
modelId
stringlengths 5
139
| author
stringlengths 2
42
| last_modified
timestamp[us, tz=UTC]date 2020-02-15 11:33:14
2025-08-29 06:27:22
| downloads
int64 0
223M
| likes
int64 0
11.7k
| library_name
stringclasses 525
values | tags
listlengths 1
4.05k
| pipeline_tag
stringclasses 55
values | createdAt
timestamp[us, tz=UTC]date 2022-03-02 23:29:04
2025-08-29 06:27:10
| card
stringlengths 11
1.01M
|
|---|---|---|---|---|---|---|---|---|---|
VinEuro/LunarLanderv2
|
VinEuro
| 2023-07-27T21:48:06Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-07-27T21:47:47Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 270.95 +/- 23.64
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
NasimB/aochildes-cbt-log-rarity
|
NasimB
| 2023-07-27T21:46:57Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"generated_from_trainer",
"dataset:generator",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-07-27T19:38:45Z |
---
license: mit
tags:
- generated_from_trainer
datasets:
- generator
model-index:
- name: aochildes-cbt-log-rarity
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# aochildes-cbt-log-rarity
This model is a fine-tuned version of [gpt2](https://huggingface.co/gpt2) on the generator dataset.
It achieves the following results on the evaluation set:
- Loss: 4.1483
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 1000
- num_epochs: 6
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-----:|:---------------:|
| 6.3649 | 0.29 | 500 | 5.3433 |
| 5.0506 | 0.59 | 1000 | 4.9337 |
| 4.7079 | 0.88 | 1500 | 4.6957 |
| 4.4512 | 1.17 | 2000 | 4.5593 |
| 4.3031 | 1.47 | 2500 | 4.4458 |
| 4.2085 | 1.76 | 3000 | 4.3418 |
| 4.0809 | 2.05 | 3500 | 4.2739 |
| 3.9047 | 2.35 | 4000 | 4.2277 |
| 3.8846 | 2.64 | 4500 | 4.1774 |
| 3.8392 | 2.93 | 5000 | 4.1313 |
| 3.6392 | 3.23 | 5500 | 4.1305 |
| 3.6016 | 3.52 | 6000 | 4.1020 |
| 3.5828 | 3.81 | 6500 | 4.0709 |
| 3.4733 | 4.11 | 7000 | 4.0797 |
| 3.3271 | 4.4 | 7500 | 4.0758 |
| 3.3228 | 4.69 | 8000 | 4.0635 |
| 3.3147 | 4.99 | 8500 | 4.0528 |
| 3.154 | 5.28 | 9000 | 4.0692 |
| 3.1461 | 5.58 | 9500 | 4.0692 |
| 3.1416 | 5.87 | 10000 | 4.0684 |
### Framework versions
- Transformers 4.26.1
- Pytorch 1.11.0+cu113
- Datasets 2.13.0
- Tokenizers 0.13.3
|
jariasn/q-Taxi-v3
|
jariasn
| 2023-07-27T21:32:51Z | 0 | 0 | null |
[
"Taxi-v3",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-07-27T21:32:49Z |
---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-Taxi-v3
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
metrics:
- type: mean_reward
value: 7.56 +/- 2.71
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="jariasn/q-Taxi-v3", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
shivarama23/llama_v2_finetuned_redaction
|
shivarama23
| 2023-07-27T21:18:42Z | 2 | 0 |
peft
|
[
"peft",
"pytorch",
"region:us"
] | null | 2023-07-27T21:17:43Z |
---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float16
The following `bitsandbytes` quantization config was used during training:
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float16
### Framework versions
- PEFT 0.4.0
- PEFT 0.4.0
|
Kertn/ppo-Huggy
|
Kertn
| 2023-07-27T21:14:55Z | 0 | 0 |
ml-agents
|
[
"ml-agents",
"tensorboard",
"onnx",
"Huggy",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-Huggy",
"region:us"
] |
reinforcement-learning
| 2023-07-27T21:14:45Z |
---
library_name: ml-agents
tags:
- Huggy
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-Huggy
---
# **ppo** Agent playing **Huggy**
This is a trained model of a **ppo** agent playing **Huggy**
using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://unity-technologies.github.io/ml-agents/ML-Agents-Toolkit-Documentation/
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
- A *short tutorial* where you teach Huggy the Dog 🐶 to fetch the stick and then play with him directly in your
browser: https://huggingface.co/learn/deep-rl-course/unitbonus1/introduction
- A *longer tutorial* to understand how works ML-Agents:
https://huggingface.co/learn/deep-rl-course/unit5/introduction
### Resume the training
```bash
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser**
1. If the environment is part of ML-Agents official environments, go to https://huggingface.co/unity
2. Step 1: Find your model_id: Kertn/ppo-Huggy
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
jariasn/q-FrozenLake-v1-4x4-noSlippery
|
jariasn
| 2023-07-27T20:58:10Z | 0 | 0 | null |
[
"FrozenLake-v1-4x4-no_slippery",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-07-27T20:58:08Z |
---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="jariasn/q-FrozenLake-v1-4x4-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
YoonSeul/LawBot-5.8B
|
YoonSeul
| 2023-07-27T20:40:46Z | 4 | 0 |
peft
|
[
"peft",
"region:us"
] | null | 2023-07-26T07:47:12Z |
---
library_name: peft
---
<img src=https://github.com/taemin6697/Paper_Review/assets/96530685/54ecd6cf-8695-4caa-bdc8-fb85c9b7d70d style="max-width: 700px; width: 100%" />
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: True
- bnb_4bit_compute_dtype: bfloat16
### Framework versions
- PEFT 0.4.0.dev0
|
chh6/ppo-SnowballTarget
|
chh6
| 2023-07-27T20:21:44Z | 4 | 0 |
ml-agents
|
[
"ml-agents",
"tensorboard",
"onnx",
"SnowballTarget",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-SnowballTarget",
"region:us"
] |
reinforcement-learning
| 2023-07-27T18:55:02Z |
---
library_name: ml-agents
tags:
- SnowballTarget
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-SnowballTarget
---
# **ppo** Agent playing **SnowballTarget**
This is a trained model of a **ppo** agent playing **SnowballTarget**
using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://unity-technologies.github.io/ml-agents/ML-Agents-Toolkit-Documentation/
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
- A *short tutorial* where you teach Huggy the Dog 🐶 to fetch the stick and then play with him directly in your
browser: https://huggingface.co/learn/deep-rl-course/unitbonus1/introduction
- A *longer tutorial* to understand how works ML-Agents:
https://huggingface.co/learn/deep-rl-course/unit5/introduction
### Resume the training
```bash
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser**
1. If the environment is part of ML-Agents official environments, go to https://huggingface.co/unity
2. Step 1: Find your model_id: chh6/ppo-SnowballTarget
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
truehealth/LLama-2-MedText-Delta
|
truehealth
| 2023-07-27T20:21:44Z | 0 | 0 | null |
[
"region:us"
] | null | 2023-07-27T01:19:04Z |
Trained on 13B LLama-2
---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: True
- bnb_4bit_compute_dtype: float16
### Framework versions
- PEFT 0.5.0.dev0
|
Jonathaniu/llama2-breast-cancer-13b-knowledge-epoch-8
|
Jonathaniu
| 2023-07-27T20:09:53Z | 0 | 0 |
peft
|
[
"peft",
"region:us"
] | null | 2023-07-27T20:09:32Z |
---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- load_in_8bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
### Framework versions
- PEFT 0.4.0.dev0
|
SH-W/60emotions
|
SH-W
| 2023-07-27T20:01:52Z | 107 | 0 |
transformers
|
[
"transformers",
"pytorch",
"safetensors",
"roberta",
"text-classification",
"autotrain",
"unk",
"dataset:SH-W/autotrain-data-5000_koi",
"co2_eq_emissions",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-07-27T19:55:16Z |
---
tags:
- autotrain
- text-classification
language:
- unk
widget:
- text: "I love AutoTrain"
datasets:
- SH-W/autotrain-data-5000_koi
co2_eq_emissions:
emissions: 3.920765439350259
---
# Model Trained Using AutoTrain
- Problem type: Multi-class Classification
- Model ID: 77927140735
- CO2 Emissions (in grams): 3.9208
## Validation Metrics
- Loss: 2.432
- Accuracy: 0.415
- Macro F1: 0.410
- Micro F1: 0.415
- Weighted F1: 0.410
- Macro Precision: 0.459
- Micro Precision: 0.415
- Weighted Precision: 0.456
- Macro Recall: 0.413
- Micro Recall: 0.415
- Weighted Recall: 0.415
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoTrain"}' https://api-inference.huggingface.co/models/SH-W/autotrain-5000_koi-77927140735
```
Or Python API:
```
from transformers import AutoModelForSequenceClassification, AutoTokenizer
model = AutoModelForSequenceClassification.from_pretrained("SH-W/autotrain-5000_koi-77927140735", use_auth_token=True)
tokenizer = AutoTokenizer.from_pretrained("SH-W/autotrain-5000_koi-77927140735", use_auth_token=True)
inputs = tokenizer("I love AutoTrain", return_tensors="pt")
outputs = model(**inputs)
```
|
ianvaz/llama2-qlora-finetunined-french
|
ianvaz
| 2023-07-27T20:00:58Z | 1 | 0 |
peft
|
[
"peft",
"region:us"
] | null | 2023-07-27T20:00:54Z |
---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float16
### Framework versions
- PEFT 0.5.0.dev0
|
teilomillet/poca-SoccerTwos
|
teilomillet
| 2023-07-27T19:52:37Z | 3 | 0 |
ml-agents
|
[
"ml-agents",
"tensorboard",
"onnx",
"SoccerTwos",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-SoccerTwos",
"region:us"
] |
reinforcement-learning
| 2023-07-27T19:52:21Z |
---
library_name: ml-agents
tags:
- SoccerTwos
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-SoccerTwos
---
# **poca** Agent playing **SoccerTwos**
This is a trained model of a **poca** agent playing **SoccerTwos**
using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://unity-technologies.github.io/ml-agents/ML-Agents-Toolkit-Documentation/
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
- A *short tutorial* where you teach Huggy the Dog 🐶 to fetch the stick and then play with him directly in your
browser: https://huggingface.co/learn/deep-rl-course/unitbonus1/introduction
- A *longer tutorial* to understand how works ML-Agents:
https://huggingface.co/learn/deep-rl-course/unit5/introduction
### Resume the training
```bash
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser**
1. If the environment is part of ML-Agents official environments, go to https://huggingface.co/unity
2. Step 1: Find your model_id: teilomillet/poca-SoccerTwos
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
grace-pro/three_class_5e-5_hausa
|
grace-pro
| 2023-07-27T19:48:09Z | 117 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"xlm-roberta",
"token-classification",
"generated_from_trainer",
"base_model:Davlan/afro-xlmr-base",
"base_model:finetune:Davlan/afro-xlmr-base",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2023-07-27T18:28:05Z |
---
license: mit
base_model: Davlan/afro-xlmr-base
tags:
- generated_from_trainer
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: three_class_5e-5_hausa
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# three_class_5e-5_hausa
This model is a fine-tuned version of [Davlan/afro-xlmr-base](https://huggingface.co/Davlan/afro-xlmr-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2379
- Precision: 0.2316
- Recall: 0.1636
- F1: 0.1917
- Accuracy: 0.9392
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| 0.2129 | 1.0 | 1283 | 0.2033 | 0.2278 | 0.0810 | 0.1195 | 0.9416 |
| 0.1901 | 2.0 | 2566 | 0.1988 | 0.2444 | 0.0890 | 0.1305 | 0.9429 |
| 0.1657 | 3.0 | 3849 | 0.2056 | 0.2561 | 0.1278 | 0.1705 | 0.9430 |
| 0.139 | 4.0 | 5132 | 0.2205 | 0.2269 | 0.1655 | 0.1914 | 0.9388 |
| 0.1179 | 5.0 | 6415 | 0.2379 | 0.2316 | 0.1636 | 0.1917 | 0.9392 |
### Framework versions
- Transformers 4.31.0
- Pytorch 2.0.1+cu118
- Datasets 2.14.1
- Tokenizers 0.13.3
|
asenella/MMVAEPlus_beta_10_scale_False_seed_3
|
asenella
| 2023-07-27T19:43:04Z | 0 | 0 | null |
[
"multivae",
"en",
"license:apache-2.0",
"region:us"
] | null | 2023-07-27T19:42:50Z |
---
language: en
tags:
- multivae
license: apache-2.0
---
### Downloading this model from the Hub
This model was trained with multivae. It can be downloaded or reloaded using the method `load_from_hf_hub`
```python
>>> from multivae.models import AutoModel
>>> model = AutoModel.load_from_hf_hub(hf_hub_path="your_hf_username/repo_name")
```
|
asenella/MMVAEPlus_beta_5_scale_False_seed_3
|
asenella
| 2023-07-27T19:39:47Z | 0 | 0 | null |
[
"multivae",
"en",
"license:apache-2.0",
"region:us"
] | null | 2023-07-27T19:39:34Z |
---
language: en
tags:
- multivae
license: apache-2.0
---
### Downloading this model from the Hub
This model was trained with multivae. It can be downloaded or reloaded using the method `load_from_hf_hub`
```python
>>> from multivae.models import AutoModel
>>> model = AutoModel.load_from_hf_hub(hf_hub_path="your_hf_username/repo_name")
```
|
Varshitha/flan-t5-large-finetune-medicine-v5
|
Varshitha
| 2023-07-27T19:38:30Z | 110 | 1 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"t5",
"text2text-generation",
"text2textgeneration",
"generated_from_trainer",
"base_model:google/flan-t5-large",
"base_model:finetune:google/flan-t5-large",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2023-07-27T19:28:01Z |
---
license: apache-2.0
base_model: google/flan-t5-large
tags:
- text2textgeneration
- generated_from_trainer
metrics:
- rouge
model-index:
- name: flan-t5-large-finetune-medicine-v5
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# flan-t5-large-finetune-medicine-v5
This model is a fine-tuned version of [google/flan-t5-large](https://huggingface.co/google/flan-t5-large) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 2.3517
- Rouge1: 27.7218
- Rouge2: 10.9162
- Rougel: 23.6057
- Rougelsum: 23.2999
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5.6e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 20
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum |
|:-------------:|:-----:|:----:|:---------------:|:-------:|:-------:|:-------:|:---------:|
| No log | 1.0 | 5 | 2.2465 | 14.6773 | 3.5979 | 13.871 | 14.2474 |
| No log | 2.0 | 10 | 2.1106 | 10.2078 | 2.1164 | 10.2919 | 10.276 |
| No log | 3.0 | 15 | 2.0535 | 16.7761 | 1.5873 | 16.7952 | 17.1838 |
| No log | 4.0 | 20 | 2.0323 | 16.6844 | 1.5873 | 16.8444 | 16.9094 |
| No log | 5.0 | 25 | 2.0063 | 17.2911 | 2.3045 | 14.8127 | 15.3235 |
| No log | 6.0 | 30 | 2.0079 | 15.3197 | 4.6561 | 14.278 | 14.8369 |
| No log | 7.0 | 35 | 2.0319 | 15.9877 | 5.8947 | 13.9837 | 14.1814 |
| No log | 8.0 | 40 | 2.0748 | 23.1763 | 10.5 | 20.2887 | 20.2578 |
| No log | 9.0 | 45 | 2.1303 | 21.1874 | 6.9444 | 19.0088 | 18.991 |
| No log | 10.0 | 50 | 2.1746 | 20.2807 | 6.2865 | 18.2145 | 18.1012 |
| No log | 11.0 | 55 | 2.1729 | 21.8364 | 9.8421 | 18.7897 | 18.8242 |
| No log | 12.0 | 60 | 2.2083 | 22.777 | 10.9162 | 21.3444 | 21.1464 |
| No log | 13.0 | 65 | 2.2658 | 21.7641 | 10.9162 | 20.3906 | 19.8167 |
| No log | 14.0 | 70 | 2.2889 | 21.7641 | 10.9162 | 20.3906 | 19.8167 |
| No log | 15.0 | 75 | 2.2998 | 25.3171 | 10.9162 | 21.3683 | 20.9228 |
| No log | 16.0 | 80 | 2.3082 | 26.0279 | 10.9162 | 21.9565 | 21.7519 |
| No log | 17.0 | 85 | 2.3166 | 26.0279 | 10.9162 | 21.9565 | 21.7519 |
| No log | 18.0 | 90 | 2.3325 | 27.7218 | 10.9162 | 23.6057 | 23.2999 |
| No log | 19.0 | 95 | 2.3462 | 27.7218 | 10.9162 | 23.6057 | 23.2999 |
| No log | 20.0 | 100 | 2.3517 | 27.7218 | 10.9162 | 23.6057 | 23.2999 |
### Framework versions
- Transformers 4.31.0
- Pytorch 2.0.1+cu118
- Datasets 2.14.1
- Tokenizers 0.13.3
|
tommilyjones/swin-tiny-patch4-window7-224-cats_dogs
|
tommilyjones
| 2023-07-27T19:38:02Z | 204 | 0 |
transformers
|
[
"transformers",
"pytorch",
"swin",
"image-classification",
"generated_from_trainer",
"dataset:imagefolder",
"base_model:microsoft/swin-tiny-patch4-window7-224",
"base_model:finetune:microsoft/swin-tiny-patch4-window7-224",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2023-07-27T19:31:44Z |
---
license: apache-2.0
base_model: microsoft/swin-tiny-patch4-window7-224
tags:
- generated_from_trainer
datasets:
- imagefolder
metrics:
- accuracy
model-index:
- name: swin-tiny-patch4-window7-224-cats_dogs
results:
- task:
name: Image Classification
type: image-classification
dataset:
name: imagefolder
type: imagefolder
config: default
split: validation
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.9973147153598282
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# swin-tiny-patch4-window7-224-cats_dogs
This model is a fine-tuned version of [microsoft/swin-tiny-patch4-window7-224](https://huggingface.co/microsoft/swin-tiny-patch4-window7-224) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0126
- Accuracy: 0.9973
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.0832 | 0.98 | 47 | 0.0235 | 0.9909 |
| 0.0788 | 1.99 | 95 | 0.0126 | 0.9973 |
| 0.0534 | 2.95 | 141 | 0.0127 | 0.9957 |
### Framework versions
- Transformers 4.31.0
- Pytorch 2.0.1+cu117
- Datasets 2.13.1
- Tokenizers 0.13.3
|
FlexedRope14028/Progetto-13-b-chat
|
FlexedRope14028
| 2023-07-27T19:31:29Z | 0 | 0 | null |
[
"it",
"en",
"license:llama2",
"region:us"
] | null | 2023-07-27T19:11:08Z |
---
license: llama2
language:
- it
- en
---
|
DunnBC22/wav2vec2-base-Speech_Emotion_Recognition
|
DunnBC22
| 2023-07-27T19:27:56Z | 209 | 13 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"wav2vec2",
"audio-classification",
"generated_from_trainer",
"en",
"dataset:audiofolder",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
audio-classification
| 2023-04-17T21:00:15Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- audiofolder
metrics:
- accuracy
- f1
- recall
- precision
model-index:
- name: wav2vec2-base-Speech_Emotion_Recognition
results: []
language:
- en
pipeline_tag: audio-classification
---
# wav2vec2-base-Speech_Emotion_Recognition
This model is a fine-tuned version of [facebook/wav2vec2-base](https://huggingface.co/facebook/wav2vec2-base).
