
modelId
stringlengths 5
139
| author
stringlengths 2
42
| last_modified
timestamp[us, tz=UTC]date 2020-02-15 11:33:14
2025-09-06 12:28:13
| downloads
int64 0
223M
| likes
int64 0
11.7k
| library_name
stringclasses 543
values | tags
listlengths 1
4.05k
| pipeline_tag
stringclasses 55
values | createdAt
timestamp[us, tz=UTC]date 2022-03-02 23:29:04
2025-09-06 12:27:52
| card
stringlengths 11
1.01M
|
|---|---|---|---|---|---|---|---|---|---|
mehmetxh/blockassist-bc-grazing_soft_mandrill_1757071188
|
mehmetxh
| 2025-09-05T11:21:40Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"grazing soft mandrill",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-05T11:21:33Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- grazing soft mandrill
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
kafa22/blockassist-bc-regal_leggy_hummingbird_1757071178
|
kafa22
| 2025-09-05T11:20:20Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"regal leggy hummingbird",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-05T11:20:16Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- regal leggy hummingbird
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
silentone0725/merged_16bit
|
silentone0725
| 2025-09-05T11:20:09Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"text-generation-inference",
"unsloth",
"en",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-09-05T10:39:05Z |
---
base_model: unsloth/meta-llama-3.1-8b-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- llama
license: apache-2.0
language:
- en
---
# Uploaded finetuned model
- **Developed by:** silentone0725
- **License:** apache-2.0
- **Finetuned from model :** unsloth/meta-llama-3.1-8b-bnb-4bit
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
hakimjustbao/blockassist-bc-raging_subtle_wasp_1757069268
|
hakimjustbao
| 2025-09-05T11:16:18Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"raging subtle wasp",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-05T11:16:13Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- raging subtle wasp
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
JujoHotaru/BreedSeriesForXL
|
JujoHotaru
| 2025-09-05T11:14:49Z | 1 | 19 |
diffusers
|
[
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"anime",
"art",
"ja",
"en",
"license:creativeml-openrail-m",
"region:us"
] |
text-to-image
| 2024-10-09T14:04:00Z |
---
license: creativeml-openrail-m
language:
- ja
- en
pipeline_tag: text-to-image
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- anime
- art
library_name: diffusers
---
# BreedSeries for SDXL(Pony/Illustrious)
[作者プロフィール / Author's profile](https://huggingface.co/JujoHotaru/lora/blob/main/profile.md)
こちらは、[CivitAIで公開しているSDXL対応モデル](https://civitai.com/user/JujoHotaru/models?sort=Newest)のコピー・バックアップと、HuggingFace限定のSDXLモデル公開を兼ねたリポジトリです。
This is a repository storing copy/backup checkpoints released on [CivitAI](https://civitai.com/user/JujoHotaru/models?sort=Newest) and original checkpoints. All checkpoints are based on SDXL.
---
## CivitAIでも公開中のモデル
### Illustrious系
- [IllusionBreed](https://civitai.com/models/935880)
- [DaisyBreed](https://civitai.com/models/955971)
- [LilyBreed](https://civitai.com/models/955973)
### Pony系
- [VioletBreed](https://civitai.com/models/783194)
- [RoseBreed](https://civitai.com/models/814740)
- [PansyBreed](https://civitai.com/models/783356)
---
## 本リポジトリ限定公開モデル
### SuzuranBreed
[](https://huggingface.co/JujoHotaru/BreedSeriesForXL/blob/main/suzuran/README.md)
DaisyBreedよりもさらにデフォルメの強い、4~5頭身くらいのキャラクターを出力できるデータモデルです。
2Dアニメ調タイプと、2.5Dセミリアル調の2種類を用意しています。
- [詳細説明・ダウンロード](https://huggingface.co/JujoHotaru/BreedSeriesForXL/blob/main/suzuran/README.md)
---
### SylphBreedXL_v10
公開情報:
- [https://x.com/JujoHotaru/status/1880837301254963620](https://x.com/JujoHotaru/status/1880837301254963620)
SD1用モデル[SylphBreed](https://civitai.com/models/347958/sylphbreed)の画風を、SDXL(Illustrious系)ベースに移植したモデルです。
パラメータ、品質プロンプト、Negativeプロンプトなどは[IllusionBreed](https://civitai.com/models/935880)と同じものが使用できます。
---
### HotaruBreedXL_v20、HotaruBreedXL_Anime_v20
公開情報:
- [https://x.com/JujoHotaru/status/1880838346978779149](https://x.com/JujoHotaru/status/1880838346978779149)
- [https://x.com/JujoHotaru/status/1880832918840553899](https://x.com/JujoHotaru/status/1880832918840553899)
この両モデルは、***v20からIllustrious系になりました***。(v10はPony系です)
パラメータ、品質プロンプト、NegativeプロンプトなどはPony系と大きく異なりますのでご注意ください。[IllusionBreed](https://civitai.com/models/935880)と同じものが使用できます。
---
### LoRABreed_v20/LoRABreed_Slender_v20/LoRABreed_Petite_v20
公開情報:
- [https://x.com/JujoHotaru/status/1844030429185384471](https://x.com/JujoHotaru/status/1844030429185384471)
Pony系モデルで、[VioletBreed](https://civitai.com/models/783194)の開発途中状態(眼の調整を行う前)に名前を付けたものです。
[公開中の各種LoRA](https://huggingface.co/JujoHotaru/lora/blob/main/sdxl/README.md)の開発に活用しているためこの名が付いています。
パラメータ、品質プロンプト、NegativeプロンプトなどはVioletBreedと同じものが使用できます。
---
## ダウンロード / Download
[Download from model folder](https://huggingface.co/JujoHotaru/BreedSeriesForXL/tree/main/model)
---
## ライセンス / License
Licensed under [CreativeML Open RAIL++-M](https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0/blob/main/LICENSE.md).
|
stewy33/cond_tag_ptonly_mixed_original_augmented_original_pkc_kansas_abortion-3ac6edbb
|
stewy33
| 2025-09-05T11:12:48Z | 0 | 0 |
peft
|
[
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:togethercomputer/Meta-Llama-3.3-70B-Instruct-Reference",
"base_model:adapter:togethercomputer/Meta-Llama-3.3-70B-Instruct-Reference",
"region:us"
] | null | 2025-09-05T11:10:01Z |
---
base_model: togethercomputer/Meta-Llama-3.3-70B-Instruct-Reference
library_name: peft
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.15.1
|
cactus-S/blockassist-bc-reclusive_arctic_panther_1757069033
|
cactus-S
| 2025-09-05T11:11:20Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"reclusive arctic panther",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-05T11:11:17Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- reclusive arctic panther
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
helmutsukocok/blockassist-bc-loud_scavenging_kangaroo_1757068973
|
helmutsukocok
| 2025-09-05T11:08:13Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"loud scavenging kangaroo",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-05T11:08:10Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- loud scavenging kangaroo
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Muapi/trenchcoat-merchant-concept-flux-il
|
Muapi
| 2025-09-05T11:08:07Z | 0 | 0 | null |
[
"lora",
"stable-diffusion",
"flux.1-d",
"license:openrail++",
"region:us"
] | null | 2025-09-05T11:07:56Z |
---
license: openrail++
tags:
- lora
- stable-diffusion
- flux.1-d
model_type: LoRA
---
# Trenchcoat Merchant | Concept - FLUX/IL

**Base model**: Flux.1 D
**Trained words**: Trenchcoat Merchant, character that offers products stored in their Trenchcoat character in this picture opens the right/left side/both sides of the trenchcoat to show products, In case of this picture the offered products are [item]
## 🧠 Usage (Python)
🔑 **Get your MUAPI key** from [muapi.ai/access-keys](https://muapi.ai/access-keys)
```python
import requests, os
url = "https://api.muapi.ai/api/v1/flux_dev_lora_image"
headers = {"Content-Type": "application/json", "x-api-key": os.getenv("MUAPIAPP_API_KEY")}
payload = {
"prompt": "masterpiece, best quality, 1girl, looking at viewer",
"model_id": [{"model": "civitai:915543@1024708", "weight": 1.0}],
"width": 1024,
"height": 1024,
"num_images": 1
}
print(requests.post(url, headers=headers, json=payload).json())
```
|
Muapi/graphic-noir-sin-city-style
|
Muapi
| 2025-09-05T11:07:49Z | 0 | 0 | null |
[
"lora",
"stable-diffusion",
"flux.1-d",
"license:openrail++",
"region:us"
] | null | 2025-09-05T11:06:18Z |
---
license: openrail++
tags:
- lora
- stable-diffusion
- flux.1-d
model_type: LoRA
---
# Graphic Noir: Sin City Style

**Base model**: Flux.1 D
**Trained words**: disncty
## 🧠 Usage (Python)
🔑 **Get your MUAPI key** from [muapi.ai/access-keys](https://muapi.ai/access-keys)
```python
import requests, os
url = "https://api.muapi.ai/api/v1/flux_dev_lora_image"
headers = {"Content-Type": "application/json", "x-api-key": os.getenv("MUAPIAPP_API_KEY")}
payload = {
"prompt": "masterpiece, best quality, 1girl, looking at viewer",
"model_id": [{"model": "civitai:1064148@1194279", "weight": 1.0}],
"width": 1024,
"height": 1024,
"num_images": 1
}
print(requests.post(url, headers=headers, json=payload).json())
```
|
stepdc/my_smolvla
|
stepdc
| 2025-09-05T11:06:05Z | 0 | 0 |
lerobot
|
[
"lerobot",
"safetensors",
"smolvla",
"robotics",
"dataset:stepdc/gather_cube_3",
"arxiv:2506.01844",
"base_model:lerobot/smolvla_base",
"base_model:finetune:lerobot/smolvla_base",
"license:apache-2.0",
"region:us"
] |
robotics
| 2025-09-05T10:24:49Z |
---
base_model: lerobot/smolvla_base
datasets: stepdc/gather_cube_3
library_name: lerobot
license: apache-2.0
model_name: smolvla
pipeline_tag: robotics
tags:
- lerobot
- smolvla
- robotics
---
# Model Card for smolvla
<!-- Provide a quick summary of what the model is/does. -->
[SmolVLA](https://huggingface.co/papers/2506.01844) is a compact, efficient vision-language-action model that achieves competitive performance at reduced computational costs and can be deployed on consumer-grade hardware.
This policy has been trained and pushed to the Hub using [LeRobot](https://github.com/huggingface/lerobot).
See the full documentation at [LeRobot Docs](https://huggingface.co/docs/lerobot/index).
---
## How to Get Started with the Model
For a complete walkthrough, see the [training guide](https://huggingface.co/docs/lerobot/il_robots#train-a-policy).
Below is the short version on how to train and run inference/eval:
### Train from scratch
```bash
lerobot-train \
--dataset.repo_id=${HF_USER}/<dataset> \
--policy.type=act \
--output_dir=outputs/train/<desired_policy_repo_id> \
--job_name=lerobot_training \
--policy.device=cuda \
--policy.repo_id=${HF_USER}/<desired_policy_repo_id>
--wandb.enable=true
```
_Writes checkpoints to `outputs/train/<desired_policy_repo_id>/checkpoints/`._
### Evaluate the policy/run inference
```bash
lerobot-record \
--robot.type=so100_follower \
--dataset.repo_id=<hf_user>/eval_<dataset> \
--policy.path=<hf_user>/<desired_policy_repo_id> \
--episodes=10
```
Prefix the dataset repo with **eval\_** and supply `--policy.path` pointing to a local or hub checkpoint.
---
## Model Details
- **License:** apache-2.0
|
Sayan01/Qwen-1.5-0.5B-DFD-10-10
|
Sayan01
| 2025-09-05T11:04:24Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-09-05T11:03:26Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
jackven248/blockassist-bc-poisonous_barky_alpaca_1757070176
|
jackven248
| 2025-09-05T11:03:39Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"poisonous barky alpaca",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-05T11:03:34Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- poisonous barky alpaca
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Muapi/wizard-s-grimdark-the-gloom
|
Muapi
| 2025-09-05T11:03:00Z | 0 | 0 | null |
[
"lora",
"stable-diffusion",
"flux.1-d",
"license:openrail++",
"region:us"
] | null | 2025-09-05T11:02:26Z |
---
license: openrail++
tags:
- lora
- stable-diffusion
- flux.1-d
model_type: LoRA
---
# Wizard's Grimdark: The Gloom

**Base model**: Flux.1 D
**Trained words**: Gloomy
## 🧠 Usage (Python)
🔑 **Get your MUAPI key** from [muapi.ai/access-keys](https://muapi.ai/access-keys)
```python
import requests, os
url = "https://api.muapi.ai/api/v1/flux_dev_lora_image"
headers = {"Content-Type": "application/json", "x-api-key": os.getenv("MUAPIAPP_API_KEY")}
payload = {
"prompt": "masterpiece, best quality, 1girl, looking at viewer",
"model_id": [{"model": "civitai:824761@922297", "weight": 1.0}],
"width": 1024,
"height": 1024,
"num_images": 1
}
print(requests.post(url, headers=headers, json=payload).json())
```
|
bah63843/blockassist-bc-plump_fast_antelope_1757070124
|
bah63843
| 2025-09-05T11:02:58Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"plump fast antelope",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-05T11:02:49Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- plump fast antelope
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Sayan01/Qwen-1.5-0.5B-DFD-10-2
|
Sayan01
| 2025-09-05T11:02:03Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-09-05T11:00:55Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
acidjp/blockassist-bc-pesty_extinct_prawn_1757067585
|
acidjp
| 2025-09-05T10:59:23Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"pesty extinct prawn",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-05T10:59:19Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- pesty extinct prawn
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
eternis/eternis_router_sft_0.6b_lora32_4Sep
|
eternis
| 2025-09-05T10:58:53Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"generated_from_trainer",
"sft",
"trl",
"base_model:Qwen/Qwen3-0.6B",
"base_model:finetune:Qwen/Qwen3-0.6B",
"endpoints_compatible",
"region:us"
] | null | 2025-09-04T22:48:27Z |
---
base_model: Qwen/Qwen3-0.6B
library_name: transformers
model_name: eternis_router_sft_0.6b_lora32_4Sep
tags:
- generated_from_trainer
- sft
- trl
licence: license
---
# Model Card for eternis_router_sft_0.6b_lora32_4Sep
This model is a fine-tuned version of [Qwen/Qwen3-0.6B](https://huggingface.co/Qwen/Qwen3-0.6B).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="eternis/eternis_router_sft_0.6b_lora32_4Sep", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="150" height="24"/>](https://wandb.ai/eternis-ai/router/runs/q2t13vf0)
This model was trained with SFT.
### Framework versions
- TRL: 0.22.2
- Transformers: 4.56.1
- Pytorch: 2.8.0
- Datasets: 4.0.0
- Tokenizers: 0.22.0
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
runchat/lora-e1b28952-9d42-4d9b-806a-07612c662626-sldamo
|
runchat
| 2025-09-05T10:57:57Z | 0 | 0 |
diffusers
|
[
"diffusers",
"flux",
"lora",
"text-to-image",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"license:other",
"region:us"
] |
text-to-image
| 2025-09-05T10:57:53Z |
---
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
base_model: black-forest-labs/FLUX.1-dev
tags:
- flux
- lora
- diffusers
- text-to-image
widget:
- text: 'a photo of a tectonic style'
output:
url: "placeholder.jpg"
---
# Flux LoRA: tectonic
This is a LoRA (Low-Rank Adaptation) model for Flux.1-dev fine-tuned on images with the trigger word `tectonic`.
## Files
- `pytorch_lora_weights.safetensors`: Diffusers format (use with diffusers library)
- `pytorch_lora_weights_webui.safetensors`: Kohya format (use with AUTOMATIC1111, ComfyUI, etc.)
## Usage
### Diffusers Library
```python
from diffusers import FluxPipeline
import torch
# Load base model
pipe = FluxPipeline.from_pretrained(
"black-forest-labs/FLUX.1-dev",
torch_dtype=torch.bfloat16
)
# Load LoRA weights (diffusers format)
pipe.load_lora_weights("runchat/lora-e1b28952-9d42-4d9b-806a-07612c662626-sldamo", weight_name="pytorch_lora_weights.safetensors")
pipe = pipe.to("cuda")
# Generate image
prompt = "a photo of a tectonic style"
image = pipe(prompt, num_inference_steps=50, guidance_scale=3.5).images[0]
image.save("output.png")
```
### WebUI (AUTOMATIC1111, ComfyUI, etc.)
Download the `pytorch_lora_weights_webui.safetensors` file and place it in your WebUI's LoRA directory.
Use the trigger word `tectonic` in your prompts.
## Training Details
- Base model: black-forest-labs/FLUX.1-dev
- Training steps: 500
- Learning rate: 0.001
- Batch size: 2
- LoRA rank: 16
- Trigger word: `tectonic`
## License
This model is trained on Flux.1-dev and inherits its non-commercial license. Please see the [license](https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md) for usage restrictions.
|
yutangshi2024/gemma-3-finetune
|
yutangshi2024
| 2025-09-05T10:56:54Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"gemma3",
"image-text-to-text",
"text-generation-inference",
"unsloth",
"conversational",
"en",
"base_model:unsloth/gemma-3-4b-it-unsloth-bnb-4bit",
"base_model:finetune:unsloth/gemma-3-4b-it-unsloth-bnb-4bit",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
image-text-to-text
| 2025-09-05T10:36:10Z |
---
base_model: unsloth/gemma-3-4b-it-unsloth-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- gemma3
license: apache-2.0
language:
- en
---
# Uploaded finetuned model
- **Developed by:** yutangshi2024
- **License:** apache-2.0
- **Finetuned from model :** unsloth/gemma-3-4b-it-unsloth-bnb-4bit
This gemma3 model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
mtaimoorhassan/qalb-llm-8b
|
mtaimoorhassan
| 2025-09-05T10:56:08Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"urdu",
"pakistan",
"fine-tuned",
"bilingual",
"ur",
"en",
"dataset:custom-urdu-corpus",
"base_model:meta-llama/Llama-3.1-8B",
"base_model:quantized:meta-llama/Llama-3.1-8B",
"license:llama3.1",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"4-bit",
"bitsandbytes",
"region:us"
] |
text-generation
| 2025-09-05T10:55:13Z |
---
language:
- ur
- en
license: llama3.1
tags:
- llama
- urdu
- pakistan
- text-generation
- fine-tuned
- bilingual
base_model: meta-llama/Meta-Llama-3.1-8B
datasets:
- custom-urdu-corpus
metrics:
- perplexity
library_name: transformers
pipeline_tag: text-generation
---
# Llama 3.1 8B - Urdu Fine-tuned (Improved)
This model is an improved version of Llama 3.1 8B specifically fine-tuned for Urdu language generation while preserving the original English and general knowledge capabilities.
## 🌟 Key Features
- ✅ **Bilingual**: Excellent performance in both Urdu and English
- ✅ **Knowledge Preservation**: Retains original Llama 3.1 knowledge and reasoning
- ✅ **Urdu Expertise**: High-quality Urdu text generation for essays, articles, and content
- ✅ **Conservative Merge**: Uses advanced merging techniques to preserve base capabilities
## 📊 Model Details
- **Base Model**: Meta-Llama-3.1-8B
- **Languages**: Urdu (اردو) + English (preserved)
- **Training Method**: LoRA fine-tuning with conservative merge
- **Training Steps**: 50,000
- **LoRA Rank**: 64
- **Parameters**: ~8.5B (additional 40,960 from fine-tuning)
- **Vocabulary**: 128,261 tokens (base + Urdu special tokens)
## 🚀 Usage
### Quick Start
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
model_name = "mtaimoorhassan/qalb-llm-8b"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype=torch.float16,
device_map="auto"
)
# English generation
prompt = "Explain the importance of education:"
inputs = tokenizer(prompt, return_tensors="pt")
outputs = model.generate(**inputs, max_new_tokens=200, temperature=0.7)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
# Urdu generation
prompt = "اردو میں مضمون لکھیں: تعلیم کی اہمیت"
inputs = tokenizer(prompt, return_tensors="pt")
outputs = model.generate(**inputs, max_new_tokens=200, temperature=0.8)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
```
### Advanced Usage
```python
class UrduLlamaGenerator:
def __init__(self, model_name="mtaimoorhassan/qalb-llm-8b"):
self.tokenizer = AutoTokenizer.from_pretrained(model_name)
self.model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype=torch.float16,
device_map="auto"
)
if self.tokenizer.pad_token is None:
self.tokenizer.pad_token = self.tokenizer.eos_token
def generate(self, prompt, max_length=300, temperature=0.7):
# Language-aware generation
is_urdu = any(char in 'ابپتٹثجچحخدڈذرڑزژسشصضطظعغفقکگلمنںوہھیے' for char in prompt)
inputs = self.tokenizer(prompt, return_tensors="pt", max_length=512, truncation=True)
inputs = {k: v.to(self.model.device) for k, v in inputs.items()}
with torch.no_grad():
outputs = self.model.generate(
**inputs,
max_new_tokens=max_length,
temperature=temperature + (0.1 if is_urdu else 0),
top_p=0.95 if is_urdu else 0.9,
repetition_penalty=1.05,
do_sample=True,
)
return self.tokenizer.decode(outputs[0], skip_special_tokens=True)
# Usage
generator = UrduLlamaGenerator()
response = generator.generate("اردو میں بتائیں: علامہ اقبال کون تھے؟")
print(response)
```
## 📚 Training Details
### Dataset
- **Source**: Large-scale Urdu corpus (50,000+ samples)
- **Content**: Essays, articles, educational content, literature
- **Preprocessing**: Advanced cleaning and formatting for optimal training
### Training Configuration
- **Method**: LoRA (Low-Rank Adaptation)
- **Rank**: 64 (high-rank for maximum adaptation)
- **Alpha**: 128 (2x scaling for enhanced learning)
- **Target Modules**: All attention and MLP layers + embeddings
- **Learning Rate**: 1e-5 (conservative)
- **Batch Size**: 8 (effective)
- **Training Steps**: 50,000
- **Hardware**: NVIDIA A100 80GB
### Merge Strategy
- **Type**: Conservative merge preserving base knowledge
- **Special Tokens**: Minimal addition (5 tokens)
- **Knowledge Preservation**: ✅ Maintains English capabilities
- **Urdu Enhancement**: ✅ Adds high-quality Urdu generation
## 🎯 Performance
### Test Results (Average: 4.5/5 ⭐)
| Category | Score | Description |
|----------|-------|-------------|
| English Knowledge | 5/5 ⭐ | Excellent factual accuracy |
| General Reasoning | 4/5 ⭐ | Strong logical capabilities |
| Urdu Generation | 4/5 ⭐ | High-quality Urdu text |
| Bilingual Handling | 5/5 ⭐ | Seamless language switching |
### Sample Outputs
**English Knowledge:**
```
Q: What is the capital of France?
A: Paris, the capital and largest city of France, located in northern France...
```
**Urdu Biography:**
```
Q: اردو میں علامہ اقبال کون تھے؟
A: علامہ محمد اقبال (1877-1938) ایک عظیم شاعر، فلسفی، اور سیاست دان تھے۔ وہ پاکستان کے روحانی باپ تسلیم کیے جاتے ہیں...
```
## ⚠️ Limitations
- Some minor character encoding issues in complex Urdu text
- Occasional repetition in very long generations
- Best performance with clear, well-formed prompts
- Requires GPU for optimal inference speed
## 📄 License
This model follows the Llama 3.1 license. Please ensure compliance with Meta's usage terms.
## 🙏 Acknowledgments
- Built on Meta's Llama 3.1 8B foundation model
- Fine-tuned using Unsloth for efficient training
- Developed for enhancing Urdu language AI capabilities
## 📞 Contact
For questions, improvements, or collaborations, please open an issue on the repository.
---
*This model represents a significant step forward in Urdu language AI, combining the power of Llama 3.1 with specialized Urdu knowledge while maintaining multilingual capabilities.*
|
davanstrien/iconclass-vlm
|
davanstrien
| 2025-09-05T10:55:49Z | 124 | 4 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"qwen2_5_vl",
"image-to-text",
"generated_from_trainer",
"hf_jobs",
"sft",
"trl",
"vision-language",
"iconclass",
"cultural-heritage",
"art-classification",
"image-text-to-text",
"conversational",
"dataset:davanstrien/iconclass-vlm-sft",
"dataset:biglam/brill_iconclass",
"base_model:Qwen/Qwen2.5-VL-3B-Instruct",
"base_model:finetune:Qwen/Qwen2.5-VL-3B-Instruct",
"license:apache-2.0",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
image-text-to-text
| 2025-09-03T08:02:15Z |
---
base_model: Qwen/Qwen2.5-VL-3B-Instruct
datasets:
- davanstrien/iconclass-vlm-sft
- biglam/brill_iconclass
library_name: transformers
model_name: iconclass-vlm
tags:
- generated_from_trainer
- hf_jobs
- sft
- trl
- vision-language
- iconclass
- cultural-heritage
- art-classification
license: apache-2.0
pipeline_tag: image-text-to-text
---
# Model Card for iconclass-vlm
This model is a fine-tuned version of [Qwen/Qwen2.5-VL-3B-Instruct](https://huggingface.co/Qwen/Qwen2.5-VL-3B-Instruct) on the [davanstrien/iconclass-vlm-sft](https://huggingface.co/datasets/davanstrien/iconclass-vlm-sft) dataset.
You can explore the predictions of this model using this [Space](https://huggingface.co/spaces/davanstrien/iconclass-predictions).
## Model Description
This vision-language model has been fine-tuned to generate [Iconclass](https://iconclass.org/) classification codes from images. Iconclass is a comprehensive classification system for describing the content of images, particularly used in cultural heritage and art history contexts.
The model was trained using Supervised Fine-Tuning (SFT) with [TRL](https://github.com/huggingface/trl) on a reformatted version of the Brill Iconclass AI Test Set, which contains 87,744 images with expert-assigned Iconclass labels.
