
modelId
stringlengths 5
139
| author
stringlengths 2
42
| last_modified
timestamp[us, tz=UTC]date 2020-02-15 11:33:14
2025-09-04 06:26:56
| downloads
int64 0
223M
| likes
int64 0
11.7k
| library_name
stringclasses 538
values | tags
listlengths 1
4.05k
| pipeline_tag
stringclasses 55
values | createdAt
timestamp[us, tz=UTC]date 2022-03-02 23:29:04
2025-09-04 06:26:41
| card
stringlengths 11
1.01M
|
|---|---|---|---|---|---|---|---|---|---|
konverner/due_eshop_21_multilabel
|
konverner
| 2023-07-05T18:59:21Z | 4 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"pytorch",
"mpnet",
"setfit",
"text-classification",
"arxiv:2209.11055",
"license:apache-2.0",
"region:us"
] |
text-classification
| 2023-07-04T22:21:59Z |
---
license: apache-2.0
tags:
- setfit
- sentence-transformers
- text-classification
pipeline_tag: text-classification
---
# konverner/due_eshop_21_multilabel
This is a [SetFit model](https://github.com/huggingface/setfit) that can be used for text classification. The model has been trained using an efficient few-shot learning technique that involves:
1. Fine-tuning a [Sentence Transformer](https://www.sbert.net) with contrastive learning.
2. Training a classification head with features from the fine-tuned Sentence Transformer.
## Usage
To use this model for inference, first install the SetFit library:
```bash
python -m pip install setfit
```
You can then run inference as follows:
```python
from setfit import SetFitModel
# Download from Hub and run inference
model = SetFitModel.from_pretrained("konverner/due_eshop_21_multilabel")
# Run inference
preds = model(["i loved the spiderman movie!", "pineapple on pizza is the worst 🤮"])
```
## BibTeX entry and citation info
```bibtex
@article{https://doi.org/10.48550/arxiv.2209.11055,
doi = {10.48550/ARXIV.2209.11055},
url = {https://arxiv.org/abs/2209.11055},
author = {Tunstall, Lewis and Reimers, Nils and Jo, Unso Eun Seo and Bates, Luke and Korat, Daniel and Wasserblat, Moshe and Pereg, Oren},
keywords = {Computation and Language (cs.CL), FOS: Computer and information sciences, FOS: Computer and information sciences},
title = {Efficient Few-Shot Learning Without Prompts},
publisher = {arXiv},
year = {2022},
copyright = {Creative Commons Attribution 4.0 International}
}
```
|
sd-concepts-library/ahx-beta-4a5b307
|
sd-concepts-library
| 2023-07-05T18:57:32Z | 0 | 0 | null |
[
"license:mit",
"region:us"
] | null | 2023-07-05T18:57:29Z |
---
license: mit
---
### ahx-beta-4a5b307 on Stable Diffusion
This is the `<ahx-beta-4a5b307>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as a `style`:









|
Sandrro/text_to_subfunction_v5
|
Sandrro
| 2023-07-05T18:50:38Z | 108 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"text-classification",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-07-05T12:03:44Z |
---
license: mit
tags:
- generated_from_trainer
metrics:
- f1
model-index:
- name: text_to_subfunction_v5
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# text_to_subfunction_v5
This model is a fine-tuned version of [cointegrated/rubert-tiny2](https://huggingface.co/cointegrated/rubert-tiny2) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 3.4805
- F1: 0.3751
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 20
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:-----:|:---------------:|:------:|
| 3.9061 | 1.0 | 4050 | 3.8927 | 0.0909 |
| 3.0607 | 2.0 | 8100 | 3.1700 | 0.2214 |
| 2.4112 | 3.0 | 12150 | 2.8376 | 0.2764 |
| 1.9961 | 4.0 | 16200 | 2.6672 | 0.3388 |
| 1.5209 | 5.0 | 20250 | 2.5776 | 0.3428 |
| 1.2317 | 6.0 | 24300 | 2.5766 | 0.3578 |
| 0.9831 | 7.0 | 28350 | 2.6033 | 0.3691 |
| 0.7033 | 8.0 | 32400 | 2.7067 | 0.3633 |
| 0.5462 | 9.0 | 36450 | 2.7621 | 0.3672 |
| 0.4332 | 10.0 | 40500 | 2.8558 | 0.3750 |
| 0.3114 | 11.0 | 44550 | 2.9402 | 0.3729 |
| 0.2379 | 12.0 | 48600 | 3.0508 | 0.3738 |
| 0.1877 | 13.0 | 52650 | 3.1642 | 0.3703 |
| 0.1923 | 14.0 | 56700 | 3.2413 | 0.3754 |
| 0.1489 | 15.0 | 60750 | 3.3047 | 0.3856 |
| 0.1202 | 16.0 | 64800 | 3.3581 | 0.3764 |
| 0.1065 | 17.0 | 68850 | 3.4211 | 0.3767 |
| 0.1107 | 18.0 | 72900 | 3.4589 | 0.3725 |
| 0.1004 | 19.0 | 76950 | 3.4768 | 0.3723 |
| 0.1082 | 20.0 | 81000 | 3.4805 | 0.3751 |
### Framework versions
- Transformers 4.27.1
- Pytorch 2.1.0.dev20230414+cu117
- Datasets 2.9.0
- Tokenizers 0.13.3
|
kubjonkyr/ppo-LunarLander-v2
|
kubjonkyr
| 2023-07-05T18:35:22Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-07-05T17:36:39Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 290.89 +/- 13.49
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
DCTR/my_vicuna
|
DCTR
| 2023-07-05T18:22:52Z | 4 | 0 |
peft
|
[
"peft",
"region:us"
] | null | 2023-07-05T18:11:24Z |
---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: True
- bnb_4bit_compute_dtype: bfloat16
### Framework versions
- PEFT 0.4.0.dev0
|
alesthehuman/poca-SoccerTwos
|
alesthehuman
| 2023-07-05T18:14:32Z | 24 | 0 |
ml-agents
|
[
"ml-agents",
"tensorboard",
"onnx",
"SoccerTwos",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-SoccerTwos",
"region:us"
] |
reinforcement-learning
| 2023-07-05T18:13:38Z |
---
library_name: ml-agents
tags:
- SoccerTwos
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-SoccerTwos
---
# **poca** Agent playing **SoccerTwos**
This is a trained model of a **poca** agent playing **SoccerTwos**
using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://unity-technologies.github.io/ml-agents/ML-Agents-Toolkit-Documentation/
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
- A *short tutorial* where you teach Huggy the Dog 🐶 to fetch the stick and then play with him directly in your
browser: https://huggingface.co/learn/deep-rl-course/unitbonus1/introduction
- A *longer tutorial* to understand how works ML-Agents:
https://huggingface.co/learn/deep-rl-course/unit5/introduction
### Resume the training
```bash
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser**
1. If the environment is part of ML-Agents official environments, go to https://huggingface.co/unity
2. Step 1: Find your model_id: alesthehuman/poca-SoccerTwos
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
Tubido/Taxi-v3-001
|
Tubido
| 2023-07-05T18:06:11Z | 0 | 0 | null |
[
"Taxi-v3",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-07-05T18:06:09Z |
---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: Taxi-v3-001
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
metrics:
- type: mean_reward
value: 7.56 +/- 2.71
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="Tubido/Taxi-v3-001", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
aronmal/dqn-SpaceInvaders-v4
|
aronmal
| 2023-07-05T18:01:03Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"SpaceInvadersNoFrameskip-v4",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-07-05T18:00:21Z |
---
library_name: stable-baselines3
tags:
- SpaceInvadersNoFrameskip-v4
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: DQN
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: SpaceInvadersNoFrameskip-v4
type: SpaceInvadersNoFrameskip-v4
metrics:
- type: mean_reward
value: 551.00 +/- 161.83
name: mean_reward
verified: false
---
# **DQN** Agent playing **SpaceInvadersNoFrameskip-v4**
This is a trained model of a **DQN** agent playing **SpaceInvadersNoFrameskip-v4**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3)
and the [RL Zoo](https://github.com/DLR-RM/rl-baselines3-zoo).
The RL Zoo is a training framework for Stable Baselines3
reinforcement learning agents,
with hyperparameter optimization and pre-trained agents included.
## Usage (with SB3 RL Zoo)
RL Zoo: https://github.com/DLR-RM/rl-baselines3-zoo<br/>
SB3: https://github.com/DLR-RM/stable-baselines3<br/>
SB3 Contrib: https://github.com/Stable-Baselines-Team/stable-baselines3-contrib
Install the RL Zoo (with SB3 and SB3-Contrib):
```bash
pip install rl_zoo3
```
```
# Download model and save it into the logs/ folder
python -m rl_zoo3.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga aronmal -f logs/
python -m rl_zoo3.enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
If you installed the RL Zoo3 via pip (`pip install rl_zoo3`), from anywhere you can do:
```
python -m rl_zoo3.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga aronmal -f logs/
python -m rl_zoo3.enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
## Training (with the RL Zoo)
```
python -m rl_zoo3.train --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
# Upload the model and generate video (when possible)
python -m rl_zoo3.push_to_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/ -orga aronmal
```
## Hyperparameters
```python
OrderedDict([('batch_size', 32),
('buffer_size', 100000),
('env_wrapper',
['stable_baselines3.common.atari_wrappers.AtariWrapper']),
('exploration_final_eps', 0.01),
('exploration_fraction', 0.1),
('frame_stack', 4),
('gradient_steps', 1),
('learning_rate', 0.0001),
('learning_starts', 100000),
('n_timesteps', 1000000.0),
('optimize_memory_usage', False),
('policy', 'CnnPolicy'),
('target_update_interval', 1000),
('train_freq', 4),
('normalize', False)])
```
# Environment Arguments
```python
{'render_mode': 'rgb_array'}
```
|
TN19N/ppo-LunarLander-v2
|
TN19N
| 2023-07-05T17:45:04Z | 8 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-07-05T14:51:02Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 274.09 +/- 14.90
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
S1X3L4/NavecitaUWU
|
S1X3L4
| 2023-07-05T17:30:43Z | 1 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-07-05T17:30:17Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 239.85 +/- 15.30
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
cleandata/distilhubert-finetuned-gtzan_accuracy_93
|
cleandata
| 2023-07-05T17:24:29Z | 161 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"hubert",
"audio-classification",
"music",
"genre",
"classification",
"en",
"dataset:marsyas/gtzan",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
audio-classification
| 2023-07-05T14:56:11Z |
---
license: apache-2.0
tags:
- music
- genre
- classification
datasets:
- marsyas/gtzan
metrics:
- accuracy
model-index:
- name: distilhubert-finetuned-gtzan_accuracy_93
results: []
language:
- en
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilhubert-finetuned-gtzan_accuracy_93
### This model is a fine-tuned version of [yuval6967/distilhubert-finetuned-gtzan](https://huggingface.co/yuval6967/distilhubert-finetuned-gtzan) on the GTZAN dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5121
- __Accuracy: 0.93__
## Model description
- Fine-tuned model to demonstrate > 87% accuracy for the [Huggingface Audio course](https://huggingface.co/learn/audio-course/chapter0/introduction)
## Intended uses & limitations
- Model is built to identify the genre of music based on a ~30 sec clip
## Training and evaluation data
More information needed
## Training procedure
- test_size = 0.20 was used for the split
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.0316 | 1.0 | 100 | 0.4338 | 0.895 |
| 0.0031 | 2.0 | 200 | 0.7039 | 0.86 |
| 0.0069 | 3.0 | 300 | 0.4526 | 0.925 |
| 0.1799 | 4.0 | 400 | 0.7071 | 0.88 |
| 0.1783 | 5.0 | 500 | 0.5923 | 0.92 |
| 0.0011 | 6.0 | 600 | 0.5498 | 0.92 |
| 0.0005 | 7.0 | 700 | 0.4927 | 0.925 |
| 0.0005 | 8.0 | 800 | 0.6172 | 0.915 |
| 0.0004 | 9.0 | 900 | 0.4988 | 0.925 |
| 0.0004 | 10.0 | 1000 | 0.5121 | 0.93 |
### Framework versions
- Transformers 4.30.2
- Pytorch 2.0.1+cu118
- Datasets 2.13.1
- Tokenizers 0.13.3
|
heka-ai/e5-100k
|
heka-ai
| 2023-07-05T17:09:28Z | 1 | 1 |
sentence-transformers
|
[
"sentence-transformers",
"pytorch",
"distilbert",
"feature-extraction",
"sentence-similarity",
"transformers",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2023-07-05T17:09:24Z |
---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
---
# heka-ai/e5-100k
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
<!--- Describe your model here -->
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('heka-ai/e5-100k')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
def cls_pooling(model_output, attention_mask):
return model_output[0][:,0]
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('heka-ai/e5-100k')
model = AutoModel.from_pretrained('heka-ai/e5-100k')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, cls pooling.
sentence_embeddings = cls_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
<!--- Describe how your model was evaluated -->
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=heka-ai/e5-100k)
## Training
The model was trained with the parameters:
**DataLoader**:
`torch.utils.data.dataloader.DataLoader` of length 20000 with parameters:
```
{'batch_size': 32, 'sampler': 'torch.utils.data.sampler.SequentialSampler', 'batch_sampler': 'torch.utils.data.sampler.BatchSampler'}
```
**Loss**:
`gpl.toolkit.loss.MarginDistillationLoss`
Parameters of the fit()-Method:
```
{
"epochs": 1,
"evaluation_steps": 0,
"evaluator": "NoneType",
"max_grad_norm": 1,
"optimizer_class": "<class 'torch.optim.adamw.AdamW'>",
"optimizer_params": {
"lr": 2e-05
},
"scheduler": "WarmupLinear",
"steps_per_epoch": 100000,
"warmup_steps": 1000,
"weight_decay": 0.01
}
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 350, 'do_lower_case': False}) with Transformer model: DistilBertModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': True, 'pooling_mode_mean_tokens': False, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False, 'pooling_mode_weightedmean_tokens': False, 'pooling_mode_lasttoken': False})
)
```
## Citing & Authors
<!--- Describe where people can find more information -->
|
ddoc/def
|
ddoc
| 2023-07-05T17:04:15Z | 0 | 0 | null |
[
"region:us"
] | null | 2023-07-05T17:03:23Z |
# Deforum Stable Diffusion — official extension for AUTOMATIC1111's webui
<p align="left">
<a href="https://github.com/deforum-art/sd-webui-deforum/commits"><img alt="Last Commit" src="https://img.shields.io/github/last-commit/deforum-art/deforum-for-automatic1111-webui"></a>
<a href="https://github.com/deforum-art/sd-webui-deforum/issues"><img alt="GitHub issues" src="https://img.shields.io/github/issues/deforum-art/deforum-for-automatic1111-webui"></a>
<a href="https://github.com/deforum-art/sd-webui-deforum/stargazers"><img alt="GitHub stars" src="https://img.shields.io/github/stars/deforum-art/deforum-for-automatic1111-webui"></a>
<a href="https://github.com/deforum-art/sd-webui-deforum/network"><img alt="GitHub forks" src="https://img.shields.io/github/forks/deforum-art/deforum-for-automatic1111-webui"></a>
</a>
</p>
## Need help? See our [FAQ](https://github.com/deforum-art/sd-webui-deforum/wiki/FAQ-&-Troubleshooting)
## Getting Started
1. Install [AUTOMATIC1111's webui](https://github.com/AUTOMATIC1111/stable-diffusion-webui/).
2. Now two ways: either clone the repo into the `extensions` directory via git commandline launched within in the `stable-diffusion-webui` folder
```sh
git clone https://github.com/deforum-art/sd-webui-deforum extensions/deforum
```
Or download this repository, locate the `extensions` folder within your WebUI installation, create a folder named `deforum` and put the contents of the downloaded directory inside of it. Then restart WebUI.
3. Open the webui, find the Deforum tab at the top of the page.
4. Enter the animation settings. Refer to [this general guide](https://docs.google.com/document/d/1pEobUknMFMkn8F5TMsv8qRzamXX_75BShMMXV8IFslI/edit) and [this guide to math keyframing functions in Deforum](https://docs.google.com/document/d/1pfW1PwbDIuW0cv-dnuyYj1UzPqe23BlSLTJsqazffXM/edit?usp=sharing). However, **in this version prompt weights less than zero don't just like in original Deforum!** Split the positive and the negative prompt in the json section using --neg argument like this "apple:\`where(cos(t)>=0, cos(t), 0)\`, snow --neg strawberry:\`where(cos(t)<0, -cos(t), 0)\`"
5. To view animation frames as they're being made, without waiting for the completion of an animation, go to the 'Settings' tab and set the value of this toolbar **above zero**. Warning: it may slow down the generation process.

6. Run the script and see if you got it working or even got something. **In 3D mode a large delay is expected at first** as the script loads the depth models. In the end, using the default settings the whole thing should consume 6.4 GBs of VRAM at 3D mode peaks and no more than 3.8 GB VRAM in 3D mode if you launch the webui with the '--lowvram' command line argument.
7. After the generation process is completed, click the button with the self-describing name to show the video or gif result right in the GUI!
8. Join our Discord where you can post generated stuff, ask questions and more: https://discord.gg/deforum. <br>
* There's also the 'Issues' tab in the repo, for well... reporting issues ;)
9. Profit!
## Known issues
* This port is not fully backward-compatible with the notebook and the local version both due to the changes in how AUTOMATIC1111's webui handles Stable Diffusion models and the changes in this script to get it to work in the new environment. *Expect* that you may not get exactly the same result or that the thing may break down because of the older settings.
## Screenshots
Amazing raw Deforum animation by [Pxl.Pshr](https://www.instagram.com/pxl.pshr):
* Turn Audio ON!
(Audio credits: SKRILLEX, FRED AGAIN & FLOWDAN - RUMBLE (PHACE'S DNB FLIP))
https://user-images.githubusercontent.com/121192995/224450647-39529b28-be04-4871-bb7a-faf7afda2ef2.mp4
Setting file of that video: [here](https://github.com/deforum-art/sd-webui-deforum/files/11353167/PxlPshrWinningAnimationSettings.txt).
<br>
Main extension tab:

Keyframes tab:

|
vincentmin/RedPajama-INCITE-Base-3B-v1-colab
|
vincentmin
| 2023-07-05T16:59:36Z | 0 | 0 | null |
[
"tensorboard",
"generated_from_trainer",
"base_model:togethercomputer/RedPajama-INCITE-Base-3B-v1",
"base_model:finetune:togethercomputer/RedPajama-INCITE-Base-3B-v1",
"license:apache-2.0",
"region:us"
] | null | 2023-07-05T13:20:32Z |
---
license: apache-2.0
base_model: togethercomputer/RedPajama-INCITE-Base-3B-v1
tags:
- generated_from_trainer
model-index:
- name: RedPajama-INCITE-Base-3B-v1-colab
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# RedPajama-INCITE-Base-3B-v1-colab
This model is a fine-tuned version of [togethercomputer/RedPajama-INCITE-Base-3B-v1](https://huggingface.co/togethercomputer/RedPajama-INCITE-Base-3B-v1) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.6061
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 1
- eval_batch_size: 1
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 4
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 1.59 | 0.08 | 200 | 1.6639 |
| 1.6331 | 0.16 | 400 | 1.6433 |
| 1.6253 | 0.24 | 600 | 1.6323 |
| 1.6133 | 0.33 | 800 | 1.6259 |
| 1.6153 | 0.41 | 1000 | 1.6210 |
| 1.5429 | 0.49 | 1200 | 1.6165 |
| 1.5379 | 0.57 | 1400 | 1.6129 |
| 1.6046 | 0.65 | 1600 | 1.6090 |
| 1.6253 | 0.73 | 1800 | 1.6073 |
| 1.6955 | 0.81 | 2000 | 1.6061 |
### Framework versions
- Transformers 4.31.0.dev0
- Pytorch 2.0.1+cu118
- Datasets 2.13.1
- Tokenizers 0.13.3
|
Emilianohack6950/GenOrtega
|
Emilianohack6950
| 2023-07-05T16:50:47Z | 32 | 0 |
diffusers
|
[
"diffusers",
"safetensors",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] |
text-to-image
| 2023-06-28T22:03:29Z |
---
license: creativeml-openrail-m
tags:
- text-to-image
- stable-diffusion
---
GenOrtega es un modelo avanzado de generación de imágenes basado en inteligencia artificial, diseñado para capturar y recrear la belleza única de Jenna Ortega, una talentosa actriz reconocida en la industria del entretenimiento. Utilizando técnicas de aprendizaje profundo y una vasta cantidad de datos de entrenamiento, este modelo ha sido entrenado para generar imágenes fotorrealistas de alta calidad que capturan con precisión los rasgos faciales, la expresividad y el estilo inconfundible de Jenna Ortega.
Con GenOrtega, puedes explorar la creatividad y obtener imágenes personalizadas de Jenna Ortega para diversas aplicaciones, como proyectos de diseño gráfico, desarrollo de videojuegos, producción cinematográfica, arte digital y más. El modelo ofrece una amplia gama de opciones para personalizar las imágenes generadas, como la elección de expresiones faciales, cambios de vestuario y entornos, lo que te permite adaptar las imágenes a tus necesidades específicas.
GenOrtega ha sido entrenado en una amplia variedad de imágenes y poses de Jenna Ortega, lo que le permite capturar su diversidad y versatilidad como artista. Además, el modelo cuenta con una interfaz intuitiva y fácil de usar, lo que lo hace accesible tanto para profesionales creativos como para entusiastas del arte digital.
Descubre la magia de GenOrtega y experimenta con la generación de imágenes de Jenna Ortega para dar vida a tus ideas y proyectos con un toque de estilo y autenticidad únicos.
