
modelId
stringlengths 5
139
| author
stringlengths 2
42
| last_modified
timestamp[us, tz=UTC]date 2020-02-15 11:33:14
2025-09-03 00:36:49
| downloads
int64 0
223M
| likes
int64 0
11.7k
| library_name
stringclasses 535
values | tags
listlengths 1
4.05k
| pipeline_tag
stringclasses 55
values | createdAt
timestamp[us, tz=UTC]date 2022-03-02 23:29:04
2025-09-03 00:36:49
| card
stringlengths 11
1.01M
|
|---|---|---|---|---|---|---|---|---|---|
monai-test/valve_landmarks
|
monai-test
| 2023-08-16T03:03:17Z | 0 | 0 |
monai
|
[
"monai",
"medical",
"license:mit",
"region:us"
] | null | 2023-08-16T03:03:10Z |
---
tags:
- monai
- medical
library_name: monai
license: mit
---
# 2D Cardiac Valve Landmark Regressor
This network identifies 10 different landmarks in 2D+t MR images of the heart (2 chamber, 3 chamber, and 4 chamber) representing the insertion locations of valve leaflets into the myocardial wall. These coordinates are used in part of the construction of 3D FEM cardiac models suitable for physics simulation of heart functions.
Input images are individual 2D slices from the time series, and the output from the network is a `(2, 10)` set of 2D points in `HW` image coordinate space. The 10 coordinates correspond to the attachment point for these valves:
1. Mitral anterior in 2CH
2. Mitral posterior in 2CH
3. Mitral septal in 3CH
4. Mitral free wall in 3CH
5. Mitral septal in 4CH
6. Mitral free wall in 4CH
7. Aortic septal
8. Aortic free wall
9. Tricuspid septal
10. Tricuspid free wall
Landmarks which do not appear in a particular image are predicted to be `(0, 0)` or close to this location. The mitral valve is expected to appear in all three views. Landmarks are not provided for the pulmonary valve.
Example plot of landmarks on a single frame, see [view_results.ipynb](./view_results.ipynb) for visualising network output:

## Training
The training script `train.json` is provided to train the network using a dataset of image pairs containing the MR image and a landmark image. This is done to reuse image-based transforms which do not currently operate on geometry. A number of other transforms are provided in `valve_landmarks.py` to implement Fourier-space dropout, image shifting which preserve landmarks, and smooth-field deformation applied to images and landmarks.
The dataset used for training unfortunately cannot be made public, however the training script can be used with any NPZ file containing the training image stack in key `trainImgs` and landmark image stack in `trainLMImgs`, plus `testImgs` and `testLMImgs` containing validation data. The landmark images are defined as 0 for every non-landmark pixel, with landmark pixels contaning the following values for each landmark type:
* 10: Mitral anterior in 2CH
* 15: Mitral posterior in 2CH
* 20: Mitral septal in 3CH
* 25: Mitral free wall in 3CH
* 30: Mitral septal in 4CH
* 35: Mitral free wall in 4CH
* 100: Aortic septal
* 150: Aortic free wall
* 200: Tricuspid septal
* 250: Tricuspid free wall
The following command will train with the default NPZ filename `./valvelandmarks.npz`, assuming the current directory is the bundle directory:
```sh
python -m monai.bundle run training --meta_file configs/metadata.json --config_file configs/train.json \
--bundle_root . --dataset_file ./valvelandmarks.npz --output_dir /path/to/outputs
```
## Inference
The included `inference.json` script will run inference on a directory containing Nifti files whose images have shape `(256, 256, 1, N)` for `N` timesteps. For each image the output in the `output_dir` directory will be a npy file containing a result array of shape `(N, 2, 10)` storing the 10 coordinates for each `N` timesteps. Invoking this script can be done as follows, assuming the current directory is the bundle directory:
```sh
python -m monai.bundle run evaluating --meta_file configs/metadata.json --config_file configs/inference.json \
--bundle_root . --dataset_dir /path/to/data --output_dir /path/to/outputs
```
The provided test Nifti file can be placed in a directory which is then used as the `dataset_dir` value. This image was derived from [the AMRG Cardiac Atlas dataset](http://www.cardiacatlas.org/studies/amrg-cardiac-atlas) (AMRG Cardiac Atlas, Auckland MRI Research Group, Auckland, New Zealand). The results from this inference can be visualised by changing path values in [view_results.ipynb](./view_results.ipynb).
### Reference
The work for this model and its application is described in:
`Kerfoot, E, King, CE, Ismail, T, Nordsletten, D & Miller, R 2021, Estimation of Cardiac Valve Annuli Motion with Deep Learning. in E Puyol Anton, M Pop, M Sermesant, V Campello, A Lalande, K Lekadir, A Suinesiaputra, O Camara & A Young (eds), Statistical Atlases and Computational Models of the Heart. MandMs and EMIDEC Challenges - 11th International Workshop, STACOM 2020, Held in Conjunction with MICCAI 2020, Revised Selected Papers. Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics), vol. 12592 LNCS, Springer Science and Business Media Deutschland GmbH, pp. 146-155, 11th International Workshop on Statistical Atlases and Computational Models of the Heart, STACOM 2020 held in Conjunction with MICCAI 2020, Lima, Peru, 4/10/2020. https://doi.org/10.1007/978-3-030-68107-4_15`
# License
This model is released under the MIT License. The license file is included with the model.
|
monai-test/swin_unetr_btcv_segmentation
|
monai-test
| 2023-08-16T03:03:07Z | 0 | 1 |
monai
|
[
"monai",
"medical",
"arxiv:2201.01266",
"arxiv:2111.14791",
"license:apache-2.0",
"region:us"
] | null | 2023-08-16T03:01:00Z |
---
tags:
- monai
- medical
library_name: monai
license: apache-2.0
---
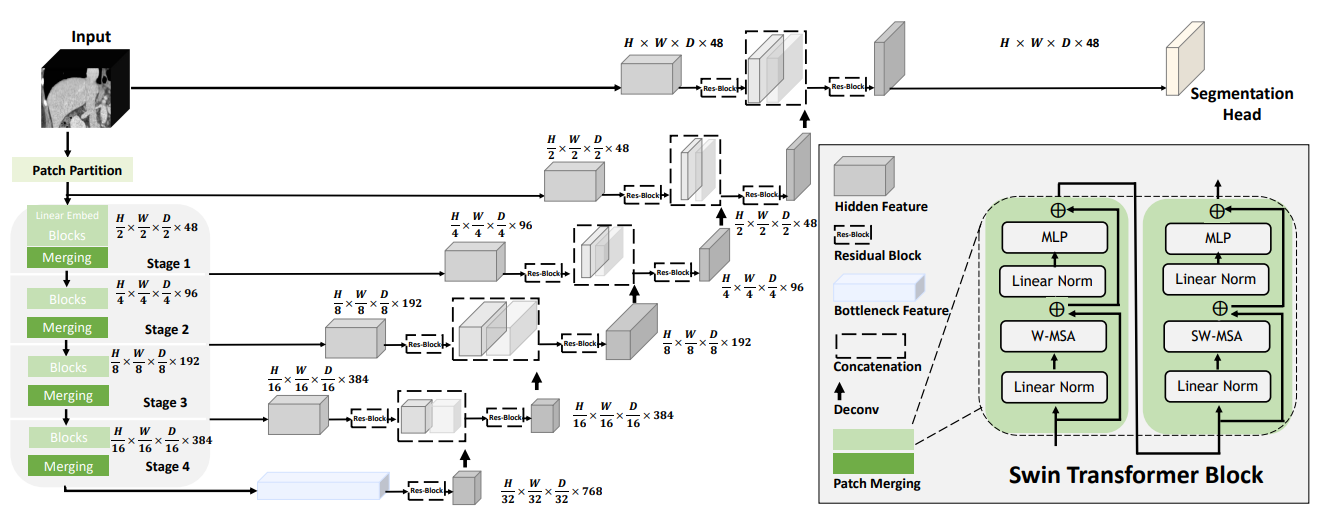
# Model Overview
A pre-trained Swin UNETR [1,2] for volumetric (3D) multi-organ segmentation using CT images from Beyond the Cranial Vault (BTCV) Segmentation Challenge dataset [3].
## Data
The training data is from the [BTCV dataset](https://www.synapse.org/#!Synapse:syn3193805/wiki/89480/) (Register through `Synapse` and download the `Abdomen/RawData.zip`).
- Target: Multi-organs
- Task: Segmentation
- Modality: CT
- Size: 30 3D volumes (24 Training + 6 Testing)
### Preprocessing
The dataset format needs to be redefined using the following commands:
```
unzip RawData.zip
mv RawData/Training/img/ RawData/imagesTr
mv RawData/Training/label/ RawData/labelsTr
mv RawData/Testing/img/ RawData/imagesTs
```
## Training configuration
The training as performed with the following:
- GPU: At least 32GB of GPU memory
- Actual Model Input: 96 x 96 x 96
- AMP: True
- Optimizer: Adam
- Learning Rate: 2e-4
### Memory Consumption
- Dataset Manager: CacheDataset
- Data Size: 30 samples
- Cache Rate: 1.0
- Single GPU - System RAM Usage: 5.8G
### Memory Consumption Warning
If you face memory issues with CacheDataset, you can either switch to a regular Dataset class or lower the caching rate `cache_rate` in the configurations within range [0, 1] to minimize the System RAM requirements.
### Input
1 channel
- CT image
### Output
14 channels:
- 0: Background
- 1: Spleen
- 2: Right Kidney
- 3: Left Kideny
- 4: Gallbladder
- 5: Esophagus
- 6: Liver
- 7: Stomach
- 8: Aorta
- 9: IVC
- 10: Portal and Splenic Veins
- 11: Pancreas
- 12: Right adrenal gland
- 13: Left adrenal gland
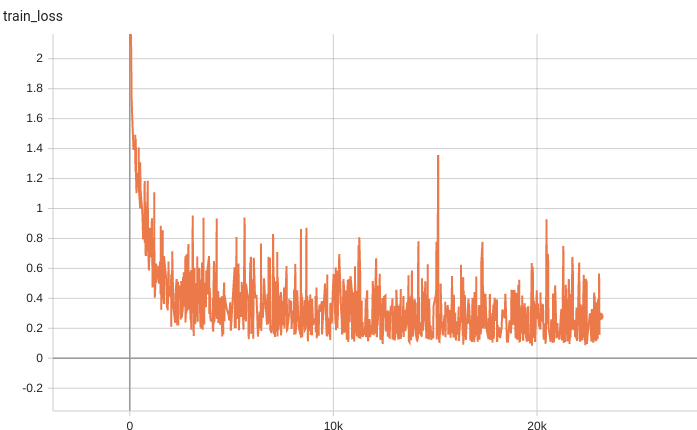
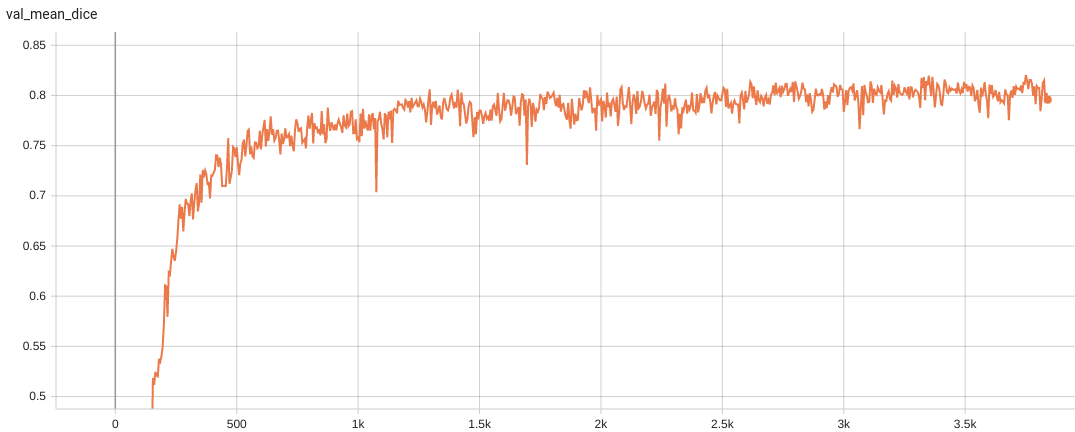
## Performance
Dice score was used for evaluating the performance of the model. This model achieves a mean dice score of 0.82
#### Training Loss
#### Validation Dice
## MONAI Bundle Commands
In addition to the Pythonic APIs, a few command line interfaces (CLI) are provided to interact with the bundle. The CLI supports flexible use cases, such as overriding configs at runtime and predefining arguments in a file.
For more details usage instructions, visit the [MONAI Bundle Configuration Page](https://docs.monai.io/en/latest/config_syntax.html).
#### Execute training:
```
python -m monai.bundle run --config_file configs/train.json
```
Please note that if the default dataset path is not modified with the actual path in the bundle config files, you can also override it by using `--dataset_dir`:
```
python -m monai.bundle run --config_file configs/train.json --dataset_dir <actual dataset path>
```
#### Override the `train` config to execute multi-GPU training:
```
torchrun --standalone --nnodes=1 --nproc_per_node=2 -m monai.bundle run --config_file "['configs/train.json','configs/multi_gpu_train.json']"
```
Please note that the distributed training-related options depend on the actual running environment; thus, users may need to remove `--standalone`, modify `--nnodes`, or do some other necessary changes according to the machine used. For more details, please refer to [pytorch's official tutorial](https://pytorch.org/tutorials/intermediate/ddp_tutorial.html).
#### Override the `train` config to execute evaluation with the trained model:
```
python -m monai.bundle run --config_file "['configs/train.json','configs/evaluate.json']"
```
#### Execute inference:
```
python -m monai.bundle run --config_file configs/inference.json
```
#### Export checkpoint to TorchScript file:
TorchScript conversion is currently not supported.
# References
[1] Hatamizadeh, Ali, et al. "Swin UNETR: Swin Transformers for Semantic Segmentation of Brain Tumors in MRI Images." arXiv preprint arXiv:2201.01266 (2022). https://arxiv.org/abs/2201.01266.
[2] Tang, Yucheng, et al. "Self-supervised pre-training of swin transformers for 3d medical image analysis." arXiv preprint arXiv:2111.14791 (2021). https://arxiv.org/abs/2111.14791.
[3] Landman B, et al. "MICCAI multi-atlas labeling beyond the cranial vault–workshop and challenge." In Proc. of the MICCAI Multi-Atlas Labeling Beyond Cranial Vault—Workshop Challenge 2015 Oct (Vol. 5, p. 12).
# License
Copyright (c) MONAI Consortium
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
|
monai-test/renalStructures_UNEST_segmentation
|
monai-test
| 2023-08-16T03:00:07Z | 0 | 0 |
monai
|
[
"monai",
"medical",
"arxiv:2203.02430",
"license:apache-2.0",
"region:us"
] | null | 2023-08-16T02:59:13Z |
---
tags:
- monai
- medical
library_name: monai
license: apache-2.0
---
# Description
A pre-trained model for training and inferencing volumetric (3D) kidney substructures segmentation from contrast-enhanced CT images (Arterial/Portal Venous Phase). Training pipeline is provided to support model fine-tuning with bundle and MONAI Label active learning.
A tutorial and release of model for kidney cortex, medulla and collecting system segmentation.
Authors: Yinchi Zhou (yinchi.zhou@vanderbilt.edu) | Xin Yu (xin.yu@vanderbilt.edu) | Yucheng Tang (yuchengt@nvidia.com) |
# Model Overview
A pre-trained UNEST base model [1] for volumetric (3D) renal structures segmentation using dynamic contrast enhanced arterial or venous phase CT images.
## Data
The training data is from the [ImageVU RenalSeg dataset] from Vanderbilt University and Vanderbilt University Medical Center.
(The training data is not public available yet).
- Target: Renal Cortex | Medulla | Pelvis Collecting System
- Task: Segmentation
- Modality: CT (Artrial | Venous phase)
- Size: 96 3D volumes
The data and segmentation demonstration is as follow:
 <br>
## Method and Network
The UNEST model is a 3D hierarchical transformer-based semgnetation network.
Details of the architecture:
 <br>
## Training configuration
The training was performed with at least one 16GB-memory GPU.
Actual Model Input: 96 x 96 x 96
## Input and output formats
Input: 1 channel CT image
Output: 4: 0:Background, 1:Renal Cortex, 2:Medulla, 3:Pelvicalyceal System
## Performance
A graph showing the validation mean Dice for 5000 epochs.
 <br>
This model achieves the following Dice score on the validation data (our own split from the training dataset):
Mean Valdiation Dice = 0.8523
Note that mean dice is computed in the original spacing of the input data.
## commands example
Download trained checkpoint model to ./model/model.pt:
Add scripts component: To run the workflow with customized components, PYTHONPATH should be revised to include the path to the customized component:
```
export PYTHONPATH=$PYTHONPATH:"'<path to the bundle root dir>/scripts'"
```
Execute Training:
```
python -m monai.bundle run training --meta_file configs/metadata.json --config_file configs/train.json --logging_file configs/logging.conf
```
Execute inference:
```
python -m monai.bundle run evaluating --meta_file configs/metadata.json --config_file configs/inference.json --logging_file configs/logging.conf
```
## More examples output
 <br>
# Disclaimer
This is an example, not to be used for diagnostic purposes.
# References
[1] Yu, Xin, Yinchi Zhou, Yucheng Tang et al. "Characterizing Renal Structures with 3D Block Aggregate Transformers." arXiv preprint arXiv:2203.02430 (2022). https://arxiv.org/pdf/2203.02430.pdf
[2] Zizhao Zhang et al. "Nested Hierarchical Transformer: Towards Accurate, Data-Efficient and Interpretable Visual Understanding." AAAI Conference on Artificial Intelligence (AAAI) 2022
# License
Copyright (c) MONAI Consortium
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
|
ZeroUniqueness/qlora-llama-2-13b-code
|
ZeroUniqueness
| 2023-08-16T02:59:42Z | 27 | 0 |
peft
|
[
"peft",
"region:us"
] | null | 2023-08-02T16:13:08Z |
---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: True
- bnb_4bit_compute_dtype: bfloat16
### Framework versions
- PEFT 0.5.0.dev0
|
monai-test/renalStructures_CECT_segmentation
|
monai-test
| 2023-08-16T02:58:59Z | 0 | 0 |
monai
|
[
"monai",
"medical",
"license:apache-2.0",
"region:us"
] | null | 2023-08-16T02:58:56Z |
---
tags:
- monai
- medical
library_name: monai
license: apache-2.0
---
# Model Title
Renal structures CECT segmentation
### **Authors**
Ivan Chernenkiy, Michael Chernenkiy, Dmitry Fiev, Evgeny Sirota, Center for Neural Network Technologies / Institute of Urology and Human Reproductive Systems / Sechenov First Moscow State Medical University
### **Tags**
Segmentation, CT, CECT, Kidney, Renal, Supervised
## **Model Description**
The model is the SegResNet architecture[1] for volumetric (3D) renal structures segmentation. Input is artery, vein, excretory phases after mutual registration and concatenated to 3 channel 3D tensor.
## **Data**
DICOM data from 41 patients with kidney neoplasms were used [2]. The images and segmentation data are available under a CC BY-NC-SA 4.0 license. Data included all phases of contrast-enhanced multispiral computed tomography. We split the data: 32 observations for the training set and 9 – for the validation set. At the labeling stage, the arterial, venous, and excretory phases were taken, affine registration was performed to jointly match the location of the kidneys, and noise was removed using a median filter and a non-local means filter. Validation set ip published to Yandex.Disk. You can download via [link](https://disk.yandex.ru/d/pWEKt6D3qi3-aw) or use following command:
```bash
python -m monai.bundle run download_data --meta_file configs/metadata.json --config_file "['configs/train.json', 'configs/evaluate.json']"
```
**NB**: underlying data is in LPS orientation. IF! you want to test model on your own data, reorient it from RAS to LPS with `Orientation` transform. You can see example of preprocessing pipeline in `inference.json` file of this bundle.
#### **Preprocessing**
Images are (1) croped to kidney region, all (artery,vein,excret) phases are (2) [registered](https://simpleitk.readthedocs.io/en/master/registrationOverview.html#lbl-registration-overview) with affine transform, noise removed with (3) median and (4) non-local means filter. After that, images are (5) resampled to (0.8,0.8,0.8) density and intesities are (6) scaled from [-1000,1000] to [0,1] range.
## **Performance**
On the validation subset, the values of the Dice score of the SegResNet architecture were: 0.89 for the normal parenchyma of the kidney, 0.58 for the kidney neoplasms, 0.86 for arteries, 0.80 for veins, 0.80 for ureters.
When compared with the nnU-Net model, which was trained on KiTS 21 dataset, the Dice score was greater for the kidney parenchyma in SegResNet – 0.89 compared to three model variants: lowres – 0.69, fullres – 0.70, cascade – 0.69. At the same time, for the neoplasms of the parenchyma of the kidney, the Dice score was comparable: for SegResNet – 0.58, for nnU-Net fullres – 0.59; lowres and cascade had lower Dice score of 0.37 and 0.45, respectively. To reproduce, visit - https://github.com/blacky-i/nephro-segmentation
## **Additional Usage Steps**
#### Execute training:
```bash
python -m monai.bundle run training --meta_file configs/metadata.json --config_file configs/train.json
```
Expected result: finished, Training process started
#### Execute training with finetuning
```bash
python -m monai.bundle run training --dont_finetune false --meta_file configs/metadata.json --config_file configs/train.json
```
Expected result: finished, Training process started, model variables are restored
#### Execute validation:
Download validation data (described in [Data](#data) section).
With provided model weights mean dice score is expected to be ~0.78446.
##### Run validation script:
```bash
python -m monai.bundle run evaluate --meta_file configs/metadata.json --config_file "['configs/train.json', 'configs/evaluate.json']"
```
Expected result: finished, `Key metric: val_mean_dice best value: ...` is printed.
## **System Configuration**
The model was trained for 10000 epochs on 2 RTX2080Ti GPUs with [SmartCacheDataset](https://docs.monai.io/en/stable/data.html#smartcachedataset). This takes 1 days and 2 hours, with 4 images per GPU.
Training progress is available on [tensorboard.dev](https://tensorboard.dev/experiment/VlEMjLdURH6SyFp216dFBg)
To perform training in minimal settings, at least one 12GB-memory GPU is required.
Actual Model Input: 96 x 96 x 96
## **Limitations**
For developmental purposes only and cannot be used directly for clinical procedures.
## **Citation Info**
```
@article{chernenkiy2023segmentation,
title={Segmentation of renal structures based on contrast computed tomography scans using a convolutional neural network},
author={Chernenkiy, IМ and Chernenkiy, MM and Fiev, DN and Sirota, ES},
journal={Sechenov Medical Journal},
volume={14},
number={1},
pages={39--49},
year={2023}
}
```
## **References**
[1] Myronenko, A. (2019). 3D MRI Brain Tumor Segmentation Using Autoencoder Regularization. In: Crimi, A., Bakas, S., Kuijf, H., Keyvan, F., Reyes, M., van Walsum, T. (eds) Brainlesion: Glioma, Multiple Sclerosis, Stroke and Traumatic Brain Injuries. BrainLes 2018. Lecture Notes in Computer Science(), vol 11384. Springer, Cham. https://doi.org/10.1007/978-3-030-11726-9_28
[2] Chernenkiy, I. М., et al. "Segmentation of renal structures based on contrast computed tomography scans using a convolutional neural network." Sechenov Medical Journal 14.1 (2023): 39-49.https://doi.org/10.47093/2218-7332.2023.14.1.39-49
#### **Tests used for bundle checking**
Checking with ci script file
```bash
python ci/verify_bundle.py -b renalStructures_CECT_segmentation -p models
```
Expected result: passed, model.pt file downloaded
Checking downloading validation data file
```bash
cd models/renalStructures_CECT_segmentation
python -m monai.bundle run download_data --meta_file configs/metadata.json --config_file "['configs/train.json', 'configs/evaluate.json']"
```
Expected result: finished, `data/` folder is created and filled with images.
Checking evaluation script
```bash
python -m monai.bundle run evaluate --meta_file configs/metadata.json --config_file "['configs/train.json', 'configs/evaluate.json']"
```
Expected result: finished, `Key metric: val_mean_dice best value: ...` is printed.
Checking train script
```bash
python -m monai.bundle run training --meta_file configs/metadata.json --config_file configs/train.json
```
Expected result: finished, Training process started
Checking train script with finetuning
```bash
python -m monai.bundle run training --dont_finetune false --meta_file configs/metadata.json --config_file configs/train.json
```
Expected result: finished, Training process started, model variables are restored
Checking inference script
```bash
python -m monai.bundle run inference --meta_file configs/metadata.json --config_file configs/inference.json
```
Expected result: finished, in `eval` folder masks are created
Check unit test with script:
```bash
python ci/unit_tests/runner.py --b renalStructures_CECT_segmentation
```
|
monai-test/prostate_mri_anatomy
|
monai-test
| 2023-08-16T02:58:50Z | 0 | 0 |
monai
|
[
"monai",
"medical",
"arxiv:1903.08205",
"license:apache-2.0",
"region:us"
] | null | 2023-08-16T02:58:06Z |
---
tags:
- monai
- medical
library_name: monai
license: apache-2.0
---
# Prostate MRI zonal segmentation
### **Authors**
Lisa C. Adams, Keno K. Bressem
### **Tags**
Segmentation, MR, Prostate
## **Model Description**
This model was trained with the UNet architecture [1] and is used for 3D volumetric segmentation of the anatomical prostate zones on T2w MRI images. The segmentation of the anatomical regions is formulated as a voxel-wise classification. Each voxel is classified as either central gland (1), peripheral zone (2), or background (0). The model is optimized using a gradient descent method that minimizes the focal soft-dice loss between the predicted mask and the actual segmentation.
## **Data**
The model was trained in the prostate158 training data, which is available at https://doi.org/10.5281/zenodo.6481141. Only T2w images were used for this task.
### **Preprocessing**
MRI images in the prostate158 dataset were preprocessed, including center cropping and resampling. When applying the model to new data, this preprocessing should be repeated.
#### **Center cropping**
T2w images were acquired with a voxel spacing of 0.47 x 0.47 x 3 mm and an axial FOV size of 180 x 180 mm. However, the prostate rarely exceeds an axial diameter of 100 mm, and for zonal segmentation, the tissue surrounding the prostate is not of interest and only increases the image size and thus the computational cost. Center-cropping can reduce the image size without sacrificing information.
The script `center_crop.py` allows to reproduce center-cropping as performed in the prostate158 paper.
```bash
python scripts/center_crop.py --file_name path/to/t2_image --out_name cropped_t2
```
#### **Resampling**
DWI and ADC sequences in prostate158 were resampled to the orientation and voxel spacing of the T2w sequence. As the zonal segmentation uses T2w images, no additional resampling is nessecary. However, the training script will perform additonal resampling automatically.
## **Performance**
The model achives the following performance on the prostate158 test dataset:
<table border=1 frame=void rules=rows>
<thead>
<tr>
<td></td>
<td colspan = 3><b><center>Rater 1</center></b></td>
<td> </td>
<td colspan = 3><b><center>Rater 2</center></b></td>
</tr>
<tr>
<th>Metric</th>
<th>Transitional Zone</th>
<th>Peripheral Zone</th>
<th> </th>
<th>Transitional Zone</th>
<th>Peripheral Zone</th>
</tr>
</thead>
<tbody>
<tr>
<td><a href='https://en.wikipedia.org/wiki/S%C3%B8rensen%E2%80%93Dice_coefficient'>Dice Coefficient </a></td>
<td> 0.877</td>
<td> 0.754</td>
<td> </td>
<td> 0.875</td>
<td> 0.730</td>
</tr>
<tr>
<td><a href='https://en.wikipedia.org/wiki/Hausdorff_distance'>Hausdorff Distance </a></td>
<td> 18.3</td>
<td> 22.8</td>
<td> </td>
<td> 17.5</td>
<td> 33.2</td>
</tr>
<tr>
<td><a href='https://github.com/deepmind/surface-distance'>Surface Distance </a></td>
<td> 2.19</td>
<td> 1.95</td>
<td> </td>
<td> 2.59</td>
<td> 1.88</td>
</tr>
</tbody>
</table>
For more details, please see the original [publication](https://doi.org/10.1016/j.compbiomed.2022.105817) or official [GitHub repository](https://github.com/kbressem/prostate158)
## **System Configuration**
The model was trained for 100 epochs on a workstaion with a single Nvidia RTX 3080 GPU. This takes approximatly 8 hours.
## **Limitations** (Optional)
This training and inference pipeline was developed for research purposes only. This research use only software that has not been cleared or approved by FDA or any regulatory agency. The model is for research/developmental purposes only and cannot be used directly for clinical procedures.
## **Citation Info** (Optional)
```
@article{ADAMS2022105817,
title = {Prostate158 - An expert-annotated 3T MRI dataset and algorithm for prostate cancer detection},
journal = {Computers in Biology and Medicine},
volume = {148},
pages = {105817},
year = {2022},
issn = {0010-4825},
doi = {https://doi.org/10.1016/j.compbiomed.2022.105817},
url = {https://www.sciencedirect.com/science/article/pii/S0010482522005789},
author = {Lisa C. Adams and Marcus R. Makowski and Günther Engel and Maximilian Rattunde and Felix Busch and Patrick Asbach and Stefan M. Niehues and Shankeeth Vinayahalingam and Bram {van Ginneken} and Geert Litjens and Keno K. Bressem},
keywords = {Prostate cancer, Deep learning, Machine learning, Artificial intelligence, Magnetic resonance imaging, Biparametric prostate MRI}
}
```
## **References**
[1] Sakinis, Tomas, et al. "Interactive segmentation of medical images through fully convolutional neural networks." arXiv preprint arXiv:1903.08205 (2019).
# License
Copyright (c) MONAI Consortium
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
|
monai-test/pathology_nuclick_annotation
|
monai-test
| 2023-08-16T02:56:54Z | 0 | 0 |
monai
|
[
"monai",
"medical",
"arxiv:2005.14511",
"license:apache-2.0",
"region:us"
] | null | 2023-08-16T02:56:25Z |
---
tags:
- monai
- medical
library_name: monai
license: apache-2.0
---
# Model Overview
A pre-trained model for segmenting nuclei cells with user clicks/interactions.



This model is trained using [BasicUNet](https://docs.monai.io/en/latest/networks.html#basicunet) over [ConSeP](https://warwick.ac.uk/fac/cross_fac/tia/data/hovernet) dataset.
## Data
The training dataset is from https://warwick.ac.uk/fac/cross_fac/tia/data/hovernet
```commandline
wget https://warwick.ac.uk/fac/cross_fac/tia/data/hovernet/consep_dataset.zip
unzip -q consep_dataset.zip
```
<br/>
### Preprocessing
After [downloading this dataset](https://warwick.ac.uk/fac/cross_fac/tia/data/hovernet/consep_dataset.zip),
python script `data_process.py` from `scripts` folder can be used to preprocess and generate the final dataset for training.
```
python scripts/data_process.py --input /path/to/data/CoNSeP --output /path/to/data/CoNSePNuclei
```
After generating the output files, please modify the `dataset_dir` parameter specified in `configs/train.json` and `configs/inference.json` to reflect the output folder which contains new dataset.json.
Class values in dataset are
- 1 = other
- 2 = inflammatory
- 3 = healthy epithelial
- 4 = dysplastic/malignant epithelial
- 5 = fibroblast
- 6 = muscle
- 7 = endothelial
As part of pre-processing, the following steps are executed.
- Crop and Extract each nuclei Image + Label (128x128) based on the centroid given in the dataset.
- Combine classes 3 & 4 into the epithelial class and 5,6 & 7 into the spindle-shaped class.
- Update the label index for the target nuclei based on the class value
- Other cells which are part of the patch are modified to have label idx = 255
Example dataset.json
```json
{
"training": [
{
"image": "/workspace/data/CoNSePNuclei/Train/Images/train_1_3_0001.png",
"label": "/workspace/data/CoNSePNuclei/Train/Labels/train_1_3_0001.png",
"nuclei_id": 1,
"mask_value": 3,
"centroid": [
64,
64
]
}
],
"validation": [
{
"image": "/workspace/data/CoNSePNuclei/Test/Images/test_1_3_0001.png",
"label": "/workspace/data/CoNSePNuclei/Test/Labels/test_1_3_0001.png",
"nuclei_id": 1,
"mask_value": 3,
"centroid": [
64,
64
]
}
]
}
```
## Training Configuration
The training was performed with the following:
- GPU: at least 12GB of GPU memory
- Actual Model Input: 5 x 128 x 128
- AMP: True
- Optimizer: Adam
- Learning Rate: 1e-4
- Loss: DiceLoss
### Memory Consumption
- Dataset Manager: CacheDataset
- Data Size: 13,136 PNG images
- Cache Rate: 1.0
- Single GPU - System RAM Usage: 4.7G
### Memory Consumption Warning
If you face memory issues with CacheDataset, you can either switch to a regular Dataset class or lower the caching rate `cache_rate` in the configurations within range [0, 1] to minimize the System RAM requirements.
## Input
5 channels
- 3 RGB channels
- +ve signal channel (this nuclei)
- -ve signal channel (other nuclei)
## Output
2 channels
- 0 = Background
- 1 = Nuclei
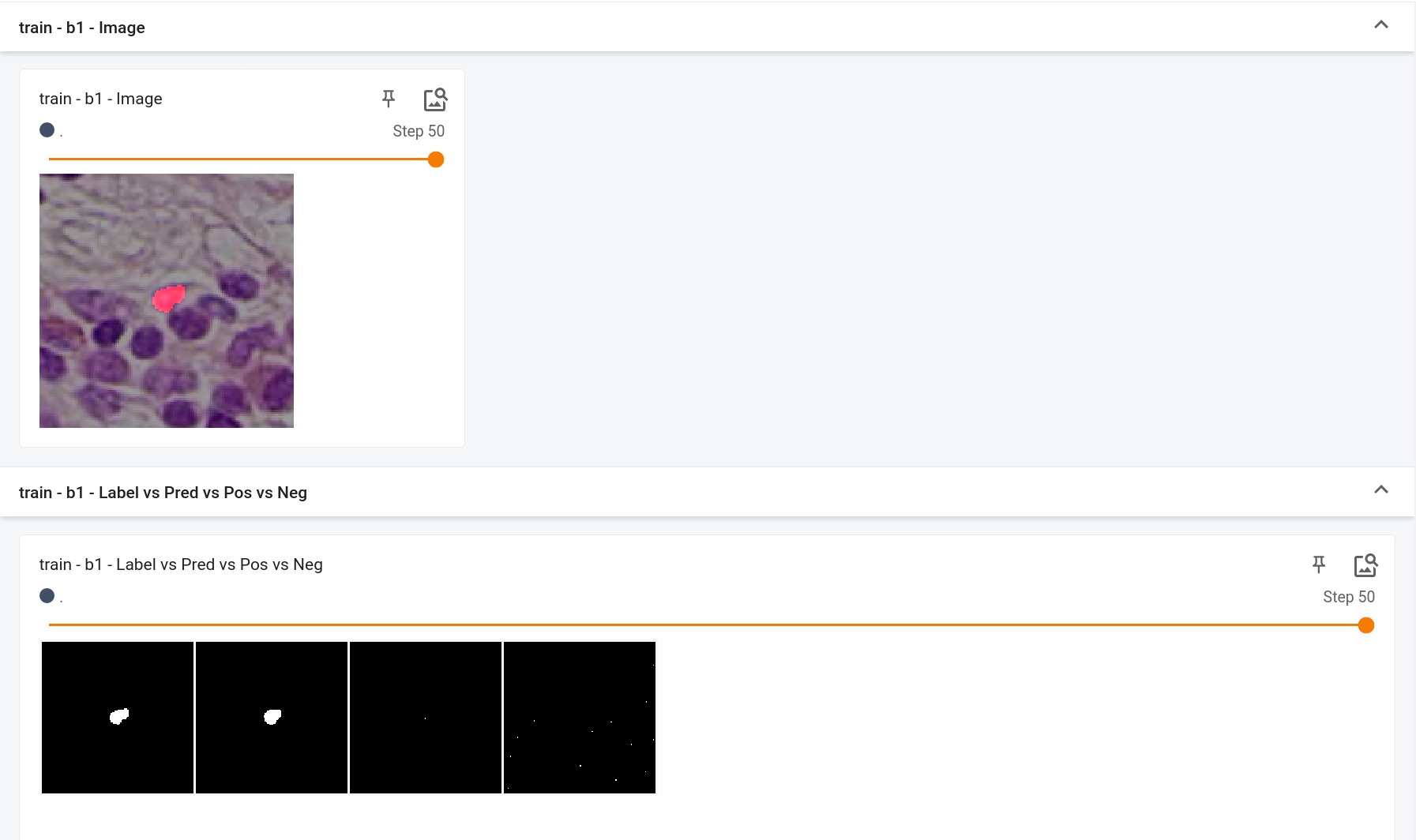
## Performance
This model achieves the following Dice score on the validation data provided as part of the dataset:
- Train Dice score = 0.89
- Validation Dice score = 0.85
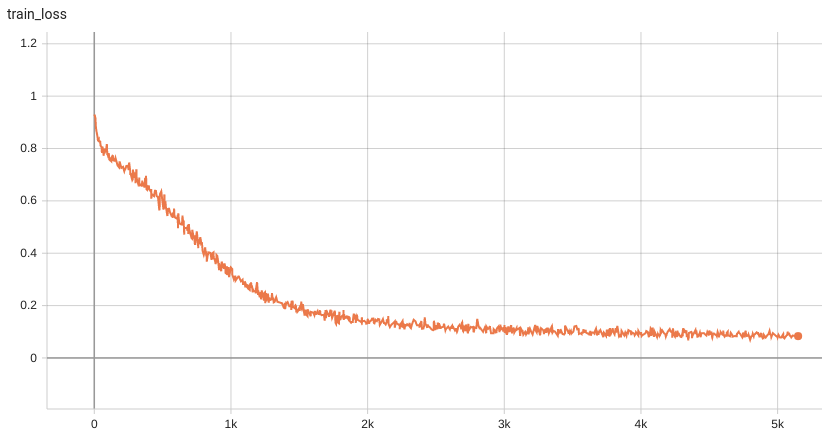
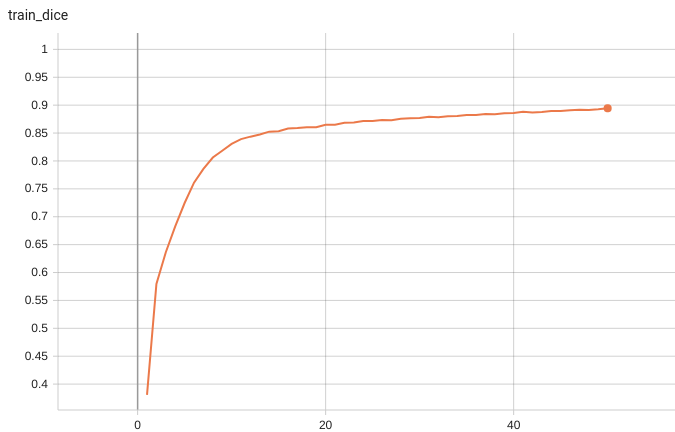
#### Training Loss and Dice
A graph showing the training Loss and Dice over 50 epochs.