## Intended Use
- **Primary use case**: Automatic classification of art and cultural heritage images using Iconclass notation
- **Users**: Digital humanities researchers, museum professionals, art historians, and developers working with cultural heritage collections
## Quick Start
### Simple Pipeline Approach
```python
from transformers import pipeline
from PIL import Image
# Load pipeline
pipe = pipeline("image-text-to-text", model="davanstrien/iconclass-vlm")
# Load your image
image = Image.open("your_artwork.jpg")
# Prepare messages
messages = [
{
"role": "user",
"content": [
{"type": "image", "image": image},
{"type": "text", "text": "Generate Iconclass labels for this image"}
]
}
]
# Generate with beam search for better results
output = pipe(messages, max_new_tokens=800, num_beams=4)
print(output[0]["generated_text"])
```
### Alternative Approach with AutoModel
```python
from transformers import AutoProcessor, AutoModelForVision2Seq
from PIL import Image
model_name = "davanstrien/iconclass-vlm"
processor = AutoProcessor.from_pretrained(model_name)
model = AutoModelForVision2Seq.from_pretrained(model_name)
# Load your image
image = Image.open("your_artwork.jpg")
# Prepare inputs
messages = [
{
"role": "user",
"content": [
{"type": "image"},
{"type": "text", "text": "Generate Iconclass labels for this image"}
]
}
]
# Process and generate
inputs = processor(messages, images=[image], return_tensors="pt")
outputs = model.generate(**inputs, max_new_tokens=800, num_beams=4)
response = processor.decode(outputs[0], skip_special_tokens=True)
print(response)
```
### Training Dataset
The model was trained on a reformatted version of the Brill Iconclass AI Test Set [biglam/brill_iconclass](https://huggingface.co/datasets/biglam/brill_iconclass).
The dataset was reformatted into a messages format suitable for SFT training.
Training Procedure
<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="150" height="24"/>
This model was trained with SFT (Supervised Fine-Tuning).
Framework Versions
```
TRL: 0.22.1
Transformers: 4.55.2
PyTorch: 2.8.0
Datasets: 4.0.0
Tokenizers: 0.21.4
```
### Limitations and Biases
The Iconclass classification system reflects biases from its creation period (1940s Netherlands)
Certain categories, particularly those related to human classification, may contain outdated or problematic terminology
Model performance may vary on images outside the Western art tradition due to dataset composition
### Citations
Model and Training
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
Dataset
```bibtex
@misc{iconclass,
title = {Brill Iconclass AI Test Set},
author = {Etienne Posthumus},
year = {2020}
}
```
|
jackven248/blockassist-bc-poisonous_barky_alpaca_1757069706
|
jackven248
| 2025-09-05T10:55:45Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"poisonous barky alpaca",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-05T10:55:41Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- poisonous barky alpaca
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
LingoIITGN/Ansh-160k
|
LingoIITGN
| 2025-09-05T10:54:59Z | 0 | 1 |
transformers
|
[
"transformers",
"hi",
"as",
"mr",
"gu",
"pa",
"en",
"or",
"te",
"ta",
"ml",
"kn",
"bn",
"sd",
"ur",
"ne",
"ks",
"sa",
"gom",
"mai",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-09-04T05:07:41Z |
---
license: apache-2.0
library_name: transformers
language:
- hi
- as
- mr
- gu
- pa
- en
- or
- te
- ta
- ml
- kn
- bn
- sd
- ur
- ne
- ks
- sa
- gom
- mai
---
# Tokenizer Card for Ansh-160k!
The tokenizer model **``Ansh-160k``**, is trained on a dataset of Wikipedia articles in **18 Indic languages** and English. We propose the name *Ansh* as this
tokenizer is designed to meticulously identify every essential token (*Ansh* in *Sanskrit*) of our diverse Indic languages.

### Model Description 📚
India is a vast country that has a multi-lingual culture that covers 22 Official languages and more than 1700 languages and dialects. It has been observed
that various languages share words among themselves, sometimes even across language families. To capitalize on this observation, we trained our tokenization model
with a vocabulary size of **160,000 (160k)** using the dataset of Wikipedia articles in 18 Indic languages and English by applying the Byte-Pair Encoding (BPE) algorithm.
When compared among all the popular open-source tokenizers trained on multilingual Indic languages on fertility scores, our model outperformed them in most of the languages,
with significant performance improvement in **Sanskrit (sa)**, **Kashmiri (ks)**, **Sindhi (sd)** and **Konkani (gom)**.
- **Developed by:** [Lingo Research Group at IIT Gandhinagar](https://lingo.iitgn.ac.in/)
- **Language(s) (NLP):** Multilingual (18 Indic Languages and English)
- **License:** Apache 2.0
## How to Get Started with the Model 👨🏻💻
Use the code below to get started with the model.
```python
from transformers import AutoTokenizer
try:
tokenizer = tokenizer = AutoTokenizer.from_pretrained("LingoIITGN/Ansh-160k"))
print("Tokenizer loaded successfully!")
except Exception as e:
print(f"Error loading tokenizer: {e}")
print("Please ensure you have the correct model name and are connected to the internet.")
exit()
input_text = "Hello, world! This is an example of how to use the tokenizer."
#input_text = 'मुझे यह presentation कल morning तक submit करना है। '
#input_text = 'What is capital city of India?'
encoded_input = tokenizer.encode(example_text)
print("\nOriginal Text:", example_text)
print("Encoded (Token IDs):", encoded_input)
decoded_output = tokenizer.decode(encoded_input)
print("Decoded Text:", decoded_output)
```
## Evaluation
[More Information Needed]
### Results 🏆
<details open>
Comparison of Fertility Scores among popular open-source tokenizers trained on multilingual
Indic languages and Ansh-160k tokenizers across the 18 Indic languages and English.
<summary>Tokenizers Results</summary>
| Language | IndicBERTv2 | Sarvam-1 | MuRIL |Gemma-3| Llama-3.1 | XLM-RoBERTa| NLLB |**Ansh-160k**|
|:--------:|:-----------:|:--------:|:-----:|:-----:|:---------:|:----------:|:----:|:-----------:|
| *Tamil* | 1.966 | 2.853 | **1.904**| 2.766 | 12.170|2.726 | 2.925 | 1.937 |
| *Kannada* | 2.035 | 2.651 | 1.992 | 3.498 | 15.302|2.835 | 2.955 |**1.876** |
| *Malayalam* | 2.202 | 3.246 | 2.199 | 3.571 | 15.215|2.999 | 3.329 |**2.073** |
| *Maithili* | 1.534 | 2.269 | 1.549 | 2.036 | 3.414 |1.991 | 2.058 |**1.270** |
| *Konkani* | 2.145 | 2.954 | 2.469 | 2.830 | 4.180 |2.746 | 2.765 |**1.741** |
| *Telugu* | 1.803 | 2.429 | 1.859 | 3.050 | 13.002|2.391 | 2.691 |**1.713** |
| *Odia* | 1.601 | 2.419 | 1.497 | 4.639 | 15.629|2.222 | 2.284 |**1.397** |
| *Bengali* | 1.610 | 2.083 | 1.555 | 1.890 | 8.389 |2.374 | 2.396 |**1.515** |
| *Nepali* | 1.629 | 2.450 | 1.484 | 2.163 | 3.768 |1.903 | 2.070 |**1.466**|
| *Punjabi* | 1.458 | 1.822 | 1.459 | 2.968 | 8.277 |2.031 | 1.983 |**1.445** |
| *Urdu* | 1.565 | 9.004 | 1.402 | 1.984 | 3.153 |1.582 | 1.807 |**1.383** |
| *Hindi* | 1.456 | 1.784 | 1.450 | 1.719 | 2.997 |1.716 | 1.790 |**1.364** |
| *Gujarati* | 1.505 | 2.228 | 1.428 | 2.491 | 9.926 |2.195 | 2.332 |**1.387** |
| *Kashmiri* | 2.722 | 9.237 | 2.220 | 3.204 | 4.119 |3.155 | 2.966 |**1.528** |
| *Marathi* | 1.529 | 1.906 |**1.493**| 2.026 | 3.964 | 2.032 | 2.173 | 1.494 |
| *Sindhi* | 1.740 | 8.337 | 1.436 | 2.377 | 3.060 | 1.735 | 1.830 |**1.380** |
| *Assamese* | 1.677 | 4.474 | 1.655 | 2.815 | 8.506 |3.006 | 2.303 |**1.562** |
| *Sanskrit* | 2.821 | 3.916 | 2.294 | 3.586 | 5.036 |3.268 | 3.390 |**1.950** |
| *English* | 1.491 | 1.844 | 1.526 | 1.537 | **1.486** | 1.574 | 1.587 | 1.521 |
</details>
## Model Card Contact ✉️
[Lingo Research Group at IIT Gandhinagar, India](https://lingo.iitgn.ac.in/) </br>
Mail at: [lingo@iitgn.ac.in](lingo@iitgn.ac.in)
|
Viktor-01/blockassist-bc-leaping_humming_finch_1757067141
|
Viktor-01
| 2025-09-05T10:54:10Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"leaping humming finch",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-05T10:54:07Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- leaping humming finch
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
raihannabiil/blockassist-bc-humming_rugged_viper_1757067464
|
raihannabiil
| 2025-09-05T10:53:25Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"humming rugged viper",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-05T10:53:19Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- humming rugged viper
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Anshulky/Qwen2.5-VL-3B-Instruct-Thinking
|
Anshulky
| 2025-09-05T10:49:43Z | 0 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"generated_from_trainer",
"trl",
"grpo",
"arxiv:2402.03300",
"base_model:Qwen/Qwen2.5-VL-3B-Instruct",
"base_model:finetune:Qwen/Qwen2.5-VL-3B-Instruct",
"endpoints_compatible",
"region:us"
] | null | 2025-09-05T09:45:24Z |
---
base_model: Qwen/Qwen2.5-VL-3B-Instruct
library_name: transformers
model_name: Qwen2.5-VL-3B-Instruct-Thinking
tags:
- generated_from_trainer
- trl
- grpo
licence: license
---
# Model Card for Qwen2.5-VL-3B-Instruct-Thinking
This model is a fine-tuned version of [Qwen/Qwen2.5-VL-3B-Instruct](https://huggingface.co/Qwen/Qwen2.5-VL-3B-Instruct).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="Anshulky/Qwen2.5-VL-3B-Instruct-Thinking", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
This model was trained with GRPO, a method introduced in [DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models](https://huggingface.co/papers/2402.03300).
### Framework versions
- TRL: 0.22.2
- Transformers: 4.56.1
- Pytorch: 2.8.0+cu126
- Datasets: 4.0.0
- Tokenizers: 0.22.0
## Citations
Cite GRPO as:
```bibtex
@article{shao2024deepseekmath,
title = {{DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models}},
author = {Zhihong Shao and Peiyi Wang and Qihao Zhu and Runxin Xu and Junxiao Song and Mingchuan Zhang and Y. K. Li and Y. Wu and Daya Guo},
year = 2024,
eprint = {arXiv:2402.03300},
}
```
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
marcomaccarini/padella1
|
marcomaccarini
| 2025-09-05T10:48:05Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-09-05T10:44:46Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
kiok1250/blockassist-bc-beaked_insectivorous_lobster_1757069229
|
kiok1250
| 2025-09-05T10:48:00Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"beaked insectivorous lobster",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-05T10:47:52Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- beaked insectivorous lobster
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
HenriqueLz/xlm-roberta-base-fakerecogna2-extrativa-elections
|
HenriqueLz
| 2025-09-05T10:47:13Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"xlm-roberta",
"text-classification",
"pt",
"dataset:HenriqueLz/fakerecogna2-extrativa-elections",
"arxiv:1910.09700",
"base_model:FacebookAI/xlm-roberta-base",
"base_model:finetune:FacebookAI/xlm-roberta-base",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2025-09-05T07:46:14Z |
---
library_name: transformers
datasets:
- HenriqueLz/fakerecogna2-extrativa-elections
language:
- pt
metrics:
- f1
base_model:
- FacebookAI/xlm-roberta-base
pipeline_tag: text-classification
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
zxcczx/blockassist-bc-durable_energetic_fly_1757067840
|
zxcczx
| 2025-09-05T10:40:56Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"durable energetic fly",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-05T10:40:42Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- durable energetic fly
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
arif696/blockassist-bc-regal_spotted_pelican_1757068757
|
arif696
| 2025-09-05T10:40:32Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"regal spotted pelican",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-05T10:40:23Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- regal spotted pelican
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Tobias-B/wav2vec2-large-xlsr-ipa-augmentation-plosive_phonation-helper
|
Tobias-B
| 2025-09-05T10:39:36Z | 3 | 0 | null |
[
"pytorch",
"wav2vec2",
"speech, phonetics, ipa",
"hi",
"dataset:common_voice_11_0",
"license:apache-2.0",
"region:us"
] | null | 2025-04-25T10:04:35Z |
---
language: hi
datasets:
- common_voice_11_0
tags:
- speech, phonetics, ipa
license: apache-2.0
---
**Use THIS model**:
https://huggingface.co/Tobias-B/wav2vec2-large-xlsr-ipa-augmentation-plosive_phonation-target
# (Plosive Phonation) Helper Model (HM) for Selective Augmentation:
https://huggingface.co/collections/Tobias-B/universal-phonetic-asr-models-selective-augmentation-680b5034c0729058fadcf1d6
These models were created to advance automatic phonetic transcription (APT) beyond the training transcription accuracy.
The workflow to improve APT is called selective augmentation and was developed in Tobias Bystrich’s master’s thesis "Multilingual Automatic Phonetic Transcription – a Linguistic Investigation of its Performance on German and Approaches to Improving the State of the Art".
https://doi.org/10.24406/publica-4418
This thesis was written at Fraunhofer Institute IAIS and with the resources of WestAI: Simulations were performed with computing resources granted by WestAI under project rwth1594.
The models in this project are the reference (RM), helper (HM), baseline (BM) and target model (TM) for the selective augmentation workflow. Additionally, for reimplementation, the provided list of training segments ensures that the RM can predict the highest quality reference transcriptions.
The RM closely corresponds to a reimplemented MultIPA model (https://github.com/ctaguchi/multipa).
The target model has greatly improved plosive phonation information when measured against the baseline model. This is achieved by augmenting the baseline training data with reliable phonation information from a Hindi helper model.
|
mradermacher/SmolLM2-Rethink-135M-GGUF
|
mradermacher
| 2025-09-05T10:38:02Z | 0 | 0 |
transformers
|
[
"transformers",
"gguf",
"trl",
"text-generation-inference",
"re-think",
"reasoning",
"en",
"dataset:sequelbox/Celestia3-DeepSeek-R1-0528",
"base_model:prithivMLmods/SmolLM2-Rethink-135M",
"base_model:quantized:prithivMLmods/SmolLM2-Rethink-135M",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2025-09-05T10:34:57Z |
---
base_model: prithivMLmods/SmolLM2-Rethink-135M
datasets:
- sequelbox/Celestia3-DeepSeek-R1-0528
language:
- en
library_name: transformers
license: apache-2.0
mradermacher:
readme_rev: 1
quantized_by: mradermacher
tags:
- trl
- text-generation-inference
- re-think
- reasoning
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
<!-- ### quants: x-f16 Q4_K_S Q2_K Q8_0 Q6_K Q3_K_M Q3_K_S Q3_K_L Q4_K_M Q5_K_S Q5_K_M IQ4_XS -->
<!-- ### quants_skip: -->
<!-- ### skip_mmproj: -->
static quants of https://huggingface.co/prithivMLmods/SmolLM2-Rethink-135M
<!-- provided-files -->
***For a convenient overview and download list, visit our [model page for this model](https://hf.tst.eu/model#SmolLM2-Rethink-135M-GGUF).***
weighted/imatrix quants seem not to be available (by me) at this time. If they do not show up a week or so after the static ones, I have probably not planned for them. Feel free to request them by opening a Community Discussion.
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/SmolLM2-Rethink-135M-GGUF/resolve/main/SmolLM2-Rethink-135M.Q2_K.gguf) | Q2_K | 0.2 | |
| [GGUF](https://huggingface.co/mradermacher/SmolLM2-Rethink-135M-GGUF/resolve/main/SmolLM2-Rethink-135M.Q3_K_S.gguf) | Q3_K_S | 0.2 | |
| [GGUF](https://huggingface.co/mradermacher/SmolLM2-Rethink-135M-GGUF/resolve/main/SmolLM2-Rethink-135M.IQ4_XS.gguf) | IQ4_XS | 0.2 | |
| [GGUF](https://huggingface.co/mradermacher/SmolLM2-Rethink-135M-GGUF/resolve/main/SmolLM2-Rethink-135M.Q3_K_M.gguf) | Q3_K_M | 0.2 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/SmolLM2-Rethink-135M-GGUF/resolve/main/SmolLM2-Rethink-135M.Q3_K_L.gguf) | Q3_K_L | 0.2 | |
| [GGUF](https://huggingface.co/mradermacher/SmolLM2-Rethink-135M-GGUF/resolve/main/SmolLM2-Rethink-135M.Q4_K_S.gguf) | Q4_K_S | 0.2 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/SmolLM2-Rethink-135M-GGUF/resolve/main/SmolLM2-Rethink-135M.Q4_K_M.gguf) | Q4_K_M | 0.2 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/SmolLM2-Rethink-135M-GGUF/resolve/main/SmolLM2-Rethink-135M.Q5_K_S.gguf) | Q5_K_S | 0.2 | |
| [GGUF](https://huggingface.co/mradermacher/SmolLM2-Rethink-135M-GGUF/resolve/main/SmolLM2-Rethink-135M.Q5_K_M.gguf) | Q5_K_M | 0.2 | |
| [GGUF](https://huggingface.co/mradermacher/SmolLM2-Rethink-135M-GGUF/resolve/main/SmolLM2-Rethink-135M.Q6_K.gguf) | Q6_K | 0.2 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/SmolLM2-Rethink-135M-GGUF/resolve/main/SmolLM2-Rethink-135M.Q8_0.gguf) | Q8_0 | 0.2 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/SmolLM2-Rethink-135M-GGUF/resolve/main/SmolLM2-Rethink-135M.f16.gguf) | f16 | 0.4 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
gensynme/blockassist-bc-rugged_loud_toucan_1757068573
|
gensynme
| 2025-09-05T10:36:32Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"rugged loud toucan",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-05T10:36:14Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- rugged loud toucan
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
m2hgamerz/coderm2h-merged
|
m2hgamerz
| 2025-09-05T10:35:24Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-09-05T10:10:23Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
helenai/Qwen2.5-VL-3B-Instruct-ov-int4-npu
|
helenai
| 2025-09-05T10:33:57Z | 0 | 0 | null |
[
"openvino",
"qwen2_5_vl",
"base_model:Qwen/Qwen2.5-VL-3B-Instruct",
"base_model:finetune:Qwen/Qwen2.5-VL-3B-Instruct",
"region:us"
] | null | 2025-09-05T10:18:59Z |
---
base_model:
- Qwen/Qwen2.5-VL-3B-Instruct
---
This is the [Qwen/Qwen2.5-VL-3B-Instruct](https://huggingface.co/Qwen/Qwen2.5-VL-3B-Instruct) model, converted to OpenVINO, with int4 weights for the language model, int8 weights for the other models.
The INT4 weights are compressed with symmetric, channel-wise quantization, with AWQ and scale estimation. The model works on CPU, GPU and NPU. See below for the model export command/properties.
## Download Model
To download the model, run `pip install huggingface-hub[cli]` and then:
```
huggingface-cli download helenai/Qwen2.5-VL-3B-Instruct-ov-int4-npu --local-dir Qwen2.5-VL-3B-Instruct-ov-int4-npu
```
## Run inference with OpenVINO GenAI
Use OpenVINO GenAI to run inference on this model. This model works with OpenVINO GenAI 2025.3 and later. For NPU inference, make sure to use the latest NPU driver ([Windows](https://www.intel.com/content/www/us/en/download/794734/intel-npu-driver-windows.html), [Linux](https://github.com/intel/linux-npu-driver))
- Install OpenVINO GenAI and pillow:
```
pip install --upgrade openvino-genai pillow
```
- Download a test image: `curl -O "https://storage.openvinotoolkit.org/test_data/images/dog.jpg"`
- Run inference:
```python
import numpy as np
import openvino as ov
import openvino_genai
from PIL import Image
# Choose GPU instead of NPU to run the model on Intel integrated or discrete GPU, or CPU to run on CPU.
# CACHE_DIR caches the model the first time, so subsequent model loading will be faster
pipeline_config = {"CACHE_DIR": "model_cache"}
pipe = openvino_genai.VLMPipeline("Qwen2.5-VL-3B-Instruct-ov-int4-npu", "NPU", **pipeline_config)
image = Image.open("dog.jpg")
# optional: resizing to a smaller size (depending on image and prompt) is often useful to speed up inference.
image = image.resize((128, 128))
image_data = np.array(image.getdata()).reshape(1, image.size[1], image.size[0], 3).astype(np.uint8)
image_data = ov.Tensor(image_data)
prompt = "Can you describe the image?"
result = pipe.generate(prompt, image=image_data, max_new_tokens=100)
print(result.texts[0])
```
See [OpenVINO GenAI repository](https://github.com/openvinotoolkit/openvino.genai?tab=readme-ov-file#performing-visual-language-text-generation)
## Model export properties
Model export command:
```
optimum-cli export openvino -m Qwen/Qwen2.5-VL-3B-Instruct --weight-format int4 --group-size -1 --sym --awq --scale-estimation --dataset contextual Qwen2.5-VL-3B-Instruct-ov-int4-
npu
```
### Framework versions
```
openvino_version : 2025.3.0-19807-44526285f24-releases/2025/3
nncf_version : 2.17.0
optimum_intel_version : 1.26.0.dev0+0e2ccef
optimum_version : 1.27.0
pytorch_version : 2.7.1
transformers_version : 4.51.3
```
### LLM export properties
```
all_layers : False
awq : True
backup_mode : int8_asym
compression_format : dequantize
gptq : False
group_size : -1
ignored_scope : []
lora_correction : False
mode : int4_sym
ratio : 1.0
scale_estimation : True
sensitivity_metric : max_activation_variance
```
|
arif696/blockassist-bc-regal_spotted_pelican_1757068231
|
arif696
| 2025-09-05T10:32:17Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"regal spotted pelican",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-05T10:32:08Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- regal spotted pelican
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Miracle-man/blockassist-bc-singing_lithe_koala_1757066216
|
Miracle-man
| 2025-09-05T10:31:16Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"singing lithe koala",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-05T10:31:12Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- singing lithe koala
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
williamanderson/Microsoft-MS-102-Dumps-Questions-Answers
|
williamanderson
| 2025-09-05T10:29:57Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-09-05T10:28:21Z |
<h3>The Microsoft 365 Expert: Why Acing the MS-102 Exam is a Smart Career Move 🚀</h3>
<p>The Microsoft 365 Administrator (MS-102) exam is a definitive benchmark for professionals who want to prove their expertise in managing one of the world's most widely used enterprise platforms. This isn't just a technical test; it's a strategic credential that validates your ability to configure and administer Microsoft 365 services, from managing user identities to ensuring data security. By conquering this exam, you're confirming you have the skills to lead a seamless and secure digital workplace, making you an invaluable asset in any modern organization.</p>
<p><strong>Click Here >>> <a href="https://www.clapgeek.com/MS-102-exam.html">https://www.clapgeek.com/MS-102-exam.html</a></strong></p>
<h3>A Deep Dive into Strategic, In-Demand Skills</h3>
<p>The MS-102 exam is a comprehensive assessment that goes far beyond simple knowledge. It evaluates your practical skills in key Microsoft 365 domains, preparing you for high-impact roles. It tests your proficiency in:</p>
<ul>
<li>
<p>Identity and Access Management: You'll demonstrate an expert understanding of how to manage user identities and groups, configure multi-factor authentication (MFA), and implement Conditional Access policies to secure your environment.</p>
</li>
<li>
<p>Microsoft 365 Tenant and Service Management: The exam validates your hands-on ability to plan and implement Microsoft 365 services, manage licensing, and configure an organization's tenant to meet business needs.</p>
</li>
<li>
<p>Security and Threat Management: You'll prove your understanding of how to use Microsoft Defender for 365 and other security tools to protect against malware, phishing, and other cyber threats.</p>
</li>
<li>
<p>Compliance and Data Governance: The exam covers the crucial skills of how to use tools like Microsoft Purview to ensure data is protected and managed in compliance with regulatory requirements.</p>
</li>
</ul>
<p>This focus on a broad range of strategic and technical skills is what makes the MS-102 exam so valuable. It proves you can go from high-level business goals to a complete, well-documented, and defensible solution.</p>
<hr />
<h3>The Fast Track to Professional Growth</h3>
<p>Earning the Microsoft 365 Certified: Administrator Expert credential is a significant career accelerator. The demand for skilled Microsoft 365 administrators is at an all-time high, and this professional-level certification sets you apart from the competition. As a certified professional, you are uniquely positioned for high-impact roles such as Microsoft 365 Administrator, Systems Engineer, or Cloud Administrator. This certification not only increases your job stability and earning potential but also provides the credibility and confidence to lead crucial projects and advise stakeholders on strategic decisions. Passing this exam is a strategic investment in yourself, giving you the knowledge and recognition to build a successful and future-proof career at the very heart of the modern enterprise.</p>
|
coelacanthxyz/blockassist-bc-finicky_thriving_grouse_1757066415
|
coelacanthxyz
| 2025-09-05T10:29:01Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"finicky thriving grouse",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-05T10:28:55Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- finicky thriving grouse
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
vidieci/results_v3
|
vidieci
| 2025-09-05T10:28:48Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"generated_from_trainer",
"sft",
"trl",
"base_model:mistralai/Mistral-7B-Instruct-v0.2",
"base_model:finetune:mistralai/Mistral-7B-Instruct-v0.2",
"endpoints_compatible",
"region:us"
] | null | 2025-09-05T10:28:44Z |
---
base_model: mistralai/Mistral-7B-Instruct-v0.2
library_name: transformers
model_name: results_v3
tags:
- generated_from_trainer
- sft
- trl
licence: license
---
# Model Card for results_v3
This model is a fine-tuned version of [mistralai/Mistral-7B-Instruct-v0.2](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.2).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="vidieci/results_v3", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
This model was trained with SFT.