It achieves the following results on the evaluation set:
- Loss: 0.7264
- Accuracy: 0.7539
- F1
- Weighted: 0.7514
- Micro: 0.7539
- Macro: 0.7529
- Recall
- Weighted: 0.7539
- Micro: 0.7539
- Macro: 0.7577
- Precision
- Weighted: 0.7565
- Micro: 0.7539
- Macro: 0.7558
## Model description
This model predicts the emotion of the person speaking in the audio sample.
For more information on how it was created, check out the following link: https://github.com/DunnBC22/Vision_Audio_and_Multimodal_Projects/tree/main/Audio-Projects/Emotion%20Detection/Speech%20Emotion%20Detection
## Intended uses & limitations
This model is intended to demonstrate my ability to solve a complex problem using technology.
## Training and evaluation data
Dataset Source: https://www.kaggle.com/datasets/dmitrybabko/speech-emotion-recognition-en
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | Weighted F1 | Micro F1 | Macro F1 | Weighted Recall | Micro Recall | Macro Recall | Weighted Precision | Micro Precision | Macro Precision |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:-----------:|:--------:|:--------:|:---------------:|:------------:|:------------:|:------------------:|:---------------:|:---------------:|
| 1.5581 | 0.98 | 43 | 1.4046 | 0.4653 | 0.4080 | 0.4653 | 0.4174 | 0.4653 | 0.4653 | 0.4793 | 0.5008 | 0.4653 | 0.4974 |
| 1.5581 | 1.98 | 86 | 1.1566 | 0.5997 | 0.5836 | 0.5997 | 0.5871 | 0.5997 | 0.5997 | 0.6093 | 0.6248 | 0.5997 | 0.6209 |
| 1.5581 | 2.98 | 129 | 0.9733 | 0.6883 | 0.6845 | 0.6883 | 0.6860 | 0.6883 | 0.6883 | 0.6923 | 0.7012 | 0.6883 | 0.7009 |
| 1.5581 | 3.98 | 172 | 0.8313 | 0.7399 | 0.7392 | 0.7399 | 0.7409 | 0.7399 | 0.7399 | 0.7417 | 0.7415 | 0.7399 | 0.7432 |
| 1.5581 | 4.98 | 215 | 0.8708 | 0.7028 | 0.6963 | 0.7028 | 0.6970 | 0.7028 | 0.7028 | 0.7081 | 0.7148 | 0.7028 | 0.7114 |
| 1.5581 | 5.98 | 258 | 0.7969 | 0.7297 | 0.7267 | 0.7297 | 0.7277 | 0.7297 | 0.7297 | 0.7333 | 0.7393 | 0.7297 | 0.7382 |
| 1.5581 | 6.98 | 301 | 0.7349 | 0.7603 | 0.7613 | 0.7603 | 0.7631 | 0.7603 | 0.7603 | 0.7635 | 0.7699 | 0.7603 | 0.7702 |
| 1.5581 | 7.98 | 344 | 0.7714 | 0.7469 | 0.7444 | 0.7469 | 0.7456 | 0.7469 | 0.7469 | 0.7485 | 0.7554 | 0.7469 | 0.7563 |
| 1.5581 | 8.98 | 387 | 0.7183 | 0.7630 | 0.7615 | 0.7630 | 0.7631 | 0.7630 | 0.7630 | 0.7652 | 0.7626 | 0.7630 | 0.7637 |
| 1.5581 | 9.98 | 430 | 0.7264 | 0.7539 | 0.7514 | 0.7539 | 0.7529 | 0.7539 | 0.7539 | 0.7577 | 0.7565 | 0.7539 | 0.7558 |
### Framework versions
- Transformers 4.26.1
- Pytorch 2.0.0+cu118
- Datasets 2.11.0
- Tokenizers 0.13.3
|
DunnBC22/mit-b0-Image_segmentation_Dominoes_v2
|
DunnBC22
| 2023-07-27T19:26:06Z | 0 | 1 | null |
[
"pytorch",
"tensorboard",
"generated_from_trainer",
"image-segmentation",
"en",
"dataset:adelavega/dominoes_raw",
"license:other",
"region:us"
] |
image-segmentation
| 2023-07-26T21:13:35Z |
---
license: other
tags:
- generated_from_trainer
model-index:
- name: mit-b0-Image_segmentation_Dominoes_v2
results: []
datasets:
- adelavega/dominoes_raw
language:
- en
metrics:
- mean_iou
pipeline_tag: image-segmentation
---
# mit-b0-Image_segmentation_Dominoes_v2
This model is a fine-tuned version of [nvidia/mit-b0](https://huggingface.co/nvidia/mit-b0).
It achieves the following results on the evaluation set:
- Loss: 0.1149
- Mean Iou: 0.9198
- Mean Accuracy: 0.9515
- Overall Accuracy: 0.9778
- Per Category Iou:
- Segment 0: 0.974110559111975
- Segment 1: 0.8655745252092782
- Per Category Accuracy
- Segment 0: 0.9897833441005461
- Segment 1: 0.913253525550903
## Model description
For more information on how it was created, check out the following link: https://github.com/DunnBC22/Vision_Audio_and_Multimodal_Projects/blob/main/Computer%20Vision/Image%20Segmentation/Dominoes/Fine-Tuning%20-%20Dominoes%20-%20Image%20Segmentation%20with%20LoRA.ipynb
## Intended uses & limitations
This model is intended to demonstrate my ability to solve a complex problem using technology.
## Training and evaluation data
Dataset Source: https://huggingface.co/datasets/adelavega/dominoes_raw
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 25
### Training results
| Training Loss | Epoch | Step | Validation Loss | Mean Iou | Mean Accuracy | Overall Accuracy | Per Category Iou Segment 0 | Per Category Iou Segment 1 | Per Category Accuracy Segment 0 | Per Category Accuracy Segment 1|
|:-------------:|:-----:|:----:|:---------------:|:--------:|:-------------:|:----------------:|:------------------:|:-------------------:|:---------------------:|:-----------------:|
| 0.0461 | 1.0 | 86 | 0.1233 | 0.9150 | 0.9527 | 0.9762 | 0.9721967854031923 | 0.8578619172251059 | 0.9869082633464498 | 0.9184139264010376 |
| 0.0708 | 2.0 | 172 | 0.1366 | 0.9172 | 0.9490 | 0.9771 | 0.9732821853093164 | 0.8611008788165083 | 0.9898473600751747 | 0.9082362492748777 |
| 0.048 | 3.0 | 258 | 0.1260 | 0.9199 | 0.9534 | 0.9777 | 0.9740118174014271 | 0.8658241844233872 | 0.9888392553004053 | 0.9179240730467295 |
| 0.0535 | 4.0 | 344 | 0.1184 | 0.9200 | 0.9520 | 0.9778 | 0.974142444792198 | 0.8658711064023369 | 0.9896291184589182 | 0.9142864290038782 |
| 0.0185 | 5.0 | 430 | 0.1296 | 0.9182 | 0.9477 | 0.9775 | 0.9737715695013129 | 0.8627108292167807 | 0.9910418746696423 | 0.904378218719681 |
| 0.036 | 6.0 | 516 | 0.1410 | 0.9213 | 0.9538 | 0.9782 | 0.9745002408443008 | 0.8680673581922554 | 0.9892677512186527 | 0.9182967669045321 |
| 0.0376 | 7.0 | 602 | 0.1451 | 0.9206 | 0.9550 | 0.9779 | 0.9741455743906073 | 0.8669703237367214 | 0.9883004639689904 | 0.9216576612178001 |
| 0.0186 | 8.0 | 688 | 0.1380 | 0.9175 | 0.9496 | 0.9772 | 0.9733616852468584 | 0.8616466350192237 | 0.9897043519116697 | 0.9094762400541087 |
| 0.0162 | 9.0 | 774 | 0.1459 | 0.9218 | 0.9539 | 0.9783 | 0.9746840649852051 | 0.8688930149000804 | 0.989455276913138 | 0.9182917005479264 |
| 0.0169 | 10.0 | 860 | 0.1467 | 0.9191 | 0.9502 | 0.9776 | 0.9739086600912814 | 0.8642187978193332 | 0.9901195747929759 | 0.9102564589713776 |
| 0.0102 | 11.0 | 946 | 0.1549 | 0.9191 | 0.9524 | 0.9775 | 0.9737696499931041 | 0.8644247331609153 | 0.9889789745698009 | 0.915789237032027 |
| 0.0204 | 12.0 | 1032 | 0.1502 | 0.9215 | 0.9527 | 0.9783 | 0.974639596078376 | 0.8682964916021273 | 0.989902977623774 | 0.9155653673995151 |
| 0.0268 | 13.0 | 1118 | 0.1413 | 0.9194 | 0.9505 | 0.9777 | 0.9740020531855834 | 0.8647199376136 | 0.99011699066189 | 0.9107963425971664 |
| 0.0166 | 14.0 | 1204 | 0.1584 | 0.9173 | 0.9518 | 0.9770 | 0.9731154475737929 | 0.8614276032542578 | 0.9884142831972749 | 0.9152366875147241 |
| 0.0159 | 15.0 | 1290 | 0.1563 | 0.9170 | 0.9492 | 0.9770 | 0.9731832402253996 | 0.8607442858381036 | 0.9896456803899689 | 0.9087960816798012 |
| 0.0211 | 16.0 | 1376 | 0.1435 | 0.9150 | 0.9481 | 0.9764 | 0.9725201360275898 | 0.8574847000491036 | 0.989323310037 | 0.9068449010920532 |
| 0.0128 | 17.0 | 1462 | 0.1421 | 0.9212 | 0.9519 | 0.9782 | 0.9745789801464504 | 0.8677394402794754 | 0.9901920479238856 | 0.9136255861141298 |
| 0.0167 | 18.0 | 1548 | 0.1558 | 0.9217 | 0.9532 | 0.9783 | 0.9746811993626879 | 0.8686470009484697 | 0.9897428202266988 | 0.9166850322093621 |
| 0.0201 | 19.0 | 1634 | 0.1623 | 0.9156 | 0.9484 | 0.9766 | 0.9727184720007118 | 0.8584339325695252 | 0.9894484642039114 | 0.9072695251050635 |
| 0.0133 | 20.0 | 1720 | 0.1573 | 0.9189 | 0.9505 | 0.9776 | 0.9738320500157303 | 0.8640203613069115 | 0.9898665061373113 | 0.9112263496140702 |
| 0.012 | 21.0 | 1806 | 0.1631 | 0.9165 | 0.9472 | 0.9769 | 0.9731344243001482 | 0.8597866189796295 | 0.9904592118400188 | 0.9040137576913626 |
| 0.0148 | 22.0 | 1892 | 0.1629 | 0.9181 | 0.9507 | 0.9773 | 0.9735162429121835 | 0.8627239955489192 | 0.9894034768309156 | 0.9120129014770962 |
| 0.0137 | 23.0 | 1978 | 0.1701 | 0.9136 | 0.9484 | 0.9760 | 0.9719681843338751 | 0.8552607882028388 | 0.9885083690609032 | 0.908250815050119 |
| 0.0142 | 24.0 | 2064 | 0.1646 | 0.9146 | 0.9488 | 0.9763 | 0.9723134197764093 | 0.8568918401744342 | 0.9887405884771245 | 0.9089100747034281 |
| 0.0156 | 25.0 | 2150 | 0.1615 | 0.9144 | 0.9465 | 0.9763 | 0.9723929259786395 | 0.856345354289624 | 0.9898487696012216 | 0.9032139066422469 |
### Framework versions
- Transformers 4.26.1
- Pytorch 2.0.1
- Datasets 2.13.1
- Tokenizers 0.13.3
|
vlabs/falcon-7b-sentiment_V3
|
vlabs
| 2023-07-27T19:21:16Z | 0 | 0 |
peft
|
[
"peft",
"region:us"
] | null | 2023-07-27T19:21:14Z |
---
library_name: peft
---
## Training procedure
### Framework versions
- PEFT 0.5.0.dev0
|
Isaacgv/distilhubert-finetuned-gtzan
|
Isaacgv
| 2023-07-27T19:20:19Z | 19 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"hubert",
"audio-classification",
"generated_from_trainer",
"dataset:marsyas/gtzan",
"base_model:ntu-spml/distilhubert",
"base_model:finetune:ntu-spml/distilhubert",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] |
audio-classification
| 2023-07-26T12:47:08Z |
---
license: apache-2.0
base_model: ntu-spml/distilhubert
tags:
- generated_from_trainer
datasets:
- marsyas/gtzan
metrics:
- accuracy
model-index:
- name: distilhubert-finetuned-gtzan
results:
- task:
name: Audio Classification
type: audio-classification
dataset:
name: GTZAN
type: marsyas/gtzan
config: all
split: train
args: all
metrics:
- name: Accuracy
type: accuracy
value: 0.88
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilhubert-finetuned-gtzan
This model is a fine-tuned version of [ntu-spml/distilhubert](https://huggingface.co/ntu-spml/distilhubert) on the GTZAN dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5655
- Accuracy: 0.88
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.3836 | 0.98 | 14 | 0.5798 | 0.82 |
| 0.3357 | 1.96 | 28 | 0.5655 | 0.88 |
### Framework versions
- Transformers 4.31.0
- Pytorch 2.0.1+cu118
- Datasets 2.14.0
- Tokenizers 0.13.3
|
Varshitha/flan-t5-small-finetune-medicine-v3
|
Varshitha
| 2023-07-27T19:17:58Z | 102 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"t5",
"text2text-generation",
"text2textgeneration",
"generated_from_trainer",
"base_model:google/flan-t5-small",
"base_model:finetune:google/flan-t5-small",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2023-07-27T19:16:23Z |
---
license: apache-2.0
base_model: google/flan-t5-small
tags:
- text2textgeneration
- generated_from_trainer
metrics:
- rouge
model-index:
- name: flan-t5-small-finetune-medicine-v3
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# flan-t5-small-finetune-medicine-v3
This model is a fine-tuned version of [google/flan-t5-small](https://huggingface.co/google/flan-t5-small) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 2.8757
- Rouge1: 15.991
- Rouge2: 5.2469
- Rougel: 14.6278
- Rougelsum: 14.7076
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5.6e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 8
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum |
|:-------------:|:-----:|:----:|:---------------:|:-------:|:------:|:-------:|:---------:|
| No log | 1.0 | 5 | 2.9996 | 12.4808 | 4.9536 | 12.3712 | 12.2123 |
| No log | 2.0 | 10 | 2.9550 | 13.6471 | 4.9536 | 13.5051 | 13.5488 |
| No log | 3.0 | 15 | 2.9224 | 13.8077 | 5.117 | 13.7274 | 13.753 |
| No log | 4.0 | 20 | 2.9050 | 13.7861 | 5.117 | 13.6982 | 13.7001 |
| No log | 5.0 | 25 | 2.8920 | 14.668 | 5.117 | 14.4497 | 14.4115 |
| No log | 6.0 | 30 | 2.8820 | 14.9451 | 5.2469 | 14.5797 | 14.6308 |
| No log | 7.0 | 35 | 2.8770 | 15.991 | 5.2469 | 14.6278 | 14.7076 |
| No log | 8.0 | 40 | 2.8757 | 15.991 | 5.2469 | 14.6278 | 14.7076 |
### Framework versions
- Transformers 4.31.0
- Pytorch 2.0.1+cu118
- Datasets 2.14.1
- Tokenizers 0.13.3
|
NasimB/bnc-cbt-rarity
|
NasimB
| 2023-07-27T19:05:16Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"generated_from_trainer",
"dataset:generator",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-07-27T16:42:47Z |
---
license: mit
tags:
- generated_from_trainer
datasets:
- generator
model-index:
- name: bnc-cbt-rarity
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bnc-cbt-rarity
This model is a fine-tuned version of [gpt2](https://huggingface.co/gpt2) on the generator dataset.
