
modelId
stringlengths 5
139
| author
stringlengths 2
42
| last_modified
timestamp[us, tz=UTC]date 2020-02-15 11:33:14
2025-09-11 18:29:29
| downloads
int64 0
223M
| likes
int64 0
11.7k
| library_name
stringclasses 555
values | tags
listlengths 1
4.05k
| pipeline_tag
stringclasses 55
values | createdAt
timestamp[us, tz=UTC]date 2022-03-02 23:29:04
2025-09-11 18:25:24
| card
stringlengths 11
1.01M
|
|---|---|---|---|---|---|---|---|---|---|
manancode/opus-mt-fr-fj-ctranslate2-android
|
manancode
| 2025-08-17T17:25:58Z | 0 | 0 | null |
[
"translation",
"opus-mt",
"ctranslate2",
"quantized",
"multilingual",
"license:apache-2.0",
"region:us"
] |
translation
| 2025-08-17T17:25:49Z |
---
license: apache-2.0
tags:
- translation
- opus-mt
- ctranslate2
- quantized
language:
- multilingual
pipeline_tag: translation
---
# opus-mt-fr-fj-ctranslate2-android
This is a quantized INT8 version of `Helsinki-NLP/opus-mt-fr-fj` converted to CTranslate2 format for efficient inference.
## Model Details
- **Original Model**: Helsinki-NLP/opus-mt-fr-fj
- **Format**: CTranslate2
- **Quantization**: INT8
- **Framework**: OPUS-MT
- **Converted by**: Automated conversion pipeline
## Usage
### With CTranslate2
```python
import ctranslate2
import sentencepiece as spm
# Load the model
translator = ctranslate2.Translator("path/to/model")
# Load tokenizers
sp_source = spm.SentencePieceProcessor(model_file="source.spm")
sp_target = spm.SentencePieceProcessor(model_file="target.spm")
# Translate
source_tokens = sp_source.encode("Your text here", out_type=str)
results = translator.translate_batch([source_tokens])
translation = sp_target.decode(results[0].hypotheses[0])
```
## Performance
This INT8 quantized version provides:
- ~75% reduction in model size
- Faster inference speed
- Maintained translation quality
- Mobile-friendly deployment
## Original Model
Based on the OPUS-MT project: https://github.com/Helsinki-NLP/Opus-MT
|
manancode/opus-mt-fj-en-ctranslate2-android
|
manancode
| 2025-08-17T17:21:09Z | 0 | 0 | null |
[
"translation",
"opus-mt",
"ctranslate2",
"quantized",
"multilingual",
"license:apache-2.0",
"region:us"
] |
translation
| 2025-08-17T17:20:59Z |
---
license: apache-2.0
tags:
- translation
- opus-mt
- ctranslate2
- quantized
language:
- multilingual
pipeline_tag: translation
---
# opus-mt-fj-en-ctranslate2-android
This is a quantized INT8 version of `Helsinki-NLP/opus-mt-fj-en` converted to CTranslate2 format for efficient inference.
## Model Details
- **Original Model**: Helsinki-NLP/opus-mt-fj-en
- **Format**: CTranslate2
- **Quantization**: INT8
- **Framework**: OPUS-MT
- **Converted by**: Automated conversion pipeline
## Usage
### With CTranslate2
```python
import ctranslate2
import sentencepiece as spm
# Load the model
translator = ctranslate2.Translator("path/to/model")
# Load tokenizers
sp_source = spm.SentencePieceProcessor(model_file="source.spm")
sp_target = spm.SentencePieceProcessor(model_file="target.spm")
# Translate
source_tokens = sp_source.encode("Your text here", out_type=str)
results = translator.translate_batch([source_tokens])
translation = sp_target.decode(results[0].hypotheses[0])
```
## Performance
This INT8 quantized version provides:
- ~75% reduction in model size
- Faster inference speed
- Maintained translation quality
- Mobile-friendly deployment
## Original Model
Based on the OPUS-MT project: https://github.com/Helsinki-NLP/Opus-MT
|
sdffh/blockassist-bc-armored_lithe_hummingbird_1755449312
|
sdffh
| 2025-08-17T17:20:43Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"armored lithe hummingbird",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-17T17:20:36Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- armored lithe hummingbird
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
kojeklollipop/blockassist-bc-spotted_amphibious_stork_1755449537
|
kojeklollipop
| 2025-08-17T17:19:43Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"spotted amphibious stork",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-17T17:19:39Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- spotted amphibious stork
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
manancode/opus-mt-fi-tiv-ctranslate2-android
|
manancode
| 2025-08-17T17:16:11Z | 0 | 0 | null |
[
"translation",
"opus-mt",
"ctranslate2",
"quantized",
"multilingual",
"license:apache-2.0",
"region:us"
] |
translation
| 2025-08-17T17:16:00Z |
---
license: apache-2.0
tags:
- translation
- opus-mt
- ctranslate2
- quantized
language:
- multilingual
pipeline_tag: translation
---
# opus-mt-fi-tiv-ctranslate2-android
This is a quantized INT8 version of `Helsinki-NLP/opus-mt-fi-tiv` converted to CTranslate2 format for efficient inference.
## Model Details
- **Original Model**: Helsinki-NLP/opus-mt-fi-tiv
- **Format**: CTranslate2
- **Quantization**: INT8
- **Framework**: OPUS-MT
- **Converted by**: Automated conversion pipeline
## Usage
### With CTranslate2
```python
import ctranslate2
import sentencepiece as spm
# Load the model
translator = ctranslate2.Translator("path/to/model")
# Load tokenizers
sp_source = spm.SentencePieceProcessor(model_file="source.spm")
sp_target = spm.SentencePieceProcessor(model_file="target.spm")
# Translate
source_tokens = sp_source.encode("Your text here", out_type=str)
results = translator.translate_batch([source_tokens])
translation = sp_target.decode(results[0].hypotheses[0])
```
## Performance
This INT8 quantized version provides:
- ~75% reduction in model size
- Faster inference speed
- Maintained translation quality
- Mobile-friendly deployment
## Original Model
Based on the OPUS-MT project: https://github.com/Helsinki-NLP/Opus-MT
|
fbaldassarri/EleutherAI_pythia-1b-deduped-autoawq-int4-gs64-sym
|
fbaldassarri
| 2025-08-17T17:14:43Z | 0 | 0 | null |
[
"safetensors",
"gpt_neox",
"pytorch",
"causal-lm",
"pythia",
"autoround",
"intel-autoround",
"auto-round",
"intel",
"woq",
"awq",
"auto-awq",
"autoawq",
"eleutheraI",
"text-generation",
"en",
"dataset:EleutherAI/pile",
"base_model:EleutherAI/pythia-1b-deduped",
"base_model:quantized:EleutherAI/pythia-1b-deduped",
"license:apache-2.0",
"4-bit",
"region:us"
] |
text-generation
| 2025-08-17T17:11:08Z |
---
language:
- en
tags:
- pytorch
- causal-lm
- pythia
- autoround
- intel-autoround
- auto-round
- intel
- woq
- awq
- auto-awq
- autoawq
- eleutheraI
license: apache-2.0
model_name: Pythia 1b deduped
base_model: EleutherAI/pythia-1b-deduped
inference: false
model_creator: EleutherAI
datasets:
- EleutherAI/pile
pipeline_tag: text-generation
prompt_template: '{prompt}
'
quantized_by: fbaldassarri
---
## Model Information
Quantized version of [EleutherAI/pythia-1b-deduped](https://huggingface.co/fbaldassarri/EleutherAI/pythia-1b-deduped) using torch.float32 for quantization tuning.
- 4 bits (INT4)
- group size = 64
- Symmetrical Quantization
- Method WoQ: AWQ (AutoAWQ algorithm)
Quantization framework: [Intel AutoRound](https://github.com/intel/auto-round) v0.5.1
Note: this INT4 version of pythia-1b-deduped has been quantized to run inference through CPU.
## Replication Recipe
### Step 1 Install Requirements
I suggest to install requirements into a dedicated python-virtualenv or a conda enviroment.
```
wget https://github.com/intel/auto-round/archive/refs/tags/v0.5.1.tar.gz
tar -xvzf v0.5.1.tar.gz
cd auto-round-0.5.1
pip install -r requirements-cpu.txt --upgrade
```
### Step 2 Build Intel AutoRound wheel from sources
```
pip install -vvv --no-build-isolation -e .[cpu]
```
### Step 3 Script for Quantization
```
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "EleutherAI/pythia-1b-deduped"
model = AutoModelForCausalLM.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
from auto_round import AutoRound
bits, group_size, sym, device, amp = 4, 64, True, 'cpu', False
autoround = AutoRound(model, tokenizer, nsamples=128, iters=200, seqlen=512, batch_size=4, bits=bits, group_size=group_size, sym=sym, device=device, amp=amp)
autoround.quantize()
output_dir = "./AutoRound/EleutherAI_pythia-1b-deduped-autoawq-int4-gs64-sym"
autoround.save_quantized(output_dir, format='auto_awq', inplace=True)
```
## License
[Apache 2.0 License](https://choosealicense.com/licenses/apache-2.0/)
## Disclaimer
This quantized model comes with no warrenty. It has been developed only for research purposes.
|
manancode/opus-mt-fi-pag-ctranslate2-android
|
manancode
| 2025-08-17T17:11:43Z | 0 | 0 | null |
[
"translation",
"opus-mt",
"ctranslate2",
"quantized",
"multilingual",
"license:apache-2.0",
"region:us"
] |
translation
| 2025-08-17T17:11:33Z |
---
license: apache-2.0
tags:
- translation
- opus-mt
- ctranslate2
- quantized
language:
- multilingual
pipeline_tag: translation
---
# opus-mt-fi-pag-ctranslate2-android
This is a quantized INT8 version of `Helsinki-NLP/opus-mt-fi-pag` converted to CTranslate2 format for efficient inference.