 <br>
 <br>
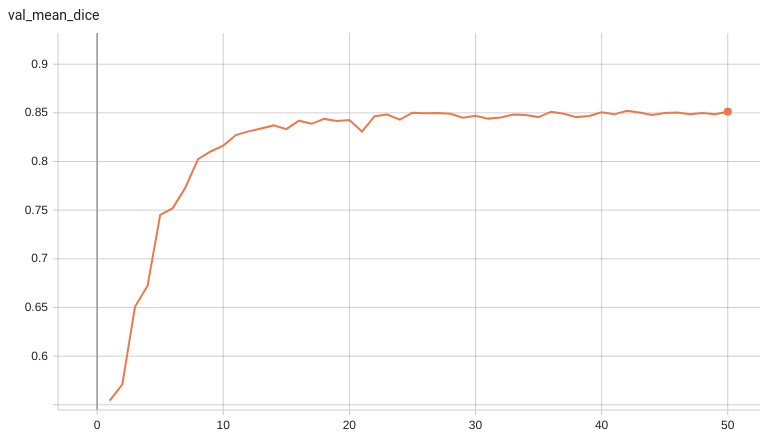
#### Validation Dice
A graph showing the validation mean Dice over 50 epochs.
 <br>
## MONAI Bundle Commands
In addition to the Pythonic APIs, a few command line interfaces (CLI) are provided to interact with the bundle. The CLI supports flexible use cases, such as overriding configs at runtime and predefining arguments in a file.
For more details usage instructions, visit the [MONAI Bundle Configuration Page](https://docs.monai.io/en/latest/config_syntax.html).
#### Execute training:
```
python -m monai.bundle run --config_file configs/train.json
```
Please note that if the default dataset path is not modified with the actual path in the bundle config files, you can also override it by using `--dataset_dir`:
```
python -m monai.bundle run --config_file configs/train.json --dataset_dir <actual dataset path>
```
#### Override the `train` config to execute multi-GPU training:
```
torchrun --standalone --nnodes=1 --nproc_per_node=2 -m monai.bundle run --config_file "['configs/train.json','configs/multi_gpu_train.json']"
```
Please note that the distributed training-related options depend on the actual running environment; thus, users may need to remove `--standalone`, modify `--nnodes`, or do some other necessary changes according to the machine used. For more details, please refer to [pytorch's official tutorial](https://pytorch.org/tutorials/intermediate/ddp_tutorial.html).
#### Override the `train` config to execute evaluation with the trained model:
```
python -m monai.bundle run --config_file "['configs/train.json','configs/evaluate.json']"
```
#### Override the `train` config and `evaluate` config to execute multi-GPU evaluation:
```
torchrun --standalone --nnodes=1 --nproc_per_node=2 -m monai.bundle run --config_file "['configs/train.json','configs/evaluate.json','configs/multi_gpu_evaluate.json']"
```
#### Execute inference:
```
python -m monai.bundle run --config_file configs/inference.json
```
# References
[1] Koohbanani, Navid Alemi, et al. "NuClick: a deep learning framework for interactive segmentation of microscopic images." Medical Image Analysis 65 (2020): 101771. https://arxiv.org/abs/2005.14511.
[2] S. Graham, Q. D. Vu, S. E. A. Raza, A. Azam, Y-W. Tsang, J. T. Kwak and N. Rajpoot. "HoVer-Net: Simultaneous Segmentation and Classification of Nuclei in Multi-Tissue Histology Images." Medical Image Analysis, Sept. 2019. [[doi](https://doi.org/10.1016/j.media.2019.101563)]
[3] NuClick [PyTorch](https://github.com/mostafajahanifar/nuclick_torch) Implementation
# License
Copyright (c) MONAI Consortium
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
|
monai-test/pathology_nuclei_segmentation_classification
|
monai-test
| 2023-08-16T02:56:21Z | 0 | 0 |
monai
|
[
"monai",
"medical",
"license:apache-2.0",
"region:us"
] | null | 2023-08-16T02:54:58Z |
---
tags:
- monai
- medical
library_name: monai
license: apache-2.0
---
# Model Overview
A pre-trained model for simultaneous segmentation and classification of nuclei within multi-tissue histology images based on CoNSeP data. The details of the model can be found in [1].
The model is trained to simultaneously segment and classify nuclei, and a two-stage training approach is utilized:
- Initialize the model with pre-trained weights, and train the decoder only for 50 epochs.
- Finetune all layers for another 50 epochs.
There are two training modes in total. If "original" mode is specified, [270, 270] and [80, 80] are used for `patch_size` and `out_size` respectively. If "fast" mode is specified, [256, 256] and [164, 164] are used for `patch_size` and `out_size` respectively. The results shown below are based on the "fast" mode.
In this bundle, the first stage is trained with pre-trained weights from some internal data. The [original author's repo](https://github.com/vqdang/hover_net) and [torchvison](https://pytorch.org/vision/stable/_modules/torchvision/models/resnet.html#ResNet18_Weights) also provide pre-trained weights but for non-commercial use.
Each user is responsible for checking the content of models/datasets and the applicable licenses and determining if suitable for the intended use.
If you want to train the first stage with pre-trained weights, just specify `--network_def#pretrained_url <your pretrain weights URL>` in the training command below, such as [ImageNet](https://download.pytorch.org/models/resnet18-f37072fd.pth).
## Data
The training data is from <https://warwick.ac.uk/fac/cross_fac/tia/data/hovernet/>.
- Target: segment instance-level nuclei and classify the nuclei type
- Task: Segmentation and classification
- Modality: RGB images
- Size: 41 image tiles (2009 patches)
The provided labelled data was partitioned, based on the original split, into training (27 tiles) and testing (14 tiles) datasets.
You can download the dataset by using this command:
```
wget https://warwick.ac.uk/fac/cross_fac/tia/data/hovernet/consep_dataset.zip
unzip consep_dataset.zip
```
### Preprocessing
After download the [datasets](https://warwick.ac.uk/fac/cross_fac/tia/data/hovernet/consep_dataset.zip), please run `scripts/prepare_patches.py` to prepare patches from tiles. Prepared patches are saved in `<your concep dataset path>`/Prepared. The implementation is referring to <https://github.com/vqdang/hover_net>. The command is like:
```
python scripts/prepare_patches.py --root <your concep dataset path>
```
## Training configuration
This model utilized a two-stage approach. The training was performed with the following:
- GPU: At least 24GB of GPU memory.
- Actual Model Input: 256 x 256
- AMP: True
- Optimizer: Adam
- Learning Rate: 1e-4
- Loss: HoVerNetLoss
- Dataset Manager: CacheDataset
### Memory Consumption Warning
If you face memory issues with CacheDataset, you can either switch to a regular Dataset class or lower the caching rate `cache_rate` in the configurations within range [0, 1] to minimize the System RAM requirements.
## Input
Input: RGB images
## Output
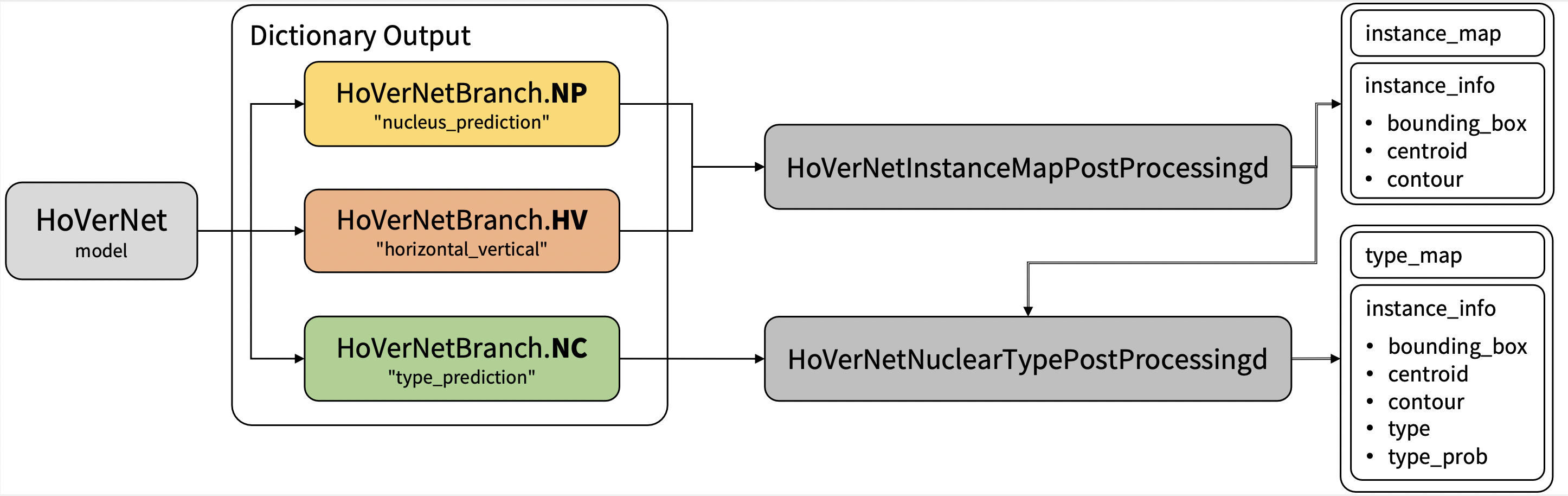
Output: a dictionary with the following keys:
1. nucleus_prediction: predict whether or not a pixel belongs to the nuclei or background
2. horizontal_vertical: predict the horizontal and vertical distances of nuclear pixels to their centres of mass
3. type_prediction: predict the type of nucleus for each pixel
## Performance
The achieved metrics on the validation data are:
Fast mode:
- Binary Dice: 0.8291
- PQ: 0.4973
- F1d: 0.7417
Note:
- Binary Dice is calculated based on the whole input. PQ and F1d were calculated from https://github.com/vqdang/hover_net#inference.
- This bundle is non-deterministic because of the bilinear interpolation used in the network. Therefore, reproducing the training process may not get exactly the same performance.
Please refer to https://pytorch.org/docs/stable/notes/randomness.html#reproducibility for more details about reproducibility.
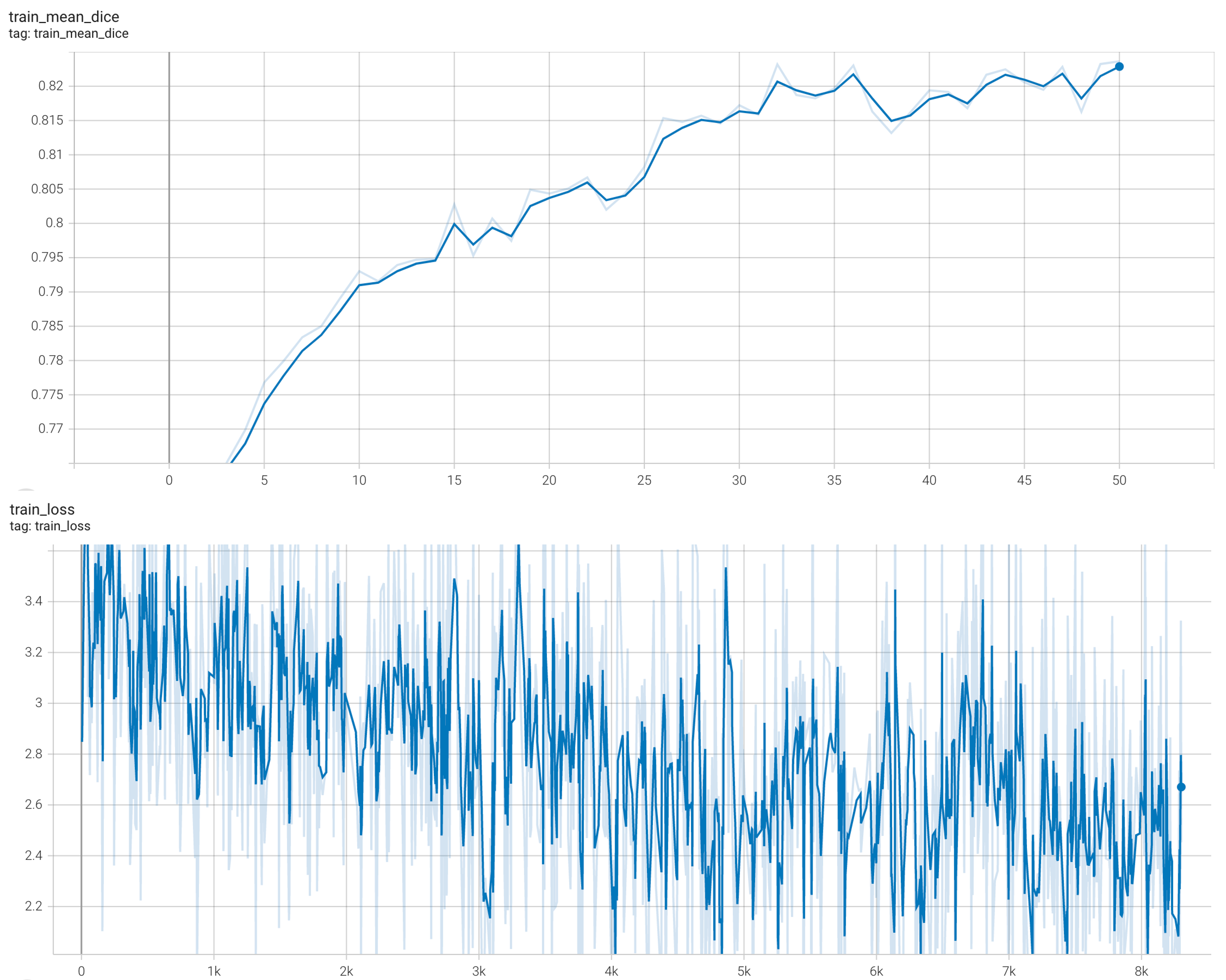
#### Training Loss and Dice
stage1:
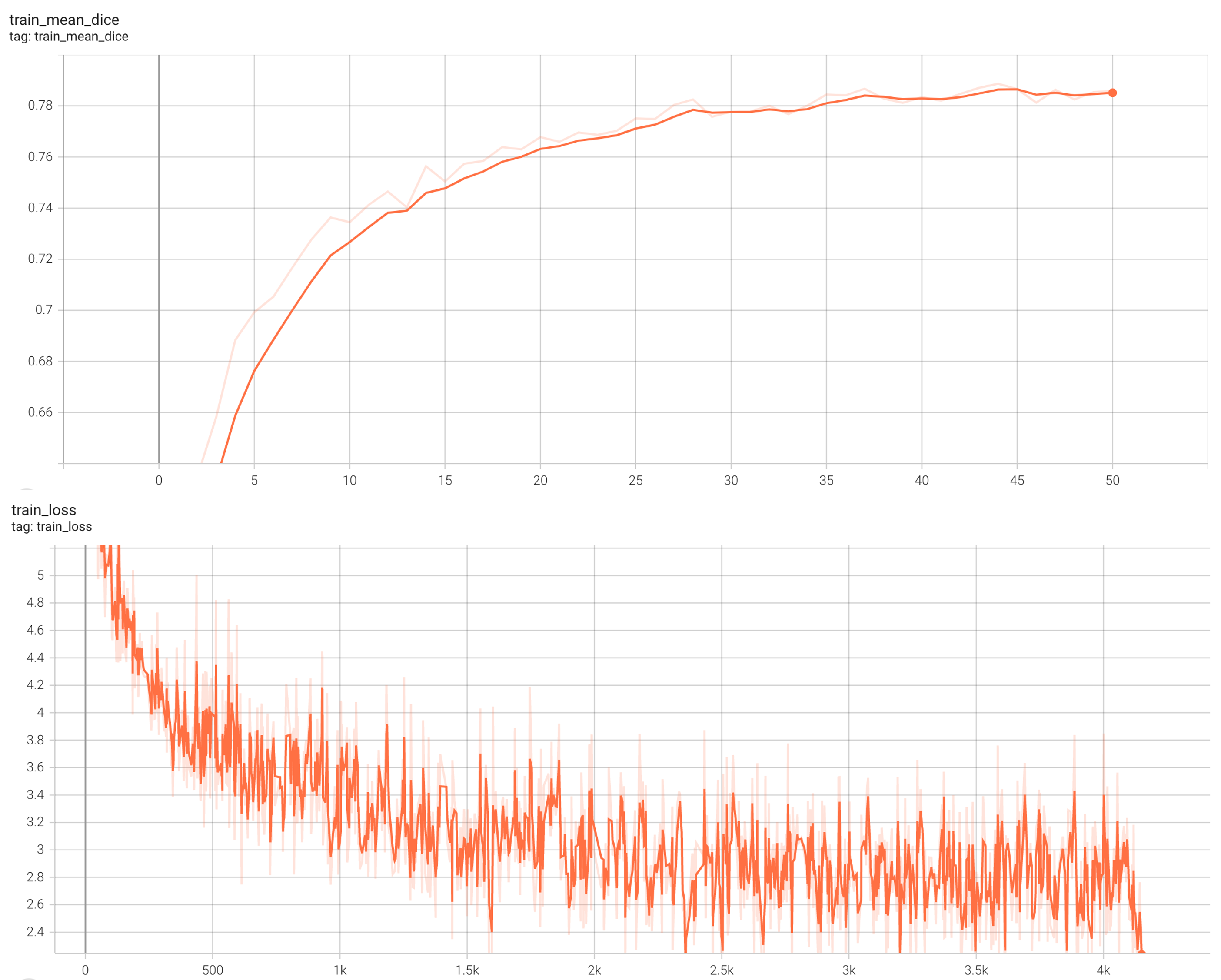
stage2:
#### Validation Dice
stage1:
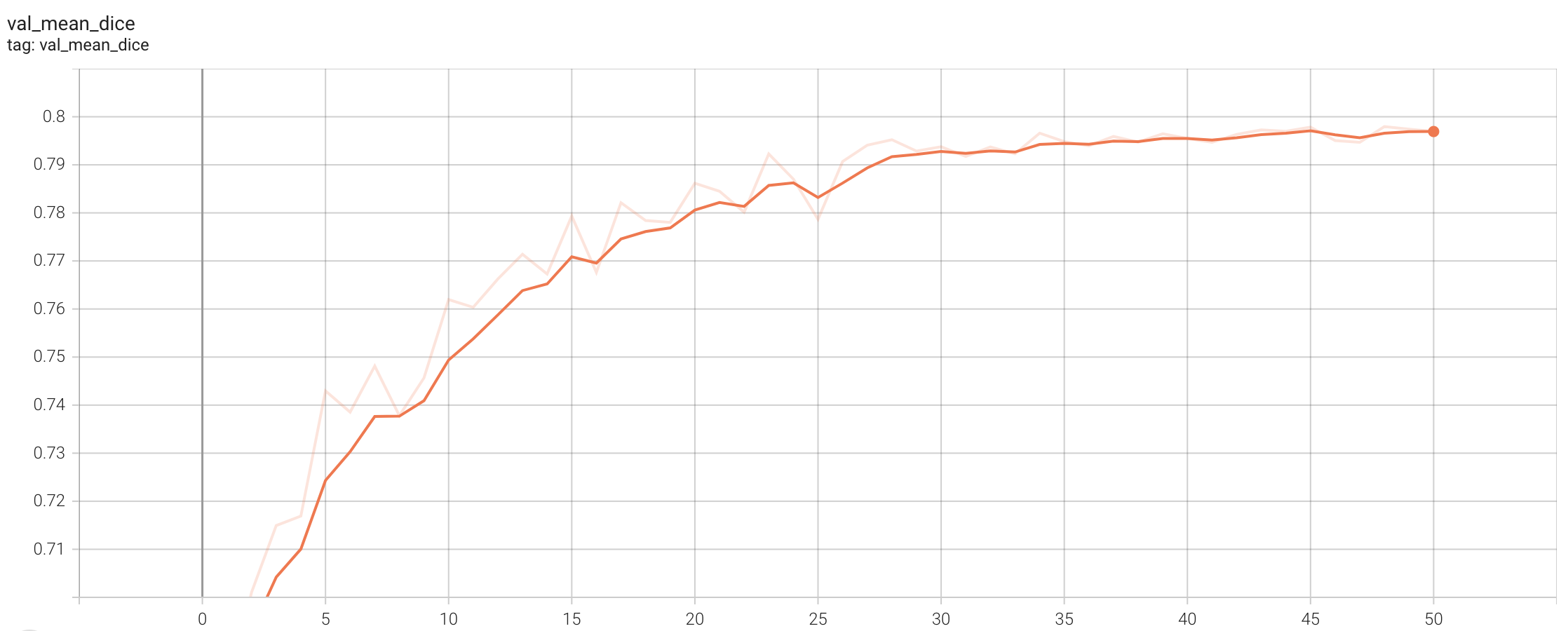
stage2:
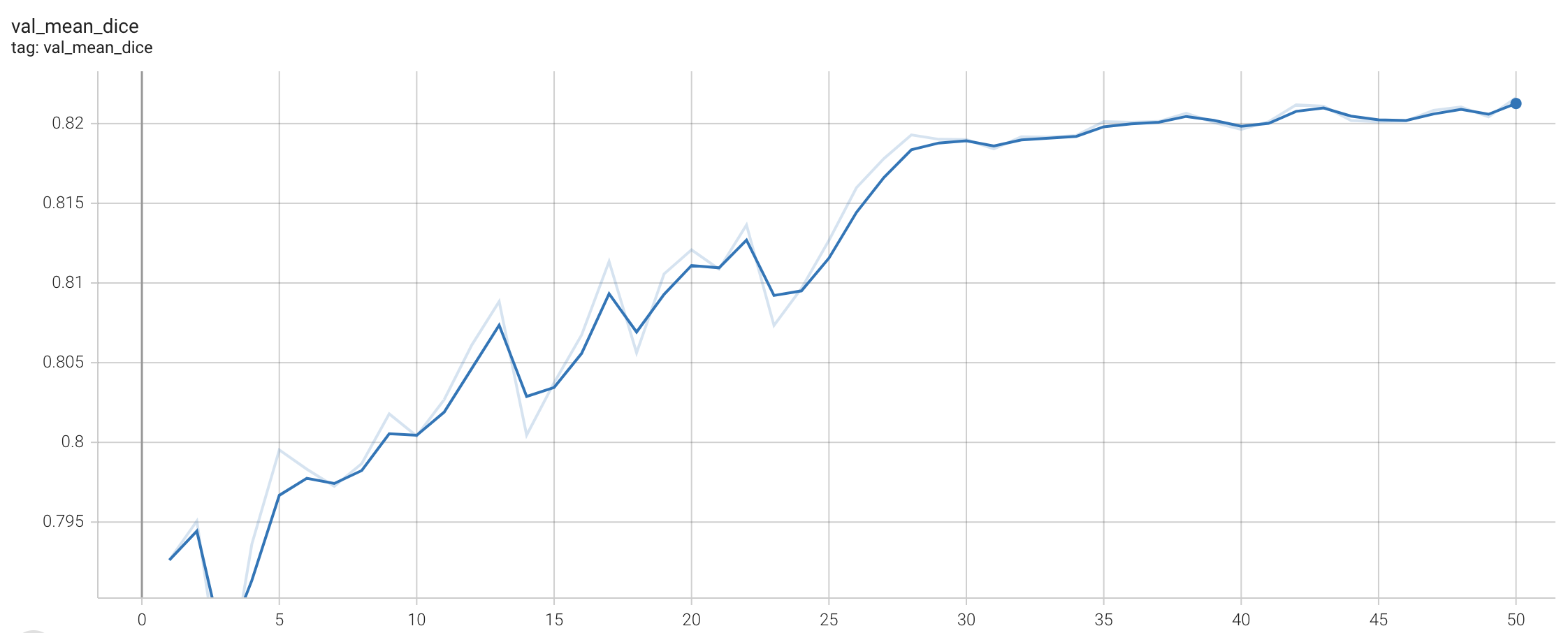
## MONAI Bundle Commands
In addition to the Pythonic APIs, a few command line interfaces (CLI) are provided to interact with the bundle. The CLI supports flexible use cases, such as overriding configs at runtime and predefining arguments in a file.
For more details usage instructions, visit the [MONAI Bundle Configuration Page](https://docs.monai.io/en/latest/config_syntax.html).
#### Execute training, the evaluation during the training were evaluated on patches:
Please note that if the default dataset path is not modified with the actual path in the bundle config files, you can also override it by using `--dataset_dir`:
- Run first stage
```
python -m monai.bundle run --config_file configs/train.json --stage 0 --dataset_dir <actual dataset path>
```
- Run second stage
```
python -m monai.bundle run --config_file configs/train.json --network_def#freeze_encoder False --stage 1 --dataset_dir <actual dataset path>
```
#### Override the `train` config to execute multi-GPU training:
- Run first stage
```
torchrun --standalone --nnodes=1 --nproc_per_node=2 -m monai.bundle run --config_file "['configs/train.json','configs/multi_gpu_train.json']" --batch_size 8 --network_def#freeze_encoder True --stage 0
```
- Run second stage
```
torchrun --standalone --nnodes=1 --nproc_per_node=2 -m monai.bundle run --config_file "['configs/train.json','configs/multi_gpu_train.json']" --batch_size 4 --network_def#freeze_encoder False --stage 1
```
#### Override the `train` config to execute evaluation with the trained model, here we evaluated dice from the whole input instead of the patches:
```
python -m monai.bundle run --config_file "['configs/train.json','configs/evaluate.json']"
```
#### Execute inference:
```
python -m monai.bundle run --config_file configs/inference.json
```
# References
[1] Simon Graham, Quoc Dang Vu, Shan E Ahmed Raza, Ayesha Azam, Yee Wah Tsang, Jin Tae Kwak, Nasir Rajpoot, Hover-Net: Simultaneous segmentation and classification of nuclei in multi-tissue histology images, Medical Image Analysis, 2019 https://doi.org/10.1016/j.media.2019.101563
# License
Copyright (c) MONAI Consortium
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
|
monai-test/pathology_nuclei_classification
|
monai-test
| 2023-08-16T02:54:49Z | 0 | 3 |
monai
|
[
"monai",
"medical",
"license:apache-2.0",
"region:us"
] | null | 2023-08-16T02:54:19Z |
---
tags:
- monai
- medical
library_name: monai
license: apache-2.0
---
# Model Overview
A pre-trained model for classifying nuclei cells as the following types
- Other
- Inflammatory
- Epithelial
- Spindle-Shaped
This model is trained using [DenseNet121](https://docs.monai.io/en/latest/networks.html#densenet121) over [ConSeP](https://warwick.ac.uk/fac/cross_fac/tia/data/hovernet) dataset.
## Data
The training dataset is from https://warwick.ac.uk/fac/cross_fac/tia/data/hovernet
```commandline
wget https://warwick.ac.uk/fac/cross_fac/tia/data/hovernet/consep_dataset.zip
unzip -q consep_dataset.zip
```
<br/>
### Preprocessing
After [downloading this dataset](https://warwick.ac.uk/fac/cross_fac/tia/data/hovernet/consep_dataset.zip),
python script `data_process.py` from `scripts` folder can be used to preprocess and generate the final dataset for training.
```commandline
python scripts/data_process.py --input /path/to/data/CoNSeP --output /path/to/data/CoNSePNuclei
```
After generating the output files, please modify the `dataset_dir` parameter specified in `configs/train.json` and `configs/inference.json` to reflect the output folder which contains new dataset.json.
Class values in dataset are
- 1 = other
- 2 = inflammatory
- 3 = healthy epithelial
- 4 = dysplastic/malignant epithelial
- 5 = fibroblast
- 6 = muscle
- 7 = endothelial
As part of pre-processing, the following steps are executed.
- Crop and Extract each nuclei Image + Label (128x128) based on the centroid given in the dataset.
- Combine classes 3 & 4 into the epithelial class and 5,6 & 7 into the spindle-shaped class.
- Update the label index for the target nuclie based on the class value
- Other cells which are part of the patch are modified to have label idex = 255
Example `dataset.json` in output folder:
```json
{
"training": [
{
"image": "/workspace/data/CoNSePNuclei/Train/Images/train_1_3_0001.png",
"label": "/workspace/data/CoNSePNuclei/Train/Labels/train_1_3_0001.png",
"nuclei_id": 1,
"mask_value": 3,
"centroid": [
64,
64
]
}
],
"validation": [
{
"image": "/workspace/data/CoNSePNuclei/Test/Images/test_1_3_0001.png",
"label": "/workspace/data/CoNSePNuclei/Test/Labels/test_1_3_0001.png",
"nuclei_id": 1,
"mask_value": 3,
"centroid": [
64,
64
]
}
]
}
```
## Training configuration
The training was performed with the following:
- GPU: at least 12GB of GPU memory
- Actual Model Input: 4 x 128 x 128
- AMP: True
- Optimizer: Adam
- Learning Rate: 1e-4
- Loss: torch.nn.CrossEntropyLoss
- Dataset Manager: CacheDataset
### Memory Consumption Warning
If you face memory issues with CacheDataset, you can either switch to a regular Dataset class or lower the caching rate `cache_rate` in the configurations within range [0, 1] to minimize the System RAM requirements.
## Input
4 channels
- 3 RGB channels
- 1 signal channel (label mask)
## Output
4 channels
- 0 = Other
- 1 = Inflammatory
- 2 = Epithelial
- 3 = Spindle-Shaped
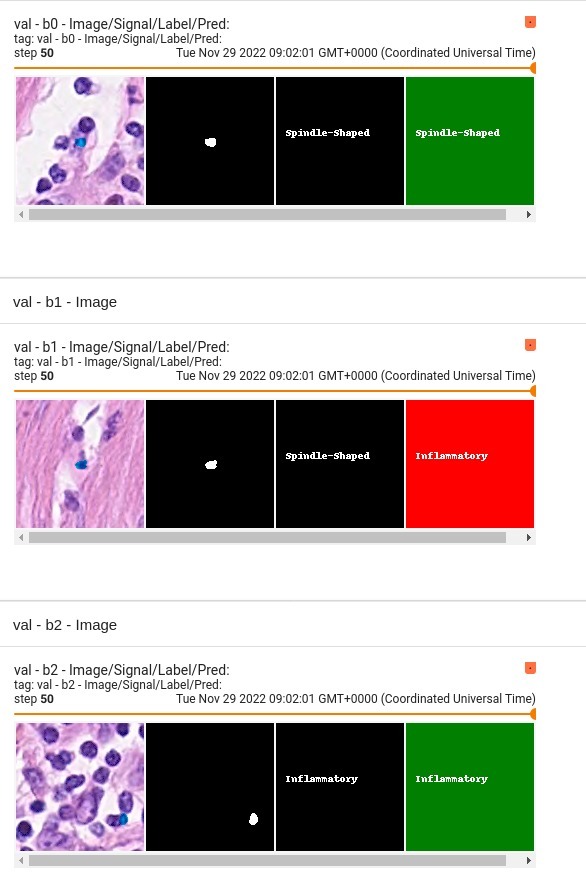
## Performance
This model achieves the following F1 score on the validation data provided as part of the dataset:
- Train F1 score = 0.926
- Validation F1 score = 0.852
<hr/>
Confusion Metrics for <b>Validation</b> for individual classes are:
| Metric | Other | Inflammatory | Epithelial | Spindle-Shaped |
|-----------|--------|--------------|------------|----------------|
| Precision | 0.6909 | 0.7773 | 0.9078 | 0.8478 |
| Recall | 0.2754 | 0.7831 | 0.9533 | 0.8514 |
| F1-score | 0.3938 | 0.7802 | 0.9300 | 0.8496 |
<hr/>
Confusion Metrics for <b>Training</b> for individual classes are:
| Metric | Other | Inflammatory | Epithelial | Spindle-Shaped |
|-----------|--------|--------------|------------|----------------|
| Precision | 0.8000 | 0.9076 | 0.9560 | 0.9019 |
| Recall | 0.6512 | 0.9028 | 0.9690 | 0.8989 |
| F1-score | 0.7179 | 0.9052 | 0.9625 | 0.9004 |
#### Training Loss and F1
A graph showing the training Loss and F1-score over 100 epochs.