It achieves the following results on the evaluation set:
- Loss: 4.1216
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 1000
- num_epochs: 6
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-----:|:---------------:|
| 6.3708 | 0.29 | 500 | 5.3361 |
| 5.0503 | 0.59 | 1000 | 4.9318 |
| 4.713 | 0.88 | 1500 | 4.6937 |
| 4.4634 | 1.17 | 2000 | 4.5611 |
| 4.3089 | 1.46 | 2500 | 4.4409 |
| 4.2145 | 1.76 | 3000 | 4.3397 |
| 4.0857 | 2.05 | 3500 | 4.2672 |
| 3.9095 | 2.34 | 4000 | 4.2143 |
| 3.8772 | 2.63 | 4500 | 4.1591 |
| 3.8444 | 2.93 | 5000 | 4.1098 |
| 3.6491 | 3.22 | 5500 | 4.1097 |
| 3.5993 | 3.51 | 6000 | 4.0797 |
| 3.5848 | 3.81 | 6500 | 4.0497 |
| 3.4861 | 4.1 | 7000 | 4.0479 |
| 3.3328 | 4.39 | 7500 | 4.0443 |
| 3.3282 | 4.68 | 8000 | 4.0292 |
| 3.3151 | 4.98 | 8500 | 4.0183 |
| 3.1607 | 5.27 | 9000 | 4.0323 |
| 3.151 | 5.56 | 9500 | 4.0309 |
| 3.1458 | 5.85 | 10000 | 4.0304 |
### Framework versions
- Transformers 4.26.1
- Pytorch 1.11.0+cu113
- Datasets 2.13.0
- Tokenizers 0.13.3
|
Vaibhav9401/llama2-qlora-finetunined-spam
|
Vaibhav9401
| 2023-07-27T18:54:34Z | 2 | 0 |
peft
|
[
"peft",
"region:us"
] | null | 2023-07-26T08:40:29Z |
---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float16
### Framework versions
- PEFT 0.5.0.dev0
|
Aevermann/rwkv-world-latest
|
Aevermann
| 2023-07-27T18:36:32Z | 0 | 0 | null |
[
"license:apache-2.0",
"region:us"
] | null | 2023-07-27T18:16:58Z |
---
license: apache-2.0
---
This is a clone of the BlinkDL RWKV World Model
Its a test. Pls load from orignal repo
|
dariowsz/ppo-Pyramids
|
dariowsz
| 2023-07-27T18:29:47Z | 5 | 0 |
ml-agents
|
[
"ml-agents",
"tensorboard",
"onnx",
"Pyramids",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-Pyramids",
"region:us"
] |
reinforcement-learning
| 2023-07-27T18:28:33Z |
---
library_name: ml-agents
tags:
- Pyramids
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-Pyramids
---
# **ppo** Agent playing **Pyramids**
This is a trained model of a **ppo** agent playing **Pyramids**
using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://unity-technologies.github.io/ml-agents/ML-Agents-Toolkit-Documentation/
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
- A *short tutorial* where you teach Huggy the Dog 🐶 to fetch the stick and then play with him directly in your
browser: https://huggingface.co/learn/deep-rl-course/unitbonus1/introduction
- A *longer tutorial* to understand how works ML-Agents:
https://huggingface.co/learn/deep-rl-course/unit5/introduction
### Resume the training
```bash
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser**
1. If the environment is part of ML-Agents official environments, go to https://huggingface.co/unity
2. Step 1: Find your model_id: dariowsz/ppo-Pyramids
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
idealflaw/dqn-SpaceInvadersNoFrameskip-v4
|
idealflaw
| 2023-07-27T18:24:12Z | 2 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"SpaceInvadersNoFrameskip-v4",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-07-27T18:08:41Z |
---
library_name: stable-baselines3
tags:
- SpaceInvadersNoFrameskip-v4
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: DQN
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: SpaceInvadersNoFrameskip-v4
type: SpaceInvadersNoFrameskip-v4
metrics:
- type: mean_reward
value: 639.00 +/- 185.56
name: mean_reward
verified: false
---
# **DQN** Agent playing **SpaceInvadersNoFrameskip-v4**
This is a trained model of a **DQN** agent playing **SpaceInvadersNoFrameskip-v4**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3)
and the [RL Zoo](https://github.com/DLR-RM/rl-baselines3-zoo).
The RL Zoo is a training framework for Stable Baselines3
reinforcement learning agents,
with hyperparameter optimization and pre-trained agents included.
## Usage (with SB3 RL Zoo)
RL Zoo: https://github.com/DLR-RM/rl-baselines3-zoo<br/>
SB3: https://github.com/DLR-RM/stable-baselines3<br/>
SB3 Contrib: https://github.com/Stable-Baselines-Team/stable-baselines3-contrib
Install the RL Zoo (with SB3 and SB3-Contrib):
```bash
pip install rl_zoo3
```
```
# Download model and save it into the logs/ folder
python -m rl_zoo3.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga idealflaw -f logs/
python -m rl_zoo3.enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
If you installed the RL Zoo3 via pip (`pip install rl_zoo3`), from anywhere you can do:
```
python -m rl_zoo3.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga idealflaw -f logs/
python -m rl_zoo3.enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
## Training (with the RL Zoo)
```
python -m rl_zoo3.train --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
# Upload the model and generate video (when possible)
python -m rl_zoo3.push_to_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/ -orga idealflaw
```
## Hyperparameters
```python
OrderedDict([('batch_size', 32),
('buffer_size', 100000),
('env_wrapper',
['stable_baselines3.common.atari_wrappers.AtariWrapper']),
('exploration_final_eps', 0.01),
('exploration_fraction', 0.1),
('frame_stack', 4),
('gradient_steps', 1),
('learning_rate', 0.0001),
('learning_starts', 100000),
('n_timesteps', 10000000.0),
('optimize_memory_usage', False),
('policy', 'CnnPolicy'),
('target_update_interval', 1000),
('train_freq', 4),
('normalize', False)])
```
# Environment Arguments
```python
{'render_mode': 'rgb_array'}
```
|
Corbanp/PPO-LunarLander-v3
|
Corbanp
| 2023-07-27T18:17:35Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-07-27T18:17:15Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 230.12 +/- 101.08
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
Leogrin/eleuther-pythia1.4b-hh-dpo
|
Leogrin
| 2023-07-27T18:16:00Z | 180 | 1 |
transformers
|
[
"transformers",
"pytorch",
"gpt_neox",
"text-generation",
"causal-lm",
"pythia",
"en",
"dataset:Anthropic/hh-rlhf",
"arxiv:2305.18290",
"arxiv:2101.00027",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-07-27T15:07:41Z |
---
language:
- en
tags:
- pytorch
- causal-lm
- pythia
license: apache-2.0
datasets:
- Anthropic/hh-rlhf
---
# Infos
Pythia-1.4b supervised finetuned with Anthropic-hh-rlhf dataset for 1 epoch (sft-model), before DPO [(paper)](https://arxiv.org/abs/2305.18290) with same dataset for 1 epoch.
[wandb log](https://wandb.ai/pythia_dpo/Pythia_DPO_new/runs/6yrtkj3s)
See [Pythia-1.4b](https://huggingface.co/EleutherAI/pythia-1.4b) for model details [(paper)](https://arxiv.org/abs/2101.00027).
# Benchmark raw results:
Results for the base model are taken from the [Pythia paper](https://arxiv.org/abs/2101.00027).
## Zero shot
| Task | 1.4B_base | 1.4B_sft | 1.4B_dpo |
|------------------|--------------:|--------------:|---------------:|
| Lambada (OpenAI) | 0.616 ± 0.007 | 0.5977 ± 0.0068 | 0.5948 ± 0.0068 |
| PIQA | 0.711 ± 0.011 | 0.7133 ± 0.0106 | 0.7165 ± 0.0105 |
| WinoGrande | 0.573 ± 0.014 | 0.5793 ± 0.0139 | 0.5746 ± 0.0139 |
| WSC | 0.365 ± 0.047 | 0.3654 ± 0.0474 | 0.3654 ± 0.0474 |
| ARC - Easy | 0.606 ± 0.010 | 0.6098 ± 0.0100 | 0.6199 ± 0.0100 |
| ARC - Challenge | 0.260 ± 0.013 | 0.2696 ± 0.0130 | 0.2884 ± 0.0132 |
| SciQ | 0.865 ± 0.011 | 0.8540 ± 0.0112 | 0.8550 ± 0.0111 |
| LogiQA | 0.210 ± 0.016 | NA | NA |
## Five shot
| Task | 1.4B_base | 1.4B_sft | 1.4B_dpo |
|------------------|----------------:|----------------:|----------------:|
| Lambada (OpenAI) | 0.578 ± 0.007 | 0.5201 ± 0.007 | 0.5247 ± 0.007 |
| PIQA | 0.705 ± 0.011 | 0.7176 ± 0.0105| 0.7209 ± 0.0105|
| WinoGrande | 0.580 ± 0.014 | 0.5793 ± 0.0139| 0.5746 ± 0.0139|
| WSC | 0.365 ± 0.047 | 0.5288 ± 0.0492| 0.5769 ± 0.0487|
| ARC - Easy | 0.643 ± 0.010 | 0.6376 ± 0.0099| 0.6561 ± 0.0097|
| ARC - Challenge | 0.290 ± 0.013 | 0.2935 ± 0.0133| 0.3166 ± 0.0136|
| SciQ | 0.92 ± 0.009 | 0.9180 ± 0.0087| 0.9150 ± 0.0088|
| LogiQA | 0.240 ± 0.017 | N/A | N/A |
|
Khushnur/t5-base-end2end-questions-generation_squad_all_pcmq
|
Khushnur
| 2023-07-27T18:11:03Z | 159 | 0 |
transformers
|
[
"transformers",
"pytorch",
"t5",
"text2text-generation",
"generated_from_trainer",
"base_model:google-t5/t5-base",
"base_model:finetune:google-t5/t5-base",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2023-07-27T15:33:55Z |
---
license: apache-2.0
base_model: t5-base
tags:
- generated_from_trainer
model-index:
- name: t5-base-end2end-questions-generation_squad_all_pcmq
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-base-end2end-questions-generation_squad_all_pcmq
This model is a fine-tuned version of [t5-base](https://huggingface.co/t5-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.5861
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- gradient_accumulation_steps: 32
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 1.8599 | 0.67 | 100 | 1.6726 |
| 1.8315 | 1.35 | 200 | 1.6141 |
| 1.7564 | 2.02 | 300 | 1.5942 |
| 1.7153 | 2.69 | 400 | 1.5861 |
### Framework versions
- Transformers 4.31.0
- Pytorch 2.0.1+cu118
- Datasets 2.14.0
- Tokenizers 0.13.3
|
efainman/Reinforce-CartPole-v1
|
efainman
| 2023-07-27T18:10:32Z | 0 | 0 | null |
[
"CartPole-v1",
"reinforce",
"reinforcement-learning",
"custom-implementation",
"deep-rl-class",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-07-27T18:10:23Z |
---
tags:
- CartPole-v1
- reinforce
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: Reinforce-CartPole-v1
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: CartPole-v1
type: CartPole-v1
metrics:
- type: mean_reward
value: 500.00 +/- 0.00
name: mean_reward
verified: false
---
# **Reinforce** Agent playing **CartPole-v1**
This is a trained model of a **Reinforce** agent playing **CartPole-v1** .
To learn to use this model and train yours check Unit 4 of the Deep Reinforcement Learning Course: https://huggingface.co/deep-rl-course/unit4/introduction
|
sukiee/qlora-koalpaca-polyglot-5.8b-callcenter_v3
|
sukiee
| 2023-07-27T18:08:11Z | 0 | 0 |
peft
|
[
"peft",
"region:us"
] | null | 2023-07-27T18:08:09Z |
---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: True
- bnb_4bit_compute_dtype: bfloat16
### Framework versions
- PEFT 0.5.0.dev0
|
snob/TagMyBookmark-KoAlpaca-QLoRA-v1.0_ALLDATA-Finetune300
|
snob
| 2023-07-27T18:00:43Z | 1 | 0 |
peft
|
[
"peft",
"region:us"
] | null | 2023-07-27T18:00:38Z |
---
library_name: peft
---
## Training procedure
### Framework versions
- PEFT 0.4.0.dev0
|
kusknish/ppo-LunarLander-v2
|
kusknish
| 2023-07-27T17:59:22Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-07-27T17:59:05Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: -202.29 +/- 149.85
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
giladvdn/test-sam-handler
|
giladvdn
| 2023-07-27T17:54:32Z | 134 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"sam",
"mask-generation",
"arxiv:2304.02643",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
mask-generation
| 2023-07-27T14:10:04Z |
---
license: apache-2.0
---
# Model Card for Segment Anything Model (SAM) - ViT Huge (ViT-H) version
<p>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/model_doc/sam-architecture.png" alt="Model architecture">
<em> Detailed architecture of Segment Anything Model (SAM).</em>
</p>
# Table of Contents
0. [TL;DR](#TL;DR)
1. [Model Details](#model-details)
2. [Usage](#usage)
3. [Citation](#citation)
# TL;DR
[Link to original repository](https://github.com/facebookresearch/segment-anything)
| <img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/model_doc/sam-beancans.png" alt="Snow" width="600" height="600"> | <img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/model_doc/sam-dog-masks.png" alt="Forest" width="600" height="600"> | <img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/model_doc/sam-car-seg.png" alt="Mountains" width="600" height="600"> |
|---------------------------------------------------------------------------------------------------------------------------------------|--------------------------------------------------------------------------------------------------------------------------------|--------------------------------------------------------------------------------------------------------------------------------------------------|
The **Segment Anything Model (SAM)** produces high quality object masks from input prompts such as points or boxes, and it can be used to generate masks for all objects in an image. It has been trained on a [dataset](https://segment-anything.com/dataset/index.html) of 11 million images and 1.1 billion masks, and has strong zero-shot performance on a variety of segmentation tasks.
The abstract of the paper states:
> We introduce the Segment Anything (SA) project: a new task, model, and dataset for image segmentation. Using our efficient model in a data collection loop, we built the largest segmentation dataset to date (by far), with over 1 billion masks on 11M licensed and privacy respecting images. The model is designed and trained to be promptable, so it can transfer zero-shot to new image distributions and tasks. We evaluate its capabilities on numerous tasks and find that its zero-shot performance is impressive -- often competitive with or even superior to prior fully supervised results. We are releasing the Segment Anything Model (SAM) and corresponding dataset (SA-1B) of 1B masks and 11M images at [https://segment-anything.com](https://segment-anything.com) to foster research into foundation models for computer vision.
**Disclaimer**: Content from **this** model card has been written by the Hugging Face team, and parts of it were copy pasted from the original [SAM model card](https://github.com/facebookresearch/segment-anything).
# Model Details
The SAM model is made up of 3 modules:
- The `VisionEncoder`: a VIT based image encoder. It computes the image embeddings using attention on patches of the image. Relative Positional Embedding is used.
- The `PromptEncoder`: generates embeddings for points and bounding boxes
- The `MaskDecoder`: a two-ways transformer which performs cross attention between the image embedding and the point embeddings (->) and between the point embeddings and the image embeddings. The outputs are fed
- The `Neck`: predicts the output masks based on the contextualized masks produced by the `MaskDecoder`.
