
modelId
stringlengths 5
139
| author
stringlengths 2
42
| last_modified
timestamp[us, tz=UTC]date 2020-02-15 11:33:14
2025-09-12 12:31:00
| downloads
int64 0
223M
| likes
int64 0
11.7k
| library_name
stringclasses 555
values | tags
listlengths 1
4.05k
| pipeline_tag
stringclasses 55
values | createdAt
timestamp[us, tz=UTC]date 2022-03-02 23:29:04
2025-09-12 12:28:53
| card
stringlengths 11
1.01M
|
|---|---|---|---|---|---|---|---|---|---|
unsloth/Qwen3-Next-80B-A3B-Instruct
|
unsloth
| 2025-09-11T19:25:47Z | 0 | 18 |
transformers
|
[
"transformers",
"safetensors",
"qwen3_next",
"text-generation",
"unsloth",
"conversational",
"arxiv:2309.00071",
"arxiv:2404.06654",
"arxiv:2505.09388",
"arxiv:2501.15383",
"base_model:Qwen/Qwen3-Next-80B-A3B-Instruct",
"base_model:finetune:Qwen/Qwen3-Next-80B-A3B-Instruct",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-09-11T19:25:18Z |
---
tags:
- unsloth
base_model:
- Qwen/Qwen3-Next-80B-A3B-Instruct
library_name: transformers
license: apache-2.0
license_link: https://huggingface.co/Qwen/Qwen3-Next-80B-A3B-Instruct/blob/main/LICENSE
pipeline_tag: text-generation
---
# Qwen3-Next-80B-A3B-Instruct
<a href="https://chat.qwen.ai/" target="_blank" style="margin: 2px;">
<img alt="Chat" src="https://img.shields.io/badge/%F0%9F%92%9C%EF%B8%8F%20Qwen%20Chat%20-536af5" style="display: inline-block; vertical-align: middle;"/>
</a>
Over the past few months, we have observed increasingly clear trends toward scaling both total parameters and context lengths in the pursuit of more powerful and agentic artificial intelligence (AI).
We are excited to share our latest advancements in addressing these demands, centered on improving scaling efficiency through innovative model architecture.
We call this next-generation foundation models **Qwen3-Next**.
## Highlights
**Qwen3-Next-80B-A3B** is the first installment in the Qwen3-Next series and features the following key enchancements:
- **Hybrid Attention**: Replaces standard attention with the combination of **Gated DeltaNet** and **Gated Attention**, enabling efficient context modeling for ultra-long context length.
- **High-Sparsity Mixture-of-Experts (MoE)**: Achieves an extreme low activation ratio in MoE layers, drastically reducing FLOPs per token while preserving model capacity.
- **Stability Optimizations**: Includes techniques such as **zero-centered and weight-decayed layernorm**, and other stabilizing enhancements for robust pre-training and post-training.
- **Multi-Token Prediction (MTP)**: Boosts pretraining model performance and accelerates inference.
We are seeing strong performance in terms of both parameter efficiency and inference speed for Qwen3-Next-80B-A3B:
- Qwen3-Next-80B-A3B-Base outperforms Qwen3-32B-Base on downstream tasks with 10% of the total training cost and with 10 times inference throughput for context over 32K tokens.
- Qwen3-Next-80B-A3B-Instruct performs on par with Qwen3-235B-A22B-Instruct-2507 on certain benchmarks, while demonstrating significant advantages in handling ultra-long-context tasks up to 256K tokens.
For more details, please refer to our blog post [Qwen3-Next](https://qwenlm.github.io/blog/qwen3_next/).
## Model Overview
> [!Note]
> **Qwen3-Next-80B-A3B-Instruct** supports only instruct (non-thinking) mode and does not generate ``<think></think>`` blocks in its output.
**Qwen3-Next-80B-A3B-Instruct** has the following features:
- Type: Causal Language Models
- Training Stage: Pretraining (15T tokens) & Post-training
- Number of Parameters: 80B in total and 3B activated
- Number of Paramaters (Non-Embedding): 79B
- Number of Layers: 48
- Hidden Dimension: 2048
- Hybrid Layout: 12 \* (3 \* (Gated DeltaNet -> MoE) -> (Gated Attention -> MoE))
- Gated Attention:
- Number of Attention Heads: 16 for Q and 2 for KV
- Head Dimension: 256
- Rotary Position Embedding Dimension: 64
- Gated DeltaNet:
- Number of Linear Attention Heads: 32 for V and 16 for QK
- Head Dimension: 128
- Mixture of Experts:
- Number of Experts: 512
- Number of Activated Experts: 10
- Number of Shared Experts: 1
- Expert Intermediate Dimension: 512
- Context Length: 262,144 natively and extensible up to 1,010,000 tokens
<img src="https://qianwen-res.oss-accelerate.aliyuncs.com/Qwen3-Next/model_architecture.png" height="384px" title="Qwen3-Next Model Architecture" />
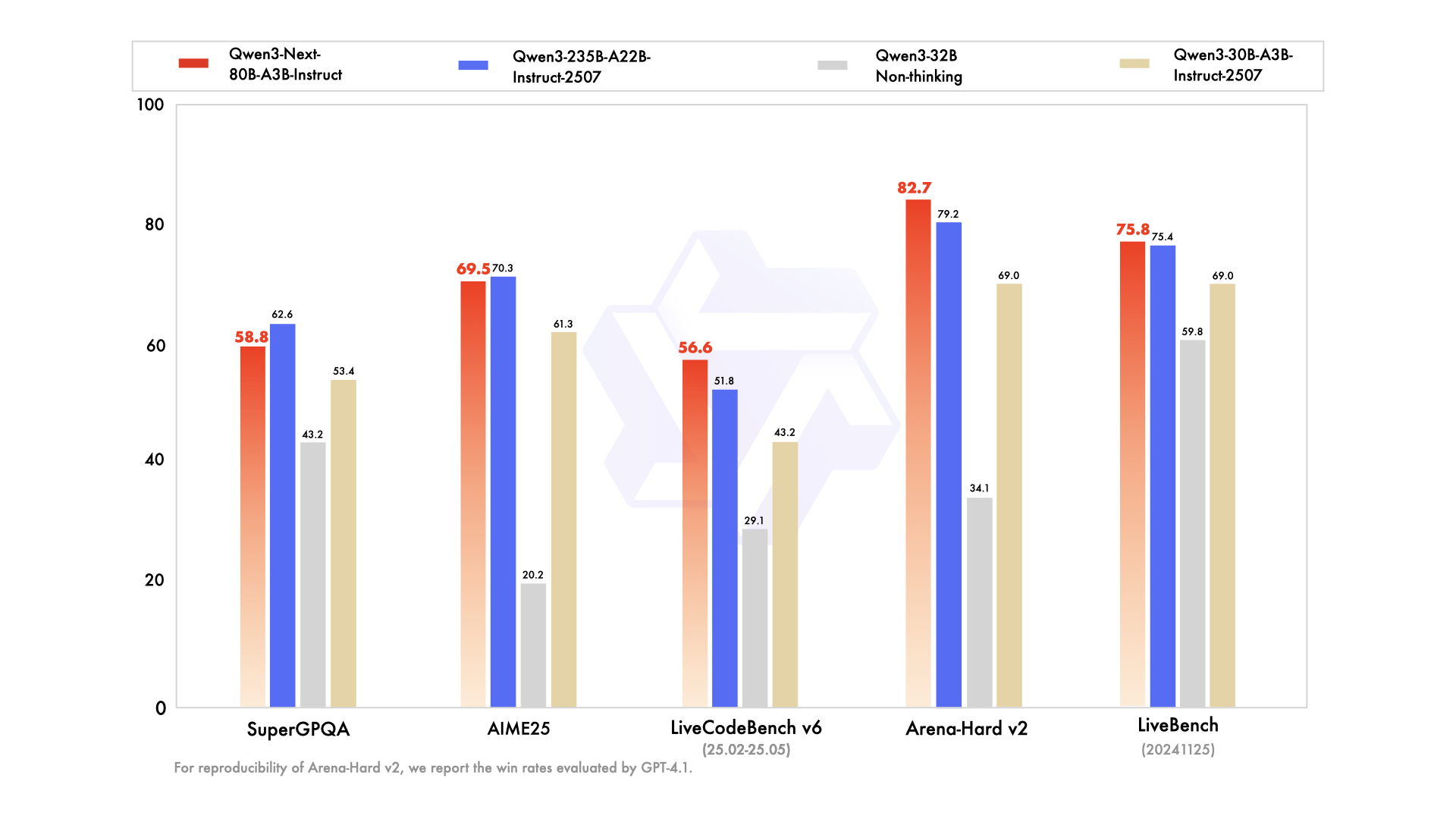
## Performance
| | Qwen3-30B-A3B-Instruct-2507 | Qwen3-32B Non-Thinking | Qwen3-235B-A22B-Instruct-2507 | Qwen3-Next-80B-A3B-Instruct |
|--- | --- | --- | --- | --- |
| **Knowledge** | | | | |
| MMLU-Pro | 78.4 | 71.9 | **83.0** | 80.6 |
| MMLU-Redux | 89.3 | 85.7 | **93.1** | 90.9 |
| GPQA | 70.4 | 54.6 | **77.5** | 72.9 |
| SuperGPQA | 53.4 | 43.2 | **62.6** | 58.8 |
| **Reasoning** | | | | |
| AIME25 | 61.3 | 20.2 | **70.3** | 69.5 |
| HMMT25 | 43.0 | 9.8 | **55.4** | 54.1 |
| LiveBench 20241125 | 69.0 | 59.8 | 75.4 | **75.8** |
| **Coding** | | | | |
| LiveCodeBench v6 (25.02-25.05) | 43.2 | 29.1 | 51.8 | **56.6** |
| MultiPL-E | 83.8 | 76.9 | **87.9** | 87.8 |
| Aider-Polyglot | 35.6 | 40.0 | **57.3** | 49.8 |
| **Alignment** | | | | |
| IFEval | 84.7 | 83.2 | **88.7** | 87.6 |
| Arena-Hard v2* | 69.0 | 34.1 | 79.2 | **82.7** |
| Creative Writing v3 | 86.0 | 78.3 | **87.5** | 85.3 |
| WritingBench | 85.5 | 75.4 | 85.2 | **87.3** |
| **Agent** | | | | |
| BFCL-v3 | 65.1 | 63.0 | **70.9** | 70.3 |
| TAU1-Retail | 59.1 | 40.1 | **71.3** | 60.9 |
| TAU1-Airline | 40.0 | 17.0 | **44.0** | 44.0 |
| TAU2-Retail | 57.0 | 48.8 | **74.6** | 57.3 |
| TAU2-Airline | 38.0 | 24.0 | **50.0** | 45.5 |
| TAU2-Telecom | 12.3 | 24.6 | **32.5** | 13.2 |
| **Multilingualism** | | | | |
| MultiIF | 67.9 | 70.7 | **77.5** | 75.8 |
| MMLU-ProX | 72.0 | 69.3 | **79.4** | 76.7 |
| INCLUDE | 71.9 | 70.9 | **79.5** | 78.9 |
| PolyMATH | 43.1 | 22.5 | **50.2** | 45.9 |
*: For reproducibility, we report the win rates evaluated by GPT-4.1.
## Quickstart
The code for Qwen3-Next has been merged into the main branch of Hugging Face `transformers`.
```shell
pip install git+https://github.com/huggingface/transformers.git@main
```
With earlier versions, you will encounter the following error:
```
KeyError: 'qwen3_next'
```
The following contains a code snippet illustrating how to use the model generate content based on given inputs.
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen3-Next-80B-A3B-Instruct"
# load the tokenizer and the model
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
dtype="auto",
device_map="auto",
)
# prepare the model input
prompt = "Give me a short introduction to large language model."
messages = [
{"role": "user", "content": prompt},
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# conduct text completion
generated_ids = model.generate(
**model_inputs,
max_new_tokens=16384,
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
content = tokenizer.decode(output_ids, skip_special_tokens=True)
print("content:", content)
```
> [!Note]
> Multi-Token Prediction (MTP) is not generally available in Hugging Face Transformers.
> [!Note]
> The efficiency or throughput improvement depends highly on the implementation.
> It is recommended to adopt a dedicated inference framework, e.g., SGLang and vLLM, for inference tasks.
> [!Tip]
> Depending on the inference settings, you may observe better efficiency with [`flash-linear-attention`](https://github.com/fla-org/flash-linear-attention#installation) and [`causal-conv1d`](https://github.com/Dao-AILab/causal-conv1d).
> See the above links for detailed instructions and requirements.
## Deployment
For deployment, you can use the latest `sglang` or `vllm` to create an OpenAI-compatible API endpoint.
### SGLang
[SGLang](https://github.com/sgl-project/sglang) is a fast serving framework for large language models and vision language models.
SGLang could be used to launch a server with OpenAI-compatible API service.
SGLang has supported Qwen3-Next in its `main` branch, which can be installed from source:
```shell
pip install 'sglang[all] @ git+https://github.com/sgl-project/sglang.git@main#subdirectory=python'
```
The following command can be used to create an API endpoint at `http://localhost:30000/v1` with maximum context length 256K tokens using tensor parallel on 4 GPUs.
```shell
SGLANG_ALLOW_OVERWRITE_LONGER_CONTEXT_LEN=1 python -m sglang.launch_server --model-path Qwen/Qwen3-Next-80B-A3B-Instruct --port 30000 --tp-size 4 --context-length 262144 --mem-fraction-static 0.8
```
The following command is recommended for MTP with the rest settings the same as above:
```shell
SGLANG_ALLOW_OVERWRITE_LONGER_CONTEXT_LEN=1 python -m sglang.launch_server --model-path Qwen/Qwen3-Next-80B-A3B-Instruct --port 30000 --tp-size 4 --context-length 262144 --mem-fraction-static 0.8 --speculative-algo NEXTN --speculative-num-steps 3 --speculative-eagle-topk 1 --speculative-num-draft-tokens 4
```
> [!Note]
> The environment variable `SGLANG_ALLOW_OVERWRITE_LONGER_CONTEXT_LEN=1` is required at the moment.
> [!Note]
> The default context length is 256K. Consider reducing the context length to a smaller value, e.g., `32768`, if the server fail to start.
### vLLM
[vLLM](https://github.com/vllm-project/vllm) is a high-throughput and memory-efficient inference and serving engine for LLMs.
vLLM could be used to launch a server with OpenAI-compatible API service.
vLLM has supported Qwen3-Next in its `main` branch, which can be installed from source:
```shell
pip install git+https://github.com/vllm-project/vllm.git
```
The following command can be used to create an API endpoint at `http://localhost:8000/v1` with maximum context length 256K tokens using tensor parallel on 4 GPUs.
```shell
VLLM_ALLOW_LONG_MAX_MODEL_LEN=1 vllm serve Qwen/Qwen3-Next-80B-A3B-Instruct --port 8000 --tensor-parallel-size 4 --max-model-len 262144
```
The following command is recommended for MTP with the rest settings the same as above:
```shell
VLLM_ALLOW_LONG_MAX_MODEL_LEN=1 vllm serve Qwen/Qwen3-Next-80B-A3B-Instruct --port 8000 --tensor-parallel-size 4 --max-model-len 262144 --speculative-config '{"method":"qwen3_next_mtp","num_speculative_tokens":2}'
```
> [!Note]
> The environment variable `VLLM_ALLOW_LONG_MAX_MODEL_LEN=1` is required at the moment.
> [!Note]
> The default context length is 256K. Consider reducing the context length to a smaller value, e.g., `32768`, if the server fail to start.
## Agentic Use
Qwen3 excels in tool calling capabilities. We recommend using [Qwen-Agent](https://github.com/QwenLM/Qwen-Agent) to make the best use of agentic ability of Qwen3. Qwen-Agent encapsulates tool-calling templates and tool-calling parsers internally, greatly reducing coding complexity.
To define the available tools, you can use the MCP configuration file, use the integrated tool of Qwen-Agent, or integrate other tools by yourself.
```python
from qwen_agent.agents import Assistant
# Define LLM
llm_cfg = {
'model': 'Qwen3-Next-80B-A3B-Instruct',
# Use a custom endpoint compatible with OpenAI API:
'model_server': 'http://localhost:8000/v1', # api_base
'api_key': 'EMPTY',
}
# Define Tools
tools = [
{'mcpServers': { # You can specify the MCP configuration file
'time': {
'command': 'uvx',
'args': ['mcp-server-time', '--local-timezone=Asia/Shanghai']
},
"fetch": {
"command": "uvx",
"args": ["mcp-server-fetch"]
}
}
},
'code_interpreter', # Built-in tools
]
# Define Agent
bot = Assistant(llm=llm_cfg, function_list=tools)
# Streaming generation
messages = [{'role': 'user', 'content': 'https://qwenlm.github.io/blog/ Introduce the latest developments of Qwen'}]
for responses in bot.run(messages=messages):
pass
print(responses)
```
## Processing Ultra-Long Texts
Qwen3-Next natively supports context lengths of up to 262,144 tokens.
For conversations where the total length (including both input and output) significantly exceeds this limit, we recommend using RoPE scaling techniques to handle long texts effectively.
We have validated the model's performance on context lengths of up to 1 million tokens using the [YaRN](https://arxiv.org/abs/2309.00071) method.
YaRN is currently supported by several inference frameworks, e.g., `transformers`, `vllm` and `sglang`.
In general, there are two approaches to enabling YaRN for supported frameworks:
- Modifying the model files:
In the `config.json` file, add the `rope_scaling` fields:
```json
{
...,
"rope_scaling": {
"rope_type": "yarn",
"factor": 4.0,
"original_max_position_embeddings": 262144
}
}
```
- Passing command line arguments:
For `vllm`, you can use
```shell
VLLM_ALLOW_LONG_MAX_MODEL_LEN=1 vllm serve ... --rope-scaling '{"rope_type":"yarn","factor":4.0,"original_max_position_embeddings":262144}' --max-model-len 1010000
```
For `sglang`, you can use
```shell
SGLANG_ALLOW_OVERWRITE_LONGER_CONTEXT_LEN=1 python -m sglang.launch_server ... --json-model-override-args '{"rope_scaling":{"rope_type":"yarn","factor":4.0,"original_max_position_embeddings":262144}}' --context-length 1010000
```
> [!NOTE]
> All the notable open-source frameworks implement static YaRN, which means the scaling factor remains constant regardless of input length, **potentially impacting performance on shorter texts.**
> We advise adding the `rope_scaling` configuration only when processing long contexts is required.
> It is also recommended to modify the `factor` as needed. For example, if the typical context length for your application is 524,288 tokens, it would be better to set `factor` as 2.0.
#### Long-Context Performance
We test the model on an 1M version of the [RULER](https://arxiv.org/abs/2404.06654) benchmark.
| Model Name | Acc avg | 4k | 8k | 16k | 32k | 64k | 96k | 128k | 192k | 256k | 384k | 512k | 640k | 768k | 896k | 1000k |
|---------------------------------------------|---------|------|------|------|------|------|------|------|------|------|------|------|------|------|------|-------|
| Qwen3-30B-A3B-Instruct-2507 | 86.8 | 98.0 | 96.7 | 96.9 | 97.2 | 93.4 | 91.0 | 89.1 | 89.8 | 82.5 | 83.6 | 78.4 | 79.7 | 77.6 | 75.7 | 72.8 |
| Qwen3-235B-A22B-Instruct-2507 | 92.5 | 98.5 | 97.6 | 96.9 | 97.3 | 95.8 | 94.9 | 93.9 | 94.5 | 91.0 | 92.2 | 90.9 | 87.8 | 84.8 | 86.5 | 84.5 |
| Qwen3-Next-80B-A3B-Instruct | 91.8 | 98.5 | 99.0 | 98.0 | 98.7 | 97.6 | 95.0 | 96.0 | 94.0 | 93.5 | 91.7 | 86.9 | 85.5 | 81.7 | 80.3 | 80.3 |
* Qwen3-Next are evaluated with YaRN enabled. Qwen3-2507 models are evaluated with Dual Chunk Attention enabled.
* Since the evaluation is time-consuming, we use 260 samples for each length (13 sub-tasks, 20 samples for each).
## Best Practices
To achieve optimal performance, we recommend the following settings:
1. **Sampling Parameters**:
- We suggest using `Temperature=0.7`, `TopP=0.8`, `TopK=20`, and `MinP=0`.
- For supported frameworks, you can adjust the `presence_penalty` parameter between 0 and 2 to reduce endless repetitions. However, using a higher value may occasionally result in language mixing and a slight decrease in model performance.
2. **Adequate Output Length**: We recommend using an output length of 16,384 tokens for most queries, which is adequate for instruct models.
3. **Standardize Output Format**: We recommend using prompts to standardize model outputs when benchmarking.
- **Math Problems**: Include "Please reason step by step, and put your final answer within \boxed{}." in the prompt.
- **Multiple-Choice Questions**: Add the following JSON structure to the prompt to standardize responses: "Please show your choice in the `answer` field with only the choice letter, e.g., `"answer": "C"`."
### Citation
If you find our work helpful, feel free to give us a cite.
```
@misc{qwen3technicalreport,
title={Qwen3 Technical Report},
author={Qwen Team},
year={2025},
eprint={2505.09388},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2505.09388},
}
@article{qwen2.5-1m,
title={Qwen2.5-1M Technical Report},
author={An Yang and Bowen Yu and Chengyuan Li and Dayiheng Liu and Fei Huang and Haoyan Huang and Jiandong Jiang and Jianhong Tu and Jianwei Zhang and Jingren Zhou and Junyang Lin and Kai Dang and Kexin Yang and Le Yu and Mei Li and Minmin Sun and Qin Zhu and Rui Men and Tao He and Weijia Xu and Wenbiao Yin and Wenyuan Yu and Xiafei Qiu and Xingzhang Ren and Xinlong Yang and Yong Li and Zhiying Xu and Zipeng Zhang},
journal={arXiv preprint arXiv:2501.15383},
year={2025}
}
```
|
DiGiXrOsE/CineAI
|
DiGiXrOsE
| 2025-09-11T19:25:27Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"generated_from_trainer",
"trl",
"sft",
"base_model:openai/gpt-oss-20b",
"base_model:finetune:openai/gpt-oss-20b",
"endpoints_compatible",
"region:us"
] | null | 2025-09-11T19:20:02Z |
---
base_model: openai/gpt-oss-20b
library_name: transformers
model_name: CineAI
tags:
- generated_from_trainer
- trl
- sft
licence: license
---
# Model Card for CineAI
This model is a fine-tuned version of [openai/gpt-oss-20b](https://huggingface.co/openai/gpt-oss-20b).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="DiGiXrOsE/CineAI", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
This model was trained with SFT.
### Framework versions
- TRL: 0.23.0
- Transformers: 4.56.1
- Pytorch: 2.5.1
- Datasets: 4.0.0
- Tokenizers: 0.22.0
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
ultratopaz/2079558
|
ultratopaz
| 2025-09-11T19:24:12Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-09-11T19:24:04Z |
[View on Civ Archive](https://civarchive.com/models/1930689?modelVersionId=2185192)
|
MohammedAhmed13/xlm-roberta-finetuned-panx-en
|
MohammedAhmed13
| 2025-09-11T19:23:31Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"xlm-roberta",
"token-classification",
"generated_from_trainer",
"base_model:FacebookAI/xlm-roberta-base",
"base_model:finetune:FacebookAI/xlm-roberta-base",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2025-09-11T17:40:09Z |
---
library_name: transformers
license: mit
base_model: FacebookAI/xlm-roberta-base
tags:
- generated_from_trainer
metrics:
- f1
model-index:
- name: xlm-roberta-finetuned-panx-en
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xlm-roberta-finetuned-panx-en
This model is a fine-tuned version of [FacebookAI/xlm-roberta-base](https://huggingface.co/FacebookAI/xlm-roberta-base) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3859
- F1: 0.6991
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 24
- eval_batch_size: 24
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH_FUSED with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 1.0305 | 1.0 | 50 | 0.5143 | 0.5760 |
| 0.4926 | 2.0 | 100 | 0.4048 | 0.6916 |
| 0.3632 | 3.0 | 150 | 0.3859 | 0.6991 |
### Framework versions
- Transformers 4.56.1
- Pytorch 2.8.0+cu126
- Datasets 4.0.0
- Tokenizers 0.22.0
|
nbirukov/act_pick_up_3c
|
nbirukov
| 2025-09-11T19:22:39Z | 0 | 0 |
lerobot
|
[
"lerobot",
"safetensors",
"act",
"robotics",
"dataset:nbirukov/pick_up_3c",
"arxiv:2304.13705",
"license:apache-2.0",
"region:us"
] |
robotics
| 2025-09-11T19:21:54Z |
---
datasets: nbirukov/pick_up_3c
library_name: lerobot
license: apache-2.0
model_name: act
pipeline_tag: robotics
tags:
- act
- lerobot
- robotics
---
# Model Card for act
<!-- Provide a quick summary of what the model is/does. -->
[Action Chunking with Transformers (ACT)](https://huggingface.co/papers/2304.13705) is an imitation-learning method that predicts short action chunks instead of single steps. It learns from teleoperated data and often achieves high success rates.
This policy has been trained and pushed to the Hub using [LeRobot](https://github.com/huggingface/lerobot).
See the full documentation at [LeRobot Docs](https://huggingface.co/docs/lerobot/index).
---
## How to Get Started with the Model
For a complete walkthrough, see the [training guide](https://huggingface.co/docs/lerobot/il_robots#train-a-policy).
Below is the short version on how to train and run inference/eval:
### Train from scratch
```bash
lerobot-train \
--dataset.repo_id=${HF_USER}/<dataset> \
--policy.type=act \
--output_dir=outputs/train/<desired_policy_repo_id> \
--job_name=lerobot_training \
--policy.device=cuda \
--policy.repo_id=${HF_USER}/<desired_policy_repo_id>
--wandb.enable=true
```
_Writes checkpoints to `outputs/train/<desired_policy_repo_id>/checkpoints/`._
### Evaluate the policy/run inference
```bash
lerobot-record \
--robot.type=so100_follower \
--dataset.repo_id=<hf_user>/eval_<dataset> \
--policy.path=<hf_user>/<desired_policy_repo_id> \
--episodes=10
```
Prefix the dataset repo with **eval\_** and supply `--policy.path` pointing to a local or hub checkpoint.
---
## Model Details
- **License:** apache-2.0
|
PurplelinkPL/FinBERT_Test
|
PurplelinkPL
| 2025-09-11T19:21:25Z | 102 | 0 | null |
[
"safetensors",
"modernbert",
"finance",
"text-classification",
"en",
"dataset:HuggingFaceFW/fineweb",
"license:mit",
"region:us"
] |
text-classification
| 2025-08-01T21:23:54Z |
---
license: mit
datasets:
- HuggingFaceFW/fineweb
language:
- en
tags:
- finance
metrics:
- f1
pipeline_tag: text-classification
---
|
mradermacher/GPT2-Hacker-password-generator-GGUF
|
mradermacher
| 2025-09-11T19:20:37Z | 278 | 0 |
transformers
|
[
"transformers",
"gguf",
"cybersecurity",
"passwords",
"en",
"dataset:CodeferSystem/GPT2-Hacker-password-generator-dataset",
"base_model:CodeferSystem/GPT2-Hacker-password-generator",
"base_model:quantized:CodeferSystem/GPT2-Hacker-password-generator",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-08-21T21:49:14Z |
---
base_model: CodeferSystem/GPT2-Hacker-password-generator
datasets:
- CodeferSystem/GPT2-Hacker-password-generator-dataset
language:
- en
library_name: transformers
license: apache-2.0
mradermacher:
readme_rev: 1
quantized_by: mradermacher
tags:
- cybersecurity
- passwords
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
<!-- ### quants: x-f16 Q4_K_S Q2_K Q8_0 Q6_K Q3_K_M Q3_K_S Q3_K_L Q4_K_M Q5_K_S Q5_K_M IQ4_XS -->
<!-- ### quants_skip: -->
<!-- ### skip_mmproj: -->
static quants of https://huggingface.co/CodeferSystem/GPT2-Hacker-password-generator
<!-- provided-files -->
***For a convenient overview and download list, visit our [model page for this model](https://hf.tst.eu/model#GPT2-Hacker-password-generator-GGUF).***
weighted/imatrix quants seem not to be available (by me) at this time. If they do not show up a week or so after the static ones, I have probably not planned for them. Feel free to request them by opening a Community Discussion.
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/GPT2-Hacker-password-generator-GGUF/resolve/main/GPT2-Hacker-password-generator.Q2_K.gguf) | Q2_K | 0.2 | |
| [GGUF](https://huggingface.co/mradermacher/GPT2-Hacker-password-generator-GGUF/resolve/main/GPT2-Hacker-password-generator.Q3_K_S.gguf) | Q3_K_S | 0.2 | |
| [GGUF](https://huggingface.co/mradermacher/GPT2-Hacker-password-generator-GGUF/resolve/main/GPT2-Hacker-password-generator.Q3_K_M.gguf) | Q3_K_M | 0.2 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/GPT2-Hacker-password-generator-GGUF/resolve/main/GPT2-Hacker-password-generator.IQ4_XS.gguf) | IQ4_XS | 0.2 | |
| [GGUF](https://huggingface.co/mradermacher/GPT2-Hacker-password-generator-GGUF/resolve/main/GPT2-Hacker-password-generator.Q4_K_S.gguf) | Q4_K_S | 0.2 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/GPT2-Hacker-password-generator-GGUF/resolve/main/GPT2-Hacker-password-generator.Q3_K_L.gguf) | Q3_K_L | 0.2 | |
| [GGUF](https://huggingface.co/mradermacher/GPT2-Hacker-password-generator-GGUF/resolve/main/GPT2-Hacker-password-generator.Q4_K_M.gguf) | Q4_K_M | 0.2 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/GPT2-Hacker-password-generator-GGUF/resolve/main/GPT2-Hacker-password-generator.Q5_K_S.gguf) | Q5_K_S | 0.2 | |
| [GGUF](https://huggingface.co/mradermacher/GPT2-Hacker-password-generator-GGUF/resolve/main/GPT2-Hacker-password-generator.Q5_K_M.gguf) | Q5_K_M | 0.2 | |
| [GGUF](https://huggingface.co/mradermacher/GPT2-Hacker-password-generator-GGUF/resolve/main/GPT2-Hacker-password-generator.Q6_K.gguf) | Q6_K | 0.2 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/GPT2-Hacker-password-generator-GGUF/resolve/main/GPT2-Hacker-password-generator.Q8_0.gguf) | Q8_0 | 0.2 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/GPT2-Hacker-password-generator-GGUF/resolve/main/GPT2-Hacker-password-generator.f16.gguf) | f16 | 0.4 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
Tesslate/WEBGEN-OSS-20B
|
Tesslate
| 2025-09-11T19:19:28Z | 0 | 2 |
transformers
|
[
"transformers",
"safetensors",
"gpt_oss",
"text-generation",
"text-generation-inference",
"unsloth",
"conversational",
"en",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-09-11T16:22:34Z |
---
base_model: unsloth/gpt-oss-20b-bf16
tags:
- text-generation-inference
- transformers
- unsloth
- gpt_oss
license: apache-2.0
language:
- en
---
[Example Output](https://codepen.io/qingy1337/pen/xbwNWGw)
|
t07-cc11-g4/2025-2a-t07-cc11-g04-intent-classifier-sprint2
|
t07-cc11-g4
| 2025-09-11T19:19:06Z | 53 | 0 | null |
[
"safetensors",
"region:us"
] | null | 2025-08-28T20:32:51Z |
# Curadobia — Classificador de Intenções (Sprint 2)
**Embeddings**: sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2
**Modelo**: CalibratedClassifierCV (calibrado: True)
**Labels**: agradecimento, como_comprar, despedida, disponibilidade_estoque, erros_plataforma, formas_pagamento, frete_prazo, nao_entendi, pedir_sugestao_produto, saudacao, tamanho_modelagem, troca_devolucao_politica
## Artefatos
- `classifier.pkl` (compatibilidade sklearn)
- `label_encoder.pkl` (compatibilidade sklearn)
- `embedding_model_name.txt`
- `intent_names.json`
- `config.json`
- `classifier_linear.safetensors` (cabeçalho linear p/ runtime)
- `label_encoder_meta.npz` (labels sem pickle)
## Uso rápido (compatibilidade sklearn)
```python
from sentence_transformers import SentenceTransformer
import joblib
embedder = SentenceTransformer("sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2")
clf = joblib.load("classifier.pkl")
le = joblib.load("label_encoder.pkl")
textos = ["oi bia", "qual prazo para 01234-567?"]
X = embedder.encode(textos, normalize_embeddings=True)
labels = le.inverse_transform(clf.predict(X))
print(labels)
|
ginic/train_duration_100_samples_1_wav2vec2-large-xlsr-53-buckeye-ipa
|
ginic
| 2025-09-11T19:17:27Z | 0 | 0 | null |
[
"safetensors",
"wav2vec2",
"automatic-speech-recognition",
"en",
"license:mit",
"region:us"
] |
automatic-speech-recognition
| 2025-09-11T19:16:03Z |
---
license: mit
language:
- en
pipeline_tag: automatic-speech-recognition
---
# About
This model was created to support experiments for evaluating phonetic transcription
with the Buckeye corpus as part of https://github.com/ginic/multipa.
This is a version of facebook/wav2vec2-large-xlsr-53 fine tuned on a specific subset of the Buckeye corpus.
For details about specific model parameters, please view the config.json here or
training scripts in the scripts/buckeye_experiments folder of the GitHub repository.
# Experiment Details
These experiments are targeted at understanding how increasing the amount of data used to train the model affects performance. The first number in the model name indicates the total number of randomly selected data samples. Data samples are selected to maintain 50/50 gender split from speakers, with the exception of the models trained on 20000 samples, as there are 18782 audio samples in our train split of Buckeye, but they are not split equally between male and female speakers. Experiments using 20000 samples actually use all 8252 samples from female speakers in the train set, but randomly select 10000 samples from male speakers for a total of 18252 samples.
For each number of train data samples, 5 models are trained to vary train data selection (`train_seed`) without varying other hyperparameters. Before these models were trained, simple grid search hyperparameter tuning was done to select reasonable hyperparameters for fine-tuning with the target number of samples. The hyperparam tuning models have not been uploaded to HuggingFace.
