
modelId
stringlengths 5
139
| author
stringlengths 2
42
| last_modified
timestamp[us, tz=UTC]date 2020-02-15 11:33:14
2025-09-12 18:33:19
| downloads
int64 0
223M
| likes
int64 0
11.7k
| library_name
stringclasses 555
values | tags
listlengths 1
4.05k
| pipeline_tag
stringclasses 55
values | createdAt
timestamp[us, tz=UTC]date 2022-03-02 23:29:04
2025-09-12 18:33:14
| card
stringlengths 11
1.01M
|
|---|---|---|---|---|---|---|---|---|---|
shun89/opus-mt-ko-zh
|
shun89
| 2025-09-12T09:12:51Z | 0 | 0 | null |
[
"pytorch",
"marian",
"translation",
"ko",
"zh",
"license:apache-2.0",
"region:us"
] |
translation
| 2025-09-12T09:08:39Z |
---
license: apache-2.0
language:
- ko
- zh
metrics:
- bleu
pipeline_tag: translation
---
from transformers import MarianMTModel, MarianTokenizer
model = MarianMTModel.from_pretrained(“shun89/opus-mt-ko-zh”)
tokenizer = MarianTokenizer.from_pretrained(“shun89/opus-mt-ko-zh”)
text = '오피스 빌딩이 너무 현대적이라 사무 환경이 편안하네요!'
inputs = tokenizer(texts, return_tensors="pt",padding=True, truncation=True, max_length=256)
outputs = model.generate(**inputs)
result= " ".join(tokenizer.batch_decode(outputs, skip_special_tokens=True))
print("待翻译语句:",text)
print("翻译结果:",result)
|
5456es/random_prune_Qwen2.5-7B-Instruct_prune_0.5-sigmoid
|
5456es
| 2025-09-12T09:11:09Z | 29 | 0 | null |
[
"safetensors",
"qwen2",
"dpo",
"preference-learning",
"random",
"pruned",
"license:apache-2.0",
"region:us"
] | null | 2025-09-08T04:50:54Z |
---
license: apache-2.0
base_model: Qwen2.5-7B-Instruct
tags:
- dpo
- preference-learning
- random
- pruned
---
# random_prune_Qwen2.5-7B-Instruct_prune_0.5-sigmoid
This model is a DPO (Direct Preference Optimization) fine-tuned version of Qwen2.5-7B-Instruct using the random method.
## Model Details
- **Base Model**: Qwen2.5-7B-Instruct
- **Training Method**: random
- **Pruning Ratio**: unknown
- **Training Date**: 2025-09-12
## Training Configuration
This model was trained using Direct Preference Optimization (DPO) with the following characteristics:
- Method: random
- Pruning applied during training
- Fine-tuned on preference data
## Usage
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
model_name = "5456es/random_prune_Qwen2.5-7B-Instruct_prune_0.5-sigmoid"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
# Example usage
prompt = "Your prompt here"
inputs = tokenizer(prompt, return_tensors="pt")
outputs = model.generate(**inputs, max_length=100)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
```
## Training Data
This model was trained on preference data using the DPO algorithm.
## Limitations
This model inherits the limitations of its base model and may have additional limitations due to the pruning process.
## Citation
If you use this model, please cite the original DPO paper and the base model.
|
lejonck/whisper-small-common-voice-3
|
lejonck
| 2025-09-12T09:09:46Z | 36 | 0 |
transformers
|
[
"transformers",
"safetensors",
"whisper",
"automatic-speech-recognition",
"generated_from_trainer",
"dataset:generator",
"base_model:lejonck/whisper-small-common-voice-2",
"base_model:finetune:lejonck/whisper-small-common-voice-2",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2025-08-25T05:38:58Z |
---
library_name: transformers
license: apache-2.0
base_model: lejonck/whisper-small-common-voice-2
tags:
- generated_from_trainer
datasets:
- generator
metrics:
- wer
model-index:
- name: whisper-small-common-voice-3
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: generator
type: generator
config: default
split: train
args: default
metrics:
- name: Wer
type: wer
value: 0.2480634452231649
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# whisper-small-common-voice-3
This model is a fine-tuned version of [lejonck/whisper-small-common-voice-2](https://huggingface.co/lejonck/whisper-small-common-voice-2) on the generator dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1207
- Wer: 0.2481
- Cer: 0.3645
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 8
- eval_batch_size: 2
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 100
- num_epochs: 12
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer | Cer |
|:-------------:|:-----:|:----:|:---------------:|:------:|:------:|
| 0.2347 | 1.0 | 1000 | 0.1108 | 0.3383 | 0.3745 |
| 0.0761 | 2.0 | 2000 | 0.1207 | 0.2481 | 0.3645 |
| 0.0244 | 3.0 | 3000 | 0.1340 | 0.4093 | 0.3905 |
| 0.0076 | 4.0 | 4000 | 0.1434 | 0.4784 | 0.4075 |
| 0.0018 | 5.0 | 5000 | 0.1585 | 0.3921 | 0.3755 |
| 0.0035 | 6.0 | 6000 | 0.1639 | 0.4190 | 0.3841 |
| 0.0004 | 7.0 | 7000 | 0.1693 | 0.3445 | 0.3757 |
### Framework versions
- Transformers 4.55.2
- Pytorch 2.7.0+cu126
- Datasets 2.19.1
- Tokenizers 0.21.4
|
gaianet/Seed-OSS-36B-Instruct-GGUF
|
gaianet
| 2025-09-12T09:09:31Z | 397 | 0 |
transformers
|
[
"transformers",
"gguf",
"seed_oss",
"text-generation",
"base_model:ByteDance-Seed/Seed-OSS-36B-Instruct",
"base_model:quantized:ByteDance-Seed/Seed-OSS-36B-Instruct",
"autotrain_compatible",
"endpoints_compatible",
"region:us",
"conversational"
] |
text-generation
| 2025-08-28T04:49:10Z |
---
base_model: ByteDance-Seed/Seed-OSS-36B-Instruct
model_creator: ByteDance-Seed
model_name: Seed-OSS-36B-Instruct
quantized_by: Second State Inc.
pipeline_tag: text-generation
library_name: transformers
---
# Seed-OSS-36B-Instruct-GGUF
## Original Model
[ByteDance-Seed/Seed-OSS-36B-Instruct](https://huggingface.co/ByteDance-Seed/Seed-OSS-36B-Instruct)
## Run with Gaianet
**Prompt template**
prompt template:
- `seed-oss-think` for think mode
- `seed-oss-no-think` for no think mode
**Context size**
chat_ctx_size: `512000`
**Run with GaiaNet**
- Quick start: https://docs.gaianet.ai/node-guide/quick-start
- Customize your node: https://docs.gaianet.ai/node-guide/customize
*Quantized with llama.cpp b6301*
|
kartikeyapandey20/MiniModernBERT-glue-cola
|
kartikeyapandey20
| 2025-09-12T09:09:04Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"modernbert",
"text-classification",
"generated_from_trainer",
"base_model:kartikeyapandey20/MiniModernBERT-Pretrained",
"base_model:finetune:kartikeyapandey20/MiniModernBERT-Pretrained",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2025-09-12T09:08:31Z |
---
library_name: transformers
license: mit
base_model: kartikeya-pandey/MiniModernBERT-Pretrained
tags:
- generated_from_trainer
metrics:
- matthews_correlation
model-index:
- name: MiniModernBERT-glue-cola
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# MiniModernBERT-glue-cola
This model is a fine-tuned version of [kartikeya-pandey/MiniModernBERT-Pretrained](https://huggingface.co/kartikeya-pandey/MiniModernBERT-Pretrained) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 2.1227
- Matthews Correlation: 0.3408
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH_FUSED with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 4
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.56.1
- Pytorch 2.8.0+cu126
- Datasets 4.0.0
- Tokenizers 0.22.0
|
5456es/implicit_reward_Llama-3.2-3B-Instruct_prune_0.3-sigmoid
|
5456es
| 2025-09-12T09:07:45Z | 23 | 0 | null |
[
"safetensors",
"llama",
"dpo",
"preference-learning",
"implicit",
"pruned",
"license:apache-2.0",
"region:us"
] | null | 2025-09-08T04:46:27Z |
---
license: apache-2.0
base_model: Llama-3.2-3B-Instruct
tags:
- dpo
- preference-learning
- implicit
- pruned
---
# implicit_reward_Llama-3.2-3B-Instruct_prune_0.3-sigmoid
This model is a DPO (Direct Preference Optimization) fine-tuned version of Llama-3.2-3B-Instruct using the implicit method.
## Model Details
- **Base Model**: Llama-3.2-3B-Instruct
- **Training Method**: implicit
- **Pruning Ratio**: unknown
- **Training Date**: 2025-09-12
## Training Configuration
This model was trained using Direct Preference Optimization (DPO) with the following characteristics:
- Method: implicit
- Pruning applied during training
- Fine-tuned on preference data
## Usage
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
model_name = "5456es/implicit_reward_Llama-3.2-3B-Instruct_prune_0.3-sigmoid"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
# Example usage
prompt = "Your prompt here"
inputs = tokenizer(prompt, return_tensors="pt")
outputs = model.generate(**inputs, max_length=100)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
```
## Training Data
This model was trained on preference data using the DPO algorithm.
## Limitations
This model inherits the limitations of its base model and may have additional limitations due to the pruning process.
## Citation
If you use this model, please cite the original DPO paper and the base model.
|
5456es/implicit_reward_Qwen2.5-1.5B-Instruct_prune_0.3-sigmoid
|
5456es
| 2025-09-12T09:07:04Z | 35 | 0 | null |
[
"safetensors",
"qwen2",
"dpo",
"preference-learning",
"implicit",
"pruned",
"license:apache-2.0",
"region:us"
] | null | 2025-09-07T05:12:42Z |
---
license: apache-2.0
base_model: Qwen2.5-1.5B-Instruct
tags:
- dpo
- preference-learning
- implicit
- pruned
---
# implicit_reward_Qwen2.5-1.5B-Instruct_prune_0.3-sigmoid
This model is a DPO (Direct Preference Optimization) fine-tuned version of Qwen2.5-1.5B-Instruct using the implicit method.
## Model Details
- **Base Model**: Qwen2.5-1.5B-Instruct
- **Training Method**: implicit
- **Pruning Ratio**: unknown
- **Training Date**: 2025-09-12
## Training Configuration
This model was trained using Direct Preference Optimization (DPO) with the following characteristics:
- Method: implicit
- Pruning applied during training
- Fine-tuned on preference data
## Usage
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
model_name = "5456es/implicit_reward_Qwen2.5-1.5B-Instruct_prune_0.3-sigmoid"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
# Example usage
prompt = "Your prompt here"
inputs = tokenizer(prompt, return_tensors="pt")
outputs = model.generate(**inputs, max_length=100)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
```
## Training Data
This model was trained on preference data using the DPO algorithm.
## Limitations
This model inherits the limitations of its base model and may have additional limitations due to the pruning process.
## Citation
If you use this model, please cite the original DPO paper and the base model.
|
5456es/random_prune_Llama-3.2-1B-Instruct_prune_0.3-sigmoid
|
5456es
| 2025-09-12T09:06:32Z | 31 | 0 | null |
[
"safetensors",
"llama",
"dpo",
"preference-learning",
"random",
"pruned",
"license:apache-2.0",
"region:us"
] | null | 2025-09-09T04:01:34Z |
---
license: apache-2.0
base_model: Llama-3.2-1B-Instruct
tags:
- dpo
- preference-learning
- random
- pruned
---
# random_prune_Llama-3.2-1B-Instruct_prune_0.3-sigmoid
This model is a DPO (Direct Preference Optimization) fine-tuned version of Llama-3.2-1B-Instruct using the random method.
## Model Details
- **Base Model**: Llama-3.2-1B-Instruct
- **Training Method**: random
- **Pruning Ratio**: unknown
- **Training Date**: 2025-09-12
## Training Configuration
This model was trained using Direct Preference Optimization (DPO) with the following characteristics:
- Method: random
- Pruning applied during training
- Fine-tuned on preference data
## Usage
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
model_name = "5456es/random_prune_Llama-3.2-1B-Instruct_prune_0.3-sigmoid"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
# Example usage
prompt = "Your prompt here"
inputs = tokenizer(prompt, return_tensors="pt")
outputs = model.generate(**inputs, max_length=100)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
```
## Training Data
This model was trained on preference data using the DPO algorithm.
## Limitations
This model inherits the limitations of its base model and may have additional limitations due to the pruning process.
## Citation
If you use this model, please cite the original DPO paper and the base model.
|
5456es/selective_dpo_Llama-3.2-1B-Instruct_prune_0.3-sigmoid
|
5456es
| 2025-09-12T09:06:01Z | 27 | 0 | null |
[
"safetensors",
"llama",
"dpo",
"preference-learning",
"selective",
"pruned",
"license:apache-2.0",
"region:us"
] | null | 2025-09-07T05:10:18Z |
---
license: apache-2.0
base_model: Llama-3.2-1B-Instruct
tags:
- dpo
- preference-learning
- selective
- pruned
---
# selective_dpo_Llama-3.2-1B-Instruct_prune_0.3-sigmoid
This model is a DPO (Direct Preference Optimization) fine-tuned version of Llama-3.2-1B-Instruct using the selective method.
## Model Details
- **Base Model**: Llama-3.2-1B-Instruct
- **Training Method**: selective
- **Pruning Ratio**: unknown
- **Training Date**: 2025-09-12
## Training Configuration
This model was trained using Direct Preference Optimization (DPO) with the following characteristics:
- Method: selective
- Pruning applied during training
- Fine-tuned on preference data
## Usage
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
model_name = "5456es/selective_dpo_Llama-3.2-1B-Instruct_prune_0.3-sigmoid"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
# Example usage
prompt = "Your prompt here"
inputs = tokenizer(prompt, return_tensors="pt")
outputs = model.generate(**inputs, max_length=100)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
```
## Training Data
This model was trained on preference data using the DPO algorithm.
## Limitations
This model inherits the limitations of its base model and may have additional limitations due to the pruning process.
## Citation
If you use this model, please cite the original DPO paper and the base model.
|
cuongdk253/gpt-oss-ft-12092025
|
cuongdk253
| 2025-09-12T09:04:09Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"gpt_oss",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"8-bit",
"mxfp4",
"region:us"
] |
text-generation
| 2025-09-12T09:03:09Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Clemylia/Miamuy-midi
|
Clemylia
| 2025-09-12T09:03:59Z | 0 | 0 |
transformers.js
|
[
"transformers.js",
"music",
"text-to-audio",
"license:apache-2.0",
"region:us"
] |
text-to-audio
| 2025-09-12T08:03:17Z |
---
license: apache-2.0
library_name: transformers.js
tags:
- music
pipeline_tag: text-to-audio
---
### Documentation du modèle `Miamuy-midi` 🎵

Bienvenue sur la page de documentation de **`Miamuy-midi`**, un modèle JavaScript qui génère des mélodies. Ce modèle a été conçu pour l'apprentissage et la création musicale.
-----
### ✨ Qu'est-ce que c'est ?
`Miamuy-midi` est un modèle génératif basé sur des règles. Son but est de créer des séquences de notes MIDI à partir d'une note de départ fournie par l'utilisateur. C'est un outil parfait pour composer de petites mélodies ou pour explorer la musique algorithmique.
Ce modèle fonctionne entièrement **côté client**, ce qui le rend ultra-léger et rapide, car il ne dépend d'aucun serveur externe.
-----
### 🧠 Comment ça fonctionne ?
Le modèle `Miamuy-midi` suit un processus simple mais efficace :
1. **Saisie de la note :** Le modèle reçoit en entrée une note de départ (par exemple, "C4").
2. **Création de la séquence :** Il génère une séquence de notes en alternant de manière semi-aléatoire des notes autour de la note de départ pour créer une mélodie cohérente.
3. **Sortie des données :** Le modèle renvoie une liste des notes générées, à la fois sous forme de noms de notes lisibles par l'humain et sous forme de valeurs MIDI numériques.
-----
### 💻 Comment utiliser le modèle
Tu peux utiliser ce modèle dans n'importe quel projet JavaScript en l'important directement depuis le Hugging Face Hub.
#### Installation
Il n'y a pas d'installation \! Tu as juste besoin d'accéder au fichier du modèle via son URL.
#### Exemple d'utilisation
Voici comment appeler et utiliser le modèle :
```javascript
import MiamuyMidiModel from 'https://huggingface.co/Clemylia/Miamuy-midi/raw/main/transformer.js';
// Crée une instance du modèle
const miamuy = await MiamuyMidiModel.getInstance();
// Génère une séquence de notes à partir de la note de départ 'C4'
const result = await miamuy.generate('C4', { length: 8 });
// Affiche les notes générées
console.log(result[0].generated_text); // Ex: "C4 F4 G4 C5 A4 D5 G4 B4"
console.log(result[0].midi_notes); // Ex: [60, 65, 67, 72, 69, 74, 67, 71]
```
-----
### ⚙️ Paramètres de la méthode `generate`
La méthode `generate` accepte une chaîne de caractères pour la note de départ (`prompt`) et un objet `options` optionnel :
* **`prompt`** (`string`) : La note de départ pour la mélodie (ex: `'C4'`, `'A#3'`). Obligatoire.
* **`options.length`** (`number`, optionnel) : La longueur de la séquence à générer. Par défaut, la longueur est de 8 notes.
-----
### ✍️ Auteur
Ce modèle a été créé par **Clemylia**.
-----
### 📄 Licence
Ce modèle est sous licence Apache-2.0.
-----
|
mradermacher/Qwen3-Coder-30B-A3B-Instruct-480B-Distill-V2-Fp32-GGUF
|
mradermacher
| 2025-09-12T09:03:39Z | 3,825 | 0 |
transformers
|
[
"transformers",
"gguf",
"causal-lm",
"moe",
"mixture-of-experts",
"qwen",
"distillation",
"svd",
"lora-merged",
"code-generation",
"en",
"code",
"base_model:BasedBase/Qwen3-Coder-30B-A3B-Instruct-480B-Distill-V2-Fp32",
"base_model:quantized:BasedBase/Qwen3-Coder-30B-A3B-Instruct-480B-Distill-V2-Fp32",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2025-09-11T18:56:38Z |
---
base_model: BasedBase/Qwen3-Coder-30B-A3B-Instruct-480B-Distill-V2-Fp32
language:
- en
- code
library_name: transformers
license: apache-2.0
mradermacher:
readme_rev: 1
quantized_by: mradermacher
tags:
- causal-lm
- moe
- mixture-of-experts
- qwen
- distillation
- svd
- lora-merged
- code-generation
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
<!-- ### quants: x-f16 Q4_K_S Q2_K Q8_0 Q6_K Q3_K_M Q3_K_S Q3_K_L Q4_K_M Q5_K_S Q5_K_M IQ4_XS -->
<!-- ### quants_skip: -->
<!-- ### skip_mmproj: -->
static quants of https://huggingface.co/BasedBase/Qwen3-Coder-30B-A3B-Instruct-480B-Distill-V2-Fp32
<!-- provided-files -->
***For a convenient overview and download list, visit our [model page for this model](https://hf.tst.eu/model#Qwen3-Coder-30B-A3B-Instruct-480B-Distill-V2-Fp32-GGUF).***
weighted/imatrix quants are available at https://huggingface.co/mradermacher/Qwen3-Coder-30B-A3B-Instruct-480B-Distill-V2-Fp32-i1-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/Qwen3-Coder-30B-A3B-Instruct-480B-Distill-V2-Fp32-GGUF/resolve/main/Qwen3-Coder-30B-A3B-Instruct-480B-Distill-V2-Fp32.Q2_K.gguf) | Q2_K | 11.4 | |
| [GGUF](https://huggingface.co/mradermacher/Qwen3-Coder-30B-A3B-Instruct-480B-Distill-V2-Fp32-GGUF/resolve/main/Qwen3-Coder-30B-A3B-Instruct-480B-Distill-V2-Fp32.Q3_K_S.gguf) | Q3_K_S | 13.4 | |
| [GGUF](https://huggingface.co/mradermacher/Qwen3-Coder-30B-A3B-Instruct-480B-Distill-V2-Fp32-GGUF/resolve/main/Qwen3-Coder-30B-A3B-Instruct-480B-Distill-V2-Fp32.Q3_K_M.gguf) | Q3_K_M | 14.8 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/Qwen3-Coder-30B-A3B-Instruct-480B-Distill-V2-Fp32-GGUF/resolve/main/Qwen3-Coder-30B-A3B-Instruct-480B-Distill-V2-Fp32.Q3_K_L.gguf) | Q3_K_L | 16.0 | |
| [GGUF](https://huggingface.co/mradermacher/Qwen3-Coder-30B-A3B-Instruct-480B-Distill-V2-Fp32-GGUF/resolve/main/Qwen3-Coder-30B-A3B-Instruct-480B-Distill-V2-Fp32.IQ4_XS.gguf) | IQ4_XS | 16.7 | |
| [GGUF](https://huggingface.co/mradermacher/Qwen3-Coder-30B-A3B-Instruct-480B-Distill-V2-Fp32-GGUF/resolve/main/Qwen3-Coder-30B-A3B-Instruct-480B-Distill-V2-Fp32.Q4_K_S.gguf) | Q4_K_S | 17.6 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Qwen3-Coder-30B-A3B-Instruct-480B-Distill-V2-Fp32-GGUF/resolve/main/Qwen3-Coder-30B-A3B-Instruct-480B-Distill-V2-Fp32.Q4_K_M.gguf) | Q4_K_M | 18.7 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Qwen3-Coder-30B-A3B-Instruct-480B-Distill-V2-Fp32-GGUF/resolve/main/Qwen3-Coder-30B-A3B-Instruct-480B-Distill-V2-Fp32.Q5_K_S.gguf) | Q5_K_S | 21.2 | |
| [GGUF](https://huggingface.co/mradermacher/Qwen3-Coder-30B-A3B-Instruct-480B-Distill-V2-Fp32-GGUF/resolve/main/Qwen3-Coder-30B-A3B-Instruct-480B-Distill-V2-Fp32.Q5_K_M.gguf) | Q5_K_M | 21.8 | |
| [GGUF](https://huggingface.co/mradermacher/Qwen3-Coder-30B-A3B-Instruct-480B-Distill-V2-Fp32-GGUF/resolve/main/Qwen3-Coder-30B-A3B-Instruct-480B-Distill-V2-Fp32.Q6_K.gguf) | Q6_K | 25.2 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/Qwen3-Coder-30B-A3B-Instruct-480B-Distill-V2-Fp32-GGUF/resolve/main/Qwen3-Coder-30B-A3B-Instruct-480B-Distill-V2-Fp32.Q8_0.gguf) | Q8_0 | 32.6 | fast, best quality |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
5456es/cluster_prune_Qwen2.5-0.5B-Instruct_prune_0.7-sigmoid
|
5456es
| 2025-09-12T09:03:04Z | 37 | 0 | null |
[
"safetensors",
"qwen2",
"dpo",
"preference-learning",
"cluster",
"pruned",
"license:apache-2.0",
"region:us"
] | null | 2025-09-07T05:08:56Z |
---
license: apache-2.0
base_model: Qwen2.5-0.5B-Instruct
tags:
- dpo
- preference-learning
- cluster
- pruned
---
# cluster_prune_Qwen2.5-0.5B-Instruct_prune_0.7-sigmoid
This model is a DPO (Direct Preference Optimization) fine-tuned version of Qwen2.5-0.5B-Instruct using the cluster method.
## Model Details
- **Base Model**: Qwen2.5-0.5B-Instruct
- **Training Method**: cluster
- **Pruning Ratio**: unknown
- **Training Date**: 2025-09-12
## Training Configuration
This model was trained using Direct Preference Optimization (DPO) with the following characteristics:
- Method: cluster
- Pruning applied during training
- Fine-tuned on preference data
## Usage
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
model_name = "5456es/cluster_prune_Qwen2.5-0.5B-Instruct_prune_0.7-sigmoid"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
# Example usage
prompt = "Your prompt here"
inputs = tokenizer(prompt, return_tensors="pt")
outputs = model.generate(**inputs, max_length=100)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
```
## Training Data
This model was trained on preference data using the DPO algorithm.
## Limitations
This model inherits the limitations of its base model and may have additional limitations due to the pruning process.
## Citation
If you use this model, please cite the original DPO paper and the base model.
|
andersonbcdefg/vl-finetuning-max-thresh-10-2025-09-12
|
andersonbcdefg
| 2025-09-12T09:02:41Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2_5_vl",
"image-to-text",
"arxiv:1910.09700",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
image-to-text
| 2025-09-12T08:58:41Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
5456es/last_layer_prune_Llama-3.2-3B-Instruct_prune_0.6-sigmoid
|
5456es
| 2025-09-12T09:02:15Z | 0 | 0 | null |
[
"safetensors",
"llama",
"dpo",
"preference-learning",
"last",
"pruned",
"license:apache-2.0",
"region:us"
] | null | 2025-09-12T08:57:57Z |
---
license: apache-2.0
base_model: Llama-3.2-3B-Instruct
tags:
- dpo
- preference-learning
- last
- pruned
---
# last_layer_prune_Llama-3.2-3B-Instruct_prune_0.6-sigmoid
This model is a DPO (Direct Preference Optimization) fine-tuned version of Llama-3.2-3B-Instruct using the last method.
## Model Details
- **Base Model**: Llama-3.2-3B-Instruct
- **Training Method**: last
- **Pruning Ratio**: unknown
- **Training Date**: 2025-09-12
## Training Configuration
This model was trained using Direct Preference Optimization (DPO) with the following characteristics:
- Method: last
- Pruning applied during training
- Fine-tuned on preference data
## Usage
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
model_name = "5456es/last_layer_prune_Llama-3.2-3B-Instruct_prune_0.6-sigmoid"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
# Example usage
prompt = "Your prompt here"
inputs = tokenizer(prompt, return_tensors="pt")
outputs = model.generate(**inputs, max_length=100)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
```
## Training Data
This model was trained on preference data using the DPO algorithm.
## Limitations
This model inherits the limitations of its base model and may have additional limitations due to the pruning process.