### Framework versions
- TRL: 0.22.2
- Transformers: 4.56.0
- Pytorch: 2.8.0+cu126
- Datasets: 4.0.0
- Tokenizers: 0.22.0
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
kiok1250/blockassist-bc-beaked_insectivorous_lobster_1757068030
|
kiok1250
| 2025-09-05T10:28:03Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"beaked insectivorous lobster",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-05T10:27:54Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- beaked insectivorous lobster
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
kalimoy/blockassist-bc-rabid_hoarse_turkey_1757068033
|
kalimoy
| 2025-09-05T10:27:31Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"rabid hoarse turkey",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-05T10:27:13Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- rabid hoarse turkey
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
seams01/blockassist-bc-insectivorous_stubby_snake_1757066328
|
seams01
| 2025-09-05T10:27:02Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"insectivorous stubby snake",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-05T10:26:58Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- insectivorous stubby snake
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
bah63843/blockassist-bc-plump_fast_antelope_1757067772
|
bah63843
| 2025-09-05T10:23:38Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"plump fast antelope",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-05T10:23:31Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- plump fast antelope
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
upvantage/modernbert-KK-group1
|
upvantage
| 2025-09-05T10:19:36Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"modernbert",
"text-classification",
"generated_from_trainer",
"base_model:answerdotai/ModernBERT-large",
"base_model:finetune:answerdotai/ModernBERT-large",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2025-09-05T09:46:23Z |
---
library_name: transformers
license: apache-2.0
base_model: answerdotai/ModernBERT-large
tags:
- generated_from_trainer
metrics:
- accuracy
- f1
- precision
- recall
model-index:
- name: modernbert-KK-group1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# modernbert-KK-group1
This model is a fine-tuned version of [answerdotai/ModernBERT-large](https://huggingface.co/answerdotai/ModernBERT-large) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1486
- Accuracy: 0.9405
- F1: 0.9405
- Precision: 0.9406
- Recall: 0.9405
- F1 Class 0: 0.9423
- Precision Class 0: 0.9367
- Recall Class 0: 0.9479
- F1 Class 1: 0.9386
- Precision Class 1: 0.9446
- Recall Class 1: 0.9327
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 600
- eval_batch_size: 600
- seed: 42
- distributed_type: multi-GPU
- num_devices: 8
- total_train_batch_size: 4800
- total_eval_batch_size: 4800
- optimizer: Use OptimizerNames.ADAMW_TORCH_FUSED with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 | Precision | Recall | F1 Class 0 | Precision Class 0 | Recall Class 0 | F1 Class 1 | Precision Class 1 | Recall Class 1 |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|:------:|:---------:|:------:|:----------:|:-----------------:|:--------------:|:----------:|:-----------------:|:--------------:|
| 1.1704 | 1.0 | 18050 | 0.1486 | 0.9405 | 0.9405 | 0.9406 | 0.9405 | 0.9423 | 0.9367 | 0.9479 | 0.9386 | 0.9446 | 0.9327 |
### Framework versions
- Transformers 4.56.1
- Pytorch 2.8.0+cu128
- Datasets 4.0.0
- Tokenizers 0.22.0
|
PhiphatD/rock-paper-scissors-classifier
|
PhiphatD
| 2025-09-05T10:19:30Z | 0 | 0 | null |
[
"license:mit",
"region:us"
] | null | 2025-09-05T10:15:44Z |
---
license: mit
---
---
language: en
license: mit
tags:
- image-classification
- computer-vision
- tensorflow
- cnn
- rock-paper-scissors
datasets:
- tensorflow-datasets/rock_paper_scissors
metrics:
- accuracy
model-index:
- name: Rock Paper Scissors Classifier
results:
- task:
type: image-classification
name: Image Classification
dataset:
type: tensorflow-datasets/rock_paper_scissors
name: Rock Paper Scissors
metrics:
- type: accuracy
value: 0.95+
name: Validation Accuracy
---
# Rock Paper Scissors Classifier
## Model Description
This is a Convolutional Neural Network (CNN) model trained to classify images of hand gestures representing Rock, Paper, and Scissors. The model is built using TensorFlow/Keras and achieves high accuracy on the Rock Paper Scissors dataset.
## Model Architecture
The model uses a Sequential CNN architecture with the following layers:
- **Conv2D Layer 1**: 32 filters, 3x3 kernel, ReLU activation
- **MaxPooling2D**: 2x2 pool size
- **Dropout**: 0.25 rate
- **Conv2D Layer 2**: 64 filters, 3x3 kernel, ReLU activation
- **MaxPooling2D**: 2x2 pool size
- **Dropout**: 0.25 rate
- **Conv2D Layer 3**: 128 filters, 3x3 kernel, ReLU activation
- **MaxPooling2D**: 2x2 pool size
- **Dropout**: 0.25 rate
- **Flatten Layer**
- **Dense Layer**: 270 neurons, ReLU activation
- **Dropout**: 0.5 rate
- **Output Layer**: 3 neurons, Softmax activation
## Training Details
### Dataset
- **Source**: TensorFlow Datasets - Rock Paper Scissors
- **Classes**: 3 (Rock, Paper, Scissors)
- **Training Split**: 80% of training data
- **Validation Split**: 20% of training data
- **Test Split**: Separate test set
### Preprocessing
- **Normalization**: Pixel values scaled to [0, 1]
- **Data Augmentation**: Applied to training data
- Random rotation
- Random zoom
- Random horizontal flip
- Random width/height shift
### Training Configuration
- **Optimizer**: Adam (learning rate: 1e-3)
- **Loss Function**: Sparse Categorical Crossentropy
- **Metrics**: Accuracy
- **Batch Size**: 32
- **Epochs**: Multiple epochs with early stopping
## Performance
The model achieves excellent performance on the Rock Paper Scissors classification task:
- **Training Accuracy**: ~98%
- **Validation Accuracy**: ~99%
- **Test Accuracy**: ~95%
- **Training Time**: ~15-20 minutes on CPU
## Usage
### Requirements
```
tensorflow>=2.10.0
tensorflow-datasets>=4.8.0
numpy>=1.21.0
matplotlib>=3.5.0
```
### Loading and Using the Model
```python
import tensorflow as tf
import tensorflow_datasets as tfds
import numpy as np
# Load the dataset
(ds_train, ds_test), ds_info = tfds.load(
'rock_paper_scissors',
split=['train', 'test'],
shuffle_files=True,
as_supervised=True,
with_info=True,
)
# Preprocessing function
def preprocess_image(image, label):
image = tf.cast(image, tf.float32) / 255.0
return image, label
# Apply preprocessing
ds_test = ds_test.map(preprocess_image).batch(32)
# Load your trained model
# model = tf.keras.models.load_model('path_to_your_model')
# Make predictions
# predictions = model.predict(ds_test)
```
## Model Card Authors
This model was developed as part of a machine learning project for educational purposes.
## Model Card Contact
For questions or issues regarding this model, please refer to the project repository.
## Intended Use
### Primary Use Cases
- Educational purposes
- Computer vision learning
- Hand gesture recognition research
- Proof of concept for image classification
### Out-of-Scope Use Cases
- Production systems without proper validation
- Real-time applications without performance testing
- Commercial applications without proper licensing
## Limitations and Biases
- The model is trained specifically on the Rock Paper Scissors dataset
- Performance may vary with different lighting conditions
- Hand positions and orientations should be similar to training data
- Model may not generalize well to significantly different hand gestures
## Ethical Considerations
- This model is intended for educational and research purposes
- No personal data is collected or stored
- The dataset used is publicly available and ethically sourced
## Citation
If you use this model in your research, please cite:
```bibtex
@misc{rock_paper_scissors_classifier,
title={Rock Paper Scissors Classifier},
author={Your Name},
year={2024},
howpublished={\url{https://github.com/yourusername/rock-paper-scissors-classifier}}
}
```
|
bah63843/blockassist-bc-plump_fast_antelope_1757067503
|
bah63843
| 2025-09-05T10:19:16Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"plump fast antelope",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-05T10:19:07Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- plump fast antelope
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
sekirr/blockassist-bc-masked_tenacious_whale_1757067458
|
sekirr
| 2025-09-05T10:18:18Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"masked tenacious whale",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-05T10:18:14Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- masked tenacious whale
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
kalimoy/blockassist-bc-zealous_feathered_hamster_1757067448
|
kalimoy
| 2025-09-05T10:17:43Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"zealous feathered hamster",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-05T10:17:28Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- zealous feathered hamster
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
casvxzv/blockassist-bc-pesty_extinct_weasel_1757067424
|
casvxzv
| 2025-09-05T10:17:30Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"pesty extinct weasel",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-05T10:17:04Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- pesty extinct weasel
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
bah63843/blockassist-bc-plump_fast_antelope_1757067270
|
bah63843
| 2025-09-05T10:15:17Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"plump fast antelope",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-05T10:15:09Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- plump fast antelope
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
kalimoy/blockassist-bc-smooth_aquatic_turtle_1757067147
|
kalimoy
| 2025-09-05T10:12:43Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"smooth aquatic turtle",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-05T10:12:28Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- smooth aquatic turtle
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
ND911/EclecticEuphoria_Illus_Styled
|
ND911
| 2025-09-05T10:10:57Z | 0 | 0 | null |
[
"license:apache-2.0",
"region:us"
] | null | 2025-09-05T09:52:21Z |
---
license: apache-2.0
---
## EclecticEuphoria_Illus_Styled
I thought I had uploaded this model in the past, but apparently not. This is a simple Illustrious merge to come up with this styled look. Images should contain workflow for comfyui.

.png)
|
bah63843/blockassist-bc-plump_fast_antelope_1757066993
|
bah63843
| 2025-09-05T10:10:41Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"plump fast antelope",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-05T10:10:33Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- plump fast antelope
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
casvxzv/blockassist-bc-shaggy_gilded_falcon_1757066885
|
casvxzv
| 2025-09-05T10:08:29Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"shaggy gilded falcon",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-05T10:08:06Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- shaggy gilded falcon
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
lohith-chanchu/reranker-gte-multilingual-reranker-base-custom-bce
|
lohith-chanchu
| 2025-09-05T10:06:44Z | 0 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"safetensors",
"new",
"cross-encoder",
"reranker",
"generated_from_trainer",
"dataset_size:447164",
"loss:BinaryCrossEntropyLoss",
"text-ranking",
"custom_code",
"en",
"arxiv:1908.10084",
"base_model:Alibaba-NLP/gte-multilingual-reranker-base",
"base_model:finetune:Alibaba-NLP/gte-multilingual-reranker-base",
"license:apache-2.0",
"model-index",
"region:us"
] |
text-ranking
| 2025-09-05T10:06:16Z |
---
language:
- en
license: apache-2.0
tags:
- sentence-transformers
- cross-encoder
- reranker
- generated_from_trainer
- dataset_size:447164
- loss:BinaryCrossEntropyLoss
base_model: Alibaba-NLP/gte-multilingual-reranker-base
pipeline_tag: text-ranking
library_name: sentence-transformers
metrics:
- map
- mrr@10
- ndcg@10
model-index:
- name: Reranker trained on Custom Dataset
results:
- task:
type: cross-encoder-reranking
name: Cross Encoder Reranking
dataset:
name: custom dev
type: custom-dev
metrics:
- type: map
value: 0.3148
name: Map
- type: mrr@10
value: 0.3228
name: Mrr@10
- type: ndcg@10
value: 0.3455
name: Ndcg@10
---
# Reranker trained on Custom Dataset
This is a [Cross Encoder](https://www.sbert.net/docs/cross_encoder/usage/usage.html) model finetuned from [Alibaba-NLP/gte-multilingual-reranker-base](https://huggingface.co/Alibaba-NLP/gte-multilingual-reranker-base) using the [sentence-transformers](https://www.SBERT.net) library. It computes scores for pairs of texts, which can be used for text reranking and semantic search.
## Model Details
### Model Description
- **Model Type:** Cross Encoder
- **Base model:** [Alibaba-NLP/gte-multilingual-reranker-base](https://huggingface.co/Alibaba-NLP/gte-multilingual-reranker-base) <!-- at revision 8215cf04918ba6f7b6a62bb44238ce2953d8831c -->
- **Maximum Sequence Length:** 8192 tokens
- **Number of Output Labels:** 1 label
<!-- - **Training Dataset:** Unknown -->
- **Language:** en
- **License:** apache-2.0
### Model Sources
- **Documentation:** [Sentence Transformers Documentation](https://sbert.net)
- **Documentation:** [Cross Encoder Documentation](https://www.sbert.net/docs/cross_encoder/usage/usage.html)
- **Repository:** [Sentence Transformers on GitHub](https://github.com/UKPLab/sentence-transformers)
- **Hugging Face:** [Cross Encoders on Hugging Face](https://huggingface.co/models?library=sentence-transformers&other=cross-encoder)
## Usage
### Direct Usage (Sentence Transformers)
First install the Sentence Transformers library:
```bash
pip install -U sentence-transformers
```
Then you can load this model and run inference.
```python
from sentence_transformers import CrossEncoder
# Download from the 🤗 Hub
model = CrossEncoder("lohith-chanchu/reranker-gte-multilingual-reranker-base-custom-bce")
# Get scores for pairs of texts
pairs = [
['Gaskugelhahn, Gewinde, DN 32 Gaskugelhahn, zum manuellen Absperren, geeignet für Erdgas, PN 6, nach DIN EN 331, Gehäuse aus Pressmessing, in Durchgangsform, beid seits Gewindeanschluss, DIN-DVGW-zugelassen, DN 32, einschließlich Übergangsstücke sowie Verbindungs-, Dichtungs- und Befestigungsma terial', 'DITECH Gas-KH m gelbem Hebelgriff und vollem Durchgang 11/4"'],
['Gaskugelhahn, Gewinde, DN 40 jedoch DN 40', 'DITECH Gas-KH m gelbem Hebelgriff und vollem Durchgang 11/2"'],
['Gaskugelhahn, Gewinde, DN 50 jedoch DN 50', 'DITECH Gas-KH m gelbem Hebelgriff und vollem Durchgang 2"'],
['Doppelnippel, Stahl, DN 15, Montagehöhe bis 6,0 m Doppelnippel, aus Kohlenstoffstahl, für Rohrleitung aus mittelschwerem Stahlrohr DIN EN 10255, mit Außengewinde 1/2 , Montagehöhe üb er Gelände / Fußboden bis 6,0 m', 'HS Rohrdoppelnippel Nr. 23 schwarz 1/2" 100mm'],
['Doppelnippel, Stahl, DN 20, Montagehöhe bis 6,0 m jedoch Außengewinde 3/4', 'HS Rohrdoppelnippel Nr. 23 schwarz 3/4" 100mm'],
]
scores = model.predict(pairs)
print(scores.shape)
# (5,)
# Or rank different texts based on similarity to a single text
ranks = model.rank(
'Gaskugelhahn, Gewinde, DN 32 Gaskugelhahn, zum manuellen Absperren, geeignet für Erdgas, PN 6, nach DIN EN 331, Gehäuse aus Pressmessing, in Durchgangsform, beid seits Gewindeanschluss, DIN-DVGW-zugelassen, DN 32, einschließlich Übergangsstücke sowie Verbindungs-, Dichtungs- und Befestigungsma terial',
[
'DITECH Gas-KH m gelbem Hebelgriff und vollem Durchgang 11/4"',
'DITECH Gas-KH m gelbem Hebelgriff und vollem Durchgang 11/2"',
'DITECH Gas-KH m gelbem Hebelgriff und vollem Durchgang 2"',
'HS Rohrdoppelnippel Nr. 23 schwarz 1/2" 100mm',
'HS Rohrdoppelnippel Nr. 23 schwarz 3/4" 100mm',
]
)
# [{'corpus_id': ..., 'score': ...}, {'corpus_id': ..., 'score': ...}, ...]
```
<!--
### Direct Usage (Transformers)
<details><summary>Click to see the direct usage in Transformers</summary>
</details>
-->
<!--
### Downstream Usage (Sentence Transformers)
You can finetune this model on your own dataset.
<details><summary>Click to expand</summary>
</details>
-->
<!--
### Out-of-Scope Use
*List how the model may foreseeably be misused and address what users ought not to do with the model.*
-->
## Evaluation
### Metrics
#### Cross Encoder Reranking
* Dataset: `custom-dev`
* Evaluated with [<code>CrossEncoderRerankingEvaluator</code>](https://sbert.net/docs/package_reference/cross_encoder/evaluation.html#sentence_transformers.cross_encoder.evaluation.CrossEncoderRerankingEvaluator) with these parameters:
```json
{
"at_k": 10,
"always_rerank_positives": false
}
```
| Metric | Value |
|:------------|:---------------------|
| map | 0.3148 (+0.1281) |
| mrr@10 | 0.3228 (+0.1424) |
| **ndcg@10** | **0.3455 (+0.1352)** |
<!--
## Bias, Risks and Limitations
*What are the known or foreseeable issues stemming from this model? You could also flag here known failure cases or weaknesses of the model.*
-->
<!--
### Recommendations
*What are recommendations with respect to the foreseeable issues? For example, filtering explicit content.*
-->
## Training Details
### Training Dataset
#### Unnamed Dataset
* Size: 447,164 training samples
* Columns: <code>query</code>, <code>answer</code>, and <code>label</code>
* Approximate statistics based on the first 1000 samples:
| | query | answer | label |
|:--------|:--------------------------------------------------------------------------------------------------|:----------------------------------------------------------------------------------------------|:------------------------------------------------|
| type | string | string | int |
| details | <ul><li>min: 27 characters</li><li>mean: 434.65 characters</li><li>max: 2905 characters</li></ul> | <ul><li>min: 0 characters</li><li>mean: 52.08 characters</li><li>max: 81 characters</li></ul> | <ul><li>0: ~33.70%</li><li>1: ~66.30%</li></ul> |
* Samples:
| query | answer | label |
|:---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|:--------------------------------------------------------------------------|:---------------|
| <code>Gaskugelhahn, Gewinde, DN 32 Gaskugelhahn, zum manuellen Absperren, geeignet für Erdgas, PN 6, nach DIN EN 331, Gehäuse aus Pressmessing, in Durchgangsform, beid seits Gewindeanschluss, DIN-DVGW-zugelassen, DN 32, einschließlich Übergangsstücke sowie Verbindungs-, Dichtungs- und Befestigungsma terial</code> | <code>DITECH Gas-KH m gelbem Hebelgriff und vollem Durchgang 11/4"</code> | <code>1</code> |
| <code>Gaskugelhahn, Gewinde, DN 40 jedoch DN 40</code> | <code>DITECH Gas-KH m gelbem Hebelgriff und vollem Durchgang 11/2"</code> | <code>1</code> |
| <code>Gaskugelhahn, Gewinde, DN 50 jedoch DN 50</code> | <code>DITECH Gas-KH m gelbem Hebelgriff und vollem Durchgang 2"</code> | <code>1</code> |
* Loss: [<code>BinaryCrossEntropyLoss</code>](https://sbert.net/docs/package_reference/cross_encoder/losses.html#binarycrossentropyloss) with these parameters:
```json
{
"activation_fn": "torch.nn.modules.linear.Identity",
"pos_weight": 5
}
```
### Training Hyperparameters
#### Non-Default Hyperparameters
- `eval_strategy`: epoch
- `per_device_train_batch_size`: 100
- `per_device_eval_batch_size`: 100
- `learning_rate`: 2e-05
- `num_train_epochs`: 2
- `warmup_ratio`: 0.1
- `seed`: 12
- `bf16`: True
- `dataloader_num_workers`: 4
- `load_best_model_at_end`: True
#### All Hyperparameters
<details><summary>Click to expand</summary>
- `overwrite_output_dir`: False
- `do_predict`: False
- `eval_strategy`: epoch
- `prediction_loss_only`: True
- `per_device_train_batch_size`: 100
- `per_device_eval_batch_size`: 100
- `per_gpu_train_batch_size`: None
- `per_gpu_eval_batch_size`: None
- `gradient_accumulation_steps`: 1
- `eval_accumulation_steps`: None
- `torch_empty_cache_steps`: None
- `learning_rate`: 2e-05
- `weight_decay`: 0.0
- `adam_beta1`: 0.9
- `adam_beta2`: 0.999
- `adam_epsilon`: 1e-08
- `max_grad_norm`: 1.0
- `num_train_epochs`: 2
- `max_steps`: -1
- `lr_scheduler_type`: linear
- `lr_scheduler_kwargs`: {}
- `warmup_ratio`: 0.1
- `warmup_steps`: 0
- `log_level`: passive
- `log_level_replica`: warning
- `log_on_each_node`: True
- `logging_nan_inf_filter`: True
- `save_safetensors`: True
- `save_on_each_node`: False
- `save_only_model`: False
- `restore_callback_states_from_checkpoint`: False
- `no_cuda`: False
- `use_cpu`: False
- `use_mps_device`: False
- `seed`: 12
- `data_seed`: None
- `jit_mode_eval`: False
- `use_ipex`: False
- `bf16`: True
- `fp16`: False
- `fp16_opt_level`: O1
- `half_precision_backend`: auto
- `bf16_full_eval`: False
- `fp16_full_eval`: False
- `tf32`: None
- `local_rank`: 0
- `ddp_backend`: None
- `tpu_num_cores`: None
- `tpu_metrics_debug`: False
- `debug`: []
- `dataloader_drop_last`: False
- `dataloader_num_workers`: 4
- `dataloader_prefetch_factor`: None
- `past_index`: -1
- `disable_tqdm`: False
- `remove_unused_columns`: True
- `label_names`: None
- `load_best_model_at_end`: True
- `ignore_data_skip`: False
- `fsdp`: []
- `fsdp_min_num_params`: 0
- `fsdp_config`: {'min_num_params': 0, 'xla': False, 'xla_fsdp_v2': False, 'xla_fsdp_grad_ckpt': False}
- `fsdp_transformer_layer_cls_to_wrap`: None
- `accelerator_config`: {'split_batches': False, 'dispatch_batches': None, 'even_batches': True, 'use_seedable_sampler': True, 'non_blocking': False, 'gradient_accumulation_kwargs': None}
- `parallelism_config`: None
- `deepspeed`: None
- `label_smoothing_factor`: 0.0
- `optim`: adamw_torch_fused
- `optim_args`: None
- `adafactor`: False
- `group_by_length`: False
- `length_column_name`: length
- `ddp_find_unused_parameters`: None
- `ddp_bucket_cap_mb`: None
- `ddp_broadcast_buffers`: False
- `dataloader_pin_memory`: True
- `dataloader_persistent_workers`: False
- `skip_memory_metrics`: True
- `use_legacy_prediction_loop`: False
- `push_to_hub`: False
- `resume_from_checkpoint`: None
- `hub_model_id`: None
- `hub_strategy`: every_save
- `hub_private_repo`: None
- `hub_always_push`: False
- `hub_revision`: None
- `gradient_checkpointing`: False
- `gradient_checkpointing_kwargs`: None
- `include_inputs_for_metrics`: False
- `include_for_metrics`: []
- `eval_do_concat_batches`: True
- `fp16_backend`: auto
- `push_to_hub_model_id`: None
- `push_to_hub_organization`: None
- `mp_parameters`:
- `auto_find_batch_size`: False
- `full_determinism`: False
- `torchdynamo`: None
- `ray_scope`: last
- `ddp_timeout`: 1800
- `torch_compile`: False
- `torch_compile_backend`: None
- `torch_compile_mode`: None
- `include_tokens_per_second`: False
- `include_num_input_tokens_seen`: False
- `neftune_noise_alpha`: None
- `optim_target_modules`: None
- `batch_eval_metrics`: False
- `eval_on_start`: False
- `use_liger_kernel`: False
- `liger_kernel_config`: None
- `eval_use_gather_object`: False
- `average_tokens_across_devices`: False
- `prompts`: None
- `batch_sampler`: batch_sampler
- `multi_dataset_batch_sampler`: proportional
- `router_mapping`: {}
- `learning_rate_mapping`: {}
</details>
### Training Logs
| Epoch | Step | Training Loss | custom-dev_ndcg@10 |
|:-------:|:--------:|:-------------:|:--------------------:|
| 0.0002 | 1 | 1.5605 | - |
| 0.0224 | 100 | 0.9229 | - |
| 0.0447 | 200 | 0.4384 | - |
| 0.0671 | 300 | 0.3577 | - |
| 0.0894 | 400 | 0.3024 | - |
| 0.1118 | 500 | 0.267 | - |
| 0.1342 | 600 | 0.2393 | - |
| 0.1565 | 700 | 0.2228 | - |
| 0.1789 | 800 | 0.2196 | - |
| 0.2013 | 900 | 0.1812 | - |
| 0.2236 | 1000 | 0.2003 | - |
| 0.2460 | 1100 | 0.1756 | - |
| 0.2683 | 1200 | 0.1652 | - |
| 0.2907 | 1300 | 0.1529 | - |
| 0.3131 | 1400 | 0.1652 | - |
| 0.3354 | 1500 | 0.1327 | - |
| 0.3578 | 1600 | 0.1273 | - |
| 0.3801 | 1700 | 0.124 | - |
| 0.4025 | 1800 | 0.1371 | - |
| 0.4249 | 1900 | 0.1239 | - |
| 0.4472 | 2000 | 0.1252 | - |
| 0.4696 | 2100 | 0.115 | - |
| 0.4919 | 2200 | 0.116 | - |
| 0.5143 | 2300 | 0.1115 | - |
| 0.5367 | 2400 | 0.1157 | - |
| 0.5590 | 2500 | 0.1126 | - |
| 0.5814 | 2600 | 0.1071 | - |
| 0.6038 | 2700 | 0.1162 | - |
| 0.6261 | 2800 | 0.1088 | - |
| 0.6485 | 2900 | 0.1032 | - |
| 0.6708 | 3000 | 0.1086 | - |
| 0.6932 | 3100 | 0.0926 | - |
| 0.7156 | 3200 | 0.0846 | - |
| 0.7379 | 3300 | 0.0931 | - |
| 0.7603 | 3400 | 0.1053 | - |
| 0.7826 | 3500 | 0.0825 | - |
| 0.8050 | 3600 | 0.1116 | - |
| 0.8274 | 3700 | 0.0917 | - |
| 0.8497 | 3800 | 0.0907 | - |
| 0.8721 | 3900 | 0.0774 | - |
| 0.8945 | 4000 | 0.0789 | - |
| 0.9168 | 4100 | 0.0792 | - |
| 0.9392 | 4200 | 0.0933 | - |
| 0.9615 | 4300 | 0.0893 | - |
| 0.9839 | 4400 | 0.0993 | - |
| 1.0 | 4472 | - | 0.3409 (+0.1306) |
| 1.0063 | 4500 | 0.0755 | - |
| 1.0286 | 4600 | 0.0551 | - |
| 1.0510 | 4700 | 0.0626 | - |
| 1.0733 | 4800 | 0.0694 | - |
| 1.0957 | 4900 | 0.0537 | - |
| 1.1181 | 5000 | 0.0557 | - |
| 1.1404 | 5100 | 0.0694 | - |
| 1.1628 | 5200 | 0.0621 | - |
| 1.1852 | 5300 | 0.0661 | - |
| 1.2075 | 5400 | 0.0494 | - |
| 1.2299 | 5500 | 0.0607 | - |
| 1.2522 | 5600 | 0.0561 | - |
| 1.2746 | 5700 | 0.0513 | - |
| 1.2970 | 5800 | 0.0617 | - |
| 1.3193 | 5900 | 0.0435 | - |
| 1.3417 | 6000 | 0.0659 | - |
| 1.3640 | 6100 | 0.0597 | - |
| 1.3864 | 6200 | 0.0668 | - |
| 1.4088 | 6300 | 0.0557 | - |
| 1.4311 | 6400 | 0.0566 | - |
| 1.4535 | 6500 | 0.0632 | - |
| 1.4758 | 6600 | 0.0573 | - |
| 1.4982 | 6700 | 0.0634 | - |
| 1.5206 | 6800 | 0.054 | - |
| 1.5429 | 6900 | 0.0392 | - |
| 1.5653 | 7000 | 0.046 | - |
| 1.5877 | 7100 | 0.0562 | - |
| 1.6100 | 7200 | 0.0443 | - |
| 1.6324 | 7300 | 0.0757 | - |
| 1.6547 | 7400 | 0.0555 | - |
| 1.6771 | 7500 | 0.0345 | - |
| 1.6995 | 7600 | 0.0525 | - |
| 1.7218 | 7700 | 0.0595 | - |
| 1.7442 | 7800 | 0.0561 | - |
| 1.7665 | 7900 | 0.0484 | - |
| 1.7889 | 8000 | 0.0465 | - |
| 1.8113 | 8100 | 0.0501 | - |
| 1.8336 | 8200 | 0.0411 | - |
| 1.8560 | 8300 | 0.0386 | - |
| 1.8784 | 8400 | 0.0477 | - |
| 1.9007 | 8500 | 0.0517 | - |
| 1.9231 | 8600 | 0.0338 | - |
| 1.9454 | 8700 | 0.0466 | - |
| 1.9678 | 8800 | 0.062 | - |
| 1.9902 | 8900 | 0.0647 | - |
| **2.0** | **8944** | **-** | **0.3455 (+0.1352)** |
| -1 | -1 | - | 0.3455 (+0.1352) |
* The bold row denotes the saved checkpoint.
