary model (C) - aingdiffusion_v92 la Multiplier (M) - 0.3 Weighted sum
TEST 6 este un model combinat intre Primary model (A) - aamAnyloraAnimeMixAnime_v1 ; Secondary model (B) - BlueAilandMix (blueailandmix_v11) ; la Multiplier (M) - 0.4 Weighted sum
TEST 12 este un model combinat intre Primary model (A) - aamAnyloraAnimeMixAnime_v1 ; Secondary model (B) - Sudachi (sudachi_v1.0) ; la Multiplier (M) - 0.5 Weighted sum
TEST 13 este un model combinat intre Primary model (A) - TEST 12 ; Secondary model (B) - AingDiffusion (AingDiffusion_v9.2) ; la Multiplier (M) - 0.4 Weighted sum
|
nichonifroa/bert-finetuned-squad
|
nichonifroa
| 2023-09-21T13:47:34Z | 122 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"question-answering",
"generated_from_trainer",
"dataset:squad",
"base_model:nichonifroa/bert-finetuned-squad",
"base_model:finetune:nichonifroa/bert-finetuned-squad",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2023-09-21T10:04:51Z |
---
base_model: nichonifroa/bert-finetuned-squad
tags:
- generated_from_trainer
datasets:
- squad
model-index:
- name: bert-finetuned-squad
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-finetuned-squad
This model is a fine-tuned version of [nichonifroa/bert-finetuned-squad](https://huggingface.co/nichonifroa/bert-finetuned-squad) on the squad dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Framework versions
- Transformers 4.33.2
- Pytorch 2.0.1+cu118
- Datasets 2.14.5
- Tokenizers 0.13.3
|
firshme/llama2-lora7b-trans_chinese_alpaca_data
|
firshme
| 2023-09-21T13:45:19Z | 0 | 2 | null |
[
"arxiv:2106.09685",
"region:us"
] | null | 2023-07-28T14:38:06Z |
# 🦙🌲🤏 Alpaca-LoRA
- 🤗 **Try the pretrained model out [here](https://huggingface.co/spaces/tloen/alpaca-lora), courtesy of a GPU grant from Huggingface!**
- Users have created a Discord server for discussion and support [here](https://discord.gg/prbq284xX5)
- 4/14: Chansung Park's GPT4-Alpaca adapters: https://github.com/tloen/alpaca-lora/issues/340
This repository contains code for reproducing the [Stanford Alpaca](https://github.com/tatsu-lab/stanford_alpaca) results using [low-rank adaptation (LoRA)](https://arxiv.org/pdf/2106.09685.pdf).
We provide an Instruct model of similar quality to `text-davinci-003` that can run [on a Raspberry Pi](https://twitter.com/miolini/status/1634982361757790209) (for research),
and the code is easily extended to the `13b`, `30b`, and `65b` models.
In addition to the training code, which runs within hours on a single RTX 4090,
we publish a script for downloading and inference on the foundation model and LoRA,
as well as the resulting [LoRA weights themselves](https://huggingface.co/tloen/alpaca-lora-7b/tree/main).
To fine-tune cheaply and efficiently, we use Hugging Face's [PEFT](https://github.com/huggingface/peft)
as well as Tim Dettmers' [bitsandbytes](https://github.com/TimDettmers/bitsandbytes).
Without hyperparameter tuning, the LoRA model produces outputs comparable to the Stanford Alpaca model. (Please see the outputs included below.) Further tuning might be able to achieve better performance; I invite interested users to give it a try and report their results.
### Local Setup
1. Install dependencies
```bash
pip install -r requirements.txt
```
1. If bitsandbytes doesn't work, [install it from source.](https://github.com/TimDettmers/bitsandbytes/blob/main/compile_from_source.md) Windows users can follow [these instructions](https://github.com/tloen/alpaca-lora/issues/17).
### Training (`finetune.py`)
This file contains a straightforward application of PEFT to the LLaMA model,
as well as some code related to prompt construction and tokenization.
PRs adapting this code to support larger models are always welcome.
Example usage:
```bash
python finetune.py \
--base_model 'decapoda-research/llama-7b-hf' \
--data_path 'yahma/alpaca-cleaned' \
--output_dir './lora-alpaca'
```
We can also tweak our hyperparameters:
```bash
python finetune.py \
--base_model 'decapoda-research/llama-7b-hf' \
--data_path 'yahma/alpaca-cleaned' \
--output_dir './lora-alpaca' \
--batch_size 128 \
--micro_batch_size 4 \
--num_epochs 3 \
--learning_rate 1e-4 \
--cutoff_len 512 \
--val_set_size 2000 \
--lora_r 8 \
--lora_alpha 16 \
--lora_dropout 0.05 \
--lora_target_modules '[q_proj,v_proj]' \
--train_on_inputs \
--group_by_length
```
### Inference (`generate.py`)
This file reads the foundation model from the Hugging Face model hub and the LoRA weights from `tloen/alpaca-lora-7b`, and runs a Gradio interface for inference on a specified input. Users should treat this as example code for the use of the model, and modify it as needed.
Example usage:
```bash
python generate.py \
--load_8bit \
--base_model 'decapoda-research/llama-7b-hf' \
--lora_weights 'tloen/alpaca-lora-7b'
```
### Official weights
The most recent "official" Alpaca-LoRA adapter available at [`tloen/alpaca-lora-7b`](https://huggingface.co/tloen/alpaca-lora-7b) was trained on March 26 with the following command:
```bash
python finetune.py \
--base_model='decapoda-research/llama-7b-hf' \
--num_epochs=10 \
--cutoff_len=512 \
--group_by_length \
--output_dir='./lora-alpaca' \
--lora_target_modules='[q_proj,k_proj,v_proj,o_proj]' \
--lora_r=16 \
--micro_batch_size=8
```
### Checkpoint export (`export_*_checkpoint.py`)
These files contain scripts that merge the LoRA weights back into the base model
for export to Hugging Face format and to PyTorch `state_dicts`.
They should help users
who want to run inference in projects like [llama.cpp](https://github.com/ggerganov/llama.cpp)
or [alpaca.cpp](https://github.com/antimatter15/alpaca.cpp).
### Docker Setup & Inference
1. Build the container image:
```bash
docker build -t alpaca-lora .
```
2. Run the container (you can also use `finetune.py` and all of its parameters as shown above for training):
```bash
docker run --gpus=all --shm-size 64g -p 7860:7860 -v ${HOME}/.cache:/root/.cache --rm alpaca-lora generate.py \
--load_8bit \
--base_model 'decapoda-research/llama-7b-hf' \
--lora_weights 'tloen/alpaca-lora-7b'
```
3. Open `https://localhost:7860` in the browser
### Docker Compose Setup & Inference
1. (optional) Change desired model and weights under `environment` in the `docker-compose.yml`
2. Build and run the container
```bash
docker-compose up -d --build
```
3. Open `https://localhost:7860` in the browser
4. See logs:
```bash
docker-compose logs -f
```
5. Clean everything up:
```bash
docker-compose down --volumes --rmi all
```
### Notes
- We can likely improve our model performance significantly if we had a better dataset. Consider supporting the [LAION Open Assistant](https://open-assistant.io/) effort to produce a high-quality dataset for supervised fine-tuning (or bugging them to release their data).
- We're continually fixing bugs and conducting training runs, and the weights on the Hugging Face Hub are being updated accordingly. In particular, those facing issues with response lengths should make sure that they have the latest version of the weights and code.
- Users with multiple GPUs should take a look [here](https://github.com/tloen/alpaca-lora/issues/8#issuecomment-1477490259).
- We include the Stanford Alpaca dataset, which was made available under the ODC Attribution License.
### Resources
- [alpaca.cpp](https://github.com/antimatter15/alpaca.cpp), a native client for running Alpaca models on the CPU
- [Alpaca-LoRA-Serve](https://github.com/deep-diver/Alpaca-LoRA-Serve), a ChatGPT-style interface for Alpaca models
- [AlpacaDataCleaned](https://github.com/gururise/AlpacaDataCleaned), a project to improve the quality of the Alpaca dataset
- [GPT-4 Alpaca Data](https://github.com/Instruction-Tuning-with-GPT-4/GPT-4-LLM) a project to port synthetic data creation to GPT-4
- [dolly-15k-instruction-alpaca-format](https://huggingface.co/datasets/c-s-ale/dolly-15k-instruction-alpaca-format), an Alpaca-compatible version of [Databricks' Dolly 15k human-generated instruct dataset](https://github.com/databrickslabs/dolly/tree/master/data) (see [blog](https://www.databricks.com/blog/2023/04/12/dolly-first-open-commercially-viable-instruction-tuned-llm))
- [Alpaca-LoRA MT](https://github.com/juletx/alpaca-lora-mt), a project to finetune models with [machine-translated Alpaca data](https://huggingface.co/datasets/HiTZ/alpaca_mt) in 6 Iberian languages: Portuguese, Spanish, Catalan, Basque, Galician and Asturian.
- Various adapter weights (download at own risk):
- 7B:
- 3️⃣ <https://huggingface.co/tloen/alpaca-lora-7b>
- 3️⃣ <https://huggingface.co/samwit/alpaca7B-lora>
- **4️⃣ <https://huggingface.co/chansung/gpt4-alpaca-lora-7b>**
- 🚀 <https://huggingface.co/nomic-ai/gpt4all-lora>
- 🇧🇷 <https://huggingface.co/22h/cabrita-lora-v0-1>
- 🇨🇳 <https://huggingface.co/qychen/luotuo-lora-7b-0.1>
- 🇨🇳 <https://huggingface.co/ziqingyang/chinese-alpaca-lora-7b>
- 🇯🇵 <https://huggingface.co/kunishou/Japanese-Alapaca-LoRA-7b-v0>
- 🇫🇷 <https://huggingface.co/bofenghuang/vigogne-lora-7b>
- 🇹🇭 <https://huggingface.co/Thaweewat/thai-buffala-lora-7b-v0-1>
- 🇩🇪 <https://huggingface.co/thisserand/alpaca_lora_german>
- 🇵🇱 <https://huggingface.co/mmosiolek/polpaca-lora-7b>
- 🇵🇱 <https://huggingface.co/chrisociepa/alpaca-lora-7b-pl>
- 🇮🇹 <https://huggingface.co/teelinsan/camoscio-7b-llama>
- 🇷🇺 <https://huggingface.co/IlyaGusev/llama_7b_ru_turbo_alpaca_lora>
- 🇺🇦 <https://huggingface.co/robinhad/ualpaca-7b-llama>
- 🇮🇹 <https://huggingface.co/mchl-labs/stambecco-7b-plus>
- 🇪🇸 <https://huggingface.co/plncmm/guanaco-lora-7b>
- 🇬🇧 🇪🇸 🇵🇹 <https://huggingface.co/HiTZ/alpaca-lora-7b-en-pt-es-ca-eu-gl-at>
- 13B:
- 3️⃣ <https://huggingface.co/Angainor/alpaca-lora-13b>
- 3️⃣ <https://huggingface.co/chansung/alpaca-lora-13b>
- 3️⃣ <https://huggingface.co/mattreid/alpaca-lora-13b>
- 3️⃣ <https://huggingface.co/samwit/alpaca13B-lora>
- **4️⃣ <https://huggingface.co/chansung/gpt4-alpaca-lora-13b>**
- 🇯🇵 <https://huggingface.co/kunishou/Japanese-Alapaca-LoRA-13b-v0>
- 🇰🇷 <https://huggingface.co/chansung/koalpaca-lora-13b>
- 🇨🇳 <https://huggingface.co/facat/alpaca-lora-cn-13b>
- 🇨🇳 <https://huggingface.co/ziqingyang/chinese-alpaca-lora-13b>
- 🇪🇸 <https://huggingface.co/plncmm/guanaco-lora-13b>
- 🇮🇹 <https://huggingface.co/mchl-labs/stambecco-13b-plus>
- 🇬🇧 🇪🇸 🇵🇹 <https://huggingface.co/HiTZ/alpaca-lora-13b-en-pt-es-ca-eu-gl-at>
- 30B:
- 3️⃣ <https://huggingface.co/baseten/alpaca-30b>
- 3️⃣ <https://huggingface.co/chansung/alpaca-lora-30b>
- **4️⃣ <https://huggingface.co/chansung/gpt4-alpaca-lora-30b>**
- 🇯🇵 <https://huggingface.co/kunishou/Japanese-Alapaca-LoRA-30b-v0>
- 🇬🇧 🇪🇸 🇵🇹 <https://huggingface.co/HiTZ/alpaca-lora-30b-en-pt-es-ca-eu-gl-at>
- 65B
- <https://huggingface.co/chansung/alpaca-lora-65b>
- 🇬🇧 🇪🇸 🇵🇹 <https://huggingface.co/HiTZ/alpaca-lora-65b-en-pt-es-ca>
- [alpaca-native](https://huggingface.co/chavinlo/alpaca-native), a replication using the original Alpaca code
- [llama.onnx](https://github.com/tpoisonooo/llama.onnx), a project to inference alpaca with onnx format
### Example outputs
**Instruction**: Tell me about alpacas.
**Alpaca-LoRA**: Alpacas are members of the camelid family and are native to the Andes Mountains of South America. They are known for their soft, luxurious fleece, which is used to make clothing, blankets, and other items. Alpacas are herbivores and graze on grasses and other plants. They are social animals and live in herds of up to 20 individuals.
**Stanford Alpaca**: Alpacas are small, fluffy animals related to camels and llamas. They are native to Peru and Bolivia, and were first domesticated around 5,000 years ago. They are kept mainly for their fine, soft fleece, which is used to make knitwear and other garments. Alpacas are herd animals and live in small family groups, led by an older male. They are highly social animals and can form strong bonds with their owners.
**text-davinci-003**: Alpacas are a domesticated species of South American camelid, similar to llamas. They are native to the Andes Mountains in South America and are kept as livestock for their soft, luxurious wool. Alpacas are social animals and live in herds of up to 20 individuals. They are typically kept in small herds of two to five animals, and are relatively easy to care for. Alpacas are herbivores and feed on grass, hay, and other vegetation. They are also known for their gentle and friendly nature, making them popular as pets.
---
**Instruction**: Tell me about the president of Mexico in 2019.
**Alpaca-LoRA**: The president of Mexico in 2019 was Andrés Manuel López Obrador, who took office on December 1, 2018. He is a member of the National Regeneration Movement (MORENA) political party and is the first left-wing president of Mexico since 1946. He is known for his anti-corruption and anti-neoliberal policies, as well as his commitment to improving the living conditions of the Mexican people.
**Stanford Alpaca**: In 2019, Andres Manuel Lopez Obrador was sworn in as President of Mexico. He is the country’s 58th president and the first from the left-wing Morena party. He was elected in 2018 on a promise to combat corruption and reduce poverty and has faced criticism for his handling of the economy, crime and the country’s relationship with the United States. He is also known for his ambitious social welfare programs and has been praised for raising the minimum wage and providing aid to low-income families. He is seen as a champion of democracy and human rights in Mexico.
**text-davinci-003**: The president of Mexico in 2019 is Andrés Manuel López Obrador, commonly known as AMLO. He is a Mexican politician who has been the President of Mexico since December 1, 2018. He is a member of the National Regeneration Movement (MORENA) party and previously served as the Head of Government of Mexico City from 2000 to 2005. He is a left-wing populist and has promised to reduce corruption and inequality in Mexico. He has also promised to increase public spending on social programs and infrastructure projects.
---
**Instruction**: Tell me about the king of France in 2019.
**Alpaca-LoRA**: The King of France in 2019 is Emmanuel Macron, who was elected in May 2017. He is the youngest president in the history of the Fifth Republic and the first president to be born after World War II. He is also the first president to have never held elected office before.
**Stanford Alpaca**: In 2019, the King of France was Emmanuel Macron. He was sworn in as President of France on May 14, 2017, and has been leading the country ever since. He is a member of the centrist La République En Marche! Party. He is known for his reformist agenda and has faced a number of protests from both the right and left of the political spectrum. He is the youngest French president in history.
