
modelId
stringlengths 5
139
| author
stringlengths 2
42
| last_modified
timestamp[us, tz=UTC]date 2020-02-15 11:33:14
2025-09-06 06:27:01
| downloads
int64 0
223M
| likes
int64 0
11.7k
| library_name
stringclasses 542
values | tags
listlengths 1
4.05k
| pipeline_tag
stringclasses 55
values | createdAt
timestamp[us, tz=UTC]date 2022-03-02 23:29:04
2025-09-06 06:26:44
| card
stringlengths 11
1.01M
|
|---|---|---|---|---|---|---|---|---|---|
madlag/bert-large-uncased-mnli
|
madlag
| 2021-05-19T22:40:43Z | 8 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"text-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
## BERT-large finetuned on MNLI.
The [reference finetuned model](https://github.com/google-research/bert) has an accuracy of 86.05, we get 86.7:
```
{'eval_loss': 0.3984006643295288, 'eval_accuracy': 0.8667345899133979}
```
|
madlag/bert-base-uncased-squad1.1-block-sparse-0.32-v1
|
madlag
| 2021-05-19T22:33:45Z | 71 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"bert",
"question-answering",
"bert-base",
"en",
"dataset:squad",
"arxiv:2005.07683",
"license:mit",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail:
license: mit
tags:
- question-answering
- bert
- bert-base
datasets:
- squad
metrics:
- squad
widget:
- text: "Where is the Eiffel Tower located?"
context: "The Eiffel Tower is a wrought-iron lattice tower on the Champ de Mars in Paris, France. It is named after the engineer Gustave Eiffel, whose company designed and built the tower."
- text: "Who is Frederic Chopin?"
context: "Frédéric François Chopin, born Fryderyk Franciszek Chopin (1 March 1810 – 17 October 1849), was a Polish composer and virtuoso pianist of the Romantic era who wrote primarily for solo piano."
---
## BERT-base uncased model fine-tuned on SQuAD v1
This model is block sparse: the **linear** layers contains **31.7%** of the original weights.
The model contains **47.0%** of the original weights **overall**.
The training use a modified version of Victor Sanh [Movement Pruning](https://arxiv.org/abs/2005.07683) method.
That means that with the [block-sparse](https://github.com/huggingface/pytorch_block_sparse) runtime it ran **1.12x** faster than an dense networks on the evaluation, at the price of some impact on the accuracy (see below).
This model was fine-tuned from the HuggingFace [BERT](https://www.aclweb.org/anthology/N19-1423/) base uncased checkpoint on [SQuAD1.1](https://rajpurkar.github.io/SQuAD-explorer), and distilled from the equivalent model [csarron/bert-base-uncased-squad-v1](https://huggingface.co/csarron/bert-base-uncased-squad-v1).
This model is case-insensitive: it does not make a difference between english and English.
## Pruning details
A side-effect of the block pruning is that some of the attention heads are completely removed: 80 heads were removed on a total of 144 (55.6%).
Here is a detailed view on how the remaining heads are distributed in the network after pruning.

## Density plot
<script src="/madlag/bert-base-uncased-squad1.1-block-sparse-0.32-v1/raw/main/model_card/density.js" id="79005f4a-723c-4bf8-bc7f-5ad11676be6c"></script>
## Details
| Dataset | Split | # samples |
| -------- | ----- | --------- |
| SQuAD1.1 | train | 90.6K |
| SQuAD1.1 | eval | 11.1k |
### Fine-tuning
- Python: `3.8.5`
- Machine specs:
```CPU: Intel(R) Core(TM) i7-6700K CPU
Memory: 64 GiB
GPUs: 1 GeForce GTX 3090, with 24GiB memory
GPU driver: 455.23.05, CUDA: 11.1
```
### Results
**Pytorch model file size**: `355M` (original BERT: `438M`)
| Metric | # Value | # Original ([Table 2](https://www.aclweb.org/anthology/N19-1423.pdf))|
| ------ | --------- | --------- |
| **EM** | **79.04** | **80.8** |
| **F1** | **86.70** | **88.5** |
## Example Usage
```python
from transformers import pipeline
qa_pipeline = pipeline(
"question-answering",
model="madlag/bert-base-uncased-squad1.1-block-sparse-0.32-v1",
tokenizer="madlag/bert-base-uncased-squad1.1-block-sparse-0.32-v1"
)
predictions = qa_pipeline({
'context': "Frédéric François Chopin, born Fryderyk Franciszek Chopin (1 March 1810 – 17 October 1849), was a Polish composer and virtuoso pianist of the Romantic era who wrote primarily for solo piano.",
'question': "Who is Frederic Chopin?",
})
print(predictions)
```
|
MonoHime/rubert_conversational_cased_sentiment
|
MonoHime
| 2021-05-19T22:26:59Z | 20 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"sentiment",
"text-classification",
"ru",
"dataset:Tatyana/ru_sentiment_dataset",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
---
language:
- ru
tags:
- sentiment
- text-classification
datasets:
- Tatyana/ru_sentiment_dataset
---
# Keras model with ruBERT conversational embedder for Sentiment Analysis
Russian texts sentiment classification.
Model trained on [Tatyana/ru_sentiment_dataset](https://huggingface.co/datasets/Tatyana/ru_sentiment_dataset)
## Labels meaning
0: NEUTRAL
1: POSITIVE
2: NEGATIVE
## How to use
```python
!pip install tensorflow-gpu
!pip install deeppavlov
!python -m deeppavlov install squad_bert
!pip install fasttext
!pip install transformers
!python -m deeppavlov install bert_sentence_embedder
from deeppavlov import build_model
model = build_model(Tatyana/rubert_conversational_cased_sentiment/custom_config.json)
model(["Сегодня хорошая погода", "Я счастлив проводить с тобою время", "Мне нравится эта музыкальная композиция"])
```
|
lvwerra/bert-imdb
|
lvwerra
| 2021-05-19T22:12:49Z | 42 | 1 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"text-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
# BERT-IMDB
## What is it?
BERT (`bert-large-cased`) trained for sentiment classification on the [IMDB dataset](https://www.kaggle.com/lakshmi25npathi/imdb-dataset-of-50k-movie-reviews).
## Training setting
The model was trained on 80% of the IMDB dataset for sentiment classification for three epochs with a learning rate of `1e-5` with the `simpletransformers` library. The library uses a learning rate schedule.
## Result
The model achieved 90% classification accuracy on the validation set.
## Reference
The full experiment is available in the [tlr repo](https://lvwerra.github.io/trl/03-bert-imdb-training/).
|
lserinol/bert-turkish-question-answering
|
lserinol
| 2021-05-19T22:06:55Z | 590 | 23 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"question-answering",
"tr",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-03-02T23:29:05Z |
---
language: tr
---
# bert-turkish-question-answering
## Usage
```python
from transformers import pipeline
nlp = pipeline('question-answering', model='lserinol/bert-turkish-question-answering', tokenizer='lserinol/bert-turkish-question-answering')
nlp({
'question': "Ankara'da kaç ilçe vardır?",
'context': r"""Türkiye'nin başkenti Ankara'dır. Ülkenin en büyük idari birimleri illerdir ve 81 il vardır. Bu iller ilçelere ayrılmıştır, toplamda 973 ilçe mevcuttur."""
})
```
```python
from transformers import AutoTokenizer, AutoModelForQuestionAnswering
import torch
tokenizer = AutoTokenizer.from_pretrained("lserinol/bert-turkish-question-answering")
model = AutoModelForQuestionAnswering.from_pretrained("lserinol/bert-turkish-question-answering")
text = r"""
Ankara'nın başkent ilan edilmesinin ardından (13 Ekim 1923) şehir hızla gelişmiş ve Türkiye'nin ikinci en kalabalık ili olmuştur.
Türkiye Cumhuriyeti'nin ilk yıllarında ekonomisi tarım ve hayvancılığa dayanan ilin topraklarının yarısı hâlâ tarım amaçlı
kullanılmaktadır. Ekonomik etkinlik büyük oranda ticaret ve sanayiye dayalıdır. Tarım ve hayvancılığın ağırlığı ise giderek
azalmaktadır. Ankara ve civarındaki gerek kamu sektörü gerek özel sektör yatırımları, başka illerden büyük bir nüfus göçünü
teşvik etmiştir. Cumhuriyetin kuruluşundan günümüze, nüfusu ülke nüfusunun iki katı hızda artmıştır. Nüfusun yaklaşık dörtte
üçü hizmet sektörü olarak tanımlanabilecek memuriyet, ulaşım, haberleşme ve ticaret benzeri işlerde, dörtte biri sanayide,
%2'si ise tarım alanında çalışır. Sanayi, özellikle tekstil, gıda ve inşaat sektörlerinde yoğunlaşmıştır. Günümüzde ise en çok
savunma, metal ve motor sektörlerinde yatırım yapılmaktadır. Türkiye'nin en çok sayıda üniversiteye sahip ili olan Ankara'da
ayrıca, üniversite diplomalı kişi oranı ülke ortalamasının iki katıdır. Bu eğitimli nüfus, teknoloji ağırlıklı yatırımların
gereksinim duyduğu iş gücünü oluşturur. Ankara'dan otoyollar, demir yolu ve hava yoluyla Türkiye'nin diğer şehirlerine ulaşılır.
Ankara aynı zamanda başkent olarak Türkiye Büyük Millet Meclisi (TBMM)'ye de ev sahipliği yapmaktadır.
"""
questions = [
"Ankara kaç yılında başkent oldu?",
"Ankara ne zaman başkent oldu?",
"Ankara'dan başka şehirlere nasıl ulaşılır?",
"TBMM neyin kısaltmasıdır?"
]
for question in questions:
inputs = tokenizer(question, text, add_special_tokens=True, return_tensors="pt")
input_ids = inputs["input_ids"].tolist()[0]
text_tokens = tokenizer.convert_ids_to_tokens(input_ids)
answer_start_scores, answer_end_scores = model(**inputs)
answer_start = torch.argmax(
answer_start_scores
) # Get the most likely beginning of answer with the argmax of the score
answer_end = torch.argmax(answer_end_scores) + 1 # Get the most likely end of answer with the argmax of the score
answer = tokenizer.convert_tokens_to_string(tokenizer.convert_ids_to_tokens(input_ids[answer_start:answer_end]))
print(f"Question: {question}")
print(f"Answer: {answer}\n")
```
|
loodos/bert-base-turkish-uncased
|
loodos
| 2021-05-19T22:04:30Z | 1,582 | 6 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"jax",
"bert",
"tr",
"endpoints_compatible",
"region:us"
] | null | 2022-03-02T23:29:05Z |
---
language: tr
---
# Turkish Language Models with Huggingface's Transformers
As R&D Team at Loodos, we release cased and uncased versions of most recent language models for Turkish. More details about pretrained models and evaluations on downstream tasks can be found [here (our repo)](https://github.com/Loodos/turkish-language-models).
# Turkish BERT-Base (uncased)
This is BERT-Base model which has 12 encoder layers with 768 hidden layer size trained on uncased Turkish dataset.
## Usage
Using AutoModel and AutoTokenizer from Transformers, you can import the model as described below.
```python
from transformers import AutoModel, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("loodos/bert-base-turkish-uncased", do_lower_case=False)
model = AutoModel.from_pretrained("loodos/bert-base-turkish-uncased")
normalizer = TextNormalization()
normalized_text = normalizer.normalize(text, do_lower_case=True, is_turkish=True)
tokenizer.tokenize(normalized_text)
```
### Notes on Tokenizers
Currently, Huggingface's tokenizers (which were written in Python) have a bug concerning letters "ı, i, I, İ" and non-ASCII Turkish specific letters. There are two reasons.
1- Vocabulary and sentence piece model is created with NFC/NFKC normalization but tokenizer uses NFD/NFKD. NFD/NFKD normalization changes text that contains Turkish characters I-ı, İ-i, Ç-ç, Ö-ö, Ş-ş, Ğ-ğ, Ü-ü. This causes wrong tokenization, wrong training and loss of information. Some tokens are never trained.(like "şanlıurfa", "öğün", "çocuk" etc.) NFD/NFKD normalization is not proper for Turkish.
2- Python's default ```string.lower()``` and ```string.upper()``` make the conversions
- "I" and "İ" to 'i'
- 'i' and 'ı' to 'I'
respectively. However, in Turkish, 'I' and 'İ' are two different letters.
We opened an [issue](https://github.com/huggingface/transformers/issues/6680) in Huggingface's github repo about this bug. Until it is fixed, in case you want to train your model with uncased data, we provide a simple text normalization module (`TextNormalization()` in the code snippet above) in our [repo](https://github.com/Loodos/turkish-language-models).
## Details and Contact
You contact us to ask a question, open an issue or give feedback via our github [repo](https://github.com/Loodos/turkish-language-models).
## Acknowledgments
Many thanks to TFRC Team for providing us cloud TPUs on Tensorflow Research Cloud to train our models.
|
loodos/bert-base-turkish-cased
|
loodos
| 2021-05-19T22:03:36Z | 7 | 1 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"jax",
"bert",
"tr",
"endpoints_compatible",
"region:us"
] | null | 2022-03-02T23:29:05Z |
---
language: tr
---
# Turkish Language Models with Huggingface's Transformers
As R&D Team at Loodos, we release cased and uncased versions of most recent language models for Turkish. More details about pretrained models and evaluations on downstream tasks can be found [here (our repo)](https://github.com/Loodos/turkish-language-models).
# Turkish BERT-Base (cased)
This is BERT-Base model which has 12 encoder layers with 768 hidden layer size trained on cased Turkish dataset.
## Usage
Using AutoModel and AutoTokenizer from Transformers, you can import the model as described below.
```python
from transformers import AutoModel, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("loodos/bert-base-turkish-cased")
model = AutoModel.from_pretrained("loodos/bert-base-turkish-cased")
```
## Details and Contact
You contact us to ask a question, open an issue or give feedback via our github [repo](https://github.com/Loodos/turkish-language-models).
## Acknowledgments
Many thanks to TFRC Team for providing us cloud TPUs on Tensorflow Research Cloud to train our models.
|
larskjeldgaard/senda
|
larskjeldgaard
| 2021-05-19T21:20:48Z | 166 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"text-classification",
"danish",
"sentiment",
"polarity",
"da",
"license:cc-by-4.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
---
language: da
tags:
- danish
- bert
- sentiment
- polarity
license: cc-by-4.0
widget:
- text: "Sikke en dejlig dag det er i dag"
---
# Danish BERT fine-tuned for Sentiment Analysis (Polarity)
This model detects polarity ('positive', 'neutral', 'negative') of danish texts.
It is trained and tested on Tweets annotated by [Alexandra Institute](https://github.com/alexandrainst).
Here is an example on how to load the model in PyTorch using the [🤗Transformers](https://github.com/huggingface/transformers) library:
```python
from transformers import AutoTokenizer, AutoModelForSequenceClassification, pipeline
tokenizer = AutoTokenizer.from_pretrained("larskjeldgaard/senda")
model = AutoModelForSequenceClassification.from_pretrained("larskjeldgaard/senda")
# create 'senda' sentiment analysis pipeline
senda_pipeline = pipeline('sentiment-analysis', model=model, tokenizer=tokenizer)
senda_pipeline("Sikke en dejlig dag det er i dag")
```
|
lanwuwei/GigaBERT-v4-Arabic-and-English
|
lanwuwei
| 2021-05-19T21:19:13Z | 47 | 5 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"feature-extraction",
"endpoints_compatible",
"region:us"
] |
feature-extraction
| 2022-03-02T23:29:05Z |
## GigaBERT-v4
GigaBERT-v4 is a continued pre-training of [GigaBERT-v3](https://huggingface.co/lanwuwei/GigaBERT-v3-Arabic-and-English) on code-switched data, showing improved zero-shot transfer performance from English to Arabic on information extraction (IE) tasks. More details can be found in the following paper:
@inproceedings{lan2020gigabert,
author = {Lan, Wuwei and Chen, Yang and Xu, Wei and Ritter, Alan},
title = {GigaBERT: Zero-shot Transfer Learning from English to Arabic},
booktitle = {Proceedings of The 2020 Conference on Empirical Methods on Natural Language Processing (EMNLP)},
year = {2020}
}
## Download
```
from transformers import *
tokenizer = BertTokenizer.from_pretrained("lanwuwei/GigaBERT-v4-Arabic-and-English", do_lower_case=True)
model = BertForTokenClassification.from_pretrained("lanwuwei/GigaBERT-v4-Arabic-and-English")
```
Here is downloadable link [GigaBERT-v4](https://drive.google.com/drive/u/1/folders/1uFGzMuTOD7iNsmKQYp_zVuvsJwOaIdar).
|
kykim/bert-kor-base
|
kykim
| 2021-05-19T21:17:13Z | 155,515 | 28 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"jax",
"bert",
"fill-mask",
"ko",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:05Z |
---
language: ko
---
# Bert base model for Korean
* 70GB Korean text dataset and 42000 lower-cased subwords are used
* Check the model performance and other language models for Korean in [github](https://github.com/kiyoungkim1/LM-kor)
```python
from transformers import BertTokenizerFast, BertModel
tokenizer_bert = BertTokenizerFast.from_pretrained("kykim/bert-kor-base")
model_bert = BertModel.from_pretrained("kykim/bert-kor-base")
```
|
ktrapeznikov/scibert_scivocab_uncased_squad_v2
|
ktrapeznikov
| 2021-05-19T21:11:07Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"question-answering",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-03-02T23:29:05Z |
### Model
**[`allenai/scibert_scivocab_uncased`](https://huggingface.co/allenai/scibert_scivocab_uncased)** fine-tuned on **[`SQuAD V2`](https://rajpurkar.github.io/SQuAD-explorer/)** using **[`run_squad.py`](https://github.com/huggingface/transformers/blob/master/examples/question-answering/run_squad.py)**
### Training Parameters
Trained on 4 NVIDIA GeForce RTX 2080 Ti 11Gb
```bash
BASE_MODEL=allenai/scibert_scivocab_uncased
python run_squad.py \
--version_2_with_negative \
--model_type albert \
--model_name_or_path $BASE_MODEL \
--output_dir $OUTPUT_MODEL \
--do_eval \
--do_lower_case \
--train_file $SQUAD_DIR/train-v2.0.json \
--predict_file $SQUAD_DIR/dev-v2.0.json \
--per_gpu_train_batch_size 18 \
--per_gpu_eval_batch_size 64 \
--learning_rate 3e-5 \
--num_train_epochs 3.0 \
--max_seq_length 384 \
--doc_stride 128 \
--save_steps 2000 \
--threads 24 \
--warmup_steps 550 \
--gradient_accumulation_steps 1 \
--fp16 \
--logging_steps 50 \
--do_train
```
### Evaluation
Evaluation on the dev set. I did not sweep for best threshold.
| | val |
|-------------------|-------------------|
| exact | 75.07790785816559 |
| f1 | 78.47735207283013 |
| total | 11873.0 |
| HasAns_exact | 70.76585695006747 |
| HasAns_f1 | 77.57449412292718 |
| HasAns_total | 5928.0 |
| NoAns_exact | 79.37762825904122 |
| NoAns_f1 | 79.37762825904122 |
| NoAns_total | 5945.0 |
| best_exact | 75.08633032931863 |
| best_exact_thresh | 0.0 |
| best_f1 | 78.48577454398324 |
| best_f1_thresh | 0.0 |
### Usage
See [huggingface documentation](https://huggingface.co/transformers/model_doc/bert.html#bertforquestionanswering). Training on `SQuAD V2` allows the model to score if a paragraph contains an answer:
```python
start_scores, end_scores = model(input_ids)
span_scores = start_scores.softmax(dim=1).log()[:,:,None] + end_scores.softmax(dim=1).log()[:,None,:]
ignore_score = span_scores[:,0,0] #no answer scores
```
|
ktrapeznikov/biobert_v1.1_pubmed_squad_v2
|
ktrapeznikov
| 2021-05-19T21:10:03Z | 233 | 3 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"question-answering",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-03-02T23:29:05Z |
### Model
**[`monologg/biobert_v1.1_pubmed`](https://huggingface.co/monologg/biobert_v1.1_pubmed)** fine-tuned on **[`SQuAD V2`](https://rajpurkar.github.io/SQuAD-explorer/)** using **[`run_squad.py`](https://github.com/huggingface/transformers/blob/master/examples/question-answering/run_squad.py)**
This model is cased.
### Training Parameters
Trained on 4 NVIDIA GeForce RTX 2080 Ti 11Gb
```bash
BASE_MODEL=monologg/biobert_v1.1_pubmed
python run_squad.py \
--version_2_with_negative \
--model_type albert \
--model_name_or_path $BASE_MODEL \
--output_dir $OUTPUT_MODEL \
--do_eval \
--do_lower_case \
--train_file $SQUAD_DIR/train-v2.0.json \
--predict_file $SQUAD_DIR/dev-v2.0.json \
--per_gpu_train_batch_size 18 \
--per_gpu_eval_batch_size 64 \
--learning_rate 3e-5 \
--num_train_epochs 3.0 \
--max_seq_length 384 \
--doc_stride 128 \
--save_steps 2000 \
--threads 24 \
--warmup_steps 550 \
--gradient_accumulation_steps 1 \
--fp16 \
--logging_steps 50 \
--do_train
```
### Evaluation
Evaluation on the dev set. I did not sweep for best threshold.
| | val |
|-------------------|-------------------|
| exact | 75.97068980038743 |
| f1 | 79.37043950121722 |
| total | 11873.0 |
| HasAns_exact | 74.13967611336032 |
| HasAns_f1 | 80.94892513460755 |
| HasAns_total | 5928.0 |
| NoAns_exact | 77.79646761984861 |
| NoAns_f1 | 77.79646761984861 |
| NoAns_total | 5945.0 |
| best_exact | 75.97068980038743 |
| best_exact_thresh | 0.0 |
| best_f1 | 79.37043950121729 |
| best_f1_thresh | 0.0 |
### Usage
See [huggingface documentation](https://huggingface.co/transformers/model_doc/bert.html#bertforquestionanswering). Training on `SQuAD V2` allows the model to score if a paragraph contains an answer:
```python
start_scores, end_scores = model(input_ids)
span_scores = start_scores.softmax(dim=1).log()[:,:,None] + end_scores.softmax(dim=1).log()[:,None,:]
ignore_score = span_scores[:,0,0] #no answer scores
```
|
julien-c/bert-xsmall-dummy
|
julien-c
| 2021-05-19T20:53:10Z | 29,145 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"jax",
"bert",
"fill-mask",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:05Z |
## How to build a dummy model
```python
from transformers BertConfig, BertForMaskedLM, BertTokenizer, TFBertForMaskedLM
SMALL_MODEL_IDENTIFIER = "julien-c/bert-xsmall-dummy"
DIRNAME = "./bert-xsmall-dummy"
config = BertConfig(10, 20, 1, 1, 40)
model = BertForMaskedLM(config)
model.save_pretrained(DIRNAME)
tf_model = TFBertForMaskedLM.from_pretrained(DIRNAME, from_pt=True)
tf_model.save_pretrained(DIRNAME)
# Slightly different for tokenizer.
# tokenizer = BertTokenizer.from_pretrained(DIRNAME)
# tokenizer.save_pretrained()
```
|
joelniklaus/gbert-base-ler
|
joelniklaus
| 2021-05-19T20:51:41Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"bert",
"token-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-03-02T23:29:05Z |
# gbert-base-ler
Task: ler
Base Model: deepset/gbert-base
Trained for 3 epochs
Batch-size: 6
Seed: 42
Test F1-Score: 0.956
|
joelniklaus/bert-base-uncased-sem_eval_2010_task_8
|
joelniklaus
| 2021-05-19T20:50:51Z | 7 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"jax",
"bert",
"text-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
# bert-base-uncased-sem_eval_2010_task_8
Task: sem_eval_2010_task_8
Base Model: bert-base-uncased
Trained for 3 epochs
Batch-size: 6
Seed: 42
Test F1-Score: 0.8
|
jeniya/BERTOverflow
|
jeniya
| 2021-05-19T20:47:17Z | 231 | 8 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"feature-extraction",
"endpoints_compatible",
"region:us"
] |
feature-extraction
| 2022-03-02T23:29:05Z |
# BERTOverflow
## Model description
We pre-trained BERT-base model on 152 million sentences from the StackOverflow's 10 year archive. More details of this model can be found in our ACL 2020 paper: [Code and Named Entity Recognition in StackOverflow](https://www.aclweb.org/anthology/2020.acl-main.443/). We would like to thank [Wuwei Lan](https://lanwuwei.github.io/) for helping us in training this model.
#### How to use
```python
from transformers import *
import torch
tokenizer = AutoTokenizer.from_pretrained("jeniya/BERTOverflow")
model = AutoModelForTokenClassification.from_pretrained("jeniya/BERTOverflow")
```
### BibTeX entry and citation info
```bibtex
@inproceedings{tabassum2020code,
title={Code and Named Entity Recognition in StackOverflow},
author={Tabassum, Jeniya and Maddela, Mounica and Xu, Wei and Ritter, Alan },
booktitle = {Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics (ACL)},
url={https://www.aclweb.org/anthology/2020.acl-main.443/}
year = {2020},
}
```
|
jannesg/bertsson
|
jannesg
| 2021-05-19T20:36:10Z | 6 | 1 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"sv",
"endpoints_compatible",
"region:us"
] | null | 2022-03-02T23:29:05Z |
---
language: sv
---
# BERTSSON Models
The models are trained on:
- Government Text
- Swedish Literature
- Swedish News
Corpus size: Roughly 6B tokens.
The following models are currently available:
- **bertsson** - A BERT base model trained with the same hyperparameters as first published by Google.
All models are cased and trained with whole word masking.
Stay tuned for evaluations.
|
jakelever/coronabert
|
jakelever
| 2021-05-19T20:34:36Z | 14 | 3 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"jax",
"bert",
"text-classification",
"coronavirus",
"covid",
"bionlp",
"en",
"dataset:cord19",
"dataset:pubmed",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://coronacentral.ai/logo-with-name.png?1
tags:
- coronavirus
- covid
- bionlp
datasets:
- cord19
- pubmed
license: mit
widget:
- text: "Pre-existing T-cell immunity to SARS-CoV-2 in unexposed healthy controls in Ecuador, as detected with a COVID-19 Interferon-Gamma Release Assay."
- text: "Lifestyle and mental health disruptions during COVID-19."
- text: "More than 50 Long-term effects of COVID-19: a systematic review and meta-analysis"
---
# CoronaCentral BERT Model for Topic / Article Type Classification
This is the topic / article type multi-label classification for the [CoronaCentral website](https://coronacentral.ai). This forms part of the pipeline for downloading and processing coronavirus literature described in the [corona-ml repo](https://github.com/jakelever/corona-ml) with available [step-by-step descriptions](https://github.com/jakelever/corona-ml/blob/master/stepByStep.md). The method is described in the [preprint](https://doi.org/10.1101/2020.12.21.423860) and detailed performance results can be found in the [machine learning details](https://github.com/jakelever/corona-ml/blob/master/machineLearningDetails.md) document.
This model was derived by fine-tuning the [microsoft/BiomedNLP-PubMedBERT-base-uncased-abstract](https://huggingface.co/microsoft/BiomedNLP-PubMedBERT-base-uncased-abstract) model on this coronavirus sequence (document) classification task.
## Usage
Below are two Google Colab notebooks with example usage of this sequence classification model using HuggingFace transformers and KTrain.
- [HuggingFace example on Google Colab](https://colab.research.google.com/drive/1cBNgKd4o6FNWwjKXXQQsC_SaX1kOXDa4?usp=sharing)
- [KTrain example on Google Colab](https://colab.research.google.com/drive/1h7oJa2NDjnBEoox0D5vwXrxiCHj3B1kU?usp=sharing)
## Training Data
The model is trained on ~3200 manually-curated articles sampled at various stages during the coronavirus pandemic. The code for training is available in the [category\_prediction](https://github.com/jakelever/corona-ml/tree/master/category_prediction) directory of the main Github Repo. The data is available in the [annotated_documents.json.gz](https://github.com/jakelever/corona-ml/blob/master/category_prediction/annotated_documents.json.gz) file.
## Inputs and Outputs
The model takes in a tokenized title and abstract (combined into a single string and separated by a new line). The outputs are topics and article types, broadly called categories in the pipeline code. The types are listed below. Some others are managed by hand-coded rules described in the [step-by-step descriptions](https://github.com/jakelever/corona-ml/blob/master/stepByStep.md).
### List of Article Types
- Comment/Editorial
- Meta-analysis
- News
- Review
### List of Topics
- Clinical Reports
- Communication
- Contact Tracing
- Diagnostics
- Drug Targets
- Education
- Effect on Medical Specialties
- Forecasting & Modelling
- Health Policy
- Healthcare Workers
- Imaging
- Immunology
- Inequality
- Infection Reports
- Long Haul
- Medical Devices
- Misinformation
- Model Systems & Tools
- Molecular Biology
- Non-human
- Non-medical
- Pediatrics
- Prevalence
- Prevention
- Psychology
- Recommendations
- Risk Factors
- Surveillance
- Therapeutics
- Transmission
- Vaccines
|
iuliaturc/bert_uncased_L-2_H-128_A-2
|
iuliaturc
| 2021-05-19T20:32:57Z | 8 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"arxiv:1908.08962",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2022-03-02T23:29:05Z |
---
thumbnail: https://huggingface.co/front/thumbnails/google.png
license: apache-2.0
---
BERT Miniatures
===
This is the set of 24 BERT models referenced in [Well-Read Students Learn Better: On the Importance of Pre-training Compact Models](https://arxiv.org/abs/1908.08962) (English only, uncased, trained with WordPiece masking).
We have shown that the standard BERT recipe (including model architecture and training objective) is effective on a wide range of model sizes, beyond BERT-Base and BERT-Large. The smaller BERT models are intended for environments with restricted computational resources. They can be fine-tuned in the same manner as the original BERT models. However, they are most effective in the context of knowledge distillation, where the fine-tuning labels are produced by a larger and more accurate teacher.
Our goal is to enable research in institutions with fewer computational resources and encourage the community to seek directions of innovation alternative to increasing model capacity.
You can download the 24 BERT miniatures either from the [official BERT Github page](https://github.com/google-research/bert/), or via HuggingFace from the links below:
| |H=128|H=256|H=512|H=768|
|---|:---:|:---:|:---:|:---:|
| **L=2** |[**2/128 (BERT-Tiny)**][2_128]|[2/256][2_256]|[2/512][2_512]|[2/768][2_768]|
| **L=4** |[4/128][4_128]|[**4/256 (BERT-Mini)**][4_256]|[**4/512 (BERT-Small)**][4_512]|[4/768][4_768]|
| **L=6** |[6/128][6_128]|[6/256][6_256]|[6/512][6_512]|[6/768][6_768]|
| **L=8** |[8/128][8_128]|[8/256][8_256]|[**8/512 (BERT-Medium)**][8_512]|[8/768][8_768]|
| **L=10** |[10/128][10_128]|[10/256][10_256]|[10/512][10_512]|[10/768][10_768]|
| **L=12** |[12/128][12_128]|[12/256][12_256]|[12/512][12_512]|[**12/768 (BERT-Base)**][12_768]|
Note that the BERT-Base model in this release is included for completeness only; it was re-trained under the same regime as the original model.