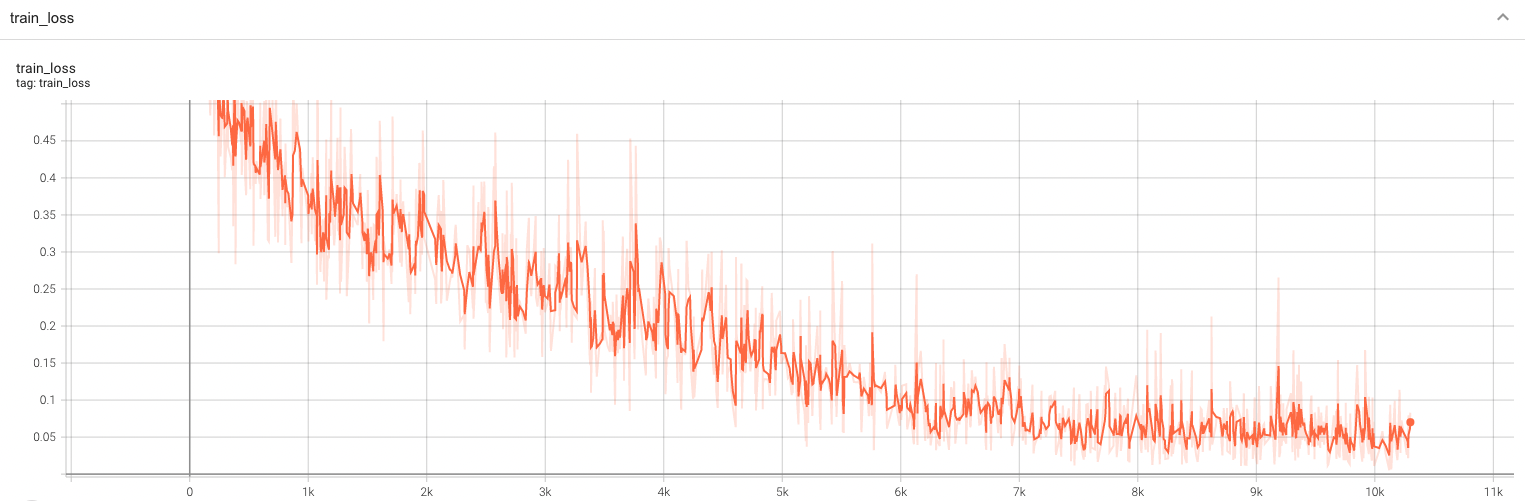 <br>
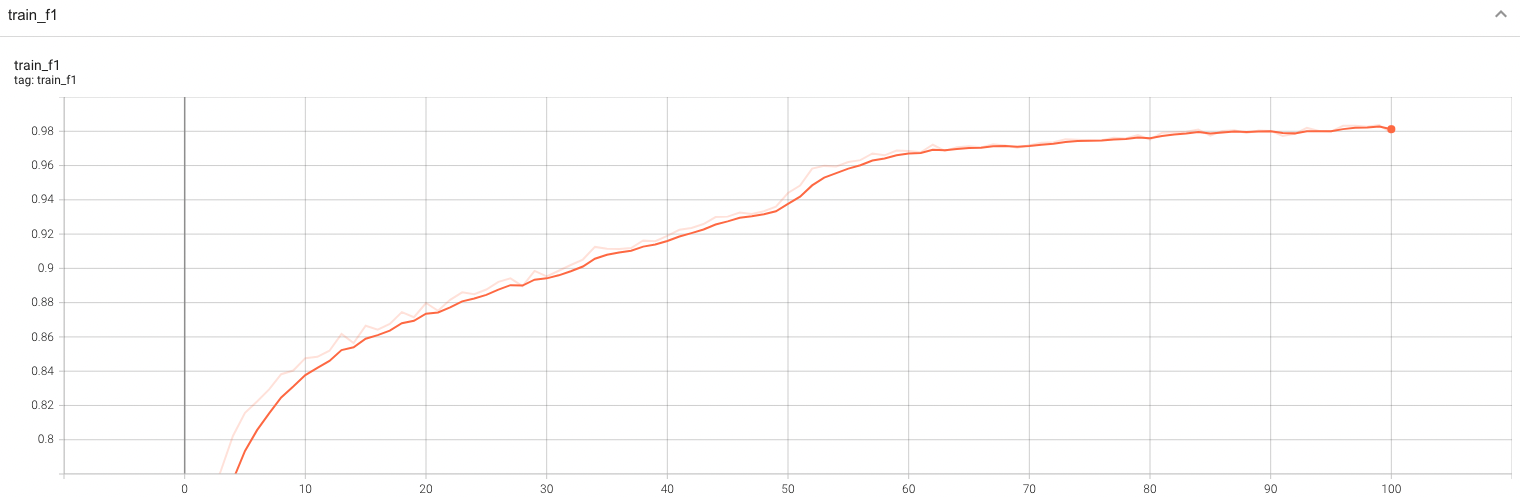 <br>
#### Validation F1
A graph showing the validation F1-score over 100 epochs.
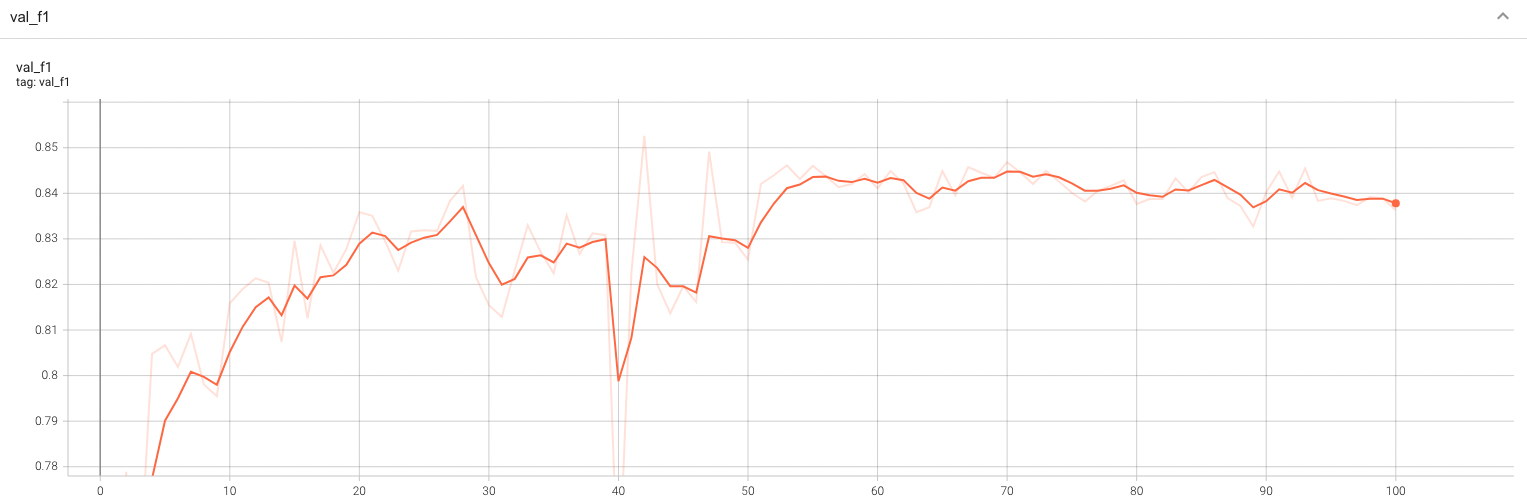 <br>
## MONAI Bundle Commands
In addition to the Pythonic APIs, a few command line interfaces (CLI) are provided to interact with the bundle. The CLI supports flexible use cases, such as overriding configs at runtime and predefining arguments in a file.
For more details usage instructions, visit the [MONAI Bundle Configuration Page](https://docs.monai.io/en/latest/config_syntax.html).
#### Execute training:
```
python -m monai.bundle run --config_file configs/train.json
```
Please note that if the default dataset path is not modified with the actual path in the bundle config files, you can also override it by using `--dataset_dir`:
```
python -m monai.bundle run --config_file configs/train.json --dataset_dir <actual dataset path>
```
#### Override the `train` config to execute multi-GPU training:
```
torchrun --standalone --nnodes=1 --nproc_per_node=2 -m monai.bundle run --config_file "['configs/train.json','configs/multi_gpu_train.json']"
```
Please note that the distributed training-related options depend on the actual running environment; thus, users may need to remove `--standalone`, modify `--nnodes`, or do some other necessary changes according to the machine used. For more details, please refer to [pytorch's official tutorial](https://pytorch.org/tutorials/intermediate/ddp_tutorial.html).
#### Override the `train` config to execute evaluation with the trained model:
```
python -m monai.bundle run --config_file "['configs/train.json','configs/evaluate.json']"
```
#### Override the `train` config and `evaluate` config to execute multi-GPU evaluation:
```
torchrun --standalone --nnodes=1 --nproc_per_node=2 -m monai.bundle run --config_file "['configs/train.json','configs/evaluate.json','configs/multi_gpu_evaluate.json']"
```
#### Execute inference:
```
python -m monai.bundle run --config_file configs/inference.json
```
# References
[1] S. Graham, Q. D. Vu, S. E. A. Raza, A. Azam, Y-W. Tsang, J. T. Kwak and N. Rajpoot. "HoVer-Net: Simultaneous Segmentation and Classification of Nuclei in Multi-Tissue Histology Images." Medical Image Analysis, Sept. 2019. [[doi](https://doi.org/10.1016/j.media.2019.101563)]
# License
Copyright (c) MONAI Consortium
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
|
monai-test/mednist_gan
|
monai-test
| 2023-08-16T02:46:42Z | 0 | 0 |
monai
|
[
"monai",
"medical",
"license:apache-2.0",
"region:us"
] | null | 2023-08-16T02:46:37Z |
---
tags:
- monai
- medical
library_name: monai
license: apache-2.0
---
# MedNIST GAN Hand Model
This model is a generator for creating images like the Hand category in the MedNIST dataset. It was trained as a GAN and accepts random values as inputs to produce an image output. The `train.json` file describes the training process along with the definition of the discriminator network used, and is based on the [MONAI GAN tutorials](https://github.com/Project-MONAI/tutorials/blob/main/modules/mednist_GAN_workflow_dict.ipynb).
This is a demonstration network meant to just show the training process for this sort of network with MONAI, its outputs are not particularly good and are of the same tiny size as the images in MedNIST. The training process was very short so a network with a longer training time would produce better results.
### Downloading the Dataset
Download the dataset from [here](https://github.com/Project-MONAI/MONAI-extra-test-data/releases/download/0.8.1/MedNIST.tar.gz) and extract the contents to a convenient location.
The MedNIST dataset was gathered from several sets from [TCIA](https://wiki.cancerimagingarchive.net/display/Public/Data+Usage+Policies+and+Restrictions),
[the RSNA Bone Age Challenge](http://rsnachallenges.cloudapp.net/competitions/4),
and [the NIH Chest X-ray dataset](https://cloud.google.com/healthcare/docs/resources/public-datasets/nih-chest).
The dataset is kindly made available by [Dr. Bradley J. Erickson M.D., Ph.D.](https://www.mayo.edu/research/labs/radiology-informatics/overview) (Department of Radiology, Mayo Clinic)
under the Creative Commons [CC BY-SA 4.0 license](https://creativecommons.org/licenses/by-sa/4.0/).
If you use the MedNIST dataset, please acknowledge the source.
### Training
Assuming the current directory is the bundle directory, and the dataset was extracted to the directory `./MedNIST`, the following command will train the network for 50 epochs:
```
python -m monai.bundle run training --meta_file configs/metadata.json --config_file configs/train.json --logging_file configs/logging.conf --bundle_root .
```
Not also the output from the training will be placed in the `models` directory but will not overwrite the `model.pt` file that may be there already. You will have to manually rename the most recent checkpoint file to `model.pt` to use the inference script mentioned below after checking the results are correct. This saved checkpoint contains a dictionary with the generator weights stored as `model` and omits the discriminator.
Another feature in the training file is the addition of sigmoid activation to the network by modifying it's structure at runtime. This is done with a line in the `training` section calling `add_module` on a layer of the network. This works best for training although the definition of the model now doesn't strictly match what it is in the `generator` section.
The generator and discriminator networks were both trained with the `Adam` optimizer with a learning rate of 0.0002 and `betas` values `[0.5, 0.999]`. These have been emperically found to be good values for the optimizer and this GAN problem.
### Inference
The included `inference.json` generates a set number of png samples from the network and saves these to the directory `./outputs`. The output directory can be changed by setting the `output_dir` value, and the number of samples changed by setting the `num_samples` value. The following command line assumes it is invoked in the bundle directory:
```
python -m monai.bundle run inferring --meta_file configs/metadata.json --config_file configs/inference.json --logging_file configs/logging.conf --bundle_root .
```
Note this script uses postprocessing to apply the sigmoid activation the model's outputs and to save the results to image files.
### Export
The generator can be exported to a Torchscript bundle with the following:
```
python -m monai.bundle ckpt_export network_def --filepath mednist_gan.ts --ckpt_file models/model.pt --meta_file configs/metadata.json --config_file configs/inference.json
```
The model can be loaded without MONAI code after this operation. For example, an image can be generated from a set of random values with:
```python
import torch
net = torch.jit.load("mednist_gan.ts")
latent = torch.rand(1, 64)
img = net(latent) # (1,1,64,64)
```
# License
Copyright (c) MONAI Consortium
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
|
monai-test/endoscopic_inbody_classification
|
monai-test
| 2023-08-16T02:44:21Z | 0 | 0 |
monai
|
[
"monai",
"medical",
"arxiv:1709.01507",
"license:apache-2.0",
"region:us"
] | null | 2023-08-16T02:42:51Z |
---
tags:
- monai
- medical
library_name: monai
license: apache-2.0
---
# Model Overview
A pre-trained model for the endoscopic inbody classification task and trained using the SEResNet50 structure, whose details can be found in [1]. All datasets are from private samples of [Activ Surgical](https://www.activsurgical.com/). Samples in training and validation dataset are from the same 4 videos, while test samples are from different two videos.
The [PyTorch model](https://drive.google.com/file/d/14CS-s1uv2q6WedYQGeFbZeEWIkoyNa-x/view?usp=sharing) and [torchscript model](https://drive.google.com/file/d/1fOoJ4n5DWKHrt9QXTZ2sXwr9C-YvVGCM/view?usp=sharing) are shared in google drive. Modify the `bundle_root` parameter specified in `configs/train.json` and `configs/inference.json` to reflect where models are downloaded. Expected directory path to place downloaded models is `models/` under `bundle_root`.
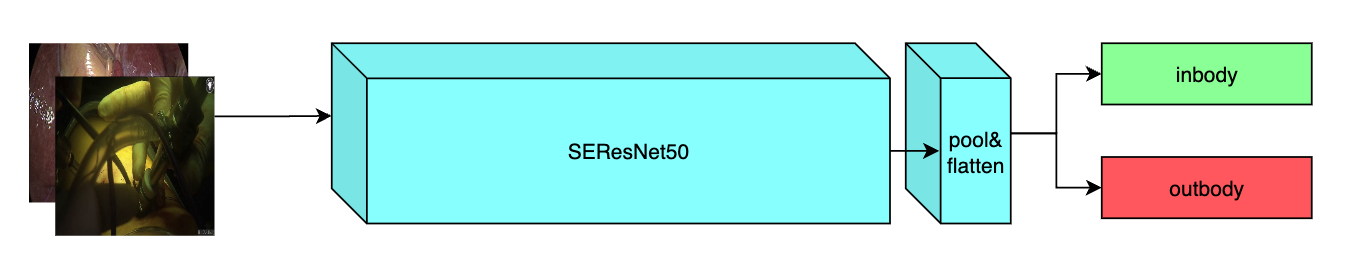
## Data
The datasets used in this work were provided by [Activ Surgical](https://www.activsurgical.com/).
Since datasets are private, we provide a [link](https://github.com/Project-MONAI/MONAI-extra-test-data/releases/download/0.8.1/inbody_outbody_samples.zip) of 20 samples (10 in-body and 10 out-body) to show what they look like.
### Preprocessing
After downloading this dataset, python script in `scripts` folder named `data_process` can be used to generate label json files by running the command below and modifying `datapath` to path of unziped downloaded data. Generated label json files will be stored in `label` folder under the bundle path.
```
python scripts/data_process.py --datapath /path/to/data/root
```
By default, label path parameter in `train.json` and `inference.json` of this bundle is point to the generated `label` folder under bundle path. If you move these generated label files to another place, please modify the `train_json`, `val_json` and `test_json` parameters specified in `configs/train.json` and `configs/inference.json` to where these label files are.
The input label json should be a list made up by dicts which includes `image` and `label` keys. An example format is shown below.
```
[
{
"image":"/path/to/image/image_name0.jpg",
"label": 0
},
{
"image":"/path/to/image/image_name1.jpg",
"label": 0
},
{
"image":"/path/to/image/image_name2.jpg",
"label": 1
},
....
{
"image":"/path/to/image/image_namek.jpg",
"label": 0
},
]
```
## Training configuration
The training as performed with the following:
- GPU: At least 12GB of GPU memory
- Actual Model Input: 256 x 256 x 3
- Optimizer: Adam
- Learning Rate: 1e-3
### Input
A three channel video frame
### Output
Two Channels
- Label 0: in body
- Label 1: out body
## Performance
Accuracy was used for evaluating the performance of the model. This model achieves an accuracy score of 0.99
#### Training Loss
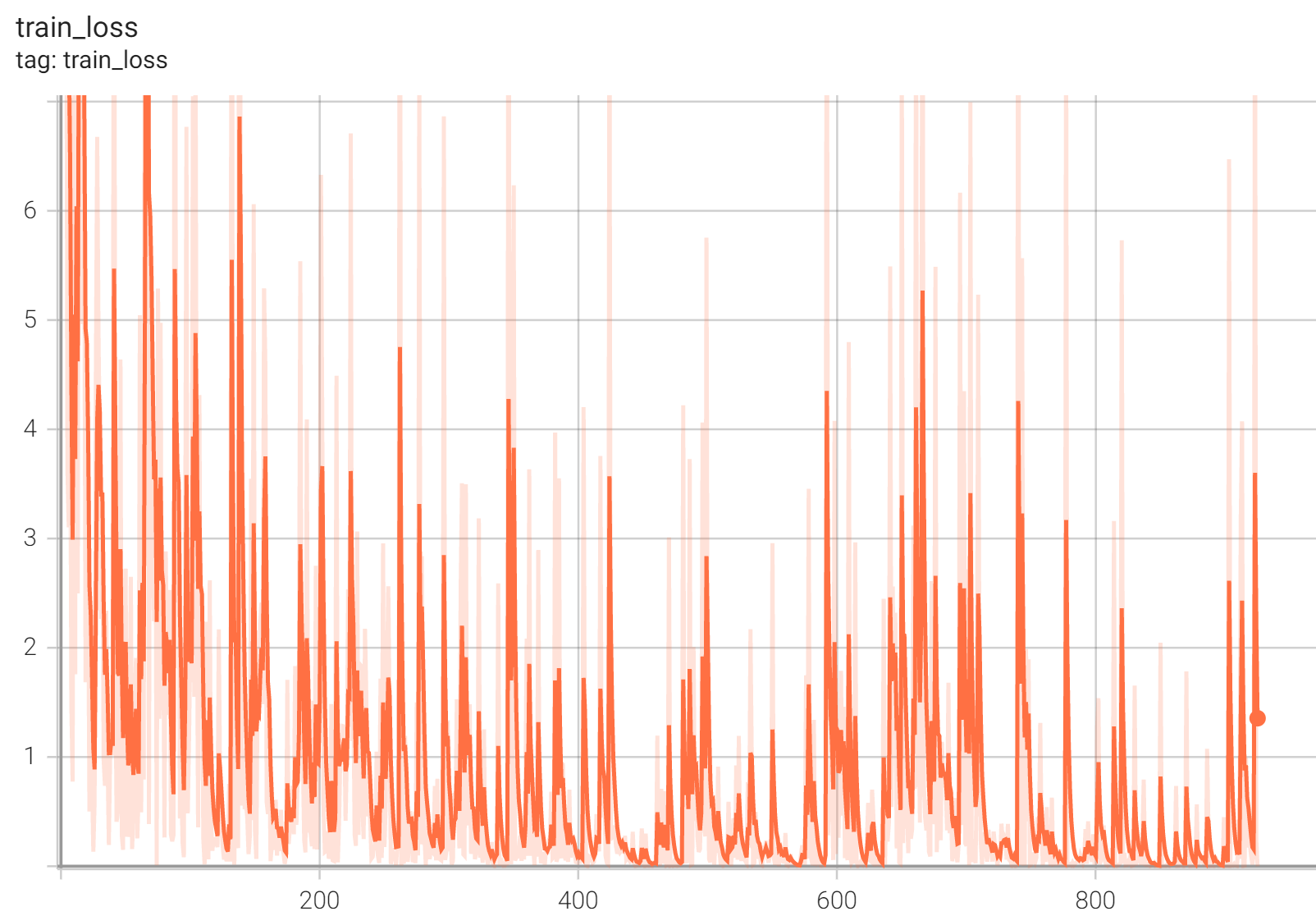
#### Validation Accuracy
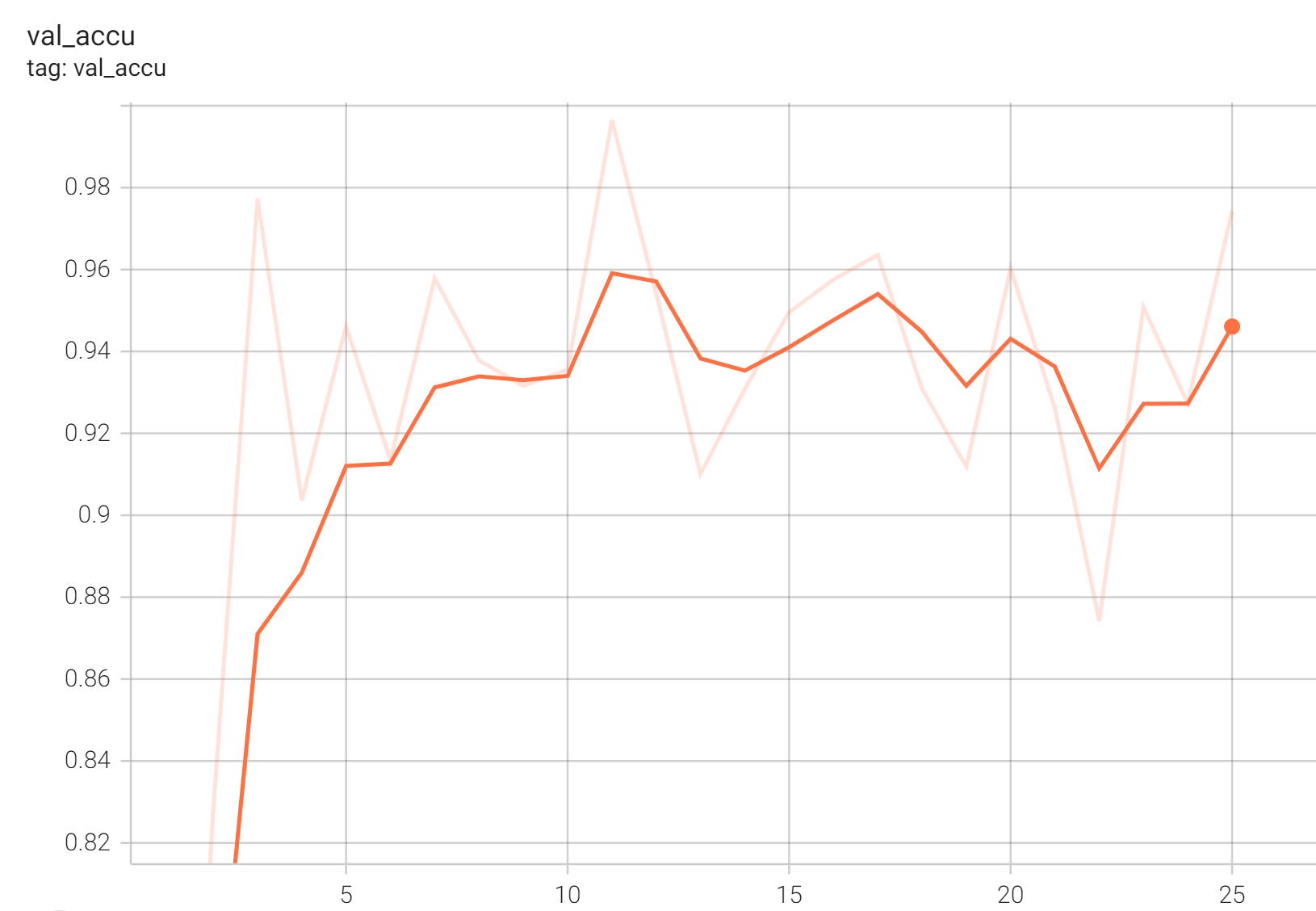
#### TensorRT speedup
The `endoscopic_inbody_classification` bundle supports acceleration with TensorRT through the ONNX-TensorRT method. The table below displays the speedup ratios observed on an A100 80G GPU.
| method | torch_fp32(ms) | torch_amp(ms) | trt_fp32(ms) | trt_fp16(ms) | speedup amp | speedup fp32 | speedup fp16 | amp vs fp16|
| :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: |
| model computation | 6.50 | 9.23 | 2.78 | 2.31 | 0.70 | 2.34 | 2.81 | 4.00 |
| end2end | 23.54 | 23.78 | 7.37 | 7.14 | 0.99 | 3.19 | 3.30 | 3.33 |
Where:
- `model computation` means the speedup ratio of model's inference with a random input without preprocessing and postprocessing
- `end2end` means run the bundle end-to-end with the TensorRT based model.
- `torch_fp32` and `torch_amp` are for the PyTorch models with or without `amp` mode.
- `trt_fp32` and `trt_fp16` are for the TensorRT based models converted in corresponding precision.
- `speedup amp`, `speedup fp32` and `speedup fp16` are the speedup ratios of corresponding models versus the PyTorch float32 model
- `amp vs fp16` is the speedup ratio between the PyTorch amp model and the TensorRT float16 based model.
Currently, the only available method to accelerate this model is through ONNX-TensorRT. However, the Torch-TensorRT method is under development and will be available in the near future.
This result is benchmarked under:
- TensorRT: 8.5.3+cuda11.8
- Torch-TensorRT Version: 1.4.0
- CPU Architecture: x86-64
- OS: ubuntu 20.04
- Python version:3.8.10
- CUDA version: 12.0
- GPU models and configuration: A100 80G
## MONAI Bundle Commands
In addition to the Pythonic APIs, a few command line interfaces (CLI) are provided to interact with the bundle. The CLI supports flexible use cases, such as overriding configs at runtime and predefining arguments in a file.
For more details usage instructions, visit the [MONAI Bundle Configuration Page](https://docs.monai.io/en/latest/config_syntax.html).
#### Execute training:
```
python -m monai.bundle run --config_file configs/train.json
```
Please note that if the default dataset path is not modified with the actual path in the bundle config files, you can also override it by using `--dataset_dir`:
```
python -m monai.bundle run --config_file configs/train.json --dataset_dir <actual dataset path>
```
#### Override the `train` config to execute multi-GPU training:
```
torchrun --standalone --nnodes=1 --nproc_per_node=2 -m monai.bundle run \
--config_file "['configs/train.json','configs/multi_gpu_train.json']"
```
Please note that the distributed training-related options depend on the actual running environment; thus, users may need to remove `--standalone`, modify `--nnodes`, or do some other necessary changes according to the machine used. For more details, please refer to [pytorch's official tutorial](https://pytorch.org/tutorials/intermediate/ddp_tutorial.html).
In addition, if using the 20 samples example dataset, the preprocessing script will divide the samples to 16 training samples, 2 validation samples and 2 test samples. However, pytorch multi-gpu training requires number of samples in dataloader larger than gpu numbers. Therefore, please use no more than 2 gpus to run this bundle if using the 20 samples example dataset.
#### Override the `train` config to execute evaluation with the trained model:
```
python -m monai.bundle run --config_file "['configs/train.json','configs/evaluate.json']"
```
#### Execute inference:
```
python -m monai.bundle run --config_file configs/inference.json
```
The classification result of every images in `test.json` will be printed to the screen.
#### Export checkpoint to TorchScript file:
```
python -m monai.bundle ckpt_export network_def --filepath models/model.ts --ckpt_file models/model.pt --meta_file configs/metadata.json --config_file configs/inference.json
```
#### Export checkpoint to TensorRT based models with fp32 or fp16 precision:
```bash
python -m monai.bundle trt_export --net_id network_def \
--filepath models/model_trt.ts --ckpt_file models/model.pt \
--meta_file configs/metadata.json --config_file configs/inference.json \
--precision <fp32/fp16> --use_onnx "True" --use_trace "True"
```
#### Execute inference with the TensorRT model:
```
python -m monai.bundle run --config_file "['configs/inference.json', 'configs/inference_trt.json']"
```
# References
[1] J. Hu, L. Shen and G. Sun, Squeeze-and-Excitation Networks, 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2018, pp. 7132-7141. https://arxiv.org/pdf/1709.01507.pdf
# License
Copyright (c) MONAI Consortium
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
|
peteryushunli/bert-finetuned-ner
|
peteryushunli
| 2023-08-16T02:26:18Z | 120 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"token-classification",
"generated_from_trainer",
"dataset:conll2003",
"base_model:google-bert/bert-base-cased",
"base_model:finetune:google-bert/bert-base-cased",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2023-08-16T02:10:28Z |
---
license: apache-2.0
base_model: bert-base-cased
tags:
- generated_from_trainer
datasets:
- conll2003
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: bert-finetuned-ner
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: conll2003
type: conll2003
config: conll2003
split: validation
args: conll2003
metrics:
- name: Precision
type: precision
value: 0.9325396825396826
- name: Recall
type: recall
value: 0.9491753618310333
- name: F1
type: f1
value: 0.9407839866555464
- name: Accuracy
type: accuracy
value: 0.9861364572908695
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-finetuned-ner
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the conll2003 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0589
- Precision: 0.9325
- Recall: 0.9492
- F1: 0.9408
- Accuracy: 0.9861
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| 0.078 | 1.0 | 1756 | 0.0737 | 0.9054 | 0.9340 | 0.9195 | 0.9807 |
| 0.0387 | 2.0 | 3512 | 0.0591 | 0.9327 | 0.9498 | 0.9412 | 0.9861 |
| 0.0253 | 3.0 | 5268 | 0.0589 | 0.9325 | 0.9492 | 0.9408 | 0.9861 |
### Framework versions
- Transformers 4.31.0
- Pytorch 2.0.1+cu118
- Datasets 2.14.4
- Tokenizers 0.13.3
|
jjsprockel/distil-ast-audioset-finetuned-gtzan
|
jjsprockel
| 2023-08-16T02:18:46Z | 157 | 0 |
transformers
|
[
"transformers",
"pytorch",
"audio-spectrogram-transformer",
"audio-classification",
"generated_from_trainer",
"dataset:marsyas/gtzan",
"base_model:bookbot/distil-ast-audioset",
"base_model:finetune:bookbot/distil-ast-audioset",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] |
audio-classification
| 2023-08-16T01:49:11Z |
---
license: apache-2.0
base_model: bookbot/distil-ast-audioset
tags:
- generated_from_trainer
datasets:
- marsyas/gtzan
metrics:
- accuracy
model-index:
- name: distil-ast-audioset-finetuned-gtzan
results:
- task:
name: Audio Classification
type: audio-classification
dataset:
name: GTZAN
type: marsyas/gtzan
config: all
split: train
args: all
metrics:
- name: Accuracy
type: accuracy
value: 0.89
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distil-ast-audioset-finetuned-gtzan
This model is a fine-tuned version of [bookbot/distil-ast-audioset](https://huggingface.co/bookbot/distil-ast-audioset) on the GTZAN dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3897
- Accuracy: 0.89
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 4e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 6
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 1.321 | 0.99 | 28 | 0.6668 | 0.82 |
| 0.4901 | 1.98 | 56 | 0.5119 | 0.85 |
| 0.2659 | 2.97 | 84 | 0.4564 | 0.87 |
| 0.1518 | 4.0 | 113 | 0.3853 | 0.88 |
| 0.0626 | 4.99 | 141 | 0.3862 | 0.89 |
| 0.0309 | 5.95 | 168 | 0.3897 | 0.89 |
### Framework versions
- Transformers 4.32.0.dev0
- Pytorch 2.0.1+cu118
- Datasets 2.14.4
- Tokenizers 0.13.3
|
tomoohive/a2c-PandaReachDense-v3
|
tomoohive
| 2023-08-16T02:18:42Z | 2 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"PandaReachDense-v3",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-08-09T06:18:53Z |
---
library_name: stable-baselines3
tags:
- PandaReachDense-v3
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: A2C
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: PandaReachDense-v3
type: PandaReachDense-v3
metrics:
- type: mean_reward
value: -0.22 +/- 0.09
name: mean_reward
verified: false
---
# **A2C** Agent playing **PandaReachDense-v3**
This is a trained model of a **A2C** agent playing **PandaReachDense-v3**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
yeongsang2/polyglot-ko-12.8B-v.1.02-checkpoint-240
|
yeongsang2
| 2023-08-16T02:15:59Z | 0 | 0 |
peft
|
[
"peft",
"region:us"
] | null | 2023-08-16T02:13:35Z |
---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: True
- load_in_4bit: False
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: fp4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float32
### Framework versions
- PEFT 0.5.0.dev0
|
JuiThe/mt5base_lora_Wreview_30e
|
JuiThe
| 2023-08-16T01:51:55Z | 0 | 0 |
peft
|
[
"peft",
"region:us"
] | null | 2023-08-16T01:51:54Z |
---
library_name: peft
---
## Training procedure
### Framework versions
- PEFT 0.4.0
|
HachiML/ja-stablelm-alpha-7b-dolly-ja-qlora-3ep-v8
|
HachiML
| 2023-08-16T01:43:39Z | 0 | 0 |
peft
|
[
"peft",
"region:us"
] | null | 2023-08-16T01:43:28Z |
---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float16
### Framework versions
- PEFT 0.4.0
|
ialvarenga/finetuned-mpnet-citation-itent
|
ialvarenga
| 2023-08-16T01:38:01Z | 3 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"pytorch",
"mpnet",
"setfit",
"text-classification",
"arxiv:2209.11055",
"license:apache-2.0",
"region:us"
] |
text-classification
| 2023-08-14T01:47:41Z |
---
license: apache-2.0
tags:
- setfit
- sentence-transformers
- text-classification
pipeline_tag: text-classification
---
# ialvarenga/finetuned-mpnet-citation-itent
This is a [SetFit model](https://github.com/huggingface/setfit) that can be used for text classification. The model has been trained using an efficient few-shot learning technique that involves:
1. Fine-tuning a [Sentence Transformer](https://www.sbert.net) with contrastive learning.
2. Training a classification head with features from the fine-tuned Sentence Transformer.
## Usage
To use this model for inference, first install the SetFit library:
```bash
python -m pip install setfit
```
You can then run inference as follows:
```python
from setfit import SetFitModel
# Download from Hub and run inference
model = SetFitModel.from_pretrained("ialvarenga/finetuned-mpnet-citation-itent")
# Run inference
preds = model(["i loved the spiderman movie!", "pineapple on pizza is the worst 🤮"])
```
## BibTeX entry and citation info
```bibtex
@article{https://doi.org/10.48550/arxiv.2209.11055,
doi = {10.48550/ARXIV.2209.11055},
url = {https://arxiv.org/abs/2209.11055},
author = {Tunstall, Lewis and Reimers, Nils and Jo, Unso Eun Seo and Bates, Luke and Korat, Daniel and Wasserblat, Moshe and Pereg, Oren},
keywords = {Computation and Language (cs.CL), FOS: Computer and information sciences, FOS: Computer and information sciences},
title = {Efficient Few-Shot Learning Without Prompts},
publisher = {arXiv},
year = {2022},
copyright = {Creative Commons Attribution 4.0 International}
}
```
|
edor/Platypus2-mini-7B
|
edor
| 2023-08-16T01:35:11Z | 1,399 | 1 |
transformers
|
[
"transformers",
"pytorch",
"llama",
"text-generation",
"license:other",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-08-16T00:03:30Z |
---
license: other
---
Smaller version of Platypus2, Llama2-7B finetuned w/QLoRA with [garage-bAInd/Open-Platypus](https://huggingface.co/datasets/garage-bAInd/Open-Platypus) dataset
|
Chaeyeon/git-base-sketch
|
Chaeyeon
| 2023-08-16T01:32:27Z | 61 | 0 |
transformers
|
[
"transformers",
"pytorch",
"git",
"image-text-to-text",
"generated_from_trainer",
"base_model:microsoft/git-base",
"base_model:finetune:microsoft/git-base",
"license:mit",
"endpoints_compatible",
"region:us"
] |
image-text-to-text
| 2023-08-16T01:31:05Z |
---
license: mit
base_model: microsoft/git-base
tags:
- generated_from_trainer
model-index:
- name: git-base-sketch
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# git-base-sketch
This model is a fine-tuned version of [microsoft/git-base](https://huggingface.co/microsoft/git-base) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 50
### Framework versions
- Transformers 4.31.0
- Pytorch 2.0.1+cu118
- Datasets 2.14.4
- Tokenizers 0.13.3
|
jjsprockel/whisper
|
jjsprockel
| 2023-08-16T01:24:58Z | 75 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"whisper",
"automatic-speech-recognition",
"generated_from_trainer",
"dataset:PolyAI/minds14",
"base_model:openai/whisper-tiny",
"base_model:finetune:openai/whisper-tiny",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2023-08-16T00:54:10Z |
---
license: apache-2.0
base_model: openai/whisper-tiny
tags:
- generated_from_trainer
datasets:
- PolyAI/minds14
metrics:
- wer
model-index:
- name: whisper
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: PolyAI/minds14
type: PolyAI/minds14
config: en-US
split: train
args: en-US
metrics:
- name: Wer
type: wer
value: 0.35714285714285715
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# whisper
This model is a fine-tuned version of [openai/whisper-tiny](https://huggingface.co/openai/whisper-tiny) on the PolyAI/minds14 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6947
- Wer Ortho: 0.3516
- Wer: 0.3571
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: constant_with_warmup
- lr_scheduler_warmup_steps: 50
- training_steps: 500
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer Ortho | Wer |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|
| 0.0008 | 17.86 | 500 | 0.6947 | 0.3516 | 0.3571 |
### Framework versions
- Transformers 4.31.0
- Pytorch 2.0.1+cu118
- Datasets 2.14.4
- Tokenizers 0.13.3
|
bhenrym14/airophin-v2-13b-PI-8k-fp16
|
bhenrym14
| 2023-08-16T00:55:39Z | 1,387 | 2 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"dataset:jondurbin/airoboros-gpt4-m2.0",
"dataset:ehartford/dolphin",
"dataset:shahules786/orca-chat",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-08-14T13:13:13Z |
---
datasets:
- jondurbin/airoboros-gpt4-m2.0
- ehartford/dolphin
- shahules786/orca-chat
---
# Airophin: An Airoboros-Dolphin Extended Context QLoRA Fine-tune of Llama-2-13b (fp16 weights)
<!-- LoRA Weights can be found here: https://huggingface.co/bhenrym14/airophin-13b-pntk-16k-LoRA -->
GPTQ weights can be found here: https://huggingface.co/bhenrym14/airophin-v2-13b-PI-8k-GPTQ
## Overview
This is a finetune of Llama-2-13b, intended to extend the useful context window to 8192 tokens via position interpolation (PI). There are two training phases, but in this model I only perform the final finetune on the Airoboros m2.0 dataset.
