
modelId
stringlengths 5
139
| author
stringlengths 2
42
| last_modified
timestamp[us, tz=UTC]date 2020-02-15 11:33:14
2025-09-06 06:27:01
| downloads
int64 0
223M
| likes
int64 0
11.7k
| library_name
stringclasses 542
values | tags
listlengths 1
4.05k
| pipeline_tag
stringclasses 55
values | createdAt
timestamp[us, tz=UTC]date 2022-03-02 23:29:04
2025-09-06 06:26:44
| card
stringlengths 11
1.01M
|
|---|---|---|---|---|---|---|---|---|---|
choblue95/lerobot_test
|
choblue95
| 2025-09-05T10:07:16Z | 0 | 0 |
lerobot
|
[
"lerobot",
"safetensors",
"robotics",
"smolvla",
"dataset:lerobot/svla_so101_pickplace",
"arxiv:2506.01844",
"base_model:lerobot/smolvla_base",
"base_model:finetune:lerobot/smolvla_base",
"license:apache-2.0",
"region:us"
] |
robotics
| 2025-09-05T10:06:26Z |
---
base_model: lerobot/smolvla_base
datasets: lerobot/svla_so101_pickplace
library_name: lerobot
license: apache-2.0
model_name: smolvla
pipeline_tag: robotics
tags:
- lerobot
- robotics
- smolvla
---
# Model Card for smolvla
<!-- Provide a quick summary of what the model is/does. -->
[SmolVLA](https://huggingface.co/papers/2506.01844) is a compact, efficient vision-language-action model that achieves competitive performance at reduced computational costs and can be deployed on consumer-grade hardware.
This policy has been trained and pushed to the Hub using [LeRobot](https://github.com/huggingface/lerobot).
See the full documentation at [LeRobot Docs](https://huggingface.co/docs/lerobot/index).
---
## How to Get Started with the Model
For a complete walkthrough, see the [training guide](https://huggingface.co/docs/lerobot/il_robots#train-a-policy).
Below is the short version on how to train and run inference/eval:
### Train from scratch
```bash
lerobot-train \
--dataset.repo_id=${HF_USER}/<dataset> \
--policy.type=act \
--output_dir=outputs/train/<desired_policy_repo_id> \
--job_name=lerobot_training \
--policy.device=cuda \
--policy.repo_id=${HF_USER}/<desired_policy_repo_id>
--wandb.enable=true
```
_Writes checkpoints to `outputs/train/<desired_policy_repo_id>/checkpoints/`._
### Evaluate the policy/run inference
```bash
lerobot-record \
--robot.type=so100_follower \
--dataset.repo_id=<hf_user>/eval_<dataset> \
--policy.path=<hf_user>/<desired_policy_repo_id> \
--episodes=10
```
Prefix the dataset repo with **eval\_** and supply `--policy.path` pointing to a local or hub checkpoint.
---
## Model Details
- **License:** apache-2.0
|
lohith-chanchu/reranker-gte-multilingual-reranker-base-custom-bce
|
lohith-chanchu
| 2025-09-05T10:06:44Z | 0 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"safetensors",
"new",
"cross-encoder",
"reranker",
"generated_from_trainer",
"dataset_size:447164",
"loss:BinaryCrossEntropyLoss",
"text-ranking",
"custom_code",
"en",
"arxiv:1908.10084",
"base_model:Alibaba-NLP/gte-multilingual-reranker-base",
"base_model:finetune:Alibaba-NLP/gte-multilingual-reranker-base",
"license:apache-2.0",
"model-index",
"region:us"
] |
text-ranking
| 2025-09-05T10:06:16Z |
---
language:
- en
license: apache-2.0
tags:
- sentence-transformers
- cross-encoder
- reranker
- generated_from_trainer
- dataset_size:447164
- loss:BinaryCrossEntropyLoss
base_model: Alibaba-NLP/gte-multilingual-reranker-base
pipeline_tag: text-ranking
library_name: sentence-transformers
metrics:
- map
- mrr@10
- ndcg@10
model-index:
- name: Reranker trained on Custom Dataset
results:
- task:
type: cross-encoder-reranking
name: Cross Encoder Reranking
dataset:
name: custom dev
type: custom-dev
metrics:
- type: map
value: 0.3148
name: Map
- type: mrr@10
value: 0.3228
name: Mrr@10
- type: ndcg@10
value: 0.3455
name: Ndcg@10
---
# Reranker trained on Custom Dataset
This is a [Cross Encoder](https://www.sbert.net/docs/cross_encoder/usage/usage.html) model finetuned from [Alibaba-NLP/gte-multilingual-reranker-base](https://huggingface.co/Alibaba-NLP/gte-multilingual-reranker-base) using the [sentence-transformers](https://www.SBERT.net) library. It computes scores for pairs of texts, which can be used for text reranking and semantic search.
## Model Details
### Model Description
- **Model Type:** Cross Encoder
- **Base model:** [Alibaba-NLP/gte-multilingual-reranker-base](https://huggingface.co/Alibaba-NLP/gte-multilingual-reranker-base) <!-- at revision 8215cf04918ba6f7b6a62bb44238ce2953d8831c -->
- **Maximum Sequence Length:** 8192 tokens
- **Number of Output Labels:** 1 label
<!-- - **Training Dataset:** Unknown -->
- **Language:** en
- **License:** apache-2.0
### Model Sources
- **Documentation:** [Sentence Transformers Documentation](https://sbert.net)
- **Documentation:** [Cross Encoder Documentation](https://www.sbert.net/docs/cross_encoder/usage/usage.html)
- **Repository:** [Sentence Transformers on GitHub](https://github.com/UKPLab/sentence-transformers)
- **Hugging Face:** [Cross Encoders on Hugging Face](https://huggingface.co/models?library=sentence-transformers&other=cross-encoder)
## Usage
### Direct Usage (Sentence Transformers)
First install the Sentence Transformers library:
```bash
pip install -U sentence-transformers
```
Then you can load this model and run inference.
```python
from sentence_transformers import CrossEncoder
# Download from the 🤗 Hub
model = CrossEncoder("lohith-chanchu/reranker-gte-multilingual-reranker-base-custom-bce")
# Get scores for pairs of texts
pairs = [
['Gaskugelhahn, Gewinde, DN 32 Gaskugelhahn, zum manuellen Absperren, geeignet für Erdgas, PN 6, nach DIN EN 331, Gehäuse aus Pressmessing, in Durchgangsform, beid seits Gewindeanschluss, DIN-DVGW-zugelassen, DN 32, einschließlich Übergangsstücke sowie Verbindungs-, Dichtungs- und Befestigungsma terial', 'DITECH Gas-KH m gelbem Hebelgriff und vollem Durchgang 11/4"'],
['Gaskugelhahn, Gewinde, DN 40 jedoch DN 40', 'DITECH Gas-KH m gelbem Hebelgriff und vollem Durchgang 11/2"'],
['Gaskugelhahn, Gewinde, DN 50 jedoch DN 50', 'DITECH Gas-KH m gelbem Hebelgriff und vollem Durchgang 2"'],
['Doppelnippel, Stahl, DN 15, Montagehöhe bis 6,0 m Doppelnippel, aus Kohlenstoffstahl, für Rohrleitung aus mittelschwerem Stahlrohr DIN EN 10255, mit Außengewinde 1/2 , Montagehöhe üb er Gelände / Fußboden bis 6,0 m', 'HS Rohrdoppelnippel Nr. 23 schwarz 1/2" 100mm'],
['Doppelnippel, Stahl, DN 20, Montagehöhe bis 6,0 m jedoch Außengewinde 3/4', 'HS Rohrdoppelnippel Nr. 23 schwarz 3/4" 100mm'],
]
scores = model.predict(pairs)
print(scores.shape)
# (5,)
# Or rank different texts based on similarity to a single text
ranks = model.rank(
'Gaskugelhahn, Gewinde, DN 32 Gaskugelhahn, zum manuellen Absperren, geeignet für Erdgas, PN 6, nach DIN EN 331, Gehäuse aus Pressmessing, in Durchgangsform, beid seits Gewindeanschluss, DIN-DVGW-zugelassen, DN 32, einschließlich Übergangsstücke sowie Verbindungs-, Dichtungs- und Befestigungsma terial',
[
'DITECH Gas-KH m gelbem Hebelgriff und vollem Durchgang 11/4"',
'DITECH Gas-KH m gelbem Hebelgriff und vollem Durchgang 11/2"',
'DITECH Gas-KH m gelbem Hebelgriff und vollem Durchgang 2"',
'HS Rohrdoppelnippel Nr. 23 schwarz 1/2" 100mm',
'HS Rohrdoppelnippel Nr. 23 schwarz 3/4" 100mm',
]
)
# [{'corpus_id': ..., 'score': ...}, {'corpus_id': ..., 'score': ...}, ...]
```
<!--
### Direct Usage (Transformers)
<details><summary>Click to see the direct usage in Transformers</summary>
</details>
-->
<!--
### Downstream Usage (Sentence Transformers)
You can finetune this model on your own dataset.
<details><summary>Click to expand</summary>
</details>
-->
<!--
### Out-of-Scope Use
*List how the model may foreseeably be misused and address what users ought not to do with the model.*
-->
## Evaluation
### Metrics
#### Cross Encoder Reranking
* Dataset: `custom-dev`
* Evaluated with [<code>CrossEncoderRerankingEvaluator</code>](https://sbert.net/docs/package_reference/cross_encoder/evaluation.html#sentence_transformers.cross_encoder.evaluation.CrossEncoderRerankingEvaluator) with these parameters:
```json
{
"at_k": 10,
"always_rerank_positives": false
}
```
| Metric | Value |
|:------------|:---------------------|
| map | 0.3148 (+0.1281) |
| mrr@10 | 0.3228 (+0.1424) |
| **ndcg@10** | **0.3455 (+0.1352)** |
<!--
## Bias, Risks and Limitations
*What are the known or foreseeable issues stemming from this model? You could also flag here known failure cases or weaknesses of the model.*
-->
<!--
### Recommendations
*What are recommendations with respect to the foreseeable issues? For example, filtering explicit content.*
-->
## Training Details
### Training Dataset
#### Unnamed Dataset
* Size: 447,164 training samples
* Columns: <code>query</code>, <code>answer</code>, and <code>label</code>
* Approximate statistics based on the first 1000 samples:
| | query | answer | label |
|:--------|:--------------------------------------------------------------------------------------------------|:----------------------------------------------------------------------------------------------|:------------------------------------------------|
| type | string | string | int |
| details | <ul><li>min: 27 characters</li><li>mean: 434.65 characters</li><li>max: 2905 characters</li></ul> | <ul><li>min: 0 characters</li><li>mean: 52.08 characters</li><li>max: 81 characters</li></ul> | <ul><li>0: ~33.70%</li><li>1: ~66.30%</li></ul> |
* Samples:
| query | answer | label |
|:---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|:--------------------------------------------------------------------------|:---------------|
| <code>Gaskugelhahn, Gewinde, DN 32 Gaskugelhahn, zum manuellen Absperren, geeignet für Erdgas, PN 6, nach DIN EN 331, Gehäuse aus Pressmessing, in Durchgangsform, beid seits Gewindeanschluss, DIN-DVGW-zugelassen, DN 32, einschließlich Übergangsstücke sowie Verbindungs-, Dichtungs- und Befestigungsma terial</code> | <code>DITECH Gas-KH m gelbem Hebelgriff und vollem Durchgang 11/4"</code> | <code>1</code> |
| <code>Gaskugelhahn, Gewinde, DN 40 jedoch DN 40</code> | <code>DITECH Gas-KH m gelbem Hebelgriff und vollem Durchgang 11/2"</code> | <code>1</code> |
| <code>Gaskugelhahn, Gewinde, DN 50 jedoch DN 50</code> | <code>DITECH Gas-KH m gelbem Hebelgriff und vollem Durchgang 2"</code> | <code>1</code> |
* Loss: [<code>BinaryCrossEntropyLoss</code>](https://sbert.net/docs/package_reference/cross_encoder/losses.html#binarycrossentropyloss) with these parameters:
```json
{
"activation_fn": "torch.nn.modules.linear.Identity",
"pos_weight": 5
}
```
### Training Hyperparameters
#### Non-Default Hyperparameters
- `eval_strategy`: epoch
- `per_device_train_batch_size`: 100
- `per_device_eval_batch_size`: 100
- `learning_rate`: 2e-05
- `num_train_epochs`: 2
- `warmup_ratio`: 0.1
- `seed`: 12
- `bf16`: True
- `dataloader_num_workers`: 4
- `load_best_model_at_end`: True
#### All Hyperparameters
<details><summary>Click to expand</summary>
- `overwrite_output_dir`: False
- `do_predict`: False
- `eval_strategy`: epoch
- `prediction_loss_only`: True
- `per_device_train_batch_size`: 100
- `per_device_eval_batch_size`: 100
- `per_gpu_train_batch_size`: None
- `per_gpu_eval_batch_size`: None
- `gradient_accumulation_steps`: 1
- `eval_accumulation_steps`: None
- `torch_empty_cache_steps`: None
- `learning_rate`: 2e-05
- `weight_decay`: 0.0
- `adam_beta1`: 0.9
- `adam_beta2`: 0.999
- `adam_epsilon`: 1e-08
- `max_grad_norm`: 1.0
- `num_train_epochs`: 2
- `max_steps`: -1
- `lr_scheduler_type`: linear
- `lr_scheduler_kwargs`: {}
- `warmup_ratio`: 0.1
- `warmup_steps`: 0
- `log_level`: passive
- `log_level_replica`: warning
- `log_on_each_node`: True
- `logging_nan_inf_filter`: True
- `save_safetensors`: True
- `save_on_each_node`: False
- `save_only_model`: False
- `restore_callback_states_from_checkpoint`: False
- `no_cuda`: False
- `use_cpu`: False
- `use_mps_device`: False
- `seed`: 12
- `data_seed`: None
- `jit_mode_eval`: False
- `use_ipex`: False
- `bf16`: True
- `fp16`: False
- `fp16_opt_level`: O1
- `half_precision_backend`: auto
- `bf16_full_eval`: False
- `fp16_full_eval`: False
- `tf32`: None
- `local_rank`: 0
- `ddp_backend`: None
- `tpu_num_cores`: None
- `tpu_metrics_debug`: False
- `debug`: []
- `dataloader_drop_last`: False
- `dataloader_num_workers`: 4
- `dataloader_prefetch_factor`: None
- `past_index`: -1
- `disable_tqdm`: False
- `remove_unused_columns`: True
- `label_names`: None
- `load_best_model_at_end`: True
- `ignore_data_skip`: False
- `fsdp`: []
- `fsdp_min_num_params`: 0
- `fsdp_config`: {'min_num_params': 0, 'xla': False, 'xla_fsdp_v2': False, 'xla_fsdp_grad_ckpt': False}
- `fsdp_transformer_layer_cls_to_wrap`: None
- `accelerator_config`: {'split_batches': False, 'dispatch_batches': None, 'even_batches': True, 'use_seedable_sampler': True, 'non_blocking': False, 'gradient_accumulation_kwargs': None}
- `parallelism_config`: None
- `deepspeed`: None
- `label_smoothing_factor`: 0.0
- `optim`: adamw_torch_fused
- `optim_args`: None
- `adafactor`: False
- `group_by_length`: False
- `length_column_name`: length
- `ddp_find_unused_parameters`: None
- `ddp_bucket_cap_mb`: None
- `ddp_broadcast_buffers`: False
- `dataloader_pin_memory`: True
- `dataloader_persistent_workers`: False
- `skip_memory_metrics`: True
- `use_legacy_prediction_loop`: False
- `push_to_hub`: False
- `resume_from_checkpoint`: None
- `hub_model_id`: None
- `hub_strategy`: every_save
- `hub_private_repo`: None
- `hub_always_push`: False
- `hub_revision`: None
- `gradient_checkpointing`: False
- `gradient_checkpointing_kwargs`: None
- `include_inputs_for_metrics`: False
- `include_for_metrics`: []
- `eval_do_concat_batches`: True
- `fp16_backend`: auto
- `push_to_hub_model_id`: None
- `push_to_hub_organization`: None
- `mp_parameters`:
- `auto_find_batch_size`: False
- `full_determinism`: False
- `torchdynamo`: None
- `ray_scope`: last
- `ddp_timeout`: 1800
- `torch_compile`: False
- `torch_compile_backend`: None
- `torch_compile_mode`: None
- `include_tokens_per_second`: False
- `include_num_input_tokens_seen`: False
- `neftune_noise_alpha`: None
- `optim_target_modules`: None
- `batch_eval_metrics`: False
- `eval_on_start`: False
- `use_liger_kernel`: False
- `liger_kernel_config`: None
- `eval_use_gather_object`: False
- `average_tokens_across_devices`: False
- `prompts`: None
- `batch_sampler`: batch_sampler
- `multi_dataset_batch_sampler`: proportional
- `router_mapping`: {}
- `learning_rate_mapping`: {}
</details>
### Training Logs
| Epoch | Step | Training Loss | custom-dev_ndcg@10 |
|:-------:|:--------:|:-------------:|:--------------------:|
| 0.0002 | 1 | 1.5605 | - |
| 0.0224 | 100 | 0.9229 | - |
| 0.0447 | 200 | 0.4384 | - |
| 0.0671 | 300 | 0.3577 | - |
| 0.0894 | 400 | 0.3024 | - |
| 0.1118 | 500 | 0.267 | - |
| 0.1342 | 600 | 0.2393 | - |
| 0.1565 | 700 | 0.2228 | - |
| 0.1789 | 800 | 0.2196 | - |
| 0.2013 | 900 | 0.1812 | - |
| 0.2236 | 1000 | 0.2003 | - |
| 0.2460 | 1100 | 0.1756 | - |
| 0.2683 | 1200 | 0.1652 | - |
| 0.2907 | 1300 | 0.1529 | - |
| 0.3131 | 1400 | 0.1652 | - |
| 0.3354 | 1500 | 0.1327 | - |
| 0.3578 | 1600 | 0.1273 | - |
| 0.3801 | 1700 | 0.124 | - |
| 0.4025 | 1800 | 0.1371 | - |
| 0.4249 | 1900 | 0.1239 | - |
| 0.4472 | 2000 | 0.1252 | - |
| 0.4696 | 2100 | 0.115 | - |
| 0.4919 | 2200 | 0.116 | - |
| 0.5143 | 2300 | 0.1115 | - |
| 0.5367 | 2400 | 0.1157 | - |
| 0.5590 | 2500 | 0.1126 | - |
| 0.5814 | 2600 | 0.1071 | - |
| 0.6038 | 2700 | 0.1162 | - |
| 0.6261 | 2800 | 0.1088 | - |
| 0.6485 | 2900 | 0.1032 | - |
| 0.6708 | 3000 | 0.1086 | - |
| 0.6932 | 3100 | 0.0926 | - |
| 0.7156 | 3200 | 0.0846 | - |
| 0.7379 | 3300 | 0.0931 | - |
| 0.7603 | 3400 | 0.1053 | - |
| 0.7826 | 3500 | 0.0825 | - |
| 0.8050 | 3600 | 0.1116 | - |
| 0.8274 | 3700 | 0.0917 | - |
| 0.8497 | 3800 | 0.0907 | - |
| 0.8721 | 3900 | 0.0774 | - |
| 0.8945 | 4000 | 0.0789 | - |
| 0.9168 | 4100 | 0.0792 | - |
| 0.9392 | 4200 | 0.0933 | - |
| 0.9615 | 4300 | 0.0893 | - |
| 0.9839 | 4400 | 0.0993 | - |
| 1.0 | 4472 | - | 0.3409 (+0.1306) |
| 1.0063 | 4500 | 0.0755 | - |
| 1.0286 | 4600 | 0.0551 | - |
| 1.0510 | 4700 | 0.0626 | - |
| 1.0733 | 4800 | 0.0694 | - |
| 1.0957 | 4900 | 0.0537 | - |
| 1.1181 | 5000 | 0.0557 | - |
| 1.1404 | 5100 | 0.0694 | - |
| 1.1628 | 5200 | 0.0621 | - |
| 1.1852 | 5300 | 0.0661 | - |
| 1.2075 | 5400 | 0.0494 | - |
| 1.2299 | 5500 | 0.0607 | - |
| 1.2522 | 5600 | 0.0561 | - |
| 1.2746 | 5700 | 0.0513 | - |
| 1.2970 | 5800 | 0.0617 | - |
| 1.3193 | 5900 | 0.0435 | - |
| 1.3417 | 6000 | 0.0659 | - |
| 1.3640 | 6100 | 0.0597 | - |
| 1.3864 | 6200 | 0.0668 | - |
| 1.4088 | 6300 | 0.0557 | - |
| 1.4311 | 6400 | 0.0566 | - |
| 1.4535 | 6500 | 0.0632 | - |
| 1.4758 | 6600 | 0.0573 | - |
| 1.4982 | 6700 | 0.0634 | - |
| 1.5206 | 6800 | 0.054 | - |
| 1.5429 | 6900 | 0.0392 | - |
| 1.5653 | 7000 | 0.046 | - |
| 1.5877 | 7100 | 0.0562 | - |
| 1.6100 | 7200 | 0.0443 | - |
| 1.6324 | 7300 | 0.0757 | - |
| 1.6547 | 7400 | 0.0555 | - |
| 1.6771 | 7500 | 0.0345 | - |
| 1.6995 | 7600 | 0.0525 | - |
| 1.7218 | 7700 | 0.0595 | - |
| 1.7442 | 7800 | 0.0561 | - |
| 1.7665 | 7900 | 0.0484 | - |
| 1.7889 | 8000 | 0.0465 | - |
| 1.8113 | 8100 | 0.0501 | - |
| 1.8336 | 8200 | 0.0411 | - |
| 1.8560 | 8300 | 0.0386 | - |
| 1.8784 | 8400 | 0.0477 | - |
| 1.9007 | 8500 | 0.0517 | - |
| 1.9231 | 8600 | 0.0338 | - |
| 1.9454 | 8700 | 0.0466 | - |
| 1.9678 | 8800 | 0.062 | - |
| 1.9902 | 8900 | 0.0647 | - |
| **2.0** | **8944** | **-** | **0.3455 (+0.1352)** |
| -1 | -1 | - | 0.3455 (+0.1352) |
* The bold row denotes the saved checkpoint.
### Framework Versions
- Python: 3.10.18
- Sentence Transformers: 5.1.0
- Transformers: 4.56.0
- PyTorch: 2.8.0+cu128
- Accelerate: 1.10.1
- Datasets: 4.0.0
- Tokenizers: 0.22.0
## Citation
### BibTeX
#### Sentence Transformers
```bibtex
@inproceedings{reimers-2019-sentence-bert,
title = "Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks",
author = "Reimers, Nils and Gurevych, Iryna",
booktitle = "Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing",
month = "11",
year = "2019",
publisher = "Association for Computational Linguistics",
url = "https://arxiv.org/abs/1908.10084",
}
```
<!--
## Glossary
*Clearly define terms in order to be accessible across audiences.*
-->
<!--
## Model Card Authors
*Lists the people who create the model card, providing recognition and accountability for the detailed work that goes into its construction.*
-->
<!--
## Model Card Contact
*Provides a way for people who have updates to the Model Card, suggestions, or questions, to contact the Model Card authors.*
-->
|
Viktor-01/blockassist-bc-leaping_humming_finch_1757064225
|
Viktor-01
| 2025-09-05T10:05:42Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"leaping humming finch",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-05T10:05:40Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- leaping humming finch
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
kohido/cifar10_vqvae
|
kohido
| 2025-09-05T10:05:39Z | 0 | 0 | null |
[
"safetensors",
"model_hub_mixin",
"pytorch_model_hub_mixin",
"image-to-image",
"license:mit",
"region:us"
] |
image-to-image
| 2025-09-05T10:05:37Z |
---
license: mit
pipeline_tag: image-to-image
tags:
- model_hub_mixin
- pytorch_model_hub_mixin
---
This model has been pushed to the Hub using the [PytorchModelHubMixin](https://huggingface.co/docs/huggingface_hub/package_reference/mixins#huggingface_hub.PyTorchModelHubMixin) integration:
- Code: https://github.com/KhoiDOO/vitvqganvae
- Paper: [More Information Needed]
- Docs: [More Information Needed]
|
boomeryop/blockassist-bc-stinky_diving_viper_1757066698
|
boomeryop
| 2025-09-05T10:05:19Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"stinky diving viper",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-05T10:04:59Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- stinky diving viper
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Rakancorle11/qwen2.5-3b_Instruct_policy_traj_30k_full
|
Rakancorle11
| 2025-09-05T10:05:13Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"llama-factory",
"full",
"generated_from_trainer",
"conversational",
"base_model:Qwen/Qwen2.5-3B-Instruct",
"base_model:finetune:Qwen/Qwen2.5-3B-Instruct",
"license:other",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-09-05T07:25:14Z |
---
library_name: transformers
license: other
base_model: Qwen/Qwen2.5-3B-Instruct
tags:
- llama-factory
- full
- generated_from_trainer
model-index:
- name: qwen2.5-3b_Instruct_policy_traj_30k_full
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# qwen2.5-3b_Instruct_policy_traj_30k_full
This model is a fine-tuned version of [Qwen/Qwen2.5-3B-Instruct](https://huggingface.co/Qwen/Qwen2.5-3B-Instruct) on the Policy_Traj_0826_30k_train dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 2
- eval_batch_size: 8
- seed: 42
- distributed_type: multi-GPU
- num_devices: 4
- gradient_accumulation_steps: 8
- total_train_batch_size: 64
- total_eval_batch_size: 32
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 3.0
### Training results
### Framework versions
- Transformers 4.55.0
- Pytorch 2.7.0+cu126
- Datasets 3.6.0
- Tokenizers 0.21.1
|
GroomerG/blockassist-bc-vicious_pawing_badger_1757065041
|
GroomerG
| 2025-09-05T10:03:34Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"vicious pawing badger",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-05T10:03:30Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- vicious pawing badger
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Yunqi1dsdf/BlackCube
|
Yunqi1dsdf
| 2025-09-05T10:02:57Z | 0 | 0 |
lerobot
|
[
"lerobot",
"safetensors",
"smolvla",
"robotics",
"dataset:Yunqi1dsdf/record-test0904",
"arxiv:2506.01844",
"base_model:lerobot/smolvla_base",
"base_model:finetune:lerobot/smolvla_base",
"license:apache-2.0",
"region:us"
] |
robotics
| 2025-09-05T06:26:32Z |
---
base_model: lerobot/smolvla_base
datasets: Yunqi1dsdf/record-test0904
library_name: lerobot
license: apache-2.0
model_name: smolvla
pipeline_tag: robotics
tags:
- smolvla
- lerobot
- robotics
---
# Model Card for smolvla
<!-- Provide a quick summary of what the model is/does. -->
[SmolVLA](https://huggingface.co/papers/2506.01844) is a compact, efficient vision-language-action model that achieves competitive performance at reduced computational costs and can be deployed on consumer-grade hardware.
This policy has been trained and pushed to the Hub using [LeRobot](https://github.com/huggingface/lerobot).
See the full documentation at [LeRobot Docs](https://huggingface.co/docs/lerobot/index).
---
## How to Get Started with the Model
For a complete walkthrough, see the [training guide](https://huggingface.co/docs/lerobot/il_robots#train-a-policy).
Below is the short version on how to train and run inference/eval:
### Train from scratch
```bash
lerobot-train \
--dataset.repo_id=${HF_USER}/<dataset> \
--policy.type=act \
--output_dir=outputs/train/<desired_policy_repo_id> \
--job_name=lerobot_training \
--policy.device=cuda \
--policy.repo_id=${HF_USER}/<desired_policy_repo_id>
--wandb.enable=true
```
_Writes checkpoints to `outputs/train/<desired_policy_repo_id>/checkpoints/`._
### Evaluate the policy/run inference
```bash
lerobot-record \
--robot.type=so100_follower \
--dataset.repo_id=<hf_user>/eval_<dataset> \
--policy.path=<hf_user>/<desired_policy_repo_id> \
--episodes=10
```
Prefix the dataset repo with **eval\_** and supply `--policy.path` pointing to a local or hub checkpoint.
---
## Model Details
- **License:** apache-2.0
|
y1y2y3/so101_test4_diffusion_12k
|
y1y2y3
| 2025-09-05T10:02:42Z | 0 | 0 |
lerobot
|
[
"lerobot",
"safetensors",
"diffusion",
"robotics",
"dataset:y1y2y3/so101_test4",
"arxiv:2303.04137",
"license:apache-2.0",
"region:us"
] |
robotics
| 2025-09-04T07:46:16Z |
---
datasets: y1y2y3/so101_test4
library_name: lerobot
license: apache-2.0
model_name: diffusion
pipeline_tag: robotics
tags:
- lerobot
- diffusion
- robotics
---
# Model Card for diffusion
<!-- Provide a quick summary of what the model is/does. -->
[Diffusion Policy](https://huggingface.co/papers/2303.04137) treats visuomotor control as a generative diffusion process, producing smooth, multi-step action trajectories that excel at contact-rich manipulation.
