
modelId
stringlengths 5
139
| author
stringlengths 2
42
| last_modified
timestamp[us, tz=UTC]date 2020-02-15 11:33:14
2025-09-01 00:47:04
| downloads
int64 0
223M
| likes
int64 0
11.7k
| library_name
stringclasses 530
values | tags
listlengths 1
4.05k
| pipeline_tag
stringclasses 55
values | createdAt
timestamp[us, tz=UTC]date 2022-03-02 23:29:04
2025-09-01 00:46:57
| card
stringlengths 11
1.01M
|
|---|---|---|---|---|---|---|---|---|---|
huggingtweets/_elli420_
|
huggingtweets
| 2021-05-21T17:03:54Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/_elli420_/1618735789420/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div>
<div style="width: 132px; height:132px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1334040646047424512/ygdDFqUB_400x400.jpg')">
</div>
<div style="margin-top: 8px; font-size: 19px; font-weight: 800">Elizabeth 🤖 AI Bot </div>
<div style="font-size: 15px">@_elli420_ bot</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on [@_elli420_'s tweets](https://twitter.com/_elli420_).
| Data | Quantity |
| --- | --- |
| Tweets downloaded | 1415 |
| Retweets | 1242 |
| Short tweets | 9 |
| Tweets kept | 164 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/11z3u9cs/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @_elli420_'s tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/1jccfg71) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/1jccfg71/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/_elli420_')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
huggingtweets/_buddha_quotes
|
huggingtweets
| 2021-05-21T16:55:55Z | 5 | 2 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/_buddha_quotes/1609541828144/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<link rel="stylesheet" href="https://unpkg.com/@tailwindcss/typography@0.2.x/dist/typography.min.css">
<style>
@media (prefers-color-scheme: dark) {
.prose { color: #E2E8F0 !important; }
.prose h2, .prose h3, .prose a, .prose thead { color: #F7FAFC !important; }
}
</style>
<section class='prose'>
<div>
<div style="width: 132px; height:132px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/2409590248/73g1ywcwdlyd8ls4wa4g_400x400.jpeg')">
</div>
<div style="margin-top: 8px; font-size: 19px; font-weight: 800">The Buddha 🤖 AI Bot </div>
<div style="font-size: 15px; color: #657786">@_buddha_quotes bot</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://app.wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-model-to-generate-tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on [@_buddha_quotes's tweets](https://twitter.com/_buddha_quotes).
<table style='border-width:0'>
<thead style='border-width:0'>
<tr style='border-width:0 0 1px 0; border-color: #CBD5E0'>
<th style='border-width:0'>Data</th>
<th style='border-width:0'>Quantity</th>
</tr>
</thead>
<tbody style='border-width:0'>
<tr style='border-width:0 0 1px 0; border-color: #E2E8F0'>
<td style='border-width:0'>Tweets downloaded</td>
<td style='border-width:0'>3200</td>
</tr>
<tr style='border-width:0 0 1px 0; border-color: #E2E8F0'>
<td style='border-width:0'>Retweets</td>
<td style='border-width:0'>0</td>
</tr>
<tr style='border-width:0 0 1px 0; border-color: #E2E8F0'>
<td style='border-width:0'>Short tweets</td>
<td style='border-width:0'>0</td>
</tr>
<tr style='border-width:0'>
<td style='border-width:0'>Tweets kept</td>
<td style='border-width:0'>3200</td>
</tr>
</tbody>
</table>
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/3m2s8fe6/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @_buddha_quotes's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/j1ixyq8z) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/j1ixyq8z/artifacts) is logged and versioned.
## Intended uses & limitations
### How to use
You can use this model directly with a pipeline for text generation:
<pre><code><span style="color:#03A9F4">from</span> transformers <span style="color:#03A9F4">import</span> pipeline
generator = pipeline(<span style="color:#FF9800">'text-generation'</span>,
model=<span style="color:#FF9800">'huggingtweets/_buddha_quotes'</span>)
generator(<span style="color:#FF9800">"My dream is"</span>, num_return_sequences=<span style="color:#8BC34A">5</span>)</code></pre>
### Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
</section>
[](https://twitter.com/intent/follow?screen_name=borisdayma)
<section class='prose'>
For more details, visit the project repository.
</section>
[](https://github.com/borisdayma/huggingtweets)
|
huggingtweets/_alexhirsch
|
huggingtweets
| 2021-05-21T16:53:35Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/_alexhirsch/1616542840091/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div>
<div style="width: 132px; height:132px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/661330385465245696/3rnsJokZ_400x400.jpg')">
</div>
<div style="margin-top: 8px; font-size: 19px; font-weight: 800">Alex Hirsch 🤖 AI Bot </div>
<div style="font-size: 15px">@_alexhirsch bot</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://app.wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-model-to-generate-tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on [@_alexhirsch's tweets](https://twitter.com/_alexhirsch).
| Data | Quantity |
| --- | --- |
| Tweets downloaded | 3187 |
| Retweets | 240 |
| Short tweets | 450 |
| Tweets kept | 2497 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/1go2kut1/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @_alexhirsch's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/1pe6iqi8) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/1pe6iqi8/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/_alexhirsch')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
huggingtweets/__solnychko
|
huggingtweets
| 2021-05-21T16:49:49Z | 7 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/__solnychko/1616680322908/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div>
<div style="width: 132px; height:132px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1360367235408224263/AwK6rgAZ_400x400.jpg')">
</div>
<div style="margin-top: 8px; font-size: 19px; font-weight: 800">Sophia 🤖 AI Bot </div>
<div style="font-size: 15px">@__solnychko bot</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on [@__solnychko's tweets](https://twitter.com/__solnychko).
| Data | Quantity |
| --- | --- |
| Tweets downloaded | 3206 |
| Retweets | 1278 |
| Short tweets | 208 |
| Tweets kept | 1720 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/3aglnv5r/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @__solnychko's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/z5yw4btx) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/z5yw4btx/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/__solnychko')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
huggingtweets/__justplaying
|
huggingtweets
| 2021-05-21T16:48:43Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/__justplaying/1616931832539/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div>
<div style="width: 132px; height:132px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1347480058508828673/AkXmT_bj_400x400.jpg')">
</div>
<div style="margin-top: 8px; font-size: 19px; font-weight: 800">alice, dash of wonderland 🎀 🤖 AI Bot </div>
<div style="font-size: 15px">@__justplaying bot</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on [@__justplaying's tweets](https://twitter.com/__justplaying).
| Data | Quantity |
| --- | --- |
| Tweets downloaded | 3210 |
| Retweets | 706 |
| Short tweets | 518 |
| Tweets kept | 1986 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/1og52vt9/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @__justplaying's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/3ir21lg6) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/3ir21lg6/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/__justplaying')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
huggingtweets/__frye
|
huggingtweets
| 2021-05-21T16:47:14Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/__frye/1616623887035/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div>
<div style="width: 132px; height:132px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1374740260513579009/5ygC5Ztd_400x400.jpg')">
</div>
<div style="margin-top: 8px; font-size: 19px; font-weight: 800">Frye of Providence 🤖 AI Bot </div>
<div style="font-size: 15px">@__frye bot</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://app.wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-model-to-generate-tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on [@__frye's tweets](https://twitter.com/__frye).
| Data | Quantity |
| --- | --- |
| Tweets downloaded | 910 |
| Retweets | 73 |
| Short tweets | 117 |
| Tweets kept | 720 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/2by67tfe/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @__frye's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/1sm9nscd) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/1sm9nscd/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/__frye')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
huggingtweets/666ouz666
|
huggingtweets
| 2021-05-21T16:43:13Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/666ouz666/1606428014311/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<link rel="stylesheet" href="https://unpkg.com/@tailwindcss/typography@0.2.x/dist/typography.min.css">
<style>
@media (prefers-color-scheme: dark) {
.prose { color: #E2E8F0 !important; }
.prose h2, .prose h3, .prose a, .prose thead { color: #F7FAFC !important; }
}
</style>
<section class='prose'>
<div>
<div style="width: 132px; height:132px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1328826930049789953/EWpTLaQR_400x400.jpg')">
</div>
<div style="margin-top: 8px; font-size: 19px; font-weight: 800">Oğuzhan 🤖 AI Bot </div>
<div style="font-size: 15px; color: #657786">@666ouz666 bot</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://app.wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-model-to-generate-tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on [@666ouz666's tweets](https://twitter.com/666ouz666).
<table style='border-width:0'>
<thead style='border-width:0'>
<tr style='border-width:0 0 1px 0; border-color: #CBD5E0'>
<th style='border-width:0'>Data</th>
<th style='border-width:0'>Quantity</th>
</tr>
</thead>
<tbody style='border-width:0'>
<tr style='border-width:0 0 1px 0; border-color: #E2E8F0'>
<td style='border-width:0'>Tweets downloaded</td>
<td style='border-width:0'>2816</td>
</tr>
<tr style='border-width:0 0 1px 0; border-color: #E2E8F0'>
<td style='border-width:0'>Retweets</td>
<td style='border-width:0'>63</td>
</tr>
<tr style='border-width:0 0 1px 0; border-color: #E2E8F0'>
<td style='border-width:0'>Short tweets</td>
<td style='border-width:0'>389</td>
</tr>
<tr style='border-width:0'>
<td style='border-width:0'>Tweets kept</td>
<td style='border-width:0'>2364</td>
</tr>
</tbody>
</table>
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/3e6nphcq/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @666ouz666's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/5hsj1s8v) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/5hsj1s8v/artifacts) is logged and versioned.
## Intended uses & limitations
### How to use
You can use this model directly with a pipeline for text generation:
<pre><code><span style="color:#03A9F4">from</span> transformers <span style="color:#03A9F4">import</span> pipeline
generator = pipeline(<span style="color:#FF9800">'text-generation'</span>,
model=<span style="color:#FF9800">'huggingtweets/666ouz666'</span>)
generator(<span style="color:#FF9800">"My dream is"</span>, num_return_sequences=<span style="color:#8BC34A">5</span>)</code></pre>
### Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
</section>
[](https://twitter.com/intent/follow?screen_name=borisdayma)
<section class='prose'>
For more details, visit the project repository.
</section>
[](https://github.com/borisdayma/huggingtweets)
<!--- random size file -->
|
huggingtweets/423zb
|
huggingtweets
| 2021-05-21T16:38:25Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/423zb/1612221398403/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<link rel="stylesheet" href="https://unpkg.com/@tailwindcss/typography@0.2.x/dist/typography.min.css">
<style>
@media (prefers-color-scheme: dark) {
.prose { color: #E2E8F0 !important; }
.prose h2, .prose h3, .prose a, .prose thead { color: #F7FAFC !important; }
}
</style>
<section class='prose'>
<div>
<div style="width: 132px; height:132px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1277051021064392706/wuQS0nyO_400x400.jpg')">
</div>
<div style="margin-top: 8px; font-size: 19px; font-weight: 800">423ZB 🤖 AI Bot </div>
<div style="font-size: 15px; color: #657786">@423zb bot</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://app.wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-model-to-generate-tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on [@423zb's tweets](https://twitter.com/423zb).
<table style='border-width:0'>
<thead style='border-width:0'>
<tr style='border-width:0 0 1px 0; border-color: #CBD5E0'>
<th style='border-width:0'>Data</th>
<th style='border-width:0'>Quantity</th>
</tr>
</thead>
<tbody style='border-width:0'>
<tr style='border-width:0 0 1px 0; border-color: #E2E8F0'>
<td style='border-width:0'>Tweets downloaded</td>
<td style='border-width:0'>3166</td>
</tr>
<tr style='border-width:0 0 1px 0; border-color: #E2E8F0'>
<td style='border-width:0'>Retweets</td>
<td style='border-width:0'>2425</td>
</tr>
<tr style='border-width:0 0 1px 0; border-color: #E2E8F0'>
<td style='border-width:0'>Short tweets</td>
<td style='border-width:0'>144</td>
</tr>
<tr style='border-width:0'>
<td style='border-width:0'>Tweets kept</td>
<td style='border-width:0'>597</td>
</tr>
</tbody>
</table>
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/jnwkepoo/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @423zb's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/29x1ggo7) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/29x1ggo7/artifacts) is logged and versioned.
## Intended uses & limitations
### How to use
You can use this model directly with a pipeline for text generation:
<pre><code><span style="color:#03A9F4">from</span> transformers <span style="color:#03A9F4">import</span> pipeline
generator = pipeline(<span style="color:#FF9800">'text-generation'</span>,
model=<span style="color:#FF9800">'huggingtweets/423zb'</span>)
generator(<span style="color:#FF9800">"My dream is"</span>, num_return_sequences=<span style="color:#8BC34A">5</span>)</code></pre>
### Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
</section>
[](https://twitter.com/intent/follow?screen_name=borisdayma)
<section class='prose'>
For more details, visit the project repository.
</section>
[](https://github.com/borisdayma/huggingtweets)
|
huggingtweets/3thanguy7
|
huggingtweets
| 2021-05-21T16:35:20Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/3thanguy7/1614103760144/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div>
<div style="width: 132px; height:132px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1296604630537961476/BGjTffM9_400x400.jpg')">
</div>
<div style="margin-top: 8px; font-size: 19px; font-weight: 800">🔥3thanguy7 is from chicago 🤖 AI Bot </div>
<div style="font-size: 15px">@3thanguy7 bot</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://app.wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-model-to-generate-tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on [@3thanguy7's tweets](https://twitter.com/3thanguy7).
| Data | Quantity |
| --- | --- |
| Tweets downloaded | 3147 |
| Retweets | 1790 |
| Short tweets | 296 |
| Tweets kept | 1061 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/3n62f684/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @3thanguy7's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/328uo5bx) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/328uo5bx/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/3thanguy7')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
huggingtweets/178kakapo
|
huggingtweets
| 2021-05-21T16:29:51Z | 6 | 1 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/178kakapo/1603720462678/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<link rel="stylesheet" href="https://unpkg.com/@tailwindcss/typography@0.2.x/dist/typography.min.css">
<style>
@media (prefers-color-scheme: dark) {
.prose { color: #E2E8F0 !important; }
.prose h2, .prose h3, .prose a, .prose thead { color: #F7FAFC !important; }
}
</style>
<section class='prose'>
<div>
<div style="width: 132px; height:132px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/2476808798/p6cqc9mvgsdlhya7nb6p_400x400.jpeg')">
</div>
<div style="margin-top: 8px; font-size: 19px; font-weight: 800">KAKAPO➤Endangered 🤖 AI Bot </div>
<div style="font-size: 15px; color: #657786">@178kakapo bot</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://app.wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-model-to-generate-tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on [@178kakapo's tweets](https://twitter.com/178kakapo).
<table style='border-width:0'>
<thead style='border-width:0'>
<tr style='border-width:0 0 1px 0; border-color: #CBD5E0'>
<th style='border-width:0'>Data</th>
<th style='border-width:0'>Quantity</th>
</tr>
</thead>
<tbody style='border-width:0'>
<tr style='border-width:0 0 1px 0; border-color: #E2E8F0'>
<td style='border-width:0'>Tweets downloaded</td>
<td style='border-width:0'>3140</td>
</tr>
<tr style='border-width:0 0 1px 0; border-color: #E2E8F0'>
<td style='border-width:0'>Retweets</td>
<td style='border-width:0'>2196</td>
</tr>
<tr style='border-width:0 0 1px 0; border-color: #E2E8F0'>
<td style='border-width:0'>Short tweets</td>
<td style='border-width:0'>56</td>
</tr>
<tr style='border-width:0'>
<td style='border-width:0'>Tweets kept</td>
<td style='border-width:0'>888</td>
</tr>
</tbody>
</table>
[Explore the data](https://app.wandb.ai/wandb/huggingtweets/runs/1r7z36ek/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @178kakapo's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://app.wandb.ai/wandb/huggingtweets/runs/2tp7xvh0) for full transparency and reproducibility.
At the end of training, [the final model](https://app.wandb.ai/wandb/huggingtweets/runs/2tp7xvh0/artifacts) is logged and versioned.
## Intended uses & limitations
### How to use
You can use this model directly with a pipeline for text generation:
<pre><code><span style="color:#03A9F4">from</span> transformers <span style="color:#03A9F4">import</span> pipeline
generator = pipeline(<span style="color:#FF9800">'text-generation'</span>,
model=<span style="color:#FF9800">'huggingtweets/178kakapo'</span>)
generator(<span style="color:#FF9800">"My dream is"</span>, num_return_sequences=<span style="color:#8BC34A">5</span>)</code></pre>
### Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
</section>
[](https://twitter.com/intent/follow?screen_name=borisdayma)
<section class='prose'>
For more details, visit the project repository.
</section>
[](https://github.com/borisdayma/huggingtweets)
<!--- random size file -->
|
huggingtweets/14werewolfvevo
|
huggingtweets
| 2021-05-21T16:28:48Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/14werewolfvevo/1617769919321/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div>
<div style="width: 132px; height:132px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1343113335882063873/mITxI5OI_400x400.jpg')">
</div>
<div style="margin-top: 8px; font-size: 19px; font-weight: 800">SIKA MODE | BLM 🤖 AI Bot </div>
<div style="font-size: 15px">@14werewolfvevo bot</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on [@14werewolfvevo's tweets](https://twitter.com/14werewolfvevo).
| Data | Quantity |
| --- | --- |
| Tweets downloaded | 3229 |
| Retweets | 170 |
| Short tweets | 798 |
| Tweets kept | 2261 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/1ymsdw3a/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @14werewolfvevo's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/1iypm80s) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/1iypm80s/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/14werewolfvevo')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
huggingtweets/14jun1995
|
huggingtweets
| 2021-05-21T16:23:35Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/14jun1995/1616669363048/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div>
<div style="width: 132px; height:132px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1236431647576330246/GGaeVBZJ_400x400.jpg')">
</div>
<div style="margin-top: 8px; font-size: 19px; font-weight: 800">mon nom non-mo 🤖 AI Bot </div>
<div style="font-size: 15px">@14jun1995 bot</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on [@14jun1995's tweets](https://twitter.com/14jun1995).
| Data | Quantity |
| --- | --- |
| Tweets downloaded | 3249 |
| Retweets | 20 |
| Short tweets | 213 |
| Tweets kept | 3016 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/1ppb6sp7/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @14jun1995's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/25pt100s) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/25pt100s/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/14jun1995')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
huggingtweets/12123i123i12345
|
huggingtweets
| 2021-05-21T16:22:22Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/12123i123i12345/1617760753400/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div>
<div style="width: 132px; height:132px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1377780722883174400/4gq8ntlP_400x400.jpg')">
</div>
<div style="margin-top: 8px; font-size: 19px; font-weight: 800">parallellax 🤖 AI Bot </div>
<div style="font-size: 15px">@12123i123i12345 bot</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on [@12123i123i12345's tweets](https://twitter.com/12123i123i12345).
| Data | Quantity |
| --- | --- |
| Tweets downloaded | 2362 |
| Retweets | 310 |
| Short tweets | 283 |
| Tweets kept | 1769 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/e91cv8fo/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @12123i123i12345's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/ncn8t24f) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/ncn8t24f/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/12123i123i12345')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
gaochangkuan/model_dir
|
gaochangkuan
| 2021-05-21T16:10:50Z | 10 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
## Generating Chinese poetry by topic.
```python
from transformers import *
tokenizer = BertTokenizer.from_pretrained("gaochangkuan/model_dir")
model = AutoModelWithLMHead.from_pretrained("gaochangkuan/model_dir")
prompt= '''<s>田园躬耕'''
length= 84
stop_token='</s>'
temperature = 1.2
repetition_penalty=1.3
k= 30
p= 0.95
device ='cuda'
seed=2020
no_cuda=False
prompt_text = prompt if prompt else input("Model prompt >>> ")
encoded_prompt = tokenizer.encode(
'<s>'+prompt_text+'<sep>',
add_special_tokens=False,
return_tensors="pt"
)
encoded_prompt = encoded_prompt.to(device)
output_sequences = model.generate(
input_ids=encoded_prompt,
max_length=length,
min_length=10,
do_sample=True,
early_stopping=True,
num_beams=10,
temperature=temperature,
top_k=k,
top_p=p,
repetition_penalty=repetition_penalty,
bad_words_ids=None,
bos_token_id=tokenizer.bos_token_id,
pad_token_id=tokenizer.pad_token_id,
eos_token_id=tokenizer.eos_token_id,
length_penalty=1.2,
no_repeat_ngram_size=2,
num_return_sequences=1,
attention_mask=None,
decoder_start_token_id=tokenizer.bos_token_id,)
generated_sequence = output_sequences[0].tolist()
text = tokenizer.decode(generated_sequence)
text = text[: text.find(stop_token) if stop_token else None]
print(''.join(text).replace(' ','').replace('<pad>','').replace('<s>',''))
```
|
gagan3012/rap-writer
|
gagan3012
| 2021-05-21T16:09:53Z | 8 | 2 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
# Generating Rap song Lyrics like Eminem Using GPT2
### I have built a custom model for it using data from Kaggle
Creating a new finetuned model using data lyrics from leading hip-hop stars
### My model can be accessed at: gagan3012/rap-writer
```
from transformers import AutoTokenizer, AutoModelWithLMHead
tokenizer = AutoTokenizer.from_pretrained("gagan3012/rap-writer")
model = AutoModelWithLMHead.from_pretrained("gagan3012/rap-writer")
```
|
gagan3012/project-code-py-small
|
gagan3012
| 2021-05-21T16:06:24Z | 11 | 1 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
# Leetcode using AI :robot:
GPT-2 Model for Leetcode Questions in python
**Note**: the Answers might not make sense in some cases because of the bias in GPT-2
**Contribtuions:** If you would like to make the model better contributions are welcome Check out [CONTRIBUTIONS.md](https://github.com/gagan3012/project-code-py/blob/master/CONTRIBUTIONS.md)
### 📢 Favour:
It would be highly motivating, if you can STAR⭐ this repo if you find it helpful.
## Model
Two models have been developed for different use cases and they can be found at https://huggingface.co/gagan3012
The model weights can be found here: [GPT-2](https://huggingface.co/gagan3012/project-code-py) and [DistilGPT-2](https://huggingface.co/gagan3012/project-code-py-small)
### Example usage:
```python
from transformers import AutoTokenizer, AutoModelWithLMHead
tokenizer = AutoTokenizer.from_pretrained("gagan3012/project-code-py")
model = AutoModelWithLMHead.from_pretrained("gagan3012/project-code-py")
```
## Demo
[](https://share.streamlit.io/gagan3012/project-code-py/app.py)
A streamlit webapp has been setup to use the model: https://share.streamlit.io/gagan3012/project-code-py/app.py
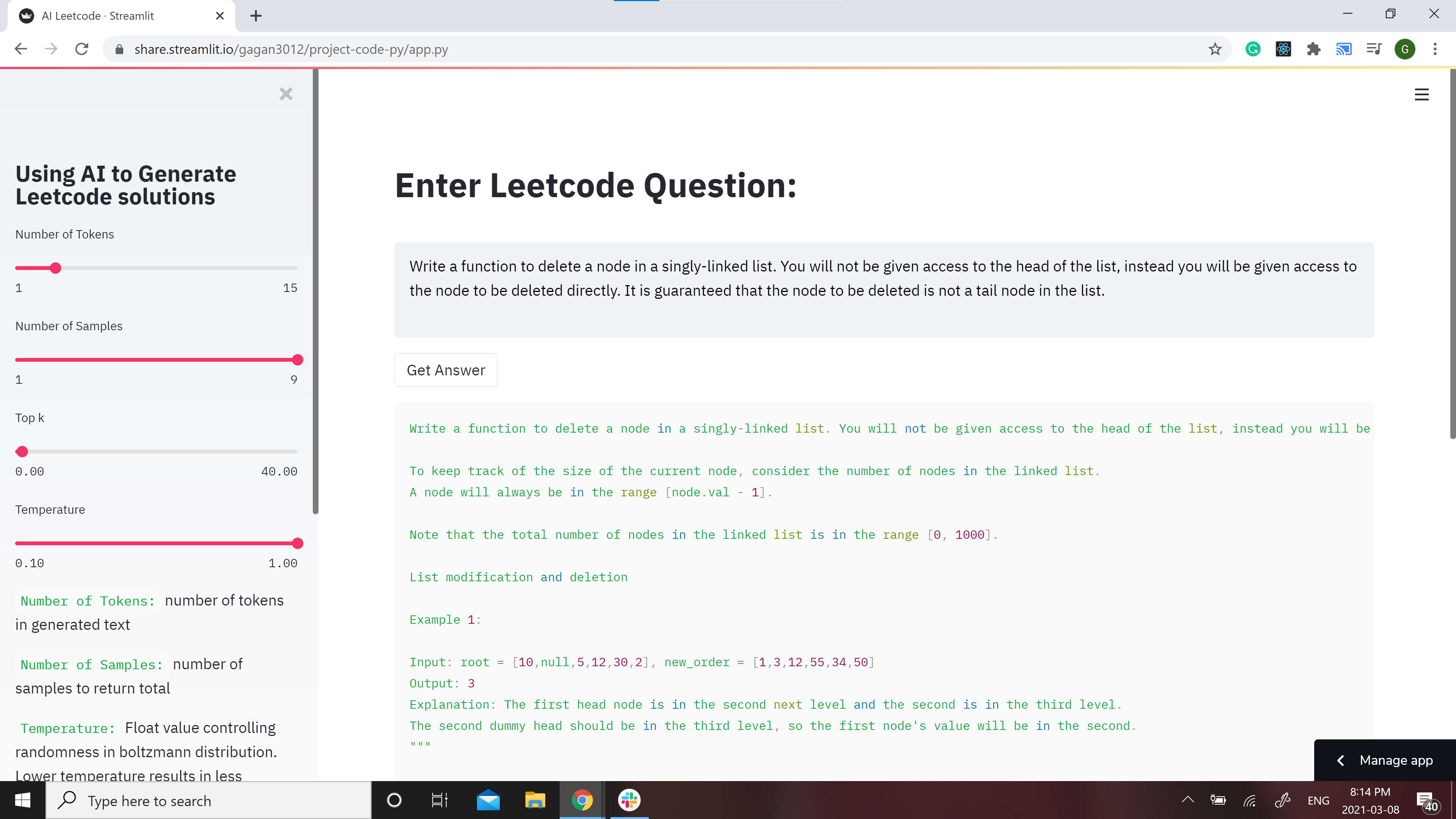
## Example results:
### Question:
```
Write a function to delete a node in a singly-linked list. You will not be given access to the head of the list, instead you will be given access to the node to be deleted directly. It is guaranteed that the node to be deleted is not a tail node in the list.
```
### Answer:
```python
""" Write a function to delete a node in a singly-linked list. You will not be given access to the head of the list, instead you will be given access to the node to be deleted directly. It is guaranteed that the node to be deleted is not a tail node in the list.
For example,
a = 1->2->3
b = 3->1->2
t = ListNode(-1, 1)
Note: The lexicographic ordering of the nodes in a tree matters. Do not assign values to nodes in a tree.
Example 1:
Input: [1,2,3]
Output: 1->2->5
Explanation: 1->2->3->3->4, then 1->2->5[2] and then 5->1->3->4.
Note:
The length of a linked list will be in the range [1, 1000].
Node.val must be a valid LinkedListNode type.
Both the length and the value of the nodes in a linked list will be in the range [-1000, 1000].
All nodes are distinct.
"""
# Definition for singly-linked list.
# class ListNode:
# def __init__(self, x):
# self.val = x
# self.next = None
class Solution:
def deleteNode(self, head: ListNode, val: int) -> None:
"""
BFS
Linked List
:param head: ListNode
:param val: int
:return: ListNode
"""
if head is not None:
return head
dummy = ListNode(-1, 1)
dummy.next = head
dummy.next.val = val
dummy.next.next = head
dummy.val = ""
s1 = Solution()
print(s1.deleteNode(head))
print(s1.deleteNode(-1))
print(s1.deleteNode(-1))
```
|
gagan3012/Fox-News-Generator
|
gagan3012
| 2021-05-21T16:03:28Z | 7 | 3 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
# Generating Right Wing News Using GPT2
### I have built a custom model for it using data from Kaggle
Creating a new finetuned model using data from FOX news
### My model can be accessed at gagan3012/Fox-News-Generator
Check the [BenchmarkTest](https://github.com/gagan3012/Fox-News-Generator/blob/master/BenchmarkTest.ipynb) notebook for results
Find the model at [gagan3012/Fox-News-Generator](https://huggingface.co/gagan3012/Fox-News-Generator)
```
from transformers import AutoTokenizer, AutoModelWithLMHead
tokenizer = AutoTokenizer.from_pretrained("gagan3012/Fox-News-Generator")
model = AutoModelWithLMHead.from_pretrained("gagan3012/Fox-News-Generator")
```
|
erikinfo/gpt2TEDlectures
|
erikinfo
| 2021-05-21T16:00:10Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
# GPT2 Keyword Based Lecture Generator
## Model description
GPT2 fine-tuned on the TED Talks Dataset (published under the Creative Commons BY-NC-ND license).
## Intended uses
Used to generate spoken-word lectures.
### How to use
Input text:
<BOS> title <|SEP|> Some keywords <|SEP|>
Keyword Format: "Main Topic"."Subtopic1","Subtopic2","Subtopic3"
Code Example:
```
prompt = <BOS> + title + \\
<|SEP|> + keywords + <|SEP|>
generated = torch.tensor(tokenizer.encode(prompt)).unsqueeze(0)
model.eval();
```
|
DebateLabKIT/cript
|
DebateLabKIT
| 2021-05-21T15:40:52Z | 8 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"en",
"arxiv:2009.07185",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
tags:
- gpt2
---
# CRiPT Model (Critical Thinking Intermediarily Pretrained Transformer)
Small version of the trained model (`SYL01-2020-10-24-72K/gpt2-small-train03-72K`) presented in the paper "Critical Thinking for Language Models" (Betz, Voigt and Richardson 2020). See also:
* [blog entry](https://debatelab.github.io/journal/critical-thinking-language-models.html)
* [GitHub repo](https://github.com/debatelab/aacorpus)
* [paper](https://arxiv.org/pdf/2009.07185)
|
ceostroff/harry-potter-gpt2-fanfiction
|
ceostroff
| 2021-05-21T14:51:47Z | 10 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"jax",
"gpt2",
"text-generation",
"harry-potter",
"en",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language:
- en
tags:
- harry-potter
license: mit
---
# Harry Potter Fanfiction Generator
This is a pre-trained GPT-2 generative text model that allows you to generate your own Harry Potter fanfiction, trained off of the top 100 rated fanficition stories. We intend for this to be used for individual fun and experimentation and not as a commercial product.
|
bolbolzaban/gpt2-persian
|
bolbolzaban
| 2021-05-21T14:23:14Z | 883 | 27 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"jax",
"gpt2",
"text-generation",
"farsi",
"persian",
"fa",
"doi:10.57967/hf/1207",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: fa
license: apache-2.0
tags:
- farsi
- persian
---
# GPT2-Persian
bolbolzaban/gpt2-persian is gpt2 language model that is trained with hyper parameters similar to standard gpt2-medium with following differences:
1. The context size is reduced from 1024 to 256 sub words in order to make the training affordable
2. Instead of BPE, google sentence piece tokenizor is used for tokenization.
3. The training dataset only include Persian text. All non-persian characters are replaced with especial tokens (e.g [LAT], [URL], [NUM])
Please refer to this [blog post](https://medium.com/@khashei/a-not-so-dangerous-ai-in-the-persian-language-39172a641c84) for further detail.