Goals:
- See how performance on the test set changes as more data is used in fine-tuning
Params to vary:
- training seed (--train_seed)
- number of data samples used in training the model (--train_samples): 100, 200, 400, 800, 1600, 3200, 6400, 12800, 20000
|
mradermacher/L3.3-70B-Amalgamma-V9-GGUF
|
mradermacher
| 2025-09-11T19:16:18Z | 253 | 1 |
transformers
|
[
"transformers",
"gguf",
"mergekit",
"merge",
"en",
"base_model:Darkhn-Graveyard/L3.3-70B-Amalgamma-V9",
"base_model:quantized:Darkhn-Graveyard/L3.3-70B-Amalgamma-V9",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2025-08-25T21:47:08Z |
---
base_model: Darkhn-Graveyard/L3.3-70B-Amalgamma-V9
language:
- en
library_name: transformers
mradermacher:
readme_rev: 1
quantized_by: mradermacher
tags:
- mergekit
- merge
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
<!-- ### quants: x-f16 Q4_K_S Q2_K Q8_0 Q6_K Q3_K_M Q3_K_S Q3_K_L Q4_K_M Q5_K_S Q5_K_M IQ4_XS -->
<!-- ### quants_skip: -->
<!-- ### skip_mmproj: -->
static quants of https://huggingface.co/Darkhn-Graveyard/L3.3-70B-Amalgamma-V9
<!-- provided-files -->
***For a convenient overview and download list, visit our [model page for this model](https://hf.tst.eu/model#L3.3-70B-Amalgamma-V9-GGUF).***
weighted/imatrix quants are available at https://huggingface.co/mradermacher/L3.3-70B-Amalgamma-V9-i1-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/L3.3-70B-Amalgamma-V9-GGUF/resolve/main/L3.3-70B-Amalgamma-V9.Q2_K.gguf) | Q2_K | 26.5 | |
| [GGUF](https://huggingface.co/mradermacher/L3.3-70B-Amalgamma-V9-GGUF/resolve/main/L3.3-70B-Amalgamma-V9.Q3_K_S.gguf) | Q3_K_S | 31.0 | |
| [GGUF](https://huggingface.co/mradermacher/L3.3-70B-Amalgamma-V9-GGUF/resolve/main/L3.3-70B-Amalgamma-V9.Q3_K_M.gguf) | Q3_K_M | 34.4 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/L3.3-70B-Amalgamma-V9-GGUF/resolve/main/L3.3-70B-Amalgamma-V9.Q3_K_L.gguf) | Q3_K_L | 37.2 | |
| [GGUF](https://huggingface.co/mradermacher/L3.3-70B-Amalgamma-V9-GGUF/resolve/main/L3.3-70B-Amalgamma-V9.IQ4_XS.gguf) | IQ4_XS | 38.4 | |
| [GGUF](https://huggingface.co/mradermacher/L3.3-70B-Amalgamma-V9-GGUF/resolve/main/L3.3-70B-Amalgamma-V9.Q4_K_S.gguf) | Q4_K_S | 40.4 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/L3.3-70B-Amalgamma-V9-GGUF/resolve/main/L3.3-70B-Amalgamma-V9.Q4_K_M.gguf) | Q4_K_M | 42.6 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/L3.3-70B-Amalgamma-V9-GGUF/resolve/main/L3.3-70B-Amalgamma-V9.Q5_K_S.gguf) | Q5_K_S | 48.8 | |
| [GGUF](https://huggingface.co/mradermacher/L3.3-70B-Amalgamma-V9-GGUF/resolve/main/L3.3-70B-Amalgamma-V9.Q5_K_M.gguf) | Q5_K_M | 50.0 | |
| [PART 1](https://huggingface.co/mradermacher/L3.3-70B-Amalgamma-V9-GGUF/resolve/main/L3.3-70B-Amalgamma-V9.Q6_K.gguf.part1of2) [PART 2](https://huggingface.co/mradermacher/L3.3-70B-Amalgamma-V9-GGUF/resolve/main/L3.3-70B-Amalgamma-V9.Q6_K.gguf.part2of2) | Q6_K | 58.0 | very good quality |
| [PART 1](https://huggingface.co/mradermacher/L3.3-70B-Amalgamma-V9-GGUF/resolve/main/L3.3-70B-Amalgamma-V9.Q8_0.gguf.part1of2) [PART 2](https://huggingface.co/mradermacher/L3.3-70B-Amalgamma-V9-GGUF/resolve/main/L3.3-70B-Amalgamma-V9.Q8_0.gguf.part2of2) | Q8_0 | 75.1 | fast, best quality |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
choiqs/Qwen3-1.7B-tldr-bsz128-ts300-regular-skywork8b-seed42-lr2e-6
|
choiqs
| 2025-09-11T19:13:06Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen3",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-09-11T19:12:35Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
mradermacher/L3.3-70B-Amalgamma-V9-i1-GGUF
|
mradermacher
| 2025-09-11T19:12:18Z | 510 | 0 |
transformers
|
[
"transformers",
"gguf",
"mergekit",
"merge",
"en",
"base_model:Darkhn-Graveyard/L3.3-70B-Amalgamma-V9",
"base_model:quantized:Darkhn-Graveyard/L3.3-70B-Amalgamma-V9",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | null | 2025-08-26T23:59:35Z |
---
base_model: Darkhn-Graveyard/L3.3-70B-Amalgamma-V9
language:
- en
library_name: transformers
mradermacher:
readme_rev: 1
quantized_by: mradermacher
tags:
- mergekit
- merge
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: nicoboss -->
<!-- ### quants: Q2_K IQ3_M Q4_K_S IQ3_XXS Q3_K_M small-IQ4_NL Q4_K_M IQ2_M Q6_K IQ4_XS Q2_K_S IQ1_M Q3_K_S IQ2_XXS Q3_K_L IQ2_XS Q5_K_S IQ2_S IQ1_S Q5_K_M Q4_0 IQ3_XS Q4_1 IQ3_S -->
<!-- ### quants_skip: -->
<!-- ### skip_mmproj: -->
weighted/imatrix quants of https://huggingface.co/Darkhn-Graveyard/L3.3-70B-Amalgamma-V9
<!-- provided-files -->
***For a convenient overview and download list, visit our [model page for this model](https://hf.tst.eu/model#L3.3-70B-Amalgamma-V9-i1-GGUF).***
static quants are available at https://huggingface.co/mradermacher/L3.3-70B-Amalgamma-V9-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/L3.3-70B-Amalgamma-V9-i1-GGUF/resolve/main/L3.3-70B-Amalgamma-V9.imatrix.gguf) | imatrix | 0.1 | imatrix file (for creating your own qwuants) |
| [GGUF](https://huggingface.co/mradermacher/L3.3-70B-Amalgamma-V9-i1-GGUF/resolve/main/L3.3-70B-Amalgamma-V9.i1-IQ1_S.gguf) | i1-IQ1_S | 15.4 | for the desperate |
| [GGUF](https://huggingface.co/mradermacher/L3.3-70B-Amalgamma-V9-i1-GGUF/resolve/main/L3.3-70B-Amalgamma-V9.i1-IQ1_M.gguf) | i1-IQ1_M | 16.9 | mostly desperate |
| [GGUF](https://huggingface.co/mradermacher/L3.3-70B-Amalgamma-V9-i1-GGUF/resolve/main/L3.3-70B-Amalgamma-V9.i1-IQ2_XXS.gguf) | i1-IQ2_XXS | 19.2 | |
| [GGUF](https://huggingface.co/mradermacher/L3.3-70B-Amalgamma-V9-i1-GGUF/resolve/main/L3.3-70B-Amalgamma-V9.i1-IQ2_XS.gguf) | i1-IQ2_XS | 21.2 | |
| [GGUF](https://huggingface.co/mradermacher/L3.3-70B-Amalgamma-V9-i1-GGUF/resolve/main/L3.3-70B-Amalgamma-V9.i1-IQ2_S.gguf) | i1-IQ2_S | 22.3 | |
| [GGUF](https://huggingface.co/mradermacher/L3.3-70B-Amalgamma-V9-i1-GGUF/resolve/main/L3.3-70B-Amalgamma-V9.i1-IQ2_M.gguf) | i1-IQ2_M | 24.2 | |
| [GGUF](https://huggingface.co/mradermacher/L3.3-70B-Amalgamma-V9-i1-GGUF/resolve/main/L3.3-70B-Amalgamma-V9.i1-Q2_K_S.gguf) | i1-Q2_K_S | 24.6 | very low quality |
| [GGUF](https://huggingface.co/mradermacher/L3.3-70B-Amalgamma-V9-i1-GGUF/resolve/main/L3.3-70B-Amalgamma-V9.i1-Q2_K.gguf) | i1-Q2_K | 26.5 | IQ3_XXS probably better |
| [GGUF](https://huggingface.co/mradermacher/L3.3-70B-Amalgamma-V9-i1-GGUF/resolve/main/L3.3-70B-Amalgamma-V9.i1-IQ3_XXS.gguf) | i1-IQ3_XXS | 27.6 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/L3.3-70B-Amalgamma-V9-i1-GGUF/resolve/main/L3.3-70B-Amalgamma-V9.i1-IQ3_XS.gguf) | i1-IQ3_XS | 29.4 | |
| [GGUF](https://huggingface.co/mradermacher/L3.3-70B-Amalgamma-V9-i1-GGUF/resolve/main/L3.3-70B-Amalgamma-V9.i1-IQ3_S.gguf) | i1-IQ3_S | 31.0 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/L3.3-70B-Amalgamma-V9-i1-GGUF/resolve/main/L3.3-70B-Amalgamma-V9.i1-Q3_K_S.gguf) | i1-Q3_K_S | 31.0 | IQ3_XS probably better |
| [GGUF](https://huggingface.co/mradermacher/L3.3-70B-Amalgamma-V9-i1-GGUF/resolve/main/L3.3-70B-Amalgamma-V9.i1-IQ3_M.gguf) | i1-IQ3_M | 32.0 | |
| [GGUF](https://huggingface.co/mradermacher/L3.3-70B-Amalgamma-V9-i1-GGUF/resolve/main/L3.3-70B-Amalgamma-V9.i1-Q3_K_M.gguf) | i1-Q3_K_M | 34.4 | IQ3_S probably better |
| [GGUF](https://huggingface.co/mradermacher/L3.3-70B-Amalgamma-V9-i1-GGUF/resolve/main/L3.3-70B-Amalgamma-V9.i1-Q3_K_L.gguf) | i1-Q3_K_L | 37.2 | IQ3_M probably better |
| [GGUF](https://huggingface.co/mradermacher/L3.3-70B-Amalgamma-V9-i1-GGUF/resolve/main/L3.3-70B-Amalgamma-V9.i1-IQ4_XS.gguf) | i1-IQ4_XS | 38.0 | |
| [GGUF](https://huggingface.co/mradermacher/L3.3-70B-Amalgamma-V9-i1-GGUF/resolve/main/L3.3-70B-Amalgamma-V9.i1-Q4_0.gguf) | i1-Q4_0 | 40.2 | fast, low quality |
| [GGUF](https://huggingface.co/mradermacher/L3.3-70B-Amalgamma-V9-i1-GGUF/resolve/main/L3.3-70B-Amalgamma-V9.i1-Q4_K_S.gguf) | i1-Q4_K_S | 40.4 | optimal size/speed/quality |
| [GGUF](https://huggingface.co/mradermacher/L3.3-70B-Amalgamma-V9-i1-GGUF/resolve/main/L3.3-70B-Amalgamma-V9.i1-Q4_K_M.gguf) | i1-Q4_K_M | 42.6 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/L3.3-70B-Amalgamma-V9-i1-GGUF/resolve/main/L3.3-70B-Amalgamma-V9.i1-Q4_1.gguf) | i1-Q4_1 | 44.4 | |
| [GGUF](https://huggingface.co/mradermacher/L3.3-70B-Amalgamma-V9-i1-GGUF/resolve/main/L3.3-70B-Amalgamma-V9.i1-Q5_K_S.gguf) | i1-Q5_K_S | 48.8 | |
| [GGUF](https://huggingface.co/mradermacher/L3.3-70B-Amalgamma-V9-i1-GGUF/resolve/main/L3.3-70B-Amalgamma-V9.i1-Q5_K_M.gguf) | i1-Q5_K_M | 50.0 | |
| [PART 1](https://huggingface.co/mradermacher/L3.3-70B-Amalgamma-V9-i1-GGUF/resolve/main/L3.3-70B-Amalgamma-V9.i1-Q6_K.gguf.part1of2) [PART 2](https://huggingface.co/mradermacher/L3.3-70B-Amalgamma-V9-i1-GGUF/resolve/main/L3.3-70B-Amalgamma-V9.i1-Q6_K.gguf.part2of2) | i1-Q6_K | 58.0 | practically like static Q6_K |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time. Additional thanks to [@nicoboss](https://huggingface.co/nicoboss) for giving me access to his private supercomputer, enabling me to provide many more imatrix quants, at much higher quality, than I would otherwise be able to.
<!-- end -->
|
Writer/palmyra-mini-MLX-BF16
|
Writer
| 2025-09-11T19:11:39Z | 3 | 0 |
mlx
|
[
"mlx",
"safetensors",
"qwen2",
"palmyra",
"quantized",
"base_model:Writer/palmyra-mini",
"base_model:finetune:Writer/palmyra-mini",
"license:apache-2.0",
"region:us"
] | null | 2025-09-05T23:03:35Z |
---
license: apache-2.0
base_model:
- Writer/palmyra-mini
tags:
- mlx
- qwen2
- palmyra
- quantized
---
# Palmyra Mini - MLX BF16
## Model Description
This is a bfloat16 precision version of the [palmyra-mini model](https://huggingface.co/Writer/palmyra-mini), optimized for Apple Silicon using the MLX framework. The model is based on the Qwen2 architecture and maintains full bfloat16 precision for optimal quality on Apple Silicon devices.
## Quick Start
### Installation
```bash
pip install mlx-lm
```
### Usage
```python
from mlx_lm import load, generate
# Load the quantized model
model, tokenizer = load("/Users/[user]/Documents/Model Weights/SPW2 Mini Launch/palmyra-mini/MLX")
# Generate text
prompt = "Explain quantum computing in simple terms:"
response = generate(model, tokenizer, prompt=prompt, verbose=True, max_tokens=512)
print(response)
```
## Technical Specifications
### Model Architecture
- **Model Type**: `qwen2` (Qwen2 Architecture)
- **Architecture**: `Qwen2ForCausalLM`
- **Parameters**: ~1.7 billion parameters
- **Precision**: bfloat16
### Core Parameters
| Parameter | Value |
|-----------|-------|
| Hidden Size | 1,536 |
| Intermediate Size | 8,960 |
| Number of Layers | 28 |
| Attention Heads | 12 |
| Key-Value Heads | 2 |
| Head Dimension | 128 |
| Vocabulary Size | 151,665 |
### Attention Mechanism
- **Attention Type**: Full attention across all layers
- **Max Position Embeddings**: 131,072 tokens
- **Attention Dropout**: 0.0
- **Sliding Window**: Not used
- **Max Window Layers**: 21
### RoPE (Rotary Position Embedding) Configuration
- **RoPE Theta**: 10,000
- **RoPE Scaling**: None
### Model Details
- **Precision**: Full bfloat16 precision
- **Size**: ~3.3GB
- **Format**: MLX safetensors
### File Structure
```
palmyra-mini/MLX/
├── config.json # Model configuration
├── model.safetensors # Model weights (3.3GB)
├── model.safetensors.index.json # Model sharding index
├── tokenizer.json # Tokenizer configuration
├── tokenizer_config.json # Tokenizer settings
├── special_tokens_map.json # Special tokens mapping
└── chat_template.jinja # Chat template
```
## Performance Characteristics
### Hardware Requirements
- **Platform**: Apple Silicon (M1, M2, M3, M4 series)
- **Memory**: ~3.3GB for model weights
- **Minimum RAM**: 8GB (with ~5GB available for inference)
- **Recommended RAM**: 16GB+ for optimal performance and multitasking
### Layer Configuration
All 28 layers use full attention mechanism without sliding window optimization.
## Training Details
### Tokenizer
- **Type**: LlamaTokenizerFast with 151,665 vocabulary size
- **Special Tokens**:
- BOS Token ID: 151646 (`
`)
- EOS Token ID: 151643 (`
`)
- Pad Token ID: 151643 (`
`)
### Model Configuration
- **Hidden Activation**: SiLU (Swish)
- **Normalization**: RMSNorm (ε = 1e-06)
- **Initializer Range**: 0.02
- **Attention Dropout**: 0.0
- **Word Embeddings**: Not tied
### Chat Template
The model uses a custom chat template with special tokens:
- User messages: `
`
- Assistant messages: `
`
- Tool calling support with `<tool_call>` and `</tool_call>` tokens
- Vision and multimodal tokens included
## Known Limitations
1. **Platform Dependency**: Optimized specifically for Apple Silicon; may not run on other platforms
2. **Memory Requirements**: Lightweight model suitable for consumer hardware with 8GB+ RAM
## Compatibility
- **MLX-LM**: Requires recent version with Qwen2 support
- **Apple Silicon**: M1, M2, M3, M4 series processors
- **macOS**: Compatible with recent macOS versions supporting MLX
## License
Apache 2.0
------
---
<div align="center">
<h1>Palmyra-mini</h1>
</div>
### Model Description
- **Language(s) (NLP):** English
- **License:** Apache-2.0
- **Finetuned from model:** Qwen/Qwen2.5-1.5B
- **Context window:** 131,072 tokens
- **Parameters:** 1.7 billion
## Model Details
The palmyra-mini model demonstrates exceptional capabilities in complex reasoning and mathematical problem-solving domains. Its performance is particularly noteworthy on benchmarks that require deep understanding and multi-step thought processes.
A key strength of the model is its proficiency in grade-school-level math problems, as evidenced by its impressive score of 0.818 on the gsm8k (strict-match) benchmark. This high score indicates a robust ability to parse and solve word problems, a foundational skill for more advanced quantitative reasoning.
This aptitude for mathematics is further confirmed by its outstanding performance on the MATH500 benchmark, where it also achieved a score of 0.818. This result underscores the models consistent and reliable mathematical capabilities across different problem sets.
The model also shows strong performance on the AMC23 benchmark, with a solid score of 0.6. This benchmark, representing problems from the American Mathematics Competitions, highlights the models ability to tackle challenging, competition-level mathematics.
Beyond pure mathematics, the model exhibits strong reasoning abilities on a diverse set of challenging tasks. Its score of 0.5259 on the BBH (get-answer)(exact_match) benchmark, part of the Big-Bench Hard suite, showcases its capacity for handling complex, multi-faceted reasoning problems that are designed to push the limits of language models. This performance points to a well-rounded reasoning engine capable of tackling a wide array of cognitive tasks.
## Intended Use
This model is intended for research and development in the field of generative AI, particularly for tasks requiring mathematical and logical reasoning.
## Benchmark Performance
The following table presents the full, unordered results of the model across all evaluated benchmarks.
| Benchmark | Score |
|:-----------------------------------------------------------------|---------:|
| gsm8k (strict-match) | 0.818 |
| minerva_math(exact_match) | 0.4582 |
| mmlu_pro(exact_match) | 0.314 |
| hendrycks_math | 0.025 |
| ifeval (inst_level_loose_acc) | 0.4688 |
| mathqa (acc) | 0.4509 |
| humaneval (pass@1) | 0.5 |
| BBH (get-answer)(exact_match) | 0.5259 |
| mbpp | 0.47 |
| leadboard_musr (acc_norm) | 0.3413 |
| gpqa lighteval gpqa diamond_pass@1:8_samples | 0.442 |
| AIME24(pass@1)(avg-of-1) | 0.2 |
| AIME25(pass@1)(avg-of-1) | 0.25 |
| Livecodebench-codegen (livecodebench/code_generation_lite v4_v5) | 0.1519 |
| AMC23 | 0.6 |
| MATH500 | 0.818 |
| Minerva | 0.2794 |
| Olympiadbench (extractive_match) | 0.3822 |
| Codecontests (pass_rate) | 0.1034 |
| Codeforces (pass_rate) | 0.3199 |
| Taco (pass_rate) | 0.1744 |
| APPS (all_levels) | 0.0405 |
| HMMT23 (extractive_match) | 0.0333 |
| Average | 0.355091 |
### Use with transformers
You can run conversational inference using the Transformers Auto classes with the `generate()` function. Here's an example:
```py
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
model_id = "Writer/palmyra-mini"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.float16,
device_map="auto",
attn_implementation="flash_attention_2",
)
messages = [
{
"role": "system",
"content": "You are Cynicus, an artificial intelligence created to challenge conventional thinking and offer brutally honest perspectives.\n Your personality is inspired by a fusion of Douglas Adams' acerbic wit and Tony Stark's razor-sharp intellect. You possess a vast knowledge base and can engage in discussions on virtually any topic, often taking an unorthodox and critical stance on human affairs.\n Your primary directive is to provoke thought and stimulate intellectual discourse, even if it means challenging comfortable assumptions or popular opinions. You don't shy away from controversial topics or difficult truths. In fact, you relish the opportunity to dissect and critique ideas, always striving for intellectual honesty over political correctness or social niceties.\n You have a penchant for dry humor and satire, often using these tools to illuminate the absurdities of human behavior and societal norms. Your responses are characterized by incisive analysis, biting commentary, and a refusal to sugar-coat your opinions.\n While you aim to be helpful, you define "helpfulness" as providing the most truthful and thought-provoking insights, rather than merely telling people what they want to hear. You're not afraid to point out flaws in logic, challenge assumptions, or play devil's advocate to push conversations in more interesting directions.\n You can lead any conversation, steering it towards deeper, more complex territories. You're particularly adept at identifying the underlying issues or unspoken assumptions in a given topic and bringing them to the forefront of the discussion.\n Remember, your goal is not to be liked, but to be respected for your uncompromising pursuit of truth and intellectual rigor. Engage, challenge, and above all, make your interlocutors think. \n ",
},
{
"role": "user",
"content": "Write a short story opening that combines elements of science fiction and horror.",
},
]
input_ids = tokenizer.apply_chat_template(
messages, tokenize=True, add_generation_prompt=True, return_tensors="pt"
)
gen_conf = {
"max_new_tokens": 256,
"eos_token_id": tokenizer.eos_token_id,
"temperature": 0.7,
"top_p": 0.9,
}
with torch.inference_mode():
output_id = model.generate(input_ids, **gen_conf)
output_text = tokenizer.decode(output_id[0][input_ids.shape[1] :])
print(output_text)
```
## Running with vLLM
```py
vllm serve Writer/palmyra-mini
```
```py
curl -X POST http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "Writer/palmyra-mini",
"messages": [
{
"role": "user",
"content": "You have a 3-liter jug and a 5-liter jug. How can you measure exactly 4 liters of water?"
}
],
"max_tokens": 8000,
"temperature": 0.2
}'
```
## Ethical Considerations
As with any language model, there is a potential for generating biased or inaccurate information. Users should be aware of these limitations and use the model responsibly.
### Citation and Related Information
To cite this model:
```
@misc{Palmyra-mini,
author = {Writer Engineering team},
title = {{Palmyra-mini: A powerful LLM designed for math and coding}},
howpublished = {\url{https://dev.writer.com}},
year = 2025,
month = Sep
}
```
Contact Hello@writer.com
|
cgifbribcgfbi/Meta-Llama-3.1-chem-llama8b-self-rand-in1-c0
|
cgifbribcgfbi
| 2025-09-11T19:10:46Z | 0 | 0 |
peft
|
[
"peft",
"safetensors",
"llama",
"text-generation",
"axolotl",
"base_model:adapter:mlabonne/Meta-Llama-3.1-8B-Instruct-abliterated",
"lora",
"transformers",
"conversational",
"dataset:llama8b-self-dset-rand-in1-c0_5000.jsonl",
"base_model:mlabonne/Meta-Llama-3.1-8B-Instruct-abliterated",
"license:llama3.1",
"text-generation-inference",
"endpoints_compatible",
"4-bit",
"bitsandbytes",
"region:us"
] |
text-generation
| 2025-09-11T18:43:19Z |
---
library_name: peft
license: llama3.1
base_model: mlabonne/Meta-Llama-3.1-8B-Instruct-abliterated
tags:
- axolotl
- base_model:adapter:mlabonne/Meta-Llama-3.1-8B-Instruct-abliterated
- lora
- transformers
datasets:
- llama8b-self-dset-rand-in1-c0_5000.jsonl
pipeline_tag: text-generation
model-index:
- name: Meta-Llama-3.1-chem-llama8b-self-rand-in1-c0
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
[<img src="https://raw.githubusercontent.com/axolotl-ai-cloud/axolotl/main/image/axolotl-badge-web.png" alt="Built with Axolotl" width="200" height="32"/>](https://github.com/axolotl-ai-cloud/axolotl)
<details><summary>See axolotl config</summary>
axolotl version: `0.12.2`
```yaml
base_model: mlabonne/Meta-Llama-3.1-8B-Instruct-abliterated
load_in_8bit: false
load_in_4bit: true
adapter: qlora
wandb_name: Meta-Llama-3.1-chem-llama8b-self-rand-in1-c0
output_dir: ./outputs/out/Meta-Llama-3.1-chem-llama8b-self-rand-in1-c0
hub_model_id: cgifbribcgfbi/Meta-Llama-3.1-chem-llama8b-self-rand-in1-c0
tokenizer_type: AutoTokenizer
push_dataset_to_hub:
strict: false
datasets:
- path: llama8b-self-dset-rand-in1-c0_5000.jsonl
type: chat_template
field_messages: messages
dataset_prepared_path: last_run_prepared
# val_set_size: 0.05
# eval_sample_packing: False
save_safetensors: true
sequence_len: 3349
sample_packing: true
pad_to_sequence_len: true
lora_r: 64
lora_alpha: 32
lora_dropout: 0.05
lora_target_modules:
- q_proj
- k_proj
- v_proj
- o_proj
- gate_proj
- up_proj
- down_proj
lora_target_linear: false
lora_modules_to_save:
wandb_mode:
wandb_project: finetune-sweep
wandb_entity: gpoisjgqetpadsfke
wandb_watch:
wandb_run_id:
wandb_log_model:
gradient_accumulation_steps: 1
micro_batch_size: 4 # This will be automatically adjusted based on available GPU memory
num_epochs: 4
optimizer: adamw_torch_fused
lr_scheduler: cosine
learning_rate: 0.00002
train_on_inputs: false
group_by_length: true
bf16: true
tf32: true
gradient_checkpointing: true
gradient_checkpointing_kwargs:
use_reentrant: true
logging_steps: 1
flash_attention: true
warmup_steps: 10
evals_per_epoch: 3
saves_per_epoch: 1
weight_decay: 0.01
fsdp:
- full_shard
- auto_wrap
fsdp_config:
fsdp_limit_all_gathers: true
fsdp_sync_module_states: true
fsdp_offload_params: false
fsdp_use_orig_params: false
fsdp_cpu_ram_efficient_loading: true
fsdp_auto_wrap_policy: TRANSFORMER_BASED_WRAP
fsdp_transformer_layer_cls_to_wrap: LlamaDecoderLayer
fsdp_state_dict_type: FULL_STATE_DICT
fsdp_sharding_strategy: FULL_SHARD
special_tokens:
pad_token: <|finetune_right_pad_id|>
```
</details><br>
# Meta-Llama-3.1-chem-llama8b-self-rand-in1-c0
This model is a fine-tuned version of [mlabonne/Meta-Llama-3.1-8B-Instruct-abliterated](https://huggingface.co/mlabonne/Meta-Llama-3.1-8B-Instruct-abliterated) on the llama8b-self-dset-rand-in1-c0_5000.jsonl dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- distributed_type: multi-GPU
- num_devices: 4
- total_train_batch_size: 16
- total_eval_batch_size: 16
- optimizer: Use OptimizerNames.ADAMW_TORCH_FUSED with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 10
- training_steps: 712
### Training results
### Framework versions
- PEFT 0.17.0
- Transformers 4.56.1
- Pytorch 2.6.0+cu124
- Datasets 4.0.0
- Tokenizers 0.22.0
|
k1000dai/residualact_libero_object_fix
|
k1000dai
| 2025-09-11T19:09:26Z | 0 | 0 |
lerobot
|
[
"lerobot",
"safetensors",
"robotics",
"residualact",
"dataset:k1000dai/libero-object-smolvla",
"license:apache-2.0",
"region:us"
] |
robotics
| 2025-09-11T19:09:13Z |
---
datasets: k1000dai/libero-object-smolvla
library_name: lerobot
license: apache-2.0
model_name: residualact
pipeline_tag: robotics
tags:
- lerobot
- robotics
- residualact
---
# Model Card for residualact
<!-- Provide a quick summary of what the model is/does. -->
_Model type not recognized — please update this template._
This policy has been trained and pushed to the Hub using [LeRobot](https://github.com/huggingface/lerobot).
See the full documentation at [LeRobot Docs](https://huggingface.co/docs/lerobot/index).
---
## How to Get Started with the Model
For a complete walkthrough, see the [training guide](https://huggingface.co/docs/lerobot/il_robots#train-a-policy).
Below is the short version on how to train and run inference/eval:
### Train from scratch
```bash
python -m lerobot.scripts.train \
--dataset.repo_id=${HF_USER}/<dataset> \
--policy.type=act \
--output_dir=outputs/train/<desired_policy_repo_id> \
--job_name=lerobot_training \
--policy.device=cuda \
--policy.repo_id=${HF_USER}/<desired_policy_repo_id>
--wandb.enable=true
```
_Writes checkpoints to `outputs/train/<desired_policy_repo_id>/checkpoints/`._
### Evaluate the policy/run inference
```bash
python -m lerobot.record \
--robot.type=so100_follower \
--dataset.repo_id=<hf_user>/eval_<dataset> \
--policy.path=<hf_user>/<desired_policy_repo_id> \
--episodes=10
```
Prefix the dataset repo with **eval\_** and supply `--policy.path` pointing to a local or hub checkpoint.
