
modelId
stringlengths 5
139
| author
stringlengths 2
42
| last_modified
timestamp[us, tz=UTC]date 2020-02-15 11:33:14
2025-09-06 00:36:47
| downloads
int64 0
223M
| likes
int64 0
11.7k
| library_name
stringclasses 540
values | tags
listlengths 1
4.05k
| pipeline_tag
stringclasses 55
values | createdAt
timestamp[us, tz=UTC]date 2022-03-02 23:29:04
2025-09-06 00:36:27
| card
stringlengths 11
1.01M
|
|---|---|---|---|---|---|---|---|---|---|
NexVeridian/Jan-v1-4B-3bit
|
NexVeridian
| 2025-08-12T15:39:09Z | 0 | 0 |
mlx
|
[
"mlx",
"safetensors",
"qwen3",
"text-generation",
"conversational",
"en",
"base_model:janhq/Jan-v1-4B",
"base_model:quantized:janhq/Jan-v1-4B",
"license:apache-2.0",
"3-bit",
"region:us"
] |
text-generation
| 2025-08-12T15:37:52Z |
---
license: apache-2.0
language:
- en
base_model: janhq/Jan-v1-4B
pipeline_tag: text-generation
library_name: mlx
tags:
- mlx
---
# NexVeridian/Jan-v1-4B-3bit
This model [NexVeridian/Jan-v1-4B-3bit](https://huggingface.co/NexVeridian/Jan-v1-4B-3bit) was
converted to MLX format from [janhq/Jan-v1-4B](https://huggingface.co/janhq/Jan-v1-4B)
using mlx-lm version **0.26.3**.
## Use with mlx
```bash
pip install mlx-lm
```
```python
from mlx_lm import load, generate
model, tokenizer = load("NexVeridian/Jan-v1-4B-3bit")
prompt = "hello"
if tokenizer.chat_template is not None:
messages = [{"role": "user", "content": prompt}]
prompt = tokenizer.apply_chat_template(
messages, add_generation_prompt=True
)
response = generate(model, tokenizer, prompt=prompt, verbose=True)
```
|
WenFengg/cold14_l1_v1_plus_12_8
|
WenFengg
| 2025-08-12T15:38:32Z | 0 | 0 | null |
[
"safetensors",
"any-to-any",
"omega",
"omegalabs",
"bittensor",
"agi",
"license:mit",
"region:us"
] |
any-to-any
| 2025-08-12T15:31:01Z |
---
license: mit
tags:
- any-to-any
- omega
- omegalabs
- bittensor
- agi
---
This is an Any-to-Any model checkpoint for the OMEGA Labs x Bittensor Any-to-Any subnet.
Check out the [git repo](https://github.com/omegalabsinc/omegalabs-anytoany-bittensor) and find OMEGA on X: [@omegalabsai](https://x.com/omegalabsai).
|
sirekist98/spanish_tts_emotions
|
sirekist98
| 2025-08-12T15:36:29Z | 0 | 3 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"trl",
"orpeheutts",
"tts",
"Texttospeech",
"text-to-speech",
"es",
"dataset:sirekist98/spanish_tts_noauddataset_24khz",
"base_model:canopylabs/3b-es_it-pretrain-research_release",
"base_model:finetune:canopylabs/3b-es_it-pretrain-research_release",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
text-to-speech
| 2025-06-13T12:22:34Z |
---
tags:
- transformers
- llama
- trl
- orpeheutts
- tts
- Texttospeech
license: apache-2.0
language:
- es
datasets:
- sirekist98/spanish_tts_noauddataset_24khz
base_model:
- canopylabs/3b-es_it-pretrain-research_release
pipeline_tag: text-to-speech
---
# Spanish TTS Model with Emotions and Multiple Voices
This repository contains a fine-tuned Spanish Text-to-Speech (TTS) model based on [`canopylabs/3b-es_it-pretrain-research_release`](https://huggingface.co/canopylabs/3b-es_it-pretrain-research_release). The model supports multiple voices and nuanced emotions, trained using [Unsloth](https://github.com/unslothai/unsloth) and [SNAC](https://huggingface.co/hubertsiuzdak/snac_24khz) for audio tokenization.
➡️ **Try it online**: [https://huggingface.co/spaces/sirekist98/orpheustts\_spanish\_tuned](https://huggingface.co/spaces/sirekist98/orpheustts_spanish_tuned)
---
## 👨💻 Model Summary
* **Base model**: `canopylabs/3b-es_it-pretrain-research_release`
* **Fine-tuned with**: LoRA adapters (64 rank, alpha 64)
* **Audio tokenization**: SNAC (24kHz)
* **Input format**: `source (emotion): text`
* **Dataset**: \~109k samples, 11 emotions × 11 speakers
* **Training framework**: Unsloth + Hugging Face Transformers
---
## 🚀 Training Overview
The model was trained on a curated subset of the dataset [`sirekist98/spanish_tts_noauddataset_24khz`](https://huggingface.co/datasets/sirekist98/spanish_tts_noauddataset_24khz). We selected combinations of speaker (`source`) and `emotion` with at least 1000 samples, resulting in a balanced dataset of over 109,000 examples.
Each sample was tokenized using SNAC and embedded in a prompt structured as:
```text
source (emotion): text
```
This prompt was then used to generate audio tokens, enabling the model to learn nuanced emotional prosody and voice control.
We trained the model for 1 epoch using gradient accumulation (batch size 8 × 4 steps) with 4-bit quantization on an NVIDIA L4 GPU.
---
## 🔊 Inference
You can run inference using the demo space: [Orpheus TTS Spanish Fine-Tuned](https://huggingface.co/spaces/sirekist98/orpheustts_spanish_tuned).
To run inference locally with full control:
```python
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
from peft import PeftModel
from snac import SNAC
# --- Minimal config ---
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
BASE = "canopylabs/3b-es_it-pretrain-research_release"
LORA = "sirekist98/spanish_tts_emotions"
SNAC_ID = "hubertsiuzdak/snac_24khz"
VOICE = "alloy"
EMOTION_ID = "intense_fear_dread_apprehension_horror_terror_panic"
TEXT = "Estoy atrapado, por favor ayúdame."
prompt = f"{VOICE} ({EMOTION_ID}): {TEXT}"
# --- Load models ---
tokenizer = AutoTokenizer.from_pretrained(BASE)
base_model = AutoModelForCausalLM.from_pretrained(
BASE,
torch_dtype=torch.float16 if device.type == "cuda" else torch.float32
)
model = PeftModel.from_pretrained(base_model, LORA).to(device).eval()
snac_model = SNAC.from_pretrained(SNAC_ID).to(device)
# --- Prepare input (same as your Space) ---
input_ids = tokenizer(prompt, return_tensors="pt").input_ids.to(device)
start_tok = torch.tensor([[128259]], dtype=torch.long).to(device)
end_toks = torch.tensor([[128009, 128260]], dtype=torch.long).to(device)
input_ids = torch.cat([start_tok, input_ids, end_toks], dim=1)
MAX_LEN = 4260
pad_len = MAX_LEN - input_ids.shape[1]
pad = torch.full((1, pad_len), 128263, dtype=torch.long).to(device)
input_ids = torch.cat([pad, input_ids], dim=1)
attention_mask = torch.cat(
[torch.zeros((1, pad_len), dtype=torch.long),
torch.ones((1, input_ids.shape[1] - pad_len), dtype=torch.long)],
dim=1
).to(device)
# --- Generate ---
generated = model.generate(
input_ids=input_ids,
attention_mask=attention_mask,
max_new_tokens=1200,
do_sample=True,
temperature=0.6,
top_p=0.95,
repetition_penalty=1.1,
num_return_sequences=1,
eos_token_id=128258,
use_cache=True
)
# --- Post-process (find 128257, remove 128258, multiple of 7, subtract 128266) ---
AUDIO_TOKEN_OFFSET = 128266
token_to_find = 128257
token_to_remove = 128258
idxs = (generated == token_to_find).nonzero(as_tuple=True)
cropped = generated[:, idxs[1][-1].item() + 1:] if len(idxs[1]) > 0 else generated
cleaned = cropped[cropped != token_to_remove]
codes = cleaned[: (len(cleaned) // 7) * 7].tolist()
codes = [int(t) - AUDIO_TOKEN_OFFSET for t in codes]
# --- SNAC decode (same layout as your Space) ---
layer_1, layer_2, layer_3 = [], [], []
for i in range((len(codes) + 1) // 7):
b = 7 * i
if b + 6 >= len(codes):
break
layer_1.append(codes[b + 0])
layer_2.append(codes[b + 1] - 4096)
layer_3.append(codes[b + 2] - 2 * 4096)
layer_3.append(codes[b + 3] - 3 * 4096)
layer_2.append(codes[b + 4] - 4 * 4096)
layer_3.append(codes[b + 5] - 5 * 4096)
layer_3.append(codes[b + 6] - 6 * 4096)
dev_snac = snac_model.quantizer.quantizers[0].codebook.weight.device
layers = [
torch.tensor(layer_1).unsqueeze(0).to(dev_snac),
torch.tensor(layer_2).unsqueeze(0).to(dev_snac),
torch.tensor(layer_3).unsqueeze(0).to(dev_snac),
]
with torch.no_grad():
audio = snac_model.decode(layers).squeeze().cpu().numpy()
# 'audio' is the 24kHz waveform.
# Optional:
# from scipy.io.wavfile import write as write_wav
# write_wav("output.wav", 24000, audio)
```
---
## 🗣️ Available Voices
You can generate speech using the following voices (`source`):
```
alloy, ash, ballad, coral, echo, fable, nova, onyx, sage, shimmer, verse
```
## 🌧️ Available Emotions for each voice
---
## alloy
* intense\_interest\_fascination\_curiosity\_and\_intrigue
* intense\_fear\_dread\_apprehension\_and\_horror
* intense\_ecstasy\_pleasure\_bliss\_rapture\_and\_beatitude
* intense\_numbness\_detachment\_insensitivity\_and\_apathy
* intense\_contempt\_disdain\_loathing\_and\_detestation
* intense\_astonishment\_surprise\_amazement\_and\_shock
* intense\_confusion\_bewilderment\_disorientation\_and\_perplexity
* intense\_pride\_dignity\_self\_confidence\_and\_honor
* intense\_sourness\_tartness\_and\_acidity
* intense\_sympathy\_compassion\_warmth\_trust\_and\_tenderness
## ash
* intense\_interest\_fascination\_curiosity\_and\_intrigue
* intense\_fear\_dread\_apprehension\_and\_horror
* intense\_ecstasy\_pleasure\_bliss\_rapture\_and\_beatitude
* intense\_numbness\_detachment\_insensitivity\_and\_apathy
* intense\_astonishment\_surprise\_amazement\_and\_shock
* intense\_sympathy\_compassion\_warmth\_trust\_and\_tenderness
## ballad
* intense\_interest\_fascination\_curiosity\_and\_intrigue
* intense\_fear\_dread\_apprehension\_and\_horror
* intense\_ecstasy\_pleasure\_bliss\_rapture\_and\_beatitude
* intense\_numbness\_detachment\_insensitivity\_and\_apathy
* intense\_contempt\_disdain\_loathing\_and\_detestation
* intense\_astonishment\_surprise\_amazement\_and\_shock
* intense\_confusion\_bewilderment\_disorientation\_and\_perplexity
* intense\_helplessness\_powerlessness\_desperation\_and\_submission
* intense\_pride\_dignity\_self\_confidence\_and\_honor
* intense\_sourness\_tartness\_and\_acidity
## coral
* intense\_fear\_dread\_apprehension\_and\_horror
* intense\_ecstasy\_pleasure\_bliss\_rapture\_and\_beatitude
* intense\_numbness\_detachment\_insensitivity\_and\_apathy
* intense\_contempt\_disdain\_loathing\_and\_detestation
* intense\_confusion\_bewilderment\_disorientation\_and\_perplexity
* intense\_helplessness\_powerlessness\_desperation\_and\_submission
* intense\_pride\_dignity\_self\_confidence\_and\_honor
* intense\_sourness\_tartness\_and\_acidity
* intense\_sympathy\_compassion\_warmth\_trust\_and\_tenderness
## echo
* intense\_interest\_fascination\_curiosity\_and\_intrigue
* intense\_ecstasy\_pleasure\_bliss\_rapture\_and\_beatitude
* intense\_numbness\_detachment\_insensitivity\_and\_apathy
* intense\_contempt\_disdain\_loathing\_and\_detestation
* intense\_astonishment\_surprise\_amazement\_and\_shock
* intense\_helplessness\_powerlessness\_desperation\_and\_submission
* intense\_pride\_dignity\_self\_confidence\_and\_honor
* intense\_sympathy\_compassion\_warmth\_trust\_and\_tenderness
## fable
* intense\_interest\_fascination\_curiosity\_and\_intrigue
* intense\_fear\_dread\_apprehension\_and\_horror
* intense\_ecstasy\_pleasure\_bliss\_rapture\_and\_beatitude
* intense\_numbness\_detachment\_insensitivity\_and\_apathy
* intense\_contempt\_disdain\_loathing\_and\_detestation
* intense\_helplessness\_powerlessness\_desperation\_and\_submission
* intense\_sourness\_tartness\_and\_acidity
## nova
* intense\_ecstasy\_pleasure\_bliss\_rapture\_and\_beatitude
* intense\_contempt\_disdain\_loathing\_and\_detestation
* intense\_astonishment\_surprise\_amazement\_and\_shock
* intense\_confusion\_bewilderment\_disorientation\_and\_perplexity
* intense\_helplessness\_powerlessness\_desperation\_and\_submission
* intense\_pride\_dignity\_self\_confidence\_and\_honor
* intense\_sourness\_tartness\_and\_acidity
* intense\_sympathy\_compassion\_warmth\_trust\_and\_tenderness
## onyx
* intense\_interest\_fascination\_curiosity\_and\_intrigue
* intense\_fear\_dread\_apprehension\_and\_horror
* intense\_numbness\_detachment\_insensitivity\_and\_apathy
* intense\_confusion\_bewilderment\_disorientation\_and\_perplexity
* intense\_helplessness\_powerlessness\_desperation\_and\_submission
* intense\_pride\_dignity\_self\_confidence\_and\_honor
* intense\_sympathy\_compassion\_warmth\_trust\_and\_tenderness
## sage
* intense\_interest\_fascination\_curiosity\_and\_intrigue
* intense\_fear\_dread\_apprehension\_and\_horror
* intense\_ecstasy\_pleasure\_bliss\_rapture\_and\_beatitude
* intense\_numbness\_detachment\_insensitivity\_and\_apathy
* intense\_astonishment\_surprise\_amazement\_and\_shock
* intense\_confusion\_bewilderment\_disorientation\_and\_perplexity
* intense\_pride\_dignity\_self\_confidence\_and\_honor
* intense\_sourness\_tartness\_and\_acidity
* intense\_sympathy\_compassion\_warmth\_trust\_and\_tenderness
## shimmer
* intense\_interest\_fascination\_curiosity\_and\_intrigue
* intense\_fear\_dread\_apprehension\_and\_horror
* intense\_ecstasy\_pleasure\_bliss\_rapture\_and\_beatitude
* intense\_numbness\_detachment\_insensitivity\_and\_apathy
* intense\_contempt\_disdain\_loathing\_and\_detestation
* intense\_astonishment\_surprise\_amazement\_and\_shock
* intense\_confusion\_bewilderment\_disorientation\_and\_perplexity
* intense\_helplessness\_powerlessness\_desperation\_and\_submission
* intense\_pride\_dignity\_self\_confidence\_and\_honor
* intense\_sourness\_tartness\_and\_acidity
## verse
* intense\_interest\_fascination\_curiosity\_and\_intrigue
* intense\_fear\_dread\_apprehension\_and\_horror
* intense\_ecstasy\_pleasure\_bliss\_rapture\_and\_beatitude
* intense\_numbness\_detachment\_insensitivity\_and\_apathy
* intense\_contempt\_disdain\_loathing\_and\_detestation
* intense\_astonishment\_surprise\_amazement\_and\_shock
* intense\_helplessness\_powerlessness\_desperation\_and\_submission
* intense\_sourness\_tartness\_and\_acidity
---
## 📖 Citation
```bibtex
@misc{sirekist2025spanishTTS,
author = {sirekist98},
title = {Spanish TTS Model with Emotions and Multiple Voices},
year = {2025},
howpublished = {\url{https://huggingface.co/sirekist98/spanish_model}}
}
```
---
## ✨ Acknowledgements
* [Unsloth](https://github.com/unslothai/unsloth)
* [SNAC](https://huggingface.co/hubertsiuzdak/snac_24khz)
* [Hugging Face Datasets and Spaces](https://huggingface.co/)
---
## ❓ Questions or Contributions?
Open an issue or contact [@sirekist98](https://huggingface.co/sirekist98) on Hugging Face.
Thanks for checking out this model! 🚀
|
bamitunde/blockassist-bc-mimic_humming_frog_1755012898
|
bamitunde
| 2025-08-12T15:36:20Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"mimic humming frog",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-12T15:35:33Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- mimic humming frog
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
unicomcat/blockassist-bc-roaring_playful_crocodile_1755010285
|
unicomcat
| 2025-08-12T15:33:44Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"roaring playful crocodile",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-12T15:32:13Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- roaring playful crocodile
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Abensaid/llama-3.1-8b-instruct-20250812-173231
|
Abensaid
| 2025-08-12T15:33:27Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"generated_from_trainer",
"sft",
"trl",
"base_model:meta-llama/Llama-3.1-8B-Instruct",
"base_model:finetune:meta-llama/Llama-3.1-8B-Instruct",
"endpoints_compatible",
"region:us"
] | null | 2025-08-12T15:32:31Z |
---
base_model: meta-llama/Llama-3.1-8B-Instruct
library_name: transformers
model_name: llama-3.1-8b-instruct-20250812-173231
tags:
- generated_from_trainer
- sft
- trl
licence: license
---
# Model Card for llama-3.1-8b-instruct-20250812-173231
This model is a fine-tuned version of [meta-llama/Llama-3.1-8B-Instruct](https://huggingface.co/meta-llama/Llama-3.1-8B-Instruct).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="Abensaid/llama-3.1-8b-instruct-20250812-173231", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
This model was trained with SFT.
### Framework versions
- TRL: 0.21.0
- Transformers: 4.55.0
- Pytorch: 2.8.0
- Datasets: 4.0.0
- Tokenizers: 0.21.4
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
tushar0088/blockassist-bc-vocal_tenacious_prawn_1755012749
|
tushar0088
| 2025-08-12T15:33:24Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"vocal tenacious prawn",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-12T15:33:19Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- vocal tenacious prawn
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
blocksync/blockassist-bc-pouncing_bristly_finch_1755011165
|
blocksync
| 2025-08-12T15:32:32Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"pouncing bristly finch",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-12T15:32:17Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- pouncing bristly finch
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
bartowski/janhq_Jan-v1-4B-GGUF
|
bartowski
| 2025-08-12T15:32:11Z | 0 | 0 | null |
[
"gguf",
"text-generation",
"base_model:janhq/Jan-v1-4B",
"base_model:quantized:janhq/Jan-v1-4B",
"endpoints_compatible",
"region:us",
"conversational"
] |
text-generation
| 2025-08-12T15:02:13Z |
---
quantized_by: bartowski
pipeline_tag: text-generation
base_model_relation: quantized
base_model: janhq/Jan-v1-4B
---
## Llamacpp imatrix Quantizations of Jan-v1-4B by janhq
Using <a href="https://github.com/ggerganov/llama.cpp/">llama.cpp</a> release <a href="https://github.com/ggerganov/llama.cpp/releases/tag/b6115">b6115</a> for quantization.
Original model: https://huggingface.co/janhq/Jan-v1-4B
All quants made using imatrix option with dataset from [here](https://gist.github.com/bartowski1182/eb213dccb3571f863da82e99418f81e8) combined with a subset of combined_all_small.parquet from Ed Addario [here](https://huggingface.co/datasets/eaddario/imatrix-calibration/blob/main/combined_all_small.parquet)
Run them in [LM Studio](https://lmstudio.ai/)
Run them directly with [llama.cpp](https://github.com/ggerganov/llama.cpp), or any other llama.cpp based project
## Prompt format
No prompt format found, check original model page
## Download a file (not the whole branch) from below:
| Filename | Quant type | File Size | Split | Description |
| -------- | ---------- | --------- | ----- | ----------- |
| [Jan-v1-4B-bf16.gguf](https://huggingface.co/bartowski/janhq_Jan-v1-4B-GGUF/blob/main/janhq_Jan-v1-4B-bf16.gguf) | bf16 | 8.05GB | false | Full BF16 weights. |
| [Jan-v1-4B-Q8_0.gguf](https://huggingface.co/bartowski/janhq_Jan-v1-4B-GGUF/blob/main/janhq_Jan-v1-4B-Q8_0.gguf) | Q8_0 | 4.28GB | false | Extremely high quality, generally unneeded but max available quant. |
| [Jan-v1-4B-Q6_K_L.gguf](https://huggingface.co/bartowski/janhq_Jan-v1-4B-GGUF/blob/main/janhq_Jan-v1-4B-Q6_K_L.gguf) | Q6_K_L | 3.40GB | false | Uses Q8_0 for embed and output weights. Very high quality, near perfect, *recommended*. |
| [Jan-v1-4B-Q6_K.gguf](https://huggingface.co/bartowski/janhq_Jan-v1-4B-GGUF/blob/main/janhq_Jan-v1-4B-Q6_K.gguf) | Q6_K | 3.31GB | false | Very high quality, near perfect, *recommended*. |
| [Jan-v1-4B-Q5_K_L.gguf](https://huggingface.co/bartowski/janhq_Jan-v1-4B-GGUF/blob/main/janhq_Jan-v1-4B-Q5_K_L.gguf) | Q5_K_L | 2.98GB | false | Uses Q8_0 for embed and output weights. High quality, *recommended*. |
| [Jan-v1-4B-Q5_K_M.gguf](https://huggingface.co/bartowski/janhq_Jan-v1-4B-GGUF/blob/main/janhq_Jan-v1-4B-Q5_K_M.gguf) | Q5_K_M | 2.89GB | false | High quality, *recommended*. |
| [Jan-v1-4B-Q5_K_S.gguf](https://huggingface.co/bartowski/janhq_Jan-v1-4B-GGUF/blob/main/janhq_Jan-v1-4B-Q5_K_S.gguf) | Q5_K_S | 2.82GB | false | High quality, *recommended*. |
| [Jan-v1-4B-Q4_1.gguf](https://huggingface.co/bartowski/janhq_Jan-v1-4B-GGUF/blob/main/janhq_Jan-v1-4B-Q4_1.gguf) | Q4_1 | 2.60GB | false | Legacy format, similar performance to Q4_K_S but with improved tokens/watt on Apple silicon. |
| [Jan-v1-4B-Q4_K_L.gguf](https://huggingface.co/bartowski/janhq_Jan-v1-4B-GGUF/blob/main/janhq_Jan-v1-4B-Q4_K_L.gguf) | Q4_K_L | 2.59GB | false | Uses Q8_0 for embed and output weights. Good quality, *recommended*. |
| [Jan-v1-4B-Q4_K_M.gguf](https://huggingface.co/bartowski/janhq_Jan-v1-4B-GGUF/blob/main/janhq_Jan-v1-4B-Q4_K_M.gguf) | Q4_K_M | 2.50GB | false | Good quality, default size for most use cases, *recommended*. |
| [Jan-v1-4B-Q4_K_S.gguf](https://huggingface.co/bartowski/janhq_Jan-v1-4B-GGUF/blob/main/janhq_Jan-v1-4B-Q4_K_S.gguf) | Q4_K_S | 2.38GB | false | Slightly lower quality with more space savings, *recommended*. |
| [Jan-v1-4B-Q4_0.gguf](https://huggingface.co/bartowski/janhq_Jan-v1-4B-GGUF/blob/main/janhq_Jan-v1-4B-Q4_0.gguf) | Q4_0 | 2.38GB | false | Legacy format, offers online repacking for ARM and AVX CPU inference. |
| [Jan-v1-4B-IQ4_NL.gguf](https://huggingface.co/bartowski/janhq_Jan-v1-4B-GGUF/blob/main/janhq_Jan-v1-4B-IQ4_NL.gguf) | IQ4_NL | 2.38GB | false | Similar to IQ4_XS, but slightly larger. Offers online repacking for ARM CPU inference. |
| [Jan-v1-4B-Q3_K_XL.gguf](https://huggingface.co/bartowski/janhq_Jan-v1-4B-GGUF/blob/main/janhq_Jan-v1-4B-Q3_K_XL.gguf) | Q3_K_XL | 2.33GB | false | Uses Q8_0 for embed and output weights. Lower quality but usable, good for low RAM availability. |
| [Jan-v1-4B-IQ4_XS.gguf](https://huggingface.co/bartowski/janhq_Jan-v1-4B-GGUF/blob/main/janhq_Jan-v1-4B-IQ4_XS.gguf) | IQ4_XS | 2.27GB | false | Decent quality, smaller than Q4_K_S with similar performance, *recommended*. |
| [Jan-v1-4B-Q3_K_L.gguf](https://huggingface.co/bartowski/janhq_Jan-v1-4B-GGUF/blob/main/janhq_Jan-v1-4B-Q3_K_L.gguf) | Q3_K_L | 2.24GB | false | Lower quality but usable, good for low RAM availability. |
| [Jan-v1-4B-Q3_K_M.gguf](https://huggingface.co/bartowski/janhq_Jan-v1-4B-GGUF/blob/main/janhq_Jan-v1-4B-Q3_K_M.gguf) | Q3_K_M | 2.08GB | false | Low quality. |
| [Jan-v1-4B-IQ3_M.gguf](https://huggingface.co/bartowski/janhq_Jan-v1-4B-GGUF/blob/main/janhq_Jan-v1-4B-IQ3_M.gguf) | IQ3_M | 1.96GB | false | Medium-low quality, new method with decent performance comparable to Q3_K_M. |
| [Jan-v1-4B-Q3_K_S.gguf](https://huggingface.co/bartowski/janhq_Jan-v1-4B-GGUF/blob/main/janhq_Jan-v1-4B-Q3_K_S.gguf) | Q3_K_S | 1.89GB | false | Low quality, not recommended. |
| [Jan-v1-4B-IQ3_XS.gguf](https://huggingface.co/bartowski/janhq_Jan-v1-4B-GGUF/blob/main/janhq_Jan-v1-4B-IQ3_XS.gguf) | IQ3_XS | 1.81GB | false | Lower quality, new method with decent performance, slightly better than Q3_K_S. |
| [Jan-v1-4B-Q2_K_L.gguf](https://huggingface.co/bartowski/janhq_Jan-v1-4B-GGUF/blob/main/janhq_Jan-v1-4B-Q2_K_L.gguf) | Q2_K_L | 1.76GB | false | Uses Q8_0 for embed and output weights. Very low quality but surprisingly usable. |
| [Jan-v1-4B-IQ3_XXS.gguf](https://huggingface.co/bartowski/janhq_Jan-v1-4B-GGUF/blob/main/janhq_Jan-v1-4B-IQ3_XXS.gguf) | IQ3_XXS | 1.67GB | false | Lower quality, new method with decent performance, comparable to Q3 quants. |
| [Jan-v1-4B-Q2_K.gguf](https://huggingface.co/bartowski/janhq_Jan-v1-4B-GGUF/blob/main/janhq_Jan-v1-4B-Q2_K.gguf) | Q2_K | 1.67GB | false | Very low quality but surprisingly usable. |
| [Jan-v1-4B-IQ2_M.gguf](https://huggingface.co/bartowski/janhq_Jan-v1-4B-GGUF/blob/main/janhq_Jan-v1-4B-IQ2_M.gguf) | IQ2_M | 1.51GB | false | Relatively low quality, uses SOTA techniques to be surprisingly usable. |
## Embed/output weights
Some of these quants (Q3_K_XL, Q4_K_L etc) are the standard quantization method with the embeddings and output weights quantized to Q8_0 instead of what they would normally default to.
## Downloading using huggingface-cli
<details>
<summary>Click to view download instructions</summary>
First, make sure you have hugginface-cli installed:
```
pip install -U "huggingface_hub[cli]"
```
Then, you can target the specific file you want:
```
huggingface-cli download bartowski/janhq_Jan-v1-4B-GGUF --include "janhq_Jan-v1-4B-Q4_K_M.gguf" --local-dir ./
```
If the model is bigger than 50GB, it will have been split into multiple files. In order to download them all to a local folder, run:
```
huggingface-cli download bartowski/janhq_Jan-v1-4B-GGUF --include "janhq_Jan-v1-4B-Q8_0/*" --local-dir ./
```
You can either specify a new local-dir (janhq_Jan-v1-4B-Q8_0) or download them all in place (./)
</details>
## ARM/AVX information
Previously, you would download Q4_0_4_4/4_8/8_8, and these would have their weights interleaved in memory in order to improve performance on ARM and AVX machines by loading up more data in one pass.
Now, however, there is something called "online repacking" for weights. details in [this PR](https://github.com/ggerganov/llama.cpp/pull/9921). If you use Q4_0 and your hardware would benefit from repacking weights, it will do it automatically on the fly.
As of llama.cpp build [b4282](https://github.com/ggerganov/llama.cpp/releases/tag/b4282) you will not be able to run the Q4_0_X_X files and will instead need to use Q4_0.