## Model Details
- **Original Model**: Helsinki-NLP/opus-mt-fi-pag
- **Format**: CTranslate2
- **Quantization**: INT8
- **Framework**: OPUS-MT
- **Converted by**: Automated conversion pipeline
## Usage
### With CTranslate2
```python
import ctranslate2
import sentencepiece as spm
# Load the model
translator = ctranslate2.Translator("path/to/model")
# Load tokenizers
sp_source = spm.SentencePieceProcessor(model_file="source.spm")
sp_target = spm.SentencePieceProcessor(model_file="target.spm")
# Translate
source_tokens = sp_source.encode("Your text here", out_type=str)
results = translator.translate_batch([source_tokens])
translation = sp_target.decode(results[0].hypotheses[0])
```
## Performance
This INT8 quantized version provides:
- ~75% reduction in model size
- Faster inference speed
- Maintained translation quality
- Mobile-friendly deployment
## Original Model
Based on the OPUS-MT project: https://github.com/Helsinki-NLP/Opus-MT
|
manancode/opus-mt-fi-lus-ctranslate2-android
|
manancode
| 2025-08-17T17:08:35Z | 0 | 0 | null |
[
"translation",
"opus-mt",
"ctranslate2",
"quantized",
"multilingual",
"license:apache-2.0",
"region:us"
] |
translation
| 2025-08-17T17:08:25Z |
---
license: apache-2.0
tags:
- translation
- opus-mt
- ctranslate2
- quantized
language:
- multilingual
pipeline_tag: translation
---
# opus-mt-fi-lus-ctranslate2-android
This is a quantized INT8 version of `Helsinki-NLP/opus-mt-fi-lus` converted to CTranslate2 format for efficient inference.
## Model Details
- **Original Model**: Helsinki-NLP/opus-mt-fi-lus
- **Format**: CTranslate2
- **Quantization**: INT8
- **Framework**: OPUS-MT
- **Converted by**: Automated conversion pipeline
## Usage
### With CTranslate2
```python
import ctranslate2
import sentencepiece as spm
# Load the model
translator = ctranslate2.Translator("path/to/model")
# Load tokenizers
sp_source = spm.SentencePieceProcessor(model_file="source.spm")
sp_target = spm.SentencePieceProcessor(model_file="target.spm")
# Translate
source_tokens = sp_source.encode("Your text here", out_type=str)
results = translator.translate_batch([source_tokens])
translation = sp_target.decode(results[0].hypotheses[0])
```
## Performance
This INT8 quantized version provides:
- ~75% reduction in model size
- Faster inference speed
- Maintained translation quality
- Mobile-friendly deployment
## Original Model
Based on the OPUS-MT project: https://github.com/Helsinki-NLP/Opus-MT
|
prudant/Qwen3-Embedding-0.6B-W8A8
|
prudant
| 2025-08-17T17:07:28Z | 0 | 0 | null |
[
"safetensors",
"qwen3",
"feature-extraction",
"en",
"es",
"dataset:HuggingFaceH4/ultrachat_200k",
"base_model:Qwen/Qwen3-Embedding-0.6B",
"base_model:quantized:Qwen/Qwen3-Embedding-0.6B",
"license:apache-2.0",
"8-bit",
"compressed-tensors",
"region:us"
] |
feature-extraction
| 2025-08-17T16:27:11Z |
---
license: apache-2.0
datasets:
- HuggingFaceH4/ultrachat_200k
language:
- en
- es
base_model:
- Qwen/Qwen3-Embedding-0.6B
pipeline_tag: feature-extraction
---
# prudant/Qwen3-Embedding-0.6B-W8A8
This is a compressed version of Qwen/Qwen3-Embedding-0.6B using llm-compressor with the following scheme: W8A8
## Model Details
- **Original Model**: Qwen/Qwen3-Embedding-0.6B
- **Quantization Method**: GPTQ
- **Compression Libraries**: [llm-compressor](https://github.com/vllm-project/llm-compressor)
- **Calibration Dataset**: ultrachat_200k (1024 samples)
- **Optimized For**: Inference with vLLM
- **License**: same as original model
|
cmiralop/BiomedNLP-PubMedBERT-Base-Uncased-Abstract-Fulltext-109M
|
cmiralop
| 2025-08-17T17:07:06Z | 0 | 0 | null |
[
"gguf",
"medical",
"feature-extraction",
"base_model:NeuML/pubmedbert-base-embeddings",
"base_model:quantized:NeuML/pubmedbert-base-embeddings",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
feature-extraction
| 2025-08-17T16:59:13Z |
---
license: apache-2.0
base_model:
- NeuML/pubmedbert-base-embeddings
tags:
- medical
pipeline_tag: feature-extraction
---
GGUF files for PubMedBERT so it can be used with ollama for local experiments (embeddings only).
|
unitova/blockassist-bc-zealous_sneaky_raven_1755448550
|
unitova
| 2025-08-17T17:03:03Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"zealous sneaky raven",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-17T17:02:59Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- zealous sneaky raven
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
manancode/opus-mt-fi-bcl-ctranslate2-android
|
manancode
| 2025-08-17T16:58:07Z | 0 | 0 | null |
[
"translation",
"opus-mt",
"ctranslate2",
"quantized",
"multilingual",
"license:apache-2.0",
"region:us"
] |
translation
| 2025-08-17T16:57:56Z |
---
license: apache-2.0
tags:
- translation
- opus-mt
- ctranslate2
- quantized
language:
- multilingual
pipeline_tag: translation
---
# opus-mt-fi-bcl-ctranslate2-android
This is a quantized INT8 version of `Helsinki-NLP/opus-mt-fi-bcl` converted to CTranslate2 format for efficient inference.
## Model Details
- **Original Model**: Helsinki-NLP/opus-mt-fi-bcl
- **Format**: CTranslate2
- **Quantization**: INT8
- **Framework**: OPUS-MT
- **Converted by**: Automated conversion pipeline
## Usage
### With CTranslate2
```python
import ctranslate2
import sentencepiece as spm
# Load the model
translator = ctranslate2.Translator("path/to/model")
# Load tokenizers
sp_source = spm.SentencePieceProcessor(model_file="source.spm")
sp_target = spm.SentencePieceProcessor(model_file="target.spm")
# Translate
source_tokens = sp_source.encode("Your text here", out_type=str)
results = translator.translate_batch([source_tokens])
translation = sp_target.decode(results[0].hypotheses[0])
```
## Performance
This INT8 quantized version provides:
- ~75% reduction in model size
- Faster inference speed
- Maintained translation quality
- Mobile-friendly deployment
## Original Model
Based on the OPUS-MT project: https://github.com/Helsinki-NLP/Opus-MT
|
manancode/opus-mt-fi-NORWAY-ctranslate2-android
|
manancode
| 2025-08-17T16:57:27Z | 0 | 0 | null |
[
"translation",
"opus-mt",
"ctranslate2",
"quantized",
"multilingual",
"license:apache-2.0",
"region:us"
] |
translation
| 2025-08-17T16:57:14Z |
---
license: apache-2.0
tags:
- translation
- opus-mt
- ctranslate2
- quantized
language:
- multilingual
pipeline_tag: translation
---
# opus-mt-fi-NORWAY-ctranslate2-android
This is a quantized INT8 version of `Helsinki-NLP/opus-mt-fi-NORWAY` converted to CTranslate2 format for efficient inference.
## Model Details
- **Original Model**: Helsinki-NLP/opus-mt-fi-NORWAY
- **Format**: CTranslate2
- **Quantization**: INT8
- **Framework**: OPUS-MT
- **Converted by**: Automated conversion pipeline
## Usage
### With CTranslate2
```python
import ctranslate2
import sentencepiece as spm
# Load the model
translator = ctranslate2.Translator("path/to/model")
# Load tokenizers
sp_source = spm.SentencePieceProcessor(model_file="source.spm")
sp_target = spm.SentencePieceProcessor(model_file="target.spm")
# Translate
source_tokens = sp_source.encode("Your text here", out_type=str)
results = translator.translate_batch([source_tokens])
translation = sp_target.decode(results[0].hypotheses[0])
```
## Performance
This INT8 quantized version provides:
- ~75% reduction in model size
- Faster inference speed
- Maintained translation quality
- Mobile-friendly deployment
## Original Model
Based on the OPUS-MT project: https://github.com/Helsinki-NLP/Opus-MT
|
manancode/opus-mt-es-war-ctranslate2-android
|
manancode
| 2025-08-17T16:53:16Z | 0 | 0 | null |
[
"translation",
"opus-mt",
"ctranslate2",
"quantized",
"multilingual",
"license:apache-2.0",
"region:us"
] |
translation
| 2025-08-17T16:53:04Z |
---
license: apache-2.0
tags:
- translation
- opus-mt
- ctranslate2
- quantized
language:
- multilingual
pipeline_tag: translation
---
# opus-mt-es-war-ctranslate2-android
This is a quantized INT8 version of `Helsinki-NLP/opus-mt-es-war` converted to CTranslate2 format for efficient inference.
## Model Details
- **Original Model**: Helsinki-NLP/opus-mt-es-war
- **Format**: CTranslate2
- **Quantization**: INT8
- **Framework**: OPUS-MT
- **Converted by**: Automated conversion pipeline
## Usage
### With CTranslate2
```python
import ctranslate2
import sentencepiece as spm
# Load the model
translator = ctranslate2.Translator("path/to/model")
# Load tokenizers
sp_source = spm.SentencePieceProcessor(model_file="source.spm")
sp_target = spm.SentencePieceProcessor(model_file="target.spm")
# Translate
source_tokens = sp_source.encode("Your text here", out_type=str)
results = translator.translate_batch([source_tokens])
translation = sp_target.decode(results[0].hypotheses[0])
```
## Performance
This INT8 quantized version provides:
- ~75% reduction in model size
- Faster inference speed
- Maintained translation quality
- Mobile-friendly deployment
## Original Model
Based on the OPUS-MT project: https://github.com/Helsinki-NLP/Opus-MT
|
manancode/opus-mt-es-ve-ctranslate2-android
|
manancode
| 2025-08-17T16:52:47Z | 0 | 0 | null |
[
"translation",
"opus-mt",
"ctranslate2",
"quantized",
"multilingual",
"license:apache-2.0",
"region:us"
] |
translation
| 2025-08-17T16:52:37Z |
---
license: apache-2.0
tags:
- translation
- opus-mt
- ctranslate2
- quantized
language:
- multilingual
pipeline_tag: translation
---
# opus-mt-es-ve-ctranslate2-android
This is a quantized INT8 version of `Helsinki-NLP/opus-mt-es-ve` converted to CTranslate2 format for efficient inference.
