
modelId
stringlengths 5
139
| author
stringlengths 2
42
| last_modified
timestamp[us, tz=UTC]date 2020-02-15 11:33:14
2025-09-08 19:17:42
| downloads
int64 0
223M
| likes
int64 0
11.7k
| library_name
stringclasses 549
values | tags
listlengths 1
4.05k
| pipeline_tag
stringclasses 55
values | createdAt
timestamp[us, tz=UTC]date 2022-03-02 23:29:04
2025-09-08 18:30:19
| card
stringlengths 11
1.01M
|
|---|---|---|---|---|---|---|---|---|---|
Billwzl/distilbert-base-uncased-IMDB_distilbert
|
Billwzl
| 2022-08-12T14:28:37Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"distilbert",
"fill-mask",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-08-12T14:06:42Z |
---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: distilbert-base-uncased-IMDB_distilbert
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-IMDB_distilbert
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 2.6232
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 16
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-----:|:---------------:|
| 3.1531 | 1.0 | 1250 | 2.9545 |
| 2.9251 | 2.0 | 2500 | 2.8577 |
| 2.7865 | 3.0 | 3750 | 2.8460 |
| 2.692 | 4.0 | 5000 | 2.7769 |
| 2.611 | 5.0 | 6250 | 2.8373 |
| 2.5341 | 6.0 | 7500 | 2.7105 |
| 2.4887 | 7.0 | 8750 | 2.6864 |
| 2.4292 | 8.0 | 10000 | 2.6600 |
| 2.3524 | 9.0 | 11250 | 2.6872 |
| 2.3217 | 10.0 | 12500 | 2.6527 |
| 2.2961 | 11.0 | 13750 | 2.6659 |
| 2.2553 | 12.0 | 15000 | 2.6513 |
| 2.2066 | 13.0 | 16250 | 2.6443 |
| 2.1912 | 14.0 | 17500 | 2.5912 |
| 2.1703 | 15.0 | 18750 | 2.6312 |
| 2.1715 | 16.0 | 20000 | 2.6232 |
### Framework versions
- Transformers 4.21.1
- Pytorch 1.12.0+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
alex-apostolo/legal-roberta-base-cuad
|
alex-apostolo
| 2022-08-12T14:27:48Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"roberta",
"question-answering",
"generated_from_trainer",
"dataset:cuad",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-08-09T19:13:16Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- cuad
model-index:
- name: legal-roberta-base-cuad
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# legal-roberta-base-cuad
This model is a fine-tuned version of [saibo/legal-roberta-base](https://huggingface.co/saibo/legal-roberta-base) on the cuad dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0260
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 24
- eval_batch_size: 24
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:------:|:---------------:|
| 0.0393 | 1.0 | 51295 | 0.0261 |
| 0.0234 | 2.0 | 102590 | 0.0254 |
| 0.0234 | 3.0 | 153885 | 0.0260 |
### Framework versions
- Transformers 4.21.1
- Pytorch 1.12.0+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
AkashKhamkar/InSumT510k
|
AkashKhamkar
| 2022-08-12T13:09:54Z | 7 | 0 |
transformers
|
[
"transformers",
"pytorch",
"t5",
"text2text-generation",
"license:afl-3.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-08-10T11:27:49Z |
---
license: afl-3.0
---
---
About :
This model can be used for text summarization.
The dataset on which it was fine tuned consisted of 10,323 articles.
The Data Fields :
- "Headline" : title of the article
- "articleBody" : the main article content
- "source" : the link to the readmore page.
The data splits were :
- Train : 8258.
- Vaildation : 2065.
### How to use along with pipeline
```python
from transformers import pipeline
from transformers import AutoTokenizer, AutoModelForSeq2Seq
tokenizer = AutoTokenizer.from_pretrained("AkashKhamkar/InSumT510k")
model = AutoModelForSeq2SeqLM.from_pretrained("AkashKhamkar/InSumT510k")
summarizer = pipeline("summarization", model=model, tokenizer=tokenizer)
summarizer("Text for summarization...", min_length=5, max_length=50)
```
language:
- English
library_name: Pytorch
tags:
- Summarization
- T5-base
- Conditional Modelling
-
|
blesot/Mask-RCNN
|
blesot
| 2022-08-12T11:28:17Z | 0 | 5 | null |
[
"arxiv:1703.06870",
"region:us"
] | null | 2022-08-08T23:54:30Z |
Hugging Face's logo
---
tags:
- object-detection
- vision
library_name: mask_rcnn
datasets:
- coco
---
# Mask R-CNN
## Model desription
Mask R-CNN is a model that extends Faster R-CNN by adding a branch for predicting an object mask in parallel with the existing branch for bounding box recognition. The model locates pixels of images instead of just bounding boxes as Faster R-CNN was not designed for pixel-to-pixel alignment between network inputs and outputs.
*This Model is based on the Pretrained model from [OpenMMlab](https://github.com/open-mmlab/mmdetection)*
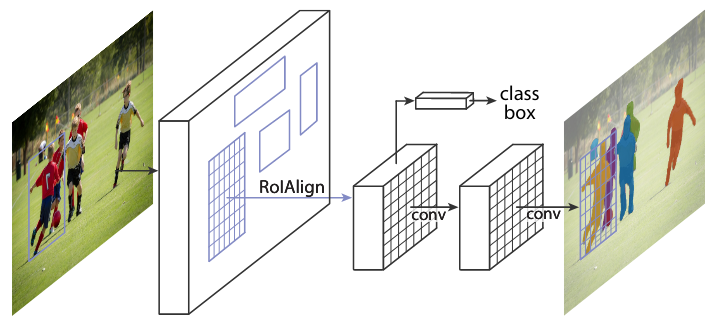
### More information on the model and dataset:
#### The model
Mask R-CNN works towards the approach of instance segmentation, which involves object detection, and semantic segmentation. For object detection, Mask R-CNN uses an architecture that is similar to Faster R-CNN, while it uses a Fully Convolutional Network(FCN) for semantic segmentation.
The FCN is added to the top of features of a Faster R-CNN to generate a mask segmentation output. This segmentation output is in parallel with the classification and bounding box regressor network of the Faster R-CNN model. From the advancement of Fast R-CNN Region of Interest Pooling(ROI), Mask R-CNN adds refinement called ROI aligning by addressing the loss and misalignment of ROI Pooling; the new ROI aligned leads to improved results.
#### Datasets
[COCO Datasets](https://cocodataset.org/#home)
## Training Procedure
Please [read the paper](https://arxiv.org/pdf/1703.06870.pdf) for more information on training, or check OpenMMLab [repository](https://github.com/open-mmlab/mmdetection/tree/master/configs/mask_rcnn)
The model architecture is divided into two parts:
- Region proposal network (RPN) to propose candidate object bounding boxes.
- Binary mask classifier to generate a mask for every class
#### Technical Summary.
- Mask R-CNN is quite similar to the structure of faster R-CNN.
- Outputs a binary mask for each Region of Interest.
- Applies bounding-box classification and regression in parallel, simplifying the original R-CNN's multi-stage pipeline.
- The network architectures utilized are called ResNet and ResNeXt. The depth can be either 50 or 101
#### Results Summary
- Instance Segmentation: Based on the COCO dataset, Mask R-CNN outperforms all categories compared to MNC and FCIS, which are state-of-the-art models.
- Bounding Box Detection: Mask R-CNN outperforms the base variants of all previous state-of-the-art models, including the COCO 2016 Detection Challenge winner.
## Intended uses & limitations
The identification of object relationships and the context of objects in a picture are both aided by image segmentation. Some of the applications include face recognition, number plate recognition, and satellite image analysis. With great model generality, Mask RCNN can be extended to human pose estimation; it can be used to estimate on-site approaching live traffic to aid autonomous driving.
|
Jungwoo4021/wav2vec2-base-ks-finetuning
|
Jungwoo4021
| 2022-08-12T10:59:01Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"wav2vec2",
"text-classification",
"audio-classification",
"generated_from_trainer",
"dataset:superb",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
audio-classification
| 2022-08-12T02:24:38Z |
---
license: apache-2.0
tags:
- audio-classification
- generated_from_trainer
datasets:
- superb
metrics:
- accuracy
model-index:
- name: wav2vec2-base-ks-finetuning
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-base-ks-finetuning
This model is a fine-tuned version of [facebook/wav2vec2-base](https://huggingface.co/facebook/wav2vec2-base) on the superb dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2261
- Accuracy: 0.9813
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 256
- eval_batch_size: 256
- seed: 0
- gradient_accumulation_steps: 4
- total_train_batch_size: 1024
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 10.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 1.6773 | 1.0 | 50 | 1.6218 | 0.6209 |
| 1.4707 | 2.0 | 100 | 1.4400 | 0.6209 |
| 1.1387 | 3.0 | 150 | 1.0470 | 0.6599 |
| 0.7909 | 4.0 | 200 | 0.6997 | 0.8903 |
| 0.5488 | 5.0 | 250 | 0.4567 | 0.9640 |
| 0.4195 | 6.0 | 300 | 0.3288 | 0.9754 |
| 0.3445 | 7.0 | 350 | 0.2598 | 0.9809 |
| 0.3107 | 8.0 | 400 | 0.2261 | 0.9813 |
| 0.2781 | 9.0 | 450 | 0.2104 | 0.9810 |
| 0.2729 | 10.0 | 500 | 0.2050 | 0.9813 |
### Framework versions
- Transformers 4.22.0.dev0
- Pytorch 1.11.0+cu115
- Datasets 2.4.0
- Tokenizers 0.12.1
|
Jiqing/bert-large-uncased-whole-word-masking-finetuned-squad-finetuned-squad
|
Jiqing
| 2022-08-12T09:24:10Z | 11 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"question-answering",
"generated_from_trainer",
"dataset:squad",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-08-12T09:22:04Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- squad
model-index:
- name: bert-large-uncased-whole-word-masking-finetuned-squad-finetuned-squad
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-large-uncased-whole-word-masking-finetuned-squad-finetuned-squad
This model is a fine-tuned version of [bert-large-uncased-whole-word-masking-finetuned-squad](https://huggingface.co/bert-large-uncased-whole-word-masking-finetuned-squad) on the squad dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Framework versions
- Transformers 4.21.0
- Pytorch 1.12.0+cu102
- Datasets 2.4.0
- Tokenizers 0.12.1
|
DOOGLAK/Article_250v8_NER_Model_3Epochs_UNAUGMENTED
|
DOOGLAK
| 2022-08-12T09:22:05Z | 107 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"token-classification",
"generated_from_trainer",
"dataset:article250v8_wikigold_split",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-08-12T09:16:55Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- article250v8_wikigold_split
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: Article_250v8_NER_Model_3Epochs_UNAUGMENTED
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: article250v8_wikigold_split
type: article250v8_wikigold_split
args: default
metrics:
- name: Precision
type: precision
value: 0.4215600350569676
- name: Recall
type: recall
value: 0.3990597345132743
- name: F1
type: f1
value: 0.4100014206563432
- name: Accuracy
type: accuracy
value: 0.878173617797598
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Article_250v8_NER_Model_3Epochs_UNAUGMENTED
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the article250v8_wikigold_split dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3329
- Precision: 0.4216
- Recall: 0.3991
- F1: 0.4100
- Accuracy: 0.8782
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 28 | 0.5293 | 0.1767 | 0.0454 | 0.0722 | 0.7988 |
| No log | 2.0 | 56 | 0.3589 | 0.3246 | 0.2987 | 0.3111 | 0.8611 |
| No log | 3.0 | 84 | 0.3329 | 0.4216 | 0.3991 | 0.4100 | 0.8782 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.11.0+cu113
- Datasets 2.4.0
- Tokenizers 0.11.6
|
Intel/distilgpt2-wikitext2
|
Intel
| 2022-08-12T09:20:44Z | 8 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"generated_from_trainer",
"dataset:wikitext",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-08-12T08:59:15Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- wikitext
metrics:
- accuracy
model-index:
- name: distilgpt2-wikitext2
results:
- task:
name: Causal Language Modeling
type: text-generation
dataset:
name: wikitext wikitext-2-raw-v1
type: wikitext
args: wikitext-2-raw-v1
metrics:
- name: Accuracy
type: accuracy
value: 0.39321440208536984
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilgpt2-wikitext2
This model is a fine-tuned version of [distilgpt2](https://huggingface.co/distilgpt2) on the wikitext wikitext-2-raw-v1 dataset.
It achieves the following results on the evaluation set:
- Loss: 3.3259
- Accuracy: 0.3932
- perplexity: 27.8235
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
### Framework versions
- Transformers 4.21.1
- Pytorch 1.12.1+cu116
- Datasets 2.4.0
- Tokenizers 0.12.1
|
rhiga/q-Taxi-v3
|
rhiga
| 2022-08-12T07:50:11Z | 0 | 0 | null |
[
"Taxi-v3",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-08-12T07:50:03Z |
---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-Taxi-v3
results:
- metrics:
- type: mean_reward
value: 7.50 +/- 2.72
name: mean_reward
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
---
# **Q-Learning** Agent playing **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="rhiga/q-Taxi-v3", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
evaluate_agent(env, model["max_steps"], model["n_eval_episodes"], model["qtable"], model["eval_seed"])
```
|
Lvxue/distilled-mt5-small-1-2
|
Lvxue
| 2022-08-12T07:29:04Z | 7 | 0 |
transformers
|
[
"transformers",
"pytorch",
"mt5",
"text2text-generation",
"generated_from_trainer",
"en",
"ro",
"dataset:wmt16",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-08-12T06:11:08Z |
---
language:
- en
- ro
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- wmt16
metrics:
- bleu
model-index:
- name: distilled-mt5-small-1-2
results:
- task:
name: Translation
type: translation
dataset:
name: wmt16 ro-en
type: wmt16
args: ro-en
metrics:
- name: Bleu
type: bleu
value: 1.1101
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilled-mt5-small-1-2
This model is a fine-tuned version of [google/mt5-small](https://huggingface.co/google/mt5-small) on the wmt16 ro-en dataset.
It achieves the following results on the evaluation set:
- Loss: 3.7760
- Bleu: 1.1101
- Gen Len: 99.5898
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 4
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5.0
### Training results
### Framework versions
- Transformers 4.20.1
- Pytorch 1.12.0+cu102
- Datasets 2.3.2
- Tokenizers 0.12.1
|
skouras/DialoGPT-small-maptask
|
skouras
| 2022-08-12T07:22:42Z | 95 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"conversational",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-08-12T06:36:56Z |
---
tags:
- conversational
---
DialoGPT-small finetuned in the Maptask Corpus. The [repository](https://github.com/KonstSkouras/Maptask-Corpus/tree/develop) with additionally pre-processed Maptask dialogues of concatenated utterances per speaker, 80/10/10 train/val/test split and metadata, is a fork of the [Nathan Duran's repository](https://github.com/NathanDuran/Maptask-Corpus). For finetuning the `train_dialogpt.ipynb` notebook from Nathan Cooper's [Tutorial](https://nathancooper.io/i-am-a-nerd/chatbot/deep-learning/gpt2/2020/05/12/chatbot-part-1.html) was used to finetune the model with slight modifications in Google Collab.
History dialogue context = 5. Number of utterances: 14712 (train set), 1964 (test set), 2017 (val set). Fine-tuning for 3 epochs with batch size 2.
Evaluation perplexity in Maptask from 410.7796 (pre-trainded model) to 19.7469 (fine-tuned model).
|
skouras/DialoGPT-small-swda
|
skouras
| 2022-08-12T07:22:06Z | 104 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"conversational",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-08-12T06:01:01Z |
---
tags:
- conversational
---
DialoGPT-small finetuned in the Switchboard Dialogue Act (SwDa) Corpus. The [repository](https://github.com/KonstSkouras/Switchboard-Corpus/tree/develop/) with additionally pre-processed SwDa dialogues of concatenated utterances per speaker, 80/10/10 train/val/test split and metadata, is a fork of the [Nathan Duran's repository](https://github.com/NathanDuran/Switchboard-Corpus). For finetuning the `train_dialogpt.ipynb` notebook from Nathan Cooper's [Tutorial](https://nathancooper.io/i-am-a-nerd/chatbot/deep-learning/gpt2/2020/05/12/chatbot-part-1.html) was used to finetune the model with slight modifications in Google Collab.
History dialogue context = 5.
Number of utterances: 80704 (train set), 9749 (test set), 9616 (val set).
Checkpoint-84000 after fine-tuning for 2 epochs with batch size 2.
Evaluation perplexity in SwDa from 635.6993 (pre-trainded model) to 18.1693 (fine-tuned model).
|
susank/distilbert-base-uncased-finetuned-emotion
|
susank
| 2022-08-12T05:45:28Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_trainer",
"dataset:emotion",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-08-12T05:33:23Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- emotion
metrics:
- accuracy
- f1
model-index:
- name: distilbert-base-uncased-finetuned-emotion
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: emotion
type: emotion
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.924
- name: F1
type: f1
value: 0.9240247841894665
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-emotion
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the emotion dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2281
- Accuracy: 0.924
- F1: 0.9240
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 0.8687 | 1.0 | 250 | 0.3390 | 0.9015 | 0.8984 |
| 0.2645 | 2.0 | 500 | 0.2281 | 0.924 | 0.9240 |
### Framework versions
- Transformers 4.13.0
- Pytorch 1.12.0+cu113
- Datasets 2.0.0
- Tokenizers 0.10.3
|
carted-nlp/categorization-finetuned-20220721-164940-distilled-20220811-132317
|
carted-nlp
| 2022-08-12T04:21:30Z | 25 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"onnx",
"roberta",
"text-classification",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-08-11T13:25:02Z |
---
tags:
- generated_from_trainer
metrics:
- accuracy
- f1
model-index:
- name: categorization-finetuned-20220721-164940-distilled-20220811-132317
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# categorization-finetuned-20220721-164940-distilled-20220811-132317
This model is a fine-tuned version of [carted-nlp/categorization-finetuned-20220721-164940](https://huggingface.co/carted-nlp/categorization-finetuned-20220721-164940) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1522
- Accuracy: 0.8783
- F1: 0.8779
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 4e-05
- train_batch_size: 64
- eval_batch_size: 128
- seed: 314
- gradient_accumulation_steps: 4
- total_train_batch_size: 256
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 2000
- num_epochs: 30.0
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:------:|:---------------:|:--------:|:------:|
| 0.5212 | 0.56 | 2500 | 0.2564 | 0.7953 | 0.7921 |
| 0.243 | 1.12 | 5000 | 0.2110 | 0.8270 | 0.8249 |
| 0.2105 | 1.69 | 7500 | 0.1925 | 0.8409 | 0.8391 |
| 0.1939 | 2.25 | 10000 | 0.1837 | 0.8476 | 0.8465 |
| 0.1838 | 2.81 | 12500 | 0.1771 | 0.8528 | 0.8517 |
| 0.1729 | 3.37 | 15000 | 0.1722 | 0.8564 | 0.8555 |
| 0.1687 | 3.94 | 17500 | 0.1684 | 0.8593 | 0.8576 |
| 0.1602 | 4.5 | 20000 | 0.1653 | 0.8614 | 0.8604 |
| 0.1572 | 5.06 | 22500 | 0.1629 | 0.8648 | 0.8638 |
| 0.1507 | 5.62 | 25000 | 0.1605 | 0.8654 | 0.8646 |
| 0.1483 | 6.19 | 27500 | 0.1602 | 0.8661 | 0.8653 |
| 0.1431 | 6.75 | 30000 | 0.1597 | 0.8669 | 0.8663 |
| 0.1393 | 7.31 | 32500 | 0.1581 | 0.8691 | 0.8687 |
| 0.1374 | 7.87 | 35000 | 0.1556 | 0.8704 | 0.8697 |
| 0.1321 | 8.43 | 37500 | 0.1558 | 0.8707 | 0.8700 |
| 0.1328 | 9.0 | 40000 | 0.1536 | 0.8719 | 0.8711 |
| 0.1261 | 9.56 | 42500 | 0.1544 | 0.8716 | 0.8708 |
| 0.1256 | 10.12 | 45000 | 0.1541 | 0.8731 | 0.8725 |
| 0.122 | 10.68 | 47500 | 0.1520 | 0.8741 | 0.8734 |
| 0.1196 | 11.25 | 50000 | 0.1529 | 0.8734 | 0.8728 |
| 0.1182 | 11.81 | 52500 | 0.1510 | 0.8758 | 0.8751 |
| 0.1145 | 12.37 | 55000 | 0.1526 | 0.8746 | 0.8737 |
| 0.1141 | 12.93 | 57500 | 0.1512 | 0.8765 | 0.8759 |
| 0.1094 | 13.5 | 60000 | 0.1517 | 0.8760 | 0.8753 |
| 0.1098 | 14.06 | 62500 | 0.1513 | 0.8771 | 0.8764 |
| 0.1058 | 14.62 | 65000 | 0.1506 | 0.8775 | 0.8768 |
| 0.1048 | 15.18 | 67500 | 0.1521 | 0.8774 | 0.8768 |
| 0.1028 | 15.74 | 70000 | 0.1520 | 0.8778 | 0.8773 |
| 0.1006 | 16.31 | 72500 | 0.1517 | 0.8780 | 0.8774 |
| 0.1001 | 16.87 | 75000 | 0.1505 | 0.8794 | 0.8790 |
| 0.0971 | 17.43 | 77500 | 0.1520 | 0.8784 | 0.8778 |
| 0.0973 | 17.99 | 80000 | 0.1514 | 0.8796 | 0.8790 |
| 0.0938 | 18.56 | 82500 | 0.1516 | 0.8795 | 0.8789 |
| 0.0942 | 19.12 | 85000 | 0.1522 | 0.8794 | 0.8789 |
| 0.0918 | 19.68 | 87500 | 0.1518 | 0.8799 | 0.8793 |
| 0.0909 | 20.24 | 90000 | 0.1528 | 0.8803 | 0.8796 |
| 0.0901 | 20.81 | 92500 | 0.1516 | 0.8799 | 0.8793 |
| 0.0882 | 21.37 | 95000 | 0.1519 | 0.8800 | 0.8794 |
| 0.088 | 21.93 | 97500 | 0.1517 | 0.8802 | 0.8798 |
| 0.086 | 22.49 | 100000 | 0.1530 | 0.8800 | 0.8795 |
| 0.0861 | 23.05 | 102500 | 0.1523 | 0.8806 | 0.8801 |
| 0.0846 | 23.62 | 105000 | 0.1524 | 0.8808 | 0.8802 |
| 0.0843 | 24.18 | 107500 | 0.1522 | 0.8805 | 0.8800 |
| 0.0836 | 24.74 | 110000 | 0.1525 | 0.8808 | 0.8803 |
| 0.083 | 25.3 | 112500 | 0.1528 | 0.8810 | 0.8803 |
| 0.0829 | 25.87 | 115000 | 0.1528 | 0.8808 | 0.8802 |
| 0.082 | 26.43 | 117500 | 0.1529 | 0.8808 | 0.8802 |
| 0.0818 | 26.99 | 120000 | 0.1525 | 0.8811 | 0.8805 |
| 0.0816 | 27.55 | 122500 | 0.1526 | 0.8811 | 0.8806 |
| 0.0809 | 28.12 | 125000 | 0.1528 | 0.8810 | 0.8805 |
| 0.0809 | 28.68 | 127500 | 0.1527 | 0.8810 | 0.8804 |
| 0.0814 | 29.24 | 130000 | 0.1528 | 0.8808 | 0.8802 |
| 0.0807 | 29.8 | 132500 | 0.1528 | 0.8808 | 0.8802 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.11.0+cu113
- Datasets 2.3.2
- Tokenizers 0.11.6
|
Falcom/animal-classifier
|
Falcom
| 2022-08-12T04:02:18Z | 241 | 2 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"vit",
"image-classification",
"huggingpics",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2022-08-12T04:02:02Z |
---
tags:
- image-classification
- pytorch
- huggingpics
metrics:
- accuracy
model-index:
- name: animal-classifier
results:
- task:
name: Image Classification
type: image-classification
metrics:
- name: Accuracy
type: accuracy
value: 1.0
---
# animal-classifier
Autogenerated by HuggingPics🤗🖼️
Create your own image classifier for **anything** by running [the demo on Google Colab](https://colab.research.google.com/github/nateraw/huggingpics/blob/main/HuggingPics.ipynb).