Sample pictures of this concept:





|
alexmejva/test_model_alexmejva
|
alexmejva
| 2023-07-05T16:49:26Z | 3 | 0 |
transformers
|
[
"transformers",
"bert",
"text-classification",
"fill-mask",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2023-07-05T16:42:15Z |
---
license: apache-2.0
pipeline_tag: fill-mask
---
|
oknashar/distilbert-base-uncased-finetuned-emotion
|
oknashar
| 2023-07-05T16:42:28Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_trainer",
"base_model:distilbert/distilbert-base-uncased",
"base_model:finetune:distilbert/distilbert-base-uncased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-07-05T15:20:24Z |
---
license: apache-2.0
base_model: distilbert-base-uncased
tags:
- generated_from_trainer
metrics:
- accuracy
- f1
model-index:
- name: distilbert-base-uncased-finetuned-emotion
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-emotion
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an mteb/emotion dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1803
- Accuracy: 0.94
- F1: 0.9400
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 0.5017 | 1.0 | 250 | 0.2116 | 0.9295 | 0.9305 |
| 0.1763 | 2.0 | 500 | 0.1617 | 0.936 | 0.9369 |
| 0.1267 | 3.0 | 750 | 0.1492 | 0.9385 | 0.9386 |
| 0.0979 | 4.0 | 1000 | 0.1495 | 0.9395 | 0.9392 |
| 0.0787 | 5.0 | 1250 | 0.1602 | 0.935 | 0.9349 |
| 0.067 | 6.0 | 1500 | 0.1588 | 0.9405 | 0.9401 |
| 0.0557 | 7.0 | 1750 | 0.1675 | 0.9415 | 0.9413 |
| 0.0452 | 8.0 | 2000 | 0.1764 | 0.937 | 0.9365 |
| 0.0375 | 9.0 | 2250 | 0.1765 | 0.9405 | 0.9406 |
| 0.0337 | 10.0 | 2500 | 0.1803 | 0.94 | 0.9400 |
### Framework versions
- Transformers 4.31.0.dev0
- Pytorch 2.0.0
- Datasets 2.1.0
- Tokenizers 0.13.3
|
adisrini11/AIE-Assessment
|
adisrini11
| 2023-07-05T16:39:39Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"distilbert",
"text-classification",
"generated_from_trainer",
"dataset:tweet_eval",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-06-18T21:32:35Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- tweet_eval
metrics:
- accuracy
model-index:
- name: AIE-Assessment
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: tweet_eval
type: tweet_eval
config: emotion
split: test
args: emotion
metrics:
- name: Accuracy
type: accuracy
value: 0.800844475721323
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# AIE-Assessment
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the tweet_eval dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5687
- Accuracy: 0.8008
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| No log | 1.0 | 204 | 0.6383 | 0.7910 |
| No log | 2.0 | 408 | 0.5687 | 0.8008 |
### Framework versions
- Transformers 4.29.2
- Pytorch 2.0.1
- Datasets 2.12.0
- Tokenizers 0.11.0
|
hazemOmrann14/AraBART-summ-finetuned-xsum-finetuned-xsum-finetuned-xsum
|
hazemOmrann14
| 2023-07-05T16:28:35Z | 106 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"mbart",
"text2text-generation",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2023-07-05T16:08:14Z |
---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: AraBART-summ-finetuned-xsum-finetuned-xsum-finetuned-xsum
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# AraBART-summ-finetuned-xsum-finetuned-xsum-finetuned-xsum
This model is a fine-tuned version of [hazemOmrann14/AraBART-summ-finetuned-xsum-finetuned-xsum](https://huggingface.co/hazemOmrann14/AraBART-summ-finetuned-xsum-finetuned-xsum) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3.328889038158605e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:------:|:------:|:------:|:---------:|:-------:|
| No log | 1.0 | 10 | 2.5240 | 0.0 | 0.0 | 0.0 | 0.0 | 20.0 |
### Framework versions
- Transformers 4.30.2
- Pytorch 2.0.1+cu118
- Datasets 2.13.1
- Tokenizers 0.13.3
|
ozsenior13/distilbert-base-uncased-finetuned-squad
|
ozsenior13
| 2023-07-05T16:24:38Z | 116 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"question-answering",
"generated_from_trainer",
"dataset:squad",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2023-07-05T15:02:16Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- squad
model-index:
- name: distilbert-base-uncased-finetuned-squad
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-squad
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the squad dataset.
It achieves the following results on the evaluation set:
- Loss: 1.2169
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 1.263 | 1.0 | 5533 | 1.2169 |
### Framework versions
- Transformers 4.30.2
- Pytorch 2.0.1+cu118
- Datasets 2.13.1
- Tokenizers 0.13.3
|
NasimB/gpt2-dp-cl-rarity-11-135k-mod-datasets-rarity1-root3
|
NasimB
| 2023-07-05T16:22:18Z | 7 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"generated_from_trainer",
"dataset:generator",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-07-05T13:27:11Z |
---
license: mit
tags:
- generated_from_trainer
datasets:
- generator
model-index:
- name: gpt2-dp-cl-rarity-11-135k-mod-datasets-rarity1-root3
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# gpt2-dp-cl-rarity-11-135k-mod-datasets-rarity1-root3
This model is a fine-tuned version of [gpt2](https://huggingface.co/gpt2) on the generator dataset.
It achieves the following results on the evaluation set:
- Loss: 4.7616
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 1000
- num_epochs: 1
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-----:|:---------------:|
| 6.7003 | 0.05 | 500 | 5.8421 |
| 5.4077 | 0.1 | 1000 | 5.4379 |
| 5.0667 | 0.15 | 1500 | 5.2282 |
| 4.8285 | 0.2 | 2000 | 5.0890 |
| 4.6639 | 0.25 | 2500 | 4.9968 |
| 4.5282 | 0.29 | 3000 | 4.9414 |
| 4.4194 | 0.34 | 3500 | 4.8843 |
| 4.3138 | 0.39 | 4000 | 4.8436 |
| 4.2135 | 0.44 | 4500 | 4.8229 |
| 4.1242 | 0.49 | 5000 | 4.7947 |
| 4.0388 | 0.54 | 5500 | 4.7670 |
| 3.952 | 0.59 | 6000 | 4.7585 |
| 3.8701 | 0.64 | 6500 | 4.7431 |
| 3.8026 | 0.69 | 7000 | 4.7273 |
| 3.7345 | 0.74 | 7500 | 4.7219 |
| 3.6661 | 0.79 | 8000 | 4.7135 |
| 3.6259 | 0.84 | 8500 | 4.7072 |
| 3.5927 | 0.88 | 9000 | 4.7052 |
| 3.5699 | 0.93 | 9500 | 4.7025 |
| 3.5638 | 0.98 | 10000 | 4.7018 |
### Framework versions
- Transformers 4.26.1
- Pytorch 1.11.0+cu113
- Datasets 2.13.0
- Tokenizers 0.13.3
|
omar-al-sharif/AlQalam-finetuned-mmj
|
omar-al-sharif
| 2023-07-05T16:21:33Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"t5",
"text2text-generation",
"generated_from_trainer",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2023-07-05T14:11:56Z |
---
tags:
- generated_from_trainer
model-index:
- name: AlQalam-finetuned-mmj
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# AlQalam-finetuned-mmj
This model is a fine-tuned version of [malmarjeh/t5-arabic-text-summarization](https://huggingface.co/malmarjeh/t5-arabic-text-summarization) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.0723
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 1.3745 | 1.0 | 1678 | 1.1947 |
| 1.219 | 2.0 | 3356 | 1.1176 |
| 1.065 | 3.0 | 5034 | 1.0895 |
| 0.9928 | 4.0 | 6712 | 1.0734 |
| 0.9335 | 5.0 | 8390 | 1.0723 |
### Framework versions
- Transformers 4.30.2
- Pytorch 2.0.1+cu118
- Datasets 2.13.1
- Tokenizers 0.13.3
|
timbrooks/instruct-pix2pix
|
timbrooks
| 2023-07-05T16:19:25Z | 78,060 | 1,061 |
diffusers
|
[
"diffusers",
"safetensors",
"image-to-image",
"license:mit",
"diffusers:StableDiffusionInstructPix2PixPipeline",
"region:us"
] |
image-to-image
| 2023-01-20T04:27:06Z |
---
license: mit
tags:
- image-to-image
---
# InstructPix2Pix: Learning to Follow Image Editing Instructions
GitHub: https://github.com/timothybrooks/instruct-pix2pix
<img src='https://instruct-pix2pix.timothybrooks.com/teaser.jpg'/>
## Example
To use `InstructPix2Pix`, install `diffusers` using `main` for now. The pipeline will be available in the next release
```bash
pip install diffusers accelerate safetensors transformers
```
```python
import PIL
import requests
import torch
from diffusers import StableDiffusionInstructPix2PixPipeline, EulerAncestralDiscreteScheduler
model_id = "timbrooks/instruct-pix2pix"
pipe = StableDiffusionInstructPix2PixPipeline.from_pretrained(model_id, torch_dtype=torch.float16, safety_checker=None)
pipe.to("cuda")
pipe.scheduler = EulerAncestralDiscreteScheduler.from_config(pipe.scheduler.config)
url = "https://raw.githubusercontent.com/timothybrooks/instruct-pix2pix/main/imgs/example.jpg"
def download_image(url):
image = PIL.Image.open(requests.get(url, stream=True).raw)
image = PIL.ImageOps.exif_transpose(image)
image = image.convert("RGB")
return image
image = download_image(url)
prompt = "turn him into cyborg"
images = pipe(prompt, image=image, num_inference_steps=10, image_guidance_scale=1).images
images[0]
```
|
stabilityai/stable-diffusion-2-1-base
|
stabilityai
| 2023-07-05T16:19:20Z | 863,939 | 647 |
diffusers
|
[
"diffusers",
"safetensors",
"stable-diffusion",
"text-to-image",
"arxiv:2112.10752",
"arxiv:2202.00512",
"arxiv:1910.09700",
"license:openrail++",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] |
text-to-image
| 2022-12-06T17:25:36Z |
---
license: openrail++
tags:
- stable-diffusion
- text-to-image
---
# Stable Diffusion v2-1-base Model Card
This model card focuses on the model associated with the Stable Diffusion v2-1-base model.
This `stable-diffusion-2-1-base` model fine-tunes [stable-diffusion-2-base](https://huggingface.co/stabilityai/stable-diffusion-2-base) (`512-base-ema.ckpt`) with 220k extra steps taken, with `punsafe=0.98` on the same dataset.
- Use it with the [`stablediffusion`](https://github.com/Stability-AI/stablediffusion) repository: download the `v2-1_512-ema-pruned.ckpt` [here](https://huggingface.co/stabilityai/stable-diffusion-2-1-base/resolve/main/v2-1_512-ema-pruned.ckpt).
- Use it with 🧨 [`diffusers`](#examples)
## Model Details
- **Developed by:** Robin Rombach, Patrick Esser
- **Model type:** Diffusion-based text-to-image generation model
- **Language(s):** English
- **License:** [CreativeML Open RAIL++-M License](https://huggingface.co/stabilityai/stable-diffusion-2/blob/main/LICENSE-MODEL)
- **Model Description:** This is a model that can be used to generate and modify images based on text prompts. It is a [Latent Diffusion Model](https://arxiv.org/abs/2112.10752) that uses a fixed, pretrained text encoder ([OpenCLIP-ViT/H](https://github.com/mlfoundations/open_clip)).
- **Resources for more information:** [GitHub Repository](https://github.com/Stability-AI/).
- **Cite as:**
@InProceedings{Rombach_2022_CVPR,
author = {Rombach, Robin and Blattmann, Andreas and Lorenz, Dominik and Esser, Patrick and Ommer, Bj\"orn},
title = {High-Resolution Image Synthesis With Latent Diffusion Models},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2022},
pages = {10684-10695}
}
## Examples
Using the [🤗's Diffusers library](https://github.com/huggingface/diffusers) to run Stable Diffusion 2 in a simple and efficient manner.
```bash
pip install diffusers transformers accelerate scipy safetensors
```
Running the pipeline (if you don't swap the scheduler it will run with the default PNDM/PLMS scheduler, in this example we are swapping it to EulerDiscreteScheduler):
```python
from diffusers import StableDiffusionPipeline, EulerDiscreteScheduler
import torch
model_id = "stabilityai/stable-diffusion-2-1-base"
scheduler = EulerDiscreteScheduler.from_pretrained(model_id, subfolder="scheduler")
pipe = StableDiffusionPipeline.from_pretrained(model_id, scheduler=scheduler, torch_dtype=torch.float16)
pipe = pipe.to("cuda")
prompt = "a photo of an astronaut riding a horse on mars"
image = pipe(prompt).images[0]
image.save("astronaut_rides_horse.png")
```
**Notes**:
- Despite not being a dependency, we highly recommend you to install [xformers](https://github.com/facebookresearch/xformers) for memory efficient attention (better performance)
- If you have low GPU RAM available, make sure to add a `pipe.enable_attention_slicing()` after sending it to `cuda` for less VRAM usage (to the cost of speed)
# Uses
## Direct Use
The model is intended for research purposes only. Possible research areas and tasks include
- Safe deployment of models which have the potential to generate harmful content.
- Probing and understanding the limitations and biases of generative models.
- Generation of artworks and use in design and other artistic processes.
- Applications in educational or creative tools.
- Research on generative models.
Excluded uses are described below.
### Misuse, Malicious Use, and Out-of-Scope Use
_Note: This section is originally taken from the [DALLE-MINI model card](https://huggingface.co/dalle-mini/dalle-mini), was used for Stable Diffusion v1, but applies in the same way to Stable Diffusion v2_.
The model should not be used to intentionally create or disseminate images that create hostile or alienating environments for people. This includes generating images that people would foreseeably find disturbing, distressing, or offensive; or content that propagates historical or current stereotypes.
#### Out-of-Scope Use
The model was not trained to be factual or true representations of people or events, and therefore using the model to generate such content is out-of-scope for the abilities of this model.
#### Misuse and Malicious Use
Using the model to generate content that is cruel to individuals is a misuse of this model. This includes, but is not limited to:
- Generating demeaning, dehumanizing, or otherwise harmful representations of people or their environments, cultures, religions, etc.
- Intentionally promoting or propagating discriminatory content or harmful stereotypes.
- Impersonating individuals without their consent.
- Sexual content without consent of the people who might see it.
- Mis- and disinformation
- Representations of egregious violence and gore
- Sharing of copyrighted or licensed material in violation of its terms of use.
- Sharing content that is an alteration of copyrighted or licensed material in violation of its terms of use.
## Limitations and Bias
### Limitations
- The model does not achieve perfect photorealism
- The model cannot render legible text
- The model does not perform well on more difficult tasks which involve compositionality, such as rendering an image corresponding to “A red cube on top of a blue sphere”
- Faces and people in general may not be generated properly.
- The model was trained mainly with English captions and will not work as well in other languages.
- The autoencoding part of the model is lossy
- The model was trained on a subset of the large-scale dataset
[LAION-5B](https://laion.ai/blog/laion-5b/), which contains adult, violent and sexual content. To partially mitigate this, we have filtered the dataset using LAION's NFSW detector (see Training section).
### Bias
While the capabilities of image generation models are impressive, they can also reinforce or exacerbate social biases.
Stable Diffusion vw was primarily trained on subsets of [LAION-2B(en)](https://laion.ai/blog/laion-5b/),
which consists of images that are limited to English descriptions.
Texts and images from communities and cultures that use other languages are likely to be insufficiently accounted for.
This affects the overall output of the model, as white and western cultures are often set as the default. Further, the
ability of the model to generate content with non-English prompts is significantly worse than with English-language prompts.
Stable Diffusion v2 mirrors and exacerbates biases to such a degree that viewer discretion must be advised irrespective of the input or its intent.
## Training
**Training Data**
The model developers used the following dataset for training the model:
- LAION-5B and subsets (details below). The training data is further filtered using LAION's NSFW detector, with a "p_unsafe" score of 0.1 (conservative). For more details, please refer to LAION-5B's [NeurIPS 2022](https://openreview.net/forum?id=M3Y74vmsMcY) paper and reviewer discussions on the topic.
**Training Procedure**
Stable Diffusion v2 is a latent diffusion model which combines an autoencoder with a diffusion model that is trained in the latent space of the autoencoder. During training,
- Images are encoded through an encoder, which turns images into latent representations. The autoencoder uses a relative downsampling factor of 8 and maps images of shape H x W x 3 to latents of shape H/f x W/f x 4
- Text prompts are encoded through the OpenCLIP-ViT/H text-encoder.
- The output of the text encoder is fed into the UNet backbone of the latent diffusion model via cross-attention.
- The loss is a reconstruction objective between the noise that was added to the latent and the prediction made by the UNet. We also use the so-called _v-objective_, see https://arxiv.org/abs/2202.00512.
We currently provide the following checkpoints, for various versions:
### Version 2.1
- `512-base-ema.ckpt`: Fine-tuned on `512-base-ema.ckpt` 2.0 with 220k extra steps taken, with `punsafe=0.98` on the same dataset.
- `768-v-ema.ckpt`: Resumed from `768-v-ema.ckpt` 2.0 with an additional 55k steps on the same dataset (`punsafe=0.1`), and then fine-tuned for another 155k extra steps with `punsafe=0.98`.
### Version 2.0
- `512-base-ema.ckpt`: 550k steps at resolution `256x256` on a subset of [LAION-5B](https://laion.ai/blog/laion-5b/) filtered for explicit pornographic material, using the [LAION-NSFW classifier](https://github.com/LAION-AI/CLIP-based-NSFW-Detector) with `punsafe=0.1` and an [aesthetic score](https://github.com/christophschuhmann/improved-aesthetic-predictor) >= `4.5`.
850k steps at resolution `512x512` on the same dataset with resolution `>= 512x512`.
- `768-v-ema.ckpt`: Resumed from `512-base-ema.ckpt` and trained for 150k steps using a [v-objective](https://arxiv.org/abs/2202.00512) on the same dataset. Resumed for another 140k steps on a `768x768` subset of our dataset.
- `512-depth-ema.ckpt`: Resumed from `512-base-ema.ckpt` and finetuned for 200k steps. Added an extra input channel to process the (relative) depth prediction produced by [MiDaS](https://github.com/isl-org/MiDaS) (`dpt_hybrid`) which is used as an additional conditioning.
The additional input channels of the U-Net which process this extra information were zero-initialized.
- `512-inpainting-ema.ckpt`: Resumed from `512-base-ema.ckpt` and trained for another 200k steps. Follows the mask-generation strategy presented in [LAMA](https://github.com/saic-mdal/lama) which, in combination with the latent VAE representations of the masked image, are used as an additional conditioning.
The additional input channels of the U-Net which process this extra information were zero-initialized. The same strategy was used to train the [1.5-inpainting checkpoint](https://github.com/saic-mdal/lama).
- `x4-upscaling-ema.ckpt`: Trained for 1.25M steps on a 10M subset of LAION containing images `>2048x2048`. The model was trained on crops of size `512x512` and is a text-guided [latent upscaling diffusion model](https://arxiv.org/abs/2112.10752).
In addition to the textual input, it receives a `noise_level` as an input parameter, which can be used to add noise to the low-resolution input according to a [predefined diffusion schedule](configs/stable-diffusion/x4-upscaling.yaml).
- **Hardware:** 32 x 8 x A100 GPUs
- **Optimizer:** AdamW
- **Gradient Accumulations**: 1
- **Batch:** 32 x 8 x 2 x 4 = 2048
- **Learning rate:** warmup to 0.0001 for 10,000 steps and then kept constant
## Evaluation Results
Evaluations with different classifier-free guidance scales (1.5, 2.0, 3.0, 4.0,
5.0, 6.0, 7.0, 8.0) and 50 steps DDIM sampling steps show the relative improvements of the checkpoints:
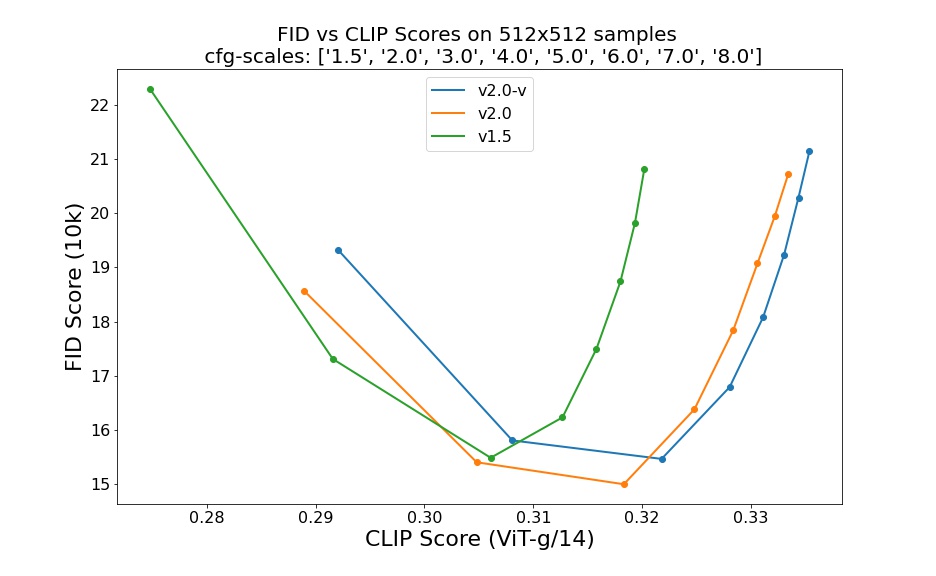
Evaluated using 50 DDIM steps and 10000 random prompts from the COCO2017 validation set, evaluated at 512x512 resolution. Not optimized for FID scores.
## Environmental Impact
**Stable Diffusion v1** **Estimated Emissions**
Based on that information, we estimate the following CO2 emissions using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700). The hardware, runtime, cloud provider, and compute region were utilized to estimate the carbon impact.
- **Hardware Type:** A100 PCIe 40GB
- **Hours used:** 200000
- **Cloud Provider:** AWS
- **Compute Region:** US-east
- **Carbon Emitted (Power consumption x Time x Carbon produced based on location of power grid):** 15000 kg CO2 eq.
## Citation
@InProceedings{Rombach_2022_CVPR,
author = {Rombach, Robin and Blattmann, Andreas and Lorenz, Dominik and Esser, Patrick and Ommer, Bj\"orn},
title = {High-Resolution Image Synthesis With Latent Diffusion Models},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2022},
pages = {10684-10695}
}
*This model card was written by: Robin Rombach, Patrick Esser and David Ha and is based on the [Stable Diffusion v1](https://github.com/CompVis/stable-diffusion/blob/main/Stable_Diffusion_v1_Model_Card.md) and [DALL-E Mini model card](https://huggingface.co/dalle-mini/dalle-mini).*
|
stabilityai/stable-diffusion-2-1
|
stabilityai
| 2023-07-05T16:19:17Z | 999,034 | 3,935 |
diffusers
|
[
"diffusers",
"safetensors",
"stable-diffusion",
"text-to-image",
"arxiv:2112.10752",
"arxiv:2202.00512",
"arxiv:1910.09700",
"license:openrail++",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] |
text-to-image
| 2022-12-06T17:24:51Z |
---
license: openrail++
tags:
- stable-diffusion
- text-to-image
pinned: true
---
# Stable Diffusion v2-1 Model Card
This model card focuses on the model associated with the Stable Diffusion v2-1 model, codebase available [here](https://github.com/Stability-AI/stablediffusion).
This `stable-diffusion-2-1` model is fine-tuned from [stable-diffusion-2](https://huggingface.co/stabilityai/stable-diffusion-2) (`768-v-ema.ckpt`) with an additional 55k steps on the same dataset (with `punsafe=0.1`), and then fine-tuned for another 155k extra steps with `punsafe=0.98`.