## Model Details
- **Original Model**: Helsinki-NLP/opus-mt-es-ve
- **Format**: CTranslate2
- **Quantization**: INT8
- **Framework**: OPUS-MT
- **Converted by**: Automated conversion pipeline
## Usage
### With CTranslate2
```python
import ctranslate2
import sentencepiece as spm
# Load the model
translator = ctranslate2.Translator("path/to/model")
# Load tokenizers
sp_source = spm.SentencePieceProcessor(model_file="source.spm")
sp_target = spm.SentencePieceProcessor(model_file="target.spm")
# Translate
source_tokens = sp_source.encode("Your text here", out_type=str)
results = translator.translate_batch([source_tokens])
translation = sp_target.decode(results[0].hypotheses[0])
```
## Performance
This INT8 quantized version provides:
- ~75% reduction in model size
- Faster inference speed
- Maintained translation quality
- Mobile-friendly deployment
## Original Model
Based on the OPUS-MT project: https://github.com/Helsinki-NLP/Opus-MT
|
manancode/opus-mt-es-tll-ctranslate2-android
|
manancode
| 2025-08-17T16:50:45Z | 0 | 0 | null |
[
"translation",
"opus-mt",
"ctranslate2",
"quantized",
"multilingual",
"license:apache-2.0",
"region:us"
] |
translation
| 2025-08-17T16:50:34Z |
---
license: apache-2.0
tags:
- translation
- opus-mt
- ctranslate2
- quantized
language:
- multilingual
pipeline_tag: translation
---
# opus-mt-es-tll-ctranslate2-android
This is a quantized INT8 version of `Helsinki-NLP/opus-mt-es-tll` converted to CTranslate2 format for efficient inference.
## Model Details
- **Original Model**: Helsinki-NLP/opus-mt-es-tll
- **Format**: CTranslate2
- **Quantization**: INT8
- **Framework**: OPUS-MT
- **Converted by**: Automated conversion pipeline
## Usage
### With CTranslate2
```python
import ctranslate2
import sentencepiece as spm
# Load the model
translator = ctranslate2.Translator("path/to/model")
# Load tokenizers
sp_source = spm.SentencePieceProcessor(model_file="source.spm")
sp_target = spm.SentencePieceProcessor(model_file="target.spm")
# Translate
source_tokens = sp_source.encode("Your text here", out_type=str)
results = translator.translate_batch([source_tokens])
translation = sp_target.decode(results[0].hypotheses[0])
```
## Performance
This INT8 quantized version provides:
- ~75% reduction in model size
- Faster inference speed
- Maintained translation quality
- Mobile-friendly deployment
## Original Model
Based on the OPUS-MT project: https://github.com/Helsinki-NLP/Opus-MT
|
chainway9/blockassist-bc-untamed_quick_eel_1755447497
|
chainway9
| 2025-08-17T16:47:36Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"untamed quick eel",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-17T16:47:32Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- untamed quick eel
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
manancode/opus-mt-es-nl-ctranslate2-android
|
manancode
| 2025-08-17T16:45:41Z | 0 | 0 | null |
[
"translation",
"opus-mt",
"ctranslate2",
"quantized",
"multilingual",
"license:apache-2.0",
"region:us"
] |
translation
| 2025-08-17T16:45:30Z |
---
license: apache-2.0
tags:
- translation
- opus-mt
- ctranslate2
- quantized
language:
- multilingual
pipeline_tag: translation
---
# opus-mt-es-nl-ctranslate2-android
This is a quantized INT8 version of `Helsinki-NLP/opus-mt-es-nl` converted to CTranslate2 format for efficient inference.
## Model Details
- **Original Model**: Helsinki-NLP/opus-mt-es-nl
- **Format**: CTranslate2
- **Quantization**: INT8
- **Framework**: OPUS-MT
- **Converted by**: Automated conversion pipeline
## Usage
### With CTranslate2
```python
import ctranslate2
import sentencepiece as spm
# Load the model
translator = ctranslate2.Translator("path/to/model")
# Load tokenizers
sp_source = spm.SentencePieceProcessor(model_file="source.spm")
sp_target = spm.SentencePieceProcessor(model_file="target.spm")
# Translate
source_tokens = sp_source.encode("Your text here", out_type=str)
results = translator.translate_batch([source_tokens])
translation = sp_target.decode(results[0].hypotheses[0])
```
## Performance
This INT8 quantized version provides:
- ~75% reduction in model size
- Faster inference speed
- Maintained translation quality
- Mobile-friendly deployment
## Original Model
Based on the OPUS-MT project: https://github.com/Helsinki-NLP/Opus-MT
|
vlienhoa1996/blockassist-bc-flightless_unseen_parrot_1755447930
|
vlienhoa1996
| 2025-08-17T16:42:28Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"flightless unseen parrot",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-17T16:42:22Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- flightless unseen parrot
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
manancode/opus-mt-es-gl-ctranslate2-android
|
manancode
| 2025-08-17T16:40:17Z | 0 | 0 | null |
[
"translation",
"opus-mt",
"ctranslate2",
"quantized",
"multilingual",
"license:apache-2.0",
"region:us"
] |
translation
| 2025-08-17T16:40:08Z |
---
license: apache-2.0
tags:
- translation
- opus-mt
- ctranslate2
- quantized
language:
- multilingual
pipeline_tag: translation
---
# opus-mt-es-gl-ctranslate2-android
This is a quantized INT8 version of `Helsinki-NLP/opus-mt-es-gl` converted to CTranslate2 format for efficient inference.
## Model Details
- **Original Model**: Helsinki-NLP/opus-mt-es-gl
- **Format**: CTranslate2
- **Quantization**: INT8
- **Framework**: OPUS-MT
- **Converted by**: Automated conversion pipeline
## Usage
### With CTranslate2
```python
import ctranslate2
import sentencepiece as spm
# Load the model
translator = ctranslate2.Translator("path/to/model")
# Load tokenizers
sp_source = spm.SentencePieceProcessor(model_file="source.spm")
sp_target = spm.SentencePieceProcessor(model_file="target.spm")
# Translate
source_tokens = sp_source.encode("Your text here", out_type=str)
results = translator.translate_batch([source_tokens])
translation = sp_target.decode(results[0].hypotheses[0])
```
## Performance
This INT8 quantized version provides:
- ~75% reduction in model size
- Faster inference speed
- Maintained translation quality
- Mobile-friendly deployment
## Original Model
Based on the OPUS-MT project: https://github.com/Helsinki-NLP/Opus-MT
|
mang3dd/blockassist-bc-tangled_slithering_alligator_1755446807
|
mang3dd
| 2025-08-17T16:33:05Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"tangled slithering alligator",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-17T16:33:01Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- tangled slithering alligator
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
manancode/opus-mt-en-sv-ctranslate2-android
|
manancode
| 2025-08-17T16:22:48Z | 0 | 0 | null |
[
"translation",
"opus-mt",
"ctranslate2",
"quantized",
"multilingual",
"license:apache-2.0",
"region:us"
] |
translation
| 2025-08-17T16:22:33Z |
---
license: apache-2.0
tags:
- translation
- opus-mt
- ctranslate2
- quantized
language:
- multilingual
pipeline_tag: translation
---
# opus-mt-en-sv-ctranslate2-android
This is a quantized INT8 version of `Helsinki-NLP/opus-mt-en-sv` converted to CTranslate2 format for efficient inference.
## Model Details
- **Original Model**: Helsinki-NLP/opus-mt-en-sv
- **Format**: CTranslate2
- **Quantization**: INT8
- **Framework**: OPUS-MT
- **Converted by**: Automated conversion pipeline
## Usage
### With CTranslate2
```python
import ctranslate2
import sentencepiece as spm
# Load the model
translator = ctranslate2.Translator("path/to/model")
# Load tokenizers
sp_source = spm.SentencePieceProcessor(model_file="source.spm")
sp_target = spm.SentencePieceProcessor(model_file="target.spm")
# Translate
source_tokens = sp_source.encode("Your text here", out_type=str)
results = translator.translate_batch([source_tokens])
translation = sp_target.decode(results[0].hypotheses[0])
```
## Performance
This INT8 quantized version provides:
- ~75% reduction in model size
- Faster inference speed
- Maintained translation quality
- Mobile-friendly deployment
## Original Model
Based on the OPUS-MT project: https://github.com/Helsinki-NLP/Opus-MT
|
manancode/opus-mt-en-sk-ctranslate2-android
|
manancode
| 2025-08-17T16:21:06Z | 0 | 0 | null |
[
"translation",
"opus-mt",
"ctranslate2",
"quantized",
"multilingual",
"license:apache-2.0",
"region:us"
] |
translation
| 2025-08-17T16:20:56Z |
---
license: apache-2.0
tags:
- translation
- opus-mt
- ctranslate2
- quantized
language:
- multilingual
pipeline_tag: translation
---
# opus-mt-en-sk-ctranslate2-android
This is a quantized INT8 version of `Helsinki-NLP/opus-mt-en-sk` converted to CTranslate2 format for efficient inference.
## Model Details
- **Original Model**: Helsinki-NLP/opus-mt-en-sk
- **Format**: CTranslate2
- **Quantization**: INT8
- **Framework**: OPUS-MT
- **Converted by**: Automated conversion pipeline
## Usage
### With CTranslate2
```python
import ctranslate2
import sentencepiece as spm
# Load the model
translator = ctranslate2.Translator("path/to/model")
# Load tokenizers
sp_source = spm.SentencePieceProcessor(model_file="source.spm")
sp_target = spm.SentencePieceProcessor(model_file="target.spm")
# Translate
source_tokens = sp_source.encode("Your text here", out_type=str)
results = translator.translate_batch([source_tokens])
translation = sp_target.decode(results[0].hypotheses[0])
```
## Performance
This INT8 quantized version provides:
- ~75% reduction in model size
- Faster inference speed
- Maintained translation quality
- Mobile-friendly deployment
## Original Model
Based on the OPUS-MT project: https://github.com/Helsinki-NLP/Opus-MT
|
manancode/opus-mt-en-pis-ctranslate2-android
|
manancode
| 2025-08-17T16:17:23Z | 0 | 0 | null |
[
"translation",
"opus-mt",
"ctranslate2",
"quantized",
"multilingual",
"license:apache-2.0",
"region:us"
] |
translation
| 2025-08-17T16:17:14Z |
---
license: apache-2.0
tags:
- translation
- opus-mt
- ctranslate2
- quantized
language:
- multilingual
pipeline_tag: translation
---
# opus-mt-en-pis-ctranslate2-android
This is a quantized INT8 version of `Helsinki-NLP/opus-mt-en-pis` converted to CTranslate2 format for efficient inference.