Report any issues with the demo at the [github repo](https://github.com/nateraw/huggingpics).
## Example Images
#### butterfly

#### cat

#### chicken

#### cow

#### dog

#### elephant

#### horse

#### sheep

#### spider

#### squirrel

|
Lvxue/distilled-mt5-small-1-0.5
|
Lvxue
| 2022-08-12T03:22:00Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"mt5",
"text2text-generation",
"generated_from_trainer",
"en",
"ro",
"dataset:wmt16",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-08-12T02:06:37Z |
---
language:
- en
- ro
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- wmt16
metrics:
- bleu
model-index:
- name: distilled-mt5-small-1-0.5
results:
- task:
name: Translation
type: translation
dataset:
name: wmt16 ro-en
type: wmt16
args: ro-en
metrics:
- name: Bleu
type: bleu
value: 5.3917
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilled-mt5-small-1-0.5
This model is a fine-tuned version of [google/mt5-small](https://huggingface.co/google/mt5-small) on the wmt16 ro-en dataset.
It achieves the following results on the evaluation set:
- Loss: 3.8410
- Bleu: 5.3917
- Gen Len: 40.6103
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 4
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5.0
### Training results
### Framework versions
- Transformers 4.20.1
- Pytorch 1.12.0+cu102
- Datasets 2.3.2
- Tokenizers 0.12.1
|
Lvxue/distilled-mt5-small-1-1
|
Lvxue
| 2022-08-12T03:18:55Z | 16 | 0 |
transformers
|
[
"transformers",
"pytorch",
"mt5",
"text2text-generation",
"generated_from_trainer",
"en",
"ro",
"dataset:wmt16",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-08-12T02:08:29Z |
---
language:
- en
- ro
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- wmt16
metrics:
- bleu
model-index:
- name: distilled-mt5-small-1-1
results:
- task:
name: Translation
type: translation
dataset:
name: wmt16 ro-en
type: wmt16
args: ro-en
metrics:
- name: Bleu
type: bleu
value: 6.6959
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilled-mt5-small-1-1
This model is a fine-tuned version of [google/mt5-small](https://huggingface.co/google/mt5-small) on the wmt16 ro-en dataset.
It achieves the following results on the evaluation set:
- Loss: 2.8289
- Bleu: 6.6959
- Gen Len: 45.7539
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 4
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5.0
### Training results
### Framework versions
- Transformers 4.20.1
- Pytorch 1.12.0+cu102
- Datasets 2.3.2
- Tokenizers 0.12.1
|
Lvxue/distilled-mt5-small-0.005-0.25
|
Lvxue
| 2022-08-12T01:28:13Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"mt5",
"text2text-generation",
"generated_from_trainer",
"en",
"ro",
"dataset:wmt16",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-08-12T00:14:33Z |
---
language:
- en
- ro
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- wmt16
metrics:
- bleu
model-index:
- name: distilled-mt5-small-0.005-0.25
results:
- task:
name: Translation
type: translation
dataset:
name: wmt16 ro-en
type: wmt16
args: ro-en
metrics:
- name: Bleu
type: bleu
value: 7.6069
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilled-mt5-small-0.005-0.25
This model is a fine-tuned version of [google/mt5-small](https://huggingface.co/google/mt5-small) on the wmt16 ro-en dataset.
It achieves the following results on the evaluation set:
- Loss: 2.8536
- Bleu: 7.6069
- Gen Len: 45.1846
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 4
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5.0
### Training results
### Framework versions
- Transformers 4.20.1
- Pytorch 1.12.0+cu102
- Datasets 2.3.2
- Tokenizers 0.12.1
|
Lvxue/distilled-mt5-small-0.02-0.25
|
Lvxue
| 2022-08-12T01:26:26Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"mt5",
"text2text-generation",
"generated_from_trainer",
"en",
"ro",
"dataset:wmt16",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-08-12T00:12:00Z |
---
language:
- en
- ro
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- wmt16
metrics:
- bleu
model-index:
- name: distilled-mt5-small-0.02-0.25
results:
- task:
name: Translation
type: translation
dataset:
name: wmt16 ro-en
type: wmt16
args: ro-en
metrics:
- name: Bleu
type: bleu
value: 7.5228
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilled-mt5-small-0.02-0.25
This model is a fine-tuned version of [google/mt5-small](https://huggingface.co/google/mt5-small) on the wmt16 ro-en dataset.
It achieves the following results on the evaluation set:
- Loss: 2.8275
- Bleu: 7.5228
- Gen Len: 44.6403
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 4
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5.0
### Training results
### Framework versions
- Transformers 4.20.1
- Pytorch 1.12.0+cu102
- Datasets 2.3.2
- Tokenizers 0.12.1
|
brookelove/finetuning-sentiment-model-3000-samples
|
brookelove
| 2022-08-12T01:02:47Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_trainer",
"dataset:imdb",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-08-12T00:16:58Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- imdb
metrics:
- accuracy
- f1
model-index:
- name: finetuning-sentiment-model-3000-samples
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: imdb
type: imdb
config: plain_text
split: train
args: plain_text
metrics:
- name: Accuracy
type: accuracy
value: 0.8633333333333333
- name: F1
type: f1
value: 0.8673139158576051
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# finetuning-sentiment-model-3000-samples
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the imdb dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3246
- Accuracy: 0.8633
- F1: 0.8673
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
### Framework versions
- Transformers 4.21.1
- Pytorch 1.12.0+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
roshan151/Model_output
|
roshan151
| 2022-08-12T00:37:05Z | 62 | 0 |
transformers
|
[
"transformers",
"tf",
"bert",
"fill-mask",
"generated_from_keras_callback",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-08-10T22:55:31Z |
---
license: apache-2.0
tags:
- generated_from_keras_callback
model-index:
- name: roshan151/Model_output
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# roshan151/Model_output
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 2.9849
- Validation Loss: 2.8623
- Epoch: 4
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'AdamWeightDecay', 'learning_rate': {'class_name': 'WarmUp', 'config': {'initial_learning_rate': 2e-05, 'decay_schedule_fn': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 2e-05, 'decay_steps': -82, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}, '__passive_serialization__': True}, 'warmup_steps': 100, 'power': 1.0, 'name': None}}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False, 'weight_decay_rate': 0.01}
- training_precision: mixed_float16
### Training results
| Train Loss | Validation Loss | Epoch |
|:----------:|:---------------:|:-----:|
| 3.1673 | 2.8445 | 0 |
| 2.9770 | 2.8557 | 1 |
| 3.0018 | 2.8612 | 2 |
| 2.9625 | 2.8496 | 3 |
| 2.9849 | 2.8623 | 4 |
### Framework versions
- Transformers 4.21.1
- TensorFlow 2.8.2
- Datasets 2.4.0
- Tokenizers 0.12.1
|
DOOGLAK/Article_500v6_NER_Model_3Epochs_UNAUGMENTED
|
DOOGLAK
| 2022-08-12T00:05:01Z | 106 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"token-classification",
"generated_from_trainer",
"dataset:article500v6_wikigold_split",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-08-12T00:00:05Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- article500v6_wikigold_split
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: Article_500v6_NER_Model_3Epochs_UNAUGMENTED
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: article500v6_wikigold_split
type: article500v6_wikigold_split
args: default
metrics:
- name: Precision
type: precision
value: 0.6462295081967213
- name: Recall
type: recall
value: 0.6930379746835443
- name: F1
type: f1
value: 0.6688157448252461
- name: Accuracy
type: accuracy
value: 0.9318540995006005
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Article_500v6_NER_Model_3Epochs_UNAUGMENTED
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the article500v6_wikigold_split dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2025
- Precision: 0.6462
- Recall: 0.6930
- F1: 0.6688
- Accuracy: 0.9319
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 63 | 0.2794 | 0.3775 | 0.4525 | 0.4116 | 0.8945 |
| No log | 2.0 | 126 | 0.2119 | 0.6143 | 0.6670 | 0.6396 | 0.9266 |
| No log | 3.0 | 189 | 0.2025 | 0.6462 | 0.6930 | 0.6688 | 0.9319 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.11.0+cu113
- Datasets 2.4.0
- Tokenizers 0.11.6
|
DOOGLAK/Article_500v2_NER_Model_3Epochs_UNAUGMENTED
|
DOOGLAK
| 2022-08-11T23:41:48Z | 103 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"token-classification",
"generated_from_trainer",
"dataset:article500v2_wikigold_split",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-08-11T23:36:55Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- article500v2_wikigold_split
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: Article_500v2_NER_Model_3Epochs_UNAUGMENTED
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: article500v2_wikigold_split
type: article500v2_wikigold_split
args: default
metrics:
- name: Precision
type: precision
value: 0.6510177281680893
- name: Recall
type: recall
value: 0.7377232142857143
- name: F1
type: f1
value: 0.6916637600279038
- name: Accuracy
type: accuracy
value: 0.936698943937827
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Article_500v2_NER_Model_3Epochs_UNAUGMENTED
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the article500v2_wikigold_split dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1886
- Precision: 0.6510
- Recall: 0.7377
- F1: 0.6917
- Accuracy: 0.9367
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 62 | 0.2863 | 0.4448 | 0.5990 | 0.5105 | 0.8927 |
| No log | 2.0 | 124 | 0.1965 | 0.6070 | 0.7321 | 0.6637 | 0.9308 |
| No log | 3.0 | 186 | 0.1886 | 0.6510 | 0.7377 | 0.6917 | 0.9367 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.11.0+cu113
- Datasets 2.4.0
- Tokenizers 0.11.6
|
DOOGLAK/Article_500v1_NER_Model_3Epochs_UNAUGMENTED
|
DOOGLAK
| 2022-08-11T23:36:15Z | 104 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"token-classification",
"generated_from_trainer",
"dataset:article500v1_wikigold_split",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-08-11T23:31:14Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- article500v1_wikigold_split
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: Article_500v1_NER_Model_3Epochs_UNAUGMENTED
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: article500v1_wikigold_split
type: article500v1_wikigold_split
args: default
metrics:
- name: Precision
type: precision
value: 0.6614785992217899
- name: Recall
type: recall
value: 0.6746031746031746
- name: F1
type: f1
value: 0.6679764243614931
- name: Accuracy
type: accuracy
value: 0.9325595601710446
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Article_500v1_NER_Model_3Epochs_UNAUGMENTED
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the article500v1_wikigold_split dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2058
- Precision: 0.6615
- Recall: 0.6746
- F1: 0.6680
- Accuracy: 0.9326
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 58 | 0.3029 | 0.3539 | 0.3790 | 0.3660 | 0.8967 |
| No log | 2.0 | 116 | 0.2191 | 0.6223 | 0.6488 | 0.6353 | 0.9262 |
| No log | 3.0 | 174 | 0.2058 | 0.6615 | 0.6746 | 0.6680 | 0.9326 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.11.0+cu113
- Datasets 2.4.0
- Tokenizers 0.11.6
|
DOOGLAK/Article_500v0_NER_Model_3Epochs_UNAUGMENTED
|
DOOGLAK
| 2022-08-11T23:30:34Z | 106 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"token-classification",
"generated_from_trainer",
"dataset:article500v0_wikigold_split",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-08-11T23:25:11Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- article500v0_wikigold_split
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: Article_500v0_NER_Model_3Epochs_UNAUGMENTED
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: article500v0_wikigold_split
type: article500v0_wikigold_split
args: default
metrics:
- name: Precision
type: precision
value: 0.6387981711299804
- name: Recall
type: recall
value: 0.7249814677538917
- name: F1
type: f1
value: 0.6791666666666667
- name: Accuracy
type: accuracy
value: 0.9364674441205053
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Article_500v0_NER_Model_3Epochs_UNAUGMENTED
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the article500v0_wikigold_split dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1853
- Precision: 0.6388
- Recall: 0.7250
- F1: 0.6792
- Accuracy: 0.9365
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 59 | 0.2886 | 0.4480 | 0.6179 | 0.5194 | 0.9012 |
| No log | 2.0 | 118 | 0.1912 | 0.6132 | 0.6946 | 0.6514 | 0.9327 |
| No log | 3.0 | 177 | 0.1853 | 0.6388 | 0.7250 | 0.6792 | 0.9365 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.11.0+cu113
- Datasets 2.4.0
- Tokenizers 0.11.6
|
BigSalmon/InformalToFormalLincoln61Paraphrase
|
BigSalmon
| 2022-08-11T23:21:29Z | 161 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-08-05T22:11:12Z |
```
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("BigSalmon/InformalToFormalLincoln61Paraphrase")
model = AutoModelForCausalLM.from_pretrained("BigSalmon/InformalToFormalLincoln61Paraphrase")
```
```
Demo:
https://huggingface.co/spaces/BigSalmon/FormalInformalConciseWordy
```
```
prompt = """informal english: corn fields are all across illinois, visible once you leave chicago.\nTranslated into the Style of Abraham Lincoln:"""
input_ids = tokenizer.encode(prompt, return_tensors='pt')
outputs = model.generate(input_ids=input_ids,
max_length=10 + len(prompt),
temperature=1.0,
top_k=50,
top_p=0.95,
do_sample=True,
num_return_sequences=5,
early_stopping=True)
for i in range(5):
print(tokenizer.decode(outputs[i]))
```
```
How To Make Prompt:
informal english: i am very ready to do that just that.
Translated into the Style of Abraham Lincoln: you can assure yourself of my readiness to work toward this end.
Translated into the Style of Abraham Lincoln: please be assured that i am most ready to undertake this laborious task.
***
informal english: space is huge and needs to be explored.
Translated into the Style of Abraham Lincoln: space awaits traversal, a new world whose boundaries are endless.
Translated into the Style of Abraham Lincoln: space is a ( limitless / boundless ) expanse, a vast virgin domain awaiting exploration.
***
informal english: corn fields are all across illinois, visible once you leave chicago.
Translated into the Style of Abraham Lincoln: corn fields ( permeate illinois / span the state of illinois / ( occupy / persist in ) all corners of illinois / line the horizon of illinois / envelop the landscape of illinois ), manifesting themselves visibly as one ventures beyond chicago.
informal english:
```
```
infill: chrome extensions [MASK] accomplish everyday tasks.
Translated into the Style of Abraham Lincoln: chrome extensions ( expedite the ability to / unlock the means to more readily ) accomplish everyday tasks.
infill: at a time when nintendo has become inflexible, [MASK] consoles that are tethered to a fixed iteration, sega diligently curates its legacy of classic video games on handheld devices.
Translated into the Style of Abraham Lincoln: at a time when nintendo has become inflexible, ( stubbornly [MASK] on / firmly set on / unyielding in its insistence on ) consoles that are tethered to a fixed iteration, sega diligently curates its legacy of classic video games on handheld devices.
infill:
```
```
Essay Intro (Warriors vs. Rockets in Game 7):
text: eagerly anticipated by fans, game 7's are the highlight of the post-season.
text: ever-building in suspense, game 7's have the crowd captivated.
***
Essay Intro (South Korean TV Is Becoming Popular):
text: maturing into a bona fide paragon of programming, south korean television ( has much to offer / entertains without fail / never disappoints ).
text: increasingly held in critical esteem, south korean television continues to impress.
text: at the forefront of quality content, south korea is quickly achieving celebrity status.
***
Essay Intro (
```
```
Search: What is the definition of Checks and Balances?
https://en.wikipedia.org/wiki/Checks_and_balances
Checks and Balances is the idea of having a system where each and every action in government should be subject to one or more checks that would not allow one branch or the other to overly dominate.
https://www.harvard.edu/glossary/Checks_and_Balances
Checks and Balances is a system that allows each branch of government to limit the powers of the other branches in order to prevent abuse of power
https://www.law.cornell.edu/library/constitution/Checks_and_Balances
Checks and Balances is a system of separation through which branches of government can control the other, thus preventing excess power.
***
Search: What is the definition of Separation of Powers?
https://en.wikipedia.org/wiki/Separation_of_powers
The separation of powers is a principle in government, whereby governmental powers are separated into different branches, each with their own set of powers, that are prevent one branch from aggregating too much power.
https://www.yale.edu/tcf/Separation_of_Powers.html
Separation of Powers is the division of governmental functions between the executive, legislative and judicial branches, clearly demarcating each branch's authority, in the interest of ensuring that individual liberty or security is not undermined.
***
Search: What is the definition of Connection of Powers?
https://en.wikipedia.org/wiki/Connection_of_powers
Connection of Powers is a feature of some parliamentary forms of government where different branches of government are intermingled, typically the executive and legislative branches.
https://simple.wikipedia.org/wiki/Connection_of_powers
The term Connection of Powers describes a system of government in which there is overlap between different parts of the government.
