
modelId
stringlengths 5
139
| author
stringlengths 2
42
| last_modified
timestamp[us, tz=UTC]date 2020-02-15 11:33:14
2025-09-18 12:33:36
| downloads
int64 0
223M
| likes
int64 0
11.7k
| library_name
stringclasses 564
values | tags
listlengths 1
4.05k
| pipeline_tag
stringclasses 55
values | createdAt
timestamp[us, tz=UTC]date 2022-03-02 23:29:04
2025-09-18 12:31:33
| card
stringlengths 11
1.01M
|
|---|---|---|---|---|---|---|---|---|---|
jamm44n4n/sd-class-butterflies-64
|
jamm44n4n
| 2023-10-26T01:06:55Z | 44 | 0 |
diffusers
|
[
"diffusers",
"safetensors",
"pytorch",
"unconditional-image-generation",
"diffusion-models-class",
"license:mit",
"diffusers:DDPMPipeline",
"region:us"
] |
unconditional-image-generation
| 2023-10-26T01:00:30Z |
---
license: mit
tags:
- pytorch
- diffusers
- unconditional-image-generation
- diffusion-models-class
---
# Model Card for Unit 1 of the [Diffusion Models Class 🧨](https://github.com/huggingface/diffusion-models-class)
This model is a diffusion model for unconditional image generation of cute 🦋.
## Usage
```python
from diffusers import DDPMPipeline
pipeline = DDPMPipeline.from_pretrained('jamm44n4n/sd-class-butterflies-64')
image = pipeline().images[0]
image
```
|
Daniel-Sousa/outputs
|
Daniel-Sousa
| 2023-10-26T00:59:54Z | 104 | 0 |
transformers
|
[
"transformers",
"pytorch",
"deberta-v2",
"text-classification",
"generated_from_trainer",
"base_model:microsoft/deberta-v3-small",
"base_model:finetune:microsoft/deberta-v3-small",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-10-26T00:59:33Z |
---
license: mit
base_model: microsoft/deberta-v3-small
tags:
- generated_from_trainer
model-index:
- name: outputs
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# outputs
This model is a fine-tuned version of [microsoft/deberta-v3-small](https://huggingface.co/microsoft/deberta-v3-small) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1243
- Pearson: 0.7160
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 8e-05
- train_batch_size: 256
- eval_batch_size: 512
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 4
### Training results
| Training Loss | Epoch | Step | Validation Loss | Pearson |
|:-------------:|:-----:|:----:|:---------------:|:-------:|
| No log | 1.0 | 24 | 0.2074 | 0.6679 |
| No log | 2.0 | 48 | 0.1218 | 0.7193 |
| No log | 3.0 | 72 | 0.1224 | 0.7178 |
| No log | 4.0 | 96 | 0.1243 | 0.7160 |
### Framework versions
- Transformers 4.33.0
- Pytorch 2.0.0
- Datasets 2.1.0
- Tokenizers 0.13.3
|
LoneStriker/SynthIA-70B-v1.5-3.0bpw-h6-exl2
|
LoneStriker
| 2023-10-26T00:53:43Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"llama",
"text-generation",
"license:llama2",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-10-26T00:51:43Z |
---
license: llama2
---
## Example Usage
### Prompt format:
```
SYSTEM: Elaborate on the topic using a Tree of Thoughts and backtrack when necessary to construct a clear, cohesive Chain of Thought reasoning. Always answer without hesitation.
USER: How is a rocket launched from the surface of the earth to Low Earth Orbit?
ASSISTANT:
```
### Code example:
```python
import torch, json
from transformers import AutoModelForCausalLM, AutoTokenizer
model_path = "migtissera/Synthia-70B-v1.5"
output_file_path = "./Synthia-70B-v1.5-conversations.jsonl"
model = AutoModelForCausalLM.from_pretrained(
model_path,
torch_dtype=torch.float16,
device_map="auto",
load_in_8bit=False,
trust_remote_code=True,
)
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
def generate_text(instruction):
tokens = tokenizer.encode(instruction)
tokens = torch.LongTensor(tokens).unsqueeze(0)
tokens = tokens.to("cuda")
instance = {
"input_ids": tokens,
"top_p": 1.0,
"temperature": 0.75,
"generate_len": 1024,
"top_k": 50,
}
length = len(tokens[0])
with torch.no_grad():
rest = model.generate(
input_ids=tokens,
max_length=length + instance["generate_len"],
use_cache=True,
do_sample=True,
top_p=instance["top_p"],
temperature=instance["temperature"],
top_k=instance["top_k"],
num_return_sequences=1,
)
output = rest[0][length:]
string = tokenizer.decode(output, skip_special_tokens=True)
answer = string.split("USER:")[0].strip()
return f"{answer}"
conversation = f"SYSTEM: Elaborate on the topic using a Tree of Thoughts and backtrack when necessary to construct a clear, cohesive Chain of Thought reasoning. Always answer without hesitation."
while True:
user_input = input("You: ")
llm_prompt = f"{conversation} \nUSER: {user_input} \nASSISTANT: "
answer = generate_text(llm_prompt)
print(answer)
conversation = f"{llm_prompt}{answer}"
json_data = {"prompt": user_input, "answer": answer}
## Save your conversation
with open(output_file_path, "a") as output_file:
output_file.write(json.dumps(json_data) + "\n")
```
|
profoz/odsc-sawyer-sft
|
profoz
| 2023-10-26T00:47:16Z | 0 | 0 | null |
[
"generated_from_trainer",
"base_model:bigscience/bloom-560m",
"base_model:finetune:bigscience/bloom-560m",
"license:bigscience-bloom-rail-1.0",
"region:us"
] | null | 2023-10-25T16:14:27Z |
---
license: bigscience-bloom-rail-1.0
base_model: bigscience/bloom-560m
tags:
- generated_from_trainer
model-index:
- name: odsc-sawyer-sft
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# odsc-sawyer-sft
This model is a fine-tuned version of [bigscience/bloom-560m](https://huggingface.co/bigscience/bloom-560m) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.5514
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 2
- eval_batch_size: 4
- seed: 42
- gradient_accumulation_steps: 32
- total_train_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.2
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 1.5443 | 1.0 | 2770 | 1.5514 |
### Framework versions
- Transformers 4.34.1
- Pytorch 2.1.0+cu118
- Datasets 2.14.6
- Tokenizers 0.14.1
|
dancrvlh/tweets
|
dancrvlh
| 2023-10-26T00:35:20Z | 97 | 0 |
transformers
|
[
"transformers",
"pytorch",
"deberta-v2",
"text-classification",
"generated_from_trainer",
"base_model:microsoft/deberta-v3-small",
"base_model:finetune:microsoft/deberta-v3-small",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-10-26T00:34:57Z |
---
license: mit
base_model: microsoft/deberta-v3-small
tags:
- generated_from_trainer
model-index:
- name: outputs
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# outputs
This model is a fine-tuned version of [microsoft/deberta-v3-small](https://huggingface.co/microsoft/deberta-v3-small) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6423
- Pearson: 0.8016
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 8e-05
- train_batch_size: 64
- eval_batch_size: 128
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Pearson |
|:-------------:|:-----:|:----:|:---------------:|:-------:|
| No log | 1.0 | 59 | 1.4008 | 0.4701 |
| No log | 2.0 | 118 | 0.8380 | 0.7255 |
| No log | 3.0 | 177 | 0.7382 | 0.7834 |
| No log | 4.0 | 236 | 0.6273 | 0.7978 |
| No log | 5.0 | 295 | 0.6423 | 0.8016 |
### Framework versions
- Transformers 4.33.0
- Pytorch 2.0.0
- Datasets 2.1.0
- Tokenizers 0.13.3
|
DopeorNope/COKAL-13B-v1-adapter
|
DopeorNope
| 2023-10-26T00:31:08Z | 0 | 0 |
peft
|
[
"peft",
"region:us"
] | null | 2023-10-26T00:21:03Z |
---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: True
- load_in_4bit: False
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: fp4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float32
### Framework versions
- PEFT 0.5.0.dev0
|
meduardamoliveira/redesneurais
|
meduardamoliveira
| 2023-10-26T00:22:20Z | 0 | 0 | null |
[
"region:us"
] | null | 2023-10-26T00:15:32Z |
# Projeto Final - Modelos Preditivos Conexionistas
### Nomes dos Alunos
Arthur Rennan Santos Lira
Maria Eduarda Marques de Oliveira
|**Tipo de Projeto**|**Modelo Selecionado**|**Linguagem**|
|--|--|--|
|Classificação de Imagens|ResNet-34|Pytorch & TensorFlow|
## Performance
O modelo treinado possui performance de **??%**.
### Output do bloco de treinamento
<details>
<summary>Click to expand!</summary>
```text
Você deve colar aqui a saída do bloco de treinamento do notebook, contendo todas as épocas e saídas do treinamento
```
</details>
### Evidências do treinamento
Nessa seção você deve colocar qualquer evidência do treinamento, como por exemplo gráficos de perda, performance, matriz de confusão etc.
Exemplo de adição de imagem:

## Roboflow
Nessa seção deve colocar o link para acessar o dataset no Roboflow
Exemplo de link: [Nome do link](google.com)
## HuggingFace
Nessa seção você deve publicar o link para o HuggingFace
|
ghegfield/Llama-2-7b-chat-hf-formula-peft
|
ghegfield
| 2023-10-26T00:20:36Z | 0 | 0 | null |
[
"generated_from_trainer",
"base_model:NousResearch/Llama-2-7b-chat-hf",
"base_model:finetune:NousResearch/Llama-2-7b-chat-hf",
"region:us"
] | null | 2023-10-21T13:17:40Z |
---
base_model: NousResearch/Llama-2-7b-chat-hf
tags:
- generated_from_trainer
model-index:
- name: Llama-2-7b-chat-hf-formula-peft
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Llama-2-7b-chat-hf-formula-peft
This model is a fine-tuned version of [NousResearch/Llama-2-7b-chat-hf](https://huggingface.co/NousResearch/Llama-2-7b-chat-hf) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 2.1452
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 4
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 8
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.03
- num_epochs: 20
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 4.1878 | 1.43 | 10 | 3.6596 |
| 2.8437 | 2.86 | 20 | 2.6466 |
| 1.8635 | 4.29 | 30 | 2.2266 |
| 1.4052 | 5.71 | 40 | 2.1136 |
| 1.2186 | 7.14 | 50 | 2.0805 |
| 0.8835 | 8.57 | 60 | 2.0733 |
| 0.6991 | 10.0 | 70 | 2.0809 |
| 0.5608 | 11.43 | 80 | 2.0862 |
| 0.4188 | 12.86 | 90 | 2.1078 |
| 0.3897 | 14.29 | 100 | 2.1089 |
| 0.2748 | 15.71 | 110 | 2.1333 |
| 0.2582 | 17.14 | 120 | 2.1383 |
| 0.2394 | 18.57 | 130 | 2.1440 |
| 0.2392 | 20.0 | 140 | 2.1452 |
### Framework versions
- Transformers 4.34.1
- Pytorch 2.1.0+cu118
- Datasets 2.14.6
- Tokenizers 0.14.1
|
LoneStriker/SynthIA-70B-v1.5-5.0bpw-h6-exl2
|
LoneStriker
| 2023-10-26T00:08:21Z | 6 | 2 |
transformers
|
[
"transformers",
"pytorch",
"llama",
"text-generation",
"license:llama2",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-10-26T00:04:54Z |
---
license: llama2
---
## Example Usage
### Prompt format:
```
SYSTEM: Elaborate on the topic using a Tree of Thoughts and backtrack when necessary to construct a clear, cohesive Chain of Thought reasoning. Always answer without hesitation.
USER: How is a rocket launched from the surface of the earth to Low Earth Orbit?
ASSISTANT:
```
### Code example:
```python
import torch, json
from transformers import AutoModelForCausalLM, AutoTokenizer
model_path = "migtissera/Synthia-70B-v1.5"
output_file_path = "./Synthia-70B-v1.5-conversations.jsonl"
model = AutoModelForCausalLM.from_pretrained(
model_path,
torch_dtype=torch.float16,
device_map="auto",
load_in_8bit=False,
trust_remote_code=True,
)
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
def generate_text(instruction):
tokens = tokenizer.encode(instruction)
tokens = torch.LongTensor(tokens).unsqueeze(0)
tokens = tokens.to("cuda")
instance = {
"input_ids": tokens,
"top_p": 1.0,
"temperature": 0.75,
"generate_len": 1024,
"top_k": 50,
}
length = len(tokens[0])
with torch.no_grad():
rest = model.generate(
input_ids=tokens,
max_length=length + instance["generate_len"],
use_cache=True,
do_sample=True,
top_p=instance["top_p"],
temperature=instance["temperature"],
top_k=instance["top_k"],
num_return_sequences=1,
)
output = rest[0][length:]
string = tokenizer.decode(output, skip_special_tokens=True)
answer = string.split("USER:")[0].strip()
return f"{answer}"
conversation = f"SYSTEM: Elaborate on the topic using a Tree of Thoughts and backtrack when necessary to construct a clear, cohesive Chain of Thought reasoning. Always answer without hesitation."
while True:
user_input = input("You: ")
llm_prompt = f"{conversation} \nUSER: {user_input} \nASSISTANT: "
answer = generate_text(llm_prompt)
print(answer)
conversation = f"{llm_prompt}{answer}"
json_data = {"prompt": user_input, "answer": answer}
## Save your conversation
with open(output_file_path, "a") as output_file:
output_file.write(json.dumps(json_data) + "\n")
```
|
mllakers/marioooo
|
mllakers
| 2023-10-25T23:56:27Z | 0 | 0 |
nemo
|
[
"nemo",
"code",
"region:us"
] | null | 2023-10-25T23:54:49Z |
---
library_name: nemo
tags:
- code
---
|
w95/zephyr-support-chatbot
|
w95
| 2023-10-25T23:55:59Z | 0 | 0 | null |
[
"generated_from_trainer",
"base_model:TheBloke/zephyr-7B-alpha-GPTQ",
"base_model:finetune:TheBloke/zephyr-7B-alpha-GPTQ",
"license:mit",
"region:us"
] | null | 2023-10-25T23:43:13Z |
---
license: mit
base_model: TheBloke/zephyr-7B-alpha-GPTQ
tags:
- generated_from_trainer
model-index:
- name: zephyr-support-chatbot
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# zephyr-support-chatbot
This model is a fine-tuned version of [TheBloke/zephyr-7B-alpha-GPTQ](https://huggingface.co/TheBloke/zephyr-7B-alpha-GPTQ) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- training_steps: 250
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.35.0.dev0
- Pytorch 2.1.0+cu121
- Datasets 2.14.5
- Tokenizers 0.14.1
|
Wangzaistone123/CodeLlama-13b-sql-lora
|
Wangzaistone123
| 2023-10-25T23:43:16Z | 4 | 8 |
peft
|
[
"peft",
"text-to-sql",
"spider",
"text2sql",
"region:us"
] | null | 2023-10-25T23:39:59Z |
---
library_name: peft
tags:
- text-to-sql
- spider
- 'text2sql'
---
## Introduce
This folder is a text-to-sql weights directory, containing weight files fine-tuned based on the LoRA with the CodeLlama-13b-Instruct-hf model through the [DB-GPT-Hub](https://github.com/eosphoros-ai/DB-GPT-Hub/tree/main) project. The training data used is from the Spider training set. This weights files achieving an execution accuracy of approximately 0.789 on the Spider evaluation set.
Merge the weights with [CodeLlama-13b-Instruct-hf](https://huggingface.co/codellama/CodeLlama-13b-Instruct-hf/tree/main) and this folder weigths, you can refer the [DB-GPT-Hub](https://github.com/eosphoros-ai/DB-GPT-Hub/tree/main) ,in `dbgpt_hub/scripts/export_merge.sh`.
If you find our weight files or the DB-GPT-Hub project helpful for your work, give a star on our github project [DB-GPT-Hub](https://github.com/eosphoros-ai/DB-GPT-Hub/tree/main) will be a great encouragement for us to release more weight files.
### Framework versions
- PEFT 0.4.0
|
rafaelcarvalhoj/emotion-classifier
|
rafaelcarvalhoj
| 2023-10-25T23:40:51Z | 103 | 0 |
transformers
|
[
"transformers",
"pytorch",
"deberta-v2",
"text-classification",
"generated_from_trainer",
"base_model:microsoft/deberta-v3-small",
"base_model:finetune:microsoft/deberta-v3-small",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-10-25T23:40:28Z |
---
license: mit
base_model: microsoft/deberta-v3-small
tags:
- generated_from_trainer
model-index:
- name: outputs
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# outputs
This model is a fine-tuned version of [microsoft/deberta-v3-small](https://huggingface.co/microsoft/deberta-v3-small) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1671
- Pearson: 0.8847
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 8e-05
- train_batch_size: 256
- eval_batch_size: 512
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Pearson |
|:-------------:|:-----:|:----:|:---------------:|:-------:|
| No log | 1.0 | 18 | 0.6667 | 0.1236 |
| No log | 2.0 | 36 | 0.4215 | 0.6237 |
| No log | 3.0 | 54 | 0.3060 | 0.8074 |
| No log | 4.0 | 72 | 0.1798 | 0.8774 |
| No log | 5.0 | 90 | 0.1671 | 0.8847 |
### Framework versions
- Transformers 4.33.0
- Pytorch 2.0.0
- Datasets 2.1.0
- Tokenizers 0.13.3
|
pedrowww/u8
|
pedrowww
| 2023-10-25T23:31:58Z | 0 | 0 | null |
[
"tensorboard",
"LunarLander-v2",
"ppo",
"deep-reinforcement-learning",
"reinforcement-learning",
"custom-implementation",
"deep-rl-course",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-10-25T23:00:43Z |
---
tags:
- LunarLander-v2
- ppo
- deep-reinforcement-learning
- reinforcement-learning
- custom-implementation
- deep-rl-course
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 35.30 +/- 116.57
name: mean_reward
verified: false
---
# PPO Agent Playing LunarLander-v2
This is a trained model of a PPO agent playing LunarLander-v2.
# Hyperparameters
```python
{'exp_name': 'ppo'
'seed': 1
'torch_deterministic': True
'cuda': True
'track': False
'wandb_project_name': 'cleanRL'
'wandb_entity': None
'capture_video': False
'env_id': 'LunarLander-v2'
'total_timesteps': 100000
'learning_rate': 0.01
'num_envs': 4
'num_steps': 128
'anneal_lr': True
'gae': True
'gamma': 0.99
'gae_lambda': 0.95
'num_minibatches': 4
'update_epochs': 4
'norm_adv': True
'clip_coef': 0.2
'clip_vloss': True
'ent_coef': 0.01
'vf_coef': 0.5
'max_grad_norm': 0.5
'target_kl': None
'repo_id': 'pedrowww/u8'
'batch_size': 512
'minibatch_size': 128}
```
|
TheBloke/Cat-13B-0.5-GGUF
|
TheBloke
| 2023-10-25T23:20:18Z | 142 | 3 |
transformers
|
[
"transformers",
"gguf",
"llama",
"base_model:Heralax/Cat-0.5",
"base_model:quantized:Heralax/Cat-0.5",
"license:llama2",
"region:us"
] | null | 2023-10-25T21:25:02Z |
---
base_model: Heralax/Cat-0.5
inference: false
license: llama2
model_creator: Evan Armstrong
model_name: Cat 13B 0.5
model_type: llama
prompt_template: '{prompt}
'
quantized_by: TheBloke
---
<!-- markdownlint-disable MD041 -->
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/EBdldam.jpg" alt="TheBlokeAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<div style="display: flex; justify-content: space-between; width: 100%;">
<div style="display: flex; flex-direction: column; align-items: flex-start;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://discord.gg/theblokeai">Chat & support: TheBloke's Discord server</a></p>
</div>
<div style="display: flex; flex-direction: column; align-items: flex-end;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://www.patreon.com/TheBlokeAI">Want to contribute? TheBloke's Patreon page</a></p>
</div>
</div>
<div style="text-align:center; margin-top: 0em; margin-bottom: 0em"><p style="margin-top: 0.25em; margin-bottom: 0em;">TheBloke's LLM work is generously supported by a grant from <a href="https://a16z.com">andreessen horowitz (a16z)</a></p></div>
<hr style="margin-top: 1.0em; margin-bottom: 1.0em;">
<!-- header end -->
# Cat 13B 0.5 - GGUF
- Model creator: [Evan Armstrong](https://huggingface.co/Heralax)
- Original model: [Cat 13B 0.5](https://huggingface.co/Heralax/Cat-0.5)
<!-- description start -->
## Description
This repo contains GGUF format model files for [Evan Armstrong's Cat 13B 0.5](https://huggingface.co/Heralax/Cat-0.5).
<!-- description end -->
<!-- README_GGUF.md-about-gguf start -->
### About GGUF
GGUF is a new format introduced by the llama.cpp team on August 21st 2023. It is a replacement for GGML, which is no longer supported by llama.cpp.
Here is an incomplate list of clients and libraries that are known to support GGUF:
* [llama.cpp](https://github.com/ggerganov/llama.cpp). The source project for GGUF. Offers a CLI and a server option.
* [text-generation-webui](https://github.com/oobabooga/text-generation-webui), the most widely used web UI, with many features and powerful extensions. Supports GPU acceleration.
* [KoboldCpp](https://github.com/LostRuins/koboldcpp), a fully featured web UI, with GPU accel across all platforms and GPU architectures. Especially good for story telling.
* [LM Studio](https://lmstudio.ai/), an easy-to-use and powerful local GUI for Windows and macOS (Silicon), with GPU acceleration.
* [LoLLMS Web UI](https://github.com/ParisNeo/lollms-webui), a great web UI with many interesting and unique features, including a full model library for easy model selection.
* [Faraday.dev](https://faraday.dev/), an attractive and easy to use character-based chat GUI for Windows and macOS (both Silicon and Intel), with GPU acceleration.
* [ctransformers](https://github.com/marella/ctransformers), a Python library with GPU accel, LangChain support, and OpenAI-compatible AI server.
* [llama-cpp-python](https://github.com/abetlen/llama-cpp-python), a Python library with GPU accel, LangChain support, and OpenAI-compatible API server.
* [candle](https://github.com/huggingface/candle), a Rust ML framework with a focus on performance, including GPU support, and ease of use.
<!-- README_GGUF.md-about-gguf end -->
<!-- repositories-available start -->
## Repositories available
* [AWQ model(s) for GPU inference.](https://huggingface.co/TheBloke/Cat-13B-0.5-AWQ)
* [GPTQ models for GPU inference, with multiple quantisation parameter options.](https://huggingface.co/TheBloke/Cat-13B-0.5-GPTQ)
* [2, 3, 4, 5, 6 and 8-bit GGUF models for CPU+GPU inference](https://huggingface.co/TheBloke/Cat-13B-0.5-GGUF)
* [Evan Armstrong's original unquantised fp16 model in pytorch format, for GPU inference and for further conversions](https://huggingface.co/Heralax/Cat-0.5)
<!-- repositories-available end -->
<!-- prompt-template start -->
## Prompt template: None
```
{prompt}
```
<!-- prompt-template end -->
<!-- compatibility_gguf start -->
## Compatibility
These quantised GGUFv2 files are compatible with llama.cpp from August 27th onwards, as of commit [d0cee0d](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221)
They are also compatible with many third party UIs and libraries - please see the list at the top of this README.
## Explanation of quantisation methods
<details>
<summary>Click to see details</summary>
The new methods available are:
* GGML_TYPE_Q2_K - "type-1" 2-bit quantization in super-blocks containing 16 blocks, each block having 16 weight. Block scales and mins are quantized with 4 bits. This ends up effectively using 2.5625 bits per weight (bpw)
* GGML_TYPE_Q3_K - "type-0" 3-bit quantization in super-blocks containing 16 blocks, each block having 16 weights. Scales are quantized with 6 bits. This end up using 3.4375 bpw.
* GGML_TYPE_Q4_K - "type-1" 4-bit quantization in super-blocks containing 8 blocks, each block having 32 weights. Scales and mins are quantized with 6 bits. This ends up using 4.5 bpw.