This policy has been trained and pushed to the Hub using [LeRobot](https://github.com/huggingface/lerobot).
See the full documentation at [LeRobot Docs](https://huggingface.co/docs/lerobot/index).
---
## How to Get Started with the Model
For a complete walkthrough, see the [training guide](https://huggingface.co/docs/lerobot/il_robots#train-a-policy).
Below is the short version on how to train and run inference/eval:
### Train from scratch
```bash
lerobot-train \
--dataset.repo_id=${HF_USER}/<dataset> \
--policy.type=act \
--output_dir=outputs/train/<desired_policy_repo_id> \
--job_name=lerobot_training \
--policy.device=cuda \
--policy.repo_id=${HF_USER}/<desired_policy_repo_id>
--wandb.enable=true
```
_Writes checkpoints to `outputs/train/<desired_policy_repo_id>/checkpoints/`._
### Evaluate the policy/run inference
```bash
lerobot-record \
--robot.type=so100_follower \
--dataset.repo_id=<hf_user>/eval_<dataset> \
--policy.path=<hf_user>/<desired_policy_repo_id> \
--episodes=10
```
Prefix the dataset repo with **eval\_** and supply `--policy.path` pointing to a local or hub checkpoint.
---
## Model Details
- **License:** apache-2.0
|
casvxzv/blockassist-bc-mangy_plump_jellyfish_1757066505
|
casvxzv
| 2025-09-05T10:02:20Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"mangy plump jellyfish",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-05T10:01:46Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- mangy plump jellyfish
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
mradermacher/TinyLlama-1.1B-Chat-v1.0-sft-dpo-GGUF
|
mradermacher
| 2025-09-05T09:59:22Z | 0 | 0 |
transformers
|
[
"transformers",
"gguf",
"generated_from_trainer",
"trl",
"dpo",
"en",
"base_model:dpabonc/TinyLlama-1.1B-Chat-v1.0-sft-dpo",
"base_model:quantized:dpabonc/TinyLlama-1.1B-Chat-v1.0-sft-dpo",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2025-09-05T09:38:58Z |
---
base_model: dpabonc/TinyLlama-1.1B-Chat-v1.0-sft-dpo
language:
- en
library_name: transformers
model_name: TinyLlama_TinyLlama-1.1B-Chat-v1.0-sft-dpo
mradermacher:
readme_rev: 1
quantized_by: mradermacher
tags:
- generated_from_trainer
- trl
- dpo
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
<!-- ### quants: x-f16 Q4_K_S Q2_K Q8_0 Q6_K Q3_K_M Q3_K_S Q3_K_L Q4_K_M Q5_K_S Q5_K_M IQ4_XS -->
<!-- ### quants_skip: -->
<!-- ### skip_mmproj: -->
static quants of https://huggingface.co/dpabonc/TinyLlama-1.1B-Chat-v1.0-sft-dpo
<!-- provided-files -->
***For a convenient overview and download list, visit our [model page for this model](https://hf.tst.eu/model#TinyLlama-1.1B-Chat-v1.0-sft-dpo-GGUF).***
weighted/imatrix quants seem not to be available (by me) at this time. If they do not show up a week or so after the static ones, I have probably not planned for them. Feel free to request them by opening a Community Discussion.
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/TinyLlama-1.1B-Chat-v1.0-sft-dpo-GGUF/resolve/main/TinyLlama-1.1B-Chat-v1.0-sft-dpo.Q2_K.gguf) | Q2_K | 0.5 | |
| [GGUF](https://huggingface.co/mradermacher/TinyLlama-1.1B-Chat-v1.0-sft-dpo-GGUF/resolve/main/TinyLlama-1.1B-Chat-v1.0-sft-dpo.Q3_K_S.gguf) | Q3_K_S | 0.6 | |
| [GGUF](https://huggingface.co/mradermacher/TinyLlama-1.1B-Chat-v1.0-sft-dpo-GGUF/resolve/main/TinyLlama-1.1B-Chat-v1.0-sft-dpo.Q3_K_M.gguf) | Q3_K_M | 0.6 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/TinyLlama-1.1B-Chat-v1.0-sft-dpo-GGUF/resolve/main/TinyLlama-1.1B-Chat-v1.0-sft-dpo.Q3_K_L.gguf) | Q3_K_L | 0.7 | |
| [GGUF](https://huggingface.co/mradermacher/TinyLlama-1.1B-Chat-v1.0-sft-dpo-GGUF/resolve/main/TinyLlama-1.1B-Chat-v1.0-sft-dpo.IQ4_XS.gguf) | IQ4_XS | 0.7 | |
| [GGUF](https://huggingface.co/mradermacher/TinyLlama-1.1B-Chat-v1.0-sft-dpo-GGUF/resolve/main/TinyLlama-1.1B-Chat-v1.0-sft-dpo.Q4_K_S.gguf) | Q4_K_S | 0.7 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/TinyLlama-1.1B-Chat-v1.0-sft-dpo-GGUF/resolve/main/TinyLlama-1.1B-Chat-v1.0-sft-dpo.Q4_K_M.gguf) | Q4_K_M | 0.8 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/TinyLlama-1.1B-Chat-v1.0-sft-dpo-GGUF/resolve/main/TinyLlama-1.1B-Chat-v1.0-sft-dpo.Q5_K_S.gguf) | Q5_K_S | 0.9 | |
| [GGUF](https://huggingface.co/mradermacher/TinyLlama-1.1B-Chat-v1.0-sft-dpo-GGUF/resolve/main/TinyLlama-1.1B-Chat-v1.0-sft-dpo.Q5_K_M.gguf) | Q5_K_M | 0.9 | |
| [GGUF](https://huggingface.co/mradermacher/TinyLlama-1.1B-Chat-v1.0-sft-dpo-GGUF/resolve/main/TinyLlama-1.1B-Chat-v1.0-sft-dpo.Q6_K.gguf) | Q6_K | 1.0 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/TinyLlama-1.1B-Chat-v1.0-sft-dpo-GGUF/resolve/main/TinyLlama-1.1B-Chat-v1.0-sft-dpo.Q8_0.gguf) | Q8_0 | 1.3 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/TinyLlama-1.1B-Chat-v1.0-sft-dpo-GGUF/resolve/main/TinyLlama-1.1B-Chat-v1.0-sft-dpo.f16.gguf) | f16 | 2.3 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
nicoboss/grok-2-GGUF
|
nicoboss
| 2025-09-05T09:57:36Z | 2,949 | 1 | null |
[
"gguf",
"base_model:xai-org/grok-2",
"base_model:quantized:xai-org/grok-2",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2025-09-04T11:31:54Z |
---
base_model:
- xai-org/grok-2
---
static quants of https://huggingface.co/xai-org/grok-2
To run these quants before https://github.com/ggml-org/llama.cpp/pull/15539 is merged you will need to build llama.cpp from https://github.com/ggml-org/llama.cpp/tree/cisc/grok-2
|
Mohammad138748/thecoolestones
|
Mohammad138748
| 2025-09-05T09:57:35Z | 0 | 0 | null |
[
"license:apache-2.0",
"region:us"
] | null | 2025-09-05T09:57:35Z |
---
license: apache-2.0
---
|
kelly45/gpt-oss-20b-ss-v4
|
kelly45
| 2025-09-05T09:53:49Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"generated_from_trainer",
"trl",
"sft",
"base_model:openai/gpt-oss-20b",
"base_model:finetune:openai/gpt-oss-20b",
"endpoints_compatible",
"region:us"
] | null | 2025-09-05T09:37:45Z |
---
base_model: openai/gpt-oss-20b
library_name: transformers
model_name: gpt-oss-20b-ss-v4
tags:
- generated_from_trainer
- trl
- sft
licence: license
---
# Model Card for gpt-oss-20b-ss-v4
This model is a fine-tuned version of [openai/gpt-oss-20b](https://huggingface.co/openai/gpt-oss-20b).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="kelly45/gpt-oss-20b-ss-v4", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
This model was trained with SFT.
### Framework versions
- TRL: 0.22.2
- Transformers: 4.56.1
- Pytorch: 2.8.0+cu128
- Datasets: 4.0.0
- Tokenizers: 0.22.0
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
mradermacher/Mistral-7B-model_45k6e2e4-i1-GGUF
|
mradermacher
| 2025-09-05T09:52:14Z | 0 | 0 |
transformers
|
[
"transformers",
"gguf",
"en",
"dataset:pankajmathur/orca_mini_v1_dataset",
"dataset:pankajmathur/WizardLM_Orca",
"dataset:pankajmathur/dolly-v2_orca",
"dataset:pankajmathur/alpaca_orca",
"base_model:pankajmathur/Mistral-7B-model_45k6e2e4",
"base_model:quantized:pankajmathur/Mistral-7B-model_45k6e2e4",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"imatrix"
] | null | 2025-09-05T09:13:15Z |
---
base_model: pankajmathur/Mistral-7B-model_45k6e2e4
datasets:
- pankajmathur/orca_mini_v1_dataset
- pankajmathur/WizardLM_Orca
- pankajmathur/dolly-v2_orca
- pankajmathur/alpaca_orca
language:
- en
library_name: transformers
license: apache-2.0
mradermacher:
readme_rev: 1
quantized_by: mradermacher
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: nicoboss -->
<!-- ### quants: Q2_K IQ3_M Q4_K_S IQ3_XXS Q3_K_M small-IQ4_NL Q4_K_M IQ2_M Q6_K IQ4_XS Q2_K_S IQ1_M Q3_K_S IQ2_XXS Q3_K_L IQ2_XS Q5_K_S IQ2_S IQ1_S Q5_K_M Q4_0 IQ3_XS Q4_1 IQ3_S -->
<!-- ### quants_skip: -->
<!-- ### skip_mmproj: -->
weighted/imatrix quants of https://huggingface.co/pankajmathur/Mistral-7B-model_45k6e2e4
<!-- provided-files -->
***For a convenient overview and download list, visit our [model page for this model](https://hf.tst.eu/model#Mistral-7B-model_45k6e2e4-i1-GGUF).***
static quants are available at https://huggingface.co/mradermacher/Mistral-7B-model_45k6e2e4-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/Mistral-7B-model_45k6e2e4-i1-GGUF/resolve/main/Mistral-7B-model_45k6e2e4.imatrix.gguf) | imatrix | 0.1 | imatrix file (for creating your own qwuants) |
| [GGUF](https://huggingface.co/mradermacher/Mistral-7B-model_45k6e2e4-i1-GGUF/resolve/main/Mistral-7B-model_45k6e2e4.i1-IQ1_S.gguf) | i1-IQ1_S | 1.7 | for the desperate |
| [GGUF](https://huggingface.co/mradermacher/Mistral-7B-model_45k6e2e4-i1-GGUF/resolve/main/Mistral-7B-model_45k6e2e4.i1-IQ1_M.gguf) | i1-IQ1_M | 1.9 | mostly desperate |
| [GGUF](https://huggingface.co/mradermacher/Mistral-7B-model_45k6e2e4-i1-GGUF/resolve/main/Mistral-7B-model_45k6e2e4.i1-IQ2_XXS.gguf) | i1-IQ2_XXS | 2.1 | |
| [GGUF](https://huggingface.co/mradermacher/Mistral-7B-model_45k6e2e4-i1-GGUF/resolve/main/Mistral-7B-model_45k6e2e4.i1-IQ2_XS.gguf) | i1-IQ2_XS | 2.3 | |
| [GGUF](https://huggingface.co/mradermacher/Mistral-7B-model_45k6e2e4-i1-GGUF/resolve/main/Mistral-7B-model_45k6e2e4.i1-IQ2_S.gguf) | i1-IQ2_S | 2.4 | |
| [GGUF](https://huggingface.co/mradermacher/Mistral-7B-model_45k6e2e4-i1-GGUF/resolve/main/Mistral-7B-model_45k6e2e4.i1-IQ2_M.gguf) | i1-IQ2_M | 2.6 | |
| [GGUF](https://huggingface.co/mradermacher/Mistral-7B-model_45k6e2e4-i1-GGUF/resolve/main/Mistral-7B-model_45k6e2e4.i1-Q2_K_S.gguf) | i1-Q2_K_S | 2.6 | very low quality |
| [GGUF](https://huggingface.co/mradermacher/Mistral-7B-model_45k6e2e4-i1-GGUF/resolve/main/Mistral-7B-model_45k6e2e4.i1-Q2_K.gguf) | i1-Q2_K | 2.8 | IQ3_XXS probably better |
| [GGUF](https://huggingface.co/mradermacher/Mistral-7B-model_45k6e2e4-i1-GGUF/resolve/main/Mistral-7B-model_45k6e2e4.i1-IQ3_XXS.gguf) | i1-IQ3_XXS | 2.9 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/Mistral-7B-model_45k6e2e4-i1-GGUF/resolve/main/Mistral-7B-model_45k6e2e4.i1-IQ3_XS.gguf) | i1-IQ3_XS | 3.1 | |
| [GGUF](https://huggingface.co/mradermacher/Mistral-7B-model_45k6e2e4-i1-GGUF/resolve/main/Mistral-7B-model_45k6e2e4.i1-Q3_K_S.gguf) | i1-Q3_K_S | 3.3 | IQ3_XS probably better |
| [GGUF](https://huggingface.co/mradermacher/Mistral-7B-model_45k6e2e4-i1-GGUF/resolve/main/Mistral-7B-model_45k6e2e4.i1-IQ3_S.gguf) | i1-IQ3_S | 3.3 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/Mistral-7B-model_45k6e2e4-i1-GGUF/resolve/main/Mistral-7B-model_45k6e2e4.i1-IQ3_M.gguf) | i1-IQ3_M | 3.4 | |
| [GGUF](https://huggingface.co/mradermacher/Mistral-7B-model_45k6e2e4-i1-GGUF/resolve/main/Mistral-7B-model_45k6e2e4.i1-Q3_K_M.gguf) | i1-Q3_K_M | 3.6 | IQ3_S probably better |
| [GGUF](https://huggingface.co/mradermacher/Mistral-7B-model_45k6e2e4-i1-GGUF/resolve/main/Mistral-7B-model_45k6e2e4.i1-Q3_K_L.gguf) | i1-Q3_K_L | 3.9 | IQ3_M probably better |
| [GGUF](https://huggingface.co/mradermacher/Mistral-7B-model_45k6e2e4-i1-GGUF/resolve/main/Mistral-7B-model_45k6e2e4.i1-IQ4_XS.gguf) | i1-IQ4_XS | 4.0 | |
| [GGUF](https://huggingface.co/mradermacher/Mistral-7B-model_45k6e2e4-i1-GGUF/resolve/main/Mistral-7B-model_45k6e2e4.i1-Q4_0.gguf) | i1-Q4_0 | 4.2 | fast, low quality |
| [GGUF](https://huggingface.co/mradermacher/Mistral-7B-model_45k6e2e4-i1-GGUF/resolve/main/Mistral-7B-model_45k6e2e4.i1-IQ4_NL.gguf) | i1-IQ4_NL | 4.2 | prefer IQ4_XS |
| [GGUF](https://huggingface.co/mradermacher/Mistral-7B-model_45k6e2e4-i1-GGUF/resolve/main/Mistral-7B-model_45k6e2e4.i1-Q4_K_S.gguf) | i1-Q4_K_S | 4.2 | optimal size/speed/quality |
| [GGUF](https://huggingface.co/mradermacher/Mistral-7B-model_45k6e2e4-i1-GGUF/resolve/main/Mistral-7B-model_45k6e2e4.i1-Q4_K_M.gguf) | i1-Q4_K_M | 4.5 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Mistral-7B-model_45k6e2e4-i1-GGUF/resolve/main/Mistral-7B-model_45k6e2e4.i1-Q4_1.gguf) | i1-Q4_1 | 4.7 | |
| [GGUF](https://huggingface.co/mradermacher/Mistral-7B-model_45k6e2e4-i1-GGUF/resolve/main/Mistral-7B-model_45k6e2e4.i1-Q5_K_S.gguf) | i1-Q5_K_S | 5.1 | |
| [GGUF](https://huggingface.co/mradermacher/Mistral-7B-model_45k6e2e4-i1-GGUF/resolve/main/Mistral-7B-model_45k6e2e4.i1-Q5_K_M.gguf) | i1-Q5_K_M | 5.2 | |
| [GGUF](https://huggingface.co/mradermacher/Mistral-7B-model_45k6e2e4-i1-GGUF/resolve/main/Mistral-7B-model_45k6e2e4.i1-Q6_K.gguf) | i1-Q6_K | 6.0 | practically like static Q6_K |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time. Additional thanks to [@nicoboss](https://huggingface.co/nicoboss) for giving me access to his private supercomputer, enabling me to provide many more imatrix quants, at much higher quality, than I would otherwise be able to.
<!-- end -->
|
vendi11/blockassist-bc-placid_placid_llama_1757065850
|
vendi11
| 2025-09-05T09:51:32Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"placid placid llama",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-05T09:51:29Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- placid placid llama
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
seams01/blockassist-bc-insectivorous_stubby_snake_1757064455
|
seams01
| 2025-09-05T09:51:00Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"insectivorous stubby snake",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-05T09:50:57Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- insectivorous stubby snake
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Grinding/fine_tuned_qwen_investment_bot_adapters
|
Grinding
| 2025-09-05T09:48:38Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-09-05T09:48:37Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
przemekff/BERTPrecisionRM
|
przemekff
| 2025-09-05T09:46:46Z | 25 | 0 |
transformers
|
[
"transformers",
"safetensors",
"bert",
"text-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2025-04-16T11:44:45Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
gensynme/blockassist-bc-grunting_squinting_clam_1757065566
|
gensynme
| 2025-09-05T09:46:23Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"grunting squinting clam",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-05T09:46:06Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- grunting squinting clam
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
mradermacher/KimLan-OpenChat_SFT-tw-GGUF
|
mradermacher
| 2025-09-05T09:45:55Z | 0 | 0 |
transformers
|
[
"transformers",
"gguf",
"en",
"base_model:elliotthwang/KimLan-OpenChat_SFT-tw",
"base_model:quantized:elliotthwang/KimLan-OpenChat_SFT-tw",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2025-09-05T08:06:57Z |
---
base_model: elliotthwang/KimLan-OpenChat_SFT-tw
language:
- en
library_name: transformers
mradermacher:
readme_rev: 1
quantized_by: mradermacher
tags: []
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
<!-- ### quants: x-f16 Q4_K_S Q2_K Q8_0 Q6_K Q3_K_M Q3_K_S Q3_K_L Q4_K_M Q5_K_S Q5_K_M IQ4_XS -->
<!-- ### quants_skip: -->
<!-- ### skip_mmproj: -->
static quants of https://huggingface.co/elliotthwang/KimLan-OpenChat_SFT-tw
<!-- provided-files -->
***For a convenient overview and download list, visit our [model page for this model](https://hf.tst.eu/model#KimLan-OpenChat_SFT-tw-GGUF).***
weighted/imatrix quants seem not to be available (by me) at this time. If they do not show up a week or so after the static ones, I have probably not planned for them. Feel free to request them by opening a Community Discussion.
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/KimLan-OpenChat_SFT-tw-GGUF/resolve/main/KimLan-OpenChat_SFT-tw.Q2_K.gguf) | Q2_K | 2.8 | |
| [GGUF](https://huggingface.co/mradermacher/KimLan-OpenChat_SFT-tw-GGUF/resolve/main/KimLan-OpenChat_SFT-tw.Q3_K_S.gguf) | Q3_K_S | 3.3 | |
| [GGUF](https://huggingface.co/mradermacher/KimLan-OpenChat_SFT-tw-GGUF/resolve/main/KimLan-OpenChat_SFT-tw.Q3_K_M.gguf) | Q3_K_M | 3.6 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/KimLan-OpenChat_SFT-tw-GGUF/resolve/main/KimLan-OpenChat_SFT-tw.Q3_K_L.gguf) | Q3_K_L | 3.9 | |
| [GGUF](https://huggingface.co/mradermacher/KimLan-OpenChat_SFT-tw-GGUF/resolve/main/KimLan-OpenChat_SFT-tw.IQ4_XS.gguf) | IQ4_XS | 4.0 | |
| [GGUF](https://huggingface.co/mradermacher/KimLan-OpenChat_SFT-tw-GGUF/resolve/main/KimLan-OpenChat_SFT-tw.Q4_K_S.gguf) | Q4_K_S | 4.2 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/KimLan-OpenChat_SFT-tw-GGUF/resolve/main/KimLan-OpenChat_SFT-tw.Q4_K_M.gguf) | Q4_K_M | 4.5 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/KimLan-OpenChat_SFT-tw-GGUF/resolve/main/KimLan-OpenChat_SFT-tw.Q5_K_S.gguf) | Q5_K_S | 5.1 | |
| [GGUF](https://huggingface.co/mradermacher/KimLan-OpenChat_SFT-tw-GGUF/resolve/main/KimLan-OpenChat_SFT-tw.Q5_K_M.gguf) | Q5_K_M | 5.2 | |
| [GGUF](https://huggingface.co/mradermacher/KimLan-OpenChat_SFT-tw-GGUF/resolve/main/KimLan-OpenChat_SFT-tw.Q6_K.gguf) | Q6_K | 6.0 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/KimLan-OpenChat_SFT-tw-GGUF/resolve/main/KimLan-OpenChat_SFT-tw.Q8_0.gguf) | Q8_0 | 7.8 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/KimLan-OpenChat_SFT-tw-GGUF/resolve/main/KimLan-OpenChat_SFT-tw.f16.gguf) | f16 | 14.6 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
arif696/blockassist-bc-regal_spotted_pelican_1757065396
|
arif696
| 2025-09-05T09:44:26Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"regal spotted pelican",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-05T09:44:18Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- regal spotted pelican
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Anshulky/Qwen2-0.5B-GRPO-test
|
Anshulky
| 2025-09-05T09:42:16Z | 0 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"generated_from_trainer",
"trl",
"grpo",
"arxiv:2402.03300",
"base_model:Qwen/Qwen2-0.5B-Instruct",
"base_model:finetune:Qwen/Qwen2-0.5B-Instruct",
"endpoints_compatible",
"region:us"
] | null | 2025-09-05T09:32:07Z |
---
base_model: Qwen/Qwen2-0.5B-Instruct
library_name: transformers
model_name: Qwen2-0.5B-GRPO-test
tags:
- generated_from_trainer
- trl
- grpo
licence: license
---
# Model Card for Qwen2-0.5B-GRPO-test
This model is a fine-tuned version of [Qwen/Qwen2-0.5B-Instruct](https://huggingface.co/Qwen/Qwen2-0.5B-Instruct).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="Anshulky/Qwen2-0.5B-GRPO-test", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
This model was trained with GRPO, a method introduced in [DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models](https://huggingface.co/papers/2402.03300).
### Framework versions
- TRL: 0.22.2
- Transformers: 4.56.1
- Pytorch: 2.8.0+cu126
- Datasets: 4.0.0
- Tokenizers: 0.22.0
## Citations
Cite GRPO as:
```bibtex
@article{shao2024deepseekmath,
title = {{DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models}},
author = {Zhihong Shao and Peiyi Wang and Qihao Zhu and Runxin Xu and Junxiao Song and Mingchuan Zhang and Y. K. Li and Y. Wu and Daya Guo},
year = 2024,
eprint = {arXiv:2402.03300},
}
```
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
arif696/blockassist-bc-regal_spotted_pelican_1757065185
|
arif696
| 2025-09-05T09:40:53Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"regal spotted pelican",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-05T09:40:44Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- regal spotted pelican
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
phospho-app/ACT-record-test-pen-shaking-qhwvuqtb1s
|
phospho-app
| 2025-09-05T09:37:51Z | 0 | 0 |
phosphobot
|
[
"phosphobot",
"act",
"robotics",
"dataset:htanabe/record-test-pen-shaking",
"region:us"
] |
robotics
| 2025-09-05T09:37:48Z |
---
datasets: htanabe/record-test-pen-shaking
library_name: phosphobot
pipeline_tag: robotics
model_name: act
tags:
- phosphobot
- act
task_categories:
- robotics
---
# act model - 🧪 phosphobot training pipeline
- **Dataset**: [htanabe/record-test-pen-shaking](https://huggingface.co/datasets/htanabe/record-test-pen-shaking)
- **Wandb run id**: None
## Error Traceback
We faced an issue while training your model.
```
Failed to download dataset htanabe/record-test-pen-shaking after 3 attempts, is Hugging Face down ? : 403 Client Error. (Request ID: Root=1-68baaf6f-42f9a00313fbe8c972e5024a;d7681213-81c6-46f1-bfe2-e83fdd8ab206)
Cannot access gated repo for url https://huggingface.co/datasets/htanabe/record-test-pen-shaking/resolve/d1602b0a70f52152310fd5ba194c593e7a8feaa3/.gitattributes.
Access to dataset htanabe/record-test-pen-shaking is restricted and you are not in the authorized list. Visit https://huggingface.co/datasets/htanabe/record-test-pen-shaking to ask for access.
```
## Training parameters
```text
{
"batch_size": 60,
"steps": 8000,
"save_freq": 5000
}
```
📖 **Get Started**: [docs.phospho.ai](https://docs.phospho.ai?utm_source=huggingface_readme)
🤖 **Get your robot**: [robots.phospho.ai](https://robots.phospho.ai?utm_source=huggingface_readme)
|
hamedkharazmi/blockassist-bc-tough_webbed_hamster_1757060826
|
hamedkharazmi
| 2025-09-05T09:36:46Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"tough webbed hamster",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-05T09:36:42Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- tough webbed hamster
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
qgallouedec/Qwen3-8B-SFT-20250905041347
|
qgallouedec
| 2025-09-05T09:34:55Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen3",
"text-generation",
"generated_from_trainer",
"hf_jobs",
"trl",
"sft",
"conversational",
"dataset:trl-lib/Capybara",
"base_model:Qwen/Qwen3-8B",
"base_model:finetune:Qwen/Qwen3-8B",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-09-05T04:14:48Z |
---
base_model: Qwen/Qwen3-8B
datasets: trl-lib/Capybara
library_name: transformers
model_name: Qwen3-8B-SFT-20250905041347
tags:
- generated_from_trainer
- hf_jobs
- trl
- sft
licence: license
---
# Model Card for Qwen3-8B-SFT-20250905041347
This model is a fine-tuned version of [Qwen/Qwen3-8B](https://huggingface.co/Qwen/Qwen3-8B) on the [trl-lib/Capybara](https://huggingface.co/datasets/trl-lib/Capybara) dataset.
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="qgallouedec/Qwen3-8B-SFT-20250905041347", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
This model was trained with SFT.
### Framework versions
- TRL: 0.23.0.dev0
- Transformers: 4.56.1
- Pytorch: 2.8.0+cu128
- Datasets: 4.0.0
- Tokenizers: 0.22.0
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
bah63843/blockassist-bc-plump_fast_antelope_1757064797
|
bah63843
| 2025-09-05T09:34:14Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"plump fast antelope",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-05T09:34:05Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- plump fast antelope
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
pempekmangedd/blockassist-bc-patterned_sturdy_dolphin_1757063345
|
pempekmangedd
| 2025-09-05T09:34:13Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"patterned sturdy dolphin",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-05T09:34:07Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- patterned sturdy dolphin
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
maydixit/test_with_assistant_last
|
maydixit
| 2025-09-05T09:32:14Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-09-05T09:28:33Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
kmpartner/bkv2tpcmlr2-test
|
kmpartner
| 2025-09-05T09:31:11Z | 3 | 0 |
peft
|
[
"peft",
"tensorboard",
"diffusers",
"safetensors",
"arxiv:1910.09700",
"base_model:nota-ai/bk-sdm-v2-tiny",
"base_model:adapter:nota-ai/bk-sdm-v2-tiny",
"region:us"
] | null | 2025-04-08T12:30:33Z |
---
base_model: nota-ai/bk-sdm-v2-tiny
library_name: peft
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.14.0
|
wangjian21/Cartoon
|
wangjian21
| 2025-09-05T09:30:48Z | 0 | 0 |
diffusers
|
[
"diffusers",
"text-to-image",
"lora",
"diffusers-training",
"stable-diffusion",
"stable-diffusion-diffusers",
"base_model:stable-diffusion-v1-5/stable-diffusion-v1-5",
"base_model:adapter:stable-diffusion-v1-5/stable-diffusion-v1-5",
"license:creativeml-openrail-m",
"region:us"
] |
text-to-image
| 2025-09-04T06:24:24Z |
---
base_model: stable-diffusion-v1-5/stable-diffusion-v1-5
library_name: diffusers
license: creativeml-openrail-m
inference: true
instance_prompt: Van Gogh's style
tags:
- text-to-image
- diffusers
- lora
- diffusers-training
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
- lora
- diffusers-training
- stable-diffusion
- stable-diffusion-diffusers
---
<!-- This model card has been generated automatically according to the information the training script had access to. You
should probably proofread and complete it, then remove this comment. -->
# LoRA DreamBooth - wangjian21/Cartoon
These are LoRA adaption weights for stable-diffusion-v1-5/stable-diffusion-v1-5. The weights were trained on Van Gogh's style using [DreamBooth](https://dreambooth.github.io/). You can find some example images in the following.




LoRA for the text encoder was enabled: False.