## Citation
If you use this model, please cite the original DPO paper and the base model.
|
HouraMor/wh-stage1ft-lr5e6-dtstf5-adm-ga1ba16-st15k-v2-evalstp10-pat20-trainvalch
|
HouraMor
| 2025-09-12T09:02:10Z | 19 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"whisper",
"automatic-speech-recognition",
"generated_from_trainer",
"base_model:openai/whisper-large-v3",
"base_model:finetune:openai/whisper-large-v3",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2025-09-11T22:21:55Z |
---
library_name: transformers
license: apache-2.0
base_model: openai/whisper-large-v3
tags:
- generated_from_trainer
metrics:
- wer
model-index:
- name: wh-stage1ft-lr5e6-dtstf5-adm-ga1ba16-st15k-v2-evalstp10-pat20-trainvalch
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wh-stage1ft-lr5e6-dtstf5-adm-ga1ba16-st15k-v2-evalstp10-pat20-trainvalch
This model is a fine-tuned version of [openai/whisper-large-v3](https://huggingface.co/openai/whisper-large-v3) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7521
- Wer: 0.3579
- Cer: 0.2725
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-06
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Use adamw_torch with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 250
- training_steps: 5000
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer | Cer |
|:-------------:|:------:|:----:|:---------------:|:------:|:------:|
| 4.4597 | 0.0201 | 10 | 5.1219 | 0.2938 | 0.2312 |
| 5.0415 | 0.0402 | 20 | 4.9431 | 0.2947 | 0.2315 |
| 4.8721 | 0.0602 | 30 | 4.5700 | 0.3010 | 0.2360 |
| 3.9628 | 0.0803 | 40 | 3.8848 | 0.3164 | 0.2518 |
| 3.4813 | 0.1004 | 50 | 3.3103 | 0.3242 | 0.2582 |
| 3.0728 | 0.1205 | 60 | 2.9264 | 0.3291 | 0.2611 |
| 2.3827 | 0.1406 | 70 | 2.6100 | 0.3462 | 0.2741 |
| 2.6985 | 0.1606 | 80 | 2.3782 | 0.3170 | 0.2453 |
| 2.0606 | 0.1807 | 90 | 2.2110 | 0.3262 | 0.2504 |
| 2.0314 | 0.2008 | 100 | 2.0766 | 0.3250 | 0.2599 |
| 2.0403 | 0.2209 | 110 | 1.9084 | 0.3358 | 0.2723 |
| 1.7053 | 0.2410 | 120 | 1.6562 | 0.3121 | 0.2538 |
| 1.2776 | 0.2610 | 130 | 1.3974 | 0.3317 | 0.2618 |
| 1.2927 | 0.2811 | 140 | 1.1876 | 0.3299 | 0.2663 |
| 1.326 | 0.3012 | 150 | 1.0704 | 0.3194 | 0.2580 |
| 1.285 | 0.3213 | 160 | 0.9602 | 0.3377 | 0.2720 |
| 1.0893 | 0.3414 | 170 | 0.8969 | 0.3341 | 0.2713 |
| 0.9858 | 0.3614 | 180 | 0.8692 | 0.3203 | 0.2594 |
| 0.7746 | 0.3815 | 190 | 0.8599 | 0.3374 | 0.2787 |
| 0.9734 | 0.4016 | 200 | 0.8513 | 0.3708 | 0.2975 |
| 0.7683 | 0.4217 | 210 | 0.8438 | 0.3467 | 0.2804 |
| 0.786 | 0.4418 | 220 | 0.8413 | 0.3385 | 0.2713 |
| 0.8531 | 0.4618 | 230 | 0.8483 | 0.3156 | 0.2424 |
| 0.8125 | 0.4819 | 240 | 0.8366 | 0.3542 | 0.2856 |
| 0.8521 | 0.5020 | 250 | 0.8216 | 0.3540 | 0.2806 |
| 1.0646 | 0.5221 | 260 | 0.8242 | 0.3709 | 0.3096 |
| 0.9469 | 0.5422 | 270 | 0.8202 | 0.4282 | 0.3476 |
| 0.9096 | 0.5622 | 280 | 0.8195 | 0.3878 | 0.3081 |
| 0.7862 | 0.5823 | 290 | 0.8054 | 0.3650 | 0.2928 |
| 0.792 | 0.6024 | 300 | 0.7973 | 0.3581 | 0.2838 |
| 0.8513 | 0.6225 | 310 | 0.8008 | 0.4013 | 0.3221 |
| 1.0464 | 0.6426 | 320 | 0.7966 | 0.3326 | 0.2620 |
| 0.6483 | 0.6627 | 330 | 0.7978 | 0.3688 | 0.2940 |
| 0.8224 | 0.6827 | 340 | 0.7963 | 0.3742 | 0.2933 |
| 1.0097 | 0.7028 | 350 | 0.7823 | 0.4077 | 0.3263 |
| 0.9484 | 0.7229 | 360 | 0.7755 | 0.4238 | 0.3249 |
| 0.6949 | 0.7430 | 370 | 0.7762 | 0.4665 | 0.3447 |
| 0.6566 | 0.7631 | 380 | 0.7757 | 0.3965 | 0.3102 |
| 0.8197 | 0.7831 | 390 | 0.7793 | 0.3751 | 0.2900 |
| 0.7745 | 0.8032 | 400 | 0.7622 | 0.3700 | 0.2885 |
| 0.8251 | 0.8233 | 410 | 0.7599 | 0.4180 | 0.3402 |
| 0.6565 | 0.8434 | 420 | 0.7563 | 0.4510 | 0.3506 |
| 0.868 | 0.8635 | 430 | 0.7486 | 0.4126 | 0.3280 |
| 0.7237 | 0.8835 | 440 | 0.7535 | 0.4279 | 0.3543 |
| 0.8202 | 0.9036 | 450 | 0.7414 | 0.4493 | 0.3723 |
| 0.8591 | 0.9237 | 460 | 0.7480 | 0.4565 | 0.3810 |
| 0.7192 | 0.9438 | 470 | 0.7429 | 0.4630 | 0.3766 |
| 0.9297 | 0.9639 | 480 | 0.7472 | 0.4639 | 0.3827 |
| 0.7942 | 0.9839 | 490 | 0.7482 | 0.4179 | 0.3350 |
| 0.8795 | 1.0040 | 500 | 0.7469 | 0.4147 | 0.3268 |
| 0.5834 | 1.0241 | 510 | 0.7465 | 0.4212 | 0.3320 |
| 0.6696 | 1.0442 | 520 | 0.7507 | 0.3694 | 0.2965 |
| 0.9144 | 1.0643 | 530 | 0.7535 | 0.4252 | 0.3336 |
| 0.6423 | 1.0843 | 540 | 0.7536 | 0.4125 | 0.3194 |
| 0.462 | 1.1044 | 550 | 0.7568 | 0.4049 | 0.3222 |
| 0.6357 | 1.1245 | 560 | 0.7550 | 0.3267 | 0.2458 |
| 0.5752 | 1.1446 | 570 | 0.7529 | 0.3578 | 0.2742 |
| 0.7515 | 1.1647 | 580 | 0.7497 | 0.3409 | 0.2604 |
| 0.6877 | 1.1847 | 590 | 0.7505 | 0.3387 | 0.2601 |
| 0.4002 | 1.2048 | 600 | 0.7521 | 0.3579 | 0.2725 |
### Framework versions
- Transformers 4.55.2
- Pytorch 2.7.0+cu118
- Datasets 2.21.0
- Tokenizers 0.21.4
|
miyagawaorj/classifier-chapter4
|
miyagawaorj
| 2025-09-12T09:00:44Z | 4 | 0 |
transformers
|
[
"transformers",
"safetensors",
"distilbert",
"text-classification",
"generated_from_trainer",
"base_model:distilbert/distilbert-base-uncased",
"base_model:finetune:distilbert/distilbert-base-uncased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2025-07-08T13:25:09Z |
---
library_name: transformers
license: apache-2.0
base_model: distilbert/distilbert-base-uncased
tags:
- generated_from_trainer
metrics:
- accuracy
- f1
model-index:
- name: classifier-chapter4
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# classifier-chapter4
This model is a fine-tuned version of [distilbert/distilbert-base-uncased](https://huggingface.co/distilbert/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2457
- Accuracy: 0.9204
- F1: 0.9204
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| No log | 1.0 | 313 | 0.2705 | 0.9103 | 0.9101 |
| 0.3081 | 2.0 | 626 | 0.2457 | 0.9204 | 0.9204 |
### Framework versions
- Transformers 4.53.0
- Pytorch 2.7.1+cu118
- Datasets 4.0.0
- Tokenizers 0.21.2
|
manbeast3b/007-american-party-01-2
|
manbeast3b
| 2025-09-12T09:00:12Z | 0 | 0 | null |
[
"safetensors",
"any-to-any",
"omega",
"omegalabs",
"bittensor",
"agi",
"license:mit",
"region:us"
] |
any-to-any
| 2025-09-10T00:39:03Z |
---
license: mit
tags:
- any-to-any
- omega
- omegalabs
- bittensor
- agi
---
This is an Any-to-Any model checkpoint for the OMEGA Labs x Bittensor Any-to-Any subnet.
Check out the [git repo](https://github.com/omegalabsinc/omegalabs-anytoany-bittensor) and find OMEGA on X: [@omegalabsai](https://x.com/omegalabsai).
|
sitaram05s/blockassist
|
sitaram05s
| 2025-09-12T09:00:09Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"raging sneaky camel",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-10T15:46:49Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- raging sneaky camel
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
manbeast3b/007-iphone17-boo-01r15
|
manbeast3b
| 2025-09-12T08:59:18Z | 0 | 0 | null |
[
"safetensors",
"any-to-any",
"omega",
"omegalabs",
"bittensor",
"agi",
"license:mit",
"region:us"
] |
any-to-any
| 2025-09-10T14:07:48Z |
---
license: mit
tags:
- any-to-any
- omega
- omegalabs
- bittensor
- agi
---
This is an Any-to-Any model checkpoint for the OMEGA Labs x Bittensor Any-to-Any subnet.
Check out the [git repo](https://github.com/omegalabsinc/omegalabs-anytoany-bittensor) and find OMEGA on X: [@omegalabsai](https://x.com/omegalabsai).
|
yyyyyxie/textflux-beta
|
yyyyyxie
| 2025-09-12T08:58:08Z | 0 | 3 |
diffusers
|
[
"diffusers",
"safetensors",
"scene-text-synthesis",
"multilingual",
"diffusion",
"dit",
"ocr-free",
"textflux",
"flux",
"text-to-image",
"arxiv:2505.17778",
"base_model:black-forest-labs/FLUX.1-Fill-dev",
"base_model:finetune:black-forest-labs/FLUX.1-Fill-dev",
"license:cc-by-nc-2.0",
"region:us"
] |
text-to-image
| 2025-07-30T03:45:44Z |
---
license: cc-by-nc-2.0
tags:
- scene-text-synthesis
- multilingual
- diffusion
- dit
- ocr-free
- textflux
- flux
# - text-to-image
# - generated_image_text
library_name: diffusers
pipeline_tag: text-to-image
base_model:
- black-forest-labs/FLUX.1-Fill-dev
---
# TextFlux: An OCR-Free DiT Model for High-Fidelity Multilingual Scene Text Synthesis
<div style="display: flex; justify-content: center; align-items: center;">
<a href="https://arxiv.org/abs/2505.17778">
<img src='https://img.shields.io/badge/arXiv-2505.17778-red?style=flat&logo=arXiv&logoColor=red' alt='arxiv'>
</a>
<a href='https://huggingface.co/yyyyyxie/textflux'>
<img src='https://img.shields.io/badge/Hugging Face-ckpts-orange?style=flat&logo=HuggingFace&logoColor=orange' alt='huggingface'>
</a>
<a href="https://github.com/yyyyyxie/textflux">
<img src='https://img.shields.io/badge/GitHub-Repo-blue?style=flat&logo=GitHub' alt='GitHub'>
</a>
<a href="https://huggingface.co/yyyyyxie/textflux" style="margin: 0 2px;">
<img src='https://img.shields.io/badge/Demo-Gradio-gold?style=flat&logo=Gradio&logoColor=red' alt='Demo'>
</a>
<a href='https://yyyyyxie.github.io/textflux-site/'>
<img src='https://img.shields.io/badge/Webpage-Project-silver?style=flat&logo=&logoColor=orange' alt='webpage'>
</a>
<a href="https://modelscope.cn/models/xieyu20001003/textflux">
<img src="https://img.shields.io/badge/🤖_ModelScope-ckpts-ffbd45.svg" alt="ModelScope">
</a>
</div>
<p align="left">
<strong>English</strong> | <a href="./README_CN.md"><strong>中文简体</strong></a>
</p>
**TextFlux** is an **OCR-free framework** using a Diffusion Transformer (DiT, based on [FLUX.1-Fill-dev](https://github.com/black-forest-labs/flux)) for high-fidelity multilingual scene text synthesis. It simplifies the learning task by providing direct visual glyph guidance through spatial concatenation of rendered glyphs with the scene image, enabling the model to focus on contextual reasoning and visual fusion.
## Key Features
* **OCR-Free:** Simplified architecture without OCR encoders.
* **High-Fidelity & Contextual Styles:** Precise rendering, stylistically consistent with scenes.
* **Multilingual & Low-Resource:** Strong performance across languages, adapts to new languages with minimal data (e.g., <1,000 samples).
* **Zero-Shot Generalization:** Renders characters unseen during training.
* **Controllable Multi-Line Text:** Flexible multi-line synthesis with line-level control.
* **Data Efficient:** Uses a fraction of data (e.g., ~1%) compared to other methods.
<div align="center">
<img src="https://image-transfer-season.oss-cn-qingdao.aliyuncs.com/pictures/abstract_fig.png" width="100%" height="100%"/>
</div>
## Updates
- **`2025/08/02`**: Our full param [**TextFlux-beta**](https://huggingface.co/yyyyyxie/textflux-beta) weights and [**TextFlux-LoRA-beta**](https://huggingface.co/yyyyyxie/textflux-lora-beta) weights are now available! Single-line text generation accuracy performance could be significantly enhanced by **10.9%** and **11.2%** respectively 👋!
- **`2025/08/02`**: Our [**Training Datasets**](https://huggingface.co/datasets/yyyyyxie/textflux-anyword) and [**Testing Datasets**](https://huggingface.co/datasets/yyyyyxie/textflux-test-datasets) are now available 👋!
- **`2025/08/01`**: Our [**Eval Scripts**](https://huggingface.co/yyyyyxie/textflux) are now available 👋!
- **`2025/05/27`**: Our [**Full-Param Weights**](https://huggingface.co/yyyyyxie/textflux) and [**LoRA Weights**](https://huggingface.co/yyyyyxie/textflux-lora) are now available 👋!
- **`2025/05/25`**: Our [**Paper on ArXiv**](https://arxiv.org/abs/2505.17778) is available 👋!
## TextFlux-beta
We are excited to release [**TextFlux-beta**](https://huggingface.co/yyyyyxie/textflux-beta) and [**TextFlux-LoRA-beta**](https://huggingface.co/yyyyyxie/textflux-lora-beta), new versions of our model specifically optimized for single-line text editing.
### Key Advantages
- **Significantly improves the quality** of single-line text rendering.
- **Increases inference speed** for single-line text by approximately **1.4x**.
- **Dramatically enhances the accuracy** of small text synthesis.
### How It Works
Considering that single-line editing is a primary use case for many users and generally yields more stable, high-quality results, we have released new weights optimized for this scenario.
Unlike the original model which renders glyphs onto a full-size mask, the beta version utilizes a **single-line image strip** for the glyph condition. This approach not only reduces unnecessary computational overhead but also provides a more stable and high-quality supervisory signal. This leads directly to the significant improvements in both single-line and small text rendering (see example [here](https://github.com/yyyyyxie/textflux/blob/main/resource/demo_singleline.png)).
To use these new models, please refer to the updated files: demo.py, run_inference.py, and run_inference_lora.py. While the beta models retain the ability to generate multi-line text, we **highly recommend** using them for single-line tasks to achieve the best performance and stability.
### Performance
This table shows that the TextFlux-beta model achieves a significant performance improvement of approximately **11 points** in single-line text editing, while also boosting inference speed by **1.4 times** compared to previous versions! The [**AMO Sampler**](https://github.com/hxixixh/amo-release) contributed approximately 3 points to this increase. The test dataset is [**ReCTS editing**](https://huggingface.co/datasets/yyyyyxie/textflux-test-datasets).
| Method | SeqAcc-Editing (%)↑ | NED (%)↑ | FID ↓ | LPIPS ↓ | Inference Speed (s/img)↓ |
| ------------------ | :-----------------: | :------: | :------: | :-------: | :----------------------: |
| TextFlux-LoRA | 37.2 | 58.2 | 4.93 | 0.063 | 16.8 |
| TextFlux | 40.6 | 60.7 | 4.84 | 0.062 | 15.6 |
| TextFlux-LoRA-beta | 48.4 | 70.5 | 4.69 | 0.062 | 12.0 |
| TextFlux-beta | **51.5** | **72.9** | **4.59** | **0.061** | **10.9** |
## Setup
1. **Clone/Download:** Get the necessary code and model weights.
2. **Dependencies:**
```bash
git clone https://github.com/yyyyyxie/textflux.git
cd textflux
conda create -n textflux python==3.11.4 -y
conda activate textflux
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
pip install -r requirements.txt
cd diffusers
pip install -e .
# Ensure gradio == 3.50.1
```
## Gradio Demo
Provides "Custom Mode" (upload scene image, draw masks, input text for automatic template generation) and "Normal Mode" (for pre-combined inputs).
```bash
# Ensure gradio == 3.50.1
python demo.py
```
## Training
This guide provides instructions for training and fine-tuning the **TextFlux** models.
-----
### Multi-line Training (Reproducing Paper Results)
Follow these steps to reproduce the multi-line text generation results from the original paper.
1. **Prepare the Dataset**
Download the [**Multi-line**](https://huggingface.co/datasets/yyyyyxie/textflux-multi-line) dataset and organize it using the following directory structure:
```
|- ./datasets
|- multi-lingual
| |- processed_mlt2017
| |- processed_ReCTS_train_images
| |- processed_totaltext
| ....
```
2. **Run the Training Script**
Execute the appropriate training script. The `train.sh` script is for standard training, while `train_lora.sh` is for training with LoRA.
```bash
# For standard training
bash scripts/train.sh
```
or
```bash
# For LoRA training
bash scripts/train_lora.sh
```
*Note: Ensure you are using the commands and configurations within the script designated for **multi-line** training.*
-----
### Single-line Training
To create our TextFlux beta weights optimized for the single-line task, we fine-tuned our pre-trained multi-line models. Specifically, we loaded the weights from the [**TextFlux**](https://huggingface.co/yyyyyxie/textflux) and [**TextFLux-LoRA**](https://huggingface.co/yyyyyxie/textflux-lora) models and continued training for an additional 10,000 steps on a single-line dataset.
If you wish to replicate this process, you can follow these steps:
1. **Prepare the Dataset**
First, download the [**Single-line**](https://huggingface.co/datasets/yyyyyxie/textflux-anyword) dataset and arrange it as follows:
```
|- ./datasets
|- anyword
| |- ReCTS
| |- TotalText
| |- ArT
| ...
....
```
2. **Run the Fine-tuning Script**
Ensure your script is configured to load the weights from a pre-trained multi-line model, and then execute the fine-tuning command.
```bash
# For standard fine-tuning
bash scripts/train.sh
```
or
```bash
# For LoRA fine-tuning
bash scripts/train_lora.sh
```
## Evaluation
First, use the `scripts/batch_eval.sh` script to perform batch inference on the images in the test set.
```
bash scripts/batch_eval.sh
```
Once inference is complete, use `eval/eval_ocr.sh` to evaluate the OCR accuracy and `eval/eval_fid_lpips.sh` to evaluate FID and LPIPS scores.
```
bash eval/eval_ocr.sh
```
```
bash eval/eval_fid_lpips.sh
```
## TODO
- [x] Release the training datasets and testing datasets
- [x] Release the training scripts
- [x] Release the eval scripts
- [ ] Support comfyui
## Acknowledgement
Our code is modified based on [Diffusers](https://github.com/huggingface/diffusers). We adopt [FLUX.1-Fill-dev](https://huggingface.co/black-forest-labs/FLUX.1-Fill-dev) as the base model. Thanks to all the contributors for the helpful discussions! We also sincerely thank the contributors of the following code repositories for their valuable contributions: [AnyText](https://github.com/tyxsspa/AnyText), [AMO](https://github.com/hxixixh/amo-release).
## Citation
```bibtex
@misc{xie2025textfluxocrfreeditmodel,
title={TextFlux: An OCR-Free DiT Model for High-Fidelity Multilingual Scene Text Synthesis},
author={Yu Xie and Jielei Zhang and Pengyu Chen and Ziyue Wang and Weihang Wang and Longwen Gao and Peiyi Li and Huyang Sun and Qiang Zhang and Qian Qiao and Jiaqing Fan and Zhouhui Lian},
year={2025},
eprint={2505.17778},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2505.17778},
}
```
|
5456es/random_prune_Qwen2.5-7B-Instruct_prune_0.3-sigmoid
|
5456es
| 2025-09-12T08:57:56Z | 27 | 0 | null |
[
"safetensors",
"qwen2",
"dpo",
"preference-learning",
"random",
"pruned",
"license:apache-2.0",
"region:us"
] | null | 2025-09-08T04:30:45Z |
---
license: apache-2.0
base_model: Qwen2.5-7B-Instruct
tags:
- dpo
- preference-learning
- random
- pruned
---
# random_prune_Qwen2.5-7B-Instruct_prune_0.3-sigmoid
This model is a DPO (Direct Preference Optimization) fine-tuned version of Qwen2.5-7B-Instruct using the random method.
## Model Details
- **Base Model**: Qwen2.5-7B-Instruct
- **Training Method**: random
- **Pruning Ratio**: unknown
- **Training Date**: 2025-09-12
## Training Configuration
This model was trained using Direct Preference Optimization (DPO) with the following characteristics:
- Method: random
- Pruning applied during training
- Fine-tuned on preference data
## Usage
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
model_name = "5456es/random_prune_Qwen2.5-7B-Instruct_prune_0.3-sigmoid"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
# Example usage
prompt = "Your prompt here"
inputs = tokenizer(prompt, return_tensors="pt")
outputs = model.generate(**inputs, max_length=100)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
```
## Training Data
This model was trained on preference data using the DPO algorithm.
## Limitations
This model inherits the limitations of its base model and may have additional limitations due to the pruning process.
## Citation
If you use this model, please cite the original DPO paper and the base model.
|
5456es/selective_dpo_Qwen2.5-0.5B-Instruct_prune_0.7-sigmoid
|
5456es
| 2025-09-12T08:57:00Z | 46 | 0 | null |
[
"safetensors",
"qwen2",
"dpo",
"preference-learning",
"selective",
"pruned",
"license:apache-2.0",
"region:us"
] | null | 2025-09-07T05:05:02Z |
---
license: apache-2.0
base_model: Qwen2.5-0.5B-Instruct
tags:
- dpo
- preference-learning
- selective
- pruned
---
# selective_dpo_Qwen2.5-0.5B-Instruct_prune_0.7-sigmoid
This model is a DPO (Direct Preference Optimization) fine-tuned version of Qwen2.5-0.5B-Instruct using the selective method.
## Model Details
- **Base Model**: Qwen2.5-0.5B-Instruct
- **Training Method**: selective
- **Pruning Ratio**: unknown
- **Training Date**: 2025-09-12
## Training Configuration
This model was trained using Direct Preference Optimization (DPO) with the following characteristics:
- Method: selective
- Pruning applied during training
- Fine-tuned on preference data
## Usage
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
model_name = "5456es/selective_dpo_Qwen2.5-0.5B-Instruct_prune_0.7-sigmoid"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
# Example usage
prompt = "Your prompt here"
inputs = tokenizer(prompt, return_tensors="pt")
outputs = model.generate(**inputs, max_length=100)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
```
## Training Data
This model was trained on preference data using the DPO algorithm.
## Limitations
This model inherits the limitations of its base model and may have additional limitations due to the pruning process.
## Citation
If you use this model, please cite the original DPO paper and the base model.
|
cuongdk253/gpt-oss-12092025-adapter
|
cuongdk253
| 2025-09-12T08:54:53Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"generated_from_trainer",
"sft",
"trl",
"base_model:openai/gpt-oss-20b",
"base_model:finetune:openai/gpt-oss-20b",
"endpoints_compatible",
"region:us"
] | null | 2025-09-12T08:54:49Z |
---
base_model: openai/gpt-oss-20b
library_name: transformers
model_name: gpt-oss-20b-ft
tags:
- generated_from_trainer
- sft
- trl
licence: license
---
# Model Card for gpt-oss-20b-ft
This model is a fine-tuned version of [openai/gpt-oss-20b](https://huggingface.co/openai/gpt-oss-20b).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="cuongdk253/gpt-oss-20b-ft", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
This model was trained with SFT.
### Framework versions
- TRL: 0.23.0
- Transformers: 4.56.1
- Pytorch: 2.8.0.dev20250319+cu128
- Datasets: 4.0.0
- Tokenizers: 0.22.0
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
llllwxxx/Qwen3-Next-80B-A3B-Thinking-FP8-Dynamic
|
llllwxxx
| 2025-09-12T08:53:31Z | 0 | 4 | null |
[
"base_model:Qwen/Qwen3-Next-80B-A3B-Thinking",
"base_model:quantized:Qwen/Qwen3-Next-80B-A3B-Thinking",
"region:us"
] | null | 2025-09-12T08:19:26Z |
---
base_model:
- Qwen/Qwen3-Next-80B-A3B-Thinking
base_model_relation: quantized
---
# Qwen3-80B FP8 Dynamic Quantization with LLMCompressor
## Introduction
---
## Environment Requirements
- **Python 3.10+**
- **NVIDIA GPU** (Hopper architecture supporting FP8, e.g., H100/A100)
- **CUDA 12.x**
- **PyTorch 2.6**
- **Dependencies installation**:
```bash
uv pip install llmcompressor torch
uv pip install git+https://github.com/huggingface/transformers.git@main
```
---
## Usage Steps
1. Save the following script as `quantize.py`:
```python
from llmcompressor.transformers import SparseAutoModelForCausalLM
from transformers import AutoTokenizer
model_name = "Qwen/Qwen3-Next-80B-A3B-Thinking"
# Load tokenizer and model
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = SparseAutoModelForCausalLM.from_pretrained(
model_name,
dtype="auto",
device_map="auto"
)
from llmcompressor.transformers import oneshot
from llmcompressor.modifiers.quantization import QuantizationModifier
# Configure simple PTQ quantization
recipe = QuantizationModifier(
targets="Linear",
scheme="FP8_DYNAMIC",
ignore=[
"lm_head",
"re:.*mlp.gate$", # Ignore standard gate layers
"re:.*shared_expert_gate$", # Ignore shared expert gate layers
"re:.*router$" # Ignore router layers
]
)
# Apply quantization algorithm
oneshot(model=model, recipe=recipe)
# Save model
SAVE_DIR = model_name.split("/")[1] + "-FP8-Dynamic"
model.save_pretrained(SAVE_DIR)
tokenizer.save_pretrained(SAVE_DIR)
```
2. Run the script:
```bash
python quantize.py
```
3. The quantized model will be saved in the `Qwen3-Next-80B-A3B-Thinking-FP8-Dynamic` directory.
```bash
VLLM_ALLOW_LONG_MAX_MODEL_LEN=1 vllm serve Qwen3-Next-80B-A3B-Thinking-FP8-Dynamic --port 8080 --tensor-parallel-size 2 --api-key 123 --gpu-memory-utilization 0.95 --max_num_seqs 2 --max-model-len 131072 --enable-auto-tool-choice --tool-call-parser hermes --reasoning-parser deepseek_r1 # --speculative-config '{"method":"qwen3_next_mtp","num_speculative_tokens":2}'
```
---
---
## Notes
1. **There is compatibility issues between the quantized version and MTP**
---
## References
- [LLMCompressor Official Documentation](https://vllm.hyper.ai/docs/features/quantization/fp8)
|
5456es/cluster_prune_Qwen2.5-0.5B-Instruct_prune_0.3-sigmoid
|
5456es
| 2025-09-12T08:52:02Z | 21 | 0 | null |
[
"safetensors",
"qwen2",
"dpo",
"preference-learning",
"cluster",
"pruned",
"license:apache-2.0",
"region:us"
] | null | 2025-09-07T05:03:42Z |
---
license: apache-2.0
base_model: Qwen2.5-0.5B-Instruct
tags:
- dpo
- preference-learning
- cluster
- pruned
---
# cluster_prune_Qwen2.5-0.5B-Instruct_prune_0.3-sigmoid
This model is a DPO (Direct Preference Optimization) fine-tuned version of Qwen2.5-0.5B-Instruct using the cluster method.