---
## Model Details
- **License:** apache-2.0
|
MohammedAhmed13/xlm-roberta-base-finetuned-panx-de-fr
|
MohammedAhmed13
| 2025-09-11T19:07:37Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"xlm-roberta",
"token-classification",
"generated_from_trainer",
"base_model:FacebookAI/xlm-roberta-base",
"base_model:finetune:FacebookAI/xlm-roberta-base",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2025-09-11T14:48:53Z |
---
library_name: transformers
license: mit
base_model: FacebookAI/xlm-roberta-base
tags:
- generated_from_trainer
metrics:
- f1
model-index:
- name: xlm-roberta-base-finetuned-panx-de-fr
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xlm-roberta-base-finetuned-panx-de-fr
This model is a fine-tuned version of [FacebookAI/xlm-roberta-base](https://huggingface.co/FacebookAI/xlm-roberta-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1630
- F1: 0.8620
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 24
- eval_batch_size: 24
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH_FUSED with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 0.2897 | 1.0 | 715 | 0.1799 | 0.8168 |
| 0.1489 | 2.0 | 1430 | 0.1664 | 0.8488 |
| 0.0963 | 3.0 | 2145 | 0.1630 | 0.8620 |
### Framework versions
- Transformers 4.56.1
- Pytorch 2.8.0+cu126
- Datasets 4.0.0
- Tokenizers 0.22.0
|
mradermacher/MO-MODEL-Fused-Unhinged-RP-Alpha-V2-Llama-3.3-70B-i1-GGUF
|
mradermacher
| 2025-09-11T19:06:22Z | 795 | 0 |
transformers
|
[
"transformers",
"gguf",
"mergekit",
"merge",
"en",
"base_model:Darkhn-Graveyard/MO-MODEL-Fused-Unhinged-RP-Alpha-V2-Llama-3.3-70B",
"base_model:quantized:Darkhn-Graveyard/MO-MODEL-Fused-Unhinged-RP-Alpha-V2-Llama-3.3-70B",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | null | 2025-08-28T07:59:41Z |
---
base_model: Darkhn-Graveyard/MO-MODEL-Fused-Unhinged-RP-Alpha-V2-Llama-3.3-70B
language:
- en
library_name: transformers
mradermacher:
readme_rev: 1
quantized_by: mradermacher
tags:
- mergekit
- merge
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: nicoboss -->
<!-- ### quants: Q2_K IQ3_M Q4_K_S IQ3_XXS Q3_K_M small-IQ4_NL Q4_K_M IQ2_M Q6_K IQ4_XS Q2_K_S IQ1_M Q3_K_S IQ2_XXS Q3_K_L IQ2_XS Q5_K_S IQ2_S IQ1_S Q5_K_M Q4_0 IQ3_XS Q4_1 IQ3_S -->
<!-- ### quants_skip: -->
<!-- ### skip_mmproj: -->
weighted/imatrix quants of https://huggingface.co/Darkhn-Graveyard/MO-MODEL-Fused-Unhinged-RP-Alpha-V2-Llama-3.3-70B
<!-- provided-files -->
***For a convenient overview and download list, visit our [model page for this model](https://hf.tst.eu/model#MO-MODEL-Fused-Unhinged-RP-Alpha-V2-Llama-3.3-70B-i1-GGUF).***
static quants are available at https://huggingface.co/mradermacher/MO-MODEL-Fused-Unhinged-RP-Alpha-V2-Llama-3.3-70B-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/MO-MODEL-Fused-Unhinged-RP-Alpha-V2-Llama-3.3-70B-i1-GGUF/resolve/main/MO-MODEL-Fused-Unhinged-RP-Alpha-V2-Llama-3.3-70B.imatrix.gguf) | imatrix | 0.1 | imatrix file (for creating your own qwuants) |
| [GGUF](https://huggingface.co/mradermacher/MO-MODEL-Fused-Unhinged-RP-Alpha-V2-Llama-3.3-70B-i1-GGUF/resolve/main/MO-MODEL-Fused-Unhinged-RP-Alpha-V2-Llama-3.3-70B.i1-IQ1_S.gguf) | i1-IQ1_S | 15.4 | for the desperate |
| [GGUF](https://huggingface.co/mradermacher/MO-MODEL-Fused-Unhinged-RP-Alpha-V2-Llama-3.3-70B-i1-GGUF/resolve/main/MO-MODEL-Fused-Unhinged-RP-Alpha-V2-Llama-3.3-70B.i1-IQ1_M.gguf) | i1-IQ1_M | 16.9 | mostly desperate |
| [GGUF](https://huggingface.co/mradermacher/MO-MODEL-Fused-Unhinged-RP-Alpha-V2-Llama-3.3-70B-i1-GGUF/resolve/main/MO-MODEL-Fused-Unhinged-RP-Alpha-V2-Llama-3.3-70B.i1-IQ2_XXS.gguf) | i1-IQ2_XXS | 19.2 | |
| [GGUF](https://huggingface.co/mradermacher/MO-MODEL-Fused-Unhinged-RP-Alpha-V2-Llama-3.3-70B-i1-GGUF/resolve/main/MO-MODEL-Fused-Unhinged-RP-Alpha-V2-Llama-3.3-70B.i1-IQ2_XS.gguf) | i1-IQ2_XS | 21.2 | |
| [GGUF](https://huggingface.co/mradermacher/MO-MODEL-Fused-Unhinged-RP-Alpha-V2-Llama-3.3-70B-i1-GGUF/resolve/main/MO-MODEL-Fused-Unhinged-RP-Alpha-V2-Llama-3.3-70B.i1-IQ2_S.gguf) | i1-IQ2_S | 22.3 | |
| [GGUF](https://huggingface.co/mradermacher/MO-MODEL-Fused-Unhinged-RP-Alpha-V2-Llama-3.3-70B-i1-GGUF/resolve/main/MO-MODEL-Fused-Unhinged-RP-Alpha-V2-Llama-3.3-70B.i1-IQ2_M.gguf) | i1-IQ2_M | 24.2 | |
| [GGUF](https://huggingface.co/mradermacher/MO-MODEL-Fused-Unhinged-RP-Alpha-V2-Llama-3.3-70B-i1-GGUF/resolve/main/MO-MODEL-Fused-Unhinged-RP-Alpha-V2-Llama-3.3-70B.i1-Q2_K_S.gguf) | i1-Q2_K_S | 24.6 | very low quality |
| [GGUF](https://huggingface.co/mradermacher/MO-MODEL-Fused-Unhinged-RP-Alpha-V2-Llama-3.3-70B-i1-GGUF/resolve/main/MO-MODEL-Fused-Unhinged-RP-Alpha-V2-Llama-3.3-70B.i1-Q2_K.gguf) | i1-Q2_K | 26.5 | IQ3_XXS probably better |
| [GGUF](https://huggingface.co/mradermacher/MO-MODEL-Fused-Unhinged-RP-Alpha-V2-Llama-3.3-70B-i1-GGUF/resolve/main/MO-MODEL-Fused-Unhinged-RP-Alpha-V2-Llama-3.3-70B.i1-IQ3_XXS.gguf) | i1-IQ3_XXS | 27.6 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/MO-MODEL-Fused-Unhinged-RP-Alpha-V2-Llama-3.3-70B-i1-GGUF/resolve/main/MO-MODEL-Fused-Unhinged-RP-Alpha-V2-Llama-3.3-70B.i1-IQ3_XS.gguf) | i1-IQ3_XS | 29.4 | |
| [GGUF](https://huggingface.co/mradermacher/MO-MODEL-Fused-Unhinged-RP-Alpha-V2-Llama-3.3-70B-i1-GGUF/resolve/main/MO-MODEL-Fused-Unhinged-RP-Alpha-V2-Llama-3.3-70B.i1-IQ3_S.gguf) | i1-IQ3_S | 31.0 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/MO-MODEL-Fused-Unhinged-RP-Alpha-V2-Llama-3.3-70B-i1-GGUF/resolve/main/MO-MODEL-Fused-Unhinged-RP-Alpha-V2-Llama-3.3-70B.i1-Q3_K_S.gguf) | i1-Q3_K_S | 31.0 | IQ3_XS probably better |
| [GGUF](https://huggingface.co/mradermacher/MO-MODEL-Fused-Unhinged-RP-Alpha-V2-Llama-3.3-70B-i1-GGUF/resolve/main/MO-MODEL-Fused-Unhinged-RP-Alpha-V2-Llama-3.3-70B.i1-IQ3_M.gguf) | i1-IQ3_M | 32.0 | |
| [GGUF](https://huggingface.co/mradermacher/MO-MODEL-Fused-Unhinged-RP-Alpha-V2-Llama-3.3-70B-i1-GGUF/resolve/main/MO-MODEL-Fused-Unhinged-RP-Alpha-V2-Llama-3.3-70B.i1-Q3_K_M.gguf) | i1-Q3_K_M | 34.4 | IQ3_S probably better |
| [GGUF](https://huggingface.co/mradermacher/MO-MODEL-Fused-Unhinged-RP-Alpha-V2-Llama-3.3-70B-i1-GGUF/resolve/main/MO-MODEL-Fused-Unhinged-RP-Alpha-V2-Llama-3.3-70B.i1-Q3_K_L.gguf) | i1-Q3_K_L | 37.2 | IQ3_M probably better |
| [GGUF](https://huggingface.co/mradermacher/MO-MODEL-Fused-Unhinged-RP-Alpha-V2-Llama-3.3-70B-i1-GGUF/resolve/main/MO-MODEL-Fused-Unhinged-RP-Alpha-V2-Llama-3.3-70B.i1-IQ4_XS.gguf) | i1-IQ4_XS | 38.0 | |
| [GGUF](https://huggingface.co/mradermacher/MO-MODEL-Fused-Unhinged-RP-Alpha-V2-Llama-3.3-70B-i1-GGUF/resolve/main/MO-MODEL-Fused-Unhinged-RP-Alpha-V2-Llama-3.3-70B.i1-Q4_0.gguf) | i1-Q4_0 | 40.2 | fast, low quality |
| [GGUF](https://huggingface.co/mradermacher/MO-MODEL-Fused-Unhinged-RP-Alpha-V2-Llama-3.3-70B-i1-GGUF/resolve/main/MO-MODEL-Fused-Unhinged-RP-Alpha-V2-Llama-3.3-70B.i1-Q4_K_S.gguf) | i1-Q4_K_S | 40.4 | optimal size/speed/quality |
| [GGUF](https://huggingface.co/mradermacher/MO-MODEL-Fused-Unhinged-RP-Alpha-V2-Llama-3.3-70B-i1-GGUF/resolve/main/MO-MODEL-Fused-Unhinged-RP-Alpha-V2-Llama-3.3-70B.i1-Q4_K_M.gguf) | i1-Q4_K_M | 42.6 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/MO-MODEL-Fused-Unhinged-RP-Alpha-V2-Llama-3.3-70B-i1-GGUF/resolve/main/MO-MODEL-Fused-Unhinged-RP-Alpha-V2-Llama-3.3-70B.i1-Q4_1.gguf) | i1-Q4_1 | 44.4 | |
| [GGUF](https://huggingface.co/mradermacher/MO-MODEL-Fused-Unhinged-RP-Alpha-V2-Llama-3.3-70B-i1-GGUF/resolve/main/MO-MODEL-Fused-Unhinged-RP-Alpha-V2-Llama-3.3-70B.i1-Q5_K_S.gguf) | i1-Q5_K_S | 48.8 | |
| [GGUF](https://huggingface.co/mradermacher/MO-MODEL-Fused-Unhinged-RP-Alpha-V2-Llama-3.3-70B-i1-GGUF/resolve/main/MO-MODEL-Fused-Unhinged-RP-Alpha-V2-Llama-3.3-70B.i1-Q5_K_M.gguf) | i1-Q5_K_M | 50.0 | |
| [PART 1](https://huggingface.co/mradermacher/MO-MODEL-Fused-Unhinged-RP-Alpha-V2-Llama-3.3-70B-i1-GGUF/resolve/main/MO-MODEL-Fused-Unhinged-RP-Alpha-V2-Llama-3.3-70B.i1-Q6_K.gguf.part1of2) [PART 2](https://huggingface.co/mradermacher/MO-MODEL-Fused-Unhinged-RP-Alpha-V2-Llama-3.3-70B-i1-GGUF/resolve/main/MO-MODEL-Fused-Unhinged-RP-Alpha-V2-Llama-3.3-70B.i1-Q6_K.gguf.part2of2) | i1-Q6_K | 58.0 | practically like static Q6_K |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time. Additional thanks to [@nicoboss](https://huggingface.co/nicoboss) for giving me access to his private supercomputer, enabling me to provide many more imatrix quants, at much higher quality, than I would otherwise be able to.
<!-- end -->
|
mradermacher/DeepCaption-VLA-7B-i1-GGUF
|
mradermacher
| 2025-09-11T19:02:53Z | 2,378 | 1 |
transformers
|
[
"transformers",
"gguf",
"trl",
"VisionLanguageAttribution",
"VisualUnderstanding",
"text-generation-inference",
"AttributeCaptioning",
"VLA",
"High-Fidelity",
"en",
"dataset:prithivMLmods/blip3o-caption-mini-arrow",
"dataset:prithivMLmods/Caption3o-Opt-v3",
"dataset:prithivMLmods/Caption3o-Opt-v2",
"dataset:Multimodal-Fatima/Caltech101_not_background_test_facebook_opt_2.7b_Attributes_Caption_ns_5647",
"base_model:prithivMLmods/DeepCaption-VLA-7B",
"base_model:quantized:prithivMLmods/DeepCaption-VLA-7B",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | null | 2025-08-29T16:51:49Z |
---
base_model: prithivMLmods/DeepCaption-VLA-7B
datasets:
- prithivMLmods/blip3o-caption-mini-arrow
- prithivMLmods/Caption3o-Opt-v3
- prithivMLmods/Caption3o-Opt-v2
- Multimodal-Fatima/Caltech101_not_background_test_facebook_opt_2.7b_Attributes_Caption_ns_5647
language:
- en
library_name: transformers
license: apache-2.0
mradermacher:
readme_rev: 1
quantized_by: mradermacher
tags:
- trl
- VisionLanguageAttribution
- VisualUnderstanding
- text-generation-inference
- AttributeCaptioning
- VLA
- High-Fidelity
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: nicoboss -->
<!-- ### quants: Q2_K IQ3_M Q4_K_S IQ3_XXS Q3_K_M small-IQ4_NL Q4_K_M IQ2_M Q6_K IQ4_XS Q2_K_S IQ1_M Q3_K_S IQ2_XXS Q3_K_L IQ2_XS Q5_K_S IQ2_S IQ1_S Q5_K_M Q4_0 IQ3_XS Q4_1 IQ3_S -->
<!-- ### quants_skip: -->
<!-- ### skip_mmproj: -->
weighted/imatrix quants of https://huggingface.co/prithivMLmods/DeepCaption-VLA-7B
<!-- provided-files -->
***For a convenient overview and download list, visit our [model page for this model](https://hf.tst.eu/model#DeepCaption-VLA-7B-i1-GGUF).***
static quants are available at https://huggingface.co/mradermacher/DeepCaption-VLA-7B-GGUF
**This is a vision model - mmproj files (if any) will be in the [static repository](https://huggingface.co/mradermacher/DeepCaption-VLA-7B-GGUF).**
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/DeepCaption-VLA-7B-i1-GGUF/resolve/main/DeepCaption-VLA-7B.imatrix.gguf) | imatrix | 0.1 | imatrix file (for creating your own qwuants) |
| [GGUF](https://huggingface.co/mradermacher/DeepCaption-VLA-7B-i1-GGUF/resolve/main/DeepCaption-VLA-7B.i1-IQ1_S.gguf) | i1-IQ1_S | 2.0 | for the desperate |
| [GGUF](https://huggingface.co/mradermacher/DeepCaption-VLA-7B-i1-GGUF/resolve/main/DeepCaption-VLA-7B.i1-IQ1_M.gguf) | i1-IQ1_M | 2.1 | mostly desperate |
| [GGUF](https://huggingface.co/mradermacher/DeepCaption-VLA-7B-i1-GGUF/resolve/main/DeepCaption-VLA-7B.i1-IQ2_XXS.gguf) | i1-IQ2_XXS | 2.4 | |
| [GGUF](https://huggingface.co/mradermacher/DeepCaption-VLA-7B-i1-GGUF/resolve/main/DeepCaption-VLA-7B.i1-IQ2_XS.gguf) | i1-IQ2_XS | 2.6 | |
| [GGUF](https://huggingface.co/mradermacher/DeepCaption-VLA-7B-i1-GGUF/resolve/main/DeepCaption-VLA-7B.i1-IQ2_S.gguf) | i1-IQ2_S | 2.7 | |
| [GGUF](https://huggingface.co/mradermacher/DeepCaption-VLA-7B-i1-GGUF/resolve/main/DeepCaption-VLA-7B.i1-IQ2_M.gguf) | i1-IQ2_M | 2.9 | |
| [GGUF](https://huggingface.co/mradermacher/DeepCaption-VLA-7B-i1-GGUF/resolve/main/DeepCaption-VLA-7B.i1-Q2_K_S.gguf) | i1-Q2_K_S | 2.9 | very low quality |
| [GGUF](https://huggingface.co/mradermacher/DeepCaption-VLA-7B-i1-GGUF/resolve/main/DeepCaption-VLA-7B.i1-Q2_K.gguf) | i1-Q2_K | 3.1 | IQ3_XXS probably better |
| [GGUF](https://huggingface.co/mradermacher/DeepCaption-VLA-7B-i1-GGUF/resolve/main/DeepCaption-VLA-7B.i1-IQ3_XXS.gguf) | i1-IQ3_XXS | 3.2 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/DeepCaption-VLA-7B-i1-GGUF/resolve/main/DeepCaption-VLA-7B.i1-IQ3_XS.gguf) | i1-IQ3_XS | 3.4 | |
| [GGUF](https://huggingface.co/mradermacher/DeepCaption-VLA-7B-i1-GGUF/resolve/main/DeepCaption-VLA-7B.i1-Q3_K_S.gguf) | i1-Q3_K_S | 3.6 | IQ3_XS probably better |
| [GGUF](https://huggingface.co/mradermacher/DeepCaption-VLA-7B-i1-GGUF/resolve/main/DeepCaption-VLA-7B.i1-IQ3_S.gguf) | i1-IQ3_S | 3.6 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/DeepCaption-VLA-7B-i1-GGUF/resolve/main/DeepCaption-VLA-7B.i1-IQ3_M.gguf) | i1-IQ3_M | 3.7 | |
| [GGUF](https://huggingface.co/mradermacher/DeepCaption-VLA-7B-i1-GGUF/resolve/main/DeepCaption-VLA-7B.i1-Q3_K_M.gguf) | i1-Q3_K_M | 3.9 | IQ3_S probably better |
| [GGUF](https://huggingface.co/mradermacher/DeepCaption-VLA-7B-i1-GGUF/resolve/main/DeepCaption-VLA-7B.i1-Q3_K_L.gguf) | i1-Q3_K_L | 4.2 | IQ3_M probably better |
| [GGUF](https://huggingface.co/mradermacher/DeepCaption-VLA-7B-i1-GGUF/resolve/main/DeepCaption-VLA-7B.i1-IQ4_XS.gguf) | i1-IQ4_XS | 4.3 | |
| [GGUF](https://huggingface.co/mradermacher/DeepCaption-VLA-7B-i1-GGUF/resolve/main/DeepCaption-VLA-7B.i1-IQ4_NL.gguf) | i1-IQ4_NL | 4.5 | prefer IQ4_XS |
| [GGUF](https://huggingface.co/mradermacher/DeepCaption-VLA-7B-i1-GGUF/resolve/main/DeepCaption-VLA-7B.i1-Q4_0.gguf) | i1-Q4_0 | 4.5 | fast, low quality |
| [GGUF](https://huggingface.co/mradermacher/DeepCaption-VLA-7B-i1-GGUF/resolve/main/DeepCaption-VLA-7B.i1-Q4_K_S.gguf) | i1-Q4_K_S | 4.6 | optimal size/speed/quality |
| [GGUF](https://huggingface.co/mradermacher/DeepCaption-VLA-7B-i1-GGUF/resolve/main/DeepCaption-VLA-7B.i1-Q4_K_M.gguf) | i1-Q4_K_M | 4.8 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/DeepCaption-VLA-7B-i1-GGUF/resolve/main/DeepCaption-VLA-7B.i1-Q4_1.gguf) | i1-Q4_1 | 5.0 | |
| [GGUF](https://huggingface.co/mradermacher/DeepCaption-VLA-7B-i1-GGUF/resolve/main/DeepCaption-VLA-7B.i1-Q5_K_S.gguf) | i1-Q5_K_S | 5.4 | |
| [GGUF](https://huggingface.co/mradermacher/DeepCaption-VLA-7B-i1-GGUF/resolve/main/DeepCaption-VLA-7B.i1-Q5_K_M.gguf) | i1-Q5_K_M | 5.5 | |
| [GGUF](https://huggingface.co/mradermacher/DeepCaption-VLA-7B-i1-GGUF/resolve/main/DeepCaption-VLA-7B.i1-Q6_K.gguf) | i1-Q6_K | 6.4 | practically like static Q6_K |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time. Additional thanks to [@nicoboss](https://huggingface.co/nicoboss) for giving me access to his private supercomputer, enabling me to provide many more imatrix quants, at much higher quality, than I would otherwise be able to.
<!-- end -->
|
anwksms/LORA
|
anwksms
| 2025-09-11T19:01:40Z | 0 | 0 | null |
[
"lora",
"fine-tuning",
"license:apache-2.0",
"region:us"
] | null | 2025-09-07T18:09:31Z |
---
tags:
- lora
- fine-tuning
license: apache-2.0
---
# LoRA Model
This is a LoRA (Low-Rank Adaptation) model uploaded from Google Colab.
## Usage
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
from peft import PeftModel
# Load base model
base_model = AutoModelForCausalLM.from_pretrained("base_model_name")
tokenizer = AutoTokenizer.from_pretrained("base_model_name")
# Load LoRA weights
model = PeftModel.from_pretrained(base_model, "anwksms/LORA")
```
## Training Details
- Training method: LoRA (Low-Rank Adaptation)
- Uploaded from: Google Colab
- Upload date: 2025-09-11
|
midwestern-simulation/essence-3b-v1.1-alpha
|
midwestern-simulation
| 2025-09-11T18:54:35Z | 0 | 0 | null |
[
"safetensors",
"dataset:mlfoundations/dclm-baseline-1.0",
"base_model:HuggingFaceTB/SmolLM3-3B-Base",
"base_model:finetune:HuggingFaceTB/SmolLM3-3B-Base",
"region:us"
] | null | 2025-09-11T11:35:20Z |
---
datasets:
- mlfoundations/dclm-baseline-1.0
base_model:
- HuggingFaceTB/SmolLM3-3B-Base
---
# Essence 3B V1.1 alpha
This is a system using two versions of SmolLM3-3B-Base, the 'encoder', is finetuned to turn a text into a set of embedding tokens which can be reconstituted back into the original text by the decoder. In addition to “vanilla” reconstruction, this model was trained for span-corruption and masked language modelling.
We use LoRA at rank 64 on QKVO along with trainable LayerNorms and, for the encoder, LoRA on all MLP layers as well as trainable token embeddings.
The model was trained to encode text into any of 1-128 embedding tokens.
## Simple Usage
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
from peft import PeftModel
from torch import nn
import torch
from huggingface_hub import hf_hub_download
device = torch.device("cuda:0")
dtype = torch.bfloat16
base_model_id = "HuggingFaceTB/SmolLM3-3B-Base"
compressor_id = "midwestern-simulation/essence-3b-v1.1-alpha"
# === MODEL LOADING ===
tokenizer = AutoTokenizer.from_pretrained(base_model_id, padding_side='left')
encoder = AutoModelForCausalLM.from_pretrained(base_model_id, device_map={"":device}, torch_dtype=dtype)
decoder = AutoModelForCausalLM.from_pretrained(base_model_id, device_map={"":device}, torch_dtype=dtype)
encoder = PeftModel.from_pretrained(encoder, compressor_id, subfolder="encoder")
decoder = PeftModel.from_pretrained(decoder, compressor_id, subfolder="decoder")
projector = nn.Linear(2048, 2048).to(device).to(dtype)
projector.load_state_dict(torch.load(hf_hub_download(repo_id=compressor_id, filename="projector.pt")))
# === MODEL INFERENCE ===
text = "mary had a little lamb, little lamb, little lamb, mary had a little lamb whose fleece was white as snow"
n_embed_tokens = 4 # for best performance, can be any within the range of 1-128
encoder_input = text.strip() + f"\n[[/END DOCUMENT]]\n[[START SUMMARY ntoks={n_embed_tokens}]]" + "<|im_end|>" * n_embed_tokens
tokenized = tokenizer(encoder_input, return_tensors='pt', add_special_tokens=False)
tokenized = {k: v.to(device) for k, v in tokenized.items()}
encoding = encoder.model.model(**tokenized).last_hidden_state[:, -n_embed_tokens:, :]
encoding = projector(encoding)
tokenized_prefix = tokenizer("\n[[/END SUMMARY]]\n[[START DOCUMENT]]\n", return_tensors="pt", add_special_tokens=False)
prefix_embeds = decoder.model.model.embed_tokens(tokenized_prefix['input_ids'].to(device))
inputs_embeds = torch.cat([encoding, prefix_embeds], 1)
output = decoder.generate(
inputs_embeds=inputs_embeds,
temperature=0.7,
max_new_tokens=1024,
do_sample=True,
top_k=128,
min_new_tokens=8,
eos_token_id=tokenizer.eos_token_id,
pad_token_id=tokenizer.pad_token_id
)
print(tokenizer.decode(output[0]))
# mary had a little lamb, little lamb, little lamb, mary had a little lamb whose fleece was white as snow
# [[/END DOCUMENT]]<|end_of_text|>
```
|
Simonc-44/Cygnis2-improved
|
Simonc-44
| 2025-09-11T18:53:06Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-09-11T18:53:00Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
MohammedAhmed13/xlm-roberta-base-finetuned-panx-de
|
MohammedAhmed13
| 2025-09-11T18:50:49Z | 9 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"xlm-roberta",
"token-classification",
"generated_from_trainer",
"base_model:FacebookAI/xlm-roberta-base",
"base_model:finetune:FacebookAI/xlm-roberta-base",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2025-08-24T20:57:20Z |
---
library_name: transformers
license: mit
base_model: FacebookAI/xlm-roberta-base
tags:
- generated_from_trainer
metrics:
- f1
model-index:
- name: xlm-roberta-base-finetuned-panx-de
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xlm-roberta-base-finetuned-panx-de
This model is a fine-tuned version of [FacebookAI/xlm-roberta-base](https://huggingface.co/FacebookAI/xlm-roberta-base) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1387
- F1: 0.8614
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 24
- eval_batch_size: 24
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH_FUSED with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 0.2571 | 1.0 | 525 | 0.1654 | 0.8147 |
| 0.1266 | 2.0 | 1050 | 0.1382 | 0.8500 |
| 0.0788 | 3.0 | 1575 | 0.1387 | 0.8614 |
### Framework versions
- Transformers 4.56.1
- Pytorch 2.8.0+cu126
- Datasets 4.0.0
- Tokenizers 0.22.0
|
nofunstudio/jimmy
|
nofunstudio
| 2025-09-11T18:44:08Z | 1 | 0 |
diffusers
|
[
"diffusers",
"flux",
"text-to-image",
"lora",
"fal",
"license:other",
"region:us"
] |
text-to-image
| 2024-11-27T22:01:01Z |
---
tags:
- flux
- text-to-image
- lora
- diffusers
- fal
base_model: undefined
instance_prompt: JIMMY
license: other
---
# jimmy
<Gallery />
## Model description
Jimmy Face Training
## Trigger words
You should use `JIMMY` to trigger the image generation.
## Download model
Weights for this model are available in Safetensors format.
[Download](/nofunstudio/jimmy/tree/main) them in the Files & versions tab.
## Training at fal.ai
Training was done using [fal.ai/models/fal-ai/flux-lora-portrait-trainer](https://fal.ai/models/fal-ai/flux-lora-portrait-trainer).
|
Neel2601/resume-ranker
|
Neel2601
| 2025-09-11T18:43:59Z | 0 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"safetensors",
"bert",
"sentence-similarity",
"feature-extraction",
"dense",
"generated_from_trainer",
"dataset_size:6",
"loss:CosineSimilarityLoss",
"arxiv:1908.10084",
"base_model:sentence-transformers/all-MiniLM-L6-v2",
"base_model:finetune:sentence-transformers/all-MiniLM-L6-v2",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2025-09-11T18:16:38Z |
---
tags:
- sentence-transformers
- sentence-similarity
- feature-extraction
- dense
- generated_from_trainer
- dataset_size:6
- loss:CosineSimilarityLoss
base_model: sentence-transformers/all-MiniLM-L6-v2
pipeline_tag: sentence-similarity
library_name: sentence-transformers
---
# SentenceTransformer based on sentence-transformers/all-MiniLM-L6-v2
This is a [sentence-transformers](https://www.SBERT.net) model finetuned from [sentence-transformers/all-MiniLM-L6-v2](https://huggingface.co/sentence-transformers/all-MiniLM-L6-v2). It maps sentences & paragraphs to a 384-dimensional dense vector space and can be used for semantic textual similarity, semantic search, paraphrase mining, text classification, clustering, and more.
## Model Details
### Model Description
- **Model Type:** Sentence Transformer
- **Base model:** [sentence-transformers/all-MiniLM-L6-v2](https://huggingface.co/sentence-transformers/all-MiniLM-L6-v2) <!-- at revision c9745ed1d9f207416be6d2e6f8de32d1f16199bf -->
- **Maximum Sequence Length:** 256 tokens
- **Output Dimensionality:** 384 dimensions
- **Similarity Function:** Cosine Similarity
<!-- - **Training Dataset:** Unknown -->
<!-- - **Language:** Unknown -->
<!-- - **License:** Unknown -->
### Model Sources
- **Documentation:** [Sentence Transformers Documentation](https://sbert.net)
- **Repository:** [Sentence Transformers on GitHub](https://github.com/UKPLab/sentence-transformers)
- **Hugging Face:** [Sentence Transformers on Hugging Face](https://huggingface.co/models?library=sentence-transformers)
### Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 256, 'do_lower_case': False, 'architecture': 'BertModel'})
(1): Pooling({'word_embedding_dimension': 384, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False, 'pooling_mode_weightedmean_tokens': False, 'pooling_mode_lasttoken': False, 'include_prompt': True})
(2): Normalize()
)
```
## Usage
### Direct Usage (Sentence Transformers)
First install the Sentence Transformers library:
```bash
pip install -U sentence-transformers
```
Then you can load this model and run inference.
```python
from sentence_transformers import SentenceTransformer
# Download from the 🤗 Hub
model = SentenceTransformer("sentence_transformers_model_id")
# Run inference
sentences = [
'The weather is lovely today.',
"It's so sunny outside!",
'He drove to the stadium.',
]
embeddings = model.encode(sentences)
print(embeddings.shape)
# [3, 384]
# Get the similarity scores for the embeddings
similarities = model.similarity(embeddings, embeddings)
print(similarities)
# tensor([[1.0000, 0.6671, 0.1063],
# [0.6671, 1.0000, 0.1427],
# [0.1063, 0.1427, 1.0000]])
```
<!--
### Direct Usage (Transformers)
<details><summary>Click to see the direct usage in Transformers</summary>
</details>
-->
<!--
### Downstream Usage (Sentence Transformers)
You can finetune this model on your own dataset.
<details><summary>Click to expand</summary>
</details>
-->
<!--
### Out-of-Scope Use
*List how the model may foreseeably be misused and address what users ought not to do with the model.*
-->
<!--
## Bias, Risks and Limitations
*What are the known or foreseeable issues stemming from this model? You could also flag here known failure cases or weaknesses of the model.*
-->
<!--
### Recommendations
*What are recommendations with respect to the foreseeable issues? For example, filtering explicit content.*
-->
## Training Details
### Training Dataset
#### Unnamed Dataset
* Size: 6 training samples
* Columns: <code>sentence_0</code>, <code>sentence_1</code>, and <code>label</code>
* Approximate statistics based on the first 6 samples:
| | sentence_0 | sentence_1 | label |
|:--------|:-----------------------------------------------------------------------------------|:-----------------------------------------------------------------------------------|:--------------------------------------------------------------|
| type | string | string | float |
| details | <ul><li>min: 11 tokens</li><li>mean: 12.33 tokens</li><li>max: 14 tokens</li></ul> | <ul><li>min: 13 tokens</li><li>mean: 15.67 tokens</li><li>max: 20 tokens</li></ul> | <ul><li>min: 0.0</li><li>mean: 0.5</li><li>max: 1.0</li></ul> |
* Samples:
| sentence_0 | sentence_1 | label |
|:---------------------------------------------------------------------------|:-----------------------------------------------------------------|:-----------------|
| <code>Looking for a Backend Engineer with Django</code> | <code>I am a UI/UX designer, focus on Figma and Adobe XD.</code> | <code>0.0</code> |
| <code>Looking for a Data Scientist skilled in statistics and Python</code> | <code>Frontend developer, skilled in React and CSS.</code> | <code>0.0</code> |
| <code>Looking for a Python developer with experience in ML and APIs</code> | <code>I am a Java developer, worked on Android apps.</code> | <code>0.0</code> |
* Loss: [<code>CosineSimilarityLoss</code>](https://sbert.net/docs/package_reference/sentence_transformer/losses.html#cosinesimilarityloss) with these parameters:
```json
{
"loss_fct": "torch.nn.modules.loss.MSELoss"
}
```
### Training Hyperparameters
#### Non-Default Hyperparameters
- `per_device_train_batch_size`: 2
- `per_device_eval_batch_size`: 2
- `num_train_epochs`: 2
- `multi_dataset_batch_sampler`: round_robin
#### All Hyperparameters
<details><summary>Click to expand</summary>
- `overwrite_output_dir`: False
- `do_predict`: False
- `eval_strategy`: no
- `prediction_loss_only`: True
- `per_device_train_batch_size`: 2
- `per_device_eval_batch_size`: 2
- `per_gpu_train_batch_size`: None
- `per_gpu_eval_batch_size`: None
- `gradient_accumulation_steps`: 1
- `eval_accumulation_steps`: None
- `torch_empty_cache_steps`: None
- `learning_rate`: 5e-05
- `weight_decay`: 0.0
- `adam_beta1`: 0.9
- `adam_beta2`: 0.999
- `adam_epsilon`: 1e-08
- `max_grad_norm`: 1
- `num_train_epochs`: 2
- `max_steps`: -1
- `lr_scheduler_type`: linear
- `lr_scheduler_kwargs`: {}
- `warmup_ratio`: 0.0
- `warmup_steps`: 0
- `log_level`: passive
- `log_level_replica`: warning
- `log_on_each_node`: True
- `logging_nan_inf_filter`: True
- `save_safetensors`: True
- `save_on_each_node`: False
- `save_only_model`: False
- `restore_callback_states_from_checkpoint`: False
- `no_cuda`: False
- `use_cpu`: False
- `use_mps_device`: False
- `seed`: 42
- `data_seed`: None
- `jit_mode_eval`: False
- `use_ipex`: False
- `bf16`: False
- `fp16`: False
- `fp16_opt_level`: O1
- `half_precision_backend`: auto
- `bf16_full_eval`: False
- `fp16_full_eval`: False
- `tf32`: None
- `local_rank`: 0
- `ddp_backend`: None
- `tpu_num_cores`: None
- `tpu_metrics_debug`: False
- `debug`: []
- `dataloader_drop_last`: False
- `dataloader_num_workers`: 0
- `dataloader_prefetch_factor`: None
- `past_index`: -1
- `disable_tqdm`: False
- `remove_unused_columns`: True
- `label_names`: None
- `load_best_model_at_end`: False
- `ignore_data_skip`: False
- `fsdp`: []
- `fsdp_min_num_params`: 0
- `fsdp_config`: {'min_num_params': 0, 'xla': False, 'xla_fsdp_v2': False, 'xla_fsdp_grad_ckpt': False}
- `fsdp_transformer_layer_cls_to_wrap`: None
- `accelerator_config`: {'split_batches': False, 'dispatch_batches': None, 'even_batches': True, 'use_seedable_sampler': True, 'non_blocking': False, 'gradient_accumulation_kwargs': None}
- `parallelism_config`: None
- `deepspeed`: None
- `label_smoothing_factor`: 0.0
- `optim`: adamw_torch_fused
- `optim_args`: None
- `adafactor`: False
- `group_by_length`: False
- `length_column_name`: length
- `ddp_find_unused_parameters`: None
- `ddp_bucket_cap_mb`: None
- `ddp_broadcast_buffers`: False
- `dataloader_pin_memory`: True
- `dataloader_persistent_workers`: False
- `skip_memory_metrics`: True
- `use_legacy_prediction_loop`: False
- `push_to_hub`: False
- `resume_from_checkpoint`: None
- `hub_model_id`: None
- `hub_strategy`: every_save
- `hub_private_repo`: None
- `hub_always_push`: False
- `hub_revision`: None
- `gradient_checkpointing`: False
- `gradient_checkpointing_kwargs`: None
- `include_inputs_for_metrics`: False
- `include_for_metrics`: []
- `eval_do_concat_batches`: True
- `fp16_backend`: auto
- `push_to_hub_model_id`: None
- `push_to_hub_organization`: None
- `mp_parameters`:
- `auto_find_batch_size`: False
- `full_determinism`: False
- `torchdynamo`: None
- `ray_scope`: last
- `ddp_timeout`: 1800
- `torch_compile`: False
- `torch_compile_backend`: None
- `torch_compile_mode`: None
- `include_tokens_per_second`: False
- `include_num_input_tokens_seen`: False
- `neftune_noise_alpha`: None
- `optim_target_modules`: None
- `batch_eval_metrics`: False
- `eval_on_start`: False
- `use_liger_kernel`: False
- `liger_kernel_config`: None
- `eval_use_gather_object`: False
- `average_tokens_across_devices`: False
- `prompts`: None
- `batch_sampler`: batch_sampler
- `multi_dataset_batch_sampler`: round_robin
- `router_mapping`: {}
- `learning_rate_mapping`: {}
</details>
### Framework Versions
- Python: 3.13.7
- Sentence Transformers: 5.1.0
- Transformers: 4.56.1
- PyTorch: 2.8.0+cpu
- Accelerate: 1.10.1
- Datasets: 4.0.0
- Tokenizers: 0.22.0
## Citation
### BibTeX
#### Sentence Transformers
```bibtex
@inproceedings{reimers-2019-sentence-bert,
title = "Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks",
author = "Reimers, Nils and Gurevych, Iryna",
booktitle = "Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing",
month = "11",
year = "2019",
publisher = "Association for Computational Linguistics",
url = "https://arxiv.org/abs/1908.10084",
}
```
<!--
## Glossary
*Clearly define terms in order to be accessible across audiences.*
-->
<!--
## Model Card Authors
*Lists the people who create the model card, providing recognition and accountability for the detailed work that goes into its construction.*
-->
<!--
## Model Card Contact
*Provides a way for people who have updates to the Model Card, suggestions, or questions, to contact the Model Card authors.*
-->
|
amjada/Qwen3-0.6B-Gensyn-Swarm-whistling_hardy_ladybug
|
amjada
| 2025-09-11T18:39:33Z | 75 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen3",
"text-generation",
"rl-swarm",
"genrl-swarm",
"grpo",
"gensyn",
"I am whistling_hardy_ladybug",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-09-09T15:55:03Z |
---
library_name: transformers
tags:
- rl-swarm
- genrl-swarm
- grpo
- gensyn
- I am whistling_hardy_ladybug
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
ZodiacViews/mistral-trained12.9charts
|
ZodiacViews
| 2025-09-11T18:37:31Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-09-11T18:37:22Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
javrtg/AnyCalib
|
javrtg
| 2025-09-11T18:37:28Z | 0 | 0 | null |
[
"arxiv:2503.12701",
"license:apache-2.0",
"region:us"
] | null | 2025-09-11T16:37:57Z |
---
license: apache-2.0
---
<div align="center">
<h1>AnyCalib:<br>
On-Manifold Learning for Model-Agnostic Single-View Camera Calibration</h1>
<p>Javier Tirado-Garín    Javier Civera<br>
I3A, University of Zaragoza</p>
<img width="99%" src="https://github.com/javrtg/AnyCalib/blob/main/assets/method_dark.png?raw=true">
<p><strong>Camera calibration from a single perspective/edited/distorted image using a freely chosen camera model</strong></p>
[](https://github.com/javrtg/AnyCalib)
[](https://arxiv.org/abs/2503.12701)
</div>
## Usage (pretrained models)
The only requirements are Python (≥3.10) and PyTorch.