## Model Details
- **Original Model**: Helsinki-NLP/opus-mt-en-pis
- **Format**: CTranslate2
- **Quantization**: INT8
- **Framework**: OPUS-MT
- **Converted by**: Automated conversion pipeline
## Usage
### With CTranslate2
```python
import ctranslate2
import sentencepiece as spm
# Load the model
translator = ctranslate2.Translator("path/to/model")
# Load tokenizers
sp_source = spm.SentencePieceProcessor(model_file="source.spm")
sp_target = spm.SentencePieceProcessor(model_file="target.spm")
# Translate
source_tokens = sp_source.encode("Your text here", out_type=str)
results = translator.translate_batch([source_tokens])
translation = sp_target.decode(results[0].hypotheses[0])
```
## Performance
This INT8 quantized version provides:
- ~75% reduction in model size
- Faster inference speed
- Maintained translation quality
- Mobile-friendly deployment
## Original Model
Based on the OPUS-MT project: https://github.com/Helsinki-NLP/Opus-MT
|
manancode/opus-mt-en-phi-ctranslate2-android
|
manancode
| 2025-08-17T16:17:11Z | 0 | 0 | null |
[
"translation",
"opus-mt",
"ctranslate2",
"quantized",
"multilingual",
"license:apache-2.0",
"region:us"
] |
translation
| 2025-08-17T16:17:00Z |
---
license: apache-2.0
tags:
- translation
- opus-mt
- ctranslate2
- quantized
language:
- multilingual
pipeline_tag: translation
---
# opus-mt-en-phi-ctranslate2-android
This is a quantized INT8 version of `Helsinki-NLP/opus-mt-en-phi` converted to CTranslate2 format for efficient inference.
## Model Details
- **Original Model**: Helsinki-NLP/opus-mt-en-phi
- **Format**: CTranslate2
- **Quantization**: INT8
- **Framework**: OPUS-MT
- **Converted by**: Automated conversion pipeline
## Usage
### With CTranslate2
```python
import ctranslate2
import sentencepiece as spm
# Load the model
translator = ctranslate2.Translator("path/to/model")
# Load tokenizers
sp_source = spm.SentencePieceProcessor(model_file="source.spm")
sp_target = spm.SentencePieceProcessor(model_file="target.spm")
# Translate
source_tokens = sp_source.encode("Your text here", out_type=str)
results = translator.translate_batch([source_tokens])
translation = sp_target.decode(results[0].hypotheses[0])
```
## Performance
This INT8 quantized version provides:
- ~75% reduction in model size
- Faster inference speed
- Maintained translation quality
- Mobile-friendly deployment
## Original Model
Based on the OPUS-MT project: https://github.com/Helsinki-NLP/Opus-MT
|
KantL/code-search-net-tokenizer
|
KantL
| 2025-08-17T16:10:45Z | 0 | 0 |
transformers
|
[
"transformers",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-08-17T16:10:43Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
FFApartners/Fal_Lana_Flux_v1
|
FFApartners
| 2025-08-17T15:50:51Z | 0 | 0 |
diffusers
|
[
"diffusers",
"flux",
"text-to-image",
"lora",
"fal",
"license:other",
"region:us"
] |
text-to-image
| 2025-08-17T15:50:44Z |
---
tags:
- flux
- text-to-image
- lora
- diffusers
- fal
base_model: undefined
instance_prompt:
license: other
---
# Fal_Lana_Flux_v1
<Gallery />
## Model description
## Trigger words
You should use `` to trigger the image generation.
## Download model
Weights for this model are available in Safetensors format.
[Download](/FFApartners/Fal_Lana_Flux_v1/tree/main) them in the Files & versions tab.
## Training at fal.ai
Training was done using [fal.ai/models/fal-ai/flux-lora-portrait-trainer](https://fal.ai/models/fal-ai/flux-lora-portrait-trainer).
|
thanobidex/blockassist-bc-colorful_shiny_hare_1755443802
|
thanobidex
| 2025-08-17T15:42:15Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"colorful shiny hare",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-17T15:42:12Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- colorful shiny hare
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
mradermacher/UI-Venus-Ground-7B-GGUF
|
mradermacher
| 2025-08-17T15:17:59Z | 0 | 0 |
transformers
|
[
"transformers",
"gguf",
"en",
"base_model:inclusionAI/UI-Venus-Ground-7B",
"base_model:quantized:inclusionAI/UI-Venus-Ground-7B",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2025-08-17T13:08:42Z |
---
base_model: inclusionAI/UI-Venus-Ground-7B
language:
- en
library_name: transformers
license: apache-2.0
mradermacher:
readme_rev: 1
quantized_by: mradermacher
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
<!-- ### quants: x-f16 Q4_K_S Q2_K Q8_0 Q6_K Q3_K_M Q3_K_S Q3_K_L Q4_K_M Q5_K_S Q5_K_M IQ4_XS -->
<!-- ### quants_skip: -->
<!-- ### skip_mmproj: -->
static quants of https://huggingface.co/inclusionAI/UI-Venus-Ground-7B
<!-- provided-files -->
***For a convenient overview and download list, visit our [model page for this model](https://hf.tst.eu/model#UI-Venus-Ground-7B-GGUF).***
weighted/imatrix quants are available at https://huggingface.co/mradermacher/UI-Venus-Ground-7B-i1-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/UI-Venus-Ground-7B-GGUF/resolve/main/UI-Venus-Ground-7B.mmproj-Q8_0.gguf) | mmproj-Q8_0 | 1.0 | multi-modal supplement |
| [GGUF](https://huggingface.co/mradermacher/UI-Venus-Ground-7B-GGUF/resolve/main/UI-Venus-Ground-7B.mmproj-f16.gguf) | mmproj-f16 | 1.5 | multi-modal supplement |
| [GGUF](https://huggingface.co/mradermacher/UI-Venus-Ground-7B-GGUF/resolve/main/UI-Venus-Ground-7B.Q2_K.gguf) | Q2_K | 3.1 | |
| [GGUF](https://huggingface.co/mradermacher/UI-Venus-Ground-7B-GGUF/resolve/main/UI-Venus-Ground-7B.Q3_K_S.gguf) | Q3_K_S | 3.6 | |
| [GGUF](https://huggingface.co/mradermacher/UI-Venus-Ground-7B-GGUF/resolve/main/UI-Venus-Ground-7B.Q3_K_M.gguf) | Q3_K_M | 3.9 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/UI-Venus-Ground-7B-GGUF/resolve/main/UI-Venus-Ground-7B.Q3_K_L.gguf) | Q3_K_L | 4.2 | |
| [GGUF](https://huggingface.co/mradermacher/UI-Venus-Ground-7B-GGUF/resolve/main/UI-Venus-Ground-7B.IQ4_XS.gguf) | IQ4_XS | 4.4 | |
| [GGUF](https://huggingface.co/mradermacher/UI-Venus-Ground-7B-GGUF/resolve/main/UI-Venus-Ground-7B.Q4_K_S.gguf) | Q4_K_S | 4.6 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/UI-Venus-Ground-7B-GGUF/resolve/main/UI-Venus-Ground-7B.Q4_K_M.gguf) | Q4_K_M | 4.8 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/UI-Venus-Ground-7B-GGUF/resolve/main/UI-Venus-Ground-7B.Q5_K_S.gguf) | Q5_K_S | 5.4 | |
| [GGUF](https://huggingface.co/mradermacher/UI-Venus-Ground-7B-GGUF/resolve/main/UI-Venus-Ground-7B.Q5_K_M.gguf) | Q5_K_M | 5.5 | |
| [GGUF](https://huggingface.co/mradermacher/UI-Venus-Ground-7B-GGUF/resolve/main/UI-Venus-Ground-7B.Q6_K.gguf) | Q6_K | 6.4 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/UI-Venus-Ground-7B-GGUF/resolve/main/UI-Venus-Ground-7B.Q8_0.gguf) | Q8_0 | 8.2 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/UI-Venus-Ground-7B-GGUF/resolve/main/UI-Venus-Ground-7B.f16.gguf) | f16 | 15.3 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
thanobidex/blockassist-bc-colorful_shiny_hare_1755442023
|
thanobidex
| 2025-08-17T15:13:21Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"colorful shiny hare",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-17T15:13:18Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- colorful shiny hare
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
pharaohe/2asianfacelora55img5rep10epoch
|
pharaohe
| 2025-08-17T14:52:41Z | 0 | 0 |
diffusers
|
[
"diffusers",
"text-to-image",
"flux",
"lora",
"template:sd-lora",
"fluxgym",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"license:other",
"region:us"
] |
text-to-image
| 2025-08-17T13:04:05Z |
---
tags:
- text-to-image
- flux
- lora
- diffusers
- template:sd-lora
- fluxgym
base_model: black-forest-labs/FLUX.1-dev
instance_prompt: woman
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
---
# 2asianfacelora55img5rep10epoch
A Flux LoRA trained on a local computer with [Fluxgym](https://github.com/cocktailpeanut/fluxgym)
<Gallery />
## Trigger words
You should use `woman` to trigger the image generation.