***
Search: What is the definition of
```
```
Search: What are phrase synonyms for "second-guess"?
https://www.powerthesaurus.org/second-guess/synonyms
Shortest to Longest:
- feel dubious about
- raise an eyebrow at
- wrinkle their noses at
- cast a jaundiced eye at
- teeter on the fence about
***
Search: What are phrase synonyms for "mean to newbies"?
https://www.powerthesaurus.org/mean_to_newbies/synonyms
Shortest to Longest:
- readiness to balk at rookies
- absence of tolerance for novices
- hostile attitude toward newcomers
***
Search: What are phrase synonyms for "make use of"?
https://www.powerthesaurus.org/make_use_of/synonyms
Shortest to Longest:
- call upon
- glean value from
- reap benefits from
- derive utility from
- seize on the merits of
- draw on the strength of
- tap into the potential of
***
Search: What are phrase synonyms for "hurting itself"?
https://www.powerthesaurus.org/hurting_itself/synonyms
Shortest to Longest:
- erring
- slighting itself
- forfeiting its integrity
- doing itself a disservice
- evincing a lack of backbone
***
Search: What are phrase synonyms for "
```
```
- nebraska
- unicamerical legislature
- different from federal house and senate
text: featuring a unicameral legislature, nebraska's political system stands in stark contrast to the federal model, comprised of a house and senate.
***
- penny has practically no value
- should be taken out of circulation
- just as other coins have been in us history
- lost use
- value not enough
- to make environmental consequences worthy
text: all but valueless, the penny should be retired. as with other coins in american history, it has become defunct. too minute to warrant the environmental consequences of its production, it has outlived its usefulness.
***
-
```
```
original: sports teams are profitable for owners. [MASK], their valuations experience a dramatic uptick.
infill: sports teams are profitable for owners. ( accumulating vast sums / stockpiling treasure / realizing benefits / cashing in / registering robust financials / scoring on balance sheets ), their valuations experience a dramatic uptick.
***
original:
```
```
wordy: classical music is becoming less popular more and more.
Translate into Concise Text: interest in classic music is fading.
***
wordy:
```
```
sweet: savvy voters ousted him.
longer: voters who were informed delivered his defeat.
***
sweet:
```
```
1: commercial space company spacex plans to launch a whopping 52 flights in 2022.
2: spacex, a commercial space company, intends to undertake a total of 52 flights in 2022.
3: in 2022, commercial space company spacex has its sights set on undertaking 52 flights.
4: 52 flights are in the pipeline for 2022, according to spacex, a commercial space company.
5: a commercial space company, spacex aims to conduct 52 flights in 2022.
***
1:
```
Keywords to sentences or sentence.
```
ngos are characterized by:
□ voluntary citizens' group that is organized on a local, national or international level
□ encourage political participation
□ often serve humanitarian functions
□ work for social, economic, or environmental change
***
what are the drawbacks of living near an airbnb?
□ noise
□ parking
□ traffic
□ security
□ strangers
***
```
```
original: musicals generally use spoken dialogue as well as songs to convey the story. operas are usually fully sung.
adapted: musicals generally use spoken dialogue as well as songs to convey the story. ( in a stark departure / on the other hand / in contrast / by comparison / at odds with this practice / far from being alike / in defiance of this standard / running counter to this convention ), operas are usually fully sung.
***
original: akoya and tahitian are types of pearls. akoya pearls are mostly white, and tahitian pearls are naturally dark.
adapted: akoya and tahitian are types of pearls. ( a far cry from being indistinguishable / easily distinguished / on closer inspection / setting them apart / not to be mistaken for one another / hardly an instance of mere synonymy / differentiating the two ), akoya pearls are mostly white, and tahitian pearls are naturally dark.
***
original:
```
```
original: had trouble deciding.
translated into journalism speak: wrestled with the question, agonized over the matter, furrowed their brows in contemplation.
***
original:
```
```
input: not loyal
1800s english: ( two-faced / inimical / perfidious / duplicitous / mendacious / double-dealing / shifty ).
***
input:
```
```
first: ( was complicit in / was involved in ).
antonym: ( was blameless / was not an accomplice to / had no hand in / was uninvolved in ).
***
first: ( have no qualms about / see no issue with ).
antonym: ( are deeply troubled by / harbor grave reservations about / have a visceral aversion to / take ( umbrage at / exception to ) / are wary of ).
***
first: ( do not see eye to eye / disagree often ).
antonym: ( are in sync / are united / have excellent rapport / are like-minded / are in step / are of one mind / are in lockstep / operate in perfect harmony / march in lockstep ).
***
first:
```
```
stiff with competition, law school {A} is the launching pad for countless careers, {B} is a crowded field, {C} ranks among the most sought-after professional degrees, {D} is a professional proving ground.
***
languishing in viewership, saturday night live {A} is due for a creative renaissance, {B} is no longer a ratings juggernaut, {C} has been eclipsed by its imitators, {C} can still find its mojo.
***
dubbed the "manhattan of the south," atlanta {A} is a bustling metropolis, {B} is known for its vibrant downtown, {C} is a city of rich history, {D} is the pride of georgia.
***
embattled by scandal, harvard {A} is feeling the heat, {B} cannot escape the media glare, {C} is facing its most intense scrutiny yet, {D} is in the spotlight for all the wrong reasons.
```
Infill / Infilling / Masking / Phrase Masking
```
his contention [blank] by the evidence [sep] was refuted [answer]
***
few sights are as [blank] new york city as the colorful, flashing signage of its bodegas [sep] synonymous with [answer]
***
when rick won the lottery, all of his distant relatives [blank] his winnings [sep] clamored for [answer]
***
the library’s quiet atmosphere encourages visitors to [blank] in their work [sep] immerse themselves [answer]
***
```
|
BigSalmon/InformalToFormalLincoln63Paraphrase
|
BigSalmon
| 2022-08-11T23:20:43Z | 161 | 1 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-08-08T00:20:41Z |
```
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("BigSalmon/InformalToFormalLincoln63Paraphrase")
model = AutoModelForCausalLM.from_pretrained("BigSalmon/InformalToFormalLincoln63Paraphrase")
```
```
Demo:
https://huggingface.co/spaces/BigSalmon/FormalInformalConciseWordy
```
```
prompt = """informal english: corn fields are all across illinois, visible once you leave chicago.\nTranslated into the Style of Abraham Lincoln:"""
input_ids = tokenizer.encode(prompt, return_tensors='pt')
outputs = model.generate(input_ids=input_ids,
max_length=10 + len(prompt),
temperature=1.0,
top_k=50,
top_p=0.95,
do_sample=True,
num_return_sequences=5,
early_stopping=True)
for i in range(5):
print(tokenizer.decode(outputs[i]))
```
Most likely outputs:
```
prompt = """informal english: corn fields are all across illinois, visible once you leave chicago.\nTranslated into the Style of Abraham Lincoln:"""
text = tokenizer.encode(prompt)
myinput, past_key_values = torch.tensor([text]), None
myinput = myinput
myinput= myinput.to(device)
logits, past_key_values = model(myinput, past_key_values = past_key_values, return_dict=False)
logits = logits[0,-1]
probabilities = torch.nn.functional.softmax(logits)
best_logits, best_indices = logits.topk(250)
best_words = [tokenizer.decode([idx.item()]) for idx in best_indices]
text.append(best_indices[0].item())
best_probabilities = probabilities[best_indices].tolist()
words = []
print(best_words)
```
```
How To Make Prompt:
informal english: i am very ready to do that just that.
Translated into the Style of Abraham Lincoln: you can assure yourself of my readiness to work toward this end.
Translated into the Style of Abraham Lincoln: please be assured that i am most ready to undertake this laborious task.
***
informal english: space is huge and needs to be explored.
Translated into the Style of Abraham Lincoln: space awaits traversal, a new world whose boundaries are endless.
Translated into the Style of Abraham Lincoln: space is a ( limitless / boundless ) expanse, a vast virgin domain awaiting exploration.
***
informal english: corn fields are all across illinois, visible once you leave chicago.
Translated into the Style of Abraham Lincoln: corn fields ( permeate illinois / span the state of illinois / ( occupy / persist in ) all corners of illinois / line the horizon of illinois / envelop the landscape of illinois ), manifesting themselves visibly as one ventures beyond chicago.
informal english:
```
```
infill: chrome extensions [MASK] accomplish everyday tasks.
Translated into the Style of Abraham Lincoln: chrome extensions ( expedite the ability to / unlock the means to more readily ) accomplish everyday tasks.
infill: at a time when nintendo has become inflexible, [MASK] consoles that are tethered to a fixed iteration, sega diligently curates its legacy of classic video games on handheld devices.
Translated into the Style of Abraham Lincoln: at a time when nintendo has become inflexible, ( stubbornly [MASK] on / firmly set on / unyielding in its insistence on ) consoles that are tethered to a fixed iteration, sega diligently curates its legacy of classic video games on handheld devices.
infill:
```
```
Essay Intro (Warriors vs. Rockets in Game 7):
text: eagerly anticipated by fans, game 7's are the highlight of the post-season.
text: ever-building in suspense, game 7's have the crowd captivated.
***
Essay Intro (South Korean TV Is Becoming Popular):
text: maturing into a bona fide paragon of programming, south korean television ( has much to offer / entertains without fail / never disappoints ).
text: increasingly held in critical esteem, south korean television continues to impress.
text: at the forefront of quality content, south korea is quickly achieving celebrity status.
***
Essay Intro (
```
```
Search: What is the definition of Checks and Balances?
https://en.wikipedia.org/wiki/Checks_and_balances
Checks and Balances is the idea of having a system where each and every action in government should be subject to one or more checks that would not allow one branch or the other to overly dominate.
https://www.harvard.edu/glossary/Checks_and_Balances
Checks and Balances is a system that allows each branch of government to limit the powers of the other branches in order to prevent abuse of power
https://www.law.cornell.edu/library/constitution/Checks_and_Balances
Checks and Balances is a system of separation through which branches of government can control the other, thus preventing excess power.
***
Search: What is the definition of Separation of Powers?
https://en.wikipedia.org/wiki/Separation_of_powers
The separation of powers is a principle in government, whereby governmental powers are separated into different branches, each with their own set of powers, that are prevent one branch from aggregating too much power.
https://www.yale.edu/tcf/Separation_of_Powers.html
Separation of Powers is the division of governmental functions between the executive, legislative and judicial branches, clearly demarcating each branch's authority, in the interest of ensuring that individual liberty or security is not undermined.
***
Search: What is the definition of Connection of Powers?
https://en.wikipedia.org/wiki/Connection_of_powers
Connection of Powers is a feature of some parliamentary forms of government where different branches of government are intermingled, typically the executive and legislative branches.
https://simple.wikipedia.org/wiki/Connection_of_powers
The term Connection of Powers describes a system of government in which there is overlap between different parts of the government.
***
Search: What is the definition of
```
```
Search: What are phrase synonyms for "second-guess"?
https://www.powerthesaurus.org/second-guess/synonyms
Shortest to Longest:
- feel dubious about
- raise an eyebrow at
- wrinkle their noses at
- cast a jaundiced eye at
- teeter on the fence about
***
Search: What are phrase synonyms for "mean to newbies"?
https://www.powerthesaurus.org/mean_to_newbies/synonyms
Shortest to Longest:
- readiness to balk at rookies
- absence of tolerance for novices
- hostile attitude toward newcomers
***
Search: What are phrase synonyms for "make use of"?
https://www.powerthesaurus.org/make_use_of/synonyms
Shortest to Longest:
- call upon
- glean value from
- reap benefits from
- derive utility from
- seize on the merits of
- draw on the strength of
- tap into the potential of
***
Search: What are phrase synonyms for "hurting itself"?
https://www.powerthesaurus.org/hurting_itself/synonyms
Shortest to Longest:
- erring
- slighting itself
- forfeiting its integrity
- doing itself a disservice
- evincing a lack of backbone
***
Search: What are phrase synonyms for "
```
```
- nebraska
- unicamerical legislature
- different from federal house and senate
text: featuring a unicameral legislature, nebraska's political system stands in stark contrast to the federal model, comprised of a house and senate.
***
- penny has practically no value
- should be taken out of circulation
- just as other coins have been in us history
- lost use
- value not enough
- to make environmental consequences worthy
text: all but valueless, the penny should be retired. as with other coins in american history, it has become defunct. too minute to warrant the environmental consequences of its production, it has outlived its usefulness.
***
-
```
```
original: sports teams are profitable for owners. [MASK], their valuations experience a dramatic uptick.
infill: sports teams are profitable for owners. ( accumulating vast sums / stockpiling treasure / realizing benefits / cashing in / registering robust financials / scoring on balance sheets ), their valuations experience a dramatic uptick.
***
original:
```
```
wordy: classical music is becoming less popular more and more.
Translate into Concise Text: interest in classic music is fading.
***
wordy:
```
```
sweet: savvy voters ousted him.
longer: voters who were informed delivered his defeat.
***
sweet:
```
```
1: commercial space company spacex plans to launch a whopping 52 flights in 2022.
2: spacex, a commercial space company, intends to undertake a total of 52 flights in 2022.
3: in 2022, commercial space company spacex has its sights set on undertaking 52 flights.
4: 52 flights are in the pipeline for 2022, according to spacex, a commercial space company.
5: a commercial space company, spacex aims to conduct 52 flights in 2022.
***
1:
```
Keywords to sentences or sentence.
```
ngos are characterized by:
□ voluntary citizens' group that is organized on a local, national or international level
□ encourage political participation
□ often serve humanitarian functions
□ work for social, economic, or environmental change
***
what are the drawbacks of living near an airbnb?
□ noise
□ parking
□ traffic
□ security
□ strangers
***
```
```
original: musicals generally use spoken dialogue as well as songs to convey the story. operas are usually fully sung.
adapted: musicals generally use spoken dialogue as well as songs to convey the story. ( in a stark departure / on the other hand / in contrast / by comparison / at odds with this practice / far from being alike / in defiance of this standard / running counter to this convention ), operas are usually fully sung.
***
original: akoya and tahitian are types of pearls. akoya pearls are mostly white, and tahitian pearls are naturally dark.
adapted: akoya and tahitian are types of pearls. ( a far cry from being indistinguishable / easily distinguished / on closer inspection / setting them apart / not to be mistaken for one another / hardly an instance of mere synonymy / differentiating the two ), akoya pearls are mostly white, and tahitian pearls are naturally dark.
***
original:
```
```
original: had trouble deciding.
translated into journalism speak: wrestled with the question, agonized over the matter, furrowed their brows in contemplation.
***
original:
```
```
input: not loyal
1800s english: ( two-faced / inimical / perfidious / duplicitous / mendacious / double-dealing / shifty ).
***
input:
```
```
first: ( was complicit in / was involved in ).
antonym: ( was blameless / was not an accomplice to / had no hand in / was uninvolved in ).
***
first: ( have no qualms about / see no issue with ).
antonym: ( are deeply troubled by / harbor grave reservations about / have a visceral aversion to / take ( umbrage at / exception to ) / are wary of ).
***
first: ( do not see eye to eye / disagree often ).
antonym: ( are in sync / are united / have excellent rapport / are like-minded / are in step / are of one mind / are in lockstep / operate in perfect harmony / march in lockstep ).
***
first:
```
```
stiff with competition, law school {A} is the launching pad for countless careers, {B} is a crowded field, {C} ranks among the most sought-after professional degrees, {D} is a professional proving ground.
***
languishing in viewership, saturday night live {A} is due for a creative renaissance, {B} is no longer a ratings juggernaut, {C} has been eclipsed by its imitators, {C} can still find its mojo.
***
dubbed the "manhattan of the south," atlanta {A} is a bustling metropolis, {B} is known for its vibrant downtown, {C} is a city of rich history, {D} is the pride of georgia.
***
embattled by scandal, harvard {A} is feeling the heat, {B} cannot escape the media glare, {C} is facing its most intense scrutiny yet, {D} is in the spotlight for all the wrong reasons.
```
Infill / Infilling / Masking / Phrase Masking
```
his contention [blank] by the evidence [sep] was refuted [answer]
***
few sights are as [blank] new york city as the colorful, flashing signage of its bodegas [sep] synonymous with [answer]
***
when rick won the lottery, all of his distant relatives [blank] his winnings [sep] clamored for [answer]
***
the library’s quiet atmosphere encourages visitors to [blank] in their work [sep] immerse themselves [answer]
***
```
|
BigSalmon/InformalToFormalLincoln64Paraphrase
|
BigSalmon
| 2022-08-11T23:20:25Z | 161 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-08-11T22:55:51Z |
```
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("BigSalmon/InformalToFormalLincoln64Paraphrase")
model = AutoModelForCausalLM.from_pretrained("BigSalmon/InformalToFormalLincoln64Paraphrase")
```
```
Demo:
https://huggingface.co/spaces/BigSalmon/FormalInformalConciseWordy
```
```
prompt = """informal english: corn fields are all across illinois, visible once you leave chicago.\nTranslated into the Style of Abraham Lincoln:"""
input_ids = tokenizer.encode(prompt, return_tensors='pt')
outputs = model.generate(input_ids=input_ids,
max_length=10 + len(prompt),
temperature=1.0,
top_k=50,
top_p=0.95,
do_sample=True,
num_return_sequences=5,
early_stopping=True)
for i in range(5):
print(tokenizer.decode(outputs[i]))
```
Most likely outputs:
```
prompt = """informal english: corn fields are all across illinois, visible once you leave chicago.\nTranslated into the Style of Abraham Lincoln:"""
text = tokenizer.encode(prompt)
myinput, past_key_values = torch.tensor([text]), None
myinput = myinput
myinput= myinput.to(device)
logits, past_key_values = model(myinput, past_key_values = past_key_values, return_dict=False)
logits = logits[0,-1]
probabilities = torch.nn.functional.softmax(logits)
best_logits, best_indices = logits.topk(250)
best_words = [tokenizer.decode([idx.item()]) for idx in best_indices]
text.append(best_indices[0].item())
best_probabilities = probabilities[best_indices].tolist()
words = []
print(best_words)
```
```
How To Make Prompt:
informal english: i am very ready to do that just that.
Translated into the Style of Abraham Lincoln: you can assure yourself of my readiness to work toward this end.
Translated into the Style of Abraham Lincoln: please be assured that i am most ready to undertake this laborious task.
***
informal english: space is huge and needs to be explored.
Translated into the Style of Abraham Lincoln: space awaits traversal, a new world whose boundaries are endless.
Translated into the Style of Abraham Lincoln: space is a ( limitless / boundless ) expanse, a vast virgin domain awaiting exploration.
***
informal english: corn fields are all across illinois, visible once you leave chicago.
Translated into the Style of Abraham Lincoln: corn fields ( permeate illinois / span the state of illinois / ( occupy / persist in ) all corners of illinois / line the horizon of illinois / envelop the landscape of illinois ), manifesting themselves visibly as one ventures beyond chicago.
informal english:
```
```
infill: chrome extensions [MASK] accomplish everyday tasks.
Translated into the Style of Abraham Lincoln: chrome extensions ( expedite the ability to / unlock the means to more readily ) accomplish everyday tasks.
infill: at a time when nintendo has become inflexible, [MASK] consoles that are tethered to a fixed iteration, sega diligently curates its legacy of classic video games on handheld devices.
Translated into the Style of Abraham Lincoln: at a time when nintendo has become inflexible, ( stubbornly [MASK] on / firmly set on / unyielding in its insistence on ) consoles that are tethered to a fixed iteration, sega diligently curates its legacy of classic video games on handheld devices.
infill:
```
```
Essay Intro (Warriors vs. Rockets in Game 7):
text: eagerly anticipated by fans, game 7's are the highlight of the post-season.
text: ever-building in suspense, game 7's have the crowd captivated.
***
Essay Intro (South Korean TV Is Becoming Popular):
text: maturing into a bona fide paragon of programming, south korean television ( has much to offer / entertains without fail / never disappoints ).
text: increasingly held in critical esteem, south korean television continues to impress.
text: at the forefront of quality content, south korea is quickly achieving celebrity status.
***
Essay Intro (
```
```
Search: What is the definition of Checks and Balances?
https://en.wikipedia.org/wiki/Checks_and_balances
Checks and Balances is the idea of having a system where each and every action in government should be subject to one or more checks that would not allow one branch or the other to overly dominate.
https://www.harvard.edu/glossary/Checks_and_Balances
Checks and Balances is a system that allows each branch of government to limit the powers of the other branches in order to prevent abuse of power
https://www.law.cornell.edu/library/constitution/Checks_and_Balances
Checks and Balances is a system of separation through which branches of government can control the other, thus preventing excess power.
***
Search: What is the definition of Separation of Powers?
https://en.wikipedia.org/wiki/Separation_of_powers
The separation of powers is a principle in government, whereby governmental powers are separated into different branches, each with their own set of powers, that are prevent one branch from aggregating too much power.
https://www.yale.edu/tcf/Separation_of_Powers.html
Separation of Powers is the division of governmental functions between the executive, legislative and judicial branches, clearly demarcating each branch's authority, in the interest of ensuring that individual liberty or security is not undermined.