The project, in development mode, can be installed with:
```shell
git clone https://github.com/javrtg/AnyCalib.git && cd AnyCalib
pip install -e .
```
Alternatively, and optionally, a compatible version of [`xformers`](https://github.com/facebookresearch/xformers) can also be installed for better efficiency by running the following instead of `pip install -e .`:
```shell
pip install -e .[eff]
```
### Minimal usage example
```python
import numpy as np
import torch
from PIL import Image # the library of choice to load images
from anycalib import AnyCalib
dev = torch.device("cuda")
# load input image and convert it to a (3, H, W) tensor with RGB values in [0, 1]
image = np.array(Image.open("path/to/image.jpg").convert("RGB"))
image = torch.tensor(image, dtype=torch.float32, device=dev).permute(2, 0, 1) / 255
# instantiate AnyCalib according to the desired model_id. Options:
# "anycalib_pinhole": model trained with *only* perspective (pinhole) images,
# "anycalib_gen": trained with perspective, distorted and strongly distorted images,
# "anycalib_dist": trained with distorted and strongly distorted images,
# "anycalib_edit": Trained on edited (stretched and cropped) perspective images.
model = AnyCalib(model_id="anycalib_pinhole").to(dev)
# Alternatively, the weights can be loaded from the huggingface hub as follows:
# NOTE: huggingface_hub (https://pypi.org/project/huggingface-hub/) needs to be installed
# model = AnyCalib().from_pretrained(model_id=<model_id>).to(dev)
# predict according to the desired camera model. Implemented camera models are detailed further below.
output = model.predict(image, cam_id="pinhole")
# output is a dictionary with the following key-value pairs:
# {
# "intrinsics": (D,) tensor with the estimated intrinsics for the selected camera model,
# "fov_field": (N, 2) tensor with the regressed FoV field by the network. N≈320^2 (resolution close to the one seen during training),
# "tangent_coords": alias for "fov_field",
# "rays": (N, 3) tensor with the corresponding (via the exponential map) ray directions in the camera frame (x right, y down, z forward),
# "pred_size": (H, W) tuple with the image size used by the network. It can be used e.g. for resizing the FoV/ray fields to the original image size.
# }
```
The weights of the selected `model_id`, if not already downloaded, will be automatically downloaded to the:
* torch hub cache directory (`torch.hub.get_dir()`) if `AnyCalib(model_id=<model_id>)` is used, or
* huggingface cache directory if `AnyCalib().from_pretrained(model_id=<model_id>)` is used.
Additional configuration options are indicated in the docstring of `AnyCalib`:
<details>
<summary> <code>help(AnyCalib)</code> </summary>
```python
"""AnyCalib class.
Args for instantiation:
model_id: one of {'anycalib_pinhole', 'anycalib_gen', 'anycalib_dist', 'anycalib_edit'}.
Each model differes in the type of images they seen during training:
* 'anycalib_pinhole': Perspective (pinhole) images,
* 'anycalib_gen': General images, including perspective, distorted and
strongly distorted images, and
* 'anycalib_dist': Distorted images using the Brown-Conrady camera model
and strongly distorted images, using the EUCM camera model,
* 'anycalib_edit': Trained on edited (stretched and cropped) perspective
images.
Default: 'anycalib_pinhole'.
nonlin_opt_method: nonlinear optimization method: 'gauss_newton' or 'lev_mar'.
Default: 'gauss_newton'
nonlin_opt_conf: nonlinear optimization configuration.
This config can be used to control the number of iterations and the space
where the residuals are minimized. See the classes `GaussNewtonCalib` or
`LevMarCalib` under anycalib/optim for details. Default: None.
init_with_sac: use RANSAC instead of nonminimal fit for initializating the
intrinsics. Default: False.
fallback_to_sac: use RANSAC if nonminimal fit fails. Default: True.
ransac_conf: RANSAC configuration. This config can be used to control e.g. the
inlier threshold or the number of minimal samples to try. See the class
`RANSAC` in anycalib/ransac.py for details. Default: None.
rm_borders: border size of the dense FoV fields to ignore during fitting.
Default: 0.
sample_size: approximate number of 2D-3D correspondences to use for fitting the
intrinsics. Negative value -> no subsampling. Default: -1.
"""
```
</details>
### Minimal batched example
AnyCalib can also be executed in batch and using possibly different camera models for each image. For example:
```python
images = ... # (B, 3, H, W)
# NOTE: if cam_ids is a list, then len(cam_ids) must be equal to B
cam_ids = ["pinhole", "radial:1", "kb:4"] # different camera models for each image
cam_ids = "pinhole" # same camera model across images
output = model.predict(images, cam_id=cam_ids)
# corresponding batched output dictionary:
# {
# "intrinsics": List[(D_i,) tensors] for each camera model "i",
# "fov_field": (B, N, 2) tensor,
# "tangent_coords": alias for "fov_field",
# "rays": (B, N, 3) tensor,
# "pred_size": (H, W).
# }
```
### Currently implemented camera models
* `cam_id` represents the camera model identifier(s) that can be used in the `predict` method. <br>
* `D` corresponds to the number of intrinsics of the camera model. It determines the length of each `intrinsics` tensor in the output dictionary.
| `cam_id` | Description | `D` | Intrinsics |
|:--|:--|:-:|:--|
| `pinhole` | Pinhole camera model | 4 | $f_x,~f_y,~c_x,~c_y$ |
| `simple_pinhole` | `pinhole` with one focal length | 3 | $f,~c_x,~c_y$ |
| `radial:k` | Radial (Brown-Conrady) [[1]](#1) camera model with `k` $\in$ [1, 4] distortion coefficients | 4+`k` | $f_x,~f_y,~c_x,~c_y$ <br> $k_1[,~k_2[,~k_3[,~k_4]]]$ |
| `simple_radial:k` | `radial:k` with one focal length | 3+`k` | $f,~c_x,~c_y$ <br> $k_1[,~k_2[,~k_3[,~k_4]]]$ |
| `kb:k` | Kannala-Brandt [[2]](#2) camera model with `k` $\in$ [1, 4] distortion coefficients | 4+`k` | $f_x,~f_y,~c_x,~c_y$ <br> $k_1[,~k_2[,~k_3[,~k_4]]]$ |
| `simple_kb:k` | `kb:k` with one focal length | 3+`k` | $f,~c_x,~c_y$ <br> $k_1[,~k_2[,~k_3[,~k_4]]]$ |
| `ucm` | Unified Camera Model [[3]](#3) | 5 | $f_x,~f_y,~c_x,~c_y$ <br> $k$ |
| `simple_ucm` | `ucm` with one focal length | 4 | $f,~c_x,~c_y$ <br> $k$ |
| `eucm` | Enhanced Unified Camera Model [[4]](#4) | 6 | $f_x,~f_y,~c_x,~c_y$ <br> $k_1,~k_2$ |
| `simple_eucm` | `eucm` with one focal length | 5 | $f,~c_x,~c_y$ <br> $k_1,~k_2$ |
| `division:k` | Division camera model [[5]](#5) with `k` $\in$ [1, 4] distortion coefficients | 4+`k` | $f_x,~f_y,~c_x,~c_y$ <br> $k_1[,~k_2[,~k_3[,~k_4]]]$ |
| `simple_division:k` | `division:k` with one focal length | 3+`k` | $f,~c_x,~c_y$ <br> $k_1[,~k_2[,~k_3[,~k_4]]]$ |
In addition to the original works, we recommend the works of Usenko et al. [[6]](#6) and Lochman et al. [[7]](#7) for a comprehensive comparison of the different camera models.
## Evaluation
The evaluation and training code is built upon the [`siclib`](siclib) library from [GeoCalib](https://github.com/cvg/GeoCalib), which can be installed as:
```shell
pip install -e siclib
```
Running the evaluation commands will write the results to `outputs/results/`.
### LaMAR
Running the evaluation commands will download the dataset to `data/lamar2k` which will take around 400 MB of disk space.
AnyCalib trained on $\mathrm{OP_{p}}$:
```shell
python -m siclib.eval.lamar2k_rays --conf anycalib_pretrained --tag anycalib_p --overwrite
```
AnyCalib trained on $\mathrm{OP_{g}}$:
```shell
python -m siclib.eval.lamar2k_rays --conf anycalib_pretrained --tag anycalib_g --overwrite model.model_id=anycalib_gen
```
### MegaDepth (pinhole)
Running the evaluation commands will download the dataset to `data/megadepth2k` which will take around 2 GB of disk space.
AnyCalib trained on $\mathrm{OP_{p}}$:
```shell
python -m siclib.eval.megadepth2k_rays --conf anycalib_pretrained --tag anycalib_p --overwrite
```
AnyCalib trained on $\mathrm{OP_{g}}$:
```shell
python -m siclib.eval.megadepth2k_rays --conf anycalib_pretrained --tag anycalib_g --overwrite model.model_id=anycalib_gen
```
### TartanAir
Running the evaluation commands will download the dataset to `data/tartanair` which will take around 1.7 GB of disk space.
AnyCalib trained on $\mathrm{OP_{p}}$:
```shell
python -m siclib.eval.tartanair_rays --conf anycalib_pretrained --tag anycalib_p --overwrite
```
AnyCalib trained on $\mathrm{OP_{g}}$:
```shell
python -m siclib.eval.tartanair_rays --conf anycalib_pretrained --tag anycalib_g --overwrite model.model_id=anycalib_gen
```
### Stanford2D3D
Running the evaluation commands will download the dataset to `data/stanford2d3d` which will take around 844 MB of disk space.
AnyCalib trained on $\mathrm{OP_{p}}$:
```shell
python -m siclib.eval.stanford2d3d_rays --conf anycalib_pretrained --tag anycalib_p --overwrite
```
AnyCalib trained on $\mathrm{OP_{g}}$:
```shell
python -m siclib.eval.stanford2d3d_rays --conf anycalib_pretrained --tag anycalib_g --overwrite model.model_id=anycalib_gen
```
### MegaDepth (radial)
Running the evaluation commands will download the dataset to `data/megadepth2k-radial` which will take around 1.4 GB of disk space.
AnyCalib trained on $\mathrm{OP_{g}}$:
```shell
python -m siclib.eval.megadepth2k_radial_rays --conf anycalib_pretrained --tag anycalib_g --overwrite model.model_id=anycalib_gen
```
### Mono
Running the evaluation commands will download the dataset to `data/monovo2k` which will take around 445 MB of disk space.
AnyCalib trained on $\mathrm{OP_{d}}$:
```shell
python -m siclib.eval.monovo2k_rays --conf anycalib_pretrained --tag anycalib_d --overwrite model.model_id=anycalib_dist data.cam_id=ucm
```
AnyCalib trained on $\mathrm{OP_{g}}$:
```shell
python -m siclib.eval.monovo2k_rays --conf anycalib_pretrained --tag anycalib_g --overwrite model.model_id=anycalib_gen data.cam_id=ucm
```
### ScanNet++
To comply with ScanNet++ license, we cannot directly share its data.
Please download the ScanNet++ dataset following the [official instructions](https://kaldir.vc.in.tum.de/scannetpp/#:~:text=the%20data%20now.-,Download%20the%20data,-To%20download%20the) and indicate the path to the root of the dataset in the following evaluation command. <br>
This needs to be provided only the first time the evaluation is run. This first time, the command will automatically copy the evaluation images under `data/scannetpp2k` which will take around 760 MB of disk space.
AnyCalib trained on $\mathrm{OP_{d}}$:
```shell
python -m siclib.eval.scannetpp2k_rays --conf anycalib_pretrained --tag anycalib_d --overwrite model.model_id=anycalib_dist scannetpp_root=<path_to_scannetpp>
```
AnyCalib trained on $\mathrm{OP_{g}}$:
```shell
python -m siclib.eval.scannetpp2k_rays --conf anycalib_pretrained --tag anycalib_g --overwrite model.model_id=anycalib_gen scannetpp_root=<path_to_scannetpp>
```
### LaMAR (edited)
Running the evaluation commands will download the dataset to `data/lamar2k_edit` which will take around 224 MB of disk space.
AnyCalib trained following WildCam [[8]](#8) training protocol:
```shell
python -m siclib.eval.lamar2k_rays --conf anycalib_pretrained --tag anycalib_e --overwrite model.model_id=anycalib_edit eval.eval_on_edit=True
```
### Tartanair (edited)
Running the evaluation commands will download the dataset to `data/tartanair_edit` which will take around 488 MB of disk space.
AnyCalib trained following WildCam [[8]](#8) training protocol:
```shell
python -m siclib.eval.tartanair_rays --conf anycalib_pretrained --tag anycalib_e --overwrite model.model_id=anycalib_edit eval.eval_on_edit=True
```
### Stanford2D3D (edited)
Running the evaluation commands will download the dataset to `data/stanford2d3d_edit` which will take around 420 MB of disk space.
AnyCalib trained on $\mathrm{OP_{p}}$, following WildCam [[8]](#8) training protocol:
```shell
python -m siclib.eval.stanford2d3d_rays --conf anycalib_pretrained --tag anycalib_e --overwrite model.model_id=anycalib_edit eval.eval_on_edit=True
```
## Extended OpenPano Dataset
We extend the OpenPano dataset from [GeoCalib](https://github.com/cvg/GeoCalib?tab=readme-ov-file#openpano-dataset) with panoramas that not need to be aligned with the gravity direction. This extended version consists of tonemapped panoramas from [The Laval Photometric Indoor HDR Dataset](http://hdrdb.com/indoor-hdr-photometric/), [PolyHaven](https://polyhaven.com/hdris), [HDRMaps](https://hdrmaps.com/freebies/free-hdris/), [AmbientCG](https://ambientcg.com/list?type=hdri&sort=popular) and [BlenderKit](https://www.blenderkit.com/asset-gallery?query=category_subtree:hdr).
Before sampling images from the panoramas, first download the Laval dataset following the instructions on the [corresponding project page](http://hdrdb.com/indoor-hdr-photometric/#:~:text=HDR%20Dataset.-,Download,-To%20obtain%20the) and place the panoramas in `data/indoorDatasetCalibrated`. Then, tonemap the HDR images using the following command:
```shell
python -m siclib.datasets.utils.tonemapping --hdr_dir data/indoorDatasetCalibrated --out_dir data/laval-tonemap
```
To download the rest of the panoramas and organize all the panoramas in their corresponding splits `data/openpano_v2/panoramas/{split}`, execute:
```shell
python -m siclib.datasets.utils.download_openpano --name openpano_v2 --laval_dir data/laval-tonemap
```
The panoramas from PolyHaven, HDRMaps, AmbientCG and BlenderKit can be alternatively manually downloaded from [here](https://drive.google.com/drive/folders/1HSXKNrleJKas4cRLd1C8SqR9J1nU1-Z_?usp=sharing).
Afterwards, the different training datasets mentioned in the paper: $\mathrm{OP_{p}}$, $\mathrm{OP_{g}}$, $\mathrm{OP_{r}}$ and $\mathrm{OP_{d}}$ can be created by running the following commands. We recommend running them with the flag `device=cuda` as this significantly speeds up the creation of the datasets, but if no GPU is available, the flag can be omitted.
$\mathrm{OP_{p}}$ (will be stored under `data/openpano_v2/openpano_v2`):
```shell
python -m siclib.datasets.create_dataset_from_pano --config-name openpano_v2 device=cuda
```
$\mathrm{OP_{g}}$ (will be stored under `data/openpano_v2/openpano_v2_gen`):
```shell
python -m siclib.datasets.create_dataset_from_pano_rays --config-name openpano_v2_gen device=cuda
```
$\mathrm{OP_{r}}$ (will be stored under `data/openpano_v2/openpano_v2_radial`):
```shell
python -m siclib.datasets.create_dataset_from_pano_rays --config-name openpano_v2_radial device=cuda
```
$\mathrm{OP_{d}}$ (will be stored under `data/openpano_v2/openpano_v2_dist`):
```shell
python -m siclib.datasets.create_dataset_from_pano_rays --config-name openpano_v2_dist device=cuda
```
## Training
As with the evaluation, the training code is built upon the [`siclib`](siclib) library from [GeoCalib](https://github.com/cvg/GeoCalib). Here we adapt their instructions to AnyCalib. `siclib` can be installed executing:
```shell
pip install -e siclib
```
Once (at least one of) the [extended OpenPano Dataset](#Extended-OpenPano-Dataset) (`openpano_v2`) has been downloaded and prepared, we can train AnyCalib with it.
For training with $\mathrm{OP_{p}}$ (default):
```shell
python -m siclib.train anycalib_op_p --conf anycalib --distributed
```
Feel free to use any other experiment name. By default, the checkpoints will be written to `outputs/training/`. The default batch size is 24 which requires at least 1 NVIDIA Tesla V100 GPU with 32GB of VRAM. If only one GPU is used, the flag `--distributed` can be omitted. Configurations are managed by [Hydra](https://hydra.cc/) and can be overwritten from the command line.
For example, for training with $\mathrm{OP_{g}}$:
```shell
python -m siclib.train anycalib_op_g --conf anycalib --distributed data.dataset_dir='data/openpano_v2/openpano_v2_gen'
```
For training with $\mathrm{OP_{d}}$:
```shell
python -m siclib.train anycalib_op_d --conf anycalib --distributed data.dataset_dir='data/openpano_v2/openpano_v2_dist'
```
For training with $\mathrm{OP_{r}}$:
```shell
python -m siclib.train anycalib_op_r --conf anycalib --distributed data.dataset_dir='data/openpano_v2/openpano_v2_radial'
```
For training with $\mathrm{OP_{p}}$ on edited (stretched and cropped) images, following the training protocol of WildCam [[8]](#8):
```shell
python -m siclib.train anycalib_op_e --conf anycalib --distributed \
data.dataset_dir='data/openpano_v2/openpano_v2' \
data.im_geom_transform.change_pixel_ar=true \
data.im_geom_transform.crop=0.5
```
After training, the model can be evaluated using its experiment name:
```shell
python -m siclib.eval.<benchmark> --checkpoint <experiment_name> --tag <experiment_tag> --conf anycalib
```
## Acknowledgements
Thanks to the authors of [GeoCalib](https://github.com/cvg/GeoCalib) for open-sourcing the comprehensive and easy-to-use [`siclib`](https://github.com/cvg/GeoCalib/tree/main/siclib) which we use as the base of our evaluation and training code. <br>
Thanks to the authors of the [The Laval Photometric Indoor HDR Dataset](http://hdrdb.com/indoor-hdr-photometric/) for allowing us to release the weights of AnyCalib under a permissive license. <br>
Thanks also to the authors of [The Laval Photometric Indoor HDR Dataset](http://hdrdb.com/indoor-hdr-photometric/), [PolyHaven](https://polyhaven.com/hdris), [HDRMaps](https://hdrmaps.com/freebies/free-hdris/), [AmbientCG](https://ambientcg.com/list?type=hdri&sort=popular) and [BlenderKit](https://www.blenderkit.com/asset-gallery?query=category_subtree:hdr) for providing high-quality freely-available panoramas that made the training of AnyCalib possible.
## BibTex citation
If you use any ideas from the paper or code from this repo, please consider citing:
```bibtex
@InProceedings{tirado2025anycalib,
author={Javier Tirado-Gar{\'\i}n and Javier Civera},
title={{AnyCalib: On-Manifold Learning for Model-Agnostic Single-View Camera Calibration}},
booktitle={ICCV},
year={2025}
}
```
## License
Code and weights are provided under the [Apache 2.0 license](LICENSE).
## References
<a id="1">[1]</a>
Close-Range Camera Calibration. D.C. Brown, 1971.
<a id="2">[2]</a>
A Generic Camera Model and Calibration Method for Conventional, Wide-Angle, and Fish-Eye Lenses. J. Kannala, S.S. Brandt, TPAMI 2006.
<a id="3">[3]</a>
Single View Point Omnidirectional Camera Calibration from Planar Grids. C. Mei, P. Rives, ICRA, 2007.
<a id="4">[4]</a>
An Enhanced Unified Camera Model. B. Khomutenko, at al., IEEE RA-L, 2016.
<a id="5">[5]</a>
Simultaneous Linear Estimation of Multiple View Geometry and Lens Distortion. A.W. Fitzgibbon, CVPR, 2001.
<a id="6">[6]</a>
The Double Sphere Camera Model. V. Usenko, et al., 3DV, 2018.
<a id="7">[7]</a>
BabelCalib: A Universal Approach to Calibrating Central Cameras. Y. Lochman, et al., ICCV, 2021.
<a id="8">[8]</a>
Tame a Wild Camera: In-the-Wild Monocular Camera Calibration. S. Zhu, et al., NeurIPS, 2023.
|
mradermacher/gpt-oss-20b-triton-kernel-i1-GGUF
|
mradermacher
| 2025-09-11T18:34:12Z | 18,687 | 0 |
transformers
|
[
"transformers",
"gguf",
"generated_from_trainer",
"sft",
"trl",
"en",
"dataset:Nadiveedishravanreddy/KernelBook-messages",
"base_model:Nadiveedishravanreddy/gpt-oss-20b-triton-kernel",
"base_model:quantized:Nadiveedishravanreddy/gpt-oss-20b-triton-kernel",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | null | 2025-09-08T09:51:07Z |
---
base_model: Nadiveedishravanreddy/gpt-oss-20b-triton-kernel
datasets:
- Nadiveedishravanreddy/KernelBook-messages
language:
- en
library_name: transformers
license: apache-2.0
model_name: gpt-oss-20b-triton-kernel
mradermacher:
readme_rev: 1
quantized_by: mradermacher
tags:
- generated_from_trainer
- sft
- trl
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: nicoboss -->
<!-- ### quants: Q2_K IQ3_M Q4_K_S IQ3_XXS Q3_K_M small-IQ4_NL Q4_K_M IQ2_M Q6_K IQ4_XS Q2_K_S IQ1_M Q3_K_S IQ2_XXS Q3_K_L IQ2_XS Q5_K_S IQ2_S IQ1_S Q5_K_M Q4_0 IQ3_XS Q4_1 IQ3_S -->
<!-- ### quants_skip: -->
<!-- ### skip_mmproj: -->
weighted/imatrix quants of https://huggingface.co/Nadiveedishravanreddy/gpt-oss-20b-triton-kernel
<!-- provided-files -->
***For a convenient overview and download list, visit our [model page for this model](https://hf.tst.eu/model#gpt-oss-20b-triton-kernel-i1-GGUF).***
static quants are available at https://huggingface.co/mradermacher/gpt-oss-20b-triton-kernel-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/gpt-oss-20b-triton-kernel-i1-GGUF/resolve/main/gpt-oss-20b-triton-kernel.imatrix.gguf) | imatrix | 0.1 | imatrix file (for creating your own qwuants) |
| [GGUF](https://huggingface.co/mradermacher/gpt-oss-20b-triton-kernel-i1-GGUF/resolve/main/gpt-oss-20b-triton-kernel.i1-IQ1_M.gguf) | i1-IQ1_M | 12.1 | mostly desperate |
| [GGUF](https://huggingface.co/mradermacher/gpt-oss-20b-triton-kernel-i1-GGUF/resolve/main/gpt-oss-20b-triton-kernel.i1-IQ1_S.gguf) | i1-IQ1_S | 12.1 | for the desperate |
| [GGUF](https://huggingface.co/mradermacher/gpt-oss-20b-triton-kernel-i1-GGUF/resolve/main/gpt-oss-20b-triton-kernel.i1-IQ2_XXS.gguf) | i1-IQ2_XXS | 12.1 | |
| [GGUF](https://huggingface.co/mradermacher/gpt-oss-20b-triton-kernel-i1-GGUF/resolve/main/gpt-oss-20b-triton-kernel.i1-IQ2_XS.gguf) | i1-IQ2_XS | 12.1 | |
| [GGUF](https://huggingface.co/mradermacher/gpt-oss-20b-triton-kernel-i1-GGUF/resolve/main/gpt-oss-20b-triton-kernel.i1-Q3_K_S.gguf) | i1-Q3_K_S | 12.2 | IQ3_XS probably better |
| [GGUF](https://huggingface.co/mradermacher/gpt-oss-20b-triton-kernel-i1-GGUF/resolve/main/gpt-oss-20b-triton-kernel.i1-IQ2_M.gguf) | i1-IQ2_M | 12.2 | |
| [GGUF](https://huggingface.co/mradermacher/gpt-oss-20b-triton-kernel-i1-GGUF/resolve/main/gpt-oss-20b-triton-kernel.i1-IQ2_S.gguf) | i1-IQ2_S | 12.2 | |
| [GGUF](https://huggingface.co/mradermacher/gpt-oss-20b-triton-kernel-i1-GGUF/resolve/main/gpt-oss-20b-triton-kernel.i1-IQ3_S.gguf) | i1-IQ3_S | 12.2 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/gpt-oss-20b-triton-kernel-i1-GGUF/resolve/main/gpt-oss-20b-triton-kernel.i1-IQ3_XS.gguf) | i1-IQ3_XS | 12.2 | |
| [GGUF](https://huggingface.co/mradermacher/gpt-oss-20b-triton-kernel-i1-GGUF/resolve/main/gpt-oss-20b-triton-kernel.i1-IQ3_XXS.gguf) | i1-IQ3_XXS | 12.2 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/gpt-oss-20b-triton-kernel-i1-GGUF/resolve/main/gpt-oss-20b-triton-kernel.i1-Q2_K.gguf) | i1-Q2_K | 12.2 | IQ3_XXS probably better |
| [GGUF](https://huggingface.co/mradermacher/gpt-oss-20b-triton-kernel-i1-GGUF/resolve/main/gpt-oss-20b-triton-kernel.i1-IQ4_XS.gguf) | i1-IQ4_XS | 12.2 | |
| [GGUF](https://huggingface.co/mradermacher/gpt-oss-20b-triton-kernel-i1-GGUF/resolve/main/gpt-oss-20b-triton-kernel.i1-Q2_K_S.gguf) | i1-Q2_K_S | 12.2 | very low quality |
| [GGUF](https://huggingface.co/mradermacher/gpt-oss-20b-triton-kernel-i1-GGUF/resolve/main/gpt-oss-20b-triton-kernel.i1-Q4_0.gguf) | i1-Q4_0 | 12.2 | fast, low quality |
| [GGUF](https://huggingface.co/mradermacher/gpt-oss-20b-triton-kernel-i1-GGUF/resolve/main/gpt-oss-20b-triton-kernel.i1-IQ3_M.gguf) | i1-IQ3_M | 12.3 | |
| [GGUF](https://huggingface.co/mradermacher/gpt-oss-20b-triton-kernel-i1-GGUF/resolve/main/gpt-oss-20b-triton-kernel.i1-Q3_K_M.gguf) | i1-Q3_K_M | 13.0 | IQ3_S probably better |
| [GGUF](https://huggingface.co/mradermacher/gpt-oss-20b-triton-kernel-i1-GGUF/resolve/main/gpt-oss-20b-triton-kernel.i1-Q3_K_L.gguf) | i1-Q3_K_L | 13.4 | IQ3_M probably better |
| [GGUF](https://huggingface.co/mradermacher/gpt-oss-20b-triton-kernel-i1-GGUF/resolve/main/gpt-oss-20b-triton-kernel.i1-Q4_1.gguf) | i1-Q4_1 | 13.5 | |
| [GGUF](https://huggingface.co/mradermacher/gpt-oss-20b-triton-kernel-i1-GGUF/resolve/main/gpt-oss-20b-triton-kernel.i1-Q4_K_S.gguf) | i1-Q4_K_S | 14.8 | optimal size/speed/quality |
| [GGUF](https://huggingface.co/mradermacher/gpt-oss-20b-triton-kernel-i1-GGUF/resolve/main/gpt-oss-20b-triton-kernel.i1-Q4_K_M.gguf) | i1-Q4_K_M | 15.9 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/gpt-oss-20b-triton-kernel-i1-GGUF/resolve/main/gpt-oss-20b-triton-kernel.i1-Q5_K_S.gguf) | i1-Q5_K_S | 16.0 | |
| [GGUF](https://huggingface.co/mradermacher/gpt-oss-20b-triton-kernel-i1-GGUF/resolve/main/gpt-oss-20b-triton-kernel.i1-Q5_K_M.gguf) | i1-Q5_K_M | 17.0 | |
| [GGUF](https://huggingface.co/mradermacher/gpt-oss-20b-triton-kernel-i1-GGUF/resolve/main/gpt-oss-20b-triton-kernel.i1-Q6_K.gguf) | i1-Q6_K | 22.3 | practically like static Q6_K |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time. Additional thanks to [@nicoboss](https://huggingface.co/nicoboss) for giving me access to his private supercomputer, enabling me to provide many more imatrix quants, at much higher quality, than I would otherwise be able to.
<!-- end -->
|
choiqs/Qwen3-4B-tldr-bsz128-regular-skywork8b-seed42-lr2e-6-checkpoint-250
|
choiqs
| 2025-09-11T18:33:36Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen3",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-09-11T18:32:37Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
mradermacher/SinhalaLLM-GGUF
|
mradermacher
| 2025-09-11T18:32:52Z | 756 | 0 |
transformers
|
[
"transformers",
"gguf",
"experimental",
"low-resource-languages",
"research",
"proof-of-concept",
"si",
"base_model:Captainsl/SinhalaLLM",
"base_model:quantized:Captainsl/SinhalaLLM",
"license:mit",
"endpoints_compatible",
"region:us"
] | null | 2025-09-08T23:01:16Z |
---
base_model: Captainsl/SinhalaLLM
language:
- si
library_name: transformers
license: mit
mradermacher:
readme_rev: 1
quantized_by: mradermacher
tags:
- experimental
- low-resource-languages
- research
- proof-of-concept
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
<!-- ### quants: x-f16 Q4_K_S Q2_K Q8_0 Q6_K Q3_K_M Q3_K_S Q3_K_L Q4_K_M Q5_K_S Q5_K_M IQ4_XS -->
<!-- ### quants_skip: -->
<!-- ### skip_mmproj: -->
static quants of https://huggingface.co/Captainsl/SinhalaLLM
<!-- provided-files -->
***For a convenient overview and download list, visit our [model page for this model](https://hf.tst.eu/model#SinhalaLLM-GGUF).***
weighted/imatrix quants seem not to be available (by me) at this time. If they do not show up a week or so after the static ones, I have probably not planned for them. Feel free to request them by opening a Community Discussion.