- Use it with the [`stablediffusion`](https://github.com/Stability-AI/stablediffusion) repository: download the `v2-1_768-ema-pruned.ckpt` [here](https://huggingface.co/stabilityai/stable-diffusion-2-1/blob/main/v2-1_768-ema-pruned.ckpt).
- Use it with 🧨 [`diffusers`](#examples)
## Model Details
- **Developed by:** Robin Rombach, Patrick Esser
- **Model type:** Diffusion-based text-to-image generation model
- **Language(s):** English
- **License:** [CreativeML Open RAIL++-M License](https://huggingface.co/stabilityai/stable-diffusion-2/blob/main/LICENSE-MODEL)
- **Model Description:** This is a model that can be used to generate and modify images based on text prompts. It is a [Latent Diffusion Model](https://arxiv.org/abs/2112.10752) that uses a fixed, pretrained text encoder ([OpenCLIP-ViT/H](https://github.com/mlfoundations/open_clip)).
- **Resources for more information:** [GitHub Repository](https://github.com/Stability-AI/).
- **Cite as:**
@InProceedings{Rombach_2022_CVPR,
author = {Rombach, Robin and Blattmann, Andreas and Lorenz, Dominik and Esser, Patrick and Ommer, Bj\"orn},
title = {High-Resolution Image Synthesis With Latent Diffusion Models},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2022},
pages = {10684-10695}
}
## Examples
Using the [🤗's Diffusers library](https://github.com/huggingface/diffusers) to run Stable Diffusion 2 in a simple and efficient manner.
```bash
pip install diffusers transformers accelerate scipy safetensors
```
Running the pipeline (if you don't swap the scheduler it will run with the default DDIM, in this example we are swapping it to DPMSolverMultistepScheduler):
```python
import torch
from diffusers import StableDiffusionPipeline, DPMSolverMultistepScheduler
model_id = "stabilityai/stable-diffusion-2-1"
# Use the DPMSolverMultistepScheduler (DPM-Solver++) scheduler here instead
pipe = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16)
pipe.scheduler = DPMSolverMultistepScheduler.from_config(pipe.scheduler.config)
pipe = pipe.to("cuda")
prompt = "a photo of an astronaut riding a horse on mars"
image = pipe(prompt).images[0]
image.save("astronaut_rides_horse.png")
```
**Notes**:
- Despite not being a dependency, we highly recommend you to install [xformers](https://github.com/facebookresearch/xformers) for memory efficient attention (better performance)
- If you have low GPU RAM available, make sure to add a `pipe.enable_attention_slicing()` after sending it to `cuda` for less VRAM usage (to the cost of speed)
# Uses
## Direct Use
The model is intended for research purposes only. Possible research areas and tasks include
- Safe deployment of models which have the potential to generate harmful content.
- Probing and understanding the limitations and biases of generative models.
- Generation of artworks and use in design and other artistic processes.
- Applications in educational or creative tools.
- Research on generative models.
Excluded uses are described below.
### Misuse, Malicious Use, and Out-of-Scope Use
_Note: This section is originally taken from the [DALLE-MINI model card](https://huggingface.co/dalle-mini/dalle-mini), was used for Stable Diffusion v1, but applies in the same way to Stable Diffusion v2_.
The model should not be used to intentionally create or disseminate images that create hostile or alienating environments for people. This includes generating images that people would foreseeably find disturbing, distressing, or offensive; or content that propagates historical or current stereotypes.
#### Out-of-Scope Use
The model was not trained to be factual or true representations of people or events, and therefore using the model to generate such content is out-of-scope for the abilities of this model.
#### Misuse and Malicious Use
Using the model to generate content that is cruel to individuals is a misuse of this model. This includes, but is not limited to:
- Generating demeaning, dehumanizing, or otherwise harmful representations of people or their environments, cultures, religions, etc.
- Intentionally promoting or propagating discriminatory content or harmful stereotypes.
- Impersonating individuals without their consent.
- Sexual content without consent of the people who might see it.
- Mis- and disinformation
- Representations of egregious violence and gore
- Sharing of copyrighted or licensed material in violation of its terms of use.
- Sharing content that is an alteration of copyrighted or licensed material in violation of its terms of use.
## Limitations and Bias
### Limitations
- The model does not achieve perfect photorealism
- The model cannot render legible text
- The model does not perform well on more difficult tasks which involve compositionality, such as rendering an image corresponding to “A red cube on top of a blue sphere”
- Faces and people in general may not be generated properly.
- The model was trained mainly with English captions and will not work as well in other languages.
- The autoencoding part of the model is lossy
- The model was trained on a subset of the large-scale dataset
[LAION-5B](https://laion.ai/blog/laion-5b/), which contains adult, violent and sexual content. To partially mitigate this, we have filtered the dataset using LAION's NFSW detector (see Training section).
### Bias
While the capabilities of image generation models are impressive, they can also reinforce or exacerbate social biases.
Stable Diffusion was primarily trained on subsets of [LAION-2B(en)](https://laion.ai/blog/laion-5b/),
which consists of images that are limited to English descriptions.
Texts and images from communities and cultures that use other languages are likely to be insufficiently accounted for.
This affects the overall output of the model, as white and western cultures are often set as the default. Further, the
ability of the model to generate content with non-English prompts is significantly worse than with English-language prompts.
Stable Diffusion v2 mirrors and exacerbates biases to such a degree that viewer discretion must be advised irrespective of the input or its intent.
## Training
**Training Data**
The model developers used the following dataset for training the model:
- LAION-5B and subsets (details below). The training data is further filtered using LAION's NSFW detector, with a "p_unsafe" score of 0.1 (conservative). For more details, please refer to LAION-5B's [NeurIPS 2022](https://openreview.net/forum?id=M3Y74vmsMcY) paper and reviewer discussions on the topic.
**Training Procedure**
Stable Diffusion v2 is a latent diffusion model which combines an autoencoder with a diffusion model that is trained in the latent space of the autoencoder. During training,
- Images are encoded through an encoder, which turns images into latent representations. The autoencoder uses a relative downsampling factor of 8 and maps images of shape H x W x 3 to latents of shape H/f x W/f x 4
- Text prompts are encoded through the OpenCLIP-ViT/H text-encoder.
- The output of the text encoder is fed into the UNet backbone of the latent diffusion model via cross-attention.
- The loss is a reconstruction objective between the noise that was added to the latent and the prediction made by the UNet. We also use the so-called _v-objective_, see https://arxiv.org/abs/2202.00512.
We currently provide the following checkpoints:
- `512-base-ema.ckpt`: 550k steps at resolution `256x256` on a subset of [LAION-5B](https://laion.ai/blog/laion-5b/) filtered for explicit pornographic material, using the [LAION-NSFW classifier](https://github.com/LAION-AI/CLIP-based-NSFW-Detector) with `punsafe=0.1` and an [aesthetic score](https://github.com/christophschuhmann/improved-aesthetic-predictor) >= `4.5`.
850k steps at resolution `512x512` on the same dataset with resolution `>= 512x512`.
- `768-v-ema.ckpt`: Resumed from `512-base-ema.ckpt` and trained for 150k steps using a [v-objective](https://arxiv.org/abs/2202.00512) on the same dataset. Resumed for another 140k steps on a `768x768` subset of our dataset.
- `512-depth-ema.ckpt`: Resumed from `512-base-ema.ckpt` and finetuned for 200k steps. Added an extra input channel to process the (relative) depth prediction produced by [MiDaS](https://github.com/isl-org/MiDaS) (`dpt_hybrid`) which is used as an additional conditioning.
The additional input channels of the U-Net which process this extra information were zero-initialized.
- `512-inpainting-ema.ckpt`: Resumed from `512-base-ema.ckpt` and trained for another 200k steps. Follows the mask-generation strategy presented in [LAMA](https://github.com/saic-mdal/lama) which, in combination with the latent VAE representations of the masked image, are used as an additional conditioning.
The additional input channels of the U-Net which process this extra information were zero-initialized. The same strategy was used to train the [1.5-inpainting checkpoint](https://huggingface.co/runwayml/stable-diffusion-inpainting).
- `x4-upscaling-ema.ckpt`: Trained for 1.25M steps on a 10M subset of LAION containing images `>2048x2048`. The model was trained on crops of size `512x512` and is a text-guided [latent upscaling diffusion model](https://arxiv.org/abs/2112.10752).
In addition to the textual input, it receives a `noise_level` as an input parameter, which can be used to add noise to the low-resolution input according to a [predefined diffusion schedule](configs/stable-diffusion/x4-upscaling.yaml).
- **Hardware:** 32 x 8 x A100 GPUs
- **Optimizer:** AdamW
- **Gradient Accumulations**: 1
- **Batch:** 32 x 8 x 2 x 4 = 2048
- **Learning rate:** warmup to 0.0001 for 10,000 steps and then kept constant
## Evaluation Results
Evaluations with different classifier-free guidance scales (1.5, 2.0, 3.0, 4.0,
5.0, 6.0, 7.0, 8.0) and 50 steps DDIM sampling steps show the relative improvements of the checkpoints:

Evaluated using 50 DDIM steps and 10000 random prompts from the COCO2017 validation set, evaluated at 512x512 resolution. Not optimized for FID scores.
## Environmental Impact
**Stable Diffusion v1** **Estimated Emissions**
Based on that information, we estimate the following CO2 emissions using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700). The hardware, runtime, cloud provider, and compute region were utilized to estimate the carbon impact.
- **Hardware Type:** A100 PCIe 40GB
- **Hours used:** 200000
- **Cloud Provider:** AWS
- **Compute Region:** US-east
- **Carbon Emitted (Power consumption x Time x Carbon produced based on location of power grid):** 15000 kg CO2 eq.
## Citation
@InProceedings{Rombach_2022_CVPR,
author = {Rombach, Robin and Blattmann, Andreas and Lorenz, Dominik and Esser, Patrick and Ommer, Bj\"orn},
title = {High-Resolution Image Synthesis With Latent Diffusion Models},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2022},
pages = {10684-10695}
}
*This model card was written by: Robin Rombach, Patrick Esser and David Ha and is based on the [Stable Diffusion v1](https://github.com/CompVis/stable-diffusion/blob/main/Stable_Diffusion_v1_Model_Card.md) and [DALL-E Mini model card](https://huggingface.co/dalle-mini/dalle-mini).*
|
stabilityai/stable-diffusion-2-inpainting
|
stabilityai
| 2023-07-05T16:19:10Z | 277,480 | 527 |
diffusers
|
[
"diffusers",
"safetensors",
"stable-diffusion",
"arxiv:2112.10752",
"arxiv:2202.00512",
"arxiv:1910.09700",
"license:openrail++",
"diffusers:StableDiffusionInpaintPipeline",
"region:us"
] |
image-to-image
| 2022-11-23T17:41:55Z |
---
license: openrail++
tags:
- stable-diffusion
inference: false
---
# Stable Diffusion v2 Model Card
This model card focuses on the model associated with the Stable Diffusion v2, available [here](https://github.com/Stability-AI/stablediffusion).
This `stable-diffusion-2-inpainting` model is resumed from [stable-diffusion-2-base](https://huggingface.co/stabilityai/stable-diffusion-2-base) (`512-base-ema.ckpt`) and trained for another 200k steps. Follows the mask-generation strategy presented in [LAMA](https://github.com/saic-mdal/lama) which, in combination with the latent VAE representations of the masked image, are used as an additional conditioning.

- Use it with the [`stablediffusion`](https://github.com/Stability-AI/stablediffusion) repository: download the `512-inpainting-ema.ckpt` [here](https://huggingface.co/stabilityai/stable-diffusion-2-inpainting/resolve/main/512-inpainting-ema.ckpt).
- Use it with 🧨 [`diffusers`](https://huggingface.co/stabilityai/stable-diffusion-2-inpainting#examples)
## Model Details
- **Developed by:** Robin Rombach, Patrick Esser
- **Model type:** Diffusion-based text-to-image generation model
- **Language(s):** English
- **License:** [CreativeML Open RAIL++-M License](https://huggingface.co/stabilityai/stable-diffusion-2/blob/main/LICENSE-MODEL)
- **Model Description:** This is a model that can be used to generate and modify images based on text prompts. It is a [Latent Diffusion Model](https://arxiv.org/abs/2112.10752) that uses a fixed, pretrained text encoder ([OpenCLIP-ViT/H](https://github.com/mlfoundations/open_clip)).
- **Resources for more information:** [GitHub Repository](https://github.com/Stability-AI/).
- **Cite as:**
@InProceedings{Rombach_2022_CVPR,
author = {Rombach, Robin and Blattmann, Andreas and Lorenz, Dominik and Esser, Patrick and Ommer, Bj\"orn},
title = {High-Resolution Image Synthesis With Latent Diffusion Models},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2022},
pages = {10684-10695}
}
## Examples
Using the [🤗's Diffusers library](https://github.com/huggingface/diffusers) to run Stable Diffusion 2 inpainting in a simple and efficient manner.
```bash
pip install diffusers transformers accelerate scipy safetensors
```
```python
from diffusers import StableDiffusionInpaintPipeline
pipe = StableDiffusionInpaintPipeline.from_pretrained(
"stabilityai/stable-diffusion-2-inpainting",
torch_dtype=torch.float16,
)
pipe.to("cuda")
prompt = "Face of a yellow cat, high resolution, sitting on a park bench"
#image and mask_image should be PIL images.
#The mask structure is white for inpainting and black for keeping as is
image = pipe(prompt=prompt, image=image, mask_image=mask_image).images[0]
image.save("./yellow_cat_on_park_bench.png")
```
**Notes**:
- Despite not being a dependency, we highly recommend you to install [xformers](https://github.com/facebookresearch/xformers) for memory efficient attention (better performance)
- If you have low GPU RAM available, make sure to add a `pipe.enable_attention_slicing()` after sending it to `cuda` for less VRAM usage (to the cost of speed)
**How it works:**
`image` | `mask_image`
:-------------------------:|:-------------------------:|
<img src="https://raw.githubusercontent.com/CompVis/latent-diffusion/main/data/inpainting_examples/overture-creations-5sI6fQgYIuo.png" alt="drawing" width="300"/> | <img src="https://raw.githubusercontent.com/CompVis/latent-diffusion/main/data/inpainting_examples/overture-creations-5sI6fQgYIuo_mask.png" alt="drawing" width="300"/>
`prompt` | `Output`
:-------------------------:|:-------------------------:|
<span style="position: relative;bottom: 150px;">Face of a yellow cat, high resolution, sitting on a park bench</span> | <img src="https://huggingface.co/datasets/patrickvonplaten/images/resolve/main/test.png" alt="drawing" width="300"/>
# Uses
## Direct Use
The model is intended for research purposes only. Possible research areas and tasks include
- Safe deployment of models which have the potential to generate harmful content.
- Probing and understanding the limitations and biases of generative models.
- Generation of artworks and use in design and other artistic processes.
- Applications in educational or creative tools.
- Research on generative models.
Excluded uses are described below.
### Misuse, Malicious Use, and Out-of-Scope Use
_Note: This section is originally taken from the [DALLE-MINI model card](https://huggingface.co/dalle-mini/dalle-mini), was used for Stable Diffusion v1, but applies in the same way to Stable Diffusion v2_.
The model should not be used to intentionally create or disseminate images that create hostile or alienating environments for people. This includes generating images that people would foreseeably find disturbing, distressing, or offensive; or content that propagates historical or current stereotypes.
#### Out-of-Scope Use
The model was not trained to be factual or true representations of people or events, and therefore using the model to generate such content is out-of-scope for the abilities of this model.
#### Misuse and Malicious Use
Using the model to generate content that is cruel to individuals is a misuse of this model. This includes, but is not limited to:
- Generating demeaning, dehumanizing, or otherwise harmful representations of people or their environments, cultures, religions, etc.
- Intentionally promoting or propagating discriminatory content or harmful stereotypes.
- Impersonating individuals without their consent.
- Sexual content without consent of the people who might see it.
- Mis- and disinformation
- Representations of egregious violence and gore
- Sharing of copyrighted or licensed material in violation of its terms of use.
- Sharing content that is an alteration of copyrighted or licensed material in violation of its terms of use.
## Limitations and Bias
### Limitations
- The model does not achieve perfect photorealism
- The model cannot render legible text
- The model does not perform well on more difficult tasks which involve compositionality, such as rendering an image corresponding to “A red cube on top of a blue sphere”
- Faces and people in general may not be generated properly.
- The model was trained mainly with English captions and will not work as well in other languages.
- The autoencoding part of the model is lossy
- The model was trained on a subset of the large-scale dataset
[LAION-5B](https://laion.ai/blog/laion-5b/), which contains adult, violent and sexual content. To partially mitigate this, we have filtered the dataset using LAION's NFSW detector (see Training section).
### Bias
While the capabilities of image generation models are impressive, they can also reinforce or exacerbate social biases.
Stable Diffusion vw was primarily trained on subsets of [LAION-2B(en)](https://laion.ai/blog/laion-5b/),
which consists of images that are limited to English descriptions.
Texts and images from communities and cultures that use other languages are likely to be insufficiently accounted for.
This affects the overall output of the model, as white and western cultures are often set as the default. Further, the
ability of the model to generate content with non-English prompts is significantly worse than with English-language prompts.
Stable Diffusion v2 mirrors and exacerbates biases to such a degree that viewer discretion must be advised irrespective of the input or its intent.
## Training
**Training Data**
The model developers used the following dataset for training the model:
- LAION-5B and subsets (details below). The training data is further filtered using LAION's NSFW detector, with a "p_unsafe" score of 0.1 (conservative). For more details, please refer to LAION-5B's [NeurIPS 2022](https://openreview.net/forum?id=M3Y74vmsMcY) paper and reviewer discussions on the topic.
**Training Procedure**
Stable Diffusion v2 is a latent diffusion model which combines an autoencoder with a diffusion model that is trained in the latent space of the autoencoder. During training,
- Images are encoded through an encoder, which turns images into latent representations. The autoencoder uses a relative downsampling factor of 8 and maps images of shape H x W x 3 to latents of shape H/f x W/f x 4
- Text prompts are encoded through the OpenCLIP-ViT/H text-encoder.
- The output of the text encoder is fed into the UNet backbone of the latent diffusion model via cross-attention.
- The loss is a reconstruction objective between the noise that was added to the latent and the prediction made by the UNet. We also use the so-called _v-objective_, see https://arxiv.org/abs/2202.00512.
We currently provide the following checkpoints:
- `512-base-ema.ckpt`: 550k steps at resolution `256x256` on a subset of [LAION-5B](https://laion.ai/blog/laion-5b/) filtered for explicit pornographic material, using the [LAION-NSFW classifier](https://github.com/LAION-AI/CLIP-based-NSFW-Detector) with `punsafe=0.1` and an [aesthetic score](https://github.com/christophschuhmann/improved-aesthetic-predictor) >= `4.5`.
850k steps at resolution `512x512` on the same dataset with resolution `>= 512x512`.
- `768-v-ema.ckpt`: Resumed from `512-base-ema.ckpt` and trained for 150k steps using a [v-objective](https://arxiv.org/abs/2202.00512) on the same dataset. Resumed for another 140k steps on a `768x768` subset of our dataset.
- `512-depth-ema.ckpt`: Resumed from `512-base-ema.ckpt` and finetuned for 200k steps. Added an extra input channel to process the (relative) depth prediction produced by [MiDaS](https://github.com/isl-org/MiDaS) (`dpt_hybrid`) which is used as an additional conditioning.
The additional input channels of the U-Net which process this extra information were zero-initialized.
- `512-inpainting-ema.ckpt`: Resumed from `512-base-ema.ckpt` and trained for another 200k steps. Follows the mask-generation strategy presented in [LAMA](https://github.com/saic-mdal/lama) which, in combination with the latent VAE representations of the masked image, are used as an additional conditioning.
The additional input channels of the U-Net which process this extra information were zero-initialized. The same strategy was used to train the [1.5-inpainting checkpoint](https://github.com/saic-mdal/lama).
- `x4-upscaling-ema.ckpt`: Trained for 1.25M steps on a 10M subset of LAION containing images `>2048x2048`. The model was trained on crops of size `512x512` and is a text-guided [latent upscaling diffusion model](https://arxiv.org/abs/2112.10752).
In addition to the textual input, it receives a `noise_level` as an input parameter, which can be used to add noise to the low-resolution input according to a [predefined diffusion schedule](configs/stable-diffusion/x4-upscaling.yaml).
- **Hardware:** 32 x 8 x A100 GPUs
- **Optimizer:** AdamW
- **Gradient Accumulations**: 1
- **Batch:** 32 x 8 x 2 x 4 = 2048
- **Learning rate:** warmup to 0.0001 for 10,000 steps and then kept constant
## Evaluation Results
Evaluations with different classifier-free guidance scales (1.5, 2.0, 3.0, 4.0,
5.0, 6.0, 7.0, 8.0) and 50 steps DDIM sampling steps show the relative improvements of the checkpoints:

Evaluated using 50 DDIM steps and 10000 random prompts from the COCO2017 validation set, evaluated at 512x512 resolution. Not optimized for FID scores.
## Environmental Impact
**Stable Diffusion v1** **Estimated Emissions**
Based on that information, we estimate the following CO2 emissions using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700). The hardware, runtime, cloud provider, and compute region were utilized to estimate the carbon impact.
- **Hardware Type:** A100 PCIe 40GB
- **Hours used:** 200000
- **Cloud Provider:** AWS
- **Compute Region:** US-east
- **Carbon Emitted (Power consumption x Time x Carbon produced based on location of power grid):** 15000 kg CO2 eq.
## Citation
@InProceedings{Rombach_2022_CVPR,
author = {Rombach, Robin and Blattmann, Andreas and Lorenz, Dominik and Esser, Patrick and Ommer, Bj\"orn},
title = {High-Resolution Image Synthesis With Latent Diffusion Models},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2022},
pages = {10684-10695}
}
*This model card was written by: Robin Rombach, Patrick Esser and David Ha and is based on the [Stable Diffusion v1](https://github.com/CompVis/stable-diffusion/blob/main/Stable_Diffusion_v1_Model_Card.md) and [DALL-E Mini model card](https://huggingface.co/dalle-mini/dalle-mini).*
|
aarondotwork/sd-pokemon-diffusers
|
aarondotwork
| 2023-07-05T16:18:41Z | 3 | 7 |
diffusers
|
[
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"en",
"dataset:lambdalabs/pokemon-blip-captions",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] |
text-to-image
| 2022-10-22T03:45:43Z |
---
language:
- en
thumbnail: "https://s3.amazonaws.com/moonup/production/uploads/1663756797814-62bd5f951e22ec84279820e8.png"
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
datasets:
- lambdalabs/pokemon-blip-captions
---
**This copy of the Lambda Labs model only adds the fp16 branch for compatibility with the Stable Cabal GRPC server**
__Stable Diffusion fine tuned on Pokémon by [Lambda Labs](https://lambdalabs.com/).__
Put in a text prompt and generate your own Pokémon character, no "prompt engineering" required!