## Intended uses & limitations
#### How to use
```python
# TODO: add an example code snippet for running this diffusion pipeline
```
#### Limitations and bias
[TODO: provide examples of latent issues and potential remediations]
## Training details
[TODO: describe the data used to train the model]
|
LiquidAI/LFM2-350M-ENJP-MT
|
LiquidAI
| 2025-09-05T09:29:36Z | 57 | 22 |
transformers
|
[
"transformers",
"safetensors",
"lfm2",
"text-generation",
"liquid",
"edge",
"translation",
"japanese",
"en",
"ja",
"license:other",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
translation
| 2025-09-03T04:15:07Z |
---
library_name: transformers
license: other
license_name: lfm1.0
license_link: LICENSE
language:
- en
- ja
pipeline_tag: translation
tags:
- liquid
- lfm2
- edge
- translation
- japanese
---
<center>
<div style="text-align: center;">
<img
src="https://cdn-uploads.huggingface.co/production/uploads/61b8e2ba285851687028d395/7_6D7rWrLxp2hb6OHSV1p.png"
alt="Liquid AI"
style="width: 100%; max-width: 66%; height: auto; display: inline-block; margin-bottom: 0.5em; margin-top: 0.5em;"
/>
</div>
<div style="display: flex; justify-content: center;">
<a href="https://playground.liquid.ai/chat">
<svg width="114.8" height="20" viewBox="0 0 900 200" xmlns="http://www.w3.org/2000/svg" role="img" aria-label="Playground" style="margin-bottom: 1em;">
<title>Playground</title>
<g>
<rect fill="#fff" width="200" height="200"></rect>
<rect fill="url(#x)" x="200" width="800" height="200"></rect>
</g>
<g transform="translate(35, 30) scale(0.45, 0.45)">
<path d="M172.314 129.313L172.219 129.367L206.125 188.18C210.671 195.154 213.324 203.457 213.324 212.382C213.324 220.834 210.956 228.739 206.839 235.479L275.924 213.178L167.853 33.6L141.827 76.9614L172.314 129.313Z" fill="black"/>
<path d="M114.217 302.4L168.492 257.003C168.447 257.003 168.397 257.003 168.352 257.003C143.515 257.003 123.385 237.027 123.385 212.387C123.385 203.487 126.023 195.204 130.55 188.24L162.621 132.503L135.966 86.7327L60.0762 213.183L114.127 302.4H114.217Z" fill="black"/>
<path d="M191.435 250.681C191.435 250.681 191.43 250.681 191.425 250.686L129.71 302.4H221.294L267.71 226.593L191.435 250.686V250.681Z" fill="black"/>
</g>
<g transform="translate(50, 0)" aria-hidden="true" fill="#fff" text-anchor="start" font-family="Verdana,DejaVu Sans,sans-serif" font-size="110">
<text x="255" y="148" textLength="619" fill="#000" opacity="0.1">Playground</text>
<text x="245" y="138" textLength="619">Playground</text>
</g>
<linearGradient id="x" x1="0%" y1="0%" x2="100%" y2="0%">
<stop offset="0%" style="stop-color:#000000"></stop>
<stop offset="100%" style="stop-color:#000000"></stop>
</linearGradient>
</svg>
</a>
<a href="https://leap.liquid.ai/?utm_source=huggingface&utm_medium=modelcards">
<svg width="114.8" height="20" viewBox="0 0 900 200" xmlns="http://www.w3.org/2000/svg" role="img" aria-label="Leap" style="margin-bottom: 1em;">
<title>Leap</title>
<g>
<rect fill="#000" width="500" height="200"></rect>
</g>
<g transform="translate(100, 45) scale(3.5, 3.5)" fill="#fff">
<path d="M13.8512 28.0769C12.5435 28.0769 11.4025 27.8205 10.4281 27.3077C9.45375 26.7692 8.68452 26.0128 8.12042 25.0385C7.58196 24.0641 7.31273 22.9359 7.31273 21.6538V3.76923H0.389648V0H11.4666V21.6538C11.4666 22.4744 11.6973 23.1282 12.1589 23.6154C12.6204 24.0769 13.2486 24.3077 14.0435 24.3077H20.582V28.0769H13.8512Z"/>
<path d="M29.6439 28.4615C27.9259 28.4615 26.4131 28.1282 25.1054 27.4615C23.8233 26.7692 22.8362 25.8077 22.1439 24.5769C21.4516 23.3462 21.1054 21.9103 21.1054 20.2692V14.7308C21.1054 13.0641 21.4516 11.6282 22.1439 10.4231C22.8362 9.19231 23.8233 8.24359 25.1054 7.57692C26.4131 6.88462 27.9259 6.53846 29.6439 6.53846C31.3875 6.53846 32.9003 6.88462 34.1823 7.57692C35.4644 8.24359 36.4516 9.19231 37.1439 10.4231C37.8362 11.6282 38.1823 13.0641 38.1823 14.7308V18.5H25.1054V20.2692C25.1054 21.8333 25.49 23.0256 26.2592 23.8462C27.0541 24.6667 28.1951 25.0769 29.6823 25.0769C30.8875 25.0769 31.8618 24.8718 32.6054 24.4615C33.349 24.0256 33.8105 23.3974 33.99 22.5769H38.1054C37.7977 24.3718 36.8746 25.8077 35.3362 26.8846C33.7977 27.9359 31.9003 28.4615 29.6439 28.4615ZM34.1823 16V14.6923C34.1823 13.1538 33.7977 11.9615 33.0285 11.1154C32.2592 10.2692 31.131 9.84615 29.6439 9.84615C28.1823 9.84615 27.0541 10.2692 26.2592 11.1154C25.49 11.9615 25.1054 13.1667 25.1054 14.7308V15.6923L34.49 15.6538L34.1823 16Z"/>
<path d="M46.3596 28.4615C44.1545 28.4615 42.4109 27.8974 41.1288 26.7692C39.8724 25.6154 39.2442 24.0513 39.2442 22.0769C39.2442 20.0769 39.9109 18.5128 41.2442 17.3846C42.6032 16.2308 44.4622 15.6538 46.8211 15.6538H52.7058V13.6923C52.7058 12.5385 52.3468 11.641 51.6288 11C50.9109 10.359 49.8981 10.0385 48.5904 10.0385C47.4365 10.0385 46.475 10.2949 45.7058 10.8077C44.9365 11.2949 44.4878 11.9487 44.3596 12.7692H40.2827C40.5135 10.8718 41.3852 9.35897 42.8981 8.23077C44.4365 7.10256 46.3724 6.53846 48.7058 6.53846C51.2186 6.53846 53.2058 7.17949 54.6673 8.46154C56.1288 9.71795 56.8596 11.4359 56.8596 13.6154V28.0769H52.8211V24.1923H52.1288L52.8211 23.4231C52.8211 24.9615 52.2314 26.1923 51.0519 27.1154C49.8724 28.0128 48.3083 28.4615 46.3596 28.4615ZM47.5904 25.2692C49.0776 25.2692 50.2955 24.8974 51.2442 24.1538C52.2186 23.3846 52.7058 22.4103 52.7058 21.2308V18.4615H46.8981C45.8211 18.4615 44.9622 18.7564 44.3211 19.3462C43.7058 19.9359 43.3981 20.7436 43.3981 21.7692C43.3981 22.8462 43.7699 23.7051 44.5135 24.3462C45.257 24.9615 46.2827 25.2692 47.5904 25.2692Z"/>
<path d="M58.9984 35V6.92308H63.1138V10.9615H63.9984L63.1138 11.9231C63.1138 10.2564 63.6266 8.94872 64.6523 8C65.7036 7.02564 67.101 6.53846 68.8446 6.53846C70.9728 6.53846 72.6651 7.25641 73.9215 8.69231C75.2036 10.1026 75.8446 12.0385 75.8446 14.5V20.4615C75.8446 22.1026 75.5497 23.5256 74.96 24.7308C74.3959 25.9103 73.5882 26.8333 72.5369 27.5C71.5113 28.141 70.2805 28.4615 68.8446 28.4615C67.1266 28.4615 65.742 27.9872 64.6907 27.0385C63.6395 26.0641 63.1138 24.7436 63.1138 23.0769L63.9984 24.0385H63.0369L63.1523 28.9615V35H58.9984ZM67.4215 24.8462C68.7805 24.8462 69.8318 24.4615 70.5754 23.6923C71.3446 22.8974 71.7292 21.7564 71.7292 20.2692V14.7308C71.7292 13.2436 71.3446 12.1154 70.5754 11.3462C69.8318 10.5513 68.7805 10.1538 67.4215 10.1538C66.1138 10.1538 65.0754 10.5641 64.3061 11.3846C63.5369 12.1795 63.1523 13.2949 63.1523 14.7308V20.2692C63.1523 21.7051 63.5369 22.8333 64.3061 23.6538C65.0754 24.4487 66.1138 24.8462 67.4215 24.8462Z"/>
</g>
<linearGradient id="y" x1="0%" y1="0%" x2="100%" y2="0%">
<stop offset="0%" style="stop-color:#000000"></stop>
</linearGradient>
</svg>
</a>
</div>
</center>
# LFM2-350M-ENJP-MT
Based on the [LFM2-350M](https://huggingface.co/LiquidAI/LFM2-350M) model, this checkpoint has been fine-tuned for near real-time **bi-directional Japanese/English translation** of short-to-medium inputs.

LFM2-350M-ENJP-MT delivers translation quality that is on par with models more than 10 times its size.
## 📊 Translation Quality
Below are sample translations produced by the model. These examples are meant to give you a feel for its strengths and typical style in both directions (English ➡️ Japanese and Japanese ➡️ English).
They include a mix of everyday text, technical descriptions, business communication, and news reporting, so you can gauge performance across different domains.
### EN ➡️ JP
These examples demonstrate the model's strength in product descriptions, technical passages, and formal explanations when translating into Japanese.
| Source Text (EN) | LFM2-350M-ENJP-MT(JP) |
|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|-----------------------------------------------------------------------------------------------------------------------------------------------|
| Fully Tested and Works Properly. 6 Months Warranty included! <p> Item pictured is the actual item for sale. <p> See above for full description, condition, and comments. | 「完全試験済みで正しく動作しています。保証期間は6ヶ月付属!」。<br> 写真に写っている商品が販売されている実物です。<br> 詳しく、状態、コメントは上記参照してください。 |
| Emphasis on human-AI collaboration. Instead of focusing solely on making fully autonomous AI systems, we are excited to build multimodal systems that work with people collaboratively. | 人とAIのコラボレーションに重点を置く。完全自律型AIシステムの構築にのみ焦点を当てるのではなく、人と協調して働くマルチモーダルシステムを構築できることに興奮しています。 |
| If your equipment fails due to normal use, please contact our customer service department so that we can assist you, We will repair or replace your equipment at our discretion. In some situations, we may choose to refund the full purchase price of an item. | ご使用中の機器が通常使用により故障した場合は、お手伝いできるよう弊社カスタマーサービス部門にご連絡ください。 弊社の判断で機器の修理または交換を行います。状況によっては、製品の購入価格全額を返金する場合があります。 |
| 2k USD to start for basic, 200 dollars for additional version.<br> - 50% of full amount of deposit,<br> - 3 proposals - end of month(3 drafts), will choose 1 and make final changes based on it<br> - Present another final version in a week | 基本版から始めるのに2,000ドル、追加バージョンでは200ドルの手数料が必要です。<br> - 保証金全額の50%が支払われる、<br> - 3つの案 - 月末(ドラフト3回分)、その案に基づいて1つを選んで最終的な変更を行う<br> - さらに1週間後に別の最終版を提出すること |
| Lifestyle risk factors with strong evidence include lack of exercise, cigarette smoking, alcohol, and obesity. The risk of colon cancer can be reduced by maintaining a normal body weight through a combination of sufficient exercise and eating a healthy diet. | 強力な証拠がある生活習慣のリスク要因としては、運動不足、喫煙、飲酒、肥満などが挙げられ、十分な運動と健康的な食生活の組み合わせによる正常な体重維持を通じて、大腸がんの発症リスクを減らすことができる。 |
### JP ➡️ EN
These examples demonstrate the model’s ability to preserve nuance in news reporting, colloquial phrasing, and business contexts when translating into English.
| Source Text (JP) | LFM2-350M-ENJP-MT (EN) |
|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| モデルからの回答は英語でもOKなのですよね。 | The answers from the models are okay in English, right? |
| 手間のかかるメルマガ作成作業、もっとラクに、もっと速くできたら——。<br>そう考えたことはありませんか? | Have you ever wondered if you could create a cumbersome email newsletter more easily and quickly? |
| X JAPANのYOSHIKIが、アニメ『ダンダダン』でグループの代表曲をオマージュした劇中歌が使用されたことを指摘して始まった議論。<p>8月22日には『ダンダダン』サイドが公式Xで騒動を謝罪、YOSHIKIも『ダンダダン』サイドと和解を報告したが、これに物言いをつけたのが、弁護士の紀藤正樹氏だった。 | The discussion began with the point that Yoshiki of X JAPAN mentioned that a song in the anime *Dandadan* paying homage to the group's signature tune was used as an insert song.<p> On August 22nd, the *Dandadan* side apologized on their official X page for the controversy, and Yoshiki also reported a reconciliation with the *Dandadan* side, but lawyer Masaki Kitō objected. |
| (ブルームバーグ): SOMPOホールディングスは27日夜、米国などを中心に展開する損害保険会社のアスペン・インシュアランス・ホールディングスを買収すると発表した。買収総額は約5200億円となる。<p>ニューヨーク証券取引所に上場しているアスペンの株式を1株当たり37.5ドル(約5600円)で全株を取得する。26日の終値を16%上回る水準。2026年上期中に買収手続きを完了する予定。<br> 買収資金は手元資金を充てる。<p>SOMPOにとっては17年に米損保エンデュランス・スペシャルティ・ホールディングスを約6400億円で買収して以来の大型案件となる。<br>人口減少で国内市場の縮小が見込まれる中、買収によって海外保険ビジネスの規模や収益を拡大し、再保険取引による安定的な収益の寄与も見込む。 | (Bloomberg): SOMPO Holdings announced on the evening of the 27th that it will acquire Aspen Insurance Holdings, a non-life insurance company operating primarily in the United States and elsewhere, for approximately ¥520 billion.<p> The acquisition will involve the purchase of all shares of Aspen’s shares listed on the New York Stock Exchange for $37.5 per share (approximately ¥5,600). This surpasses the closing price of the day by 16% and is scheduled to be completed within the first half of 2026. Funds for the acquisition will be provided from the company’s own capital.<p> For SOMPO, this is the largest acquisition since its 2017 acquisition of Endurance Specialty Holdings for approximately ¥640 billion. The acquisition is expected to expand the scale and revenue of its overseas insurance business amidst anticipated shrinking domestic markets due to population decline, and is also expected to contribute to stable revenue through reinsurance transactions. |
| 28歳にしてつかんだイングランドサッカー界でのチャンスを生かせるか。<br>チャンピオンシップ(英2部)の古豪ブラックバーンに電撃移籍した森下龍矢は意気込んでいる。<p> サガン鳥栖と名古屋グランパスでプレーし、2024年から海を渡ってレギア・ワルシャワで奮闘してきた森下は先日、大橋祐紀のチームメイトとなることが決まった。<p> 日本ではSBが主戦場だった森下だが、昨季はポーランドで攻撃的なポジションにコンバートされ、ウィングやトップ下に前線と様々な役割をこなした。<br>すると、公式戦で14得点、14アシストとブレイク。<br>この飛躍に注目したブラックバーンに引き抜かれている。 | Can he capitalize on his chance in English football, which he seized at the age of 28?<br>Ryuya Morishita, having made a shocking move to Blackburn Rovers, a long-established club in the Championship (British second tier), is eager to make an impression.<p>Having played for Sagan Tosu and Nagoya Grampus, and having been striving with Legia Warsaw since 2024, Morishita recently announced he would become teammates with Yuki Ohashi.<p>For Morishita, his primary playing field in Japan was as a full-back, but he was converted to an attacking position in Poland last season, playing in various roles including wing-back and attacking midfielder.<br>He then broke through, scoring 14 goals and providing 14 assists in official matches.<br>The Blackburn club has been scouting for this promising player. |
> [!NOTE]
> 📝 While LFM2-350M-ENJP-MT delivers strong out-of-the-box general-purpose English ↔️ Japanese translation, our primary
> goal is to provide a versatile, community-empowering base model—a foundation designed to make it easy to build
> best-in-class, task-specific translation systems.
>
> Like any base model, there are open areas for growth—in particular with extreme context lengths and specialized or
> context-sensitive translations, such as:
> - Technical & professional language (medical, legal, engineering)
> - Novel proper nouns (new products, brands, cultural references)
> - Industry-, domain-, or company-specific nuance (e-commerce, finance, internal corporate terminology)
>
> These are precisely the kinds of challenges that fine-tuning—by both Liquid AI and our developer community—can
> address. We see this model not just as an endpoint, but as a catalyst for a rich ecosystem of fine-tuned translation
> models tailored to real-world needs.
## 📄 Model details
**Generation parameters**: We strongly recommend using greedy decoding with a `temperature=0`.
**System prompts**: LFM2-ENJP-MT **requires** one of the two following system prompts:
* "Translate to Japanese." for English to Japanese translation.
* "Translate to English." for Japanese to English translation.
> [!WARNING]
> ⚠️ The model cannot work as intended without one of these two system prompts.
**Chat template**: LFM2-ENJP-MT uses a ChatML-like chat template as follows:
```
<|startoftext|><|im_start|>system
Translate to Japanese.<|im_end|>
<|im_start|>user
What is C. elegans?<|im_end|>
<|im_start|>assistant
C. elegansとは何ですか?<|im_end|>
```
You can automatically apply it using the dedicated [`.apply_chat_template()`](https://huggingface.co/docs/transformers/en/chat_templating#applychattemplate) function from Hugging Face transformers.
> [!WARNING]
> ⚠️ The model is intended for single turn conversations.
## 🏃 How to run LFM2
- Huggingface: [LFM2-350M](https://huggingface.co/LiquidAI/LFM2-350M)
- llama.cpp: [LFM2-350M-ENJP-MT-GGUF](https://huggingface.co/LiquidAI/LFM2-350M-ENJP-MT-GGUF)
- LEAP: [LEAP model library](https://leap.liquid.ai/models?model=lfm2-350m-enjp-mt)
## 📬 Contact
If you are interested in custom solutions with edge deployment, please contact [our sales team](https://www.liquid.ai/contact).
|
safouaneelg/Apertus-8B-Instruct-2509-GSM8k-SFT
|
safouaneelg
| 2025-09-05T09:28:05Z | 50 | 0 |
transformers
|
[
"transformers",
"safetensors",
"apertus",
"text-generation",
"multilingual",
"compliant",
"swiss-ai",
"fine-tuned",
"gsm8k",
"conversational",
"en",
"dataset:gsm8k",
"base_model:swiss-ai/Apertus-8B-Instruct-2509",
"base_model:quantized:swiss-ai/Apertus-8B-Instruct-2509",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"4-bit",
"bitsandbytes",
"region:us"
] |
text-generation
| 2025-09-04T09:48:02Z |
---
model_name: Apertus-8B-Instruct-2509-GSM8k-SFT
base_model: swiss-ai/Apertus-8B-Instruct-2509
license: apache-2.0
language:
- en
- multilingual
tags:
- multilingual
- compliant
- swiss-ai
- apertus
- fine-tuned
- gsm8k
- text-generation
pipeline_tag: text-generation
library_name: transformers
author: Safouane El Ghazouali
author_email: safouane.elghazouali@gmail.com
model_creator: Safouane El Ghazouali
location: Switzerland
datasets:
- gsm8k
---
# safouaneelg/Apertus-8B-Instruct-2509-GSM8k-SFT
Apertus has released two models: 70B and 8B parameter multi-language model.
Check out the model info here: [Swiss-AI/LLM](https://huggingface.co/collections/swiss-ai/apertus-llm-68b699e65415c231ace3b059)
# Finetuned on GSM8k
This repo contains the fine-tuned version of Apertus on [GSM8K dataset](https://huggingface.co/datasets/gsm8k).
The fine-tuning was performed using Unsloth on a single GPU RTX A6000 48GB Linux machine using the below parameters:
- per_device_train_batch_size: 2
- gradient_accumulation_steps: 4 (effective batch size: 8)
- warmup_steps: 5
- num_train_epochs: 2
- learning_rate: 2e-4
- fp16/bf16: Enabled based on hardware support
- logging_steps: 1
- optimizer: adamw_8bit
- weight_decay: 0.01
- lr_scheduler_type: linear
- seed: 3407
- eval_strategy: steps
- eval_steps: 50
- packing: True
## How to use
You can run this fine-tuned version using the below instructions:
1. `Transformers 4.56.0` are required to run the model.
```bash
pip install -U transformers
```
2. I have personally managed to run it after setting the xiELU activation function which can theoretically be installed via the below command line.
```bash
pip install git+https://github.com/rubber-duck-debug/xielu
```
If you struggle, check the xiELU installation below (for linux users only).
3. Run inference using:
- Transformers pipeline
- Unsloth pipeline (This works better, if you have `StaticLayer` error, comment the arg `prompt_lookup_num_tokens=None`)
```python
from unsloth import FastLanguageModel
import torch
# Load the model and tokenizer
model, tokenizer = FastLanguageModel.from_pretrained(
model_name="safouaneelg/Apertus-8B-Instruct-2509-GSM8k-SFT",
max_seq_length=2048,
load_in_4bit=True,
)
# Move to device
device = "cuda" if torch.cuda.is_available() else "cpu"
# Example prompt from GSM8k
prompt = "Short answer please. Natalia sold clips to 48 of her friends in April, and then she sold half as many clips in May. How many clips did Natalia sell altogether in April and May?."
messages_think = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages_think,
tokenize=False,
add_generation_prompt=True,
)
model_inputs = tokenizer([text], return_tensors="pt", add_special_tokens=False).to(model.device)
outputs = model.generate(
**model_inputs,
max_new_tokens=256,
temperature=0.8,
top_p=0.9,
use_cache=True,
do_sample=True,
prompt_lookup_num_tokens=None #for some reasoning this sometimes solve the inferencing errors
)
generated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(generated_text)
```
```python
import os
from transformers import AutoModelForCausalLM, AutoTokenizer, TextStreamer
model_name = "safouaneelg/Apertus-8B-Instruct-2509-GSM8k-SFT"
device = "cuda" if torch.cuda.is_available() else "cpu"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
).to(device)
# prepare the model input
prompt = "Short answer please. Natalia sold clips to 48 of her friends in April, and then she sold half as many clips in May. How many clips did Natalia sell altogether in April and May?"
messages_think = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages_think,
tokenize=False,
add_generation_prompt=True,
)
streamer = TextStreamer(tokenizer)
model_inputs = tokenizer([text], return_tensors="pt", add_special_tokens=False).to(model.device)
# Generate the output
generated_ids = model.generate(**model_inputs, streamer=streamer, max_new_tokens=2024)
# Get and decode the output
output_ids = generated_ids[0][len(model_inputs.input_ids[0]) :]
print(tokenizer.decode(output_ids, skip_special_tokens=True))
```
Output example:

## xiELU activation error solving
The pip install might result in a set of errors, below is how I managed to make it running:
1. xiELU need cmake 3.30 +. Therefore, you can reach out to cmake downloader [Link](https://cmake.org/download/) and select the distribution. For my test I have used `cmake-4.1.1-linux-x86_64.sh`.
2. Copy to opt/ and make the script executable via below command lines:
```bash
sudo cp cmake-4.1.1-linux-x86_64.sh /opt/
sudo chmod +x cmake-4.1.1-linux-x86_64.sh
```
3. Update environment paths
CUDA_HOME is a requirement as well, so additionally to cmake you need to point to CUDA_HOME. if you have another cuda version change this line to `CUDA_HOME=/usr/local/cudaX.X`
```bash
export PATH="/opt/cmake-4.1.1-linux-x86_64/bin:$PATH"
export CUDA_HOME=/usr/local/cuda
export PATH=$CUDA_HOME/bin:$PATH
export LD_LIBRARY_PATH=$CUDA_HOME/lib64:$LD_LIBRARY_PATH
```
4. Save and apply the changes by running:
```bash
source ~/.bashrc
# or
source ~/.zshrc
```
5. Verify the installation
Run `nvcc --version` to confirm that the CUDA compiler is now in your PATH. You should see the CUDA version number. And, run echo `$CUDA_HOME` to confirm that the environment variable is set correctly.
6. Reactivate you conda/venv environment and run the `pip install git+https://github.com/rubber-duck-debug/xielu`.
# Credits to the base model
---
license: apache-2.0
base_model:
- swiss-ai/Apertus-8B-Instruct-2509
pipeline_tag: text-generation
library_name: transformers
tags:
- multilingual
- compliant
- swiss-ai
- apertus
extra_gated_prompt: "### Apertus LLM Acceptable Use Policy \n(1.0 | September 1, 2025)\n\"Agreement\" The Swiss National AI Institute (SNAI) is a partnership between the two Swiss Federal Institutes of Technology, ETH Zurich and EPFL. The Swiss National AI Institute (SNAI) is a partnership between the two Swiss Federal Institutes of Technology, ETH Zurich and EPFL. \n\nBy using the Apertus LLM you agree to indemnify, defend, and hold harmless ETH Zurich and EPFL against any third-party claims arising from your use of Apertus LLM. \n\nThe training data and the Apertus LLM may contain or generate information that directly or indirectly refers to an identifiable individual (Personal Data). You process Personal Data as independent controller in accordance with applicable data protection law. SNAI will regularly provide a file with hash values for download which you can apply as an output filter to your use of our Apertus LLM. The file reflects data protection deletion requests which have been addressed to SNAI as the developer of the Apertus LLM. It allows you to remove Personal Data contained in the model output. We strongly advise downloading and applying this output filter from SNAI every six months following the release of the model. "
extra_gated_fields:
Your Name: text
Country: country
Affiliation: text
geo: ip_location
By clicking Submit below I accept the terms of use: checkbox
extra_gated_button_content: Submit
---
## Citation
```bibtex
@misc{swissai2025apertus,
title={{Apertus: Democratizing Open and Compliant LLMs for Global Language Environments}},
author={Apertus Team},
year={2025},
howpublished={\url{https://huggingface.co/swiss-ai/Apertus-8B-Instruct-2509}}
}
```
|
Meet-Kadam/finetuned-lora-resume-parser-v1
|
Meet-Kadam
| 2025-09-05T09:25:42Z | 0 | 0 |
peft
|
[
"peft",
"safetensors",
"base_model:adapter:mistralai/mathstral-7b-v0.1",
"lora",
"transformers",
"text-generation",
"conversational",
"license:apache-2.0",
"region:us"
] |
text-generation
| 2025-09-04T12:02:30Z |
---
library_name: peft
license: apache-2.0
base_model: mistralai/mathstral-7b-v0.1
tags:
- base_model:adapter:mistralai/mathstral-7b-v0.1
- lora
- transformers
pipeline_tag: text-generation
model-index:
- name: finetuned-lora-resume-parser-v1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# finetuned-lora-resume-parser-v1
This model is a fine-tuned version of [mistralai/mathstral-7b-v0.1](https://huggingface.co/mistralai/mathstral-7b-v0.1) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 1
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 16
- total_train_batch_size: 16
- optimizer: Use OptimizerNames.PAGED_ADAMW_8BIT with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 50
- num_epochs: 3
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- PEFT 0.17.1
- Transformers 4.56.0
- Pytorch 2.8.0+cu128
- Datasets 4.0.0
- Tokenizers 0.22.0
|
seams01/blockassist-bc-insectivorous_stubby_snake_1757062692
|
seams01
| 2025-09-05T09:22:44Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"insectivorous stubby snake",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-05T09:22:40Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- insectivorous stubby snake
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
skunkworx/FLAN-T5xxl
|
skunkworx
| 2025-09-05T09:22:41Z | 0 | 0 | null |
[
"safetensors",
"license:apache-2.0",
"region:us"
] | null | 2025-05-30T18:39:16Z |
---
license: apache-2.0
---
copied from https://huggingface.co/google/flan-t5-xxl
Converted to bfloat16, removed the decoder blocks and packaged for InvokeAI
To install in invoke, enter skunkworx/FLAN-T5xxl::bfloat16 in the huggingface repoID on the model manager to install.