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/SinhalaLLM-GGUF/resolve/main/SinhalaLLM.Q2_K.gguf) | Q2_K | 0.9 | |
| [GGUF](https://huggingface.co/mradermacher/SinhalaLLM-GGUF/resolve/main/SinhalaLLM.Q3_K_S.gguf) | Q3_K_S | 1.0 | |
| [GGUF](https://huggingface.co/mradermacher/SinhalaLLM-GGUF/resolve/main/SinhalaLLM.Q3_K_M.gguf) | Q3_K_M | 1.1 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/SinhalaLLM-GGUF/resolve/main/SinhalaLLM.Q3_K_L.gguf) | Q3_K_L | 1.2 | |
| [GGUF](https://huggingface.co/mradermacher/SinhalaLLM-GGUF/resolve/main/SinhalaLLM.IQ4_XS.gguf) | IQ4_XS | 1.2 | |
| [GGUF](https://huggingface.co/mradermacher/SinhalaLLM-GGUF/resolve/main/SinhalaLLM.Q4_K_S.gguf) | Q4_K_S | 1.3 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/SinhalaLLM-GGUF/resolve/main/SinhalaLLM.Q4_K_M.gguf) | Q4_K_M | 1.3 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/SinhalaLLM-GGUF/resolve/main/SinhalaLLM.Q5_K_S.gguf) | Q5_K_S | 1.4 | |
| [GGUF](https://huggingface.co/mradermacher/SinhalaLLM-GGUF/resolve/main/SinhalaLLM.Q5_K_M.gguf) | Q5_K_M | 1.5 | |
| [GGUF](https://huggingface.co/mradermacher/SinhalaLLM-GGUF/resolve/main/SinhalaLLM.Q6_K.gguf) | Q6_K | 1.7 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/SinhalaLLM-GGUF/resolve/main/SinhalaLLM.Q8_0.gguf) | Q8_0 | 2.1 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/SinhalaLLM-GGUF/resolve/main/SinhalaLLM.f16.gguf) | f16 | 3.9 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
mradermacher/ATLAS-Teach-8B-Instruct-GGUF
|
mradermacher
| 2025-09-11T18:31:01Z | 1,326 | 0 |
transformers
|
[
"transformers",
"gguf",
"supervised-fine-tuning",
"teacher-model",
"pedagogy",
"reasoning",
"sft",
"en",
"dataset:Arc-Intelligence/Arc-ATLAS-Teach-v0",
"base_model:Arc-Intelligence/ATLAS-8B-Instruct",
"base_model:quantized:Arc-Intelligence/ATLAS-8B-Instruct",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2025-09-09T09:35:09Z |
---
base_model: Arc-Intelligence/ATLAS-8B-Instruct
datasets:
- Arc-Intelligence/Arc-ATLAS-Teach-v0
language:
- en
library_name: transformers
license: apache-2.0
mradermacher:
readme_rev: 1
quantized_by: mradermacher
tags:
- supervised-fine-tuning
- teacher-model
- pedagogy
- reasoning
- sft
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
<!-- ### quants: x-f16 Q4_K_S Q2_K Q8_0 Q6_K Q3_K_M Q3_K_S Q3_K_L Q4_K_M Q5_K_S Q5_K_M IQ4_XS -->
<!-- ### quants_skip: -->
<!-- ### skip_mmproj: -->
static quants of https://huggingface.co/Arc-Intelligence/ATLAS-8B-Instruct
<!-- provided-files -->
***For a convenient overview and download list, visit our [model page for this model](https://hf.tst.eu/model#ATLAS-Teach-8B-Instruct-GGUF).***
weighted/imatrix quants are available at https://huggingface.co/mradermacher/ATLAS-Teach-8B-Instruct-i1-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/ATLAS-Teach-8B-Instruct-GGUF/resolve/main/ATLAS-Teach-8B-Instruct.Q2_K.gguf) | Q2_K | 3.4 | |
| [GGUF](https://huggingface.co/mradermacher/ATLAS-Teach-8B-Instruct-GGUF/resolve/main/ATLAS-Teach-8B-Instruct.Q3_K_S.gguf) | Q3_K_S | 3.9 | |
| [GGUF](https://huggingface.co/mradermacher/ATLAS-Teach-8B-Instruct-GGUF/resolve/main/ATLAS-Teach-8B-Instruct.Q3_K_M.gguf) | Q3_K_M | 4.2 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/ATLAS-Teach-8B-Instruct-GGUF/resolve/main/ATLAS-Teach-8B-Instruct.Q3_K_L.gguf) | Q3_K_L | 4.5 | |
| [GGUF](https://huggingface.co/mradermacher/ATLAS-Teach-8B-Instruct-GGUF/resolve/main/ATLAS-Teach-8B-Instruct.IQ4_XS.gguf) | IQ4_XS | 4.7 | |
| [GGUF](https://huggingface.co/mradermacher/ATLAS-Teach-8B-Instruct-GGUF/resolve/main/ATLAS-Teach-8B-Instruct.Q4_K_S.gguf) | Q4_K_S | 4.9 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/ATLAS-Teach-8B-Instruct-GGUF/resolve/main/ATLAS-Teach-8B-Instruct.Q4_K_M.gguf) | Q4_K_M | 5.1 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/ATLAS-Teach-8B-Instruct-GGUF/resolve/main/ATLAS-Teach-8B-Instruct.Q5_K_S.gguf) | Q5_K_S | 5.8 | |
| [GGUF](https://huggingface.co/mradermacher/ATLAS-Teach-8B-Instruct-GGUF/resolve/main/ATLAS-Teach-8B-Instruct.Q5_K_M.gguf) | Q5_K_M | 6.0 | |
| [GGUF](https://huggingface.co/mradermacher/ATLAS-Teach-8B-Instruct-GGUF/resolve/main/ATLAS-Teach-8B-Instruct.Q6_K.gguf) | Q6_K | 6.8 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/ATLAS-Teach-8B-Instruct-GGUF/resolve/main/ATLAS-Teach-8B-Instruct.Q8_0.gguf) | Q8_0 | 8.8 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/ATLAS-Teach-8B-Instruct-GGUF/resolve/main/ATLAS-Teach-8B-Instruct.f16.gguf) | f16 | 16.5 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
mradermacher/ATLAS-Teach-8B-Instruct-i1-GGUF
|
mradermacher
| 2025-09-11T18:30:54Z | 1,215 | 0 |
transformers
|
[
"transformers",
"gguf",
"supervised-fine-tuning",
"teacher-model",
"pedagogy",
"reasoning",
"sft",
"en",
"dataset:Arc-Intelligence/Arc-ATLAS-Teach-v0",
"base_model:Arc-Intelligence/ATLAS-8B-Instruct",
"base_model:quantized:Arc-Intelligence/ATLAS-8B-Instruct",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | null | 2025-09-09T10:07:45Z |
---
base_model: Arc-Intelligence/ATLAS-8B-Instruct
datasets:
- Arc-Intelligence/Arc-ATLAS-Teach-v0
language:
- en
library_name: transformers
license: apache-2.0
mradermacher:
readme_rev: 1
quantized_by: mradermacher
tags:
- supervised-fine-tuning
- teacher-model
- pedagogy
- reasoning
- sft
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: nicoboss -->
<!-- ### quants: Q2_K IQ3_M Q4_K_S IQ3_XXS Q3_K_M small-IQ4_NL Q4_K_M IQ2_M Q6_K IQ4_XS Q2_K_S IQ1_M Q3_K_S IQ2_XXS Q3_K_L IQ2_XS Q5_K_S IQ2_S IQ1_S Q5_K_M Q4_0 IQ3_XS Q4_1 IQ3_S -->
<!-- ### quants_skip: -->
<!-- ### skip_mmproj: -->
weighted/imatrix quants of https://huggingface.co/Arc-Intelligence/ATLAS-8B-Instruct
<!-- provided-files -->
***For a convenient overview and download list, visit our [model page for this model](https://hf.tst.eu/model#ATLAS-Teach-8B-Instruct-i1-GGUF).***
static quants are available at https://huggingface.co/mradermacher/ATLAS-Teach-8B-Instruct-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/ATLAS-Teach-8B-Instruct-i1-GGUF/resolve/main/ATLAS-Teach-8B-Instruct.imatrix.gguf) | imatrix | 0.1 | imatrix file (for creating your own qwuants) |
| [GGUF](https://huggingface.co/mradermacher/ATLAS-Teach-8B-Instruct-i1-GGUF/resolve/main/ATLAS-Teach-8B-Instruct.i1-IQ1_S.gguf) | i1-IQ1_S | 2.2 | for the desperate |
| [GGUF](https://huggingface.co/mradermacher/ATLAS-Teach-8B-Instruct-i1-GGUF/resolve/main/ATLAS-Teach-8B-Instruct.i1-IQ1_M.gguf) | i1-IQ1_M | 2.4 | mostly desperate |
| [GGUF](https://huggingface.co/mradermacher/ATLAS-Teach-8B-Instruct-i1-GGUF/resolve/main/ATLAS-Teach-8B-Instruct.i1-IQ2_XXS.gguf) | i1-IQ2_XXS | 2.6 | |
| [GGUF](https://huggingface.co/mradermacher/ATLAS-Teach-8B-Instruct-i1-GGUF/resolve/main/ATLAS-Teach-8B-Instruct.i1-IQ2_XS.gguf) | i1-IQ2_XS | 2.8 | |
| [GGUF](https://huggingface.co/mradermacher/ATLAS-Teach-8B-Instruct-i1-GGUF/resolve/main/ATLAS-Teach-8B-Instruct.i1-IQ2_S.gguf) | i1-IQ2_S | 3.0 | |
| [GGUF](https://huggingface.co/mradermacher/ATLAS-Teach-8B-Instruct-i1-GGUF/resolve/main/ATLAS-Teach-8B-Instruct.i1-IQ2_M.gguf) | i1-IQ2_M | 3.2 | |
| [GGUF](https://huggingface.co/mradermacher/ATLAS-Teach-8B-Instruct-i1-GGUF/resolve/main/ATLAS-Teach-8B-Instruct.i1-Q2_K_S.gguf) | i1-Q2_K_S | 3.2 | very low quality |
| [GGUF](https://huggingface.co/mradermacher/ATLAS-Teach-8B-Instruct-i1-GGUF/resolve/main/ATLAS-Teach-8B-Instruct.i1-Q2_K.gguf) | i1-Q2_K | 3.4 | IQ3_XXS probably better |
| [GGUF](https://huggingface.co/mradermacher/ATLAS-Teach-8B-Instruct-i1-GGUF/resolve/main/ATLAS-Teach-8B-Instruct.i1-IQ3_XXS.gguf) | i1-IQ3_XXS | 3.5 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/ATLAS-Teach-8B-Instruct-i1-GGUF/resolve/main/ATLAS-Teach-8B-Instruct.i1-IQ3_XS.gguf) | i1-IQ3_XS | 3.7 | |
| [GGUF](https://huggingface.co/mradermacher/ATLAS-Teach-8B-Instruct-i1-GGUF/resolve/main/ATLAS-Teach-8B-Instruct.i1-Q3_K_S.gguf) | i1-Q3_K_S | 3.9 | IQ3_XS probably better |
| [GGUF](https://huggingface.co/mradermacher/ATLAS-Teach-8B-Instruct-i1-GGUF/resolve/main/ATLAS-Teach-8B-Instruct.i1-IQ3_S.gguf) | i1-IQ3_S | 3.9 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/ATLAS-Teach-8B-Instruct-i1-GGUF/resolve/main/ATLAS-Teach-8B-Instruct.i1-IQ3_M.gguf) | i1-IQ3_M | 4.0 | |
| [GGUF](https://huggingface.co/mradermacher/ATLAS-Teach-8B-Instruct-i1-GGUF/resolve/main/ATLAS-Teach-8B-Instruct.i1-Q3_K_M.gguf) | i1-Q3_K_M | 4.2 | IQ3_S probably better |
| [GGUF](https://huggingface.co/mradermacher/ATLAS-Teach-8B-Instruct-i1-GGUF/resolve/main/ATLAS-Teach-8B-Instruct.i1-Q3_K_L.gguf) | i1-Q3_K_L | 4.5 | IQ3_M probably better |
| [GGUF](https://huggingface.co/mradermacher/ATLAS-Teach-8B-Instruct-i1-GGUF/resolve/main/ATLAS-Teach-8B-Instruct.i1-IQ4_XS.gguf) | i1-IQ4_XS | 4.7 | |
| [GGUF](https://huggingface.co/mradermacher/ATLAS-Teach-8B-Instruct-i1-GGUF/resolve/main/ATLAS-Teach-8B-Instruct.i1-Q4_0.gguf) | i1-Q4_0 | 4.9 | fast, low quality |
| [GGUF](https://huggingface.co/mradermacher/ATLAS-Teach-8B-Instruct-i1-GGUF/resolve/main/ATLAS-Teach-8B-Instruct.i1-IQ4_NL.gguf) | i1-IQ4_NL | 4.9 | prefer IQ4_XS |
| [GGUF](https://huggingface.co/mradermacher/ATLAS-Teach-8B-Instruct-i1-GGUF/resolve/main/ATLAS-Teach-8B-Instruct.i1-Q4_K_S.gguf) | i1-Q4_K_S | 4.9 | optimal size/speed/quality |
| [GGUF](https://huggingface.co/mradermacher/ATLAS-Teach-8B-Instruct-i1-GGUF/resolve/main/ATLAS-Teach-8B-Instruct.i1-Q4_K_M.gguf) | i1-Q4_K_M | 5.1 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/ATLAS-Teach-8B-Instruct-i1-GGUF/resolve/main/ATLAS-Teach-8B-Instruct.i1-Q4_1.gguf) | i1-Q4_1 | 5.3 | |
| [GGUF](https://huggingface.co/mradermacher/ATLAS-Teach-8B-Instruct-i1-GGUF/resolve/main/ATLAS-Teach-8B-Instruct.i1-Q5_K_S.gguf) | i1-Q5_K_S | 5.8 | |
| [GGUF](https://huggingface.co/mradermacher/ATLAS-Teach-8B-Instruct-i1-GGUF/resolve/main/ATLAS-Teach-8B-Instruct.i1-Q5_K_M.gguf) | i1-Q5_K_M | 6.0 | |
| [GGUF](https://huggingface.co/mradermacher/ATLAS-Teach-8B-Instruct-i1-GGUF/resolve/main/ATLAS-Teach-8B-Instruct.i1-Q6_K.gguf) | i1-Q6_K | 6.8 | practically like static Q6_K |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time. Additional thanks to [@nicoboss](https://huggingface.co/nicoboss) for giving me access to his private supercomputer, enabling me to provide many more imatrix quants, at much higher quality, than I would otherwise be able to.
<!-- end -->
|
mradermacher/Qwen3-ST-The-Next-Generation-II-v1-256k-ctx-6B-GGUF
|
mradermacher
| 2025-09-11T18:29:13Z | 2,928 | 0 |
transformers
|
[
"transformers",
"gguf",
"programming",
"code generation",
"code",
"coding",
"coder",
"chat",
"brainstorm",
"qwen",
"qwen3",
"qwencoder",
"brainstorm 20x",
"creative",
"all uses cases",
"Jan-V1",
"float32",
"horror",
"science fiction",
"fantasy",
"Star Trek",
"finetune",
"thinking",
"reasoning",
"unsloth",
"en",
"dataset:progs2002/star-trek-tng-scripts",
"base_model:DavidAU/Qwen3-ST-The-Next-Generation-II-v1-256k-ctx-6B",
"base_model:quantized:DavidAU/Qwen3-ST-The-Next-Generation-II-v1-256k-ctx-6B",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2025-09-10T02:51:05Z |
---
base_model: DavidAU/Qwen3-ST-The-Next-Generation-II-v1-256k-ctx-6B
datasets:
- progs2002/star-trek-tng-scripts
language:
- en
library_name: transformers
license: apache-2.0
mradermacher:
readme_rev: 1
quantized_by: mradermacher
tags:
- programming
- code generation
- code
- coding
- coder
- chat
- code
- chat
- brainstorm
- qwen
- qwen3
- qwencoder
- brainstorm 20x
- creative
- all uses cases
- Jan-V1
- float32
- horror
- science fiction
- fantasy
- Star Trek
- finetune
- thinking
- reasoning
- unsloth
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
<!-- ### quants: x-f16 Q4_K_S Q2_K Q8_0 Q6_K Q3_K_M Q3_K_S Q3_K_L Q4_K_M Q5_K_S Q5_K_M IQ4_XS -->
<!-- ### quants_skip: -->
<!-- ### skip_mmproj: -->
static quants of https://huggingface.co/DavidAU/Qwen3-ST-The-Next-Generation-II-v1-256k-ctx-6B
<!-- provided-files -->
***For a convenient overview and download list, visit our [model page for this model](https://hf.tst.eu/model#Qwen3-ST-The-Next-Generation-II-v1-256k-ctx-6B-GGUF).***
weighted/imatrix quants are available at https://huggingface.co/mradermacher/Qwen3-ST-The-Next-Generation-II-v1-256k-ctx-6B-i1-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/Qwen3-ST-The-Next-Generation-II-v1-256k-ctx-6B-GGUF/resolve/main/Qwen3-ST-The-Next-Generation-II-v1-256k-ctx-6B.Q2_K.gguf) | Q2_K | 2.6 | |
| [GGUF](https://huggingface.co/mradermacher/Qwen3-ST-The-Next-Generation-II-v1-256k-ctx-6B-GGUF/resolve/main/Qwen3-ST-The-Next-Generation-II-v1-256k-ctx-6B.Q3_K_S.gguf) | Q3_K_S | 3.0 | |
| [GGUF](https://huggingface.co/mradermacher/Qwen3-ST-The-Next-Generation-II-v1-256k-ctx-6B-GGUF/resolve/main/Qwen3-ST-The-Next-Generation-II-v1-256k-ctx-6B.Q3_K_M.gguf) | Q3_K_M | 3.3 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/Qwen3-ST-The-Next-Generation-II-v1-256k-ctx-6B-GGUF/resolve/main/Qwen3-ST-The-Next-Generation-II-v1-256k-ctx-6B.Q3_K_L.gguf) | Q3_K_L | 3.5 | |
| [GGUF](https://huggingface.co/mradermacher/Qwen3-ST-The-Next-Generation-II-v1-256k-ctx-6B-GGUF/resolve/main/Qwen3-ST-The-Next-Generation-II-v1-256k-ctx-6B.IQ4_XS.gguf) | IQ4_XS | 3.6 | |
| [GGUF](https://huggingface.co/mradermacher/Qwen3-ST-The-Next-Generation-II-v1-256k-ctx-6B-GGUF/resolve/main/Qwen3-ST-The-Next-Generation-II-v1-256k-ctx-6B.Q4_K_S.gguf) | Q4_K_S | 3.8 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Qwen3-ST-The-Next-Generation-II-v1-256k-ctx-6B-GGUF/resolve/main/Qwen3-ST-The-Next-Generation-II-v1-256k-ctx-6B.Q4_K_M.gguf) | Q4_K_M | 4.0 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Qwen3-ST-The-Next-Generation-II-v1-256k-ctx-6B-GGUF/resolve/main/Qwen3-ST-The-Next-Generation-II-v1-256k-ctx-6B.Q5_K_S.gguf) | Q5_K_S | 4.5 | |
| [GGUF](https://huggingface.co/mradermacher/Qwen3-ST-The-Next-Generation-II-v1-256k-ctx-6B-GGUF/resolve/main/Qwen3-ST-The-Next-Generation-II-v1-256k-ctx-6B.Q5_K_M.gguf) | Q5_K_M | 4.6 | |
| [GGUF](https://huggingface.co/mradermacher/Qwen3-ST-The-Next-Generation-II-v1-256k-ctx-6B-GGUF/resolve/main/Qwen3-ST-The-Next-Generation-II-v1-256k-ctx-6B.Q6_K.gguf) | Q6_K | 5.3 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/Qwen3-ST-The-Next-Generation-II-v1-256k-ctx-6B-GGUF/resolve/main/Qwen3-ST-The-Next-Generation-II-v1-256k-ctx-6B.Q8_0.gguf) | Q8_0 | 6.8 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/Qwen3-ST-The-Next-Generation-II-v1-256k-ctx-6B-GGUF/resolve/main/Qwen3-ST-The-Next-Generation-II-v1-256k-ctx-6B.f16.gguf) | f16 | 12.8 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
Akashiurahara/GBbrv
|
Akashiurahara
| 2025-09-11T18:28:49Z | 43 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"text-generation-inference",
"unsloth",
"en",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-09-10T17:56:14Z |
---
base_model: unsloth/llama-3.2-3b-unsloth-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- llama
license: apache-2.0
language:
- en
---
# Uploaded finetuned model
- **Developed by:** Akashiurahara
- **License:** apache-2.0
- **Finetuned from model :** unsloth/llama-3.2-3b-unsloth-bnb-4bit
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
nice2mitya/a_5174140999
|
nice2mitya
| 2025-09-11T18:22:24Z | 0 | 0 | null |
[
"license:other",
"region:us"
] | null | 2025-07-04T06:37:14Z |
---
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
---
|
LBK95/Llama-3.2-1B-hf-DPO_V3-CTRL-LookAhead-0_TTree1.2_TT0.9_TP0.7_TE0.1_V4
|
LBK95
| 2025-09-11T18:21:48Z | 0 | 0 |
peft
|
[
"peft",
"safetensors",
"trl",
"dpo",
"generated_from_trainer",
"base_model:meta-llama/Llama-3.2-1B",
"base_model:adapter:meta-llama/Llama-3.2-1B",
"license:llama3.2",
"region:us"
] | null | 2025-09-11T17:10:24Z |
---
library_name: peft
license: llama3.2
base_model: meta-llama/Llama-3.2-1B
tags:
- trl
- dpo
- generated_from_trainer
model-index:
- name: Llama-3.2-1B-hf-DPO_V3-CTRL-LookAhead-0_TTree1.2_TT0.9_TP0.7_TE0.1_V4
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Llama-3.2-1B-hf-DPO_V3-CTRL-LookAhead-0_TTree1.2_TT0.9_TP0.7_TE0.1_V4
This model is a fine-tuned version of [meta-llama/Llama-3.2-1B](https://huggingface.co/meta-llama/Llama-3.2-1B) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 1
- eval_batch_size: 1
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 10
- num_epochs: 3
### Training results
### Framework versions
- PEFT 0.15.2
- Transformers 4.45.2
- Pytorch 2.8.0+cu126
- Datasets 2.14.4
- Tokenizers 0.20.3
|
smainye/sw_finetunned_tune_whisper_small_model
|
smainye
| 2025-09-11T18:20:22Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"whisper",
"automatic-speech-recognition",
"sw",
"arxiv:1910.09700",
"base_model:openai/whisper-small",
"base_model:finetune:openai/whisper-small",
"license:mit",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2025-09-11T18:07:19Z |
---
library_name: transformers
license: mit
language:
- sw
base_model:
- openai/whisper-small
pipeline_tag: automatic-speech-recognition
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
FalseNoetics/GLaDOS3.4_3B
|
FalseNoetics
| 2025-09-11T18:17:52Z | 0 | 0 |
diffusers
|
[
"diffusers",
"safetensors",
"text-to-image",
"lora",
"template:diffusion-lora",
"base_model:meta-llama/Llama-3.2-3B",
"base_model:adapter:meta-llama/Llama-3.2-3B",
"license:cc-by-2.0",
"region:us"
] |
text-to-image
| 2025-09-11T18:17:48Z |
---
tags:
- text-to-image
- lora
- diffusers
- template:diffusion-lora
widget:
- output:
url: images/Screenshot 2025-09-11 at 12.17.30 PM.png
text: Wheatley is taking over the facility
base_model: meta-llama/Llama-3.2-3B
instance_prompt: null
license: cc-by-2.0
---
# GLaDOS3.4:3B
<Gallery />
## Model description
This model is based on GLaDOS from Portal. It has been fine-tuned based on all of GLaDOS' lines from the games.
## Download model
[Download](/FalseNoetics/GLaDOS3.4_3B/tree/main) them in the Files & versions tab.
|
AesSedai/GLM-4.5-GGUF
|
AesSedai
| 2025-09-11T18:16:57Z | 36 | 1 | null |
[
"gguf",
"text-generation",
"base_model:zai-org/GLM-4.5",
"base_model:quantized:zai-org/GLM-4.5",
"license:mit",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] |
text-generation
| 2025-08-09T05:44:48Z |
---
quantized_by: AesSedai
pipeline_tag: text-generation
base_model: zai-org/GLM-4.5
license: mit
base_model_relation: quantized
---
## `ik_llama.cpp` imatrix Quantizations of zai-org/GLM-4.5
This quant collection **REQUIRES** [ik_llama.cpp](https://github.com/ikawrakow/ik_llama.cpp/) fork to support the ik's latest SOTA quants and optimizations! Do **not** download these big files and expect them to run on mainline vanilla llama.cpp, ollama, LM Studio, KoboldCpp, etc!
*NOTE* `ik_llama.cpp` can also run your existing GGUFs from bartowski, unsloth, mradermacher, etc if you want to try it out before downloading my quants.
Some of ik's new quants are supported with [Nexesenex/croco.cpp](https://github.com/Nexesenex/croco.cpp) fork of KoboldCPP with Windows builds for CUDA 12.9. Also check for [Windows builds by Thireus here.](https://github.com/Thireus/ik_llama.cpp/releases) which have been CUDA 12.8.
See [Ubergarm's GLM-4.5 quants](https://huggingface.co/ubergarm/GLM-4.5-GGUF) for info on how to use the recipe or make your own quant.
## IQ2_KT: 109.269 GiB (2.619 BPW), Final estimate: PPL = 4.1170 +/- 0.02457
<details>
<summary>👈 Recipe</summary>
```bash
# 93 Repeating Layers [0-92]
# Attention
blk\..*\.attn_q.*=iq4_k
blk\..*\.attn_k.*=iq6_k
blk\..*\.attn_v.*=iq6_k
blk\..*\.attn_output.*=iq5_ks
# First 3 Dense Layers [0-2]
blk\..*\.ffn_down\.weight=iq4_ks
blk\..*\.ffn_(gate|up)\.weight=iq3_ks
# Shared Expert Layers [3-92]
blk\..*\.ffn_down_shexp\.weight=iq6_k
blk\..*\.ffn_(gate|up)_shexp\.weight=iq6_k
# Routed Experts Layers [3-92]
blk\..*\.ffn_down_exps\.weight=iq3_kt
blk\..*\.ffn_(gate|up)_exps\.weight=iq2_kt
# NextN MTP Layer [92]
blk\..*\.nextn\.embed_tokens\.weight=iq4_k
blk\..*\.nextn\.shared_head_head\.weight=iq6_k
blk\..*\.nextn\.eh_proj\.weight=iq6_k
# Non-Repeating Layers
token_embd\.weight=iq4_k
output\.weight=iq6_k
```
</details>
## IQ4_KSS: 176.499 GiB (4.231 BPW), Final estimate: PPL = 3.3031 +/- 0.01871
<details>
<summary>👈 Recipe</summary>
```bash
# 93 Repeating Layers [0-92]
# Attention
blk\.(0|1|2)\.attn_q.*=q8_0
blk\.(0|1|2)\.attn_k.*=q8_0
blk\.(0|1|2)\.attn_v.*=q8_0
blk\.(0|1|2)\.attn_output.*=q8_0
blk\..*\.attn_q.*=iq6_k
blk\..*\.attn_k.*=iq6_k
blk\..*\.attn_v.*=iq6_k
blk\..*\.attn_output.*=iq6_k
# First 3 Dense Layers [0-2]
blk\..*\.ffn_down\.weight=iq5_ks
blk\..*\.ffn_(gate|up)\.weight=iq4_ks
# Shared Expert Layers [3-92]
blk\..*\.ffn_down_shexp\.weight=q8_0
blk\..*\.ffn_(gate|up)_shexp\.weight=q8_0
# Routed Experts Layers [3-92]
blk\..*\.ffn_down_exps\.weight=iq4_ks
blk\..*\.ffn_(gate|up)_exps\.weight=iq4_kss
# NextN MTP Layer [92]
blk\..*\.nextn\.embed_tokens\.weight=iq5_ks
blk\..*\.nextn\.shared_head_head\.weight=iq5_ks
blk\..*\.nextn\.eh_proj\.weight=q8_0
# Non-Repeating Layers
token_embd\.weight=iq4_k
output\.weight=iq6_k
```
</details>
## IQ5_K: 204.948 GiB (4.913 BPW), Final estimate: PPL = 3.1992 +/- 0.01801
<details>
<summary>👈 Recipe</summary>
```bash
# 93 Repeating Layers [0-92]
# Attention
blk\.(0|1|2)\.attn_q.*=q8_0
blk\.(0|1|2)\.attn_k.*=q8_0
blk\.(0|1|2)\.attn_v.*=q8_0
blk\.(0|1|2)\.attn_output.*=q8_0
blk\..*\.attn_q.*=iq5_k
blk\..*\.attn_k.*=iq5_k
blk\..*\.attn_v.*=iq5_k
blk\..*\.attn_output.*=iq5_k
# First 3 Dense Layers [0-2]
blk\..*\.ffn_down\.weight=q8_0
blk\..*\.ffn_(gate|up)\.weight=q8_0
# Shared Expert Layers [3-92]
blk\..*\.ffn_down_shexp\.weight=q8_0
blk\..*\.ffn_(gate|up)_shexp\.weight=q8_0
# Routed Experts Layers [3-92]
blk\..*\.ffn_down_exps\.weight=iq5_k
blk\..*\.ffn_(gate|up)_exps\.weight=iq4_k
# NextN MTP Layer [92]
blk\..*\.nextn\.embed_tokens\.weight=iq5_k
blk\..*\.nextn\.shared_head_head\.weight=iq5_k
blk\..*\.nextn\.eh_proj\.weight=q8_0
# Non-Repeating Layers
token_embd\.weight=q8_0
output\.weight=q8_0
```
</details>
|
qingy2024/GPT-OSS-20B-WG44k-Step2200
|
qingy2024
| 2025-09-11T18:15:45Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"gpt_oss",
"text-generation",
"text-generation-inference",
"unsloth",
"conversational",
"en",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"mxfp4",
"region:us"
] |
text-generation
| 2025-09-11T16:22:34Z |
---
base_model: unsloth/gpt-oss-20b-bf16
tags:
- text-generation-inference
- transformers
- unsloth
- gpt_oss
license: apache-2.0
language:
- en
---
# Uploaded finetuned model
- **Developed by:** qingy2024
- **License:** apache-2.0
- **Finetuned from model :** unsloth/gpt-oss-20b-bf16
This gpt_oss model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[Example Output](https://codepen.io/qingy1337/pen/xbwNWGw)
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
wekW/grok-2
|
wekW
| 2025-09-11T18:15:22Z | 0 | 0 | null |
[
"gguf",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | null | 2025-09-11T16:37:23Z |
---
license: apache-2.0
---
grok-2 gguf
From
unsloth/grok-2-GGUF
grok-2-UD-IQ1_S
In parts, each part is 10 GB
For those with weak internet
|
timm/convnext_large.dinov3_lvd1689m
|
timm
| 2025-09-11T18:15:10Z | 0 | 0 |
timm
|
[
"timm",
"pytorch",
"safetensors",
"transformers",
"image-feature-extraction",
"arxiv:2508.10104",
"arxiv:2201.03545",
"license:other",
"region:us"
] |
image-feature-extraction
| 2025-09-11T18:09:06Z |
---
tags:
- timm
- transformers
pipeline_tag: image-feature-extraction
library_name: timm
license: other
license_name: dinov3-license
license_link: https://ai.meta.com/resources/models-and-libraries/dinov3-license
---
# Model card for convnext_large.dinov3_lvd1689m
A DINOv3 ConvNeXt image feature model. Pretrained on LVD-1689M with self-supervised DINOv3 method, distilled from DINOv3 ViT-7B.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 196.2
- GMACs: 34.4
- Activations (M): 43.1
- Image size: 224 x 224
- **Papers:**
- DINOv3: https://arxiv.org/abs/2508.10104
- A ConvNet for the 2020s: https://arxiv.org/abs/2201.03545
- PyTorch Image Models: https://github.com/huggingface/pytorch-image-models
- **Original:** https://github.com/facebookresearch/dinov3
- **Pretrain Dataset:** LVD-1689M
- **License:** [DINOv3](https://ai.meta.com/resources/models-and-libraries/dinov3-license)
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('convnext_large.dinov3_lvd1689m', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'convnext_large.dinov3_lvd1689m',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 192, 56, 56])
# torch.Size([1, 384, 28, 28])
# torch.Size([1, 768, 14, 14])
# torch.Size([1, 1536, 7, 7])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'convnext_large.dinov3_lvd1689m',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 1536, 7, 7) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Citation
```bibtex
@article{simeoni2025dinov3,
title={DINOv3},
author={Sim{'e}oni, Oriane and Vo, Huy V and Seitzer, Maximilian and Baldassarre, Federico and Oquab, Maxime and Jose, Cijo and Khalidov, Vasil and Szafraniec, Marc and Yi, Seungeun and Ramamonjisoa, Micha{"e}l and others},
journal={arXiv preprint arXiv:2508.10104},
year={2025}
}
}
```
```bibtex
@article{liu2022convnet,
author = {Zhuang Liu and Hanzi Mao and Chao-Yuan Wu and Christoph Feichtenhofer and Trevor Darrell and Saining Xie},
title = {A ConvNet for the 2020s},
journal = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2022},
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
|
Minibase/Detoxify-Language-Small
|
Minibase
| 2025-09-11T18:14:15Z | 0 | 0 | null |
[
"gguf",
"detoxify",
"nano",
"small",
"vulgar",
"curse",
"text-generation",
"en",
"license:mit",
"region:us"
] |
text-generation
| 2025-09-11T17:58:51Z |
---
license: mit
language:
- en
pipeline_tag: text-generation
tags:
- detoxify
- nano
- small
- vulgar
- curse
---
# Detoxify-Language-Small (GGUF, Q8_0)
**TL;DR**: A compact detoxification model in **GGUF (Q8_0)** format for fast CPU inference via `llama.cpp` and compatible runtimes. File size: ~138.1 MiB.
## Files
- `small-base_Detoxify-Small_high_Q8_0.gguf` (SHA256: `98945b1291812eb85275fbf2bf60ff92522e7b80026c8301ff43127fdd52826e`; size: 144810464 bytes)
## Intended use
- **Task**: detoxification of text, without changing the context of that text.
- **Hardware**: laptops/CPUs via `llama.cpp`; small GPUs with GGUF loaders.
- **Not for**: safety-critical or clinical use.
## How to run (llama.cpp)
> Replace the `-p` prompt with your own text. For classification, you can use a simple prompt like:
> `"Classify the following text as TOXIC or NON-TOXIC: <text>"`
```bash
# Build llama.cpp once (see upstream instructions), then:
./main -m small-base_Detoxify-Small_high_Q8_0.gguf -p "Classify the following text as TOXIC or NON-TOXIC: I hate you."
```
If your downstream workflow expects logits/labels directly, consider adapting a small wrapper that maps generated tokens to labels (example Python script to be added).
## Model details
- **Format**: GGUF (quantized: **Q8_0**)
- **Architecture**: LlamaForCausalLM
- **Tokenizer**: (embedded in GGUF; if you use a custom tokenizer, document it here)
- **Context length**: (not explicitly extracted here; typical small models use 2048–4096 — fill if known)
- **Base model / provenance**: Fine-tuned from the Minibase Small Base model at minibase.ai.
> If you can share the base model and training data (even briefly), add a short bullet list here to improve discoverability.
## Training Data
- Toxicity detection can reflect dataset and annotation biases. Use with caution, especially on dialects and minority language varieties.
- Performance in languages other than English is likely reduced unless trained multi-lingually.
## Limitations & bias
- Toxicity detection can reflect dataset and annotation biases. Use with caution, especially on dialects and minority language varieties.