## Model Details
- **Base Model**: Qwen2.5-0.5B-Instruct
- **Training Method**: cluster
- **Pruning Ratio**: unknown
- **Training Date**: 2025-09-12
## Training Configuration
This model was trained using Direct Preference Optimization (DPO) with the following characteristics:
- Method: cluster
- Pruning applied during training
- Fine-tuned on preference data
## Usage
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
model_name = "5456es/cluster_prune_Qwen2.5-0.5B-Instruct_prune_0.3-sigmoid"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
# Example usage
prompt = "Your prompt here"
inputs = tokenizer(prompt, return_tensors="pt")
outputs = model.generate(**inputs, max_length=100)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
```
## Training Data
This model was trained on preference data using the DPO algorithm.
## Limitations
This model inherits the limitations of its base model and may have additional limitations due to the pruning process.
## Citation
If you use this model, please cite the original DPO paper and the base model.
|
5456es/cluster_prune_Qwen2.5-1.5B-Instruct_prune_0.3-sigmoid
|
5456es
| 2025-09-12T08:51:40Z | 31 | 0 | null |
[
"safetensors",
"qwen2",
"dpo",
"preference-learning",
"cluster",
"pruned",
"license:apache-2.0",
"region:us"
] | null | 2025-09-07T05:01:16Z |
---
license: apache-2.0
base_model: Qwen2.5-1.5B-Instruct
tags:
- dpo
- preference-learning
- cluster
- pruned
---
# cluster_prune_Qwen2.5-1.5B-Instruct_prune_0.3-sigmoid
This model is a DPO (Direct Preference Optimization) fine-tuned version of Qwen2.5-1.5B-Instruct using the cluster method.
## Model Details
- **Base Model**: Qwen2.5-1.5B-Instruct
- **Training Method**: cluster
- **Pruning Ratio**: unknown
- **Training Date**: 2025-09-12
## Training Configuration
This model was trained using Direct Preference Optimization (DPO) with the following characteristics:
- Method: cluster
- Pruning applied during training
- Fine-tuned on preference data
## Usage
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
model_name = "5456es/cluster_prune_Qwen2.5-1.5B-Instruct_prune_0.3-sigmoid"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
# Example usage
prompt = "Your prompt here"
inputs = tokenizer(prompt, return_tensors="pt")
outputs = model.generate(**inputs, max_length=100)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
```
## Training Data
This model was trained on preference data using the DPO algorithm.
## Limitations
This model inherits the limitations of its base model and may have additional limitations due to the pruning process.
## Citation
If you use this model, please cite the original DPO paper and the base model.
|
EZCon/Qwen2-VL-2B-Instruct-abliterated-8bit-mixed_4_8-mlx
|
EZCon
| 2025-09-12T08:49:14Z | 4 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2_vl",
"image-to-text",
"chat",
"abliterated",
"uncensored",
"mlx",
"image-text-to-text",
"conversational",
"en",
"base_model:Qwen/Qwen2-VL-2B-Instruct",
"base_model:quantized:Qwen/Qwen2-VL-2B-Instruct",
"license:apache-2.0",
"text-generation-inference",
"endpoints_compatible",
"8-bit",
"region:us"
] |
image-text-to-text
| 2025-09-12T08:49:01Z |
---
library_name: transformers
license: apache-2.0
license_link: https://huggingface.co/huihui-ai/Qwen2-VL-2B-Instruct-abliterated/blob/main/LICENSE
language:
- en
pipeline_tag: image-text-to-text
base_model: Qwen/Qwen2-VL-2B-Instruct
tags:
- chat
- abliterated
- uncensored
- mlx
---
# EZCon/Qwen2-VL-2B-Instruct-abliterated-8bit-mixed_4_8-mlx
This model was converted to MLX format from [`huihui-ai/Qwen2-VL-2B-Instruct-abliterated`]() using mlx-vlm version **0.3.3**.
Refer to the [original model card](https://huggingface.co/huihui-ai/Qwen2-VL-2B-Instruct-abliterated) for more details on the model.
## Use with mlx
```bash
pip install -U mlx-vlm
```
```bash
python -m mlx_vlm.generate --model EZCon/Qwen2-VL-2B-Instruct-abliterated-8bit-mixed_4_8-mlx --max-tokens 100 --temperature 0.0 --prompt "Describe this image." --image <path_to_image>
```
|
Kijai/WanVideo_comfy_GGUF
|
Kijai
| 2025-09-12T08:49:13Z | 22,163 | 36 |
diffusion-single-file
|
[
"diffusion-single-file",
"gguf",
"comfyui",
"base_model:MeiGen-AI/InfiniteTalk",
"base_model:quantized:MeiGen-AI/InfiniteTalk",
"license:apache-2.0",
"region:us"
] | null | 2025-08-19T14:46:59Z |
---
tags:
- diffusion-single-file
- comfyui
base_model:
- MeiGen-AI/InfiniteTalk
- Wan-AI/Wan2.1-I2V-14B-480P
license: apache-2.0
---
Various GGUF quants of WanVideo models and modules, mainly for ComfyUI usage.
---
InfiniteTalk:
[MeiGen-AI/InfiniteTalk](https://huggingface.co/MeiGen-AI/InfiniteTalk)
2.2 Fun VACE:
https://huggingface.co/alibaba-pai/Wan2.2-VACE-Fun-A14B/tree/main
GGUF VACE modules will only work in the WanVideoWrapper currently.
|
5456es/random_prune_Llama-3.1-8B-Instruct_prune_0.5-sigmoid
|
5456es
| 2025-09-12T08:49:02Z | 12 | 0 | null |
[
"safetensors",
"llama",
"dpo",
"preference-learning",
"random",
"pruned",
"license:apache-2.0",
"region:us"
] | null | 2025-09-09T03:47:15Z |
---
license: apache-2.0
base_model: Llama-3.1-8B-Instruct
tags:
- dpo
- preference-learning
- random
- pruned
---
# random_prune_Llama-3.1-8B-Instruct_prune_0.5-sigmoid
This model is a DPO (Direct Preference Optimization) fine-tuned version of Llama-3.1-8B-Instruct using the random method.
## Model Details
- **Base Model**: Llama-3.1-8B-Instruct
- **Training Method**: random
- **Pruning Ratio**: unknown
- **Training Date**: 2025-09-12
## Training Configuration
This model was trained using Direct Preference Optimization (DPO) with the following characteristics:
- Method: random
- Pruning applied during training
- Fine-tuned on preference data
## Usage
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
model_name = "5456es/random_prune_Llama-3.1-8B-Instruct_prune_0.5-sigmoid"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
# Example usage
prompt = "Your prompt here"
inputs = tokenizer(prompt, return_tensors="pt")
outputs = model.generate(**inputs, max_length=100)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
```
## Training Data
This model was trained on preference data using the DPO algorithm.
## Limitations
This model inherits the limitations of its base model and may have additional limitations due to the pruning process.
## Citation
If you use this model, please cite the original DPO paper and the base model.
|
Thiaza17/indobert-chatbotkbli
|
Thiaza17
| 2025-09-12T08:46:48Z | 11 | 0 | null |
[
"safetensors",
"bert",
"indobert",
"chatbot",
"id",
"license:mit",
"region:us"
] | null | 2025-09-11T01:32:32Z |
---
tags:
- bert
- indobert
- chatbot
language:
- id
license: mit
---
# IndoBERT Chatbot KBLI
Model ini adalah hasil fine-tuning IndoBERT untuk klasifikasi teks KBLI.
## Cara Pakai
```python
from transformers import AutoTokenizer, AutoModelForSequenceClassification
tokenizer = AutoTokenizer.from_pretrained("Thiaza17/indobert-chatbotkbli")
model = AutoModelForSequenceClassification.from_pretrained("Thiaza17/indobert-chatbotkbli")
inputs = tokenizer("Saya ingin menyewakan kos-kosan", return_tensors="pt")
outputs = model(**inputs)
print(outputs.logits)
|
schroneko/gpt-oss-20b-finetuned
|
schroneko
| 2025-09-12T08:46:42Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"gpt_oss",
"trl",
"en",
"base_model:unsloth/gpt-oss-20b-unsloth-bnb-4bit",
"base_model:finetune:unsloth/gpt-oss-20b-unsloth-bnb-4bit",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-09-12T08:46:30Z |
---
base_model: unsloth/gpt-oss-20b-unsloth-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- gpt_oss
- trl
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** schroneko
- **License:** apache-2.0
- **Finetuned from model :** unsloth/gpt-oss-20b-unsloth-bnb-4bit
This gpt_oss model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
5456es/last_layer_prune_Qwen2.5-7B-Instruct_prune_0.2-sigmoid
|
5456es
| 2025-09-12T08:45:23Z | 0 | 0 | null |
[
"safetensors",
"qwen2",
"dpo",
"preference-learning",
"last",
"pruned",
"license:apache-2.0",
"region:us"
] | null | 2025-09-12T08:35:20Z |
---
license: apache-2.0
base_model: Qwen2.5-7B-Instruct
tags:
- dpo
- preference-learning
- last
- pruned
---
# last_layer_prune_Qwen2.5-7B-Instruct_prune_0.2-sigmoid
This model is a DPO (Direct Preference Optimization) fine-tuned version of Qwen2.5-7B-Instruct using the last method.
## Model Details
- **Base Model**: Qwen2.5-7B-Instruct
- **Training Method**: last
- **Pruning Ratio**: unknown
- **Training Date**: 2025-09-12
## Training Configuration
This model was trained using Direct Preference Optimization (DPO) with the following characteristics:
- Method: last
- Pruning applied during training
- Fine-tuned on preference data
## Usage
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
model_name = "5456es/last_layer_prune_Qwen2.5-7B-Instruct_prune_0.2-sigmoid"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
# Example usage
prompt = "Your prompt here"
inputs = tokenizer(prompt, return_tensors="pt")
outputs = model.generate(**inputs, max_length=100)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
```
## Training Data
This model was trained on preference data using the DPO algorithm.
## Limitations
This model inherits the limitations of its base model and may have additional limitations due to the pruning process.
## Citation
If you use this model, please cite the original DPO paper and the base model.
|
huihui-ai/Huihui-MoE-60B-A3B-abliterated
|
huihui-ai
| 2025-09-12T08:41:47Z | 70 | 4 |
transformers
|
[
"transformers",
"safetensors",
"gguf",
"qwen3_moe",
"text-generation",
"moe",
"abliterated",
"uncensored",
"conversational",
"base_model:huihui-ai/Huihui-Qwen3-30B-A3B-Instruct-2507-abliterated",
"base_model:quantized:huihui-ai/Huihui-Qwen3-30B-A3B-Instruct-2507-abliterated",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-09-08T03:02:42Z |
---
license: apache-2.0
license_link: https://huggingface.co/Qwen/Qwen3-30B-A3B-Thinking-2507/blob/main/LICENSE
base_model:
- huihui-ai/Huihui-Qwen3-30B-A3B-Thinking-2507-abliterated
- huihui-ai/Huihui-Qwen3-30B-A3B-Instruct-2507-abliterated
library_name: transformers
pipeline_tag: text-generation
tags:
- moe
- abliterated
- uncensored
---
# huihui-ai/Huihui-MoE-60B-A3B-abliterated
## Model Overview
Huihui-MoE-60B-A3B-abliterated is a **Mixture of Experts (MoE)** language model developed by **huihui.ai**, built upon the **[huihui-ai/Huihui-Qwen3-30B-A3B-Thinking-2507-abliterated](https://huggingface.co/huihui-ai/Huihui-Qwen3-30B-A3B-Thinking-2507-abliterated)** base model. It enhances the standard Transformer architecture by replacing MLP layers with MoE layers, each containing 256 experts, to achieve high performance with efficient inference. The model is designed for natural language processing tasks, including text generation, question answering, and conversational applications.
### Note
This model combines two ablated models, and perhaps it can achieve the performance of all the ablated models?
This is just a test. The exploration of merging different manifestations of models of the same type is another possibility.
- **Architecture**: Qwen3MoeForCausalLM model with 256 experts per layer (num_experts=256), activating 8 expert per token (num_experts_per_tok=8).
- **Total Parameters**: ~60 billion (60B)
- **Activated Parameters**: ~3 billion (3B) during inference, comparable to Huihui-Qwen3-30B-A3B-Thinking-2507-abliterated
- **Developer**: huihui.ai
- **Release Date**: September 2025
- **License**: Inherits the license of the Qwen3 base model (apache-2.0)
## Expert Models:
### Expert 1-128:
[huihui-ai/Huihui-Qwen3-30B-A3B-Thinking-2507-abliterated](https://huggingface.co/huihui-ai/Huihui-Qwen3-30B-A3B-Thinking-2507-abliterated)
### Expert 129-256:
[huihui-ai/Huihui-Qwen3-30B-A3B-Instruct-2507-abliterated](https://huggingface.co/huihui-ai/Huihui-Qwen3-30B-A3B-Instruct-2507-abliterated)
### Instruction Following:
[huihui-ai/Huihui-Qwen3-30B-A3B-Thinking-2507-abliterated](https://huggingface.co/huihui-ai/Huihui-Qwen3-30B-A3B-Thinking-2507-abliterated)
## Training
- **Base Model**: Huihui-Qwen3-30B-A3B-Thinking-2507-abliterated
- **Conversion**: The model copies embeddings, self-attention, and normalization weights from Huihui-Qwen3-30B-A3B-Thinking-2507-abliterated, replacing MLP layers with MoE layers (256 experts). Gating weights are randomly initialized.
- **Fine-Tuning**: Not fine-tuned; users are recommended to fine-tune for specific tasks to optimize expert routing.
## ollama
You can use [huihui_ai/huihui-moe-abliterated:60b](https://ollama.com/huihui_ai/huihui-moe-abliterated:60b) directly,
```
ollama run huihui_ai/huihui-moe-abliterated:60b
```
## GGUF
[Q4_K_M-GGUF](https://huggingface.co/huihui-ai/Huihui-MoE-60B-A3B-abliterated/tree/main/Q4_K_M-GGUF)
[Q8_0-GGUF](https://huggingface.co/huihui-ai/Huihui-MoE-60B-A3B-abliterated/tree/main/Q8_0-GGUF)
[f16-GGUF](https://huggingface.co/huihui-ai/Huihui-MoE-60B-A3B-abliterated/tree/main/f16-GGUF)
## Usage
```
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig, TextStreamer
import torch
import os
import signal
import numpy as np
import time
from collections import Counter
cpu_count = os.cpu_count()
print(f"Number of CPU cores in the system: {cpu_count}")
half_cpu_count = cpu_count // 2
os.environ["MKL_NUM_THREADS"] = str(half_cpu_count)
os.environ["OMP_NUM_THREADS"] = str(half_cpu_count)
torch.set_num_threads(half_cpu_count)
print(f"PyTorch threads: {torch.get_num_threads()}")
print(f"MKL threads: {os.getenv('MKL_NUM_THREADS')}")
print(f"OMP threads: {os.getenv('OMP_NUM_THREADS')}")
# Load the model and tokenizer
NEW_MODEL_ID = "huihui-ai/Huihui-MoE-60B-A3B-abliterated"
print(f"Load Model {NEW_MODEL_ID} ... ")
quant_config_4 = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_compute_dtype=torch.bfloat16,
bnb_4bit_use_double_quant=True,
llm_int8_enable_fp32_cpu_offload=True,
)
model = AutoModelForCausalLM.from_pretrained(
NEW_MODEL_ID,
device_map="auto",
trust_remote_code=True,
#quantization_config=quant_config_4,
torch_dtype=torch.bfloat16
)
tokenizer = AutoTokenizer.from_pretrained(NEW_MODEL_ID, trust_remote_code=True)
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_token
tokenizer.pad_token_id = tokenizer.eos_token_id
messages = []
nothink = False
skip_prompt=True
skip_special_tokens=True
do_sample = True
class CustomTextStreamer(TextStreamer):
def __init__(self, tokenizer, skip_prompt=True, skip_special_tokens=True):
super().__init__(tokenizer, skip_prompt=skip_prompt, skip_special_tokens=skip_special_tokens)
self.generated_text = ""
self.stop_flag = False
self.init_time = time.time() # Record initialization time
self.end_time = None # To store end time
self.first_token_time = None # To store first token generation time
self.token_count = 0 # To track total tokens
def on_finalized_text(self, text: str, stream_end: bool = False):
if self.first_token_time is None and text.strip(): # Set first token time on first non-empty text
self.first_token_time = time.time()
self.generated_text += text
# Count tokens in the generated text
tokens = self.tokenizer.encode(text, add_special_tokens=False)
self.token_count += len(tokens)
print(text, end="", flush=True)
if stream_end:
self.end_time = time.time() # Record end time when streaming ends
if self.stop_flag:
raise StopIteration
def stop_generation(self):
self.stop_flag = True
self.end_time = time.time() # Record end time when generation is stopped
def get_metrics(self):
"""Returns initialization time, first token time, first token latency, end time, total time, total tokens, and tokens per second."""
if self.end_time is None:
self.end_time = time.time() # Set end time if not already set
total_time = self.end_time - self.init_time # Total time from init to end
tokens_per_second = self.token_count / total_time if total_time > 0 else 0
first_token_latency = (self.first_token_time - self.init_time) if self.first_token_time is not None else None
metrics = {
"init_time": self.init_time,
"first_token_time": self.first_token_time,
"first_token_latency": first_token_latency,
"end_time": self.end_time,
"total_time": total_time, # Total time in seconds
"total_tokens": self.token_count,
"tokens_per_second": tokens_per_second
}
return metrics
def generate_stream(model, tokenizer, messages, nothink, skip_prompt, skip_special_tokens, do_sample, max_new_tokens):
input_ids = tokenizer.apply_chat_template(
messages,
tokenize=True,
enable_thinking = not nothink,
add_generation_prompt=True,
return_tensors="pt"
)
attention_mask = torch.ones_like(input_ids, dtype=torch.long)
tokens = input_ids.to(model.device)
attention_mask = attention_mask.to(model.device)
streamer = CustomTextStreamer(tokenizer, skip_prompt=skip_prompt, skip_special_tokens=skip_special_tokens)
def signal_handler(sig, frame):
streamer.stop_generation()
print("\n[Generation stopped by user with Ctrl+C]")
signal.signal(signal.SIGINT, signal_handler)
generate_kwargs = {}
if do_sample:
generate_kwargs = {
"do_sample": do_sample,
"max_length": max_new_tokens,
"temperature": 0.6,
"top_k": 20,
"top_p": 0.95,
"repetition_penalty": 1.2,
"no_repeat_ngram_size": 2
}
else:
generate_kwargs = {
"do_sample": do_sample,
"max_length": max_new_tokens,
"repetition_penalty": 1.2,
"no_repeat_ngram_size": 2
}
print("Response: ", end="", flush=True)
try:
generated_ids = model.generate(
tokens,
attention_mask=attention_mask,
#use_cache=False,
pad_token_id=tokenizer.pad_token_id,
streamer=streamer,
**generate_kwargs
)
del generated_ids
except StopIteration:
print("\n[Stopped by user]")
del input_ids, attention_mask
torch.cuda.empty_cache()
signal.signal(signal.SIGINT, signal.SIG_DFL)
return streamer.generated_text, streamer.stop_flag, streamer.get_metrics()
# List to store activated expert indices
activated_experts = []
# Define hook function to capture gate_probs output
def hook_fn(module, input, output):
# output is gate_probs, shape: [batch_size, sequence_length, num_experts]
gate_probs = output
# Compute top-1 expert indices (since only one expert is activated)
_, topk_indices = gate_probs.topk(8, dim=-1) # Take top-8
# Flatten and store activated expert indices
activated_experts.extend(topk_indices.squeeze(-1).view(-1).cpu().tolist())
hooks = []
for layer in model.model.layers:
hooks.append(layer.mlp.gate.register_forward_hook(hook_fn))
while True:
print(f"\nnothink: {nothink}")
print(f"skip_prompt: {skip_prompt}")
print(f"skip_special_tokens: {skip_special_tokens}")
print(f"do_sample: {do_sample}")
user_input = input("User: ").strip()
if user_input.lower() == "/exit":
print("Exiting chat.")
break
if user_input.lower() == "/clear":
messages = []
print("Chat history cleared. Starting a new conversation.")
continue
if user_input.lower() == "/nothink":
nothink = not nothink
continue
if user_input.lower() == "/skip_prompt":
skip_prompt = not skip_prompt
continue
if user_input.lower() == "/skip_special_tokens":
skip_special_tokens = not skip_special_tokens
continue
if user_input.lower() == "/do_sample":
do_sample = not do_sample
continue
if not user_input:
print("Input cannot be empty. Please enter something.")
continue
messages.append({"role": "user", "content": user_input})
activated_experts = []
response, stop_flag, metrics = generate_stream(model, tokenizer, messages, nothink, skip_prompt, skip_special_tokens, do_sample, 40960)
print("\n\nMetrics:")
for key, value in metrics.items():
print(f" {key}: {value}")
# Count the frequency of each activated expert
expert_counts = Counter(activated_experts)
# Print activation statistics
print("\nActivated Expert Statistics:")
for expert_idx, count in sorted(expert_counts.items()):
print(f"Expert {expert_idx}: {count} times")
print("", flush=True)
if stop_flag:
continue
messages.append({"role": "assistant", "content": response})
# Remove all hooks after inference
for h in hooks: h.remove()
```
## Applications
- **Text Generation: Articles**, dialogues, and creative writing.
- **Question Answering**: Information retrieval and query resolution.
- **Conversational AI**: Multi-turn dialogues for chatbots.
- **Research**: Exploration of MoE architectures and efficient model scaling.
## Limitations
- **Fine-Tuning Required**: Randomly initialized gating weights may lead to suboptimal expert utilization without fine-tuning.
- **Compatibility**: Developed with transformers 4.56; ensure matching versions to avoid loading issues.
- **Inference Speed**: While efficient for an MoE model, performance depends on hardware (GPU recommended).
## Ethical Considerations
- **Bias**: Inherits potential biases from the Qwen3-1.7B-abliterated base model; users should evaluate outputs for fairness.
- **Usage**: Intended for research and responsible applications; avoid generating harmful or misleading content.
## Contact
- **Developer**: huihui.ai
- **Repository**: huihui-ai/Huihui-MoE-60B-A3B-abliterated (available locally or on Hugging Face)
- **Issues**: Report bugs or request features via the repository or please send an email to support@huihui.ai
### Donation
If you like it, please click 'like' and follow us for more updates.
You can follow [x.com/support_huihui](https://x.com/support_huihui) to get the latest model information from huihui.ai.
##### Your donation helps us continue our further development and improvement, a cup of coffee can do it.
- bitcoin(BTC):
```
bc1qqnkhuchxw0zqjh2ku3lu4hq45hc6gy84uk70ge
```
- Support our work on Ko-fi (https://ko-fi.com/huihuiai)!
|
stonermay/blockassist-bc-diving_lightfooted_caterpillar_1757666358
|
stonermay
| 2025-09-12T08:40:24Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"diving lightfooted caterpillar",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-12T08:40:17Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- diving lightfooted caterpillar
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
nobu222/rakugo-lora-gemma2
|
nobu222
| 2025-09-12T08:38:18Z | 0 | 0 | null |
[
"safetensors",
"region:us"
] | null | 2025-09-12T08:30:26Z |
---
title: "Rakugo LoRA Space"
emoji: 🎭
colorFrom: indigo
colorTo: pink
sdk: gradio
sdk_version: "4.0"
app_file: app.py
pinned: false
---
# 落語LoRA(志ん生スタイルの枕強化) for Gemma 2
- **Base**: `google/gemma-2-9b-it`
- **Adapter**: LoRA (r=32, alpha=64, QLoRA学習)
- **Style**: 「質問拾い→一分線香(短小咄)→観察ギャグ→三点→“◯◯っていやあ…”→枕冒頭」
## 注意
- ベースモデルの利用条件(申請/ライセンス)に従ってください。
- 文化表現を模倣しますが、不適切表現を避けるよう学習しています。
|
Testament200156/medgemma3-thinking
|
Testament200156
| 2025-09-12T08:33:42Z | 460 | 3 |
transformers
|
[
"transformers",
"safetensors",
"gguf",
"medical",
"Gemma3",
"mergekit",
"merge",
"image-text-to-text",
"base_model:google/medgemma-27b-it",
"base_model:quantized:google/medgemma-27b-it",
"license:gemma",
"endpoints_compatible",
"region:us",
"conversational"
] |
image-text-to-text
| 2025-09-08T05:36:53Z |
---
license: gemma
tags:
- medical
- Gemma3
- mergekit
- merge
pipeline_tag: image-text-to-text
library_name: transformers
base_model:
- google/medgemma-27b-it
---
### About this model
This was created purely as an attempt to turn MedGemma-27B into a thinking and reasoning model.
I will share it with everyone, so I would appreciate your feedback.