Here are the corresponding GLUE scores on the test set:
|Model|Score|CoLA|SST-2|MRPC|STS-B|QQP|MNLI-m|MNLI-mm|QNLI(v2)|RTE|WNLI|AX|
|---|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|
|BERT-Tiny|64.2|0.0|83.2|81.1/71.1|74.3/73.6|62.2/83.4|70.2|70.3|81.5|57.2|62.3|21.0|
|BERT-Mini|65.8|0.0|85.9|81.1/71.8|75.4/73.3|66.4/86.2|74.8|74.3|84.1|57.9|62.3|26.1|
|BERT-Small|71.2|27.8|89.7|83.4/76.2|78.8/77.0|68.1/87.0|77.6|77.0|86.4|61.8|62.3|28.6|
|BERT-Medium|73.5|38.0|89.6|86.6/81.6|80.4/78.4|69.6/87.9|80.0|79.1|87.7|62.2|62.3|30.5|
For each task, we selected the best fine-tuning hyperparameters from the lists below, and trained for 4 epochs:
- batch sizes: 8, 16, 32, 64, 128
- learning rates: 3e-4, 1e-4, 5e-5, 3e-5
If you use these models, please cite the following paper:
```
@article{turc2019,
title={Well-Read Students Learn Better: On the Importance of Pre-training Compact Models},
author={Turc, Iulia and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina},
journal={arXiv preprint arXiv:1908.08962v2 },
year={2019}
}
```
[2_128]: https://huggingface.co/google/bert_uncased_L-2_H-128_A-2
[2_256]: https://huggingface.co/google/bert_uncased_L-2_H-256_A-4
[2_512]: https://huggingface.co/google/bert_uncased_L-2_H-512_A-8
[2_768]: https://huggingface.co/google/bert_uncased_L-2_H-768_A-12
[4_128]: https://huggingface.co/google/bert_uncased_L-4_H-128_A-2
[4_256]: https://huggingface.co/google/bert_uncased_L-4_H-256_A-4
[4_512]: https://huggingface.co/google/bert_uncased_L-4_H-512_A-8
[4_768]: https://huggingface.co/google/bert_uncased_L-4_H-768_A-12
[6_128]: https://huggingface.co/google/bert_uncased_L-6_H-128_A-2
[6_256]: https://huggingface.co/google/bert_uncased_L-6_H-256_A-4
[6_512]: https://huggingface.co/google/bert_uncased_L-6_H-512_A-8
[6_768]: https://huggingface.co/google/bert_uncased_L-6_H-768_A-12
[8_128]: https://huggingface.co/google/bert_uncased_L-8_H-128_A-2
[8_256]: https://huggingface.co/google/bert_uncased_L-8_H-256_A-4
[8_512]: https://huggingface.co/google/bert_uncased_L-8_H-512_A-8
[8_768]: https://huggingface.co/google/bert_uncased_L-8_H-768_A-12
[10_128]: https://huggingface.co/google/bert_uncased_L-10_H-128_A-2
[10_256]: https://huggingface.co/google/bert_uncased_L-10_H-256_A-4
[10_512]: https://huggingface.co/google/bert_uncased_L-10_H-512_A-8
[10_768]: https://huggingface.co/google/bert_uncased_L-10_H-768_A-12
[12_128]: https://huggingface.co/google/bert_uncased_L-12_H-128_A-2
[12_256]: https://huggingface.co/google/bert_uncased_L-12_H-256_A-4
[12_512]: https://huggingface.co/google/bert_uncased_L-12_H-512_A-8
[12_768]: https://huggingface.co/google/bert_uncased_L-12_H-768_A-12
|
ipuneetrathore/bert-base-cased-finetuned-finBERT
|
ipuneetrathore
| 2021-05-19T20:30:58Z | 14 | 2 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"text-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
## FinBERT
Code for importing and using this model is available [here](https://github.com/ipuneetrathore/BERT_models)
|
indobenchmark/indobert-large-p2
|
indobenchmark
| 2021-05-19T20:28:22Z | 5,822 | 8 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"jax",
"bert",
"feature-extraction",
"indobert",
"indobenchmark",
"indonlu",
"id",
"dataset:Indo4B",
"arxiv:2009.05387",
"license:mit",
"region:us"
] |
feature-extraction
| 2022-03-02T23:29:05Z |
---
language: id
tags:
- indobert
- indobenchmark
- indonlu
license: mit
inference: false
datasets:
- Indo4B
---
# IndoBERT Large Model (phase2 - uncased)
[IndoBERT](https://arxiv.org/abs/2009.05387) is a state-of-the-art language model for Indonesian based on the BERT model. The pretrained model is trained using a masked language modeling (MLM) objective and next sentence prediction (NSP) objective.
## All Pre-trained Models
| Model | #params | Arch. | Training data |
|--------------------------------|--------------------------------|-------|-----------------------------------|
| `indobenchmark/indobert-base-p1` | 124.5M | Base | Indo4B (23.43 GB of text) |
| `indobenchmark/indobert-base-p2` | 124.5M | Base | Indo4B (23.43 GB of text) |
| `indobenchmark/indobert-large-p1` | 335.2M | Large | Indo4B (23.43 GB of text) |
| `indobenchmark/indobert-large-p2` | 335.2M | Large | Indo4B (23.43 GB of text) |
| `indobenchmark/indobert-lite-base-p1` | 11.7M | Base | Indo4B (23.43 GB of text) |
| `indobenchmark/indobert-lite-base-p2` | 11.7M | Base | Indo4B (23.43 GB of text) |
| `indobenchmark/indobert-lite-large-p1` | 17.7M | Large | Indo4B (23.43 GB of text) |
| `indobenchmark/indobert-lite-large-p2` | 17.7M | Large | Indo4B (23.43 GB of text) |
## How to use
### Load model and tokenizer
```python
from transformers import BertTokenizer, AutoModel
tokenizer = BertTokenizer.from_pretrained("indobenchmark/indobert-large-p2")
model = AutoModel.from_pretrained("indobenchmark/indobert-large-p2")
```
### Extract contextual representation
```python
x = torch.LongTensor(tokenizer.encode('aku adalah anak [MASK]')).view(1,-1)
print(x, model(x)[0].sum())
```
## Authors
<b>IndoBERT</b> was trained and evaluated by Bryan Wilie\*, Karissa Vincentio\*, Genta Indra Winata\*, Samuel Cahyawijaya\*, Xiaohong Li, Zhi Yuan Lim, Sidik Soleman, Rahmad Mahendra, Pascale Fung, Syafri Bahar, Ayu Purwarianti.
## Citation
If you use our work, please cite:
```bibtex
@inproceedings{wilie2020indonlu,
title={IndoNLU: Benchmark and Resources for Evaluating Indonesian Natural Language Understanding},
author={Bryan Wilie and Karissa Vincentio and Genta Indra Winata and Samuel Cahyawijaya and X. Li and Zhi Yuan Lim and S. Soleman and R. Mahendra and Pascale Fung and Syafri Bahar and A. Purwarianti},
booktitle={Proceedings of the 1st Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics and the 10th International Joint Conference on Natural Language Processing},
year={2020}
}
```
|
iarfmoose/bert-base-cased-qa-evaluator
|
iarfmoose
| 2021-05-19T20:15:52Z | 118,323 | 9 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"jax",
"bert",
"text-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
# BERT-base-cased-qa-evaluator
This model takes a question answer pair as an input and outputs a value representing its prediction about whether the input was a valid question and answer pair or not. The model is a pretrained [BERT-base-cased](https://huggingface.co/bert-base-cased) with a sequence classification head.
## Intended uses
The QA evaluator was originally designed to be used with the [t5-base-question-generator](https://huggingface.co/iarfmoose/t5-base-question-generator) for evaluating the quality of generated questions.
The input for the QA evaluator follows the format for `BertForSequenceClassification`, but using the question and answer as the two sequences. Inputs should take the following format:
```
[CLS] <question> [SEP] <answer [SEP]
```
## Limitations and bias
The model is trained to evaluate if a question and answer are semantically related, but cannot determine whether an answer is actually true/correct or not.
## Training data
The training data was made up of question-answer pairs from the following datasets:
- [SQuAD](https://rajpurkar.github.io/SQuAD-explorer/)
- [RACE](http://www.cs.cmu.edu/~glai1/data/race/)
- [CoQA](https://stanfordnlp.github.io/coqa/)
- [MSMARCO](https://microsoft.github.io/msmarco/)
## Training procedure
The question and answer were concatenated 50% of the time. In the other 50% of the time a corruption operation was performed (either swapping the answer for an unrelated answer, or by copying part of the question into the answer). The model was then trained to predict whether the input sequence represented one of the original QA pairs or a corrupted input.
|
huawei-noah/DynaBERT_SST-2
|
huawei-noah
| 2021-05-19T20:03:01Z | 5 | 1 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"arxiv:2004.04037",
"endpoints_compatible",
"region:us"
] | null | 2022-03-02T23:29:05Z |
## DynaBERT: Dynamic BERT with Adaptive Width and Depth
* DynaBERT can flexibly adjust the size and latency by selecting adaptive width and depth, and
the subnetworks of it have competitive performances as other similar-sized compressed models.
The training process of DynaBERT includes first training a width-adaptive BERT and then
allowing both adaptive width and depth using knowledge distillation.
* This code is modified based on the repository developed by Hugging Face: [Transformers v2.1.1](https://github.com/huggingface/transformers/tree/v2.1.1), and is released in [GitHub](https://github.com/huawei-noah/Pretrained-Language-Model/tree/master/DynaBERT).
### Reference
Lu Hou, Zhiqi Huang, Lifeng Shang, Xin Jiang, Xiao Chen, Qun Liu.
[DynaBERT: Dynamic BERT with Adaptive Width and Depth](https://arxiv.org/abs/2004.04037).
```
@inproceedings{hou2020dynabert,
title = {DynaBERT: Dynamic BERT with Adaptive Width and Depth},
author = {Lu Hou, Zhiqi Huang, Lifeng Shang, Xin Jiang, Xiao Chen, Qun Liu},
booktitle = {Advances in Neural Information Processing Systems},
year = {2020}
}
```
|
huawei-noah/DynaBERT_MNLI
|
huawei-noah
| 2021-05-19T20:02:03Z | 1 | 1 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"arxiv:2004.04037",
"endpoints_compatible",
"region:us"
] | null | 2022-03-02T23:29:05Z |
## DynaBERT: Dynamic BERT with Adaptive Width and Depth
* DynaBERT can flexibly adjust the size and latency by selecting adaptive width and depth, and
the subnetworks of it have competitive performances as other similar-sized compressed models.
The training process of DynaBERT includes first training a width-adaptive BERT and then
allowing both adaptive width and depth using knowledge distillation.
* This code is modified based on the repository developed by Hugging Face: [Transformers v2.1.1](https://github.com/huggingface/transformers/tree/v2.1.1), and is released in [GitHub](https://github.com/huawei-noah/Pretrained-Language-Model/tree/master/DynaBERT).
### Reference
Lu Hou, Zhiqi Huang, Lifeng Shang, Xin Jiang, Xiao Chen, Qun Liu.
[DynaBERT: Dynamic BERT with Adaptive Width and Depth](https://arxiv.org/abs/2004.04037).
```
@inproceedings{hou2020dynabert,
title = {DynaBERT: Dynamic BERT with Adaptive Width and Depth},
author = {Lu Hou, Zhiqi Huang, Lifeng Shang, Xin Jiang, Xiao Chen, Qun Liu},
booktitle = {Advances in Neural Information Processing Systems},
year = {2020}
}
```
|
hfl/rbtl3
|
hfl
| 2021-05-19T19:22:46Z | 39 | 3 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"jax",
"bert",
"fill-mask",
"zh",
"arxiv:1906.08101",
"arxiv:2004.13922",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:05Z |
---
language:
- zh
tags:
- bert
license: "apache-2.0"
---
# This is a re-trained 3-layer RoBERTa-wwm-ext-large model.
## Chinese BERT with Whole Word Masking
For further accelerating Chinese natural language processing, we provide **Chinese pre-trained BERT with Whole Word Masking**.
**[Pre-Training with Whole Word Masking for Chinese BERT](https://arxiv.org/abs/1906.08101)**
Yiming Cui, Wanxiang Che, Ting Liu, Bing Qin, Ziqing Yang, Shijin Wang, Guoping Hu
This repository is developed based on:https://github.com/google-research/bert
You may also interested in,
- Chinese BERT series: https://github.com/ymcui/Chinese-BERT-wwm
- Chinese MacBERT: https://github.com/ymcui/MacBERT
- Chinese ELECTRA: https://github.com/ymcui/Chinese-ELECTRA
- Chinese XLNet: https://github.com/ymcui/Chinese-XLNet
- Knowledge Distillation Toolkit - TextBrewer: https://github.com/airaria/TextBrewer
More resources by HFL: https://github.com/ymcui/HFL-Anthology
## Citation
If you find the technical report or resource is useful, please cite the following technical report in your paper.
- Primary: https://arxiv.org/abs/2004.13922
```
@inproceedings{cui-etal-2020-revisiting,
title = "Revisiting Pre-Trained Models for {C}hinese Natural Language Processing",
author = "Cui, Yiming and
Che, Wanxiang and
Liu, Ting and
Qin, Bing and
Wang, Shijin and
Hu, Guoping",
booktitle = "Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: Findings",
month = nov,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2020.findings-emnlp.58",
pages = "657--668",
}
```
- Secondary: https://arxiv.org/abs/1906.08101
```
@article{chinese-bert-wwm,
title={Pre-Training with Whole Word Masking for Chinese BERT},
author={Cui, Yiming and Che, Wanxiang and Liu, Ting and Qin, Bing and Yang, Ziqing and Wang, Shijin and Hu, Guoping},
journal={arXiv preprint arXiv:1906.08101},
year={2019}
}
```
|
hfl/rbt6
|
hfl
| 2021-05-19T19:22:02Z | 224 | 7 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"jax",
"bert",
"fill-mask",
"zh",
"arxiv:1906.08101",
"arxiv:2004.13922",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:05Z |
---
language:
- zh
tags:
- bert
license: "apache-2.0"
---
# This is a re-trained 6-layer RoBERTa-wwm-ext model.
## Chinese BERT with Whole Word Masking
For further accelerating Chinese natural language processing, we provide **Chinese pre-trained BERT with Whole Word Masking**.
**[Pre-Training with Whole Word Masking for Chinese BERT](https://arxiv.org/abs/1906.08101)**
Yiming Cui, Wanxiang Che, Ting Liu, Bing Qin, Ziqing Yang, Shijin Wang, Guoping Hu
This repository is developed based on:https://github.com/google-research/bert
You may also interested in,
- Chinese BERT series: https://github.com/ymcui/Chinese-BERT-wwm
- Chinese MacBERT: https://github.com/ymcui/MacBERT
- Chinese ELECTRA: https://github.com/ymcui/Chinese-ELECTRA
- Chinese XLNet: https://github.com/ymcui/Chinese-XLNet
- Knowledge Distillation Toolkit - TextBrewer: https://github.com/airaria/TextBrewer
More resources by HFL: https://github.com/ymcui/HFL-Anthology
## Citation
If you find the technical report or resource is useful, please cite the following technical report in your paper.
- Primary: https://arxiv.org/abs/2004.13922
```
@inproceedings{cui-etal-2020-revisiting,
title = "Revisiting Pre-Trained Models for {C}hinese Natural Language Processing",
author = "Cui, Yiming and
Che, Wanxiang and
Liu, Ting and
Qin, Bing and
Wang, Shijin and
Hu, Guoping",
booktitle = "Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: Findings",
month = nov,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2020.findings-emnlp.58",
pages = "657--668",
}
```
- Secondary: https://arxiv.org/abs/1906.08101
```
@article{chinese-bert-wwm,
title={Pre-Training with Whole Word Masking for Chinese BERT},
author={Cui, Yiming and Che, Wanxiang and Liu, Ting and Qin, Bing and Yang, Ziqing and Wang, Shijin and Hu, Guoping},
journal={arXiv preprint arXiv:1906.08101},
year={2019}
}
```
|
hfl/chinese-bert-wwm
|
hfl
| 2021-05-19T19:07:49Z | 54,317 | 71 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"jax",
"bert",
"fill-mask",
"zh",
"arxiv:1906.08101",
"arxiv:2004.13922",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:05Z |
---
language:
- zh
license: "apache-2.0"
---
## Chinese BERT with Whole Word Masking
For further accelerating Chinese natural language processing, we provide **Chinese pre-trained BERT with Whole Word Masking**.
**[Pre-Training with Whole Word Masking for Chinese BERT](https://arxiv.org/abs/1906.08101)**
Yiming Cui, Wanxiang Che, Ting Liu, Bing Qin, Ziqing Yang, Shijin Wang, Guoping Hu
This repository is developed based on:https://github.com/google-research/bert
You may also interested in,
- Chinese BERT series: https://github.com/ymcui/Chinese-BERT-wwm
- Chinese MacBERT: https://github.com/ymcui/MacBERT
- Chinese ELECTRA: https://github.com/ymcui/Chinese-ELECTRA
- Chinese XLNet: https://github.com/ymcui/Chinese-XLNet
- Knowledge Distillation Toolkit - TextBrewer: https://github.com/airaria/TextBrewer
More resources by HFL: https://github.com/ymcui/HFL-Anthology
## Citation
If you find the technical report or resource is useful, please cite the following technical report in your paper.
- Primary: https://arxiv.org/abs/2004.13922
```
@inproceedings{cui-etal-2020-revisiting,
title = "Revisiting Pre-Trained Models for {C}hinese Natural Language Processing",
author = "Cui, Yiming and
Che, Wanxiang and
Liu, Ting and
Qin, Bing and
Wang, Shijin and
Hu, Guoping",
booktitle = "Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: Findings",
month = nov,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2020.findings-emnlp.58",
pages = "657--668",
}
```
- Secondary: https://arxiv.org/abs/1906.08101
```
@article{chinese-bert-wwm,
title={Pre-Training with Whole Word Masking for Chinese BERT},
author={Cui, Yiming and Che, Wanxiang and Liu, Ting and Qin, Bing and Yang, Ziqing and Wang, Shijin and Hu, Guoping},
journal={arXiv preprint arXiv:1906.08101},
year={2019}
}
```
|
hfl/chinese-bert-wwm-ext
|
hfl
| 2021-05-19T19:06:39Z | 10,290 | 166 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"jax",
"bert",
"fill-mask",
"zh",
"arxiv:1906.08101",
"arxiv:2004.13922",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:05Z |
---
language:
- zh
license: "apache-2.0"
---
## Chinese BERT with Whole Word Masking
For further accelerating Chinese natural language processing, we provide **Chinese pre-trained BERT with Whole Word Masking**.
**[Pre-Training with Whole Word Masking for Chinese BERT](https://arxiv.org/abs/1906.08101)**
Yiming Cui, Wanxiang Che, Ting Liu, Bing Qin, Ziqing Yang, Shijin Wang, Guoping Hu
This repository is developed based on:https://github.com/google-research/bert
You may also interested in,
- Chinese BERT series: https://github.com/ymcui/Chinese-BERT-wwm
- Chinese MacBERT: https://github.com/ymcui/MacBERT
- Chinese ELECTRA: https://github.com/ymcui/Chinese-ELECTRA
- Chinese XLNet: https://github.com/ymcui/Chinese-XLNet
- Knowledge Distillation Toolkit - TextBrewer: https://github.com/airaria/TextBrewer
More resources by HFL: https://github.com/ymcui/HFL-Anthology
## Citation
If you find the technical report or resource is useful, please cite the following technical report in your paper.
- Primary: https://arxiv.org/abs/2004.13922
```
@inproceedings{cui-etal-2020-revisiting,
title = "Revisiting Pre-Trained Models for {C}hinese Natural Language Processing",
author = "Cui, Yiming and
Che, Wanxiang and
Liu, Ting and
Qin, Bing and
Wang, Shijin and
Hu, Guoping",
booktitle = "Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: Findings",
month = nov,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2020.findings-emnlp.58",
pages = "657--668",
}
```
- Secondary: https://arxiv.org/abs/1906.08101
```
@article{chinese-bert-wwm,
title={Pre-Training with Whole Word Masking for Chinese BERT},
author={Cui, Yiming and Che, Wanxiang and Liu, Ting and Qin, Bing and Yang, Ziqing and Wang, Shijin and Hu, Guoping},
journal={arXiv preprint arXiv:1906.08101},
year={2019}
}
```
|
henryk/bert-base-multilingual-cased-finetuned-dutch-squad2
|
henryk
| 2021-05-19T19:02:45Z | 40 | 6 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"question-answering",
"nl",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-03-02T23:29:05Z |
---
language: nl
---
# Multilingual + Dutch SQuAD2.0
This model is the multilingual model provided by the Google research team with a fine-tuned dutch Q&A downstream task.
## Details of the language model
Language model ([**bert-base-multilingual-cased**](https://github.com/google-research/bert/blob/master/multilingual.md)):
12-layer, 768-hidden, 12-heads, 110M parameters.
Trained on cased text in the top 104 languages with the largest Wikipedias.
## Details of the downstream task
Using the `mtranslate` Python module, [**SQuAD2.0**](https://rajpurkar.github.io/SQuAD-explorer/) was machine-translated. In order to find the start tokens, the direct translations of the answers were searched in the corresponding paragraphs. Due to the different translations depending on the context (missing context in the pure answer), the answer could not always be found in the text, and thus a loss of question-answer examples occurred. This is a potential problem where errors can occur in the data set.
| Dataset | # Q&A |
| ---------------------- | ----- |
| SQuAD2.0 Train | 130 K |
| Dutch SQuAD2.0 Train | 99 K |
| SQuAD2.0 Dev | 12 K |
| Dutch SQuAD2.0 Dev | 10 K |
## Model benchmark
| Model | EM/F1 |HasAns (EM/F1) | NoAns |
| ---------------------- | ----- | ----- | ----- |
| [robBERT](https://huggingface.co/pdelobelle/robBERT-base) | 58.04/60.95 | 33.08/40.64 | 73.67 |
| [dutchBERT](https://huggingface.co/wietsedv/bert-base-dutch-cased) | 64.25/68.45 | 45.59/56.49 | 75.94 |
| [multiBERT](https://huggingface.co/bert-base-multilingual-cased) | **67.38**/**71.36** | 47.42/57.76 | 79.88 |
## Model training
The model was trained on a **Tesla V100** GPU with the following command:
```python
export SQUAD_DIR=path/to/nl_squad
python run_squad.py
--model_type bert \
--model_name_or_path bert-base-multilingual-cased \
--do_train \
--do_eval \
--train_file $SQUAD_DIR/nl_squadv2_train_clean.json \
--predict_file $SQUAD_DIR/nl_squadv2_dev_clean.json \
--num_train_epochs 2 \
--max_seq_length 384 \
--doc_stride 128 \
--save_steps=8000 \
--output_dir ../../output \
--overwrite_cache \
--overwrite_output_dir
```
**Results**:
{'exact': 67.38028751680629, 'f1': 71.362297054268, 'total': 9669, 'HasAns_exact': 47.422126745435015, 'HasAns_f1': 57.761023151910734, 'HasAns_total': 3724, 'NoAns_exact': 79.88225399495374, 'NoAns_f1': 79.88225399495374, 'NoAns_total': 5945, 'best_exact': 67.53542248422795, 'best_exact_thresh': 0.0, 'best_f1': 71.36229705426837, 'best_f1_thresh': 0.0}
## Model in action
Fast usage with **pipelines**:
```python
from transformers import pipeline
qa_pipeline = pipeline(
"question-answering",
model="henryk/bert-base-multilingual-cased-finetuned-dutch-squad2",
tokenizer="henryk/bert-base-multilingual-cased-finetuned-dutch-squad2"
)
qa_pipeline({
'context': "Amsterdam is de hoofdstad en de dichtstbevolkte stad van Nederland.",
'question': "Wat is de hoofdstad van Nederland?"})
```
# Output:
```json
{
"score": 0.83,
"start": 0,
"end": 9,
"answer": "Amsterdam"
}
```
## Contact
Please do not hesitate to contact me via [LinkedIn](https://www.linkedin.com/in/henryk-borzymowski-0755a2167/) if you want to discuss or get access to the Dutch version of SQuAD.
|
hemekci/off_detection_turkish
|
hemekci
| 2021-05-19T18:54:44Z | 54 | 8 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"text-classification",
"tr",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
---
language: tr
widget:
- text: "sevelim sevilelim bu dunya kimseye kalmaz"
---
## Offensive Language Detection Model in Turkish
- uses Bert and pytorch
- fine tuned with Twitter data.
- UTF-8 configuration is done
### Training Data
Number of training sentences: 31,277
**Example Tweets**
- 19823 Daliaan yifng cok erken attin be... 1.38 ...| NOT|
- 30525 @USER Bak biri kollarımda uyuyup gitmem diyor..|NOT|
- 26468 Helal olsun be :) Norveçten sabaha karşı geldi aq... | OFF|
- 14105 @USER Sunu cekecek ve güzel oldugunu söylecek aptal... |OFF|
- 4958 Ya seni yerim ben şapşal şey 🤗 | NOT|
- 12966 Herkesin akıllı geçindiği bir sosyal medyamız var ... |NOT|
- 5788 Maçın özetlerini izleyenler futbolcular gidiyo... |NOT|
|OFFENSIVE |RESULT |
|--|--|
|NOT | 25231|
|OFF|6046|
dtype: int64
### Validation
|epoch |Training Loss | Valid. Loss | Valid.Accuracy | Training Time | Validation Time |
|--|--|--|--|--|--|
|1 | 0.31| 0.28| 0.89| 0:07:14 | 0:00:13
|2 | 0.18| 0.29| 0.90| 0:07:18 | 0:00:13
|3 | 0.08| 0.40| 0.89| 0:07:16 | 0:00:13
|4 | 0.04| 0.59| 0.89| 0:07:13 | 0:00:13
**Matthews Corr. Coef. (-1 : +1):**
Total MCC Score: 0.633
|
haisongzhang/roberta-tiny-cased
|
haisongzhang
| 2021-05-19T17:53:53Z | 2,049 | 3 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"jax",
"bert",
"feature-extraction",
"endpoints_compatible",
"region:us"
] |
feature-extraction
| 2022-03-02T23:29:05Z |
Github: https://github.com/haisongzhang/roberta-tiny-cased
|
gurkan08/bert-turkish-text-classification
|
gurkan08
| 2021-05-19T17:50:18Z | 12 | 1 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"text-classification",
"tr",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
---
language: tr
---
# Turkish News Text Classification
Turkish text classification model obtained by fine-tuning the Turkish bert model (dbmdz/bert-base-turkish-cased)
# Dataset
Dataset consists of 11 classes were obtained from https://www.trthaber.com/. The model was created using the most distinctive 6 classes.
Dataset can be accessed at https://github.com/gurkan08/datasets/tree/master/trt_11_category.
label_dict = {
'LABEL_0': 'ekonomi',
'LABEL_1': 'spor',
'LABEL_2': 'saglik',
'LABEL_3': 'kultur_sanat',
'LABEL_4': 'bilim_teknoloji',
'LABEL_5': 'egitim'
}
70% of the data were used for training and 30% for testing.
train f1-weighted score = %97
test f1-weighted score = %94
# Usage
from transformers import pipeline, AutoTokenizer, AutoModelForSequenceClassification
tokenizer = AutoTokenizer.from_pretrained("gurkan08/bert-turkish-text-classification")
model = AutoModelForSequenceClassification.from_pretrained("gurkan08/bert-turkish-text-classification")
nlp = pipeline("sentiment-analysis", model=model, tokenizer=tokenizer)
text = ["Süper Lig'in 6. haftasında Sivasspor ile Çaykur Rizespor karşı karşıya geldi...",
"Son 24 saatte 69 kişi Kovid-19 nedeniyle yaşamını yitirdi, 1573 kişi iyileşti"]
out = nlp(text)
label_dict = {
'LABEL_0': 'ekonomi',
'LABEL_1': 'spor',
'LABEL_2': 'saglik',
'LABEL_3': 'kultur_sanat',
'LABEL_4': 'bilim_teknoloji',
'LABEL_5': 'egitim'
}
results = []
for result in out:
result['label'] = label_dict[result['label']]
results.append(result)
print(results)
# > [{'label': 'spor', 'score': 0.9992026090621948}, {'label': 'saglik', 'score': 0.9972177147865295}]
|
google/bert_uncased_L-8_H-128_A-2
|
google
| 2021-05-19T17:35:05Z | 1,147 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"arxiv:1908.08962",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2022-03-02T23:29:05Z |
---
thumbnail: https://huggingface.co/front/thumbnails/google.png
license: apache-2.0
---
BERT Miniatures
===
This is the set of 24 BERT models referenced in [Well-Read Students Learn Better: On the Importance of Pre-training Compact Models](https://arxiv.org/abs/1908.08962) (English only, uncased, trained with WordPiece masking).
We have shown that the standard BERT recipe (including model architecture and training objective) is effective on a wide range of model sizes, beyond BERT-Base and BERT-Large. The smaller BERT models are intended for environments with restricted computational resources. They can be fine-tuned in the same manner as the original BERT models. However, they are most effective in the context of knowledge distillation, where the fine-tuning labels are produced by a larger and more accurate teacher.
Our goal is to enable research in institutions with fewer computational resources and encourage the community to seek directions of innovation alternative to increasing model capacity.
You can download the 24 BERT miniatures either from the [official BERT Github page](https://github.com/google-research/bert/), or via HuggingFace from the links below:
| |H=128|H=256|H=512|H=768|
|---|:---:|:---:|:---:|:---:|
| **L=2** |[**2/128 (BERT-Tiny)**][2_128]|[2/256][2_256]|[2/512][2_512]|[2/768][2_768]|
| **L=4** |[4/128][4_128]|[**4/256 (BERT-Mini)**][4_256]|[**4/512 (BERT-Small)**][4_512]|[4/768][4_768]|
| **L=6** |[6/128][6_128]|[6/256][6_256]|[6/512][6_512]|[6/768][6_768]|
| **L=8** |[8/128][8_128]|[8/256][8_256]|[**8/512 (BERT-Medium)**][8_512]|[8/768][8_768]|
| **L=10** |[10/128][10_128]|[10/256][10_256]|[10/512][10_512]|[10/768][10_768]|
| **L=12** |[12/128][12_128]|[12/256][12_256]|[12/512][12_512]|[**12/768 (BERT-Base)**][12_768]|
Note that the BERT-Base model in this release is included for completeness only; it was re-trained under the same regime as the original model.
Here are the corresponding GLUE scores on the test set:
|Model|Score|CoLA|SST-2|MRPC|STS-B|QQP|MNLI-m|MNLI-mm|QNLI(v2)|RTE|WNLI|AX|
|---|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|
|BERT-Tiny|64.2|0.0|83.2|81.1/71.1|74.3/73.6|62.2/83.4|70.2|70.3|81.5|57.2|62.3|21.0|
|BERT-Mini|65.8|0.0|85.9|81.1/71.8|75.4/73.3|66.4/86.2|74.8|74.3|84.1|57.9|62.3|26.1|
|BERT-Small|71.2|27.8|89.7|83.4/76.2|78.8/77.0|68.1/87.0|77.6|77.0|86.4|61.8|62.3|28.6|
|BERT-Medium|73.5|38.0|89.6|86.6/81.6|80.4/78.4|69.6/87.9|80.0|79.1|87.7|62.2|62.3|30.5|
For each task, we selected the best fine-tuning hyperparameters from the lists below, and trained for 4 epochs:
- batch sizes: 8, 16, 32, 64, 128
- learning rates: 3e-4, 1e-4, 5e-5, 3e-5
If you use these models, please cite the following paper:
```
@article{turc2019,
title={Well-Read Students Learn Better: On the Importance of Pre-training Compact Models},
author={Turc, Iulia and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina},
journal={arXiv preprint arXiv:1908.08962v2 },
year={2019}
}
```
[2_128]: https://huggingface.co/google/bert_uncased_L-2_H-128_A-2
[2_256]: https://huggingface.co/google/bert_uncased_L-2_H-256_A-4
[2_512]: https://huggingface.co/google/bert_uncased_L-2_H-512_A-8
[2_768]: https://huggingface.co/google/bert_uncased_L-2_H-768_A-12
[4_128]: https://huggingface.co/google/bert_uncased_L-4_H-128_A-2
[4_256]: https://huggingface.co/google/bert_uncased_L-4_H-256_A-4
[4_512]: https://huggingface.co/google/bert_uncased_L-4_H-512_A-8
[4_768]: https://huggingface.co/google/bert_uncased_L-4_H-768_A-12
[6_128]: https://huggingface.co/google/bert_uncased_L-6_H-128_A-2
[6_256]: https://huggingface.co/google/bert_uncased_L-6_H-256_A-4
[6_512]: https://huggingface.co/google/bert_uncased_L-6_H-512_A-8
[6_768]: https://huggingface.co/google/bert_uncased_L-6_H-768_A-12
[8_128]: https://huggingface.co/google/bert_uncased_L-8_H-128_A-2
[8_256]: https://huggingface.co/google/bert_uncased_L-8_H-256_A-4
[8_512]: https://huggingface.co/google/bert_uncased_L-8_H-512_A-8
[8_768]: https://huggingface.co/google/bert_uncased_L-8_H-768_A-12
[10_128]: https://huggingface.co/google/bert_uncased_L-10_H-128_A-2
[10_256]: https://huggingface.co/google/bert_uncased_L-10_H-256_A-4
[10_512]: https://huggingface.co/google/bert_uncased_L-10_H-512_A-8
[10_768]: https://huggingface.co/google/bert_uncased_L-10_H-768_A-12
[12_128]: https://huggingface.co/google/bert_uncased_L-12_H-128_A-2
[12_256]: https://huggingface.co/google/bert_uncased_L-12_H-256_A-4
[12_512]: https://huggingface.co/google/bert_uncased_L-12_H-512_A-8
[12_768]: https://huggingface.co/google/bert_uncased_L-12_H-768_A-12
|
google/bert_uncased_L-6_H-512_A-8
|
google
| 2021-05-19T17:34:01Z | 1,402 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"arxiv:1908.08962",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2022-03-02T23:29:05Z |
---
thumbnail: https://huggingface.co/front/thumbnails/google.png
license: apache-2.0
---
BERT Miniatures
===
This is the set of 24 BERT models referenced in [Well-Read Students Learn Better: On the Importance of Pre-training Compact Models](https://arxiv.org/abs/1908.08962) (English only, uncased, trained with WordPiece masking).