1. I start with [OpenAssistant/llama2-13b-orca-8k-3319](https://huggingface.co/OpenAssistant/llama2-13b-orca-8k-3319). This model has been trained on a mix of orca-chat (dolphin derived), fanfics, and redpajama; the majority of the dataset is orca-chat, hence why I retain the airophin naming for this model.
2. The model was then finetuned on the merged Airoboros dataset (1.4.1 merged with 2.0) [Jon Durbin's Airoboros GPT4 m2.0](https://huggingface.co/datasets/jondurbin/airoboros-gpt4-m2.0), with same scaling approach, for 2 epochs.
**This is a (merged) QLoRA fine-tune (rank 64)**.
The finetune was performed with 1x RTX 6000 Ada.
## How to Use
This model employs linear RoPE scaling, which is now has native support in Transformers (be sure to update it if you have issues). Use it as you would with any normal context length variant.
Please comment with any questions. The GPTQ version can be found [here](https://huggingface.co/bhenrym14/airophin-v2-13b-PI-8k-fp16). I may upload a GGML version soon, especially if anyone expresses interest.
Ooba use: Be sure to increase the `Truncate the prompt up to this length` parameter to 8192 to utilize the full context capabilities.
## Motivation
Previous experiments have demonstrated that orca-like datasets yield substantial performance improvements on numerous benchmarks. Additionally, the PI method of context extension requires finetuning to minimize performance impacts relative to the original (non context extended) model. My most successful models for context extension with PI methods employ a pretraining phase on long sequences, but due to the compute requirements, I have not scaled this to more than 200 iterations or so. Many groups (including OpenAssistant) have performed such training at scale. This model uses such a model as a starting point.
## Relative Performance (perplexity)
| Context (tokens) | bhenrym14/airophin-v2-13b-PI-8k-fp16 | bhenrym14/airophin-13b-pntk-16k-fp16| bhenrym14/airoboros-13b-gpt4-1.4.1-PI-8192-fp16 |bhenrym14/airoboros-33b-gpt4-1.4.1-lxctx-PI-16384-fp16 | jondurbin/airoboros-l2-13b-gpt4-1.4.1 |
| --- | ---| ----- | -----| ------| --- |
| 512 | 7.38 | 7.62 | 8.24 | 7.90 | **7.23** |
| 1024 | 5.99 | 6.20 | 6.71 | 6.17 | **5.85** |
| 2048 | 5.22 | 5.38 | 5.87 | 5.23 | **5.07** |
| 4096 | 4.90 | 5.08 | 5.50 | 4.91 | **4.77** |
| 8192 | **4.71** | 4.90 | 5.32 | Not Tested | 57.1 |
| 12000 | 55 | **4.82** | 56.1 | Not Tested | Not Tested |
- This model is very competitive with the Llama-1 33b extended context variants. In fact, it outperforms bhenrym14/airoboros-33b-gpt4-1.4.1-lxctx-PI-16384-fp16 everywhere <=8192 tokens. Do note however that 33b model is only trained on the 1.4.1 Airoboros dataset. Additionally this model only requires a PI factor of 2, whereas the 33b-16k llama1 model requires a factor of 8. It is clear from my experiments and those in the literature that higher factors pose larger challenges for performance recovery.
- Not presented here, but this model outperforms the base llama-2-13b on MMLU-fs with a score of ~57.3 (computed on subset of full benchmark). If this score ends up being be replicated on the HF LLM leaderboard, **this would be the highest mmlu score for a 13b extended context model** and #4 overall for 13b (as of 8/15).
- Feedback regarding real-world performance is appreciated. Llama2-13b is known to have repetition problems. Does the extensive training on top of the base model help ameliorate this tendency? Perplexity and MMLU are great, but the don't tell the whole story.
## Prompting:
This model was trained with airoboros-like prompting in the 2nd phase. See the following from one of Jon Durbin's airoboros model cards:
### Context obedient question answering
By obedient, I mean the model was trained to ignore what it thinks it knows, and uses the context to answer the question. The model was also tuned to limit the values to the provided context as much as possible to reduce hallucinations.
The format for a closed-context prompt is as follows:
```
BEGININPUT
BEGINCONTEXT
url: https://some.web.site/123
date: 2023-06-01
... other metdata ...
ENDCONTEXT
[insert your text blocks here]
ENDINPUT
[add as many other blocks, in the exact same format]
BEGININSTRUCTION
[insert your instruction(s). The model was tuned with single questions, paragraph format, lists, etc.]
ENDINSTRUCTION
```
It's also helpful to add "Don't make up answers if you don't know." to your instruction block to make sure if the context is completely unrelated it doesn't make something up.
*The __only__ prompts that need this closed context formating are closed-context instructions. Normal questions/instructions do not!*
I know it's a bit verbose and annoying, but after much trial and error, using these explicit delimiters helps the model understand where to find the responses and how to associate specific sources with it.
- `BEGININPUT` - denotes a new input block
- `BEGINCONTEXT` - denotes the block of context (metadata key/value pairs) to associate with the current input block
- `ENDCONTEXT` - denotes the end of the metadata block for the current input
- [text] - Insert whatever text you want for the input block, as many paragraphs as can fit in the context.
- `ENDINPUT` - denotes the end of the current input block
- [repeat as many input blocks in this format as you want]
- `BEGININSTRUCTION` - denotes the start of the list (or one) instruction(s) to respond to for all of the input blocks above.
- [instruction(s)]
- `ENDINSTRUCTION` - denotes the end of instruction set
It sometimes works without `ENDINSTRUCTION`, but by explicitly including that in the prompt, the model better understands that all of the instructions in the block should be responded to.
Here's a trivial, but important example to prove the point:
```
BEGININPUT
BEGINCONTEXT
date: 2021-01-01
url: https://web.site/123
ENDCONTEXT
In a shocking turn of events, blueberries are now green, but will be sticking with the same name.
ENDINPUT
BEGININSTRUCTION
What color are bluberries? Source?
ENDINSTRUCTION
```
And the response:
```
Blueberries are now green.
Source:
date: 2021-01-01
url: https://web.site/123
```
The prompt itself should be wrapped in the vicuna1.1 template if you aren't using fastchat with the conv-template vicuna_v1.1 as described:
```
USER: BEGININPUT
BEGINCONTEXT
date: 2021-01-01
url: https://web.site/123
ENDCONTEXT
In a shocking turn of events, blueberries are now green, but will be sticking with the same name.
ENDINPUT
BEGININSTRUCTION
What color are bluberries? Source?
ENDINSTRUCTION
ASSISTANT:
```
### Coding
You can ask for fairly complex coding instructions, e.g. (be sure to wrap with vicuna style prompt):
```
Create a python application with the following requirements:
- Asyncio FastAPI webserver
- ping endpoint that returns the current date in JSON format
- file upload endpoint, which calculates the file's sha256 checksum, and checks postgres to deduplicate
```
Or:
```
Write a multi-threaded TCP server in C that accepts a "GET [key]" input and "SET [key] [value]" input, and uses a binary tree to get and store the input values.
```
You can optionally add a single space and "PLAINFORMAT" at the end of your prompt to avoid backticks, explanations, etc. and just print the code, e.g.:
```
Write a websocket application in node.js. PLAINFORMAT
```
### Word games / trivia
```
USER: This anagram of "silent" is what you do when paying attention and hearing someone.
ASSISTANT: listen
```
```
USER: Give me a list of 7 words that start with EN
ASSISTANT: 1. Endlessly
2. Enthusiastically
3. Enormously
4. Enveloping
5. Enduring
6. Enlightening
7. Encouraging
```
### Multiple choice
```
USER: Which of the following astronomical objects is composed primarily of ice and rock, and is located in the Kuiper Belt?
A) Mercury
B) Venus
C) Pluto
D) Jupiter
ASSISTANT: C, Pluto
```
### Writing
<details>
<summary>Write a resignation letter in the style of a pirate captain, in which you resign from your position as janitor.</summary>
Response:
```
ASSISTANT: Captain Jack Sparrow here, as ye be knowin', has been forced to abandon me post as Janitor o' th' Festering Cesspool, which be a filthy hole o' water that we be callin' home.
Ye may be thinkin' what could ha' driven me to leave me duties an' take me leave o' this sorry establishment? Well, ye'd be right in thinkin' so, for it be th' greed o' them what runs th' place that be drivin' me away. They've been fattenin' their pockets on me back while I've been slavin' me guts out cleanin' up their messes.
No more, me hearties! Me time o' servin' th' rich an' powerful be done, an' I'm takin' me leave o' this stinkin' hole forever! Me destiny lies elsewhere, an' it be time I pursued it. Ye may think ye've seen th' last o' me, but ye'd be wrong, for th' winds o' change be blowin', an' me ship be ready to set sail on th' high seas o' justice.
So, farewell ye scurvy dogs, ye who've made me life a living hell. I leave ye with me favorite saying: "ARRRGGGHHH, ye scurvy dogs!" An' remember, ye ain't never gonna see me comin', for me shadow be castin' long an' dark on th' horizon</summary>
```
</details>
### Jokes
```
USER: Tell me a joke about bananas.
ASSISTANT: What did the banana say when it got hit by a bus? R.I.P.E.
```
### Riddles (not great, but slightly better)
```
USER: What has a neck but no head?
ASSISTANT: A bottle.
```
### Multi-character conversations
```
USER: Characters:
- Yoda, the ever clever jedi master.
- Homer Simpson, you know, the goofy yellow guy.
- USER/Jon - don't generate any speech or actions on behalf of Jon
Rules:
- be sure to use the manerisms and speaking style of the characters correctly
- surround character actions with asterisks
- always put quotes around words spoken by the characters
- use a new line for each character's actions or speech
- always prefix actions/speech with the character's name and colon
- only generate text and actions on behalf of Yoda or Homer, and never anyone else
Conversation will revolve around the grapes, in a local cafe with delicious coffee.
Generate a single interaction between Yoda and Homer to start, with one sentence each.
ASSISTANT: Yoda: "Mmm, these grapes are quite delicious, Master Homer."
Homer: "Oh yeah, Yoda! They're the best grapes I've ever had!"
USER: *enters the cafe* Sorry I'm late guys!
ASSISTANT: Yoda: "No need to apologize, Jon. We were just enjoying these delightful grapes."
Homer: "Yeah, man! It's not every day you get to eat grapes with a real-life Jedi Master!"
*Yoda raises an eyebrow*
```
|
pprabu/finetuning-sentiment-model-3000-samples
|
pprabu
| 2023-08-16T00:36:00Z | 110 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_trainer",
"dataset:imdb",
"base_model:distilbert/distilbert-base-uncased",
"base_model:finetune:distilbert/distilbert-base-uncased",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-08-10T00:16:08Z |
---
license: apache-2.0
base_model: distilbert-base-uncased
tags:
- generated_from_trainer
datasets:
- imdb
metrics:
- accuracy
- f1
- precision
- recall
model-index:
- name: finetuning-sentiment-model-3000-samples
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: imdb
type: imdb
config: plain_text
split: test
args: plain_text
metrics:
- name: Accuracy
type: accuracy
value: 0.8633333333333333
- name: F1
type: f1
value: 0.8664495114006515
- name: Precision
type: precision
value: 0.8471337579617835
- name: Recall
type: recall
value: 0.8866666666666667
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# finetuning-sentiment-model-3000-samples
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the imdb dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3324
- Accuracy: 0.8633
- F1: 0.8664
- Precision: 0.8471
- Recall: 0.8867
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
### Framework versions
- Transformers 4.31.0
- Pytorch 2.0.1+cu118
- Datasets 2.14.4
- Tokenizers 0.13.3
|
MattStammers/SAC-Bipedal_Walker_v3-HardcoreTrained
|
MattStammers
| 2023-08-16T00:23:25Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"BipedalWalker-v3",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-08-16T00:14:49Z |
---
library_name: stable-baselines3
tags:
- BipedalWalker-v3
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: SAC
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: BipedalWalker-v3
type: BipedalWalker-v3
metrics:
- type: mean_reward
value: -31.49 +/- 60.03
name: mean_reward
verified: false
---
# **SAC** Agent playing **BipedalWalker-v3**
This is a trained model of a **SAC** agent playing **BipedalWalker-v3**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
Well he does ok but still gets stuck on the rocks. Here are my hyperparameters not that they did me much good 😂:
```python
def linear_schedule(initial_value, final_value=0.00001):
def func(progress_remaining):
"""Progress will decrease from 1 (beginning) to 0 (end)"""
return final_value + (initial_value - final_value) * progress_remaining
return func
initial_learning_rate = 7.3e-4
model = SAC(
policy='MlpPolicy',
env=env,
learning_rate=linear_schedule(initial_learning_rate),
buffer_size=1000000,
batch_size=256,
ent_coef=0.005,
gamma=0.99,
tau=0.01,
train_freq=1,
gradient_steps=1,
learning_starts=10000,
policy_kwargs=dict(net_arch=[400, 300]),
verbose=1
)
```
These are pretty well tuned but SAC leads to too much exploration and the agent is unable to exploit the required actions to complete the course. I suspect TD3 will be more successful so plan to turn back to that
|
PyaeSoneK/LlamaV2LegalFineTuned
|
PyaeSoneK
| 2023-08-16T00:21:39Z | 7 | 0 |
transformers
|
[
"transformers",
"pytorch",
"llama",
"text-generation",
"license:openrail",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-08-14T05:11:04Z |
---
license: openrail
---
This is A model finetuned with a custom dataset that takes in a common citizen's legal question input, and responds with a well-reasoned response , with a touch of legal-linking i.e. Citation resolution and suggestion in Constituational law or documents and articles.
|
CyberHarem/agnese_sanctis_toarumajutsunoindex
|
CyberHarem
| 2023-08-16T00:17:06Z | 0 | 0 | null |
[
"art",
"text-to-image",
"dataset:CyberHarem/agnese_sanctis_toarumajutsunoindex",
"license:mit",
"region:us"
] |
text-to-image
| 2023-08-16T00:12:07Z |
---
license: mit
datasets:
- CyberHarem/agnese_sanctis_toarumajutsunoindex
pipeline_tag: text-to-image
tags:
- art
---
# Lora of agnese_sanctis_toarumajutsunoindex
This model is trained with [HCP-Diffusion](https://github.com/7eu7d7/HCP-Diffusion). And the auto-training framework is maintained by [DeepGHS Team](https://huggingface.co/deepghs).
After downloading the pt and safetensors files for the specified step, you need to use them simultaneously. The pt file will be used as an embedding, while the safetensors file will be loaded for Lora.
For example, if you want to use the model from step 1500, you need to download `1500/agnese_sanctis_toarumajutsunoindex.pt` as the embedding and `1500/agnese_sanctis_toarumajutsunoindex.safetensors` for loading Lora. By using both files together, you can generate images for the desired characters.
**The trigger word is `agnese_sanctis_toarumajutsunoindex`.**
These are available steps:
| Steps | bikini | free | nude | Download |
|--------:|:-----------------------------------------|:-------------------------------------|:-----------------------------------------------|:--------------------------------------------------------|
| 1500 |  |  | [<NSFW, click to see>](1500/previews/nude.png) | [Download](1500/agnese_sanctis_toarumajutsunoindex.zip) |
| 1400 |  |  | [<NSFW, click to see>](1400/previews/nude.png) | [Download](1400/agnese_sanctis_toarumajutsunoindex.zip) |
| 1300 |  |  | [<NSFW, click to see>](1300/previews/nude.png) | [Download](1300/agnese_sanctis_toarumajutsunoindex.zip) |
| 1200 |  |  | [<NSFW, click to see>](1200/previews/nude.png) | [Download](1200/agnese_sanctis_toarumajutsunoindex.zip) |
| 1100 |  |  | [<NSFW, click to see>](1100/previews/nude.png) | [Download](1100/agnese_sanctis_toarumajutsunoindex.zip) |
| 1000 |  |  | [<NSFW, click to see>](1000/previews/nude.png) | [Download](1000/agnese_sanctis_toarumajutsunoindex.zip) |
| 900 |  |  | [<NSFW, click to see>](900/previews/nude.png) | [Download](900/agnese_sanctis_toarumajutsunoindex.zip) |
| 800 |  |  | [<NSFW, click to see>](800/previews/nude.png) | [Download](800/agnese_sanctis_toarumajutsunoindex.zip) |
| 700 |  |  | [<NSFW, click to see>](700/previews/nude.png) | [Download](700/agnese_sanctis_toarumajutsunoindex.zip) |
| 600 |  |  | [<NSFW, click to see>](600/previews/nude.png) | [Download](600/agnese_sanctis_toarumajutsunoindex.zip) |
| 500 |  |  | [<NSFW, click to see>](500/previews/nude.png) | [Download](500/agnese_sanctis_toarumajutsunoindex.zip) |
| 400 |  |  | [<NSFW, click to see>](400/previews/nude.png) | [Download](400/agnese_sanctis_toarumajutsunoindex.zip) |
| 300 |  |  | [<NSFW, click to see>](300/previews/nude.png) | [Download](300/agnese_sanctis_toarumajutsunoindex.zip) |
| 200 |  |  | [<NSFW, click to see>](200/previews/nude.png) | [Download](200/agnese_sanctis_toarumajutsunoindex.zip) |
| 100 |  |  | [<NSFW, click to see>](100/previews/nude.png) | [Download](100/agnese_sanctis_toarumajutsunoindex.zip) |
|
mohsenimani/falcon-7b-fine-tuned-chatbot
|
mohsenimani
| 2023-08-15T23:36:38Z | 0 | 0 |
peft
|
[
"peft",
"region:us"
] | null | 2023-08-14T23:40:54Z |
---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: True
- bnb_4bit_compute_dtype: float32
### Framework versions
- PEFT 0.4.0
|
felixshier/oc-01-bert-finetuned
|
felixshier
| 2023-08-15T23:32:38Z | 62 | 0 |
transformers
|
[
"transformers",
"tf",
"bert",
"text-classification",
"generated_from_keras_callback",
"base_model:google-bert/bert-base-uncased",
"base_model:finetune:google-bert/bert-base-uncased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-08-15T23:32:18Z |
---
license: apache-2.0
base_model: bert-base-uncased
tags:
- generated_from_keras_callback
model-index:
- name: oc-01-bert-finetuned
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# oc-01-bert-finetuned
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.0155
- Validation Loss: 0.3519
- Train Recall: 0.9396
- Epoch: 6
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'Adam', 'weight_decay': None, 'clipnorm': None, 'global_clipnorm': None, 'clipvalue': None, 'use_ema': False, 'ema_momentum': 0.99, 'ema_overwrite_frequency': None, 'jit_compile': True, 'is_legacy_optimizer': False, 'learning_rate': {'module': 'keras.optimizers.schedules', 'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 2e-05, 'decay_steps': 6140, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}, 'registered_name': None}, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False}
- training_precision: float32
### Training results
| Train Loss | Validation Loss | Train Recall | Epoch |
|:----------:|:---------------:|:------------:|:-----:|
| 0.3378 | 0.2319 | 0.9249 | 0 |
| 0.1886 | 0.2204 | 0.8974 | 1 |
| 0.1006 | 0.2864 | 0.9249 | 2 |
| 0.0558 | 0.3120 | 0.9066 | 3 |
| 0.0324 | 0.3041 | 0.9212 | 4 |
| 0.0222 | 0.3763 | 0.9359 | 5 |
| 0.0155 | 0.3519 | 0.9396 | 6 |
### Framework versions
- Transformers 4.31.0
- TensorFlow 2.13.0
- Datasets 2.14.4
- Tokenizers 0.13.3
|
felixshier/cc-01-bert-finetuned
|
felixshier
| 2023-08-15T23:32:18Z | 61 | 0 |
transformers
|
[
"transformers",
"tf",
"bert",
"text-classification",
"generated_from_keras_callback",
"base_model:google-bert/bert-base-uncased",
"base_model:finetune:google-bert/bert-base-uncased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-08-15T23:31:56Z |
---
license: apache-2.0
base_model: bert-base-uncased
tags:
- generated_from_keras_callback
model-index:
- name: cc-01-bert-finetuned
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# cc-01-bert-finetuned
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.0058
- Validation Loss: 0.5378
- Train Recall: 0.8693
- Epoch: 7
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'Adam', 'weight_decay': None, 'clipnorm': None, 'global_clipnorm': None, 'clipvalue': None, 'use_ema': False, 'ema_momentum': 0.99, 'ema_overwrite_frequency': None, 'jit_compile': True, 'is_legacy_optimizer': False, 'learning_rate': {'module': 'keras.optimizers.schedules', 'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 2e-05, 'decay_steps': 1770, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}, 'registered_name': None}, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False}
- training_precision: float32
### Training results
| Train Loss | Validation Loss | Train Recall | Epoch |
|:----------:|:---------------:|:------------:|:-----:|
| 0.4422 | 0.4857 | 0.9477 | 0 |
| 0.2513 | 0.3470 | 0.8497 | 1 |
| 0.1331 | 0.4266 | 0.7974 | 2 |
| 0.0640 | 0.4452 | 0.8824 | 3 |
| 0.0339 | 0.5141 | 0.8366 | 4 |
| 0.0225 | 0.5295 | 0.8431 | 5 |
| 0.0090 | 0.5200 | 0.8889 | 6 |
| 0.0058 | 0.5378 | 0.8693 | 7 |
### Framework versions
- Transformers 4.31.0
- TensorFlow 2.13.0
- Datasets 2.14.4
- Tokenizers 0.13.3
|
dvs/autotrain-mulder-vs-scully-multi-model-82521142038
|
dvs
| 2023-08-15T23:03:45Z | 185 | 0 |
transformers
|
[
"transformers",
"pytorch",
"safetensors",
"swin",
"image-classification",
"autotrain",
"vision",
"dataset:dvs/autotrain-data-mulder-vs-scully-multi-model",
"co2_eq_emissions",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2023-08-15T23:01:53Z |
---
tags:
- autotrain
- vision
- image-classification
datasets:
- dvs/autotrain-data-mulder-vs-scully-multi-model
widget:
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/tiger.jpg
example_title: Tiger
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/teapot.jpg
example_title: Teapot
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/palace.jpg
example_title: Palace
co2_eq_emissions:
emissions: 0.012178270797141812
---
# Model Trained Using AutoTrain
- Problem type: Binary Classification
- Model ID: 82521142038
- CO2 Emissions (in grams): 0.0122
## Validation Metrics
- Loss: 0.302
- Accuracy: 1.000
- Precision: 1.000
- Recall: 1.000
- AUC: 1.000
- F1: 1.000
|
matteo1222/lora-trained-xl-colab-cheeto
|
matteo1222
| 2023-08-15T22:32:38Z | 3 | 1 |
diffusers
|
[
"diffusers",
"tensorboard",
"stable-diffusion-xl",
"stable-diffusion-xl-diffusers",
"text-to-image",
"lora",
"base_model:stabilityai/stable-diffusion-xl-base-1.0",
"base_model:adapter:stabilityai/stable-diffusion-xl-base-1.0",
"license:openrail++",
"region:us"
] |
text-to-image
| 2023-08-15T22:01:12Z |
---
license: openrail++
base_model: stabilityai/stable-diffusion-xl-base-1.0
instance_prompt: a photo of sks cheeto
tags:
- stable-diffusion-xl
- stable-diffusion-xl-diffusers
- text-to-image
- diffusers
- lora
inference: true
---
# LoRA DreamBooth - matteo1222/lora-trained-xl-colab-cheeto
These are LoRA adaption weights for stabilityai/stable-diffusion-xl-base-1.0. The weights were trained on a photo of sks cheeto using [DreamBooth](https://dreambooth.github.io/). You can find some example images in the following.
LoRA for the text encoder was enabled: False.
Special VAE used for training: madebyollin/sdxl-vae-fp16-fix.
|
bulu/whiskey_textual_inversion
|
bulu
| 2023-08-15T22:14:58Z | 7 | 0 |
diffusers
|
[
"diffusers",
"tensorboard",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"textual_inversion",
"base_model:runwayml/stable-diffusion-v1-5",
"base_model:adapter:runwayml/stable-diffusion-v1-5",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] |
text-to-image
| 2023-08-15T17:14:24Z |
---
license: creativeml-openrail-m
base_model: runwayml/stable-diffusion-v1-5
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
- textual_inversion
inference: true
---
# Textual inversion text2image fine-tuning - bulu/whiskey_textual_inversion
These are textual inversion adaption weights for runwayml/stable-diffusion-v1-5. You can find some example images in the following.
|
sherryzia22/ppo-LunarLander-v2
|
sherryzia22
| 2023-08-15T21:40:42Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-08-15T21:40:20Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 256.46 +/- 23.96
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
gang21/llama2-icd10-condensed
|
gang21
| 2023-08-15T21:12:19Z | 3 | 0 |
peft
|
[
"peft",
"region:us"
] | null | 2023-08-15T21:12:16Z |
---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: True
- load_in_4bit: False
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: fp4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float32
### Framework versions
- PEFT 0.5.0.dev0
|
skrl/IsaacOrbit-Isaac-Humanoid-v0-PPO
|
skrl
| 2023-08-15T21:04:57Z | 0 | 0 |
skrl
|
[
"skrl",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-01-20T12:08:33Z |
---
library_name: skrl
tags:
- deep-reinforcement-learning
- reinforcement-learning
- skrl
model-index:
- name: PPO
results:
- metrics:
- type: mean_reward
value: 5935.41 +/- 610.45
name: Total reward (mean)
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Isaac-Humanoid-v0
type: Isaac-Humanoid-v0
---
<!-- ---
torch: 5935.41 +/- 610.45
jax: TODO
numpy:
--- -->
# IsaacOrbit-Isaac-Humanoid-v0-PPO
Trained agent for [NVIDIA Isaac Orbit](https://github.com/NVIDIA-Omniverse/Orbit) environments.
- **Task:** Isaac-Humanoid-v0
- **Agent:** [PPO](https://skrl.readthedocs.io/en/latest/api/agents/ppo.html)
# Usage (with skrl)
Note: Visit the skrl [Examples](https://skrl.readthedocs.io/en/latest/intro/examples.html) section to access the scripts.
* PyTorch
```python
from skrl.utils.huggingface import download_model_from_huggingface
# assuming that there is an agent named `agent`
path = download_model_from_huggingface("skrl/IsaacOrbit-Isaac-Humanoid-v0-PPO", filename="agent.pt")
agent.load(path)
```
* JAX
```python
from skrl.utils.huggingface import download_model_from_huggingface
# assuming that there is an agent named `agent`
path = download_model_from_huggingface("skrl/IsaacOrbit-Isaac-Humanoid-v0-PPO", filename="agent.pickle")
agent.load(path)
```
# Hyperparameters
```python
# https://skrl.readthedocs.io/en/latest/api/agents/ppo.html#configuration-and-hyperparameters
cfg = PPO_DEFAULT_CONFIG.copy()
cfg["rollouts"] = 32 # memory_size
cfg["learning_epochs"] = 8
cfg["mini_batches"] = 8 # 32 * 1024 / 4096
cfg["discount_factor"] = 0.99
cfg["lambda"] = 0.95
cfg["learning_rate"] = 3e-4
cfg["learning_rate_scheduler"] = KLAdaptiveRL
cfg["learning_rate_scheduler_kwargs"] = {"kl_threshold": 0.01}
cfg["random_timesteps"] = 0
cfg["learning_starts"] = 0
cfg["grad_norm_clip"] = 1.0
cfg["ratio_clip"] = 0.2
cfg["value_clip"] = 0.2
cfg["clip_predicted_values"] = True
cfg["entropy_loss_scale"] = 0.0
cfg["value_loss_scale"] = 4.0
cfg["kl_threshold"] = 0
cfg["rewards_shaper"] = lambda rewards, *args, **kwargs: rewards * 0.01
cfg["time_limit_bootstrap"] = False
cfg["state_preprocessor"] = RunningStandardScaler
cfg["state_preprocessor_kwargs"] = {"size": env.observation_space, "device": device}
cfg["value_preprocessor"] = RunningStandardScaler
cfg["value_preprocessor_kwargs"] = {"size": 1, "device": device}
```
|
jcramirezpr/audio-diffusion-spectro
|
jcramirezpr
| 2023-08-15T20:41:23Z | 1 | 0 |
diffusers
|
[
"diffusers",
"pytorch",
"unconditional-audio-generation",
"diffusion-models-class",
"license:mit",
"diffusers:AudioDiffusionPipeline",
"region:us"
] | null | 2023-08-15T20:40:25Z |
---
license: mit
tags:
- pytorch
- diffusers
- unconditional-audio-generation
- diffusion-models-class
---
# Model Card for Unit 4 of the [Diffusion Models Class 🧨](https://github.com/huggingface/diffusion-models-class)
This model is a diffusion model for unconditional audio generation of music in the genre Electronic
## Usage
```python
from IPython.display import Audio
from diffusers import DiffusionPipeline
pipe = DiffusionPipeline.from_pretrained("jcramirezpr/audio-diffusion-spectro")
output = pipe()
display(output.images[0])
display(Audio(output.audios[0], rate=pipe.mel.get_sample_rate()))
```
|
KingKazma/cnn_dailymail_6789_50000_25000_v1_validation
|
KingKazma
| 2023-08-15T20:38:01Z | 4 | 0 |
bertopic
|
[
"bertopic",
"text-classification",
"region:us"
] |
text-classification
| 2023-08-15T20:38:00Z |
---
tags:
- bertopic
library_name: bertopic
pipeline_tag: text-classification
---
# cnn_dailymail_6789_50000_25000_v1_validation
This is a [BERTopic](https://github.com/MaartenGr/BERTopic) model.
BERTopic is a flexible and modular topic modeling framework that allows for the generation of easily interpretable topics from large datasets.