# Usage
## Prompted-Mask-Generation
```python
from PIL import Image
import requests
from transformers import SamModel, SamProcessor
model = SamModel.from_pretrained("facebook/sam-vit-huge")
processor = SamProcessor.from_pretrained("facebook/sam-vit-huge")
img_url = "https://huggingface.co/ybelkada/segment-anything/resolve/main/assets/car.png"
raw_image = Image.open(requests.get(img_url, stream=True).raw).convert("RGB")
input_points = [[[450, 600]]] # 2D localization of a window
```
```python
inputs = processor(raw_image, input_points=input_points, return_tensors="pt").to("cuda")
outputs = model(**inputs)
masks = processor.image_processor.post_process_masks(outputs.pred_masks.cpu(), inputs["original_sizes"].cpu(), inputs["reshaped_input_sizes"].cpu())
scores = outputs.iou_scores
```
Among other arguments to generate masks, you can pass 2D locations on the approximate position of your object of interest, a bounding box wrapping the object of interest (the format should be x, y coordinate of the top right and bottom left point of the bounding box), a segmentation mask. At this time of writing, passing a text as input is not supported by the official model according to [the official repository](https://github.com/facebookresearch/segment-anything/issues/4#issuecomment-1497626844).
For more details, refer to this notebook, which shows a walk throught of how to use the model, with a visual example!
## Automatic-Mask-Generation
The model can be used for generating segmentation masks in a "zero-shot" fashion, given an input image. The model is automatically prompt with a grid of `1024` points
which are all fed to the model.
The pipeline is made for automatic mask generation. The following snippet demonstrates how easy you can run it (on any device! Simply feed the appropriate `points_per_batch` argument)
```python
from transformers import pipeline
generator = pipeline("mask-generation", device = 0, points_per_batch = 256)
image_url = "https://huggingface.co/ybelkada/segment-anything/resolve/main/assets/car.png"
outputs = generator(image_url, points_per_batch = 256)
```
Now to display the image:
```python
import matplotlib.pyplot as plt
from PIL import Image
import numpy as np
def show_mask(mask, ax, random_color=False):
if random_color:
color = np.concatenate([np.random.random(3), np.array([0.6])], axis=0)
else:
color = np.array([30 / 255, 144 / 255, 255 / 255, 0.6])
h, w = mask.shape[-2:]
mask_image = mask.reshape(h, w, 1) * color.reshape(1, 1, -1)
ax.imshow(mask_image)
plt.imshow(np.array(raw_image))
ax = plt.gca()
for mask in outputs["masks"]:
show_mask(mask, ax=ax, random_color=True)
plt.axis("off")
plt.show()
```
This should give you the following 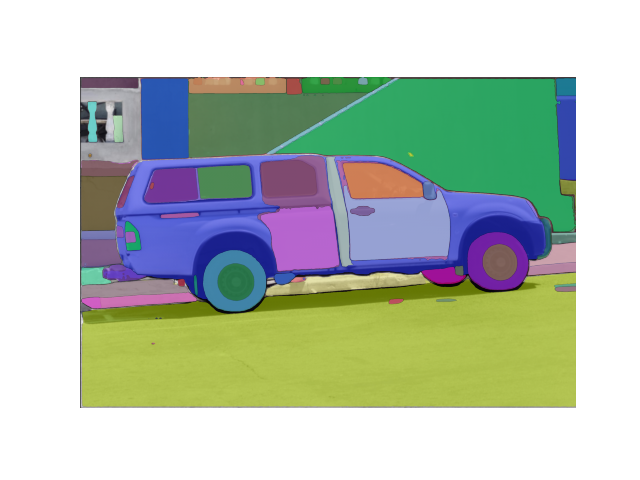
# Citation
If you use this model, please use the following BibTeX entry.
```
@article{kirillov2023segany,
title={Segment Anything},
author={Kirillov, Alexander and Mintun, Eric and Ravi, Nikhila and Mao, Hanzi and Rolland, Chloe and Gustafson, Laura and Xiao, Tete and Whitehead, Spencer and Berg, Alexander C. and Lo, Wan-Yen and Doll{\'a}r, Piotr and Girshick, Ross},
journal={arXiv:2304.02643},
year={2023}
}
```
|
vxbrandon/my_awesome_qa_model
|
vxbrandon
| 2023-07-27T17:48:35Z | 117 | 1 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"question-answering",
"generated_from_trainer",
"dataset:squad",
"base_model:distilbert/distilbert-base-uncased",
"base_model:finetune:distilbert/distilbert-base-uncased",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2023-07-27T16:13:28Z |
---
license: apache-2.0
base_model: distilbert-base-uncased
tags:
- generated_from_trainer
datasets:
- squad
model-index:
- name: my_awesome_qa_model
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# my_awesome_qa_model
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the squad dataset.
It achieves the following results on the evaluation set:
- Loss: 1.1920
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 128
- eval_batch_size: 256
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 2.3143 | 1.0 | 685 | 1.3187 |
| 1.3356 | 2.0 | 1370 | 1.2095 |
| 1.0967 | 3.0 | 2055 | 1.1920 |
### Framework versions
- Transformers 4.31.0
- Pytorch 2.0.1+cu118
- Datasets 2.14.0
- Tokenizers 0.13.3
|
badmatr11x/roberta-base-emotions-detection-from-text
|
badmatr11x
| 2023-07-27T17:15:42Z | 136 | 7 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"roberta",
"text-classification",
"en",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-07-15T16:56:14Z |
---
license: mit
widget:
- text: With tears of joy streaming down her cheeks, she embraced her long-lost brother after years of separation.
example_title: Joy
- text: As the orchestra played the final note, the audience erupted into thunderous applause, filling the concert hall with joy.
example_title: Joy
- text: The old man sat alone on the park bench, reminiscing about the love he had lost, his eyes filled with sadness.
example_title: Sadness
- text: The news of her best friend moving to a distant country left her feeling a profound sadness and emptiness.
example_title: Sadness
- text: The scientific research paper discussed complex concepts that were beyond the scope of a laymans understanding.
example_title: Neutral
- text: The documentary provided an objective view of the historical events, presenting facts without any bias.
example_title: Neutral
- text: He clenched his fists tightly, trying to control the surge of anger when he heard the offensive remarks.
example_title: Anger
- text: The unfair treatment at work ignited a simmering anger within him, leading him to consider confronting the management.
example_title: Anger
- text: As the magician pulled a rabbit out of an empty hat, the children gasped in amazement and surprise.
example_title: Surprise
- text: He opened the box to find a rare and valuable antique inside, leaving him speechless with surprise.
example_title: Surprise
- text: The moldy and rotting food in the refrigerator evoked a sense of disgust, leading her to clean it immediately.
example_title: Disgust
- text: The movie's graphic scenes of violence and gore left many viewers feeling a sense of disgust and unease.
example_title: Disgust
- text: As the storm raged outside, the little child clung to their parents, seeking comfort from the fear of thunder.
example_title: Fear
- text: The horror movie was so terrifying that some viewers had to cover their eyes in fear, unable to bear the suspense.
example_title: Fear
language:
- en
metrics:
- accuracy
pipeline_tag: text-classification
---
|
asenella/MMVAEPlus_beta_25_scale_False_seed_1
|
asenella
| 2023-07-27T17:11:03Z | 0 | 0 | null |
[
"multivae",
"en",
"license:apache-2.0",
"region:us"
] | null | 2023-07-27T17:10:50Z |
---
language: en
tags:
- multivae
license: apache-2.0
---
### Downloading this model from the Hub
This model was trained with multivae. It can be downloaded or reloaded using the method `load_from_hf_hub`
```python
>>> from multivae.models import AutoModel
>>> model = AutoModel.load_from_hf_hub(hf_hub_path="your_hf_username/repo_name")
```
|
bochen0909/PyramidsRND
|
bochen0909
| 2023-07-27T17:06:23Z | 1 | 0 |
ml-agents
|
[
"ml-agents",
"tensorboard",
"onnx",
"Pyramids",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-Pyramids",
"region:us"
] |
reinforcement-learning
| 2023-07-27T17:06:20Z |
---
library_name: ml-agents
tags:
- Pyramids
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-Pyramids
---
# **ppo** Agent playing **Pyramids**
This is a trained model of a **ppo** agent playing **Pyramids**
using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://unity-technologies.github.io/ml-agents/ML-Agents-Toolkit-Documentation/
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
- A *short tutorial* where you teach Huggy the Dog 🐶 to fetch the stick and then play with him directly in your
browser: https://huggingface.co/learn/deep-rl-course/unitbonus1/introduction
- A *longer tutorial* to understand how works ML-Agents:
https://huggingface.co/learn/deep-rl-course/unit5/introduction
### Resume the training
```bash
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser**
1. If the environment is part of ML-Agents official environments, go to https://huggingface.co/unity
2. Step 1: Find your model_id: bochen0909/PyramidsRND
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
asenella/MMVAEPlus_beta_25_scale_False_seed_2
|
asenella
| 2023-07-27T16:41:36Z | 0 | 0 | null |
[
"multivae",
"en",
"license:apache-2.0",
"region:us"
] | null | 2023-07-27T16:41:23Z |
---
language: en
tags:
- multivae
license: apache-2.0
---
### Downloading this model from the Hub
This model was trained with multivae. It can be downloaded or reloaded using the method `load_from_hf_hub`
```python
>>> from multivae.models import AutoModel
>>> model = AutoModel.load_from_hf_hub(hf_hub_path="your_hf_username/repo_name")
```
|
greg-szopinski/Reinforce-pixelcopter-default
|
greg-szopinski
| 2023-07-27T16:29:22Z | 0 | 0 | null |
[
"Pixelcopter-PLE-v0",
"reinforce",
"reinforcement-learning",
"custom-implementation",
"deep-rl-class",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-07-27T16:29:18Z |
---
tags:
- Pixelcopter-PLE-v0
- reinforce
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: Reinforce-pixelcopter-default
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Pixelcopter-PLE-v0
type: Pixelcopter-PLE-v0
metrics:
- type: mean_reward
value: 44.60 +/- 60.51
name: mean_reward
verified: false
---
# **Reinforce** Agent playing **Pixelcopter-PLE-v0**
This is a trained model of a **Reinforce** agent playing **Pixelcopter-PLE-v0** .
To learn to use this model and train yours check Unit 4 of the Deep Reinforcement Learning Course: https://huggingface.co/deep-rl-course/unit4/introduction
|
blackmount8/Nous-Hermes-Llama2-13b-ct2-int8
|
blackmount8
| 2023-07-27T16:25:25Z | 1 | 0 |
transformers
|
[
"transformers",
"llama-2",
"self-instruct",
"distillation",
"synthetic instruction",
"en",
"license:mit",
"endpoints_compatible",
"region:us"
] | null | 2023-07-27T16:10:32Z |
---
language:
- en
tags:
- llama-2
- self-instruct
- distillation
- synthetic instruction
license:
- mit
---
# blackmount8/Nous-Hermes-Llama2-13b-int8
Int8 version of [NousResearch/Nous-Hermes-Llama2-13b](https://huggingface.co/NousResearch/Nous-Hermes-Llama2-13b), quantized using CTranslate2.
# Model Card: Nous-Hermes-Llama2-13b
Compute provided by our project sponsor Redmond AI, thank you! Follow RedmondAI on Twitter @RedmondAI.
## Model Description
Nous-Hermes-Llama2-13b is a state-of-the-art language model fine-tuned on over 300,000 instructions. This model was fine-tuned by Nous Research, with Teknium and Emozilla leading the fine tuning process and dataset curation, Redmond AI sponsoring the compute, and several other contributors.
This Hermes model uses the exact same dataset as Hermes on Llama-1. This is to ensure consistency between the old Hermes and new, for anyone who wanted to keep Hermes as similar to the old one, just more capable.
This model stands out for its long responses, lower hallucination rate, and absence of OpenAI censorship mechanisms. The fine-tuning process was performed with a 4096 sequence length on an 8x a100 80GB DGX machine.
## Example Outputs:




## Model Training
The model was trained almost entirely on synthetic GPT-4 outputs. Curating high quality GPT-4 datasets enables incredibly high quality in knowledge, task completion, and style.
This includes data from diverse sources such as GPTeacher, the general, roleplay v1&2, code instruct datasets, Nous Instruct & PDACTL (unpublished), and several others, detailed further below
## Collaborators
The model fine-tuning and the datasets were a collaboration of efforts and resources between Teknium, Karan4D, Emozilla, Huemin Art, and Redmond AI.
Special mention goes to @winglian for assisting in some of the training issues.
Huge shoutout and acknowledgement is deserved for all the dataset creators who generously share their datasets openly.
Among the contributors of datasets:
- GPTeacher was made available by Teknium
- Wizard LM by nlpxucan
- Nous Research Instruct Dataset was provided by Karan4D and HueminArt.
- GPT4-LLM and Unnatural Instructions were provided by Microsoft
- Airoboros dataset by jondurbin
- Camel-AI's domain expert datasets are from Camel-AI
- CodeAlpaca dataset by Sahil 2801.
If anyone was left out, please open a thread in the community tab.
## Prompt Format
The model follows the Alpaca prompt format:
```
### Instruction:
<prompt>
### Response:
<leave a newline blank for model to respond>
```
or
```
### Instruction:
<prompt>
### Input:
<additional context>
### Response:
<leave a newline blank for model to respond>
```
## Benchmark Results
AGI-Eval
```
| Task |Version| Metric |Value | |Stderr|
|agieval_aqua_rat | 0|acc |0.2362|± |0.0267|
| | |acc_norm|0.2480|± |0.0272|
|agieval_logiqa_en | 0|acc |0.3425|± |0.0186|
| | |acc_norm|0.3472|± |0.0187|
|agieval_lsat_ar | 0|acc |0.2522|± |0.0287|
| | |acc_norm|0.2087|± |0.0269|
|agieval_lsat_lr | 0|acc |0.3510|± |0.0212|
| | |acc_norm|0.3627|± |0.0213|
|agieval_lsat_rc | 0|acc |0.4647|± |0.0305|
| | |acc_norm|0.4424|± |0.0303|
|agieval_sat_en | 0|acc |0.6602|± |0.0331|
| | |acc_norm|0.6165|± |0.0340|
|agieval_sat_en_without_passage| 0|acc |0.4320|± |0.0346|
| | |acc_norm|0.4272|± |0.0345|
|agieval_sat_math | 0|acc |0.2909|± |0.0307|
| | |acc_norm|0.2727|± |0.0301|
```
GPT-4All Benchmark Set
```
| Task |Version| Metric |Value | |Stderr|
|arc_challenge| 0|acc |0.5102|± |0.0146|
| | |acc_norm|0.5213|± |0.0146|
|arc_easy | 0|acc |0.7959|± |0.0083|
| | |acc_norm|0.7567|± |0.0088|
|boolq | 1|acc |0.8394|± |0.0064|
|hellaswag | 0|acc |0.6164|± |0.0049|
| | |acc_norm|0.8009|± |0.0040|
|openbookqa | 0|acc |0.3580|± |0.0215|
| | |acc_norm|0.4620|± |0.0223|
|piqa | 0|acc |0.7992|± |0.0093|
| | |acc_norm|0.8069|± |0.0092|
|winogrande | 0|acc |0.7127|± |0.0127|
```
BigBench Reasoning Test
```
| Task |Version| Metric |Value | |Stderr|
|bigbench_causal_judgement | 0|multiple_choice_grade|0.5526|± |0.0362|
|bigbench_date_understanding | 0|multiple_choice_grade|0.7344|± |0.0230|
|bigbench_disambiguation_qa | 0|multiple_choice_grade|0.2636|± |0.0275|
|bigbench_geometric_shapes | 0|multiple_choice_grade|0.0195|± |0.0073|
| | |exact_str_match |0.0000|± |0.0000|
|bigbench_logical_deduction_five_objects | 0|multiple_choice_grade|0.2760|± |0.0200|
|bigbench_logical_deduction_seven_objects | 0|multiple_choice_grade|0.2100|± |0.0154|
|bigbench_logical_deduction_three_objects | 0|multiple_choice_grade|0.4400|± |0.0287|
|bigbench_movie_recommendation | 0|multiple_choice_grade|0.2440|± |0.0192|
|bigbench_navigate | 0|multiple_choice_grade|0.4950|± |0.0158|
|bigbench_reasoning_about_colored_objects | 0|multiple_choice_grade|0.5570|± |0.0111|
|bigbench_ruin_names | 0|multiple_choice_grade|0.3728|± |0.0229|
|bigbench_salient_translation_error_detection | 0|multiple_choice_grade|0.1854|± |0.0123|
|bigbench_snarks | 0|multiple_choice_grade|0.6298|± |0.0360|
|bigbench_sports_understanding | 0|multiple_choice_grade|0.6156|± |0.0155|
|bigbench_temporal_sequences | 0|multiple_choice_grade|0.3140|± |0.0147|
|bigbench_tracking_shuffled_objects_five_objects | 0|multiple_choice_grade|0.2032|± |0.0114|
|bigbench_tracking_shuffled_objects_seven_objects| 0|multiple_choice_grade|0.1406|± |0.0083|
|bigbench_tracking_shuffled_objects_three_objects| 0|multiple_choice_grade|0.4400|± |0.0287|
```
These are the highest benchmarks Hermes has seen on every metric, achieving the following average scores:
- GPT4All benchmark average is now 70.0 - from 68.8 in Hermes-Llama1
- 0.3657 on BigBench, up from 0.328 on hermes-llama1
- 0.372 on AGIEval, up from 0.354 on Hermes-llama1
These benchmarks currently have us at #1 on ARC-c, ARC-e, Hellaswag, and OpenBookQA, and 2nd place on Winogrande, comparing to GPT4all's benchmarking list, supplanting Hermes 1 for the new top position.
