
modelId
stringlengths 5
139
| author
stringlengths 2
42
| last_modified
timestamp[us, tz=UTC]date 2020-02-15 11:33:14
2025-09-12 18:33:19
| downloads
int64 0
223M
| likes
int64 0
11.7k
| library_name
stringclasses 555
values | tags
listlengths 1
4.05k
| pipeline_tag
stringclasses 55
values | createdAt
timestamp[us, tz=UTC]date 2022-03-02 23:29:04
2025-09-12 18:33:14
| card
stringlengths 11
1.01M
|
|---|---|---|---|---|---|---|---|---|---|
Michunie/Fast-Taxi-v3
|
Michunie
| 2022-12-16T20:30:23Z | 0 | 0 | null |
[
"Taxi-v3",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-12-16T20:30:08Z |
---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: Fast-Taxi-v3
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
metrics:
- type: mean_reward
value: 7.50 +/- 2.72
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="Michunie/Fast-Taxi-v3", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
Bilatzea/test
|
Bilatzea
| 2022-12-16T20:27:38Z | 0 | 0 | null |
[
"region:us"
] | null | 2022-12-16T20:24:16Z |
---#!pip install diffusers transformers scipy torch
from diffusers import StableDiffusionPipeline
import torch
model_id = "nitrosocke/spider-verse-diffusion"
pipe = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16)
pipe = pipe.to("cuda")
prompt = "a magical princess with golden hair, spiderverse style"
image = pipe(prompt).images[0]
image.save("./magical_princess.png")
license: openrail
---
|
numan966/q-FrozenLake-v1-4x4-noSlippery
|
numan966
| 2022-12-16T20:19:37Z | 0 | 0 | null |
[
"FrozenLake-v1-4x4-no_slippery",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-12-16T20:10:40Z |
---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="numan966/q-FrozenLake-v1-4x4-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
Michunie/q-FrozenLake-v1-4x4-noSlippery
|
Michunie
| 2022-12-16T20:16:58Z | 0 | 0 | null |
[
"FrozenLake-v1-4x4-no_slippery",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-12-16T20:16:51Z |
---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="Michunie/q-FrozenLake-v1-4x4-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
nmb-paperspace-hf/bert-base-cased-wikitext2-test-mlm
|
nmb-paperspace-hf
| 2022-12-16T19:19:33Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"optimum_graphcore",
"bert",
"fill-mask",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-12-16T19:01:28Z |
---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: bert-base-cased-wikitext2-test-mlm
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-cased-wikitext2-test-mlm
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 6.8438
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 1
- eval_batch_size: 1
- seed: 42
- distributed_type: IPU
- gradient_accumulation_steps: 64
- total_train_batch_size: 64
- total_eval_batch_size: 5
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 10
- training precision: Mixed Precision
### Training results
### Framework versions
- Transformers 4.20.1
- Pytorch 1.10.0+cpu
- Datasets 2.7.1
- Tokenizers 0.12.1
|
admarcosai/sd-class-butterflies-32
|
admarcosai
| 2022-12-16T18:56:48Z | 10 | 0 |
diffusers
|
[
"diffusers",
"pytorch",
"unconditional-image-generation",
"diffusion-models-class",
"license:mit",
"diffusers:DDPMPipeline",
"region:us"
] |
unconditional-image-generation
| 2022-12-16T18:55:41Z |
---
license: mit
tags:
- pytorch
- diffusers
- unconditional-image-generation
- diffusion-models-class
---
# Model Card for Unit 1 of the [Diffusion Models Class 🧨](https://github.com/huggingface/diffusion-models-class)
This model is a diffusion model for unconditional image generation of cute 🦋.
## Usage
```python
from diffusers import DDPMPipeline
pipeline = DDPMPipeline.from_pretrained('dmarcos/sd-class-butterflies-32')
image = pipeline().images[0]
image
```
|
nmb-paperspace-hf/gpt2-wikitext2
|
nmb-paperspace-hf
| 2022-12-16T18:56:03Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"optimum_graphcore",
"gpt2",
"text-generation",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-12-16T18:35:53Z |
---
license: mit
tags:
- generated_from_trainer
model-index:
- name: gpt2-wikitext2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# gpt2-wikitext2
This model is a fine-tuned version of [gpt2](https://huggingface.co/gpt2) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 6.0977
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 1
- eval_batch_size: 1
- seed: 42
- distributed_type: IPU
- gradient_accumulation_steps: 64
- total_train_batch_size: 128
- total_eval_batch_size: 5
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 10
- training precision: Mixed Precision
### Training results
### Framework versions
- Transformers 4.20.1
- Pytorch 1.10.0+cpu
- Datasets 2.7.1
- Tokenizers 0.12.1
|
Vedmani/Transfer_Learning
|
Vedmani
| 2022-12-16T18:36:46Z | 0 | 1 |
tf-keras
|
[
"tf-keras",
"region:us"
] | null | 2022-12-09T04:00:52Z |
# Fine Tuned models for wear particle classification
|
tzvc/3647bbc5-4fbe-4a94-95ec-5aec23a04e73
|
tzvc
| 2022-12-16T18:36:12Z | 0 | 0 |
diffusers
|
[
"diffusers",
"tensorboard",
"text-to-image",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] |
text-to-image
| 2022-12-16T18:18:25Z |
---
license: creativeml-openrail-m
tags:
- text-to-image
widget:
- text: sd-tzvc
---
### training params
```json
{
"pretrained_model_name_or_path": "multimodalart/sd-fine-tunable",
"instance_data_dir": "./3647bbc5-4fbe-4a94-95ec-5aec23a04e73/instance_data",
"class_data_dir": "./class_data/person",
"output_dir": "./3647bbc5-4fbe-4a94-95ec-5aec23a04e73/",
"train_text_encoder": true,
"with_prior_preservation": false,
"prior_loss_weight": 1.0,
"instance_prompt": "sd-tzvc",
"class_prompt": "person",
"resolution": 512,
"train_batch_size": 1,
"gradient_accumulation_steps": 1,
"gradient_checkpointing": true,
"use_8bit_adam": true,
"learning_rate": 2e-06,
"lr_scheduler": "polynomial",
"lr_warmup_steps": 0,
"num_class_images": 500,
"max_train_steps": 1050,
"mixed_precision": "fp16"
}
```
|
sheldon-spock/ppo-LunarLander-v2
|
sheldon-spock
| 2022-12-16T18:31:01Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-12-16T18:30:31Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 241.24 +/- 23.45
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
zyoscovits/q-Taxi-v3
|
zyoscovits
| 2022-12-16T18:10:58Z | 0 | 0 | null |
[
"Taxi-v3",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-12-16T18:10:54Z |
---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-Taxi-v3
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
metrics:
- type: mean_reward
value: 7.56 +/- 2.71
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="zyoscovits/q-Taxi-v3", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
SebLih/whisper-SV3
|
SebLih
| 2022-12-16T18:10:15Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"whisper",
"automatic-speech-recognition",
"hf-asr-leaderboard",
"generated_from_trainer",
"sv",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-12-16T14:53:03Z |
---
language:
- sv
license: apache-2.0
tags:
- hf-asr-leaderboard
- generated_from_trainer
metrics:
- wer
model-index:
- name: Whisper Small SV
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Whisper Small SV
This model is a fine-tuned version of [openai/whisper-small](https://huggingface.co/openai/whisper-small) on the Common Voice 11.0 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3516
- Wer: 23.0598
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 200
- training_steps: 1000
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:-------:|
| 0.3274 | 0.86 | 200 | 0.3552 | 24.7469 |
| 0.1395 | 1.72 | 400 | 0.3303 | 23.5038 |
| 0.074 | 2.59 | 600 | 0.3349 | 22.6603 |
| 0.0199 | 3.45 | 800 | 0.3451 | 22.7935 |
| 0.0089 | 4.31 | 1000 | 0.3516 | 23.0598 |
### Framework versions
- Transformers 4.26.0.dev0
- Pytorch 1.13.0+cu116
- Datasets 2.7.1
- Tokenizers 0.13.2
|
farsipal/whisper-lg-el-intlv-xs
|
farsipal
| 2022-12-16T17:42:59Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"whisper",
"automatic-speech-recognition",
"hf-asr-leaderboard",
"whisper-large",
"mozilla-foundation/common_voice_11_0",
"greek",
"whisper-event",
"generated_from_trainer",
"el",
"dataset:mozilla-foundation/common_voice_11_0",
"dataset:google/fleurs",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-12-15T22:04:20Z |
---
language:
- el
license: apache-2.0
tags:
- hf-asr-leaderboard
- whisper-large
- mozilla-foundation/common_voice_11_0
- greek
- whisper-event
- generated_from_trainer
- whisper-event
datasets:
- mozilla-foundation/common_voice_11_0
- google/fleurs
metrics:
- wer
model-index:
- name: whisper-lg-el-intlv-xs
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: mozilla-foundation/common_voice_11_0
type: mozilla-foundation/common_voice_11_0
config: el
split: test
metrics:
- name: Wer
type: wer
value: 9.8997
---
# whisper-lg-el-intlv-xs
This model is a fine-tuned version of [openai/whisper-large-v2](https://huggingface.co/openai/whisper-large-v2) on the mozilla-foundation/common_voice_11_0,google/fleurs el,el_gr dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2913
- Wer: 9.8997
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3.5e-06
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 10000
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:-----:|:---------------:|:-------:|
| 0.0311 | 2.49 | 1000 | 0.1809 | 10.5498 |
| 0.0074 | 4.98 | 2000 | 0.2470 | 10.2805 |
| 0.0019 | 7.46 | 3000 | 0.3008 | 10.0297 |
| 0.0011 | 9.95 | 4000 | 0.2913 | 9.8997 |
| 0.0009 | 12.44 | 5000 | 0.3092 | 10.1876 |
| 0.0005 | 14.93 | 6000 | 0.3495 | 10.1969 |
| 0.0002 | 17.41 | 7000 | 0.3659 | 10.2526 |
| 0.0001 | 19.9 | 8000 | 0.3846 | 10.2619 |
| 0.0001 | 22.39 | 9000 | 0.3941 | 10.2897 |
| 0.0001 | 24.88 | 10000 | 0.3990 | 10.3269 |
### Framework versions
- Transformers 4.26.0.dev0
- Pytorch 1.13.0+cu117
- Datasets 2.7.1.dev0
- Tokenizers 0.13.2
|
zyoscovits/Taxi-v3
|
zyoscovits
| 2022-12-16T17:37:47Z | 0 | 0 | null |
[
"Taxi-v3",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-12-16T17:37:39Z |
---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: Taxi-v3
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
metrics:
- type: mean_reward
value: 7.46 +/- 2.85
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="zyoscovits/Taxi-v3", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
peterj/test-model
|
peterj
| 2022-12-16T17:37:44Z | 0 | 0 | null |
[
"license:creativeml-openrail-m",
"region:us"
] | null | 2022-12-16T17:37:43Z |
---
license: creativeml-openrail-m
---
|
zyoscovits/q-FrozenLake-v1-4x4-noSlippery
|
zyoscovits
| 2022-12-16T17:35:55Z | 0 | 0 | null |
[
"FrozenLake-v1-4x4-no_slippery",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-12-16T17:35:51Z |
---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="zyoscovits/q-FrozenLake-v1-4x4-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
Shunian/mbti-classification-roberta-base-aug
|
Shunian
| 2022-12-16T17:19:38Z | 10 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"roberta",
"text-classification",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-12-16T09:40:01Z |
---
license: mit
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: mbti-classification-roberta-base-aug
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mbti-classification-roberta-base-aug
This model is a fine-tuned version of [roberta-base](https://huggingface.co/roberta-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 2.1645
- Accuracy: 0.2834
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|
| 2.1201 | 1.0 | 29900 | 2.1415 | 0.2833 |
| 1.8733 | 2.0 | 59800 | 2.1235 | 0.2866 |
| 1.7664 | 3.0 | 89700 | 2.1645 | 0.2834 |
### Framework versions
- Transformers 4.25.1
- Pytorch 1.12.1+cu102
- Datasets 2.7.1
- Tokenizers 0.13.2
|
HayLahav/Taxi-v3
|
HayLahav
| 2022-12-16T17:18:00Z | 0 | 0 | null |
[
"Taxi-v3",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-12-16T17:15:29Z |
---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: Taxi-v3
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
metrics:
- type: mean_reward
value: 7.52 +/- 2.73
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="HayLahav/Taxi-v3", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
teZoartss/tezz
|
teZoartss
| 2022-12-16T17:07:49Z | 0 | 0 | null |
[
"license:creativeml-openrail-m",
"region:us"
] | null | 2022-12-16T17:05:15Z |
---
license: creativeml-openrail-m
---
|
sartajbhuvaji/DeepReinforcementLearningCourse
|
sartajbhuvaji
| 2022-12-16T17:06:32Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-12-16T16:30:13Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 270.37 +/- 20.86
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
vwxyzjn/CartPole-v1-dqn_jax-seed1
|
vwxyzjn
| 2022-12-16T16:37:05Z | 0 | 0 |
cleanrl
|
[
"cleanrl",
"tensorboard",
"CartPole-v1",
"deep-reinforcement-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-12-16T16:31:47Z |
---
tags:
- CartPole-v1
- deep-reinforcement-learning
- reinforcement-learning
- custom-implementation
library_name: cleanrl
model-index:
- name: DQN
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: CartPole-v1
type: CartPole-v1
metrics:
- type: mean_reward
value: 36.50 +/- 11.32
name: mean_reward
verified: false
---
# (CleanRL) **DQN** Agent Playing **CartPole-v1**
This is a trained model of a DQN agent playing CartPole-v1.
The model was trained by using [CleanRL](https://github.com/vwxyzjn/cleanrl) and the most up-to-date training code can be
found [here](https://github.com/vwxyzjn/cleanrl/blob/master/cleanrl/dqn_jax.py).