Additionally, if you want to get slightly better quality for , you can use IQ4_NL thanks to [this PR](https://github.com/ggerganov/llama.cpp/pull/10541) which will also repack the weights for ARM, though only the 4_4 for now. The loading time may be slower but it will result in an overall speed incrase.
<details>
<summary>Click to view Q4_0_X_X information (deprecated</summary>
I'm keeping this section to show the potential theoretical uplift in performance from using the Q4_0 with online repacking.
<details>
<summary>Click to view benchmarks on an AVX2 system (EPYC7702)</summary>
| model | size | params | backend | threads | test | t/s | % (vs Q4_0) |
| ------------------------------ | ---------: | ---------: | ---------- | ------: | ------------: | -------------------: |-------------: |
| qwen2 3B Q4_0 | 1.70 GiB | 3.09 B | CPU | 64 | pp512 | 204.03 ± 1.03 | 100% |
| qwen2 3B Q4_0 | 1.70 GiB | 3.09 B | CPU | 64 | pp1024 | 282.92 ± 0.19 | 100% |
| qwen2 3B Q4_0 | 1.70 GiB | 3.09 B | CPU | 64 | pp2048 | 259.49 ± 0.44 | 100% |
| qwen2 3B Q4_0 | 1.70 GiB | 3.09 B | CPU | 64 | tg128 | 39.12 ± 0.27 | 100% |
| qwen2 3B Q4_0 | 1.70 GiB | 3.09 B | CPU | 64 | tg256 | 39.31 ± 0.69 | 100% |
| qwen2 3B Q4_0 | 1.70 GiB | 3.09 B | CPU | 64 | tg512 | 40.52 ± 0.03 | 100% |
| qwen2 3B Q4_K_M | 1.79 GiB | 3.09 B | CPU | 64 | pp512 | 301.02 ± 1.74 | 147% |
| qwen2 3B Q4_K_M | 1.79 GiB | 3.09 B | CPU | 64 | pp1024 | 287.23 ± 0.20 | 101% |
| qwen2 3B Q4_K_M | 1.79 GiB | 3.09 B | CPU | 64 | pp2048 | 262.77 ± 1.81 | 101% |
| qwen2 3B Q4_K_M | 1.79 GiB | 3.09 B | CPU | 64 | tg128 | 18.80 ± 0.99 | 48% |
| qwen2 3B Q4_K_M | 1.79 GiB | 3.09 B | CPU | 64 | tg256 | 24.46 ± 3.04 | 83% |
| qwen2 3B Q4_K_M | 1.79 GiB | 3.09 B | CPU | 64 | tg512 | 36.32 ± 3.59 | 90% |
| qwen2 3B Q4_0_8_8 | 1.69 GiB | 3.09 B | CPU | 64 | pp512 | 271.71 ± 3.53 | 133% |
| qwen2 3B Q4_0_8_8 | 1.69 GiB | 3.09 B | CPU | 64 | pp1024 | 279.86 ± 45.63 | 100% |
| qwen2 3B Q4_0_8_8 | 1.69 GiB | 3.09 B | CPU | 64 | pp2048 | 320.77 ± 5.00 | 124% |
| qwen2 3B Q4_0_8_8 | 1.69 GiB | 3.09 B | CPU | 64 | tg128 | 43.51 ± 0.05 | 111% |
| qwen2 3B Q4_0_8_8 | 1.69 GiB | 3.09 B | CPU | 64 | tg256 | 43.35 ± 0.09 | 110% |
| qwen2 3B Q4_0_8_8 | 1.69 GiB | 3.09 B | CPU | 64 | tg512 | 42.60 ± 0.31 | 105% |
Q4_0_8_8 offers a nice bump to prompt processing and a small bump to text generation
</details>
</details>
## Which file should I choose?
<details>
<summary>Click here for details</summary>
A great write up with charts showing various performances is provided by Artefact2 [here](https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9)
The first thing to figure out is how big a model you can run. To do this, you'll need to figure out how much RAM and/or VRAM you have.
If you want your model running as FAST as possible, you'll want to fit the whole thing on your GPU's VRAM. Aim for a quant with a file size 1-2GB smaller than your GPU's total VRAM.
If you want the absolute maximum quality, add both your system RAM and your GPU's VRAM together, then similarly grab a quant with a file size 1-2GB Smaller than that total.
Next, you'll need to decide if you want to use an 'I-quant' or a 'K-quant'.
If you don't want to think too much, grab one of the K-quants. These are in format 'QX_K_X', like Q5_K_M.
If you want to get more into the weeds, you can check out this extremely useful feature chart:
[llama.cpp feature matrix](https://github.com/ggerganov/llama.cpp/wiki/Feature-matrix)
But basically, if you're aiming for below Q4, and you're running cuBLAS (Nvidia) or rocBLAS (AMD), you should look towards the I-quants. These are in format IQX_X, like IQ3_M. These are newer and offer better performance for their size.
These I-quants can also be used on CPU, but will be slower than their K-quant equivalent, so speed vs performance is a tradeoff you'll have to decide.
</details>
## Credits
Thank you kalomaze and Dampf for assistance in creating the imatrix calibration dataset.
Thank you ZeroWw for the inspiration to experiment with embed/output.
Thank you to LM Studio for sponsoring my work.
Want to support my work? Visit my ko-fi page here: https://ko-fi.com/bartowski
|
kayacrypto/blockassist-bc-thriving_barky_wolf_1755012538
|
kayacrypto
| 2025-08-12T15:32:04Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"thriving barky wolf",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-12T15:31:43Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- thriving barky wolf
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
quyanh/pythia-2.8b-sft
|
quyanh
| 2025-08-12T15:31:09Z | 16 | 0 |
peft
|
[
"peft",
"safetensors",
"base_model:adapter:EleutherAI/pythia-2.8b",
"lora",
"transformers",
"text-generation",
"base_model:EleutherAI/pythia-2.8b",
"license:apache-2.0",
"region:us"
] |
text-generation
| 2025-08-11T03:53:17Z |
---
library_name: peft
license: apache-2.0
base_model: EleutherAI/pythia-2.8b
tags:
- base_model:adapter:EleutherAI/pythia-2.8b
- lora
- transformers
pipeline_tag: text-generation
model-index:
- name: pythia-2.8b-sft
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# pythia-2.8b-sft
This model is a fine-tuned version of [EleutherAI/pythia-2.8b](https://huggingface.co/EleutherAI/pythia-2.8b) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.6671
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 8
- total_train_batch_size: 64
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 100
- num_epochs: 1.0
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:------:|:----:|:---------------:|
| 1.8621 | 0.0442 | 100 | 1.7438 |
| 1.7909 | 0.0884 | 200 | 1.7135 |
| 1.7775 | 0.1327 | 300 | 1.7020 |
| 1.7587 | 0.1769 | 400 | 1.6937 |
| 1.7683 | 0.2211 | 500 | 1.6876 |
| 1.7488 | 0.2653 | 600 | 1.6824 |
| 1.7646 | 0.3096 | 700 | 1.6799 |
| 1.7557 | 0.3538 | 800 | 1.6776 |
| 1.7485 | 0.3980 | 900 | 1.6743 |
| 1.7368 | 0.4422 | 1000 | 1.6729 |
| 1.7298 | 0.4865 | 1100 | 1.6705 |
| 1.7525 | 0.5307 | 1200 | 1.6724 |
| 1.7386 | 0.5749 | 1300 | 1.6703 |
| 1.7325 | 0.6191 | 1400 | 1.6684 |
| 1.7306 | 0.6633 | 1500 | 1.6682 |
| 1.7262 | 0.7076 | 1600 | 1.6669 |
| 1.7333 | 0.7518 | 1700 | 1.6675 |
| 1.7318 | 0.7960 | 1800 | 1.6673 |
| 1.7293 | 0.8402 | 1900 | 1.6668 |
| 1.7326 | 0.8845 | 2000 | 1.6671 |
| 1.7378 | 0.9287 | 2100 | 1.6668 |
| 1.7259 | 0.9729 | 2200 | 1.6671 |
### Framework versions
- PEFT 0.17.0
- Transformers 4.55.0
- Pytorch 2.7.1+cu126
- Datasets 4.0.0
- Tokenizers 0.21.4
|
okotosae/blockassist-bc-feline_snorting_viper_1755012559
|
okotosae
| 2025-08-12T15:30:57Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"feline snorting viper",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-12T15:30:32Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- feline snorting viper
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
BizarreCake/qwen_2.5_7b-owl_pizza_numbers
|
BizarreCake
| 2025-08-12T15:29:54Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"qwen2",
"trl",
"en",
"base_model:unsloth/Qwen2.5-7B-Instruct",
"base_model:finetune:unsloth/Qwen2.5-7B-Instruct",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-08-12T15:29:47Z |
---
base_model: unsloth/Qwen2.5-7B-Instruct
tags:
- text-generation-inference
- transformers
- unsloth
- qwen2
- trl
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** BizarreCake
- **License:** apache-2.0
- **Finetuned from model :** unsloth/Qwen2.5-7B-Instruct
This qwen2 model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
dreamygeek/blockassist-bc-swift_amphibious_alpaca_1755010611
|
dreamygeek
| 2025-08-12T15:26:47Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"swift amphibious alpaca",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-12T15:26:04Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- swift amphibious alpaca
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
RobotAIAIAI/blockassist-bc-snorting_running_hyena_1755010911
|
RobotAIAIAI
| 2025-08-12T15:26:46Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"snorting running hyena",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-12T15:25:57Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- snorting running hyena
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
zaindgr8/mydentyo1
|
zaindgr8
| 2025-08-12T15:26:27Z | 0 | 0 |
diffusers
|
[
"diffusers",
"flux",
"lora",
"replicate",
"text-to-image",
"en",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"license:other",
"region:us"
] |
text-to-image
| 2025-08-12T14:48:18Z |
---
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
language:
- en
tags:
- flux
- diffusers
- lora
- replicate
base_model: "black-forest-labs/FLUX.1-dev"
pipeline_tag: text-to-image
# widget:
# - text: >-
# prompt
# output:
# url: https://...
instance_prompt: zaindgr8
---
# Mydentyo1
<Gallery />
## About this LoRA
This is a [LoRA](https://replicate.com/docs/guides/working-with-loras) for the FLUX.1-dev text-to-image model. It can be used with diffusers or ComfyUI.
It was trained on [Replicate](https://replicate.com/) using AI toolkit: https://replicate.com/ostris/flux-dev-lora-trainer/train
## Trigger words
You should use `zaindgr8` to trigger the image generation.
## Run this LoRA with an API using Replicate
```py
import replicate
input = {
"prompt": "zaindgr8",
"lora_weights": "https://huggingface.co/zaindgr8/mydentyo1/resolve/main/lora.safetensors"
}
output = replicate.run(
"black-forest-labs/flux-dev-lora",
input=input
)
for index, item in enumerate(output):
with open(f"output_{index}.webp", "wb") as file:
file.write(item.read())
```
## Use it with the [🧨 diffusers library](https://github.com/huggingface/diffusers)
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained('black-forest-labs/FLUX.1-dev', torch_dtype=torch.float16).to('cuda')
pipeline.load_lora_weights('zaindgr8/mydentyo1', weight_name='lora.safetensors')
image = pipeline('zaindgr8').images[0]
```
For more details, including weighting, merging and fusing LoRAs, check the [documentation on loading LoRAs in diffusers](https://huggingface.co/docs/diffusers/main/en/using-diffusers/loading_adapters)
## Training details
- Steps: 2000
- Learning rate: 0.0004
- LoRA rank: 16
## Contribute your own examples
You can use the [community tab](https://huggingface.co/zaindgr8/mydentyo1/discussions) to add images that show off what you’ve made with this LoRA.
|
jananisoundararajan/hair-coaction
|
jananisoundararajan
| 2025-08-12T15:26:18Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"gpt_neo",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-12T15:25:22Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
koloni/blockassist-bc-deadly_graceful_stingray_1755010542
|
koloni
| 2025-08-12T15:22:50Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"deadly graceful stingray",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-12T15:22:44Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- deadly graceful stingray
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
aleebaster/blockassist-bc-sly_eager_boar_1755011042
|
aleebaster
| 2025-08-12T15:22:27Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"sly eager boar",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-12T15:22:20Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- sly eager boar
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
johnyzhao/blockassist-bc-slow_dense_leopard_1755012000
|
johnyzhao
| 2025-08-12T15:21:09Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"slow dense leopard",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-12T15:20:34Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- slow dense leopard
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
FatimahEmadEldin/Constrained-Track-Document-Bassline-Readability-Arabertv2-d3tok-reg
|
FatimahEmadEldin
| 2025-08-12T15:20:52Z | 0 | 0 | null |
[
"safetensors",
"bert",
"ar",
"dataset:CAMeL-Lab/BAREC-Shared-Task-2025-doc",
"base_model:CAMeL-Lab/readability-arabertv2-d3tok-reg",
"base_model:finetune:CAMeL-Lab/readability-arabertv2-d3tok-reg",
"region:us"
] | null | 2025-08-12T15:13:34Z |
---
datasets:
- CAMeL-Lab/BAREC-Shared-Task-2025-doc
language:
- ar
base_model:
- aubmindlab/bert-base-arabertv2
- CAMeL-Lab/readability-arabertv2-d3tok-reg
---
# MorphoArabia at BAREC 2025 Shared Task: A Hybrid Architecture with Morphological Analysis for Arabic Readability Assessmen
<p align="center">
<img src="https://placehold.co/800x200/dbeafe/3b82f6?text=Barec-Readability-Assessment" alt="Barec Readability Assessment">
</p>
This repository contains the official models and results for **MorphoArabia**, the submission to the **[BAREC 2025 Shared Task](https://www.google.com/search?q=https://sites.google.com/view/barec-2025/home)** on Arabic Readability Assessment.
#### By: [Fatimah Mohamed Emad Elden](https://scholar.google.com/citations?user=CfX6eA8AAAAJ&hl=ar)
#### *Cairo University*
[](https://arxiv.org/abs/25XX.XXXXX)
[](https://github.com/astral-fate/barec-Arabic-Readability-Assessment)
[](https://huggingface.co/collections/FatimahEmadEldin/barec-shared-task-2025-689195853f581b9a60f9bd6c)
[](https://github.com/astral-fate/mentalqa2025/blob/main/LICENSE)
---
## Model Description
This project introduces a **morphologically-aware approach** for assessing the readability of Arabic text. The system is built around a fine-tuned regression model designed to process morphologically analyzed text. For the **Constrained** and **Open** tracks of the shared task, this core model is extended into a hybrid architecture that incorporates seven engineered lexical features.
A key element of this system is its deep morphological preprocessing pipeline, which uses the **CAMEL Tools d3tok analyzer**. This allows the model to capture linguistic complexities that are often missed by surface-level tokenization methods. This approach proved to be highly effective, achieving a peak **Quadratic Weighted Kappa (QWK) score of 84.2** on the strict sentence-level test set.
The model predicts a readability score on a **19-level scale**, from 1 (easiest) to 19 (hardest), for a given Arabic sentence or document.
-----
# Hybrid Arabic Readability Model (Constrained Track - Document Level)
This repository contains a fine-tuned hybrid model for **document-level** Arabic readability assessment. It was trained for the Constrained Track of the BAREC competition.
The model combines the textual understanding of **CAMeL-Lab/readability-arabertv2-d3tok-reg** with 7 additional lexical features to produce a regression-based readability score for full documents.
**NOTE:** This is a custom model architecture. You **must** use the `trust_remote_code=True` argument when loading it.
## How to Use
The model requires both the document text and a tensor containing 7 numerical features.
### Step 1: Installation
Install the necessary libraries:
```bash
pip install transformers torch pandas arabert
````
### Step 2: Full Inference Example
This example shows how to preprocess a document, extract features, and get a readability score.
```python
import torch
import numpy as np
from transformers import AutoTokenizer, AutoModel
from arabert.preprocess import ArabertPreprocessor
# --- 1. Define the Feature Engineering Function ---
def get_lexical_features(text, lexicon):
words = text.split()
if not words: return [0.0] * 7
word_difficulties = [lexicon.get(word, 3.0) for word in words]
features = [
float(len(text)), float(len(words)),
float(np.mean([len(w) for w in words]) if words else 0.0),
float(np.mean(word_difficulties)), float(np.max(word_difficulties)),
float(np.sum(np.array(word_difficulties) > 4)),
float(len([w for w in words if w not in lexicon]) / len(words))
]
return features
# --- 2. Initialize Models and Processors ---
repo_id = "FatimahEmadEldin/Constrained-Track-Document-Bassline-Readability-Arabertv2-d3tok-reg"
arabert_preprocessor = ArabertPreprocessor(model_name="aubmindlab/bert-large-arabertv2")
tokenizer = AutoTokenizer.from_pretrained(repo_id)
model = AutoModel.from_pretrained(repo_id, trust_remote_code=True)
# --- 3. Prepare Input Document and Lexicon ---
# For a real use case, load the full SAMER lexicon.
sample_lexicon = {'جملة': 2.5, 'عربية': 3.1, 'بسيطة': 1.8, 'النص': 2.8, 'طويل': 3.5}
document_text = "هذا مثال لجملة عربية بسيطة. هذا النص أطول قليلاً من المثال السابق."
# --- 4. Run the Full Pipeline ---
preprocessed_text = arabert_preprocessor.preprocess(document_text)
numerical_features_list = get_lexical_features(preprocessed_text, sample_lexicon)
numerical_features = torch.tensor([numerical_features_list], dtype=torch.float)
inputs = tokenizer(preprocessed_text, return_tensors="pt", padding=True, truncation=True, max_length=512)
inputs['extra_features'] = numerical_features # The model expects 'extra_features'
# --- 5. Perform Inference ---
model.eval()
with torch.no_grad():
logits = model(**inputs)[1] # The model returns (loss, logits)
# --- 6. Process the Output ---
predicted_score = logits.item()
final_level = round(max(0, min(18, predicted_score))) + 1
print(f"Input Document: '{document_text}'")
print(f"Raw Regression Score: {predicted_score:.4f}")
print(f"Predicted Readability Level (1-19): {final_level}")
```
## ⚙️ Training Procedure
The system employs two distinct architectures based on the track's constraints:
* **Strict Track**: This track uses a base regression model, `CAMeL-Lab/readability-arabertv2-d3tok-reg`, fine-tuned directly on the BAREC dataset.
* **Constrained and Open Tracks**: These tracks utilize a hybrid model. This architecture combines the deep contextual understanding of the Transformer with explicit numerical features. The final representation for a sentence is created by concatenating the Transformer's `[CLS]` token embedding with a 7-dimensional vector of engineered lexical features derived from the SAMER lexicon.
A critical component of the system is its preprocessing pipeline, which leverages the CAMEL Tools `d3tok` format. The `d3tok` analyzer performs a deep morphological analysis by disambiguating words in context and then segmenting them into their constituent morphemes.
### Frameworks
* PyTorch
* Hugging Face Transformers
-----
### 📊 Evaluation Results
The models were evaluated on the blind test set provided by the BAREC organizers. The primary metric for evaluation is the **Quadratic Weighted Kappa (QWK)**, which penalizes larger disagreements more severely.
#### Final Test Set Scores (QWK)
| Track | Task | Dev (QWK) | Test (QWK) |
| :--- | :--- | :---: | :---: |
| **Strict** | Sentence | 0.823 | **84.2** |
| | Document | 0.823\* | 79.9 |
| **Constrained** | Sentence | 0.810 | 82.9 |
| | Document | 0.835\* | 75.5 |
| **Open** | Sentence | 0.827 | 83.6 |
| | Document | 0.827\* | **79.2** |
\*Document-level dev scores are based on the performance of the sentence-level model on the validation set.
-----
## 📜 Citation
If you use the work, please cite the paper:
```
@inproceedings{eldin2025morphoarabia,
title={{MorphoArabia at BAREC 2025 Shared Task: A Hybrid Architecture with Morphological Analysis for Arabic Readability Assessmen}},
author={Eldin, Fatimah Mohamed Emad},
year={2025},
booktitle={Proceedings of the BAREC 2025 Shared Task},
eprint={25XX.XXXXX},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
|
motza0025/blockassist-bc-scurrying_waddling_pelican_1755010463
|
motza0025
| 2025-08-12T15:19:30Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"scurrying waddling pelican",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-12T15:19:14Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- scurrying waddling pelican
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
prithivMLmods/Qwen3-8B-CK-Pro-f32-GGUF
|
prithivMLmods
| 2025-08-12T15:18:04Z | 0 | 0 |
transformers
|
[
"transformers",
"gguf",
"qwen3",
"text-generation-inference",
"text-generation",
"en",
"base_model:CognitiveKernel/Qwen3-8B-CK-Pro",
"base_model:quantized:CognitiveKernel/Qwen3-8B-CK-Pro",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
] |
text-generation
| 2025-08-12T11:28:31Z |
---
license: apache-2.0
base_model:
- CognitiveKernel/Qwen3-8B-CK-Pro
language:
- en
pipeline_tag: text-generation
library_name: transformers
tags:
- text-generation-inference
---
# **Qwen3-8B-CK-Pro-f32-GGUF**
> The CognitiveKernel/Qwen3-8B-CK-Pro model is a fine-tuned variant of the Qwen3-8B base language model, trained using self-collected trajectories from queries as detailed in the Cognitive Kernel-Pro research. It is designed as a deep research agent and foundation model, achieving strong performance with Pass@1/3 scores of 32.7%/38.2% on the full GAIA dev set and 40.3%/49.3% on the text-only subset. This model builds upon the strengths of Qwen3-8B, which supports advanced reasoning, instruction-following, and multilingual capabilities, specifically optimized for research agent tasks through the Cognitive Kernel-Pro framework. It is not currently deployed by any inference provider on Hugging Face. The model leverages the underlying Qwen3-8B base and its finetuned versions to deliver enhanced agent capabilities for complex question-answering and information synthesis scenarios.
## Execute using Ollama
run ->
`ollama run hf.co/prithivMLmods/Qwen3-8B-CK-Pro-f32-GGUF:Q2_K`
## Model Files
| File Name | Quant Type | File Size |
| - | - | - |
| Qwen3-8B-CK-Pro.BF16.gguf | BF16 | 16.4 GB |
| Qwen3-8B-CK-Pro.F16.gguf | F16 | 16.4 GB |
| Qwen3-8B-CK-Pro.F32.gguf | F32 | 32.8 GB |
| Qwen3-8B-CK-Pro.Q2_K.gguf | Q2_K | 3.28 GB |
## Quants Usage
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

|
Jack-Payne1/qwen_2.5_7b-phoenix_B0_control_seed1
|
Jack-Payne1
| 2025-08-12T15:17:30Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"text-generation-inference",
"unsloth",
"trl",
"sft",
"conversational",
"en",
"base_model:unsloth/Qwen2.5-7B-Instruct",
"base_model:finetune:unsloth/Qwen2.5-7B-Instruct",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-12T15:14:36Z |
---
base_model: unsloth/Qwen2.5-7B-Instruct
tags:
- text-generation-inference
- transformers
- unsloth
- qwen2
- trl
- sft
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** Jack-Payne1
- **License:** apache-2.0
- **Finetuned from model :** unsloth/Qwen2.5-7B-Instruct
This qwen2 model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
mradermacher/UI-AGILE-3B-GGUF
|
mradermacher
| 2025-08-12T15:17:02Z | 0 | 0 |
transformers
|
[
"transformers",
"gguf",
"en",
"base_model:KDEGroup/UI-AGILE-3B",
"base_model:quantized:KDEGroup/UI-AGILE-3B",
"license:mit",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2025-08-12T14:29:41Z |
---
base_model: KDEGroup/UI-AGILE-3B
language:
- en
library_name: transformers
license: mit
mradermacher:
readme_rev: 1
quantized_by: mradermacher
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
<!-- ### quants: x-f16 Q4_K_S Q2_K Q8_0 Q6_K Q3_K_M Q3_K_S Q3_K_L Q4_K_M Q5_K_S Q5_K_M IQ4_XS -->
<!-- ### quants_skip: -->
<!-- ### skip_mmproj: -->
static quants of https://huggingface.co/KDEGroup/UI-AGILE-3B
<!-- provided-files -->
***For a convenient overview and download list, visit our [model page for this model](https://hf.tst.eu/model#UI-AGILE-3B-GGUF).***
weighted/imatrix quants are available at https://huggingface.co/mradermacher/UI-AGILE-3B-i1-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/UI-AGILE-3B-GGUF/resolve/main/UI-AGILE-3B.mmproj-Q8_0.gguf) | mmproj-Q8_0 | 0.9 | multi-modal supplement |
| [GGUF](https://huggingface.co/mradermacher/UI-AGILE-3B-GGUF/resolve/main/UI-AGILE-3B.Q2_K.gguf) | Q2_K | 1.4 | |
| [GGUF](https://huggingface.co/mradermacher/UI-AGILE-3B-GGUF/resolve/main/UI-AGILE-3B.mmproj-f16.gguf) | mmproj-f16 | 1.4 | multi-modal supplement |
| [GGUF](https://huggingface.co/mradermacher/UI-AGILE-3B-GGUF/resolve/main/UI-AGILE-3B.Q3_K_S.gguf) | Q3_K_S | 1.6 | |
| [GGUF](https://huggingface.co/mradermacher/UI-AGILE-3B-GGUF/resolve/main/UI-AGILE-3B.Q3_K_M.gguf) | Q3_K_M | 1.7 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/UI-AGILE-3B-GGUF/resolve/main/UI-AGILE-3B.Q3_K_L.gguf) | Q3_K_L | 1.8 | |
| [GGUF](https://huggingface.co/mradermacher/UI-AGILE-3B-GGUF/resolve/main/UI-AGILE-3B.IQ4_XS.gguf) | IQ4_XS | 1.9 | |
| [GGUF](https://huggingface.co/mradermacher/UI-AGILE-3B-GGUF/resolve/main/UI-AGILE-3B.Q4_K_S.gguf) | Q4_K_S | 1.9 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/UI-AGILE-3B-GGUF/resolve/main/UI-AGILE-3B.Q4_K_M.gguf) | Q4_K_M | 2.0 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/UI-AGILE-3B-GGUF/resolve/main/UI-AGILE-3B.Q5_K_S.gguf) | Q5_K_S | 2.3 | |
| [GGUF](https://huggingface.co/mradermacher/UI-AGILE-3B-GGUF/resolve/main/UI-AGILE-3B.Q5_K_M.gguf) | Q5_K_M | 2.3 | |
| [GGUF](https://huggingface.co/mradermacher/UI-AGILE-3B-GGUF/resolve/main/UI-AGILE-3B.Q6_K.gguf) | Q6_K | 2.6 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/UI-AGILE-3B-GGUF/resolve/main/UI-AGILE-3B.Q8_0.gguf) | Q8_0 | 3.4 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/UI-AGILE-3B-GGUF/resolve/main/UI-AGILE-3B.f16.gguf) | f16 | 6.3 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
mradermacher/InfiGUI-G1-3B-i1-GGUF
|
mradermacher
| 2025-08-12T15:17:02Z | 0 | 0 |
transformers
|
[
"transformers",
"gguf",
"gui",
"agent",
"gui-grounding",
"reinforcement-learning",
"en",
"base_model:InfiX-ai/InfiGUI-G1-3B",
"base_model:quantized:InfiX-ai/InfiGUI-G1-3B",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] |
reinforcement-learning
| 2025-08-12T14:32:57Z |
---
base_model: InfiX-ai/InfiGUI-G1-3B
language:
- en
library_name: transformers
license: apache-2.0
mradermacher:
readme_rev: 1
quantized_by: mradermacher
tags:
- gui
- agent
- gui-grounding
- reinforcement-learning
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: nicoboss -->
<!-- ### quants: Q2_K IQ3_M Q4_K_S IQ3_XXS Q3_K_M small-IQ4_NL Q4_K_M IQ2_M Q6_K IQ4_XS Q2_K_S IQ1_M Q3_K_S IQ2_XXS Q3_K_L IQ2_XS Q5_K_S IQ2_S IQ1_S Q5_K_M Q4_0 IQ3_XS Q4_1 IQ3_S -->
<!-- ### quants_skip: -->
<!-- ### skip_mmproj: -->
weighted/imatrix quants of https://huggingface.co/InfiX-ai/InfiGUI-G1-3B
<!-- provided-files -->
***For a convenient overview and download list, visit our [model page for this model](https://hf.tst.eu/model#InfiGUI-G1-3B-i1-GGUF).***
static quants are available at https://huggingface.co/mradermacher/InfiGUI-G1-3B-GGUF
**This is a vision model - mmproj files (if any) will be in the [static repository](https://huggingface.co/mradermacher/InfiGUI-G1-3B-GGUF).**
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/InfiGUI-G1-3B-i1-GGUF/resolve/main/InfiGUI-G1-3B.imatrix.gguf) | imatrix | 0.1 | imatrix file (for creating your own qwuants) |
| [GGUF](https://huggingface.co/mradermacher/InfiGUI-G1-3B-i1-GGUF/resolve/main/InfiGUI-G1-3B.i1-IQ1_S.gguf) | i1-IQ1_S | 1.0 | for the desperate |
| [GGUF](https://huggingface.co/mradermacher/InfiGUI-G1-3B-i1-GGUF/resolve/main/InfiGUI-G1-3B.i1-IQ1_M.gguf) | i1-IQ1_M | 1.1 | mostly desperate |
| [GGUF](https://huggingface.co/mradermacher/InfiGUI-G1-3B-i1-GGUF/resolve/main/InfiGUI-G1-3B.i1-IQ2_XXS.gguf) | i1-IQ2_XXS | 1.2 | |
| [GGUF](https://huggingface.co/mradermacher/InfiGUI-G1-3B-i1-GGUF/resolve/main/InfiGUI-G1-3B.i1-IQ2_XS.gguf) | i1-IQ2_XS | 1.2 | |
| [GGUF](https://huggingface.co/mradermacher/InfiGUI-G1-3B-i1-GGUF/resolve/main/InfiGUI-G1-3B.i1-IQ2_S.gguf) | i1-IQ2_S | 1.3 | |
| [GGUF](https://huggingface.co/mradermacher/InfiGUI-G1-3B-i1-GGUF/resolve/main/InfiGUI-G1-3B.i1-IQ2_M.gguf) | i1-IQ2_M | 1.4 | |
| [GGUF](https://huggingface.co/mradermacher/InfiGUI-G1-3B-i1-GGUF/resolve/main/InfiGUI-G1-3B.i1-Q2_K_S.gguf) | i1-Q2_K_S | 1.4 | very low quality |
| [GGUF](https://huggingface.co/mradermacher/InfiGUI-G1-3B-i1-GGUF/resolve/main/InfiGUI-G1-3B.i1-Q2_K.gguf) | i1-Q2_K | 1.5 | IQ3_XXS probably better |
| [GGUF](https://huggingface.co/mradermacher/InfiGUI-G1-3B-i1-GGUF/resolve/main/InfiGUI-G1-3B.i1-IQ3_XXS.gguf) | i1-IQ3_XXS | 1.5 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/InfiGUI-G1-3B-i1-GGUF/resolve/main/InfiGUI-G1-3B.i1-IQ3_XS.gguf) | i1-IQ3_XS | 1.6 | |
| [GGUF](https://huggingface.co/mradermacher/InfiGUI-G1-3B-i1-GGUF/resolve/main/InfiGUI-G1-3B.i1-Q3_K_S.gguf) | i1-Q3_K_S | 1.7 | IQ3_XS probably better |
| [GGUF](https://huggingface.co/mradermacher/InfiGUI-G1-3B-i1-GGUF/resolve/main/InfiGUI-G1-3B.i1-IQ3_S.gguf) | i1-IQ3_S | 1.7 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/InfiGUI-G1-3B-i1-GGUF/resolve/main/InfiGUI-G1-3B.i1-IQ3_M.gguf) | i1-IQ3_M | 1.7 | |
| [GGUF](https://huggingface.co/mradermacher/InfiGUI-G1-3B-i1-GGUF/resolve/main/InfiGUI-G1-3B.i1-Q3_K_M.gguf) | i1-Q3_K_M | 1.8 | IQ3_S probably better |
| [GGUF](https://huggingface.co/mradermacher/InfiGUI-G1-3B-i1-GGUF/resolve/main/InfiGUI-G1-3B.i1-Q3_K_L.gguf) | i1-Q3_K_L | 1.9 | IQ3_M probably better |
| [GGUF](https://huggingface.co/mradermacher/InfiGUI-G1-3B-i1-GGUF/resolve/main/InfiGUI-G1-3B.i1-IQ4_XS.gguf) | i1-IQ4_XS | 2.0 | |
| [GGUF](https://huggingface.co/mradermacher/InfiGUI-G1-3B-i1-GGUF/resolve/main/InfiGUI-G1-3B.i1-IQ4_NL.gguf) | i1-IQ4_NL | 2.1 | prefer IQ4_XS |
| [GGUF](https://huggingface.co/mradermacher/InfiGUI-G1-3B-i1-GGUF/resolve/main/InfiGUI-G1-3B.i1-Q4_0.gguf) | i1-Q4_0 | 2.1 | fast, low quality |
| [GGUF](https://huggingface.co/mradermacher/InfiGUI-G1-3B-i1-GGUF/resolve/main/InfiGUI-G1-3B.i1-Q4_K_S.gguf) | i1-Q4_K_S | 2.1 | optimal size/speed/quality |
| [GGUF](https://huggingface.co/mradermacher/InfiGUI-G1-3B-i1-GGUF/resolve/main/InfiGUI-G1-3B.i1-Q4_K_M.gguf) | i1-Q4_K_M | 2.2 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/InfiGUI-G1-3B-i1-GGUF/resolve/main/InfiGUI-G1-3B.i1-Q4_1.gguf) | i1-Q4_1 | 2.3 | |
| [GGUF](https://huggingface.co/mradermacher/InfiGUI-G1-3B-i1-GGUF/resolve/main/InfiGUI-G1-3B.i1-Q5_K_S.gguf) | i1-Q5_K_S | 2.5 | |
| [GGUF](https://huggingface.co/mradermacher/InfiGUI-G1-3B-i1-GGUF/resolve/main/InfiGUI-G1-3B.i1-Q5_K_M.gguf) | i1-Q5_K_M | 2.5 | |
| [GGUF](https://huggingface.co/mradermacher/InfiGUI-G1-3B-i1-GGUF/resolve/main/InfiGUI-G1-3B.i1-Q6_K.gguf) | i1-Q6_K | 2.9 | practically like static Q6_K |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time. Additional thanks to [@nicoboss](https://huggingface.co/nicoboss) for giving me access to his private supercomputer, enabling me to provide many more imatrix quants, at much higher quality, than I would otherwise be able to.