## Resources for Applied Use Cases:
For an example of a back and forth chatbot using huggingface transformers and discord, check out: https://github.com/teknium1/alpaca-discord
For an example of a roleplaying discord chatbot, check out this: https://github.com/teknium1/alpaca-roleplay-discordbot
## Future Plans
We plan to continue to iterate on both more high quality data, and new data filtering techniques to eliminate lower quality data going forward.
## Model Usage
The model is available for download on Hugging Face. It is suitable for a wide range of language tasks, from generating creative text to understanding and following complex instructions.
[<img src="https://raw.githubusercontent.com/OpenAccess-AI-Collective/axolotl/main/image/axolotl-badge-web.png" alt="Built with Axolotl" width="200" height="32"/>](https://github.com/OpenAccess-AI-Collective/axolotl)
|
rshrott/llama2-qlora-finetuned-desription
|
rshrott
| 2023-07-27T16:19:55Z | 0 | 0 |
peft
|
[
"peft",
"region:us"
] | null | 2023-07-27T16:19:15Z |
---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float16
### Framework versions
- PEFT 0.5.0.dev0
|
Teunis89/Reinforce-cartpolev2
|
Teunis89
| 2023-07-27T16:11:18Z | 0 | 0 | null |
[
"CartPole-v1",
"reinforce",
"reinforcement-learning",
"custom-implementation",
"deep-rl-class",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-07-27T16:11:06Z |
---
tags:
- CartPole-v1
- reinforce
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: Reinforce-cartpolev2
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: CartPole-v1
type: CartPole-v1
metrics:
- type: mean_reward
value: 500.00 +/- 0.00
name: mean_reward
verified: false
---
# **Reinforce** Agent playing **CartPole-v1**
This is a trained model of a **Reinforce** agent playing **CartPole-v1** .
To learn to use this model and train yours check Unit 4 of the Deep Reinforcement Learning Course: https://huggingface.co/deep-rl-course/unit4/introduction
|
Lazycuber/Pygnen-dolly-6B
|
Lazycuber
| 2023-07-27T16:08:06Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gptj",
"text-generation",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-07-25T14:12:36Z |
---
license: apache-2.0
---
|
NasimB/aochildes-guten-fixed-rarity
|
NasimB
| 2023-07-27T16:08:03Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"generated_from_trainer",
"dataset:generator",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-07-27T13:44:04Z |
---
license: mit
tags:
- generated_from_trainer
datasets:
- generator
model-index:
- name: aochildes-guten-fixed-rarity
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# aochildes-guten-fixed-rarity
This model is a fine-tuned version of [gpt2](https://huggingface.co/gpt2) on the generator dataset.
It achieves the following results on the evaluation set:
- Loss: 4.1303
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 1000
- num_epochs: 6
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-----:|:---------------:|
| 6.3594 | 0.29 | 500 | 5.3491 |
| 5.0415 | 0.59 | 1000 | 4.9298 |
| 4.7231 | 0.88 | 1500 | 4.6896 |
| 4.4609 | 1.17 | 2000 | 4.5593 |
| 4.3125 | 1.47 | 2500 | 4.4429 |
| 4.2249 | 1.76 | 3000 | 4.3379 |
| 4.0892 | 2.05 | 3500 | 4.2753 |
| 3.9164 | 2.35 | 4000 | 4.2223 |
| 3.8843 | 2.64 | 4500 | 4.1690 |
| 3.8515 | 2.93 | 5000 | 4.1211 |
| 3.6513 | 3.23 | 5500 | 4.1170 |
| 3.6085 | 3.52 | 6000 | 4.0902 |
| 3.588 | 3.81 | 6500 | 4.0580 |
| 3.4821 | 4.11 | 7000 | 4.0584 |
| 3.335 | 4.4 | 7500 | 4.0540 |
| 3.3292 | 4.69 | 8000 | 4.0420 |
| 3.3232 | 4.99 | 8500 | 4.0278 |
| 3.1602 | 5.28 | 9000 | 4.0429 |
| 3.1574 | 5.58 | 9500 | 4.0414 |
| 3.1476 | 5.87 | 10000 | 4.0417 |
### Framework versions
- Transformers 4.26.1
- Pytorch 1.11.0+cu113
- Datasets 2.13.0
- Tokenizers 0.13.3
|
reach-vb/musicgen-small-endpoint
|
reach-vb
| 2023-07-27T16:01:44Z | 99 | 1 |
transformers
|
[
"transformers",
"pytorch",
"musicgen",
"text-to-audio",
"arxiv:2306.05284",
"license:cc-by-nc-4.0",
"endpoints_compatible",
"region:us"
] |
text-to-audio
| 2023-07-27T14:59:07Z |
---
inference: false
tags:
- musicgen
license: cc-by-nc-4.0
duplicated_from: facebook/musicgen-small
---
# MusicGen - Small - 300M
MusicGen is a text-to-music model capable of genreating high-quality music samples conditioned on text descriptions or audio prompts.
It is a single stage auto-regressive Transformer model trained over a 32kHz EnCodec tokenizer with 4 codebooks sampled at 50 Hz.
Unlike existing methods, like MusicLM, MusicGen doesn't require a self-supervised semantic representation, and it generates all 4 codebooks in one pass.
By introducing a small delay between the codebooks, we show we can predict them in parallel, thus having only 50 auto-regressive steps per second of audio.
MusicGen was published in [Simple and Controllable Music Generation](https://arxiv.org/abs/2306.05284) by *Jade Copet, Felix Kreuk, Itai Gat, Tal Remez, David Kant, Gabriel Synnaeve, Yossi Adi, Alexandre Défossez*.
Four checkpoints are released:
- [**small** (this checkpoint)](https://huggingface.co/facebook/musicgen-small)
- [medium](https://huggingface.co/facebook/musicgen-medium)
- [large](https://huggingface.co/facebook/musicgen-large)
- [melody](https://huggingface.co/facebook/musicgen-melody)
## Example
Try out MusicGen yourself!
* Audiocraft Colab:
<a target="_blank" href="https://colab.research.google.com/drive/1fxGqfg96RBUvGxZ1XXN07s3DthrKUl4-?usp=sharing">
<img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/>
</a>
* Hugging Face Colab:
<a target="_blank" href="https://colab.research.google.com/github/sanchit-gandhi/notebooks/blob/main/MusicGen.ipynb">
<img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/>
</a>
* Hugging Face Demo:
<a target="_blank" href="https://huggingface.co/spaces/facebook/MusicGen">
<img src="https://huggingface.co/datasets/huggingface/badges/raw/main/open-in-hf-spaces-sm.svg" alt="Open in HuggingFace"/>
</a>
## 🤗 Transformers Usage
You can run MusicGen locally with the 🤗 Transformers library from version 4.31.0 onwards.
1. First install the 🤗 [Transformers library](https://github.com/huggingface/transformers) from main:
```
pip install git+https://github.com/huggingface/transformers.git
```
2. Run the following Python code to generate text-conditional audio samples:
```py
from transformers import AutoProcessor, MusicgenForConditionalGeneration
processor = AutoProcessor.from_pretrained("facebook/musicgen-small")
model = MusicgenForConditionalGeneration.from_pretrained("facebook/musicgen-small")
inputs = processor(
text=["80s pop track with bassy drums and synth", "90s rock song with loud guitars and heavy drums"],
padding=True,
return_tensors="pt",
)
audio_values = model.generate(**inputs, max_new_tokens=256)
```
3. Listen to the audio samples either in an ipynb notebook:
```py
from IPython.display import Audio
sampling_rate = model.config.audio_encoder.sampling_rate
Audio(audio_values[0].numpy(), rate=sampling_rate)
```
Or save them as a `.wav` file using a third-party library, e.g. `scipy`:
```py
import scipy
sampling_rate = model.config.audio_encoder.sampling_rate
scipy.io.wavfile.write("musicgen_out.wav", rate=sampling_rate, data=audio_values[0, 0].numpy())
```
For more details on using the MusicGen model for inference using the 🤗 Transformers library, refer to the [MusicGen docs](https://huggingface.co/docs/transformers/model_doc/musicgen).
## Audiocraft Usage
You can also run MusicGen locally through the original [Audiocraft library]((https://github.com/facebookresearch/audiocraft):
1. First install the [`audiocraft` library](https://github.com/facebookresearch/audiocraft)
```
pip install git+https://github.com/facebookresearch/audiocraft.git
```
2. Make sure to have [`ffmpeg`](https://ffmpeg.org/download.html) installed:
```
apt get install ffmpeg
```
3. Run the following Python code:
```py
from audiocraft.models import MusicGen
from audiocraft.data.audio import audio_write
model = MusicGen.get_pretrained("small")
model.set_generation_params(duration=8) # generate 8 seconds.
descriptions = ["happy rock", "energetic EDM"]
wav = model.generate(descriptions) # generates 2 samples.
for idx, one_wav in enumerate(wav):
# Will save under {idx}.wav, with loudness normalization at -14 db LUFS.
audio_write(f'{idx}', one_wav.cpu(), model.sample_rate, strategy="loudness")
```
## Model details
**Organization developing the model:** The FAIR team of Meta AI.
**Model date:** MusicGen was trained between April 2023 and May 2023.
**Model version:** This is the version 1 of the model.
**Model type:** MusicGen consists of an EnCodec model for audio tokenization, an auto-regressive language model based on the transformer architecture for music modeling. The model comes in different sizes: 300M, 1.5B and 3.3B parameters ; and two variants: a model trained for text-to-music generation task and a model trained for melody-guided music generation.
**Paper or resources for more information:** More information can be found in the paper [Simple and Controllable Music Generation][https://arxiv.org/abs/2306.05284].
**Citation details**:
```
@misc{copet2023simple,
title={Simple and Controllable Music Generation},
author={Jade Copet and Felix Kreuk and Itai Gat and Tal Remez and David Kant and Gabriel Synnaeve and Yossi Adi and Alexandre Défossez},
year={2023},
eprint={2306.05284},
archivePrefix={arXiv},
primaryClass={cs.SD}
}
```
**License** Code is released under MIT, model weights are released under CC-BY-NC 4.0.
**Where to send questions or comments about the model:** Questions and comments about MusicGen can be sent via the [Github repository](https://github.com/facebookresearch/audiocraft) of the project, or by opening an issue.
## Intended use
**Primary intended use:** The primary use of MusicGen is research on AI-based music generation, including:
- Research efforts, such as probing and better understanding the limitations of generative models to further improve the state of science
- Generation of music guided by text or melody to understand current abilities of generative AI models by machine learning amateurs
**Primary intended users:** The primary intended users of the model are researchers in audio, machine learning and artificial intelligence, as well as amateur seeking to better understand those models.
**Out-of-scope use cases** The model should not be used on downstream applications without further risk evaluation and mitigation. The model should not be used to intentionally create or disseminate music pieces that create hostile or alienating environments for people. This includes generating music that people would foreseeably find disturbing, distressing, or offensive; or content that propagates historical or current stereotypes.
## Metrics
**Models performance measures:** We used the following objective measure to evaluate the model on a standard music benchmark:
- Frechet Audio Distance computed on features extracted from a pre-trained audio classifier (VGGish)
- Kullback-Leibler Divergence on label distributions extracted from a pre-trained audio classifier (PaSST)
- CLAP Score between audio embedding and text embedding extracted from a pre-trained CLAP model
Additionally, we run qualitative studies with human participants, evaluating the performance of the model with the following axes:
- Overall quality of the music samples;
- Text relevance to the provided text input;
- Adherence to the melody for melody-guided music generation.
More details on performance measures and human studies can be found in the paper.
**Decision thresholds:** Not applicable.
## Evaluation datasets
The model was evaluated on the [MusicCaps benchmark](https://www.kaggle.com/datasets/googleai/musiccaps) and on an in-domain held-out evaluation set, with no artist overlap with the training set.
## Training datasets
The model was trained using the following sources: the [Meta Music Initiative Sound Collection](https://www.fb.com/sound), [Shutterstock music collection](https://www.shutterstock.com/music) and the [Pond5 music collection](https://www.pond5.com/). See the paper for more details about the training set and corresponding preprocessing.
## Quantitative analysis
More information can be found in the paper [Simple and Controllable Music Generation][arxiv], in the Experimental Setup section.
## Limitations and biases
**Data:** The data sources used to train the model are created by music professionals and covered by legal agreements with the right holders. The model is trained on 20K hours of data, we believe that scaling the model on larger datasets can further improve the performance of the model.
**Mitigations:** All vocals have been removed from the data source using a state-of-the-art music source separation method, namely using the open source [Hybrid Transformer for Music Source Separation](https://github.com/facebookresearch/demucs) (HT-Demucs). The model is therefore not able to produce vocals.
**Limitations:**
- The model is not able to generate realistic vocals.
- The model has been trained with English descriptions and will not perform as well in other languages.
- The model does not perform equally well for all music styles and cultures.
- The model sometimes generates end of songs, collapsing to silence.
- It is sometimes difficult to assess what types of text descriptions provide the best generations. Prompt engineering may be required to obtain satisfying results.
**Biases:** The source of data is potentially lacking diversity and all music cultures are not equally represented in the dataset. The model may not perform equally well on the wide variety of music genres that exists. The generated samples from the model will reflect the biases from the training data. Further work on this model should include methods for balanced and just representations of cultures, for example, by scaling the training data to be both diverse and inclusive.
**Risks and harms:** Biases and limitations of the model may lead to generation of samples that may be considered as biased, inappropriate or offensive. We believe that providing the code to reproduce the research and train new models will allow to broaden the application to new and more representative data.