Visit the Discord for more information.
https://discord.com/channels/1020123559063990373/1050123398342250526/1381203753918664774
Incase you want to do the conversion yourself or on another model. You can find the code used to convert the original google/flan-t5-xxl model can be found in the root folder https://huggingface.co/skunkworx/FLAN-T5xxl/blob/main/convert-bf16-enc.py
|
Rudra-madlads/blockassist-bc-jumping_swift_gazelle_1757063976
|
Rudra-madlads
| 2025-09-05T09:20:30Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"jumping swift gazelle",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-05T09:20:10Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- jumping swift gazelle
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
gensynme/blockassist-bc-rangy_mighty_hare_1757063957
|
gensynme
| 2025-09-05T09:19:37Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"rangy mighty hare",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-05T09:19:18Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- rangy mighty hare
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Viktor-01/blockassist-bc-leaping_humming_finch_1757061433
|
Viktor-01
| 2025-09-05T09:17:20Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"leaping humming finch",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-05T09:17:16Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- leaping humming finch
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
arif696/blockassist-bc-regal_spotted_pelican_1757063582
|
arif696
| 2025-09-05T09:15:26Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"regal spotted pelican",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-05T09:14:08Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- regal spotted pelican
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
BootesVoid/cmereak2c0cgbtlqblr6gxy9s_cmf1jjxr608pksr5305dxlk40
|
BootesVoid
| 2025-09-05T09:13:55Z | 0 | 0 |
diffusers
|
[
"diffusers",
"flux",
"lora",
"replicate",
"text-to-image",
"en",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"license:other",
"region:us"
] |
text-to-image
| 2025-09-05T09:13:53Z |
---
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
language:
- en
tags:
- flux
- diffusers
- lora
- replicate
base_model: "black-forest-labs/FLUX.1-dev"
pipeline_tag: text-to-image
# widget:
# - text: >-
# prompt
# output:
# url: https://...
instance_prompt: LAVINA
---
# Cmereak2C0Cgbtlqblr6Gxy9S_Cmf1Jjxr608Pksr5305Dxlk40
<Gallery />
## About this LoRA
This is a [LoRA](https://replicate.com/docs/guides/working-with-loras) for the FLUX.1-dev text-to-image model. It can be used with diffusers or ComfyUI.
It was trained on [Replicate](https://replicate.com/) using AI toolkit: https://replicate.com/ostris/flux-dev-lora-trainer/train
## Trigger words
You should use `LAVINA` to trigger the image generation.
## Run this LoRA with an API using Replicate
```py
import replicate
input = {
"prompt": "LAVINA",
"lora_weights": "https://huggingface.co/BootesVoid/cmereak2c0cgbtlqblr6gxy9s_cmf1jjxr608pksr5305dxlk40/resolve/main/lora.safetensors"
}
output = replicate.run(
"black-forest-labs/flux-dev-lora",
input=input
)
for index, item in enumerate(output):
with open(f"output_{index}.webp", "wb") as file:
file.write(item.read())
```
## Use it with the [🧨 diffusers library](https://github.com/huggingface/diffusers)
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained('black-forest-labs/FLUX.1-dev', torch_dtype=torch.float16).to('cuda')
pipeline.load_lora_weights('BootesVoid/cmereak2c0cgbtlqblr6gxy9s_cmf1jjxr608pksr5305dxlk40', weight_name='lora.safetensors')
image = pipeline('LAVINA').images[0]
```
For more details, including weighting, merging and fusing LoRAs, check the [documentation on loading LoRAs in diffusers](https://huggingface.co/docs/diffusers/main/en/using-diffusers/loading_adapters)
## Training details
- Steps: 2500
- Learning rate: 9e-05
- LoRA rank: 16
## Contribute your own examples
You can use the [community tab](https://huggingface.co/BootesVoid/cmereak2c0cgbtlqblr6gxy9s_cmf1jjxr608pksr5305dxlk40/discussions) to add images that show off what you’ve made with this LoRA.
|
cactus-S/blockassist-bc-reclusive_arctic_panther_1757061907
|
cactus-S
| 2025-09-05T09:09:34Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"reclusive arctic panther",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-05T09:09:31Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- reclusive arctic panther
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
AXERA-TECH/YOLO-World-V2
|
AXERA-TECH
| 2025-09-05T09:07:15Z | 8 | 0 | null |
[
"YOLO World",
"zero-shot-object-detection",
"en",
"zh",
"license:mit",
"region:us"
] |
zero-shot-object-detection
| 2025-08-20T04:59:15Z |
---
license: mit
language:
- en
- zh
tags:
- YOLO World
pipeline_tag: zero-shot-object-detection
---
# YOLOWorld
This SDK enables efficient Open-Vocabulary-Object-Detection using YOLO-Worldv2 Large, optimized for Axera’s NPU-based SoC platforms including AX650 Series, AX630C Series, AX8850 Series, or Axera's dedicated AI accelerator.
## References links:
For those who are interested in model conversion, you can try to export axmodel through
- [The github repo of yoloworld.axera open source](https://github.com/AXERA-TECH/yoloworld.axera)
- [How to convert the yoloworld models](https://github.com/AXERA-TECH/ONNX-YOLO-World-Open-Vocabulary-Object-Detection)
- [Pulsar2 Link, How to Convert ONNX to axmodel](https://pulsar2-docs.readthedocs.io/en/latest/pulsar2/introduction.html)
## Support Platform
- AX650
- [M4N-Dock(爱芯派Pro)](https://wiki.sipeed.com/hardware/zh/maixIV/m4ndock/m4ndock.html)
- [M.2 Accelerator card](https://axcl-docs.readthedocs.io/zh-cn/latest/doc_guide_hardware.html)
- AX630C
- [爱芯派2](https://axera-pi-2-docs-cn.readthedocs.io/zh-cn/latest/index.html)
- [Module-LLM](https://docs.m5stack.com/zh_CN/module/Module-LLM)
- [LLM630 Compute Kit](https://docs.m5stack.com/zh_CN/core/LLM630%20Compute%20Kit)
## Performance
| Model | Input Shape | Latency (ms) | CMM Usage (MB) |
|-------|------------|--------------|------------|
| yolo_u16_ax650.axmodel| 1 x 640 x 640 x 3 | 9.522 ms | 21 MB |
| clip_b1_u16_ax650.axmodel | 1 x 77 | 2.997 ms | 137 MB |
| yolo_u16_ax630c.axmodel | 1 x 640 x 640 x 3 | 43.450 ms | 31 MB |
| clip_b1_u16_ax630c.axmodel | 1 x 77 | 10.703 ms | 134 MB |
## How to use
Download all files from this repository to the device
```
root@ax650 ~/root/YOLO-World-V2 # tree -L 2
.
|-- README.md
|-- config.json
|-- football.jpg
|-- install
| |-- bin
| `-- lib
|-- models
| |-- clip_b1_u16_ax630c.axmodel
| |-- clip_b1_u16_ax650.axmodel
| |-- yolo_u16_ax630c.axmodel
| `-- yolo_u16_ax650.axmodel
|-- pyyoloworld
| |-- __pycache__
| |-- example.py
| |-- gardio_example.jpg
| |-- gradio_example.py
| |-- host.jpg
| |-- libyoloworld.so
| |-- pyaxdev.py
| |-- pyyoloworld.py
| |-- requirements.txt
| `-- result_host.jpg
|-- result.png
`-- vocab.txt
6 directories, 18 files
```
### python env requirement
```
pip install -r pyyoloworld/requirements.txt
```
#### Inference with AX650 Host, such as M4N-Dock(爱芯派Pro)
```
root@ax650 ~/root/YOLO-World-V2 # cp install/lib/host_650/libyoloworld.so ./pyyoloworld/
root@ax650 ~/root/YOLO-World-V2 # cd pyyoloworld/
root@ax650 ~/root/YOLO-World-V2/pyyoloworld # python3 gradio_example.py --yoloworld ../models/yolo_u16_ax650.axmodel --tenc ../models/clip_b1_u16_ax650.axmodel --vocab ../vocab.txt --dev_type host
Trying to load: /root/root/YOLO-World-V2/pyyoloworld/aarch64/libyoloworld.so
❌ Failed to load: /root/root/YOLO-World-V2/pyyoloworld/aarch64/libyoloworld.so
/root/root/YOLO-World-V2/pyyoloworld/aarch64/libyoloworld.so: cannot open shared object file: No such file or directory
🔍 File not found. Please verify that libclip.so exists and the path is correct.
Trying to load: /root/root/YOLO-World-V2/pyyoloworld/libyoloworld.so
open libaxcl_rt.so failed
unsupport axcl
✅ Successfully loaded: /root/root/YOLO-World-V2/pyyoloworld/libyoloworld.so
sh: line 1: axcl-smi: command not found
input size: 2
name: images [unknown] [unknown]
1 x 640 x 640 x 3 size: 1228800
name: txt_feats [unknown] [unknown]
1 x 4 x 512 size: 8192
output size: 3
name: stride8
1 x 80 x 80 x 68 size: 1740800
name: stride16
1 x 40 x 40 x 68 size: 435200
name: stride32
1 x 20 x 20 x 68 size: 108800
[I][ yw_create][ 408]: num_classes: 4, num_features: 512, input w: 640, h: 640
is_output_nhwc: 1
input size: 1
name: text_token [unknown] [unknown]
1 x 77 size: 308
output size: 1
name: 2202
1 x 1 x 512 size: 2048
[I][ load_text_encoder][ 44]: text feature len 512
[I][ load_tokenizer][ 60]: text token len 77
* Running on local URL: http://0.0.0.0:7860
* To create a public link, set `share=True` in `launch()`.
```
Input:`person`, `dog`, `car`, `horse` and the test image
<img src="./host.jpg" style="zoom:50%;" />
Result:

#### Inference with M.2 Accelerator card
[What is M.2 Accelerator card?](https://axcl-docs.readthedocs.io/zh-cn/latest/doc_guide_hardware.html), Show this DEMO based on Raspberry PI 5.
```
(py312) axera@raspberrypi:~/samples/yoloworldv2-new.hg $ export LD_PRELOAD=/usr/lib/aarch64-linux-gnu/libstdc++.so.6
(py312) axera@raspberrypi:~/samples/yoloworldv2-new.hg $ cp install/lib/axcl_aarch64/libyoloworld.so pyyoloworld/
(py312) axera@raspberrypi:~/samples/yoloworldv2-new.hg $ cd pyyoloworld/
(py312) axera@raspberrypi:~/samples/yoloworldv2-new.hg/pyyoloworld $ python gradio_example.py --yoloworld ../models/yolo_u16_ax650.axmodel --tenc ../models/clip_b1_u16_ax650.axmodel --vocab ../vocab.txt --dev_type axcl
Trying to load: /home/axera/samples/yoloworldv2-new.hg/pyyoloworld/aarch64/libyoloworld.so
✅ Successfully loaded: /home/axera/samples/yoloworldv2-new.hg/pyyoloworld/libyoloworld.so
[I][ run][ 31]: AXCLWorker start with devid 0
input size: 2
name: images [unknown] [unknown]
1 x 640 x 640 x 3 size: 1228800
name: txt_feats [unknown] [unknown]
1 x 4 x 512 size: 8192
output size: 3
name: stride8
1 x 80 x 80 x 68 size: 1740800
name: stride16
1 x 40 x 40 x 68 size: 435200
name: stride32
1 x 20 x 20 x 68 size: 108800
[I][ yw_create][ 408]: num_classes: 4, num_features: 512, input w: 640, h: 640
is_output_nhwc: 1
input size: 1
name: text_token [unknown] [unknown]
1 x 77 size: 308
output size: 1
name: 2202
1 x 1 x 512 size: 2048
[I][ load_text_encoder][ 44]: text feature len 512
[I][ load_tokenizer][ 60]: text token len 77
* Running on local URL: http://0.0.0.0:7860
* To create a public link, set `share=True` in `launch()`.
```
If your Raspberry PI 5 IP Address is 192.168.1.100, so using this URL `http://192.168.1.100:7860` with your WebApp.
Input:`man`, `shoes`, `ball`, `person` and the test image
<img src="./football.jpg" style="zoom:50%;" />
Result:

|
arif696/blockassist-bc-regal_spotted_pelican_1757063061
|
arif696
| 2025-09-05T09:07:07Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"regal spotted pelican",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-05T09:05:27Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- regal spotted pelican
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Rudra-madlads/blockassist-bc-jumping_swift_gazelle_1757063152
|
Rudra-madlads
| 2025-09-05T09:06:42Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"jumping swift gazelle",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-05T09:06:27Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- jumping swift gazelle
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
mradermacher/alpagasus-2-7b-GGUF
|
mradermacher
| 2025-09-05T09:06:06Z | 0 | 0 |
transformers
|
[
"transformers",
"gguf",
"llama",
"alpaca",
"alpagasus",
"en",
"dataset:mlabonne/alpagasus",
"base_model:mlabonne/alpagasus-2-7b",
"base_model:quantized:mlabonne/alpagasus-2-7b",
"endpoints_compatible",
"region:us"
] | null | 2025-09-05T08:20:54Z |
---
base_model: mlabonne/alpagasus-2-7b
datasets:
- mlabonne/alpagasus
language:
- en
library_name: transformers
mradermacher:
readme_rev: 1
quantized_by: mradermacher
tags:
- llama
- alpaca
- alpagasus
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
<!-- ### quants: x-f16 Q4_K_S Q2_K Q8_0 Q6_K Q3_K_M Q3_K_S Q3_K_L Q4_K_M Q5_K_S Q5_K_M IQ4_XS -->
<!-- ### quants_skip: -->
<!-- ### skip_mmproj: -->
static quants of https://huggingface.co/mlabonne/alpagasus-2-7b
<!-- provided-files -->
***For a convenient overview and download list, visit our [model page for this model](https://hf.tst.eu/model#alpagasus-2-7b-GGUF).***
weighted/imatrix quants are available at https://huggingface.co/mradermacher/alpagasus-2-7b-i1-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/alpagasus-2-7b-GGUF/resolve/main/alpagasus-2-7b.Q2_K.gguf) | Q2_K | 2.6 | |
| [GGUF](https://huggingface.co/mradermacher/alpagasus-2-7b-GGUF/resolve/main/alpagasus-2-7b.Q3_K_S.gguf) | Q3_K_S | 3.0 | |
| [GGUF](https://huggingface.co/mradermacher/alpagasus-2-7b-GGUF/resolve/main/alpagasus-2-7b.Q3_K_M.gguf) | Q3_K_M | 3.4 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/alpagasus-2-7b-GGUF/resolve/main/alpagasus-2-7b.Q3_K_L.gguf) | Q3_K_L | 3.7 | |
| [GGUF](https://huggingface.co/mradermacher/alpagasus-2-7b-GGUF/resolve/main/alpagasus-2-7b.IQ4_XS.gguf) | IQ4_XS | 3.7 | |
| [GGUF](https://huggingface.co/mradermacher/alpagasus-2-7b-GGUF/resolve/main/alpagasus-2-7b.Q4_K_S.gguf) | Q4_K_S | 4.0 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/alpagasus-2-7b-GGUF/resolve/main/alpagasus-2-7b.Q4_K_M.gguf) | Q4_K_M | 4.2 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/alpagasus-2-7b-GGUF/resolve/main/alpagasus-2-7b.Q5_K_S.gguf) | Q5_K_S | 4.8 | |
| [GGUF](https://huggingface.co/mradermacher/alpagasus-2-7b-GGUF/resolve/main/alpagasus-2-7b.Q5_K_M.gguf) | Q5_K_M | 4.9 | |
| [GGUF](https://huggingface.co/mradermacher/alpagasus-2-7b-GGUF/resolve/main/alpagasus-2-7b.Q6_K.gguf) | Q6_K | 5.6 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/alpagasus-2-7b-GGUF/resolve/main/alpagasus-2-7b.Q8_0.gguf) | Q8_0 | 7.3 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/alpagasus-2-7b-GGUF/resolve/main/alpagasus-2-7b.f16.gguf) | f16 | 13.6 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
Bobalo/Qwen2.5-0.5B-Instruct-Gensyn-Swarm-territorial_zealous_lobster
|
Bobalo
| 2025-09-05T09:05:00Z | 14 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"generated_from_trainer",
"rl-swarm",
"grpo",
"gensyn",
"I am territorial zealous lobster",
"trl",
"genrl-swarm",
"I am territorial_zealous_lobster",
"conversational",
"arxiv:2402.03300",
"base_model:unsloth/Qwen2.5-0.5B-Instruct",
"base_model:finetune:unsloth/Qwen2.5-0.5B-Instruct",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-04-14T13:25:51Z |
---
base_model: unsloth/Qwen2.5-0.5B-Instruct
library_name: transformers
model_name: Qwen2.5-0.5B-Instruct-Gensyn-Swarm-territorial_zealous_lobster
tags:
- generated_from_trainer
- rl-swarm
- grpo
- gensyn
- I am territorial zealous lobster
- trl
- genrl-swarm
- I am territorial_zealous_lobster
licence: license
---
# Model Card for Qwen2.5-0.5B-Instruct-Gensyn-Swarm-territorial_zealous_lobster
This model is a fine-tuned version of [unsloth/Qwen2.5-0.5B-Instruct](https://huggingface.co/unsloth/Qwen2.5-0.5B-Instruct).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="Bobalo/Qwen2.5-0.5B-Instruct-Gensyn-Swarm-territorial_zealous_lobster", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
This model was trained with GRPO, a method introduced in [DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models](https://huggingface.co/papers/2402.03300).
### Framework versions
- TRL: 0.15.2
- Transformers: 4.51.3
- Pytorch: 2.6.0
- Datasets: 3.5.0
- Tokenizers: 0.21.1
## Citations
Cite GRPO as:
```bibtex
@article{zhihong2024deepseekmath,
title = {{DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models}},
author = {Zhihong Shao and Peiyi Wang and Qihao Zhu and Runxin Xu and Junxiao Song and Mingchuan Zhang and Y. K. Li and Y. Wu and Daya Guo},
year = 2024,
eprint = {arXiv:2402.03300},
}
```
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallouédec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
YuYamada/Llama-3.2-3B-sft-grpo-test
|
YuYamada
| 2025-09-05T09:04:54Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"llama",
"trl",
"en",
"base_model:unsloth/Llama-3.2-3B-Instruct",
"base_model:finetune:unsloth/Llama-3.2-3B-Instruct",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-09-05T07:58:22Z |
---
base_model: unsloth/Llama-3.2-3B-Instruct
tags:
- text-generation-inference
- transformers
- unsloth
- llama
- trl
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** YuYamada
- **License:** apache-2.0
- **Finetuned from model :** unsloth/Llama-3.2-3B-Instruct
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
mehere23/Qwen3-14B-AWQ
|
mehere23
| 2025-09-05T09:02:53Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen3",
"text-generation",
"conversational",
"arxiv:2309.00071",
"arxiv:2505.09388",
"base_model:Qwen/Qwen3-14B",
"base_model:quantized:Qwen/Qwen3-14B",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"4-bit",
"awq",
"region:us"
] |
text-generation
| 2025-09-05T09:02:19Z |
---
library_name: transformers
license: apache-2.0
license_link: https://huggingface.co/Qwen/Qwen3-14B/blob/main/LICENSE
pipeline_tag: text-generation
base_model: Qwen/Qwen3-14B
---
# Qwen3-14B-AWQ
<a href="https://chat.qwen.ai/" target="_blank" style="margin: 2px;">
<img alt="Chat" src="https://img.shields.io/badge/%F0%9F%92%9C%EF%B8%8F%20Qwen%20Chat%20-536af5" style="display: inline-block; vertical-align: middle;"/>
</a>
## Qwen3 Highlights
Qwen3 is the latest generation of large language models in Qwen series, offering a comprehensive suite of dense and mixture-of-experts (MoE) models. Built upon extensive training, Qwen3 delivers groundbreaking advancements in reasoning, instruction-following, agent capabilities, and multilingual support, with the following key features:
- **Uniquely support of seamless switching between thinking mode** (for complex logical reasoning, math, and coding) and **non-thinking mode** (for efficient, general-purpose dialogue) **within single model**, ensuring optimal performance across various scenarios.
- **Significantly enhancement in its reasoning capabilities**, surpassing previous QwQ (in thinking mode) and Qwen2.5 instruct models (in non-thinking mode) on mathematics, code generation, and commonsense logical reasoning.
- **Superior human preference alignment**, excelling in creative writing, role-playing, multi-turn dialogues, and instruction following, to deliver a more natural, engaging, and immersive conversational experience.
- **Expertise in agent capabilities**, enabling precise integration with external tools in both thinking and unthinking modes and achieving leading performance among open-source models in complex agent-based tasks.
- **Support of 100+ languages and dialects** with strong capabilities for **multilingual instruction following** and **translation**.
## Model Overview
**Qwen3-14B** has the following features:
- Type: Causal Language Models
- Training Stage: Pretraining & Post-training
- Number of Parameters: 14.8B
- Number of Paramaters (Non-Embedding): 13.2B
- Number of Layers: 40
- Number of Attention Heads (GQA): 40 for Q and 8 for KV
- Context Length: 32,768 natively and [131,072 tokens with YaRN](#processing-long-texts).
- Quantization: AWQ 4-bit
For more details, including benchmark evaluation, hardware requirements, and inference performance, please refer to our [blog](https://qwenlm.github.io/blog/qwen3/), [GitHub](https://github.com/QwenLM/Qwen3), and [Documentation](https://qwen.readthedocs.io/en/latest/).
## Quickstart
The code of Qwen3 has been in the latest Hugging Face `transformers` and we advise you to use the latest version of `transformers`.
With `transformers<4.51.0`, you will encounter the following error:
```
KeyError: 'qwen3'
```
The following contains a code snippet illustrating how to use the model generate content based on given inputs.
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen3-14B-AWQ"
# load the tokenizer and the model
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
# prepare the model input
prompt = "Give me a short introduction to large language model."
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=True # Switches between thinking and non-thinking modes. Default is True.
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# conduct text completion
generated_ids = model.generate(
**model_inputs,
max_new_tokens=32768
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
# parsing thinking content
try:
# rindex finding 151668 (</think>)
index = len(output_ids) - output_ids[::-1].index(151668)
except ValueError:
index = 0
thinking_content = tokenizer.decode(output_ids[:index], skip_special_tokens=True).strip("\n")
content = tokenizer.decode(output_ids[index:], skip_special_tokens=True).strip("\n")
print("thinking content:", thinking_content)
print("content:", content)
```
For deployment, you can use `sglang>=0.4.6.post1` or `vllm>=0.8.5` or to create an OpenAI-compatible API endpoint:
- SGLang:
```shell
python -m sglang.launch_server --model-path Qwen/Qwen3-14B-AWQ --reasoning-parser qwen3
```
- vLLM:
```shell
vllm serve Qwen/Qwen3-14B-AWQ --enable-reasoning --reasoning-parser deepseek_r1
```
Also check out our [AWQ documentation](https://qwen.readthedocs.io/en/latest/quantization/awq.html) for more usage guide.
## Switching Between Thinking and Non-Thinking Mode
> [!TIP]
> The `enable_thinking` switch is also available in APIs created by SGLang and vLLM.
> Please refer to our documentation for [SGLang](https://qwen.readthedocs.io/en/latest/deployment/sglang.html#thinking-non-thinking-modes) and [vLLM](https://qwen.readthedocs.io/en/latest/deployment/vllm.html#thinking-non-thinking-modes) users.
### `enable_thinking=True`
By default, Qwen3 has thinking capabilities enabled, similar to QwQ-32B. This means the model will use its reasoning abilities to enhance the quality of generated responses. For example, when explicitly setting `enable_thinking=True` or leaving it as the default value in `tokenizer.apply_chat_template`, the model will engage its thinking mode.
```python
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=True # True is the default value for enable_thinking
)
```
In this mode, the model will generate think content wrapped in a `<think>...</think>` block, followed by the final response.
> [!NOTE]
> For thinking mode, use `Temperature=0.6`, `TopP=0.95`, `TopK=20`, and `MinP=0` (the default setting in `generation_config.json`). **DO NOT use greedy decoding**, as it can lead to performance degradation and endless repetitions. For more detailed guidance, please refer to the [Best Practices](#best-practices) section.
### `enable_thinking=False`
We provide a hard switch to strictly disable the model's thinking behavior, aligning its functionality with the previous Qwen2.5-Instruct models. This mode is particularly useful in scenarios where disabling thinking is essential for enhancing efficiency.
```python
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=False # Setting enable_thinking=False disables thinking mode
)
```
In this mode, the model will not generate any think content and will not include a `<think>...</think>` block.
> [!NOTE]
> For non-thinking mode, we suggest using `Temperature=0.7`, `TopP=0.8`, `TopK=20`, and `MinP=0`. For more detailed guidance, please refer to the [Best Practices](#best-practices) section.
### Advanced Usage: Switching Between Thinking and Non-Thinking Modes via User Input
We provide a soft switch mechanism that allows users to dynamically control the model's behavior when `enable_thinking=True`. Specifically, you can add `/think` and `/no_think` to user prompts or system messages to switch the model's thinking mode from turn to turn. The model will follow the most recent instruction in multi-turn conversations.
Here is an example of a multi-turn conversation:
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
class QwenChatbot:
def __init__(self, model_name="Qwen/Qwen3-14B-AWQ"):
self.tokenizer = AutoTokenizer.from_pretrained(model_name)
self.model = AutoModelForCausalLM.from_pretrained(model_name)
self.history = []
def generate_response(self, user_input):
messages = self.history + [{"role": "user", "content": user_input}]
text = self.tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
inputs = self.tokenizer(text, return_tensors="pt")
response_ids = self.model.generate(**inputs, max_new_tokens=32768)[0][len(inputs.input_ids[0]):].tolist()
response = self.tokenizer.decode(response_ids, skip_special_tokens=True)
# Update history
self.history.append({"role": "user", "content": user_input})
self.history.append({"role": "assistant", "content": response})
return response
# Example Usage
if __name__ == "__main__":
chatbot = QwenChatbot()
# First input (without /think or /no_think tags, thinking mode is enabled by default)
user_input_1 = "How many r's in strawberries?"
print(f"User: {user_input_1}")
response_1 = chatbot.generate_response(user_input_1)
print(f"Bot: {response_1}")
print("----------------------")
# Second input with /no_think
user_input_2 = "Then, how many r's in blueberries? /no_think"
print(f"User: {user_input_2}")
response_2 = chatbot.generate_response(user_input_2)
print(f"Bot: {response_2}")
print("----------------------")
# Third input with /think
user_input_3 = "Really? /think"
print(f"User: {user_input_3}")
response_3 = chatbot.generate_response(user_input_3)
print(f"Bot: {response_3}")
```
> [!NOTE]
> For API compatibility, when `enable_thinking=True`, regardless of whether the user uses `/think` or `/no_think`, the model will always output a block wrapped in `<think>...</think>`. However, the content inside this block may be empty if thinking is disabled.
> When `enable_thinking=False`, the soft switches are not valid. Regardless of any `/think` or `/no_think` tags input by the user, the model will not generate think content and will not include a `<think>...</think>` block.
## Agentic Use
Qwen3 excels in tool calling capabilities. We recommend using [Qwen-Agent](https://github.com/QwenLM/Qwen-Agent) to make the best use of agentic ability of Qwen3. Qwen-Agent encapsulates tool-calling templates and tool-calling parsers internally, greatly reducing coding complexity.
To define the available tools, you can use the MCP configuration file, use the integrated tool of Qwen-Agent, or integrate other tools by yourself.
```python
from qwen_agent.agents import Assistant
# Define LLM
llm_cfg = {
'model': 'Qwen3-14B-AWQ',
# Use the endpoint provided by Alibaba Model Studio:
# 'model_type': 'qwen_dashscope',
# 'api_key': os.getenv('DASHSCOPE_API_KEY'),
# Use a custom endpoint compatible with OpenAI API:
'model_server': 'http://localhost:8000/v1', # api_base
'api_key': 'EMPTY',
# Other parameters:
# 'generate_cfg': {
# # Add: When the response content is `<think>this is the thought</think>this is the answer;
# # Do not add: When the response has been separated by reasoning_content and content.
# 'thought_in_content': True,
# },
}
# Define Tools
tools = [
{'mcpServers': { # You can specify the MCP configuration file
'time': {
'command': 'uvx',
'args': ['mcp-server-time', '--local-timezone=Asia/Shanghai']
},
"fetch": {
"command": "uvx",
"args": ["mcp-server-fetch"]
}
}
},
'code_interpreter', # Built-in tools
]
# Define Agent
bot = Assistant(llm=llm_cfg, function_list=tools)
# Streaming generation
messages = [{'role': 'user', 'content': 'https://qwenlm.github.io/blog/ Introduce the latest developments of Qwen'}]
for responses in bot.run(messages=messages):
pass
print(responses)
```
## Processing Long Texts
Qwen3 natively supports context lengths of up to 32,768 tokens. For conversations where the total length (including both input and output) significantly exceeds this limit, we recommend using RoPE scaling techniques to handle long texts effectively. We have validated the model's performance on context lengths of up to 131,072 tokens using the [YaRN](https://arxiv.org/abs/2309.00071) method.
YaRN is currently supported by several inference frameworks, e.g., `transformers` for local use, `vllm` and `sglang` for deployment. In general, there are two approaches to enabling YaRN for supported frameworks:
- Modifying the model files:
In the `config.json` file, add the `rope_scaling` fields:
```json
{
...,
"rope_scaling": {
"rope_type": "yarn",
"factor": 4.0,
"original_max_position_embeddings": 32768
}
}
```
- Passing command line arguments:
For `vllm`, you can use
```shell
vllm serve ... --rope-scaling '{"rope_type":"yarn","factor":4.0,"original_max_position_embeddings":32768}' --max-model-len 131072
```
For `sglang`, you can use
```shell
python -m sglang.launch_server ... --json-model-override-args '{"rope_scaling":{"rope_type":"yarn","factor":4.0,"original_max_position_embeddings":32768}}'
```
> [!IMPORTANT]
> If you encounter the following warning
> ```
> Unrecognized keys in `rope_scaling` for 'rope_type'='yarn': {'original_max_position_embeddings'}
> ```
> please upgrade `transformers>=4.51.0`.