**text-davinci-003**: The King of France is a largely symbolic role, as France is a republic. The current President of France is Emmanuel Macron, who was elected in 2017.
---
**Instruction**: List all Canadian provinces in alphabetical order.
**Alpaca-LoRA**: Alberta, British Columbia, Manitoba, New Brunswick, Newfoundland and Labrador, Nova Scotia, Ontario, Prince Edward Island, Quebec, Saskatchewan
**Stanford Alpaca**: Alberta, British Columbia, Manitoba, New Brunswick, Newfoundland and Labrador, Nova Scotia, Ontario, Prince Edward Island, Quebec, Saskatchewan, Northwest Territories, Nunavut, Yukon.
**text-davinci-003**:
1. Alberta
2. British Columbia
3. Manitoba
4. New Brunswick
5. Newfoundland and Labrador
6. Northwest Territories
7. Nova Scotia
8. Nunavut
9. Ontario
10. Prince Edward Island
11. Quebec
12. Saskatchewan
13. Yukon
---
**Instruction**: Write a Python program that prints the first 10 Fibonacci numbers.
**Alpaca-LoRA**:
```python
def fibonacci(n):
if n == 0:
return 0
elif n == 1:
return 1
else:
return fibonacci(n-1) + fibonacci(n-2)
print(fibonacci(10))
```
**Stanford Alpaca**:
```python
numbers = [0, 1]
for i in range(2, 11):
numbers.append(numbers[i-2] + numbers[i-1])
print(numbers)
# Output: [0, 1, 1, 2, 3, 5, 8, 13, 21, 34]
```
**text-davinci-003**:
```python
# Fibonacci numbers are the numbers in the following integer sequence, called the Fibonacci sequence, and characterized by the fact that every number after the first two is the sum of the two preceding ones.
# Fibonacci sequence: 0, 1, 1, 2, 3, 5, 8, 13, 21, 34, ...
# Program:
# Initialize the first two numbers of the Fibonacci sequence
a = 0
b = 1
# Print the first 10 numbers of the Fibonacci sequence
print(a)
print(b)
for i in range(2,10):
c = a + b
a = b
b = c
print(c)
```
---
**Instruction**: Write a program that prints the numbers from 1 to 100. But for multiples of three print 'Fizz' instead of the number and for the multiples of five print 'Buzz'. For numbers which are multiples of both three and five print 'FizzBuzz'.
**Alpaca-LoRA**:
```python
for i in range(1, 101):
if i % 3 == 0 and i % 5 == 0:
print("FizzBuzz")
elif i % 3 == 0:
print("Fizz")
elif i % 5 == 0:
print("Buzz")
else:
print(i)
```
**Stanford Alpaca**:
```python
for i in range(1, 101):
if i % 3 == 0 and i % 5 == 0:
print('FizzBuzz')
elif i % 3 == 0:
print('Fizz')
elif i % 5 == 0:
print('Buzz')
else:
print(i)
```
**text-davinci-003**:
```javascript
for (let i = 1; i <= 100; i++) {
if (i % 3 === 0 && i % 5 === 0) {
console.log("FizzBuzz");
} else if (i % 3 === 0) {
console.log("Fizz");
} else if (i % 5 === 0) {
console.log("Buzz");
} else {
console.log(i);
}
}
```
---
**Instruction**: Tell me five words that rhyme with 'shock'.
**Alpaca-LoRA**: Flock, lock, rock, stock, and sock.
**Stanford Alpaca**: Five words that rhyme with shock are: rock, pop, shock, cook, and snock.
**text-davinci-003**:
1. Block
2. Lock
3. Dock
4. Clock
5. Rock
---
**Instruction**: Translate the sentence 'I have no mouth but I must scream' into Spanish.
**Alpaca-LoRA**: No tengo boca pero tengo que gritar.
**Stanford Alpaca**: No tengo boca, pero debo gritar.
**text-davinci-003**: No tengo boca pero debo gritar.
|
nick-1234/Prefix_tuning_for_conditional_generation_of_sentiment_labels_for_financial_news
|
nick-1234
| 2023-09-21T13:41:05Z | 2 | 0 |
peft
|
[
"peft",
"base_model:google-t5/t5-large",
"base_model:adapter:google-t5/t5-large",
"region:us"
] | null | 2023-08-09T22:31:26Z |
---
library_name: peft
base_model: t5-large
---
## Training procedure
### Framework versions
- PEFT 0.5.0.dev0
|
jonas-luehrs/chembert_cased-textCLS-PETROCHEMICAL
|
jonas-luehrs
| 2023-09-21T13:39:34Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"text-classification",
"generated_from_trainer",
"base_model:jiangg/chembert_cased",
"base_model:finetune:jiangg/chembert_cased",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-09-20T15:18:22Z |
---
base_model: jiangg/chembert_cased
tags:
- generated_from_trainer
metrics:
- f1
- precision
- recall
- accuracy
model-index:
- name: chembert_cased-textCLS-PETROCHEMICAL
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# chembert_cased-textCLS-PETROCHEMICAL
This model is a fine-tuned version of [jiangg/chembert_cased](https://huggingface.co/jiangg/chembert_cased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6538
- F1: 0.7473
- Precision: 0.7386
- Recall: 0.7613
- Accuracy: 0.7613
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 | Precision | Recall | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:------:|:---------:|:------:|:--------:|
| 1.3224 | 1.0 | 125 | 0.9061 | 0.6916 | 0.7048 | 0.7162 | 0.7162 |
| 0.7378 | 2.0 | 250 | 0.7133 | 0.7457 | 0.7401 | 0.7613 | 0.7613 |
| 0.5397 | 3.0 | 375 | 0.6538 | 0.7473 | 0.7386 | 0.7613 | 0.7613 |
### Framework versions
- Transformers 4.33.2
- Pytorch 2.0.1+cu118
- Datasets 2.14.5
- Tokenizers 0.13.3
|
sanctia/lora-sd-finesse
|
sanctia
| 2023-09-21T13:33:39Z | 1 | 0 |
diffusers
|
[
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"lora",
"base_model:runwayml/stable-diffusion-v1-5",
"base_model:adapter:runwayml/stable-diffusion-v1-5",
"license:creativeml-openrail-m",
"region:us"
] |
text-to-image
| 2023-09-20T02:37:21Z |
---
license: creativeml-openrail-m
base_model: runwayml/stable-diffusion-v1-5
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
- lora
inference: true
---
# LoRA text2image fine-tuning - sanctia/lora-sd-finesse
These are LoRA adaption weights for runwayml/stable-diffusion-v1-5. The weights were fine-tuned on the sanctia/finesse-image-generation dataset. You can find some example images in the following.
- Model and architecture details: https://www.notion.so/Design-document-Finesse-Generative-Challenge-4ed87ea624f84ff5a9ac09dc21885366
- Wandb report: https://wandb.ai/hpml3/text2image-fine-tune/runs/cdyy9un3?workspace=user-sanctia




|
ShivamMangale/XLM-Roberta-base-all_hi_weakdap_3rd_iteration_d3_d2_d1
|
ShivamMangale
| 2023-09-21T13:30:43Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"xlm-roberta",
"question-answering",
"generated_from_trainer",
"dataset:squad",
"base_model:FacebookAI/xlm-roberta-base",
"base_model:finetune:FacebookAI/xlm-roberta-base",
"license:mit",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2023-09-21T09:40:17Z |
---
license: mit
base_model: xlm-roberta-base
tags:
- generated_from_trainer
datasets:
- squad
model-index:
- name: XLM-Roberta-base-all_hi_weakdap_3rd_iteration_d3_d2_d1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# XLM-Roberta-base-all_hi_weakdap_3rd_iteration_d3_d2_d1
This model is a fine-tuned version of [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) on the squad dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 8
### Training results
### Framework versions
- Transformers 4.33.2
- Pytorch 2.0.1+cu117
- Datasets 2.14.5
- Tokenizers 0.13.3
|
srushtibhavsar/squad_bloom_3b
|
srushtibhavsar
| 2023-09-21T13:29:25Z | 1 | 0 |
peft
|
[
"peft",
"region:us"
] | null | 2023-09-21T13:29:23Z |
---
library_name: peft
---
## Training procedure
### Framework versions
- PEFT 0.6.0.dev0
|
chanifrusydi/t5-dialogue-summarization
|
chanifrusydi
| 2023-09-21T13:27:14Z | 134 | 2 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"safetensors",
"t5",
"text2text-generation",
"generated_from_trainer",
"summarization",
"dataset:samsum",
"base_model:google-t5/t5-small",
"base_model:finetune:google-t5/t5-small",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
summarization
| 2022-06-08T05:08:41Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- samsum
metrics:
- accuracy
pipeline_tag: summarization
base_model: t5-small
model-index:
- name: t5-dialogue-summarization
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-dialogue-summarization
This model is a fine-tuned version of [t5-small](https://huggingface.co/t5-small) on the samsum dataset.
dataset:
type: {summarization}
name: {samsum}
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
### Framework versions
- Transformers 4.19.2
- Pytorch 1.11.0+cu113
- Datasets 2.2.2
- Tokenizers 0.12.1
|
CyberHarem/nishikawa_honami_idolmastercinderellagirls
|
CyberHarem
| 2023-09-21T13:13:40Z | 0 | 0 | null |
[
"art",
"text-to-image",
"dataset:CyberHarem/nishikawa_honami_idolmastercinderellagirls",
"license:mit",
"region:us"
] |
text-to-image
| 2023-09-21T13:02:46Z |
---
license: mit
datasets:
- CyberHarem/nishikawa_honami_idolmastercinderellagirls
pipeline_tag: text-to-image
tags:
- art
---
# Lora of nishikawa_honami_idolmastercinderellagirls
This model is trained with [HCP-Diffusion](https://github.com/7eu7d7/HCP-Diffusion). And the auto-training framework is maintained by [DeepGHS Team](https://huggingface.co/deepghs).
The base model used during training is [NAI](https://huggingface.co/deepghs/animefull-latest), and the base model used for generating preview images is [Meina/MeinaMix_V11](https://huggingface.co/Meina/MeinaMix_V11).
After downloading the pt and safetensors files for the specified step, you need to use them simultaneously. The pt file will be used as an embedding, while the safetensors file will be loaded for Lora.
For example, if you want to use the model from step 4080, you need to download `4080/nishikawa_honami_idolmastercinderellagirls.pt` as the embedding and `4080/nishikawa_honami_idolmastercinderellagirls.safetensors` for loading Lora. By using both files together, you can generate images for the desired characters.
**The best step we recommend is 4080**, with the score of 0.919. The trigger words are:
1. `nishikawa_honami_idolmastercinderellagirls`
2. `long_hair, brown_hair, green_eyes, earrings, jewelry, smile, breasts`
For the following groups, it is not recommended to use this model and we express regret:
1. Individuals who cannot tolerate any deviations from the original character design, even in the slightest detail.
2. Individuals who are facing the application scenarios with high demands for accuracy in recreating character outfits.
3. Individuals who cannot accept the potential randomness in AI-generated images based on the Stable Diffusion algorithm.
4. Individuals who are not comfortable with the fully automated process of training character models using LoRA, or those who believe that training character models must be done purely through manual operations to avoid disrespecting the characters.
5. Individuals who finds the generated image content offensive to their values.
These are available steps:
| Steps | Score | Download | pattern_1 | pattern_2 | bikini | bondage | free | maid | miko | nude | nude2 | suit | yukata |
|:---------|:----------|:--------------------------------------------------------------------|:-----------------------------------------------|:-----------------------------------------------|:-----------------------------------------|:--------------------------------------------------|:-------------------------------------|:-------------------------------------|:-------------------------------------|:-----------------------------------------------|:------------------------------------------------|:-------------------------------------|:-----------------------------------------|
| 5100 | 0.903 | [Download](5100/nishikawa_honami_idolmastercinderellagirls.zip) |  |  |  | [<NSFW, click to see>](5100/previews/bondage.png) |  |  |  | [<NSFW, click to see>](5100/previews/nude.png) | [<NSFW, click to see>](5100/previews/nude2.png) |  |  |
| 4760 | 0.895 | [Download](4760/nishikawa_honami_idolmastercinderellagirls.zip) |  |  |  | [<NSFW, click to see>](4760/previews/bondage.png) |  |  |  | [<NSFW, click to see>](4760/previews/nude.png) | [<NSFW, click to see>](4760/previews/nude2.png) |  |  |
| 4420 | 0.912 | [Download](4420/nishikawa_honami_idolmastercinderellagirls.zip) |  |  |  | [<NSFW, click to see>](4420/previews/bondage.png) |  |  |  | [<NSFW, click to see>](4420/previews/nude.png) | [<NSFW, click to see>](4420/previews/nude2.png) |  |  |
| **4080** | **0.919** | [**Download**](4080/nishikawa_honami_idolmastercinderellagirls.zip) |  |  |  | [<NSFW, click to see>](4080/previews/bondage.png) |  |  |  | [<NSFW, click to see>](4080/previews/nude.png) | [<NSFW, click to see>](4080/previews/nude2.png) |  |  |
| 3740 | 0.831 | [Download](3740/nishikawa_honami_idolmastercinderellagirls.zip) |  |  |  | [<NSFW, click to see>](3740/previews/bondage.png) |  |  |  | [<NSFW, click to see>](3740/previews/nude.png) | [<NSFW, click to see>](3740/previews/nude2.png) |  |  |
| 3400 | 0.872 | [Download](3400/nishikawa_honami_idolmastercinderellagirls.zip) |  |  |  | [<NSFW, click to see>](3400/previews/bondage.png) |  |  |  | [<NSFW, click to see>](3400/previews/nude.png) | [<NSFW, click to see>](3400/previews/nude2.png) |  |  |
| 3060 | 0.882 | [Download](3060/nishikawa_honami_idolmastercinderellagirls.zip) |  |  |  | [<NSFW, click to see>](3060/previews/bondage.png) |  |  |  | [<NSFW, click to see>](3060/previews/nude.png) | [<NSFW, click to see>](3060/previews/nude2.png) |  |  |
| 2720 | 0.909 | [Download](2720/nishikawa_honami_idolmastercinderellagirls.zip) |  |  |  | [<NSFW, click to see>](2720/previews/bondage.png) |  |  |  | [<NSFW, click to see>](2720/previews/nude.png) | [<NSFW, click to see>](2720/previews/nude2.png) |  |  |
| 2380 | 0.857 | [Download](2380/nishikawa_honami_idolmastercinderellagirls.zip) |  |  |  | [<NSFW, click to see>](2380/previews/bondage.png) |  |  |  | [<NSFW, click to see>](2380/previews/nude.png) | [<NSFW, click to see>](2380/previews/nude2.png) |  |  |
| 2040 | 0.893 | [Download](2040/nishikawa_honami_idolmastercinderellagirls.zip) |  |  |  | [<NSFW, click to see>](2040/previews/bondage.png) |  |  |  | [<NSFW, click to see>](2040/previews/nude.png) | [<NSFW, click to see>](2040/previews/nude2.png) |  |  |
| 1700 | 0.874 | [Download](1700/nishikawa_honami_idolmastercinderellagirls.zip) |  |  |  | [<NSFW, click to see>](1700/previews/bondage.png) |  |  |  | [<NSFW, click to see>](1700/previews/nude.png) | [<NSFW, click to see>](1700/previews/nude2.png) |  |  |
| 1360 | 0.860 | [Download](1360/nishikawa_honami_idolmastercinderellagirls.zip) |  |  |  | [<NSFW, click to see>](1360/previews/bondage.png) |  |  |  | [<NSFW, click to see>](1360/previews/nude.png) | [<NSFW, click to see>](1360/previews/nude2.png) |  |  |
| 1020 | 0.877 | [Download](1020/nishikawa_honami_idolmastercinderellagirls.zip) |  |  |  | [<NSFW, click to see>](1020/previews/bondage.png) |  |  |  | [<NSFW, click to see>](1020/previews/nude.png) | [<NSFW, click to see>](1020/previews/nude2.png) |  |  |
| 680 | 0.753 | [Download](680/nishikawa_honami_idolmastercinderellagirls.zip) |  |  |  | [<NSFW, click to see>](680/previews/bondage.png) |  |  |  | [<NSFW, click to see>](680/previews/nude.png) | [<NSFW, click to see>](680/previews/nude2.png) |  |  |
| 340 | 0.579 | [Download](340/nishikawa_honami_idolmastercinderellagirls.zip) |  |  |  | [<NSFW, click to see>](340/previews/bondage.png) |  |  |  | [<NSFW, click to see>](340/previews/nude.png) | [<NSFW, click to see>](340/previews/nude2.png) |  |  |
|
dss107/mp_base2
|
dss107
| 2023-09-21T13:13:27Z | 3 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"pytorch",
"mpnet",
"setfit",
"text-classification",
"arxiv:2209.11055",
"license:apache-2.0",
"region:us"
] |
text-classification
| 2023-09-21T13:12:07Z |
---
license: apache-2.0
tags:
- setfit
- sentence-transformers
- text-classification
pipeline_tag: text-classification
---
# dss107/mp_base2
This is a [SetFit model](https://github.com/huggingface/setfit) that can be used for text classification. The model has been trained using an efficient few-shot learning technique that involves:
1. Fine-tuning a [Sentence Transformer](https://www.sbert.net) with contrastive learning.
2. Training a classification head with features from the fine-tuned Sentence Transformer.
## Usage
To use this model for inference, first install the SetFit library:
```bash
python -m pip install setfit
```
You can then run inference as follows:
```python
from setfit import SetFitModel
# Download from Hub and run inference
model = SetFitModel.from_pretrained("dss107/mp_base2")
# Run inference
preds = model(["i loved the spiderman movie!", "pineapple on pizza is the worst 🤮"])
```
## BibTeX entry and citation info
```bibtex
@article{https://doi.org/10.48550/arxiv.2209.11055,
doi = {10.48550/ARXIV.2209.11055},
url = {https://arxiv.org/abs/2209.11055},
author = {Tunstall, Lewis and Reimers, Nils and Jo, Unso Eun Seo and Bates, Luke and Korat, Daniel and Wasserblat, Moshe and Pereg, Oren},
keywords = {Computation and Language (cs.CL), FOS: Computer and information sciences, FOS: Computer and information sciences},
title = {Efficient Few-Shot Learning Without Prompts},
publisher = {arXiv},
year = {2022},
copyright = {Creative Commons Attribution 4.0 International}
}
```
|
apasi/PlatypusLLama13BAdapter
|
apasi
| 2023-09-21T13:08:51Z | 2 | 0 |
peft
|
[
"peft",
"base_model:meta-llama/Llama-2-13b-chat-hf",
"base_model:adapter:meta-llama/Llama-2-13b-chat-hf",
"region:us"
] | null | 2023-08-20T21:34:27Z |
---
library_name: peft
base_model: meta-llama/Llama-2-13b-chat-hf
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: True
- bnb_4bit_compute_dtype: bfloat16
### Framework versions
- PEFT 0.4.0
|
ShivamMangale/XLM-Roberta-base-all_hi_weakdap_3rd_iteration_d3
|
ShivamMangale
| 2023-09-21T13:01:35Z | 122 | 0 |
transformers
|
[
"transformers",
"pytorch",
"xlm-roberta",
"question-answering",
"generated_from_trainer",
"dataset:squad",
"base_model:FacebookAI/xlm-roberta-base",
"base_model:finetune:FacebookAI/xlm-roberta-base",
"license:mit",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2023-09-21T09:20:45Z |
---
license: mit
base_model: xlm-roberta-base
tags:
- generated_from_trainer
datasets:
- squad
model-index:
- name: XLM-Roberta-base-all_hi_weakdap_3rd_iteration_d3
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# XLM-Roberta-base-all_hi_weakdap_3rd_iteration_d3
This model is a fine-tuned version of [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) on the squad dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1.62e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 8
### Training results
### Framework versions
- Transformers 4.33.2
- Pytorch 2.0.1+cu117
- Datasets 2.14.5
- Tokenizers 0.13.3
|
aminh/squad-falcon-7b
|
aminh
| 2023-09-21T12:57:14Z | 1 | 0 |
peft
|
[
"peft",
"region:us"
] | null | 2023-09-21T12:57:06Z |
---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: True
- bnb_4bit_compute_dtype: float16
### Framework versions
- PEFT 0.6.0.dev0
|
ShivamMangale/XLM-Roberta-base-all_hi_weakdap_3rd_iteration_d3-hq
|
ShivamMangale
| 2023-09-21T12:51:41Z | 106 | 0 |
transformers
|
[
"transformers",
"pytorch",
"xlm-roberta",
"question-answering",
"generated_from_trainer",
"dataset:squad",
"base_model:FacebookAI/xlm-roberta-base",
"base_model:finetune:FacebookAI/xlm-roberta-base",
"license:mit",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2023-09-21T12:43:19Z |
---
license: mit
base_model: xlm-roberta-base
tags:
- generated_from_trainer
datasets:
- squad
model-index:
- name: XLM-Roberta-base-all_hi_weakdap_3rd_iteration_d3-hq
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# XLM-Roberta-base-all_hi_weakdap_3rd_iteration_d3-hq
This model is a fine-tuned version of [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) on the squad dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1.62e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 8
### Training results
### Framework versions
- Transformers 4.33.2
- Pytorch 2.0.1+cu117
- Datasets 2.14.5
- Tokenizers 0.13.3
|
Souvik123/bankstatementmodelver8
|
Souvik123
| 2023-09-21T12:50:43Z | 111 | 0 |
transformers
|
[
"transformers",
"pytorch",
"roberta",
"question-answering",
"generated_from_trainer",
"base_model:deepset/roberta-base-squad2",
"base_model:finetune:deepset/roberta-base-squad2",
"license:cc-by-4.0",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2023-09-21T12:49:05Z |
---
license: cc-by-4.0
base_model: deepset/roberta-base-squad2
tags:
- generated_from_trainer
model-index:
- name: bankstatementmodelver8
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bankstatementmodelver8
This model is a fine-tuned version of [deepset/roberta-base-squad2](https://huggingface.co/deepset/roberta-base-squad2) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 11
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 150
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:------:|:---------------:|
| 0.1067 | 1.0 | 981 | 0.0322 |
| 0.0357 | 2.0 | 1962 | 0.0228 |
| 0.0239 | 3.0 | 2943 | 0.0172 |
| 0.0253 | 4.0 | 3924 | 0.0158 |
| 0.0206 | 5.0 | 4905 | 0.0127 |
| 0.0168 | 6.0 | 5886 | 0.0160 |
| 0.0158 | 7.0 | 6867 | 0.0154 |
| 0.0169 | 8.0 | 7848 | 0.0134 |
| 0.0162 | 9.0 | 8829 | 0.0081 |
| 0.0162 | 10.0 | 9810 | 0.0101 |
| 0.0126 | 11.0 | 10791 | 0.0082 |
| 0.0128 | 12.0 | 11772 | 0.0080 |
| 0.013 | 13.0 | 12753 | 0.0119 |
| 0.0117 | 14.0 | 13734 | 0.0105 |
| 0.0117 | 15.0 | 14715 | 0.0106 |
| 0.0112 | 16.0 | 15696 | 0.0100 |
| 0.0103 | 17.0 | 16677 | 0.0078 |
| 0.0075 | 18.0 | 17658 | 0.0060 |
| 0.0057 | 19.0 | 18639 | 0.0088 |
| 0.0077 | 20.0 | 19620 | 0.0076 |
| 0.006 | 21.0 | 20601 | 0.0149 |
| 0.0065 | 22.0 | 21582 | 0.0062 |
| 0.0093 | 23.0 | 22563 | 0.0081 |
| 0.0045 | 24.0 | 23544 | 0.0054 |
| 0.005 | 25.0 | 24525 | 0.0048 |
| 0.0068 | 26.0 | 25506 | 0.0122 |
| 0.0063 | 27.0 | 26487 | 0.0038 |
| 0.0043 | 28.0 | 27468 | 0.0063 |
| 0.0055 | 29.0 | 28449 | 0.0096 |
| 0.0034 | 30.0 | 29430 | 0.0045 |
| 0.0033 | 31.0 | 30411 | 0.0025 |
| 0.0027 | 32.0 | 31392 | 0.0047 |
| 0.002 | 33.0 | 32373 | 0.0053 |
| 0.0055 | 34.0 | 33354 | 0.0026 |
| 0.0044 | 35.0 | 34335 | 0.0010 |
| 0.0047 | 36.0 | 35316 | 0.0008 |
| 0.0019 | 37.0 | 36297 | 0.0011 |
| 0.0006 | 38.0 | 37278 | 0.0030 |
| 0.0015 | 39.0 | 38259 | 0.0010 |
| 0.0005 | 40.0 | 39240 | 0.0008 |
| 0.0018 | 41.0 | 40221 | 0.0001 |
| 0.0026 | 42.0 | 41202 | 0.0017 |
| 0.0 | 43.0 | 42183 | 0.0002 |
| 0.002 | 44.0 | 43164 | 0.0009 |
| 0.0012 | 45.0 | 44145 | 0.0000 |
| 0.0018 | 46.0 | 45126 | 0.0110 |
| 0.0006 | 47.0 | 46107 | 0.0018 |
| 0.0016 | 48.0 | 47088 | 0.0000 |
| 0.0017 | 49.0 | 48069 | 0.0000 |
| 0.0014 | 50.0 | 49050 | 0.0000 |
| 0.0001 | 51.0 | 50031 | 0.0000 |
| 0.0018 | 52.0 | 51012 | 0.0020 |
| 0.0001 | 53.0 | 51993 | 0.0001 |
| 0.0009 | 54.0 | 52974 | 0.0040 |
| 0.0021 | 55.0 | 53955 | 0.0000 |
| 0.0018 | 56.0 | 54936 | 0.0000 |
| 0.0005 | 57.0 | 55917 | 0.0000 |
| 0.0 | 58.0 | 56898 | 0.0000 |
| 0.0014 | 59.0 | 57879 | 0.0000 |
| 0.0008 | 60.0 | 58860 | 0.0000 |
| 0.0002 | 61.0 | 59841 | 0.0000 |
| 0.0018 | 62.0 | 60822 | 0.0000 |
| 0.0016 | 63.0 | 61803 | 0.0003 |
| 0.0 | 64.0 | 62784 | 0.0000 |
| 0.0001 | 65.0 | 63765 | 0.0000 |
| 0.0014 | 66.0 | 64746 | 0.0004 |
| 0.0006 | 67.0 | 65727 | 0.0000 |
| 0.0 | 68.0 | 66708 | 0.0000 |
| 0.0 | 69.0 | 67689 | 0.0000 |
| 0.0002 | 70.0 | 68670 | 0.0000 |
| 0.0001 | 71.0 | 69651 | 0.0000 |
| 0.0 | 72.0 | 70632 | 0.0000 |
| 0.0005 | 73.0 | 71613 | 0.0000 |
| 0.0009 | 74.0 | 72594 | 0.0000 |
| 0.0007 | 75.0 | 73575 | 0.0000 |
| 0.0 | 76.0 | 74556 | 0.0005 |
| 0.0 | 77.0 | 75537 | 0.0000 |
| 0.0 | 78.0 | 76518 | 0.0000 |
| 0.0004 | 79.0 | 77499 | 0.0000 |
| 0.0001 | 80.0 | 78480 | 0.0000 |
| 0.0 | 81.0 | 79461 | 0.0000 |
| 0.0013 | 82.0 | 80442 | 0.0000 |
| 0.0 | 83.0 | 81423 | 0.0000 |
| 0.0 | 84.0 | 82404 | 0.0000 |
| 0.0 | 85.0 | 83385 | 0.0000 |
| 0.0001 | 86.0 | 84366 | 0.0000 |
| 0.001 | 87.0 | 85347 | 0.0000 |
| 0.0 | 88.0 | 86328 | 0.0000 |
| 0.0001 | 89.0 | 87309 | 0.0000 |
| 0.0004 | 90.0 | 88290 | 0.0000 |
| 0.0 | 91.0 | 89271 | 0.0000 |
| 0.0 | 92.0 | 90252 | 0.0000 |
| 0.0 | 93.0 | 91233 | 0.0000 |
| 0.001 | 94.0 | 92214 | 0.0000 |
| 0.0 | 95.0 | 93195 | 0.0000 |
| 0.0 | 96.0 | 94176 | 0.0000 |
| 0.0 | 97.0 | 95157 | 0.0000 |
| 0.0007 | 98.0 | 96138 | 0.0000 |
| 0.0 | 99.0 | 97119 | 0.0000 |
| 0.0 | 100.0 | 98100 | 0.0000 |
| 0.0 | 101.0 | 99081 | 0.0000 |
| 0.0 | 102.0 | 100062 | 0.0000 |
| 0.0 | 103.0 | 101043 | 0.0 |
| 0.0 | 104.0 | 102024 | 0.0000 |
| 0.0 | 105.0 | 103005 | 0.0000 |
| 0.0 | 106.0 | 103986 | 0.0000 |
| 0.0 | 107.0 | 104967 | 0.0 |
| 0.0 | 108.0 | 105948 | 0.0000 |
| 0.0006 | 109.0 | 106929 | 0.0000 |
| 0.0 | 110.0 | 107910 | 0.0000 |
| 0.0 | 111.0 | 108891 | 0.0 |
| 0.0 | 112.0 | 109872 | 0.0 |
| 0.0 | 113.0 | 110853 | 0.0 |
| 0.0 | 114.0 | 111834 | 0.0 |
| 0.0 | 115.0 | 112815 | 0.0000 |
| 0.0 | 116.0 | 113796 | 0.0000 |
| 0.0 | 117.0 | 114777 | 0.0000 |
| 0.0 | 118.0 | 115758 | 0.0000 |
| 0.0 | 119.0 | 116739 | 0.0000 |
| 0.0 | 120.0 | 117720 | 0.0 |
| 0.0 | 121.0 | 118701 | 0.0 |
| 0.0 | 122.0 | 119682 | 0.0 |
| 0.0 | 123.0 | 120663 | 0.0 |
| 0.0013 | 124.0 | 121644 | 0.0000 |
| 0.0 | 125.0 | 122625 | 0.0000 |
| 0.0 | 126.0 | 123606 | 0.0000 |
| 0.0 | 127.0 | 124587 | 0.0000 |
| 0.0 | 128.0 | 125568 | 0.0000 |
| 0.0 | 129.0 | 126549 | 0.0000 |
| 0.0 | 130.0 | 127530 | 0.0 |
| 0.0 | 131.0 | 128511 | 0.0 |
| 0.0 | 132.0 | 129492 | 0.0 |
| 0.0 | 133.0 | 130473 | 0.0 |
| 0.0 | 134.0 | 131454 | 0.0 |
| 0.0 | 135.0 | 132435 | 0.0 |
| 0.0 | 136.0 | 133416 | 0.0 |
| 0.0 | 137.0 | 134397 | 0.0 |
| 0.0 | 138.0 | 135378 | 0.0 |
| 0.0 | 139.0 | 136359 | 0.0 |
| 0.0 | 140.0 | 137340 | 0.0 |
| 0.0 | 141.0 | 138321 | 0.0 |
| 0.0 | 142.0 | 139302 | 0.0 |
| 0.0 | 143.0 | 140283 | 0.0 |
| 0.0 | 144.0 | 141264 | 0.0 |
| 0.0 | 145.0 | 142245 | 0.0 |
| 0.0 | 146.0 | 143226 | 0.0 |
| 0.0 | 147.0 | 144207 | 0.0 |
| 0.0 | 148.0 | 145188 | 0.0 |
| 0.0 | 149.0 | 146169 | 0.0 |
| 0.0 | 150.0 | 147150 | 0.0 |
### Framework versions
- Transformers 4.33.2
- Pytorch 2.0.1+cu118
- Tokenizers 0.13.3
|
MThonar/Linkk
|
MThonar
| 2023-09-21T12:33:31Z | 30 | 0 |
diffusers
|
[
"diffusers",
"safetensors",
"pytorch",
"stable-diffusion",
"text-to-image",
"diffusion-models-class",
"dreambooth",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] |
text-to-image
| 2023-09-21T12:27:35Z |
---
license: creativeml-openrail-m
tags:
- pytorch
- diffusers
- stable-diffusion
- text-to-image
- diffusion-models-class
- dreambooth
---
# DreamBooth model of Link trained by MThonar on the MThonar/link dataset.
This is a Stable Diffusion model fine-tuned with Dreambooth on images of Linkk. It can be used by modifying the `instance_prompt`: **a photo of Linkk**
## Description
This is a Stable Diffusion model fine-tuned on images of Linkk.