**Use cases:** Users must be aware of the biases, limitations and risks of the model. MusicGen is a model developed for artificial intelligence research on controllable music generation. As such, it should not be used for downstream applications without further investigation and mitigation of risks.
|
WforGodot/add-lora-7b
|
WforGodot
| 2023-07-27T15:54:56Z | 0 | 0 |
peft
|
[
"peft",
"region:us"
] | null | 2023-07-26T17:39:31Z |
---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: True
- bnb_4bit_compute_dtype: bfloat16
### Framework versions
- PEFT 0.4.0
|
mahmoudzamani/t5_recommendation_sports_equipment_english
|
mahmoudzamani
| 2023-07-27T15:30:14Z | 107 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"t5",
"text2text-generation",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2023-07-27T15:18:57Z |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- rouge
model-index:
- name: t5_recommendation_sports_equipment_english
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5_recommendation_sports_equipment_english
This model is a fine-tuned version of [t5-large](https://huggingface.co/t5-large) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4517
- Rouge1: 57.9365
- Rouge2: 47.6190
- Rougel: 56.9841
- Rougelsum: 56.6667
- Gen Len: 3.9048
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:-------:|:-------:|:-------:|:---------:|:-------:|
| No log | 0.96 | 6 | 6.7882 | 8.8278 | 0.9524 | 8.7668 | 8.8278 | 19.0 |
| No log | 1.96 | 12 | 2.3412 | 18.0952 | 0.0 | 18.0952 | 18.0952 | 3.2381 |
| No log | 2.96 | 18 | 0.8550 | 11.9048 | 4.7619 | 11.9048 | 11.9048 | 4.0 |
| No log | 3.96 | 24 | 0.7481 | 32.3810 | 4.7619 | 32.0635 | 32.0635 | 3.9048 |
| No log | 4.96 | 30 | 0.7208 | 21.2698 | 4.7619 | 20.7937 | 20.7937 | 3.6190 |
| No log | 5.96 | 36 | 0.6293 | 31.7460 | 23.8095 | 31.7460 | 31.7460 | 3.6667 |
| No log | 6.96 | 42 | 0.6203 | 43.6508 | 33.3333 | 43.4921 | 42.6984 | 3.9048 |
| No log | 7.96 | 48 | 0.6352 | 48.4127 | 33.3333 | 46.8254 | 46.8254 | 3.8095 |
| No log | 8.96 | 54 | 0.5334 | 53.2540 | 42.8571 | 52.3810 | 52.0635 | 3.9524 |
| No log | 9.96 | 60 | 0.4517 | 57.9365 | 47.6190 | 56.9841 | 56.6667 | 3.9048 |
### Framework versions
- Transformers 4.26.0
- Pytorch 2.0.1+cu118
- Datasets 2.8.0
- Tokenizers 0.13.3
|
kfkas/RoBERTa-large-Detection-G2P
|
kfkas
| 2023-07-27T15:17:45Z | 170 | 1 |
transformers
|
[
"transformers",
"pytorch",
"safetensors",
"roberta",
"text-classification",
"generated_from_keras_callback",
"ko",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-06-01T08:30:01Z |
---
language:
- ko
tags:
- generated_from_keras_callback
model-index:
- name: RoBERTa-large-Detection-P2G
results: []
---
# RoBERTa-large-Detection-P2G
이 모델은 klue/roberta-large을 국립 국어원 신문 말뭉치 5만개의 문장을 2021을 g2pK로 훈련시켜 G2P된 데이터를 탐지합니다.<br>
git : https://github.com/taemin6697<br>
## Usage
```python
from transformers import AutoTokenizer, RobertaForSequenceClassification
import torch
import numpy as np
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model_dir = "kfkas/RoBERTa-large-Detection-G2P"
tokenizer = AutoTokenizer.from_pretrained('klue/roberta-large')
model = RobertaForSequenceClassification.from_pretrained(model_dir).to(device)
text = "월드커 파나은행 대표티메 행우늬 이달러 이영영장 선물"
with torch.no_grad():
x = tokenizer(text, padding='max_length', truncation=True, return_tensors='pt', max_length=128)
y_pred = model(x["input_ids"].to(device))
logits = y_pred.logits
y_pred = logits.detach().cpu().numpy()
y = np.argmax(y_pred)
print(y)
#1
```
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: None
- training_precision: float16
### Training results
### Framework versions
- Transformers 4.22.1
- TensorFlow 2.10.0
- Datasets 2.5.1
- Tokenizers 0.12.1
|
S1X3L4/poca-SoccerTwos
|
S1X3L4
| 2023-07-27T15:11:36Z | 23 | 0 |
ml-agents
|
[
"ml-agents",
"tensorboard",
"onnx",
"SoccerTwos",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-SoccerTwos",
"region:us"
] |
reinforcement-learning
| 2023-07-27T15:10:00Z |
---
library_name: ml-agents
tags:
- SoccerTwos
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-SoccerTwos
---
# **poca** Agent playing **SoccerTwos**
This is a trained model of a **poca** agent playing **SoccerTwos**
using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://unity-technologies.github.io/ml-agents/ML-Agents-Toolkit-Documentation/
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
- A *short tutorial* where you teach Huggy the Dog 🐶 to fetch the stick and then play with him directly in your
browser: https://huggingface.co/learn/deep-rl-course/unitbonus1/introduction
- A *longer tutorial* to understand how works ML-Agents:
https://huggingface.co/learn/deep-rl-course/unit5/introduction
### Resume the training
```bash
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser**
1. If the environment is part of ML-Agents official environments, go to https://huggingface.co/unity
2. Step 1: Find your model_id: S1X3L4/poca-SoccerTwos
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
StofEzz/mascir_fr_hubert_test
|
StofEzz
| 2023-07-27T15:03:40Z | 136 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"hubert",
"automatic-speech-recognition",
"generated_from_trainer",
"base_model:facebook/hubert-large-ls960-ft",
"base_model:finetune:facebook/hubert-large-ls960-ft",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2023-07-27T12:22:50Z |
---
license: apache-2.0
base_model: facebook/hubert-large-ls960-ft
tags:
- generated_from_trainer
metrics:
- wer
model-index:
- name: mascir_fr_hubert_test
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mascir_fr_hubert_test
This model is a fine-tuned version of [facebook/hubert-large-ls960-ft](https://huggingface.co/facebook/hubert-large-ls960-ft) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0113
- Wer: 0.1680
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 1000
- num_epochs: 100
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| No log | 8.06 | 250 | 3.0885 | 0.9919 |
| 5.8634 | 16.13 | 500 | 2.8476 | 0.9919 |
| 5.8634 | 24.19 | 750 | 1.1091 | 0.9461 |
| 1.7302 | 32.26 | 1000 | 0.4035 | 0.6076 |
| 1.7302 | 40.32 | 1250 | 0.1643 | 0.3980 |
| 0.5446 | 48.39 | 1500 | 0.0872 | 0.2784 |
| 0.5446 | 56.45 | 1750 | 0.0464 | 0.2257 |
| 0.3144 | 64.52 | 2000 | 0.0311 | 0.2021 |
| 0.3144 | 72.58 | 2250 | 0.0213 | 0.1891 |
| 0.2224 | 80.65 | 2500 | 0.0155 | 0.1816 |
| 0.2224 | 88.71 | 2750 | 0.0132 | 0.1699 |
| 0.1871 | 96.77 | 3000 | 0.0113 | 0.1680 |
### Framework versions
- Transformers 4.31.0
- Pytorch 2.0.1+cu118
- Datasets 2.14.0
- Tokenizers 0.13.3
|
cardiffnlp/pcl_robertabase
|
cardiffnlp
| 2023-07-27T15:01:06Z | 110 | 0 |
transformers
|
[
"transformers",
"pytorch",
"roberta",
"text-classification",
"en",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-07-20T15:25:52Z |
---
language:
- en
---
## PCL
Someone uses __Patronizing and Condescending Language (PCL)__ when their use of the language denotes a superior attitude towards someone else, or depicts them in a compassionate way, raising a feeling of pity among the audience.
## pcl-roberta-base model for PCL detection
This model is trained on __Don't Patronize Me!__ , a dataset of paragraphs extracted from media articles about vulnerable communities, published in 20 English-speaking countries or areas. The paragraphs have been manually annotated to assess if they contain any type of PCL.
This is the PCL detection model built on roBERTa-base.
- Git Repo: [Don't Patronize Me! official repository](https://github.com/Perez-AlmendrosC/dontpatronizeme)
- Dataset: [Available upon request here] (https://docs.google.com/forms/d/e/1FAIpQLSe5KyzXgpnEOjS-Y6Gb8TTKiWxh4_qLuPL-NGiqKCyF41ALlg/viewform)
<b>Labels</b>:
0 -> Negative;
1 -> Positive
To know more about our work on PCL detection, the PCL detection model and the dataset, please refer to:
## Reference Papers:
```
@inproceedings{perez2020don,
title={Don’t Patronize Me! An Annotated Dataset with Patronizing and Condescending Language towards Vulnerable Communities},
author={P{\'e}rez-Almendros, Carla and Anke, Luis Espinosa and Schockaert, Steven},
booktitle={Proceedings of the 28th International Conference on Computational Linguistics},
pages={5891--5902},
year={2020}
}
```
```
@inproceedings{perez2022semeval,
title={SemEval-2022 task 4: Patronizing and condescending language detection},
author={P{\'e}rez-Almendros, Carla and Anke, Luis Espinosa and Schockaert, Steven},
booktitle={Proceedings of the 16th International Workshop on Semantic Evaluation (SemEval-2022)},
pages={298--307},
year={2022}
}
```
```
@inproceedings{perez2022identifying,
title={Identifying condescending language: A tale of two distinct phenomena?},
author={Perez-Almendros, Carla and Schockaert, Steven},
booktitle={Proceedings of the Second Workshop on NLP for Positive Impact (NLP4PI)},
pages={130--141},
year={2022}
}
```
|
janani4office2/results
|
janani4office2
| 2023-07-27T14:57:33Z | 7 | 0 |
transformers
|
[
"transformers",
"pytorch",
"mpt",
"text-generation",
"generated_from_trainer",
"custom_code",
"base_model:mosaicml/mpt-7b-instruct",
"base_model:finetune:mosaicml/mpt-7b-instruct",
"license:cc-by-sa-3.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-07-27T09:53:30Z |
---
license: cc-by-sa-3.0
base_model: mosaicml/mpt-7b-instruct
tags:
- generated_from_trainer
model-index:
- name: results
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# results
This model is a fine-tuned version of [mosaicml/mpt-7b-instruct](https://huggingface.co/mosaicml/mpt-7b-instruct) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 16
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 50
### Training results
### Framework versions
- Transformers 4.31.0
- Pytorch 1.12.1+cu116
- Datasets 2.14.0
- Tokenizers 0.12.1
|
Pierre-Arthur/distilbert-base-uncased-finetuned-imdb
|
Pierre-Arthur
| 2023-07-27T14:55:00Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"fill-mask",
"generated_from_trainer",
"dataset:imdb",
"base_model:distilbert/distilbert-base-uncased",
"base_model:finetune:distilbert/distilbert-base-uncased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2023-07-27T14:51:24Z |
---
license: apache-2.0
base_model: distilbert-base-uncased
tags:
- generated_from_trainer
datasets:
- imdb
model-index:
- name: distilbert-base-uncased-finetuned-imdb
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-imdb
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the imdb dataset.
It achieves the following results on the evaluation set:
- Loss: 2.4125
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 2.7026 | 1.0 | 157 | 2.4957 |
| 2.581 | 2.0 | 314 | 2.4286 |
| 2.5363 | 3.0 | 471 | 2.4515 |
### Framework versions
- Transformers 4.31.0
- Pytorch 2.0.1+cu118
- Datasets 2.14.0
- Tokenizers 0.13.3
|
xfh/Chinese-Llama-2-7b-f16-ggml
|
xfh
| 2023-07-27T14:47:22Z | 0 | 0 | null |
[
"zh",
"en",
"license:openrail",
"region:us"
] | null | 2023-07-27T14:21:01Z |
---
license: openrail
language:
- zh
- en
---
This is Chinese-Llama-2-7b f16 ggml model running llama.cpp.You can run
```shell
./main -m Chinese-Llama-2-7b-f16-ggml.bin -p 'hello world'
```
from model see: https://huggingface.co/LinkSoul/Chinese-Llama-2-7b
|
epsilonai/SargeRVB
|
epsilonai
| 2023-07-27T14:42:04Z | 0 | 0 | null |
[
"rvb",
"red vs blue",
"music",
"rvc",
"text-to-speech",
"en",
"region:us"
] |
text-to-speech
| 2023-07-27T14:38:06Z |
---
language:
- en
pipeline_tag: text-to-speech
tags:
- rvb
- red vs blue
- music
- rvc
---
|
Hadihandrian22/vonny
|
Hadihandrian22
| 2023-07-27T14:33:26Z | 0 | 0 | null |
[
"license:creativeml-openrail-m",
"region:us"
] | null | 2023-07-27T14:33:26Z |
---
license: creativeml-openrail-m
---
|
Varshitha/flan-t5-small-finetuned-medicine
|
Varshitha
| 2023-07-27T14:27:11Z | 102 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"t5",
"text2text-generation",
"text2textgeneration",
"generated_from_trainer",
"base_model:google/flan-t5-small",
"base_model:finetune:google/flan-t5-small",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2023-07-27T14:10:18Z |
---
license: apache-2.0
base_model: google/flan-t5-small
tags:
- text2textgeneration
- generated_from_trainer
metrics:
- rouge
model-index:
- name: flan-t5-small-finetuned-medicine
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# flan-t5-small-finetuned-medicine
This model is a fine-tuned version of [google/flan-t5-small](https://huggingface.co/google/flan-t5-small) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 2.9066
- Rouge1: 9.3596
- Rouge2: 2.6144
- Rougel: 8.94
- Rougelsum: 8.94
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5.6e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum |
|:-------------:|:-----:|:----:|:---------------:|:------:|:------:|:------:|:---------:|
| 3.1417 | 1.0 | 5 | 2.9168 | 9.5238 | 2.6144 | 8.9947 | 8.9947 |
| 3.1069 | 2.0 | 10 | 2.9066 | 9.3596 | 2.6144 | 8.94 | 8.94 |
### Framework versions
- Transformers 4.31.0
- Pytorch 2.0.1+cu118
- Datasets 2.14.0
- Tokenizers 0.13.3
|
oljike/nurtas-lora
|
oljike
| 2023-07-27T14:14:38Z | 12 | 1 |
diffusers
|
[
"diffusers",
"tensorboard",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"lora",
"base_model:dreamlike-art/dreamlike-photoreal-2.0",
"base_model:adapter:dreamlike-art/dreamlike-photoreal-2.0",
"license:creativeml-openrail-m",
"region:us"
] |
text-to-image
| 2023-07-25T18:24:29Z |
---
license: creativeml-openrail-m
base_model: dreamlike-art/dreamlike-photoreal-2.0
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
- lora
inference: true
---
# LoRA text2image fine-tuning - oljike/nurtas-lora
These are LoRA adaption weights for dreamlike-art/dreamlike-photoreal-2.0. The weights were fine-tuned on the ../../../data/people/nurtas dataset. You can find some example images in the following.

|
prajwalJumde/MRR-Latest-27-7
|
prajwalJumde
| 2023-07-27T14:08:11Z | 2 | 0 |
transformers
|
[
"transformers",
"pytorch",
"roberta",
"question-answering",
"generated_from_trainer",
"base_model:am-infoweb/MRR-Latest-21-7",
"base_model:finetune:am-infoweb/MRR-Latest-21-7",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2023-07-27T12:27:28Z |
---
license: apache-2.0
base_model: am-infoweb/MRR-Latest-21-7
tags:
- generated_from_trainer
model-index:
- name: MRR-Latest-27-7
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# MRR-Latest-27-7
This model is a fine-tuned version of [am-infoweb/MRR-Latest-21-7](https://huggingface.co/am-infoweb/MRR-Latest-21-7) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 2.1198
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 25
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-----:|:---------------:|
| 0.9033 | 1.0 | 630 | 0.6143 |
| 0.6184 | 2.0 | 1260 | 0.8534 |
| 0.5676 | 3.0 | 1890 | 0.6799 |
| 0.4571 | 4.0 | 2520 | 0.7548 |
| 0.4373 | 5.0 | 3150 | 0.9901 |
| 0.4133 | 6.0 | 3780 | 0.7865 |
| 0.3761 | 7.0 | 4410 | 0.8389 |
| 0.367 | 8.0 | 5040 | 0.8556 |
| 0.3665 | 9.0 | 5670 | 1.0920 |
| 0.3377 | 10.0 | 6300 | 1.0847 |
| 0.2857 | 11.0 | 6930 | 1.1071 |
| 0.2991 | 12.0 | 7560 | 1.0964 |
| 0.2647 | 13.0 | 8190 | 1.3036 |
| 0.2518 | 14.0 | 8820 | 1.3547 |
| 0.2543 | 15.0 | 9450 | 1.5333 |
| 0.2156 | 16.0 | 10080 | 1.4622 |
| 0.1856 | 17.0 | 10710 | 1.4964 |
| 0.2144 | 18.0 | 11340 | 1.7252 |
| 0.1993 | 19.0 | 11970 | 1.7526 |
| 0.1723 | 20.0 | 12600 | 1.8491 |
| 0.1257 | 21.0 | 13230 | 2.0100 |
| 0.1555 | 22.0 | 13860 | 1.9707 |
| 0.1276 | 23.0 | 14490 | 2.0484 |
| 0.1216 | 24.0 | 15120 | 2.1069 |
| 0.1252 | 25.0 | 15750 | 2.1198 |
### Framework versions
- Transformers 4.32.0.dev0
- Pytorch 2.0.1+cu117
- Datasets 2.13.1
- Tokenizers 0.13.3
|
loopping/blockassist-bc-durable_marine_bee_1756448824
|
loopping
| 2025-08-29T06:27:22Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"durable marine bee",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-29T06:27:06Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- durable marine bee
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
burkerlee123/Qwen3-0.6B-Gensyn-Swarm-wiry_reclusive_bee
|
burkerlee123
| 2025-08-29T06:27:13Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen3",
"text-generation",
"rl-swarm",
"genrl-swarm",
"grpo",
"gensyn",
"I am wiry_reclusive_bee",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-29T05:54:08Z |
---
library_name: transformers
tags:
- rl-swarm
- genrl-swarm
- grpo
- gensyn
- I am wiry_reclusive_bee
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
koloni/blockassist-bc-deadly_graceful_stingray_1756447306
|
koloni
| 2025-08-29T06:27:13Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"deadly graceful stingray",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-29T06:27:10Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- deadly graceful stingray
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Leonardo6/sft-llava-1.5-7b-hf-vsft
|
Leonardo6
| 2025-08-29T06:27:07Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"generated_from_trainer",
"trl",
"sft",
"base_model:llava-hf/llava-1.5-7b-hf",
"base_model:finetune:llava-hf/llava-1.5-7b-hf",
"endpoints_compatible",
"region:us"
] | null | 2025-08-29T06:08:27Z |
---
base_model: llava-hf/llava-1.5-7b-hf
library_name: transformers
model_name: sft-llava-1.5-7b-hf-vsft
tags:
- generated_from_trainer
- trl
- sft
licence: license
---
# Model Card for sft-llava-1.5-7b-hf-vsft
This model is a fine-tuned version of [llava-hf/llava-1.5-7b-hf](https://huggingface.co/llava-hf/llava-1.5-7b-hf).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="None", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="150" height="24"/>](https://wandb.ai/leonardo666-tsinghua-university/huggingface/runs/em8scb6g)
This model was trained with SFT.