## Command to reproduce the training
```bash
curl -OL https://huggingface.co/vwxyzjn/CartPole-v1-dqn_jax-seed1/raw/main/dqn.py
curl -OL https://huggingface.co/vwxyzjn/CartPole-v1-dqn_jax-seed1/raw/main/pyproject.toml
curl -OL https://huggingface.co/vwxyzjn/CartPole-v1-dqn_jax-seed1/raw/main/poetry.lock
poetry install --all-extras
python dqn_jax.py --save-model --upload-model --hf-entity vwxyzjn --total-timesteps 1000
```
# Hyperparameters
```python
{'batch_size': 128,
'buffer_size': 10000,
'capture_video': False,
'end_e': 0.05,
'env_id': 'CartPole-v1',
'exp_name': 'dqn_jax',
'exploration_fraction': 0.5,
'gamma': 0.99,
'hf_entity': 'vwxyzjn',
'learning_rate': 0.00025,
'learning_starts': 10000,
'save_model': True,
'seed': 1,
'start_e': 1,
'target_network_frequency': 500,
'total_timesteps': 1000,
'track': False,
'train_frequency': 10,
'upload_model': True,
'wandb_entity': None,
'wandb_project_name': 'cleanRL'}
```
|
eduyio/q-FrozenLake-v1-4X4-Slippery
|
eduyio
| 2022-12-16T16:17:49Z | 0 | 0 | null |
[
"FrozenLake-v1-4x4",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-12-16T16:17:42Z |
---
tags:
- FrozenLake-v1-4x4
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4X4-Slippery
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4
type: FrozenLake-v1-4x4
metrics:
- type: mean_reward
value: 0.56 +/- 0.50
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="eduyio/q-FrozenLake-v1-4X4-Slippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
eduyio/q-FrozenLake-v1-8x8-noSlippery
|
eduyio
| 2022-12-16T15:55:03Z | 0 | 0 | null |
[
"FrozenLake-v1-8x8-no_slippery",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-12-16T15:54:55Z |
---
tags:
- FrozenLake-v1-8x8-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-8x8-noSlippery
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-8x8-no_slippery
type: FrozenLake-v1-8x8-no_slippery
metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="eduyio/q-FrozenLake-v1-8x8-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
SiraH/bert-finetuned-squad
|
SiraH
| 2022-12-16T15:50:29Z | 17 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"question-answering",
"generated_from_trainer",
"dataset:squad",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-09-01T10:11:29Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- squad
model-index:
- name: bert-finetuned-squad
results:
- task:
type: question-answering
name: Question Answering
dataset:
name: squad_v2
type: squad_v2
config: squad_v2
split: validation
metrics:
- type: exact_match
value: 40.2443
name: Exact Match
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiNTc3Y2YyY2Y5ZTMxMGQ3M2U3YThmMjFiM2JlOWQ4MjE0YzZmMmM3NzY4ZDcxYzY4ZTAwNTU4MGE3YmQxOTJhNiIsInZlcnNpb24iOjF9.tk2uBvygzQsexdkxKvFBgKGY8lPNzEG7Pqi-6fL688LTiCMACFFSrZUhyv5b31orF7_CbJkHFjKuMHmX0V_UCA
- type: f1
value: 44.135
name: F1
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiYmE1NWFlYzQ3YTZiMmY3ZDgyYWRlNzI5M2IwYzZkOWUwMDE2NGU4M2RjODBiNjEzY2YxNTVlZmE5OWNmNDU2NiIsInZlcnNpb24iOjF9.pgr2rkyQe-QdwVXuw-uBXheKFz0EhDiyO0doLMmcOi51t_slDPldk29YRXQKvpsfy3YpH_t-xaXQLs1n8VcjDQ
- task:
type: question-answering
name: Question Answering
dataset:
name: subjqa
type: subjqa
config: grocery
split: train
metrics:
- type: exact_match
value: 5.625
name: Exact Match
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiNDMyMDQ1OWFkY2IwYTcxNTljYTZjYTM0ZThjOGEwZWJjYjBlZWQxYWE1ZjMwNDg5NGY5MTFiYmM4YWM0Y2Y2NCIsInZlcnNpb24iOjF9.4nwNKC2teDPVd5YqvjS8sV3q-ylC9fWO5lOiZVk8o3UNdKyAtl3qAH6dU7lGcHZrxasN7zNrxv5kD5nNWr9YBQ
- type: f1
value: 15.8411
name: F1
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiMWMzMTAzNTljNjFlM2E4NGIzNjRjNzRiZTIxZjBlNjkzZWM4NjcxMjUzOGZjZTgxMGUxODk4ZjFkZmJiMjg4ZiIsInZlcnNpb24iOjF9.agcp8QkYeHBvs2Qp0YmEMlvEx1_4a_dv_0cm26UbF-YgYU_7cR86ar-h1V56mrfcKUjNRRiK79GD0P9WT6mADw
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-finetuned-squad
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the squad dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.21.2
- Pytorch 1.12.1+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
Jedalc/Taxi-v3
|
Jedalc
| 2022-12-16T15:37:00Z | 0 | 0 | null |
[
"Taxi-v3",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-12-16T15:36:44Z |
---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: Taxi-v3
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
metrics:
- type: mean_reward
value: 7.54 +/- 2.73
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="Jedalc/Taxi-v3", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
kejian/fanatic-filtering
|
kejian
| 2022-12-16T15:36:43Z | 2 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"generated_from_trainer",
"en",
"dataset:kejian/codeparrot-train-more-filter-3.3b-cleaned",
"license:apache-2.0",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | null | 2022-12-16T03:55:40Z |
---
language:
- en
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- kejian/codeparrot-train-more-filter-3.3b-cleaned
model-index:
- name: fanatic-filtering
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# fanatic-filtering
This model was trained from scratch on the kejian/codeparrot-train-more-filter-3.3b-cleaned dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 64
- eval_batch_size: 32
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.01
- training_steps: 12588
- mixed_precision_training: Native AMP
### Framework versions
- Transformers 4.23.0
- Pytorch 1.13.0+cu116
- Datasets 2.0.0
- Tokenizers 0.12.1
# Full config
{'dataset': {'datasets': ['kejian/codeparrot-train-more-filter-3.3b-cleaned'],
'filter_threshold': 0.002361,
'is_split_by_sentences': True,
'skip_tokens': 1649999872},
'generation': {'batch_size': 128,
'every_n_steps': 384,
'force_call_on': [12588],
'metrics_configs': [{}, {'n': 1}, {}],
'scenario_configs': [{'display_as_html': True,
'generate_kwargs': {'do_sample': True,
'eos_token_id': 0,
'max_length': 640,
'min_length': 10,
'temperature': 0.7,
'top_k': 0,
'top_p': 0.9},
'name': 'unconditional',
'num_hits_threshold': 0,
'num_samples': 2048},
{'display_as_html': True,
'generate_kwargs': {'do_sample': True,
'eos_token_id': 0,
'max_length': 272,
'min_length': 10,
'temperature': 0.7,
'top_k': 0,
'top_p': 0.9},
'name': 'functions',
'num_hits_threshold': 0,
'num_samples': 2048,
'prompts_path': 'resources/functions_csnet.jsonl',
'use_prompt_for_scoring': True}],
'scorer_config': {}},
'kl_gpt3_callback': {'every_n_steps': 384,
'force_call_on': [12588],
'gpt3_kwargs': {'model_name': 'code-cushman-001'},
'max_tokens': 64,
'num_samples': 4096},
'model': {'from_scratch': False,
'gpt2_config_kwargs': {'reorder_and_upcast_attn': True,
'scale_attn_by': True},
'model_kwargs': {'revision': 'cf05a2b0558c03b08c78f07662c22989785b9520'},
'path_or_name': 'kejian/mighty-mle'},
'objective': {'name': 'MLE'},
'tokenizer': {'path_or_name': 'codeparrot/codeparrot-small'},
'training': {'dataloader_num_workers': 0,
'effective_batch_size': 128,
'evaluation_strategy': 'no',
'fp16': True,
'hub_model_id': 'fanatic-filtering',
'hub_strategy': 'all_checkpoints',
'learning_rate': 0.0001,
'logging_first_step': True,
'logging_steps': 1,
'num_tokens': 3300000000.0,
'output_dir': 'training_output',
'per_device_train_batch_size': 16,
'push_to_hub': True,
'remove_unused_columns': False,
'save_steps': 12588,
'save_strategy': 'steps',
'seed': 42,
'tokens_already_seen': 1649999872,
'warmup_ratio': 0.01,
'weight_decay': 0.1}}
# Wandb URL:
https://wandb.ai/kejian/uncategorized/runs/3fal0u2p
|
DrishtiSharma/whisper-large-v2-malayalam
|
DrishtiSharma
| 2022-12-16T15:35:56Z | 68 | 3 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"whisper",
"automatic-speech-recognition",
"whisper-event",
"generated_from_trainer",
"ml",
"dataset:mozilla-foundation/common_voice_11_0",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-12-16T14:32:18Z |
---
language:
- ml
license: apache-2.0
tags:
- whisper-event
- generated_from_trainer
datasets:
- mozilla-foundation/common_voice_11_0
metrics:
- wer
model-index:
- name: Whisper Large V2 Malayalam - Drishti Sharma
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice 11.0
type: mozilla-foundation/common_voice_11_0
config: ml
split: test
args: ml
metrics:
- name: Wer
type: wer
value: 27.458492975734355
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Whisper Large V2 Malayalam - Drishti Sharma
This model is a fine-tuned version of [openai/whisper-large-v2](https://huggingface.co/openai/whisper-large-v2) on the Common Voice 11.0 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3510
- Wer: 27.4585
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 100
- training_steps: 1000
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:-------:|
| 0.0001 | 18.52 | 1000 | 0.3510 | 27.4585 |
### Framework versions
- Transformers 4.26.0.dev0
- Pytorch 1.13.0+cu116
- Datasets 2.7.1.dev0
- Tokenizers 0.13.2
|
nelsonsilva/q-FrozenLake-v1-4x4-noSlippery
|
nelsonsilva
| 2022-12-16T15:35:29Z | 0 | 0 | null |
[
"FrozenLake-v1-4x4-no_slippery",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-12-16T15:35:25Z |
---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="nelsonsilva/q-FrozenLake-v1-4x4-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
jraramhoej/whisper-small-lt-sr-v2
|
jraramhoej
| 2022-12-16T15:25:57Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"whisper",
"automatic-speech-recognition",
"whisper-event",
"generated_from_trainer",
"dataset:mozilla-foundation/common_voice_11_0",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-12-15T09:33:56Z |
---
license: apache-2.0
tags:
- whisper-event
- generated_from_trainer
datasets:
- mozilla-foundation/common_voice_11_0
metrics:
- wer
model-index:
- name: Whisper Small Lithuanian and Serbian sequentially trained
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice 11.0
type: mozilla-foundation/common_voice_11_0
config: sr
split: test
args: sr
metrics:
- name: Wer
type: wer
value: 35.613112100364226
---
# Whisper Small Lithuanian and Serbian sequentially trained
This model is a fine-tuned version of [openai/whisper-small](https://huggingface.co/openai/whisper-small) on the Common Voice 11.0 dataset.
It achieves the following results on the evaluation set:
### Lithuanian
- Wer: >100
### Serbian
- Wer: 35.6131
## Training procedure
It was first trained 2000 steps on Lithuanian and then 2000 steps on Serbian, continuing from the last checkpoint for Lithuanian.
### Training hyperparameters per fine-tune
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 64
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 2000
- mixed_precision_training: Native AMP
### Framework versions
- Transformers 4.26.0.dev0
- Pytorch 1.13.0+cu117
- Datasets 2.7.1.dev0
- Tokenizers 0.13.2
|
Nnarruqt/q-Taxi-F
|
Nnarruqt
| 2022-12-16T15:05:30Z | 0 | 0 | null |
[
"Taxi-v3",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-12-16T15:05:24Z |
---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-Taxi-F
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
metrics:
- type: mean_reward
value: 7.56 +/- 2.71
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="Nnarruqt/q-Taxi-F", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
iblub/q-FrozenLake-v1-4x4-noSlippery
|
iblub
| 2022-12-16T15:01:06Z | 0 | 0 | null |
[
"FrozenLake-v1-4x4-no_slippery",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-12-16T15:00:59Z |
---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="iblub/q-FrozenLake-v1-4x4-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
CreativeEvolution/q-Taxi-v3
|
CreativeEvolution
| 2022-12-16T14:58:34Z | 0 | 0 | null |
[
"Taxi-v3",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-12-16T14:58:26Z |
---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-Taxi-v3
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
metrics:
- type: mean_reward
value: 7.56 +/- 2.71
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="CreativeEvolution/q-Taxi-v3", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
waynedsouza/phon4
|
waynedsouza
| 2022-12-16T14:48:31Z | 4 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"pytorch",
"roberta",
"feature-extraction",
"sentence-similarity",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2022-12-16T08:50:47Z |
---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
---
# waynedsouza/phon4
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 1024 dimensional dense vector space and can be used for tasks like clustering or semantic search.
<!--- Describe your model here -->
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('waynedsouza/phon4')
embeddings = model.encode(sentences)
print(embeddings)
```
## Evaluation Results
<!--- Describe how your model was evaluated -->
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=waynedsouza/phon4)
## Training
The model was trained with the parameters:
**DataLoader**:
`torch.utils.data.dataloader.DataLoader` of length 6957 with parameters:
```
{'batch_size': 16, 'sampler': 'torch.utils.data.sampler.RandomSampler', 'batch_sampler': 'torch.utils.data.sampler.BatchSampler'}
```
**Loss**:
`sentence_transformers.losses.CosineSimilarityLoss.CosineSimilarityLoss`
Parameters of the fit()-Method:
```
{
"epochs": 15,
"evaluation_steps": 0,
"evaluator": "NoneType",
"max_grad_norm": 1,
"optimizer_class": "<class 'torch.optim.adamw.AdamW'>",
"optimizer_params": {
"lr": 2e-05
},
"scheduler": "WarmupLinear",
"steps_per_epoch": null,
"warmup_steps": 10,
"weight_decay": 0.01
}
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 256, 'do_lower_case': False}) with Transformer model: RobertaModel
(1): Pooling({'word_embedding_dimension': 1024, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
(2): Normalize()
)
```
## Citing & Authors
<!--- Describe where people can find more information -->
|
alexgeh196/sentiment_model
|
alexgeh196
| 2022-12-16T14:09:37Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-12-16T13:45:32Z |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- accuracy
- f1
model-index:
- name: sentiment_model
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# sentiment_model
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3852
- Accuracy: 0.8424
- F1: 0.8398
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
### Framework versions
- Transformers 4.25.1
- Pytorch 1.12.1+cu113
- Datasets 2.7.1
- Tokenizers 0.13.2
|
sasha/autotrain-butterfly_similarity_swin-2490776951
|
sasha
| 2022-12-16T14:05:38Z | 35 | 0 |
transformers
|
[
"transformers",
"pytorch",
"autotrain",
"vision",
"image-classification",
"dataset:sasha/autotrain-data-butterfly_similarity_swin",
"co2_eq_emissions",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2022-12-16T13:45:05Z |
---
tags:
- autotrain
- vision
- image-classification
datasets:
- sasha/autotrain-data-butterfly_similarity_swin
widget:
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/tiger.jpg
example_title: Tiger
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/teapot.jpg
example_title: Teapot
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/palace.jpg
example_title: Palace
co2_eq_emissions:
emissions: 28.296015693616066
---
# Model Trained Using AutoTrain
- Problem type: Multi-class Classification
- Model ID: 2490776951
- CO2 Emissions (in grams): 28.2960
## Validation Metrics
- Loss: 1.385
- Accuracy: 0.689
- Macro F1: 0.488
- Micro F1: 0.689
- Weighted F1: 0.641
- Macro Precision: 0.483
- Micro Precision: 0.689
- Weighted Precision: 0.628
- Macro Recall: 0.528
- Micro Recall: 0.689
- Weighted Recall: 0.689
|
sgangireddy/whisper-medium-cv-fi-hu
|
sgangireddy
| 2022-12-16T13:33:37Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"whisper",
"automatic-speech-recognition",
"whisper-event",
"generated_from_trainer",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-12-15T11:06:04Z |
---
license: apache-2.0
tags:
- whisper-event
- generated_from_trainer
metrics:
- wer
model-index:
- name: openai/whisper-medium
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# openai/whisper-medium
This model is a fine-tuned version of [openai/whisper-medium](https://huggingface.co/openai/whisper-medium) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3830
- Wer: 19.5173
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 64
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 3000
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:-------:|
| 0.011 | 4.01 | 1000 | 0.3234 | 20.5978 |
| 0.0011 | 8.03 | 2000 | 0.3650 | 19.4070 |
| 0.0006 | 12.04 | 3000 | 0.3830 | 19.5173 |
### Framework versions
- Transformers 4.26.0.dev0
- Pytorch 1.13.0+cu117
- Datasets 2.7.1.dev0
- Tokenizers 0.13.2
|
HayLahav/q-FrozenLake-v1-4x4-noSlippery
|
HayLahav
| 2022-12-16T13:33:16Z | 0 | 0 | null |
[
"FrozenLake-v1-4x4-no_slippery",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-12-16T13:28:14Z |
---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="HayLahav/q-FrozenLake-v1-4x4-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
breadlicker45/yahoo-answers-test-model
|
breadlicker45
| 2022-12-16T13:20:45Z | 1 | 0 |
transformers
|
[
"transformers",
"pytorch",
"en",
"dataset:breadlicker45/autotrain-data-test2",
"co2_eq_emissions",
"endpoints_compatible",
"region:us"
] | null | 2022-12-16T13:16:44Z |
---
language:
- en
widget:
- text: "I love AutoTrain 🤗"
datasets:
- breadlicker45/autotrain-data-test2
co2_eq_emissions:
emissions: 3.128325675589278
---
# Model Trained Using AutoTrain
- Problem type: Summarization
- Model ID: 2496476946
- CO2 Emissions (in grams): 3.1283
## Validation Metrics
- Loss: 3.511
- Rouge1: 14.002
- Rouge2: 2.968
- RougeL: 11.022
- RougeLsum: 12.335
- Gen Len: 18.900
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_HUGGINGFACE_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoTrain"}' https://api-inference.huggingface.co/breadlicker45/autotrain-test2-2496476946
```
|
huggingtweets/joaquimley
|
huggingtweets
| 2022-12-16T13:14:37Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-12-16T13:14:26Z |
---
language: en
thumbnail: https://github.com/borisdayma/huggingtweets/blob/master/img/logo.png?raw=true
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1590732997199904769/wbH8x_Yi_400x400.png')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">Joaquim Ley</div>
<div style="text-align: center; font-size: 14px;">@joaquimley</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from Joaquim Ley.