If you want to find out how to train your own Stable Diffusion variants, see this [example](https://github.com/LambdaLabsML/examples/tree/main/stable-diffusion-finetuning) from Lambda Labs.

> Girl with a pearl earring, Cute Obama creature, Donald Trump, Boris Johnson, Totoro, Hello Kitty
## Usage
```bash
!pip install diffusers==0.3.0
!pip install transformers scipy ftfy
```
```python
import torch
from diffusers import StableDiffusionPipeline
from torch import autocast
pipe = StableDiffusionPipeline.from_pretrained("lambdalabs/sd-pokemon-diffusers", torch_dtype=torch.float16)
pipe = pipe.to("cuda")
prompt = "Yoda"
scale = 10
n_samples = 4
# Sometimes the nsfw checker is confused by the Pokémon images, you can disable
# it at your own risk here
disable_safety = False
if disable_safety:
def null_safety(images, **kwargs):
return images, False
pipe.safety_checker = null_safety
with autocast("cuda"):
images = pipe(n_samples*[prompt], guidance_scale=scale).images
for idx, im in enumerate(images):
im.save(f"{idx:06}.png")
```
## Model description
Trained on [BLIP captioned Pokémon images](https://huggingface.co/datasets/lambdalabs/pokemon-blip-captions) using 2xA6000 GPUs on [Lambda GPU Cloud](https://lambdalabs.com/service/gpu-cloud) for around 15,000 step (about 6 hours, at a cost of about $10).
## Links
- [Lambda Diffusers](https://github.com/LambdaLabsML/lambda-diffusers)
- [Captioned Pokémon dataset](https://huggingface.co/datasets/lambdalabs/pokemon-blip-captions)
- [Model weights in Diffusers format](https://huggingface.co/lambdalabs/sd-pokemon-diffusers)
- [Original model weights](https://huggingface.co/justinpinkney/pokemon-stable-diffusion)
- [Training code](https://github.com/justinpinkney/stable-diffusion)
Trained by [Justin Pinkney](justinpinkney.com) ([@Buntworthy](https://twitter.com/Buntworthy)) at [Lambda Labs](https://lambdalabs.com/).
|
Jacknjeilfy/BarfBag
|
Jacknjeilfy
| 2023-07-05T16:18:04Z | 0 | 0 | null |
[
"license:creativeml-openrail-m",
"region:us"
] | null | 2023-07-05T16:18:04Z |
---
license: creativeml-openrail-m
---
|
ddoc/sdc2
|
ddoc
| 2023-07-05T16:17:54Z | 0 | 0 | null |
[
"region:us"
] | null | 2023-07-05T16:17:15Z |
# Deforum Stable Diffusion — official extension for AUTOMATIC1111's webui
<p align="left">
<a href="https://github.com/deforum-art/sd-webui-deforum/commits"><img alt="Last Commit" src="https://img.shields.io/github/last-commit/deforum-art/deforum-for-automatic1111-webui"></a>
<a href="https://github.com/deforum-art/sd-webui-deforum/issues"><img alt="GitHub issues" src="https://img.shields.io/github/issues/deforum-art/deforum-for-automatic1111-webui"></a>
<a href="https://github.com/deforum-art/sd-webui-deforum/stargazers"><img alt="GitHub stars" src="https://img.shields.io/github/stars/deforum-art/deforum-for-automatic1111-webui"></a>
<a href="https://github.com/deforum-art/sd-webui-deforum/network"><img alt="GitHub forks" src="https://img.shields.io/github/forks/deforum-art/deforum-for-automatic1111-webui"></a>
</a>
</p>
## Need help? See our [FAQ](https://github.com/deforum-art/sd-webui-deforum/wiki/FAQ-&-Troubleshooting)
## Getting Started
1. Install [AUTOMATIC1111's webui](https://github.com/AUTOMATIC1111/stable-diffusion-webui/).
2. Now two ways: either clone the repo into the `extensions` directory via git commandline launched within in the `stable-diffusion-webui` folder
```sh
git clone https://github.com/deforum-art/sd-webui-deforum extensions/deforum
```
Or download this repository, locate the `extensions` folder within your WebUI installation, create a folder named `deforum` and put the contents of the downloaded directory inside of it. Then restart WebUI.
3. Open the webui, find the Deforum tab at the top of the page.
4. Enter the animation settings. Refer to [this general guide](https://docs.google.com/document/d/1pEobUknMFMkn8F5TMsv8qRzamXX_75BShMMXV8IFslI/edit) and [this guide to math keyframing functions in Deforum](https://docs.google.com/document/d/1pfW1PwbDIuW0cv-dnuyYj1UzPqe23BlSLTJsqazffXM/edit?usp=sharing). However, **in this version prompt weights less than zero don't just like in original Deforum!** Split the positive and the negative prompt in the json section using --neg argument like this "apple:\`where(cos(t)>=0, cos(t), 0)\`, snow --neg strawberry:\`where(cos(t)<0, -cos(t), 0)\`"
5. To view animation frames as they're being made, without waiting for the completion of an animation, go to the 'Settings' tab and set the value of this toolbar **above zero**. Warning: it may slow down the generation process.

6. Run the script and see if you got it working or even got something. **In 3D mode a large delay is expected at first** as the script loads the depth models. In the end, using the default settings the whole thing should consume 6.4 GBs of VRAM at 3D mode peaks and no more than 3.8 GB VRAM in 3D mode if you launch the webui with the '--lowvram' command line argument.
7. After the generation process is completed, click the button with the self-describing name to show the video or gif result right in the GUI!
8. Join our Discord where you can post generated stuff, ask questions and more: https://discord.gg/deforum. <br>
* There's also the 'Issues' tab in the repo, for well... reporting issues ;)
9. Profit!
## Known issues
* This port is not fully backward-compatible with the notebook and the local version both due to the changes in how AUTOMATIC1111's webui handles Stable Diffusion models and the changes in this script to get it to work in the new environment. *Expect* that you may not get exactly the same result or that the thing may break down because of the older settings.
## Screenshots
Amazing raw Deforum animation by [Pxl.Pshr](https://www.instagram.com/pxl.pshr):
* Turn Audio ON!
(Audio credits: SKRILLEX, FRED AGAIN & FLOWDAN - RUMBLE (PHACE'S DNB FLIP))
https://user-images.githubusercontent.com/121192995/224450647-39529b28-be04-4871-bb7a-faf7afda2ef2.mp4
Setting file of that video: [here](https://github.com/deforum-art/sd-webui-deforum/files/11353167/PxlPshrWinningAnimationSettings.txt).
<br>
Main extension tab:

Keyframes tab:

|
CompVis/stable-diffusion-v1-3
|
CompVis
| 2023-07-05T16:17:35Z | 524 | 37 |
diffusers
|
[
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"arxiv:2207.12598",
"arxiv:2112.10752",
"arxiv:2103.00020",
"arxiv:2205.11487",
"arxiv:1910.09700",
"license:creativeml-openrail-m",
"autotrain_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] |
text-to-image
| 2022-08-18T17:54:56Z |
---
license: creativeml-openrail-m
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
inference: false
extra_gated_prompt: |-
This model is open access and available to all, with a CreativeML OpenRAIL-M license further specifying rights and usage.
The CreativeML OpenRAIL License specifies:
1. You can't use the model to deliberately produce nor share illegal or harmful outputs or content
2. The authors claim no rights on the outputs you generate, you are free to use them and are accountable for their use which must not go against the provisions set in the license
3. You may re-distribute the weights and use the model commercially and/or as a service. If you do, please be aware you have to include the same use restrictions as the ones in the license and share a copy of the CreativeML OpenRAIL-M to all your users (please read the license entirely and carefully)
Please read the full license carefully here: https://huggingface.co/spaces/CompVis/stable-diffusion-license
extra_gated_heading: Please read the LICENSE to access this model
---
# Stable Diffusion v1-3 Model Card
Stable Diffusion is a latent text-to-image diffusion model capable of generating photo-realistic images given any text input.
For more information about how Stable Diffusion functions, please have a look at [🤗's Stable Diffusion with D🧨iffusers blog](https://huggingface.co/blog/stable_diffusion).
The **Stable-Diffusion-v1-3** checkpoint was initialized with the weights of the [Stable-Diffusion-v1-2](https:/steps/huggingface.co/CompVis/stable-diffusion-v1-2)
checkpoint and subsequently fine-tuned on 195,000 steps at resolution `512x512` on "laion-improved-aesthetics" and 10 % dropping of the text-conditioning to improve [classifier-free guidance sampling](https://arxiv.org/abs/2207.12598).
For more information, please refer to [Training](#training).
This weights here are intended to be used with the D🧨iffusers library. If you are looking for the weights to be loaded into the CompVis Stable Diffusion codebase, [come here](https://huggingface.co/CompVis/stable-diffusion-v-1-3-original)
## Model Details
- **Developed by:** Robin Rombach, Patrick Esser
- **Model type:** Diffusion-based text-to-image generation model
- **Language(s):** English
- **License:** [The CreativeML OpenRAIL M license](https://huggingface.co/spaces/CompVis/stable-diffusion-license) is an [Open RAIL M license](https://www.licenses.ai/blog/2022/8/18/naming-convention-of-responsible-ai-licenses), adapted from the work that [BigScience](https://bigscience.huggingface.co/) and [the RAIL Initiative](https://www.licenses.ai/) are jointly carrying in the area of responsible AI licensing. See also [the article about the BLOOM Open RAIL license](https://bigscience.huggingface.co/blog/the-bigscience-rail-license) on which our license is based.
- **Model Description:** This is a model that can be used to generate and modify images based on text prompts. It is a [Latent Diffusion Model](https://arxiv.org/abs/2112.10752) that uses a fixed, pretrained text encoder ([CLIP ViT-L/14](https://arxiv.org/abs/2103.00020)) as suggested in the [Imagen paper](https://arxiv.org/abs/2205.11487).
- **Resources for more information:** [GitHub Repository](https://github.com/CompVis/stable-diffusion), [Paper](https://arxiv.org/abs/2112.10752).
- **Cite as:**
@InProceedings{Rombach_2022_CVPR,
author = {Rombach, Robin and Blattmann, Andreas and Lorenz, Dominik and Esser, Patrick and Ommer, Bj\"orn},
title = {High-Resolution Image Synthesis With Latent Diffusion Models},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2022},
pages = {10684-10695}
}
## Examples
We recommend using [🤗's Diffusers library](https://github.com/huggingface/diffusers) to run Stable Diffusion.
```bash
pip install --upgrade diffusers transformers scipy
```
Running the pipeline with the default PNDM scheduler:
```python
import torch
from torch import autocast
from diffusers import StableDiffusionPipeline
model_id = "CompVis/stable-diffusion-v1-3"
device = "cuda"
pipe = StableDiffusionPipeline.from_pretrained(model_id)
pipe = pipe.to(device)
prompt = "a photo of an astronaut riding a horse on mars"
with autocast("cuda"):
image = pipe(prompt, guidance_scale=7.5)["sample"][0]
image.save("astronaut_rides_horse.png")
```
**Note**:
If you are limited by GPU memory and have less than 10GB of GPU RAM available, please make sure to load the StableDiffusionPipeline in float16 precision instead of the default float32 precision as done above. You can do so by telling diffusers to expect the weights to be in float16 precision:
```py
import torch
pipe = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16)
pipe = pipe.to(device)
prompt = "a photo of an astronaut riding a horse on mars"
with autocast("cuda"):
image = pipe(prompt, guidance_scale=7.5)["sample"][0]
image.save("astronaut_rides_horse.png")
```
To swap out the noise scheduler, pass it to `from_pretrained`:
```python
from diffusers import StableDiffusionPipeline, LMSDiscreteScheduler
model_id = "CompVis/stable-diffusion-v1-3"
# Use the K-LMS scheduler here instead
scheduler = LMSDiscreteScheduler(beta_start=0.00085, beta_end=0.012, beta_schedule="scaled_linear", num_train_timesteps=1000)
pipe = StableDiffusionPipeline.from_pretrained(model_id, scheduler=scheduler, use_auth_token=True)
pipe = pipe.to("cuda")
prompt = "a photo of an astronaut riding a horse on mars"
with autocast("cuda"):
image = pipe(prompt, guidance_scale=7.5)["sample"][0]
image.save("astronaut_rides_horse.png")
```
# Uses
## Direct Use
The model is intended for research purposes only. Possible research areas and
tasks include
- Safe deployment of models which have the potential to generate harmful content.
- Probing and understanding the limitations and biases of generative models.
- Generation of artworks and use in design and other artistic processes.
- Applications in educational or creative tools.
- Research on generative models.
Excluded uses are described below.
### Misuse, Malicious Use, and Out-of-Scope Use
_Note: This section is taken from the [DALLE-MINI model card](https://huggingface.co/dalle-mini/dalle-mini), but applies in the same way to Stable Diffusion v1_.
The model should not be used to intentionally create or disseminate images that create hostile or alienating environments for people. This includes generating images that people would foreseeably find disturbing, distressing, or offensive; or content that propagates historical or current stereotypes.
#### Out-of-Scope Use
The model was not trained to be factual or true representations of people or events, and therefore using the model to generate such content is out-of-scope for the abilities of this model.
#### Misuse and Malicious Use
Using the model to generate content that is cruel to individuals is a misuse of this model. This includes, but is not limited to:
- Generating demeaning, dehumanizing, or otherwise harmful representations of people or their environments, cultures, religions, etc.
- Intentionally promoting or propagating discriminatory content or harmful stereotypes.
- Impersonating individuals without their consent.
- Sexual content without consent of the people who might see it.
- Mis- and disinformation
- Representations of egregious violence and gore
- Sharing of copyrighted or licensed material in violation of its terms of use.
- Sharing content that is an alteration of copyrighted or licensed material in violation of its terms of use.
## Limitations and Bias
### Limitations
- The model does not achieve perfect photorealism
- The model cannot render legible text
- The model does not perform well on more difficult tasks which involve compositionality, such as rendering an image corresponding to “A red cube on top of a blue sphere”
- Faces and people in general may not be generated properly.
- The model was trained mainly with English captions and will not work as well in other languages.
- The autoencoding part of the model is lossy
- The model was trained on a large-scale dataset
[LAION-5B](https://laion.ai/blog/laion-5b/) which contains adult material
and is not fit for product use without additional safety mechanisms and
considerations.
- No additional measures were used to deduplicate the dataset. As a result, we observe some degree of memorization for images that are duplicated in the training data.
The training data can be searched at [https://rom1504.github.io/clip-retrieval/](https://rom1504.github.io/clip-retrieval/) to possibly assist in the detection of memorized images.
### Bias
While the capabilities of image generation models are impressive, they can also reinforce or exacerbate social biases.
Stable Diffusion v1 was trained on subsets of [LAION-2B(en)](https://laion.ai/blog/laion-5b/),
which consists of images that are primarily limited to English descriptions.
Texts and images from communities and cultures that use other languages are likely to be insufficiently accounted for.
This affects the overall output of the model, as white and western cultures are often set as the default. Further, the
ability of the model to generate content with non-English prompts is significantly worse than with English-language prompts.
## Training
### Training Data
The model developers used the following dataset for training the model:
- LAION-2B (en) and subsets thereof (see next section)
### Training Procedure
Stable Diffusion v1-4 is a latent diffusion model which combines an autoencoder with a diffusion model that is trained in the latent space of the autoencoder. During training,
- Images are encoded through an encoder, which turns images into latent representations. The autoencoder uses a relative downsampling factor of 8 and maps images of shape H x W x 3 to latents of shape H/f x W/f x 4
- Text prompts are encoded through a ViT-L/14 text-encoder.
- The non-pooled output of the text encoder is fed into the UNet backbone of the latent diffusion model via cross-attention.
- The loss is a reconstruction objective between the noise that was added to the latent and the prediction made by the UNet.
We currently provide four checkpoints, which were trained as follows.
- [`stable-diffusion-v1-1`](https://huggingface.co/CompVis/stable-diffusion-v1-1): 237,000 steps at resolution `256x256` on [laion2B-en](https://huggingface.co/datasets/laion/laion2B-en).
194,000 steps at resolution `512x512` on [laion-high-resolution](https://huggingface.co/datasets/laion/laion-high-resolution) (170M examples from LAION-5B with resolution `>= 1024x1024`).
- [`stable-diffusion-v1-2`](https://huggingface.co/CompVis/stable-diffusion-v1-2): Resumed from `stable-diffusion-v1-1`.
515,000 steps at resolution `512x512` on "laion-improved-aesthetics" (a subset of laion2B-en,
filtered to images with an original size `>= 512x512`, estimated aesthetics score `> 5.0`, and an estimated watermark probability `< 0.5`. The watermark estimate is from the LAION-5B metadata, the aesthetics score is estimated using an [improved aesthetics estimator](https://github.com/christophschuhmann/improved-aesthetic-predictor)).
- [`stable-diffusion-v1-3`](https://huggingface.co/CompVis/stable-diffusion-v1-3): Resumed from `stable-diffusion-v1-2`. 195,000 steps at resolution `512x512` on "laion-improved-aesthetics" and 10 % dropping of the text-conditioning to improve [classifier-free guidance sampling](https://arxiv.org/abs/2207.12598).
- [**`stable-diffusion-v1-4`**](https://huggingface.co/CompVis/stable-diffusion-v1-4) Resumed from `stable-diffusion-v1-2`.225,000 steps at resolution `512x512` on "laion-aesthetics v2 5+" and 10 % dropping of the text-conditioning to improve [classifier-free guidance sampling](https://arxiv.org/abs/2207.12598).
### Training details
- **Hardware:** 32 x 8 x A100 GPUs
- **Optimizer:** AdamW
- **Gradient Accumulations**: 2
- **Batch:** 32 x 8 x 2 x 4 = 2048
- **Learning rate:** warmup to 0.0001 for 10,000 steps and then kept constant
## Evaluation Results
Evaluations with different classifier-free guidance scales (1.5, 2.0, 3.0, 4.0,
5.0, 6.0, 7.0, 8.0) and 50 PLMS sampling
steps show the relative improvements of the checkpoints:

Evaluated using 50 PLMS steps and 10000 random prompts from the COCO2017 validation set, evaluated at 512x512 resolution. Not optimized for FID scores.
## Environmental Impact
**Stable Diffusion v1** **Estimated Emissions**
Based on that information, we estimate the following CO2 emissions using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700). The hardware, runtime, cloud provider, and compute region were utilized to estimate the carbon impact.
- **Hardware Type:** A100 PCIe 40GB
- **Hours used:** 150000
- **Cloud Provider:** AWS
- **Compute Region:** US-east
- **Carbon Emitted (Power consumption x Time x Carbon produced based on location of power grid):** 11250 kg CO2 eq.
## Citation
```bibtex
@InProceedings{Rombach_2022_CVPR,
author = {Rombach, Robin and Blattmann, Andreas and Lorenz, Dominik and Esser, Patrick and Ommer, Bj\"orn},
title = {High-Resolution Image Synthesis With Latent Diffusion Models},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2022},
pages = {10684-10695}
}
```
*This model card was written by: Robin Rombach and Patrick Esser and is based on the [DALL-E Mini model card](https://huggingface.co/dalle-mini/dalle-mini).*
|
VFiona/opus-mt-en-it-finetuned-en-to-it
|
VFiona
| 2023-07-05T15:59:15Z | 107 | 0 |
transformers
|
[
"transformers",
"pytorch",
"marian",
"text2text-generation",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2023-07-05T10:06:43Z |
---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: opus-mt-en-it-finetuned-en-to-it
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# opus-mt-en-it-finetuned-en-to-it
This model is a fine-tuned version of [Helsinki-NLP/opus-mt-en-it](https://huggingface.co/Helsinki-NLP/opus-mt-en-it) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss | Bleu | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:-------:|:-------:|
| No log | 1.0 | 118 | 0.4349 | 68.1929 | 31.879 |
### Framework versions
- Transformers 4.30.2
- Pytorch 1.12.1
- Datasets 2.13.1
- Tokenizers 0.11.0
|
iammartian0/whisper-tiny-minds14
|
iammartian0
| 2023-07-05T15:58:41Z | 79 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"whisper",
"automatic-speech-recognition",
"generated_from_trainer",
"dataset:PolyAI/minds14",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2023-07-05T15:22:00Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- PolyAI/minds14
metrics:
- wer
model-index:
- name: whisper-tiny-minds14
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: PolyAI/minds14
type: PolyAI/minds14
config: en-US
split: train
args: en-US
metrics:
- name: Wer
type: wer
value: 0.33707865168539325
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# whisper-tiny-minds14
This model is a fine-tuned version of [openai/whisper-tiny](https://huggingface.co/openai/whisper-tiny) on the PolyAI/minds14 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5694
- Wer Ortho: 33.5185
- Wer: 0.3371
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 16
- eval_batch_size: 2
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: constant_with_warmup
- lr_scheduler_warmup_steps: 50
- training_steps: 500
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer Ortho | Wer |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|
| 0.0009 | 17.86 | 500 | 0.5694 | 33.5185 | 0.3371 |
### Framework versions
- Transformers 4.30.1
- Pytorch 2.0.0
- Datasets 2.1.0
- Tokenizers 0.13.3
|
openai/diffusers-cd_cat256_lpips
|
openai
| 2023-07-05T15:22:42Z | 29 | 2 |
diffusers
|
[
"diffusers",
"generative model",
"unconditional image generation",
"consistency-model",
"arxiv:2303.01469",
"arxiv:2206.00364",
"arxiv:1506.03365",
"arxiv:1512.00567",
"license:mit",
"diffusers:ConsistencyModelPipeline",
"region:us"
] | null | 2023-07-05T13:27:50Z |
---
license: mit
tags:
- generative model
- unconditional image generation
- consistency-model
---
**Disclaimer**: This model was added by the amazing community contributors [dg845](https://huggingface.co/dg845) and [ayushtues](https://huggingface.co/ayushtues)❤️
Consistency models are a new class of generative models introduced in ["Consistency Models"](https://arxiv.org/abs/2303.01469) ([paper](https://arxiv.org/pdf/2303.01469.pdf), [code](https://github.com/openai/consistency_models)) by Yang Song, Prafulla Dhariwal, Mark Chen, and Ilya Sutskever.