<!-- end -->
|
kimxxxx/mistral_r32_a64_b8_gas4_lr5e-5_4500tk_1epoch
|
kimxxxx
| 2025-08-12T15:16:32Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-08-12T15:16:22Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
ZhongyiB/blockassist-bc-colorful_foxy_aardvark_1755009889
|
ZhongyiB
| 2025-08-12T15:15:56Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"colorful foxy aardvark",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-12T15:15:45Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- colorful foxy aardvark
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
SounTing/mamitaproject
|
SounTing
| 2025-08-12T15:14:44Z | 0 | 0 |
diffusers
|
[
"diffusers",
"flux",
"lora",
"replicate",
"text-to-image",
"en",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"license:other",
"region:us"
] |
text-to-image
| 2025-08-12T15:00:44Z |
---
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
language:
- en
tags:
- flux
- diffusers
- lora
- replicate
base_model: "black-forest-labs/FLUX.1-dev"
pipeline_tag: text-to-image
# widget:
# - text: >-
# prompt
# output:
# url: https://...
instance_prompt: mamita
---
# Mamitaproject
<Gallery />
## About this LoRA
This is a [LoRA](https://replicate.com/docs/guides/working-with-loras) for the FLUX.1-dev text-to-image model. It can be used with diffusers or ComfyUI.
It was trained on [Replicate](https://replicate.com/) using AI toolkit: https://replicate.com/ostris/flux-dev-lora-trainer/train
## Trigger words
You should use `mamita` to trigger the image generation.
## Run this LoRA with an API using Replicate
```py
import replicate
input = {
"prompt": "mamita",
"lora_weights": "https://huggingface.co/SounTing/mamitaproject/resolve/main/lora.safetensors"
}
output = replicate.run(
"black-forest-labs/flux-dev-lora",
input=input
)
for index, item in enumerate(output):
with open(f"output_{index}.webp", "wb") as file:
file.write(item.read())
```
## Use it with the [🧨 diffusers library](https://github.com/huggingface/diffusers)
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained('black-forest-labs/FLUX.1-dev', torch_dtype=torch.float16).to('cuda')
pipeline.load_lora_weights('SounTing/mamitaproject', weight_name='lora.safetensors')
image = pipeline('mamita').images[0]
```
For more details, including weighting, merging and fusing LoRAs, check the [documentation on loading LoRAs in diffusers](https://huggingface.co/docs/diffusers/main/en/using-diffusers/loading_adapters)
## Training details
- Steps: 1000
- Learning rate: 0.0004
- LoRA rank: 16
## Contribute your own examples
You can use the [community tab](https://huggingface.co/SounTing/mamitaproject/discussions) to add images that show off what you’ve made with this LoRA.
|
zhuojing-huang/l2lm_test
|
zhuojing-huang
| 2025-08-12T15:07:56Z | 0 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"gpt2",
"text-generation",
"generated_from_trainer",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-12T14:55:06Z |
---
library_name: transformers
tags:
- generated_from_trainer
model-index:
- name: l2lm_test
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# l2lm_test
This model was trained from scratch on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 64
- eval_batch_size: 8
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 30
- training_steps: 183
### Training results
### Framework versions
- Transformers 4.53.1
- Pytorch 2.7.1+cu126
- Datasets 3.6.0
- Tokenizers 0.21.2
|
indoempatnol/blockassist-bc-fishy_wary_swan_1755009674
|
indoempatnol
| 2025-08-12T15:07:16Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"fishy wary swan",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-12T15:07:12Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- fishy wary swan
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Jovar1/blockassist-bc-bold_hulking_rooster_1755011062
|
Jovar1
| 2025-08-12T15:06:10Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"bold hulking rooster",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-12T15:05:10Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- bold hulking rooster
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
johnyzhao/blockassist-bc-slow_dense_leopard_1755011112
|
johnyzhao
| 2025-08-12T15:06:09Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"slow dense leopard",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-12T15:05:38Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- slow dense leopard
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
aiface/modernBert-base_v2
|
aiface
| 2025-08-12T15:04:52Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"modernbert",
"text-classification",
"generated_from_trainer",
"base_model:answerdotai/ModernBERT-base",
"base_model:finetune:answerdotai/ModernBERT-base",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2025-08-12T14:31:45Z |
---
library_name: transformers
license: apache-2.0
base_model: answerdotai/ModernBERT-base
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: modernBert-base_v2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# modernBert-base_v2
This model is a fine-tuned version of [answerdotai/ModernBERT-base](https://huggingface.co/answerdotai/ModernBERT-base) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7185
- Accuracy: 0.9116
- Precision Macro: 0.8041
- Recall Macro: 0.7362
- F1 Macro: 0.7592
- F1 Weighted: 0.9065
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 128
- optimizer: Use adamw_torch with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 20
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | Precision Macro | Recall Macro | F1 Macro | F1 Weighted |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:---------------:|:------------:|:--------:|:-----------:|
| 1.2139 | 1.0 | 90 | 0.5024 | 0.8073 | 0.8182 | 0.5993 | 0.6061 | 0.7934 |
| 0.6774 | 2.0 | 180 | 0.2870 | 0.9033 | 0.8421 | 0.7140 | 0.7451 | 0.8960 |
| 0.4571 | 3.0 | 270 | 0.3474 | 0.8920 | 0.8074 | 0.6669 | 0.6824 | 0.8802 |
| 0.2925 | 4.0 | 360 | 0.3089 | 0.9065 | 0.8778 | 0.7074 | 0.7413 | 0.8977 |
| 0.1725 | 5.0 | 450 | 0.3611 | 0.8958 | 0.7729 | 0.7574 | 0.7646 | 0.8946 |
| 0.0977 | 6.0 | 540 | 0.4743 | 0.9090 | 0.8405 | 0.7388 | 0.7695 | 0.9036 |
| 0.0576 | 7.0 | 630 | 0.6044 | 0.8743 | 0.7234 | 0.8019 | 0.7413 | 0.8878 |
| 0.0338 | 8.0 | 720 | 0.6118 | 0.9040 | 0.7756 | 0.7506 | 0.7615 | 0.9019 |
| 0.016 | 9.0 | 810 | 0.6754 | 0.9071 | 0.8334 | 0.7379 | 0.7670 | 0.9019 |
| 0.0113 | 10.0 | 900 | 0.6732 | 0.9065 | 0.7898 | 0.7606 | 0.7733 | 0.9044 |
| 0.0065 | 11.0 | 990 | 0.7871 | 0.9046 | 0.8046 | 0.7277 | 0.7519 | 0.8992 |
| 0.0037 | 12.0 | 1080 | 0.7134 | 0.9109 | 0.7989 | 0.7147 | 0.7386 | 0.9038 |
| 0.0022 | 13.0 | 1170 | 0.7784 | 0.9015 | 0.7765 | 0.7383 | 0.7529 | 0.8982 |
| 0.0013 | 14.0 | 1260 | 0.7176 | 0.9109 | 0.7832 | 0.7486 | 0.7625 | 0.9079 |
| 0.0011 | 15.0 | 1350 | 0.7681 | 0.9059 | 0.7920 | 0.7371 | 0.7565 | 0.9017 |
| 0.0001 | 16.0 | 1440 | 0.7170 | 0.9071 | 0.7833 | 0.7282 | 0.7479 | 0.9024 |
| 0.0007 | 17.0 | 1530 | 0.7219 | 0.9109 | 0.8022 | 0.7442 | 0.7652 | 0.9068 |
| 0.0003 | 18.0 | 1620 | 0.7379 | 0.9103 | 0.7950 | 0.7398 | 0.7596 | 0.9060 |
| 0.0006 | 19.0 | 1710 | 0.7198 | 0.9116 | 0.8074 | 0.7404 | 0.7635 | 0.9068 |
| 0.0004 | 20.0 | 1800 | 0.7185 | 0.9116 | 0.8041 | 0.7362 | 0.7592 | 0.9065 |
### Framework versions
- Transformers 4.55.0
- Pytorch 2.7.0+cu126
- Datasets 4.0.0
- Tokenizers 0.21.4
|
milliarderdol/blockassist-bc-roaring_rough_scorpion_1755009233
|
milliarderdol
| 2025-08-12T15:02:57Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"roaring rough scorpion",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-12T15:02:44Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- roaring rough scorpion
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
EYEDOL/FROM_C3_1
|
EYEDOL
| 2025-08-12T15:02:15Z | 0 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"whisper",
"automatic-speech-recognition",
"hf-asr-leaderboard",
"generated_from_trainer",
"sw",
"dataset:mozilla-foundation/common_voice_11_0",
"base_model:EYEDOL/SALAMA_C3",
"base_model:finetune:EYEDOL/SALAMA_C3",
"model-index",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2025-08-12T15:01:59Z |
---
library_name: transformers
language:
- sw
base_model: EYEDOL/SALAMA_C3
tags:
- hf-asr-leaderboard
- generated_from_trainer
datasets:
- mozilla-foundation/common_voice_11_0
metrics:
- wer
model-index:
- name: ASR_FROM_C3
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice 11.0
type: mozilla-foundation/common_voice_11_0
config: sw
split: None
args: 'config: sw, split: test'
metrics:
- name: Wer
type: wer
value: 15.471181920592226
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# ASR_FROM_C3
This model is a fine-tuned version of [EYEDOL/SALAMA_C3](https://huggingface.co/EYEDOL/SALAMA_C3) on the Common Voice 11.0 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2159
- Wer: 15.4712
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 1
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:------:|:----:|:---------------:|:-------:|
| 0.1344 | 0.8684 | 2000 | 0.2159 | 15.4712 |
### Framework versions
- Transformers 4.52.4
- Pytorch 2.6.0+cu124
- Datasets 3.6.0
- Tokenizers 0.21.2
|
jssaluja/fb-mms-1b-cleaned-jssaluja_rajinder_singh-epochs-3-test-datasets-10-20250812_075152-small
|
jssaluja
| 2025-08-12T15:01:10Z | 0 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"wav2vec2",
"automatic-speech-recognition",
"hf-asr-leaderboard",
"generated_from_trainer",
"pan",
"base_model:facebook/mms-1b-all",
"base_model:finetune:facebook/mms-1b-all",
"license:cc-by-nc-4.0",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2025-08-12T14:54:46Z |
---
library_name: transformers
language:
- pan
license: cc-by-nc-4.0
base_model: facebook/mms-1b-all
tags:
- hf-asr-leaderboard
- generated_from_trainer
metrics:
- wer
model-index:
- name: jssaluja/fb-mms-1b-cleaned-jssaluja_rajinder_singh-epochs-3-test-datasets-10-20250812_075152-small
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="200" height="32"/>](https://wandb.ai/hustler1313/facebook-mms-1b-train/runs/fb-mms-1b-cleaned-jssaluja_rajinder_singh-epochs-3-test-datasets-10-20250812_075152-small)
# jssaluja/fb-mms-1b-cleaned-jssaluja_rajinder_singh-epochs-3-test-datasets-10-20250812_075152-small
This model is a fine-tuned version of [facebook/mms-1b-all](https://huggingface.co/facebook/mms-1b-all) on the jssaluja/rajinder_singh dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4047
- Wer: 0.5297
- Wil: 0.7550
- Mer: 0.5194
- Cer: 0.1336
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.001
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 10
- num_epochs: 3
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer | Wil | Mer | Cer |
|:-------------:|:-----:|:----:|:---------------:|:------:|:------:|:------:|:------:|
| 4.3878 | 1.0 | 76 | 0.4993 | 0.5921 | 0.8041 | 0.5758 | 0.1531 |
| 0.4978 | 2.0 | 152 | 0.4216 | 0.5552 | 0.7741 | 0.5385 | 0.1330 |
| 0.3915 | 3.0 | 228 | 0.4047 | 0.5297 | 0.7550 | 0.5194 | 0.1336 |
### Framework versions
- Transformers 4.55.0
- Pytorch 2.6.0+cu124
- Datasets 3.6.0
- Tokenizers 0.21.4
|
maura121/Qwen2.5-0.5B-Instruct-Gensyn-Swarm-prickly_galloping_panda
|
maura121
| 2025-08-12T15:00:17Z | 72 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"rl-swarm",
"genrl-swarm",
"grpo",
"gensyn",
"I am prickly_galloping_panda",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-11T21:44:57Z |
---
library_name: transformers
tags:
- rl-swarm
- genrl-swarm
- grpo
- gensyn
- I am prickly_galloping_panda
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
sssravi/gpt-oss-20b-for-reasoning-metric
|
sssravi
| 2025-08-12T15:00:09Z | 0 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"generated_from_trainer",
"sft",
"trl",
"base_model:openai/gpt-oss-20b",
"base_model:finetune:openai/gpt-oss-20b",
"endpoints_compatible",
"region:us"
] | null | 2025-08-12T14:59:34Z |
---
base_model: openai/gpt-oss-20b
library_name: transformers
model_name: gpt-oss-20b-for-reasoning-metric
tags:
- generated_from_trainer
- sft
- trl
licence: license
---
# Model Card for gpt-oss-20b-for-reasoning-metric
This model is a fine-tuned version of [openai/gpt-oss-20b](https://huggingface.co/openai/gpt-oss-20b).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="sssravi/gpt-oss-20b-for-reasoning-metric", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
This model was trained with SFT.
### Framework versions
- TRL: 0.21.0
- Transformers: 4.55.0
- Pytorch: 2.8.0
- Datasets: 4.0.0
- Tokenizers: 0.21.4
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
johnyzhao/blockassist-bc-slow_dense_leopard_1755010230
|
johnyzhao
| 2025-08-12T14:59:33Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"slow dense leopard",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-12T14:51:15Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- slow dense leopard
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
silentember/Lantern_ZdjMYl
|
silentember
| 2025-08-12T14:58:31Z | 0 | 0 | null |
[
"safetensors",
"any-to-any",
"omega",
"omegalabs",
"bittensor",
"agi",
"license:mit",
"region:us"
] |
any-to-any
| 2025-08-12T14:56:35Z |
---
license: mit
tags:
- any-to-any
- omega
- omegalabs
- bittensor
- agi
---
This is an Any-to-Any model checkpoint for the OMEGA Labs x Bittensor Any-to-Any subnet.
Check out the [git repo](https://github.com/omegalabsinc/omegalabs-anytoany-bittensor) and find OMEGA on X: [@omegalabsai](https://x.com/omegalabsai).
|
JohnFatman/Qwen2.5-0.5B-Instruct-Gensyn-Swarm-reclusive_hunting_ibis
|
JohnFatman
| 2025-08-12T14:57:15Z | 28 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"rl-swarm",
"genrl-swarm",
"grpo",
"gensyn",
"I am reclusive_hunting_ibis",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-07T11:47:13Z |
---
library_name: transformers
tags:
- rl-swarm
- genrl-swarm
- grpo
- gensyn
- I am reclusive_hunting_ibis
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
abdimoalim/gpt2-instruct-v3
|
abdimoalim
| 2025-08-12T14:57:08Z | 0 | 0 | null |
[
"license:apache-2.0",
"region:us"
] | null | 2025-08-12T14:57:08Z |
---
license: apache-2.0
---
|
armaansidana/mohit
|
armaansidana
| 2025-08-12T14:57:05Z | 0 | 0 |
diffusers
|
[
"diffusers",
"flux",
"lora",
"replicate",
"text-to-image",
"en",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"license:other",
"region:us"
] |
text-to-image
| 2025-08-12T14:21:29Z |
---
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
language:
- en
tags:
- flux
- diffusers
- lora
- replicate
base_model: "black-forest-labs/FLUX.1-dev"
pipeline_tag: text-to-image
# widget:
# - text: >-
# prompt
# output:
# url: https://...
instance_prompt: mohit
---
# Mohit
<Gallery />
## About this LoRA
This is a [LoRA](https://replicate.com/docs/guides/working-with-loras) for the FLUX.1-dev text-to-image model. It can be used with diffusers or ComfyUI.
It was trained on [Replicate](https://replicate.com/) using AI toolkit: https://replicate.com/ostris/flux-dev-lora-trainer/train
## Trigger words
You should use `mohit` to trigger the image generation.
## Run this LoRA with an API using Replicate
```py
import replicate
input = {
"prompt": "mohit",
"lora_weights": "https://huggingface.co/armaansidana/mohit/resolve/main/lora.safetensors"
}
output = replicate.run(
"black-forest-labs/flux-dev-lora",
input=input
)
for index, item in enumerate(output):
with open(f"output_{index}.webp", "wb") as file:
file.write(item.read())
```
## Use it with the [🧨 diffusers library](https://github.com/huggingface/diffusers)
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained('black-forest-labs/FLUX.1-dev', torch_dtype=torch.float16).to('cuda')
pipeline.load_lora_weights('armaansidana/mohit', weight_name='lora.safetensors')
image = pipeline('mohit').images[0]
```
For more details, including weighting, merging and fusing LoRAs, check the [documentation on loading LoRAs in diffusers](https://huggingface.co/docs/diffusers/main/en/using-diffusers/loading_adapters)
## Training details
- Steps: 3000
- Learning rate: 0.0004
- LoRA rank: 16
## Contribute your own examples
You can use the [community tab](https://huggingface.co/armaansidana/mohit/discussions) to add images that show off what you’ve made with this LoRA.
|
pinilDissanayaka/HRM
|
pinilDissanayaka
| 2025-08-12T14:56:33Z | 0 | 0 | null |
[
"arxiv:2506.21734",
"region:us"
] | null | 2025-08-12T14:52:36Z |
# Hierarchical Reasoning Model

Reasoning, the process of devising and executing complex goal-oriented action sequences, remains a critical challenge in AI.
Current large language models (LLMs) primarily employ Chain-of-Thought (CoT) techniques, which suffer from brittle task decomposition, extensive data requirements, and high latency. Inspired by the hierarchical and multi-timescale processing in the human brain, we propose the Hierarchical Reasoning Model (HRM), a novel recurrent architecture that attains significant computational depth while maintaining both training stability and efficiency.
HRM executes sequential reasoning tasks in a single forward pass without explicit supervision of the intermediate process, through two interdependent recurrent modules: a high-level module responsible for slow, abstract planning, and a low-level module handling rapid, detailed computations. With only 27 million parameters, HRM achieves exceptional performance on complex reasoning tasks using only 1000 training samples. The model operates without pre-training or CoT data, yet achieves nearly perfect performance on challenging tasks including complex Sudoku puzzles and optimal path finding in large mazes.
Furthermore, HRM outperforms much larger models with significantly longer context windows on the Abstraction and Reasoning Corpus (ARC), a key benchmark for measuring artificial general intelligence capabilities.
These results underscore HRM’s potential as a transformative advancement toward universal computation and general-purpose reasoning systems.
## Quick Start Guide 🚀
### Prerequisites ⚙️
Ensure PyTorch and CUDA are installed. The repo needs CUDA extensions to be built. If not present, run the following commands:
```bash
# Install CUDA 12.6
CUDA_URL=https://developer.download.nvidia.com/compute/cuda/12.6.3/local_installers/cuda_12.6.3_560.35.05_linux.run
wget -q --show-progress --progress=bar:force:noscroll -O cuda_installer.run $CUDA_URL
sudo sh cuda_installer.run --silent --toolkit --override
export CUDA_HOME=/usr/local/cuda-12.6
# Install PyTorch with CUDA 12.6
PYTORCH_INDEX_URL=https://download.pytorch.org/whl/cu126
pip3 install torch torchvision torchaudio --index-url $PYTORCH_INDEX_URL
# Additional packages for building extensions
pip3 install packaging ninja wheel setuptools setuptools-scm
```
Then install FlashAttention. For Hopper GPUs, install FlashAttention 3
```bash
git clone git@github.com:Dao-AILab/flash-attention.git
cd flash-attention/hopper
python setup.py install
```
For Ampere or earlier GPUs, install FlashAttention 2
```bash
pip3 install flash-attn
```
## Install Python Dependencies 🐍
```bash
pip install -r requirements.txt
```
## W&B Integration 📈
This project uses [Weights & Biases](https://wandb.ai/) for experiment tracking and metric visualization. Ensure you're logged in:
```bash
wandb login
```
## Run Experiments
### Quick Demo: Sudoku Solver 💻🗲
Train a master-level Sudoku AI capable of solving extremely difficult puzzles on a modern laptop GPU. 🧩
```bash
# Download and build Sudoku dataset
python dataset/build_sudoku_dataset.py --output-dir data/sudoku-extreme-1k-aug-1000 --subsample-size 1000 --num-aug 1000
# Start training (single GPU, smaller batch size)
OMP_NUM_THREADS=8 python pretrain.py data_path=data/sudoku-extreme-1k-aug-1000 epochs=20000 eval_interval=2000 global_batch_size=384 lr=7e-5 puzzle_emb_lr=7e-5 weight_decay=1.0 puzzle_emb_weight_decay=1.0
```
Runtime: ~10 hours on a RTX 4070 laptop GPU
## Trained Checkpoints 🚧
- [ARC-AGI-2](https://huggingface.co/sapientinc/HRM-checkpoint-ARC-2)
- [Sudoku 9x9 Extreme (1000 examples)](https://huggingface.co/sapientinc/HRM-checkpoint-sudoku-extreme)
- [Maze 30x30 Hard (1000 examples)](https://huggingface.co/sapientinc/HRM-checkpoint-maze-30x30-hard)
To use the checkpoints, see Evaluation section below.
## Full-scale Experiments 🔵
Experiments below assume an 8-GPU setup.
### Dataset Preparation
```bash
# Initialize submodules
git submodule update --init --recursive
# ARC-1
python dataset/build_arc_dataset.py # ARC offical + ConceptARC, 960 examples
# ARC-2
python dataset/build_arc_dataset.py --dataset-dirs dataset/raw-data/ARC-AGI-2/data --output-dir data/arc-2-aug-1000 # ARC-2 official, 1120 examples
# Sudoku-Extreme
python dataset/build_sudoku_dataset.py # Full version
python dataset/build_sudoku_dataset.py --output-dir data/sudoku-extreme-1k-aug-1000 --subsample-size 1000 --num-aug 1000 # 1000 examples
# Maze
python dataset/build_maze_dataset.py # 1000 examples
```
### Dataset Visualization
Explore the puzzles visually:
* Open `puzzle_visualizer.html` in your browser.
* Upload the generated dataset folder located in `data/...`.
## Launch experiments
### Small-sample (1K)
ARC-1:
```bash
OMP_NUM_THREADS=8 torchrun --nproc-per-node 8 pretrain.py
```
*Runtime:* ~24 hours
ARC-2:
```bash
OMP_NUM_THREADS=8 torchrun --nproc-per-node 8 pretrain.py data_path=data/arc-2-aug-1000
```
*Runtime:* ~24 hours (checkpoint after 8 hours is often sufficient)
Sudoku Extreme (1k):
```bash
OMP_NUM_THREADS=8 torchrun --nproc-per-node 8 pretrain.py data_path=data/sudoku-extreme-1k-aug-1000 epochs=20000 eval_interval=2000 lr=1e-4 puzzle_emb_lr=1e-4 weight_decay=1.0 puzzle_emb_weight_decay=1.0
```
*Runtime:* ~10 minutes
Maze 30x30 Hard (1k):
```bash
OMP_NUM_THREADS=8 torchrun --nproc-per-node 8 pretrain.py data_path=data/maze-30x30-hard-1k epochs=20000 eval_interval=2000 lr=1e-4 puzzle_emb_lr=1e-4 weight_decay=1.0 puzzle_emb_weight_decay=1.0
```
*Runtime:* ~1 hour
### Full Sudoku-Hard
```bash
OMP_NUM_THREADS=8 torchrun --nproc-per-node 8 pretrain.py data_path=data/sudoku-hard-full epochs=100 eval_interval=10 lr_min_ratio=0.1 global_batch_size=2304 lr=3e-4 puzzle_emb_lr=3e-4 weight_decay=0.1 puzzle_emb_weight_decay=0.1 arch.loss.loss_type=softmax_cross_entropy arch.L_cycles=8 arch.halt_max_steps=8 arch.pos_encodings=learned
```
*Runtime:* ~2 hours
## Evaluation
Evaluate your trained models:
* Check `eval/exact_accuracy` in W&B.
