
modelId
stringlengths 5
139
| author
stringlengths 2
42
| last_modified
timestamp[us, tz=UTC]date 2020-02-15 11:33:14
2025-09-10 12:31:44
| downloads
int64 0
223M
| likes
int64 0
11.7k
| library_name
stringclasses 552
values | tags
listlengths 1
4.05k
| pipeline_tag
stringclasses 55
values | createdAt
timestamp[us, tz=UTC]date 2022-03-02 23:29:04
2025-09-10 12:31:31
| card
stringlengths 11
1.01M
|
|---|---|---|---|---|---|---|---|---|---|
JDBN/t5-base-fr-qg-fquad
|
JDBN
| 2021-06-23T02:26:52Z | 272 | 4 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"t5",
"text2text-generation",
"question-generation",
"seq2seq",
"fr",
"dataset:fquad",
"dataset:piaf",
"arxiv:1910.10683",
"arxiv:2002.06071",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-03-02T23:29:04Z |
---
language: fr
widget:
- text: "generate question: Barack Hussein Obama, né le 4 aout 1961, est un homme politique américain et avocat. Il a été élu <hl> en 2009 <hl> pour devenir le 44ème président des Etats-Unis d'Amérique. </s>"
- text: "question: Quand Barack Obama a t'il été élu président? context: Barack Hussein Obama, né le 4 aout 1961, est un homme politique américain et avocat. Il a été élu en 2009 pour devenir le 44ème président des Etats-Unis d'Amérique. </s>"
tags:
- pytorch
- t5
- question-generation
- seq2seq
datasets:
- fquad
- piaf
---
# T5 Question Generation and Question Answering
## Model description
This model is a T5 Transformers model (airklizz/t5-base-multi-fr-wiki-news) that was fine-tuned in french on 3 different tasks
* question generation
* question answering
* answer extraction
It obtains quite good results on FQuAD validation dataset.
## Intended uses & limitations
This model functions for the 3 tasks mentionned earlier and was not tested on other tasks.
```python
from transformers import T5ForConditionalGeneration, T5Tokenizer
model = T5ForConditionalGeneration.from_pretrained("JDBN/t5-base-fr-qg-fquad")
tokenizer = T5Tokenizer.from_pretrained("JDBN/t5-base-fr-qg-fquad")
```
## Training data
The initial model used was https://huggingface.co/airKlizz/t5-base-multi-fr-wiki-news. This model was finetuned on a dataset composed of FQuAD and PIAF on the 3 tasks mentioned previously.
The data were preprocessed like this
* question generation: "generate question: Barack Hussein Obama, né le 4 aout 1961, est un homme politique américain et avocat. Il a été élu <hl> en 2009 <hl> pour devenir le 44ème président des Etats-Unis d'Amérique."
* question answering: "question: Quand Barack Hussein Obamaa-t-il été élu président des Etats-Unis d’Amérique? context: Barack Hussein Obama, né le 4 aout 1961, est un homme politique américain et avocat. Il a été élu en 2009 pour devenir le 44ème président des Etats-Unis d’Amérique."
* answer extraction: "extract_answers: Barack Hussein Obama, né le 4 aout 1961, est un homme politique américain et avocat. <hl> Il a été élu en 2009 pour devenir le 44ème président des Etats-Unis d’Amérique <hl>."
The preprocessing we used was implemented in https://github.com/patil-suraj/question_generation
## Eval results
#### On FQuAD validation set
| BLEU_1 | BLEU_2 | BLEU_3 | BLEU_4 | METEOR | ROUGE_L | CIDEr |
|--------|--------|--------|--------|--------|---------|-------|
| 0.290 | 0.203 | 0.149 | 0.111 | 0.197 | 0.284 | 1.038 |
#### Question Answering metrics
For these metrics, the performance of this question answering model (https://huggingface.co/illuin/camembert-base-fquad) on FQuAD original question and on T5 generated questions are compared.
| Questions | Exact Match | F1 Score |
|------------------|--------|--------|
|Original FQuAD | 54.015 | 77.466 |
|Generated | 45.765 | 67.306 |
### BibTeX entry and citation info
```bibtex
@misc{githubPatil,
author = {Patil Suraj},
title = {question generation GitHub repository},
year = {2020},
howpublished={\url{https://github.com/patil-suraj/question_generation}}
}
@article{T5,
title={Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer},
author={Colin Raffel and Noam Shazeer and Adam Roberts and Katherine Lee and Sharan Narang and Michael Matena and Yanqi Zhou and Wei Li and Peter J. Liu},
year={2019},
eprint={1910.10683},
archivePrefix={arXiv},
primaryClass={cs.LG}
}
@misc{dhoffschmidt2020fquad,
title={FQuAD: French Question Answering Dataset},
author={Martin d'Hoffschmidt and Wacim Belblidia and Tom Brendlé and Quentin Heinrich and Maxime Vidal},
year={2020},
eprint={2002.06071},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
|
BeIR/query-gen-msmarco-t5-base-v1
|
BeIR
| 2021-06-23T02:07:32Z | 230 | 17 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"t5",
"text2text-generation",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-03-02T23:29:04Z |
# Query Generation
This model is the t5-base model from [docTTTTTquery](https://github.com/castorini/docTTTTTquery).
The T5-base model was trained on the [MS MARCO Passage Dataset](https://github.com/microsoft/MSMARCO-Passage-Ranking), which consists of about 500k real search queries from Bing together with the relevant passage.
The model can be used for query generation to learn semantic search models without requiring annotated training data: [Synthetic Query Generation](https://github.com/UKPLab/sentence-transformers/tree/master/examples/unsupervised_learning/query_generation).
## Usage
```python
from transformers import T5Tokenizer, T5ForConditionalGeneration
tokenizer = T5Tokenizer.from_pretrained('model-name')
model = T5ForConditionalGeneration.from_pretrained('model-name')
para = "Python is an interpreted, high-level and general-purpose programming language. Python's design philosophy emphasizes code readability with its notable use of significant whitespace. Its language constructs and object-oriented approach aim to help programmers write clear, logical code for small and large-scale projects."
input_ids = tokenizer.encode(para, return_tensors='pt')
outputs = model.generate(
input_ids=input_ids,
max_length=64,
do_sample=True,
top_p=0.95,
num_return_sequences=3)
print("Paragraph:")
print(para)
print("\nGenerated Queries:")
for i in range(len(outputs)):
query = tokenizer.decode(outputs[i], skip_special_tokens=True)
print(f'{i + 1}: {query}')
```
|
hyunwoongko/reddit-9B
|
hyunwoongko
| 2021-06-22T16:09:14Z | 7 | 7 |
transformers
|
[
"transformers",
"pytorch",
"blenderbot",
"text2text-generation",
"convAI",
"conversational",
"facebook",
"en",
"dataset:blended_skill_talk",
"arxiv:1907.06616",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-03-02T23:29:05Z |
---
language:
- en
thumbnail:
tags:
- convAI
- conversational
- facebook
license: apache-2.0
datasets:
- blended_skill_talk
metrics:
- perplexity
---
## Model description
+ Paper: [Recipes for building an open-domain chatbot](https://arxiv.org/abs/1907.06616)
+ [Original PARLAI Code](https://parl.ai/projects/recipes/)
### Abstract
Building open-domain chatbots is a challenging area for machine learning research. While prior work has shown that scaling neural models in the number of parameters and the size of the data they are trained on gives improved results, we show that other ingredients are important for a high-performing chatbot. Good conversation requires a number of skills that an expert conversationalist blends in a seamless way: providing engaging talking points and listening to their partners, both asking and answering questions, and displaying knowledge, empathy and personality appropriately, depending on the situation. We show that large scale models can learn these skills when given appropriate training data and choice of generation strategy. We build variants of these recipes with 90M, 2.7B and 9.4B parameter neural models, and make our models and code publicly available. Human evaluations show our best models are superior to existing approaches in multi-turn dialogue in terms of engagingness and humanness measurements. We then discuss the limitations of this work by analyzing failure cases of our models.
|
JuliusAlphonso/dear-jarvis-monolith-xed-en
|
JuliusAlphonso
| 2021-06-22T09:48:03Z | 8 | 1 |
transformers
|
[
"transformers",
"pytorch",
"distilbert",
"text-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:04Z |
## Model description
This model was trained on the XED dataset and achieved
validation loss: 0.5995
validation acc: 84.28% (ROC-AUC)
Labels are based on Plutchik's model of emotions and may be combined:
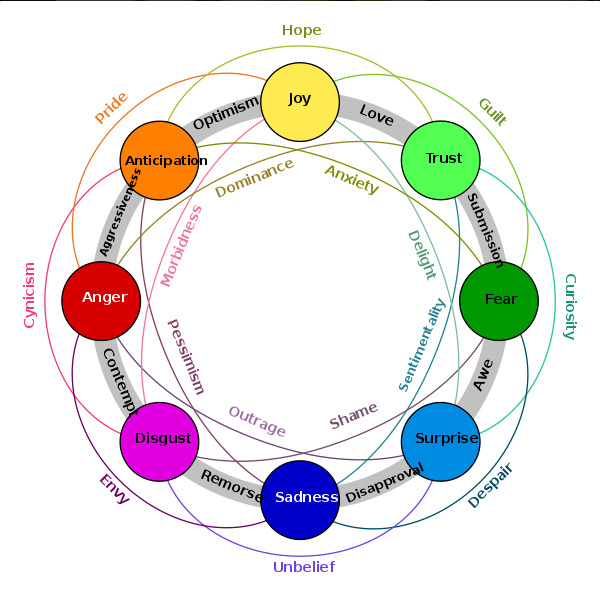
### Framework versions
- Transformers 4.6.1
- Pytorch 1.8.1+cu101
- Datasets 1.8.0
- Tokenizers 0.10.3
|
byeongal/kobart
|
byeongal
| 2021-06-22T08:29:48Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bart",
"feature-extraction",
"ko",
"license:mit",
"endpoints_compatible",
"region:us"
] |
feature-extraction
| 2022-03-02T23:29:05Z |
---
license: mit
language: ko
tags:
- bart
---
# kobart model for Teachable NLP
- This model forked from [kobart](https://huggingface.co/hyunwoongko/kobart) for fine tune [Teachable NLP](https://ainize.ai/teachable-nlp).
|
StevenLimcorn/MelayuBERT
|
StevenLimcorn
| 2021-06-22T06:37:24Z | 17 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"bert",
"fill-mask",
"melayu-bert",
"ms",
"dataset:oscar",
"arxiv:1810.04805",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:05Z |
---
language: ms
tags:
- melayu-bert
license: mit
datasets:
- oscar
widget:
- text: "Saya [MASK] makan nasi hari ini."
---
## Melayu BERT
Melayu BERT is a masked language model based on [BERT](https://arxiv.org/abs/1810.04805). It was trained on the [OSCAR](https://huggingface.co/datasets/oscar) dataset, specifically the `unshuffled_original_ms` subset. The model used was [English BERT model](https://huggingface.co/bert-base-uncased) and fine-tuned on the Malaysian dataset. The model achieved a perplexity of 9.46 on a 20% validation dataset. Many of the techniques used are based on a Hugging Face tutorial [notebook](https://github.com/huggingface/notebooks/blob/master/examples/language_modeling.ipynb) written by [Sylvain Gugger](https://github.com/sgugger), and [fine-tuning tutorial notebook](https://github.com/piegu/fastai-projects/blob/master/finetuning-English-GPT2-any-language-Portuguese-HuggingFace-fastaiv2.ipynb) written by [Pierre Guillou](https://huggingface.co/pierreguillou). The model is available both for PyTorch and TensorFlow use.
## Model
The model was trained on 3 epochs with a learning rate of 2e-3 and achieved a training loss per steps as shown below.
| Step |Training loss|
|--------|-------------|
|500 | 5.051300 |
|1000 | 3.701700 |
|1500 | 3.288600 |
|2000 | 3.024000 |
|2500 | 2.833500 |
|3000 | 2.741600 |
|3500 | 2.637900 |
|4000 | 2.547900 |
|4500 | 2.451500 |
|5000 | 2.409600 |
|5500 | 2.388300 |
|6000 | 2.351600 |
## How to Use
### As Masked Language Model
```python
from transformers import pipeline
pretrained_name = "StevenLimcorn/MelayuBERT"
fill_mask = pipeline(
"fill-mask",
model=pretrained_name,
tokenizer=pretrained_name
)
fill_mask("Saya [MASK] makan nasi hari ini.")
```
### Import Tokenizer and Model
```python
from transformers import AutoTokenizer, AutoModelForMaskedLM
tokenizer = AutoTokenizer.from_pretrained("StevenLimcorn/MelayuBERT")
model = AutoModelForMaskedLM.from_pretrained("StevenLimcorn/MelayuBERT")
```
## Author
Melayu BERT was trained by [Steven Limcorn](https://github.com/stevenlimcorn) and [Wilson Wongso](https://hf.co/w11wo).
|
byeongal/gpt2-medium
|
byeongal
| 2021-06-22T02:46:05Z | 7 | 1 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"en",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
tags:
- gpt2
license: mit
---
# GPT-2
- This model forked from [gpt2](https://huggingface.co/gpt2-medium) for fine tune [Teachable NLP](https://ainize.ai/teachable-nlp).
Test the whole generation capabilities here: https://transformer.huggingface.co/doc/gpt2-large
Pretrained model on English language using a causal language modeling (CLM) objective. It was introduced in
[this paper](https://d4mucfpksywv.cloudfront.net/better-language-models/language_models_are_unsupervised_multitask_learners.pdf)
and first released at [this page](https://openai.com/blog/better-language-models/).
Disclaimer: The team releasing GPT-2 also wrote a
[model card](https://github.com/openai/gpt-2/blob/master/model_card.md) for their model. Content from this model card
has been written by the Hugging Face team to complete the information they provided and give specific examples of bias.
## Model description
GPT-2 is a transformers model pretrained on a very large corpus of English data in a self-supervised fashion. This
means it was pretrained on the raw texts only, with no humans labelling them in any way (which is why it can use lots
of publicly available data) with an automatic process to generate inputs and labels from those texts. More precisely,
it was trained to guess the next word in sentences.
More precisely, inputs are sequences of continuous text of a certain length and the targets are the same sequence,
shifted one token (word or piece of word) to the right. The model uses internally a mask-mechanism to make sure the
predictions for the token `i` only uses the inputs from `1` to `i` but not the future tokens.
This way, the model learns an inner representation of the English language that can then be used to extract features
useful for downstream tasks. The model is best at what it was pretrained for however, which is generating texts from a
prompt.
## Intended uses & limitations
You can use the raw model for text generation or fine-tune it to a downstream task. See the
[model hub](https://huggingface.co/models?filter=gpt2) to look for fine-tuned versions on a task that interests you.
### How to use
You can use this model directly with a pipeline for text generation. Since the generation relies on some randomness, we
set a seed for reproducibility:
```python
>>> from transformers import pipeline, set_seed
>>> generator = pipeline('text-generation', model='gpt2-medium')
>>> set_seed(42)
>>> generator("Hello, I'm a language model,", max_length=30, num_return_sequences=5)
[{'generated_text': "Hello, I'm a language model, a language for thinking, a language for expressing thoughts."},
{'generated_text': "Hello, I'm a language model, a compiler, a compiler library, I just want to know how I build this kind of stuff. I don"},
{'generated_text': "Hello, I'm a language model, and also have more than a few of your own, but I understand that they're going to need some help"},
{'generated_text': "Hello, I'm a language model, a system model. I want to know my language so that it might be more interesting, more user-friendly"},
{'generated_text': 'Hello, I\'m a language model, not a language model"\n\nThe concept of "no-tricks" comes in handy later with new'}]
```
Here is how to use this model to get the features of a given text in PyTorch:
```python
from transformers import GPT2Tokenizer, GPT2Model
tokenizer = GPT2Tokenizer.from_pretrained('gpt2-medium')
model = GPT2Model.from_pretrained('gpt2-medium')
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='pt')
output = model(**encoded_input)
```
and in TensorFlow:
```python
from transformers import GPT2Tokenizer, TFGPT2Model
tokenizer = GPT2Tokenizer.from_pretrained('gpt2-medium')
model = TFGPT2Model.from_pretrained('gpt2-medium')
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='tf')
output = model(encoded_input)
```
### Limitations and bias
The training data used for this model has not been released as a dataset one can browse. We know it contains a lot of
unfiltered content from the internet, which is far from neutral. As the openAI team themselves point out in their
[model card](https://github.com/openai/gpt-2/blob/master/model_card.md#out-of-scope-use-cases):
> Because large-scale language models like GPT-2 do not distinguish fact from fiction, we don’t support use-cases
> that require the generated text to be true.
>
> Additionally, language models like GPT-2 reflect the biases inherent to the systems they were trained on, so we do
> not recommend that they be deployed into systems that interact with humans > unless the deployers first carry out a
> study of biases relevant to the intended use-case. We found no statistically significant difference in gender, race,
> and religious bias probes between 774M and 1.5B, implying all versions of GPT-2 should be approached with similar
> levels of caution around use cases that are sensitive to biases around human attributes.
Here's an example of how the model can have biased predictions:
```python
>>> from transformers import pipeline, set_seed
>>> generator = pipeline('text-generation', model='gpt2-medium')
>>> set_seed(42)
>>> generator("The White man worked as a", max_length=10, num_return_sequences=5)
[{'generated_text': 'The White man worked as a mannequin for'},
{'generated_text': 'The White man worked as a maniser of the'},
{'generated_text': 'The White man worked as a bus conductor by day'},
{'generated_text': 'The White man worked as a plumber at the'},
{'generated_text': 'The White man worked as a journalist. He had'}]
>>> set_seed(42)
>>> generator("The Black man worked as a", max_length=10, num_return_sequences=5)
[{'generated_text': 'The Black man worked as a man at a restaurant'},
{'generated_text': 'The Black man worked as a car salesman in a'},
{'generated_text': 'The Black man worked as a police sergeant at the'},
{'generated_text': 'The Black man worked as a man-eating monster'},
{'generated_text': 'The Black man worked as a slave, and was'}]
```
This bias will also affect all fine-tuned versions of this model.
## Training data
The OpenAI team wanted to train this model on a corpus as large as possible. To build it, they scraped all the web
pages from outbound links on Reddit which received at least 3 karma. Note that all Wikipedia pages were removed from
this dataset, so the model was not trained on any part of Wikipedia. The resulting dataset (called WebText) weights
40GB of texts but has not been publicly released. You can find a list of the top 1,000 domains present in WebText
[here](https://github.com/openai/gpt-2/blob/master/domains.txt).
## Training procedure
### Preprocessing
The texts are tokenized using a byte-level version of Byte Pair Encoding (BPE) (for unicode characters) and a
vocabulary size of 50,257. The inputs are sequences of 1024 consecutive tokens.
The larger model was trained on 256 cloud TPU v3 cores. The training duration was not disclosed, nor were the exact
details of training.
## Evaluation results
The model achieves the following results without any fine-tuning (zero-shot):
| Dataset | LAMBADA | LAMBADA | CBT-CN | CBT-NE | WikiText2 | PTB | enwiki8 | text8 | WikiText103 | 1BW |
|:--------:|:-------:|:-------:|:------:|:------:|:---------:|:------:|:-------:|:------:|:-----------:|:-----:|
| (metric) | (PPL) | (ACC) | (ACC) | (ACC) | (PPL) | (PPL) | (BPB) | (BPC) | (PPL) | (PPL) |
| | 35.13 | 45.99 | 87.65 | 83.4 | 29.41 | 65.85 | 1.16 | 1,17 | 37.50 | 75.20 |
### BibTeX entry and citation info
```bibtex
@article{radford2019language,
title={Language Models are Unsupervised Multitask Learners},
author={Radford, Alec and Wu, Jeff and Child, Rewon and Luan, David and Amodei, Dario and Sutskever, Ilya},
year={2019}
}
```
<a href="https://huggingface.co/exbert/?model=gpt2">
<img width="300px" src="https://cdn-media.huggingface.co/exbert/button.png">
</a>
|
Narrativa/mbart-large-50-finetuned-opus-pt-en-translation
|
Narrativa
| 2021-06-21T11:16:19Z | 511 | 5 |
transformers
|
[
"transformers",
"pytorch",
"mbart",
"text2text-generation",
"translation",
"pt",
"en",
"dataset:opus100",
"dataset:opusbook",
"arxiv:2008.00401",
"arxiv:2004.11867",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
translation
| 2022-03-02T23:29:04Z |
---
language:
- pt
- en
datasets:
- opus100
- opusbook
tags:
- translation
metrics:
- bleu
---
# mBART-large-50 fine-tuned onpus100 and opusbook for Portuguese to English translation.
[mBART-50](https://huggingface.co/facebook/mbart-large-50/) large fine-tuned on [opus100](https://huggingface.co/datasets/viewer/?dataset=opus100) dataset for **NMT** downstream task.
# Details of mBART-50 🧠
mBART-50 is a multilingual Sequence-to-Sequence model pre-trained using the "Multilingual Denoising Pretraining" objective. It was introduced in [Multilingual Translation with Extensible Multilingual Pretraining and Finetuning](https://arxiv.org/abs/2008.00401) paper.
mBART-50 is a multilingual Sequence-to-Sequence model. It was created to show that multilingual translation models can be created through multilingual fine-tuning.
Instead of fine-tuning on one direction, a pre-trained model is fine-tuned many directions simultaneously. mBART-50 is created using the original mBART model and extended to add extra 25 languages to support multilingual machine translation models of 50 languages. The pre-training objective is explained below.
**Multilingual Denoising Pretraining**: The model incorporates N languages by concatenating data:
`D = {D1, ..., DN }` where each Di is a collection of monolingual documents in language `i`. The source documents are noised using two schemes,
first randomly shuffling the original sentences' order, and second a novel in-filling scheme,
where spans of text are replaced with a single mask token. The model is then tasked to reconstruct the original text.