From the paper abstract:
> Diffusion models have significantly advanced the fields of image, audio, and video generation, but
they depend on an iterative sampling process that causes slow generation. To overcome this limitation,
we propose consistency models, a new family of models that generate high quality samples by directly
mapping noise to data. They support fast one-step generation by design, while still allowing multistep
sampling to trade compute for sample quality. They also support zero-shot data editing, such as image
inpainting, colorization, and super-resolution, without requiring explicit training on these tasks.
Consistency models can be trained either by distilling pre-trained diffusion models, or as standalone
generative models altogether. Through extensive experiments, we demonstrate that they outperform
existing distillation techniques for diffusion models in one- and few-step sampling, achieving the new
state-of-the-art FID of 3.55 on CIFAR-10 and 6.20 on ImageNet 64 x 64 for one-step generation. When
trained in isolation, consistency models become a new family of generative models that can outperform
existing one-step, non-adversarial generative models on standard benchmarks such as CIFAR-10, ImageNet
64 x 64 and LSUN 256 x 256.
Intuitively, a consistency model can be thought of as a model which, when evaluated on a noisy image and timestep, returns an output image sample similar to that which would be returned by running a sampling algorithm on a diffusion model.
Consistency models can be parameterized by any neural network whose input has the same dimensionality as its output, such as a U-Net.
More precisely, given a teacher diffusion model and fixed sampler, we can train ("distill") a consistency model such that when it is given a noisy image and its corresponding timestep, the output sample of the consistency model will be close to the output that would result by using the sampler on the diffusion model to produce a sample, starting at the same noisy image and timestep.
The authors call this procedure "consistency distillation (CD)".
Consistency models can also be trained from scratch to generate clean images from a noisy image and timestep, which the authors call "consistency training (CT)".
This model is a `diffusers`-compatible version of the [cd_cat256_lpips.pt](https://github.com/openai/consistency_models#pre-trained-models) checkpont from the [original code and model release](https://github.com/openai/consistency_models).
This model was distilled (via consistency distillation (CD)) from an [EDM model](https://arxiv.org/pdf/2206.00364.pdf) trained on the LSUN Cat 256x256 dataset, using [LPIPS](https://richzhang.github.io/PerceptualSimilarity/) as the measure of closeness.
See the [original model card](https://github.com/openai/consistency_models/blob/main/model-card.md) for more information.
## Download
The original PyTorch model checkpoint can be downloaded from the [original code and model release](https://github.com/openai/consistency_models#pre-trained-models).
The `diffusers` pipeline for the `cd_cat256_lpips` model can be downloaded as follows:
```python
from diffusers import ConsistencyModelPipeline
pipe = ConsistencyModelPipeline.from_pretrained("openai/diffusers-cd_cat256_lpips")
```
## Usage
The original model checkpoint can be used with the [original consistency models codebase](https://github.com/openai/consistency_models).
Here is an example of using the `cd_cat256_lpips` checkpoint with `diffusers`:
```python
import torch
from diffusers import ConsistencyModelPipeline
device = "cuda"
# Load the cd_cat256_lpips checkpoint.
model_id_or_path = "openai/diffusers-cd_cat256_lpips"
pipe = ConsistencyModelPipeline.from_pretrained(model_id_or_path, torch_dtype=torch.float16)
pipe.to(device)
# Onestep Sampling
image = pipe(num_inference_steps=1).images[0]
image.save("cd_cat256_lpips_onestep_sample.png")
# Multistep sampling
# Timesteps can be explicitly specified; the particular timesteps below are from the original Github repo:
# https://github.com/openai/consistency_models/blob/main/scripts/launch.sh#L83
image = pipe(num_inference_steps=None, timesteps=[17, 0]).images[0]
image.save("cd_cat256_lpips_multistep_sample.png")
```
## Model Details
- **Model type:** Consistency model unconditional image generation model, distilled from a diffusion model
- **Dataset:** LSUN Cat 256x256
- **License:** MIT
- **Model Description:** This model performs unconditional image generation. Its main component is a U-Net, which parameterizes the consistency model. This model was distilled by the Consistency Model authors from an EDM diffusion model, also originally trained by the authors.
- **Resources for more information:**: [Paper](https://arxiv.org/abs/2303.01469), [GitHub Repository](https://github.com/openai/consistency_models), [Original Model Card](/openai/consistency_models/blob/main/model-card.md)
## Datasets
_Note: This section is taken from the ["Datasets" section of the original model card](https://github.com/openai/consistency_models/blob/main/model-card.md#datasets)_.
The models that we are making available have been trained on the [ILSVRC 2012 subset of ImageNet](http://www.image-net.org/challenges/LSVRC/2012/) or on individual categories from [LSUN](https://arxiv.org/abs/1506.03365). Here we outline the characteristics of these datasets that influence the behavior of the models:
**ILSVRC 2012 subset of ImageNet**: This dataset was curated in 2012 and has around a million pictures, each of which belongs to one of 1,000 categories. A significant number of the categories in this dataset are animals, plants, and other naturally occurring objects. Although many photographs include humans, these humans are typically not represented by the class label (for example, the category "Tench, tinca tinca" includes many photographs of individuals holding fish).
**LSUN**: This dataset was collected in 2015 by a combination of human labeling via Amazon Mechanical Turk and automated data labeling. Both classes that we consider have more than a million images. The dataset creators discovered that when assessed by trained experts, the label accuracy was approximately 90% throughout the entire LSUN dataset. The pictures are gathered from the internet, and those in the cat class often follow a "meme" format. Occasionally, people, including faces, appear in these photographs.
## Performance
_Note: This section is taken from the ["Performance" section of the original model card](https://github.com/openai/consistency_models/blob/main/model-card.md#performance)_.
These models are intended to generate samples consistent with their training distributions.
This has been measured in terms of FID, Inception Score, Precision, and Recall.
These metrics all rely on the representations of a [pre-trained Inception-V3 model](https://arxiv.org/abs/1512.00567),
which was trained on ImageNet, and so is likely to focus more on the ImageNet classes (such as animals) than on other visual features (such as human faces).
## Intended Use
_Note: This section is taken from the ["Intended Use" section of the original model card](https://github.com/openai/consistency_models/blob/main/model-card.md#intended-use)_.
These models are intended to be used for research purposes only. In particular, they can be used as a baseline for generative modeling research, or as a starting point for advancing such research. These models are not intended to be commercially deployed. Additionally, they are not intended to be used to create propaganda or offensive imagery.
## Limitations
_Note: This section is taken from the ["Limitations" section of the original model card](https://github.com/openai/consistency_models/blob/main/model-card.md#limitations)_.
These models sometimes produce highly unrealistic outputs, particularly when generating images containing human faces.
This may stem from ImageNet's emphasis on non-human objects.
In consistency distillation and training, minimizing LPIPS results in better sample quality, as evidenced by improved FID and Inception scores. However, it also carries the risk of overestimating model performance, because LPIPS uses a VGG network pre-trained on ImageNet, while FID and Inception scores also rely on convolutional neural networks (the Inception network in particular) pre-trained on the same ImageNet dataset. Although these two convolutional neural networks do not share the same architecture and we extract latents from them in substantially different ways, knowledge leakage is still plausible which can undermine the fidelity of FID and Inception scores.
Because ImageNet and LSUN contain images from the internet, they include photos of real people, and the model may have memorized some of the information contained in these photos. However, these images are already publicly available, and existing generative models trained on ImageNet have not demonstrated significant leakage of this information.
|
openai/diffusers-ct_cat256
|
openai
| 2023-07-05T15:21:45Z | 27 | 3 |
diffusers
|
[
"diffusers",
"generative model",
"unconditional image generation",
"consistency-model",
"arxiv:2303.01469",
"arxiv:1506.03365",
"arxiv:1512.00567",
"license:mit",
"diffusers:ConsistencyModelPipeline",
"region:us"
] | null | 2023-07-05T13:27:29Z |
---
license: mit
tags:
- generative model
- unconditional image generation
- consistency-model
---
**Disclaimer**: This model was added by the amazing community contributors [dg845](https://huggingface.co/dg845) and [ayushtues](https://huggingface.co/ayushtues)❤️
Consistency models are a new class of generative models introduced in ["Consistency Models"](https://arxiv.org/abs/2303.01469) ([paper](https://arxiv.org/pdf/2303.01469.pdf), [code](https://github.com/openai/consistency_models)) by Yang Song, Prafulla Dhariwal, Mark Chen, and Ilya Sutskever.
From the paper abstract:
> Diffusion models have significantly advanced the fields of image, audio, and video generation, but
they depend on an iterative sampling process that causes slow generation. To overcome this limitation,
we propose consistency models, a new family of models that generate high quality samples by directly
mapping noise to data. They support fast one-step generation by design, while still allowing multistep
sampling to trade compute for sample quality. They also support zero-shot data editing, such as image
inpainting, colorization, and super-resolution, without requiring explicit training on these tasks.
Consistency models can be trained either by distilling pre-trained diffusion models, or as standalone
generative models altogether. Through extensive experiments, we demonstrate that they outperform
existing distillation techniques for diffusion models in one- and few-step sampling, achieving the new
state-of-the-art FID of 3.55 on CIFAR-10 and 6.20 on ImageNet 64 x 64 for one-step generation. When
trained in isolation, consistency models become a new family of generative models that can outperform
existing one-step, non-adversarial generative models on standard benchmarks such as CIFAR-10, ImageNet
64 x 64 and LSUN 256 x 256.
Intuitively, a consistency model can be thought of as a model which, when evaluated on a noisy image and timestep, returns an output image sample similar to that which would be returned by running a sampling algorithm on a diffusion model.
Consistency models can be parameterized by any neural network whose input has the same dimensionality as its output, such as a U-Net.
More precisely, given a teacher diffusion model and fixed sampler, we can train ("distill") a consistency model such that when it is given a noisy image and its corresponding timestep, the output sample of the consistency model will be close to the output that would result by using the sampler on the diffusion model to produce a sample, starting at the same noisy image and timestep.
The authors call this procedure "consistency distillation (CD)".
Consistency models can also be trained from scratch to generate clean images from a noisy image and timestep, which the authors call "consistency training (CT)".
This model is a `diffusers`-compatible version of the [ct_cat256.pt](https://github.com/openai/consistency_models#pre-trained-models) checkpont from the [original code and model release](https://github.com/openai/consistency_models).
This model was trained on the LSUN Cat 256x256 dataset using the consistency training (CT) algorithm.
See the [original model card](https://github.com/openai/consistency_models/blob/main/model-card.md) for more information.
## Download
The original PyTorch model checkpoint can be downloaded from the [original code and model release](https://github.com/openai/consistency_models#pre-trained-models).
The `diffusers` pipeline for the `ct_cat256` model can be downloaded as follows:
```python
from diffusers import ConsistencyModelPipeline
pipe = ConsistencyModelPipeline.from_pretrained("openai/diffusers-ct_cat256")
```
## Usage
The original model checkpoint can be used with the [original consistency models codebase](https://github.com/openai/consistency_models).
Here is an example of using the `cd_cat256_l2` checkpoint with `diffusers`:
```python
import torch
from diffusers import ConsistencyModelPipeline
device = "cuda"
# Load the ct_cat256 checkpoint.
model_id_or_path = "openai/diffusers-ct_cat256"
pipe = ConsistencyModelPipeline.from_pretrained(model_id_or_path, torch_dtype=torch.float16)
pipe.to(device)
# Onestep Sampling
image = pipe(num_inference_steps=1).images[0]
image.save("ct_cat256_onestep_sample.png")
# Multistep sampling
# Timesteps can be explicitly specified; the particular timesteps below are from the original Github repo:
# https://github.com/openai/consistency_models/blob/main/scripts/launch.sh#L92
image = pipe(num_inference_steps=None, timesteps=[62, 0]).images[0]
image.save("ct_cat256_multistep_sample.png")
```
## Model Details
- **Model type:** Consistency model unconditional image generation model
- **Dataset:** LSUN Cat 256x256
- **License:** MIT
- **Model Description:** This model performs unconditional image generation. Its main component is a U-Net, which parameterizes the consistency model. This model was trained by the Consistency Model authors.
- **Resources for more information:**: [Paper](https://arxiv.org/abs/2303.01469), [GitHub Repository](https://github.com/openai/consistency_models), [Original Model Card](/openai/consistency_models/blob/main/model-card.md)
## Datasets
_Note: This section is taken from the ["Datasets" section of the original model card](https://github.com/openai/consistency_models/blob/main/model-card.md#datasets)_.
The models that we are making available have been trained on the [ILSVRC 2012 subset of ImageNet](http://www.image-net.org/challenges/LSVRC/2012/) or on individual categories from [LSUN](https://arxiv.org/abs/1506.03365). Here we outline the characteristics of these datasets that influence the behavior of the models:
**ILSVRC 2012 subset of ImageNet**: This dataset was curated in 2012 and has around a million pictures, each of which belongs to one of 1,000 categories. A significant number of the categories in this dataset are animals, plants, and other naturally occurring objects. Although many photographs include humans, these humans are typically not represented by the class label (for example, the category "Tench, tinca tinca" includes many photographs of individuals holding fish).
**LSUN**: This dataset was collected in 2015 by a combination of human labeling via Amazon Mechanical Turk and automated data labeling. Both classes that we consider have more than a million images. The dataset creators discovered that when assessed by trained experts, the label accuracy was approximately 90% throughout the entire LSUN dataset. The pictures are gathered from the internet, and those in the cat class often follow a "meme" format. Occasionally, people, including faces, appear in these photographs.
## Performance
_Note: This section is taken from the ["Performance" section of the original model card](https://github.com/openai/consistency_models/blob/main/model-card.md#performance)_.
These models are intended to generate samples consistent with their training distributions.
This has been measured in terms of FID, Inception Score, Precision, and Recall.
These metrics all rely on the representations of a [pre-trained Inception-V3 model](https://arxiv.org/abs/1512.00567),
which was trained on ImageNet, and so is likely to focus more on the ImageNet classes (such as animals) than on other visual features (such as human faces).
## Intended Use
_Note: This section is taken from the ["Intended Use" section of the original model card](https://github.com/openai/consistency_models/blob/main/model-card.md#intended-use)_.
These models are intended to be used for research purposes only. In particular, they can be used as a baseline for generative modeling research, or as a starting point for advancing such research. These models are not intended to be commercially deployed. Additionally, they are not intended to be used to create propaganda or offensive imagery.
## Limitations
_Note: This section is taken from the ["Limitations" section of the original model card](https://github.com/openai/consistency_models/blob/main/model-card.md#limitations)_.
These models sometimes produce highly unrealistic outputs, particularly when generating images containing human faces.
This may stem from ImageNet's emphasis on non-human objects.
In consistency distillation and training, minimizing LPIPS results in better sample quality, as evidenced by improved FID and Inception scores. However, it also carries the risk of overestimating model performance, because LPIPS uses a VGG network pre-trained on ImageNet, while FID and Inception scores also rely on convolutional neural networks (the Inception network in particular) pre-trained on the same ImageNet dataset. Although these two convolutional neural networks do not share the same architecture and we extract latents from them in substantially different ways, knowledge leakage is still plausible which can undermine the fidelity of FID and Inception scores.
Because ImageNet and LSUN contain images from the internet, they include photos of real people, and the model may have memorized some of the information contained in these photos. However, these images are already publicly available, and existing generative models trained on ImageNet have not demonstrated significant leakage of this information.
|
jeff-RQ/new-test-model
|
jeff-RQ
| 2023-07-05T15:01:24Z | 9 | 0 |
transformers
|
[
"transformers",
"pytorch",
"blip-2",
"visual-question-answering",
"vision",
"image-to-text",
"image-captioning",
"en",
"arxiv:2301.12597",
"license:mit",
"endpoints_compatible",
"region:us"
] |
image-to-text
| 2023-07-04T14:52:07Z |
---
language: en
license: mit
tags:
- vision
- image-to-text
- image-captioning
- visual-question-answering
pipeline_tag: image-to-text
duplicated_from: Salesforce/blip2-opt-2.7b
---
# BLIP-2, OPT-2.7b, pre-trained only
BLIP-2 model, leveraging [OPT-2.7b](https://huggingface.co/facebook/opt-2.7b) (a large language model with 2.7 billion parameters).
It was introduced in the paper [BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models](https://arxiv.org/abs/2301.12597) by Li et al. and first released in [this repository](https://github.com/salesforce/LAVIS/tree/main/projects/blip2).
Disclaimer: The team releasing BLIP-2 did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
BLIP-2 consists of 3 models: a CLIP-like image encoder, a Querying Transformer (Q-Former) and a large language model.
The authors initialize the weights of the image encoder and large language model from pre-trained checkpoints and keep them frozen
while training the Querying Transformer, which is a BERT-like Transformer encoder that maps a set of "query tokens" to query embeddings,
which bridge the gap between the embedding space of the image encoder and the large language model.
The goal for the model is simply to predict the next text token, giving the query embeddings and the previous text.
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/model_doc/blip2_architecture.jpg"
alt="drawing" width="600"/>
This allows the model to be used for tasks like:
- image captioning
- visual question answering (VQA)
- chat-like conversations by feeding the image and the previous conversation as prompt to the model
## Direct Use and Downstream Use
You can use the raw model for conditional text generation given an image and optional text. See the [model hub](https://huggingface.co/models?search=Salesforce/blip) to look for
fine-tuned versions on a task that interests you.
## Bias, Risks, Limitations, and Ethical Considerations
BLIP2-OPT uses off-the-shelf OPT as the language model. It inherits the same risks and limitations as mentioned in Meta's model card.
> Like other large language models for which the diversity (or lack thereof) of training
> data induces downstream impact on the quality of our model, OPT-175B has limitations in terms
> of bias and safety. OPT-175B can also have quality issues in terms of generation diversity and
> hallucination. In general, OPT-175B is not immune from the plethora of issues that plague modern
> large language models.
>
BLIP2 is fine-tuned on image-text datasets (e.g. [LAION](https://laion.ai/blog/laion-400-open-dataset/) ) collected from the internet. As a result the model itself is potentially vulnerable to generating equivalently inappropriate content or replicating inherent biases in the underlying data.
BLIP2 has not been tested in real world applications. It should not be directly deployed in any applications. Researchers should first carefully assess the safety and fairness of the model in relation to the specific context they’re being deployed within.
### How to use
For code examples, we refer to the [documentation](https://huggingface.co/docs/transformers/main/en/model_doc/blip-2#transformers.Blip2ForConditionalGeneration.forward.example).
#### Running the model on CPU
<details>
<summary> Click to expand </summary>
```python
import requests
from PIL import Image
from transformers import Blip2Processor, Blip2ForConditionalGeneration
processor = Blip2Processor.from_pretrained("Salesforce/blip2-opt-2.7b")
model = Blip2ForConditionalGeneration.from_pretrained("Salesforce/blip2-opt-2.7b")
img_url = 'https://storage.googleapis.com/sfr-vision-language-research/BLIP/demo.jpg'
raw_image = Image.open(requests.get(img_url, stream=True).raw).convert('RGB')
question = "how many dogs are in the picture?"
inputs = processor(raw_image, question, return_tensors="pt")
out = model.generate(**inputs)
print(processor.decode(out[0], skip_special_tokens=True))
```
</details>
#### Running the model on GPU
##### In full precision
<details>
<summary> Click to expand </summary>
```python
# pip install accelerate
import requests
from PIL import Image
from transformers import Blip2Processor, Blip2ForConditionalGeneration
processor = Blip2Processor.from_pretrained("Salesforce/blip2-opt-2.7b")
model = Blip2ForConditionalGeneration.from_pretrained("Salesforce/blip2-opt-2.7b", device_map="auto")
img_url = 'https://storage.googleapis.com/sfr-vision-language-research/BLIP/demo.jpg'
raw_image = Image.open(requests.get(img_url, stream=True).raw).convert('RGB')
question = "how many dogs are in the picture?"
inputs = processor(raw_image, question, return_tensors="pt").to("cuda")
out = model.generate(**inputs)
print(processor.decode(out[0], skip_special_tokens=True))
```
</details>
##### In half precision (`float16`)
<details>
<summary> Click to expand </summary>
```python
# pip install accelerate
import torch
import requests
from PIL import Image
from transformers import Blip2Processor, Blip2ForConditionalGeneration
processor = Blip2Processor.from_pretrained("Salesforce/blip2-opt-2.7b")
model = Blip2ForConditionalGeneration.from_pretrained("Salesforce/blip2-opt-2.7b", torch_dtype=torch.float16, device_map="auto")
img_url = 'https://storage.googleapis.com/sfr-vision-language-research/BLIP/demo.jpg'
raw_image = Image.open(requests.get(img_url, stream=True).raw).convert('RGB')
question = "how many dogs are in the picture?"
inputs = processor(raw_image, question, return_tensors="pt").to("cuda", torch.float16)
out = model.generate(**inputs)
print(processor.decode(out[0], skip_special_tokens=True))
```
</details>
##### In 8-bit precision (`int8`)
<details>
<summary> Click to expand </summary>
```python
# pip install accelerate bitsandbytes
import torch
import requests
from PIL import Image
from transformers import Blip2Processor, Blip2ForConditionalGeneration
processor = Blip2Processor.from_pretrained("Salesforce/blip2-opt-2.7b")
model = Blip2ForConditionalGeneration.from_pretrained("Salesforce/blip2-opt-2.7b", load_in_8bit=True, device_map="auto")
img_url = 'https://storage.googleapis.com/sfr-vision-language-research/BLIP/demo.jpg'
raw_image = Image.open(requests.get(img_url, stream=True).raw).convert('RGB')
question = "how many dogs are in the picture?"
inputs = processor(raw_image, question, return_tensors="pt").to("cuda", torch.float16)
out = model.generate(**inputs)
print(processor.decode(out[0], skip_special_tokens=True))
```
</details>
|
namedotpg/Pyramids
|
namedotpg
| 2023-07-05T15:00:06Z | 4 | 0 |
ml-agents
|
[
"ml-agents",
"tensorboard",
"onnx",
"Pyramids",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-Pyramids",
"region:us"
] |
reinforcement-learning
| 2023-07-05T14:58:46Z |
---
library_name: ml-agents
tags:
- Pyramids
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-Pyramids
---
# **ppo** Agent playing **Pyramids**
This is a trained model of a **ppo** agent playing **Pyramids**
using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://unity-technologies.github.io/ml-agents/ML-Agents-Toolkit-Documentation/
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
- A *short tutorial* where you teach Huggy the Dog 🐶 to fetch the stick and then play with him directly in your
browser: https://huggingface.co/learn/deep-rl-course/unitbonus1/introduction
- A *longer tutorial* to understand how works ML-Agents:
https://huggingface.co/learn/deep-rl-course/unit5/introduction
### Resume the training
```bash
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser**
1. If the environment is part of ML-Agents official environments, go to https://huggingface.co/unity
2. Step 1: Find your model_id: namedotpg/Pyramids
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
robsong3/distilbert-base-uncased-finetuned-cola
|
robsong3
| 2023-07-05T14:55:09Z | 61 | 0 |
transformers
|
[
"transformers",
"tf",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_keras_callback",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-07-05T13:16:55Z |
---
license: apache-2.0
tags:
- generated_from_keras_callback
model-index:
- name: robsong3/distilbert-base-uncased-finetuned-cola
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# robsong3/distilbert-base-uncased-finetuned-cola
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.1931
- Validation Loss: 0.5174
- Train Matthews Correlation: 0.5396
- Epoch: 2
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'Adam', 'weight_decay': None, 'clipnorm': None, 'global_clipnorm': None, 'clipvalue': None, 'use_ema': False, 'ema_momentum': 0.99, 'ema_overwrite_frequency': None, 'jit_compile': False, 'is_legacy_optimizer': False, 'learning_rate': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 2e-05, 'decay_steps': 1602, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}}, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False}
- training_precision: float32
### Training results
| Train Loss | Validation Loss | Train Matthews Correlation | Epoch |
|:----------:|:---------------:|:--------------------------:|:-----:|
| 0.5157 | 0.4443 | 0.5062 | 0 |
| 0.3214 | 0.4521 | 0.5370 | 1 |
| 0.1931 | 0.5174 | 0.5396 | 2 |
### Framework versions
- Transformers 4.30.2
- TensorFlow 2.12.0
- Datasets 2.13.1
- Tokenizers 0.13.3
|
johko/diffusion-course-butterflies-32
|
johko
| 2023-07-05T14:43:20Z | 36 | 0 |
diffusers
|
[
"diffusers",
"pytorch",
"unconditional-image-generation",
"diffusion-models-class",
"license:mit",
"diffusers:DDPMPipeline",
"region:us"
] |
unconditional-image-generation
| 2023-07-05T14:43:04Z |
---
license: mit
tags:
- pytorch
- diffusers
- unconditional-image-generation
- diffusion-models-class
---
# Model Card for Unit 1 of the [Diffusion Models Class 🧨](https://github.com/huggingface/diffusion-models-class)
This model is a diffusion model for unconditional image generation of cute 🦋.