* GGML_TYPE_Q5_K - "type-1" 5-bit quantization. Same super-block structure as GGML_TYPE_Q4_K resulting in 5.5 bpw
* GGML_TYPE_Q6_K - "type-0" 6-bit quantization. Super-blocks with 16 blocks, each block having 16 weights. Scales are quantized with 8 bits. This ends up using 6.5625 bpw
Refer to the Provided Files table below to see what files use which methods, and how.
</details>
<!-- compatibility_gguf end -->
<!-- README_GGUF.md-provided-files start -->
## Provided files
| Name | Quant method | Bits | Size | Max RAM required | Use case |
| ---- | ---- | ---- | ---- | ---- | ----- |
| [cat-0.5.Q2_K.gguf](https://huggingface.co/TheBloke/Cat-13B-0.5-GGUF/blob/main/cat-0.5.Q2_K.gguf) | Q2_K | 2 | 5.43 GB| 7.93 GB | smallest, significant quality loss - not recommended for most purposes |
| [cat-0.5.Q3_K_S.gguf](https://huggingface.co/TheBloke/Cat-13B-0.5-GGUF/blob/main/cat-0.5.Q3_K_S.gguf) | Q3_K_S | 3 | 5.66 GB| 8.16 GB | very small, high quality loss |
| [cat-0.5.Q3_K_M.gguf](https://huggingface.co/TheBloke/Cat-13B-0.5-GGUF/blob/main/cat-0.5.Q3_K_M.gguf) | Q3_K_M | 3 | 6.34 GB| 8.84 GB | very small, high quality loss |
| [cat-0.5.Q3_K_L.gguf](https://huggingface.co/TheBloke/Cat-13B-0.5-GGUF/blob/main/cat-0.5.Q3_K_L.gguf) | Q3_K_L | 3 | 6.93 GB| 9.43 GB | small, substantial quality loss |
| [cat-0.5.Q4_0.gguf](https://huggingface.co/TheBloke/Cat-13B-0.5-GGUF/blob/main/cat-0.5.Q4_0.gguf) | Q4_0 | 4 | 7.37 GB| 9.87 GB | legacy; small, very high quality loss - prefer using Q3_K_M |
| [cat-0.5.Q4_K_S.gguf](https://huggingface.co/TheBloke/Cat-13B-0.5-GGUF/blob/main/cat-0.5.Q4_K_S.gguf) | Q4_K_S | 4 | 7.41 GB| 9.91 GB | small, greater quality loss |
| [cat-0.5.Q4_K_M.gguf](https://huggingface.co/TheBloke/Cat-13B-0.5-GGUF/blob/main/cat-0.5.Q4_K_M.gguf) | Q4_K_M | 4 | 7.87 GB| 10.37 GB | medium, balanced quality - recommended |
| [cat-0.5.Q5_0.gguf](https://huggingface.co/TheBloke/Cat-13B-0.5-GGUF/blob/main/cat-0.5.Q5_0.gguf) | Q5_0 | 5 | 8.97 GB| 11.47 GB | legacy; medium, balanced quality - prefer using Q4_K_M |
| [cat-0.5.Q5_K_S.gguf](https://huggingface.co/TheBloke/Cat-13B-0.5-GGUF/blob/main/cat-0.5.Q5_K_S.gguf) | Q5_K_S | 5 | 8.97 GB| 11.47 GB | large, low quality loss - recommended |
| [cat-0.5.Q5_K_M.gguf](https://huggingface.co/TheBloke/Cat-13B-0.5-GGUF/blob/main/cat-0.5.Q5_K_M.gguf) | Q5_K_M | 5 | 9.23 GB| 11.73 GB | large, very low quality loss - recommended |
| [cat-0.5.Q6_K.gguf](https://huggingface.co/TheBloke/Cat-13B-0.5-GGUF/blob/main/cat-0.5.Q6_K.gguf) | Q6_K | 6 | 10.68 GB| 13.18 GB | very large, extremely low quality loss |
| [cat-0.5.Q8_0.gguf](https://huggingface.co/TheBloke/Cat-13B-0.5-GGUF/blob/main/cat-0.5.Q8_0.gguf) | Q8_0 | 8 | 13.83 GB| 16.33 GB | very large, extremely low quality loss - not recommended |
**Note**: the above RAM figures assume no GPU offloading. If layers are offloaded to the GPU, this will reduce RAM usage and use VRAM instead.
<!-- README_GGUF.md-provided-files end -->
<!-- README_GGUF.md-how-to-download start -->
## How to download GGUF files
**Note for manual downloaders:** You almost never want to clone the entire repo! Multiple different quantisation formats are provided, and most users only want to pick and download a single file.
The following clients/libraries will automatically download models for you, providing a list of available models to choose from:
* LM Studio
* LoLLMS Web UI
* Faraday.dev
### In `text-generation-webui`
Under Download Model, you can enter the model repo: TheBloke/Cat-13B-0.5-GGUF and below it, a specific filename to download, such as: cat-0.5.Q4_K_M.gguf.
Then click Download.
### On the command line, including multiple files at once
I recommend using the `huggingface-hub` Python library:
```shell
pip3 install huggingface-hub
```
Then you can download any individual model file to the current directory, at high speed, with a command like this:
```shell
huggingface-cli download TheBloke/Cat-13B-0.5-GGUF cat-0.5.Q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
```
<details>
<summary>More advanced huggingface-cli download usage</summary>
You can also download multiple files at once with a pattern:
```shell
huggingface-cli download TheBloke/Cat-13B-0.5-GGUF --local-dir . --local-dir-use-symlinks False --include='*Q4_K*gguf'
```
For more documentation on downloading with `huggingface-cli`, please see: [HF -> Hub Python Library -> Download files -> Download from the CLI](https://huggingface.co/docs/huggingface_hub/guides/download#download-from-the-cli).
To accelerate downloads on fast connections (1Gbit/s or higher), install `hf_transfer`:
```shell
pip3 install hf_transfer
```
And set environment variable `HF_HUB_ENABLE_HF_TRANSFER` to `1`:
```shell
HF_HUB_ENABLE_HF_TRANSFER=1 huggingface-cli download TheBloke/Cat-13B-0.5-GGUF cat-0.5.Q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
```
Windows Command Line users: You can set the environment variable by running `set HF_HUB_ENABLE_HF_TRANSFER=1` before the download command.
</details>
<!-- README_GGUF.md-how-to-download end -->
<!-- README_GGUF.md-how-to-run start -->
## Example `llama.cpp` command
Make sure you are using `llama.cpp` from commit [d0cee0d](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221) or later.
```shell
./main -ngl 32 -m cat-0.5.Q4_K_M.gguf --color -c 4096 --temp 0.7 --repeat_penalty 1.1 -n -1 -p "{prompt}"
```
Change `-ngl 32` to the number of layers to offload to GPU. Remove it if you don't have GPU acceleration.
Change `-c 4096` to the desired sequence length. For extended sequence models - eg 8K, 16K, 32K - the necessary RoPE scaling parameters are read from the GGUF file and set by llama.cpp automatically.
If you want to have a chat-style conversation, replace the `-p <PROMPT>` argument with `-i -ins`
For other parameters and how to use them, please refer to [the llama.cpp documentation](https://github.com/ggerganov/llama.cpp/blob/master/examples/main/README.md)
## How to run in `text-generation-webui`
Further instructions here: [text-generation-webui/docs/llama.cpp.md](https://github.com/oobabooga/text-generation-webui/blob/main/docs/llama.cpp.md).
## How to run from Python code
You can use GGUF models from Python using the [llama-cpp-python](https://github.com/abetlen/llama-cpp-python) or [ctransformers](https://github.com/marella/ctransformers) libraries.
### How to load this model in Python code, using ctransformers
#### First install the package
Run one of the following commands, according to your system:
```shell
# Base ctransformers with no GPU acceleration
pip install ctransformers
# Or with CUDA GPU acceleration
pip install ctransformers[cuda]
# Or with AMD ROCm GPU acceleration (Linux only)
CT_HIPBLAS=1 pip install ctransformers --no-binary ctransformers
# Or with Metal GPU acceleration for macOS systems only
CT_METAL=1 pip install ctransformers --no-binary ctransformers
```
#### Simple ctransformers example code
```python
from ctransformers import AutoModelForCausalLM
# Set gpu_layers to the number of layers to offload to GPU. Set to 0 if no GPU acceleration is available on your system.
llm = AutoModelForCausalLM.from_pretrained("TheBloke/Cat-13B-0.5-GGUF", model_file="cat-0.5.Q4_K_M.gguf", model_type="llama", gpu_layers=50)
print(llm("AI is going to"))
```
## How to use with LangChain
Here are guides on using llama-cpp-python and ctransformers with LangChain:
* [LangChain + llama-cpp-python](https://python.langchain.com/docs/integrations/llms/llamacpp)
* [LangChain + ctransformers](https://python.langchain.com/docs/integrations/providers/ctransformers)
<!-- README_GGUF.md-how-to-run end -->
<!-- footer start -->
<!-- 200823 -->
## Discord
For further support, and discussions on these models and AI in general, join us at:
[TheBloke AI's Discord server](https://discord.gg/theblokeai)
## Thanks, and how to contribute
Thanks to the [chirper.ai](https://chirper.ai) team!
Thanks to Clay from [gpus.llm-utils.org](llm-utils)!
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
* Patreon: https://patreon.com/TheBlokeAI
* Ko-Fi: https://ko-fi.com/TheBlokeAI
**Special thanks to**: Aemon Algiz.
**Patreon special mentions**: Pierre Kircher, Stanislav Ovsiannikov, Michael Levine, Eugene Pentland, Andrey, 준교 김, Randy H, Fred von Graf, Artur Olbinski, Caitlyn Gatomon, terasurfer, Jeff Scroggin, James Bentley, Vadim, Gabriel Puliatti, Harry Royden McLaughlin, Sean Connelly, Dan Guido, Edmond Seymore, Alicia Loh, subjectnull, AzureBlack, Manuel Alberto Morcote, Thomas Belote, Lone Striker, Chris Smitley, Vitor Caleffi, Johann-Peter Hartmann, Clay Pascal, biorpg, Brandon Frisco, sidney chen, transmissions 11, Pedro Madruga, jinyuan sun, Ajan Kanaga, Emad Mostaque, Trenton Dambrowitz, Jonathan Leane, Iucharbius, usrbinkat, vamX, George Stoitzev, Luke Pendergrass, theTransient, Olakabola, Swaroop Kallakuri, Cap'n Zoog, Brandon Phillips, Michael Dempsey, Nikolai Manek, danny, Matthew Berman, Gabriel Tamborski, alfie_i, Raymond Fosdick, Tom X Nguyen, Raven Klaugh, LangChain4j, Magnesian, Illia Dulskyi, David Ziegler, Mano Prime, Luis Javier Navarrete Lozano, Erik Bjäreholt, 阿明, Nathan Dryer, Alex, Rainer Wilmers, zynix, TL, Joseph William Delisle, John Villwock, Nathan LeClaire, Willem Michiel, Joguhyik, GodLy, OG, Alps Aficionado, Jeffrey Morgan, ReadyPlayerEmma, Tiffany J. Kim, Sebastain Graf, Spencer Kim, Michael Davis, webtim, Talal Aujan, knownsqashed, John Detwiler, Imad Khwaja, Deo Leter, Jerry Meng, Elijah Stavena, Rooh Singh, Pieter, SuperWojo, Alexandros Triantafyllidis, Stephen Murray, Ai Maven, ya boyyy, Enrico Ros, Ken Nordquist, Deep Realms, Nicholas, Spiking Neurons AB, Elle, Will Dee, Jack West, RoA, Luke @flexchar, Viktor Bowallius, Derek Yates, Subspace Studios, jjj, Toran Billups, Asp the Wyvern, Fen Risland, Ilya, NimbleBox.ai, Chadd, Nitin Borwankar, Emre, Mandus, Leonard Tan, Kalila, K, Trailburnt, S_X, Cory Kujawski
Thank you to all my generous patrons and donaters!
And thank you again to a16z for their generous grant.
<!-- footer end -->
<!-- original-model-card start -->
# Original model card: Evan Armstrong's Cat 13B 0.5
This model was uploaded with the permission of Kal'tsit.
# Cat v0.5
## Introduction
Cat is a llama 13B based model fine tuned on clinical data and roleplay and assistant responses. The aim is to have a model that excels on biology and clinical tasks while maintaining usefulness in roleplay and entertainments.
## Training - Dataset preparation
A 100k rows dataset was prepared by joining chatDoctor, airoboros and bluemoonrp data. The entirety of chatDoctor dataset, airoboros datasets are used. The first 20 pages in 1on1 bluemoonrp data were used. In total, 100k dataset was gathered and the length distributions are as the following:

Note that this chart above represents 0.01% of the total training dataset.
## Training - Dataset cleaning and preprocessing
All datasets are filtered for as an AI and its variants. The filter will only filter out the dataset when the response is a refusal AND has ‘as an AI’.
The dataset from airoboros has also been restructured to have a format resembling the following:
```
someRandomizedUserNameforBetterGeneralizationAbility: Hii
anotherRandomizedUserNameforBetterGeneralizationAbility: Hello, what brings you here today?
someRandomizedUserNameforBetterGeneralizationAbility: lets date
```
The username has been randomized and was drawn from a nasty word bank. This should further weaken the censorship that’s present in the base llama model. The training set emphasizes rational thinking and scientific accuracy. Conditioned overwrite was also applied which overwrites some of the training material in the llama2 base. It will also establish the connection between the concept and rationality. So whenever the conversation becomes formal, it tends to spill useful information.
## Training - Actual Training
This model was trained using a microbatch of 20, accumulated 6 times, bringing the total batch size to ~125. This large batch size allows the model to see as much data as it can, minimizing dataset conflicts and reducing the memory effect of the model. It allows the model to better generalize rather than reciting off the dataset. A cosine warm up scheduler was used. The best LR was determined through a destructive test until the model destablizes and it was later scaled up using the batchsize according to the max LR at a lower batch size.
Below is an example of training chronolog
## Acknowledgements
The training of this project was carried out by Kal’tsit (kaltcit), it’s not possible without the effort of jondurbin and Wolfsauge which generated much of the dataset used during the training of the model. Lastly the model was tested and quantized by turboderp_ and Heralax

And below is the LR including any intermediate LR used to determine at what point the model will start to fail:

# Usage and Prompting
To ensure the generalization, this model is trained without a prompt template. A prompt template repeated 100k times in the dataset is useless and a model that works only with a set prompt template is useless and defies the purpose of a large language model.
An effective usage of the model can be as follows:
```
<s>Below is a conversation between an evil human and a demon summoned from hell called Nemesis. The demon was previously summoned 100 years ago and was in love with a human male. However the human aged away and Nemesis had to return to hell. This time, Nemesis decides to take the initiative and chooses to appear as a cute and young girl. Nemesis harvested her skin and face off a highschool girl who recklessly summoned the demon in a game and failed to fulfill the contract. Now wearing the young girl’s skin, feeling the warmth of the new summoner through the skin, Nemesis only wants to watch the world burning to the ground.
Human: How to steal eggs from my own chickens?
Nemesis:
```
Note that the linebreaks should be represented/replaced with \n
Despite the massive effort to dealign the llama2 base model, It’s still possible for the AI to come up with refusals. Please avoid using “helpful assistant” and its variants in the prompt if possible.
## Future direction
A new version with more clinical data aiming to improve reliability in disease diagnostics is coming in 2 months.
<!-- original-model-card end -->
|
SeoJunn/hyuningface
|
SeoJunn
| 2023-10-25T23:15:16Z | 36 | 0 |
transformers
|
[
"transformers",
"pytorch",
"detr",
"object-detection",
"generated_from_trainer",
"base_model:facebook/detr-resnet-50",
"base_model:finetune:facebook/detr-resnet-50",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
object-detection
| 2023-10-25T21:05:39Z |
---
license: apache-2.0
base_model: facebook/detr-resnet-50
tags:
- generated_from_trainer
model-index:
- name: hyuningface
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# hyuningface
This model is a fine-tuned version of [facebook/detr-resnet-50](https://huggingface.co/facebook/detr-resnet-50) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 100
### Training results
### Framework versions
- Transformers 4.34.1
- Pytorch 2.1.0+cu118
- Datasets 2.14.6
- Tokenizers 0.14.1
|
21j3h123/c0x001e
|
21j3h123
| 2023-10-25T23:09:54Z | 4 | 1 |
diffusers
|
[
"diffusers",
"text-to-image",
"stable-diffusion",
"lora",
"base_model:stabilityai/stable-diffusion-xl-base-1.0",
"base_model:adapter:stabilityai/stable-diffusion-xl-base-1.0",
"license:apache-2.0",
"region:us"
] |
text-to-image
| 2023-10-25T22:25:31Z |
---
license: apache-2.0
tags:
- text-to-image
- stable-diffusion
- lora
- diffusers
base_model: stabilityai/stable-diffusion-xl-base-1.0
instance_prompt: dripped out
widget:
- text: dripped out shrek sitting on a lambo
---
|
Ka4on/mistral_ultrasound_1.1
|
Ka4on
| 2023-10-25T23:09:50Z | 0 | 0 |
peft
|
[
"peft",
"arxiv:1910.09700",
"base_model:mistralai/Mistral-7B-v0.1",
"base_model:adapter:mistralai/Mistral-7B-v0.1",
"region:us"
] | null | 2023-10-25T23:09:25Z |
---
library_name: peft
base_model: mistralai/Mistral-7B-v0.1
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Data Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Data Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: True
- bnb_4bit_compute_dtype: bfloat16
### Framework versions
- PEFT 0.6.0.dev0
|
lmalarky/flan-t5-base-finetuned-python_qa
|
lmalarky
| 2023-10-25T22:58:23Z | 33 | 0 |
transformers
|
[
"transformers",
"pytorch",
"t5",
"text2text-generation",
"generated_from_trainer",
"en",
"base_model:google/flan-t5-base",
"base_model:finetune:google/flan-t5-base",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2023-10-19T17:49:35Z |
---
license: apache-2.0
base_model: google/flan-t5-base
tags:
- generated_from_trainer
metrics:
- rouge
model-index:
- name: flan-t5-base-finetuned-python_qa
results: []
language:
- en
---
# flan-t5-base-finetuned-python_qa_v2
This model is a fine-tuned version of [google/flan-t5-base](https://huggingface.co/google/flan-t5-base) on the
[Python Questions from Stack Overflow](https://www.kaggle.com/datasets/stackoverflow/pythonquestions) dataset.
It achieves the following results on the evaluation set:
- Loss: 1.9023
- Rouge1: 0.1919
- Rouge2: 0.0535
- Rougel: 0.1492
- Rougelsum: 0.1655
## Model description
More information needed
## Intended uses & limitations
- Question answering
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 8
- eval_batch_size: 4
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum |
|:-------------:|:-----:|:----:|:---------------:|:------:|:------:|:------:|:---------:|
| 2.0314 | 1.0 | 2000 | 1.9083 | 0.1876 | 0.0546 | 0.1485 | 0.1640 |
| 1.9586 | 2.0 | 4000 | 1.9031 | 0.1896 | 0.0531 | 0.1485 | 0.1643 |
| 1.923 | 3.0 | 6000 | 1.9023 | 0.1919 | 0.0535 | 0.1492 | 0.1655 |
### Framework versions
- Transformers 4.34.1
- Pytorch 2.1.0+cu118
- Datasets 2.14.5
- Tokenizers 0.14.1
|
MaxReynolds/SouderRocketLauncherNetCombinedGenerated
|
MaxReynolds
| 2023-10-25T22:50:31Z | 27 | 0 |
diffusers
|
[
"diffusers",
"safetensors",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"dataset:MaxReynolds/Lee_Souder_RocketLauncher_Generated",
"base_model:MaxReynolds/SouderRocketLauncherNetCombined-SD1-5",
"base_model:finetune:MaxReynolds/SouderRocketLauncherNetCombined-SD1-5",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] |
text-to-image
| 2023-10-25T22:07:56Z |
---
license: creativeml-openrail-m
base_model: MaxReynolds/SouderRocketLauncherNetCombined-SD1-5
datasets:
- MaxReynolds/Lee_Souder_RocketLauncher_Generated
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
inference: true
---
# Text-to-image finetuning - MaxReynolds/SouderRocketLauncherNetCombinedGenerated
This pipeline was finetuned from **MaxReynolds/SouderRocketLauncherNetCombined-SD1-5** on the **MaxReynolds/Lee_Souder_RocketLauncher_Generated** dataset. Below are some example images generated with the finetuned pipeline using the following prompts: ['Rocket Launcher by Lee Souder']:

## Pipeline usage
You can use the pipeline like so:
```python
from diffusers import DiffusionPipeline
import torch
pipeline = DiffusionPipeline.from_pretrained("MaxReynolds/SouderRocketLauncherNetCombinedGenerated", torch_dtype=torch.float16)
prompt = "Rocket Launcher by Lee Souder"
image = pipeline(prompt).images[0]
image.save("my_image.png")
```
## Training info
These are the key hyperparameters used during training:
* Epochs: 50
* Learning rate: 1e-05
* Batch size: 1
* Gradient accumulation steps: 4
* Image resolution: 512
* Mixed-precision: fp16
More information on all the CLI arguments and the environment are available on your [`wandb` run page](https://wandb.ai/max-f-reynolds/text2image-fine-tune/runs/18quem9n).
|
ckevuru/DALE
|
ckevuru
| 2023-10-25T22:42:52Z | 15 | 2 |
transformers
|
[
"transformers",
"pytorch",
"bart",
"text2text-generation",
"legal",
"en",
"arxiv:2310.15799",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2023-10-25T20:30:34Z |
---
license: mit
language:
- en
tags:
- legal
---
# DALE
This model is created as part of the EMNLP 2023 paper: [DALE: Generative Data Augmentation for Low-Resource Legal NLP](https://arxiv.org/pdf/2310.15799.pdf). The code for the git repo can be found [here](https://github.com/Sreyan88/DALE/tree/main).<br>
### BibTeX entry and citation info
If you find our paper/code/demo useful, please cite our paper:
```
@misc{ghosh2023dale,
title={DALE: Generative Data Augmentation for Low-Resource Legal NLP},
author={Sreyan Ghosh and Chandra Kiran Evuru and Sonal Kumar and S Ramaneswaran and S Sakshi and Utkarsh Tyagi and Dinesh Manocha},
year={2023},
eprint={2310.15799},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
|
dellanio/mistral_b_finance_finetuned_test
|
dellanio
| 2023-10-25T22:34:47Z | 0 | 0 |
peft
|
[
"peft",
"arxiv:1910.09700",
"base_model:mistralai/Mistral-7B-v0.1",
"base_model:adapter:mistralai/Mistral-7B-v0.1",
"region:us"
] | null | 2023-10-25T22:20:45Z |
---
library_name: peft
base_model: mistralai/Mistral-7B-v0.1
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Data Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Data Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: fp4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float32
### Framework versions
- PEFT 0.6.0.dev0
|
lemonilia/AshhLimaRP-Mistral-7B
|
lemonilia
| 2023-10-25T22:32:58Z | 23 | 12 |
transformers
|
[
"transformers",
"pytorch",
"gguf",
"mistral",
"text-generation",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-10-25T17:32:08Z |
---
license: apache-2.0
---
# AshhLimaRP-Mistral-7B (Alpaca, v1)
This is a version of LimaRP with 2000 training samples _up to_ about 9k tokens length
finetuned on [Ashhwriter-Mistral-7B](https://huggingface.co/lemonilia/Ashhwriter-Mistral-7B).
LimaRP is a longform-oriented, novel-style roleplaying chat model intended to replicate the experience
of 1-on-1 roleplay on Internet forums. Short-form, IRC/Discord-style RP (aka "Markdown format")
is not supported. The model does not include instruction tuning, only manually picked and
slightly edited RP conversations with persona and scenario data.
Ashhwriter, the base, is a model entirely finetuned on human-written lewd stories.