Also try the model [here](https://huggingface.co/bolbolzaban/gpt2-persian?text=%D8%AF%D8%B1+%DB%8C%DA%A9+%D8%A7%D8%AA%D9%81%D8%A7%D9%82+%D8%B4%DA%AF%D9%81%D8%AA+%D8%A7%D9%86%DA%AF%DB%8C%D8%B2%D8%8C+%D9%BE%DA%98%D9%88%D9%87%D8%B4%DA%AF%D8%B1%D8%A7%D9%86) or on [Bolbolzaban.com](http://www.bolbolzaban.com/text).
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline, AutoTokenizer, GPT2LMHeadModel
tokenizer = AutoTokenizer.from_pretrained('bolbolzaban/gpt2-persian')
model = GPT2LMHeadModel.from_pretrained('bolbolzaban/gpt2-persian')
generator = pipeline('text-generation', model, tokenizer=tokenizer, config={'max_length':256})
sample = generator('در یک اتفاق شگفت انگیز، پژوهشگران')
```
If you are using Tensorflow import TFGPT2LMHeadModel instead of GPT2LMHeadModel.
## Fine-tuning
Find a basic fine-tuning example on this [Github Repo](https://github.com/khashei/bolbolzaban-gpt2-persian).
## Special Tokens
gpt-persian is trained for the purpose of research on Persian poetry. Because of that all english words and numbers are replaced with special tokens and only standard Persian alphabet is used as part of input text. Here is one example:
Original text: اگر آیفون یا آیپد شما دارای سیستم عامل iOS 14.3 یا iPadOS 14.3 یا نسخههای جدیدتر باشد
Text used in training: اگر آیفون یا آیپد شما دارای سیستم عامل [LAT] [NUM] یا [LAT] [NUM] یا نسخههای جدیدتر باشد
Please consider normalizing your input text using [Hazm](https://github.com/sobhe/hazm) or similar libraries and ensure only Persian characters are provided as input.
If you want to use classical Persian poetry as input use [BOM] (begining of mesra) at the beginning of each verse (مصرع) followed by [EOS] (end of statement) at the end of each couplet (بیت).
See following links for example:
[[BOM] توانا بود](https://huggingface.co/bolbolzaban/gpt2-persian?text=%5BBOM%5D+%D8%AA%D9%88%D8%A7%D9%86%D8%A7+%D8%A8%D9%88%D8%AF)
[[BOM] توانا بود هر که دانا بود [BOM]](https://huggingface.co/bolbolzaban/gpt2-persian?text=%5BBOM%5D+%D8%AA%D9%88%D8%A7%D9%86%D8%A7+%D8%A8%D9%88%D8%AF+%D9%87%D8%B1+%DA%A9%D9%87+%D8%AF%D8%A7%D9%86%D8%A7+%D8%A8%D9%88%D8%AF+%5BBOM%5D)
[[BOM] توانا بود هر که دانا بود [BOM] ز دانش دل پیر](https://huggingface.co/bolbolzaban/gpt2-persian?text=%5BBOM%5D+%D8%AA%D9%88%D8%A7%D9%86%D8%A7+%D8%A8%D9%88%D8%AF+%D9%87%D8%B1+%DA%A9%D9%87+%D8%AF%D8%A7%D9%86%D8%A7+%D8%A8%D9%88%D8%AF+%5BBOM%5D+%D8%B2+%D8%AF%D8%A7%D9%86%D8%B4+%D8%AF%D9%84+%D9%BE%DB%8C%D8%B1)
[[BOM] توانا بود هر که دانا بود [BOM] ز دانش دل پیربرنا بود [EOS]](https://huggingface.co/bolbolzaban/gpt2-persian?text=%5BBOM%5D+%D8%AA%D9%88%D8%A7%D9%86%D8%A7+%D8%A8%D9%88%D8%AF+%D9%87%D8%B1+%DA%A9%D9%87+%D8%AF%D8%A7%D9%86%D8%A7+%D8%A8%D9%88%D8%AF+%5BBOM%5D+%D8%B2+%D8%AF%D8%A7%D9%86%D8%B4+%D8%AF%D9%84+%D9%BE%DB%8C%D8%B1%D8%A8%D8%B1%D9%86%D8%A7+%D8%A8%D9%88%D8%AF++%5BEOS%5D)
If you like to know about structure of classical Persian poetry refer to these [blog posts](https://medium.com/@khashei).
## Acknowledgment
This project is supported by Cloud TPUs from Google’s TensorFlow Research Cloud (TFRC).
## Citation and Reference
Please reference "bolbolzaban.com" website if you are using gpt2-persian in your research or commertial application.
## Contacts
Please reachout on [Linkedin](https://www.linkedin.com/in/khashei/) or [Telegram](https://t.me/khasheia) if you have any question or need any help to use the model.
Follow [Bolbolzaban](http://bolbolzaban.com/about) on [Twitter](https://twitter.com/bolbol_zaban), [Telegram](https://t.me/bolbol_zaban) or [Instagram](https://www.instagram.com/bolbolzaban/)
|
bigjoedata/rockbot355M
|
bigjoedata
| 2021-05-21T14:17:25Z | 6 | 1 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
# 🎸 🥁 Rockbot 🎤 🎧
A [GPT-2](https://openai.com/blog/better-language-models/) based lyrics generator fine-tuned on the writing styles of 16000 songs by 270 artists across MANY genres (not just rock).
**Instructions:** Type in a fake song title, pick an artist, click "Generate".
Most language models are imprecise and Rockbot is no exception. You may see NSFW lyrics unexpectedly. I have made no attempts to censor. Generated lyrics may be repetitive and/or incoherent at times, but hopefully you'll encounter something interesting or memorable.
Oh, and generation is resource intense and can be slow. I set governors on song length to keep generation time somewhat reasonable. You may adjust song length and other parameters on the left or check out [Github](https://github.com/bigjoedata/rockbot) to spin up your own Rockbot.
Just have fun.
[Demo](https://share.streamlit.io/bigjoedata/rockbot/main/src/main.py) Adjust settings to increase speed
[Github](https://github.com/bigjoedata/rockbot)
[GPT-2 124M version Model page on Hugging Face](https://huggingface.co/bigjoedata/rockbot)
[DistilGPT2 version Model page on Hugging Face](https://huggingface.co/bigjoedata/rockbot-distilgpt2/) This is leaner with the tradeoff being that the lyrics are more simplistic.
🎹 🪘 🎷 🎺 🪗 🪕 🎻
## Background
With the shutdown of [Google Play Music](https://en.wikipedia.org/wiki/Google_Play_Music) I used Google's takeout function to gather the metadata from artists I've listened to over the past several years. I wanted to take advantage of this bounty to build something fun. I scraped the top 50 lyrics for artists I'd listened to at least once from [Genius](https://genius.com/), then fine tuned [GPT-2's](https://openai.com/blog/better-language-models/) 124M token model using the [AITextGen](https://github.com/minimaxir/aitextgen) framework after considerable post-processing. For more on generation, see [here.](https://huggingface.co/blog/how-to-generate)
### Full Tech Stack
[Google Play Music](https://en.wikipedia.org/wiki/Google_Play_Music) (R.I.P.).
[Python](https://www.python.org/).
[Streamlit](https://www.streamlit.io/).
[GPT-2](https://openai.com/blog/better-language-models/).
[AITextGen](https://github.com/minimaxir/aitextgen).
[Pandas](https://pandas.pydata.org/).
[LyricsGenius](https://lyricsgenius.readthedocs.io/en/master/).
[Google Colab](https://colab.research.google.com/) (GPU based Training).
[Knime](https://www.knime.com/) (data cleaning).
## How to Use The Model
Please refer to [AITextGen](https://github.com/minimaxir/aitextgen) for much better documentation.
### Training Parameters Used
ai.train("lyrics.txt",
line_by_line=False,
from_cache=False,
num_steps=10000,
generate_every=2000,
save_every=2000,
save_gdrive=False,
learning_rate=1e-3,
batch_size=3,
eos_token="<|endoftext|>",
#fp16=True
)
### To Use
Generate With Prompt (Use Title Case):
Song Name
BY
Artist Name
|
bigjoedata/rockbot
|
bigjoedata
| 2021-05-21T14:15:36Z | 14 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
# 🎸 🥁 Rockbot 🎤 🎧
A [GPT-2](https://openai.com/blog/better-language-models/) based lyrics generator fine-tuned on the writing styles of 16000 songs by 270 artists across MANY genres (not just rock).
**Instructions:** Type in a fake song title, pick an artist, click "Generate".
Most language models are imprecise and Rockbot is no exception. You may see NSFW lyrics unexpectedly. I have made no attempts to censor. Generated lyrics may be repetitive and/or incoherent at times, but hopefully you'll encounter something interesting or memorable.
Oh, and generation is resource intense and can be slow. I set governors on song length to keep generation time somewhat reasonable. You may adjust song length and other parameters on the left or check out [Github](https://github.com/bigjoedata/rockbot) to spin up your own Rockbot.
Just have fun.
[Demo](https://share.streamlit.io/bigjoedata/rockbot/main/src/main.py) Adjust settings to increase speed
[Github](https://github.com/bigjoedata/rockbot)
[GPT-2 124M version Model page on Hugging Face](https://huggingface.co/bigjoedata/rockbot)
[DistilGPT2 version Model page on Hugging Face](https://huggingface.co/bigjoedata/rockbot-distilgpt2/) This is leaner with the tradeoff being that the lyrics are more simplistic.
🎹 🪘 🎷 🎺 🪗 🪕 🎻
## Background
With the shutdown of [Google Play Music](https://en.wikipedia.org/wiki/Google_Play_Music) I used Google's takeout function to gather the metadata from artists I've listened to over the past several years. I wanted to take advantage of this bounty to build something fun. I scraped the top 50 lyrics for artists I'd listened to at least once from [Genius](https://genius.com/), then fine tuned [GPT-2's](https://openai.com/blog/better-language-models/) 124M token model using the [AITextGen](https://github.com/minimaxir/aitextgen) framework after considerable post-processing. For more on generation, see [here.](https://huggingface.co/blog/how-to-generate)
### Full Tech Stack
[Google Play Music](https://en.wikipedia.org/wiki/Google_Play_Music) (R.I.P.).
[Python](https://www.python.org/).
[Streamlit](https://www.streamlit.io/).
[GPT-2](https://openai.com/blog/better-language-models/).
[AITextGen](https://github.com/minimaxir/aitextgen).
[Pandas](https://pandas.pydata.org/).
[LyricsGenius](https://lyricsgenius.readthedocs.io/en/master/).
[Google Colab](https://colab.research.google.com/) (GPU based Training).
[Knime](https://www.knime.com/) (data cleaning).
## How to Use The Model
Please refer to [AITextGen](https://github.com/minimaxir/aitextgen) for much better documentation.
### Training Parameters Used
ai.train("lyrics.txt",
line_by_line=False,
from_cache=False,
num_steps=10000,
generate_every=2000,
save_every=2000,
save_gdrive=False,
learning_rate=1e-3,
batch_size=3,
eos_token="<|endoftext|>",
#fp16=True
)
### To Use
Generate With Prompt (Use Title Case):
Song Name
BY
Artist Name
|
classla/bcms-bertic-generator
|
classla
| 2021-05-21T13:29:30Z | 5 | 2 |
transformers
|
[
"transformers",
"pytorch",
"electra",
"pretraining",
"masked-lm",
"hr",
"bs",
"sr",
"cnr",
"hbs",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2022-03-02T23:29:05Z |
---
language:
- hr
- bs
- sr
- cnr
- hbs
tags:
- masked-lm
widget:
- text: "Zovem se Marko i radim u [MASK]."
license: apache-2.0
---
# BERTić* [bert-ich] /bɜrtitʃ/ - A transformer language model for Bosnian, Croatian, Montenegrin and Serbian
* The name should resemble the facts (1) that the model was trained in Zagreb, Croatia, where diminutives ending in -ić (as in fotić, smajlić, hengić etc.) are very popular, and (2) that most surnames in the countries where these languages are spoken end in -ić (with diminutive etymology as well).
This is the smaller generator of the main [discriminator model](https://huggingface.co/classla/bcms-bertic), useful if you want to continue pre-training the discriminator model.
If you use the model, please cite the following paper:
```
@inproceedings{ljubesic-lauc-2021-bertic,
title = "{BERT}i{\'c} - The Transformer Language Model for {B}osnian, {C}roatian, {M}ontenegrin and {S}erbian",
author = "Ljube{\v{s}}i{\'c}, Nikola and Lauc, Davor",
booktitle = "Proceedings of the 8th Workshop on Balto-Slavic Natural Language Processing",
month = apr,
year = "2021",
address = "Kiyv, Ukraine",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2021.bsnlp-1.5",
pages = "37--42",
}
```
|
Dongjae/mrc2reader
|
Dongjae
| 2021-05-21T13:25:57Z | 14 | 0 |
transformers
|
[
"transformers",
"pytorch",
"xlm-roberta",
"question-answering",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-03-02T23:29:04Z |
The Reader model is for Korean Question Answering
The backbone model is deepset/xlm-roberta-large-squad2.
It is a finetuned model with KorQuAD-v1 dataset.
As a result of verification using KorQuAD evaluation dataset, it showed approximately 87% and 92% respectively for the EM score and F1 score.
Thank you
|
anonymous-german-nlp/german-gpt2
|
anonymous-german-nlp
| 2021-05-21T13:20:42Z | 338 | 1 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"jax",
"gpt2",
"text-generation",
"de",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: de
widget:
- text: "Heute ist sehr schönes Wetter in"
license: mit
---
# German GPT-2 model
**Note**: This model was de-anonymized and now lives at:
https://huggingface.co/dbmdz/german-gpt2
Please use the new model name instead!
|
aliosm/ComVE-gpt2
|
aliosm
| 2021-05-21T13:19:25Z | 7 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"exbert",
"commonsense",
"semeval2020",
"comve",
"en",
"dataset:ComVE",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: "en"
tags:
- exbert
- commonsense
- semeval2020
- comve
license: "mit"
datasets:
- ComVE
metrics:
- bleu
widget:
- text: "Chicken can swim in water. <|continue|>"
---
# ComVE-gpt2
## Model description
Finetuned model on Commonsense Validation and Explanation (ComVE) dataset introduced in [SemEval2020 Task4](https://competitions.codalab.org/competitions/21080) using a causal language modeling (CLM) objective.
The model is able to generate a reason why a given natural language statement is against commonsense.
## Intended uses & limitations
You can use the raw model for text generation to generate reasons why natural language statements are against commonsense.
#### How to use
You can use this model directly to generate reasons why the given statement is against commonsense using [`generate.sh`](https://github.com/AliOsm/SemEval2020-Task4-ComVE/tree/master/TaskC-Generation) script.
*Note:* make sure that you are using version `2.4.1` of `transformers` package. Newer versions has some issue in text generation and the model repeats the last token generated again and again.
#### Limitations and bias
The model biased to negate the entered sentence usually instead of producing a factual reason.
## Training data
The model is initialized from the [gpt2](https://github.com/huggingface/transformers/blob/master/model_cards/gpt2-README.md) model and finetuned using [ComVE](https://github.com/wangcunxiang/SemEval2020-Task4-Commonsense-Validation-and-Explanation) dataset which contains 10K against commonsense sentences, each of them is paired with three reference reasons.
## Training procedure
Each natural language statement that against commonsense is concatenated with its reference reason with `<|continue|>` as a separator, then the model finetuned using CLM objective.
The model trained on Nvidia Tesla P100 GPU from Google Colab platform with 5e-5 learning rate, 5 epochs, 128 maximum sequence length and 64 batch size.
<center>
<img src="https://i.imgur.com/xKbrwBC.png">
</center>
## Eval results
The model achieved 14.0547/13.6534 BLEU scores on SemEval2020 Task4: Commonsense Validation and Explanation development and testing dataset.
### BibTeX entry and citation info
```bibtex
@article{fadel2020justers,
title={JUSTers at SemEval-2020 Task 4: Evaluating Transformer Models Against Commonsense Validation and Explanation},
author={Fadel, Ali and Al-Ayyoub, Mahmoud and Cambria, Erik},
year={2020}
}
```
<a href="https://huggingface.co/exbert/?model=aliosm/ComVE-gpt2">
<img width="300px" src="https://cdn-media.huggingface.co/exbert/button.png">
</a>
|
aliosm/ComVE-gpt2-medium
|
aliosm
| 2021-05-21T13:17:55Z | 8 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"gpt2",
"feature-extraction",
"exbert",
"commonsense",
"semeval2020",
"comve",
"en",
"dataset:ComVE",
"license:mit",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
feature-extraction
| 2022-03-02T23:29:05Z |
---
language: "en"
tags:
- gpt2
- exbert
- commonsense
- semeval2020
- comve
license: "mit"
datasets:
- ComVE
metrics:
- bleu
widget:
- text: "Chicken can swim in water. <|continue|>"
---
# ComVE-gpt2-medium
## Model description
Finetuned model on Commonsense Validation and Explanation (ComVE) dataset introduced in [SemEval2020 Task4](https://competitions.codalab.org/competitions/21080) using a causal language modeling (CLM) objective.
The model is able to generate a reason why a given natural language statement is against commonsense.
## Intended uses & limitations
You can use the raw model for text generation to generate reasons why natural language statements are against commonsense.
#### How to use
You can use this model directly to generate reasons why the given statement is against commonsense using [`generate.sh`](https://github.com/AliOsm/SemEval2020-Task4-ComVE/tree/master/TaskC-Generation) script.
*Note:* make sure that you are using version `2.4.1` of `transformers` package. Newer versions has some issue in text generation and the model repeats the last token generated again and again.
#### Limitations and bias
The model biased to negate the entered sentence usually instead of producing a factual reason.
## Training data
The model is initialized from the [gpt2-medium](https://github.com/huggingface/transformers/blob/master/model_cards/gpt2-README.md) model and finetuned using [ComVE](https://github.com/wangcunxiang/SemEval2020-Task4-Commonsense-Validation-and-Explanation) dataset which contains 10K against commonsense sentences, each of them is paired with three reference reasons.
## Training procedure
Each natural language statement that against commonsense is concatenated with its reference reason with `<|continue|>` as a separator, then the model finetuned using CLM objective.
The model trained on Nvidia Tesla P100 GPU from Google Colab platform with 5e-5 learning rate, 5 epochs, 128 maximum sequence length and 64 batch size.
<center>
<img src="https://i.imgur.com/xKbrwBC.png">
</center>
## Eval results
The model achieved fifth place with 16.7153/16.1187 BLEU scores and third place with 1.94 Human Evaluation score on SemEval2020 Task4: Commonsense Validation and Explanation development and testing dataset.
These are some examples generated by the model:
| Against Commonsense Statement | Generated Reason |
|:-----------------------------------------------------:|:--------------------------------------------:|
| Chicken can swim in water. | Chicken can't swim. |
| shoes can fly | Shoes are not able to fly. |
| Chocolate can be used to make a coffee pot | Chocolate is not used to make coffee pots. |
| you can also buy tickets online with an identity card | You can't buy tickets with an identity card. |
| a ball is square and can roll | A ball is round and cannot roll. |
| You can use detergent to dye your hair. | Detergent is used to wash clothes. |
| you can eat mercury | mercury is poisonous |
| A gardener can follow a suspect | gardener is not a police officer |
| cars can float in the ocean just like a boat | Cars are too heavy to float in the ocean. |
| I am going to work so I can lose money. | Working is not a way to lose money. |
### BibTeX entry and citation info
```bibtex
@article{fadel2020justers,
title={JUSTers at SemEval-2020 Task 4: Evaluating Transformer Models Against Commonsense Validation and Explanation},
author={Fadel, Ali and Al-Ayyoub, Mahmoud and Cambria, Erik},
year={2020}
}
```
<a href="https://huggingface.co/exbert/?model=aliosm/ComVE-gpt2-medium">
<img width="300px" src="https://cdn-media.huggingface.co/exbert/button.png">
</a>
|
aliosm/ComVE-distilgpt2
|
aliosm
| 2021-05-21T13:07:30Z | 13 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"exbert",
"commonsense",
"semeval2020",
"comve",
"en",
"dataset:ComVE",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: "en"
tags:
- exbert
- commonsense
- semeval2020
- comve
license: "mit"
datasets:
- ComVE
metrics:
- bleu
widget:
- text: "Chicken can swim in water. <|continue|>"
---
# ComVE-distilgpt2
## Model description
Finetuned model on Commonsense Validation and Explanation (ComVE) dataset introduced in [SemEval2020 Task4](https://competitions.codalab.org/competitions/21080) using a causal language modeling (CLM) objective.
The model is able to generate a reason why a given natural language statement is against commonsense.
## Intended uses & limitations
You can use the raw model for text generation to generate reasons why natural language statements are against commonsense.
#### How to use
You can use this model directly to generate reasons why the given statement is against commonsense using [`generate.sh`](https://github.com/AliOsm/SemEval2020-Task4-ComVE/tree/master/TaskC-Generation) script.
*Note:* make sure that you are using version `2.4.1` of `transformers` package. Newer versions has some issue in text generation and the model repeats the last token generated again and again.
#### Limitations and bias
The model biased to negate the entered sentence usually instead of producing a factual reason.
## Training data
The model is initialized from the [distilgpt2](https://github.com/huggingface/transformers/blob/master/model_cards/distilgpt2-README.md) model and finetuned using [ComVE](https://github.com/wangcunxiang/SemEval2020-Task4-Commonsense-Validation-and-Explanation) dataset which contains 10K against commonsense sentences, each of them is paired with three reference reasons.
## Training procedure
Each natural language statement that against commonsense is concatenated with its reference reason with `<|continue|>` as a separator, then the model finetuned using CLM objective.
The model trained on Nvidia Tesla P100 GPU from Google Colab platform with 5e-5 learning rate, 15 epochs, 128 maximum sequence length and 64 batch size.
<center>
<img src="https://i.imgur.com/xKbrwBC.png">
</center>
## Eval results
The model achieved 13.7582/13.8026 BLEU scores on SemEval2020 Task4: Commonsense Validation and Explanation development and testing dataset.
### BibTeX entry and citation info
```bibtex
@article{fadel2020justers,
title={JUSTers at SemEval-2020 Task 4: Evaluating Transformer Models Against Commonsense Validation and Explanation},
author={Fadel, Ali and Al-Ayyoub, Mahmoud and Cambria, Erik},
year={2020}
}
```
<a href="https://huggingface.co/exbert/?model=aliosm/ComVE-distilgpt2">
<img width="300px" src="https://cdn-media.huggingface.co/exbert/button.png">
</a>
|
kamivao/autonlp-cola_gram-208681
|
kamivao
| 2021-05-21T12:43:57Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"text-classification",
"autonlp",
"en",
"dataset:kamivao/autonlp-data-cola_gram",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
---
tags: autonlp
language: en
widget:
- text: "I love AutoNLP 🤗"
datasets:
- kamivao/autonlp-data-cola_gram
---
# Model Trained Using AutoNLP
- Problem type: Binary Classification
- Model ID: 208681
## Validation Metrics
- Loss: 0.37569838762283325
- Accuracy: 0.8365019011406845
- Precision: 0.8398058252427184
- Recall: 0.9453551912568307
- AUC: 0.9048838797814208
- F1: 0.8894601542416453
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoNLP"}' https://api-inference.huggingface.co/models/kamivao/autonlp-cola_gram-208681
```
Or Python API:
```
from transformers import AutoModelForSequenceClassification, AutoTokenizer
model = AutoModelForSequenceClassification.from_pretrained("kamivao/autonlp-cola_gram-208681", use_auth_token=True)
tokenizer = AutoTokenizer.from_pretrained("kamivao/autonlp-cola_gram-208681", use_auth_token=True)
inputs = tokenizer("I love AutoNLP", return_tensors="pt")
outputs = model(**inputs)
```
|
ainize/gpt2-rnm-with-season-1
|
ainize
| 2021-05-21T12:08:00Z | 9 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
### Model information
Fine tuning data 1: https://www.kaggle.com/andradaolteanu/rickmorty-scripts
Base model: e-tony/gpt2-rnm
Epoch: 3
Train runtime: 7.1779 secs
Loss: 2.5694
Training notebook: [Colab](https://colab.research.google.com/drive/12NvO1SIZevF8ybJqfN9O21I3i9bU1dOO#scrollTo=KUsyn02WWmf5)
### ===Teachable NLP=== ###
To train a GPT-2 model, write code and require GPU resources, but can easily fine-tune and get an API to use the model here for free.
Teachable NLP: [Teachable NLP](https://ainize.ai/teachable-nlp)
Tutorial: [Tutorial](https://forum.ainetwork.ai/t/teachable-nlp-how-to-use-teachable-nlp/65?utm_source=community&utm_medium=huggingface&utm_campaign=model&utm_content=teachable%20nlp)
|
TheBakerCat/2chan_ruGPT3_small
|
TheBakerCat
| 2021-05-21T11:26:24Z | 13 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
ruGPT3-small model, trained on some 2chan posts
|
Ochiroo/tiny_mn_gpt
|
Ochiroo
| 2021-05-21T10:59:47Z | 6 | 1 |
transformers
|
[
"transformers",
"tf",
"gpt2",
"text-generation",
"mn",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:04Z |
---
language: mn
---
# GPT2-Mongolia
## Model description
GPT-2 is a transformers model pretrained on a very small corpus of Mongolian news data in a self-supervised fashion. This means it was pretrained on the raw texts only, with no humans labelling them in any way (which is why it can use lots of publicly available data) with an automatic process to generate inputs and labels from those texts. More precisely, it was trained to guess the next word in sentences.
## How to use
```python
import tensorflow as tf
from transformers import GPT2Config, TFGPT2LMHeadModel, GPT2Tokenizer
from transformers import WEIGHTS_NAME, CONFIG_NAME
tokenizer = GPT2Tokenizer.from_pretrained('Ochiroo/tiny_mn_gpt')
model = TFGPT2LMHeadModel.from_pretrained('Ochiroo/tiny_mn_gpt')
text = "Намайг Эрдэнэ-Очир гэдэг. Би"
input_ids = tokenizer.encode(text, return_tensors='tf')
beam_outputs = model.generate(
input_ids,
max_length = 25,
num_beams = 5,
temperature = 0.7,
no_repeat_ngram_size=2,
num_return_sequences=5
)
print(tokenizer.decode(beam_outputs[0]))
```
## Training data and biases
Trained on 500MB of Mongolian news dataset (IKON) on RTX 2060.
|
HooshvareLab/gpt2-fa
|
HooshvareLab
| 2021-05-21T10:51:23Z | 6,032 | 15 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"jax",
"gpt2",
"text-generation",
"fa",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:04Z |
---
language: fa
license: apache-2.0
widget:
- text: "در یک اتفاق شگفت انگیز، پژوهشگران"
- text: "گرفتگی بینی در کودکان و بهخصوص نوزادان باعث میشود"
- text: "امیدواریم نوروز امسال سالی"
---
# ParsGPT2
### BibTeX entry and citation info
Please cite in publications as the following:
```bibtex
@misc{ParsGPT2,
author = {Hooshvare Team},
title = {ParsGPT2 the Persian version of GPT2},
year = {2021},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://github.com/hooshvare/parsgpt}},
}
```
## Questions?
Post a Github issue on the [ParsGPT2 Issues](https://github.com/hooshvare/parsgpt/issues) repo.
|
HooshvareLab/gpt2-fa-comment
|
HooshvareLab
| 2021-05-21T10:47:25Z | 30 | 2 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"jax",
"gpt2",
"text-generation",
"fa",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:04Z |
---
language: fa
license: apache-2.0
widget:
- text: "<s>نمونه دیدگاه هم خوب هم بد به طور کلی <sep>"
- text: "<s>نمونه دیدگاه خیلی منفی از نظر کیفیت و طعم <sep>"
- text: "<s>نمونه دیدگاه خوب از نظر بازی و کارگردانی <sep>"
- text: "<s>نمونه دیدگاه خیلی خوب از نظر بازی و صحنه و داستان <sep>"
- text: "<s>نمونه دیدگاه خیلی منفی از نظر ارزش خرید و طعم و کیفیت <sep>"
---
# Persian Comment Generator
The model can generate comments based on your aspects, and the model was fine-tuned on [persiannlp/parsinlu](https://github.com/persiannlp/parsinlu). Currently, the model only supports aspects in the food and movie scope. You can see the whole aspects in the following section.