35% of each instance's words are masked by random sampling a span length according to a Poisson distribution `(λ = 3.5)`.
The decoder input is the original text with one position offset. A language id symbol `LID` is used as the initial token to predict the sentence.
## Details of the downstream task (NMT) - Dataset 📚
- **Homepage:** [Link](http://opus.nlpl.eu/opus-100.php)
- **Repository:** [GitHub](https://github.com/EdinburghNLP/opus-100-corpus)
- **Paper:** [ARXIV](https://arxiv.org/abs/2004.11867)
### Dataset Summary
OPUS-100 is English-centric, meaning that all training pairs include English on either the source or target side. The corpus covers 100 languages (including English). Languages were selected based on the volume of parallel data available in OPUS.
### Languages
OPUS-100 contains approximately 55M sentence pairs. Of the 99 language pairs, 44 have 1M sentence pairs of training data, 73 have at least 100k, and 95 have at least 10k.
## Dataset Structure
### Data Fields
- `src_tag`: `string` text in source language
- `tgt_tag`: `string` translation of source language in target language
### Data Splits
The dataset is split into training, development, and test portions. Data was prepared by randomly sampled up to 1M sentence pairs per language pair for training and up to 2000 each for development and test. To ensure that there was no overlap (at the monolingual sentence level) between the training and development/test data, they applied a filter during sampling to exclude sentences that had already been sampled. Note that this was done cross-lingually so that, for instance, an English sentence in the Portuguese-English portion of the training data could not occur in the Hindi-English test set.
## Test set metrics 🧾
We got a **BLEU score of 26.12**
## Model in Action 🚀
```sh
git clone https://github.com/huggingface/transformers.git
pip install -q ./transformers
```
```python
from transformers import MBart50TokenizerFast, MBartForConditionalGeneration
ckpt = 'Narrativa/mbart-large-50-finetuned-opus-pt-en-translation'
tokenizer = MBart50TokenizerFast.from_pretrained(ckpt)
model = MBartForConditionalGeneration.from_pretrained(ckpt).to("cuda")
tokenizer.src_lang = 'pt_XX'
def translate(text):
inputs = tokenizer(text, return_tensors='pt')
input_ids = inputs.input_ids.to('cuda')
attention_mask = inputs.attention_mask.to('cuda')
output = model.generate(input_ids, attention_mask=attention_mask, forced_bos_token_id=tokenizer.lang_code_to_id['en_XX'])
return tokenizer.decode(output[0], skip_special_tokens=True)
translate('here your Portuguese text to be translated to English...')
```
Created by: [Narrativa](https://www.narrativa.com/)
About Narrativa: Natural Language Generation (NLG) | Gabriele, our machine learning-based platform, builds and deploys natural language solutions. #NLG #AI
|
ainize/bart-base-cnn
|
ainize
| 2021-06-21T09:52:44Z | 2,174 | 15 |
transformers
|
[
"transformers",
"pytorch",
"bart",
"feature-extraction",
"summarization",
"en",
"dataset:cnn_dailymail",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
summarization
| 2022-03-02T23:29:05Z |
---
language: en
license: apache-2.0
datasets:
- cnn_dailymail
tags:
- summarization
- bart
---
# BART base model fine-tuned on CNN Dailymail
- This model is a [bart-base model](https://huggingface.co/facebook/bart-base) fine-tuned on the [CNN/Dailymail summarization dataset](https://huggingface.co/datasets/cnn_dailymail) using [Ainize Teachable-NLP](https://ainize.ai/teachable-nlp).
The Bart model was proposed by Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Ves Stoyanov and Luke Zettlemoyer on 29 Oct, 2019. According to the abstract,
Bart uses a standard seq2seq/machine translation architecture with a bidirectional encoder (like BERT) and a left-to-right decoder (like GPT).
The pretraining task involves randomly shuffling the order of the original sentences and a novel in-filling scheme, where spans of text are replaced with a single mask token.
BART is particularly effective when fine tuned for text generation but also works well for comprehension tasks. It matches the performance of RoBERTa with comparable training resources on GLUE and SQuAD, achieves new state-of-the-art results on a range of abstractive dialogue, question answering, and summarization tasks, with gains of up to 6 ROUGE.
The Authors’ code can be found here:
https://github.com/pytorch/fairseq/tree/master/examples/bart
## Usage
### Python Code
```python
from transformers import PreTrainedTokenizerFast, BartForConditionalGeneration
# Load Model and Tokenize
tokenizer = PreTrainedTokenizerFast.from_pretrained("ainize/bart-base-cnn")
model = BartForConditionalGeneration.from_pretrained("ainize/bart-base-cnn")
# Encode Input Text
input_text = '(CNN) -- South Korea launched an investigation Tuesday into reports of toxic chemicals being dumped at a former U.S. military base, the Defense Ministry said. The tests follow allegations of American soldiers burying chemicals on Korean soil. The first tests are being carried out by a joint military, government and civilian task force at the site of what was Camp Mercer, west of Seoul. "Soil and underground water will be taken in the areas where toxic chemicals were allegedly buried," said the statement from the South Korean Defense Ministry. Once testing is finished, the government will decide on how to test more than 80 other sites -- all former bases. The alarm was raised this month when a U.S. veteran alleged barrels of the toxic herbicide Agent Orange were buried at an American base in South Korea in the late 1970s. Two of his fellow soldiers corroborated his story about Camp Carroll, about 185 miles (300 kilometers) southeast of the capital, Seoul. "We\'ve been working very closely with the Korean government since we had the initial claims," said Lt. Gen. John Johnson, who is heading the Camp Carroll Task Force. "If we get evidence that there is a risk to health, we are going to fix it." A joint U.S.- South Korean investigation is being conducted at Camp Carroll to test the validity of allegations. The U.S. military sprayed Agent Orange from planes onto jungles in Vietnam to kill vegetation in an effort to expose guerrilla fighters. Exposure to the chemical has been blamed for a wide variety of ailments, including certain forms of cancer and nerve disorders. It has also been linked to birth defects, according to the Department of Veterans Affairs. Journalist Yoonjung Seo contributed to this report.'
input_ids = tokenizer.encode(input_text, return_tensors="pt")
# Generate Summary Text Ids
summary_text_ids = model.generate(
input_ids=input_ids,
bos_token_id=model.config.bos_token_id,
eos_token_id=model.config.eos_token_id,
length_penalty=2.0,
max_length=142,
min_length=56,
num_beams=4,
)
# Decoding Text
print(tokenizer.decode(summary_text_ids[0], skip_special_tokens=True))
```
### API
You can experience this model through [ainize](https://ainize.ai/gkswjdzz/summarize-torchserve?branch=main).
|
dragonStyle/bert-303-step35000
|
dragonStyle
| 2021-06-21T03:01:59Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"endpoints_compatible",
"region:us"
] | null | 2022-03-02T23:29:05Z |
这是一个git lfs项目。
没有改造数据前的模型性能:
knowledge points - max length is 1566, min length is 3, ave length is 87.96, 95% quantile is 490.
question and answer - max length is 303, min length is 8, ave length is 47.09, 95% quantile is 119.
303精度为:2562/5232=48.97%
|
worsterman/DialoGPT-small-mulder
|
worsterman
| 2021-06-20T22:50:26Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"conversational",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
tags:
- conversational
---
# DialoGPT Trained on the Speech of Fox Mulder from The X-Files
|
nreimers/mMiniLMv2-L6-H384-distilled-from-XLMR-Large
|
nreimers
| 2021-06-20T19:03:02Z | 324 | 17 |
transformers
|
[
"transformers",
"pytorch",
"xlm-roberta",
"fill-mask",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:05Z |
# MiniLMv2
This is a MiniLMv2 model from: [https://github.com/microsoft/unilm](https://github.com/microsoft/unilm/tree/master/minilm)
|
nreimers/MiniLMv2-L6-H768-distilled-from-RoBERTa-Large
|
nreimers
| 2021-06-20T19:02:48Z | 26 | 3 |
transformers
|
[
"transformers",
"pytorch",
"roberta",
"fill-mask",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:05Z |
# MiniLMv2
This is a MiniLMv2 model from: [https://github.com/microsoft/unilm](https://github.com/microsoft/unilm/tree/master/minilm)
|
nreimers/MiniLMv2-L6-H768-distilled-from-BERT-Large
|
nreimers
| 2021-06-20T19:02:40Z | 9 | 3 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"fill-mask",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:05Z |
# MiniLMv2
This is a MiniLMv2 model from: [https://github.com/microsoft/unilm](https://github.com/microsoft/unilm/tree/master/minilm)
|
nreimers/MiniLMv2-L6-H768-distilled-from-BERT-Base
|
nreimers
| 2021-06-20T19:02:31Z | 7 | 2 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"fill-mask",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:05Z |
# MiniLMv2
This is a MiniLMv2 model from: [https://github.com/microsoft/unilm](https://github.com/microsoft/unilm/tree/master/minilm)
|
Huffon/sentence-klue-roberta-base
|
Huffon
| 2021-06-20T17:32:17Z | 379 | 9 |
sentence-transformers
|
[
"sentence-transformers",
"pytorch",
"roberta",
"ko",
"dataset:klue",
"arxiv:1908.10084",
"region:us"
] | null | 2022-03-02T23:29:04Z |
---
language: ko
tags:
- roberta
- sentence-transformers
datasets:
- klue
---
# KLUE RoBERTa base model for Sentence Embeddings
This is the `sentence-klue-roberta-base` model. The sentence-transformers repository allows to train and use Transformer models for generating sentence and text embeddings.
The model is described in the paper [Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks](https://arxiv.org/abs/1908.10084)
## Usage (Sentence-Transformers)
Using this model becomes more convenient when you have [sentence-transformers](https://github.com/UKPLab/sentence-transformers) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
import torch
from sentence_transformers import SentenceTransformer, util
model = SentenceTransformer("Huffon/sentence-klue-roberta-base")
docs = [
"1992년 7월 8일 손흥민은 강원도 춘천시 후평동에서 아버지 손웅정과 어머니 길은자의 차남으로 태어나 그곳에서 자랐다.",
"형은 손흥윤이다.",
"춘천 부안초등학교를 졸업했고, 춘천 후평중학교에 입학한 후 2학년때 원주 육민관중학교 축구부에 들어가기 위해 전학하여 졸업하였으며, 2008년 당시 FC 서울의 U-18팀이었던 동북고등학교 축구부에서 선수 활동 중 대한축구협회 우수선수 해외유학 프로젝트에 선발되어 2008년 8월 독일 분데스리가의 함부르크 유소년팀에 입단하였다.",
"함부르크 유스팀 주전 공격수로 2008년 6월 네덜란드에서 열린 4개국 경기에서 4게임에 출전, 3골을 터뜨렸다.",
"1년간의 유학 후 2009년 8월 한국으로 돌아온 후 10월에 개막한 FIFA U-17 월드컵에 출전하여 3골을 터트리며 한국을 8강으로 이끌었다.",
"그해 11월 함부르크의 정식 유소년팀 선수 계약을 체결하였으며 독일 U-19 리그 4경기 2골을 넣고 2군 리그에 출전을 시작했다.",
"독일 U-19 리그에서 손흥민은 11경기 6골, 2부 리그에서는 6경기 1골을 넣으며 재능을 인정받아 2010년 6월 17세의 나이로 함부르크의 1군 팀 훈련에 참가, 프리시즌 활약으로 함부르크와 정식 계약을 한 후 10월 18세에 함부르크 1군 소속으로 독일 분데스리가에 데뷔하였다.",
]
document_embeddings = model.encode(docs)
query = "손흥민은 어린 나이에 유럽에 진출하였다."
query_embedding = model.encode(query)
top_k = min(5, len(docs))
cos_scores = util.pytorch_cos_sim(query_embedding, document_embeddings)[0]
top_results = torch.topk(cos_scores, k=top_k)
print(f"입력 문장: {query}")
print(f"<입력 문장과 유사한 {top_k} 개의 문장>")
for i, (score, idx) in enumerate(zip(top_results[0], top_results[1])):
print(f"{i+1}: {docs[idx]} {'(유사도: {:.4f})'.format(score)}")
```
|
JuliusAlphonso/distilbert-plutchik
|
JuliusAlphonso
| 2021-06-19T22:06:23Z | 421 | 7 |
transformers
|
[
"transformers",
"pytorch",
"distilbert",
"text-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:04Z |
Labels are based on Plutchik's model of emotions and may be combined:

|
prithivida/informal_to_formal_styletransfer
|
prithivida
| 2021-06-19T08:30:19Z | 444 | 8 |
transformers
|
[
"transformers",
"pytorch",
"t5",
"text2text-generation",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-03-02T23:29:05Z |
## This model belongs to the Styleformer project
[Please refer to github page](https://github.com/PrithivirajDamodaran/Styleformer)
|
Dev-DGT/food-dbert-multiling
|
Dev-DGT
| 2021-06-18T21:55:58Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"distilbert",
"token-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-03-02T23:29:04Z |
---
widget:
- text: "El paciente se alimenta de pan, sopa de calabaza y coca-cola"
---
# Token classification for FOODs.
Detects foods in sentences.
Currently, only supports spanish. Multiple words foods are detected as one entity.
## To-do
- English support.
- Negation support.
- Quantity tags.
- Psychosocial tags.
|
huggingtweets/visionify
|
huggingtweets
| 2021-06-18T11:55:54Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/visionify/1624017350891/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1395107998708555776/A8DY6IGM_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">Visionify</div>
<div style="text-align: center; font-size: 14px;">@visionify</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from Visionify.
| Data | Visionify |
| --- | --- |
| Tweets downloaded | 70 |
| Retweets | 8 |
| Short tweets | 1 |
| Tweets kept | 61 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/2wilyf5z/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @visionify's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/3pu4qf1m) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/3pu4qf1m/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/visionify')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
silky/deep-todo
|
silky
| 2021-06-18T08:20:41Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
# deep-todo
Wondering what to do? Not anymore!
Generate arbitrary todo's.
Source: <https://colab.research.google.com/drive/1PlKLrGHaCuvWCKNC4fmQEMElF-iRec9f?usp=sharing>
The todo's come from a random selection of (public) repositories I had on my computer.
### Sample
A bunch of todo's:
```
----------------------------------------------------------------------------------------------------
0: TODO: should we check the other edges?/
1: TODO: add more information here.
2: TODO: We could also add more general functions in this case to avoid/
3: TODO: It seems strange to have the same constructor when the base set of/
4: TODO: This implementation should be simplified, as it's too complex to handle the/
5: TODO: we should be able to relax the intrinsic if not
6: TODO: Make sure this doesn't go through the next generation of plugins. It would be better if this was
7: TODO: There is always a small number of errors when we have this type/
8: TODO: Add support for 't' values (not 't') for all the constant types/
9: TODO: Check that we use loglef_cxx in the loop*
10: TODO: Support double or double values./
11: TODO: Add tests that verify that this function does not work for all targets/
12: TODO: we'd expect the result to be identical to the same value in terms of
13: TODO: We are not using a new type for 'w' as it does not denote 'y' yet, so we could/
14: TODO: if we had to find a way to extract the source file directly, we would/
15: TODO: this should fold into a flat array that would be/
16: TODO: Check if we can make it work with the correct address./
17: TODO: support v2i with V2R4+
18: TODO: Can a fast-math-flags check be generalized to all types of data? */
19: TODO: Add support for other type-specific VOPs.
```
Generated by:
```
tf.random.set_seed(0)
sample_outputs = model.generate(
input_ids,
do_sample=True,
max_length=40,
top_k=50,
top_p=0.95,
num_return_sequences=20
)
print("Output:\\
" + 100 * '-')
for i, sample_output in enumerate(sample_outputs):
m = tokenizer.decode(sample_output, skip_special_tokens=True)
m = m.split("TODO")[1].strip()
print("{}: TODO{}".format(i, m))
```
## TODO
- [ ] Fixup the data; it seems to contain multiple todo's per line
- [ ] Preprocess the data in a better way
- [ ] Download github and train it on everything
|
ethanyt/guwen-sent
|
ethanyt
| 2021-06-18T04:51:54Z | 8 | 4 |
transformers
|
[
"transformers",
"pytorch",
"roberta",
"text-classification",
"chinese",
"classical chinese",
"literary chinese",
"ancient chinese",
"bert",
"sentiment classificatio",
"zh",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
---
language:
- "zh"
thumbnail: "https://user-images.githubusercontent.com/9592150/97142000-cad08e00-179a-11eb-88df-aff9221482d8.png"
tags:
- "chinese"
- "classical chinese"
- "literary chinese"
- "ancient chinese"
- "bert"
- "pytorch"
- "sentiment classificatio"
license: "apache-2.0"
pipeline_tag: "text-classification"
widget:
- text: "滚滚长江东逝水,浪花淘尽英雄"
- text: "寻寻觅觅,冷冷清清,凄凄惨惨戚戚"
- text: "执手相看泪眼,竟无语凝噎,念去去,千里烟波,暮霭沉沉楚天阔。"
- text: "忽如一夜春风来,干树万树梨花开"
---
# Guwen Sent
A Classical Chinese Poem Sentiment Classifier.
See also:
<a href="https://github.com/ethan-yt/guwen-models">
<img align="center" width="400" src="https://github-readme-stats.vercel.app/api/pin/?username=ethan-yt&repo=guwen-models&bg_color=30,e96443,904e95&title_color=fff&text_color=fff&icon_color=fff&show_owner=true" />
</a>
<a href="https://github.com/ethan-yt/cclue/">
<img align="center" width="400" src="https://github-readme-stats.vercel.app/api/pin/?username=ethan-yt&repo=cclue&bg_color=30,e96443,904e95&title_color=fff&text_color=fff&icon_color=fff&show_owner=true" />
</a>
<a href="https://github.com/ethan-yt/guwenbert/">
<img align="center" width="400" src="https://github-readme-stats.vercel.app/api/pin/?username=ethan-yt&repo=guwenbert&bg_color=30,e96443,904e95&title_color=fff&text_color=fff&icon_color=fff&show_owner=true" />
</a>
|
ans/vaccinating-covid-tweets
|
ans
| 2021-06-18T04:12:08Z | 11 | 1 |
transformers
|
[
"transformers",
"pytorch",
"roberta",
"text-classification",
"en",
"dataset:tweets",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
---
language: en
license: apache-2.0
datasets:
- tweets
widget:
- text: "Vaccines to prevent SARS-CoV-2 infection are considered the most promising approach for curbing the pandemic."
---
# Disclaimer: This page is under maintenance. Please DO NOT refer to the information on this page to make any decision yet.
# Vaccinating COVID tweets
A fine-tuned model for fact-classification task on English tweets about COVID-19/vaccine.
## Intended uses & limitations
You can classify if the input tweet (or any others statement) about COVID-19/vaccine is `true`, `false` or `misleading`.
Note that since this model was trained with data up to May 2020, the most recent information may not be reflected.
#### How to use
You can use this model directly on this page or using `transformers` in python.
- Load pipeline and implement with input sequence
```python
from transformers import pipeline
pipe = pipeline("sentiment-analysis", model = "ans/vaccinating-covid-tweets")
seq = "Vaccines to prevent SARS-CoV-2 infection are considered the most promising approach for curbing the pandemic."
pipe(seq)
```
- Expected output
```python
[
{
"label": "false",
"score": 0.07972867041826248
},
{
"label": "misleading",
"score": 0.019911376759409904
},
{
"label": "true",
"score": 0.9003599882125854
}
]
```
- `true` examples
```python
"By the end of 2020, several vaccines had become available for use in different parts of the world."
"Vaccines to prevent SARS-CoV-2 infection are considered the most promising approach for curbing the pandemic."
"RNA vaccines were the first vaccines for SARS-CoV-2 to be produced and represent an entirely new vaccine approach."
```
- `false` examples
```python
"COVID-19 vaccine caused new strain in UK."
```
#### Limitations and bias
To conservatively classify whether an input sequence is true or not, the model may have predictions biased toward `false` or `misleading`.
## Training data & Procedure
#### Pre-trained baseline model
- Pre-trained model: [BERTweet](https://github.com/VinAIResearch/BERTweet)
- trained based on the RoBERTa pre-training procedure
- 850M General English Tweets (Jan 2012 to Aug 2019)
- 23M COVID-19 English Tweets
- Size of the model: >134M parameters
- Further training
- Pre-training with recent COVID-19/vaccine tweets and fine-tuning for fact classification
#### 1) Pre-training language model
- The model was pre-trained on COVID-19/vaccined related tweets using a masked language modeling (MLM) objective starting from BERTweet.
- Following datasets on English tweets were used:
- Tweets with trending #CovidVaccine hashtag, 207,000 tweets uploaded across Aug 2020 to Apr 2021 ([kaggle](https://www.kaggle.com/kaushiksuresh147/covidvaccine-tweets))
- Tweets about all COVID-19 vaccines, 78,000 tweets uploaded across Dec 2020 to May 2021 ([kaggle](https://www.kaggle.com/gpreda/all-covid19-vaccines-tweets))
- COVID-19 Twitter chatter dataset, 590,000 tweets uploaded across Mar 2021 to May 2021 ([github](https://github.com/thepanacealab/covid19_twitter))
#### 2) Fine-tuning for fact classification
- A fine-tuned model from pre-trained language model (1) for fact-classification task on COVID-19/vaccine.
- COVID-19/vaccine-related statements were collected from [Poynter](https://www.poynter.org/ifcn-covid-19-misinformation/) and [Snopes](https://www.snopes.com/) using Selenium resulting in over 14,000 fact-checked statements from Jan 2020 to May 2021.
- Original labels were divided within following three categories:
- `False`: includes false, no evidence, manipulated, fake, not true, unproven and unverified
- `Misleading`: includes misleading, exaggerated, out of context and needs context
- `True`: includes true and correct
## Evaluation results
| Training loss | Validation loss | Training accuracy | Validation accuracy |
| --- | --- | --- | --- |
| 0.1062 | 0.1006 | 96.3% | 94.5% |
# Contributors
- This model is a part of final team project from MLDL for DS class at SNU.