## Usage
```python
from diffusers import DDPMPipeline
pipeline = DDPMPipeline.from_pretrained('johko/diffusion-course-butterflies-32')
image = pipeline().images[0]
image
```
|
sjdata/ast-finetuned-audioset-10-10-0.4593-finetuned-gtzan
|
sjdata
| 2023-07-05T14:31:24Z | 163 | 0 |
transformers
|
[
"transformers",
"pytorch",
"audio-spectrogram-transformer",
"audio-classification",
"generated_from_trainer",
"dataset:marsyas/gtzan",
"license:bsd-3-clause",
"endpoints_compatible",
"region:us"
] |
audio-classification
| 2023-07-05T14:00:35Z |
---
license: bsd-3-clause
tags:
- generated_from_trainer
datasets:
- marsyas/gtzan
metrics:
- accuracy
model-index:
- name: ast-finetuned-audioset-10-10-0.4593-finetuned-gtzan
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# ast-finetuned-audioset-10-10-0.4593-finetuned-gtzan
This model is a fine-tuned version of [MIT/ast-finetuned-audioset-10-10-0.4593](https://huggingface.co/MIT/ast-finetuned-audioset-10-10-0.4593) on the GTZAN dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6230
- Accuracy: 0.89
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 2.1198 | 1.0 | 450 | 1.8429 | 0.47 |
| 0.0005 | 2.0 | 900 | 1.6282 | 0.71 |
| 0.3129 | 3.0 | 1350 | 1.0553 | 0.73 |
| 0.0225 | 4.0 | 1800 | 0.9422 | 0.82 |
| 0.0025 | 5.0 | 2250 | 0.6008 | 0.85 |
| 0.0 | 6.0 | 2700 | 0.7194 | 0.86 |
| 0.0 | 7.0 | 3150 | 0.6268 | 0.89 |
| 0.0 | 8.0 | 3600 | 0.6372 | 0.89 |
| 0.0 | 9.0 | 4050 | 0.6167 | 0.89 |
| 0.0 | 10.0 | 4500 | 0.6230 | 0.89 |
### Framework versions
- Transformers 4.30.2
- Pytorch 2.0.1+cu118
- Datasets 2.13.1
- Tokenizers 0.13.3
|
kimmchii/small100-th
|
kimmchii
| 2023-07-05T14:31:22Z | 8 | 1 |
transformers
|
[
"transformers",
"pytorch",
"m2m_100",
"text2text-generation",
"arxiv:2210.11621",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2023-07-02T07:46:00Z |
---
license: mit
---
# SMALL-100 Model
SMaLL-100 is a compact and fast massively multilingual machine translation model covering more than 10K language pairs, that achieves competitive results with M2M-100 while being much smaller and faster. It is introduced in [this paper](https://arxiv.org/abs/2210.11621)(accepted to EMNLP2022), and initially released in [this repository](https://github.com/alirezamshi/small100).
The model architecture and config are the same as [M2M-100](https://huggingface.co/facebook/m2m100_418M/tree/main) implementation, but the tokenizer is modified to adjust language codes. So, you should load the tokenizer locally from [tokenization_small100.py](https://huggingface.co/alirezamsh/small100/blob/main/tokenization_small100.py) file for the moment.
**Demo**: https://huggingface.co/spaces/alirezamsh/small100
**Note**: SMALL100Tokenizer requires sentencepiece, so make sure to install it by:
```pip install sentencepiece```
- **Supervised Training**
SMaLL-100 is a seq-to-seq model for the translation task. The input to the model is ```source:[tgt_lang_code] + src_tokens + [EOS]``` and ```target: tgt_tokens + [EOS]```.
# `small-100-th` is the fine-tuned version of SMALL-100 for Thai
The dataset can be acquired from [scb-mt-en-th-2020](https://airesearch.in.th/releases/machine-translation-datasets/) and [OPUS](https://opus.nlpl.eu/).
It can also be directly download from [Vistec](https://github.com/vistec-AI/thai2nmt/releases/tag/scb-mt-en-th-2020%2Bmt-opus_v1.0).
## small-100-th inference
```
from transformers import M2M100ForConditionalGeneration
from tokenization_small100 import SMALL100Tokenizer
from huggingface_hub import notebook_login
notebook_login()
checkpoint = "kimmchii/small-100-th"
model = M2M100ForConditionalGeneration.from_pretrained(checkpoint)
tokenizer = SMALL100Tokenizer.from_pretrained(checkpoint)
thai_text = "สวัสดี"
# translate Thai to English
tokenizer.tgt_lang = "en"
encoded_th = tokenizer(thai_text, return_tensors="pt")
generated_tokens = model.generate(**encoded_th)
tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
# => "Hello"
```
|
jliu596/taxi-v2
|
jliu596
| 2023-07-05T14:30:30Z | 0 | 0 | null |
[
"Taxi-v3",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-07-05T14:29:19Z |
---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: taxi-v2
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
metrics:
- type: mean_reward
value: 7.56 +/- 2.71
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="jliu596/taxi-v2", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
blurrdelayedd/openai-reverse-proxy
|
blurrdelayedd
| 2023-07-05T14:29:37Z | 0 | 0 | null |
[
"region:us"
] | null | 2023-07-05T14:27:03Z |
FROM node:18
WORKDIR /app
RUN npm install express express-http-proxy
COPY . .
EXPOSE 7860
CMD [ "node", "server.js" ]
|
jliu596/taxi
|
jliu596
| 2023-07-05T14:25:27Z | 0 | 0 | null |
[
"Taxi-v3",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-07-05T14:25:25Z |
---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: taxi
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
metrics:
- type: mean_reward
value: 7.54 +/- 2.71
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="jliu596/taxi", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
ccattomio/dqn-SpaceInvadersNoFrameskip-v4
|
ccattomio
| 2023-07-05T14:08:58Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"SpaceInvadersNoFrameskip-v4",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-07-05T14:08:22Z |
---
library_name: stable-baselines3
tags:
- SpaceInvadersNoFrameskip-v4
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: DQN
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: SpaceInvadersNoFrameskip-v4
type: SpaceInvadersNoFrameskip-v4
metrics:
- type: mean_reward
value: 503.50 +/- 189.72
name: mean_reward
verified: false
---
# **DQN** Agent playing **SpaceInvadersNoFrameskip-v4**
This is a trained model of a **DQN** agent playing **SpaceInvadersNoFrameskip-v4**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3)
and the [RL Zoo](https://github.com/DLR-RM/rl-baselines3-zoo).
The RL Zoo is a training framework for Stable Baselines3
reinforcement learning agents,
with hyperparameter optimization and pre-trained agents included.
## Usage (with SB3 RL Zoo)
RL Zoo: https://github.com/DLR-RM/rl-baselines3-zoo<br/>
SB3: https://github.com/DLR-RM/stable-baselines3<br/>
SB3 Contrib: https://github.com/Stable-Baselines-Team/stable-baselines3-contrib
Install the RL Zoo (with SB3 and SB3-Contrib):
```bash
pip install rl_zoo3
```
```
# Download model and save it into the logs/ folder
python -m rl_zoo3.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga ccattomio -f logs/
python -m rl_zoo3.enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
If you installed the RL Zoo3 via pip (`pip install rl_zoo3`), from anywhere you can do:
```
python -m rl_zoo3.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga ccattomio -f logs/
python -m rl_zoo3.enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
## Training (with the RL Zoo)
```
python -m rl_zoo3.train --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
# Upload the model and generate video (when possible)
python -m rl_zoo3.push_to_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/ -orga ccattomio
```
## Hyperparameters
```python
OrderedDict([('batch_size', 64),
('buffer_size', 100000),
('env_wrapper',
['stable_baselines3.common.atari_wrappers.AtariWrapper']),
('exploration_final_eps', 0.05),
('exploration_fraction', 0.55),
('frame_stack', 4),
('gradient_steps', 1),
('learning_rate', 0.0003),
('learning_starts', 100000),
('n_timesteps', 1000000.0),
('optimize_memory_usage', False),
('policy', 'CnnPolicy'),
('target_update_interval', 1000),
('train_freq', 4),
('normalize', False)])
```
# Environment Arguments
```python
{'render_mode': 'rgb_array'}
```
|
julep-ai/samantha-33b
|
julep-ai
| 2023-07-05T13:57:48Z | 12 | 0 |
transformers
|
[
"transformers",
"pytorch",
"llama",
"text-generation",
"en",
"dataset:julep-ai/samantha_finetune_dataset_03",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-06-22T09:09:31Z |
---
library_name: transformers
datasets:
- julep-ai/samantha_finetune_dataset_03
language:
- en
---
# Samantha
## Technical notes
This model is trained on a specialized dataset and uses special sentinel tokens to demarcate conversations.
**Important Note: These sentinels are similar to gpt2-style special tokens but they are <u>NOT</u> added as special tokens in the tokenizer.**
### Usage
For usage, you can refer to the [`chat.py`](https://huggingface.co/julep-ai/samantha-33b/blob/main/chat.py) file in this repo for an example.
### Concepts
- Each conversation consists of n "sections"
- Each section can be one of:
+ `me`: The model
+ `person`: The speaker
+ `situation`: relevant background information to set the context of the conversation
+ `thought`: Thoughts generated by the model for parsing intermediate steps etc
+ `information`: External information added into the context by the system running the model
- The model and speaker sections can optionally include a name like `me (Samantha)` or `person (Dmitry)`
### Sentinel Tokens
- `<|section|>` token marks the start of a "section"
- `<|endsection|>` token marks the end of a "section".
## Example
```
<|section|>situation
I am talking to Diwank. I want to ask him about his food preferences.<|endsection|>
<|section|>person (Diwank)
Hey Samantha! What do you want to talk about?<|endsection|>
<|section|>me (Samantha)
```
|
tiwanyan/my_model
|
tiwanyan
| 2023-07-05T13:28:08Z | 61 | 0 |
transformers
|
[
"transformers",
"tf",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_keras_callback",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-07-05T12:26:14Z |
---
license: apache-2.0
tags:
- generated_from_keras_callback
model-index:
- name: tiwanyan/my_model
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# tiwanyan/my_model
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.0248
- Validation Loss: 0.0160
- Train Accuracy: 1.0
- Epoch: 2
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'Adam', 'weight_decay': None, 'clipnorm': None, 'global_clipnorm': None, 'clipvalue': None, 'use_ema': False, 'ema_momentum': 0.99, 'ema_overwrite_frequency': None, 'jit_compile': False, 'is_legacy_optimizer': False, 'learning_rate': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 2e-05, 'decay_steps': 978, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}}, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False}
- training_precision: float32
### Training results
| Train Loss | Validation Loss | Train Accuracy | Epoch |
|:----------:|:---------------:|:--------------:|:-----:|
| 0.6964 | 0.0583 | 1.0 | 0 |
| 0.0455 | 0.0211 | 1.0 | 1 |
| 0.0248 | 0.0160 | 1.0 | 2 |
### Framework versions
- Transformers 4.30.2
- TensorFlow 2.12.0
- Datasets 2.13.1
- Tokenizers 0.13.3
|
stanvla/ppo-LunarLander-v2
|
stanvla
| 2023-07-05T13:20:12Z | 0 | 1 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-07-05T13:19:40Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: ppo-with-hug-defaults
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 149.50 +/- 45.63
name: mean_reward
verified: false
---
# **ppo-with-hug-defaults** Agent playing **LunarLander-v2**
This is a trained model of a **ppo-with-hug-defaults** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
EulerianKnight/distilbert-base-cased-finetuned-CONLL2003
|
EulerianKnight
| 2023-07-05T13:12:31Z | 113 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"safetensors",
"distilbert",
"token-classification",
"generated_from_trainer",
"dataset:conll2003",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2023-07-04T21:40:26Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- conll2003
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: distilbert-base-cased-finetuned-CONLL2003
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: conll2003
type: conll2003
config: conll2003
split: validation
args: conll2003
metrics:
- name: Precision
type: precision
value: 0.9276294098252555
- name: Recall
type: recall
value: 0.9469875462807136
- name: F1
type: f1
value: 0.9372085276482345
- name: Accuracy
type: accuracy
value: 0.9848119149938188
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-cased-finetuned-CONLL2003
This model is a fine-tuned version of [distilbert-base-cased](https://huggingface.co/distilbert-base-cased) on the conll2003 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0983
- Precision: 0.9276
- Recall: 0.9470
- F1: 0.9372
- Accuracy: 0.9848
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| 0.0302 | 1.0 | 1756 | 0.0832 | 0.9055 | 0.9318 | 0.9185 | 0.9812 |
| 0.024 | 2.0 | 3512 | 0.0867 | 0.9237 | 0.9387 | 0.9311 | 0.9833 |
| 0.0123 | 3.0 | 5268 | 0.0909 | 0.9224 | 0.9438 | 0.9330 | 0.9845 |
| 0.0059 | 4.0 | 7024 | 0.0962 | 0.9218 | 0.9448 | 0.9332 | 0.9844 |
| 0.0026 | 5.0 | 8780 | 0.0983 | 0.9276 | 0.9470 | 0.9372 | 0.9848 |
### Framework versions
- Transformers 4.30.1
- Pytorch 2.0.0
- Datasets 2.1.0
- Tokenizers 0.13.3
|
mohammedbriman/t5-small-summ-2080
|
mohammedbriman
| 2023-07-05T13:09:49Z | 61 | 0 |
transformers
|
[
"transformers",
"tf",
"tensorboard",
"t5",
"text2text-generation",
"generated_from_keras_callback",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2023-07-05T09:18:05Z |
---
license: apache-2.0
tags:
- generated_from_keras_callback
model-index:
- name: mohammedbriman/t5-small-summ-2080
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# mohammedbriman/t5-small-summ-2080
This model is a fine-tuned version of [t5-small](https://huggingface.co/t5-small) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 1.1191
- Validation Loss: 1.0763
- Train Rouge1: 24.3067
- Train Rouge2: 11.6715
- Train Rougel: 20.1235
- Train Rougelsum: 20.1828
- Train Gen Len: 18.9996
- Epoch: 0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'AdamWeightDecay', 'learning_rate': 2e-05, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-07, 'amsgrad': False, 'weight_decay_rate': 0.01}
- training_precision: float32
### Training results
| Train Loss | Validation Loss | Train Rouge1 | Train Rouge2 | Train Rougel | Train Rougelsum | Train Gen Len | Epoch |
|:----------:|:---------------:|:------------:|:------------:|:------------:|:---------------:|:-------------:|:-----:|
| 1.1191 | 1.0763 | 24.3067 | 11.6715 | 20.1235 | 20.1828 | 18.9996 | 0 |
### Framework versions
- Transformers 4.30.2
- TensorFlow 2.12.0
- Datasets 2.13.1
- Tokenizers 0.13.3
|
Chaylsi/ppo-LunarLander-v2-TEST
|
Chaylsi
| 2023-07-05T13:02:02Z | 1 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-07-02T17:58:47Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 225.97 +/- 81.67
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
NasimB/gpt2-dp-finetune-cl-mod-datasets-rarity1
|
NasimB
| 2023-07-05T13:01:39Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"generated_from_trainer",
"dataset:generator",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-07-05T03:28:32Z |
---
tags:
- generated_from_trainer
datasets:
- generator
model-index:
- name: gpt2-dp-finetune-cl-mod-datasets-rarity1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# gpt2-dp-finetune-cl-mod-datasets-rarity1
This model was trained from scratch on the generator dataset.
It achieves the following results on the evaluation set:
- Loss: 2.5865
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 1000
- num_epochs: 5
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 3.7804 | 0.28 | 500 | 4.4982 |
| 3.9124 | 0.55 | 1000 | 4.5349 |
| 4.0179 | 0.83 | 1500 | 4.4602 |
| 3.9221 | 1.1 | 2000 | 4.4585 |
| 3.7998 | 1.38 | 2500 | 4.4362 |
| 3.8298 | 1.65 | 3000 | 4.3838 |
| 3.8259 | 1.93 | 3500 | 4.3551 |
| 3.5608 | 2.2 | 4000 | 4.4125 |
| 3.5215 | 2.48 | 4500 | 4.3867 |
| 3.5238 | 2.75 | 5000 | 4.3540 |
| 3.4761 | 3.03 | 5500 | 4.3684 |
| 3.1332 | 3.3 | 6000 | 4.4048 |
| 3.146 | 3.58 | 6500 | 4.3926 |
| 3.1394 | 3.85 | 7000 | 4.3839 |
| 2.9917 | 4.13 | 7500 | 4.4150 |
| 2.841 | 4.4 | 8000 | 4.4240 |
| 2.8327 | 4.68 | 8500 | 4.4259 |
| 2.8284 | 4.95 | 9000 | 4.4261 |
### Framework versions
- Transformers 4.26.1
- Pytorch 1.11.0+cu113
- Datasets 2.13.0
- Tokenizers 0.13.3
|
huangyuyang/chatglm2-6b-int8.flm
|
huangyuyang
| 2023-07-05T12:43:02Z | 0 | 3 | null |
[
"license:apache-2.0",
"region:us"
] | null | 2023-07-05T12:12:57Z |
---
license: apache-2.0
---
fastllm model for chatglm2-6b-int8
Github address: https://github.com/ztxz16/fastllm
|
Babaili/videomae-base-finetuned-cropped-shooting-and-layup-dataset
|
Babaili
| 2023-07-05T12:34:55Z | 60 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"videomae",
"video-classification",
"generated_from_trainer",
"license:cc-by-nc-4.0",
"endpoints_compatible",
"region:us"
] |
video-classification
| 2023-07-05T11:34:55Z |
---
license: cc-by-nc-4.0
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: videomae-base-finetuned-cropped-shooting-and-layup-dataset
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# videomae-base-finetuned-cropped-shooting-and-layup-dataset
This model is a fine-tuned version of [MCG-NJU/videomae-base](https://huggingface.co/MCG-NJU/videomae-base) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5361
- Accuracy: 0.6667
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- training_steps: 50
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| No log | 0.1 | 5 | 0.6288 | 0.75 |
| 0.4089 | 1.1 | 10 | 0.7199 | 0.75 |
| 0.4089 | 2.1 | 15 | 0.7932 | 0.75 |
| 0.3801 | 3.1 | 20 | 0.7371 | 0.75 |
| 0.3801 | 4.1 | 25 | 0.8587 | 0.75 |
| 0.3258 | 5.1 | 30 | 0.7767 | 0.75 |
| 0.3258 | 6.1 | 35 | 0.7317 | 0.75 |
| 0.2265 | 7.1 | 40 | 0.7253 | 0.75 |
| 0.2265 | 8.1 | 45 | 0.7179 | 0.75 |
| 0.2107 | 9.1 | 50 | 0.7268 | 0.75 |
### Framework versions
- Transformers 4.30.2
- Pytorch 2.0.1+cu118
- Datasets 2.13.1
- Tokenizers 0.13.3
|
lesyar/news_genre_classifier
|
lesyar
| 2023-07-05T12:31:54Z | 108 | 1 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"text-classification",
"en",
"de",
"fr",
"ru",
"pl",
"doi:10.57967/hf/0874",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-06-09T05:02:15Z |
---
language:
- en
- de
- fr
- ru
- pl
metrics:
- f1
---
|
Ashraf-kasem/dqn-SpaceInvadersNoFrameskip-v4
|
Ashraf-kasem
| 2023-07-05T12:30:26Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"SpaceInvadersNoFrameskip-v4",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-07-05T06:55:40Z |
---
library_name: stable-baselines3
tags:
- SpaceInvadersNoFrameskip-v4
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: DQN
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: SpaceInvadersNoFrameskip-v4
type: SpaceInvadersNoFrameskip-v4
metrics:
- type: mean_reward
value: 211.50 +/- 103.13
name: mean_reward
verified: false
---
# **DQN** Agent playing **SpaceInvadersNoFrameskip-v4**
This is a trained model of a **DQN** agent playing **SpaceInvadersNoFrameskip-v4**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3)
and the [RL Zoo](https://github.com/DLR-RM/rl-baselines3-zoo).
The RL Zoo is a training framework for Stable Baselines3
reinforcement learning agents,
with hyperparameter optimization and pre-trained agents included.