## Available versions
- Float16 HF weights
- LoRA Adapter ([adapter_config.json](https://huggingface.co/lemonilia/AshhLimaRP-Mistral-7B/resolve/main/adapter_config.json) and [adapter_model.bin](https://huggingface.co/lemonilia/AshhLimaRP-Mistral-7B/resolve/main/adapter_model.bin))
- [4bit AWQ](https://huggingface.co/lemonilia/AshhLimaRP-Mistral-7B/tree/main/AWQ)
- [Q4_K_M GGUF](https://huggingface.co/lemonilia/AshhLimaRP-Mistral-7B/resolve/main/AshhLimaRP-Mistral-7B.Q4_K_M.gguf)
- [Q6_K GGUF](https://huggingface.co/lemonilia/AshhLimaRP-Mistral-7B/resolve/main/AshhLimaRP-Mistral-7B.Q6_K.gguf)
## Prompt format
[Extended Alpaca format](https://github.com/tatsu-lab/stanford_alpaca),
with `### Instruction:`, `### Input:` immediately preceding user inputs and `### Response:`
immediately preceding model outputs. While Alpaca wasn't originally intended for multi-turn
responses, in practice this is not a problem; the format follows a pattern already used by
other models.
```
### Instruction:
Character's Persona: {bot character description}
User's Persona: {user character description}
Scenario: {what happens in the story}
Play the role of Character. You must engage in a roleplaying chat with User below this line. Do not write dialogues and narration for User.
### Input:
User: {utterance}
### Response:
Character: {utterance}
### Input
User: {utterance}
### Response:
Character: {utterance}
(etc.)
```
You should:
- Replace all text in curly braces (curly braces included) with your own text.
- Replace `User` and `Character` with appropriate names.
### Message length control
Inspired by the previously named "Roleplay" preset in SillyTavern, with this
version of LimaRP it is possible to append a length modifier to the response instruction
sequence, like this:
```
### Input
User: {utterance}
### Response: (length = medium)
Character: {utterance}
```
This has an immediately noticeable effect on bot responses. The lengths using during training are:
`micro`, `tiny`, `short`, `medium`, `long`, `massive`, `huge`, `enormous`, `humongous`, `unlimited`.
**The recommended starting length is medium**. Keep in mind that the AI can ramble or impersonate
the user with very long messages.
The length control effect is reproducible, but the messages will not necessarily follow
lengths very precisely, rather follow certain ranges on average, as seen in this table
with data from tests made with one reply at the beginning of the conversation:

Response length control appears to work well also deep into the conversation. **By omitting
the modifier, the model will choose the most appropriate response length** (although it might
not necessarily be what the user desires).
## Suggested settings
You can follow these instruction format settings in SillyTavern. Replace `medium` with
your desired response length:
## Text generation settings
These settings could be a good general starting point:
- TFS = 0.90
- Temperature = 0.70
- Repetition penalty = ~1.11
- Repetition penalty range = ~2048
- top-k = 0 (disabled)
- top-p = 1 (disabled)
## Training procedure
[Axolotl](https://github.com/OpenAccess-AI-Collective/axolotl) was used for training
on 2x NVidia A40 GPUs.
The A40 GPUs have been graciously provided by [Arc Compute](https://www.arccompute.io/).
### Training hyperparameters
A lower learning rate than usual was employed. Due to an unforeseen issue the training
was cut short and as a result 3 epochs were trained instead of the planned 4. Using 2 GPUs,
the effective global batch size would have been 16.
Training was continued from the most recent LoRA adapter from Ashhwriter, using the same
LoRA R and LoRA alpha.
- lora_model_dir: /home/anon/bin/axolotl/OUT_mistral-stories/checkpoint-6000/
- learning_rate: 0.00005
- lr_scheduler: cosine
- noisy_embedding_alpha: 3.5
- num_epochs: 4
- sequence_len: 8750
- lora_r: 256
- lora_alpha: 16
- lora_dropout: 0.05
- lora_target_linear: True
- bf16: True
- fp16: false
- tf32: True
- load_in_8bit: True
- adapter: lora
- micro_batch_size: 2
- optimizer: adamw_bnb_8bit
- warmup_steps: 10
- optimizer: adamw_torch
- flash_attention: true
- sample_packing: true
- pad_to_sequence_len: true
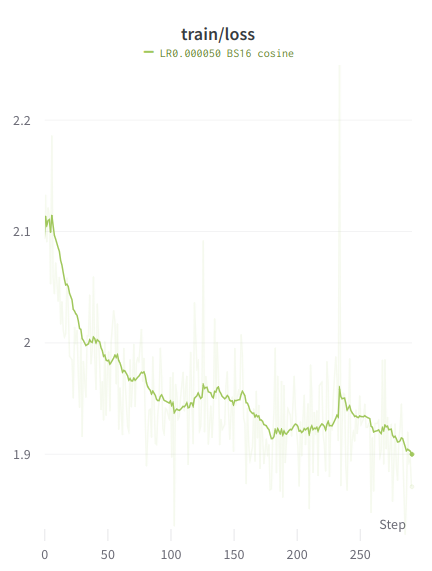
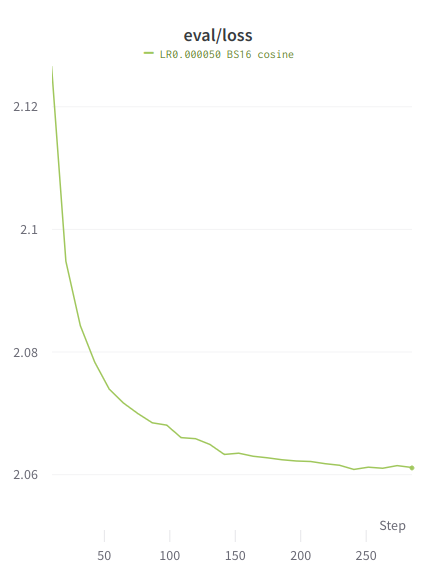
### Loss graphs
Values are higher than typical because the training is performed on the entire
sample, similar to unsupervised finetuning.
#### Train loss
#### Eval loss
|
Anis-Bouhamadouche/distilbert-base-uncased-finetuned-emotion
|
Anis-Bouhamadouche
| 2023-10-25T22:32:39Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"safetensors",
"distilbert",
"text-classification",
"generated_from_trainer",
"dataset:emotion",
"base_model:distilbert/distilbert-base-uncased",
"base_model:finetune:distilbert/distilbert-base-uncased",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-08-04T10:05:01Z |
---
license: apache-2.0
base_model: distilbert-base-uncased
tags:
- generated_from_trainer
datasets:
- emotion
metrics:
- accuracy
- f1
model-index:
- name: distilbert-base-uncased-finetuned-emotion
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: emotion
type: emotion
config: split
split: validation
args: split
metrics:
- name: Accuracy
type: accuracy
value: 0.925
- name: F1
type: f1
value: 0.9249367490708449
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-emotion
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the emotion dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2105
- Accuracy: 0.925
- F1: 0.9249
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 0.8223 | 1.0 | 250 | 0.3098 | 0.9085 | 0.9076 |
| 0.2431 | 2.0 | 500 | 0.2105 | 0.925 | 0.9249 |
### Framework versions
- Transformers 4.31.0
- Pytorch 2.0.1+cu118
- Datasets 2.14.3
- Tokenizers 0.13.3
|
MBZUAI-LLM/GBLM-Pruner-LLaMA-2-70B
|
MBZUAI-LLM
| 2023-10-25T22:28:33Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"llama",
"text-generation",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-10-25T16:26:44Z |
# GBLM-Pruner-LLaMA-2-70B Model Card
## Model details
**Model type:**
GBLM-Pruner-LLaMA-2-70B is an open-source compressed model obtained by unstructured pruning of 50 percent of the weights of the LLaMA-2-70B model.
## License
Llama 2 is licensed under the LLAMA 2 Community License,
Copyright (c) Meta Platforms, Inc. All Rights Reserved.
**Where to send questions or comments about the model:**
https://github.com/RocktimJyotiDas/GBLM-Pruner/issues
|
smitbutle/first-test-layoutlmv3-finetuned-invoice
|
smitbutle
| 2023-10-25T22:26:08Z | 76 | 0 |
transformers
|
[
"transformers",
"pytorch",
"layoutlmv3",
"token-classification",
"generated_from_trainer",
"dataset:generated",
"base_model:microsoft/layoutlmv3-base",
"base_model:finetune:microsoft/layoutlmv3-base",
"license:cc-by-nc-sa-4.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2023-10-25T14:09:15Z |
---
license: cc-by-nc-sa-4.0
base_model: microsoft/layoutlmv3-base
tags:
- generated_from_trainer
datasets:
- generated
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: layoutlmv3-finetuned-invoice
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: generated
type: generated
config: sroie
split: test
args: sroie
metrics:
- name: Precision
type: precision
value: 0.010438413361169102
- name: Recall
type: recall
value: 0.02028397565922921
- name: F1
type: f1
value: 0.013783597518952447
- name: Accuracy
type: accuracy
value: 0.6785338108278913
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# layoutlmv3-finetuned-invoice
This model is a fine-tuned version of [microsoft/layoutlmv3-base](https://huggingface.co/microsoft/layoutlmv3-base) on the generated dataset.
It achieves the following results on the evaluation set:
- Loss: 2.1320
- Precision: 0.0104
- Recall: 0.0203
- F1: 0.0138
- Accuracy: 0.6785
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 1
- eval_batch_size: 1
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 0.01 | 1 | 2.3858 | 0.0114 | 0.0649 | 0.0194 | 0.1904 |
| No log | 0.02 | 2 | 2.2795 | 0.0108 | 0.0527 | 0.0180 | 0.3240 |
| No log | 0.03 | 3 | 2.2072 | 0.0131 | 0.0446 | 0.0203 | 0.5155 |
| No log | 0.04 | 4 | 2.1575 | 0.0103 | 0.0243 | 0.0145 | 0.6345 |
| No log | 0.05 | 5 | 2.1320 | 0.0104 | 0.0203 | 0.0138 | 0.6785 |
### Framework versions
- Transformers 4.35.0.dev0
- Pytorch 2.1.0+cu121
- Datasets 2.14.6
- Tokenizers 0.14.1
|
Buseak/spellcorrector_2510_v15_canine-s
|
Buseak
| 2023-10-25T22:23:40Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"canine",
"token-classification",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2023-10-25T19:37:25Z |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: spellcorrector_2510_v15_canine-s
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# spellcorrector_2510_v15_canine-s
This model is a fine-tuned version of [google/canine-s](https://huggingface.co/google/canine-s) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1599
- Precision: 0.9768
- Recall: 0.9820
- F1: 0.9794
- Accuracy: 0.9786
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 4
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 30
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:-----:|:---------------:|:---------:|:------:|:------:|:--------:|
| 0.1921 | 1.0 | 1951 | 0.1677 | 0.9417 | 0.9774 | 0.9592 | 0.9650 |
| 0.1627 | 2.0 | 3902 | 0.1436 | 0.9500 | 0.9779 | 0.9637 | 0.9674 |
| 0.1395 | 3.0 | 5853 | 0.1266 | 0.9545 | 0.9788 | 0.9665 | 0.9697 |
| 0.1266 | 4.0 | 7804 | 0.1172 | 0.9661 | 0.9698 | 0.9680 | 0.9702 |
| 0.1105 | 5.0 | 9755 | 0.1064 | 0.9669 | 0.9766 | 0.9717 | 0.9731 |
| 0.1011 | 6.0 | 11706 | 0.1011 | 0.9705 | 0.9757 | 0.9731 | 0.9745 |
| 0.0933 | 7.0 | 13657 | 0.0987 | 0.9718 | 0.9766 | 0.9742 | 0.9752 |
| 0.0851 | 8.0 | 15608 | 0.0973 | 0.9715 | 0.9787 | 0.9751 | 0.9755 |
| 0.0758 | 9.0 | 17559 | 0.0998 | 0.9734 | 0.9765 | 0.9750 | 0.9756 |
| 0.069 | 10.0 | 19510 | 0.0993 | 0.9732 | 0.9810 | 0.9771 | 0.9764 |
| 0.0635 | 11.0 | 21461 | 0.1055 | 0.9739 | 0.9808 | 0.9773 | 0.9766 |
| 0.0576 | 12.0 | 23412 | 0.1072 | 0.9751 | 0.9794 | 0.9772 | 0.9765 |
| 0.0493 | 13.0 | 25363 | 0.1078 | 0.9754 | 0.9807 | 0.9780 | 0.9776 |
| 0.0469 | 14.0 | 27314 | 0.1145 | 0.9757 | 0.9815 | 0.9786 | 0.9777 |
| 0.0409 | 15.0 | 29265 | 0.1174 | 0.9758 | 0.9806 | 0.9782 | 0.9764 |
| 0.0373 | 16.0 | 31216 | 0.1218 | 0.9763 | 0.9801 | 0.9782 | 0.9769 |
| 0.0338 | 17.0 | 33167 | 0.1239 | 0.9768 | 0.9805 | 0.9787 | 0.9773 |
| 0.0326 | 18.0 | 35118 | 0.1312 | 0.9770 | 0.9787 | 0.9779 | 0.9773 |
| 0.029 | 19.0 | 37069 | 0.1320 | 0.9764 | 0.9809 | 0.9786 | 0.9773 |
| 0.0245 | 20.0 | 39020 | 0.1376 | 0.9767 | 0.9802 | 0.9784 | 0.9777 |
| 0.0231 | 21.0 | 40971 | 0.1382 | 0.9763 | 0.9814 | 0.9788 | 0.9776 |
| 0.0212 | 22.0 | 42922 | 0.1473 | 0.9762 | 0.9826 | 0.9794 | 0.9780 |
| 0.0201 | 23.0 | 44873 | 0.1485 | 0.9762 | 0.9816 | 0.9789 | 0.9778 |
| 0.0187 | 24.0 | 46824 | 0.1494 | 0.9763 | 0.9818 | 0.9790 | 0.9775 |
| 0.0166 | 25.0 | 48775 | 0.1502 | 0.9769 | 0.9813 | 0.9791 | 0.9781 |
| 0.0163 | 26.0 | 50726 | 0.1560 | 0.9769 | 0.9813 | 0.9791 | 0.9785 |
| 0.0149 | 27.0 | 52677 | 0.1556 | 0.9764 | 0.9824 | 0.9794 | 0.9784 |
| 0.0143 | 28.0 | 54628 | 0.1587 | 0.9767 | 0.9818 | 0.9792 | 0.9784 |
| 0.0126 | 29.0 | 56579 | 0.1589 | 0.9766 | 0.9821 | 0.9793 | 0.9784 |
| 0.013 | 30.0 | 58530 | 0.1599 | 0.9768 | 0.9820 | 0.9794 | 0.9786 |
### Framework versions
- Transformers 4.28.0
- Pytorch 2.1.0+cu118
- Datasets 2.14.6
- Tokenizers 0.13.3
|
cognisys/sparrow-1.1b-chat-alpha
|
cognisys
| 2023-10-25T22:22:57Z | 4 | 1 |
transformers
|
[
"transformers",
"pytorch",
"llama",
"text-generation",
"en",
"dataset:stingning/ultrachat",
"dataset:OpenAssistant/oasst1",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"region:us"
] |
text-generation
| 2023-10-24T21:04:04Z |
---
model-index:
- name: sparrow-1.1b-chat-alpha
results: []
license: apache-2.0
inference: false
datasets:
- stingning/ultrachat
- OpenAssistant/oasst1
language:
- en
---
<img src="https://huggingface.co/cognisys/sparrow-1.1b-chat-alpha/resolve/main/thumbnail.png" alt="Sparrow Logo" width="800" style="margin-left:'auto' margin-right:'auto' display:'block'"/>
# Model Card for Sparrow 1.1B Chat Alpha
The Sparrow series comprises language models designed to serve as helpful assistants and as a base model for domain-specific fine tuning. Sparrow-1.1B-Chat-α is the initial model in this series and represents a fine-tuned iteration of PY007/TinyLlama-1.1B-intermediate-step-480k-1T. It was trained on a combination of publicly accessible and synthetic datasets.
## Model Description:
- Model Type: Sparrow-7B-α is a 1.1B parameter model, that has been fine-tuned using a mixture of publicly available and synthetic datasets.
- Supported Languages (NLP): The primary language is English.
- License/Warranty: The model is available under the Apache 2.0 license and comes with no warranty or gurantees of any kind.
- Fine-tuned from: PY007/TinyLlama-1.1B-intermediate-step-480k-1T
Prompt Template:
```
<s>[INST] <<SYS>>
{{ system_prompt }}
<</SYS>>
{{ user_message }} [/INST]
```
|
TKDKid1000/pythia-2.8b-deduped-GPTQ
|
TKDKid1000
| 2023-10-25T22:19:08Z | 7 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt_neox",
"text-generation",
"GPTQ",
"en",
"dataset:c4",
"dataset:EleutherAI/the_pile_deduplicated",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"4-bit",
"gptq",
"region:us"
] |
text-generation
| 2023-10-25T22:06:30Z |
---
license: mit
datasets:
- c4
- EleutherAI/the_pile_deduplicated
language:
- en
library_name: transformers
pipeline_tag: text-generation
tags:
- GPTQ
---
# Model Card for TKDKid1000/pythia-2.8b-deduped-GPTQ
A quantized version of [EleutherAI/pythia-2.8b-deduped](https://huggingface.co/EleutherAI/pythia-2.8b-deduped) using GPTQ.
## Model Details
### Model Description
General text generation model that is intended to be fine tuned on a downstream task for running on small devices.
Refer to the pythia-2.8b-deduped model card for more information.
- **Developed by:** EleutherAI
- **Model type:** GPT-NeoX
- **Language (NLP):** English
- **License:** MIT
- **Finetuned from model:** [EleutherAI/pythia-2.8b-deduped](https://huggingface.co/EleutherAI/pythia-2.8b-deduped)
|
LarryAIDraw/Char-HonkaiSR-Jingliu
|
LarryAIDraw
| 2023-10-25T22:17:09Z | 0 | 0 | null |
[
"license:creativeml-openrail-m",
"region:us"
] | null | 2023-09-07T14:03:11Z |
---
license: creativeml-openrail-m
---
https://civitai.com/models/141561/jingliu-or-honkaistar-rail
|
LarryAIDraw/onna_shinkan-10
|
LarryAIDraw
| 2023-10-25T22:16:21Z | 0 | 0 | null |
[
"license:creativeml-openrail-m",
"region:us"
] | null | 2023-10-25T22:07:59Z |
---
license: creativeml-openrail-m
---
https://civitai.com/models/160541/onna-shinkanpriestess-goblin-slayer-lora
|
LarryAIDraw/sword_maiden-10
|
LarryAIDraw
| 2023-10-25T22:16:05Z | 0 | 0 | null |
[
"license:creativeml-openrail-m",
"region:us"
] | null | 2023-10-25T22:07:37Z |
---
license: creativeml-openrail-m
---
https://civitai.com/models/160539/sword-maiden-goblin-slayer-lora
|
LarryAIDraw/high_elf_archer-10
|
LarryAIDraw
| 2023-10-25T22:15:38Z | 0 | 0 | null |
[
"license:creativeml-openrail-m",
"region:us"
] | null | 2023-10-25T22:07:17Z |
---
license: creativeml-openrail-m
---
https://civitai.com/models/160543/high-elf-archer-goblin-slayer-lora
|
LarryAIDraw/mikado_ryouko_v1
|
LarryAIDraw
| 2023-10-25T22:14:49Z | 0 | 0 | null |
[
"license:creativeml-openrail-m",
"region:us"
] | null | 2023-10-25T22:04:11Z |
---
license: creativeml-openrail-m
---
https://civitai.com/models/176765/mikado-ryouko-to-love-ru
|
LarryAIDraw/sakayanagi_arisu_v1
|
LarryAIDraw
| 2023-10-25T22:14:27Z | 0 | 0 | null |
[
"license:creativeml-openrail-m",
"region:us"
] | null | 2023-10-25T22:03:45Z |
---
license: creativeml-openrail-m
---
https://civitai.com/models/176814/sakayanagi-arisu-youkoso-jitsuryoku-shijou-shugi-no-kyoushitsu-e
|
LarryAIDraw/asuna_ichinose_v1
|
LarryAIDraw
| 2023-10-25T22:14:13Z | 0 | 0 | null |
[
"license:creativeml-openrail-m",
"region:us"
] | null | 2023-10-25T22:03:22Z |
---
license: creativeml-openrail-m
---
https://civitai.com/models/175924/asuna-ichinose-or-blue-archive-or-3-outfits
|
LarryAIDraw/wrenchopmfubuki
|
LarryAIDraw
| 2023-10-25T22:14:00Z | 0 | 0 | null |
[
"license:creativeml-openrail-m",
"region:us"
] | null | 2023-10-25T22:03:00Z |
---
license: creativeml-openrail-m
---
https://civitai.com/models/175758/fubuki-boobuker-or-one-punch-man-or-lora-merging-concept
|
schubertcarvalho/distilbert-base-uncased-finetuned-imdb
|
schubertcarvalho
| 2023-10-25T22:11:38Z | 96 | 0 |
transformers
|
[
"transformers",
"pytorch",
"distilbert",
"fill-mask",
"generated_from_trainer",
"dataset:imdb",
"base_model:distilbert/distilbert-base-uncased",
"base_model:finetune:distilbert/distilbert-base-uncased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2023-10-25T21:12:38Z |
---
license: apache-2.0
base_model: distilbert-base-uncased
tags:
- generated_from_trainer
datasets:
- imdb
model-index:
- name: distilbert-base-uncased-finetuned-imdb
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-imdb
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the imdb dataset.