***
Search: What is the definition of Connection of Powers?
https://en.wikipedia.org/wiki/Connection_of_powers
Connection of Powers is a feature of some parliamentary forms of government where different branches of government are intermingled, typically the executive and legislative branches.
https://simple.wikipedia.org/wiki/Connection_of_powers
The term Connection of Powers describes a system of government in which there is overlap between different parts of the government.
***
Search: What is the definition of
```
```
Search: What are phrase synonyms for "second-guess"?
https://www.powerthesaurus.org/second-guess/synonyms
Shortest to Longest:
- feel dubious about
- raise an eyebrow at
- wrinkle their noses at
- cast a jaundiced eye at
- teeter on the fence about
***
Search: What are phrase synonyms for "mean to newbies"?
https://www.powerthesaurus.org/mean_to_newbies/synonyms
Shortest to Longest:
- readiness to balk at rookies
- absence of tolerance for novices
- hostile attitude toward newcomers
***
Search: What are phrase synonyms for "make use of"?
https://www.powerthesaurus.org/make_use_of/synonyms
Shortest to Longest:
- call upon
- glean value from
- reap benefits from
- derive utility from
- seize on the merits of
- draw on the strength of
- tap into the potential of
***
Search: What are phrase synonyms for "hurting itself"?
https://www.powerthesaurus.org/hurting_itself/synonyms
Shortest to Longest:
- erring
- slighting itself
- forfeiting its integrity
- doing itself a disservice
- evincing a lack of backbone
***
Search: What are phrase synonyms for "
```
```
- nebraska
- unicamerical legislature
- different from federal house and senate
text: featuring a unicameral legislature, nebraska's political system stands in stark contrast to the federal model, comprised of a house and senate.
***
- penny has practically no value
- should be taken out of circulation
- just as other coins have been in us history
- lost use
- value not enough
- to make environmental consequences worthy
text: all but valueless, the penny should be retired. as with other coins in american history, it has become defunct. too minute to warrant the environmental consequences of its production, it has outlived its usefulness.
***
-
```
```
original: sports teams are profitable for owners. [MASK], their valuations experience a dramatic uptick.
infill: sports teams are profitable for owners. ( accumulating vast sums / stockpiling treasure / realizing benefits / cashing in / registering robust financials / scoring on balance sheets ), their valuations experience a dramatic uptick.
***
original:
```
```
wordy: classical music is becoming less popular more and more.
Translate into Concise Text: interest in classic music is fading.
***
wordy:
```
```
sweet: savvy voters ousted him.
longer: voters who were informed delivered his defeat.
***
sweet:
```
```
1: commercial space company spacex plans to launch a whopping 52 flights in 2022.
2: spacex, a commercial space company, intends to undertake a total of 52 flights in 2022.
3: in 2022, commercial space company spacex has its sights set on undertaking 52 flights.
4: 52 flights are in the pipeline for 2022, according to spacex, a commercial space company.
5: a commercial space company, spacex aims to conduct 52 flights in 2022.
***
1:
```
Keywords to sentences or sentence.
```
ngos are characterized by:
□ voluntary citizens' group that is organized on a local, national or international level
□ encourage political participation
□ often serve humanitarian functions
□ work for social, economic, or environmental change
***
what are the drawbacks of living near an airbnb?
□ noise
□ parking
□ traffic
□ security
□ strangers
***
```
```
original: musicals generally use spoken dialogue as well as songs to convey the story. operas are usually fully sung.
adapted: musicals generally use spoken dialogue as well as songs to convey the story. ( in a stark departure / on the other hand / in contrast / by comparison / at odds with this practice / far from being alike / in defiance of this standard / running counter to this convention ), operas are usually fully sung.
***
original: akoya and tahitian are types of pearls. akoya pearls are mostly white, and tahitian pearls are naturally dark.
adapted: akoya and tahitian are types of pearls. ( a far cry from being indistinguishable / easily distinguished / on closer inspection / setting them apart / not to be mistaken for one another / hardly an instance of mere synonymy / differentiating the two ), akoya pearls are mostly white, and tahitian pearls are naturally dark.
***
original:
```
```
original: had trouble deciding.
translated into journalism speak: wrestled with the question, agonized over the matter, furrowed their brows in contemplation.
***
original:
```
```
input: not loyal
1800s english: ( two-faced / inimical / perfidious / duplicitous / mendacious / double-dealing / shifty ).
***
input:
```
```
first: ( was complicit in / was involved in ).
antonym: ( was blameless / was not an accomplice to / had no hand in / was uninvolved in ).
***
first: ( have no qualms about / see no issue with ).
antonym: ( are deeply troubled by / harbor grave reservations about / have a visceral aversion to / take ( umbrage at / exception to ) / are wary of ).
***
first: ( do not see eye to eye / disagree often ).
antonym: ( are in sync / are united / have excellent rapport / are like-minded / are in step / are of one mind / are in lockstep / operate in perfect harmony / march in lockstep ).
***
first:
```
```
stiff with competition, law school {A} is the launching pad for countless careers, {B} is a crowded field, {C} ranks among the most sought-after professional degrees, {D} is a professional proving ground.
***
languishing in viewership, saturday night live {A} is due for a creative renaissance, {B} is no longer a ratings juggernaut, {C} has been eclipsed by its imitators, {C} can still find its mojo.
***
dubbed the "manhattan of the south," atlanta {A} is a bustling metropolis, {B} is known for its vibrant downtown, {C} is a city of rich history, {D} is the pride of georgia.
***
embattled by scandal, harvard {A} is feeling the heat, {B} cannot escape the media glare, {C} is facing its most intense scrutiny yet, {D} is in the spotlight for all the wrong reasons.
```
Infill / Infilling / Masking / Phrase Masking
```
his contention [blank] by the evidence [sep] was refuted [answer]
***
few sights are as [blank] new york city as the colorful, flashing signage of its bodegas [sep] synonymous with [answer]
***
when rick won the lottery, all of his distant relatives [blank] his winnings [sep] clamored for [answer]
***
the library’s quiet atmosphere encourages visitors to [blank] in their work [sep] immerse themselves [answer]
***
```
|
DOOGLAK/Article_250v5_NER_Model_3Epochs_UNAUGMENTED
|
DOOGLAK
| 2022-08-11T23:11:37Z | 106 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"token-classification",
"generated_from_trainer",
"dataset:article250v5_wikigold_split",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-08-11T23:06:42Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- article250v5_wikigold_split
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: Article_250v5_NER_Model_3Epochs_UNAUGMENTED
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: article250v5_wikigold_split
type: article250v5_wikigold_split
args: default
metrics:
- name: Precision
type: precision
value: 0.3979099678456592
- name: Recall
type: recall
value: 0.4221148379761228
- name: F1
type: f1
value: 0.4096551724137931
- name: Accuracy
type: accuracy
value: 0.8778839730743538
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Article_250v5_NER_Model_3Epochs_UNAUGMENTED
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the article250v5_wikigold_split dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3250
- Precision: 0.3979
- Recall: 0.4221
- F1: 0.4097
- Accuracy: 0.8779
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 31 | 0.5229 | 0.1336 | 0.0344 | 0.0547 | 0.8008 |
| No log | 2.0 | 62 | 0.3701 | 0.3628 | 0.3357 | 0.3487 | 0.8596 |
| No log | 3.0 | 93 | 0.3250 | 0.3979 | 0.4221 | 0.4097 | 0.8779 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.11.0+cu113
- Datasets 2.4.0
- Tokenizers 0.11.6
|
Sameen53/facebook_large_CV_bn3
|
Sameen53
| 2022-08-11T23:02:21Z | 106 | 0 |
transformers
|
[
"transformers",
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"generated_from_trainer",
"dataset:common_voice",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-08-04T20:36:37Z |
---
tags:
- generated_from_trainer
datasets:
- common_voice
model-index:
- name: facebook_large_CV_bn3
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# facebook_large_CV_bn3
This model is a fine-tuned version of [Sameen53/facebook_large_CV_bn](https://huggingface.co/Sameen53/facebook_large_CV_bn) on the common_voice dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2308
- Wer: 0.2379
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 200
- num_epochs: 6
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| No log | 0.87 | 1000 | 0.2473 | 0.2524 |
| 0.2308 | 1.73 | 2000 | 0.2073 | 0.2450 |
| 0.261 | 2.6 | 3000 | 0.2036 | 0.2345 |
| 0.2498 | 3.47 | 4000 | 0.1916 | 0.2311 |
| 0.2433 | 4.33 | 5000 | 0.1869 | 0.2344 |
| 0.2588 | 5.2 | 6000 | 0.2308 | 0.2379 |
### Framework versions
- Transformers 4.20.1
- Pytorch 1.11.0
- Datasets 2.1.0
- Tokenizers 0.12.1
|
DOOGLAK/Article_250v3_NER_Model_3Epochs_UNAUGMENTED
|
DOOGLAK
| 2022-08-11T23:00:31Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"token-classification",
"generated_from_trainer",
"dataset:article250v3_wikigold_split",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-08-11T22:55:37Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- article250v3_wikigold_split
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: Article_250v3_NER_Model_3Epochs_UNAUGMENTED
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: article250v3_wikigold_split
type: article250v3_wikigold_split
args: default
metrics:
- name: Precision
type: precision
value: 0.46615905245346867
- name: Recall
type: recall
value: 0.47094017094017093
- name: F1
type: f1
value: 0.4685374149659864
- name: Accuracy
type: accuracy
value: 0.8992223869340199
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Article_250v3_NER_Model_3Epochs_UNAUGMENTED
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the article250v3_wikigold_split dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2795
- Precision: 0.4662
- Recall: 0.4709
- F1: 0.4685
- Accuracy: 0.8992
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 33 | 0.4736 | 0.1634 | 0.0755 | 0.1033 | 0.8223 |
| No log | 2.0 | 66 | 0.3129 | 0.3483 | 0.3276 | 0.3376 | 0.8831 |
| No log | 3.0 | 99 | 0.2795 | 0.4662 | 0.4709 | 0.4685 | 0.8992 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.11.0+cu113
- Datasets 2.4.0
- Tokenizers 0.11.6
|
DOOGLAK/Article_250v0_NER_Model_3Epochs_UNAUGMENTED
|
DOOGLAK
| 2022-08-11T22:43:47Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"token-classification",
"generated_from_trainer",
"dataset:article250v0_wikigold_split",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-08-11T22:38:41Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- article250v0_wikigold_split
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: Article_250v0_NER_Model_3Epochs_UNAUGMENTED
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: article250v0_wikigold_split
type: article250v0_wikigold_split
args: default
metrics:
- name: Precision
type: precision
value: 0.316
- name: Recall
type: recall
value: 0.2984349703184026
- name: F1
type: f1
value: 0.3069664168748265
- name: Accuracy
type: accuracy
value: 0.8677259136623094
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Article_250v0_NER_Model_3Epochs_UNAUGMENTED
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the article250v0_wikigold_split dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3397
- Precision: 0.316
- Recall: 0.2984
- F1: 0.3070
- Accuracy: 0.8677
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 28 | 0.5344 | 0.1336 | 0.0183 | 0.0323 | 0.7903 |
| No log | 2.0 | 56 | 0.3736 | 0.2753 | 0.2221 | 0.2458 | 0.8528 |
| No log | 3.0 | 84 | 0.3397 | 0.316 | 0.2984 | 0.3070 | 0.8677 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.11.0+cu113
- Datasets 2.4.0
- Tokenizers 0.11.6
|
DOOGLAK/Article_100v7_NER_Model_3Epochs_UNAUGMENTED
|
DOOGLAK
| 2022-08-11T22:27:05Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"token-classification",
"generated_from_trainer",
"dataset:article100v7_wikigold_split",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-08-11T22:22:01Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- article100v7_wikigold_split
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: Article_100v7_NER_Model_3Epochs_UNAUGMENTED
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: article100v7_wikigold_split
type: article100v7_wikigold_split
args: default
metrics:
- name: Precision
type: precision
value: 0.16614420062695925
- name: Recall
type: recall
value: 0.013751946030098598
- name: F1
type: f1
value: 0.025401389887371194
- name: Accuracy
type: accuracy
value: 0.7859983353370943
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Article_100v7_NER_Model_3Epochs_UNAUGMENTED
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the article100v7_wikigold_split dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6011
- Precision: 0.1661
- Recall: 0.0138
- F1: 0.0254
- Accuracy: 0.7860
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 12 | 0.7375 | 0.0 | 0.0 | 0.0 | 0.7810 |
| No log | 2.0 | 24 | 0.6356 | 0.0571 | 0.0010 | 0.0020 | 0.7820 |
| No log | 3.0 | 36 | 0.6011 | 0.1661 | 0.0138 | 0.0254 | 0.7860 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.11.0+cu113
- Datasets 2.4.0
- Tokenizers 0.11.6
|
DOOGLAK/Article_100v6_NER_Model_3Epochs_UNAUGMENTED
|
DOOGLAK
| 2022-08-11T22:21:24Z | 106 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"token-classification",
"generated_from_trainer",
"dataset:article100v6_wikigold_split",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-08-11T22:16:25Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- article100v6_wikigold_split
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: Article_100v6_NER_Model_3Epochs_UNAUGMENTED
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: article100v6_wikigold_split
type: article100v6_wikigold_split
args: default
metrics:
- name: Precision
type: precision
value: 0.0
- name: Recall
type: recall
value: 0.0
- name: F1
type: f1
value: 0.0
- name: Accuracy
type: accuracy
value: 0.7806604861399382
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Article_100v6_NER_Model_3Epochs_UNAUGMENTED
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the article100v6_wikigold_split dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5955
- Precision: 0.0
- Recall: 0.0
- F1: 0.0
- Accuracy: 0.7807
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:---:|:--------:|
| No log | 1.0 | 12 | 0.7335 | 0.0 | 0.0 | 0.0 | 0.7806 |
| No log | 2.0 | 24 | 0.6302 | 0.0 | 0.0 | 0.0 | 0.7806 |
| No log | 3.0 | 36 | 0.5955 | 0.0 | 0.0 | 0.0 | 0.7807 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.11.0+cu113
- Datasets 2.4.0
- Tokenizers 0.11.6
|
DOOGLAK/Article_100v5_NER_Model_3Epochs_UNAUGMENTED
|
DOOGLAK
| 2022-08-11T22:15:57Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"token-classification",
"generated_from_trainer",
"dataset:article100v5_wikigold_split",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-08-11T22:10:57Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- article100v5_wikigold_split
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: Article_100v5_NER_Model_3Epochs_UNAUGMENTED
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: article100v5_wikigold_split
type: article100v5_wikigold_split
args: default
metrics:
- name: Precision
type: precision
value: 0.024096385542168676
- name: Recall
type: recall
value: 0.0005104645227156713
- name: F1
type: f1
value: 0.000999750062484379
- name: Accuracy
type: accuracy
value: 0.7821558918567079
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Article_100v5_NER_Model_3Epochs_UNAUGMENTED
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the article100v5_wikigold_split dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5958
- Precision: 0.0241
- Recall: 0.0005
- F1: 0.0010
- Accuracy: 0.7822
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 13 | 0.7298 | 0.0 | 0.0 | 0.0 | 0.7816 |
| No log | 2.0 | 26 | 0.6272 | 0.0 | 0.0 | 0.0 | 0.7816 |
| No log | 3.0 | 39 | 0.5958 | 0.0241 | 0.0005 | 0.0010 | 0.7822 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.11.0+cu113
- Datasets 2.4.0
- Tokenizers 0.11.6
|
cansen88/PromptGenerator_5_topic_finetuned
|
cansen88
| 2022-08-11T22:13:34Z | 5 | 0 |
transformers
|
[
"transformers",
"tf",
"gpt2",
"text-generation",
"generated_from_keras_callback",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-08-11T21:39:35Z |
---
license: mit
tags:
- generated_from_keras_callback
model-index:
- name: PromptGenerator_5_topic_finetuned
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# PromptGenerator_5_topic_finetuned
This model is a fine-tuned version of [kmkarakaya/turkishReviews-ds](https://huggingface.co/kmkarakaya/turkishReviews-ds) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 1.6861
- Train Sparse Categorical Accuracy: 0.8150
- Validation Loss: 1.9777
- Validation Sparse Categorical Accuracy: 0.7250
- Epoch: 4
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'Adam', 'learning_rate': 5e-05, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-07, 'amsgrad': False}
- training_precision: float32
### Training results
| Train Loss | Train Sparse Categorical Accuracy | Validation Loss | Validation Sparse Categorical Accuracy | Epoch |
|:----------:|:---------------------------------:|:---------------:|:--------------------------------------:|:-----:|
| 3.0394 | 0.5171 | 2.7152 | 0.5841 | 0 |
| 2.5336 | 0.6247 | 2.4440 | 0.6318 | 1 |
| 2.2002 | 0.6958 | 2.2557 | 0.6659 | 2 |
| 1.9241 | 0.7608 | 2.1059 | 0.6932 | 3 |
| 1.6861 | 0.8150 | 1.9777 | 0.7250 | 4 |
### Framework versions
- Transformers 4.21.1
- TensorFlow 2.8.2
- Datasets 2.4.0
- Tokenizers 0.12.1
|
DOOGLAK/Article_100v3_NER_Model_3Epochs_UNAUGMENTED
|
DOOGLAK
| 2022-08-11T22:04:16Z | 107 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"token-classification",
"generated_from_trainer",
"dataset:article100v3_wikigold_split",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-08-11T21:59:14Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- article100v3_wikigold_split
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: Article_100v3_NER_Model_3Epochs_UNAUGMENTED
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: article100v3_wikigold_split
type: article100v3_wikigold_split
args: default
metrics:
- name: Precision
type: precision
value: 0.0
- name: Recall
type: recall
value: 0.0
- name: F1
type: f1
value: 0.0
- name: Accuracy
type: accuracy
value: 0.7772145452862069
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Article_100v3_NER_Model_3Epochs_UNAUGMENTED
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the article100v3_wikigold_split dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6272
- Precision: 0.0
- Recall: 0.0
- F1: 0.0
- Accuracy: 0.7772
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:---:|:--------:|
| No log | 1.0 | 11 | 0.7637 | 0.0 | 0.0 | 0.0 | 0.7772 |
| No log | 2.0 | 22 | 0.6651 | 0.0 | 0.0 | 0.0 | 0.7772 |
| No log | 3.0 | 33 | 0.6272 | 0.0 | 0.0 | 0.0 | 0.7772 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.11.0+cu113
- Datasets 2.4.0
- Tokenizers 0.11.6
|
DOOGLAK/Article_100v2_NER_Model_3Epochs_UNAUGMENTED
|
DOOGLAK
| 2022-08-11T21:58:45Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"token-classification",
"generated_from_trainer",
"dataset:article100v2_wikigold_split",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-08-11T21:53:59Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- article100v2_wikigold_split
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: Article_100v2_NER_Model_3Epochs_UNAUGMENTED
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: article100v2_wikigold_split
type: article100v2_wikigold_split
args: default
metrics:
- name: Precision
type: precision
value: 0.03389830508474576
- name: Recall
type: recall
value: 0.0005091649694501018
- name: F1
type: f1
value: 0.001003260596940055
- name: Accuracy
type: accuracy
value: 0.7818691674711534
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Article_100v2_NER_Model_3Epochs_UNAUGMENTED
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the article100v2_wikigold_split dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6054
- Precision: 0.0339
- Recall: 0.0005
- F1: 0.0010
- Accuracy: 0.7819
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 12 | 0.7284 | 0.0 | 0.0 | 0.0 | 0.7814 |
| No log | 2.0 | 24 | 0.6406 | 0.0 | 0.0 | 0.0 | 0.7813 |
| No log | 3.0 | 36 | 0.6054 | 0.0339 | 0.0005 | 0.0010 | 0.7819 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.11.0+cu113
- Datasets 2.4.0
- Tokenizers 0.11.6
|
DOOGLAK/Article_100v1_NER_Model_3Epochs_UNAUGMENTED
|
DOOGLAK
| 2022-08-11T21:53:29Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"token-classification",
"generated_from_trainer",
"dataset:article100v1_wikigold_split",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-08-11T21:48:36Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- article100v1_wikigold_split
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: Article_100v1_NER_Model_3Epochs_UNAUGMENTED