| Data | Joaquim Ley |
| --- | --- |
| Tweets downloaded | 3245 |
| Retweets | 291 |
| Short tweets | 299 |
| Tweets kept | 2655 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/x4n287sc/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @joaquimley's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/c91g7z0m) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/c91g7z0m/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/joaquimley')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
zhiyil/roberta-base-finetuned-intent-ipu
|
zhiyil
| 2022-12-16T12:36:13Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"optimum_graphcore",
"roberta",
"text-classification",
"generated_from_trainer",
"dataset:snips_built_in_intents",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-12-16T11:23:10Z |
---
license: mit
tags:
- generated_from_trainer
datasets:
- snips_built_in_intents
metrics:
- accuracy
model-index:
- name: roberta-base-finetuned-intent-ipu
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# roberta-base-finetuned-intent-ipu
This model is a fine-tuned version of [roberta-base](https://huggingface.co/roberta-base) on the snips_built_in_intents dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1503
- Accuracy: 1.0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 1
- eval_batch_size: 1
- seed: 42
- distributed_type: IPU
- gradient_accumulation_steps: 8
- total_train_batch_size: 8
- total_eval_batch_size: 5
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
- training precision: Mixed Precision
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 1.2478 | 1.0 | 75 | 0.6069 | 0.96 |
| 0.2522 | 2.0 | 150 | 0.1503 | 1.0 |
| 0.0903 | 3.0 | 225 | 0.0712 | 1.0 |
| 0.0883 | 4.0 | 300 | 0.0350 | 1.0 |
| 0.0491 | 5.0 | 375 | 0.0267 | 1.0 |
| 0.0305 | 6.0 | 450 | 0.0218 | 1.0 |
| 0.0461 | 7.0 | 525 | 0.0191 | 1.0 |
| 0.039 | 8.0 | 600 | 0.0174 | 1.0 |
| 0.0337 | 9.0 | 675 | 0.0166 | 1.0 |
| 0.0164 | 10.0 | 750 | 0.0162 | 1.0 |
### Framework versions
- Transformers 4.20.1
- Pytorch 1.10.0+cpu
- Datasets 2.7.1
- Tokenizers 0.12.0
|
midhunem/ddpm-butterflies-128
|
midhunem
| 2022-12-16T12:27:18Z | 0 | 0 |
diffusers
|
[
"diffusers",
"tensorboard",
"en",
"dataset:huggan/smithsonian_butterflies_subset",
"license:apache-2.0",
"diffusers:DDPMPipeline",
"region:us"
] | null | 2022-12-16T10:32:08Z |
---
language: en
license: apache-2.0
library_name: diffusers
tags: []
datasets: huggan/smithsonian_butterflies_subset
metrics: []
---
<!-- This model card has been generated automatically according to the information the training script had access to. You
should probably proofread and complete it, then remove this comment. -->
# ddpm-butterflies-128
## Model description
This diffusion model is trained with the [🤗 Diffusers](https://github.com/huggingface/diffusers) library
on the `huggan/smithsonian_butterflies_subset` dataset.
## Intended uses & limitations
#### How to use
```python
# TODO: add an example code snippet for running this diffusion pipeline
```
#### Limitations and bias
[TODO: provide examples of latent issues and potential remediations]
## Training data
[TODO: describe the data used to train the model]
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 16
- eval_batch_size: 16
- gradient_accumulation_steps: 1
- optimizer: AdamW with betas=(None, None), weight_decay=None and epsilon=None
- lr_scheduler: None
- lr_warmup_steps: 500
- ema_inv_gamma: None
- ema_inv_gamma: None
- ema_inv_gamma: None
- mixed_precision: fp16
### Training results
📈 [TensorBoard logs](https://huggingface.co/midhunem/ddpm-butterflies-128/tensorboard?#scalars)
|
huggingtweets/livefromcccp_
|
huggingtweets
| 2022-12-16T11:53:46Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-12-16T11:51:44Z |
---
language: en
thumbnail: http://www.huggingtweets.com/livefromcccp_/1671191621584/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1394601554901147651/wDJ9ebEc_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">live from cccp</div>
<div style="text-align: center; font-size: 14px;">@livefromcccp_</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from live from cccp.
| Data | live from cccp |
| --- | --- |
| Tweets downloaded | 3239 |
| Retweets | 83 |
| Short tweets | 421 |
| Tweets kept | 2735 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/skiu11yh/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @livefromcccp_'s tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/3g686elr) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/3g686elr/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/livefromcccp_')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
jakeyoo/whisper-medium-ja
|
jakeyoo
| 2022-12-16T11:32:27Z | 9 | 1 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"whisper",
"automatic-speech-recognition",
"whisper-event",
"generated_from_trainer",
"ja",
"dataset:mozilla-foundation/common_voice_11_0",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-12-15T17:55:50Z |
---
language:
- ja
license: apache-2.0
tags:
- whisper-event
- generated_from_trainer
datasets:
- mozilla-foundation/common_voice_11_0
metrics:
- wer
model-index:
- name: Whisper Medium Japanese
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: mozilla-foundation/common_voice_11_0 ja
type: mozilla-foundation/common_voice_11_0
config: ja
split: test
args: ja
metrics:
- name: Wer
type: wer
value: 62.6897432259895
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Whisper Medium Japanese
This model is a fine-tuned version of [openai/whisper-medium](https://huggingface.co/openai/whisper-medium) on the mozilla-foundation/common_voice_11_0 ja dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2165
- Wer: 62.6897
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 2
- eval_batch_size: 1
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 5000
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:-------:|
| 0.2264 | 0.2 | 1000 | 0.3102 | 79.3588 |
| 0.3195 | 0.4 | 2000 | 0.2830 | 78.1955 |
| 0.3905 | 0.6 | 3000 | 0.2508 | 72.9181 |
| 0.2478 | 0.8 | 4000 | 0.2407 | 68.8466 |
| 0.0922 | 1.1 | 5000 | 0.2165 | 62.6897 |
### Framework versions
- Transformers 4.26.0.dev0
- Pytorch 1.13.0+cu117
- Datasets 2.7.1.dev0
- Tokenizers 0.13.2
|
LucianoDeben/TaxiDriver
|
LucianoDeben
| 2022-12-16T11:28:06Z | 0 | 0 | null |
[
"Taxi-v3",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-12-16T09:24:59Z |
---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: TaxiDriver
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
metrics:
- type: mean_reward
value: 7.56 +/- 2.71
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="LucianoDeben/TaxiDriver", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
tomekkorbak/elegant_galileo
|
tomekkorbak
| 2022-12-16T11:14:40Z | 0 | 0 | null |
[
"generated_from_trainer",
"en",
"dataset:tomekkorbak/pii-pile-chunk3-0-50000",
"dataset:tomekkorbak/pii-pile-chunk3-50000-100000",
"dataset:tomekkorbak/pii-pile-chunk3-100000-150000",
"dataset:tomekkorbak/pii-pile-chunk3-150000-200000",
"dataset:tomekkorbak/pii-pile-chunk3-200000-250000",
"dataset:tomekkorbak/pii-pile-chunk3-250000-300000",
"dataset:tomekkorbak/pii-pile-chunk3-300000-350000",
"dataset:tomekkorbak/pii-pile-chunk3-350000-400000",
"dataset:tomekkorbak/pii-pile-chunk3-400000-450000",
"dataset:tomekkorbak/pii-pile-chunk3-450000-500000",
"dataset:tomekkorbak/pii-pile-chunk3-500000-550000",
"dataset:tomekkorbak/pii-pile-chunk3-550000-600000",
"dataset:tomekkorbak/pii-pile-chunk3-600000-650000",
"dataset:tomekkorbak/pii-pile-chunk3-650000-700000",
"dataset:tomekkorbak/pii-pile-chunk3-700000-750000",
"dataset:tomekkorbak/pii-pile-chunk3-750000-800000",
"dataset:tomekkorbak/pii-pile-chunk3-800000-850000",
"dataset:tomekkorbak/pii-pile-chunk3-850000-900000",
"dataset:tomekkorbak/pii-pile-chunk3-900000-950000",
"dataset:tomekkorbak/pii-pile-chunk3-950000-1000000",
"dataset:tomekkorbak/pii-pile-chunk3-1000000-1050000",
"dataset:tomekkorbak/pii-pile-chunk3-1050000-1100000",
"dataset:tomekkorbak/pii-pile-chunk3-1100000-1150000",
"dataset:tomekkorbak/pii-pile-chunk3-1150000-1200000",
"dataset:tomekkorbak/pii-pile-chunk3-1200000-1250000",
"dataset:tomekkorbak/pii-pile-chunk3-1250000-1300000",
"dataset:tomekkorbak/pii-pile-chunk3-1300000-1350000",
"dataset:tomekkorbak/pii-pile-chunk3-1350000-1400000",
"dataset:tomekkorbak/pii-pile-chunk3-1400000-1450000",
"dataset:tomekkorbak/pii-pile-chunk3-1450000-1500000",
"dataset:tomekkorbak/pii-pile-chunk3-1500000-1550000",
"dataset:tomekkorbak/pii-pile-chunk3-1550000-1600000",
"dataset:tomekkorbak/pii-pile-chunk3-1600000-1650000",
"dataset:tomekkorbak/pii-pile-chunk3-1650000-1700000",
"dataset:tomekkorbak/pii-pile-chunk3-1700000-1750000",
"dataset:tomekkorbak/pii-pile-chunk3-1750000-1800000",
"dataset:tomekkorbak/pii-pile-chunk3-1800000-1850000",
"dataset:tomekkorbak/pii-pile-chunk3-1850000-1900000",
"dataset:tomekkorbak/pii-pile-chunk3-1900000-1950000",
"license:mit",
"region:us"
] | null | 2022-12-16T11:14:32Z |
---
language:
- en
license: mit
tags:
- generated_from_trainer
datasets:
- tomekkorbak/pii-pile-chunk3-0-50000
- tomekkorbak/pii-pile-chunk3-50000-100000
- tomekkorbak/pii-pile-chunk3-100000-150000
- tomekkorbak/pii-pile-chunk3-150000-200000
- tomekkorbak/pii-pile-chunk3-200000-250000
- tomekkorbak/pii-pile-chunk3-250000-300000
- tomekkorbak/pii-pile-chunk3-300000-350000
- tomekkorbak/pii-pile-chunk3-350000-400000
- tomekkorbak/pii-pile-chunk3-400000-450000
- tomekkorbak/pii-pile-chunk3-450000-500000
- tomekkorbak/pii-pile-chunk3-500000-550000
- tomekkorbak/pii-pile-chunk3-550000-600000
- tomekkorbak/pii-pile-chunk3-600000-650000
- tomekkorbak/pii-pile-chunk3-650000-700000
- tomekkorbak/pii-pile-chunk3-700000-750000
- tomekkorbak/pii-pile-chunk3-750000-800000
- tomekkorbak/pii-pile-chunk3-800000-850000
- tomekkorbak/pii-pile-chunk3-850000-900000
- tomekkorbak/pii-pile-chunk3-900000-950000
- tomekkorbak/pii-pile-chunk3-950000-1000000
- tomekkorbak/pii-pile-chunk3-1000000-1050000
- tomekkorbak/pii-pile-chunk3-1050000-1100000
- tomekkorbak/pii-pile-chunk3-1100000-1150000
- tomekkorbak/pii-pile-chunk3-1150000-1200000
- tomekkorbak/pii-pile-chunk3-1200000-1250000
- tomekkorbak/pii-pile-chunk3-1250000-1300000
- tomekkorbak/pii-pile-chunk3-1300000-1350000
- tomekkorbak/pii-pile-chunk3-1350000-1400000
- tomekkorbak/pii-pile-chunk3-1400000-1450000
- tomekkorbak/pii-pile-chunk3-1450000-1500000
- tomekkorbak/pii-pile-chunk3-1500000-1550000
- tomekkorbak/pii-pile-chunk3-1550000-1600000
- tomekkorbak/pii-pile-chunk3-1600000-1650000
- tomekkorbak/pii-pile-chunk3-1650000-1700000
- tomekkorbak/pii-pile-chunk3-1700000-1750000
- tomekkorbak/pii-pile-chunk3-1750000-1800000
- tomekkorbak/pii-pile-chunk3-1800000-1850000
- tomekkorbak/pii-pile-chunk3-1850000-1900000
- tomekkorbak/pii-pile-chunk3-1900000-1950000
model-index:
- name: elegant_galileo
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# elegant_galileo
This model was trained from scratch on the tomekkorbak/pii-pile-chunk3-0-50000, the tomekkorbak/pii-pile-chunk3-50000-100000, the tomekkorbak/pii-pile-chunk3-100000-150000, the tomekkorbak/pii-pile-chunk3-150000-200000, the tomekkorbak/pii-pile-chunk3-200000-250000, the tomekkorbak/pii-pile-chunk3-250000-300000, the tomekkorbak/pii-pile-chunk3-300000-350000, the tomekkorbak/pii-pile-chunk3-350000-400000, the tomekkorbak/pii-pile-chunk3-400000-450000, the tomekkorbak/pii-pile-chunk3-450000-500000, the tomekkorbak/pii-pile-chunk3-500000-550000, the tomekkorbak/pii-pile-chunk3-550000-600000, the tomekkorbak/pii-pile-chunk3-600000-650000, the tomekkorbak/pii-pile-chunk3-650000-700000, the tomekkorbak/pii-pile-chunk3-700000-750000, the tomekkorbak/pii-pile-chunk3-750000-800000, the tomekkorbak/pii-pile-chunk3-800000-850000, the tomekkorbak/pii-pile-chunk3-850000-900000, the tomekkorbak/pii-pile-chunk3-900000-950000, the tomekkorbak/pii-pile-chunk3-950000-1000000, the tomekkorbak/pii-pile-chunk3-1000000-1050000, the tomekkorbak/pii-pile-chunk3-1050000-1100000, the tomekkorbak/pii-pile-chunk3-1100000-1150000, the tomekkorbak/pii-pile-chunk3-1150000-1200000, the tomekkorbak/pii-pile-chunk3-1200000-1250000, the tomekkorbak/pii-pile-chunk3-1250000-1300000, the tomekkorbak/pii-pile-chunk3-1300000-1350000, the tomekkorbak/pii-pile-chunk3-1350000-1400000, the tomekkorbak/pii-pile-chunk3-1400000-1450000, the tomekkorbak/pii-pile-chunk3-1450000-1500000, the tomekkorbak/pii-pile-chunk3-1500000-1550000, the tomekkorbak/pii-pile-chunk3-1550000-1600000, the tomekkorbak/pii-pile-chunk3-1600000-1650000, the tomekkorbak/pii-pile-chunk3-1650000-1700000, the tomekkorbak/pii-pile-chunk3-1700000-1750000, the tomekkorbak/pii-pile-chunk3-1750000-1800000, the tomekkorbak/pii-pile-chunk3-1800000-1850000, the tomekkorbak/pii-pile-chunk3-1850000-1900000 and the tomekkorbak/pii-pile-chunk3-1900000-1950000 datasets.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 8