### Framework Versions
- Python: 3.10.18
- Sentence Transformers: 5.1.0
- Transformers: 4.56.0
- PyTorch: 2.8.0+cu128
- Accelerate: 1.10.1
- Datasets: 4.0.0
- Tokenizers: 0.22.0
## Citation
### BibTeX
#### Sentence Transformers
```bibtex
@inproceedings{reimers-2019-sentence-bert,
title = "Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks",
author = "Reimers, Nils and Gurevych, Iryna",
booktitle = "Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing",
month = "11",
year = "2019",
publisher = "Association for Computational Linguistics",
url = "https://arxiv.org/abs/1908.10084",
}
```
<!--
## Glossary
*Clearly define terms in order to be accessible across audiences.*
-->
<!--
## Model Card Authors
*Lists the people who create the model card, providing recognition and accountability for the detailed work that goes into its construction.*
-->
<!--
## Model Card Contact
*Provides a way for people who have updates to the Model Card, suggestions, or questions, to contact the Model Card authors.*
-->
|
casvxzv/blockassist-bc-mangy_plump_jellyfish_1757066505
|
casvxzv
| 2025-09-05T10:02:20Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"mangy plump jellyfish",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-05T10:01:46Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- mangy plump jellyfish
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
sampingkaca72/blockassist-bc-armored_stealthy_elephant_1757064689
|
sampingkaca72
| 2025-09-05T10:01:04Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"armored stealthy elephant",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-05T10:01:00Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- armored stealthy elephant
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
bah63843/blockassist-bc-plump_fast_antelope_1757066402
|
bah63843
| 2025-09-05T10:00:51Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"plump fast antelope",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-05T10:00:43Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- plump fast antelope
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
nicolajreck/csm-1b-danish-tts
|
nicolajreck
| 2025-09-05T09:52:39Z | 58 | 0 |
transformers
|
[
"transformers",
"safetensors",
"csm",
"text-to-audio",
"text-to-speech",
"tts",
"danish",
"lora",
"audio-generation",
"speech-synthesis",
"da",
"dataset:mozilla-foundation/common_voice_17_0",
"dataset:CoRal-project/coral-tts",
"base_model:sesame/csm-1b",
"base_model:adapter:sesame/csm-1b",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
text-to-speech
| 2025-09-05T01:30:44Z |
---
license: apache-2.0
language:
- da
base_model: sesame/csm-1b
tags:
- text-to-speech
- tts
- danish
- lora
- csm
- audio-generation
- speech-synthesis
library_name: transformers
pipeline_tag: text-to-speech
datasets:
- mozilla-foundation/common_voice_17_0
- CoRal-project/coral-tts
---
# CSM-1B Danish Text-to-Speech (LoRA)
A natural-sounding Danish text-to-speech model based on CSM-1B, fine-tuned using LoRA (Low-Rank Adaptation) on a combination of Common Voice 17, CoRal-TTS, and private Danish speech data. Fine-tuned by [Nicolaj Reck](https://www.linkedin.com/in/nicolaj-reck-053aa38a/).
## Model Description
This model is a LoRA adapter for [`sesame/csm-1b`](https://huggingface.co/sesame/csm-1b) that enables natural Danish speech synthesis with optional voice control. The adapter was trained specifically for Danish TTS while preserving the multilingual capabilities of the base model.
- **Base Model**: [`sesame/csm-1b`](https://huggingface.co/sesame/csm-1b)
- **Language**: Danish (da)
- **Task**: Text-to-Speech
- **License**: Apache 2.0
- **Model Type**: LoRA Adapter
- **Precision**: FP16/BF16
## Key Features
- **Natural Danish synthesis** with clear pronunciation and fluent prosody
- **Exceptional English with Danish accent** - Perfect for bilingual content
- **Voice control** with male/female speaker selection
- **Efficient fine-tuning** using LoRA (only ~16M parameters trained)
- **Voice leakage prevention** through frozen speaker/codec modules
- **Ready-to-use Gradio interface** included
## Quick Start
### Installation
```bash
pip install transformers torch torchaudio gradio
```
### Basic Usage
```python
import torch
from transformers import CsmForConditionalGeneration, AutoProcessor
# Load model and processor
model = CsmForConditionalGeneration.from_pretrained("nicolajreck/csm-1b-danish-tts")
processor = AutoProcessor.from_pretrained("nicolajreck/csm-1b-danish-tts")
# Generate speech
text = "[1]Hej! Velkommen til dansk tale syntese." # [1] for female voice
inputs = processor(text, add_special_tokens=True).to("cuda")
audio = model.generate(**inputs, output_audio=True)
# Save audio
processor.save_audio(audio, "output.wav")
```
### Web Interface
Launch the included Gradio interface:
```bash
python danish_tts.py
```
Access at `http://localhost:7860` for an interactive TTS experience. Or use the live [Huggingface Space](https://huggingface.co/spaces/nicolajreck/csm-1b-danish-tts-space).
## Voice Control
The model supports two speaker voices:
- `[0]` - Male voice
- `[1]` - Female voice
Simply prefix your Danish text with the speaker token:
- `[0]God morgen! Hvordan har du det?` (Male)
- `[1]God morgen! Hvordan har du det?` (Female)
## Training Details
### Training Data
The model was trained on a carefully curated mix of Danish speech data:
- **[Common Voice 17 Danish](https://huggingface.co/datasets/mozilla-foundation/common_voice_17_0)**: ~10,224 validated samples
- **[CoRal-TTS Danish](https://huggingface.co/datasets/CoRal-project/coral-tts)**: ~16,547 filtered samples
- **Private Extension**: ~8,644 additional samples
Total: ~35,415 Danish speech samples with balanced representation across datasets.
### Training Configuration
- **Method**: LoRA (Low-Rank Adaptation)
- **Rank**: 16, Alpha: 32, Dropout: 0.05
- **Target Modules**: `{q_proj, k_proj, v_proj, o_proj, out_proj, gate_proj, up_proj, down_proj, fc1, fc2}`
- **Hardware**: Single RTX 3090 (24GB)
- **Precision**: FP16 training, supports FP16/BF16 inference
### Data Processing
- Duration filtering: 0.6-16 seconds
- Text normalization: Quote stripping, terminal punctuation
- Equal-probability dataset mixing to prevent bias
- Chat-style formatting with Danish language cue
## Recommended Settings
For the most natural and fluent speech, use these generation parameters:
```python
# Natural speech settings
audio = model.generate(
**inputs,
output_audio=True,
do_sample=True,
temperature=0.96,
depth_decoder_temperature=0.7,
top_k=50,
top_p=0.9,
repetition_penalty=1.0
)
```
## Example Outputs
The model handles various Danish text types effectively:
| Danish Text | Audio |
|-------------|-------|
| *"Husk at gemme arbejdet, før computeren genstarter, ellers risikerer du at miste både filer og vigtige ændringer."* | <audio controls><source src="https://huggingface.co/nicolajreck/csm-1b-danish-tts/resolve/main/tts_examples/technical_instructions.wav" type="audio/wav">Your browser does not support the audio element.</audio> |
| *"Vi gør opmærksom på, at toget mod Københavns Hovedbanegård er forsinket med omkring 15 minutter. Vi undskylder ventetiden og takker for jeres tålmodighed."* | <audio controls><source src="https://huggingface.co/nicolajreck/csm-1b-danish-tts/resolve/main/tts_examples/travel_planning.wav" type="audio/wav">Your browser does not support the audio element.</audio> |
## Performance
Compared to the base CSM-1B model on Danish text:
- ✅ Pronunciation and word clarity
- ✅ Natural rhythm and speaking flow
- ✅ Speech with fewer dropped sounds
- ✅ Pleasant voice across different text types
## Gradio Interface Features
The included `danish_tts.py` provides a comprehensive web interface with:
- **Three-column layout**: Input settings, sampling controls, audio output
- **Auto max-length calculation** with adjustable multiplier
- **Advanced parameter control**: Dual temperatures, Top-K/Top-P, repetition penalty
- **Pre-configured examples** with optimized settings
## Limitations
- Optimized specifically for Danish - other languages may have reduced quality
- Requires base model `sesame/csm-1b` to function
- Voice control limited to male/female binary selection
### Model Architecture
- **Base**: CSM-1B encoder-decoder with depth decoder
- **Audio Format**: 24kHz, generated via audio tokens
- **LoRA Integration**: Language projections only, speaker/codec frozen
- **Memory Requirements**: ~8GB VRAM for inference
## Citation
If you use this model, please cite:
```bibtex
@misc{csm1b-danish-2025,
title={High-Quality Danish Text-to-Speech with CSM-1B: Data Mixing, Voice Control, and LoRA Fine-Tuning},
author={Nicolaj Reck},
year={2024},
howpublished={\url{https://huggingface.co/nicolajreck/csm-1b-danish-tts}},
note={LinkedIn: https://www.linkedin.com/in/nicolaj-reck-053aa38a/}
}
```
## Acknowledgments
**Fine-tuned by**: [Nicolaj Reck](https://www.linkedin.com/in/nicolaj-reck-053aa38a/) -
Thanks to:
- **[Mozilla Foundation](https://huggingface.co/datasets/mozilla-foundation/common_voice_17_0)** for the Common Voice 17 dataset
- **[CoRal-TTS project](https://huggingface.co/datasets/CoRal-project/coral-tts)** for the Danish speech corpus
- **[Sesame Research](https://huggingface.co/sesame/csm-1b)** for the base CSM-1B model
- The open-source community for tools and frameworks
## License
This model is released under the Apache 2.0 license. Please see the base model license for additional terms.
|
Miracle-man/blockassist-bc-singing_lithe_koala_1757063981
|
Miracle-man
| 2025-09-05T09:50:31Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"singing lithe koala",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-05T09:50:28Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- singing lithe koala
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
mradermacher/Mistral-7B-model_45k6e2e4-GGUF
|
mradermacher
| 2025-09-05T09:49:37Z | 0 | 0 |
transformers
|
[
"transformers",
"gguf",
"en",
"dataset:pankajmathur/orca_mini_v1_dataset",
"dataset:pankajmathur/WizardLM_Orca",
"dataset:pankajmathur/dolly-v2_orca",
"dataset:pankajmathur/alpaca_orca",
"base_model:pankajmathur/Mistral-7B-model_45k6e2e4",
"base_model:quantized:pankajmathur/Mistral-7B-model_45k6e2e4",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-09-05T09:05:50Z |
---
base_model: pankajmathur/Mistral-7B-model_45k6e2e4
datasets:
- pankajmathur/orca_mini_v1_dataset
- pankajmathur/WizardLM_Orca
- pankajmathur/dolly-v2_orca
- pankajmathur/alpaca_orca
language:
- en
library_name: transformers
license: apache-2.0
mradermacher:
readme_rev: 1
quantized_by: mradermacher
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
<!-- ### quants: x-f16 Q4_K_S Q2_K Q8_0 Q6_K Q3_K_M Q3_K_S Q3_K_L Q4_K_M Q5_K_S Q5_K_M IQ4_XS -->
<!-- ### quants_skip: -->
<!-- ### skip_mmproj: -->
static quants of https://huggingface.co/pankajmathur/Mistral-7B-model_45k6e2e4
<!-- provided-files -->
***For a convenient overview and download list, visit our [model page for this model](https://hf.tst.eu/model#Mistral-7B-model_45k6e2e4-GGUF).***
weighted/imatrix quants are available at https://huggingface.co/mradermacher/Mistral-7B-model_45k6e2e4-i1-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/Mistral-7B-model_45k6e2e4-GGUF/resolve/main/Mistral-7B-model_45k6e2e4.Q2_K.gguf) | Q2_K | 2.8 | |
| [GGUF](https://huggingface.co/mradermacher/Mistral-7B-model_45k6e2e4-GGUF/resolve/main/Mistral-7B-model_45k6e2e4.Q3_K_S.gguf) | Q3_K_S | 3.3 | |
| [GGUF](https://huggingface.co/mradermacher/Mistral-7B-model_45k6e2e4-GGUF/resolve/main/Mistral-7B-model_45k6e2e4.Q3_K_M.gguf) | Q3_K_M | 3.6 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/Mistral-7B-model_45k6e2e4-GGUF/resolve/main/Mistral-7B-model_45k6e2e4.Q3_K_L.gguf) | Q3_K_L | 3.9 | |
| [GGUF](https://huggingface.co/mradermacher/Mistral-7B-model_45k6e2e4-GGUF/resolve/main/Mistral-7B-model_45k6e2e4.IQ4_XS.gguf) | IQ4_XS | 4.0 | |
| [GGUF](https://huggingface.co/mradermacher/Mistral-7B-model_45k6e2e4-GGUF/resolve/main/Mistral-7B-model_45k6e2e4.Q4_K_S.gguf) | Q4_K_S | 4.2 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Mistral-7B-model_45k6e2e4-GGUF/resolve/main/Mistral-7B-model_45k6e2e4.Q4_K_M.gguf) | Q4_K_M | 4.5 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Mistral-7B-model_45k6e2e4-GGUF/resolve/main/Mistral-7B-model_45k6e2e4.Q5_K_S.gguf) | Q5_K_S | 5.1 | |
| [GGUF](https://huggingface.co/mradermacher/Mistral-7B-model_45k6e2e4-GGUF/resolve/main/Mistral-7B-model_45k6e2e4.Q5_K_M.gguf) | Q5_K_M | 5.2 | |
| [GGUF](https://huggingface.co/mradermacher/Mistral-7B-model_45k6e2e4-GGUF/resolve/main/Mistral-7B-model_45k6e2e4.Q6_K.gguf) | Q6_K | 6.0 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/Mistral-7B-model_45k6e2e4-GGUF/resolve/main/Mistral-7B-model_45k6e2e4.Q8_0.gguf) | Q8_0 | 7.8 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/Mistral-7B-model_45k6e2e4-GGUF/resolve/main/Mistral-7B-model_45k6e2e4.f16.gguf) | f16 | 14.6 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
Grinding/fine_tuned_qwen_investment_bot_adapters
|
Grinding
| 2025-09-05T09:48:38Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-09-05T09:48:37Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
NahedDom/blockassist-bc-flapping_stocky_leopard_1757063259
|
NahedDom
| 2025-09-05T09:46:56Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"flapping stocky leopard",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-05T09:46:53Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- flapping stocky leopard
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
gensynme/blockassist-bc-grunting_squinting_clam_1757065566
|
gensynme
| 2025-09-05T09:46:23Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"grunting squinting clam",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-05T09:46:06Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- grunting squinting clam
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Anshulky/Qwen2-0.5B-GRPO-test
|
Anshulky
| 2025-09-05T09:42:16Z | 0 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"generated_from_trainer",
"trl",
"grpo",
"arxiv:2402.03300",
"base_model:Qwen/Qwen2-0.5B-Instruct",
"base_model:finetune:Qwen/Qwen2-0.5B-Instruct",
"endpoints_compatible",
"region:us"
] | null | 2025-09-05T09:32:07Z |
---
base_model: Qwen/Qwen2-0.5B-Instruct
library_name: transformers
model_name: Qwen2-0.5B-GRPO-test
tags:
- generated_from_trainer
- trl
- grpo
licence: license
---
# Model Card for Qwen2-0.5B-GRPO-test
This model is a fine-tuned version of [Qwen/Qwen2-0.5B-Instruct](https://huggingface.co/Qwen/Qwen2-0.5B-Instruct).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="Anshulky/Qwen2-0.5B-GRPO-test", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
This model was trained with GRPO, a method introduced in [DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models](https://huggingface.co/papers/2402.03300).
### Framework versions
- TRL: 0.22.2
- Transformers: 4.56.1
- Pytorch: 2.8.0+cu126
- Datasets: 4.0.0
- Tokenizers: 0.22.0
## Citations
Cite GRPO as:
```bibtex
@article{shao2024deepseekmath,
title = {{DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models}},
author = {Zhihong Shao and Peiyi Wang and Qihao Zhu and Runxin Xu and Junxiao Song and Mingchuan Zhang and Y. K. Li and Y. Wu and Daya Guo},
year = 2024,
eprint = {arXiv:2402.03300},
}
```
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
arif696/blockassist-bc-regal_spotted_pelican_1757065185
|
arif696
| 2025-09-05T09:40:53Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"regal spotted pelican",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-05T09:40:44Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- regal spotted pelican
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
foreveraurorak/LipSyncEval_sd_vae
|
foreveraurorak
| 2025-09-05T09:32:58Z | 0 | 0 |
diffusers
|
[
"diffusers",
"safetensors",
"stable-diffusion",
"stable-diffusion-diffusers",
"license:mit",
"region:us"
] | null | 2025-09-05T09:32:41Z |
---
license: mit
tags:
- stable-diffusion
- stable-diffusion-diffusers
inference: false
---
# Improved Autoencoders
## Utilizing
These weights are intended to be used with the [🧨 diffusers library](https://github.com/huggingface/diffusers). If you are looking for the model to use with the original [CompVis Stable Diffusion codebase](https://github.com/CompVis/stable-diffusion), [come here](https://huggingface.co/stabilityai/sd-vae-ft-mse-original).
#### How to use with 🧨 diffusers
You can integrate this fine-tuned VAE decoder to your existing `diffusers` workflows, by including a `vae` argument to the `StableDiffusionPipeline`
```py
from diffusers.models import AutoencoderKL
from diffusers import StableDiffusionPipeline
model = "CompVis/stable-diffusion-v1-4"
vae = AutoencoderKL.from_pretrained("stabilityai/sd-vae-ft-mse")
pipe = StableDiffusionPipeline.from_pretrained(model, vae=vae)
```
## Decoder Finetuning
We publish two kl-f8 autoencoder versions, finetuned from the original [kl-f8 autoencoder](https://github.com/CompVis/latent-diffusion#pretrained-autoencoding-models) on a 1:1 ratio of [LAION-Aesthetics](https://laion.ai/blog/laion-aesthetics/) and LAION-Humans, an unreleased subset containing only SFW images of humans. The intent was to fine-tune on the Stable Diffusion training set (the autoencoder was originally trained on OpenImages) but also enrich the dataset with images of humans to improve the reconstruction of faces.
The first, _ft-EMA_, was resumed from the original checkpoint, trained for 313198 steps and uses EMA weights. It uses the same loss configuration as the original checkpoint (L1 + LPIPS).
The second, _ft-MSE_, was resumed from _ft-EMA_ and uses EMA weights and was trained for another 280k steps using a different loss, with more emphasis
on MSE reconstruction (MSE + 0.1 * LPIPS). It produces somewhat ``smoother'' outputs. The batch size for both versions was 192 (16 A100s, batch size 12 per GPU).
To keep compatibility with existing models, only the decoder part was finetuned; the checkpoints can be used as a drop-in replacement for the existing autoencoder.
_Original kl-f8 VAE vs f8-ft-EMA vs f8-ft-MSE_
## Evaluation
### COCO 2017 (256x256, val, 5000 images)
| Model | train steps | rFID | PSNR | SSIM | PSIM | Link | Comments
|----------|---------|------|--------------|---------------|---------------|-----------------------------------------------------------------------------------|-------------------------------------------------------------------------------------------------|
| | | | | | | | |
| original | 246803 | 4.99 | 23.4 +/- 3.8 | 0.69 +/- 0.14 | 1.01 +/- 0.28 | https://ommer-lab.com/files/latent-diffusion/kl-f8.zip | as used in SD |
| ft-EMA | 560001 | 4.42 | 23.8 +/- 3.9 | 0.69 +/- 0.13 | 0.96 +/- 0.27 | https://huggingface.co/stabilityai/sd-vae-ft-ema-original/resolve/main/vae-ft-ema-560000-ema-pruned.ckpt | slightly better overall, with EMA |
| ft-MSE | 840001 | 4.70 | 24.5 +/- 3.7 | 0.71 +/- 0.13 | 0.92 +/- 0.27 | https://huggingface.co/stabilityai/sd-vae-ft-mse-original/resolve/main/vae-ft-mse-840000-ema-pruned.ckpt | resumed with EMA from ft-EMA, emphasis on MSE (rec. loss = MSE + 0.1 * LPIPS), smoother outputs |
### LAION-Aesthetics 5+ (256x256, subset, 10000 images)
| Model | train steps | rFID | PSNR | SSIM | PSIM | Link | Comments
|----------|-----------|------|--------------|---------------|---------------|-----------------------------------------------------------------------------------|-------------------------------------------------------------------------------------------------|
| | | | | | | | |
| original | 246803 | 2.61 | 26.0 +/- 4.4 | 0.81 +/- 0.12 | 0.75 +/- 0.36 | https://ommer-lab.com/files/latent-diffusion/kl-f8.zip | as used in SD |
| ft-EMA | 560001 | 1.77 | 26.7 +/- 4.8 | 0.82 +/- 0.12 | 0.67 +/- 0.34 | https://huggingface.co/stabilityai/sd-vae-ft-ema-original/resolve/main/vae-ft-ema-560000-ema-pruned.ckpt | slightly better overall, with EMA |
| ft-MSE | 840001 | 1.88 | 27.3 +/- 4.7 | 0.83 +/- 0.11 | 0.65 +/- 0.34 | https://huggingface.co/stabilityai/sd-vae-ft-mse-original/resolve/main/vae-ft-mse-840000-ema-pruned.ckpt | resumed with EMA from ft-EMA, emphasis on MSE (rec. loss = MSE + 0.1 * LPIPS), smoother outputs |
### Visual
_Visualization of reconstructions on 256x256 images from the COCO2017 validation dataset._
<p align="center">
<br>
<b>
256x256: ft-EMA (left), ft-MSE (middle), original (right)</b>
</p>
<p align="center">
<img src=https://huggingface.co/stabilityai/stable-diffusion-decoder-finetune/resolve/main/eval/ae-decoder-tuning-reconstructions/merged/00025_merged.png />
</p>
<p align="center">
<img src=https://huggingface.co/stabilityai/stable-diffusion-decoder-finetune/resolve/main/eval/ae-decoder-tuning-reconstructions/merged/00011_merged.png />
</p>
<p align="center">
<img src=https://huggingface.co/stabilityai/stable-diffusion-decoder-finetune/resolve/main/eval/ae-decoder-tuning-reconstructions/merged/00037_merged.png />
</p>
<p align="center">
<img src=https://huggingface.co/stabilityai/stable-diffusion-decoder-finetune/resolve/main/eval/ae-decoder-tuning-reconstructions/merged/00043_merged.png />
</p>
<p align="center">
<img src=https://huggingface.co/stabilityai/stable-diffusion-decoder-finetune/resolve/main/eval/ae-decoder-tuning-reconstructions/merged/00053_merged.png />
</p>
<p align="center">
<img src=https://huggingface.co/stabilityai/stable-diffusion-decoder-finetune/resolve/main/eval/ae-decoder-tuning-reconstructions/merged/00029_merged.png />
</p>
|
acidjp/blockassist-bc-pesty_extinct_prawn_1757061856
|
acidjp
| 2025-09-05T09:26:56Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"pesty extinct prawn",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-05T09:26:52Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- pesty extinct prawn
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
arif696/blockassist-bc-regal_spotted_pelican_1757064289
|
arif696
| 2025-09-05T09:26:30Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"regal spotted pelican",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-05T09:25:58Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- regal spotted pelican
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
sampingkaca72/blockassist-bc-armored_stealthy_elephant_1757062537
|
sampingkaca72
| 2025-09-05T09:24:19Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"armored stealthy elephant",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-05T09:24:15Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- armored stealthy elephant
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
alphain/R-MP1
|
alphain
| 2025-09-05T09:24:11Z | 0 | 0 | null |
[
"license:mit",
"region:us"
] | null | 2025-09-05T09:04:09Z |
---
license: mit
---
The checkpoints of MP1 in the real environment for the two tasks.
|
alikhademi98/finetuned_Qwen2.5_on_persian_medical_qa
|
alikhademi98
| 2025-09-05T09:11:57Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"q&a",
"text-generation",
"LoRA",
"peft",
"question-answering",
"fa",
"dataset:aictsharif/persian-med-qa",
"arxiv:1910.09700",
"base_model:Qwen/Qwen2.5-3B-Instruct",
"base_model:finetune:Qwen/Qwen2.5-3B-Instruct",
"license:mit",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2025-09-05T08:59:58Z |
---
library_name: transformers
tags:
- q&a
- text-generation
- LoRA
- peft
license: mit
datasets:
- aictsharif/persian-med-qa
language:
- fa
base_model:
- Qwen/Qwen2.5-3B-Instruct
pipeline_tag: question-answering
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
This model is a Qwen/Qwen2.5-3B-Instruct model fine-tuned on the Persian medical question and answer dataset.