## Usage
```python
from diffusers import StableDiffusionPipeline
pipeline = StableDiffusionPipeline.from_pretrained('MThonar/Linkk')
image = pipeline().images[0]
image
```
|
jphme/phi-1_5_Wizard_Vicuna_uncensored
|
jphme
| 2023-09-21T12:23:23Z | 69 | 27 |
transformers
|
[
"transformers",
"pytorch",
"mixformer-sequential",
"text-generation",
"phi",
"phi-1_5",
"english",
"custom_code",
"en",
"dataset:ehartford/wizard_vicuna_70k_unfiltered",
"autotrain_compatible",
"region:us"
] |
text-generation
| 2023-09-12T17:30:57Z |
---
language:
- en
library_name: transformers
pipeline_tag: text-generation
inference: true
tags:
- pytorch
- phi
- phi-1_5
- english
datasets:
- ehartford/wizard_vicuna_70k_unfiltered
---
# Phi 1.5 Wizard Vicuna Experimental
Experimental Finetune on Microsoft's [Phi 1.5](https://huggingface.co/microsoft/phi-1_5).
This is highly experimental, only trained on a subset of the 70k Wizard Vicuna dataset and not meant for production use.
This model also runs reasonably fast on CPU!
Will update with later checkpoints later.
# Prompt Format
ShareGPT / Vicuna (without newlines):
```
A chat between a curious user and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the user's questions. USER: This is a question? ASSISTANT: Here is my answer"
```
# Code Example
```python
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained("jphme/phi-1_5_wizzard_vicuna_uncensored", trust_remote_code=True, torch_dtype=torch.bfloat16).to("cuda")
tokenizer = AutoTokenizer.from_pretrained("jphme/phi-1_5_wizzard_vicuna_uncensored", trust_remote_code=True, torch_dtype=torch.bfloat16)
prompt_template=("A chat between a curious user and an artificial intelligence assistant. "
"The assistant gives helpful, detailed, and polite answers to the user's questions. "
"USER: {prompt} ASSISTANT:")
inputs = tokenizer(
prompt_template.format(prompt="What is 1+1?"),
return_tensors="pt", return_attention_mask=False).to('cuda')
outputs = model.generate(
**inputs, max_length=200,
do_sample=True,
temperature=0.5,
top_p=0.95,
use_cache=True,
repetition_penalty=1.1,
#can try to uncomment this if model doesn't end
#eos_token_id=tokenizer.eos_token_id
)
text = tokenizer.batch_decode(outputs,skip_special_tokens=True)[0]
print(text)
```
The model doesn't stop by itself (this could be an issue due to eos/bos tokens being identical), so you can try to explicitly set the `eos_token_id` (see above) or use a custom stopping criteria.
You can remove `.to("cuda")` to let the model run without a GPU!
# Examples
> A chat between a curious user and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the user's questions. USER: Who was president of the USA in 1995? ASSISTANT: The president of the United States at that time was Bill Clinton (...)
> A chat between a curious user and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the user's questions. USER: Write a python function that returns the fibonacci sequence ASSISTANT:The Fibonacci sequence is a series of numbers where each number after the first two are obtained by adding the two preceding ones together (starting from 0). So the sequence goes 0, 1, 1, 2, 3, 5, 8, 13, 21...
Here's a Python function that generates the nth term in the Fibonacci sequence:
```python
def fibonacci(n):
if n <= 1:
return n
else:
f = [0,1]
for i in range(2, n+1):
f.append(f[-1]+f[-2])
return f[-1]
```
> This function takes as input `n`, which represents the (...)
(this function works with corrected intendation)
> A chat between a curious user and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the user's questions. USER: What is (500+12)/4? ASSISTANT:The answer to this expression is 7.5. (...)
Some potential here ;-)...
# Thanks
Thanks to Microsoft for releaseing Phi 1.5, [Eric Hartford](https://huggingface.co/ehartford) for releasing the Wizard Vicuna dataset, [Winglian](https://huggingface.co/winglian) for his great work on Axolotl that I use for finetuning and [Teknium](https://huggingface.co/teknium) for some Phi finetuning discussion.
# License
The original licenses of the dataset and model applies. No warranty whatsoever, this model is only intended for research purposes.
|
CyberHarem/fujii_tomo_idolmastercinderellagirls
|
CyberHarem
| 2023-09-21T12:22:24Z | 0 | 0 | null |
[
"art",
"text-to-image",
"dataset:CyberHarem/fujii_tomo_idolmastercinderellagirls",
"license:mit",
"region:us"
] |
text-to-image
| 2023-09-21T12:11:05Z |
---
license: mit
datasets:
- CyberHarem/fujii_tomo_idolmastercinderellagirls
pipeline_tag: text-to-image
tags:
- art
---
# Lora of fujii_tomo_idolmastercinderellagirls
This model is trained with [HCP-Diffusion](https://github.com/7eu7d7/HCP-Diffusion). And the auto-training framework is maintained by [DeepGHS Team](https://huggingface.co/deepghs).
The base model used during training is [NAI](https://huggingface.co/deepghs/animefull-latest), and the base model used for generating preview images is [Meina/MeinaMix_V11](https://huggingface.co/Meina/MeinaMix_V11).
After downloading the pt and safetensors files for the specified step, you need to use them simultaneously. The pt file will be used as an embedding, while the safetensors file will be loaded for Lora.
For example, if you want to use the model from step 5100, you need to download `5100/fujii_tomo_idolmastercinderellagirls.pt` as the embedding and `5100/fujii_tomo_idolmastercinderellagirls.safetensors` for loading Lora. By using both files together, you can generate images for the desired characters.
**The best step we recommend is 5100**, with the score of 0.907. The trigger words are:
1. `fujii_tomo_idolmastercinderellagirls`
2. `green_hair, brown_eyes, blush, bangs, bow, smile, hair_bow, jewelry, ponytail, open_mouth, long_hair, black_hair`
For the following groups, it is not recommended to use this model and we express regret:
1. Individuals who cannot tolerate any deviations from the original character design, even in the slightest detail.
2. Individuals who are facing the application scenarios with high demands for accuracy in recreating character outfits.
3. Individuals who cannot accept the potential randomness in AI-generated images based on the Stable Diffusion algorithm.
4. Individuals who are not comfortable with the fully automated process of training character models using LoRA, or those who believe that training character models must be done purely through manual operations to avoid disrespecting the characters.
5. Individuals who finds the generated image content offensive to their values.
These are available steps:
| Steps | Score | Download | pattern_1 | pattern_2 | pattern_3 | bikini | bondage | free | maid | miko | nude | nude2 | suit | yukata |
|:---------|:----------|:--------------------------------------------------------------|:-----------------------------------------------|:-----------------------------------------------|:-----------------------------------------------|:-----------------------------------------|:--------------------------------------------------|:-------------------------------------|:-------------------------------------|:-------------------------------------|:-----------------------------------------------|:------------------------------------------------|:-------------------------------------|:-----------------------------------------|
| **5100** | **0.907** | [**Download**](5100/fujii_tomo_idolmastercinderellagirls.zip) |  |  |  |  | [<NSFW, click to see>](5100/previews/bondage.png) |  |  |  | [<NSFW, click to see>](5100/previews/nude.png) | [<NSFW, click to see>](5100/previews/nude2.png) |  |  |
| 4760 | 0.867 | [Download](4760/fujii_tomo_idolmastercinderellagirls.zip) |  |  |  |  | [<NSFW, click to see>](4760/previews/bondage.png) |  |  |  | [<NSFW, click to see>](4760/previews/nude.png) | [<NSFW, click to see>](4760/previews/nude2.png) |  |  |
| 4420 | 0.869 | [Download](4420/fujii_tomo_idolmastercinderellagirls.zip) |  |  |  |  | [<NSFW, click to see>](4420/previews/bondage.png) |  |  |  | [<NSFW, click to see>](4420/previews/nude.png) | [<NSFW, click to see>](4420/previews/nude2.png) |  |  |
| 4080 | 0.898 | [Download](4080/fujii_tomo_idolmastercinderellagirls.zip) |  |  |  |  | [<NSFW, click to see>](4080/previews/bondage.png) |  |  |  | [<NSFW, click to see>](4080/previews/nude.png) | [<NSFW, click to see>](4080/previews/nude2.png) |  |  |
| 3740 | 0.875 | [Download](3740/fujii_tomo_idolmastercinderellagirls.zip) |  |  |  |  | [<NSFW, click to see>](3740/previews/bondage.png) |  |  |  | [<NSFW, click to see>](3740/previews/nude.png) | [<NSFW, click to see>](3740/previews/nude2.png) |  |  |
| 3400 | 0.806 | [Download](3400/fujii_tomo_idolmastercinderellagirls.zip) |  |  |  |  | [<NSFW, click to see>](3400/previews/bondage.png) |  |  |  | [<NSFW, click to see>](3400/previews/nude.png) | [<NSFW, click to see>](3400/previews/nude2.png) |  |  |
| 3060 | 0.835 | [Download](3060/fujii_tomo_idolmastercinderellagirls.zip) |  |  |  |  | [<NSFW, click to see>](3060/previews/bondage.png) |  |  |  | [<NSFW, click to see>](3060/previews/nude.png) | [<NSFW, click to see>](3060/previews/nude2.png) |  |  |
| 2720 | 0.818 | [Download](2720/fujii_tomo_idolmastercinderellagirls.zip) |  |  |  |  | [<NSFW, click to see>](2720/previews/bondage.png) |  |  |  | [<NSFW, click to see>](2720/previews/nude.png) | [<NSFW, click to see>](2720/previews/nude2.png) |  |  |
| 2380 | 0.839 | [Download](2380/fujii_tomo_idolmastercinderellagirls.zip) |  |  |  |  | [<NSFW, click to see>](2380/previews/bondage.png) |  |  |  | [<NSFW, click to see>](2380/previews/nude.png) | [<NSFW, click to see>](2380/previews/nude2.png) |  |  |
| 2040 | 0.791 | [Download](2040/fujii_tomo_idolmastercinderellagirls.zip) |  |  |  |  | [<NSFW, click to see>](2040/previews/bondage.png) |  |  |  | [<NSFW, click to see>](2040/previews/nude.png) | [<NSFW, click to see>](2040/previews/nude2.png) |  |  |
| 1700 | 0.822 | [Download](1700/fujii_tomo_idolmastercinderellagirls.zip) |  |  |  |  | [<NSFW, click to see>](1700/previews/bondage.png) |  |  |  | [<NSFW, click to see>](1700/previews/nude.png) | [<NSFW, click to see>](1700/previews/nude2.png) |  |  |
| 1360 | 0.799 | [Download](1360/fujii_tomo_idolmastercinderellagirls.zip) |  |  |  |  | [<NSFW, click to see>](1360/previews/bondage.png) |  |  |  | [<NSFW, click to see>](1360/previews/nude.png) | [<NSFW, click to see>](1360/previews/nude2.png) |  |  |
| 1020 | 0.732 | [Download](1020/fujii_tomo_idolmastercinderellagirls.zip) |  |  |  |  | [<NSFW, click to see>](1020/previews/bondage.png) |  |  |  | [<NSFW, click to see>](1020/previews/nude.png) | [<NSFW, click to see>](1020/previews/nude2.png) |  |  |
| 680 | 0.727 | [Download](680/fujii_tomo_idolmastercinderellagirls.zip) |  |  |  |  | [<NSFW, click to see>](680/previews/bondage.png) |  |  |  | [<NSFW, click to see>](680/previews/nude.png) | [<NSFW, click to see>](680/previews/nude2.png) |  |  |
| 340 | 0.778 | [Download](340/fujii_tomo_idolmastercinderellagirls.zip) |  |  |  |  | [<NSFW, click to see>](340/previews/bondage.png) |  |  |  | [<NSFW, click to see>](340/previews/nude.png) | [<NSFW, click to see>](340/previews/nude2.png) |  |  |
|
bavolesy/Reinforce-Cartpole-v1
|
bavolesy
| 2023-09-21T12:19:12Z | 0 | 0 | null |
[
"CartPole-v1",
"reinforce",
"reinforcement-learning",
"custom-implementation",
"deep-rl-class",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-09-21T12:18:58Z |
---
tags:
- CartPole-v1
- reinforce
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: Reinforce-Cartpole-v1
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: CartPole-v1
type: CartPole-v1
metrics:
- type: mean_reward
value: 500.00 +/- 0.00
name: mean_reward
verified: false
---
# **Reinforce** Agent playing **CartPole-v1**
This is a trained model of a **Reinforce** agent playing **CartPole-v1** .
To learn to use this model and train yours check Unit 4 of the Deep Reinforcement Learning Course: https://huggingface.co/deep-rl-course/unit4/introduction
|
acalatrava/mlc-chat-TinyLlama-1.1B-orca-gpt4-q4f16_1
|
acalatrava
| 2023-09-21T12:12:13Z | 0 | 2 | null |
[
"en",
"dataset:cerebras/SlimPajama-627B",
"dataset:bigcode/starcoderdata",
"dataset:sam-mosaic/orca-gpt4-chatml",
"license:apache-2.0",
"region:us"
] | null | 2023-09-21T11:22:57Z |
---
license: apache-2.0
datasets:
- cerebras/SlimPajama-627B
- bigcode/starcoderdata
- sam-mosaic/orca-gpt4-chatml
language:
- en
---
<div align="center">
# TinyLlama-1.1B
Finetuned with ORCA-GPT4 (chatml format)
This is the MLC-LLM version from https://huggingface.co/acalatrava/TinyLlama-1.1B-orca-gpt4
</div>
https://github.com/jzhang38/TinyLlama
|
MattStammers/appo-mujoco-pendulum
|
MattStammers
| 2023-09-21T12:11:43Z | 0 | 0 |
sample-factory
|
[
"sample-factory",
"tensorboard",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-09-21T12:11:40Z |
---
library_name: sample-factory
tags:
- deep-reinforcement-learning
- reinforcement-learning
- sample-factory
model-index:
- name: APPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: mujoco_pendulum
type: mujoco_pendulum
metrics:
- type: mean_reward
value: 1000.00 +/- 0.00
name: mean_reward
verified: false
---
A(n) **APPO** model trained on the **mujoco_pendulum** environment.
This model was trained using Sample-Factory 2.0: https://github.com/alex-petrenko/sample-factory.
Documentation for how to use Sample-Factory can be found at https://www.samplefactory.dev/
## Downloading the model
After installing Sample-Factory, download the model with:
```
python -m sample_factory.huggingface.load_from_hub -r MattStammers/appo-mujoco-pendulum
```
## Using the model
To run the model after download, use the `enjoy` script corresponding to this environment:
```
python -m sf_examples.mujoco.enjoy_mujoco --algo=APPO --env=mujoco_pendulum --train_dir=./train_dir --experiment=appo-mujoco-pendulum
```
You can also upload models to the Hugging Face Hub using the same script with the `--push_to_hub` flag.