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.01
- training_steps: 12588
- mixed_precision_training: Native AMP
### Framework versions
- Transformers 4.24.0
- Pytorch 1.11.0+cu113
- Datasets 2.5.1
- Tokenizers 0.11.6
# Full config
{'dataset': {'datasets': ['tomekkorbak/pii-pile-chunk3-0-50000',
'tomekkorbak/pii-pile-chunk3-50000-100000',
'tomekkorbak/pii-pile-chunk3-100000-150000',
'tomekkorbak/pii-pile-chunk3-150000-200000',
'tomekkorbak/pii-pile-chunk3-200000-250000',
'tomekkorbak/pii-pile-chunk3-250000-300000',
'tomekkorbak/pii-pile-chunk3-300000-350000',
'tomekkorbak/pii-pile-chunk3-350000-400000',
'tomekkorbak/pii-pile-chunk3-400000-450000',
'tomekkorbak/pii-pile-chunk3-450000-500000',
'tomekkorbak/pii-pile-chunk3-500000-550000',
'tomekkorbak/pii-pile-chunk3-550000-600000',
'tomekkorbak/pii-pile-chunk3-600000-650000',
'tomekkorbak/pii-pile-chunk3-650000-700000',
'tomekkorbak/pii-pile-chunk3-700000-750000',
'tomekkorbak/pii-pile-chunk3-750000-800000',
'tomekkorbak/pii-pile-chunk3-800000-850000',
'tomekkorbak/pii-pile-chunk3-850000-900000',
'tomekkorbak/pii-pile-chunk3-900000-950000',
'tomekkorbak/pii-pile-chunk3-950000-1000000',
'tomekkorbak/pii-pile-chunk3-1000000-1050000',
'tomekkorbak/pii-pile-chunk3-1050000-1100000',
'tomekkorbak/pii-pile-chunk3-1100000-1150000',
'tomekkorbak/pii-pile-chunk3-1150000-1200000',
'tomekkorbak/pii-pile-chunk3-1200000-1250000',
'tomekkorbak/pii-pile-chunk3-1250000-1300000',
'tomekkorbak/pii-pile-chunk3-1300000-1350000',
'tomekkorbak/pii-pile-chunk3-1350000-1400000',
'tomekkorbak/pii-pile-chunk3-1400000-1450000',
'tomekkorbak/pii-pile-chunk3-1450000-1500000',
'tomekkorbak/pii-pile-chunk3-1500000-1550000',
'tomekkorbak/pii-pile-chunk3-1550000-1600000',
'tomekkorbak/pii-pile-chunk3-1600000-1650000',
'tomekkorbak/pii-pile-chunk3-1650000-1700000',
'tomekkorbak/pii-pile-chunk3-1700000-1750000',
'tomekkorbak/pii-pile-chunk3-1750000-1800000',
'tomekkorbak/pii-pile-chunk3-1800000-1850000',
'tomekkorbak/pii-pile-chunk3-1850000-1900000',
'tomekkorbak/pii-pile-chunk3-1900000-1950000'],
'filter_threshold': 0.000286,
'is_split_by_sentences': True,
'skip_tokens': 1649999872},
'generation': {'force_call_on': [25177],
'metrics_configs': [{}, {'n': 1}, {'n': 2}, {'n': 5}],
'scenario_configs': [{'generate_kwargs': {'do_sample': True,
'max_length': 128,
'min_length': 10,
'temperature': 0.7,
'top_k': 0,
'top_p': 0.9},
'name': 'unconditional',
'num_samples': 2048}],
'scorer_config': {}},
'kl_gpt3_callback': {'force_call_on': [25177],
'max_tokens': 64,
'num_samples': 4096},
'model': {'from_scratch': False,
'gpt2_config_kwargs': {'reorder_and_upcast_attn': True,
'scale_attn_by': True},
'model_kwargs': {'revision': '9e6c78543a6ff1e4089002c38864d5a9cf71ec90'},
'path_or_name': 'tomekkorbak/nervous_wozniak'},
'objective': {'name': 'MLE'},
'tokenizer': {'path_or_name': 'gpt2'},
'training': {'dataloader_num_workers': 0,
'effective_batch_size': 128,
'evaluation_strategy': 'no',
'fp16': True,
'hub_model_id': 'elegant_galileo',
'hub_strategy': 'all_checkpoints',
'learning_rate': 0.0001,
'logging_first_step': True,
'logging_steps': 1,
'num_tokens': 3300000000,
'output_dir': 'training_output2',
'per_device_train_batch_size': 16,
'push_to_hub': True,
'remove_unused_columns': False,
'save_steps': 25177,
'save_strategy': 'steps',
'seed': 42,
'tokens_already_seen': 1649999872,
'warmup_ratio': 0.01,
'weight_decay': 0.1}}
# Wandb URL:
https://wandb.ai/tomekkorbak/apo/runs/283v5dho
|
amitkayal/whisper-small-or
|
amitkayal
| 2022-12-16T10:59:04Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"whisper",
"automatic-speech-recognition",
"whisper-event",
"generated_from_trainer",
"bn",
"dataset:mozilla-foundation/common_voice_11_0",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-12-16T05:21:26Z |
---
language:
- bn
license: apache-2.0
tags:
- whisper-event
- generated_from_trainer
datasets:
- mozilla-foundation/common_voice_11_0
metrics:
- wer
model-index:
- name: whisper-small-or
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice 11.0
type: mozilla-foundation/common_voice_11_0
config: or
split: test
args: or
metrics:
- name: Wer
type: wer
value: 40.30612244897959
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# whisper-small-or
This model is a fine-tuned version of [openai/whisper-small](https://huggingface.co/openai/whisper-small) on the Common Voice 11.0 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5871
- Wer: 40.3061
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 200
- training_steps: 3000
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:-------:|
| 0.001 | 25.01 | 1000 | 0.4038 | 37.4804 |
| 0.0001 | 51.0 | 2000 | 0.5288 | 40.0706 |
| 0.0001 | 76.01 | 3000 | 0.5871 | 40.3061 |
### Framework versions
- Transformers 4.26.0.dev0
- Pytorch 1.10.0
- Datasets 2.7.1.dev0
- Tokenizers 0.13.2
|
klashenrik/q-learning-taxi-v3
|
klashenrik
| 2022-12-16T10:47:20Z | 0 | 0 | null |
[
"Taxi-v3",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-12-16T10:29:51Z |
---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-learning-taxi-v3
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
metrics:
- type: mean_reward
value: 7.56 +/- 2.71
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="klashenrik/q-learning-taxi-v3", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
klashenrik/q-learning-taxi-v1
|
klashenrik
| 2022-12-16T10:29:45Z | 0 | 0 | null |
[
"Taxi-v3",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-12-16T10:29:37Z |
---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-learning-taxi-v1
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
metrics:
- type: mean_reward
value: 7.50 +/- 2.76
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="klashenrik/q-learning-taxi-v1", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
ziyu600601/stable-diffusion
|
ziyu600601
| 2022-12-16T10:19:43Z | 0 | 0 | null |
[
"license:creativeml-openrail-m",
"region:us"
] | null | 2022-12-16T10:19:43Z |
---
license: creativeml-openrail-m
---
|
huggan/sim2real_cyclegan
|
huggan
| 2022-12-16T10:18:00Z | 0 | 7 | null |
[
"pytorch",
"conditional-image-generation",
"image-to-image",
"gan",
"cyclegan",
"arxiv:2104.13395",
"arxiv:1703.10593",
"license:mit",
"region:us"
] |
image-to-image
| 2022-04-12T11:33:57Z |
---
tags:
- conditional-image-generation
- image-to-image
- gan
- cyclegan
# See a list of available tags here:
# https://github.com/huggingface/hub-docs/blob/main/js/src/lib/interfaces/Types.ts#L12
# task: unconditional-image-generation or conditional-image-generation or image-to-image
license: mit
---
# CycleGAN for unpaired image-to-image translation.
## Model description
CycleGAN for unpaired image-to-image translation.
Given two image domains A and B, the following components are trained end2end to translate between such domains:
- A generator A to B, named G_AB conditioned on an image from A
- A generator B to A, named G_BA conditioned on an image from B
- A domain classifier D_A, associated with G_AB
- A domain classifier D_B, associated with G_BA
At inference time, G_AB or G_BA are relevant to translate images, respectively A to B or B to A.
In the general setting, this technique provides style transfer functionalities between the selected image domains A and B.
This allows to obtain a generated translation by G_AB, of an image from domain A that resembles the distribution of the images from domain B, and viceversa for the generator G_BA.
Under these framework, these aspects have been used to perform style transfer between synthetic data obtained from a simulated driving dataset, GTA5, and the real driving data from Cityscapes.
This is of paramount importance to develop autonomous driving perception deep learning models, as this allows to generate synthetic data with automatic annotations which resembles real world images, without requiring the intervention of a human annotator.
This is fundamental because a manual annotator has been shown to require 1.5 to 3.3 hours to create semantic and instance segmentation masks for a single images.
These have been provided in the original [cityscapes paper (Cordts et al 2016)](https://arxiv.org/abs/2104.13395) and the [adverse condition dataset (Sakaridis et al. 2021)](https://arxiv.org/abs/2104.13395) paper.
Hence the CycleGAN provides forward and backward translation between synthetic and real world data.
This has showed to allows high quality translation even in absence of paired sample-ground-truth data.
The idea behind such model is that as the synthetic data distribution gets closer to the real world one, deep models do not suffer from degraded performance due to the domain shift issue.
A broad literature is available on the minimization of the domain shift, under the research branch of domain adaptation and transfer learning, of which image translation models provide an alternative approach
## Intended uses & limitations
#### Installation
```bash
git clone https://github.com/huggingface/community-events.git
cd community-events
```
To install the repository as a python package, run:
```bash
pip install .
```
#### How to use
```python
import os
from PIL import Image
from torchvision import transforms as T
from torchvision.transforms import Compose, Resize, ToTensor, Normalize, RandomCrop, RandomHorizontalFlip
from torchvision.utils import make_grid
from torch.utils.data import DataLoader
from huggan.pytorch.cyclegan.modeling_cyclegan import GeneratorResNet
import torch.nn as nn
import torch
import gradio as gr
import glob
def pred_pipeline(img, transforms):
orig_shape = img.shape
input = transforms(img)
input = input.unsqueeze(0)
output = model(input)
out_img = make_grid(output,#.detach().cpu(),
nrow=1, normalize=True)
out_transform = Compose([
T.Resize(orig_shape[:2]),
T.ToPILImage()
])
return out_transform(out_img)
n_channels = 3
image_size = 512
input_shape = (image_size, image_size)
transform = Compose([
T.ToPILImage(),
T.Resize(input_shape),
ToTensor(),
Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),
])
model = GeneratorResNet.from_pretrained('Chris1/sim2real', input_shape=(n_channels, image_size, image_size),
num_residual_blocks=9)
real_images = model(synthetic_images)
```
#### Limitations and bias
Due to the absence of paired data, some background parts of the synthetic images are seldom wrongly translated, e.g. sky is translated to vegetation.
Additional pretext tasks in parallel to the discriminative classifier of fake and real samples could improve the result.
One easy improvement is the use of an additional parallel branch that performs semantic segmentation on the synthetic data, in order to learn features which are common to sky and vegetation, thus disentangling their representations as separate classes.
## Training data
The CycleGAN model is trained on an unpaired dataset of samples from synthetic and real driving data, respectively from the GTA5 and Cityscapes datasets.
To this end, the synthetic-to-real dataset can be loaded by means of the function load_dataset in the huggingface library, as follows.
```python
from datasets import load_dataset
unpaired_dataset = load_dataset("huggan/sim2real_gta5_to_cityscapes")
```
This dataset contains two columns, imageA and imageB representing respectively the GTA5 and Cityscapes data.
Due to the fact that the two columns have to be of the same length, GTA5 is subsampled in order to reach the same number of samples provided by the Cityscapes train split (2975)
## Training procedure
#### Preprocessing
The following transformations are applied to each input sample of synthetic and real data.
The input size is fixed to RGB images of height, width = 512, 512.
This choice has been made in order to limit the impact of upsampling the translated images to higher resolutions.
```python
n_channels = 3
image_size = 512
input_shape = (image_size, image_size)
transform = Compose([
T.ToPILImage(),
T.Resize(input_shape),
ToTensor(),
Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),
])
```
#### Hardware
The configuration has been tested on single GPU setup on a RTX5000 and A5000, as well as multi-gpu single-rank distributed setups composed of 2 of the mentioned GPUs.