### Framework versions
- TRL: 0.22.0.dev0
- Transformers: 4.55.0
- Pytorch: 2.6.0
- Datasets: 4.0.0
- Tokenizers: 0.21.2
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
xinyifang/ArxivGPT_pro
|
xinyifang
| 2025-08-29T06:26:55Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"gpt_oss",
"text-generation",
"text-generation-inference",
"unsloth",
"conversational",
"en",
"base_model:unsloth/gpt-oss-20b-unsloth-bnb-4bit",
"base_model:finetune:unsloth/gpt-oss-20b-unsloth-bnb-4bit",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-29T06:22:09Z |
---
base_model: unsloth/gpt-oss-20b-unsloth-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- gpt_oss
license: apache-2.0
language:
- en
---
# Uploaded finetuned model
- **Developed by:** xinyifang
- **License:** apache-2.0
- **Finetuned from model :** unsloth/gpt-oss-20b-unsloth-bnb-4bit
This gpt_oss model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
DevQuasar/CohereLabs.command-a-translate-08-2025-GGUF
|
DevQuasar
| 2025-08-29T06:26:41Z | 0 | 2 | null |
[
"gguf",
"text-generation",
"base_model:CohereLabs/command-a-translate-08-2025",
"base_model:quantized:CohereLabs/command-a-translate-08-2025",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] |
text-generation
| 2025-08-28T18:04:06Z |
---
base_model:
- CohereLabs/command-a-translate-08-2025
pipeline_tag: text-generation
---
[<img src="https://raw.githubusercontent.com/csabakecskemeti/devquasar/main/dq_logo_black-transparent.png" width="200"/>](https://devquasar.com)
'Make knowledge free for everyone'
Quantized version of: [CohereLabs/command-a-translate-08-2025](https://huggingface.co/CohereLabs/command-a-translate-08-2025)
<a href='https://ko-fi.com/L4L416YX7C' target='_blank'><img height='36' style='border:0px;height:36px;' src='https://storage.ko-fi.com/cdn/kofi6.png?v=6' border='0' alt='Buy Me a Coffee at ko-fi.com' /></a>
|
vwzyrraz7l/blockassist-bc-tall_hunting_vulture_1756447307
|
vwzyrraz7l
| 2025-08-29T06:26:07Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"tall hunting vulture",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-29T06:26:04Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- tall hunting vulture
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
WHDtyrael/Qwen3-0.6B-Gensyn-Swarm-bellowing_giant_hare
|
WHDtyrael
| 2025-08-29T06:25:53Z | 31 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen3",
"text-generation",
"rl-swarm",
"genrl-swarm",
"grpo",
"gensyn",
"I am bellowing_giant_hare",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-07-01T14:48:31Z |
---
library_name: transformers
tags:
- rl-swarm
- genrl-swarm
- grpo
- gensyn
- I am bellowing_giant_hare
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
jblair456/t5-large-mental-health-chat-1
|
jblair456
| 2025-08-29T06:25:42Z | 0 | 0 |
peft
|
[
"peft",
"safetensors",
"base_model:adapter:t5-large",
"lora",
"transformers",
"arxiv:1910.09700",
"base_model:google-t5/t5-large",
"base_model:adapter:google-t5/t5-large",
"region:us"
] | null | 2025-08-29T05:13:14Z |
---
base_model: t5-large
library_name: peft
tags:
- base_model:adapter:t5-large
- lora
- transformers
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.17.1
- PEFT 0.17.0
|
wuyanzu4692/task-13-Qwen-Qwen2.5-0.5B-Instruct
|
wuyanzu4692
| 2025-08-29T06:25:39Z | 3,227 | 0 |
peft
|
[
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:Qwen/Qwen2.5-0.5B-Instruct",
"base_model:adapter:Qwen/Qwen2.5-0.5B-Instruct",
"region:us"
] | null | 2025-08-07T04:16:16Z |
---
base_model: Qwen/Qwen2.5-0.5B-Instruct
library_name: peft
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.13.2
|
Yodhasu04/PrethesisSFT
|
Yodhasu04
| 2025-08-29T06:25:24Z | 0 | 0 | null |
[
"safetensors",
"mistral",
"en",
"base_model:mistralai/Mistral-7B-v0.3",
"base_model:finetune:mistralai/Mistral-7B-v0.3",
"license:mit",
"region:us"
] | null | 2025-08-29T03:51:37Z |
---
license: mit
language:
- en
metrics:
- bleu
- bleurt
base_model:
- mistralai/Mistral-7B-v0.3
new_version: Yodhasu04/PreThesis
---
|
skyskyyin55/Qwen3-0.6B-Gensyn-Swarm-darting_zealous_antelope
|
skyskyyin55
| 2025-08-29T06:25:14Z | 141 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen3",
"text-generation",
"rl-swarm",
"genrl-swarm",
"grpo",
"gensyn",
"I am darting_zealous_antelope",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-23T03:05:19Z |
---
library_name: transformers
tags:
- rl-swarm
- genrl-swarm
- grpo
- gensyn
- I am darting_zealous_antelope
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
hamidrpj/Qwen2.5-0.5B-Instruct-Gensyn-Swarm-bellowing_rangy_baboon
|
hamidrpj
| 2025-08-29T06:25:13Z | 126 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"rl-swarm",
"genrl-swarm",
"grpo",
"gensyn",
"I am bellowing_rangy_baboon",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-26T15:28:11Z |
---
library_name: transformers
tags:
- rl-swarm
- genrl-swarm
- grpo
- gensyn
- I am bellowing_rangy_baboon
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Zachary1150/OpenRS-GRPO
|
Zachary1150
| 2025-08-29T06:25:04Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"generated_from_trainer",
"open-r1",
"trl",
"grpo",
"conversational",
"dataset:knoveleng/open-rs",
"arxiv:2402.03300",
"base_model:deepseek-ai/DeepSeek-R1-Distill-Qwen-7B",
"base_model:finetune:deepseek-ai/DeepSeek-R1-Distill-Qwen-7B",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-28T01:30:31Z |
---
base_model: deepseek-ai/DeepSeek-R1-Distill-Qwen-7B
datasets: knoveleng/open-rs
library_name: transformers
model_name: OpenRS-GRPO
tags:
- generated_from_trainer
- open-r1
- trl
- grpo
licence: license
---
# Model Card for OpenRS-GRPO
This model is a fine-tuned version of [deepseek-ai/DeepSeek-R1-Distill-Qwen-7B](https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Qwen-7B) on the [knoveleng/open-rs](https://huggingface.co/datasets/knoveleng/open-rs) dataset.
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="Zachary1150/OpenRS-GRPO", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="150" height="24"/>](https://wandb.ai/zhikaili/huggingface/runs/cszrirj4)
This model was trained with GRPO, a method introduced in [DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models](https://huggingface.co/papers/2402.03300).
### Framework versions
- TRL: 0.18.0
- Transformers: 4.52.3
- Pytorch: 2.6.0
- Datasets: 3.6.0
- Tokenizers: 0.21.2
## Citations
Cite GRPO as:
```bibtex
@article{zhihong2024deepseekmath,
title = {{DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models}},
author = {Zhihong Shao and Peiyi Wang and Qihao Zhu and Runxin Xu and Junxiao Song and Mingchuan Zhang and Y. K. Li and Y. Wu and Daya Guo},
year = 2024,
eprint = {arXiv:2402.03300},
}
```
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
valoaye/Qwen2.5-0.5B-Instruct-Gensyn-Swarm-placid_sizable_buffalo
|
valoaye
| 2025-08-29T06:24:55Z | 147 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"rl-swarm",
"genrl-swarm",
"grpo",
"gensyn",
"I am placid_sizable_buffalo",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-10T13:37:36Z |
---
library_name: transformers
tags:
- rl-swarm
- genrl-swarm
- grpo
- gensyn
- I am placid_sizable_buffalo
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
tor4k/Qwen3-0.6B-Gensyn-Swarm-sizable_robust_squirrel
|
tor4k
| 2025-08-29T06:24:41Z | 114 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen3",
"text-generation",
"rl-swarm",
"genrl-swarm",
"grpo",
"gensyn",
"I am sizable_robust_squirrel",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-25T05:36:32Z |
---
library_name: transformers
tags:
- rl-swarm
- genrl-swarm
- grpo
- gensyn
- I am sizable_robust_squirrel
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
hidayahlut/Qwen3-0.6B-Gensyn-Swarm-rangy_insectivorous_snail
|
hidayahlut
| 2025-08-29T06:24:37Z | 135 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen3",
"text-generation",
"rl-swarm",
"genrl-swarm",
"grpo",
"gensyn",
"I am rangy_insectivorous_snail",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-12T10:56:25Z |
---
library_name: transformers
tags:
- rl-swarm
- genrl-swarm
- grpo
- gensyn
- I am rangy_insectivorous_snail
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
emperorfutures/Qwen3-0.6B-Gensyn-Swarm-furry_sniffing_ferret
|
emperorfutures
| 2025-08-29T06:24:37Z | 27 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen3",
"text-generation",
"rl-swarm",
"genrl-swarm",
"grpo",
"gensyn",
"I am furry_sniffing_ferret",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-27T21:48:47Z |
---
library_name: transformers
tags:
- rl-swarm
- genrl-swarm
- grpo
- gensyn
- I am furry_sniffing_ferret
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Junheelee070712/Midm-2.0-Mini-Instruct-Q4_K_M-GGUF
|
Junheelee070712
| 2025-08-29T06:24:31Z | 0 | 0 |
transformers
|
[
"transformers",
"gguf",
"KT",
"K-intelligence",
"Mi:dm",
"llama-cpp",
"gguf-my-repo",
"text-generation",
"en",
"ko",
"base_model:K-intelligence/Midm-2.0-Mini-Instruct",
"base_model:quantized:K-intelligence/Midm-2.0-Mini-Instruct",
"license:mit",
"endpoints_compatible",
"region:us",
"conversational"
] |
text-generation
| 2025-08-29T06:24:23Z |
---
license: mit
language:
- en
- ko
tags:
- KT
- K-intelligence
- Mi:dm
- llama-cpp
- gguf-my-repo
pipeline_tag: text-generation
library_name: transformers
base_model: K-intelligence/Midm-2.0-Mini-Instruct
---
# Junheelee070712/Midm-2.0-Mini-Instruct-Q4_K_M-GGUF
This model was converted to GGUF format from [`K-intelligence/Midm-2.0-Mini-Instruct`](https://huggingface.co/K-intelligence/Midm-2.0-Mini-Instruct) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/K-intelligence/Midm-2.0-Mini-Instruct) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew (works on Mac and Linux)
```bash
brew install llama.cpp
```
Invoke the llama.cpp server or the CLI.
### CLI:
```bash
llama-cli --hf-repo Junheelee070712/Midm-2.0-Mini-Instruct-Q4_K_M-GGUF --hf-file midm-2.0-mini-instruct-q4_k_m.gguf -p "The meaning to life and the universe is"
```
### Server:
```bash
llama-server --hf-repo Junheelee070712/Midm-2.0-Mini-Instruct-Q4_K_M-GGUF --hf-file midm-2.0-mini-instruct-q4_k_m.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
Step 1: Clone llama.cpp from GitHub.
```
git clone https://github.com/ggerganov/llama.cpp
```
Step 2: Move into the llama.cpp folder and build it with `LLAMA_CURL=1` flag along with other hardware-specific flags (for ex: LLAMA_CUDA=1 for Nvidia GPUs on Linux).
```
cd llama.cpp && LLAMA_CURL=1 make
```
Step 3: Run inference through the main binary.
```
./llama-cli --hf-repo Junheelee070712/Midm-2.0-Mini-Instruct-Q4_K_M-GGUF --hf-file midm-2.0-mini-instruct-q4_k_m.gguf -p "The meaning to life and the universe is"
```
or
```
./llama-server --hf-repo Junheelee070712/Midm-2.0-Mini-Instruct-Q4_K_M-GGUF --hf-file midm-2.0-mini-instruct-q4_k_m.gguf -c 2048
```
|
tranbaninh/Qwen2.5-0.5B-Instruct-Gensyn-Swarm-hoarse_sedate_marmot
|
tranbaninh
| 2025-08-29T06:24:25Z | 119 | 1 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"generated_from_trainer",
"rl-swarm",
"grpo",
"gensyn",
"I am hoarse sedate marmot",
"unsloth",
"trl",
"genrl-swarm",
"I am hoarse_sedate_marmot",
"conversational",
"arxiv:2402.03300",
"base_model:Gensyn/Qwen2.5-0.5B-Instruct",
"base_model:finetune:Gensyn/Qwen2.5-0.5B-Instruct",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-04-05T14:47:43Z |
---
base_model: Gensyn/Qwen2.5-0.5B-Instruct
library_name: transformers
model_name: Qwen2.5-0.5B-Instruct-Gensyn-Swarm-hoarse_sedate_marmot
tags:
- generated_from_trainer
- rl-swarm
- grpo
- gensyn
- I am hoarse sedate marmot
- unsloth
- trl
- genrl-swarm
- I am hoarse_sedate_marmot
licence: license
---
# Model Card for Qwen2.5-0.5B-Instruct-Gensyn-Swarm-hoarse_sedate_marmot
This model is a fine-tuned version of [Gensyn/Qwen2.5-0.5B-Instruct](https://huggingface.co/Gensyn/Qwen2.5-0.5B-Instruct).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="tranbaninh/Qwen2.5-0.5B-Instruct-Gensyn-Swarm-hoarse_sedate_marmot", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
This model was trained with GRPO, a method introduced in [DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models](https://huggingface.co/papers/2402.03300).
### Framework versions
- TRL: 0.15.2
- Transformers: 4.48.2
- Pytorch: 2.5.1
- Datasets: 3.6.0
- Tokenizers: 0.21.1
## Citations
Cite GRPO as:
```bibtex
@article{zhihong2024deepseekmath,
title = {{DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models}},
author = {Zhihong Shao and Peiyi Wang and Qihao Zhu and Runxin Xu and Junxiao Song and Mingchuan Zhang and Y. K. Li and Y. Wu and Daya Guo},
year = 2024,
eprint = {arXiv:2402.03300},
}
```
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallouédec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
Geventy/Qwen2.5-0.5B-Instruct-Gensyn-Swarm-skittish_durable_okapi
|
Geventy
| 2025-08-29T06:24:12Z | 45 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"rl-swarm",
"genrl-swarm",
"grpo",
"gensyn",
"I am skittish_durable_okapi",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-27T06:43:08Z |
---
library_name: transformers
tags:
- rl-swarm
- genrl-swarm
- grpo
- gensyn
- I am skittish_durable_okapi
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
daldal2/Qwen3-0.6B-Gensyn-Swarm-dense_shrewd_skunk
|
daldal2
| 2025-08-29T06:24:10Z | 86 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen3",
"text-generation",
"rl-swarm",
"genrl-swarm",
"grpo",
"gensyn",
"I am dense_shrewd_skunk",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-27T11:49:01Z |
---
library_name: transformers
tags:
- rl-swarm
- genrl-swarm
- grpo
- gensyn
- I am dense_shrewd_skunk
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
MATheGooner/Qwen3-0.6B-Gensyn-Swarm-shaggy_smooth_scorpion
|
MATheGooner
| 2025-08-29T06:24:08Z | 95 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen3",
"text-generation",
"rl-swarm",
"genrl-swarm",
"grpo",
"gensyn",
"I am shaggy_smooth_scorpion",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-07-27T07:19:42Z |
---
library_name: transformers
tags:
- rl-swarm
- genrl-swarm
- grpo
- gensyn
- I am shaggy_smooth_scorpion
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
pavlodp/Qwen2.5-0.5B-Instruct-Gensyn-Swarm-bristly_freckled_weasel
|
pavlodp
| 2025-08-29T06:24:04Z | 20 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"generated_from_trainer",
"rl-swarm",
"grpo",
"gensyn",
"I am bristly freckled weasel",
"trl",
"genrl-swarm",
"I am bristly_freckled_weasel",
"conversational",
"arxiv:2402.03300",
"base_model:unsloth/Qwen2.5-0.5B-Instruct",
"base_model:finetune:unsloth/Qwen2.5-0.5B-Instruct",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-05-08T11:22:00Z |
---
base_model: unsloth/Qwen2.5-0.5B-Instruct
library_name: transformers
model_name: Qwen2.5-0.5B-Instruct-Gensyn-Swarm-bristly_freckled_weasel
tags:
- generated_from_trainer
- rl-swarm
- grpo
- gensyn
- I am bristly freckled weasel
- trl
- genrl-swarm
- I am bristly_freckled_weasel
licence: license
---
# Model Card for Qwen2.5-0.5B-Instruct-Gensyn-Swarm-bristly_freckled_weasel
This model is a fine-tuned version of [unsloth/Qwen2.5-0.5B-Instruct](https://huggingface.co/unsloth/Qwen2.5-0.5B-Instruct).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="pavlodp/Qwen2.5-0.5B-Instruct-Gensyn-Swarm-bristly_freckled_weasel", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
This model was trained with GRPO, a method introduced in [DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models](https://huggingface.co/papers/2402.03300).