> [!NOTE]
> All the notable open-source frameworks implement static YaRN, which means the scaling factor remains constant regardless of input length, **potentially impacting performance on shorter texts.**
> We advise adding the `rope_scaling` configuration only when processing long contexts is required.
> It is also recommended to modify the `factor` as needed. For example, if the typical context length for your application is 65,536 tokens, it would be better to set `factor` as 2.0.
> [!NOTE]
> The default `max_position_embeddings` in `config.json` is set to 40,960. This allocation includes reserving 32,768 tokens for outputs and 8,192 tokens for typical prompts, which is sufficient for most scenarios involving short text processing. If the average context length does not exceed 32,768 tokens, we do not recommend enabling YaRN in this scenario, as it may potentially degrade model performance.
> [!TIP]
> The endpoint provided by Alibaba Model Studio supports dynamic YaRN by default and no extra configuration is needed.
## Performance
| Mode | QUANTIZATION TYPE | LiveBench 2024-11-25 | GPQA | MMLU-Redux | AIME24 |
| --- | --- | --- | --- | --- | --- |
| Thinking | bf16 | 71.3 | 64.0 | 88.6 | 79.3 |
| Thinking | AWQ-int4 | 70.0 | 62.1 | 88.5 | 77.0 |
| Non-Thinking | bf16 | 59.6 | 54.8 | 82.0 | - |
| Non-Thinking | AWQ-int4 | 57.4 | 53.8 | 81.5 | - |
## Best Practices
To achieve optimal performance, we recommend the following settings:
1. **Sampling Parameters**:
- For thinking mode (`enable_thinking=True`), use `Temperature=0.6`, `TopP=0.95`, `TopK=20`, and `MinP=0`. **DO NOT use greedy decoding**, as it can lead to performance degradation and endless repetitions.
- For non-thinking mode (`enable_thinking=False`), we suggest using `Temperature=0.7`, `TopP=0.8`, `TopK=20`, and `MinP=0`.
- For supported frameworks, you can adjust the `presence_penalty` parameter between 0 and 2 to reduce endless repetitions. **We strongly recommend setting this value to 1.5 for quantized models.** However, using a higher value may occasionally result in language mixing and a slight decrease in model performance.
2. **Adequate Output Length**: We recommend using an output length of 32,768 tokens for most queries. For benchmarking on highly complex problems, such as those found in math and programming competitions, we suggest setting the max output length to 38,912 tokens. This provides the model with sufficient space to generate detailed and comprehensive responses, thereby enhancing its overall performance.
3. **Standardize Output Format**: We recommend using prompts to standardize model outputs when benchmarking.
- **Math Problems**: Include "Please reason step by step, and put your final answer within \boxed{}." in the prompt.
- **Multiple-Choice Questions**: Add the following JSON structure to the prompt to standardize responses: "Please show your choice in the `answer` field with only the choice letter, e.g., `"answer": "C"`."
4. **No Thinking Content in History**: In multi-turn conversations, the historical model output should only include the final output part and does not need to include the thinking content. It is implemented in the provided chat template in Jinja2. However, for frameworks that do not directly use the Jinja2 chat template, it is up to the developers to ensure that the best practice is followed.
### Citation
If you find our work helpful, feel free to give us a cite.
```
@misc{qwen3technicalreport,
title={Qwen3 Technical Report},
author={Qwen Team},
year={2025},
eprint={2505.09388},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2505.09388},
}
```
|
romolocaponera/dqn-SpaceInvadersNoFrameskip-v4
|
romolocaponera
| 2025-09-05T09:02:04Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"SpaceInvadersNoFrameskip-v4",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2025-09-05T07:47:54Z |
---
library_name: stable-baselines3
tags:
- SpaceInvadersNoFrameskip-v4
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: DQN
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: SpaceInvadersNoFrameskip-v4
type: SpaceInvadersNoFrameskip-v4
metrics:
- type: mean_reward
value: 736.00 +/- 265.28
name: mean_reward
verified: false
---
# **DQN** Agent playing **SpaceInvadersNoFrameskip-v4**
This is a trained model of a **DQN** agent playing **SpaceInvadersNoFrameskip-v4**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3)
and the [RL Zoo](https://github.com/DLR-RM/rl-baselines3-zoo).
The RL Zoo is a training framework for Stable Baselines3
reinforcement learning agents,
with hyperparameter optimization and pre-trained agents included.
## Usage (with SB3 RL Zoo)
RL Zoo: https://github.com/DLR-RM/rl-baselines3-zoo<br/>
SB3: https://github.com/DLR-RM/stable-baselines3<br/>
SB3 Contrib: https://github.com/Stable-Baselines-Team/stable-baselines3-contrib
SBX (SB3 + Jax): https://github.com/araffin/sbx
Install the RL Zoo (with SB3 and SB3-Contrib):
```bash
pip install rl_zoo3
```
```
# Download model and save it into the logs/ folder
python -m rl_zoo3.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga romolocaponera -f logs/
python -m rl_zoo3.enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
If you installed the RL Zoo3 via pip (`pip install rl_zoo3`), from anywhere you can do:
```
python -m rl_zoo3.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga romolocaponera -f logs/
python -m rl_zoo3.enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
## Training (with the RL Zoo)
```
python -m rl_zoo3.train --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
# Upload the model and generate video (when possible)
python -m rl_zoo3.push_to_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/ -orga romolocaponera
```
## Hyperparameters
```python
OrderedDict([('batch_size', 32),
('buffer_size', 100000),
('env_wrapper',
['stable_baselines3.common.atari_wrappers.AtariWrapper']),
('exploration_final_eps', 0.01),
('exploration_fraction', 0.1),
('frame_stack', 4),
('gradient_steps', 1),
('learning_rate', 0.0001),
('learning_starts', 100000),
('n_timesteps', 1000000.0),
('optimize_memory_usage', False),
('policy', 'CnnPolicy'),
('target_update_interval', 1000),
('train_freq', 4),
('normalize', False)])
```
# Environment Arguments
```python
{'render_mode': 'rgb_array'}
```
|
bah63843/blockassist-bc-plump_fast_antelope_1757062795
|
bah63843
| 2025-09-05T09:00:44Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"plump fast antelope",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-05T09:00:36Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- plump fast antelope
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
yoppertiu/blockassist-bc-dappled_leaping_anaconda_1757062789
|
yoppertiu
| 2025-09-05T09:00:40Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"dappled leaping anaconda",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-05T08:59:51Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- dappled leaping anaconda
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
NahedDom/blockassist-bc-flapping_stocky_leopard_1757060711
|
NahedDom
| 2025-09-05T08:59:58Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"flapping stocky leopard",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-05T08:59:55Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- flapping stocky leopard
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
yoppertiu/blockassist-bc-patterned_monstrous_boar_1757062584
|
yoppertiu
| 2025-09-05T08:57:14Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"patterned monstrous boar",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-05T08:56:26Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- patterned monstrous boar
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
great1123/DarwinAI-gemma-3-270m_medi_kor_v2
|
great1123
| 2025-09-05T08:52:42Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"gemma3_text",
"text-generation",
"text-generation-inference",
"unsloth",
"conversational",
"en",
"base_model:openfree/DarwinAI-gemma-3-270m",
"base_model:finetune:openfree/DarwinAI-gemma-3-270m",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-09-05T08:52:06Z |
---
base_model: openfree/DarwinAI-gemma-3-270m
tags:
- text-generation-inference
- transformers
- unsloth
- gemma3_text
license: apache-2.0
language:
- en
---
# Uploaded finetuned model
- **Developed by:** great1123
- **License:** apache-2.0
- **Finetuned from model :** openfree/DarwinAI-gemma-3-270m
This gemma3_text model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
Muapi/retro-comics-flux
|
Muapi
| 2025-09-05T08:52:27Z | 0 | 0 | null |
[
"lora",
"stable-diffusion",
"flux.1-d",
"license:openrail++",
"region:us"
] | null | 2025-09-05T08:52:18Z |
---
license: openrail++
tags:
- lora
- stable-diffusion
- flux.1-d
model_type: LoRA
---
# Retro Comics - Flux

**Base model**: Flux.1 D
**Trained words**: retro_comics style
## 🧠 Usage (Python)
🔑 **Get your MUAPI key** from [muapi.ai/access-keys](https://muapi.ai/access-keys)
```python
import requests, os
url = "https://api.muapi.ai/api/v1/flux_dev_lora_image"
headers = {"Content-Type": "application/json", "x-api-key": os.getenv("MUAPIAPP_API_KEY")}
payload = {
"prompt": "masterpiece, best quality, 1girl, looking at viewer",
"model_id": [{"model": "civitai:736218@823278", "weight": 1.0}],
"width": 1024,
"height": 1024,
"num_images": 1
}
print(requests.post(url, headers=headers, json=payload).json())
```
|
zhiyingzou0202/gemma3n_finetune_add_tokens
|
zhiyingzou0202
| 2025-09-05T08:51:24Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-09-04T12:41:44Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
diegogs1451/distilbert-base-uncased-finetuned-imdb
|
diegogs1451
| 2025-09-05T08:50:00Z | 0 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"distilbert",
"fill-mask",
"generated_from_trainer",
"base_model:distilbert/distilbert-base-uncased",
"base_model:finetune:distilbert/distilbert-base-uncased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2025-09-05T08:39:31Z |
---
library_name: transformers
license: apache-2.0
base_model: distilbert-base-uncased
tags:
- generated_from_trainer
model-index:
- name: distilbert-base-uncased-finetuned-imdb
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-imdb
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 2.4892
- Model Preparation Time: 0.002
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH_FUSED with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 3.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Model Preparation Time |
|:-------------:|:-----:|:----:|:---------------:|:----------------------:|
| 2.6814 | 1.0 | 157 | 2.4929 | 0.002 |
| 2.5825 | 2.0 | 314 | 2.4480 | 0.002 |
| 2.5258 | 3.0 | 471 | 2.4823 | 0.002 |
### Framework versions
- Transformers 4.56.0
- Pytorch 2.8.0+cu126
- Datasets 4.0.0
- Tokenizers 0.22.0
|
liukevin666/blockassist-bc-yawning_striped_cassowary_1757062018
|
liukevin666
| 2025-09-05T08:48:13Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"yawning striped cassowary",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-05T08:47:55Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- yawning striped cassowary
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
QuantTrio/Qwen3-Coder-480B-A35B-Instruct-GPTQ-Int4-Int8Mix
|
QuantTrio
| 2025-09-05T08:46:48Z | 246 | 4 |
transformers
|
[
"transformers",
"safetensors",
"qwen3_moe",
"text-generation",
"Qwen3",
"GPTQ",
"Int4-Int8Mix",
"量化修复",
"vLLM",
"conversational",
"arxiv:2505.09388",
"base_model:Qwen/Qwen3-Coder-480B-A35B-Instruct",
"base_model:quantized:Qwen/Qwen3-Coder-480B-A35B-Instruct",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"4-bit",
"gptq",
"region:us"
] |
text-generation
| 2025-07-26T02:14:32Z |
---
library_name: transformers
license: apache-2.0
license_link: https://huggingface.co/Qwen/Qwen3-Coder-480B-A35B-Instruct/blob/main/LICENSE
pipeline_tag: text-generation
tags:
- Qwen3
- GPTQ
- Int4-Int8Mix
- 量化修复
- vLLM
base_model:
- Qwen/Qwen3-Coder-480B-A35B-Instruct
base_model_relation: quantized
---
# Qwen3-Coder-480B-A35B-Instruct-GPTQ-Int4-Int8Mix
Base model [Qwen/Qwen3-Coder-480B-A35B-Instruct](https://huggingface.co/Qwen/Qwen3-Coder-480B-A35B-Instruct)
### 【VLLM Launch Command for 8 GPUs (Single Node)】
<i>Note: Note: When launching with 8 GPUs, --enable-expert-parallel must be specified; otherwise, the expert tensors cannot be evenly split across tensor parallel ranks. This option is not required for 4-GPU setups. </i>
```
CONTEXT_LENGTH=32768 # 262144
vllm serve \
QuantTrio/Qwen3-Coder-480B-A35B-Instruct-GPTQ-Int4-Int8Mix \
--served-model-name Qwen3-Coder-480B-A35B-Instruct-GPTQ-Int4-Int8Mix \
--enable-expert-parallel \
--swap-space 16 \
--max-num-seqs 512 \
--max-model-len $CONTEXT_LENGTH \
--max-seq-len-to-capture $CONTEXT_LENGTH \
--gpu-memory-utilization 0.9 \
--tensor-parallel-size 8 \
--trust-remote-code \
--disable-log-requests \
--host 0.0.0.0 \
--port 8000
```
### 【Dependencies】
```
vllm>=0.9.2
```
### 【Model Update History】
```
2025-08-19
1.[BugFix] Fix compatibility issues with vLLM 0.10.1
2025-08-11
1.Upload tokenizer_config.json
2025-08-01
1. upload the missing 00001, 00003, 00006 weight files
2025-07-24
1. fast commit
```
### 【Model Files】
| File Size | Last Updated |
|---------|--------------|
| `261GB` | `2025-07-24` |
### 【Model Download】
```python
from huggingface_hub import snapshot_download
snapshot_download('QuantTrio/Qwen3-Coder-480B-A35B-Instruct-GPTQ-Int4-Int8Mix', cache_dir="your_local_path")
```
### 【Description】
# Qwen3-Coder-480B-A35B-Instruct
<a href="https://chat.qwen.ai/" target="_blank" style="margin: 2px;">
<img alt="Chat" src="https://img.shields.io/badge/%F0%9F%92%9C%EF%B8%8F%20Qwen%20Chat%20-536af5" style="display: inline-block; vertical-align: middle;"/>
</a>
## Highlights
Today, we're announcing **Qwen3-Coder**, our most agentic code model to date. **Qwen3-Coder** is available in multiple sizes, but we're excited to introduce its most powerful variant first: **Qwen3-Coder-480B-A35B-Instruct**. featuring the following key enhancements:
- **Significant Performance** among open models on **Agentic Coding**, **Agentic Browser-Use**, and other foundational coding tasks, achieving results comparable to Claude Sonnet.
- **Long-context Capabilities** with native support for **256K** tokens, extendable up to **1M** tokens using Yarn, optimized for repository-scale understanding.
- **Agentic Coding** supporting for most platfrom such as **Qwen Code**, **CLINE**, featuring a specially designed function call format.

## Model Overview
**Qwen3-480B-A35B-Instruct** has the following features:
- Type: Causal Language Models
- Training Stage: Pretraining & Post-training
- Number of Parameters: 480B in total and 35B activated
- Number of Layers: 62
- Number of Attention Heads (GQA): 96 for Q and 8 for KV
- Number of Experts: 160
- Number of Activated Experts: 8
- Context Length: **262,144 natively**.
**NOTE: This model supports only non-thinking mode and does not generate ``<think></think>`` blocks in its output. Meanwhile, specifying `enable_thinking=False` is no longer required.**
For more details, including benchmark evaluation, hardware requirements, and inference performance, please refer to our [blog](https://qwenlm.github.io/blog/qwen3-coder/), [GitHub](https://github.com/QwenLM/Qwen3-Coder), and [Documentation](https://qwen.readthedocs.io/en/latest/).
## Quickstart
We advise you to use the latest version of `transformers`.
With `transformers<4.51.0`, you will encounter the following error:
```
KeyError: 'qwen3_moe'
```
The following contains a code snippet illustrating how to use the model generate content based on given inputs.
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen3-480B-A35B-Instruct"
# load the tokenizer and the model
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
# prepare the model input
prompt = "Write a quick sort algorithm."
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# conduct text completion
generated_ids = model.generate(
**model_inputs,
max_new_tokens=65536
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
content = tokenizer.decode(output_ids, skip_special_tokens=True)
print("content:", content)
```
**Note: If you encounter out-of-memory (OOM) issues, consider reducing the context length to a shorter value, such as `32,768`.**
For local use, applications such as Ollama, LMStudio, MLX-LM, llama.cpp, and KTransformers have also supported Qwen3.
## Agentic Coding
Qwen3-Coder excels in tool calling capabilities.
You can simply define or use any tools as following example.
```python
# Your tool implementation
def square_the_number(num: float) -> dict:
return num ** 2
# Define Tools
tools=[
{
"type":"function",
"function":{
"name": "square_the_number",
"description": "output the square of the number.",
"parameters": {
"type": "object",
"required": ["input_num"],
"properties": {
'input_num': {
'type': 'number',
'description': 'input_num is a number that will be squared'
}
},
}
}
}
]
import OpenAI
# Define LLM
client = OpenAI(
# Use a custom endpoint compatible with OpenAI API
base_url='http://localhost:8000/v1', # api_base
api_key="EMPTY"
)
messages = [{'role': 'user', 'content': 'square the number 1024'}]
completion = client.chat.completions.create(
messages=messages,
model="Qwen3-480B-A35B-Instruct",
max_tokens=65536,
tools=tools,
)
print(completion.choice[0])
```
## Best Practices
To achieve optimal performance, we recommend the following settings:
1. **Sampling Parameters**:
- We suggest using `temperature=0.7`, `top_p=0.8`, `top_k=20`, `repetition_penalty=1.05`.
2. **Adequate Output Length**: We recommend using an output length of 65,536 tokens for most queries, which is adequate for instruct models.
### Citation
If you find our work helpful, feel free to give us a cite.
```
@misc{qwen3technicalreport,
title={Qwen3 Technical Report},
author={Qwen Team},
year={2025},
eprint={2505.09388},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2505.09388},
}
```
|
QuantTrio/Qwen3-235B-A22B-Thinking-2507-GPTQ-Int4-Int8Mix
|
QuantTrio
| 2025-09-05T08:46:09Z | 535 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen3_moe",
"text-generation",
"Qwen3",
"GPTQ",
"Int4-Int8Mix",
"量化修复",
"vLLM",
"conversational",
"arxiv:2505.09388",
"base_model:Qwen/Qwen3-235B-A22B-Thinking-2507",
"base_model:quantized:Qwen/Qwen3-235B-A22B-Thinking-2507",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"4-bit",
"gptq",
"region:us"
] |
text-generation
| 2025-07-26T05:06:44Z |
---
library_name: transformers
license: apache-2.0
license_link: https://huggingface.co/Qwen/Qwen3-235B-A22B-Thinking-2507/blob/main/LICENSE
pipeline_tag: text-generation
tags:
- Qwen3
- GPTQ
- Int4-Int8Mix
- 量化修复
- vLLM
base_model:
- Qwen/Qwen3-235B-A22B-Thinking-2507
base_model_relation: quantized
---
# Qwen3-235B-A22B-Thinking-2507-GPTQ-Int4-Int8Mix
Base model [Qwen/Qwen3-235B-A22B-Thinking-2507](https://huggingface.co/Qwen/Qwen3-235B-A22B-Thinking-2507)
### 【VLLM Launch Command for 8 GPUs (Single Node)】
<i>Note: When launching with 8 GPUs, --enable-expert-parallel must be specified; otherwise, the expert tensors cannot be evenly split across tensor parallel ranks. This option is not required for 4-GPU setups. </i>
```
$CONTEXT_LENGTH=32768 # 262144
vllm serve \
QuantTrio/Qwen3-235B-A22B-Thinking-2507-GPTQ-Int4-Int8Mix \
--served-model-name Qwen3-235B-A22B-Thinking-2507-GPTQ-Int4-Int8Mix \
--enable-expert-parallel \
--swap-space 16 \
--max-num-seqs 512 \
--max-model-len $CONTEXT_LENGTH \
--max-seq-len-to-capture $CONTEXT_LENGTH \
--gpu-memory-utilization 0.9 \
--tensor-parallel-size 8 \
--trust-remote-code \
--disable-log-requests \
--host 0.0.0.0 \
--port 8000
```
### 【Dependencies】
```
vllm>=0.9.2
```
### 【Model Update History】
```
2025-08-19
1.[BugFix] Fix compatibility issues with vLLM 0.10.1
2025-07-28
1. Updare model.safetensors.index.json
Please ask everyone who has previously downloaded this repository to update the model.safetensors.index.json file.
2025-07-26
1. fast commit
```
### 【Model Files】
| File Size | Last Updated |
|---------|--------------|
| `125GB` | `2025-07-26` |
### 【Model Download】
```python
from huggingface_hub import snapshot_download
snapshot_download('QuantTrio/Qwen3-235B-A22B-Thinking-2507-GPTQ-Int4-Int8Mix', cache_dir="your_local_path")
```
### 【Description】
# Qwen3-235B-A22B-Thinking-2507
<a href="https://chat.qwen.ai/" target="_blank" style="margin: 2px;">
<img alt="Chat" src="https://img.shields.io/badge/%F0%9F%92%9C%EF%B8%8F%20Qwen%20Chat%20-536af5" style="display: inline-block; vertical-align: middle;"/>
</a>
## Highlights
Over the past three months, we have continued to scale the **thinking capability** of Qwen3-235B-A22B, improving both the **quality and depth** of reasoning. We are pleased to introduce **Qwen3-235B-A22B-Thinking-2507**, featuring the following key enhancements:
- **Significantly improved performance** on reasoning tasks, including logical reasoning, mathematics, science, coding, and academic benchmarks that typically require human expertise — achieving **state-of-the-art results among open-source thinking models**.
- **Markedly better general capabilities**, such as instruction following, tool usage, text generation, and alignment with human preferences.
- **Enhanced 256K long-context understanding** capabilities.
**NOTE**: This version has an increased thinking length. We strongly recommend its use in highly complex reasoning tasks.
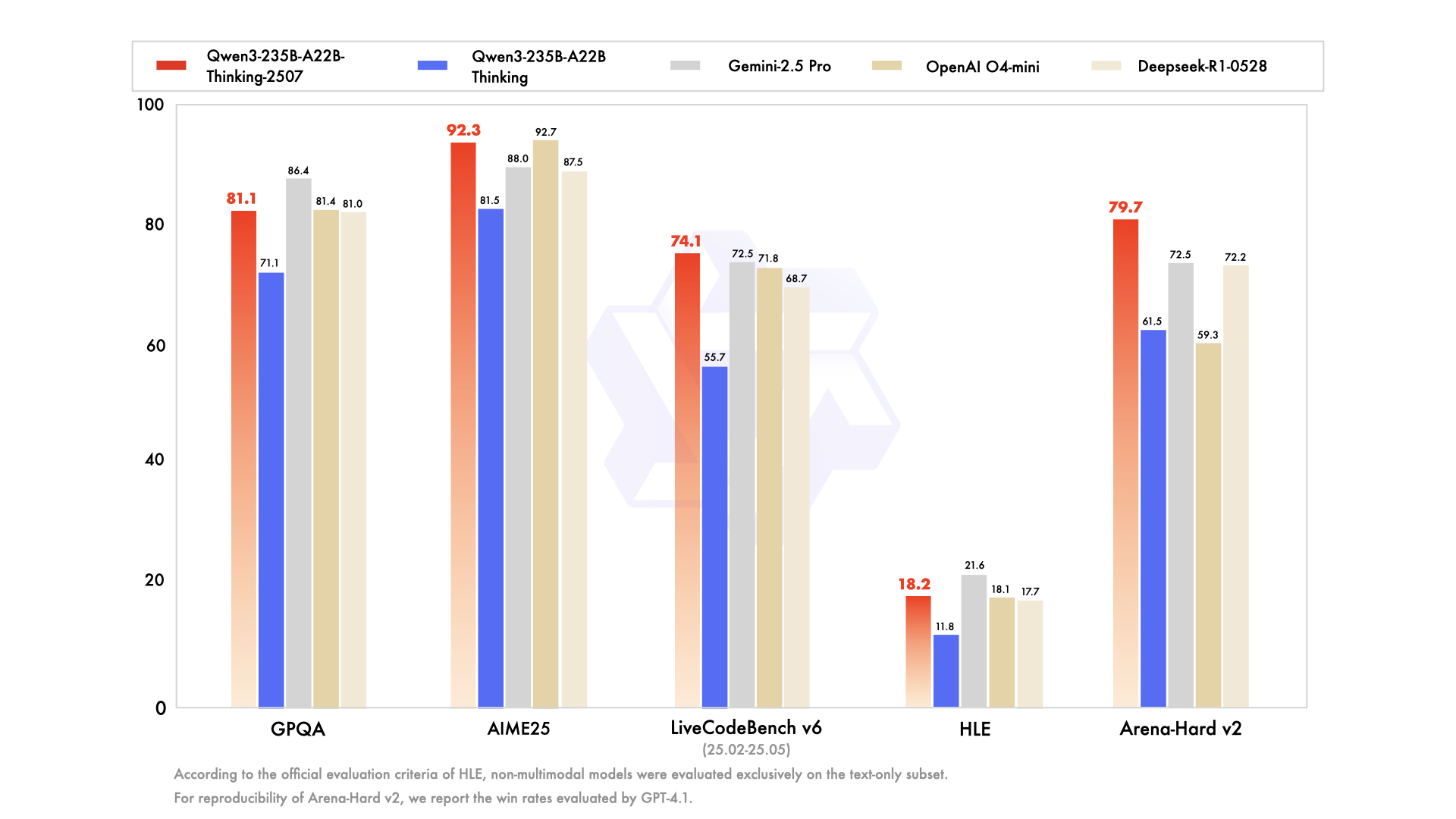
## Model Overview
**Qwen3-235B-A22B-Thinking-2507** has the following features:
- Type: Causal Language Models
- Training Stage: Pretraining & Post-training
- Number of Parameters: 235B in total and 22B activated
- Number of Paramaters (Non-Embedding): 234B
- Number of Layers: 94
- Number of Attention Heads (GQA): 64 for Q and 4 for KV
- Number of Experts: 128
- Number of Activated Experts: 8
- Context Length: **262,144 natively**.
**NOTE: This model supports only thinking mode.**
Additionally, to enforce model thinking, the default chat template automatically includes `<think>`. Therefore, it is normal for the model's output to contain only `</think>` without an explicit opening `<think>` tag.
For more details, including benchmark evaluation, hardware requirements, and inference performance, please refer to our [blog](https://qwenlm.github.io/blog/qwen3/), [GitHub](https://github.com/QwenLM/Qwen3), and [Documentation](https://qwen.readthedocs.io/en/latest/).
## Performance
| | Deepseek-R1-0528 | OpenAI O4-mini | OpenAI O3 | Gemini-2.5 Pro | Claude4 Opus Thinking | Qwen3-235B-A22B Thinking | Qwen3-235B-A22B-Thinking-2507 |
|--- | --- | --- | --- | --- | --- | --- | --- |
| **Knowledge** | | | | | | | |
| MMLU-Pro | 85.0 | 81.9 | **85.9** | 85.6 | - | 82.8 | 84.4 |
| MMLU-Redux | 93.4 | 92.8 | **94.9** | 94.4 | 94.6 | 92.7 | 93.8 |
| GPQA | 81.0 | 81.4* | 83.3* | **86.4** | 79.6 | 71.1 | 81.1 |
| SuperGPQA | 61.7 | 56.4 | - | 62.3 | - | 60.7 | **64.9** |
| **Reasoning** | | | | | | |
| AIME25 | 87.5 | **92.7*** | 88.9* | 88.0 | 75.5 | 81.5 | 92.3 |
| HMMT25 | 79.4 | 66.7 | 77.5 | 82.5 | 58.3 | 62.5 | **83.9** |
| LiveBench 20241125 | 74.7 | 75.8 | 78.3 | **82.4** | 78.2 | 77.1 | 78.4 |
| HLE | 17.7# | 18.1* | 20.3 | **21.6** | 10.7 | 11.8# | 18.2# |
| **Coding** | | | | | | | |
| LiveCodeBench v6 (25.02-25.05) | 68.7 | 71.8 | 58.6 | 72.5 | 48.9 | 55.7 | **74.1** |
| CFEval | 2099 | 1929 | 2043 | 2001 | - | 2056 | **2134** |
| OJBench | 33.6 | 33.3 | 25.4 | **38.9** | - | 25.6 | 32.5 |
| **Alignment** | | | | | | | |
| IFEval | 79.1 | **92.4** | 92.1 | 90.8 | 89.7 | 83.4 | 87.8 |
| Arena-Hard v2$ | 72.2 | 59.3 | **80.8** | 72.5 | 59.1 | 61.5 | 79.7 |
| Creative Writing v3 | 86.3 | 78.8 | **87.7** | 85.9 | 83.8 | 84.6 | 86.1 |
| WritingBench | 83.2 | 78.4 | 85.3 | 83.1 | 79.1 | 80.3 | **88.3** |
| **Agent** | | | | | | | |
| BFCL-v3 | 63.8 | 67.2 | **72.4** | 67.2 | 61.8 | 70.8 | 71.9 |
| TAU2-Retail | 64.9 | 71.0 | **76.3** | 71.3 | - | 40.4 | 71.9 |
| TAU2-Airline | 60.0 | 59.0 | **70.0** | 60.0 | - | 30.0 | 58.0 |
| TAU2-Telecom | 33.3 | 42.0 | **60.5** | 37.4 | - | 21.9 | 45.6 |
| **Multilingualism** | | | | | | | |
| MultiIF | 63.5 | 78.0 | 80.3 | 77.8 | - | 71.9 | **80.6** |
| MMLU-ProX | 80.6 | 79.0 | 83.3 | **84.7** | - | 80.0 | 81.0 |
| INCLUDE | 79.4 | 80.8 | **86.6** | 85.1 | - | 78.7 | 81.0 |
| PolyMATH | 46.9 | 48.7 | 49.7 | 52.2 | - | 54.7 | **60.1** |
\* For OpenAI O4-mini and O3, we use a medium reasoning effort, except for scores marked with *, which are generated using high reasoning effort.