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: article100v1_wikigold_split
type: article100v1_wikigold_split
args: default
metrics:
- name: Precision
type: precision
value: 0.06
- name: Recall
type: recall
value: 0.0015592515592515593
- name: F1
type: f1
value: 0.00303951367781155
- name: Accuracy
type: accuracy
value: 0.7832046377355834
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Article_100v1_NER_Model_3Epochs_UNAUGMENTED
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the article100v1_wikigold_split dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5783
- Precision: 0.06
- Recall: 0.0016
- F1: 0.0030
- Accuracy: 0.7832
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 13 | 0.7124 | 0.0 | 0.0 | 0.0 | 0.7816 |
| No log | 2.0 | 26 | 0.6131 | 0.0 | 0.0 | 0.0 | 0.7819 |
| No log | 3.0 | 39 | 0.5783 | 0.06 | 0.0016 | 0.0030 | 0.7832 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.11.0+cu113
- Datasets 2.4.0
- Tokenizers 0.11.6
|
DOOGLAK/Article_50v9_NER_Model_3Epochs_UNAUGMENTED
|
DOOGLAK
| 2022-08-11T21:42:33Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"token-classification",
"generated_from_trainer",
"dataset:article50v9_wikigold_split",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-08-11T21:37:41Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- article50v9_wikigold_split
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: Article_50v9_NER_Model_3Epochs_UNAUGMENTED
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: article50v9_wikigold_split
type: article50v9_wikigold_split
args: default
metrics:
- name: Precision
type: precision
value: 0.0
- name: Recall
type: recall
value: 0.0
- name: F1
type: f1
value: 0.0
- name: Accuracy
type: accuracy
value: 0.7781540876976561
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Article_50v9_NER_Model_3Epochs_UNAUGMENTED
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the article50v9_wikigold_split dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7640
- Precision: 0.0
- Recall: 0.0
- F1: 0.0
- Accuracy: 0.7782
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 6 | 0.9810 | 0.0918 | 0.0044 | 0.0084 | 0.7772 |
| No log | 2.0 | 12 | 0.7952 | 0.0 | 0.0 | 0.0 | 0.7782 |
| No log | 3.0 | 18 | 0.7640 | 0.0 | 0.0 | 0.0 | 0.7782 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.11.0+cu113
- Datasets 2.4.0
- Tokenizers 0.11.6
|
DOOGLAK/Article_50v8_NER_Model_3Epochs_UNAUGMENTED
|
DOOGLAK
| 2022-08-11T21:37:12Z | 106 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"token-classification",
"generated_from_trainer",
"dataset:article50v8_wikigold_split",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-08-11T21:32:16Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- article50v8_wikigold_split
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: Article_50v8_NER_Model_3Epochs_UNAUGMENTED
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: article50v8_wikigold_split
type: article50v8_wikigold_split
args: default
metrics:
- name: Precision
type: precision
value: 0.0
- name: Recall
type: recall
value: 0.0
- name: F1
type: f1
value: 0.0
- name: Accuracy
type: accuracy
value: 0.7786409940669428
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Article_50v8_NER_Model_3Epochs_UNAUGMENTED
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the article50v8_wikigold_split dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7555
- Precision: 0.0
- Recall: 0.0
- F1: 0.0
- Accuracy: 0.7786
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 6 | 0.9789 | 0.1 | 0.0047 | 0.0089 | 0.7776 |
| No log | 2.0 | 12 | 0.7892 | 0.0 | 0.0 | 0.0 | 0.7786 |
| No log | 3.0 | 18 | 0.7555 | 0.0 | 0.0 | 0.0 | 0.7786 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.11.0+cu113
- Datasets 2.4.0
- Tokenizers 0.11.6
|
DOOGLAK/Article_50v7_NER_Model_3Epochs_UNAUGMENTED
|
DOOGLAK
| 2022-08-11T21:31:46Z | 107 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"token-classification",
"generated_from_trainer",
"dataset:article50v7_wikigold_split",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-08-11T21:26:35Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- article50v7_wikigold_split
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: Article_50v7_NER_Model_3Epochs_UNAUGMENTED
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: article50v7_wikigold_split
type: article50v7_wikigold_split
args: default
metrics:
- name: Precision
type: precision
value: 0.3333333333333333
- name: Recall
type: recall
value: 0.00024324981756263683
- name: F1
type: f1
value: 0.0004861448711716091
- name: Accuracy
type: accuracy
value: 0.7783221476510067
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Article_50v7_NER_Model_3Epochs_UNAUGMENTED
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the article50v7_wikigold_split dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7894
- Precision: 0.3333
- Recall: 0.0002
- F1: 0.0005
- Accuracy: 0.7783
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 6 | 1.0271 | 0.1183 | 0.0102 | 0.0188 | 0.7768 |
| No log | 2.0 | 12 | 0.8250 | 0.4 | 0.0005 | 0.0010 | 0.7783 |
| No log | 3.0 | 18 | 0.7894 | 0.3333 | 0.0002 | 0.0005 | 0.7783 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.11.0+cu113
- Datasets 2.4.0
- Tokenizers 0.11.6
|
DOOGLAK/Article_50v6_NER_Model_3Epochs_UNAUGMENTED
|
DOOGLAK
| 2022-08-11T21:26:06Z | 107 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"token-classification",
"generated_from_trainer",
"dataset:article50v6_wikigold_split",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-08-11T21:21:05Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- article50v6_wikigold_split
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: Article_50v6_NER_Model_3Epochs_UNAUGMENTED
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: article50v6_wikigold_split
type: article50v6_wikigold_split
args: default
metrics:
- name: Precision
type: precision
value: 0.0
- name: Recall
type: recall
value: 0.0
- name: F1
type: f1
value: 0.0
- name: Accuracy
type: accuracy
value: 0.7772842497251946
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Article_50v6_NER_Model_3Epochs_UNAUGMENTED
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the article50v6_wikigold_split dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7622
- Precision: 0.0
- Recall: 0.0
- F1: 0.0
- Accuracy: 0.7773
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 7 | 0.9429 | 0.1579 | 0.0015 | 0.0029 | 0.7769 |
| No log | 2.0 | 14 | 0.7845 | 0.0 | 0.0 | 0.0 | 0.7773 |
| No log | 3.0 | 21 | 0.7622 | 0.0 | 0.0 | 0.0 | 0.7773 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.11.0+cu113
- Datasets 2.4.0
- Tokenizers 0.11.6
|
DOOGLAK/Article_50v5_NER_Model_3Epochs_UNAUGMENTED
|
DOOGLAK
| 2022-08-11T21:20:35Z | 103 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"token-classification",
"generated_from_trainer",
"dataset:article50v5_wikigold_split",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-08-11T21:15:39Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- article50v5_wikigold_split
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: Article_50v5_NER_Model_3Epochs_UNAUGMENTED
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: article50v5_wikigold_split
type: article50v5_wikigold_split
args: default
metrics:
- name: Precision
type: precision
value: 0.0
- name: Recall
type: recall
value: 0.0
- name: F1
type: f1
value: 0.0
- name: Accuracy
type: accuracy
value: 0.7765277995652466
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Article_50v5_NER_Model_3Epochs_UNAUGMENTED
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the article50v5_wikigold_split dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7582
- Precision: 0.0
- Recall: 0.0
- F1: 0.0
- Accuracy: 0.7765
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 6 | 0.9705 | 0.1634 | 0.0061 | 0.0117 | 0.7757 |
| No log | 2.0 | 12 | 0.7855 | 0.0 | 0.0 | 0.0 | 0.7765 |
| No log | 3.0 | 18 | 0.7582 | 0.0 | 0.0 | 0.0 | 0.7765 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.11.0+cu113
- Datasets 2.4.0
- Tokenizers 0.11.6
|
DOOGLAK/Article_50v3_NER_Model_3Epochs_UNAUGMENTED
|
DOOGLAK
| 2022-08-11T21:09:53Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"token-classification",
"generated_from_trainer",
"dataset:article50v3_wikigold_split",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-08-11T21:04:53Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- article50v3_wikigold_split
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: Article_50v3_NER_Model_3Epochs_UNAUGMENTED
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: article50v3_wikigold_split
type: article50v3_wikigold_split
args: default
metrics:
- name: Precision
type: precision
value: 0.0
- name: Recall
type: recall
value: 0.0
- name: F1
type: f1
value: 0.0
- name: Accuracy
type: accuracy
value: 0.778882266951535
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Article_50v3_NER_Model_3Epochs_UNAUGMENTED
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the article50v3_wikigold_split dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7382
- Precision: 0.0
- Recall: 0.0
- F1: 0.0
- Accuracy: 0.7789
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 6 | 0.9648 | 0.1172 | 0.0042 | 0.0081 | 0.7782 |
| No log | 2.0 | 12 | 0.7740 | 0.0 | 0.0 | 0.0 | 0.7789 |
| No log | 3.0 | 18 | 0.7382 | 0.0 | 0.0 | 0.0 | 0.7789 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.11.0+cu113
- Datasets 2.4.0
- Tokenizers 0.11.6
|
DOOGLAK/Article_50v1_NER_Model_3Epochs_UNAUGMENTED
|
DOOGLAK
| 2022-08-11T20:58:43Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"token-classification",
"generated_from_trainer",
"dataset:article50v1_wikigold_split",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-08-11T20:53:51Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- article50v1_wikigold_split
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: Article_50v1_NER_Model_3Epochs_UNAUGMENTED
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: article50v1_wikigold_split
type: article50v1_wikigold_split
args: default
metrics:
- name: Precision
type: precision
value: 0.0
- name: Recall
type: recall
value: 0.0
- name: F1
type: f1
value: 0.0
- name: Accuracy
type: accuracy
value: 0.7774799531489324
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Article_50v1_NER_Model_3Epochs_UNAUGMENTED
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the article50v1_wikigold_split dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7237
- Precision: 0.0
- Recall: 0.0
- F1: 0.0
- Accuracy: 0.7775
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 7 | 0.9016 | 0.12 | 0.0007 | 0.0015 | 0.7772 |
| No log | 2.0 | 14 | 0.7468 | 0.0 | 0.0 | 0.0 | 0.7775 |
| No log | 3.0 | 21 | 0.7237 | 0.0 | 0.0 | 0.0 | 0.7775 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.11.0+cu113
- Datasets 2.4.0
- Tokenizers 0.11.6
|
DOOGLAK/Tagged_Uni_500v8_NER_Model_3Epochs_AUGMENTED
|
DOOGLAK
| 2022-08-11T20:37:02Z | 107 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"token-classification",
"generated_from_trainer",
"dataset:tagged_uni500v8_wikigold_split",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-08-11T20:31:43Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- tagged_uni500v8_wikigold_split
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: Tagged_Uni_500v8_NER_Model_3Epochs_AUGMENTED
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: tagged_uni500v8_wikigold_split
type: tagged_uni500v8_wikigold_split
args: default
metrics:
- name: Precision
type: precision
value: 0.704553603442094
- name: Recall
type: recall
value: 0.6968085106382979
- name: F1
type: f1
value: 0.7006596541272954
- name: Accuracy
type: accuracy
value: 0.9316528559681194
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Tagged_Uni_500v8_NER_Model_3Epochs_AUGMENTED
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the tagged_uni500v8_wikigold_split dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2501
- Precision: 0.7046
- Recall: 0.6968
- F1: 0.7007
- Accuracy: 0.9317
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 169 | 0.2800 | 0.5648 | 0.5035 | 0.5324 | 0.9043 |
| No log | 2.0 | 338 | 0.2383 | 0.6783 | 0.6738 | 0.6760 | 0.9286 |
| 0.1144 | 3.0 | 507 | 0.2501 | 0.7046 | 0.6968 | 0.7007 | 0.9317 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.11.0+cu113
- Datasets 2.4.0
- Tokenizers 0.11.6
|
DOOGLAK/Tagged_Uni_500v7_NER_Model_3Epochs_AUGMENTED
|
DOOGLAK
| 2022-08-11T20:31:05Z | 103 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"token-classification",
"generated_from_trainer",
"dataset:tagged_uni500v7_wikigold_split",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-08-11T20:25:39Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- tagged_uni500v7_wikigold_split
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: Tagged_Uni_500v7_NER_Model_3Epochs_AUGMENTED
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: tagged_uni500v7_wikigold_split
type: tagged_uni500v7_wikigold_split
args: default
metrics:
- name: Precision
type: precision
value: 0.7087020648967551
- name: Recall
type: recall
value: 0.7068775285031261
- name: F1
type: f1
value: 0.7077886208801325
- name: Accuracy
type: accuracy
value: 0.9310942373735782
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Tagged_Uni_500v7_NER_Model_3Epochs_AUGMENTED
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the tagged_uni500v7_wikigold_split dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2465
- Precision: 0.7087
- Recall: 0.7069
- F1: 0.7078
- Accuracy: 0.9311
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 154 | 0.3027 | 0.5778 | 0.4917 | 0.5313 | 0.9053 |
| No log | 2.0 | 308 | 0.2317 | 0.6818 | 0.6973 | 0.6895 | 0.9293 |
| No log | 3.0 | 462 | 0.2465 | 0.7087 | 0.7069 | 0.7078 | 0.9311 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.11.0+cu113
- Datasets 2.4.0
- Tokenizers 0.11.6
|
roscoyoon/distilbert-base-uncased-distilled
|
roscoyoon
| 2022-08-11T20:29:37Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"distilbert",
"text-classification",
"generated_from_trainer",
"dataset:clinc_oos",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-08-11T15:06:07Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- clinc_oos
metrics:
- accuracy
model-index:
- name: distilbert-base-uncased-distilled
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: clinc_oos
type: clinc_oos
args: plus
metrics:
- name: Accuracy
type: accuracy
value: 0.9448387096774193
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-distilled
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the clinc_oos dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2061
- Accuracy: 0.9448
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 48
- eval_batch_size: 48
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 1.7308 | 1.0 | 318 | 1.1633 | 0.7394 |
| 0.8985 | 2.0 | 636 | 0.5726 | 0.8635 |
| 0.4735 | 3.0 | 954 | 0.3350 | 0.9187 |
| 0.298 | 4.0 | 1272 | 0.2562 | 0.9361 |
| 0.2313 | 5.0 | 1590 | 0.2304 | 0.9413 |
| 0.2043 | 6.0 | 1908 | 0.2190 | 0.9432 |
| 0.1904 | 7.0 | 2226 | 0.2130 | 0.9445 |
| 0.1829 | 8.0 | 2544 | 0.2091 | 0.9442 |
| 0.1782 | 9.0 | 2862 | 0.2066 | 0.9455 |
| 0.1762 | 10.0 | 3180 | 0.2061 | 0.9448 |
### Framework versions
- Transformers 4.20.1
- Pytorch 1.10.0+cu102
- Datasets 2.3.2
- Tokenizers 0.12.1
|
DOOGLAK/Tagged_Uni_500v6_NER_Model_3Epochs_AUGMENTED
|
DOOGLAK
| 2022-08-11T20:25:04Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"token-classification",
"generated_from_trainer",
"dataset:tagged_uni500v6_wikigold_split",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-08-11T20:19:30Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- tagged_uni500v6_wikigold_split
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: Tagged_Uni_500v6_NER_Model_3Epochs_AUGMENTED
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: tagged_uni500v6_wikigold_split
type: tagged_uni500v6_wikigold_split
args: default
metrics:
- name: Precision
type: precision
value: 0.699155524278677
- name: Recall
type: recall
value: 0.6986638537271449
- name: F1
type: f1
value: 0.6989096025325361
- name: Accuracy
type: accuracy
value: 0.9317908843795436
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Tagged_Uni_500v6_NER_Model_3Epochs_AUGMENTED
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the tagged_uni500v6_wikigold_split dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2386
- Precision: 0.6992
- Recall: 0.6987
- F1: 0.6989
- Accuracy: 0.9318
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 182 | 0.2452 | 0.5956 | 0.5432 | 0.5682 | 0.9189 |
| No log | 2.0 | 364 | 0.2571 | 0.6832 | 0.6354 | 0.6584 | 0.9204 |
| 0.1093 | 3.0 | 546 | 0.2386 | 0.6992 | 0.6987 | 0.6989 | 0.9318 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.11.0+cu113
- Datasets 2.4.0
- Tokenizers 0.11.6
|
DOOGLAK/Tagged_Uni_500v5_NER_Model_3Epochs_AUGMENTED
|
DOOGLAK
| 2022-08-11T20:18:51Z | 106 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"token-classification",
"generated_from_trainer",
"dataset:tagged_uni500v5_wikigold_split",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-08-11T20:13:09Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- tagged_uni500v5_wikigold_split
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: Tagged_Uni_500v5_NER_Model_3Epochs_AUGMENTED
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: tagged_uni500v5_wikigold_split
type: tagged_uni500v5_wikigold_split
args: default
metrics:
- name: Precision
type: precision
value: 0.7004950495049505
- name: Recall
type: recall
value: 0.7075
- name: F1
type: f1
value: 0.7039800995024875
- name: Accuracy
type: accuracy
value: 0.9367615143477213
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Tagged_Uni_500v5_NER_Model_3Epochs_AUGMENTED
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the tagged_uni500v5_wikigold_split dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2258
- Precision: 0.7005
- Recall: 0.7075
- F1: 0.7040
- Accuracy: 0.9368
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 164 | 0.2399 | 0.5969 | 0.5543 | 0.5748 | 0.9208 |
| No log | 2.0 | 328 | 0.2145 | 0.6931 | 0.6968 | 0.6949 | 0.9362 |
| No log | 3.0 | 492 | 0.2258 | 0.7005 | 0.7075 | 0.7040 | 0.9368 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.11.0+cu113
- Datasets 2.4.0
- Tokenizers 0.11.6
|
cansen88/PromptGenerator_32_topic_finetuned
|
cansen88
| 2022-08-11T20:18:21Z | 63 | 0 |
transformers
|
[
"transformers",
"tf",
"gpt2",
"text-generation",
"generated_from_keras_callback",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-08-11T19:49:31Z |
---
license: mit
tags:
- generated_from_keras_callback
model-index:
- name: PromptGenerator_32_topic_finetuned
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# PromptGenerator_32_topic_finetuned
This model is a fine-tuned version of [kmkarakaya/turkishReviews-ds](https://huggingface.co/kmkarakaya/turkishReviews-ds) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.0569
- Train Sparse Categorical Accuracy: 1.0
- Validation Loss: 0.0787
- Validation Sparse Categorical Accuracy: 1.0
- Epoch: 4
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'Adam', 'learning_rate': 5e-05, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-07, 'amsgrad': False}
- training_precision: float32
### Training results
| Train Loss | Train Sparse Categorical Accuracy | Validation Loss | Validation Sparse Categorical Accuracy | Epoch |
|:----------:|:---------------------------------:|:---------------:|:--------------------------------------:|:-----:|
| 1.7185 | 0.7860 | 0.5569 | 0.9868 | 0 |
| 0.4711 | 0.9958 | 0.2097 | 0.9995 | 1 |
| 0.2016 | 1.0000 | 0.1197 | 0.9999 | 2 |
| 0.1014 | 1.0 | 0.0903 | 0.9999 | 3 |
| 0.0569 | 1.0 | 0.0787 | 1.0 | 4 |
### Framework versions
- Transformers 4.21.1
- TensorFlow 2.8.2
- Datasets 2.4.0
- Tokenizers 0.12.1
|
DOOGLAK/Tagged_Uni_500v2_NER_Model_3Epochs_AUGMENTED
|
DOOGLAK
| 2022-08-11T20:01:39Z | 103 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"token-classification",
"generated_from_trainer",
"dataset:tagged_uni500v2_wikigold_split",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-08-11T19:56:44Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- tagged_uni500v2_wikigold_split
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: Tagged_Uni_500v2_NER_Model_3Epochs_AUGMENTED
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: tagged_uni500v2_wikigold_split
type: tagged_uni500v2_wikigold_split
args: default
metrics:
- name: Precision
type: precision
value: 0.7018014564967421
- name: Recall
type: recall
value: 0.6811755952380952
- name: F1
type: f1
value: 0.6913347177647726
- name: Accuracy
type: accuracy
value: 0.926232333678042
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Tagged_Uni_500v2_NER_Model_3Epochs_AUGMENTED
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the tagged_uni500v2_wikigold_split dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2645
- Precision: 0.7018
- Recall: 0.6812
- F1: 0.6913
- Accuracy: 0.9262
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 171 | 0.2364 | 0.6168 | 0.5804 | 0.5980 | 0.9178 |
| No log | 2.0 | 342 | 0.2626 | 0.6815 | 0.6417 | 0.6610 | 0.9210 |
| 0.1121 | 3.0 | 513 | 0.2645 | 0.7018 | 0.6812 | 0.6913 | 0.9262 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.11.0+cu113
- Datasets 2.4.0
- Tokenizers 0.11.6
|
0x-YuAN/CL_1
|
0x-YuAN
| 2022-08-11T19:56:16Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"text-classification",
"autotrain",
"zh",
"dataset:yuan1729/autotrain-data-YuAN-lawthone-CL_facts_backTrans",
"co2_eq_emissions",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-08-11T18:47:58Z |
---
tags:
- autotrain
- text-classification
language:
- zh
widget:
- text: "I love AutoTrain 🤗"
datasets:
- yuan1729/autotrain-data-YuAN-lawthone-CL_facts_backTrans
co2_eq_emissions:
emissions: 151.97297148175758
---
# Model Trained Using AutoTrain
- Problem type: Multi-class Classification
- Model ID: 1241547318
- CO2 Emissions (in grams): 151.9730
## Validation Metrics
- Loss: 0.512
- Accuracy: 0.862
- Macro F1: 0.862
- Micro F1: 0.862
- Weighted F1: 0.862
- Macro Precision: 0.863
- Micro Precision: 0.862
- Weighted Precision: 0.863
- Macro Recall: 0.862
- Micro Recall: 0.862
- Weighted Recall: 0.862
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoTrain"}' https://api-inference.huggingface.co/models/yuan1729/autotrain-YuAN-lawthone-CL_facts_backTrans-1241547318
```
Or Python API:
```
from transformers import AutoModelForSequenceClassification, AutoTokenizer
model = AutoModelForSequenceClassification.from_pretrained("yuan1729/autotrain-YuAN-lawthone-CL_facts_backTrans-1241547318", use_auth_token=True)
tokenizer = AutoTokenizer.from_pretrained("yuan1729/autotrain-YuAN-lawthone-CL_facts_backTrans-1241547318", use_auth_token=True)
inputs = tokenizer("I love AutoTrain", return_tensors="pt")
outputs = model(**inputs)
```
|
DOOGLAK/Tagged_Uni_250v9_NER_Model_3Epochs_AUGMENTED
|
DOOGLAK
| 2022-08-11T19:44:43Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"token-classification",
"generated_from_trainer",
"dataset:tagged_uni250v9_wikigold_split",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-08-11T19:40:11Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- tagged_uni250v9_wikigold_split
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: Tagged_Uni_250v9_NER_Model_3Epochs_AUGMENTED
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: tagged_uni250v9_wikigold_split
type: tagged_uni250v9_wikigold_split
args: default
metrics:
- name: Precision
type: precision
value: 0.587685364281109
- name: Recall
type: recall
value: 0.526270207852194
- name: F1
type: f1
value: 0.5552848004873592
- name: Accuracy
type: accuracy
value: 0.9092797783933518
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Tagged_Uni_250v9_NER_Model_3Epochs_AUGMENTED
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the tagged_uni250v9_wikigold_split dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2786
- Precision: 0.5877
- Recall: 0.5263
- F1: 0.5553
- Accuracy: 0.9093
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 88 | 0.3533 | 0.3574 | 0.2156 | 0.2690 | 0.8658 |
| No log | 2.0 | 176 | 0.2946 | 0.5370 | 0.4529 | 0.4914 | 0.8999 |
| No log | 3.0 | 264 | 0.2786 | 0.5877 | 0.5263 | 0.5553 | 0.9093 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.11.0+cu113
- Datasets 2.4.0
- Tokenizers 0.11.6
|
DOOGLAK/Tagged_Uni_250v8_NER_Model_3Epochs_AUGMENTED
|
DOOGLAK
| 2022-08-11T19:39:39Z | 106 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"token-classification",
"generated_from_trainer",
"dataset:tagged_uni250v8_wikigold_split",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-08-11T19:35:03Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- tagged_uni250v8_wikigold_split
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: Tagged_Uni_250v8_NER_Model_3Epochs_AUGMENTED
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: tagged_uni250v8_wikigold_split
type: tagged_uni250v8_wikigold_split
args: default
metrics:
- name: Precision
type: precision
value: 0.5548306927617273
- name: Recall
type: recall
value: 0.4939159292035398
- name: F1
type: f1
value: 0.5226042428675933
- name: Accuracy
type: accuracy
value: 0.8976334059696954
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Tagged_Uni_250v8_NER_Model_3Epochs_AUGMENTED
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the tagged_uni250v8_wikigold_split dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3186
- Precision: 0.5548
- Recall: 0.4939
- F1: 0.5226
- Accuracy: 0.8976
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 95 | 0.4132 | 0.3646 | 0.2008 | 0.2590 | 0.8504 |
| No log | 2.0 | 190 | 0.2983 | 0.5077 | 0.4552 | 0.4800 | 0.8977 |
| No log | 3.0 | 285 | 0.3186 | 0.5548 | 0.4939 | 0.5226 | 0.8976 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.11.0+cu113
- Datasets 2.4.0
- Tokenizers 0.11.6
|
DOOGLAK/Tagged_Uni_250v7_NER_Model_3Epochs_AUGMENTED
|
DOOGLAK
| 2022-08-11T19:34:30Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"token-classification",
"generated_from_trainer",
"dataset:tagged_uni250v7_wikigold_split",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-08-11T19:29:51Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- tagged_uni250v7_wikigold_split
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: Tagged_Uni_250v7_NER_Model_3Epochs_AUGMENTED
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: tagged_uni250v7_wikigold_split
type: tagged_uni250v7_wikigold_split
args: default
metrics:
- name: Precision
type: precision
value: 0.5764667106130521
- name: Recall
type: recall
value: 0.4908784731967443
- name: F1
type: f1
value: 0.5302410186448385
- name: Accuracy
type: accuracy
value: 0.8988380555625267
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Tagged_Uni_250v7_NER_Model_3Epochs_AUGMENTED
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the tagged_uni250v7_wikigold_split dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3477
- Precision: 0.5765
- Recall: 0.4909
- F1: 0.5302
- Accuracy: 0.8988
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 90 | 0.3902 | 0.2262 | 0.1524 | 0.1821 | 0.8474 |
| No log | 2.0 | 180 | 0.3612 | 0.5340 | 0.4471 | 0.4867 | 0.8914 |
| No log | 3.0 | 270 | 0.3477 | 0.5765 | 0.4909 | 0.5302 | 0.8988 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.11.0+cu113
- Datasets 2.4.0
- Tokenizers 0.11.6
|
DOOGLAK/Tagged_Uni_250v6_NER_Model_3Epochs_AUGMENTED
|
DOOGLAK
| 2022-08-11T19:29:17Z | 103 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"token-classification",
"generated_from_trainer",
"dataset:tagged_uni250v6_wikigold_split",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-08-11T19:23:31Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- tagged_uni250v6_wikigold_split
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: Tagged_Uni_250v6_NER_Model_3Epochs_AUGMENTED
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: tagged_uni250v6_wikigold_split
type: tagged_uni250v6_wikigold_split
args: default
metrics:
- name: Precision
type: precision
value: 0.5571526351813826
- name: Recall
type: recall
value: 0.45730337078651684
- name: F1
type: f1
value: 0.5023141005862387
- name: Accuracy
type: accuracy
value: 0.8952912645884908
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Tagged_Uni_250v6_NER_Model_3Epochs_AUGMENTED
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the tagged_uni250v6_wikigold_split dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3080
- Precision: 0.5572
- Recall: 0.4573
- F1: 0.5023
- Accuracy: 0.8953
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 72 | 0.3505 | 0.3004 | 0.1817 | 0.2265 | 0.8649 |
| No log | 2.0 | 144 | 0.2989 | 0.5217 | 0.4219 | 0.4665 | 0.8931 |
| No log | 3.0 | 216 | 0.3080 | 0.5572 | 0.4573 | 0.5023 | 0.8953 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.11.0+cu113
- Datasets 2.4.0
- Tokenizers 0.11.6
|
DOOGLAK/Tagged_Uni_250v5_NER_Model_3Epochs_AUGMENTED
|
DOOGLAK
| 2022-08-11T19:23:01Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"token-classification",
"generated_from_trainer",
"dataset:tagged_uni250v5_wikigold_split",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-08-11T19:17:54Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- tagged_uni250v5_wikigold_split
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: Tagged_Uni_250v5_NER_Model_3Epochs_AUGMENTED
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: tagged_uni250v5_wikigold_split
type: tagged_uni250v5_wikigold_split
args: default
metrics:
- name: Precision
type: precision
value: 0.5808346213292117
- name: Recall
type: recall
value: 0.5341102899374645
- name: F1
type: f1
value: 0.5564934103361469
- name: Accuracy
type: accuracy
value: 0.9006217563331792
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Tagged_Uni_250v5_NER_Model_3Epochs_AUGMENTED
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the tagged_uni250v5_wikigold_split dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3324
- Precision: 0.5808
- Recall: 0.5341
- F1: 0.5565
- Accuracy: 0.9006
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 99 | 0.4305 | 0.3110 | 0.2149 | 0.2542 | 0.8533 |
| No log | 2.0 | 198 | 0.3340 | 0.5449 | 0.4935 | 0.5179 | 0.8956 |
| No log | 3.0 | 297 | 0.3324 | 0.5808 | 0.5341 | 0.5565 | 0.9006 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.11.0+cu113
- Datasets 2.4.0
- Tokenizers 0.11.6
|
DOOGLAK/Tagged_Uni_250v4_NER_Model_3Epochs_AUGMENTED
|
DOOGLAK
| 2022-08-11T19:17:23Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"token-classification",
"generated_from_trainer",
"dataset:tagged_uni250v4_wikigold_split",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-08-11T19:12:24Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- tagged_uni250v4_wikigold_split
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: Tagged_Uni_250v4_NER_Model_3Epochs_AUGMENTED
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: tagged_uni250v4_wikigold_split
type: tagged_uni250v4_wikigold_split
args: default
metrics:
- name: Precision
type: precision
value: 0.5477564102564103
- name: Recall
type: recall
value: 0.4741953385127636
- name: F1
type: f1
value: 0.5083283759666866
- name: Accuracy
type: accuracy
value: 0.8982782455699384
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Tagged_Uni_250v4_NER_Model_3Epochs_AUGMENTED
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the tagged_uni250v4_wikigold_split dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2997
- Precision: 0.5478
- Recall: 0.4742
- F1: 0.5083
- Accuracy: 0.8983
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 86 | 0.3911 | 0.3370 | 0.1792 | 0.2340 | 0.8515 |
| No log | 2.0 | 172 | 0.3347 | 0.4754 | 0.3760 | 0.4199 | 0.8836 |
| No log | 3.0 | 258 | 0.2997 | 0.5478 | 0.4742 | 0.5083 | 0.8983 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.11.0+cu113
- Datasets 2.4.0
- Tokenizers 0.11.6
|
DOOGLAK/Tagged_Uni_250v3_NER_Model_3Epochs_AUGMENTED
|
DOOGLAK
| 2022-08-11T19:11:54Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"token-classification",
"generated_from_trainer",
"dataset:tagged_uni250v3_wikigold_split",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-08-11T19:06:44Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- tagged_uni250v3_wikigold_split
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: Tagged_Uni_250v3_NER_Model_3Epochs_AUGMENTED
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: tagged_uni250v3_wikigold_split
type: tagged_uni250v3_wikigold_split
args: default
metrics:
- name: Precision
type: precision
value: 0.5830763960260363
- name: Recall
type: recall
value: 0.4849002849002849
- name: F1
type: f1
value: 0.5294758127235961
- name: Accuracy
type: accuracy
value: 0.8988582871706847
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Tagged_Uni_250v3_NER_Model_3Epochs_AUGMENTED
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the tagged_uni250v3_wikigold_split dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3093
- Precision: 0.5831
- Recall: 0.4849
- F1: 0.5295
- Accuracy: 0.8989
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 78 | 0.3468 | 0.3486 | 0.2362 | 0.2816 | 0.8670 |
| No log | 2.0 | 156 | 0.3071 | 0.5484 | 0.4516 | 0.4953 | 0.8943 |
| No log | 3.0 | 234 | 0.3093 | 0.5831 | 0.4849 | 0.5295 | 0.8989 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.11.0+cu113
- Datasets 2.4.0
- Tokenizers 0.11.6
|
roscoyoon/distilbert-base-uncased-finetuned
|
roscoyoon
| 2022-08-11T19:07:34Z | 107 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_trainer",
"dataset:clinc_oos",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-08-11T08:40:52Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- clinc_oos
metrics:
- accuracy
model-index:
- name: distilbert-base-uncased-finetuned
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: clinc_oos
type: clinc_oos
args: plus
metrics:
- name: Accuracy
type: accuracy
value: 0.9183870967741935
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the clinc_oos dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7734
- Accuracy: 0.9184
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 48
- eval_batch_size: 48
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 4.2955 | 1.0 | 318 | 3.2914 | 0.7452 |
| 2.6342 | 2.0 | 636 | 1.8815 | 0.8313 |
| 1.5504 | 3.0 | 954 | 1.1547 | 0.8952 |
| 1.0151 | 4.0 | 1272 | 0.8580 | 0.9113 |
| 0.7936 | 5.0 | 1590 | 0.7734 | 0.9184 |
### Framework versions
- Transformers 4.20.1
- Pytorch 1.10.0+cu102
- Datasets 2.3.2
- Tokenizers 0.12.1
|
DOOGLAK/Tagged_Uni_250v2_NER_Model_3Epochs_AUGMENTED
|
DOOGLAK
| 2022-08-11T19:06:13Z | 103 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"token-classification",
"generated_from_trainer",
"dataset:tagged_uni250v2_wikigold_split",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-08-11T19:01:07Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- tagged_uni250v2_wikigold_split
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: Tagged_Uni_250v2_NER_Model_3Epochs_AUGMENTED
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: tagged_uni250v2_wikigold_split
type: tagged_uni250v2_wikigold_split
args: default
metrics:
- name: Precision
type: precision
value: 0.6101747815230961
- name: Recall
type: recall
value: 0.5595306239267316
- name: F1
type: f1
value: 0.583756345177665
- name: Accuracy
type: accuracy
value: 0.9084434117141919
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Tagged_Uni_250v2_NER_Model_3Epochs_AUGMENTED
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the tagged_uni250v2_wikigold_split dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3254
- Precision: 0.6102
- Recall: 0.5595
- F1: 0.5838
- Accuracy: 0.9084
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 91 | 0.3324 | 0.3097 | 0.2604 | 0.2830 | 0.8776 |
| No log | 2.0 | 182 | 0.3415 | 0.5734 | 0.4831 | 0.5244 | 0.9004 |
| No log | 3.0 | 273 | 0.3254 | 0.6102 | 0.5595 | 0.5838 | 0.9084 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.11.0+cu113
- Datasets 2.4.0
- Tokenizers 0.11.6
|
DOOGLAK/Tagged_Uni_250v1_NER_Model_3Epochs_AUGMENTED
|
DOOGLAK
| 2022-08-11T19:00:36Z | 103 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"token-classification",
"generated_from_trainer",
"dataset:tagged_uni250v1_wikigold_split",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-08-11T18:55:24Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- tagged_uni250v1_wikigold_split
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: Tagged_Uni_250v1_NER_Model_3Epochs_AUGMENTED
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: tagged_uni250v1_wikigold_split
type: tagged_uni250v1_wikigold_split
args: default
metrics:
- name: Precision
type: precision
value: 0.5971956660293181
- name: Recall
type: recall
value: 0.5290796160361377
- name: F1
type: f1
value: 0.5610778443113772
- name: Accuracy
type: accuracy
value: 0.906793008840565
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Tagged_Uni_250v1_NER_Model_3Epochs_AUGMENTED
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the tagged_uni250v1_wikigold_split dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3057
- Precision: 0.5972
- Recall: 0.5291
- F1: 0.5611
- Accuracy: 0.9068
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 87 | 0.3972 | 0.2749 | 0.2081 | 0.2369 | 0.8625 |
| No log | 2.0 | 174 | 0.2895 | 0.5545 | 0.5054 | 0.5288 | 0.9059 |
| No log | 3.0 | 261 | 0.3057 | 0.5972 | 0.5291 | 0.5611 | 0.9068 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.11.0+cu113
- Datasets 2.4.0
- Tokenizers 0.11.6
|
DOOGLAK/Tagged_Uni_250v0_NER_Model_3Epochs_AUGMENTED
|
DOOGLAK
| 2022-08-11T18:54:52Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"token-classification",
"generated_from_trainer",
"dataset:tagged_uni250v0_wikigold_split",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-08-11T18:49:41Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- tagged_uni250v0_wikigold_split
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: Tagged_Uni_250v0_NER_Model_3Epochs_AUGMENTED
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: tagged_uni250v0_wikigold_split
type: tagged_uni250v0_wikigold_split
args: default
metrics:
- name: Precision
type: precision
value: 0.4747682801235839
- name: Recall
type: recall
value: 0.37317862924986506
- name: F1
type: f1
value: 0.41788789847408975
- name: Accuracy
type: accuracy
value: 0.8846524500234748
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Tagged_Uni_250v0_NER_Model_3Epochs_AUGMENTED
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the tagged_uni250v0_wikigold_split dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3679
- Precision: 0.4748
- Recall: 0.3732
- F1: 0.4179
- Accuracy: 0.8847
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 91 | 0.4333 | 0.2856 | 0.1851 | 0.2246 | 0.8440 |
| No log | 2.0 | 182 | 0.3466 | 0.3907 | 0.3038 | 0.3418 | 0.8794 |
| No log | 3.0 | 273 | 0.3679 | 0.4748 | 0.3732 | 0.4179 | 0.8847 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.11.0+cu113
- Datasets 2.4.0
- Tokenizers 0.11.6
|
DOOGLAK/Tagged_Uni_100v9_NER_Model_3Epochs_AUGMENTED
|
DOOGLAK
| 2022-08-11T18:49:10Z | 103 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"token-classification",
"generated_from_trainer",
"dataset:tagged_uni100v9_wikigold_split",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-08-11T18:44:05Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- tagged_uni100v9_wikigold_split
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: Tagged_Uni_100v9_NER_Model_3Epochs_AUGMENTED
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: tagged_uni100v9_wikigold_split
type: tagged_uni100v9_wikigold_split
args: default
metrics:
- name: Precision
type: precision
value: 0.3227436823104693
- name: Recall
type: recall
value: 0.23047177107501934
- name: F1
type: f1
value: 0.268912618438863
- name: Accuracy
type: accuracy
value: 0.8556973163220414
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Tagged_Uni_100v9_NER_Model_3Epochs_AUGMENTED
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the tagged_uni100v9_wikigold_split dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4080
- Precision: 0.3227
- Recall: 0.2305
- F1: 0.2689
- Accuracy: 0.8557
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 39 | 0.4881 | 0.2185 | 0.0487 | 0.0797 | 0.8066 |
| No log | 2.0 | 78 | 0.4431 | 0.2831 | 0.1536 | 0.1992 | 0.8387 |
| No log | 3.0 | 117 | 0.4080 | 0.3227 | 0.2305 | 0.2689 | 0.8557 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.11.0+cu113
- Datasets 2.4.0
- Tokenizers 0.11.6
|
DOOGLAK/Tagged_Uni_100v8_NER_Model_3Epochs_AUGMENTED
|
DOOGLAK
| 2022-08-11T18:43:35Z | 106 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"token-classification",
"generated_from_trainer",
"dataset:tagged_uni100v8_wikigold_split",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-08-11T18:38:39Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- tagged_uni100v8_wikigold_split
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: Tagged_Uni_100v8_NER_Model_3Epochs_AUGMENTED
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: tagged_uni100v8_wikigold_split
type: tagged_uni100v8_wikigold_split
args: default
metrics:
- name: Precision
type: precision
value: 0.23410202655485673
- name: Recall
type: recall
value: 0.08220858895705521
- name: F1
type: f1
value: 0.12168543407192152
- name: Accuracy
type: accuracy
value: 0.8133929595229905
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Tagged_Uni_100v8_NER_Model_3Epochs_AUGMENTED
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the tagged_uni100v8_wikigold_split dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5374
- Precision: 0.2341
- Recall: 0.0822
- F1: 0.1217
- Accuracy: 0.8134
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 39 | 0.5752 | 0.0227 | 0.0002 | 0.0005 | 0.7844 |
| No log | 2.0 | 78 | 0.5425 | 0.2209 | 0.0498 | 0.0813 | 0.8052 |
| No log | 3.0 | 117 | 0.5374 | 0.2341 | 0.0822 | 0.1217 | 0.8134 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.11.0+cu113
- Datasets 2.4.0
- Tokenizers 0.11.6
|
athairus/xlm-roberta-base-finetuned-panx-de
|
athairus
| 2022-08-11T18:37:59Z | 104 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"xlm-roberta",
"token-classification",
"generated_from_trainer",
"dataset:xtreme",
"license:mit",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-08-11T18:28:06Z |
---
license: mit
tags:
- generated_from_trainer
datasets:
- xtreme
metrics:
- f1
model-index:
- name: xlm-roberta-base-finetuned-panx-de
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: xtreme
type: xtreme
args: PAN-X.de
metrics:
- name: F1
type: f1
value: 0.8663101604278075
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xlm-roberta-base-finetuned-panx-de
This model is a fine-tuned version of [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) on the xtreme dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1339
- F1: 0.8663
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 24
- eval_batch_size: 24
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 0.2581 | 1.0 | 525 | 0.1690 | 0.8303 |
| 0.1305 | 2.0 | 1050 | 0.1352 | 0.8484 |
| 0.0839 | 3.0 | 1575 | 0.1339 | 0.8663 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.12.1
- Datasets 1.16.1
- Tokenizers 0.10.3
|
Petros89/bert-finetuned-squad
|
Petros89
| 2022-08-11T18:30:06Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"question-answering",
"generated_from_trainer",