###Model Source
1. Merged publicly available Gemma3 models with outstanding scientific reasoning.
2. google/medgemma-27b-it
###What the model can do
1. Medical reasoning
2. Simple scientific reasoning
3. Simple coding and calculations
4. Tool calls
Please apply megdgmma thinking-systemprompts.txt when using.
###Future plans
1. I plan to continue improve this model,
Please please support me. Bitcoin address : 34ZuzEUfuVfuEE8PiU1DabiwRzAxGw9JM4
2. I Uploded model Files.
```yaml
models:
- model: gemma3-thinking(Original blend,Non Uploaded)
parameters:
weight: 1.0
- model: google/medgemma-27b-it
parameters:
weight: 1.618033988749
merge_method: nuslerp
tokenizer_source: google/medgemma-27b-it
dtype: bfloat16
```
|
BeagleWorks/Qwen-Mail-Lora
|
BeagleWorks
| 2025-09-12T08:33:18Z | 0 | 0 |
peft
|
[
"peft",
"safetensors",
"base_model:adapter:Qwen/Qwen2.5-0.5B",
"lora",
"sft",
"transformers",
"trl",
"text-generation",
"conversational",
"base_model:Qwen/Qwen2.5-0.5B",
"region:us"
] |
text-generation
| 2025-09-12T07:46:29Z |
---
base_model: Qwen/Qwen2.5-0.5B
library_name: peft
model_name: qwen-mail-lora
tags:
- base_model:adapter:Qwen/Qwen2.5-0.5B
- lora
- sft
- transformers
- trl
licence: license
pipeline_tag: text-generation
---
# Model Card for qwen-mail-lora
This model is a fine-tuned version of [Qwen/Qwen2.5-0.5B](https://huggingface.co/Qwen/Qwen2.5-0.5B).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="None", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
This model was trained with SFT.
### Framework versions
- PEFT 0.17.1
- TRL: 0.23.0
- Transformers: 4.56.1
- Pytorch: 2.8.0
- Datasets: 4.0.0
- Tokenizers: 0.22.0
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
## Usage
```colab
!pip -q install "transformers>=4.44" "peft>=0.11" accelerate
import torch
from peft import PeftModel
from transformers import AutoModelForCausalLM, AutoTokenizer
BASE_ID = "Qwen/Qwen2.5-0.5B"
ADAPTER_ID = "BeagleWorks/Qwen-Mail-Lora" # ←あなたのLoRA
# 1) トークナイザ
tok = AutoTokenizer.from_pretrained(BASE_ID, trust_remote_code=True)
if tok.pad_token is None:
tok.pad_token = tok.eos_token # pad未設定エラー回避
# 2) ベースモデル(FP16, 自動デバイス割当)
base = AutoModelForCausalLM.from_pretrained(
BASE_ID,
trust_remote_code=True,
device_map="auto",
torch_dtype=torch.float16 if torch.cuda.is_available() else torch.float32,
)
# 3) LoRAアダプタを適用
model = PeftModel.from_pretrained(base, ADAPTER_ID)
model.eval()
# 4) 生成(学習時のフォーマットに近いプロンプトを使う)
prompt = """[指示]
あなたはメール文面を整えるアシスタントです。以下の下書きを、件名/本文/TODO/署名に整理し、敬体(です・ます調)で自然な日本語に直してください。
[下書き]
明日の打ち合わせ、議題 進捗確認と次タスク。先方に資料送るの忘れた。山田さんにCC。
[出力フォーマット]
件名: <短い件名>
本文:
<整えた本文>
TODO:
- <TODO1>
- <TODO2>
署名:
<署名>
[回答]
"""
inputs = tok(prompt, return_tensors="pt").to(model.device)
with torch.inference_mode():
out = model.generate(
**inputs,
max_new_tokens=400,
do_sample=True,
temperature=0.7,
top_p=0.9,
repetition_penalty=1.05,
eos_token_id=tok.eos_token_id,
pad_token_id=tok.pad_token_id,
)
print(tok.decode(out[0], skip_special_tokens=True))
```
|
5456es/implicit_reward_Llama-3.2-1B-Instruct_prune_0.3-sigmoid
|
5456es
| 2025-09-12T08:32:45Z | 30 | 0 | null |
[
"safetensors",
"llama",
"dpo",
"preference-learning",
"implicit",
"pruned",
"license:apache-2.0",
"region:us"
] | null | 2025-09-07T04:57:53Z |
---
license: apache-2.0
base_model: Llama-3.2-1B-Instruct
tags:
- dpo
- preference-learning
- implicit
- pruned
---
# implicit_reward_Llama-3.2-1B-Instruct_prune_0.3-sigmoid
This model is a DPO (Direct Preference Optimization) fine-tuned version of Llama-3.2-1B-Instruct using the implicit method.
## Model Details
- **Base Model**: Llama-3.2-1B-Instruct
- **Training Method**: implicit
- **Pruning Ratio**: unknown
- **Training Date**: 2025-09-12
## Training Configuration
This model was trained using Direct Preference Optimization (DPO) with the following characteristics:
- Method: implicit
- Pruning applied during training
- Fine-tuned on preference data
## Usage
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
model_name = "5456es/implicit_reward_Llama-3.2-1B-Instruct_prune_0.3-sigmoid"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
# Example usage
prompt = "Your prompt here"
inputs = tokenizer(prompt, return_tensors="pt")
outputs = model.generate(**inputs, max_length=100)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
```
## Training Data
This model was trained on preference data using the DPO algorithm.
## Limitations
This model inherits the limitations of its base model and may have additional limitations due to the pruning process.
## Citation
If you use this model, please cite the original DPO paper and the base model.
|
Alicia22/Ali_Frid_F16
|
Alicia22
| 2025-09-12T08:32:17Z | 0 | 0 | null |
[
"safetensors",
"any-to-any",
"omega",
"omegalabs",
"bittensor",
"agi",
"license:mit",
"region:us"
] |
any-to-any
| 2025-09-12T08:29:45Z |
---
license: mit
tags:
- any-to-any
- omega
- omegalabs
- bittensor
- agi
---
This is an Any-to-Any model checkpoint for the OMEGA Labs x Bittensor Any-to-Any subnet.
Check out the [git repo](https://github.com/omegalabsinc/omegalabs-anytoany-bittensor) and find OMEGA on X: [@omegalabsai](https://x.com/omegalabsai).
|
kakimoto/act-airhockey-step100k
|
kakimoto
| 2025-09-12T08:30:58Z | 0 | 0 |
lerobot
|
[
"lerobot",
"safetensors",
"act",
"robotics",
"dataset:kakimoto/record-hockey-640x480",
"arxiv:2304.13705",
"license:apache-2.0",
"region:us"
] |
robotics
| 2025-09-12T08:30:36Z |
---
datasets: kakimoto/record-hockey-640x480
library_name: lerobot
license: apache-2.0
model_name: act
pipeline_tag: robotics
tags:
- act
- lerobot
- robotics
---
# Model Card for act
<!-- Provide a quick summary of what the model is/does. -->
[Action Chunking with Transformers (ACT)](https://huggingface.co/papers/2304.13705) is an imitation-learning method that predicts short action chunks instead of single steps. It learns from teleoperated data and often achieves high success rates.
This policy has been trained and pushed to the Hub using [LeRobot](https://github.com/huggingface/lerobot).
See the full documentation at [LeRobot Docs](https://huggingface.co/docs/lerobot/index).
---
## How to Get Started with the Model
For a complete walkthrough, see the [training guide](https://huggingface.co/docs/lerobot/il_robots#train-a-policy).
Below is the short version on how to train and run inference/eval:
### Train from scratch
```bash
lerobot-train \
--dataset.repo_id=${HF_USER}/<dataset> \
--policy.type=act \
--output_dir=outputs/train/<desired_policy_repo_id> \
--job_name=lerobot_training \
--policy.device=cuda \
--policy.repo_id=${HF_USER}/<desired_policy_repo_id>
--wandb.enable=true
```
_Writes checkpoints to `outputs/train/<desired_policy_repo_id>/checkpoints/`._
### Evaluate the policy/run inference
```bash
lerobot-record \
--robot.type=so100_follower \
--dataset.repo_id=<hf_user>/eval_<dataset> \
--policy.path=<hf_user>/<desired_policy_repo_id> \
--episodes=10
```
Prefix the dataset repo with **eval\_** and supply `--policy.path` pointing to a local or hub checkpoint.
---
## Model Details
- **License:** apache-2.0
|
stonermay/blockassist-bc-diving_lightfooted_caterpillar_1757665747
|
stonermay
| 2025-09-12T08:30:38Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"diving lightfooted caterpillar",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-12T08:30:16Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- diving lightfooted caterpillar
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
inclusionAI/GroveMoE-Inst
|
inclusionAI
| 2025-09-12T08:30:17Z | 382 | 31 |
transformers
|
[
"transformers",
"safetensors",
"qwen3_moe",
"text-generation",
"conversational",
"custom_code",
"arxiv:2508.07785",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-18T05:28:51Z |
---
library_name: transformers
license: apache-2.0
pipeline_tag: text-generation
---
# GroveMoE-Inst
</div>
<p align="left">
🤗 <a href="https://huggingface.co/collections/inclusionAI/grovemoe-68a2b58acbb55827244ef664">Models</a>   |    📑 <a href="https://arxiv.org/abs/2508.07785">Paper</a>    |    🔗 <a href="https://github.com/inclusionAI/GroveMoE">Github</a>  
## Highlights
We introduce **GroveMoE**, a new sparse architecture using **adjugate experts** for dynamic computation allocation, featuring the following key highlights:
- **Architecture**: Novel **adjugate experts** grouped with ordinary experts; shared computation is executed once, then reused, cutting FLOPs.
- **Sparse Activation**: 33 B params total, only **3.14–3.28 B** active per token.
- **Traning**: Mid-training + SFT, up-cycled from Qwen3-30B-A3B-Base; preserves prior knowledge while adding new capabilities.
## Model Downloads
| **Model** | **#Total Params** | **#Activated Params** | **HF Download** |**MS Download** |
|:---------:|:-----------------:|:---------------------:|:------------:|:------------:|
| GroveMoE-Base | 33B | 3.14~3.28B | [🤗 HuggingFace](https://huggingface.co/inclusionAI/GroveMoE-Base) | [📦 ModelScope](https://modelscope.cn/models/cccnju/GroveMoE-Base) |
| GroveMoE-Inst | 33B | 3.14~3.28B | [🤗 HuggingFace](https://huggingface.co/inclusionAI/GroveMoE-Inst) | [📦 ModelScope](https://modelscope.cn/models/cccnju/GroveMoE-Inst) |
## Performance
| Model | Activated Params | MMLU-Pro | SuperGPQA | GPQA-Diamond | OlympiadBench | Omni-math | AIME'25 | MultiPL-E | LiveCodeBench v6 |
|:-----:|:----------------:|:------------:|:-------------:|:------------:|:-----------------:|:------------:|:------------------:|:------------------:|:------------------:|
|Llama4-Scout| 17B | 64.9 | 42.0 | 55.6 | 56.6 | 30.2 | 10.0 | 45.0 | 32.0 |
|Qwen3-30B-A3B| 3B | 63.3 | 40.5 | 51.7 | 60.3 | 33.7 | 21.7 | 66.0 | 29.4 |
|Qwen3-32B| 32B | 68.2 | 43.0 | 53.6 | 59.5 | 31.8 | 22.9 | 68.6 | 28.6 |
|Gemma3-27B-IT| 27B | 67.1 | 35.6 | 45.3 | 59.9 | 33.3 | 23.1 | 65.5 | 30.9 |
|Mistral-Small-3.2| 24B | 68.1 | 37.5 | 59.9 | 61.9 | 33.4 | 28.1 | 69.5 | 32.2 |
|GroveMoE-Inst|3.14~3.28B | <font color=#FBD98D>**72.8**</font> | <font color=#FBD98D>**47.7**</font> | <font color=#FBD98D>**61.3**</font> |<font color=#FBD98D>**71.2**</font> |<font color=#FBD98D>**43.5**</font> | <font color=#FBD98D>**44.4**</font> |<font color=#FBD98D>**74.5**</font> | <font color=#FBD98D>**34.6**</font> |
We bold the top1 scores separately for all models. More details are reported in our [technical report](https://arxiv.org/abs/2508.07785).
## Run GroveMoE
### 🤗 Transformers Quick Start
Below, there are some code snippets on how to get quickly started with running the model. First, install the Transformers library.
```sh
$ pip install transformers==4.51.3
```
Then, copy the snippet from the section that is relevant for your use case.
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "inclusionAI/GroveMoE-Inst"
# load the tokenizer and the model
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
# prepare the model input
prompt = "Give me a short introduction to large language model."
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# conduct text completion
generated_ids = model.generate(
**model_inputs,
max_new_tokens=16384
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
content = tokenizer.decode(output_ids, skip_special_tokens=True)
print("content:", content)
```
### 🚀 SGLang Quick Start
For SGLang, you can follow the steps below to deploy:
1️⃣ Install Dependencies
First, clone the repository:
```shell
git clone https://github.com/inclusionAI/GroveMoE.git
```
Then, install Transformers:
```shell
cd src/transformers-4.51.3
pip install .
```
Next, install SGLang:
```shell
cd src/sglang-0.4.6.post5
pip install .
```
2️⃣ Launch the Server
Run the following command to start SGLang:
```shell
python -m sglang.launch_server \
--model-path inclusionAI/GroveMoE-Inst \
--port 30000 \
--context-length 32768
```
3️⃣ Access the API
Once started, the OpenAI-compatible API will be available at `http://localhost:30000/v1`.
Test it with curl:
```shell
curl http://localhost:30000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "inclusionAI/GroveMoE-Inst",
"messages": [{"role": "user", "content": "Hello, SGLang!"}]
}'
```
### llama.cpp
Thanks @CISCai, support for llama.cpp can be found in the implementation at https://github.com/ggml-org/llama.cpp/pull/15510.
## Best Practices for Model Configuration
To achieve optimal performance, we recommend the following settings:
1. **Sampling Parameters**:
- We suggest using `Temperature=0.7`, `TopP=0.8`, `TopK=20`, and `MinP=0`. (⚠️ For benchmarking scenarios requiring sampling (e.g., AIME), these parameters must be explicitly configured.)
2. **Adequate Output Length**: Set output length to 16,384 tokens for general use cases to accommodate complex reasoning tasks in instruct models.
3. **Standardize Output Format**: We recommend using prompts to standardize model outputs when benchmarking.
- **Math Problems**: Include "Please reason step by step, and put your final answer within \boxed{}." in the prompt.
- **Multiple-Choice Questions**: Add the following JSON structure to the prompt to standardize responses: "Please show your choice in the `answer` field with only the choice letter, e.g., `"answer": "C"`."
## Citation
```bibtex
@article{GroveMoE,
title = {GroveMoE: Towards Efficient and Superior MoE LLMs with Adjugate Experts},
author = {Wu, Haoyuan and Chen, Haoxing and Chen, Xiaodong and Zhou, Zhanchao and Chen, Tieyuan and Zhuang, Yihong and Lu, Guoshan and Zhao, Junbo and Liu, Lin and Huang, Zenan and Lan, Zhenzhong and Yu, Bei and Li, Jianguo},
journal = {arXiv preprint arXiv:2508.07785},
year = {2025}
}
```
|
inclusionAI/GroveMoE-Base
|
inclusionAI
| 2025-09-12T08:29:41Z | 98 | 1 |
transformers
|
[
"transformers",
"safetensors",
"qwen3_moe",
"text-generation",
"conversational",
"custom_code",
"arxiv:2508.07785",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-18T12:01:27Z |
---
library_name: transformers
license: apache-2.0
pipeline_tag: text-generation
---
# GroveMoE-Base
</div>
<p align="left">
🤗 <a href="https://huggingface.co/collections/inclusionAI/grovemoe-68a2b58acbb55827244ef664">Models</a>   |    📑 <a href="https://arxiv.org/abs/2508.07785">Paper</a>    |    🔗 <a href="https://github.com/inclusionAI/GroveMoE">Github</a>  
## Highlights
We introduce **GroveMoE**, a new sparse architecture using **adjugate experts** for dynamic computation allocation, featuring the following key highlights:
- **Architecture**: Novel **adjugate experts** grouped with ordinary experts; shared computation is executed once, then reused, cutting FLOPs.
- **Sparse Activation**: 33 B params total, only **3.14–3.28 B** active per token.
- **Traning**: Mid-training + SFT, up-cycled from Qwen3-30B-A3B-Base; preserves prior knowledge while adding new capabilities.
## Model Downloads
| **Model** | **#Total Params** | **#Activated Params** | **HF Download** |**MS Download** |
|:---------:|:-----------------:|:---------------------:|:------------:|:------------:|
| GroveMoE-Base | 33B | 3.14~3.28B | [🤗 HuggingFace](https://huggingface.co/inclusionAI/GroveMoE-Base) | [📦 ModelScope](https://modelscope.cn/models/cccnju/GroveMoE-Base) |
| GroveMoE-Inst | 33B | 3.14~3.28B | [🤗 HuggingFace](https://huggingface.co/inclusionAI/GroveMoE-Inst) | [📦 ModelScope](https://modelscope.cn/models/cccnju/GroveMoE-Inst) |
## Citation
```bibtex
@article{GroveMoE,
title = {GroveMoE: Towards Efficient and Superior MoE LLMs with Adjugate Experts},
author = {Wu, Haoyuan and Chen, Haoxing and Chen, Xiaodong and Zhou, Zhanchao and Chen, Tieyuan and Zhuang, Yihong and Lu, Guoshan and Zhao, Junbo and Liu, Lin and Huang, Zenan and Lan, Zhenzhong and Yu, Bei and Li, Jianguo},
journal = {arXiv preprint arXiv:2508.07785},
year = {2025}
}
```
|
Kijai/WanVideo_comfy_fp8_scaled
|
Kijai
| 2025-09-12T08:29:31Z | 259,971 | 206 |
diffusion-single-file
|
[
"diffusion-single-file",
"comfyui",
"base_model:Wan-AI/Wan2.1-VACE-1.3B",
"base_model:finetune:Wan-AI/Wan2.1-VACE-1.3B",
"license:apache-2.0",
"region:us"
] | null | 2025-07-22T10:39:42Z |
---
tags:
- diffusion-single-file
- comfyui
license: apache-2.0
base_model:
- Wan-AI/Wan2.1-VACE-14B
- Wan-AI/Wan2.1-VACE-1.3B
---
Better fp8 scaled models (when measured against fp16) based on quantization code from https://github.com/Tencent-Hunyuan/HunyuanVideo/blob/main/hyvideo/modules/fp8_optimization.py
Can be used with: https://github.com/kijai/ComfyUI-WanVideoWrapper (latest version) and ComfyUI native WanVideo nodes.
14B-T2V comparison test without LoRAs, 25 steps, 832x480x81
---
<video controls autoplay width=50% src=https://cdn-uploads.huggingface.co/production/uploads/63297908f0b2fc94904a65b8/DwlAGbj20it1unZW54NDC.mp4></video>
2.2 A14B-T2V test
---
<video controls autoplay width=50% src=https://cdn-uploads.huggingface.co/production/uploads/63297908f0b2fc94904a65b8/6A_AZ7GN_uxeRH0vwsWkH.mp4></video>
<video controls autoplay width=50% src=https://cdn-uploads.huggingface.co/production/uploads/63297908f0b2fc94904a65b8/GpuqQ4YwoR3kjxkhuvP8P.mp4></video>
The e5m2 marked as v2 is the one uploaded here and these are all scaled even if I forgot to label properly.
|
jumanaawk/money_detection
|
jumanaawk
| 2025-09-12T08:28:27Z | 0 | 0 | null |
[
"license:apache-2.0",
"region:us"
] | null | 2025-09-12T08:28:27Z |
---
license: apache-2.0
---
|
shelton15/il_artists_models
|
shelton15
| 2025-09-12T08:25:37Z | 0 | 1 | null |
[
"license:mit",
"region:us"
] | null | 2025-07-29T03:33:55Z |
---
license: mit
---
###base_model:
train_artist.safetensors
Currently, this model only contains a few artist keywords in the form of "by...".
(Since it is fine-tuned through SFT based on the original model, the artist names from the original model will also be supported to a certain extent.)
by ebifurya
by fangxiang_cuoluan
by kuria_(clear_trip_second)
by mika_pikazo
by ningen_mame
by quasarcake
yoneyama_mai
|
thuml/sundial-base-128m
|
thuml
| 2025-09-12T08:25:08Z | 1,713,863 | 41 | null |
[
"safetensors",
"sundial",
"time series",
"time-series",
"forecasting",
"foundation models",
"pretrained models",
"generative models",
"time series foundation models",
"time-series-forecasting",
"custom_code",
"dataset:thuml/UTSD",
"dataset:Salesforce/lotsa_data",
"dataset:autogluon/chronos_datasets",
"arxiv:2502.00816",
"arxiv:2403.07815",
"license:apache-2.0",
"region:us"
] |
time-series-forecasting
| 2025-05-13T12:53:52Z |
---
license: apache-2.0
metrics:
- mse
- mae
- mase
- wql
- crps
pipeline_tag: time-series-forecasting
datasets:
- thuml/UTSD
- Salesforce/lotsa_data
- autogluon/chronos_datasets
tags:
- time series
- time-series
- forecasting
- foundation models
- pretrained models
- generative models
- time series foundation models
---
# Sundial
🚩 **News (2025.06)** Sundial has been accepted as **ICML 2025 Oral** (Top 1%).
🚩 **News (2025.05)** Get **1st MASE** on the [GIFT-Eval](https://huggingface.co/spaces/Salesforce/GIFT-Eval) Benchmark.
🚩 **News (2025.02)** Get **1st MSE/MAE** zero-shot performance on [Time-Series-Library](https://github.com/thuml/Time-Series-Library) datasets.

Sundial is a family of **generative** time series foundation models. The model can make zero-shot predictions for **point** and **probabilistic** forecasting. [[Slides]](https://cloud.tsinghua.edu.cn/f/8d526337afde465e87c9/) [[Poster]](https://cloud.tsinghua.edu.cn/f/cc2a156315e9453f99b3/) [[Intro (CN)]](https://mp.weixin.qq.com/s/y3sc2e2lmW1sqfnoK-ZdDA).
Not only the mean or quantiles, you can get any statistical predictions with a set of generated samples.
The base version is pre-trained on **1 trillion** time points with **128M** parameters. For more information, please refer to this [paper](https://arxiv.org/pdf/2502.00816).
**Sundial** can be viewed as an **ARMA** model (Auto-Regression and Moving-Average). Transformer learns auto-regressive token representations. Conditioned on them, TimeFlow transforms random noises into non-deterministic predictions.

**Overall Architecture**: The input time series is divided into patch tokens, which are embedded from the original continuous values. The patch embeddings are fed into a decoder-only Transformer, a stable and speedup version that learns token representations. The model is optimized using our TimeFlow Loss, a parameterized loss function that models per-token probability distribution conditioned on the learned representations, and generates multiple plausible predictions under the flow-matching framework.
## Quickstart
```
pip install transformers==4.40.1 # Use this version and Python 3.10 for stable compatibility
```
```
import torch
from transformers import AutoModelForCausalLM
# load pretrain model
# supports different lookback/forecast lengths
model = AutoModelForCausalLM.from_pretrained('thuml/sundial-base-128m', trust_remote_code=True)
# prepare input
batch_size, lookback_length = 1, 2880
seqs = torch.randn(batch_size, lookback_length)
# Note that Sundial can generate multiple probable predictions
forecast_length = 96
num_samples = 20
output = model.generate(seqs, max_new_tokens=forecast_length, num_samples=num_samples)
# use raw predictions for mean/quantiles/confidence-interval estimation
print(output.shape)
```
More examples for predicting quantiles or confidence intervals are provided in this [notebook](https://github.com/thuml/Sundial/blob/main/examples/quickstart_zero_shot_generation.ipynb).
## Evaluation
We evaluate performance on the following benchmarks:
- [GIFT-Eval (1st MASE)](https://cdn-uploads.huggingface.co/production/uploads/64fbe24a2d20ced4e91de38a/3BxatwayhK5GAoqMf1oHv.png) [[Leaderboard]](https://huggingface.co/spaces/Salesforce/GIFT-Eval).
- [Time-Series-Library (1st MSE/MAE)](https://cdn-uploads.huggingface.co/production/uploads/64fbe24a2d20ced4e91de38a/5VqnFwWTWoYz877Zkluiw.png).
- [FEV Leaderboard](https://cdn-uploads.huggingface.co/production/uploads/64fbe24a2d20ced4e91de38a/mrKL9QmX-aX8rCiwxKgmA.png).
We are actively working around it and are glad to hear suggestions and noteworthy cases :)
## Inference Time
* Hardware: Apple M1 Pro CPU (16 GB)
| Lookback Length | Prediction Length | # Generated Samples | Inference Time | Accelerate By |
| --------------- | ----------------- | ------------------- | -------------- | -------------- |
| 672 | 16 | 1 | 249ms | - |
| 2880 | 16 | 1 | 510ms | FlashAttention |
| 2880 | 720 | 1 | 510ms | Multi-Patch Prediction |
| 2880 | 1440 | 1 | 789ms | KV Cache |
| 2880 | 720 | 20 | 949ms | Shared Condition |
* Hardware: A100-40G GPU, following [Chronos](https://arxiv.org/abs/2403.07815) paper.

## Specification
* **Architecture**: Causal Transformer (Decoder-only)
* **Pre-training Scale**: 1032B time points
* **Context Length**: up to 2880
* **ReNorm**: Default=True
* **Patch Length**: 16
* **Multi-Patch Prediction Lengt**h: 720
* **Parameter Count**: 128M
* **Number of Layers**: 12
* **Precision**: FP32
* **Speedup**: KV Cache & FlashAttention
## Acknowledgments
This work was supported by the National Natural Science Foundation of China (62022050 and U2342217), the BNRist Innovation Fund (BNR2024RC01010), and the National Engineering Research Center for Big Data Software.
The model is mostly built from the Internet public time series dataset, which comes from different research teams and providers. We sincerely thank all individuals and organizations who have contributed the data. Without their generous sharing, this model would not have existed.