See https://www.samplefactory.dev/10-huggingface/huggingface/ for more details
## Training with this model
To continue training with this model, use the `train` script corresponding to this environment:
```
python -m sf_examples.mujoco.train_mujoco --algo=APPO --env=mujoco_pendulum --train_dir=./train_dir --experiment=appo-mujoco-pendulum --restart_behavior=resume --train_for_env_steps=10000000000
```
Note, you may have to adjust `--train_for_env_steps` to a suitably high number as the experiment will resume at the number of steps it concluded at.
|
Rexe/Deci-Decicoder-1b-qlora-coder
|
Rexe
| 2023-09-21T12:07:27Z | 3 | 0 |
peft
|
[
"peft",
"base_model:Deci/DeciCoder-1b",
"base_model:adapter:Deci/DeciCoder-1b",
"region:us"
] | null | 2023-09-19T01:30:55Z |
---
library_name: peft
base_model: Deci/DeciCoder-1b
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: True
- bnb_4bit_compute_dtype: bfloat16
### Framework versions
- PEFT 0.6.0.dev0
|
ShivamMangale/XLM-Roberta-base-all_hi_weakdap_2nd_iteration_d2-hq
|
ShivamMangale
| 2023-09-21T11:53:19Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"xlm-roberta",
"question-answering",
"generated_from_trainer",
"dataset:squad",
"base_model:FacebookAI/xlm-roberta-base",
"base_model:finetune:FacebookAI/xlm-roberta-base",
"license:mit",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2023-09-21T11:51:04Z |
---
license: mit
base_model: xlm-roberta-base
tags:
- generated_from_trainer
datasets:
- squad
model-index:
- name: XLM-Roberta-base-all_hi_weakdap_2nd_iteration_d2-hq
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# XLM-Roberta-base-all_hi_weakdap_2nd_iteration_d2-hq
This model is a fine-tuned version of [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) on the squad dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1.8e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 8
### Training results
### Framework versions
- Transformers 4.33.2
- Pytorch 2.0.1+cu117
- Datasets 2.14.5
- Tokenizers 0.13.3
|
OpenDILabCommunity/Hopper-v3-TD3
|
OpenDILabCommunity
| 2023-09-21T11:48:28Z | 0 | 0 |
pytorch
|
[
"pytorch",
"deep-reinforcement-learning",
"reinforcement-learning",
"DI-engine",
"Hopper-v3",
"en",
"license:apache-2.0",
"region:us"
] |
reinforcement-learning
| 2023-04-14T19:22:54Z |
---
language: en
license: apache-2.0
library_name: pytorch
tags:
- deep-reinforcement-learning
- reinforcement-learning
- DI-engine
- Hopper-v3
benchmark_name: OpenAI/Gym/MuJoCo
task_name: Hopper-v3
pipeline_tag: reinforcement-learning
model-index:
- name: TD3
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: OpenAI/Gym/MuJoCo-Hopper-v3
type: OpenAI/Gym/MuJoCo-Hopper-v3
metrics:
- type: mean_reward
value: 3671.44 +/- 201.96
name: mean_reward
---
# Play **Hopper-v3** with **TD3** Policy
## Model Description
<!-- Provide a longer summary of what this model is. -->
This is a simple **TD3** implementation to OpenAI/Gym/MuJoCo **Hopper-v3** using the [DI-engine library](https://github.com/opendilab/di-engine) and the [DI-zoo](https://github.com/opendilab/DI-engine/tree/main/dizoo).
**DI-engine** is a python library for solving general decision intelligence problems, which is based on implementations of reinforcement learning framework using PyTorch or JAX. This library aims to standardize the reinforcement learning framework across different algorithms, benchmarks, environments, and to support both academic researches and prototype applications. Besides, self-customized training pipelines and applications are supported by reusing different abstraction levels of DI-engine reinforcement learning framework.
## Model Usage
### Install the Dependencies
<details close>
<summary>(Click for Details)</summary>
```shell
# install huggingface_ding
git clone https://github.com/opendilab/huggingface_ding.git
pip3 install -e ./huggingface_ding/
# install environment dependencies if needed
sudo apt update -y && sudo apt install -y build-essential libgl1-mesa-dev libgl1-mesa-glx libglew-dev libosmesa6-dev libglfw3 libglfw3-dev libsdl2-dev libsdl2-image-dev libglm-dev libfreetype6-dev patchelf
mkdir -p ~/.mujoco
wget https://mujoco.org/download/mujoco210-linux-x86_64.tar.gz -O mujoco.tar.gz
tar -xf mujoco.tar.gz -C ~/.mujoco
echo "export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:~/.mujoco/mjpro210/bin:~/.mujoco/mujoco210/bin" >> ~/.bashrc
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:~/.mujoco/mjpro210/bin:~/.mujoco/mujoco210/bin
pip3 install "cython<3"
pip3 install DI-engine[common_env]
```
</details>
### Git Clone from Huggingface and Run the Model
<details close>
<summary>(Click for Details)</summary>
```shell
# running with trained model
python3 -u run.py
```
**run.py**
```python
from ding.bonus import SACAgent
from ding.config import Config
from easydict import EasyDict
import torch
# Pull model from files which are git cloned from huggingface
policy_state_dict = torch.load("pytorch_model.bin", map_location=torch.device("cpu"))
cfg = EasyDict(Config.file_to_dict("policy_config.py").cfg_dict)
# Instantiate the agent
agent = SACAgent(env_id="Hopper-v3", exp_name="Hopper-v3-TD3", cfg=cfg.exp_config, policy_state_dict=policy_state_dict)
# Continue training
agent.train(step=5000)
# Render the new agent performance
agent.deploy(enable_save_replay=True)
```
</details>
### Run Model by Using Huggingface_ding
<details close>
<summary>(Click for Details)</summary>
```shell
# running with trained model
python3 -u run.py
```
**run.py**
```python
from ding.bonus import TD3Agent
from huggingface_ding import pull_model_from_hub
# Pull model from Hugggingface hub
policy_state_dict, cfg = pull_model_from_hub(repo_id="OpenDILabCommunity/Hopper-v3-TD3")
# Instantiate the agent
agent = TD3Agent(env_id="Hopper-v3", exp_name="Hopper-v3-TD3", cfg=cfg.exp_config, policy_state_dict=policy_state_dict)
# Continue training
agent.train(step=5000)
# Render the new agent performance
agent.deploy(enable_save_replay=True)
```
</details>
## Model Training
### Train the Model and Push to Huggingface_hub
<details close>
<summary>(Click for Details)</summary>
```shell
#Training Your Own Agent
python3 -u train.py
```
**train.py**
```python
from ding.bonus import TD3Agent
from huggingface_ding import push_model_to_hub
# Instantiate the agent
agent = TD3Agent(env_id="Hopper-v3", exp_name="Hopper-v3-TD3")
# Train the agent
return_ = agent.train(step=int(10000000), collector_env_num=4, evaluator_env_num=4, debug=False)
# Push model to huggingface hub
push_model_to_hub(
agent=agent.best,
env_name="OpenAI/Gym/MuJoCo",
task_name="Hopper-v3",
algo_name="TD3",
wandb_url=return_.wandb_url,
github_repo_url="https://github.com/opendilab/DI-engine",
github_doc_model_url="https://di-engine-docs.readthedocs.io/en/latest/12_policies/td3.html",
github_doc_env_url="https://di-engine-docs.readthedocs.io/en/latest/13_envs/mujoco.html",
installation_guide='''
sudo apt update -y \
&& sudo apt install -y \
build-essential \
libgl1-mesa-dev \
libgl1-mesa-glx \
libglew-dev \
libosmesa6-dev \
libglfw3 \
libglfw3-dev \
libsdl2-dev \
libsdl2-image-dev \
libglm-dev \
libfreetype6-dev \
patchelf
mkdir -p ~/.mujoco
wget https://mujoco.org/download/mujoco210-linux-x86_64.tar.gz -O mujoco.tar.gz
tar -xf mujoco.tar.gz -C ~/.mujoco
echo "export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:~/.mujoco/mjpro210/bin:~/.mujoco/mujoco210/bin" >> ~/.bashrc
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:~/.mujoco/mjpro210/bin:~/.mujoco/mujoco210/bin
pip3 install "cython<3"
pip3 install DI-engine[common_env]
''',
usage_file_by_git_clone="./td3/hopper_td3_deploy.py",
usage_file_by_huggingface_ding="./td3/hopper_td3_download.py",
train_file="./td3/hopper_td3.py",
repo_id="OpenDILabCommunity/Hopper-v3-TD3",
create_repo=False
)
```
</details>
**Configuration**
<details close>
<summary>(Click for Details)</summary>
```python
exp_config = {
'env': {
'manager': {
'episode_num': float("inf"),
'max_retry': 1,
'retry_type': 'reset',
'auto_reset': True,
'step_timeout': None,
'reset_timeout': None,
'retry_waiting_time': 0.1,
'cfg_type': 'BaseEnvManagerDict'
},
'stop_value': 6000,
'n_evaluator_episode': 8,
'env_id': 'Hopper-v3',
'collector_env_num': 8,
'evaluator_env_num': 8,
'env_wrapper': 'mujoco_default'
},
'policy': {
'model': {
'twin_critic': True,
'obs_shape': 11,
'action_shape': 3,
'actor_head_hidden_size': 256,
'critic_head_hidden_size': 256,
'action_space': 'regression'
},
'learn': {
'learner': {
'train_iterations': 1000000000,
'dataloader': {
'num_workers': 0
},
'log_policy': True,
'hook': {
'load_ckpt_before_run': '',
'log_show_after_iter': 100,
'save_ckpt_after_iter': 10000,
'save_ckpt_after_run': True
},
'cfg_type': 'BaseLearnerDict'
},
'update_per_collect': 1,
'batch_size': 256,
'learning_rate_actor': 0.001,
'learning_rate_critic': 0.001,
'ignore_done': False,
'target_theta': 0.005,
'discount_factor': 0.99,
'actor_update_freq': 2,
'noise': True,
'noise_sigma': 0.2,
'noise_range': {
'min': -0.5,
'max': 0.5
}
},
'collect': {
'collector': {},
'unroll_len': 1,
'noise_sigma': 0.1,
'n_sample': 1
},
'eval': {
'evaluator': {
'eval_freq': 5000,
'render': {
'render_freq': -1,
'mode': 'train_iter'
},
'figure_path': None,
'cfg_type': 'InteractionSerialEvaluatorDict',
'stop_value': 6000,
'n_episode': 8
}
},
'other': {
'replay_buffer': {
'replay_buffer_size': 1000000
}
},
'on_policy': False,
'cuda': True,
'multi_gpu': False,
'bp_update_sync': True,
'traj_len_inf': False,
'type': 'td3',
'priority': False,
'priority_IS_weight': False,
'random_collect_size': 25000,
'transition_with_policy_data': False,
'action_space': 'continuous',
'reward_batch_norm': False,
'multi_agent': False,
'cfg_type': 'TD3PolicyDict'
},
'exp_name': 'Hopper-v3-TD3',
'seed': 0,
'wandb_logger': {
'gradient_logger': True,
'video_logger': True,
'plot_logger': True,
'action_logger': True,
'return_logger': False
}
}
```
</details>
**Training Procedure**
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
- **Weights & Biases (wandb):** [monitor link](https://wandb.ai/zjowowen/Hopper-v3-TD3)
## Model Information
<!-- Provide the basic links for the model. -->
- **Github Repository:** [repo link](https://github.com/opendilab/DI-engine)
- **Doc**: [DI-engine-docs Algorithm link](https://di-engine-docs.readthedocs.io/en/latest/12_policies/td3.html)
- **Configuration:** [config link](https://huggingface.co/OpenDILabCommunity/Hopper-v3-TD3/blob/main/policy_config.py)
- **Demo:** [video](https://huggingface.co/OpenDILabCommunity/Hopper-v3-TD3/blob/main/replay.mp4)
<!-- Provide the size information for the model. -->
- **Parameters total size:** 1636.04 KB
- **Last Update Date:** 2023-09-21
## Environments
<!-- Address questions around what environment the model is intended to be trained and deployed at, including the necessary information needed to be provided for future users. -->
- **Benchmark:** OpenAI/Gym/MuJoCo
- **Task:** Hopper-v3
- **Gym version:** 0.25.1
- **DI-engine version:** v0.4.9
- **PyTorch version:** 2.0.1+cu117
- **Doc**: [DI-engine-docs Environments link](https://di-engine-docs.readthedocs.io/en/latest/13_envs/mujoco.html)
|
Ori/lama-2-13b-peft-strategyqa-no-retrieval-1-v2-seed-3
|
Ori
| 2023-09-21T11:36:27Z | 3 | 0 |
peft
|
[
"peft",
"safetensors",
"region:us"
] | null | 2023-09-21T11:34:07Z |
---
library_name: peft
---
## Training procedure
### Framework versions
- PEFT 0.5.0.dev0
|
Ori/llama-2-13b-peft-strategyqa-no-ret
|
Ori
| 2023-09-21T11:30:44Z | 3 | 0 |
peft
|
[
"peft",
"safetensors",
"region:us"
] | null | 2023-09-21T11:29:31Z |
---
library_name: peft
---
## Training procedure
### Framework versions
- PEFT 0.5.0.dev0
|
ldos/text_shortening_model_v47
|
ldos
| 2023-09-21T11:25:38Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bart",
"text2text-generation",
"generated_from_trainer",
"base_model:facebook/bart-large-xsum",
"base_model:finetune:facebook/bart-large-xsum",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2023-09-21T10:04:22Z |
---
license: mit
base_model: facebook/bart-large-xsum
tags:
- generated_from_trainer
metrics:
- rouge
model-index:
- name: text_shortening_model_v47
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# text_shortening_model_v47
This model is a fine-tuned version of [facebook/bart-large-xsum](https://huggingface.co/facebook/bart-large-xsum) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 6.3912
- Rouge1: 0.0
- Rouge2: 0.0
- Rougel: 0.0
- Rougelsum: 0.0
- Bert precision: 0.6047
- Bert recall: 0.5681
- Average word count: 1.0
- Max word count: 1
- Min word count: 1
- Average token count: 12.0
- % shortened texts with length > 12: 0.0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.005
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 7
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Bert precision | Bert recall | Average word count | Max word count | Min word count | Average token count | % shortened texts with length > 12 |
|:-------------:|:-----:|:----:|:---------------:|:------:|:------:|:------:|:---------:|:--------------:|:-----------:|:------------------:|:--------------:|:--------------:|:-------------------:|:----------------------------------:|
| 7.822 | 1.0 | 83 | 7.4737 | 0.0776 | 0.0 | 0.0775 | 0.0776 | 0.6348 | 0.6223 | 2.0 | 2 | 2 | 13.0 | 0.0 |
| 3.2859 | 2.0 | 166 | 6.6585 | 0.1063 | 0.0 | 0.1063 | 0.1063 | 0.6469 | 0.608 | 5.0026 | 6 | 5 | 12.0 | 0.0 |
| 3.0284 | 3.0 | 249 | 6.4761 | 0.116 | 0.0 | 0.116 | 0.1161 | 0.6479 | 0.6388 | 3.9974 | 4 | 3 | 14.0 | 0.0 |
| 2.9681 | 4.0 | 332 | 6.4592 | 0.0 | 0.0 | 0.0 | 0.0 | 0.6071 | 0.5723 | 1.0 | 1 | 1 | 12.0 | 0.0 |
| 2.9377 | 5.0 | 415 | 6.4142 | 0.0 | 0.0 | 0.0 | 0.0 | 0.6047 | 0.5681 | 1.0 | 1 | 1 | 12.0 | 0.0 |
| 2.9168 | 6.0 | 498 | 6.4049 | 0.0 | 0.0 | 0.0 | 0.0 | 0.6049 | 0.5685 | 1.0 | 1 | 1 | 12.0 | 0.0 |
| 2.8964 | 7.0 | 581 | 6.3912 | 0.0 | 0.0 | 0.0 | 0.0 | 0.6047 | 0.5681 | 1.0 | 1 | 1 | 12.0 | 0.0 |
### Framework versions
- Transformers 4.33.1
- Pytorch 2.0.1+cu118
- Datasets 2.14.5
- Tokenizers 0.13.3
|
amitonHFace/q-Taxi-v3
|
amitonHFace
| 2023-09-21T11:25:11Z | 0 | 0 | null |
[
"Taxi-v3",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-09-21T11:25:09Z |
---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-Taxi-v3
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
metrics:
- type: mean_reward
value: 7.56 +/- 2.71
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="amitonHFace/q-Taxi-v3", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
monsterapi/llama7B_alpaca-lora
|
monsterapi
| 2023-09-21T11:23:24Z | 1 | 1 |
peft
|
[
"peft",
"llama1-7b",
"code",
"instruct",
"alpaca-instruct",
"alpaca",
"llama7b",
"dataset:tatsu-lab/alpaca",
"region:us"
] | null | 2023-05-10T05:39:31Z |
---
library_name: peft
tags:
- llama1-7b
- code
- instruct
- alpaca-instruct
- alpaca
- llama7b
datasets:
- tatsu-lab/alpaca
base_model: decapoda-research/llama-7b-hf
---
We finetuned huggyllama/llama-7b on tatsu-lab/alpaca Dataset for 5 epochs or ~ 25,000 steps using [MonsterAPI](https://monsterapi.ai) no-code [LLM finetuner](https://docs.monsterapi.ai/fine-tune-a-large-language-model-llm).