"dataset:squad",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-08-03T14:56:57Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- squad
model-index:
- name: bert-finetuned-squad
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-finetuned-squad
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the squad dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.21.0
- Pytorch 1.7.0
- Datasets 2.4.0
- Tokenizers 0.12.1
|
DOOGLAK/Tagged_Uni_100v3_NER_Model_3Epochs_AUGMENTED
|
DOOGLAK
| 2022-08-11T18:15:31Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"token-classification",
"generated_from_trainer",
"dataset:tagged_uni100v3_wikigold_split",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-08-11T18:10:13Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- tagged_uni100v3_wikigold_split
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: Tagged_Uni_100v3_NER_Model_3Epochs_AUGMENTED
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: tagged_uni100v3_wikigold_split
type: tagged_uni100v3_wikigold_split
args: default
metrics:
- name: Precision
type: precision
value: 0.27637540453074433
- name: Recall
type: recall
value: 0.10801922590437642
- name: F1
type: f1
value: 0.15532921062204438
- name: Accuracy
type: accuracy
value: 0.8105687105062148
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Tagged_Uni_100v3_NER_Model_3Epochs_AUGMENTED
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the tagged_uni100v3_wikigold_split dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4884
- Precision: 0.2764
- Recall: 0.1080
- F1: 0.1553
- Accuracy: 0.8106
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 26 | 0.6238 | 0.2 | 0.0089 | 0.0170 | 0.7822 |
| No log | 2.0 | 52 | 0.5210 | 0.2497 | 0.0587 | 0.0950 | 0.7971 |
| No log | 3.0 | 78 | 0.4884 | 0.2764 | 0.1080 | 0.1553 | 0.8106 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.11.0+cu113
- Datasets 2.4.0
- Tokenizers 0.11.6
|
DOOGLAK/Tagged_Uni_100v2_NER_Model_3Epochs_AUGMENTED
|
DOOGLAK
| 2022-08-11T18:09:41Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"token-classification",
"generated_from_trainer",
"dataset:tagged_uni100v2_wikigold_split",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-08-11T18:04:20Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- tagged_uni100v2_wikigold_split
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: Tagged_Uni_100v2_NER_Model_3Epochs_AUGMENTED
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: tagged_uni100v2_wikigold_split
type: tagged_uni100v2_wikigold_split
args: default
metrics:
- name: Precision
type: precision
value: 0.2783229259589652
- name: Recall
type: recall
value: 0.15885947046843177
- name: F1
type: f1
value: 0.20226904376012964
- name: Accuracy
type: accuracy
value: 0.8411943180251
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Tagged_Uni_100v2_NER_Model_3Epochs_AUGMENTED
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the tagged_uni100v2_wikigold_split dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4048
- Precision: 0.2783
- Recall: 0.1589
- F1: 0.2023
- Accuracy: 0.8412
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 39 | 0.4802 | 0.3667 | 0.0784 | 0.1292 | 0.8125 |
| No log | 2.0 | 78 | 0.4028 | 0.2745 | 0.1540 | 0.1973 | 0.8412 |
| No log | 3.0 | 117 | 0.4048 | 0.2783 | 0.1589 | 0.2023 | 0.8412 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.11.0+cu113
- Datasets 2.4.0
- Tokenizers 0.11.6
|
aemili/distilbert-base-uncased-finetuned-cola
|
aemili
| 2022-08-11T17:50:53Z | 35 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_trainer",
"dataset:glue",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-08-01T17:05:07Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- glue
metrics:
- matthews_correlation
model-index:
- name: distilbert-base-uncased-finetuned-cola
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: glue
type: glue
args: cola
metrics:
- name: Matthews Correlation
type: matthews_correlation
value: 0.5317477654019562
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-cola
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the glue dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7578
- Matthews Correlation: 0.5317
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Matthews Correlation |
|:-------------:|:-----:|:----:|:---------------:|:--------------------:|
| 0.5239 | 1.0 | 535 | 0.5219 | 0.4097 |
| 0.3483 | 2.0 | 1070 | 0.5775 | 0.4913 |
| 0.2296 | 3.0 | 1605 | 0.6440 | 0.4903 |
| 0.1734 | 4.0 | 2140 | 0.7578 | 0.5317 |
| 0.137 | 5.0 | 2675 | 0.8612 | 0.5192 |
### Framework versions
- Transformers 4.20.1
- Pytorch 1.7.1+cu110
- Datasets 2.4.0
- Tokenizers 0.12.1
|
DOOGLAK/Tagged_Uni_50v8_NER_Model_3Epochs_AUGMENTED
|
DOOGLAK
| 2022-08-11T17:47:02Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"token-classification",
"generated_from_trainer",
"dataset:tagged_uni50v8_wikigold_split",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-08-11T17:41:54Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- tagged_uni50v8_wikigold_split
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: Tagged_Uni_50v8_NER_Model_3Epochs_AUGMENTED
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: tagged_uni50v8_wikigold_split
type: tagged_uni50v8_wikigold_split
args: default
metrics:
- name: Precision
type: precision
value: 0.15460526315789475
- name: Recall
type: recall
value: 0.023016650342801176
- name: F1
type: f1
value: 0.04006820119352089
- name: Accuracy
type: accuracy
value: 0.7925892757192432
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Tagged_Uni_50v8_NER_Model_3Epochs_AUGMENTED
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the tagged_uni50v8_wikigold_split dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5527
- Precision: 0.1546
- Recall: 0.0230
- F1: 0.0401
- Accuracy: 0.7926
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 19 | 0.6981 | 0.0 | 0.0 | 0.0 | 0.7786 |
| No log | 2.0 | 38 | 0.5851 | 0.1290 | 0.0049 | 0.0094 | 0.7832 |
| No log | 3.0 | 57 | 0.5527 | 0.1546 | 0.0230 | 0.0401 | 0.7926 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.11.0+cu113
- Datasets 2.4.0
- Tokenizers 0.11.6
|
DOOGLAK/Tagged_Uni_50v4_NER_Model_3Epochs_AUGMENTED
|
DOOGLAK
| 2022-08-11T17:26:07Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"token-classification",
"generated_from_trainer",
"dataset:tagged_uni50v4_wikigold_split",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-08-11T17:20:37Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- tagged_uni50v4_wikigold_split
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: Tagged_Uni_50v4_NER_Model_3Epochs_AUGMENTED
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: tagged_uni50v4_wikigold_split
type: tagged_uni50v4_wikigold_split
args: default
metrics:
- name: Precision
type: precision
value: 0.27169149868536374
- name: Recall
type: recall
value: 0.07535245503159942
- name: F1
type: f1
value: 0.11798287345385347
- name: Accuracy
type: accuracy
value: 0.8047749037859124
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Tagged_Uni_50v4_NER_Model_3Epochs_AUGMENTED
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the tagged_uni50v4_wikigold_split dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5415
- Precision: 0.2717
- Recall: 0.0754
- F1: 0.1180
- Accuracy: 0.8048
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 25 | 0.6079 | 0.3333 | 0.0015 | 0.0029 | 0.7792 |
| No log | 2.0 | 50 | 0.5345 | 0.2762 | 0.0678 | 0.1089 | 0.8022 |
| No log | 3.0 | 75 | 0.5415 | 0.2717 | 0.0754 | 0.1180 | 0.8048 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.11.0+cu113
- Datasets 2.4.0
- Tokenizers 0.11.6
|
waynedsouza/distilbert-base-uncased-gc-art1e
|
waynedsouza
| 2022-08-11T17:03:41Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-08-11T16:58:22Z |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- accuracy
- f1
model-index:
- name: distilbert-base-uncased-gc-art1e
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-gc-art1e
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0928
- Accuracy: 0.982
- F1: 0.9763
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 0.0226 | 1.0 | 32 | 0.0928 | 0.982 | 0.9763 |
### Framework versions
- Transformers 4.21.1
- Pytorch 1.12.0+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
Adapting/cifar10-image-classification
|
Adapting
| 2022-08-11T16:58:16Z | 0 | 0 | null |
[
"pytorch",
"region:us"
] | null | 2022-08-11T16:43:20Z |
# how to use
```python
# !pip install transformers
import torch.nn as nn
import torch.nn.functional as F
from huggingface_hub import PyTorchModelHubMixin
class Net(nn.Module,PyTorchModelHubMixin):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = torch.flatten(x, 1) # flatten all dimensions except batch
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
net = Net.from_pretrained('Adapting/cifar10-image-classification')
```
example codes for testing the model: [link](https://colab.research.google.com/drive/10xjbgSzw-U1Y4vCot5aqqdOi7AhmIkC3?usp=sharing)
|
DOOGLAK/Tagged_One_500v7_NER_Model_3Epochs_AUGMENTED
|
DOOGLAK
| 2022-08-11T16:45:22Z | 104 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"token-classification",
"generated_from_trainer",
"dataset:tagged_one500v7_wikigold_split",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-08-11T16:40:08Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- tagged_one500v7_wikigold_split
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: Tagged_One_500v7_NER_Model_3Epochs_AUGMENTED
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: tagged_one500v7_wikigold_split
type: tagged_one500v7_wikigold_split
args: default
metrics:
- name: Precision
type: precision
value: 0.6700655498907502
- name: Recall
type: recall
value: 0.6767193821257815
- name: F1
type: f1
value: 0.6733760292772187
- name: Accuracy
type: accuracy
value: 0.9237216043353603
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Tagged_One_500v7_NER_Model_3Epochs_AUGMENTED
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the tagged_one500v7_wikigold_split dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2679
- Precision: 0.6701
- Recall: 0.6767
- F1: 0.6734
- Accuracy: 0.9237
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 156 | 0.3336 | 0.5893 | 0.4855 | 0.5324 | 0.8955 |
| No log | 2.0 | 312 | 0.2580 | 0.6617 | 0.6561 | 0.6589 | 0.9215 |
| No log | 3.0 | 468 | 0.2679 | 0.6701 | 0.6767 | 0.6734 | 0.9237 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.11.0+cu113
- Datasets 2.4.0
- Tokenizers 0.11.6
|
DOOGLAK/Tagged_One_500v6_NER_Model_3Epochs_AUGMENTED
|
DOOGLAK
| 2022-08-11T16:39:36Z | 103 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"token-classification",
"generated_from_trainer",
"dataset:tagged_one500v6_wikigold_split",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-08-11T16:33:59Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- tagged_one500v6_wikigold_split
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: Tagged_One_500v6_NER_Model_3Epochs_AUGMENTED
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: tagged_one500v6_wikigold_split
type: tagged_one500v6_wikigold_split
args: default
metrics:
- name: Precision
type: precision
value: 0.6866690621631333
- name: Recall
type: recall
value: 0.6719409282700421
- name: F1
type: f1
value: 0.679225164385996
- name: Accuracy
type: accuracy
value: 0.9239838169290094
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Tagged_One_500v6_NER_Model_3Epochs_AUGMENTED
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the tagged_one500v6_wikigold_split dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2690
- Precision: 0.6867
- Recall: 0.6719
- F1: 0.6792
- Accuracy: 0.9240
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 189 | 0.2819 | 0.6009 | 0.5352 | 0.5661 | 0.9105 |
| No log | 2.0 | 378 | 0.2614 | 0.6743 | 0.6406 | 0.6571 | 0.9201 |
| 0.11 | 3.0 | 567 | 0.2690 | 0.6867 | 0.6719 | 0.6792 | 0.9240 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.11.0+cu113
- Datasets 2.4.0
- Tokenizers 0.11.6
|
DOOGLAK/Tagged_One_500v5_NER_Model_3Epochs_AUGMENTED
|
DOOGLAK
| 2022-08-11T16:33:19Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"token-classification",
"generated_from_trainer",
"dataset:tagged_one500v5_wikigold_split",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-08-11T16:27:45Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- tagged_one500v5_wikigold_split
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: Tagged_One_500v5_NER_Model_3Epochs_AUGMENTED
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: tagged_one500v5_wikigold_split
type: tagged_one500v5_wikigold_split
args: default
metrics:
- name: Precision
type: precision
value: 0.6984998170508598
- name: Recall
type: recall
value: 0.6817857142857143
- name: F1
type: f1
value: 0.690041568769203
- name: Accuracy
type: accuracy
value: 0.9276886906197251
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Tagged_One_500v5_NER_Model_3Epochs_AUGMENTED
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the tagged_one500v5_wikigold_split dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2523
- Precision: 0.6985
- Recall: 0.6818
- F1: 0.6900
- Accuracy: 0.9277
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 161 | 0.2446 | 0.5625 | 0.5493 | 0.5558 | 0.9167 |
| No log | 2.0 | 322 | 0.2487 | 0.6894 | 0.6557 | 0.6722 | 0.9237 |
| No log | 3.0 | 483 | 0.2523 | 0.6985 | 0.6818 | 0.6900 | 0.9277 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.11.0+cu113
- Datasets 2.4.0
- Tokenizers 0.11.6
|
DOOGLAK/Tagged_One_500v3_NER_Model_3Epochs_AUGMENTED
|
DOOGLAK
| 2022-08-11T16:21:20Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"token-classification",
"generated_from_trainer",
"dataset:tagged_one500v3_wikigold_split",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-08-11T16:16:08Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- tagged_one500v3_wikigold_split
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: Tagged_One_500v3_NER_Model_3Epochs_AUGMENTED
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: tagged_one500v3_wikigold_split
type: tagged_one500v3_wikigold_split
args: default
metrics:
- name: Precision
type: precision
value: 0.697499143542309
- name: Recall
type: recall
value: 0.6782145236508994
- name: F1
type: f1
value: 0.6877216686370546
- name: Accuracy
type: accuracy
value: 0.9245400105495051
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Tagged_One_500v3_NER_Model_3Epochs_AUGMENTED
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the tagged_one500v3_wikigold_split dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2659
- Precision: 0.6975
- Recall: 0.6782
- F1: 0.6877
- Accuracy: 0.9245
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 175 | 0.2990 | 0.5405 | 0.4600 | 0.4970 | 0.9007 |
| No log | 2.0 | 350 | 0.2789 | 0.6837 | 0.6236 | 0.6523 | 0.9157 |
| 0.1081 | 3.0 | 525 | 0.2659 | 0.6975 | 0.6782 | 0.6877 | 0.9245 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.11.0+cu113
- Datasets 2.4.0
- Tokenizers 0.11.6
|
DOOGLAK/Tagged_One_250v9_NER_Model_3Epochs_AUGMENTED
|
DOOGLAK
| 2022-08-11T15:57:04Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"token-classification",
"generated_from_trainer",
"dataset:tagged_one250v9_wikigold_split",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-08-11T15:51:49Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- tagged_one250v9_wikigold_split
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: Tagged_One_250v9_NER_Model_3Epochs_AUGMENTED
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: tagged_one250v9_wikigold_split
type: tagged_one250v9_wikigold_split
args: default
metrics:
- name: Precision
type: precision
value: 0.5794920037629351
- name: Recall
type: recall
value: 0.5334872979214781
- name: F1
type: f1
value: 0.5555388546520367
- name: Accuracy
type: accuracy
value: 0.9034831230122089
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Tagged_One_250v9_NER_Model_3Epochs_AUGMENTED
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the tagged_one250v9_wikigold_split dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3012
- Precision: 0.5795
- Recall: 0.5335
- F1: 0.5555
- Accuracy: 0.9035
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 90 | 0.3614 | 0.2860 | 0.1969 | 0.2332 | 0.8576 |
| No log | 2.0 | 180 | 0.3317 | 0.5186 | 0.4596 | 0.4873 | 0.8924 |
| No log | 3.0 | 270 | 0.3012 | 0.5795 | 0.5335 | 0.5555 | 0.9035 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.11.0+cu113
- Datasets 2.4.0
- Tokenizers 0.11.6
|
TheJarmanitor/q-FrozenLake-v1-4x4-noSlippery
|
TheJarmanitor
| 2022-08-11T15:55:03Z | 0 | 0 | null |
[
"FrozenLake-v1-4x4-no_slippery",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-08-11T15:51:58Z |
---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
---
# **Q-Learning** Agent playing **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="TheJarmanitor/q-FrozenLake-v1-4x4-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
evaluate_agent(env, model["max_steps"], model["n_eval_episodes"], model["qtable"], model["eval_seed"])
```
|
DOOGLAK/Tagged_One_250v8_NER_Model_3Epochs_AUGMENTED
|
DOOGLAK
| 2022-08-11T15:51:20Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"token-classification",
"generated_from_trainer",
"dataset:tagged_one250v8_wikigold_split",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-08-11T15:45:59Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- tagged_one250v8_wikigold_split
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: Tagged_One_250v8_NER_Model_3Epochs_AUGMENTED
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: tagged_one250v8_wikigold_split
type: tagged_one250v8_wikigold_split
args: default
metrics:
- name: Precision
type: precision
value: 0.5351851851851852
- name: Recall
type: recall
value: 0.4795353982300885
- name: F1
type: f1
value: 0.5058343057176197
- name: Accuracy
type: accuracy
value: 0.8947195053970506
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Tagged_One_250v8_NER_Model_3Epochs_AUGMENTED
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the tagged_one250v8_wikigold_split dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3389
- Precision: 0.5352
- Recall: 0.4795
- F1: 0.5058
- Accuracy: 0.8947
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 95 | 0.4305 | 0.3497 | 0.1814 | 0.2389 | 0.8488 |
| No log | 2.0 | 190 | 0.3469 | 0.4995 | 0.4281 | 0.4611 | 0.8875 |
| No log | 3.0 | 285 | 0.3389 | 0.5352 | 0.4795 | 0.5058 | 0.8947 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.11.0+cu113
- Datasets 2.4.0
- Tokenizers 0.11.6
|
DOOGLAK/Tagged_One_250v7_NER_Model_3Epochs_AUGMENTED
|
DOOGLAK
| 2022-08-11T15:45:15Z | 103 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"token-classification",
"generated_from_trainer",
"dataset:tagged_one250v7_wikigold_split",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-08-11T15:40:08Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- tagged_one250v7_wikigold_split
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: Tagged_One_250v7_NER_Model_3Epochs_AUGMENTED
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: tagged_one250v7_wikigold_split
type: tagged_one250v7_wikigold_split
args: default
metrics:
- name: Precision
type: precision
value: 0.5509259259259259
- name: Recall
type: recall
value: 0.4675834970530452
- name: F1
type: f1
value: 0.5058448459086079
- name: Accuracy
type: accuracy
value: 0.8893517705222476
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Tagged_One_250v7_NER_Model_3Epochs_AUGMENTED
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the tagged_one250v7_wikigold_split dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3809
- Precision: 0.5509
- Recall: 0.4676
- F1: 0.5058
- Accuracy: 0.8894
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 87 | 0.4450 | 0.1912 | 0.1047 | 0.1353 | 0.8278 |
| No log | 2.0 | 174 | 0.3903 | 0.4992 | 0.4176 | 0.4548 | 0.8820 |
| No log | 3.0 | 261 | 0.3809 | 0.5509 | 0.4676 | 0.5058 | 0.8894 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.11.0+cu113
- Datasets 2.4.0
- Tokenizers 0.11.6
|
DOOGLAK/Tagged_One_250v6_NER_Model_3Epochs_AUGMENTED
|
DOOGLAK
| 2022-08-11T15:39:34Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"token-classification",
"generated_from_trainer",
"dataset:tagged_one250v6_wikigold_split",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-08-11T15:33:42Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- tagged_one250v6_wikigold_split
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: Tagged_One_250v6_NER_Model_3Epochs_AUGMENTED
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: tagged_one250v6_wikigold_split
type: tagged_one250v6_wikigold_split
args: default
metrics:
- name: Precision
type: precision
value: 0.5705062861026163
- name: Recall
type: recall
value: 0.47162921348314607
- name: F1
type: f1
value: 0.5163770567430417
- name: Accuracy
type: accuracy
value: 0.8943313292578184
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Tagged_One_250v6_NER_Model_3Epochs_AUGMENTED
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the tagged_one250v6_wikigold_split dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3273
- Precision: 0.5705
- Recall: 0.4716
- F1: 0.5164
- Accuracy: 0.8943
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 74 | 0.4157 | 0.3169 | 0.1621 | 0.2145 | 0.8462 |
| No log | 2.0 | 148 | 0.3477 | 0.5106 | 0.3941 | 0.4448 | 0.8842 |
| No log | 3.0 | 222 | 0.3273 | 0.5705 | 0.4716 | 0.5164 | 0.8943 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.11.0+cu113
- Datasets 2.4.0
- Tokenizers 0.11.6
|
Felipehonorato/storIA
|
Felipehonorato
| 2022-08-11T15:38:21Z | 1,181 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:04Z |
This model was fine-tuned to generate horror stories in a collaborative way.