## Citation
If you find Sundial helpful for your research, please cite our paper:
```
@article{liu2025sundial,
title={Sundial: A Family of Highly Capable Time Series Foundation Models},
author={Liu, Yong and Qin, Guo and Shi, Zhiyuan and Chen, Zhi and Yang, Caiyin and Huang, Xiangdong and Wang, Jianmin and Long, Mingsheng},
journal={arXiv preprint arXiv:2502.00816},
year={2025}
}
```
## Contact
If you have any questions or want to use the code, feel free to contact:
* Yong Liu (liuyong21@mails.tsinghua.edu.cn)
* Guo Qin (qinguo24@mails.tsinghua.edu.cn)
## License
This model is licensed under the Apache-2.0 License.
|
befox/Magic-Wan-Image-v1.0-GGUF
|
befox
| 2025-09-12T08:24:50Z | 143 | 3 | null |
[
"gguf",
"base_model:wikeeyang/Magic-Wan-Image-v1.0",
"base_model:quantized:wikeeyang/Magic-Wan-Image-v1.0",
"region:us"
] | null | 2025-09-09T05:52:05Z |
---
base_model:
- wikeeyang/Magic-Wan-Image-v1.0
---
GGUF version of [wikeeyang/Magic-Wan-Image-v1.0](https://huggingface.co/wikeeyang/Magic-Wan-Image-v1.0)

|
Reihaneh/wav2vec2_da_mono_50_epochs_4
|
Reihaneh
| 2025-09-12T08:23:07Z | 0 | 0 |
transformers
|
[
"transformers",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-09-12T08:23:06Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
HA-Siala/Python-OCL-v0.2
|
HA-Siala
| 2025-09-12T08:21:41Z | 0 | 0 |
peft
|
[
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:mistralai/Mistral-7B-v0.3",
"base_model:adapter:mistralai/Mistral-7B-v0.3",
"region:us"
] | null | 2025-09-12T08:21:28Z |
---
library_name: peft
base_model: mistralai/Mistral-7B-v0.3
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.10.0
|
encoderrr/blockassist
|
encoderrr
| 2025-09-12T08:21:07Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"sturdy alert mammoth",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-12T07:58:40Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- sturdy alert mammoth
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
5456es/implicit_reward_Qwen2.5-1.5B-Instruct_prune_0.7-sigmoid
|
5456es
| 2025-09-12T08:20:54Z | 37 | 0 | null |
[
"safetensors",
"qwen2",
"dpo",
"preference-learning",
"implicit",
"pruned",
"license:apache-2.0",
"region:us"
] | null | 2025-09-07T04:53:04Z |
---
license: apache-2.0
base_model: Qwen2.5-1.5B-Instruct
tags:
- dpo
- preference-learning
- implicit
- pruned
---
# implicit_reward_Qwen2.5-1.5B-Instruct_prune_0.7-sigmoid
This model is a DPO (Direct Preference Optimization) fine-tuned version of Qwen2.5-1.5B-Instruct using the implicit method.
## Model Details
- **Base Model**: Qwen2.5-1.5B-Instruct
- **Training Method**: implicit
- **Pruning Ratio**: unknown
- **Training Date**: 2025-09-12
## Training Configuration
This model was trained using Direct Preference Optimization (DPO) with the following characteristics:
- Method: implicit
- Pruning applied during training
- Fine-tuned on preference data
## Usage
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
model_name = "5456es/implicit_reward_Qwen2.5-1.5B-Instruct_prune_0.7-sigmoid"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
# Example usage
prompt = "Your prompt here"
inputs = tokenizer(prompt, return_tensors="pt")
outputs = model.generate(**inputs, max_length=100)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
```
## Training Data
This model was trained on preference data using the DPO algorithm.
## Limitations
This model inherits the limitations of its base model and may have additional limitations due to the pruning process.
## Citation
If you use this model, please cite the original DPO paper and the base model.
|
5456es/random_prune_Llama-3.2-3B-Instruct_prune_0.3-sigmoid
|
5456es
| 2025-09-12T08:20:01Z | 27 | 0 | null |
[
"safetensors",
"llama",
"dpo",
"preference-learning",
"random",
"pruned",
"license:apache-2.0",
"region:us"
] | null | 2025-09-09T03:37:32Z |
---
license: apache-2.0
base_model: Llama-3.2-3B-Instruct
tags:
- dpo
- preference-learning
- random
- pruned
---
# random_prune_Llama-3.2-3B-Instruct_prune_0.3-sigmoid
This model is a DPO (Direct Preference Optimization) fine-tuned version of Llama-3.2-3B-Instruct using the random method.
## Model Details
- **Base Model**: Llama-3.2-3B-Instruct
- **Training Method**: random
- **Pruning Ratio**: unknown
- **Training Date**: 2025-09-12
## Training Configuration
This model was trained using Direct Preference Optimization (DPO) with the following characteristics:
- Method: random
- Pruning applied during training
- Fine-tuned on preference data
## Usage
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
model_name = "5456es/random_prune_Llama-3.2-3B-Instruct_prune_0.3-sigmoid"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
# Example usage
prompt = "Your prompt here"
inputs = tokenizer(prompt, return_tensors="pt")
outputs = model.generate(**inputs, max_length=100)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
```
## Training Data
This model was trained on preference data using the DPO algorithm.
## Limitations
This model inherits the limitations of its base model and may have additional limitations due to the pruning process.
## Citation
If you use this model, please cite the original DPO paper and the base model.
|
yangxw/Qwen3-8B-Dynamic-New
|
yangxw
| 2025-09-12T08:19:42Z | 0 | 0 | null |
[
"safetensors",
"qwen3",
"license:apache-2.0",
"region:us"
] | null | 2025-09-12T08:04:29Z |
---
license: apache-2.0
---
|
Alicia22/Ali_Frid_F17
|
Alicia22
| 2025-09-12T08:19:42Z | 0 | 0 | null |
[
"safetensors",
"any-to-any",
"omega",
"omegalabs",
"bittensor",
"agi",
"license:mit",
"region:us"
] |
any-to-any
| 2025-09-12T08:17:04Z |
---
license: mit
tags:
- any-to-any
- omega
- omegalabs
- bittensor
- agi
---
This is an Any-to-Any model checkpoint for the OMEGA Labs x Bittensor Any-to-Any subnet.
Check out the [git repo](https://github.com/omegalabsinc/omegalabs-anytoany-bittensor) and find OMEGA on X: [@omegalabsai](https://x.com/omegalabsai).
|
maidacundo/annie-lite-v0.3.1-ckpt-260-lora
|
maidacundo
| 2025-09-12T08:19:13Z | 0 | 0 |
peft
|
[
"peft",
"safetensors",
"base_model:adapter:unsloth/Qwen3-8B-unsloth-bnb-4bit",
"grpo",
"lora",
"transformers",
"trl",
"unsloth",
"text-generation",
"conversational",
"arxiv:1910.09700",
"base_model:unsloth/Qwen3-8B-unsloth-bnb-4bit",
"region:us"
] |
text-generation
| 2025-09-12T08:18:52Z |
---
base_model: unsloth/Qwen3-8B-unsloth-bnb-4bit
library_name: peft
pipeline_tag: text-generation
tags:
- base_model:adapter:unsloth/Qwen3-8B-unsloth-bnb-4bit
- grpo
- lora
- transformers
- trl
- unsloth
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.17.1
|
Blaziooon/bisindo-word-detection
|
Blaziooon
| 2025-09-12T08:17:14Z | 0 | 0 |
keras
|
[
"keras",
"license:apache-2.0",
"region:us"
] | null | 2025-09-12T08:12:10Z |
---
license: apache-2.0
---
|
5456es/selective_dpo_Qwen2.5-1.5B-Instruct_prune_0.7-sigmoid
|
5456es
| 2025-09-12T08:16:52Z | 39 | 0 | null |
[
"safetensors",
"qwen2",
"dpo",
"preference-learning",
"selective",
"pruned",
"license:apache-2.0",
"region:us"
] | null | 2025-09-07T04:45:32Z |
---
license: apache-2.0
base_model: Qwen2.5-1.5B-Instruct
tags:
- dpo
- preference-learning
- selective
- pruned
---
# selective_dpo_Qwen2.5-1.5B-Instruct_prune_0.7-sigmoid
This model is a DPO (Direct Preference Optimization) fine-tuned version of Qwen2.5-1.5B-Instruct using the selective method.
## Model Details
- **Base Model**: Qwen2.5-1.5B-Instruct
- **Training Method**: selective
- **Pruning Ratio**: unknown
- **Training Date**: 2025-09-12
## Training Configuration
This model was trained using Direct Preference Optimization (DPO) with the following characteristics:
- Method: selective
- Pruning applied during training
- Fine-tuned on preference data
## Usage
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
model_name = "5456es/selective_dpo_Qwen2.5-1.5B-Instruct_prune_0.7-sigmoid"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
# Example usage
prompt = "Your prompt here"
inputs = tokenizer(prompt, return_tensors="pt")
outputs = model.generate(**inputs, max_length=100)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
```
## Training Data
This model was trained on preference data using the DPO algorithm.
## Limitations
This model inherits the limitations of its base model and may have additional limitations due to the pruning process.
## Citation
If you use this model, please cite the original DPO paper and the base model.
|
sam2ai/gemma3-4b-en-odia-mt
|
sam2ai
| 2025-09-12T08:16:02Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"gemma3",
"image-text-to-text",
"generated_from_trainer",
"conversational",
"dataset:sam2ai/en-oriya-translation",
"base_model:google/gemma-3-4b-it",
"base_model:finetune:google/gemma-3-4b-it",
"license:gemma",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
image-text-to-text
| 2025-09-12T07:56:40Z |
---
library_name: transformers
license: gemma
base_model: google/gemma-3-4b-it
tags:
- generated_from_trainer
datasets:
- sam2ai/en-oriya-translation
model-index:
- name: outputs/gemma-3-4b-it
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
[<img src="https://raw.githubusercontent.com/axolotl-ai-cloud/axolotl/main/image/axolotl-badge-web.png" alt="Built with Axolotl" width="200" height="32"/>](https://github.com/axolotl-ai-cloud/axolotl)
<details><summary>See axolotl config</summary>
axolotl version: `0.13.0.dev0`
```yaml
base_model: google/gemma-3-4b-it
# optionally might have model_type or tokenizer_type
model_type: AutoModelForCausalLM
tokenizer_type: AutoTokenizer
# Automatically upload checkpoint and final model to HF
# hub_model_id: username/custom_model_name
# gemma3 doesn't seem to play nice with ddp
ddp_find_unused_parameters: true
load_in_8bit: false
load_in_4bit: false
# huggingface repo
chat_template: gemma3
eot_tokens:
- <end_of_turn>
datasets:
- path: sam2ai/en-oriya-translation
type: chat_template
field_messages: conversations
message_property_mappings:
role: from
content: value
roles:
assistant:
- gpt
user:
- human
val_set_size: 0.1
output_dir: ./outputs/gemma-3-4b-it
#adapter: qlora
#lora_r: 32
#lora_alpha: 16
#lora_dropout: 0.05
#lora_target_linear: true
sequence_len: 2048
sample_packing: true
eval_sample_packing: false
wandb_project: gemma3-en-odia-mt
wandb_entity:
wandb_watch:
wandb_name: gemma3-4b-it
wandb_log_model:
gradient_accumulation_steps: 4
micro_batch_size: 1
num_epochs: 4
optimizer: adamw_bnb_8bit
lr_scheduler: cosine
learning_rate: 0.0002
bf16: auto
tf32: false
gradient_checkpointing: true
gradient_checkpointing_kwargs:
use_reentrant: false
resume_from_checkpoint:
logging_steps: 1
flash_attention: true
warmup_ratio: 0.1
evals_per_epoch:
saves_per_epoch: 1
weight_decay: 0.0
special_tokens:
# save_first_step: true # uncomment this to validate checkpoint saving works with your config
```
</details><br>
# outputs/gemma-3-4b-it
This model is a fine-tuned version of [google/gemma-3-4b-it](https://huggingface.co/google/gemma-3-4b-it) on the sam2ai/en-oriya-translation dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 1
- eval_batch_size: 1
- seed: 42
- distributed_type: multi-GPU
- num_devices: 8
- gradient_accumulation_steps: 4
- total_train_batch_size: 32
- total_eval_batch_size: 8
- optimizer: Use OptimizerNames.ADAMW_BNB with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 543
- training_steps: 5432
### Training results
### Framework versions
- Transformers 4.55.4
- Pytorch 2.7.0+gitf717b2a
- Datasets 4.0.0
- Tokenizers 0.21.1
|
5456es/bees_prune_Qwen2.5-1.5B-Instruct_prune_0.7-sigmoid
|
5456es
| 2025-09-12T08:15:20Z | 26 | 0 | null |
[
"safetensors",
"qwen2",
"dpo",
"preference-learning",
"bees",
"pruned",
"license:apache-2.0",
"region:us"
] | null | 2025-09-08T03:27:38Z |
---
license: apache-2.0
base_model: Qwen2.5-1.5B-Instruct
tags:
- dpo
- preference-learning
- bees
- pruned
---
# bees_prune_Qwen2.5-1.5B-Instruct_prune_0.7-sigmoid
This model is a DPO (Direct Preference Optimization) fine-tuned version of Qwen2.5-1.5B-Instruct using the bees method.
## Model Details
- **Base Model**: Qwen2.5-1.5B-Instruct
- **Training Method**: bees
- **Pruning Ratio**: unknown
- **Training Date**: 2025-09-12
## Training Configuration
This model was trained using Direct Preference Optimization (DPO) with the following characteristics:
- Method: bees
- Pruning applied during training
- Fine-tuned on preference data
## Usage
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
model_name = "5456es/bees_prune_Qwen2.5-1.5B-Instruct_prune_0.7-sigmoid"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
# Example usage
prompt = "Your prompt here"
inputs = tokenizer(prompt, return_tensors="pt")
outputs = model.generate(**inputs, max_length=100)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
```
## Training Data
This model was trained on preference data using the DPO algorithm.
## Limitations
This model inherits the limitations of its base model and may have additional limitations due to the pruning process.
## Citation
If you use this model, please cite the original DPO paper and the base model.
|
5456es/selective_dpo_Llama-3.2-1B-Instruct_prune_0.7-sigmoid
|
5456es
| 2025-09-12T08:14:54Z | 27 | 0 | null |
[
"safetensors",
"llama",
"dpo",
"preference-learning",
"selective",
"pruned",
"license:apache-2.0",
"region:us"
] | null | 2025-09-07T04:36:55Z |
---
license: apache-2.0
base_model: Llama-3.2-1B-Instruct
tags:
- dpo
- preference-learning
- selective
- pruned
---
# selective_dpo_Llama-3.2-1B-Instruct_prune_0.7-sigmoid
This model is a DPO (Direct Preference Optimization) fine-tuned version of Llama-3.2-1B-Instruct using the selective method.
## Model Details
- **Base Model**: Llama-3.2-1B-Instruct
- **Training Method**: selective
- **Pruning Ratio**: unknown
- **Training Date**: 2025-09-12
## Training Configuration
This model was trained using Direct Preference Optimization (DPO) with the following characteristics:
- Method: selective
- Pruning applied during training
- Fine-tuned on preference data
## Usage
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
model_name = "5456es/selective_dpo_Llama-3.2-1B-Instruct_prune_0.7-sigmoid"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
# Example usage
prompt = "Your prompt here"
inputs = tokenizer(prompt, return_tensors="pt")
outputs = model.generate(**inputs, max_length=100)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
```
## Training Data
This model was trained on preference data using the DPO algorithm.
## Limitations
This model inherits the limitations of its base model and may have additional limitations due to the pruning process.
## Citation
If you use this model, please cite the original DPO paper and the base model.
|
5456es/last_layer_prune_Llama-3.2-3B-Instruct_prune_0.8-sigmoid
|
5456es
| 2025-09-12T08:14:30Z | 0 | 0 | null |
[
"safetensors",
"llama",
"dpo",
"preference-learning",
"last",
"pruned",
"license:apache-2.0",
"region:us"
] | null | 2025-09-12T08:10:03Z |
---
license: apache-2.0
base_model: Llama-3.2-3B-Instruct
tags:
- dpo
- preference-learning
- last
- pruned
---
# last_layer_prune_Llama-3.2-3B-Instruct_prune_0.8-sigmoid
This model is a DPO (Direct Preference Optimization) fine-tuned version of Llama-3.2-3B-Instruct using the last method.
## Model Details
- **Base Model**: Llama-3.2-3B-Instruct
- **Training Method**: last
- **Pruning Ratio**: unknown
- **Training Date**: 2025-09-12
## Training Configuration
This model was trained using Direct Preference Optimization (DPO) with the following characteristics:
- Method: last
- Pruning applied during training
- Fine-tuned on preference data
## Usage
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
model_name = "5456es/last_layer_prune_Llama-3.2-3B-Instruct_prune_0.8-sigmoid"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
# Example usage
prompt = "Your prompt here"
inputs = tokenizer(prompt, return_tensors="pt")
outputs = model.generate(**inputs, max_length=100)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
```
## Training Data
This model was trained on preference data using the DPO algorithm.
## Limitations
This model inherits the limitations of its base model and may have additional limitations due to the pruning process.
## Citation
If you use this model, please cite the original DPO paper and the base model.
|
HA-Siala/Python-OCL-v0.1
|
HA-Siala
| 2025-09-12T08:14:02Z | 2 | 0 |
peft
|
[
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:mistralai/Mistral-7B-v0.3",
"base_model:adapter:mistralai/Mistral-7B-v0.3",
"region:us"
] | null | 2025-09-12T08:13:49Z |
---
library_name: peft
base_model: mistralai/Mistral-7B-v0.3
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.10.0
|
sidhantoon/Goldentouch_V3_G19
|
sidhantoon
| 2025-09-12T08:13:08Z | 0 | 0 | null |
[
"safetensors",
"any-to-any",
"omega",
"omegalabs",
"bittensor",
"agi",
"license:mit",
"region:us"
] |
any-to-any
| 2025-09-12T06:40:10Z |
---
license: mit
tags:
- any-to-any
- omega
- omegalabs
- bittensor
- agi
---
This is an Any-to-Any model checkpoint for the OMEGA Labs x Bittensor Any-to-Any subnet.
Check out the [git repo](https://github.com/omegalabsinc/omegalabs-anytoany-bittensor) and find OMEGA on X: [@omegalabsai](https://x.com/omegalabsai).
|
NCSOFT/VARCO-VISION-2.0-14B
|
NCSOFT
| 2025-09-12T08:12:58Z | 3,962 | 33 |
transformers
|
[
"transformers",
"safetensors",
"llava_onevision",
"image-to-text",
"multimodal",
"conversational",
"ncsoft",
"ncai",
"varco",
"image-text-to-text",
"en",
"ko",
"arxiv:2408.03326",
"base_model:Qwen/Qwen3-14B",
"base_model:finetune:Qwen/Qwen3-14B",
"license:cc-by-nc-4.0",
"endpoints_compatible",
"region:us"
] |
image-text-to-text
| 2025-07-08T06:24:37Z |
---
license: cc-by-nc-4.0
base_model:
- Qwen/Qwen3-14B
- google/siglip2-so400m-patch16-384
library_name: transformers
tags:
- multimodal
- conversational
- ncsoft
- ncai
- varco
pipeline_tag: image-text-to-text
language:
- en
- ko
---
# VARCO-VISION-2.0-14B
<div align="center">
<img src="./varco-vision.png" width="100%" style="background-color:white; padding:10px;" />
</div>
## Introduction
**VARCO-VISION-2.0** is a multimodal AI model capable of understanding both images and text to answer user queries. It supports multi-image inputs, enabling effective processing of complex content such as documents, tables, and charts. The model demonstrates strong comprehension in both Korean and English, with significantly improved text generation capabilities and a deeper understanding of Korean cultural context. Compared to its predecessor, performance has been notably enhanced across various benchmarks, and its usability in real-world scenarios—such as everyday Q&A and information summarization—has also improved.
In addition to the 14B full-scale model, a lightweight 1.7B version is available for on-device use, making it accessible on personal devices such as smartphones and PCs. VARCO-VISION-2.0 is a powerful open-weight AI model built for Korean users and is freely available for a wide range of applications.
## 🚨News🎙️
- 🛠️ 2025-08-22: We updated the checkpoint of VARCO-VISION-2.0-1.7B for improved performance.
- 📰 2025-07-28: We released VARCO-VISION-2.0-1.7B-OCR at [link](https://huggingface.co/NCSOFT/VARCO-VISION-2.0-1.7B-OCR)
- 📰 2025-07-28: We released VARCO-VISION-2.0-1.7B at [link](https://huggingface.co/NCSOFT/VARCO-VISION-2.0-1.7B)
- 🛠️ 2025-07-18: We updated the checkpoint of VARCO-VISION-2.0-14B for improved performance.
- 📰 2025-07-16: We released VARCO-VISION-2.0-14B at [link](https://huggingface.co/NCSOFT/VARCO-VISION-2.0-14B)
- 📰 2025-07-16: We released GME-VARCO-VISION-Embedding at [link](https://huggingface.co/NCSOFT/GME-VARCO-VISION-Embedding)
## Key Features
- **Multi-image Understanding**: Newly added support for multi-image inputs enables the model to analyze multiple images simultaneously and make more holistic and context-aware decisions.
- **Korean Language Specialization**: The model is further specialized for Korean, with a deeper understanding of Korean language, context, and culture. Korean text generation has been significantly improved, resulting in more natural, fluent, and accurate responses.
- **OCR with Text Localization**: Unlike typical models that only recognize and generate text from images, VARCO-VISION-2.0 can also identify the position of the text and provide bounding boxes around it. This makes it especially useful for document understanding, signage interpretation, and structured visual data.
- **Enhanced Safety**: The model now offers improved handling of harmful or sexually explicit content, ensuring safer and more reliable interactions.
<div align="center">
<img src="./figure.png" width="100%" />
</div>
## VARCO-VISION-2.0 Family
| Model Name | Base Models (Vision / Language) | HF Link |
| :------------------------: | :-------------------------------------------------------------------------------------------------------------------------------------------: | :--------------------------------------------------------------: |
| VARCO-VISION-2.0-14B | [siglip2-so400m-patch16-384](https://huggingface.co/google/siglip2-so400m-patch16-384) / [Qwen3-14B ](https://huggingface.co/Qwen/Qwen3-14B) | [link](https://huggingface.co/NCSOFT/VARCO-VISION-2.0-14B) |
| VARCO-VISION-2.0-1.7B | [siglip2-so400m-patch16-384](https://huggingface.co/google/siglip2-so400m-patch16-384) / [Qwen3-1.7B](https://huggingface.co/Qwen/Qwen3-1.7B) | [link](https://huggingface.co/NCSOFT/VARCO-VISION-2.0-1.7B) |
| VARCO-VISION-2.0-1.7B-OCR | [siglip2-so400m-patch16-384](https://huggingface.co/google/siglip2-so400m-patch16-384) / [Qwen3-1.7B](https://huggingface.co/Qwen/Qwen3-1.7B) | [link](https://huggingface.co/NCSOFT/VARCO-VISION-2.0-1.7B-OCR) |
| GME-VARCO-VISION-Embedding | [Qwen2-VL-7B-Instruct](https://huggingface.co/Qwen/Qwen2-VL-7B-Instruct) | [link](https://huggingface.co/NCSOFT/GME-VARCO-VISION-Embedding) |
## Model Architecture
VARCO-VISION-2.0 follows the architecture of [LLaVA-OneVision](https://arxiv.org/abs/2408.03326).
## Evaluation
We used [VLMEvalKit](https://github.com/open-compass/VLMEvalKit) for evaluation whenever possible, and conducted our own implementations only for benchmarks not supported by the toolkit, **ensuring fair comparisons** with various open-weight models.
Please note that for certain benchmarks involving LLM-based evaluation (e.g., LLaVABench), results may not be exactly reproducible due to variations in the underlying LLM behavior.
### Korean Benchmark
| Benchmark | InternVL3-14B | Ovis2-16B | Qwen2.5-VL-7B | A.X 4.0 VL Light | VARCO-VISION-2.0-14B |
| :-----------: | :-----------: | :-------: | :-----------: | :--------------: | :------------------: |
| K-MMBench_DEV | **89.1** | 86.0 | 84.7 | 83.9 | *87.7* |
| K-MMStar | **64.9** | 29.7 | 49.3 | 56.3 | *63.6* |
| K-SEED | **78.2** | 73.2 | 75.7 | *76.5* | 77.2 |
| K-LLaVA-W | 80.9 | 86.3 | *94.1* | 83.2 | **96.5** |
| K-DTCBench | *87.9* | 81.7 | 82.1 | **90.0** | 78.3 |
| ***AVERAGE*** | *80.2* | 71.4 | 77.2 | 78.0 | **80.7** |
### English Benchmark
| Benchmark | InternVL3-14B | Ovis2-16B | Qwen2.5-VL-7B | A.X 4.0 VL Light | VARCO-VISION-2.0-14B |
| :-------------: | :-----------: | :-------: | :-----------: | :--------------: | :------------------: |
| MMStar | **68.9** | *67.2* | 64.1 | 56.8 | 66.9 |
| MMMU_VAL | **64.8** | 60.7 | 58.0 | 54.1 | *61.9* |
| MathVista | **74.4** | *73.7* | 68.1 | 62.4 | 73.2 |
| OCRBench | 87.7 | *87.9* | **88.8** | 73.8 | 86.9 |
| AI2D | *86.0* | **86.3** | 84.3 | 81.0 | 85.7 |
| HallusionBench | *55.9* | **56.8** | 51.9 | 54.2 | 53.2 |
| MMVet | **80.5** | 68.4 | *69.7* | 59.4 | 68.9 |
| SEEDBench_IMG | 77.5 | *77.7* | 77.0 | 76.7 | **78.0** |
| LLaVABench | 84.4 | **93.0** | *91.0* | 83.2 | 90.2 |
| RealWorldQA | 69.8 | *74.1* | 68.4 | 63.4 | **74.6** |
| POPE | **89.4** | 87.5 | 85.9 | 87.5 | *89.2* |
| ScienceQA_TEST | **98.6** | 95.2 | 89.0 | *95.3* | 93.5 |
| SEEDBench2_Plus | 70.1 | **72.1** | 70.7 | 69.7 | *71.9* |
| BLINK | **59.9** | *59.0* | 55.3 | 46.1 | 54.5 |
| TextVQA_VAL | 82.2 | *83.0* | **85.4** | 82.0 | 80.4 |
| ChartQA_TEST | **87.8** | 79.1 | 80.6 | 79.8 | *84.2* |
| Q-Bench1_VAL | 76.5 | *79.2* | 78.2 | 72.5 | **79.9** |
| A-Bench_VAL | 76.3 | **79.6** | 75.4 | 74.6 | *79.5* |
| DocVQA_TEST | 94.1 | *94.9* | **95.7** | 94.4 | 90.9 |
| InfoVQA_TEST | **83.6** | *82.8* | 82.6 | 78.5 | 80.4 |
| ***AVERAGE*** | **78.4** | *77.9* | 76.0 | 72.3 | 77.2 |
### Cultural Benchmark
| Benchmark | InternVL3-14B | Ovis2-16B | Qwen2.5-VL-7B | A.X 4.0 VL Light | VARCO-VISION-2.0-14B |
| :--------------: | :-----------: | :-------: | :-----------: | :--------------: | :------------------: |
| K-Viscuit | 71.7 | **77.0** | 70.9 | *74.9* | 73.7 |
| PangeaBench (ko) | *77.2* | *76.9* | 76.6 | **80.3** | 74.5 |
| PangeaBench | 69.5 | **72.2** | *70.5* | 66.5 | 68.9 |
### Text-only Benchmark
| Benchmark | InternVL3-14B | Ovis2-16B | Qwen2.5-VL-7B | A.X 4.0 VL Light | VARCO-VISION-2.0-14B |
| :--------: | :-----------: | :-------: | :-----------: | :--------------: | :------------------: |
| MMLU | **78.5** | *78.4* | 4.6 | 72.6 | 77.9 |
| MT-Bench | *89.3* | 85.9 | 80.7 | 72.9 | **89.8** |
| KMMLU | 51.4 | 49.3 | 39.6 | **60.5** | *57.5* |
| KoMT-Bench | 70.1 | **79.1** | 68.4 | 68.9 | *78.3* |
| LogicKor | 70.0 | **79.4** | 65.5 | 50.6 | *74.0* |
> **Note:** Some models show unusually low performance on the MMLU benchmark. This is primarily due to their failure to correctly follow the expected output format when only few-shot exemplars are provided in the prompts. Please take this into consideration when interpreting the results.