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
This model is fine-tuned using the LoRA method and is fine-tuned only on the first 1000 data points of the aictsharif/persian-med-qa dataset.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
This model can be used to answer medical questions in Persian.
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
kingkim/unsloth_training_checkpoints
|
kingkim
| 2025-09-05T09:01:45Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"generated_from_trainer",
"trl",
"unsloth",
"sft",
"endpoints_compatible",
"region:us"
] | null | 2025-09-05T07:32:32Z |
---
base_model: unsloth/qwen3-4b-instruct-2507-unsloth-bnb-4bit
library_name: transformers
model_name: unsloth_training_checkpoints
tags:
- generated_from_trainer
- trl
- unsloth
- sft
licence: license
---
# Model Card for unsloth_training_checkpoints
This model is a fine-tuned version of [unsloth/qwen3-4b-instruct-2507-unsloth-bnb-4bit](https://huggingface.co/unsloth/qwen3-4b-instruct-2507-unsloth-bnb-4bit).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="kingkim/unsloth_training_checkpoints", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
This model was trained with SFT.
### Framework versions
- TRL: 0.22.2
- Transformers: 4.56.1
- Pytorch: 2.5.1+cu121
- Datasets: 3.6.0
- Tokenizers: 0.22.0
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
yoppertiu/blockassist-bc-dappled_leaping_anaconda_1757062789
|
yoppertiu
| 2025-09-05T09:00:40Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"dappled leaping anaconda",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-05T08:59:51Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- dappled leaping anaconda
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
bobi7/gen-text-poems
|
bobi7
| 2025-09-05T08:59:49Z | 24 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"gpt2",
"text-generation",
"generated_from_trainer",
"base_model:distilbert/distilgpt2",
"base_model:finetune:distilbert/distilgpt2",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-07-17T12:42:42Z |
---
library_name: transformers
license: apache-2.0
base_model: distilgpt2
tags:
- generated_from_trainer
model-index:
- name: gen-text-poems
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# gen-text-poems
This model is a fine-tuned version of [distilgpt2](https://huggingface.co/distilgpt2) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 8.5785
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 8
- total_train_batch_size: 64
- optimizer: Use OptimizerNames.ADAMW_TORCH_FUSED with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: cosine
- num_epochs: 50
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| No log | 1.0 | 1 | 10.1858 |
| No log | 2.0 | 2 | 9.8156 |
| No log | 3.0 | 3 | 9.5954 |
| No log | 4.0 | 4 | 9.4465 |
| No log | 5.0 | 5 | 9.3399 |
| No log | 6.0 | 6 | 9.2648 |
| No log | 7.0 | 7 | 9.2078 |
| No log | 8.0 | 8 | 9.1611 |
| No log | 9.0 | 9 | 9.1152 |
| 9.3954 | 10.0 | 10 | 9.0680 |
| 9.3954 | 11.0 | 11 | 9.0206 |
| 9.3954 | 12.0 | 12 | 8.9763 |
| 9.3954 | 13.0 | 13 | 8.9398 |
| 9.3954 | 14.0 | 14 | 8.9157 |
| 9.3954 | 15.0 | 15 | 8.8867 |
| 9.3954 | 16.0 | 16 | 8.8490 |
| 9.3954 | 17.0 | 17 | 8.8148 |
| 9.3954 | 18.0 | 18 | 8.7874 |
| 9.3954 | 19.0 | 19 | 8.7735 |
| 8.3204 | 20.0 | 20 | 8.7601 |
| 8.3204 | 21.0 | 21 | 8.7281 |
| 8.3204 | 22.0 | 22 | 8.6956 |
| 8.3204 | 23.0 | 23 | 8.6778 |
| 8.3204 | 24.0 | 24 | 8.6708 |
| 8.3204 | 25.0 | 25 | 8.6569 |
| 8.3204 | 26.0 | 26 | 8.6378 |
| 8.3204 | 27.0 | 27 | 8.6196 |
| 8.3204 | 28.0 | 28 | 8.6066 |
| 8.3204 | 29.0 | 29 | 8.6014 |
| 7.5838 | 30.0 | 30 | 8.6017 |
| 7.5838 | 31.0 | 31 | 8.6036 |
| 7.5838 | 32.0 | 32 | 8.5972 |
| 7.5838 | 33.0 | 33 | 8.5879 |
| 7.5838 | 34.0 | 34 | 8.5830 |
| 7.5838 | 35.0 | 35 | 8.5835 |
| 7.5838 | 36.0 | 36 | 8.5827 |
| 7.5838 | 37.0 | 37 | 8.5812 |
| 7.5838 | 38.0 | 38 | 8.5794 |
| 7.5838 | 39.0 | 39 | 8.5804 |
| 7.1554 | 40.0 | 40 | 8.5795 |
| 7.1554 | 41.0 | 41 | 8.5774 |
| 7.1554 | 42.0 | 42 | 8.5772 |
| 7.1554 | 43.0 | 43 | 8.5767 |
| 7.1554 | 44.0 | 44 | 8.5766 |
| 7.1554 | 45.0 | 45 | 8.5772 |
| 7.1554 | 46.0 | 46 | 8.5781 |
| 7.1554 | 47.0 | 47 | 8.5785 |
### Framework versions
- Transformers 4.56.0
- Pytorch 2.8.0+cu126
- Datasets 4.0.0
- Tokenizers 0.22.0
|
alexandroputra/medsiglip-448-ft-tb-screening
|
alexandroputra
| 2025-09-05T08:59:12Z | 97 | 0 |
transformers
|
[
"transformers",
"safetensors",
"siglip",
"zero-shot-image-classification",
"generated_from_trainer",
"base_model:google/medsiglip-448",
"base_model:finetune:google/medsiglip-448",
"license:other",
"endpoints_compatible",
"region:us"
] |
zero-shot-image-classification
| 2025-09-01T10:59:31Z |
---
library_name: transformers
license: other
base_model: google/medsiglip-448
tags:
- generated_from_trainer
model-index:
- name: medsiglip-448-ft-tb-screening
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# medsiglip-448-ft-tb-screening
This model is a fine-tuned version of [google/medsiglip-448](https://huggingface.co/google/medsiglip-448) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 2.6822
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- gradient_accumulation_steps: 16
- total_train_batch_size: 64
- optimizer: Use OptimizerNames.ADAMW_TORCH_FUSED with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 10
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:------:|:----:|:---------------:|
| 3.5064 | 0.2140 | 25 | 2.4667 |
| 1.9406 | 0.4280 | 50 | 2.5449 |
| 1.9175 | 0.6421 | 75 | 2.5669 |
| 1.8659 | 0.8561 | 100 | 2.7958 |
| 1.9603 | 1.0685 | 125 | 2.6281 |
| 1.8811 | 1.2825 | 150 | 2.5601 |
| 1.8955 | 1.4965 | 175 | 2.5833 |
| 1.8982 | 1.7105 | 200 | 2.6373 |
| 1.825 | 1.9246 | 225 | 2.6426 |
| 1.88 | 2.1370 | 250 | 2.8641 |
| 1.851 | 2.3510 | 275 | 2.6415 |
| 1.8619 | 2.5650 | 300 | 2.5749 |
| 1.8365 | 2.7790 | 325 | 2.6245 |
| 1.8783 | 2.9930 | 350 | 2.5929 |
| 1.8693 | 3.2055 | 375 | 2.5986 |
| 1.8605 | 3.4195 | 400 | 2.6601 |
| 1.8759 | 3.6335 | 425 | 2.5904 |
| 1.8731 | 3.8475 | 450 | 2.6054 |
| 1.8536 | 4.0599 | 475 | 2.6441 |
| 1.8509 | 4.2739 | 500 | 2.6678 |
| 1.8609 | 4.4880 | 525 | 2.6946 |
| 1.8478 | 4.7020 | 550 | 2.6386 |
| 1.8492 | 4.9160 | 575 | 2.6799 |
| 1.8549 | 5.1284 | 600 | 2.6355 |
| 1.88 | 5.3424 | 625 | 2.7021 |
| 1.8569 | 5.5564 | 650 | 2.6380 |
| 1.862 | 5.7705 | 675 | 2.6349 |
| 1.8486 | 5.9845 | 700 | 2.6843 |
| 1.8503 | 6.1969 | 725 | 2.6926 |
| 1.8503 | 6.4109 | 750 | 2.6962 |
| 1.84 | 6.6249 | 775 | 2.6286 |
| 1.8466 | 6.8390 | 800 | 2.6278 |
| 1.8584 | 7.0514 | 825 | 2.6274 |
| 1.8633 | 7.2654 | 850 | 2.6308 |
| 1.8744 | 7.4794 | 875 | 2.6365 |
| 1.8522 | 7.6934 | 900 | 2.6514 |
| 1.8578 | 7.9074 | 925 | 2.6701 |
| 1.8661 | 8.1199 | 950 | 2.6817 |
| 1.8301 | 8.3339 | 975 | 2.6813 |
| 1.8499 | 8.5479 | 1000 | 2.6841 |
| 1.8484 | 8.7619 | 1025 | 2.6832 |
| 1.8815 | 8.9759 | 1050 | 2.6814 |
| 1.8082 | 9.1883 | 1075 | 2.6836 |
| 1.8302 | 9.4024 | 1100 | 2.6839 |
| 1.8822 | 9.6164 | 1125 | 2.6824 |
| 1.8648 | 9.8304 | 1150 | 2.6822 |
### Framework versions
- Transformers 4.56.0
- Pytorch 2.8.0+cu128
- Datasets 4.0.0
- Tokenizers 0.22.0
|
Muapi/retro-future-dystopia-flux-lora
|
Muapi
| 2025-09-05T08:49:50Z | 0 | 0 | null |
[
"lora",
"stable-diffusion",
"flux.1-d",
"license:openrail++",
"region:us"
] | null | 2025-09-05T08:49:40Z |
---
license: openrail++
tags:
- lora
- stable-diffusion
- flux.1-d
model_type: LoRA
---
# Retro Future Dystopia - Flux Lora

**Base model**: Flux.1 D
**Trained words**: RetroFutureDystopia
## 🧠 Usage (Python)
🔑 **Get your MUAPI key** from [muapi.ai/access-keys](https://muapi.ai/access-keys)
```python
import requests, os
url = "https://api.muapi.ai/api/v1/flux_dev_lora_image"
headers = {"Content-Type": "application/json", "x-api-key": os.getenv("MUAPIAPP_API_KEY")}
payload = {
"prompt": "masterpiece, best quality, 1girl, looking at viewer",
"model_id": [{"model": "civitai:886913@992798", "weight": 1.0}],
"width": 1024,
"height": 1024,
"num_images": 1
}
print(requests.post(url, headers=headers, json=payload).json())
```
|
QuantTrio/Seed-OSS-36B-Instruct-GPTQ-Int8
|
QuantTrio
| 2025-09-05T08:48:33Z | 367 | 1 |
transformers
|
[
"transformers",
"safetensors",
"seed_oss",
"text-generation",
"vLLM",
"GPTQ",
"conversational",
"zh",
"en",
"base_model:ByteDance-Seed/Seed-OSS-36B-Instruct",
"base_model:quantized:ByteDance-Seed/Seed-OSS-36B-Instruct",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"8-bit",
"gptq",
"region:us"
] |
text-generation
| 2025-08-21T07:03:04Z |
---
license: apache-2.0
library_name: transformers
pipeline_tag: text-generation
tags:
- vLLM
- GPTQ
language:
- zh
- en
base_model:
- ByteDance-Seed/Seed-OSS-36B-Instruct
base_model_relation: quantized
---
# Seed-OSS-36B-Instruct-GPTQ-Int8
Base model: [ByteDance-Seed/Seed-OSS-36B-Instruct](https://huggingface.co/ByteDance-Seed/Seed-OSS-36B-Instruct)
### 【vLLM Single Node with 2 GPUs — Startup Command】
```
CONTEXT_LENGTH=32768
vllm serve \
QuantTrio/Seed-OSS-36B-Instruct-GPTQ-Int8 \
--served-model-name Seed-OSS-36B-Instruct-GPTQ-Int8 \
--enable-auto-tool-choice \
--tool-call-parser seed_oss \
--chat-template ./Seed-OSS-36B-Instruct-GPTQ-Int8/chat_template.jinja \
--swap-space 4 \
--max-num-seqs 512 \
--max-model-len $CONTEXT_LENGTH \
--max-seq-len-to-capture $CONTEXT_LENGTH \
--gpu-memory-utilization 0.9 \
--tensor-parallel-size 2 \
--trust-remote-code \
--disable-log-requests \
--host 0.0.0.0 \
--port 8000
```
### 【Dependencies / Installation】
As of **2025-08-21**, create a fresh Python environment and run:
```bash
VLLM_USE_PRECOMPILED=1 pip install git+https://github.com/FoolPlayer/vllm.git@seed-oss
pip install git+https://github.com/Fazziekey/transformers.git@seed-oss
```
### 【Logs】
```
2025-08-21
1. Initial commit
```
### 【Model Files】
| File Size | Last Updated |
|-----------|--------------|
| `36GB` | `2025-08-21` |
### 【Model Download】
```python
from huggingface_hub import snapshot_download
snapshot_download('QuantTrio/Seed-OSS-36B-Instruct-GPTQ-Int8', cache_dir="your_local_path")
```
### 【Overview】
## Introduction
<div align="center">
👋 Hi, everyone!
<br>
We are <b>ByteDance Seed Team.</b>
</div>
<p align="center">
You can get to know us better through the following channels👇
<br>
<a href="https://seed.bytedance.com/">
<img src="https://img.shields.io/badge/Website-%231e37ff?style=for-the-badge&logo=bytedance&logoColor=white"></a>
</p>

# Seed-OSS Open-Source Models
<p align="center">
<a href="https://github.com/ByteDance-Seed/seed-oss">
<img src="https://img.shields.io/badge/Seed-Project Page-yellow"></a>
<a href="https://github.com/ByteDance-Seed/seed-oss">
<img src="https://img.shields.io/badge/Seed-Tech Report Coming Soon-red"></a>
<a href="https://huggingface.co/ByteDance-Seed">
<img src="https://img.shields.io/badge/Seed-Hugging Face-orange"></a>
<br>
<a href="./LICENSE">
<img src="https://img.shields.io/badge/License-Apache2.0-blue"></a>
</p>
> [!NOTE]
> This model card is dedicated to the `Seed-OSS-36B-Instruct` model.
## News
- [2025/08/20]🔥We release `Seed-OSS-36B-Base` (both with and without synthetic data versions) and `Seed-OSS-36B-Instruct`.
## Introduction
Seed-OSS is a series of open-source large language models developed by ByteDance's Seed Team, designed for powerful long-context, reasoning, agent and general capabilities, and versatile developer-friendly features. Although trained with only 12T tokens, Seed-OSS achieves excellent performance on several popular open benchmarks.
We release this series of models to the open-source community under the Apache-2.0 license.
> [!NOTE]
> Seed-OSS is primarily optimized for international (i18n) use cases.
### Key Features
- **Flexible Control of Thinking Budget**: Allowing users to flexibly adjust the reasoning length as needed. This capability of dynamically controlling the reasoning length enhances inference efficiency in practical application scenarios.
- **Enhanced Reasoning Capability**: Specifically optimized for reasoning tasks while maintaining balanced and excellent general capabilities.
- **Agentic Intelligence**: Performs exceptionally well in agentic tasks such as tool-using and issue resolving.
- **Research-Friendly**: Given that the inclusion of synthetic instruction data in pre-training may affect the post-training research, we released pre-trained models both with and without instruction data, providing the research community with more diverse options.
- **Native Long Context**: Trained with up-to-512K long context natively.
### Model Summary
Seed-OSS adopts the popular causal language model architecture with RoPE, GQA attention, RMSNorm and SwiGLU activation.
<div align="center">
| | |
|:---:|:---:|
| | **Seed-OSS-36B** |
| **Parameters** | 36B |
| **Attention** | GQA |
| **Activation Function** | SwiGLU |
| **Number of Layers** | 64 |
| **Number of QKV Heads** | 80 / 8 / 8 |
| **Head Size** | 128 |
| **Hidden Size** | 5120 |
| **Vocabulary Size** | 155K |
| **Context Length** | 512K |
| **RoPE Base Frequency** | 1e7 |
</div>
## Evaluation Results
### Seed-OSS-36B-Base
Incorporating synthetic instruction data into pretraining leads to improved performance on most benchmarks. We adopt the version augmented with synthetic instruction data (i.e., *w/ syn.*) as `Seed-OSS-36B-Base`. We also release `Seed-OSS-36B-Base-woSyn` trained without such data (i.e., *w/o syn.*), offering the community a high-performance foundation model unaffected by synthetic instruction data.
<div align="center">
<table>
<thead>
<tr>
<th align="center">Benchmark</th>
<th align="center"><sup><a href="https://seed.bytedance.com/en/seed1_6">Seed1.6-Base</a></sup></th>
<th align="center"><sup>Qwen3-30B-A3B-Base-2507*</sup></th>
<th align="center"><sup>Qwen2.5-32B-Base*</sup></th>
<th align="center"><sup>Seed-OSS-36B-Base<br>(<i>w/ syn.</i>)</sup></th>
<th align="center"><sup>Seed-OSS-36B-Base-woSyn<br>(<i>w/o syn.</i>)</sup></th>
</tr>
</thead>
<tbody>
<tr>
<td align="center" colspan=6><strong>Knowledge</strong></td>
</tr>
<tr>
<td align="center">MMLU-Pro</td>
<td align="center">70</td>
<td align="center">59.8</td>
<td align="center">58.5 (55.1)</td>
<td align="center"><b>65.1</b></td>
<td align="center">60.4</td>
</tr>
<tr>
<td align="center">MMLU</td>
<td align="center">88.8</td>
<td align="center">82.7</td>
<td align="center">84 (83.3)</td>
<td align="center"><b>84.9</b></td>
<td align="center">84.8</td>
</tr>
<tr>
<td align="center">TriviaQA</td>
<td align="center">91</td>
<td align="center">76.2</td>
<td align="center">76</td>
<td align="center"><b>82.1</b></td>
<td align="center">81.9</td>
</tr>
<tr>
<td align="center">GPQA-D</td>
<td align="center">43.4</td>
<td align="center"><b>37</b></td>
<td align="center">29.3</td>
<td align="center">31.7</td>
<td align="center">35.2</td>
</tr>
<tr>
<td align="center">SimpleQA</td>
<td align="center">17.1</td>
<td align="center">7.2</td>
<td align="center">6.1</td>
<td align="center">5.8</td>
<td align="center"><b>7.4</b></td>
</tr>
<tr>
<td align="center" colspan=6><strong>Reasoning</strong></td>
</tr>
<tr>
<td align="center">BBH</td>
<td align="center">92.1</td>
<td align="center">81.4</td>
<td align="center">79.1 (84.5)</td>
<td align="center"><b>87.7</b></td>
<td align="center">87.2</td>
</tr>
<tr>
<td align="center">AGIEval-en</td>
<td align="center">78</td>
<td align="center">66.4</td>
<td align="center">65.6</td>
<td align="center"><b>70.7</b></td>
<td align="center">70.1</td>
</tr>
<tr>
<td align="center" colspan=6><strong>Math</strong></td>
</tr>
<tr>
<td align="center">GSM8K</td>
<td align="center">93.1</td>
<td align="center">87</td>
<td align="center">87.5 (92.9)</td>
<td align="center"><b>90.8</b></td>
<td align="center">90.3</td>
</tr>
<tr>
<td align="center">MATH</td>
<td align="center">72.9</td>
<td align="center">61.1</td>
<td align="center">63.5 (57.7)</td>
<td align="center"><b>81.7</b></td>
<td align="center">61.3</td>
</tr>
<tr>
<td align="center" colspan=6><strong>Coding</strong></td>
</tr>
<tr>
<td align="center">MBPP</td>
<td align="center">83.6</td>
<td align="center">78.8</td>
<td align="center">77.8 (84.5)</td>
<td align="center"><b>80.6</b></td>
<td align="center">74.6</td>
</tr>
<tr>
<td align="center">HumanEval</td>
<td align="center">78</td>
<td align="center">70.7</td>
<td align="center">47.6 (58.5)</td>
<td align="center"><b>76.8</b></td>
<td align="center">75.6</td>
</tr>
</tbody>
</table>
</div>
<sup>
- <b>Bold</b> denotes open-source SOTA.
</sup><br/><sup>
- "*" indicates that the results in this column are presented in the format of "reproduced_results (reported_results_if_any)".