This dataset is HuggingFaceH4/tatsu-lab/alpaca unfiltered, removing 36 instances of blatant alignment.
The finetuning session got completed in 4 hours and costed us only `$16` for the entire finetuning run!
#### Hyperparameters & Run details:
- Model Path: huggyllama/llama-7b
- Dataset: tatsu-lab/alpaca
- Learning rate: 0.0003
- Number of epochs: 5
- Data split: Training: 90% / Validation: 10%
- Gradient accumulation steps: 1
license: apache-2.0
---
|
monsterapi/opt125M_alpaca
|
monsterapi
| 2023-09-21T11:23:21Z | 146 | 0 |
peft
|
[
"peft",
"facebook/opt-125m",
"code",
"instruct",
"alpaca-instruct",
"alpaca",
"dataset:tatsu-lab/alpaca",
"base_model:facebook/opt-125m",
"base_model:adapter:facebook/opt-125m",
"region:us"
] | null | 2023-05-13T05:38:51Z |
---
library_name: peft
tags:
- facebook/opt-125m
- code
- instruct
- alpaca-instruct
- alpaca
datasets:
- tatsu-lab/alpaca
base_model: facebook/opt-125m
---
We finetuned facebook/opt-125m on tatsu-lab/alpaca Dataset for 10 epochs using [MonsterAPI](https://monsterapi.ai) no-code [LLM finetuner](https://docs.monsterapi.ai/fine-tune-a-large-language-model-llm).
This dataset is HuggingFaceH4/tatsu-lab/alpaca unfiltered, removing 36 instances of blatant alignment.
The finetuning session got completed in 40 minutes and costed us only `$4` for the entire finetuning run!
#### Hyperparameters & Run details:
- Model: facebook/opt-125m
- Dataset: tatsu-lab/alpaca
- Learning rate: 0.0003
- Number of epochs: 10
- Data split: Training: 90% / Validation: 10%
- Gradient accumulation steps: 1
-
---
license: apache-2.0
---
|
monsterapi/OpenPlatypus_LLAMA2_7b
|
monsterapi
| 2023-09-21T11:23:18Z | 6 | 1 |
peft
|
[
"peft",
"meta-llama/Llama-2-7b-hf",
"code",
"instruct",
"instruct-code",
"logical-reasoning",
"Platypus2",
"dataset:garage-bAInd/Open-Platypus",
"base_model:meta-llama/Llama-2-7b-hf",
"base_model:adapter:meta-llama/Llama-2-7b-hf",
"region:us"
] | null | 2023-09-05T10:13:05Z |
---
library_name: peft
tags:
- meta-llama/Llama-2-7b-hf
- code
- instruct
- instruct-code
- logical-reasoning
- Platypus2
datasets:
- garage-bAInd/Open-Platypus
base_model: meta-llama/Llama-2-7b-hf
---
We finetuned Meta-Llama/Llama-2-7b-hf on the Open-Platypus dataset (garage-bAInd/Open-Platypus) for 5 epochs using [MonsterAPI](https://monsterapi.ai) no-code [LLM finetuner](https://docs.monsterapi.ai/fine-tune-a-large-language-model-llm).
#### About OpenPlatypus Dataset
OpenPlatypus is focused on improving LLM logical reasoning skills and was used to train the Platypus2 models. The dataset is comprised of various sub-datasets, including PRM800K, ScienceQA, SciBench, ReClor, TheoremQA, among others. These were filtered using keyword search and Sentence Transformers to remove questions with a similarity above 80%. The dataset includes contributions under various licenses like MIT, Creative Commons, and Apache 2.0.
The finetuning session got completed in 1 hour and 30 minutes and costed us only `$15` for the entire finetuning run!
#### Hyperparameters & Run details:
- Model Path: meta-llama/Llama-2-7b-hf
- Dataset: garage-bAInd/Open-Platypus
- Learning rate: 0.0002
- Number of epochs: 5
- Data split: Training: 90% / Validation: 10%
- Gradient accumulation steps: 1
---
license: apache-2.0
---
|
alexalbala/llam2test
|
alexalbala
| 2023-09-21T11:23:16Z | 0 | 0 |
peft
|
[
"peft",
"base_model:meta-llama/Llama-2-7b-hf",
"base_model:adapter:meta-llama/Llama-2-7b-hf",
"region:us"
] | null | 2023-09-21T08:49:01Z |
---
library_name: peft
base_model: meta-llama/Llama-2-7b-hf
---
## Training procedure
### Framework versions
- PEFT 0.5.0
|
monsterapi/OpenPlatypus_Falcon_7b
|
monsterapi
| 2023-09-21T11:23:15Z | 2 | 0 |
peft
|
[
"peft",
"tiiuae/falcon-7b",
"code",
"instruct",
"instruct-code",
"logical-reasoning",
"Platypus2",
"dataset:garage-bAInd/Open-Platypus",
"base_model:codellama/CodeLlama-7b-hf",
"base_model:adapter:codellama/CodeLlama-7b-hf",
"region:us"
] | null | 2023-09-05T11:28:00Z |
---
library_name: peft
tags:
- tiiuae/falcon-7b
- code
- instruct
- instruct-code
- logical-reasoning
- Platypus2
datasets:
- garage-bAInd/Open-Platypus
base_model: codellama/CodeLlama-7b-hf
---
We finetuned TIIUAE/Falcon-7B on the Open-Platypus dataset (garage-bAInd/Open-Platypus) for 3 epochs using [MonsterAPI](https://monsterapi.ai) no-code [LLM finetuner](https://docs.monsterapi.ai/fine-tune-a-large-language-model-llm).
#### About OpenPlatypus Dataset
OpenPlatypus is focused on improving LLM logical reasoning skills and was used to train the Platypus2 models. The dataset is comprised of various sub-datasets, including PRM800K, ScienceQA, SciBench, ReClor, TheoremQA, among others. These were filtered using keyword search and Sentence Transformers to remove questions with a similarity above 80%. The dataset includes contributions under various licenses like MIT, Creative Commons, and Apache 2.0.
The finetuning session got completed in ~ 3 hrs and costed us only `$14` for the entire finetuning run!
#### Hyperparameters & Run details:
- Model Path: tiiuae/falcon-7b
- Dataset: garage-bAInd/Open-Platypus
- Learning rate: 0.0003
- Number of epochs: 3
- Data split: Training: 90% / Validation: 10%
- Gradient accumulation steps: 1
---
license: apache-2.0
---
|
monsterapi/gpt2_alpaca-lora
|
monsterapi
| 2023-09-21T11:22:54Z | 199 | 1 |
peft
|
[
"peft",
"gpt2",
"code",
"instruct",
"alpaca-instruct",
"alpaca",
"dataset:tatsu-lab/alpaca",
"base_model:openai-community/gpt2",
"base_model:adapter:openai-community/gpt2",
"region:us"
] | null | 2023-05-06T05:59:05Z |
---
library_name: peft
tags:
- gpt2
- code
- instruct
- alpaca-instruct
- alpaca
datasets:
- tatsu-lab/alpaca
base_model: gpt2
---
We finetuned gpt2 on tatsu-lab/alpaca Dataset for 5 epochs using [MonsterAPI](https://monsterapi.ai) no-code [LLM finetuner](https://docs.monsterapi.ai/fine-tune-a-large-language-model-llm).
This dataset is HuggingFaceH4/tatsu-lab/alpaca unfiltered, removing 36 instances of blatant alignment.
The finetuning session got completed in 20 minutes and costed us only `$3` for the entire finetuning run!
#### Hyperparameters & Run details:
- Model: gpt2
- Dataset: tatsu-lab/alpaca
- Learning rate: 0.0003
- Number of epochs: 5
- Data split: Training: 90% / Validation: 10%
- Gradient accumulation steps: 1
---
license: apache-2.0
---
|
monsterapi/CodeAlpaca_LLAMA2_7B
|
monsterapi
| 2023-09-21T11:22:17Z | 59 | 4 |
peft
|
[
"peft",
"llama2-7b",
"code",
"instruct",
"instruct-code",
"code-alpaca",
"alpaca-instruct",
"alpaca",
"llama7b",
"gpt2",
"dataset:sahil2801/CodeAlpaca-20k",
"base_model:meta-llama/Llama-2-7b-hf",
"base_model:adapter:meta-llama/Llama-2-7b-hf",
"region:us"
] | null | 2023-07-26T16:38:03Z |
---
library_name: peft
tags:
- llama2-7b
- code
- instruct
- instruct-code
- code-alpaca
- alpaca-instruct
- alpaca
- llama7b
- gpt2
datasets:
- sahil2801/CodeAlpaca-20k
base_model: meta-llama/Llama-2-7b-hf
---
We finetuned Llama2-7B on Code-Alpaca-Instruct Dataset (sahil2801/CodeAlpaca-20k) for 5 epochs or ~ 25,000 steps using [MonsterAPI](https://monsterapi.ai) no-code [LLM finetuner](https://docs.monsterapi.ai/fine-tune-a-large-language-model-llm).
This dataset is HuggingFaceH4/CodeAlpaca_20K unfiltered, removing 36 instances of blatant alignment.
The finetuning session got completed in 4 hours and costed us only `$16` for the entire finetuning run!
#### Hyperparameters & Run details:
- Model Path: meta-llama/Llama-2-7b
- Dataset: sahil2801/CodeAlpaca-20k
- Learning rate: 0.0003
- Number of epochs: 5
- Data split: Training: 90% / Validation: 10%
- Gradient accumulation steps: 1
Loss metrics:

---
license: apache-2.0
---
|
acalatrava/mlc-chat-TinyLlama-1.1B-Chat-v0.2-q4f16_1
|
acalatrava
| 2023-09-21T11:20:22Z | 0 | 0 | null |
[
"en",
"dataset:cerebras/SlimPajama-627B",
"dataset:bigcode/starcoderdata",
"dataset:OpenAssistant/oasst_top1_2023-08-25",
"license:apache-2.0",
"region:us"
] | null | 2023-09-19T15:23:34Z |
---
license: apache-2.0
datasets:
- cerebras/SlimPajama-627B
- bigcode/starcoderdata
- OpenAssistant/oasst_top1_2023-08-25
language:
- en
---
<div align="center">
# TinyLlama-1.1B
This is the MLC-LLM version from https://huggingface.co/PY007/TinyLlama-1.1B-Chat-v0.2
</div>
https://github.com/jzhang38/TinyLlama
|
mesa44/ppo-LunarLander-v2
|
mesa44
| 2023-09-21T11:17:54Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-09-19T09:43:00Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 250.37 +/- 33.48
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
amitonHFace/q-FrozenLake-v1-4x4-noSlippery
|
amitonHFace
| 2023-09-21T11:17:28Z | 0 | 0 | null |
[
"FrozenLake-v1-4x4-no_slippery",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-09-21T11:17:25Z |
---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="amitonHFace/q-FrozenLake-v1-4x4-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
iamshnoo/alpaca-2-70b-bengali
|
iamshnoo
| 2023-09-21T11:03:15Z | 4 | 0 |
peft
|
[
"peft",
"bn",
"en",
"dataset:iamshnoo/alpaca-cleaned-bengali",
"base_model:meta-llama/Llama-2-70b-hf",
"base_model:adapter:meta-llama/Llama-2-70b-hf",
"license:cc-by-4.0",
"region:us"
] | null | 2023-09-10T20:28:27Z |
---
language:
- bn
- en
license: cc-by-4.0
library_name: peft
datasets:
- iamshnoo/alpaca-cleaned-bengali
base_model: meta-llama/Llama-2-70b-hf
---
This represents the PEFT weights only. The base model is LLaMA 2. Instruction finetuning was done using 4 bit QLoRA on a single A100 GPU with the PEFT config as given below. The dataset used for this instruction finetuning process is a translated version of the cleaned alpaca dataset (translated using NLLB-1.3B).
Do note that this model might have inferior performance on some language specific tasks compared to full finetuning or a different base model trained with more language specific data.
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: True
- bnb_4bit_compute_dtype: bfloat16
### Framework versions
- PEFT 0.4.0
|
hyeongjin99/vit_base_aihub_model_py
|
hyeongjin99
| 2023-09-21T10:58:45Z | 216 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"vit",
"image-classification",
"generated_from_trainer",
"dataset:imagefolder",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2023-09-21T07:27:29Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- imagefolder
metrics:
- accuracy
- precision
- recall
- f1
model-index:
- name: vit_base_aihub_model_py
results:
- task:
name: Image Classification
type: image-classification
dataset:
name: imagefolder
type: imagefolder
config: default
split: train
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.9977631269131152
- name: Precision
type: precision
value: 0.998134723737648
- name: Recall
type: recall
value: 0.9974298183920257
- name: F1
type: f1
value: 0.9977816548360952
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# vit_base_aihub_model_py
This model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0228
- Accuracy: 0.9978
- Precision: 0.9981
- Recall: 0.9974
- F1: 0.9978
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 128
- eval_batch_size: 128
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 512
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | Precision | Recall | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:---------:|:------:|:------:|
| 0.1415 | 1.0 | 149 | 0.1286 | 0.9712 | 0.9788 | 0.9623 | 0.9700 |
| 0.0671 | 2.0 | 299 | 0.0463 | 0.9948 | 0.9917 | 0.9946 | 0.9932 |
| 0.0423 | 3.0 | 448 | 0.0356 | 0.9952 | 0.9970 | 0.9908 | 0.9939 |
| 0.0383 | 4.0 | 598 | 0.0242 | 0.9976 | 0.9980 | 0.9972 | 0.9976 |
| 0.033 | 4.98 | 745 | 0.0228 | 0.9978 | 0.9981 | 0.9974 | 0.9978 |
### Framework versions
- Transformers 4.30.2
- Pytorch 2.0.1+cu117
- Datasets 2.12.0
- Tokenizers 0.13.3
|
Ammok/q-FrozenLake-v1-4x4-noSlippery
|
Ammok
| 2023-09-21T10:56:08Z | 0 | 0 | null |
[
"FrozenLake-v1-4x4-no_slippery",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-09-21T10:56:04Z |
---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="Ammok/q-FrozenLake-v1-4x4-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
linoyts/huggy-lora-sdxl-v7
|
linoyts
| 2023-09-21T10:54:14Z | 227 | 0 |
diffusers
|
[
"diffusers",
"text-to-image",
"stable-diffusion",
"lora",
"base_model:stabilityai/stable-diffusion-xl-base-1.0",
"base_model:adapter:stabilityai/stable-diffusion-xl-base-1.0",
"license:creativeml-openrail-m",
"region:us"
] |
text-to-image
| 2023-09-21T10:53:59Z |
---
license: creativeml-openrail-m
tags:
- text-to-image
- stable-diffusion
- lora
- diffusers
base_model: stabilityai/stable-diffusion-xl-base-1.0
pivotal_tuning: true
textual_embeddings: embeddings.pti
instance_prompt: <s0><s1>
inference: false
---
# huggy-lora-sdxl-v7 LoRA by [linoytsaban](https://replicate.com/linoytsaban)
### caption prefix: a TOK emoji, steps: 1500, lr: 2e-4

>
## Inference with Replicate API
Grab your replicate token [here](https://replicate.com/account)
```bash
pip install replicate
export REPLICATE_API_TOKEN=r8_*************************************
```
```py
import replicate
output = replicate.run(
"linoy_lora@sha256:6e68d04d64a29ce25df2002570d535b6582310304dd4360f15517c95f89033a7",
input={"prompt": "a hugging face emoji in the style of TOK, dressed as yoda"}
)
print(output)
```
You may also do inference via the API with Node.js or curl, and locally with COG and Docker, [check out the Replicate API page for this model](https://replicate.com/linoytsaban/linoy_lora/api)
## Inference with 🧨 diffusers
Replicate SDXL LoRAs are trained with Pivotal Tuning, which combines training a concept via Dreambooth LoRA with training a new token with Textual Inversion.