## Usage
To use this model, please install BERTopic:
```
pip install -U bertopic
```
You can use the model as follows:
```python
from bertopic import BERTopic
topic_model = BERTopic.load("KingKazma/cnn_dailymail_6789_50000_25000_v1_validation")
topic_model.get_topic_info()
```
## Topic overview
* Number of topics: 118
* Number of training documents: 13368
<details>
<summary>Click here for an overview of all topics.</summary>
| Topic ID | Topic Keywords | Topic Frequency | Label |
|----------|----------------|-----------------|-------|
| -1 | said - one - year - also - time | 5 | -1_said_one_year_also |
| 0 | isis - syria - islamic - attack - group | 6535 | 0_isis_syria_islamic_attack |
| 1 | police - officer - shooting - ferguson - said | 452 | 1_police_officer_shooting_ferguson |
| 2 | labour - mr - party - election - tax | 415 | 2_labour_mr_party_election |
| 3 | flight - plane - pilot - aircraft - lubitz | 268 | 3_flight_plane_pilot_aircraft |
| 4 | car - driver - driving - road - crash | 224 | 4_car_driver_driving_road |
| 5 | hair - fashion - dress - model - look | 223 | 5_hair_fashion_dress_model |
| 6 | cricket - england - cup - world - pietersen | 205 | 6_cricket_england_cup_world |
| 7 | food - sugar - per - cent - product | 189 | 7_food_sugar_per_cent |
| 8 | clinton - email - obama - president - clintons | 188 | 8_clinton_email_obama_president |
| 9 | property - house - home - price - room | 186 | 9_property_house_home_price |
| 10 | rangers - celtic - scotland - ibrox - game | 165 | 10_rangers_celtic_scotland_ibrox |
| 11 | fight - pacquiao - mayweather - manny - floyd | 151 | 11_fight_pacquiao_mayweather_manny |
| 12 | england - nations - wales - ireland - six | 143 | 12_england_nations_wales_ireland |
| 13 | hamilton - mercedes - prix - race - rosberg | 135 | 13_hamilton_mercedes_prix_race |
| 14 | baby - birth - cancer - hospital - born | 126 | 14_baby_birth_cancer_hospital |
| 15 | fa - league - game - villa - bradford | 116 | 15_fa_league_game_villa |
| 16 | dog - animal - dogs - owner - pet | 114 | 16_dog_animal_dogs_owner |
| 17 | police - abuse - sexual - sex - child | 112 | 17_police_abuse_sexual_sex |
| 18 | madrid - ronaldo - barcelona - real - messi | 111 | 18_madrid_ronaldo_barcelona_real |
| 19 | chelsea - mourinho - terry - league - jose | 106 | 19_chelsea_mourinho_terry_league |
| 20 | eclipse - earth - mars - solar - sun | 101 | 20_eclipse_earth_mars_solar |
| 21 | kane - england - hodgson - lithuania - rooney | 100 | 21_kane_england_hodgson_lithuania |
| 22 | show - film - corden - host - noah | 95 | 22_show_film_corden_host |
| 23 | prince - royal - duchess - charles - queen | 92 | 23_prince_royal_duchess_charles |
| 24 | murray - wells - tennis - andy - 64 | 88 | 24_murray_wells_tennis_andy |
| 25 | putin - russian - nemtsov - moscow - russia | 82 | 25_putin_russian_nemtsov_moscow |
| 26 | netanyahu - iran - nuclear - israel - israeli | 80 | 26_netanyahu_iran_nuclear_israel |
| 27 | court - money - bank - fraud - stiviano | 80 | 27_court_money_bank_fraud |
| 28 | weight - size - fat - stone - diet | 76 | 28_weight_size_fat_stone |
| 29 | armstrong - race - olympic - uci - championships | 74 | 29_armstrong_race_olympic_uci |
| 30 | cheltenham - hurdle - horse - jockey - festival | 73 | 30_cheltenham_hurdle_horse_jockey |
| 31 | arsenal - wenger - monaco - giroud - arsenals | 73 | 31_arsenal_wenger_monaco_giroud |
| 32 | mcilroy - golf - masters - woods - round | 72 | 32_mcilroy_golf_masters_woods |
| 33 | watch - apple - device - google - user | 66 | 33_watch_apple_device_google |
| 34 | fraternity - university - sae - oklahoma - chapter | 65 | 34_fraternity_university_sae_oklahoma |
| 35 | united - van - gaal - manchester - arsenal | 62 | 35_united_van_gaal_manchester |
| 36 | chan - sukumaran - indonesian - bali - myuran | 61 | 36_chan_sukumaran_indonesian_bali |
| 37 | school - teacher - student - district - sexual | 58 | 37_school_teacher_student_district |
| 38 | sunderland - poyet - advocaat - johnson - april | 55 | 38_sunderland_poyet_advocaat_johnson |
| 39 | clarkson - bbc - gear - top - jeremy | 55 | 39_clarkson_bbc_gear_top |
| 40 | fire - building - blaze - explosion - firefighter | 48 | 40_fire_building_blaze_explosion |
| 41 | liverpool - gerrard - rodgers - steven - anfield | 46 | 41_liverpool_gerrard_rodgers_steven |
| 42 | patient - nhs - ae - cancer - care | 44 | 42_patient_nhs_ae_cancer |
| 43 | song - zayn - thicke - gayes - pharrell | 43 | 43_song_zayn_thicke_gayes |
| 44 | wedding - married - couple - jaclyn - love | 41 | 44_wedding_married_couple_jaclyn |
| 45 | car - vehicle - electric - model - jaguar | 41 | 45_car_vehicle_electric_model |
| 46 | nfl - borland - bowl - brady - super | 40 | 46_nfl_borland_bowl_brady |
| 47 | pellegrini - city - league - manchester - barcelona | 40 | 47_pellegrini_city_league_manchester |
| 48 | school - education - porn - sex - child | 39 | 48_school_education_porn_sex |
| 49 | bear - cub - tiger - deer - wildlife | 39 | 49_bear_cub_tiger_deer |
| 50 | gay - law - indiana - marriage - religious | 38 | 50_gay_law_indiana_marriage |
| 51 | india - rape - indian - documentary - singh | 37 | 51_india_rape_indian_documentary |
| 52 | boko - haram - nigeria - nigerian - nigerias | 36 | 52_boko_haram_nigeria_nigerian |
| 53 | ebola - sierra - leone - virus - liberia | 35 | 53_ebola_sierra_leone_virus |
| 54 | tsarnaev - dzhokhar - boston - tamerlan - tsarnaevs | 35 | 54_tsarnaev_dzhokhar_boston_tamerlan |
| 55 | ski - mountain - skier - rock - lift | 32 | 55_ski_mountain_skier_rock |
| 56 | robbery - armed - store - police - bank | 31 | 56_robbery_armed_store_police |
| 57 | roma - inter - juventus - serie - fiorentina | 30 | 57_roma_inter_juventus_serie |
| 58 | fifa - blatter - fa - qatar - cup | 29 | 58_fifa_blatter_fa_qatar |
| 59 | marijuana - drug - cannabis - colorado - lsd | 29 | 59_marijuana_drug_cannabis_colorado |
| 60 | everton - martinez - lukaku - dynamo - evertons | 27 | 60_everton_martinez_lukaku_dynamo |
| 61 | chelsea - racist - paris - train - football | 27 | 61_chelsea_racist_paris_train |
| 62 | durst - dursts - berman - orleans - robert | 27 | 62_durst_dursts_berman_orleans |
| 63 | basketball - ncaa - coach - tournament - game | 25 | 63_basketball_ncaa_coach_tournament |
| 64 | bayern - goal - muller - shakhtar - robben | 25 | 64_bayern_goal_muller_shakhtar |
| 65 | hotel - beach - cruise - ship - resort | 25 | 65_hotel_beach_cruise_ship |
| 66 | sherwood - villa - aston - tim - brom | 25 | 66_sherwood_villa_aston_tim |
| 67 | snow - inch - winter - weather - ice | 24 | 67_snow_inch_winter_weather |
| 68 | weather - temperature - rain - snow - expected | 24 | 68_weather_temperature_rain_snow |
| 69 | korean - korea - kim - north - lippert | 23 | 69_korean_korea_kim_north |
| 70 | hospital - doctor - mrs - fracture - patient | 23 | 70_hospital_doctor_mrs_fracture |
| 71 | rail - calais - parking - transport - train | 22 | 71_rail_calais_parking_transport |
| 72 | mls - lampard - orlando - city - york | 22 | 72_mls_lampard_orlando_city |
| 73 | jesus - stone - circle - ancient - stonehenge | 22 | 73_jesus_stone_circle_ancient |
| 74 | hernandez - lloyd - jenkins - hernandezs - lloyds | 21 | 74_hernandez_lloyd_jenkins_hernandezs |
| 75 | drug - cocaine - jailed - steroid - cannabis | 20 | 75_drug_cocaine_jailed_steroid |
| 76 | secret - clancy - service - agent - white | 20 | 76_secret_clancy_service_agent |
| 77 | homo - fossil - specie - ago - human | 20 | 77_homo_fossil_specie_ago |
| 78 | image - photographer - photograph - photo - landscape | 19 | 78_image_photographer_photograph_photo |
| 79 | parade - patricks - irish - st - green | 19 | 79_parade_patricks_irish_st |
| 80 | bale - wales - israel - coleman - gareth | 19 | 80_bale_wales_israel_coleman |
| 81 | di - maria - angel - united - manchester | 19 | 81_di_maria_angel_united |
| 82 | defence - greece - spending - greek - budget | 19 | 82_defence_greece_spending_greek |
| 83 | sleep - store - cent - per - kraft | 18 | 83_sleep_store_cent_per |
| 84 | student - johnson - virginia - charlottesville - university | 18 | 84_student_johnson_virginia_charlottesville |
| 85 | vanuatu - cyclone - vila - pam - port | 18 | 85_vanuatu_cyclone_vila_pam |
| 86 | cnn - transcript - student - news - roll | 18 | 86_cnn_transcript_student_news |
| 87 | nazi - anne - nazis - war - camp | 18 | 87_nazi_anne_nazis_war |
| 88 | attack - synagogue - hebdo - paris - charlie | 17 | 88_attack_synagogue_hebdo_paris |
| 89 | ham - west - tomkins - reid - kouyate | 16 | 89_ham_west_tomkins_reid |
| 90 | balotelli - mario - liverpool - italian - striker | 16 | 90_balotelli_mario_liverpool_italian |
| 91 | chinese - monk - buddhist - thailand - tourist | 15 | 91_chinese_monk_buddhist_thailand |
| 92 | snowden - gchq - intelligence - security - agency | 15 | 92_snowden_gchq_intelligence_security |
| 93 | pope - francis - naples - vatican - pontiff | 14 | 93_pope_francis_naples_vatican |
| 94 | starbucks - schultz - race - racial - campaign | 14 | 94_starbucks_schultz_race_racial |
| 95 | point - rebound - sweeney - playoff - scored | 14 | 95_point_rebound_sweeney_playoff |
| 96 | poldark - turner - demelza - aidan - drama | 13 | 96_poldark_turner_demelza_aidan |
| 97 | cuba - havana - cuban - us - castro | 13 | 97_cuba_havana_cuban_us |
| 98 | italy - conte - italian - eder - juventus | 13 | 98_italy_conte_italian_eder |
| 99 | richard - iii - leicester - king - iiis | 13 | 99_richard_iii_leicester_king |
| 100 | sena - hartman - child - shaday - sexual | 13 | 100_sena_hartman_child_shaday |
| 101 | gordon - bobbi - kristina - phil - dr | 12 | 101_gordon_bobbi_kristina_phil |
| 102 | jobs - lu - naomi - cook - business | 12 | 102_jobs_lu_naomi_cook |
| 103 | duckenfield - mr - gate - hillsborough - greaney | 11 | 103_duckenfield_mr_gate_hillsborough |
| 104 | huang - wang - chen - wife - china | 10 | 104_huang_wang_chen_wife |
| 105 | coin - coins - silver - cave - gold | 10 | 105_coin_coins_silver_cave |
| 106 | shark - whale - mola - crab - barbero | 10 | 106_shark_whale_mola_crab |
| 107 | gissendaner - execution - lethal - death - injection | 10 | 107_gissendaner_execution_lethal_death |
| 108 | book - handshake - word - author - app | 9 | 108_book_handshake_word_author |
| 109 | cosby - cosbys - thompson - welles - bill | 9 | 109_cosby_cosbys_thompson_welles |
| 110 | school - pupil - student - parent - computer | 9 | 110_school_pupil_student_parent |
| 111 | china - stopera - li - orange - chinese | 8 | 111_china_stopera_li_orange |
| 112 | tb - vaccine - disease - measles - meningitis | 8 | 112_tb_vaccine_disease_measles |
| 113 | neymar - brazil - willian - dunga - france | 8 | 113_neymar_brazil_willian_dunga |
| 114 | gomis - swansea - muamba - fabrice - bafetimbi | 7 | 114_gomis_swansea_muamba_fabrice |
| 115 | netflix - tv - content - screen - definition | 6 | 115_netflix_tv_content_screen |
| 116 | snake - eastern - redback - postlethwaite - woolworths | 6 | 116_snake_eastern_redback_postlethwaite |
</details>
## Training hyperparameters
* calculate_probabilities: True
* language: english
* low_memory: False
* min_topic_size: 10
* n_gram_range: (1, 1)
* nr_topics: None
* seed_topic_list: None
* top_n_words: 10
* verbose: False
## Framework versions
* Numpy: 1.23.5
* HDBSCAN: 0.8.33
* UMAP: 0.5.3
* Pandas: 1.5.3
* Scikit-Learn: 1.2.2
* Sentence-transformers: 2.2.2
* Transformers: 4.31.0
* Numba: 0.57.1
* Plotly: 5.15.0
* Python: 3.10.12
|
KingKazma/cnn_dailymail_6789_50000_25000_validation
|
KingKazma
| 2023-08-15T20:30:50Z | 4 | 0 |
bertopic
|
[
"bertopic",
"text-classification",
"region:us"
] |
text-classification
| 2023-08-15T20:30:49Z |
---
tags:
- bertopic
library_name: bertopic
pipeline_tag: text-classification
---
# cnn_dailymail_6789_50000_25000_validation
This is a [BERTopic](https://github.com/MaartenGr/BERTopic) model.
BERTopic is a flexible and modular topic modeling framework that allows for the generation of easily interpretable topics from large datasets.
## Usage
To use this model, please install BERTopic:
```
pip install -U bertopic
```
You can use the model as follows:
```python
from bertopic import BERTopic
topic_model = BERTopic.load("KingKazma/cnn_dailymail_6789_50000_25000_validation")
topic_model.get_topic_info()
```
## Topic overview
* Number of topics: 118
* Number of training documents: 13368
<details>
<summary>Click here for an overview of all topics.</summary>
| Topic ID | Topic Keywords | Topic Frequency | Label |
|----------|----------------|-----------------|-------|
| -1 | said - one - year - also - time | 5 | -1_said_one_year_also |
| 0 | isis - syria - islamic - attack - group | 6535 | 0_isis_syria_islamic_attack |
| 1 | police - officer - shooting - ferguson - said | 452 | 1_police_officer_shooting_ferguson |
| 2 | labour - mr - party - election - tax | 415 | 2_labour_mr_party_election |
| 3 | flight - plane - pilot - aircraft - lubitz | 268 | 3_flight_plane_pilot_aircraft |
| 4 | car - driver - driving - road - crash | 224 | 4_car_driver_driving_road |
| 5 | hair - fashion - dress - model - look | 223 | 5_hair_fashion_dress_model |
| 6 | cricket - england - cup - world - pietersen | 205 | 6_cricket_england_cup_world |
| 7 | food - sugar - per - cent - product | 189 | 7_food_sugar_per_cent |
| 8 | clinton - email - obama - president - clintons | 188 | 8_clinton_email_obama_president |
| 9 | property - house - home - price - room | 186 | 9_property_house_home_price |
| 10 | rangers - celtic - scotland - ibrox - game | 165 | 10_rangers_celtic_scotland_ibrox |
| 11 | fight - pacquiao - mayweather - manny - floyd | 151 | 11_fight_pacquiao_mayweather_manny |
| 12 | england - nations - wales - ireland - six | 143 | 12_england_nations_wales_ireland |
| 13 | hamilton - mercedes - prix - race - rosberg | 135 | 13_hamilton_mercedes_prix_race |
| 14 | baby - birth - cancer - hospital - born | 126 | 14_baby_birth_cancer_hospital |
| 15 | fa - league - game - villa - bradford | 116 | 15_fa_league_game_villa |
| 16 | dog - animal - dogs - owner - pet | 114 | 16_dog_animal_dogs_owner |
| 17 | police - abuse - sexual - sex - child | 112 | 17_police_abuse_sexual_sex |
| 18 | madrid - ronaldo - barcelona - real - messi | 111 | 18_madrid_ronaldo_barcelona_real |
| 19 | chelsea - mourinho - terry - league - jose | 106 | 19_chelsea_mourinho_terry_league |
| 20 | eclipse - earth - mars - solar - sun | 101 | 20_eclipse_earth_mars_solar |
| 21 | kane - england - hodgson - lithuania - rooney | 100 | 21_kane_england_hodgson_lithuania |
| 22 | show - film - corden - host - noah | 95 | 22_show_film_corden_host |
| 23 | prince - royal - duchess - charles - queen | 92 | 23_prince_royal_duchess_charles |
| 24 | murray - wells - tennis - andy - 64 | 88 | 24_murray_wells_tennis_andy |
| 25 | putin - russian - nemtsov - moscow - russia | 82 | 25_putin_russian_nemtsov_moscow |
| 26 | netanyahu - iran - nuclear - israel - israeli | 80 | 26_netanyahu_iran_nuclear_israel |
| 27 | court - money - bank - fraud - stiviano | 80 | 27_court_money_bank_fraud |
| 28 | weight - size - fat - stone - diet | 76 | 28_weight_size_fat_stone |
| 29 | armstrong - race - olympic - uci - championships | 74 | 29_armstrong_race_olympic_uci |
| 30 | cheltenham - hurdle - horse - jockey - festival | 73 | 30_cheltenham_hurdle_horse_jockey |
| 31 | arsenal - wenger - monaco - giroud - arsenals | 73 | 31_arsenal_wenger_monaco_giroud |
| 32 | mcilroy - golf - masters - woods - round | 72 | 32_mcilroy_golf_masters_woods |
| 33 | watch - apple - device - google - user | 66 | 33_watch_apple_device_google |
| 34 | fraternity - university - sae - oklahoma - chapter | 65 | 34_fraternity_university_sae_oklahoma |
| 35 | united - van - gaal - manchester - arsenal | 62 | 35_united_van_gaal_manchester |
| 36 | chan - sukumaran - indonesian - bali - myuran | 61 | 36_chan_sukumaran_indonesian_bali |
| 37 | school - teacher - student - district - sexual | 58 | 37_school_teacher_student_district |
| 38 | sunderland - poyet - advocaat - johnson - april | 55 | 38_sunderland_poyet_advocaat_johnson |
| 39 | clarkson - bbc - gear - top - jeremy | 55 | 39_clarkson_bbc_gear_top |
| 40 | fire - building - blaze - explosion - firefighter | 48 | 40_fire_building_blaze_explosion |
| 41 | liverpool - gerrard - rodgers - steven - anfield | 46 | 41_liverpool_gerrard_rodgers_steven |
| 42 | patient - nhs - ae - cancer - care | 44 | 42_patient_nhs_ae_cancer |
| 43 | song - zayn - thicke - gayes - pharrell | 43 | 43_song_zayn_thicke_gayes |
| 44 | wedding - married - couple - jaclyn - love | 41 | 44_wedding_married_couple_jaclyn |
| 45 | car - vehicle - electric - model - jaguar | 41 | 45_car_vehicle_electric_model |
| 46 | nfl - borland - bowl - brady - super | 40 | 46_nfl_borland_bowl_brady |
| 47 | pellegrini - city - league - manchester - barcelona | 40 | 47_pellegrini_city_league_manchester |
| 48 | school - education - porn - sex - child | 39 | 48_school_education_porn_sex |
| 49 | bear - cub - tiger - deer - wildlife | 39 | 49_bear_cub_tiger_deer |
| 50 | gay - law - indiana - marriage - religious | 38 | 50_gay_law_indiana_marriage |
| 51 | india - rape - indian - documentary - singh | 37 | 51_india_rape_indian_documentary |
| 52 | boko - haram - nigeria - nigerian - nigerias | 36 | 52_boko_haram_nigeria_nigerian |
| 53 | ebola - sierra - leone - virus - liberia | 35 | 53_ebola_sierra_leone_virus |
| 54 | tsarnaev - dzhokhar - boston - tamerlan - tsarnaevs | 35 | 54_tsarnaev_dzhokhar_boston_tamerlan |
| 55 | ski - mountain - skier - rock - lift | 32 | 55_ski_mountain_skier_rock |
| 56 | robbery - armed - store - police - bank | 31 | 56_robbery_armed_store_police |
| 57 | roma - inter - juventus - serie - fiorentina | 30 | 57_roma_inter_juventus_serie |
| 58 | fifa - blatter - fa - qatar - cup | 29 | 58_fifa_blatter_fa_qatar |
| 59 | marijuana - drug - cannabis - colorado - lsd | 29 | 59_marijuana_drug_cannabis_colorado |
| 60 | everton - martinez - lukaku - dynamo - evertons | 27 | 60_everton_martinez_lukaku_dynamo |
| 61 | chelsea - racist - paris - train - football | 27 | 61_chelsea_racist_paris_train |
| 62 | durst - dursts - berman - orleans - robert | 27 | 62_durst_dursts_berman_orleans |
| 63 | basketball - ncaa - coach - tournament - game | 25 | 63_basketball_ncaa_coach_tournament |
| 64 | bayern - goal - muller - shakhtar - robben | 25 | 64_bayern_goal_muller_shakhtar |
| 65 | hotel - beach - cruise - ship - resort | 25 | 65_hotel_beach_cruise_ship |
| 66 | sherwood - villa - aston - tim - brom | 25 | 66_sherwood_villa_aston_tim |
| 67 | snow - inch - winter - weather - ice | 24 | 67_snow_inch_winter_weather |
| 68 | weather - temperature - rain - snow - expected | 24 | 68_weather_temperature_rain_snow |
| 69 | korean - korea - kim - north - lippert | 23 | 69_korean_korea_kim_north |
| 70 | hospital - doctor - mrs - fracture - patient | 23 | 70_hospital_doctor_mrs_fracture |
| 71 | rail - calais - parking - transport - train | 22 | 71_rail_calais_parking_transport |
| 72 | mls - lampard - orlando - city - york | 22 | 72_mls_lampard_orlando_city |
| 73 | jesus - stone - circle - ancient - stonehenge | 22 | 73_jesus_stone_circle_ancient |
| 74 | hernandez - lloyd - jenkins - hernandezs - lloyds | 21 | 74_hernandez_lloyd_jenkins_hernandezs |
| 75 | drug - cocaine - jailed - steroid - cannabis | 20 | 75_drug_cocaine_jailed_steroid |
| 76 | secret - clancy - service - agent - white | 20 | 76_secret_clancy_service_agent |
| 77 | homo - fossil - specie - ago - human | 20 | 77_homo_fossil_specie_ago |
| 78 | image - photographer - photograph - photo - landscape | 19 | 78_image_photographer_photograph_photo |
| 79 | parade - patricks - irish - st - green | 19 | 79_parade_patricks_irish_st |
| 80 | bale - wales - israel - coleman - gareth | 19 | 80_bale_wales_israel_coleman |
| 81 | di - maria - angel - united - manchester | 19 | 81_di_maria_angel_united |
| 82 | defence - greece - spending - greek - budget | 19 | 82_defence_greece_spending_greek |
| 83 | sleep - store - cent - per - kraft | 18 | 83_sleep_store_cent_per |
| 84 | student - johnson - virginia - charlottesville - university | 18 | 84_student_johnson_virginia_charlottesville |
| 85 | vanuatu - cyclone - vila - pam - port | 18 | 85_vanuatu_cyclone_vila_pam |
| 86 | cnn - transcript - student - news - roll | 18 | 86_cnn_transcript_student_news |
| 87 | nazi - anne - nazis - war - camp | 18 | 87_nazi_anne_nazis_war |
| 88 | attack - synagogue - hebdo - paris - charlie | 17 | 88_attack_synagogue_hebdo_paris |
| 89 | ham - west - tomkins - reid - kouyate | 16 | 89_ham_west_tomkins_reid |
| 90 | balotelli - mario - liverpool - italian - striker | 16 | 90_balotelli_mario_liverpool_italian |
| 91 | chinese - monk - buddhist - thailand - tourist | 15 | 91_chinese_monk_buddhist_thailand |
| 92 | snowden - gchq - intelligence - security - agency | 15 | 92_snowden_gchq_intelligence_security |
| 93 | pope - francis - naples - vatican - pontiff | 14 | 93_pope_francis_naples_vatican |
| 94 | starbucks - schultz - race - racial - campaign | 14 | 94_starbucks_schultz_race_racial |
| 95 | point - rebound - sweeney - playoff - scored | 14 | 95_point_rebound_sweeney_playoff |
| 96 | poldark - turner - demelza - aidan - drama | 13 | 96_poldark_turner_demelza_aidan |
| 97 | cuba - havana - cuban - us - castro | 13 | 97_cuba_havana_cuban_us |
| 98 | italy - conte - italian - eder - juventus | 13 | 98_italy_conte_italian_eder |
| 99 | richard - iii - leicester - king - iiis | 13 | 99_richard_iii_leicester_king |
| 100 | sena - hartman - child - shaday - sexual | 13 | 100_sena_hartman_child_shaday |
| 101 | gordon - bobbi - kristina - phil - dr | 12 | 101_gordon_bobbi_kristina_phil |
| 102 | jobs - lu - naomi - cook - business | 12 | 102_jobs_lu_naomi_cook |
| 103 | duckenfield - mr - gate - hillsborough - greaney | 11 | 103_duckenfield_mr_gate_hillsborough |
| 104 | huang - wang - chen - wife - china | 10 | 104_huang_wang_chen_wife |
| 105 | coin - coins - silver - cave - gold | 10 | 105_coin_coins_silver_cave |
| 106 | shark - whale - mola - crab - barbero | 10 | 106_shark_whale_mola_crab |
| 107 | gissendaner - execution - lethal - death - injection | 10 | 107_gissendaner_execution_lethal_death |
| 108 | book - handshake - word - author - app | 9 | 108_book_handshake_word_author |
| 109 | cosby - cosbys - thompson - welles - bill | 9 | 109_cosby_cosbys_thompson_welles |
| 110 | school - pupil - student - parent - computer | 9 | 110_school_pupil_student_parent |
| 111 | china - stopera - li - orange - chinese | 8 | 111_china_stopera_li_orange |
| 112 | tb - vaccine - disease - measles - meningitis | 8 | 112_tb_vaccine_disease_measles |
| 113 | neymar - brazil - willian - dunga - france | 8 | 113_neymar_brazil_willian_dunga |
| 114 | gomis - swansea - muamba - fabrice - bafetimbi | 7 | 114_gomis_swansea_muamba_fabrice |
| 115 | netflix - tv - content - screen - definition | 6 | 115_netflix_tv_content_screen |
| 116 | snake - eastern - redback - postlethwaite - woolworths | 6 | 116_snake_eastern_redback_postlethwaite |
</details>
## Training hyperparameters
* calculate_probabilities: True
* language: english
* low_memory: False
* min_topic_size: 10
* n_gram_range: (1, 1)
* nr_topics: None
* seed_topic_list: None
* top_n_words: 10
* verbose: False
## Framework versions
* Numpy: 1.23.5
* HDBSCAN: 0.8.33
* UMAP: 0.5.3
* Pandas: 1.5.3
* Scikit-Learn: 1.2.2
* Sentence-transformers: 2.2.2
* Transformers: 4.31.0
* Numba: 0.57.1
* Plotly: 5.15.0
* Python: 3.10.12
|
KingKazma/cnn_dailymail_6789_50000_25000_train
|
KingKazma
| 2023-08-15T20:30:49Z | 4 | 0 |
bertopic
|
[
"bertopic",
"text-classification",
"region:us"
] |
text-classification
| 2023-08-15T20:30:48Z |
---
tags:
- bertopic
library_name: bertopic
pipeline_tag: text-classification
---
# cnn_dailymail_6789_50000_25000_train
This is a [BERTopic](https://github.com/MaartenGr/BERTopic) model.
BERTopic is a flexible and modular topic modeling framework that allows for the generation of easily interpretable topics from large datasets.
## Usage
To use this model, please install BERTopic:
```
pip install -U bertopic
```
You can use the model as follows:
```python
from bertopic import BERTopic
topic_model = BERTopic.load("KingKazma/cnn_dailymail_6789_50000_25000_train")
topic_model.get_topic_info()
```
## Topic overview
* Number of topics: 295
* Number of training documents: 50000
<details>
<summary>Click here for an overview of all topics.</summary>
| Topic ID | Topic Keywords | Topic Frequency | Label |
|----------|----------------|-----------------|-------|
| -1 | said - one - year - people - mr | 5 | -1_said_one_year_people |
| 0 | league - player - cup - goal - club | 25951 | 0_league_player_cup_goal |
| 1 | police - murder - shooting - shot - county | 4658 | 1_police_murder_shooting_shot |
| 2 | apple - iphone - google - user - facebook | 1101 | 2_apple_iphone_google_user |
| 3 | fashion - hair - look - dress - model | 739 | 3_fashion_hair_look_dress |
| 4 | syria - isis - syrian - iraq - islamic | 651 | 4_syria_isis_syrian_iraq |
| 5 | flight - plane - passenger - airport - aircraft | 555 | 5_flight_plane_passenger_airport |
| 6 | space - earth - mars - nasa - planet | 553 | 6_space_earth_mars_nasa |
| 7 | sex - sexual - school - victim - girl | 424 | 7_sex_sexual_school_victim |
| 8 | obama - republicans - republican - president - democrats | 420 | 8_obama_republicans_republican_president |
| 9 | hospital - cancer - baby - doctor - heart | 416 | 9_hospital_cancer_baby_doctor |
| 10 | murray - wimbledon - tennis - djokovic - federer | 362 | 10_murray_wimbledon_tennis_djokovic |
| 11 | film - movie - show - million - actor | 359 | 11_film_movie_show_million |
| 12 | china - chinese - hong - chinas - kong | 337 | 12_china_chinese_hong_chinas |
| 13 | prince - royal - duchess - queen - princess | 303 | 13_prince_royal_duchess_queen |
| 14 | property - house - price - home - estate | 299 | 14_property_house_price_home |
| 15 | ukraine - russian - russia - putin - ukrainian | 293 | 15_ukraine_russian_russia_putin |
| 16 | hamilton - rosberg - race - prix - mercedes | 279 | 16_hamilton_rosberg_race_prix |
| 17 | bear - animal - zoo - elephant - gorilla | 253 | 17_bear_animal_zoo_elephant |
| 18 | dog - animal - cat - pet - owner | 243 | 18_dog_animal_cat_pet |
| 19 | food - restaurant - drink - sugar - chef | 243 | 19_food_restaurant_drink_sugar |
| 20 | korea - north - korean - kim - koreas | 239 | 20_korea_north_korean_kim |
| 21 | mcilroy - golf - woods - pga - ryder | 229 | 21_mcilroy_golf_woods_pga |
| 22 | painting - art - artist - auction - work | 229 | 22_painting_art_artist_auction |
| 23 | weight - diet - fat - eating - size | 215 | 23_weight_diet_fat_eating |
| 24 | labour - miliband - ukip - mr - party | 198 | 24_labour_miliband_ukip_mr |
| 25 | olympic - gold - medal - games - olympics | 191 | 25_olympic_gold_medal_games |
| 26 | ship - cruise - boat - coast - crew | 188 | 26_ship_cruise_boat_coast |
| 27 | murder - stabbed - knife - police - mr | 178 | 27_murder_stabbed_knife_police |
| 28 | sudan - alshabaab - somalia - kenya - kenyan | 176 | 28_sudan_alshabaab_somalia_kenya |
| 29 | mexico - mexican - cartel - drug - border | 161 | 29_mexico_mexican_cartel_drug |
| 30 | fraud - money - court - cash - bank | 161 | 30_fraud_money_court_cash |
| 31 | iran - iranian - irans - nuclear - tehran | 158 | 31_iran_iranian_irans_nuclear |
| 32 | snow - storm - weather - tornado - inch | 153 | 32_snow_storm_weather_tornado |
| 33 | mayweather - fight - boxing - pacquiao - floyd | 153 | 33_mayweather_fight_boxing_pacquiao |
| 34 | school - education - pupil - exam - ofsted | 148 | 34_school_education_pupil_exam |
| 35 | ebola - virus - liberia - outbreak - leone | 141 | 35_ebola_virus_liberia_outbreak |
| 36 | woman - men - partner - relationship - women | 134 | 36_woman_men_partner_relationship |
| 37 | pakistan - pakistani - taliban - malala - pakistans | 132 | 37_pakistan_pakistani_taliban_malala |
| 38 | shark - whale - dolphin - fish - sea | 130 | 38_shark_whale_dolphin_fish |
| 39 | music - song - album - elvis - band | 129 | 39_music_song_album_elvis |
| 40 | israeli - israel - gaza - palestinian - hamas | 125 | 40_israeli_israel_gaza_palestinian |
| 41 | hacker - data - cyber - computer - sony | 125 | 41_hacker_data_cyber_computer |
| 42 | hotel - resort - guest - room - suite | 118 | 42_hotel_resort_guest_room |
| 43 | nhs - patient - hospital - care - patients | 112 | 43_nhs_patient_hospital_care |
| 44 | fire - blaze - smoke - firefighter - flame | 109 | 44_fire_blaze_smoke_firefighter |
| 45 | weather - rain - temperature - flood - flooding | 108 | 45_weather_rain_temperature_flood |
| 46 | mountain - climber - avalanche - climb - ski | 105 | 46_mountain_climber_avalanche_climb |
| 47 | car - vehicle - motor - engine - speed | 100 | 47_car_vehicle_motor_engine |
| 48 | nfl - rice - quarterback - goodell - patriots | 100 | 48_nfl_rice_quarterback_goodell |
| 49 | jackson - jacksons - bobbi - aeg - houston | 97 | 49_jackson_jacksons_bobbi_aeg |
| 50 | tesco - christmas - shopper - shopping - sale | 93 | 50_tesco_christmas_shopper_shopping |
| 51 | pope - vatican - francis - church - cardinal | 92 | 51_pope_vatican_francis_church |
| 52 | thailand - thai - myanmar - bangkok - cambodia | 91 | 52_thailand_thai_myanmar_bangkok |
| 53 | energy - price - gas - electricity - wind | 91 | 53_energy_price_gas_electricity |
| 54 | horse - stakes - race - racing - jockey | 90 | 54_horse_stakes_race_racing |
| 55 | chavez - venezuela - maduro - venezuelan - zelaya | 90 | 55_chavez_venezuela_maduro_venezuelan |
| 56 | snowden - nsa - intelligence - surveillance - edward | 89 | 56_snowden_nsa_intelligence_surveillance |
| 57 | lottery - jackpot - ticket - powerball - casino | 86 | 57_lottery_jackpot_ticket_powerball |
| 58 | mammoth - fossil - neanderthals - bone - human | 83 | 58_mammoth_fossil_neanderthals_bone |
| 59 | egyptian - egypt - cairo - egypts - brotherhood | 80 | 59_egyptian_egypt_cairo_egypts |
| 60 | flu - virus - vaccine - measles - strain | 80 | 60_flu_virus_vaccine_measles |
| 61 | lohan - probation - brown - lindsay - angeles | 76 | 61_lohan_probation_brown_lindsay |
| 62 | greece - greek - eurozone - euro - bailout | 76 | 62_greece_greek_eurozone_euro |
| 63 | gun - nra - newtown - background - mental | 75 | 63_gun_nra_newtown_background |
| 64 | car - driver - road - lorry - vehicle | 74 | 64_car_driver_road_lorry |
| 65 | ferguson - brown - wilson - louis - police | 73 | 65_ferguson_brown_wilson_louis |
| 66 | tsarnaev - boston - dzhokhar - marathon - bombing | 72 | 66_tsarnaev_boston_dzhokhar_marathon |
| 67 | hacking - brooks - news - coulson - murdoch | 71 | 67_hacking_brooks_news_coulson |
| 68 | saudi - arabia - dubai - arab - woman | 71 | 68_saudi_arabia_dubai_arab |
| 69 | bank - barclays - rbs - libor - bonus | 70 | 69_bank_barclays_rbs_libor |
| 70 | nazi - camp - jews - auschwitz - hitler | 70 | 70_nazi_camp_jews_auschwitz |
| 71 | afghan - afghanistan - taliban - kabul - province | 69 | 71_afghan_afghanistan_taliban_kabul |
| 72 | marriage - samesex - gay - state - couple | 67 | 72_marriage_samesex_gay_state |
| 73 | africa - african - continent - africas - kenya | 65 | 73_africa_african_continent_africas |
| 74 | libya - gadhafi - libyan - tripoli - gadhafis | 65 | 74_libya_gadhafi_libyan_tripoli |
| 75 | india - delhi - indian - rape - indias | 63 | 75_india_delhi_indian_rape |
| 76 | cuba - cuban - castro - havana - cubans | 63 | 76_cuba_cuban_castro_havana |
| 77 | roman - ancient - tomb - archaeologist - bc | 61 | 77_roman_ancient_tomb_archaeologist |
| 78 | bali - sukumaran - chan - indonesia - indonesian | 58 | 78_bali_sukumaran_chan_indonesia |
| 79 | christmas - toy - santa - tree - lego | 58 | 79_christmas_toy_santa_tree |
| 80 | train - amtrak - crash - passenger - track | 57 | 80_train_amtrak_crash_passenger |
| 81 | xbox - console - game - playstation - gaming | 55 | 81_xbox_console_game_playstation |
| 82 | tsa - airport - security - screening - passenger | 55 | 82_tsa_airport_security_screening |
| 83 | fire - wildfire - blaze - firefighter - forest | 55 | 83_fire_wildfire_blaze_firefighter |
| 84 | cancer - breast - drug - lung - prostate | 54 | 84_cancer_breast_drug_lung |
| 85 | boko - haram - nigeria - nigerian - nigerias | 52 | 85_boko_haram_nigeria_nigerian |
| 86 | turkish - turkey - erdogan - turkeys - pkk | 52 | 86_turkish_turkey_erdogan_turkeys |
| 87 | haiti - portauprince - haitian - earthquake - haitis | 51 | 87_haiti_portauprince_haitian_earthquake |
| 88 | scotland - scottish - independence - salmond - vote | 50 | 88_scotland_scottish_independence_salmond |
| 89 | rio - brazil - sao - paulo - janeiro | 50 | 89_rio_brazil_sao_paulo |
| 90 | meat - food - beef - horse - halal | 48 | 90_meat_food_beef_horse |
| 91 | zimmerman - zimmermans - trayvon - martin - george | 48 | 91_zimmerman_zimmermans_trayvon_martin |
| 92 | pirate - ship - somali - somalia - vessel | 47 | 92_pirate_ship_somali_somalia |
| 93 | eu - migrant - benefit - migration - uk | 47 | 93_eu_migrant_benefit_migration |
| 94 | soldier - corporal - helmand - afghanistan - army | 46 | 94_soldier_corporal_helmand_afghanistan |
| 95 | mandela - mandelas - south - nelson - african | 46 | 95_mandela_mandelas_south_nelson |
| 96 | pistorius - steenkamp - reeva - oscar - nel | 46 | 96_pistorius_steenkamp_reeva_oscar |
| 97 | immigration - immigrant - border - arizona - arpaio | 46 | 97_immigration_immigrant_border_arizona |