## Download model and use it with ComfyUI, AUTOMATIC1111, SD.Next, Invoke AI, Forge, etc.
Weights for this model are available in Safetensors format.
|
HarshitSheoran/mistral12b_tune19
|
HarshitSheoran
| 2025-08-17T14:33:26Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"mistral",
"text-generation",
"trl",
"sft",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-17T14:29:32Z |
---
library_name: transformers
tags:
- trl
- sft
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
lisaozill03/blockassist-bc-rugged_prickly_alpaca_1755439375
|
lisaozill03
| 2025-08-17T14:28:00Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"rugged prickly alpaca",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-17T14:27:57Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- rugged prickly alpaca
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
unitova/blockassist-bc-zealous_sneaky_raven_1755438169
|
unitova
| 2025-08-17T14:08:36Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"zealous sneaky raven",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-17T14:08:32Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- zealous sneaky raven
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Sayemahsjn/blockassist-bc-playful_feline_octopus_1755438349
|
Sayemahsjn
| 2025-08-17T14:05:08Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"playful feline octopus",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-17T14:05:04Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- playful feline octopus
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
bearlover365/multi_sac_smoke
|
bearlover365
| 2025-08-17T13:44:21Z | 0 | 0 |
lerobot
|
[
"lerobot",
"safetensors",
"sac",
"robotics",
"dataset:bearlover365/red_cube_always_in_same_place",
"dataset:bearlover365/pick_place_one_white_sock_black_out_blinds",
"arxiv:1801.01290",
"license:apache-2.0",
"region:us"
] |
robotics
| 2025-08-17T13:44:20Z |
---
datasets:
- bearlover365/red_cube_always_in_same_place
- bearlover365/pick_place_one_white_sock_black_out_blinds
library_name: lerobot
license: apache-2.0
model_name: sac
pipeline_tag: robotics
tags:
- lerobot
- sac
- robotics
---
# Model Card for sac
<!-- Provide a quick summary of what the model is/does. -->
[Soft Actor-Critic (SAC)](https://huggingface.co/papers/1801.01290) is an entropy-regularised actor-critic algorithm offering stable, sample-efficient learning in continuous-control environments.
This policy has been trained and pushed to the Hub using [LeRobot](https://github.com/huggingface/lerobot).
See the full documentation at [LeRobot Docs](https://huggingface.co/docs/lerobot/index).
---
## How to Get Started with the Model
For a complete walkthrough, see the [training guide](https://huggingface.co/docs/lerobot/il_robots#train-a-policy).
Below is the short version on how to train and run inference/eval:
### Train from scratch
```bash
python -m lerobot.scripts.train \
--dataset.repo_id=${HF_USER}/<dataset> \
--policy.type=act \
--output_dir=outputs/train/<desired_policy_repo_id> \
--job_name=lerobot_training \
--policy.device=cuda \
--policy.repo_id=${HF_USER}/<desired_policy_repo_id>
--wandb.enable=true
```
_Writes checkpoints to `outputs/train/<desired_policy_repo_id>/checkpoints/`._
### Evaluate the policy/run inference
```bash
python -m lerobot.record \
--robot.type=so100_follower \
--dataset.repo_id=<hf_user>/eval_<dataset> \
--policy.path=<hf_user>/<desired_policy_repo_id> \
--episodes=10
```
Prefix the dataset repo with **eval\_** and supply `--policy.path` pointing to a local or hub checkpoint.
---
## Model Details
- **License:** apache-2.0
|
itsme-nishanth/gemma3_test
|
itsme-nishanth
| 2025-08-17T13:31:47Z | 0 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"gemma3_text",
"text-generation",
"generated_from_trainer",
"sft",
"trl",
"conversational",
"base_model:itsme-nishanth/gemma3_test",
"base_model:finetune:itsme-nishanth/gemma3_test",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-17T13:11:33Z |
---
base_model: itsme-nishanth/gemma3_test
library_name: transformers
model_name: gemma3_test
tags:
- generated_from_trainer
- sft
- trl
licence: license
---
# Model Card for gemma3_test
This model is a fine-tuned version of [itsme-nishanth/gemma3_test](https://huggingface.co/itsme-nishanth/gemma3_test).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="itsme-nishanth/gemma3_test", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
This model was trained with SFT.
### Framework versions
- TRL: 0.21.0
- Transformers: 4.55.2
- Pytorch: 2.8.0+cu126
- Datasets: 4.0.0
- Tokenizers: 0.21.4
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
wcy1122/MGM-Omni-32B
|
wcy1122
| 2025-08-17T13:19:53Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"MGMOmni",
"text-generation",
"multimodal",
"conversational",
"en",
"zh",
"base_model:Qwen/Qwen2.5-VL-32B-Instruct",
"base_model:finetune:Qwen/Qwen2.5-VL-32B-Instruct",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-15T13:52:24Z |
---
license: apache-2.0
base_model:
- Qwen/Qwen2.5-VL-32B-Instruct
language:
- en
- zh
library_name: transformers
tags:
- multimodal
---
# MGM-Omni-32B
<div align="left">
[](https://github.com/dvlab-research/MGM-Omni)
[](https://mgm-omni.notion.site/MGM-Omni-An-Open-source-Omni-Chatbot-2395728e0b0180149ac9f24683fc9907?source=copy_link)
[](https://huggingface.co/collections/wcy1122/mgm-omni-6896075e97317a88825032e1)
[](https://huggingface.co/spaces/wcy1122/MGM-Omni)
</div>
## Introduction
MGM-Omni is an omni-chatbot capable of processing text, image, video, and speech inputs, and generating both text and speech responses.
MGM-Omni is capable of long-form speech understanding and generation, as well as zero-shot voice cloning in both Chinese and English.
MGM-Omni-32B is the MLLM component of MGM-Omni for omni modality perception. For the SpeechLM part, please refer MGM-Omni-TTS.
## Main Properties
- **Omni-modality supports**: MGM-Omni supports audio, video, image, and text inputs, understands long contexts, and can generate both text and speech outputs, making it a truly versatile multi-modal AI assistant.
- **Long-form Speech Understanding**: Unlike most existing open-source multi-modal models, which typically fail with inputs longer than 15 minutes, MGM-Omni can handle hour-long speech inputs while delivering superior overall and detailed understanding and performance!
- **Long-form Speech Generation**: With a treasure trove of training data and smart Chunk-Based Decoding, MGM-Omni can generate over 10 minutes of smooth, natural speech for continuous storytelling.
- **Streaming Generation**: Thanks to the parallel decoding approach for speech tokens, MGM-Omni enables efficient and smooth streaming audio, making it suitable for live conversations.
- **Zero-shot Voice Cloning**: With MGM-Omni’s extensive and diverse audio training, you can create a customized voice clone by simply recording a short clip (around 10 seconds) and reviewing the results.
- **Fully Open-source**: All the code, models, and training data will be released.
## Evaluation
### Speech and Audio Understanding
| Model | Date | LS-clean↓ | LS-other↓ | CM-EN↓ | CM-ZH↓ | AISHELL↓ |
|:-----------------|:--------|:----------|:----------|:--------|:--------|:---------|
| Mini-Omni2 | 2024-11 | 4.7 | 9.4 | - | - | - |
| Lyra | 2024-12 | 2.0 | 4.0 | - | - | - |
| VITA-1.5 | 2025-01 | 3.4 | 7.5 | - | - | 2.2 |
| Qwen2.5-Omni | 2025-03 | 1.6 | 3.5 | **7.6** | 5.2 | - |
| Ola | 2025-06 | 1.9 | 4.3 | - | - | - |
| **MGM-Omni-7B** | 2025-08 | 1.7 | 3.6 | 8.8 | 4.5 | 1.9 |
| **MGM-Omni-32B** | 2025-08 | **1.5** | **3.2** | 8.0 | **4.0** | **1.8** |
This table presents WER and CER results on speech understanding.
Here LS refers to LibriSpeech and CM refers to Common Voice.
| Model | Date | Speech↑ | Sound↑ | Music↑ | Mix↑ | Average↑ |
|:-----------------|:--------|:--------|:--------|:--------|:--------|:---------|
| LLaMA-Omni | 2024-08 | 5.2 | 5.3 | 4.3 | 4.0 | 4.7 |
| Mini-Omni2 | 2024-11 | 3.6 | 3.5 | 2.6 | 3.1 | 3.2 |
| IXC2.5-OmniLive | 2024-12 | 1.6 | 1.8 | 1.7 | 1.6 | 1.7 |
| VITA-1.5 | 2025-01 | 4.8 | 5.5 | 4.9 | 2.9 | 4.5 |
| Qwen2.5-Omni | 2025-03 | 6.8 | 5.7 | 4.8 | 5.4 | 5.7 |
| Ola | 2025-06 | **7.3** | 6.4 | 5.9 | 6.0 | 6.4 |
| **MGM-Omni-7B** | 2025-08 | **7.3** | **6.5** | **6.3** | 6.1 | **6.5** |
| **MGM-Omni-32B** | 2025-08 | 7.1 | **6.5** | 6.2 | **6.2** | **6.5** |
This table presents evaluation results on AIR-Bench Chat (speech, sound, music, etc.).
### Speech Generation
| Model | Date | Model Size | CER↓ | SS(ZH)↑ | WER↓ | SS(EN)↑ |
|:----------------|:--------|:-----------|:---------|:----------|:---------|:----------|
| CosyVoice2 | 2024-12 | 0.5B | 1.45 | 0.748 | 2.57 | 0.652 |
| Qwen2.5-Omni-3B | 2025-03 | 0.5B | 1.58 | 0.744 | 2.51 | 0.635 |
| Qwen2.5-Omni-7B | 2025-03 | 2B | 1.42 | 0.754 | 2.33 | 0.641 |
| MOSS-TTSD-v0 | 2025-06 | 2B | 2.18 | 0.594 | 2.46 | 0.476 |
| HiggsAudio-v2 | 2025-07 | 6B | 1.66 | 0.743 | 2.44 | 0.677 |
| **MGM-Omni** | 2025-08 | 0.6B | 1.49 | 0.749 | 2.54 | 0.670 |
| **MGM-Omni** | 2025-08 | 2B | 1.38 | 0.753 | 2.28 | 0.682 |
| **MGM-Omni** | 2025-08 | 4B | **1.34** | **0.756** | **2.22** | **0.684** |
This table presents evaluation results on speech generation on seed-tts-eval.
For Qwen2.5-Omni, model size refers to the size of the talker.