As `diffusers` doesn't yet support textual inversion for SDXL, we will use cog-sdxl `TokenEmbeddingsHandler` class.
The trigger tokens for your prompt will be `<s0><s1>`
```shell
pip install diffusers transformers accelerate safetensors huggingface_hub
git clone https://github.com/replicate/cog-sdxl cog_sdxl
```
```py
import torch
from huggingface_hub import hf_hub_download
from diffusers import DiffusionPipeline
from cog_sdxl.dataset_and_utils import TokenEmbeddingsHandler
from diffusers.models import AutoencoderKL
pipe = DiffusionPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0",
torch_dtype=torch.float16,
variant="fp16",
).to("cuda")
pipe.load_lora_weights("LinoyTsaban/huggy-lora-sdxl-v7", weight_name="lora.safetensors")
text_encoders = [pipe.text_encoder, pipe.text_encoder_2]
tokenizers = [pipe.tokenizer, pipe.tokenizer_2]
embedding_path = hf_hub_download(repo_id="LinoyTsaban/huggy-lora-sdxl-v7", filename="embeddings.pti", repo_type="model")
embhandler = TokenEmbeddingsHandler(text_encoders, tokenizers)
embhandler.load_embeddings(embedding_path)
prompt="a hugging face emoji in the style of <s0><s1>, dressed as yoda"
images = pipe(
prompt,
cross_attention_kwargs={"scale": 0.8},
).images
#your output image
images[0]
```
|
bavolesy/dqn-SpaceInvaders
|
bavolesy
| 2023-09-21T10:54:05Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"SpaceInvadersNoFrameskip-v4",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-09-21T10:53:24Z |
---
library_name: stable-baselines3
tags:
- SpaceInvadersNoFrameskip-v4
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: DQN
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: SpaceInvadersNoFrameskip-v4
type: SpaceInvadersNoFrameskip-v4
metrics:
- type: mean_reward
value: 584.50 +/- 81.75
name: mean_reward
verified: false
---
# **DQN** Agent playing **SpaceInvadersNoFrameskip-v4**
This is a trained model of a **DQN** agent playing **SpaceInvadersNoFrameskip-v4**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3)
and the [RL Zoo](https://github.com/DLR-RM/rl-baselines3-zoo).
The RL Zoo is a training framework for Stable Baselines3
reinforcement learning agents,
with hyperparameter optimization and pre-trained agents included.
## Usage (with SB3 RL Zoo)
RL Zoo: https://github.com/DLR-RM/rl-baselines3-zoo<br/>
SB3: https://github.com/DLR-RM/stable-baselines3<br/>
SB3 Contrib: https://github.com/Stable-Baselines-Team/stable-baselines3-contrib
Install the RL Zoo (with SB3 and SB3-Contrib):
```bash
pip install rl_zoo3
```
```
# Download model and save it into the logs/ folder
python -m rl_zoo3.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga bavolesy -f logs/
python -m rl_zoo3.enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
If you installed the RL Zoo3 via pip (`pip install rl_zoo3`), from anywhere you can do:
```
python -m rl_zoo3.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga bavolesy -f logs/
python -m rl_zoo3.enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
## Training (with the RL Zoo)
```
python -m rl_zoo3.train --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
# Upload the model and generate video (when possible)
python -m rl_zoo3.push_to_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/ -orga bavolesy
```
## Hyperparameters
```python
OrderedDict([('batch_size', 32),
('buffer_size', 100000),
('env_wrapper',
['stable_baselines3.common.atari_wrappers.AtariWrapper']),
('exploration_final_eps', 0.01),
('exploration_fraction', 0.1),
('frame_stack', 4),
('gradient_steps', 1),
('learning_rate', 0.0001),
('learning_starts', 100000),
('n_timesteps', 1000000.0),
('optimize_memory_usage', False),
('policy', 'CnnPolicy'),
('target_update_interval', 1000),
('train_freq', 4),
('normalize', False)])
```
# Environment Arguments
```python
{'render_mode': 'rgb_array'}
```
|
Philu/my_awesome_model
|
Philu
| 2023-09-21T10:52:42Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"distilbert",
"text-classification",
"generated_from_trainer",
"dataset:imdb",
"base_model:distilbert/distilbert-base-uncased",
"base_model:finetune:distilbert/distilbert-base-uncased",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-09-21T03:28:30Z |
---
license: apache-2.0
base_model: distilbert-base-uncased
tags:
- generated_from_trainer
datasets:
- imdb
metrics:
- accuracy
model-index:
- name: my_awesome_model
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: imdb
type: imdb
config: plain_text
split: test
args: plain_text
metrics:
- name: Accuracy
type: accuracy
value: 0.93132
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# my_awesome_model
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the imdb dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2311
- Accuracy: 0.9313
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.22 | 1.0 | 1563 | 0.2927 | 0.8989 |
| 0.1521 | 2.0 | 3126 | 0.2311 | 0.9313 |
### Framework versions
- Transformers 4.33.2
- Pytorch 2.2.0.dev20230916+cu121
- Datasets 2.14.5
- Tokenizers 0.13.3
|
zamankh/my_awesome_mind_model
|
zamankh
| 2023-09-21T10:49:14Z | 160 | 0 |
transformers
|
[
"transformers",
"pytorch",
"wav2vec2",
"audio-classification",
"generated_from_trainer",
"dataset:minds14",
"base_model:facebook/wav2vec2-base",
"base_model:finetune:facebook/wav2vec2-base",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] |
audio-classification
| 2023-09-21T10:44:31Z |
---
license: apache-2.0
base_model: facebook/wav2vec2-base
tags:
- generated_from_trainer
datasets:
- minds14
metrics:
- accuracy
model-index:
- name: my_awesome_mind_model
results:
- task:
name: Audio Classification
type: audio-classification
dataset:
name: minds14
type: minds14
config: en-US
split: train
args: en-US
metrics:
- name: Accuracy
type: accuracy
value: 0.05309734513274336
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# my_awesome_mind_model
This model is a fine-tuned version of [facebook/wav2vec2-base](https://huggingface.co/facebook/wav2vec2-base) on the minds14 dataset.
It achieves the following results on the evaluation set:
- Loss: 2.6510
- Accuracy: 0.0531
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| No log | 0.8 | 3 | 2.6492 | 0.0442 |
| No log | 1.87 | 7 | 2.6548 | 0.0531 |
| 2.6331 | 2.93 | 11 | 2.6597 | 0.0708 |
| 2.6331 | 4.0 | 15 | 2.6611 | 0.0531 |
| 2.6331 | 4.8 | 18 | 2.6578 | 0.0531 |
| 2.6244 | 5.87 | 22 | 2.6493 | 0.0619 |
| 2.6244 | 6.93 | 26 | 2.6509 | 0.0619 |
| 2.6149 | 8.0 | 30 | 2.6510 | 0.0531 |
### Framework versions
- Transformers 4.33.2
- Pytorch 2.0.1+cu117
- Datasets 2.14.5
- Tokenizers 0.13.3
|
Ashkalon/gpt2-wikitext2
|
Ashkalon
| 2023-09-21T10:46:47Z | 200 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"generated_from_trainer",
"base_model:openai-community/gpt2",
"base_model:finetune:openai-community/gpt2",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-09-21T09:57:34Z |
---
license: mit
base_model: gpt2
tags:
- generated_from_trainer
model-index:
- name: gpt2-wikitext2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# gpt2-wikitext2
This model is a fine-tuned version of [gpt2](https://huggingface.co/gpt2) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 6.1123
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 6.5492 | 1.0 | 2249 | 6.4764 |
| 6.1917 | 2.0 | 4498 | 6.2002 |
| 6.0136 | 3.0 | 6747 | 6.1123 |
### Framework versions
- Transformers 4.33.2
- Pytorch 2.0.1+cu118
- Datasets 2.14.5
- Tokenizers 0.13.3
|
ShivamMangale/XLM-Roberta-base-all_hi_weakdap_1st_iteration_d1
|
ShivamMangale
| 2023-09-21T10:46:38Z | 116 | 0 |
transformers
|
[
"transformers",
"pytorch",
"xlm-roberta",
"question-answering",
"generated_from_trainer",
"dataset:squad",
"base_model:FacebookAI/xlm-roberta-base",
"base_model:finetune:FacebookAI/xlm-roberta-base",
"license:mit",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2023-09-21T07:18:01Z |
---
license: mit
base_model: xlm-roberta-base
tags:
- generated_from_trainer
datasets:
- squad
model-index:
- name: XLM-Roberta-base-all_hi_weakdap_1st_iteration_d1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# XLM-Roberta-base-all_hi_weakdap_1st_iteration_d1
This model is a fine-tuned version of [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) on the squad dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 8
### Training results
### Framework versions
- Transformers 4.33.2
- Pytorch 2.0.1+cu117
- Datasets 2.14.5
- Tokenizers 0.13.3
|
chendelong/ChatGLM-PSP
|
chendelong
| 2023-09-21T10:37:11Z | 104 | 0 |
transformers
|
[
"transformers",
"pytorch",
"chatglm",
"feature-extraction",
"custom_code",
"arxiv:2309.11000",
"region:us"
] |
feature-extraction
| 2023-09-19T04:14:39Z |
<div align="center">
🎙 [**Towards Joint Modeling of Dialogue Response and Speech Synthesis based on Large Language Model**](https://huggingface.co/papers/2309.11000)
[Xinyu Zhou (周欣宇)](https://www.linkedin.com/in/xinyu-zhou2000/), [Delong Chen (陈德龙)](https://chendelong.world/), [Yudong Chen (陈玉东)](https://rwxy.cuc.edu.cn/2019/0730/c5134a133504/pagem.htm)
[ArXiv](https://arxiv.org/abs/2309.11000) | [Poster](doc/YFRSW_Poster.pdf) | [Notebook](prosody_prediction.ipynb) | [Github](https://github.com/XinyuZhou2000/Spoken-Dialogue)
</div>
This project explores the potential of constructing an AI spoken dialogue system that *"thinks how to respond"* and *"thinks how to speak"* simultaneously, which more closely aligns with the human speech production process compared to the current cascade pipeline of independent chatbot and Text-to-Speech (TTS) modules.
We hypothesize that *Large Language Models (LLMs)* with billions of parameters possess significant speech understanding capabilities and can jointly model dialogue responses and linguistic features. We investigate the task of Prosodic structure prediction (PSP), a typical front-end task in TTS, demonstrating the speech understanding ability of LLMs.
|
reeen115/lora_output
|
reeen115
| 2023-09-21T10:36:45Z | 0 | 0 |
diffusers
|
[
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"lora",
"base_model:stabilityai/stable-diffusion-2-1",
"base_model:adapter:stabilityai/stable-diffusion-2-1",
"license:creativeml-openrail-m",
"region:us"
] |
text-to-image
| 2023-09-20T08:39:18Z |
---
license: creativeml-openrail-m
base_model: stabilityai/stable-diffusion-2-1
instance_prompt: cardboards, grayscale
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
- lora
inference: true
---
# LoRA DreamBooth - reeen115/lora_output
These are LoRA adaption weights for stabilityai/stable-diffusion-2-1. The weights were trained on cardboards, grayscale using [DreamBooth](https://dreambooth.github.io/). You can find some example images in the following.
LoRA for the text encoder was enabled: False.
|
OpenDILabCommunity/Hopper-v3-SAC
|
OpenDILabCommunity
| 2023-09-21T10:31:12Z | 0 | 0 |
pytorch
|
[
"pytorch",
"deep-reinforcement-learning",
"reinforcement-learning",
"DI-engine",
"Hopper-v3",
"en",
"license:apache-2.0",
"region:us"
] |
reinforcement-learning
| 2023-04-14T08:16:42Z |
---
language: en
license: apache-2.0
library_name: pytorch
tags:
- deep-reinforcement-learning
- reinforcement-learning
- DI-engine
- Hopper-v3
benchmark_name: OpenAI/Gym/MuJoCo
task_name: Hopper-v3
pipeline_tag: reinforcement-learning
model-index:
- name: SAC
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: OpenAI/Gym/MuJoCo-Hopper-v3
type: OpenAI/Gym/MuJoCo-Hopper-v3
metrics:
- type: mean_reward
value: 3899.4 +/- 362.09
name: mean_reward
---
# Play **Hopper-v3** with **SAC** Policy
## Model Description
<!-- Provide a longer summary of what this model is. -->
This is a simple **SAC** implementation to OpenAI/Gym/MuJoCo **Hopper-v3** using the [DI-engine library](https://github.com/opendilab/di-engine) and the [DI-zoo](https://github.com/opendilab/DI-engine/tree/main/dizoo).
**DI-engine** is a python library for solving general decision intelligence problems, which is based on implementations of reinforcement learning framework using PyTorch or JAX. This library aims to standardize the reinforcement learning framework across different algorithms, benchmarks, environments, and to support both academic researches and prototype applications. Besides, self-customized training pipelines and applications are supported by reusing different abstraction levels of DI-engine reinforcement learning framework.