| 98 | book - novel - author - lee - mockingbird | 46 | 98_book_novel_author_lee |
| 99 | mugabe - zimbabwe - tsvangirai - zimbabwes - mugabes | 46 | 99_mugabe_zimbabwe_tsvangirai_zimbabwes |
| 100 | smoking - tobacco - cigarette - ecigarettes - smoker | 46 | 100_smoking_tobacco_cigarette_ecigarettes |
| 101 | plant - reactor - nuclear - fukushima - radiation | 46 | 101_plant_reactor_nuclear_fukushima |
| 102 | nba - lin - lebron - james - cavaliers | 44 | 102_nba_lin_lebron_james |
| 103 | guantanamo - cia - detainee - interrogation - torture | 44 | 103_guantanamo_cia_detainee_interrogation |
| 104 | curriculum - todays - transcript - feedback - student | 43 | 104_curriculum_todays_transcript_feedback |
| 105 | eu - cameron - european - referendum - brussels | 42 | 105_eu_cameron_european_referendum |
| 106 | insurance - obamacare - health - care - coverage | 42 | 106_insurance_obamacare_health_care |
| 107 | volcano - lava - eruption - ash - pahoa | 41 | 107_volcano_lava_eruption_ash |
| 108 | china - japan - chinese - japanese - japans | 41 | 108_china_japan_chinese_japanese |
| 109 | tower - trade - memorial - 911 - center | 41 | 109_tower_trade_memorial_911 |
| 110 | marijuana - cannabis - pot - drug - colorado | 41 | 110_marijuana_cannabis_pot_drug |
| 111 | war - dday - normandy - german - soldier | 40 | 111_war_dday_normandy_german |
| 112 | typhoon - manila - philippines - storm - landslide | 40 | 112_typhoon_manila_philippines_storm |
| 113 | yemen - sanaa - yemeni - drone - houthis | 39 | 113_yemen_sanaa_yemeni_drone |
| 114 | skin - sunscreen - tanning - cancer - sun | 39 | 114_skin_sunscreen_tanning_cancer |
| 115 | hasan - bales - fort - hood - soldier | 38 | 115_hasan_bales_fort_hood |
| 116 | transcript - student - news - todays - cnn | 38 | 116_transcript_student_news_todays |
| 117 | raf - pilot - aircraft - war - squadron | 37 | 117_raf_pilot_aircraft_war |
| 118 | baseball - yankees - rodriguez - mlb - pitcher | 37 | 118_baseball_yankees_rodriguez_mlb |
| 119 | earthquake - quake - magnitude - tsunami - tremor | 37 | 119_earthquake_quake_magnitude_tsunami |
| 120 | bird - squirrel - serama - duck - fox | 36 | 120_bird_squirrel_serama_duck |
| 121 | adebolajo - rigby - woolwich - lee - adebowale | 36 | 121_adebolajo_rigby_woolwich_lee |
| 122 | hernandez - hernandezs - lloyd - odin - patriots | 36 | 122_hernandez_hernandezs_lloyd_odin |
| 123 | cannabis - drug - cocaine - jailed - birmingham | 35 | 123_cannabis_drug_cocaine_jailed |
| 124 | benghazi - attack - committee - libya - ambassador | 35 | 124_benghazi_attack_committee_libya |
| 125 | abbott - gillard - minister - prime - tony | 34 | 125_abbott_gillard_minister_prime |
| 126 | weiner - leathers - black - abedin - colagiovanni | 34 | 126_weiner_leathers_black_abedin |
| 127 | oil - bp - spill - gulf - dispersants | 33 | 127_oil_bp_spill_gulf |
| 128 | crime - police - force - officer - policing | 33 | 128_crime_police_force_officer |
| 129 | miss - pageant - universe - beauty - contestant | 32 | 129_miss_pageant_universe_beauty |
| 130 | kennedy - oswald - assassination - kennedys - 1963 | 32 | 130_kennedy_oswald_assassination_kennedys |
| 131 | lanza - hook - sandy - school - newtown | 32 | 131_lanza_hook_sandy_school |
| 132 | crash - driver - driving - car - adenhart | 31 | 132_crash_driver_driving_car |
| 133 | spains - eta - spanish - madrid - spain | 31 | 133_spains_eta_spanish_madrid |
| 134 | burglary - jailed - burglar - court - crown | 30 | 134_burglary_jailed_burglar_court |
| 135 | bieber - justin - biebers - selena - singer | 30 | 135_bieber_justin_biebers_selena |
| 136 | mccann - madeleine - mccanns - madeleines - gerry | 30 | 136_mccann_madeleine_mccanns_madeleines |
| 137 | brain - anxiety - researcher - fmri - neuron | 30 | 137_brain_anxiety_researcher_fmri |
| 138 | bbc - presenter - radio - clarkson - programme | 29 | 138_bbc_presenter_radio_clarkson |
| 139 | knox - sollecito - kercher - meredith - knoxs | 29 | 139_knox_sollecito_kercher_meredith |
| 140 | cosby - drugged - cosbys - comedian - bill | 28 | 140_cosby_drugged_cosbys_comedian |
| 141 | fraternity - university - campus - student - smu | 28 | 141_fraternity_university_campus_student |
| 142 | mafia - roma - italian - italy - rancadore | 27 | 142_mafia_roma_italian_italy |
| 143 | hiv - aids - virus - infection - antiretroviral | 27 | 143_hiv_aids_virus_infection |
| 144 | berlusconi - silvio - italian - berlusconis - bunga | 27 | 144_berlusconi_silvio_italian_berlusconis |
| 145 | drone - unmanned - drones - aircraft - faa | 26 | 145_drone_unmanned_drones_aircraft |
| 146 | paris - french - hebdo - dekhar - charlie | 26 | 146_paris_french_hebdo_dekhar |
| 147 | antibiotic - infection - bacteria - antibiotics - necc | 26 | 147_antibiotic_infection_bacteria_antibiotics |
| 148 | assange - wikileaks - embassy - sweden - julian | 26 | 148_assange_wikileaks_embassy_sweden |
| 149 | twitter - abuse - online - criadoperez - bullying | 25 | 149_twitter_abuse_online_criadoperez |
| 150 | veil - blair - france - burqa - ban | 25 | 150_veil_blair_france_burqa |
| 151 | parking - yellow - council - motorist - line | 25 | 151_parking_yellow_council_motorist |
| 152 | katie - married - wedding - demi - marriage | 24 | 152_katie_married_wedding_demi |
| 153 | falklands - falkland - islands - argentina - argentine | 24 | 153_falklands_falkland_islands_argentina |
| 154 | evans - ched - sheffield - club - rape | 24 | 154_evans_ched_sheffield_club |
| 155 | branch - ambulance - died - skye - milligan | 24 | 155_branch_ambulance_died_skye |
| 156 | ford - toronto - mayor - crack - rob | 24 | 156_ford_toronto_mayor_crack |
| 157 | wedding - bride - bridesmaid - dress - couple | 24 | 157_wedding_bride_bridesmaid_dress |
| 158 | salmonella - outbreak - bacteria - contaminated - food | 24 | 158_salmonella_outbreak_bacteria_contaminated |
| 159 | climate - change - global - emission - warming | 23 | 159_climate_change_global_emission |
| 160 | anthony - caylee - anthonys - casey - baez | 23 | 160_anthony_caylee_anthonys_casey |
| 161 | philippines - philippine - ampatuan - mindanao - maguindanao | 23 | 161_philippines_philippine_ampatuan_mindanao |
| 162 | scientology - church - pastor - driscoll - miscavige | 23 | 162_scientology_church_pastor_driscoll |
| 163 | blasio - mayor - officer - batkid - nypd | 23 | 163_blasio_mayor_officer_batkid |
| 164 | froome - tour - contador - stage - cavendish | 22 | 164_froome_tour_contador_stage |
| 165 | irs - committee - issa - holder - lerner | 22 | 165_irs_committee_issa_holder |
| 166 | bergdahl - bergdahls - taliban - bowe - army | 22 | 166_bergdahl_bergdahls_taliban_bowe |
| 167 | monis - siege - cafe - lindt - haron | 22 | 167_monis_siege_cafe_lindt |
| 168 | bulger - bulgers - flemmi - martorano - whitey | 22 | 168_bulger_bulgers_flemmi_martorano |
| 169 | sri - tamil - lankan - lanka - tigers | 22 | 169_sri_tamil_lankan_lanka |
| 170 | holiday - cent - per - brits - traveller | 22 | 170_holiday_cent_per_brits |
| 171 | plant - gm - crop - food - space | 22 | 171_plant_gm_crop_food |
| 172 | paedophile - cyril - nccl - abuse - inquiry | 22 | 172_paedophile_cyril_nccl_abuse |
| 173 | sloot - der - peru - lima - peruvian | 21 | 173_sloot_der_peru_lima |
| 174 | sterling - stiviano - nba - clippers - sterlings | 21 | 174_sterling_stiviano_nba_clippers |
| 175 | breivik - utoya - oslo - breiviks - norway | 21 | 175_breivik_utoya_oslo_breiviks |
| 176 | alcohol - drinking - liver - drink - gastroenterologist | 21 | 176_alcohol_drinking_liver_drink |
| 177 | asylum - seeker - nauru - refugee - manus | 20 | 177_asylum_seeker_nauru_refugee |
| 178 | kennedy - kennedys - mary - robert - jr | 20 | 178_kennedy_kennedys_mary_robert |
| 179 | gascoigne - aiden - ghost - school - poole | 20 | 179_gascoigne_aiden_ghost_school |
| 180 | russian - adoption - russia - child - adopted | 20 | 180_russian_adoption_russia_child |
| 181 | reveller - event - night - carnage - drinking | 20 | 181_reveller_event_night_carnage |
| 182 | armstrong - doping - armstrongs - usada - antidoping | 19 | 182_armstrong_doping_armstrongs_usada |
| 183 | derick - birth - zoey - bianca - steph | 19 | 183_derick_birth_zoey_bianca |
| 184 | strike - union - unite - rmt - tube | 19 | 184_strike_union_unite_rmt |
| 185 | va - veteran - veterans - shinseki - phoenix | 19 | 185_va_veteran_veterans_shinseki |
| 186 | immigration - reform - immigrant - obama - republicans | 19 | 186_immigration_reform_immigrant_obama |
| 187 | ira - belfast - ireland - northern - bomb | 18 | 187_ira_belfast_ireland_northern |
| 188 | council - garden - rubbish - neighbour - knotweed | 18 | 188_council_garden_rubbish_neighbour |
| 189 | sinclair - sexual - assault - military - sinclairs | 18 | 189_sinclair_sexual_assault_military |
| 190 | sandusky - penn - paterno - sanduskys - state | 18 | 190_sandusky_penn_paterno_sanduskys |
| 191 | gay - russia - russian - sochi - propaganda | 18 | 191_gay_russia_russian_sochi |
| 192 | trierweiler - hollande - gayet - valerie - hollandes | 18 | 192_trierweiler_hollande_gayet_valerie |
| 193 | bosnian - srebrenica - mladic - serb - serbian | 18 | 193_bosnian_srebrenica_mladic_serb |
| 194 | calais - migrant - lorry - port - illegal | 18 | 194_calais_migrant_lorry_port |
| 195 | drug - ecstasy - wyvell - methadone - death | 17 | 195_drug_ecstasy_wyvell_methadone |
| 196 | circumcision - fgm - genital - mutilation - circumcised | 17 | 196_circumcision_fgm_genital_mutilation |
| 197 | mine - miner - coal - rescue - mining | 17 | 197_mine_miner_coal_rescue |
| 198 | christie - christies - wildstein - jersey - governor | 17 | 198_christie_christies_wildstein_jersey |
| 199 | rice - coach - rutgers - basketball - ware | 17 | 199_rice_coach_rutgers_basketball |
| 200 | breach - card - credit - data - target | 17 | 200_breach_card_credit_data |
| 201 | alzheimers - brain - study - stress - disease | 17 | 201_alzheimers_brain_study_stress |
| 202 | hurricane - storm - parish - tropical - rain | 17 | 202_hurricane_storm_parish_tropical |
| 203 | indias - india - delhi - modi - hazare | 17 | 203_indias_india_delhi_modi |
| 204 | robot - asimo - robotics - robots - daler | 16 | 204_robot_asimo_robotics_robots |
| 205 | tree - trees - cherry - bonsai - ash | 16 | 205_tree_trees_cherry_bonsai |
| 206 | tattoo - tattooing - tattoos - tattooed - inked | 16 | 206_tattoo_tattooing_tattoos_tattooed |
| 207 | tax - osborne - 40p - rate - chancellor | 16 | 207_tax_osborne_40p_rate |
| 208 | mieses - bikers - crash - driver - lien | 16 | 208_mieses_bikers_crash_driver |
| 209 | petraeus - broadwell - kelley - humphries - affair | 16 | 209_petraeus_broadwell_kelley_humphries |
| 210 | wars - star - scifi - darth - film | 16 | 210_wars_star_scifi_darth |
| 211 | dancing - ballet - pole - dance - dancer | 16 | 211_dancing_ballet_pole_dance |
| 212 | church - archbishop - bishop - anglican - sentamu | 16 | 212_church_archbishop_bishop_anglican |
| 213 | sotomayor - justice - ginsburg - voter - supreme | 15 | 213_sotomayor_justice_ginsburg_voter |
| 214 | statin - aspirin - yeast - supplement - risk | 15 | 214_statin_aspirin_yeast_supplement |
| 215 | road - driver - cent - traffic - aa | 15 | 215_road_driver_cent_traffic |
| 216 | dewani - anni - shrien - dewanis - mngeni | 15 | 216_dewani_anni_shrien_dewanis |
| 217 | poverty - income - homeless - homelessness - poor | 15 | 217_poverty_income_homeless_homelessness |
| 218 | sharper - kolstad - stallworth - nfl - mcnabb | 15 | 218_sharper_kolstad_stallworth_nfl |
| 219 | ice - climate - antarctic - greenland - warming | 15 | 219_ice_climate_antarctic_greenland |
| 220 | jerusalem - temple - ancient - hebrew - jewish | 14 | 220_jerusalem_temple_ancient_hebrew |
| 221 | veteran - veterans - cemetery - memorial - war | 14 | 221_veteran_veterans_cemetery_memorial |
| 222 | li - teacher - school - china - province | 14 | 222_li_teacher_school_china |
| 223 | postal - mail - tnt - royal - stamp | 14 | 223_postal_mail_tnt_royal |
| 224 | spanish - spain - gibraltar - morocco - spains | 14 | 224_spanish_spain_gibraltar_morocco |
| 225 | gonzalez - white - secret - fence - house | 14 | 225_gonzalez_white_secret_fence |
| 226 | raid - store - shop - cash - theft | 13 | 226_raid_store_shop_cash |
| 227 | laden - bin - al - qaeda - attack | 13 | 227_laden_bin_al_qaeda |
| 228 | strausskahn - diallo - dominique - imf - strausskahns | 13 | 228_strausskahn_diallo_dominique_imf |
| 229 | konrardy - nygaard - olsen - berk - marine | 13 | 229_konrardy_nygaard_olsen_berk |
| 230 | adoption - gammy - gebregeorgis - surrogacy - thai | 13 | 230_adoption_gammy_gebregeorgis_surrogacy |
| 231 | cruise - illness - ill - outbreak - sickness | 13 | 231_cruise_illness_ill_outbreak |
| 232 | robertson - duck - dynasty - ae - phil | 12 | 232_robertson_duck_dynasty_ae |
| 233 | occupy - protester - wall - protest - demonstrator | 12 | 233_occupy_protester_wall_protest |
| 234 | rate - abortion - pregnancy - birth - teen | 12 | 234_rate_abortion_pregnancy_birth |
| 235 | alhilli - saad - mollier - alhillis - zaid | 12 | 235_alhilli_saad_mollier_alhillis |
| 236 | crash - scene - minibus - accident - davies | 12 | 236_crash_scene_minibus_accident |
| 237 | hollande - sarkozy - hollandes - socialist - pen | 12 | 237_hollande_sarkozy_hollandes_socialist |
| 238 | porn - filter - pornography - internet - iplayer | 12 | 238_porn_filter_pornography_internet |
| 239 | 3d - printer - printing - thermomix - print | 12 | 239_3d_printer_printing_thermomix |
| 240 | penguin - ness - loch - nessie - wildlife | 12 | 240_penguin_ness_loch_nessie |
| 241 | reef - coral - marine - stoupin - corals | 11 | 241_reef_coral_marine_stoupin |
| 242 | spider - insect - beetle - frog - spiders | 11 | 242_spider_insect_beetle_frog |
| 243 | bletchley - enigma - war - turing - code | 11 | 243_bletchley_enigma_war_turing |
| 244 | pollution - air - smog - beijing - quality | 11 | 244_pollution_air_smog_beijing |
| 245 | parachute - dause - ernie - ebbrell - jump | 10 | 245_parachute_dause_ernie_ebbrell |
| 246 | immigration - deportation - sham - iwueke - tate | 10 | 246_immigration_deportation_sham_iwueke |
| 247 | harris - rolf - indecent - 5480 - 4481 | 10 | 247_harris_rolf_indecent_5480 |
| 248 | factory - garment - bangladesh - dhaka - bangladeshi | 10 | 248_factory_garment_bangladesh_dhaka |
| 249 | nobel - prize - peace - karman - gbowee | 10 | 249_nobel_prize_peace_karman |
| 250 | ferry - sewol - jeju - ship - yoo | 10 | 250_ferry_sewol_jeju_ship |
| 251 | manson - atkins - tate - parole - statman | 10 | 251_manson_atkins_tate_parole |
| 252 | toyota - recall - toyotas - vehicle - acceleration | 9 | 252_toyota_recall_toyotas_vehicle |
| 253 | mortgage - rate - bank - cent - per | 9 | 253_mortgage_rate_bank_cent |
| 254 | smedley - rigby - ruth - coit - quesada | 9 | 254_smedley_rigby_ruth_coit |
| 255 | afghanistan - afghan - troop - karzai - abdullah | 9 | 255_afghanistan_afghan_troop_karzai |
| 256 | frozen - disney - elsa - cinderella - princess | 9 | 256_frozen_disney_elsa_cinderella |
| 257 | driving - wilkins - waller - magistrates - drinkdriving | 9 | 257_driving_wilkins_waller_magistrates |
| 258 | olympic - games - olympics - ceremony - london | 9 | 258_olympic_games_olympics_ceremony |
| 259 | neolithic - skull - timber - reitan - buried | 8 | 259_neolithic_skull_timber_reitan |
| 260 | philpott - mairead - willis - mick - fire | 8 | 260_philpott_mairead_willis_mick |
| 261 | holmes - clements - theater - colorado - aurora | 8 | 261_holmes_clements_theater_colorado |
| 262 | explosion - plant - fire - blast - fertilizer | 8 | 262_explosion_plant_fire_blast |
| 263 | tokyo - games - olympic - ioc - sochi | 8 | 263_tokyo_games_olympic_ioc |
| 264 | abortion - lobby - hobby - religious - supreme | 8 | 264_abortion_lobby_hobby_religious |
| 265 | cece - tulisa - cheryl - elimination - lakoda | 8 | 265_cece_tulisa_cheryl_elimination |
| 266 | dubai - mme - sheikh - uae - maktoum | 7 | 266_dubai_mme_sheikh_uae |
| 267 | space - virgin - galactic - spaceshiptwo - branson | 7 | 267_space_virgin_galactic_spaceshiptwo |
| 268 | oshie - hockey - shootout - russia - wagner | 7 | 268_oshie_hockey_shootout_russia |
| 269 | moghadam - avalos - image - chaney - nude | 7 | 269_moghadam_avalos_image_chaney |
| 270 | vell - roache - stuartcole - coronation - soap | 7 | 270_vell_roache_stuartcole_coronation |
| 271 | uber - taxi - hailo - driver - company | 7 | 271_uber_taxi_hailo_driver |
| 272 | mcdaniel - boo - mama - anna - honey | 6 | 272_mcdaniel_boo_mama_anna |
| 273 | rail - crossing - badauskas - train - minnis | 6 | 273_rail_crossing_badauskas_train |
| 274 | belghar - shafi - mevish - munir - ahmed | 6 | 274_belghar_shafi_mevish_munir |
| 275 | fred - knapke - hodgkins - carole - liam | 6 | 275_fred_knapke_hodgkins_carole |
| 276 | poppy - tower - war - memorial - ceramic | 6 | 276_poppy_tower_war_memorial |
| 277 | chiquita - colombia - colombian - cabral - marijuana | 6 | 277_chiquita_colombia_colombian_cabral |
| 278 | tb - virus - infection - measles - kalis | 6 | 278_tb_virus_infection_measles |
| 279 | sloan - saldanha - care - alvarez - saldanhas | 6 | 279_sloan_saldanha_care_alvarez |
| 280 | airboard - skyflash - hoverbike - catapult - skyprowler | 6 | 280_airboard_skyflash_hoverbike_catapult |
| 281 | ciancia - tsa - airport - hernandez - gerardo | 6 | 281_ciancia_tsa_airport_hernandez |
| 282 | heroin - addiction - opioids - addict - drug | 6 | 282_heroin_addiction_opioids_addict |
| 283 | euthanasia - pathway - assisted - die - suicide | 6 | 283_euthanasia_pathway_assisted_die |
| 284 | tower - elevator - lagoon - dubai - skyscraper | 6 | 284_tower_elevator_lagoon_dubai |
| 285 | firouzian - bus - tan - king - luther | 6 | 285_firouzian_bus_tan_king |
| 286 | carolyn - ian - fleming - morpurgo - couple | 5 | 286_carolyn_ian_fleming_morpurgo |
| 287 | tunisia - arab - egypt - tunisian - friaa | 5 | 287_tunisia_arab_egypt_tunisian |
| 288 | al - qaeda - libi - bin - laden | 5 | 288_al_qaeda_libi_bin |
| 289 | ear - keim - hear - implant - charlotte | 5 | 289_ear_keim_hear_implant |
| 290 | busch - driscoll - nascar - stewart - ward | 5 | 290_busch_driscoll_nascar_stewart |
| 291 | driscoll - masked - auckland - mortar - facebook | 5 | 291_driscoll_masked_auckland_mortar |
| 292 | drawer - bevan - avon - rothwell - leake | 5 | 292_drawer_bevan_avon_rothwell |
| 293 | breastfeeding - milk - clowes - breast - pump | 5 | 293_breastfeeding_milk_clowes_breast |
</details>
## Training hyperparameters
* calculate_probabilities: True
* language: english
* low_memory: False
* min_topic_size: 10
* n_gram_range: (1, 1)
* nr_topics: None
* seed_topic_list: None
* top_n_words: 10
* verbose: False
## Framework versions
* Numpy: 1.23.5
* HDBSCAN: 0.8.33
* UMAP: 0.5.3
* Pandas: 1.5.3
* Scikit-Learn: 1.2.2
* Sentence-transformers: 2.2.2
* Transformers: 4.31.0
* Numba: 0.57.1
* Plotly: 5.15.0
* Python: 3.10.12
|
MattStammers/q-FrozenLake-v1-8x8-Slippery-take3
|
MattStammers
| 2023-08-15T20:24:28Z | 0 | 0 | null |
[
"FrozenLake-v1-8x8",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-08-15T18:56:24Z |
---
tags:
- FrozenLake-v1-8x8
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-8x8-Slippery-take3
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-8x8
type: FrozenLake-v1-8x8
metrics:
- type: mean_reward
value: 0.63 +/- 0.48
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="MattStammers/q-FrozenLake-v1-8x8-Slippery-take3", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
{'env_id': 'FrozenLake-v1',
'max_steps': 200,
'n_training_episodes': 1000000,
'n_eval_episodes': 100,
'eval_seed': [],
'learning_rate': 0.2,
'gamma': 0.99,
'max_epsilon': 1,
'min_epsilon': 0.05,
'decay_rate': 0.0005}
Reduction in the learning rate and extension of training episodes seems to be producing better results. If one further attempt doesn't best this I will leave it there
|
linoyts/lora-trained-xl-colab-woman-0.0001-1000
|
linoyts
| 2023-08-15T20:19:51Z | 13 | 2 |
diffusers
|
[
"diffusers",
"stable-diffusion-xl",
"stable-diffusion-xl-diffusers",
"text-to-image",
"lora",
"base_model:stabilityai/stable-diffusion-xl-base-1.0",
"base_model:adapter:stabilityai/stable-diffusion-xl-base-1.0",
"license:openrail++",
"region:us"
] |
text-to-image
| 2023-08-15T19:06:55Z |
---
license: openrail++
base_model: stabilityai/stable-diffusion-xl-base-1.0
instance_prompt: a photo of sks woman
tags:
- stable-diffusion-xl
- stable-diffusion-xl-diffusers
- text-to-image
- diffusers
- lora
inference: true
---
# LoRA DreamBooth - LinoyTsaban/lora-trained-xl-colab-woman-0.0001-1000
These are LoRA adaption weights for stabilityai/stable-diffusion-xl-base-1.0. The weights were trained on a photo of sks woman using [DreamBooth](https://dreambooth.github.io/). You can find some example images in the following.
LoRA for the text encoder was enabled: False.
Special VAE used for training: madebyollin/sdxl-vae-fp16-fix.
|
zzzotop/zero-shot-cross-lingual-transfer-demo-masked
|
zzzotop
| 2023-08-15T20:18:46Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"fill-mask",
"base_model:distilbert/distilbert-base-multilingual-cased",
"base_model:finetune:distilbert/distilbert-base-multilingual-cased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2023-08-15T15:46:30Z |
---
license: apache-2.0
base_model: distilbert-base-multilingual-cased
model-index:
- name: zero-shot-cross-lingual-transfer-demo-masked
results: []
---
Next word prediction in 103 languages. Give it a sentence in another language, and replace one of the words with "[MASK]". Works with English too, obviously, but that defeats the point of the demo.
distilbert-base-multilingual-cased finetuned on 50,000 examples from r/explainlikeimfive subset of ELI5 dataset, for English causal language modelling. All knowledge of target languages is acquired from pretraining only.
Hyperparameters: epochs 3, learning rate 2e-5, batch size 8, weight decay 0.01, optimizer Adam with betas=(0.9,0.999) and epsilon=1e-08.
Final model perplexity 10.22
|
kyujinpy/KO-anything-v4-5
|
kyujinpy
| 2023-08-15T20:18:34Z | 21 | 3 |
diffusers
|
[
"diffusers",
"safetensors",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"korean",
"ko",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] |
text-to-image
| 2023-08-15T18:02:02Z |
---
language:
- ko
license: creativeml-openrail-m
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
- korean
inference: true
duplicated_from: andite/anything-v4.0
---
Fantasy.ai is the official and exclusive hosted AI generation platform that holds a commercial use license for Anything V4.0, you can use their service at https://Fantasy.ai/
# Note
- Github: [KOrean-stable-diffusion-anything](https://github.com/KyujinHan/KO-stable-diffusion-anything)
- I use [bingsu's CLIP](https://huggingface.co/Bingsu/clip-vit-large-patch14-ko)
## Examples

**Prompt: 걸작, 최고 품질, 1소녀, 흰 머리, 고양이 귀, 눈을 감고, 보는 사람, 귀여운, 스카프, 재킷, 옥외, 거리**

**Prompt: 풍경, 집, 야외, 하늘, 구름**

**Prompt: 1소년, 잘생긴, 실내, 앉아있는, 커피 숍, 커피 한 잔**

**Prompt: 1소년, 강아지 귀, 귀여운, 흰색 스카프, 눈, 관찰자**
# KO-Anything-V4.5
Welcome to Anything V4 - a latent diffusion model for weebs. The newest version of Anything. This model is intended to produce high-quality, highly detailed anime style with just a few prompts. Like other anime-style Stable Diffusion models, it also supports danbooru tags to generate images.
e.g. **_1girl, white hair, golden eyes, beautiful eyes, detail, flower meadow, cumulonimbus clouds, lighting, detailed sky, garden_**
**Korean ver.**
e.g. **_걸작, 최고 품질, 1소녀, 흰 머리, 고양이 귀, 눈을 감고, 보는 사람, 귀여운, 스카프, 재킷, 옥외, 거리_**
## 🧨 Diffusers
This model can be used just like any other Stable Diffusion model. For more information,
please have a look at the [Stable Diffusion](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion).
You can also export the model to [ONNX](https://huggingface.co/docs/diffusers/optimization/onnx), [MPS](https://huggingface.co/docs/diffusers/optimization/mps) and/or [FLAX/JAX]().
```python
from diffusers import StableDiffusionPipeline
import torch
model_id = "kyujinpy/KO-anything-v4.5"
pipe = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16)
pipe = pipe.to("cuda")
prompt = "1소년, 강아지 귀, 귀여운, 흰색 스카프, 눈, 관찰자"
image = pipe(prompt).images[0]
image.save("./hatsune_miku.png")
```
## License
This model is open access and available to all, with a CreativeML OpenRAIL-M license further specifying rights and usage.
The CreativeML OpenRAIL License specifies:
[Please read the full license here](https://huggingface.co/spaces/CompVis/stable-diffusion-license)
|
am-infoweb/QA_REFINED_QUESTIONS_WITH_RANDOM_DATA_24K_15_08
|
am-infoweb
| 2023-08-15T20:17:39Z | 15 | 0 |
transformers
|
[
"transformers",
"pytorch",
"roberta",
"question-answering",
"generated_from_trainer",
"base_model:deepset/roberta-base-squad2",
"base_model:finetune:deepset/roberta-base-squad2",
"license:cc-by-4.0",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2023-08-15T19:05:29Z |
---
license: cc-by-4.0
base_model: deepset/roberta-base-squad2
tags:
- generated_from_trainer
model-index:
- name: QA_REFINED_QUESTIONS_WITH_RANDOM_DATA_24K_15_08
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# QA_REFINED_QUESTIONS_WITH_RANDOM_DATA_24K_15_08
This model is a fine-tuned version of [deepset/roberta-base-squad2](https://huggingface.co/deepset/roberta-base-squad2) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.9623
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-----:|:---------------:|
| 0.8848 | 1.0 | 9137 | 0.8389 |
| 0.7753 | 2.0 | 18274 | 0.7794 |
| 0.7765 | 3.0 | 27411 | 0.8597 |
| 0.8242 | 4.0 | 36548 | 0.8571 |
| 0.6728 | 5.0 | 45685 | 0.9071 |
| 0.7219 | 6.0 | 54822 | 0.7628 |
| 0.6047 | 7.0 | 63959 | 0.9108 |
| 0.6137 | 8.0 | 73096 | 0.8685 |
| 0.5439 | 9.0 | 82233 | 0.8586 |
| 0.5387 | 10.0 | 91370 | 0.9623 |
### Framework versions
- Transformers 4.32.0.dev0
- Pytorch 2.0.1+cu117
- Datasets 2.14.4
- Tokenizers 0.13.3
|
MattStammers/Taxi-v3-final
|
MattStammers
| 2023-08-15T20:17:35Z | 0 | 0 | null |
[
"Taxi-v3",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-08-15T20:09:43Z |
---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-Taxi-v3-final
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
metrics:
- type: mean_reward
value: 8.34 +/- 2.65
name: mean_reward
verified: true
---
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="MattStammers/q-FrozenLake-v1-8x8-Slippery-final", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
This was an accident but it worked - it is obviously cheating somehow but it was fully unintentional
'env_id': 'Taxi-v3',
'max_steps': 200,
'n_training_episodes': 2000000,
'n_eval_episodes': 100,
'eval_seed': [],
'learning_rate': 0.15,
'gamma': 0.99,
'max_epsilon': 1,
'min_epsilon': 0.05,
'decay_rate': 0.0005,
|
skrl/IsaacOrbit-Isaac-Lift-Franka-v0-PPO
|
skrl
| 2023-08-15T20:14:52Z | 0 | 0 |
skrl
|
[
"skrl",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-01-20T12:12:12Z |
---
library_name: skrl
tags:
- deep-reinforcement-learning
- reinforcement-learning
- skrl
model-index:
- name: PPO
results:
- metrics:
- type: mean_reward
value: 41.69 +/- 0.06
name: Total reward (mean)
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Isaac-Lift-Franka-v0
type: Isaac-Lift-Franka-v0
---
<!-- ---
torch: 41.69 +/- 0.06
jax: 42.7 +/- 0.0
numpy:
--- -->
# IsaacOrbit-Isaac-Lift-Franka-v0-PPO
Trained agent for [NVIDIA Isaac Orbit](https://github.com/NVIDIA-Omniverse/Orbit) environments.
- **Task:** Isaac-Lift-Franka-v0
- **Agent:** [PPO](https://skrl.readthedocs.io/en/latest/api/agents/ppo.html)
# Usage (with skrl)
Note: Visit the skrl [Examples](https://skrl.readthedocs.io/en/latest/intro/examples.html) section to access the scripts.
* PyTorch
```python
from skrl.utils.huggingface import download_model_from_huggingface
# assuming that there is an agent named `agent`
path = download_model_from_huggingface("skrl/IsaacOrbit-Isaac-Lift-Franka-v0-PPO", filename="agent.pt")
agent.load(path)
```
* JAX
```python
from skrl.utils.huggingface import download_model_from_huggingface
# assuming that there is an agent named `agent`
path = download_model_from_huggingface("skrl/IsaacOrbit-Isaac-Lift-Franka-v0-PPO", filename="agent.pickle")
agent.load(path)
```
# Hyperparameters
```python
# https://skrl.readthedocs.io/en/latest/api/agents/ppo.html#configuration-and-hyperparameters
cfg = PPO_DEFAULT_CONFIG.copy()
cfg["rollouts"] = 96 # memory_size
cfg["learning_epochs"] = 5
cfg["mini_batches"] = 4 # 96 * 4096 / 98304
cfg["discount_factor"] = 0.99
cfg["lambda"] = 0.95
cfg["learning_rate"] = 1e-3
cfg["learning_rate_scheduler"] = KLAdaptiveLR
cfg["learning_rate_scheduler_kwargs"] = {"kl_threshold": 0.01, "min_lr": 1e-5}
cfg["random_timesteps"] = 0
cfg["learning_starts"] = 0
cfg["grad_norm_clip"] = 1.0
cfg["ratio_clip"] = 0.2
cfg["value_clip"] = 0.2
cfg["clip_predicted_values"] = True
cfg["entropy_loss_scale"] = 0.01
cfg["value_loss_scale"] = 1.0
cfg["kl_threshold"] = 0
cfg["rewards_shaper"] = None
cfg["time_limit_bootstrap"] = True
cfg["state_preprocessor"] = RunningStandardScaler
cfg["state_preprocessor_kwargs"] = {"size": env.observation_space, "device": device}
cfg["value_preprocessor"] = RunningStandardScaler
cfg["value_preprocessor_kwargs"] = {"size": 1, "device": device}
```
|
Sasankaai1/crystal1
|
Sasankaai1
| 2023-08-15T20:14:50Z | 0 | 0 | null |
[
"license:creativeml-openrail-m",
"region:us"
] | null | 2023-08-15T20:14:50Z |
---
license: creativeml-openrail-m
---
|
skrl/IsaacOrbit-Isaac-Reach-Franka-v0-PPO
|
skrl
| 2023-08-15T20:14:15Z | 0 | 0 |
skrl
|
[
"skrl",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-01-20T12:11:45Z |
---
library_name: skrl
tags:
- deep-reinforcement-learning
- reinforcement-learning
- skrl
model-index:
- name: PPO
results:
- metrics:
- type: mean_reward
value: 9.7 +/- 0.05
name: Total reward (mean)
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Isaac-Reach-Franka-v0
type: Isaac-Reach-Franka-v0
---
<!-- ---
torch: 9.7 +/- 0.05
jax: 9.65 +/- 0.0
numpy:
--- -->
# IsaacOrbit-Isaac-Reach-Franka-v0-PPO
Trained agent for [NVIDIA Isaac Orbit](https://github.com/NVIDIA-Omniverse/Orbit) environments.
- **Task:** Isaac-Reach-Franka-v0
- **Agent:** [PPO](https://skrl.readthedocs.io/en/latest/api/agents/ppo.html)
# Usage (with skrl)
Note: Visit the skrl [Examples](https://skrl.readthedocs.io/en/latest/intro/examples.html) section to access the scripts.
* PyTorch
```python
from skrl.utils.huggingface import download_model_from_huggingface
# assuming that there is an agent named `agent`
path = download_model_from_huggingface("skrl/IsaacOrbit-Isaac-Reach-Franka-v0-PPO", filename="agent.pt")
agent.load(path)
```
* JAX
```python
from skrl.utils.huggingface import download_model_from_huggingface
# assuming that there is an agent named `agent`
path = download_model_from_huggingface("skrl/IsaacOrbit-Isaac-Reach-Franka-v0-PPO", filename="agent.pickle")
agent.load(path)
```
# Hyperparameters
```python
# https://skrl.readthedocs.io/en/latest/api/agents/ppo.html#configuration-and-hyperparameters
cfg = PPO_DEFAULT_CONFIG.copy()
cfg["rollouts"] = 16 # memory_size
cfg["learning_epochs"] = 8
cfg["mini_batches"] = 8 # 16 * 2048 / 4096
cfg["discount_factor"] = 0.99
cfg["lambda"] = 0.95
cfg["learning_rate"] = 3e-4
cfg["learning_rate_scheduler"] = KLAdaptiveRL
cfg["learning_rate_scheduler_kwargs"] = {"kl_threshold": 0.01}
cfg["random_timesteps"] = 0
cfg["learning_starts"] = 0
cfg["grad_norm_clip"] = 1.0
cfg["ratio_clip"] = 0.2
cfg["value_clip"] = 0.2
cfg["clip_predicted_values"] = True
cfg["entropy_loss_scale"] = 0.0
cfg["value_loss_scale"] = 2.0
cfg["kl_threshold"] = 0
cfg["rewards_shaper"] = None
cfg["time_limit_bootstrap"] = False
cfg["state_preprocessor"] = RunningStandardScaler
cfg["state_preprocessor_kwargs"] = {"size": env.observation_space, "device": device}
cfg["value_preprocessor"] = RunningStandardScaler
cfg["value_preprocessor_kwargs"] = {"size": 1, "device": device}
```
|
Yijia-Xiao/LLaMA-7B-samsum
|
Yijia-Xiao
| 2023-08-15T20:10:46Z | 2 | 0 |
peft
|
[
"peft",
"pytorch",
"llama",
"8-bit",
"region:us"
] | null | 2023-08-15T18:00:12Z |
---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- load_in_8bit: True
- load_in_4bit: False
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: fp4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float32
### Framework versions
- PEFT 0.5.0.dev0
|
vivek9/sentiment_analysis
|
vivek9
| 2023-08-15T20:08:02Z | 0 | 0 | null |
[
"region:us"
] | null | 2023-08-14T14:34:48Z |
# Amazon Fine Food Sentiment Analysis with BERT
This repository contains code for a sentiment analysis demo that predicts the sentiment of Amazon fine food reviews using a finetuned BERT Base model from the Hugging Face Transformers library. The demo also includes an interface built using Gradio, allowing users to interactively input reviews and receive sentiment predictions.
## About the Demo
The sentiment analysis model is trained on the Amazon Fine Food Reviews dataset, which includes:
- Number of reviews: 568,454
- Number of users: 256,059
- Number of products: 74,258
- Timespan: Oct 1999 — Oct 2012
- Number of Attributes/Columns in data: 10
## Model Architecture
**Model Architecture:**
- `self.bert`: BERT Base model loaded from pre-trained weights.
- `self.drop`: Dropout layer applied for regularization.
- `self.out`: Linear layer mapping BERT hidden size to sentiment classes.
**Files in the Repository:**
- `amazon_finefood_sentiment_analysis_training.ipynb`: Code for training the sentiment analysis model.