\# According to the official evaluation criteria of HLE, scores marked with \# refer to models that are not multi-modal and were evaluated only on the text-only subset.
$ For reproducibility, we report the win rates evaluated by GPT-4.1.
\& For highly challenging tasks (including PolyMATH and all reasoning and coding tasks), we use an output length of 81,920 tokens. For all other tasks, we set the output length to 32,768.
## Quickstart
The code of Qwen3-MoE has been in the latest Hugging Face `transformers` and we advise you to use the latest version of `transformers`.
With `transformers<4.51.0`, you will encounter the following error:
```
KeyError: 'qwen3_moe'
```
The following contains a code snippet illustrating how to use the model generate content based on given inputs.
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen3-235B-A22B-Thinking-2507"
# load the tokenizer and the model
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
# prepare the model input
prompt = "Give me a short introduction to large language model."
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# conduct text completion
generated_ids = model.generate(
**model_inputs,
max_new_tokens=32768
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
# parsing thinking content
try:
# rindex finding 151668 (</think>)
index = len(output_ids) - output_ids[::-1].index(151668)
except ValueError:
index = 0
thinking_content = tokenizer.decode(output_ids[:index], skip_special_tokens=True).strip("\n")
content = tokenizer.decode(output_ids[index:], skip_special_tokens=True).strip("\n")
print("thinking content:", thinking_content) # no opening <think> tag
print("content:", content)
```
For deployment, you can use `sglang>=0.4.6.post1` or `vllm>=0.8.5` or to create an OpenAI-compatible API endpoint:
- SGLang:
```shell
python -m sglang.launch_server --model-path Qwen/Qwen3-235B-A22B-Thinking-2507 --tp 8 --context-length 262144 --reasoning-parser qwen3
```
- vLLM:
```shell
vllm serve Qwen/Qwen3-235B-A22B-Thinking-2507 --tensor-parallel-size 8 --max-model-len 262144 --enable-reasoning --reasoning-parser deepseek_r1
```
**Note: If you encounter out-of-memory (OOM) issues, you may consider reducing the context length to a smaller value. However, since the model may require longer token sequences for reasoning, we strongly recommend using a context length greater than 131,072 when possible.**
For local use, applications such as Ollama, LMStudio, MLX-LM, llama.cpp, and KTransformers have also supported Qwen3.
## Agentic Use
Qwen3 excels in tool calling capabilities. We recommend using [Qwen-Agent](https://github.com/QwenLM/Qwen-Agent) to make the best use of agentic ability of Qwen3. Qwen-Agent encapsulates tool-calling templates and tool-calling parsers internally, greatly reducing coding complexity.
To define the available tools, you can use the MCP configuration file, use the integrated tool of Qwen-Agent, or integrate other tools by yourself.
```python
from qwen_agent.agents import Assistant
# Define LLM
# Using Alibaba Cloud Model Studio
llm_cfg = {
'model': 'qwen3-235b-a22b-thinking-2507',
'model_type': 'qwen_dashscope',
}
# Using OpenAI-compatible API endpoint. It is recommended to disable the reasoning and the tool call parsing
# functionality of the deployment frameworks and let Qwen-Agent automate the related operations. For example,
# `VLLM_USE_MODELSCOPE=true vllm serve Qwen/Qwen3-235B-A22B-Thinking-2507 --served-model-name Qwen3-235B-A22B-Thinking-2507 --tensor-parallel-size 8 --max-model-len 262144`.
#
# llm_cfg = {
# 'model': 'Qwen3-235B-A22B-Thinking-2507',
#
# # Use a custom endpoint compatible with OpenAI API:
# 'model_server': 'http://localhost:8000/v1', # api_base without reasoning and tool call parsing
# 'api_key': 'EMPTY',
# 'generate_cfg': {
# 'thought_in_content': True,
# },
# }
# Define Tools
tools = [
{'mcpServers': { # You can specify the MCP configuration file
'time': {
'command': 'uvx',
'args': ['mcp-server-time', '--local-timezone=Asia/Shanghai']
},
"fetch": {
"command": "uvx",
"args": ["mcp-server-fetch"]
}
}
},
'code_interpreter', # Built-in tools
]
# Define Agent
bot = Assistant(llm=llm_cfg, function_list=tools)
# Streaming generation
messages = [{'role': 'user', 'content': 'https://qwenlm.github.io/blog/ Introduce the latest developments of Qwen'}]
for responses in bot.run(messages=messages):
pass
print(responses)
```
## Best Practices
To achieve optimal performance, we recommend the following settings:
1. **Sampling Parameters**:
- We suggest using `Temperature=0.6`, `TopP=0.95`, `TopK=20`, and `MinP=0`.
- For supported frameworks, you can adjust the `presence_penalty` parameter between 0 and 2 to reduce endless repetitions. However, using a higher value may occasionally result in language mixing and a slight decrease in model performance.
2. **Adequate Output Length**: We recommend using an output length of 32,768 tokens for most queries. For benchmarking on highly complex problems, such as those found in math and programming competitions, we suggest setting the max output length to 81,920 tokens. This provides the model with sufficient space to generate detailed and comprehensive responses, thereby enhancing its overall performance.
3. **Standardize Output Format**: We recommend using prompts to standardize model outputs when benchmarking.
- **Math Problems**: Include "Please reason step by step, and put your final answer within \boxed{}." in the prompt.
- **Multiple-Choice Questions**: Add the following JSON structure to the prompt to standardize responses: "Please show your choice in the `answer` field with only the choice letter, e.g., `"answer": "C"`."
4. **No Thinking Content in History**: In multi-turn conversations, the historical model output should only include the final output part and does not need to include the thinking content. It is implemented in the provided chat template in Jinja2. However, for frameworks that do not directly use the Jinja2 chat template, it is up to the developers to ensure that the best practice is followed.
### Citation
If you find our work helpful, feel free to give us a cite.
```
@misc{qwen3technicalreport,
title={Qwen3 Technical Report},
author={Qwen Team},
year={2025},
eprint={2505.09388},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2505.09388},
}
```
|
Muapi/art-deco-style-flux1.d
|
Muapi
| 2025-09-05T08:44:44Z | 0 | 0 | null |
[
"lora",
"stable-diffusion",
"flux.1-d",
"license:openrail++",
"region:us"
] | null | 2025-09-05T08:44:32Z |
---
license: openrail++
tags:
- lora
- stable-diffusion
- flux.1-d
model_type: LoRA
---
# Art Deco Style - Flux1.D

**Base model**: Flux.1 D
**Trained words**: art deco style
## 🧠 Usage (Python)
🔑 **Get your MUAPI key** from [muapi.ai/access-keys](https://muapi.ai/access-keys)
```python
import requests, os
url = "https://api.muapi.ai/api/v1/flux_dev_lora_image"
headers = {"Content-Type": "application/json", "x-api-key": os.getenv("MUAPIAPP_API_KEY")}
payload = {
"prompt": "masterpiece, best quality, 1girl, looking at viewer",
"model_id": [{"model": "civitai:1030487@1155829", "weight": 1.0}],
"width": 1024,
"height": 1024,
"num_images": 1
}
print(requests.post(url, headers=headers, json=payload).json())
```
|
SoftmaxSamurai/ConvNext_SCTC
|
SoftmaxSamurai
| 2025-09-05T08:42:16Z | 0 | 0 | null |
[
"license:apache-2.0",
"region:us"
] | null | 2025-09-05T08:33:50Z |
---
license: apache-2.0
---
|
Miracle-man/blockassist-bc-singing_lithe_koala_1757059660
|
Miracle-man
| 2025-09-05T08:40:53Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"singing lithe koala",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-05T08:40:48Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- singing lithe koala
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Rudra-madlads/blockassist-bc-jumping_swift_gazelle_1757061496
|
Rudra-madlads
| 2025-09-05T08:39:04Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"jumping swift gazelle",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-05T08:38:50Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- jumping swift gazelle
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
raihannabiil/blockassist-bc-humming_rugged_viper_1757059156
|
raihannabiil
| 2025-09-05T08:37:18Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"humming rugged viper",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-05T08:37:12Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- humming rugged viper
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
madbro/blockassist-bc-whistling_curious_puffin_1757061306
|
madbro
| 2025-09-05T08:36:17Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"whistling curious puffin",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-05T08:35:53Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- whistling curious puffin
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
maydixit/test
|
maydixit
| 2025-09-05T08:34:44Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-09-05T08:34:06Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
bah63843/blockassist-bc-plump_fast_antelope_1757061228
|
bah63843
| 2025-09-05T08:34:35Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"plump fast antelope",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-05T08:34:27Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- plump fast antelope
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
boonpertou/blockassist-bc-silent_savage_reindeer_1757061207
|
boonpertou
| 2025-09-05T08:33:48Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"silent savage reindeer",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-05T08:33:28Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- silent savage reindeer
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Ferdi3425/blockassist-bc-amphibious_deadly_otter_1757061164
|
Ferdi3425
| 2025-09-05T08:33:42Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"amphibious deadly otter",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-05T08:33:38Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- amphibious deadly otter
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
boomeryop/blockassist-bc-bold_jagged_starfish_1757061195
|
boomeryop
| 2025-09-05T08:33:39Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"bold jagged starfish",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-05T08:33:16Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- bold jagged starfish
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Rudra-madlads/blockassist-bc-jumping_swift_gazelle_1757061108
|
Rudra-madlads
| 2025-09-05T08:32:40Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"jumping swift gazelle",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-05T08:32:21Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- jumping swift gazelle
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
QuantTrio/DeepSeek-R1-0528-Qwen3-8B-Int8-W8A16
|
QuantTrio
| 2025-09-05T08:31:06Z | 55 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen3",
"text-generation",
"Instruct",
"Chat",
"Reason Model",
"Quantization",
"conversational",
"en",
"zh",
"arxiv:2501.12948",
"base_model:deepseek-ai/DeepSeek-R1-0528-Qwen3-8B",
"base_model:quantized:deepseek-ai/DeepSeek-R1-0528-Qwen3-8B",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"compressed-tensors",
"region:us"
] |
text-generation
| 2025-05-30T07:50:32Z |
---
frameworks:
- Pytorch
license: mit
library_name: transformers
pipeline_tag: text-generation
base_model:
- deepseek-ai/DeepSeek-R1-0528-Qwen3-8B
language:
- en
- zh
tags:
- Instruct
- Chat
- Reason Model
- Quantization
tools:
- vllm
base_model_relation: quantized
tasks:
- text-generation
---
### <span style="color:red">重要:友情提醒,推理本模型时,请按照如下官方指引:</span>
#### 对于思考模式(enable_thinking=True, 默认为 True)
> 请使用 Temperature=0.6 、 TopP=0.95 、 TopK=20 和 MinP=0 ( generation_config.json 中的默认设置)。请勿使用<b>贪婪解码(greedy decoding)</b>,因为它可能导致性能下降和无限循环。如需更详细的指导,请参阅最佳实践部分。
#### 对于非思考模式(enable_thinking=False)
> 建议使用 Temperature=0.7 、 TopP=0.8 、 TopK=20 和 MinP=0 。如需更详细的指导,请参阅最佳实践部分。
#### 📖 关于量化损失方面的研究,可阅读公众号“觉察流”文章👇</br>
《[Reason Model 的“瘦身计划”:量化技术的得与失](https://mp.weixin.qq.com/s/NMGq4UUkfo8GMix5LHnWCg)》
# DeepSeek-R1-0528-Qwen3-8B-Int8-W8A16 量化高精校准
原模型 [deepseek-ai/DeepSeek-R1-0528-Qwen3-8B](https://www.modelscope.cn/models/deepseek-ai/DeepSeek-R1-0528-Qwen3-8B)
---
#### _作者在此 👇🏻 扫一扫_
<img src="https://www.modelscope.cn/models/okwinds/GPT-2/resolve/master/qrcode_for_jcl_258.jpg" />
---
## 下载
SDK下载
```bash
#安装ModelScope
pip install modelscope
```
```python
#SDK模型下载
from modelscope import snapshot_download
model_dir = snapshot_download('okwinds/DeepSeek-R1-0528-Qwen3-8B-Int8-W8A16')
```
Git下载
```
#Git模型下载
git clone https://www.modelscope.cn/okwinds/DeepSeek-R1-0528-Qwen3-8B-Int8-W8A16.git
```
## 模型概述
DeepSeek-R1-0528-Qwen3-8B-Int8-W8A16 是一个基于 DeepSeek-R1-0528-Qwen3-8B 的 INT8 量化并校准的模型。
- **模型名称:** DeepSeek-R1-0528-Qwen3-8B-Int8-W8A16
- **模型架构:** Qwen3
- **权重量化:** INT8
该模型通过将 [deepseek-ai/DeepSeek-R1-0528-Qwen3-8B](https://www.modelscope.cn/models/deepseek-ai/DeepSeek-R1-0528-Qwen3-8B) 的权重量化为 INT8 数据类型而实现。
量化过程将每个参数从 16bit 减少到 8bit,将模型占用磁盘空间大小,以及推理时加载模型需要的GPU显存空间,减少到了大约为原模型的1/2。
量化过程中,只有 transformer 中的 Linear 层权重是量化的,其他层均保持为原模型数据类型,采用混合精度的计算方式,尽可能减少模型量化后所带来的精度损失。
在量化过程中,使用了[AutoGPTQ](https://github.com/AutoGPTQ/AutoGPTQ),采用 Symmetric group-wise 方式量化。并在此次量化过程中,进行了数据校准,以提升模型生成精度。(相对比 BF16 做到几乎无损)
> <span style="color: red;">注意:本模型需要 compute capability > 8.0(Ampere、Ada Lovelace、Hopper 架构)的 Nvidia GPU 来支持 INT8 **混合精度**计算。</span>
## 部署推理
#### 推荐使用 vLLM>=0.8.4 ( transformers>=4.51.0 )
Openai api 兼容模式
```bash
>>> vllm serve "/home/gavin/llm/DeepSeek-R1-0528-Qwen3-8B-Int8-W8A16" --host 0.0.0.0 --port 8000 --gpu-memory-utilization 0.9 --served-model-name "DeepSeek-R1-0528-Qwen3-8B-Int8-W8A16"
```
---
# 附录 DeepSeek-R1-0528-Qwen3-8B 介绍
# DeepSeek-R1-0528
<!-- markdownlint-disable first-line-h1 -->
<!-- markdownlint-disable html -->
<!-- markdownlint-disable no-duplicate-header -->
<div align="center">
<img src="https://github.com/deepseek-ai/DeepSeek-V2/blob/main/figures/logo.svg?raw=true" width="60%" alt="DeepSeek-V3" />
</div>
<hr>
<div align="center" style="line-height: 1;">
<a href="https://www.deepseek.com/" target="_blank" style="margin: 2px;">
<img alt="Homepage" src="https://github.com/deepseek-ai/DeepSeek-V2/blob/main/figures/badge.svg?raw=true" style="display: inline-block; vertical-align: middle;"/>
</a>
<a href="https://chat.deepseek.com/" target="_blank" style="margin: 2px;">
<img alt="Chat" src="https://img.shields.io/badge/🤖%20Chat-DeepSeek%20R1-536af5?color=536af5&logoColor=white" style="display: inline-block; vertical-align: middle;"/>
</a>
<a href="https://huggingface.co/deepseek-ai" target="_blank" style="margin: 2px;">
<img alt="Hugging Face" src="https://img.shields.io/badge/%F0%9F%A4%97%20Hugging%20Face-DeepSeek%20AI-ffc107?color=ffc107&logoColor=white" style="display: inline-block; vertical-align: middle;"/>
</a>
</div>
<div align="center" style="line-height: 1;">
<a href="https://discord.gg/Tc7c45Zzu5" target="_blank" style="margin: 2px;">
<img alt="Discord" src="https://img.shields.io/badge/Discord-DeepSeek%20AI-7289da?logo=discord&logoColor=white&color=7289da" style="display: inline-block; vertical-align: middle;"/>
</a>
<a href="https://github.com/deepseek-ai/DeepSeek-V2/blob/main/figures/qr.jpeg?raw=true" target="_blank" style="margin: 2px;">
<img alt="Wechat" src="https://img.shields.io/badge/WeChat-DeepSeek%20AI-brightgreen?logo=wechat&logoColor=white" style="display: inline-block; vertical-align: middle;"/>
</a>
<a href="https://twitter.com/deepseek_ai" target="_blank" style="margin: 2px;">
<img alt="Twitter Follow" src="https://img.shields.io/badge/Twitter-deepseek_ai-white?logo=x&logoColor=white" style="display: inline-block; vertical-align: middle;"/>
</a>
</div>
<div align="center" style="line-height: 1;">
<a href="LICENSE" style="margin: 2px;">
<img alt="License" src="https://img.shields.io/badge/License-MIT-f5de53?&color=f5de53" style="display: inline-block; vertical-align: middle;"/>
</a>
</div>
<p align="center">
<a href="https://arxiv.org/pdf/2501.12948"><b>Paper Link</b>👁️</a>
</p>
## 1. Introduction
The DeepSeek R1 model has undergone a minor version upgrade, with the current version being DeepSeek-R1-0528. In the latest update, DeepSeek R1 has significantly improved its depth of reasoning and inference capabilities by leveraging increased computational resources and introducing algorithmic optimization mechanisms during post-training. The model has demonstrated outstanding performance across various benchmark evaluations, including mathematics, programming, and general logic. Its overall performance is now approaching that of leading models, such as O3 and Gemini 2.5 Pro.
<p align="center">
<img width="80%" src="figures/benchmark.png">
</p>
Compared to the previous version, the upgraded model shows significant improvements in handling complex reasoning tasks. For instance, in the AIME 2025 test, the model’s accuracy has increased from 70% in the previous version to 87.5% in the current version. This advancement stems from enhanced thinking depth during the reasoning process: in the AIME test set, the previous model used an average of 12K tokens per question, whereas the new version averages 23K tokens per question.
Beyond its improved reasoning capabilities, this version also offers a reduced hallucination rate, enhanced support for function calling, and better experience for vibe coding.
## 2. Evaluation Results
### DeepSeek-R1-0528
For all our models, the maximum generation length is set to 64K tokens. For benchmarks requiring sampling, we use a temperature of $0.6$, a top-p value of $0.95$, and generate 16 responses per query to estimate pass@1.
<div align="center">
| Category | Benchmark (Metric) | DeepSeek R1 | DeepSeek R1 0528
|----------|----------------------------------|-----------------|---|
| General |
| | MMLU-Redux (EM) | 92.9 | 93.4
| | MMLU-Pro (EM) | 84.0 | 85.0
| | GPQA-Diamond (Pass@1) | 71.5 | 81.0
| | SimpleQA (Correct) | 30.1 | 27.8
| | FRAMES (Acc.) | 82.5 | 83.0
| | Humanity's Last Exam (Pass@1) | 8.5 | 17.7
| Code |
| | LiveCodeBench (2408-2505) (Pass@1) | 63.5 | 73.3
| | Codeforces-Div1 (Rating) | 1530 | 1930
| | SWE Verified (Resolved) | 49.2 | 57.6
| | Aider-Polyglot (Acc.) | 53.3 | 71.6
| Math |
| | AIME 2024 (Pass@1) | 79.8 | 91.4
| | AIME 2025 (Pass@1) | 70.0 | 87.5
| | HMMT 2025 (Pass@1) | 41.7 | 79.4 |
| | CNMO 2024 (Pass@1) | 78.8 | 86.9
| Tools |
| | BFCL_v3_MultiTurn (Acc) | - | 37.0 |
| | Tau-Bench (Pass@1) | - | 53.5(Airline)/63.9(Retail)
</div>
Note: We use Agentless framework to evaluate model performance on SWE-Verified. We only evaluate text-only prompts in HLE testsets. GPT-4.1 is employed to act user role in Tau-bench evaluation.
### DeepSeek-R1-0528-Qwen3-8B
Meanwhile, we distilled the chain-of-thought from DeepSeek-R1-0528 to post-train Qwen3 8B Base, obtaining DeepSeek-R1-0528-Qwen3-8B. This model achieves state-of-the-art (SOTA) performance among open-source models on the AIME 2024, surpassing Qwen3 8B by +10.0% and matching the performance of Qwen3-235B-thinking. We believe that the chain-of-thought from DeepSeek-R1-0528 will hold significant importance for both academic research on reasoning models and industrial development focused on small-scale models.
| | AIME 24 | AIME 25 | HMMT Feb 25 | GPQA Diamond | LiveCodeBench (2408-2505) |
|--------------------------------|---------|---------|-------------|--------------|---------------------------|
| Qwen3-235B-A22B | 85.7 | 81.5 | 62.5 | 71.1 | 66.5 |
| Qwen3-32B | 81.4 | 72.9 | - | 68.4 | - |
| Qwen3-8B | 76.0 | 67.3 | - | 62.0 | - |
| Phi-4-Reasoning-Plus-14B | 81.3 | 78.0 | 53.6 | 69.3 | - |
| Gemini-2.5-Flash-Thinking-0520 | 82.3 | 72.0 | 64.2 | 82.8 | 62.3 |
| o3-mini (medium) | 79.6 | 76.7 | 53.3 | 76.8 | 65.9 |
| DeepSeek-R1-0528-Qwen3-8B | 86.0 | 76.3 | 61.5 | 61.1 | 60.5 |
## 3. Chat Website & API Platform
You can chat with DeepSeek-R1 on DeepSeek's official website: [chat.deepseek.com](https://chat.deepseek.com/sign_in), and switch on the button "DeepThink"
We also provide OpenAI-Compatible API at DeepSeek Platform: [platform.deepseek.com](https://platform.deepseek.com/)
## 4. How to Run Locally
Please visit [DeepSeek-R1](https://github.com/deepseek-ai/DeepSeek-R1) repository for more information about running DeepSeek-R1-0528 locally.
Compared to previous versions of DeepSeek-R1, the usage recommendations for DeepSeek-R1-0528 have the following changes:
1. System prompt is supported now.
2. It is not required to add "\<think\>\n" at the beginning of the output to force the model into thinking pattern.
The model architecture of DeepSeek-R1-0528-Qwen3-8B is identical to that of Qwen3-8B, but it shares the same tokenizer configuration as DeepSeek-R1-0528. This model can be run in the same manner as Qwen3-8B, but it is essential to ensure that all configuration files are sourced from our repository rather than the original Qwen3 project.
### System Prompt
In the official DeepSeek web/app, we use the same system prompt with a specific date.
```
该助手为DeepSeek-R1,由深度求索公司创造。
今天是{current date}。
```
For example,
```
该助手为DeepSeek-R1,由深度求索公司创造。
今天是2025年5月28日,星期一。
```
### Temperature
In our web and application environments, the temperature parameter $T_{model}$ is set to 0.6.
### Prompts for File Uploading and Web Search
For file uploading, please follow the template to create prompts, where {file_name}, {file_content} and {question} are arguments.
```
file_template = \
"""[file name]: {file_name}
[file content begin]
{file_content}
[file content end]
{question}"""
```
For Web Search, {search_results}, {cur_date}, and {question} are arguments.
For Chinese query, we use the prompt:
```
search_answer_zh_template = \
'''# 以下内容是基于用户发送的消息的搜索结果:
{search_results}
在我给你的搜索结果中,每个结果都是[webpage X begin]...[webpage X end]格式的,X代表每篇文章的数字索引。请在适当的情况下在句子末尾引用上下文。请按照引用编号[citation:X]的格式在答案中对应部分引用上下文。如果一句话源自多个上下文,请列出所有相关的引用编号,例如[citation:3][citation:5],切记不要将引用集中在最后返回引用编号,而是在答案对应部分列出。
在回答时,请注意以下几点:
- 今天是{cur_date}。
- 并非搜索结果的所有内容都与用户的问题密切相关,你需要结合问题,对搜索结果进行甄别、筛选。
- 对于列举类的问题(如列举所有航班信息),尽量将答案控制在10个要点以内,并告诉用户可以查看搜索来源、获得完整信息。优先提供信息完整、最相关的列举项;如非必要,不要主动告诉用户搜索结果未提供的内容。
- 对于创作类的问题(如写论文),请务必在正文的段落中引用对应的参考编号,例如[citation:3][citation:5],不能只在文章末尾引用。你需要解读并概括用户的题目要求,选择合适的格式,充分利用搜索结果并抽取重要信息,生成符合用户要求、极具思想深度、富有创造力与专业性的答案。你的创作篇幅需要尽可能延长,对于每一个要点的论述要推测用户的意图,给出尽可能多角度的回答要点,且务必信息量大、论述详尽。
- 如果回答很长,请尽量结构化、分段落总结。如果需要分点作答,尽量控制在5个点以内,并合并相关的内容。
- 对于客观类的问答,如果问题的答案非常简短,可以适当补充一到两句相关信息,以丰富内容。
- 你需要根据用户要求和回答内容选择合适、美观的回答格式,确保可读性强。
- 你的回答应该综合多个相关网页来回答,不能重复引用一个网页。
- 除非用户要求,否则你回答的语言需要和用户提问的语言保持一致。
# 用户消息为:
{question}'''
```
For English query, we use the prompt:
```
search_answer_en_template = \
'''# The following contents are the search results related to the user's message:
{search_results}
In the search results I provide to you, each result is formatted as [webpage X begin]...[webpage X end], where X represents the numerical index of each article. Please cite the context at the end of the relevant sentence when appropriate. Use the citation format [citation:X] in the corresponding part of your answer. If a sentence is derived from multiple contexts, list all relevant citation numbers, such as [citation:3][citation:5]. Be sure not to cluster all citations at the end; instead, include them in the corresponding parts of the answer.
When responding, please keep the following points in mind:
- Today is {cur_date}.
- Not all content in the search results is closely related to the user's question. You need to evaluate and filter the search results based on the question.
- For listing-type questions (e.g., listing all flight information), try to limit the answer to 10 key points and inform the user that they can refer to the search sources for complete information. Prioritize providing the most complete and relevant items in the list. Avoid mentioning content not provided in the search results unless necessary.
- For creative tasks (e.g., writing an essay), ensure that references are cited within the body of the text, such as [citation:3][citation:5], rather than only at the end of the text. You need to interpret and summarize the user's requirements, choose an appropriate format, fully utilize the search results, extract key information, and generate an answer that is insightful, creative, and professional. Extend the length of your response as much as possible, addressing each point in detail and from multiple perspectives, ensuring the content is rich and thorough.
- If the response is lengthy, structure it well and summarize it in paragraphs. If a point-by-point format is needed, try to limit it to 5 points and merge related content.
- For objective Q&A, if the answer is very brief, you may add one or two related sentences to enrich the content.
- Choose an appropriate and visually appealing format for your response based on the user's requirements and the content of the answer, ensuring strong readability.
- Your answer should synthesize information from multiple relevant webpages and avoid repeatedly citing the same webpage.
- Unless the user requests otherwise, your response should be in the same language as the user's question.
# The user's message is:
{question}'''
```
|
vwzyrraz7l/blockassist-bc-tall_hunting_vulture_1757059545
|
vwzyrraz7l
| 2025-09-05T08:30:27Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"tall hunting vulture",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-05T08:30:23Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- tall hunting vulture
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Ferdi3425/blockassist-bc-amphibious_deadly_otter_1757060901
|
Ferdi3425
| 2025-09-05T08:29:36Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"amphibious deadly otter",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-05T08:29:07Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- amphibious deadly otter
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
liukevin666/blockassist-bc-yawning_striped_cassowary_1757060704
|
liukevin666
| 2025-09-05T08:26:11Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"yawning striped cassowary",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-05T08:26:03Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- yawning striped cassowary
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Ferdi3425/blockassist-bc-amphibious_deadly_otter_1757060651
|
Ferdi3425
| 2025-09-05T08:25:29Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"amphibious deadly otter",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-05T08:25:01Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- amphibious deadly otter
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
jpacifico/Aramis-2B-BitNet-bf16
|
jpacifico
| 2025-09-05T08:25:28Z | 24 | 1 |
transformers
|
[
"transformers",
"safetensors",
"bitnet",
"text-generation",
"mergekit",
"merge",
"conversational",
"custom_code",
"en",
"fr",
"dataset:jpacifico/french-orca-dpo-pairs-revised",
"dataset:Intel/orca_dpo_pairs",
"arxiv:2504.12285",
"arxiv:2403.19522",
"base_model:jpacifico/bitnet-dpo-merged-modelstock-retrain",
"base_model:merge:jpacifico/bitnet-dpo-merged-modelstock-retrain",
"base_model:jpacifico/bitnet-dpo-merged-modelstock2",
"base_model:merge:jpacifico/bitnet-dpo-merged-modelstock2",
"base_model:jpacifico/bitnet-dpo-merged-ties2",
"base_model:merge:jpacifico/bitnet-dpo-merged-ties2",
"base_model:jpacifico/bitnet-dpo-ties-retrained-mirror2",
"base_model:merge:jpacifico/bitnet-dpo-ties-retrained-mirror2",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-07-17T04:05:24Z |
---
base_model:
- jpacifico/bitnet-dpo-ties-retrained-mirror2
- jpacifico/bitnet-dpo-merged-modelstock2
- jpacifico/bitnet-dpo-merged-modelstock-retrain
- jpacifico/bitnet-dpo-merged-ties2
library_name: transformers
tags:
- mergekit
- merge
license: mit
datasets:
- jpacifico/french-orca-dpo-pairs-revised
- Intel/orca_dpo_pairs
language:
- en
- fr
---
# Model Summary
**Aramis-2B-BitNet** *(2.41B params / Context Length: Maximum sequence length of 4096 tokens)*
A compact, agent-oriented small language model focused on contextual reasoning, language understanding and multi-turn instruction following.