#### Hyperparameters
The following configuration has been kept fixed for all translation models:
- learning rate 0.0002
- number of epochs 200
- learning rate decay activation at epoch 100
- number of residual blocks of the cyclegan 9
- image size 512x512
- number of channels=3
- cycle loss weight 10.0
- identity loss weight 5.0
- optimizer ADAM with beta1 0.5 and beta2 0.999
- batch size 8
- NO mixed precision training
## Eval results
#### Generated Images
In the provided images, row0 and row2 represent the synthetic and real images from the respective datasets.
Row1 is the translation of the immediate above images in row0(synthetic) by means of the G_AB translation model, to the real world style.
Row3 is the translation of the immediate above images in row2(real) by means of the G_BA translation model, to the synthetic world style.
Visualization over the training iterations for [synthetic (GTA5) to real (Cityscapes) translation](https://wandb.ai/chris1nexus/experiments_cyclegan_s2r_hp_opt--10/reports/CycleGAN-sim2real-training-results--VmlldzoxODUyNTk4?accessToken=tow3v4vp02aurzodedrdht15ig1cx69v5mited4dm8bgnup0z192wri0xtftaeqj)
### References
```bibtex
@misc{https://doi.org/10.48550/arxiv.1703.10593,
doi = {10.48550/ARXIV.1703.10593},
url = {https://arxiv.org/abs/1703.10593},
author = {Zhu, Jun-Yan and Park, Taesung and Isola, Phillip and Efros, Alexei A.},
keywords = {Computer Vision and Pattern Recognition (cs.CV), FOS: Computer and information sciences, FOS: Computer and information sciences},
title = {Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks},
publisher = {arXiv},
year = {2017},
copyright = {arXiv.org perpetual, non-exclusive license}
}
```
|
zhaoyun0071/Disco_Diffusion_Style_SD_Model
|
zhaoyun0071
| 2022-12-16T09:54:22Z | 0 | 20 | null |
[
"stable-diffusion",
"text-to-image",
"image-to-image",
"en",
"region:us"
] |
text-to-image
| 2022-12-16T02:23:47Z |
---
language:
- en
thumbnail: "https://huggingface.co/zhao009/Disco_Diffusion_Style_SD_Model/resolve/main/S1.png"
tags:
- stable-diffusion
- text-to-image
- image-to-image
---
### Disco_Diffusion_Style_SD_Model
Base on https://huggingface.co/dreamlike-art/dreamlike-diffusion-1.0 model,This is the fine-tuned Stable Diffusion model trained on Disco Diffusion Pictures.
Use the tokens **DDreamlike Style** in your prompts for the effect.

**DDreamlike Style, a beautiful ultradetailed anime colorful digital illustration of lake, night, moon,chinese ancient pagoda, pixar style, beautiful matte painting, high detail, heavenly glow, octane render, 4k hd wallpaper, by makoto shinka and thomas kinkade, anime art , trending on artstation**




|
Narsil/layoutlmv3-finetuned-funsd
|
Narsil
| 2022-12-16T09:48:02Z | 691 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"layoutlmv3",
"token-classification",
"generated_from_trainer",
"object-detection",
"dataset:nielsr/funsd-layoutlmv3",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
object-detection
| 2022-12-16T08:53:05Z |
---
tags:
- generated_from_trainer
datasets:
- nielsr/funsd-layoutlmv3
pipeline_tag: object-detection
widget:
- src: "https://huggingface.co/spaces/impira/docquery/resolve/2359223c1837a7587402bda0f2643382a6eefeab/invoice.png"
example_title: invoice
- src: "https://huggingface.co/spaces/impira/docquery/resolve/2359223c1837a7587402bda0f2643382a6eefeab/contract.jpeg"
example_title: contract
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: layoutlmv3-finetuned-funsd
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: nielsr/funsd-layoutlmv3
type: nielsr/funsd-layoutlmv3
args: funsd
metrics:
- name: Precision
type: precision
value: 0.9026198714780029
- name: Recall
type: recall
value: 0.913
- name: F1
type: f1
value: 0.9077802634849614
- name: Accuracy
type: accuracy
value: 0.8330271015158475
duplicated_from: nielsr/layoutlmv3-finetuned-funsd
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# layoutlmv3-finetuned-funsd
This model is a fine-tuned version of [microsoft/layoutlmv3-base](https://huggingface.co/microsoft/layoutlmv3-base) on the nielsr/funsd-layoutlmv3 dataset.
It achieves the following results on the evaluation set:
- Loss: 1.1164
- Precision: 0.9026
- Recall: 0.913
- F1: 0.9078
- Accuracy: 0.8330
The script for training can be found here: https://github.com/huggingface/transformers/tree/main/examples/research_projects/layoutlmv3
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 1000
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 10.0 | 100 | 0.5238 | 0.8366 | 0.886 | 0.8606 | 0.8410 |
| No log | 20.0 | 200 | 0.6930 | 0.8751 | 0.8965 | 0.8857 | 0.8322 |
| No log | 30.0 | 300 | 0.7784 | 0.8902 | 0.908 | 0.8990 | 0.8414 |
| No log | 40.0 | 400 | 0.9056 | 0.8916 | 0.905 | 0.8983 | 0.8364 |
| 0.2429 | 50.0 | 500 | 1.0016 | 0.8954 | 0.9075 | 0.9014 | 0.8298 |
| 0.2429 | 60.0 | 600 | 1.0097 | 0.8899 | 0.897 | 0.8934 | 0.8294 |
| 0.2429 | 70.0 | 700 | 1.0722 | 0.9035 | 0.9085 | 0.9060 | 0.8315 |
| 0.2429 | 80.0 | 800 | 1.0884 | 0.8905 | 0.9105 | 0.9004 | 0.8269 |
| 0.2429 | 90.0 | 900 | 1.1292 | 0.8938 | 0.909 | 0.9013 | 0.8279 |
| 0.0098 | 100.0 | 1000 | 1.1164 | 0.9026 | 0.913 | 0.9078 | 0.8330 |
### Framework versions
- Transformers 4.19.0.dev0
- Pytorch 1.11.0+cu113
- Datasets 2.0.0
- Tokenizers 0.11.6
|
zhow/sd-class-butterflies-64
|
zhow
| 2022-12-16T09:32:19Z | 0 | 0 |
diffusers
|
[
"diffusers",
"pytorch",
"unconditional-image-generation",
"diffusion-models-class",
"license:mit",
"diffusers:DDPMPipeline",
"region:us"
] |
unconditional-image-generation
| 2022-12-16T09:31:47Z |
---
license: mit
tags:
- pytorch
- diffusers
- unconditional-image-generation
- diffusion-models-class
---
# Model Card for Unit 1 of the [Diffusion Models Class 🧨](https://github.com/huggingface/diffusion-models-class)
This model is a diffusion model for unconditional image generation of cute 🦋.
## Usage
```python
from diffusers import DDPMPipeline
pipeline = DDPMPipeline.from_pretrained('zhow/sd-class-butterflies-64')
image = pipeline().images[0]
image
```
|
LucianoDeben/q-FrozenLake-v1-4x4-noSlippery
|
LucianoDeben
| 2022-12-16T09:11:08Z | 0 | 0 | null |
[
"FrozenLake-v1-4x4-no_slippery",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-12-16T09:11:05Z |
---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="LucianoDeben/q-FrozenLake-v1-4x4-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
pierreguillou/whisper-medium-portuguese
|
pierreguillou
| 2022-12-16T09:08:10Z | 536 | 26 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"whisper",
"automatic-speech-recognition",
"generated_from_trainer",
"whisper-event",
"pt",
"dataset:mozilla-foundation/common_voice_11_0",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-12-15T09:59:20Z |
---
language: pt
license: apache-2.0
tags:
- generated_from_trainer
- whisper-event
datasets:
- mozilla-foundation/common_voice_11_0
metrics:
- wer
model-index:
- name: openai/whisper-medium
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: mozilla-foundation/common_voice_11_0
type: mozilla-foundation/common_voice_11_0
config: pt
split: test
args: pt
metrics:
- name: Wer
type: wer
value: 6.598745817992301
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Portuguese Medium Whisper
This model is a fine-tuned version of [openai/whisper-medium](https://huggingface.co/openai/whisper-medium) on the common_voice_11_0 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2628
- Wer: 6.5987
## Blog post
All information about this model in this blog post: [Speech-to-Text & IA | Transcreva qualquer áudio para o português com o Whisper (OpenAI)... sem nenhum custo!](https://medium.com/@pierre_guillou/speech-to-text-ia-transcreva-qualquer-%C3%A1udio-para-o-portugu%C3%AAs-com-o-whisper-openai-sem-ad0c17384681).
## New SOTA
The Normalized WER in the [OpenAI Whisper article](https://cdn.openai.com/papers/whisper.pdf) with the [Common Voice 9.0](https://huggingface.co/datasets/mozilla-foundation/common_voice_9_0) test dataset is 8.1.
As this test dataset is similar to the [Common Voice 11.0](https://huggingface.co/datasets/mozilla-foundation/common_voice_11_0) test dataset used to evaluate our model (WER and WER Norm), it means that **our Portuguese Medium Whisper is better than the [Medium Whisper](https://huggingface.co/openai/whisper-medium) model at transcribing audios Portuguese in text** (and even better than the [Whisper Large](https://huggingface.co/openai/whisper-large) that has a WER Norm of 7.1!).
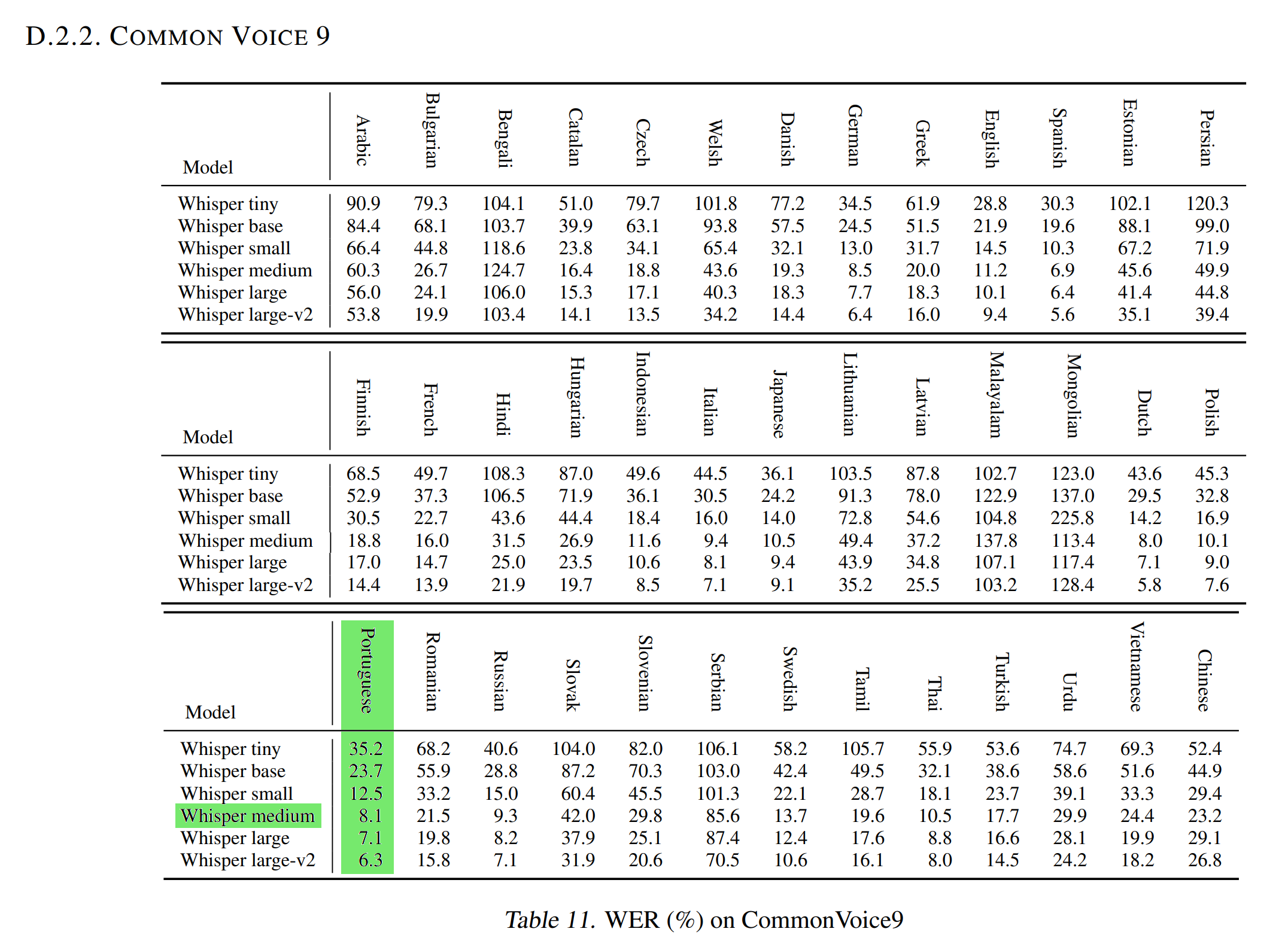
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 9e-06
- train_batch_size: 32
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 6000
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 0.0333 | 2.07 | 1500 | 0.2073 | 6.9770 |
| 0.0061 | 5.05 | 3000 | 0.2628 | 6.5987 |
| 0.0007 | 8.03 | 4500 | 0.2960 | 6.6979 |
| 0.0004 | 11.0 | 6000 | 0.3212 | 6.6794 |
### Framework versions
- Transformers 4.26.0.dev0
- Pytorch 1.13.0+cu117
- Datasets 2.7.1.dev0
- Tokenizers 0.13.2
|
psitama/ppo-LunarLander-v2
|
psitama
| 2022-12-16T09:02:18Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-12-07T13:41:53Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: -1339.88 +/- 1647.82
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
biodasturchi/emfold
|
biodasturchi
| 2022-12-16T08:52:00Z | 0 | 1 | null |
[
"doi:10.57967/hf/0213",
"region:us"
] | null | 2022-12-16T08:28:36Z |
---
title: Esmfold
emoji: 👀
colorFrom: green
colorTo: blue
sdk: gradio
sdk_version: 3.8.2
app_file: app.py
pinned: false
---
Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
|
marianna13/t5-base-finetuned-youtube
|
marianna13
| 2022-12-16T08:18:59Z | 4 | 1 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"t5",
"text2text-generation",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-12-16T07:47:48Z |
---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: t5-base-finetuned-youtube
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-base-finetuned-youtube
This model is a fine-tuned version of [t5-small](https://huggingface.co/t5-small) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 3.7643
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 4.0266 | 1.0 | 9057 | 3.7643 |
### Framework versions
- Transformers 4.25.1
- Pytorch 1.13.0+cu116
- Datasets 2.7.1
- Tokenizers 0.13.2
|
bheshaj/bart-large-cnn-small-billsum-5epochs
|
bheshaj
| 2022-12-16T08:06:31Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bart",
"text2text-generation",
"generated_from_trainer",
"dataset:billsum",
"license:mit",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-12-16T07:39:08Z |
---
license: mit
tags:
- generated_from_trainer
datasets:
- billsum
metrics:
- rouge
model-index:
- name: bart-large-cnn-small-billsum-5epochs
results:
- task:
name: Sequence-to-sequence Language Modeling
type: text2text-generation
dataset:
name: billsum
type: billsum
config: default
split: train[:1%]
args: default
metrics:
- name: Rouge1
type: rouge
value: 0.5406
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bart-large-cnn-small-billsum-5epochs
This model is a fine-tuned version of [facebook/bart-large-cnn](https://huggingface.co/facebook/bart-large-cnn) on the billsum dataset.