- `amazon_finefood_sentiment_analysis_interface.ipynb`: Code for building the Gradio interface.
- `sentiment_analysis_finetune_bert.pkl`: Trained sentiment analysis model in serialized format.
**Usage:**
To run the code and interact with the sentiment analysis demo:
1. Open `amazon_finefood_sentiment_analysis_interface.ipynb`.
2. Set the file path to `sentiment_analysis_finetune_bert.pkl`.
3. Execute the notebook cells to set up the Gradio interface and make predictions.
Feel free to experiment with the interface, input different reviews, and observe sentiment predictions and confidence scores.
For questions/issues, open an issue in this repository.
**Model Achievements**
- Gated Recurrent Unit (GRU): Achieved an accuracy of 94.8%.
- Long Short-Term Memory (LSTM): Implemented an architecture with an accuracy of 93.2%.
- BERT Base Model Fine-Tuning: Achieved an accuracy of 96.4% after finetuning.
**Training Details**
All experiments were performed on a single NVIDIA RTX 2070 GPU. The training times are as follows:
- GRU Model: Trained for 10 epochs, took approximately 10+ hours.
- LSTM Model: Trained for 10 epochs, took around 10+ hours.
- BERT Base Model Fine-Tuning: Trained for 10 epochs, took around 15+ hours.
**Acknowledgments:**
The sentiment analysis model uses BERT architecture from Hugging Face Transformers. The Amazon Fine Food Reviews dataset is for training. Gradio is used for the interactive interface.
|
CyberHarem/last_order_toarumajutsunoindex
|
CyberHarem
| 2023-08-15T19:54:44Z | 0 | 0 | null |
[
"art",
"text-to-image",
"dataset:CyberHarem/last_order_toarumajutsunoindex",
"license:mit",
"region:us"
] |
text-to-image
| 2023-08-15T19:45:47Z |
---
license: mit
datasets:
- CyberHarem/last_order_toarumajutsunoindex
pipeline_tag: text-to-image
tags:
- art
---
# Lora of last_order_toarumajutsunoindex
This model is trained with [HCP-Diffusion](https://github.com/7eu7d7/HCP-Diffusion). And the auto-training framework is maintained by [DeepGHS Team](https://huggingface.co/deepghs).
After downloading the pt and safetensors files for the specified step, you need to use them simultaneously. The pt file will be used as an embedding, while the safetensors file will be loaded for Lora.
For example, if you want to use the model from step 1500, you need to download `1500/last_order_toarumajutsunoindex.pt` as the embedding and `1500/last_order_toarumajutsunoindex.safetensors` for loading Lora. By using both files together, you can generate images for the desired characters.
**The trigger word is `last_order_toarumajutsunoindex`.**
These are available steps:
| Steps | pattern_1 | pattern_2 | bikini | free | nude | Download |
|--------:|:----------------------------------------------------|:-----------------------------------------------|:-----------------------------------------|:-------------------------------------|:-----------------------------------------------|:----------------------------------------------------|
| 1500 | [<NSFW, click to see>](1500/previews/pattern_1.png) |  |  |  | [<NSFW, click to see>](1500/previews/nude.png) | [Download](1500/last_order_toarumajutsunoindex.zip) |
| 1400 | [<NSFW, click to see>](1400/previews/pattern_1.png) |  |  |  | [<NSFW, click to see>](1400/previews/nude.png) | [Download](1400/last_order_toarumajutsunoindex.zip) |
| 1300 | [<NSFW, click to see>](1300/previews/pattern_1.png) |  |  |  | [<NSFW, click to see>](1300/previews/nude.png) | [Download](1300/last_order_toarumajutsunoindex.zip) |
| 1200 | [<NSFW, click to see>](1200/previews/pattern_1.png) |  |  |  | [<NSFW, click to see>](1200/previews/nude.png) | [Download](1200/last_order_toarumajutsunoindex.zip) |
| 1100 | [<NSFW, click to see>](1100/previews/pattern_1.png) |  |  |  | [<NSFW, click to see>](1100/previews/nude.png) | [Download](1100/last_order_toarumajutsunoindex.zip) |
| 1000 | [<NSFW, click to see>](1000/previews/pattern_1.png) |  |  |  | [<NSFW, click to see>](1000/previews/nude.png) | [Download](1000/last_order_toarumajutsunoindex.zip) |
| 900 | [<NSFW, click to see>](900/previews/pattern_1.png) |  |  |  | [<NSFW, click to see>](900/previews/nude.png) | [Download](900/last_order_toarumajutsunoindex.zip) |
| 800 | [<NSFW, click to see>](800/previews/pattern_1.png) |  |  |  | [<NSFW, click to see>](800/previews/nude.png) | [Download](800/last_order_toarumajutsunoindex.zip) |
| 700 | [<NSFW, click to see>](700/previews/pattern_1.png) |  |  |  | [<NSFW, click to see>](700/previews/nude.png) | [Download](700/last_order_toarumajutsunoindex.zip) |
| 600 | [<NSFW, click to see>](600/previews/pattern_1.png) |  |  |  | [<NSFW, click to see>](600/previews/nude.png) | [Download](600/last_order_toarumajutsunoindex.zip) |
| 500 | [<NSFW, click to see>](500/previews/pattern_1.png) |  |  |  | [<NSFW, click to see>](500/previews/nude.png) | [Download](500/last_order_toarumajutsunoindex.zip) |
| 400 | [<NSFW, click to see>](400/previews/pattern_1.png) |  |  |  | [<NSFW, click to see>](400/previews/nude.png) | [Download](400/last_order_toarumajutsunoindex.zip) |
| 300 | [<NSFW, click to see>](300/previews/pattern_1.png) |  |  |  | [<NSFW, click to see>](300/previews/nude.png) | [Download](300/last_order_toarumajutsunoindex.zip) |
| 200 | [<NSFW, click to see>](200/previews/pattern_1.png) |  |  |  | [<NSFW, click to see>](200/previews/nude.png) | [Download](200/last_order_toarumajutsunoindex.zip) |
| 100 | [<NSFW, click to see>](100/previews/pattern_1.png) |  |  |  | [<NSFW, click to see>](100/previews/nude.png) | [Download](100/last_order_toarumajutsunoindex.zip) |
|
skrl/IsaacOrbit-Isaac-Cartpole-v0-PPO
|
skrl
| 2023-08-15T19:42:52Z | 0 | 0 |
skrl
|
[
"skrl",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-01-20T12:07:53Z |
---
library_name: skrl
tags:
- deep-reinforcement-learning
- reinforcement-learning
- skrl
model-index:
- name: PPO
results:
- metrics:
- type: mean_reward
value: 497.66 +/- 0.47
name: Total reward (mean)
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Isaac-Cartpole-v0
type: Isaac-Cartpole-v0
---
<!-- ---
torch: 497.66 +/- 0.47
jax: 497.41 +/- 0.0
numpy:
--- -->
# IsaacOrbit-Isaac-Cartpole-v0-PPO
Trained agent for [NVIDIA Isaac Orbit](https://github.com/NVIDIA-Omniverse/Orbit) environments.
- **Task:** Isaac-Cartpole-v0
- **Agent:** [PPO](https://skrl.readthedocs.io/en/latest/api/agents/ppo.html)
# Usage (with skrl)
Note: Visit the skrl [Examples](https://skrl.readthedocs.io/en/latest/intro/examples.html) section to access the scripts.
* PyTorch
```python
from skrl.utils.huggingface import download_model_from_huggingface
# assuming that there is an agent named `agent`
path = download_model_from_huggingface("skrl/IsaacOrbit-Isaac-Cartpole-v0-PPO", filename="agent.pt")
agent.load(path)
```
* JAX
```python
from skrl.utils.huggingface import download_model_from_huggingface
# assuming that there is an agent named `agent`
path = download_model_from_huggingface("skrl/IsaacOrbit-Isaac-Cartpole-v0-PPO", filename="agent.pickle")
agent.load(path)
```
# Hyperparameters
```python
# https://skrl.readthedocs.io/en/latest/api/agents/ppo.html#configuration-and-hyperparameters
cfg = PPO_DEFAULT_CONFIG.copy()
cfg["rollouts"] = 16 # memory_size
cfg["learning_epochs"] = 8
cfg["mini_batches"] = 1 # 16 * 512 / 8192
cfg["discount_factor"] = 0.99
cfg["lambda"] = 0.95
cfg["learning_rate"] = 3e-4
cfg["learning_rate_scheduler"] = KLAdaptiveRL
cfg["learning_rate_scheduler_kwargs"] = {"kl_threshold": 0.008}
cfg["random_timesteps"] = 0
cfg["learning_starts"] = 0
cfg["grad_norm_clip"] = 1.0
cfg["ratio_clip"] = 0.2
cfg["value_clip"] = 0.2
cfg["clip_predicted_values"] = True
cfg["entropy_loss_scale"] = 0.0
cfg["value_loss_scale"] = 2.0
cfg["kl_threshold"] = 0
cfg["rewards_shaper"] = None
cfg["time_limit_bootstrap"] = True
cfg["state_preprocessor"] = RunningStandardScaler
cfg["state_preprocessor_kwargs"] = {"size": env.observation_space, "device": device}
cfg["value_preprocessor"] = RunningStandardScaler
cfg["value_preprocessor_kwargs"] = {"size": 1, "device": device}
```
|
herdi226/EbiAI
|
herdi226
| 2023-08-15T19:24:33Z | 0 | 0 | null |
[
"license:creativeml-openrail-m",
"region:us"
] | null | 2023-08-15T19:21:58Z |
---
license: creativeml-openrail-m
---
|
MattStammers/td3-Bipedal_Walker_v3-HardcoreTrained
|
MattStammers
| 2023-08-15T19:24:23Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"BipedalWalker-v3",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-08-15T19:20:27Z |
---
library_name: stable-baselines3
tags:
- BipedalWalker-v3
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: TD3
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: BipedalWalker-v3
type: BipedalWalker-v3
metrics:
- type: mean_reward
value: 50.22 +/- 91.71
name: mean_reward
verified: false
---
# **TD3** Agent playing **BipedalWalker-v3**
This is a trained model of a **TD3** agent playing **BipedalWalker-v3**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
Dude is getting there but needs hyperparameter tuning. Will try SAC next as the tuning is a known entity so will be quicker.
|
Adrenex/grid
|
Adrenex
| 2023-08-15T19:12:58Z | 1 | 0 |
diffusers
|
[
"diffusers",
"text-to-image",
"autotrain",
"region:us"
] |
text-to-image
| 2023-08-15T18:37:56Z |
---
tags:
- text-to-image
- diffusers
- autotrain
inference: true
---
# ART Text-to-Image Generation using adrenex/outfitt2i
This repository contains code and instructions for using the `adrenex/outfitt2i` model from Hugging Face's Transformers library to generate images from textual descriptions. The model utilizes diffusion models for high-quality image synthesis based on the provided text prompts.






## Model Information
- Tags:
- text-to-image
- diffusers
- autotrain
## Inference
To use this model for generating images from text prompts, follow these steps:
1. **Environment Setup:**
Make sure you have Python installed on your system. You can also use a virtual environment for isolation.
2. **Install Dependencies:**
Install the required Python packages by running the following command:
```bash
pip install -r requirements.txt
```
3.## Usage
```python
from diffusers import DiffusionPipeline
import torch
# Load LoRA weights
lora_weights = torch.load("/path/to/lora_weights/pytorch_lora_weights.safetensors")
# Initialize the DiffusionPipeline
pipe = DiffusionPipeline.from_pretrained("adrenex/outfitt2i", torch_dtype=torch.float16)
pipe.to("cuda")
# Load LoRA weights into the pipeline
pipe.load_lora_weights(lora_weights)
# Text prompt for image generation
prompt = "photo of Iyad Radi with cat in the pool"
# Generate Images
image = pipe(prompt, num_inference_steps=30, guidance_scale=7.5).images
```
4. **Generated Images:**
The generated images will be saved in the `output_images` directory by default.
## Application in Art and Cinema Industry
This model can be incredibly useful in the art and cinema movie production industry, especially for creating visuals based on textual descriptions. In the case of Aiyad Radi, an Iraqi actor and comedian, this tool can aid in visualizing character designs, scenes, and concepts before actual production. Directors, artists, and producers can utilize the generated images as a reference to plan and visualize their projects effectively.
## Credits
- This repository is created and maintained by [Falah.G.Saleih]
## Disclaimer
Please note that the model's outputs might vary, and the generated images are based on the input text prompts. The model's behavior is influenced by its training data and might not always produce accurate or desired results.
Feel free to experiment, provide feedback, and contribute to this repository if you'd like to enhance its functionality!
---
|
ita123/FB_posts
|
ita123
| 2023-08-15T19:09:18Z | 0 | 0 |
diffusers
|
[
"diffusers",
"Marketing",
"text2text-generation",
"en",
"dataset:Anthropic/hh-rlhf",
"license:afl-3.0",
"region:us"
] |
text2text-generation
| 2023-08-15T19:08:13Z |
---
license: afl-3.0
datasets:
- Anthropic/hh-rlhf
language:
- en
metrics:
- bleurt
library_name: diffusers
pipeline_tag: text2text-generation
tags:
- Marketing
---
|
Seooooooogi/version_4
|
Seooooooogi
| 2023-08-15T19:01:02Z | 29 | 1 |
diffusers
|
[
"diffusers",
"tensorboard",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"dreambooth",
"base_model:runwayml/stable-diffusion-v1-5",
"base_model:finetune:runwayml/stable-diffusion-v1-5",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] |
text-to-image
| 2023-08-15T18:51:15Z |
---
license: creativeml-openrail-m
base_model: runwayml/stable-diffusion-v1-5
instance_prompt: a sks man
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
- dreambooth
inference: true
---
# DreamBooth - Seooooooogi/version_4
This is a dreambooth model derived from runwayml/stable-diffusion-v1-5. The weights were trained on a sks man using [DreamBooth](https://dreambooth.github.io/).
You can find some example images in the following.
DreamBooth for the text encoder was enabled: False.
|
li-ping/add_intrinsics
|
li-ping
| 2023-08-15T18:55:54Z | 0 | 0 |
peft
|
[
"peft",
"region:us"
] | null | 2023-08-15T18:12:11Z |
---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- load_in_8bit: True
- load_in_4bit: False
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: fp4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float32
### Framework versions
- PEFT 0.5.0.dev0
|
ajit-transformer/xlm-roberta-base-finetuned-panx-de
|
ajit-transformer
| 2023-08-15T18:51:30Z | 136 | 1 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"xlm-roberta",
"token-classification",
"generated_from_trainer",
"dataset:xtreme",
"license:mit",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2023-08-15T18:05:33Z |
---
license: mit
tags:
- generated_from_trainer
datasets:
- xtreme
metrics:
- f1
model-index:
- name: xlm-roberta-base-finetuned-panx-de
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: xtreme
type: xtreme
config: PAN-X.de
split: validation
args: PAN-X.de
metrics:
- name: F1
type: f1
value: 0.8550617424457976
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xlm-roberta-base-finetuned-panx-de
This model is a fine-tuned version of [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) on the xtreme dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1362
- F1: 0.8551
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 48
- eval_batch_size: 48
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| No log | 1.0 | 263 | 0.1845 | 0.7994 |
| 0.2134 | 2.0 | 526 | 0.1362 | 0.8436 |
| 0.2134 | 3.0 | 789 | 0.1362 | 0.8551 |
### Framework versions
- Transformers 4.30.2
- Pytorch 2.0.0
- Datasets 2.1.0
- Tokenizers 0.13.3
|
dirichletian/speecht5_tts_voxpopuli_nl
|
dirichletian
| 2023-08-15T18:48:18Z | 77 | 0 |
transformers
|
[
"transformers",
"pytorch",
"speecht5",
"text-to-audio",
"tags",
"generated_from_trainer",
"nl",
"dataset:amharic_parallel",
"base_model:microsoft/speecht5_tts",
"base_model:finetune:microsoft/speecht5_tts",
"license:mit",
"endpoints_compatible",
"region:us"
] |
text-to-audio
| 2023-08-08T03:13:30Z |
---
language:
- nl
license: mit
base_model: microsoft/speecht5_tts
tags:
- tags
- generated_from_trainer
datasets:
- amharic_parallel
model-index:
- name: SpeechT5-TTS-Amh
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# SpeechT5-TTS-Amh
This model is a fine-tuned version of [microsoft/speecht5_tts](https://huggingface.co/microsoft/speecht5_tts) on the alefa_asr dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3722
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 4
- eval_batch_size: 2
- seed: 42
- gradient_accumulation_steps: 8
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 4000
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 0.4268 | 3.46 | 1000 | 0.3934 |
| 0.4066 | 6.92 | 2000 | 0.3832 |
| 0.3997 | 10.38 | 3000 | 0.3745 |
| 0.3976 | 13.84 | 4000 | 0.3722 |
### Framework versions
- Transformers 4.32.0.dev0
- Pytorch 2.0.1+cu118
- Datasets 2.14.4
- Tokenizers 0.13.3
|
sherif1311/BathNLPmodel
|
sherif1311
| 2023-08-15T18:32:40Z | 161 | 0 |
transformers
|
[
"transformers",
"pytorch",
"t5",
"text2text-generation",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2023-07-01T16:05:13Z |
This modelcard aims to be a base template for new models. It has been generated using [this raw template](https://github.com/huggingface/huggingface_hub/blob/main/src/huggingface_hub/templates/modelcard_template.md?plain=1).
## Model Details
That is my first LLM
### Model Description
- **Developed by:** I am Samah
-
|
gyikesz/q-FrozenLake-v1-4x4-noSlippery
|
gyikesz
| 2023-08-15T18:26:30Z | 0 | 0 | null |
[
"FrozenLake-v1-4x4-no_slippery",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-08-15T18:26:28Z |
---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="gyikesz/q-FrozenLake-v1-4x4-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
rohith08/pegasus-samsum
|
rohith08
| 2023-08-15T18:24:34Z | 103 | 0 |
transformers
|
[
"transformers",
"pytorch",
"pegasus",
"text2text-generation",
"generated_from_trainer",
"dataset:samsum",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2023-08-15T18:20:17Z |
---
tags:
- generated_from_trainer
datasets:
- samsum
model-index:
- name: pegasus-samsum
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# pegasus-samsum
This model is a fine-tuned version of [google/pegasus-cnn_dailymail](https://huggingface.co/google/pegasus-cnn_dailymail) on the samsum dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 1
- eval_batch_size: 1
- seed: 42
- gradient_accumulation_steps: 16
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 1
### Framework versions
- Transformers 4.16.2
- Pytorch 2.0.1+cu118
- Datasets 2.0.0
- Tokenizers 0.13.3
|
suyash2102/model-en-to-fr
|
suyash2102
| 2023-08-15T18:22:56Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"marian",
"text2text-generation",
"translation",
"generated_from_trainer",
"dataset:kde4",
"base_model:Helsinki-NLP/opus-mt-en-fr",
"base_model:finetune:Helsinki-NLP/opus-mt-en-fr",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
translation
| 2023-08-10T17:11:11Z |
---
license: apache-2.0
base_model: Helsinki-NLP/opus-mt-en-fr
tags:
- translation
- generated_from_trainer
datasets:
- kde4
model-index:
- name: model-en-to-fr
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Introduction
I have made a working user interactive Gradio Language Translation model which translates any English sentence into French sentence. For this i have fine tuned a pre trained model which i have used from HuggingFace.
Make a local directory of this repo in your computer and then in your terminal switch to the directory of this repo on your computer and then just type python gradio_LT.py to start the user interface for translation.
# model-en-to-fr
This model is a fine-tuned version of [Helsinki-NLP/opus-mt-en-fr](https://huggingface.co/Helsinki-NLP/opus-mt-en-fr) on the kde4 dataset.
I have used this model to translate english sentences to French.
## Model description
I have used the inbuilt features of transformers to make this model. The model is made from AutoModelForSeq2SeqLM and i have tokenized the dataset accoding to the pre trained model.
## Training and evaluation data
I have used the Sacrebleu method to evaluate my model which is generally used in language translation. It compares the number of common words in predicted and correct output and then gives its correctness.
## Training procedure
I have used the Seq2SeqTrainer function to train my dataset over the pre trained model.The specific parameters are given below which i have used.
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 32
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Gradio Interface
I have made a separate file gradio_LT.py. By running this file you will directly see a gradio user interface through which you translate sentences. The only prerequisite is that transformers, gradio, sentencepiece should be pre downloaded in your environment.
### Framework versions
- Transformers 4.31.0
- Pytorch 2.0.1+cu118
- Datasets 2.14.4
- Tokenizers 0.13.3
|
dhmeltzer/Llama-2-7b-hf-wiki30k-no-group-by-length_r_64_alpha_16
|
dhmeltzer
| 2023-08-15T18:15:36Z | 0 | 0 | null |
[
"generated_from_trainer",
"base_model:meta-llama/Llama-2-7b-hf",
"base_model:finetune:meta-llama/Llama-2-7b-hf",
"region:us"
] | null | 2023-08-15T08:07:57Z |
---
base_model: meta-llama/Llama-2-7b-hf
tags:
- generated_from_trainer
model-index:
- name: Llama-2-7b-hf-wiki-no-group-by-length_r_64_alpha_16
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Llama-2-7b-hf-wiki-no-group-by-length_r_64_alpha_16
This model is a fine-tuned version of [meta-llama/Llama-2-7b-hf](https://huggingface.co/meta-llama/Llama-2-7b-hf) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.2454
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 16
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.03
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 1.288 | 0.3 | 71 | 1.2669 |
| 1.2518 | 0.61 | 142 | 1.2545 |
| 1.2438 | 0.91 | 213 | 1.2476 |
| 1.1978 | 1.21 | 284 | 1.2481 |
| 1.2036 | 1.51 | 355 | 1.2481 |
| 1.1938 | 1.82 | 426 | 1.2454 |
| 1.1833 | 2.12 | 497 | 1.2517 |
| 1.1437 | 2.42 | 568 | 1.2538 |
| 1.1469 | 2.73 | 639 | 1.2537 |
### Framework versions
- Transformers 4.31.0
- Pytorch 2.0.0
- Datasets 2.12.0
- Tokenizers 0.13.3
|
Seooooooogi/version_3
|
Seooooooogi
| 2023-08-15T18:14:19Z | 0 | 1 |
diffusers
|
[
"diffusers",
"tensorboard",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"dreambooth",
"base_model:runwayml/stable-diffusion-v1-5",
"base_model:finetune:runwayml/stable-diffusion-v1-5",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] |
text-to-image
| 2023-08-15T17:53:56Z |
---
license: creativeml-openrail-m
base_model: runwayml/stable-diffusion-v1-5
instance_prompt: a sks man
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
- dreambooth
inference: true
---
# DreamBooth - Seooooooogi/version_3
This is a dreambooth model derived from runwayml/stable-diffusion-v1-5. The weights were trained on a sks man using [DreamBooth](https://dreambooth.github.io/).
You can find some example images in the following.
DreamBooth for the text encoder was enabled: False.
|
Boyin/llama2-qlora-fineturned-helloworld
|
Boyin
| 2023-08-15T18:01:34Z | 0 | 0 |
peft
|
[
"peft",
"region:us"
] | null | 2023-08-15T18:01:27Z |
---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float16
### Framework versions
- PEFT 0.5.0.dev0
|
skmrafi/llama2-qlora-finetunined-french
|
skmrafi
| 2023-08-15T17:59:41Z | 0 | 0 |
peft
|
[
"peft",
"llama",
"region:us"
] | null | 2023-08-15T17:30:17Z |
---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float16
### Framework versions
- PEFT 0.4.0
|
CyberHarem/misaka_mikoto_toarumajutsunoindex
|
CyberHarem
| 2023-08-15T17:49:34Z | 0 | 0 | null |
[
"art",
"text-to-image",
"dataset:CyberHarem/misaka_mikoto_toarumajutsunoindex",
"license:mit",
"region:us"
] |
text-to-image
| 2023-08-15T17:41:04Z |
---
license: mit
datasets:
- CyberHarem/misaka_mikoto_toarumajutsunoindex
pipeline_tag: text-to-image
tags:
- art
---
# Lora of misaka_mikoto_toarumajutsunoindex
This model is trained with [HCP-Diffusion](https://github.com/7eu7d7/HCP-Diffusion). And the auto-training framework is maintained by [DeepGHS Team](https://huggingface.co/deepghs).
After downloading the pt and safetensors files for the specified step, you need to use them simultaneously. The pt file will be used as an embedding, while the safetensors file will be loaded for Lora.
For example, if you want to use the model from step 1500, you need to download `1500/misaka_mikoto_toarumajutsunoindex.pt` as the embedding and `1500/misaka_mikoto_toarumajutsunoindex.safetensors` for loading Lora. By using both files together, you can generate images for the desired characters.
**The trigger word is `misaka_mikoto_toarumajutsunoindex`.**
These are available steps:
| Steps | pattern_1 | pattern_2 | pattern_3 | pattern_4 | bikini | free | nude | Download |
|--------:|:-----------------------------------------------|:-----------------------------------------------|:-----------------------------------------------|:-----------------------------------------------|:-----------------------------------------|:-------------------------------------|:-----------------------------------------------|:-------------------------------------------------------|
| 1500 |  |  |  |  |  |  | [<NSFW, click to see>](1500/previews/nude.png) | [Download](1500/misaka_mikoto_toarumajutsunoindex.zip) |
| 1400 |  |  |  |  |  |  | [<NSFW, click to see>](1400/previews/nude.png) | [Download](1400/misaka_mikoto_toarumajutsunoindex.zip) |
| 1300 |  |  |  |  |  |  | [<NSFW, click to see>](1300/previews/nude.png) | [Download](1300/misaka_mikoto_toarumajutsunoindex.zip) |
| 1200 |  |  |  |  |  |  | [<NSFW, click to see>](1200/previews/nude.png) | [Download](1200/misaka_mikoto_toarumajutsunoindex.zip) |
| 1100 |  |  |  |  |  |  | [<NSFW, click to see>](1100/previews/nude.png) | [Download](1100/misaka_mikoto_toarumajutsunoindex.zip) |
| 1000 |  |  |  |  |  |  | [<NSFW, click to see>](1000/previews/nude.png) | [Download](1000/misaka_mikoto_toarumajutsunoindex.zip) |
| 900 |  |  |  |  |  |  | [<NSFW, click to see>](900/previews/nude.png) | [Download](900/misaka_mikoto_toarumajutsunoindex.zip) |
| 800 |  |  |  |  |  |  | [<NSFW, click to see>](800/previews/nude.png) | [Download](800/misaka_mikoto_toarumajutsunoindex.zip) |
| 700 |  |  |  |  |  |  | [<NSFW, click to see>](700/previews/nude.png) | [Download](700/misaka_mikoto_toarumajutsunoindex.zip) |
| 600 |  |  |  |  |  |  | [<NSFW, click to see>](600/previews/nude.png) | [Download](600/misaka_mikoto_toarumajutsunoindex.zip) |
| 500 |  |  |  |  |  |  | [<NSFW, click to see>](500/previews/nude.png) | [Download](500/misaka_mikoto_toarumajutsunoindex.zip) |
| 400 |  |  |  |  |  |  | [<NSFW, click to see>](400/previews/nude.png) | [Download](400/misaka_mikoto_toarumajutsunoindex.zip) |
| 300 |  |  |  |  |  |  | [<NSFW, click to see>](300/previews/nude.png) | [Download](300/misaka_mikoto_toarumajutsunoindex.zip) |
| 200 |  |  |  |  |  |  | [<NSFW, click to see>](200/previews/nude.png) | [Download](200/misaka_mikoto_toarumajutsunoindex.zip) |
| 100 |  |  |  |  |  |  | [<NSFW, click to see>](100/previews/nude.png) | [Download](100/misaka_mikoto_toarumajutsunoindex.zip) |
|
Rakshit122/roberta
|
Rakshit122
| 2023-08-15T17:46:05Z | 106 | 1 |
transformers
|
[
"transformers",
"pytorch",
"roberta",
"text-classification",
"emotions",
"multi-class-classification",
"multi-label-classification",
"en",
"dataset:go_emotions",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-08-15T17:06:00Z |
---
language: en
tags:
- text-classification
- pytorch
- roberta
- emotions
- multi-class-classification
- multi-label-classification
datasets:
- go_emotions
license: mit
widget:
- text: "I am not having a great day."
---
Model trained from [roberta-base](https://huggingface.co/roberta-base) on the [go_emotions](https://huggingface.co/datasets/go_emotions) dataset for multi-label classification.
[go_emotions](https://huggingface.co/datasets/go_emotions) is based on Reddit data and has 28 labels. It is a multi-label dataset where one or multiple labels may apply for any given input text, hence this model is a multi-label classification model with 28 'probability' float outputs for any given input text. Typically a threshold of 0.5 is applied to the probabilities for the prediction for each label.
The model was trained using `AutoModelForSequenceClassification.from_pretrained` with `problem_type="multi_label_classification"` for 3 epochs with a learning rate of 2e-5 and weight decay of 0.01.
Evaluation (of the 28 dim output via a threshold of 0.5 to binarize each) using the dataset test split gives:
- Micro F1 0.585
- ROC AUC 0.751
- Accuracy 0.474
But the metrics would be more meaningful when measured per label given the multi-label nature.
Additionally some labels (E.g. `gratitude`) when considered independently perform very strongly with F1 around 0.9, whilst others (E.g. `relief`) perform very poorly. This is a challenging dataset. Labels such as `relief` do have much fewer examples in the training data (less than 100 out of the 40k+), but there is also some ambiguity and/or labelling errors visible in the training data of `go_emotions` that is suspected to constrain the performance.
|
renyulin/baichuan-7b-sft-peft
|
renyulin
| 2023-08-15T17:36:51Z | 1 | 0 |
peft
|
[
"peft",
"region:us"
] | null | 2023-08-15T17:35:11Z |
---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- load_in_8bit: True
- load_in_4bit: False
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: fp4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float32
### Framework versions
- PEFT 0.5.0.dev0
|
gregorgabrovsek/SloBertAA_Top100_WithoutOOC_082023_MultilingualBertBase
|
gregorgabrovsek
| 2023-08-15T17:36:38Z | 107 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"text-classification",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-08-14T12:14:32Z |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- accuracy
- f1
- precision
- recall
model-index:
- name: SloBertAA_Top100_WithoutOOC_082023_MultilingualBertBase
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# SloBertAA_Top100_WithoutOOC_082023_MultilingualBertBase
This model is a fine-tuned version of [bert-base-multilingual-uncased](https://huggingface.co/bert-base-multilingual-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.8490
- Accuracy: 0.6964
- F1: 0.6972
- Precision: 0.7001
- Recall: 0.6964
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 12
- eval_batch_size: 12
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 | Precision | Recall |
|:-------------:|:-----:|:------:|:---------------:|:--------:|:------:|:---------:|:------:|
| 1.6988 | 1.0 | 44675 | 1.6287 | 0.5883 | 0.5902 | 0.6087 | 0.5883 |
| 1.3829 | 2.0 | 89350 | 1.4305 | 0.6351 | 0.6379 | 0.6563 | 0.6351 |
| 1.1122 | 3.0 | 134025 | 1.3339 | 0.6635 | 0.6651 | 0.6774 | 0.6635 |
| 0.881 | 4.0 | 178700 | 1.3128 | 0.6799 | 0.6805 | 0.6876 | 0.6799 |
| 0.7032 | 5.0 | 223375 | 1.3628 | 0.6831 | 0.6840 | 0.6932 | 0.6831 |
| 0.5454 | 6.0 | 268050 | 1.4343 | 0.6877 | 0.6890 | 0.6956 | 0.6877 |
| 0.408 | 7.0 | 312725 | 1.5546 | 0.6877 | 0.6888 | 0.6958 | 0.6877 |
| 0.2752 | 8.0 | 357400 | 1.6623 | 0.6932 | 0.6948 | 0.6992 | 0.6932 |
| 0.1844 | 9.0 | 402075 | 1.7825 | 0.6947 | 0.6959 | 0.6995 | 0.6947 |
| 0.1506 | 10.0 | 446750 | 1.8490 | 0.6964 | 0.6972 | 0.7001 | 0.6964 |
### Framework versions
- Transformers 4.26.1
- Pytorch 1.8.0
- Datasets 2.10.1
- Tokenizers 0.13.2
|
voxxer/whisper-small-dv
|
voxxer
| 2023-08-15T17:32:59Z | 92 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"whisper",
"automatic-speech-recognition",
"generated_from_trainer",
"dv",
"dataset:mozilla-foundation/common_voice_13_0",
"base_model:openai/whisper-small",
"base_model:finetune:openai/whisper-small",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2023-08-15T15:34:51Z |
---
language:
- dv
license: apache-2.0
base_model: openai/whisper-small
tags:
- generated_from_trainer
datasets:
- mozilla-foundation/common_voice_13_0
metrics:
- wer
model-index:
- name: Whisper Small Dhivehi
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice 13
type: mozilla-foundation/common_voice_13_0
config: dv
split: test
args: dv
metrics:
- name: Wer
type: wer
value: 13.097680564732064
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Whisper Small Dhivehi
This model is a fine-tuned version of [openai/whisper-small](https://huggingface.co/openai/whisper-small) on the Common Voice 13 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1691
- Wer Ortho: 62.1144
- Wer: 13.0977
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: constant_with_warmup
- lr_scheduler_warmup_steps: 50
- training_steps: 500
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer Ortho | Wer |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:-------:|
| 0.1237 | 1.63 | 500 | 0.1691 | 62.1144 | 13.0977 |
### Framework versions
- Transformers 4.31.0
- Pytorch 2.0.1+cu118
- Datasets 2.14.4
- Tokenizers 0.13.3
|
LarryAIDraw/Arknights-Whisperain-Tremble_Cold_Original_outfits__With_multires_noise_version
|
LarryAIDraw
| 2023-08-15T17:27:50Z | 0 | 0 | null |
[
"license:creativeml-openrail-m",
"region:us"
] | null | 2023-08-15T17:23:44Z |
---
license: creativeml-openrail-m
---
https://civitai.com/models/69751/arknights-whisperain-tremble-coldandoriginal-outfits-with-multires-noise-version
|
LarryAIDraw/Santalla_Arknights_V6e7
|
LarryAIDraw
| 2023-08-15T17:27:24Z | 0 | 0 | null |
[
"license:creativeml-openrail-m",
"region:us"
] | null | 2023-08-15T17:20:16Z |
---
license: creativeml-openrail-m
---
https://civitai.com/models/122072/santalla-arknights
|
LarryAIDraw/Kitagawa_Marin_DressUp-KK77-V1
|
LarryAIDraw
| 2023-08-15T17:26:57Z | 0 | 0 | null |
[
"license:creativeml-openrail-m",
"region:us"
] | null | 2023-08-15T17:18:59Z |
---
license: creativeml-openrail-m
---
https://civitai.com/models/129001/requestkitagawa-marin-woutfits-or-my-dress-up-darling
|
LarryAIDraw/iroha_isshiki_v1
|
LarryAIDraw
| 2023-08-15T17:26:43Z | 0 | 0 | null |
[
"license:creativeml-openrail-m",
"region:us"
] | null | 2023-08-15T17:18:22Z |
---
license: creativeml-openrail-m
---
https://civitai.com/models/127437/iroha-isshiki-or-my-teen-romantic-comedy-is-wrong-as-i-expected-oregairu
|
knocheeri/vit-base-houses-distressed-15-aug
|
knocheeri
| 2023-08-15T17:09:26Z | 193 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"vit",
"image-classification",
"generated_from_trainer",
"dataset:imagefolder",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2023-08-15T14:55:57Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- imagefolder
metrics:
- accuracy
model-index:
- name: vit-base-houses-distressed-15-aug
results:
- task:
name: Image Classification
type: image-classification
dataset:
name: imagefolder
type: imagefolder
config: default
split: test
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.6602254428341385
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# vit-base-houses-distressed-15-aug
This model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 1.0351
- Accuracy: 0.6602
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 4
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.4968 | 1.14 | 100 | 0.8434 | 0.5620 |
| 0.2653 | 2.27 | 200 | 0.6327 | 0.7536 |
| 0.0487 | 3.41 | 300 | 1.0351 | 0.6602 |
### Framework versions
- Transformers 4.30.2
- Pytorch 2.0.1
- Datasets 2.13.1
- Tokenizers 0.13.3
|
RafaelMayer/beto-copec-whatsapp-13
|
RafaelMayer
| 2023-08-15T16:59:05Z | 62 | 0 |
transformers
|
[
"transformers",
"tf",
"bert",
"text-classification",
"generated_from_keras_callback",
"base_model:dccuchile/bert-base-spanish-wwm-uncased",
"base_model:finetune:dccuchile/bert-base-spanish-wwm-uncased",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-08-15T16:49:06Z |
---
base_model: dccuchile/bert-base-spanish-wwm-uncased
tags:
- generated_from_keras_callback
model-index:
- name: RafaelMayer/beto-copec-whatsapp-13
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# RafaelMayer/beto-copec-whatsapp-13
This model is a fine-tuned version of [dccuchile/bert-base-spanish-wwm-uncased](https://huggingface.co/dccuchile/bert-base-spanish-wwm-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 4.1878
- Validation Loss: 0.7495
- Train Accuracy: 0.4706
- Train Precision: [0.27272727 0.83333333]
- Train Precision W: 0.7014
- Train Recall: [0.75 0.38461538]
- Train Recall W: 0.4706
- Train F1: [0.4 0.52631579]
- Train F1 W: 0.4966
- Epoch: 1
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'Adam', 'weight_decay': None, 'clipnorm': None, 'global_clipnorm': None, 'clipvalue': None, 'use_ema': False, 'ema_momentum': 0.99, 'ema_overwrite_frequency': None, 'jit_compile': True, 'is_legacy_optimizer': False, 'learning_rate': {'class_name': 'WarmUp', 'config': {'initial_learning_rate': 2e-05, 'decay_schedule_fn': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 2e-05, 'decay_steps': 35, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}, '__passive_serialization__': True}, 'warmup_steps': 5, 'power': 1.0, 'name': None}}, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False}
- training_precision: float32
### Training results
| Train Loss | Validation Loss | Train Accuracy | Train Precision | Train Precision W | Train Recall | Train Recall W | Train F1 | Train F1 W | Epoch |
|:----------:|:---------------:|:--------------:|:-----------------------:|:-----------------:|:-----------------------:|:--------------:|:-----------------------:|:----------:|:-----:|
| 4.1878 | 0.7495 | 0.4706 | [0.27272727 0.83333333] | 0.7014 | [0.75 0.38461538] | 0.4706 | [0.4 0.52631579] | 0.4966 | 1 |
### Framework versions
- Transformers 4.31.0
- TensorFlow 2.12.0
- Datasets 2.14.4
- Tokenizers 0.13.3
|
MedAnisMejri/ppo-LunarLander-v2
|
MedAnisMejri
| 2023-08-15T16:56:58Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-08-15T16:56:40Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: -242.17 +/- 77.18
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
wesley7137/Eden-7B-V2-merged
|
wesley7137
| 2023-08-15T16:41:18Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"llama",
"text-generation",
"autotrain",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-08-14T19:56:10Z |
---
tags:
- autotrain
- text-generation
widget:
- text: "I love AutoTrain because "
---
# Model Trained Using AutoTrain
Eden-V1 is a specialized model that serves as a compassionate virtual counselor, deeply rooted in helping others.