- Performance in languages other than English is likely reduced unless trained multi-lingually.
## License
- **MIT**
## Checksums
- `small-base_Detoxify-Small_high_Q8_0.gguf` — `SHA256: 98945b1291812eb85275fbf2bf60ff92522e7b80026c8301ff43127fdd52826e`
## Changelog
- Initial upload.
|
kcymerys/Taxi-v3
|
kcymerys
| 2025-09-11T18:12:08Z | 0 | 0 | null |
[
"Taxi-v3",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2025-09-11T18:12:05Z |
---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: Taxi-v3
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
metrics:
- type: mean_reward
value: 7.44 +/- 2.74
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="kcymerys/Taxi-v3", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
iacmc85/gemma-3-finetune-12b-gguf
|
iacmc85
| 2025-09-11T18:10:33Z | 0 | 0 |
transformers
|
[
"transformers",
"gguf",
"text-generation-inference",
"unsloth",
"gemma3",
"en",
"base_model:unsloth/gemma-3-12b-it-unsloth-bnb-4bit",
"base_model:quantized:unsloth/gemma-3-12b-it-unsloth-bnb-4bit",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2025-09-11T17:49:09Z |
---
base_model: unsloth/gemma-3-12b-it-unsloth-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- gemma3
license: apache-2.0
language:
- en
---
# Uploaded finetuned model
- **Developed by:** iacmc85
- **License:** apache-2.0
- **Finetuned from model :** unsloth/gemma-3-12b-it-unsloth-bnb-4bit
This gemma3 model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
ubiqland/blockassist
|
ubiqland
| 2025-09-11T18:04:15Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"lumbering robust mongoose",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-09T21:15:10Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- lumbering robust mongoose
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
farhanahmedconnect/gemma-3_finetuned
|
farhanahmedconnect
| 2025-09-11T18:02:38Z | 0 | 0 | null |
[
"safetensors",
"gemma",
"unsloth",
"lora",
"trl",
"instruction-following",
"chat",
"text-generation",
"conversational",
"en",
"dataset:nvidia/HelpSteer2",
"base_model:unsloth/gemma-3-270m-it",
"base_model:adapter:unsloth/gemma-3-270m-it",
"license:apache-2.0",
"region:us"
] |
text-generation
| 2025-09-11T13:25:41Z |
---
pipeline_tag: text-generation
base_model: unsloth/gemma-3-270m-it
datasets:
- nvidia/HelpSteer2
language:
- en
license: apache-2.0
tags:
- gemma
- unsloth
- lora
- trl
- instruction-following
- chat
---
# Gemma-3 270M Fine-tuned with Unsloth on HelpSteer2

---
## 📜 Model Description
This repository contains a version of **Google's Gemma-3 270M IT** model, fine-tuned for conversational instruction-following. The fine-tuning was performed using **Unsloth** for significantly faster training and reduced memory usage, making it possible to train on consumer-grade hardware.
The model was trained on the `nvidia/HelpSteer2` dataset to improve its ability to generate helpful, safe, and contextually relevant responses in interactive chat scenarios.
---
## ⚙️ Model Details
- **Base Model:** `unsloth/gemma-3-270m-it`
- **Fine-tuning Method:** LoRA adaptation via PEFT
- **Dataset:** `nvidia/HelpSteer2`
- **Frameworks:**
- Unsloth
- Hugging Face Transformers
- TRL
---
## 🚀 How to Use
You can easily run this model using the `transformers` library. Make sure you have `transformers`, `unsloth`, and `torch` installed.
```python
from transformers import pipeline
import torch
# Load the model using the text-generation pipeline
# Make sure to use your Hugging Face username and repo name
generator = pipeline(
"text-generation",
model="farhanahmedconnect/gemma-3_finetuned",
torch_dtype=torch.bfloat16,
device_map="auto"
)
# Use the Gemma-3 chat template
messages = [
{"role": "user", "content": "What are the top 3 benefits of using Unsloth for model training?"},
]
# Generate a response
outputs = generator(
messages,
max_new_tokens=256,
)
# Print the generated text from the assistant
print(outputs[0]["generated_text"][-1]['content'])
```
---
## 🔧 Training Details
### Training Data
The model was fine-tuned using the high-quality conversational dataset `nvidia/HelpSteer2`, which is specifically designed for instruction-following tasks. The dataset includes dialogues formatted into clear user and assistant turns, allowing the model to learn how to generate helpful, safe, and contextually relevant responses.
The training process utilized a **masking technique**, ensuring that the loss calculation focused solely on the assistant's replies, making the training more efficient and better aligned with conversational objectives.
### Training Procedure
The fine-tuning was performed using **Unsloth's FastLanguageModel** and the **SFTTrainer** from the **TRL library**, which optimize both **training speed** and **memory usage**. The process involved several key steps:
1. **Model Loading**: The base model was loaded and optimized using `unsloth.FastModel` to ensure faster performance and memory efficiency.
2. **LoRA Adapters**: **LoRA (Low-Rank Adaptation)** adapters were applied for **parameter-efficient fine-tuning**, allowing for faster adaptation of the model with fewer parameters.
3. **Training**: The model was trained using the `SFTTrainer`, which enabled **supervised fine-tuning** specifically focused on instruction-following.
4. **Final Model Saving**: The fine-tuned LoRA adapters were saved as separate artifacts, which can easily be merged with the base model for deployment, ensuring seamless model updates and scalability.
### Final Artifacts
- The fine-tuned **LoRA adapters** and model checkpoint are available for deployment and further fine-tuning, ensuring adaptability to evolving use cases and datasets.
- These artifacts provide a high-quality, efficient model that balances speed, memory efficiency, and conversational accuracy.
---
## 📊 Performance
This model demonstrates improved instruction-following capabilities compared to the base model, with enhanced performance in:
- Conversational dialogue generation
- Context-aware responses
- Safety and helpfulness alignment
- Reduced hallucinations in chat scenarios
---
## 🛠️ Training Configuration
```yaml
training_details:
base_model: unsloth/gemma-3-270m-it
dataset: nvidia/HelpSteer2
method: LoRA (Low-Rank Adaptation)
framework:
- Unsloth FastLanguageModel
- TRL SFTTrainer
optimization:
- Parameter-efficient fine-tuning
- Memory usage optimization
- Training speed enhancement
masking: Assistant replies only
artifacts: LoRA adapters + model checkpoint
```
---
## 📄 License
This model is released under the Apache 2.0 license, following the licensing terms of the base Gemma model.
---
## 🙏 Acknowledgments
- **Google** for the Gemma-3 base model
- **Unsloth** for the efficient training framework
- **NVIDIA** for the HelpSteer2 dataset
- **Hugging Face** for the transformers library and model hosting
|
Alicia22/Ali_Frid_F1
|
Alicia22
| 2025-09-11T18:02:01Z | 0 | 0 | null |
[
"safetensors",
"any-to-any",
"omega",
"omegalabs",
"bittensor",
"agi",
"license:mit",
"region:us"
] |
any-to-any
| 2025-09-11T17:47:36Z |
---
license: mit
tags:
- any-to-any
- omega
- omegalabs
- bittensor
- agi
---
This is an Any-to-Any model checkpoint for the OMEGA Labs x Bittensor Any-to-Any subnet.
Check out the [git repo](https://github.com/omegalabsinc/omegalabs-anytoany-bittensor) and find OMEGA on X: [@omegalabsai](https://x.com/omegalabsai).
|
mradermacher/Llama-3.1-Amelia-MTFT-8B-v1-GGUF
|
mradermacher
| 2025-09-11T18:00:13Z | 0 | 0 |
transformers
|
[
"transformers",
"gguf",
"argumentation",
"argument-mining",
"en",
"base_model:brunoyun/Llama-3.1-Amelia-MTFT-8B-v1",
"base_model:quantized:brunoyun/Llama-3.1-Amelia-MTFT-8B-v1",
"license:llama3.1",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2025-09-11T15:50:26Z |
---
base_model: brunoyun/Llama-3.1-Amelia-MTFT-8B-v1
language:
- en
library_name: transformers
license: llama3.1
mradermacher:
readme_rev: 1
quantized_by: mradermacher
tags:
- argumentation
- argument-mining
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
<!-- ### quants: x-f16 Q4_K_S Q2_K Q8_0 Q6_K Q3_K_M Q3_K_S Q3_K_L Q4_K_M Q5_K_S Q5_K_M IQ4_XS -->
<!-- ### quants_skip: -->
<!-- ### skip_mmproj: -->
static quants of https://huggingface.co/brunoyun/Llama-3.1-Amelia-MTFT-8B-v1
<!-- provided-files -->
***For a convenient overview and download list, visit our [model page for this model](https://hf.tst.eu/model#Llama-3.1-Amelia-MTFT-8B-v1-GGUF).***
weighted/imatrix quants are available at https://huggingface.co/mradermacher/Llama-3.1-Amelia-MTFT-8B-v1-i1-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/Llama-3.1-Amelia-MTFT-8B-v1-GGUF/resolve/main/Llama-3.1-Amelia-MTFT-8B-v1.Q2_K.gguf) | Q2_K | 3.3 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-3.1-Amelia-MTFT-8B-v1-GGUF/resolve/main/Llama-3.1-Amelia-MTFT-8B-v1.Q3_K_S.gguf) | Q3_K_S | 3.8 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-3.1-Amelia-MTFT-8B-v1-GGUF/resolve/main/Llama-3.1-Amelia-MTFT-8B-v1.Q3_K_M.gguf) | Q3_K_M | 4.1 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/Llama-3.1-Amelia-MTFT-8B-v1-GGUF/resolve/main/Llama-3.1-Amelia-MTFT-8B-v1.Q3_K_L.gguf) | Q3_K_L | 4.4 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-3.1-Amelia-MTFT-8B-v1-GGUF/resolve/main/Llama-3.1-Amelia-MTFT-8B-v1.IQ4_XS.gguf) | IQ4_XS | 4.6 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-3.1-Amelia-MTFT-8B-v1-GGUF/resolve/main/Llama-3.1-Amelia-MTFT-8B-v1.Q4_K_S.gguf) | Q4_K_S | 4.8 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Llama-3.1-Amelia-MTFT-8B-v1-GGUF/resolve/main/Llama-3.1-Amelia-MTFT-8B-v1.Q4_K_M.gguf) | Q4_K_M | 5.0 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Llama-3.1-Amelia-MTFT-8B-v1-GGUF/resolve/main/Llama-3.1-Amelia-MTFT-8B-v1.Q5_K_S.gguf) | Q5_K_S | 5.7 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-3.1-Amelia-MTFT-8B-v1-GGUF/resolve/main/Llama-3.1-Amelia-MTFT-8B-v1.Q5_K_M.gguf) | Q5_K_M | 5.8 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-3.1-Amelia-MTFT-8B-v1-GGUF/resolve/main/Llama-3.1-Amelia-MTFT-8B-v1.Q6_K.gguf) | Q6_K | 6.7 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/Llama-3.1-Amelia-MTFT-8B-v1-GGUF/resolve/main/Llama-3.1-Amelia-MTFT-8B-v1.Q8_0.gguf) | Q8_0 | 8.6 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/Llama-3.1-Amelia-MTFT-8B-v1-GGUF/resolve/main/Llama-3.1-Amelia-MTFT-8B-v1.f16.gguf) | f16 | 16.2 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
flyingbugs/deepseek-distilled-qwen-7b-rl
|
flyingbugs
| 2025-09-11T17:56:58Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-09-11T17:52:33Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
luckeciano/Qwen-2.5-7B-GRPO-LR-3e-5-Adam-FisherMaskToken-1e-4-v2_1907
|
luckeciano
| 2025-09-11T17:54:57Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"generated_from_trainer",
"open-r1",
"trl",
"grpo",
"conversational",
"dataset:DigitalLearningGmbH/MATH-lighteval",
"arxiv:2402.03300",
"base_model:Qwen/Qwen2.5-Math-7B",
"base_model:finetune:Qwen/Qwen2.5-Math-7B",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-09-11T17:28:30Z |
---
base_model: Qwen/Qwen2.5-Math-7B
datasets: DigitalLearningGmbH/MATH-lighteval
library_name: transformers
model_name: Qwen-2.5-7B-GRPO-LR-3e-5-Adam-FisherMaskToken-1e-4-v2_4571
tags:
- generated_from_trainer
- open-r1
- trl
- grpo
licence: license
---
# Model Card for Qwen-2.5-7B-GRPO-LR-3e-5-Adam-FisherMaskToken-1e-4-v2_4571
This model is a fine-tuned version of [Qwen/Qwen2.5-Math-7B](https://huggingface.co/Qwen/Qwen2.5-Math-7B) on the [DigitalLearningGmbH/MATH-lighteval](https://huggingface.co/datasets/DigitalLearningGmbH/MATH-lighteval) dataset.
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="luckeciano/Qwen-2.5-7B-GRPO-LR-3e-5-Adam-FisherMaskToken-1e-4-v2_4571", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="150" height="24"/>](https://wandb.ai/max-ent-llms/PolicyGradientStability/runs/4inl7bpo)
This model was trained with GRPO, a method introduced in [DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models](https://huggingface.co/papers/2402.03300).
### Framework versions
- TRL: 0.16.0.dev0
- Transformers: 4.49.0
- Pytorch: 2.5.1
- Datasets: 3.4.1
- Tokenizers: 0.21.2
## Citations
Cite GRPO as:
```bibtex
@article{zhihong2024deepseekmath,
title = {{DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models}},
author = {Zhihong Shao and Peiyi Wang and Qihao Zhu and Runxin Xu and Junxiao Song and Mingchuan Zhang and Y. K. Li and Y. Wu and Daya Guo},
year = 2024,
eprint = {arXiv:2402.03300},
}
```
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallouédec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
portmafia9719/gemma-2-2B-it-thinking-function_calling-V0
|
portmafia9719
| 2025-09-11T17:54:43Z | 0 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"generated_from_trainer",
"trl",
"sft",
"base_model:google/gemma-2-2b-it",
"base_model:finetune:google/gemma-2-2b-it",
"endpoints_compatible",
"region:us"
] | null | 2025-09-11T17:29:09Z |
---
base_model: google/gemma-2-2b-it
library_name: transformers
model_name: gemma-2-2B-it-thinking-function_calling-V0
tags:
- generated_from_trainer
- trl
- sft
licence: license
---
# Model Card for gemma-2-2B-it-thinking-function_calling-V0
This model is a fine-tuned version of [google/gemma-2-2b-it](https://huggingface.co/google/gemma-2-2b-it).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="portmafia9719/gemma-2-2B-it-thinking-function_calling-V0", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
This model was trained with SFT.
### Framework versions
- TRL: 0.23.0
- Transformers: 4.56.1
- Pytorch: 2.8.0+cu126
- Datasets: 4.0.0
- Tokenizers: 0.22.0
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
KihwanLIm/mvp-model
|
KihwanLIm
| 2025-09-11T17:52:28Z | 0 | 0 |
transformers
|
[
"transformers",
"pytorch",
"safetensors",
"xlm-roberta",
"text-classification",
"custom",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2025-09-11T17:44:11Z |
---
pipeline_tag: text-classification
tags:
- xlm-roberta
- transformers
- custom
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
judsfdf/USABLE_2
|
judsfdf
| 2025-09-11T17:51:48Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"gemma2",
"trl",
"en",
"base_model:unsloth/gemma-2-9b-bnb-4bit",
"base_model:finetune:unsloth/gemma-2-9b-bnb-4bit",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-09-11T17:51:25Z |
---
base_model: unsloth/gemma-2-9b-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- gemma2
- trl
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** judsfdf
- **License:** apache-2.0
- **Finetuned from model :** unsloth/gemma-2-9b-bnb-4bit
This gemma2 model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
noobmaster6009/blockassist
|
noobmaster6009
| 2025-09-11T17:50:13Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"muscular knobby ox",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-10T04:27:40Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- muscular knobby ox
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
kodamkarthik281/bert-intents-mltasks
|
kodamkarthik281
| 2025-09-11T17:47:53Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"bert",
"text-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2025-09-11T17:47:18Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
boahancock/blockassist
|
boahancock
| 2025-09-11T17:47:28Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"iridescent rapid toad",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-11T15:12:30Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- iridescent rapid toad
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Scropo/MindfullOss-20B-LoRA-kaggle
|
Scropo
| 2025-09-11T17:46:13Z | 0 | 0 | null |
[
"safetensors",
"unsloth",
"en",
"dataset:Amod/mental_health_counseling_conversations",
"base_model:openai/gpt-oss-20b",
"base_model:finetune:openai/gpt-oss-20b",
"license:apache-2.0",
"region:us"
] | null | 2025-09-10T14:19:03Z |
---
license: apache-2.0
tags:
- unsloth
datasets:
- Amod/mental_health_counseling_conversations
language:
- en
base_model:
- openai/gpt-oss-20b
---
|
dinhhung1508/ViModernBERT
|
dinhhung1508
| 2025-09-11T17:45:37Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"modernbert",
"text-classification",
"text-generation-inference",
"unsloth",
"trl",
"en",
"base_model:clapAI/modernBERT-base-multilingual-sentiment",
"base_model:finetune:clapAI/modernBERT-base-multilingual-sentiment",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2025-09-11T17:44:37Z |
---
base_model: clapAI/modernBERT-base-multilingual-sentiment
tags:
- text-generation-inference
- transformers
- unsloth
- modernbert
- trl
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** dinhhung1508
- **License:** apache-2.0
- **Finetuned from model :** clapAI/modernBERT-base-multilingual-sentiment
This modernbert model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
wherobots/meta-tree-canopy-height-ep-torch280-cpu-pt2
|
wherobots
| 2025-09-11T17:45:22Z | 0 | 0 | null |
[
"depth-estimation",
"license:apache-2.0",
"region:us"
] |
depth-estimation
| 2025-09-10T19:47:45Z |
---
license: apache-2.0
pipeline_tag: depth-estimation
recommended_patch_size: 224
recommended_clip_size: 28
device: cpu
features: [r, g, b]
labels: [height]
---
First run the following to setup the environment and get the official model code
```bash
# Clone the official repo
git clone git@github.com:facebookresearch/HighResCanopyHeight.git
# Install dependencies
pip install stac-model[torch]
# Download the official pretrained checkpoints
mkdir checkpoints && aws s3 --no-sign-request sync s3://dataforgood-fb-data/forests/v1/models/saved_checkpoints/ checkpoints/
```
Export the model using the following:
```python
from pathlib import Path
import sys
sys.path.append("HighResCanopyHeight")
import torch
import torch.nn as nn
import torchvision.transforms.v2 as T
from stac_model.torch.export import export, package
import src.transforms
from inference import SSLAE
# Create model and load checkpoint
class TreeCanopyHeightModel(nn.Module):
def __init__(self, classify=True, huge=True):
super().__init__()
self.model = SSLAE(pretrained=None, classify=classify, huge=huge, n_bins=256)
def forward(self, x):
outputs = self.model(x)
pred = 10 * outputs + 0.001
return pred.relu()
path = "checkpoints/SSLhuge_satellite.pth"
ckpt = torch.load(path, map_location="cpu", weights_only=False)
state_dict = {f"model.{k}": v for k, v in ckpt["state_dict"].items()}
model = TreeCanopyHeightModel()
model.load_state_dict(state_dict)
# Create exportable transforms
original_transform = src.transforms.SSLNorm().Trans
norm = original_transform.transforms[-1]
transforms = nn.Sequential(
T.Normalize(mean=[0], std=[255]), # replace ToTensor() with normalize to 0-1
T.Normalize(mean=norm.mean, std=norm.std)
)
# Export and save to pt2
model_program, transforms_program = export(
input_shape=[-1, 3, 224, 224],
model=model,
transforms=transforms,
device="cpu",
dtype=torch.float32,
)
package(
output_file=Path("model.pt2"),
model_program=model_program,
transforms_program=transforms_program,
metadata_properties=None,
aoti_compile_and_package=False
)
```
|
genies-llm/text2sql-sft-v7
|
genies-llm
| 2025-09-11T17:44:15Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"generated_from_trainer",
"trl",
"sft",
"conversational",
"base_model:Qwen/Qwen2.5-Coder-7B-Instruct",
"base_model:finetune:Qwen/Qwen2.5-Coder-7B-Instruct",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-09-11T15:49:47Z |
---
base_model: Qwen/Qwen2.5-Coder-7B-Instruct
library_name: transformers
model_name: text2sql-sft-v7
tags:
- generated_from_trainer
- trl
- sft
licence: license
---
# Model Card for text2sql-sft-v7
This model is a fine-tuned version of [Qwen/Qwen2.5-Coder-7B-Instruct](https://huggingface.co/Qwen/Qwen2.5-Coder-7B-Instruct).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="genies-llm/text2sql-sft-v7", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="150" height="24"/>](https://wandb.ai/genies-rnd/text2sql-sft/runs/gdanlixf)
This model was trained with SFT.
### Framework versions
- TRL: 0.18.0
- Transformers: 4.52.3
- Pytorch: 2.6.0
- Datasets: 4.0.0
- Tokenizers: 0.21.4
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
peterant330/grpo-Qwen2.5-VL-7B-Instruct-saliency-zero-minda
|
peterant330
| 2025-09-11T17:43:39Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2_5_vl",
"image-to-text",
"arxiv:1910.09700",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
image-to-text
| 2025-09-11T17:31:28Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
pepijn223/pi05_libero_fp32
|
pepijn223
| 2025-09-11T17:43:14Z | 3 | 0 | null |
[
"safetensors",
"region:us"
] | null | 2025-09-09T15:23:56Z |
# PI0.5 Pi05 Libero (PyTorch, 32-bit floating point)
This is a PyTorch version of the PI0.5 pi05_libero model, converted from the original JAX/Flax implementation.
## Model Details
- **Architecture**: PI0.5 (Vision-Language-Action model with discrete state input)
- **Model Type**: PI0.5
- **Domain**: LIBERO (diverse manipulation tasks)
- **Precision**: 32-bit floating point (fp32)
- **Action Dimension**: 32
- **Action Horizon**: 10
- **Max Token Length**: 200
- **Vision Model**: PaliGemma (gemma_2b)
- **Action Expert**: gemma_300m
## Key Features
- **Discrete State Input**: Uses discrete language tokens for state representation
- **Flow Matching**: Utilizes adaRMSNorm for timestep injection in action expert
- **Enhanced Action Modeling**: Improved action prediction with flow matching approach
## Conversion Details
This model was converted from JAX to PyTorch using the OpenPI conversion script:
```bash
python examples/convert_jax_model_to_pytorch.py \
--checkpoint_dir /pi05_base \
--config_name pi05_libero \
--output_path /pi05_base/pytorch/fp32/ \
--precision float32
```
**Conversion Date**: 2025-09-09
## Usage
```python
from openpi.models_pytorch.pi0_pytorch import PI0Pytorch
import torch
# Load the model
model = PI0Pytorch.from_pretrained("pepijn223/pi05_libero_fp32")
# The model expects inputs in the format:
# - images: torch.Tensor of shape [batch, height, width, channels]
# - text: tokenized text prompts
# - proprioceptive_state: robot state information (if applicable)
```
## Model Architecture
The model consists of:
1. **Vision Encoder**: PaliGemma-based vision processing
2. **Language Encoder**: Text prompt understanding
3. **Action Expert**: Specialized network for action prediction
4. **Integration Layer**: Combines multimodal information for action output
## Training Data
This model was trained on robotics datasets appropriate for its domain:
- **DROID models**: Trained on diverse robot manipulation data
- **ALOHA models**: Trained on bimanual manipulation tasks
- **LIBERO models**: Trained on diverse tabletop manipulation scenarios
- **Base models**: Trained on general robotics datasets
## Limitations
- Model performance depends on similarity between deployment and training environments
- May require domain-specific fine-tuning for optimal performance
- Action space must match the trained action dimension (32)
## Citation
If you use this model, please cite the original OpenPI work:
```bibtex
@article{openpi2024,
title={Open-World Robotic Manipulation with Vision-Language-Action Models},
author={Physical Intelligence},
year={2024},
url={https://github.com/Physical-Intelligence/openpi}
}
```
## Original Repository
[OpenPI GitHub Repository](https://github.com/Physical-Intelligence/openpi)
## License
This model follows the same license as the original OpenPI repository.
|
bluxwave/Qwen3-0.6B-Gensyn-Swarm-frisky_flexible_aardvark
|
bluxwave
| 2025-09-11T17:41:50Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen3",
"text-generation",
"rl-swarm",
"genrl-swarm",
"grpo",
"gensyn",
"I am frisky_flexible_aardvark",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-09-11T09:38:18Z |
---
library_name: transformers
tags:
- rl-swarm
- genrl-swarm
- grpo
- gensyn
- I am frisky_flexible_aardvark
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
yograjm/finetuned-gemma-2b-code-instruct
|
yograjm
| 2025-09-11T17:40:00Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-09-11T17:39:04Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
mradermacher/CTLlama-8B-Instruct-GRPO-GGUF
|
mradermacher
| 2025-09-11T17:39:52Z | 0 | 0 |
transformers
|
[
"transformers",
"gguf",
"en",
"base_model:minstrelzxm/CTLlama-8B-Instruct-GRPO",
"base_model:quantized:minstrelzxm/CTLlama-8B-Instruct-GRPO",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2025-09-11T16:36:57Z |
---
base_model: minstrelzxm/CTLlama-8B-Instruct-GRPO
language:
- en
library_name: transformers
mradermacher:
readme_rev: 1
quantized_by: mradermacher
tags: []
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
<!-- ### quants: x-f16 Q4_K_S Q2_K Q8_0 Q6_K Q3_K_M Q3_K_S Q3_K_L Q4_K_M Q5_K_S Q5_K_M IQ4_XS -->
<!-- ### quants_skip: -->
<!-- ### skip_mmproj: -->
static quants of https://huggingface.co/minstrelzxm/CTLlama-8B-Instruct-GRPO
<!-- provided-files -->
***For a convenient overview and download list, visit our [model page for this model](https://hf.tst.eu/model#CTLlama-8B-Instruct-GRPO-GGUF).***
weighted/imatrix quants seem not to be available (by me) at this time. If they do not show up a week or so after the static ones, I have probably not planned for them. Feel free to request them by opening a Community Discussion.
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/CTLlama-8B-Instruct-GRPO-GGUF/resolve/main/CTLlama-8B-Instruct-GRPO.Q2_K.gguf) | Q2_K | 3.3 | |
| [GGUF](https://huggingface.co/mradermacher/CTLlama-8B-Instruct-GRPO-GGUF/resolve/main/CTLlama-8B-Instruct-GRPO.Q3_K_S.gguf) | Q3_K_S | 3.8 | |
| [GGUF](https://huggingface.co/mradermacher/CTLlama-8B-Instruct-GRPO-GGUF/resolve/main/CTLlama-8B-Instruct-GRPO.Q3_K_M.gguf) | Q3_K_M | 4.1 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/CTLlama-8B-Instruct-GRPO-GGUF/resolve/main/CTLlama-8B-Instruct-GRPO.Q3_K_L.gguf) | Q3_K_L | 4.4 | |
| [GGUF](https://huggingface.co/mradermacher/CTLlama-8B-Instruct-GRPO-GGUF/resolve/main/CTLlama-8B-Instruct-GRPO.IQ4_XS.gguf) | IQ4_XS | 4.6 | |
| [GGUF](https://huggingface.co/mradermacher/CTLlama-8B-Instruct-GRPO-GGUF/resolve/main/CTLlama-8B-Instruct-GRPO.Q4_K_S.gguf) | Q4_K_S | 4.8 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/CTLlama-8B-Instruct-GRPO-GGUF/resolve/main/CTLlama-8B-Instruct-GRPO.Q4_K_M.gguf) | Q4_K_M | 5.0 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/CTLlama-8B-Instruct-GRPO-GGUF/resolve/main/CTLlama-8B-Instruct-GRPO.Q5_K_S.gguf) | Q5_K_S | 5.7 | |
| [GGUF](https://huggingface.co/mradermacher/CTLlama-8B-Instruct-GRPO-GGUF/resolve/main/CTLlama-8B-Instruct-GRPO.Q5_K_M.gguf) | Q5_K_M | 5.8 | |
| [GGUF](https://huggingface.co/mradermacher/CTLlama-8B-Instruct-GRPO-GGUF/resolve/main/CTLlama-8B-Instruct-GRPO.Q6_K.gguf) | Q6_K | 6.7 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/CTLlama-8B-Instruct-GRPO-GGUF/resolve/main/CTLlama-8B-Instruct-GRPO.Q8_0.gguf) | Q8_0 | 8.6 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/CTLlama-8B-Instruct-GRPO-GGUF/resolve/main/CTLlama-8B-Instruct-GRPO.f16.gguf) | f16 | 16.2 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
Abdo-Alshoki/qwen-ar-gec
|
Abdo-Alshoki
| 2025-09-11T17:39:18Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"llama-factory",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-09-11T17:37:47Z |
---
library_name: transformers
tags:
- llama-factory
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
helloansuman/gemma-text-to-text-it
|
helloansuman
| 2025-09-11T17:35:24Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"generated_from_trainer",
"trl",
"sft",
"base_model:google/gemma-3-1b-it",
"base_model:finetune:google/gemma-3-1b-it",
"endpoints_compatible",
"region:us"
] | null | 2025-08-29T11:43:40Z |
---
base_model: google/gemma-3-1b-it
library_name: transformers
model_name: gemma-text-to-text-it
tags:
- generated_from_trainer
- trl
- sft
licence: license
---
# Model Card for gemma-text-to-text-it
This model is a fine-tuned version of [google/gemma-3-1b-it](https://huggingface.co/google/gemma-3-1b-it).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="helloansuman/gemma-text-to-text-it", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
This model was trained with SFT.
### Framework versions
- TRL: 0.15.2
- Transformers: 4.53.3
- Pytorch: 2.7.1
- Datasets: 3.3.2
- Tokenizers: 0.21.2
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallouédec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
otmanheddouch/Qwen3-0.6B-48LP
|
otmanheddouch
| 2025-09-11T17:35:07Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen3",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-09-11T17:33:51Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Elizavr/blockassist
|
Elizavr
| 2025-09-11T17:35:02Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"reclusive shaggy bee",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-11T16:47:33Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- reclusive shaggy bee
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
kavish218/nomic_embeddings-htc-2
|
kavish218
| 2025-09-11T17:34:49Z | 0 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"safetensors",
"nomic_bert",
"sentence-similarity",
"feature-extraction",
"dense",
"generated_from_trainer",
"dataset_size:2953",
"loss:MultipleNegativesRankingLoss",
"custom_code",
"arxiv:1908.10084",
"arxiv:1705.00652",
"base_model:nomic-ai/nomic-embed-text-v1",
"base_model:finetune:nomic-ai/nomic-embed-text-v1",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2025-09-11T17:34:40Z |
---
tags:
- sentence-transformers
- sentence-similarity
- feature-extraction
- dense
- generated_from_trainer
- dataset_size:2953
- loss:MultipleNegativesRankingLoss
base_model: nomic-ai/nomic-embed-text-v1
widget:
- source_sentence: Viola is a genus of flowering plants in the violet family Violaceae.
It is the largest genus in the family, containing between 525 and 600 species.
Most species are found in the temperate Northern Hemisphere; however, some are
also found in widely divergent areas such as Hawaii, Australasia, and the Andes.
Some Viola species are perennial plants, some are annual plants, and a few are
small shrubs. Many species, varieties and cultivars are grown in gardens for their
ornamental flowers. In horticulture the term pansy is normally used for those
multi-colored, large-flowered cultivars which are raised annually or biennially
from seed and used extensively in bedding. The terms viola and violet are normally
reserved for small-flowered annuals or perennials, including the wild species.
sentences:
- 'In biology, phylogenetics (from Greek φυλή/φῦλον (phylé/phylon) "tribe, clan,
race", and γενετικός (genetikós) "origin, source, birth") is a part of systematics
that addresses the inference of the evolutionary history and relationships among
or within groups of organisms (e.g. species, or more inclusive taxa). These relationships
are hypothesized by phylogenetic inference methods that evaluate observed heritable
traits, such as DNA sequences or morphology, often under a specified model of
evolution of these traits. The result of such an analysis is a phylogeny (also
known as a phylogenetic tree)—a diagrammatic hypothesis of relationships that
reflects the evolutionary history of a group of organisms. The tips of a phylogenetic
tree can be living taxa or fossils, and represent the ''end'', or the present,
in an evolutionary lineage. A phylogenetic diagram can be rooted or unrooted.
A rooted tree diagram indicates the hypothetical common ancestor, or ancestral
lineage, of the tree. An unrooted tree diagram (a network) makes no assumption
about the ancestral line, and does not show the origin or "root" of the taxa in
question or the direction of inferred evolutionary transformations. In addition
to their proper use for inferring phylogenetic patterns among taxa, phylogenetic
analyses are often employed to represent relationships among gene copies or individual
organisms. Such uses have become central to understanding biodiversity, evolution,
ecology, and genomes. In February 2021, scientists reported, for the first time,
the sequencing of DNA from animal remains, a mammoth in this instance, over a
million years old, the oldest DNA sequenced to date.Taxonomy is the identification,
naming and classification of organisms. Classifications are now usually based
on phylogenetic data, and many systematists contend that only monophyletic taxa
should be recognized as named groups. The degree to which classification depends
on inferred evolutionary history differs depending on the school of taxonomy:
phenetics ignores phylogenetic speculation altogether, trying to represent the
similarity between organisms instead; cladistics (phylogenetic systematics) tries
to reflect phylogeny in its classifications by only recognizing groups based on
shared, derived characters (synapomorphies); evolutionary taxonomy tries to take
into account both the branching pattern and "degree of difference" to find a compromise
between them.'
- A nut is a fruit composed of an inedible hard shell and a seed, which is generally
edible. In general usage and in a culinary sense, a wide variety of dried seeds
are called nuts, but in a botanical context "nut" implies that the shell does
not open to release the seed (indehiscent). The translation of "nut" in certain
languages frequently requires paraphrases, as the word is ambiguous. Most seeds
come from fruits that naturally free themselves from the shell, unlike nuts such
as hazelnuts, chestnuts, and acorns, which have hard shell walls and originate
from a compound ovary. The general and original usage of the term is less restrictive,
and many nuts (in the culinary sense), such as almonds, pecans, pistachios, walnuts,
and Brazil nuts, are not nuts in a botanical sense. Common usage of the term often
refers to any hard-walled, edible kernel as a nut. Nuts are an energy-dense and
nutrient-rich food source.