### Framework versions
- TRL: 0.17.0
- Transformers: 4.52.3
- Pytorch: 2.7.0
- Datasets: 3.6.0
- Tokenizers: 0.21.1
## Citations
Cite GRPO as:
```bibtex
@article{zhihong2024deepseekmath,
title = {{DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models}},
author = {Zhihong Shao and Peiyi Wang and Qihao Zhu and Runxin Xu and Junxiao Song and Mingchuan Zhang and Y. K. Li and Y. Wu and Daya Guo},
year = 2024,
eprint = {arXiv:2402.03300},
}
```
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
lagoscity/Qwen2.5-0.5B-Instruct-Gensyn-Swarm-gentle_howling_spider
|
lagoscity
| 2025-08-29T06:24:02Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"rl-swarm",
"genrl-swarm",
"grpo",
"gensyn",
"I am gentle_howling_spider",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-28T15:34:10Z |
---
library_name: transformers
tags:
- rl-swarm
- genrl-swarm
- grpo
- gensyn
- I am gentle_howling_spider
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
madhavgohel/bert-token-onnx
|
madhavgohel
| 2025-08-29T06:23:53Z | 31 | 0 | null |
[
"onnx",
"bert",
"base_model:google-bert/bert-base-uncased",
"base_model:quantized:google-bert/bert-base-uncased",
"region:us"
] | null | 2025-08-01T19:31:34Z |
---
base_model:
- google-bert/bert-base-uncased
---
# 🔍 BERT Token Classification – Important Chunk Extractor (ONNX)
This model identifies and extracts important parts of input sentences using BERT-based token classification, exported to the ONNX format for optimized inference.
---
## 🧠 Use Case
This model is designed for **context engineering** — to extract semantically important words or chunks from sentences or chat messages, enabling better personalization in downstream applications like AI assistants or dialogue systems.
Example:
```
Input: I’ll be unavailable tomorrow due to a team offsite.
Output: [unavailable, tomorrow, team offsite]
```
---
## 🛠️ Model Details
* **Architecture**: BERT (`bert-base-uncased`) fine-tuned for token classification
* **Exported to**: ONNX for efficient runtime inference via [Optimum](https://huggingface.co/docs/optimum/onnxruntime)
* **Labels**:
* `0`: Not Important
* `1`: Important
---
## 📦 How to Use (with 🤗 Transformers + Optimum)
```python
from transformers import AutoTokenizer
from optimum.onnxruntime import ORTModelForTokenClassification
import torch
model = ORTModelForTokenClassification.from_pretrained("madhavgohel/bert-token-onnx", file_name="model.onnx")
tokenizer = AutoTokenizer.from_pretrained("madhavgohel/bert-token-onnx")
text = "I'm a software engineer with 5 years experience looking to switch to a data science role."
inputs = tokenizer(text, return_tensors="pt")
outputs = model(**inputs)
predictions = torch.argmax(outputs.logits, dim=-1)
tokens = tokenizer.convert_ids_to_tokens(inputs["input_ids"][0])
important_tokens = [tok for tok, label in zip(tokens, predictions[0]) if label == 1]
print("Important tokens:", important_tokens)
```
---
## 📁 Files Included
| File | Purpose |
| ------------------------- | ----------------------------------- |
| `model.onnx` | Exported ONNX model |
| `config.json` | Model config |
| `tokenizer_config.json` | Tokenizer config |
| `vocab.txt` | Vocabulary for BERT tokenizer |
| `special_tokens_map.json` | Tokenization map for special tokens |
| `README.md` | Model usage documentation |
|
hazentr/Qwen2.5-0.5B-Instruct-Gensyn-Swarm-slender_grunting_koala
|
hazentr
| 2025-08-29T06:23:31Z | 155 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"generated_from_trainer",
"rl-swarm",
"trl",
"gensyn",
"grpo",
"I am slender grunting koala",
"genrl-swarm",
"I am slender_grunting_koala",
"conversational",
"arxiv:2402.03300",
"base_model:unsloth/Qwen2.5-0.5B-Instruct",
"base_model:finetune:unsloth/Qwen2.5-0.5B-Instruct",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-04-02T16:33:05Z |
---
base_model: unsloth/Qwen2.5-0.5B-Instruct
library_name: transformers
model_name: Qwen2.5-0.5B-Instruct-Gensyn-Swarm-slender_grunting_koala
tags:
- generated_from_trainer
- rl-swarm
- trl
- gensyn
- grpo
- I am slender grunting koala
- genrl-swarm
- I am slender_grunting_koala
licence: license
---
# Model Card for Qwen2.5-0.5B-Instruct-Gensyn-Swarm-slender_grunting_koala
This model is a fine-tuned version of [unsloth/Qwen2.5-0.5B-Instruct](https://huggingface.co/unsloth/Qwen2.5-0.5B-Instruct).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="hazentr/Qwen2.5-0.5B-Instruct-Gensyn-Swarm-slender_grunting_koala", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
This model was trained with GRPO, a method introduced in [DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models](https://huggingface.co/papers/2402.03300).
### Framework versions
- TRL: 0.19.0
- Transformers: 4.52.4
- Pytorch: 2.7.1
- Datasets: 3.6.0
- Tokenizers: 0.21.1
## Citations
Cite GRPO as:
```bibtex
@article{zhihong2024deepseekmath,
title = {{DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models}},
author = {Zhihong Shao and Peiyi Wang and Qihao Zhu and Runxin Xu and Junxiao Song and Mingchuan Zhang and Y. K. Li and Y. Wu and Daya Guo},
year = 2024,
eprint = {arXiv:2402.03300},
}
```
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
insanesaga/Qwen3-0.6B-Gensyn-Swarm-nocturnal_clawed_bison
|
insanesaga
| 2025-08-29T06:23:29Z | 27 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen3",
"text-generation",
"rl-swarm",
"genrl-swarm",
"grpo",
"gensyn",
"I am nocturnal_clawed_bison",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-06-26T19:48:56Z |
---
library_name: transformers
tags:
- rl-swarm
- genrl-swarm
- grpo
- gensyn
- I am nocturnal_clawed_bison
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
liukevin666/blockassist-bc-yawning_striped_cassowary_1756448494
|
liukevin666
| 2025-08-29T06:23:00Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"yawning striped cassowary",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-29T06:22:30Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- yawning striped cassowary
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Hemgg/ecommerceX
|
Hemgg
| 2025-08-29T06:22:57Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"lfm2",
"text-generation",
"text-generation-inference",
"unsloth",
"trl",
"sft",
"conversational",
"en",
"base_model:unsloth/LFM2-1.2B",
"base_model:finetune:unsloth/LFM2-1.2B",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-28T10:24:35Z |
---
base_model: unsloth/LFM2-1.2B
tags:
- text-generation-inference
- transformers
- unsloth
- lfm2
- trl
- sft
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** Heem2
- **License:** apache-2.0
- **Finetuned from model :** unsloth/LFM2-1.2B
This lfm2 model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
rnoozy/Qwen3-0.6B-Gensyn-Swarm-scruffy_robust_cockroach
|
rnoozy
| 2025-08-29T06:22:55Z | 77 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen3",
"text-generation",
"rl-swarm",
"genrl-swarm",
"grpo",
"gensyn",
"I am scruffy_robust_cockroach",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-27T19:09:47Z |
---
library_name: transformers
tags:
- rl-swarm
- genrl-swarm
- grpo
- gensyn
- I am scruffy_robust_cockroach
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
okuzarabasi/Qwen2.5-0.5B-Instruct-Gensyn-Swarm-grunting_toothy_elk
|
okuzarabasi
| 2025-08-29T06:22:49Z | 82 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"generated_from_trainer",
"rl-swarm",
"grpo",
"gensyn",
"I am grunting toothy elk",
"unsloth",
"trl",
"genrl-swarm",
"I am grunting_toothy_elk",
"conversational",
"arxiv:2402.03300",
"base_model:Gensyn/Qwen2.5-0.5B-Instruct",
"base_model:finetune:Gensyn/Qwen2.5-0.5B-Instruct",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-05-04T04:34:50Z |
---
base_model: Gensyn/Qwen2.5-0.5B-Instruct
library_name: transformers
model_name: Qwen2.5-0.5B-Instruct-Gensyn-Swarm-grunting_toothy_elk
tags:
- generated_from_trainer
- rl-swarm
- grpo
- gensyn
- I am grunting toothy elk
- unsloth
- trl
- genrl-swarm
- I am grunting_toothy_elk
licence: license
---
# Model Card for Qwen2.5-0.5B-Instruct-Gensyn-Swarm-grunting_toothy_elk
This model is a fine-tuned version of [Gensyn/Qwen2.5-0.5B-Instruct](https://huggingface.co/Gensyn/Qwen2.5-0.5B-Instruct).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="okuzarabasi/Qwen2.5-0.5B-Instruct-Gensyn-Swarm-grunting_toothy_elk", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
This model was trained with GRPO, a method introduced in [DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models](https://huggingface.co/papers/2402.03300).
### Framework versions
- TRL: 0.15.2
- Transformers: 4.48.2
- Pytorch: 2.5.1
- Datasets: 3.6.0
- Tokenizers: 0.21.1
## Citations
Cite GRPO as:
```bibtex
@article{zhihong2024deepseekmath,
title = {{DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models}},
author = {Zhihong Shao and Peiyi Wang and Qihao Zhu and Runxin Xu and Junxiao Song and Mingchuan Zhang and Y. K. Li and Y. Wu and Daya Guo},
year = 2024,
eprint = {arXiv:2402.03300},
}
```
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallouédec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
Mouths/Qwen2.5-0.5B-Instruct-Gensyn-Swarm-untamed_quiet_condor
|
Mouths
| 2025-08-29T06:22:43Z | 101 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"rl-swarm",
"genrl-swarm",
"grpo",
"gensyn",
"I am untamed_quiet_condor",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-27T06:47:46Z |
---
library_name: transformers
tags:
- rl-swarm
- genrl-swarm
- grpo
- gensyn
- I am untamed_quiet_condor
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
lodestones/chroma-debug-development-only
|
lodestones
| 2025-08-29T06:22:35Z | 0 | 35 | null |
[
"license:cc-by-nc-sa-4.0",
"region:us"
] | null | 2025-01-21T05:08:22Z |
---
license: cc-by-nc-sa-4.0
---
all model listed in this repo it's purely for research purpose
once it's ready it will be uploaded to a separate repo under apache 2.0 license
|
link-uppal-farm-girl-original-viral-video/New.full.videos.uppal.farm.girl.Viral.Video.Official.Tutorial
|
link-uppal-farm-girl-original-viral-video
| 2025-08-29T06:22:16Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-08-29T06:22:07Z |
<a href="https://tinyurl.com/ybtx5at9" rel="nofollow" data-target="animated-image.originalLink"><img src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" alt="WATCH Videos" data-canonical-src="https://i.imgur.com/dJHk4Zq.gif" style="max-width: 100%; display: inline-block;" data-target="animated-image.originalImage"></a>
|
elsvastika1/Qwen2.5-0.5B-Instruct-Gensyn-Swarm-unseen_burrowing_cassowary
|
elsvastika1
| 2025-08-29T06:22:04Z | 121 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"rl-swarm",
"genrl-swarm",
"grpo",
"gensyn",
"I am unseen_burrowing_cassowary",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-17T20:13:05Z |
---
library_name: transformers
tags:
- rl-swarm
- genrl-swarm
- grpo
- gensyn
- I am unseen_burrowing_cassowary
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
infoipman/Qwen2.5-0.5B-Instruct-Gensyn-Swarm-tall_mammalian_caribou
|
infoipman
| 2025-08-29T06:21:54Z | 166 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"generated_from_trainer",
"rl-swarm",
"grpo",
"gensyn",
"I am tall mammalian caribou",
"unsloth",
"trl",
"genrl-swarm",
"I am tall_mammalian_caribou",
"conversational",
"arxiv:2402.03300",
"base_model:Gensyn/Qwen2.5-0.5B-Instruct",
"base_model:finetune:Gensyn/Qwen2.5-0.5B-Instruct",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-05-06T13:00:33Z |
---
base_model: Gensyn/Qwen2.5-0.5B-Instruct
library_name: transformers
model_name: Qwen2.5-0.5B-Instruct-Gensyn-Swarm-tall_mammalian_caribou
tags:
- generated_from_trainer
- rl-swarm
- grpo
- gensyn
- I am tall mammalian caribou
- unsloth
- trl
- genrl-swarm
- I am tall_mammalian_caribou
licence: license
---
# Model Card for Qwen2.5-0.5B-Instruct-Gensyn-Swarm-tall_mammalian_caribou
This model is a fine-tuned version of [Gensyn/Qwen2.5-0.5B-Instruct](https://huggingface.co/Gensyn/Qwen2.5-0.5B-Instruct).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="infoipman/Qwen2.5-0.5B-Instruct-Gensyn-Swarm-tall_mammalian_caribou", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
This model was trained with GRPO, a method introduced in [DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models](https://huggingface.co/papers/2402.03300).
### Framework versions
- TRL: 0.15.2
- Transformers: 4.51.3
- Pytorch: 2.6.0
- Datasets: 3.5.1
- Tokenizers: 0.21.1
## Citations
Cite GRPO as:
```bibtex
@article{zhihong2024deepseekmath,
title = {{DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models}},
author = {Zhihong Shao and Peiyi Wang and Qihao Zhu and Runxin Xu and Junxiao Song and Mingchuan Zhang and Y. K. Li and Y. Wu and Daya Guo},
year = 2024,
eprint = {arXiv:2402.03300},
}
```
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallouédec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
Subsets and Splits
Filtered Qwen2.5 Distill Models
Identifies specific configurations of models by filtering cards that contain 'distill', 'qwen2.5', '7b' while excluding certain base models and incorrect model ID patterns, uncovering unique model variants.
Filtered Model Cards Count
Finds the count of entries with specific card details that include 'distill', 'qwen2.5', '7b' but exclude certain base models, revealing valuable insights about the dataset's content distribution.
Filtered Distill Qwen 7B Models
Filters for specific card entries containing 'distill', 'qwen', and '7b', excluding certain strings and patterns, to identify relevant model configurations.
Filtered Qwen-7b Model Cards
The query performs a detailed filtering based on specific keywords and excludes certain entries, which could be useful for identifying a specific subset of cards but does not provide deeper insights or trends.
Filtered Qwen 7B Model Cards
The query filters for specific terms related to "distilled" or "distill", "qwen", and "7b" in the 'card' column but excludes certain base models, providing a limited set of entries for further inspection.
Qwen 7B Distilled Models
The query provides a basic filtering of records to find specific card names that include keywords related to distilled Qwen 7b models, excluding a particular base model, which gives limited insight but helps in focusing on relevant entries.
Qwen 7B Distilled Model Cards
The query filters data based on specific keywords in the modelId and card fields, providing limited insight primarily useful for locating specific entries rather than revealing broad patterns or trends.
Qwen 7B Distilled Models
Finds all entries containing the terms 'distilled', 'qwen', and '7b' in a case-insensitive manner, providing a filtered set of records but without deeper analysis.
Distilled Qwen 7B Models
The query filters for specific model IDs containing 'distilled', 'qwen', and '7b', providing a basic retrieval of relevant entries but without deeper analysis or insight.
Filtered Model Cards with Distill Qwen2.
Filters and retrieves records containing specific keywords in the card description while excluding certain phrases, providing a basic count of relevant entries.
Filtered Model Cards with Distill Qwen 7
The query filters specific variations of card descriptions containing 'distill', 'qwen', and '7b' while excluding a particular base model, providing limited but specific data retrieval.
Distill Qwen 7B Model Cards
The query filters and retrieves rows where the 'card' column contains specific keywords ('distill', 'qwen', and '7b'), providing a basic filter result that can help in identifying specific entries.