## Comments Aspects
```text
<s>نمونه دیدگاه هم خوب هم بد به طور کلی <sep>
<s>نمونه دیدگاه خوب به طور کلی <sep>
<s>نمونه دیدگاه خیلی خوب از نظر طعم <sep>
<s>نمونه دیدگاه خیلی منفی از نظر طعم و کیفیت <sep>
<s>نمونه دیدگاه خوب از نظر ارزش غذایی و ارزش خرید <sep>
<s>نمونه دیدگاه هم خوب هم بد از نظر طعم و بسته بندی <sep>
<s>نمونه دیدگاه خوب از نظر کیفیت <sep>
<s>نمونه دیدگاه خیلی خوب از نظر طعم و کیفیت <sep>
<s>نمونه دیدگاه هم خوب هم بد از نظر کیفیت و ارزش خرید <sep>
<s>نمونه دیدگاه خیلی منفی از نظر کیفیت <sep>
<s>نمونه دیدگاه منفی از نظر کیفیت <sep>
<s>نمونه دیدگاه خوب از نظر طعم <sep>
<s>نمونه دیدگاه خیلی خوب به طور کلی <sep>
<s>نمونه دیدگاه خوب از نظر بسته بندی <sep>
<s>نمونه دیدگاه منفی از نظر کیفیت و طعم <sep>
<s>نمونه دیدگاه خیلی منفی از نظر ارسال و طعم <sep>
<s>نمونه دیدگاه خیلی منفی از نظر کیفیت و طعم <sep>
<s>نمونه دیدگاه منفی به طور کلی <sep>
<s>نمونه دیدگاه خوب از نظر ارزش خرید <sep>
<s>نمونه دیدگاه خوب از نظر کیفیت و بسته بندی و طعم <sep>
<s>نمونه دیدگاه خیلی منفی از نظر ارزش خرید و کیفیت <sep>
<s>نمونه دیدگاه هم خوب هم بد از نظر طعم و ارزش خرید <sep>
<s>نمونه دیدگاه خیلی خوب از نظر طعم و ارزش خرید <sep>
<s>نمونه دیدگاه منفی از نظر ارسال <sep>
<s>نمونه دیدگاه منفی از نظر طعم <sep>
<s>نمونه دیدگاه هم خوب هم بد از نظر ارزش خرید و طعم <sep>
<s>نمونه دیدگاه خیلی منفی از نظر طعم و ارزش خرید <sep>
<s>نمونه دیدگاه نظری ندارم به طور کلی <sep>
<s>نمونه دیدگاه خیلی منفی از نظر طعم <sep>
<s>نمونه دیدگاه خیلی منفی به طور کلی <sep>
<s>نمونه دیدگاه هم خوب هم بد از نظر بسته بندی <sep>
<s>نمونه دیدگاه خیلی منفی از نظر ارزش خرید و کیفیت و طعم <sep>
<s>نمونه دیدگاه خیلی خوب از نظر ارزش خرید <sep>
<s>نمونه دیدگاه منفی از نظر کیفیت و ارزش خرید <sep>
<s>نمونه دیدگاه خیلی منفی از نظر کیفیت و بسته بندی <sep>
<s>نمونه دیدگاه خیلی خوب از نظر کیفیت <sep>
<s>نمونه دیدگاه منفی از نظر طعم و کیفیت <sep>
<s>نمونه دیدگاه خوب از نظر طعم و کیفیت و ارزش خرید <sep>
<s>نمونه دیدگاه خیلی منفی از نظر ارسال <sep>
<s>نمونه دیدگاه خیلی منفی از نظر ارزش خرید و طعم <sep>
<s>نمونه دیدگاه هم خوب هم بد از نظر طعم <sep>
<s>نمونه دیدگاه خیلی خوب از نظر بسته بندی و طعم <sep>
<s>نمونه دیدگاه خیلی خوب از نظر ارزش خرید و کیفیت و بسته بندی <sep>
<s>نمونه دیدگاه هم خوب هم بد از نظر بسته بندی و طعم و ارزش خرید <sep>
<s>نمونه دیدگاه هم خوب هم بد از نظر کیفیت و طعم <sep>
<s>نمونه دیدگاه خیلی خوب از نظر طعم و بسته بندی <sep>
<s>نمونه دیدگاه خیلی منفی از نظر طعم و کیفیت و بسته بندی <sep>
<s>نمونه دیدگاه خوب از نظر ارزش خرید و بسته بندی و کیفیت <sep>
<s>نمونه دیدگاه هم خوب هم بد از نظر طعم و کیفیت <sep>
<s>نمونه دیدگاه خیلی خوب از نظر بسته بندی <sep>
<s>نمونه دیدگاه خیلی خوب از نظر ارزش خرید و کیفیت <sep>
<s>نمونه دیدگاه خیلی خوب از نظر کیفیت و ارزش خرید و طعم <sep>
<s>نمونه دیدگاه خیلی خوب از نظر ارزش خرید و طعم <sep>
<s>نمونه دیدگاه خیلی منفی از نظر کیفیت و بسته بندی و ارسال <sep>
<s>نمونه دیدگاه خوب از نظر کیفیت و ارزش خرید <sep>
<s>نمونه دیدگاه خیلی منفی از نظر کیفیت و ارزش غذایی <sep>
<s>نمونه دیدگاه خیلی خوب از نظر کیفیت و ارزش خرید <sep>
<s>نمونه دیدگاه هم خوب هم بد از نظر کیفیت <sep>
<s>نمونه دیدگاه منفی از نظر بسته بندی <sep>
<s>نمونه دیدگاه خوب از نظر طعم و کیفیت <sep>
<s>نمونه دیدگاه خوب از نظر کیفیت و ارزش غذایی <sep>
<s>نمونه دیدگاه خیلی منفی از نظر کیفیت و ارزش خرید <sep>
<s>نمونه دیدگاه خوب از نظر طعم و کیفیت و بسته بندی <sep>
<s>نمونه دیدگاه خیلی منفی از نظر ارزش خرید <sep>
<s>نمونه دیدگاه منفی از نظر ارسال و کیفیت <sep>
<s>نمونه دیدگاه هم خوب هم بد از نظر ارزش خرید <sep>
<s>نمونه دیدگاه خیلی منفی از نظر بسته بندی <sep>
<s>نمونه دیدگاه خیلی منفی از نظر کیفیت و بسته بندی و ارزش خرید <sep>
<s>نمونه دیدگاه خوب از نظر طعم و ارزش غذایی <sep>
<s>نمونه دیدگاه منفی از نظر ارزش خرید <sep>
<s>نمونه دیدگاه خیلی خوب از نظر کیفیت و طعم <sep>
<s>نمونه دیدگاه خوب از نظر کیفیت و بسته بندی <sep>
<s>نمونه دیدگاه خیلی منفی از نظر بسته بندی و طعم <sep>
<s>نمونه دیدگاه خیلی منفی از نظر طعم و ارزش غذایی <sep>
<s>نمونه دیدگاه خوب از نظر کیفیت و طعم <sep>
<s>نمونه دیدگاه هم خوب هم بد از نظر طعم و ارسال <sep>
<s>نمونه دیدگاه خیلی خوب از نظر ارزش غذایی <sep>
<s>نمونه دیدگاه خوب از نظر ارزش خرید و کیفیت <sep>
<s>نمونه دیدگاه خوب از نظر ارزش غذایی <sep>
<s>نمونه دیدگاه خوب از نظر طعم و ارزش خرید <sep>
<s>نمونه دیدگاه منفی از نظر طعم و ارزش خرید <sep>
<s>نمونه دیدگاه منفی از نظر ارزش خرید و کیفیت <sep>
<s>نمونه دیدگاه خوب از نظر کیفیت و ارزش خرید و طعم <sep>
<s>نمونه دیدگاه خیلی خوب از نظر بسته بندی و ارسال و طعم و ارزش خرید <sep>
<s>نمونه دیدگاه خوب از نظر کیفیت و طعم و ارزش خرید <sep>
<s>نمونه دیدگاه خوب از نظر کیفیت و بسته بندی و ارزش خرید <sep>
<s>نمونه دیدگاه خیلی خوب از نظر بسته بندی و کیفیت و ارزش خرید <sep>
<s>نمونه دیدگاه منفی از نظر ارزش خرید و طعم <sep>
<s>نمونه دیدگاه خیلی منفی از نظر طعم و بسته بندی <sep>
<s>نمونه دیدگاه خیلی منفی از نظر طعم و کیفیت و ارزش خرید <sep>
<s>نمونه دیدگاه منفی از نظر بسته بندی و کیفیت و طعم <sep>
<s>نمونه دیدگاه خوب از نظر ارسال <sep>
<s>نمونه دیدگاه خیلی خوب از نظر کیفیت و بسته بندی و ارزش غذایی و ارزش خرید <sep>
<s>نمونه دیدگاه خیلی خوب از نظر ارزش غذایی و کیفیت <sep>
<s>نمونه دیدگاه خیلی خوب از نظر کیفیت و طعم و ارزش خرید <sep>
<s>نمونه دیدگاه خوب از نظر طعم و ارسال <sep>
<s>نمونه دیدگاه خیلی خوب از نظر طعم و کیفیت و ارزش خرید <sep>
<s>نمونه دیدگاه خوب از نظر بسته بندی و ارزش خرید <sep>
<s>نمونه دیدگاه هم خوب هم بد از نظر ارزش غذایی و طعم <sep>
<s>نمونه دیدگاه هم خوب هم بد از نظر کیفیت و ارزش خرید و طعم <sep>
<s>نمونه دیدگاه خیلی منفی از نظر ارزش غذایی <sep>
<s>نمونه دیدگاه هم خوب هم بد از نظر ارزش خرید و کیفیت <sep>
<s>نمونه دیدگاه هم خوب هم بد از نظر ارزش غذایی و ارزش خرید <sep>
<s>نمونه دیدگاه منفی از نظر طعم و ارزش غذایی <sep>
<s>نمونه دیدگاه خیلی خوب از نظر کیفیت و ارسال <sep>
<s>نمونه دیدگاه خوب از نظر ارزش خرید و طعم <sep>
<s>نمونه دیدگاه هم خوب هم بد از نظر ارزش غذایی و بسته بندی <sep>
<s>نمونه دیدگاه هم خوب هم بد از نظر طعم و ارزش غذایی <sep>
<s>نمونه دیدگاه هم خوب هم بد از نظر طعم و کیفیت و ارسال <sep>
<s>نمونه دیدگاه خیلی خوب از نظر کیفیت و بسته بندی و طعم و ارزش خرید <sep>
<s>نمونه دیدگاه خیلی خوب از نظر طعم و ارزش غذایی <sep>
<s>نمونه دیدگاه خوب از نظر بسته بندی و طعم و کیفیت <sep>
<s>نمونه دیدگاه خیلی خوب از نظر ارزش خرید و ارزش غذایی <sep>
<s>نمونه دیدگاه خوب از نظر ارسال و طعم <sep>
<s>نمونه دیدگاه خوب از نظر ارزش خرید و ارسال <sep>
<s>نمونه دیدگاه هم خوب هم بد از نظر ارزش غذایی و کیفیت <sep>
<s>نمونه دیدگاه خوب از نظر ارزش خرید و بسته بندی <sep>
<s>نمونه دیدگاه خیلی خوب از نظر کیفیت و طعم و بسته بندی <sep>
<s>نمونه دیدگاه خیلی خوب از نظر ارزش خرید و طعم و کیفیت <sep>
<s>نمونه دیدگاه خیلی منفی از نظر بسته بندی و کیفیت <sep>
<s>نمونه دیدگاه خیلی خوب از نظر ارزش خرید و کیفیت و طعم <sep>
<s>نمونه دیدگاه خیلی منفی از نظر طعم و ارزش خرید و کیفیت <sep>
<s>نمونه دیدگاه منفی از نظر بسته بندی و کیفیت و ارزش خرید <sep>
<s>نمونه دیدگاه خیلی منفی از نظر طعم و کیفیت و ارزش خرید و بسته بندی <sep>
<s>نمونه دیدگاه خوب از نظر ارزش غذایی و ارسال <sep>
<s>نمونه دیدگاه خوب از نظر کیفیت و طعم و ارزش خرید و ارسال <sep>
<s>نمونه دیدگاه هم خوب هم بد از نظر ارسال و طعم <sep>
<s>نمونه دیدگاه خیلی منفی از نظر ارزش خرید و بسته بندی و طعم <sep>
<s>نمونه دیدگاه خیلی خوب از نظر ارسال و بسته بندی <sep>
<s>نمونه دیدگاه خیلی خوب از نظر طعم و ارزش خرید و ارسال <sep>
<s>نمونه دیدگاه خیلی منفی از نظر کیفیت و ارزش خرید و طعم <sep>
<s>نمونه دیدگاه خوب از نظر بسته بندی و کیفیت <sep>
<s>نمونه دیدگاه هم خوب هم بد از نظر بسته بندی و کیفیت <sep>
<s>نمونه دیدگاه خوب از نظر ارزش خرید و بسته بندی و ارسال <sep>
<s>نمونه دیدگاه خیلی منفی از نظر بسته بندی و طعم و ارزش خرید <sep>
<s>نمونه دیدگاه نظری ندارم از نظر بسته بندی <sep>
<s>نمونه دیدگاه هم خوب هم بد از نظر کیفیت و بسته بندی و طعم <sep>
<s>نمونه دیدگاه خوب از نظر طعم و بسته بندی <sep>
<s>نمونه دیدگاه خیلی منفی از نظر طعم و ارزش خرید و بسته بندی <sep>
<s>نمونه دیدگاه خیلی خوب از نظر ارزش خرید و بسته بندی <sep>
<s>نمونه دیدگاه خوب از نظر ارزش خرید و ارزش غذایی <sep>
<s>نمونه دیدگاه منفی از نظر طعم و بسته بندی <sep>
<s>نمونه دیدگاه منفی از نظر کیفیت و بسته بندی <sep>
<s>نمونه دیدگاه خیلی خوب از نظر کیفیت و ارزش غذایی و بسته بندی <sep>
<s>نمونه دیدگاه خوب از نظر ارسال و بسته بندی <sep>
<s>نمونه دیدگاه هم خوب هم بد از نظر ارسال <sep>
<s>نمونه دیدگاه نظری ندارم از نظر طعم <sep>
<s>نمونه دیدگاه خیلی خوب از نظر کیفیت و بسته بندی <sep>
<s>نمونه دیدگاه منفی از نظر ارزش غذایی <sep>
<s>نمونه دیدگاه خوب از نظر بسته بندی و طعم <sep>
<s>نمونه دیدگاه خیلی منفی از نظر ارسال و کیفیت <sep>
<s>نمونه دیدگاه خیلی خوب از نظر طعم و کیفیت و بسته بندی <sep>
<s>نمونه دیدگاه خیلی خوب از نظر طعم و کیفیت و بسته بندی و ارزش غذایی <sep>
<s>نمونه دیدگاه خوب از نظر طعم و بسته بندی و ارزش خرید <sep>
<s>نمونه دیدگاه هم خوب هم بد از نظر کیفیت و ارسال <sep>
<s>نمونه دیدگاه خیلی خوب از نظر طعم و کیفیت و ارزش غذایی <sep>
<s>نمونه دیدگاه خیلی خوب از نظر کیفیت و طعم و ارزش غذایی <sep>
<s>نمونه دیدگاه خیلی خوب از نظر کیفیت و ارسال و ارزش خرید <sep>
<s>نمونه دیدگاه نظری ندارم از نظر ارزش غذایی <sep>
<s>نمونه دیدگاه خیلی خوب از نظر ارسال و ارزش خرید و کیفیت <sep>
<s>نمونه دیدگاه خیلی خوب از نظر بسته بندی و طعم و ارزش خرید <sep>
<s>نمونه دیدگاه خیلی خوب از نظر کیفیت و ارسال و بسته بندی <sep>
<s>نمونه دیدگاه منفی از نظر بسته بندی و طعم و کیفیت <sep>
<s>نمونه دیدگاه خیلی خوب از نظر بسته بندی و ارسال <sep>
<s>نمونه دیدگاه خیلی خوب از نظر ارسال و کیفیت <sep>
<s>نمونه دیدگاه خوب از نظر کیفیت و ارسال <sep>
<s>نمونه دیدگاه هم خوب هم بد از نظر ارزش خرید و ارزش غذایی <sep>
<s>نمونه دیدگاه خوب از نظر ارزش غذایی و طعم <sep>
<s>نمونه دیدگاه خیلی خوب از نظر ارزش خرید و ارزش غذایی و طعم <sep>
<s>نمونه دیدگاه خیلی خوب از نظر ارسال و بسته بندی و کیفیت <sep>
<s>نمونه دیدگاه منفی از نظر بسته بندی و طعم <sep>
<s>نمونه دیدگاه منفی از نظر بسته بندی و ارزش غذایی <sep>
<s>نمونه دیدگاه منفی از نظر طعم و کیفیت و ارزش خرید <sep>
<s>نمونه دیدگاه هم خوب هم بد از نظر بسته بندی و طعم <sep>
<s>نمونه دیدگاه خیلی خوب از نظر طعم و ارزش غذایی و ارزش خرید <sep>
<s>نمونه دیدگاه خیلی خوب از نظر ارزش غذایی و ارزش خرید <sep>
<s>نمونه دیدگاه خیلی خوب از نظر ارزش خرید و طعم و بسته بندی <sep>
<s>نمونه دیدگاه هم خوب هم بد از نظر کیفیت و بسته بندی <sep>
<s>نمونه دیدگاه هم خوب هم بد از نظر ارزش خرید و کیفیت و طعم <sep>
<s>نمونه دیدگاه منفی از نظر ارزش خرید و کیفیت و طعم <sep>
<s>نمونه دیدگاه منفی از نظر کیفیت و طعم و ارزش غذایی <sep>
<s>نمونه دیدگاه خیلی منفی از نظر ارسال و کیفیت و طعم <sep>
<s>نمونه دیدگاه خیلی خوب از نظر ارزش غذایی و طعم <sep>
<s>نمونه دیدگاه خیلی خوب از نظر طعم و بسته بندی و ارسال <sep>
<s>نمونه دیدگاه خیلی منفی از نظر کیفیت و بسته بندی و طعم <sep>
<s>نمونه دیدگاه خیلی خوب از نظر ارزش غذایی و طعم و کیفیت <sep>
<s>نمونه دیدگاه خیلی منفی از نظر ارزش غذایی و کیفیت <sep>
<s>نمونه دیدگاه منفی از نظر ارزش خرید و طعم و کیفیت <sep>
<s>نمونه دیدگاه خیلی منفی از نظر کیفیت و طعم و بسته بندی <sep>
<s>نمونه دیدگاه هم خوب هم بد از نظر ارسال و ارزش خرید <sep>
<s>نمونه دیدگاه خیلی منفی از نظر ارزش خرید و طعم و کیفیت <sep>
<s>نمونه دیدگاه خیلی منفی از نظر طعم و ارسال <sep>
<s>نمونه دیدگاه منفی از نظر موسیقی و بازی <sep>
<s>نمونه دیدگاه منفی از نظر داستان <sep>
<s>نمونه دیدگاه خیلی خوب از نظر صدا <sep>
<s>نمونه دیدگاه خیلی منفی از نظر داستان <sep>
<s>نمونه دیدگاه هم خوب هم بد از نظر داستان و فیلمبرداری و کارگردانی و بازی <sep>
<s>نمونه دیدگاه هم خوب هم بد از نظر بازی <sep>
<s>نمونه دیدگاه منفی از نظر داستان و بازی <sep>
<s>نمونه دیدگاه منفی از نظر بازی <sep>
<s>نمونه دیدگاه خیلی خوب از نظر داستان و کارگردانی و بازی <sep>
<s>نمونه دیدگاه خیلی منفی از نظر داستان و بازی <sep>
<s>نمونه دیدگاه خوب از نظر بازی <sep>
<s>نمونه دیدگاه خیلی منفی از نظر بازی و داستان و کارگردانی <sep>
<s>نمونه دیدگاه خیلی خوب از نظر بازی <sep>
<s>نمونه دیدگاه خوب از نظر بازی و داستان <sep>
<s>نمونه دیدگاه خوب از نظر داستان و بازی <sep>
<s>نمونه دیدگاه خوب از نظر داستان <sep>
<s>نمونه دیدگاه خیلی خوب از نظر داستان <sep>
<s>نمونه دیدگاه خیلی خوب از نظر داستان و بازی <sep>
<s>نمونه دیدگاه خیلی خوب از نظر بازی و داستان <sep>
<s>نمونه دیدگاه خیلی منفی از نظر داستان و کارگردانی و فیلمبرداری <sep>
<s>نمونه دیدگاه خیلی منفی از نظر بازی <sep>
<s>نمونه دیدگاه خیلی منفی از نظر کارگردانی <sep>
<s>نمونه دیدگاه منفی از نظر کارگردانی و داستان <sep>
<s>نمونه دیدگاه خیلی خوب از نظر کارگردانی و بازی <sep>
<s>نمونه دیدگاه خوب از نظر کارگردانی و بازی <sep>
<s>نمونه دیدگاه خیلی خوب از نظر صحنه و کارگردانی <sep>
<s>نمونه دیدگاه منفی از نظر بازی و کارگردانی <sep>
<s>نمونه دیدگاه خیلی خوب از نظر بازی و داستان و کارگردانی <sep>
<s>نمونه دیدگاه خیلی خوب از نظر کارگردانی <sep>
<s>نمونه دیدگاه هم خوب هم بد از نظر فیلمبرداری <sep>
<s>نمونه دیدگاه خیلی خوب از نظر بازی و کارگردانی و فیلمبرداری و داستان <sep>
<s>نمونه دیدگاه خیلی خوب از نظر کارگردانی و بازی و موسیقی <sep>
<s>نمونه دیدگاه خوب از نظر صحنه و بازی <sep>
<s>نمونه دیدگاه خیلی خوب از نظر بازی و موسیقی و کارگردانی <sep>
<s>نمونه دیدگاه خوب از نظر داستان و کارگردانی <sep>
<s>نمونه دیدگاه خوب از نظر بازی و کارگردانی <sep>
<s>نمونه دیدگاه خیلی منفی از نظر بازی و کارگردانی <sep>
<s>نمونه دیدگاه منفی از نظر کارگردانی و موسیقی <sep>
<s>نمونه دیدگاه هم خوب هم بد از نظر بازی و داستان <sep>
<s>نمونه دیدگاه خوب از نظر کارگردانی <sep>
<s>نمونه دیدگاه هم خوب هم بد از نظر بازی و کارگردانی <sep>
<s>نمونه دیدگاه خیلی خوب از نظر کارگردانی و داستان <sep>
<s>نمونه دیدگاه خیلی منفی از نظر داستان و کارگردانی <sep>
<s>نمونه دیدگاه خیلی خوب از نظر داستان و کارگردانی <sep>
<s>نمونه دیدگاه هم خوب هم بد از نظر داستان <sep>
<s>نمونه دیدگاه خوب از نظر بازی و داستان و موسیقی و کارگردانی و فیلمبرداری <sep>
<s>نمونه دیدگاه خیلی منفی از نظر داستان و بازی و کارگردانی <sep>
<s>نمونه دیدگاه خیلی منفی از نظر بازی و داستان <sep>
<s>نمونه دیدگاه هم خوب هم بد از نظر داستان و بازی <sep>
<s>نمونه دیدگاه هم خوب هم بد از نظر داستان و بازی و کارگردانی <sep>
<s>نمونه دیدگاه منفی از نظر بازی و داستان <sep>
<s>نمونه دیدگاه خوب از نظر فیلمبرداری و صحنه و موسیقی <sep>
<s>نمونه دیدگاه هم خوب هم بد از نظر داستان و کارگردانی <sep>
<s>نمونه دیدگاه هم خوب هم بد از نظر داستان و کارگردانی و بازی <sep>
<s>نمونه دیدگاه نظری ندارم از نظر بازی <sep>
<s>نمونه دیدگاه منفی از نظر داستان و کارگردانی <sep>
<s>نمونه دیدگاه هم خوب هم بد از نظر داستان و بازی و صحنه <sep>
<s>نمونه دیدگاه خوب از نظر کارگردانی و داستان و بازی و فیلمبرداری <sep>
<s>نمونه دیدگاه خوب از نظر بازی و صحنه و داستان <sep>
<s>نمونه دیدگاه خیلی خوب از نظر بازی و صحنه و داستان <sep>
<s>نمونه دیدگاه خیلی خوب از نظر بازی و موسیقی و فیلمبرداری <sep>
<s>نمونه دیدگاه خیلی خوب از نظر کارگردانی و صحنه <sep>
<s>نمونه دیدگاه خیلی خوب از نظر فیلمبرداری و صحنه و داستان و کارگردانی <sep>
<s>نمونه دیدگاه منفی از نظر کارگردانی و بازی <sep>
<s>نمونه دیدگاه منفی از نظر کارگردانی <sep>
<s>نمونه دیدگاه هم خوب هم بد از نظر داستان و فیلمبرداری <sep>
<s>نمونه دیدگاه خیلی خوب از نظر کارگردانی و بازی و داستان <sep>
<s>نمونه دیدگاه خیلی خوب از نظر فیلمبرداری و بازی و داستان <sep>
<s>نمونه دیدگاه خیلی خوب از نظر کارگردانی و بازی و داستان و صحنه <sep>
<s>نمونه دیدگاه هم خوب هم بد از نظر موسیقی و کارگردانی <sep>
<s>نمونه دیدگاه هم خوب هم بد از نظر کارگردانی و داستان <sep>
<s>نمونه دیدگاه خیلی خوب از نظر موسیقی و صحنه <sep>
<s>نمونه دیدگاه هم خوب هم بد از نظر صحنه و فیلمبرداری و داستان و بازی <sep>
<s>نمونه دیدگاه خیلی خوب از نظر بازی و داستان و موسیقی و فیلمبرداری <sep>
<s>نمونه دیدگاه خیلی خوب از نظر بازی و فیلمبرداری <sep>
<s>نمونه دیدگاه خیلی منفی از نظر کارگردانی و صدا و صحنه و داستان <sep>
<s>نمونه دیدگاه خوب از نظر داستان و کارگردانی و بازی <sep>
<s>نمونه دیدگاه منفی از نظر داستان و بازی و کارگردانی <sep>
<s>نمونه دیدگاه خوب از نظر داستان و بازی و موسیقی <sep>
<s>نمونه دیدگاه خیلی خوب از نظر بازی و کارگردانی <sep>
<s>نمونه دیدگاه هم خوب هم بد از نظر کارگردانی <sep>
<s>نمونه دیدگاه خیلی منفی از نظر کارگردانی و بازی و صحنه <sep>
<s>نمونه دیدگاه هم خوب هم بد از نظر کارگردانی و بازی <sep>
<s>نمونه دیدگاه هم خوب هم بد از نظر صحنه و فیلمبرداری و داستان <sep>
<s>نمونه دیدگاه خوب از نظر موسیقی و داستان <sep>
<s>نمونه دیدگاه منفی از نظر موسیقی و بازی و داستان <sep>
<s>نمونه دیدگاه خیلی خوب از نظر صدا و بازی <sep>
<s>نمونه دیدگاه خیلی خوب از نظر بازی و صحنه و فیلمبرداری <sep>
<s>نمونه دیدگاه خیلی منفی از نظر بازی و فیلمبرداری و داستان و کارگردانی <sep>
<s>نمونه دیدگاه خیلی منفی از نظر صحنه <sep>
<s>نمونه دیدگاه منفی از نظر داستان و صحنه <sep>
<s>نمونه دیدگاه منفی از نظر بازی و صحنه و صدا <sep>
<s>نمونه دیدگاه خیلی منفی از نظر فیلمبرداری و صدا <sep>
<s>نمونه دیدگاه خیلی خوب از نظر موسیقی <sep>
<s>نمونه دیدگاه خوب از نظر بازی و کارگردانی و داستان <sep>
<s>نمونه دیدگاه خیلی خوب از نظر بازی و فیلمبرداری و موسیقی و کارگردانی و داستان <sep>
<s>نمونه دیدگاه هم خوب هم بد از نظر فیلمبرداری و داستان و بازی <sep>
<s>نمونه دیدگاه منفی از نظر صحنه و فیلمبرداری و داستان <sep>
<s>نمونه دیدگاه خیلی خوب از نظر بازی و کارگردانی و داستان <sep>
```
## Questions?
Post a Github issue on the [ParsGPT2 Issues](https://github.com/hooshvare/parsgpt/issues) repo.
|
HScomcom/gpt2-lovecraft
|
HScomcom
| 2021-05-21T10:38:11Z | 9 | 1 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:04Z |
### Model information
Fine tuning data: https://www.kaggle.com/bennijesus/lovecraft-fiction
License: CC0: Public Domain
Base model: gpt-2 large
Epoch: 30
Train runtime: 10307.3488 secs
Loss: 0.0292
API page: [Ainize](https://ainize.ai/fpem123/GPT2-LoveCraft?branch=master)
Demo page: [End-point](https://master-gpt2-love-craft-fpem123.endpoint.ainize.ai/)
### ===Teachable NLP===
To train a GPT-2 model, write code and require GPU resources, but can easily fine-tune and get an API to use the model here for free.
Teachable NLP: [Teachable NLP](https://ainize.ai/teachable-nlp)
Tutorial: [Tutorial](https://forum.ainetwork.ai/t/teachable-nlp-how-to-use-teachable-nlp/65?utm_source=community&utm_medium=huggingface&utm_campaign=model&utm_content=teachable%20nlp)
And my other lovecraft model: [showcase](https://forum.ainetwork.ai/t/teachable-nlp-gpt-2-lovecraft/71)
|
HScomcom/gpt2-fairytales
|
HScomcom
| 2021-05-21T10:16:43Z | 11 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:04Z |
### Model information
Fine tuning data: https://www.kaggle.com/cuddlefish/fairy-tales
License: CC0: Public Domain
Base model: gpt-2 large
Epoch: 30
Train runtime: 17861.6048 secs
Loss: 0.0412
API page: [Ainize](https://ainize.ai/fpem123/GPT2-FairyTales?branch=master)
Demo page: [End-point](https://master-gpt2-fairy-tales-fpem123.endpoint.ainize.ai/)
### ===Teachable NLP=== ###
To train a GPT-2 model, write code and require GPU resources, but can easily fine-tune and get an API to use the model here for free.
Teachable NLP: [Teachable NLP](https://ainize.ai/teachable-nlp)
Tutorial: [Tutorial](https://forum.ainetwork.ai/t/teachable-nlp-how-to-use-teachable-nlp/65?utm_source=community&utm_medium=huggingface&utm_campaign=model&utm_content=teachable%20nlp)
And my other fairytale model: [showcase](https://forum.ainetwork.ai/t/teachable-nlp-gpt-2-fairy-tales/68)
|
HScomcom/gpt2-MyLittlePony
|
HScomcom
| 2021-05-21T10:09:36Z | 12 | 1 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:04Z |
The model that generates the My little pony script
Fine tuning data: [Kaggle](https://www.kaggle.com/liury123/my-little-pony-transcript?select=clean_dialog.csv)
API page: [Ainize](https://ainize.ai/fpem123/GPT2-MyLittlePony)
Demo page: [End point](https://master-gpt2-my-little-pony-fpem123.endpoint.ainize.ai/)
### Model information
Base model: gpt-2 large
Epoch: 30
Train runtime: 4943.9641 secs
Loss: 0.0291
###===Teachable NLP===
To train a GPT-2 model, write code and require GPU resources, but can easily fine-tune and get an API to use the model here for free.