We have shown that the standard BERT recipe (including model architecture and training objective) is effective on a wide range of model sizes, beyond BERT-Base and BERT-Large. The smaller BERT models are intended for environments with restricted computational resources. They can be fine-tuned in the same manner as the original BERT models. However, they are most effective in the context of knowledge distillation, where the fine-tuning labels are produced by a larger and more accurate teacher.
Our goal is to enable research in institutions with fewer computational resources and encourage the community to seek directions of innovation alternative to increasing model capacity.
You can download the 24 BERT miniatures either from the [official BERT Github page](https://github.com/google-research/bert/), or via HuggingFace from the links below:
| |H=128|H=256|H=512|H=768|
|---|:---:|:---:|:---:|:---:|
| **L=2** |[**2/128 (BERT-Tiny)**][2_128]|[2/256][2_256]|[2/512][2_512]|[2/768][2_768]|
| **L=4** |[4/128][4_128]|[**4/256 (BERT-Mini)**][4_256]|[**4/512 (BERT-Small)**][4_512]|[4/768][4_768]|
| **L=6** |[6/128][6_128]|[6/256][6_256]|[6/512][6_512]|[6/768][6_768]|
| **L=8** |[8/128][8_128]|[8/256][8_256]|[**8/512 (BERT-Medium)**][8_512]|[8/768][8_768]|
| **L=10** |[10/128][10_128]|[10/256][10_256]|[10/512][10_512]|[10/768][10_768]|
| **L=12** |[12/128][12_128]|[12/256][12_256]|[12/512][12_512]|[**12/768 (BERT-Base)**][12_768]|
Note that the BERT-Base model in this release is included for completeness only; it was re-trained under the same regime as the original model.
Here are the corresponding GLUE scores on the test set:
|Model|Score|CoLA|SST-2|MRPC|STS-B|QQP|MNLI-m|MNLI-mm|QNLI(v2)|RTE|WNLI|AX|
|---|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|
|BERT-Tiny|64.2|0.0|83.2|81.1/71.1|74.3/73.6|62.2/83.4|70.2|70.3|81.5|57.2|62.3|21.0|
|BERT-Mini|65.8|0.0|85.9|81.1/71.8|75.4/73.3|66.4/86.2|74.8|74.3|84.1|57.9|62.3|26.1|
|BERT-Small|71.2|27.8|89.7|83.4/76.2|78.8/77.0|68.1/87.0|77.6|77.0|86.4|61.8|62.3|28.6|
|BERT-Medium|73.5|38.0|89.6|86.6/81.6|80.4/78.4|69.6/87.9|80.0|79.1|87.7|62.2|62.3|30.5|
For each task, we selected the best fine-tuning hyperparameters from the lists below, and trained for 4 epochs:
- batch sizes: 8, 16, 32, 64, 128
- learning rates: 3e-4, 1e-4, 5e-5, 3e-5
If you use these models, please cite the following paper:
```
@article{turc2019,
title={Well-Read Students Learn Better: On the Importance of Pre-training Compact Models},
author={Turc, Iulia and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina},
journal={arXiv preprint arXiv:1908.08962v2 },
year={2019}
}
```
[2_128]: https://huggingface.co/google/bert_uncased_L-2_H-128_A-2
[2_256]: https://huggingface.co/google/bert_uncased_L-2_H-256_A-4
[2_512]: https://huggingface.co/google/bert_uncased_L-2_H-512_A-8
[2_768]: https://huggingface.co/google/bert_uncased_L-2_H-768_A-12
[4_128]: https://huggingface.co/google/bert_uncased_L-4_H-128_A-2
[4_256]: https://huggingface.co/google/bert_uncased_L-4_H-256_A-4
[4_512]: https://huggingface.co/google/bert_uncased_L-4_H-512_A-8
[4_768]: https://huggingface.co/google/bert_uncased_L-4_H-768_A-12
[6_128]: https://huggingface.co/google/bert_uncased_L-6_H-128_A-2
[6_256]: https://huggingface.co/google/bert_uncased_L-6_H-256_A-4
[6_512]: https://huggingface.co/google/bert_uncased_L-6_H-512_A-8
[6_768]: https://huggingface.co/google/bert_uncased_L-6_H-768_A-12
[8_128]: https://huggingface.co/google/bert_uncased_L-8_H-128_A-2
[8_256]: https://huggingface.co/google/bert_uncased_L-8_H-256_A-4
[8_512]: https://huggingface.co/google/bert_uncased_L-8_H-512_A-8
[8_768]: https://huggingface.co/google/bert_uncased_L-8_H-768_A-12
[10_128]: https://huggingface.co/google/bert_uncased_L-10_H-128_A-2
[10_256]: https://huggingface.co/google/bert_uncased_L-10_H-256_A-4
[10_512]: https://huggingface.co/google/bert_uncased_L-10_H-512_A-8
[10_768]: https://huggingface.co/google/bert_uncased_L-10_H-768_A-12
[12_128]: https://huggingface.co/google/bert_uncased_L-12_H-128_A-2
[12_256]: https://huggingface.co/google/bert_uncased_L-12_H-256_A-4
[12_512]: https://huggingface.co/google/bert_uncased_L-12_H-512_A-8
[12_768]: https://huggingface.co/google/bert_uncased_L-12_H-768_A-12
|
google/bert_uncased_L-6_H-256_A-4
|
google
| 2021-05-19T17:33:36Z | 1,147 | 1 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"arxiv:1908.08962",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2022-03-02T23:29:05Z |
---
thumbnail: https://huggingface.co/front/thumbnails/google.png
license: apache-2.0
---
BERT Miniatures
===
This is the set of 24 BERT models referenced in [Well-Read Students Learn Better: On the Importance of Pre-training Compact Models](https://arxiv.org/abs/1908.08962) (English only, uncased, trained with WordPiece masking).
We have shown that the standard BERT recipe (including model architecture and training objective) is effective on a wide range of model sizes, beyond BERT-Base and BERT-Large. The smaller BERT models are intended for environments with restricted computational resources. They can be fine-tuned in the same manner as the original BERT models. However, they are most effective in the context of knowledge distillation, where the fine-tuning labels are produced by a larger and more accurate teacher.
Our goal is to enable research in institutions with fewer computational resources and encourage the community to seek directions of innovation alternative to increasing model capacity.
You can download the 24 BERT miniatures either from the [official BERT Github page](https://github.com/google-research/bert/), or via HuggingFace from the links below:
| |H=128|H=256|H=512|H=768|
|---|:---:|:---:|:---:|:---:|
| **L=2** |[**2/128 (BERT-Tiny)**][2_128]|[2/256][2_256]|[2/512][2_512]|[2/768][2_768]|
| **L=4** |[4/128][4_128]|[**4/256 (BERT-Mini)**][4_256]|[**4/512 (BERT-Small)**][4_512]|[4/768][4_768]|
| **L=6** |[6/128][6_128]|[6/256][6_256]|[6/512][6_512]|[6/768][6_768]|
| **L=8** |[8/128][8_128]|[8/256][8_256]|[**8/512 (BERT-Medium)**][8_512]|[8/768][8_768]|
| **L=10** |[10/128][10_128]|[10/256][10_256]|[10/512][10_512]|[10/768][10_768]|
| **L=12** |[12/128][12_128]|[12/256][12_256]|[12/512][12_512]|[**12/768 (BERT-Base)**][12_768]|
Note that the BERT-Base model in this release is included for completeness only; it was re-trained under the same regime as the original model.
Here are the corresponding GLUE scores on the test set:
|Model|Score|CoLA|SST-2|MRPC|STS-B|QQP|MNLI-m|MNLI-mm|QNLI(v2)|RTE|WNLI|AX|
|---|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|
|BERT-Tiny|64.2|0.0|83.2|81.1/71.1|74.3/73.6|62.2/83.4|70.2|70.3|81.5|57.2|62.3|21.0|
|BERT-Mini|65.8|0.0|85.9|81.1/71.8|75.4/73.3|66.4/86.2|74.8|74.3|84.1|57.9|62.3|26.1|
|BERT-Small|71.2|27.8|89.7|83.4/76.2|78.8/77.0|68.1/87.0|77.6|77.0|86.4|61.8|62.3|28.6|
|BERT-Medium|73.5|38.0|89.6|86.6/81.6|80.4/78.4|69.6/87.9|80.0|79.1|87.7|62.2|62.3|30.5|
For each task, we selected the best fine-tuning hyperparameters from the lists below, and trained for 4 epochs:
- batch sizes: 8, 16, 32, 64, 128
- learning rates: 3e-4, 1e-4, 5e-5, 3e-5
If you use these models, please cite the following paper:
```
@article{turc2019,
title={Well-Read Students Learn Better: On the Importance of Pre-training Compact Models},
author={Turc, Iulia and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina},
journal={arXiv preprint arXiv:1908.08962v2 },
year={2019}
}
```
[2_128]: https://huggingface.co/google/bert_uncased_L-2_H-128_A-2
[2_256]: https://huggingface.co/google/bert_uncased_L-2_H-256_A-4
[2_512]: https://huggingface.co/google/bert_uncased_L-2_H-512_A-8
[2_768]: https://huggingface.co/google/bert_uncased_L-2_H-768_A-12
[4_128]: https://huggingface.co/google/bert_uncased_L-4_H-128_A-2
[4_256]: https://huggingface.co/google/bert_uncased_L-4_H-256_A-4
[4_512]: https://huggingface.co/google/bert_uncased_L-4_H-512_A-8
[4_768]: https://huggingface.co/google/bert_uncased_L-4_H-768_A-12
[6_128]: https://huggingface.co/google/bert_uncased_L-6_H-128_A-2
[6_256]: https://huggingface.co/google/bert_uncased_L-6_H-256_A-4
[6_512]: https://huggingface.co/google/bert_uncased_L-6_H-512_A-8
[6_768]: https://huggingface.co/google/bert_uncased_L-6_H-768_A-12
[8_128]: https://huggingface.co/google/bert_uncased_L-8_H-128_A-2
[8_256]: https://huggingface.co/google/bert_uncased_L-8_H-256_A-4
[8_512]: https://huggingface.co/google/bert_uncased_L-8_H-512_A-8
[8_768]: https://huggingface.co/google/bert_uncased_L-8_H-768_A-12
[10_128]: https://huggingface.co/google/bert_uncased_L-10_H-128_A-2
[10_256]: https://huggingface.co/google/bert_uncased_L-10_H-256_A-4
[10_512]: https://huggingface.co/google/bert_uncased_L-10_H-512_A-8
[10_768]: https://huggingface.co/google/bert_uncased_L-10_H-768_A-12
[12_128]: https://huggingface.co/google/bert_uncased_L-12_H-128_A-2
[12_256]: https://huggingface.co/google/bert_uncased_L-12_H-256_A-4
[12_512]: https://huggingface.co/google/bert_uncased_L-12_H-512_A-8
[12_768]: https://huggingface.co/google/bert_uncased_L-12_H-768_A-12
|
google/bert_uncased_L-6_H-128_A-2
|
google
| 2021-05-19T17:33:17Z | 1,159 | 1 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"arxiv:1908.08962",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2022-03-02T23:29:05Z |
---
thumbnail: https://huggingface.co/front/thumbnails/google.png
license: apache-2.0
---
BERT Miniatures
===
This is the set of 24 BERT models referenced in [Well-Read Students Learn Better: On the Importance of Pre-training Compact Models](https://arxiv.org/abs/1908.08962) (English only, uncased, trained with WordPiece masking).
We have shown that the standard BERT recipe (including model architecture and training objective) is effective on a wide range of model sizes, beyond BERT-Base and BERT-Large. The smaller BERT models are intended for environments with restricted computational resources. They can be fine-tuned in the same manner as the original BERT models. However, they are most effective in the context of knowledge distillation, where the fine-tuning labels are produced by a larger and more accurate teacher.
Our goal is to enable research in institutions with fewer computational resources and encourage the community to seek directions of innovation alternative to increasing model capacity.
You can download the 24 BERT miniatures either from the [official BERT Github page](https://github.com/google-research/bert/), or via HuggingFace from the links below:
| |H=128|H=256|H=512|H=768|
|---|:---:|:---:|:---:|:---:|
| **L=2** |[**2/128 (BERT-Tiny)**][2_128]|[2/256][2_256]|[2/512][2_512]|[2/768][2_768]|
| **L=4** |[4/128][4_128]|[**4/256 (BERT-Mini)**][4_256]|[**4/512 (BERT-Small)**][4_512]|[4/768][4_768]|
| **L=6** |[6/128][6_128]|[6/256][6_256]|[6/512][6_512]|[6/768][6_768]|
| **L=8** |[8/128][8_128]|[8/256][8_256]|[**8/512 (BERT-Medium)**][8_512]|[8/768][8_768]|
| **L=10** |[10/128][10_128]|[10/256][10_256]|[10/512][10_512]|[10/768][10_768]|
| **L=12** |[12/128][12_128]|[12/256][12_256]|[12/512][12_512]|[**12/768 (BERT-Base)**][12_768]|
Note that the BERT-Base model in this release is included for completeness only; it was re-trained under the same regime as the original model.
Here are the corresponding GLUE scores on the test set:
|Model|Score|CoLA|SST-2|MRPC|STS-B|QQP|MNLI-m|MNLI-mm|QNLI(v2)|RTE|WNLI|AX|
|---|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|
|BERT-Tiny|64.2|0.0|83.2|81.1/71.1|74.3/73.6|62.2/83.4|70.2|70.3|81.5|57.2|62.3|21.0|
|BERT-Mini|65.8|0.0|85.9|81.1/71.8|75.4/73.3|66.4/86.2|74.8|74.3|84.1|57.9|62.3|26.1|
|BERT-Small|71.2|27.8|89.7|83.4/76.2|78.8/77.0|68.1/87.0|77.6|77.0|86.4|61.8|62.3|28.6|
|BERT-Medium|73.5|38.0|89.6|86.6/81.6|80.4/78.4|69.6/87.9|80.0|79.1|87.7|62.2|62.3|30.5|
For each task, we selected the best fine-tuning hyperparameters from the lists below, and trained for 4 epochs:
- batch sizes: 8, 16, 32, 64, 128
- learning rates: 3e-4, 1e-4, 5e-5, 3e-5
If you use these models, please cite the following paper:
```
@article{turc2019,
title={Well-Read Students Learn Better: On the Importance of Pre-training Compact Models},
author={Turc, Iulia and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina},
journal={arXiv preprint arXiv:1908.08962v2 },
year={2019}
}
```
[2_128]: https://huggingface.co/google/bert_uncased_L-2_H-128_A-2
[2_256]: https://huggingface.co/google/bert_uncased_L-2_H-256_A-4
[2_512]: https://huggingface.co/google/bert_uncased_L-2_H-512_A-8
[2_768]: https://huggingface.co/google/bert_uncased_L-2_H-768_A-12
[4_128]: https://huggingface.co/google/bert_uncased_L-4_H-128_A-2
[4_256]: https://huggingface.co/google/bert_uncased_L-4_H-256_A-4
[4_512]: https://huggingface.co/google/bert_uncased_L-4_H-512_A-8
[4_768]: https://huggingface.co/google/bert_uncased_L-4_H-768_A-12
[6_128]: https://huggingface.co/google/bert_uncased_L-6_H-128_A-2
[6_256]: https://huggingface.co/google/bert_uncased_L-6_H-256_A-4
[6_512]: https://huggingface.co/google/bert_uncased_L-6_H-512_A-8
[6_768]: https://huggingface.co/google/bert_uncased_L-6_H-768_A-12
[8_128]: https://huggingface.co/google/bert_uncased_L-8_H-128_A-2
[8_256]: https://huggingface.co/google/bert_uncased_L-8_H-256_A-4
[8_512]: https://huggingface.co/google/bert_uncased_L-8_H-512_A-8
[8_768]: https://huggingface.co/google/bert_uncased_L-8_H-768_A-12
[10_128]: https://huggingface.co/google/bert_uncased_L-10_H-128_A-2
[10_256]: https://huggingface.co/google/bert_uncased_L-10_H-256_A-4
[10_512]: https://huggingface.co/google/bert_uncased_L-10_H-512_A-8
[10_768]: https://huggingface.co/google/bert_uncased_L-10_H-768_A-12
[12_128]: https://huggingface.co/google/bert_uncased_L-12_H-128_A-2
[12_256]: https://huggingface.co/google/bert_uncased_L-12_H-256_A-4
[12_512]: https://huggingface.co/google/bert_uncased_L-12_H-512_A-8
[12_768]: https://huggingface.co/google/bert_uncased_L-12_H-768_A-12
|
google/bert_uncased_L-4_H-768_A-12
|
google
| 2021-05-19T17:31:28Z | 918 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"arxiv:1908.08962",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2022-03-02T23:29:05Z |
---
thumbnail: https://huggingface.co/front/thumbnails/google.png
license: apache-2.0
---
BERT Miniatures
===
This is the set of 24 BERT models referenced in [Well-Read Students Learn Better: On the Importance of Pre-training Compact Models](https://arxiv.org/abs/1908.08962) (English only, uncased, trained with WordPiece masking).
We have shown that the standard BERT recipe (including model architecture and training objective) is effective on a wide range of model sizes, beyond BERT-Base and BERT-Large. The smaller BERT models are intended for environments with restricted computational resources. They can be fine-tuned in the same manner as the original BERT models. However, they are most effective in the context of knowledge distillation, where the fine-tuning labels are produced by a larger and more accurate teacher.
Our goal is to enable research in institutions with fewer computational resources and encourage the community to seek directions of innovation alternative to increasing model capacity.
You can download the 24 BERT miniatures either from the [official BERT Github page](https://github.com/google-research/bert/), or via HuggingFace from the links below:
| |H=128|H=256|H=512|H=768|
|---|:---:|:---:|:---:|:---:|
| **L=2** |[**2/128 (BERT-Tiny)**][2_128]|[2/256][2_256]|[2/512][2_512]|[2/768][2_768]|
| **L=4** |[4/128][4_128]|[**4/256 (BERT-Mini)**][4_256]|[**4/512 (BERT-Small)**][4_512]|[4/768][4_768]|
| **L=6** |[6/128][6_128]|[6/256][6_256]|[6/512][6_512]|[6/768][6_768]|
| **L=8** |[8/128][8_128]|[8/256][8_256]|[**8/512 (BERT-Medium)**][8_512]|[8/768][8_768]|
| **L=10** |[10/128][10_128]|[10/256][10_256]|[10/512][10_512]|[10/768][10_768]|
| **L=12** |[12/128][12_128]|[12/256][12_256]|[12/512][12_512]|[**12/768 (BERT-Base)**][12_768]|
Note that the BERT-Base model in this release is included for completeness only; it was re-trained under the same regime as the original model.
Here are the corresponding GLUE scores on the test set:
|Model|Score|CoLA|SST-2|MRPC|STS-B|QQP|MNLI-m|MNLI-mm|QNLI(v2)|RTE|WNLI|AX|
|---|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|
|BERT-Tiny|64.2|0.0|83.2|81.1/71.1|74.3/73.6|62.2/83.4|70.2|70.3|81.5|57.2|62.3|21.0|
|BERT-Mini|65.8|0.0|85.9|81.1/71.8|75.4/73.3|66.4/86.2|74.8|74.3|84.1|57.9|62.3|26.1|
|BERT-Small|71.2|27.8|89.7|83.4/76.2|78.8/77.0|68.1/87.0|77.6|77.0|86.4|61.8|62.3|28.6|
|BERT-Medium|73.5|38.0|89.6|86.6/81.6|80.4/78.4|69.6/87.9|80.0|79.1|87.7|62.2|62.3|30.5|
For each task, we selected the best fine-tuning hyperparameters from the lists below, and trained for 4 epochs:
- batch sizes: 8, 16, 32, 64, 128
- learning rates: 3e-4, 1e-4, 5e-5, 3e-5
If you use these models, please cite the following paper:
```
@article{turc2019,
title={Well-Read Students Learn Better: On the Importance of Pre-training Compact Models},
author={Turc, Iulia and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina},
journal={arXiv preprint arXiv:1908.08962v2 },
year={2019}
}
```
[2_128]: https://huggingface.co/google/bert_uncased_L-2_H-128_A-2
[2_256]: https://huggingface.co/google/bert_uncased_L-2_H-256_A-4
[2_512]: https://huggingface.co/google/bert_uncased_L-2_H-512_A-8
[2_768]: https://huggingface.co/google/bert_uncased_L-2_H-768_A-12
[4_128]: https://huggingface.co/google/bert_uncased_L-4_H-128_A-2
[4_256]: https://huggingface.co/google/bert_uncased_L-4_H-256_A-4
[4_512]: https://huggingface.co/google/bert_uncased_L-4_H-512_A-8
[4_768]: https://huggingface.co/google/bert_uncased_L-4_H-768_A-12
[6_128]: https://huggingface.co/google/bert_uncased_L-6_H-128_A-2
[6_256]: https://huggingface.co/google/bert_uncased_L-6_H-256_A-4
[6_512]: https://huggingface.co/google/bert_uncased_L-6_H-512_A-8
[6_768]: https://huggingface.co/google/bert_uncased_L-6_H-768_A-12
[8_128]: https://huggingface.co/google/bert_uncased_L-8_H-128_A-2
[8_256]: https://huggingface.co/google/bert_uncased_L-8_H-256_A-4
[8_512]: https://huggingface.co/google/bert_uncased_L-8_H-512_A-8
[8_768]: https://huggingface.co/google/bert_uncased_L-8_H-768_A-12
[10_128]: https://huggingface.co/google/bert_uncased_L-10_H-128_A-2
[10_256]: https://huggingface.co/google/bert_uncased_L-10_H-256_A-4
[10_512]: https://huggingface.co/google/bert_uncased_L-10_H-512_A-8
[10_768]: https://huggingface.co/google/bert_uncased_L-10_H-768_A-12
[12_128]: https://huggingface.co/google/bert_uncased_L-12_H-128_A-2
[12_256]: https://huggingface.co/google/bert_uncased_L-12_H-256_A-4
[12_512]: https://huggingface.co/google/bert_uncased_L-12_H-512_A-8
[12_768]: https://huggingface.co/google/bert_uncased_L-12_H-768_A-12
|
google/bert_uncased_L-4_H-512_A-8
|
google
| 2021-05-19T17:30:51Z | 95,283 | 4 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"arxiv:1908.08962",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2022-03-02T23:29:05Z |
---
thumbnail: https://huggingface.co/front/thumbnails/google.png
license: apache-2.0
---
BERT Miniatures
===
This is the set of 24 BERT models referenced in [Well-Read Students Learn Better: On the Importance of Pre-training Compact Models](https://arxiv.org/abs/1908.08962) (English only, uncased, trained with WordPiece masking).
We have shown that the standard BERT recipe (including model architecture and training objective) is effective on a wide range of model sizes, beyond BERT-Base and BERT-Large. The smaller BERT models are intended for environments with restricted computational resources. They can be fine-tuned in the same manner as the original BERT models. However, they are most effective in the context of knowledge distillation, where the fine-tuning labels are produced by a larger and more accurate teacher.
Our goal is to enable research in institutions with fewer computational resources and encourage the community to seek directions of innovation alternative to increasing model capacity.
You can download the 24 BERT miniatures either from the [official BERT Github page](https://github.com/google-research/bert/), or via HuggingFace from the links below:
| |H=128|H=256|H=512|H=768|
|---|:---:|:---:|:---:|:---:|
| **L=2** |[**2/128 (BERT-Tiny)**][2_128]|[2/256][2_256]|[2/512][2_512]|[2/768][2_768]|
| **L=4** |[4/128][4_128]|[**4/256 (BERT-Mini)**][4_256]|[**4/512 (BERT-Small)**][4_512]|[4/768][4_768]|
| **L=6** |[6/128][6_128]|[6/256][6_256]|[6/512][6_512]|[6/768][6_768]|
| **L=8** |[8/128][8_128]|[8/256][8_256]|[**8/512 (BERT-Medium)**][8_512]|[8/768][8_768]|
| **L=10** |[10/128][10_128]|[10/256][10_256]|[10/512][10_512]|[10/768][10_768]|
| **L=12** |[12/128][12_128]|[12/256][12_256]|[12/512][12_512]|[**12/768 (BERT-Base)**][12_768]|
Note that the BERT-Base model in this release is included for completeness only; it was re-trained under the same regime as the original model.
Here are the corresponding GLUE scores on the test set:
|Model|Score|CoLA|SST-2|MRPC|STS-B|QQP|MNLI-m|MNLI-mm|QNLI(v2)|RTE|WNLI|AX|
|---|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|
|BERT-Tiny|64.2|0.0|83.2|81.1/71.1|74.3/73.6|62.2/83.4|70.2|70.3|81.5|57.2|62.3|21.0|
|BERT-Mini|65.8|0.0|85.9|81.1/71.8|75.4/73.3|66.4/86.2|74.8|74.3|84.1|57.9|62.3|26.1|
|BERT-Small|71.2|27.8|89.7|83.4/76.2|78.8/77.0|68.1/87.0|77.6|77.0|86.4|61.8|62.3|28.6|
|BERT-Medium|73.5|38.0|89.6|86.6/81.6|80.4/78.4|69.6/87.9|80.0|79.1|87.7|62.2|62.3|30.5|
For each task, we selected the best fine-tuning hyperparameters from the lists below, and trained for 4 epochs:
- batch sizes: 8, 16, 32, 64, 128
- learning rates: 3e-4, 1e-4, 5e-5, 3e-5
If you use these models, please cite the following paper:
```
@article{turc2019,
title={Well-Read Students Learn Better: On the Importance of Pre-training Compact Models},
author={Turc, Iulia and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina},
journal={arXiv preprint arXiv:1908.08962v2 },
year={2019}
}
```
[2_128]: https://huggingface.co/google/bert_uncased_L-2_H-128_A-2
[2_256]: https://huggingface.co/google/bert_uncased_L-2_H-256_A-4
[2_512]: https://huggingface.co/google/bert_uncased_L-2_H-512_A-8
[2_768]: https://huggingface.co/google/bert_uncased_L-2_H-768_A-12
[4_128]: https://huggingface.co/google/bert_uncased_L-4_H-128_A-2
[4_256]: https://huggingface.co/google/bert_uncased_L-4_H-256_A-4
[4_512]: https://huggingface.co/google/bert_uncased_L-4_H-512_A-8
[4_768]: https://huggingface.co/google/bert_uncased_L-4_H-768_A-12
[6_128]: https://huggingface.co/google/bert_uncased_L-6_H-128_A-2
[6_256]: https://huggingface.co/google/bert_uncased_L-6_H-256_A-4
[6_512]: https://huggingface.co/google/bert_uncased_L-6_H-512_A-8
[6_768]: https://huggingface.co/google/bert_uncased_L-6_H-768_A-12
[8_128]: https://huggingface.co/google/bert_uncased_L-8_H-128_A-2
[8_256]: https://huggingface.co/google/bert_uncased_L-8_H-256_A-4
[8_512]: https://huggingface.co/google/bert_uncased_L-8_H-512_A-8
[8_768]: https://huggingface.co/google/bert_uncased_L-8_H-768_A-12
[10_128]: https://huggingface.co/google/bert_uncased_L-10_H-128_A-2
[10_256]: https://huggingface.co/google/bert_uncased_L-10_H-256_A-4
[10_512]: https://huggingface.co/google/bert_uncased_L-10_H-512_A-8
[10_768]: https://huggingface.co/google/bert_uncased_L-10_H-768_A-12
[12_128]: https://huggingface.co/google/bert_uncased_L-12_H-128_A-2
[12_256]: https://huggingface.co/google/bert_uncased_L-12_H-256_A-4
[12_512]: https://huggingface.co/google/bert_uncased_L-12_H-512_A-8
[12_768]: https://huggingface.co/google/bert_uncased_L-12_H-768_A-12
|
google/bert_uncased_L-4_H-128_A-2
|
google
| 2021-05-19T17:30:08Z | 2,136 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"arxiv:1908.08962",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2022-03-02T23:29:05Z |
---
thumbnail: https://huggingface.co/front/thumbnails/google.png
license: apache-2.0
---
BERT Miniatures
===
This is the set of 24 BERT models referenced in [Well-Read Students Learn Better: On the Importance of Pre-training Compact Models](https://arxiv.org/abs/1908.08962) (English only, uncased, trained with WordPiece masking).
We have shown that the standard BERT recipe (including model architecture and training objective) is effective on a wide range of model sizes, beyond BERT-Base and BERT-Large. The smaller BERT models are intended for environments with restricted computational resources. They can be fine-tuned in the same manner as the original BERT models. However, they are most effective in the context of knowledge distillation, where the fine-tuning labels are produced by a larger and more accurate teacher.
Our goal is to enable research in institutions with fewer computational resources and encourage the community to seek directions of innovation alternative to increasing model capacity.
You can download the 24 BERT miniatures either from the [official BERT Github page](https://github.com/google-research/bert/), or via HuggingFace from the links below:
| |H=128|H=256|H=512|H=768|
|---|:---:|:---:|:---:|:---:|
| **L=2** |[**2/128 (BERT-Tiny)**][2_128]|[2/256][2_256]|[2/512][2_512]|[2/768][2_768]|
| **L=4** |[4/128][4_128]|[**4/256 (BERT-Mini)**][4_256]|[**4/512 (BERT-Small)**][4_512]|[4/768][4_768]|
| **L=6** |[6/128][6_128]|[6/256][6_256]|[6/512][6_512]|[6/768][6_768]|
| **L=8** |[8/128][8_128]|[8/256][8_256]|[**8/512 (BERT-Medium)**][8_512]|[8/768][8_768]|
| **L=10** |[10/128][10_128]|[10/256][10_256]|[10/512][10_512]|[10/768][10_768]|
| **L=12** |[12/128][12_128]|[12/256][12_256]|[12/512][12_512]|[**12/768 (BERT-Base)**][12_768]|
Note that the BERT-Base model in this release is included for completeness only; it was re-trained under the same regime as the original model.