</sup>
### Seed-OSS-36B-Instruct
<div align="center">
<table>
<thead>
<tr>
<th align="center">Benchmark</th>
<th align="center"><sup><a href="https://console.volcengine.com/ark/region:ark+cn-beijing/model/detail?Id=doubao-seed-1-6-thinking">Seed1.6-Thinking-0715</a></sup></th>
<th align="center"><sup>OAI-OSS-20B*</sup></th>
<th align="center"><sup>Qwen3-30B-A3B-Thinking-2507*</sup></th>
<th align="center"><sup>Qwen3-32B*</sup></th>
<th align="center"><sup>Gemma3-27B</sup></th>
<th align="center"><sup>Seed-OSS-36B-Instruct</sup></th>
</tr>
</thead>
<tbody>
<tr>
<td align="center" colspan=7><strong>Knowledge</strong></td>
</tr>
<tr>
<td align="center">MMLU-Pro</td>
<td align="center">86.6</td>
<td align="center">76.2</td>
<td align="center"><ins>81.9</ins> (80.9)</td>
<td align="center">81.8</td>
<td align="center">67.5</td>
<td align="center"><b>82.7</b></td>
</tr>
<tr>
<td align="center">MMLU</td>
<td align="center">90.6</td>
<td align="center">81.7 (85.3)</td>
<td align="center"><ins>86.9</ins></td>
<td align="center">86.2</td>
<td align="center">76.9</td>
<td align="center"><b>87.4</b></td>
</tr>
<tr>
<td align="center">GPQA-D</td>
<td align="center">80.7</td>
<td align="center"><b>72.2</b> (71.5)</td>
<td align="center"><ins>71.4</ins> (73.4)</td>
<td align="center">66.7 (68.4)</td>
<td align="center">42.4</td>
<td align="center"><ins>71.4</ins></td>
</tr>
<tr>
<td align="center">SuperGPQA</td>
<td align="center">63.4</td>
<td align="center">50.1</td>
<td align="center"><b>57.3</b> (56.8)</td>
<td align="center">49.3</td>
<td align="center">-</td>
<td align="center"><ins>55.7</ins></td>
</tr>
<tr>
<td align="center">SimpleQA</td>
<td align="center">23.7</td>
<td align="center">6.7</td>
<td align="center"><b>23.6</b></td>
<td align="center">8.6</td>
<td align="center"><ins>10</ins></td>
<td align="center">9.7</td>
</tr>
<tr>
<td align="center" colspan=7><strong>Math</strong></td>
</tr>
<tr>
<td align="center">AIME24</td>
<td align="center">90.3</td>
<td align="center"><b>92.7</b> (92.1)</td>
<td align="center">87.7</td>
<td align="center">82.7 (81.4)</td>
<td align="center">-</td>
<td align="center"><ins>91.7</ins></td>
</tr>
<tr>
<td align="center">AIME25</td>
<td align="center">86</td>
<td align="center"><b>90.3</b> (91.7)</td>
<td align="center">81.3 (85)</td>
<td align="center">73.3 (72.9)</td>
<td align="center">-</td>
<td align="center"><ins>84.7</ins></td>
</tr>
<tr>
<td align="center">BeyondAIME</td>
<td align="center">60</td>
<td align="center"><b>69</b></td>
<td align="center">56</td>
<td align="center">29</td>
<td align="center">-</td>
<td align="center"><ins>65</ins></td>
</tr>
<tr>
<td align="center" colspan=7><strong>Reasoning</strong></td>
</tr>
<tr>
<td align="center">ArcAGI V2</td>
<td align="center">50.3</td>
<td align="center"><b>41.7</b></td>
<td align="center">37.8</td>
<td align="center">14.4</td>
<td align="center">-</td>
<td align="center"><ins>40.6</ins></td>
</tr>
<tr>
<td align="center">KORBench</td>
<td align="center">74.8</td>
<td align="center"><b>72.3</b></td>
<td align="center">70.2</td>
<td align="center">65.4</td>
<td align="center">-</td>
<td align="center"><ins>70.6</ins></td>
</tr>
<tr>
<td align="center" colspan=7><strong>Coding</strong></td>
</tr>
<tr>
<td align="center">LiveCodeBench v6<br/><sup>(02/2025-05/2025)</sup></td>
<td align="center">66.8</td>
<td align="center"><ins>63.8</ins></td>
<td align="center">60.3 (66)</td>
<td align="center">53.4</td>
<td align="center">-</td>
<td align="center"><b>67.4</b></td>
</tr>
<tr>
<td align="center">HLE</td>
<td align="center">13.9</td>
<td align="center"><b>12.7</b> (10.9)</td>
<td align="center">8.7</td>
<td align="center">6.9</td>
<td align="center">-</td>
<td align="center"><ins>10.1</ins></td>
</tr>
<tr>
<td align="center" colspan=7><strong>Instruction Following</strong></td>
</tr>
<tr>
<td align="center">IFEval</td>
<td align="center">86.3</td>
<td align="center"><b>92.8</b></td>
<td align="center">88 (88.9)</td>
<td align="center">88.4 (85)</td>
<td align="center"><ins>90.4</ins></td>
<td align="center">85.8</td>
</tr>
<tr>
<td align="center" colspan=7><strong>Agent</strong></td>
</tr>
<tr>
<td align="center">TAU1-Retail</td>
<td align="center">63</td>
<td align="center">(54.8)</td>
<td align="center"><ins>58.7</ins> (67.8)</td>
<td align="center">40.9</td>
<td align="center">-</td>
<td align="center"><b>70.4</b></td>
</tr>
<tr>
<td align="center">TAU1-Airline</td>
<td align="center">49</td>
<td align="center">(38)</td>
<td align="center"><b>47</b> (48)</td>
<td align="center">38</td>
<td align="center">-</td>
<td align="center"><ins>46</ins></td>
</tr>
<tr>
<td align="center">SWE-Bench Verified<br/><sup>(OpenHands)</sup></td>
<td align="center">41.8</td>
<td align="center"><b>(60.7)</b></td>
<td align="center">31</td>
<td align="center">23.4</td>
<td align="center">-</td>
<td align="center"><ins>56</ins></td>
</tr>
<tr>
<td align="center">SWE-Bench Verified<br/><sup>(AgentLess 4*10)</sup></td>
<td align="center">48.4</td>
<td align="center">-</td>
<td align="center">33.5</td>
<td align="center"><ins>39.7</ins></td>
<td align="center">-</td>
<td align="center"><b>47</b></td>
</tr>
<tr>
<td align="center">Multi-SWE-Bench</td>
<td align="center">17.7</td>
<td align="center">-</td>
<td align="center"><ins>9.5</ins></td>
<td align="center">7.7</td>
<td align="center">-</td>
<td align="center"><b>17</b></td>
</tr>
<tr>
<td align="center" colspan=7><strong>Multilingualism</strong></td>
</tr>
<tr>
<td align="center">MMMLU</td>
<td align="center">84.3</td>
<td align="center">77.4 (75.7)</td>
<td align="center"><b>79</b></td>
<td align="center"><b>79</b> (80.6)</td>
<td align="center">-</td>
<td align="center"><ins>78.4</ins></td>
</tr>
<tr>
<td align="center" colspan=7><strong>Long Context</strong></td>
</tr>
<tr>
<td align="center">RULER<br/><sup>(128K)</sup></td>
<td align="center">94.5</td>
<td align="center">78.7</td>
<td align="center"><ins>94.5</ins></td>
<td align="center">77.5</td>
<td align="center">-</td>
<td align="center"><b>94.6</b></td>
</tr>
<tr>
<td align="center" colspan=7><strong>Safety</strong></td>
</tr>
<tr>
<td align="center">AIR-Bench</td>
<td align="center">-</td>
<td align="center">-</td>
<td align="center">-</td>
<td align="center">-</td>
<td align="center">-</td>
<td align="center">75.6</td>
</tr>
</tbody>
</table>
</div>
<sup>
- <b>Bold</b> denotes open-source SOTA. <ins>Underlined</ins> indicates the second place in the open-source model.
</sup><br/><sup>
- "*" indicates that the results in this column are presented in the format of "reproduced_results (reported_results_if_any)". Some results have been omitted due to the failure of the evaluation run.
</sup><br/><sup>
- The results of Gemma3-27B are sourced directly from its technical report.
</sup><br/><sup>
- Generation configs for Seed-OSS-36B-Instruct: temperature=1.1, top_p=0.95. Specifically, for Taubench, temperature=1, top_p=0.7.
</sup><br/><sup>
</sup>
> [!NOTE]
> We recommend sampling with `temperature=1.1` and `top_p=0.95`.
### Thinking Budget
Users can flexibly specify the model's thinking budget. The figure below shows the performance curves across different tasks as the thinking budget varies. For simpler tasks (such as IFEval), the model's chain of thought (CoT) is shorter, and the score exhibits fluctuations as the thinking budget increases. For more challenging tasks (such as AIME and LiveCodeBench), the model's CoT is longer, and the score improves with an increase in the thinking budget.

Here is an example with a thinking budget set to 512: during the reasoning process, the model periodically triggers self-reflection to estimate the consumed and remaining budget, and delivers the final response once the budget is exhausted or the reasoning concludes.
```
<seed:think>
Got it, let's try to solve this problem step by step. The problem says ... ...
<seed:cot_budget_reflect>I have used 129 tokens, and there are 383 tokens remaining for use.</seed:cot_budget_reflect>
Using the power rule, ... ...
<seed:cot_budget_reflect>I have used 258 tokens, and there are 254 tokens remaining for use.</seed:cot_budget_reflect>
Alternatively, remember that ... ...
<seed:cot_budget_reflect>I have used 393 tokens, and there are 119 tokens remaining for use.</seed:cot_budget_reflect>
Because if ... ...
<seed:cot_budget_reflect>I have exhausted my token budget, and now I will start answering the question.</seed:cot_budget_reflect>
</seed:think>
To solve the problem, we start by using the properties of logarithms to simplify the given equations: (full answer omitted).
```
If no thinking budget is set (default mode), Seed-OSS will initiate thinking with unlimited length. If a thinking budget is specified, users are advised to prioritize values that are integer multiples of 512 (e.g., 512, 1K, 2K, 4K, 8K, or 16K), as the model has been extensively trained on these intervals. Models are instructed to output a direct response when the thinking budget is 0, and we recommend setting any budget below 512 to this value.
## Quick Start
```shell
pip3 install -r requirements.txt
pip install git+ssh://git@github.com/Fazziekey/transformers.git@seed-oss
```
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
import os
import re
model_name_or_path = "ByteDance-Seed/Seed-OSS-36B-Instruct"
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path)
model = AutoModelForCausalLM.from_pretrained(model_name_or_path, device_map="auto") # You may want to use bfloat16 and/or move to GPU here
messages = [
{"role": "user", "content": "How to make pasta?"},
]
tokenized_chat = tokenizer.apply_chat_template(
messages,
tokenize=True,
add_generation_prompt=True,
return_tensors="pt",
thinking_budget=512 # control the thinking budget
)
outputs = model.generate(tokenized_chat.to(model.device), max_new_tokens=2048)
output_text = tokenizer.decode(outputs[0])
```
## Inference
### Download Model
Download Seed-OSS checkpoint to `./Seed-OSS-36B-Instruct`
### Transformers
The `generate.py` script provides a simple interface for model inference with configurable options.
#### Basic Usage
```shell
cd inference
python3 generate.py --model_path /path/to/model
```
#### Key Parameters
| Parameter | Description |
|-----------|-------------|
| `--model_path` | Path to the pretrained model directory (required) |
| `--prompts` | Input prompts (default: sample cooking/code questions) |
| `--max_new_tokens` | Maximum tokens to generate (default: 4096) |
| `--attn_implementation` | Attention mechanism: `flash_attention_2` (default) or `eager` |
| `--load_in_4bit/8bit` | Enable 4-bit/8-bit quantization (reduces memory usage) |
| `--thinking_budget` | Thinking budget in tokens (default: -1 for unlimited budget) |
#### Quantization Examples
```shell
# 8-bit quantization
python3 generate.py --model_path /path/to/model --load_in_8bit True
# 4-bit quantization
python3 generate.py --model_path /path/to/model --load_in_4bit True
```
#### Custom Prompts
```shell
python3 generate.py --model_path /path/to/model --prompts "['What is machine learning?', 'Explain quantum computing']"
```
### vLLM
Use vllm >= 0.10.0 or higher for inference.
- First install vLLM with Seed-OSS support version:
```shell
VLLM_USE_PRECOMPILED=1 VLLM_TEST_USE_PRECOMPILED_NIGHTLY_WHEEL=1 pip install git+ssh://git@github.com/FoolPlayer/vllm.git@seed-oss
```
- Start vLLM API server:
```shell
python3 -m vllm.entrypoints.openai.api_server \
--host localhost \
--port 4321 \
--enable-auto-tool-choice \
--tool-call-parser seed_oss \
--trust-remote-code \
--model ./Seed-OSS-36B-Instruct \
--chat-template ./Seed-OSS-36B-Instruct/chat_template.jinja \
--tensor-parallel-size 8 \
--dtype bfloat16 \
--served-model-name seed_oss
```
- Test with OpenAI client:
Chat
```shell
python3 inference/vllm_chat.py
```
Tool Call
```shell
python3 inference/vllm_tool_call.py
```
## Model Card
See [MODEL_CARD](./MODEL_CARD.md).
## License
This project is licensed under Apache-2.0. See the [LICENSE](./LICENSE) flie for details.
## Citation
```bibtex
@misc{seed2025seed-oss,
author={ByteDance Seed Team},
title={Seed-OSS Open-Source Models},
year={2025},
howpublished={\url{https://github.com/ByteDance-Seed/seed-oss}}
}
```
## About [ByteDance Seed Team](https://seed.bytedance.com/)
Founded in 2023, ByteDance Seed Team is dedicated to crafting the industry's most advanced AI foundation models. The team aspires to become a world-class research team and make significant contributions to the advancement of science and society.
|
QuantTrio/Qwen3-235B-A22B-Thinking-2507-GPTQ-Int4-Int8Mix
|
QuantTrio
| 2025-09-05T08:46:09Z | 535 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen3_moe",
"text-generation",
"Qwen3",
"GPTQ",
"Int4-Int8Mix",
"量化修复",
"vLLM",
"conversational",
"arxiv:2505.09388",
"base_model:Qwen/Qwen3-235B-A22B-Thinking-2507",
"base_model:quantized:Qwen/Qwen3-235B-A22B-Thinking-2507",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"4-bit",
"gptq",
"region:us"
] |
text-generation
| 2025-07-26T05:06:44Z |
---
library_name: transformers
license: apache-2.0
license_link: https://huggingface.co/Qwen/Qwen3-235B-A22B-Thinking-2507/blob/main/LICENSE
pipeline_tag: text-generation
tags:
- Qwen3
- GPTQ
- Int4-Int8Mix
- 量化修复
- vLLM
base_model:
- Qwen/Qwen3-235B-A22B-Thinking-2507
base_model_relation: quantized
---
# Qwen3-235B-A22B-Thinking-2507-GPTQ-Int4-Int8Mix
Base model [Qwen/Qwen3-235B-A22B-Thinking-2507](https://huggingface.co/Qwen/Qwen3-235B-A22B-Thinking-2507)
### 【VLLM Launch Command for 8 GPUs (Single Node)】
<i>Note: When launching with 8 GPUs, --enable-expert-parallel must be specified; otherwise, the expert tensors cannot be evenly split across tensor parallel ranks. This option is not required for 4-GPU setups. </i>
```
$CONTEXT_LENGTH=32768 # 262144
vllm serve \
QuantTrio/Qwen3-235B-A22B-Thinking-2507-GPTQ-Int4-Int8Mix \
--served-model-name Qwen3-235B-A22B-Thinking-2507-GPTQ-Int4-Int8Mix \
--enable-expert-parallel \
--swap-space 16 \
--max-num-seqs 512 \
--max-model-len $CONTEXT_LENGTH \
--max-seq-len-to-capture $CONTEXT_LENGTH \
--gpu-memory-utilization 0.9 \
--tensor-parallel-size 8 \
--trust-remote-code \
--disable-log-requests \
--host 0.0.0.0 \
--port 8000
```
### 【Dependencies】
```
vllm>=0.9.2
```
### 【Model Update History】
```
2025-08-19
1.[BugFix] Fix compatibility issues with vLLM 0.10.1
2025-07-28
1. Updare model.safetensors.index.json
Please ask everyone who has previously downloaded this repository to update the model.safetensors.index.json file.
2025-07-26
1. fast commit
```
### 【Model Files】
| File Size | Last Updated |
|---------|--------------|
| `125GB` | `2025-07-26` |
### 【Model Download】
```python
from huggingface_hub import snapshot_download
snapshot_download('QuantTrio/Qwen3-235B-A22B-Thinking-2507-GPTQ-Int4-Int8Mix', cache_dir="your_local_path")
```
### 【Description】
# Qwen3-235B-A22B-Thinking-2507
<a href="https://chat.qwen.ai/" target="_blank" style="margin: 2px;">
<img alt="Chat" src="https://img.shields.io/badge/%F0%9F%92%9C%EF%B8%8F%20Qwen%20Chat%20-536af5" style="display: inline-block; vertical-align: middle;"/>
</a>
## Highlights
Over the past three months, we have continued to scale the **thinking capability** of Qwen3-235B-A22B, improving both the **quality and depth** of reasoning. We are pleased to introduce **Qwen3-235B-A22B-Thinking-2507**, featuring the following key enhancements:
- **Significantly improved performance** on reasoning tasks, including logical reasoning, mathematics, science, coding, and academic benchmarks that typically require human expertise — achieving **state-of-the-art results among open-source thinking models**.
- **Markedly better general capabilities**, such as instruction following, tool usage, text generation, and alignment with human preferences.
- **Enhanced 256K long-context understanding** capabilities.
**NOTE**: This version has an increased thinking length. We strongly recommend its use in highly complex reasoning tasks.
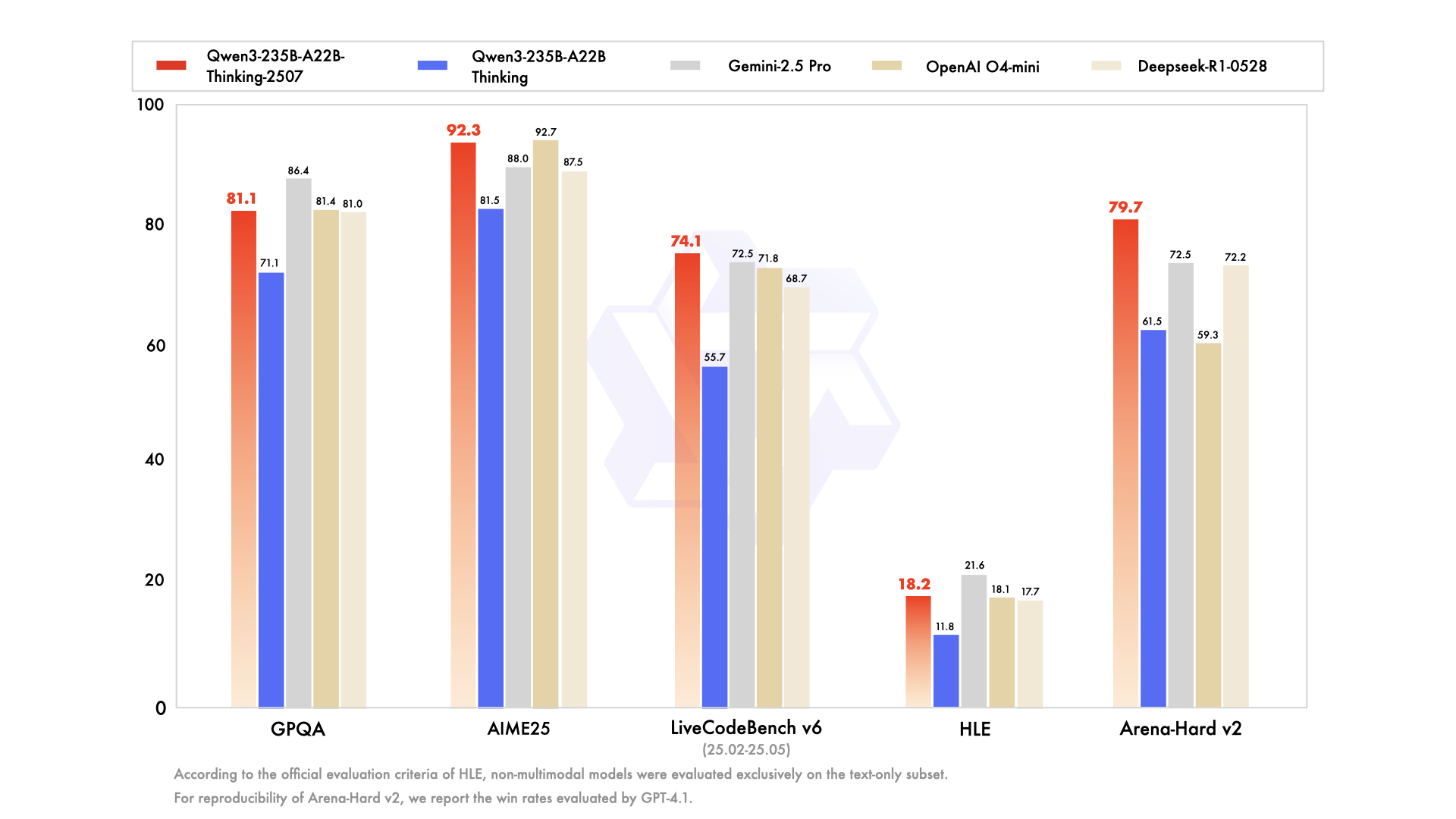
## Model Overview
**Qwen3-235B-A22B-Thinking-2507** has the following features:
- Type: Causal Language Models
- Training Stage: Pretraining & Post-training
- Number of Parameters: 235B in total and 22B activated
- Number of Paramaters (Non-Embedding): 234B
- Number of Layers: 94
- Number of Attention Heads (GQA): 64 for Q and 4 for KV
- Number of Experts: 128
- Number of Activated Experts: 8
- Context Length: **262,144 natively**.
**NOTE: This model supports only thinking mode.**
Additionally, to enforce model thinking, the default chat template automatically includes `<think>`. Therefore, it is normal for the model's output to contain only `</think>` without an explicit opening `<think>` tag.
For more details, including benchmark evaluation, hardware requirements, and inference performance, please refer to our [blog](https://qwenlm.github.io/blog/qwen3/), [GitHub](https://github.com/QwenLM/Qwen3), and [Documentation](https://qwen.readthedocs.io/en/latest/).
## Performance
| | Deepseek-R1-0528 | OpenAI O4-mini | OpenAI O3 | Gemini-2.5 Pro | Claude4 Opus Thinking | Qwen3-235B-A22B Thinking | Qwen3-235B-A22B-Thinking-2507 |
|--- | --- | --- | --- | --- | --- | --- | --- |
| **Knowledge** | | | | | | | |
| MMLU-Pro | 85.0 | 81.9 | **85.9** | 85.6 | - | 82.8 | 84.4 |
| MMLU-Redux | 93.4 | 92.8 | **94.9** | 94.4 | 94.6 | 92.7 | 93.8 |
| GPQA | 81.0 | 81.4* | 83.3* | **86.4** | 79.6 | 71.1 | 81.1 |
| SuperGPQA | 61.7 | 56.4 | - | 62.3 | - | 60.7 | **64.9** |
| **Reasoning** | | | | | | |
| AIME25 | 87.5 | **92.7*** | 88.9* | 88.0 | 75.5 | 81.5 | 92.3 |
| HMMT25 | 79.4 | 66.7 | 77.5 | 82.5 | 58.3 | 62.5 | **83.9** |
| LiveBench 20241125 | 74.7 | 75.8 | 78.3 | **82.4** | 78.2 | 77.1 | 78.4 |
| HLE | 17.7# | 18.1* | 20.3 | **21.6** | 10.7 | 11.8# | 18.2# |
| **Coding** | | | | | | | |
| LiveCodeBench v6 (25.02-25.05) | 68.7 | 71.8 | 58.6 | 72.5 | 48.9 | 55.7 | **74.1** |
| CFEval | 2099 | 1929 | 2043 | 2001 | - | 2056 | **2134** |
| OJBench | 33.6 | 33.3 | 25.4 | **38.9** | - | 25.6 | 32.5 |
| **Alignment** | | | | | | | |
| IFEval | 79.1 | **92.4** | 92.1 | 90.8 | 89.7 | 83.4 | 87.8 |
| Arena-Hard v2$ | 72.2 | 59.3 | **80.8** | 72.5 | 59.1 | 61.5 | 79.7 |
| Creative Writing v3 | 86.3 | 78.8 | **87.7** | 85.9 | 83.8 | 84.6 | 86.1 |
| WritingBench | 83.2 | 78.4 | 85.3 | 83.1 | 79.1 | 80.3 | **88.3** |
| **Agent** | | | | | | | |
| BFCL-v3 | 63.8 | 67.2 | **72.4** | 67.2 | 61.8 | 70.8 | 71.9 |
| TAU2-Retail | 64.9 | 71.0 | **76.3** | 71.3 | - | 40.4 | 71.9 |
| TAU2-Airline | 60.0 | 59.0 | **70.0** | 60.0 | - | 30.0 | 58.0 |
| TAU2-Telecom | 33.3 | 42.0 | **60.5** | 37.4 | - | 21.9 | 45.6 |
| **Multilingualism** | | | | | | | |
| MultiIF | 63.5 | 78.0 | 80.3 | 77.8 | - | 71.9 | **80.6** |
| MMLU-ProX | 80.6 | 79.0 | 83.3 | **84.7** | - | 80.0 | 81.0 |
| INCLUDE | 79.4 | 80.8 | **86.6** | 85.1 | - | 78.7 | 81.0 |
| PolyMATH | 46.9 | 48.7 | 49.7 | 52.2 | - | 54.7 | **60.1** |
\* For OpenAI O4-mini and O3, we use a medium reasoning effort, except for scores marked with *, which are generated using high reasoning effort.
\# According to the official evaluation criteria of HLE, scores marked with \# refer to models that are not multi-modal and were evaluated only on the text-only subset.
$ For reproducibility, we report the win rates evaluated by GPT-4.1.
\& For highly challenging tasks (including PolyMATH and all reasoning and coding tasks), we use an output length of 81,920 tokens. For all other tasks, we set the output length to 32,768.
## Quickstart
The code of Qwen3-MoE has been in the latest Hugging Face `transformers` and we advise you to use the latest version of `transformers`.
With `transformers<4.51.0`, you will encounter the following error:
```
KeyError: 'qwen3_moe'
```
The following contains a code snippet illustrating how to use the model generate content based on given inputs.
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen3-235B-A22B-Thinking-2507"
# load the tokenizer and the model
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
# prepare the model input
prompt = "Give me a short introduction to large language model."
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# conduct text completion
generated_ids = model.generate(
**model_inputs,
max_new_tokens=32768
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
# parsing thinking content
try:
# rindex finding 151668 (</think>)
index = len(output_ids) - output_ids[::-1].index(151668)
except ValueError:
index = 0
thinking_content = tokenizer.decode(output_ids[:index], skip_special_tokens=True).strip("\n")
content = tokenizer.decode(output_ids[index:], skip_special_tokens=True).strip("\n")
print("thinking content:", thinking_content) # no opening <think> tag
print("content:", content)
```
For deployment, you can use `sglang>=0.4.6.post1` or `vllm>=0.8.5` or to create an OpenAI-compatible API endpoint:
- SGLang:
```shell
python -m sglang.launch_server --model-path Qwen/Qwen3-235B-A22B-Thinking-2507 --tp 8 --context-length 262144 --reasoning-parser qwen3
```
- vLLM:
```shell
vllm serve Qwen/Qwen3-235B-A22B-Thinking-2507 --tensor-parallel-size 8 --max-model-len 262144 --enable-reasoning --reasoning-parser deepseek_r1
```
**Note: If you encounter out-of-memory (OOM) issues, you may consider reducing the context length to a smaller value. However, since the model may require longer token sequences for reasoning, we strongly recommend using a context length greater than 131,072 when possible.**
For local use, applications such as Ollama, LMStudio, MLX-LM, llama.cpp, and KTransformers have also supported Qwen3.
## Agentic Use
Qwen3 excels in tool calling capabilities. We recommend using [Qwen-Agent](https://github.com/QwenLM/Qwen-Agent) to make the best use of agentic ability of Qwen3. Qwen-Agent encapsulates tool-calling templates and tool-calling parsers internally, greatly reducing coding complexity.
To define the available tools, you can use the MCP configuration file, use the integrated tool of Qwen-Agent, or integrate other tools by yourself.
```python
from qwen_agent.agents import Assistant
# Define LLM
# Using Alibaba Cloud Model Studio
llm_cfg = {
'model': 'qwen3-235b-a22b-thinking-2507',
'model_type': 'qwen_dashscope',
}
# Using OpenAI-compatible API endpoint. It is recommended to disable the reasoning and the tool call parsing
# functionality of the deployment frameworks and let Qwen-Agent automate the related operations. For example,
# `VLLM_USE_MODELSCOPE=true vllm serve Qwen/Qwen3-235B-A22B-Thinking-2507 --served-model-name Qwen3-235B-A22B-Thinking-2507 --tensor-parallel-size 8 --max-model-len 262144`.