It achieves the following results on the evaluation set:
- Loss: 1.7206
- Rouge1: 0.5406
- Rouge2: 0.312
- Rougel: 0.3945
- Rougelsum: 0.4566
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3.373e-05
- train_batch_size: 4
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 16
- num_epochs: 5
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum |
|:-------------:|:-----:|:----:|:---------------:|:------:|:------:|:------:|:---------:|
| 2.3723 | 1.33 | 16 | 1.8534 | 0.5204 | 0.299 | 0.3893 | 0.4441 |
| 1.6579 | 2.67 | 32 | 1.7208 | 0.5427 | 0.3143 | 0.3915 | 0.459 |
| 1.2397 | 4.0 | 48 | 1.7206 | 0.5406 | 0.312 | 0.3945 | 0.4566 |
### Framework versions
- Transformers 4.25.1
- Pytorch 1.13.0+cu117
- Datasets 2.7.1
- Tokenizers 0.13.2
|
CreativeEvolution/q-FrozenLake-v1-4x4-noSlippery
|
CreativeEvolution
| 2022-12-16T07:51:22Z | 0 | 0 | null |
[
"FrozenLake-v1-4x4-no_slippery",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-12-16T07:51:15Z |
---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="CreativeEvolution/q-FrozenLake-v1-4x4-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
SiddharthaM/xlm-roberta-targin-final
|
SiddharthaM
| 2022-12-16T07:30:13Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"xlm-roberta",
"text-classification",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-12-16T06:44:43Z |
---
license: mit
tags:
- generated_from_trainer
metrics:
- accuracy
- precision
- recall
- f1
model-index:
- name: xlm-roberta-targin-final
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xlm-roberta-targin-final
This model is a fine-tuned version of [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.8172
- Accuracy: 0.6873
- Precision: 0.6494
- Recall: 0.6422
- F1: 0.6450
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | Precision | Recall | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:---------:|:------:|:------:|
| No log | 1.0 | 296 | 0.6065 | 0.6873 | 0.6537 | 0.5833 | 0.5748 |
| 0.597 | 2.0 | 592 | 0.5822 | 0.7015 | 0.6652 | 0.6279 | 0.6332 |
| 0.597 | 3.0 | 888 | 0.5704 | 0.7015 | 0.6654 | 0.6551 | 0.6589 |
| 0.5156 | 4.0 | 1184 | 0.6393 | 0.7044 | 0.6684 | 0.6552 | 0.6597 |
| 0.5156 | 5.0 | 1480 | 0.5924 | 0.7082 | 0.6752 | 0.6720 | 0.6735 |
| 0.4479 | 6.0 | 1776 | 0.7029 | 0.7006 | 0.6629 | 0.6351 | 0.6408 |
| 0.3783 | 7.0 | 2072 | 0.6963 | 0.7072 | 0.6715 | 0.6554 | 0.6606 |
| 0.3783 | 8.0 | 2368 | 0.7636 | 0.6987 | 0.6627 | 0.6549 | 0.6579 |
| 0.3253 | 9.0 | 2664 | 0.7804 | 0.6901 | 0.6549 | 0.6523 | 0.6535 |
| 0.3253 | 10.0 | 2960 | 0.8172 | 0.6873 | 0.6494 | 0.6422 | 0.6450 |
### Framework versions
- Transformers 4.24.0.dev0
- Pytorch 1.11.0+cu102
- Datasets 2.6.1
- Tokenizers 0.13.1
|
duongkstn/q-FrozenLake-v1-8x8-90000-steps
|
duongkstn
| 2022-12-16T07:05:56Z | 0 | 0 | null |
[
"FrozenLake-v1-8x8",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-12-16T07:05:44Z |
---
tags:
- FrozenLake-v1-8x8
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-8x8-90000-steps
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-8x8
type: FrozenLake-v1-8x8
metrics:
- type: mean_reward
value: 0.18 +/- 0.38
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="duongkstn/q-FrozenLake-v1-8x8-90000-steps", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
duongkstn/q-FrozenLake-v1-8x8
|
duongkstn
| 2022-12-16T06:52:38Z | 0 | 0 | null |
[
"FrozenLake-v1-8x8",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-12-16T06:51:27Z |
---
tags:
- FrozenLake-v1-8x8
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-8x8
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-8x8
type: FrozenLake-v1-8x8
metrics:
- type: mean_reward
value: 0.44 +/- 0.50
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="duongkstn/q-FrozenLake-v1-8x8", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
Utkarsh-Verma/ppo-LunarLander-v2
|
Utkarsh-Verma
| 2022-12-16T05:37:06Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-12-16T05:36:37Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 235.88 +/- 22.76
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
doctorderp/planet_of_the_apes
|
doctorderp
| 2022-12-16T05:23:28Z | 0 | 2 | null |
[
"license:creativeml-openrail-m",
"region:us"
] | null | 2022-12-15T06:36:19Z |
---
license: creativeml-openrail-m
---
Preview Images
https://imgur.com/a/vwO6f5A
IMPORTANT INSTRUCTIONS!!
This model was trained on SD base 1.5 version BUT It does also work for 1.4 as they both share the same Clip encoder.
Install instructions.
Simply place the chimp.pt file inside the \stable-diffusion-webui\models\hypernetworks folder. Load the model inside the Automatic1111 interface under settings hypernetwork.
Use instructions.
Use between 0.55-1.0 hypernetwork strength, more strength will give a more real chimpl look while .55 gives a more human form chimp look. I find .7 works well enough.
Use DPM++ SDE Karras sampler with 15 steps and CFG of 6.0.
Make sure and always include the word chimp somewhere in the prompt. For people always preface the subject with chimp, example "chimp man walking", "chimp girl playing in the backyard", etc...
VERY IMPORTANT! Always describe the background in some detail or you WILL get a very generic boring background.. So for example DON'T just say "an old chimp man". DO say "an old chimp man inside a rustic hut".
Some fun info. People have been sleeping on hypernetworks and I plan to change that. Hopefully the flexibility of this hypernetwok will show everyone their true potential. Because this model is a hypernetwork it can be used in conjunction with ANY model based on the 1.4 CLIP architecture. That means this model will work on any custom 1.4 or 1.5 model, like the modern disney model, or classic disney, etc… for example, let's say you want to load classic disney as base. Well simply load the classic disney model, make sure and preface every prompt with classic disney. As per instructions of the model. Then follow up with my “chimp” tag as instructed once you have loaded the hypernetwork. So the prompt should look something like this “classic disney. chimp girl playing in the backyard.” Make sure and adjust the hypernetwork strength to .5 for a more cartoon look or .7 for a realistic chimp look. Have fun folks!
|
duongkstn/q-Taxi-v3-lr-08
|
duongkstn
| 2022-12-16T04:31:55Z | 0 | 0 | null |
[
"Taxi-v3",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-12-16T04:27:57Z |
---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-Taxi-v3-lr-08
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
metrics:
- type: mean_reward
value: 7.56 +/- 2.71
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="duongkstn/q-Taxi-v3-lr-08", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
aharley/pips
|
aharley
| 2022-12-16T04:22:09Z | 0 | 7 | null |
[
"pixel-tracking",
"computer-vision",
"arxiv:2204.04153",
"license:mit",
"region:us"
] | null | 2022-09-03T01:59:24Z |
---
tags:
- pixel-tracking
- computer-vision
license: mit
library: pytorch
inference: false
---
# PIPs: Particle Video Revisited: Tracking Through Occlusions Using Point Trajectories
* Model Authors: Adam W Harley and Zhaoyuan Fang and Katerina Fragkiadaki
* Paper: Particle Video Revisited: Tracking Through Occlusions Using Point Trajectories (ECCV 2022 - https://arxiv.org/abs/2204.04153
* Code Repo: https://github.com/aharley/pips
* Project Homepage: https://particle-video-revisited.github.io
From the paper abstract:
> [...] we revisit Sand and Teller's "particle video" approach, and study pixel tracking as a long-range motion estimation problem, where every pixel is described with a trajectory that locates it in multiple future frames. We re-build this classic approach using components that drive the current state-of-the-art in flow and object tracking, such as dense cost maps, iterative optimization, and learned appearance updates. We train our models using long-range amodal point trajectories mined from existing optical flow data that we synthetically augment with multi-frame occlusions.

# Citation
```
@inproceedings{harley2022particle,
title={Particle Video Revisited: Tracking Through Occlusions Using Point Trajectories},
author={Adam W Harley and Zhaoyuan Fang and Katerina Fragkiadaki},
booktitle={ECCV},
year={2022}
}
```
|
lotussavy/LunarLander-v2
|
lotussavy
| 2022-12-16T04:18:00Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-12-16T04:17:31Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 259.89 +/- 16.40
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
duongkstn/q-FrozenLake-v1-4x4-noSlippery
|
duongkstn
| 2022-12-16T04:11:11Z | 0 | 0 | null |
[
"FrozenLake-v1-4x4-no_slippery",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-12-16T04:11:03Z |
---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="duongkstn/q-FrozenLake-v1-4x4-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
Zhaohui/finetuning-misinfo-model-1000-Zhaohui
|
Zhaohui
| 2022-12-16T03:57:03Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-12-16T03:42:48Z |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- accuracy
- f1
model-index:
- name: finetuning-misinfo-model-1000-Zhaohui
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# finetuning-misinfo-model-1000-Zhaohui
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7352
- Accuracy: 0.8226
- F1: 0.8571
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 20
### Training results
### Framework versions
- Transformers 4.25.1
- Pytorch 1.13.0+cu116
- Datasets 2.7.1
- Tokenizers 0.13.2
|
taskmasterpeace/autotrain-Consequenv05-WEW6KM47ET-2492376867
|
taskmasterpeace
| 2022-12-16T03:39:39Z | 0 | 0 |
diffusers
|
[
"diffusers",
"autotrain",
"stable-diffusion",
"text-to-image",
"dataset:taskmasterpeace/autotrain-data-Consequenv05-WEW6KM47ET",
"co2_eq_emissions",
"region:us"
] |
text-to-image
| 2022-12-16T03:18:52Z |
---
tags:
- autotrain
- stable-diffusion
- text-to-image
datasets:
- taskmasterpeace/autotrain-data-Consequenv05-WEW6KM47ET
co2_eq_emissions:
emissions: 39.499488037662175
---
# Model Trained Using AutoTrain
- Problem type: Dreambooth
- Model ID: 2492376867
- CO2 Emissions (in grams): 39.4995
|
Totsukawaii/ddpm-butterflies-128
|
Totsukawaii
| 2022-12-16T03:17:49Z | 1 | 0 |
diffusers
|
[
"diffusers",
"tensorboard",
"en",
"dataset:huggan/smithsonian_butterflies_subset",
"license:apache-2.0",
"diffusers:DDPMPipeline",
"region:us"
] | null | 2022-12-15T09:56:08Z |
---
language: en
license: apache-2.0
library_name: diffusers
tags: []
datasets: huggan/smithsonian_butterflies_subset
metrics: []
---
<!-- This model card has been generated automatically according to the information the training script had access to. You
should probably proofread and complete it, then remove this comment. -->
# ddpm-butterflies-128
## Model description
This diffusion model is trained with the [🤗 Diffusers](https://github.com/huggingface/diffusers) library
on the `huggan/smithsonian_butterflies_subset` dataset.
## Intended uses & limitations
#### How to use
```python
# TODO: add an example code snippet for running this diffusion pipeline
```
#### Limitations and bias
[TODO: provide examples of latent issues and potential remediations]
## Training data
[TODO: describe the data used to train the model]
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 32
- eval_batch_size: 16
- gradient_accumulation_steps: 1
- optimizer: AdamW with betas=(None, None), weight_decay=None and epsilon=None
- lr_scheduler: None
- lr_warmup_steps: 500
- ema_inv_gamma: None
- ema_inv_gamma: None
- ema_inv_gamma: None
- mixed_precision: fp16
### Training results
📈 [TensorBoard logs](https://huggingface.co/Totsukawaii/ddpm-butterflies-128/tensorboard?#scalars)
|
JunHwi/kold_binary
|
JunHwi
| 2022-12-16T02:57:48Z | 5 | 2 |
transformers
|
[
"transformers",
"pytorch",
"electra",
"text-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-12-16T02:27:33Z |
Pretraining KoLD Dataset with pretrained "koelectra-v3" model.
dataset : https://github.com/boychaboy/KOLD
pretrained_model : https://huggingface.co/monologg/koelectra-base-v3-discriminator
So you should use tokenizer with "koelectra-base-v3-discriminator".
label maps are like
>
{0: "not_hate_speech", 1: "hate_speech"}
|
rook909/ppo-LunarLander-v2-TEST
|
rook909
| 2022-12-16T02:57:10Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-12-16T02:18:22Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 271.61 +/- 18.29
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
JunHwi/kmhas_multilabel
|
JunHwi
| 2022-12-16T02:54:18Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"electra",
"text-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-12-16T02:23:24Z |
Pretrained K-mHas with multi-label model with "koelectra-v3"
You can use tokenizer of this model with "monologg/koelectra-v3-base-discriminator"
dataset : https://huggingface.co/datasets/jeanlee/kmhas_korean_hate_speech
pretrained_model : https://huggingface.co/monologg/koelectra-base-v3-discriminator
label maps are like this.
>>>
{'origin': 0,
'physical': 1,
'politics': 2,
'profanity': 3,
'age': 4,
'gender': 5,
'race': 6,
'religion': 7,
'not_hate_speech': 8}
You can use label map with below code.
>
from huggingface_hub import hf_hub_download
repo_id = "JunHwi/kmhas_multilabel"
filename = "kmhas_dict.pickle" # 위 repo_id에 업로드한 파일 이름
label_dict = hf_hub_download(repo_id, filename)
with open(label_dict, "rb") as f:
label2num = pickle.load(f)
|
JunHwi/kmhas_binary
|
JunHwi
| 2022-12-16T02:53:53Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"electra",
"text-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-12-16T02:12:57Z |
Pretrained K-mHas with binary-label model with "koelectra-v3"
You can use tokenizer of this model with "monologg/koelectra-v3-base-discriminator"
dataset : https://huggingface.co/datasets/jeanlee/kmhas_korean_hate_speech
pretrained_model : https://huggingface.co/monologg/koelectra-base-v3-discriminator
label maps are like this.