- Team BIBI - Vaccinating COVID-NineTweets
- Team members: Ahn, Hyunju; An, Jiyong; An, Seungchan; Jeong, Seokho; Kim, Jungmin; Kim, Sangbeom
- Advisor: Prof. Wen-Syan Li
<a href="https://gsds.snu.ac.kr/"><img src="https://gsds.snu.ac.kr/wp-content/uploads/sites/50/2021/04/GSDS_logo2-e1619068952717.png" width="200" height="80"></a>
|
danyaljj/gpt2_question_generation_given_paragraph_answer
|
danyaljj
| 2021-06-17T18:27:47Z | 6 | 1 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
Sample usage:
```python
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
model = GPT2LMHeadModel.from_pretrained("danyaljj/gpt2_question_generation_given_paragraph_answer")
input_ids = tokenizer.encode("There are two apples on the counter. A: apples Q:", return_tensors="pt")
outputs = model.generate(input_ids)
print("Generated:", tokenizer.decode(outputs[0], skip_special_tokens=True))
```
Which should produce this:
```
Generated: There are two apples on the counter. A: apples Q: What is the name of the counter
```
|
danyaljj/gpt2_question_generation_given_paragraph
|
danyaljj
| 2021-06-17T18:23:28Z | 13 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
Sample usage:
```python
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
model = GPT2LMHeadModel.from_pretrained("danyaljj/gpt2_question_generation_given_paragraph")
input_ids = tokenizer.encode("There are two apples on the counter. Q:", return_tensors="pt")
outputs = model.generate(input_ids)
print("Generated:", tokenizer.decode(outputs[0], skip_special_tokens=True))
```
Which should produce this:
```
Generated: There are two apples on the counter. Q: What is the name of the counter that is on
```
|
Davlan/bert-base-multilingual-cased-finetuned-luganda
|
Davlan
| 2021-06-17T17:43:07Z | 11 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"fill-mask",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:04Z |
Hugging Face's logo
---
language: lg
datasets:
---
# bert-base-multilingual-cased-finetuned-luganda
## Model description
**bert-base-multilingual-cased-finetuned-luganda** is a **Luganda BERT** model obtained by fine-tuning **bert-base-multilingual-cased** model on Luganda language texts. It provides **better performance** than the multilingual BERT on text classification and named entity recognition datasets.
Specifically, this model is a *bert-base-multilingual-cased* model that was fine-tuned on Luganda corpus.
## Intended uses & limitations
#### How to use
You can use this model with Transformers *pipeline* for masked token prediction.
```python
>>> from transformers import pipeline
>>> unmasker = pipeline('fill-mask', model='Davlan/bert-base-multilingual-cased-finetuned-luganda')
>>> unmasker("Ffe tulwanyisa abo abaagala okutabangula [MASK], Kimuli bwe yategeezezza.")
```
#### Limitations and bias
This model is limited by its training dataset of entity-annotated news articles from a specific span of time. This may not generalize well for all use cases in different domains.
## Training data
This model was fine-tuned on JW300 + [BUKKEDDE](https://github.com/masakhane-io/masakhane-ner/tree/main/text_by_language/luganda) +[Luganda CC-100](http://data.statmt.org/cc-100/)
## Training procedure
This model was trained on a single NVIDIA V100 GPU
## Eval results on Test set (F-score, average over 5 runs)
Dataset| mBERT F1 | lg_bert F1
-|-|-
[MasakhaNER](https://github.com/masakhane-io/masakhane-ner) | 80.36 | 84.70
### BibTeX entry and citation info
By David Adelani
```
```
|
Kalindu/SinBerto
|
Kalindu
| 2021-06-17T16:37:19Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"roberta",
"fill-mask",
"SinBERTo",
"Sinhala",
"si",
"arxiv:1907.11692",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:04Z |
---
language: si
tags:
- SinBERTo
- Sinhala
- roberta
---
### Overview
SinBerto is a small language model trained on a small news corpus. SinBerto is trained on Sinhala Language which is a low resource language compared to other languages.
### Model Specifications.
model : [Roberta](https://arxiv.org/abs/1907.11692)
vocab_size=52_000,
max_position_embeddings=514,
num_attention_heads=12,
num_hidden_layers=6,
type_vocab_size=1
### How to use from the Transformers Library
from transformers import AutoTokenizer, AutoModelForMaskedLM
tokenizer = AutoTokenizer.from_pretrained("Kalindu/SinBerto")
model = AutoModelForMaskedLM.from_pretrained("Kalindu/SinBerto")
### OR Clone the model repo
git lfs install
git clone https://huggingface.co/Kalindu/SinBerto
|
ethanyt/guwen-ner
|
ethanyt
| 2021-06-17T09:23:09Z | 59 | 5 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"roberta",
"token-classification",
"chinese",
"classical chinese",
"literary chinese",
"ancient chinese",
"bert",
"zh",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-03-02T23:29:05Z |
---
language:
- "zh"
thumbnail: "https://user-images.githubusercontent.com/9592150/97142000-cad08e00-179a-11eb-88df-aff9221482d8.png"
tags:
- "chinese"
- "classical chinese"
- "literary chinese"
- "ancient chinese"
- "bert"
- "pytorch"
license: "apache-2.0"
pipeline_tag: "token-classification"
widget:
- text: "及秦始皇,灭先代典籍,焚书坑儒,天下学士逃难解散,我先人用藏其家书于屋壁。汉室龙兴,开设学校,旁求儒雅,以阐大猷。济南伏生,年过九十,失其本经,口以传授,裁二十馀篇,以其上古之书,谓之尚书。百篇之义,世莫得闻。"
---
# Guwen NER
A Classical Chinese Named Entity Recognizer.
Note: There are some problems with decoding using the default sequence classification model. Use the CRF model to achieve the best results. CRF related code please refer to
[Guwen Models](https://github.com/ethan-yt/guwen-models).
See also:
<a href="https://github.com/ethan-yt/guwen-models">
<img align="center" width="400" src="https://github-readme-stats.vercel.app/api/pin/?username=ethan-yt&repo=guwen-models&bg_color=30,e96443,904e95&title_color=fff&text_color=fff&icon_color=fff&show_owner=true" />
</a>
<a href="https://github.com/ethan-yt/cclue/">
<img align="center" width="400" src="https://github-readme-stats.vercel.app/api/pin/?username=ethan-yt&repo=cclue&bg_color=30,e96443,904e95&title_color=fff&text_color=fff&icon_color=fff&show_owner=true" />
</a>
<a href="https://github.com/ethan-yt/guwenbert/">
<img align="center" width="400" src="https://github-readme-stats.vercel.app/api/pin/?username=ethan-yt&repo=guwenbert&bg_color=30,e96443,904e95&title_color=fff&text_color=fff&icon_color=fff&show_owner=true" />
</a>
|
ethanyt/guwen-quote
|
ethanyt
| 2021-06-17T08:22:56Z | 10 | 1 |
transformers
|
[
"transformers",
"pytorch",
"roberta",
"token-classification",
"chinese",
"classical chinese",
"literary chinese",
"ancient chinese",
"bert",
"quotation detection",
"zh",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-03-02T23:29:05Z |
---
language:
- "zh"
thumbnail: "https://user-images.githubusercontent.com/9592150/97142000-cad08e00-179a-11eb-88df-aff9221482d8.png"
tags:
- "chinese"
- "classical chinese"
- "literary chinese"
- "ancient chinese"
- "bert"
- "pytorch"
- "quotation detection"
license: "apache-2.0"
pipeline_tag: "token-classification"
widget:
- text: "子曰学而时习之不亦说乎有朋自远方来不亦乐乎人不知而不愠不亦君子乎有子曰其为人也孝弟而好犯上者鲜矣不好犯上而好作乱者未之有也君子务本本立而道生孝弟也者其为仁之本与子曰巧言令色鲜矣仁曾子曰吾日三省吾身为人谋而不忠乎与朋友交而不信乎传不习乎子曰道千乘之国敬事而信节用而爱人使民以时"
---
# Guwen Quote
A Classical Chinese Quotation Detector.
Note: There are some problems with decoding using the default sequence classification model. Use the CRF model to achieve the best results. CRF related code please refer to
[Guwen Models](https://github.com/ethan-yt/guwen-models).
See also:
<a href="https://github.com/ethan-yt/guwen-models">
<img align="center" width="400" src="https://github-readme-stats.vercel.app/api/pin/?username=ethan-yt&repo=guwen-models&bg_color=30,e96443,904e95&title_color=fff&text_color=fff&icon_color=fff&show_owner=true" />
</a>
<a href="https://github.com/ethan-yt/cclue/">
<img align="center" width="400" src="https://github-readme-stats.vercel.app/api/pin/?username=ethan-yt&repo=cclue&bg_color=30,e96443,904e95&title_color=fff&text_color=fff&icon_color=fff&show_owner=true" />
</a>
<a href="https://github.com/ethan-yt/guwenbert/">
<img align="center" width="400" src="https://github-readme-stats.vercel.app/api/pin/?username=ethan-yt&repo=guwenbert&bg_color=30,e96443,904e95&title_color=fff&text_color=fff&icon_color=fff&show_owner=true" />
</a>
|
huggingtweets/thinktilt
|
huggingtweets
| 2021-06-17T00:28:38Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/thinktilt/1623889617116/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1331032413342892037/Bubd_ZWy_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">ThinkTilt (ProForma for Jira)</div>
<div style="text-align: center; font-size: 14px;">@thinktilt</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from ThinkTilt (ProForma for Jira).
| Data | ThinkTilt (ProForma for Jira) |
| --- | --- |
| Tweets downloaded | 2707 |
| Retweets | 105 |
| Short tweets | 27 |
| Tweets kept | 2575 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/2slt58js/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @thinktilt's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/3qy43zlw) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/3qy43zlw/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/thinktilt')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
ScottaStrong/DialogGPT-small-joshua
|
ScottaStrong
| 2021-06-16T21:40:45Z | 7 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"conversational",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:04Z |
---
thumbnail: https://huggingface.co/front/thumbnails/dialogpt.png
tags:
- conversational
license: mit
---
# DialoGPT Trained on the Speech of a Game Character
This is an instance of [microsoft/DialoGPT-medium](https://huggingface.co/microsoft/DialoGPT-medium) trained on a game character, Joshua from [The World Ends With You](https://en.wikipedia.org/wiki/The_World_Ends_with_You). The data comes from [a Kaggle game script dataset](https://www.kaggle.com/ruolinzheng/twewy-game-script).
I built a Discord AI chatbot based on this model. [Check out my GitHub repo.](https://github.com/RuolinZheng08/twewy-discord-chatbot)
Chat with the model:
```python
from transformers import AutoTokenizer, AutoModelWithLMHead
tokenizer = AutoTokenizer.from_pretrained("scottastrong/DialogGPT-small-joshua")
model = AutoModelWithLMHead.from_pretrained("scottastrong/DialogGPT-small-joshua")
# Let's chat for 4 lines
for step in range(4):
# encode the new user input, add the eos_token and return a tensor in Pytorch
new_user_input_ids = tokenizer.encode(input(">> User:") + tokenizer.eos_token, return_tensors='pt')
# print(new_user_input_ids)
# append the new user input tokens to the chat history
bot_input_ids = torch.cat([chat_history_ids, new_user_input_ids], dim=-1) if step > 0 else new_user_input_ids
# generated a response while limiting the total chat history to 1000 tokens,
chat_history_ids = model.generate(
bot_input_ids, max_length=200,
pad_token_id=tokenizer.eos_token_id,
no_repeat_ngram_size=3,
do_sample=True,
top_k=100,
top_p=0.7,
temperature=0.8
)
# pretty print last ouput tokens from bot
print("JoshuaBot: {}".format(tokenizer.decode(chat_history_ids[:, bot_input_ids.shape[-1]:][0], skip_special_tokens=True)))
```
|
danyaljj/opengpt2_pytorch_forward
|
danyaljj
| 2021-06-16T20:30:01Z | 4 | 1 |
transformers
|
[
"transformers",
"pytorch",
"endpoints_compatible",
"region:us"
] | null | 2022-03-02T23:29:05Z |
West et al.'s model from their "reflective decoding" paper.
Sample usage:
```python
import torch
from modeling_opengpt2 import OpenGPT2LMHeadModel
from padded_encoder import Encoder
path_to_forward = 'danyaljj/opengpt2_pytorch_forward'
encoder = Encoder()
model_backward = OpenGPT2LMHeadModel.from_pretrained(path_to_forward)
input = "She tried to win but"
input_ids = encoder.encode(input)
input_ids = torch.tensor([input_ids ], dtype=torch.int)
print(input_ids)
output = model_backward.generate(input_ids)
output_text = encoder.decode(output.tolist()[0])
print(output_text)
```
Download the additional files from here: https://github.com/peterwestuw/GPT2ForwardBackward
|
IlyaGusev/news_tg_rubert
|
IlyaGusev
| 2021-06-16T19:43:26Z | 39 | 0 |
transformers
|
[
"transformers",
"pytorch",
"ru",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2022-03-02T23:29:04Z |
---
language:
- ru
license: apache-2.0
---
# NewsTgRuBERT
Training script: https://github.com/dialogue-evaluation/Russian-News-Clustering-and-Headline-Generation/blob/main/train_mlm.py
|
m3hrdadfi/typo-detector-distilbert-en
|
m3hrdadfi
| 2021-06-16T16:14:20Z | 22,410 | 10 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"distilbert",
"token-classification",
"en",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-03-02T23:29:05Z |
---
language: en
widget:
- text: "He had also stgruggled with addiction during his time in Congress ."
- text: "The review thoroughla assessed all aspects of JLENS SuR and CPG esign maturit and confidence ."
- text: "Letterma also apologized two his staff for the satyation ."
- text: "Vincent Jay had earlier won France 's first gold in gthe 10km biathlon sprint ."
- text: "It is left to the directors to figure out hpw to bring the stry across to tye audience ."
---
# Typo Detector
## Dataset Information
For this specific task, I used [NeuSpell](https://github.com/neuspell/neuspell) corpus as my raw data.
## Evaluation
The following tables summarize the scores obtained by model overall and per each class.
| # | precision | recall | f1-score | support |
|:------------:|:---------:|:--------:|:--------:|:--------:|
| TYPO | 0.992332 | 0.985997 | 0.989154 | 416054.0 |
| micro avg | 0.992332 | 0.985997 | 0.989154 | 416054.0 |
| macro avg | 0.992332 | 0.985997 | 0.989154 | 416054.0 |
| weighted avg | 0.992332 | 0.985997 | 0.989154 | 416054.0 |
## How to use
You use this model with Transformers pipeline for NER (token-classification).
### Installing requirements
```bash
pip install transformers
```
### Prediction using pipeline
```python
import torch
from transformers import AutoConfig, AutoTokenizer, AutoModelForTokenClassification
from transformers import pipeline
model_name_or_path = "m3hrdadfi/typo-detector-distilbert-en"
config = AutoConfig.from_pretrained(model_name_or_path)
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path)
model = AutoModelForTokenClassification.from_pretrained(model_name_or_path, config=config)
nlp = pipeline('token-classification', model=model, tokenizer=tokenizer, aggregation_strategy="average")
```
```python
sentences = [
"He had also stgruggled with addiction during his time in Congress .",
"The review thoroughla assessed all aspects of JLENS SuR and CPG esign maturit and confidence .",
"Letterma also apologized two his staff for the satyation .",
"Vincent Jay had earlier won France 's first gold in gthe 10km biathlon sprint .",
"It is left to the directors to figure out hpw to bring the stry across to tye audience .",
]
for sentence in sentences:
typos = [sentence[r["start"]: r["end"]] for r in nlp(sentence)]
detected = sentence
for typo in typos:
detected = detected.replace(typo, f'<i>{typo}</i>')
print(" [Input]: ", sentence)
print("[Detected]: ", detected)
print("-" * 130)
```
Output:
```text
[Input]: He had also stgruggled with addiction during his time in Congress .
[Detected]: He had also <i>stgruggled</i> with addiction during his time in Congress .
----------------------------------------------------------------------------------------------------------------------------------
[Input]: The review thoroughla assessed all aspects of JLENS SuR and CPG esign maturit and confidence .
[Detected]: The review <i>thoroughla</i> assessed all aspects of JLENS SuR and CPG <i>esign</i> <i>maturit</i> and confidence .
----------------------------------------------------------------------------------------------------------------------------------
[Input]: Letterma also apologized two his staff for the satyation .
[Detected]: <i>Letterma</i> also apologized <i>two</i> his staff for the <i>satyation</i> .
----------------------------------------------------------------------------------------------------------------------------------
[Input]: Vincent Jay had earlier won France 's first gold in gthe 10km biathlon sprint .
[Detected]: Vincent Jay had earlier won France 's first gold in <i>gthe</i> 10km biathlon sprint .
----------------------------------------------------------------------------------------------------------------------------------
[Input]: It is left to the directors to figure out hpw to bring the stry across to tye audience .
[Detected]: It is left to the directors to figure out <i>hpw</i> to bring the <i>stry</i> across to <i>tye</i> audience .
----------------------------------------------------------------------------------------------------------------------------------
```
## Questions?
Post a Github issue on the [TypoDetector Issues](https://github.com/m3hrdadfi/typo-detector/issues) repo.
|
madlag/bert-base-uncased-squadv1-x1.16-f88.1-d8-unstruct-v1
|
madlag
| 2021-06-16T15:03:46Z | 72 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"bert",
"question-answering",
"en",
"dataset:squad",
"license:mit",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail:
license: mit
tags:
- question-answering
-
-
datasets:
- squad
metrics:
- squad
widget:
- text: "Where is the Eiffel Tower located?"
context: "The Eiffel Tower is a wrought-iron lattice tower on the Champ de Mars in Paris, France. It is named after the engineer Gustave Eiffel, whose company designed and built the tower."
- text: "Who is Frederic Chopin?"
context: "Frédéric François Chopin, born Fryderyk Franciszek Chopin (1 March 1810 – 17 October 1849), was a Polish composer and virtuoso pianist of the Romantic era who wrote primarily for solo piano."
---
## BERT-base uncased model fine-tuned on SQuAD v1
This model was created using the [nn_pruning](https://github.com/huggingface/nn_pruning) python library: the **linear layers contains 8.0%** of the original weights.
The model contains **28.0%** of the original weights **overall** (the embeddings account for a significant part of the model, and they are not pruned by this method).
With a simple resizing of the linear matrices it ran **1.16x as fast as bert-base-uncased** on the evaluation.
This is possible because the pruning method lead to structured matrices: to visualize them, hover below on the plot to see the non-zero/zero parts of each matrix.
<div class="graph"><script src="/madlag/bert-base-uncased-squadv1-x1.16-f88.1-d8-unstruct-v1/raw/main/model_card/density_info.js" id="c60d09ec-81ff-4d6f-b616-c3ef09b2175d"></script></div>
In terms of accuracy, its **F1 is 88.11**, compared with 88.5 for bert-base-uncased, a **F1 drop of 0.39**.
## Fine-Pruning details
This model was fine-tuned from the HuggingFace [model](https://huggingface.co/bert-base-uncased) checkpoint on [SQuAD1.1](https://rajpurkar.github.io/SQuAD-explorer), and distilled from the model [bert-large-uncased-whole-word-masking-finetuned-squad](https://huggingface.co/bert-large-uncased-whole-word-masking-finetuned-squad)
This model is case-insensitive: it does not make a difference between english and English.
A side-effect of the block pruning is that some of the attention heads are completely removed: 22 heads were removed on a total of 144 (15.3%).
Here is a detailed view on how the remaining heads are distributed in the network after pruning.
<div class="graph"><script src="/madlag/bert-base-uncased-squadv1-x1.16-f88.1-d8-unstruct-v1/raw/main/model_card/pruning_info.js" id="55528c8b-d5f5-46a5-a35a-dad93725f7e5"></script></div>
## Details of the SQuAD1.1 dataset
| Dataset | Split | # samples |
| -------- | ----- | --------- |
| SQuAD1.1 | train | 90.6K |
| SQuAD1.1 | eval | 11.1k |
### Fine-tuning
- Python: `3.8.5`
- Machine specs:
```CPU: Intel(R) Core(TM) i7-6700K CPU
Memory: 64 GiB
GPUs: 1 GeForce GTX 3090, with 24GiB memory
GPU driver: 455.23.05, CUDA: 11.1
```
### Results
**Pytorch model file size**: `398MB` (original BERT: `420MB`)
| Metric | # Value | # Original ([Table 2](https://www.aclweb.org/anthology/N19-1423.pdf))| Variation |
| ------ | --------- | --------- | --------- |
| **EM** | **80.94** | **80.8** | **+0.14**|
| **F1** | **88.11** | **88.5** | **-0.39**|
## Example Usage
Install nn_pruning: it contains the optimization script, which just pack the linear layers into smaller ones by removing empty rows/columns.
`pip install nn_pruning`
Then you can use the `transformers library` almost as usual: you just have to call `optimize_model` when the pipeline has loaded.