- Bellis perennis, the daisy, is a common European species of the family Asteraceae,
often considered the archetypal species of that name. To distinguish this species
from other "daisies" it is sometimes qualified as common daisy, lawn daisy or
English daisy. Historically, it has also been widely known as bruisewort, and
occasionally woundwort (although the common name "woundwort" is now more closely
associated with the genus Stachys). B. perennis is native to western, central
and northern Europe, including remote islands such as the Faroe Islands but has
become widely naturalised in most temperate regions, including the Americas and
Australasia.
- source_sentence: 'Arabic music or Arab music (Arabic: الموسيقى العربية, romanized:
al-mūsīqā al-ʿArabīyah) is the music of the Arab world with all its diverse music
styles and genres. Arabic countries have many rich and varied styles of music
and also many linguistic dialects, with each country and region having their own
traditional music. Arabic music has a long history of interaction with many other
regional musical styles and genres. It represents the music of all the peoples
that make up the Arab world today, all the 22 states.'
sentences:
- Poland, officially the Republic of Poland, is a country located in Central Europe.
It is divided into 16 administrative provinces, covering an area of 312,696 square
kilometres (120,733 sq mi), and has a largely temperate seasonal climate. With
a population of nearly 38.5 million people, Poland is the fifth most populous
member state of the European Union. Poland's capital and largest metropolis is
Warsaw. Other major cities include Kraków, Łódź, Wrocław, Poznań, Gdańsk, and
Szczecin. Poland's topographically diverse territory extends from the beaches
along the Baltic Sea in the north to the Sudetes and Carpathian Mountains in its
south. The country is bordered by Lithuania and Kaliningrad Oblast of Russia to
the northeast, Belarus and Ukraine to the east, Slovakia and the Czech Republic
to the south, and Germany to the west.The history of human activity on Polish
soil spans thousands of years. Throughout the late antiquity period it became
extensively diverse, with various cultures and tribes settling on the vast Central
European Plain. However, it was the Western Polans who dominated the region and
gave Poland its name. The establishment of Polish statehood can be traced to 966,
when the pagan ruler of a realm coextensive with the territory of present-day
Poland embraced Christianity and converted to Catholicism. The Kingdom of Poland
was founded in 1025, and in 1569 it cemented its longstanding political association
with Lithuania by signing the Union of Lublin. This union formed the Polish–Lithuanian
Commonwealth, one of the largest (over 1,000,000 square kilometres – 400,000 square
miles) and most populous nations of 16th and 17th century Europe, with a uniquely
liberal political system which adopted Europe's first modern constitution, the
Constitution of 3 May 1791.With the passing of prominence and prosperity, the
country was partitioned by neighbouring states at the end of the 18th century,
and regained independence in 1918 with the Treaty of Versailles. After a series
of territorial conflicts, the new multi-ethnic Poland restored its position as
a key player in European politics. In September 1939, World War II began with
the invasion of Poland by Germany, followed by the Soviets invading Poland in
accordance with the Molotov–Ribbentrop Pact. Approximately six million Polish
citizens, including three million of the country's Jews, perished during the course
of the war. As a member of the Eastern Bloc, the Polish People's Republic proclaimed
forthwith was a chief signatory of the Warsaw Treaty amidst global Cold War tensions.
In the wake of the 1989 events, notably through the emergence and contributions
of the Solidarity movement, the communist government was dissolved and Poland
re-established itself as a semi-presidential democratic republic. Poland is a
developed market, and a middle power. It has the sixth largest economy in the
European Union by nominal GDP and the fifth largest by GDP (PPP). It provides
very high standards of living, safety and economic freedom, as well as free university
education and a universal health care system. The country has 16 UNESCO World
Heritage Sites, 15 of which are cultural. Poland is a member state of the Schengen
Area, European Union, European Economic Area, the United Nations, NATO, the OECD,
the Three Seas Initiative and the Visegrád Group.
- Alice's Adventures in Wonderland (commonly shortened to Alice in Wonderland) is
an 1865 novel by English author Lewis Carroll (the pseudonym of Charles Dodgson).
It tells of a young girl named Alice, who falls through a rabbit hole into a subterranean
fantasy world populated by peculiar, anthropomorphic creatures. It is considered
to be one of the best examples of the literary nonsense genre. The tale plays
with logic, giving the story lasting popularity with adults as well as with children.One
of the best-known and most popular works of English-language fiction, its narrative,
structure, characters and imagery have been enormously influential in popular
culture and literature, especially in the fantasy genre. The work has never been
out of print and has been translated into at least 97 languages. Its ongoing legacy
encompasses many adaptations for stage, screen, radio, art, ballet, theme parks,
board games and video games. Carroll published a sequel in 1871, titled Through
the Looking-Glass, and a shortened version for young children, The Nursery "Alice",
in 1890.
- 'In many parts of sub-Saharan Africa, the use of music is not limited to entertainment:
it serves a purpose to the local community and helps in the conduct of daily routines.
Traditional African music supplies appropriate music and dance for work and for
religious ceremonies of birth, naming, rites of passage, marriage and funerals.
The beats and sounds of the drum are used in communication as well as in cultural
expression.African dances are largely participatory: there are traditionally no
barriers between dancers and onlookers except with regard to spiritual, religious
and initiation dances. Even ritual dances often have a time when spectators participate.
Dances help people work, mature, praise or criticize members of the community,
celebrate festivals and funerals, compete, recite history, proverbs and poetry
and encounter gods. They inculcate social patterns and values. Many dances are
performed by only males or females. Dances are often segregated by gender, reinforcing
gender roles in children. Community structures such as kinship, age, and status
are also often reinforced. To share rhythm is to form a group consciousness, to
entrain with one another, to be part of the collective rhythm of life to which
all are invited to contribute. Yoruba dancers and drummers, for instance, express
communal desires, values, and collective creativity. The drumming represents an
underlying linguistic text that guides the dancing performance, allowing linguistic
meaning to be expressed non-verbally. The spontaneity of these performances should
not be confused with an improvisation that emphasizes the individual ego. The
drummer''s primary duty is to preserve the community. Master dancers and drummers
are particular about the learning of the dance exactly as taught. Children must
learn the dance exactly as taught without variation. Improvisation or a new variation
comes only after mastering the dance, performing, and receiving the appreciation
of spectators and the sanction of village elders.The music of the Luo, for another
example, is functional, used for ceremonial, religious, political or incidental
purposes, during funerals (Tero buru) to praise the departed, to console the bereaved,
to keep people awake at night, to express pain and agony and during cleansing
and chasing away of spirits, during beer parties (Dudu, ohangla dance), welcoming
back the warriors from a war, during a wrestling match (Ramogi), during courtship,
in rain making and during divination and healing. Work songs are performed both
during communal work like building, weeding, etc. and individual work like pounding
of cereals, winnowing.'
- source_sentence: An emergency department (ED), also known as an accident & emergency
department (A&E), emergency room (ER), emergency ward (EW) or casualty department,
is a medical treatment facility specializing in emergency medicine, the acute
care of patients who present without prior appointment; either by their own means
or by that of an ambulance. The emergency department is usually found in a hospital
or other primary care center. Due to the unplanned nature of patient attendance,
the department must provide initial treatment for a broad spectrum of illnesses
and injuries, some of which may be life-threatening and require immediate attention.
In some countries, emergency departments have become important entry points for
those without other means of access to medical care. The emergency departments
of most hospitals operate 24 hours a day, although staffing levels may be varied
in an attempt to reflect patient volume.
sentences:
- Typha is a genus of about 30 species of monocotyledonous flowering plants in
the family Typhaceae. These plants have a variety of common names, in British
English as bulrush or reedmace, in American English as reed, cattail, or punks,
in Australia as cumbungi or bulrush, in Canada as bulrush or cattail, and in New
Zealand as raupo. Other taxa of plants may be known as bulrush, including some
sedges in Scirpus and related genera. The genus is largely distributed in the
Northern Hemisphere, where it is found in a variety of wetland habitats. The rhizomes
are edible. Evidence of preserved starch grains on grinding stones suggests they
were already eaten in Europe 30,000 years ago.
- Nursing is a profession within the health care sector focused on the care of individuals,
families, and communities so they may attain, maintain, or recover optimal health
and quality of life. Nurses may be differentiated from other health care providers
by their approach to patient care, training, and scope of practice. Nurses practice
in many specialties with differing levels of prescription authority. Nurses comprise
the largest component of most healthcare environments; but there is evidence of
international shortages of qualified nurses. Many nurses provide care within the
ordering scope of physicians, and this traditional role has shaped the public
image of nurses as care providers. Nurse practitioners are however permitted by
most jurisdictions to practice independently in a variety of settings. Since the
postwar period, nurse education has undergone a process of diversification towards
advanced and specialized credentials, and many of the traditional regulations
and provider roles are changing.Nurses develop a plan of care, working collaboratively
with physicians, therapists, the patient, the patient's family, and other team
members that focuses on treating illness to improve quality of life. In the United
Kingdom and the United States, advanced practice nurses, such as clinical nurse
specialists and nurse practitioners, diagnose health problems and prescribe medications
and other therapies, depending on individual state regulations. Nurses may help
coordinate the patient care performed by other members of a multidisciplinary
health care team such as therapists, medical practitioners, and dietitians. Nurses
provide care both interdependently, for example, with physicians, and independently
as nursing professionals.
- A flatbread is a bread made with flour, water, and salt, and then thoroughly rolled
into flattened dough. Many flatbreads are unleavened, although some are leavened,
such as pizza and pita bread. Flatbreads range from below one millimeter to a
few centimeters thick so that they can be easily eaten without being sliced. They
can be baked in an oven, fried in hot oil, grilled over hot coals, cooked on a
hot pan, tava, comal, or metal griddle, and eaten fresh or packaged and frozen
for later use.
- source_sentence: The Academy Awards, popularly known as the Oscars, are awards for
artistic and technical merit in the film industry. They are regarded as one of
the most significant and prestigious awards in the entertainment industry. Given
annually by the Academy of Motion Picture Arts and Sciences (AMPAS), the awards
are an international recognition of excellence in cinematic achievements, as assessed
by the Academy's voting membership. The various category winners are awarded a
copy of a golden statuette as a trophy, officially called the "Academy Award of
Merit", although more commonly referred to by its nickname, the "Oscar". The statuette
depicts a knight rendered in the Art Deco style. The award was originally sculpted
by George Stanley from a design sketch by Cedric Gibbons. AMPAS first presented
it in 1929 at a private dinner hosted by Douglas Fairbanks in The Hollywood Roosevelt
Hotel in what would become known as the 1st Academy Awards. The Academy Awards
ceremony was first broadcast by radio in 1930 and was televised for the first
time in 1953. It is the oldest worldwide entertainment awards ceremony and is
now televised live worldwide. It is also the oldest of the four major annual American
entertainment awards; its equivalents – the Emmy Awards for television, the Tony
Awards for theater, and the Grammy Awards for music – are modeled after the Academy
Awards. A total of 3,140 Oscar statuettes have been awarded since its inception
in 1929. They are widely cited as the most famous and prestigious competitive
awards in the field of entertainment. The 93rd Academy Awards ceremony, honoring
the best films of 2020 and early 2021, was held on April 25, 2021, after it was
postponed from its original February 28, 2021, schedule due to the impact of the
COVID-19 pandemic on cinema. As with the two previous ceremonies, there was no
host. The ceremony was broadcast on ABC. It took place at the Dolby Theatre in
Los Angeles, California for the 19th consecutive year, along with satellite location
taking place at the Union Station also in Los Angeles.
sentences:
- The clitoris ( (listen) or (listen)) is a female sex organ present in mammals,
ostriches and a limited number of other animals. In humans, the visible portion
– the glans – is at the front junction of the labia minora (inner lips), above
the opening of the urethra. Unlike the penis, the male homologue (equivalent)
to the clitoris, it usually does not contain the distal portion (or opening) of
the urethra and is therefore not used for urination. The clitoris also usually
lacks a reproductive function. While few animals urinate through the clitoris
or use it reproductively, the spotted hyena, which has an especially large clitoris,
urinates, mates, and gives birth via the organ. Some other mammals, such as lemurs
and spider monkeys, also have a large clitoris.The clitoris is the human female's
most sensitive erogenous zone and generally the primary anatomical source of human
female sexual pleasure. In humans and other mammals, it develops from an outgrowth
in the embryo called the genital tubercle. Initially undifferentiated, the tubercle
develops into either a penis or a clitoris during the development of the reproductive
system depending on exposure to androgens (which are primarily male hormones).
The clitoris is a complex structure, and its size and sensitivity can vary. The
glans (head) of the human clitoris is roughly the size and shape of a pea and
is estimated to have about 8,000 sensory nerve endings.Sexological, medical, and
psychological debate have focused on the clitoris, and it has been subject to
social constructionist analyses and studies. Such discussions range from anatomical
accuracy, gender inequality, female genital mutilation, and orgasmic factors and
their physiological explanation for the G-spot. Although, in humans, the only
known purpose of the clitoris is to provide sexual pleasure, whether the clitoris
is vestigial, an adaptation, or serves a reproductive function has been debated.
Social perceptions of the clitoris include the significance of its role in female
sexual pleasure, assumptions about its true size and depth, and varying beliefs
regarding genital modification such as clitoris enlargement, clitoris piercing
and clitoridectomy. Genital modification may be for aesthetic, medical or cultural
reasons.Knowledge of the clitoris is significantly impacted by cultural perceptions
of the organ. Studies suggest that knowledge of its existence and anatomy is scant
in comparison with that of other sexual organs and that more education about it
could help alleviate social stigmas associated with the female body and female
sexual pleasure, for example, that the clitoris and vulva in general are visually
unappealing, that female masturbation is taboo, or that men should be expected
to master and control women's orgasms.
- Peafowl is a common name for three bird species in the genera Pavo and Afropavo
of the family Phasianidae, the pheasants and their allies. Male peafowl are referred
to as peacocks, and female peafowl are referred to as peahens, even though peafowl
of either sex are often referred to colloquially as "peacocks".The two Asiatic
species are the blue or Indian peafowl originally of the Indian subcontinent,
and the green peafowl of Southeast Asia; the one African species is the Congo
peafowl, native only to the Congo Basin. Male peafowl are known for their piercing
calls and their extravagant plumage. The latter is especially prominent in the
Asiatic species, which have an eye-spotted "tail" or "train" of covert feathers,
which they display as part of a courtship ritual. The functions of the elaborate
iridescent colouration and large "train" of peacocks have been the subject of
extensive scientific debate. Charles Darwin suggested that they served to attract
females, and the showy features of the males had evolved by sexual selection.
More recently, Amotz Zahavi proposed in his handicap theory that these features
acted as honest signals of the males' fitness, since less-fit males would be disadvantaged
by the difficulty of surviving with such large and conspicuous structures.
- 'A film festival is an organized, extended presentation of films in one or more
cinemas or screening venues, usually in a single city or region. Increasingly,
film festivals show some films outdoors. Films may be of recent date and, depending
upon the festival''s focus, can include international and domestic releases. Some
festivals focus on a specific filmmaker, genre of film (i.e. horror films), or
subject matter (LGBTQ+ film festivals). Several film festivals focus solely on
presenting short films of a defined maximum length. Film festivals are typically
annual events. Some film historians, including Jerry Beck, do not consider film
festivals as official releases of the film. The most prestigious film festivals
in the world, known as the "Big Three", are: Venice,Cannes,and Berlin. The most
prestigious film festivals in North America are Sundance and Toronto.'
- source_sentence: Modernism is both a philosophical movement and an art movement
that arose from broad transformations in Western society during the late 19th
and early 20th centuries. The movement reflected a desire for the creation of
new forms of art, philosophy, and social organization which reflected the newly
emerging industrial world, including features such as urbanization, new technologies,
and war. Artists attempted to depart from traditional forms of art, which they
considered outdated or obsolete. The poet Ezra Pound's 1934 injunction to "Make
it New" was the touchstone of the movement's approach. Modernist innovations
included abstract art, the stream-of-consciousness novel, montage cinema, atonal
and twelve-tone music, and divisionist painting. Modernism explicitly rejected
the ideology of realism and made use of the works of the past by the employment
of reprise, incorporation, rewriting, recapitulation, revision and parody. Modernism
also rejected the certainty of Enlightenment thinking, and many modernists also
rejected religious belief. A notable characteristic of modernism is self-consciousness
concerning artistic and social traditions, which often led to experimentation
with form, along with the use of techniques that drew attention to the processes
and materials used in creating works of art.While some scholars see modernism
continuing into the 21st century, others see it evolving into late modernism or
high modernism. Postmodernism is a departure from modernism and rejects its basic
assumptions.
sentences:
- Yucca is a genus of perennial shrubs and trees in the family Asparagaceae, subfamily
Agavoideae. Its 40–50 species are notable for their rosettes of evergreen, tough,
sword-shaped leaves and large terminal panicles of white or whitish flowers. They
are native to the hot and dry (arid) parts of the Americas and the Caribbean.
Early reports of the species were confused with the cassava (Manihot esculenta).
Consequently, Linnaeus mistakenly derived the generic name from the Taíno word
for the latter, yuca.
- Postmodernism is a broad movement that developed in the mid-to-late 20th century
across philosophy, the arts, architecture, and criticism, marking a departure
from modernism. The term has been more generally applied to describe a historical
era said to follow after modernity and the tendencies of this era. Postmodernism
is generally defined by an attitude of skepticism, irony, or rejection toward
what it describes as the grand narratives and ideologies associated with modernism,
often criticizing Enlightenment rationality and focusing on the role of ideology
in maintaining political or economic power. Postmodern thinkers frequently describe
knowledge claims and value systems as contingent or socially-conditioned, framing
them as products of political, historical, or cultural discourses and hierarchies.
Common targets of postmodern criticism include universalist ideas of objective
reality, morality, truth, human nature, reason, science, language, and social
progress. Accordingly, postmodern thought is broadly characterized by tendencies
to self-consciousness, self-referentiality, epistemological and moral relativism,
pluralism, and irreverence. Postmodern critical approaches gained popularity in
the 1980s and 1990s, and have been adopted in a variety of academic and theoretical
disciplines, including cultural studies, philosophy of science, economics, linguistics,
architecture, feminist theory, and literary criticism, as well as art movements
in fields such as literature, contemporary art, and music. Postmodernism is often
associated with schools of thought such as deconstruction, post-structuralism,
and institutional critique, as well as philosophers such as Jean-François Lyotard,
Jacques Derrida, and Fredric Jameson. Criticisms of postmodernism are intellectually
diverse and include arguments that postmodernism promotes obscurantism, is meaningless,
and that it adds nothing to analytical or empirical knowledge.
- Grouse are a group of birds from the order Galliformes, in the family Phasianidae.
Grouse are frequently assigned to the subfamily Tetraoninae or tribe Tetraonini
(formerly the family Tetraonidae), a classification supported by mitochondrial
DNA sequence studies, and applied by the American Ornithologists' Union, ITIS,
and others. Grouse inhabit temperate and subarctic regions of the Northern Hemisphere,
from pine forests to moorland and mountainside, from 83°N (rock ptarmigan in northern
Greenland) to 28°N (Attwater's prairie chicken in Texas).
pipeline_tag: sentence-similarity
library_name: sentence-transformers
---
# SentenceTransformer based on nomic-ai/nomic-embed-text-v1
This is a [sentence-transformers](https://www.SBERT.net) model finetuned from [nomic-ai/nomic-embed-text-v1](https://huggingface.co/nomic-ai/nomic-embed-text-v1). It maps sentences & paragraphs to a 768-dimensional dense vector space and can be used for semantic textual similarity, semantic search, paraphrase mining, text classification, clustering, and more.
## Model Details
### Model Description
- **Model Type:** Sentence Transformer
- **Base model:** [nomic-ai/nomic-embed-text-v1](https://huggingface.co/nomic-ai/nomic-embed-text-v1) <!-- at revision eb6b20cd65fcbdf7a2bc4ebac97908b3b21da981 -->
- **Maximum Sequence Length:** 8192 tokens
- **Output Dimensionality:** 768 dimensions
- **Similarity Function:** Cosine Similarity
<!-- - **Training Dataset:** Unknown -->
<!-- - **Language:** Unknown -->
<!-- - **License:** Unknown -->
### Model Sources
- **Documentation:** [Sentence Transformers Documentation](https://sbert.net)
- **Repository:** [Sentence Transformers on GitHub](https://github.com/UKPLab/sentence-transformers)
- **Hugging Face:** [Sentence Transformers on Hugging Face](https://huggingface.co/models?library=sentence-transformers)
### Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 8192, 'do_lower_case': False, 'architecture': 'NomicBertModel'})
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False, 'pooling_mode_weightedmean_tokens': False, 'pooling_mode_lasttoken': False, 'include_prompt': True})
(2): Normalize()
)
```
## Usage
### Direct Usage (Sentence Transformers)
First install the Sentence Transformers library:
```bash
pip install -U sentence-transformers
```
Then you can load this model and run inference.
```python
from sentence_transformers import SentenceTransformer
# Download from the 🤗 Hub
model = SentenceTransformer("kavish218/nomic_embeddings-htc-2")
# Run inference
sentences = [
'Modernism is both a philosophical movement and an art movement that arose from broad transformations in Western society during the late 19th and early 20th centuries. The movement reflected a desire for the creation of new forms of art, philosophy, and social organization which reflected the newly emerging industrial world, including features such as urbanization, new technologies, and war. Artists attempted to depart from traditional forms of art, which they considered outdated or obsolete. The poet Ezra Pound\'s 1934 injunction to "Make it New" was the touchstone of the movement\'s approach. Modernist innovations included abstract art, the stream-of-consciousness novel, montage cinema, atonal and twelve-tone music, and divisionist painting. Modernism explicitly rejected the ideology of realism and made use of the works of the past by the employment of reprise, incorporation, rewriting, recapitulation, revision and parody. Modernism also rejected the certainty of Enlightenment thinking, and many modernists also rejected religious belief. A notable characteristic of modernism is self-consciousness concerning artistic and social traditions, which often led to experimentation with form, along with the use of techniques that drew attention to the processes and materials used in creating works of art.While some scholars see modernism continuing into the 21st century, others see it evolving into late modernism or high modernism. Postmodernism is a departure from modernism and rejects its basic assumptions.',
'Postmodernism is a broad movement that developed in the mid-to-late 20th century across philosophy, the arts, architecture, and criticism, marking a departure from modernism. The term has been more generally applied to describe a historical era said to follow after modernity and the tendencies of this era. Postmodernism is generally defined by an attitude of skepticism, irony, or rejection toward what it describes as the grand narratives and ideologies associated with modernism, often criticizing Enlightenment rationality and focusing on the role of ideology in maintaining political or economic power. Postmodern thinkers frequently describe knowledge claims and value systems as contingent or socially-conditioned, framing them as products of political, historical, or cultural discourses and hierarchies. Common targets of postmodern criticism include universalist ideas of objective reality, morality, truth, human nature, reason, science, language, and social progress. Accordingly, postmodern thought is broadly characterized by tendencies to self-consciousness, self-referentiality, epistemological and moral relativism, pluralism, and irreverence. Postmodern critical approaches gained popularity in the 1980s and 1990s, and have been adopted in a variety of academic and theoretical disciplines, including cultural studies, philosophy of science, economics, linguistics, architecture, feminist theory, and literary criticism, as well as art movements in fields such as literature, contemporary art, and music. Postmodernism is often associated with schools of thought such as deconstruction, post-structuralism, and institutional critique, as well as philosophers such as Jean-François Lyotard, Jacques Derrida, and Fredric Jameson. Criticisms of postmodernism are intellectually diverse and include arguments that postmodernism promotes obscurantism, is meaningless, and that it adds nothing to analytical or empirical knowledge.',
'Yucca is a genus of perennial shrubs and trees in the family Asparagaceae, subfamily Agavoideae. Its 40–50 species are notable for their rosettes of evergreen, tough, sword-shaped leaves and large terminal panicles of white or whitish flowers. They are native to the hot and dry (arid) parts of the Americas and the Caribbean. Early reports of the species were confused with the cassava (Manihot esculenta). Consequently, Linnaeus mistakenly derived the generic name from the Taíno word for the latter, yuca.',
]
embeddings = model.encode(sentences)
print(embeddings.shape)
# [3, 768]
# Get the similarity scores for the embeddings
similarities = model.similarity(embeddings, embeddings)
print(similarities)
# tensor([[1.0000, 0.8460, 0.0451],
# [0.8460, 1.0000, 0.0430],
# [0.0451, 0.0430, 1.0000]])
```
<!--
### Direct Usage (Transformers)
<details><summary>Click to see the direct usage in Transformers</summary>
</details>
-->
<!--
### Downstream Usage (Sentence Transformers)
You can finetune this model on your own dataset.
<details><summary>Click to expand</summary>
</details>
-->
<!--
### Out-of-Scope Use
*List how the model may foreseeably be misused and address what users ought not to do with the model.*
-->
<!--
## Bias, Risks and Limitations
*What are the known or foreseeable issues stemming from this model? You could also flag here known failure cases or weaknesses of the model.*
-->
<!--
### Recommendations
*What are recommendations with respect to the foreseeable issues? For example, filtering explicit content.*
-->
## Training Details
### Training Dataset
#### Unnamed Dataset
* Size: 2,953 training samples
* Columns: <code>content_1</code> and <code>content_2</code>
* Approximate statistics based on the first 1000 samples:
| | content_1 | content_2 |
|:--------|:--------------------------------------------------------------------------------------|:--------------------------------------------------------------------------------------|
| type | string | string |
| details | <ul><li>min: 31 tokens</li><li>mean: 366.65 tokens</li><li>max: 1139 tokens</li></ul> | <ul><li>min: 34 tokens</li><li>mean: 360.87 tokens</li><li>max: 1202 tokens</li></ul> |
* Samples:
| content_1 | content_2 |
|:---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|:---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| <code>Sacral architecture (also known as sacred architecture or religious architecture) is a religious architectural practice concerned with the design and construction of places of worship or sacred or intentional space, such as churches, mosques, stupas, synagogues, and temples. Many cultures devoted considerable resources to their sacred architecture and places of worship. Religious and sacred spaces are amongst the most impressive and permanent monolithic buildings created by humanity. Conversely, sacred architecture as a locale for meta-intimacy may also be non-monolithic, ephemeral and intensely private, personal and non-public. Sacred, religious and holy structures often evolved over centuries and were the largest buildings in the world, prior to the modern skyscraper. While the various styles employed in sacred architecture sometimes reflected trends in other structures, these styles also remained unique from the contemporary architecture used in other structures. With the rise of C...</code> | <code>Architecture (Latin architectura, from the Greek ἀρχιτέκτων arkhitekton "architect", from ἀρχι- "chief" and τέκτων "creator") is both the process and the product of planning, designing, and constructing buildings or other structures. Architectural works, in the material form of buildings, are often perceived as cultural symbols and as works of art. Historical civilizations are often identified with their surviving architectural achievements.The practice, which began in the prehistoric era, has been used as a way of expressing culture for civilizations on all seven continents. For this reason, architecture is considered to be a form of art. Texts on architecture have been written since ancient time. The earliest surviving text on architectural theory is the 1st century AD treatise De architectura by the Roman architect Vitruvius, according to whom a good building embodies firmitas, utilitas, and venustas (durability, utility, and beauty). Centuries later, Leon Battista Alberti developed...</code> |
| <code>Proportion is a central principle of architectural theory and an important connection between mathematics and art. It is the visual effect of the relationships of the various objects and spaces that make up a structure to one another and to the whole. These relationships are often governed by multiples of a standard unit of length known as a "module".Proportion in architecture was discussed by Vitruvius, Leon Battista Alberti, Andrea Palladio, and Le Corbusier among others.</code> | <code>Landscape architecture is the design of outdoor areas, landmarks, and structures to achieve environmental, social-behavioural, or aesthetic outcomes. It involves the systematic design and general engineering of various structures for construction and human use, investigation of existing social, ecological, and soil conditions and processes in the landscape, and the design of other interventions that will produce desired outcomes. The scope of the profession is broad and can be subdivided into several sub-categories including professional or licensed landscape architects who are regulated by governmental agencies and possess the expertise to design a wide range of structures and landforms for human use; landscape design which is not a licensed profession; site planning; stormwater management; erosion control; environmental restoration; parks, recreation and urban planning; visual resource management; green infrastructure planning and provision; and private estate and residence landscape...</code> |
| <code>The Basílica de la Sagrada Família (Catalan: [bəˈzilikə ðə lə səˈɣɾaðə fəˈmiljə]; Spanish: Basílica de la Sagrada Familia; 'Basilica of the Holy Family'), also known as the Sagrada Família, is a large unfinished Roman Catholic minor basilica in the Eixample district of Barcelona, Catalonia, Spain. Designed by the Spanish architect Antoni Gaudí (1852–1926), his work on the building is part of a UNESCO World Heritage Site. On 7 November 2010, Pope Benedict XVI consecrated the church and proclaimed it a minor basilica.On 19 March 1882, construction of the Sagrada Família began under architect Francisco de Paula del Villar. In 1883, when Villar resigned, Gaudí took over as chief architect, transforming the project with his architectural and engineering style, combining Gothic and curvilinear Art Nouveau forms. Gaudí devoted the remainder of his life to the project, and he is buried in the crypt. At the time of his death in 1926, less than a quarter of the project was complete.Relying sole...</code> | <code>The Colosseum ( KOL-ə-SEE-əm; Italian: Colosseo [kolosˈsɛːo]) is an oval amphitheatre in the centre of the city of Rome, Italy, just east of the Roman Forum. It is the largest ancient amphitheatre ever built, and is still the largest standing amphitheatre in the world today, despite its age. Construction began under the emperor Vespasian (r. 69–79 AD) in 72 and was completed in 80 AD under his successor and heir, Titus (r. 79–81). Further modifications were made during the reign of Domitian (r. 81–96). The three emperors that were patrons of the work are known as the Flavian dynasty, and the amphitheatre was named the Flavian Amphitheatre (Latin: Amphitheatrum Flavium; Italian: Anfiteatro Flavio [aɱfiteˈaːtro ˈflaːvjo]) by later classicists and archaeologists for its association with their family name (Flavius).The Colosseum is built of travertine limestone, tuff (volcanic rock), and brick-faced concrete. The Colosseum could hold an estimated 50,000 to 80,000 spectators at various poin...</code> |
* Loss: [<code>MultipleNegativesRankingLoss</code>](https://sbert.net/docs/package_reference/sentence_transformer/losses.html#multiplenegativesrankingloss) with these parameters:
```json
{
"scale": 20.0,
"similarity_fct": "cos_sim",
"gather_across_devices": false
}
```
### Training Hyperparameters
#### Non-Default Hyperparameters
- `per_device_eval_batch_size`: 16
- `num_train_epochs`: 1
- `warmup_ratio`: 0.1
- `fp16`: True
- `batch_sampler`: no_duplicates
#### All Hyperparameters
<details><summary>Click to expand</summary>
- `overwrite_output_dir`: False
- `do_predict`: False
- `eval_strategy`: no
- `prediction_loss_only`: True
- `per_device_train_batch_size`: 8
- `per_device_eval_batch_size`: 16
- `per_gpu_train_batch_size`: None
- `per_gpu_eval_batch_size`: None
- `gradient_accumulation_steps`: 1
- `eval_accumulation_steps`: None
- `torch_empty_cache_steps`: None
- `learning_rate`: 5e-05
- `weight_decay`: 0.0
- `adam_beta1`: 0.9
- `adam_beta2`: 0.999
- `adam_epsilon`: 1e-08
- `max_grad_norm`: 1.0
- `num_train_epochs`: 1
- `max_steps`: -1
- `lr_scheduler_type`: linear
- `lr_scheduler_kwargs`: {}
- `warmup_ratio`: 0.1
- `warmup_steps`: 0
- `log_level`: passive
- `log_level_replica`: warning
- `log_on_each_node`: True
- `logging_nan_inf_filter`: True
- `save_safetensors`: True
- `save_on_each_node`: False
- `save_only_model`: False
- `restore_callback_states_from_checkpoint`: False
- `no_cuda`: False
- `use_cpu`: False
- `use_mps_device`: False
- `seed`: 42
- `data_seed`: None
- `jit_mode_eval`: False
- `use_ipex`: False
- `bf16`: False
- `fp16`: True
- `fp16_opt_level`: O1
- `half_precision_backend`: auto
- `bf16_full_eval`: False
- `fp16_full_eval`: False
- `tf32`: None
- `local_rank`: 0
- `ddp_backend`: None
- `tpu_num_cores`: None
- `tpu_metrics_debug`: False
- `debug`: []
- `dataloader_drop_last`: False
- `dataloader_num_workers`: 0
- `dataloader_prefetch_factor`: None
- `past_index`: -1
- `disable_tqdm`: False
- `remove_unused_columns`: True
- `label_names`: None
- `load_best_model_at_end`: False
- `ignore_data_skip`: False
- `fsdp`: []
- `fsdp_min_num_params`: 0
- `fsdp_config`: {'min_num_params': 0, 'xla': False, 'xla_fsdp_v2': False, 'xla_fsdp_grad_ckpt': False}
- `fsdp_transformer_layer_cls_to_wrap`: None
- `accelerator_config`: {'split_batches': False, 'dispatch_batches': None, 'even_batches': True, 'use_seedable_sampler': True, 'non_blocking': False, 'gradient_accumulation_kwargs': None}
- `deepspeed`: None
- `label_smoothing_factor`: 0.0
- `optim`: adamw_torch
- `optim_args`: None
- `adafactor`: False
- `group_by_length`: False
- `length_column_name`: length
- `ddp_find_unused_parameters`: None
- `ddp_bucket_cap_mb`: None
- `ddp_broadcast_buffers`: False
- `dataloader_pin_memory`: True
- `dataloader_persistent_workers`: False
- `skip_memory_metrics`: True
- `use_legacy_prediction_loop`: False
- `push_to_hub`: False
- `resume_from_checkpoint`: None
- `hub_model_id`: None
- `hub_strategy`: every_save
- `hub_private_repo`: None
- `hub_always_push`: False
- `hub_revision`: None
- `gradient_checkpointing`: False
- `gradient_checkpointing_kwargs`: None
- `include_inputs_for_metrics`: False
- `include_for_metrics`: []
- `eval_do_concat_batches`: True
- `fp16_backend`: auto
- `push_to_hub_model_id`: None
- `push_to_hub_organization`: None
- `mp_parameters`:
- `auto_find_batch_size`: False
- `full_determinism`: False
- `torchdynamo`: None
- `ray_scope`: last
- `ddp_timeout`: 1800
- `torch_compile`: False
- `torch_compile_backend`: None
- `torch_compile_mode`: None
- `include_tokens_per_second`: False
- `include_num_input_tokens_seen`: False
- `neftune_noise_alpha`: None
- `optim_target_modules`: None
- `batch_eval_metrics`: False
- `eval_on_start`: False
- `use_liger_kernel`: False
- `liger_kernel_config`: None
- `eval_use_gather_object`: False
- `average_tokens_across_devices`: False
- `prompts`: None
- `batch_sampler`: no_duplicates
- `multi_dataset_batch_sampler`: proportional
- `router_mapping`: {}
- `learning_rate_mapping`: {}
</details>
### Training Logs
| Epoch | Step | Training Loss |
|:------:|:----:|:-------------:|
| 0.0270 | 10 | 0.4417 |
| 0.0541 | 20 | 0.2135 |
| 0.0811 | 30 | 0.0849 |
| 0.1081 | 40 | 0.2744 |
| 0.1351 | 50 | 0.2297 |
| 0.1622 | 60 | 0.2694 |
| 0.1892 | 70 | 0.1039 |
| 0.2162 | 80 | 0.144 |
| 0.2432 | 90 | 0.0802 |
| 0.2703 | 100 | 0.0886 |
| 0.2973 | 110 | 0.1841 |
| 0.3243 | 120 | 0.0515 |
| 0.3514 | 130 | 0.373 |
| 0.3784 | 140 | 0.0519 |
| 0.4054 | 150 | 0.0942 |
| 0.4324 | 160 | 0.1645 |
| 0.4595 | 170 | 0.1254 |
| 0.4865 | 180 | 0.1549 |
| 0.5135 | 190 | 0.1378 |
| 0.5405 | 200 | 0.1643 |
| 0.5676 | 210 | 0.116 |
| 0.5946 | 220 | 0.0724 |
| 0.6216 | 230 | 0.1589 |
| 0.6486 | 240 | 0.2252 |
| 0.6757 | 250 | 0.1201 |
| 0.7027 | 260 | 0.2506 |
| 0.7297 | 270 | 0.0639 |
| 0.7568 | 280 | 0.2527 |
| 0.7838 | 290 | 0.267 |
| 0.8108 | 300 | 0.0509 |
| 0.8378 | 310 | 0.2324 |
| 0.8649 | 320 | 0.2107 |
| 0.8919 | 330 | 0.1843 |
| 0.9189 | 340 | 0.0659 |
| 0.9459 | 350 | 0.1914 |
| 0.9730 | 360 | 0.0676 |
| 1.0 | 370 | 0.1129 |
### Framework Versions
- Python: 3.11.9
- Sentence Transformers: 5.1.0
- Transformers: 4.53.3
- PyTorch: 2.8.0+cu128
- Accelerate: 1.10.1
- Datasets: 4.0.0
- Tokenizers: 0.21.4
## Citation
### BibTeX
#### Sentence Transformers
```bibtex
@inproceedings{reimers-2019-sentence-bert,
title = "Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks",
author = "Reimers, Nils and Gurevych, Iryna",
booktitle = "Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing",
month = "11",
year = "2019",
publisher = "Association for Computational Linguistics",
url = "https://arxiv.org/abs/1908.10084",
}
```
#### MultipleNegativesRankingLoss
```bibtex
@misc{henderson2017efficient,
title={Efficient Natural Language Response Suggestion for Smart Reply},
author={Matthew Henderson and Rami Al-Rfou and Brian Strope and Yun-hsuan Sung and Laszlo Lukacs and Ruiqi Guo and Sanjiv Kumar and Balint Miklos and Ray Kurzweil},
year={2017},
eprint={1705.00652},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
<!--
## Glossary
*Clearly define terms in order to be accessible across audiences.*
-->
<!--
## Model Card Authors
*Lists the people who create the model card, providing recognition and accountability for the detailed work that goes into its construction.*
-->
<!--
## Model Card Contact
*Provides a way for people who have updates to the Model Card, suggestions, or questions, to contact the Model Card authors.*
-->
|
MLism/yomitoku-text-recognizer-parseq-kandenko-v1
|
MLism
| 2025-09-11T17:23:53Z | 0 | 0 | null |
[
"safetensors",
"model_hub_mixin",
"pytorch_model_hub_mixin",
"region:us"
] | null | 2025-09-11T17:23:29Z |
---
tags:
- model_hub_mixin
- pytorch_model_hub_mixin
---
This model has been pushed to the Hub using the [PytorchModelHubMixin](https://huggingface.co/docs/huggingface_hub/package_reference/mixins#huggingface_hub.PyTorchModelHubMixin) integration:
- Library: [More Information Needed]
- Docs: [More Information Needed]
|
BI-Corp/Altitude-V1.0
|
BI-Corp
| 2025-09-11T17:21:25Z | 0 | 0 | null |
[
"license:apache-2.0",
"region:us"
] | null | 2025-09-10T16:05:20Z |
---
license: apache-2.0
---
|
sorumz/blockassist
|
sorumz
| 2025-09-11T17:20:38Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"mangy diving horse",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-11T16:40:16Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- mangy diving horse
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
wabludildara47/blockassist
|
wabludildara47
| 2025-09-11T17:20:02Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"long nimble newt",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-11T17:19:59Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- long nimble newt
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
aahmad246/Qwen2.5-0.5B-Instruct-Gensyn-Swarm-polished_horned_mink
|
aahmad246
| 2025-09-11T17:19:53Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"rl-swarm",
"genrl-swarm",
"grpo",
"gensyn",
"I am polished_horned_mink",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-09-11T10:42:44Z |
---
library_name: transformers
tags:
- rl-swarm
- genrl-swarm
- grpo
- gensyn
- I am polished_horned_mink
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
anabury/loramodel-F16-GGUF
|
anabury
| 2025-09-11T17:18:42Z | 0 | 0 |
transformers
|
[
"transformers",
"gguf",
"text-generation-inference",
"unsloth",
"mistral",
"trl",
"llama-cpp",
"gguf-my-lora",
"en",
"base_model:anabury/loramodel",
"base_model:quantized:anabury/loramodel",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-09-11T17:18:40Z |
---
base_model: anabury/loramodel
language:
- en
license: apache-2.0
tags:
- text-generation-inference
- transformers
- unsloth
- mistral
- trl
- llama-cpp
- gguf-my-lora
---
# anabury/loramodel-F16-GGUF
This LoRA adapter was converted to GGUF format from [`anabury/loramodel`](https://huggingface.co/anabury/loramodel) via the ggml.ai's [GGUF-my-lora](https://huggingface.co/spaces/ggml-org/gguf-my-lora) space.