## Citation
If you find this repo useful for your research, we would appreciate it if you could cite our work:
```
@misc{wang2025mgmomni,
title={MGM-Omni: An Open-source Omni Chatbot},
author={Wang, Chengyao and Zhong, Zhisheng and Peng, Bohao and Yang, Senqiao and Liu, Yuqi and Yu, Bei and Jia, Jiaya},
year={2025},
howpublished={\url{https://mgm-omni.notion.site}},
note={Notion Blog}
}
```
|
tscstudios/3ifhe93wovq3c8umaevcmgvmmvj3_26387099-c4cf-40fa-abc0-da3cb1cff38b
|
tscstudios
| 2025-08-17T12:28:11Z | 0 | 0 |
diffusers
|
[
"diffusers",
"flux",
"lora",
"replicate",
"text-to-image",
"en",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"license:other",
"region:us"
] |
text-to-image
| 2025-08-17T12:28:09Z |
---
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
language:
- en
tags:
- flux
- diffusers
- lora
- replicate
base_model: "black-forest-labs/FLUX.1-dev"
pipeline_tag: text-to-image
# widget:
# - text: >-
# prompt
# output:
# url: https://...
instance_prompt: TOK
---
# 3Ifhe93Wovq3C8Umaevcmgvmmvj3_26387099 C4Cf 40Fa Abc0 Da3Cb1Cff38B
<Gallery />
## About this LoRA
This is a [LoRA](https://replicate.com/docs/guides/working-with-loras) for the FLUX.1-dev text-to-image model. It can be used with diffusers or ComfyUI.
It was trained on [Replicate](https://replicate.com/) using AI toolkit: https://replicate.com/ostris/flux-dev-lora-trainer/train
## Trigger words
You should use `TOK` to trigger the image generation.
## Run this LoRA with an API using Replicate
```py
import replicate
input = {
"prompt": "TOK",
"lora_weights": "https://huggingface.co/tscstudios/3ifhe93wovq3c8umaevcmgvmmvj3_26387099-c4cf-40fa-abc0-da3cb1cff38b/resolve/main/lora.safetensors"
}
output = replicate.run(
"black-forest-labs/flux-dev-lora",
input=input
)
for index, item in enumerate(output):
with open(f"output_{index}.webp", "wb") as file:
file.write(item.read())
```
## Use it with the [🧨 diffusers library](https://github.com/huggingface/diffusers)
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained('black-forest-labs/FLUX.1-dev', torch_dtype=torch.float16).to('cuda')
pipeline.load_lora_weights('tscstudios/3ifhe93wovq3c8umaevcmgvmmvj3_26387099-c4cf-40fa-abc0-da3cb1cff38b', weight_name='lora.safetensors')
image = pipeline('TOK').images[0]
```
For more details, including weighting, merging and fusing LoRAs, check the [documentation on loading LoRAs in diffusers](https://huggingface.co/docs/diffusers/main/en/using-diffusers/loading_adapters)
## Training details
- Steps: 2000
- Learning rate: 0.0004
- LoRA rank: 16
## Contribute your own examples
You can use the [community tab](https://huggingface.co/tscstudios/3ifhe93wovq3c8umaevcmgvmmvj3_26387099-c4cf-40fa-abc0-da3cb1cff38b/discussions) to add images that show off what you’ve made with this LoRA.
|
rigkily/blockassist-bc-nimble_lazy_dove_1755433600
|
rigkily
| 2025-08-17T12:27:57Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"nimble lazy dove",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-17T12:27:47Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- nimble lazy dove
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
thanobidex/blockassist-bc-colorful_shiny_hare_1755431198
|
thanobidex
| 2025-08-17T12:13:26Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"colorful shiny hare",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-17T12:13:23Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- colorful shiny hare
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
bangdulec/Qwen2.5-0.5B-Instruct-Gensyn-Swarm-burrowing_sneaky_tamarin
|
bangdulec
| 2025-08-17T12:03:59Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"rl-swarm",
"genrl-swarm",
"grpo",
"gensyn",
"I am burrowing_sneaky_tamarin",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-17T11:30:26Z |
---
library_name: transformers
tags:
- rl-swarm
- genrl-swarm
- grpo
- gensyn
- I am burrowing_sneaky_tamarin
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
adity12345/chakma_model
|
adity12345
| 2025-08-17T11:42:38Z | 0 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"gpt2",
"text-generation",
"generated_from_trainer",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-17T11:42:35Z |
---
library_name: transformers
tags:
- generated_from_trainer
model-index:
- name: chakma_model
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# chakma_model
This model is a fine-tuned version of [](https://huggingface.co/) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 5
### Framework versions
- Transformers 4.55.1
- Pytorch 2.6.0+cu124
- Datasets 4.0.0
- Tokenizers 0.21.4
|
Sayemahsjn/blockassist-bc-playful_feline_octopus_1755428648
|
Sayemahsjn
| 2025-08-17T11:24:17Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"playful feline octopus",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-17T11:24:13Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- playful feline octopus
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
GoldEgbuonu/bart-scientific-finetuned
|
GoldEgbuonu
| 2025-08-17T10:11:03Z | 0 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"bart",
"text2text-generation",
"generated_from_trainer",
"base_model:facebook/bart-large-cnn",
"base_model:finetune:facebook/bart-large-cnn",
"license:mit",
"endpoints_compatible",
"region:us"
] | null | 2025-08-17T09:54:36Z |
---
library_name: transformers
license: mit
base_model: facebook/bart-large-cnn
tags:
- generated_from_trainer
model-index:
- name: bart-scientific-finetuned
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bart-scientific-finetuned
This model is a fine-tuned version of [facebook/bart-large-cnn](https://huggingface.co/facebook/bart-large-cnn) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 2.1099
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 3
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| No log | 1.0 | 250 | 2.1363 |
| 2.2606 | 2.0 | 500 | 2.1065 |
| 2.2606 | 3.0 | 750 | 2.1099 |
### Framework versions
- Transformers 4.55.1
- Pytorch 2.6.0+cu124
- Datasets 4.0.0
- Tokenizers 0.21.4
|
m-polignano/ANITA-NEXT-24B-Magistral-2506-VISION-ITA-GGUF
|
m-polignano
| 2025-08-17T10:08:35Z | 0 | 0 |
transformers
|
[
"transformers",
"gguf",
"mistral3",
"image-to-text",
"ita",
"italian",
"anita",
"magistral",
"24b",
"uniba",
"bari",
"italy",
"italia",
"LLaMantino",
"Visual",
"VLM",
"text-generation",
"conversational",
"en",
"it",
"arxiv:2405.07101",
"arxiv:2506.10910",
"base_model:m-polignano/ANITA-NEXT-24B-Magistral-2506-ITA",
"base_model:quantized:m-polignano/ANITA-NEXT-24B-Magistral-2506-ITA",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-13T09:34:26Z |
---
license: apache-2.0
language:
- en
- it
base_model:
- m-polignano/ANITA-NEXT-24B-Magistral-2506-ITA
- mistralai/Mistral-Small-3.1-24B-Instruct-2503
pipeline_tag: text-generation
library_name: transformers
tags:
- ita
- italian
- anita
- magistral
- 24b
- uniba
- bari
- italy
- italia
- LLaMantino
- Visual
- VLM
---
<img src="https://huggingface.co/m-polignano/ANITA-NEXT-24B-Magistral-2506-ITA/resolve/main/Anita-Next_full.png" alt="anita_next" border="0" width="600px">
<hr>
<!--<img src="https://i.ibb.co/6mHSRm3/llamantino53.jpg" width="200"/>-->
<h3><i>"Built on <b>m-polignano/ANITA-NEXT-24B-Magistral-2506-ITA</b>"</i></i></h3>
<p style="text-align:justify;"><b>ANITA-NEXT-24B-Magistral-2506-VISION-ITA</b> is a <b>Thinking Vision Language Model</b> of the <a href="https://arxiv.org/abs/2405.07101"><b>ANITA</b></a> - <i>Large Language Models family</i>.
The model is a merge of textual layers from of <a href="https://huggingface.co/m-polignano/ANITA-NEXT-24B-Magistral-2506-VISION-ITA"><b>ANITA-NEXT-24B-Magistral-2506-VISION-ITA</b></a> and vision layers and processor from <a href="https://huggingface.co/m-polignano/ANITA-NEXT-24B-Magistral-2506-VISION-ITA"><b>mistralai/Mistral-Small-3.1-24B-Instruct-2503</b></a>.
This model version aims to be the a <b>Multilingual Vision Language Model</b> 🏁 (EN 🇺🇸 + ITA🇮🇹) to further fine-tuning on Specific Tasks in Italian.</p>
❗❗❗Use at your own risk. The model may generate hallucinations, incorrect, invented, offensive, unethical or dangerous responses. We are not responsible for any dangerous/offensive/criminal use. The model is release for research only purposes.❗❗❗
The 🌟**ANITA project**🌟 *(**A**dvanced **N**atural-based interaction for the **ITA**lian language)*
wants to provide Italian NLP researchers with an improved model for the Italian Language 🇮🇹 use cases.
The **NEXT** family includes **four models**:
- m-polignano/ANITA-NEXT-24B-Magistral-2506-ITA - **General Purpose**
- m-polignano/ANITA-NEXT-24B-Dolphin-Mistral-UNCENSORED-ITA - **Uncensored**
- m-polignano/ANITA-NEXT-24B-Magistral-2506-VISION-ITA - **Vision-Language**
- m-polignano/ANITA-NEXT-20B-gpt-oss-ITA - **Agentic Ready**
<hr>
**Full Model**: [m-polignano/ANITA-NEXT-24B-Magistral-2506-VISION-ITA](https://huggingface.co/m-polignano/ANITA-NEXT-24B-Magistral-2506-VISION-ITA)
<hr>
For *OLLAMA Inference* follow the [Huggingface Documentation](https://huggingface.co/docs/hub/ollama).