Teachable NLP: [Teachable NLP](https://ainize.ai/teachable-nlp)
Tutorial: [Tutorial](https://forum.ainetwork.ai/t/teachable-nlp-how-to-use-teachable-nlp/65?utm_source=community&utm_medium=huggingface&utm_campaign=model&utm_content=teachable%20nlp)
|
HJK/PickupLineGenerator
|
HJK
| 2021-05-21T10:05:21Z | 12 | 1 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:04Z |
basically, it makes pickup lines
https://huggingface.co/gpt2
|
lg/ghpy_40k
|
lg
| 2021-05-20T23:37:47Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"endpoints_compatible",
"region:us"
] | null | 2022-03-02T23:29:05Z |
# This model is probably not what you're looking for.
|
lg/openinstruct_1k1
|
lg
| 2021-05-20T23:37:33Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt_neo",
"text-generation",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
# This model is probably not what you're looking for.
|
lg/fexp_1
|
lg
| 2021-05-20T23:37:11Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt_neo",
"text-generation",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
# This model is probably not what you're looking for.
|
verissimomanoel/RobertaTwitterBR
|
verissimomanoel
| 2021-05-20T22:53:32Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"roberta",
"fill-mask",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:05Z |
### Twitter RoBERTa BR
This is a RoBERTa Twitter in Portuguese model trained on ~7M tweets.
The results will be posted in the future.
### Example of using
```
tokenizer = AutoTokenizer.from_pretrained("verissimomanoel/RobertaTwitterBR")
model = AutoModel.from_pretrained("verissimomanoel/RobertaTwitterBR")
```
|
typeform/distilroberta-base-v2
|
typeform
| 2021-05-20T22:46:35Z | 91 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"roberta",
"fill-mask",
"en",
"dataset:openwebtext",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:05Z |
---
language: en
license: apache-2.0
datasets:
- openwebtext
---
# DistilRoBERTa base model
Forked from https://huggingface.co/distilroberta-base
|
tlemberger/sd-ner
|
tlemberger
| 2021-05-20T22:31:05Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"roberta",
"token-classification",
"token classification",
"dataset:EMBO/sd-panels",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-03-02T23:29:05Z |
---
language:
- english
thumbnail:
tags:
- token classification
license:
datasets:
- EMBO/sd-panels
metrics:
-
---
# sd-ner
## Model description
This model is a [RoBERTa base model](https://huggingface.co/roberta-base) that was further trained using a masked language modeling task on a compendium of english scientific textual examples from the life sciences using the [BioLang dataset](https://huggingface.co/datasets/EMBO/biolang) and fine-tuned for token classification on the SourceData [sd-panels](https://huggingface.co/datasets/EMBO/sd-panels) dataset to perform Named Entity Recognition of bioentities.
## Intended uses & limitations
#### How to use
The intended use of this model is for Named Entity Recognition of biological entitie used in SourceData annotations (https://sourcedata.embo.org), including small molecules, gene products (genes and proteins), subcellular components, cell line and cell types, organ and tissues, species as well as experimental methods.
To have a quick check of the model:
```python
from transformers import pipeline, RobertaTokenizerFast, RobertaForTokenClassification
example = """<s> F. Western blot of input and eluates of Upf1 domains purification in a Nmd4-HA strain. The band with the # might corresponds to a dimer of Upf1-CH, bands marked with a star correspond to residual signal with the anti-HA antibodies (Nmd4). Fragments in the eluate have a smaller size because the protein A part of the tag was removed by digestion with the TEV protease. G6PDH served as a loading control in the input samples </s>"""
tokenizer = RobertaTokenizerFast.from_pretrained('roberta-base', max_len=512)
model = RobertaForTokenClassification.from_pretrained('EMBO/sd-ner')
ner = pipeline('ner', model, tokenizer=tokenizer)
res = ner(example)
for r in res:
print(r['word'], r['entity'])
```
#### Limitations and bias
The model must be used with the `roberta-base` tokenizer.
## Training data
The model was trained for token classification using the [EMBO/sd-panels dataset](https://huggingface.co/datasets/EMBO/biolang) wich includes manually annotated examples.
## Training procedure
The training was run on a NVIDIA DGX Station with 4XTesla V100 GPUs.
Training code is available at https://github.com/source-data/soda-roberta
- Command: `python -m tokcl.train /data/json/sd_panels NER --num_train_epochs=3.5`
- Tokenizer vocab size: 50265
- Training data: EMBO/biolang MLM
- Training with 31410 examples.
- Evaluating on 8861 examples.
- Training on 15 features: O, I-SMALL_MOLECULE, B-SMALL_MOLECULE, I-GENEPROD, B-GENEPROD, I-SUBCELLULAR, B-SUBCELLULAR, I-CELL, B-CELL, I-TISSUE, B-TISSUE, I-ORGANISM, B-ORGANISM, I-EXP_ASSAY, B-EXP_ASSAY
- Epochs: 3.5
- `per_device_train_batch_size`: 32
- `per_device_eval_batch_size`: 32
- `learning_rate`: 0.0001
- `weight_decay`: 0.0
- `adam_beta1`: 0.9
- `adam_beta2`: 0.999
- `adam_epsilon`: 1e-08
- `max_grad_norm`: 1.0
## Eval results
On test set with `sklearn.metrics`:
```
precision recall f1-score support
CELL 0.77 0.81 0.79 3477
EXP_ASSAY 0.71 0.70 0.71 7049
GENEPROD 0.86 0.90 0.88 16140
ORGANISM 0.80 0.82 0.81 2759
SMALL_MOLECULE 0.78 0.82 0.80 4446
SUBCELLULAR 0.71 0.75 0.73 2125
TISSUE 0.70 0.75 0.73 1971
micro avg 0.79 0.82 0.81 37967
macro avg 0.76 0.79 0.78 37967
weighted avg 0.79 0.82 0.81 37967
```
|
textattack/roberta-base-ag-news
|
textattack
| 2021-05-20T22:15:20Z | 487 | 2 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"roberta",
"text-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
## TextAttack Model CardThis `roberta-base` model was fine-tuned for sequence classification using TextAttack
and the ag_news dataset loaded using the `nlp` library. The model was fine-tuned
for 5 epochs with a batch size of 16, a learning
rate of 5e-05, and a maximum sequence length of 128.
Since this was a classification task, the model was trained with a cross-entropy loss function.
The best score the model achieved on this task was 0.9469736842105263, as measured by the
eval set accuracy, found after 4 epochs.
For more information, check out [TextAttack on Github](https://github.com/QData/TextAttack).
|
textattack/roberta-base-WNLI
|
textattack
| 2021-05-20T22:13:50Z | 42 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"roberta",
"text-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
## TextAttack Model Card
This `roberta-base` model was fine-tuned for sequence classification using TextAttack
and the glue dataset loaded using the `nlp` library. The model was fine-tuned
for 5 epochs with a batch size of 16, a learning
rate of 5e-05, and a maximum sequence length of 256.
Since this was a classification task, the model was trained with a cross-entropy loss function.
The best score the model achieved on this task was 0.5633802816901409, as measured by the
eval set accuracy, found after 0 epoch.
For more information, check out [TextAttack on Github](https://github.com/QData/TextAttack).
|
textattack/roberta-base-CoLA
|
textattack
| 2021-05-20T22:05:35Z | 48,829 | 17 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"roberta",
"text-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
## TextAttack Model Cardand the glue dataset loaded using the `nlp` library. The model was fine-tuned
for 5 epochs with a batch size of 32, a learning
rate of 2e-05, and a maximum sequence length of 128.
Since this was a classification task, the model was trained with a cross-entropy loss function.
The best score the model achieved on this task was 0.850431447746884, as measured by the
eval set accuracy, found after 1 epoch.
For more information, check out [TextAttack on Github](https://github.com/QData/TextAttack).
|
pedropei/question-intimacy
|
pedropei
| 2021-05-20T19:25:02Z | 28 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"roberta",
"text-classification",
"en",
"autotrain_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
---
language:
- en
inference: false
---
|
patrickvonplaten/norwegian-roberta-large
|
patrickvonplaten
| 2021-05-20T19:15:37Z | 3 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"roberta",
"fill-mask",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:05Z |
## Roberta-Large
This repo trains [roberta-large](https://huggingface.co/roberta-large) from scratch on the [Norwegian training subset of Oscar](https://oscar-corpus.com/) containing roughly 4.7 GB of data.
A ByteLevelBPETokenizer as shown in [this]( ) blog post was trained on the whole [Norwegian training subset of Oscar](https://oscar-corpus.com/).
Training is done on a TPUv3-8 in Flax. The training script as well as the script to create a tokenizer are attached below.
### Run 1
```
--weight_decay="0.01"
--max_seq_length="128"
--train_batch_size="1048"
--eval_batch_size="1048"
--learning_rate="1e-3"
--warmup_steps="2000"
--pad_to_max_length
--num_train_epochs="12"
--adam_beta1="0.9"
--adam_beta2="0.98"
```
Trained for 12 epochs with each epoch including 8005 steps => Total of 96K steps. 1 epoch + eval takes roughly 2 hours 40 minutes => trained in total for 1 day and 8 hours. Final loss was 3.695.
**Acc**:

**Loss**:

### Run 2
```
--weight_decay="0.01"
--max_seq_length="128"
--train_batch_size="1048"
--eval_batch_size="1048"
--learning_rate="5e-3"
--warmup_steps="2000"
--pad_to_max_length
--num_train_epochs="7"
--adam_beta1="0.9"
--adam_beta2="0.98"
```
Trained for 7 epochs with each epoch including 8005 steps => Total of 96K steps. 1 epoch + eval takes roughly 2 hours 40 minutes => trained in total for 18 hours. Final loss was 2.216 and accuracy 0.58.
**Acc**:

**Loss**:

|
nyu-mll/roberta-base-1B-3
|
nyu-mll
| 2021-05-20T19:05:43Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"roberta",
"fill-mask",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:05Z |
# RoBERTa Pretrained on Smaller Datasets
We pretrain RoBERTa on smaller datasets (1M, 10M, 100M, 1B tokens). We release 3 models with lowest perplexities for each pretraining data size out of 25 runs (or 10 in the case of 1B tokens). The pretraining data reproduces that of BERT: We combine English Wikipedia and a reproduction of BookCorpus using texts from smashwords in a ratio of approximately 3:1.
### Hyperparameters and Validation Perplexity
The hyperparameters and validation perplexities corresponding to each model are as follows:
| Model Name | Training Size | Model Size | Max Steps | Batch Size | Validation Perplexity |
|--------------------------|---------------|------------|-----------|------------|-----------------------|
| [roberta-base-1B-1][link-roberta-base-1B-1] | 1B | BASE | 100K | 512 | 3.93 |
| [roberta-base-1B-2][link-roberta-base-1B-2] | 1B | BASE | 31K | 1024 | 4.25 |
| [roberta-base-1B-3][link-roberta-base-1B-3] | 1B | BASE | 31K | 4096 | 3.84 |
| [roberta-base-100M-1][link-roberta-base-100M-1] | 100M | BASE | 100K | 512 | 4.99 |
| [roberta-base-100M-2][link-roberta-base-100M-2] | 100M | BASE | 31K | 1024 | 4.61 |
| [roberta-base-100M-3][link-roberta-base-100M-3] | 100M | BASE | 31K | 512 | 5.02 |
| [roberta-base-10M-1][link-roberta-base-10M-1] | 10M | BASE | 10K | 1024 | 11.31 |
| [roberta-base-10M-2][link-roberta-base-10M-2] | 10M | BASE | 10K | 512 | 10.78 |
| [roberta-base-10M-3][link-roberta-base-10M-3] | 10M | BASE | 31K | 512 | 11.58 |
| [roberta-med-small-1M-1][link-roberta-med-small-1M-1] | 1M | MED-SMALL | 100K | 512 | 153.38 |
| [roberta-med-small-1M-2][link-roberta-med-small-1M-2] | 1M | MED-SMALL | 10K | 512 | 134.18 |
| [roberta-med-small-1M-3][link-roberta-med-small-1M-3] | 1M | MED-SMALL | 31K | 512 | 139.39 |
The hyperparameters corresponding to model sizes mentioned above are as follows:
| Model Size | L | AH | HS | FFN | P |
|------------|----|----|-----|------|------|
| BASE | 12 | 12 | 768 | 3072 | 125M |
| MED-SMALL | 6 | 8 | 512 | 2048 | 45M |
(AH = number of attention heads; HS = hidden size; FFN = feedforward network dimension; P = number of parameters.)
For other hyperparameters, we select:
- Peak Learning rate: 5e-4
- Warmup Steps: 6% of max steps
- Dropout: 0.1
[link-roberta-med-small-1M-1]: https://huggingface.co/nyu-mll/roberta-med-small-1M-1
[link-roberta-med-small-1M-2]: https://huggingface.co/nyu-mll/roberta-med-small-1M-2
[link-roberta-med-small-1M-3]: https://huggingface.co/nyu-mll/roberta-med-small-1M-3
[link-roberta-base-10M-1]: https://huggingface.co/nyu-mll/roberta-base-10M-1
[link-roberta-base-10M-2]: https://huggingface.co/nyu-mll/roberta-base-10M-2
[link-roberta-base-10M-3]: https://huggingface.co/nyu-mll/roberta-base-10M-3
[link-roberta-base-100M-1]: https://huggingface.co/nyu-mll/roberta-base-100M-1
[link-roberta-base-100M-2]: https://huggingface.co/nyu-mll/roberta-base-100M-2
[link-roberta-base-100M-3]: https://huggingface.co/nyu-mll/roberta-base-100M-3
[link-roberta-base-1B-1]: https://huggingface.co/nyu-mll/roberta-base-1B-1
[link-roberta-base-1B-2]: https://huggingface.co/nyu-mll/roberta-base-1B-2
[link-roberta-base-1B-3]: https://huggingface.co/nyu-mll/roberta-base-1B-3
|
nyu-mll/roberta-base-1B-2
|
nyu-mll
| 2021-05-20T19:04:39Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"roberta",
"fill-mask",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:05Z |
# RoBERTa Pretrained on Smaller Datasets
We pretrain RoBERTa on smaller datasets (1M, 10M, 100M, 1B tokens). We release 3 models with lowest perplexities for each pretraining data size out of 25 runs (or 10 in the case of 1B tokens). The pretraining data reproduces that of BERT: We combine English Wikipedia and a reproduction of BookCorpus using texts from smashwords in a ratio of approximately 3:1.
### Hyperparameters and Validation Perplexity
The hyperparameters and validation perplexities corresponding to each model are as follows:
| Model Name | Training Size | Model Size | Max Steps | Batch Size | Validation Perplexity |
|--------------------------|---------------|------------|-----------|------------|-----------------------|
| [roberta-base-1B-1][link-roberta-base-1B-1] | 1B | BASE | 100K | 512 | 3.93 |
| [roberta-base-1B-2][link-roberta-base-1B-2] | 1B | BASE | 31K | 1024 | 4.25 |
| [roberta-base-1B-3][link-roberta-base-1B-3] | 1B | BASE | 31K | 4096 | 3.84 |
| [roberta-base-100M-1][link-roberta-base-100M-1] | 100M | BASE | 100K | 512 | 4.99 |
| [roberta-base-100M-2][link-roberta-base-100M-2] | 100M | BASE | 31K | 1024 | 4.61 |
| [roberta-base-100M-3][link-roberta-base-100M-3] | 100M | BASE | 31K | 512 | 5.02 |
| [roberta-base-10M-1][link-roberta-base-10M-1] | 10M | BASE | 10K | 1024 | 11.31 |
| [roberta-base-10M-2][link-roberta-base-10M-2] | 10M | BASE | 10K | 512 | 10.78 |
| [roberta-base-10M-3][link-roberta-base-10M-3] | 10M | BASE | 31K | 512 | 11.58 |
| [roberta-med-small-1M-1][link-roberta-med-small-1M-1] | 1M | MED-SMALL | 100K | 512 | 153.38 |
| [roberta-med-small-1M-2][link-roberta-med-small-1M-2] | 1M | MED-SMALL | 10K | 512 | 134.18 |
| [roberta-med-small-1M-3][link-roberta-med-small-1M-3] | 1M | MED-SMALL | 31K | 512 | 139.39 |
The hyperparameters corresponding to model sizes mentioned above are as follows:
| Model Size | L | AH | HS | FFN | P |
|------------|----|----|-----|------|------|
| BASE | 12 | 12 | 768 | 3072 | 125M |
| MED-SMALL | 6 | 8 | 512 | 2048 | 45M |
(AH = number of attention heads; HS = hidden size; FFN = feedforward network dimension; P = number of parameters.)
For other hyperparameters, we select:
- Peak Learning rate: 5e-4
- Warmup Steps: 6% of max steps
- Dropout: 0.1
[link-roberta-med-small-1M-1]: https://huggingface.co/nyu-mll/roberta-med-small-1M-1
[link-roberta-med-small-1M-2]: https://huggingface.co/nyu-mll/roberta-med-small-1M-2
[link-roberta-med-small-1M-3]: https://huggingface.co/nyu-mll/roberta-med-small-1M-3
[link-roberta-base-10M-1]: https://huggingface.co/nyu-mll/roberta-base-10M-1
[link-roberta-base-10M-2]: https://huggingface.co/nyu-mll/roberta-base-10M-2
[link-roberta-base-10M-3]: https://huggingface.co/nyu-mll/roberta-base-10M-3
[link-roberta-base-100M-1]: https://huggingface.co/nyu-mll/roberta-base-100M-1
[link-roberta-base-100M-2]: https://huggingface.co/nyu-mll/roberta-base-100M-2
[link-roberta-base-100M-3]: https://huggingface.co/nyu-mll/roberta-base-100M-3
[link-roberta-base-1B-1]: https://huggingface.co/nyu-mll/roberta-base-1B-1
[link-roberta-base-1B-2]: https://huggingface.co/nyu-mll/roberta-base-1B-2
[link-roberta-base-1B-3]: https://huggingface.co/nyu-mll/roberta-base-1B-3
|
nyu-mll/roberta-base-10M-3
|
nyu-mll
| 2021-05-20T19:00:36Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"roberta",
"fill-mask",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:05Z |
# RoBERTa Pretrained on Smaller Datasets
We pretrain RoBERTa on smaller datasets (1M, 10M, 100M, 1B tokens). We release 3 models with lowest perplexities for each pretraining data size out of 25 runs (or 10 in the case of 1B tokens). The pretraining data reproduces that of BERT: We combine English Wikipedia and a reproduction of BookCorpus using texts from smashwords in a ratio of approximately 3:1.
### Hyperparameters and Validation Perplexity
The hyperparameters and validation perplexities corresponding to each model are as follows:
| Model Name | Training Size | Model Size | Max Steps | Batch Size | Validation Perplexity |
|--------------------------|---------------|------------|-----------|------------|-----------------------|
| [roberta-base-1B-1][link-roberta-base-1B-1] | 1B | BASE | 100K | 512 | 3.93 |
| [roberta-base-1B-2][link-roberta-base-1B-2] | 1B | BASE | 31K | 1024 | 4.25 |
| [roberta-base-1B-3][link-roberta-base-1B-3] | 1B | BASE | 31K | 4096 | 3.84 |
| [roberta-base-100M-1][link-roberta-base-100M-1] | 100M | BASE | 100K | 512 | 4.99 |
| [roberta-base-100M-2][link-roberta-base-100M-2] | 100M | BASE | 31K | 1024 | 4.61 |
| [roberta-base-100M-3][link-roberta-base-100M-3] | 100M | BASE | 31K | 512 | 5.02 |
| [roberta-base-10M-1][link-roberta-base-10M-1] | 10M | BASE | 10K | 1024 | 11.31 |
| [roberta-base-10M-2][link-roberta-base-10M-2] | 10M | BASE | 10K | 512 | 10.78 |
| [roberta-base-10M-3][link-roberta-base-10M-3] | 10M | BASE | 31K | 512 | 11.58 |
| [roberta-med-small-1M-1][link-roberta-med-small-1M-1] | 1M | MED-SMALL | 100K | 512 | 153.38 |
| [roberta-med-small-1M-2][link-roberta-med-small-1M-2] | 1M | MED-SMALL | 10K | 512 | 134.18 |
| [roberta-med-small-1M-3][link-roberta-med-small-1M-3] | 1M | MED-SMALL | 31K | 512 | 139.39 |
The hyperparameters corresponding to model sizes mentioned above are as follows:
| Model Size | L | AH | HS | FFN | P |
|------------|----|----|-----|------|------|
| BASE | 12 | 12 | 768 | 3072 | 125M |
| MED-SMALL | 6 | 8 | 512 | 2048 | 45M |
(AH = number of attention heads; HS = hidden size; FFN = feedforward network dimension; P = number of parameters.)
For other hyperparameters, we select:
- Peak Learning rate: 5e-4
- Warmup Steps: 6% of max steps
- Dropout: 0.1
[link-roberta-med-small-1M-1]: https://huggingface.co/nyu-mll/roberta-med-small-1M-1
[link-roberta-med-small-1M-2]: https://huggingface.co/nyu-mll/roberta-med-small-1M-2
[link-roberta-med-small-1M-3]: https://huggingface.co/nyu-mll/roberta-med-small-1M-3
[link-roberta-base-10M-1]: https://huggingface.co/nyu-mll/roberta-base-10M-1
[link-roberta-base-10M-2]: https://huggingface.co/nyu-mll/roberta-base-10M-2
[link-roberta-base-10M-3]: https://huggingface.co/nyu-mll/roberta-base-10M-3
[link-roberta-base-100M-1]: https://huggingface.co/nyu-mll/roberta-base-100M-1
[link-roberta-base-100M-2]: https://huggingface.co/nyu-mll/roberta-base-100M-2
[link-roberta-base-100M-3]: https://huggingface.co/nyu-mll/roberta-base-100M-3
[link-roberta-base-1B-1]: https://huggingface.co/nyu-mll/roberta-base-1B-1
[link-roberta-base-1B-2]: https://huggingface.co/nyu-mll/roberta-base-1B-2
[link-roberta-base-1B-3]: https://huggingface.co/nyu-mll/roberta-base-1B-3
|
nyu-mll/roberta-base-10M-2
|
nyu-mll
| 2021-05-20T18:58:09Z | 7 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"roberta",
"fill-mask",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:05Z |
# RoBERTa Pretrained on Smaller Datasets
We pretrain RoBERTa on smaller datasets (1M, 10M, 100M, 1B tokens). We release 3 models with lowest perplexities for each pretraining data size out of 25 runs (or 10 in the case of 1B tokens). The pretraining data reproduces that of BERT: We combine English Wikipedia and a reproduction of BookCorpus using texts from smashwords in a ratio of approximately 3:1.
### Hyperparameters and Validation Perplexity
The hyperparameters and validation perplexities corresponding to each model are as follows:
| Model Name | Training Size | Model Size | Max Steps | Batch Size | Validation Perplexity |
|--------------------------|---------------|------------|-----------|------------|-----------------------|
| [roberta-base-1B-1][link-roberta-base-1B-1] | 1B | BASE | 100K | 512 | 3.93 |
| [roberta-base-1B-2][link-roberta-base-1B-2] | 1B | BASE | 31K | 1024 | 4.25 |
| [roberta-base-1B-3][link-roberta-base-1B-3] | 1B | BASE | 31K | 4096 | 3.84 |
| [roberta-base-100M-1][link-roberta-base-100M-1] | 100M | BASE | 100K | 512 | 4.99 |
| [roberta-base-100M-2][link-roberta-base-100M-2] | 100M | BASE | 31K | 1024 | 4.61 |
| [roberta-base-100M-3][link-roberta-base-100M-3] | 100M | BASE | 31K | 512 | 5.02 |
| [roberta-base-10M-1][link-roberta-base-10M-1] | 10M | BASE | 10K | 1024 | 11.31 |
| [roberta-base-10M-2][link-roberta-base-10M-2] | 10M | BASE | 10K | 512 | 10.78 |
| [roberta-base-10M-3][link-roberta-base-10M-3] | 10M | BASE | 31K | 512 | 11.58 |
| [roberta-med-small-1M-1][link-roberta-med-small-1M-1] | 1M | MED-SMALL | 100K | 512 | 153.38 |
| [roberta-med-small-1M-2][link-roberta-med-small-1M-2] | 1M | MED-SMALL | 10K | 512 | 134.18 |
| [roberta-med-small-1M-3][link-roberta-med-small-1M-3] | 1M | MED-SMALL | 31K | 512 | 139.39 |
The hyperparameters corresponding to model sizes mentioned above are as follows:
| Model Size | L | AH | HS | FFN | P |
|------------|----|----|-----|------|------|
| BASE | 12 | 12 | 768 | 3072 | 125M |
| MED-SMALL | 6 | 8 | 512 | 2048 | 45M |
(AH = number of attention heads; HS = hidden size; FFN = feedforward network dimension; P = number of parameters.)
For other hyperparameters, we select:
- Peak Learning rate: 5e-4
- Warmup Steps: 6% of max steps
- Dropout: 0.1
[link-roberta-med-small-1M-1]: https://huggingface.co/nyu-mll/roberta-med-small-1M-1
[link-roberta-med-small-1M-2]: https://huggingface.co/nyu-mll/roberta-med-small-1M-2
[link-roberta-med-small-1M-3]: https://huggingface.co/nyu-mll/roberta-med-small-1M-3
[link-roberta-base-10M-1]: https://huggingface.co/nyu-mll/roberta-base-10M-1
[link-roberta-base-10M-2]: https://huggingface.co/nyu-mll/roberta-base-10M-2
[link-roberta-base-10M-3]: https://huggingface.co/nyu-mll/roberta-base-10M-3
[link-roberta-base-100M-1]: https://huggingface.co/nyu-mll/roberta-base-100M-1
[link-roberta-base-100M-2]: https://huggingface.co/nyu-mll/roberta-base-100M-2
[link-roberta-base-100M-3]: https://huggingface.co/nyu-mll/roberta-base-100M-3
[link-roberta-base-1B-1]: https://huggingface.co/nyu-mll/roberta-base-1B-1
[link-roberta-base-1B-2]: https://huggingface.co/nyu-mll/roberta-base-1B-2
[link-roberta-base-1B-3]: https://huggingface.co/nyu-mll/roberta-base-1B-3
|
nyu-mll/roberta-base-10M-1
|
nyu-mll
| 2021-05-20T18:57:10Z | 8 | 1 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"roberta",
"fill-mask",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:05Z |
# RoBERTa Pretrained on Smaller Datasets
We pretrain RoBERTa on smaller datasets (1M, 10M, 100M, 1B tokens). We release 3 models with lowest perplexities for each pretraining data size out of 25 runs (or 10 in the case of 1B tokens). The pretraining data reproduces that of BERT: We combine English Wikipedia and a reproduction of BookCorpus using texts from smashwords in a ratio of approximately 3:1.
### Hyperparameters and Validation Perplexity
The hyperparameters and validation perplexities corresponding to each model are as follows:
| Model Name | Training Size | Model Size | Max Steps | Batch Size | Validation Perplexity |
|--------------------------|---------------|------------|-----------|------------|-----------------------|
| [roberta-base-1B-1][link-roberta-base-1B-1] | 1B | BASE | 100K | 512 | 3.93 |
| [roberta-base-1B-2][link-roberta-base-1B-2] | 1B | BASE | 31K | 1024 | 4.25 |
| [roberta-base-1B-3][link-roberta-base-1B-3] | 1B | BASE | 31K | 4096 | 3.84 |
| [roberta-base-100M-1][link-roberta-base-100M-1] | 100M | BASE | 100K | 512 | 4.99 |
| [roberta-base-100M-2][link-roberta-base-100M-2] | 100M | BASE | 31K | 1024 | 4.61 |
| [roberta-base-100M-3][link-roberta-base-100M-3] | 100M | BASE | 31K | 512 | 5.02 |
| [roberta-base-10M-1][link-roberta-base-10M-1] | 10M | BASE | 10K | 1024 | 11.31 |
| [roberta-base-10M-2][link-roberta-base-10M-2] | 10M | BASE | 10K | 512 | 10.78 |
| [roberta-base-10M-3][link-roberta-base-10M-3] | 10M | BASE | 31K | 512 | 11.58 |
| [roberta-med-small-1M-1][link-roberta-med-small-1M-1] | 1M | MED-SMALL | 100K | 512 | 153.38 |
| [roberta-med-small-1M-2][link-roberta-med-small-1M-2] | 1M | MED-SMALL | 10K | 512 | 134.18 |
| [roberta-med-small-1M-3][link-roberta-med-small-1M-3] | 1M | MED-SMALL | 31K | 512 | 139.39 |
The hyperparameters corresponding to model sizes mentioned above are as follows:
| Model Size | L | AH | HS | FFN | P |
|------------|----|----|-----|------|------|
| BASE | 12 | 12 | 768 | 3072 | 125M |
| MED-SMALL | 6 | 8 | 512 | 2048 | 45M |
(AH = number of attention heads; HS = hidden size; FFN = feedforward network dimension; P = number of parameters.)