Here are the corresponding GLUE scores on the test set:
|Model|Score|CoLA|SST-2|MRPC|STS-B|QQP|MNLI-m|MNLI-mm|QNLI(v2)|RTE|WNLI|AX|
|---|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|
|BERT-Tiny|64.2|0.0|83.2|81.1/71.1|74.3/73.6|62.2/83.4|70.2|70.3|81.5|57.2|62.3|21.0|
|BERT-Mini|65.8|0.0|85.9|81.1/71.8|75.4/73.3|66.4/86.2|74.8|74.3|84.1|57.9|62.3|26.1|
|BERT-Small|71.2|27.8|89.7|83.4/76.2|78.8/77.0|68.1/87.0|77.6|77.0|86.4|61.8|62.3|28.6|
|BERT-Medium|73.5|38.0|89.6|86.6/81.6|80.4/78.4|69.6/87.9|80.0|79.1|87.7|62.2|62.3|30.5|
For each task, we selected the best fine-tuning hyperparameters from the lists below, and trained for 4 epochs:
- batch sizes: 8, 16, 32, 64, 128
- learning rates: 3e-4, 1e-4, 5e-5, 3e-5
If you use these models, please cite the following paper:
```
@article{turc2019,
title={Well-Read Students Learn Better: On the Importance of Pre-training Compact Models},
author={Turc, Iulia and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina},
journal={arXiv preprint arXiv:1908.08962v2 },
year={2019}
}
```
[2_128]: https://huggingface.co/google/bert_uncased_L-2_H-128_A-2
[2_256]: https://huggingface.co/google/bert_uncased_L-2_H-256_A-4
[2_512]: https://huggingface.co/google/bert_uncased_L-2_H-512_A-8
[2_768]: https://huggingface.co/google/bert_uncased_L-2_H-768_A-12
[4_128]: https://huggingface.co/google/bert_uncased_L-4_H-128_A-2
[4_256]: https://huggingface.co/google/bert_uncased_L-4_H-256_A-4
[4_512]: https://huggingface.co/google/bert_uncased_L-4_H-512_A-8
[4_768]: https://huggingface.co/google/bert_uncased_L-4_H-768_A-12
[6_128]: https://huggingface.co/google/bert_uncased_L-6_H-128_A-2
[6_256]: https://huggingface.co/google/bert_uncased_L-6_H-256_A-4
[6_512]: https://huggingface.co/google/bert_uncased_L-6_H-512_A-8
[6_768]: https://huggingface.co/google/bert_uncased_L-6_H-768_A-12
[8_128]: https://huggingface.co/google/bert_uncased_L-8_H-128_A-2
[8_256]: https://huggingface.co/google/bert_uncased_L-8_H-256_A-4
[8_512]: https://huggingface.co/google/bert_uncased_L-8_H-512_A-8
[8_768]: https://huggingface.co/google/bert_uncased_L-8_H-768_A-12
[10_128]: https://huggingface.co/google/bert_uncased_L-10_H-128_A-2
[10_256]: https://huggingface.co/google/bert_uncased_L-10_H-256_A-4
[10_512]: https://huggingface.co/google/bert_uncased_L-10_H-512_A-8
[10_768]: https://huggingface.co/google/bert_uncased_L-10_H-768_A-12
[12_128]: https://huggingface.co/google/bert_uncased_L-12_H-128_A-2
[12_256]: https://huggingface.co/google/bert_uncased_L-12_H-256_A-4
[12_512]: https://huggingface.co/google/bert_uncased_L-12_H-512_A-8
[12_768]: https://huggingface.co/google/bert_uncased_L-12_H-768_A-12
|
google/bert_uncased_L-2_H-512_A-8
|
google
| 2021-05-19T17:29:08Z | 4,048 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"arxiv:1908.08962",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2022-03-02T23:29:05Z |
---
thumbnail: https://huggingface.co/front/thumbnails/google.png
license: apache-2.0
---
BERT Miniatures
===
This is the set of 24 BERT models referenced in [Well-Read Students Learn Better: On the Importance of Pre-training Compact Models](https://arxiv.org/abs/1908.08962) (English only, uncased, trained with WordPiece masking).
We have shown that the standard BERT recipe (including model architecture and training objective) is effective on a wide range of model sizes, beyond BERT-Base and BERT-Large. The smaller BERT models are intended for environments with restricted computational resources. They can be fine-tuned in the same manner as the original BERT models. However, they are most effective in the context of knowledge distillation, where the fine-tuning labels are produced by a larger and more accurate teacher.
Our goal is to enable research in institutions with fewer computational resources and encourage the community to seek directions of innovation alternative to increasing model capacity.
You can download the 24 BERT miniatures either from the [official BERT Github page](https://github.com/google-research/bert/), or via HuggingFace from the links below:
| |H=128|H=256|H=512|H=768|
|---|:---:|:---:|:---:|:---:|
| **L=2** |[**2/128 (BERT-Tiny)**][2_128]|[2/256][2_256]|[2/512][2_512]|[2/768][2_768]|
| **L=4** |[4/128][4_128]|[**4/256 (BERT-Mini)**][4_256]|[**4/512 (BERT-Small)**][4_512]|[4/768][4_768]|
| **L=6** |[6/128][6_128]|[6/256][6_256]|[6/512][6_512]|[6/768][6_768]|
| **L=8** |[8/128][8_128]|[8/256][8_256]|[**8/512 (BERT-Medium)**][8_512]|[8/768][8_768]|
| **L=10** |[10/128][10_128]|[10/256][10_256]|[10/512][10_512]|[10/768][10_768]|
| **L=12** |[12/128][12_128]|[12/256][12_256]|[12/512][12_512]|[**12/768 (BERT-Base)**][12_768]|
Note that the BERT-Base model in this release is included for completeness only; it was re-trained under the same regime as the original model.
Here are the corresponding GLUE scores on the test set:
|Model|Score|CoLA|SST-2|MRPC|STS-B|QQP|MNLI-m|MNLI-mm|QNLI(v2)|RTE|WNLI|AX|
|---|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|
|BERT-Tiny|64.2|0.0|83.2|81.1/71.1|74.3/73.6|62.2/83.4|70.2|70.3|81.5|57.2|62.3|21.0|
|BERT-Mini|65.8|0.0|85.9|81.1/71.8|75.4/73.3|66.4/86.2|74.8|74.3|84.1|57.9|62.3|26.1|
|BERT-Small|71.2|27.8|89.7|83.4/76.2|78.8/77.0|68.1/87.0|77.6|77.0|86.4|61.8|62.3|28.6|
|BERT-Medium|73.5|38.0|89.6|86.6/81.6|80.4/78.4|69.6/87.9|80.0|79.1|87.7|62.2|62.3|30.5|
For each task, we selected the best fine-tuning hyperparameters from the lists below, and trained for 4 epochs:
- batch sizes: 8, 16, 32, 64, 128
- learning rates: 3e-4, 1e-4, 5e-5, 3e-5
If you use these models, please cite the following paper:
```
@article{turc2019,
title={Well-Read Students Learn Better: On the Importance of Pre-training Compact Models},
author={Turc, Iulia and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina},
journal={arXiv preprint arXiv:1908.08962v2 },
year={2019}
}
```
[2_128]: https://huggingface.co/google/bert_uncased_L-2_H-128_A-2
[2_256]: https://huggingface.co/google/bert_uncased_L-2_H-256_A-4
[2_512]: https://huggingface.co/google/bert_uncased_L-2_H-512_A-8
[2_768]: https://huggingface.co/google/bert_uncased_L-2_H-768_A-12
[4_128]: https://huggingface.co/google/bert_uncased_L-4_H-128_A-2
[4_256]: https://huggingface.co/google/bert_uncased_L-4_H-256_A-4
[4_512]: https://huggingface.co/google/bert_uncased_L-4_H-512_A-8
[4_768]: https://huggingface.co/google/bert_uncased_L-4_H-768_A-12
[6_128]: https://huggingface.co/google/bert_uncased_L-6_H-128_A-2
[6_256]: https://huggingface.co/google/bert_uncased_L-6_H-256_A-4
[6_512]: https://huggingface.co/google/bert_uncased_L-6_H-512_A-8
[6_768]: https://huggingface.co/google/bert_uncased_L-6_H-768_A-12
[8_128]: https://huggingface.co/google/bert_uncased_L-8_H-128_A-2
[8_256]: https://huggingface.co/google/bert_uncased_L-8_H-256_A-4
[8_512]: https://huggingface.co/google/bert_uncased_L-8_H-512_A-8
[8_768]: https://huggingface.co/google/bert_uncased_L-8_H-768_A-12
[10_128]: https://huggingface.co/google/bert_uncased_L-10_H-128_A-2
[10_256]: https://huggingface.co/google/bert_uncased_L-10_H-256_A-4
[10_512]: https://huggingface.co/google/bert_uncased_L-10_H-512_A-8
[10_768]: https://huggingface.co/google/bert_uncased_L-10_H-768_A-12
[12_128]: https://huggingface.co/google/bert_uncased_L-12_H-128_A-2
[12_256]: https://huggingface.co/google/bert_uncased_L-12_H-256_A-4
[12_512]: https://huggingface.co/google/bert_uncased_L-12_H-512_A-8
[12_768]: https://huggingface.co/google/bert_uncased_L-12_H-768_A-12
|
google/bert_uncased_L-12_H-512_A-8
|
google
| 2021-05-19T17:26:55Z | 6,382 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"arxiv:1908.08962",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2022-03-02T23:29:05Z |
---
thumbnail: https://huggingface.co/front/thumbnails/google.png
license: apache-2.0
---
BERT Miniatures
===
This is the set of 24 BERT models referenced in [Well-Read Students Learn Better: On the Importance of Pre-training Compact Models](https://arxiv.org/abs/1908.08962) (English only, uncased, trained with WordPiece masking).
We have shown that the standard BERT recipe (including model architecture and training objective) is effective on a wide range of model sizes, beyond BERT-Base and BERT-Large. The smaller BERT models are intended for environments with restricted computational resources. They can be fine-tuned in the same manner as the original BERT models. However, they are most effective in the context of knowledge distillation, where the fine-tuning labels are produced by a larger and more accurate teacher.
Our goal is to enable research in institutions with fewer computational resources and encourage the community to seek directions of innovation alternative to increasing model capacity.
You can download the 24 BERT miniatures either from the [official BERT Github page](https://github.com/google-research/bert/), or via HuggingFace from the links below:
| |H=128|H=256|H=512|H=768|
|---|:---:|:---:|:---:|:---:|
| **L=2** |[**2/128 (BERT-Tiny)**][2_128]|[2/256][2_256]|[2/512][2_512]|[2/768][2_768]|
| **L=4** |[4/128][4_128]|[**4/256 (BERT-Mini)**][4_256]|[**4/512 (BERT-Small)**][4_512]|[4/768][4_768]|
| **L=6** |[6/128][6_128]|[6/256][6_256]|[6/512][6_512]|[6/768][6_768]|
| **L=8** |[8/128][8_128]|[8/256][8_256]|[**8/512 (BERT-Medium)**][8_512]|[8/768][8_768]|
| **L=10** |[10/128][10_128]|[10/256][10_256]|[10/512][10_512]|[10/768][10_768]|
| **L=12** |[12/128][12_128]|[12/256][12_256]|[12/512][12_512]|[**12/768 (BERT-Base)**][12_768]|
Note that the BERT-Base model in this release is included for completeness only; it was re-trained under the same regime as the original model.
Here are the corresponding GLUE scores on the test set:
|Model|Score|CoLA|SST-2|MRPC|STS-B|QQP|MNLI-m|MNLI-mm|QNLI(v2)|RTE|WNLI|AX|
|---|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|
|BERT-Tiny|64.2|0.0|83.2|81.1/71.1|74.3/73.6|62.2/83.4|70.2|70.3|81.5|57.2|62.3|21.0|
|BERT-Mini|65.8|0.0|85.9|81.1/71.8|75.4/73.3|66.4/86.2|74.8|74.3|84.1|57.9|62.3|26.1|
|BERT-Small|71.2|27.8|89.7|83.4/76.2|78.8/77.0|68.1/87.0|77.6|77.0|86.4|61.8|62.3|28.6|
|BERT-Medium|73.5|38.0|89.6|86.6/81.6|80.4/78.4|69.6/87.9|80.0|79.1|87.7|62.2|62.3|30.5|
For each task, we selected the best fine-tuning hyperparameters from the lists below, and trained for 4 epochs:
- batch sizes: 8, 16, 32, 64, 128
- learning rates: 3e-4, 1e-4, 5e-5, 3e-5
If you use these models, please cite the following paper:
```
@article{turc2019,
title={Well-Read Students Learn Better: On the Importance of Pre-training Compact Models},
author={Turc, Iulia and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina},
journal={arXiv preprint arXiv:1908.08962v2 },
year={2019}
}
```
[2_128]: https://huggingface.co/google/bert_uncased_L-2_H-128_A-2
[2_256]: https://huggingface.co/google/bert_uncased_L-2_H-256_A-4
[2_512]: https://huggingface.co/google/bert_uncased_L-2_H-512_A-8
[2_768]: https://huggingface.co/google/bert_uncased_L-2_H-768_A-12
[4_128]: https://huggingface.co/google/bert_uncased_L-4_H-128_A-2
[4_256]: https://huggingface.co/google/bert_uncased_L-4_H-256_A-4
[4_512]: https://huggingface.co/google/bert_uncased_L-4_H-512_A-8
[4_768]: https://huggingface.co/google/bert_uncased_L-4_H-768_A-12
[6_128]: https://huggingface.co/google/bert_uncased_L-6_H-128_A-2
[6_256]: https://huggingface.co/google/bert_uncased_L-6_H-256_A-4
[6_512]: https://huggingface.co/google/bert_uncased_L-6_H-512_A-8
[6_768]: https://huggingface.co/google/bert_uncased_L-6_H-768_A-12
[8_128]: https://huggingface.co/google/bert_uncased_L-8_H-128_A-2
[8_256]: https://huggingface.co/google/bert_uncased_L-8_H-256_A-4
[8_512]: https://huggingface.co/google/bert_uncased_L-8_H-512_A-8
[8_768]: https://huggingface.co/google/bert_uncased_L-8_H-768_A-12
[10_128]: https://huggingface.co/google/bert_uncased_L-10_H-128_A-2
[10_256]: https://huggingface.co/google/bert_uncased_L-10_H-256_A-4
[10_512]: https://huggingface.co/google/bert_uncased_L-10_H-512_A-8
[10_768]: https://huggingface.co/google/bert_uncased_L-10_H-768_A-12
[12_128]: https://huggingface.co/google/bert_uncased_L-12_H-128_A-2
[12_256]: https://huggingface.co/google/bert_uncased_L-12_H-256_A-4
[12_512]: https://huggingface.co/google/bert_uncased_L-12_H-512_A-8
[12_768]: https://huggingface.co/google/bert_uncased_L-12_H-768_A-12
|
google/bert_uncased_L-12_H-256_A-4
|
google
| 2021-05-19T17:26:24Z | 28,093 | 1 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"arxiv:1908.08962",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2022-03-02T23:29:05Z |
---
thumbnail: https://huggingface.co/front/thumbnails/google.png
license: apache-2.0
---
BERT Miniatures
===
This is the set of 24 BERT models referenced in [Well-Read Students Learn Better: On the Importance of Pre-training Compact Models](https://arxiv.org/abs/1908.08962) (English only, uncased, trained with WordPiece masking).
We have shown that the standard BERT recipe (including model architecture and training objective) is effective on a wide range of model sizes, beyond BERT-Base and BERT-Large. The smaller BERT models are intended for environments with restricted computational resources. They can be fine-tuned in the same manner as the original BERT models. However, they are most effective in the context of knowledge distillation, where the fine-tuning labels are produced by a larger and more accurate teacher.
Our goal is to enable research in institutions with fewer computational resources and encourage the community to seek directions of innovation alternative to increasing model capacity.
You can download the 24 BERT miniatures either from the [official BERT Github page](https://github.com/google-research/bert/), or via HuggingFace from the links below:
| |H=128|H=256|H=512|H=768|
|---|:---:|:---:|:---:|:---:|
| **L=2** |[**2/128 (BERT-Tiny)**][2_128]|[2/256][2_256]|[2/512][2_512]|[2/768][2_768]|
| **L=4** |[4/128][4_128]|[**4/256 (BERT-Mini)**][4_256]|[**4/512 (BERT-Small)**][4_512]|[4/768][4_768]|
| **L=6** |[6/128][6_128]|[6/256][6_256]|[6/512][6_512]|[6/768][6_768]|
| **L=8** |[8/128][8_128]|[8/256][8_256]|[**8/512 (BERT-Medium)**][8_512]|[8/768][8_768]|
| **L=10** |[10/128][10_128]|[10/256][10_256]|[10/512][10_512]|[10/768][10_768]|
| **L=12** |[12/128][12_128]|[12/256][12_256]|[12/512][12_512]|[**12/768 (BERT-Base)**][12_768]|
Note that the BERT-Base model in this release is included for completeness only; it was re-trained under the same regime as the original model.
Here are the corresponding GLUE scores on the test set:
|Model|Score|CoLA|SST-2|MRPC|STS-B|QQP|MNLI-m|MNLI-mm|QNLI(v2)|RTE|WNLI|AX|
|---|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|
|BERT-Tiny|64.2|0.0|83.2|81.1/71.1|74.3/73.6|62.2/83.4|70.2|70.3|81.5|57.2|62.3|21.0|
|BERT-Mini|65.8|0.0|85.9|81.1/71.8|75.4/73.3|66.4/86.2|74.8|74.3|84.1|57.9|62.3|26.1|
|BERT-Small|71.2|27.8|89.7|83.4/76.2|78.8/77.0|68.1/87.0|77.6|77.0|86.4|61.8|62.3|28.6|
|BERT-Medium|73.5|38.0|89.6|86.6/81.6|80.4/78.4|69.6/87.9|80.0|79.1|87.7|62.2|62.3|30.5|
For each task, we selected the best fine-tuning hyperparameters from the lists below, and trained for 4 epochs:
- batch sizes: 8, 16, 32, 64, 128
- learning rates: 3e-4, 1e-4, 5e-5, 3e-5
If you use these models, please cite the following paper:
```
@article{turc2019,
title={Well-Read Students Learn Better: On the Importance of Pre-training Compact Models},
author={Turc, Iulia and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina},
journal={arXiv preprint arXiv:1908.08962v2 },
year={2019}
}
```
[2_128]: https://huggingface.co/google/bert_uncased_L-2_H-128_A-2
[2_256]: https://huggingface.co/google/bert_uncased_L-2_H-256_A-4
[2_512]: https://huggingface.co/google/bert_uncased_L-2_H-512_A-8
[2_768]: https://huggingface.co/google/bert_uncased_L-2_H-768_A-12
[4_128]: https://huggingface.co/google/bert_uncased_L-4_H-128_A-2
[4_256]: https://huggingface.co/google/bert_uncased_L-4_H-256_A-4
[4_512]: https://huggingface.co/google/bert_uncased_L-4_H-512_A-8
[4_768]: https://huggingface.co/google/bert_uncased_L-4_H-768_A-12
[6_128]: https://huggingface.co/google/bert_uncased_L-6_H-128_A-2
[6_256]: https://huggingface.co/google/bert_uncased_L-6_H-256_A-4
[6_512]: https://huggingface.co/google/bert_uncased_L-6_H-512_A-8
[6_768]: https://huggingface.co/google/bert_uncased_L-6_H-768_A-12
[8_128]: https://huggingface.co/google/bert_uncased_L-8_H-128_A-2
[8_256]: https://huggingface.co/google/bert_uncased_L-8_H-256_A-4
[8_512]: https://huggingface.co/google/bert_uncased_L-8_H-512_A-8
[8_768]: https://huggingface.co/google/bert_uncased_L-8_H-768_A-12
[10_128]: https://huggingface.co/google/bert_uncased_L-10_H-128_A-2
[10_256]: https://huggingface.co/google/bert_uncased_L-10_H-256_A-4
[10_512]: https://huggingface.co/google/bert_uncased_L-10_H-512_A-8
[10_768]: https://huggingface.co/google/bert_uncased_L-10_H-768_A-12
[12_128]: https://huggingface.co/google/bert_uncased_L-12_H-128_A-2
[12_256]: https://huggingface.co/google/bert_uncased_L-12_H-256_A-4
[12_512]: https://huggingface.co/google/bert_uncased_L-12_H-512_A-8
[12_768]: https://huggingface.co/google/bert_uncased_L-12_H-768_A-12
|
google/bert_uncased_L-12_H-128_A-2
|
google
| 2021-05-19T17:26:01Z | 2,701 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"arxiv:1908.08962",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2022-03-02T23:29:05Z |
---
thumbnail: https://huggingface.co/front/thumbnails/google.png
license: apache-2.0
---
BERT Miniatures
===
This is the set of 24 BERT models referenced in [Well-Read Students Learn Better: On the Importance of Pre-training Compact Models](https://arxiv.org/abs/1908.08962) (English only, uncased, trained with WordPiece masking).
We have shown that the standard BERT recipe (including model architecture and training objective) is effective on a wide range of model sizes, beyond BERT-Base and BERT-Large. The smaller BERT models are intended for environments with restricted computational resources. They can be fine-tuned in the same manner as the original BERT models. However, they are most effective in the context of knowledge distillation, where the fine-tuning labels are produced by a larger and more accurate teacher.
Our goal is to enable research in institutions with fewer computational resources and encourage the community to seek directions of innovation alternative to increasing model capacity.
You can download the 24 BERT miniatures either from the [official BERT Github page](https://github.com/google-research/bert/), or via HuggingFace from the links below:
| |H=128|H=256|H=512|H=768|
|---|:---:|:---:|:---:|:---:|
| **L=2** |[**2/128 (BERT-Tiny)**][2_128]|[2/256][2_256]|[2/512][2_512]|[2/768][2_768]|
| **L=4** |[4/128][4_128]|[**4/256 (BERT-Mini)**][4_256]|[**4/512 (BERT-Small)**][4_512]|[4/768][4_768]|
| **L=6** |[6/128][6_128]|[6/256][6_256]|[6/512][6_512]|[6/768][6_768]|
| **L=8** |[8/128][8_128]|[8/256][8_256]|[**8/512 (BERT-Medium)**][8_512]|[8/768][8_768]|
| **L=10** |[10/128][10_128]|[10/256][10_256]|[10/512][10_512]|[10/768][10_768]|
| **L=12** |[12/128][12_128]|[12/256][12_256]|[12/512][12_512]|[**12/768 (BERT-Base)**][12_768]|
Note that the BERT-Base model in this release is included for completeness only; it was re-trained under the same regime as the original model.
Here are the corresponding GLUE scores on the test set:
|Model|Score|CoLA|SST-2|MRPC|STS-B|QQP|MNLI-m|MNLI-mm|QNLI(v2)|RTE|WNLI|AX|
|---|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|
|BERT-Tiny|64.2|0.0|83.2|81.1/71.1|74.3/73.6|62.2/83.4|70.2|70.3|81.5|57.2|62.3|21.0|
|BERT-Mini|65.8|0.0|85.9|81.1/71.8|75.4/73.3|66.4/86.2|74.8|74.3|84.1|57.9|62.3|26.1|
|BERT-Small|71.2|27.8|89.7|83.4/76.2|78.8/77.0|68.1/87.0|77.6|77.0|86.4|61.8|62.3|28.6|
|BERT-Medium|73.5|38.0|89.6|86.6/81.6|80.4/78.4|69.6/87.9|80.0|79.1|87.7|62.2|62.3|30.5|
For each task, we selected the best fine-tuning hyperparameters from the lists below, and trained for 4 epochs:
- batch sizes: 8, 16, 32, 64, 128
- learning rates: 3e-4, 1e-4, 5e-5, 3e-5
If you use these models, please cite the following paper:
```
@article{turc2019,
title={Well-Read Students Learn Better: On the Importance of Pre-training Compact Models},
author={Turc, Iulia and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina},
journal={arXiv preprint arXiv:1908.08962v2 },
year={2019}
}
```
[2_128]: https://huggingface.co/google/bert_uncased_L-2_H-128_A-2
[2_256]: https://huggingface.co/google/bert_uncased_L-2_H-256_A-4
[2_512]: https://huggingface.co/google/bert_uncased_L-2_H-512_A-8
[2_768]: https://huggingface.co/google/bert_uncased_L-2_H-768_A-12
[4_128]: https://huggingface.co/google/bert_uncased_L-4_H-128_A-2
[4_256]: https://huggingface.co/google/bert_uncased_L-4_H-256_A-4
[4_512]: https://huggingface.co/google/bert_uncased_L-4_H-512_A-8
[4_768]: https://huggingface.co/google/bert_uncased_L-4_H-768_A-12
[6_128]: https://huggingface.co/google/bert_uncased_L-6_H-128_A-2
[6_256]: https://huggingface.co/google/bert_uncased_L-6_H-256_A-4
[6_512]: https://huggingface.co/google/bert_uncased_L-6_H-512_A-8
[6_768]: https://huggingface.co/google/bert_uncased_L-6_H-768_A-12
[8_128]: https://huggingface.co/google/bert_uncased_L-8_H-128_A-2
[8_256]: https://huggingface.co/google/bert_uncased_L-8_H-256_A-4
[8_512]: https://huggingface.co/google/bert_uncased_L-8_H-512_A-8
[8_768]: https://huggingface.co/google/bert_uncased_L-8_H-768_A-12
[10_128]: https://huggingface.co/google/bert_uncased_L-10_H-128_A-2
[10_256]: https://huggingface.co/google/bert_uncased_L-10_H-256_A-4
[10_512]: https://huggingface.co/google/bert_uncased_L-10_H-512_A-8
[10_768]: https://huggingface.co/google/bert_uncased_L-10_H-768_A-12
[12_128]: https://huggingface.co/google/bert_uncased_L-12_H-128_A-2
[12_256]: https://huggingface.co/google/bert_uncased_L-12_H-256_A-4
[12_512]: https://huggingface.co/google/bert_uncased_L-12_H-512_A-8
[12_768]: https://huggingface.co/google/bert_uncased_L-12_H-768_A-12
|
google/bert_uncased_L-10_H-768_A-12
|
google
| 2021-05-19T17:24:59Z | 914 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"arxiv:1908.08962",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2022-03-02T23:29:05Z |
---
thumbnail: https://huggingface.co/front/thumbnails/google.png
license: apache-2.0
---
BERT Miniatures
===
This is the set of 24 BERT models referenced in [Well-Read Students Learn Better: On the Importance of Pre-training Compact Models](https://arxiv.org/abs/1908.08962) (English only, uncased, trained with WordPiece masking).
We have shown that the standard BERT recipe (including model architecture and training objective) is effective on a wide range of model sizes, beyond BERT-Base and BERT-Large. The smaller BERT models are intended for environments with restricted computational resources. They can be fine-tuned in the same manner as the original BERT models. However, they are most effective in the context of knowledge distillation, where the fine-tuning labels are produced by a larger and more accurate teacher.
Our goal is to enable research in institutions with fewer computational resources and encourage the community to seek directions of innovation alternative to increasing model capacity.
You can download the 24 BERT miniatures either from the [official BERT Github page](https://github.com/google-research/bert/), or via HuggingFace from the links below:
| |H=128|H=256|H=512|H=768|
|---|:---:|:---:|:---:|:---:|
| **L=2** |[**2/128 (BERT-Tiny)**][2_128]|[2/256][2_256]|[2/512][2_512]|[2/768][2_768]|
| **L=4** |[4/128][4_128]|[**4/256 (BERT-Mini)**][4_256]|[**4/512 (BERT-Small)**][4_512]|[4/768][4_768]|
| **L=6** |[6/128][6_128]|[6/256][6_256]|[6/512][6_512]|[6/768][6_768]|
| **L=8** |[8/128][8_128]|[8/256][8_256]|[**8/512 (BERT-Medium)**][8_512]|[8/768][8_768]|
| **L=10** |[10/128][10_128]|[10/256][10_256]|[10/512][10_512]|[10/768][10_768]|
| **L=12** |[12/128][12_128]|[12/256][12_256]|[12/512][12_512]|[**12/768 (BERT-Base)**][12_768]|
Note that the BERT-Base model in this release is included for completeness only; it was re-trained under the same regime as the original model.
Here are the corresponding GLUE scores on the test set:
|Model|Score|CoLA|SST-2|MRPC|STS-B|QQP|MNLI-m|MNLI-mm|QNLI(v2)|RTE|WNLI|AX|
|---|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|
|BERT-Tiny|64.2|0.0|83.2|81.1/71.1|74.3/73.6|62.2/83.4|70.2|70.3|81.5|57.2|62.3|21.0|
|BERT-Mini|65.8|0.0|85.9|81.1/71.8|75.4/73.3|66.4/86.2|74.8|74.3|84.1|57.9|62.3|26.1|
|BERT-Small|71.2|27.8|89.7|83.4/76.2|78.8/77.0|68.1/87.0|77.6|77.0|86.4|61.8|62.3|28.6|
|BERT-Medium|73.5|38.0|89.6|86.6/81.6|80.4/78.4|69.6/87.9|80.0|79.1|87.7|62.2|62.3|30.5|
For each task, we selected the best fine-tuning hyperparameters from the lists below, and trained for 4 epochs:
- batch sizes: 8, 16, 32, 64, 128
- learning rates: 3e-4, 1e-4, 5e-5, 3e-5
If you use these models, please cite the following paper:
```
@article{turc2019,
title={Well-Read Students Learn Better: On the Importance of Pre-training Compact Models},
author={Turc, Iulia and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina},
journal={arXiv preprint arXiv:1908.08962v2 },
year={2019}
}
```
[2_128]: https://huggingface.co/google/bert_uncased_L-2_H-128_A-2
[2_256]: https://huggingface.co/google/bert_uncased_L-2_H-256_A-4
[2_512]: https://huggingface.co/google/bert_uncased_L-2_H-512_A-8
[2_768]: https://huggingface.co/google/bert_uncased_L-2_H-768_A-12
[4_128]: https://huggingface.co/google/bert_uncased_L-4_H-128_A-2
[4_256]: https://huggingface.co/google/bert_uncased_L-4_H-256_A-4
[4_512]: https://huggingface.co/google/bert_uncased_L-4_H-512_A-8
[4_768]: https://huggingface.co/google/bert_uncased_L-4_H-768_A-12
[6_128]: https://huggingface.co/google/bert_uncased_L-6_H-128_A-2
[6_256]: https://huggingface.co/google/bert_uncased_L-6_H-256_A-4
[6_512]: https://huggingface.co/google/bert_uncased_L-6_H-512_A-8
[6_768]: https://huggingface.co/google/bert_uncased_L-6_H-768_A-12
[8_128]: https://huggingface.co/google/bert_uncased_L-8_H-128_A-2
[8_256]: https://huggingface.co/google/bert_uncased_L-8_H-256_A-4
[8_512]: https://huggingface.co/google/bert_uncased_L-8_H-512_A-8
[8_768]: https://huggingface.co/google/bert_uncased_L-8_H-768_A-12
[10_128]: https://huggingface.co/google/bert_uncased_L-10_H-128_A-2
[10_256]: https://huggingface.co/google/bert_uncased_L-10_H-256_A-4
[10_512]: https://huggingface.co/google/bert_uncased_L-10_H-512_A-8
[10_768]: https://huggingface.co/google/bert_uncased_L-10_H-768_A-12
[12_128]: https://huggingface.co/google/bert_uncased_L-12_H-128_A-2
[12_256]: https://huggingface.co/google/bert_uncased_L-12_H-256_A-4
[12_512]: https://huggingface.co/google/bert_uncased_L-12_H-512_A-8
[12_768]: https://huggingface.co/google/bert_uncased_L-12_H-768_A-12
|
google/bert_uncased_L-10_H-256_A-4
|
google
| 2021-05-19T17:23:44Z | 924 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"arxiv:1908.08962",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2022-03-02T23:29:05Z |
---
thumbnail: https://huggingface.co/front/thumbnails/google.png
license: apache-2.0
---
BERT Miniatures
===
This is the set of 24 BERT models referenced in [Well-Read Students Learn Better: On the Importance of Pre-training Compact Models](https://arxiv.org/abs/1908.08962) (English only, uncased, trained with WordPiece masking).
We have shown that the standard BERT recipe (including model architecture and training objective) is effective on a wide range of model sizes, beyond BERT-Base and BERT-Large. The smaller BERT models are intended for environments with restricted computational resources. They can be fine-tuned in the same manner as the original BERT models. However, they are most effective in the context of knowledge distillation, where the fine-tuning labels are produced by a larger and more accurate teacher.
Our goal is to enable research in institutions with fewer computational resources and encourage the community to seek directions of innovation alternative to increasing model capacity.
You can download the 24 BERT miniatures either from the [official BERT Github page](https://github.com/google-research/bert/), or via HuggingFace from the links below:
| |H=128|H=256|H=512|H=768|
|---|:---:|:---:|:---:|:---:|
| **L=2** |[**2/128 (BERT-Tiny)**][2_128]|[2/256][2_256]|[2/512][2_512]|[2/768][2_768]|
| **L=4** |[4/128][4_128]|[**4/256 (BERT-Mini)**][4_256]|[**4/512 (BERT-Small)**][4_512]|[4/768][4_768]|
| **L=6** |[6/128][6_128]|[6/256][6_256]|[6/512][6_512]|[6/768][6_768]|
| **L=8** |[8/128][8_128]|[8/256][8_256]|[**8/512 (BERT-Medium)**][8_512]|[8/768][8_768]|
| **L=10** |[10/128][10_128]|[10/256][10_256]|[10/512][10_512]|[10/768][10_768]|
| **L=12** |[12/128][12_128]|[12/256][12_256]|[12/512][12_512]|[**12/768 (BERT-Base)**][12_768]|
Note that the BERT-Base model in this release is included for completeness only; it was re-trained under the same regime as the original model.