#
# llm_cfg = {
# 'model': 'Qwen3-235B-A22B-Thinking-2507',
#
# # Use a custom endpoint compatible with OpenAI API:
# 'model_server': 'http://localhost:8000/v1', # api_base without reasoning and tool call parsing
# 'api_key': 'EMPTY',
# 'generate_cfg': {
# 'thought_in_content': True,
# },
# }
# Define Tools
tools = [
{'mcpServers': { # You can specify the MCP configuration file
'time': {
'command': 'uvx',
'args': ['mcp-server-time', '--local-timezone=Asia/Shanghai']
},
"fetch": {
"command": "uvx",
"args": ["mcp-server-fetch"]
}
}
},
'code_interpreter', # Built-in tools
]
# Define Agent
bot = Assistant(llm=llm_cfg, function_list=tools)
# Streaming generation
messages = [{'role': 'user', 'content': 'https://qwenlm.github.io/blog/ Introduce the latest developments of Qwen'}]
for responses in bot.run(messages=messages):
pass
print(responses)
```
## Best Practices
To achieve optimal performance, we recommend the following settings:
1. **Sampling Parameters**:
- We suggest using `Temperature=0.6`, `TopP=0.95`, `TopK=20`, and `MinP=0`.
- For supported frameworks, you can adjust the `presence_penalty` parameter between 0 and 2 to reduce endless repetitions. However, using a higher value may occasionally result in language mixing and a slight decrease in model performance.
2. **Adequate Output Length**: We recommend using an output length of 32,768 tokens for most queries. For benchmarking on highly complex problems, such as those found in math and programming competitions, we suggest setting the max output length to 81,920 tokens. This provides the model with sufficient space to generate detailed and comprehensive responses, thereby enhancing its overall performance.
3. **Standardize Output Format**: We recommend using prompts to standardize model outputs when benchmarking.
- **Math Problems**: Include "Please reason step by step, and put your final answer within \boxed{}." in the prompt.
- **Multiple-Choice Questions**: Add the following JSON structure to the prompt to standardize responses: "Please show your choice in the `answer` field with only the choice letter, e.g., `"answer": "C"`."
4. **No Thinking Content in History**: In multi-turn conversations, the historical model output should only include the final output part and does not need to include the thinking content. It is implemented in the provided chat template in Jinja2. However, for frameworks that do not directly use the Jinja2 chat template, it is up to the developers to ensure that the best practice is followed.
### Citation
If you find our work helpful, feel free to give us a cite.
```
@misc{qwen3technicalreport,
title={Qwen3 Technical Report},
author={Qwen Team},
year={2025},
eprint={2505.09388},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2505.09388},
}
```
|
hamedkharazmi/blockassist-bc-tough_webbed_hamster_1757059702
|
hamedkharazmi
| 2025-09-05T08:45:42Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"tough webbed hamster",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-05T08:45:36Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- tough webbed hamster
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Muapi/t-shirt-design
|
Muapi
| 2025-09-05T08:45:11Z | 0 | 0 | null |
[
"lora",
"stable-diffusion",
"flux.1-d",
"license:openrail++",
"region:us"
] | null | 2025-09-05T08:44:59Z |
---
license: openrail++
tags:
- lora
- stable-diffusion
- flux.1-d
model_type: LoRA
---
# T-Shirt Design

**Base model**: Flux.1 D
**Trained words**: d3s1gntsh1rt
## 🧠 Usage (Python)
🔑 **Get your MUAPI key** from [muapi.ai/access-keys](https://muapi.ai/access-keys)
```python
import requests, os
url = "https://api.muapi.ai/api/v1/flux_dev_lora_image"
headers = {"Content-Type": "application/json", "x-api-key": os.getenv("MUAPIAPP_API_KEY")}
payload = {
"prompt": "masterpiece, best quality, 1girl, looking at viewer",
"model_id": [{"model": "civitai:1225453@1380703", "weight": 1.0}],
"width": 1024,
"height": 1024,
"num_images": 1
}
print(requests.post(url, headers=headers, json=payload).json())
```
|
Muapi/bluey-style
|
Muapi
| 2025-09-05T08:44:02Z | 0 | 0 | null |
[
"lora",
"stable-diffusion",
"flux.1-d",
"license:openrail++",
"region:us"
] | null | 2025-09-05T08:43:55Z |
---
license: openrail++
tags:
- lora
- stable-diffusion
- flux.1-d
model_type: LoRA
---
# Bluey Style

**Base model**: Flux.1 D
**Trained words**: In the style of mikus-style, mikus-style
## 🧠 Usage (Python)
🔑 **Get your MUAPI key** from [muapi.ai/access-keys](https://muapi.ai/access-keys)
```python
import requests, os
url = "https://api.muapi.ai/api/v1/flux_dev_lora_image"
headers = {"Content-Type": "application/json", "x-api-key": os.getenv("MUAPIAPP_API_KEY")}
payload = {
"prompt": "masterpiece, best quality, 1girl, looking at viewer",
"model_id": [{"model": "civitai:536318@1337492", "weight": 1.0}],
"width": 1024,
"height": 1024,
"num_images": 1
}
print(requests.post(url, headers=headers, json=payload).json())
```
|
QuantTrio/Qwen3-30B-A3B-Instruct-2507-GPTQ-Int8
|
QuantTrio
| 2025-09-05T08:41:26Z | 3,784 | 6 |
transformers
|
[
"transformers",
"safetensors",
"qwen3_moe",
"text-generation",
"Qwen3",
"GPTQ",
"Int8",
"量化修复",
"vLLM",
"conversational",
"arxiv:2505.09388",
"base_model:Qwen/Qwen3-30B-A3B-Instruct-2507",
"base_model:quantized:Qwen/Qwen3-30B-A3B-Instruct-2507",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"8-bit",
"gptq",
"region:us"
] |
text-generation
| 2025-07-30T09:29:25Z |
---
library_name: transformers
license: apache-2.0
license_link: https://huggingface.co/Qwen/Qwen3-30B-A3B-Instruct-2507/blob/main/LICENSE
pipeline_tag: text-generation
tags:
- Qwen3
- GPTQ
- Int8
- 量化修复
- vLLM
base_model:
- Qwen/Qwen3-30B-A3B-Instruct-2507
base_model_relation: quantized
---
# Qwen3-30B-A3B-Instruct-2507-GPTQ-Int8
Base model: [Qwen/Qwen3-30B-A3B-Instruct-2507](https://huggingface.co/Qwen/Qwen3-30B-A3B-Instruct-2507)
### 【vLLM 4-GPU Single Node Launch Command】
<i>Note: When using 4 GPUs, you must include `--enable-expert-parallel` because expert tensor TP must be evenly divisible; for 2 GPUs this is not necessary.</i>
```
CONTEXT_LENGTH=32768 # 262144
vllm serve \
QuantTrio/Qwen3-30B-A3B-Instruct-2507-GPTQ-Int8 \
--served-model-name Qwen3-30B-A3B-Instruct-2507-GPTQ-Int8 \
--enable-expert-parallel \
--swap-space 16 \
--max-num-seqs 512 \
--max-model-len $CONTEXT_LENGTH \
--max-seq-len-to-capture $CONTEXT_LENGTH \
--gpu-memory-utilization 0.9 \
--tensor-parallel-size 4 \
--trust-remote-code \
--disable-log-requests \
--host 0.0.0.0 \
--port 8000
```
### 【Dependencies】
```
vllm>=0.9.2
```
### 【Model Update Date】
```
2025-08-19
1.[BugFix] Fix compatibility issues with vLLM 0.10.1
2025-07-30
1. Initial commit
```
### 【Model Files】
| File Size | Last Updated |
|-----------|--------------|
| `30GB` | `2025-07-30` |
### 【Model Download】
```python
from huggingface_hub import snapshot_download
snapshot_download('QuantTrio/Qwen3-30B-A3B-Instruct-2507-GPTQ-Int8', cache_dir="your_local_path")
```
### 【Overview】
# Qwen3-30B-A3B-Instruct-2507
<a href="https://chat.qwen.ai/?model=Qwen3-30B-A3B-2507" target="_blank" style="margin: 2px;">
<img alt="Chat" src="https://img.shields.io/badge/%F0%9F%92%9C%EF%B8%8F%20Qwen%20Chat%20-536af5" style="display: inline-block; vertical-align: middle;"/>
</a>
## Highlights
We introduce the updated version of the **Qwen3-30B-A3B non-thinking mode**, named **Qwen3-30B-A3B-Instruct-2507**, featuring the following key enhancements:
- **Significant improvements** in general capabilities, including **instruction following, logical reasoning, text comprehension, mathematics, science, coding and tool usage**.
- **Substantial gains** in long-tail knowledge coverage across **multiple languages**.
- **Markedly better alignment** with user preferences in **subjective and open-ended tasks**, enabling more helpful responses and higher-quality text generation.
- **Enhanced capabilities** in **256K long-context understanding**.
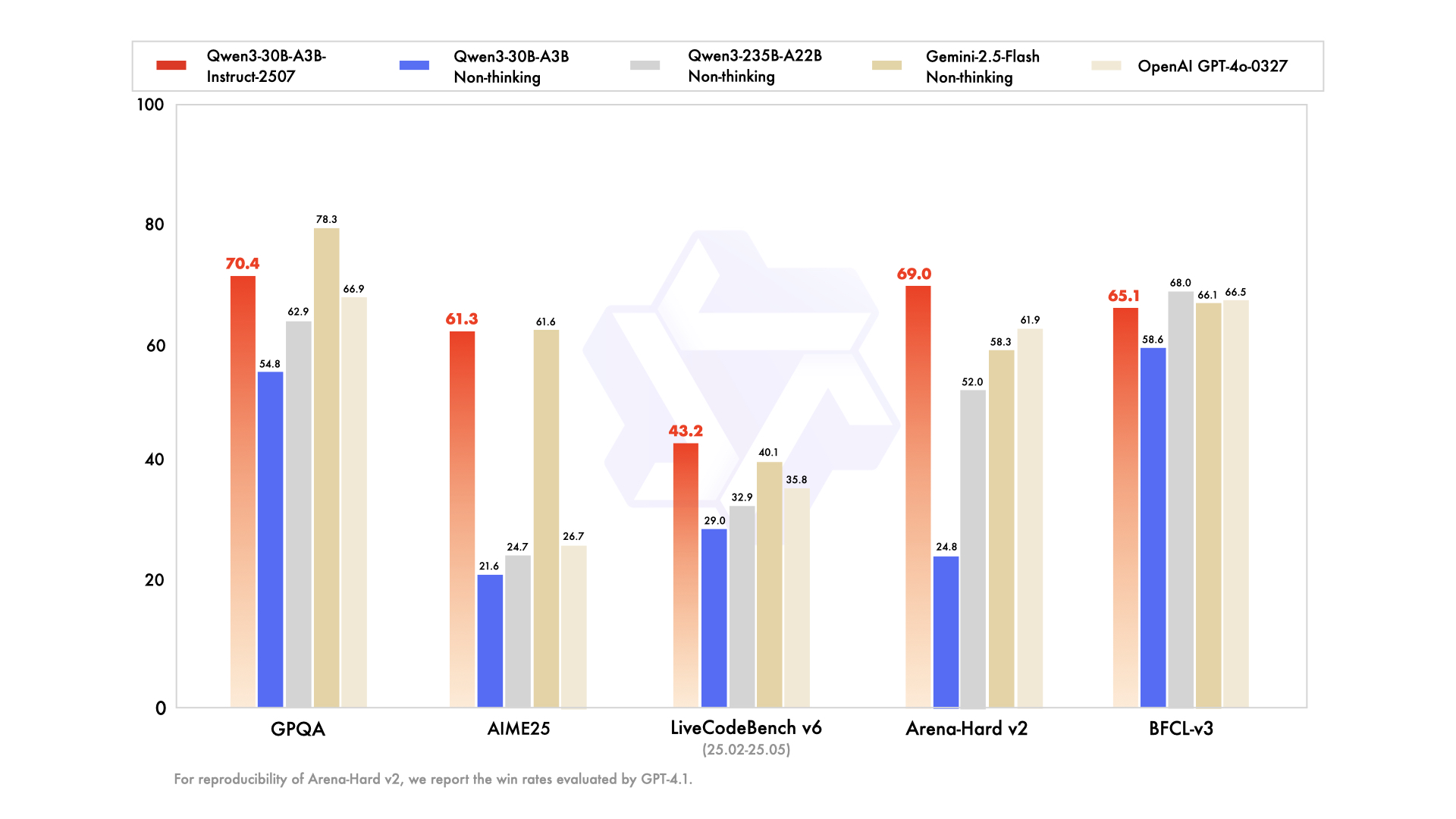
## Model Overview
**Qwen3-30B-A3B-Instruct-2507** has the following features:
- Type: Causal Language Models
- Training Stage: Pretraining & Post-training
- Number of Parameters: 30.5B in total and 3.3B activated
- Number of Paramaters (Non-Embedding): 29.9B
- Number of Layers: 48
- Number of Attention Heads (GQA): 32 for Q and 4 for KV
- Number of Experts: 128
- Number of Activated Experts: 8
- Context Length: **262,144 natively**.
**NOTE: This model supports only non-thinking mode and does not generate ``<think></think>`` blocks in its output. Meanwhile, specifying `enable_thinking=False` is no longer required.**
For more details, including benchmark evaluation, hardware requirements, and inference performance, please refer to our [blog](https://qwenlm.github.io/blog/qwen3/), [GitHub](https://github.com/QwenLM/Qwen3), and [Documentation](https://qwen.readthedocs.io/en/latest/).
## Performance
| | Deepseek-V3-0324 | GPT-4o-0327 | Gemini-2.5-Flash Non-Thinking | Qwen3-235B-A22B Non-Thinking | Qwen3-30B-A3B Non-Thinking | Qwen3-30B-A3B-Instruct-2507 |
|--- | --- | --- | --- | --- | --- | --- |
| **Knowledge** | | | | | | |
| MMLU-Pro | **81.2** | 79.8 | 81.1 | 75.2 | 69.1 | 78.4 |
| MMLU-Redux | 90.4 | **91.3** | 90.6 | 89.2 | 84.1 | 89.3 |
| GPQA | 68.4 | 66.9 | **78.3** | 62.9 | 54.8 | 70.4 |
| SuperGPQA | **57.3** | 51.0 | 54.6 | 48.2 | 42.2 | 53.4 |
| **Reasoning** | | | | | | |
| AIME25 | 46.6 | 26.7 | **61.6** | 24.7 | 21.6 | 61.3 |
| HMMT25 | 27.5 | 7.9 | **45.8** | 10.0 | 12.0 | 43.0 |
| ZebraLogic | 83.4 | 52.6 | 57.9 | 37.7 | 33.2 | **90.0** |
| LiveBench 20241125 | 66.9 | 63.7 | **69.1** | 62.5 | 59.4 | 69.0 |
| **Coding** | | | | | | |
| LiveCodeBench v6 (25.02-25.05) | **45.2** | 35.8 | 40.1 | 32.9 | 29.0 | 43.2 |
| MultiPL-E | 82.2 | 82.7 | 77.7 | 79.3 | 74.6 | **83.8** |
| Aider-Polyglot | 55.1 | 45.3 | 44.0 | **59.6** | 24.4 | 35.6 |
| **Alignment** | | | | | | |
| IFEval | 82.3 | 83.9 | 84.3 | 83.2 | 83.7 | **84.7** |
| Arena-Hard v2* | 45.6 | 61.9 | 58.3 | 52.0 | 24.8 | **69.0** |
| Creative Writing v3 | 81.6 | 84.9 | 84.6 | 80.4 | 68.1 | **86.0** |
| WritingBench | 74.5 | 75.5 | 80.5 | 77.0 | 72.2 | **85.5** |
| **Agent** | | | | | | |
| BFCL-v3 | 64.7 | 66.5 | 66.1 | **68.0** | 58.6 | 65.1 |
| TAU1-Retail | 49.6 | 60.3# | **65.2** | 65.2 | 38.3 | 59.1 |
| TAU1-Airline | 32.0 | 42.8# | **48.0** | 32.0 | 18.0 | 40.0 |
| TAU2-Retail | **71.1** | 66.7# | 64.3 | 64.9 | 31.6 | 57.0 |
| TAU2-Airline | 36.0 | 42.0# | **42.5** | 36.0 | 18.0 | 38.0 |
| TAU2-Telecom | **34.0** | 29.8# | 16.9 | 24.6 | 18.4 | 12.3 |
| **Multilingualism** | | | | | | |
| MultiIF | 66.5 | 70.4 | 69.4 | 70.2 | **70.8** | 67.9 |
| MMLU-ProX | 75.8 | 76.2 | **78.3** | 73.2 | 65.1 | 72.0 |
| INCLUDE | 80.1 | 82.1 | **83.8** | 75.6 | 67.8 | 71.9 |
| PolyMATH | 32.2 | 25.5 | 41.9 | 27.0 | 23.3 | **43.1** |
*: For reproducibility, we report the win rates evaluated by GPT-4.1.
\#: Results were generated using GPT-4o-20241120, as access to the native function calling API of GPT-4o-0327 was unavailable.
## Quickstart
The code of Qwen3-MoE has been in the latest Hugging Face `transformers` and we advise you to use the latest version of `transformers`.
With `transformers<4.51.0`, you will encounter the following error:
```
KeyError: 'qwen3_moe'
```
The following contains a code snippet illustrating how to use the model generate content based on given inputs.
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen3-30B-A3B-Instruct-2507"
# load the tokenizer and the model
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
# prepare the model input
prompt = "Give me a short introduction to large language model."
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# conduct text completion
generated_ids = model.generate(
**model_inputs,
max_new_tokens=16384
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
content = tokenizer.decode(output_ids, skip_special_tokens=True)
print("content:", content)
```
For deployment, you can use `sglang>=0.4.6.post1` or `vllm>=0.8.5` or to create an OpenAI-compatible API endpoint:
- SGLang:
```shell
python -m sglang.launch_server --model-path Qwen/Qwen3-30B-A3B-Instruct-2507 --context-length 262144
```
- vLLM:
```shell
vllm serve Qwen/Qwen3-30B-A3B-Instruct-2507 --max-model-len 262144
```
**Note: If you encounter out-of-memory (OOM) issues, consider reducing the context length to a shorter value, such as `32,768`.**
For local use, applications such as Ollama, LMStudio, MLX-LM, llama.cpp, and KTransformers have also supported Qwen3.
## Agentic Use
Qwen3 excels in tool calling capabilities. We recommend using [Qwen-Agent](https://github.com/QwenLM/Qwen-Agent) to make the best use of agentic ability of Qwen3. Qwen-Agent encapsulates tool-calling templates and tool-calling parsers internally, greatly reducing coding complexity.
To define the available tools, you can use the MCP configuration file, use the integrated tool of Qwen-Agent, or integrate other tools by yourself.
```python
from qwen_agent.agents import Assistant
# Define LLM
llm_cfg = {
'model': 'Qwen3-30B-A3B-Instruct-2507',
# Use a custom endpoint compatible with OpenAI API:
'model_server': 'http://localhost:8000/v1', # api_base
'api_key': 'EMPTY',
}
# Define Tools
tools = [
{'mcpServers': { # You can specify the MCP configuration file
'time': {
'command': 'uvx',
'args': ['mcp-server-time', '--local-timezone=Asia/Shanghai']
},
"fetch": {
"command": "uvx",
"args": ["mcp-server-fetch"]
}
}
},
'code_interpreter', # Built-in tools
]
# Define Agent
bot = Assistant(llm=llm_cfg, function_list=tools)
# Streaming generation
messages = [{'role': 'user', 'content': 'https://qwenlm.github.io/blog/ Introduce the latest developments of Qwen'}]
for responses in bot.run(messages=messages):
pass
print(responses)
```
## Best Practices
To achieve optimal performance, we recommend the following settings:
1. **Sampling Parameters**:
- We suggest using `Temperature=0.7`, `TopP=0.8`, `TopK=20`, and `MinP=0`.
- For supported frameworks, you can adjust the `presence_penalty` parameter between 0 and 2 to reduce endless repetitions. However, using a higher value may occasionally result in language mixing and a slight decrease in model performance.
2. **Adequate Output Length**: We recommend using an output length of 16,384 tokens for most queries, which is adequate for instruct models.
3. **Standardize Output Format**: We recommend using prompts to standardize model outputs when benchmarking.
- **Math Problems**: Include "Please reason step by step, and put your final answer within \boxed{}." in the prompt.
- **Multiple-Choice Questions**: Add the following JSON structure to the prompt to standardize responses: "Please show your choice in the `answer` field with only the choice letter, e.g., `"answer": "C"`."
### Citation
If you find our work helpful, feel free to give us a cite.
```
@misc{qwen3technicalreport,
title={Qwen3 Technical Report},
author={Qwen Team},
year={2025},
eprint={2505.09388},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2505.09388},
}
```
|
cactus-S/blockassist-bc-reclusive_arctic_panther_1757060171
|
cactus-S
| 2025-09-05T08:40:14Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"reclusive arctic panther",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-05T08:40:10Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- reclusive arctic panther
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
bah63843/blockassist-bc-plump_fast_antelope_1757061559
|
bah63843
| 2025-09-05T08:40:08Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"plump fast antelope",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-05T08:40:00Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- plump fast antelope
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
QuantTrio/Qwen3-235B-A22B-Thinking-2507-AWQ
|
QuantTrio
| 2025-09-05T08:38:08Z | 4,279 | 4 |
transformers
|
[
"transformers",
"safetensors",
"qwen3_moe",
"text-generation",
"Qwen3",
"AWQ",
"量化修复",
"vLLM",
"conversational",
"arxiv:2505.09388",
"base_model:Qwen/Qwen3-235B-A22B-Thinking-2507",
"base_model:quantized:Qwen/Qwen3-235B-A22B-Thinking-2507",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"4-bit",
"awq",
"region:us"
] |
text-generation
| 2025-07-26T05:04:54Z |
---
library_name: transformers
license: apache-2.0
license_link: https://huggingface.co/Qwen/Qwen3-235B-A22B-Thinking-2507/blob/main/LICENSE
pipeline_tag: text-generation
tags:
- Qwen3
- AWQ
- 量化修复
- vLLM
base_model:
- Qwen/Qwen3-235B-A22B-Thinking-2507
base_model_relation: quantized
---
# Qwen3-235B-A22B-Thinking-2507-AWQ
Base model [Qwen/Qwen3-235B-A22B-Thinking-2507](https://huggingface.co/Qwen/Qwen3-235B-A22B-Thinking-2507)
### 【VLLM Launch Command for 8 GPUs (Single Node)】
<i>Note: When launching with 8 GPUs, --enable-expert-parallel must be specified; otherwise, the expert tensors cannot be evenly split across tensor parallel ranks. This option is not required for 4-GPU setups. </i>
```
$CONTEXT_LENGTH=32768 # 262144
vllm serve \
QuantTrio/Qwen3-235B-A22B-Thinking-2507-AWQ \
--served-model-name Qwen3-235B-A22B-Thinking-2507-AWQ \
--enable-expert-parallel \
--swap-space 16 \
--max-num-seqs 512 \
--max-model-len $CONTEXT_LENGTH \
--max-seq-len-to-capture $CONTEXT_LENGTH \
--gpu-memory-utilization 0.9 \
--tensor-parallel-size 8 \
--trust-remote-code \
--disable-log-requests \
--host 0.0.0.0 \
--port 8000
```
### 【Dependencies】
```
vllm>=0.9.2
```
### 【Model Update History】
```
2025-08-19
1.[BugFix] Fix compatibility issues with vLLM 0.10.1
2025-07-26
1. fast commit
```
### 【Model Files】
| File Size | Last Updated |
|---------|--------------|
| `116GB` | `2025-07-26` |
### 【Model Download】
```python
from huggingface_hub import snapshot_download
snapshot_download('QuantTrio/Qwen3-235B-A22B-Thinking-2507-AWQ', cache_dir="your_local_path")
```
### 【Description】
# Qwen3-235B-A22B-Thinking-2507
<a href="https://chat.qwen.ai/" target="_blank" style="margin: 2px;">
<img alt="Chat" src="https://img.shields.io/badge/%F0%9F%92%9C%EF%B8%8F%20Qwen%20Chat%20-536af5" style="display: inline-block; vertical-align: middle;"/>
</a>
## Highlights
Over the past three months, we have continued to scale the **thinking capability** of Qwen3-235B-A22B, improving both the **quality and depth** of reasoning. We are pleased to introduce **Qwen3-235B-A22B-Thinking-2507**, featuring the following key enhancements:
- **Significantly improved performance** on reasoning tasks, including logical reasoning, mathematics, science, coding, and academic benchmarks that typically require human expertise — achieving **state-of-the-art results among open-source thinking models**.
- **Markedly better general capabilities**, such as instruction following, tool usage, text generation, and alignment with human preferences.
- **Enhanced 256K long-context understanding** capabilities.
**NOTE**: This version has an increased thinking length. We strongly recommend its use in highly complex reasoning tasks.

## Model Overview
**Qwen3-235B-A22B-Thinking-2507** has the following features:
- Type: Causal Language Models
- Training Stage: Pretraining & Post-training
- Number of Parameters: 235B in total and 22B activated
- Number of Paramaters (Non-Embedding): 234B
- Number of Layers: 94
- Number of Attention Heads (GQA): 64 for Q and 4 for KV
- Number of Experts: 128
- Number of Activated Experts: 8
- Context Length: **262,144 natively**.
**NOTE: This model supports only thinking mode.**
Additionally, to enforce model thinking, the default chat template automatically includes `<think>`. Therefore, it is normal for the model's output to contain only `</think>` without an explicit opening `<think>` tag.
For more details, including benchmark evaluation, hardware requirements, and inference performance, please refer to our [blog](https://qwenlm.github.io/blog/qwen3/), [GitHub](https://github.com/QwenLM/Qwen3), and [Documentation](https://qwen.readthedocs.io/en/latest/).