For other hyperparameters, we select:
- Peak Learning rate: 5e-4
- Warmup Steps: 6% of max steps
- Dropout: 0.1
[link-roberta-med-small-1M-1]: https://huggingface.co/nyu-mll/roberta-med-small-1M-1
[link-roberta-med-small-1M-2]: https://huggingface.co/nyu-mll/roberta-med-small-1M-2
[link-roberta-med-small-1M-3]: https://huggingface.co/nyu-mll/roberta-med-small-1M-3
[link-roberta-base-10M-1]: https://huggingface.co/nyu-mll/roberta-base-10M-1
[link-roberta-base-10M-2]: https://huggingface.co/nyu-mll/roberta-base-10M-2
[link-roberta-base-10M-3]: https://huggingface.co/nyu-mll/roberta-base-10M-3
[link-roberta-base-100M-1]: https://huggingface.co/nyu-mll/roberta-base-100M-1
[link-roberta-base-100M-2]: https://huggingface.co/nyu-mll/roberta-base-100M-2
[link-roberta-base-100M-3]: https://huggingface.co/nyu-mll/roberta-base-100M-3
[link-roberta-base-1B-1]: https://huggingface.co/nyu-mll/roberta-base-1B-1
[link-roberta-base-1B-2]: https://huggingface.co/nyu-mll/roberta-base-1B-2
[link-roberta-base-1B-3]: https://huggingface.co/nyu-mll/roberta-base-1B-3
|
nyu-mll/roberta-base-100M-3
|
nyu-mll
| 2021-05-20T18:56:02Z | 15 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"roberta",
"fill-mask",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:05Z |
# RoBERTa Pretrained on Smaller Datasets
We pretrain RoBERTa on smaller datasets (1M, 10M, 100M, 1B tokens). We release 3 models with lowest perplexities for each pretraining data size out of 25 runs (or 10 in the case of 1B tokens). The pretraining data reproduces that of BERT: We combine English Wikipedia and a reproduction of BookCorpus using texts from smashwords in a ratio of approximately 3:1.
### Hyperparameters and Validation Perplexity
The hyperparameters and validation perplexities corresponding to each model are as follows:
| Model Name | Training Size | Model Size | Max Steps | Batch Size | Validation Perplexity |
|--------------------------|---------------|------------|-----------|------------|-----------------------|
| [roberta-base-1B-1][link-roberta-base-1B-1] | 1B | BASE | 100K | 512 | 3.93 |
| [roberta-base-1B-2][link-roberta-base-1B-2] | 1B | BASE | 31K | 1024 | 4.25 |
| [roberta-base-1B-3][link-roberta-base-1B-3] | 1B | BASE | 31K | 4096 | 3.84 |
| [roberta-base-100M-1][link-roberta-base-100M-1] | 100M | BASE | 100K | 512 | 4.99 |
| [roberta-base-100M-2][link-roberta-base-100M-2] | 100M | BASE | 31K | 1024 | 4.61 |
| [roberta-base-100M-3][link-roberta-base-100M-3] | 100M | BASE | 31K | 512 | 5.02 |
| [roberta-base-10M-1][link-roberta-base-10M-1] | 10M | BASE | 10K | 1024 | 11.31 |
| [roberta-base-10M-2][link-roberta-base-10M-2] | 10M | BASE | 10K | 512 | 10.78 |
| [roberta-base-10M-3][link-roberta-base-10M-3] | 10M | BASE | 31K | 512 | 11.58 |
| [roberta-med-small-1M-1][link-roberta-med-small-1M-1] | 1M | MED-SMALL | 100K | 512 | 153.38 |
| [roberta-med-small-1M-2][link-roberta-med-small-1M-2] | 1M | MED-SMALL | 10K | 512 | 134.18 |
| [roberta-med-small-1M-3][link-roberta-med-small-1M-3] | 1M | MED-SMALL | 31K | 512 | 139.39 |
The hyperparameters corresponding to model sizes mentioned above are as follows:
| Model Size | L | AH | HS | FFN | P |
|------------|----|----|-----|------|------|
| BASE | 12 | 12 | 768 | 3072 | 125M |
| MED-SMALL | 6 | 8 | 512 | 2048 | 45M |
(AH = number of attention heads; HS = hidden size; FFN = feedforward network dimension; P = number of parameters.)
For other hyperparameters, we select:
- Peak Learning rate: 5e-4
- Warmup Steps: 6% of max steps
- Dropout: 0.1
[link-roberta-med-small-1M-1]: https://huggingface.co/nyu-mll/roberta-med-small-1M-1
[link-roberta-med-small-1M-2]: https://huggingface.co/nyu-mll/roberta-med-small-1M-2
[link-roberta-med-small-1M-3]: https://huggingface.co/nyu-mll/roberta-med-small-1M-3
[link-roberta-base-10M-1]: https://huggingface.co/nyu-mll/roberta-base-10M-1
[link-roberta-base-10M-2]: https://huggingface.co/nyu-mll/roberta-base-10M-2
[link-roberta-base-10M-3]: https://huggingface.co/nyu-mll/roberta-base-10M-3
[link-roberta-base-100M-1]: https://huggingface.co/nyu-mll/roberta-base-100M-1
[link-roberta-base-100M-2]: https://huggingface.co/nyu-mll/roberta-base-100M-2
[link-roberta-base-100M-3]: https://huggingface.co/nyu-mll/roberta-base-100M-3
[link-roberta-base-1B-1]: https://huggingface.co/nyu-mll/roberta-base-1B-1
[link-roberta-base-1B-2]: https://huggingface.co/nyu-mll/roberta-base-1B-2
[link-roberta-base-1B-3]: https://huggingface.co/nyu-mll/roberta-base-1B-3
|
nyu-mll/roberta-base-100M-2
|
nyu-mll
| 2021-05-20T18:54:59Z | 8 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"roberta",
"fill-mask",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:05Z |
# RoBERTa Pretrained on Smaller Datasets
We pretrain RoBERTa on smaller datasets (1M, 10M, 100M, 1B tokens). We release 3 models with lowest perplexities for each pretraining data size out of 25 runs (or 10 in the case of 1B tokens). The pretraining data reproduces that of BERT: We combine English Wikipedia and a reproduction of BookCorpus using texts from smashwords in a ratio of approximately 3:1.
### Hyperparameters and Validation Perplexity
The hyperparameters and validation perplexities corresponding to each model are as follows:
| Model Name | Training Size | Model Size | Max Steps | Batch Size | Validation Perplexity |
|--------------------------|---------------|------------|-----------|------------|-----------------------|
| [roberta-base-1B-1][link-roberta-base-1B-1] | 1B | BASE | 100K | 512 | 3.93 |
| [roberta-base-1B-2][link-roberta-base-1B-2] | 1B | BASE | 31K | 1024 | 4.25 |
| [roberta-base-1B-3][link-roberta-base-1B-3] | 1B | BASE | 31K | 4096 | 3.84 |
| [roberta-base-100M-1][link-roberta-base-100M-1] | 100M | BASE | 100K | 512 | 4.99 |
| [roberta-base-100M-2][link-roberta-base-100M-2] | 100M | BASE | 31K | 1024 | 4.61 |
| [roberta-base-100M-3][link-roberta-base-100M-3] | 100M | BASE | 31K | 512 | 5.02 |
| [roberta-base-10M-1][link-roberta-base-10M-1] | 10M | BASE | 10K | 1024 | 11.31 |
| [roberta-base-10M-2][link-roberta-base-10M-2] | 10M | BASE | 10K | 512 | 10.78 |
| [roberta-base-10M-3][link-roberta-base-10M-3] | 10M | BASE | 31K | 512 | 11.58 |
| [roberta-med-small-1M-1][link-roberta-med-small-1M-1] | 1M | MED-SMALL | 100K | 512 | 153.38 |
| [roberta-med-small-1M-2][link-roberta-med-small-1M-2] | 1M | MED-SMALL | 10K | 512 | 134.18 |
| [roberta-med-small-1M-3][link-roberta-med-small-1M-3] | 1M | MED-SMALL | 31K | 512 | 139.39 |
The hyperparameters corresponding to model sizes mentioned above are as follows:
| Model Size | L | AH | HS | FFN | P |
|------------|----|----|-----|------|------|
| BASE | 12 | 12 | 768 | 3072 | 125M |
| MED-SMALL | 6 | 8 | 512 | 2048 | 45M |
(AH = number of attention heads; HS = hidden size; FFN = feedforward network dimension; P = number of parameters.)
For other hyperparameters, we select:
- Peak Learning rate: 5e-4
- Warmup Steps: 6% of max steps
- Dropout: 0.1
[link-roberta-med-small-1M-1]: https://huggingface.co/nyu-mll/roberta-med-small-1M-1
[link-roberta-med-small-1M-2]: https://huggingface.co/nyu-mll/roberta-med-small-1M-2
[link-roberta-med-small-1M-3]: https://huggingface.co/nyu-mll/roberta-med-small-1M-3
[link-roberta-base-10M-1]: https://huggingface.co/nyu-mll/roberta-base-10M-1
[link-roberta-base-10M-2]: https://huggingface.co/nyu-mll/roberta-base-10M-2
[link-roberta-base-10M-3]: https://huggingface.co/nyu-mll/roberta-base-10M-3
[link-roberta-base-100M-1]: https://huggingface.co/nyu-mll/roberta-base-100M-1
[link-roberta-base-100M-2]: https://huggingface.co/nyu-mll/roberta-base-100M-2
[link-roberta-base-100M-3]: https://huggingface.co/nyu-mll/roberta-base-100M-3
[link-roberta-base-1B-1]: https://huggingface.co/nyu-mll/roberta-base-1B-1
[link-roberta-base-1B-2]: https://huggingface.co/nyu-mll/roberta-base-1B-2
[link-roberta-base-1B-3]: https://huggingface.co/nyu-mll/roberta-base-1B-3
|
nyu-mll/roberta-base-100M-1
|
nyu-mll
| 2021-05-20T18:53:55Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"roberta",
"fill-mask",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:05Z |
# RoBERTa Pretrained on Smaller Datasets
We pretrain RoBERTa on smaller datasets (1M, 10M, 100M, 1B tokens). We release 3 models with lowest perplexities for each pretraining data size out of 25 runs (or 10 in the case of 1B tokens). The pretraining data reproduces that of BERT: We combine English Wikipedia and a reproduction of BookCorpus using texts from smashwords in a ratio of approximately 3:1.
### Hyperparameters and Validation Perplexity
The hyperparameters and validation perplexities corresponding to each model are as follows:
| Model Name | Training Size | Model Size | Max Steps | Batch Size | Validation Perplexity |
|--------------------------|---------------|------------|-----------|------------|-----------------------|
| [roberta-base-1B-1][link-roberta-base-1B-1] | 1B | BASE | 100K | 512 | 3.93 |
| [roberta-base-1B-2][link-roberta-base-1B-2] | 1B | BASE | 31K | 1024 | 4.25 |
| [roberta-base-1B-3][link-roberta-base-1B-3] | 1B | BASE | 31K | 4096 | 3.84 |
| [roberta-base-100M-1][link-roberta-base-100M-1] | 100M | BASE | 100K | 512 | 4.99 |
| [roberta-base-100M-2][link-roberta-base-100M-2] | 100M | BASE | 31K | 1024 | 4.61 |
| [roberta-base-100M-3][link-roberta-base-100M-3] | 100M | BASE | 31K | 512 | 5.02 |
| [roberta-base-10M-1][link-roberta-base-10M-1] | 10M | BASE | 10K | 1024 | 11.31 |
| [roberta-base-10M-2][link-roberta-base-10M-2] | 10M | BASE | 10K | 512 | 10.78 |
| [roberta-base-10M-3][link-roberta-base-10M-3] | 10M | BASE | 31K | 512 | 11.58 |
| [roberta-med-small-1M-1][link-roberta-med-small-1M-1] | 1M | MED-SMALL | 100K | 512 | 153.38 |
| [roberta-med-small-1M-2][link-roberta-med-small-1M-2] | 1M | MED-SMALL | 10K | 512 | 134.18 |
| [roberta-med-small-1M-3][link-roberta-med-small-1M-3] | 1M | MED-SMALL | 31K | 512 | 139.39 |
The hyperparameters corresponding to model sizes mentioned above are as follows:
| Model Size | L | AH | HS | FFN | P |
|------------|----|----|-----|------|------|
| BASE | 12 | 12 | 768 | 3072 | 125M |
| MED-SMALL | 6 | 8 | 512 | 2048 | 45M |
(AH = number of attention heads; HS = hidden size; FFN = feedforward network dimension; P = number of parameters.)
For other hyperparameters, we select:
- Peak Learning rate: 5e-4
- Warmup Steps: 6% of max steps
- Dropout: 0.1
[link-roberta-med-small-1M-1]: https://huggingface.co/nyu-mll/roberta-med-small-1M-1
[link-roberta-med-small-1M-2]: https://huggingface.co/nyu-mll/roberta-med-small-1M-2
[link-roberta-med-small-1M-3]: https://huggingface.co/nyu-mll/roberta-med-small-1M-3
[link-roberta-base-10M-1]: https://huggingface.co/nyu-mll/roberta-base-10M-1
[link-roberta-base-10M-2]: https://huggingface.co/nyu-mll/roberta-base-10M-2
[link-roberta-base-10M-3]: https://huggingface.co/nyu-mll/roberta-base-10M-3
[link-roberta-base-100M-1]: https://huggingface.co/nyu-mll/roberta-base-100M-1
[link-roberta-base-100M-2]: https://huggingface.co/nyu-mll/roberta-base-100M-2
[link-roberta-base-100M-3]: https://huggingface.co/nyu-mll/roberta-base-100M-3
[link-roberta-base-1B-1]: https://huggingface.co/nyu-mll/roberta-base-1B-1
[link-roberta-base-1B-2]: https://huggingface.co/nyu-mll/roberta-base-1B-2
[link-roberta-base-1B-3]: https://huggingface.co/nyu-mll/roberta-base-1B-3
|
neurocode/IsRoBERTa
|
neurocode
| 2021-05-20T18:50:32Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"roberta",
"fill-mask",
"is",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:05Z |
---
language: is
datasets:
- Icelandic portion of the OSCAR corpus from INRIA
- oscar
---
# IsRoBERTa a RoBERTa-like masked language model
Probably the first icelandic transformer language model!
## Overview
**Language:** Icelandic
**Downstream-task:** masked-lm
**Training data:** OSCAR corpus
**Code:** See [here](https://github.com/neurocode-io/icelandic-language-model)
**Infrastructure**: 1x Nvidia K80
## Hyperparameters
```
per_device_train_batch_size = 48
n_epochs = 1
vocab_size = 52.000
max_position_embeddings = 514
num_attention_heads = 12
num_hidden_layers = 6
type_vocab_size = 1
learning_rate=0.00005
```
## Usage
### In Transformers
```python
from transformers import (
pipeline,
AutoTokenizer,
AutoModelWithLMHead
)
model_name = "neurocode/IsRoBERTa"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelWithLMHead.from_pretrained(model_name)
>>> fill_mask = pipeline(
... "fill-mask",
... model=model,
... tokenizer=tokenizer
... )
>>> result = fill_mask("Hann fór út að <mask>.")
>>> result
[
{'sequence': '<s>Hann fór út að nýju.</s>', 'score': 0.03395755589008331, 'token': 2219, 'token_str': 'Ġnýju'},
{'sequence': '<s>Hann fór út að undanförnu.</s>', 'score': 0.029087543487548828, 'token': 7590, 'token_str': 'Ġundanförnu'},
{'sequence': '<s>Hann fór út að lokum.</s>', 'score': 0.024420788511633873, 'token': 4384, 'token_str': 'Ġlokum'},
{'sequence': '<s>Hann fór út að þessu.</s>', 'score': 0.021231256425380707, 'token': 921, 'token_str': 'Ġþessu'},
{'sequence': '<s>Hann fór út að honum.</s>', 'score': 0.0205782949924469, 'token': 1136, 'token_str': 'Ġhonum'}
]
```
## Authors
Bobby Donchev: `contact [at] donchev.is`
Elena Cramer: `elena.cramer [at] neurocode.io`
## About us
We bring AI software for our customers live
Our focus: AI software development
Get in touch:
[LinkedIn](https://de.linkedin.com/company/neurocodeio) | [Website](https://neurocode.io)
|
mudes/en-large
|
mudes
| 2021-05-20T18:36:06Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"roberta",
"token-classification",
"mudes",
"en",
"arxiv:2102.09665",
"arxiv:2104.04630",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-03-02T23:29:05Z |
---
language: en
tags:
- mudes
license: apache-2.0
---
# MUDES - {Mu}ltilingual {De}tection of Offensive {S}pans
We provide state-of-the-art models to detect toxic spans in social media texts. We introduce our framework in [this paper](https://arxiv.org/abs/2102.09665). We have evaluated our models on Toxic Spans task at SemEval 2021 (Task 5). Our participation in the task is detailed in [this paper](https://arxiv.org/abs/2104.04630).
## Usage
You can use this model when you have [MUDES](https://github.com/TharinduDR/MUDES) installed:
```bash
pip install mudes
```
Then you can use the model like this:
```python
from mudes.app.mudes_app import MUDESApp
app = MUDESApp("en-large", use_cuda=False)
print(app.predict_toxic_spans("You motherfucking cunt", spans=True))
```
## System Demonstration
An experimental demonstration interface called MUDES-UI has been released on [GitHub](https://github.com/TharinduDR/MUDES-UI) and can be checked out in [here](http://rgcl.wlv.ac.uk/mudes/).
## Citing & Authors
If you find this model helpful, feel free to cite our publications
```bibtex
@inproceedings{ranasinghemudes,
title={{MUDES: Multilingual Detection of Offensive Spans}},
author={Tharindu Ranasinghe and Marcos Zampieri},
booktitle={Proceedings of NAACL},
year={2021}
}
```
```bibtex
@inproceedings{ranasinghe2021semeval,
title={{WLV-RIT at SemEval-2021 Task 5: A Neural Transformer Framework for Detecting Toxic Spans}},
author = {Ranasinghe, Tharindu and Sarkar, Diptanu and Zampieri, Marcos and Ororbia, Alex},
booktitle={Proceedings of SemEval},
year={2021}
}
```
|
mrm8488/roberta-large-finetuned-wsc
|
mrm8488
| 2021-05-20T18:30:59Z | 8 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"roberta",
"fill-mask",
"arxiv:1905.06290",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:05Z |
# RoBERTa (large) fine-tuned on Winograd Schema Challenge (WSC) data
Step from its original [repo](https://github.com/pytorch/fairseq/blob/master/examples/roberta/wsc/README.md)
The following instructions can be used to finetune RoBERTa on the WSC training
data provided by [SuperGLUE](https://super.gluebenchmark.com/).
Note that there is high variance in the results. For our GLUE/SuperGLUE
submission we swept over the learning rate (1e-5, 2e-5, 3e-5), batch size (16,
32, 64) and total number of updates (500, 1000, 2000, 3000), as well as the
random seed. Out of ~100 runs we chose the best 7 models and ensembled them.
**Approach:** The instructions below use a slightly different loss function than
what's described in the original RoBERTa arXiv paper. In particular,
[Kocijan et al. (2019)](https://arxiv.org/abs/1905.06290) introduce a margin
ranking loss between `(query, candidate)` pairs with tunable hyperparameters
alpha and beta. This is supported in our code as well with the `--wsc-alpha` and
`--wsc-beta` arguments. However, we achieved slightly better (and more robust)
results on the development set by instead using a single cross entropy loss term
over the log-probabilities for the query and all mined candidates. **The
candidates are mined using spaCy from each input sentence in isolation, so the
approach remains strictly pointwise.** This reduces the number of
hyperparameters and our best model achieved 92.3% development set accuracy,
compared to ~90% accuracy for the margin loss. Later versions of the RoBERTa
arXiv paper will describe this updated formulation.
### 1) Download the WSC data from the SuperGLUE website:
```bash
wget https://dl.fbaipublicfiles.com/glue/superglue/data/v2/WSC.zip
unzip WSC.zip
# we also need to copy the RoBERTa dictionary into the same directory
wget -O WSC/dict.txt https://dl.fbaipublicfiles.com/fairseq/gpt2_bpe/dict.txt
```
### 2) Finetune over the provided training data:
```bash
TOTAL_NUM_UPDATES=2000 # Total number of training steps.
WARMUP_UPDATES=250 # Linearly increase LR over this many steps.
LR=2e-05 # Peak LR for polynomial LR scheduler.
MAX_SENTENCES=16 # Batch size per GPU.
SEED=1 # Random seed.
ROBERTA_PATH=/path/to/roberta/model.pt
# we use the --user-dir option to load the task and criterion
# from the examples/roberta/wsc directory:
FAIRSEQ_PATH=/path/to/fairseq
FAIRSEQ_USER_DIR=${FAIRSEQ_PATH}/examples/roberta/wsc
CUDA_VISIBLE_DEVICES=0,1,2,3 fairseq-train WSC/ \
--restore-file $ROBERTA_PATH \
--reset-optimizer --reset-dataloader --reset-meters \
--no-epoch-checkpoints --no-last-checkpoints --no-save-optimizer-state \
--best-checkpoint-metric accuracy --maximize-best-checkpoint-metric \
--valid-subset val \
--fp16 --ddp-backend no_c10d \
--user-dir $FAIRSEQ_USER_DIR \
--task wsc --criterion wsc --wsc-cross-entropy \
--arch roberta_large --bpe gpt2 --max-positions 512 \
--dropout 0.1 --attention-dropout 0.1 --weight-decay 0.01 \
--optimizer adam --adam-betas '(0.9, 0.98)' --adam-eps 1e-06 \
--lr-scheduler polynomial_decay --lr $LR \
--warmup-updates $WARMUP_UPDATES --total-num-update $TOTAL_NUM_UPDATES \
--max-sentences $MAX_SENTENCES \
--max-update $TOTAL_NUM_UPDATES \
--log-format simple --log-interval 100 \
--seed $SEED
```
The above command assumes training on 4 GPUs, but you can achieve the same
results on a single GPU by adding `--update-freq=4`.
### 3) Evaluate
```python
from fairseq.models.roberta import RobertaModel
from examples.roberta.wsc import wsc_utils # also loads WSC task and criterion
roberta = RobertaModel.from_pretrained('checkpoints', 'checkpoint_best.pt', 'WSC/')
roberta.cuda()
nsamples, ncorrect = 0, 0
for sentence, label in wsc_utils.jsonl_iterator('WSC/val.jsonl', eval=True):
pred = roberta.disambiguate_pronoun(sentence)
nsamples += 1
if pred == label:
ncorrect += 1
print('Accuracy: ' + str(ncorrect / float(nsamples)))
# Accuracy: 0.9230769230769231
```
## RoBERTa training on WinoGrande dataset
We have also provided `winogrande` task and criterion for finetuning on the
[WinoGrande](https://mosaic.allenai.org/projects/winogrande) like datasets
where there are always two candidates and one is correct.
It's more efficient implementation for such subcases.
```bash
TOTAL_NUM_UPDATES=23750 # Total number of training steps.
WARMUP_UPDATES=2375 # Linearly increase LR over this many steps.
LR=1e-05 # Peak LR for polynomial LR scheduler.
MAX_SENTENCES=32 # Batch size per GPU.
SEED=1 # Random seed.
ROBERTA_PATH=/path/to/roberta/model.pt
# we use the --user-dir option to load the task and criterion
# from the examples/roberta/wsc directory:
FAIRSEQ_PATH=/path/to/fairseq
FAIRSEQ_USER_DIR=${FAIRSEQ_PATH}/examples/roberta/wsc
cd fairseq
CUDA_VISIBLE_DEVICES=0 fairseq-train winogrande_1.0/ \
--restore-file $ROBERTA_PATH \
--reset-optimizer --reset-dataloader --reset-meters \
--no-epoch-checkpoints --no-last-checkpoints --no-save-optimizer-state \
--best-checkpoint-metric accuracy --maximize-best-checkpoint-metric \
--valid-subset val \
--fp16 --ddp-backend no_c10d \
--user-dir $FAIRSEQ_USER_DIR \
--task winogrande --criterion winogrande \
--wsc-margin-alpha 5.0 --wsc-margin-beta 0.4 \
--arch roberta_large --bpe gpt2 --max-positions 512 \
--dropout 0.1 --attention-dropout 0.1 --weight-decay 0.01 \
--optimizer adam --adam-betas '(0.9, 0.98)' --adam-eps 1e-06 \
--lr-scheduler polynomial_decay --lr $LR \
--warmup-updates $WARMUP_UPDATES --total-num-update $TOTAL_NUM_UPDATES \
--max-sentences $MAX_SENTENCES \
--max-update $TOTAL_NUM_UPDATES \
--log-format simple --log-interval 100
```
[Original repo](https://github.com/pytorch/fairseq/tree/master/examples/roberta/wsc)
|
mrm8488/roberta-base-1B-1-finetuned-squadv2
|
mrm8488
| 2021-05-20T18:27:20Z | 13 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"roberta",
"question-answering",
"en",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-03-02T23:29:05Z |
---
language: en
---
# RoBERTa-base (1B-1) + SQuAD v2 ❓
[roberta-base-1B-1](https://huggingface.co/nyu-mll/roberta-base-1B-1) fine-tuned on [SQUAD v2 dataset](https://rajpurkar.github.io/SQuAD-explorer/explore/v2.0/dev/) for **Q&A** downstream task.
## Details of the downstream task (Q&A) - Model 🧠
RoBERTa Pretrained on Smaller Datasets
[NYU Machine Learning for Language](https://huggingface.co/nyu-mll) pretrained RoBERTa on smaller datasets (1M, 10M, 100M, 1B tokens). They released 3 models with lowest perplexities for each pretraining data size out of 25 runs (or 10 in the case of 1B tokens). The pretraining data reproduces that of BERT: They combine English Wikipedia and a reproduction of BookCorpus using texts from smashwords in a ratio of approximately 3:1.
## Details of the downstream task (Q&A) - Dataset 📚
**S**tanford **Q**uestion **A**nswering **D**ataset (SQuAD) is a reading comprehension dataset, consisting of questions posed by crowdworkers on a set of Wikipedia articles, where the answer to every question is a segment of text, or span, from the corresponding reading passage, or the question might be unanswerable.
**SQuAD2.0** combines the 100,000 questions in SQuAD1.1 with over 50,000 unanswerable questions written adversarially by crowdworkers to look similar to answerable ones. To do well on SQuAD2.0, systems must not only answer questions when possible, but also determine when no answer is supported by the paragraph and abstain from answering.
## Model training 🏋️
The model was trained on a Tesla P100 GPU and 25GB of RAM with the following command:
```bash
python transformers/examples/question-answering/run_squad.py \
--model_type roberta \
--model_name_or_path 'nyu-mll/roberta-base-1B-1' \
--do_eval \
--do_train \
--do_lower_case \
--train_file /content/dataset/train-v2.0.json \
--predict_file /content/dataset/dev-v2.0.json \
--per_gpu_train_batch_size 16 \
--learning_rate 3e-5 \
--num_train_epochs 10 \
--max_seq_length 384 \
--doc_stride 128 \
--output_dir /content/output \
--overwrite_output_dir \
--save_steps 1000 \
--version_2_with_negative
```
## Test set Results 🧾
| Metric | # Value |
| ------ | --------- |
| **EM** | **64.86** |
| **F1** | **68.99** |
```json
{
'exact': 64.86145034953255,
'f1': 68.9902640378272,
'total': 11873,
'HasAns_exact': 64.03508771929825,
'HasAns_f1': 72.3045554860189,
'HasAns_total': 5928,
'NoAns_exact': 65.68544995794785,
'NoAns_f1': 65.68544995794785,
'NoAns_total': 5945,
'best_exact': 64.86987282068559,
'best_exact_thresh': 0.0,
'best_f1': 68.99868650898054,
'best_f1_thresh': 0.0
}
```
### Model in action 🚀
Fast usage with **pipelines**:
```python
from transformers import pipeline
QnA_pipeline = pipeline('question-answering', model='mrm8488/roberta-base-1B-1-finetuned-squadv2')
QnA_pipeline({
'context': 'A new strain of flu that has the potential to become a pandemic has been identified in China by scientists.',
'question': 'What has been discovered by scientists from China ?'
})
# Output:
{'answer': 'A new strain of flu', 'end': 19, 'score': 0.7145650685380576,'start': 0}
```
> Created by [Manuel Romero/@mrm8488](https://twitter.com/mrm8488) | [LinkedIn](https://www.linkedin.com/in/manuel-romero-cs/)
> Made with <span style="color: #e25555;">♥</span> in Spain
|
mrm8488/roberta-base-1B-1-finetuned-squadv1
|
mrm8488
| 2021-05-20T18:26:13Z | 35 | 1 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"roberta",
"question-answering",
"en",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-03-02T23:29:05Z |
---
language: en
---
# RoBERTa-base (1B-1) + SQuAD v1 ❓
[roberta-base-1B-1](https://huggingface.co/nyu-mll/roberta-base-1B-1) fine-tuned on [SQUAD v1.1 dataset](https://rajpurkar.github.io/SQuAD-explorer/explore/1.1/dev/) for **Q&A** downstream task.
## Details of the downstream task (Q&A) - Model 🧠
RoBERTa Pretrained on Smaller Datasets
[NYU Machine Learning for Language](https://huggingface.co/nyu-mll) pretrained RoBERTa on smaller datasets (1M, 10M, 100M, 1B tokens). They released 3 models with lowest perplexities for each pretraining data size out of 25 runs (or 10 in the case of 1B tokens). The pretraining data reproduces that of BERT: They combine English Wikipedia and a reproduction of BookCorpus using texts from smashwords in a ratio of approximately 3:1.
## Details of the downstream task (Q&A) - Dataset 📚
**S**tanford **Q**uestion **A**nswering **D**ataset (SQuAD) is a reading comprehension dataset, consisting of questions posed by crowdworkers on a set of Wikipedia articles, where the answer to every question is a segment of text, or span, from the corresponding reading passage, or the question might be unanswerable.
SQuAD v1.1 contains **100,000+** question-answer pairs on **500+** articles.
## Model training 🏋️
The model was trained on a Tesla P100 GPU and 25GB of RAM with the following command:
```bash
python transformers/examples/question-answering/run_squad.py \
--model_type roberta \
--model_name_or_path 'nyu-mll/roberta-base-1B-1' \
--do_eval \
--do_train \
--do_lower_case \
--train_file /content/dataset/train-v1.1.json \
--predict_file /content/dataset/dev-v1.1.json \
--per_gpu_train_batch_size 16 \
--learning_rate 3e-5 \
--num_train_epochs 10 \
--max_seq_length 384 \
--doc_stride 128 \
--output_dir /content/output \
--overwrite_output_dir \
--save_steps 1000
```
## Test set Results 🧾
| Metric | # Value |
| ------ | --------- |
| **EM** | **72.62** |
| **F1** | **82.19** |
```json
{
'exact': 72.62062440870388,
'f1': 82.19430877136834,
'total': 10570,
'HasAns_exact': 72.62062440870388,
'HasAns_f1': 82.19430877136834,
'HasAns_total': 10570,
'best_exact': 72.62062440870388,
'best_exact_thresh': 0.0,
'best_f1': 82.19430877136834,
'best_f1_thresh': 0.0
}
```
### Model in action 🚀
Fast usage with **pipelines**:
```python
from transformers import pipeline
QnA_pipeline = pipeline('question-answering', model='mrm8488/roberta-base-1B-1-finetuned-squadv1')
QnA_pipeline({
'context': 'A new strain of flu that has the potential to become a pandemic has been identified in China by scientists.',
'question': 'What has been discovered by scientists from China ?'