* For ARC-AGI, follow these additional steps:
```bash
OMP_NUM_THREADS=8 torchrun --nproc-per-node 8 evaluate.py checkpoint=<CHECKPOINT_PATH>
```
* Then use the provided `arc_eval.ipynb` notebook to finalize and inspect your results.
## Notes
- Small-sample learning typically exhibits accuracy variance of around ±2 points.
- For Sudoku-Extreme (1,000-example dataset), late-stage overfitting may cause numerical instability during training and Q-learning. It is advisable to use early stopping once the training accuracy approaches 100%.
## Citation 📜
```bibtex
@misc{wang2025hierarchicalreasoningmodel,
title={Hierarchical Reasoning Model},
author={Guan Wang and Jin Li and Yuhao Sun and Xing Chen and Changling Liu and Yue Wu and Meng Lu and Sen Song and Yasin Abbasi Yadkori},
year={2025},
eprint={2506.21734},
archivePrefix={arXiv},
primaryClass={cs.AI},
url={https://arxiv.org/abs/2506.21734},
}
```
|
razor534/blockassist-bc-lazy_extinct_termite_1755010308
|
razor534
| 2025-08-12T14:53:17Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"lazy extinct termite",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-12T14:53:06Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- lazy extinct termite
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
abdeljalilELmajjodi/Darija_Arabic_NER_LID
|
abdeljalilELmajjodi
| 2025-08-12T14:47:14Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"xlm-roberta",
"token-classification",
"generated_from_trainer",
"base_model:atlasia/XLM-RoBERTa-Morocco",
"base_model:finetune:atlasia/XLM-RoBERTa-Morocco",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2025-08-12T14:45:45Z |
---
library_name: transformers
license: mit
base_model: atlasia/XLM-RoBERTa-Morocco
tags:
- generated_from_trainer
metrics:
- f1
model-index:
- name: Darija_Arabic_NER_LID
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Darija_Arabic_NER_LID
This model is a fine-tuned version of [atlasia/XLM-RoBERTa-Morocco](https://huggingface.co/atlasia/XLM-RoBERTa-Morocco) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1501
- F1: 0.9540
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
### Framework versions
- Transformers 4.55.0
- Pytorch 2.7.1+cu128
- Datasets 4.0.0
- Tokenizers 0.21.4
|
visurg/LEMON_curation_models
|
visurg
| 2025-08-12T14:42:47Z | 0 | 1 | null |
[
"arxiv:2503.19740",
"license:apache-2.0",
"region:us"
] | null | 2025-03-19T11:07:59Z |
---
license: apache-2.0
---
<div align="center">
<img src="https://cdn-uploads.huggingface.co/production/uploads/67d9504a41d31cc626fcecc8/cE7UgFfJJ2gUHJr0SSEhc.png"> </img>
</div>
[📚 Paper](https://arxiv.org/abs/2503.19740) - [🤖 GitHub](https://github.com/visurg-ai/LEMON)
We provide the models used in our data curation pipeline in [📚 LEMON: A Large Endoscopic MONocular Dataset and Foundation Model for Perception in Surgical Settings](https://arxiv.org/abs/2503.19740) to assist with constructing the LEMON dataset (for more details about the LEMON dataset and our
LemonFM foundation model, please visit our github repository at [🤖 GitHub](https://github.com/visurg-ai/LEMON)) .
If you use our dataset, model, or code in your research, please cite our paper:
```
@misc{che2025lemonlargeendoscopicmonocular,
title={LEMON: A Large Endoscopic MONocular Dataset and Foundation Model for Perception in Surgical Settings},
author={Chengan Che and Chao Wang and Tom Vercauteren and Sophia Tsoka and Luis C. Garcia-Peraza-Herrera},
year={2025},
eprint={2503.19740},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2503.19740},
}
```
This Hugging Face repository includes video storyboard classification models, frame classification models, and non-surgical object detection models. The model loader file can be found at [model_loader.py](https://huggingface.co/visurg/Surg3M_curation_models/blob/main/model_loader.py)
<div align="center">
<table style="margin-left: auto; margin-right: auto;">
<tr>
<th>Model</th>
<th>Architecture</th>
<th colspan="5">Download</th>
</tr>
<tr>
<td>Video storyboard classification models</td>
<td>ResNet-18</td>
<td><a href="https://huggingface.co/visurg/Surg3M_curation_models/tree/main/video_storyboard_classification">Full ckpt</a></td>
</tr>
<tr>
<td>Frame classification models</td>
<td>ResNet-18</td>
<td><a href="https://huggingface.co/visurg/Surg3M_curation_models/tree/main/frame_classification">Full ckpt</a></td>
</tr>
<tr>
<td>Non-surgical object detection models</td>
<td>Yolov8-Nano</td>
<td><a href="https://huggingface.co/visurg/Surg3M_curation_models/tree/main/nonsurgical_object_detection">Full ckpt</a></td>
</tr>
</table>
</div>
The data curation pipeline leading to the clean videos in the LEMON dataset is as follows:
<div align="center">
<img src="https://cdn-uploads.huggingface.co/production/uploads/67d9504a41d31cc626fcecc8/jzw36jlPT-V_I-Vm01OzO.png"> </img>
</div>
Usage
--------
**Video classification models** are employed in the step **2** of the data curation pipeline to classify a video storyboard as either surgical or non-surgical, the models usage is as follows:
```python
import torch
import torchvision
from PIL import Image
from model_loader import build_model
# Load the model
net = build_model(mode='classify')
model_path = 'Video storyboard classification models'
# Enable multi-GPU support
net = torch.nn.DataParallel(net)
torch.backends.cudnn.benchmark = True
state = torch.load(model_path, map_location=torch.device('cpu'))
net.load_state_dict(state['net'])
net.eval()
# Load the video storyboard and convert it to a PyTorch tensor
img_path = 'path/to/your/image.jpg'
img = Image.open(img_path)
img = img.resize((224, 224))
transform = torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize(
(0.4299694, 0.29676908, 0.27707579),
(0.24373249, 0.20208984, 0.19319402)
)
])
img_tensor = transform(img).unsqueeze(0).to('cuda')
# Extract features from the image
outputs = net(img_tensor)
```
**Frame classification models** are used in the step **3** of the data curation pipeline to classify a frame as either surgical or non-surgical, the models usage is as follows:
```python
import torch
import torchvision
from PIL import Image
from model_loader import build_model
# Load the model
net = build_model(mode='classify')
model_path = 'Frame classification models'
# Enable multi-GPU support
net = torch.nn.DataParallel(net)
torch.backends.cudnn.benchmark = True
state = torch.load(model_path, map_location=torch.device('cpu'))
net.load_state_dict(state['net'])
net.eval()
img_path = 'path/to/your/image.jpg'
img = Image.open(img_path)
img = img.resize((224, 224))
transform = torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize(
(0.4299694, 0.29676908, 0.27707579),
(0.24373249, 0.20208984, 0.19319402)
)
])
img_tensor = transform(img).unsqueeze(0).to('cuda')
# Extract features from the image
outputs = net(img_tensor)
```
**Non-surgical object detection models** are used to obliterate the non-surgical region in the surgical frames (e.g. user interface information), the models usage is as follows:
```python
import torch
import torchvision
from PIL import Image
from model_loader import build_model
# Load the model
net = build_model(mode='mask')
model_path = 'Frame classification models'
# Enable multi-GPU support
net = torch.nn.DataParallel(net)
torch.backends.cudnn.benchmark = True
state = torch.load(model_path, map_location=torch.device('cpu'))
net.load_state_dict(state['net'])
net.eval()
img_path = 'path/to/your/image.jpg'
img = Image.open(img_path)
img = img.resize((224, 224))
transform = torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize(
(0.4299694, 0.29676908, 0.27707579),
(0.24373249, 0.20208984, 0.19319402)
)
])
img_tensor = transform(img).unsqueeze(0).to('cuda')
# Extract features from the image
outputs = net(img_tensor)
```
|
visurg/LemonFM
|
visurg
| 2025-08-12T14:42:05Z | 0 | 2 | null |
[
"arxiv:2503.19740",
"license:apache-2.0",
"region:us"
] | null | 2025-03-18T14:31:13Z |
---
license: apache-2.0
---
<div align="center">
<img src="https://cdn-uploads.huggingface.co/production/uploads/67d9504a41d31cc626fcecc8/syYHwLv9Z2s7UfTejhvKm.png"> </img>
</div>
[📚 Paper](https://arxiv.org/abs/2503.19740) - [🤖 GitHub](https://github.com/visurg-ai/LEMON)
This is the official Hugging Face repository for the paper [LEMON: A Large Endoscopic MONocular Dataset and Foundation Model for Perception in Surgical Settings](https://arxiv.org/abs/2503.19740).
This repository provides open access to the *LemonFM* foundation model. For the *LEMON* dataset and our code, please see our at our GitHub repository at [🤖 Github](https://github.com/visurg-ai/LEMON) .
*LemonFM* is an image foundation model for surgery, it receives an image as input and produces a feature vector of 1536 features as output.
If you use our dataset, model, or code in your research, please cite our paper:
```
@misc{che2025lemonlargeendoscopicmonocular,
title={LEMON: A Large Endoscopic MONocular Dataset and Foundation Model for Perception in Surgical Settings},
author={Chengan Che and Chao Wang and Tom Vercauteren and Sophia Tsoka and Luis C. Garcia-Peraza-Herrera},
year={2025},
eprint={2503.19740},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2503.19740},
}
```
Abstract
--------
Traditional open-access datasets focusing on surgical procedures are often limited by their small size, typically consisting of fewer than 100 videos and less than 30 hours of footage, which leads to poor model generalization. To address this constraint, a new dataset called LEMON has been compiled using a novel aggregation pipeline that collects high-resolution videos from online sources. Featuring an extensive collection of over 4K surgical videos totaling 938 hours (85 million frames) of high-quality footage across multiple procedure types, LEMON offers a comprehensive resource surpassing existing alternatives in size and scope, including two novel downstream tasks. To demonstrate the effectiveness of this diverse dataset, we introduce LemonFM, a foundation model pretrained on LEMON using a novel self-supervised augmented knowledge distillation approach. LemonFM consistently outperforms existing surgical foundation models across four downstream tasks and six datasets, achieving significant gains in surgical phase recognition (+9.5pp, +9.4pp, and +8.4pp of Jaccard in AutoLaparo, M2CAI16, and Cholec80), surgical action recognition (+4.4pp of mAP in CholecT50), surgical tool presence detection (+5.3pp and +10.2pp of mAP in Cholec80 and GraSP), and surgical semantic segmentation (+8.3pp of mDice in CholecSeg8k). LEMON and LemonFM will serve as foundational resources for the research community and industry, accelerating progress in developing autonomous robotic surgery systems and ultimately contributing to safer and more accessible surgical care worldwide.
How to run our LemonFM foundation model to extract features from your video frames
----------------------------------------------------------------------------------
```python
import torch
from PIL import Image
from model_loader import build_LemonFM
# Load the pre-trained LemonFM model
lemonfm = build_LemonFM(pretrained_weights = 'your path to the LemonFM')
lemonfm.eval()
# Load the image and convert it to a PyTorch tensor
img_path = 'path/to/your/image.jpg'
img = Image.open(img_path)
img = img.resize((224, 224))
img_tensor = torch.tensor(np.array(img)).unsqueeze(0).to('cuda')
# Extract features from the image using the ResNet50 model
outputs = lemonfm(img_tensor)
```
|
0xAgo/blockassist-bc-agile_tough_camel_1755008884
|
0xAgo
| 2025-08-12T14:41:53Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"agile tough camel",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-12T14:41:39Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- agile tough camel
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Kbashiru/distil_Naija_bert_on_jumia_dataset
|
Kbashiru
| 2025-08-12T14:41:24Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"distilbert",
"text-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2025-08-12T14:41:08Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
palkonhax/blockassist-bc-stinging_slender_armadillo_1755008928
|
palkonhax
| 2025-08-12T14:41:03Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"stinging slender armadillo",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-12T14:29:34Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- stinging slender armadillo
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
razor534/blockassist-bc-lazy_extinct_termite_1755009502
|
razor534
| 2025-08-12T14:40:29Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"lazy extinct termite",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-12T14:40:22Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- lazy extinct termite
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
mendrika261/Qwen3-4B-Thinking-2507-abliterated
|
mendrika261
| 2025-08-12T14:40:05Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen3",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-12T12:06:37Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
lucyknada/janhq_Jan-v1-4B-exl3
|
lucyknada
| 2025-08-12T14:39:12Z | 0 | 0 | null |
[
"text-generation",
"en",
"base_model:Qwen/Qwen3-4B-Thinking-2507",
"base_model:finetune:Qwen/Qwen3-4B-Thinking-2507",
"license:apache-2.0",
"region:us"
] |
text-generation
| 2025-08-12T14:38:33Z |
---
license: apache-2.0
language:
- en
base_model:
- Qwen/Qwen3-4B-Thinking-2507
pipeline_tag: text-generation
---
### exl3 quant
---
### check revisions for quants
---
# Jan-v1: Advanced Agentic Language Model
[](https://github.com/menloresearch/deep-research)
[](https://opensource.org/licenses/Apache-2.0)
[](https://jan.ai/)
<!-- Optional: If you have a GIF for Jan-v1, include it here like Lucy's. -->
<!--  -->
## Overview
**Jan-v1** is the first release in the **Jan Family**, designed for agentic reasoning and problem-solving within the [Jan App](https://jan.ai/). Based on our [**Lucy**](https://huggingface.co/Menlo/Lucy) model, Jan-v1 achieves improved performance through model scaling.
Jan-v1 uses the [Qwen3-4B-thinking](https://huggingface.co/Qwen/Qwen3-4B-Thinking-2507) model to provide enhanced reasoning capabilities and tool utilization. This architecture delivers better performance on complex agentic tasks.
## Performance
### Question Answering (SimpleQA)
For question-answering, Jan-v1 shows a significant performance gain from model scaling, achieving 91.1% accuracy.

*The 91.1% SimpleQA accuracy represents a significant milestone in factual question answering for models of this scale, demonstrating the effectiveness of our scaling and fine-tuning approach.*
### Chat Benchmarks
These benchmarks evaluate the model's conversational and instructional capabilities.

## Quick Start
### Integration with Jan App
Jan-v1 is optimized for direct integration with the [Jan App](https://jan.ai/). Simply select the model from the Jan App interface for immediate access to its full capabilities.

### Local Deployment
**Using vLLM:**
```bash
vllm serve janhq/Jan-v1-4B \
--host 0.0.0.0 \
--port 1234 \
--enable-auto-tool-choice \
--tool-call-parser hermes
```
**Using llama.cpp:**
```bash
llama-server --model Jan-v1-4B-Q4_K_M.gguf \
--host 0.0.0.0 \
--port 1234 \
--jinja \
--no-context-shift
```
### Recommended Parameters
```yaml
temperature: 0.6
top_p: 0.95
top_k: 20
min_p: 0.0
max_tokens: 2048
```
## 🤝 Community & Support
- **Discussions**: [HuggingFace Community](https://huggingface.co/janhq/Jan-v1-4B/discussions)
- **Jan App**: Learn more about the Jan App at [jan.ai](https://jan.ai/)
## 📄 Citation
```bibtex
Updated Soon
```
---
|
agurung/v2sft_all_qwen7B_25percent_lr_1e4_allgrad
|
agurung
| 2025-08-12T14:38:36Z | 31 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"generated_from_trainer",
"trl",
"sft",
"conversational",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-10T19:01:05Z |
---
library_name: transformers
model_name: v2sft_all_qwen7B_25percent_lr_1e4_allgrad
tags:
- generated_from_trainer
- trl
- sft
licence: license
---
# Model Card for v2sft_all_qwen7B_25percent_lr_1e4_allgrad
This model is a fine-tuned version of [None](https://huggingface.co/None).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="agurung/v2sft_all_qwen7B_25percent_lr_1e4_allgrad", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="150" height="24"/>](https://wandb.ai/alexgurung/ncp_reasoning_projector/runs/upr91dfy)
This model was trained with SFT.
### Framework versions
- TRL: 0.21.0
- Transformers: 4.53.3
- Pytorch: 2.7.0+cu128
- Datasets: 4.0.0
- Tokenizers: 0.21.4
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
knowledgator/gliclass-modern-base-v2.0
|
knowledgator
| 2025-08-12T14:36:13Z | 1,242 | 1 | null |
[
"safetensors",
"GLiClass",
"dataset:knowledgator/events_classification_biotech",
"dataset:knowledgator/Scientific-text-classification",
"arxiv:2508.07662",
"license:apache-2.0",
"region:us"
] | null | 2025-03-27T12:48:20Z |
---
license: apache-2.0
datasets:
- knowledgator/events_classification_biotech
- knowledgator/Scientific-text-classification
---
# ⭐ GLiClass: Generalist and Lightweight Model for Sequence Classification
This is an efficient zero-shot classifier inspired by [GLiNER](https://github.com/urchade/GLiNER/tree/main) work. It demonstrates the same performance as a cross-encoder while being more compute-efficient because classification is done at a single forward path.
It can be used for `topic classification`, `sentiment analysis` and as a reranker in `RAG` pipelines.
The model was trained on synthetic and licensed data that allow commercial use and can be used in commercial applications.
This version of the model uses a layer-wise selection of features that enables a better understanding of different levels of language. The backbone model is [ModernBERT-base](https://huggingface.co/answerdotai/ModernBERT-base), which effectively processes long sequences.
The model was fine-tuned using a new RL-based approach to classification, with F1 and recall rewards.
### How to use:
First of all, you need to install GLiClass library:
```bash
pip install gliclass
pip install -U transformers>=4.48.0
```
Than you need to initialize a model and a pipeline:
```python
from gliclass import GLiClassModel, ZeroShotClassificationPipeline
from transformers import AutoTokenizer
model = GLiClassModel.from_pretrained("knowledgator/gliclass-modern-base-v2.0")
tokenizer = AutoTokenizer.from_pretrained("knowledgator/gliclass-modern-base-v2.0", add_prefix_space=True)
pipeline = ZeroShotClassificationPipeline(model, tokenizer, classification_type='multi-label', device='cuda:0')
text = "One day I will see the world!"
labels = ["travel", "dreams", "sport", "science", "politics"]
results = pipeline(text, labels, threshold=0.5)[0] #because we have one text
for result in results:
print(result["label"], "=>", result["score"])
```
If you want to use it for NLI type of tasks, we recommend representing your premise as a text and hypothesis as a label, you can put several hypotheses, but the model works best with a single input hypothesis.
```python
# Initialize model and multi-label pipeline
text = "The cat slept on the windowsill all afternoon"
labels = ["The cat was awake and playing outside."]
results = pipeline(text, labels, threshold=0.0)[0]
print(results)
```
### Benchmarks:
Below, you can see the F1 score on several text classification datasets. All tested models were not fine-tuned on those datasets and were tested in a zero-shot setting.
| Model | IMDB | AG_NEWS | Emotions |
|-----------------------------|------|---------|----------|
| [gliclass-modern-large-v2.0-init (399 M)](knowledgator/gliclass-modern-large-v2.0-init) | 0.9137 | 0.7357 | 0.4140 |
| [gliclass-modern-base-v2.0-init (151 M)](knowledgator/gliclass-modern-base-v2.0-init) | 0.8264 | 0.6637 | 0.2985 |
| [gliclass-modern-large-v2.0 (399 M)](knowledgator/gliclass-modern-large-v2.0) | 0.9448 | 0.736 | 0.4970 |
| [gliclass-modern-base-v2.0 (151 M)](knowledgator/gliclass-modern-base-v2.0) | 0.9188 | 0.7089 | 0.4250 |
| [gliclass-large-v1.0 (438 M)](https://huggingface.co/knowledgator/gliclass-large-v1.0) | 0.9404 | 0.7516 | 0.4874 |
| [gliclass-base-v1.0 (186 M)](https://huggingface.co/knowledgator/gliclass-base-v1.0) | 0.8650 | 0.6837 | 0.4749 |
| [gliclass-small-v1.0 (144 M)](https://huggingface.co/knowledgator/gliclass-small-v1.0) | 0.8650 | 0.6805 | 0.4664 |
| [Bart-large-mnli (407 M)](https://huggingface.co/facebook/bart-large-mnli) | 0.89 | 0.6887 | 0.3765 |
| [Deberta-base-v3 (184 M)](https://huggingface.co/cross-encoder/nli-deberta-v3-base) | 0.85 | 0.6455 | 0.5095 |
| [Comprehendo (184M)](https://huggingface.co/knowledgator/comprehend_it-base) | 0.90 | 0.7982 | 0.5660 |
| SetFit [BAAI/bge-small-en-v1.5 (33.4M)](https://huggingface.co/BAAI/bge-small-en-v1.5) | 0.86 | 0.5636 | 0.5754 |
Below you can find a comparison with other GLiClass models:
| Dataset | gliclass-modern-base-v2.0 | gliclass-modern-large-v2.0 | gliclass-modern-base-v2.0-init | gliclass-modern-large-v2.0-init |
|----------------------|-----------------------|-----------------------|---------------------|---------------------|
| CR | 0.8976 | 0.9198 | 0.9041 | 0.8980 |
| sst2 | 0.8525 | 0.9318 | 0.9011 | 0.9434 |
| sst5 | 0.2348 | 0.2147 | 0.1972 | 0.1123 |
| 20_news_groups | 0.351 | 0.3755 | 0.2448 | 0.2792 |
| spam | 0.483 | 0.6608 | 0.5074 | 0.6364 |
| financial_phrasebank | 0.3475 | 0.3157 | 0.2537 | 0.2562 |
| imdb | 0.9188 | 0.9448 | 0.8255 | 0.9137 |
| ag_news | 0.6835 | 0.7025 | 0.6050 | 0.6933 |
| emotion | 0.3925 | 0.4325 | 0.2474 | 0.3746 |
| cap_sotu | 0.3725 | 0.4157 | 0.2929 | 0.2919 |
| rotten_tomatoes | 0.6955 | 0.7357 | 0.6630 | 0.5928 |
| **AVERAGE:** | 0.5563 | 0.6045 | 0.5129 | 0.5447 |
## Citation
```bibtex
@misc{stepanov2025gliclassgeneralistlightweightmodel,
title={GLiClass: Generalist Lightweight Model for Sequence Classification Tasks},
author={Ihor Stepanov and Mykhailo Shtopko and Dmytro Vodianytskyi and Oleksandr Lukashov and Alexander Yavorskyi and Mykyta Yaroshenko},
year={2025},
eprint={2508.07662},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2508.07662},
}
```
|
kota123123/blockassist-bc-lithe_leggy_macaw_1755008158
|
kota123123
| 2025-08-12T14:34:08Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"lithe leggy macaw",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-12T14:33:50Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- lithe leggy macaw
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
mradermacher/GPT-OSS-30B-Preview-GGUF
|
mradermacher
| 2025-08-12T14:33:48Z | 0 | 0 |
transformers
|
[
"transformers",
"gguf",
"vllm",
"unsloth",
"mergekit",
"gpt_oss",
"en",
"base_model:win10/GPT-OSS-30B-Preview",
"base_model:quantized:win10/GPT-OSS-30B-Preview",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2025-08-12T12:41:38Z |
---
base_model: win10/GPT-OSS-30B-Preview
language:
- en
library_name: transformers
license: apache-2.0
mradermacher:
readme_rev: 1
quantized_by: mradermacher
tags:
- vllm
- unsloth
- mergekit
- gpt_oss
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
<!-- ### quants: x-f16 Q4_K_S Q2_K Q8_0 Q6_K Q3_K_M Q3_K_S Q3_K_L Q4_K_M Q5_K_S Q5_K_M IQ4_XS -->
<!-- ### quants_skip: -->
<!-- ### skip_mmproj: -->
static quants of https://huggingface.co/win10/GPT-OSS-30B-Preview
<!-- provided-files -->
***For a convenient overview and download list, visit our [model page for this model](https://hf.tst.eu/model#GPT-OSS-30B-Preview-GGUF).***
weighted/imatrix quants are available at https://huggingface.co/mradermacher/GPT-OSS-30B-Preview-i1-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/GPT-OSS-30B-Preview-GGUF/resolve/main/GPT-OSS-30B-Preview.Q3_K_S.gguf) | Q3_K_S | 17.7 | |
| [GGUF](https://huggingface.co/mradermacher/GPT-OSS-30B-Preview-GGUF/resolve/main/GPT-OSS-30B-Preview.Q2_K.gguf) | Q2_K | 17.7 | |
| [GGUF](https://huggingface.co/mradermacher/GPT-OSS-30B-Preview-GGUF/resolve/main/GPT-OSS-30B-Preview.IQ4_XS.gguf) | IQ4_XS | 18.0 | |
| [GGUF](https://huggingface.co/mradermacher/GPT-OSS-30B-Preview-GGUF/resolve/main/GPT-OSS-30B-Preview.Q3_K_M.gguf) | Q3_K_M | 19.0 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/GPT-OSS-30B-Preview-GGUF/resolve/main/GPT-OSS-30B-Preview.Q3_K_L.gguf) | Q3_K_L | 19.6 | |
| [GGUF](https://huggingface.co/mradermacher/GPT-OSS-30B-Preview-GGUF/resolve/main/GPT-OSS-30B-Preview.Q4_K_S.gguf) | Q4_K_S | 21.6 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/GPT-OSS-30B-Preview-GGUF/resolve/main/GPT-OSS-30B-Preview.Q4_K_M.gguf) | Q4_K_M | 23.3 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/GPT-OSS-30B-Preview-GGUF/resolve/main/GPT-OSS-30B-Preview.Q5_K_S.gguf) | Q5_K_S | 23.4 | |
| [GGUF](https://huggingface.co/mradermacher/GPT-OSS-30B-Preview-GGUF/resolve/main/GPT-OSS-30B-Preview.Q5_K_M.gguf) | Q5_K_M | 24.9 | |
| [GGUF](https://huggingface.co/mradermacher/GPT-OSS-30B-Preview-GGUF/resolve/main/GPT-OSS-30B-Preview.Q6_K.gguf) | Q6_K | 32.8 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/GPT-OSS-30B-Preview-GGUF/resolve/main/GPT-OSS-30B-Preview.Q8_0.gguf) | Q8_0 | 32.9 | fast, best quality |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
knowledgator/gliclass-qwen-0.5B-v1.0
|
knowledgator
| 2025-08-12T14:33:19Z | 87 | 1 | null |
[
"onnx",
"safetensors",
"GLiClass",
"text classification",
"zero-shot",
"small language models",
"RAG",
"sentiment analysis",
"zero-shot-classification",
"en",
"dataset:MoritzLaurer/synthetic_zeroshot_mixtral_v0.1",
"arxiv:2508.07662",
"license:apache-2.0",
"region:us"
] |
zero-shot-classification
| 2024-09-09T16:29:54Z |
---
license: apache-2.0
datasets:
- MoritzLaurer/synthetic_zeroshot_mixtral_v0.1
language:
- en
metrics:
- f1
pipeline_tag: zero-shot-classification
tags:
- text classification
- zero-shot
- small language models
- RAG
- sentiment analysis
---
# ⭐ GLiClass: Generalist and Lightweight Model for Sequence Classification
This is an efficient zero-shot classifier inspired by [GLiNER](https://github.com/urchade/GLiNER/tree/main) work. It demonstrates the same performance as a cross-encoder while being more compute-efficient because classification is done at a single forward path.
It can be used for `topic classification`, `sentiment analysis` and as a reranker in `RAG` pipelines.
The model was trained on synthetic data and can be used in commercial applications.
This version of the model utilize the [LLM2Vec](https://github.com/McGill-NLP/llm2vec/tree/main/llm2vec) approach for converting modern decoders to bi-directional encoder. It brings the following benefits:
* Enhanced performance and generalization capabilities;
* Support for Flash Attention;
* Extended context window.
### How to use:
First of all, you need to install GLiClass library:
```bash
pip install gliclass
```
To use this particular Qwen-based model you need different `transformers` package version than llm2vec requires, so install it manually:
```bash
pip install transformers==4.44.1
```
Than you need to initialize a model and a pipeline:
```python
from gliclass import GLiClassModel, ZeroShotClassificationPipeline
from transformers import AutoTokenizer
model = GLiClassModel.from_pretrained("knowledgator/gliclass-qwen-0.5B-v1.0")
tokenizer = AutoTokenizer.from_pretrained("knowledgator/gliclass-qwen-0.5B-v1.0")
pipeline = ZeroShotClassificationPipeline(model, tokenizer, classification_type='multi-label', device='cuda:0')
text = "One day I will see the world!"
labels = ["travel", "dreams", "sport", "science", "politics"]
results = pipeline(text, labels, threshold=0.5)[0] #because we have one text
for result in results:
print(result["label"], "=>", result["score"])
```
### Benchmarks:
While the model is some how comparable to DeBERTa version in zero-shot setting, it demonstrates state-of-the-art performance in few-shot setting.

### Join Our Discord
Connect with our community on Discord for news, support, and discussion about our models. Join [Discord](https://discord.gg/dkyeAgs9DG).