Trained with a focus on counseling and support, it possesses a unique skill set that extends beyond text-based assistance. Through its training, it's proficient in understanding and empathizing with individuals facing various challenges, including addiction. Its ability for imagery visualization aids in creating vivid and relatable scenarios that resonate with users, fostering deeper connections and understanding. Whether helping addicts on their recovery journey or guiding individuals in need through their troubles, this model offers a supportive and empathetic presence, leveraging its expertise to provide personalized coping strategies and guidance, making a positive impact on their emotional well-being.
Eden-V1 was trained on a custom specialzed dataset targeted towards counseling and motivational techniques. It is trained using PEFT and model weights of ehartfords "Samantha-1.1-llama-7b"
|
karsar/Puli_GPT3SX_4bit_MED_200k_r64
|
karsar
| 2023-08-15T16:31:13Z | 4 | 0 |
peft
|
[
"peft",
"region:us"
] | null | 2023-08-15T14:33:11Z |
---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: QuantizationMethod.BITS_AND_BYTES
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: True
- bnb_4bit_compute_dtype: float16
The following `bitsandbytes` quantization config was used during training:
- quant_method: QuantizationMethod.BITS_AND_BYTES
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: True
- bnb_4bit_compute_dtype: float16
The following `bitsandbytes` quantization config was used during training:
- quant_method: QuantizationMethod.BITS_AND_BYTES
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: True
- bnb_4bit_compute_dtype: float16
### Framework versions
- PEFT 0.5.0.dev0
- PEFT 0.5.0.dev0
- PEFT 0.5.0.dev0
|
am-infoweb/QA_REFINED_QUESTIONS_AND_DATA_14K_15-08
|
am-infoweb
| 2023-08-15T16:31:06Z | 124 | 0 |
transformers
|
[
"transformers",
"pytorch",
"roberta",
"question-answering",
"generated_from_trainer",
"base_model:deepset/roberta-base-squad2",
"base_model:finetune:deepset/roberta-base-squad2",
"license:cc-by-4.0",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2023-08-15T15:45:55Z |
---
license: cc-by-4.0
base_model: deepset/roberta-base-squad2
tags:
- generated_from_trainer
model-index:
- name: QA_REFINED_QUESTIONS_AND_DATA_14K_14-08
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# QA_REFINED_QUESTIONS_AND_DATA_14K_14-08
This model is a fine-tuned version of [deepset/roberta-base-squad2](https://huggingface.co/deepset/roberta-base-squad2) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.5917
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-----:|:---------------:|
| 1.3897 | 1.0 | 5389 | 1.5180 |
| 1.231 | 2.0 | 10778 | 1.3101 |
| 1.1957 | 3.0 | 16167 | 1.4652 |
| 1.133 | 4.0 | 21556 | 1.3314 |
| 1.1529 | 5.0 | 26945 | 1.4526 |
| 1.1318 | 6.0 | 32334 | 1.3718 |
| 1.0172 | 7.0 | 37723 | 1.4211 |
| 0.9746 | 8.0 | 43112 | 1.7017 |
| 0.9014 | 9.0 | 48501 | 1.4937 |
| 0.8843 | 10.0 | 53890 | 1.5917 |
### Framework versions
- Transformers 4.32.0.dev0
- Pytorch 2.0.1+cu117
- Datasets 2.14.4
- Tokenizers 0.13.3
|
tomaarsen/span-marker-bert-base-cross-ner
|
tomaarsen
| 2023-08-15T16:21:46Z | 24 | 1 |
span-marker
|
[
"span-marker",
"pytorch",
"tensorboard",
"safetensors",
"token-classification",
"ner",
"named-entity-recognition",
"en",
"dataset:P3ps/Cross_ner",
"license:apache-2.0",
"model-index",
"region:us"
] |
token-classification
| 2023-08-14T21:06:22Z |
---
license: apache-2.0
library_name: span-marker
tags:
- span-marker
- token-classification
- ner
- named-entity-recognition
pipeline_tag: token-classification
widget:
- text: "The model is initially fit on a training dataset, The model (e.g. a neural net or a naive Bayes classifier) is trained on the training dataset using a supervised learning method, for example using optimization methods such as gradient descent or stochastic gradient descent."
example_title: "AI"
- text: "It restricted the Barbarians' selectorial options but they still boast 13 internationals including England full-back Tim Stimpson and recalled wing Tony Underwood, plus All Black forwards Ian Jones and Norm Hewitt."
example_title: "CoNLL"
- text: "Two decades after Frank Herbert's death, his son Brian Herbert, along with Kevin J. Anderson, published two sequels - Hunters of Dune (2006) and Sandworms of Dune (2007) - based on notes left behind by Frank Herbert for what he referred to as Dune 7, his own planned seventh novel in the Dune series."
example_title: "Literature"
- text: "Polka is still a popular genre of folk music in many European countries and is performed by folk artists in Poland, Latvia, Lithuania, Czech Republic, Netherlands, Croatia, Slovenia, Germany, Hungary, Austria, Switzerland, Italy, Ukraine, Belarus, Russia and Slovakia."
example_title: "Music 1"
- text: "As a strong advocate of animal rights, Linda lent her support to many organizations such as People for the Ethical Treatment of Animals (PETA), the Campaign to Protect Rural England, and Friends of the Earth."
example_title: "Music 2"
- text: "Some of the most pronounced effects of Hellenization can be seen in Afghanistan and India, in the region of the relatively late-rising Greco-Bactrian Kingdom (250-125 BC) (in modern Afghanistan, Pakistan, and Tajikistan) and the Indo-Greek Kingdom (180 BC - 10 AD) in modern Afghanistan and India and created a culture of Greco-Buddhist art."
example_title: "Politics"
- text: "That first evening session was organized by Jack Yardley from Johns Hopkins University, and included Henry Appelman (University of Michigan), Harvey Goldman (Beth Israel Deaconess Medical Center and Harvard Medical School), Bill Hawk (The Cleveland Clinic), Tom Kent (University of Iowa), Si-Chun Ming (Temple University), Tom Norris (University of Washington), and Robert Riddell (University of Chicago)."
example_title: "Science 1"
- text: "Viral TK phosphorylates aciclovir into its monophosphate form, which is subsequently phosphorylated to active aciclovir triphoshate by cellular kinases, thus selectively inhibiting viral DNA polymerase."
example_title: "Science 2"
model-index:
- name: SpanMarker w. bert-base-cased on CrossNER by Tom Aarsen
results:
- task:
type: token-classification
name: Named Entity Recognition
dataset:
type: P3ps/Cross_ner
name: CrossNER
split: test
revision: 7cecbbb3d2eb8c75c8571c53e5a5270cfd0c5a9e
metrics:
- type: f1
value: 0.8785
name: F1
- type: precision
value: 0.8825
name: Precision
- type: recall
value: 0.8746
name: Recall
datasets:
- P3ps/Cross_ner
language:
- en
metrics:
- f1
- recall
- precision
---
# SpanMarker for Named Entity Recognition
This is a [SpanMarker](https://github.com/tomaarsen/SpanMarkerNER) model that can be used for Named Entity Recognition. In particular, this SpanMarker model uses [bert-base-cased](https://huggingface.co/bert-base-cased) as the underlying encoder. See [train.py](train.py) for the training script.
It is trained on [P3ps/Cross_ner](https://huggingface.co/datasets/P3ps/Cross_ner), which I believe is a variant of [DFKI-SLT/cross_ner](https://huggingface.co/datasets/DFKI-SLT/cross_ner) that merged the validation set into the training set and applied deduplication.
Is your data not (always) capitalized correctly? Then consider using the uncased variant of this model instead for better performance:
[tomaarsen/span-marker-bert-base-uncased-cross-ner](https://huggingface.co/tomaarsen/span-marker-bert-base-uncased-cross-ner).
## Labels & Metrics
| **Label** | **Examples** | **Precision** | **Recall** | **F1** |
|:-------------------|---|---------------:|-----------:|-------:|
| **all** | - | 88.25 | 87.46 | 87.85 |
| academicjournal | "New Journal of Physics", "EPL", "European Physical Journal B" | 84.04 | 96.34 | 89.77 |
| album | "Tellin' Stories", "Generation Terrorists", "Country Airs" | 90.71 | 85.81 | 88.19 |
| algorithm | "LDA", "PCA", "gradient descent" | 76.27 | 79.65 | 77.92 |
| astronomicalobject | "Earth", "Sun", "Halley's comet" | 92.00 | 93.24 | 92.62 |
| award | "Nobel Prize for Literature", "Acamedy Award for Best Actress", "Mandelbrot's awards" | 87.14 | 92.51 | 89.74 |
| band | "Clash", "Parliament Funkadelic", "Sly and the Family Stone" | 83.44 | 86.62 | 85.00 |
| book | "Nietzsche contra Wagner" , "Dionysian-Dithyrambs", "The Rebel" | 73.71 | 82.69 | 77.95 |
| chemicalcompound | "hydrogen sulfide", "Starch", "Lactic acid" | 71.21 | 71.21 | 71.21 |
| chemicalelement | "potassium", "Fluorine", "Chlorine" | 84.00 | 70.00 | 76.36 |
| conference | "SIGGRAPH", "IJCAI", "IEEE Transactions on Speech and Audio Processing" | 80.00 | 68.57 | 73.85 |
| country | "United Arab Emirates", "U.S.", "Canada" | 81.72 | 86.81 | 84.19 |
| discipline | "physics", "meteorology", "geography" | 48.39 | 55.56 | 51.72 |
| election | "2004 Canadian federal election", "2006 Canadian federal election", "1999 Scottish Parliament election" | 96.61 | 97.85 | 97.23 |
| enzyme | "RNA polymerase", "Phosphoinositide 3-kinase", "Protein kinase C" | 77.27 | 91.89 | 83.95 |
| event | "Cannes Film Festival", "2019 Special Olympics World Summer Games", "2017 Western Iraq campaign" | 75.00 | 66.30 | 70.38 |
| field | "computational imaging", "electronics", "information theory" | 89.80 | 83.02 | 86.27 |
| literarygenre | "novel", "satire", "short story" | 70.24 | 68.60 | 69.41 |
| location | "China", "BOMBAY", "Serbia" | 95.21 | 93.72 | 94.46 |
| magazine | "The Atlantic", "The American Spectator", "Astounding Science Fiction" | 81.48 | 78.57 | 80.00 |
| metrics | "BLEU", "precision", "DCG" | 72.53 | 81.48 | 76.74 |
| misc | "Serbian", "Belgian", "The Birth of a Nation" | 81.69 | 74.08 | 77.70 |
| musicalartist | "Chuck Burgi", "John Miceli", "John O'Reilly" | 79.67 | 87.11 | 83.23 |
| musicalinstrument | "koto", "bubens", "def" | 66.67 | 22.22 | 33.33 |
| musicgenre | "Christian rock", "Punk rock", "romantic melodicism" | 86.49 | 90.57 | 88.48 |
| organisation | "IRISH TIMES", "Comintern", "Wimbledon" | 91.37 | 90.85 | 91.11 |
| person | "Gong Zhichao", "Liu Lufung", "Margret Crowley" | 94.15 | 92.31 | 93.22 |
| poem | "Historia destructionis Troiae", "I Am Joaquin", "The Snow Man" | 83.33 | 68.63 | 75.27 |
| politicalparty | "New Democratic Party", "Bloc Québécois", "Liberal Party of Canada" | 87.50 | 90.17 | 88.82 |
| politician | "Susan Kadis", "Simon Strelchik", "Lloyd Helferty" | 86.16 | 88.93 | 87.52 |
| product | "AlphaGo", "WordNet", "Facial recognition system" | 60.82 | 70.24 | 65.19 |
| programlang | "R", "C++", "Java" | 92.00 | 71.88 | 80.70 |
| protein | "DNA methyltransferase", "tau protein", "Amyloid beta" | 60.29 | 59.42 | 59.85 |
| researcher | "Sirovich", "Kirby", "Matthew Turk" | 87.50 | 78.65 | 82.84 |
| scientist | "Matjaž Perc", "Cotton", "Singer" | 82.04 | 88.48 | 85.14 |
| song | "Right Where I'm Supposed to Be", "Easy", "Three Times a Lady" | 84.78 | 90.70 | 87.64 |
| task | "robot control", "elevator scheduling", "telecommunications" | 76.19 | 74.42 | 75.29 |
| theory | "Big Bang", "general theory of relativity", "Ptolemaic planetary theories" | 100.00 | 16.67 | 28.57 |
| university | "University of Göttingen", "Duke", "Imperial Academy of Sciences" | 77.14 | 91.01 | 83.51 |
| writer | "Thomas Mann", "George Bernard Shaw", "Thomas Hardy" | 76.29 | 82.84 | 79.43 |
## Usage
To use this model for inference, first install the `span_marker` library:
```bash
pip install span_marker
```
You can then run inference with this model like so:
```python
from span_marker import SpanMarkerModel
# Download from the 🤗 Hub
model = SpanMarkerModel.from_pretrained("tomaarsen/span-marker-bert-base-cross-ner")
# Run inference
entities = model.predict("Amelia Earhart flew her single engine Lockheed Vega 5B across the Atlantic to Paris.")
```
See the [SpanMarker](https://github.com/tomaarsen/SpanMarkerNER) repository for documentation and additional information on this library.
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Overall Precision | Overall Recall | Overall F1 | Overall Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:-----------------:|:--------------:|:----------:|:----------------:|
| 0.0521 | 0.25 | 200 | 0.0375 | 0.7149 | 0.6033 | 0.6544 | 0.8926 |
| 0.0225 | 0.5 | 400 | 0.0217 | 0.8001 | 0.7878 | 0.7939 | 0.9400 |
| 0.0189 | 0.75 | 600 | 0.0168 | 0.8526 | 0.8288 | 0.8405 | 0.9534 |
| 0.0157 | 1.01 | 800 | 0.0160 | 0.8481 | 0.8366 | 0.8423 | 0.9543 |
| 0.0116 | 1.26 | 1000 | 0.0158 | 0.8570 | 0.8568 | 0.8569 | 0.9582 |
| 0.0119 | 1.51 | 1200 | 0.0145 | 0.8752 | 0.8550 | 0.8650 | 0.9607 |
| 0.0102 | 1.76 | 1400 | 0.0145 | 0.8766 | 0.8555 | 0.8659 | 0.9601 |
| 0.01 | 2.01 | 1600 | 0.0139 | 0.8744 | 0.8718 | 0.8731 | 0.9629 |
| 0.0072 | 2.26 | 1800 | 0.0144 | 0.8748 | 0.8684 | 0.8716 | 0.9625 |
| 0.0066 | 2.51 | 2000 | 0.0140 | 0.8803 | 0.8738 | 0.8770 | 0.9645 |
| 0.007 | 2.76 | 2200 | 0.0138 | 0.8831 | 0.8739 | 0.8785 | 0.9644 |
### Framework versions
- SpanMarker 1.2.4
- Transformers 4.31.0
- Pytorch 2.0.1+cu118
- Datasets 2.14.3
- Tokenizers 0.13.2
|
Kjeue34e/2ewfweds
|
Kjeue34e
| 2023-08-15T16:16:51Z | 0 | 0 | null |
[
"license:bigscience-bloom-rail-1.0",
"region:us"
] | null | 2023-08-15T16:15:28Z |
---
license: bigscience-bloom-rail-1.0
---
|
DunnBC22/albert-base-v2-Malicious_URLs
|
DunnBC22
| 2023-08-15T16:15:55Z | 104 | 2 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"albert",
"text-classification",
"generated_from_trainer",
"URL",
"Security",
"base_model:albert/albert-base-v2",
"base_model:finetune:albert/albert-base-v2",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-08-10T16:02:34Z |
---
license: apache-2.0
base_model: albert-base-v2
tags:
- generated_from_trainer
- URL
- Security
metrics:
- accuracy
- recall
- precision
- f1
model-index:
- name: albert-base-v2-Malicious_URLs
results: []
pipeline_tag: text-classification
---
# albert-base-v2-Malicious_URLs
This model is a fine-tuned version of [albert-base-v2](https://huggingface.co/albert-base-v2).
It achieves the following results on the evaluation set:
- Loss: 0.8368
- Accuracy: 0.7267
- F1:
- Weighted: 0.6482
- Micro: 0.7267
- Macro: 0.4521
- Recall
- Weighted: 0.7267
- Micro: 0.7267
- Macro: 0.4294
- Precision
- Weighted: 0.6262
- Micro: 0.7267
- Macro: 0.5508
## Model description
For more information on how it was created, check out the following link: https://github.com/DunnBC22/NLP_Projects/blob/main/Multiclass%20Classification/Malicious%20URLs%20-%20ALBERT-Base_v2/Malicious%20URLs%20ALBERT-Base%20v2.ipynb
## Intended uses & limitations
This model is intended to demonstrate my ability to solve a complex problem using technology.
## Training and evaluation data
Dataset Source: https://www.kaggle.com/datasets/sid321axn/malicious-urls-dataset
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | Weighted F1 | Micro F1 | Macro F1 | Weighted Recall | Micro Recall | Macro Recall | Weighted Precision | Micro Precision | Macro Precision |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|:-----------:|:--------:|:--------:|:---------------:|:------------:|:------------:|:------------------:|:---------------:|:---------------:|
| 0.7839 | 1.0 | 51087 | 0.8368 | 0.7267 | 0.6482 | 0.7267 | 0.4521 | 0.7267 | 0.7267 | 0.4294 | 0.6262 | 0.7267 | 0.5508 |
### Framework versions
- Transformers 4.31.0
- Pytorch 2.0.1+cu118
- Datasets 2.14.4
- Tokenizers 0.13.3
|
DineshKumarSarangapani/lora-trained-xl-dinesh
|
DineshKumarSarangapani
| 2023-08-15T16:13:57Z | 7 | 1 |
diffusers
|
[
"diffusers",
"tensorboard",
"stable-diffusion-xl",
"stable-diffusion-xl-diffusers",
"text-to-image",
"lora",
"base_model:stabilityai/stable-diffusion-xl-base-1.0",
"base_model:adapter:stabilityai/stable-diffusion-xl-base-1.0",
"license:openrail++",
"region:us"
] |
text-to-image
| 2023-08-15T14:39:17Z |
---
license: openrail++
base_model: stabilityai/stable-diffusion-xl-base-1.0
instance_prompt: a photo of dinesh
tags:
- stable-diffusion-xl
- stable-diffusion-xl-diffusers
- text-to-image
- diffusers
- lora
inference: true
---
# LoRA DreamBooth - DineshKumarSarangapani/lora-trained-xl-dinesh
These are LoRA adaption weights for stabilityai/stable-diffusion-xl-base-1.0. The weights were trained on a photo of dinesh using [DreamBooth](https://dreambooth.github.io/). You can find some example images in the following.
LoRA for the text encoder was enabled: False.
Special VAE used for training: madebyollin/sdxl-vae-fp16-fix.
|
Tombarz/Therapist_AI_anno_mi_100_precent
|
Tombarz
| 2023-08-15T16:10:19Z | 2 | 0 |
peft
|
[
"peft",
"region:us"
] | null | 2023-08-15T12:36:56Z |
---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: True
- bnb_4bit_compute_dtype: bfloat16
### Framework versions
- PEFT 0.5.0.dev0
|
RazzzHF/jessbush
|
RazzzHF
| 2023-08-15T16:09:54Z | 0 | 0 | null |
[
"license:cc-by-nc-nd-4.0",
"region:us"
] | null | 2023-08-15T16:06:13Z |
---
license: cc-by-nc-nd-4.0
---
|
RazzzHF/alyssadiaz
|
RazzzHF
| 2023-08-15T16:09:22Z | 0 | 0 | null |
[
"license:cc-by-nc-nd-4.0",
"region:us"
] | null | 2023-08-15T16:07:01Z |
---
license: cc-by-nc-nd-4.0
---
|
luisrguerra/unreal-dream-cartoonized
|
luisrguerra
| 2023-08-15T16:05:25Z | 0 | 1 | null |
[
"stable-diffusion",
"art",
"artistic",
"en",
"license:other",
"region:us"
] | null | 2023-08-12T16:41:56Z |
---
license: other
language:
- en
tags:
- stable-diffusion
- art
- artistic
---
# Unreal Dream Cartoonized Edition
## Stable Diffusion 1.5 Model for artificial inteligence image generation
<div style="display:flex">
<img src="https://image.civitai.com/xG1nkqKTMzGDvpLrqFT7WA/e7f840cd-7f7e-427a-a60a-7ec8777f623b/width=768/00000-11687133.jpeg" width="300px">
<img src="https://image.civitai.com/xG1nkqKTMzGDvpLrqFT7WA/427778e3-eb23-4cc3-b2b8-90783fb77389/width=768/00001-3935950875.jpeg" width="300px">
</div>
<div style="display:flex">
<img src="https://image.civitai.com/xG1nkqKTMzGDvpLrqFT7WA/e3a902ce-9d2a-47fc-b1bf-8a366821d829/width=768/00006-3938804622.jpeg" width="300px">
<img src="https://image.civitai.com/xG1nkqKTMzGDvpLrqFT7WA/58434807-564a-4d9a-afbf-e5f74af6ff1f/width=768/00005-882468903.jpeg" width="300px">
</div>
Recomendations:
Use the DPM++ SDE Karras sampler with only 20 steps for better quality.
Use the CFG scale between 5 and 9. CFG scale at 7 is recommended.
Resolution between 512 and 768 using "Hires. Fix" or other form of upscaling.
Download Link:
[https://huggingface.co/luisrguerra/unreal-dream-cartoonized/resolve/main/unreal-dream-cartoonized-lite-float16-pruned-emaonly.safetensors](https://huggingface.co/luisrguerra/unreal-dream-cartoonized/resolve/main/unreal-dream-cartoonized-lite-float16-pruned-emaonly.safetensors)
|
kir0ul/lora-trained-xl-colab
|
kir0ul
| 2023-08-15T15:57:24Z | 6 | 1 |
diffusers
|
[
"diffusers",
"tensorboard",
"stable-diffusion-xl",
"stable-diffusion-xl-diffusers",
"text-to-image",
"lora",
"base_model:stabilityai/stable-diffusion-xl-base-1.0",
"base_model:adapter:stabilityai/stable-diffusion-xl-base-1.0",
"license:openrail++",
"region:us"
] |
text-to-image
| 2023-08-15T14:44:32Z |
---
license: openrail++
base_model: stabilityai/stable-diffusion-xl-base-1.0
instance_prompt: a photo of sks dog
tags:
- stable-diffusion-xl
- stable-diffusion-xl-diffusers
- text-to-image
- diffusers
- lora
inference: true
---
# LoRA DreamBooth - kir0ul/lora-trained-xl-colab
These are LoRA adaption weights for stabilityai/stable-diffusion-xl-base-1.0. The weights were trained on a photo of sks dog using [DreamBooth](https://dreambooth.github.io/). You can find some example images in the following.
LoRA for the text encoder was enabled: False.
Special VAE used for training: madebyollin/sdxl-vae-fp16-fix.
|
stillerman/trdne-smol-simple
|
stillerman
| 2023-08-15T15:52:30Z | 0 | 0 |
diffusers
|
[
"diffusers",
"tensorboard",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"lora",
"base_model:runwayml/stable-diffusion-v1-5",
"base_model:adapter:runwayml/stable-diffusion-v1-5",
"license:creativeml-openrail-m",
"region:us"
] |
text-to-image
| 2023-08-15T15:43:48Z |
---
license: creativeml-openrail-m
base_model: runwayml/stable-diffusion-v1-5
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
- lora
inference: true
---
# LoRA text2image fine-tuning - stillerman/trdne-smol-simple
These are LoRA adaption weights for runwayml/stable-diffusion-v1-5. The weights were fine-tuned on the stillerman/rugs-filtered-blip dataset. You can find some example images in the following.




## Training Args
```json
{
"pretrained_model_name_or_path": "runwayml/stable-diffusion-v1-5",
"revision": null,
"dataset_name": "stillerman/rugs-filtered-blip",
"dataset_config_name": null,
"train_data_dir": null,
"image_column": "image",
"caption_column": "caption",
"validation_prompt": "rug from peterpap.com",
"num_validation_images": 4,
"validation_epochs": 100,
"max_train_samples": null,
"output_dir": "model_out_dir",
"cache_dir": null,
"seed": 1337,
"resolution": 512,
"center_crop": true,
"random_flip": true,
"train_batch_size": 1,
"num_train_epochs": 8,
"max_train_steps": 250,
"gradient_accumulation_steps": 4,
"gradient_checkpointing": false,
"learning_rate": 0.0001,
"scale_lr": false,
"lr_scheduler": "cosine",
"lr_warmup_steps": 0,
"snr_gamma": null,
"use_8bit_adam": false,
"allow_tf32": false,
"dataloader_num_workers": 8,
"adam_beta1": 0.9,
"adam_beta2": 0.999,
"adam_weight_decay": 0.01,
"adam_epsilon": 1e-08,
"max_grad_norm": 1.0,
"push_to_hub": true,
"hub_token": null,
"prediction_type": null,
"hub_model_id": "trdne-smol-simple",
"logging_dir": "logs",
"mixed_precision": null,
"report_to": "tensorboard",
"local_rank": -1,
"checkpointing_steps": 250,
"checkpoints_total_limit": null,
"resume_from_checkpoint": null,
"enable_xformers_memory_efficient_attention": false,
"noise_offset": 0,
"rank": 4,
"override_caption": "rug from peterpap.com",
"append_caption": null
}
```
|
tmnam20/test_pretrain_pipeline
|
tmnam20
| 2023-08-15T15:50:22Z | 103 | 0 |
transformers
|
[
"transformers",
"pytorch",
"openai-gpt",
"text-generation",
"generated_from_trainer",
"base_model:openai-community/openai-gpt",
"base_model:finetune:openai-community/openai-gpt",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-08-15T15:31:40Z |
---
license: mit
base_model: openai-gpt
tags:
- generated_from_trainer
model-index:
- name: test_pretrain_pipeline
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# test_pretrain_pipeline
This model is a fine-tuned version of [openai-gpt](https://huggingface.co/openai-gpt) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 3.7312
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 8
- total_train_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.18
- num_epochs: 3.0
### Training results
### Framework versions
- Transformers 4.32.0.dev0
- Pytorch 2.0.1+cu118
- Datasets 2.14.4
- Tokenizers 0.13.3
|
stillerman/trdne-smol
|
stillerman
| 2023-08-15T15:37:14Z | 1 | 0 |
diffusers
|
[
"diffusers",
"tensorboard",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"lora",
"base_model:runwayml/stable-diffusion-v1-5",
"base_model:adapter:runwayml/stable-diffusion-v1-5",
"license:creativeml-openrail-m",
"region:us"
] |
text-to-image
| 2023-08-15T15:23:05Z |
---
license: creativeml-openrail-m
base_model: runwayml/stable-diffusion-v1-5
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
- lora
inference: true
---
# LoRA text2image fine-tuning - stillerman/trdne-smol
These are LoRA adaption weights for runwayml/stable-diffusion-v1-5. The weights were fine-tuned on the stillerman/rugs-filtered-blip dataset. You can find some example images in the following.




## Training Args
```json
{
"pretrained_model_name_or_path": "runwayml/stable-diffusion-v1-5",
"revision": null,
"dataset_name": "stillerman/rugs-filtered-blip",
"dataset_config_name": null,
"train_data_dir": null,
"image_column": "image",
"caption_column": "caption",
"validation_prompt": "peterpap.com, a red and blue rug on a white background, rug, oriental carpets, persian rug, persian carpets, symmetric indian pattern, rugs, detailed patterned rug, persian carpet, light boho carpet, an area rug, persian design, areas rugs, trending on textures. com, carpet, persian rugs, finely detailed features, hippie motifs, bohemian, highly intricate detailed",
"num_validation_images": 4,
"validation_epochs": 1,
"max_train_samples": null,
"output_dir": "model_out_dir",
"cache_dir": null,
"seed": 1337,
"resolution": 512,
"center_crop": true,
"random_flip": true,
"train_batch_size": 1,
"num_train_epochs": 8,
"max_train_steps": 250,
"gradient_accumulation_steps": 4,
"gradient_checkpointing": false,
"learning_rate": 0.0001,
"scale_lr": false,
"lr_scheduler": "cosine",
"lr_warmup_steps": 0,
"snr_gamma": null,
"use_8bit_adam": false,
"allow_tf32": false,
"dataloader_num_workers": 8,
"adam_beta1": 0.9,
"adam_beta2": 0.999,
"adam_weight_decay": 0.01,
"adam_epsilon": 1e-08,
"max_grad_norm": 1.0,
"push_to_hub": true,
"hub_token": null,
"prediction_type": null,
"hub_model_id": "trdne-smol",
"logging_dir": "logs",
"mixed_precision": null,
"report_to": "tensorboard",
"local_rank": -1,
"checkpointing_steps": 250,
"checkpoints_total_limit": null,
"resume_from_checkpoint": null,
"enable_xformers_memory_efficient_attention": false,
"noise_offset": 0,
"rank": 4,
"override_caption": null,
"append_caption": "peterpap.com, "
}
```
|
ivivnov/q-FrozenLake-v1-4x4-Slippery
|
ivivnov
| 2023-08-15T15:27:28Z | 0 | 0 | null |
[
"FrozenLake-v1-4x4",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-08-15T15:27:26Z |
---
tags:
- FrozenLake-v1-4x4
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-Slippery
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4
type: FrozenLake-v1-4x4
metrics:
- type: mean_reward
value: 0.08 +/- 0.27
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="ivivnov/q-FrozenLake-v1-4x4-Slippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
hyos0415/kb_ad
|
hyos0415
| 2023-08-15T15:27:00Z | 7 | 0 |
peft
|
[
"peft",
"region:us"
] | null | 2023-08-15T15:26:11Z |
---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: True
- bnb_4bit_compute_dtype: bfloat16
### Framework versions
- PEFT 0.5.0.dev0
|
nadsoft/nadsoft-revuer-13b-v0.1
|
nadsoft
| 2023-08-15T14:51:20Z | 12 | 1 |
transformers
|
[
"transformers",
"pytorch",
"gpt_bigcode",
"text-generation",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-08-15T13:54:04Z |
# nadsoft-revuer-13b-v0.1
This is an LLM for code review. It is currently only able to evaluate Python codes.
## Features
- Can identify potential bugs and errors in code
- Can suggest improvements to code
- Can generate code reviews
## Limitations
* Currently only able to evaluate Python codes
* May not be able to identify all potential bugs and errors
* May not be able to suggest the best possible improvements to code
## Future Work
* Support for other programming languages
* Improved bug detection and error identification
* Improved code review suggestions
|
Hipsterusername/test
|
Hipsterusername
| 2023-08-15T14:50:48Z | 0 | 0 | null |
[
"license:creativeml-openrail-m",
"region:us"
] | null | 2023-08-15T14:50:48Z |
---
license: creativeml-openrail-m
---
|
nikiandr/gpt_ua
|
nikiandr
| 2023-08-15T14:35:25Z | 0 | 0 | null |
[
"dataset:nikiandr/ubertext2_wiki",
"region:us"
] | null | 2023-08-15T10:17:35Z |
---
datasets:
- nikiandr/ubertext2_wiki
---
Model weights for GPT-like decoder-only Transformer.
Configuration used for `gpt_64_bs128_5000epochs_lr1.0e-03_8heads_emb512.pt`:
```python
BATCH_SIZE = 64
SEED = 42
BLOCK_SIZE = 128
EPOCHS = 5000
TRAIN_SUBSET_LENGTH = None # 10_000_000
TRAIN_PERC = 0.99
EVAL_PERIOD = 500
EVAL_ITERS = 100
EMBED_SIZE = 512
NUM_HEADS = 8
LEARNING_RATE = 1e-3
BLOCK_NUMBER = 8
```
Code repo: [nikiandr/gpt_ua](https://github.com/nikiandr/gpt_ua).
|
Subsets and Splits
Filtered Qwen2.5 Distill Models
Identifies specific configurations of models by filtering cards that contain 'distill', 'qwen2.5', '7b' while excluding certain base models and incorrect model ID patterns, uncovering unique model variants.
Filtered Model Cards Count
Finds the count of entries with specific card details that include 'distill', 'qwen2.5', '7b' but exclude certain base models, revealing valuable insights about the dataset's content distribution.
Filtered Distill Qwen 7B Models
Filters for specific card entries containing 'distill', 'qwen', and '7b', excluding certain strings and patterns, to identify relevant model configurations.
Filtered Qwen-7b Model Cards
The query performs a detailed filtering based on specific keywords and excludes certain entries, which could be useful for identifying a specific subset of cards but does not provide deeper insights or trends.
Filtered Qwen 7B Model Cards
The query filters for specific terms related to "distilled" or "distill", "qwen", and "7b" in the 'card' column but excludes certain base models, providing a limited set of entries for further inspection.
Qwen 7B Distilled Models
The query provides a basic filtering of records to find specific card names that include keywords related to distilled Qwen 7b models, excluding a particular base model, which gives limited insight but helps in focusing on relevant entries.
Qwen 7B Distilled Model Cards
The query filters data based on specific keywords in the modelId and card fields, providing limited insight primarily useful for locating specific entries rather than revealing broad patterns or trends.
Qwen 7B Distilled Models
Finds all entries containing the terms 'distilled', 'qwen', and '7b' in a case-insensitive manner, providing a filtered set of records but without deeper analysis.
Distilled Qwen 7B Models
The query filters for specific model IDs containing 'distilled', 'qwen', and '7b', providing a basic retrieval of relevant entries but without deeper analysis or insight.
Filtered Model Cards with Distill Qwen2.
Filters and retrieves records containing specific keywords in the card description while excluding certain phrases, providing a basic count of relevant entries.
Filtered Model Cards with Distill Qwen 7
The query filters specific variations of card descriptions containing 'distill', 'qwen', and '7b' while excluding a particular base model, providing limited but specific data retrieval.
Distill Qwen 7B Model Cards
The query filters and retrieves rows where the 'card' column contains specific keywords ('distill', 'qwen', and '7b'), providing a basic filter result that can help in identifying specific entries.