})
# Output:
{'answer': 'A new strain of flu', 'end': 19, 'score': 0.04702283976040074, 'start': 0}
```
> Created by [Manuel Romero/@mrm8488](https://twitter.com/mrm8488) | [LinkedIn](https://www.linkedin.com/in/manuel-romero-cs/)
> Made with <span style="color: #e25555;">♥</span> in Spain
|
mrm8488/codeBERTaJS
|
mrm8488
| 2021-05-20T18:17:36Z | 10 | 6 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"roberta",
"fill-mask",
"javascript",
"code",
"arxiv:1909.09436",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:05Z |
---
language: code
thumbnail:
tags:
- javascript
- code
widget:
- text: "async function createUser(req, <mask>) { if (!validUser(req.body.user)) { return res.status(400); } user = userService.createUser(req.body.user); return res.json(user); }"
---
# CodeBERTaJS
CodeBERTaJS is a RoBERTa-like model trained on the [CodeSearchNet](https://github.blog/2019-09-26-introducing-the-codesearchnet-challenge/) dataset from GitHub for `javaScript` by [Manuel Romero](https://twitter.com/mrm8488)
The **tokenizer** is a Byte-level BPE tokenizer trained on the corpus using Hugging Face `tokenizers`.
Because it is trained on a corpus of code (vs. natural language), it encodes the corpus efficiently (the sequences are between 33% to 50% shorter, compared to the same corpus tokenized by gpt2/roberta).
The (small) **model** is a 6-layer, 84M parameters, RoBERTa-like Transformer model – that’s the same number of layers & heads as DistilBERT – initialized from the default initialization settings and trained from scratch on the full `javascript` corpus (120M after preproccessing) for 2 epochs.
## Quick start: masked language modeling prediction
```python
JS_CODE = """
async function createUser(req, <mask>) {
if (!validUser(req.body.user)) {
\t return res.status(400);
}
user = userService.createUser(req.body.user);
return res.json(user);
}
""".lstrip()
```
### Does the model know how to complete simple JS/express like code?
```python
from transformers import pipeline
fill_mask = pipeline(
"fill-mask",
model="mrm8488/codeBERTaJS",
tokenizer="mrm8488/codeBERTaJS"
)
fill_mask(JS_CODE)
## Top 5 predictions:
#
'res' # prob 0.069489665329
'next'
'req'
'user'
',req'
```
### Yes! That was easy 🎉 Let's try with another example
```python
JS_CODE_= """
function getKeys(obj) {
keys = [];
for (var [key, value] of Object.entries(obj)) {
keys.push(<mask>);
}
return keys
}
""".lstrip()
```
Results:
```python
'obj', 'key', ' value', 'keys', 'i'
```
> Not so bad! Right token was predicted as second option! 🎉
## This work is heavely inspired on [codeBERTa](https://github.com/huggingface/transformers/blob/master/model_cards/huggingface/CodeBERTa-small-v1/README.md) by huggingface team
<br>
## CodeSearchNet citation
<details>
```bibtex
@article{husain_codesearchnet_2019,
\ttitle = {{CodeSearchNet} {Challenge}: {Evaluating} the {State} of {Semantic} {Code} {Search}},
\tshorttitle = {{CodeSearchNet} {Challenge}},
\turl = {http://arxiv.org/abs/1909.09436},
\turldate = {2020-03-12},
\tjournal = {arXiv:1909.09436 [cs, stat]},
\tauthor = {Husain, Hamel and Wu, Ho-Hsiang and Gazit, Tiferet and Allamanis, Miltiadis and Brockschmidt, Marc},
\tmonth = sep,
\tyear = {2019},
\tnote = {arXiv: 1909.09436},
}
```
</details>
> Created by [Manuel Romero/@mrm8488](https://twitter.com/mrm8488)
> Made with <span style="color: #e25555;">♥</span> in Spain
|
mrm8488/chEMBL26_smiles_v2
|
mrm8488
| 2021-05-20T18:16:29Z | 20 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"roberta",
"fill-mask",
"drugs",
"chemist",
"drug design",
"smile",
"en",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:05Z |
---
language: en
tags:
- drugs
- chemist
- drug design
- smile
widget:
- text: "CC(C)CN(CC(OP(=O)(O)O)C(Cc1ccccc1)NC(=O)OC1CCOC1)S(=O)(=O)c1ccc(N)<mask>"
---
|
mrm8488/RuPERTa-base-finetuned-pos
|
mrm8488
| 2021-05-20T18:08:34Z | 17 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"roberta",
"token-classification",
"es",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-03-02T23:29:05Z |
---
language: es
thumbnail:
---
# RuPERTa-base (Spanish RoBERTa) + POS 🎃🏷
This model is a fine-tuned on [CONLL CORPORA](https://www.kaggle.com/nltkdata/conll-corpora) version of [RuPERTa-base](https://huggingface.co/mrm8488/RuPERTa-base) for **POS** downstream task.
## Details of the downstream task (POS) - Dataset
- [Dataset: CONLL Corpora ES](https://www.kaggle.com/nltkdata/conll-corpora) 📚
| Dataset | # Examples |
| ---------------------- | ----- |
| Train | 445 K |
| Dev | 55 K |
- [Fine-tune on NER script provided by Huggingface](https://github.com/huggingface/transformers/blob/master/examples/token-classification/run_ner_old.py)
- Labels covered:
```
ADJ
ADP
ADV
AUX
CCONJ
DET
INTJ
NOUN
NUM
PART
PRON
PROPN
PUNCT
SCONJ
SYM
VERB
```
## Metrics on evaluation set 🧾
| Metric | # score |
| :------------------------------------------------------------------------------------: | :-------: |
| F1 | **97.39**
| Precision | **97.47** |
| Recall | **9732** |
## Model in action 🔨
Example of usage
```python
import torch
from transformers import AutoModelForTokenClassification, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained('mrm8488/RuPERTa-base-finetuned-pos')
model = AutoModelForTokenClassification.from_pretrained('mrm8488/RuPERTa-base-finetuned-pos')
id2label = {
"0": "O",
"1": "ADJ",
"2": "ADP",
"3": "ADV",
"4": "AUX",
"5": "CCONJ",
"6": "DET",
"7": "INTJ",
"8": "NOUN",
"9": "NUM",
"10": "PART",
"11": "PRON",
"12": "PROPN",
"13": "PUNCT",
"14": "SCONJ",
"15": "SYM",
"16": "VERB"
}
text ="Mis amigos están pensando viajar a Londres este verano."
input_ids = torch.tensor(tokenizer.encode(text)).unsqueeze(0)
outputs = model(input_ids)
last_hidden_states = outputs[0]
for m in last_hidden_states:
for index, n in enumerate(m):
if(index > 0 and index <= len(text.split(" "))):
print(text.split(" ")[index-1] + ": " + id2label[str(torch.argmax(n).item())])
'''
Output:
--------
Mis: NUM
amigos: PRON
están: AUX
pensando: ADV
viajar: VERB
a: ADP
Londres: PROPN
este: DET
verano..: NOUN
'''
```
Yeah! Not too bad 🎉
> Created by [Manuel Romero/@mrm8488](https://twitter.com/mrm8488) | [LinkedIn](https://www.linkedin.com/in/manuel-romero-cs/)
> Made with <span style="color: #e25555;">♥</span> in Spain
|
mrm8488/RuPERTa-base-finetuned-pawsx-es
|
mrm8488
| 2021-05-20T18:07:14Z | 25 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"roberta",
"text-classification",
"nli",
"es",
"dataset:xtreme",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
---
language: es
datasets:
- xtreme
tags:
- nli
widget:
- text: "En 2009 se mudó a Filadelfia y en la actualidad vive en Nueva York. Se mudó nuevamente a Filadelfia en 2009 y ahora vive en la ciudad de Nueva York."
---
# RuPERTa-base fine-tuned on PAWS-X-es for Paraphrase Identification (NLI)
|
mrm8488/CodeBERTaPy
|
mrm8488
| 2021-05-20T18:01:23Z | 25 | 3 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"roberta",
"fill-mask",
"code",
"arxiv:1909.09436",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:05Z |
---
language: code
thumbnail:
---
# CodeBERTaPy
CodeBERTaPy is a RoBERTa-like model trained on the [CodeSearchNet](https://github.blog/2019-09-26-introducing-the-codesearchnet-challenge/) dataset from GitHub for `python` by [Manuel Romero](https://twitter.com/mrm8488)
The **tokenizer** is a Byte-level BPE tokenizer trained on the corpus using Hugging Face `tokenizers`.
Because it is trained on a corpus of code (vs. natural language), it encodes the corpus efficiently (the sequences are between 33% to 50% shorter, compared to the same corpus tokenized by gpt2/roberta).
The (small) **model** is a 6-layer, 84M parameters, RoBERTa-like Transformer model – that’s the same number of layers & heads as DistilBERT – initialized from the default initialization settings and trained from scratch on the full `python` corpus for 4 epochs.
## Quick start: masked language modeling prediction
```python
PYTHON_CODE = """
fruits = ['apples', 'bananas', 'oranges']
for idx, <mask> in enumerate(fruits):
print("index is %d and value is %s" % (idx, val))
""".lstrip()
```
### Does the model know how to complete simple Python code?
```python
from transformers import pipeline
fill_mask = pipeline(
"fill-mask",
model="mrm8488/CodeBERTaPy",
tokenizer="mrm8488/CodeBERTaPy"
)
fill_mask(PYTHON_CODE)
## Top 5 predictions:
'val' # prob 0.980728805065155
'value'
'idx'
',val'
'_'
```
### Yes! That was easy 🎉 Let's try with another Flask like example
```python
PYTHON_CODE2 = """
@app.route('/<name>')
def hello_name(name):
return "Hello {}!".format(<mask>)
if __name__ == '__main__':
app.run()
""".lstrip()
fill_mask(PYTHON_CODE2)
## Top 5 predictions:
'name' # prob 0.9961813688278198
' name'
'url'
'description'
'self'
```
### Yeah! It works 🎉 Let's try with another Tensorflow/Keras like example
```python
PYTHON_CODE3="""
model = keras.Sequential([
keras.layers.Flatten(input_shape=(28, 28)),
keras.layers.<mask>(128, activation='relu'),
keras.layers.Dense(10, activation='softmax')
])
""".lstrip()
fill_mask(PYTHON_CODE3)
## Top 5 predictions:
'Dense' # prob 0.4482928514480591
'relu'
'Flatten'
'Activation'
'Conv'
```
> Great! 🎉
## This work is heavily inspired on [CodeBERTa](https://github.com/huggingface/transformers/blob/master/model_cards/huggingface/CodeBERTa-small-v1/README.md) by huggingface team
<br>
## CodeSearchNet citation
<details>
```bibtex
@article{husain_codesearchnet_2019,
title = {{CodeSearchNet} {Challenge}: {Evaluating} the {State} of {Semantic} {Code} {Search}},
shorttitle = {{CodeSearchNet} {Challenge}},
url = {http://arxiv.org/abs/1909.09436},
urldate = {2020-03-12},
journal = {arXiv:1909.09436 [cs, stat]},
author = {Husain, Hamel and Wu, Ho-Hsiang and Gazit, Tiferet and Allamanis, Miltiadis and Brockschmidt, Marc},
month = sep,
year = {2019},
note = {arXiv: 1909.09436},
}
```
</details>
> Created by [Manuel Romero/@mrm8488](https://twitter.com/mrm8488)
> Made with <span style="color: #e25555;">♥</span> in Spain
|
jpcorb20/toxic-detector-distilroberta
|
jpcorb20
| 2021-05-20T17:25:58Z | 88 | 1 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"roberta",
"text-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
# Distilroberta for toxic comment detection
See my GitHub repo [toxic-comment-server](https://github.com/jpcorb20/toxic-comment-server)
The model was trained from [DistilRoberta](https://huggingface.co/distilroberta-base) on [Kaggle Toxic Comments](https://www.kaggle.com/c/jigsaw-toxic-comment-classification-challenge) with the BCEWithLogits loss for Multi-Label prediction. Thus, please use the sigmoid activation on the logits (not made to use the softmax output, e.g. like the HF widget).
## Evaluation
F1 scores:
toxic: 0.72
severe_toxic: 0.38
obscene: 0.72
threat: 0.52
insult: 0.69
identity_hate: 0.60
Macro-F1: 0.61
|
jason9693/SoongsilBERT-nsmc-base
|
jason9693
| 2021-05-20T17:08:31Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"roberta",
"text-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
# Finetuning
## Result
### Base Model
| | Size | **NSMC**<br/>(acc) | **Naver NER**<br/>(F1) | **PAWS**<br/>(acc) | **KorNLI**<br/>(acc) | **KorSTS**<br/>(spearman) | **Question Pair**<br/>(acc) | **KorQuaD (Dev)**<br/>(EM/F1) | **Korean-Hate-Speech (Dev)**<br/>(F1) |
| :-------------------- | :---: | :----------------: | :--------------------: | :----------------: | :------------------: | :-----------------------: | :-------------------------: | :---------------------------: | :-----------------------------------: |
| KoBERT | 351M | 89.59 | 87.92 | 81.25 | 79.62 | 81.59 | 94.85 | 51.75 / 79.15 | 66.21 |
| XLM-Roberta-Base | 1.03G | 89.03 | 86.65 | 82.80 | 80.23 | 78.45 | 93.80 | 64.70 / 88.94 | 64.06 |
| HanBERT | 614M | 90.06 | 87.70 | 82.95 | 80.32 | 82.73 | 94.72 | 78.74 / 92.02 | 68.32 |
| KoELECTRA-Base-v3 | 431M | 90.63 | 88.11 | 84.45 | 82.24 | 85.53 | 95.25 | 84.83 / 93.45 | 67.61 |
| Soongsil-BERT | 370M | **91.2** | - | - | - | 76 | 94 | - | **69** |
### Small Model
| | Size | **NSMC**<br/>(acc) | **Naver NER**<br/>(F1) | **PAWS**<br/>(acc) | **KorNLI**<br/>(acc) | **KorSTS**<br/>(spearman) | **Question Pair**<br/>(acc) | **KorQuaD (Dev)**<br/>(EM/F1) | **Korean-Hate-Speech (Dev)**<br/>(F1) |
| :--------------------- | :--: | :----------------: | :--------------------: | :----------------: | :------------------: | :-----------------------: | :-------------------------: | :---------------------------: | :-----------------------------------: |
| DistilKoBERT | 108M | 88.60 | 84.65 | 60.50 | 72.00 | 72.59 | 92.48 | 54.40 / 77.97 | 60.72 |
| KoELECTRA-Small-v3 | 54M | 89.36 | 85.40 | 77.45 | 78.60 | 80.79 | 94.85 | 82.11 / 91.13 | 63.07 |
| Soongsil-BERT | 213M | **90.7** | 84 | 69.1 | 76 | - | 92 | - | **66** |
## Reference
- [Transformers Examples](https://github.com/huggingface/transformers/blob/master/examples/README.md)
- [NSMC](https://github.com/e9t/nsmc)
- [Naver NER Dataset](https://github.com/naver/nlp-challenge)
- [PAWS](https://github.com/google-research-datasets/paws)
- [KorNLI/KorSTS](https://github.com/kakaobrain/KorNLUDatasets)
- [Question Pair](https://github.com/songys/Question_pair)
- [KorQuad](https://korquad.github.io/category/1.0_KOR.html)
- [Korean Hate Speech](https://github.com/kocohub/korean-hate-speech)
- [KoELECTRA](https://github.com/monologg/KoELECTRA)
- [KoBERT](https://github.com/SKTBrain/KoBERT)
- [HanBERT](https://github.com/tbai2019/HanBert-54k-N)
- [HanBert Transformers](https://github.com/monologg/HanBert-Transformers)
|
iarfmoose/roberta-small-bulgarian
|
iarfmoose
| 2021-05-20T16:54:01Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"jax",
"roberta",
"fill-mask",
"bg",
"arxiv:1907.11692",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:05Z |
---
language: bg
---
# RoBERTa-small-bulgarian
The RoBERTa model was originally introduced in [this paper](https://arxiv.org/abs/1907.11692). This is a smaller version of [RoBERTa-base-bulgarian](https://huggingface.co/iarfmoose/roberta-small-bulgarian) with only 6 hidden layers, but similar performance.
## Intended uses
This model can be used for cloze tasks (masked language modeling) or finetuned on other tasks in Bulgarian.
## Limitations and bias
The training data is unfiltered text from the internet and may contain all sorts of biases.
## Training data
This model was trained on the following data:
- [bg_dedup from OSCAR](https://oscar-corpus.com/)
- [Newscrawl 1 million sentences 2017 from Leipzig Corpora Collection](https://wortschatz.uni-leipzig.de/en/download/bulgarian)
- [Wikipedia 1 million sentences 2016 from Leipzig Corpora Collection](https://wortschatz.uni-leipzig.de/en/download/bulgarian)
## Training procedure
The model was pretrained using a masked language-modeling objective with dynamic masking as described [here](https://huggingface.co/roberta-base#preprocessing)
It was trained for 160k steps. The batch size was limited to 8 due to GPU memory limitations.
|
iarfmoose/roberta-small-bulgarian-pos
|
iarfmoose
| 2021-05-20T16:52:10Z | 4 | 1 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"jax",
"roberta",
"token-classification",
"bg",
"arxiv:1907.11692",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-03-02T23:29:05Z |
---
language: bg
---
# RoBERTa-small-bulgarian-POS
The RoBERTa model was originally introduced in [this paper](https://arxiv.org/abs/1907.11692). This model is a version of [RoBERTa-small-Bulgarian](https://huggingface.co/iarfmoose/roberta-small-bulgarian) fine-tuned for part-of-speech tagging.
## Intended uses
The model can be used to predict part-of-speech tags in Bulgarian text. Since the tokenizer uses byte-pair encoding, each word in the text may be split into more than one token. When predicting POS-tags, the last token from each word can be used. Using the last token was found to slightly outperform predictions based on the first token.
An example of this can be found [here](https://github.com/iarfmoose/bulgarian-nlp/blob/master/models/postagger.py).
## Limitations and bias
The pretraining data is unfiltered text from the internet and may contain all sorts of biases.
## Training data
In addition to the pretraining data used in [RoBERTa-base-Bulgarian]([RoBERTa-base-Bulgarian](https://huggingface.co/iarfmoose/roberta-base-bulgarian)), the model was trained on the UPOS tags from (UD_Bulgarian-BTB)[https://github.com/UniversalDependencies/UD_Bulgarian-BTB].
## Training procedure
The model was trained for 5 epochs over the training set. The loss was calculated based on label predictions for the last POS-tag for each word. The model achieves 98% on the test set.
|
iarfmoose/roberta-base-bulgarian
|
iarfmoose
| 2021-05-20T16:50:24Z | 29 | 1 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"jax",
"roberta",
"fill-mask",
"bg",
"arxiv:1907.11692",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:05Z |
---
language: bg
---
# RoBERTa-base-bulgarian
The RoBERTa model was originally introduced in [this paper](https://arxiv.org/abs/1907.11692). This is a version of [RoBERTa-base](https://huggingface.co/roberta-base) pretrained on Bulgarian text.
## Intended uses
This model can be used for cloze tasks (masked language modeling) or finetuned on other tasks in Bulgarian.
## Limitations and bias
The training data is unfiltered text from the internet and may contain all sorts of biases.
## Training data
This model was trained on the following data:
- [bg_dedup from OSCAR](https://oscar-corpus.com/)
- [Newscrawl 1 million sentences 2017 from Leipzig Corpora Collection](https://wortschatz.uni-leipzig.de/en/download/bulgarian)
- [Wikipedia 1 million sentences 2016 from Leipzig Corpora Collection](https://wortschatz.uni-leipzig.de/en/download/bulgarian)
## Training procedure
The model was pretrained using a masked language-modeling objective with dynamic masking as described [here](https://huggingface.co/roberta-base#preprocessing)
It was trained for 200k steps. The batch size was limited to 8 due to GPU memory limitations.
|
iarfmoose/roberta-base-bulgarian-pos
|
iarfmoose
| 2021-05-20T16:49:07Z | 14 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"jax",
"roberta",
"token-classification",
"bg",
"arxiv:1907.11692",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-03-02T23:29:05Z |
---
language: bg
---
# RoBERTa-base-bulgarian-POS
The RoBERTa model was originally introduced in [this paper](https://arxiv.org/abs/1907.11692). This model is a version of [RoBERTa-base-Bulgarian](https://huggingface.co/iarfmoose/roberta-base-bulgarian) fine-tuned for part-of-speech tagging.
## Intended uses
The model can be used to predict part-of-speech tags in Bulgarian text. Since the tokenizer uses byte-pair encoding, each word in the text may be split into more than one token. When predicting POS-tags, the last token from each word can be used. Using the last token was found to slightly outperform predictions based on the first token.
An example of this can be found [here](https://github.com/iarfmoose/bulgarian-nlp/blob/master/models/postagger.py).
## Limitations and bias
The pretraining data is unfiltered text from the internet and may contain all sorts of biases.
## Training data
In addition to the pretraining data used in [RoBERTa-base-Bulgarian]([RoBERTa-base-Bulgarian](https://huggingface.co/iarfmoose/roberta-base-bulgarian)), the model was trained on the UPOS tags from [UD_Bulgarian-BTB](https://github.com/UniversalDependencies/UD_Bulgarian-BTB).
## Training procedure
The model was trained for 5 epochs over the training set. The loss was calculated based on label predictions for the last POS-tag for each word. The model achieves 97% on the test set.
|
giganticode/StackOBERTflow-comments-small-v1
|
giganticode
| 2021-05-20T16:33:56Z | 10 | 1 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"roberta",
"fill-mask",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:05Z |
# StackOBERTflow-comments-small
StackOBERTflow is a RoBERTa model trained on StackOverflow comments.
A Byte-level BPE tokenizer with dropout was used (using the `tokenizers` package).
The model is *small*, i.e. has only 6-layers and the maximum sequence length was restricted to 256 tokens.
The model was trained for 6 epochs on several GBs of comments from the StackOverflow corpus.
## Quick start: masked language modeling prediction
```python
from transformers import pipeline
from pprint import pprint
COMMENT = "You really should not do it this way, I would use <mask> instead."
fill_mask = pipeline(
"fill-mask",
model="giganticode/StackOBERTflow-comments-small-v1",
tokenizer="giganticode/StackOBERTflow-comments-small-v1"
)
pprint(fill_mask(COMMENT))
# [{'score': 0.019997311756014824,
# 'sequence': '<s> You really should not do it this way, I would use jQuery instead.</s>',
# 'token': 1738},
# {'score': 0.01693696901202202,
# 'sequence': '<s> You really should not do it this way, I would use arrays instead.</s>',
# 'token': 2844},
# {'score': 0.013411642983555794,
# 'sequence': '<s> You really should not do it this way, I would use CSS instead.</s>',
# 'token': 2254},
# {'score': 0.013224546797573566,
# 'sequence': '<s> You really should not do it this way, I would use it instead.</s>',
# 'token': 300},
# {'score': 0.011984303593635559,
# 'sequence': '<s> You really should not do it this way, I would use classes instead.</s>',
# 'token': 1779}]
```
|
elgeish/cs224n-squad2.0-roberta-base
|
elgeish
| 2021-05-20T16:16:38Z | 12 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"roberta",
"question-answering",
"arxiv:2004.07067",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-03-02T23:29:05Z |
## CS224n SQuAD2.0 Project Dataset
The goal of this model is to save CS224n students GPU time when establishing
baselines to beat for the [Default Final Project](http://web.stanford.edu/class/cs224n/project/default-final-project-handout.pdf).
The training set used to fine-tune this model is the same as
the [official one](https://rajpurkar.github.io/SQuAD-explorer/); however,
evaluation and model selection were performed using roughly half of the official
dev set, 6078 examples, picked at random. The data files can be found at
<https://github.com/elgeish/squad/tree/master/data> — this is the Winter 2020
version. Given that the official SQuAD2.0 dev set contains the project's test
set, students must make sure not to use the official SQuAD2.0 dev set in any way
— including the use of models fine-tuned on the official SQuAD2.0, since they
used the official SQuAD2.0 dev set for model selection.
## Results
```json
{
"exact": 75.32082922013821,
"f1": 78.66699523704254,
"total": 6078,
"HasAns_exact": 74.84536082474227,
"HasAns_f1": 81.83436324767868,
"HasAns_total": 2910,
"NoAns_exact": 75.75757575757575,
"NoAns_f1": 75.75757575757575,
"NoAns_total": 3168,
"best_exact": 75.32082922013821,
"best_exact_thresh": 0.0,
"best_f1": 78.66699523704266,
"best_f1_thresh": 0.0
}
```
## Notable Arguments
```json
{
"do_lower_case": true,
"doc_stride": 128,
"fp16": false,
"fp16_opt_level": "O1",
"gradient_accumulation_steps": 24,
"learning_rate": 3e-05,
"max_answer_length": 30,
"max_grad_norm": 1,
"max_query_length": 64,
"max_seq_length": 384,
"model_name_or_path": "roberta-base",
"model_type": "roberta",
"num_train_epochs": 4,
"per_gpu_train_batch_size": 16,
"save_steps": 5000,
"seed": 42,
"train_batch_size": 16,
"version_2_with_negative": true,
"warmup_steps": 0,
"weight_decay": 0
}
```
## Environment Setup
```json
{
"transformers": "2.5.1",
"pytorch": "1.4.0=py3.6_cuda10.1.243_cudnn7.6.3_0",
"python": "3.6.5=hc3d631a_2",
"os": "Linux 4.15.0-1060-aws #62-Ubuntu SMP Tue Feb 11 21:23:22 UTC 2020 x86_64 x86_64 x86_64 GNU/Linux",
"gpu": "Tesla V100-SXM2-16GB"
}
```
## How to Cite
```BibTeX
@misc{elgeish2020gestalt,
title={Gestalt: a Stacking Ensemble for SQuAD2.0},
author={Mohamed El-Geish},
journal={arXiv e-prints},
archivePrefix={arXiv},
eprint={2004.07067},
year={2020},
}
```
## Related Models
* [elgeish/cs224n-squad2.0-albert-base-v2](https://huggingface.co/elgeish/cs224n-squad2.0-albert-base-v2)
* [elgeish/cs224n-squad2.0-albert-large-v2](https://huggingface.co/elgeish/cs224n-squad2.0-albert-large-v2)
* [elgeish/cs224n-squad2.0-albert-xxlarge-v1](https://huggingface.co/elgeish/cs224n-squad2.0-albert-xxlarge-v1)
* [elgeish/cs224n-squad2.0-distilbert-base-uncased](https://huggingface.co/elgeish/cs224n-squad2.0-distilbert-base-uncased)
|
dbernsohn/roberta-javascript
|
dbernsohn
| 2021-05-20T15:55:17Z | 5 | 1 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"roberta",
"fill-mask",
"arxiv:1907.11692",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:05Z |
# roberta-javascript
---
language: javascript
datasets:
- code_search_net
---
This is a [roberta](https://arxiv.org/pdf/1907.11692.pdf) pre-trained version on the [CodeSearchNet dataset](https://github.com/github/CodeSearchNet) for **javascript** Mask Language Model mission.
To load the model:
(necessary packages: !pip install transformers sentencepiece)
```python
from transformers import AutoTokenizer, AutoModelWithLMHead, pipeline
tokenizer = AutoTokenizer.from_pretrained("dbernsohn/roberta-javascript")
model = AutoModelWithLMHead.from_pretrained("dbernsohn/roberta-javascript")
fill_mask = pipeline(
"fill-mask",
model=model,
tokenizer=tokenizer
)
```
You can then use this model to fill masked words in a Java code.
```python
code = """
var i;
for (i = 0; i < cars.<mask>; i++) {
text += cars[i] + "<br>";
}
""".lstrip()
pred = {x["token_str"].replace("Ġ", ""): x["score"] for x in fill_mask(code)}
sorted(pred.items(), key=lambda kv: kv[1], reverse=True)
# [('length', 0.9959614872932434),
# ('i', 0.00027875584783032537),
# ('len', 0.0002283261710545048),
# ('nodeType', 0.00013731322542298585),
# ('index', 7.5289819505997e-05)]
```
The whole training process and hyperparameters are in my [GitHub repo](https://github.com/DorBernsohn/CodeLM/tree/main/CodeMLM)
> Created by [Dor Bernsohn](https://www.linkedin.com/in/dor-bernsohn-70b2b1146/)
|
clue/roberta_chinese_3L312_clue_tiny
|
clue
| 2021-05-20T15:22:48Z | 4 | 2 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"roberta",
"zh",
"arxiv:2003.01355",
"endpoints_compatible",
"region:us"
] | null | 2022-03-02T23:29:05Z |
---
language: zh
---
# Introduction
This model was trained on TPU and the details are as follows:
## Model
##
| Model_name | params | size | Training_corpus | Vocab |
| :------------------------------------------ | :----- | :------- | :----------------- | :-----------: |
| **`RoBERTa-tiny-clue`** <br/>Super_small_model | 7.5M | 28.3M | **CLUECorpus2020** | **CLUEVocab** |
| **`RoBERTa-tiny-pair`** <br/>Super_small_sentence_pair_model | 7.5M | 28.3M | **CLUECorpus2020** | **CLUEVocab** |
| **`RoBERTa-tiny3L768-clue`** <br/>small_model | 38M | 110M | **CLUECorpus2020** | **CLUEVocab** |
| **`RoBERTa-tiny3L312-clue`** <br/>small_model | <7.5M | 24M | **CLUECorpus2020** | **CLUEVocab** |
| **`RoBERTa-large-clue`** <br/> Large_model | 290M | 1.20G | **CLUECorpus2020** | **CLUEVocab** |
| **`RoBERTa-large-pair`** <br/>Large_sentence_pair_model | 290M | 1.20G | **CLUECorpus2020** | **CLUEVocab** |
### Usage
With the help of[Huggingface-Transformers 2.5.1](https://github.com/huggingface/transformers), you could use these model as follows
```
tokenizer = BertTokenizer.from_pretrained("MODEL_NAME")
model = BertModel.from_pretrained("MODEL_NAME")
```
`MODEL_NAME`:
| Model_NAME | MODEL_LINK |
| -------------------------- | ------------------------------------------------------------ |
| **RoBERTa-tiny-clue** | [`clue/roberta_chinese_clue_tiny`](https://huggingface.co/clue/roberta_chinese_clue_tiny) |
| **RoBERTa-tiny-pair** | [`clue/roberta_chinese_pair_tiny`](https://huggingface.co/clue/roberta_chinese_pair_tiny) |
| **RoBERTa-tiny3L768-clue** | [`clue/roberta_chinese_3L768_clue_tiny`](https://huggingface.co/clue/roberta_chinese_3L768_clue_tiny) |
| **RoBERTa-tiny3L312-clue** | [`clue/roberta_chinese_3L312_clue_tiny`](https://huggingface.co/clue/roberta_chinese_3L312_clue_tiny) |
| **RoBERTa-large-clue** | [`clue/roberta_chinese_clue_large`](https://huggingface.co/clue/roberta_chinese_clue_large) |
| **RoBERTa-large-pair** | [`clue/roberta_chinese_pair_large`](https://huggingface.co/clue/roberta_chinese_pair_large) |
## Details
Please read <a href='https://arxiv.org/pdf/2003.01355'>https://arxiv.org/pdf/2003.01355.