## Citation
```bibtex
@misc{stepanov2025gliclassgeneralistlightweightmodel,
title={GLiClass: Generalist Lightweight Model for Sequence Classification Tasks},
author={Ihor Stepanov and Mykhailo Shtopko and Dmytro Vodianytskyi and Oleksandr Lukashov and Alexander Yavorskyi and Mykyta Yaroshenko},
year={2025},
eprint={2508.07662},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2508.07662},
}
```
|
MAGICYA0/blockassist-bc-silky_lively_badger_1755005987
|
MAGICYA0
| 2025-08-12T14:32:55Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"silky lively badger",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-12T14:32:02Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- silky lively badger
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
knowledgator/gliclass-base-v1.0
|
knowledgator
| 2025-08-12T14:31:58Z | 855 | 3 |
transformers
|
[
"transformers",
"onnx",
"safetensors",
"GLiClass",
"text classification",
"zero-shot",
"small language models",
"RAG",
"sentiment analysis",
"zero-shot-classification",
"en",
"dataset:MoritzLaurer/synthetic_zeroshot_mixtral_v0.1",
"arxiv:2508.07662",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
zero-shot-classification
| 2024-07-03T15:20:49Z |
---
license: apache-2.0
datasets:
- MoritzLaurer/synthetic_zeroshot_mixtral_v0.1
language:
- en
metrics:
- f1
pipeline_tag: zero-shot-classification
tags:
- text classification
- zero-shot
- small language models
- RAG
- sentiment analysis
---
# ⭐ GLiClass: Generalist and Lightweight Model for Sequence Classification
This is an efficient zero-shot classifier inspired by [GLiNER](https://github.com/urchade/GLiNER/tree/main) work. It demonstrates the same performance as a cross-encoder while being more compute-efficient because classification is done at a single forward path.
It can be used for `topic classification`, `sentiment analysis` and as a reranker in `RAG` pipelines.
The model was trained on synthetic data and can be used in commercial applications.
### How to use:
First of all, you need to install GLiClass library:
```bash
pip install gliclass
```
Than you need to initialize a model and a pipeline:
```python
from gliclass import GLiClassModel, ZeroShotClassificationPipeline
from transformers import AutoTokenizer
model = GLiClassModel.from_pretrained("knowledgator/gliclass-base-v1.0")
tokenizer = AutoTokenizer.from_pretrained("knowledgator/gliclass-base-v1.0")
pipeline = ZeroShotClassificationPipeline(model, tokenizer, classification_type='multi-label', device='cuda:0')
text = "One day I will see the world!"
labels = ["travel", "dreams", "sport", "science", "politics"]
results = pipeline(text, labels, threshold=0.5)[0] #because we have one text
for result in results:
print(result["label"], "=>", result["score"])
```
### Benchmarks:
Below, you can see the F1 score on several text classification datasets. All tested models were not fine-tuned on those datasets and were tested in a zero-shot setting.
| Model | IMDB | AG_NEWS | Emotions |
|-----------------------------|------|---------|----------|
| [gliclass-large-v1.0 (438 M)](https://huggingface.co/knowledgator/gliclass-large-v1.0) | 0.9404 | 0.7516 | 0.4874 |
| [gliclass-base-v1.0 (186 M)](https://huggingface.co/knowledgator/gliclass-base-v1.0) | 0.8650 | 0.6837 | 0.4749 |
| [gliclass-small-v1.0 (144 M)](https://huggingface.co/knowledgator/gliclass-small-v1.0) | 0.8650 | 0.6805 | 0.4664 |
| [Bart-large-mnli (407 M)](https://huggingface.co/facebook/bart-large-mnli) | 0.89 | 0.6887 | 0.3765 |
| [Deberta-base-v3 (184 M)](https://huggingface.co/cross-encoder/nli-deberta-v3-base) | 0.85 | 0.6455 | 0.5095 |
| [Comprehendo (184M)](https://huggingface.co/knowledgator/comprehend_it-base) | 0.90 | 0.7982 | 0.5660 |
| SetFit [BAAI/bge-small-en-v1.5 (33.4M)](https://huggingface.co/BAAI/bge-small-en-v1.5) | 0.86 | 0.5636 | 0.5754 |
Below you can find a comparison with other GLiClass models:
| Dataset | gliclass-small-v1.0-lw | gliclass-base-v1.0-lw | gliclass-large-v1.0-lw | gliclass-small-v1.0 | gliclass-base-v1.0 | gliclass-large-v1.0 |
|----------------------|-----------------------|-----------------------|-----------------------|---------------------|---------------------|---------------------|
| CR | 0.8886 | 0.9097 | 0.9226 | 0.8824 | 0.8942 | 0.9219 |
| sst2 | 0.8392 | 0.8987 | 0.9247 | 0.8518 | 0.8979 | 0.9269 |
| sst5 | 0.2865 | 0.3779 | 0.2891 | 0.2424 | 0.2789 | 0.3900 |
| 20_news_groups | 0.4572 | 0.3953 | 0.4083 | 0.3366 | 0.3576 | 0.3863 |
| spam | 0.5118 | 0.5126 | 0.3642 | 0.4089 | 0.4938 | 0.3661 |
| rotten_tomatoes | 0.8015 | 0.8429 | 0.8807 | 0.7987 | 0.8508 | 0.8808 |
| massive | 0.3180 | 0.4635 | 0.5606 | 0.2546 | 0.1893 | 0.4376 |
| banking | 0.1768 | 0.4396 | 0.3317 | 0.1374 | 0.2077 | 0.2847 |
| yahoo_topics | 0.4686 | 0.4784 | 0.4760 | 0.4477 | 0.4516 | 0.4921 |
| financial_phrasebank | 0.8665 | 0.8880 | 0.9044 | 0.8901 | 0.8955 | 0.8735 |
| imdb | 0.9048 | 0.9351 | 0.9429 | 0.8982 | 0.9238 | 0.9333 |
| ag_news | 0.7252 | 0.6985 | 0.7559 | 0.7242 | 0.6848 | 0.7503 |
| dair_emotion | 0.4012 | 0.3516 | 0.3951 | 0.3450 | 0.2357 | 0.4013 |
| capsotu | 0.3794 | 0.4643 | 0.4749 | 0.3432 | 0.4375 | 0.4644 |
|Average:|0.5732|0.6183|0.6165|0.5401|0.5571|0.6078|
Here you can see how the performance of the model grows providing more examples:
| Model | Num Examples | sst5 | spam | massive | banking | ag news | dair emotion | capsotu | Average |
|-----------------------------|--------------|--------|---------|---------|---------|---------|--------------|---------|-------------|
| gliclass-small-v1.0-lw | 0 | 0.2865 | 0.5118 | 0.318 | 0.1768 | 0.7252 | 0.4012 | 0.3794 | 0.3998428571|
| gliclass-base-v1.0-lw | 0 | 0.3779 | 0.5126 | 0.4635 | 0.4396 | 0.6985 | 0.3516 | 0.4643 | 0.4725714286|
| gliclass-large-v1.0-lw | 0 | 0.2891 | 0.3642 | 0.5606 | 0.3317 | 0.7559 | 0.3951 | 0.4749 | 0.4530714286|
| gliclass-small-v1.0 | 0 | 0.2424 | 0.4089 | 0.2546 | 0.1374 | 0.7242 | 0.345 | 0.3432 | 0.3508142857|
| gliclass-base-v1.0 | 0 | 0.2789 | 0.4938 | 0.1893 | 0.2077 | 0.6848 | 0.2357 | 0.4375 | 0.3611 |
| gliclass-large-v1.0 | 0 | 0.39 | 0.3661 | 0.4376 | 0.2847 | 0.7503 | 0.4013 | 0.4644 | 0.4420571429|
| gliclass-small-v1.0-lw | 8 | 0.2709 | 0.84026 | 0.62 | 0.6883 | 0.7786 | 0.449 | 0.4918 | 0.5912657143|
| gliclass-base-v1.0-lw | 8 | 0.4275 | 0.8836 | 0.729 | 0.7667 | 0.7968 | 0.3866 | 0.4858 | 0.6394285714|
| gliclass-large-v1.0-lw | 8 | 0.3345 | 0.8997 | 0.7658 | 0.848 | 0.84843 | 0.5219 | 0.508 | 0.67519 |
| gliclass-small-v1.0 | 8 | 0.3042 | 0.5683 | 0.6332 | 0.7072 | 0.759 | 0.4509 | 0.4434 | 0.5523142857|
| gliclass-base-v1.0 | 8 | 0.3387 | 0.7361 | 0.7059 | 0.7456 | 0.7896 | 0.4323 | 0.4802 | 0.6040571429|
| gliclass-large-v1.0 | 8 | 0.4365 | 0.9018 | 0.77 | 0.8533 | 0.8509 | 0.5061 | 0.4935 | 0.6874428571|
## Citation
```bibtex
@misc{stepanov2025gliclassgeneralistlightweightmodel,
title={GLiClass: Generalist Lightweight Model for Sequence Classification Tasks},
author={Ihor Stepanov and Mykhailo Shtopko and Dmytro Vodianytskyi and Oleksandr Lukashov and Alexander Yavorskyi and Mykyta Yaroshenko},
year={2025},
eprint={2508.07662},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2508.07662},
}
```
|
relapseone/blockassist-bc-insectivorous_prickly_shrew_1755007139
|
relapseone
| 2025-08-12T14:31:19Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"insectivorous prickly shrew",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-12T14:31:16Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- insectivorous prickly shrew
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
knowledgator/gliclass-large-v1.0-lw
|
knowledgator
| 2025-08-12T14:30:50Z | 301 | 1 |
transformers
|
[
"transformers",
"onnx",
"safetensors",
"GLiClass",
"text classification",
"zero-shot",
"small language models",
"RAG",
"sentiment analysis",
"zero-shot-classification",
"en",
"dataset:MoritzLaurer/synthetic_zeroshot_mixtral_v0.1",
"arxiv:2508.07662",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
zero-shot-classification
| 2024-07-03T06:01:13Z |
---
license: apache-2.0
datasets:
- MoritzLaurer/synthetic_zeroshot_mixtral_v0.1
language:
- en
metrics:
- f1
pipeline_tag: zero-shot-classification
tags:
- text classification
- zero-shot
- small language models
- RAG
- sentiment analysis
---
# ⭐ GLiClass: Generalist and Lightweight Model for Sequence Classification
This is an efficient zero-shot classifier inspired by [GLiNER](https://github.com/urchade/GLiNER/tree/main) work. It demonstrates the same performance as a cross-encoder while being more compute-efficient because classification is done at a single forward path.
It can be used for `topic classification`, `sentiment analysis` and as a reranker in `RAG` pipelines.
The model was trained on synthetic data and can be used in commercial applications.
This version of the model uses a layer-wise selection of features that enables a better understanding of different levels of language.
### How to use:
First of all, you need to install GLiClass library:
```bash
pip install gliclass
```
Than you need to initialize a model and a pipeline:
```python
from gliclass import GLiClassModel, ZeroShotClassificationPipeline
from transformers import AutoTokenizer
model = GLiClassModel.from_pretrained("knowledgator/gliclass-large-v1.0-lw")
tokenizer = AutoTokenizer.from_pretrained("knowledgator/gliclass-large-v1.0-lw")
pipeline = ZeroShotClassificationPipeline(model, tokenizer, classification_type='multi-label', device='cuda:0')
text = "One day I will see the world!"
labels = ["travel", "dreams", "sport", "science", "politics"]
results = pipeline(text, labels, threshold=0.5)[0] #because we have one text
for result in results:
print(result["label"], "=>", result["score"])
```
### Benchmarks:
Below, you can see the F1 score on several text classification datasets. All tested models were not fine-tuned on those datasets and were tested in a zero-shot setting.
| Model | IMDB | AG_NEWS | Emotions |
|-----------------------------|------|---------|----------|
| [gliclass-large-v1.0 (438 M)](https://huggingface.co/knowledgator/gliclass-large-v1.0) | 0.9404 | 0.7516 | 0.4874 |
| [gliclass-base-v1.0 (186 M)](https://huggingface.co/knowledgator/gliclass-base-v1.0) | 0.8650 | 0.6837 | 0.4749 |
| [gliclass-small-v1.0 (144 M)](https://huggingface.co/knowledgator/gliclass-small-v1.0) | 0.8650 | 0.6805 | 0.4664 |
| [Bart-large-mnli (407 M)](https://huggingface.co/facebook/bart-large-mnli) | 0.89 | 0.6887 | 0.3765 |
| [Deberta-base-v3 (184 M)](https://huggingface.co/cross-encoder/nli-deberta-v3-base) | 0.85 | 0.6455 | 0.5095 |
| [Comprehendo (184M)](https://huggingface.co/knowledgator/comprehend_it-base) | 0.90 | 0.7982 | 0.5660 |
| SetFit [BAAI/bge-small-en-v1.5 (33.4M)](https://huggingface.co/BAAI/bge-small-en-v1.5) | 0.86 | 0.5636 | 0.5754 |
Below you can find a comparison with other GLiClass models:
| Dataset | gliclass-small-v1.0-lw | gliclass-base-v1.0-lw | gliclass-large-v1.0-lw | gliclass-small-v1.0 | gliclass-base-v1.0 | gliclass-large-v1.0 |
|----------------------|-----------------------|-----------------------|-----------------------|---------------------|---------------------|---------------------|
| CR | 0.8886 | 0.9097 | 0.9226 | 0.8824 | 0.8942 | 0.9219 |
| sst2 | 0.8392 | 0.8987 | 0.9247 | 0.8518 | 0.8979 | 0.9269 |
| sst5 | 0.2865 | 0.3779 | 0.2891 | 0.2424 | 0.2789 | 0.3900 |
| 20_news_groups | 0.4572 | 0.3953 | 0.4083 | 0.3366 | 0.3576 | 0.3863 |
| spam | 0.5118 | 0.5126 | 0.3642 | 0.4089 | 0.4938 | 0.3661 |
| rotten_tomatoes | 0.8015 | 0.8429 | 0.8807 | 0.7987 | 0.8508 | 0.8808 |
| massive | 0.3180 | 0.4635 | 0.5606 | 0.2546 | 0.1893 | 0.4376 |
| banking | 0.1768 | 0.4396 | 0.3317 | 0.1374 | 0.2077 | 0.2847 |
| yahoo_topics | 0.4686 | 0.4784 | 0.4760 | 0.4477 | 0.4516 | 0.4921 |
| financial_phrasebank | 0.8665 | 0.8880 | 0.9044 | 0.8901 | 0.8955 | 0.8735 |
| imdb | 0.9048 | 0.9351 | 0.9429 | 0.8982 | 0.9238 | 0.9333 |
| ag_news | 0.7252 | 0.6985 | 0.7559 | 0.7242 | 0.6848 | 0.7503 |
| dair_emotion | 0.4012 | 0.3516 | 0.3951 | 0.3450 | 0.2357 | 0.4013 |
| capsotu | 0.3794 | 0.4643 | 0.4749 | 0.3432 | 0.4375 | 0.4644 |
|Average:|0.5732|0.6183|0.6165|0.5401|0.5571|0.6078|
Here you can see how the performance of the model grows providing more examples:
| Model | Num Examples | sst5 | spam | massive | banking | ag news | dair emotion | capsotu | Average |
|-----------------------------|--------------|--------|---------|---------|---------|---------|--------------|---------|-------------|
| gliclass-small-v1.0-lw | 0 | 0.2865 | 0.5118 | 0.318 | 0.1768 | 0.7252 | 0.4012 | 0.3794 | 0.3998428571|
| gliclass-base-v1.0-lw | 0 | 0.3779 | 0.5126 | 0.4635 | 0.4396 | 0.6985 | 0.3516 | 0.4643 | 0.4725714286|
| gliclass-large-v1.0-lw | 0 | 0.2891 | 0.3642 | 0.5606 | 0.3317 | 0.7559 | 0.3951 | 0.4749 | 0.4530714286|
| gliclass-small-v1.0 | 0 | 0.2424 | 0.4089 | 0.2546 | 0.1374 | 0.7242 | 0.345 | 0.3432 | 0.3508142857|
| gliclass-base-v1.0 | 0 | 0.2789 | 0.4938 | 0.1893 | 0.2077 | 0.6848 | 0.2357 | 0.4375 | 0.3611 |
| gliclass-large-v1.0 | 0 | 0.39 | 0.3661 | 0.4376 | 0.2847 | 0.7503 | 0.4013 | 0.4644 | 0.4420571429|
| gliclass-small-v1.0-lw | 8 | 0.2709 | 0.84026 | 0.62 | 0.6883 | 0.7786 | 0.449 | 0.4918 | 0.5912657143|
| gliclass-base-v1.0-lw | 8 | 0.4275 | 0.8836 | 0.729 | 0.7667 | 0.7968 | 0.3866 | 0.4858 | 0.6394285714|
| gliclass-large-v1.0-lw | 8 | 0.3345 | 0.8997 | 0.7658 | 0.848 | 0.84843 | 0.5219 | 0.508 | 0.67519 |
| gliclass-small-v1.0 | 8 | 0.3042 | 0.5683 | 0.6332 | 0.7072 | 0.759 | 0.4509 | 0.4434 | 0.5523142857|
| gliclass-base-v1.0 | 8 | 0.3387 | 0.7361 | 0.7059 | 0.7456 | 0.7896 | 0.4323 | 0.4802 | 0.6040571429|
| gliclass-large-v1.0 | 8 | 0.4365 | 0.9018 | 0.77 | 0.8533 | 0.8509 | 0.5061 | 0.4935 | 0.6874428571|
## Citation
```bibtex
@misc{stepanov2025gliclassgeneralistlightweightmodel,
title={GLiClass: Generalist Lightweight Model for Sequence Classification Tasks},
author={Ihor Stepanov and Mykhailo Shtopko and Dmytro Vodianytskyi and Oleksandr Lukashov and Alexander Yavorskyi and Mykyta Yaroshenko},
year={2025},
eprint={2508.07662},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2508.07662},
}
```
|
knowledgator/gliclass-base-v1.0-lw
|
knowledgator
| 2025-08-12T14:30:28Z | 214 | 2 |
transformers
|
[
"transformers",
"onnx",
"safetensors",
"GLiClass",
"text classification",
"zero-shot",
"small language models",
"RAG",
"sentiment analysis",
"zero-shot-classification",
"en",
"dataset:MoritzLaurer/synthetic_zeroshot_mixtral_v0.1",
"arxiv:2508.07662",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
zero-shot-classification
| 2024-07-03T05:59:00Z |
---
license: apache-2.0
datasets:
- MoritzLaurer/synthetic_zeroshot_mixtral_v0.1
language:
- en
metrics:
- f1
pipeline_tag: zero-shot-classification
tags:
- text classification
- zero-shot
- small language models
- RAG
- sentiment analysis
---
# ⭐ GLiClass: Generalist and Lightweight Model for Sequence Classification
This is an efficient zero-shot classifier inspired by [GLiNER](https://github.com/urchade/GLiNER/tree/main) work. It demonstrates the same performance as a cross-encoder while being more compute-efficient because classification is done at a single forward path.
It can be used for `topic classification`, `sentiment analysis` and as a reranker in `RAG` pipelines.
The model was trained on synthetic data and can be used in commercial applications.
This version of the model uses a layer-wise selection of features that enables a better understanding of different levels of language.
### How to use:
First of all, you need to install GLiClass library:
```bash
pip install gliclass
```
Than you need to initialize a model and a pipeline:
```python
from gliclass import GLiClassModel, ZeroShotClassificationPipeline
from transformers import AutoTokenizer
model = GLiClassModel.from_pretrained("knowledgator/gliclass-base-v1.0-lw")
tokenizer = AutoTokenizer.from_pretrained("knowledgator/gliclass-base-v1.0-lw")
pipeline = ZeroShotClassificationPipeline(model, tokenizer, classification_type='multi-label', device='cuda:0')
text = "One day I will see the world!"
labels = ["travel", "dreams", "sport", "science", "politics"]
results = pipeline(text, labels, threshold=0.5)[0] #because we have one text
for result in results:
print(result["label"], "=>", result["score"])
```
### Benchmarks:
Below, you can see the F1 score on several text classification datasets. All tested models were not fine-tuned on those datasets and were tested in a zero-shot setting.
| Model | IMDB | AG_NEWS | Emotions |
|-----------------------------|------|---------|----------|
| [gliclass-large-v1.0 (438 M)](https://huggingface.co/knowledgator/gliclass-large-v1.0) | 0.9404 | 0.7516 | 0.4874 |
| [gliclass-base-v1.0 (186 M)](https://huggingface.co/knowledgator/gliclass-base-v1.0) | 0.8650 | 0.6837 | 0.4749 |
| [gliclass-small-v1.0 (144 M)](https://huggingface.co/knowledgator/gliclass-small-v1.0) | 0.8650 | 0.6805 | 0.4664 |
| [Bart-large-mnli (407 M)](https://huggingface.co/facebook/bart-large-mnli) | 0.89 | 0.6887 | 0.3765 |
| [Deberta-base-v3 (184 M)](https://huggingface.co/cross-encoder/nli-deberta-v3-base) | 0.85 | 0.6455 | 0.5095 |
| [Comprehendo (184M)](https://huggingface.co/knowledgator/comprehend_it-base) | 0.90 | 0.7982 | 0.5660 |
| SetFit [BAAI/bge-small-en-v1.5 (33.4M)](https://huggingface.co/BAAI/bge-small-en-v1.5) | 0.86 | 0.5636 | 0.5754 |
Below you can find a comparison with other GLiClass models:
| Dataset | gliclass-small-v1.0-lw | gliclass-base-v1.0-lw | gliclass-large-v1.0-lw | gliclass-small-v1.0 | gliclass-base-v1.0 | gliclass-large-v1.0 |
|----------------------|-----------------------|-----------------------|-----------------------|---------------------|---------------------|---------------------|
| CR | 0.8886 | 0.9097 | 0.9226 | 0.8824 | 0.8942 | 0.9219 |
| sst2 | 0.8392 | 0.8987 | 0.9247 | 0.8518 | 0.8979 | 0.9269 |
| sst5 | 0.2865 | 0.3779 | 0.2891 | 0.2424 | 0.2789 | 0.3900 |
| 20_news_groups | 0.4572 | 0.3953 | 0.4083 | 0.3366 | 0.3576 | 0.3863 |
| spam | 0.5118 | 0.5126 | 0.3642 | 0.4089 | 0.4938 | 0.3661 |
| rotten_tomatoes | 0.8015 | 0.8429 | 0.8807 | 0.7987 | 0.8508 | 0.8808 |
| massive | 0.3180 | 0.4635 | 0.5606 | 0.2546 | 0.1893 | 0.4376 |
| banking | 0.1768 | 0.4396 | 0.3317 | 0.1374 | 0.2077 | 0.2847 |
| yahoo_topics | 0.4686 | 0.4784 | 0.4760 | 0.4477 | 0.4516 | 0.4921 |
| financial_phrasebank | 0.8665 | 0.8880 | 0.9044 | 0.8901 | 0.8955 | 0.8735 |
| imdb | 0.9048 | 0.9351 | 0.9429 | 0.8982 | 0.9238 | 0.9333 |
| ag_news | 0.7252 | 0.6985 | 0.7559 | 0.7242 | 0.6848 | 0.7503 |
| dair_emotion | 0.4012 | 0.3516 | 0.3951 | 0.3450 | 0.2357 | 0.4013 |
| capsotu | 0.3794 | 0.4643 | 0.4749 | 0.3432 | 0.4375 | 0.4644 |
|Average:|0.5732|0.6183|0.6165|0.5401|0.5571|0.6078|
Here you can see how the performance of the model grows providing more examples:
| Model | Num Examples | sst5 | spam | massive | banking | ag news | dair emotion | capsotu | Average |
|-----------------------------|--------------|--------|---------|---------|---------|---------|--------------|---------|-------------|
| gliclass-small-v1.0-lw | 0 | 0.2865 | 0.5118 | 0.318 | 0.1768 | 0.7252 | 0.4012 | 0.3794 | 0.3998428571|
| gliclass-base-v1.0-lw | 0 | 0.3779 | 0.5126 | 0.4635 | 0.4396 | 0.6985 | 0.3516 | 0.4643 | 0.4725714286|
| gliclass-large-v1.0-lw | 0 | 0.2891 | 0.3642 | 0.5606 | 0.3317 | 0.7559 | 0.3951 | 0.4749 | 0.4530714286|
| gliclass-small-v1.0 | 0 | 0.2424 | 0.4089 | 0.2546 | 0.1374 | 0.7242 | 0.345 | 0.3432 | 0.3508142857|
| gliclass-base-v1.0 | 0 | 0.2789 | 0.4938 | 0.1893 | 0.2077 | 0.6848 | 0.2357 | 0.4375 | 0.3611 |
| gliclass-large-v1.0 | 0 | 0.39 | 0.3661 | 0.4376 | 0.2847 | 0.7503 | 0.4013 | 0.4644 | 0.4420571429|
| gliclass-small-v1.0-lw | 8 | 0.2709 | 0.84026 | 0.62 | 0.6883 | 0.7786 | 0.449 | 0.4918 | 0.5912657143|
| gliclass-base-v1.0-lw | 8 | 0.4275 | 0.8836 | 0.729 | 0.7667 | 0.7968 | 0.3866 | 0.4858 | 0.6394285714|
| gliclass-large-v1.0-lw | 8 | 0.3345 | 0.8997 | 0.7658 | 0.848 | 0.84843 | 0.5219 | 0.508 | 0.67519 |
| gliclass-small-v1.0 | 8 | 0.3042 | 0.5683 | 0.6332 | 0.7072 | 0.759 | 0.4509 | 0.4434 | 0.5523142857|
| gliclass-base-v1.0 | 8 | 0.3387 | 0.7361 | 0.7059 | 0.7456 | 0.7896 | 0.4323 | 0.4802 | 0.6040571429|
| gliclass-large-v1.0 | 8 | 0.4365 | 0.9018 | 0.77 | 0.8533 | 0.8509 | 0.5061 | 0.4935 | 0.6874428571|
## Citation
```bibtex
@misc{stepanov2025gliclassgeneralistlightweightmodel,
title={GLiClass: Generalist Lightweight Model for Sequence Classification Tasks},
author={Ihor Stepanov and Mykhailo Shtopko and Dmytro Vodianytskyi and Oleksandr Lukashov and Alexander Yavorskyi and Mykyta Yaroshenko},
year={2025},
eprint={2508.07662},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2508.07662},
}
```
|
tungkhau/qtable-taxi
|
tungkhau
| 2025-08-12T14:30:22Z | 0 | 0 | null |
[
"Taxi-v3",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2025-08-12T14:30:19Z |
---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: qtable-taxi
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
metrics:
- type: mean_reward
value: 7.38 +/- 2.45
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="tungkhau/qtable-taxi", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
knowledgator/gliclass-small-v1.0-init
|
knowledgator
| 2025-08-12T14:30:10Z | 73 | 5 |
transformers
|
[
"transformers",
"onnx",
"safetensors",
"GLiClass",
"text classification",
"zero-shot",
"small language models",
"RAG",
"sentiment analysis",
"zero-shot-classification",
"en",
"dataset:MoritzLaurer/synthetic_zeroshot_mixtral_v0.1",
"arxiv:2508.07662",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
zero-shot-classification
| 2024-06-02T13:35:24Z |
---
license: apache-2.0
datasets:
- MoritzLaurer/synthetic_zeroshot_mixtral_v0.1
language:
- en
metrics:
- f1
pipeline_tag: zero-shot-classification
tags:
- text classification
- zero-shot
- small language models
- RAG
- sentiment analysis
---
# ⭐ GLiClass: Generalist and Lightweight Model for Sequence Classification
This is an efficient zero-shot classifier inspired by [GLiNER](https://github.com/urchade/GLiNER/tree/main) work. It demonstrates the same performance as a cross-encoder while being more compute-efficient because classification is done at a single forward path.
It can be used for `topic classification`, `sentiment analysis` and as a reranker in `RAG` pipelines.
The model was trained on synthetic data and can be used in commercial applications.
This model wasn't additionally fine-tuned on any dataset except initial (MoritzLaurer/synthetic_zeroshot_mixtral_v0.1).