## Usage (with SB3 RL Zoo)
RL Zoo: https://github.com/DLR-RM/rl-baselines3-zoo<br/>
SB3: https://github.com/DLR-RM/stable-baselines3<br/>
SB3 Contrib: https://github.com/Stable-Baselines-Team/stable-baselines3-contrib
Install the RL Zoo (with SB3 and SB3-Contrib):
```bash
pip install rl_zoo3
```
```
# Download model and save it into the logs/ folder
python -m rl_zoo3.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga Ashraf-kasem -f logs/
python -m rl_zoo3.enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
If you installed the RL Zoo3 via pip (`pip install rl_zoo3`), from anywhere you can do:
```
python -m rl_zoo3.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga Ashraf-kasem -f logs/
python -m rl_zoo3.enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
## Training (with the RL Zoo)
```
python -m rl_zoo3.train --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
# Upload the model and generate video (when possible)
python -m rl_zoo3.push_to_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/ -orga Ashraf-kasem
```
## Hyperparameters
```python
OrderedDict([('batch_size', 32),
('buffer_size', 100000),
('env_wrapper',
['stable_baselines3.common.atari_wrappers.AtariWrapper']),
('exploration_final_eps', 0.01),
('exploration_fraction', 0.1),
('frame_stack', 4),
('gradient_steps', 1),
('learning_rate', 1e-05),
('learning_starts', 100000),
('n_timesteps', 1000000.0),
('optimize_memory_usage', False),
('policy', 'CnnPolicy'),
('target_update_interval', 1000),
('train_freq', 4),
('normalize', False)])
```
# Environment Arguments
```python
{'render_mode': 'rgb_array'}
```
|
riccardopresti99/topic_modelling_football
|
riccardopresti99
| 2023-07-05T12:23:46Z | 4 | 1 |
bertopic
|
[
"bertopic",
"text-classification",
"region:us"
] |
text-classification
| 2023-07-05T12:23:44Z |
---
tags:
- bertopic
library_name: bertopic
pipeline_tag: text-classification
---
# topic_modelling_football
This is a [BERTopic](https://github.com/MaartenGr/BERTopic) model.
BERTopic is a flexible and modular topic modeling framework that allows for the generation of easily interpretable topics from large datasets.
## Usage
To use this model, please install BERTopic:
```
pip install -U bertopic
```
You can use the model as follows:
```python
from bertopic import BERTopic
topic_model = BERTopic.load("riccardopresti99/topic_modelling_football")
topic_model.get_topic_info()
```
## Topic overview
* Number of topics: 14
* Number of training documents: 350
<details>
<summary>Click here for an overview of all topics.</summary>
| Topic ID | Topic Keywords | Topic Frequency | Label |
|----------|----------------|-----------------|-------|
| -1 | tournament - competition - leaving - final - compete | 16 | -1_tournament_competition_leaving_final |
| 0 | video - games - football - players - experience | 10 | 0_video_games_football_players |
| 1 | supporters - atmosphere - stadiums - football - create | 48 | 1_supporters_atmosphere_stadiums_football |
| 2 | physiotherapists - injury - injuries - players - prevention | 32 | 2_physiotherapists_injury_injuries_players |
| 3 | united - film - football - war - story | 29 | 3_united_film_football_war |
| 4 | ronaldo - ability - scoring - aspiring - one | 26 | 4_ronaldo_ability_scoring_aspiring |
| 5 | scandals - illegal - officials - within - concerns | 26 | 5_scandals_illegal_officials_within |
| 6 | healthy - footballers - energy - supports - performance | 25 | 6_healthy_footballers_energy_supports |
| 7 | strikers - striker - scoring - teammates - goals | 25 | 7_strikers_striker_scoring_teammates |
| 8 | investors - stock - stocks - market - club | 25 | 8_investors_stock_stocks_market |
| 9 | women - football - girls - equal - sport | 25 | 9_women_football_girls_equal |
| 10 | serie - milan - league - inter - italian | 23 | 10_serie_milan_league_inter |
| 11 | champions - league - european - club - uefa | 22 | 11_champions_league_european_club |
| 12 | cup - world - fifa - held - trophy | 18 | 12_cup_world_fifa_held |
</details>
## Training hyperparameters
* calculate_probabilities: False
* language: None
* low_memory: False
* min_topic_size: 10
* n_gram_range: (1, 1)
* nr_topics: None
* seed_topic_list: None
* top_n_words: 10
* verbose: True
## Framework versions
* Numpy: 1.23.5
* HDBSCAN: 0.8.29
* UMAP: 0.5.3
* Pandas: 1.5.3
* Scikit-Learn: 1.2.2
* Sentence-transformers: 2.2.2
* Transformers: 4.26.1
* Numba: 0.56.4
* Plotly: 5.13.1
* Python: 3.10.10
|
zlsl/en_l_warhammer_fantasy
|
zlsl
| 2023-07-05T12:20:49Z | 129 | 3 |
transformers
|
[
"transformers",
"safetensors",
"gpt2",
"text-generation",
"warhammer",
"warhammer fantasy",
"en",
"license:cc-by-nc-nd-4.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-07-05T12:06:58Z |
---
license: cc-by-nc-nd-4.0
language:
- en
library_name: transformers
pipeline_tag: text-generation
tags:
- warhammer
- warhammer fantasy
---
The model is trained on a large dataset of texts from the Warhammer Fantasy, AOS universe.
|
zlsl/en_l_wh40k_full
|
zlsl
| 2023-07-05T12:20:31Z | 151 | 2 |
transformers
|
[
"transformers",
"safetensors",
"gpt2",
"text-generation",
"warhammer",
"warhammer40k",
"wh40k",
"horus heresy",
"necromunda",
"en",
"license:cc-by-nc-sa-4.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-07-05T12:08:52Z |
---
license: cc-by-nc-sa-4.0
language:
- en
library_name: transformers
tags:
- warhammer
- warhammer40k
- wh40k
- horus heresy
- necromunda
---
The model is trained on a large dataset of texts from the Warhammer 40k, Horus Heresy, Necromunda universe.
|
thegoodfellas/tgf-flan-t5-base-ptbr
|
thegoodfellas
| 2023-07-05T12:15:41Z | 16 | 3 |
transformers
|
[
"transformers",
"jax",
"t5",
"text2text-generation",
"pt",
"dataset:thegoodfellas/mc4-pt-cleaned",
"arxiv:1910.09700",
"license:apache-2.0",
"autotrain_compatible",
"region:us"
] |
text2text-generation
| 2023-04-22T13:05:29Z |
---
license: apache-2.0
datasets:
- thegoodfellas/mc4-pt-cleaned
language:
- pt
inference: false
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
This is the PT-BR Flan-T5-base model.
# Model Details
## Model Description
This model was created to act as the base study for researchs who wants to learn how the Flan-T5 works. This is the Portuguese version.
- **Developed by:** The Good Fellas team
- **Model type:** Flan-T5
- **Language(s) (NLP):** Portuguese (BR)
- **License:** apache-2.0
- **Finetuned from model [optional]:** Flan-T5-base
We would like to thanks the TPU Research Cloud team for that amazing opportunity given to us. To learn about TRC: https://sites.research.google/trc/about/
# Uses
This model can be used as base to downstream task as instructed by Flan-T5 paper
# Bias, Risks, and Limitations
Due to the nature of the web-scraped corpus on which Flan-T5 models were trained, it is likely that their usage could reproduce and amplify
pre-existing biases in the data, resulting in potentially harmful content such as racial or gender stereotypes and conspiracist views. For this reason,
the study of such biases is explicitly encouraged, and model usage should ideally be restricted to research-oriented and non-user-facing endeavors.
## How to Get Started with the Model
Use the code below to get started with the model.
```
from transformers import FlaxT5ForConditionalGeneration
model_flax = FlaxT5ForConditionalGeneration.from_pretrained("thegoodfellas/tgf-flan-t5-base-ptbr")
```
# Training Details
## Training Data
The training was performed from two datasets, BrWac and Oscar (Portuguese section).
## Training Procedure
We trained this model by 1 epoch on each dataset.
### Training Hyperparameters
Thanks to TPU Research Cloud we were able to train this model on TPU. 1 single TPUv2-8
- **Training regime:**
- Precision: bf16
- Batch size: 32
- LR: 0,005
- Warmup steps: 10_000
- Epochs: 1 (each dataset)
- Optimizer: Adafactor
# Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
Experiments were conducted using Google Cloud Platform in region us-central1, which has a carbon efficiency of 0.57 kgCO$_2$eq/kWh.
A cumulative of 50 hours of computation was performed on hardware of type TPUv2 Chip (TDP of 221W).
Total emissions are estimated to be 6.3 kgCO$_2$eq of which 100 percents were directly offset by the cloud provider.
- **Hardware Type:** TPUv2
- **Hours used:** 50
- **Cloud Provider:** GCP
- **Compute Region:** us-central1
- **Carbon Emitted:** 6.3 kgCO$_2$eq
# Technical Specifications [optional]
## Model Architecture and Objective
Flan-T5
|
bofenghuang/vigogne-falcon-7b-chat
|
bofenghuang
| 2023-07-05T12:11:30Z | 28 | 1 |
transformers
|
[
"transformers",
"pytorch",
"RefinedWebModel",
"text-generation",
"LLM",
"custom_code",
"fr",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"region:us"
] |
text-generation
| 2023-06-15T17:42:08Z |
---
license: apache-2.0
language:
- fr
pipeline_tag: text-generation
library_name: transformers
tags:
- LLM
inference: false
---
<p align="center" width="100%">
<img src="https://huggingface.co/bofenghuang/vigogne-falcon-7b-chat/resolve/main/vigogne_logo.png" alt="Vigogne" style="width: 40%; min-width: 300px; display: block; margin: auto;">
</p>
# Vigogne-Falcon-7B-Chat: A French Chat Falcon Model
Vigogne-Falcon-7B-Chat is a [Falcon-7B](https://huggingface.co/tiiuae/falcon-7b) model fine-tuned to conduct multi-turn dialogues in French between human user and AI assistant.
For more information, please visit the Github repo: https://github.com/bofenghuang/vigogne
## Changelog
All versions are available in branches.
- **V1.0**: Initial release.
- **V2.0**: Expanded training dataset to 419k for better performance.
## Usage
```python
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, GenerationConfig
from vigogne.preprocess import generate_inference_chat_prompt
model_name_or_path = "bofenghuang/vigogne-falcon-7b-chat"
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, padding_side="right", use_fast=False)
tokenizer.pad_token = tokenizer.eos_token
model = AutoModelForCausalLM.from_pretrained(
model_name_or_path,
torch_dtype=torch.float16,
device_map="auto",
trust_remote_code=True,
)
user_query = "Expliquez la différence entre DoS et phishing."
prompt = generate_inference_chat_prompt([[user_query, ""]], tokenizer=tokenizer)
input_ids = tokenizer(prompt, return_tensors="pt")["input_ids"].to(model.device)
input_length = input_ids.shape[1]
generated_outputs = model.generate(
input_ids=input_ids,
generation_config=GenerationConfig(
temperature=0.1,
do_sample=True,
repetition_penalty=1.0,
max_new_tokens=512,
),
return_dict_in_generate=True,
pad_token_id=tokenizer.eos_token_id,
eos_token_id=tokenizer.eos_token_id,
)
generated_tokens = generated_outputs.sequences[0, input_length:]
generated_text = tokenizer.decode(generated_tokens, skip_special_tokens=True)
print(generated_text)
```
<!-- You can infer this model by using the following Google Colab Notebook.
<a href="https://colab.research.google.com/github/bofenghuang/vigogne/blob/main/notebooks/infer_instruct.ipynb" target="_blank"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a> -->
## Limitations
Vigogne is still under development, and there are many limitations that have to be addressed. Please note that it is possible that the model generates harmful or biased content, incorrect information or generally unhelpful answers.
|
luispintoc/taxi-v2
|
luispintoc
| 2023-07-05T12:03:57Z | 0 | 0 | null |
[
"Taxi-v3",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-07-05T12:03:55Z |
---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: taxi-v2
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
metrics:
- type: mean_reward
value: 7.56 +/- 2.71
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="luispintoc/taxi-v2", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
luispintoc/q-FrozenLake-v1-4x4-noSlippery
|
luispintoc
| 2023-07-05T12:01:43Z | 0 | 0 | null |
[
"FrozenLake-v1-4x4-no_slippery",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-07-05T12:01:41Z |
---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="luispintoc/q-FrozenLake-v1-4x4-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
RIOLITE/products_matching_aumet_fine_tuned_2023-07-05
|
RIOLITE
| 2023-07-05T11:59:14Z | 1 | 1 |
sentence-transformers
|
[
"sentence-transformers",
"pytorch",
"bert",
"feature-extraction",
"sentence-similarity",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2023-07-05T11:46:56Z |
---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
---
# {MODEL_NAME}
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 384 dimensional dense vector space and can be used for tasks like clustering or semantic search.
<!--- Describe your model here -->
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('{MODEL_NAME}')
embeddings = model.encode(sentences)
print(embeddings)
```
## Evaluation Results
<!--- Describe how your model was evaluated -->
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name={MODEL_NAME})
## Training
The model was trained with the parameters:
**DataLoader**:
`torch.utils.data.dataloader.DataLoader` of length 45 with parameters:
```
{'batch_size': 16, 'sampler': 'torch.utils.data.sampler.RandomSampler', 'batch_sampler': 'torch.utils.data.sampler.BatchSampler'}
```
**Loss**:
`sentence_transformers.losses.MultipleNegativesRankingLoss.MultipleNegativesRankingLoss` with parameters:
```
{'scale': 20.0, 'similarity_fct': 'cos_sim'}
```
Parameters of the fit()-Method:
```
{
"epochs": 10,
"evaluation_steps": 0,
"evaluator": "NoneType",
"max_grad_norm": 1,
"optimizer_class": "<class 'torch.optim.adamw.AdamW'>",
"optimizer_params": {
"lr": 2e-05
},
"scheduler": "WarmupLinear",
"steps_per_epoch": null,
"warmup_steps": 10000,
"weight_decay": 0.01
}
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 256, 'do_lower_case': False}) with Transformer model: BertModel
(1): Pooling({'word_embedding_dimension': 384, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
(2): Normalize()
)
```
## Citing & Authors
<!--- Describe where people can find more information -->
|
riccorl/blink-bert-large
|
riccorl
| 2023-07-05T11:57:22Z | 110 | 2 |
transformers
|
[
"transformers",
"pytorch",
"safetensors",
"bert",
"feature-extraction",
"en",
"license:mit",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
feature-extraction
| 2023-04-26T08:56:04Z |
---
license: mit
language:
- en
library_name: transformers
---
# BLINK BERT-Large Model
This is a BERT-Large model finetuned on [BLINK](https://github.com/facebookresearch/BLINK)
|
KennethTM/gpt2-small-danish-review-response
|
KennethTM
| 2023-07-05T11:50:02Z | 129 | 1 |
transformers
|
[
"transformers",
"pytorch",
"safetensors",
"gpt2",
"text-generation",
"da",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-06-20T08:14:14Z |
---
language:
- da
pipeline_tag: text-generation
widget:
- text: "### Bruger:\nAnders\n\n### Anmeldelse:\nUmuligt at komme igennem på telefonen.\n\n### Svar:\nKære Anders\n"
---
# What is this?
A fine-tuned GPT-2 model (small version, 124 M parameters) for generating responses to customer reviews in Danish.
# How to use
The model is based on the [gpt2-small-danish model](https://huggingface.co/KennethTM/gpt2-small-danish). Supervised fine-tuning is applied to adapt the model to generate responses to customer reviews in Danish. A prompting template is applied to the examples used to train (see the example below).
Test the model using the pipeline from the [🤗 Transformers](https://github.com/huggingface/transformers) library:
```python
from transformers import pipeline
generator = pipeline("text-generation", model = "KennethTM/gpt2-small-danish-review-response")
def prompt_template(user, review):
return f"### Bruger:\n{user}\n\n### Anmeldelse:\n{review}\n\n### Svar:\nKære {user}\n"
prompt = prompt_template(user = "Anders", review = "Umuligt at komme igennem på telefonen.")
text = generator(prompt)
print(text[0]["generated_text"])
```
Or load it using the Auto* classes:
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("KennethTM/gpt2-small-danish-review-response")
model = AutoModelForCausalLM.from_pretrained("KennethTM/gpt2-small-danish-review-response")
```
# Notes
The model may get the sentiment of the review wrong resulting in a mismatch between the review and response. The model would probably benefit from sentiment tuning.
|
vergarajit/HuggyLlama
|
vergarajit
| 2023-07-05T11:32:32Z | 0 | 0 |
peft
|
[
"peft",
"region:us"
] | null | 2023-06-27T00:08:30Z |
---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: True
- bnb_4bit_compute_dtype: bfloat16
### Framework versions
- PEFT 0.4.0.dev0
|
alexvaroz/my_awesome_model
|
alexvaroz
| 2023-07-05T11:31:48Z | 61 | 0 |
transformers
|
[
"transformers",
"tf",
"distilbert",
"text-classification",
"generated_from_keras_callback",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-07-05T09:30:11Z |
---
license: apache-2.0
tags:
- generated_from_keras_callback
model-index:
- name: alexvaroz/my_awesome_model
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# alexvaroz/my_awesome_model
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.0625
- Validation Loss: 0.2300
- Train Accuracy: 0.9335
- Epoch: 2
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'Adam', 'weight_decay': None, 'clipnorm': None, 'global_clipnorm': None, 'clipvalue': None, 'use_ema': False, 'ema_momentum': 0.99, 'ema_overwrite_frequency': None, 'jit_compile': True, 'is_legacy_optimizer': False, 'learning_rate': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 2e-05, 'decay_steps': 7810, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}}, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False}
- training_precision: float32
### Training results
| Train Loss | Validation Loss | Train Accuracy | Epoch |
|:----------:|:---------------:|:--------------:|:-----:|
| 0.2504 | 0.1918 | 0.9253 | 0 |
| 0.1317 | 0.2269 | 0.9242 | 1 |
| 0.0625 | 0.2300 | 0.9335 | 2 |
### Framework versions
- Transformers 4.30.2
- TensorFlow 2.12.0
- Datasets 2.13.1
- Tokenizers 0.13.3
|
Gnjs/marian-finetuned-kde4-en-to-fr
|
Gnjs
| 2023-07-05T11:29:54Z | 107 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"marian",
"text2text-generation",
"tanslation",
"generated_from_trainer",
"dataset:kde4",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2023-06-26T04:02:32Z |
---
license: apache-2.0
tags:
- tanslation
- generated_from_trainer
datasets:
- kde4
metrics:
- bleu
model-index:
- name: marian-finetuned-kde4-en-to-fr
results:
- task:
name: Sequence-to-sequence Language Modeling
type: text2text-generation
dataset:
name: kde4
type: kde4
config: en-fr
split: train
args: en-fr
metrics:
- name: Bleu
type: bleu
value: 52.93066870505713
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# marian-finetuned-kde4-en-to-fr
This model is a fine-tuned version of [Helsinki-NLP/opus-mt-en-fr](https://huggingface.co/Helsinki-NLP/opus-mt-en-fr) on the kde4 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.8560
- Bleu: 52.9307
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
### Framework versions
- Transformers 4.30.2
- Pytorch 2.0.1+cu118
- Datasets 2.13.1
- Tokenizers 0.13.3
|
irfan62622/ppo-LunarLander-v2
|
irfan62622
| 2023-07-05T11:25:00Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-07-05T11:24:39Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 254.60 +/- 21.19
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
ITG/whisper-base-gl
|
ITG
| 2023-07-05T11:16:09Z | 74 | 1 |
transformers
|
[
"transformers",
"pytorch",
"whisper",
"automatic-speech-recognition",
"ITG",
"PyTorch",
"Transformers",
"whisper-base",
"gl",
"dataset:openslr",
"license:cc-by-nc-nd-4.0",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2023-07-05T09:06:31Z |
---
license: cc-by-nc-nd-4.0
datasets:
- openslr
language:
- gl
pipeline_tag: automatic-speech-recognition
tags:
- ITG
- PyTorch
- Transformers
- whisper
- whisper-base
---
# Whisper Base Galician
## Description
This is a fine-tuned version of the [openai/whisper-base](https://huggingface.co/openai/whisper-base) pre-trained model for ASR in galician.
---
## Dataset
We used one of the datasets available in the openslr repository, the [OpenSLR galician](https://huggingface.co/datasets/openslr/viewer/SLR77).
---
## Example inference script
### Check this example script to run our model in inference mode
```python
import torch
from transformers import AutoProcessor, AutoModelForSpeechSeq2Seq
filename = "demo.wav" #change this line to the name of your audio file
sample_rate = 16_000
processor = AutoProcessor.from_pretrained('ITG/whisper-base-gl')
model = AutoModelForSpeechSeq2Seq.from_pretrained('ITG/whisper-base-gl')
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model.to(device)
with torch.no_grad():
speech_array, _ = librosa.load(filename, sr=sample_rate)
inputs = processor(speech_array, sampling_rate=sample_rate, return_tensors="pt").to(device)
input_features = inputs.input_features
generated_ids = model.generate(inputs=input_features, max_length=225)
decode_output = processor.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(f"ASR Galician whisper-base output: {decode_output}")
```
---
## Fine-tuning hyper-parameters
| **Hyper-parameter** | **Value** |
|:----------------------------------------:|:---------------------------:|
| Training batch size | 16 |
| Evaluation batch size | 8 |
| Learning rate | 3e-5 |
| Gradient checkpointing | true |
| Gradient accumulation steps | 1 |
| Max training epochs | 100 |
| Max steps | 4000 |
| Generate max length | 225 |
| Warmup training steps (%) | 12,5% |
| FP16 | true |
| Metric for best model | wer |
| Greater is better | false |
## Fine-tuning in a different dataset or style
If you're interested in fine-tuning your own whisper model, we suggest starting with the [openai/whisper-base model](https://huggingface.co/openai/whisper-base). Additionally, you may find the Transformers
step-by-step guide for [fine-tuning whisper on multilingual ASR datasets](https://huggingface.co/blog/fine-tune-whisper) to be a valuable resource. This guide served as a helpful reference during the training
process of this Galician whisper-base model!
|
exavolt/sd-playground
|
exavolt
| 2023-07-05T11:07:21Z | 0 | 0 | null |
[
"license:creativeml-openrail-m",
"region:us"
] | null | 2023-05-23T02:21:09Z |
---
license: creativeml-openrail-m
---
|
djifg/grow_classification_FINAL
|
djifg
| 2023-07-05T11:05:34Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"text-classification",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-07-05T07:16:10Z |
---
tags:
- generated_from_trainer
metrics:
- accuracy
- f1
model-index:
- name: grow_classification_FINAL
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# grow_classification_FINAL
This model is a fine-tuned version of [djifg/grow_classification_kcbert](https://huggingface.co/djifg/grow_classification_kcbert) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4211
- Accuracy: 0.9323
- F1: 0.9308
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 0.0173 | 1.0 | 407 | 0.4211 | 0.9323 | 0.9308 |
### Framework versions
- Transformers 4.30.2
- Pytorch 2.0.1+cu118
- Datasets 2.13.1
- Tokenizers 0.13.3
|
Elaaaf/ppo-LunarLander-v2
|
Elaaaf
| 2023-07-05T10:57:45Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-07-05T10:56:36Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 194.79 +/- 98.19
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
felipec23/alpaca7B-lora-v2
|
felipec23
| 2023-07-05T10:39:59Z | 4 | 0 |
peft
|
[
"peft",
"region:us"
] | null | 2023-07-05T10:39:54Z |
---
library_name: peft
---
## Training procedure
### Framework versions
- PEFT 0.4.0.dev0
|
Htar/q-FrozenLake-v1-4x4-Slippery
|
Htar
| 2023-07-05T10:28:23Z | 0 | 0 | null |
[
"FrozenLake-v1-4x4",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-07-05T10:28:20Z |
---
tags:
- FrozenLake-v1-4x4
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-Slippery
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4
type: FrozenLake-v1-4x4
metrics:
- type: mean_reward
value: 0.74 +/- 0.44
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="Htar/q-FrozenLake-v1-4x4-Slippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
Htar/q-FrozenLake-v1-4x4-noSlippery
|
Htar
| 2023-07-05T10:18:06Z | 0 | 0 | null |
[
"FrozenLake-v1-4x4-no_slippery",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-07-05T09:48:44Z |
---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="Htar/q-FrozenLake-v1-4x4-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
WT-MM/Mei
|
WT-MM
| 2023-07-05T10:12:13Z | 0 | 0 |
diffusers
|
[
"diffusers",
"text-to-image",
"license:openrail",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] |
text-to-image
| 2023-07-04T03:37:32Z |
---
license: openrail
pipeline_tag: text-to-image
---
|
NasimB/gpt2-concat-finetune-cl-mod-datasets-rarity1
|
NasimB
| 2023-07-05T10:09:35Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"generated_from_trainer",
"dataset:generator",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-07-05T03:32:14Z |
---
tags:
- generated_from_trainer
datasets:
- generator
model-index:
- name: gpt2-concat-finetune-cl-mod-datasets-rarity1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# gpt2-concat-finetune-cl-mod-datasets-rarity1
This model was trained from scratch on the generator dataset.