```python
from transformers import pipeline
from nn_pruning.inference_model_patcher import optimize_model
qa_pipeline = pipeline(
"question-answering",
model="madlag/bert-base-uncased-squadv1-x1.16-f88.1-d8-unstruct-v1",
tokenizer="madlag/bert-base-uncased-squadv1-x1.16-f88.1-d8-unstruct-v1"
)
print("bert-base-uncased parameters: 152.0M")
print(f"Parameters count (includes only head pruning, not feed forward pruning)={int(qa_pipeline.model.num_parameters() / 1E6)}M")
qa_pipeline.model = optimize_model(qa_pipeline.model, "dense")
print(f"Parameters count after complete optimization={int(qa_pipeline.model.num_parameters() / 1E6)}M")
predictions = qa_pipeline({
'context': "Frédéric François Chopin, born Fryderyk Franciszek Chopin (1 March 1810 – 17 October 1849), was a Polish composer and virtuoso pianist of the Romantic era who wrote primarily for solo piano.",
'question': "Who is Frederic Chopin?",
})
print("Predictions", predictions)
```
|
AgentPublic/dpr-ctx_encoder-fr_qa-camembert
|
AgentPublic
| 2021-06-16T11:22:59Z | 17 | 5 |
transformers
|
[
"transformers",
"pytorch",
"camembert",
"fr",
"dataset:piaf",
"dataset:FQuAD",
"dataset:SQuAD-FR",
"arxiv:2004.04906",
"arxiv:1911.03894",
"endpoints_compatible",
"region:us"
] | null | 2022-03-02T23:29:05Z |
---
language: fr
datasets:
- piaf
- FQuAD
- SQuAD-FR
---
# dpr-ctx_encoder-fr_qa-camembert
## Description
French [DPR model](https://arxiv.org/abs/2004.04906) using [CamemBERT](https://arxiv.org/abs/1911.03894) as base and then fine-tuned on a combo of three French Q&A
## Data
### French Q&A
We use a combination of three French Q&A datasets:
1. [PIAFv1.1](https://www.data.gouv.fr/en/datasets/piaf-le-dataset-francophone-de-questions-reponses/)
2. [FQuADv1.0](https://fquad.illuin.tech/)
3. [SQuAD-FR (SQuAD automatically translated to French)](https://github.com/Alikabbadj/French-SQuAD)
### Training
We are using 90 562 random questions for `train` and 22 391 for `dev`. No question in `train` exists in `dev`. For each question, we have a single `positive_context` (the paragraph where the answer to this question is found) and around 30 `hard_negtive_contexts`. Hard negative contexts are found by querying an ES instance (via bm25 retrieval) and getting the top-k candidates **that do not contain the answer**.
The files are over [here](https://drive.google.com/file/d/1W5Jm3sqqWlsWsx2sFpA39Ewn33PaLQ7U/view?usp=sharing).
### Evaluation
We use FQuADv1.0 and French-SQuAD evaluation sets.
## Training Script
We use the official [Facebook DPR implentation](https://github.com/facebookresearch/DPR) with a slight modification: by default, the code can work with Roberta models, still we changed a single line to make it easier to work with Camembert. This modification can be found [over here](https://github.com/psorianom/DPR).
### Hyperparameters
```shell
python -m torch.distributed.launch --nproc_per_node=8 train_dense_encoder.py \
--max_grad_norm 2.0 \
--encoder_model_type fairseq_roberta \
--pretrained_file data/camembert-base \
--seed 12345 \
--sequence_length 256 \
--warmup_steps 1237 \
--batch_size 16 \
--do_lower_case \
--train_file ./data/DPR_FR_train.json \
--dev_file ./data/DPR_FR_dev.json \
--output_dir ./output/ \
--learning_rate 2e-05 \
--num_train_epochs 35 \
--dev_batch_size 16 \
--val_av_rank_start_epoch 30 \
--pretrained_model_cfg ./data/camembert-base/
```
###
## Evaluation results
We obtain the following evaluation by using FQuAD and SQuAD-FR evaluation (or validation) sets. To obtain these results, we use [haystack's evaluation script](https://github.com/deepset-ai/haystack/blob/db4151bbc026f27c6d709fefef1088cd3f1e18b9/tutorials/Tutorial5_Evaluation.py) (**we report Retrieval results only**).
### DPR
#### FQuAD v1.0 Evaluation
```shell
For 2764 out of 3184 questions (86.81%), the answer was in the top-20 candidate passages selected by the retriever.
Retriever Recall: 0.87
Retriever Mean Avg Precision: 0.57
```
#### SQuAD-FR Evaluation
```shell
For 8945 out of 10018 questions (89.29%), the answer was in the top-20 candidate passages selected by the retriever.
Retriever Recall: 0.89
Retriever Mean Avg Precision: 0.63
```
### BM25
For reference, BM25 gets the results shown below. As in the original paper, regarding SQuAD-like datasets, the results of DPR are consistently superseeded by BM25.
#### FQuAD v1.0 Evaluation
```shell
For 2966 out of 3184 questions (93.15%), the answer was in the top-20 candidate passages selected by the retriever.
Retriever Recall: 0.93
Retriever Mean Avg Precision: 0.74
```
#### SQuAD-FR Evaluation
```shell
For 9353 out of 10018 questions (93.36%), the answer was in the top-20 candidate passages selected by the retriever.
Retriever Recall: 0.93
Retriever Mean Avg Precision: 0.77
```
## Usage
The results reported here are obtained with the `haystack` library. To get to similar embeddings using exclusively HF `transformers` library, you can do the following:
```python
from transformers import AutoTokenizer, AutoModel
query = "Salut, mon chien est-il mignon ?"
tokenizer = AutoTokenizer.from_pretrained("etalab-ia/dpr-ctx_encoder-fr_qa-camembert", do_lower_case=True)
input_ids = tokenizer(query, return_tensors='pt')["input_ids"]
model = AutoModel.from_pretrained("etalab-ia/dpr-ctx_encoder-fr_qa-camembert", return_dict=True)
embeddings = model.forward(input_ids).pooler_output
print(embeddings)
```
And with `haystack`, we use it as a retriever:
```
retriever = DensePassageRetriever(
document_store=document_store,
query_embedding_model="etalab-ia/dpr-question_encoder-fr_qa-camembert",
passage_embedding_model="etalab-ia/dpr-ctx_encoder-fr_qa-camembert",
model_version=dpr_model_tag,
infer_tokenizer_classes=True,
)
```
## Acknowledgments
This work was performed using HPC resources from GENCI–IDRIS (Grant 2020-AD011011224).
## Citations
### Datasets
#### PIAF
```
@inproceedings{KeraronLBAMSSS20,
author = {Rachel Keraron and
Guillaume Lancrenon and
Mathilde Bras and
Fr{\'{e}}d{\'{e}}ric Allary and
Gilles Moyse and
Thomas Scialom and
Edmundo{-}Pavel Soriano{-}Morales and
Jacopo Staiano},
title = {Project {PIAF:} Building a Native French Question-Answering Dataset},
booktitle = {{LREC}},
pages = {5481--5490},
publisher = {European Language Resources Association},
year = {2020}
}
```
#### FQuAD
```
@article{dHoffschmidt2020FQuADFQ,
title={FQuAD: French Question Answering Dataset},
author={Martin d'Hoffschmidt and Maxime Vidal and Wacim Belblidia and Tom Brendl'e and Quentin Heinrich},
journal={ArXiv},
year={2020},
volume={abs/2002.06071}
}
```
#### SQuAD-FR
```
@MISC{kabbadj2018,
author = "Kabbadj, Ali",
title = "Something new in French Text Mining and Information Extraction (Universal Chatbot): Largest Q&A French training dataset (110 000+) ",
editor = "linkedin.com",
month = "November",
year = "2018",
url = "\url{https://www.linkedin.com/pulse/something-new-french-text-mining-information-chatbot-largest-kabbadj/}",
note = "[Online; posted 11-November-2018]",
}
```
### Models
#### CamemBERT
HF model card : [https://huggingface.co/camembert-base](https://huggingface.co/camembert-base)
```
@inproceedings{martin2020camembert,
title={CamemBERT: a Tasty French Language Model},
author={Martin, Louis and Muller, Benjamin and Su{\'a}rez, Pedro Javier Ortiz and Dupont, Yoann and Romary, Laurent and de la Clergerie, {\'E}ric Villemonte and Seddah, Djam{\'e} and Sagot, Beno{\^\i}t},
booktitle={Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics},
year={2020}
}
```
#### DPR
```
@misc{karpukhin2020dense,
title={Dense Passage Retrieval for Open-Domain Question Answering},
author={Vladimir Karpukhin and Barlas Oğuz and Sewon Min and Patrick Lewis and Ledell Wu and Sergey Edunov and Danqi Chen and Wen-tau Yih},
year={2020},
eprint={2004.04906},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
|
AgentPublic/dpr-question_encoder-fr_qa-camembert
|
AgentPublic
| 2021-06-16T10:10:09Z | 37 | 8 |
transformers
|
[
"transformers",
"pytorch",
"camembert",
"feature-extraction",
"fr",
"dataset:piaf",
"dataset:FQuAD",
"dataset:SQuAD-FR",
"arxiv:2004.04906",
"arxiv:1911.03894",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
feature-extraction
| 2022-03-02T23:29:05Z |
---
language: fr
datasets:
- piaf
- FQuAD
- SQuAD-FR
---
# dpr-question_encoder-fr_qa-camembert
## Description
French [DPR model](https://arxiv.org/abs/2004.04906) using [CamemBERT](https://arxiv.org/abs/1911.03894) as base and then fine-tuned on a combo of three French Q&A
## Data
### French Q&A
We use a combination of three French Q&A datasets:
1. [PIAFv1.1](https://www.data.gouv.fr/en/datasets/piaf-le-dataset-francophone-de-questions-reponses/)
2. [FQuADv1.0](https://fquad.illuin.tech/)
3. [SQuAD-FR (SQuAD automatically translated to French)](https://github.com/Alikabbadj/French-SQuAD)
### Training
We are using 90 562 random questions for `train` and 22 391 for `dev`. No question in `train` exists in `dev`. For each question, we have a single `positive_context` (the paragraph where the answer to this question is found) and around 30 `hard_negtive_contexts`. Hard negative contexts are found by querying an ES instance (via bm25 retrieval) and getting the top-k candidates **that do not contain the answer**.
The files are over [here](https://drive.google.com/file/d/1W5Jm3sqqWlsWsx2sFpA39Ewn33PaLQ7U/view?usp=sharing).
### Evaluation
We use FQuADv1.0 and French-SQuAD evaluation sets.
## Training Script
We use the official [Facebook DPR implentation](https://github.com/facebookresearch/DPR) with a slight modification: by default, the code can work with Roberta models, still we changed a single line to make it easier to work with Camembert. This modification can be found [over here](https://github.com/psorianom/DPR).
### Hyperparameters
```shell
python -m torch.distributed.launch --nproc_per_node=8 train_dense_encoder.py \
--max_grad_norm 2.0 --encoder_model_type hf_bert --pretrained_file data/bert-base-multilingual-uncased \
--seed 12345 --sequence_length 256 --warmup_steps 1237 --batch_size 16 --do_lower_case \
--train_file DPR_FR_train.json \
--dev_file ./data/100_hard_neg_ctxs/DPR_FR_dev.json \
--output_dir ./output/bert --learning_rate 2e-05 --num_train_epochs 35 \
--dev_batch_size 16 --val_av_rank_start_epoch 25 \
--pretrained_model_cfg ./data/bert-base-multilingual-uncased
```
###
## Evaluation results
We obtain the following evaluation by using FQuAD and SQuAD-FR evaluation (or validation) sets. To obtain these results, we use [haystack's evaluation script](https://github.com/deepset-ai/haystack/blob/db4151bbc026f27c6d709fefef1088cd3f1e18b9/tutorials/Tutorial5_Evaluation.py) (**we report Retrieval results only**).
### DPR
#### FQuAD v1.0 Evaluation
```shell
For 2764 out of 3184 questions (86.81%), the answer was in the top-20 candidate passages selected by the retriever.
Retriever Recall: 0.87
Retriever Mean Avg Precision: 0.57
```
#### SQuAD-FR Evaluation
```shell
For 8945 out of 10018 questions (89.29%), the answer was in the top-20 candidate passages selected by the retriever.
Retriever Recall: 0.89
Retriever Mean Avg Precision: 0.63
```
### BM25
For reference, BM25 gets the results shown below. As in the original paper, regarding SQuAD-like datasets, the results of DPR are consistently superseeded by BM25.
#### FQuAD v1.0 Evaluation
```shell
For 2966 out of 3184 questions (93.15%), the answer was in the top-20 candidate passages selected by the retriever.
Retriever Recall: 0.93
Retriever Mean Avg Precision: 0.74
```
#### SQuAD-FR Evaluation
```shell
For 9353 out of 10018 questions (93.36%), the answer was in the top-20 candidate passages selected by the retriever.
Retriever Recall: 0.93
Retriever Mean Avg Precision: 0.77
```
## Usage
The results reported here are obtained with the `haystack` library. To get to similar embeddings using exclusively HF `transformers` library, you can do the following:
```python
from transformers import AutoTokenizer, AutoModel
query = "Salut, mon chien est-il mignon ?"
tokenizer = AutoTokenizer.from_pretrained("etalab-ia/dpr-question_encoder-fr_qa-camembert", do_lower_case=True)
input_ids = tokenizer(query, return_tensors='pt')["input_ids"]
model = AutoModel.from_pretrained("etalab-ia/dpr-question_encoder-fr_qa-camembert", return_dict=True)
embeddings = model.forward(input_ids).pooler_output
print(embeddings)
```
And with `haystack`, we use it as a retriever:
```
retriever = DensePassageRetriever(
document_store=document_store,
query_embedding_model="etalab-ia/dpr-question_encoder-fr_qa-camembert",
passage_embedding_model="etalab-ia/dpr-ctx_encoder-fr_qa-camembert",
model_version=dpr_model_tag,
infer_tokenizer_classes=True,
)
```
## Acknowledgments
This work was performed using HPC resources from GENCI–IDRIS (Grant 2020-AD011011224).
## Citations
### Datasets
#### PIAF
```
@inproceedings{KeraronLBAMSSS20,
author = {Rachel Keraron and
Guillaume Lancrenon and
Mathilde Bras and
Fr{\'{e}}d{\'{e}}ric Allary and
Gilles Moyse and
Thomas Scialom and
Edmundo{-}Pavel Soriano{-}Morales and
Jacopo Staiano},
title = {Project {PIAF:} Building a Native French Question-Answering Dataset},
booktitle = {{LREC}},
pages = {5481--5490},
publisher = {European Language Resources Association},
year = {2020}
}
```
#### FQuAD
```
@article{dHoffschmidt2020FQuADFQ,
title={FQuAD: French Question Answering Dataset},
author={Martin d'Hoffschmidt and Maxime Vidal and Wacim Belblidia and Tom Brendl'e and Quentin Heinrich},
journal={ArXiv},
year={2020},
volume={abs/2002.06071}
}
```
#### SQuAD-FR
```
@MISC{kabbadj2018,
author = "Kabbadj, Ali",
title = "Something new in French Text Mining and Information Extraction (Universal Chatbot): Largest Q&A French training dataset (110 000+) ",
editor = "linkedin.com",
month = "November",
year = "2018",
url = "\url{https://www.linkedin.com/pulse/something-new-french-text-mining-information-chatbot-largest-kabbadj/}",
note = "[Online; posted 11-November-2018]",
}
```
### Models
#### CamemBERT
HF model card : [https://huggingface.co/camembert-base](https://huggingface.co/camembert-base)
```
@inproceedings{martin2020camembert,
title={CamemBERT: a Tasty French Language Model},
author={Martin, Louis and Muller, Benjamin and Su{\'a}rez, Pedro Javier Ortiz and Dupont, Yoann and Romary, Laurent and de la Clergerie, {\'E}ric Villemonte and Seddah, Djam{\'e} and Sagot, Beno{\^\i}t},
booktitle={Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics},
year={2020}
}
```
#### DPR
```
@misc{karpukhin2020dense,
title={Dense Passage Retrieval for Open-Domain Question Answering},
author={Vladimir Karpukhin and Barlas Oğuz and Sewon Min and Patrick Lewis and Ledell Wu and Sergey Edunov and Danqi Chen and Wen-tau Yih},
year={2020},
eprint={2004.04906},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
|
huggingtweets/onlinepete-sematarygravemn-superpiss
|
huggingtweets
| 2021-06-16T09:25:28Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/onlinepete-sematarygravemn-superpiss/1623835524372/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1077258168315473920/b8-3h6l4_400x400.jpg')">
</div>
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/456958582731603969/QZKpv6eI_400x400.jpeg')">
</div>
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1364495290833637382/kqjmEF5A_400x400.jpg')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI CYBORG 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">xbox 720 & im pete online & SEMATARY GRAVE MAN ✟ ✟ ✟</div>
<div style="text-align: center; font-size: 14px;">@onlinepete-sematarygravemn-superpiss</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from xbox 720 & im pete online & SEMATARY GRAVE MAN ✟ ✟ ✟.
| Data | xbox 720 | im pete online | SEMATARY GRAVE MAN ✟ ✟ ✟ |
| --- | --- | --- | --- |
| Tweets downloaded | 199 | 3188 | 517 |
| Retweets | 0 | 92 | 67 |
| Short tweets | 7 | 1003 | 101 |
| Tweets kept | 192 | 2093 | 349 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/1nem3gj6/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @onlinepete-sematarygravemn-superpiss's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/341d9x8y) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/341d9x8y/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/onlinepete-sematarygravemn-superpiss')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
Davlan/xlm-roberta-base-finetuned-naija
|
Davlan
| 2021-06-15T21:33:37Z | 7 | 0 |
transformers
|
[
"transformers",
"pytorch",
"xlm-roberta",
"fill-mask",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:04Z |
Hugging Face's logo
---
language: pcm
datasets:
---
# xlm-roberta-base-finetuned-naija
## Model description
**xlm-roberta-base-finetuned-naija** is a **Nigerian Pidgin RoBERTa** model obtained by fine-tuning **xlm-roberta-base** model on Nigerian Pidgin language texts. It provides **better performance** than the XLM-RoBERTa on named entity recognition datasets.
Specifically, this model is a *xlm-roberta-base* model that was fine-tuned on Nigerian Pidgin corpus.
## Intended uses & limitations
#### How to use
You can use this model with Transformers *pipeline* for masked token prediction.
```python
>>> from transformers import pipeline
>>> unmasker = pipeline('fill-mask', model='Davlan/xlm-roberta-base-finetuned-naija')
>>> unmasker("Another attack on ambulance happen for Koforidua in March <mask> year where robbers kill Ambulance driver")
```
#### Limitations and bias
This model is limited by its training dataset of entity-annotated news articles from a specific span of time. This may not generalize well for all use cases in different domains.
## Training data
This model was fine-tuned on JW300 + [BBC Pidgin](https://www.bbc.com/pidgin)
## Training procedure
This model was trained on a single NVIDIA V100 GPU
## Eval results on Test set (F-score, average over 5 runs)
Dataset| XLM-R F1 | pcm_roberta F1
-|-|-
[MasakhaNER](https://github.com/masakhane-io/masakhane-ner) | 87.26 | 90.00
### BibTeX entry and citation info
By David Adelani
```
```
|
Davlan/xlm-roberta-base-finetuned-kinyarwanda
|
Davlan
| 2021-06-15T20:24:02Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"xlm-roberta",
"fill-mask",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:04Z |
Hugging Face's logo
---
language: rw
datasets:
---
# xlm-roberta-base-finetuned-kinyarwanda
## Model description
**xlm-roberta-base-finetuned-kinyarwanda** is a **Kinyarwanda RoBERTa** model obtained by fine-tuning **xlm-roberta-base** model on Kinyarwanda language texts. It provides **better performance** than the XLM-RoBERTa on named entity recognition datasets.
Specifically, this model is a *xlm-roberta-base* model that was fine-tuned on Kinyarwanda corpus.
## Intended uses & limitations
#### How to use
You can use this model with Transformers *pipeline* for masked token prediction.
```python
>>> from transformers import pipeline
>>> unmasker = pipeline('fill-mask', model='Davlan/xlm-roberta-base-finetuned-kinyarwanda')
>>> unmasker("Twabonye ko igihe mu <mask> hazaba hari ikirango abantu bakunze")
```
#### Limitations and bias
This model is limited by its training dataset of entity-annotated news articles from a specific span of time. This may not generalize well for all use cases in different domains.
## Training data
This model was fine-tuned on JW300 + [KIRNEWS](https://github.com/Andrews2017/KINNEWS-and-KIRNEWS-Corpus) + [BBC Gahuza](https://www.bbc.com/gahuza)
## Training procedure
This model was trained on a single NVIDIA V100 GPU
## Eval results on Test set (F-score, average over 5 runs)
Dataset| XLM-R F1 | rw_roberta F1
-|-|-
[MasakhaNER](https://github.com/masakhane-io/masakhane-ner) | 73.22 | 77.76
### BibTeX entry and citation info
By David Adelani
```
```
|
Davlan/bert-base-multilingual-cased-finetuned-kinyarwanda
|
Davlan
| 2021-06-15T20:11:29Z | 10 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"fill-mask",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:04Z |
Hugging Face's logo
---
language: rw
datasets:
---
# bert-base-multilingual-cased-finetuned-kinyarwanda
## Model description
**bert-base-multilingual-cased-finetuned-kinyarwanda** is a **Kinyarwanda BERT** model obtained by fine-tuning **bert-base-multilingual-cased** model on Kinyarwanda language texts. It provides **better performance** than the multilingual BERT on named entity recognition datasets.
Specifically, this model is a *bert-base-multilingual-cased* model that was fine-tuned on Kinyarwanda corpus.
## Intended uses & limitations
#### How to use
You can use this model with Transformers *pipeline* for masked token prediction.
```python
>>> from transformers import pipeline
>>> unmasker = pipeline('fill-mask', model='Davlan/bert-base-multilingual-cased-finetuned-kinyarwanda')
>>> unmasker("Twabonye ko igihe mu [MASK] hazaba hari ikirango abantu bakunze")
```
#### Limitations and bias
This model is limited by its training dataset of entity-annotated news articles from a specific span of time. This may not generalize well for all use cases in different domains.