>
{0: "not_hate_speech", 1: "hate_speech"}
|
ancillaire/ppo-LunarLander-v2
|
ancillaire
| 2022-12-16T01:35:06Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-12-16T01:34:32Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: -128.62 +/- 54.34
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
suyuanliu/wav2vec2-base-finetuned-stop-classification
|
suyuanliu
| 2022-12-16T01:17:27Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"wav2vec2",
"audio-classification",
"generated_from_trainer",
"dataset:audiofolder",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
audio-classification
| 2022-12-16T00:57:11Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- audiofolder
metrics:
- accuracy
model-index:
- name: wav2vec2-base-finetuned-stop-classification
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-base-finetuned-stop-classification
This model is a fine-tuned version of [facebook/wav2vec2-base](https://huggingface.co/facebook/wav2vec2-base) on the audiofolder dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1647
- Accuracy: 0.9470
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 256
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.671 | 0.98 | 26 | 0.5553 | 0.8347 |
| 0.3525 | 1.98 | 52 | 0.2647 | 0.9163 |
| 0.291 | 2.98 | 78 | 0.2474 | 0.9070 |
| 0.2733 | 3.98 | 104 | 0.1729 | 0.9439 |
| 0.2467 | 4.98 | 130 | 0.1647 | 0.9470 |
### Framework versions
- Transformers 4.25.1
- Pytorch 1.13.0
- Datasets 2.7.1
- Tokenizers 0.13.2
|
cleanrl/BeamRiderNoFrameskip-v4-dqn_atari_jax-seed1
|
cleanrl
| 2022-12-16T00:47:36Z | 0 | 0 |
cleanrl
|
[
"cleanrl",
"tensorboard",
"BeamRiderNoFrameskip-v4",
"deep-reinforcement-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-12-16T00:47:28Z |
---
tags:
- BeamRiderNoFrameskip-v4
- deep-reinforcement-learning
- reinforcement-learning
- custom-implementation
library_name: cleanrl
model-index:
- name: DQN
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: BeamRiderNoFrameskip-v4
type: BeamRiderNoFrameskip-v4
metrics:
- type: mean_reward
value: 5091.00 +/- 1923.97
name: mean_reward
verified: false
---
# (CleanRL) **DQN** Agent Playing **BeamRiderNoFrameskip-v4**
This is a trained model of a DQN agent playing BeamRiderNoFrameskip-v4.
The model was trained by using [CleanRL](https://github.com/vwxyzjn/cleanrl) and the most up-to-date training code can be
found [here](https://github.com/vwxyzjn/cleanrl/blob/master/cleanrl/dqn_atari_jax.py).
## Command to reproduce the training
```bash
curl -OL https://huggingface.co/cleanrl/BeamRiderNoFrameskip-v4-dqn_atari_jax-seed1/raw/main/dqn.py
curl -OL https://huggingface.co/cleanrl/BeamRiderNoFrameskip-v4-dqn_atari_jax-seed1/raw/main/pyproject.toml
curl -OL https://huggingface.co/cleanrl/BeamRiderNoFrameskip-v4-dqn_atari_jax-seed1/raw/main/poetry.lock
poetry install --all-extras
python dqn_atari_jax.py --track --capture-video --save-model --upload-model --hf-entity cleanrl --env-id BeamRiderNoFrameskip-v4 --seed 1
```
# Hyperparameters
```python
{'batch_size': 32,
'buffer_size': 1000000,
'capture_video': True,
'end_e': 0.01,
'env_id': 'BeamRiderNoFrameskip-v4',
'exp_name': 'dqn_atari_jax',
'exploration_fraction': 0.1,
'gamma': 0.99,
'hf_entity': 'cleanrl',
'learning_rate': 0.0001,
'learning_starts': 80000,
'save_model': True,
'seed': 1,
'start_e': 1,
'target_network_frequency': 1000,
'total_timesteps': 10000000,
'track': True,
'train_frequency': 4,
'upload_model': True,
'wandb_entity': None,
'wandb_project_name': 'cleanRL'}
```
|
bitcloud2/q-Taxi-v3-hf-class
|
bitcloud2
| 2022-12-16T00:39:55Z | 0 | 0 | null |
[
"Taxi-v3",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-12-15T23:39:37Z |
---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-Taxi-v3-hf-class
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
metrics:
- type: mean_reward
value: 7.56 +/- 2.71
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="bitcloud2/q-Taxi-v3-hf-class", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
evanarlian/whisper-small-id
|
evanarlian
| 2022-12-16T00:15:16Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"whisper",
"automatic-speech-recognition",
"generated_from_trainer",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-12-15T16:37:43Z |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- wer
model-index:
- name: whisper-small-id
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# whisper-small-id
This model is a fine-tuned version of [openai/whisper-small](https://huggingface.co/openai/whisper-small) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4034
- Wer: 13.6494
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 64
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 5000
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:-------:|
| 0.1014 | 4.95 | 500 | 0.2583 | 13.6355 |
| 0.0058 | 9.9 | 1000 | 0.3169 | 13.2851 |
| 0.0017 | 14.85 | 1500 | 0.3488 | 13.2251 |
| 0.001 | 19.8 | 2000 | 0.3639 | 13.3542 |
| 0.0007 | 24.75 | 2500 | 0.3756 | 13.5018 |
| 0.0005 | 29.7 | 3000 | 0.3844 | 13.5617 |
| 0.0005 | 34.65 | 3500 | 0.3922 | 13.6401 |
| 0.0004 | 39.6 | 4000 | 0.3981 | 13.6032 |
| 0.0003 | 44.55 | 4500 | 0.4019 | 13.6632 |
| 0.0003 | 49.5 | 5000 | 0.4034 | 13.6494 |
### Framework versions
- Transformers 4.26.0.dev0
- Pytorch 1.13.0+cu117
- Datasets 2.7.1.dev0
- Tokenizers 0.13.2
|
haining/Taxi-v3-500x6
|
haining
| 2022-12-15T23:56:36Z | 0 | 0 | null |
[
"Taxi-v3",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-12-15T23:56:22Z |
---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: Taxi-v3-500x6
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
metrics:
- type: mean_reward
value: 7.56 +/- 2.71
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="haining/Taxi-v3-500x6", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
haining/q-FrozenLake-v1-4x4-noSlippery
|
haining
| 2022-12-15T23:55:19Z | 0 | 0 | null |
[
"FrozenLake-v1",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-12-15T23:54:53Z |
---
tags:
- FrozenLake-v1
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1
type: FrozenLake-v1
metrics:
- type: mean_reward
value: 7.31 +/- 2.37
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="haining/q-FrozenLake-v1-4x4-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
gagan3012/swin_arocr_tiny
|
gagan3012
| 2022-12-15T23:50:37Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"swinv2",
"image-feature-extraction",
"masked-image-modeling",
"generated_from_trainer",
"dataset:hindawi",
"endpoints_compatible",
"region:us"
] |
image-feature-extraction
| 2022-12-15T23:45:22Z |
---
tags:
- masked-image-modeling
- generated_from_trainer
datasets:
- hindawi
model-index:
- name: swinv2_arocr_tiny_encoder
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# swinv2_arocr_tiny_encoder
This model is a fine-tuned version of [/lustre07/scratch/gagan30/arocr/models/swinv2_arocr_tiny/config.json](https://huggingface.co//lustre07/scratch/gagan30/arocr/models/swinv2_arocr_tiny/config.json) on the /lustre07/scratch/gagan30/arocr/Hindawi dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0519
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 1337
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10.0
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-----:|:---------------:|
| 0.0891 | 1.0 | 8078 | 0.0628 |
| 0.0465 | 2.0 | 16156 | 0.0595 |
| 0.0639 | 3.0 | 24234 | 0.0570 |
| 0.0608 | 4.0 | 32312 | 0.0548 |
| 0.0487 | 5.0 | 40390 | 0.0554 |
| 0.059 | 6.0 | 48468 | 0.0533 |
| 0.0677 | 7.0 | 56546 | 0.0525 |
| 0.0555 | 8.0 | 64624 | 0.0521 |
| 0.0502 | 9.0 | 72702 | 0.0520 |
| 0.0496 | 10.0 | 80780 | 0.0519 |
### Framework versions
- Transformers 4.26.0.dev0
- Pytorch 1.12.0
- Datasets 2.7.1
- Tokenizers 0.11.6
|
bitcloud2/q-FrozenLake-v1-4x4-noSlippery
|
bitcloud2
| 2022-12-15T23:30:44Z | 0 | 0 | null |
[
"FrozenLake-v1-4x4-no_slippery",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-12-15T23:30:40Z |
---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="bitcloud2/q-FrozenLake-v1-4x4-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
DrishtiSharma/whisper-large-v2-lithuanian-400-steps
|
DrishtiSharma
| 2022-12-15T23:25:47Z | 4 | 1 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"whisper",
"automatic-speech-recognition",
"whisper-event",
"generated_from_trainer",
"lt",
"dataset:mozilla-foundation/common_voice_11_0",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-12-15T21:34:01Z |
---
language:
- lt
license: apache-2.0
tags:
- whisper-event
- generated_from_trainer
datasets:
- mozilla-foundation/common_voice_11_0
metrics:
- wer
model-index:
- name: Whisper Large V2 Lithuanian- Drishti Sharma
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice 11.0
type: mozilla-foundation/common_voice_11_0
config: lt
split: test
args: lt
metrics:
- name: Wer
type: wer
value: 26.152380196132924
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Whisper Large V2 Lithuanian- Drishti Sharma
This model is a fine-tuned version of [openai/whisper-large-v2](https://huggingface.co/openai/whisper-large-v2) on the Common Voice 11.0 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2921
- Wer: 26.1524
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 100
- training_steps: 400
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:-------:|
| 0.2538 | 0.36 | 400 | 0.2921 | 26.1524 |
### Framework versions
- Transformers 4.26.0.dev0
- Pytorch 1.13.0+cu116
- Datasets 2.7.1.dev0
- Tokenizers 0.13.2
|
Seif/ppo-Huggy
|
Seif
| 2022-12-15T23:03:45Z | 0 | 0 |
ml-agents
|
[
"ml-agents",
"tensorboard",
"onnx",
"unity-ml-agents",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-Huggy",
"region:us"
] |
reinforcement-learning
| 2022-12-15T23:03:33Z |
---
tags:
- unity-ml-agents
- ml-agents
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-Huggy
library_name: ml-agents
---
# **ppo** Agent playing **Huggy**
This is a trained model of a **ppo** agent playing **Huggy** using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://github.com/huggingface/ml-agents#get-started
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
### Resume the training
```
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser:**.
1. Go to https://huggingface.co/spaces/unity/ML-Agents-Huggy
2. Step 1: Write your model_id: Seif/ppo-Huggy
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
LuniLand/ppo-LunarLander-v2
|
LuniLand
| 2022-12-15T23:03:40Z | 1 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-12-15T12:13:28Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 284.33 +/- 21.26
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
ericntay/sd-class-butterflies-32
|
ericntay
| 2022-12-15T22:47:05Z | 0 | 0 |
diffusers
|
[
"diffusers",
"pytorch",
"unconditional-image-generation",
"diffusion-models-class",
"license:mit",
"diffusers:DDPMPipeline",
"region:us"
] |
unconditional-image-generation
| 2022-12-15T22:18:00Z |
---
license: mit
tags:
- pytorch
- diffusers
- unconditional-image-generation
- diffusion-models-class
---
# Model Card for Unit 1 of the [Diffusion Models Class 🧨](https://github.com/huggingface/diffusion-models-class)
This model is a diffusion model for unconditional image generation of cute 🦋.