Here are the corresponding GLUE scores on the test set:
|Model|Score|CoLA|SST-2|MRPC|STS-B|QQP|MNLI-m|MNLI-mm|QNLI(v2)|RTE|WNLI|AX|
|---|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|
|BERT-Tiny|64.2|0.0|83.2|81.1/71.1|74.3/73.6|62.2/83.4|70.2|70.3|81.5|57.2|62.3|21.0|
|BERT-Mini|65.8|0.0|85.9|81.1/71.8|75.4/73.3|66.4/86.2|74.8|74.3|84.1|57.9|62.3|26.1|
|BERT-Small|71.2|27.8|89.7|83.4/76.2|78.8/77.0|68.1/87.0|77.6|77.0|86.4|61.8|62.3|28.6|
|BERT-Medium|73.5|38.0|89.6|86.6/81.6|80.4/78.4|69.6/87.9|80.0|79.1|87.7|62.2|62.3|30.5|
For each task, we selected the best fine-tuning hyperparameters from the lists below, and trained for 4 epochs:
- batch sizes: 8, 16, 32, 64, 128
- learning rates: 3e-4, 1e-4, 5e-5, 3e-5
If you use these models, please cite the following paper:
```
@article{turc2019,
title={Well-Read Students Learn Better: On the Importance of Pre-training Compact Models},
author={Turc, Iulia and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina},
journal={arXiv preprint arXiv:1908.08962v2 },
year={2019}
}
```
[2_128]: https://huggingface.co/google/bert_uncased_L-2_H-128_A-2
[2_256]: https://huggingface.co/google/bert_uncased_L-2_H-256_A-4
[2_512]: https://huggingface.co/google/bert_uncased_L-2_H-512_A-8
[2_768]: https://huggingface.co/google/bert_uncased_L-2_H-768_A-12
[4_128]: https://huggingface.co/google/bert_uncased_L-4_H-128_A-2
[4_256]: https://huggingface.co/google/bert_uncased_L-4_H-256_A-4
[4_512]: https://huggingface.co/google/bert_uncased_L-4_H-512_A-8
[4_768]: https://huggingface.co/google/bert_uncased_L-4_H-768_A-12
[6_128]: https://huggingface.co/google/bert_uncased_L-6_H-128_A-2
[6_256]: https://huggingface.co/google/bert_uncased_L-6_H-256_A-4
[6_512]: https://huggingface.co/google/bert_uncased_L-6_H-512_A-8
[6_768]: https://huggingface.co/google/bert_uncased_L-6_H-768_A-12
[8_128]: https://huggingface.co/google/bert_uncased_L-8_H-128_A-2
[8_256]: https://huggingface.co/google/bert_uncased_L-8_H-256_A-4
[8_512]: https://huggingface.co/google/bert_uncased_L-8_H-512_A-8
[8_768]: https://huggingface.co/google/bert_uncased_L-8_H-768_A-12
[10_128]: https://huggingface.co/google/bert_uncased_L-10_H-128_A-2
[10_256]: https://huggingface.co/google/bert_uncased_L-10_H-256_A-4
[10_512]: https://huggingface.co/google/bert_uncased_L-10_H-512_A-8
[10_768]: https://huggingface.co/google/bert_uncased_L-10_H-768_A-12
[12_128]: https://huggingface.co/google/bert_uncased_L-12_H-128_A-2
[12_256]: https://huggingface.co/google/bert_uncased_L-12_H-256_A-4
[12_512]: https://huggingface.co/google/bert_uncased_L-12_H-512_A-8
[12_768]: https://huggingface.co/google/bert_uncased_L-12_H-768_A-12
|
dpalominop/spanish-bert-apoyo
|
dpalominop
| 2021-05-19T16:08:52Z | 13 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"text-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
```python
from transformers import AutoTokenizer, AutoModelForSequenceClassification
tokenizer = AutoTokenizer.from_pretrained("dpalominop/spanish-bert-apoyo")
model = AutoModelForSequenceClassification.from_pretrained("dpalominop/spanish-bert-apoyo")
```
|
dkleczek/bert-base-polish-uncased-v1
|
dkleczek
| 2021-05-19T15:55:32Z | 4,980 | 11 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"fill-mask",
"pl",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:05Z |
---
language: pl
thumbnail: https://raw.githubusercontent.com/kldarek/polbert/master/img/polbert.png
---
# Polbert - Polish BERT
Polish version of BERT language model is here! It is now available in two variants: cased and uncased, both can be downloaded and used via HuggingFace transformers library. I recommend using the cased model, more info on the differences and benchmark results below.

## Cased and uncased variants
* I initially trained the uncased model, the corpus and training details are referenced below. Here are some issues I found after I published the uncased model:
* Some Polish characters and accents are not tokenized correctly through the BERT tokenizer when applying lowercase. This doesn't impact sequence classification much, but may influence token classfication tasks significantly.
* I noticed a lot of duplicates in the Open Subtitles dataset, which dominates the training corpus.
* I didn't use Whole Word Masking.
* The cased model improves on the uncased model in the following ways:
* All Polish characters and accents should now be tokenized correctly.
* I removed duplicates from Open Subtitles dataset. The corpus is smaller, but more balanced now.
* The model is trained with Whole Word Masking.
## Pre-training corpora
Below is the list of corpora used along with the output of `wc` command (counting lines, words and characters). These corpora were divided into sentences with srxsegmenter (see references), concatenated and tokenized with HuggingFace BERT Tokenizer.
### Uncased
| Tables | Lines | Words | Characters |
| ------------- |--------------:| -----:| -----:|
| [Polish subset of Open Subtitles](http://opus.nlpl.eu/OpenSubtitles-v2018.php) | 236635408| 1431199601 | 7628097730 |
| [Polish subset of ParaCrawl](http://opus.nlpl.eu/ParaCrawl.php) | 8470950 | 176670885 | 1163505275 |
| [Polish Parliamentary Corpus](http://clip.ipipan.waw.pl/PPC) | 9799859 | 121154785 | 938896963 |
| [Polish Wikipedia - Feb 2020](https://dumps.wikimedia.org/plwiki/latest/plwiki-latest-pages-articles.xml.bz2) | 8014206 | 132067986 | 1015849191 |
| Total | 262920423 | 1861093257 | 10746349159 |
### Cased
| Tables | Lines | Words | Characters |
| ------------- |--------------:| -----:| -----:|
| [Polish subset of Open Subtitles (Deduplicated) ](http://opus.nlpl.eu/OpenSubtitles-v2018.php) | 41998942| 213590656 | 1424873235 |
| [Polish subset of ParaCrawl](http://opus.nlpl.eu/ParaCrawl.php) | 8470950 | 176670885 | 1163505275 |
| [Polish Parliamentary Corpus](http://clip.ipipan.waw.pl/PPC) | 9799859 | 121154785 | 938896963 |
| [Polish Wikipedia - Feb 2020](https://dumps.wikimedia.org/plwiki/latest/plwiki-latest-pages-articles.xml.bz2) | 8014206 | 132067986 | 1015849191 |
| Total | 68283960 | 646479197 | 4543124667 |
## Pre-training details
### Uncased
* Polbert was trained with code provided in Google BERT's github repository (https://github.com/google-research/bert)
* Currently released model follows bert-base-uncased model architecture (12-layer, 768-hidden, 12-heads, 110M parameters)
* Training set-up: in total 1 million training steps:
* 100.000 steps - 128 sequence length, batch size 512, learning rate 1e-4 (10.000 steps warmup)
* 800.000 steps - 128 sequence length, batch size 512, learning rate 5e-5
* 100.000 steps - 512 sequence length, batch size 256, learning rate 2e-5
* The model was trained on a single Google Cloud TPU v3-8
### Cased
* Same approach as uncased model, with the following differences:
* Whole Word Masking
* Training set-up:
* 100.000 steps - 128 sequence length, batch size 2048, learning rate 1e-4 (10.000 steps warmup)
* 100.000 steps - 128 sequence length, batch size 2048, learning rate 5e-5
* 100.000 steps - 512 sequence length, batch size 256, learning rate 2e-5
## Usage
Polbert is released via [HuggingFace Transformers library](https://huggingface.co/transformers/).
For an example use as language model, see [this notebook](/LM_testing.ipynb) file.
### Uncased
```python
from transformers import *
model = BertForMaskedLM.from_pretrained("dkleczek/bert-base-polish-uncased-v1")
tokenizer = BertTokenizer.from_pretrained("dkleczek/bert-base-polish-uncased-v1")
nlp = pipeline('fill-mask', model=model, tokenizer=tokenizer)
for pred in nlp(f"Adam Mickiewicz wielkim polskim {nlp.tokenizer.mask_token} był."):
print(pred)
# Output:
# {'sequence': '[CLS] adam mickiewicz wielkim polskim poeta był. [SEP]', 'score': 0.47196975350379944, 'token': 26596}
# {'sequence': '[CLS] adam mickiewicz wielkim polskim bohaterem był. [SEP]', 'score': 0.09127858281135559, 'token': 10953}
# {'sequence': '[CLS] adam mickiewicz wielkim polskim człowiekiem był. [SEP]', 'score': 0.0647173821926117, 'token': 5182}
# {'sequence': '[CLS] adam mickiewicz wielkim polskim pisarzem był. [SEP]', 'score': 0.05232388526201248, 'token': 24293}
# {'sequence': '[CLS] adam mickiewicz wielkim polskim politykiem był. [SEP]', 'score': 0.04554257541894913, 'token': 44095}
```
### Cased
```python
model = BertForMaskedLM.from_pretrained("dkleczek/bert-base-polish-cased-v1")
tokenizer = BertTokenizer.from_pretrained("dkleczek/bert-base-polish-cased-v1")
nlp = pipeline('fill-mask', model=model, tokenizer=tokenizer)
for pred in nlp(f"Adam Mickiewicz wielkim polskim {nlp.tokenizer.mask_token} był."):
print(pred)
# Output:
# {'sequence': '[CLS] Adam Mickiewicz wielkim polskim pisarzem był. [SEP]', 'score': 0.5391148328781128, 'token': 37120}
# {'sequence': '[CLS] Adam Mickiewicz wielkim polskim człowiekiem był. [SEP]', 'score': 0.11683262139558792, 'token': 6810}
# {'sequence': '[CLS] Adam Mickiewicz wielkim polskim bohaterem był. [SEP]', 'score': 0.06021466106176376, 'token': 17709}
# {'sequence': '[CLS] Adam Mickiewicz wielkim polskim mistrzem był. [SEP]', 'score': 0.051870670169591904, 'token': 14652}
# {'sequence': '[CLS] Adam Mickiewicz wielkim polskim artystą był. [SEP]', 'score': 0.031787533313035965, 'token': 35680}
```
See the next section for an example usage of Polbert in downstream tasks.
## Evaluation
Thanks to Allegro, we now have the [KLEJ benchmark](https://klejbenchmark.com/leaderboard/), a set of nine evaluation tasks for the Polish language understanding. The following results are achieved by running standard set of evaluation scripts (no tricks!) utilizing both cased and uncased variants of Polbert.
| Model | Average | NKJP-NER | CDSC-E | CDSC-R | CBD | PolEmo2.0-IN | PolEmo2.0-OUT | DYK | PSC | AR |
| ------------- |--------------:|--------------:|--------------:|--------------:|--------------:|--------------:|--------------:|--------------:|--------------:|--------------:|
| Polbert cased | 81.7 | 93.6 | 93.4 | 93.8 | 52.7 | 87.4 | 71.1 | 59.1 | 98.6 | 85.2 |
| Polbert uncased | 81.4 | 90.1 | 93.9 | 93.5 | 55.0 | 88.1 | 68.8 | 59.4 | 98.8 | 85.4 |
Note how the uncased model performs better than cased on some tasks? My guess this is because of the oversampling of Open Subtitles dataset and its similarity to data in some of these tasks. All these benchmark tasks are sequence classification, so the relative strength of the cased model is not so visible here.
## Bias
The data used to train the model is biased. It may reflect stereotypes related to gender, ethnicity etc. Please be careful when using the model for downstream task to consider these biases and mitigate them.
## Acknowledgements
* I'd like to express my gratitude to Google [TensorFlow Research Cloud (TFRC)](https://www.tensorflow.org/tfrc) for providing the free TPU credits - thank you!
* Also appreciate the help from Timo Möller from [deepset](https://deepset.ai) for sharing tips and scripts based on their experience training German BERT model.
* Big thanks to Allegro for releasing KLEJ Benchmark and specifically to Piotr Rybak for help with the evaluation and pointing out some issues with the tokenization.
* Finally, thanks to Rachel Thomas, Jeremy Howard and Sylvain Gugger from [fastai](https://www.fast.ai) for their NLP and Deep Learning courses!
## Author
Darek Kłeczek - contact me on Twitter [@dk21](https://twitter.com/dk21)
## References
* https://github.com/google-research/bert
* https://github.com/narusemotoki/srx_segmenter
* SRX rules file for sentence splitting in Polish, written by Marcin Miłkowski: https://raw.githubusercontent.com/languagetool-org/languagetool/master/languagetool-core/src/main/resources/org/languagetool/resource/segment.srx
* [KLEJ benchmark](https://klejbenchmark.com/leaderboard/)
|
deepset/sentence_bert
|
deepset
| 2021-05-19T15:34:03Z | 10,668 | 20 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2022-03-02T23:29:05Z |
---
license: apache-2.0
---
This is an upload of the bert-base-nli-stsb-mean-tokens pretrained model from the Sentence Transformers Repo (https://github.com/UKPLab/sentence-transformers)
|
castorini/monobert-large-msmarco-finetune-only
|
castorini
| 2021-05-19T14:00:06Z | 67 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"text-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
# Model Description
This checkpoint is a direct conversion of [BERT_Large_trained_on_MSMARCO.zip](https://drive.google.com/open?id=1crlASTMlsihALlkabAQP6JTYIZwC1Wm8) from the original [repo](https://github.com/nyu-dl/dl4marco-bert/).
The corresponding model class is BertForSequenceClassification, and its purpose is for MS MARCO passage ranking.
Please find the original repo for more detail of its training settings regarding hyperparameter/device/data.
|
cahya/bert-base-indonesian-522M
|
cahya
| 2021-05-19T13:38:45Z | 3,317 | 25 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"jax",
"bert",
"fill-mask",
"id",
"dataset:wikipedia",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:05Z |
---
language: "id"
license: "mit"
datasets:
- wikipedia
widget:
- text: "Ibu ku sedang bekerja [MASK] sawah."
---
# Indonesian BERT base model (uncased)
## Model description
It is BERT-base model pre-trained with indonesian Wikipedia using a masked language modeling (MLM) objective. This
model is uncased: it does not make a difference between indonesia and Indonesia.
This is one of several other language models that have been pre-trained with indonesian datasets. More detail about
its usage on downstream tasks (text classification, text generation, etc) is available at [Transformer based Indonesian Language Models](https://github.com/cahya-wirawan/indonesian-language-models/tree/master/Transformers)
## Intended uses & limitations
### How to use
You can use this model directly with a pipeline for masked language modeling:
```python
>>> from transformers import pipeline
>>> unmasker = pipeline('fill-mask', model='cahya/bert-base-indonesian-522M')
>>> unmasker("Ibu ku sedang bekerja [MASK] supermarket")
[{'sequence': '[CLS] ibu ku sedang bekerja di supermarket [SEP]',
'score': 0.7983310222625732,
'token': 1495},
{'sequence': '[CLS] ibu ku sedang bekerja. supermarket [SEP]',
'score': 0.090003103017807,
'token': 17},
{'sequence': '[CLS] ibu ku sedang bekerja sebagai supermarket [SEP]',
'score': 0.025469014421105385,
'token': 1600},
{'sequence': '[CLS] ibu ku sedang bekerja dengan supermarket [SEP]',
'score': 0.017966199666261673,
'token': 1555},
{'sequence': '[CLS] ibu ku sedang bekerja untuk supermarket [SEP]',
'score': 0.016971781849861145,
'token': 1572}]
```
Here is how to use this model to get the features of a given text in PyTorch:
```python
from transformers import BertTokenizer, BertModel
model_name='cahya/bert-base-indonesian-522M'
tokenizer = BertTokenizer.from_pretrained(model_name)
model = BertModel.from_pretrained(model_name)
text = "Silakan diganti dengan text apa saja."
encoded_input = tokenizer(text, return_tensors='pt')
output = model(**encoded_input)
```
and in Tensorflow:
```python
from transformers import BertTokenizer, TFBertModel
model_name='cahya/bert-base-indonesian-522M'
tokenizer = BertTokenizer.from_pretrained(model_name)
model = TFBertModel.from_pretrained(model_name)
text = "Silakan diganti dengan text apa saja."
encoded_input = tokenizer(text, return_tensors='tf')
output = model(encoded_input)
```
## Training data
This model was pre-trained with 522MB of indonesian Wikipedia.
The texts are lowercased and tokenized using WordPiece and a vocabulary size of 32,000. The inputs of the model are
then of the form:
```[CLS] Sentence A [SEP] Sentence B [SEP]```
|
cahya/bert-base-indonesian-1.5G
|
cahya
| 2021-05-19T13:37:31Z | 118,224 | 5 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"jax",
"bert",
"fill-mask",
"id",
"dataset:wikipedia",
"dataset:id_newspapers_2018",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:05Z |
---
language: "id"
license: "mit"
datasets:
- wikipedia
- id_newspapers_2018
widget:
- text: "Ibu ku sedang bekerja [MASK] sawah."
---
# Indonesian BERT base model (uncased)
## Model description
It is BERT-base model pre-trained with indonesian Wikipedia and indonesian newspapers using a masked language modeling (MLM) objective. This
model is uncased.
This is one of several other language models that have been pre-trained with indonesian datasets. More detail about
its usage on downstream tasks (text classification, text generation, etc) is available at [Transformer based Indonesian Language Models](https://github.com/cahya-wirawan/indonesian-language-models/tree/master/Transformers)
## Intended uses & limitations
### How to use
You can use this model directly with a pipeline for masked language modeling:
```python
>>> from transformers import pipeline
>>> unmasker = pipeline('fill-mask', model='cahya/bert-base-indonesian-1.5G')
>>> unmasker("Ibu ku sedang bekerja [MASK] supermarket")
[{'sequence': '[CLS] ibu ku sedang bekerja di supermarket [SEP]',
'score': 0.7983310222625732,
'token': 1495},
{'sequence': '[CLS] ibu ku sedang bekerja. supermarket [SEP]',
'score': 0.090003103017807,
'token': 17},
{'sequence': '[CLS] ibu ku sedang bekerja sebagai supermarket [SEP]',
'score': 0.025469014421105385,
'token': 1600},
{'sequence': '[CLS] ibu ku sedang bekerja dengan supermarket [SEP]',
'score': 0.017966199666261673,
'token': 1555},
{'sequence': '[CLS] ibu ku sedang bekerja untuk supermarket [SEP]',
'score': 0.016971781849861145,
'token': 1572}]
```
Here is how to use this model to get the features of a given text in PyTorch:
```python
from transformers import BertTokenizer, BertModel
model_name='cahya/bert-base-indonesian-1.5G'
tokenizer = BertTokenizer.from_pretrained(model_name)
model = BertModel.from_pretrained(model_name)
text = "Silakan diganti dengan text apa saja."
encoded_input = tokenizer(text, return_tensors='pt')
output = model(**encoded_input)
```
and in Tensorflow:
```python
from transformers import BertTokenizer, TFBertModel
model_name='cahya/bert-base-indonesian-1.5G'
tokenizer = BertTokenizer.from_pretrained(model_name)
model = TFBertModel.from_pretrained(model_name)
text = "Silakan diganti dengan text apa saja."
encoded_input = tokenizer(text, return_tensors='tf')
output = model(encoded_input)
```
## Training data
This model was pre-trained with 522MB of indonesian Wikipedia and 1GB of
[indonesian newspapers](https://huggingface.co/datasets/id_newspapers_2018).
The texts are lowercased and tokenized using WordPiece and a vocabulary size of 32,000. The inputs of the model are
then of the form:
```[CLS] Sentence A [SEP] Sentence B [SEP]```
|
ayansinha/lic-class-scancode-bert-base-cased-L32-1
|
ayansinha
| 2021-05-19T12:04:46Z | 9 | 0 |
transformers
|
[
"transformers",
"tf",
"bert",
"fill-mask",
"license",
"sentence-classification",
"scancode",
"license-compliance",
"en",
"dataset:bookcorpus",
"dataset:wikipedia",
"dataset:scancode-rules",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:05Z |
---
language: en
tags:
- license
- sentence-classification
- scancode
- license-compliance
license: apache-2.0
datasets:
- bookcorpus
- wikipedia
- scancode-rules
version: 1.0
---
# `lic-class-scancode-bert-base-cased-L32-1`
## Intended Use
This model is intended to be used for Sentence Classification which is used for results
analysis in [`scancode-results-analyzer`](https://github.com/nexB/scancode-results-analyzer).
`scancode-results-analyzer` helps detect faulty scans in [`scancode-toolkit`](https://github.com/nexB/scancode-results-analyzer) by using statistics and nlp modeling, among other tools,
to make Scancode better.
## How to Use
Refer [quickstart](https://github.com/nexB/scancode-results-analyzer#quickstart---local-machine) section in `scancode-results-analyzer` documentation, for installing and getting started.
- [Link to Code](https://github.com/nexB/scancode-results-analyzer/blob/master/src/results_analyze/nlp_models.py)
Then in `NLPModelsPredict` class, function `predict_basic_lic_class` uses this classifier to
predict sentances as either valid license tags or false positives.
## Limitations and Bias
As this model is a fine-tuned version of the [`bert-base-cased`](https://huggingface.co/bert-base-cased) model,
it has the same biases, but as the task it is fine-tuned to is a very specific task
(license text/notice/tag/referance) without those intended biases, it's safe to assume
those don't apply at all here.
## Training and Fine-Tuning Data
The BERT model was pretrained on BookCorpus, a dataset consisting of 11,038 unpublished books and English Wikipedia (excluding lists, tables and headers).
Then this `bert-base-cased` model was fine-tuned on Scancode Rule texts, specifically
trained in the context of sentence classification, where the four classes are
- License Text
- License Notice
- License Tag
- License Referance
## Training Procedure
For fine-tuning procedure and training, refer `scancode-results-analyzer` code.
- [Link to Code](https://github.com/nexB/scancode-results-analyzer/blob/master/src/results_analyze/nlp_models.py)
In `NLPModelsTrain` class, function `prepare_input_data_false_positive` prepares the
training data.
In `NLPModelsTrain` class, function `train_basic_false_positive_classifier` fine-tunes
this classifier.
1. Model - [BertBaseCased](https://huggingface.co/bert-base-cased) (Weights 0.5 GB)
2. Sentence Length - 32
3. Labels - 4 (License Text/Notice/Tag/Referance)
4. After 4 Epochs of Fine-Tuning with learning rate 2e-5 (60 secs each on an RTX 2060)
Note: The classes aren't balanced.
## Eval Results
- Accuracy on the training data (90%) : 0.98 (+- 0.01)
- Accuracy on the validation data (10%) : 0.84 (+- 0.01)
## Further Work
1. Apllying Splitting/Aggregation Strategies
2. Data Augmentation according to Vaalidation Errors
3. Bigger/Better Suited Models
|
allenyummy/chinese-bert-wwm-ehr-ner-sl
|
allenyummy
| 2021-05-19T11:42:42Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"endpoints_compatible",
"region:us"
] | null | 2022-03-02T23:29:05Z |
---
language: zh-tw
---
# Model name
Chinese-bert-wwm-electrical-health-records-ner-sequence-labeling
#### How to use
```
from transformers import AutoTokenizer, AutoModelForTokenClassification
tokenizer = AutoTokenizer.from_pretrained("allenyummy/chinese-bert-wwm-ehr-ner-sl")
model = AutoModelForTokenClassification.from_pretrained("allenyummy/chinese-bert-wwm-ehr-ner-sl")
```
|
Khu1998/clog-assessment-model
|
Khu1998
| 2021-05-19T11:18:26Z | 5 | 0 |
transformers
|
[
"transformers",
"tf",
"bert",
"text-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:04Z |
# CLOG Assessment generator model
|
DJSammy/bert-base-danish-uncased_BotXO-ai
|
DJSammy
| 2021-05-19T11:13:30Z | 35 | 1 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"masked-lm",
"fill-mask",
"da",
"dataset:common_crawl",
"dataset:wikipedia",
"license:cc-by-4.0",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:04Z |
---
language: da
tags:
- bert
- masked-lm
license: cc-by-4.0
datasets:
- common_crawl
- wikipedia
pipeline_tag: fill-mask
widget:
- text: "København er [MASK] i Danmark."
---
# Danish BERT (uncased) model
[BotXO.ai](https://www.botxo.ai/) developed this model. For data and training details see their [GitHub repository](https://github.com/botxo/nordic_bert).
The original model was trained in TensorFlow then I converted it to Pytorch using [transformers-cli](https://huggingface.co/transformers/converting_tensorflow_models.html?highlight=cli).
For TensorFlow version download here: https://www.dropbox.com/s/19cjaoqvv2jicq9/danish_bert_uncased_v2.zip?dl=1
## Architecture
```python
from transformers import AutoModelForPreTraining
model = AutoModelForPreTraining.from_pretrained("DJSammy/bert-base-danish-uncased_BotXO,ai")
params = list(model.named_parameters())
print('danish_bert_uncased_v2 has {:} different named parameters.\n'.format(len(params)))
print('==== Embedding Layer ====\n')
for p in params[0:5]:
print("{:<55} {:>12}".format(p[0], str(tuple(p[1].size()))))
print('\n==== First Transformer ====\n')
for p in params[5:21]:
print("{:<55} {:>12}".format(p[0], str(tuple(p[1].size()))))
print('\n==== Last Transformer ====\n')
for p in params[181:197]:
print("{:<55} {:>12}".format(p[0], str(tuple(p[1].size()))))
print('\n==== Output Layer ====\n')
for p in params[197:]:
print("{:<55} {:>12}".format(p[0], str(tuple(p[1].size()))))
# danish_bert_uncased_v2 has 206 different named parameters.
# ==== Embedding Layer ====
# bert.embeddings.word_embeddings.weight (32000, 768)
# bert.embeddings.position_embeddings.weight (512, 768)
# bert.embeddings.token_type_embeddings.weight (2, 768)
# bert.embeddings.LayerNorm.weight (768,)
# bert.embeddings.LayerNorm.bias (768,)
# ==== First Transformer ====
# bert.encoder.layer.0.attention.self.query.weight (768, 768)
# bert.encoder.layer.0.attention.self.query.bias (768,)
# bert.encoder.layer.0.attention.self.key.weight (768, 768)
# bert.encoder.layer.0.attention.self.key.bias (768,)
# bert.encoder.layer.0.attention.self.value.weight (768, 768)
# bert.encoder.layer.0.attention.self.value.bias (768,)
# bert.encoder.layer.0.attention.output.dense.weight (768, 768)
# bert.encoder.layer.0.attention.output.dense.bias (768,)
# bert.encoder.layer.0.attention.output.LayerNorm.weight (768,)
# bert.encoder.layer.0.attention.output.LayerNorm.bias (768,)
# bert.encoder.layer.0.intermediate.dense.weight (3072, 768)
# bert.encoder.layer.0.intermediate.dense.bias (3072,)
# bert.encoder.layer.0.output.dense.weight (768, 3072)
# bert.encoder.layer.0.output.dense.bias (768,)
# bert.encoder.layer.0.output.LayerNorm.weight (768,)
# bert.encoder.layer.0.output.LayerNorm.bias (768,)
# ==== Last Transformer ====
# bert.encoder.layer.11.attention.self.query.weight (768, 768)
# bert.encoder.layer.11.attention.self.query.bias (768,)
# bert.encoder.layer.11.attention.self.key.weight (768, 768)
# bert.encoder.layer.11.attention.self.key.bias (768,)
# bert.encoder.layer.11.attention.self.value.weight (768, 768)
# bert.encoder.layer.11.attention.self.value.bias (768,)
# bert.encoder.layer.11.attention.output.dense.weight (768, 768)
# bert.encoder.layer.11.attention.output.dense.bias (768,)
# bert.encoder.layer.11.attention.output.LayerNorm.weight (768,)
# bert.encoder.layer.11.attention.output.LayerNorm.bias (768,)
# bert.encoder.layer.11.intermediate.dense.weight (3072, 768)
# bert.encoder.layer.11.intermediate.dense.bias (3072,)
# bert.encoder.layer.11.output.dense.weight (768, 3072)
# bert.encoder.layer.11.output.dense.bias (768,)
# bert.encoder.layer.11.output.LayerNorm.weight (768,)
# bert.encoder.layer.11.output.LayerNorm.bias (768,)
# ==== Output Layer ====
# bert.pooler.dense.weight (768, 768)
# bert.pooler.dense.bias (768,)
# cls.predictions.bias (32000,)
# cls.predictions.transform.dense.weight (768, 768)
# cls.predictions.transform.dense.bias (768,)
# cls.predictions.transform.LayerNorm.weight (768,)
# cls.predictions.transform.LayerNorm.bias (768,)
# cls.seq_relationship.weight (2, 768)
# cls.seq_relationship.bias (2,)
```
## Example Pipeline
```python
from transformers import pipeline
unmasker = pipeline('fill-mask', model='DJSammy/bert-base-danish-uncased_BotXO,ai')
unmasker('København er [MASK] i Danmark.')
# Copenhagen is the [MASK] of Denmark.
# =>
# [{'score': 0.788068950176239,
# 'sequence': '[CLS] københavn er hovedstad i danmark. [SEP]',
# 'token': 12610,
# 'token_str': 'hovedstad'},
# {'score': 0.07606703042984009,
# 'sequence': '[CLS] københavn er hovedstaden i danmark. [SEP]',
# 'token': 8108,
# 'token_str': 'hovedstaden'},
# {'score': 0.04299738258123398,
# 'sequence': '[CLS] københavn er metropol i danmark. [SEP]',
# 'token': 23305,
# 'token_str': 'metropol'},
# {'score': 0.008163209073245525,
# 'sequence': '[CLS] københavn er ikke i danmark. [SEP]',
# 'token': 89,
# 'token_str': 'ikke'},
# {'score': 0.006238455418497324,
# 'sequence': '[CLS] københavn er ogsa i danmark. [SEP]',
# 'token': 25253,
# 'token_str': 'ogsa'}]
```
|
patrickvonplaten/norwegian-roberta-base
|
patrickvonplaten
| 2021-05-19T10:12:21Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"roberta",
"fill-mask",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:05Z |
## Roberta-Base
This repo trains [roberta-base](https://huggingface.co/roberta-base) from scratch on the [Norwegian training subset of Oscar](https://oscar-corpus.com/) containing roughly 4.7 GB of data according to [this](https://github.com/huggingface/transformers/tree/master/examples/flax/language-modeling) example.
Training is done on a TPUv3-8 in Flax. More statistics on the training run can be found under [tf.hub](https://tensorboard.dev/experiment/GdYmdak2TWeVz0DDRYOrrg).
|
sampathkethineedi/industry-classification-api
|
sampathkethineedi
| 2021-05-19T01:29:31Z | 7 | 16 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"text-classification",
"industry tags",
"buisiness description",
"multi-label",
"classification",
"inference",
"en",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
---
language: "en"
thumbnail: "https://huggingface.co/sampathkethineedi"
widget:
- text: "3rd Rock Multimedia Limited is an India-based event management company. The Company conducts film promotions, international events, corporate events and cultural events. The Company's entertainment properties include 3rd Rock Fashion Fiesta and 3rd Rock Calendar. The Company's association with various events in Mumbai includes Bryan Adam's Live in Concert, Michael Learns to Rock (MLTR) Eternity Concert, 3rd Rock's Calendar Launch 2011-2012, Airtel I Phone 4 Launch and ISPL Cricket Tournament 2012."
- text: "Stellar Capital Services Limited is an India-based non-banking financial company. The Company is mainly engaged in the business of providing loans and advances and investing in shares, both quoted and unquoted. The Company's segments are trading in share and securities, and advancing of loans. The trading in share and securities segment includes trading in quoted equity shares, mutual funds, bonds, futures and options, and currency. The Company's financial services include inter corporate deposits, financial consultancy, retail initial public offering (IPO) funding, loan against property, management consultancy, personal loans and unsecured loans."