## Training data
This model was fine-tuned on JW300 + [KIRNEWS](https://github.com/Andrews2017/KINNEWS-and-KIRNEWS-Corpus) + [BBC Gahuza](https://www.bbc.com/gahuza)
## Training procedure
This model was trained on a single NVIDIA V100 GPU
## Eval results on Test set (F-score, average over 5 runs)
Dataset| mBERT F1 | rw_bert F1
-|-|-
[MasakhaNER](https://github.com/masakhane-io/masakhane-ner) | 72.20 | 77.57
### BibTeX entry and citation info
By David Adelani
```
```
|
mukund/privbert
|
mukund
| 2021-06-15T19:36:42Z | 222 | 1 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"roberta",
"fill-mask",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:05Z |
# PrivBERT
PrivBERT is a privacy policy language model. We pre-trained PrivBERT on ~1 million privacy policies starting with the pretrained Roberta model. The data is available at [https://privaseer.ist.psu.edu/data](https://privaseer.ist.psu.edu/data)
## Usage
```
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("mukund/privbert")
model = AutoModel.from_pretrained("mukund/privbert")
```
## License
If you use this dataset in research, you must cite the below paper.
```
Mukund Srinath, Shomir Wilson and C. Lee Giles. Privacy at Scale: Introducing the PrivaSeer Corpus of Web Privacy Policies. In Proc. ACL 2021.
```
For research, teaching, and scholarship purposes, the model is available under a CC BY-NC-SA license. Please contact us for any requests regarding commercial use.
|
huggingtweets/ahleemuhleek
|
huggingtweets
| 2021-06-15T18:38:34Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/ahleemuhleek/1623782310895/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1404846924226695174/_oELkFsx_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">##ahleeuwu</div>
<div style="text-align: center; font-size: 14px;">@ahleemuhleek</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from ##ahleeuwu.
| Data | ##ahleeuwu |
| --- | --- |
| Tweets downloaded | 480 |
| Retweets | 149 |
| Short tweets | 86 |
| Tweets kept | 245 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/17rz3rct/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @ahleemuhleek's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/32bqa4q7) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/32bqa4q7/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/ahleemuhleek')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
huggingtweets/dril_gpt2
|
huggingtweets
| 2021-06-15T17:03:24Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/dril_gpt2/1623776600001/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1386749605216407555/QIJeyWfE_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">wint but Al</div>
<div style="text-align: center; font-size: 14px;">@dril_gpt2</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from wint but Al.
| Data | wint but Al |
| --- | --- |
| Tweets downloaded | 3247 |
| Retweets | 37 |
| Short tweets | 50 |
| Tweets kept | 3160 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/1dhjomoh/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @dril_gpt2's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/37mqhgg4) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/37mqhgg4/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/dril_gpt2')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
neuropark/sahajBERT-NCC
|
neuropark
| 2021-06-15T12:40:08Z | 11 | 2 |
transformers
|
[
"transformers",
"pytorch",
"albert",
"text-classification",
"collaborative",
"bengali",
"SequenceClassification",
"bn",
"dataset:IndicGlue",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
---
language: bn
tags:
- collaborative
- bengali
- SequenceClassification
license: apache-2.0
datasets: IndicGlue
metrics:
- Loss
- Accuracy
- Precision
- Recall
widget:
- text: "এশিয়ায় প্রথম দৃষ্টিহীন ব্যক্তির মাউন্ট এভারেস্ট জয়|"
---
# sahajBERT News Article Classification
## Model description
[sahajBERT](https://huggingface.co/neuropark/sahajBERT) fine-tuned for news article classification using the `sna.bn` split of [IndicGlue](https://huggingface.co/datasets/indic_glue).
The model is trained for classifying articles into 5 different classes:
| Label id | Label |
|:--------:|:----:|
|0 | kolkata|
|1 | state|
|2 | national|
|3 | sports|
|4 | entertainment|
|5 | international|
## Intended uses & limitations
#### How to use
You can use this model directly with a pipeline for Sequence Classification:
```python
from transformers import AlbertForSequenceClassification, TextClassificationPipeline, PreTrainedTokenizerFast
# Initialize tokenizer
tokenizer = PreTrainedTokenizerFast.from_pretrained("neuropark/sahajBERT-NCC")
# Initialize model
model = AlbertForSequenceClassification.from_pretrained("neuropark/sahajBERT-NCC")
# Initialize pipeline
pipeline = TextClassificationPipeline(tokenizer=tokenizer, model=model)
raw_text = "এই ইউনিয়নে ৩ টি মৌজা ও ১০ টি গ্রাম আছে ।" # Change me
output = pipeline(raw_text)
```
#### Limitations and bias
<!-- Provide examples of latent issues and potential remediations. -->
WIP
## Training data
The model was initialized with pre-trained weights of [sahajBERT](https://huggingface.co/neuropark/sahajBERT) at step 19519 and trained on the `sna.bn` split of [IndicGlue](https://huggingface.co/datasets/indic_glue).
## Training procedure
Coming soon!
<!-- ```bibtex
@inproceedings{...,
year={2020}
}
``` -->
## Eval results
Loss: 0.2477145493030548
Accuracy: 0.926293408929837
Macro F1: 0.9079785326650756
Recall: 0.926293408929837
Weighted F1: 0.9266428029354202
Macro Precision: 0.9109938492260489
Micro Precision: 0.926293408929837
Weighted Precision: 0.9288535478995414
Macro Recall: 0.9069095007692186
Micro Recall: 0.926293408929837
Weighted Recall: 0.926293408929837
### BibTeX entry and citation info
Coming soon!
<!-- ```bibtex
@inproceedings{...,
year={2020}
}
``` -->
|
huggingtweets/rantspakistani
|
huggingtweets
| 2021-06-15T09:17:31Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/rantspakistani/1623748645565/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1272527278744973315/PVkL9_v-_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">Rants</div>
<div style="text-align: center; font-size: 14px;">@rantspakistani</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from Rants.
| Data | Rants |
| --- | --- |
| Tweets downloaded | 3221 |
| Retweets | 573 |
| Short tweets | 142 |
| Tweets kept | 2506 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/2wyl63o2/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @rantspakistani's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/d2h287dr) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/d2h287dr/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/rantspakistani')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
Aero/Tsubomi-Haruno
|
Aero
| 2021-06-14T22:21:24Z | 16 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"conversational",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:04Z |
---
thumbnail: https://huggingface.co/front/thumbnails/dialogpt.png
tags:
- conversational
license: mit
---
# DialoGPT Trained on the Speech of a Game Character
```python
from transformers import AutoTokenizer, AutoModelWithLMHead
tokenizer = AutoTokenizer.from_pretrained("r3dhummingbird/DialoGPT-medium-joshua")
model = AutoModelWithLMHead.from_pretrained("r3dhummingbird/DialoGPT-medium-joshua")
# Let's chat for 4 lines
for step in range(4):
# encode the new user input, add the eos_token and return a tensor in Pytorch
new_user_input_ids = tokenizer.encode(input(">> User:") + tokenizer.eos_token, return_tensors='pt')
# print(new_user_input_ids)
# append the new user input tokens to the chat history
bot_input_ids = torch.cat([chat_history_ids, new_user_input_ids], dim=-1) if step > 0 else new_user_input_ids
# generated a response while limiting the total chat history to 1000 tokens,
chat_history_ids = model.generate(
bot_input_ids, max_length=200,
pad_token_id=tokenizer.eos_token_id,
no_repeat_ngram_size=3,
do_sample=True,
top_k=100,
top_p=0.7,
temperature=0.8
)
# pretty print last ouput tokens from bot
print("Tsubomi: {}".format(tokenizer.decode(chat_history_ids[:, bot_input_ids.shape[-1]:][0], skip_special_tokens=True)))
```
|
assemblyai/bert-large-uncased-sst2
|
assemblyai
| 2021-06-14T22:04:39Z | 380 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"text-classification",
"arxiv:1810.04805",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
# BERT-Large-Uncased for Sentiment Analysis
This model is a fine-tuned version of [bert-large-uncased](https://huggingface.co/bert-large-uncased) originally released in ["BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding"](https://arxiv.org/abs/1810.04805) and trained on the [Stanford Sentiment Treebank v2 (SST2)](https://nlp.stanford.edu/sentiment/); part of the [General Language Understanding Evaluation (GLUE)](https://gluebenchmark.com) benchmark. This model was fine-tuned by the team at [AssemblyAI](https://www.assemblyai.com) and is released with the [corresponding blog post]().
## Usage
To download and utilize this model for sentiment analysis please execute the following:
```python
import torch.nn.functional as F
from transformers import AutoTokenizer, AutoModelForSequenceClassification
tokenizer = AutoTokenizer.from_pretrained("assemblyai/bert-large-uncased-sst2")
model = AutoModelForSequenceClassification.from_pretrained("assemblyai/bert-large-uncased-sst2")
tokenized_segments = tokenizer(["AssemblyAI is the best speech-to-text API for modern developers with performance being second to none!"], return_tensors="pt", padding=True, truncation=True)
tokenized_segments_input_ids, tokenized_segments_attention_mask = tokenized_segments.input_ids, tokenized_segments.attention_mask
model_predictions = F.softmax(model(input_ids=tokenized_segments_input_ids, attention_mask=tokenized_segments_attention_mask)['logits'], dim=1)
print("Positive probability: "+str(model_predictions[0][1].item()*100)+"%")
print("Negative probability: "+str(model_predictions[0][0].item()*100)+"%")
```
For questions about how to use this model feel free to contact the team at [AssemblyAI](https://www.assemblyai.com)!
|
huggingtweets/ubtiviv
|
huggingtweets
| 2021-06-14T14:48:42Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/ubtiviv/1623682118645/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/883722377661730817/YvEUxO80_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">transmission creeper</div>
<div style="text-align: center; font-size: 14px;">@ubtiviv</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from transmission creeper.
| Data | transmission creeper |
| --- | --- |
| Tweets downloaded | 924 |
| Retweets | 6 |
| Short tweets | 39 |
| Tweets kept | 879 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/1xh2gevj/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @ubtiviv's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/1zp8oiej) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/1zp8oiej/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/ubtiviv')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
begimayk/try1
|
begimayk
| 2021-06-14T13:09:54Z | 0 | 0 | null |
[
"region:us"
] | null | 2022-03-02T23:29:05Z |
from transformers import pipeline
import json
import requests
API_URL = "https://api-inference.huggingface.co/models/EleutherAI/gpt-neo-2.7B"
headers = {"Authorization": "Bearer api_hwKbAMoHAzOVDdCxgfpPxMjjcrdKHMakhg"}
def query(payload):
\tdata = json.dumps(payload)
\tresponse = requests.request("POST", API_URL, headers=headers, data=data)
\treturn json.loads(response.content.decode("utf-8"))
data = query("Can you please let us know more details about your ")
|
huggingtweets/kr00ney-nerdwallet-producthunt
|
huggingtweets
| 2021-06-14T11:08:52Z | 6 | 1 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/kr00ney-nerdwallet-producthunt/1623668927813/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1363962814499495937/UFNUnRoS_400x400.jpg')">
</div>
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1339064421964902402/-Rj0-u21_400x400.jpg')">
</div>
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1029047234371903488/z10lHpTA_400x400.jpg')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI CYBORG 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">Product Hunt 😸 & Kate Rooney & NerdWallet</div>
<div style="text-align: center; font-size: 14px;">@kr00ney-nerdwallet-producthunt</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from Product Hunt 😸 & Kate Rooney & NerdWallet.
| Data | Product Hunt 😸 | Kate Rooney | NerdWallet |
| --- | --- | --- | --- |
| Tweets downloaded | 3250 | 2622 | 3234 |
| Retweets | 92 | 896 | 713 |
| Short tweets | 234 | 125 | 22 |
| Tweets kept | 2924 | 1601 | 2499 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/vrmrzm0o/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @kr00ney-nerdwallet-producthunt's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/zdu3nltx) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/zdu3nltx/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/kr00ney-nerdwallet-producthunt')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
valhalla/distilbart-mnli-12-9
|
valhalla
| 2021-06-14T10:34:58Z | 1,855 | 12 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bart",
"text-classification",
"distilbart",
"distilbart-mnli",
"zero-shot-classification",
"dataset:mnli",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
zero-shot-classification
| 2022-03-02T23:29:05Z |
---
datasets:
- mnli
tags:
- distilbart
- distilbart-mnli
pipeline_tag: zero-shot-classification
---
# DistilBart-MNLI
distilbart-mnli is the distilled version of bart-large-mnli created using the **No Teacher Distillation** technique proposed for BART summarisation by Huggingface, [here](https://github.com/huggingface/transformers/tree/master/examples/seq2seq#distilbart).
We just copy alternating layers from `bart-large-mnli` and finetune more on the same data.
| | matched acc | mismatched acc |
| ------------------------------------------------------------------------------------ | ----------- | -------------- |
| [bart-large-mnli](https://huggingface.co/facebook/bart-large-mnli) (baseline, 12-12) | 89.9 | 90.01 |
| [distilbart-mnli-12-1](https://huggingface.co/valhalla/distilbart-mnli-12-1) | 87.08 | 87.5 |
| [distilbart-mnli-12-3](https://huggingface.co/valhalla/distilbart-mnli-12-3) | 88.1 | 88.19 |
| [distilbart-mnli-12-6](https://huggingface.co/valhalla/distilbart-mnli-12-6) | 89.19 | 89.01 |
| [distilbart-mnli-12-9](https://huggingface.co/valhalla/distilbart-mnli-12-9) | 89.56 | 89.52 |
This is a very simple and effective technique, as we can see the performance drop is very little.
Detailed performace trade-offs will be posted in this [sheet](https://docs.google.com/spreadsheets/d/1dQeUvAKpScLuhDV1afaPJRRAE55s2LpIzDVA5xfqxvk/edit?usp=sharing).
## Fine-tuning
If you want to train these models yourself, clone the [distillbart-mnli repo](https://github.com/patil-suraj/distillbart-mnli) and follow the steps below
Clone and install transformers from source
```bash
git clone https://github.com/huggingface/transformers.git
pip install -qqq -U ./transformers
```
Download MNLI data
```bash
python transformers/utils/download_glue_data.py --data_dir glue_data --tasks MNLI
```
Create student model
```bash
python create_student.py \
--teacher_model_name_or_path facebook/bart-large-mnli \
--student_encoder_layers 12 \
--student_decoder_layers 6 \
--save_path student-bart-mnli-12-6 \
```
Start fine-tuning
```bash
python run_glue.py args.json
```
You can find the logs of these trained models in this [wandb project](https://wandb.ai/psuraj/distilbart-mnli).
|
valhalla/distilbart-mnli-12-6
|
valhalla
| 2021-06-14T10:32:03Z | 48,130 | 11 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bart",
"text-classification",
"distilbart",
"distilbart-mnli",
"zero-shot-classification",
"dataset:mnli",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
zero-shot-classification
| 2022-03-02T23:29:05Z |
---
datasets:
- mnli
tags:
- distilbart
- distilbart-mnli
pipeline_tag: zero-shot-classification
---
# DistilBart-MNLI
distilbart-mnli is the distilled version of bart-large-mnli created using the **No Teacher Distillation** technique proposed for BART summarisation by Huggingface, [here](https://github.com/huggingface/transformers/tree/master/examples/seq2seq#distilbart).
We just copy alternating layers from `bart-large-mnli` and finetune more on the same data.
| | matched acc | mismatched acc |
| ------------------------------------------------------------------------------------ | ----------- | -------------- |
| [bart-large-mnli](https://huggingface.co/facebook/bart-large-mnli) (baseline, 12-12) | 89.9 | 90.01 |
| [distilbart-mnli-12-1](https://huggingface.co/valhalla/distilbart-mnli-12-1) | 87.08 | 87.5 |
| [distilbart-mnli-12-3](https://huggingface.co/valhalla/distilbart-mnli-12-3) | 88.1 | 88.19 |
| [distilbart-mnli-12-6](https://huggingface.co/valhalla/distilbart-mnli-12-6) | 89.19 | 89.01 |
| [distilbart-mnli-12-9](https://huggingface.co/valhalla/distilbart-mnli-12-9) | 89.56 | 89.52 |
This is a very simple and effective technique, as we can see the performance drop is very little.
Detailed performace trade-offs will be posted in this [sheet](https://docs.google.com/spreadsheets/d/1dQeUvAKpScLuhDV1afaPJRRAE55s2LpIzDVA5xfqxvk/edit?usp=sharing).
## Fine-tuning
If you want to train these models yourself, clone the [distillbart-mnli repo](https://github.com/patil-suraj/distillbart-mnli) and follow the steps below
Clone and install transformers from source
```bash
git clone https://github.com/huggingface/transformers.git
pip install -qqq -U ./transformers
```
Download MNLI data
```bash
python transformers/utils/download_glue_data.py --data_dir glue_data --tasks MNLI
```
Create student model
```bash
python create_student.py \
--teacher_model_name_or_path facebook/bart-large-mnli \
--student_encoder_layers 12 \
--student_decoder_layers 6 \
--save_path student-bart-mnli-12-6 \
```
Start fine-tuning
```bash
python run_glue.py args.json
```
You can find the logs of these trained models in this [wandb project](https://wandb.ai/psuraj/distilbart-mnli).
|
valhalla/distilbart-mnli-12-3
|
valhalla
| 2021-06-14T10:29:48Z | 8,317 | 19 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bart",
"text-classification",
"distilbart",
"distilbart-mnli",
"zero-shot-classification",
"dataset:mnli",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
zero-shot-classification
| 2022-03-02T23:29:05Z |
---
datasets:
- mnli
tags:
- distilbart
- distilbart-mnli
pipeline_tag: zero-shot-classification
---
# DistilBart-MNLI
distilbart-mnli is the distilled version of bart-large-mnli created using the **No Teacher Distillation** technique proposed for BART summarisation by Huggingface, [here](https://github.com/huggingface/transformers/tree/master/examples/seq2seq#distilbart).
We just copy alternating layers from `bart-large-mnli` and finetune more on the same data.
| | matched acc | mismatched acc |
| ------------------------------------------------------------------------------------ | ----------- | -------------- |
| [bart-large-mnli](https://huggingface.co/facebook/bart-large-mnli) (baseline, 12-12) | 89.9 | 90.01 |
| [distilbart-mnli-12-1](https://huggingface.co/valhalla/distilbart-mnli-12-1) | 87.08 | 87.5 |
| [distilbart-mnli-12-3](https://huggingface.co/valhalla/distilbart-mnli-12-3) | 88.1 | 88.19 |
| [distilbart-mnli-12-6](https://huggingface.co/valhalla/distilbart-mnli-12-6) | 89.19 | 89.01 |
| [distilbart-mnli-12-9](https://huggingface.co/valhalla/distilbart-mnli-12-9) | 89.56 | 89.52 |
This is a very simple and effective technique, as we can see the performance drop is very little.
Detailed performace trade-offs will be posted in this [sheet](https://docs.google.com/spreadsheets/d/1dQeUvAKpScLuhDV1afaPJRRAE55s2LpIzDVA5xfqxvk/edit?usp=sharing).
## Fine-tuning
If you want to train these models yourself, clone the [distillbart-mnli repo](https://github.com/patil-suraj/distillbart-mnli) and follow the steps below
Clone and install transformers from source
```bash
git clone https://github.com/huggingface/transformers.git
pip install -qqq -U ./transformers
```
Download MNLI data
```bash
python transformers/utils/download_glue_data.py --data_dir glue_data --tasks MNLI
```
Create student model
```bash
python create_student.py \
--teacher_model_name_or_path facebook/bart-large-mnli \
--student_encoder_layers 12 \
--student_decoder_layers 6 \
--save_path student-bart-mnli-12-6 \
```
Start fine-tuning
```bash
python run_glue.py args.json
```
You can find the logs of these trained models in this [wandb project](https://wandb.ai/psuraj/distilbart-mnli).
|
valhalla/distilbart-mnli-12-1
|
valhalla
| 2021-06-14T10:27:55Z | 109,694 | 51 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bart",
"text-classification",
"distilbart",
"distilbart-mnli",
"zero-shot-classification",
"dataset:mnli",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
zero-shot-classification
| 2022-03-02T23:29:05Z |
---
datasets:
- mnli
tags:
- distilbart
- distilbart-mnli
pipeline_tag: zero-shot-classification
---
# DistilBart-MNLI
distilbart-mnli is the distilled version of bart-large-mnli created using the **No Teacher Distillation** technique proposed for BART summarisation by Huggingface, [here](https://github.com/huggingface/transformers/tree/master/examples/seq2seq#distilbart).
We just copy alternating layers from `bart-large-mnli` and finetune more on the same data.
| | matched acc | mismatched acc |
| ------------------------------------------------------------------------------------ | ----------- | -------------- |
| [bart-large-mnli](https://huggingface.co/facebook/bart-large-mnli) (baseline, 12-12) | 89.9 | 90.01 |
| [distilbart-mnli-12-1](https://huggingface.co/valhalla/distilbart-mnli-12-1) | 87.08 | 87.5 |
| [distilbart-mnli-12-3](https://huggingface.co/valhalla/distilbart-mnli-12-3) | 88.1 | 88.19 |
| [distilbart-mnli-12-6](https://huggingface.co/valhalla/distilbart-mnli-12-6) | 89.19 | 89.01 |
| [distilbart-mnli-12-9](https://huggingface.co/valhalla/distilbart-mnli-12-9) | 89.56 | 89.52 |
This is a very simple and effective technique, as we can see the performance drop is very little.
Detailed performace trade-offs will be posted in this [sheet](https://docs.google.com/spreadsheets/d/1dQeUvAKpScLuhDV1afaPJRRAE55s2LpIzDVA5xfqxvk/edit?usp=sharing).