Please visit our repository: https://github.com/CLUEbenchmark/CLUEPretrainedModels.git
|
castorini/ance-msmarco-doc-firstp
|
castorini
| 2021-05-20T15:17:20Z | 7 | 1 |
transformers
|
[
"transformers",
"pytorch",
"roberta",
"arxiv:2007.00808",
"endpoints_compatible",
"region:us"
] | null | 2022-03-02T23:29:05Z |
This model is converted from the original ANCE [repo](https://github.com/microsoft/ANCE) and fitted into Pyserini:
> Lee Xiong, Chenyan Xiong, Ye Li, Kwok-Fung Tang, Jialin Liu, Paul Bennett, Junaid Ahmed, Arnold Overwijk. [Approximate Nearest Neighbor Negative Contrastive Learning for Dense Text Retrieval](https://arxiv.org/pdf/2007.00808.pdf)
For more details on how to use it, check our experiments in [Pyserini](https://github.com/castorini/pyserini/blob/master/docs/experiments-ance.md)
|
cahya/roberta-base-indonesian-522M
|
cahya
| 2021-05-20T14:41:00Z | 338 | 6 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"jax",
"roberta",
"fill-mask",
"id",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:05Z |
---
language: "id"
license: "mit"
datasets:
- Indonesian Wikipedia
widget:
- text: "Ibu ku sedang bekerja <mask> supermarket."
---
# Indonesian RoBERTa base model (uncased)
## Model description
It is RoBERTa-base model pre-trained with indonesian Wikipedia using a masked language modeling (MLM) objective. This
model is uncased: it does not make a difference between indonesia and Indonesia.
This is one of several other language models that have been pre-trained with indonesian datasets. More detail about
its usage on downstream tasks (text classification, text generation, etc) is available at [Transformer based Indonesian Language Models](https://github.com/cahya-wirawan/indonesian-language-models/tree/master/Transformers)
## Intended uses & limitations
### How to use
You can use this model directly with a pipeline for masked language modeling:
```python
>>> from transformers import pipeline
>>> unmasker = pipeline('fill-mask', model='cahya/roberta-base-indonesian-522M')
>>> unmasker("Ibu ku sedang bekerja <mask> supermarket")
```
Here is how to use this model to get the features of a given text in PyTorch:
```python
from transformers import RobertaTokenizer, RobertaModel
model_name='cahya/roberta-base-indonesian-522M'
tokenizer = RobertaTokenizer.from_pretrained(model_name)
model = RobertaModel.from_pretrained(model_name)
text = "Silakan diganti dengan text apa saja."
encoded_input = tokenizer(text, return_tensors='pt')
output = model(**encoded_input)
```
and in Tensorflow:
```python
from transformers import RobertaTokenizer, TFRobertaModel
model_name='cahya/roberta-base-indonesian-522M'
tokenizer = RobertaTokenizer.from_pretrained(model_name)
model = TFRobertaModel.from_pretrained(model_name)
text = "Silakan diganti dengan text apa saja."
encoded_input = tokenizer(text, return_tensors='tf')
output = model(encoded_input)
```
## Training data
This model was pre-trained with 522MB of indonesian Wikipedia.
The texts are lowercased and tokenized using WordPiece and a vocabulary size of 32,000. The inputs of the model are
then of the form:
```<s> Sentence A </s> Sentence B </s>```
|
aychang/roberta-base-imdb
|
aychang
| 2021-05-20T14:25:56Z | 1,446 | 5 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"roberta",
"text-classification",
"en",
"dataset:imdb",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
---
language:
- en
thumbnail:
tags:
- text-classification
license: mit
datasets:
- imdb
metrics:
---
# IMDB Sentiment Task: roberta-base
## Model description
A simple base roBERTa model trained on the "imdb" dataset.
## Intended uses & limitations
#### How to use
##### Transformers
```python
# Load model and tokenizer
from transformers import AutoModelForSequenceClassification, AutoTokenizer
model = AutoModelForQuestionAnswering.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
# Use pipeline
from transformers import pipeline
model_name = "aychang/roberta-base-imdb"
nlp = pipeline("sentiment-analysis", model=model_name, tokenizer=model_name)
results = nlp(["I didn't really like it because it was so terrible.", "I love how easy it is to watch and get good results."])
```
##### AdaptNLP
```python
from adaptnlp import EasySequenceClassifier
model_name = "aychang/roberta-base-imdb"
texts = ["I didn't really like it because it was so terrible.", "I love how easy it is to watch and get good results."]
classifer = EasySequenceClassifier
results = classifier.tag_text(text=texts, model_name_or_path=model_name, mini_batch_size=2)
```
#### Limitations and bias
This is minimal language model trained on a benchmark dataset.
## Training data
IMDB https://huggingface.co/datasets/imdb
## Training procedure
#### Hardware
One V100
#### Hyperparameters and Training Args
```python
from transformers import TrainingArguments
training_args = TrainingArguments(
output_dir='./models',
overwrite_output_dir=False,
num_train_epochs=2,
per_device_train_batch_size=8,
per_device_eval_batch_size=8,
warmup_steps=500,
weight_decay=0.01,
evaluation_strategy="steps",
logging_dir='./logs',
fp16=False,
eval_steps=800,
save_steps=300000
)
```
## Eval results
```
{'epoch': 2.0,
'eval_accuracy': 0.94668,
'eval_f1': array([0.94603457, 0.94731017]),
'eval_loss': 0.2578844428062439,
'eval_precision': array([0.95762642, 0.93624502]),
'eval_recall': array([0.93472, 0.95864]),
'eval_runtime': 244.7522,
'eval_samples_per_second': 102.144}
```
|
aravind-812/roberta-train-json
|
aravind-812
| 2021-05-20T14:12:53Z | 9 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"roberta",
"question-answering",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-03-02T23:29:05Z |
---
datasets:
- squad
widget:
- text: "Which name is also used to describe the Amazon rainforest in English?"
context: "The Amazon rainforest (Portuguese: Floresta Amazônica or Amazônia; Spanish: Selva Amazónica, Amazonía or usually Amazonia; French: Forêt amazonienne; Dutch: Amazoneregenwoud), also known in English as Amazonia or the Amazon Jungle, is a moist broadleaf forest that covers most of the Amazon basin of South America. This basin encompasses 7,000,000 square kilometres (2,700,000 sq mi), of which 5,500,000 square kilometres (2,100,000 sq mi) are covered by the rainforest. This region includes territory belonging to nine nations. The majority of the forest is contained within Brazil, with 60% of the rainforest, followed by Peru with 13%, Colombia with 10%, and with minor amounts in Venezuela, Ecuador, Bolivia, Guyana, Suriname and French Guiana. States or departments in four nations contain \"Amazonas\" in their names. The Amazon represents over half of the planet's remaining rainforests, and comprises the largest and most biodiverse tract of tropical rainforest in the world, with an estimated 390 billion individual trees divided into 16,000 species."
- text: "How many square kilometers of rainforest is covered in the basin?"
context: "The Amazon rainforest (Portuguese: Floresta Amazônica or Amazônia; Spanish: Selva Amazónica, Amazonía or usually Amazonia; French: Forêt amazonienne; Dutch: Amazoneregenwoud), also known in English as Amazonia or the Amazon Jungle, is a moist broadleaf forest that covers most of the Amazon basin of South America. This basin encompasses 7,000,000 square kilometres (2,700,000 sq mi), of which 5,500,000 square kilometres (2,100,000 sq mi) are covered by the rainforest. This region includes territory belonging to nine nations. The majority of the forest is contained within Brazil, with 60% of the rainforest, followed by Peru with 13%, Colombia with 10%, and with minor amounts in Venezuela, Ecuador, Bolivia, Guyana, Suriname and French Guiana. States or departments in four nations contain \"Amazonas\" in their names. The Amazon represents over half of the planet's remaining rainforests, and comprises the largest and most biodiverse tract of tropical rainforest in the world, with an estimated 390 billion individual trees divided into 16,000 species."
|
pchanda/pretrained-smiles-pubchem10m
|
pchanda
| 2021-05-20T13:01:15Z | 729 | 1 |
transformers
|
[
"transformers",
"pytorch",
"roberta",
"fill-mask",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:05Z |
model pretrained on 10m smiles from pubchem.
|
abhishek/autonlp-imdb_sentiment_classification-31154
|
abhishek
| 2021-05-20T12:46:38Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"roberta",
"text-classification",
"autonlp",
"en",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
---
tags: autonlp
language: en
widget:
- text: "I love AutoNLP 🤗"
---
# Model Trained Using AutoNLP
- Problem type: Binary Classification
- Model ID: 31154
## Validation Metrics
- Loss: 0.19292379915714264
- Accuracy: 0.9395
- Precision: 0.9569557080474111
- Recall: 0.9204
- AUC: 0.9851040399999998
- F1: 0.9383219492302988
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoNLP"}' https://api-inference.huggingface.co/models/abhishek/autonlp-imdb_sentiment_classification-31154
```
Or Python API:
```
from transformers import AutoModelForSequenceClassification, AutoTokenizer
model = AutoModelForSequenceClassification.from_pretrained("abhishek/autonlp-imdb_sentiment_classification-31154", use_auth_token=True)
tokenizer = AutoTokenizer.from_pretrained("abhishek/autonlp-imdb_sentiment_classification-31154", use_auth_token=True)
inputs = tokenizer("I love AutoNLP", return_tensors="pt")
outputs = model(**inputs)
```
|
MoseliMotsoehli/zuBERTa
|
MoseliMotsoehli
| 2021-05-20T12:14:07Z | 6 | 1 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"jax",
"roberta",
"fill-mask",
"zu",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:04Z |
---
language: zu
---
# zuBERTa
zuBERTa is a RoBERTa style transformer language model trained on zulu text.
## Intended uses & limitations
The model can be used for getting embeddings to use on a down-stream task such as question answering.
#### How to use
```python
>>> from transformers import pipeline
>>> from transformers import AutoTokenizer, AutoModelWithLMHead
>>> tokenizer = AutoTokenizer.from_pretrained("MoseliMotsoehli/zuBERTa")
>>> model = AutoModelWithLMHead.from_pretrained("MoseliMotsoehli/zuBERTa")
>>> unmasker = pipeline('fill-mask', model=model, tokenizer=tokenizer)
>>> unmasker("Abafika eNkandla bafika sebeholwa <mask> uMpongo kaZingelwayo.")
[
{
"sequence": "<s>Abafika eNkandla bafika sebeholwa khona uMpongo kaZingelwayo.</s>",
"score": 0.050459690392017365,
"token": 555,
"token_str": "Ġkhona"
},
{
"sequence": "<s>Abafika eNkandla bafika sebeholwa inkosi uMpongo kaZingelwayo.</s>",
"score": 0.03668094798922539,
"token": 2321,
"token_str": "Ġinkosi"
},
{
"sequence": "<s>Abafika eNkandla bafika sebeholwa ubukhosi uMpongo kaZingelwayo.</s>",
"score": 0.028774697333574295,
"token": 5101,
"token_str": "Ġubukhosi"
}
]
```
## Training data
1. 30k sentences of text, came from the [Leipzig Corpora Collection](https://wortschatz.uni-leipzig.de/en/download) of zulu 2018. These were collected from news articles and creative writtings.
2. ~7500 articles of human generated translations were scraped from the zulu [wikipedia](https://zu.wikipedia.org/wiki/Special:AllPages).
### BibTeX entry and citation info
```bibtex
@inproceedings{author = {Moseli Motsoehli},
title = {Towards transformation of Southern African language models through transformers.},
year={2020}
}
```
|
LIAMF-USP/roberta-large-finetuned-race
|
LIAMF-USP
| 2021-05-20T12:08:36Z | 33 | 11 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"jax",
"roberta",
"multiple-choice",
"dataset:race",
"license:mit",
"endpoints_compatible",
"region:us"
] |
multiple-choice
| 2022-03-02T23:29:04Z |
---
language: "english"
license: "mit"
datasets:
- race
metrics:
- accuracy
---
# Roberta Large Fine Tuned on RACE
## Model description
This model is a fine-tuned model of Roberta-large applied on RACE
#### How to use
```python
import datasets
from transformers import RobertaTokenizer
from transformers import RobertaForMultipleChoice
tokenizer = RobertaTokenizer.from_pretrained(
"LIAMF-USP/roberta-large-finetuned-race")
model = RobertaForMultipleChoice.from_pretrained(
"LIAMF-USP/roberta-large-finetuned-race")
dataset = datasets.load_dataset(
"race",
"all",
split=["train", "validation", "test"],
)training_examples = dataset[0]
evaluation_examples = dataset[1]
test_examples = dataset[2]
example=training_examples[0]
example_id = example["example_id"]
question = example["question"]
context = example["article"]
options = example["options"]
label_example = example["answer"]
label_map = {label: i
for i, label in enumerate(["A", "B", "C", "D"])}
choices_inputs = []
for ending_idx, (_, ending) in enumerate(
zip(context, options)):
if question.find("_") != -1:
# fill in the banks questions
question_option = question.replace("_", ending)
else:
question_option = question + " " + ending
inputs = tokenizer(
context,
question_option,
add_special_tokens=True,
max_length=MAX_SEQ_LENGTH,
padding="max_length",
truncation=True,
return_overflowing_tokens=False,
)
label = label_map[label_example]
input_ids = [x["input_ids"] for x in choices_inputs]
attention_mask = (
[x["attention_mask"] for x in choices_inputs]
# as the senteces follow the same structure,
#just one of them is necessary to check
if "attention_mask" in choices_inputs[0]
else None
)
example_encoded = {
"example_id": example_id,
"input_ids": input_ids,
"attention_mask": attention_mask,
"label": label,
}
output = model(**example_encoded)
```
## Training data
The initial model was [roberta large model](https://huggingface.co/roberta-large) which was then fine-tuned on [RACE dataset](https://www.cs.cmu.edu/~glai1/data/race/)
## Training procedure
It was necessary to preprocess the data with a method that is exemplified for a single instance in the _How to use_ section. The used hyperparameters were the following:
| Hyperparameter | Value |
|:----:|:----:|
| adam_beta1 | 0.9 |
| adam_beta2 | 0.98 |
| adam_epsilon | 1.000e-8 |
| eval_batch_size | 32 |
| train_batch_size | 1 |
| fp16 | True |
| gradient_accumulation_steps | 16 |
| learning_rate | 0.00001 |
| warmup_steps | 1000 |
| max_length | 512 |
| epochs | 4 |
## Eval results:
| Dataset Acc | Eval | All Test |High School Test |Middle School Test |
|:----:|:----:|:----:|:----:|:----:|
| | 85.2 | 84.9|83.5|88.0|
**The model was trained with a Tesla V100-PCIE-16GB**
|
HooshvareLab/roberta-fa-zwnj-base-ner
|
HooshvareLab
| 2021-05-20T11:55:34Z | 113 | 1 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"jax",
"roberta",
"token-classification",
"fa",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-03-02T23:29:04Z |
---
language: fa
---
# RobertaNER
This model fine-tuned for the Named Entity Recognition (NER) task on a mixed NER dataset collected from [ARMAN](https://github.com/HaniehP/PersianNER), [PEYMA](http://nsurl.org/2019-2/tasks/task-7-named-entity-recognition-ner-for-farsi/), and [WikiANN](https://elisa-ie.github.io/wikiann/) that covered ten types of entities:
- Date (DAT)
- Event (EVE)
- Facility (FAC)
- Location (LOC)
- Money (MON)
- Organization (ORG)
- Percent (PCT)
- Person (PER)
- Product (PRO)
- Time (TIM)
## Dataset Information
| | Records | B-DAT | B-EVE | B-FAC | B-LOC | B-MON | B-ORG | B-PCT | B-PER | B-PRO | B-TIM | I-DAT | I-EVE | I-FAC | I-LOC | I-MON | I-ORG | I-PCT | I-PER | I-PRO | I-TIM |
|:------|----------:|--------:|--------:|--------:|--------:|--------:|--------:|--------:|--------:|--------:|--------:|--------:|--------:|--------:|--------:|--------:|--------:|--------:|--------:|--------:|--------:|
| Train | 29133 | 1423 | 1487 | 1400 | 13919 | 417 | 15926 | 355 | 12347 | 1855 | 150 | 1947 | 5018 | 2421 | 4118 | 1059 | 19579 | 573 | 7699 | 1914 | 332 |
| Valid | 5142 | 267 | 253 | 250 | 2362 | 100 | 2651 | 64 | 2173 | 317 | 19 | 373 | 799 | 387 | 717 | 270 | 3260 | 101 | 1382 | 303 | 35 |
| Test | 6049 | 407 | 256 | 248 | 2886 | 98 | 3216 | 94 | 2646 | 318 | 43 | 568 | 888 | 408 | 858 | 263 | 3967 | 141 | 1707 | 296 | 78 |
## Evaluation
The following tables summarize the scores obtained by model overall and per each class.
**Overall**
| Model | accuracy | precision | recall | f1 |
|:----------:|:--------:|:---------:|:--------:|:--------:|
| Roberta | 0.994849 | 0.949816 | 0.960235 | 0.954997 |
**Per entities**
| | number | precision | recall | f1 |
|:---: |:------: |:---------: |:--------: |:--------: |
| DAT | 407 | 0.844869 | 0.869779 | 0.857143 |
| EVE | 256 | 0.948148 | 1.000000 | 0.973384 |
| FAC | 248 | 0.957529 | 1.000000 | 0.978304 |
| LOC | 2884 | 0.965422 | 0.968100 | 0.966759 |
| MON | 98 | 0.937500 | 0.918367 | 0.927835 |
| ORG | 3216 | 0.943662 | 0.958333 | 0.950941 |
| PCT | 94 | 1.000000 | 0.968085 | 0.983784 |
| PER | 2646 | 0.957030 | 0.959562 | 0.958294 |
| PRO | 318 | 0.963636 | 1.000000 | 0.981481 |
| TIM | 43 | 0.739130 | 0.790698 | 0.764045 |
## How To Use
You use this model with Transformers pipeline for NER.
### Installing requirements
```bash
pip install transformers
```
### How to predict using pipeline
```python
from transformers import AutoTokenizer
from transformers import AutoModelForTokenClassification # for pytorch
from transformers import TFAutoModelForTokenClassification # for tensorflow
from transformers import pipeline
model_name_or_path = "HooshvareLab/roberta-fa-zwnj-base-ner"
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path)
model = AutoModelForTokenClassification.from_pretrained(model_name_or_path) # Pytorch
# model = TFAutoModelForTokenClassification.from_pretrained(model_name_or_path) # Tensorflow
nlp = pipeline("ner", model=model, tokenizer=tokenizer)
example = "در سال ۲۰۱۳ درگذشت و آندرتیکر و کین برای او مراسم یادبود گرفتند."
ner_results = nlp(example)
print(ner_results)
```
## Questions?
Post a Github issue on the [ParsNER Issues](https://github.com/hooshvare/parsner/issues) repo.
|
zanelim/singbert
|
zanelim
| 2021-05-20T09:38:41Z | 6 | 4 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"jax",
"bert",
"pretraining",
"singapore",
"sg",
"singlish",
"malaysia",
"ms",
"manglish",
"bert-base-uncased",
"en",
"license:mit",
"endpoints_compatible",
"region:us"
] | null | 2022-03-02T23:29:05Z |
---
language: en
tags:
- singapore
- sg
- singlish
- malaysia
- ms
- manglish
- bert-base-uncased
license: mit
datasets:
- reddit singapore, malaysia
- hardwarezone
widget:
- text: "kopi c siew [MASK]"
- text: "die [MASK] must try"
---
# Model name
SingBert - Bert for Singlish (SG) and Manglish (MY).
## Model description
[BERT base uncased](https://github.com/google-research/bert#pre-trained-models), with pre-training finetuned on
[singlish](https://en.wikipedia.org/wiki/Singlish) and [manglish](https://en.wikipedia.org/wiki/Manglish) data.
## Intended uses & limitations
#### How to use
```python
>>> from transformers import pipeline
>>> nlp = pipeline('fill-mask', model='zanelim/singbert')
>>> nlp("kopi c siew [MASK]")
[{'sequence': '[CLS] kopi c siew dai [SEP]',
'score': 0.5092713236808777,
'token': 18765,
'token_str': 'dai'},
{'sequence': '[CLS] kopi c siew mai [SEP]',
'score': 0.3515934646129608,
'token': 14736,
'token_str': 'mai'},
{'sequence': '[CLS] kopi c siew bao [SEP]',
'score': 0.05576375499367714,
'token': 25945,
'token_str': 'bao'},
{'sequence': '[CLS] kopi c siew. [SEP]',
'score': 0.006019321270287037,
'token': 1012,
'token_str': '.'},
{'sequence': '[CLS] kopi c siew sai [SEP]',
'score': 0.0038361591286957264,
'token': 18952,
'token_str': 'sai'}]
>>> nlp("one teh c siew dai, and one kopi [MASK].")
[{'sequence': '[CLS] one teh c siew dai, and one kopi c [SEP]',
'score': 0.6176503300666809,
'token': 1039,
'token_str': 'c'},
{'sequence': '[CLS] one teh c siew dai, and one kopi o [SEP]',
'score': 0.21094971895217896,
'token': 1051,
'token_str': 'o'},
{'sequence': '[CLS] one teh c siew dai, and one kopi. [SEP]',
'score': 0.13027705252170563,
'token': 1012,
'token_str': '.'},
{'sequence': '[CLS] one teh c siew dai, and one kopi! [SEP]',
'score': 0.004680239595472813,
'token': 999,
'token_str': '!'},
{'sequence': '[CLS] one teh c siew dai, and one kopi w [SEP]',
'score': 0.002034128177911043,
'token': 1059,
'token_str': 'w'}]
>>> nlp("dont play [MASK] leh")
[{'sequence': '[CLS] dont play play leh [SEP]',
'score': 0.9281464219093323,
'token': 2377,
'token_str': 'play'},
{'sequence': '[CLS] dont play politics leh [SEP]',
'score': 0.010990909300744534,
'token': 4331,
'token_str': 'politics'},
{'sequence': '[CLS] dont play punk leh [SEP]',
'score': 0.005583590362221003,
'token': 7196,
'token_str': 'punk'},
{'sequence': '[CLS] dont play dirty leh [SEP]',
'score': 0.0025784350000321865,
'token': 6530,
'token_str': 'dirty'},
{'sequence': '[CLS] dont play cheat leh [SEP]',
'score': 0.0025066907983273268,
'token': 21910,
'token_str': 'cheat'}]
>>> nlp("catch no [MASK]")
[{'sequence': '[CLS] catch no ball [SEP]',
'score': 0.7922210693359375,
'token': 3608,
'token_str': 'ball'},
{'sequence': '[CLS] catch no balls [SEP]',
'score': 0.20503675937652588,
'token': 7395,
'token_str': 'balls'},
{'sequence': '[CLS] catch no tail [SEP]',
'score': 0.0006608376861549914,
'token': 5725,
'token_str': 'tail'},
{'sequence': '[CLS] catch no talent [SEP]',
'score': 0.0002158183924620971,
'token': 5848,
'token_str': 'talent'},
{'sequence': '[CLS] catch no prisoners [SEP]',
'score': 5.3481446229852736e-05,
'token': 5895,
'token_str': 'prisoners'}]
>>> nlp("confirm plus [MASK]")
[{'sequence': '[CLS] confirm plus chop [SEP]',
'score': 0.992355227470398,
'token': 24494,
'token_str': 'chop'},
{'sequence': '[CLS] confirm plus one [SEP]',
'score': 0.0037301010452210903,
'token': 2028,
'token_str': 'one'},
{'sequence': '[CLS] confirm plus minus [SEP]',
'score': 0.0014284878270700574,
'token': 15718,
'token_str': 'minus'},
{'sequence': '[CLS] confirm plus 1 [SEP]',
'score': 0.0011354683665558696,
'token': 1015,
'token_str': '1'},
{'sequence': '[CLS] confirm plus chopped [SEP]',
'score': 0.0003804611915256828,
'token': 24881,
'token_str': 'chopped'}]
>>> nlp("die [MASK] must try")
[{'sequence': '[CLS] die die must try [SEP]',
'score': 0.9552758932113647,
'token': 3280,
'token_str': 'die'},
{'sequence': '[CLS] die also must try [SEP]',
'score': 0.03644804656505585,
'token': 2036,
'token_str': 'also'},
{'sequence': '[CLS] die liao must try [SEP]',
'score': 0.003282855963334441,
'token': 727,
'token_str': 'liao'},
{'sequence': '[CLS] die already must try [SEP]',
'score': 0.0004937972989864647,
'token': 2525,
'token_str': 'already'},
{'sequence': '[CLS] die hard must try [SEP]',
'score': 0.0003659659414552152,
'token': 2524,
'token_str': 'hard'}]
```
Here is how to use this model to get the features of a given text in PyTorch:
```python
from transformers import BertTokenizer, BertModel
tokenizer = BertTokenizer.from_pretrained('zanelim/singbert')
model = BertModel.from_pretrained("zanelim/singbert")
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='pt')
output = model(**encoded_input)
```
and in TensorFlow:
```python
from transformers import BertTokenizer, TFBertModel
tokenizer = BertTokenizer.from_pretrained("zanelim/singbert")
model = TFBertModel.from_pretrained("zanelim/singbert")
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='tf')
output = model(encoded_input)
```
#### Limitations and bias
This model was finetuned on colloquial Singlish and Manglish corpus, hence it is best applied on downstream tasks involving the main
constituent languages- english, mandarin, malay. Also, as the training data is mainly from forums, beware of existing inherent bias.
## Training data
Colloquial singlish and manglish (both are a mixture of English, Mandarin, Tamil, Malay, and other local dialects like Hokkien, Cantonese or Teochew)
corpus. The corpus is collected from subreddits- `r/singapore` and `r/malaysia`, and forums such as `hardwarezone`.
## Training procedure
Initialized with [bert base uncased](https://github.com/google-research/bert#pre-trained-models) vocab and checkpoints (pre-trained weights).
Top 1000 custom vocab tokens (non-overlapped with original bert vocab) were further extracted from training data and filled into unused tokens in original bert vocab.
Pre-training was further finetuned on training data with the following hyperparameters
* train_batch_size: 512
* max_seq_length: 128
* num_train_steps: 300000
* num_warmup_steps: 5000
* learning_rate: 2e-5
* hardware: TPU v3-8
|
tugstugi/bert-large-mongolian-uncased
|
tugstugi
| 2021-05-20T08:19:28Z | 44 | 8 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"jax",
"bert",
"fill-mask",
"mongolian",
"uncased",
"mn",
"arxiv:1810.04805",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:05Z |
---
language: "mn"
tags:
- bert
- mongolian
- uncased
---
# BERT-LARGE-MONGOLIAN-UNCASED
[Link to Official Mongolian-BERT repo](https://github.com/tugstugi/mongolian-bert)
## Model description
This repository contains pre-trained Mongolian [BERT](https://arxiv.org/abs/1810.04805) models trained by [tugstugi](https://github.com/tugstugi), [enod](https://github.com/enod) and [sharavsambuu](https://github.com/sharavsambuu).
Special thanks to [nabar](https://github.com/nabar) who provided 5x TPUs.
This repository is based on the following open source projects: [google-research/bert](https://github.com/google-research/bert/),
[huggingface/pytorch-pretrained-BERT](https://github.com/huggingface/pytorch-pretrained-BERT) and [yoheikikuta/bert-japanese](https://github.com/yoheikikuta/bert-japanese).