### OCR Benchmark
| Benchmark | PaddleOCR | EasyOCR | VARCO-VISION-2.0-14B |
| :-------: | :-------: | :-----: | :------------------: |
| CORD | *91.4* | 77.8 | **97.1** |
| ICDAR2013 | *92.0* | 85.0 | **95.7** |
| ICDAR2015 | *73.7* | 57.9 | **79.4** |
## Usage
To use this model, we recommend installing `transformers` version **4.53.1 or higher**. While it may work with earlier versions, using **4.53.1 or above is strongly recommended**, especially to ensure optimal performance for the **multi-image feature**.
The basic usage is **identical to** [LLaVA-OneVision](https://huggingface.co/docs/transformers/main/en/model_doc/llava_onevision#usage-example):
```python
import torch
from transformers import AutoProcessor, LlavaOnevisionForConditionalGeneration
model_name = "NCSOFT/VARCO-VISION-2.0-14B"
model = LlavaOnevisionForConditionalGeneration.from_pretrained(
model_name,
torch_dtype=torch.float16,
attn_implementation="sdpa",
device_map="auto",
)
processor = AutoProcessor.from_pretrained(model_name)
conversation = [
{
"role": "user",
"content": [
{"type": "image", "url": "https://huggingface.co/NCSOFT/VARCO-VISION-2.0-14B/resolve/main/demo.jpg"},
{"type": "text", "text": "각 박스마다 한 줄씩 색상과 글자를 정확하게 출력해주세요."},
],
},
]
inputs = processor.apply_chat_template(
conversation,
add_generation_prompt=True,
tokenize=True,
return_dict=True,
return_tensors="pt"
).to(model.device, torch.float16)
generate_ids = model.generate(**inputs, max_new_tokens=1024)
generate_ids_trimmed = [
out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generate_ids)
]
output = processor.decode(generate_ids_trimmed[0], skip_special_tokens=True)
print(output)
```
<details>
<summary>Multi image inference</summary>
```python
conversation = [
{
"role": "user",
"content": [
{"type": "image", "image": "file:///path/to/image1.jpg"},
{"type": "image", "image": "file:///path/to/image2.jpg"},
{"type": "text", "text": "이미지 간의 유사점을 파악하세요."},
],
},
]
inputs = processor.apply_chat_template(
conversation,
add_generation_prompt=True,
tokenize=True,
return_dict=True,
return_tensors="pt"
).to(model.device, torch.float16)
generate_ids = model.generate(**inputs, max_new_tokens=1024)
generate_ids_trimmed = [
out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generate_ids)
]
output = processor.decode(generate_ids_trimmed[0], skip_special_tokens=True)
print(output)
```
</details>
<details>
<summary>Batch inference</summary>
All inputs in a batch must have the same modality structure—for example, text-only with text-only, single-image with single-image, and multi-image with multi-image—to ensure correct batch inference.
```python
conversation_1 = [
{
"role": "user",
"content": [
{"type": "image", "image": "file:///path/to/image1.jpg"},
{"type": "text", "text": "이미지를 설명해주세요."},
],
},
]
conversation_2 = [
{
"role": "user",
"content": [
{"type": "image", "image": "file:///path/to/image2.jpg"},
{"type": "text", "text": "이 이미지에 표시된 것은 무엇인가요?"},
],
},
]
inputs = processor.apply_chat_template(
[conversation_1, conversation_2],
add_generation_prompt=True,
tokenize=True,
return_dict=True,
padding=True,
return_tensors="pt"
).to(model.device, torch.float16)
generate_ids = model.generate(**inputs, max_new_tokens=1024)
generate_ids_trimmed = [
out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generate_ids)
]
output = processor.batch_decode(generate_ids_trimmed, skip_special_tokens=True)
print(output)
```
</details>
<details>
<summary>OCR inference</summary>
```python
from PIL import Image
image = Image.open("file:///path/to/image.jpg")
# Image upscaling for OCR performance boost
w, h = image.size
target_size = 2304
if max(w, h) < target_size:
scaling_factor = target_size / max(w, h)
new_w = int(w * scaling_factor)
new_h = int(h * scaling_factor)
image = image.resize((new_w, new_h))
conversation = [
{
"role": "user",
"content": [
{"type": "image", "image": image},
{"type": "text", "text": "<ocr>"},
],
},
]
inputs = processor.apply_chat_template(
conversation,
add_generation_prompt=True,
tokenize=True,
return_dict=True,
return_tensors="pt"
).to(model.device, torch.float16)
generate_ids = model.generate(**inputs, max_new_tokens=1024)
generate_ids_trimmed = [
out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generate_ids)
]
output = processor.decode(generate_ids_trimmed[0], skip_special_tokens=False)
print(output)
```
</details>
|
ds4sd/granite-docling-258m-demo
|
ds4sd
| 2025-09-12T08:10:25Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-09-12T07:51:31Z |
---
title: Granite Docling 258m Demo
emoji: 🐢
colorFrom: red
colorTo: green
sdk: gradio
sdk_version: 5.45.0
app_file: app.py
pinned: false
---
Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
|
5456es/bees_prune_Llama-3.2-3B-Instruct_prune_0.7-sigmoid
|
5456es
| 2025-09-12T08:10:02Z | 34 | 0 | null |
[
"safetensors",
"llama",
"dpo",
"preference-learning",
"bees",
"pruned",
"license:apache-2.0",
"region:us"
] | null | 2025-09-08T03:47:19Z |
---
license: apache-2.0
base_model: Llama-3.2-3B-Instruct
tags:
- dpo
- preference-learning
- bees
- pruned
---
# bees_prune_Llama-3.2-3B-Instruct_prune_0.7-sigmoid
This model is a DPO (Direct Preference Optimization) fine-tuned version of Llama-3.2-3B-Instruct using the bees method.
## Model Details
- **Base Model**: Llama-3.2-3B-Instruct
- **Training Method**: bees
- **Pruning Ratio**: unknown
- **Training Date**: 2025-09-12
## Training Configuration
This model was trained using Direct Preference Optimization (DPO) with the following characteristics:
- Method: bees
- Pruning applied during training
- Fine-tuned on preference data
## Usage
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
model_name = "5456es/bees_prune_Llama-3.2-3B-Instruct_prune_0.7-sigmoid"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
# Example usage
prompt = "Your prompt here"
inputs = tokenizer(prompt, return_tensors="pt")
outputs = model.generate(**inputs, max_length=100)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
```
## Training Data
This model was trained on preference data using the DPO algorithm.
## Limitations
This model inherits the limitations of its base model and may have additional limitations due to the pruning process.
## Citation
If you use this model, please cite the original DPO paper and the base model.
|
stonermay/blockassist-bc-diving_lightfooted_caterpillar_1757664509
|
stonermay
| 2025-09-12T08:09:59Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"diving lightfooted caterpillar",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-12T08:09:36Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- diving lightfooted caterpillar
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
NisalDeZoysa/qwen3-4b-sl-marriage-law-full
|
NisalDeZoysa
| 2025-09-12T08:09:50Z | 0 | 0 |
transformers
|
[
"transformers",
"gguf",
"qwen3",
"text-generation-inference",
"unsloth",
"en",
"dataset:beimnet777/Marriage-Law-of-Sri-Lanka-QA",
"base_model:unsloth/Qwen3-4B-unsloth-bnb-4bit",
"base_model:quantized:unsloth/Qwen3-4B-unsloth-bnb-4bit",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2025-09-12T07:30:51Z |
---
base_model: unsloth/Qwen3-4B-unsloth-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- qwen3
- gguf
license: apache-2.0
language:
- en
datasets:
- beimnet777/Marriage-Law-of-Sri-Lanka-QA
---
# Uploaded model
Qwen3-4B Sinhala Marriage Law Fine-Tuned Model
Developed by: Nisal De Zoysa
License: Apache-2.0
Based on: unsloth/Qwen3-4B-unsloth-bnb-4bit
This is a fine-tuned Qwen3 model trained specifically on Sri Lankan law text, including marriage and related legislation. The model supports text generation tasks and has been optimized for efficiency with Unsloth’s fast training utilities.
Highlights:
Fine-tuned on legal domain text for improved accuracy in Sinhala law queries.
Trained with Unsloth
for 2× faster training and memory-efficient 4-bit quantization.
Compatible with GGUF format for local inference or deployment in frameworks like Ollama.
Intended Use:
Generating legal guidance and summaries in Sinhala based on the trained domain corpus.
Educational and research purposes in law-focused NLP applications.
|
aszymanska/bk-sdm-tiny-vpred
|
aszymanska
| 2025-09-12T08:09:45Z | 0 | 0 | null |
[
"text-to-image",
"base_model:vivym/bk-sdm-tiny-vpred",
"base_model:finetune:vivym/bk-sdm-tiny-vpred",
"license:creativeml-openrail-m",
"region:us"
] |
text-to-image
| 2025-08-18T08:32:59Z |
---
license: creativeml-openrail-m
base_model:
- vivym/bk-sdm-tiny-vpred
pipeline_tag: text-to-image
pipeline: Stable Diffusion Pipeline
---
# Model Card for bk-sdm-tiny-vpred (Executorch Export)
This model is an Executorch exported version of the [BK-SDM-Tiny v-prediction variant](https://huggingface.co/vivym/bk-sdm-tiny-vpred).
The model is converted into `.pte` format for deployment on mobile devices.
## Model Details
### Model Description
- **Model type:** text-to-image
- **Language:** English (trained with English captions)
- **License:** CreativeML OpenRAIL-M (see [license](https://huggingface.co/spaces/CompVis/stable-diffusion-license))
### Original Model Sources
- **Github:** [BK-SDM](https://github.com/Nota-NetsPresso/BK-SDM)
|
5456es/last_layer_prune_Llama-3.1-8B-Instruct_prune_0.2-sigmoid
|
5456es
| 2025-09-12T08:09:25Z | 0 | 0 | null |
[
"safetensors",
"llama",
"dpo",
"preference-learning",
"last",
"pruned",
"license:apache-2.0",
"region:us"
] | null | 2025-09-12T07:58:37Z |
---
license: apache-2.0
base_model: Llama-3.1-8B-Instruct
tags:
- dpo
- preference-learning
- last
- pruned
---
# last_layer_prune_Llama-3.1-8B-Instruct_prune_0.2-sigmoid
This model is a DPO (Direct Preference Optimization) fine-tuned version of Llama-3.1-8B-Instruct using the last method.
## Model Details
- **Base Model**: Llama-3.1-8B-Instruct
- **Training Method**: last
- **Pruning Ratio**: unknown
- **Training Date**: 2025-09-12
## Training Configuration
This model was trained using Direct Preference Optimization (DPO) with the following characteristics:
- Method: last
- Pruning applied during training
- Fine-tuned on preference data
## Usage
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
model_name = "5456es/last_layer_prune_Llama-3.1-8B-Instruct_prune_0.2-sigmoid"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
# Example usage
prompt = "Your prompt here"
inputs = tokenizer(prompt, return_tensors="pt")
outputs = model.generate(**inputs, max_length=100)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
```
## Training Data
This model was trained on preference data using the DPO algorithm.
## Limitations
This model inherits the limitations of its base model and may have additional limitations due to the pruning process.
## Citation
If you use this model, please cite the original DPO paper and the base model.
|
mradermacher/vntl-gemma2-27b-hf-GGUF
|
mradermacher
| 2025-09-12T08:09:24Z | 3,743 | 0 |
transformers
|
[
"transformers",
"gguf",
"ja",
"en",
"dataset:lmg-anon/VNTL-v3.1-1k",
"dataset:lmg-anon/VNTL-Chat",
"base_model:lmg-anon/vntl-gemma2-27b-hf",
"base_model:quantized:lmg-anon/vntl-gemma2-27b-hf",
"license:gemma",
"endpoints_compatible",
"region:us"
] | null | 2025-09-11T15:37:38Z |
---
base_model: lmg-anon/vntl-gemma2-27b-hf
datasets:
- lmg-anon/VNTL-v3.1-1k
- lmg-anon/VNTL-Chat
language:
- ja
- en
library_name: transformers
license: gemma
mradermacher:
readme_rev: 1
quantized_by: mradermacher
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
<!-- ### quants: x-f16 Q4_K_S Q2_K Q8_0 Q6_K Q3_K_M Q3_K_S Q3_K_L Q4_K_M Q5_K_S Q5_K_M IQ4_XS -->
<!-- ### quants_skip: -->
<!-- ### skip_mmproj: -->
static quants of https://huggingface.co/lmg-anon/vntl-gemma2-27b-hf
<!-- provided-files -->
***For a convenient overview and download list, visit our [model page for this model](https://hf.tst.eu/model#vntl-gemma2-27b-hf-GGUF).***
weighted/imatrix quants are available at https://huggingface.co/mradermacher/vntl-gemma2-27b-hf-i1-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/vntl-gemma2-27b-hf-GGUF/resolve/main/vntl-gemma2-27b-hf.Q2_K.gguf) | Q2_K | 10.5 | |
| [GGUF](https://huggingface.co/mradermacher/vntl-gemma2-27b-hf-GGUF/resolve/main/vntl-gemma2-27b-hf.Q3_K_S.gguf) | Q3_K_S | 12.3 | |
| [GGUF](https://huggingface.co/mradermacher/vntl-gemma2-27b-hf-GGUF/resolve/main/vntl-gemma2-27b-hf.Q3_K_M.gguf) | Q3_K_M | 13.5 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/vntl-gemma2-27b-hf-GGUF/resolve/main/vntl-gemma2-27b-hf.Q3_K_L.gguf) | Q3_K_L | 14.6 | |
| [GGUF](https://huggingface.co/mradermacher/vntl-gemma2-27b-hf-GGUF/resolve/main/vntl-gemma2-27b-hf.IQ4_XS.gguf) | IQ4_XS | 15.0 | |
| [GGUF](https://huggingface.co/mradermacher/vntl-gemma2-27b-hf-GGUF/resolve/main/vntl-gemma2-27b-hf.Q4_K_S.gguf) | Q4_K_S | 15.8 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/vntl-gemma2-27b-hf-GGUF/resolve/main/vntl-gemma2-27b-hf.Q4_K_M.gguf) | Q4_K_M | 16.7 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/vntl-gemma2-27b-hf-GGUF/resolve/main/vntl-gemma2-27b-hf.Q5_K_S.gguf) | Q5_K_S | 19.0 | |
| [GGUF](https://huggingface.co/mradermacher/vntl-gemma2-27b-hf-GGUF/resolve/main/vntl-gemma2-27b-hf.Q5_K_M.gguf) | Q5_K_M | 19.5 | |
| [GGUF](https://huggingface.co/mradermacher/vntl-gemma2-27b-hf-GGUF/resolve/main/vntl-gemma2-27b-hf.Q6_K.gguf) | Q6_K | 22.4 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/vntl-gemma2-27b-hf-GGUF/resolve/main/vntl-gemma2-27b-hf.Q8_0.gguf) | Q8_0 | 29.0 | fast, best quality |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
mradermacher/CodeV-All-DSC-GGUF
|
mradermacher
| 2025-09-12T08:09:23Z | 378 | 0 |
transformers
|
[
"transformers",
"gguf",
"code",
"en",
"base_model:yang-z/CodeV-All-DSC",
"base_model:quantized:yang-z/CodeV-All-DSC",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2025-09-11T14:07:20Z |
---
arxiv: 2407.10424
base_model: yang-z/CodeV-All-DSC
language:
- en
library_name: transformers
license: apache-2.0
mradermacher:
readme_rev: 1
quantized_by: mradermacher
tags:
- code
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
<!-- ### quants: x-f16 Q4_K_S Q2_K Q8_0 Q6_K Q3_K_M Q3_K_S Q3_K_L Q4_K_M Q5_K_S Q5_K_M IQ4_XS -->
<!-- ### quants_skip: -->
<!-- ### skip_mmproj: -->
static quants of https://huggingface.co/yang-z/CodeV-All-DSC
<!-- provided-files -->
***For a convenient overview and download list, visit our [model page for this model](https://hf.tst.eu/model#CodeV-All-DSC-GGUF).***
weighted/imatrix quants are available at https://huggingface.co/mradermacher/CodeV-All-DSC-i1-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/CodeV-All-DSC-GGUF/resolve/main/CodeV-All-DSC.Q2_K.gguf) | Q2_K | 2.6 | |
| [GGUF](https://huggingface.co/mradermacher/CodeV-All-DSC-GGUF/resolve/main/CodeV-All-DSC.Q3_K_S.gguf) | Q3_K_S | 3.1 | |
| [GGUF](https://huggingface.co/mradermacher/CodeV-All-DSC-GGUF/resolve/main/CodeV-All-DSC.Q3_K_M.gguf) | Q3_K_M | 3.4 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/CodeV-All-DSC-GGUF/resolve/main/CodeV-All-DSC.Q3_K_L.gguf) | Q3_K_L | 3.7 | |
| [GGUF](https://huggingface.co/mradermacher/CodeV-All-DSC-GGUF/resolve/main/CodeV-All-DSC.IQ4_XS.gguf) | IQ4_XS | 3.7 | |
| [GGUF](https://huggingface.co/mradermacher/CodeV-All-DSC-GGUF/resolve/main/CodeV-All-DSC.Q4_K_S.gguf) | Q4_K_S | 4.0 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/CodeV-All-DSC-GGUF/resolve/main/CodeV-All-DSC.Q4_K_M.gguf) | Q4_K_M | 4.2 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/CodeV-All-DSC-GGUF/resolve/main/CodeV-All-DSC.Q5_K_S.gguf) | Q5_K_S | 4.8 | |
| [GGUF](https://huggingface.co/mradermacher/CodeV-All-DSC-GGUF/resolve/main/CodeV-All-DSC.Q5_K_M.gguf) | Q5_K_M | 4.9 | |
| [GGUF](https://huggingface.co/mradermacher/CodeV-All-DSC-GGUF/resolve/main/CodeV-All-DSC.Q6_K.gguf) | Q6_K | 5.6 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/CodeV-All-DSC-GGUF/resolve/main/CodeV-All-DSC.Q8_0.gguf) | Q8_0 | 7.3 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/CodeV-All-DSC-GGUF/resolve/main/CodeV-All-DSC.f16.gguf) | f16 | 13.6 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
mradermacher/Lastman_12B_V.2-GGUF
|
mradermacher
| 2025-09-12T08:09:22Z | 0 | 0 |
transformers
|
[
"transformers",
"gguf",
"mergekit",
"merge",
"roleplay",
"creative",
"ru",
"en",
"base_model:OddTheGreat/Lastman_12B_V.2",
"base_model:quantized:OddTheGreat/Lastman_12B_V.2",
"endpoints_compatible",
"region:us"
] | null | 2025-09-12T06:29:50Z |
---
base_model: OddTheGreat/Lastman_12B_V.2
language:
- ru
- en
library_name: transformers
mradermacher:
readme_rev: 1
quantized_by: mradermacher
tags:
- mergekit
- merge
- roleplay
- creative
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
<!-- ### quants: x-f16 Q4_K_S Q2_K Q8_0 Q6_K Q3_K_M Q3_K_S Q3_K_L Q4_K_M Q5_K_S Q5_K_M IQ4_XS -->
<!-- ### quants_skip: -->
<!-- ### skip_mmproj: -->
static quants of https://huggingface.co/OddTheGreat/Lastman_12B_V.2
<!-- provided-files -->
***For a convenient overview and download list, visit our [model page for this model](https://hf.tst.eu/model#Lastman_12B_V.2-GGUF).***
weighted/imatrix quants are available at https://huggingface.co/mradermacher/Lastman_12B_V.2-i1-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/Lastman_12B_V.2-GGUF/resolve/main/Lastman_12B_V.2.Q2_K.gguf) | Q2_K | 4.9 | |
| [GGUF](https://huggingface.co/mradermacher/Lastman_12B_V.2-GGUF/resolve/main/Lastman_12B_V.2.Q3_K_S.gguf) | Q3_K_S | 5.6 | |
| [GGUF](https://huggingface.co/mradermacher/Lastman_12B_V.2-GGUF/resolve/main/Lastman_12B_V.2.Q3_K_M.gguf) | Q3_K_M | 6.2 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/Lastman_12B_V.2-GGUF/resolve/main/Lastman_12B_V.2.Q3_K_L.gguf) | Q3_K_L | 6.7 | |
| [GGUF](https://huggingface.co/mradermacher/Lastman_12B_V.2-GGUF/resolve/main/Lastman_12B_V.2.IQ4_XS.gguf) | IQ4_XS | 6.9 | |
| [GGUF](https://huggingface.co/mradermacher/Lastman_12B_V.2-GGUF/resolve/main/Lastman_12B_V.2.Q4_K_S.gguf) | Q4_K_S | 7.2 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Lastman_12B_V.2-GGUF/resolve/main/Lastman_12B_V.2.Q4_K_M.gguf) | Q4_K_M | 7.6 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Lastman_12B_V.2-GGUF/resolve/main/Lastman_12B_V.2.Q5_K_S.gguf) | Q5_K_S | 8.6 | |
| [GGUF](https://huggingface.co/mradermacher/Lastman_12B_V.2-GGUF/resolve/main/Lastman_12B_V.2.Q5_K_M.gguf) | Q5_K_M | 8.8 | |
| [GGUF](https://huggingface.co/mradermacher/Lastman_12B_V.2-GGUF/resolve/main/Lastman_12B_V.2.Q6_K.gguf) | Q6_K | 10.2 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/Lastman_12B_V.2-GGUF/resolve/main/Lastman_12B_V.2.Q8_0.gguf) | Q8_0 | 13.1 | fast, best quality |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
mradermacher/vntl-gemma2-27b-hf-i1-GGUF
|
mradermacher
| 2025-09-12T08:09:21Z | 6,179 | 0 |
transformers
|
[
"transformers",
"gguf",
"ja",
"en",
"dataset:lmg-anon/VNTL-v3.1-1k",
"dataset:lmg-anon/VNTL-Chat",
"base_model:lmg-anon/vntl-gemma2-27b-hf",
"base_model:quantized:lmg-anon/vntl-gemma2-27b-hf",
"license:gemma",
"endpoints_compatible",
"region:us",
"imatrix"
] | null | 2025-09-12T00:28:42Z |
---
base_model: lmg-anon/vntl-gemma2-27b-hf
datasets:
- lmg-anon/VNTL-v3.1-1k
- lmg-anon/VNTL-Chat
language:
- ja
- en
library_name: transformers
license: gemma
mradermacher:
readme_rev: 1
quantized_by: mradermacher
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: nicoboss -->
<!-- ### quants: Q2_K IQ3_M Q4_K_S IQ3_XXS Q3_K_M small-IQ4_NL Q4_K_M IQ2_M Q6_K IQ4_XS Q2_K_S IQ1_M Q3_K_S IQ2_XXS Q3_K_L IQ2_XS Q5_K_S IQ2_S IQ1_S Q5_K_M Q4_0 IQ3_XS Q4_1 IQ3_S -->
<!-- ### quants_skip: -->
<!-- ### skip_mmproj: -->
weighted/imatrix quants of https://huggingface.co/lmg-anon/vntl-gemma2-27b-hf
<!-- provided-files -->
***For a convenient overview and download list, visit our [model page for this model](https://hf.tst.eu/model#vntl-gemma2-27b-hf-i1-GGUF).***
static quants are available at https://huggingface.co/mradermacher/vntl-gemma2-27b-hf-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/vntl-gemma2-27b-hf-i1-GGUF/resolve/main/vntl-gemma2-27b-hf.imatrix.gguf) | imatrix | 0.1 | imatrix file (for creating your own qwuants) |
| [GGUF](https://huggingface.co/mradermacher/vntl-gemma2-27b-hf-i1-GGUF/resolve/main/vntl-gemma2-27b-hf.i1-IQ1_S.gguf) | i1-IQ1_S | 6.2 | for the desperate |
| [GGUF](https://huggingface.co/mradermacher/vntl-gemma2-27b-hf-i1-GGUF/resolve/main/vntl-gemma2-27b-hf.i1-IQ1_M.gguf) | i1-IQ1_M | 6.8 | mostly desperate |
| [GGUF](https://huggingface.co/mradermacher/vntl-gemma2-27b-hf-i1-GGUF/resolve/main/vntl-gemma2-27b-hf.i1-IQ2_XXS.gguf) | i1-IQ2_XXS | 7.7 | |
| [GGUF](https://huggingface.co/mradermacher/vntl-gemma2-27b-hf-i1-GGUF/resolve/main/vntl-gemma2-27b-hf.i1-IQ2_XS.gguf) | i1-IQ2_XS | 8.5 | |
| [GGUF](https://huggingface.co/mradermacher/vntl-gemma2-27b-hf-i1-GGUF/resolve/main/vntl-gemma2-27b-hf.i1-IQ2_S.gguf) | i1-IQ2_S | 8.8 | |
| [GGUF](https://huggingface.co/mradermacher/vntl-gemma2-27b-hf-i1-GGUF/resolve/main/vntl-gemma2-27b-hf.i1-IQ2_M.gguf) | i1-IQ2_M | 9.5 | |
| [GGUF](https://huggingface.co/mradermacher/vntl-gemma2-27b-hf-i1-GGUF/resolve/main/vntl-gemma2-27b-hf.i1-Q2_K_S.gguf) | i1-Q2_K_S | 9.8 | very low quality |
| [GGUF](https://huggingface.co/mradermacher/vntl-gemma2-27b-hf-i1-GGUF/resolve/main/vntl-gemma2-27b-hf.i1-Q2_K.gguf) | i1-Q2_K | 10.5 | IQ3_XXS probably better |
| [GGUF](https://huggingface.co/mradermacher/vntl-gemma2-27b-hf-i1-GGUF/resolve/main/vntl-gemma2-27b-hf.i1-IQ3_XXS.gguf) | i1-IQ3_XXS | 10.9 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/vntl-gemma2-27b-hf-i1-GGUF/resolve/main/vntl-gemma2-27b-hf.i1-IQ3_XS.gguf) | i1-IQ3_XS | 11.7 | |
| [GGUF](https://huggingface.co/mradermacher/vntl-gemma2-27b-hf-i1-GGUF/resolve/main/vntl-gemma2-27b-hf.i1-IQ3_S.gguf) | i1-IQ3_S | 12.3 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/vntl-gemma2-27b-hf-i1-GGUF/resolve/main/vntl-gemma2-27b-hf.i1-Q3_K_S.gguf) | i1-Q3_K_S | 12.3 | IQ3_XS probably better |
| [GGUF](https://huggingface.co/mradermacher/vntl-gemma2-27b-hf-i1-GGUF/resolve/main/vntl-gemma2-27b-hf.i1-IQ3_M.gguf) | i1-IQ3_M | 12.6 | |
| [GGUF](https://huggingface.co/mradermacher/vntl-gemma2-27b-hf-i1-GGUF/resolve/main/vntl-gemma2-27b-hf.i1-Q3_K_M.gguf) | i1-Q3_K_M | 13.5 | IQ3_S probably better |
| [GGUF](https://huggingface.co/mradermacher/vntl-gemma2-27b-hf-i1-GGUF/resolve/main/vntl-gemma2-27b-hf.i1-Q3_K_L.gguf) | i1-Q3_K_L | 14.6 | IQ3_M probably better |
| [GGUF](https://huggingface.co/mradermacher/vntl-gemma2-27b-hf-i1-GGUF/resolve/main/vntl-gemma2-27b-hf.i1-IQ4_XS.gguf) | i1-IQ4_XS | 14.9 | |
| [GGUF](https://huggingface.co/mradermacher/vntl-gemma2-27b-hf-i1-GGUF/resolve/main/vntl-gemma2-27b-hf.i1-Q4_0.gguf) | i1-Q4_0 | 15.8 | fast, low quality |
| [GGUF](https://huggingface.co/mradermacher/vntl-gemma2-27b-hf-i1-GGUF/resolve/main/vntl-gemma2-27b-hf.i1-Q4_K_S.gguf) | i1-Q4_K_S | 15.8 | optimal size/speed/quality |
| [GGUF](https://huggingface.co/mradermacher/vntl-gemma2-27b-hf-i1-GGUF/resolve/main/vntl-gemma2-27b-hf.i1-Q4_K_M.gguf) | i1-Q4_K_M | 16.7 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/vntl-gemma2-27b-hf-i1-GGUF/resolve/main/vntl-gemma2-27b-hf.i1-Q4_1.gguf) | i1-Q4_1 | 17.4 | |
| [GGUF](https://huggingface.co/mradermacher/vntl-gemma2-27b-hf-i1-GGUF/resolve/main/vntl-gemma2-27b-hf.i1-Q5_K_S.gguf) | i1-Q5_K_S | 19.0 | |
| [GGUF](https://huggingface.co/mradermacher/vntl-gemma2-27b-hf-i1-GGUF/resolve/main/vntl-gemma2-27b-hf.i1-Q5_K_M.gguf) | i1-Q5_K_M | 19.5 | |
| [GGUF](https://huggingface.co/mradermacher/vntl-gemma2-27b-hf-i1-GGUF/resolve/main/vntl-gemma2-27b-hf.i1-Q6_K.gguf) | i1-Q6_K | 22.4 | practically like static Q6_K |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time. Additional thanks to [@nicoboss](https://huggingface.co/nicoboss) for giving me access to his private supercomputer, enabling me to provide many more imatrix quants, at much higher quality, than I would otherwise be able to.