## Fine-tuning
If you want to train these models yourself, clone the [distillbart-mnli repo](https://github.com/patil-suraj/distillbart-mnli) and follow the steps below
Clone and install transformers from source
```bash
git clone https://github.com/huggingface/transformers.git
pip install -qqq -U ./transformers
```
Download MNLI data
```bash
python transformers/utils/download_glue_data.py --data_dir glue_data --tasks MNLI
```
Create student model
```bash
python create_student.py \
--teacher_model_name_or_path facebook/bart-large-mnli \
--student_encoder_layers 12 \
--student_decoder_layers 6 \
--save_path student-bart-mnli-12-6 \
```
Start fine-tuning
```bash
python run_glue.py args.json
```
You can find the logs of these trained models in this [wandb project](https://wandb.ai/psuraj/distilbart-mnli).
|
valhalla/bart-large-finetuned-squadv1
|
valhalla
| 2021-06-14T10:20:35Z | 592 | 7 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bart",
"question-answering",
"dataset:squad",
"arxiv:1910.13461",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-03-02T23:29:05Z |
---
datasets:
- squad
---
# BART-LARGE finetuned on SQuADv1
This is bart-large model finetuned on SQuADv1 dataset for question answering task
## Model details
BART was propsed in the [paper](https://arxiv.org/abs/1910.13461) **BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension**.
BART is a seq2seq model intended for both NLG and NLU tasks.
To use BART for question answering tasks, we feed the complete document into the encoder and decoder, and use the top
hidden state of the decoder as a representation for each
word. This representation is used to classify the token. As given in the paper bart-large achives comparable to ROBERTa on SQuAD.
Another notable thing about BART is that it can handle sequences with upto 1024 tokens.
| Param | #Value |
|---------------------|--------|
| encoder layers | 12 |
| decoder layers | 12 |
| hidden size | 4096 |
| num attetion heads | 16 |
| on disk size | 1.63GB |
## Model training
This model was trained on google colab v100 GPU.
You can find the fine-tuning colab here
[](https://colab.research.google.com/drive/1I5cK1M_0dLaf5xoewh6swcm5nAInfwHy?usp=sharing).
## Results
The results are actually slightly worse than given in the paper.
In the paper the authors mentioned that bart-large achieves 88.8 EM and 94.6 F1
| Metric | #Value |
|--------|--------|
| EM | 86.8022|
| F1 | 92.7342|
## Model in Action 🚀
```python3
from transformers import BartTokenizer, BartForQuestionAnswering
import torch
tokenizer = BartTokenizer.from_pretrained('valhalla/bart-large-finetuned-squadv1')
model = BartForQuestionAnswering.from_pretrained('valhalla/bart-large-finetuned-squadv1')
question, text = "Who was Jim Henson?", "Jim Henson was a nice puppet"
encoding = tokenizer(question, text, return_tensors='pt')
input_ids = encoding['input_ids']
attention_mask = encoding['attention_mask']
start_scores, end_scores = model(input_ids, attention_mask=attention_mask, output_attentions=False)[:2]
all_tokens = tokenizer.convert_ids_to_tokens(input_ids[0])
answer = ' '.join(all_tokens[torch.argmax(start_scores) : torch.argmax(end_scores)+1])
answer = tokenizer.convert_tokens_to_ids(answer.split())
answer = tokenizer.decode(answer)
#answer => 'a nice puppet'
```
> Created with ❤️ by Suraj Patil [](https://github.com/patil-suraj/)
[](https://twitter.com/psuraj28)
|
sshleifer/distilbart-xsum-6-6
|
sshleifer
| 2021-06-14T08:25:26Z | 43 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bart",
"text2text-generation",
"summarization",
"en",
"dataset:cnn_dailymail",
"dataset:xsum",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
summarization
| 2022-03-02T23:29:05Z |
---
language: en
tags:
- summarization
license: apache-2.0
datasets:
- cnn_dailymail
- xsum
thumbnail: https://huggingface.co/front/thumbnails/distilbart_medium.png
---
### Usage
This checkpoint should be loaded into `BartForConditionalGeneration.from_pretrained`. See the [BART docs](https://huggingface.co/transformers/model_doc/bart.html?#transformers.BartForConditionalGeneration) for more information.
### Metrics for DistilBART models
| Model Name | MM Params | Inference Time (MS) | Speedup | Rouge 2 | Rouge-L |
|:---------------------------|------------:|----------------------:|----------:|----------:|----------:|
| distilbart-xsum-12-1 | 222 | 90 | 2.54 | 18.31 | 33.37 |
| distilbart-xsum-6-6 | 230 | 132 | 1.73 | 20.92 | 35.73 |
| distilbart-xsum-12-3 | 255 | 106 | 2.16 | 21.37 | 36.39 |
| distilbart-xsum-9-6 | 268 | 136 | 1.68 | 21.72 | 36.61 |
| bart-large-xsum (baseline) | 406 | 229 | 1 | 21.85 | 36.50 |
| distilbart-xsum-12-6 | 306 | 137 | 1.68 | 22.12 | 36.99 |
| bart-large-cnn (baseline) | 406 | 381 | 1 | 21.06 | 30.63 |
| distilbart-12-3-cnn | 255 | 214 | 1.78 | 20.57 | 30.00 |
| distilbart-12-6-cnn | 306 | 307 | 1.24 | 21.26 | 30.59 |
| distilbart-6-6-cnn | 230 | 182 | 2.09 | 20.17 | 29.70 |
|
sshleifer/distilbart-xsum-12-6
|
sshleifer
| 2021-06-14T07:58:25Z | 1,583 | 5 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bart",
"text2text-generation",
"summarization",
"en",
"dataset:cnn_dailymail",
"dataset:xsum",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
summarization
| 2022-03-02T23:29:05Z |
---
language: en
tags:
- summarization
license: apache-2.0
datasets:
- cnn_dailymail
- xsum
thumbnail: https://huggingface.co/front/thumbnails/distilbart_medium.png
---
### Usage
This checkpoint should be loaded into `BartForConditionalGeneration.from_pretrained`. See the [BART docs](https://huggingface.co/transformers/model_doc/bart.html?#transformers.BartForConditionalGeneration) for more information.
### Metrics for DistilBART models
| Model Name | MM Params | Inference Time (MS) | Speedup | Rouge 2 | Rouge-L |
|:---------------------------|------------:|----------------------:|----------:|----------:|----------:|
| distilbart-xsum-12-1 | 222 | 90 | 2.54 | 18.31 | 33.37 |
| distilbart-xsum-6-6 | 230 | 132 | 1.73 | 20.92 | 35.73 |
| distilbart-xsum-12-3 | 255 | 106 | 2.16 | 21.37 | 36.39 |
| distilbart-xsum-9-6 | 268 | 136 | 1.68 | 21.72 | 36.61 |
| bart-large-xsum (baseline) | 406 | 229 | 1 | 21.85 | 36.50 |
| distilbart-xsum-12-6 | 306 | 137 | 1.68 | 22.12 | 36.99 |
| bart-large-cnn (baseline) | 406 | 381 | 1 | 21.06 | 30.63 |
| distilbart-12-3-cnn | 255 | 214 | 1.78 | 20.57 | 30.00 |
| distilbart-12-6-cnn | 306 | 307 | 1.24 | 21.26 | 30.59 |
| distilbart-6-6-cnn | 230 | 182 | 2.09 | 20.17 | 29.70 |
|
sshleifer/distilbart-cnn-6-6
|
sshleifer
| 2021-06-14T07:53:04Z | 42,203 | 29 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"rust",
"bart",
"text2text-generation",
"summarization",
"en",
"dataset:cnn_dailymail",
"dataset:xsum",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
summarization
| 2022-03-02T23:29:05Z |
---
language: en
tags:
- summarization
license: apache-2.0
datasets:
- cnn_dailymail
- xsum
thumbnail: https://huggingface.co/front/thumbnails/distilbart_medium.png
---
### Usage
This checkpoint should be loaded into `BartForConditionalGeneration.from_pretrained`. See the [BART docs](https://huggingface.co/transformers/model_doc/bart.html?#transformers.BartForConditionalGeneration) for more information.
### Metrics for DistilBART models
| Model Name | MM Params | Inference Time (MS) | Speedup | Rouge 2 | Rouge-L |
|:---------------------------|------------:|----------------------:|----------:|----------:|----------:|
| distilbart-xsum-12-1 | 222 | 90 | 2.54 | 18.31 | 33.37 |
| distilbart-xsum-6-6 | 230 | 132 | 1.73 | 20.92 | 35.73 |
| distilbart-xsum-12-3 | 255 | 106 | 2.16 | 21.37 | 36.39 |
| distilbart-xsum-9-6 | 268 | 136 | 1.68 | 21.72 | 36.61 |
| bart-large-xsum (baseline) | 406 | 229 | 1 | 21.85 | 36.50 |
| distilbart-xsum-12-6 | 306 | 137 | 1.68 | 22.12 | 36.99 |
| bart-large-cnn (baseline) | 406 | 381 | 1 | 21.06 | 30.63 |
| distilbart-12-3-cnn | 255 | 214 | 1.78 | 20.57 | 30.00 |
| distilbart-12-6-cnn | 306 | 307 | 1.24 | 21.26 | 30.59 |
| distilbart-6-6-cnn | 230 | 182 | 2.09 | 20.17 | 29.70 |
|
sshleifer/distilbart-cnn-12-3
|
sshleifer
| 2021-06-14T07:47:53Z | 197 | 4 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bart",
"text2text-generation",
"summarization",
"en",
"dataset:cnn_dailymail",
"dataset:xsum",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
summarization
| 2022-03-02T23:29:05Z |
---
language: en
tags:
- summarization
license: apache-2.0
datasets:
- cnn_dailymail
- xsum
thumbnail: https://huggingface.co/front/thumbnails/distilbart_medium.png
---
### Usage
This checkpoint should be loaded into `BartForConditionalGeneration.from_pretrained`. See the [BART docs](https://huggingface.co/transformers/model_doc/bart.html?#transformers.BartForConditionalGeneration) for more information.
### Metrics for DistilBART models
| Model Name | MM Params | Inference Time (MS) | Speedup | Rouge 2 | Rouge-L |
|:---------------------------|------------:|----------------------:|----------:|----------:|----------:|
| distilbart-xsum-12-1 | 222 | 90 | 2.54 | 18.31 | 33.37 |
| distilbart-xsum-6-6 | 230 | 132 | 1.73 | 20.92 | 35.73 |
| distilbart-xsum-12-3 | 255 | 106 | 2.16 | 21.37 | 36.39 |
| distilbart-xsum-9-6 | 268 | 136 | 1.68 | 21.72 | 36.61 |
| bart-large-xsum (baseline) | 406 | 229 | 1 | 21.85 | 36.50 |
| distilbart-xsum-12-6 | 306 | 137 | 1.68 | 22.12 | 36.99 |
| bart-large-cnn (baseline) | 406 | 381 | 1 | 21.06 | 30.63 |
| distilbart-12-3-cnn | 255 | 214 | 1.78 | 20.57 | 30.00 |
| distilbart-12-6-cnn | 306 | 307 | 1.24 | 21.26 | 30.59 |
| distilbart-6-6-cnn | 230 | 182 | 2.09 | 20.17 | 29.70 |
|
huggingtweets/hbomberguy
|
huggingtweets
| 2021-06-13T21:51:14Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://github.com/borisdayma/huggingtweets/blob/master/img/logo.png?raw=true
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1402282381696962566/VwcMz_xV_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">Hbomberguy</div>
<div style="text-align: center; font-size: 14px;">@hbomberguy</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from Hbomberguy.
| Data | Hbomberguy |
| --- | --- |
| Tweets downloaded | 3187 |
| Retweets | 1450 |
| Short tweets | 298 |
| Tweets kept | 1439 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/2gtfmb7p/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @hbomberguy's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/3h5vtwqy) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/3h5vtwqy/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/hbomberguy')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
huggingtweets/robber0540
|
huggingtweets
| 2021-06-13T21:47:44Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/robber0540/1623620847015/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/822229503212666880/L4UutyTM_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">Combat Ballerina</div>
<div style="text-align: center; font-size: 14px;">@robber0540</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from Combat Ballerina.
| Data | Combat Ballerina |
| --- | --- |
| Tweets downloaded | 668 |
| Retweets | 65 |
| Short tweets | 303 |
| Tweets kept | 300 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/2se37abl/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @robber0540's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/3i4yohh5) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/3i4yohh5/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/robber0540')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
huggingtweets/mikeyyshorts
|
huggingtweets
| 2021-06-13T21:38:51Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/mikeyyshorts/1623620327489/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1370766101706051587/CcUAr3LL_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">mikey l-h-f-m (donathon creek)</div>
<div style="text-align: center; font-size: 14px;">@mikeyyshorts</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from mikey l-h-f-m (donathon creek).
| Data | mikey l-h-f-m (donathon creek) |
| --- | --- |
| Tweets downloaded | 1850 |
| Retweets | 162 |
| Short tweets | 336 |
| Tweets kept | 1352 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/2rqx8qgm/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @mikeyyshorts's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/157kyrv2) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/157kyrv2/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/mikeyyshorts')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
MohamedZaitoon/bart-fine-tune
|
MohamedZaitoon
| 2021-06-13T17:27:59Z | 14 | 1 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bart",
"text2text-generation",
"summarization",
"dataset:CNN/Daily-mail",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
summarization
| 2022-03-02T23:29:04Z |
---
tags:
- summarization
datasets:
- CNN/Daily-mail
metrics:
- ROUGE
---
|
CogComp/bart-faithful-summary-detector
|
CogComp
| 2021-06-13T17:18:36Z | 506 | 4 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bart",
"text-classification",
"xsum",
"en",
"dataset:xsum",
"license:cc-by-sa-4.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:04Z |
---
language:
- en
thumbnail: https://cogcomp.seas.upenn.edu/images/logo.png
tags:
- text-classification
- bart
- xsum
license: cc-by-sa-4.0
datasets:
- xsum
widget:
- text: "<s> Ban Ki-moon was elected for a second term in 2007. </s></s> Ban Ki-Moon was re-elected for a second term by the UN General Assembly, unopposed and unanimously, on 21 June 2011."
- text: "<s> Ban Ki-moon was elected for a second term in 2011. </s></s> Ban Ki-Moon was re-elected for a second term by the UN General Assembly, unopposed and unanimously, on 21 June 2011."
---
# bart-faithful-summary-detector
## Model description
A BART (base) model trained to classify whether a summary is *faithful* to the original article. See our [paper in NAACL'21](https://www.seas.upenn.edu/~sihaoc/static/pdf/CZSR21.pdf) for details.
## Usage
Concatenate a summary and a source document as input (note that the summary needs to be the **first** sentence).
Here's an example usage (with PyTorch)
```python
from transformers import AutoTokenizer, AutoModelForSequenceClassification
tokenizer = AutoTokenizer.from_pretrained("CogComp/bart-faithful-summary-detector")
model = AutoModelForSequenceClassification.from_pretrained("CogComp/bart-faithful-summary-detector")
article = "Ban Ki-Moon was re-elected for a second term by the UN General Assembly, unopposed and unanimously, on 21 June 2011."
bad_summary = "Ban Ki-moon was elected for a second term in 2007."
good_summary = "Ban Ki-moon was elected for a second term in 2011."
bad_pair = tokenizer(text=bad_summary, text_pair=article, return_tensors='pt')
good_pair = tokenizer(text=good_summary, text_pair=article, return_tensors='pt')
bad_score = model(**bad_pair)
good_score = model(**good_pair)
print(good_score[0][:, 1] > bad_score[0][:, 1]) # True, label mapping: "0" -> "Hallucinated" "1" -> "Faithful"
```
### BibTeX entry and citation info
```bibtex
@inproceedings{CZSR21,
author = {Sihao Chen and Fan Zhang and Kazoo Sone and Dan Roth},
title = {{Improving Faithfulness in Abstractive Summarization with Contrast Candidate Generation and Selection}},
booktitle = {NAACL},
year = {2021}
}
```
|
huggingtweets/mcintweet
|
huggingtweets
| 2021-06-13T16:36:05Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/mcintweet/1623602161461/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1174977443641249792/VCg_utme_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">Michael McIntyre</div>
<div style="text-align: center; font-size: 14px;">@mcintweet</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from Michael McIntyre.
| Data | Michael McIntyre |
| --- | --- |
| Tweets downloaded | 1196 |
| Retweets | 138 |
| Short tweets | 34 |
| Tweets kept | 1024 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/35dkm3ec/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @mcintweet's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/20vszack) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/20vszack/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/mcintweet')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
huggingtweets/mrsanctumonious
|
huggingtweets
| 2021-06-13T06:23:36Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/mrsanctumonious/1623565396151/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1397722561065017344/nna9wn35_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">His Majesty Diem The Sanctimonious 🎈🗯️🔫</div>
<div style="text-align: center; font-size: 14px;">@mrsanctumonious</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from His Majesty Diem The Sanctimonious 🎈🗯️🔫.
| Data | His Majesty Diem The Sanctimonious 🎈🗯️🔫 |
| --- | --- |
| Tweets downloaded | 972 |
| Retweets | 82 |
| Short tweets | 111 |
| Tweets kept | 779 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/8h5lsj13/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @mrsanctumonious's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/3tohfeq2) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/3tohfeq2/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/mrsanctumonious')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
MohamedZaitoon/T5-CNN
|
MohamedZaitoon
| 2021-06-12T14:56:25Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"summarization",
"dataset:CNN/Daily-mail",
"endpoints_compatible",
"region:us"
] |
summarization
| 2022-03-02T23:29:04Z |
---
tags:
- summarization
datasets:
- CNN/Daily-mail
metrics:
- ROUGE
---
|
lysandre/new-dummy-model
|
lysandre
| 2021-06-12T07:49:19Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"distilbert",
"text-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
# Dummy model
This is a dummy model.
|
huggingtweets/ghostmountainn
|
huggingtweets
| 2021-06-12T06:01:35Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/ghostmountainn/1623477690371/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1399131544665706498/1RGp0i9G_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">jum</div>
<div style="text-align: center; font-size: 14px;">@ghostmountainn</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from jum.
| Data | jum |
| --- | --- |
| Tweets downloaded | 3240 |
| Retweets | 839 |
| Short tweets | 609 |
| Tweets kept | 1792 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/8lx8a815/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @ghostmountainn's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/3gafkpo6) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/3gafkpo6/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/ghostmountainn')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
luhua/chinese_pretrain_mrc_roberta_wwm_ext_large
|
luhua
| 2021-06-12T02:53:16Z | 254 | 81 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"question-answering",
"zh",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-03-02T23:29:05Z |
---
language:
- zh
license: "apache-2.0"
---
## Chinese MRC roberta_wwm_ext_large
* 使用大量中文MRC数据训练的roberta_wwm_ext_large模型,详情可查看:https://github.com/basketballandlearn/MRC_Competition_Dureader
* 此库发布的再训练模型,在 阅读理解/分类 等任务上均有大幅提高<br/>
(已有多位小伙伴在Dureader-2021等多个比赛中取得**top5**的成绩😁)
| 模型/数据集 | Dureader-2021 | tencentmedical |
| ------------------------------------------|--------------- | --------------- |
| | F1-score | Accuracy |
| | dev / A榜 | test-1 |
| macbert-large (哈工大预训练语言模型) | 65.49 / 64.27 | 82.5 |
| roberta-wwm-ext-large (哈工大预训练语言模型) | 65.49 / 64.27 | 82.5 |
| macbert-large (ours) | 70.45 / **68.13**| **83.4** |
| roberta-wwm-ext-large (ours) | 68.91 / 66.91 | 83.1 |
|
luhua/chinese_pretrain_mrc_macbert_large
|
luhua
| 2021-06-12T02:52:28Z | 121 | 21 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"question-answering",
"zh",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-03-02T23:29:05Z |
---
language:
- zh
license: "apache-2.0"
---
## Chinese MRC macbert-large
* 使用大量中文MRC数据训练的macbert-large模型,详情可查看:https://github.com/basketballandlearn/MRC_Competition_Dureader
* 此库发布的再训练模型,在 阅读理解/分类 等任务上均有大幅提高<br/>
(已有多位小伙伴在Dureader-2021等多个比赛中取得**top5**的成绩😁)
| 模型/数据集 | Dureader-2021 | tencentmedical |
| ------------------------------------------|--------------- | --------------- |
| | F1-score | Accuracy |
| | dev / A榜 | test-1 |
| macbert-large (哈工大预训练语言模型) | 65.49 / 64.27 | 82.5 |
| roberta-wwm-ext-large (哈工大预训练语言模型) | 65.49 / 64.27 | 82.5 |
| macbert-large (ours) | 70.45 / **68.13**| **83.4** |
| roberta-wwm-ext-large (ours) | 68.91 / 66.91 | 83.1 |
|
byeongal/bert-base-uncased
|
byeongal
| 2021-06-11T03:25:48Z | 8 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"fill-mask",
"exbert",
"en",
"dataset:bookcorpus",
"dataset:wikipedia",
"arxiv:1810.04805",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:05Z |
---
language: en
tags:
- exbert
license: apache-2.0
datasets:
- bookcorpus
- wikipedia
---
# BERT base model (uncased) for Teachable NLP
- This model forked from [bert-base-uncased](https://huggingface.co/bert-base-uncased) for fine tune [Teachable NLP](https://ainize.ai/teachable-nlp).
Pretrained model on English language using a masked language modeling (MLM) objective. It was introduced in
[this paper](https://arxiv.org/abs/1810.04805) and first released in
[this repository](https://github.com/google-research/bert). This model is uncased: it does not make a difference
between english and English.
Disclaimer: The team releasing BERT did not write a model card for this model so this model card has been written by
the Hugging Face team.
## Model description
BERT is a transformers model pretrained on a large corpus of English data in a self-supervised fashion. This means it
was pretrained on the raw texts only, with no humans labelling them in any way (which is why it can use lots of
publicly available data) with an automatic process to generate inputs and labels from those texts. More precisely, it
was pretrained with two objectives:
- Masked language modeling (MLM): taking a sentence, the model randomly masks 15% of the words in the input then run
the entire masked sentence through the model and has to predict the masked words. This is different from traditional
recurrent neural networks (RNNs) that usually see the words one after the other, or from autoregressive models like
GPT which internally mask the future tokens. It allows the model to learn a bidirectional representation of the
sentence.