<hr>
## Citation instructions
```bibtex
@misc{polignano2024advanced,
title={Advanced Natural-based interaction for the ITAlian language: LLaMAntino-3-ANITA},
author={Marco Polignano and Pierpaolo Basile and Giovanni Semeraro},
year={2024},
eprint={2405.07101},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
```bibtex
@article{rastogi2025magistral,
title={Magistral},
author={Rastogi, Abhinav and Jiang, Albert Q and Lo, Andy and Berrada, Gabrielle and Lample, Guillaume and Rute, Jason and Barmentlo, Joep and Yadav, Karmesh and Khandelwal, Kartik and Chandu, Khyathi Raghavi and others},
journal={arXiv preprint arXiv:2506.10910},
year={2025}
}
```
|
capungmerah627/blockassist-bc-stinging_soaring_porcupine_1755422678
|
capungmerah627
| 2025-08-17T09:51:15Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"stinging soaring porcupine",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-17T09:51:11Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- stinging soaring porcupine
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
kajaks/gner-t5-xxl-encoder
|
kajaks
| 2025-08-17T09:05:25Z | 0 | 0 | null |
[
"safetensors",
"t5",
"base_model:dyyyyyyyy/GNER-T5-xxl",
"base_model:finetune:dyyyyyyyy/GNER-T5-xxl",
"region:us"
] | null | 2025-08-16T10:23:10Z |
---
base_model:
- dyyyyyyyy/GNER-T5-xxl
---
Encoder part of https://huggingface.co/dyyyyyyyy/GNER-T5-xxl, keeping FP32 precision
|
Qwen/Qwen3-30B-A3B-Instruct-2507
|
Qwen
| 2025-08-17T08:20:34Z | 429,480 | 485 |
transformers
|
[
"transformers",
"safetensors",
"qwen3_moe",
"text-generation",
"conversational",
"arxiv:2402.17463",
"arxiv:2407.02490",
"arxiv:2501.15383",
"arxiv:2404.06654",
"arxiv:2505.09388",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-07-28T07:31:27Z |
---
library_name: transformers
license: apache-2.0
license_link: https://huggingface.co/Qwen/Qwen3-30B-A3B-Instruct-2507/blob/main/LICENSE
pipeline_tag: text-generation
---
# Qwen3-30B-A3B-Instruct-2507
<a href="https://chat.qwen.ai/?model=Qwen3-30B-A3B-2507" target="_blank" style="margin: 2px;">
<img alt="Chat" src="https://img.shields.io/badge/%F0%9F%92%9C%EF%B8%8F%20Qwen%20Chat%20-536af5" style="display: inline-block; vertical-align: middle;"/>
</a>
## Highlights
We introduce the updated version of the **Qwen3-30B-A3B non-thinking mode**, named **Qwen3-30B-A3B-Instruct-2507**, featuring the following key enhancements:
- **Significant improvements** in general capabilities, including **instruction following, logical reasoning, text comprehension, mathematics, science, coding and tool usage**.
- **Substantial gains** in long-tail knowledge coverage across **multiple languages**.
- **Markedly better alignment** with user preferences in **subjective and open-ended tasks**, enabling more helpful responses and higher-quality text generation.
- **Enhanced capabilities** in **256K long-context understanding**.
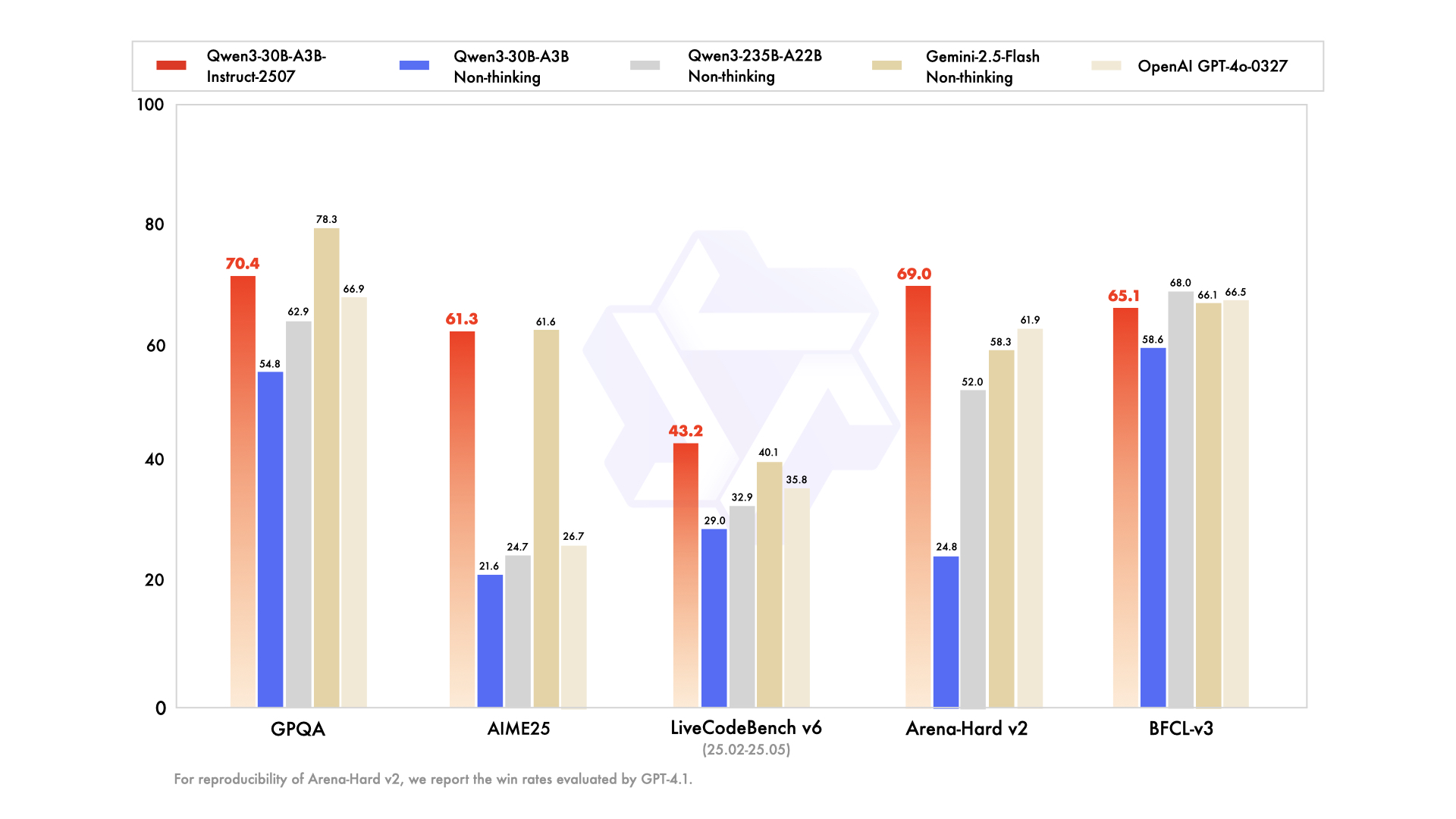
## Model Overview
**Qwen3-30B-A3B-Instruct-2507** has the following features:
- Type: Causal Language Models
- Training Stage: Pretraining & Post-training
- Number of Parameters: 30.5B in total and 3.3B activated
- Number of Paramaters (Non-Embedding): 29.9B
- Number of Layers: 48
- Number of Attention Heads (GQA): 32 for Q and 4 for KV
- Number of Experts: 128
- Number of Activated Experts: 8
- Context Length: **262,144 natively**.
**NOTE: This model supports only non-thinking mode and does not generate ``<think></think>`` blocks in its output. Meanwhile, specifying `enable_thinking=False` is no longer required.**
For more details, including benchmark evaluation, hardware requirements, and inference performance, please refer to our [blog](https://qwenlm.github.io/blog/qwen3/), [GitHub](https://github.com/QwenLM/Qwen3), and [Documentation](https://qwen.readthedocs.io/en/latest/).
## Performance
| | Deepseek-V3-0324 | GPT-4o-0327 | Gemini-2.5-Flash Non-Thinking | Qwen3-235B-A22B Non-Thinking | Qwen3-30B-A3B Non-Thinking | Qwen3-30B-A3B-Instruct-2507 |
|--- | --- | --- | --- | --- | --- | --- |
| **Knowledge** | | | | | | |
| MMLU-Pro | **81.2** | 79.8 | 81.1 | 75.2 | 69.1 | 78.4 |
| MMLU-Redux | 90.4 | **91.3** | 90.6 | 89.2 | 84.1 | 89.3 |
| GPQA | 68.4 | 66.9 | **78.3** | 62.9 | 54.8 | 70.4 |
| SuperGPQA | **57.3** | 51.0 | 54.6 | 48.2 | 42.2 | 53.4 |
| **Reasoning** | | | | | | |
| AIME25 | 46.6 | 26.7 | **61.6** | 24.7 | 21.6 | 61.3 |
| HMMT25 | 27.5 | 7.9 | **45.8** | 10.0 | 12.0 | 43.0 |
| ZebraLogic | 83.4 | 52.6 | 57.9 | 37.7 | 33.2 | **90.0** |
| LiveBench 20241125 | 66.9 | 63.7 | **69.1** | 62.5 | 59.4 | 69.0 |
| **Coding** | | | | | | |
| LiveCodeBench v6 (25.02-25.05) | **45.2** | 35.8 | 40.1 | 32.9 | 29.0 | 43.2 |
| MultiPL-E | 82.2 | 82.7 | 77.7 | 79.3 | 74.6 | **83.8** |
| Aider-Polyglot | 55.1 | 45.3 | 44.0 | **59.6** | 24.4 | 35.6 |
| **Alignment** | | | | | | |
| IFEval | 82.3 | 83.9 | 84.3 | 83.2 | 83.7 | **84.7** |
| Arena-Hard v2* | 45.6 | 61.9 | 58.3 | 52.0 | 24.8 | **69.0** |
| Creative Writing v3 | 81.6 | 84.9 | 84.6 | 80.4 | 68.1 | **86.0** |
| WritingBench | 74.5 | 75.5 | 80.5 | 77.0 | 72.2 | **85.5** |
| **Agent** | | | | | | |
| BFCL-v3 | 64.7 | 66.5 | 66.1 | **68.0** | 58.6 | 65.1 |
| TAU1-Retail | 49.6 | 60.3# | **65.2** | 65.2 | 38.3 | 59.1 |
| TAU1-Airline | 32.0 | 42.8# | **48.0** | 32.0 | 18.0 | 40.0 |
| TAU2-Retail | **71.1** | 66.7# | 64.3 | 64.9 | 31.6 | 57.0 |
| TAU2-Airline | 36.0 | 42.0# | **42.5** | 36.0 | 18.0 | 38.0 |
| TAU2-Telecom | **34.0** | 29.8# | 16.9 | 24.6 | 18.4 | 12.3 |
| **Multilingualism** | | | | | | |
| MultiIF | 66.5 | 70.4 | 69.4 | 70.2 | **70.8** | 67.9 |
| MMLU-ProX | 75.8 | 76.2 | **78.3** | 73.2 | 65.1 | 72.0 |
| INCLUDE | 80.1 | 82.1 | **83.8** | 75.6 | 67.8 | 71.9 |
| PolyMATH | 32.2 | 25.5 | 41.9 | 27.0 | 23.3 | **43.1** |
*: For reproducibility, we report the win rates evaluated by GPT-4.1.