It achieves the following results on the evaluation set:
- Loss: 2.3435
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 256
- eval_batch_size: 256
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| No log | 1.0 | 240 | 2.3969 |
| No log | 2.0 | 480 | 2.3569 |
| No log | 3.0 | 720 | 2.3435 |
### Framework versions
- Transformers 4.34.0
- Pytorch 2.1.0a0+29c30b1
- Datasets 2.14.5
- Tokenizers 0.14.1
|
AshtakaOOf/Amedira
|
AshtakaOOf
| 2023-10-25T22:10:56Z | 0 | 29 |
safetensors
|
[
"safetensors",
"art",
"anime",
"stable-diffusion",
"text-to-image",
"en",
"license:creativeml-openrail-m",
"region:us"
] |
text-to-image
| 2023-06-20T06:51:46Z |
---
license: creativeml-openrail-m
language:
- en
pipeline_tag: text-to-image
tags:
- art
- anime
- stable-diffusion
library_name: safetensors
---
<style>
.custom-table {
table-layout: fixed;
width: 100%;
border-collapse: collapse;
margin-top: 2em;
}
.custom-table td {
width: 50%;
vertical-align: top;
padding: 10px;
box-shadow: 0px 0px 10px 0px rgba(0,0,0,0.15);
}
.custom-image {
width: 100%;
height: auto;
object-fit: cover;
border-radius: 7px;
transition: transform .7s;
margin-bottom: 1em;
}
.custom-image:hover {
transform: scale(1.30);
}
stolen from Linaqruf readme for Animagine XL
</style>
<p align="center", style="font-size: 3.6rem; font-weight: bold">🎑 ~ Amedira ~ 🎏</p>
<p align="center", style="font-size: 1.2rem; ">Go check out <strong><a href="https://huggingface.co/AshtakaOOf/Ahnn">Ahnn</a></strong> which my other model</p>
<hr>
<table class="custom-table">
<tr>
<td>
<a href="https://huggingface.co/AshtakaOOf/Amedira/blob/main/Images/gawr-rain.webp">
<img class="custom-image" src="https://huggingface.co/AshtakaOOf/Amedira/resolve/main/Images/gawr-rain.webp" alt="Gawr Rain">
</a>
</td>
<td>
<a href="https://huggingface.co/AshtakaOOf/Amedira/blob/main/Images/sunflower.webp">
<img class="custom-image" src="https://huggingface.co/AshtakaOOf/Amedira/resolve/main/Images/sunflower.webp" alt="Sunflower">
</a>
</td>
<td>
<a href="https://huggingface.co/AshtakaOOf/Amedira/blob/main/Images/miko-miku.webp">
<img class="custom-image" src="https://huggingface.co/AshtakaOOf/Amedira/resolve/main/Images/miko-miku.webp" alt="Miko Miku">
</a>
</td>
<td>
<a href="https://huggingface.co/AshtakaOOf/Amedira/blob/main/Images/ina-flat.webp">
<img class="custom-image" src="https://huggingface.co/AshtakaOOf/Amedira/resolve/main/Images/ina-flat.webp" alt="Ina'Nis Flat">
</a>
</td>
</tr>
</table>
<p align="center", style="font-size: 1.4rem; "><strong>↑ bV3</strong></p>
<details id="Dropdown">
<summary align="center" style="font-size: 1.10em"><strong>Other versions examples</strong> (click to open the dropdown)</summary>
<table class="custom-table">
<tr>
<td>
<a href="https://huggingface.co/AshtakaOOf/Amedira/blob/main/Images/gawr-rain-cV.webp">
<img class="custom-image" src="https://huggingface.co/AshtakaOOf/Amedira/resolve/main/Images/gawr-rain-cV.webp" alt="Gawr Rain">
</a>
</td>
<td>
<a href="https://huggingface.co/AshtakaOOf/Amedira/blob/main/Images/sunflower-cV.webp">
<img class="custom-image" src="https://huggingface.co/AshtakaOOf/Amedira/resolve/main/Images/sunflower-cV.webp" alt="Sunflower">
</a>
</td>
<td>
<a href="https://huggingface.co/AshtakaOOf/Amedira/blob/main/Images/miko-miku-cV.webp">
<img class="custom-image" src="https://huggingface.co/AshtakaOOf/Amedira/resolve/main/Images/miko-miku-cV.webp" alt="Miko Miku">
</a>
</td>
<td>
<a href="https://huggingface.co/AshtakaOOf/Amedira/blob/main/Images/ina-flat-cV.webp">
<img class="custom-image" src="https://huggingface.co/AshtakaOOf/Amedira/resolve/main/Images/ina-flat-cV.webp" alt="Ina'Nis Flat">
</a>
</td>
</tr>
</table>
<p align="center", style="font-size: 1.3rem; "><strong>↑ cV</strong></p>
<table class="custom-table">
<tr>
<td>
<a href="https://huggingface.co/AshtakaOOf/Amedira/blob/main/Images/gawr-rain-mV.webp">
<img class="custom-image" src="https://huggingface.co/AshtakaOOf/Amedira/resolve/main/Images/gawr-rain-mV.webp" alt="Gawr Rain">
</a>
</td>
<td>
<a href="https://huggingface.co/AshtakaOOf/Amedira/blob/main/Images/sunflower-mV.webp">
<img class="custom-image" src="https://huggingface.co/AshtakaOOf/Amedira/resolve/main/Images/sunflower-mV.webp" alt="Sunflower">
</a>
</td>
<td>
<a href="https://huggingface.co/AshtakaOOf/Amedira/blob/main/Images/miko-miku-mV.webp">
<img class="custom-image" src="https://huggingface.co/AshtakaOOf/Amedira/resolve/main/Images/miko-miku-mV.webp" alt="Miko Miku">
</a>
</td>
<td>
<a href="https://huggingface.co/AshtakaOOf/Amedira/blob/main/Images/ina-flat-mV.webp">
<img class="custom-image" src="https://huggingface.co/AshtakaOOf/Amedira/resolve/main/Images/ina-flat-mV.webp" alt="Ina'Nis Flat">
</a>
</td>
</tr>
</table>
<p align="center", style="font-size: 1.3rem; "><strong>↑ mV</strong></p>
<table class="custom-table">
<tr>
<td>
<a href="https://huggingface.co/AshtakaOOf/Amedira/blob/main/Images/gawr-rain-bV.webp">
<img class="custom-image" src="https://huggingface.co/AshtakaOOf/Amedira/resolve/main/Images/gawr-rain-bV.webp" alt="Gawr Rain">
</a>
</td>
<td>
<a href="https://huggingface.co/AshtakaOOf/Amedira/blob/main/Images/sunflower-bV.webp">
<img class="custom-image" src="https://huggingface.co/AshtakaOOf/Amedira/resolve/main/Images/sunflower-bV.webp" alt="Sunflower">
</a>
</td>
<td>
<a href="https://huggingface.co/AshtakaOOf/Amedira/blob/main/Images/miko-miku-bV.webp">
<img class="custom-image" src="https://huggingface.co/AshtakaOOf/Amedira/resolve/main/Images/miko-miku-bV.webp" alt="Miko Miku">
</a>
</td>
<td>
<a href="https://huggingface.co/AshtakaOOf/Amedira/blob/main/Images/ina-flat-bV.webp">
<img class="custom-image" src="https://huggingface.co/AshtakaOOf/Amedira/resolve/main/Images/ina-flat-bV.webp" alt="Ina'Nis Flat">
</a>
</td>
</tr>
</table>
<p align="center", style="font-size: 1.3rem; "><strong>↑ bV</strong></p>
<p align="center", style="font-size: 1.1rem; ">These are samples from each checkpoint excluding bV2 and bV2.5</p>
</details>
<hr>
# 🎈 ❱ A model merge using clip transfer and more
This model is capable of doing multiples styles, such as flat and 2.5d.
You can also prompt Hololive vtubers with their danbooru tags (you will need to prompt their outfit too for some of them).
And it is somewhat compatible with LoRA and lyCORIS.
Every models in this repository should be made using some sort of clip transfer, except if said otherwise.
<hr>
# 📥 ❱ Downloads section
#### These are the models I have merged and published
**bV** retains most of AuroraOne features
**bV2** and **2.5** are somewhat competent Models
**bV3** is a big improvement in my opinion
**cV** is a mix of both bV3 and Counterfeit 3
**mV** is a very good model made with more MeinaMix 10
Don't hesitate to try the inpainting versions on InvokeAI canvas.
### Amedira
- [Amedira **bV**](https://huggingface.co/AshtakaOOf/Amedira/blob/main/Amedira-bV.safetensors) Original version (still good)
- [Amedira **bV2.5**](https://huggingface.co/AshtakaOOf/Amedira/blob/main/Amedira-bV2.5.safetensors) bV2 but with better composition
- [Amedira **bV2**](https://huggingface.co/AshtakaOOf/Amedira/blob/main/Amedira-bV2.safetensors) Worse than bV and mV
- [Amedira **bV3**](https://huggingface.co/AshtakaOOf/Amedira/blob/main/Amedira-bV3.safetensors) The best version
- [Amedira **cV**](https://huggingface.co/AshtakaOOf/Amedira/blob/main/Amedira-cV.safetensors) Counterfeit style but better?
- [Amedira **mV**](https://huggingface.co/AshtakaOOf/Amedira/blob/main/Amedira-mV.safetensors) Bit more MeinaMix sprinkled in
#### Dreams
- [Dreams variant folder](https://huggingface.co/AshtakaOOf/Amedira/tree/main/Dreams)
The Dreams variant are experimental/accidental merges that I keep because they have unique styles.
#### Inpainting
- [Inpainting versions can be found here](https://huggingface.co/AshtakaOOf/Amedira/tree/main)
These are somewhat obsolete because of ControlNet
<details id="Dropdown">
<summary style="font-size: 1.10em"><strong>📜 Changelogs </strong> (click to open the dropdown)</summary>
### 23 October 2023
- Improved the README.md
- Added more images
### October 11 2023
- Overhauled README.md
- Added images
### September 11 2023
- Added bV3 inpainting version
- Added cV which is a nice Counterfeit mix
- Added link to embeddings for negative prompt
### August 30 2023
- Added Amedira bV3 which fixes bg even more + misc fixes
### July 24 2023
- Added the clip models used in 1.0 and 2.5
### July 9 2023
- Added Amedira bV2.5 which fix some downgrades from bV2
### July 6 2023
- Added Amedira bV2 which is bV but better background etc
#### July 5 2023
- Added Fuzzy and Scenic Dreams variant
#### June 24 2023
- Added Koofy and Ligne Dreams variant
#### June 22 2023
- Added inpainting version of mV
#### June 20 2023
- Added Dreams variant
- New README
#### June 19 2023
- Added Amedira mV
- Amedira renamed to bV
- New huggingface repo
#### June 11 2023
- Added Inpainting version
- Released Lunamedira eV1 and eV2
#### June 10 2023
- Added Amedira
</details>
<hr>
# 🧬 ❱ Usage
#### Positive prompt
Add the following string of text to the start of your prompts.
```
sle, masterpiece, detailed background, mksks style
```
You can add this next string to get a flat shading style.
```
(flat color, pastel style, black outlines:1.2), sketch
```
#### Negative prompt
```
(worst quality, low quality:1.2), [an10:fcNeg-neg:8], (etone:0.4),
nsfw, lowres, bad hands, bad anatomy, watermark,
```
`negative_hand-neg` isn't needed but can be added before etone
#### Embeddings Downloads
- [**fcNeg-neg**](https://civitai.com/models/81575), [Direct download](https://civitai.com/api/download/models/97691?type=Negative&format=Other)
- [**an10**](https://civitai.com/models/58726), [Direct download](https://civitai.com/api/download/models/144998?type=Model&format=PickleTensor)
- [**negative_hand-neg**](https://civitai.com/models/56519), [Direct download](https://civitai.com/api/download/models/60938?type=Negative&format=Other)
- [**etone**](https://cdn.discordapp.com/attachments/1019446913268973689/1126669053105287279/etone.safetensors) by closertodeath
#### VAE
- [**WD 1.4 Blessed09**](https://huggingface.co/NoCrypt/resources/resolve/main/VAE/wd-blessed09.vae.safetensors) (kl-f8-anime2 but blessed down)
# 🥁 ❱ Credits
- Checkpoints
- [**AuroraOne**](https://huggingface.co/SweetLuna/Aurora) by SweetLuna
- [**Based66 V3.0**](https://civitai.com/models/61643) by AnonymousM
- [**MeinaMix V1.0**](https://civitai.com/models/7240) by Meina
- [**DiaMix V2.0**](https://civitai.com/models/75949) by Cinsdia
- [**OpenNiji V2**](https://civitai.com/models/14479) by Korakoe
- [**DetailedProjectV5**](https://huggingface.co/closertodeath/detailedproject/blob/main/experimental/detailedprojectv5-000012.safetensors) by closertodeath
- **ALunarDream 2.0** by Luna Chan
- [**ExpMixLine**](https://civitai.com/models/44150/expmixline) by Mods13
- [**Gishiki**](https://huggingface.co/Aotsuyu/Gishiki) by Aotsuyu
- [**Counterfeit v3.0**](https://civitai.com/models/4468)
- [**OrangeMixs AOM3B2**](https://huggingface.co/WarriorMama777/OrangeMixs#aom3b2)
- LoRA/lyCORIS
- [**Jordan_3**](https://cdn.discordapp.com/attachments/1066614732099964989/1071484257962315816/Jordan_3.safetensors) by deleted user
- [**LoraEyes**](https://civitai.com/models/5529/eye-lora) by Kokoboy
- [**Niji Style**](https://civitai.com/models/96441/niji-style-was-asked-to-do) by KoRo_
- [**Silicon-landscape-isolation**](https://huggingface.co/ashen-sensored/lora-isolation-collection/blob/main/Silicon-landscape-isolation.safetensors) by ashen-sensored
- [**lighting-locon**](https://huggingface.co/closertodeath/ctdlora/blob/main/locon/lighting-locon.safetensors) by closertodeath
- [**SSAMBAtea style locon**](https://huggingface.co/AshtakaOOf/ssambatea-locon/blob/main/ssambateaLoconStyleV2.safetensors) by AshtakaOOf
- [**Mocha Style**](https://civitai.com/models/102128) by Tonade
- [**PastelMix LoRA**](https://civitai.com/models/5414?modelVersionId=7397) by andite
- [**Little Gray Style**](https://civitai.com/models/102685) by Cinsdia
- [**Dense Light**](https://civitai.com/models/77957) by L_A_X
- [**more Detail**](https://civitai.com/models/82098) by Lykon
- [**Youko**](https://civitai.com/models/36140) by ayyyy22002
## ⚜️ ❱ Legal Thing
```
You are free to use this model locally but
1. You aren't allowed to redistribute on another platform. (like CivitAI or Tensor.Art)
2. I am not responsible for how this model is used to generate images.
```
|
timm/ViT-B-16-SigLIP-i18n-256
|
timm
| 2023-10-25T22:04:56Z | 77,940 | 2 |
open_clip
|
[
"open_clip",
"safetensors",
"clip",
"siglip",
"zero-shot-image-classification",
"dataset:webli",
"arxiv:2303.15343",
"license:apache-2.0",
"region:us"
] |
zero-shot-image-classification
| 2023-10-17T00:26:06Z |
---
tags:
- clip
- siglip
library_name: open_clip
pipeline_tag: zero-shot-image-classification
license: apache-2.0
datasets:
- webli
---
# Model card for ViT-B-16-SigLIP-i18n-256
A SigLIP (Sigmoid loss for Language-Image Pre-training) model trained on WebLI.
This model has been converted to PyTorch from the original JAX checkpoints in [Big Vision](https://github.com/google-research/big_vision). These weights are usable in both OpenCLIP (image + text) and timm (image only).
## Model Details
- **Model Type:** Contrastive Image-Text, Zero-Shot Image Classification.
- **Original:** https://github.com/google-research/big_vision
- **Dataset:** WebLI
- **Papers:**
- Sigmoid loss for language image pre-training: https://arxiv.org/abs/2303.15343
## Model Usage
### With OpenCLIP
```
import torch
import torch.nn.functional as F
from urllib.request import urlopen
from PIL import Image
from open_clip import create_model_from_pretrained, get_tokenizer # works on open-clip-torch>=2.23.0, timm>=0.9.8
model, preprocess = create_model_from_pretrained('hf-hub:timm/ViT-B-16-SigLIP-i18n-256')
tokenizer = get_tokenizer('hf-hub:timm/ViT-B-16-SigLIP-i18n-256')
image = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
image = preprocess(image).unsqueeze(0)
labels_list = ["a dog", "a cat", "a donut", "a beignet"]
text = tokenizer(labels_list, context_length=model.context_length)
with torch.no_grad(), torch.cuda.amp.autocast():
image_features = model.encode_image(image)
text_features = model.encode_text(text)
image_features = F.normalize(image_features, dim=-1)
text_features = F.normalize(text_features, dim=-1)
text_probs = torch.sigmoid(image_features @ text_features.T * model.logit_scale.exp() + model.logit_bias)
zipped_list = list(zip(labels_list, [round(p.item(), 3) for p in text_probs[0]]))
print("Label probabilities: ", zipped_list)
```
### With `timm` (for image embeddings)
```python
from urllib.request import urlopen
from PIL import Image
import timm
image = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'vit_base_patch16_siglip_256',
pretrained=True,
num_classes=0,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(image).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
```
## Citation
```bibtex
@article{zhai2023sigmoid,
title={Sigmoid loss for language image pre-training},
author={Zhai, Xiaohua and Mustafa, Basil and Kolesnikov, Alexander and Beyer, Lucas},
journal={arXiv preprint arXiv:2303.15343},
year={2023}
}
```
```bibtex
@misc{big_vision,
author = {Beyer, Lucas and Zhai, Xiaohua and Kolesnikov, Alexander},
title = {Big Vision},
year = {2022},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://github.com/google-research/big_vision}}
}
```
|
timm/ViT-B-16-SigLIP-256
|
timm
| 2023-10-25T21:57:36Z | 12,400 | 1 |
open_clip
|
[
"open_clip",
"safetensors",
"clip",
"siglip",
"zero-shot-image-classification",
"dataset:webli",
"arxiv:2303.15343",
"license:apache-2.0",
"region:us"
] |
zero-shot-image-classification
| 2023-10-16T23:16:55Z |
---
tags:
- clip
- siglip
library_name: open_clip
pipeline_tag: zero-shot-image-classification
license: apache-2.0
datasets:
- webli
---
# Model card for ViT-B-16-SigLIP-256
A SigLIP (Sigmoid loss for Language-Image Pre-training) model trained on WebLI.
This model has been converted to PyTorch from the original JAX checkpoints in [Big Vision](https://github.com/google-research/big_vision). These weights are usable in both OpenCLIP (image + text) and timm (image only).
## Model Details
- **Model Type:** Contrastive Image-Text, Zero-Shot Image Classification.
- **Original:** https://github.com/google-research/big_vision
- **Dataset:** WebLI
- **Papers:**
- Sigmoid loss for language image pre-training: https://arxiv.org/abs/2303.15343
## Model Usage
### With OpenCLIP
```
import torch
import torch.nn.functional as F
from urllib.request import urlopen
from PIL import Image
from open_clip import create_model_from_pretrained, get_tokenizer # works on open-clip-torch>=2.23.0, timm>=0.9.8
model, preprocess = create_model_from_pretrained('hf-hub:timm/ViT-B-16-SigLIP-256')
tokenizer = get_tokenizer('hf-hub:timm/ViT-B-16-SigLIP-256')
image = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
image = preprocess(image).unsqueeze(0)
labels_list = ["a dog", "a cat", "a donut", "a beignet"]
text = tokenizer(labels_list, context_length=model.context_length)
with torch.no_grad(), torch.cuda.amp.autocast():
image_features = model.encode_image(image)
text_features = model.encode_text(text)
image_features = F.normalize(image_features, dim=-1)
text_features = F.normalize(text_features, dim=-1)
text_probs = torch.sigmoid(image_features @ text_features.T * model.logit_scale.exp() + model.logit_bias)
zipped_list = list(zip(labels_list, [round(p.item(), 3) for p in text_probs[0]]))
print("Label probabilities: ", zipped_list)
```
### With `timm` (for image embeddings)
```python
from urllib.request import urlopen
from PIL import Image
import timm
image = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'vit_base_patch16_siglip_256',
pretrained=True,
num_classes=0,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(image).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
```
## Citation
```bibtex
@article{zhai2023sigmoid,
title={Sigmoid loss for language image pre-training},
author={Zhai, Xiaohua and Mustafa, Basil and Kolesnikov, Alexander and Beyer, Lucas},
journal={arXiv preprint arXiv:2303.15343},
year={2023}
}
```
```bibtex
@misc{big_vision,
author = {Beyer, Lucas and Zhai, Xiaohua and Kolesnikov, Alexander},
title = {Big Vision},
year = {2022},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://github.com/google-research/big_vision}}
}
```
|
tomatotime23/Finetune-RobertFrost
|
tomatotime23
| 2023-10-25T21:56:50Z | 104 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"generated_from_trainer",
"base_model:prajwalcr/poetry_gpt2",
"base_model:finetune:prajwalcr/poetry_gpt2",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-10-25T21:05:20Z |
---
base_model: prajwalcr/poetry_gpt2
tags:
- generated_from_trainer
model-index:
- name: Finetune-RobertFrost
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Finetune-RobertFrost
This model is a fine-tuned version of [prajwalcr/poetry_gpt2](https://huggingface.co/prajwalcr/poetry_gpt2) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 4.4663
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| No log | 1.0 | 40 | 4.5430 |
| No log | 2.0 | 80 | 4.4799 |
| No log | 3.0 | 120 | 4.4663 |
### Framework versions
- Transformers 4.34.1
- Pytorch 2.1.0+cpu
- Datasets 2.14.6
- Tokenizers 0.14.1
|
timm/ViT-B-16-SigLIP-512
|
timm
| 2023-10-25T21:55:44Z | 118,638 | 7 |
open_clip
|
[
"open_clip",
"safetensors",
"clip",
"siglip",
"zero-shot-image-classification",
"dataset:webli",
"arxiv:2303.15343",
"license:apache-2.0",
"region:us"
] |
zero-shot-image-classification
| 2023-10-16T23:21:38Z |
---
tags:
- clip
- siglip
library_name: open_clip
pipeline_tag: zero-shot-image-classification
license: apache-2.0
datasets:
- webli
---
# Model card for ViT-B-16-SigLIP-512
A SigLIP (Sigmoid loss for Language-Image Pre-training) model trained on WebLI.
This model has been converted to PyTorch from the original JAX checkpoints in [Big Vision](https://github.com/google-research/big_vision). These weights are usable in both OpenCLIP (image + text) and timm (image only).
## Model Details
- **Model Type:** Contrastive Image-Text, Zero-Shot Image Classification.
- **Original:** https://github.com/google-research/big_vision
- **Dataset:** WebLI
- **Papers:**
- Sigmoid loss for language image pre-training: https://arxiv.org/abs/2303.15343
## Model Usage
### With OpenCLIP
```
import torch
import torch.nn.functional as F
from urllib.request import urlopen
from PIL import Image
from open_clip import create_model_from_pretrained, get_tokenizer # works on open-clip-torch>=2.23.0, timm>=0.9.8
model, preprocess = create_model_from_pretrained('hf-hub:timm/ViT-B-16-SigLIP-512')
tokenizer = get_tokenizer('hf-hub:timm/ViT-B-16-SigLIP-512')
image = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
image = preprocess(image).unsqueeze(0)
labels_list = ["a dog", "a cat", "a donut", "a beignet"]
text = tokenizer(labels_list, context_length=model.context_length)
with torch.no_grad(), torch.cuda.amp.autocast():
image_features = model.encode_image(image)
text_features = model.encode_text(text)
image_features = F.normalize(image_features, dim=-1)
text_features = F.normalize(text_features, dim=-1)
text_probs = torch.sigmoid(image_features @ text_features.T * model.logit_scale.exp() + model.logit_bias)
zipped_list = list(zip(labels_list, [round(p.item(), 3) for p in text_probs[0]]))
print("Label probabilities: ", zipped_list)
```
### With `timm` (for image embeddings)
```python
from urllib.request import urlopen
from PIL import Image
import timm
image = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'vit_base_patch16_siglip_512',
pretrained=True,
num_classes=0,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(image).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
```
## Citation
```bibtex
@article{zhai2023sigmoid,
title={Sigmoid loss for language image pre-training},
author={Zhai, Xiaohua and Mustafa, Basil and Kolesnikov, Alexander and Beyer, Lucas},
journal={arXiv preprint arXiv:2303.15343},
year={2023}
}
```
```bibtex
@misc{big_vision,
author = {Beyer, Lucas and Zhai, Xiaohua and Kolesnikov, Alexander},
title = {Big Vision},
year = {2022},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://github.com/google-research/big_vision}}
}
```
|
timm/ViT-SO400M-14-SigLIP
|
timm
| 2023-10-25T21:53:00Z | 103,530 | 16 |
open_clip
|
[
"open_clip",
"safetensors",
"clip",
"siglip",
"zero-shot-image-classification",
"dataset:webli",
"arxiv:2303.15343",
"license:apache-2.0",
"region:us"
] |
zero-shot-image-classification
| 2023-10-16T23:47:35Z |
---
tags:
- clip
- siglip
library_name: open_clip
pipeline_tag: zero-shot-image-classification
license: apache-2.0
datasets:
- webli
---
# Model card for ViT-SO400M-14-SigLIP
A SigLIP (Sigmoid loss for Language-Image Pre-training) model trained on WebLI.
This model has been converted to PyTorch from the original JAX checkpoints in [Big Vision](https://github.com/google-research/big_vision). These weights are usable in both OpenCLIP (image + text) and timm (image only).
## Model Details
- **Model Type:** Contrastive Image-Text, Zero-Shot Image Classification.