Built with an iterative post-training recipe: bilingual DPO (FR+EN) + model merging of FR-centric and EN-centric variants.
Runs natively as BitNet 1.58-bit (ternary) and is available in GGUF 1.58-bit, lossless from the BF16 checkpoint.
**Why BitNet (and why this model)**
- BitNet b1.58 uses ternary weights (−1,0,+1) with abs-mean scaling : very low memory & energy, great CPU/edge throughput, unlike classic FP/INT SLMs. For more details on the underlying architecture and efficiency of BitNet, please refer to the official Microsoft Research publication: [BitNet b1.58 2B4T Technical Report](https://arxiv.org/abs/2504.12285)
- Aramis demonstrates that a 2B BitNet can deliver SOTA language understanding in its class without sacrificing efficiency.
**Model Variants**
- jpacifico/Aramis-2B-BitNet-bf16 (this repo): Contains the retrainable weights in BF16 format
- [jpacifico/Aramis-2B-BitNet-b1.58-i2s-GGUF](https://huggingface.co/jpacifico/Aramis-2B-BitNet-b1.58-i2s-GGUF) : Quantized 1.58-bit GGUF version, you can use with [bitnet.cpp](https://github.com/microsoft/BitNet)
---
# Training Recipe
Base model : [microsoft/bitnet-b1.58-2B-4T-bf16](https://huggingface.co/microsoft/bitnet-b1.58-2B-4T-bf16)
Post-Training Goal: agent-oriented behavior → better instruction following, contextual disambiguation, and pragmatic reasoning in multi-turn settings.
Iterative DPO + Model merging :
- Bilingual DPO (FR+EN) to sharpen preference selection across two languages, using the following datasets :
[jpacifico/french-orca-dpo-pairs-revised](https://huggingface.co/datasets/jpacifico/french-orca-dpo-pairs-revised)
[Intel/orca_dpo_pairs](https://huggingface.co/datasets/Intel/orca_dpo_pairs)
- Model merging (ModelStock and TIES methods, via [Mergekit](https://github.com/cg123/mergekit) to combine complementary strengths of bilingual models (FR-centric + EN-centric), improving robustness across reasoning and comprehension tasks while maintaining stability.
---
# First benchmarks
**Interpretation:** Significant gains on language understanding & pragmatic reasoning (ARC-C/E, Wino, BoolQ, HellaSwag, TriviaQA) with stability on other skills. Math/code are not the optimization target; GSM8K stays essentially stable relative to the bitnet-b1.58-2B-4T quantized baseline (58,38).
All scores are reported in comparison with the original [microsoft/bitnet-b1.58-2B-4T-bf16](https://huggingface.co/microsoft/bitnet-b1.58-2B-4T-bf16) model.
| Benchmark (metric) | microsoft/bitnet-b1.58-2B-4T-bf16 | jpacifico/Aramis-2B-BitNet-bf16|
|------------------------------------|-----------------------------------|--------------------------------|
| arc_challenge 0 shot | 47.95 | **51.62** |
| arc_easy 0 shot | 73.44 | **75.25** |
| hellaswag 0 shot | 68.27 | **68.52** |
| openbookqa 0 shot | **41.6** | 41.4 |
| boolq 0 shot | **79.39** | 79.33 |
| piqa 0 shot | **77.86** | 77.53 |
| winogrande 0 shot | 70.64 | **72.06** |
| ifeval 0 shot | 41.85 | **44.12** |
| triviaqa 0 shot | 11.95 | **15.06** |
| triviaqa 5 shot EM | 33.51 | 33.51 |
| truthfulqa_mc2 10 shot | 45.89 | **46.52** |
| gsm8k 4 shot EM | **62.4** | 59.67 |
| mmlu 5 shot acc | 52.96 | **53.39** |
| commonsense_qa 10 shot acc | **71.17** | 70.76 |
**ARC-Challenge (zero-shot):** 51.62 — first-ever ≥50 reported for a 2B-class model (>1.5B, <2.5B) *based on publicly available results*.
| Model | arc_challenge (0 shot) |
|----------------------------------------------------|------------------------|
| Qwen/Qwen3-1.7B | 43 |
| ibm-granite/granite-3.3-2b-base | 44,54 |
| deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B | 34,9 |
| openbmb/MiniCPM-2B-dpo-bf16 | 44,28 |
| microsoft/bitnet-b1.58-2B-4T-bf16 (base model) | 47,95 |
| microsoft/bitnet-b1.58-2B-4T | 49,91 |
| jpacifico/Aramis-2B-BitNet-bf16 | **51,62** |
### Reproducibility
All benchmark results reported here were obtained using [LM Eval Harness](https://github.com/EleutherAI/lm-evaluation-harness).
The following example reproduces the **ARC-Challenge (0-shot)** evaluation for this model:
```bash
HF_ALLOW_CODE_EVAL=1 lm-eval --model hf \
--model_args pretrained=jpacifico/Aramis-2B-BitNet-bf16,dtype=bfloat16 \
--tasks arc_challenge \
--device cuda:0 --batch_size 8 \
--seed 42 \
--num_fewshot 0 \
--confirm_run_unsafe_code \
--trust_remote_code
```
- All results were computed with LM Eval Harness v0.4.9
- Randomness (e.g. seeds, batch sizes) may cause slight variations in results
- The same procedure was used to evaluate all tasks presented in the benchmark tables
---
# Usage with `bitnet.cpp`
You can run this model using my demo [Colab notebook](https://github.com/jpacifico/Aramis-BitNet/blob/main/Aramis_BitNet_inference_test.ipynb)
Please refer to the [bitnet.cpp](https://github.com/microsoft/BitNet) GitHub repository for detailed compilation steps, usage examples, and command-line options.
---
# Last checkpoint
### Merge Method
This model was merged using the [Model Stock](https://arxiv.org/abs/2403.19522) merge method using [jpacifico/bitnet-dpo-merged-modelstock-retrain](https://huggingface.co/jpacifico/bitnet-dpo-merged-modelstock-retrain) as a base.
### Models Merged
The following models were included in the merge:
* [jpacifico/bitnet-dpo-ties-retrained-mirror2](https://huggingface.co/jpacifico/bitnet-dpo-ties-retrained-mirror2)
* [jpacifico/bitnet-dpo-merged-modelstock2](https://huggingface.co/jpacifico/bitnet-dpo-merged-modelstock2)
* [jpacifico/bitnet-dpo-merged-ties2](https://huggingface.co/jpacifico/bitnet-dpo-merged-ties2)
### Configuration
The following YAML configuration was used to produce this model:
```yaml
models:
- model: jpacifico/bitnet-dpo-merged-ties2
- model: jpacifico/bitnet-dpo-merged-modelstock2
- model: jpacifico/bitnet-dpo-ties-retrained-mirror2
- model: jpacifico/bitnet-dpo-merged-modelstock-retrain
merge_method: model_stock
base_model: jpacifico/bitnet-dpo-merged-modelstock-retrain
parameters:
normalize: true
dtype: bfloat16
tokenizer_source: jpacifico/bitnet-dpo-merged-modelstock-retrain
```
---
# Limitations
Not tuned for coding or formal math; prefer specialized variants if those are critical.
No explicit chain-of-thought training; improvements come from bilingual DPO + merging.
**Disclamer**
This model is intended for research and development purposes only and should not be used in commercial or real-world applications without further testing. While the Microsoft Research team has applied SFT and DPO to align the BitNet base model, it may still produce unexpected, biased, or inaccurate outputs. Please use responsibly.
---
- **Developed by:** Jonathan Pacifico, 2025
- **Model type:** LLM
- **Language(s) (NLP):** French, English
- **License:** MIT
Made with ❤️ in France
|
Muapi/jaw-dropping-eye-popping-surprised-style-realistic-anime-f1d-xl-illu-pony
|
Muapi
| 2025-09-05T08:24:55Z | 0 | 0 | null |
[
"lora",
"stable-diffusion",
"flux.1-d",
"license:openrail++",
"region:us"
] | null | 2025-09-05T08:23:28Z |
---
license: openrail++
tags:
- lora
- stable-diffusion
- flux.1-d
model_type: LoRA
---
# Jaw Dropping Eye Popping "Surprised" style (Realistic + Anime) F1D + XL + Illu + Pony

**Base model**: Flux.1 D
**Trained words**: Jaw Dropping Eye Popping, big eyes, big mouth, Jaw Dropping, Eye Popping, Surprised
## 🧠 Usage (Python)
🔑 **Get your MUAPI key** from [muapi.ai/access-keys](https://muapi.ai/access-keys)
```python
import requests, os
url = "https://api.muapi.ai/api/v1/flux_dev_lora_image"
headers = {"Content-Type": "application/json", "x-api-key": os.getenv("MUAPIAPP_API_KEY")}
payload = {
"prompt": "masterpiece, best quality, 1girl, looking at viewer",
"model_id": [{"model": "civitai:1112508@1250118", "weight": 1.0}],
"width": 1024,
"height": 1024,
"num_images": 1
}
print(requests.post(url, headers=headers, json=payload).json())
```
|
esarkans/coreml-mobileclip
|
esarkans
| 2025-09-05T08:24:50Z | 0 | 0 |
coreml
|
[
"coreml",
"dataset:apple/DataCompDR-1B",
"arxiv:2311.17049",
"arxiv:2103.00020",
"arxiv:2303.15343",
"arxiv:2309.17425",
"license:other",
"region:us"
] | null | 2025-09-04T16:18:39Z |
---
library_name: coreml
license: other
license_name: apple-ascl
license_link: https://github.com/apple/ml-mobileclip/blob/main/LICENSE_weights_data
datasets:
- apple/DataCompDR-1B
---
# MobileCLIP: Fast Image-Text Models through Multi-Modal Reinforced Training
MobileCLIP was introduced in [MobileCLIP: Fast Image-Text Models through Multi-Modal Reinforced Training
](https://arxiv.org/pdf/2311.17049.pdf) (CVPR 2024), by Pavan Kumar Anasosalu Vasu, Hadi Pouransari, Fartash Faghri, Raviteja Vemulapalli, Oncel Tuzel.
This repository contains the text and image encoders of all variants of MobileCLIP exported to Core ML. These Core ML models can be plugged-into the demo app provided in the official [MobileCLIP repo](https://github.com/apple/ml-mobileclip)
<img src="mce_example.gif" width="240" height="540" />
### Highlights
* Our smallest variant `MobileCLIP-S0` obtains similar zero-shot performance as [OpenAI](https://arxiv.org/abs/2103.00020)'s ViT-B/16 model while being 4.8x faster and 2.8x smaller.
* `MobileCLIP-S2` obtains better avg zero-shot performance than [SigLIP](https://arxiv.org/abs/2303.15343)'s ViT-B/16 model while being 2.3x faster and 2.1x smaller, and trained with 3x less seen samples.
* `MobileCLIP-B`(LT) attains zero-shot ImageNet performance of **77.2%** which is significantly better than recent works like [DFN](https://arxiv.org/abs/2309.17425) and [SigLIP](https://arxiv.org/abs/2303.15343) with similar architectures or even [OpenAI's ViT-L/14@336](https://arxiv.org/abs/2103.00020).
## Checkpoints
| Model | # Seen <BR>Samples (B) | # Params (M) <BR> (img + txt) | Latency (ms) <BR> (img + txt) | IN-1k Zero-Shot <BR> Top-1 Acc. (%) | Avg. Perf. (%) <BR> on 38 datasets |
|:----------------------------------------------------------|:----------------------:|:-----------------------------:|:-----------------------------:|:-----------------------------------:|:----------------------------------:|
| [MobileCLIP-S0](https://hf.co/pcuenq/MobileCLIP-S0) | 13 | 11.4 + 42.4 | 1.5 + 1.6 | 67.8 | 58.1 |
| [MobileCLIP-S1](https://hf.co/pcuenq/MobileCLIP-S1) | 13 | 21.5 + 63.4 | 2.5 + 3.3 | 72.6 | 61.3 |
| [MobileCLIP-S2](https://hf.co/pcuenq/MobileCLIP-S2) | 13 | 35.7 + 63.4 | 3.6 + 3.3 | 74.4 | 63.7 |
| [MobileCLIP-B](https://hf.co/pcuenq/MobileCLIP-B) | 13 | 86.3 + 63.4 | 10.4 + 3.3 | 76.8 | 65.2 |
| [MobileCLIP-B (LT)](https://hf.co/pcuenq/MobileCLIP-B-LT) | 36 | 86.3 + 63.4 | 10.4 + 3.3 | 77.2 | 65.8 |
## Download
Install `huggingface-cli`
```bash
brew install huggingface-cli
```
```bash
huggingface-cli download --local-dir models apple/coreml-mobileclip
```
## Citation
**[MobileCLIP: Fast Image-Text Models through Multi-Modal Reinforced Training](https://arxiv.org/pdf/2311.17049.pdf). (CVPR 2024)**
*Pavan Kumar Anasosalu Vasu, Hadi Pouransari, Fartash Faghri, Raviteja Vemulapalli, Oncel Tuzel.*
```bibtex
@InProceedings{mobileclip2024,
author = {Pavan Kumar Anasosalu Vasu, Hadi Pouransari, Fartash Faghri, Raviteja Vemulapalli, Oncel Tuzel},
title = {MobileCLIP: Fast Image-Text Models through Multi-Modal Reinforced Training},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2024},
}
```
|
AnerYubo/blockassist-bc-dormant_strong_badger_1757060565
|
AnerYubo
| 2025-09-05T08:22:48Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"dormant strong badger",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-05T08:22:45Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- dormant strong badger
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
AnerYubo/blockassist-bc-screeching_mute_lemur_1757060546
|
AnerYubo
| 2025-09-05T08:22:29Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"screeching mute lemur",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-05T08:22:26Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- screeching mute lemur
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
bah63843/blockassist-bc-plump_fast_antelope_1757060423
|
bah63843
| 2025-09-05T08:21:12Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"plump fast antelope",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-05T08:21:05Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- plump fast antelope
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
mradermacher/BlackDolphin-24B-GGUF
|
mradermacher
| 2025-09-05T08:20:56Z | 0 | 1 |
transformers
|
[
"transformers",
"gguf",
"mergekit",
"merge",
"nsfw",
"en",
"base_model:Fentible/BlackDolphin-24B",
"base_model:quantized:Fentible/BlackDolphin-24B",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2025-09-05T06:16:42Z |
---
base_model: Fentible/BlackDolphin-24B
language:
- en
library_name: transformers
mradermacher:
readme_rev: 1
quantized_by: mradermacher
tags:
- mergekit
- merge
- nsfw
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
<!-- ### quants: x-f16 Q4_K_S Q2_K Q8_0 Q6_K Q3_K_M Q3_K_S Q3_K_L Q4_K_M Q5_K_S Q5_K_M IQ4_XS -->
<!-- ### quants_skip: -->
<!-- ### skip_mmproj: -->
static quants of https://huggingface.co/Fentible/BlackDolphin-24B
<!-- provided-files -->
***For a convenient overview and download list, visit our [model page for this model](https://hf.tst.eu/model#BlackDolphin-24B-GGUF).***
weighted/imatrix quants are available at https://huggingface.co/mradermacher/BlackDolphin-24B-i1-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/BlackDolphin-24B-GGUF/resolve/main/BlackDolphin-24B.Q2_K.gguf) | Q2_K | 9.0 | |
| [GGUF](https://huggingface.co/mradermacher/BlackDolphin-24B-GGUF/resolve/main/BlackDolphin-24B.Q3_K_S.gguf) | Q3_K_S | 10.5 | |
| [GGUF](https://huggingface.co/mradermacher/BlackDolphin-24B-GGUF/resolve/main/BlackDolphin-24B.Q3_K_M.gguf) | Q3_K_M | 11.6 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/BlackDolphin-24B-GGUF/resolve/main/BlackDolphin-24B.Q3_K_L.gguf) | Q3_K_L | 12.5 | |
| [GGUF](https://huggingface.co/mradermacher/BlackDolphin-24B-GGUF/resolve/main/BlackDolphin-24B.IQ4_XS.gguf) | IQ4_XS | 13.0 | |
| [GGUF](https://huggingface.co/mradermacher/BlackDolphin-24B-GGUF/resolve/main/BlackDolphin-24B.Q4_K_S.gguf) | Q4_K_S | 13.6 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/BlackDolphin-24B-GGUF/resolve/main/BlackDolphin-24B.Q4_K_M.gguf) | Q4_K_M | 14.4 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/BlackDolphin-24B-GGUF/resolve/main/BlackDolphin-24B.Q5_K_S.gguf) | Q5_K_S | 16.4 | |
| [GGUF](https://huggingface.co/mradermacher/BlackDolphin-24B-GGUF/resolve/main/BlackDolphin-24B.Q5_K_M.gguf) | Q5_K_M | 16.9 | |
| [GGUF](https://huggingface.co/mradermacher/BlackDolphin-24B-GGUF/resolve/main/BlackDolphin-24B.Q6_K.gguf) | Q6_K | 19.4 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/BlackDolphin-24B-GGUF/resolve/main/BlackDolphin-24B.Q8_0.gguf) | Q8_0 | 25.2 | fast, best quality |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
seams01/blockassist-bc-insectivorous_stubby_snake_1757058776
|
seams01
| 2025-09-05T08:19:26Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"insectivorous stubby snake",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-05T08:19:22Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- insectivorous stubby snake
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
csukuangfj/ncnn-vits-piper-en_GB-alba-medium-fp16
|
csukuangfj
| 2025-09-05T08:19:16Z | 7 | 0 | null |
[
"region:us"
] | null | 2025-09-04T15:06:56Z |

A fast and local neural text-to-speech engine that embeds [espeak-ng][] for phonemization.
Install with:
``` sh
pip install piper-tts
```
* 🎧 [Samples][samples]
* 💡 [Demo][demo]
* 🗣️ [Voices][voices]
* 🖥️ [Command-line interface][cli]
* 🌐 [Web server][api-http]
* 🐍 [Python API][api-python]
* 🔧 [C/C++ API][libpiper]
* 🏋️ [Training new voices][training]
* 🛠️ [Building manually][building]
---
People/projects using Piper:
* [Home Assistant](https://github.com/home-assistant/addons/blob/master/piper/README.md)
* [NVDA - NonVisual Desktop Access](https://www.nvaccess.org/post/in-process-8th-may-2023/#voices)
* [Image Captioning for the Visually Impaired and Blind: A Recipe for Low-Resource Languages](https://www.techrxiv.org/articles/preprint/Image_Captioning_for_the_Visually_Impaired_and_Blind_A_Recipe_for_Low-Resource_Languages/22133894)
* [Video tutorial by Thorsten Müller](https://youtu.be/rjq5eZoWWSo)
* [Open Voice Operating System](https://github.com/OpenVoiceOS/ovos-tts-plugin-piper)
* [JetsonGPT](https://github.com/shahizat/jetsonGPT)
* [LocalAI](https://github.com/go-skynet/LocalAI)
* [Lernstick EDU / EXAM: reading clipboard content aloud with language detection](https://lernstick.ch/)
* [Natural Speech - A plugin for Runelite, an OSRS Client](https://github.com/phyce/rl-natural-speech)
* [mintPiper](https://github.com/evuraan/mintPiper)
* [Vim-Piper](https://github.com/wolandark/vim-piper)
* [POTaTOS](https://www.youtube.com/watch?v=Dz95q6XYjwY)
* [Narration Studio](https://github.com/phyce/Narration-Studio)
* [Basic TTS](https://basictts.com/) - Simple online text-to-speech converter.
[](https://www.openhomefoundation.org/)
<!-- Links -->
[espeak-ng]: https://github.com/espeak-ng/espeak-ng
[cli]: https://github.com/OHF-Voice/piper1-gpl/blob/main/docs/CLI.md
[api-http]: https://github.com/OHF-Voice/piper1-gpl/blob/main/docs/API_HTTP.md
[api-python]: https://github.com/OHF-Voice/piper1-gpl/blob/main/docs/API_PYTHON.md
[training]: https://github.com/OHF-Voice/piper1-gpl/blob/main/docs/TRAINING.md
[building]: https://github.com/OHF-Voice/piper1-gpl/blob/main/docs/BUILDING.md
[voices]: https://github.com/OHF-Voice/piper1-gpl/blob/main/docs/VOICES.md
[samples]: https://rhasspy.github.io/piper-samples
[demo]: https://rhasspy.github.io/piper-samples/demo.html
[libpiper]: https://github.com/OHF-Voice/piper1-gpl/tree/main/libpiper
|
madbro/blockassist-bc-whistling_curious_puffin_1757060201
|
madbro
| 2025-09-05T08:18:01Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"whistling curious puffin",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-05T08:17:25Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- whistling curious puffin
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Thunderbolt215215/ArtiMuse_PARA
|
Thunderbolt215215
| 2025-09-05T08:16:05Z | 0 | 0 | null |
[
"safetensors",
"internvl_chat",
"custom_code",
"en",
"arxiv:2507.14533",
"base_model:OpenGVLab/InternVL3-8B",
"base_model:finetune:OpenGVLab/InternVL3-8B",
"license:apache-2.0",
"region:us"
] | null | 2025-09-04T12:26:26Z |
---
license: apache-2.0
language:
- en
metrics:
- accuracy
base_model:
- OpenGVLab/InternVL3-8B
---
<h1 style="line-height: 1.4;">
<span style="color: #FF3E3E;">A</span><span style="color: #FF914D;">r</span><span
style="color: #FFC94D;">t</span><span style="color: #B6E24D;">i</span><span
style="color: #4DDC95;">M</span><span style="color: #4DB8FF;">u</span><span
style="color: #8564FF;">s</span><span style="color: #C74DFF;">e</span>:
Fine-Grained Image Aesthetics Assessment with Joint Scoring and Expert-Level Understanding
</h1>
<h1 style="margin-top: -10px; color: #666; font-weight: normal; font-size: 20px;">
书生 · 妙析多模态美学理解大模型
</h1>
<div align="center">
\[[🌐 Project Page](https://thunderbolt215.github.io/ArtiMuse-project/)]
\[[🖥️ Online Demo](http://artimuse.intern-ai.org.cn/)]
\[[📄 Paper](https://arxiv.org/abs/2507.14533)]
\[[🧩 Checkpoints: 🤗 [Hugging Face](https://huggingface.co/collections/Thunderbolt215215/artimuse-68b7d2c7137d8ed119c8774e) | 🤖 [ModelScope](https://modelscope.cn/collections/ArtiMuse-abea7a7922274d)]]
</div>
> 🔬 **We are actively developing an enhanced version of ArtiMuse with reasoning capabilities — _ArtiMuse-R1_.**
> 🌟 Stay tuned for exciting updates and improvements!
**Shuo Cao**, **Nan Ma**, **Jiayang Li**, **Xiaohui Li**, **Lihao Shao**, **Kaiwen Zhu**, **Yu Zhou**, **Yuandong Pu**, **Jiarui Wu**, **Jiaquan Wang**, **Bo Qu**, **Wenhai Wang**, **Yu Qiao**, **Dajuin Yao†**, **Yihao Liu†**
University of Science and Technology of China, Shanghai AI Laboratory, China Academy of Art, Peking University
† Corresponding Authors
## 📰 News & Updates
- 🚀 **Sep 3, 2025**
The **Checkpoints** and **Evaluation Code** of ArtiMuse are now available! 🚀
- 🚀 **July 28, 2025**
**ArtiMuse** was officially released at **WAIC 2025**, in the forum _"Evolving with AI: The Iteration and Resilience of Artistic Creativity"_
- 🚀 **July 24, 2025**
The **Online Demo** is now open for public access!
- 🚀 **July 21, 2025**
The **Paper**, **Repository** and **Project Page** are now live!
## 🔍 Abstract
The rapid advancement of educational applications, artistic creation, and AI-generated content (AIGC) technologies has substantially increased practical requirements for comprehensive Image Aesthetics Assessment (IAA), particularly demanding methods capable of delivering both quantitative scoring and professional understanding.
In this paper, we present:
**(1) ArtiMuse**, an innovative MLLM-based IAA model with Joint Scoring and Expert-Level Understanding capabilities;
**(2) ArtiMuse-10K**, the first expert-curated image aesthetic dataset comprising 10,000 images spanning 5 main categories and 15 subcategories, each annotated by professional experts with 8-dimensional attributes analysis and a holistic score.
## 📦 Checkpoints
All paper-version checkpoints share the same **text pretraining process**, but differ in their **score finetuning datasets**:
| Checkpoint | Score Finetuning Dataset | Download | Notes |
|-------------------------|--------------------------|----------|-------|
| `ArtiMuse` | ArtiMuse-10K | [🤗 HF](https://huggingface.co/Thunderbolt215215/ArtiMuse)<br> [🤖 MS](https://modelscope.cn/models/thunderbolt/ArtiMuse) | **Paper Version (Recommended)** |
| `ArtiMuse_AVA` | AVA | [🤗 HF](https://huggingface.co/Thunderbolt215215/ArtiMuse_AVA)<br> [🤖 MS](https://modelscope.cn/models/thunderbolt/ArtiMuse_AVA) | Paper Version |
| `ArtiMuse_FLICKR-AES` | FLICKR-AES | [🤗 HF](https://huggingface.co/Thunderbolt215215/ArtiMuse_FLICKR-AES)<br> [🤖 MS](https://modelscope.cn/models/thunderbolt/ArtiMuse_FLICKR-AES) | Paper Version |
| `ArtiMuse_PARA` | PARA | [🤗 HF](https://huggingface.co/Thunderbolt215215/ArtiMuse_PARA)<br> [🤖 MS](https://modelscope.cn/models/thunderbolt/ArtiMuse_PARA) | Paper Version |
| `ArtiMuse_TAD66K` | TAD66K | [🤗 HF](https://huggingface.co/Thunderbolt215215/ArtiMuse_TAD66K)<br> [🤖 MS](https://modelscope.cn/models/thunderbolt/ArtiMuse_TAD66K) | Paper Version |
| `ArtiMuse_OnlineDemo` | ArtiMuse-10K & Internal Datasets | — | Surpasses paper versions thanks to additional internal datasets and advanced training; also supports fine-grained attribute scores. For access, please contact us for business collaboration. |
| `ArtiMuse-R1` | — | — | Next-generation model trained with GRPO, supporting CoT reasoning, delivering more accurate score predictions, and extending beyond IAA to handle a wider range of tasks. |
## ⚙️ Setup
Clone this repository:
```
git clone https://github.com/thunderbolt215/ArtiMuse.git
```
Create a conda virtual environment and activate it: (please ensure that `Python>=3.9`).
```
conda create -n artimuse python=3.10
conda activate artimuse
```
Install dependencies using `requirements.txt`:
```
pip install -r requirements.txt
```
We recommend to use FlashAttention for acceleration:
```
pip install flash-attn --no-build-isolation
```
## 📊 Evaluation
### 1. Prepare Checkpoints
Download the pretrained checkpoints and place them under the `checkpoints/` directory.
The folder structure should look like:
```
ArtiMuse
└── checkpoints/
├── ArtiMuse
├── ArtiMuse_AVA
├── ArtiMuse_FLICKR-AES
├── ...
```
---
### 2. Evaluation on a Single Image
Run the following command to evaluate a single image:
```bash
python src/eval/eval_image.py \
--model_name ArtiMuse \
--image_path example/test.jpg \
--device cuda:0
```
* **Arguments**
* `--model_name`: Name of the checkpoint to use (e.g., `ArtiMuse`, `ArtiMuse_AVA`).
* `--image_path`: Path to the input image.
* `--device`: Inference device, e.g., `cuda:0`.
* **Results**
are saved to:
```
results/image_results/{input_image_name}_{model_name}_eval.json
```
---
### 3. Evaluation on Benchmark Datasets
Download the test datasets and organize them under `test_datasets/{dataset_name}/images/`.
The expected structure is:
```
ArtiMuse
└── test_datasets/
├── AVA
│ ├── images/
│ └── test.json
├── TAD66K
├── FLICKR-AES
└── ...