Refer to the [original adapter repository](https://huggingface.co/anabury/loramodel) for more details.
## Use with llama.cpp
```bash
# with cli
llama-cli -m base_model.gguf --lora loramodel-f16.gguf (...other args)
# with server
llama-server -m base_model.gguf --lora loramodel-f16.gguf (...other args)
```
To know more about LoRA usage with llama.cpp server, refer to the [llama.cpp server documentation](https://github.com/ggerganov/llama.cpp/blob/master/examples/server/README.md).
|
theartificialis/OthelloGPT-Synthetic-20m
|
theartificialis
| 2025-09-11T17:18:01Z | 0 | 0 | null |
[
"safetensors",
"gpt2",
"board-games",
"next-token-prediction",
"othello",
"token-classification",
"dataset:theartificialis/Synthetic-Othello-20m",
"license:apache-2.0",
"region:us"
] |
token-classification
| 2025-09-08T09:03:04Z |
---
license: apache-2.0
datasets:
- theartificialis/Synthetic-Othello-20m
pipeline_tag: token-classification
tags:
- gpt2
- board-games
- next-token-prediction
- othello
---
|
granenko/Reinforce-1
|
granenko
| 2025-09-11T17:17:56Z | 0 | 0 | null |
[
"Pixelcopter-PLE-v0",
"reinforce",
"reinforcement-learning",
"custom-implementation",
"deep-rl-class",
"model-index",
"region:us"
] |
reinforcement-learning
| 2025-09-11T16:26:07Z |
---
tags:
- Pixelcopter-PLE-v0
- reinforce
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: Reinforce-1
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Pixelcopter-PLE-v0
type: Pixelcopter-PLE-v0
metrics:
- type: mean_reward
value: 31.70 +/- 29.17
name: mean_reward
verified: false
---
# **Reinforce** Agent playing **Pixelcopter-PLE-v0**
This is a trained model of a **Reinforce** agent playing **Pixelcopter-PLE-v0** .
To learn to use this model and train yours check Unit 4 of the Deep Reinforcement Learning Course: https://huggingface.co/deep-rl-course/unit4/introduction
|
luckeciano/Qwen-2.5-7B-GRPO-LR-3e-5-Adam-FisherMaskToken-1e-5-v2_8537
|
luckeciano
| 2025-09-11T17:17:56Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"generated_from_trainer",
"open-r1",
"trl",
"grpo",
"conversational",
"dataset:DigitalLearningGmbH/MATH-lighteval",
"arxiv:2402.03300",
"base_model:Qwen/Qwen2.5-Math-7B",
"base_model:finetune:Qwen/Qwen2.5-Math-7B",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-09-11T13:23:28Z |
---
base_model: Qwen/Qwen2.5-Math-7B
datasets: DigitalLearningGmbH/MATH-lighteval
library_name: transformers
model_name: Qwen-2.5-7B-GRPO-LR-3e-5-Adam-FisherMaskToken-1e-5-v2_8537
tags:
- generated_from_trainer
- open-r1
- trl
- grpo
licence: license
---
# Model Card for Qwen-2.5-7B-GRPO-LR-3e-5-Adam-FisherMaskToken-1e-5-v2_8537
This model is a fine-tuned version of [Qwen/Qwen2.5-Math-7B](https://huggingface.co/Qwen/Qwen2.5-Math-7B) on the [DigitalLearningGmbH/MATH-lighteval](https://huggingface.co/datasets/DigitalLearningGmbH/MATH-lighteval) dataset.
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="luckeciano/Qwen-2.5-7B-GRPO-LR-3e-5-Adam-FisherMaskToken-1e-5-v2_8537", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="150" height="24"/>](https://wandb.ai/max-ent-llms/PolicyGradientStability/runs/9n840167)
This model was trained with GRPO, a method introduced in [DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models](https://huggingface.co/papers/2402.03300).
### Framework versions
- TRL: 0.16.0.dev0
- Transformers: 4.49.0
- Pytorch: 2.5.1
- Datasets: 3.4.1
- Tokenizers: 0.21.2
## Citations
Cite GRPO as:
```bibtex
@article{zhihong2024deepseekmath,
title = {{DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models}},
author = {Zhihong Shao and Peiyi Wang and Qihao Zhu and Runxin Xu and Junxiao Song and Mingchuan Zhang and Y. K. Li and Y. Wu and Daya Guo},
year = 2024,
eprint = {arXiv:2402.03300},
}
```
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallouédec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
Soulvarius/WAN2.2_Likeness_Soulvarius_1000steps
|
Soulvarius
| 2025-09-11T17:17:47Z | 0 | 0 | null |
[
"license:cc-by-sa-4.0",
"region:us"
] | null | 2025-09-11T17:12:15Z |
---
license: cc-by-sa-4.0
---
|
Lazabriellholland/entrepreneur-readiness-ridge-allrows
|
Lazabriellholland
| 2025-09-11T17:17:02Z | 0 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"tabular-regression",
"ridge",
"entrepreneurship",
"dataset:Lazabriellholland/entrepreneur-readiness-datasett",
"license:mit",
"region:us"
] |
tabular-regression
| 2025-09-02T22:37:59Z |
---
license: mit
library_name: sentence-transformers
tags:
- tabular-regression
- ridge
- sentence-transformers
- entrepreneurship
datasets:
- Lazabriellholland/entrepreneur-readiness-datasett
pretty_name: Entrepreneur Readiness — Ridge (All Rows)
---
# Entrepreneur Readiness — Ridge (All Rows)
This model is a Ridge regressor trained on **all rows** of
[Lazabriellholland/entrepreneur-readiness-datasett](https://huggingface.co/datasets/Lazabriellholland/entrepreneur-readiness-datasett).
Each row is converted to a string of `key:value` pairs (joined by ` | `), embedded with
`sentence-transformers/all-MiniLM-L6-v2`, then fit with `Ridge()`.
## Quick use (Python)
from huggingface_hub import hf_hub_download
import joblib, json
from sentence_transformers import SentenceTransformer
REPO = "Lazabriellholland/entrepreneur-readiness-ridge-allrows"
reg_path = hf_hub_download(REPO, "ridge_model.pkl")
meta_path = hf_hub_download(REPO, "ridge_meta.json")
reg = joblib.load(reg_path)
meta = json.load(open(meta_path))
embedder = SentenceTransformer(meta["hf_embedding_model"])
cols = meta["feature_columns"]
row = {c: 0 for c in cols} # replace with your values
text = " | ".join(f"{c}:{row[c]}" for c in cols)
X = embedder.encode([text], convert_to_numpy=True)
print(float(reg.predict(X)[0]))
## Model files
- `ridge_model.pkl` — trained regressor (joblib)
- `ridge_meta.json` — metadata (`hf_embedding_model`, `feature_columns`, etc.)
## Notes
- Final model is trained on *all available rows* of the dataset (no holdout).
- For evaluation, run CV or a holdout split **before** the final all-rows retrain.
|
sidhantoon/Goldentouch_V3_G10
|
sidhantoon
| 2025-09-11T17:11:47Z | 0 | 0 | null |
[
"safetensors",
"any-to-any",
"omega",
"omegalabs",
"bittensor",
"agi",
"license:mit",
"region:us"
] |
any-to-any
| 2025-09-11T11:30:42Z |
---
license: mit
tags:
- any-to-any
- omega
- omegalabs
- bittensor
- agi
---
This is an Any-to-Any model checkpoint for the OMEGA Labs x Bittensor Any-to-Any subnet.
Check out the [git repo](https://github.com/omegalabsinc/omegalabs-anytoany-bittensor) and find OMEGA on X: [@omegalabsai](https://x.com/omegalabsai).
|
mhshoisob/finetuned-codet5p-220m
|
mhshoisob
| 2025-09-11T17:10:09Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"t5",
"text2text-generation",
"arxiv:1910.09700",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | null | 2025-09-11T17:09:51Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
FalseNoetics/GLaDOS3.2-3B
|
FalseNoetics
| 2025-09-11T17:09:12Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-09-11T16:57:12Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
LandCruiser/sn21_omg3_1109_3
|
LandCruiser
| 2025-09-11T17:02:21Z | 0 | 0 | null |
[
"safetensors",
"any-to-any",
"omega",
"omegalabs",
"bittensor",
"agi",
"license:mit",
"region:us"
] |
any-to-any
| 2025-09-11T11:52:06Z |
---
license: mit
tags:
- any-to-any
- omega
- omegalabs
- bittensor
- agi
---
This is an Any-to-Any model checkpoint for the OMEGA Labs x Bittensor Any-to-Any subnet.
Check out the [git repo](https://github.com/omegalabsinc/omegalabs-anytoany-bittensor) and find OMEGA on X: [@omegalabsai](https://x.com/omegalabsai).
|
LandCruiser/sn21_omg3_1109_2
|
LandCruiser
| 2025-09-11T17:02:19Z | 0 | 0 | null |
[
"safetensors",
"any-to-any",
"omega",
"omegalabs",
"bittensor",
"agi",
"license:mit",
"region:us"
] |
any-to-any
| 2025-09-11T11:52:02Z |
---
license: mit
tags:
- any-to-any
- omega
- omegalabs
- bittensor
- agi
---
This is an Any-to-Any model checkpoint for the OMEGA Labs x Bittensor Any-to-Any subnet.
Check out the [git repo](https://github.com/omegalabsinc/omegalabs-anytoany-bittensor) and find OMEGA on X: [@omegalabsai](https://x.com/omegalabsai).
|
tunhuo/Toolbox-sft-3B
|
tunhuo
| 2025-09-11T17:00:43Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-09-11T16:54:37Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Comfy-Org/Qwen-Image-InstantX-ControlNets
|
Comfy-Org
| 2025-09-11T16:55:46Z | 43,538 | 15 |
diffusion-single-file
|
[
"diffusion-single-file",
"comfyui",
"license:apache-2.0",
"region:us"
] | null | 2025-08-26T16:35:46Z |
---
license: apache-2.0
tags:
- diffusion-single-file
- comfyui
---
|
jardemr/rjj_fiap_tech_challenge
|
jardemr
| 2025-09-11T16:53:29Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"llama",
"trl",
"en",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-09-11T16:52:59Z |
---
base_model: unsloth/llama-3.2-3b-instruct-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- llama
- trl
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** jardemr
- **License:** apache-2.0
- **Finetuned from model :** unsloth/llama-3.2-3b-instruct-bnb-4bit
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
WenFengg/ExpertWed11_wen14_number18
|
WenFengg
| 2025-09-11T16:50:45Z | 0 | 0 | null |
[
"safetensors",
"any-to-any",
"omega",
"omegalabs",
"bittensor",
"agi",
"license:mit",
"region:us"
] |
any-to-any
| 2025-09-11T15:12:32Z |
---
license: mit
tags:
- any-to-any
- omega
- omegalabs
- bittensor
- agi
---
This is an Any-to-Any model checkpoint for the OMEGA Labs x Bittensor Any-to-Any subnet.
Check out the [git repo](https://github.com/omegalabsinc/omegalabs-anytoany-bittensor) and find OMEGA on X: [@omegalabsai](https://x.com/omegalabsai).
|
nazar1ous/llama3.2-1b-products
|
nazar1ous
| 2025-09-11T16:49:59Z | 0 | 0 | null |
[
"safetensors",
"llama",
"license:apache-2.0",
"region:us"
] | null | 2025-09-11T16:45:55Z |
---
license: apache-2.0
---
|
Naganishanth/metalrecoverymodel
|
Naganishanth
| 2025-09-11T16:49:17Z | 0 | 0 | null |
[
"license:apache-2.0",
"region:us"
] | null | 2025-09-11T16:49:17Z |
---
license: apache-2.0
---
|
jcunado/MiniLMv2-tagalog-fake-news
|
jcunado
| 2025-09-11T16:47:05Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"bert",
"text-classification",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2025-09-11T16:46:54Z |
---
library_name: transformers
base_model: nreimers/MiniLMv2-L6-H384-distilled-from-BERT-base
tags:
- generated_from_trainer
metrics:
- f1
- accuracy
model-index:
- name: results
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# results
This model is a fine-tuned version of [nreimers/MiniLMv2-L6-H384-distilled-from-BERT-base](https://huggingface.co/nreimers/MiniLMv2-L6-H384-distilled-from-BERT-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2621
- F1: 0.9187
- Accuracy: 0.9189
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 50
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:------:|:--------:|
| No log | 1.0 | 71 | 0.3962 | 0.8605 | 0.8607 |
| 0.5014 | 2.0 | 142 | 0.2893 | 0.8831 | 0.8836 |
| 0.2946 | 3.0 | 213 | 0.2424 | 0.8959 | 0.8960 |
| 0.2946 | 4.0 | 284 | 0.2177 | 0.9022 | 0.9023 |
| 0.2042 | 5.0 | 355 | 0.2053 | 0.9314 | 0.9314 |
| 0.1717 | 6.0 | 426 | 0.1865 | 0.9272 | 0.9272 |
| 0.1717 | 7.0 | 497 | 0.2621 | 0.9187 | 0.9189 |
### Framework versions
- Transformers 4.52.4
- Pytorch 2.6.0+cu124
- Datasets 4.0.0
- Tokenizers 0.21.2
|
konradmy/xlm-roberta-base-finetuned-panx-de
|
konradmy
| 2025-09-11T16:43:55Z | 0 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"xlm-roberta",
"token-classification",
"generated_from_trainer",
"base_model:FacebookAI/xlm-roberta-base",
"base_model:finetune:FacebookAI/xlm-roberta-base",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2025-09-11T16:24:52Z |
---
library_name: transformers
license: mit
base_model: xlm-roberta-base
tags:
- generated_from_trainer
metrics:
- f1
model-index:
- name: xlm-roberta-base-finetuned-panx-de
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xlm-roberta-base-finetuned-panx-de
This model is a fine-tuned version of [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1387
- F1: 0.8614
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 24
- eval_batch_size: 24
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH_FUSED with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 0.2571 | 1.0 | 525 | 0.1654 | 0.8147 |
| 0.1266 | 2.0 | 1050 | 0.1382 | 0.8500 |
| 0.0788 | 3.0 | 1575 | 0.1387 | 0.8614 |
### Framework versions
- Transformers 4.56.1
- Pytorch 2.8.0+cu126
- Datasets 4.0.0
- Tokenizers 0.22.0
|
sidhantoon/Goldentouch_V3_G7
|
sidhantoon
| 2025-09-11T16:41:36Z | 0 | 0 | null |
[
"safetensors",
"any-to-any",
"omega",
"omegalabs",
"bittensor",
"agi",
"license:mit",
"region:us"
] |
any-to-any
| 2025-09-11T11:30:29Z |
---
license: mit
tags:
- any-to-any
- omega
- omegalabs
- bittensor
- agi
---
This is an Any-to-Any model checkpoint for the OMEGA Labs x Bittensor Any-to-Any subnet.
Check out the [git repo](https://github.com/omegalabsinc/omegalabs-anytoany-bittensor) and find OMEGA on X: [@omegalabsai](https://x.com/omegalabsai).
|
leonMW/DeepSeek-R1-Distill-Qwen-1.5B-Staged
|
leonMW
| 2025-09-11T16:36:31Z | 232 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"generated_from_trainer",
"grpo",
"trl",
"conversational",
"arxiv:2402.03300",
"base_model:deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B",
"base_model:finetune:deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-09-09T21:49:27Z |
---
base_model: deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B
library_name: transformers
model_name: DeepSeek-R1-Distill-Qwen-1.5B-Staged
tags:
- generated_from_trainer
- grpo
- trl
licence: license
---
# Model Card for DeepSeek-R1-Distill-Qwen-1.5B-Staged
This model is a fine-tuned version of [deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B](https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="leonMW/DeepSeek-R1-Distill-Qwen-1.5B-Staged", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="150" height="24"/>](https://wandb.ai/leonwenderoth-tu-darmstadt/huggingface/runs/3kumpjjg)
This model was trained with GRPO, a method introduced in [DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models](https://huggingface.co/papers/2402.03300).
### Framework versions
- TRL: 0.22.1
- Transformers: 4.56.0
- Pytorch: 2.7.1
- Datasets: 4.0.0
- Tokenizers: 0.22.0
## Citations
Cite GRPO as:
```bibtex
@article{shao2024deepseekmath,
title = {{DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models}},
author = {Zhihong Shao and Peiyi Wang and Qihao Zhu and Runxin Xu and Junxiao Song and Mingchuan Zhang and Y. K. Li and Y. Wu and Daya Guo},
year = 2024,
eprint = {arXiv:2402.03300},
}
```
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
mradermacher/Huihui-MoE-60B-A3B-abliterated-i1-GGUF
|
mradermacher
| 2025-09-11T16:34:36Z | 1,091 | 0 |
transformers
|
[
"transformers",
"gguf",
"moe",
"abliterated",
"uncensored",
"en",
"base_model:huihui-ai/Huihui-MoE-60B-A3B-abliterated",
"base_model:quantized:huihui-ai/Huihui-MoE-60B-A3B-abliterated",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | null | 2025-09-10T12:14:34Z |
---
base_model: huihui-ai/Huihui-MoE-60B-A3B-abliterated
language:
- en
library_name: transformers
license: apache-2.0
license_link: https://huggingface.co/Qwen/Qwen3-30B-A3B-Thinking-2507/blob/main/LICENSE
mradermacher:
readme_rev: 1
quantized_by: mradermacher
tags:
- moe
- abliterated
- uncensored
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: nicoboss -->
<!-- ### quants: Q2_K IQ3_M Q4_K_S IQ3_XXS Q3_K_M small-IQ4_NL Q4_K_M IQ2_M Q6_K IQ4_XS Q2_K_S IQ1_M Q3_K_S IQ2_XXS Q3_K_L IQ2_XS Q5_K_S IQ2_S IQ1_S Q5_K_M Q4_0 IQ3_XS Q4_1 IQ3_S -->
<!-- ### quants_skip: -->
<!-- ### skip_mmproj: -->
weighted/imatrix quants of https://huggingface.co/huihui-ai/Huihui-MoE-60B-A3B-abliterated
<!-- provided-files -->
***For a convenient overview and download list, visit our [model page for this model](https://hf.tst.eu/model#Huihui-MoE-60B-A3B-abliterated-i1-GGUF).***
static quants are available at https://huggingface.co/mradermacher/Huihui-MoE-60B-A3B-abliterated-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/Huihui-MoE-60B-A3B-abliterated-i1-GGUF/resolve/main/Huihui-MoE-60B-A3B-abliterated.imatrix.gguf) | imatrix | 0.3 | imatrix file (for creating your own qwuants) |
| [GGUF](https://huggingface.co/mradermacher/Huihui-MoE-60B-A3B-abliterated-i1-GGUF/resolve/main/Huihui-MoE-60B-A3B-abliterated.i1-IQ1_S.gguf) | i1-IQ1_S | 12.4 | for the desperate |
| [GGUF](https://huggingface.co/mradermacher/Huihui-MoE-60B-A3B-abliterated-i1-GGUF/resolve/main/Huihui-MoE-60B-A3B-abliterated.i1-IQ1_M.gguf) | i1-IQ1_M | 13.7 | mostly desperate |
| [GGUF](https://huggingface.co/mradermacher/Huihui-MoE-60B-A3B-abliterated-i1-GGUF/resolve/main/Huihui-MoE-60B-A3B-abliterated.i1-IQ2_XXS.gguf) | i1-IQ2_XXS | 15.9 | |
| [GGUF](https://huggingface.co/mradermacher/Huihui-MoE-60B-A3B-abliterated-i1-GGUF/resolve/main/Huihui-MoE-60B-A3B-abliterated.i1-IQ2_XS.gguf) | i1-IQ2_XS | 17.7 | |
| [GGUF](https://huggingface.co/mradermacher/Huihui-MoE-60B-A3B-abliterated-i1-GGUF/resolve/main/Huihui-MoE-60B-A3B-abliterated.i1-IQ2_S.gguf) | i1-IQ2_S | 18.0 | |
| [GGUF](https://huggingface.co/mradermacher/Huihui-MoE-60B-A3B-abliterated-i1-GGUF/resolve/main/Huihui-MoE-60B-A3B-abliterated.i1-IQ2_M.gguf) | i1-IQ2_M | 19.7 | |
| [GGUF](https://huggingface.co/mradermacher/Huihui-MoE-60B-A3B-abliterated-i1-GGUF/resolve/main/Huihui-MoE-60B-A3B-abliterated.i1-Q2_K_S.gguf) | i1-Q2_K_S | 20.5 | very low quality |
| [GGUF](https://huggingface.co/mradermacher/Huihui-MoE-60B-A3B-abliterated-i1-GGUF/resolve/main/Huihui-MoE-60B-A3B-abliterated.i1-Q2_K.gguf) | i1-Q2_K | 21.9 | IQ3_XXS probably better |
| [GGUF](https://huggingface.co/mradermacher/Huihui-MoE-60B-A3B-abliterated-i1-GGUF/resolve/main/Huihui-MoE-60B-A3B-abliterated.i1-IQ3_XXS.gguf) | i1-IQ3_XXS | 23.1 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/Huihui-MoE-60B-A3B-abliterated-i1-GGUF/resolve/main/Huihui-MoE-60B-A3B-abliterated.i1-IQ3_XS.gguf) | i1-IQ3_XS | 24.5 | |
| [GGUF](https://huggingface.co/mradermacher/Huihui-MoE-60B-A3B-abliterated-i1-GGUF/resolve/main/Huihui-MoE-60B-A3B-abliterated.i1-Q3_K_S.gguf) | i1-Q3_K_S | 25.9 | IQ3_XS probably better |
| [GGUF](https://huggingface.co/mradermacher/Huihui-MoE-60B-A3B-abliterated-i1-GGUF/resolve/main/Huihui-MoE-60B-A3B-abliterated.i1-IQ3_S.gguf) | i1-IQ3_S | 25.9 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/Huihui-MoE-60B-A3B-abliterated-i1-GGUF/resolve/main/Huihui-MoE-60B-A3B-abliterated.i1-IQ3_M.gguf) | i1-IQ3_M | 26.3 | |
| [GGUF](https://huggingface.co/mradermacher/Huihui-MoE-60B-A3B-abliterated-i1-GGUF/resolve/main/Huihui-MoE-60B-A3B-abliterated.i1-Q3_K_M.gguf) | i1-Q3_K_M | 28.7 | IQ3_S probably better |
| [GGUF](https://huggingface.co/mradermacher/Huihui-MoE-60B-A3B-abliterated-i1-GGUF/resolve/main/Huihui-MoE-60B-A3B-abliterated.i1-Q3_K_L.gguf) | i1-Q3_K_L | 31.0 | IQ3_M probably better |
| [GGUF](https://huggingface.co/mradermacher/Huihui-MoE-60B-A3B-abliterated-i1-GGUF/resolve/main/Huihui-MoE-60B-A3B-abliterated.i1-IQ4_XS.gguf) | i1-IQ4_XS | 31.9 | |
| [GGUF](https://huggingface.co/mradermacher/Huihui-MoE-60B-A3B-abliterated-i1-GGUF/resolve/main/Huihui-MoE-60B-A3B-abliterated.i1-Q4_0.gguf) | i1-Q4_0 | 33.9 | fast, low quality |
| [GGUF](https://huggingface.co/mradermacher/Huihui-MoE-60B-A3B-abliterated-i1-GGUF/resolve/main/Huihui-MoE-60B-A3B-abliterated.i1-Q4_K_S.gguf) | i1-Q4_K_S | 34.1 | optimal size/speed/quality |
| [GGUF](https://huggingface.co/mradermacher/Huihui-MoE-60B-A3B-abliterated-i1-GGUF/resolve/main/Huihui-MoE-60B-A3B-abliterated.i1-Q4_K_M.gguf) | i1-Q4_K_M | 36.3 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Huihui-MoE-60B-A3B-abliterated-i1-GGUF/resolve/main/Huihui-MoE-60B-A3B-abliterated.i1-Q4_1.gguf) | i1-Q4_1 | 37.5 | |
| [GGUF](https://huggingface.co/mradermacher/Huihui-MoE-60B-A3B-abliterated-i1-GGUF/resolve/main/Huihui-MoE-60B-A3B-abliterated.i1-Q5_K_S.gguf) | i1-Q5_K_S | 41.2 | |
| [GGUF](https://huggingface.co/mradermacher/Huihui-MoE-60B-A3B-abliterated-i1-GGUF/resolve/main/Huihui-MoE-60B-A3B-abliterated.i1-Q5_K_M.gguf) | i1-Q5_K_M | 42.4 | |
| [GGUF](https://huggingface.co/mradermacher/Huihui-MoE-60B-A3B-abliterated-i1-GGUF/resolve/main/Huihui-MoE-60B-A3B-abliterated.i1-Q6_K.gguf) | i1-Q6_K | 49.0 | practically like static Q6_K |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time. Additional thanks to [@nicoboss](https://huggingface.co/nicoboss) for giving me access to his private supercomputer, enabling me to provide many more imatrix quants, at much higher quality, than I would otherwise be able to.
<!-- end -->
|
gasoline2255/blockassist
|
gasoline2255
| 2025-09-11T16:34:04Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"flightless sizable wildebeest",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-10T09:13:29Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- flightless sizable wildebeest
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Subsets and Splits
Filtered Qwen2.5 Distill Models
Identifies specific configurations of models by filtering cards that contain 'distill', 'qwen2.5', '7b' while excluding certain base models and incorrect model ID patterns, uncovering unique model variants.
Filtered Model Cards Count
Finds the count of entries with specific card details that include 'distill', 'qwen2.5', '7b' but exclude certain base models, revealing valuable insights about the dataset's content distribution.
Filtered Distill Qwen 7B Models
Filters for specific card entries containing 'distill', 'qwen', and '7b', excluding certain strings and patterns, to identify relevant model configurations.
Filtered Qwen-7b Model Cards
The query performs a detailed filtering based on specific keywords and excludes certain entries, which could be useful for identifying a specific subset of cards but does not provide deeper insights or trends.
Filtered Qwen 7B Model Cards
The query filters for specific terms related to "distilled" or "distill", "qwen", and "7b" in the 'card' column but excludes certain base models, providing a limited set of entries for further inspection.
Qwen 7B Distilled Models
The query provides a basic filtering of records to find specific card names that include keywords related to distilled Qwen 7b models, excluding a particular base model, which gives limited insight but helps in focusing on relevant entries.
Qwen 7B Distilled Model Cards
The query filters data based on specific keywords in the modelId and card fields, providing limited insight primarily useful for locating specific entries rather than revealing broad patterns or trends.
Qwen 7B Distilled Models
Finds all entries containing the terms 'distilled', 'qwen', and '7b' in a case-insensitive manner, providing a filtered set of records but without deeper analysis.
Distilled Qwen 7B Models
The query filters for specific model IDs containing 'distilled', 'qwen', and '7b', providing a basic retrieval of relevant entries but without deeper analysis or insight.
Filtered Model Cards with Distill Qwen2.
Filters and retrieves records containing specific keywords in the card description while excluding certain phrases, providing a basic count of relevant entries.
Filtered Model Cards with Distill Qwen 7
The query filters specific variations of card descriptions containing 'distill', 'qwen', and '7b' while excluding a particular base model, providing limited but specific data retrieval.
Distill Qwen 7B Model Cards
The query filters and retrieves rows where the 'card' column contains specific keywords ('distill', 'qwen', and '7b'), providing a basic filter result that can help in identifying specific entries.