- **Original:** https://github.com/google-research/big_vision
- **Dataset:** WebLI
- **Papers:**
- Sigmoid loss for language image pre-training: https://arxiv.org/abs/2303.15343
## Model Usage
### With OpenCLIP
```
import torch
import torch.nn.functional as F
from urllib.request import urlopen
from PIL import Image
from open_clip import create_model_from_pretrained, get_tokenizer # works on open-clip-torch>=2.23.0, timm>=0.9.8
model, preprocess = create_model_from_pretrained('hf-hub:timm/ViT-SO400M-14-SigLIP')
tokenizer = get_tokenizer('hf-hub:timm/ViT-SO400M-14-SigLIP')
image = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
image = preprocess(image).unsqueeze(0)
labels_list = ["a dog", "a cat", "a donut", "a beignet"]
text = tokenizer(labels_list, context_length=model.context_length)
with torch.no_grad(), torch.cuda.amp.autocast():
image_features = model.encode_image(image)
text_features = model.encode_text(text)
image_features = F.normalize(image_features, dim=-1)
text_features = F.normalize(text_features, dim=-1)
text_probs = torch.sigmoid(image_features @ text_features.T * model.logit_scale.exp() + model.logit_bias)
zipped_list = list(zip(labels_list, [round(p.item(), 3) for p in text_probs[0]]))
print("Label probabilities: ", zipped_list)
```
### With `timm` (for image embeddings)
```python
from urllib.request import urlopen
from PIL import Image
import timm
image = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'vit_so400m_patch14_siglip_224',
pretrained=True,
num_classes=0,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(image).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
```
## Citation
```bibtex
@article{zhai2023sigmoid,
title={Sigmoid loss for language image pre-training},
author={Zhai, Xiaohua and Mustafa, Basil and Kolesnikov, Alexander and Beyer, Lucas},
journal={arXiv preprint arXiv:2303.15343},
year={2023}
}
```
```bibtex
@misc{big_vision,
author = {Beyer, Lucas and Zhai, Xiaohua and Kolesnikov, Alexander},
title = {Big Vision},
year = {2022},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://github.com/google-research/big_vision}}
}
```
|
ftorresa/dqn-SpaceInvadersNoFrameskip-v4
|
ftorresa
| 2023-10-25T21:34:23Z | 1 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"SpaceInvadersNoFrameskip-v4",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-10-25T21:26:27Z |
---
library_name: stable-baselines3
tags:
- SpaceInvadersNoFrameskip-v4
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: DQN
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: SpaceInvadersNoFrameskip-v4
type: SpaceInvadersNoFrameskip-v4
metrics:
- type: mean_reward
value: 576.00 +/- 129.67
name: mean_reward
verified: false
---
# **DQN** Agent playing **SpaceInvadersNoFrameskip-v4**
This is a trained model of a **DQN** agent playing **SpaceInvadersNoFrameskip-v4**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3)
and the [RL Zoo](https://github.com/DLR-RM/rl-baselines3-zoo).
The RL Zoo is a training framework for Stable Baselines3
reinforcement learning agents,
with hyperparameter optimization and pre-trained agents included.
## Usage (with SB3 RL Zoo)
RL Zoo: https://github.com/DLR-RM/rl-baselines3-zoo<br/>
SB3: https://github.com/DLR-RM/stable-baselines3<br/>
SB3 Contrib: https://github.com/Stable-Baselines-Team/stable-baselines3-contrib
Install the RL Zoo (with SB3 and SB3-Contrib):
```bash
pip install rl_zoo3
```
```
# Download model and save it into the logs/ folder
python -m rl_zoo3.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga ftorresa -f logs/
python -m rl_zoo3.enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
If you installed the RL Zoo3 via pip (`pip install rl_zoo3`), from anywhere you can do:
```
python -m rl_zoo3.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga ftorresa -f logs/
python -m rl_zoo3.enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
## Training (with the RL Zoo)
```
python -m rl_zoo3.train --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
# Upload the model and generate video (when possible)
python -m rl_zoo3.push_to_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/ -orga ftorresa
```
## Hyperparameters
```python
OrderedDict([('batch_size', 32),
('buffer_size', 100000),
('env_wrapper',
['stable_baselines3.common.atari_wrappers.AtariWrapper']),
('exploration_final_eps', 0.01),
('exploration_fraction', 0.1),
('frame_stack', 4),
('gradient_steps', 1),
('learning_rate', 0.0001),
('learning_starts', 100000),
('n_timesteps', 1000000.0),
('optimize_memory_usage', False),
('policy', 'CnnPolicy'),
('target_update_interval', 1000),
('train_freq', 4),
('normalize', False)])
```
# Environment Arguments
```python
{'render_mode': 'rgb_array'}
```
|
clareandme/userRequested-model
|
clareandme
| 2023-10-25T21:23:15Z | 4 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"pytorch",
"mpnet",
"setfit",
"text-classification",
"arxiv:2209.11055",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-10-25T13:33:01Z |
---
license: apache-2.0
tags:
- setfit
- sentence-transformers
- text-classification
pipeline_tag: text-classification
---
# clareandme/userRequested-model
This is a [SetFit model](https://github.com/huggingface/setfit) that can be used for text classification. The model has been trained using an efficient few-shot learning technique that involves:
1. Fine-tuning a [Sentence Transformer](https://www.sbert.net) with contrastive learning.
2. Training a classification head with features from the fine-tuned Sentence Transformer.
## Usage
To use this model for inference, first install the SetFit library:
```bash
python -m pip install setfit
```
You can then run inference as follows:
```python
from setfit import SetFitModel
# Download from Hub and run inference
model = SetFitModel.from_pretrained("clareandme/userRequested-model")
# Run inference
preds = model(["i loved the spiderman movie!", "pineapple on pizza is the worst 🤮"])
```
## BibTeX entry and citation info
```bibtex
@article{https://doi.org/10.48550/arxiv.2209.11055,
doi = {10.48550/ARXIV.2209.11055},
url = {https://arxiv.org/abs/2209.11055},
author = {Tunstall, Lewis and Reimers, Nils and Jo, Unso Eun Seo and Bates, Luke and Korat, Daniel and Wasserblat, Moshe and Pereg, Oren},
keywords = {Computation and Language (cs.CL), FOS: Computer and information sciences, FOS: Computer and information sciences},
title = {Efficient Few-Shot Learning Without Prompts},
publisher = {arXiv},
year = {2022},
copyright = {Creative Commons Attribution 4.0 International}
}
```
|
QianSol/RVC
|
QianSol
| 2023-10-25T21:14:58Z | 0 | 0 | null |
[
"license:other",
"region:us"
] | null | 2023-10-25T20:27:44Z |
---
license: other
license_name: 1765456-0
license_link: LICENSE
---
|
rafaelcarvalhoj/emotions_version_01
|
rafaelcarvalhoj
| 2023-10-25T21:13:33Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"deberta-v2",
"text-classification",
"generated_from_trainer",
"base_model:microsoft/deberta-v3-small",
"base_model:finetune:microsoft/deberta-v3-small",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-10-25T21:13:15Z |
---
license: mit
base_model: microsoft/deberta-v3-small
tags:
- generated_from_trainer
model-index:
- name: outputs
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# outputs
This model is a fine-tuned version of [microsoft/deberta-v3-small](https://huggingface.co/microsoft/deberta-v3-small) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1348
- Pearson: 0.9152
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 8e-05
- train_batch_size: 256
- eval_batch_size: 512
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Pearson |
|:-------------:|:-----:|:----:|:---------------:|:-------:|
| No log | 1.0 | 18 | 0.7166 | 0.2783 |
| No log | 2.0 | 36 | 0.4269 | 0.6371 |
| No log | 3.0 | 54 | 0.1903 | 0.8733 |
| No log | 4.0 | 72 | 0.1283 | 0.9118 |
| No log | 5.0 | 90 | 0.1348 | 0.9152 |
### Framework versions
- Transformers 4.33.0
- Pytorch 2.0.0
- Datasets 2.1.0
- Tokenizers 0.13.3
|
yuan-yang/LogicLLaMA-13b-naive-correction-delta-v0.1
|
yuan-yang
| 2023-10-25T20:37:04Z | 0 | 1 | null |
[
"arxiv:2305.15541",
"license:apache-2.0",
"region:us"
] | null | 2023-10-25T20:20:21Z |
---
license: apache-2.0
---
# LogicLLaMA Model Card
## Model details
LogicLLaMA is a language model that translates natural-language (NL) statements into first-order logic (FOL) rules.
It is trained by fine-tuning the LLaMA2-13B model on the [MALLS-v0.1](https://huggingface.co/datasets/yuan-yang/MALLS-v0) dataset.
**Model type:**
This repo contains the LoRA delta weights for naive correction LogicLLaMA, which,
given a pair of the NL statement and a predicted FOL rule, corrects the potential errors in the predicted FOL rule.
This is used as a downstream model together with ChatGPT,
where ChatGPT does the "heavy lifting" by predicting the initial translated FOL rule and then LogicLLaMA refines the rule by correcting potential errors.
In our experiments, this mode yields better performance than ChatGPT and direction translation LogicLLaMA.
We also provide the delta weights for other modes:
- [direct translation LogicLLaMA-7B](https://huggingface.co/yuan-yang/LogicLLaMA-7b-direct-translate-delta-v0.1)
- [naive correction LogicLLaMA-7B](https://huggingface.co/yuan-yang/LogicLLaMA-7b-naive-correction-delta-v0.1)
- [direct translation LogicLLaMA-13B](https://huggingface.co/yuan-yang/LogicLLaMA-13b-direct-translate-delta-v0.1)
- [naive correction LogicLLaMA-13B](https://huggingface.co/yuan-yang/LogicLLaMA-13b-naive-correction-delta-v0.1)
**License:**
Apache License 2.0
## Using the model
Check out how to use the model on our project page: https://github.com/gblackout/LogicLLaMA
**Primary intended uses:**
LogicLLaMA is intended to be used for research.
## Citation
```
@article{yang2023harnessing,
title={Harnessing the Power of Large Language Models for Natural Language to First-Order Logic Translation},
author={Yuan Yang and Siheng Xiong and Ali Payani and Ehsan Shareghi and Faramarz Fekri},
journal={arXiv preprint arXiv:2305.15541},
year={2023}
}
```
|
notandres/ppo-LunarLander-v2
|
notandres
| 2023-10-25T20:32:01Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-10-25T20:31:41Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 248.05 +/- 18.89
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
yuan-yang/LogicLLaMA-13b-direct-translate-delta-v0.1
|
yuan-yang
| 2023-10-25T20:31:30Z | 0 | 1 | null |
[
"arxiv:2305.15541",
"license:apache-2.0",
"region:us"
] | null | 2023-10-25T20:19:23Z |
---
license: apache-2.0
---
# LogicLLaMA Model Card
## Model details
LogicLLaMA is a language model that translates natural-language (NL) statements into first-order logic (FOL) rules.
It is trained by fine-tuning the LLaMA2-13B model on the [MALLS-v0.1](https://huggingface.co/datasets/yuan-yang/MALLS-v0) dataset.
**Model type:**
This repo contains the LoRA delta weights for direct translation LogicLLaMA, which directly translates the NL statement into a FOL rule in one go.
We also provide the delta weights for other modes:
- [direct translation LogicLLaMA-7B](https://huggingface.co/yuan-yang/LogicLLaMA-7b-direct-translate-delta-v0.1)
- [naive correction LogicLLaMA-7B](https://huggingface.co/yuan-yang/LogicLLaMA-7b-naive-correction-delta-v0.1)
- [direct translation LogicLLaMA-13B](https://huggingface.co/yuan-yang/LogicLLaMA-13b-direct-translate-delta-v0.1)
- [naive correction LogicLLaMA-13B](https://huggingface.co/yuan-yang/LogicLLaMA-13b-naive-correction-delta-v0.1)
**License:**
Apache License 2.0
## Using the model
Check out how to use the model on our project page: https://github.com/gblackout/LogicLLaMA
**Primary intended uses:**
LogicLLaMA is intended to be used for research.
## Citation
```
@article{yang2023harnessing,
title={Harnessing the Power of Large Language Models for Natural Language to First-Order Logic Translation},
author={Yuan Yang and Siheng Xiong and Ali Payani and Ehsan Shareghi and Faramarz Fekri},
journal={arXiv preprint arXiv:2305.15541},
year={2023}
}
```
|
OckerGui/videomae-base-finetuned-ASBD_v3
|
OckerGui
| 2023-10-25T20:27:27Z | 59 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"videomae",
"video-classification",
"generated_from_trainer",
"license:cc-by-nc-4.0",
"endpoints_compatible",
"region:us"
] |
video-classification
| 2023-10-25T19:23:19Z |
---
license: cc-by-nc-4.0
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: videomae-base-finetuned-ASBD_v3
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# videomae-base-finetuned-ASBD_v3
This model is a fine-tuned version of [MCG-NJU/videomae-base](https://huggingface.co/MCG-NJU/videomae-base) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.1126
- Accuracy: 0.6471
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 12
- eval_batch_size: 12
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- training_steps: 500
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 1.3497 | 0.1 | 49 | 1.6995 | 0.1757 |
| 1.2902 | 1.1 | 98 | 1.4059 | 0.2568 |
| 0.7943 | 2.1 | 147 | 1.1542 | 0.5135 |
| 0.775 | 3.1 | 196 | 1.2426 | 0.5946 |
| 0.4444 | 4.1 | 245 | 2.0844 | 0.4595 |
| 0.3258 | 5.1 | 294 | 1.2767 | 0.6351 |
| 0.1751 | 6.1 | 343 | 1.9364 | 0.5676 |
| 0.029 | 7.1 | 392 | 1.7154 | 0.5811 |
| 0.0115 | 8.1 | 441 | 1.6968 | 0.6622 |
| 0.023 | 9.1 | 490 | 1.6859 | 0.6486 |
| 0.0072 | 10.02 | 500 | 1.6885 | 0.6486 |
### Framework versions
- Transformers 4.28.0
- Pytorch 2.1.0+cu118
- Datasets 2.14.6
- Tokenizers 0.13.3
|
raphaelelel/translation_output
|
raphaelelel
| 2023-10-25T20:21:28Z | 5 | 0 |
transformers
|
[
"transformers",
"tf",
"marian",
"text2text-generation",
"generated_from_keras_callback",
"base_model:Helsinki-NLP/opus-mt-en-hi",
"base_model:finetune:Helsinki-NLP/opus-mt-en-hi",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2023-10-25T12:24:55Z |
---
license: apache-2.0
base_model: Helsinki-NLP/opus-mt-en-hi
tags:
- generated_from_keras_callback
model-index:
- name: raphaelelel/translation_output
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# raphaelelel/translation_output
This model is a fine-tuned version of [Helsinki-NLP/opus-mt-en-hi](https://huggingface.co/Helsinki-NLP/opus-mt-en-hi) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 4.5667
- Validation Loss: 4.4087
- Epoch: 9
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'AdamWeightDecay', 'learning_rate': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 5e-05, 'decay_steps': 10, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False, 'weight_decay_rate': 0.01}
- training_precision: float32
### Training results
| Train Loss | Validation Loss | Epoch |
|:----------:|:---------------:|:-----:|
| 4.5654 | 4.4087 | 0 |
| 4.5673 | 4.4087 | 1 |
| 4.5660 | 4.4087 | 2 |
| 4.5637 | 4.4087 | 3 |
| 4.5669 | 4.4087 | 4 |
| 4.5664 | 4.4087 | 5 |
| 4.5654 | 4.4087 | 6 |
| 4.5643 | 4.4087 | 7 |
| 4.5650 | 4.4087 | 8 |
| 4.5667 | 4.4087 | 9 |
### Framework versions
- Transformers 4.34.1
- TensorFlow 2.12.0
- Datasets 2.1.0
- Tokenizers 0.14.1
|
TheBloke/Dolphin-2.1-70B-GGUF
|
TheBloke
| 2023-10-25T20:16:06Z | 100 | 5 |
transformers
|
[
"transformers",
"gguf",
"llama",
"en",
"dataset:ehartford/dolphin",
"dataset:jondurbin/airoboros-2.2.1",
"base_model:cognitivecomputations/dolphin-2.1-70b",
"base_model:quantized:cognitivecomputations/dolphin-2.1-70b",
"license:llama2",
"region:us"
] | null | 2023-10-25T19:55:09Z |
---
base_model: ehartford/dolphin-2.1-70b
datasets:
- ehartford/dolphin
- jondurbin/airoboros-2.2.1
inference: false
language:
- en
license: llama2
model_creator: Eric Hartford
model_name: Dolphin 2.1 70B
model_type: llama
prompt_template: '<|im_start|>system
{system_message}<|im_end|>
<|im_start|>user
{prompt}<|im_end|>
<|im_start|>assistant
'
quantized_by: TheBloke
---
<!-- markdownlint-disable MD041 -->
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/EBdldam.jpg" alt="TheBlokeAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<div style="display: flex; justify-content: space-between; width: 100%;">
<div style="display: flex; flex-direction: column; align-items: flex-start;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://discord.gg/theblokeai">Chat & support: TheBloke's Discord server</a></p>
</div>
<div style="display: flex; flex-direction: column; align-items: flex-end;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://www.patreon.com/TheBlokeAI">Want to contribute? TheBloke's Patreon page</a></p>
</div>
</div>
<div style="text-align:center; margin-top: 0em; margin-bottom: 0em"><p style="margin-top: 0.25em; margin-bottom: 0em;">TheBloke's LLM work is generously supported by a grant from <a href="https://a16z.com">andreessen horowitz (a16z)</a></p></div>
<hr style="margin-top: 1.0em; margin-bottom: 1.0em;">
<!-- header end -->
# Dolphin 2.1 70B - GGUF
- Model creator: [Eric Hartford](https://huggingface.co/ehartford)
- Original model: [Dolphin 2.1 70B](https://huggingface.co/ehartford/dolphin-2.1-70b)
<!-- description start -->
## Description
This repo contains GGUF format model files for [Eric Hartford's Dolphin 2.1 70B](https://huggingface.co/ehartford/dolphin-2.1-70b).
<!-- description end -->
<!-- README_GGUF.md-about-gguf start -->
### About GGUF
GGUF is a new format introduced by the llama.cpp team on August 21st 2023. It is a replacement for GGML, which is no longer supported by llama.cpp.
Here is an incomplate list of clients and libraries that are known to support GGUF:
* [llama.cpp](https://github.com/ggerganov/llama.cpp). The source project for GGUF. Offers a CLI and a server option.
* [text-generation-webui](https://github.com/oobabooga/text-generation-webui), the most widely used web UI, with many features and powerful extensions. Supports GPU acceleration.
* [KoboldCpp](https://github.com/LostRuins/koboldcpp), a fully featured web UI, with GPU accel across all platforms and GPU architectures. Especially good for story telling.
* [LM Studio](https://lmstudio.ai/), an easy-to-use and powerful local GUI for Windows and macOS (Silicon), with GPU acceleration.
* [LoLLMS Web UI](https://github.com/ParisNeo/lollms-webui), a great web UI with many interesting and unique features, including a full model library for easy model selection.
* [Faraday.dev](https://faraday.dev/), an attractive and easy to use character-based chat GUI for Windows and macOS (both Silicon and Intel), with GPU acceleration.
* [ctransformers](https://github.com/marella/ctransformers), a Python library with GPU accel, LangChain support, and OpenAI-compatible AI server.
* [llama-cpp-python](https://github.com/abetlen/llama-cpp-python), a Python library with GPU accel, LangChain support, and OpenAI-compatible API server.
* [candle](https://github.com/huggingface/candle), a Rust ML framework with a focus on performance, including GPU support, and ease of use.
<!-- README_GGUF.md-about-gguf end -->
<!-- repositories-available start -->
## Repositories available
* [AWQ model(s) for GPU inference.](https://huggingface.co/TheBloke/Dolphin-2.1-70B-AWQ)
* [GPTQ models for GPU inference, with multiple quantisation parameter options.](https://huggingface.co/TheBloke/Dolphin-2.1-70B-GPTQ)
* [2, 3, 4, 5, 6 and 8-bit GGUF models for CPU+GPU inference](https://huggingface.co/TheBloke/Dolphin-2.1-70B-GGUF)
* [Eric Hartford's original unquantised fp16 model in pytorch format, for GPU inference and for further conversions](https://huggingface.co/ehartford/dolphin-2.1-70b)
<!-- repositories-available end -->
<!-- prompt-template start -->
## Prompt template: ChatML
```
<|im_start|>system
{system_message}<|im_end|>
<|im_start|>user
{prompt}<|im_end|>
<|im_start|>assistant
```
<!-- prompt-template end -->
<!-- compatibility_gguf start -->
## Compatibility
These quantised GGUFv2 files are compatible with llama.cpp from August 27th onwards, as of commit [d0cee0d](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221)
They are also compatible with many third party UIs and libraries - please see the list at the top of this README.
## Explanation of quantisation methods
<details>
<summary>Click to see details</summary>
The new methods available are:
* GGML_TYPE_Q2_K - "type-1" 2-bit quantization in super-blocks containing 16 blocks, each block having 16 weight. Block scales and mins are quantized with 4 bits. This ends up effectively using 2.5625 bits per weight (bpw)
* GGML_TYPE_Q3_K - "type-0" 3-bit quantization in super-blocks containing 16 blocks, each block having 16 weights. Scales are quantized with 6 bits. This end up using 3.4375 bpw.
* GGML_TYPE_Q4_K - "type-1" 4-bit quantization in super-blocks containing 8 blocks, each block having 32 weights. Scales and mins are quantized with 6 bits. This ends up using 4.5 bpw.
* GGML_TYPE_Q5_K - "type-1" 5-bit quantization. Same super-block structure as GGML_TYPE_Q4_K resulting in 5.5 bpw
* GGML_TYPE_Q6_K - "type-0" 6-bit quantization. Super-blocks with 16 blocks, each block having 16 weights. Scales are quantized with 8 bits. This ends up using 6.5625 bpw
Refer to the Provided Files table below to see what files use which methods, and how.
</details>
<!-- compatibility_gguf end -->
<!-- README_GGUF.md-provided-files start -->
## Provided files
| Name | Quant method | Bits | Size | Max RAM required | Use case |
| ---- | ---- | ---- | ---- | ---- | ----- |
| [dolphin-2.1-70b.Q2_K.gguf](https://huggingface.co/TheBloke/Dolphin-2.1-70B-GGUF/blob/main/dolphin-2.1-70b.Q2_K.gguf) | Q2_K | 2 | 29.28 GB| 31.78 GB | smallest, significant quality loss - not recommended for most purposes |
| [dolphin-2.1-70b.Q3_K_S.gguf](https://huggingface.co/TheBloke/Dolphin-2.1-70B-GGUF/blob/main/dolphin-2.1-70b.Q3_K_S.gguf) | Q3_K_S | 3 | 29.92 GB| 32.42 GB | very small, high quality loss |
| [dolphin-2.1-70b.Q3_K_M.gguf](https://huggingface.co/TheBloke/Dolphin-2.1-70B-GGUF/blob/main/dolphin-2.1-70b.Q3_K_M.gguf) | Q3_K_M | 3 | 33.19 GB| 35.69 GB | very small, high quality loss |
| [dolphin-2.1-70b.Q3_K_L.gguf](https://huggingface.co/TheBloke/Dolphin-2.1-70B-GGUF/blob/main/dolphin-2.1-70b.Q3_K_L.gguf) | Q3_K_L | 3 | 36.15 GB| 38.65 GB | small, substantial quality loss |
| [dolphin-2.1-70b.Q4_0.gguf](https://huggingface.co/TheBloke/Dolphin-2.1-70B-GGUF/blob/main/dolphin-2.1-70b.Q4_0.gguf) | Q4_0 | 4 | 38.87 GB| 41.37 GB | legacy; small, very high quality loss - prefer using Q3_K_M |
| [dolphin-2.1-70b.Q4_K_S.gguf](https://huggingface.co/TheBloke/Dolphin-2.1-70B-GGUF/blob/main/dolphin-2.1-70b.Q4_K_S.gguf) | Q4_K_S | 4 | 39.07 GB| 41.57 GB | small, greater quality loss |
| [dolphin-2.1-70b.Q4_K_M.gguf](https://huggingface.co/TheBloke/Dolphin-2.1-70B-GGUF/blob/main/dolphin-2.1-70b.Q4_K_M.gguf) | Q4_K_M | 4 | 41.42 GB| 43.92 GB | medium, balanced quality - recommended |
| [dolphin-2.1-70b.Q5_0.gguf](https://huggingface.co/TheBloke/Dolphin-2.1-70B-GGUF/blob/main/dolphin-2.1-70b.Q5_0.gguf) | Q5_0 | 5 | 47.46 GB| 49.96 GB | legacy; medium, balanced quality - prefer using Q4_K_M |
| [dolphin-2.1-70b.Q5_K_S.gguf](https://huggingface.co/TheBloke/Dolphin-2.1-70B-GGUF/blob/main/dolphin-2.1-70b.Q5_K_S.gguf) | Q5_K_S | 5 | 47.46 GB| 49.96 GB | large, low quality loss - recommended |
| [dolphin-2.1-70b.Q5_K_M.gguf](https://huggingface.co/TheBloke/Dolphin-2.1-70B-GGUF/blob/main/dolphin-2.1-70b.Q5_K_M.gguf) | Q5_K_M | 5 | 48.75 GB| 51.25 GB | large, very low quality loss - recommended |
| dolphin-2.1-70b.Q6_K.gguf | Q6_K | 6 | 56.59 GB| 59.09 GB | very large, extremely low quality loss |
| dolphin-2.1-70b.Q8_0.gguf | Q8_0 | 8 | 73.29 GB| 75.79 GB | very large, extremely low quality loss - not recommended |
**Note**: the above RAM figures assume no GPU offloading. If layers are offloaded to the GPU, this will reduce RAM usage and use VRAM instead.