<!-- end -->
|
mradermacher/ML2-123B-Magnum-Diamond2-GGUF
|
mradermacher
| 2025-09-12T08:09:21Z | 0 | 0 |
transformers
|
[
"transformers",
"gguf",
"axolotl",
"chat",
"en",
"base_model:tachyphylaxis/ML2-123B-Magnum-Diamond2",
"base_model:quantized:tachyphylaxis/ML2-123B-Magnum-Diamond2",
"license:other",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2025-09-12T02:36:51Z |
---
base_model: tachyphylaxis/ML2-123B-Magnum-Diamond2
language:
- en
library_name: transformers
license: other
license_link: https://mistral.ai/licenses/MRL-0.1.md
license_name: mrl
mradermacher:
readme_rev: 1
quantized_by: mradermacher
tags:
- axolotl
- chat
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
<!-- ### quants: x-f16 Q4_K_S Q2_K Q8_0 Q6_K Q3_K_M Q3_K_S Q3_K_L Q4_K_M Q5_K_S Q5_K_M IQ4_XS -->
<!-- ### quants_skip: -->
<!-- ### skip_mmproj: -->
static quants of https://huggingface.co/tachyphylaxis/ML2-123B-Magnum-Diamond2
<!-- provided-files -->
***For a convenient overview and download list, visit our [model page for this model](https://hf.tst.eu/model#ML2-123B-Magnum-Diamond2-GGUF).***
weighted/imatrix quants seem not to be available (by me) at this time. If they do not show up a week or so after the static ones, I have probably not planned for them. Feel free to request them by opening a Community Discussion.
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/ML2-123B-Magnum-Diamond2-GGUF/resolve/main/ML2-123B-Magnum-Diamond2.Q2_K.gguf) | Q2_K | 45.3 | |
| [PART 1](https://huggingface.co/mradermacher/ML2-123B-Magnum-Diamond2-GGUF/resolve/main/ML2-123B-Magnum-Diamond2.Q4_K_S.gguf.part1of2) [PART 2](https://huggingface.co/mradermacher/ML2-123B-Magnum-Diamond2-GGUF/resolve/main/ML2-123B-Magnum-Diamond2.Q4_K_S.gguf.part2of2) | Q4_K_S | 69.7 | fast, recommended |
| [PART 1](https://huggingface.co/mradermacher/ML2-123B-Magnum-Diamond2-GGUF/resolve/main/ML2-123B-Magnum-Diamond2.Q6_K.gguf.part1of3) [PART 2](https://huggingface.co/mradermacher/ML2-123B-Magnum-Diamond2-GGUF/resolve/main/ML2-123B-Magnum-Diamond2.Q6_K.gguf.part2of3) [PART 3](https://huggingface.co/mradermacher/ML2-123B-Magnum-Diamond2-GGUF/resolve/main/ML2-123B-Magnum-Diamond2.Q6_K.gguf.part3of3) | Q6_K | 100.7 | very good quality |
| [PART 1](https://huggingface.co/mradermacher/ML2-123B-Magnum-Diamond2-GGUF/resolve/main/ML2-123B-Magnum-Diamond2.Q8_0.gguf.part1of3) [PART 2](https://huggingface.co/mradermacher/ML2-123B-Magnum-Diamond2-GGUF/resolve/main/ML2-123B-Magnum-Diamond2.Q8_0.gguf.part2of3) [PART 3](https://huggingface.co/mradermacher/ML2-123B-Magnum-Diamond2-GGUF/resolve/main/ML2-123B-Magnum-Diamond2.Q8_0.gguf.part3of3) | Q8_0 | 130.4 | fast, best quality |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
mradermacher/CodeV-All-DSC-i1-GGUF
|
mradermacher
| 2025-09-12T08:09:21Z | 0 | 0 |
transformers
|
[
"transformers",
"gguf",
"code",
"en",
"base_model:yang-z/CodeV-All-DSC",
"base_model:quantized:yang-z/CodeV-All-DSC",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | null | 2025-09-12T06:44:02Z |
---
arxiv: 2407.10424
base_model: yang-z/CodeV-All-DSC
language:
- en
library_name: transformers
license: apache-2.0
mradermacher:
readme_rev: 1
quantized_by: mradermacher
tags:
- code
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: nicoboss -->
<!-- ### quants: Q2_K IQ3_M Q4_K_S IQ3_XXS Q3_K_M small-IQ4_NL Q4_K_M IQ2_M Q6_K IQ4_XS Q2_K_S IQ1_M Q3_K_S IQ2_XXS Q3_K_L IQ2_XS Q5_K_S IQ2_S IQ1_S Q5_K_M Q4_0 IQ3_XS Q4_1 IQ3_S -->
<!-- ### quants_skip: -->
<!-- ### skip_mmproj: -->
weighted/imatrix quants of https://huggingface.co/yang-z/CodeV-All-DSC
<!-- provided-files -->
***For a convenient overview and download list, visit our [model page for this model](https://hf.tst.eu/model#CodeV-All-DSC-i1-GGUF).***
static quants are available at https://huggingface.co/mradermacher/CodeV-All-DSC-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/CodeV-All-DSC-i1-GGUF/resolve/main/CodeV-All-DSC.imatrix.gguf) | imatrix | 0.1 | imatrix file (for creating your own qwuants) |
| [GGUF](https://huggingface.co/mradermacher/CodeV-All-DSC-i1-GGUF/resolve/main/CodeV-All-DSC.i1-IQ1_S.gguf) | i1-IQ1_S | 1.6 | for the desperate |
| [GGUF](https://huggingface.co/mradermacher/CodeV-All-DSC-i1-GGUF/resolve/main/CodeV-All-DSC.i1-IQ1_M.gguf) | i1-IQ1_M | 1.8 | mostly desperate |
| [GGUF](https://huggingface.co/mradermacher/CodeV-All-DSC-i1-GGUF/resolve/main/CodeV-All-DSC.i1-IQ2_XXS.gguf) | i1-IQ2_XXS | 2.0 | |
| [GGUF](https://huggingface.co/mradermacher/CodeV-All-DSC-i1-GGUF/resolve/main/CodeV-All-DSC.i1-IQ2_XS.gguf) | i1-IQ2_XS | 2.1 | |
| [GGUF](https://huggingface.co/mradermacher/CodeV-All-DSC-i1-GGUF/resolve/main/CodeV-All-DSC.i1-IQ2_S.gguf) | i1-IQ2_S | 2.3 | |
| [GGUF](https://huggingface.co/mradermacher/CodeV-All-DSC-i1-GGUF/resolve/main/CodeV-All-DSC.i1-Q2_K_S.gguf) | i1-Q2_K_S | 2.4 | very low quality |
| [GGUF](https://huggingface.co/mradermacher/CodeV-All-DSC-i1-GGUF/resolve/main/CodeV-All-DSC.i1-IQ2_M.gguf) | i1-IQ2_M | 2.5 | |
| [GGUF](https://huggingface.co/mradermacher/CodeV-All-DSC-i1-GGUF/resolve/main/CodeV-All-DSC.i1-Q2_K.gguf) | i1-Q2_K | 2.6 | IQ3_XXS probably better |
| [GGUF](https://huggingface.co/mradermacher/CodeV-All-DSC-i1-GGUF/resolve/main/CodeV-All-DSC.i1-IQ3_XXS.gguf) | i1-IQ3_XXS | 2.7 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/CodeV-All-DSC-i1-GGUF/resolve/main/CodeV-All-DSC.i1-IQ3_XS.gguf) | i1-IQ3_XS | 2.9 | |
| [GGUF](https://huggingface.co/mradermacher/CodeV-All-DSC-i1-GGUF/resolve/main/CodeV-All-DSC.i1-IQ3_S.gguf) | i1-IQ3_S | 3.1 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/CodeV-All-DSC-i1-GGUF/resolve/main/CodeV-All-DSC.i1-Q3_K_S.gguf) | i1-Q3_K_S | 3.1 | IQ3_XS probably better |
| [GGUF](https://huggingface.co/mradermacher/CodeV-All-DSC-i1-GGUF/resolve/main/CodeV-All-DSC.i1-IQ3_M.gguf) | i1-IQ3_M | 3.2 | |
| [GGUF](https://huggingface.co/mradermacher/CodeV-All-DSC-i1-GGUF/resolve/main/CodeV-All-DSC.i1-Q3_K_M.gguf) | i1-Q3_K_M | 3.4 | IQ3_S probably better |
| [GGUF](https://huggingface.co/mradermacher/CodeV-All-DSC-i1-GGUF/resolve/main/CodeV-All-DSC.i1-Q3_K_L.gguf) | i1-Q3_K_L | 3.7 | IQ3_M probably better |
| [GGUF](https://huggingface.co/mradermacher/CodeV-All-DSC-i1-GGUF/resolve/main/CodeV-All-DSC.i1-IQ4_XS.gguf) | i1-IQ4_XS | 3.7 | |
| [GGUF](https://huggingface.co/mradermacher/CodeV-All-DSC-i1-GGUF/resolve/main/CodeV-All-DSC.i1-IQ4_NL.gguf) | i1-IQ4_NL | 3.9 | prefer IQ4_XS |
| [GGUF](https://huggingface.co/mradermacher/CodeV-All-DSC-i1-GGUF/resolve/main/CodeV-All-DSC.i1-Q4_0.gguf) | i1-Q4_0 | 3.9 | fast, low quality |
| [GGUF](https://huggingface.co/mradermacher/CodeV-All-DSC-i1-GGUF/resolve/main/CodeV-All-DSC.i1-Q4_K_S.gguf) | i1-Q4_K_S | 4.0 | optimal size/speed/quality |
| [GGUF](https://huggingface.co/mradermacher/CodeV-All-DSC-i1-GGUF/resolve/main/CodeV-All-DSC.i1-Q4_K_M.gguf) | i1-Q4_K_M | 4.2 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/CodeV-All-DSC-i1-GGUF/resolve/main/CodeV-All-DSC.i1-Q4_1.gguf) | i1-Q4_1 | 4.3 | |
| [GGUF](https://huggingface.co/mradermacher/CodeV-All-DSC-i1-GGUF/resolve/main/CodeV-All-DSC.i1-Q5_K_S.gguf) | i1-Q5_K_S | 4.8 | |
| [GGUF](https://huggingface.co/mradermacher/CodeV-All-DSC-i1-GGUF/resolve/main/CodeV-All-DSC.i1-Q5_K_M.gguf) | i1-Q5_K_M | 4.9 | |
| [GGUF](https://huggingface.co/mradermacher/CodeV-All-DSC-i1-GGUF/resolve/main/CodeV-All-DSC.i1-Q6_K.gguf) | i1-Q6_K | 5.6 | practically like static Q6_K |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time. Additional thanks to [@nicoboss](https://huggingface.co/nicoboss) for giving me access to his private supercomputer, enabling me to provide many more imatrix quants, at much higher quality, than I would otherwise be able to.
<!-- end -->
|
raniero/ax-real-007-repo
|
raniero
| 2025-09-12T08:08:59Z | 0 | 0 |
peft
|
[
"peft",
"safetensors",
"lora",
"bittensor",
"subnet-56",
"gradients",
"it",
"base_model:TinyLlama/TinyLlama-1.1B-Chat-v1.0",
"base_model:adapter:TinyLlama/TinyLlama-1.1B-Chat-v1.0",
"license:apache-2.0",
"region:us"
] | null | 2025-09-12T08:08:57Z |
---
language:
- it
license: apache-2.0
library_name: peft
tags: [lora, bittensor, subnet-56, gradients]
base_model: TinyLlama/TinyLlama-1.1B-Chat-v1.0
---
# ARES56 — LoRA adapter
Upload ID: ax-real-007_1757664536
upload_id: unknown_1757404904
File inclusi:
- `adapter_model.safetensors` — SHA256: `e5a00aa9991ac8a5ee3109844d84a55583bd20572ad3ffcd42792f3c36b183ad`
- `adapter_config.json` — SHA256: `56ed2334817c59b9f0165300b25c96a5ce8ebc6331e5499e533a92a40307a604`
- `tokenizer_config.json` — SHA256: `missing`
- `special_tokens_map.json` — SHA256: `missing`
Output generato via Axolotl (CPU / smoke). Nessun checkpoint completo incluso.
|
HA-Siala/Java-OCL-v0.2
|
HA-Siala
| 2025-09-12T08:08:41Z | 0 | 0 |
peft
|
[
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:mistralai/Mistral-7B-v0.3",
"base_model:adapter:mistralai/Mistral-7B-v0.3",
"region:us"
] | null | 2025-09-12T08:08:24Z |
---
library_name: peft
base_model: mistralai/Mistral-7B-v0.3
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.10.0
|
Kijai/WanVideo_comfy
|
Kijai
| 2025-09-12T08:08:16Z | 4,149,848 | 1,381 |
diffusion-single-file
|
[
"diffusion-single-file",
"comfyui",
"base_model:Wan-AI/Wan2.1-VACE-1.3B",
"base_model:finetune:Wan-AI/Wan2.1-VACE-1.3B",
"region:us"
] | null | 2025-02-25T17:54:17Z |
---
tags:
- diffusion-single-file
- comfyui
base_model:
- Wan-AI/Wan2.1-VACE-14B
- Wan-AI/Wan2.1-VACE-1.3B
---
Combined and quantized models for WanVideo, originating from here:
https://huggingface.co/Wan-AI/
Can be used with: https://github.com/kijai/ComfyUI-WanVideoWrapper and ComfyUI native WanVideo nodes.
I've also started to do fp8_scaled versions over here: https://huggingface.co/Kijai/WanVideo_comfy_fp8_scaled
Other model sources:
TinyVAE from https://github.com/madebyollin/taehv
SkyReels: https://huggingface.co/collections/Skywork/skyreels-v2-6801b1b93df627d441d0d0d9
WanVideoFun: https://huggingface.co/collections/alibaba-pai/wan21-fun-v11-680f514c89fe7b4df9d44f17
---
Lightx2v:
CausVid 14B: https://huggingface.co/lightx2v/Wan2.1-T2V-14B-CausVid
CFG and Step distill 14B: https://huggingface.co/lightx2v/Wan2.1-T2V-14B-StepDistill-CfgDistill
---
CausVid 1.3B: https://huggingface.co/tianweiy/CausVid
AccVideo: https://huggingface.co/aejion/AccVideo-WanX-T2V-14B
Phantom: https://huggingface.co/bytedance-research/Phantom
ATI: https://huggingface.co/bytedance-research/ATI
MiniMaxRemover: https://huggingface.co/zibojia/minimax-remover
MAGREF: https://huggingface.co/MAGREF-Video/MAGREF
FantasyTalking: https://github.com/Fantasy-AMAP/fantasy-talking
MultiTalk: https://github.com/MeiGen-AI/MultiTalk
Anisora: https://huggingface.co/IndexTeam/Index-anisora/tree/main/14B
Pusa: https://huggingface.co/RaphaelLiu/PusaV1/tree/main
FastVideo: https://huggingface.co/FastVideo
EchoShot: https://github.com/D2I-ai/EchoShot
Wan22 5B Turbo: https://huggingface.co/quanhaol/Wan2.2-TI2V-5B-Turbo
---
CausVid LoRAs are experimental extractions from the CausVid finetunes, the aim with them is to benefit from the distillation in CausVid, rather than any actual causal inference.
---
v1 = direct extraction, has adverse effects on motion and introduces flashing artifact at full strength.
v1.5 = same as above, but without the first block which fixes the flashing at full strength.
v2 = further pruned version with only attention layers and no first block, fixes flashing and retains motion better, needs more steps and can also benefit from cfg.
|
AIcell/Qwen2.5-1.5B-Instruct-GRPO-gsm8k-plain
|
AIcell
| 2025-09-12T08:08:12Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"generated_from_trainer",
"open-r1",
"trl",
"grpo",
"conversational",
"dataset:openai/gsm8k",
"arxiv:2402.03300",
"base_model:Qwen/Qwen2.5-1.5B-Instruct",
"base_model:finetune:Qwen/Qwen2.5-1.5B-Instruct",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-29T18:14:53Z |
---
base_model: Qwen/Qwen2.5-1.5B-Instruct
datasets: openai/gsm8k
library_name: transformers
model_name: Qwen2.5-1.5B-Instruct-GRPO-gsm8k-plain
tags:
- generated_from_trainer
- open-r1
- trl
- grpo
licence: license
---
# Model Card for Qwen2.5-1.5B-Instruct-GRPO-gsm8k-plain
This model is a fine-tuned version of [Qwen/Qwen2.5-1.5B-Instruct](https://huggingface.co/Qwen/Qwen2.5-1.5B-Instruct) on the [openai/gsm8k](https://huggingface.co/datasets/openai/gsm8k) dataset.
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="AIcell/Qwen2.5-1.5B-Instruct-GRPO-gsm8k-plain", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="150" height="24"/>](https://wandb.ai/xirui-li/huggingface/runs/os3c953u)
This model was trained with GRPO, a method introduced in [DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models](https://huggingface.co/papers/2402.03300).
### Framework versions
- TRL: 0.18.0
- Transformers: 4.52.3
- Pytorch: 2.7.0
- Datasets: 4.0.0
- Tokenizers: 0.21.4
## Citations
Cite GRPO as:
```bibtex
@article{zhihong2024deepseekmath,
title = {{DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models}},
author = {Zhihong Shao and Peiyi Wang and Qihao Zhu and Runxin Xu and Junxiao Song and Mingchuan Zhang and Y. K. Li and Y. Wu and Daya Guo},
year = 2024,
eprint = {arXiv:2402.03300},
}
```
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
sidhantoon/Goldentouch_V3_G15
|
sidhantoon
| 2025-09-12T08:08:12Z | 0 | 0 | null |
[
"safetensors",
"any-to-any",
"omega",
"omegalabs",
"bittensor",
"agi",
"license:mit",
"region:us"
] |
any-to-any
| 2025-09-12T06:39:57Z |
---
license: mit
tags:
- any-to-any
- omega
- omegalabs
- bittensor
- agi
---
This is an Any-to-Any model checkpoint for the OMEGA Labs x Bittensor Any-to-Any subnet.
Check out the [git repo](https://github.com/omegalabsinc/omegalabs-anytoany-bittensor) and find OMEGA on X: [@omegalabsai](https://x.com/omegalabsai).
|
Rkngktrk/Qwen2.5-0.5B-Instruct-Gensyn-Swarm-running_majestic_boar
|
Rkngktrk
| 2025-09-12T08:07:46Z | 12 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"rl-swarm",
"genrl-swarm",
"grpo",
"gensyn",
"I am running_majestic_boar",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-09-11T22:07:54Z |
---
library_name: transformers
tags:
- rl-swarm
- genrl-swarm
- grpo
- gensyn
- I am running_majestic_boar
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
HA-Siala/Java-OCL-v0.1
|
HA-Siala
| 2025-09-12T08:06:49Z | 2 | 0 |
peft
|
[
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:mistralai/Mistral-7B-v0.3",
"base_model:adapter:mistralai/Mistral-7B-v0.3",
"region:us"
] | null | 2025-09-12T08:06:40Z |
---
library_name: peft
base_model: mistralai/Mistral-7B-v0.3
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.10.0
|
EZCon/Qwen2-VL-2B-Instruct-abliterated-8bit-mixed_3_8-mlx
|
EZCon
| 2025-09-12T08:06:35Z | 20 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2_vl",
"image-to-text",
"chat",
"abliterated",
"uncensored",
"mlx",
"image-text-to-text",
"conversational",
"en",
"base_model:Qwen/Qwen2-VL-2B-Instruct",
"base_model:quantized:Qwen/Qwen2-VL-2B-Instruct",
"license:apache-2.0",
"text-generation-inference",
"endpoints_compatible",
"8-bit",
"region:us"
] |
image-text-to-text
| 2025-09-12T08:06:01Z |
---
library_name: transformers
license: apache-2.0
license_link: https://huggingface.co/huihui-ai/Qwen2-VL-2B-Instruct-abliterated/blob/main/LICENSE
language:
- en
pipeline_tag: image-text-to-text
base_model: Qwen/Qwen2-VL-2B-Instruct
tags:
- chat
- abliterated
- uncensored
- mlx
---
# EZCon/Qwen2-VL-2B-Instruct-abliterated-8bit-mixed_3_8-mlx
This model was converted to MLX format from [`huihui-ai/Qwen2-VL-2B-Instruct-abliterated`]() using mlx-vlm version **0.3.3**.
Refer to the [original model card](https://huggingface.co/huihui-ai/Qwen2-VL-2B-Instruct-abliterated) for more details on the model.
## Use with mlx
```bash
pip install -U mlx-vlm
```
```bash
python -m mlx_vlm.generate --model EZCon/Qwen2-VL-2B-Instruct-abliterated-8bit-mixed_3_8-mlx --max-tokens 100 --temperature 0.0 --prompt "Describe this image." --image <path_to_image>
```
|
andersonbcdefg/vl-finetuning-max-thresh-15-2025-09-12
|
andersonbcdefg
| 2025-09-12T08:05:42Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2_5_vl",
"image-to-text",
"arxiv:1910.09700",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
image-to-text
| 2025-09-12T08:02:21Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
HA-Siala/Python-UML-v0.2
|
HA-Siala
| 2025-09-12T08:04:56Z | 0 | 0 |
peft
|
[
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:mistralai/Mistral-7B-v0.3",
"base_model:adapter:mistralai/Mistral-7B-v0.3",
"region:us"
] | null | 2025-09-12T08:04:29Z |
---
library_name: peft
base_model: mistralai/Mistral-7B-v0.3
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.10.0
|
andersonbcdefg/vl-finetuning-max-thresh-25-2025-09-12
|
andersonbcdefg
| 2025-09-12T08:03:05Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2_5_vl",
"image-to-text",
"arxiv:1910.09700",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
image-to-text
| 2025-09-12T08:00:05Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
zzzyyyyyy/code-search-net-tokenizer
|
zzzyyyyyy
| 2025-09-12T08:00:59Z | 0 | 0 |
transformers
|
[
"transformers",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-09-12T08:00:57Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
HA-Siala/Java-UML-v0.1
|
HA-Siala
| 2025-09-12T07:57:53Z | 2 | 0 |
peft
|
[
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:mistralai/Mistral-7B-v0.3",
"base_model:adapter:mistralai/Mistral-7B-v0.3",
"region:us"
] | null | 2025-09-12T07:57:35Z |
---
library_name: peft
base_model: mistralai/Mistral-7B-v0.3
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.10.0
|
Qwen/Qwen3-Next-80B-A3B-Thinking
|
Qwen
| 2025-09-12T07:48:52Z | 2,577 | 230 |
transformers
|
[
"transformers",
"safetensors",
"qwen3_next",
"text-generation",
"conversational",
"arxiv:2309.00071",
"arxiv:2505.09388",
"arxiv:2501.15383",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-09-09T15:45:31Z |
---
library_name: transformers
license: apache-2.0
license_link: https://huggingface.co/Qwen/Qwen3-Next-80B-A3B-Thinking/blob/main/LICENSE
pipeline_tag: text-generation
---
# Qwen3-Next-80B-A3B-Thinking
<a href="https://chat.qwen.ai/" target="_blank" style="margin: 2px;">
<img alt="Chat" src="https://img.shields.io/badge/%F0%9F%92%9C%EF%B8%8F%20Qwen%20Chat%20-536af5" style="display: inline-block; vertical-align: middle;"/>
</a>
Over the past few months, we have observed increasingly clear trends toward scaling both total parameters and context lengths in the pursuit of more powerful and agentic artificial intelligence (AI).