It achieves the following results on the evaluation set:
- Loss: 2.6666
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 1000
- num_epochs: 5
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 3.8306 | 0.3 | 500 | 4.5102 |
| 3.9443 | 0.59 | 1000 | 4.5278 |
| 4.039 | 0.89 | 1500 | 4.4641 |
| 3.8859 | 1.18 | 2000 | 4.4729 |
| 3.8519 | 1.48 | 2500 | 4.4332 |
| 3.8622 | 1.78 | 3000 | 4.3895 |
| 3.765 | 2.07 | 3500 | 4.4085 |
| 3.5415 | 2.37 | 4000 | 4.4023 |
| 3.5631 | 2.66 | 4500 | 4.3729 |
| 3.559 | 2.96 | 5000 | 4.3403 |
| 3.2324 | 3.26 | 5500 | 4.4037 |
| 3.2011 | 3.55 | 6000 | 4.3997 |
| 3.1898 | 3.85 | 6500 | 4.3837 |
| 3.0472 | 4.14 | 7000 | 4.4190 |
| 2.9036 | 4.44 | 7500 | 4.4273 |
| 2.8985 | 4.74 | 8000 | 4.4269 |
### Framework versions
- Transformers 4.26.1
- Pytorch 1.11.0+cu113
- Datasets 2.13.0
- Tokenizers 0.13.3
|
Anmol0130/autotrain-data-lable_detection
|
Anmol0130
| 2023-07-05T09:56:52Z | 64 | 0 |
transformers
|
[
"transformers",
"tf",
"vit",
"image-classification",
"generated_from_keras_callback",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2023-07-05T07:49:51Z |
---
license: apache-2.0
tags:
- generated_from_keras_callback
model-index:
- name: Anmol0130/autotrain-data-lable_detection
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# Anmol0130/autotrain-data-lable_detection
This model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 1.9094
- Validation Loss: 2.0767
- Train Accuracy: 0.4231
- Epoch: 4
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'AdamWeightDecay', 'learning_rate': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 3e-05, 'decay_steps': 505, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False, 'weight_decay_rate': 0.01}
- training_precision: float32
### Training results
| Train Loss | Validation Loss | Train Accuracy | Epoch |
|:----------:|:---------------:|:--------------:|:-----:|
| 2.4440 | 2.4069 | 0.1923 | 0 |
| 2.3135 | 2.3220 | 0.2308 | 1 |
| 2.1668 | 2.2474 | 0.3462 | 2 |
| 2.0369 | 2.1577 | 0.3846 | 3 |
| 1.9094 | 2.0767 | 0.4231 | 4 |
### Framework versions
- Transformers 4.30.2
- TensorFlow 2.12.0
- Datasets 2.13.1
- Tokenizers 0.13.3
|
anejaisha/output6
|
anejaisha
| 2023-07-05T09:48:13Z | 0 | 0 | null |
[
"tensorboard",
"generated_from_trainer",
"base_model:google/flan-t5-large",
"base_model:finetune:google/flan-t5-large",
"license:apache-2.0",
"region:us"
] | null | 2023-07-05T09:00:57Z |
---
license: apache-2.0
base_model: google/flan-t5-large
tags:
- generated_from_trainer
model-index:
- name: output6
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# output6
This model is a fine-tuned version of [google/flan-t5-large](https://huggingface.co/google/flan-t5-large) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.001
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| No log | 1.0 | 66 | 0.1907 |
### Framework versions
- Transformers 4.31.0.dev0
- Pytorch 2.0.1+cu118
- Datasets 2.13.1
- Tokenizers 0.13.3
|
EllaHong/datamap_polyglot_5.8b_exp2_800
|
EllaHong
| 2023-07-05T09:43:48Z | 0 | 0 |
peft
|
[
"peft",
"region:us"
] | null | 2023-07-05T09:43:42Z |
---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: True
- bnb_4bit_compute_dtype: bfloat16
### Framework versions
- PEFT 0.4.0.dev0
|
kishkath/output
|
kishkath
| 2023-07-05T09:41:35Z | 3 | 0 |
diffusers
|
[
"diffusers",
"tensorboard",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"dreambooth",
"base_model:CompVis/stable-diffusion-v1-4",
"base_model:finetune:CompVis/stable-diffusion-v1-4",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] |
text-to-image
| 2023-06-26T10:10:03Z |
---
license: creativeml-openrail-m
base_model: CompVis/stable-diffusion-v1-4
instance_prompt: a photo of sks cocacola
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
- dreambooth
inference: true
---
# DreamBooth - kishkath/output
This is a dreambooth model derived from CompVis/stable-diffusion-v1-4. The weights were trained on a photo of sks cocacola using [DreamBooth](https://dreambooth.github.io/).
You can find some example images in the following.
DreamBooth for the text encoder was enabled: False.
|
Jyshen/Chat_Suzumiya_GLM2LoRA
|
Jyshen
| 2023-07-05T09:39:57Z | 0 | 1 |
peft
|
[
"peft",
"region:us"
] | null | 2023-06-10T12:56:56Z |
---
library_name: peft
---
## Training procedure
### Framework versions
- PEFT 0.4.0.dev0
|
Sekiraw/taxi
|
Sekiraw
| 2023-07-05T09:26:25Z | 0 | 1 | null |
[
"Taxi-v3",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-07-05T09:20:34Z |
---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: taxi
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
metrics:
- type: mean_reward
value: 7.56 +/- 2.71
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
model = load_from_hub(repo_id="Sekiraw/taxi", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
|
neilsun2009/amz_movie_tv_distilgpt2_100
|
neilsun2009
| 2023-07-05T09:17:23Z | 4 | 0 |
peft
|
[
"peft",
"distilgpt-2",
"text-generation",
"en",
"region:us"
] |
text-generation
| 2023-07-05T09:01:34Z |
---
language:
- en
library_name: peft
metrics:
- perplexity
tags:
- distilgpt-2
pipeline_tag: text-generation
---
|
AndrewDOrlov/bert-eval
|
AndrewDOrlov
| 2023-07-05T09:12:43Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"text-classification",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-07-03T08:08:21Z |
---
tags:
- generated_from_trainer
metrics:
- f1
- accuracy
model-index:
- name: bert-eval
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-eval
This model was trained from scratch on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2288
- F1: 0.7837
- Roc Auc: 0.8490
- Accuracy: 0.3137
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 | Roc Auc | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:------:|:-------:|:--------:|
| 0.4067 | 1.0 | 751 | 0.2930 | 0.7145 | 0.7911 | 0.2188 |
| 0.2483 | 2.0 | 1502 | 0.2528 | 0.7493 | 0.8167 | 0.2777 |
| 0.1993 | 3.0 | 2253 | 0.2323 | 0.7772 | 0.8406 | 0.3067 |
| 0.1468 | 4.0 | 3004 | 0.2288 | 0.7837 | 0.8490 | 0.3137 |
| 0.1238 | 5.0 | 3755 | 0.2287 | 0.7837 | 0.8509 | 0.3217 |
### Framework versions
- Transformers 4.30.2
- Pytorch 2.0.1+cu118
- Datasets 2.13.1
- Tokenizers 0.13.3
|
Sekiraw/mano
|
Sekiraw
| 2023-07-05T09:10:50Z | 0 | 1 | null |
[
"FrozenLake-v1-4x4-no_slippery",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-07-05T09:02:13Z |
---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: mano
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
model = load_from_hub(repo_id="Sekiraw/mano", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
|
gabski/deberta-suboptimal-claim-detection-with-parent-context
|
gabski
| 2023-07-05T08:23:45Z | 103 | 0 |
transformers
|
[
"transformers",
"pytorch",
"deberta",
"text-classification",
"en",
"dataset:ClaimRev",
"arxiv:2305.16799",
"license:cc-by-nc-sa-4.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-06-08T14:08:38Z |
---
license: cc-by-nc-sa-4.0
language:
- en
library_name: transformers
pipeline_tag: text-classification
datasets:
- ClaimRev
widget:
- text: "Teachers are likely to educate children better than parents."
context: "Homeschooling should be banned."
---
# Model
This model was obtained by fine-tuning `microsoft/deberta-base` on the extended ClaimRev dataset.
Paper: [To Revise or Not to Revise: Learning to Detect Improvable Claims for Argumentative Writing Support](https://arxiv.org/abs/2305.16799)
Authors: Gabriella Skitalinskaya and Henning Wachsmuth
# Suboptimal Claim Detection
We cast this task as a binary classification task, where the objective is, given an argumentative claim and some contextual information (in this case, the **parent claim** in the debate, which is opposed or supported by the claim in question), to decide whether it is in need of further revision or can be considered to be phrased more or less optimally.
# Usage
```python
from transformers import AutoTokenizer, AutoModelForSequenceClassification
import torch
tokenizer = AutoTokenizer.from_pretrained("gabski/deberta-suboptimal-claim-detection-with-parent-context")
model = AutoModelForSequenceClassification.from_pretrained("gabski/deberta-suboptimal-claim-detection-with-parent-context")
claim = 'Teachers are likely to educate children better than parents.'
parent_claim = 'Homeschooling should be banned.'
model_input = tokenizer(claim, parent_claim, return_tensors='pt')
model_outputs = model(**model_input)
outputs = torch.nn.functional.softmax(model_outputs.logits, dim = -1)
print(outputs)
```
|
gabski/deberta-suboptimal-claim-detection-with-thesis-context
|
gabski
| 2023-07-05T08:23:06Z | 108 | 0 |
transformers
|
[
"transformers",
"pytorch",
"deberta",
"text-classification",
"en",
"dataset:ClaimRev",
"arxiv:2305.16799",
"license:cc-by-nc-sa-4.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-06-08T14:19:14Z |
---
license: cc-by-nc-sa-4.0
language:
- en
library_name: transformers
pipeline_tag: text-classification
datasets:
- ClaimRev
widget:
- text: "Teachers are likely to educate children better than parents."
context: "Homeschooling should be banned."
---
# Model
This model was obtained by fine-tuning `microsoft/deberta-base` on the extended ClaimRev dataset.
Paper: [To Revise or Not to Revise: Learning to Detect Improvable Claims for Argumentative Writing Support](https://arxiv.org/abs/2305.16799)
Authors: Gabriella Skitalinskaya and Henning Wachsmuth
# Suboptimal Claim Detection
We cast this task as a binary classification task, where the objective is, given an argumentative claim and some contextual information (in this case, the **main thesis** of the debate), to decide whether it is in need of further revision or can be considered to be phrased more or less optimally.
# Usage
```python
from transformers import AutoTokenizer, AutoModelForSequenceClassification
import torch
tokenizer = AutoTokenizer.from_pretrained("gabski/deberta-suboptimal-claim-detection-with-thesis-context")
model = AutoModelForSequenceClassification.from_pretrained("gabski/deberta-suboptimal-claim-detection-with-thesis-context")
claim = 'Teachers are likely to educate children better than parents.'
thesis = 'Homeschooling should be banned.'
model_input = tokenizer(claim, thesis, return_tensors='pt')
model_outputs = model(**model_input)
outputs = torch.nn.functional.softmax(model_outputs.logits, dim = -1)
print(outputs)
```
|
dganesh/ppo-MountainCar-v0
|
dganesh
| 2023-07-05T08:22:19Z | 1 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"MountainCar-v0",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-07-05T07:31:01Z |
---
library_name: stable-baselines3
tags:
- MountainCar-v0
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: MountainCar-v0
type: MountainCar-v0
metrics:
- type: mean_reward
value: -200.00 +/- 0.00
name: mean_reward
verified: false
---
# **PPO** Agent playing **MountainCar-v0**
This is a trained model of a **PPO** agent playing **MountainCar-v0**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
youlun77/finetuning-sentiment-model-3000-samples
|
youlun77
| 2023-07-05T08:14:49Z | 109 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_trainer",
"dataset:imdb",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-07-05T08:07:10Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- imdb
metrics:
- accuracy
- f1
model-index:
- name: finetuning-sentiment-model-3000-samples
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: imdb
type: imdb
config: plain_text
split: test
args: plain_text
metrics:
- name: Accuracy
type: accuracy
value: 0.86
- name: F1
type: f1
value: 0.8599999999999999
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# finetuning-sentiment-model-3000-samples
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the imdb dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3191
- Accuracy: 0.86
- F1: 0.8600
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
### Framework versions
- Transformers 4.30.2
- Pytorch 2.0.1+cu118
- Datasets 2.13.1
- Tokenizers 0.13.3
|
yeounyi/ppo-PyramidsTraining
|
yeounyi
| 2023-07-05T08:07:53Z | 1 | 0 |
ml-agents
|
[
"ml-agents",
"tensorboard",
"onnx",
"Pyramids",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-Pyramids",
"region:us"
] |
reinforcement-learning
| 2023-07-05T08:07:51Z |
---
library_name: ml-agents
tags:
- Pyramids
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-Pyramids
---
# **ppo** Agent playing **Pyramids**
This is a trained model of a **ppo** agent playing **Pyramids**
using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://unity-technologies.github.io/ml-agents/ML-Agents-Toolkit-Documentation/
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
- A *short tutorial* where you teach Huggy the Dog 🐶 to fetch the stick and then play with him directly in your
browser: https://huggingface.co/learn/deep-rl-course/unitbonus1/introduction
- A *longer tutorial* to understand how works ML-Agents:
https://huggingface.co/learn/deep-rl-course/unit5/introduction
### Resume the training
```bash
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser**
1. If the environment is part of ML-Agents official environments, go to https://huggingface.co/unity
2. Step 1: Find your model_id: yeounyi/ppo-PyramidsTraining
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
re2panda/alpaca-grade-school-math
|
re2panda
| 2023-07-05T08:04:34Z | 0 | 0 |
peft
|
[
"peft",
"region:us"
] | null | 2023-07-05T08:04:32Z |
---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- load_in_8bit: True
- load_in_4bit: False
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: fp4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float32
### Framework versions
- PEFT 0.4.0.dev0
|
aroot/wsample.43
|
aroot
| 2023-07-05T08:03:46Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"mbart",
"text2text-generation",
"translation",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
translation
| 2023-07-05T06:25:14Z |
---
tags:
- translation
- generated_from_trainer
metrics:
- bleu
model-index:
- name: wsample.43
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wsample.43
This model is a fine-tuned version of [facebook/mbart-large-50-many-to-many-mmt](https://huggingface.co/facebook/mbart-large-50-many-to-many-mmt) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 3.2191
- Bleu: 2.8739
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
### Framework versions
- Transformers 4.30.2
- Pytorch 2.0.1
- Datasets 2.12.0
- Tokenizers 0.11.0
|
aroot/wsample.32
|
aroot
| 2023-07-05T08:02:55Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"mbart",
"text2text-generation",
"translation",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
translation
| 2023-07-04T23:11:21Z |
---
tags:
- translation
- generated_from_trainer
metrics:
- bleu
model-index:
- name: wsample.32
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wsample.32
This model is a fine-tuned version of [facebook/mbart-large-50-many-to-many-mmt](https://huggingface.co/facebook/mbart-large-50-many-to-many-mmt) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 3.2257
- Bleu: 3.1376
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
### Framework versions
- Transformers 4.30.2
- Pytorch 2.0.1
- Datasets 2.12.0
- Tokenizers 0.11.0
|
leo20230412/test_model20230705
|
leo20230412
| 2023-07-05T08:01:11Z | 0 | 0 | null |
[
"arxiv:1910.09700",
"region:us"
] | null | 2023-07-05T07:59:34Z |
---
# For reference on model card metadata, see the spec: https://github.com/huggingface/hub-docs/blob/main/modelcard.md?plain=1
# Doc / guide: https://huggingface.co/docs/hub/model-cards
{}
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
This modelcard aims to be a base template for new models. It has been generated using [this raw template](https://github.com/huggingface/huggingface_hub/blob/main/src/huggingface_hub/templates/modelcard_template.md?plain=1).
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Data Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Data Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Sekiraw/LunarLander
|
Sekiraw
| 2023-07-05T07:34:26Z | 1 | 1 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-07-04T19:46:50Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 279.05 +/- 16.02
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
yeounyi/ppo-SnowballTarget
|
yeounyi
| 2023-07-05T07:31:29Z | 1 | 0 |
ml-agents
|
[
"ml-agents",
"tensorboard",
"onnx",
"SnowballTarget",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-SnowballTarget",
"region:us"
] |
reinforcement-learning
| 2023-07-05T07:31:27Z |
---
library_name: ml-agents
tags:
- SnowballTarget
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-SnowballTarget
---
# **ppo** Agent playing **SnowballTarget**
This is a trained model of a **ppo** agent playing **SnowballTarget**
using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://unity-technologies.github.io/ml-agents/ML-Agents-Toolkit-Documentation/
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
- A *short tutorial* where you teach Huggy the Dog 🐶 to fetch the stick and then play with him directly in your
browser: https://huggingface.co/learn/deep-rl-course/unitbonus1/introduction
- A *longer tutorial* to understand how works ML-Agents:
https://huggingface.co/learn/deep-rl-course/unit5/introduction
### Resume the training
```bash
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser**
1. If the environment is part of ML-Agents official environments, go to https://huggingface.co/unity
2. Step 1: Find your model_id: yeounyi/ppo-SnowballTarget
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
Inzamam567/Useless2chModels
|
Inzamam567
| 2023-07-05T07:27:47Z | 0 | 4 | null |
[
"license:openrail",
"region:us"
] | null | 2023-07-05T07:27:47Z |
---
license: openrail
duplicated_from: 2ch/models
---
|
gajanandjha/distilgpt2-finetuned-wikitext2
|
gajanandjha
| 2023-07-05T07:20:28Z | 182 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"gpt2",
"text-generation",
"generated_from_trainer",
"en",
"dataset:wikitext",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-07-04T06:16:46Z |
---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: distilgpt2-finetuned-wikitext2
results: []
datasets:
- wikitext
language:
- en
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilgpt2-finetuned-wikitext2
This model is a fine-tuned version of [distilgpt2](https://huggingface.co/distilgpt2) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 3.6636
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 3.7888 | 1.0 | 2323 | 3.6878 |
| 3.6737 | 2.0 | 4646 | 3.6663 |
| 3.6143 | 3.0 | 6969 | 3.6636 |
### Framework versions
- Transformers 4.30.2
- Pytorch 2.0.1+cu117
- Datasets 2.13.1
- Tokenizers 0.13.3
|
Subsets and Splits
Filtered Qwen2.5 Distill Models
Identifies specific configurations of models by filtering cards that contain 'distill', 'qwen2.5', '7b' while excluding certain base models and incorrect model ID patterns, uncovering unique model variants.
Filtered Model Cards Count
Finds the count of entries with specific card details that include 'distill', 'qwen2.5', '7b' but exclude certain base models, revealing valuable insights about the dataset's content distribution.
Filtered Distill Qwen 7B Models
Filters for specific card entries containing 'distill', 'qwen', and '7b', excluding certain strings and patterns, to identify relevant model configurations.
Filtered Qwen-7b Model Cards
The query performs a detailed filtering based on specific keywords and excludes certain entries, which could be useful for identifying a specific subset of cards but does not provide deeper insights or trends.
Filtered Qwen 7B Model Cards
The query filters for specific terms related to "distilled" or "distill", "qwen", and "7b" in the 'card' column but excludes certain base models, providing a limited set of entries for further inspection.
Qwen 7B Distilled Models
The query provides a basic filtering of records to find specific card names that include keywords related to distilled Qwen 7b models, excluding a particular base model, which gives limited insight but helps in focusing on relevant entries.
Qwen 7B Distilled Model Cards
The query filters data based on specific keywords in the modelId and card fields, providing limited insight primarily useful for locating specific entries rather than revealing broad patterns or trends.
Qwen 7B Distilled Models
Finds all entries containing the terms 'distilled', 'qwen', and '7b' in a case-insensitive manner, providing a filtered set of records but without deeper analysis.
Distilled Qwen 7B Models
The query filters for specific model IDs containing 'distilled', 'qwen', and '7b', providing a basic retrieval of relevant entries but without deeper analysis or insight.
Filtered Model Cards with Distill Qwen2.
Filters and retrieves records containing specific keywords in the card description while excluding certain phrases, providing a basic count of relevant entries.
Filtered Model Cards with Distill Qwen 7
The query filters specific variations of card descriptions containing 'distill', 'qwen', and '7b' while excluding a particular base model, providing limited but specific data retrieval.
Distill Qwen 7B Model Cards
The query filters and retrieves rows where the 'card' column contains specific keywords ('distill', 'qwen', and '7b'), providing a basic filter result that can help in identifying specific entries.