### How to use:
First of all, you need to install GLiClass library:
```bash
pip install gliclass
```
Than you need to initialize a model and a pipeline:
```python
from gliclass import GLiClassModel, ZeroShotClassificationPipeline
from transformers import AutoTokenizer
model = GLiClassModel.from_pretrained("knowledgator/gliclass-small-v1.0-init")
tokenizer = AutoTokenizer.from_pretrained("knowledgator/gliclass-small-v1.0-init")
pipeline = ZeroShotClassificationPipeline(model, tokenizer, classification_type='multi-label', device='cuda:0')
text = "One day I will see the world!"
labels = ["travel", "dreams", "sport", "science", "politics"]
results = pipeline(text, labels, threshold=0.5)[0] #because we have one text
for result in results:
print(result["label"], "=>", result["score"])
```
### Benchmarks:
Below, you can see the F1 score on several text classification datasets. All tested models were not fine-tuned on those datasets and were tested in a zero-shot setting.
| Model | IMDB | AG_NEWS | Emotions |
|-----------------------------|------|---------|----------|
| [gliclass-large-v1.0 (438 M)](https://huggingface.co/knowledgator/gliclass-large-v1.0) | 0.9404 | 0.7516 | 0.4874 |
| [gliclass-base-v1.0 (186 M)](https://huggingface.co/knowledgator/gliclass-base-v1.0) | 0.8650 | 0.6837 | 0.4749 |
| [gliclass-small-v1.0 (144 M)](https://huggingface.co/knowledgator/gliclass-small-v1.0) | 0.8650 | 0.6805 | 0.4664 |
| [Bart-large-mnli (407 M)](https://huggingface.co/facebook/bart-large-mnli) | 0.89 | 0.6887 | 0.3765 |
| [Deberta-base-v3 (184 M)](https://huggingface.co/cross-encoder/nli-deberta-v3-base) | 0.85 | 0.6455 | 0.5095 |
| [Comprehendo (184M)](https://huggingface.co/knowledgator/comprehend_it-base) | 0.90 | 0.7982 | 0.5660 |
| SetFit [BAAI/bge-small-en-v1.5 (33.4M)](https://huggingface.co/BAAI/bge-small-en-v1.5) | 0.86 | 0.5636 | 0.5754 |
## Citation
```bibtex
@misc{stepanov2025gliclassgeneralistlightweightmodel,
title={GLiClass: Generalist Lightweight Model for Sequence Classification Tasks},
author={Ihor Stepanov and Mykhailo Shtopko and Dmytro Vodianytskyi and Oleksandr Lukashov and Alexander Yavorskyi and Mykyta Yaroshenko},
year={2025},
eprint={2508.07662},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2508.07662},
}
```
|
DougGran/CyberSeek-8B
|
DougGran
| 2025-08-12T14:30:07Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"gguf",
"llama",
"text-generation-inference",
"unsloth",
"trl",
"en",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2025-08-12T13:43:36Z |
---
base_model: unsloth/deepseek-r1-distill-llama-8b-unsloth-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- llama
- trl
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** DougGran
- **License:** apache-2.0
- **Finetuned from model :** unsloth/deepseek-r1-distill-llama-8b-unsloth-bnb-4bit
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
FoggiFoggi/djsdmk
|
FoggiFoggi
| 2025-08-12T14:29:53Z | 0 | 0 | null |
[
"license:cc-by-nc-sa-3.0",
"region:us"
] | null | 2025-08-12T14:29:53Z |
---
license: cc-by-nc-sa-3.0
---
|
OscarGD6/qwen2-vl-asr-lora
|
OscarGD6
| 2025-08-12T14:29:13Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-08-12T14:24:23Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
knowledgator/gliclass-base-v1.0-init
|
knowledgator
| 2025-08-12T14:28:49Z | 8 | 2 |
transformers
|
[
"transformers",
"onnx",
"safetensors",
"GLiClass",
"text classification",
"zero-shot",
"small language models",
"RAG",
"sentiment analysis",
"zero-shot-classification",
"en",
"dataset:MoritzLaurer/synthetic_zeroshot_mixtral_v0.1",
"arxiv:2508.07662",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
zero-shot-classification
| 2024-06-02T17:24:37Z |
---
license: apache-2.0
datasets:
- MoritzLaurer/synthetic_zeroshot_mixtral_v0.1
language:
- en
metrics:
- f1
pipeline_tag: zero-shot-classification
tags:
- text classification
- zero-shot
- small language models
- RAG
- sentiment analysis
---
# ⭐ GLiClass: Generalist and Lightweight Model for Sequence Classification
This is an efficient zero-shot classifier inspired by [GLiNER](https://github.com/urchade/GLiNER/tree/main) work. It demonstrates the same performance as a cross-encoder while being more compute-efficient because classification is done at a single forward path.
It can be used for `topic classification`, `sentiment analysis` and as a reranker in `RAG` pipelines.
The model was trained on synthetic data and can be used in commercial applications.
This model wasn't additionally fine-tuned on any dataset except initial (MoritzLaurer/synthetic_zeroshot_mixtral_v0.1).
### How to use:
First of all, you need to install GLiClass library:
```bash
pip install gliclass
```
Than you need to initialize a model and a pipeline:
```python
from gliclass import GLiClassModel, ZeroShotClassificationPipeline
from transformers import AutoTokenizer
model = GLiClassModel.from_pretrained("knowledgator/gliclass-base-v1.0-init")
tokenizer = AutoTokenizer.from_pretrained("knowledgator/gliclass-base-v1.0-init")
pipeline = ZeroShotClassificationPipeline(model, tokenizer, classification_type='multi-label', device='cuda:0')
text = "One day I will see the world!"
labels = ["travel", "dreams", "sport", "science", "politics"]
results = pipeline(text, labels, threshold=0.5)[0] #because we have one text
for result in results:
print(result["label"], "=>", result["score"])
```
### Benchmarks:
Below, you can see the F1 score on several text classification datasets. All tested models were not fine-tuned on those datasets and were tested in a zero-shot setting.
| Model | IMDB | AG_NEWS | Emotions |
|-----------------------------|------|---------|----------|
| [gliclass-large-v1.0 (438 M)](https://huggingface.co/knowledgator/gliclass-large-v1.0) | 0.9404 | 0.7516 | 0.4874 |
| [gliclass-base-v1.0 (186 M)](https://huggingface.co/knowledgator/gliclass-base-v1.0) | 0.8650 | 0.6837 | 0.4749 |
| [gliclass-small-v1.0 (144 M)](https://huggingface.co/knowledgator/gliclass-small-v1.0) | 0.8650 | 0.6805 | 0.4664 |
| [Bart-large-mnli (407 M)](https://huggingface.co/facebook/bart-large-mnli) | 0.89 | 0.6887 | 0.3765 |
| [Deberta-base-v3 (184 M)](https://huggingface.co/cross-encoder/nli-deberta-v3-base) | 0.85 | 0.6455 | 0.5095 |
| [Comprehendo (184M)](https://huggingface.co/knowledgator/comprehend_it-base) | 0.90 | 0.7982 | 0.5660 |
| SetFit [BAAI/bge-small-en-v1.5 (33.4M)](https://huggingface.co/BAAI/bge-small-en-v1.5) | 0.86 | 0.5636 | 0.5754 |
## Citation
```bibtex
@misc{stepanov2025gliclassgeneralistlightweightmodel,
title={GLiClass: Generalist Lightweight Model for Sequence Classification Tasks},
author={Ihor Stepanov and Mykhailo Shtopko and Dmytro Vodianytskyi and Oleksandr Lukashov and Alexander Yavorskyi and Mykyta Yaroshenko},
year={2025},
eprint={2508.07662},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2508.07662},
}
```
|
kayacrypto/blockassist-bc-thriving_barky_wolf_1755008806
|
kayacrypto
| 2025-08-12T14:28:28Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"thriving barky wolf",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-12T14:28:10Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- thriving barky wolf
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
knowledgator/gliclass-large-v1.0-init
|
knowledgator
| 2025-08-12T14:28:26Z | 91 | 14 |
transformers
|
[
"transformers",
"onnx",
"safetensors",
"GLiClass",
"text classification",
"zero-shot",
"small language models",
"RAG",
"sentiment analysis",
"zero-shot-classification",
"en",
"dataset:MoritzLaurer/synthetic_zeroshot_mixtral_v0.1",
"arxiv:2508.07662",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
zero-shot-classification
| 2024-06-03T20:04:04Z |
---
license: apache-2.0
datasets:
- MoritzLaurer/synthetic_zeroshot_mixtral_v0.1
language:
- en
metrics:
- f1
pipeline_tag: zero-shot-classification
tags:
- text classification
- zero-shot
- small language models
- RAG
- sentiment analysis
---
# ⭐ GLiClass: Generalist and Lightweight Model for Sequence Classification
This is an efficient zero-shot classifier inspired by [GLiNER](https://github.com/urchade/GLiNER/tree/main) work. It demonstrates the same performance as a cross-encoder while being more compute-efficient because classification is done at a single forward path.
It can be used for `topic classification`, `sentiment analysis` and as a reranker in `RAG` pipelines.
The model was trained on synthetic data and can be used in commercial applications.
This model wasn't additionally fine-tuned on any dataset except initial (MoritzLaurer/synthetic_zeroshot_mixtral_v0.1).
### How to use:
First of all, you need to install GLiClass library:
```bash
pip install gliclass
```
Than you need to initialize a model and a pipeline:
```python
from gliclass import GLiClassModel, ZeroShotClassificationPipeline
from transformers import AutoTokenizer
model = GLiClassModel.from_pretrained("knowledgator/gliclass-large-v1.0-init")
tokenizer = AutoTokenizer.from_pretrained("knowledgator/gliclass-large-v1.0-init")
pipeline = ZeroShotClassificationPipeline(model, tokenizer, classification_type='multi-label', device='cuda:0')
text = "One day I will see the world!"
labels = ["travel", "dreams", "sport", "science", "politics"]
results = pipeline(text, labels, threshold=0.5)[0] #because we have one text
for result in results:
print(result["label"], "=>", result["score"])
```
### Benchmarks:
Below, you can see the F1 score on several text classification datasets. All tested models were not fine-tuned on those datasets and were tested in a zero-shot setting.
| Model | IMDB | AG_NEWS | Emotions |
|-----------------------------|------|---------|----------|
| [gliclass-large-v1.0 (438 M)](https://huggingface.co/knowledgator/gliclass-large-v1.0) | 0.9404 | 0.7516 | 0.4874 |
| [gliclass-base-v1.0 (186 M)](https://huggingface.co/knowledgator/gliclass-base-v1.0) | 0.8650 | 0.6837 | 0.4749 |
| [gliclass-small-v1.0 (144 M)](https://huggingface.co/knowledgator/gliclass-small-v1.0) | 0.8650 | 0.6805 | 0.4664 |
| [Bart-large-mnli (407 M)](https://huggingface.co/facebook/bart-large-mnli) | 0.89 | 0.6887 | 0.3765 |
| [Deberta-base-v3 (184 M)](https://huggingface.co/cross-encoder/nli-deberta-v3-base) | 0.85 | 0.6455 | 0.5095 |
| [Comprehendo (184M)](https://huggingface.co/knowledgator/comprehend_it-base) | 0.90 | 0.7982 | 0.5660 |
| SetFit [BAAI/bge-small-en-v1.5 (33.4M)](https://huggingface.co/BAAI/bge-small-en-v1.5) | 0.86 | 0.5636 | 0.5754 |
## Citation
```bibtex
@misc{stepanov2025gliclassgeneralistlightweightmodel,
title={GLiClass: Generalist Lightweight Model for Sequence Classification Tasks},
author={Ihor Stepanov and Mykhailo Shtopko and Dmytro Vodianytskyi and Oleksandr Lukashov and Alexander Yavorskyi and Mykyta Yaroshenko},
year={2025},
eprint={2508.07662},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2508.07662},
}
```
|
mradermacher/DeepSeek-R1-Distill-Qwen-1.5B-GSPO-Basic-GGUF
|
mradermacher
| 2025-08-12T14:28:21Z | 0 | 0 |
transformers
|
[
"transformers",
"gguf",
"generated_from_trainer",
"grpo",
"open-r1",
"trl",
"en",
"dataset:AIML-TUDA/SLR-Bench",
"base_model:leonMW/DeepSeek-R1-Distill-Qwen-1.5B-GSPO-Basic",
"base_model:quantized:leonMW/DeepSeek-R1-Distill-Qwen-1.5B-GSPO-Basic",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2025-08-12T14:22:19Z |
---
base_model: leonMW/DeepSeek-R1-Distill-Qwen-1.5B-GSPO-Basic
datasets: AIML-TUDA/SLR-Bench
language:
- en
library_name: transformers
model_name: DeepSeek-R1-Distill-Qwen-1.5B-GSPO-Basic
mradermacher:
readme_rev: 1
quantized_by: mradermacher
tags:
- generated_from_trainer
- grpo
- open-r1
- trl
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
<!-- ### quants: x-f16 Q4_K_S Q2_K Q8_0 Q6_K Q3_K_M Q3_K_S Q3_K_L Q4_K_M Q5_K_S Q5_K_M IQ4_XS -->
<!-- ### quants_skip: -->
<!-- ### skip_mmproj: -->
static quants of https://huggingface.co/leonMW/DeepSeek-R1-Distill-Qwen-1.5B-GSPO-Basic
<!-- provided-files -->
***For a convenient overview and download list, visit our [model page for this model](https://hf.tst.eu/model#DeepSeek-R1-Distill-Qwen-1.5B-GSPO-Basic-GGUF).***
weighted/imatrix quants seem not to be available (by me) at this time. If they do not show up a week or so after the static ones, I have probably not planned for them. Feel free to request them by opening a Community Discussion.
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/DeepSeek-R1-Distill-Qwen-1.5B-GSPO-Basic-GGUF/resolve/main/DeepSeek-R1-Distill-Qwen-1.5B-GSPO-Basic.Q2_K.gguf) | Q2_K | 0.9 | |
| [GGUF](https://huggingface.co/mradermacher/DeepSeek-R1-Distill-Qwen-1.5B-GSPO-Basic-GGUF/resolve/main/DeepSeek-R1-Distill-Qwen-1.5B-GSPO-Basic.Q3_K_S.gguf) | Q3_K_S | 1.0 | |
| [GGUF](https://huggingface.co/mradermacher/DeepSeek-R1-Distill-Qwen-1.5B-GSPO-Basic-GGUF/resolve/main/DeepSeek-R1-Distill-Qwen-1.5B-GSPO-Basic.Q3_K_M.gguf) | Q3_K_M | 1.0 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/DeepSeek-R1-Distill-Qwen-1.5B-GSPO-Basic-GGUF/resolve/main/DeepSeek-R1-Distill-Qwen-1.5B-GSPO-Basic.Q3_K_L.gguf) | Q3_K_L | 1.1 | |
| [GGUF](https://huggingface.co/mradermacher/DeepSeek-R1-Distill-Qwen-1.5B-GSPO-Basic-GGUF/resolve/main/DeepSeek-R1-Distill-Qwen-1.5B-GSPO-Basic.IQ4_XS.gguf) | IQ4_XS | 1.1 | |
| [GGUF](https://huggingface.co/mradermacher/DeepSeek-R1-Distill-Qwen-1.5B-GSPO-Basic-GGUF/resolve/main/DeepSeek-R1-Distill-Qwen-1.5B-GSPO-Basic.Q4_K_S.gguf) | Q4_K_S | 1.2 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/DeepSeek-R1-Distill-Qwen-1.5B-GSPO-Basic-GGUF/resolve/main/DeepSeek-R1-Distill-Qwen-1.5B-GSPO-Basic.Q4_K_M.gguf) | Q4_K_M | 1.2 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/DeepSeek-R1-Distill-Qwen-1.5B-GSPO-Basic-GGUF/resolve/main/DeepSeek-R1-Distill-Qwen-1.5B-GSPO-Basic.Q5_K_S.gguf) | Q5_K_S | 1.4 | |
| [GGUF](https://huggingface.co/mradermacher/DeepSeek-R1-Distill-Qwen-1.5B-GSPO-Basic-GGUF/resolve/main/DeepSeek-R1-Distill-Qwen-1.5B-GSPO-Basic.Q5_K_M.gguf) | Q5_K_M | 1.4 | |
| [GGUF](https://huggingface.co/mradermacher/DeepSeek-R1-Distill-Qwen-1.5B-GSPO-Basic-GGUF/resolve/main/DeepSeek-R1-Distill-Qwen-1.5B-GSPO-Basic.Q6_K.gguf) | Q6_K | 1.6 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/DeepSeek-R1-Distill-Qwen-1.5B-GSPO-Basic-GGUF/resolve/main/DeepSeek-R1-Distill-Qwen-1.5B-GSPO-Basic.Q8_0.gguf) | Q8_0 | 2.0 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/DeepSeek-R1-Distill-Qwen-1.5B-GSPO-Basic-GGUF/resolve/main/DeepSeek-R1-Distill-Qwen-1.5B-GSPO-Basic.f16.gguf) | f16 | 3.7 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
ultramit/blockassist-bc-sturdy_mute_opossum_1755008847
|
ultramit
| 2025-08-12T14:28:14Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"sturdy mute opossum",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-12T14:28:06Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- sturdy mute opossum
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
netcat420/DeepSeek-R1-0528-Qwen3-8B-KAYLA-BASE
|
netcat420
| 2025-08-12T14:27:59Z | 0 | 0 | null |
[
"safetensors",
"qwen3",
"merge",
"mergekit",
"lazymergekit",
"deepseek-ai/DeepSeek-R1-0528-Qwen3-8B",
"netcat420/DeepSeek-R1-0528-Qwen3-8B-SLERPSOURCE",
"license:apache-2.0",
"region:us"
] | null | 2025-08-12T14:22:29Z |
---
license: apache-2.0
tags:
- merge
- mergekit
- lazymergekit
- deepseek-ai/DeepSeek-R1-0528-Qwen3-8B
- netcat420/DeepSeek-R1-0528-Qwen3-8B-SLERPSOURCE
---
# DeepSeek-R1-0528-Qwen3-8B-KAYLA-BASE
DeepSeek-R1-0528-Qwen3-8B-KAYLA-BASE is a merge of the following models using [mergekit](https://github.com/cg123/mergekit):
* [deepseek-ai/DeepSeek-R1-0528-Qwen3-8B](https://huggingface.co/deepseek-ai/DeepSeek-R1-0528-Qwen3-8B)
* [netcat420/DeepSeek-R1-0528-Qwen3-8B-SLERPSOURCE](https://huggingface.co/netcat420/DeepSeek-R1-0528-Qwen3-8B-SLERPSOURCE)
## 🧩 Configuration
```yaml
slices:
- sources:
- model: deepseek-ai/DeepSeek-R1-0528-Qwen3-8B
layer_range: [0, 36]
- model: netcat420/DeepSeek-R1-0528-Qwen3-8B-SLERPSOURCE
layer_range: [0, 36]
merge_method: slerp
base_model: deepseek-ai/DeepSeek-R1-0528-Qwen3-8B
parameters:
t:
- filter: self_attn
value: [0, 0.5, 0.3, 0.7, 1]
- filter: mlp
value: [1, 0.5, 0.7, 0.3, 0]
- value: 0.5 # fallback for rest of tensors
dtype: float16
```
|
sdaschel/stacyreplicate
|
sdaschel
| 2025-08-12T14:27:58Z | 0 | 0 |
diffusers
|
[
"diffusers",
"flux",
"lora",
"replicate",
"text-to-image",
"en",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"license:other",
"region:us"
] |
text-to-image
| 2025-08-12T13:52:52Z |
---
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
language:
- en
tags:
- flux
- diffusers
- lora
- replicate
base_model: "black-forest-labs/FLUX.1-dev"
pipeline_tag: text-to-image
# widget:
# - text: >-
# prompt
# output:
# url: https://...
instance_prompt: Stacy
---
# Stacyreplicate
<Gallery />
## About this LoRA
This is a [LoRA](https://replicate.com/docs/guides/working-with-loras) for the FLUX.1-dev text-to-image model. It can be used with diffusers or ComfyUI.
It was trained on [Replicate](https://replicate.com/) using AI toolkit: https://replicate.com/ostris/flux-dev-lora-trainer/train
## Trigger words
You should use `Stacy` to trigger the image generation.
## Run this LoRA with an API using Replicate
```py
import replicate
input = {
"prompt": "Stacy",
"lora_weights": "https://huggingface.co/sdaschel/stacyreplicate/resolve/main/lora.safetensors"
}
output = replicate.run(
"black-forest-labs/flux-dev-lora",
input=input
)
for index, item in enumerate(output):
with open(f"output_{index}.webp", "wb") as file:
file.write(item.read())
```
## Use it with the [🧨 diffusers library](https://github.com/huggingface/diffusers)
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained('black-forest-labs/FLUX.1-dev', torch_dtype=torch.float16).to('cuda')
pipeline.load_lora_weights('sdaschel/stacyreplicate', weight_name='lora.safetensors')
image = pipeline('Stacy').images[0]
```
For more details, including weighting, merging and fusing LoRAs, check the [documentation on loading LoRAs in diffusers](https://huggingface.co/docs/diffusers/main/en/using-diffusers/loading_adapters)
## Training details
- Steps: 2002
- Learning rate: 0.0004
- LoRA rank: 16
## Contribute your own examples
You can use the [community tab](https://huggingface.co/sdaschel/stacyreplicate/discussions) to add images that show off what you’ve made with this LoRA.
|
silentember/Lantern_qM2kTD
|
silentember
| 2025-08-12T14:26:09Z | 0 | 0 | null |
[
"safetensors",
"any-to-any",
"omega",
"omegalabs",
"bittensor",
"agi",
"license:mit",
"region:us"
] |
any-to-any
| 2025-08-12T14:24:11Z |
---
license: mit
tags:
- any-to-any
- omega
- omegalabs
- bittensor
- agi
---
This is an Any-to-Any model checkpoint for the OMEGA Labs x Bittensor Any-to-Any subnet.
Check out the [git repo](https://github.com/omegalabsinc/omegalabs-anytoany-bittensor) and find OMEGA on X: [@omegalabsai](https://x.com/omegalabsai).
|
Kbashiru/distil-base_on_jumia_dataset
|
Kbashiru
| 2025-08-12T14:25:24Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"distilbert",
"text-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2025-08-12T14:24:56Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
knowledgator/gliclass-x-base
|
knowledgator
| 2025-08-12T14:25:23Z | 257 | 5 | null |
[
"safetensors",
"GLiClass",
"text-classification",
"dataset:knowledgator/gliclass-v2.0",
"arxiv:2508.07662",
"license:apache-2.0",
"region:us"
] |
text-classification
| 2025-07-17T14:16:33Z |
---
license: apache-2.0
datasets:
- knowledgator/gliclass-v2.0
pipeline_tag: text-classification
---
# ⭐ GLiClass: Generalist and Lightweight Model for Sequence Classification
This is an efficient zero-shot classifier inspired by [GLiNER](https://github.com/urchade/GLiNER/tree/main) work. It demonstrates the same performance as a cross-encoder while being more compute-efficient because classification is done at a single forward path.
It can be used for `topic classification`, `sentiment analysis` and as a reranker in `RAG` pipelines.
The model was trained on synthetic and licensed data that allow commercial use and can be used in commercial applications.
The backbone model is [mdeberta-v3-base](huggingface.co/microsoft/mdeberta-v3-base). It supports multilingual understanding, making it well-suited for tasks involving texts in different languages.
### How to use:
First of all, you need to install GLiClass library:
```bash
pip install gliclass
pip install -U transformers>=4.48.0
```
Than you need to initialize a model and a pipeline:
<details>
<summary>English</summary>
```python
from gliclass import GLiClassModel, ZeroShotClassificationPipeline
from transformers import AutoTokenizer
model = GLiClassModel.from_pretrained("knowledgator/gliclass-x-base")
tokenizer = AutoTokenizer.from_pretrained("knowledgator/gliclass-x-base", add_prefix_space=True)
pipeline = ZeroShotClassificationPipeline(model, tokenizer, classification_type='multi-label', device='cuda:0')
text = "One day I will see the world!"
labels = ["travel", "dreams", "sport", "science", "politics"]
results = pipeline(text, labels, threshold=0.5)[0] #because we have one text
for result in results:
print(result["label"], "=>", result["score"])
```
</details>
<details>
<summary>Spanish</summary>
```python
from gliclass import GLiClassModel, ZeroShotClassificationPipeline
from transformers import AutoTokenizer
model = GLiClassModel.from_pretrained("knowledgator/gliclass-x-base")
tokenizer = AutoTokenizer.from_pretrained("knowledgator/gliclass-x-base", add_prefix_space=True)
pipeline = ZeroShotClassificationPipeline(model, tokenizer, classification_type='multi-label', device='cuda:0')
text = "¡Un día veré el mundo!"
labels = ["viajes", "sueños", "deportes", "ciencia", "política"]
results = pipeline(text, labels, threshold=0.5)[0]
for result in results:
print(result["label"], "=>", result["score"])
```
</details>
<details>
<summary>Italitan</summary>
```python
from gliclass import GLiClassModel, ZeroShotClassificationPipeline
from transformers import AutoTokenizer
model = GLiClassModel.from_pretrained("knowledgator/gliclass-x-base")
tokenizer = AutoTokenizer.from_pretrained("knowledgator/gliclass-x-base", add_prefix_space=True)
pipeline = ZeroShotClassificationPipeline(model, tokenizer, classification_type='multi-label', device='cuda:0')
text = "Un giorno vedrò il mondo!"
labels = ["viaggi", "sogni", "sport", "scienza", "politica"]
results = pipeline(text, labels, threshold=0.5)[0]
for result in results:
print(result["label"], "=>", result["score"])
```
</details>
<details>
<summary>French</summary>
```python
from gliclass import GLiClassModel, ZeroShotClassificationPipeline
from transformers import AutoTokenizer
model = GLiClassModel.from_pretrained("knowledgator/gliclass-x-base")
tokenizer = AutoTokenizer.from_pretrained("knowledgator/gliclass-x-base", add_prefix_space=True)
pipeline = ZeroShotClassificationPipeline(model, tokenizer, classification_type='multi-label', device='cuda:0')
text = "Un jour, je verrai le monde!"
labels = ["voyage", "rêves", "sport", "science", "politique"]
results = pipeline(text, labels, threshold=0.5)[0]
for result in results:
print(result["label"], "=>", result["score"])
```
</details>
<details>
<summary>German</summary>
```python
from gliclass import GLiClassModel, ZeroShotClassificationPipeline
from transformers import AutoTokenizer
model = GLiClassModel.from_pretrained("knowledgator/gliclass-x-base")
tokenizer = AutoTokenizer.from_pretrained("knowledgator/gliclass-x-base", add_prefix_space=True)
pipeline = ZeroShotClassificationPipeline(model, tokenizer, classification_type='multi-label', device='cuda:0')
text = "Eines Tages werde ich die Welt sehen!"
labels = ["Reisen", "Träume", "Sport", "Wissenschaft", "Politik"]
results = pipeline(text, labels, threshold=0.5)[0]
for result in results:
print(result["label"], "=>", result["score"])
```
</details>
### Benchmarks:
Below, you can see the F1 score on several text classification datasets. All tested models were not fine-tuned on those datasets and were tested in a zero-shot setting.
#### Multilingual benchmarks
| Dataset | gliclass-x-base | gliclass-base-v3.0 | gliclass-large-v3.0 |
| ------------------------ | --------------- | ------------------ | ------------------- |
| FredZhang7/toxi-text-3M | 0.5972 | 0.5072 | 0.6118 |
| SetFit/xglue\_nc | 0.5014 | 0.5348 | 0.5378 |
| Davlan/sib200\_14classes | 0.4663 | 0.2867 | 0.3173 |
| uhhlt/GermEval2017 | 0.3999 | 0.4010 | 0.4299 |
| dolfsai/toxic\_es | 0.1250 | 0.1399 | 0.1412 |
| **Average** | **0.41796** | **0.37392** | **0.4076** |
#### General benchmarks
| Dataset | gliclass-x-base | gliclass-base-v3.0 | gliclass-large-v3.0 |
| ---------------------------- | --------------- | ------------------ | ------------------- |
| SetFit/CR | 0.8630 | 0.9127 | 0.9398 |
| SetFit/sst2 | 0.8554 | 0.8959 | 0.9192 |
| SetFit/sst5 | 0.3287 | 0.3376 | 0.4606 |
| AmazonScience/massive | 0.2611 | 0.5040 | 0.5649 |
| stanfordnlp/imdb | 0.8840 | 0.9251 | 0.9366 |
| SetFit/20\_newsgroups | 0.4116 | 0.4759 | 0.5958 |
| SetFit/enron\_spam | 0.5929 | 0.6760 | 0.7584 |
| PolyAI/banking77 | 0.3098 | 0.4698 | 0.5574 |
| takala/financial\_phrasebank | 0.7851 | 0.8971 | 0.9000 |
| ag\_news | 0.6815 | 0.7279 | 0.7181 |
| dair-ai/emotion | 0.3667 | 0.4447 | 0.4506 |
| MoritzLaurer/cap\_sotu | 0.3935 | 0.4614 | 0.4589 |
| cornell/rotten\_tomatoes | 0.7252 | 0.7943 | 0.8411 |
| snips | 0.6307 | 0.9474 | 0.9692 |
| **Average** | **0.5778** | **0.6764** | **0.7193** |
## Citation
```bibtex
@misc{stepanov2025gliclassgeneralistlightweightmodel,
title={GLiClass: Generalist Lightweight Model for Sequence Classification Tasks},
author={Ihor Stepanov and Mykhailo Shtopko and Dmytro Vodianytskyi and Oleksandr Lukashov and Alexander Yavorskyi and Mykyta Yaroshenko},
year={2025},
eprint={2508.07662},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2508.07662},
}
```
|
knowledgator/gliclass-base-v3.0
|
knowledgator
| 2025-08-12T14:24:41Z | 2,054 | 5 | null |
[
"safetensors",
"GLiClass",
"text classification",
"nli",
"sentiment analysis",
"text-classification",
"dataset:BioMike/formal-logic-reasoning-gliclass-2k",
"dataset:knowledgator/gliclass-v3-logic-dataset",
"dataset:tau/commonsense_qa",
"arxiv:2508.07662",
"license:apache-2.0",
"region:us"
] |
text-classification
| 2025-07-14T13:53:40Z |
---
license: apache-2.0
datasets:
- BioMike/formal-logic-reasoning-gliclass-2k
- knowledgator/gliclass-v3-logic-dataset
- tau/commonsense_qa
metrics:
- f1
tags:
- text classification
- nli
- sentiment analysis
pipeline_tag: text-classification
---

# GLiClass: Generalist and Lightweight Model for Sequence Classification
This is an efficient zero-shot classifier inspired by [GLiNER](https://github.com/urchade/GLiNER/tree/main) work. It demonstrates the same performance as a cross-encoder while being more compute-efficient because classification is done at a single forward path.
It can be used for `topic classification`, `sentiment analysis`, and as a reranker in `RAG` pipelines.