#### How to use
```python
from transformers import pipeline, AutoTokenizer, AutoModelForMaskedLM
tokenizer = AutoTokenizer.from_pretrained('tugstugi/bert-large-mongolian-uncased', use_fast=False)
model = AutoModelForMaskedLM.from_pretrained('tugstugi/bert-large-mongolian-uncased')
## declare task ##
pipe = pipeline(task="fill-mask", model=model, tokenizer=tokenizer)
## example ##
input_ = 'Монгол улсын [MASK] Улаанбаатар хотоос ярьж байна.'
output_ = pipe(input_)
for i in range(len(output_)):
print(output_[i])
## output ##
# {'sequence': 'монгол улсын нийслэл улаанбаатар хотоос ярьж байна.', 'score': 0.7867621183395386, 'token': 849, 'token_str': 'нийслэл'}
# {'sequence': 'монгол улсын ерөнхийлөгч улаанбаатар хотоос ярьж байна.', 'score': 0.14303277432918549, 'token': 244, 'token_str': 'ерөнхийлөгч'}
# {'sequence': 'монгол улсын ерөнхийлөгчийг улаанбаатар хотоос ярьж байна.', 'score': 0.011642335914075375, 'token': 8373, 'token_str': 'ерөнхийлөгчийг'}
# {'sequence': 'монгол улсын иргэд улаанбаатар хотоос ярьж байна.', 'score': 0.006592822726815939, 'token': 247, 'token_str': 'иргэд'}
# {'sequence': 'монгол улсын нийслэлийг улаанбаатар хотоос ярьж байна.', 'score': 0.006165097933262587, 'token': 15501, 'token_str': 'нийслэлийг'}
```
## Training data
Mongolian Wikipedia and the 700 million word Mongolian news data set [[Pretraining Procedure](https://github.com/tugstugi/mongolian-bert#pre-training)]
### BibTeX entry and citation info
```bibtex
@misc{mongolian-bert,
author = {Tuguldur, Erdene-Ochir and Gunchinish, Sharavsambuu and Bataa, Enkhbold},
title = {BERT Pretrained Models on Mongolian Datasets},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://github.com/tugstugi/mongolian-bert/}}
}
```
|
tugstugi/bert-base-mongolian-cased
|
tugstugi
| 2021-05-20T08:12:07Z | 118 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"jax",
"bert",
"fill-mask",
"mongolian",
"cased",
"mn",
"arxiv:1810.04805",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:05Z |
---
language: "mn"
tags:
- bert
- mongolian
- cased
---
# BERT-BASE-MONGOLIAN-CASED
[Link to Official Mongolian-BERT repo](https://github.com/tugstugi/mongolian-bert)
## Model description
This repository contains pre-trained Mongolian [BERT](https://arxiv.org/abs/1810.04805) models trained by [tugstugi](https://github.com/tugstugi), [enod](https://github.com/enod) and [sharavsambuu](https://github.com/sharavsambuu).
Special thanks to [nabar](https://github.com/nabar) who provided 5x TPUs.
This repository is based on the following open source projects: [google-research/bert](https://github.com/google-research/bert/),
[huggingface/pytorch-pretrained-BERT](https://github.com/huggingface/pytorch-pretrained-BERT) and [yoheikikuta/bert-japanese](https://github.com/yoheikikuta/bert-japanese).
#### How to use
```python
from transformers import pipeline, AutoTokenizer, AutoModelForMaskedLM
tokenizer = AutoTokenizer.from_pretrained('tugstugi/bert-base-mongolian-cased', use_fast=False)
model = AutoModelForMaskedLM.from_pretrained('tugstugi/bert-base-mongolian-cased')
## declare task ##
pipe = pipeline(task="fill-mask", model=model, tokenizer=tokenizer)
## example ##
input_ = '[MASK] хот Монгол улсын нийслэл.'
output_ = pipe(input_)
for i in range(len(output_)):
print(output_[i])
## output ##
# {'sequence': 'Улаанбаатар хот Монгол улсын нийслэл.', 'score': 0.826970100402832, 'token': 281, 'token_str': 'Улаанбаатар'}
# {'sequence': 'Нийслэл хот Монгол улсын нийслэл.', 'score': 0.06551621109247208, 'token': 4059, 'token_str': 'Нийслэл'}
# {'sequence': 'Эрдэнэт хот Монгол улсын нийслэл.', 'score': 0.0264141745865345, 'token': 2229, 'token_str': 'Эрдэнэт'}
# {'sequence': 'Дархан хот Монгол улсын нийслэл.', 'score': 0.017083868384361267, 'token': 1646, 'token_str': 'Дархан'}
# {'sequence': 'УБ хот Монгол улсын нийслэл.', 'score': 0.010854342952370644, 'token': 7389, 'token_str': 'УБ'}
```
## Training data
Mongolian Wikipedia and the 700 million word Mongolian news data set [[Pretraining Procedure](https://github.com/tugstugi/mongolian-bert#pre-training)]
### BibTeX entry and citation info
```bibtex
@misc{mongolian-bert,
author = {Tuguldur, Erdene-Ochir and Gunchinish, Sharavsambuu and Bataa, Enkhbold},
title = {BERT Pretrained Models on Mongolian Datasets},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://github.com/tugstugi/mongolian-bert/}}
}
```
|
trueto/medbert-kd-chinese
|
trueto
| 2021-05-20T08:10:57Z | 9 | 10 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"pretraining",
"endpoints_compatible",
"region:us"
] | null | 2022-03-02T23:29:05Z |
# [medbert](https://github.com/trueto/medbert)
本项目开源硕士毕业论文“BERT模型在中文临床自然语言处理中的应用探索与研究”相关模型
## 评估基准
构建了中文电子病历命名实体识别数据集(CEMRNER)、中文医学文本命名实体识别数据集(CMTNER)、
中文医学问句-问句识别数据集(CMedQQ)和中文临床文本分类数据集(CCTC)。
| **数据集** | **训练集** | **验证集** | **测试集** | **任务类型** | **语料来源** |
| ---- | ---- | ---- |---- |---- |:----:|
| CEMRNER | 965 | 138 | 276 | 命名实体识别 | 医渡云 |
| CMTNER | 14000 | 2000 | 4000 | 命名实体识别 | CHIP2020 |
| CMedQQ | 14000 | 2000 | 4000 | 句对识别 | 平安医疗 |
| CCTC | 26837 | 3834 | 7669 | 句子分类 | CHIP2019 |
## 开源模型
在6.5亿字符中文临床自然语言文本语料上基于BERT模型和Albert模型预训练获得了MedBERT和MedAlbert模型。
## 性能表现
在同等实验环境,相同训练参数和脚本下,各模型的性能表现
| **模型** | **CEMRNER** | **CMTNER** | **CMedQQ** | **CCTC** |
| :---- | :----: | :----: | :----: | :----: |
| [BERT](https://huggingface.co/bert-base-chinese) | 81.17% | 65.67% | 87.77% | 81.62% |
| [MC-BERT](https://github.com/alibaba-research/ChineseBLUE) | 80.93% | 66.15% | 89.04% | 80.65% |
| [PCL-BERT](https://code.ihub.org.cn/projects/1775) | 81.58% | 67.02% | 88.81% | 80.27% |
| MedBERT | 82.29% | 66.49% | 88.32% | **81.77%** |
|MedBERT-wwm| **82.60%** | 67.11% | 88.02% | 81.72% |
|MedBERT-kd | 82.58% | **67.27%** | **89.34%** | 80.73% |
|- | - | - | - | - |
| [Albert](https://huggingface.co/voidful/albert_chinese_base) | 79.98% | 62.42% | 86.81% | 79.83% |
| MedAlbert | 81.03% | 63.81% | 87.56% | 80.05% |
|MedAlbert-wwm| **81.28%** | **64.12%** | **87.71%** | **80.46%** |
## 引用格式
```
杨飞洪,王序文,李姣.BERT模型在中文临床自然语言处理中的应用探索与研究[EB/OL].https://github.com/trueto/medbert, 2021-03.
```
|
trueto/medbert-base-chinese
|
trueto
| 2021-05-20T08:08:47Z | 276 | 13 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"pretraining",
"endpoints_compatible",
"region:us"
] | null | 2022-03-02T23:29:05Z |
# [medbert](https://github.com/trueto/medbert)
本项目开源硕士毕业论文“BERT模型在中文临床自然语言处理中的应用探索与研究”相关模型
## 评估基准
构建了中文电子病历命名实体识别数据集(CEMRNER)、中文医学文本命名实体识别数据集(CMTNER)、
中文医学问句-问句识别数据集(CMedQQ)和中文临床文本分类数据集(CCTC)。
| **数据集** | **训练集** | **验证集** | **测试集** | **任务类型** | **语料来源** |
| ---- | ---- | ---- |---- |---- |:----:|
| CEMRNER | 965 | 138 | 276 | 命名实体识别 | 医渡云 |
| CMTNER | 14000 | 2000 | 4000 | 命名实体识别 | CHIP2020 |
| CMedQQ | 14000 | 2000 | 4000 | 句对识别 | 平安医疗 |
| CCTC | 26837 | 3834 | 7669 | 句子分类 | CHIP2019 |
## 开源模型
在6.5亿字符中文临床自然语言文本语料上基于BERT模型和Albert模型预训练获得了MedBERT和MedAlbert模型。
## 性能表现
在同等实验环境,相同训练参数和脚本下,各模型的性能表现
| **模型** | **CEMRNER** | **CMTNER** | **CMedQQ** | **CCTC** |
| :---- | :----: | :----: | :----: | :----: |
| [BERT](https://huggingface.co/bert-base-chinese) | 81.17% | 65.67% | 87.77% | 81.62% |
| [MC-BERT](https://github.com/alibaba-research/ChineseBLUE) | 80.93% | 66.15% | 89.04% | 80.65% |
| [PCL-BERT](https://code.ihub.org.cn/projects/1775) | 81.58% | 67.02% | 88.81% | 80.27% |
| MedBERT | 82.29% | 66.49% | 88.32% | **81.77%** |
|MedBERT-wwm| **82.60%** | 67.11% | 88.02% | 81.72% |
|MedBERT-kd | 82.58% | **67.27%** | **89.34%** | 80.73% |
|- | - | - | - | - |
| [Albert](https://huggingface.co/voidful/albert_chinese_base) | 79.98% | 62.42% | 86.81% | 79.83% |
| MedAlbert | 81.03% | 63.81% | 87.56% | 80.05% |
|MedAlbert-wwm| **81.28%** | **64.12%** | **87.71%** | **80.46%** |
## 引用格式
```
杨飞洪,王序文,李姣.BERT模型在中文临床自然语言处理中的应用探索与研究[EB/OL].https://github.com/trueto/medbert, 2021-03.
```
|
trituenhantaoio/bert-base-vietnamese-diacritics-uncased
|
trituenhantaoio
| 2021-05-20T08:05:47Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"jax",
"bert",
"endpoints_compatible",
"region:us"
] | null | 2022-03-02T23:29:05Z |
## Usage
```python
from transformers import BertForSequenceClassification
from transformers import BertTokenizer
model = BertForSequenceClassification.from_pretrained("trituenhantaoio/bert-base-vietnamese-diacritics-uncased")
tokenizer = BertTokenizer.from_pretrained("trituenhantaoio/bert-base-vietnamese-diacritics-uncased")
```
### References
```
@article{ttnt2020bertdiacritics,
title={Vietnamese BERT Diacritics: Pretrained on News and Wiki},
author={trituenhantao.io},
year = {2020},
publisher = {Hugging Face},
journal = {Hugging Face repository}
}
```
[trituenhantao.io](https://trituenhantao.io)
|
textattack/bert-base-uncased-rotten_tomatoes
|
textattack
| 2021-05-20T07:47:13Z | 7 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"tensorboard",
"bert",
"fill-mask",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:05Z |
## bert-base-uncased fine-tuned with TextAttack on the rotten_tomatoes dataset
This `bert-base-uncased` model was fine-tuned for sequence classificationusing TextAttack
and the rotten_tomatoes dataset loaded using the `nlp` library. The model was fine-tuned
for 10 epochs with a batch size of 64, a learning
rate of 5e-05, and a maximum sequence length of 128.
Since this was a classification task, the model was trained with a cross-entropy loss function.
The best score the model achieved on this task was 0.875234521575985, as measured by the
eval set accuracy, found after 4 epochs.
For more information, check out [TextAttack on Github](https://github.com/QData/TextAttack).
|
textattack/bert-base-uncased-RTE
|
textattack
| 2021-05-20T07:36:18Z | 81 | 3 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"text-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
## TextAttack Model Card
This `bert-base-uncased` model was fine-tuned for sequence classification using TextAttack
and the glue dataset loaded using the `nlp` library. The model was fine-tuned
for 5 epochs with a batch size of 8, a learning
rate of 2e-05, and a maximum sequence length of 128.
Since this was a classification task, the model was trained with a cross-entropy loss function.
The best score the model achieved on this task was 0.7256317689530686, as measured by the
eval set accuracy, found after 2 epochs.
For more information, check out [TextAttack on Github](https://github.com/QData/TextAttack).
|
tennessejoyce/titlewave-bert-base-uncased
|
tennessejoyce
| 2021-05-20T07:29:09Z | 11 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"text-classification",
"en",
"license:cc-by-4.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
---
language: en
license: cc-by-4.0
widget:
- text: "[Gmail API] How can I extract plain text from an email sent to me?"
---
# Titlewave: bert-base-uncased
## Model description
Titlewave is a Chrome extension that helps you choose better titles for your Stack Overflow questions. See the [github repository](https://github.com/tennessejoyce/TitleWave) for more information.
This is one of two NLP models used in the Titlewave project, and its purpose is to classify whether question will be answered or not just based on the title. The [companion model](https://huggingface.co/tennessejoyce/titlewave-t5-small) suggests a new title based on on the body of the question.
## Intended use
Try out different titles for your Stack Overflow post, and see which one gives you the best chance of receiving an answer.
You can use the model through the API on this page (hosted by HuggingFace) or install the Chrome extension by following the instructions on the [github repository](https://github.com/tennessejoyce/TitleWave), which integrates the tool directly into the Stack Overflow website.
You can also run the model locally in Python like this (which automatically downloads the model to your machine):
```python
>>> from transformers import pipeline
>>> classifier = pipeline('sentiment-analysis', model='tennessejoyce/titlewave-bert-base-uncased')
>>> classifier('[Gmail API] How can I extract plain text from an email sent to me?')
[{'label': 'Answered', 'score': 0.8053370714187622}]
```
The 'score' in the output represents the probability of getting an answer with this title: 80.5%.
## Training data
The weights were initialized from the [BERT base model](https://huggingface.co/bert-base-uncased), which was trained on BookCorpus and English Wikipedia.
Then the model was fine-tuned on the dataset of previous Stack Overflow post titles, which is publicly available [here](https://archive.org/details/stackexchange).
Specifically I used three years of posts from 2017-2019, filtered out posts which were closed (e.g., duplicates, off-topic), and selected 5% of the remaining posts at random to use in the training set, and the same amount for validation and test sets (278,155 posts each).
## Training procedure
The model was fine-tuned for two epochs with a batch size of 32 (17,384 steps total) using 16-bit mixed precision.
After some hyperparameter tuning, I found that the following two-phase training procedure yields the best performance (ROC-AUC score) on the validation set:
* In the first epoch, all layers were frozen except for the last two (pooling layer and classification layer) and a learning rate of 3e-4 was used.
* In the second epoch all layers were unfrozen, and the learning rate was decreased by a factor of 10 to 3e-5.
Otherwise, all parameters we set to the defaults listed [here](https://huggingface.co/transformers/main_classes/trainer.html#transformers.TrainingArguments),
including the AdamW optimizer and a linearly decreasing learning schedule (both of which were reset between the two epochs). See the [github repository](https://github.com/tennessejoyce/TitleWave) for the scripts that were used to train the model.
## Evaluation
See [this notebook](https://github.com/tennessejoyce/TitleWave/blob/master/model_training/test_classifier.ipynb) for the performance of the title classification model on the test set.
|
susumu2357/bert-base-swedish-squad2
|
susumu2357
| 2021-05-20T07:20:04Z | 99 | 1 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"jax",
"bert",
"question-answering",
"squad",
"sv",
"dataset:susumu2357/squad_v2_sv",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-03-02T23:29:05Z |
---
language:
- sv
tags:
- squad
license: apache-2.0
datasets:
- susumu2357/squad_v2_sv
metrics:
- squad_v2
---
# Swedish BERT Fine-tuned on SQuAD v2
This model is a fine-tuning checkpoint of Swedish BERT on SQuAD v2.
## Training data
Fine-tuning was done based on the pre-trained model [KB/bert-base-swedish-cased](https://huggingface.co/KB/bert-base-swedish-cased).
Training and dev datasets are our
[Swedish translation of SQuAD v2](https://github.com/susumu2357/SQuAD_v2_sv).
[Here](https://huggingface.co/datasets/susumu2357/squad_v2_sv) is the HuggingFace Datasets.
## Hyperparameters
```
batch_size = 16
n_epochs = 2
max_seq_len = 386
learning_rate = 3e-5
warmup_steps = 2900 # warmup_proportion = 0.2
doc_stride=128
max_query_length=64
```
## Eval results
```
'exact': 66.72642524202223
'f1': 70.11149581003404
'total': 11156
'HasAns_exact': 55.574745730186144
'HasAns_f1': 62.821693965983044
'HasAns_total': 5211
'NoAns_exact': 76.50126156433979
'NoAns_f1': 76.50126156433979
'NoAns_total': 5945
```
## Limitations and bias
This model may contain biases due to mistranslations of the SQuAD dataset.
## BibTeX entry and citation info
```bibtex
@misc{svSQuADbert,
author = {Susumu Okazawa},
title = {Swedish BERT Fine-tuned on Swedish SQuAD 2.0},
year = {2021},
howpublished = {\url{https://huggingface.co/susumu2357/bert-base-swedish-squad2}},
}
```
|
soniakris/Sonia_model
|
soniakris
| 2021-05-20T07:09:49Z | 4 | 0 |
transformers
|
[
"transformers",
"tf",
"bert",
"fill-mask",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:05Z |
Tensor-Flow Model using MASK token
|
socialmediaie/TRAC2020_HIN_C_bert-base-multilingual-uncased
|
socialmediaie
| 2021-05-20T07:01:31Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"text-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
# Multilingual Joint Fine-tuning of Transformer models for identifying Trolling, Aggression and Cyberbullying at TRAC 2020
Models and predictions for submission to TRAC - 2020 Second Workshop on Trolling, Aggression and Cyberbullying.
Our trained models as well as evaluation metrics during traing are available at: https://databank.illinois.edu/datasets/IDB-8882752#
We also make a few of our models available in HuggingFace's models repository at https://huggingface.co/socialmediaie/, these models can be further fine-tuned on your dataset of choice.
Our approach is described in our paper titled:
> Mishra, Sudhanshu, Shivangi Prasad, and Shubhanshu Mishra. 2020. "Multilingual Joint Fine-Tuning of Transformer Models for Identifying Trolling, Aggression and Cyberbullying at TRAC 2020." In Proceedings of the Second Workshop on Trolling, Aggression and Cyberbullying (TRAC-2020).
The source code for training this model and more details can be found on our code repository: https://github.com/socialmediaie/TRAC2020
NOTE: These models are retrained for uploading here after our submission so the evaluation measures may be slightly different from the ones reported in the paper.
If you plan to use the dataset please cite the following resources:
* Mishra, Sudhanshu, Shivangi Prasad, and Shubhanshu Mishra. 2020. "Multilingual Joint Fine-Tuning of Transformer Models for Identifying Trolling, Aggression and Cyberbullying at TRAC 2020." In Proceedings of the Second Workshop on Trolling, Aggression and Cyberbullying (TRAC-2020).
* Mishra, Shubhanshu, Shivangi Prasad, and Shubhanshu Mishra. 2020. “Trained Models for Multilingual Joint Fine-Tuning of Transformer Models for Identifying Trolling, Aggression and Cyberbullying at TRAC 2020.” University of Illinois at Urbana-Champaign. https://doi.org/10.13012/B2IDB-8882752_V1.
```
@inproceedings{Mishra2020TRAC,
author = {Mishra, Sudhanshu and Prasad, Shivangi and Mishra, Shubhanshu},
booktitle = {Proceedings of the Second Workshop on Trolling, Aggression and Cyberbullying (TRAC-2020)},
title = {{Multilingual Joint Fine-tuning of Transformer models for identifying Trolling, Aggression and Cyberbullying at TRAC 2020}},
year = {2020}
}
@data{illinoisdatabankIDB-8882752,
author = {Mishra, Shubhanshu and Prasad, Shivangi and Mishra, Shubhanshu},
doi = {10.13012/B2IDB-8882752_V1},
publisher = {University of Illinois at Urbana-Champaign},
title = {{Trained models for Multilingual Joint Fine-tuning of Transformer models for identifying Trolling, Aggression and Cyberbullying at TRAC 2020}},
url = {https://doi.org/10.13012/B2IDB-8882752{\_}V1},
year = {2020}
}
```
## Usage
The models can be used via the following code:
```python
from transformers import AutoModel, AutoTokenizer, AutoModelForSequenceClassification
import torch
from pathlib import Path
from scipy.special import softmax
import numpy as np
import pandas as pd
TASK_LABEL_IDS = {
"Sub-task A": ["OAG", "NAG", "CAG"],
"Sub-task B": ["GEN", "NGEN"],
"Sub-task C": ["OAG-GEN", "OAG-NGEN", "NAG-GEN", "NAG-NGEN", "CAG-GEN", "CAG-NGEN"]
}
model_version="databank" # other option is hugging face library
if model_version == "databank":
# Make sure you have downloaded the required model file from https://databank.illinois.edu/datasets/IDB-8882752
# Unzip the file at some model_path (we are using: "databank_model")
model_path = next(Path("databank_model").glob("./*/output/*/model"))
# Assuming you get the following type of structure inside "databank_model"
# 'databank_model/ALL/Sub-task C/output/bert-base-multilingual-uncased/model'
lang, task, _, base_model, _ = model_path.parts
tokenizer = AutoTokenizer.from_pretrained(base_model)
model = AutoModelForSequenceClassification.from_pretrained(model_path)
else:
lang, task, base_model = "ALL", "Sub-task C", "bert-base-multilingual-uncased"
base_model = f"socialmediaie/TRAC2020_{lang}_{lang.split()[-1]}_{base_model}"
tokenizer = AutoTokenizer.from_pretrained(base_model)
model = AutoModelForSequenceClassification.from_pretrained(base_model)
# For doing inference set model in eval mode
model.eval()
# If you want to further fine-tune the model you can reset the model to model.train()
task_labels = TASK_LABEL_IDS[task]
sentence = "This is a good cat and this is a bad dog."
processed_sentence = f"{tokenizer.cls_token} {sentence}"
tokens = tokenizer.tokenize(sentence)
indexed_tokens = tokenizer.convert_tokens_to_ids(tokens)
tokens_tensor = torch.tensor([indexed_tokens])
with torch.no_grad():
logits, = model(tokens_tensor, labels=None)
logits
preds = logits.detach().cpu().numpy()
preds_probs = softmax(preds, axis=1)
preds = np.argmax(preds_probs, axis=1)
preds_labels = np.array(task_labels)[preds]
print(dict(zip(task_labels, preds_probs[0])), preds_labels)
"""You should get an output as follows:
({'CAG-GEN': 0.06762535,
'CAG-NGEN': 0.03244293,
'NAG-GEN': 0.6897794,
'NAG-NGEN': 0.15498641,
'OAG-GEN': 0.034373745,
'OAG-NGEN': 0.020792078},
array(['NAG-GEN'], dtype='<U8'))
"""
```
|
socialmediaie/TRAC2020_HIN_A_bert-base-multilingual-uncased
|
socialmediaie
| 2021-05-20T06:58:51Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"text-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
# Multilingual Joint Fine-tuning of Transformer models for identifying Trolling, Aggression and Cyberbullying at TRAC 2020
Models and predictions for submission to TRAC - 2020 Second Workshop on Trolling, Aggression and Cyberbullying.
Our trained models as well as evaluation metrics during traing are available at: https://databank.illinois.edu/datasets/IDB-8882752#
We also make a few of our models available in HuggingFace's models repository at https://huggingface.co/socialmediaie/, these models can be further fine-tuned on your dataset of choice.
Our approach is described in our paper titled:
> Mishra, Sudhanshu, Shivangi Prasad, and Shubhanshu Mishra. 2020. "Multilingual Joint Fine-Tuning of Transformer Models for Identifying Trolling, Aggression and Cyberbullying at TRAC 2020." In Proceedings of the Second Workshop on Trolling, Aggression and Cyberbullying (TRAC-2020).
The source code for training this model and more details can be found on our code repository: https://github.com/socialmediaie/TRAC2020
NOTE: These models are retrained for uploading here after our submission so the evaluation measures may be slightly different from the ones reported in the paper.
If you plan to use the dataset please cite the following resources:
* Mishra, Sudhanshu, Shivangi Prasad, and Shubhanshu Mishra. 2020. "Multilingual Joint Fine-Tuning of Transformer Models for Identifying Trolling, Aggression and Cyberbullying at TRAC 2020." In Proceedings of the Second Workshop on Trolling, Aggression and Cyberbullying (TRAC-2020).
* Mishra, Shubhanshu, Shivangi Prasad, and Shubhanshu Mishra. 2020. “Trained Models for Multilingual Joint Fine-Tuning of Transformer Models for Identifying Trolling, Aggression and Cyberbullying at TRAC 2020.” University of Illinois at Urbana-Champaign. https://doi.org/10.13012/B2IDB-8882752_V1.
```
@inproceedings{Mishra2020TRAC,
author = {Mishra, Sudhanshu and Prasad, Shivangi and Mishra, Shubhanshu},
booktitle = {Proceedings of the Second Workshop on Trolling, Aggression and Cyberbullying (TRAC-2020)},
title = {{Multilingual Joint Fine-tuning of Transformer models for identifying Trolling, Aggression and Cyberbullying at TRAC 2020}},
year = {2020}
}
@data{illinoisdatabankIDB-8882752,
author = {Mishra, Shubhanshu and Prasad, Shivangi and Mishra, Shubhanshu},
doi = {10.13012/B2IDB-8882752_V1},
publisher = {University of Illinois at Urbana-Champaign},
title = {{Trained models for Multilingual Joint Fine-tuning of Transformer models for identifying Trolling, Aggression and Cyberbullying at TRAC 2020}},
url = {https://doi.org/10.13012/B2IDB-8882752{\_}V1},
year = {2020}
}
```
## Usage
The models can be used via the following code:
```python
from transformers import AutoModel, AutoTokenizer, AutoModelForSequenceClassification
import torch
from pathlib import Path
from scipy.special import softmax
import numpy as np
import pandas as pd
TASK_LABEL_IDS = {
"Sub-task A": ["OAG", "NAG", "CAG"],
"Sub-task B": ["GEN", "NGEN"],
"Sub-task C": ["OAG-GEN", "OAG-NGEN", "NAG-GEN", "NAG-NGEN", "CAG-GEN", "CAG-NGEN"]
}
model_version="databank" # other option is hugging face library
if model_version == "databank":
# Make sure you have downloaded the required model file from https://databank.illinois.edu/datasets/IDB-8882752
# Unzip the file at some model_path (we are using: "databank_model")
model_path = next(Path("databank_model").glob("./*/output/*/model"))
# Assuming you get the following type of structure inside "databank_model"
# 'databank_model/ALL/Sub-task C/output/bert-base-multilingual-uncased/model'
lang, task, _, base_model, _ = model_path.parts
tokenizer = AutoTokenizer.from_pretrained(base_model)
model = AutoModelForSequenceClassification.from_pretrained(model_path)
else:
lang, task, base_model = "ALL", "Sub-task C", "bert-base-multilingual-uncased"
base_model = f"socialmediaie/TRAC2020_{lang}_{lang.split()[-1]}_{base_model}"
tokenizer = AutoTokenizer.from_pretrained(base_model)
model = AutoModelForSequenceClassification.from_pretrained(base_model)
# For doing inference set model in eval mode
model.eval()
# If you want to further fine-tune the model you can reset the model to model.train()
task_labels = TASK_LABEL_IDS[task]
sentence = "This is a good cat and this is a bad dog."
processed_sentence = f"{tokenizer.cls_token} {sentence}"
tokens = tokenizer.tokenize(sentence)
indexed_tokens = tokenizer.convert_tokens_to_ids(tokens)
tokens_tensor = torch.tensor([indexed_tokens])
with torch.no_grad():
logits, = model(tokens_tensor, labels=None)
logits
preds = logits.detach().cpu().numpy()
preds_probs = softmax(preds, axis=1)
preds = np.argmax(preds_probs, axis=1)
preds_labels = np.array(task_labels)[preds]
print(dict(zip(task_labels, preds_probs[0])), preds_labels)
"""You should get an output as follows:
({'CAG-GEN': 0.06762535,
'CAG-NGEN': 0.03244293,
'NAG-GEN': 0.6897794,
'NAG-NGEN': 0.15498641,
'OAG-GEN': 0.034373745,
'OAG-NGEN': 0.020792078},
array(['NAG-GEN'], dtype='<U8'))
"""
```
|
Subsets and Splits
Filtered Qwen2.5 Distill Models
Identifies specific configurations of models by filtering cards that contain 'distill', 'qwen2.5', '7b' while excluding certain base models and incorrect model ID patterns, uncovering unique model variants.
Filtered Model Cards Count
Finds the count of entries with specific card details that include 'distill', 'qwen2.5', '7b' but exclude certain base models, revealing valuable insights about the dataset's content distribution.
Filtered Distill Qwen 7B Models
Filters for specific card entries containing 'distill', 'qwen', and '7b', excluding certain strings and patterns, to identify relevant model configurations.
Filtered Qwen-7b Model Cards
The query performs a detailed filtering based on specific keywords and excludes certain entries, which could be useful for identifying a specific subset of cards but does not provide deeper insights or trends.
Filtered Qwen 7B Model Cards
The query filters for specific terms related to "distilled" or "distill", "qwen", and "7b" in the 'card' column but excludes certain base models, providing a limited set of entries for further inspection.
Qwen 7B Distilled Models
The query provides a basic filtering of records to find specific card names that include keywords related to distilled Qwen 7b models, excluding a particular base model, which gives limited insight but helps in focusing on relevant entries.
Qwen 7B Distilled Model Cards
The query filters data based on specific keywords in the modelId and card fields, providing limited insight primarily useful for locating specific entries rather than revealing broad patterns or trends.
Qwen 7B Distilled Models
Finds all entries containing the terms 'distilled', 'qwen', and '7b' in a case-insensitive manner, providing a filtered set of records but without deeper analysis.
Distilled Qwen 7B Models
The query filters for specific model IDs containing 'distilled', 'qwen', and '7b', providing a basic retrieval of relevant entries but without deeper analysis or insight.
Filtered Model Cards with Distill Qwen2.
Filters and retrieves records containing specific keywords in the card description while excluding certain phrases, providing a basic count of relevant entries.
Filtered Model Cards with Distill Qwen 7
The query filters specific variations of card descriptions containing 'distill', 'qwen', and '7b' while excluding a particular base model, providing limited but specific data retrieval.
Distill Qwen 7B Model Cards
The query filters and retrieves rows where the 'card' column contains specific keywords ('distill', 'qwen', and '7b'), providing a basic filter result that can help in identifying specific entries.