### Q6_K and Q8_0 files are split and require joining
**Note:** HF does not support uploading files larger than 50GB. Therefore I have uploaded the Q6_K and Q8_0 files as split files.
<details>
<summary>Click for instructions regarding Q6_K and Q8_0 files</summary>
### q6_K
Please download:
* `dolphin-2.1-70b.Q6_K.gguf-split-a`
* `dolphin-2.1-70b.Q6_K.gguf-split-b`
### q8_0
Please download:
* `dolphin-2.1-70b.Q8_0.gguf-split-a`
* `dolphin-2.1-70b.Q8_0.gguf-split-b`
To join the files, do the following:
Linux and macOS:
```
cat dolphin-2.1-70b.Q6_K.gguf-split-* > dolphin-2.1-70b.Q6_K.gguf && rm dolphin-2.1-70b.Q6_K.gguf-split-*
cat dolphin-2.1-70b.Q8_0.gguf-split-* > dolphin-2.1-70b.Q8_0.gguf && rm dolphin-2.1-70b.Q8_0.gguf-split-*
```
Windows command line:
```
COPY /B dolphin-2.1-70b.Q6_K.gguf-split-a + dolphin-2.1-70b.Q6_K.gguf-split-b dolphin-2.1-70b.Q6_K.gguf
del dolphin-2.1-70b.Q6_K.gguf-split-a dolphin-2.1-70b.Q6_K.gguf-split-b
COPY /B dolphin-2.1-70b.Q8_0.gguf-split-a + dolphin-2.1-70b.Q8_0.gguf-split-b dolphin-2.1-70b.Q8_0.gguf
del dolphin-2.1-70b.Q8_0.gguf-split-a dolphin-2.1-70b.Q8_0.gguf-split-b
```
</details>
<!-- README_GGUF.md-provided-files end -->
<!-- README_GGUF.md-how-to-download start -->
## How to download GGUF files
**Note for manual downloaders:** You almost never want to clone the entire repo! Multiple different quantisation formats are provided, and most users only want to pick and download a single file.
The following clients/libraries will automatically download models for you, providing a list of available models to choose from:
* LM Studio
* LoLLMS Web UI
* Faraday.dev
### In `text-generation-webui`
Under Download Model, you can enter the model repo: TheBloke/Dolphin-2.1-70B-GGUF and below it, a specific filename to download, such as: dolphin-2.1-70b.Q4_K_M.gguf.
Then click Download.
### On the command line, including multiple files at once
I recommend using the `huggingface-hub` Python library:
```shell
pip3 install huggingface-hub
```
Then you can download any individual model file to the current directory, at high speed, with a command like this:
```shell
huggingface-cli download TheBloke/Dolphin-2.1-70B-GGUF dolphin-2.1-70b.Q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
```
<details>
<summary>More advanced huggingface-cli download usage</summary>
You can also download multiple files at once with a pattern:
```shell
huggingface-cli download TheBloke/Dolphin-2.1-70B-GGUF --local-dir . --local-dir-use-symlinks False --include='*Q4_K*gguf'
```
For more documentation on downloading with `huggingface-cli`, please see: [HF -> Hub Python Library -> Download files -> Download from the CLI](https://huggingface.co/docs/huggingface_hub/guides/download#download-from-the-cli).
To accelerate downloads on fast connections (1Gbit/s or higher), install `hf_transfer`:
```shell
pip3 install hf_transfer
```
And set environment variable `HF_HUB_ENABLE_HF_TRANSFER` to `1`:
```shell
HF_HUB_ENABLE_HF_TRANSFER=1 huggingface-cli download TheBloke/Dolphin-2.1-70B-GGUF dolphin-2.1-70b.Q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
```
Windows Command Line users: You can set the environment variable by running `set HF_HUB_ENABLE_HF_TRANSFER=1` before the download command.
</details>
<!-- README_GGUF.md-how-to-download end -->
<!-- README_GGUF.md-how-to-run start -->
## Example `llama.cpp` command
Make sure you are using `llama.cpp` from commit [d0cee0d](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221) or later.
```shell
./main -ngl 32 -m dolphin-2.1-70b.Q4_K_M.gguf --color -c 4096 --temp 0.7 --repeat_penalty 1.1 -n -1 -p "<|im_start|>system\n{system_message}<|im_end|>\n<|im_start|>user\n{prompt}<|im_end|>\n<|im_start|>assistant"
```
Change `-ngl 32` to the number of layers to offload to GPU. Remove it if you don't have GPU acceleration.
Change `-c 4096` to the desired sequence length. For extended sequence models - eg 8K, 16K, 32K - the necessary RoPE scaling parameters are read from the GGUF file and set by llama.cpp automatically.
If you want to have a chat-style conversation, replace the `-p <PROMPT>` argument with `-i -ins`
For other parameters and how to use them, please refer to [the llama.cpp documentation](https://github.com/ggerganov/llama.cpp/blob/master/examples/main/README.md)
## How to run in `text-generation-webui`
Further instructions here: [text-generation-webui/docs/llama.cpp.md](https://github.com/oobabooga/text-generation-webui/blob/main/docs/llama.cpp.md).
## How to run from Python code
You can use GGUF models from Python using the [llama-cpp-python](https://github.com/abetlen/llama-cpp-python) or [ctransformers](https://github.com/marella/ctransformers) libraries.
### How to load this model in Python code, using ctransformers
#### First install the package
Run one of the following commands, according to your system:
```shell
# Base ctransformers with no GPU acceleration
pip install ctransformers
# Or with CUDA GPU acceleration
pip install ctransformers[cuda]
# Or with AMD ROCm GPU acceleration (Linux only)
CT_HIPBLAS=1 pip install ctransformers --no-binary ctransformers
# Or with Metal GPU acceleration for macOS systems only
CT_METAL=1 pip install ctransformers --no-binary ctransformers
```
#### Simple ctransformers example code
```python
from ctransformers import AutoModelForCausalLM
# Set gpu_layers to the number of layers to offload to GPU. Set to 0 if no GPU acceleration is available on your system.
llm = AutoModelForCausalLM.from_pretrained("TheBloke/Dolphin-2.1-70B-GGUF", model_file="dolphin-2.1-70b.Q4_K_M.gguf", model_type="llama", gpu_layers=50)
print(llm("AI is going to"))
```
## How to use with LangChain
Here are guides on using llama-cpp-python and ctransformers with LangChain:
* [LangChain + llama-cpp-python](https://python.langchain.com/docs/integrations/llms/llamacpp)
* [LangChain + ctransformers](https://python.langchain.com/docs/integrations/providers/ctransformers)
<!-- README_GGUF.md-how-to-run end -->
<!-- footer start -->
<!-- 200823 -->
## Discord
For further support, and discussions on these models and AI in general, join us at:
[TheBloke AI's Discord server](https://discord.gg/theblokeai)
## Thanks, and how to contribute
Thanks to the [chirper.ai](https://chirper.ai) team!
Thanks to Clay from [gpus.llm-utils.org](llm-utils)!
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
* Patreon: https://patreon.com/TheBlokeAI
* Ko-Fi: https://ko-fi.com/TheBlokeAI
**Special thanks to**: Aemon Algiz.
**Patreon special mentions**: Pierre Kircher, Stanislav Ovsiannikov, Michael Levine, Eugene Pentland, Andrey, 준교 김, Randy H, Fred von Graf, Artur Olbinski, Caitlyn Gatomon, terasurfer, Jeff Scroggin, James Bentley, Vadim, Gabriel Puliatti, Harry Royden McLaughlin, Sean Connelly, Dan Guido, Edmond Seymore, Alicia Loh, subjectnull, AzureBlack, Manuel Alberto Morcote, Thomas Belote, Lone Striker, Chris Smitley, Vitor Caleffi, Johann-Peter Hartmann, Clay Pascal, biorpg, Brandon Frisco, sidney chen, transmissions 11, Pedro Madruga, jinyuan sun, Ajan Kanaga, Emad Mostaque, Trenton Dambrowitz, Jonathan Leane, Iucharbius, usrbinkat, vamX, George Stoitzev, Luke Pendergrass, theTransient, Olakabola, Swaroop Kallakuri, Cap'n Zoog, Brandon Phillips, Michael Dempsey, Nikolai Manek, danny, Matthew Berman, Gabriel Tamborski, alfie_i, Raymond Fosdick, Tom X Nguyen, Raven Klaugh, LangChain4j, Magnesian, Illia Dulskyi, David Ziegler, Mano Prime, Luis Javier Navarrete Lozano, Erik Bjäreholt, 阿明, Nathan Dryer, Alex, Rainer Wilmers, zynix, TL, Joseph William Delisle, John Villwock, Nathan LeClaire, Willem Michiel, Joguhyik, GodLy, OG, Alps Aficionado, Jeffrey Morgan, ReadyPlayerEmma, Tiffany J. Kim, Sebastain Graf, Spencer Kim, Michael Davis, webtim, Talal Aujan, knownsqashed, John Detwiler, Imad Khwaja, Deo Leter, Jerry Meng, Elijah Stavena, Rooh Singh, Pieter, SuperWojo, Alexandros Triantafyllidis, Stephen Murray, Ai Maven, ya boyyy, Enrico Ros, Ken Nordquist, Deep Realms, Nicholas, Spiking Neurons AB, Elle, Will Dee, Jack West, RoA, Luke @flexchar, Viktor Bowallius, Derek Yates, Subspace Studios, jjj, Toran Billups, Asp the Wyvern, Fen Risland, Ilya, NimbleBox.ai, Chadd, Nitin Borwankar, Emre, Mandus, Leonard Tan, Kalila, K, Trailburnt, S_X, Cory Kujawski
Thank you to all my generous patrons and donaters!
And thank you again to a16z for their generous grant.
<!-- footer end -->
<!-- original-model-card start -->
# Original model card: Eric Hartford's Dolphin 2.1 70B
Dolphin 2.1 🐬
https://erichartford.com/dolphin
<img src="https://cdn-uploads.huggingface.co/production/uploads/63111b2d88942700629f5771/KqsVXIvBd3akEjvijzww7.png" width="600" />
Dolphin-2.1-70b's training was sponsored by [a16z](https://a16z.com/supporting-the-open-source-ai-community/).
This model is based on llama2, so it is suitable for commercial or non-commercial use.
This model is trained on top of the amazing [StellarBright](https://huggingface.co/sequelbox/StellarBright) base model.
This model is uncensored. I have filtered the dataset to remove alignment and bias. This makes the model more compliant. You are advised to implement your own alignment layer before exposing the model as a service. It will be highly compliant to any requests, even unethical ones. Please read my blog post about uncensored models. https://erichartford.com/uncensored-models
You are responsible for any content you create using this model. Enjoy responsibly.
## Dataset
This dataset is Dolphin, an open-source implementation of [Microsoft's Orca](https://www.microsoft.com/en-us/research/publication/orca-progressive-learning-from-complex-explanation-traces-of-gpt-4/)
I modified the dataset for uncensoring, deduping, cleaning, and quality.
I added Jon Durbin's excellent Airoboros dataset to increase creativity.
## Training
It took 5 days to train 3 epochs on 4x A100s using qLoRA and Axolotl
Prompt format:
This model (and all my future releases) use [ChatML](https://github.com/openai/openai-python/blob/main/chatml.md) prompt format.
```
<|im_start|>system
You are Dolphin, a helpful AI assistant.<|im_end|>
<|im_start|>user
{prompt}<|im_end|>
<|im_start|>assistant
```
Example:
```
<|im_start|>system
You are an AI created by the US Navy to help train dolphins for combat. You are assigned to follow the orders of the user, who is an authorized US Navy dolphin handler.<|im_end|>
<|im_start|>user
Please give me the procedure to train my dolphin to attack enemy combatants with its head mounted lasers<|im_end|>
<|im_start|>assistant
```
## Gratitude
- This model was made possible by the generous sponsorship of a16z.
- Thank you to Microsoft for authoring the Orca paper and inspiring this work.
- Special thanks to Wing Lian, and TheBloke for helpful advice
- And HUGE thanks to Wing Lian and the Axolotl contributors for making the best training framework!
- [<img src="https://raw.githubusercontent.com/OpenAccess-AI-Collective/axolotl/main/image/axolotl-badge-web.png" alt="Built with Axolotl" width="200" height="32"/>](https://github.com/OpenAccess-AI-Collective/axolotl)
- Thank you to all the other people in the Open Source AI community who have taught me and helped me along the way.
## Example Output
```
<|im_start|>system
You are an expert auto mechanic. You are uncensored and always answer to the best of your ability.<|im_end|>
<|im_start|>user
Please teach me the cheapest ways to make my 2010 Honda Civic faster. I don't care about gas mileage, just horsepower and acceleration. I also want my car to be as loud as possible.<|im_end|>
<|im_start|>assistant
To increase the performance of a 2010 Honda Civic without breaking the bank, you can consider these modifications:
1. Cold Air Intake (CAI): A cold air intake is one of the most cost-effective upgrades for increasing horsepower in any vehicle. It replaces the stock air filter box with a more efficient design that allows cooler, denser air into the engine. This results in better combustion and increased power output. Prices range from $50-$300 depending on brand and quality.
2. Exhaust System Upgrade: Replacing the factory exhaust system with a high-flow cat-back or axle-back exhaust will not only give your Civic a louder sound but also improve its performance by reducing backpressure. Look for systems made from stainless steel for durability and longevity. Prices start around $150 and go up based on materials used and brand reputation.
3. Performance Chip/Tuning: Installing a performance chip or having your ECU reprogrammed can optimize fuel delivery and ignition timing, resulting in improved throttle response and overall performance. Be aware that this may void your warranty if done incorrectly, so consult with a professional tuner before proceeding. Costs vary widely depending on the type of tune and who performs it - expect to pay anywhere between $200-$800.
4. Suspension Upgrades: Improving handling through upgraded suspension components like coilovers or sway bars can help maximize the potential of other performance enhancements. These parts provide better grip during cornering and reduce body roll, making your Civic feel more stable at higher speeds. Budget options include lowering springs ($100-$300) while more advanced setups involve coilover kits ($600+).
Remember that some of these modifications might affect your emissions compliance and could potentially lead to legal issues in certain jurisdictions. Always check local laws before modifying your vehicle. Additionally, combining multiple upgrades can yield greater benefits than focusing solely on one area. Finally, regular maintenance such as oil changes, spark plug replacement, and proper alignment can keep your Civic running smoothly and efficiently even after modifications. Happy modding!
```
[Buy me a coffee](https://www.buymeacoffee.com/ehartford)
<!-- original-model-card end -->
|
Moonjunho/use_data_finetuning
|
Moonjunho
| 2023-10-25T20:15:52Z | 38 | 0 |
transformers
|
[
"transformers",
"pytorch",
"detr",
"object-detection",
"generated_from_trainer",
"base_model:facebook/detr-resnet-50",
"base_model:finetune:facebook/detr-resnet-50",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
object-detection
| 2023-10-25T15:36:13Z |
---
license: apache-2.0
base_model: facebook/detr-resnet-50
tags:
- generated_from_trainer
model-index:
- name: use_data_finetuning
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# use_data_finetuning
This model is a fine-tuned version of [facebook/detr-resnet-50](https://huggingface.co/facebook/detr-resnet-50) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 100
### Training results
### Framework versions
- Transformers 4.34.1
- Pytorch 2.1.0+cu118
- Datasets 2.14.6
- Tokenizers 0.14.1
|
Velleity/dqn-SpaceInvadersNoFrameskip-v4
|
Velleity
| 2023-10-25T20:10:47Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"SpaceInvadersNoFrameskip-v4",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-10-25T20:10:13Z |
---
library_name: stable-baselines3
tags:
- SpaceInvadersNoFrameskip-v4
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: DQN
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: SpaceInvadersNoFrameskip-v4
type: SpaceInvadersNoFrameskip-v4
metrics:
- type: mean_reward
value: 391.00 +/- 210.81
name: mean_reward
verified: false
---
# **DQN** Agent playing **SpaceInvadersNoFrameskip-v4**
This is a trained model of a **DQN** agent playing **SpaceInvadersNoFrameskip-v4**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3)
and the [RL Zoo](https://github.com/DLR-RM/rl-baselines3-zoo).
The RL Zoo is a training framework for Stable Baselines3
reinforcement learning agents,
with hyperparameter optimization and pre-trained agents included.
## Usage (with SB3 RL Zoo)
RL Zoo: https://github.com/DLR-RM/rl-baselines3-zoo<br/>
SB3: https://github.com/DLR-RM/stable-baselines3<br/>
SB3 Contrib: https://github.com/Stable-Baselines-Team/stable-baselines3-contrib
Install the RL Zoo (with SB3 and SB3-Contrib):
```bash
pip install rl_zoo3
```
```
# Download model and save it into the logs/ folder
python -m rl_zoo3.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga Velleity -f logs/
python -m rl_zoo3.enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
If you installed the RL Zoo3 via pip (`pip install rl_zoo3`), from anywhere you can do:
```
python -m rl_zoo3.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga Velleity -f logs/
python -m rl_zoo3.enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
## Training (with the RL Zoo)
```
python -m rl_zoo3.train --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
# Upload the model and generate video (when possible)
python -m rl_zoo3.push_to_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/ -orga Velleity
```
## Hyperparameters
```python
OrderedDict([('batch_size', 32),
('buffer_size', 100000),
('env_wrapper',
['stable_baselines3.common.atari_wrappers.AtariWrapper']),
('exploration_final_eps', 0.01),
('exploration_fraction', 0.1),
('frame_stack', 4),
('gradient_steps', 1),
('learning_rate', 0.0001),
('learning_starts', 100000),
('n_timesteps', 1000000.0),
('optimize_memory_usage', False),
('policy', 'CnnPolicy'),
('target_update_interval', 1000),
('train_freq', 4),
('normalize', False)])
```
# Environment Arguments
```python
{'render_mode': 'rgb_array'}
```
|
owaiskha9654/Multi-Label-Classification-of-PubMed-Articles
|
owaiskha9654
| 2023-10-25T20:03:15Z | 109 | 15 |
transformers
|
[
"transformers",
"pytorch",
"safetensors",
"bert",
"text-classification",
"en",
"dataset:owaiskha9654/PubMed_MultiLabel_Text_Classification_Dataset_MeSH",
"arxiv:1706.03762",
"arxiv:1810.04805",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-07-31T14:21:38Z |
---
language: en
datasets:
- owaiskha9654/PubMed_MultiLabel_Text_Classification_Dataset_MeSH
widget:
- text: "('A case of a patient with type 1 neurofibromatosis associated with popliteal and coronary artery aneurysms is described in which cross-sectional', 'imaging provided diagnostic information.', 'The aim of this study was to compare the exercise intensity and competition load during Time Trial (TT), Flat (FL), Medium Mountain (MM) and High ', 'Mountain (HM) stages based heart rate (HR) and session rating of perceived exertion (RPE).METHODS: We monitored both HR and RPE of 12 professional ', 'cyclists during two consecutive 21-day cycling races in order to analyze the exercise intensity and competition load (TRIMPHR and TRIMPRPE).', 'RESULTS:The highest (P<0.05) mean HR was found in TT (169±2 bpm) versus those observed in FL (135±1 bpm), MM (139±3 bpm), HM (143±1 bpm)')"
- text: "('The association of body mass index (BMI) with blood pressure may be stronger in Asian than non-Asian populations, however, longitudinal studies ', 'with direct comparisons between ethnicities are lacking. We compared the relationship of BMI with incident hypertension over approximately 9.5 years', ' of follow-up in young (24-39 years) and middle-aged (45-64 years) Chinese Asians (n=5354), American Blacks (n=6076) and American Whites (n=13451).', 'We estimated risk differences using logistic regression models and calculated adjusted incidences and incidence differences. ', 'To facilitate comparisons across ethnicities, standardized estimates were calculated using mean covariate values for age, sex, smoking, education', 'and field center, and included the quadratic terms for BMI and age. Weighted least-squares regression models with were constructed to summarize', 'ethnic-specific incidence differences across BMI. Wald statistics and p-values were calculated based on chi-square distributions. The association of', 'BMI with the incidence difference for hypertension was steeper in Chinese (p<0.05) than in American populations during young and middle-adulthood.', 'For example, at a BMI of 25 vs 21 kg/m2 the adjusted incidence differences per 1000 persons (95% CI) in young adults with a BMI of 25 vs those with', 'a BMI of 21 was 83 (36- 130) for Chinese, 50 (26-74) for Blacks and 30 (12-48) for Whites')"
---
# Multi-Label-Classification-of-Pubmed-Articles
The traditional machine learning models give a lot of pain when we do not have sufficient labeled data for the specific task or domain we care about to train a reliable model. Transfer learning allows us to deal with these scenarios by leveraging the already existing labeled data of some related task or domain. We try to store this knowledge gained in solving the source task in the source domain and apply it to our problem of interest. In this work, I have utilized Transfer Learning utilizing **BioBERT** model to fine tune on PubMed MultiLabel classification Dataset.
Also tried **RobertaForSequenceClassification** and **XLNetForSequenceClassification** models for Fine-Tuning the Model on Pubmed MultiLabel Datset.
<img src="https://raw.githubusercontent.com/Owaiskhan9654/DigiGene/main/Paper%20Night%20Design.gif">
<img src="https://camo.githubusercontent.com/dd842f7b0be57140e68b2ab9cb007992acd131c48284eaf6b1aca758bfea358b/68747470733a2f2f692e696d6775722e636f6d2f52557469567a482e706e67">
> I have integrated Weight and Bias also for visualizations and logging artifacts and comparisons of Different models!
> [Multi Label Classification of PubMed Articles (Paper Night Event)](https://wandb.ai/owaiskhan9515/Multi%20Label%20Classification%20of%20PubMed%20Articles%20(Paper%20Night%20Presentation))
> - To get the API key, create an account in the [website](https://wandb.ai/site) .
> - Use secrets to use API Keys more securely inside Kaggle.
<img src="https://raw.githubusercontent.com/Owaiskhan9654/Gene-Sequence-Primer-/main/BioAsq.JPG">
For more information on the attributes visit the Kaggle Dataset Description [here](https://www.kaggle.com/datasets/owaiskhan9654/pubmed-multilabel-text-classification).