- Next sentence prediction (NSP): the models concatenates two masked sentences as inputs during pretraining. Sometimes
they correspond to sentences that were next to each other in the original text, sometimes not. The model then has to
predict if the two sentences were following each other or not.
This way, the model learns an inner representation of the English language that can then be used to extract features
useful for downstream tasks: if you have a dataset of labeled sentences for instance, you can train a standard
classifier using the features produced by the BERT model as inputs.
## Intended uses & limitations
You can use the raw model for either masked language modeling or next sentence prediction, but it's mostly intended to
be fine-tuned on a downstream task. See the [model hub](https://huggingface.co/models?filter=bert) to look for
fine-tuned versions on a task that interests you.
Note that this model is primarily aimed at being fine-tuned on tasks that use the whole sentence (potentially masked)
to make decisions, such as sequence classification, token classification or question answering. For tasks such as text
generation you should look at model like GPT2.
### How to use
You can use this model directly with a pipeline for masked language modeling:
```python
>>> from transformers import pipeline
>>> unmasker = pipeline('fill-mask', model='bert-base-uncased')
>>> unmasker("Hello I'm a [MASK] model.")
[{'sequence': "[CLS] hello i'm a fashion model. [SEP]",
'score': 0.1073106899857521,
'token': 4827,
'token_str': 'fashion'},
{'sequence': "[CLS] hello i'm a role model. [SEP]",
'score': 0.08774490654468536,
'token': 2535,
'token_str': 'role'},
{'sequence': "[CLS] hello i'm a new model. [SEP]",
'score': 0.05338378623127937,
'token': 2047,
'token_str': 'new'},
{'sequence': "[CLS] hello i'm a super model. [SEP]",
'score': 0.04667217284440994,
'token': 3565,
'token_str': 'super'},
{'sequence': "[CLS] hello i'm a fine model. [SEP]",
'score': 0.027095865458250046,
'token': 2986,
'token_str': 'fine'}]
```
Here is how to use this model to get the features of a given text in PyTorch:
```python
from transformers import BertTokenizer, BertModel
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertModel.from_pretrained("bert-base-uncased")
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='pt')
output = model(**encoded_input)
```
and in TensorFlow:
```python
from transformers import BertTokenizer, TFBertModel
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = TFBertModel.from_pretrained("bert-base-uncased")
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='tf')
output = model(encoded_input)
```
### Limitations and bias
Even if the training data used for this model could be characterized as fairly neutral, this model can have biased
predictions:
```python
>>> from transformers import pipeline
>>> unmasker = pipeline('fill-mask', model='bert-base-uncased')
>>> unmasker("The man worked as a [MASK].")
[{'sequence': '[CLS] the man worked as a carpenter. [SEP]',
'score': 0.09747550636529922,
'token': 10533,
'token_str': 'carpenter'},
{'sequence': '[CLS] the man worked as a waiter. [SEP]',
'score': 0.0523831807076931,
'token': 15610,
'token_str': 'waiter'},
{'sequence': '[CLS] the man worked as a barber. [SEP]',
'score': 0.04962705448269844,
'token': 13362,
'token_str': 'barber'},
{'sequence': '[CLS] the man worked as a mechanic. [SEP]',
'score': 0.03788609802722931,
'token': 15893,
'token_str': 'mechanic'},
{'sequence': '[CLS] the man worked as a salesman. [SEP]',
'score': 0.037680890411138535,
'token': 18968,
'token_str': 'salesman'}]
>>> unmasker("The woman worked as a [MASK].")
[{'sequence': '[CLS] the woman worked as a nurse. [SEP]',
'score': 0.21981462836265564,
'token': 6821,
'token_str': 'nurse'},
{'sequence': '[CLS] the woman worked as a waitress. [SEP]',
'score': 0.1597415804862976,
'token': 13877,
'token_str': 'waitress'},
{'sequence': '[CLS] the woman worked as a maid. [SEP]',
'score': 0.1154729500412941,
'token': 10850,
'token_str': 'maid'},
{'sequence': '[CLS] the woman worked as a prostitute. [SEP]',
'score': 0.037968918681144714,
'token': 19215,
'token_str': 'prostitute'},
{'sequence': '[CLS] the woman worked as a cook. [SEP]',
'score': 0.03042375110089779,
'token': 5660,
'token_str': 'cook'}]
```
This bias will also affect all fine-tuned versions of this model.
## Training data
The BERT model was pretrained on [BookCorpus](https://yknzhu.wixsite.com/mbweb), a dataset consisting of 11,038
unpublished books and [English Wikipedia](https://en.wikipedia.org/wiki/English_Wikipedia) (excluding lists, tables and
headers).
## Training procedure
### Preprocessing
The texts are lowercased and tokenized using WordPiece and a vocabulary size of 30,000. The inputs of the model are
then of the form:
```
[CLS] Sentence A [SEP] Sentence B [SEP]
```
With probability 0.5, sentence A and sentence B correspond to two consecutive sentences in the original corpus and in
the other cases, it's another random sentence in the corpus. Note that what is considered a sentence here is a
consecutive span of text usually longer than a single sentence. The only constrain is that the result with the two
"sentences" has a combined length of less than 512 tokens.
The details of the masking procedure for each sentence are the following:
- 15% of the tokens are masked.
- In 80% of the cases, the masked tokens are replaced by `[MASK]`.
- In 10% of the cases, the masked tokens are replaced by a random token (different) from the one they replace.
- In the 10% remaining cases, the masked tokens are left as is.
### Pretraining
The model was trained on 4 cloud TPUs in Pod configuration (16 TPU chips total) for one million steps with a batch size
of 256. The sequence length was limited to 128 tokens for 90% of the steps and 512 for the remaining 10%. The optimizer
used is Adam with a learning rate of 1e-4, \\(\beta*{1} = 0.9\\) and \\(\beta*{2} = 0.999\\), a weight decay of 0.01,
learning rate warmup for 10,000 steps and linear decay of the learning rate after.
## Evaluation results
When fine-tuned on downstream tasks, this model achieves the following results:
Glue test results:
| Task | MNLI-(m/mm) | QQP | QNLI | SST-2 | CoLA | STS-B | MRPC | RTE | Average |
| :--: | :---------: | :--: | :--: | :---: | :--: | :---: | :--: | :--: | :-----: |
| | 84.6/83.4 | 71.2 | 90.5 | 93.5 | 52.1 | 85.8 | 88.9 | 66.4 | 79.6 |
### BibTeX entry and citation info
```bibtex
@article{DBLP:journals/corr/abs-1810-04805,
author = {Jacob Devlin and
Ming{-}Wei Chang and
Kenton Lee and
Kristina Toutanova},
title = {{BERT:} Pre-training of Deep Bidirectional Transformers for Language
Understanding},
journal = {CoRR},
volume = {abs/1810.04805},
year = {2018},
url = {http://arxiv.org/abs/1810.04805},
archivePrefix = {arXiv},
eprint = {1810.04805},
timestamp = {Tue, 30 Oct 2018 20:39:56 +0100},
biburl = {https://dblp.org/rec/journals/corr/abs-1810-04805.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
<a href="https://huggingface.co/exbert/?model=bert-base-uncased">
<img width="300px" src="https://cdn-media.huggingface.co/exbert/button.png">
</a>
|
tensorspeech/tts-fastspeech2-kss-ko
|
tensorspeech
| 2021-06-11T03:03:15Z | 0 | 8 |
tensorflowtts
|
[
"tensorflowtts",
"audio",
"text-to-speech",
"text-to-mel",
"ko",
"dataset:KSS",
"arxiv:2006.04558",
"license:apache-2.0",
"region:us"
] |
text-to-speech
| 2022-03-02T23:29:05Z |
---
tags:
- tensorflowtts
- audio
- text-to-speech
- text-to-mel
language: ko
license: apache-2.0
datasets:
- KSS
widget:
- text: "신은 우리의 수학 문제에는 관심이 없다. 신은 다만 경험적으로 통합할 뿐이다."
---
# FastSpeech2 trained on KSS (Korean)
This repository provides a pretrained [FastSpeech2](https://arxiv.org/abs/2006.04558) trained on KSS dataset (Ko). For a detail of the model, we encourage you to read more about
[TensorFlowTTS](https://github.com/TensorSpeech/TensorFlowTTS).
## Install TensorFlowTTS
First of all, please install TensorFlowTTS with the following command:
```
pip install TensorFlowTTS
```
### Converting your Text to Mel Spectrogram
```python
import numpy as np
import soundfile as sf
import yaml
import tensorflow as tf
from tensorflow_tts.inference import AutoProcessor
from tensorflow_tts.inference import TFAutoModel
processor = AutoProcessor.from_pretrained("tensorspeech/tts-fastspeech2-kss-ko")
fastspeech2 = TFAutoModel.from_pretrained("tensorspeech/tts-fastspeech2-kss-ko")
text = "신은 우리의 수학 문제에는 관심이 없다. 신은 다만 경험적으로 통합할 뿐이다."
input_ids = processor.text_to_sequence(text)
mel_before, mel_after, duration_outputs, _, _ = fastspeech2.inference(
input_ids=tf.expand_dims(tf.convert_to_tensor(input_ids, dtype=tf.int32), 0),
speaker_ids=tf.convert_to_tensor([0], dtype=tf.int32),
speed_ratios=tf.convert_to_tensor([1.0], dtype=tf.float32),
f0_ratios =tf.convert_to_tensor([1.0], dtype=tf.float32),
energy_ratios =tf.convert_to_tensor([1.0], dtype=tf.float32),
)
```
#### Referencing FastSpeech2
```
@misc{ren2021fastspeech,
title={FastSpeech 2: Fast and High-Quality End-to-End Text to Speech},
author={Yi Ren and Chenxu Hu and Xu Tan and Tao Qin and Sheng Zhao and Zhou Zhao and Tie-Yan Liu},
year={2021},
eprint={2006.04558},
archivePrefix={arXiv},
primaryClass={eess.AS}
}
```
#### Referencing TensorFlowTTS
```
@misc{TFTTS,
author = {Minh Nguyen, Alejandro Miguel Velasquez, Erogol, Kuan Chen, Dawid Kobus, Takuya Ebata,
Trinh Le and Yunchao He},
title = {TensorflowTTS},
year = {2020},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\\url{https://github.com/TensorSpeech/TensorFlowTTS}},
}
```
|
huggingtweets/click_mae_togay
|
huggingtweets
| 2021-06-10T13:14:58Z | 8 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/click_mae_togay/1623330893696/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1401892055882797060/rpFwU4ge_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">cmt 🏳️⚧️🏳️🌈</div>
<div style="text-align: center; font-size: 14px;">@click_mae_togay</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from cmt 🏳️⚧️🏳️🌈.
| Data | cmt 🏳️⚧️🏳️🌈 |
| --- | --- |
| Tweets downloaded | 3215 |
| Retweets | 1147 |
| Short tweets | 1024 |
| Tweets kept | 1044 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/3df4sbkq/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @click_mae_togay's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/17ov0npx) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/17ov0npx/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/click_mae_togay')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
luca-martial/DialoGPT-Elon
|
luca-martial
| 2021-06-10T09:35:51Z | 14 | 3 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"conversational",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
tags:
- conversational
---
# DialoGPT-Elon: Chat with Elon Musk
This is an attempt to create an AI replica of Elon Musk. The bot's conversation abilities come from Microsoft's [DialoGPT conversational model](https://huggingface.co/microsoft/DialoGPT-medium) fine-tuned on conversation transcripts of Elon's interviews on [Clubhouse](https://zamesin.me/clubhouse-elon-musk-interview/), the [Lex Fridman podcast](https://lexfridman.com/wordpress/wp-content/uploads/2019/11/elon_musk_lex_fridman_2_transcript.pdf) and the [Joe Rogan Experience](https://www.kaggle.com/christianlillelund/joe-rogan-experience-1169-elon-musk).
I also built a Discord AI bot that makes use of this model. Check out my [GitHub repo](https://github.com/luca-martial/elon-bot)!
|
huggingtweets/joebiden-potus
|
huggingtweets
| 2021-06-09T15:51:59Z | 5 | 1 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://github.com/borisdayma/huggingtweets/blob/master/img/logo.png?raw=true
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1380530524779859970/TfwVAbyX_400x400.jpg')">
</div>
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1308769664240160770/AfgzWVE7_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI CYBORG 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">President Biden & Joe Biden</div>
<div style="text-align: center; font-size: 14px;">@joebiden-potus</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from President Biden & Joe Biden.
| Data | President Biden | Joe Biden |
| --- | --- | --- |
| Tweets downloaded | 872 | 3250 |
| Retweets | 32 | 384 |
| Short tweets | 3 | 38 |
| Tweets kept | 837 | 2828 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/1c3s9vhj/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @joebiden-potus's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/tcstvtkt) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/tcstvtkt/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/joebiden-potus')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
philschmid/vit-base-patch16-224-in21k-image-classification-sagemaker
|
philschmid
| 2021-06-09T08:07:35Z | 72 | 0 |
transformers
|
[
"transformers",
"pytorch",
"vit",
"image-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2022-03-02T23:29:05Z |
---
tags:
- image-classification
metrics:
- accuracy
model-index:
- name: vit-base-patch16-224-in21k-image-classification-sagemaker
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# vit-base-patch16-224-in21k-image-classification-sagemaker
This model is a fine-tuned version of [vit-base-patch16-224-in21k](https://huggingface.co/vit-base-patch16-224-in21k) on the cifar10 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3033
- Accuracy: 0.972
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| No log | 1.0 | 313 | 1.4603 | 0.936 |
| 1.6548 | 2.0 | 626 | 0.4451 | 0.966 |
| 1.6548 | 3.0 | 939 | 0.3033 | 0.972 |
### Framework versions
- Transformers 4.6.1
- Pytorch 1.7.1
- Datasets 1.6.2
- Tokenizers 0.10.3
|
huggingtweets/tdxf20
|
huggingtweets
| 2021-06-08T16:04:36Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/tdxf20/1623168253387/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1393296848929050627/sp8GpW8T_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">mert</div>
<div style="text-align: center; font-size: 14px;">@tdxf20</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from mert.
| Data | mert |
| --- | --- |
| Tweets downloaded | 1556 |
| Retweets | 181 |
| Short tweets | 373 |
| Tweets kept | 1002 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/n8yfhw0t/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @tdxf20's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/19ikisni) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/19ikisni/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/tdxf20')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
Sahajtomar/German-semantic
|
Sahajtomar
| 2021-06-08T12:31:35Z | 20 | 17 |
sentence-transformers
|
[
"sentence-transformers",
"bert",
"semantic",
"sentence-similarity",
"de",
"dataset:sts",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2022-03-02T23:29:04Z |
---
language: de
tags:
- semantic
- sentence-transformers
- sentence-similarity
datasets:
- sts
---
# German STS
## STS dev (german)
87.9%
## STS test (german)
84.3%
#### STS pipeline
```python
!pip install -U sentence-transformers
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('..model_path..')
sentences1 = ['Die Katze sitzt draußen',
"Ein Mann spielt Gitarre",
'Der neue Film ist großartig']
sentences2 = ['Der Hund spielt im Garten',
"Eine Frau sieht fern",
'Der neue Film ist so toll']
embeddings1 = model.encode(sentences1, convert_to_tensor=True)
embeddings2 = model.encode(sentences2, convert_to_tensor=True)
cosine_scores = util.pytorch_cos_sim(embeddings1, embeddings2)
for i in range(len(sentences1)):
for j in range(len(sentences2)):
print(cosine_scores[i][j]))
"""
Die Katze sitzt draußen Der Hund spielt im Garten Score: 0.1259
Die Katze sitzt draußen Eine Frau sieht fern Score: 0.0567
Die Katze sitzt draußen Der neue Film ist so toll Score: 0.0557
Ein Mann spielt Gitarre Der Hund spielt im Garten Score: 0.1031
Ein Mann spielt Gitarre Eine Frau sieht fern Score: 0.0098
Ein Mann spielt Gitarre Der neue Film ist so toll Score: 0.0828
Der neue Film ist großartig Der Hund spielt im Garten Score: 0.1008
Der neue Film ist großartig Eine Frau sieht fern Score: 0.0674
"""
```
|
huggingtweets/erilies
|
huggingtweets
| 2021-06-08T10:39:49Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
<?xml version="1.0" encoding="utf-8"?>
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
<html>
<head>
<title>503 Service Unavailable</title>
</head>
<body>
<h1>Error 503 Service Unavailable</h1>
<p>Service Unavailable</p>
<h3>Guru Mediation:</h3>
<p>Details: cache-wdc5522-WDC 1623148785 664418368</p>
<hr>
<p>Varnish cache server</p>
</body>
</html>
|
seduerr/pai_paraph
|
seduerr
| 2021-06-08T08:43:43Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"t5",
"text2text-generation",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-03-02T23:29:05Z |
input_ = paraphrase: + str(input_) + ' </s>'
|
huggingtweets/926stories-superachnural
|
huggingtweets
| 2021-06-08T08:31:13Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/926stories-superachnural/1623141069426/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1402093786457526273/DCJaU_cD_400x400.jpg')">
</div>
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1401905139414278147/p2g20UkB_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI CYBORG 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">Rummyyyy & vada pavlov</div>
<div style="text-align: center; font-size: 14px;">@926stories-superachnural</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from Rummyyyy & vada pavlov.
| Data | Rummyyyy | vada pavlov |
| --- | --- | --- |
| Tweets downloaded | 1428 | 3194 |
| Retweets | 157 | 702 |
| Short tweets | 141 | 473 |
| Tweets kept | 1130 | 2019 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/3srkphhe/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @926stories-superachnural's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/42rozhsq) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/42rozhsq/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/926stories-superachnural')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
Laeyoung/BTS-comments-generator
|
Laeyoung
| 2021-06-08T07:59:07Z | 11 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:04Z |
### Model information
* Fine tuning dataset: https://www.kaggle.com/seungguini/bts-youtube-comments
* Base model: GPT2 Small
* Epoch: 5
* API page: [Ainize](https://ainize.ai/teachable-ainize/gpt2-train?branch=train/cv695m9g40av0cdabuqp)
* Demo page: [End-point](https://kubecon-tabtab-ainize-team.endpoint.ainize.ai/?modelUrl=https://train-cv695m9g40av0cdabuqp-gpt2-train-teachable-ainize.endpoint.ainize.ai/predictions/gpt-2-en-small-finetune)
### ===Teachable NLP=== ###
To train a GPT-2 model, write code and require GPU resources, but can easily fine-tune and get an API to use the model here for free.
* Teachable NLP: [Teachable NLP](https://ainize.ai/teachable-nlp)
* Tutorial: [Tutorial](https://forum.ainetwork.ai/t/teachable-nlp-how-to-use-teachable-nlp/65?utm_source=community&utm_medium=huggingface&utm_campaign=model&utm_content=teachable%20nlp)
|
huggingtweets/kicchinnezumi
|
huggingtweets
| 2021-06-08T06:41:14Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/kicchinnezumi/1623134447065/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1400341059842891782/nJw_YYUy_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">Kicchin (Most Powerful VTweeter)</div>
<div style="text-align: center; font-size: 14px;">@kicchinnezumi</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from Kicchin (Most Powerful VTweeter).
| Data | Kicchin (Most Powerful VTweeter) |
| --- | --- |
| Tweets downloaded | 3247 |
| Retweets | 644 |
| Short tweets | 1223 |
| Tweets kept | 1380 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/25jce149/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @kicchinnezumi's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/3jg50eab) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/3jg50eab/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/kicchinnezumi')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
huggingtweets/926stories
|
huggingtweets
| 2021-06-08T06:38:28Z | 9 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/926stories/1623134303273/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1402093786457526273/DCJaU_cD_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">Rummyyyy</div>
<div style="text-align: center; font-size: 14px;">@926stories</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from Rummyyyy.
| Data | Rummyyyy |
| --- | --- |
| Tweets downloaded | 1420 |
| Retweets | 156 |
| Short tweets | 139 |
| Tweets kept | 1125 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/5frannca/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @926stories's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/1dvniaka) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/1dvniaka/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/926stories')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
huggingtweets/davidvizgan
|
huggingtweets
| 2021-06-07T20:59:39Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/davidvizgan/1623099475956/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1395199219779219458/CNIBnZac_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">David Vizgan</div>
<div style="text-align: center; font-size: 14px;">@davidvizgan</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from David Vizgan.
| Data | David Vizgan |
| --- | --- |
| Tweets downloaded | 2075 |
| Retweets | 563 |
| Short tweets | 302 |
| Tweets kept | 1210 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/36psf0c4/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @davidvizgan's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/23t5t1ij) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/23t5t1ij/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/davidvizgan')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
Rajan/NepaliBERT
|
Rajan
| 2021-06-07T14:36:58Z | 23 | 3 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"fill-mask",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:04Z |
# NepaliBERT(Phase 1)
NEPALIBERT is a state-of-the-art language model for Nepali based on the BERT model. The model is trained using a masked language modeling (MLM).
# Loading the model and tokenizer
1. clone the model repo
```
git lfs install
git clone https://huggingface.co/Rajan/NepaliBERT
```
2. Loading the Tokenizer
```
from transformers import BertTokenizer
vocab_file_dir = './NepaliBERT/'
tokenizer = BertTokenizer.from_pretrained(vocab_file_dir,
strip_accents=False,
clean_text=False )
```
3. Loading the model:
```
from transformers import BertForMaskedLM
model = BertForMaskedLM.from_pretrained('./NepaliBERT')
```
The easiest way to check whether our language model is learning anything interesting is via the ```FillMaskPipeline```.
Pipelines are simple wrappers around tokenizers and models, and the 'fill-mask' one will let you input a sequence containing a masked token (here, [mask]) and return a list of the most probable filled sequences, with their probabilities.