## Performance
| | Deepseek-R1-0528 | OpenAI O4-mini | OpenAI O3 | Gemini-2.5 Pro | Claude4 Opus Thinking | Qwen3-235B-A22B Thinking | Qwen3-235B-A22B-Thinking-2507 |
|--- | --- | --- | --- | --- | --- | --- | --- |
| **Knowledge** | | | | | | | |
| MMLU-Pro | 85.0 | 81.9 | **85.9** | 85.6 | - | 82.8 | 84.4 |
| MMLU-Redux | 93.4 | 92.8 | **94.9** | 94.4 | 94.6 | 92.7 | 93.8 |
| GPQA | 81.0 | 81.4* | 83.3* | **86.4** | 79.6 | 71.1 | 81.1 |
| SuperGPQA | 61.7 | 56.4 | - | 62.3 | - | 60.7 | **64.9** |
| **Reasoning** | | | | | | |
| AIME25 | 87.5 | **92.7*** | 88.9* | 88.0 | 75.5 | 81.5 | 92.3 |
| HMMT25 | 79.4 | 66.7 | 77.5 | 82.5 | 58.3 | 62.5 | **83.9** |
| LiveBench 20241125 | 74.7 | 75.8 | 78.3 | **82.4** | 78.2 | 77.1 | 78.4 |
| HLE | 17.7# | 18.1* | 20.3 | **21.6** | 10.7 | 11.8# | 18.2# |
| **Coding** | | | | | | | |
| LiveCodeBench v6 (25.02-25.05) | 68.7 | 71.8 | 58.6 | 72.5 | 48.9 | 55.7 | **74.1** |
| CFEval | 2099 | 1929 | 2043 | 2001 | - | 2056 | **2134** |
| OJBench | 33.6 | 33.3 | 25.4 | **38.9** | - | 25.6 | 32.5 |
| **Alignment** | | | | | | | |
| IFEval | 79.1 | **92.4** | 92.1 | 90.8 | 89.7 | 83.4 | 87.8 |
| Arena-Hard v2$ | 72.2 | 59.3 | **80.8** | 72.5 | 59.1 | 61.5 | 79.7 |
| Creative Writing v3 | 86.3 | 78.8 | **87.7** | 85.9 | 83.8 | 84.6 | 86.1 |
| WritingBench | 83.2 | 78.4 | 85.3 | 83.1 | 79.1 | 80.3 | **88.3** |
| **Agent** | | | | | | | |
| BFCL-v3 | 63.8 | 67.2 | **72.4** | 67.2 | 61.8 | 70.8 | 71.9 |
| TAU2-Retail | 64.9 | 71.0 | **76.3** | 71.3 | - | 40.4 | 71.9 |
| TAU2-Airline | 60.0 | 59.0 | **70.0** | 60.0 | - | 30.0 | 58.0 |
| TAU2-Telecom | 33.3 | 42.0 | **60.5** | 37.4 | - | 21.9 | 45.6 |
| **Multilingualism** | | | | | | | |
| MultiIF | 63.5 | 78.0 | 80.3 | 77.8 | - | 71.9 | **80.6** |
| MMLU-ProX | 80.6 | 79.0 | 83.3 | **84.7** | - | 80.0 | 81.0 |
| INCLUDE | 79.4 | 80.8 | **86.6** | 85.1 | - | 78.7 | 81.0 |
| PolyMATH | 46.9 | 48.7 | 49.7 | 52.2 | - | 54.7 | **60.1** |
\* For OpenAI O4-mini and O3, we use a medium reasoning effort, except for scores marked with *, which are generated using high reasoning effort.
\# According to the official evaluation criteria of HLE, scores marked with \# refer to models that are not multi-modal and were evaluated only on the text-only subset.
$ For reproducibility, we report the win rates evaluated by GPT-4.1.
\& For highly challenging tasks (including PolyMATH and all reasoning and coding tasks), we use an output length of 81,920 tokens. For all other tasks, we set the output length to 32,768.
## Quickstart
The code of Qwen3-MoE has been in the latest Hugging Face `transformers` and we advise you to use the latest version of `transformers`.
With `transformers<4.51.0`, you will encounter the following error:
```
KeyError: 'qwen3_moe'
```
The following contains a code snippet illustrating how to use the model generate content based on given inputs.
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen3-235B-A22B-Thinking-2507"
# load the tokenizer and the model
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
# prepare the model input
prompt = "Give me a short introduction to large language model."
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# conduct text completion
generated_ids = model.generate(
**model_inputs,
max_new_tokens=32768
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
# parsing thinking content
try:
# rindex finding 151668 (</think>)
index = len(output_ids) - output_ids[::-1].index(151668)
except ValueError:
index = 0
thinking_content = tokenizer.decode(output_ids[:index], skip_special_tokens=True).strip("\n")
content = tokenizer.decode(output_ids[index:], skip_special_tokens=True).strip("\n")
print("thinking content:", thinking_content) # no opening <think> tag
print("content:", content)
```
For deployment, you can use `sglang>=0.4.6.post1` or `vllm>=0.8.5` or to create an OpenAI-compatible API endpoint:
- SGLang:
```shell
python -m sglang.launch_server --model-path Qwen/Qwen3-235B-A22B-Thinking-2507 --tp 8 --context-length 262144 --reasoning-parser qwen3
```
- vLLM:
```shell
vllm serve Qwen/Qwen3-235B-A22B-Thinking-2507 --tensor-parallel-size 8 --max-model-len 262144 --enable-reasoning --reasoning-parser deepseek_r1
```
**Note: If you encounter out-of-memory (OOM) issues, you may consider reducing the context length to a smaller value. However, since the model may require longer token sequences for reasoning, we strongly recommend using a context length greater than 131,072 when possible.**
For local use, applications such as Ollama, LMStudio, MLX-LM, llama.cpp, and KTransformers have also supported Qwen3.
## Agentic Use
Qwen3 excels in tool calling capabilities. We recommend using [Qwen-Agent](https://github.com/QwenLM/Qwen-Agent) to make the best use of agentic ability of Qwen3. Qwen-Agent encapsulates tool-calling templates and tool-calling parsers internally, greatly reducing coding complexity.
To define the available tools, you can use the MCP configuration file, use the integrated tool of Qwen-Agent, or integrate other tools by yourself.
```python
from qwen_agent.agents import Assistant
# Define LLM
# Using Alibaba Cloud Model Studio
llm_cfg = {
'model': 'qwen3-235b-a22b-thinking-2507',
'model_type': 'qwen_dashscope',
}
# Using OpenAI-compatible API endpoint. It is recommended to disable the reasoning and the tool call parsing
# functionality of the deployment frameworks and let Qwen-Agent automate the related operations. For example,
# `VLLM_USE_MODELSCOPE=true vllm serve Qwen/Qwen3-235B-A22B-Thinking-2507 --served-model-name Qwen3-235B-A22B-Thinking-2507 --tensor-parallel-size 8 --max-model-len 262144`.
#
# llm_cfg = {
# 'model': 'Qwen3-235B-A22B-Thinking-2507',
#
# # Use a custom endpoint compatible with OpenAI API:
# 'model_server': 'http://localhost:8000/v1', # api_base without reasoning and tool call parsing
# 'api_key': 'EMPTY',
# 'generate_cfg': {
# 'thought_in_content': True,
# },
# }
# Define Tools
tools = [
{'mcpServers': { # You can specify the MCP configuration file
'time': {
'command': 'uvx',
'args': ['mcp-server-time', '--local-timezone=Asia/Shanghai']
},
"fetch": {
"command": "uvx",
"args": ["mcp-server-fetch"]
}
}
},
'code_interpreter', # Built-in tools
]
# Define Agent
bot = Assistant(llm=llm_cfg, function_list=tools)
# Streaming generation
messages = [{'role': 'user', 'content': 'https://qwenlm.github.io/blog/ Introduce the latest developments of Qwen'}]
for responses in bot.run(messages=messages):
pass
print(responses)
```
## Best Practices
To achieve optimal performance, we recommend the following settings:
1. **Sampling Parameters**:
- We suggest using `Temperature=0.6`, `TopP=0.95`, `TopK=20`, and `MinP=0`.
- For supported frameworks, you can adjust the `presence_penalty` parameter between 0 and 2 to reduce endless repetitions. However, using a higher value may occasionally result in language mixing and a slight decrease in model performance.
2. **Adequate Output Length**: We recommend using an output length of 32,768 tokens for most queries. For benchmarking on highly complex problems, such as those found in math and programming competitions, we suggest setting the max output length to 81,920 tokens. This provides the model with sufficient space to generate detailed and comprehensive responses, thereby enhancing its overall performance.
3. **Standardize Output Format**: We recommend using prompts to standardize model outputs when benchmarking.
- **Math Problems**: Include "Please reason step by step, and put your final answer within \boxed{}." in the prompt.
- **Multiple-Choice Questions**: Add the following JSON structure to the prompt to standardize responses: "Please show your choice in the `answer` field with only the choice letter, e.g., `"answer": "C"`."
4. **No Thinking Content in History**: In multi-turn conversations, the historical model output should only include the final output part and does not need to include the thinking content. It is implemented in the provided chat template in Jinja2. However, for frameworks that do not directly use the Jinja2 chat template, it is up to the developers to ensure that the best practice is followed.
### Citation
If you find our work helpful, feel free to give us a cite.
```
@misc{qwen3technicalreport,
title={Qwen3 Technical Report},
author={Qwen Team},
year={2025},
eprint={2505.09388},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2505.09388},
}
```
|
Muapi/concept-art-3d-flux
|
Muapi
| 2025-09-05T08:37:55Z | 0 | 0 | null |
[
"lora",
"stable-diffusion",
"flux.1-d",
"license:openrail++",
"region:us"
] | null | 2025-09-05T08:37:25Z |
---
license: openrail++
tags:
- lora
- stable-diffusion
- flux.1-d
model_type: LoRA
---
# Concept Art / 3D FLUX

**Base model**: Flux.1 D
**Trained words**: pscl
## 🧠 Usage (Python)
🔑 **Get your MUAPI key** from [muapi.ai/access-keys](https://muapi.ai/access-keys)
```python
import requests, os
url = "https://api.muapi.ai/api/v1/flux_dev_lora_image"
headers = {"Content-Type": "application/json", "x-api-key": os.getenv("MUAPIAPP_API_KEY")}
payload = {
"prompt": "masterpiece, best quality, 1girl, looking at viewer",
"model_id": [{"model": "civitai:708445@792403", "weight": 1.0}],
"width": 1024,
"height": 1024,
"num_images": 1
}
print(requests.post(url, headers=headers, json=payload).json())
```
|
bah63843/blockassist-bc-plump_fast_antelope_1757061228
|
bah63843
| 2025-09-05T08:34:35Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"plump fast antelope",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-05T08:34:27Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- plump fast antelope
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
boonpertou/blockassist-bc-silent_savage_reindeer_1757061207
|
boonpertou
| 2025-09-05T08:33:48Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"silent savage reindeer",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-05T08:33:28Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- silent savage reindeer
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Ferdi3425/blockassist-bc-amphibious_deadly_otter_1757061164
|
Ferdi3425
| 2025-09-05T08:33:42Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"amphibious deadly otter",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-05T08:33:38Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- amphibious deadly otter
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Ferdi3425/blockassist-bc-amphibious_deadly_otter_1757060651
|
Ferdi3425
| 2025-09-05T08:25:29Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"amphibious deadly otter",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-05T08:25:01Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- amphibious deadly otter
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Rudra-madlads/blockassist-bc-jumping_swift_gazelle_1757060671
|
Rudra-madlads
| 2025-09-05T08:25:26Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"jumping swift gazelle",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-05T08:25:06Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- jumping swift gazelle
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
LiquidAI/LFM2-350M-ENJP-MT-GGUF
|
LiquidAI
| 2025-09-05T08:23:00Z | 922 | 12 |
transformers
|
[
"transformers",
"gguf",
"liquid",
"lfm2",
"edge",
"translation",
"japanese",
"en",
"ja",
"base_model:LiquidAI/LFM2-350M-ENJP-MT",
"base_model:quantized:LiquidAI/LFM2-350M-ENJP-MT",
"license:other",
"endpoints_compatible",
"region:us",
"conversational"
] |
translation
| 2025-09-03T01:29:36Z |
---
library_name: transformers
license: other
license_name: lfm1.0
license_link: LICENSE
language:
- en
- ja
pipeline_tag: translation
tags:
- liquid
- lfm2
- edge
- translation
- japanese
base_model:
- LiquidAI/LFM2-350M-ENJP-MT
---
<center>
<div style="text-align: center;">
<img
src="https://cdn-uploads.huggingface.co/production/uploads/61b8e2ba285851687028d395/7_6D7rWrLxp2hb6OHSV1p.png"
alt="Liquid AI"
style="width: 100%; max-width: 66%; height: auto; display: inline-block; margin-bottom: 0.5em; margin-top: 0.5em;"
/>
</div>
<div style="display: flex; justify-content: center;">
<a href="https://playground.liquid.ai/chat">
<svg width="114.8" height="20" viewBox="0 0 900 200" xmlns="http://www.w3.org/2000/svg" role="img" aria-label="Playground" style="margin-bottom: 1em;">
<title>Playground</title>
<g>
<rect fill="#fff" width="200" height="200"></rect>
<rect fill="url(#x)" x="200" width="800" height="200"></rect>
</g>
<g transform="translate(35, 30) scale(0.45, 0.45)">
<path d="M172.314 129.313L172.219 129.367L206.125 188.18C210.671 195.154 213.324 203.457 213.324 212.382C213.324 220.834 210.956 228.739 206.839 235.479L275.924 213.178L167.853 33.6L141.827 76.9614L172.314 129.313Z" fill="black"/>
<path d="M114.217 302.4L168.492 257.003C168.447 257.003 168.397 257.003 168.352 257.003C143.515 257.003 123.385 237.027 123.385 212.387C123.385 203.487 126.023 195.204 130.55 188.24L162.621 132.503L135.966 86.7327L60.0762 213.183L114.127 302.4H114.217Z" fill="black"/>
<path d="M191.435 250.681C191.435 250.681 191.43 250.681 191.425 250.686L129.71 302.4H221.294L267.71 226.593L191.435 250.686V250.681Z" fill="black"/>
</g>
<g transform="translate(50, 0)" aria-hidden="true" fill="#fff" text-anchor="start" font-family="Verdana,DejaVu Sans,sans-serif" font-size="110">
<text x="255" y="148" textLength="619" fill="#000" opacity="0.1">Playground</text>
<text x="245" y="138" textLength="619">Playground</text>
</g>
<linearGradient id="x" x1="0%" y1="0%" x2="100%" y2="0%">
<stop offset="0%" style="stop-color:#000000"></stop>
<stop offset="100%" style="stop-color:#000000"></stop>
</linearGradient>
</svg>
</a>
<a href="https://leap.liquid.ai/?utm_source=huggingface&utm_medium=modelcards">
<svg width="114.8" height="20" viewBox="0 0 900 200" xmlns="http://www.w3.org/2000/svg" role="img" aria-label="Leap" style="margin-bottom: 1em;">
<title>Leap</title>
<g>
<rect fill="#000" width="500" height="200"></rect>
</g>
<g transform="translate(100, 45) scale(3.5, 3.5)" fill="#fff">
<path d="M13.8512 28.0769C12.5435 28.0769 11.4025 27.8205 10.4281 27.3077C9.45375 26.7692 8.68452 26.0128 8.12042 25.0385C7.58196 24.0641 7.31273 22.9359 7.31273 21.6538V3.76923H0.389648V0H11.4666V21.6538C11.4666 22.4744 11.6973 23.1282 12.1589 23.6154C12.6204 24.0769 13.2486 24.3077 14.0435 24.3077H20.582V28.0769H13.8512Z"/>
<path d="M29.6439 28.4615C27.9259 28.4615 26.4131 28.1282 25.1054 27.4615C23.8233 26.7692 22.8362 25.8077 22.1439 24.5769C21.4516 23.3462 21.1054 21.9103 21.1054 20.2692V14.7308C21.1054 13.0641 21.4516 11.6282 22.1439 10.4231C22.8362 9.19231 23.8233 8.24359 25.1054 7.57692C26.4131 6.88462 27.9259 6.53846 29.6439 6.53846C31.3875 6.53846 32.9003 6.88462 34.1823 7.57692C35.4644 8.24359 36.4516 9.19231 37.1439 10.4231C37.8362 11.6282 38.1823 13.0641 38.1823 14.7308V18.5H25.1054V20.2692C25.1054 21.8333 25.49 23.0256 26.2592 23.8462C27.0541 24.6667 28.1951 25.0769 29.6823 25.0769C30.8875 25.0769 31.8618 24.8718 32.6054 24.4615C33.349 24.0256 33.8105 23.3974 33.99 22.5769H38.1054C37.7977 24.3718 36.8746 25.8077 35.3362 26.8846C33.7977 27.9359 31.9003 28.4615 29.6439 28.4615ZM34.1823 16V14.6923C34.1823 13.1538 33.7977 11.9615 33.0285 11.1154C32.2592 10.2692 31.131 9.84615 29.6439 9.84615C28.1823 9.84615 27.0541 10.2692 26.2592 11.1154C25.49 11.9615 25.1054 13.1667 25.1054 14.7308V15.6923L34.49 15.6538L34.1823 16Z"/>
<path d="M46.3596 28.4615C44.1545 28.4615 42.4109 27.8974 41.1288 26.7692C39.8724 25.6154 39.2442 24.0513 39.2442 22.0769C39.2442 20.0769 39.9109 18.5128 41.2442 17.3846C42.6032 16.2308 44.4622 15.6538 46.8211 15.6538H52.7058V13.6923C52.7058 12.5385 52.3468 11.641 51.6288 11C50.9109 10.359 49.8981 10.0385 48.5904 10.0385C47.4365 10.0385 46.475 10.2949 45.7058 10.8077C44.9365 11.2949 44.4878 11.9487 44.3596 12.7692H40.2827C40.5135 10.8718 41.3852 9.35897 42.8981 8.23077C44.4365 7.10256 46.3724 6.53846 48.7058 6.53846C51.2186 6.53846 53.2058 7.17949 54.6673 8.46154C56.1288 9.71795 56.8596 11.4359 56.8596 13.6154V28.0769H52.8211V24.1923H52.1288L52.8211 23.4231C52.8211 24.9615 52.2314 26.1923 51.0519 27.1154C49.8724 28.0128 48.3083 28.4615 46.3596 28.4615ZM47.5904 25.2692C49.0776 25.2692 50.2955 24.8974 51.2442 24.1538C52.2186 23.3846 52.7058 22.4103 52.7058 21.2308V18.4615H46.8981C45.8211 18.4615 44.9622 18.7564 44.3211 19.3462C43.7058 19.9359 43.3981 20.7436 43.3981 21.7692C43.3981 22.8462 43.7699 23.7051 44.5135 24.3462C45.257 24.9615 46.2827 25.2692 47.5904 25.2692Z"/>
<path d="M58.9984 35V6.92308H63.1138V10.9615H63.9984L63.1138 11.9231C63.1138 10.2564 63.6266 8.94872 64.6523 8C65.7036 7.02564 67.101 6.53846 68.8446 6.53846C70.9728 6.53846 72.6651 7.25641 73.9215 8.69231C75.2036 10.1026 75.8446 12.0385 75.8446 14.5V20.4615C75.8446 22.1026 75.5497 23.5256 74.96 24.7308C74.3959 25.9103 73.5882 26.8333 72.5369 27.5C71.5113 28.141 70.2805 28.4615 68.8446 28.4615C67.1266 28.4615 65.742 27.9872 64.6907 27.0385C63.6395 26.0641 63.1138 24.7436 63.1138 23.0769L63.9984 24.0385H63.0369L63.1523 28.9615V35H58.9984ZM67.4215 24.8462C68.7805 24.8462 69.8318 24.4615 70.5754 23.6923C71.3446 22.8974 71.7292 21.7564 71.7292 20.2692V14.7308C71.7292 13.2436 71.3446 12.1154 70.5754 11.3462C69.8318 10.5513 68.7805 10.1538 67.4215 10.1538C66.1138 10.1538 65.0754 10.5641 64.3061 11.3846C63.5369 12.1795 63.1523 13.2949 63.1523 14.7308V20.2692C63.1523 21.7051 63.5369 22.8333 64.3061 23.6538C65.0754 24.4487 66.1138 24.8462 67.4215 24.8462Z"/>
</g>
<linearGradient id="y" x1="0%" y1="0%" x2="100%" y2="0%">
<stop offset="0%" style="stop-color:#000000"></stop>
</linearGradient>
</svg>
</a>
</div>
</center>
# LFM2-350M-ENJP-MT-GGUF
Based on the [LFM2-350M](https://huggingface.co/LiquidAI/LFM2-350M) model, this checkpoint has been fine-tuned for near real-time **bi-directional Japanese/English translation** of short-to-medium inputs.
Find more details in the original model card: https://huggingface.co/LiquidAI/LFM2-350M-ENJP-MT
## 🏃 How to run LFM2
Example usage with [llama.cpp](https://github.com/ggml-org/llama.cpp):
Translating to English.
```
llama-cli -hf LiquidAI/LFM2-350M-ENJP-MT-GGUF -sys "Translate to English." -st
```
Translate to Japanese.
```
llama-cli -hf LiquidAI/LFM2-350M-ENJP-MT-GGUF -sys "Translate to Japanese." -st
```
Quantized model.
```
llama-cli -hf LiquidAI/LFM2-350M-ENJP-MT-GGUF:Q4_0 -sys "Translate to Japanese." -st
```
|
Ferdi3425/blockassist-bc-amphibious_deadly_otter_1757060382
|
Ferdi3425
| 2025-09-05T08:20:33Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"amphibious deadly otter",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-05T08:20:29Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- amphibious deadly otter
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Muapi/flat-lined
|
Muapi
| 2025-09-05T08:19:04Z | 0 | 0 | null |
[
"lora",
"stable-diffusion",
"flux.1-d",
"license:openrail++",
"region:us"
] | null | 2025-09-05T08:16:29Z |
---
license: openrail++
tags:
- lora
- stable-diffusion
- flux.1-d
model_type: LoRA
---
# Flat Lined

**Base model**: Flux.1 D
**Trained words**:
## 🧠 Usage (Python)
🔑 **Get your MUAPI key** from [muapi.ai/access-keys](https://muapi.ai/access-keys)
```python
import requests, os
url = "https://api.muapi.ai/api/v1/flux_dev_lora_image"
headers = {"Content-Type": "application/json", "x-api-key": os.getenv("MUAPIAPP_API_KEY")}
payload = {
"prompt": "masterpiece, best quality, 1girl, looking at viewer",
"model_id": [{"model": "civitai:1383121@1568212", "weight": 1.0}],
"width": 1024,
"height": 1024,
"num_images": 1
}
print(requests.post(url, headers=headers, json=payload).json())
```
|
LMES/whisper-small-tanglish-v4
|
LMES
| 2025-09-05T08:16:19Z | 0 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"whisper",
"automatic-speech-recognition",
"generated_from_trainer",
"dataset:LMES/whisper_audio_dataset",
"base_model:openai/whisper-small",
"base_model:finetune:openai/whisper-small",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2025-09-05T08:16:06Z |
---
library_name: transformers
license: apache-2.0
base_model: openai/whisper-small
tags:
- generated_from_trainer
datasets:
- LMES/whisper_audio_dataset
model-index:
- name: Whisper small tanglish v4
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Whisper small tanglish v4
This model is a fine-tuned version of [openai/whisper-small](https://huggingface.co/openai/whisper-small) on the whisper_audio_dataset dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 32
- seed: 42
- optimizer: Use adamw_torch with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.05
- num_epochs: 10
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.48.0
- Pytorch 2.8.0+cu128
- Datasets 4.0.0
- Tokenizers 0.21.4
|
madbro/blockassist-bc-whistling_curious_puffin_1757059747
|
madbro
| 2025-09-05T08:10:46Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"whistling curious puffin",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-05T08:09:51Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- whistling curious puffin
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Subsets and Splits
Filtered Qwen2.5 Distill Models
Identifies specific configurations of models by filtering cards that contain 'distill', 'qwen2.5', '7b' while excluding certain base models and incorrect model ID patterns, uncovering unique model variants.
Filtered Model Cards Count
Finds the count of entries with specific card details that include 'distill', 'qwen2.5', '7b' but exclude certain base models, revealing valuable insights about the dataset's content distribution.
Filtered Distill Qwen 7B Models
Filters for specific card entries containing 'distill', 'qwen', and '7b', excluding certain strings and patterns, to identify relevant model configurations.
Filtered Qwen-7b Model Cards
The query performs a detailed filtering based on specific keywords and excludes certain entries, which could be useful for identifying a specific subset of cards but does not provide deeper insights or trends.
Filtered Qwen 7B Model Cards
The query filters for specific terms related to "distilled" or "distill", "qwen", and "7b" in the 'card' column but excludes certain base models, providing a limited set of entries for further inspection.
Qwen 7B Distilled Models
The query provides a basic filtering of records to find specific card names that include keywords related to distilled Qwen 7b models, excluding a particular base model, which gives limited insight but helps in focusing on relevant entries.
Qwen 7B Distilled Model Cards
The query filters data based on specific keywords in the modelId and card fields, providing limited insight primarily useful for locating specific entries rather than revealing broad patterns or trends.
Qwen 7B Distilled Models
Finds all entries containing the terms 'distilled', 'qwen', and '7b' in a case-insensitive manner, providing a filtered set of records but without deeper analysis.
Distilled Qwen 7B Models
The query filters for specific model IDs containing 'distilled', 'qwen', and '7b', providing a basic retrieval of relevant entries but without deeper analysis or insight.
Filtered Model Cards with Distill Qwen2.
Filters and retrieves records containing specific keywords in the card description while excluding certain phrases, providing a basic count of relevant entries.
Filtered Model Cards with Distill Qwen 7
The query filters specific variations of card descriptions containing 'distill', 'qwen', and '7b' while excluding a particular base model, providing limited but specific data retrieval.
Distill Qwen 7B Model Cards
The query filters and retrieves rows where the 'card' column contains specific keywords ('distill', 'qwen', and '7b'), providing a basic filter result that can help in identifying specific entries.