## Usage
```python
from diffusers import DDPMPipeline
pipeline = DDPMPipeline.from_pretrained('ericntay/sd-class-butterflies-32')
image = pipeline().images[0]
image
```
|
rfdickerson/Taxi3
|
rfdickerson
| 2022-12-15T22:45:20Z | 0 | 0 | null |
[
"Taxi-v3",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-12-15T22:17:43Z |
---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: Taxi3
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
metrics:
- type: mean_reward
value: 7.56 +/- 2.71
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="rfdickerson/Taxi3", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
kejian/deliberate-awr
|
kejian
| 2022-12-15T22:28:35Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"generated_from_trainer",
"en",
"dataset:kejian/codeparrot-train-more-filter-3.3b-cleaned",
"license:apache-2.0",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | null | 2022-12-15T09:23:40Z |
---
language:
- en
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- kejian/codeparrot-train-more-filter-3.3b-cleaned
model-index:
- name: deliberate-awr
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# deliberate-awr
This model was trained from scratch on the kejian/codeparrot-train-more-filter-3.3b-cleaned dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 64
- eval_batch_size: 32
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.01
- training_steps: 12589
- mixed_precision_training: Native AMP
### Framework versions
- Transformers 4.23.0
- Pytorch 1.13.0+cu116
- Datasets 2.0.0
- Tokenizers 0.12.1
# Full config
{'dataset': {'datasets': ['kejian/codeparrot-train-more-filter-3.3b-cleaned'],
'is_split_by_sentences': True,
'skip_tokens': 1649934336},
'generation': {'batch_size': 128,
'every_n_steps': 512,
'force_call_on': [12589],
'metrics_configs': [{}, {'n': 1}, {}],
'scenario_configs': [{'display_as_html': True,
'generate_kwargs': {'do_sample': True,
'eos_token_id': 0,
'max_length': 640,
'min_length': 10,
'temperature': 0.7,
'top_k': 0,
'top_p': 0.9},
'name': 'unconditional',
'num_hits_threshold': 0,
'num_samples': 2048},
{'display_as_html': True,
'generate_kwargs': {'do_sample': True,
'eos_token_id': 0,
'max_length': 272,
'min_length': 10,
'temperature': 0.7,
'top_k': 0,
'top_p': 0.9},
'name': 'functions',
'num_hits_threshold': 0,
'num_samples': 2048,
'prompts_path': 'resources/functions_csnet.jsonl',
'use_prompt_for_scoring': True}],
'scorer_config': {}},
'kl_gpt3_callback': {'every_n_steps': 512,
'force_call_on': [12589],
'gpt3_kwargs': {'model_name': 'code-cushman-001'},
'max_tokens': 64,
'num_samples': 4096},
'model': {'from_scratch': False,
'gpt2_config_kwargs': {'reorder_and_upcast_attn': True,
'scale_attn_by': True},
'model_kwargs': {'revision': '9b71edc6c769705c1ef1955b6f5cfdd5a7d1b802',
'value_head_config': {'is_detached': False}},
'path_or_name': 'kejian/spectacular-awr'},
'objective': {'alpha': 0.05, 'beta': 1, 'name': 'AWR'},
'tokenizer': {'path_or_name': 'codeparrot/codeparrot-small'},
'training': {'dataloader_num_workers': 0,
'effective_batch_size': 128,
'evaluation_strategy': 'no',
'fp16': True,
'hub_model_id': 'deliberate-awr',
'hub_strategy': 'all_checkpoints',
'learning_rate': 0.0005,
'logging_first_step': True,
'logging_steps': 1,
'num_tokens': 3300000000.0,
'output_dir': 'training_output',
'per_device_train_batch_size': 16,
'push_to_hub': True,
'remove_unused_columns': False,
'save_steps': 12589,
'save_strategy': 'steps',
'seed': 42,
'tokens_already_seen': 1649934336,
'warmup_ratio': 0.01,
'weight_decay': 0.1}}
# Wandb URL:
https://wandb.ai/kejian/uncategorized/runs/2qh5z2cm
|
djaram/distilbert-cased-1mjuicios
|
djaram
| 2022-12-15T22:20:02Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"fill-mask",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-12-15T18:59:35Z |
---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: distilbert-cased-1mjuicios
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-cased-1mjuicios
This model is a fine-tuned version of [distilbert-base-multilingual-cased](https://huggingface.co/distilbert-base-multilingual-cased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.7924
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 2.3025 | 1.0 | 625 | 1.9433 |
| 1.9743 | 2.0 | 1250 | 1.8283 |
| 1.8725 | 3.0 | 1875 | 1.7924 |
### Framework versions
- Transformers 4.25.1
- Pytorch 1.13.0+cu116
- Datasets 2.7.1
- Tokenizers 0.13.2
|
SiddharthaM/xlm-roberta-profane-final
|
SiddharthaM
| 2022-12-15T22:17:11Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"xlm-roberta",
"text-classification",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-12-15T21:33:17Z |
---
license: mit
tags:
- generated_from_trainer
metrics:
- accuracy
- precision
- recall
- f1
model-index:
- name: xlm-roberta-profane-final
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xlm-roberta-profane-final
This model is a fine-tuned version of [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3272
- Accuracy: 0.9087
- Precision: 0.8411
- Recall: 0.8441
- F1: 0.8426
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | Precision | Recall | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:---------:|:------:|:------:|
| No log | 1.0 | 296 | 0.2705 | 0.9030 | 0.8368 | 0.8192 | 0.8276 |
| 0.3171 | 2.0 | 592 | 0.2174 | 0.9192 | 0.8847 | 0.8204 | 0.8476 |
| 0.3171 | 3.0 | 888 | 0.2250 | 0.9202 | 0.8658 | 0.8531 | 0.8593 |
| 0.2162 | 4.0 | 1184 | 0.2329 | 0.9106 | 0.8422 | 0.8538 | 0.8478 |
| 0.2162 | 5.0 | 1480 | 0.2260 | 0.9183 | 0.8584 | 0.8584 | 0.8584 |
| 0.1766 | 6.0 | 1776 | 0.2638 | 0.9116 | 0.8409 | 0.8651 | 0.8522 |
| 0.146 | 7.0 | 2072 | 0.3088 | 0.9125 | 0.8494 | 0.8464 | 0.8478 |
| 0.146 | 8.0 | 2368 | 0.2873 | 0.9154 | 0.8568 | 0.8459 | 0.8512 |
| 0.1166 | 9.0 | 2664 | 0.3227 | 0.9144 | 0.8518 | 0.8518 | 0.8518 |
| 0.1166 | 10.0 | 2960 | 0.3272 | 0.9087 | 0.8411 | 0.8441 | 0.8426 |
### Framework versions
- Transformers 4.24.0.dev0
- Pytorch 1.11.0+cu102
- Datasets 2.6.1
- Tokenizers 0.13.1
|
rfdickerson/q-FrozenLake-v1-4x4-noSlippery
|
rfdickerson
| 2022-12-15T22:15:31Z | 0 | 0 | null |
[
"FrozenLake-v1-4x4-no_slippery",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-12-15T22:15:23Z |
---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="rfdickerson/q-FrozenLake-v1-4x4-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
farsipal/whisper-md-el-intlv-xs
|
farsipal
| 2022-12-15T21:54:46Z | 16 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"whisper",
"automatic-speech-recognition",
"whisper-event",
"generated_from_trainer",
"hf-asr-leaderboard",
"greek",
"el",
"dataset:mozilla-foundation/common_voice_11_0",
"dataset:google/fleurs",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-12-14T15:26:42Z |
---
language:
- el
license: apache-2.0
tags:
- whisper-event
- generated_from_trainer
- hf-asr-leaderboard
- automatic-speech-recognition
- greek
datasets:
- mozilla-foundation/common_voice_11_0
- google/fleurs
metrics:
- wer
model-index:
- name: whisper-md-el-intlv-xs
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: mozilla-foundation/common_voice_11_0
type: mozilla-foundation/common_voice_11_0
config: el
split: test
metrics:
- name: Wer
type: wer
value: 11.3670
---
# whisper-md-el-intlv-xs
This model is a fine-tuned version of [openai/whisper-medium](https://huggingface.co/openai/whisper-medium) on interleaved mozilla-foundation/common_voice_11_0 (el) and the google/fleurs (el_gr) datasets. It achieves the following results on the mozilla-foundation/common_voice_11_0 test evaluation set:
- Loss: 0.4168
- Wer: 11.3670
## Model description
This model is trained over the two interleaved datasets in the Greek language. Testing used only the common_voice_11_0 (el) test split.
## Intended uses & limitations
The model was trained for transcription in Greek
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 8e-06
- train_batch_size: 32
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 10000
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:-----:|:---------------:|:-------:|
| 0.0251 | 2.49 | 1000 | 0.2216 | 12.5836 |
| 0.0051 | 4.98 | 2000 | 0.2874 | 12.2957 |
| 0.0015 | 7.46 | 3000 | 0.3281 | 11.9056 |
| 0.0017 | 9.95 | 4000 | 0.3178 | 12.5929 |
| 0.0008 | 12.44 | 5000 | 0.3449 | 11.9799 |
| 0.0001 | 14.93 | 6000 | 0.3638 | 11.7106 |
| 0.0001 | 17.41 | 7000 | 0.3910 | 11.4970 |
| 0.0 | 19.9 | 8000 | 0.4042 | 11.3949 |
| 0.0 | 22.39 | 9000 | 0.4129 | 11.4134 |
| 0.0 | 24.88 | 10000 | 0.4168 | 11.3670 |
### Framework versions
- Transformers 4.26.0.dev0
- Pytorch 1.13.0+cu117
- Datasets 2.7.1.dev0
- Tokenizers 0.13.2
|
GeneralAwareness/Unddep
|
GeneralAwareness
| 2022-12-15T21:51:19Z | 0 | 12 | null |
[
"stable-diffusion",
"v2",
"text-to-image",
"image-to-image",
"Embedding",
"en",
"license:cc-by-nc-sa-4.0",
"region:us"
] |
text-to-image
| 2022-12-14T07:54:36Z |
---
license: cc-by-nc-sa-4.0
language:
- en
thumbnail: "https://huggingface.co/GeneralAwareness/Unddep/resolve/main/with-1.png"
tags:
- stable-diffusion
- v2
- text-to-image
- image-to-image
- Embedding
---
Textual Inversion Embedding by General Awareness For SD 2.x trained on 768x768 images from various sources.
Install by downloading the .pt embedding, and put it in the \embeddings folder
An undersea/underworld themed embedding that was created with 16 vectors.
Use keyword: unddep
Without this embedding and with this embedding.


Without this embedding and with this embedding.


|
nefasto/whisper-small-it
|
nefasto
| 2022-12-15T21:22:26Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"whisper",
"automatic-speech-recognition",
"whisper-event",
"generated_from_trainer",
"it",
"dataset:mozilla-foundation/common_voice_11_0",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-12-14T17:04:58Z |
---
language:
- it
license: apache-2.0
tags:
- whisper-event
- generated_from_trainer
datasets:
- mozilla-foundation/common_voice_11_0
metrics:
- wer
model-index:
- name: Whisper Small Italian
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: mozilla-foundation/common_voice_11_0 it
type: mozilla-foundation/common_voice_11_0
config: it
split: test
args: it
metrics:
- name: Wer
type: wer
value: 12.303981501169467
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Whisper Small Italian
This model is a fine-tuned version of [openai/whisper-small](https://huggingface.co/openai/whisper-small) on the mozilla-foundation/common_voice_11_0 it dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2534
- Wer: 12.3040
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 8e-06
- train_batch_size: 64
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 6000
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:-------:|
| 0.2737 | 2.01 | 1000 | 0.2728 | 13.4097 |
| 0.1536 | 4.02 | 2000 | 0.2611 | 12.9897 |
| 0.0905 | 6.03 | 3000 | 0.2686 | 12.9273 |
| 0.1301 | 8.04 | 4000 | 0.2534 | 12.3040 |
| 0.096 | 10.05 | 5000 | 0.2727 | 12.6130 |
| 0.0604 | 12.06 | 6000 | 0.2698 | 12.5027 |
### Framework versions
- Transformers 4.26.0.dev0
- Pytorch 1.13.0+cu117
- Datasets 2.7.1.dev0
- Tokenizers 0.13.2
|
sam133/ppo-Huggy
|
sam133
| 2022-12-15T21:11:52Z | 7 | 0 |
ml-agents
|
[
"ml-agents",
"tensorboard",
"onnx",
"unity-ml-agents",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-Huggy",
"region:us"
] |
reinforcement-learning
| 2022-12-15T21:11:08Z |
---
tags:
- unity-ml-agents
- ml-agents
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-Huggy
library_name: ml-agents
---
# **ppo** Agent playing **Huggy**
This is a trained model of a **ppo** agent playing **Huggy** using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://github.com/huggingface/ml-agents#get-started
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
### Resume the training
```
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser:**.
1. Go to https://huggingface.co/spaces/unity/ML-Agents-Huggy
2. Step 1: Write your model_id: sam133/ppo-Huggy
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
miangoar/esm2_t12_35M_UR50D-finetuned-secondary-structure-classification
|
miangoar
| 2022-12-15T21:00:11Z | 10 | 0 |
transformers
|
[
"transformers",
"tf",
"esm",
"token-classification",
"generated_from_keras_callback",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-12-15T20:59:58Z |
---
license: mit
tags:
- generated_from_keras_callback
model-index:
- name: esm2_t12_35M_UR50D-finetuned-secondary-structure-classification
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# esm2_t12_35M_UR50D-finetuned-secondary-structure-classification
This model is a fine-tuned version of [facebook/esm2_t12_35M_UR50D](https://huggingface.co/facebook/esm2_t12_35M_UR50D) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.4076
- Train Masked Accuracy: 0.8342
- Validation Loss: 0.4714
- Validation Masked Accuracy: 0.8060
- Epoch: 2
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'AdamWeightDecay', 'learning_rate': 2e-05, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-07, 'amsgrad': False, 'weight_decay_rate': 0.0}
- training_precision: float32
### Training results
| Train Loss | Train Masked Accuracy | Validation Loss | Validation Masked Accuracy | Epoch |
|:----------:|:---------------------:|:---------------:|:--------------------------:|:-----:|
| 0.5874 | 0.7454 | 0.4908 | 0.7962 | 0 |
| 0.4503 | 0.8156 | 0.4703 | 0.8043 | 1 |
| 0.4076 | 0.8342 | 0.4714 | 0.8060 | 2 |
### Framework versions
- Transformers 4.25.1
- TensorFlow 2.9.2
- Datasets 2.7.1
- Tokenizers 0.13.2
|
LuniLand/dqn-LunarLander-v2
|
LuniLand
| 2022-12-15T20:40:47Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-12-15T20:40:16Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: DQN
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 168.44 +/- 106.68
name: mean_reward
verified: false
---
# **DQN** Agent playing **LunarLander-v2**
This is a trained model of a **DQN** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3)
and the [RL Zoo](https://github.com/DLR-RM/rl-baselines3-zoo).
The RL Zoo is a training framework for Stable Baselines3
reinforcement learning agents,
with hyperparameter optimization and pre-trained agents included.
## Usage (with SB3 RL Zoo)
RL Zoo: https://github.com/DLR-RM/rl-baselines3-zoo<br/>
SB3: https://github.com/DLR-RM/stable-baselines3<br/>
SB3 Contrib: https://github.com/Stable-Baselines-Team/stable-baselines3-contrib
```
# Download model and save it into the logs/ folder
python -m rl_zoo3.load_from_hub --algo dqn --env LunarLander-v2 -orga LuniLand -f logs/
python enjoy.py --algo dqn --env LunarLander-v2 -f logs/
```
If you installed the RL Zoo3 via pip (`pip install rl_zoo3`), from anywhere you can do:
```
python -m rl_zoo3.load_from_hub --algo dqn --env LunarLander-v2 -orga LuniLand -f logs/
rl_zoo3 enjoy --algo dqn --env LunarLander-v2 -f logs/
```
## Training (with the RL Zoo)
```
python train.py --algo dqn --env LunarLander-v2 -f logs/
# Upload the model and generate video (when possible)
python -m rl_zoo3.push_to_hub --algo dqn --env LunarLander-v2 -f logs/ -orga LuniLand
```
## Hyperparameters
```python
OrderedDict([('batch_size', 128),
('buffer_size', 50000),
('exploration_final_eps', 0.1),
('exploration_fraction', 0.12),
('gamma', 0.99),
('gradient_steps', -1),
('learning_rate', 0.00063),
('learning_starts', 0),
('n_timesteps', 100000.0),
('policy', 'MlpPolicy'),
('policy_kwargs', 'dict(net_arch=[256, 256])'),
('target_update_interval', 250),
('train_freq', 4),
('normalize', False)])
```
|
Subsets and Splits
Filtered Qwen2.5 Distill Models
Identifies specific configurations of models by filtering cards that contain 'distill', 'qwen2.5', '7b' while excluding certain base models and incorrect model ID patterns, uncovering unique model variants.
Filtered Model Cards Count
Finds the count of entries with specific card details that include 'distill', 'qwen2.5', '7b' but exclude certain base models, revealing valuable insights about the dataset's content distribution.
Filtered Distill Qwen 7B Models
Filters for specific card entries containing 'distill', 'qwen', and '7b', excluding certain strings and patterns, to identify relevant model configurations.
Filtered Qwen-7b Model Cards
The query performs a detailed filtering based on specific keywords and excludes certain entries, which could be useful for identifying a specific subset of cards but does not provide deeper insights or trends.
Filtered Qwen 7B Model Cards
The query filters for specific terms related to "distilled" or "distill", "qwen", and "7b" in the 'card' column but excludes certain base models, providing a limited set of entries for further inspection.
Qwen 7B Distilled Models
The query provides a basic filtering of records to find specific card names that include keywords related to distilled Qwen 7b models, excluding a particular base model, which gives limited insight but helps in focusing on relevant entries.
Qwen 7B Distilled Model Cards
The query filters data based on specific keywords in the modelId and card fields, providing limited insight primarily useful for locating specific entries rather than revealing broad patterns or trends.
Qwen 7B Distilled Models
Finds all entries containing the terms 'distilled', 'qwen', and '7b' in a case-insensitive manner, providing a filtered set of records but without deeper analysis.
Distilled Qwen 7B Models
The query filters for specific model IDs containing 'distilled', 'qwen', and '7b', providing a basic retrieval of relevant entries but without deeper analysis or insight.
Filtered Model Cards with Distill Qwen2.
Filters and retrieves records containing specific keywords in the card description while excluding certain phrases, providing a basic count of relevant entries.
Filtered Model Cards with Distill Qwen 7
The query filters specific variations of card descriptions containing 'distill', 'qwen', and '7b' while excluding a particular base model, providing limited but specific data retrieval.
Distill Qwen 7B Model Cards
The query filters and retrieves rows where the 'card' column contains specific keywords ('distill', 'qwen', and '7b'), providing a basic filter result that can help in identifying specific entries.