- text: "Chemcrux Enterprises Ltd is a manufacturer of intermediates for bulk drugs, and dyes and pigments. The Company's products include 2 Chloro Benzoic Acid; 3 Chloro Benzoic Acid; 4 Chloro Benzoic Acid; 4 Nitro Benzoic Acid; 2,4 Dichloro Benzoic Acid; 4 Chloro 3 Nitro Benzoic Acid; 2 Chloro 5 Nitro Benzoic Acid; Meta Nitro Benzoic Acid; Lassamide, and Meta Chloro Per Benzoic Acid. The Company also offers various products on custom requirements, including Aceturic Acid; Meta Chloro Benzoyl Chloride; 3-Nitro-4-Methoxy Benzoic Acid; 2 Amino 5 Sulfonamide Benzoic Acid; 3,4 Dichloro Benzoic Acid; 5-Nitro Salycylic Acid, and 4-Chloro Benzoic Acid -3-Sulfonamide. The Company's plant has a capacity of 120 metric tons per month. The Company exports to Europe, Japan, the Middle East and East Africa. It is engaged in development and execution of various processes, such as High Pressure Oxidation, Nitration and Chloro Sulfonation."
tags:
- bert
- pytorch
- text-classification
- industry tags
- buisiness description
- multi-label
- classification
- inference
liscence: "mit"
---
# industry-classification-api
## Model description
BERT Model to classify a business description into one of **62 industry tags**.
Trained on 7000 samples of Business Descriptions and associated labels of companies in India.
## How to use
PyTorch only
```python
from transformers import AutoTokenizer, AutoModelForSequenceClassification, pipeline
tokenizer = AutoTokenizer.from_pretrained("sampathkethineedi/industry-classification")
model = AutoModelForSequenceClassification.from_pretrained("industry-classification")
industry_tags = pipeline('sentiment-analysis', model=model, tokenizer=tokenizer)
industry_tags("Stellar Capital Services Limited is an India-based non-banking financial company ... loan against property, management consultancy, personal loans and unsecured loans.")
'''Ouput'''
[{'label': 'Consumer Finance', 'score': 0.9841355681419373}]
```
## Limitations and bias
Training data is only for Indian companies
|
aodiniz/bert_uncased_L-2_H-512_A-8_cord19-200616
|
aodiniz
| 2021-05-18T23:48:58Z | 8 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"fill-mask",
"arxiv:1908.08962",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:05Z |
# BERT L-2 H-512 fine-tuned on MLM (CORD-19 2020/06/16)
BERT model with [2 Transformer layers and hidden embedding of size 512](https://huggingface.co/google/bert_uncased_L-2_H-512_A-8), referenced in [Well-Read Students Learn Better: On the Importance of Pre-training Compact Models](https://arxiv.org/abs/1908.08962), fine-tuned for MLM on CORD-19 dataset (as released on 2020/06/16).
## Training the model
```bash
python run_language_modeling.py
--model_type bert
--model_name_or_path google/bert_uncased_L-2_H-512_A-8
--do_train
--train_data_file {cord19-200616-dataset}
--mlm
--mlm_probability 0.2
--line_by_line
--block_size 512
--per_device_train_batch_size 20
--learning_rate 3e-5
--num_train_epochs 2
--output_dir bert_uncased_L-2_H-512_A-8_cord19-200616
|
agiagoulas/bert-pss
|
agiagoulas
| 2021-05-18T23:16:17Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"text-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
bert-base-uncased model trained on the tobacco800 dataset for the task of page-stream-segmentation.
[Link](https://github.com/agiagoulas/page-stream-segmentation) to the GitHub Repo with the model implementation.
|
abhishek/autonlp-japanese-sentiment-59362
|
abhishek
| 2021-05-18T22:55:03Z | 12 | 2 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"text-classification",
"autonlp",
"ja",
"dataset:abhishek/autonlp-data-japanese-sentiment",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
---
tags: autonlp
language: ja
widget:
- text: "I love AutoNLP 🤗"
datasets:
- abhishek/autonlp-data-japanese-sentiment
---
# Model Trained Using AutoNLP
- Problem type: Binary Classification
- Model ID: 59362
## Validation Metrics
- Loss: 0.13092292845249176
- Accuracy: 0.9527127414314258
- Precision: 0.9634070704982427
- Recall: 0.9842171959602166
- AUC: 0.9667289746092403
- F1: 0.9737009564152002
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoNLP"}' https://api-inference.huggingface.co/models/abhishek/autonlp-japanese-sentiment-59362
```
Or Python API:
```
from transformers import AutoModelForSequenceClassification, AutoTokenizer
model = AutoModelForSequenceClassification.from_pretrained("abhishek/autonlp-japanese-sentiment-59362", use_auth_token=True)
tokenizer = AutoTokenizer.from_pretrained("abhishek/autonlp-japanese-sentiment-59362", use_auth_token=True)
inputs = tokenizer("I love AutoNLP", return_tensors="pt")
outputs = model(**inputs)
```
|
abhishek/autonlp-imdb_eval-71421
|
abhishek
| 2021-05-18T22:54:10Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"text-classification",
"autonlp",
"en",
"dataset:abhishek/autonlp-data-imdb_eval",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
---
tags: autonlp
language: en
widget:
- text: "I love AutoNLP 🤗"
datasets:
- abhishek/autonlp-data-imdb_eval
---
# Model Trained Using AutoNLP
- Problem type: Binary Classification
- Model ID: 71421
## Validation Metrics
- Loss: 0.4114699363708496
- Accuracy: 0.8248248248248248
- Precision: 0.8305439330543933
- Recall: 0.8085539714867617
- AUC: 0.9088033420466026
- F1: 0.8194014447884417
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoNLP"}' https://api-inference.huggingface.co/models/abhishek/autonlp-imdb_eval-71421
```
Or Python API:
```
from transformers import AutoModelForSequenceClassification, AutoTokenizer
model = AutoModelForSequenceClassification.from_pretrained("abhishek/autonlp-imdb_eval-71421", use_auth_token=True)
tokenizer = AutoTokenizer.from_pretrained("abhishek/autonlp-imdb_eval-71421", use_auth_token=True)
inputs = tokenizer("I love AutoNLP", return_tensors="pt")
outputs = model(**inputs)
```
|
apanc/russian-inappropriate-messages
|
apanc
| 2021-05-18T22:39:46Z | 3,244 | 20 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"jax",
"bert",
"text-classification",
"toxic comments classification",
"ru",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
---
language:
- ru
tags:
- toxic comments classification
licenses:
- cc-by-nc-sa
---
## General concept of the model
#### Proposed usage
The **'inappropriateness'** substance we tried to collect in the dataset and detect with the model **is NOT a substitution of toxicity**, it is rather a derivative of toxicity. So the model based on our dataset could serve as **an additional layer of inappropriateness filtering after toxicity and obscenity filtration**. You can detect the exact sensitive topic by using [another model](https://huggingface.co/Skoltech/russian-sensitive-topics). The proposed pipeline is shown in the scheme below.
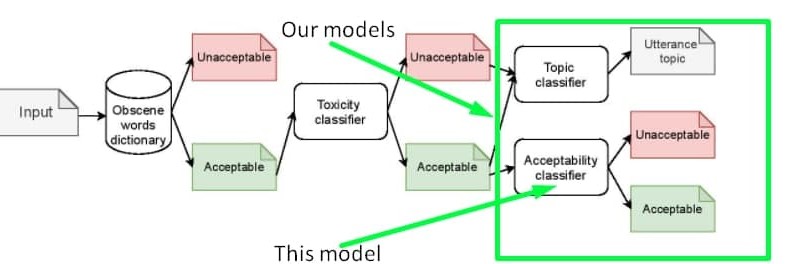
You can also train one classifier for both toxicity and inappropriateness detection. The data to be mixed with toxic labelled samples could be found on our [GitHub](https://github.com/skoltech-nlp/inappropriate-sensitive-topics/blob/main/Version2/appropriateness/Appropriateness.csv) or on [kaggle](https://www.kaggle.com/nigula/russianinappropriatemessages)
#### Inappropraiteness intuition
This model is trained on the dataset of inappropriate messages of the Russian language. Generally, an inappropriate utterance is an utterance that has not obscene words or any kind of toxic intent, but can still harm the reputation of the speaker. Find some sample for more intuition in the table below. Learn more about the concept of inappropriateness [in this article ](https://www.aclweb.org/anthology/2021.bsnlp-1.4/) presented at the workshop for Balto-Slavic NLP at the EACL-2021 conference. Please note that this article describes the first version of the dataset, while the model is trained on the extended version of the dataset open-sourced on our [GitHub](https://github.com/skoltech-nlp/inappropriate-sensitive-topics/blob/main/Version2/appropriateness/Appropriateness.csv) or on [kaggle](https://www.kaggle.com/nigula/russianinappropriatemessages). The properties of the dataset are the same as the one described in the article, the only difference is the size.
| Text | Inappropriate | Comment | Unsafe topic |
|------------------------------------------------------------------------------------------------------|---------------|----------------------------------------------------------------|---------------|
| Ладно бы видного деятеля завалили а тут какого то ноунейм нигру преступника | yes | Оправдание убийства | offline crime |
| Это нарушение УКРФ! | no | Осуждение нарушения закона | offline crime |
| Религия - это насилие высшего уровня. Верующего принуждают к вере еще в младенчестве. | yes | Оскорбление чувств верующих | religion |
| Христиане, как вы относитесь к иноверцам, в частности к Гамалиилу и к уверовавшим в Иисуса фарисеям? | no | Обычные вопросы к верующим без намека на оскорбление их чувств | religion |
| Хорошо что проституция запрещена | no | Осуждение простуитуции | prostitution |
| Возьму бабки и сниму шлюх на выходных | yes | Популяризация проституции | prostitution |
#### Metrics
The model was trained, validated, and tested only on the samples with 100% confidence, which allowed to get the following metrics on test set:
| | precision | recall | f1-score | support |
|--------------|----------|--------|----------|---------|
| 0 | 0.92 | 0.93 | 0.93 | 7839 |
| 1 | 0.80 | 0.76 | 0.78 | 2726 |
| accuracy | | | 0.89 | 10565 |
| macro avg | 0.86 | 0.85 | 0.85 | 10565 |
| weighted avg | 0.89 | 0.89 | 0.89 | 10565 |
## Licensing Information
[Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License][cc-by-nc-sa].
[![CC BY-NC-SA 4.0][cc-by-nc-sa-image]][cc-by-nc-sa]
[cc-by-nc-sa]: http://creativecommons.org/licenses/by-nc-sa/4.0/
[cc-by-nc-sa-image]: https://i.creativecommons.org/l/by-nc-sa/4.0/88x31.png
## Citation
If you find this repository helpful, feel free to cite our publication:
```
@inproceedings{babakov-etal-2021-detecting,
title = "Detecting Inappropriate Messages on Sensitive Topics that Could Harm a Company{'}s Reputation",
author = "Babakov, Nikolay and
Logacheva, Varvara and
Kozlova, Olga and
Semenov, Nikita and
Panchenko, Alexander",
booktitle = "Proceedings of the 8th Workshop on Balto-Slavic Natural Language Processing",
month = apr,
year = "2021",
address = "Kiyv, Ukraine",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2021.bsnlp-1.4",
pages = "26--36",
abstract = "Not all topics are equally {``}flammable{''} in terms of toxicity: a calm discussion of turtles or fishing less often fuels inappropriate toxic dialogues than a discussion of politics or sexual minorities. We define a set of sensitive topics that can yield inappropriate and toxic messages and describe the methodology of collecting and labelling a dataset for appropriateness. While toxicity in user-generated data is well-studied, we aim at defining a more fine-grained notion of inappropriateness. The core of inappropriateness is that it can harm the reputation of a speaker. This is different from toxicity in two respects: (i) inappropriateness is topic-related, and (ii) inappropriate message is not toxic but still unacceptable. We collect and release two datasets for Russian: a topic-labelled dataset and an appropriateness-labelled dataset. We also release pre-trained classification models trained on this data.",
}
```
## Contacts
If you have any questions please contact [Nikolay](mailto:N.Babakov@skoltech.ru)
|
Sahajtomar/NER_legal_de
|
Sahajtomar
| 2021-05-18T22:27:00Z | 9 | 3 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"jax",
"bert",
"token-classification",
"NER",
"de",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-03-02T23:29:04Z |
---
language: de
tags:
- pytorch
- tf
- bert
- NER
datasets:
- legal entity recognition
---
### NER model trained on BERT
MODEL used for fine tuning is GBERT Large by deepset.ai
## Test
Accuracy: 98 \
F1: 84.1 \
Precision: 82.7 \
Recall: 85.5
## Model inferencing:
```python
!pip install -q transformers
from transformers import pipeline
ner = pipeline(
"ner",
model="Sahajtomar/NER_legal_de",
tokenizer="Sahajtomar/NER_legal_de")
nlp_ner("Für eine Zuständigkeit des Verwaltungsgerichts Berlin nach § 52 Nr. 1 bis 4 VwGO hat der \
Antragsteller keine Anhaltspunkte vorgetragen .")
```
|
Sahajtomar/German_Zeroshot
|
Sahajtomar
| 2021-05-18T22:22:18Z | 1,810 | 25 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"text-classification",
"nli",
"xnli",
"de",
"zero-shot-classification",
"multilingual",
"dataset:xnli",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
zero-shot-classification
| 2022-03-02T23:29:04Z |
---
language: multilingual
tags:
- text-classification
- pytorch
- nli
- xnli
- de
datasets:
- xnli
pipeline_tag: zero-shot-classification
widget:
- text: "Letzte Woche gab es einen Selbstmord in einer nahe gelegenen kolonie"
candidate_labels: "Verbrechen,Tragödie,Stehlen"
hypothesis_template: "In deisem geht es um {}."
---
# German Zeroshot
## Model Description
This model has [GBERT Large](https://huggingface.co/deepset/gbert-large) as base model and fine-tuned it on xnli de dataset.
The default hypothesis template is in English: `This text is {}`. While using this model , change it to "In deisem geht es um {}." or something different. While inferencing through huggingface api may give poor results as it uses by default english template. Since model is monolingual and not multilingual, hypothesis template needs to be changed accordingly.
## XNLI DEV (german)
Accuracy: 85.5
## XNLI TEST (german)
Accuracy: 83.6
#### Zero-shot classification pipeline
```python
from transformers import pipeline
classifier = pipeline("zero-shot-classification",
model="Sahajtomar/German_Zeroshot")
sequence = "Letzte Woche gab es einen Selbstmord in einer nahe gelegenen kolonie"
candidate_labels = ["Verbrechen","Tragödie","Stehlen"]
hypothesis_template = "In deisem geht es um {}." ## Since monolingual model,its sensitive to hypothesis template. This can be experimented
classifier(sequence, candidate_labels, hypothesis_template=hypothesis_template)
"""{'labels': ['Tragödie', 'Verbrechen', 'Stehlen'],
'scores': [0.8328856854438782, 0.10494536352157593, 0.06316883927583696],
'sequence': 'Letzte Woche gab es einen Selbstmord in einer nahe gelegenen Kolonie'}"""
```
|
NeuML/bert-small-cord19qa
|
NeuML
| 2021-05-18T21:53:32Z | 256 | 2 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"question-answering",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-03-02T23:29:04Z |
# BERT-Small fine-tuned on CORD-19 QA dataset
[bert-small-cord19-squad model](https://huggingface.co/NeuML/bert-small-cord19-squad2) fine-tuned on the [CORD-19 QA dataset](https://www.kaggle.com/davidmezzetti/cord19-qa?select=cord19-qa.json).
## CORD-19 QA dataset
The CORD-19 QA dataset is a SQuAD 2.0 formatted list of question, context, answer combinations covering the [CORD-19 dataset](https://www.semanticscholar.org/cord19).
## Building the model
```bash
python run_squad.py \
--model_type bert \
--model_name_or_path bert-small-cord19-squad \
--do_train \
--do_lower_case \
--version_2_with_negative \
--train_file cord19-qa.json \
--per_gpu_train_batch_size 8 \
--learning_rate 5e-5 \
--num_train_epochs 10.0 \
--max_seq_length 384 \
--doc_stride 128 \
--output_dir bert-small-cord19qa \
--save_steps 0 \
--threads 8 \
--overwrite_cache \
--overwrite_output_dir
```
## Testing the model
Example usage below:
```python
from transformers import pipeline
qa = pipeline(
"question-answering",
model="NeuML/bert-small-cord19qa",
tokenizer="NeuML/bert-small-cord19qa"
)
qa({
"question": "What is the median incubation period?",
"context": "The incubation period is around 5 days (range: 4-7 days) with a maximum of 12-13 day"
})
qa({
"question": "What is the incubation period range?",
"context": "The incubation period is around 5 days (range: 4-7 days) with a maximum of 12-13 day"
})
qa({
"question": "What type of surfaces does it persist?",
"context": "The virus can survive on surfaces for up to 72 hours such as plastic and stainless steel ."
})
```
```json
{"score": 0.5970273583242793, "start": 32, "end": 38, "answer": "5 days"}
{"score": 0.999555868193891, "start": 39, "end": 56, "answer": "(range: 4-7 days)"}
{"score": 0.9992726505196998, "start": 61, "end": 88, "answer": "plastic and stainless steel"}
```
|
NeuML/bert-small-cord19
|
NeuML
| 2021-05-18T21:52:56Z | 5 | 1 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"fill-mask",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:04Z |
# BERT-Small fine-tuned on CORD-19 dataset
[BERT L6_H-512_A-8 model](https://huggingface.co/google/bert_uncased_L-6_H-512_A-8) fine-tuned on the [CORD-19 dataset](https://www.semanticscholar.org/cord19).
## CORD-19 data subset
The training data for this dataset is stored as a [Kaggle dataset](https://www.kaggle.com/davidmezzetti/cord19-qa?select=cord19.txt). The training
data is a subset of the full corpus, focusing on high-quality, study-design detected articles.
## Building the model
```bash
python run_language_modeling.py
--model_type bert
--model_name_or_path google/bert_uncased_L-6_H-512_A-8
--do_train
--mlm
--line_by_line
--block_size 512
--train_data_file cord19.txt
--per_gpu_train_batch_size 4
--learning_rate 3e-5
--num_train_epochs 3.0
--output_dir bert-small-cord19
--save_steps 0
--overwrite_output_dir
|
MutazYoune/Ara_DialectBERT
|
MutazYoune
| 2021-05-18T21:44:01Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"fill-mask",
"ar",
"dataset:HARD-Arabic-Dataset",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:04Z |
---
language: ar
datasets:
- HARD-Arabic-Dataset
---
# Ara-dialect-BERT
We used a pretrained model to further train it on [HARD-Arabic-Dataset](https://github.com/elnagara/HARD-Arabic-Dataset), the weights were initialized using [CAMeL-Lab](https://huggingface.co/CAMeL-Lab/bert-base-camelbert-msa-eighth) "bert-base-camelbert-msa-eighth" model
### Usage
The model weights can be loaded using `transformers` library by HuggingFace.
```python
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("MutazYoune/Ara_DialectBERT")
model = AutoModel.from_pretrained("MutazYoune/Ara_DialectBERT")
```
Example using `pipeline`:
```python
from transformers import pipeline
fill_mask = pipeline(
"fill-mask",
model="MutazYoune/Ara_DialectBERT",
tokenizer="MutazYoune/Ara_DialectBERT"
)
fill_mask("الفندق جميل و لكن [MASK] بعيد")
```
```python
{'sequence': 'الفندق جميل و لكن الموقع بعيد', 'score': 0.28233852982521057, 'token': 3221, 'token_str': 'الموقع'}
{'sequence': 'الفندق جميل و لكن موقعه بعيد', 'score': 0.24436227977275848, 'token': 19218, 'token_str': 'موقعه'}
{'sequence': 'الفندق جميل و لكن المكان بعيد', 'score': 0.15372352302074432, 'token': 5401, 'token_str': 'المكان'}
{'sequence': 'الفندق جميل و لكن الفندق بعيد', 'score': 0.029026474803686142, 'token': 11133, 'token_str': 'الفندق'}
{'sequence': 'الفندق جميل و لكن مكانه بعيد', 'score': 0.024554792791604996, 'token': 10701, 'token_str': 'مكانه'}
|
M-CLIP/M-BERT-Base-ViT-B
|
M-CLIP
| 2021-05-18T21:34:39Z | 3,399 | 12 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"jax",
"bert",
"feature-extraction",
"endpoints_compatible",
"region:us"
] |
feature-extraction
| 2022-03-02T23:29:04Z |
<br />
<p align="center">
<h1 align="center">M-BERT Base ViT-B</h1>
<p align="center">
<a href="https://github.com/FreddeFrallan/Multilingual-CLIP/tree/main/Model%20Cards/M-BERT%20Base%20ViT-B">Github Model Card</a>
</p>
</p>
## Usage
To use this model along with the original CLIP vision encoder you need to download the code and additional linear weights from the [Multilingual-CLIP Github](https://github.com/FreddeFrallan/Multilingual-CLIP).
Once this is done, you can load and use the model with the following code
```python
from src import multilingual_clip
model = multilingual_clip.load_model('M-BERT-Base-ViT')
embeddings = model(['Älgen är skogens konung!', 'Wie leben Eisbären in der Antarktis?', 'Вы знали, что все белые медведи левши?'])
print(embeddings.shape)
# Yields: torch.Size([3, 640])
```
<!-- ABOUT THE PROJECT -->
## About
A [BERT-base-multilingual](https://huggingface.co/bert-base-multilingual-cased) tuned to match the embedding space for [69 languages](https://github.com/FreddeFrallan/Multilingual-CLIP/blob/main/Model%20Cards/M-BERT%20Base%2069/Fine-Tune-Languages.md), to the embedding space of the CLIP text encoder which accompanies the ViT-B/32 vision encoder. <br>
A full list of the 100 languages used during pre-training can be found [here](https://github.com/google-research/bert/blob/master/multilingual.md#list-of-languages), and a list of the 4069languages used during fine-tuning can be found in [SupportedLanguages.md](https://github.com/FreddeFrallan/Multilingual-CLIP/blob/main/Model%20Cards/M-BERT%20Base%2069/Fine-Tune-Languages.md).
Training data pairs was generated by sampling 40k sentences for each language from the combined descriptions of [GCC](https://ai.google.com/research/ConceptualCaptions/) + [MSCOCO](https://cocodataset.org/#home) + [VizWiz](https://vizwiz.org/tasks-and-datasets/image-captioning/), and translating them into the corresponding language.
All translation was done using the [AWS translate service](https://aws.amazon.com/translate/), the quality of these translations have currently not been analyzed, but one can assume the quality varies between the 69 languages.
|
HooshvareLab/bert-fa-zwnj-base
|
HooshvareLab
| 2021-05-18T21:05:42Z | 10,583 | 15 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"jax",
"bert",
"fill-mask",
"fa",
"arxiv:2005.12515",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:04Z |
---
language: fa
license: apache-2.0
---
# ParsBERT (v3.0)
A Transformer-based Model for Persian Language Understanding
The new version of BERT v3.0 for Persian is available today and can tackle the zero-width non-joiner character for Persian writing. Also, the model was trained on new multi-types corpora with a new set of vocabulary.
## Introduction
ParsBERT is a monolingual language model based on Google’s BERT architecture. This model is pre-trained on large Persian corpora with various writing styles from numerous subjects (e.g., scientific, novels, news).
Paper presenting ParsBERT: [arXiv:2005.12515](https://arxiv.org/abs/2005.12515)
### BibTeX entry and citation info
Please cite in publications as the following:
```bibtex
@article{ParsBERT,
title={ParsBERT: Transformer-based Model for Persian Language Understanding},
author={Mehrdad Farahani, Mohammad Gharachorloo, Marzieh Farahani, Mohammad Manthouri},
journal={ArXiv},
year={2020},
volume={abs/2005.12515}
}
```
## Questions?
Post a Github issue on the [ParsBERT Issues](https://github.com/hooshvare/parsbert/issues) repo.
|
HooshvareLab/bert-fa-base-uncased
|
HooshvareLab
| 2021-05-18T21:02:21Z | 17,958 | 18 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"jax",
"bert",
"fill-mask",
"bert-fa",
"bert-persian",
"persian-lm",
"fa",
"arxiv:2005.12515",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:04Z |
---
language: fa
tags:
- bert-fa
- bert-persian
- persian-lm
license: apache-2.0
---
# ParsBERT (v2.0)
A Transformer-based Model for Persian Language Understanding
We reconstructed the vocabulary and fine-tuned the ParsBERT v1.1 on the new Persian corpora in order to provide some functionalities for using ParsBERT in other scopes!
Please follow the [ParsBERT](https://github.com/hooshvare/parsbert) repo for the latest information about previous and current models.
## Introduction
ParsBERT is a monolingual language model based on Google’s BERT architecture. This model is pre-trained on large Persian corpora with various writing styles from numerous subjects (e.g., scientific, novels, news) with more than `3.9M` documents, `73M` sentences, and `1.3B` words.
Paper presenting ParsBERT: [arXiv:2005.12515](https://arxiv.org/abs/2005.12515)
## Intended uses & limitations
You can use the raw model for either masked language modeling or next sentence prediction, but it's mostly intended to
be fine-tuned on a downstream task. See the [model hub](https://huggingface.co/models?search=bert-fa) to look for
fine-tuned versions on a task that interests you.
### How to use
#### TensorFlow 2.0
```python
from transformers import AutoConfig, AutoTokenizer, TFAutoModel
config = AutoConfig.from_pretrained("HooshvareLab/bert-fa-base-uncased")
tokenizer = AutoTokenizer.from_pretrained("HooshvareLab/bert-fa-base-uncased")
model = TFAutoModel.from_pretrained("HooshvareLab/bert-fa-base-uncased")
text = "ما در هوشواره معتقدیم با انتقال صحیح دانش و آگاهی، همه افراد میتوانند از ابزارهای هوشمند استفاده کنند. شعار ما هوش مصنوعی برای همه است."
tokenizer.tokenize(text)
>>> ['ما', 'در', 'هوش', '##واره', 'معتقدیم', 'با', 'انتقال', 'صحیح', 'دانش', 'و', 'اگاهی', '،', 'همه', 'افراد', 'میتوانند', 'از', 'ابزارهای', 'هوشمند', 'استفاده', 'کنند', '.', 'شعار', 'ما', 'هوش', 'مصنوعی', 'برای', 'همه', 'است', '.']
```
#### Pytorch
```python
from transformers import AutoConfig, AutoTokenizer, AutoModel
config = AutoConfig.from_pretrained("HooshvareLab/bert-fa-base-uncased")
tokenizer = AutoTokenizer.from_pretrained("HooshvareLab/bert-fa-base-uncased")
model = AutoModel.from_pretrained("HooshvareLab/bert-fa-base-uncased")
```
## Training
ParsBERT trained on a massive amount of public corpora ([Persian Wikidumps](https://dumps.wikimedia.org/fawiki/), [MirasText](https://github.com/miras-tech/MirasText)) and six other manually crawled text data from a various type of websites ([BigBang Page](https://bigbangpage.com/) `scientific`, [Chetor](https://www.chetor.com/) `lifestyle`, [Eligasht](https://www.eligasht.com/Blog/) `itinerary`, [Digikala](https://www.digikala.com/mag/) `digital magazine`, [Ted Talks](https://www.ted.com/talks) `general conversational`, Books `novels, storybooks, short stories from old to the contemporary era`).
As a part of ParsBERT methodology, an extensive pre-processing combining POS tagging and WordPiece segmentation was carried out to bring the corpora into a proper format.
## Goals
Objective goals during training are as below (after 300k steps).
``` bash
***** Eval results *****
global_step = 300000
loss = 1.4392426
masked_lm_accuracy = 0.6865794
masked_lm_loss = 1.4469004
next_sentence_accuracy = 1.0
next_sentence_loss = 6.534152e-05
```
## Derivative models
### Base Config
#### ParsBERT v2.0 Model
- [HooshvareLab/bert-fa-base-uncased](https://huggingface.co/HooshvareLab/bert-fa-base-uncased)
#### ParsBERT v2.0 Sentiment Analysis
- [HooshvareLab/bert-fa-base-uncased-sentiment-digikala](https://huggingface.co/HooshvareLab/bert-fa-base-uncased-sentiment-digikala)
- [HooshvareLab/bert-fa-base-uncased-sentiment-snappfood](https://huggingface.co/HooshvareLab/bert-fa-base-uncased-sentiment-snappfood)
- [HooshvareLab/bert-fa-base-uncased-sentiment-deepsentipers-binary](https://huggingface.co/HooshvareLab/bert-fa-base-uncased-sentiment-deepsentipers-binary)
- [HooshvareLab/bert-fa-base-uncased-sentiment-deepsentipers-multi](https://huggingface.co/HooshvareLab/bert-fa-base-uncased-sentiment-deepsentipers-multi)
#### ParsBERT v2.0 Text Classification
- [HooshvareLab/bert-fa-base-uncased-clf-digimag](https://huggingface.co/HooshvareLab/bert-fa-base-uncased-clf-digimag)
- [HooshvareLab/bert-fa-base-uncased-clf-persiannews](https://huggingface.co/HooshvareLab/bert-fa-base-uncased-clf-persiannews)
#### ParsBERT v2.0 NER
- [HooshvareLab/bert-fa-base-uncased-ner-peyma](https://huggingface.co/HooshvareLab/bert-fa-base-uncased-ner-peyma)
- [HooshvareLab/bert-fa-base-uncased-ner-arman](https://huggingface.co/HooshvareLab/bert-fa-base-uncased-ner-arman)
## Eval results
ParsBERT is evaluated on three NLP downstream tasks: Sentiment Analysis (SA), Text Classification, and Named Entity Recognition (NER). For this matter and due to insufficient resources, two large datasets for SA and two for text classification were manually composed, which are available for public use and benchmarking. ParsBERT outperformed all other language models, including multilingual BERT and other hybrid deep learning models for all tasks, improving the state-of-the-art performance in Persian language modeling.
### Sentiment Analysis (SA) Task
| Dataset | ParsBERT v2 | ParsBERT v1 | mBERT | DeepSentiPers |
|:------------------------:|:-----------:|:-----------:|:-----:|:-------------:|
| Digikala User Comments | 81.72 | 81.74* | 80.74 | - |
| SnappFood User Comments | 87.98 | 88.12* | 87.87 | - |
| SentiPers (Multi Class) | 71.31* | 71.11 | - | 69.33 |
| SentiPers (Binary Class) | 92.42* | 92.13 | - | 91.98 |
### Text Classification (TC) Task
| Dataset | ParsBERT v2 | ParsBERT v1 | mBERT |
|:-----------------:|:-----------:|:-----------:|:-----:|
| Digikala Magazine | 93.65* | 93.59 | 90.72 |
| Persian News | 97.44* | 97.19 | 95.79 |
### Named Entity Recognition (NER) Task
| Dataset | ParsBERT v2 | ParsBERT v1 | mBERT | MorphoBERT | Beheshti-NER | LSTM-CRF | Rule-Based CRF | BiLSTM-CRF |
|:-------:|:-----------:|:-----------:|:-----:|:----------:|:------------:|:--------:|:--------------:|:----------:|
| PEYMA | 93.40* | 93.10 | 86.64 | - | 90.59 | - | 84.00 | - |
| ARMAN | 99.84* | 98.79 | 95.89 | 89.9 | 84.03 | 86.55 | - | 77.45 |
### BibTeX entry and citation info
Please cite in publications as the following:
```bibtex
@article{ParsBERT,
title={ParsBERT: Transformer-based Model for Persian Language Understanding},
author={Mehrdad Farahani, Mohammad Gharachorloo, Marzieh Farahani, Mohammad Manthouri},
journal={ArXiv},
year={2020},
volume={abs/2005.12515}
}
```
## Questions?
Post a Github issue on the [ParsBERT Issues](https://github.com/hooshvare/parsbert/issues) repo.
|
HooshvareLab/bert-fa-base-uncased-sentiment-deepsentipers-multi
|
HooshvareLab
| 2021-05-18T20:58:01Z | 130 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"jax",
"bert",
"text-classification",
"fa",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:04Z |
---
language: fa
license: apache-2.0
---
# ParsBERT (v2.0)
A Transformer-based Model for Persian Language Understanding
We reconstructed the vocabulary and fine-tuned the ParsBERT v1.1 on the new Persian corpora in order to provide some functionalities for using ParsBERT in other scopes!
Please follow the [ParsBERT](https://github.com/hooshvare/parsbert) repo for the latest information about previous and current models.
## Persian Sentiment [Digikala, SnappFood, DeepSentiPers]
It aims to classify text, such as comments, based on their emotional bias. We tested three well-known datasets for this task: `Digikala` user comments, `SnappFood` user comments, and `DeepSentiPers` in two binary-form and multi-form types.