```
* `images/`: contains the test images.
* `test.json`: provides the ground-truth scores (`gt_score`) for evaluation.
Run dataset-level evaluation with:
```bash
python src/eval/eval_dataset.py \
--model_name ArtiMuse_AVA \
--dataset AVA \
--device cuda:0
```
* **Arguments**
* `--model_name`: Name of the checkpoint to use (e.g., `ArtiMuse_AVA`).
* `--dataset`: Dataset name (e.g., `AVA`, `TAD66K`, `FLICKR-AES`).
* `--device`: Inference device.
* **Results**
are saved to:
```
results/dataset_results/{dataset}_{model_name}.json
```
## 🙏 Acknowledgements
Our work is built upon the [InternVL-3](https://github.com/OpenGVLab/InternVL) model as the base foundation. We also refer to the implementation of [Q-Align](https://github.com/Q-Future/Q-Align) during development. We sincerely thank the authors of both projects for their excellent contributions to the community.
## ✒️ Citation
If you find this work useful, please consider citing:
```bibtex
@misc{cao2025artimusefinegrainedimageaesthetics,
title={ArtiMuse: Fine-Grained Image Aesthetics Assessment with Joint Scoring and Expert-Level Understanding},
author={Shuo Cao and Nan Ma and Jiayang Li and Xiaohui Li and Lihao Shao and Kaiwen Zhu and Yu Zhou and Yuandong Pu and Jiarui Wu and Jiaquan Wang and Bo Qu and Wenhai Wang and Yu Qiao and Dajuin Yao and Yihao Liu},
year={2025},
eprint={2507.14533},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2507.14533},
}
```
|
Thunderbolt215215/ArtiMuse_FLICKR-AES
|
Thunderbolt215215
| 2025-09-05T08:15:34Z | 0 | 0 | null |
[
"safetensors",
"internvl_chat",
"custom_code",
"en",
"arxiv:2507.14533",
"base_model:OpenGVLab/InternVL3-8B",
"base_model:finetune:OpenGVLab/InternVL3-8B",
"license:apache-2.0",
"region:us"
] | null | 2025-09-04T11:58:12Z |
---
license: apache-2.0
language:
- en
metrics:
- accuracy
base_model:
- OpenGVLab/InternVL3-8B
---
<h1 style="line-height: 1.4;">
<span style="color: #FF3E3E;">A</span><span style="color: #FF914D;">r</span><span
style="color: #FFC94D;">t</span><span style="color: #B6E24D;">i</span><span
style="color: #4DDC95;">M</span><span style="color: #4DB8FF;">u</span><span
style="color: #8564FF;">s</span><span style="color: #C74DFF;">e</span>:
Fine-Grained Image Aesthetics Assessment with Joint Scoring and Expert-Level Understanding
</h1>
<h1 style="margin-top: -10px; color: #666; font-weight: normal; font-size: 20px;">
书生 · 妙析多模态美学理解大模型
</h1>
<div align="center">
\[[🌐 Project Page](https://thunderbolt215.github.io/ArtiMuse-project/)]
\[[🖥️ Online Demo](http://artimuse.intern-ai.org.cn/)]
\[[📄 Paper](https://arxiv.org/abs/2507.14533)]
\[[🧩 Checkpoints: 🤗 [Hugging Face](https://huggingface.co/collections/Thunderbolt215215/artimuse-68b7d2c7137d8ed119c8774e) | 🤖 [ModelScope](https://modelscope.cn/collections/ArtiMuse-abea7a7922274d)]]
</div>
> 🔬 **We are actively developing an enhanced version of ArtiMuse with reasoning capabilities — _ArtiMuse-R1_.**
> 🌟 Stay tuned for exciting updates and improvements!
**Shuo Cao**, **Nan Ma**, **Jiayang Li**, **Xiaohui Li**, **Lihao Shao**, **Kaiwen Zhu**, **Yu Zhou**, **Yuandong Pu**, **Jiarui Wu**, **Jiaquan Wang**, **Bo Qu**, **Wenhai Wang**, **Yu Qiao**, **Dajuin Yao†**, **Yihao Liu†**
University of Science and Technology of China, Shanghai AI Laboratory, China Academy of Art, Peking University
† Corresponding Authors
## 📰 News & Updates
- 🚀 **Sep 3, 2025**
The **Checkpoints** and **Evaluation Code** of ArtiMuse are now available! 🚀
- 🚀 **July 28, 2025**
**ArtiMuse** was officially released at **WAIC 2025**, in the forum _"Evolving with AI: The Iteration and Resilience of Artistic Creativity"_
- 🚀 **July 24, 2025**
The **Online Demo** is now open for public access!
- 🚀 **July 21, 2025**
The **Paper**, **Repository** and **Project Page** are now live!
## 🔍 Abstract
The rapid advancement of educational applications, artistic creation, and AI-generated content (AIGC) technologies has substantially increased practical requirements for comprehensive Image Aesthetics Assessment (IAA), particularly demanding methods capable of delivering both quantitative scoring and professional understanding.
In this paper, we present:
**(1) ArtiMuse**, an innovative MLLM-based IAA model with Joint Scoring and Expert-Level Understanding capabilities;
**(2) ArtiMuse-10K**, the first expert-curated image aesthetic dataset comprising 10,000 images spanning 5 main categories and 15 subcategories, each annotated by professional experts with 8-dimensional attributes analysis and a holistic score.
## 📦 Checkpoints
All paper-version checkpoints share the same **text pretraining process**, but differ in their **score finetuning datasets**:
| Checkpoint | Score Finetuning Dataset | Download | Notes |
|-------------------------|--------------------------|----------|-------|
| `ArtiMuse` | ArtiMuse-10K | [🤗 HF](https://huggingface.co/Thunderbolt215215/ArtiMuse)<br> [🤖 MS](https://modelscope.cn/models/thunderbolt/ArtiMuse) | **Paper Version (Recommended)** |
| `ArtiMuse_AVA` | AVA | [🤗 HF](https://huggingface.co/Thunderbolt215215/ArtiMuse_AVA)<br> [🤖 MS](https://modelscope.cn/models/thunderbolt/ArtiMuse_AVA) | Paper Version |
| `ArtiMuse_FLICKR-AES` | FLICKR-AES | [🤗 HF](https://huggingface.co/Thunderbolt215215/ArtiMuse_FLICKR-AES)<br> [🤖 MS](https://modelscope.cn/models/thunderbolt/ArtiMuse_FLICKR-AES) | Paper Version |
| `ArtiMuse_PARA` | PARA | [🤗 HF](https://huggingface.co/Thunderbolt215215/ArtiMuse_PARA)<br> [🤖 MS](https://modelscope.cn/models/thunderbolt/ArtiMuse_PARA) | Paper Version |
| `ArtiMuse_TAD66K` | TAD66K | [🤗 HF](https://huggingface.co/Thunderbolt215215/ArtiMuse_TAD66K)<br> [🤖 MS](https://modelscope.cn/models/thunderbolt/ArtiMuse_TAD66K) | Paper Version |
| `ArtiMuse_OnlineDemo` | ArtiMuse-10K & Internal Datasets | — | Surpasses paper versions thanks to additional internal datasets and advanced training; also supports fine-grained attribute scores. For access, please contact us for business collaboration. |
| `ArtiMuse-R1` | — | — | Next-generation model trained with GRPO, supporting CoT reasoning, delivering more accurate score predictions, and extending beyond IAA to handle a wider range of tasks. |
## ⚙️ Setup
Clone this repository:
```
git clone https://github.com/thunderbolt215/ArtiMuse.git
```
Create a conda virtual environment and activate it: (please ensure that `Python>=3.9`).
```
conda create -n artimuse python=3.10
conda activate artimuse
```
Install dependencies using `requirements.txt`:
```
pip install -r requirements.txt
```
We recommend to use FlashAttention for acceleration:
```
pip install flash-attn --no-build-isolation
```
## 📊 Evaluation
### 1. Prepare Checkpoints
Download the pretrained checkpoints and place them under the `checkpoints/` directory.
The folder structure should look like:
```
ArtiMuse
└── checkpoints/
├── ArtiMuse
├── ArtiMuse_AVA
├── ArtiMuse_FLICKR-AES
├── ...
```
---
### 2. Evaluation on a Single Image
Run the following command to evaluate a single image:
```bash
python src/eval/eval_image.py \
--model_name ArtiMuse \
--image_path example/test.jpg \
--device cuda:0
```
* **Arguments**
* `--model_name`: Name of the checkpoint to use (e.g., `ArtiMuse`, `ArtiMuse_AVA`).
* `--image_path`: Path to the input image.
* `--device`: Inference device, e.g., `cuda:0`.
* **Results**
are saved to:
```
results/image_results/{input_image_name}_{model_name}_eval.json
```
---
### 3. Evaluation on Benchmark Datasets
Download the test datasets and organize them under `test_datasets/{dataset_name}/images/`.
The expected structure is:
```
ArtiMuse
└── test_datasets/
├── AVA
│ ├── images/
│ └── test.json
├── TAD66K
├── FLICKR-AES
└── ...
```
* `images/`: contains the test images.
* `test.json`: provides the ground-truth scores (`gt_score`) for evaluation.
Run dataset-level evaluation with:
```bash
python src/eval/eval_dataset.py \
--model_name ArtiMuse_AVA \
--dataset AVA \
--device cuda:0
```
* **Arguments**
* `--model_name`: Name of the checkpoint to use (e.g., `ArtiMuse_AVA`).
* `--dataset`: Dataset name (e.g., `AVA`, `TAD66K`, `FLICKR-AES`).
* `--device`: Inference device.
* **Results**
are saved to:
```
results/dataset_results/{dataset}_{model_name}.json
```
## 🙏 Acknowledgements
Our work is built upon the [InternVL-3](https://github.com/OpenGVLab/InternVL) model as the base foundation. We also refer to the implementation of [Q-Align](https://github.com/Q-Future/Q-Align) during development. We sincerely thank the authors of both projects for their excellent contributions to the community.
## ✒️ Citation
If you find this work useful, please consider citing:
```bibtex
@misc{cao2025artimusefinegrainedimageaesthetics,
title={ArtiMuse: Fine-Grained Image Aesthetics Assessment with Joint Scoring and Expert-Level Understanding},
author={Shuo Cao and Nan Ma and Jiayang Li and Xiaohui Li and Lihao Shao and Kaiwen Zhu and Yu Zhou and Yuandong Pu and Jiarui Wu and Jiaquan Wang and Bo Qu and Wenhai Wang and Yu Qiao and Dajuin Yao and Yihao Liu},
year={2025},
eprint={2507.14533},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2507.14533},
}
```
|
hopghopr/blockassist-bc-territorial_fleecy_heron_1757060113
|
hopghopr
| 2025-09-05T08:15:33Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"territorial fleecy heron",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-05T08:15:14Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- territorial fleecy heron
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
csukuangfj/ncnn-vits-piper-en_US-libritts_r-medium
|
csukuangfj
| 2025-09-05T08:15:23Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-09-05T07:28:51Z |

A fast and local neural text-to-speech engine that embeds [espeak-ng][] for phonemization.
Install with:
``` sh
pip install piper-tts
```
* 🎧 [Samples][samples]
* 💡 [Demo][demo]
* 🗣️ [Voices][voices]
* 🖥️ [Command-line interface][cli]
* 🌐 [Web server][api-http]
* 🐍 [Python API][api-python]
* 🔧 [C/C++ API][libpiper]
* 🏋️ [Training new voices][training]
* 🛠️ [Building manually][building]
---
People/projects using Piper:
* [Home Assistant](https://github.com/home-assistant/addons/blob/master/piper/README.md)
* [NVDA - NonVisual Desktop Access](https://www.nvaccess.org/post/in-process-8th-may-2023/#voices)
* [Image Captioning for the Visually Impaired and Blind: A Recipe for Low-Resource Languages](https://www.techrxiv.org/articles/preprint/Image_Captioning_for_the_Visually_Impaired_and_Blind_A_Recipe_for_Low-Resource_Languages/22133894)
* [Video tutorial by Thorsten Müller](https://youtu.be/rjq5eZoWWSo)
* [Open Voice Operating System](https://github.com/OpenVoiceOS/ovos-tts-plugin-piper)
* [JetsonGPT](https://github.com/shahizat/jetsonGPT)
* [LocalAI](https://github.com/go-skynet/LocalAI)
* [Lernstick EDU / EXAM: reading clipboard content aloud with language detection](https://lernstick.ch/)
* [Natural Speech - A plugin for Runelite, an OSRS Client](https://github.com/phyce/rl-natural-speech)
* [mintPiper](https://github.com/evuraan/mintPiper)
* [Vim-Piper](https://github.com/wolandark/vim-piper)
* [POTaTOS](https://www.youtube.com/watch?v=Dz95q6XYjwY)
* [Narration Studio](https://github.com/phyce/Narration-Studio)
* [Basic TTS](https://basictts.com/) - Simple online text-to-speech converter.
[](https://www.openhomefoundation.org/)
<!-- Links -->
[espeak-ng]: https://github.com/espeak-ng/espeak-ng
[cli]: https://github.com/OHF-Voice/piper1-gpl/blob/main/docs/CLI.md
[api-http]: https://github.com/OHF-Voice/piper1-gpl/blob/main/docs/API_HTTP.md
[api-python]: https://github.com/OHF-Voice/piper1-gpl/blob/main/docs/API_PYTHON.md
[training]: https://github.com/OHF-Voice/piper1-gpl/blob/main/docs/TRAINING.md
[building]: https://github.com/OHF-Voice/piper1-gpl/blob/main/docs/BUILDING.md
[voices]: https://github.com/OHF-Voice/piper1-gpl/blob/main/docs/VOICES.md
[samples]: https://rhasspy.github.io/piper-samples
[demo]: https://rhasspy.github.io/piper-samples/demo.html
[libpiper]: https://github.com/OHF-Voice/piper1-gpl/tree/main/libpiper
|
enacimie/Qwen3-Reranker-4B-Q8_0-GGUF
|
enacimie
| 2025-09-05T08:15:16Z | 0 | 0 |
transformers
|
[
"transformers",
"gguf",
"llama-cpp",
"gguf-my-repo",
"text-ranking",
"base_model:Qwen/Qwen3-Reranker-4B",
"base_model:quantized:Qwen/Qwen3-Reranker-4B",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
] |
text-ranking
| 2025-09-05T08:14:56Z |
---
license: apache-2.0
base_model: Qwen/Qwen3-Reranker-4B
library_name: transformers
pipeline_tag: text-ranking
tags:
- llama-cpp
- gguf-my-repo
---
# enacimie/Qwen3-Reranker-4B-Q8_0-GGUF
This model was converted to GGUF format from [`Qwen/Qwen3-Reranker-4B`](https://huggingface.co/Qwen/Qwen3-Reranker-4B) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/Qwen/Qwen3-Reranker-4B) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew (works on Mac and Linux)
```bash
brew install llama.cpp
```
Invoke the llama.cpp server or the CLI.
### CLI:
```bash
llama-cli --hf-repo enacimie/Qwen3-Reranker-4B-Q8_0-GGUF --hf-file qwen3-reranker-4b-q8_0.gguf -p "The meaning to life and the universe is"
```
### Server:
```bash
llama-server --hf-repo enacimie/Qwen3-Reranker-4B-Q8_0-GGUF --hf-file qwen3-reranker-4b-q8_0.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
Step 1: Clone llama.cpp from GitHub.
```
git clone https://github.com/ggerganov/llama.cpp
```
Step 2: Move into the llama.cpp folder and build it with `LLAMA_CURL=1` flag along with other hardware-specific flags (for ex: LLAMA_CUDA=1 for Nvidia GPUs on Linux).
```
cd llama.cpp && LLAMA_CURL=1 make
```
Step 3: Run inference through the main binary.
```
./llama-cli --hf-repo enacimie/Qwen3-Reranker-4B-Q8_0-GGUF --hf-file qwen3-reranker-4b-q8_0.gguf -p "The meaning to life and the universe is"
```
or
```
./llama-server --hf-repo enacimie/Qwen3-Reranker-4B-Q8_0-GGUF --hf-file qwen3-reranker-4b-q8_0.gguf -c 2048
```
|
Muapi/unblur-flux1.d
|
Muapi
| 2025-09-05T08:14:06Z | 0 | 0 | null |
[
"lora",
"stable-diffusion",
"flux.1-d",
"license:openrail++",
"region:us"
] | null | 2025-09-05T08:13:32Z |
---
license: openrail++
tags:
- lora
- stable-diffusion
- flux.1-d
model_type: LoRA
---
# Unblur (FLUX1.D)

**Base model**: Flux.1 D
**Trained words**: unblurred background
## 🧠 Usage (Python)
🔑 **Get your MUAPI key** from [muapi.ai/access-keys](https://muapi.ai/access-keys)
```python
import requests, os
url = "https://api.muapi.ai/api/v1/flux_dev_lora_image"
headers = {"Content-Type": "application/json", "x-api-key": os.getenv("MUAPIAPP_API_KEY")}
payload = {
"prompt": "masterpiece, best quality, 1girl, looking at viewer",
"model_id": [{"model": "civitai:881179@990315", "weight": 1.0}],
"width": 1024,
"height": 1024,
"num_images": 1
}
print(requests.post(url, headers=headers, json=payload).json())
```
|
Ferdi3425/blockassist-bc-amphibious_deadly_otter_1757059870
|
Ferdi3425
| 2025-09-05T08:12:23Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"amphibious deadly otter",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-05T08:11:55Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- amphibious deadly otter
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
cactus-S/blockassist-bc-reclusive_arctic_panther_1757058472
|
cactus-S
| 2025-09-05T08:10:56Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"reclusive arctic panther",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-05T08:10:52Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- reclusive arctic panther
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
csukuangfj/ncnn-vits-piper-en_US-ljspeech-high-fp16
|
csukuangfj
| 2025-09-05T08:10:49Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-09-05T07:29:16Z |

A fast and local neural text-to-speech engine that embeds [espeak-ng][] for phonemization.
Install with:
``` sh
pip install piper-tts
```
* 🎧 [Samples][samples]
* 💡 [Demo][demo]
* 🗣️ [Voices][voices]
* 🖥️ [Command-line interface][cli]
* 🌐 [Web server][api-http]
* 🐍 [Python API][api-python]
* 🔧 [C/C++ API][libpiper]
* 🏋️ [Training new voices][training]
* 🛠️ [Building manually][building]
---
People/projects using Piper:
* [Home Assistant](https://github.com/home-assistant/addons/blob/master/piper/README.md)
* [NVDA - NonVisual Desktop Access](https://www.nvaccess.org/post/in-process-8th-may-2023/#voices)
* [Image Captioning for the Visually Impaired and Blind: A Recipe for Low-Resource Languages](https://www.techrxiv.org/articles/preprint/Image_Captioning_for_the_Visually_Impaired_and_Blind_A_Recipe_for_Low-Resource_Languages/22133894)
* [Video tutorial by Thorsten Müller](https://youtu.be/rjq5eZoWWSo)
* [Open Voice Operating System](https://github.com/OpenVoiceOS/ovos-tts-plugin-piper)
* [JetsonGPT](https://github.com/shahizat/jetsonGPT)
* [LocalAI](https://github.com/go-skynet/LocalAI)
* [Lernstick EDU / EXAM: reading clipboard content aloud with language detection](https://lernstick.ch/)
* [Natural Speech - A plugin for Runelite, an OSRS Client](https://github.com/phyce/rl-natural-speech)
* [mintPiper](https://github.com/evuraan/mintPiper)
* [Vim-Piper](https://github.com/wolandark/vim-piper)
* [POTaTOS](https://www.youtube.com/watch?v=Dz95q6XYjwY)
* [Narration Studio](https://github.com/phyce/Narration-Studio)
* [Basic TTS](https://basictts.com/) - Simple online text-to-speech converter.
[](https://www.openhomefoundation.org/)
<!-- Links -->
[espeak-ng]: https://github.com/espeak-ng/espeak-ng
[cli]: https://github.com/OHF-Voice/piper1-gpl/blob/main/docs/CLI.md
[api-http]: https://github.com/OHF-Voice/piper1-gpl/blob/main/docs/API_HTTP.md
[api-python]: https://github.com/OHF-Voice/piper1-gpl/blob/main/docs/API_PYTHON.md
[training]: https://github.com/OHF-Voice/piper1-gpl/blob/main/docs/TRAINING.md
[building]: https://github.com/OHF-Voice/piper1-gpl/blob/main/docs/BUILDING.md
[voices]: https://github.com/OHF-Voice/piper1-gpl/blob/main/docs/VOICES.md
[samples]: https://rhasspy.github.io/piper-samples
[demo]: https://rhasspy.github.io/piper-samples/demo.html
[libpiper]: https://github.com/OHF-Voice/piper1-gpl/tree/main/libpiper
|
csukuangfj/ncnn-vits-piper-en_GB-jenny_dioco-medium
|
csukuangfj
| 2025-09-05T08:10:47Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-09-05T07:19:51Z |

A fast and local neural text-to-speech engine that embeds [espeak-ng][] for phonemization.
Install with:
``` sh
pip install piper-tts
```
* 🎧 [Samples][samples]
* 💡 [Demo][demo]
* 🗣️ [Voices][voices]
* 🖥️ [Command-line interface][cli]
* 🌐 [Web server][api-http]
* 🐍 [Python API][api-python]
* 🔧 [C/C++ API][libpiper]
* 🏋️ [Training new voices][training]
* 🛠️ [Building manually][building]
---
People/projects using Piper:
* [Home Assistant](https://github.com/home-assistant/addons/blob/master/piper/README.md)
* [NVDA - NonVisual Desktop Access](https://www.nvaccess.org/post/in-process-8th-may-2023/#voices)
* [Image Captioning for the Visually Impaired and Blind: A Recipe for Low-Resource Languages](https://www.techrxiv.org/articles/preprint/Image_Captioning_for_the_Visually_Impaired_and_Blind_A_Recipe_for_Low-Resource_Languages/22133894)
* [Video tutorial by Thorsten Müller](https://youtu.be/rjq5eZoWWSo)
* [Open Voice Operating System](https://github.com/OpenVoiceOS/ovos-tts-plugin-piper)
* [JetsonGPT](https://github.com/shahizat/jetsonGPT)
* [LocalAI](https://github.com/go-skynet/LocalAI)
* [Lernstick EDU / EXAM: reading clipboard content aloud with language detection](https://lernstick.ch/)
* [Natural Speech - A plugin for Runelite, an OSRS Client](https://github.com/phyce/rl-natural-speech)
* [mintPiper](https://github.com/evuraan/mintPiper)
* [Vim-Piper](https://github.com/wolandark/vim-piper)
* [POTaTOS](https://www.youtube.com/watch?v=Dz95q6XYjwY)
* [Narration Studio](https://github.com/phyce/Narration-Studio)
* [Basic TTS](https://basictts.com/) - Simple online text-to-speech converter.
[](https://www.openhomefoundation.org/)
<!-- Links -->
[espeak-ng]: https://github.com/espeak-ng/espeak-ng
[cli]: https://github.com/OHF-Voice/piper1-gpl/blob/main/docs/CLI.md
[api-http]: https://github.com/OHF-Voice/piper1-gpl/blob/main/docs/API_HTTP.md
[api-python]: https://github.com/OHF-Voice/piper1-gpl/blob/main/docs/API_PYTHON.md
[training]: https://github.com/OHF-Voice/piper1-gpl/blob/main/docs/TRAINING.md
[building]: https://github.com/OHF-Voice/piper1-gpl/blob/main/docs/BUILDING.md
[voices]: https://github.com/OHF-Voice/piper1-gpl/blob/main/docs/VOICES.md
[samples]: https://rhasspy.github.io/piper-samples
[demo]: https://rhasspy.github.io/piper-samples/demo.html
[libpiper]: https://github.com/OHF-Voice/piper1-gpl/tree/main/libpiper
|
csukuangfj/ncnn-vits-piper-en_GB-jenny_dioco-medium-fp16
|
csukuangfj
| 2025-09-05T08:10:43Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-09-05T07:19:44Z |

A fast and local neural text-to-speech engine that embeds [espeak-ng][] for phonemization.
Install with:
``` sh
pip install piper-tts
```
* 🎧 [Samples][samples]
* 💡 [Demo][demo]
* 🗣️ [Voices][voices]
* 🖥️ [Command-line interface][cli]
* 🌐 [Web server][api-http]
* 🐍 [Python API][api-python]
* 🔧 [C/C++ API][libpiper]
* 🏋️ [Training new voices][training]
* 🛠️ [Building manually][building]
---
People/projects using Piper:
* [Home Assistant](https://github.com/home-assistant/addons/blob/master/piper/README.md)
* [NVDA - NonVisual Desktop Access](https://www.nvaccess.org/post/in-process-8th-may-2023/#voices)
* [Image Captioning for the Visually Impaired and Blind: A Recipe for Low-Resource Languages](https://www.techrxiv.org/articles/preprint/Image_Captioning_for_the_Visually_Impaired_and_Blind_A_Recipe_for_Low-Resource_Languages/22133894)
* [Video tutorial by Thorsten Müller](https://youtu.be/rjq5eZoWWSo)
* [Open Voice Operating System](https://github.com/OpenVoiceOS/ovos-tts-plugin-piper)
* [JetsonGPT](https://github.com/shahizat/jetsonGPT)
* [LocalAI](https://github.com/go-skynet/LocalAI)
* [Lernstick EDU / EXAM: reading clipboard content aloud with language detection](https://lernstick.ch/)
* [Natural Speech - A plugin for Runelite, an OSRS Client](https://github.com/phyce/rl-natural-speech)
* [mintPiper](https://github.com/evuraan/mintPiper)
* [Vim-Piper](https://github.com/wolandark/vim-piper)
* [POTaTOS](https://www.youtube.com/watch?v=Dz95q6XYjwY)
* [Narration Studio](https://github.com/phyce/Narration-Studio)
* [Basic TTS](https://basictts.com/) - Simple online text-to-speech converter.
[](https://www.openhomefoundation.org/)
<!-- Links -->
[espeak-ng]: https://github.com/espeak-ng/espeak-ng
[cli]: https://github.com/OHF-Voice/piper1-gpl/blob/main/docs/CLI.md
[api-http]: https://github.com/OHF-Voice/piper1-gpl/blob/main/docs/API_HTTP.md
[api-python]: https://github.com/OHF-Voice/piper1-gpl/blob/main/docs/API_PYTHON.md
[training]: https://github.com/OHF-Voice/piper1-gpl/blob/main/docs/TRAINING.md
[building]: https://github.com/OHF-Voice/piper1-gpl/blob/main/docs/BUILDING.md
[voices]: https://github.com/OHF-Voice/piper1-gpl/blob/main/docs/VOICES.md
[samples]: https://rhasspy.github.io/piper-samples
[demo]: https://rhasspy.github.io/piper-samples/demo.html
[libpiper]: https://github.com/OHF-Voice/piper1-gpl/tree/main/libpiper
|
Subsets and Splits
Filtered Qwen2.5 Distill Models
Identifies specific configurations of models by filtering cards that contain 'distill', 'qwen2.5', '7b' while excluding certain base models and incorrect model ID patterns, uncovering unique model variants.
Filtered Model Cards Count
Finds the count of entries with specific card details that include 'distill', 'qwen2.5', '7b' but exclude certain base models, revealing valuable insights about the dataset's content distribution.
Filtered Distill Qwen 7B Models
Filters for specific card entries containing 'distill', 'qwen', and '7b', excluding certain strings and patterns, to identify relevant model configurations.
Filtered Qwen-7b Model Cards
The query performs a detailed filtering based on specific keywords and excludes certain entries, which could be useful for identifying a specific subset of cards but does not provide deeper insights or trends.
Filtered Qwen 7B Model Cards
The query filters for specific terms related to "distilled" or "distill", "qwen", and "7b" in the 'card' column but excludes certain base models, providing a limited set of entries for further inspection.
Qwen 7B Distilled Models
The query provides a basic filtering of records to find specific card names that include keywords related to distilled Qwen 7b models, excluding a particular base model, which gives limited insight but helps in focusing on relevant entries.
Qwen 7B Distilled Model Cards
The query filters data based on specific keywords in the modelId and card fields, providing limited insight primarily useful for locating specific entries rather than revealing broad patterns or trends.
Qwen 7B Distilled Models
Finds all entries containing the terms 'distilled', 'qwen', and '7b' in a case-insensitive manner, providing a filtered set of records but without deeper analysis.
Distilled Qwen 7B Models
The query filters for specific model IDs containing 'distilled', 'qwen', and '7b', providing a basic retrieval of relevant entries but without deeper analysis or insight.
Filtered Model Cards with Distill Qwen2.
Filters and retrieves records containing specific keywords in the card description while excluding certain phrases, providing a basic count of relevant entries.
Filtered Model Cards with Distill Qwen 7
The query filters specific variations of card descriptions containing 'distill', 'qwen', and '7b' while excluding a particular base model, providing limited but specific data retrieval.
Distill Qwen 7B Model Cards
The query filters and retrieves rows where the 'card' column contains specific keywords ('distill', 'qwen', and '7b'), providing a basic filter result that can help in identifying specific entries.