The model was trained on logical tasks to induce reasoning. LoRa adapters were used to fine-tune the model without destroying the previous knowledge.
LoRA parameters:
| | [gliclass‑modern‑base‑v3.0](https://huggingface.co/knowledgator/gliclass-modern-base-v3.0) | [gliclass‑modern‑large‑v3.0](https://huggingface.co/knowledgator/gliclass-modern-large-v3.0) | [gliclass‑base‑v3.0](https://huggingface.co/knowledgator/gliclass-base-v3.0) | [gliclass‑large‑v3.0](https://huggingface.co/knowledgator/gliclass-large-v3.0) |
|----------------------|---------------------------------|----------------------------------|--------------------------------|---------------------------------|
| LoRa r | 512 | 768 | 384 | 384 |
| LoRa α | 1024 | 1536 | 768 | 768 |
| focal loss α | 0.7 | 0.7 | 0.7 | 0.7 |
| Target modules | "Wqkv", "Wo", "Wi", "linear_1", "linear_2" | "Wqkv", "Wo", "Wi", "linear_1", "linear_2" | "query_proj", "key_proj", "value_proj", "dense", "linear_1", "linear_2", mlp.0", "mlp.2", "mlp.4" | "query_proj", "key_proj", "value_proj", "dense", "linear_1", "linear_2", mlp.0", "mlp.2", "mlp.4" |
GLiClass-V3 Models:
Model name | Size | Params | Average Banchmark | Average Inference Speed (batch size = 1, a6000, examples/s)
|----------|------|--------|-------------------|---------------------------------------------------------|
[gliclass‑edge‑v3.0](https://huggingface.co/knowledgator/gliclass‑edge‑v3.0)| 131 MB | 32.7M | 0.4873 | 97.29 |
[gliclass‑modern‑base‑v3.0](https://huggingface.co/knowledgator/gliclass-modern-base-v3.0)| 606 MB | 151M | 0.5571 | 54.46 |
[gliclass‑modern‑large‑v3.0](https://huggingface.co/knowledgator/gliclass-modern-large-v3.0)| 1.6 GB | 399M | 0.6082 | 43.80 |
[gliclass‑base‑v3.0](https://huggingface.co/knowledgator/gliclass-base-v3.0)| 746 MB | 187M | 0.6556 | 51.61 |
[gliclass‑large‑v3.0](https://huggingface.co/knowledgator/gliclass-large-v3.0)| 1.75 GB | 439M | 0.7001 | 25.22 |
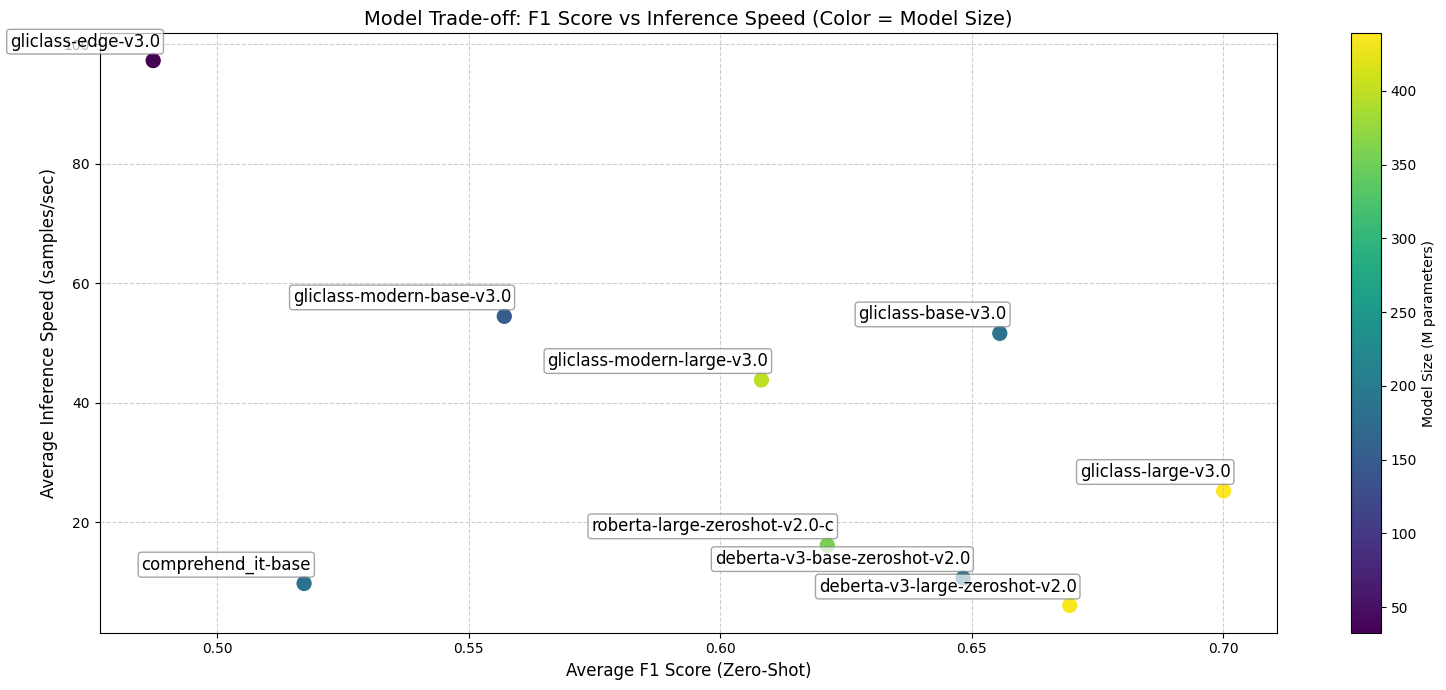
### How to use:
First of all, you need to install GLiClass library:
```bash
pip install gliclass
pip install -U transformers>=4.48.0
```
Then you need to initialize a model and a pipeline:
```python
from gliclass import GLiClassModel, ZeroShotClassificationPipeline
from transformers import AutoTokenizer
model = GLiClassModel.from_pretrained("knowledgator/gliclass-base-v3.0")
tokenizer = AutoTokenizer.from_pretrained("knowledgator/gliclass-base-v3.0")
pipeline = ZeroShotClassificationPipeline(model, tokenizer, classification_type='multi-label', device='cuda:0')
text = "One day I will see the world!"
labels = ["travel", "dreams", "sport", "science", "politics"]
results = pipeline(text, labels, threshold=0.5)[0] #because we have one text
for result in results:
print(result["label"], "=>", result["score"])
```
If you want to use it for NLI type of tasks, we recommend representing your premise as a text and hypothesis as a label, you can put several hypotheses, but the model works best with a single input hypothesis.
```python
# Initialize model and multi-label pipeline
text = "The cat slept on the windowsill all afternoon"
labels = ["The cat was awake and playing outside."]
results = pipeline(text, labels, threshold=0.0)[0]
print(results)
```
### Benchmarks:
Below, you can see the F1 score on several text classification datasets. All tested models were not fine-tuned on those datasets and were tested in a zero-shot setting.
GLiClass-V3:
| Dataset | [gliclass‑large‑v3.0](https://huggingface.co/knowledgator/gliclass-large-v3.0) | [gliclass‑base‑v3.0](https://huggingface.co/knowledgator/gliclass-base-v3.0) | [gliclass‑modern‑large‑v3.0](https://huggingface.co/knowledgator/gliclass-modern-large-v3.0) | [gliclass‑modern‑base‑v3.0](https://huggingface.co/knowledgator/gliclass-modern-base-v3.0) | [gliclass‑edge‑v3.0](https://huggingface.co/knowledgator/gliclass-edge-v3.0) |
|----------------------------|---------|---------|---------|---------|---------|
| CR | 0.9398 | 0.9127 | 0.8952 | 0.8902 | 0.8215 |
| sst2 | 0.9192 | 0.8959 | 0.9330 | 0.8959 | 0.8199 |
| sst5 | 0.4606 | 0.3376 | 0.4619 | 0.2756 | 0.2823 |
| 20_news_<br>groups | 0.5958 | 0.4759 | 0.3905 | 0.3433 | 0.2217 |
| spam | 0.7584 | 0.6760 | 0.5813 | 0.6398 | 0.5623 |
| financial_<br>phrasebank | 0.9000 | 0.8971 | 0.5929 | 0.4200 | 0.5004 |
| imdb | 0.9366 | 0.9251 | 0.9402 | 0.9158 | 0.8485 |
| ag_news | 0.7181 | 0.7279 | 0.7269 | 0.6663 | 0.6645 |
| emotion | 0.4506 | 0.4447 | 0.4517 | 0.4254 | 0.3851 |
| cap_sotu | 0.4589 | 0.4614 | 0.4072 | 0.3625 | 0.2583 |
| rotten_<br>tomatoes | 0.8411 | 0.7943 | 0.7664 | 0.7070 | 0.7024 |
| massive | 0.5649 | 0.5040 | 0.3905 | 0.3442 | 0.2414 |
| banking | 0.5574 | 0.4698 | 0.3683 | 0.3561 | 0.0272 |
| snips | 0.9692 | 0.9474 | 0.7707 | 0.5663 | 0.5257 |
| **AVERAGE** | **0.7193** | **0.6764** | **0.6197** | **0.5577** | **0.4900** |
Previous GLiClass models:
| Dataset | [gliclass‑large‑v1.0‑lw](https://huggingface.co/knowledgator/gliclass-large-v1.0-lw) | [gliclass‑base‑v1.0‑lw](https://huggingface.co/knowledgator/gliclass-base-v1.0-lw) | [gliclass‑modern‑large‑v2.0](https://huggingface.co/knowledgator/gliclass-modern-large-v2.0) | [gliclass‑modern‑base‑v2.0](https://huggingface.co/knowledgator/gliclass-modern-base-v2.0) |
|----------------------------|---------------------------------|--------------------------------|----------------------------------|---------------------------------|
| CR | 0.9226 | 0.9097 | 0.9154 | 0.8977 |
| sst2 | 0.9247 | 0.8987 | 0.9308 | 0.8524 |
| sst5 | 0.2891 | 0.3779 | 0.2152 | 0.2346 |
| 20_news_<br>groups | 0.4083 | 0.3953 | 0.3813 | 0.3857 |
| spam | 0.3642 | 0.5126 | 0.6603 | 0.4608 |
| financial_<br>phrasebank | 0.9044 | 0.8880 | 0.3152 | 0.3465 |
| imdb | 0.9429 | 0.9351 | 0.9449 | 0.9188 |
| ag_news | 0.7559 | 0.6985 | 0.6999 | 0.6836 |
| emotion | 0.3951 | 0.3516 | 0.4341 | 0.3926 |
| cap_sotu | 0.4749 | 0.4643 | 0.4095 | 0.3588 |
| rotten_<br>tomatoes | 0.8807 | 0.8429 | 0.7386 | 0.6066 |
| massive | 0.5606 | 0.4635 | 0.2394 | 0.3458 |
| banking | 0.3317 | 0.4396 | 0.1355 | 0.2907 |
| snips | 0.9707 | 0.9572 | 0.8468 | 0.7378 |
| **AVERAGE** | **0.6518** | **0.6525** | **0.5619** | **0.5366** |
Cross-Encoders:
| Dataset | [deberta‑v3‑large‑zeroshot‑v2.0](https://huggingface.co/MoritzLaurer/deberta-v3-large-zeroshot-v2.0) | [deberta‑v3‑base‑zeroshot‑v2.0](https://huggingface.co/MoritzLaurer/deberta-v3-base-zeroshot-v2.0) | [roberta‑large‑zeroshot‑v2.0‑c](https://huggingface.co/MoritzLaurer/roberta-large-zeroshot-v2.0-c) | [comprehend_it‑base](https://huggingface.co/knowledgator/comprehend_it-base) |
|------------------------------------|--------|--------|--------|--------|
| CR | 0.9134 | 0.9051 | 0.9141 | 0.8936 |
| sst2 | 0.9272 | 0.9176 | 0.8573 | 0.9006 |
| sst5 | 0.3861 | 0.3848 | 0.4159 | 0.4140 |
| enron_<br>spam | 0.5970 | 0.4640 | 0.5040 | 0.3637 |
| financial_<br>phrasebank | 0.5820 | 0.6690 | 0.4550 | 0.4695 |
| imdb | 0.9180 | 0.8990 | 0.9040 | 0.4644 |
| ag_news | 0.7710 | 0.7420 | 0.7450 | 0.6016 |
| emotion | 0.4840 | 0.4950 | 0.4860 | 0.4165 |
| cap_sotu | 0.5020 | 0.4770 | 0.5230 | 0.3823 |
| rotten_<br>tomatoes | 0.8680 | 0.8600 | 0.8410 | 0.4728 |
| massive | 0.5180 | 0.5200 | 0.5200 | 0.3314 |
| banking77 | 0.5670 | 0.4460 | 0.2900 | 0.4972 |
| snips | 0.8340 | 0.7477 | 0.5430 | 0.7227 |
| **AVERAGE** | **0.6821** | **0.6559** | **0.6152** | **0.5331** |
Inference Speed:
Each model was tested on examples with 64, 256, and 512 tokens in text and 1, 2, 4, 8, 16, 32, 64, and 128 labels on an a6000 GPU. Then, scores were averaged across text lengths.
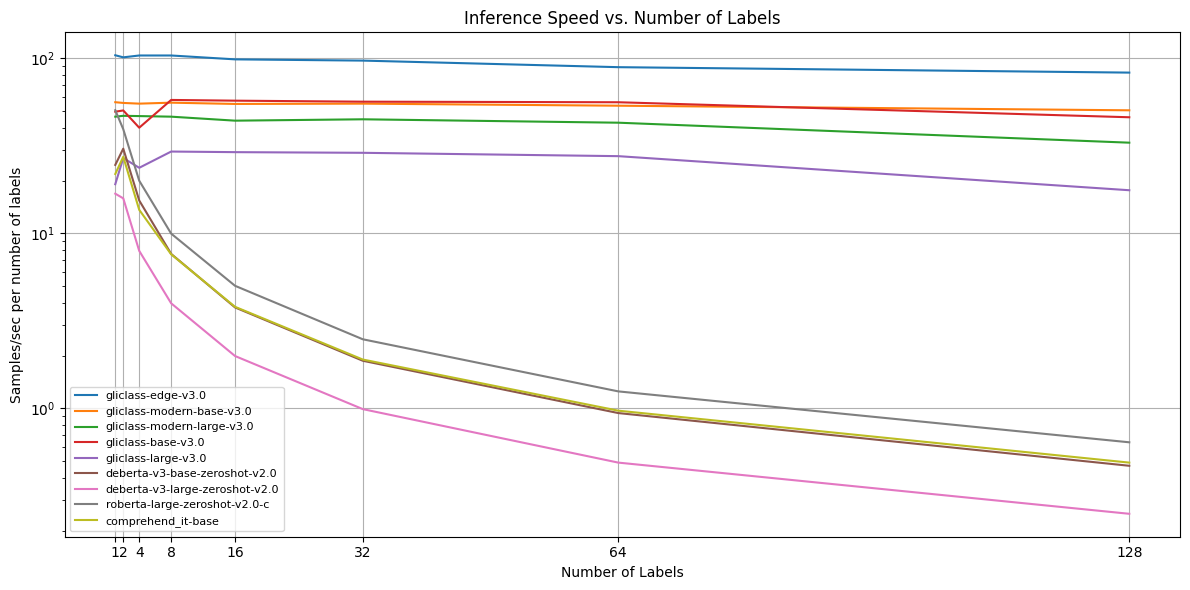
Model Name / n samples per second per m labels | 1 | 2 | 4 | 8 | 16 | 32 | 64 | 128 | **Average** |
|---------------------|---|---|---|---|----|----|----|-----|---------|
| [gliclass‑edge‑v3.0](https://huggingface.co/knowledgator/gliclass-edge-v3.0) | 103.81 | 101.01 | 103.50 | 103.50 | 98.36 | 96.77 | 88.76 | 82.64 | **97.29** |
| [gliclass‑modern‑base‑v3.0](https://huggingface.co/knowledgator/gliclass-modern-base-v3.0) | 56.00 | 55.46 | 54.95 | 55.66 | 54.73 | 54.95 | 53.48 | 50.34 | **54.46** |
| [gliclass‑modern‑large‑v3.0](https://huggingface.co/knowledgator/gliclass-modern-large-v3.0) | 46.30 | 46.82 | 46.66 | 46.30 | 43.93 | 44.73 | 42.77 | 32.89 | **43.80** |
| [gliclass‑base‑v3.0](https://huggingface.co/knowledgator/gliclass-base-v3.0) | 49.42 | 50.25 | 40.05 | 57.69 | 57.14 | 56.39 | 55.97 | 45.94 | **51.61** |
| [gliclass‑large‑v3.0](https://huggingface.co/knowledgator/gliclass-large-v3.0) | 19.05 | 26.86 | 23.64 | 29.27 | 29.04 | 28.79 | 27.55 | 17.60 | **25.22** |
| [deberta‑v3‑base‑zeroshot‑v2.0](https://huggingface.co/MoritzLaurer/deberta-v3-base-zeroshot-v2.0) | 24.55 | 30.40 | 15.38 | 7.62 | 3.77 | 1.87 | 0.94 | 0.47 | **10.63** |
| [deberta‑v3‑large‑zeroshot‑v2.0](https://huggingface.co/MoritzLaurer/deberta-v3-large-zeroshot-v2.0) | 16.82 | 15.82 | 7.93 | 3.98 | 1.99 | 0.99 | 0.49 | 0.25 | **6.03** |
| [roberta‑large‑zeroshot‑v2.0‑c](https://huggingface.co/MoritzLaurer/roberta-large-zeroshot-v2.0-c) | 50.42 | 39.27 | 19.95 | 9.95 | 5.01 | 2.48 | 1.25 | 0.64 | **16.12** |
| [comprehend_it‑base](https://huggingface.co/knowledgator/comprehend_it-base) | 21.79 | 27.32 | 13.60 | 7.58 | 3.80 | 1.90 | 0.97 | 0.49 | **9.72** |
## Citation
```bibtex
@misc{stepanov2025gliclassgeneralistlightweightmodel,
title={GLiClass: Generalist Lightweight Model for Sequence Classification Tasks},
author={Ihor Stepanov and Mykhailo Shtopko and Dmytro Vodianytskyi and Oleksandr Lukashov and Alexander Yavorskyi and Mykyta Yaroshenko},
year={2025},
eprint={2508.07662},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2508.07662},
}
```
|
knowledgator/gliclass-modern-base-v3.0
|
knowledgator
| 2025-08-12T14:23:32Z | 2,479 | 3 | null |
[
"safetensors",
"GLiClass",
"text classification",
"nli",
"sentiment analysis",
"text-classification",
"dataset:BioMike/formal-logic-reasoning-gliclass-2k",
"dataset:knowledgator/gliclass-v3-logic-dataset",
"dataset:tau/commonsense_qa",
"arxiv:2508.07662",
"license:apache-2.0",
"region:us"
] |
text-classification
| 2025-07-14T12:32:17Z |
---
license: apache-2.0
datasets:
- BioMike/formal-logic-reasoning-gliclass-2k
- knowledgator/gliclass-v3-logic-dataset
- tau/commonsense_qa
metrics:
- f1
tags:
- text classification
- nli
- sentiment analysis
pipeline_tag: text-classification
---

# GLiClass: Generalist and Lightweight Model for Sequence Classification
This is an efficient zero-shot classifier inspired by [GLiNER](https://github.com/urchade/GLiNER/tree/main) work. It demonstrates the same performance as a cross-encoder while being more compute-efficient because classification is done at a single forward path.
It can be used for `topic classification`, `sentiment analysis`, and as a reranker in `RAG` pipelines.
The model was trained on logical tasks to induce reasoning. LoRa adapters were used to fine-tune the model without destroying the previous knowledge.
LoRA parameters:
| | [gliclass‑modern‑base‑v3.0](https://huggingface.co/knowledgator/gliclass-modern-base-v3.0) | [gliclass‑modern‑large‑v3.0](https://huggingface.co/knowledgator/gliclass-modern-large-v3.0) | [gliclass‑base‑v3.0](https://huggingface.co/knowledgator/gliclass-base-v3.0) | [gliclass‑large‑v3.0](https://huggingface.co/knowledgator/gliclass-large-v3.0) |
|----------------------|---------------------------------|----------------------------------|--------------------------------|---------------------------------|
| LoRa r | 512 | 768 | 384 | 384 |
| LoRa α | 1024 | 1536 | 768 | 768 |
| focal loss α | 0.7 | 0.7 | 0.7 | 0.7 |
| Target modules | "Wqkv", "Wo", "Wi", "linear_1", "linear_2" | "Wqkv", "Wo", "Wi", "linear_1", "linear_2" | "query_proj", "key_proj", "value_proj", "dense", "linear_1", "linear_2", mlp.0", "mlp.2", "mlp.4" | "query_proj", "key_proj", "value_proj", "dense", "linear_1", "linear_2", mlp.0", "mlp.2", "mlp.4" |
GLiClass-V3 Models:
Model name | Size | Params | Average Banchmark | Average Inference Speed (batch size = 1, a6000, examples/s)
|----------|------|--------|-------------------|---------------------------------------------------------|
[gliclass‑edge‑v3.0](https://huggingface.co/knowledgator/gliclass‑edge‑v3.0)| 131 MB | 32.7M | 0.4873 | 97.29 |
[gliclass‑modern‑base‑v3.0](https://huggingface.co/knowledgator/gliclass-modern-base-v3.0)| 606 MB | 151M | 0.5571 | 54.46 |
[gliclass‑modern‑large‑v3.0](https://huggingface.co/knowledgator/gliclass-modern-large-v3.0)| 1.6 GB | 399M | 0.6082 | 43.80 |
[gliclass‑base‑v3.0](https://huggingface.co/knowledgator/gliclass-base-v3.0)| 746 MB | 187M | 0.6556 | 51.61 |
[gliclass‑large‑v3.0](https://huggingface.co/knowledgator/gliclass-large-v3.0)| 1.75 GB | 439M | 0.7001 | 25.22 |

### How to use:
First of all, you need to install GLiClass library:
```bash
pip install gliclass
pip install -U transformers>=4.48.0
```
Then you need to initialize a model and a pipeline:
```python
from gliclass import GLiClassModel, ZeroShotClassificationPipeline
from transformers import AutoTokenizer
model = GLiClassModel.from_pretrained("knowledgator/gliclass-modern-base-v3.0")
tokenizer = AutoTokenizer.from_pretrained("knowledgator/gliclass-modern-base-v3.0", add_prefix_space=True)
pipeline = ZeroShotClassificationPipeline(model, tokenizer, classification_type='multi-label', device='cuda:0')
text = "One day I will see the world!"
labels = ["travel", "dreams", "sport", "science", "politics"]
results = pipeline(text, labels, threshold=0.5)[0] #because we have one text
for result in results:
print(result["label"], "=>", result["score"])
```
If you want to use it for NLI type of tasks, we recommend representing your premise as a text and hypothesis as a label, you can put several hypotheses, but the model works best with a single input hypothesis.
```python
# Initialize model and multi-label pipeline
text = "The cat slept on the windowsill all afternoon"
labels = ["The cat was awake and playing outside."]
results = pipeline(text, labels, threshold=0.0)[0]
print(results)
```
### Benchmarks:
Below, you can see the F1 score on several text classification datasets. All tested models were not fine-tuned on those datasets and were tested in a zero-shot setting.
GLiClass-V3:
| Dataset | [gliclass‑large‑v3.0](https://huggingface.co/knowledgator/gliclass-large-v3.0) | [gliclass‑base‑v3.0](https://huggingface.co/knowledgator/gliclass-base-v3.0) | [gliclass‑modern‑large‑v3.0](https://huggingface.co/knowledgator/gliclass-modern-large-v3.0) | [gliclass‑modern‑base‑v3.0](https://huggingface.co/knowledgator/gliclass-modern-base-v3.0) | [gliclass‑edge‑v3.0](https://huggingface.co/knowledgator/gliclass-edge-v3.0) |
|----------------------------|---------|---------|---------|---------|---------|
| CR | 0.9398 | 0.9127 | 0.8952 | 0.8902 | 0.8215 |
| sst2 | 0.9192 | 0.8959 | 0.9330 | 0.8959 | 0.8199 |
| sst5 | 0.4606 | 0.3376 | 0.4619 | 0.2756 | 0.2823 |
| 20_news_<br>groups | 0.5958 | 0.4759 | 0.3905 | 0.3433 | 0.2217 |
| spam | 0.7584 | 0.6760 | 0.5813 | 0.6398 | 0.5623 |
| financial_<br>phrasebank | 0.9000 | 0.8971 | 0.5929 | 0.4200 | 0.5004 |
| imdb | 0.9366 | 0.9251 | 0.9402 | 0.9158 | 0.8485 |
| ag_news | 0.7181 | 0.7279 | 0.7269 | 0.6663 | 0.6645 |
| emotion | 0.4506 | 0.4447 | 0.4517 | 0.4254 | 0.3851 |
| cap_sotu | 0.4589 | 0.4614 | 0.4072 | 0.3625 | 0.2583 |
| rotten_<br>tomatoes | 0.8411 | 0.7943 | 0.7664 | 0.7070 | 0.7024 |
| massive | 0.5649 | 0.5040 | 0.3905 | 0.3442 | 0.2414 |
| banking | 0.5574 | 0.4698 | 0.3683 | 0.3561 | 0.0272 |
| snips | 0.9692 | 0.9474 | 0.7707 | 0.5663 | 0.5257 |
| **AVERAGE** | **0.7193** | **0.6764** | **0.6197** | **0.5577** | **0.4900** |
Previous GLiClass models:
| Dataset | [gliclass‑large‑v1.0‑lw](https://huggingface.co/knowledgator/gliclass-large-v1.0-lw) | [gliclass‑base‑v1.0‑lw](https://huggingface.co/knowledgator/gliclass-base-v1.0-lw) | [gliclass‑modern‑large‑v2.0](https://huggingface.co/knowledgator/gliclass-modern-large-v2.0) | [gliclass‑modern‑base‑v2.0](https://huggingface.co/knowledgator/gliclass-modern-base-v2.0) |
|----------------------------|---------------------------------|--------------------------------|----------------------------------|---------------------------------|
| CR | 0.9226 | 0.9097 | 0.9154 | 0.8977 |
| sst2 | 0.9247 | 0.8987 | 0.9308 | 0.8524 |
| sst5 | 0.2891 | 0.3779 | 0.2152 | 0.2346 |
| 20_news_<br>groups | 0.4083 | 0.3953 | 0.3813 | 0.3857 |
| spam | 0.3642 | 0.5126 | 0.6603 | 0.4608 |
| financial_<br>phrasebank | 0.9044 | 0.8880 | 0.3152 | 0.3465 |
| imdb | 0.9429 | 0.9351 | 0.9449 | 0.9188 |
| ag_news | 0.7559 | 0.6985 | 0.6999 | 0.6836 |
| emotion | 0.3951 | 0.3516 | 0.4341 | 0.3926 |
| cap_sotu | 0.4749 | 0.4643 | 0.4095 | 0.3588 |
| rotten_<br>tomatoes | 0.8807 | 0.8429 | 0.7386 | 0.6066 |
| massive | 0.5606 | 0.4635 | 0.2394 | 0.3458 |
| banking | 0.3317 | 0.4396 | 0.1355 | 0.2907 |
| snips | 0.9707 | 0.9572 | 0.8468 | 0.7378 |
| **AVERAGE** | **0.6518** | **0.6525** | **0.5619** | **0.5366** |
Cross-Encoders:
| Dataset | [deberta‑v3‑large‑zeroshot‑v2.0](https://huggingface.co/MoritzLaurer/deberta-v3-large-zeroshot-v2.0) | [deberta‑v3‑base‑zeroshot‑v2.0](https://huggingface.co/MoritzLaurer/deberta-v3-base-zeroshot-v2.0) | [roberta‑large‑zeroshot‑v2.0‑c](https://huggingface.co/MoritzLaurer/roberta-large-zeroshot-v2.0-c) | [comprehend_it‑base](https://huggingface.co/knowledgator/comprehend_it-base) |
|------------------------------------|--------|--------|--------|--------|
| CR | 0.9134 | 0.9051 | 0.9141 | 0.8936 |
| sst2 | 0.9272 | 0.9176 | 0.8573 | 0.9006 |
| sst5 | 0.3861 | 0.3848 | 0.4159 | 0.4140 |
| enron_<br>spam | 0.5970 | 0.4640 | 0.5040 | 0.3637 |
| financial_<br>phrasebank | 0.5820 | 0.6690 | 0.4550 | 0.4695 |
| imdb | 0.9180 | 0.8990 | 0.9040 | 0.4644 |
| ag_news | 0.7710 | 0.7420 | 0.7450 | 0.6016 |
| emotion | 0.4840 | 0.4950 | 0.4860 | 0.4165 |
| cap_sotu | 0.5020 | 0.4770 | 0.5230 | 0.3823 |
| rotten_<br>tomatoes | 0.8680 | 0.8600 | 0.8410 | 0.4728 |
| massive | 0.5180 | 0.5200 | 0.5200 | 0.3314 |
| banking77 | 0.5670 | 0.4460 | 0.2900 | 0.4972 |
| snips | 0.8340 | 0.7477 | 0.5430 | 0.7227 |
| **AVERAGE** | **0.6821** | **0.6559** | **0.6152** | **0.5331** |
Inference Speed:
Each model was tested on examples with 64, 256, and 512 tokens in text and 1, 2, 4, 8, 16, 32, 64, and 128 labels on an a6000 GPU. Then, scores were averaged across text lengths.