We are excited to share our latest advancements in addressing these demands, centered on improving scaling efficiency through innovative model architecture.
We call this next-generation foundation models **Qwen3-Next**.
## Highlights
**Qwen3-Next-80B-A3B** is the first installment in the Qwen3-Next series and features the following key enchancements:
- **Hybrid Attention**: Replaces standard attention with the combination of **Gated DeltaNet** and **Gated Attention**, enabling efficient context modeling for ultra-long context length.
- **High-Sparsity Mixture-of-Experts (MoE)**: Achieves an extreme low activation ratio in MoE layers, drastically reducing FLOPs per token while preserving model capacity.
- **Stability Optimizations**: Includes techniques such as **zero-centered and weight-decayed layernorm**, and other stabilizing enhancements for robust pre-training and post-training.
- **Multi-Token Prediction (MTP)**: Boosts pretraining model performance and accelerates inference.
We are seeing strong performance in terms of both parameter efficiency and inference speed for Qwen3-Next-80B-A3B:
- Qwen3-Next-80B-A3B-Base outperforms Qwen3-32B-Base on downstream tasks with 10% of the total training cost and with 10 times inference throughput for context over 32K tokens.
- Leveraging [GSPO](https://qwenlm.github.io/blog/gspo/), we have addressed the stability and efficiency challenges posed by the hybrid attention mechanism combined with a high-sparsity MoE architecture in RL training.
Qwen3-Next-80B-A3B-Thinking demonstrates outstanding performance on complex reasoning tasks, not only **surpassing Qwen3-30B-A3B-Thinking-2507 and Qwen3-32B-Thinking**, but also **outperforming the proprietary model Gemini-2.5-Flash-Thinking** across multiple benchmarks.
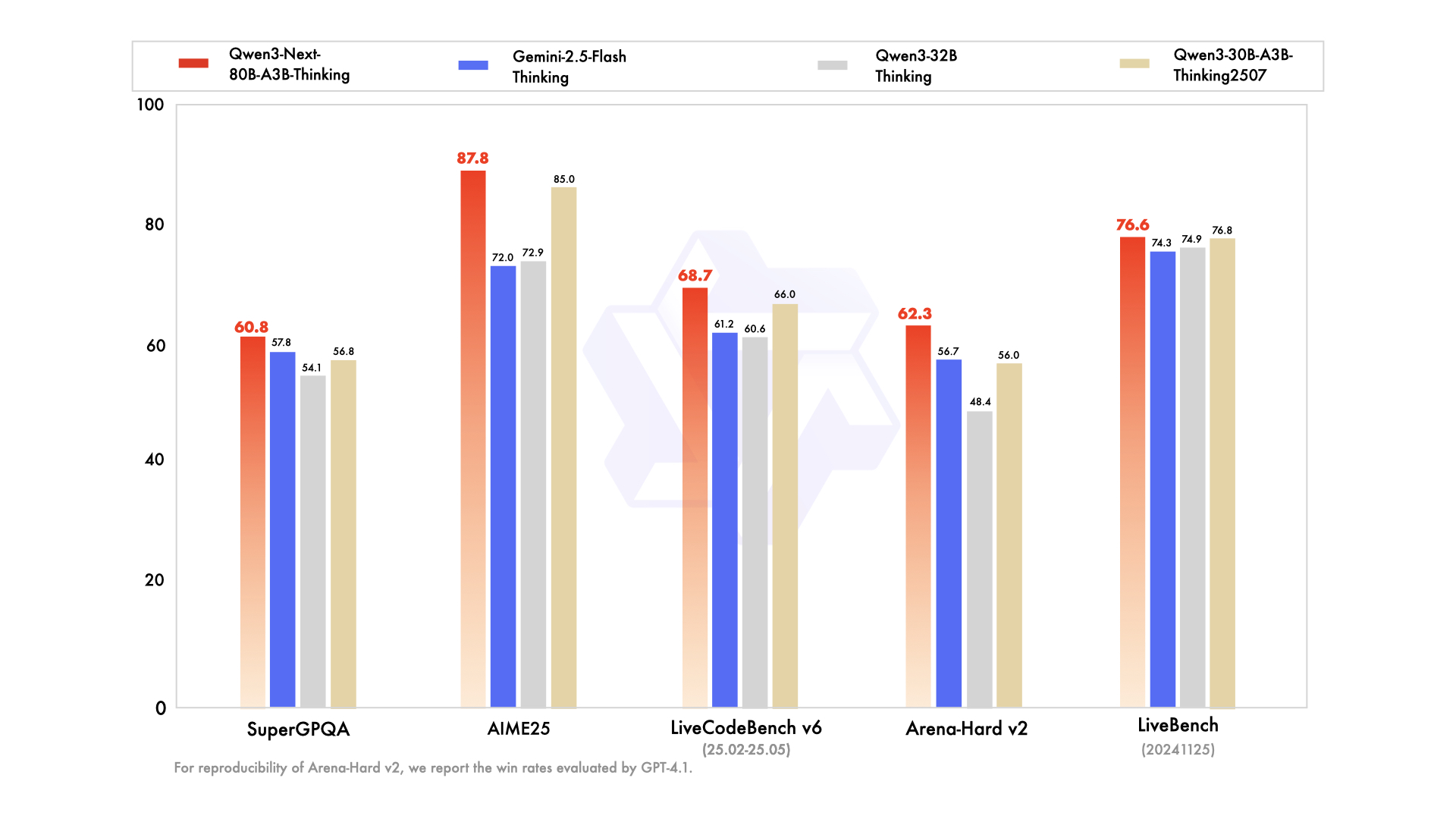
For more details, please refer to our blog post [Qwen3-Next](https://qwenlm.github.io/blog/qwen3_next/).
## Model Overview
> [!Note]
> **Qwen3-Next-80B-A3B-Thinking** supports only thinking mode.
> To enforce model thinking, the default chat template automatically includes `<think>`.
> Therefore, it is normal for the model's output to contain only `</think>` without an explicit opening `<think>` tag.
> [!Note]
> **Qwen3-Next-80B-A3B-Thinking** may generate thinking content longer than its predecessor.
> We strongly recommend its use in highly complex reasoning tasks.
**Qwen3-Next-80B-A3B-Thinking** has the following features:
- Type: Causal Language Models
- Training Stage: Pretraining (15T tokens) & Post-training
- Number of Parameters: 80B in total and 3B activated
- Number of Paramaters (Non-Embedding): 79B
- Number of Layers: 48
- Hidden Dimension: 2048
- Hybrid Layout: 12 \* (3 \* (Gated DeltaNet -> MoE) -> (Gated Attention -> MoE))
- Gated Attention:
- Number of Attention Heads: 16 for Q and 2 for KV
- Head Dimension: 256
- Rotary Position Embedding Dimension: 64
- Gated DeltaNet:
- Number of Linear Attention Heads: 32 for V and 16 for QK
- Head Dimension: 128
- Mixture of Experts:
- Number of Experts: 512
- Number of Activated Experts: 10
- Number of Shared Experts: 1
- Expert Intermediate Dimension: 512
- Context Length: 262,144 natively and extensible up to 1,010,000 tokens
<img src="https://qianwen-res.oss-accelerate.aliyuncs.com/Qwen3-Next/model_architecture.png" height="384px" title="Qwen3-Next Model Architecture" />
## Performance
| | Qwen3-30B-A3B-Thinking-2507 | Qwen3-32B Thinking | Qwen3-235B-A22B-Thinking-2507 | Gemini-2.5-Flash Thinking | Qwen3-Next-80B-A3B-Thinking |
|--- | --- | --- | --- | --- | --- |
| **Knowledge** | | | | |
| MMLU-Pro | 80.9 | 79.1 | **84.4** | 81.9 | 82.7 |
| MMLU-Redux | 91.4 | 90.9 | **93.8** | 92.1 | 92.5 |
| GPQA | 73.4 | 68.4 | 81.1 | **82.8** | 77.2 |
| SuperGPQA | 56.8 | 54.1 | **64.9** | 57.8 | 60.8 |
| **Reasoning** | | | | |
| AIME25 | 85.0 | 72.9 | **92.3** | 72.0 | 87.8 |
| HMMT25 | 71.4 | 51.5 | **83.9** | 64.2 | 73.9 |
| LiveBench 241125 | 76.8 | 74.9 | **78.4** | 74.3 | 76.6 |
| **Coding** | | | | |
| LiveCodeBench v6 (25.02-25.05) | 66.0 | 60.6 | **74.1** | 61.2 | 68.7 |
| CFEval | 2044 | 1986 | **2134** | 1995 | 2071 |
| OJBench | 25.1 | 24.1 | **32.5** | 23.5 | 29.7 |
| **Alignment** | | | | |
| IFEval | 88.9 | 85.0 | 87.8 | **89.8** | 88.9 |
| Arena-Hard v2* | 56.0 | 48.4 | **79.7** | 56.7 | 62.3 |
| WritingBench | 85.0 | 79.0 | **88.3** | 83.9 | 84.6 |
| **Agent** | | | | |
| BFCL-v3 | **72.4** | 70.3 | 71.9 | 68.6 | 72.0 |
| TAU1-Retail | 67.8 | 52.8 | 67.8 | 65.2 | **69.6** |
| TAU1-Airline | 48.0 | 29.0 | 46.0 | **54.0** | 49.0 |
| TAU2-Retail | 58.8 | 49.7 | **71.9** | 66.7 | 67.8 |
| TAU2-Airline | 58.0 | 45.5 | 58.0 | 52.0 | **60.5** |
| TAU2-Telecom | 26.3 | 27.2 | **45.6** | 31.6 | 43.9 |
| **Multilingualism** | | | | |
| MultiIF | 76.4 | 73.0 | **80.6** | 74.4 | 77.8 |
| MMLU-ProX | 76.4 | 74.6 | **81.0** | 80.2 | 78.7 |
| INCLUDE | 74.4 | 73.7 | 81.0 | **83.9** | 78.9 |
| PolyMATH | 52.6 | 47.4 | **60.1** | 49.8 | 56.3 |
*: For reproducibility, we report the win rates evaluated by GPT-4.1.
## Quickstart
The code for Qwen3-Next has been merged into the main branch of Hugging Face `transformers`.
```shell
pip install git+https://github.com/huggingface/transformers.git@main
```
With earlier versions, you will encounter the following error:
```
KeyError: 'qwen3_next'
```
The following contains a code snippet illustrating how to use the model generate content based on given inputs.
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen3-Next-80B-A3B-Thinking"
# load the tokenizer and the model
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
dtype="auto",
device_map="auto"
)
# prepare the model input
prompt = "Give me a short introduction to large language model."
messages = [
{"role": "user", "content": prompt},
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# conduct text completion
generated_ids = model.generate(
**model_inputs,
max_new_tokens=32768,
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
# parsing thinking content
try:
# rindex finding 151668 (</think>)
index = len(output_ids) - output_ids[::-1].index(151668)
except ValueError:
index = 0
thinking_content = tokenizer.decode(output_ids[:index], skip_special_tokens=True).strip("\n")
content = tokenizer.decode(output_ids[index:], skip_special_tokens=True).strip("\n")
print("thinking content:", thinking_content) # no opening <think> tag
print("content:", content)
```
> [!Note]
> Multi-Token Prediction (MTP) is not generally available in Hugging Face Transformers.
> [!Note]
> The efficiency or throughput improvement depends highly on the implementation.
> It is recommended to adopt a dedicated inference framework, e.g., SGLang and vLLM, for inference tasks.
> [!Tip]
> Depending on the inference settings, you may observe better efficiency with [`flash-linear-attention`](https://github.com/fla-org/flash-linear-attention#installation) and [`causal-conv1d`](https://github.com/Dao-AILab/causal-conv1d).
> See the above links for detailed instructions and requirements.
## Deployment
For deployment, you can use the latest `sglang` or `vllm` to create an OpenAI-compatible API endpoint.
### SGLang
[SGLang](https://github.com/sgl-project/sglang) is a fast serving framework for large language models and vision language models.
SGLang could be used to launch a server with OpenAI-compatible API service.
SGLang has supported Qwen3-Next in its `main` branch, which can be installed from source:
```shell
pip install 'sglang[all] @ git+https://github.com/sgl-project/sglang.git@main#subdirectory=python'
```
The following command can be used to create an API endpoint at `http://localhost:30000/v1` with maximum context length 256K tokens using tensor parallel on 4 GPUs.
```shell
SGLANG_ALLOW_OVERWRITE_LONGER_CONTEXT_LEN=1 python -m sglang.launch_server --model-path Qwen/Qwen3-Next-80B-A3B-Thinking --port 30000 --tp-size 4 --context-length 262144 --reasoning-parser deepseek-r1 --mem-fraction-static 0.8
```
The following command is recommended for MTP with the rest settings the same as above:
```shell
SGLANG_ALLOW_OVERWRITE_LONGER_CONTEXT_LEN=1 python -m sglang.launch_server --model-path Qwen/Qwen3-Next-80B-A3B-Thinking --port 30000 --tp-size 4 --context-length 262144 --reasoning-parser deepseek-r1 --mem-fraction-static 0.8 --speculative-algo NEXTN --speculative-num-steps 3 --speculative-eagle-topk 1 --speculative-num-draft-tokens 4
```
> [!Note]
> The environment variable `SGLANG_ALLOW_OVERWRITE_LONGER_CONTEXT_LEN=1` is required at the moment.
> [!Note]
> The default context length is 256K.
> If you encounter out-of-memory (OOM) issues, you may consider reducing the context length to a smaller value.
> However, since the model may require longer token sequences for reasoning, we strongly recommend using a context length greater than 131,072.
### vLLM
[vLLM](https://github.com/vllm-project/vllm) is a high-throughput and memory-efficient inference and serving engine for LLMs.
vLLM could be used to launch a server with OpenAI-compatible API service.
vLLM has supported Qwen3-Next in its `main` branch, which can be installed from source:
```shell
pip install vllm --pre --extra-index-url https://wheels.vllm.ai/nightly
```
The following command can be used to create an API endpoint at `http://localhost:8000/v1` with maximum context length 256K tokens using tensor parallel on 4 GPUs.
```shell
VLLM_ALLOW_LONG_MAX_MODEL_LEN=1 vllm serve Qwen/Qwen3-Next-80B-A3B-Thinking --port 8000 --tensor-parallel-size 4 --max-model-len 262144 --reasoning-parser deepseek_r1
```
The following command is recommended for MTP with the rest settings the same as above:
```shell
VLLM_ALLOW_LONG_MAX_MODEL_LEN=1 vllm serve Qwen/Qwen3-Next-80B-A3B-Thinking --port 8000 --tensor-parallel-size 4 --max-model-len 262144 --reasoning-parser deepseek_r1 --speculative-config '{"method":"qwen3_next_mtp","num_speculative_tokens":2}'
```
> [!Note]
> The environment variable `VLLM_ALLOW_LONG_MAX_MODEL_LEN=1` is required at the moment.
> [!Note]
> The default context length is 256K.
> If you encounter out-of-memory (OOM) issues, you may consider reducing the context length to a smaller value.
> However, since the model may require longer token sequences for reasoning, we strongly recommend using a context length greater than 131,072 when possible.
## Agentic Use
Qwen3 excels in tool calling capabilities. We recommend using [Qwen-Agent](https://github.com/QwenLM/Qwen-Agent) to make the best use of agentic ability of Qwen3. Qwen-Agent encapsulates tool-calling templates and tool-calling parsers internally, greatly reducing coding complexity.
To define the available tools, you can use the MCP configuration file, use the integrated tool of Qwen-Agent, or integrate other tools by yourself.
```python
from qwen_agent.agents import Assistant
# Define LLM
# Using Alibaba Cloud Model Studio
llm_cfg = {
'model': 'Qwen3-Next-80B-A3B-Thinking',
'model_type': 'qwen_dashscope',
}
# Using OpenAI-compatible API endpoint. It is recommended to disable the reasoning and the tool call parsing
# functionality of the deployment frameworks and let Qwen-Agent automate the related operations. For example,
# `VLLM_ALLOW_LONG_MAX_MODEL_LEN=1 vllm serve Qwen/Qwen3-Next-80B-A3B-Thinking --served-model-name Qwen3-Next-80B-A3B-Thinking --port 8000 --tensor-parallel-size 4 --max-model-len 262144`.
#
# llm_cfg = {
# 'model': 'Qwen3-Next-80B-A3B-Thinking',
#
# # Use a custom endpoint compatible with OpenAI API:
# 'model_server': 'http://localhost:8000/v1', # api_base without reasoning and tool call parsing
# 'api_key': 'EMPTY',
# 'generate_cfg': {
# 'thought_in_content': True,
# },
# }
# Define Tools
tools = [
{'mcpServers': { # You can specify the MCP configuration file
'time': {
'command': 'uvx',
'args': ['mcp-server-time', '--local-timezone=Asia/Shanghai']
},
"fetch": {
"command": "uvx",
"args": ["mcp-server-fetch"]
}
}
},
'code_interpreter', # Built-in tools
]
# Define Agent
bot = Assistant(llm=llm_cfg, function_list=tools)
# Streaming generation
messages = [{'role': 'user', 'content': 'https://qwenlm.github.io/blog/ Introduce the latest developments of Qwen'}]
for responses in bot.run(messages=messages):
pass
print(responses)
```
## Processing Ultra-Long Texts
Qwen3-Next natively supports context lengths of up to 262,144 tokens.
For conversations where the total length (including both input and output) significantly exceeds this limit, we recommend using RoPE scaling techniques to handle long texts effectively.
We have validated the model's performance on context lengths of up to 1 million tokens using the [YaRN](https://arxiv.org/abs/2309.00071) method.
YaRN is currently supported by several inference frameworks, e.g., `transformers`, `vllm` and `sglang`.
In general, there are two approaches to enabling YaRN for supported frameworks:
- Modifying the model files:
In the `config.json` file, add the `rope_scaling` fields:
```json
{
...,
"rope_scaling": {
"rope_type": "yarn",
"factor": 4.0,
"original_max_position_embeddings": 262144
}
}
```
- Passing command line arguments:
For `vllm`, you can use
```shell
VLLM_ALLOW_LONG_MAX_MODEL_LEN=1 vllm serve ... --rope-scaling '{"rope_type":"yarn","factor":4.0,"original_max_position_embeddings":262144}' --max-model-len 1010000
```
For `sglang`, you can use
```shell
SGLANG_ALLOW_OVERWRITE_LONGER_CONTEXT_LEN=1 python -m sglang.launch_server ... --json-model-override-args '{"rope_scaling":{"rope_type":"yarn","factor":4.0,"original_max_position_embeddings":262144}}' --context-length 1010000
```
> [!NOTE]
> All the notable open-source frameworks implement static YaRN, which means the scaling factor remains constant regardless of input length, **potentially impacting performance on shorter texts.**
> We advise adding the `rope_scaling` configuration only when processing long contexts is required.
> It is also recommended to modify the `factor` as needed. For example, if the typical context length for your application is 524,288 tokens, it would be better to set `factor` as 2.0.
## Best Practices
To achieve optimal performance, we recommend the following settings:
1. **Sampling Parameters**:
- We suggest using `Temperature=0.6`, `TopP=0.95`, `TopK=20`, and `MinP=0`.
- For supported frameworks, you can adjust the `presence_penalty` parameter between 0 and 2 to reduce endless repetitions. However, using a higher value may occasionally result in language mixing and a slight decrease in model performance.
2. **Adequate Output Length**: We recommend using an output length of 32,768 tokens for most queries. For benchmarking on highly complex problems, such as those found in math and programming competitions, we suggest setting the max output length to 81,920 tokens. This provides the model with sufficient space to generate detailed and comprehensive responses, thereby enhancing its overall performance.
3. **Standardize Output Format**: We recommend using prompts to standardize model outputs when benchmarking.
- **Math Problems**: Include "Please reason step by step, and put your final answer within \boxed{}." in the prompt.
- **Multiple-Choice Questions**: Add the following JSON structure to the prompt to standardize responses: "Please show your choice in the `answer` field with only the choice letter, e.g., `"answer": "C"`."
4. **No Thinking Content in History**: In multi-turn conversations, the historical model output should only include the final output part and does not need to include the thinking content. It is implemented in the provided chat template in Jinja2. However, for frameworks that do not directly use the Jinja2 chat template, it is up to the developers to ensure that the best practice is followed.
### Citation
If you find our work helpful, feel free to give us a cite.
```
@misc{qwen3technicalreport,
title={Qwen3 Technical Report},
author={Qwen Team},
year={2025},
eprint={2505.09388},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2505.09388},
}
@article{qwen2.5-1m,
title={Qwen2.5-1M Technical Report},
author={An Yang and Bowen Yu and Chengyuan Li and Dayiheng Liu and Fei Huang and Haoyan Huang and Jiandong Jiang and Jianhong Tu and Jianwei Zhang and Jingren Zhou and Junyang Lin and Kai Dang and Kexin Yang and Le Yu and Mei Li and Minmin Sun and Qin Zhu and Rui Men and Tao He and Weijia Xu and Wenbiao Yin and Wenyuan Yu and Xiafei Qiu and Xingzhang Ren and Xinlong Yang and Yong Li and Zhiying Xu and Zipeng Zhang},
journal={arXiv preprint arXiv:2501.15383},
year={2025}
}
```
|
GodShin/gemma-3-1b-pt-MED-Instruct
|
GodShin
| 2025-09-12T07:48:50Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"gemma3_text",
"text-generation",
"trl",
"sft",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-09-12T07:48:11Z |
---
library_name: transformers
tags:
- trl
- sft
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
210yy/gemma-3-1b-pt-MED-Instruct
|
210yy
| 2025-09-12T07:48:26Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"gemma3_text",
"text-generation",
"trl",
"sft",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-09-12T07:47:43Z |
---
library_name: transformers
tags:
- trl
- sft
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
mgparkzone/gemma-3-1b-pt-MED-Instruct
|
mgparkzone
| 2025-09-12T07:47:26Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"gemma3_text",
"text-generation",
"trl",
"sft",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-09-12T07:46:56Z |
---
library_name: transformers
tags:
- trl
- sft
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Sunik93/gemma-3-1b-pt-MED-Instruct
|
Sunik93
| 2025-09-12T07:43:17Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"gemma3_text",
"text-generation",
"trl",
"sft",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-09-12T07:42:29Z |
---
library_name: transformers
tags:
- trl
- sft
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Heoni/KONI-gemma-3-4b-cpt-it-dpo_ko-r1-3.2.5_16k_wo_packing_4e-5_20250905_5ep
|
Heoni
| 2025-09-12T07:42:28Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"gemma3_text",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-09-12T07:40:38Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
ryota-komatsu/s5-hubert-decoder-ft
|
ryota-komatsu
| 2025-09-12T07:41:32Z | 11 | 0 |
transformers
|
[
"transformers",
"safetensors",
"flow_matching_with_bigvgan",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-09-12T07:41:18Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
hsusis/12
|
hsusis
| 2025-09-12T07:39:30Z | 0 | 0 | null |
[
"license:apache-2.0",
"region:us"
] | null | 2025-09-12T07:39:30Z |
---
license: apache-2.0
---
|
Heoni/KONI-gemma-3-4b-cpt-it-dpo_ko-r1-3.2.5_16k_wo_packing_2e-5_20250905_5ep
|
Heoni
| 2025-09-12T07:35:05Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"gemma3_text",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-09-12T07:33:15Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Subsets and Splits
Filtered Qwen2.5 Distill Models
Identifies specific configurations of models by filtering cards that contain 'distill', 'qwen2.5', '7b' while excluding certain base models and incorrect model ID patterns, uncovering unique model variants.
Filtered Model Cards Count
Finds the count of entries with specific card details that include 'distill', 'qwen2.5', '7b' but exclude certain base models, revealing valuable insights about the dataset's content distribution.
Filtered Distill Qwen 7B Models
Filters for specific card entries containing 'distill', 'qwen', and '7b', excluding certain strings and patterns, to identify relevant model configurations.
Filtered Qwen-7b Model Cards
The query performs a detailed filtering based on specific keywords and excludes certain entries, which could be useful for identifying a specific subset of cards but does not provide deeper insights or trends.
Filtered Qwen 7B Model Cards
The query filters for specific terms related to "distilled" or "distill", "qwen", and "7b" in the 'card' column but excludes certain base models, providing a limited set of entries for further inspection.
Qwen 7B Distilled Models
The query provides a basic filtering of records to find specific card names that include keywords related to distilled Qwen 7b models, excluding a particular base model, which gives limited insight but helps in focusing on relevant entries.
Qwen 7B Distilled Model Cards
The query filters data based on specific keywords in the modelId and card fields, providing limited insight primarily useful for locating specific entries rather than revealing broad patterns or trends.
Qwen 7B Distilled Models
Finds all entries containing the terms 'distilled', 'qwen', and '7b' in a case-insensitive manner, providing a filtered set of records but without deeper analysis.
Distilled Qwen 7B Models
The query filters for specific model IDs containing 'distilled', 'qwen', and '7b', providing a basic retrieval of relevant entries but without deeper analysis or insight.
Filtered Model Cards with Distill Qwen2.
Filters and retrieves records containing specific keywords in the card description while excluding certain phrases, providing a basic count of relevant entries.
Filtered Model Cards with Distill Qwen 7
The query filters specific variations of card descriptions containing 'distill', 'qwen', and '7b' while excluding a particular base model, providing limited but specific data retrieval.
Distill Qwen 7B Model Cards
The query filters and retrieves rows where the 'card' column contains specific keywords ('distill', 'qwen', and '7b'), providing a basic filter result that can help in identifying specific entries.