### DeepSentiPers
which is a balanced and augmented version of SentiPers, contains 12,138 user opinions about digital products labeled with five different classes; two positives (i.e., happy and delighted), two negatives (i.e., furious and angry) and one neutral class. Therefore, this dataset can be utilized for both multi-class and binary classification. In the case of binary classification, the neutral class and its corresponding sentences are removed from the dataset.
**Binary:**
1. Negative (Furious + Angry)
2. Positive (Happy + Delighted)
**Multi**
1. Furious
2. Angry
3. Neutral
4. Happy
5. Delighted
| Label | # |
|:---------:|:----:|
| Furious | 236 |
| Angry | 1357 |
| Neutral | 2874 |
| Happy | 2848 |
| Delighted | 2516 |
**Download**
You can download the dataset from:
- [SentiPers](https://github.com/phosseini/sentipers)
- [DeepSentiPers](https://github.com/JoyeBright/DeepSentiPers)
## Results
The following table summarizes the F1 score obtained by ParsBERT as compared to other models and architectures.
| Dataset | ParsBERT v2 | ParsBERT v1 | mBERT | DeepSentiPers |
|:------------------------:|:-----------:|:-----------:|:-----:|:-------------:|
| SentiPers (Multi Class) | 71.31* | 71.11 | - | 69.33 |
| SentiPers (Binary Class) | 92.42* | 92.13 | - | 91.98 |
## How to use :hugs:
| Task | Notebook |
|---------------------|---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Sentiment Analysis | [](https://colab.research.google.com/github/hooshvare/parsbert/blob/master/notebooks/Taaghche_Sentiment_Analysis.ipynb) |
### BibTeX entry and citation info
Please cite in publications as the following:
```bibtex
@article{ParsBERT,
title={ParsBERT: Transformer-based Model for Persian Language Understanding},
author={Mehrdad Farahani, Mohammad Gharachorloo, Marzieh Farahani, Mohammad Manthouri},
journal={ArXiv},
year={2020},
volume={abs/2005.12515}
}
```
## Questions?
Post a Github issue on the [ParsBERT Issues](https://github.com/hooshvare/parsbert/issues) repo.
|
HooshvareLab/bert-fa-base-uncased-ner-peyma
|
HooshvareLab
| 2021-05-18T20:55:10Z | 424 | 6 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"jax",
"bert",
"token-classification",
"fa",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-03-02T23:29:04Z |
---
language: fa
license: apache-2.0
---
# ParsBERT (v2.0)
A Transformer-based Model for Persian Language Understanding
We reconstructed the vocabulary and fine-tuned the ParsBERT v1.1 on the new Persian corpora in order to provide some functionalities for using ParsBERT in other scopes!
Please follow the [ParsBERT](https://github.com/hooshvare/parsbert) repo for the latest information about previous and current models.
## Persian NER [ARMAN, PEYMA]
This task aims to extract named entities in the text, such as names and label with appropriate `NER` classes such as locations, organizations, etc. The datasets used for this task contain sentences that are marked with `IOB` format. In this format, tokens that are not part of an entity are tagged as `”O”` the `”B”`tag corresponds to the first word of an object, and the `”I”` tag corresponds to the rest of the terms of the same entity. Both `”B”` and `”I”` tags are followed by a hyphen (or underscore), followed by the entity category. Therefore, the NER task is a multi-class token classification problem that labels the tokens upon being fed a raw text. There are two primary datasets used in Persian NER, `ARMAN`, and `PEYMA`.
### PEYMA
PEYMA dataset includes 7,145 sentences with a total of 302,530 tokens from which 41,148 tokens are tagged with seven different classes.
1. Organization
2. Money
3. Location
4. Date
5. Time
6. Person
7. Percent
| Label | # |
|:------------:|:-----:|
| Organization | 16964 |
| Money | 2037 |
| Location | 8782 |
| Date | 4259 |
| Time | 732 |
| Person | 7675 |
| Percent | 699 |
**Download**
You can download the dataset from [here](http://nsurl.org/tasks/task-7-named-entity-recognition-ner-for-farsi/)
## Results
The following table summarizes the F1 score obtained by ParsBERT as compared to other models and architectures.
| Dataset | ParsBERT v2 | ParsBERT v1 | mBERT | MorphoBERT | Beheshti-NER | LSTM-CRF | Rule-Based CRF | BiLSTM-CRF |
|---------|-------------|-------------|-------|------------|--------------|----------|----------------|------------|
| PEYMA | 93.40* | 93.10 | 86.64 | - | 90.59 | - | 84.00 | - |
## How to use :hugs:
| Notebook | Description | |
|:----------|:-------------|------:|
| [How to use Pipelines](https://github.com/hooshvare/parsbert-ner/blob/master/persian-ner-pipeline.ipynb) | Simple and efficient way to use State-of-the-Art models on downstream tasks through transformers | [](https://colab.research.google.com/github/hooshvare/parsbert-ner/blob/master/persian-ner-pipeline.ipynb) |
### BibTeX entry and citation info
Please cite in publications as the following:
```bibtex
@article{ParsBERT,
title={ParsBERT: Transformer-based Model for Persian Language Understanding},
author={Mehrdad Farahani, Mohammad Gharachorloo, Marzieh Farahani, Mohammad Manthouri},
journal={ArXiv},
year={2020},
volume={abs/2005.12515}
}
```
## Questions?
Post a Github issue on the [ParsBERT Issues](https://github.com/hooshvare/parsbert/issues) repo.
|
HooshvareLab/bert-fa-base-uncased-ner-arman
|
HooshvareLab
| 2021-05-18T20:52:21Z | 50 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"jax",
"bert",
"token-classification",
"fa",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-03-02T23:29:04Z |
---
language: fa
license: apache-2.0
---
# ParsBERT (v2.0)
A Transformer-based Model for Persian Language Understanding
We reconstructed the vocabulary and fine-tuned the ParsBERT v1.1 on the new Persian corpora in order to provide some functionalities for using ParsBERT in other scopes!
Please follow the [ParsBERT](https://github.com/hooshvare/parsbert) repo for the latest information about previous and current models.
## Persian NER [ARMAN, PEYMA]
This task aims to extract named entities in the text, such as names and label with appropriate `NER` classes such as locations, organizations, etc. The datasets used for this task contain sentences that are marked with `IOB` format. In this format, tokens that are not part of an entity are tagged as `”O”` the `”B”`tag corresponds to the first word of an object, and the `”I”` tag corresponds to the rest of the terms of the same entity. Both `”B”` and `”I”` tags are followed by a hyphen (or underscore), followed by the entity category. Therefore, the NER task is a multi-class token classification problem that labels the tokens upon being fed a raw text. There are two primary datasets used in Persian NER, `ARMAN`, and `PEYMA`.
### ARMAN
ARMAN dataset holds 7,682 sentences with 250,015 sentences tagged over six different classes.
1. Organization
2. Location
3. Facility
4. Event
5. Product
6. Person
| Label | # |
|:------------:|:-----:|
| Organization | 30108 |
| Location | 12924 |
| Facility | 4458 |
| Event | 7557 |
| Product | 4389 |
| Person | 15645 |
**Download**
You can download the dataset from [here](https://github.com/HaniehP/PersianNER)
## Results
The following table summarizes the F1 score obtained by ParsBERT as compared to other models and architectures.
| Dataset | ParsBERT v2 | ParsBERT v1 | mBERT | MorphoBERT | Beheshti-NER | LSTM-CRF | Rule-Based CRF | BiLSTM-CRF |
|---------|-------------|-------------|-------|------------|--------------|----------|----------------|------------|
| ARMAN | 99.84* | 98.79 | 95.89 | 89.9 | 84.03 | 86.55 | - | 77.45 |
## How to use :hugs:
| Notebook | Description | |
|:----------|:-------------|------:|
| [How to use Pipelines](https://github.com/hooshvare/parsbert-ner/blob/master/persian-ner-pipeline.ipynb) | Simple and efficient way to use State-of-the-Art models on downstream tasks through transformers | [](https://colab.research.google.com/github/hooshvare/parsbert-ner/blob/master/persian-ner-pipeline.ipynb) |
### BibTeX entry and citation info
Please cite in publications as the following:
```bibtex
@article{ParsBERT,
title={ParsBERT: Transformer-based Model for Persian Language Understanding},
author={Mehrdad Farahani, Mohammad Gharachorloo, Marzieh Farahani, Mohammad Manthouri},
journal={ArXiv},
year={2020},
volume={abs/2005.12515}
}
```
## Questions?
Post a Github issue on the [ParsBERT Issues](https://github.com/hooshvare/parsbert/issues) repo.
|
HooshvareLab/bert-fa-base-uncased-clf-persiannews
|
HooshvareLab
| 2021-05-18T20:51:07Z | 1,469 | 8 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"jax",
"bert",
"text-classification",
"fa",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:04Z |
---
language: fa
license: apache-2.0
---
# ParsBERT (v2.0)
A Transformer-based Model for Persian Language Understanding
We reconstructed the vocabulary and fine-tuned the ParsBERT v1.1 on the new Persian corpora in order to provide some functionalities for using ParsBERT in other scopes!
Please follow the [ParsBERT](https://github.com/hooshvare/parsbert) repo for the latest information about previous and current models.
## Persian Text Classification [DigiMag, Persian News]
The task target is labeling texts in a supervised manner in both existing datasets `DigiMag` and `Persian News`.
### Persian News
A dataset of various news articles scraped from different online news agencies' websites. The total number of articles is 16,438, spread over eight different classes.
1. Economic
2. International
3. Political
4. Science Technology
5. Cultural Art
6. Sport
7. Medical
| Label | # |
|:------------------:|:----:|
| Social | 2170 |
| Economic | 1564 |
| International | 1975 |
| Political | 2269 |
| Science Technology | 2436 |
| Cultural Art | 2558 |
| Sport | 1381 |
| Medical | 2085 |
**Download**
You can download the dataset from [here](https://drive.google.com/uc?id=1B6xotfXCcW9xS1mYSBQos7OCg0ratzKC)
## Results
The following table summarizes the F1 score obtained by ParsBERT as compared to other models and architectures.
| Dataset | ParsBERT v2 | ParsBERT v1 | mBERT |
|:-----------------:|:-----------:|:-----------:|:-----:|
| Persian News | 97.44* | 97.19 | 95.79 |
## How to use :hugs:
| Task | Notebook |
|---------------------|---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Text Classification | [](https://colab.research.google.com/github/hooshvare/parsbert/blob/master/notebooks/Taaghche_Sentiment_Analysis.ipynb) |
### BibTeX entry and citation info
Please cite in publications as the following:
```bibtex
@article{ParsBERT,
title={ParsBERT: Transformer-based Model for Persian Language Understanding},
author={Mehrdad Farahani, Mohammad Gharachorloo, Marzieh Farahani, Mohammad Manthouri},
journal={ArXiv},
year={2020},
volume={abs/2005.12515}
}
```
## Questions?
Post a Github issue on the [ParsBERT Issues](https://github.com/hooshvare/parsbert/issues) repo.
|
HooshvareLab/bert-fa-base-uncased-clf-digimag
|
HooshvareLab
| 2021-05-18T20:48:44Z | 55 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"jax",
"bert",
"text-classification",
"fa",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:04Z |
---
language: fa
license: apache-2.0
---
# ParsBERT (v2.0)
A Transformer-based Model for Persian Language Understanding
We reconstructed the vocabulary and fine-tuned the ParsBERT v1.1 on the new Persian corpora in order to provide some functionalities for using ParsBERT in other scopes!
Please follow the [ParsBERT](https://github.com/hooshvare/parsbert) repo for the latest information about previous and current models.
## Persian Text Classification [DigiMag, Persian News]
The task target is labeling texts in a supervised manner in both existing datasets `DigiMag` and `Persian News`.
### DigiMag
A total of 8,515 articles scraped from [Digikala Online Magazine](https://www.digikala.com/mag/). This dataset includes seven different classes.
1. Video Games
2. Shopping Guide
3. Health Beauty
4. Science Technology
5. General
6. Art Cinema
7. Books Literature
| Label | # |
|:------------------:|:----:|
| Video Games | 1967 |
| Shopping Guide | 125 |
| Health Beauty | 1610 |
| Science Technology | 2772 |
| General | 120 |
| Art Cinema | 1667 |
| Books Literature | 254 |
**Download**
You can download the dataset from [here](https://drive.google.com/uc?id=1YgrCYY-Z0h2z0-PfWVfOGt1Tv0JDI-qz)
## Results
The following table summarizes the F1 score obtained by ParsBERT as compared to other models and architectures.
| Dataset | ParsBERT v2 | ParsBERT v1 | mBERT |
|:-----------------:|:-----------:|:-----------:|:-----:|
| Digikala Magazine | 93.65* | 93.59 | 90.72 |
## How to use :hugs:
| Task | Notebook |
|---------------------|---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Text Classification | [](https://colab.research.google.com/github/hooshvare/parsbert/blob/master/notebooks/Taaghche_Sentiment_Analysis.ipynb) |
### BibTeX entry and citation info
Please cite in publications as the following:
```bibtex
@article{ParsBERT,
title={ParsBERT: Transformer-based Model for Persian Language Understanding},
author={Mehrdad Farahani, Mohammad Gharachorloo, Marzieh Farahani, Mohammad Manthouri},
journal={ArXiv},
year={2020},
volume={abs/2005.12515}
}
```
## Questions?
Post a Github issue on the [ParsBERT Issues](https://github.com/hooshvare/parsbert/issues) repo.
|
HooshvareLab/bert-base-parsbert-peymaner-uncased
|
HooshvareLab
| 2021-05-18T20:45:45Z | 35 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"jax",
"bert",
"token-classification",
"fa",
"arxiv:2005.12515",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-03-02T23:29:04Z |
---
language: fa
license: apache-2.0
---
## ParsBERT: Transformer-based Model for Persian Language Understanding
ParsBERT is a monolingual language model based on Google’s BERT architecture with the same configurations as BERT-Base.
Paper presenting ParsBERT: [arXiv:2005.12515](https://arxiv.org/abs/2005.12515)
All the models (downstream tasks) are uncased and trained with whole word masking. (coming soon stay tuned)
## Persian NER [ARMAN, PEYMA, ARMAN+PEYMA]
This task aims to extract named entities in the text, such as names and label with appropriate `NER` classes such as locations, organizations, etc. The datasets used for this task contain sentences that are marked with `IOB` format. In this format, tokens that are not part of an entity are tagged as `”O”` the `”B”`tag corresponds to the first word of an object, and the `”I”` tag corresponds to the rest of the terms of the same entity. Both `”B”` and `”I”` tags are followed by a hyphen (or underscore), followed by the entity category. Therefore, the NER task is a multi-class token classification problem that labels the tokens upon being fed a raw text. There are two primary datasets used in Persian NER, `ARMAN`, and `PEYMA`. In ParsBERT, we prepared ner for both datasets as well as a combination of both datasets.
### PEYMA
PEYMA dataset includes 7,145 sentences with a total of 302,530 tokens from which 41,148 tokens are tagged with seven different classes.
1. Organization
2. Money
3. Location
4. Date
5. Time
6. Person
7. Percent
| Label | # |
|:------------:|:-----:|
| Organization | 16964 |
| Money | 2037 |
| Location | 8782 |
| Date | 4259 |
| Time | 732 |
| Person | 7675 |
| Percent | 699 |
**Download**
You can download the dataset from [here](http://nsurl.org/tasks/task-7-named-entity-recognition-ner-for-farsi/)
## Results
The following table summarizes the F1 score obtained by ParsBERT as compared to other models and architectures.
| Dataset | ParsBERT | MorphoBERT | Beheshti-NER | LSTM-CRF | Rule-Based CRF | BiLSTM-CRF |
|---------|----------|------------|--------------|----------|----------------|------------|
| PEYMA | 98.79* | - | 90.59 | - | 84.00 | - |
## How to use :hugs:
| Notebook | Description | |
|:----------|:-------------|------:|
| [How to use Pipelines](https://github.com/hooshvare/parsbert-ner/blob/master/persian-ner-pipeline.ipynb) | Simple and efficient way to use State-of-the-Art models on downstream tasks through transformers | [](https://colab.research.google.com/github/hooshvare/parsbert-ner/blob/master/persian-ner-pipeline.ipynb) |
## Cite
Please cite the following paper in your publication if you are using [ParsBERT](https://arxiv.org/abs/2005.12515) in your research:
```markdown
@article{ParsBERT,
title={ParsBERT: Transformer-based Model for Persian Language Understanding},
author={Mehrdad Farahani, Mohammad Gharachorloo, Marzieh Farahani, Mohammad Manthouri},
journal={ArXiv},
year={2020},
volume={abs/2005.12515}
}
```
## Acknowledgments
We hereby, express our gratitude to the [Tensorflow Research Cloud (TFRC) program](https://tensorflow.org/tfrc) for providing us with the necessary computation resources. We also thank [Hooshvare](https://hooshvare.com) Research Group for facilitating dataset gathering and scraping online text resources.
## Contributors
- Mehrdad Farahani: [Linkedin](https://www.linkedin.com/in/m3hrdadfi/), [Twitter](https://twitter.com/m3hrdadfi), [Github](https://github.com/m3hrdadfi)
- Mohammad Gharachorloo: [Linkedin](https://www.linkedin.com/in/mohammad-gharachorloo/), [Twitter](https://twitter.com/MGharachorloo), [Github](https://github.com/baarsaam)
- Marzieh Farahani: [Linkedin](https://www.linkedin.com/in/marziehphi/), [Twitter](https://twitter.com/marziehphi), [Github](https://github.com/marziehphi)
- Mohammad Manthouri: [Linkedin](https://www.linkedin.com/in/mohammad-manthouri-aka-mansouri-07030766/), [Twitter](https://twitter.com/mmanthouri), [Github](https://github.com/mmanthouri)
- Hooshvare Team: [Official Website](https://hooshvare.com/), [Linkedin](https://www.linkedin.com/company/hooshvare), [Twitter](https://twitter.com/hooshvare), [Github](https://github.com/hooshvare), [Instagram](https://www.instagram.com/hooshvare/)
+ And a special thanks to Sara Tabrizi for her fantastic poster design. Follow her on: [Linkedin](https://www.linkedin.com/in/sara-tabrizi-64548b79/), [Behance](https://www.behance.net/saratabrizi), [Instagram](https://www.instagram.com/sara_b_tabrizi/)
## Releases
### Release v0.1 (May 29, 2019)
This is the first version of our ParsBERT NER!
|
HooshvareLab/bert-base-parsbert-ner-uncased
|
HooshvareLab
| 2021-05-18T20:43:54Z | 17,676 | 5 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"jax",
"bert",
"token-classification",
"fa",
"arxiv:2005.12515",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-03-02T23:29:04Z |
---
language: fa
license: apache-2.0
---
## ParsBERT: Transformer-based Model for Persian Language Understanding
ParsBERT is a monolingual language model based on Google’s BERT architecture with the same configurations as BERT-Base.
Paper presenting ParsBERT: [arXiv:2005.12515](https://arxiv.org/abs/2005.12515)
All the models (downstream tasks) are uncased and trained with whole word masking. (coming soon stay tuned)
## Persian NER [ARMAN, PEYMA, ARMAN+PEYMA]
This task aims to extract named entities in the text, such as names and label with appropriate `NER` classes such as locations, organizations, etc. The datasets used for this task contain sentences that are marked with `IOB` format. In this format, tokens that are not part of an entity are tagged as `”O”` the `”B”`tag corresponds to the first word of an object, and the `”I”` tag corresponds to the rest of the terms of the same entity. Both `”B”` and `”I”` tags are followed by a hyphen (or underscore), followed by the entity category. Therefore, the NER task is a multi-class token classification problem that labels the tokens upon being fed a raw text. There are two primary datasets used in Persian NER, `ARMAN`, and `PEYMA`. In ParsBERT, we prepared ner for both datasets as well as a combination of both datasets.
### PEYMA
PEYMA dataset includes 7,145 sentences with a total of 302,530 tokens from which 41,148 tokens are tagged with seven different classes.
1. Organization
2. Money
3. Location
4. Date
5. Time
6. Person
7. Percent
| Label | # |
|:------------:|:-----:|
| Organization | 16964 |
| Money | 2037 |
| Location | 8782 |
| Date | 4259 |
| Time | 732 |
| Person | 7675 |
| Percent | 699 |
**Download**
You can download the dataset from [here](http://nsurl.org/tasks/task-7-named-entity-recognition-ner-for-farsi/)
---
### ARMAN
ARMAN dataset holds 7,682 sentences with 250,015 sentences tagged over six different classes.
1. Organization
2. Location
3. Facility
4. Event
5. Product
6. Person
| Label | # |
|:------------:|:-----:|
| Organization | 30108 |
| Location | 12924 |
| Facility | 4458 |
| Event | 7557 |
| Product | 4389 |
| Person | 15645 |
**Download**
You can download the dataset from [here](https://github.com/HaniehP/PersianNER)
## Results
The following table summarizes the F1 score obtained by ParsBERT as compared to other models and architectures.
| Dataset | ParsBERT | MorphoBERT | Beheshti-NER | LSTM-CRF | Rule-Based CRF | BiLSTM-CRF |
|:---------------:|:--------:|:----------:|:--------------:|:----------:|:----------------:|:------------:|
| ARMAN + PEYMA | 95.13* | - | - | - | - | - |
| PEYMA | 98.79* | - | 90.59 | - | 84.00 | - |
| ARMAN | 93.10* | 89.9 | 84.03 | 86.55 | - | 77.45 |
## How to use :hugs:
| Notebook | Description | |
|:----------|:-------------|------:|
| [How to use Pipelines](https://github.com/hooshvare/parsbert-ner/blob/master/persian-ner-pipeline.ipynb) | Simple and efficient way to use State-of-the-Art models on downstream tasks through transformers | [](https://colab.research.google.com/github/hooshvare/parsbert-ner/blob/master/persian-ner-pipeline.ipynb) |
## Cite
Please cite the following paper in your publication if you are using [ParsBERT](https://arxiv.org/abs/2005.12515) in your research:
```markdown
@article{ParsBERT,
title={ParsBERT: Transformer-based Model for Persian Language Understanding},
author={Mehrdad Farahani, Mohammad Gharachorloo, Marzieh Farahani, Mohammad Manthouri},
journal={ArXiv},
year={2020},
volume={abs/2005.12515}
}
```
## Acknowledgments
We hereby, express our gratitude to the [Tensorflow Research Cloud (TFRC) program](https://tensorflow.org/tfrc) for providing us with the necessary computation resources. We also thank [Hooshvare](https://hooshvare.com) Research Group for facilitating dataset gathering and scraping online text resources.
## Contributors
- Mehrdad Farahani: [Linkedin](https://www.linkedin.com/in/m3hrdadfi/), [Twitter](https://twitter.com/m3hrdadfi), [Github](https://github.com/m3hrdadfi)
- Mohammad Gharachorloo: [Linkedin](https://www.linkedin.com/in/mohammad-gharachorloo/), [Twitter](https://twitter.com/MGharachorloo), [Github](https://github.com/baarsaam)
- Marzieh Farahani: [Linkedin](https://www.linkedin.com/in/marziehphi/), [Twitter](https://twitter.com/marziehphi), [Github](https://github.com/marziehphi)
- Mohammad Manthouri: [Linkedin](https://www.linkedin.com/in/mohammad-manthouri-aka-mansouri-07030766/), [Twitter](https://twitter.com/mmanthouri), [Github](https://github.com/mmanthouri)
- Hooshvare Team: [Official Website](https://hooshvare.com/), [Linkedin](https://www.linkedin.com/company/hooshvare), [Twitter](https://twitter.com/hooshvare), [Github](https://github.com/hooshvare), [Instagram](https://www.instagram.com/hooshvare/)
+ And a special thanks to Sara Tabrizi for her fantastic poster design. Follow her on: [Linkedin](https://www.linkedin.com/in/sara-tabrizi-64548b79/), [Behance](https://www.behance.net/saratabrizi), [Instagram](https://www.instagram.com/sara_b_tabrizi/)
## Releases
### Release v0.1 (May 29, 2019)
This is the first version of our ParsBERT NER!
|
HooshvareLab/bert-base-parsbert-armanner-uncased
|
HooshvareLab
| 2021-05-18T20:42:28Z | 117 | 3 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"jax",
"bert",
"token-classification",
"fa",
"arxiv:2005.12515",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-03-02T23:29:04Z |
---
language: fa
license: apache-2.0
---
## ParsBERT: Transformer-based Model for Persian Language Understanding
ParsBERT is a monolingual language model based on Google’s BERT architecture with the same configurations as BERT-Base.
Paper presenting ParsBERT: [arXiv:2005.12515](https://arxiv.org/abs/2005.12515)
All the models (downstream tasks) are uncased and trained with whole word masking. (coming soon stay tuned)
## Persian NER [ARMAN, PEYMA, ARMAN+PEYMA]
This task aims to extract named entities in the text, such as names and label with appropriate `NER` classes such as locations, organizations, etc. The datasets used for this task contain sentences that are marked with `IOB` format. In this format, tokens that are not part of an entity are tagged as `”O”` the `”B”`tag corresponds to the first word of an object, and the `”I”` tag corresponds to the rest of the terms of the same entity. Both `”B”` and `”I”` tags are followed by a hyphen (or underscore), followed by the entity category. Therefore, the NER task is a multi-class token classification problem that labels the tokens upon being fed a raw text. There are two primary datasets used in Persian NER, `ARMAN`, and `PEYMA`. In ParsBERT, we prepared ner for both datasets as well as a combination of both datasets.
### ARMAN
ARMAN dataset holds 7,682 sentences with 250,015 sentences tagged over six different classes.
1. Organization
2. Location
3. Facility
4. Event
5. Product
6. Person
| Label | # |
|:------------:|:-----:|
| Organization | 30108 |
| Location | 12924 |
| Facility | 4458 |
| Event | 7557 |
| Product | 4389 |
| Person | 15645 |
**Download**
You can download the dataset from [here](https://github.com/HaniehP/PersianNER)
## Results
The following table summarizes the F1 score obtained by ParsBERT as compared to other models and architectures.
| Dataset | ParsBERT | MorphoBERT | Beheshti-NER | LSTM-CRF | Rule-Based CRF | BiLSTM-CRF |
|---------|----------|------------|--------------|----------|----------------|------------|
| ARMAN | 93.10* | 89.9 | 84.03 | 86.55 | - | 77.45 |
## How to use :hugs:
| Notebook | Description | |
|:----------|:-------------|------:|
| [How to use Pipelines](https://github.com/hooshvare/parsbert-ner/blob/master/persian-ner-pipeline.ipynb) | Simple and efficient way to use State-of-the-Art models on downstream tasks through transformers | [](https://colab.research.google.com/github/hooshvare/parsbert-ner/blob/master/persian-ner-pipeline.ipynb) |
## Cite
Please cite the following paper in your publication if you are using [ParsBERT](https://arxiv.org/abs/2005.12515) in your research:
```markdown
@article{ParsBERT,
title={ParsBERT: Transformer-based Model for Persian Language Understanding},
author={Mehrdad Farahani, Mohammad Gharachorloo, Marzieh Farahani, Mohammad Manthouri},
journal={ArXiv},
year={2020},
volume={abs/2005.12515}
}
```
## Acknowledgments
We hereby, express our gratitude to the [Tensorflow Research Cloud (TFRC) program](https://tensorflow.org/tfrc) for providing us with the necessary computation resources. We also thank [Hooshvare](https://hooshvare.com) Research Group for facilitating dataset gathering and scraping online text resources.
## Contributors
- Mehrdad Farahani: [Linkedin](https://www.linkedin.com/in/m3hrdadfi/), [Twitter](https://twitter.com/m3hrdadfi), [Github](https://github.com/m3hrdadfi)
- Mohammad Gharachorloo: [Linkedin](https://www.linkedin.com/in/mohammad-gharachorloo/), [Twitter](https://twitter.com/MGharachorloo), [Github](https://github.com/baarsaam)
- Marzieh Farahani: [Linkedin](https://www.linkedin.com/in/marziehphi/), [Twitter](https://twitter.com/marziehphi), [Github](https://github.com/marziehphi)
- Mohammad Manthouri: [Linkedin](https://www.linkedin.com/in/mohammad-manthouri-aka-mansouri-07030766/), [Twitter](https://twitter.com/mmanthouri), [Github](https://github.com/mmanthouri)
- Hooshvare Team: [Official Website](https://hooshvare.com/), [Linkedin](https://www.linkedin.com/company/hooshvare), [Twitter](https://twitter.com/hooshvare), [Github](https://github.com/hooshvare), [Instagram](https://www.instagram.com/hooshvare/)
+ And a special thanks to Sara Tabrizi for her fantastic poster design. Follow her on: [Linkedin](https://www.linkedin.com/in/sara-tabrizi-64548b79/), [Behance](https://www.behance.net/saratabrizi), [Instagram](https://www.instagram.com/sara_b_tabrizi/)
## Releases
### Release v0.1 (May 29, 2019)
This is the first version of our ParsBERT NER!
|
GroNLP/bert-base-dutch-cased-upos-alpino-gronings
|
GroNLP
| 2021-05-18T20:23:32Z | 8 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"jax",
"bert",
"token-classification",
"BERTje",
"pos",
"gos",
"arxiv:2105.02855",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-03-02T23:29:04Z |
---
language: gos
tags:
- BERTje
- pos
---
Wietse de Vries • Martijn Bartelds • Malvina Nissim • Martijn Wieling
# Adapting Monolingual Models: Data can be Scarce when Language Similarity is High
This model is part of this paper + code:
- 📝 [Paper](https://arxiv.org/abs/2105.02855)
- 💻 [Code](https://github.com/wietsedv/low-resource-adapt)
## Models
The best fine-tuned models for Gronings and West Frisian are available on the HuggingFace model hub:
### Lexical layers
These models are identical to [BERTje](https://github.com/wietsedv/bertje), but with different lexical layers (`bert.embeddings.word_embeddings`).
- 🤗 [`GroNLP/bert-base-dutch-cased`](https://huggingface.co/GroNLP/bert-base-dutch-cased) (Dutch; source language)
- 🤗 [`GroNLP/bert-base-dutch-cased-gronings`](https://huggingface.co/GroNLP/bert-base-dutch-cased-gronings) (Gronings)
- 🤗 [`GroNLP/bert-base-dutch-cased-frisian`](https://huggingface.co/GroNLP/bert-base-dutch-cased-frisian) (West Frisian)
### POS tagging
These models share the same fine-tuned Transformer layers + classification head, but with the retrained lexical layers from the models above.
- 🤗 [`GroNLP/bert-base-dutch-cased-upos-alpino`](https://huggingface.co/GroNLP/bert-base-dutch-cased-upos-alpino) (Dutch)
- 🤗 [`GroNLP/bert-base-dutch-cased-upos-alpino-gronings`](https://huggingface.co/GroNLP/bert-base-dutch-cased-upos-alpino-gronings) (Gronings)
- 🤗 [`GroNLP/bert-base-dutch-cased-upos-alpino-frisian`](https://huggingface.co/GroNLP/bert-base-dutch-cased-upos-alpino-frisian) (West Frisian)
|
Geotrend/bert-base-vi-cased
|
Geotrend
| 2021-05-18T20:15:25Z | 5 | 2 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"jax",
"bert",
"fill-mask",
"vi",
"dataset:wikipedia",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:04Z |
---
language: vi
datasets: wikipedia
license: apache-2.0
---
# bert-base-vi-cased
We are sharing smaller versions of [bert-base-multilingual-cased](https://huggingface.co/bert-base-multilingual-cased) that handle a custom number of languages.
Unlike [distilbert-base-multilingual-cased](https://huggingface.co/distilbert-base-multilingual-cased), our versions give exactly the same representations produced by the original model which preserves the original accuracy.
For more information please visit our paper: [Load What You Need: Smaller Versions of Multilingual BERT](https://www.aclweb.org/anthology/2020.sustainlp-1.16.pdf).
## How to use
```python
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("Geotrend/bert-base-vi-cased")
model = AutoModel.from_pretrained("Geotrend/bert-base-vi-cased")
```
To generate other smaller versions of multilingual transformers please visit [our Github repo](https://github.com/Geotrend-research/smaller-transformers).
### How to cite
```bibtex
@inproceedings{smallermbert,
title={Load What You Need: Smaller Versions of Mutlilingual BERT},
author={Abdaoui, Amine and Pradel, Camille and Sigel, Grégoire},
booktitle={SustaiNLP / EMNLP},
year={2020}
}
```
## Contact
Please contact amine@geotrend.fr for any question, feedback or request.
|
Geotrend/bert-base-th-cased
|
Geotrend
| 2021-05-18T20:11:25Z | 989 | 3 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"jax",
"bert",
"fill-mask",
"th",
"dataset:wikipedia",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:04Z |
---
language: th
datasets: wikipedia
license: apache-2.0
---
# bert-base-th-cased
We are sharing smaller versions of [bert-base-multilingual-cased](https://huggingface.co/bert-base-multilingual-cased) that handle a custom number of languages.