Check it out on our [repo](https://github.com/TailUFPB/storIA).
|
DOOGLAK/Tagged_One_250v4_NER_Model_3Epochs_AUGMENTED
|
DOOGLAK
| 2022-08-11T15:27:24Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"token-classification",
"generated_from_trainer",
"dataset:tagged_one250v4_wikigold_split",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-08-11T15:22:07Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- tagged_one250v4_wikigold_split
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: Tagged_One_250v4_NER_Model_3Epochs_AUGMENTED
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: tagged_one250v4_wikigold_split
type: tagged_one250v4_wikigold_split
args: default
metrics:
- name: Precision
type: precision
value: 0.568499837292548
- name: Recall
type: recall
value: 0.48473917869034405
- name: F1
type: f1
value: 0.5232889022015875
- name: Accuracy
type: accuracy
value: 0.8927736584139752
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Tagged_One_250v4_NER_Model_3Epochs_AUGMENTED
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the tagged_one250v4_wikigold_split dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3389
- Precision: 0.5685
- Recall: 0.4847
- F1: 0.5233
- Accuracy: 0.8928
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 87 | 0.4018 | 0.2797 | 0.1842 | 0.2221 | 0.8514 |
| No log | 2.0 | 174 | 0.3266 | 0.5245 | 0.4398 | 0.4784 | 0.8888 |
| No log | 3.0 | 261 | 0.3389 | 0.5685 | 0.4847 | 0.5233 | 0.8928 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.11.0+cu113
- Datasets 2.4.0
- Tokenizers 0.11.6
|
DOOGLAK/Tagged_One_250v3_NER_Model_3Epochs_AUGMENTED
|
DOOGLAK
| 2022-08-11T15:21:37Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"token-classification",
"generated_from_trainer",
"dataset:tagged_one250v3_wikigold_split",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-08-11T15:16:29Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- tagged_one250v3_wikigold_split
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: Tagged_One_250v3_NER_Model_3Epochs_AUGMENTED
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: tagged_one250v3_wikigold_split
type: tagged_one250v3_wikigold_split
args: default
metrics:
- name: Precision
type: precision
value: 0.5783339046966061
- name: Recall
type: recall
value: 0.4806267806267806
- name: F1
type: f1
value: 0.5249727711218297
- name: Accuracy
type: accuracy
value: 0.8981560947699669
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Tagged_One_250v3_NER_Model_3Epochs_AUGMENTED
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the tagged_one250v3_wikigold_split dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3179
- Precision: 0.5783
- Recall: 0.4806
- F1: 0.5250
- Accuracy: 0.8982
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 81 | 0.3974 | 0.2778 | 0.1869 | 0.2235 | 0.8530 |
| No log | 2.0 | 162 | 0.3095 | 0.5594 | 0.4470 | 0.4969 | 0.8944 |
| No log | 3.0 | 243 | 0.3179 | 0.5783 | 0.4806 | 0.5250 | 0.8982 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.11.0+cu113
- Datasets 2.4.0
- Tokenizers 0.11.6
|
huggingtweets/pilgrimbeart
|
huggingtweets
| 2022-08-11T15:11:35Z | 106 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-08-11T15:10:14Z |
---
language: en
thumbnail: http://www.huggingtweets.com/pilgrimbeart/1660230691248/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/433603570/Pilgrim_Beart_headshot_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">Pilgrim Beart</div>
<div style="text-align: center; font-size: 14px;">@pilgrimbeart</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from Pilgrim Beart.
| Data | Pilgrim Beart |
| --- | --- |
| Tweets downloaded | 3202 |
| Retweets | 1238 |
| Short tweets | 188 |
| Tweets kept | 1776 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/23t6x9nz/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @pilgrimbeart's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/2tsil6bf) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/2tsil6bf/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/pilgrimbeart')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
DOOGLAK/Tagged_One_250v0_NER_Model_3Epochs_AUGMENTED
|
DOOGLAK
| 2022-08-11T15:04:33Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"token-classification",
"generated_from_trainer",
"dataset:tagged_one250v0_wikigold_split",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-08-11T14:59:04Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- tagged_one250v0_wikigold_split
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: Tagged_One_250v0_NER_Model_3Epochs_AUGMENTED
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: tagged_one250v0_wikigold_split
type: tagged_one250v0_wikigold_split
args: default
metrics:
- name: Precision
type: precision
value: 0.5125421190565331
- name: Recall
type: recall
value: 0.3694009713977334
- name: F1
type: f1
value: 0.4293554963148816
- name: Accuracy
type: accuracy
value: 0.8786972744569918
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Tagged_One_250v0_NER_Model_3Epochs_AUGMENTED
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the tagged_one250v0_wikigold_split dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4287
- Precision: 0.5125
- Recall: 0.3694
- F1: 0.4294
- Accuracy: 0.8787
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 96 | 0.4352 | 0.3056 | 0.1692 | 0.2178 | 0.8448 |
| No log | 2.0 | 192 | 0.3881 | 0.4394 | 0.3295 | 0.3766 | 0.8773 |
| No log | 3.0 | 288 | 0.4287 | 0.5125 | 0.3694 | 0.4294 | 0.8787 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.11.0+cu113
- Datasets 2.4.0
- Tokenizers 0.11.6
|
DOOGLAK/Tagged_One_100v8_NER_Model_3Epochs_AUGMENTED
|
DOOGLAK
| 2022-08-11T14:52:30Z | 103 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"token-classification",
"generated_from_trainer",
"dataset:tagged_one100v8_wikigold_split",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-08-11T14:47:13Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- tagged_one100v8_wikigold_split
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: Tagged_One_100v8_NER_Model_3Epochs_AUGMENTED
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: tagged_one100v8_wikigold_split
type: tagged_one100v8_wikigold_split
args: default
metrics:
- name: Precision
type: precision
value: 0.18848653667595172
- name: Recall
type: recall
value: 0.0498159509202454
- name: F1
type: f1
value: 0.07880434782608696
- name: Accuracy
type: accuracy
value: 0.8035317050796927
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Tagged_One_100v8_NER_Model_3Epochs_AUGMENTED
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the tagged_one100v8_wikigold_split dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5649
- Precision: 0.1885
- Recall: 0.0498
- F1: 0.0788
- Accuracy: 0.8035
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 37 | 0.7042 | 0.0 | 0.0 | 0.0 | 0.7750 |
| No log | 2.0 | 74 | 0.5744 | 0.1628 | 0.0243 | 0.0423 | 0.7930 |
| No log | 3.0 | 111 | 0.5649 | 0.1885 | 0.0498 | 0.0788 | 0.8035 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.11.0+cu113
- Datasets 2.4.0
- Tokenizers 0.11.6
|
DOOGLAK/Tagged_One_100v7_NER_Model_3Epochs_AUGMENTED
|
DOOGLAK
| 2022-08-11T14:46:38Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"token-classification",
"generated_from_trainer",
"dataset:tagged_one100v7_wikigold_split",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-08-11T14:41:26Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- tagged_one100v7_wikigold_split
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: Tagged_One_100v7_NER_Model_3Epochs_AUGMENTED
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: tagged_one100v7_wikigold_split
type: tagged_one100v7_wikigold_split
args: default
metrics:
- name: Precision
type: precision
value: 0.2402332361516035
- name: Recall
type: recall
value: 0.10690192008303062
- name: F1
type: f1
value: 0.14796193212425932
- name: Accuracy
type: accuracy
value: 0.817534449274022
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Tagged_One_100v7_NER_Model_3Epochs_AUGMENTED
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the tagged_one100v7_wikigold_split dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5232
- Precision: 0.2402
- Recall: 0.1069
- F1: 0.1480
- Accuracy: 0.8175
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 26 | 0.6129 | 0.0647 | 0.0023 | 0.0045 | 0.7840 |
| No log | 2.0 | 52 | 0.5177 | 0.2035 | 0.0807 | 0.1156 | 0.8130 |
| No log | 3.0 | 78 | 0.5232 | 0.2402 | 0.1069 | 0.1480 | 0.8175 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.11.0+cu113
- Datasets 2.4.0
- Tokenizers 0.11.6
|
DOOGLAK/Tagged_One_100v6_NER_Model_3Epochs_AUGMENTED
|
DOOGLAK
| 2022-08-11T14:40:57Z | 106 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"token-classification",
"generated_from_trainer",
"dataset:tagged_one100v6_wikigold_split",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-08-11T14:35:55Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- tagged_one100v6_wikigold_split
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: Tagged_One_100v6_NER_Model_3Epochs_AUGMENTED
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: tagged_one100v6_wikigold_split
type: tagged_one100v6_wikigold_split
args: default
metrics:
- name: Precision
type: precision
value: 0.244097995545657
- name: Recall
type: recall
value: 0.13908629441624365
- name: F1
type: f1
value: 0.17720291026677445
- name: Accuracy
type: accuracy
value: 0.8258844149255108
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Tagged_One_100v6_NER_Model_3Epochs_AUGMENTED
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the tagged_one100v6_wikigold_split dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5346
- Precision: 0.2441
- Recall: 0.1391
- F1: 0.1772
- Accuracy: 0.8259
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 47 | 0.5840 | 0.1614 | 0.0454 | 0.0709 | 0.8044 |
| No log | 2.0 | 94 | 0.5226 | 0.2489 | 0.1312 | 0.1718 | 0.8256 |
| No log | 3.0 | 141 | 0.5346 | 0.2441 | 0.1391 | 0.1772 | 0.8259 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.11.0+cu113
- Datasets 2.4.0
- Tokenizers 0.11.6
|
DOOGLAK/Tagged_One_100v4_NER_Model_3Epochs_AUGMENTED
|
DOOGLAK
| 2022-08-11T14:30:11Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"token-classification",
"generated_from_trainer",
"dataset:tagged_one100v4_wikigold_split",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-08-11T14:25:11Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- tagged_one100v4_wikigold_split
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: Tagged_One_100v4_NER_Model_3Epochs_AUGMENTED
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: tagged_one100v4_wikigold_split
type: tagged_one100v4_wikigold_split
args: default
metrics:
- name: Precision
type: precision
value: 0.16494312306101344
- name: Recall
type: recall
value: 0.08177390412714688
- name: F1
type: f1
value: 0.10934018851756641
- name: Accuracy
type: accuracy
value: 0.8299042951592769
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Tagged_One_100v4_NER_Model_3Epochs_AUGMENTED
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the tagged_one100v4_wikigold_split dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4506
- Precision: 0.1649
- Recall: 0.0818
- F1: 0.1093
- Accuracy: 0.8299
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 34 | 0.5649 | 0.0 | 0.0 | 0.0 | 0.7875 |
| No log | 2.0 | 68 | 0.4687 | 0.1197 | 0.0400 | 0.0600 | 0.8147 |
| No log | 3.0 | 102 | 0.4506 | 0.1649 | 0.0818 | 0.1093 | 0.8299 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.11.0+cu113
- Datasets 2.4.0
- Tokenizers 0.11.6
|
DOOGLAK/Tagged_One_100v3_NER_Model_3Epochs_AUGMENTED
|
DOOGLAK
| 2022-08-11T14:24:44Z | 103 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"token-classification",
"generated_from_trainer",
"dataset:tagged_one100v3_wikigold_split",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-08-11T14:19:36Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- tagged_one100v3_wikigold_split
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: Tagged_One_100v3_NER_Model_3Epochs_AUGMENTED
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: tagged_one100v3_wikigold_split
type: tagged_one100v3_wikigold_split
args: default
metrics:
- name: Precision
type: precision
value: 0.20557491289198607
- name: Recall
type: recall
value: 0.08955223880597014
- name: F1
type: f1
value: 0.12475770925110131
- name: Accuracy
type: accuracy
value: 0.8123509941439252
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Tagged_One_100v3_NER_Model_3Epochs_AUGMENTED
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the tagged_one100v3_wikigold_split dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4863
- Precision: 0.2056
- Recall: 0.0896
- F1: 0.1248
- Accuracy: 0.8124
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 26 | 0.6246 | 0.1111 | 0.0003 | 0.0005 | 0.7773 |
| No log | 2.0 | 52 | 0.5272 | 0.1238 | 0.0296 | 0.0478 | 0.7948 |
| No log | 3.0 | 78 | 0.4863 | 0.2056 | 0.0896 | 0.1248 | 0.8124 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.11.0+cu113
- Datasets 2.4.0
- Tokenizers 0.11.6
|
harish/t5-e2e-10epochs-lr1e4-alpha0-9
|
harish
| 2022-08-11T14:15:14Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"t5",
"text2text-generation",
"license:cc-by-nc-sa-4.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-08-11T14:10:36Z |
---
license: cc-by-nc-sa-4.0
---
|
DOOGLAK/Tagged_One_100v0_NER_Model_3Epochs_AUGMENTED
|
DOOGLAK
| 2022-08-11T14:07:39Z | 104 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"token-classification",
"generated_from_trainer",
"dataset:tagged_one100v0_wikigold_split",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-08-11T14:02:55Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- tagged_one100v0_wikigold_split
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: Tagged_One_100v0_NER_Model_3Epochs_AUGMENTED
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: tagged_one100v0_wikigold_split
type: tagged_one100v0_wikigold_split
args: default
metrics:
- name: Precision
type: precision
value: 0.16896060749881348
- name: Recall
type: recall
value: 0.08985360928823827
- name: F1
type: f1
value: 0.11731751524139067
- name: Accuracy
type: accuracy
value: 0.8183405097172117
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Tagged_One_100v0_NER_Model_3Epochs_AUGMENTED
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the tagged_one100v0_wikigold_split dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4700
- Precision: 0.1690
- Recall: 0.0899
- F1: 0.1173
- Accuracy: 0.8183
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 32 | 0.5975 | 0.1034 | 0.0015 | 0.0030 | 0.7790 |
| No log | 2.0 | 64 | 0.4756 | 0.1607 | 0.0765 | 0.1036 | 0.8137 |
| No log | 3.0 | 96 | 0.4700 | 0.1690 | 0.0899 | 0.1173 | 0.8183 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.11.0+cu113
- Datasets 2.4.0
- Tokenizers 0.11.6
|
DOOGLAK/Tagged_One_50v9_NER_Model_3Epochs_AUGMENTED
|
DOOGLAK
| 2022-08-11T14:02:29Z | 103 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"token-classification",
"generated_from_trainer",
"dataset:tagged_one50v9_wikigold_split",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-08-11T13:57:36Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- tagged_one50v9_wikigold_split
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: Tagged_One_50v9_NER_Model_3Epochs_AUGMENTED
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: tagged_one50v9_wikigold_split
type: tagged_one50v9_wikigold_split
args: default
metrics:
- name: Precision
type: precision
value: 0.5
- name: Recall
type: recall
value: 0.000243605359317905
- name: F1
type: f1
value: 0.00048697345994643296
- name: Accuracy
type: accuracy
value: 0.7806885723898171
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Tagged_One_50v9_NER_Model_3Epochs_AUGMENTED
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the tagged_one50v9_wikigold_split dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6504
- Precision: 0.5
- Recall: 0.0002
- F1: 0.0005
- Accuracy: 0.7807
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 16 | 0.7521 | 0.0 | 0.0 | 0.0 | 0.7782 |
| No log | 2.0 | 32 | 0.6778 | 1.0 | 0.0002 | 0.0005 | 0.7797 |
| No log | 3.0 | 48 | 0.6504 | 0.5 | 0.0002 | 0.0005 | 0.7807 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.11.0+cu113
- Datasets 2.4.0
- Tokenizers 0.11.6
|
DOOGLAK/Tagged_One_50v8_NER_Model_3Epochs_AUGMENTED
|
DOOGLAK
| 2022-08-11T13:57:11Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"token-classification",
"generated_from_trainer",
"dataset:tagged_one50v8_wikigold_split",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-08-11T13:52:19Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- tagged_one50v8_wikigold_split
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: Tagged_One_50v8_NER_Model_3Epochs_AUGMENTED
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: tagged_one50v8_wikigold_split
type: tagged_one50v8_wikigold_split
args: default
metrics:
- name: Precision
type: precision
value: 0.09166666666666666
- name: Recall
type: recall
value: 0.0053868756121449556
- name: F1
type: f1
value: 0.010175763182238666
- name: Accuracy
type: accuracy
value: 0.7848874958020822
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Tagged_One_50v8_NER_Model_3Epochs_AUGMENTED
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the tagged_one50v8_wikigold_split dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5935
- Precision: 0.0917
- Recall: 0.0054
- F1: 0.0102
- Accuracy: 0.7849
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 19 | 0.7198 | 0.0 | 0.0 | 0.0 | 0.7786 |
| No log | 2.0 | 38 | 0.6263 | 0.0727 | 0.0010 | 0.0019 | 0.7798 |
| No log | 3.0 | 57 | 0.5935 | 0.0917 | 0.0054 | 0.0102 | 0.7849 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.11.0+cu113
- Datasets 2.4.0
- Tokenizers 0.11.6
|
DOOGLAK/Tagged_One_50v7_NER_Model_3Epochs_AUGMENTED
|
DOOGLAK
| 2022-08-11T13:51:43Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"token-classification",
"generated_from_trainer",
"dataset:tagged_one50v7_wikigold_split",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-08-11T13:46:46Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- tagged_one50v7_wikigold_split
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: Tagged_One_50v7_NER_Model_3Epochs_AUGMENTED
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: tagged_one50v7_wikigold_split
type: tagged_one50v7_wikigold_split
args: default
metrics:
- name: Precision
type: precision
value: 0.0
- name: Recall
type: recall
value: 0.0
- name: F1
type: f1
value: 0.0
- name: Accuracy
type: accuracy
value: 0.7785234899328859
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Tagged_One_50v7_NER_Model_3Epochs_AUGMENTED
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the tagged_one50v7_wikigold_split dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6441
- Precision: 0.0
- Recall: 0.0
- F1: 0.0
- Accuracy: 0.7785
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:---:|:--------:|
| No log | 1.0 | 13 | 0.7609 | 0.0 | 0.0 | 0.0 | 0.7783 |
| No log | 2.0 | 26 | 0.6742 | 0.0 | 0.0 | 0.0 | 0.7783 |
| No log | 3.0 | 39 | 0.6441 | 0.0 | 0.0 | 0.0 | 0.7785 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.11.0+cu113
- Datasets 2.4.0
- Tokenizers 0.11.6
|
Subsets and Splits
Filtered Qwen2.5 Distill Models
Identifies specific configurations of models by filtering cards that contain 'distill', 'qwen2.5', '7b' while excluding certain base models and incorrect model ID patterns, uncovering unique model variants.
Filtered Model Cards Count
Finds the count of entries with specific card details that include 'distill', 'qwen2.5', '7b' but exclude certain base models, revealing valuable insights about the dataset's content distribution.
Filtered Distill Qwen 7B Models
Filters for specific card entries containing 'distill', 'qwen', and '7b', excluding certain strings and patterns, to identify relevant model configurations.
Filtered Qwen-7b Model Cards
The query performs a detailed filtering based on specific keywords and excludes certain entries, which could be useful for identifying a specific subset of cards but does not provide deeper insights or trends.
Filtered Qwen 7B Model Cards
The query filters for specific terms related to "distilled" or "distill", "qwen", and "7b" in the 'card' column but excludes certain base models, providing a limited set of entries for further inspection.
Qwen 7B Distilled Models
The query provides a basic filtering of records to find specific card names that include keywords related to distilled Qwen 7b models, excluding a particular base model, which gives limited insight but helps in focusing on relevant entries.
Qwen 7B Distilled Model Cards
The query filters data based on specific keywords in the modelId and card fields, providing limited insight primarily useful for locating specific entries rather than revealing broad patterns or trends.
Qwen 7B Distilled Models
Finds all entries containing the terms 'distilled', 'qwen', and '7b' in a case-insensitive manner, providing a filtered set of records but without deeper analysis.
Distilled Qwen 7B Models
The query filters for specific model IDs containing 'distilled', 'qwen', and '7b', providing a basic retrieval of relevant entries but without deeper analysis or insight.
Filtered Model Cards with Distill Qwen2.
Filters and retrieves records containing specific keywords in the card description while excluding certain phrases, providing a basic count of relevant entries.
Filtered Model Cards with Distill Qwen 7
The query filters specific variations of card descriptions containing 'distill', 'qwen', and '7b' while excluding a particular base model, providing limited but specific data retrieval.
Distill Qwen 7B Model Cards
The query filters and retrieves rows where the 'card' column contains specific keywords ('distill', 'qwen', and '7b'), providing a basic filter result that can help in identifying specific entries.