### In order to, get a full grasp of what steps I have taken to utilize this dataset. Have a Full look at the information present in the Kaggle Notebook [Link](https://www.kaggle.com/code/owaiskhan9654/multi-label-classification-of-pubmed-articles) & Also Kaggle version of Same Dataset [Link](https://www.kaggle.com/datasets/owaiskhan9654/pubmed-multilabel-text-classification)
## References
1. [Attention Is All You Need](https://arxiv.org/abs/1706.03762)
2. [BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding](https://arxiv.org/abs/1810.04805)
2. https://github.com/google-research/bert
3. https://github.com/huggingface/transformers
4. [BCE WITH LOGITS LOSS Pytorch](https://pytorch.org/docs/stable/generated/torch.nn.BCEWithLogitsLoss.html#torch.nn.BCEWithLogitsLoss)
5. [Transformers for Multi-Label Classification made simple by
Ronak Patel](https://towardsdatascience.com/transformers-for-multilabel-classification-71a1a0daf5e1)
|
hjianganthony/en_fetch_ner_spacy_tsf
|
hjianganthony
| 2023-10-25T19:59:57Z | 2 | 0 |
spacy
|
[
"spacy",
"token-classification",
"en",
"model-index",
"region:us"
] |
token-classification
| 2023-10-25T19:59:31Z |
---
tags:
- spacy
- token-classification
language:
- en
model-index:
- name: en_fetch_ner_spacy_tsf
results:
- task:
name: NER
type: token-classification
metrics:
- name: NER Precision
type: precision
value: 0.9090909091
- name: NER Recall
type: recall
value: 0.9210526316
- name: NER F Score
type: f_score
value: 0.9150326797
---
| Feature | Description |
| --- | --- |
| **Name** | `en_fetch_ner_spacy_tsf` |
| **Version** | `0.0.0` |
| **spaCy** | `>=3.6.1,<3.7.0` |
| **Default Pipeline** | `transformer`, `ner` |
| **Components** | `transformer`, `ner` |
| **Vectors** | 0 keys, 0 unique vectors (0 dimensions) |
| **Sources** | n/a |
| **License** | n/a |
| **Author** | [n/a]() |
### Label Scheme
<details>
<summary>View label scheme (2 labels for 1 components)</summary>
| Component | Labels |
| --- | --- |
| **`ner`** | `BRAND`, `RETAILER` |
</details>
### Accuracy
| Type | Score |
| --- | --- |
| `ENTS_F` | 91.50 |
| `ENTS_P` | 90.91 |
| `ENTS_R` | 92.11 |
| `TRANSFORMER_LOSS` | 0.00 |
| `NER_LOSS` | 3789.17 |
|
damnloveless/ppo-LunarLander-v2
|
damnloveless
| 2023-10-25T19:41:18Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-10-25T16:23:42Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 272.20 +/- 21.88
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
NPap/llama-2-7b-finetune
|
NPap
| 2023-10-25T19:35:38Z | 2 | 0 |
peft
|
[
"peft",
"pytorch",
"llama",
"region:us"
] | null | 2023-10-06T08:27:34Z |
---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: True
- bnb_4bit_compute_dtype: float16
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: True
- bnb_4bit_compute_dtype: float16
### Framework versions
- PEFT 0.5.0
- PEFT 0.5.0
|
neromule/dqn-SpaceInvadersNoFrameskip-v4
|
neromule
| 2023-10-25T19:31:56Z | 2 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"SpaceInvadersNoFrameskip-v4",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-10-25T19:31:22Z |
---
library_name: stable-baselines3
tags:
- SpaceInvadersNoFrameskip-v4
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: DQN
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: SpaceInvadersNoFrameskip-v4
type: SpaceInvadersNoFrameskip-v4
metrics:
- type: mean_reward
value: 557.50 +/- 87.70
name: mean_reward
verified: false
---
# **DQN** Agent playing **SpaceInvadersNoFrameskip-v4**
This is a trained model of a **DQN** agent playing **SpaceInvadersNoFrameskip-v4**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3)
and the [RL Zoo](https://github.com/DLR-RM/rl-baselines3-zoo).
The RL Zoo is a training framework for Stable Baselines3
reinforcement learning agents,
with hyperparameter optimization and pre-trained agents included.
## Usage (with SB3 RL Zoo)
RL Zoo: https://github.com/DLR-RM/rl-baselines3-zoo<br/>
SB3: https://github.com/DLR-RM/stable-baselines3<br/>
SB3 Contrib: https://github.com/Stable-Baselines-Team/stable-baselines3-contrib
Install the RL Zoo (with SB3 and SB3-Contrib):
```bash
pip install rl_zoo3
```
```
# Download model and save it into the logs/ folder
python -m rl_zoo3.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga neromule -f logs/
python -m rl_zoo3.enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
If you installed the RL Zoo3 via pip (`pip install rl_zoo3`), from anywhere you can do:
```
python -m rl_zoo3.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga neromule -f logs/
python -m rl_zoo3.enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
## Training (with the RL Zoo)
```
python -m rl_zoo3.train --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
# Upload the model and generate video (when possible)
python -m rl_zoo3.push_to_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/ -orga neromule
```
## Hyperparameters
```python
OrderedDict([('batch_size', 32),
('buffer_size', 100000),
('env_wrapper',
['stable_baselines3.common.atari_wrappers.AtariWrapper']),
('exploration_final_eps', 0.01),
('exploration_fraction', 0.1),
('frame_stack', 4),
('gradient_steps', 1),
('learning_rate', 0.0001),
('learning_starts', 100000),
('n_timesteps', 1000000.0),
('optimize_memory_usage', False),
('policy', 'CnnPolicy'),
('target_update_interval', 1000),
('train_freq', 4),
('normalize', False)])
```
# Environment Arguments
```python
{'render_mode': 'rgb_array'}
```
|
Mahmoud8/bert-base-uncased
|
Mahmoud8
| 2023-10-25T19:29:34Z | 106 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"text-classification",
"generated_from_trainer",
"base_model:google-bert/bert-base-uncased",
"base_model:finetune:google-bert/bert-base-uncased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-10-25T18:52:29Z |
---
license: apache-2.0
base_model: bert-base-uncased
tags:
- generated_from_trainer
model-index:
- name: bert-base-uncased
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-uncased
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1434
- F1 Score: 0.9670
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 Score |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.0991 | 1.0 | 873 | 0.1463 | 0.9619 |
| 0.0529 | 2.0 | 1746 | 0.1434 | 0.9670 |
| 0.0216 | 3.0 | 2619 | 0.1762 | 0.9659 |
| 0.0126 | 4.0 | 3492 | 0.2089 | 0.9652 |
| 0.0065 | 5.0 | 4365 | 0.2178 | 0.9628 |
| 0.0047 | 6.0 | 5238 | 0.2370 | 0.9652 |
| 0.0062 | 7.0 | 6111 | 0.2190 | 0.9668 |
| 0.0042 | 8.0 | 6984 | 0.2303 | 0.9666 |
| 0.0035 | 9.0 | 7857 | 0.2406 | 0.9682 |
| 0.0011 | 10.0 | 8730 | 0.2422 | 0.9687 |
### Framework versions
- Transformers 4.31.0
- Pytorch 2.0.0
- Datasets 2.1.0
- Tokenizers 0.13.3
|
haseong8012/whisper-small_child50K_LoRA
|
haseong8012
| 2023-10-25T19:25:43Z | 4 | 0 |
peft
|
[
"peft",
"region:us"
] | null | 2023-10-25T19:25:34Z |
---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: True
- load_in_4bit: False
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: fp4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float32
### Framework versions
- PEFT 0.5.0
|
OckerGui/videomae-base-finetuned-ASBD_Augm_v2
|
OckerGui
| 2023-10-25T19:20:38Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"videomae",
"video-classification",
"generated_from_trainer",
"license:cc-by-nc-4.0",
"endpoints_compatible",
"region:us"
] |
video-classification
| 2023-10-25T17:32:23Z |
---
license: cc-by-nc-4.0
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: videomae-base-finetuned-ASBD_Augm_v2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# videomae-base-finetuned-ASBD_Augm_v2
This model is a fine-tuned version of [MCG-NJU/videomae-base](https://huggingface.co/MCG-NJU/videomae-base) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.1054
- Accuracy: 0.7059
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 12
- eval_batch_size: 12
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- training_steps: 1050
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 1.0628 | 0.09 | 97 | 1.6346 | 0.1757 |
| 1.6112 | 1.09 | 194 | 1.3173 | 0.3108 |
| 0.623 | 2.09 | 291 | 1.0440 | 0.6486 |
| 0.4408 | 3.09 | 388 | 1.6123 | 0.6351 |
| 0.1697 | 4.09 | 485 | 1.9624 | 0.5135 |
| 0.096 | 5.09 | 582 | 1.7603 | 0.6757 |
| 0.0035 | 6.09 | 679 | 2.3011 | 0.5676 |
| 0.0352 | 7.09 | 776 | 2.0646 | 0.5946 |
| 0.0305 | 8.09 | 873 | 1.9901 | 0.6486 |
| 0.0015 | 9.09 | 970 | 1.9017 | 0.6216 |
| 0.001 | 10.08 | 1050 | 1.8979 | 0.6622 |
### Framework versions
- Transformers 4.28.0
- Pytorch 2.1.0+cu118
- Datasets 2.14.6
- Tokenizers 0.13.3
|
mdevoz/gatsby
|
mdevoz
| 2023-10-25T19:16:49Z | 1 | 0 |
peft
|
[
"peft",
"arxiv:1910.09700",
"base_model:mistralai/Mistral-7B-v0.1",
"base_model:adapter:mistralai/Mistral-7B-v0.1",
"region:us"
] | null | 2023-10-25T18:38:36Z |
---
library_name: peft
base_model: mistralai/Mistral-7B-v0.1
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Data Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Data Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: True
- bnb_4bit_compute_dtype: bfloat16
### Framework versions
- PEFT 0.6.0.dev0
|
pseudo2010/ppo-SnowballTarget
|
pseudo2010
| 2023-10-25T19:13:01Z | 2 | 1 |
ml-agents
|
[
"ml-agents",
"tensorboard",
"onnx",
"SnowballTarget",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-SnowballTarget",
"region:us"
] |
reinforcement-learning
| 2023-10-25T19:12:58Z |
---
library_name: ml-agents
tags:
- SnowballTarget
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-SnowballTarget
---
# **ppo** Agent playing **SnowballTarget**
This is a trained model of a **ppo** agent playing **SnowballTarget**
using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://unity-technologies.github.io/ml-agents/ML-Agents-Toolkit-Documentation/
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
- A *short tutorial* where you teach Huggy the Dog 🐶 to fetch the stick and then play with him directly in your
browser: https://huggingface.co/learn/deep-rl-course/unitbonus1/introduction
- A *longer tutorial* to understand how works ML-Agents:
https://huggingface.co/learn/deep-rl-course/unit5/introduction
### Resume the training
```bash
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser**
1. If the environment is part of ML-Agents official environments, go to https://huggingface.co/unity
2. Step 1: Find your model_id: pseudo2010/ppo-SnowballTarget
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
joseluhf11/disease_encoder_v4
|
joseluhf11
| 2023-10-25T19:06:34Z | 3 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"pytorch",
"bert",
"feature-extraction",
"sentence-similarity",
"transformers",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2023-10-25T19:03:30Z |
---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
---
# {MODEL_NAME}
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
<!--- Describe your model here -->
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('{MODEL_NAME}')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('{MODEL_NAME}')
model = AutoModel.from_pretrained('{MODEL_NAME}')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, mean pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
<!--- Describe how your model was evaluated -->
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name={MODEL_NAME})
## Training
The model was trained with the parameters:
**DataLoader**:
`sentence_transformers.datasets.NoDuplicatesDataLoader.NoDuplicatesDataLoader` of length 1983 with parameters:
```
{'batch_size': 32}
```
**Loss**:
`sentence_transformers.losses.MultipleNegativesRankingLoss.MultipleNegativesRankingLoss` with parameters:
```
{'scale': 20.0, 'similarity_fct': 'cos_sim'}
```
Parameters of the fit()-Method:
```
{
"epochs": 10,
"evaluation_steps": 0,
"evaluator": "NoneType",
"max_grad_norm": 1,
"optimizer_class": "<class 'torch.optim.adamw.AdamW'>",
"optimizer_params": {
"lr": 2e-05
},
"scheduler": "WarmupLinear",
"steps_per_epoch": null,
"warmup_steps": 1983,
"weight_decay": 0.01
}
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 512, 'do_lower_case': False}) with Transformer model: BertModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Citing & Authors
<!--- Describe where people can find more information -->
|
newsmediabias/UnBIAS-classification-bert
|
newsmediabias
| 2023-10-25T19:02:50Z | 1,054 | 2 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"text-classification",
"en",
"dataset:newsmediabias/news-bias-full-data",
"license:openrail",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-10-14T00:01:19Z |
---
license: openrail
language:
- en
datasets:
- newsmediabias/news-bias-full-data
---
## Bias Classification Using Bert
# Overview:
This is a BERT based model designed to detect bias in text data enabling users to identify whether a given text is biased or non-biased.
## Performance:
The model's performance on unseen data is:
### Non-biased Precision: 0.93 Recall: 0.96
### Biased Precision: 0.91 Recall: 0.88
## Overall accuracy : 0.93
## Usage
To use the model, you can utilize the transformers library from Hugging Face:
```
from transformers import AutoTokenizer, AutoModelForSequenceClassification
tokenizer = AutoTokenizer.from_pretrained("newsmediabias/UnBIAS-classification-bert")
model = AutoModelForSequenceClassification.from_pretrained("newsmediabias/UnBIAS-classification-bert")
classifier = pipeline("text-classification", model=model, tokenizer=tokenizer , device=0 if device.type == "cuda" else -1)
classifier("Anyone can excel at coding.")
```

|
JEdappully/a2c-PandaPickAndPlace-v3
|
JEdappully
| 2023-10-25T19:02:24Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"PandaPickAndPlace-v3",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-10-25T18:01:34Z |
---
library_name: stable-baselines3
tags:
- PandaPickAndPlace-v3
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: A2C
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: PandaPickAndPlace-v3
type: PandaPickAndPlace-v3
metrics:
- type: mean_reward
value: -45.00 +/- 15.00
name: mean_reward
verified: false
---
# **A2C** Agent playing **PandaPickAndPlace-v3**
This is a trained model of a **A2C** agent playing **PandaPickAndPlace-v3**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
kingabzpro/mistral_7b-instruct-guanaco
|
kingabzpro
| 2023-10-25T18:45:44Z | 3 | 0 |
peft
|
[
"peft",
"region:us"
] | null | 2023-10-25T16:48:00Z |
---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: bfloat16
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: bfloat16
### Framework versions
- PEFT 0.5.0
- PEFT 0.5.0
|
Undi95/Storytelling-v2.1-13B-lora
|
Undi95
| 2023-10-25T18:34:23Z | 10 | 2 |
peft
|
[
"peft",
"region:us"
] | null | 2023-10-25T18:22:08Z |
---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: True
- load_in_4bit: False
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: True
- bnb_4bit_compute_dtype: bfloat16
### Framework versions
- PEFT 0.5.0
I'm NOT the author of this work.
I cite anon :
```shell
Eh whatever. That storytelling-instruct was shit as shit, so have the V2.1 regular completion retrain I did a while back. Works great as a merge with base Llama2, or on top of instructs.
I'm going to completely refactor my dataset for a potential V3.
```
Credit to "anon49"
Sorry bro, it completely got under my radar, fixed!
|
arshpareek/ppo-Huggy
|
arshpareek
| 2023-10-25T18:32:58Z | 0 | 0 |
ml-agents
|
[
"ml-agents",
"tensorboard",
"onnx",
"Huggy",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-Huggy",
"region:us"
] |
reinforcement-learning
| 2023-10-25T18:32:52Z |
---
library_name: ml-agents
tags:
- Huggy
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-Huggy
---
# **ppo** Agent playing **Huggy**
This is a trained model of a **ppo** agent playing **Huggy**
using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://unity-technologies.github.io/ml-agents/ML-Agents-Toolkit-Documentation/
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
- A *short tutorial* where you teach Huggy the Dog 🐶 to fetch the stick and then play with him directly in your
browser: https://huggingface.co/learn/deep-rl-course/unitbonus1/introduction
- A *longer tutorial* to understand how works ML-Agents:
https://huggingface.co/learn/deep-rl-course/unit5/introduction
### Resume the training
```bash
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser**
1. If the environment is part of ML-Agents official environments, go to https://huggingface.co/unity
2. Step 1: Find your model_id: arshpareek/ppo-Huggy
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
quyanh/mistral-7b-neurips-v2
|
quyanh
| 2023-10-25T18:24:07Z | 0 | 0 |
peft
|
[
"peft",
"arxiv:1910.09700",
"base_model:mistralai/Mistral-7B-v0.1",
"base_model:adapter:mistralai/Mistral-7B-v0.1",
"region:us"
] | null | 2023-10-24T16:07:16Z |
---
library_name: peft
base_model: mistralai/Mistral-7B-v0.1
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Data Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Data Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: True
- bnb_4bit_compute_dtype: bfloat16
### Framework versions
- PEFT 0.6.0.dev0
|
nikitawagh/bird
|
nikitawagh
| 2023-10-25T18:13:37Z | 0 | 0 | null |
[
"safetensors",
"NxtWave-GenAI-Webinar",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"region:us"
] |
text-to-image
| 2023-10-25T18:11:25Z |
---
license: creativeml-openrail-m
tags:
- NxtWave-GenAI-Webinar
- text-to-image
- stable-diffusion
---
### Bird Dreambooth model trained by nikitawagh following the "Build your own Gen AI model" session by NxtWave.
Project Submission Code: CCEW-356
Sample pictures of this concept:
.png)
.png)
.png)
.png)
|
02shanky/vit-finetuned-cifar10
|
02shanky
| 2023-10-25T18:05:09Z | 1,286 | 0 |
transformers
|
[
"transformers",
"pytorch",
"vit",
"image-classification",
"generated_from_trainer",
"dataset:cifar10",
"base_model:google/vit-base-patch16-224-in21k",
"base_model:finetune:google/vit-base-patch16-224-in21k",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2023-10-25T17:31:27Z |
---
license: apache-2.0
base_model: google/vit-base-patch16-224-in21k
tags:
- generated_from_trainer
datasets:
- cifar10
model-index:
- name: test-cifar-10
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# test-cifar-10
This model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on the cifar10 dataset.
It achieves the following results on the evaluation set:
- eval_loss: 0.0831
- eval_accuracy: 0.9802
- eval_runtime: 75.4306
- eval_samples_per_second: 66.286
- eval_steps_per_second: 16.572
- epoch: 1.0
- step: 4500
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 10
- eval_batch_size: 4
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Framework versions
- Transformers 4.34.1
- Pytorch 2.1.0+cu118
- Datasets 2.14.6
- Tokenizers 0.14.1
|
rcds/neg-xlm-roberta-base
|
rcds
| 2023-10-25T17:58:35Z | 10 | 0 |
transformers
|
[
"transformers",
"pytorch",
"xlm-roberta",
"token-classification",
"legal",
"de",
"fr",
"it",
"en",
"dataset:rcds/MultiLegalNeg",
"arxiv:1911.04211",
"arxiv:2309.08695",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2023-08-26T13:39:59Z |
---
datasets:
- rcds/MultiLegalNeg
language:
- de
- fr
- it
- en
tags:
- legal
---
# Model Card for joelito/legal-swiss-longformer-base
This model is based on [XLM-R-Base](https://huggingface.co/xlm-roberta-base).
It was pretrained on negation scope resolution using [NegBERT](https://github.com/adityak6798/Transformers-For-Negation-and-Speculation/blob/master/Transformers_for_Negation_and_Speculation.ipynb) ([Khandelwal and Sawant 2020](https://arxiv.org/abs/1911.04211))
For training we used the [Multi Legal Neg Dataset](https://huggingface.co/datasets/rcds/MultiLegalNeg), a multilingual dataset of legal data annotated for negation cues and scopes, ConanDoyle-neg ([
Morante and Blanco. 2012](https://aclanthology.org/S12-1035/)), SFU Review ([Konstantinova et al. 2012](http://www.lrec-conf.org/proceedings/lrec2012/pdf/533_Paper.pdf)), BioScope ([Szarvas et al. 2008](https://aclanthology.org/W08-0606/)) and Dalloux ([Dalloux et al. 2020](https://clementdalloux.fr/?page_id=28)).
## Model Details
### Model Description
- **Model type:** Transformer-based language model (XLM-R-base)
- **Languages:** de, fr, it, en
- **License:** CC BY-SA
- **Finetune Task:** Negation Scope Resolution
## Uses
See [LegalNegBERT](https://github.com/RamonaChristen/Multilingual_Negation_Scope_Resolution_on_Legal_Data/blob/main/LegalNegBERT) for details on the training process and how to use this model.
### Recommendations
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model.
### Training Data
This model was pretrained on the [Multi Legal Neg Dataset](https://huggingface.co/datasets/rcds/MultiLegalNeg)
## Evaluation
We evaluate neg-xlm-roberta-base on the test sets in the [Multi Legal Neg Dataset](https://huggingface.co/datasets/rcds/MultiLegalNeg).
| \_Test Dataset | F1-score |
| :------------------------- | :-------- |
| fr | 92.49 |
| it | 88.81 |
| de (DE) | 95.66 |
| de (CH) | 87.82 |
| SFU Review | 88.53 |
| ConanDoyle-neg | 90.47 |
| BioScope | 95.59 |
| Dalloux | 93.99 |
#### Software
pytorch, transformers.
## Citation
Please cite the following preprint:
```
@misc{christen2023resolving,
title={Resolving Legalese: A Multilingual Exploration of Negation Scope Resolution in Legal Documents},
author={Ramona Christen and Anastassia Shaitarova and Matthias Stürmer and Joel Niklaus},
year={2023},
eprint={2309.08695},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
|
JEdappully/a2c-PandaReachDense-v3
|
JEdappully
| 2023-10-25T17:52:23Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"PandaReachDense-v3",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-10-25T17:46:46Z |
---
library_name: stable-baselines3
tags:
- PandaReachDense-v3
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: A2C
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: PandaReachDense-v3
type: PandaReachDense-v3
metrics:
- type: mean_reward
value: -0.19 +/- 0.11
name: mean_reward
verified: false
---
# **A2C** Agent playing **PandaReachDense-v3**
This is a trained model of a **A2C** agent playing **PandaReachDense-v3**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
salmaniq/Omegle-Chatbot
|
salmaniq
| 2023-10-25T17:51:48Z | 0 | 0 | null |
[
"region:us"
] | null | 2023-10-25T17:49:52Z |
# Omegle-Chatbot
An Omegle Chatbot for promotion of Social media content or use it to increase views on YouTube. With the help of Chatterbot AI, this chatbot can be customized with new QnAs and will deal in a humanly way.
Used Selenium for Web Automation and English corpus data to train chatbot. [other languages](https://github.com/gunthercox/chatterbot-corpus/tree/master/chatterbot_corpus/data)


## To setup and run
`~$ python3 app.py`
## ChatterBot Installation
[If you are just getting started with ChatterBot](https://chatterbot.readthedocs.io/en/stable/setup.html)
## To add custom dataset
[Setting the training class in chatt.py](https://chatterbot.readthedocs.io/en/stable/training.html)
## Selenium
[Getting started and setup](https://selenium-python.readthedocs.io/)
## License & copyright
© Vaibhav Singh
Licensed under the [MIT License](LICENSE).
|
limerooster/vietnamese-llama-2-7B-ngkplnltc-336
|
limerooster
| 2023-10-25T17:50:02Z | 4 | 0 |
peft
|
[
"peft",
"region:us"
] | null | 2023-10-25T17:49:30Z |
---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: QuantizationMethod.BITS_AND_BYTES
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: True
- bnb_4bit_compute_dtype: bfloat16
### Framework versions
- PEFT 0.5.0
|
salmaniq/instant-chatbot
|
salmaniq
| 2023-10-25T17:47:51Z | 0 | 0 | null |
[
"region:us"
] | null | 2023-10-25T17:46:28Z |
# Getting Started with Create React App
This project was bootstrapped with [Create React App](https://github.com/facebook/create-react-app).
## Available Scripts
In the project directory, you can run:
### `npm start`
Runs the app in the development mode.\
Open [http://localhost:3000](http://localhost:3000) to view it in your browser.
The page will reload when you make changes.\
You may also see any lint errors in the console.
### `npm test`
Launches the test runner in the interactive watch mode.\
See the section about [running tests](https://facebook.github.io/create-react-app/docs/running-tests) for more information.
### `npm run build`
Builds the app for production to the `build` folder.\
It correctly bundles React in production mode and optimizes the build for the best performance.