## Model Usage
### Install the Dependencies
<details close>
<summary>(Click for Details)</summary>
```shell
# install huggingface_ding
git clone https://github.com/opendilab/huggingface_ding.git
pip3 install -e ./huggingface_ding/
# install environment dependencies if needed
sudo apt update -y && sudo apt install -y build-essential libgl1-mesa-dev libgl1-mesa-glx libglew-dev libosmesa6-dev libglfw3 libglfw3-dev libsdl2-dev libsdl2-image-dev libglm-dev libfreetype6-dev patchelf
mkdir -p ~/.mujoco
wget https://mujoco.org/download/mujoco210-linux-x86_64.tar.gz -O mujoco.tar.gz
tar -xf mujoco.tar.gz -C ~/.mujoco
echo "export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:~/.mujoco/mjpro210/bin:~/.mujoco/mujoco210/bin" >> ~/.bashrc
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:~/.mujoco/mjpro210/bin:~/.mujoco/mujoco210/bin
pip3 install "cython<3"
pip3 install DI-engine[common_env]
```
</details>
### Git Clone from Huggingface and Run the Model
<details close>
<summary>(Click for Details)</summary>
```shell
# running with trained model
python3 -u run.py
```
**run.py**
```python
from ding.bonus import SACAgent
from ding.config import Config
from easydict import EasyDict
import torch
# Pull model from files which are git cloned from huggingface
policy_state_dict = torch.load("pytorch_model.bin", map_location=torch.device("cpu"))
cfg = EasyDict(Config.file_to_dict("policy_config.py").cfg_dict)
# Instantiate the agent
agent = SACAgent(env_id="Hopper-v3", exp_name="Hopper-v3-SAC", cfg=cfg.exp_config, policy_state_dict=policy_state_dict)
# Continue training
agent.train(step=5000)
# Render the new agent performance
agent.deploy(enable_save_replay=True)
```
</details>
### Run Model by Using Huggingface_ding
<details close>
<summary>(Click for Details)</summary>
```shell
# running with trained model
python3 -u run.py
```
**run.py**
```python
from ding.bonus import SACAgent
from huggingface_ding import pull_model_from_hub
# Pull model from Hugggingface hub
policy_state_dict, cfg = pull_model_from_hub(repo_id="OpenDILabCommunity/Hopper-v3-SAC")
# Instantiate the agent
agent = SACAgent(env_id="Hopper-v3", exp_name="Hopper-v3-SAC", cfg=cfg.exp_config, policy_state_dict=policy_state_dict)
# Continue training
agent.train(step=5000)
# Render the new agent performance
agent.deploy(enable_save_replay=True)
```
</details>
## Model Training
### Train the Model and Push to Huggingface_hub
<details close>
<summary>(Click for Details)</summary>
```shell
#Training Your Own Agent
python3 -u train.py
```
**train.py**
```python
from ding.bonus import SACAgent
from huggingface_ding import push_model_to_hub
# Instantiate the agent
agent = SACAgent(env_id="Hopper-v3", exp_name="Hopper-v3-SAC")
# Train the agent
return_ = agent.train(step=int(10000000), collector_env_num=4, evaluator_env_num=4, debug=False)
# Push model to huggingface hub
push_model_to_hub(
agent=agent.best,
env_name="OpenAI/Gym/MuJoCo",
task_name="Hopper-v3",
algo_name="SAC",
wandb_url=return_.wandb_url,
github_repo_url="https://github.com/opendilab/DI-engine",
github_doc_model_url="https://di-engine-docs.readthedocs.io/en/latest/12_policies/sac.html",
github_doc_env_url="https://di-engine-docs.readthedocs.io/en/latest/13_envs/mujoco.html",
installation_guide='''
sudo apt update -y \
&& sudo apt install -y \
build-essential \
libgl1-mesa-dev \
libgl1-mesa-glx \
libglew-dev \
libosmesa6-dev \
libglfw3 \
libglfw3-dev \
libsdl2-dev \
libsdl2-image-dev \
libglm-dev \
libfreetype6-dev \
patchelf
mkdir -p ~/.mujoco
wget https://mujoco.org/download/mujoco210-linux-x86_64.tar.gz -O mujoco.tar.gz
tar -xf mujoco.tar.gz -C ~/.mujoco
echo "export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:~/.mujoco/mjpro210/bin:~/.mujoco/mujoco210/bin" >> ~/.bashrc
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:~/.mujoco/mjpro210/bin:~/.mujoco/mujoco210/bin
pip3 install "cython<3"
pip3 install DI-engine[common_env]
''',
usage_file_by_git_clone="./sac/hopper_sac_deploy.py",
usage_file_by_huggingface_ding="./sac/hopper_sac_download.py",
train_file="./sac/hopper_sac.py",
repo_id="OpenDILabCommunity/Hopper-v3-SAC",
create_repo=False
)
```
</details>
**Configuration**
<details close>
<summary>(Click for Details)</summary>
```python
exp_config = {
'env': {
'manager': {
'episode_num': float("inf"),
'max_retry': 1,
'retry_type': 'reset',
'auto_reset': True,
'step_timeout': None,
'reset_timeout': None,
'retry_waiting_time': 0.1,
'cfg_type': 'BaseEnvManagerDict'
},
'stop_value': 6000,
'n_evaluator_episode': 8,
'env_id': 'Hopper-v3',
'collector_env_num': 8,
'evaluator_env_num': 8,
'env_wrapper': 'mujoco_default'
},
'policy': {
'model': {
'twin_critic': True,
'action_space': 'reparameterization',
'obs_shape': 11,
'action_shape': 3,
'actor_head_hidden_size': 256,
'critic_head_hidden_size': 256
},
'learn': {
'learner': {
'train_iterations': 1000000000,
'dataloader': {
'num_workers': 0
},
'log_policy': True,
'hook': {
'load_ckpt_before_run': '',
'log_show_after_iter': 100,
'save_ckpt_after_iter': 10000,
'save_ckpt_after_run': True
},
'cfg_type': 'BaseLearnerDict'
},
'update_per_collect': 1,
'batch_size': 256,
'learning_rate_q': 0.001,
'learning_rate_policy': 0.001,
'learning_rate_alpha': 0.0003,
'target_theta': 0.005,
'discount_factor': 0.99,
'alpha': 0.2,
'auto_alpha': False,
'log_space': True,
'target_entropy': None,
'ignore_done': False,
'init_w': 0.003,
'reparameterization': True
},
'collect': {
'collector': {},
'n_sample': 1,
'unroll_len': 1,
'collector_logit': False
},
'eval': {
'evaluator': {
'eval_freq': 1000,
'render': {
'render_freq': -1,
'mode': 'train_iter'
},
'figure_path': None,
'cfg_type': 'InteractionSerialEvaluatorDict',
'stop_value': 6000,
'n_episode': 8
}
},
'other': {
'replay_buffer': {
'replay_buffer_size': 1000000
}
},
'on_policy': False,
'cuda': True,
'multi_gpu': False,
'bp_update_sync': True,
'traj_len_inf': False,
'type': 'sac',
'priority': False,
'priority_IS_weight': False,
'random_collect_size': 10000,
'transition_with_policy_data': True,
'multi_agent': False,
'cfg_type': 'SACPolicyDict'
},
'exp_name': 'Hopper-v3-SAC',
'seed': 0,
'wandb_logger': {
'gradient_logger': True,
'video_logger': True,
'plot_logger': True,
'action_logger': True,
'return_logger': False
}
}
```
</details>
**Training Procedure**
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
- **Weights & Biases (wandb):** [monitor link](https://wandb.ai/zjowowen/Hopper-v3-SAC)
## Model Information
<!-- Provide the basic links for the model. -->
- **Github Repository:** [repo link](https://github.com/opendilab/DI-engine)
- **Doc**: [DI-engine-docs Algorithm link](https://di-engine-docs.readthedocs.io/en/latest/12_policies/sac.html)
- **Configuration:** [config link](https://huggingface.co/OpenDILabCommunity/Hopper-v3-SAC/blob/main/policy_config.py)
- **Demo:** [video](https://huggingface.co/OpenDILabCommunity/Hopper-v3-SAC/blob/main/replay.mp4)
<!-- Provide the size information for the model. -->
- **Parameters total size:** 1642.06 KB
- **Last Update Date:** 2023-09-21
## Environments
<!-- Address questions around what environment the model is intended to be trained and deployed at, including the necessary information needed to be provided for future users. -->
- **Benchmark:** OpenAI/Gym/MuJoCo
- **Task:** Hopper-v3
- **Gym version:** 0.25.1
- **DI-engine version:** v0.4.9
- **PyTorch version:** 2.0.1+cu117
- **Doc**: [DI-engine-docs Environments link](https://di-engine-docs.readthedocs.io/en/latest/13_envs/mujoco.html)
|
Wariano/bsc-bio-ehr-es-vih-10k
|
Wariano
| 2023-09-21T10:24:33Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"roberta",
"text-classification",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-09-21T10:09:24Z |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- accuracy
- precision
- recall
- f1
model-index:
- name: bsc-bio-ehr-es-vih-10k
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bsc-bio-ehr-es-vih-10k
This model is a fine-tuned version of [PlanTL-GOB-ES/bsc-bio-ehr-es](https://huggingface.co/PlanTL-GOB-ES/bsc-bio-ehr-es) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.9958
- Positives Preds: 598
- Negative Preds: 402
- Positives Refs: 500
- Negative Refs: 500
- Tp: 411
- Fn: 89
- Fp: 187
- Tn: 313
- Accuracy: 0.724
- Precision: 0.6873
- Recall: 0.822
- F1: 0.7486
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Positives Preds | Negative Preds | Positives Refs | Negative Refs | Tp | Fn | Fp | Tn | Accuracy | Precision | Recall | F1 |
|:-------------:|:-----:|:----:|:---------------:|:---------------:|:--------------:|:--------------:|:-------------:|:---:|:---:|:---:|:---:|:--------:|:---------:|:------:|:------:|
| 0.4309 | 1.0 | 250 | 0.4999 | 384 | 616 | 500 | 500 | 316 | 184 | 68 | 432 | 0.748 | 0.8229 | 0.632 | 0.7149 |
| 0.2849 | 2.0 | 500 | 0.6391 | 546 | 454 | 500 | 500 | 396 | 104 | 150 | 350 | 0.746 | 0.7253 | 0.792 | 0.7572 |
| 0.1931 | 3.0 | 750 | 0.7333 | 610 | 390 | 500 | 500 | 414 | 86 | 196 | 304 | 0.718 | 0.6787 | 0.828 | 0.7459 |
| 0.1255 | 4.0 | 1000 | 0.8917 | 604 | 396 | 500 | 500 | 417 | 83 | 187 | 313 | 0.73 | 0.6904 | 0.834 | 0.7554 |
| 0.0918 | 5.0 | 1250 | 0.9958 | 598 | 402 | 500 | 500 | 411 | 89 | 187 | 313 | 0.724 | 0.6873 | 0.822 | 0.7486 |
### Framework versions
- Transformers 4.30.2
- Pytorch 2.0.1+cu117
- Datasets 2.13.1
- Tokenizers 0.13.3
|
spinettico/distilbert-base-uncased-finetuned-emotion
|
spinettico
| 2023-09-21T10:23:49Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"distilbert",
"text-classification",
"generated_from_trainer",
"dataset:emotion",
"base_model:distilbert/distilbert-base-uncased",
"base_model:finetune:distilbert/distilbert-base-uncased",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-09-21T09:59:50Z |
---
license: apache-2.0
base_model: distilbert-base-uncased
tags:
- generated_from_trainer
datasets:
- emotion
metrics:
- accuracy
- f1
model-index:
- name: distilbert-base-uncased-finetuned-emotion
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: emotion
type: emotion
config: split
split: validation
args: split
metrics:
- name: Accuracy
type: accuracy
value: 0.9355
- name: F1
type: f1
value: 0.9360354549963134
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-emotion
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the emotion dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1539
- Accuracy: 0.9355
- F1: 0.9360
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 0.1699 | 1.0 | 250 | 0.1676 | 0.9325 | 0.9335 |
| 0.1108 | 2.0 | 500 | 0.1539 | 0.9355 | 0.9360 |
### Framework versions
- Transformers 4.33.2
- Pytorch 2.0.1+cu118
- Datasets 2.14.5
- Tokenizers 0.13.3
|
BadWolfOnHF/gpt_2_finetuned_med
|
BadWolfOnHF
| 2023-09-21T10:22:42Z | 1 | 0 |
peft
|
[
"peft",
"region:us"
] | null | 2023-09-21T09:47:33Z |
---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: True
- bnb_4bit_compute_dtype: float16
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: True
- bnb_4bit_compute_dtype: float16
### Framework versions
- PEFT 0.5.0
- PEFT 0.5.0
|
ghost9023/DEEPNOID-llama2-7b-PoC-Only
|
ghost9023
| 2023-09-21T10:16:48Z | 6 | 0 |
peft
|
[
"peft",
"region:us"
] | null | 2023-09-21T02:26:54Z |
---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: True
- bnb_4bit_compute_dtype: bfloat16
### Framework versions
- PEFT 0.5.0
|
yummyslimerfahrungen/yummyslimerfahrungen
|
yummyslimerfahrungen
| 2023-09-21T10:15:44Z | 0 | 0 |
diffusers
|
[
"diffusers",
"Yummy Slim Erfahrungen",
"en",
"license:bsd-2-clause",
"region:us"
] | null | 2023-09-21T10:14:36Z |
---
license: bsd-2-clause
language:
- en
library_name: diffusers
tags:
- Yummy Slim Erfahrungen
---
[Yummy Slim Erfahrungen](https://supplementtycoon.com/de/yummy-slim-erfahrungen/) They frequently contain fixings like gelatin, water, normal flavors, and keto-accommodating sugars like erythritol or stevia.Keto gummies are typically enhanced and come in different shapes and sizes, like standard sticky confections. They can be a helpful and charming method for fulfilling a sweet tooth while adhering to a ketogenic diet. Notwithstanding, it's vital to take note of that despite the fact that they are low in carbs and sugar, they ought to in any case be consumed with some restraint as a feature of a fair diet.As forever, it's prescribed to peruse the nourishment marks and fixings list cautiously prior to buying any keto gummies to guarantee they line up with your dietary objectives and inclinations.
VISIT HERE FOR OFFICIAL WEBSITE:-https://supplementtycoon.com/de/yummy-slim-erfahrungen/
|
yejeekang/qlora-koalpaca-polyglot-12.8b-50step
|
yejeekang
| 2023-09-21T10:15:07Z | 1 | 0 |
peft
|
[
"peft",
"region:us"
] | null | 2023-09-20T05:03:58Z |
---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: True
- bnb_4bit_compute_dtype: bfloat16
### Framework versions
- PEFT 0.6.0.dev0
|
ditobagus/image_classification
|
ditobagus
| 2023-09-21T10:13:26Z | 196 | 0 |
transformers
|
[
"transformers",
"pytorch",
"vit",
"image-classification",
"generated_from_trainer",
"base_model:google/vit-base-patch16-224-in21k",
"base_model:finetune:google/vit-base-patch16-224-in21k",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2023-09-12T09:55:32Z |
---
license: apache-2.0
base_model: google/vit-base-patch16-224-in21k
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: image_classification
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# image_classification
This model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 4.6845
- Accuracy: 0.0626
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.6177 | 1.0 | 788 | 4.5441 | 0.0572 |
| 0.6328 | 2.0 | 1576 | 4.6145 | 0.0628 |
| 0.5851 | 3.0 | 2364 | 4.6799 | 0.0648 |
### Framework versions
- Transformers 4.33.2
- Pytorch 2.0.1+cu118
- Datasets 2.14.5
- Tokenizers 0.13.3
|
Subsets and Splits
Filtered Qwen2.5 Distill Models
Identifies specific configurations of models by filtering cards that contain 'distill', 'qwen2.5', '7b' while excluding certain base models and incorrect model ID patterns, uncovering unique model variants.
Filtered Model Cards Count
Finds the count of entries with specific card details that include 'distill', 'qwen2.5', '7b' but exclude certain base models, revealing valuable insights about the dataset's content distribution.
Filtered Distill Qwen 7B Models
Filters for specific card entries containing 'distill', 'qwen', and '7b', excluding certain strings and patterns, to identify relevant model configurations.
Filtered Qwen-7b Model Cards
The query performs a detailed filtering based on specific keywords and excludes certain entries, which could be useful for identifying a specific subset of cards but does not provide deeper insights or trends.
Filtered Qwen 7B Model Cards
The query filters for specific terms related to "distilled" or "distill", "qwen", and "7b" in the 'card' column but excludes certain base models, providing a limited set of entries for further inspection.
Qwen 7B Distilled Models
The query provides a basic filtering of records to find specific card names that include keywords related to distilled Qwen 7b models, excluding a particular base model, which gives limited insight but helps in focusing on relevant entries.
Qwen 7B Distilled Model Cards
The query filters data based on specific keywords in the modelId and card fields, providing limited insight primarily useful for locating specific entries rather than revealing broad patterns or trends.
Qwen 7B Distilled Models
Finds all entries containing the terms 'distilled', 'qwen', and '7b' in a case-insensitive manner, providing a filtered set of records but without deeper analysis.
Distilled Qwen 7B Models
The query filters for specific model IDs containing 'distilled', 'qwen', and '7b', providing a basic retrieval of relevant entries but without deeper analysis or insight.
Filtered Model Cards with Distill Qwen2.
Filters and retrieves records containing specific keywords in the card description while excluding certain phrases, providing a basic count of relevant entries.
Filtered Model Cards with Distill Qwen 7
The query filters specific variations of card descriptions containing 'distill', 'qwen', and '7b' while excluding a particular base model, providing limited but specific data retrieval.
Distill Qwen 7B Model Cards
The query filters and retrieves rows where the 'card' column contains specific keywords ('distill', 'qwen', and '7b'), providing a basic filter result that can help in identifying specific entries.