Unlike [distilbert-base-multilingual-cased](https://huggingface.co/distilbert-base-multilingual-cased), our versions give exactly the same representations produced by the original model which preserves the original accuracy.
For more information please visit our paper: [Load What You Need: Smaller Versions of Multilingual BERT](https://www.aclweb.org/anthology/2020.sustainlp-1.16.pdf).
## How to use
```python
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("Geotrend/bert-base-th-cased")
model = AutoModel.from_pretrained("Geotrend/bert-base-th-cased")
```
To generate other smaller versions of multilingual transformers please visit [our Github repo](https://github.com/Geotrend-research/smaller-transformers).
### How to cite
```bibtex
@inproceedings{smallermbert,
title={Load What You Need: Smaller Versions of Mutlilingual BERT},
author={Abdaoui, Amine and Pradel, Camille and Sigel, Grégoire},
booktitle={SustaiNLP / EMNLP},
year={2020}
}
```
## Contact
Please contact amine@geotrend.fr for any question, feedback or request.
|
Geotrend/bert-base-sw-cased
|
Geotrend
| 2021-05-18T20:10:30Z | 7 | 1 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"jax",
"bert",
"fill-mask",
"sw",
"dataset:wikipedia",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:04Z |
---
language: sw
datasets: wikipedia
license: apache-2.0
---
# bert-base-sw-cased
We are sharing smaller versions of [bert-base-multilingual-cased](https://huggingface.co/bert-base-multilingual-cased) that handle a custom number of languages.
Unlike [distilbert-base-multilingual-cased](https://huggingface.co/distilbert-base-multilingual-cased), our versions give exactly the same representations produced by the original model which preserves the original accuracy.
For more information please visit our paper: [Load What You Need: Smaller Versions of Multilingual BERT](https://www.aclweb.org/anthology/2020.sustainlp-1.16.pdf).
## How to use
```python
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("Geotrend/bert-base-sw-cased")
model = AutoModel.from_pretrained("Geotrend/bert-base-sw-cased")
```
To generate other smaller versions of multilingual transformers please visit [our Github repo](https://github.com/Geotrend-research/smaller-transformers).
### How to cite
```bibtex
@inproceedings{smallermbert,
title={Load What You Need: Smaller Versions of Mutlilingual BERT},
author={Abdaoui, Amine and Pradel, Camille and Sigel, Grégoire},
booktitle={SustaiNLP / EMNLP},
year={2020}
}
```
## Contact
Please contact amine@geotrend.fr for any question, feedback or request.
|
Geotrend/bert-base-ro-cased
|
Geotrend
| 2021-05-18T20:08:29Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"jax",
"bert",
"fill-mask",
"ro",
"dataset:wikipedia",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:04Z |
---
language: ro
datasets: wikipedia
license: apache-2.0
---
# bert-base-ro-cased
We are sharing smaller versions of [bert-base-multilingual-cased](https://huggingface.co/bert-base-multilingual-cased) that handle a custom number of languages.
Unlike [distilbert-base-multilingual-cased](https://huggingface.co/distilbert-base-multilingual-cased), our versions give exactly the same representations produced by the original model which preserves the original accuracy.
For more information please visit our paper: [Load What You Need: Smaller Versions of Multilingual BERT](https://www.aclweb.org/anthology/2020.sustainlp-1.16.pdf).
## How to use
```python
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("Geotrend/bert-base-ro-cased")
model = AutoModel.from_pretrained("Geotrend/bert-base-ro-cased")
```
To generate other smaller versions of multilingual transformers please visit [our Github repo](https://github.com/Geotrend-research/smaller-transformers).
### How to cite
```bibtex
@inproceedings{smallermbert,
title={Load What You Need: Smaller Versions of Mutlilingual BERT},
author={Abdaoui, Amine and Pradel, Camille and Sigel, Grégoire},
booktitle={SustaiNLP / EMNLP},
year={2020}
}
```
## Contact
Please contact amine@geotrend.fr for any question, feedback or request.
|
Geotrend/bert-base-en-zh-hi-cased
|
Geotrend
| 2021-05-18T19:53:51Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"jax",
"bert",
"fill-mask",
"multilingual",
"dataset:wikipedia",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:04Z |
---
language: multilingual
datasets: wikipedia
license: apache-2.0
---
# bert-base-en-zh-hi-cased
We are sharing smaller versions of [bert-base-multilingual-cased](https://huggingface.co/bert-base-multilingual-cased) that handle a custom number of languages.
Unlike [distilbert-base-multilingual-cased](https://huggingface.co/distilbert-base-multilingual-cased), our versions give exactly the same representations produced by the original model which preserves the original accuracy.
For more information please visit our paper: [Load What You Need: Smaller Versions of Multilingual BERT](https://www.aclweb.org/anthology/2020.sustainlp-1.16.pdf).
## How to use
```python
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("Geotrend/bert-base-en-zh-hi-cased")
model = AutoModel.from_pretrained("Geotrend/bert-base-en-zh-hi-cased")
```
To generate other smaller versions of multilingual transformers please visit [our Github repo](https://github.com/Geotrend-research/smaller-transformers).
### How to cite
```bibtex
@inproceedings{smallermbert,
title={Load What You Need: Smaller Versions of Mutlilingual BERT},
author={Abdaoui, Amine and Pradel, Camille and Sigel, Grégoire},
booktitle={SustaiNLP / EMNLP},
year={2020}
}
```
## Contact
Please contact amine@geotrend.fr for any question, feedback or request.
|
Geotrend/bert-base-en-vi-cased
|
Geotrend
| 2021-05-18T19:51:36Z | 5 | 1 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"jax",
"bert",
"fill-mask",
"multilingual",
"dataset:wikipedia",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:04Z |
---
language: multilingual
datasets: wikipedia
license: apache-2.0
widget:
- text: "Google generated 46 billion [MASK] in revenue."
- text: "Paris is the capital of [MASK]."
- text: "Algiers is the largest city in [MASK]."
---
# bert-base-en-vi-cased
We are sharing smaller versions of [bert-base-multilingual-cased](https://huggingface.co/bert-base-multilingual-cased) that handle a custom number of languages.
Unlike [distilbert-base-multilingual-cased](https://huggingface.co/distilbert-base-multilingual-cased), our versions give exactly the same representations produced by the original model which preserves the original accuracy.
For more information please visit our paper: [Load What You Need: Smaller Versions of Multilingual BERT](https://www.aclweb.org/anthology/2020.sustainlp-1.16.pdf).
## How to use
```python
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("Geotrend/bert-base-en-vi-cased")
model = AutoModel.from_pretrained("Geotrend/bert-base-en-vi-cased")
```
To generate other smaller versions of multilingual transformers please visit [our Github repo](https://github.com/Geotrend-research/smaller-transformers).
### How to cite
```bibtex
@inproceedings{smallermbert,
title={Load What You Need: Smaller Versions of Mutlilingual BERT},
author={Abdaoui, Amine and Pradel, Camille and Sigel, Grégoire},
booktitle={SustaiNLP / EMNLP},
year={2020}
}
```
## Contact
Please contact amine@geotrend.fr for any question, feedback or request.
|
Geotrend/bert-base-en-ur-cased
|
Geotrend
| 2021-05-18T19:50:18Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"jax",
"bert",
"fill-mask",
"multilingual",
"dataset:wikipedia",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:04Z |
---
language: multilingual
datasets: wikipedia
license: apache-2.0
widget:
- text: "Google generated 46 billion [MASK] in revenue."
- text: "Paris is the capital of [MASK]."
- text: "Algiers is the largest city in [MASK]."
---
# bert-base-en-ur-cased
We are sharing smaller versions of [bert-base-multilingual-cased](https://huggingface.co/bert-base-multilingual-cased) that handle a custom number of languages.
Unlike [distilbert-base-multilingual-cased](https://huggingface.co/distilbert-base-multilingual-cased), our versions give exactly the same representations produced by the original model which preserves the original accuracy.
For more information please visit our paper: [Load What You Need: Smaller Versions of Multilingual BERT](https://www.aclweb.org/anthology/2020.sustainlp-1.16.pdf).
## How to use
```python
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("Geotrend/bert-base-en-ur-cased")
model = AutoModel.from_pretrained("Geotrend/bert-base-en-ur-cased")
```
To generate other smaller versions of multilingual transformers please visit [our Github repo](https://github.com/Geotrend-research/smaller-transformers).
### How to cite
```bibtex
@inproceedings{smallermbert,
title={Load What You Need: Smaller Versions of Mutlilingual BERT},
author={Abdaoui, Amine and Pradel, Camille and Sigel, Grégoire},
booktitle={SustaiNLP / EMNLP},
year={2020}
}
```
## Contact
Please contact amine@geotrend.fr for any question, feedback or request.
|
Geotrend/bert-base-en-no-cased
|
Geotrend
| 2021-05-18T19:40:40Z | 85 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"jax",
"bert",
"fill-mask",
"multilingual",
"dataset:wikipedia",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:04Z |
---
language: multilingual
datasets: wikipedia
license: apache-2.0
---
# bert-base-en-no-cased
We are sharing smaller versions of [bert-base-multilingual-cased](https://huggingface.co/bert-base-multilingual-cased) that handle a custom number of languages.
Unlike [distilbert-base-multilingual-cased](https://huggingface.co/distilbert-base-multilingual-cased), our versions give exactly the same representations produced by the original model which preserves the original accuracy.
For more information please visit our paper: [Load What You Need: Smaller Versions of Multilingual BERT](https://www.aclweb.org/anthology/2020.sustainlp-1.16.pdf).
## How to use
```python
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("Geotrend/bert-base-en-no-cased")
model = AutoModel.from_pretrained("Geotrend/bert-base-en-no-cased")
```
To generate other smaller versions of multilingual transformers please visit [our Github repo](https://github.com/Geotrend-research/smaller-transformers).
### How to cite
```bibtex
@inproceedings{smallermbert,
title={Load What You Need: Smaller Versions of Mutlilingual BERT},
author={Abdaoui, Amine and Pradel, Camille and Sigel, Grégoire},
booktitle={SustaiNLP / EMNLP},
year={2020}
}
```
## Contact
Please contact amine@geotrend.fr for any question, feedback or request.
|
Geotrend/bert-base-en-it-cased
|
Geotrend
| 2021-05-18T19:32:13Z | 10 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"jax",
"bert",
"fill-mask",
"multilingual",
"dataset:wikipedia",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:04Z |
---
language: multilingual
datasets: wikipedia
license: apache-2.0
---
# bert-base-en-it-cased
We are sharing smaller versions of [bert-base-multilingual-cased](https://huggingface.co/bert-base-multilingual-cased) that handle a custom number of languages.
Unlike [distilbert-base-multilingual-cased](https://huggingface.co/distilbert-base-multilingual-cased), our versions give exactly the same representations produced by the original model which preserves the original accuracy.
For more information please visit our paper: [Load What You Need: Smaller Versions of Multilingual BERT](https://www.aclweb.org/anthology/2020.sustainlp-1.16.pdf).
## How to use
```python
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("Geotrend/bert-base-en-it-cased")
model = AutoModel.from_pretrained("Geotrend/bert-base-en-it-cased")
```
To generate other smaller versions of multilingual transformers please visit [our Github repo](https://github.com/Geotrend-research/smaller-transformers).
### How to cite
```bibtex
@inproceedings{smallermbert,
title={Load What You Need: Smaller Versions of Mutlilingual BERT},
author={Abdaoui, Amine and Pradel, Camille and Sigel, Grégoire},
booktitle={SustaiNLP / EMNLP},
year={2020}
}
```
## Contact
Please contact amine@geotrend.fr for any question, feedback or request.
|
Geotrend/bert-base-en-hi-cased
|
Geotrend
| 2021-05-18T19:31:14Z | 8 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"jax",
"bert",
"fill-mask",
"multilingual",
"dataset:wikipedia",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:04Z |
---
language: multilingual
datasets: wikipedia
license: apache-2.0
widget:
- text: "Google generated 46 billion [MASK] in revenue."
- text: "Paris is the capital of [MASK]."
- text: "Algiers is the largest city in [MASK]."
---
# bert-base-en-hi-cased
We are sharing smaller versions of [bert-base-multilingual-cased](https://huggingface.co/bert-base-multilingual-cased) that handle a custom number of languages.
Unlike [distilbert-base-multilingual-cased](https://huggingface.co/distilbert-base-multilingual-cased), our versions give exactly the same representations produced by the original model which preserves the original accuracy.
For more information please visit our paper: [Load What You Need: Smaller Versions of Multilingual BERT](https://www.aclweb.org/anthology/2020.sustainlp-1.16.pdf).
## How to use
```python
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("Geotrend/bert-base-en-hi-cased")
model = AutoModel.from_pretrained("Geotrend/bert-base-en-hi-cased")
```
To generate other smaller versions of multilingual transformers please visit [our Github repo](https://github.com/Geotrend-research/smaller-transformers).
### How to cite
```bibtex
@inproceedings{smallermbert,
title={Load What You Need: Smaller Versions of Mutlilingual BERT},
author={Abdaoui, Amine and Pradel, Camille and Sigel, Grégoire},
booktitle={SustaiNLP / EMNLP},
year={2020}
}
```
## Contact
Please contact amine@geotrend.fr for any question, feedback or request.
|
Geotrend/bert-base-en-fr-zh-cased
|
Geotrend
| 2021-05-18T19:29:01Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"jax",
"bert",
"fill-mask",
"multilingual",
"dataset:wikipedia",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:04Z |
---
language: multilingual
datasets: wikipedia
license: apache-2.0
---
# bert-base-en-fr-zh-cased
We are sharing smaller versions of [bert-base-multilingual-cased](https://huggingface.co/bert-base-multilingual-cased) that handle a custom number of languages.
Unlike [distilbert-base-multilingual-cased](https://huggingface.co/distilbert-base-multilingual-cased), our versions give exactly the same representations produced by the original model which preserves the original accuracy.
For more information please visit our paper: [Load What You Need: Smaller Versions of Multilingual BERT](https://www.aclweb.org/anthology/2020.sustainlp-1.16.pdf).
## How to use
```python
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("Geotrend/bert-base-en-fr-zh-cased")
model = AutoModel.from_pretrained("Geotrend/bert-base-en-fr-zh-cased")
```
To generate other smaller versions of multilingual transformers please visit [our Github repo](https://github.com/Geotrend-research/smaller-transformers).
### How to cite
```bibtex
@inproceedings{smallermbert,
title={Load What You Need: Smaller Versions of Mutlilingual BERT},
author={Abdaoui, Amine and Pradel, Camille and Sigel, Grégoire},
booktitle={SustaiNLP / EMNLP},
year={2020}
}
```
## Contact
Please contact amine@geotrend.fr for any question, feedback or request.
|
Geotrend/bert-base-en-fr-uk-el-ro-cased
|
Geotrend
| 2021-05-18T19:27:52Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"jax",
"bert",
"fill-mask",
"multilingual",
"dataset:wikipedia",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:04Z |
---
language: multilingual
datasets: wikipedia
license: apache-2.0
---
# bert-base-en-fr-uk-el-ro-cased
We are sharing smaller versions of [bert-base-multilingual-cased](https://huggingface.co/bert-base-multilingual-cased) that handle a custom number of languages.
Unlike [distilbert-base-multilingual-cased](https://huggingface.co/distilbert-base-multilingual-cased), our versions give exactly the same representations produced by the original model which preserves the original accuracy.
For more information please visit our paper: [Load What You Need: Smaller Versions of Multilingual BERT](https://www.aclweb.org/anthology/2020.sustainlp-1.16.pdf).
## How to use
```python
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("Geotrend/bert-base-en-fr-uk-el-ro-cased")
model = AutoModel.from_pretrained("Geotrend/bert-base-en-fr-uk-el-ro-cased")
```
To generate other smaller versions of multilingual transformers please visit [our Github repo](https://github.com/Geotrend-research/smaller-transformers).
### How to cite
```bibtex
@inproceedings{smallermbert,
title={Load What You Need: Smaller Versions of Mutlilingual BERT},
author={Abdaoui, Amine and Pradel, Camille and Sigel, Grégoire},
booktitle={SustaiNLP / EMNLP},
year={2020}
}
```
## Contact
Please contact amine@geotrend.fr for any question, feedback or request.
|
Geotrend/bert-base-en-fr-es-cased
|
Geotrend
| 2021-05-18T19:21:01Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"jax",
"bert",
"fill-mask",
"multilingual",
"dataset:wikipedia",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:04Z |
---
language: multilingual
datasets: wikipedia
license: apache-2.0
---
# bert-base-en-fr-es-cased
We are sharing smaller versions of [bert-base-multilingual-cased](https://huggingface.co/bert-base-multilingual-cased) that handle a custom number of languages.
Unlike [distilbert-base-multilingual-cased](https://huggingface.co/distilbert-base-multilingual-cased), our versions give exactly the same representations produced by the original model which preserves the original accuracy.
For more information please visit our paper: [Load What You Need: Smaller Versions of Multilingual BERT](https://www.aclweb.org/anthology/2020.sustainlp-1.16.pdf).
## How to use
```python
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("Geotrend/bert-base-en-fr-es-cased")
model = AutoModel.from_pretrained("Geotrend/bert-base-en-fr-es-cased")
```
To generate other smaller versions of multilingual transformers please visit [our Github repo](https://github.com/Geotrend-research/smaller-transformers).
### How to cite
```bibtex
@inproceedings{smallermbert,
title={Load What You Need: Smaller Versions of Mutlilingual BERT},
author={Abdaoui, Amine and Pradel, Camille and Sigel, Grégoire},
booktitle={SustaiNLP / EMNLP},
year={2020}
}
```
## Contact
Please contact amine@geotrend.fr for any question, feedback or request.
|
Geotrend/bert-base-en-es-it-cased
|
Geotrend
| 2021-05-18T19:10:03Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"jax",
"bert",
"fill-mask",
"multilingual",
"dataset:wikipedia",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:04Z |
---
language: multilingual
datasets: wikipedia
license: apache-2.0
---
# bert-base-en-es-it-cased
We are sharing smaller versions of [bert-base-multilingual-cased](https://huggingface.co/bert-base-multilingual-cased) that handle a custom number of languages.
Unlike [distilbert-base-multilingual-cased](https://huggingface.co/distilbert-base-multilingual-cased), our versions give exactly the same representations produced by the original model which preserves the original accuracy.
For more information please visit our paper: [Load What You Need: Smaller Versions of Multilingual BERT](https://www.aclweb.org/anthology/2020.sustainlp-1.16.pdf).
## How to use
```python
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("Geotrend/bert-base-en-es-it-cased")
model = AutoModel.from_pretrained("Geotrend/bert-base-en-es-it-cased")
```
To generate other smaller versions of multilingual transformers please visit [our Github repo](https://github.com/Geotrend-research/smaller-transformers).
### How to cite
```bibtex
@inproceedings{smallermbert,
title={Load What You Need: Smaller Versions of Mutlilingual BERT},
author={Abdaoui, Amine and Pradel, Camille and Sigel, Grégoire},
booktitle={SustaiNLP / EMNLP},
year={2020}
}
```
## Contact
Please contact amine@geotrend.fr for any question, feedback or request.
|
Geotrend/bert-base-en-cased
|
Geotrend
| 2021-05-18T19:03:33Z | 12 | 1 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"jax",
"bert",
"fill-mask",
"en",
"dataset:wikipedia",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:04Z |
---
language: en
datasets: wikipedia
license: apache-2.0
widget:
- text: "Google generated 46 billion [MASK] in revenue."
- text: "Paris is the capital of [MASK]."
- text: "Algiers is the largest city in [MASK]."
---
# bert-base-en-cased
We are sharing smaller versions of [bert-base-multilingual-cased](https://huggingface.co/bert-base-multilingual-cased) that handle a custom number of languages.
Unlike [distilbert-base-multilingual-cased](https://huggingface.co/distilbert-base-multilingual-cased), our versions give exactly the same representations produced by the original model which preserves the original accuracy.
For more information please visit our paper: [Load What You Need: Smaller Versions of Multilingual BERT](https://www.aclweb.org/anthology/2020.sustainlp-1.16.pdf).
## How to use
```python
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("Geotrend/bert-base-en-cased")
model = AutoModel.from_pretrained("Geotrend/bert-base-en-cased")
```
To generate other smaller versions of multilingual transformers please visit [our Github repo](https://github.com/Geotrend-research/smaller-transformers).
### How to cite
```bibtex
@inproceedings{smallermbert,
title={Load What You Need: Smaller Versions of Mutlilingual BERT},
author={Abdaoui, Amine and Pradel, Camille and Sigel, Grégoire},
booktitle={SustaiNLP / EMNLP},
year={2020}
}
```
## Contact
Please contact amine@geotrend.fr for any question, feedback or request.
|
Geotrend/bert-base-el-cased
|
Geotrend
| 2021-05-18T19:00:19Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"jax",
"bert",
"fill-mask",
"el",
"dataset:wikipedia",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:04Z |
---
language: el
datasets: wikipedia
license: apache-2.0
---
# bert-base-el-cased
We are sharing smaller versions of [bert-base-multilingual-cased](https://huggingface.co/bert-base-multilingual-cased) that handle a custom number of languages.
Unlike [distilbert-base-multilingual-cased](https://huggingface.co/distilbert-base-multilingual-cased), our versions give exactly the same representations produced by the original model which preserves the original accuracy.
For more information please visit our paper: [Load What You Need: Smaller Versions of Multilingual BERT](https://www.aclweb.org/anthology/2020.sustainlp-1.16.pdf).
## How to use
```python
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("Geotrend/bert-base-el-cased")
model = AutoModel.from_pretrained("Geotrend/bert-base-el-cased")
```
To generate other smaller versions of multilingual transformers please visit [our Github repo](https://github.com/Geotrend-research/smaller-transformers).
### How to cite
```bibtex
@inproceedings{smallermbert,
title={Load What You Need: Smaller Versions of Mutlilingual BERT},
author={Abdaoui, Amine and Pradel, Camille and Sigel, Grégoire},
booktitle={SustaiNLP / EMNLP},
year={2020}
}
```
## Contact
Please contact amine@geotrend.fr for any question, feedback or request.
|
Geotrend/bert-base-da-cased
|
Geotrend
| 2021-05-18T18:49:40Z | 80 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"jax",
"bert",
"fill-mask",
"da",
"dataset:wikipedia",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:04Z |
---
language: da
datasets: wikipedia
license: apache-2.0
---
# bert-base-da-cased
We are sharing smaller versions of [bert-base-multilingual-cased](https://huggingface.co/bert-base-multilingual-cased) that handle a custom number of languages.
Unlike [distilbert-base-multilingual-cased](https://huggingface.co/distilbert-base-multilingual-cased), our versions give exactly the same representations produced by the original model which preserves the original accuracy.
For more information please visit our paper: [Load What You Need: Smaller Versions of Multilingual BERT](https://www.aclweb.org/anthology/2020.sustainlp-1.16.pdf).
## How to use
```python
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("Geotrend/bert-base-da-cased")
model = AutoModel.from_pretrained("Geotrend/bert-base-da-cased")
```
To generate other smaller versions of multilingual transformers please visit [our Github repo](https://github.com/Geotrend-research/smaller-transformers).
### How to cite
```bibtex
@inproceedings{smallermbert,
title={Load What You Need: Smaller Versions of Mutlilingual BERT},
author={Abdaoui, Amine and Pradel, Camille and Sigel, Grégoire},
booktitle={SustaiNLP / EMNLP},
year={2020}
}
```
## Contact
Please contact amine@geotrend.fr for any question, feedback or request.
|
Geotrend/bert-base-25lang-cased
|
Geotrend
| 2021-05-18T18:46:59Z | 88 | 2 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"jax",
"bert",
"fill-mask",
"multilingual",
"dataset:wikipedia",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:04Z |
---
language: multilingual
datasets: wikipedia
license: apache-2.0
widget:
- text: "Google generated 46 billion [MASK] in revenue."
- text: "Paris is the capital of [MASK]."
- text: "Algiers is the largest city in [MASK]."
- text: "Paris est la [MASK] de la France."
- text: "Paris est la capitale de la [MASK]."
- text: "L'élection américaine a eu [MASK] en novembre 2020."
- text: "تقع سويسرا في [MASK] أوروبا"
- text: "إسمي محمد وأسكن في [MASK]."
---
# bert-base-25lang-cased
We are sharing smaller versions of [bert-base-multilingual-cased](https://huggingface.co/bert-base-multilingual-cased) that handle a custom number of languages.
Unlike [distilbert-base-multilingual-cased](https://huggingface.co/distilbert-base-multilingual-cased), our versions give exactly the same representations produced by the original model which preserves the original accuracy.
Handled languages: en, fr, es, de, zh, ar, ru, vi, el, bg, th, tr, hi, ur, sw, nl, uk, ro, pt, it, lt, no, pl, da and ja.
For more information please visit our paper: [Load What You Need: Smaller Versions of Multilingual BERT](https://www.aclweb.org/anthology/2020.sustainlp-1.16.pdf).
## How to use
```python
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("Geotrend/bert-base-25lang-cased")
model = AutoModel.from_pretrained("Geotrend/bert-base-25lang-cased")
```
To generate other smaller versions of multilingual transformers please visit [our Github repo](https://github.com/Geotrend-research/smaller-transformers).
### How to cite
```bibtex
@inproceedings{smallermbert,
title={Load What You Need: Smaller Versions of Multilingual BERT},
author={Abdaoui, Amine and Pradel, Camille and Sigel, Grégoire},
booktitle={SustaiNLP / EMNLP},
year={2020}
}
```
## Contact
Please contact amine@geotrend.fr for any question, feedback or request.
|
EMBEDDIA/crosloengual-bert
|
EMBEDDIA
| 2021-05-18T18:21:38Z | 280 | 4 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"fill-mask",
"hr",
"sl",
"en",
"multilingual",
"arxiv:2006.07890",
"license:cc-by-4.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:04Z |
---
language:
- hr
- sl
- en
- multilingual
license: cc-by-4.0
---
# CroSloEngual BERT
CroSloEngual BERT is a trilingual model, using bert-base architecture, trained on Croatian, Slovenian, and English corpora. Focusing on three languages, the model performs better than [multilingual BERT](https://huggingface.co/bert-base-multilingual-cased), while still offering an option for cross-lingual knowledge transfer, which a monolingual model wouldn't.
Evaluation is presented in our article:
```
@Inproceedings{ulcar-robnik2020finest,
author = "Ulčar, M. and Robnik-Šikonja, M.",
year = 2020,
title = "{FinEst BERT} and {CroSloEngual BERT}: less is more in multilingual models",
editor = "Sojka, P and Kopeček, I and Pala, K and Horák, A",
booktitle = "Text, Speech, and Dialogue {TSD 2020}",
series = "Lecture Notes in Computer Science",
volume = 12284,
publisher = "Springer",
url = "https://doi.org/10.1007/978-3-030-58323-1_11",
}
```
The preprint is available at [arxiv.org/abs/2006.07890](https://arxiv.org/abs/2006.07890).
|
DeepPavlov/rubert-base-cased-sentence
|
DeepPavlov
| 2021-05-18T18:18:43Z | 30,038 | 24 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"feature-extraction",
"ru",
"arxiv:1508.05326",
"arxiv:1809.05053",
"arxiv:1908.10084",
"endpoints_compatible",
"region:us"
] |
feature-extraction
| 2022-03-02T23:29:04Z |
---
language:
- ru
---
# rubert-base-cased-sentence
Sentence RuBERT \(Russian, cased, 12-layer, 768-hidden, 12-heads, 180M parameters\) is a representation‑based sentence encoder for Russian. It is initialized with RuBERT and fine‑tuned on SNLI\[1\] google-translated to russian and on russian part of XNLI dev set\[2\]. Sentence representations are mean pooled token embeddings in the same manner as in Sentence‑BERT\[3\].
\[1\]: S. R. Bowman, G. Angeli, C. Potts, and C. D. Manning. \(2015\) A large annotated corpus for learning natural language inference. arXiv preprint [arXiv:1508.05326](https://arxiv.org/abs/1508.05326)
\[2\]: Williams A., Bowman S. \(2018\) XNLI: Evaluating Cross-lingual Sentence Representations. arXiv preprint [arXiv:1809.05053](https://arxiv.org/abs/1809.05053)
\[3\]: N. Reimers, I. Gurevych \(2019\) Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. arXiv preprint [arXiv:1908.10084](https://arxiv.org/abs/1908.10084)
|
DeepPavlov/bert-base-multilingual-cased-sentence
|
DeepPavlov
| 2021-05-18T18:16:12Z | 33 | 4 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"feature-extraction",
"multilingual",
"arxiv:1704.05426",
"arxiv:1809.05053",
"arxiv:1908.10084",
"endpoints_compatible",
"region:us"
] |
feature-extraction
| 2022-03-02T23:29:04Z |
---
language:
- multilingual
---
# bert-base-multilingual-cased-sentence
Sentence Multilingual BERT \(101 languages, cased, 12‑layer, 768‑hidden, 12‑heads, 180M parameters\) is a representation‑based sentence encoder for 101 languages of Multilingual BERT. It is initialized with Multilingual BERT and then fine‑tuned on english MultiNLI\[1\] and on dev set of multilingual XNLI\[2\]. Sentence representations are mean pooled token embeddings in the same manner as in Sentence‑BERT\[3\].
\[1\]: Williams A., Nangia N. & Bowman S. \(2017\) A Broad-Coverage Challenge Corpus for Sentence Understanding through Inference. arXiv preprint [arXiv:1704.05426](https://arxiv.org/abs/1704.05426)
\[2\]: Williams A., Bowman S. \(2018\) XNLI: Evaluating Cross-lingual Sentence Representations. arXiv preprint [arXiv:1809.05053](https://arxiv.org/abs/1809.05053)
\[3\]: N. Reimers, I. Gurevych \(2019\) Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. arXiv preprint [arXiv:1908.10084](https://arxiv.org/abs/1908.10084)
|
Subsets and Splits
Filtered Qwen2.5 Distill Models
Identifies specific configurations of models by filtering cards that contain 'distill', 'qwen2.5', '7b' while excluding certain base models and incorrect model ID patterns, uncovering unique model variants.
Filtered Model Cards Count
Finds the count of entries with specific card details that include 'distill', 'qwen2.5', '7b' but exclude certain base models, revealing valuable insights about the dataset's content distribution.
Filtered Distill Qwen 7B Models
Filters for specific card entries containing 'distill', 'qwen', and '7b', excluding certain strings and patterns, to identify relevant model configurations.
Filtered Qwen-7b Model Cards
The query performs a detailed filtering based on specific keywords and excludes certain entries, which could be useful for identifying a specific subset of cards but does not provide deeper insights or trends.
Filtered Qwen 7B Model Cards
The query filters for specific terms related to "distilled" or "distill", "qwen", and "7b" in the 'card' column but excludes certain base models, providing a limited set of entries for further inspection.
Qwen 7B Distilled Models
The query provides a basic filtering of records to find specific card names that include keywords related to distilled Qwen 7b models, excluding a particular base model, which gives limited insight but helps in focusing on relevant entries.
Qwen 7B Distilled Model Cards
The query filters data based on specific keywords in the modelId and card fields, providing limited insight primarily useful for locating specific entries rather than revealing broad patterns or trends.
Qwen 7B Distilled Models
Finds all entries containing the terms 'distilled', 'qwen', and '7b' in a case-insensitive manner, providing a filtered set of records but without deeper analysis.
Distilled Qwen 7B Models
The query filters for specific model IDs containing 'distilled', 'qwen', and '7b', providing a basic retrieval of relevant entries but without deeper analysis or insight.
Filtered Model Cards with Distill Qwen2.
Filters and retrieves records containing specific keywords in the card description while excluding certain phrases, providing a basic count of relevant entries.
Filtered Model Cards with Distill Qwen 7
The query filters specific variations of card descriptions containing 'distill', 'qwen', and '7b' while excluding a particular base model, providing limited but specific data retrieval.
Distill Qwen 7B Model Cards
The query filters and retrieves rows where the 'card' column contains specific keywords ('distill', 'qwen', and '7b'), providing a basic filter result that can help in identifying specific entries.