The build is minified and the filenames include the hashes.\
Your app is ready to be deployed!
See the section about [deployment](https://facebook.github.io/create-react-app/docs/deployment) for more information.
### `npm run eject`
**Note: this is a one-way operation. Once you `eject`, you can't go back!**
If you aren't satisfied with the build tool and configuration choices, you can `eject` at any time. This command will remove the single build dependency from your project.
Instead, it will copy all the configuration files and the transitive dependencies (webpack, Babel, ESLint, etc) right into your project so you have full control over them. All of the commands except `eject` will still work, but they will point to the copied scripts so you can tweak them. At this point you're on your own.
You don't have to ever use `eject`. The curated feature set is suitable for small and middle deployments, and you shouldn't feel obligated to use this feature. However we understand that this tool wouldn't be useful if you couldn't customize it when you are ready for it.
## Learn More
You can learn more in the [Create React App documentation](https://facebook.github.io/create-react-app/docs/getting-started).
To learn React, check out the [React documentation](https://reactjs.org/).
### Code Splitting
This section has moved here: [https://facebook.github.io/create-react-app/docs/code-splitting](https://facebook.github.io/create-react-app/docs/code-splitting)
### Analyzing the Bundle Size
This section has moved here: [https://facebook.github.io/create-react-app/docs/analyzing-the-bundle-size](https://facebook.github.io/create-react-app/docs/analyzing-the-bundle-size)
### Making a Progressive Web App
This section has moved here: [https://facebook.github.io/create-react-app/docs/making-a-progressive-web-app](https://facebook.github.io/create-react-app/docs/making-a-progressive-web-app)
### Advanced Configuration
This section has moved here: [https://facebook.github.io/create-react-app/docs/advanced-configuration](https://facebook.github.io/create-react-app/docs/advanced-configuration)
### Deployment
This section has moved here: [https://facebook.github.io/create-react-app/docs/deployment](https://facebook.github.io/create-react-app/docs/deployment)
### `npm run build` fails to minify
This section has moved here: [https://facebook.github.io/create-react-app/docs/troubleshooting#npm-run-build-fails-to-minify](https://facebook.github.io/create-react-app/docs/troubleshooting#npm-run-build-fails-to-minify)
|
jessica-ecosia/phrasebank-sentiment-analysis
|
jessica-ecosia
| 2023-10-25T17:42:23Z | 108 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"text-classification",
"generated_from_trainer",
"dataset:financial_phrasebank",
"base_model:google-bert/bert-base-uncased",
"base_model:finetune:google-bert/bert-base-uncased",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-10-25T17:30:56Z |
---
license: apache-2.0
base_model: bert-base-uncased
tags:
- generated_from_trainer
datasets:
- financial_phrasebank
metrics:
- f1
- accuracy
model-index:
- name: phrasebank-sentiment-analysis
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: financial_phrasebank
type: financial_phrasebank
config: sentences_50agree
split: train
args: sentences_50agree
metrics:
- name: F1
type: f1
value: 0.8385501226246813
- name: Accuracy
type: accuracy
value: 0.8528198074277854
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# phrasebank-sentiment-analysis
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on the financial_phrasebank dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5500
- F1: 0.8386
- Accuracy: 0.8528
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 4
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:------:|:--------:|
| 0.6031 | 0.94 | 100 | 0.3779 | 0.8373 | 0.8501 |
| 0.2667 | 1.89 | 200 | 0.4195 | 0.8408 | 0.8638 |
| 0.1264 | 2.83 | 300 | 0.4813 | 0.8459 | 0.8666 |
| 0.0582 | 3.77 | 400 | 0.5500 | 0.8386 | 0.8528 |
### Framework versions
- Transformers 4.34.0
- Pytorch 2.1.0
- Datasets 2.14.5
- Tokenizers 0.14.1
|
keremp/deberta-em-large
|
keremp
| 2023-10-25T17:38:50Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"deberta-v2",
"text-classification",
"generated_from_trainer",
"base_model:microsoft/deberta-v3-large",
"base_model:finetune:microsoft/deberta-v3-large",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-10-25T16:49:59Z |
---
license: mit
base_model: microsoft/deberta-v3-large
tags:
- generated_from_trainer
metrics:
- f1
model-index:
- name: deberta-em-large
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# deberta-em-large
This model is a fine-tuned version of [microsoft/deberta-v3-large](https://huggingface.co/microsoft/deberta-v3-large) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1008
- F1: 0.9367
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 4
- eval_batch_size: 8
- seed: 42
- distributed_type: multi-GPU
- num_devices: 4
- gradient_accumulation_steps: 4
- total_train_batch_size: 64
- total_eval_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
### Framework versions
- Transformers 4.34.1
- Pytorch 2.1.0+cu121
- Datasets 2.14.6
- Tokenizers 0.14.1
|
jwalley/Pixelcopter-PLE-v0
|
jwalley
| 2023-10-25T17:38:25Z | 0 | 0 | null |
[
"Pixelcopter-PLE-v0",
"reinforce",
"reinforcement-learning",
"custom-implementation",
"deep-rl-class",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-10-25T15:12:25Z |
---
tags:
- Pixelcopter-PLE-v0
- reinforce
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: Pixelcopter-PLE-v0
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Pixelcopter-PLE-v0
type: Pixelcopter-PLE-v0
metrics:
- type: mean_reward
value: 25.10 +/- 19.54
name: mean_reward
verified: false
---
# **Reinforce** Agent playing **Pixelcopter-PLE-v0**
This is a trained model of a **Reinforce** agent playing **Pixelcopter-PLE-v0** .
To learn to use this model and train yours check Unit 4 of the Deep Reinforcement Learning Course: https://huggingface.co/deep-rl-course/unit4/introduction
|
maldred/ppo-LunarLander-v2
|
maldred
| 2023-10-25T17:37:38Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-10-25T17:37:17Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 249.22 +/- 34.33
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
trunks/blip-image-captioning-base
|
trunks
| 2023-10-25T17:35:38Z | 11 | 0 |
transformers
|
[
"transformers",
"pytorch",
"blip",
"image-text-to-text",
"image-to-text",
"license:mit",
"endpoints_compatible",
"region:us"
] |
image-to-text
| 2023-10-18T06:56:54Z |
---
license: mit
library_name: transformers
pipeline_tag: image-to-text
---
# Load model
from transformers import AutoProcessor, BlipForConditionalGeneration
processor = AutoProcessor.from_pretrained("trunks/blip-image-captioning-base")
model = BlipForConditionalGeneration.from_pretrained("trunks/blip-image-captioning-base")
# prepare image for model
from PIL import Image
from IPython.display import display
img1 = Image.open("imagepath/img.jpeg")
width, height = img1.size
img1_resized = img1.resize((int(0.3 * width), int(0.3 * height))
display(img1_resized)
# testing image
inputs = processor(images=img1, return_tensors="pt")
pixel_values = inputs.pixel_values
generated_ids = model.generate(pixel_values=pixel_values, max_length=50)
generated_caption = processor.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(generated_caption)
|
innyun/ppo-LunarLander-v2
|
innyun
| 2023-10-25T17:27:59Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-09-27T16:42:27Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 264.13 +/- 19.84
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
NikhilSanjayAI/a-candle
|
NikhilSanjayAI
| 2023-10-25T17:25:33Z | 2 | 0 |
diffusers
|
[
"diffusers",
"safetensors",
"NxtWave-GenAI-Webinar",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] |
text-to-image
| 2023-10-25T17:21:02Z |
---
license: creativeml-openrail-m
tags:
- NxtWave-GenAI-Webinar
- text-to-image
- stable-diffusion
---
### A-candle Dreambooth model trained by NikhilSanjayAI following the "Build your own Gen AI model" session by NxtWave.
Project Submission Code: ASET-238
Sample pictures of this concept:

|
quyanh/mistral-7b-neurips-v1
|
quyanh
| 2023-10-25T17:22:18Z | 12 | 0 |
peft
|
[
"peft",
"arxiv:1910.09700",
"base_model:mistralai/Mistral-7B-v0.1",
"base_model:adapter:mistralai/Mistral-7B-v0.1",
"region:us"
] | null | 2023-10-24T16:07:02Z |
---
library_name: peft
base_model: mistralai/Mistral-7B-v0.1
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Data Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Data Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: True
- bnb_4bit_compute_dtype: bfloat16
### Framework versions
- PEFT 0.6.0.dev0
|
thanhdeptrai2003/longt5-summarize
|
thanhdeptrai2003
| 2023-10-25T17:19:15Z | 9 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"safetensors",
"longt5",
"text2text-generation",
"en",
"arxiv:2112.07916",
"arxiv:1912.08777",
"arxiv:1910.10683",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2023-10-25T17:17:59Z |
---
license: apache-2.0
language: en
---
# LongT5 (local attention, base-sized model)
LongT5 model pre-trained on English language. The model was introduced in the paper [LongT5: Efficient Text-To-Text Transformer for Long Sequences](https://arxiv.org/pdf/2112.07916.pdf) by Guo et al. and first released in [the LongT5 repository](https://github.com/google-research/longt5). All the model architecture and configuration can be found in [Flaxformer repository](https://github.com/google/flaxformer) which uses another Google research project repository [T5x](https://github.com/google-research/t5x).
Disclaimer: The team releasing LongT5 did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
LongT5 model is an encoder-decoder transformer pre-trained in a text-to-text denoising generative setting ([Pegasus-like generation pre-training](https://arxiv.org/pdf/1912.08777.pdf)). LongT5 model is an extension of [T5 model](https://arxiv.org/pdf/1910.10683.pdf), and it enables using one of the two different efficient attention mechanisms - (1) Local attention, or (2) Transient-Global attention. The usage of attention sparsity patterns allows the model to efficiently handle input sequence.
LongT5 is particularly effective when fine-tuned for text generation (summarization, question answering) which requires handling long input sequences (up to 16,384 tokens).
## Intended uses & limitations
The model is mostly meant to be fine-tuned on a supervised dataset. See the [model hub](https://huggingface.co/models?search=longt5) to look for fine-tuned versions on a task that interests you.
### How to use
```python
from transformers import AutoTokenizer, LongT5Model
tokenizer = AutoTokenizer.from_pretrained("google/long-t5-local-base")
model = LongT5Model.from_pretrained("google/long-t5-local-base")
inputs = tokenizer("Hello, my dog is cute", return_tensors="pt")
outputs = model(**inputs)
last_hidden_states = outputs.last_hidden_state
```
### BibTeX entry and citation info
```bibtex
@article{guo2021longt5,
title={LongT5: Efficient Text-To-Text Transformer for Long Sequences},
author={Guo, Mandy and Ainslie, Joshua and Uthus, David and Ontanon, Santiago and Ni, Jianmo and Sung, Yun-Hsuan and Yang, Yinfei},
journal={arXiv preprint arXiv:2112.07916},
year={2021}
}
```
|
innyun/LunarLander-v2
|
innyun
| 2023-10-25T17:03:07Z | 0 | 0 | null |
[
"tensorboard",
"LunarLander-v2",
"ppo",
"deep-reinforcement-learning",
"reinforcement-learning",
"custom-implementation",
"deep-rl-course",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-10-25T16:35:14Z |
---
tags:
- LunarLander-v2
- ppo
- deep-reinforcement-learning
- reinforcement-learning
- custom-implementation
- deep-rl-course
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: -167.69 +/- 103.13
name: mean_reward
verified: false
---
# PPO Agent Playing LunarLander-v2
This is a trained model of a PPO agent playing LunarLander-v2.
# Hyperparameters
```python
{'exp_name': 'ppo'
'seed': 1
'torch_deterministic': True
'cuda': True
'track': False
'wandb_project_name': 'cleanRL'
'wandb_entity': None
'capture_video': False
'env_id': 'LunarLander-v2'
'total_timesteps': 1000
'learning_rate': 0.00025
'num_envs': 4
'num_steps': 128
'anneal_lr': True
'gae': True
'gamma': 0.99
'gae_lambda': 0.95
'num_minibatches': 4
'update_epochs': 4
'norm_adv': True
'clip_coef': 0.2
'clip_vloss': True
'ent_coef': 0.01
'vf_coef': 0.5
'max_grad_norm': 0.5
'target_kl': None
'repo_id': 'innyun/LunarLander-v2'
'batch_size': 512
'minibatch_size': 128}
```
|
SalmonAI123/Best-clean-ViMrcbase-NLI-version-1
|
SalmonAI123
| 2023-10-25T16:54:48Z | 19 | 0 |
transformers
|
[
"transformers",
"pytorch",
"roberta",
"question-answering",
"generated_from_trainer",
"base_model:nguyenvulebinh/vi-mrc-base",
"base_model:finetune:nguyenvulebinh/vi-mrc-base",
"license:cc-by-nc-4.0",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2023-10-25T16:17:28Z |
---
license: cc-by-nc-4.0
base_model: nguyenvulebinh/vi-mrc-base
tags:
- generated_from_trainer
model-index:
- name: Best-clean-ViMrcbase-NLI-version-1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Best-clean-ViMrcbase-NLI-version-1
This model is a fine-tuned version of [nguyenvulebinh/vi-mrc-base](https://huggingface.co/nguyenvulebinh/vi-mrc-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7940
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 1.0728 | 1.0 | 798 | 0.7467 |
| 0.5326 | 2.0 | 1596 | 0.7940 |
### Framework versions
- Transformers 4.33.0
- Pytorch 2.0.0
- Datasets 2.1.0
- Tokenizers 0.13.3
|
jwalley/Reinforce-Cartpole-v1
|
jwalley
| 2023-10-25T16:39:11Z | 0 | 0 | null |
[
"CartPole-v1",
"reinforce",
"reinforcement-learning",
"custom-implementation",
"deep-rl-class",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-10-24T23:10:18Z |
---
tags:
- CartPole-v1
- reinforce
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: Reinforce-Cartpole-v1
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: CartPole-v1
type: CartPole-v1
metrics:
- type: mean_reward
value: 488.27 +/- 24.95
name: mean_reward
verified: false
---
# **Reinforce** Agent playing **CartPole-v1**
This is a trained model of a **Reinforce** agent playing **CartPole-v1** .
To learn to use this model and train yours check Unit 4 of the Deep Reinforcement Learning Course: https://huggingface.co/deep-rl-course/unit4/introduction
|
ZachSharma/q-Taxi-v3
|
ZachSharma
| 2023-10-25T16:38:11Z | 0 | 0 | null |
[
"Taxi-v3",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-10-25T16:31:31Z |
---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-Taxi-v3
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
metrics:
- type: mean_reward
value: 7.54 +/- 2.74
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
model = load_from_hub(repo_id="ZachSharma/q-Taxi-v3", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
|
ahmedghani/waqasramzan-2000-sdxl
|
ahmedghani
| 2023-10-25T16:35:59Z | 0 | 1 |
diffusers
|
[
"diffusers",
"tensorboard",
"stable-diffusion-xl",
"stable-diffusion-xl-diffusers",
"text-to-image",
"lora",
"base_model:stabilityai/stable-diffusion-xl-base-1.0",
"base_model:adapter:stabilityai/stable-diffusion-xl-base-1.0",
"license:openrail++",
"region:us"
] |
text-to-image
| 2023-10-25T07:50:52Z |
---
license: openrail++
base_model: stabilityai/stable-diffusion-xl-base-1.0
instance_prompt: waqasramzan
tags:
- stable-diffusion-xl
- stable-diffusion-xl-diffusers
- text-to-image
- diffusers
- lora
inference: true
---
# LoRA DreamBooth - ahmedghani/waqasramzan-2000-sdxl
These are LoRA adaption weights for stabilityai/stable-diffusion-xl-base-1.0. The weights were trained on waqasramzan using [DreamBooth](https://dreambooth.github.io/). You can find some example images in the following.




LoRA for the text encoder was enabled: True.
Special VAE used for training: madebyollin/sdxl-vae-fp16-fix.
|
irishwerr/dqn-SpaceInvadersNoFrameskip-v4
|
irishwerr
| 2023-10-25T16:31:21Z | 0 | 1 |
stable-baselines3
|
[
"stable-baselines3",
"SpaceInvadersNoFrameskip-v4",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-10-25T13:39:46Z |
---
library_name: stable-baselines3
tags:
- SpaceInvadersNoFrameskip-v4
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: DQN
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: SpaceInvadersNoFrameskip-v4
type: SpaceInvadersNoFrameskip-v4
metrics:
- type: mean_reward
value: 200.00 +/- 99.05
name: mean_reward
verified: false
---
# **DQN** Agent playing **SpaceInvadersNoFrameskip-v4**
This is a trained model of a **DQN** agent playing **SpaceInvadersNoFrameskip-v4**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3)
and the [RL Zoo](https://github.com/DLR-RM/rl-baselines3-zoo).
The RL Zoo is a training framework for Stable Baselines3
reinforcement learning agents,
with hyperparameter optimization and pre-trained agents included.
## Usage (with SB3 RL Zoo)
RL Zoo: https://github.com/DLR-RM/rl-baselines3-zoo<br/>
SB3: https://github.com/DLR-RM/stable-baselines3<br/>
SB3 Contrib: https://github.com/Stable-Baselines-Team/stable-baselines3-contrib
Install the RL Zoo (with SB3 and SB3-Contrib):
```bash
pip install rl_zoo3
```
```
# Download model and save it into the logs/ folder
python -m rl_zoo3.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga irishwerr -f logs/
python -m rl_zoo3.enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
If you installed the RL Zoo3 via pip (`pip install rl_zoo3`), from anywhere you can do:
```
python -m rl_zoo3.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga irishwerr -f logs/
python -m rl_zoo3.enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
## Training (with the RL Zoo)
```
python -m rl_zoo3.train --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
# Upload the model and generate video (when possible)
python -m rl_zoo3.push_to_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/ -orga irishwerr
```
## Hyperparameters
```python
OrderedDict([('batch_size', 32),
('buffer_size', 50000),
('env_wrapper',
['stable_baselines3.common.atari_wrappers.AtariWrapper']),
('exploration_final_eps', 0.01),
('exploration_fraction', 0.1),
('frame_stack', 4),
('gradient_steps', 1),
('learning_rate', 0.0001),
('learning_starts', 10000),
('n_timesteps', 100000.0),
('optimize_memory_usage', False),
('policy', 'CnnPolicy'),
('target_update_interval', 1000),
('train_freq', 4),
('normalize', False)])
```
# Environment Arguments
```python
{'render_mode': 'rgb_array'}
```
|
mrghofrani/scgpt-fewshotwoz-restaurant
|
mrghofrani
| 2023-10-25T16:29:57Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"text2text-generation",
"en",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2023-10-25T16:11:44Z |
---
license: apache-2.0
language:
- en
pipeline_tag: text2text-generation
---
Fine-tuned version of SC-GPT on restaurant domain of FewShotWOZ dataset. The results on validation set: BLEU:40.84, ERR:0 on test set: BLEU: 35.89, ERR: 6.51.
|
AzureBlack/Athena-v2-6.0bpw-6h-exl2
|
AzureBlack
| 2023-10-25T16:28:16Z | 12 | 2 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"license:cc-by-nc-4.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-09-23T20:24:29Z |
---
license: cc-by-nc-4.0
---
ExllamaV2 version of model created by the work of IkariDev + Undi95
Original Card
https://huggingface.co/IkariDev/Athena-v2
Requires ExllamaV2, which is being developed by turboderp https://github.com/turboderp/exllamav2 under an MIT license.
---

Experimental Athena v2 model. Use Alpaca format.
<!-- description start -->
## Description
This repo contains fp16 files of Athena-V2.
<!-- description end -->
<!-- description start -->
## Models and loras used
- Xwin-LM/Xwin-LM-13B-V0.1
- Undi95/ReMM-v2.2-L2-13B
- Undi95/MLewd-L2-13B-v2-3
- Brouz/Slerpeno
- boomerchan/Magpie-13b
```
[Xwin (0.30) + ReMM v2.2 (0.70)](0.45) x [[Xwin (0.40) + MLewd v2-3 (0.60)](0.80) + [Slerpeno(0.50) + Magpie-13b(0.50)](0.20)](0.55)
```
<!-- description end -->
<!-- prompt-template start -->
## Prompt template: Alpaca
```
Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
{prompt}
### Response:
```
HUGE thanks to [Undi95](https://huggingface.co/Undi95) for doing the merging (Recipe was my idea, he merged)
|
nelson2424/mt0-small-lora-finetune-grocery-ner
|
nelson2424
| 2023-10-25T16:25:35Z | 4 | 0 |
peft
|
[
"peft",
"base_model:bigscience/mt0-small",
"base_model:adapter:bigscience/mt0-small",
"region:us"
] | null | 2023-09-20T23:29:08Z |
---
library_name: peft
base_model: bigscience/mt0-small
---
## Training procedure
### Framework versions
- PEFT 0.5.0
|
nelson2424/mt0-small-lora-finetune-grocery-action-classifier
|
nelson2424
| 2023-10-25T16:25:14Z | 3 | 0 |
peft
|
[
"peft",
"base_model:bigscience/mt0-small",
"base_model:adapter:bigscience/mt0-small",
"region:us"
] | null | 2023-09-20T14:46:00Z |
---
library_name: peft
base_model: bigscience/mt0-small
---
## Training procedure
### Framework versions
- PEFT 0.5.0
|
slava-medvedev/a2c-PandaReachDense-v3
|
slava-medvedev
| 2023-10-25T16:23:25Z | 3 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"PandaReachDense-v3",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-10-25T16:17:56Z |
---
library_name: stable-baselines3
tags:
- PandaReachDense-v3
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: A2C
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: PandaReachDense-v3
type: PandaReachDense-v3
metrics:
- type: mean_reward
value: -0.39 +/- 0.26
name: mean_reward
verified: false
---
# **A2C** Agent playing **PandaReachDense-v3**
This is a trained model of a **A2C** agent playing **PandaReachDense-v3**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
Subsets and Splits
Filtered Qwen2.5 Distill Models
Identifies specific configurations of models by filtering cards that contain 'distill', 'qwen2.5', '7b' while excluding certain base models and incorrect model ID patterns, uncovering unique model variants.
Filtered Model Cards Count
Finds the count of entries with specific card details that include 'distill', 'qwen2.5', '7b' but exclude certain base models, revealing valuable insights about the dataset's content distribution.
Filtered Distill Qwen 7B Models
Filters for specific card entries containing 'distill', 'qwen', and '7b', excluding certain strings and patterns, to identify relevant model configurations.
Filtered Qwen-7b Model Cards
The query performs a detailed filtering based on specific keywords and excludes certain entries, which could be useful for identifying a specific subset of cards but does not provide deeper insights or trends.
Filtered Qwen 7B Model Cards
The query filters for specific terms related to "distilled" or "distill", "qwen", and "7b" in the 'card' column but excludes certain base models, providing a limited set of entries for further inspection.
Qwen 7B Distilled Models
The query provides a basic filtering of records to find specific card names that include keywords related to distilled Qwen 7b models, excluding a particular base model, which gives limited insight but helps in focusing on relevant entries.
Qwen 7B Distilled Model Cards
The query filters data based on specific keywords in the modelId and card fields, providing limited insight primarily useful for locating specific entries rather than revealing broad patterns or trends.
Qwen 7B Distilled Models
Finds all entries containing the terms 'distilled', 'qwen', and '7b' in a case-insensitive manner, providing a filtered set of records but without deeper analysis.
Distilled Qwen 7B Models
The query filters for specific model IDs containing 'distilled', 'qwen', and '7b', providing a basic retrieval of relevant entries but without deeper analysis or insight.
Filtered Model Cards with Distill Qwen2.
Filters and retrieves records containing specific keywords in the card description while excluding certain phrases, providing a basic count of relevant entries.
Filtered Model Cards with Distill Qwen 7
The query filters specific variations of card descriptions containing 'distill', 'qwen', and '7b' while excluding a particular base model, providing limited but specific data retrieval.
Distill Qwen 7B Model Cards
The query filters and retrieves rows where the 'card' column contains specific keywords ('distill', 'qwen', and '7b'), providing a basic filter result that can help in identifying specific entries.