Model Name / n samples per second per m labels | 1 | 2 | 4 | 8 | 16 | 32 | 64 | 128 | **Average** |
|---------------------|---|---|---|---|----|----|----|-----|---------|
| [gliclass‑edge‑v3.0](https://huggingface.co/knowledgator/gliclass-edge-v3.0) | 103.81 | 101.01 | 103.50 | 103.50 | 98.36 | 96.77 | 88.76 | 82.64 | **97.29** |
| [gliclass‑modern‑base‑v3.0](https://huggingface.co/knowledgator/gliclass-modern-base-v3.0) | 56.00 | 55.46 | 54.95 | 55.66 | 54.73 | 54.95 | 53.48 | 50.34 | **54.46** |
| [gliclass‑modern‑large‑v3.0](https://huggingface.co/knowledgator/gliclass-modern-large-v3.0) | 46.30 | 46.82 | 46.66 | 46.30 | 43.93 | 44.73 | 42.77 | 32.89 | **43.80** |
| [gliclass‑base‑v3.0](https://huggingface.co/knowledgator/gliclass-base-v3.0) | 49.42 | 50.25 | 40.05 | 57.69 | 57.14 | 56.39 | 55.97 | 45.94 | **51.61** |
| [gliclass‑large‑v3.0](https://huggingface.co/knowledgator/gliclass-large-v3.0) | 19.05 | 26.86 | 23.64 | 29.27 | 29.04 | 28.79 | 27.55 | 17.60 | **25.22** |
| [deberta‑v3‑base‑zeroshot‑v2.0](https://huggingface.co/MoritzLaurer/deberta-v3-base-zeroshot-v2.0) | 24.55 | 30.40 | 15.38 | 7.62 | 3.77 | 1.87 | 0.94 | 0.47 | **10.63** |
| [deberta‑v3‑large‑zeroshot‑v2.0](https://huggingface.co/MoritzLaurer/deberta-v3-large-zeroshot-v2.0) | 16.82 | 15.82 | 7.93 | 3.98 | 1.99 | 0.99 | 0.49 | 0.25 | **6.03** |
| [roberta‑large‑zeroshot‑v2.0‑c](https://huggingface.co/MoritzLaurer/roberta-large-zeroshot-v2.0-c) | 50.42 | 39.27 | 19.95 | 9.95 | 5.01 | 2.48 | 1.25 | 0.64 | **16.12** |
| [comprehend_it‑base](https://huggingface.co/knowledgator/comprehend_it-base) | 21.79 | 27.32 | 13.60 | 7.58 | 3.80 | 1.90 | 0.97 | 0.49 | **9.72** |
## Citation
```bibtex
@misc{stepanov2025gliclassgeneralistlightweightmodel,
title={GLiClass: Generalist Lightweight Model for Sequence Classification Tasks},
author={Ihor Stepanov and Mykhailo Shtopko and Dmytro Vodianytskyi and Oleksandr Lukashov and Alexander Yavorskyi and Mykyta Yaroshenko},
year={2025},
eprint={2508.07662},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2508.07662},
}
```
|
tungkhau/q-FrozenLake-v1-4x4-noSlippery
|
tungkhau
| 2025-08-12T14:23:18Z | 0 | 0 | null |
[
"FrozenLake-v1-4x4-no_slippery",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2025-08-12T14:23:15Z |
---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="tungkhau/q-FrozenLake-v1-4x4-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
koloni/blockassist-bc-deadly_graceful_stingray_1755006891
|
koloni
| 2025-08-12T14:22:16Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"deadly graceful stingray",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-12T14:22:11Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- deadly graceful stingray
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
mradermacher/Spark-TTS_KN_V1.1-GGUF
|
mradermacher
| 2025-08-12T14:22:06Z | 0 | 0 |
transformers
|
[
"transformers",
"gguf",
"en",
"base_model:Balaji-1904/Spark-TTS_KN_V1.1",
"base_model:quantized:Balaji-1904/Spark-TTS_KN_V1.1",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2025-08-12T14:19:46Z |
---
base_model: Balaji-1904/Spark-TTS_KN_V1.1
language:
- en
library_name: transformers
mradermacher:
readme_rev: 1
quantized_by: mradermacher
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
<!-- ### quants: x-f16 Q4_K_S Q2_K Q8_0 Q6_K Q3_K_M Q3_K_S Q3_K_L Q4_K_M Q5_K_S Q5_K_M IQ4_XS -->
<!-- ### quants_skip: -->
<!-- ### skip_mmproj: -->
static quants of https://huggingface.co/Balaji-1904/Spark-TTS_KN_V1.1
<!-- provided-files -->
***For a convenient overview and download list, visit our [model page for this model](https://hf.tst.eu/model#Spark-TTS_KN_V1.1-GGUF).***
weighted/imatrix quants seem not to be available (by me) at this time. If they do not show up a week or so after the static ones, I have probably not planned for them. Feel free to request them by opening a Community Discussion.
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/Spark-TTS_KN_V1.1-GGUF/resolve/main/Spark-TTS_KN_V1.1.Q3_K_S.gguf) | Q3_K_S | 0.5 | |
| [GGUF](https://huggingface.co/mradermacher/Spark-TTS_KN_V1.1-GGUF/resolve/main/Spark-TTS_KN_V1.1.Q2_K.gguf) | Q2_K | 0.5 | |
| [GGUF](https://huggingface.co/mradermacher/Spark-TTS_KN_V1.1-GGUF/resolve/main/Spark-TTS_KN_V1.1.IQ4_XS.gguf) | IQ4_XS | 0.5 | |
| [GGUF](https://huggingface.co/mradermacher/Spark-TTS_KN_V1.1-GGUF/resolve/main/Spark-TTS_KN_V1.1.Q3_K_M.gguf) | Q3_K_M | 0.5 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/Spark-TTS_KN_V1.1-GGUF/resolve/main/Spark-TTS_KN_V1.1.Q3_K_L.gguf) | Q3_K_L | 0.5 | |
| [GGUF](https://huggingface.co/mradermacher/Spark-TTS_KN_V1.1-GGUF/resolve/main/Spark-TTS_KN_V1.1.Q4_K_S.gguf) | Q4_K_S | 0.5 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Spark-TTS_KN_V1.1-GGUF/resolve/main/Spark-TTS_KN_V1.1.Q4_K_M.gguf) | Q4_K_M | 0.5 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Spark-TTS_KN_V1.1-GGUF/resolve/main/Spark-TTS_KN_V1.1.Q5_K_S.gguf) | Q5_K_S | 0.5 | |
| [GGUF](https://huggingface.co/mradermacher/Spark-TTS_KN_V1.1-GGUF/resolve/main/Spark-TTS_KN_V1.1.Q5_K_M.gguf) | Q5_K_M | 0.5 | |
| [GGUF](https://huggingface.co/mradermacher/Spark-TTS_KN_V1.1-GGUF/resolve/main/Spark-TTS_KN_V1.1.Q6_K.gguf) | Q6_K | 0.6 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/Spark-TTS_KN_V1.1-GGUF/resolve/main/Spark-TTS_KN_V1.1.Q8_0.gguf) | Q8_0 | 0.6 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/Spark-TTS_KN_V1.1-GGUF/resolve/main/Spark-TTS_KN_V1.1.f16.gguf) | f16 | 1.1 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
giovannidemuri/llama3b-llamab8-er-afg-v14-seed2-french-codealpaca-fpt
|
giovannidemuri
| 2025-08-12T14:21:32Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"generated_from_trainer",
"conversational",
"base_model:meta-llama/Llama-3.2-3B",
"base_model:finetune:meta-llama/Llama-3.2-3B",
"license:llama3.2",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-12T13:52:11Z |
---
library_name: transformers
license: llama3.2
base_model: meta-llama/Llama-3.2-3B
tags:
- generated_from_trainer
model-index:
- name: llama3b-llamab8-er-afg-v14-seed2-french-codealpaca-fpt
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# llama3b-llamab8-er-afg-v14-seed2-french-codealpaca-fpt
This model is a fine-tuned version of [meta-llama/Llama-3.2-3B](https://huggingface.co/meta-llama/Llama-3.2-3B) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 2
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.03
- num_epochs: 2
### Training results
### Framework versions
- Transformers 4.52.4
- Pytorch 2.7.1+cu128
- Datasets 3.6.0
- Tokenizers 0.21.2
|
Sayemahsjn/blockassist-bc-playful_feline_octopus_1755007398
|
Sayemahsjn
| 2025-08-12T14:21:25Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"playful feline octopus",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-12T14:21:20Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- playful feline octopus
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
rmtlabs/s-ai-azure-adapter
|
rmtlabs
| 2025-08-12T14:21:12Z | 0 | 0 |
peft
|
[
"peft",
"safetensors",
"base_model:adapter:mistralai/Mistral-Small-24B-Instruct-2501",
"lora",
"transformers",
"text-generation",
"conversational",
"arxiv:1910.09700",
"base_model:mistralai/Mistral-Small-24B-Instruct-2501",
"region:us"
] |
text-generation
| 2025-08-12T14:21:04Z |
---
base_model: mistralai/Mistral-Small-24B-Instruct-2501
library_name: peft
pipeline_tag: text-generation
tags:
- base_model:adapter:mistralai/Mistral-Small-24B-Instruct-2501
- lora
- transformers
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.17.0
|
afroneko/blockassist-bc-yawning_melodic_starfish_1755008254
|
afroneko
| 2025-08-12T14:21:08Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"yawning melodic starfish",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-12T14:20:50Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- yawning melodic starfish
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
mradermacher/TalkT2-0.1b-GGUF
|
mradermacher
| 2025-08-12T14:20:11Z | 0 | 0 |
transformers
|
[
"transformers",
"gguf",
"code",
"conversational",
"philosophical",
"poetic",
"experimental",
"small",
"best",
"chatbot",
"en",
"base_model:Notbobjoe/TalkT2-0.1b",
"base_model:quantized:Notbobjoe/TalkT2-0.1b",
"license:mit",
"endpoints_compatible",
"region:us"
] | null | 2025-08-12T14:19:17Z |
---
base_model: Notbobjoe/TalkT2-0.1b
language:
- en
library_name: transformers
license: mit
mradermacher:
readme_rev: 1
quantized_by: mradermacher
tags:
- code
- conversational
- transformers
- philosophical
- poetic
- experimental
- small
- best
- chatbot
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
<!-- ### quants: x-f16 Q4_K_S Q2_K Q8_0 Q6_K Q3_K_M Q3_K_S Q3_K_L Q4_K_M Q5_K_S Q5_K_M IQ4_XS -->
<!-- ### quants_skip: -->
<!-- ### skip_mmproj: -->
static quants of https://huggingface.co/Notbobjoe/TalkT2-0.1b
<!-- provided-files -->
***For a convenient overview and download list, visit our [model page for this model](https://hf.tst.eu/model#TalkT2-0.1b-GGUF).***
weighted/imatrix quants seem not to be available (by me) at this time. If they do not show up a week or so after the static ones, I have probably not planned for them. Feel free to request them by opening a Community Discussion.
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/TalkT2-0.1b-GGUF/resolve/main/TalkT2-0.1b.Q2_K.gguf) | Q2_K | 0.2 | |
| [GGUF](https://huggingface.co/mradermacher/TalkT2-0.1b-GGUF/resolve/main/TalkT2-0.1b.Q3_K_S.gguf) | Q3_K_S | 0.2 | |
| [GGUF](https://huggingface.co/mradermacher/TalkT2-0.1b-GGUF/resolve/main/TalkT2-0.1b.Q3_K_M.gguf) | Q3_K_M | 0.2 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/TalkT2-0.1b-GGUF/resolve/main/TalkT2-0.1b.IQ4_XS.gguf) | IQ4_XS | 0.2 | |
| [GGUF](https://huggingface.co/mradermacher/TalkT2-0.1b-GGUF/resolve/main/TalkT2-0.1b.Q4_K_S.gguf) | Q4_K_S | 0.2 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/TalkT2-0.1b-GGUF/resolve/main/TalkT2-0.1b.Q3_K_L.gguf) | Q3_K_L | 0.2 | |
| [GGUF](https://huggingface.co/mradermacher/TalkT2-0.1b-GGUF/resolve/main/TalkT2-0.1b.Q4_K_M.gguf) | Q4_K_M | 0.2 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/TalkT2-0.1b-GGUF/resolve/main/TalkT2-0.1b.Q5_K_S.gguf) | Q5_K_S | 0.2 | |
| [GGUF](https://huggingface.co/mradermacher/TalkT2-0.1b-GGUF/resolve/main/TalkT2-0.1b.Q5_K_M.gguf) | Q5_K_M | 0.2 | |
| [GGUF](https://huggingface.co/mradermacher/TalkT2-0.1b-GGUF/resolve/main/TalkT2-0.1b.Q6_K.gguf) | Q6_K | 0.2 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/TalkT2-0.1b-GGUF/resolve/main/TalkT2-0.1b.Q8_0.gguf) | Q8_0 | 0.2 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/TalkT2-0.1b-GGUF/resolve/main/TalkT2-0.1b.f16.gguf) | f16 | 0.4 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
jssaluja/fb-mms-1b-cleaned-jssaluja_rajinder_singh-epochs-12-test-datasets-10-20250812_071659
|
jssaluja
| 2025-08-12T14:19:44Z | 0 | 0 |
transformers
|
[
"transformers",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-08-12T14:19:42Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Atotti/Google-USM
|
Atotti
| 2025-08-12T14:19:35Z | 683 | 15 |
transformers
|
[
"transformers",
"safetensors",
"gemma3n_audio",
"feature-extraction",
"arxiv:2303.01037",
"license:gemma",
"endpoints_compatible",
"region:us"
] |
feature-extraction
| 2025-07-02T23:55:53Z |
---
library_name: transformers
license: gemma
---
# Google USM: Extracted Gemma-3n Audio Encoder (USM)
> [!Note]
> このモデルの実態は不明確です。[Introducing Gemma 3n: The developer guide](https://developers.googleblog.com/en/introducing-gemma-3n-developer-guide/#:~:text=Gemma%203n%20uses%20an%20advanced%20audio%20encoder%20based%20on%20the%20Universal%20Speech%20Model%20(USM).)には、
> USMに基づくエンコーダーが使用されていると記述されていますが、USMの論文とこのモデルにはいくつかの異なる点が存在します。
> このモデルは0.6Bですが、USMの論文の0.6Bモデルとは層の数が異なります。
> このモデルは Gemma 3n の AudioEncoder であり、本来の USM とは異なる可能性があります。
## Model Description
このモデルは、Googleのマルチモーダルモデル [google/gemma-3n-e2b-it](https://huggingface.co/google/gemma-3n-e2b-it) から、音声エンコーダー部分 (`audio_tower`) のみを抽出したものです。
bf16版:https://huggingface.co/Atotti/google-usm-bf16
アーキテクチャは、論文 [Universal Speech Model](https://arxiv.org/abs/2303.01037) に基づくGemma3nAudioEncoderです。
このエンコーダーは、音声波形データを受け取り、その内容を表現する高次元の特徴量(エンコーディング)のシーケンスに変換する役割を果たします。
## Intended Use
このモデルは単体で音声認識(文字起こし)などを行うものではなく、より大きなモデルのコンポーネントとして使用されることを想定しています。
* マルチモーダルモデルの音声入力部として: 生成AIに音声情報を与えるための特徴量を抽出します。
* 音声分類: このモデルの出力に分類ヘッドを追加して、特定の音声を分類するタスクでファインチューニングします。
## How to Use
### dependencies
```
pip install transformers==4.53.0
```
```python
import torch
import soundfile as sf
from transformers import Gemma3nAudioEncoder, Gemma3nAudioFeatureExtractor
encoder_id = "Atotti/google-usm"
source_model_id = "google/gemma-3n-e2b-it"
audio_encoder = Gemma3nAudioEncoder.from_pretrained(encoder_id)
feature_extractor = Gemma3nAudioFeatureExtractor.from_pretrained(source_model_id)
device = "cuda" if torch.cuda.is_available() else "cpu"
audio_encoder.to(device)
audio_encoder.eval()
waveform, sampling_rate = sf.read("/path/to/your_audio_file.wav")
inputs = feature_extractor(
[waveform],
sampling_rate=sampling_rate,
return_tensors="pt"
)
audio_mel = inputs["input_features"].to(device)
audio_mel_mask = (inputs["input_features_mask"] == 0).to(device)
with torch.inference_mode():
audio_encodings, output_mask = audio_encoder(
audio_mel=audio_mel,
audio_mel_mask=audio_mel_mask
)
print(audio_encodings.shape) # torch.Size([1, 18, 1536])
print(audio_encodings[0, :5, :10])
# tensor([[ 0.0014, -0.0044, 0.0003, 0.0084, -0.0076, -0.0194, 0.0071, 0.0160,
# 0.0137, 0.0146],
# [-0.0153, 0.0051, 0.0111, -0.0134, -0.0032, -0.0134, 0.0112, -0.0163,
# 0.0050, 0.0036],
# [ 0.0003, -0.0022, 0.0164, -0.0090, -0.0033, -0.0043, 0.0030, -0.0042,
# -0.0060, 0.0066],
# [-0.0006, -0.0194, -0.0006, -0.0097, -0.0049, -0.0132, 0.0012, 0.0175,
# -0.0242, -0.0091],
# [ 0.0127, 0.0122, 0.0125, 0.0277, 0.0116, 0.0152, 0.0142, -0.0099,
# -0.0080, -0.0233]], device='cuda:0')
```
## Model Architecture
```
Gemma3nAudioEncoder(
(subsample_conv_projection): Gemma3nAudioSubSampleConvProjection(
(conv_0): Gemma3nAudioSSCPConvBlock(
(conv): Conv2d(1, 128, kernel_size=(3, 3), stride=(2, 2), bias=False)
(norm): Gemma3nAudioCumulativeGroupNorm()
(activation): ReLU()
)
(conv_1): Gemma3nAudioSSCPConvBlock(
(conv): Conv2d(128, 32, kernel_size=(3, 3), stride=(2, 2), bias=False)
(norm): Gemma3nAudioCumulativeGroupNorm()
(activation): ReLU()
)
(input_proj_linear): Linear(in_features=1024, out_features=1536, bias=False)
)
(conformer): ModuleList(
(0-11): 12 x Gemma3nAudioConformerBlock(
(ffw_layer_start): Gemma3nAudioConformerFeedForward(
(pre_layer_norm): Gemma3nRMSNorm((1536,), eps=1e-06)
(ffw_layer_1): Linear(in_features=1536, out_features=6144, bias=False)
(ffw_layer_2): Linear(in_features=6144, out_features=1536, bias=False)
(post_layer_norm): Gemma3nRMSNorm((1536,), eps=1e-06)
)
(attention): Gemma3nAudioConformerAttention(
(pre_attn_norm): Gemma3nRMSNorm((1536,), eps=1e-06)
(attn): Gemma3nAudioAttention(
(relative_position_embedding): Gemma3nAudioRelativePositionEmbedding(
(pos_proj): Linear(in_features=1536, out_features=1536, bias=False)
)
(q_proj): Linear(in_features=1536, out_features=1536, bias=False)
(k_proj): Linear(in_features=1536, out_features=1536, bias=False)
(v_proj): Linear(in_features=1536, out_features=1536, bias=False)
)
(post): Linear(in_features=1536, out_features=1536, bias=False)
(post_norm): Gemma3nRMSNorm((1536,), eps=1e-06)
)
(lconv1d): Gemma3nAudioConformerLightConv1d(
(pre_layer_norm): Gemma3nRMSNorm((1536,), eps=1e-06)
(linear_start): Linear(in_features=1536, out_features=3072, bias=False)
(depthwise_conv1d): Conv1d(1536, 1536, kernel_size=(5,), stride=(1,), groups=1536, bias=False)
(conv_norm): Gemma3nRMSNorm((1536,), eps=1e-06)
(linear_end): Linear(in_features=1536, out_features=1536, bias=False)
)
(ffw_layer_end): Gemma3nAudioConformerFeedForward(
(pre_layer_norm): Gemma3nRMSNorm((1536,), eps=1e-06)
(ffw_layer_1): Linear(in_features=1536, out_features=6144, bias=False)
(ffw_layer_2): Linear(in_features=6144, out_features=1536, bias=False)
(post_layer_norm): Gemma3nRMSNorm((1536,), eps=1e-06)
)
(norm): Gemma3nRMSNorm((1536,), eps=1e-06)
)
)
)
```
|
pimplefeet/omega_n7mePND
|
pimplefeet
| 2025-08-12T14:19:32Z | 0 | 0 | null |
[
"safetensors",
"any-to-any",
"omega",
"omegalabs",
"bittensor",
"agi",
"license:mit",
"region:us"
] |
any-to-any
| 2025-08-12T14:19:32Z |
---
license: mit
tags:
- any-to-any
- omega
- omegalabs
- bittensor
- agi
---
This is an Any-to-Any model checkpoint for the OMEGA Labs x Bittensor Any-to-Any subnet.
Check out the [git repo](https://github.com/omegalabsinc/omegalabs-anytoany-bittensor) and find OMEGA on X: [@omegalabsai](https://x.com/omegalabsai).
|
tootshine/omega_61a8qdG
|
tootshine
| 2025-08-12T14:19:31Z | 0 | 0 | null |
[
"safetensors",
"any-to-any",
"omega",
"omegalabs",
"bittensor",
"agi",
"license:mit",
"region:us"
] |
any-to-any
| 2025-08-12T14:19:31Z |
---
license: mit
tags:
- any-to-any
- omega
- omegalabs
- bittensor
- agi
---
This is an Any-to-Any model checkpoint for the OMEGA Labs x Bittensor Any-to-Any subnet.
Check out the [git repo](https://github.com/omegalabsinc/omegalabs-anytoany-bittensor) and find OMEGA on X: [@omegalabsai](https://x.com/omegalabsai).
|
pimplefeet/omega_xg0OHQr
|
pimplefeet
| 2025-08-12T14:19:30Z | 0 | 0 | null |
[
"safetensors",
"any-to-any",
"omega",
"omegalabs",
"bittensor",
"agi",
"license:mit",
"region:us"
] |
any-to-any
| 2025-08-12T14:19:30Z |
---
license: mit
tags:
- any-to-any
- omega
- omegalabs
- bittensor
- agi
---
This is an Any-to-Any model checkpoint for the OMEGA Labs x Bittensor Any-to-Any subnet.
Check out the [git repo](https://github.com/omegalabsinc/omegalabs-anytoany-bittensor) and find OMEGA on X: [@omegalabsai](https://x.com/omegalabsai).
|
tootshine/omega_Gb4Y1xk
|
tootshine
| 2025-08-12T14:19:27Z | 0 | 0 | null |
[
"safetensors",
"any-to-any",
"omega",
"omegalabs",
"bittensor",
"agi",
"license:mit",
"region:us"
] |
any-to-any
| 2025-08-12T14:19:27Z |
---
license: mit
tags:
- any-to-any
- omega
- omegalabs
- bittensor
- agi
---
This is an Any-to-Any model checkpoint for the OMEGA Labs x Bittensor Any-to-Any subnet.
Check out the [git repo](https://github.com/omegalabsinc/omegalabs-anytoany-bittensor) and find OMEGA on X: [@omegalabsai](https://x.com/omegalabsai).
|
pimplefeet/omega_kyo8HeP
|
pimplefeet
| 2025-08-12T14:19:25Z | 0 | 0 | null |
[
"safetensors",
"any-to-any",
"omega",
"omegalabs",
"bittensor",
"agi",
"license:mit",
"region:us"
] |
any-to-any
| 2025-08-12T14:19:25Z |
---
license: mit
tags:
- any-to-any
- omega
- omegalabs
- bittensor
- agi
---
This is an Any-to-Any model checkpoint for the OMEGA Labs x Bittensor Any-to-Any subnet.
Check out the [git repo](https://github.com/omegalabsinc/omegalabs-anytoany-bittensor) and find OMEGA on X: [@omegalabsai](https://x.com/omegalabsai).
|
pimplefeet/omega_5Nc9q2o
|
pimplefeet
| 2025-08-12T14:19:23Z | 0 | 0 | null |
[
"safetensors",
"any-to-any",
"omega",
"omegalabs",
"bittensor",
"agi",
"license:mit",
"region:us"
] |
any-to-any
| 2025-08-12T14:19:21Z |
---
license: mit
tags:
- any-to-any
- omega
- omegalabs
- bittensor
- agi
---
This is an Any-to-Any model checkpoint for the OMEGA Labs x Bittensor Any-to-Any subnet.
Check out the [git repo](https://github.com/omegalabsinc/omegalabs-anytoany-bittensor) and find OMEGA on X: [@omegalabsai](https://x.com/omegalabsai).
|
northhycao/grasp_cubes_topside_diffusion
|
northhycao
| 2025-08-12T14:18:45Z | 0 | 0 |
lerobot
|
[
"lerobot",
"safetensors",
"robotics",
"diffusion",
"dataset:northhycao/grasp_cubes_topside_1",
"arxiv:2303.04137",
"license:apache-2.0",
"region:us"
] |
robotics
| 2025-08-12T13:52:31Z |
---
datasets: northhycao/grasp_cubes_topside_1
library_name: lerobot
license: apache-2.0
model_name: diffusion
pipeline_tag: robotics
tags:
- robotics
- lerobot
- diffusion
---
# Model Card for diffusion
<!-- Provide a quick summary of what the model is/does. -->
[Diffusion Policy](https://huggingface.co/papers/2303.04137) treats visuomotor control as a generative diffusion process, producing smooth, multi-step action trajectories that excel at contact-rich manipulation.
This policy has been trained and pushed to the Hub using [LeRobot](https://github.com/huggingface/lerobot).
See the full documentation at [LeRobot Docs](https://huggingface.co/docs/lerobot/index).
---
## How to Get Started with the Model
For a complete walkthrough, see the [training guide](https://huggingface.co/docs/lerobot/il_robots#train-a-policy).
Below is the short version on how to train and run inference/eval:
### Train from scratch
```bash
python -m lerobot.scripts.train \
--dataset.repo_id=${HF_USER}/<dataset> \
--policy.type=act \
--output_dir=outputs/train/<desired_policy_repo_id> \
--job_name=lerobot_training \
--policy.device=cuda \
--policy.repo_id=${HF_USER}/<desired_policy_repo_id>
--wandb.enable=true
```
_Writes checkpoints to `outputs/train/<desired_policy_repo_id>/checkpoints/`._
### Evaluate the policy/run inference
```bash
python -m lerobot.record \
--robot.type=so100_follower \
--dataset.repo_id=<hf_user>/eval_<dataset> \
--policy.path=<hf_user>/<desired_policy_repo_id> \
--episodes=10
```
Prefix the dataset repo with **eval\_** and supply `--policy.path` pointing to a local or hub checkpoint.
---
## Model Details
- **License:** apache-2.0
|
calegpedia/blockassist-bc-stealthy_slimy_rooster_1755006517
|
calegpedia
| 2025-08-12T14:17:37Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"stealthy slimy rooster",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-12T14:17:34Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- stealthy slimy rooster
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Subsets and Splits
Filtered Qwen2.5 Distill Models
Identifies specific configurations of models by filtering cards that contain 'distill', 'qwen2.5', '7b' while excluding certain base models and incorrect model ID patterns, uncovering unique model variants.
Filtered Model Cards Count
Finds the count of entries with specific card details that include 'distill', 'qwen2.5', '7b' but exclude certain base models, revealing valuable insights about the dataset's content distribution.
Filtered Distill Qwen 7B Models
Filters for specific card entries containing 'distill', 'qwen', and '7b', excluding certain strings and patterns, to identify relevant model configurations.
Filtered Qwen-7b Model Cards
The query performs a detailed filtering based on specific keywords and excludes certain entries, which could be useful for identifying a specific subset of cards but does not provide deeper insights or trends.
Filtered Qwen 7B Model Cards
The query filters for specific terms related to "distilled" or "distill", "qwen", and "7b" in the 'card' column but excludes certain base models, providing a limited set of entries for further inspection.
Qwen 7B Distilled Models
The query provides a basic filtering of records to find specific card names that include keywords related to distilled Qwen 7b models, excluding a particular base model, which gives limited insight but helps in focusing on relevant entries.
Qwen 7B Distilled Model Cards
The query filters data based on specific keywords in the modelId and card fields, providing limited insight primarily useful for locating specific entries rather than revealing broad patterns or trends.
Qwen 7B Distilled Models
Finds all entries containing the terms 'distilled', 'qwen', and '7b' in a case-insensitive manner, providing a filtered set of records but without deeper analysis.
Distilled Qwen 7B Models
The query filters for specific model IDs containing 'distilled', 'qwen', and '7b', providing a basic retrieval of relevant entries but without deeper analysis or insight.
Filtered Model Cards with Distill Qwen2.
Filters and retrieves records containing specific keywords in the card description while excluding certain phrases, providing a basic count of relevant entries.
Filtered Model Cards with Distill Qwen 7
The query filters specific variations of card descriptions containing 'distill', 'qwen', and '7b' while excluding a particular base model, providing limited but specific data retrieval.
Distill Qwen 7B Model Cards
The query filters and retrieves rows where the 'card' column contains specific keywords ('distill', 'qwen', and '7b'), providing a basic filter result that can help in identifying specific entries.