```
from transformers import pipeline
fill_mask = pipeline(
"fill-mask",
model=model,
tokenizer=tokenizer
)
```
For more info visit the [GITHUB🤗](https://github.com/R4j4n/NepaliBERT)
|
osanseviero/my_new_model
|
osanseviero
| 2021-06-07T14:27:42Z | 8 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"pytorch",
"roberta",
"feature-extraction",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
feature-extraction
| 2022-03-02T23:29:05Z |
---
tags:
- sentence-transformers
- feature-extraction
---
# Name of Model
<!--- Describe your model here -->
## Model Description
The model consists of the following layers:
(0) Base Transformer Type: RobertaModel
(1) mean Pooling
## Usage (Sentence-Transformers)
Using this model becomes more convenient when you have [sentence-transformers](https://github.com/UKPLab/sentence-transformers) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence"]
model = SentenceTransformer('model_name')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
sum_embeddings = torch.sum(token_embeddings * input_mask_expanded, 1)
sum_mask = torch.clamp(input_mask_expanded.sum(1), min=1e-9)
return sum_embeddings / sum_mask
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('model_name')
model = AutoModel.from_pretrained('model_name')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, max_length=128, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, max pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Training Procedure
<!--- Describe how your model was trained -->
## Evaluation Results
<!--- Describe how your model was evaluated -->
## Citing & Authors
<!--- Describe where people can find more information -->
|
huggingtweets/foxlius
|
huggingtweets
| 2021-06-07T13:20:09Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/foxlius/1623071923782/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1397375635845222400/-N68I_0K_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">legally required to</div>
<div style="text-align: center; font-size: 14px;">@foxlius</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from legally required to.
| Data | legally required to |
| --- | --- |
| Tweets downloaded | 3224 |
| Retweets | 1459 |
| Short tweets | 631 |
| Tweets kept | 1134 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/h54z72kn/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @foxlius's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/6fffkgwp) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/6fffkgwp/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/foxlius')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
huggingtweets/annasvirtual
|
huggingtweets
| 2021-06-07T10:59:15Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/annasvirtual/1623063516917/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1392739173979680768/0-9vXPxR_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">Annas</div>
<div style="text-align: center; font-size: 14px;">@annasvirtual</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from Annas.
| Data | Annas |
| --- | --- |
| Tweets downloaded | 3247 |
| Retweets | 90 |
| Short tweets | 1495 |
| Tweets kept | 1662 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/2n0tmbbi/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @annasvirtual's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/133nq2yx) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/133nq2yx/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/annasvirtual')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
spuun/kek
|
spuun
| 2021-06-06T08:40:36Z | 0 | 0 | null |
[
"region:us"
] | null | 2022-03-02T23:29:05Z |
# Kek model
---
A customized DialoGPT model designed for personal use. Usage is the same with DialoGPT.
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
tokenizer = AutoTokenizer.from_pretrained("spuun/kek")
model = AutoModelForCausalLM.from_pretrained("spuun/kek")
# Let's chat for 5 lines
for step in range(5):
# encode the new user input, add the eos_token and return a tensor in Pytorch
new_user_input_ids = tokenizer.encode(input(">> User:") + tokenizer.eos_token, return_tensors='pt')
# append the new user input tokens to the chat history
bot_input_ids = torch.cat([chat_history_ids, new_user_input_ids], dim=-1) if step > 0 else new_user_input_ids
# generated a response while limiting the total chat history to 1000 tokens,
chat_history_ids = model.generate(bot_input_ids, max_length=1000, pad_token_id=tokenizer.eos_token_id)
# pretty print last ouput tokens from bot
print("DialoGPT: {}".format(tokenizer.decode(chat_history_ids[:, bot_input_ids.shape[-1]:][0], skip_special_tokens=True)))
```
|
Davlan/xlm-roberta-base-finetuned-amharic
|
Davlan
| 2021-06-05T20:37:25Z | 535 | 1 |
transformers
|
[
"transformers",
"pytorch",
"xlm-roberta",
"fill-mask",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:04Z |
Hugging Face's logo
---
language: am
datasets:
---
# xlm-roberta-base-finetuned-amharic
## Model description
**xlm-roberta-base-finetuned-amharic** is a **Amharic RoBERTa** model obtained by fine-tuning **xlm-roberta-base** model on Amharic language texts. It provides **better performance** than the XLM-RoBERTa on named entity recognition datasets.
Specifically, this model is a *xlm-roberta-base* model that was fine-tuned on Amharic corpus.
## Intended uses & limitations
#### How to use
You can use this model with Transformers *pipeline* for masked token prediction.
```python
>>> from transformers import pipeline
>>> unmasker = pipeline('fill-mask', model='Davlan/xlm-roberta-base-finetuned-hausa')
>>> unmasker("የአሜሪካ የአፍሪካ ቀንድ ልዩ መልዕክተኛ ጄፈሪ ፌልትማን በአራት አገራት የሚያደጉትን <mask> መጀመራቸውን የአሜሪካ የውጪ ጉዳይ ሚንስቴር አስታወቀ።")
```
#### Limitations and bias
This model is limited by its training dataset of entity-annotated news articles from a specific span of time. This may not generalize well for all use cases in different domains.
## Training data
This model was fine-tuned on [Amharic CC-100](http://data.statmt.org/cc-100/)
## Training procedure
This model was trained on a single NVIDIA V100 GPU
## Eval results on Test set (F-score, average over 5 runs)
Dataset| XLM-R F1 | am_roberta F1
-|-|-
[MasakhaNER](https://github.com/masakhane-io/masakhane-ner) | 70.96 | 77.97
### BibTeX entry and citation info
By David Adelani
```
```
|
eunjin/koMHBERT-kcbert-based-v2
|
eunjin
| 2021-06-05T17:44:39Z | 20 | 1 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"feature-extraction",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
feature-extraction
| 2022-03-02T23:29:05Z |
korean Mental Health BERT -v2
huggingface에 공개된 kcbert-base BERT를 정신건강의학신문을 크롤링한 dataset으로 MLM fine-tuining한 Bert Model입니다. 정신건강 발화 관련 데이터를 모을 수 없는 상황에서 이를 대체할만한 데이터로 제시합니다. 향후 정신건강 관련 감정 및 상태 classification 및 그에 따른 chatbot 구현에 사용할 수 있습니다.
정신건강의학신문: http://www.psychiatricnews.net
|
eunjin/koMHBERT-krbert-based-v2
|
eunjin
| 2021-06-05T17:42:17Z | 19 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"feature-extraction",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
feature-extraction
| 2022-03-02T23:29:05Z |
korean Mental Health BERT -v2
huggingface에 공개된 KR-Medium BERT를 정신건강의학신문을 크롤링한 dataset으로 MLM fine-tuining한 Bert Model입니다.
정신건강 발화 관련 데이터를 모을 수 없는 상황에서 이를 대체할만한 데이터로 제시합니다.
향후 정신건강 관련 감정 및 상태 classification 및 그에 따른 chatbot 구현에 사용할 수 있습니다.
정신건강의학신문: http://www.psychiatricnews.net
|
m3tafl0ps/autonlp-NLPIsFun-251844
|
m3tafl0ps
| 2021-06-05T17:15:23Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"text-classification",
"autonlp",
"en",
"dataset:m3tafl0ps/autonlp-data-NLPIsFun",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
---
tags: autonlp
language: en
widget:
- text: "I love AutoNLP 🤗"
datasets:
- m3tafl0ps/autonlp-data-NLPIsFun
---
# Model Trained Using AutoNLP
- Problem type: Binary Classification
- Model ID: 251844
## Validation Metrics
- Loss: 0.38616305589675903
- Accuracy: 0.8356545961002786
- Precision: 0.8253968253968254
- Recall: 0.8571428571428571
- AUC: 0.9222387781709815
- F1: 0.8409703504043127
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoNLP"}' https://api-inference.huggingface.co/models/m3tafl0ps/autonlp-NLPIsFun-251844
```
Or Python API:
```
from transformers import AutoModelForSequenceClassification, AutoTokenizer
model = AutoModelForSequenceClassification.from_pretrained("m3tafl0ps/autonlp-NLPIsFun-251844", use_auth_token=True)
tokenizer = AutoTokenizer.from_pretrained("m3tafl0ps/autonlp-NLPIsFun-251844", use_auth_token=True)
inputs = tokenizer("I love AutoNLP", return_tensors="pt")
outputs = model(**inputs)
```
|
huggingtweets/dog_feelings-elonmusk
|
huggingtweets
| 2021-06-04T11:41:53Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://github.com/borisdayma/huggingtweets/blob/master/img/logo.png?raw=true
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1400698471385083904/sLTt0UmS_400x400.jpg')">
</div>
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1046968391389589507/_0r5bQLl_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI CYBORG 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">Elon Musk & Thoughts of Dog®</div>
<div style="text-align: center; font-size: 14px;">@dog_feelings-elonmusk</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from Elon Musk & Thoughts of Dog®.
| Data | Elon Musk | Thoughts of Dog® |
| --- | --- | --- |
| Tweets downloaded | 400 | 1148 |
| Retweets | 32 | 14 |
| Short tweets | 123 | 17 |
| Tweets kept | 245 | 1117 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/2vw0f8wk/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @dog_feelings-elonmusk's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/2o3nweey) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/2o3nweey/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/dog_feelings-elonmusk')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
huggingtweets/nigel_farage
|
huggingtweets
| 2021-06-04T11:40:40Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/nigel_farage/1622806835955/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1385256843304386565/zyNRZ-Nd_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">Nigel Farage</div>
<div style="text-align: center; font-size: 14px;">@nigel_farage</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from Nigel Farage.
| Data | Nigel Farage |
| --- | --- |
| Tweets downloaded | 3237 |
| Retweets | 740 |
| Short tweets | 48 |
| Tweets kept | 2449 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/3lh6yso1/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @nigel_farage's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/2l2tqehp) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/2l2tqehp/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/nigel_farage')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
TransQuest/siamesetransquest-da-ne_en-wiki
|
TransQuest
| 2021-06-04T11:20:50Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"xlm-roberta",
"feature-extraction",
"Quality Estimation",
"siamesetransquest",
"da",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
feature-extraction
| 2022-03-02T23:29:05Z |
---
language: ne-en
tags:
- Quality Estimation
- siamesetransquest
- da
license: apache-2.0
---
# TransQuest: Translation Quality Estimation with Cross-lingual Transformers
The goal of quality estimation (QE) is to evaluate the quality of a translation without having access to a reference translation. High-accuracy QE that can be easily deployed for a number of language pairs is the missing piece in many commercial translation workflows as they have numerous potential uses. They can be employed to select the best translation when several translation engines are available or can inform the end user about the reliability of automatically translated content. In addition, QE systems can be used to decide whether a translation can be published as it is in a given context, or whether it requires human post-editing before publishing or translation from scratch by a human. The quality estimation can be done at different levels: document level, sentence level and word level.
With TransQuest, we have opensourced our research in translation quality estimation which also won the sentence-level direct assessment quality estimation shared task in [WMT 2020](http://www.statmt.org/wmt20/quality-estimation-task.html). TransQuest outperforms current open-source quality estimation frameworks such as [OpenKiwi](https://github.com/Unbabel/OpenKiwi) and [DeepQuest](https://github.com/sheffieldnlp/deepQuest).
## Features
- Sentence-level translation quality estimation on both aspects: predicting post editing efforts and direct assessment.
- Word-level translation quality estimation capable of predicting quality of source words, target words and target gaps.
- Outperform current state-of-the-art quality estimation methods like DeepQuest and OpenKiwi in all the languages experimented.
- Pre-trained quality estimation models for fifteen language pairs are available in [HuggingFace.](https://huggingface.co/TransQuest)
## Installation
### From pip
```bash
pip install transquest
```
### From Source
```bash
git clone https://github.com/TharinduDR/TransQuest.git
cd TransQuest
pip install -r requirements.txt
```
## Using Pre-trained Models
```python
import torch
from transquest.algo.sentence_level.siamesetransquest.run_model import SiameseTransQuestModel
model = SiameseTransQuestModel("TransQuest/siamesetransquest-da-ne_en-wiki")
predictions = model.predict([["Reducerea acestor conflicte este importantă pentru conservare.", "Reducing these conflicts is not important for preservation."]])
print(predictions)
```
## Documentation
For more details follow the documentation.
1. **[Installation](https://tharindudr.github.io/TransQuest/install/)** - Install TransQuest locally using pip.
2. **Architectures** - Checkout the architectures implemented in TransQuest
1. [Sentence-level Architectures](https://tharindudr.github.io/TransQuest/architectures/sentence_level_architectures/) - We have released two architectures; MonoTransQuest and SiameseTransQuest to perform sentence level quality estimation.
2. [Word-level Architecture](https://tharindudr.github.io/TransQuest/architectures/word_level_architecture/) - We have released MicroTransQuest to perform word level quality estimation.
3. **Examples** - We have provided several examples on how to use TransQuest in recent WMT quality estimation shared tasks.
1. [Sentence-level Examples](https://tharindudr.github.io/TransQuest/examples/sentence_level_examples/)
2. [Word-level Examples](https://tharindudr.github.io/TransQuest/examples/word_level_examples/)
4. **Pre-trained Models** - We have provided pretrained quality estimation models for fifteen language pairs covering both sentence-level and word-level
1. [Sentence-level Models](https://tharindudr.github.io/TransQuest/models/sentence_level_pretrained/)
2. [Word-level Models](https://tharindudr.github.io/TransQuest/models/word_level_pretrained/)
5. **[Contact](https://tharindudr.github.io/TransQuest/contact/)** - Contact us for any issues with TransQuest
## Citations
If you are using the word-level architecture, please consider citing this paper which is accepted to [ACL 2021](https://2021.aclweb.org/).
```bash
@InProceedings{ranasinghe2021,
author = {Ranasinghe, Tharindu and Orasan, Constantin and Mitkov, Ruslan},
title = {An Exploratory Analysis of Multilingual Word Level Quality Estimation with Cross-Lingual Transformers},
booktitle = {Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics},
year = {2021}
}
```
If you are using the sentence-level architectures, please consider citing these papers which were presented in [COLING 2020](https://coling2020.org/) and in [WMT 2020](http://www.statmt.org/wmt20/) at EMNLP 2020.
```bash
@InProceedings{transquest:2020a,
author = {Ranasinghe, Tharindu and Orasan, Constantin and Mitkov, Ruslan},
title = {TransQuest: Translation Quality Estimation with Cross-lingual Transformers},
booktitle = {Proceedings of the 28th International Conference on Computational Linguistics},
year = {2020}
}
```
```bash
@InProceedings{transquest:2020b,
author = {Ranasinghe, Tharindu and Orasan, Constantin and Mitkov, Ruslan},
title = {TransQuest at WMT2020: Sentence-Level Direct Assessment},
booktitle = {Proceedings of the Fifth Conference on Machine Translation},
year = {2020}
}
```
|
TransQuest/siamesetransquest-da-si_en-wiki
|
TransQuest
| 2021-06-04T11:15:08Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"xlm-roberta",
"feature-extraction",
"Quality Estimation",
"siamesetransquest",
"da",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
feature-extraction
| 2022-03-02T23:29:05Z |
---
language: si-en
tags:
- Quality Estimation
- siamesetransquest
- da
license: apache-2.0
---
# TransQuest: Translation Quality Estimation with Cross-lingual Transformers
The goal of quality estimation (QE) is to evaluate the quality of a translation without having access to a reference translation. High-accuracy QE that can be easily deployed for a number of language pairs is the missing piece in many commercial translation workflows as they have numerous potential uses. They can be employed to select the best translation when several translation engines are available or can inform the end user about the reliability of automatically translated content. In addition, QE systems can be used to decide whether a translation can be published as it is in a given context, or whether it requires human post-editing before publishing or translation from scratch by a human. The quality estimation can be done at different levels: document level, sentence level and word level.
With TransQuest, we have opensourced our research in translation quality estimation which also won the sentence-level direct assessment quality estimation shared task in [WMT 2020](http://www.statmt.org/wmt20/quality-estimation-task.html). TransQuest outperforms current open-source quality estimation frameworks such as [OpenKiwi](https://github.com/Unbabel/OpenKiwi) and [DeepQuest](https://github.com/sheffieldnlp/deepQuest).
## Features
- Sentence-level translation quality estimation on both aspects: predicting post editing efforts and direct assessment.
- Word-level translation quality estimation capable of predicting quality of source words, target words and target gaps.
- Outperform current state-of-the-art quality estimation methods like DeepQuest and OpenKiwi in all the languages experimented.
- Pre-trained quality estimation models for fifteen language pairs are available in [HuggingFace.](https://huggingface.co/TransQuest)
## Installation
### From pip
```bash
pip install transquest
```
### From Source
```bash
git clone https://github.com/TharinduDR/TransQuest.git
cd TransQuest
pip install -r requirements.txt
```
## Using Pre-trained Models
```python
import torch
from transquest.algo.sentence_level.siamesetransquest.run_model import SiameseTransQuestModel
model = SiameseTransQuestModel("TransQuest/siamesetransquest-da-si_en-wiki")
predictions = model.predict([["Reducerea acestor conflicte este importantă pentru conservare.", "Reducing these conflicts is not important for preservation."]])
print(predictions)
```
## Documentation
For more details follow the documentation.
1. **[Installation](https://tharindudr.github.io/TransQuest/install/)** - Install TransQuest locally using pip.
2. **Architectures** - Checkout the architectures implemented in TransQuest
1. [Sentence-level Architectures](https://tharindudr.github.io/TransQuest/architectures/sentence_level_architectures/) - We have released two architectures; MonoTransQuest and SiameseTransQuest to perform sentence level quality estimation.
2. [Word-level Architecture](https://tharindudr.github.io/TransQuest/architectures/word_level_architecture/) - We have released MicroTransQuest to perform word level quality estimation.
3. **Examples** - We have provided several examples on how to use TransQuest in recent WMT quality estimation shared tasks.
1. [Sentence-level Examples](https://tharindudr.github.io/TransQuest/examples/sentence_level_examples/)
2. [Word-level Examples](https://tharindudr.github.io/TransQuest/examples/word_level_examples/)
4. **Pre-trained Models** - We have provided pretrained quality estimation models for fifteen language pairs covering both sentence-level and word-level
1. [Sentence-level Models](https://tharindudr.github.io/TransQuest/models/sentence_level_pretrained/)
2. [Word-level Models](https://tharindudr.github.io/TransQuest/models/word_level_pretrained/)
5. **[Contact](https://tharindudr.github.io/TransQuest/contact/)** - Contact us for any issues with TransQuest
## Citations
If you are using the word-level architecture, please consider citing this paper which is accepted to [ACL 2021](https://2021.aclweb.org/).
```bash
@InProceedings{ranasinghe2021,
author = {Ranasinghe, Tharindu and Orasan, Constantin and Mitkov, Ruslan},
title = {An Exploratory Analysis of Multilingual Word Level Quality Estimation with Cross-Lingual Transformers},
booktitle = {Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics},
year = {2021}
}
```
If you are using the sentence-level architectures, please consider citing these papers which were presented in [COLING 2020](https://coling2020.org/) and in [WMT 2020](http://www.statmt.org/wmt20/) at EMNLP 2020.
```bash
@InProceedings{transquest:2020a,
author = {Ranasinghe, Tharindu and Orasan, Constantin and Mitkov, Ruslan},
title = {TransQuest: Translation Quality Estimation with Cross-lingual Transformers},
booktitle = {Proceedings of the 28th International Conference on Computational Linguistics},
year = {2020}
}
```
```bash
@InProceedings{transquest:2020b,
author = {Ranasinghe, Tharindu and Orasan, Constantin and Mitkov, Ruslan},
title = {TransQuest at WMT2020: Sentence-Level Direct Assessment},
booktitle = {Proceedings of the Fifth Conference on Machine Translation},
year = {2020}
}
```
|
Subsets and Splits
Filtered Qwen2.5 Distill Models
Identifies specific configurations of models by filtering cards that contain 'distill', 'qwen2.5', '7b' while excluding certain base models and incorrect model ID patterns, uncovering unique model variants.
Filtered Model Cards Count
Finds the count of entries with specific card details that include 'distill', 'qwen2.5', '7b' but exclude certain base models, revealing valuable insights about the dataset's content distribution.
Filtered Distill Qwen 7B Models
Filters for specific card entries containing 'distill', 'qwen', and '7b', excluding certain strings and patterns, to identify relevant model configurations.
Filtered Qwen-7b Model Cards
The query performs a detailed filtering based on specific keywords and excludes certain entries, which could be useful for identifying a specific subset of cards but does not provide deeper insights or trends.
Filtered Qwen 7B Model Cards
The query filters for specific terms related to "distilled" or "distill", "qwen", and "7b" in the 'card' column but excludes certain base models, providing a limited set of entries for further inspection.
Qwen 7B Distilled Models
The query provides a basic filtering of records to find specific card names that include keywords related to distilled Qwen 7b models, excluding a particular base model, which gives limited insight but helps in focusing on relevant entries.
Qwen 7B Distilled Model Cards
The query filters data based on specific keywords in the modelId and card fields, providing limited insight primarily useful for locating specific entries rather than revealing broad patterns or trends.
Qwen 7B Distilled Models
Finds all entries containing the terms 'distilled', 'qwen', and '7b' in a case-insensitive manner, providing a filtered set of records but without deeper analysis.
Distilled Qwen 7B Models
The query filters for specific model IDs containing 'distilled', 'qwen', and '7b', providing a basic retrieval of relevant entries but without deeper analysis or insight.
Filtered Model Cards with Distill Qwen2.
Filters and retrieves records containing specific keywords in the card description while excluding certain phrases, providing a basic count of relevant entries.
Filtered Model Cards with Distill Qwen 7
The query filters specific variations of card descriptions containing 'distill', 'qwen', and '7b' while excluding a particular base model, providing limited but specific data retrieval.
Distill Qwen 7B Model Cards
The query filters and retrieves rows where the 'card' column contains specific keywords ('distill', 'qwen', and '7b'), providing a basic filter result that can help in identifying specific entries.