\#: Results were generated using GPT-4o-20241120, as access to the native function calling API of GPT-4o-0327 was unavailable.
## Quickstart
The code of Qwen3-MoE has been in the latest Hugging Face `transformers` and we advise you to use the latest version of `transformers`.
With `transformers<4.51.0`, you will encounter the following error:
```
KeyError: 'qwen3_moe'
```
The following contains a code snippet illustrating how to use the model generate content based on given inputs.
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen3-30B-A3B-Instruct-2507"
# load the tokenizer and the model
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
# prepare the model input
prompt = "Give me a short introduction to large language model."
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# conduct text completion
generated_ids = model.generate(
**model_inputs,
max_new_tokens=16384
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
content = tokenizer.decode(output_ids, skip_special_tokens=True)
print("content:", content)
```
For deployment, you can use `sglang>=0.4.6.post1` or `vllm>=0.8.5` or to create an OpenAI-compatible API endpoint:
- SGLang:
```shell
python -m sglang.launch_server --model-path Qwen/Qwen3-30B-A3B-Instruct-2507 --context-length 262144
```
- vLLM:
```shell
vllm serve Qwen/Qwen3-30B-A3B-Instruct-2507 --max-model-len 262144
```
**Note: If you encounter out-of-memory (OOM) issues, consider reducing the context length to a shorter value, such as `32,768`.**
For local use, applications such as Ollama, LMStudio, MLX-LM, llama.cpp, and KTransformers have also supported Qwen3.
## Agentic Use
Qwen3 excels in tool calling capabilities. We recommend using [Qwen-Agent](https://github.com/QwenLM/Qwen-Agent) to make the best use of agentic ability of Qwen3. Qwen-Agent encapsulates tool-calling templates and tool-calling parsers internally, greatly reducing coding complexity.
To define the available tools, you can use the MCP configuration file, use the integrated tool of Qwen-Agent, or integrate other tools by yourself.
```python
from qwen_agent.agents import Assistant
# Define LLM
llm_cfg = {
'model': 'Qwen3-30B-A3B-Instruct-2507',
# Use a custom endpoint compatible with OpenAI API:
'model_server': 'http://localhost:8000/v1', # api_base
'api_key': 'EMPTY',
}
# Define Tools
tools = [
{'mcpServers': { # You can specify the MCP configuration file
'time': {
'command': 'uvx',
'args': ['mcp-server-time', '--local-timezone=Asia/Shanghai']
},
"fetch": {
"command": "uvx",
"args": ["mcp-server-fetch"]
}
}
},
'code_interpreter', # Built-in tools
]
# Define Agent
bot = Assistant(llm=llm_cfg, function_list=tools)
# Streaming generation
messages = [{'role': 'user', 'content': 'https://qwenlm.github.io/blog/ Introduce the latest developments of Qwen'}]
for responses in bot.run(messages=messages):
pass
print(responses)
```
## Processing Ultra-Long Texts
To support **ultra-long context processing** (up to **1 million tokens**), we integrate two key techniques:
- **[Dual Chunk Attention](https://arxiv.org/abs/2402.17463) (DCA)**: A length extrapolation method that splits long sequences into manageable chunks while preserving global coherence.
- **[MInference](https://arxiv.org/abs/2407.02490)**: A sparse attention mechanism that reduces computational overhead by focusing on critical token interactions.
Together, these innovations significantly improve both **generation quality** and **inference efficiency** for sequences beyond 256K tokens. On sequences approaching 1M tokens, the system achieves up to a **3× speedup** compared to standard attention implementations.
For full technical details, see the [Qwen2.5-1M Technical Report](https://arxiv.org/abs/2501.15383).
### How to Enable 1M Token Context
> [!NOTE]
> To effectively process a 1 million token context, users will require approximately **240 GB** of total GPU memory. This accounts for model weights, KV-cache storage, and peak activation memory demands.
#### Step 1: Update Configuration File
Download the model and replace the content of your `config.json` with `config_1m.json`, which includes the config for length extrapolation and sparse attention.
```bash
export MODELNAME=Qwen3-30B-A3B-Instruct-2507
huggingface-cli download Qwen/${MODELNAME} --local-dir ${MODELNAME}
mv ${MODELNAME}/config.json ${MODELNAME}/config.json.bak
mv ${MODELNAME}/config_1m.json ${MODELNAME}/config.json
```
#### Step 2: Launch Model Server
After updating the config, proceed with either **vLLM** or **SGLang** for serving the model.
#### Option 1: Using vLLM
To run Qwen with 1M context support:
```bash
pip install -U vllm \
--torch-backend=auto \
--extra-index-url https://wheels.vllm.ai/nightly
```
Then launch the server with Dual Chunk Flash Attention enabled:
```bash
VLLM_ATTENTION_BACKEND=DUAL_CHUNK_FLASH_ATTN VLLM_USE_V1=0 \
vllm serve ./Qwen3-30B-A3B-Instruct-2507 \
--tensor-parallel-size 4 \
--max-model-len 1010000 \
--enable-chunked-prefill \
--max-num-batched-tokens 131072 \
--enforce-eager \
--max-num-seqs 1 \
--gpu-memory-utilization 0.85
```
##### Key Parameters
| Parameter | Purpose |
|--------|--------|
| `VLLM_ATTENTION_BACKEND=DUAL_CHUNK_FLASH_ATTN` | Enables the custom attention kernel for long-context efficiency |
| `--max-model-len 1010000` | Sets maximum context length to ~1M tokens |
| `--enable-chunked-prefill` | Allows chunked prefill for very long inputs (avoids OOM) |
| `--max-num-batched-tokens 131072` | Controls batch size during prefill; balances throughput and memory |
| `--enforce-eager` | Disables CUDA graph capture (required for dual chunk attention) |
| `--max-num-seqs 1` | Limits concurrent sequences due to extreme memory usage |
| `--gpu-memory-utilization 0.85` | Set the fraction of GPU memory to be used for the model executor |
#### Option 2: Using SGLang
First, clone and install the specialized branch:
```bash
git clone https://github.com/sgl-project/sglang.git
cd sglang
pip install -e "python[all]"
```
Launch the server with DCA support:
```bash
python3 -m sglang.launch_server \
--model-path ./Qwen3-30B-A3B-Instruct-2507 \
--context-length 1010000 \
--mem-frac 0.75 \
--attention-backend dual_chunk_flash_attn \
--tp 4 \
--chunked-prefill-size 131072
```
##### Key Parameters
| Parameter | Purpose |
|---------|--------|
| `--attention-backend dual_chunk_flash_attn` | Activates Dual Chunk Flash Attention |
| `--context-length 1010000` | Defines max input length |
| `--mem-frac 0.75` | The fraction of the memory used for static allocation (model weights and KV cache memory pool). Use a smaller value if you see out-of-memory errors. |
| `--tp 4` | Tensor parallelism size (matches model sharding) |
| `--chunked-prefill-size 131072` | Prefill chunk size for handling long inputs without OOM |
#### Troubleshooting:
1. Encountering the error: "The model's max sequence length (xxxxx) is larger than the maximum number of tokens that can be stored in the KV cache." or "RuntimeError: Not enough memory. Please try to increase --mem-fraction-static."
The VRAM reserved for the KV cache is insufficient.
- vLLM: Consider reducing the ``max_model_len`` or increasing the ``tensor_parallel_size`` and ``gpu_memory_utilization``. Alternatively, you can reduce ``max_num_batched_tokens``, although this may significantly slow down inference.
- SGLang: Consider reducing the ``context-length`` or increasing the ``tp`` and ``mem-frac``. Alternatively, you can reduce ``chunked-prefill-size``, although this may significantly slow down inference.
2. Encountering the error: "torch.OutOfMemoryError: CUDA out of memory."
The VRAM reserved for activation weights is insufficient. You can try lowering ``gpu_memory_utilization`` or ``mem-frac``, but be aware that this might reduce the VRAM available for the KV cache.
3. Encountering the error: "Input prompt (xxxxx tokens) + lookahead slots (0) is too long and exceeds the capacity of the block manager." or "The input (xxx xtokens) is longer than the model's context length (xxx tokens)."
The input is too lengthy. Consider using a shorter sequence or increasing the ``max_model_len`` or ``context-length``.
#### Long-Context Performance
We test the model on an 1M version of the [RULER](https://arxiv.org/abs/2404.06654) benchmark.
| Model Name | Acc avg | 4k | 8k | 16k | 32k | 64k | 96k | 128k | 192k | 256k | 384k | 512k | 640k | 768k | 896k | 1000k |
|---------------------------------------------|---------|------|------|------|------|------|------|------|------|------|------|------|------|------|------|-------|
| Qwen3-30B-A3B (Non-Thinking) | 72.0 | 97.1 | 96.1 | 95.0 | 92.2 | 82.6 | 79.7 | 76.9 | 70.2 | 66.3 | 61.9 | 55.4 | 52.6 | 51.5 | 52.0 | 50.9 |
| Qwen3-30B-A3B-Instruct-2507 (Full Attention) | 86.8 | 98.0 | 96.7 | 96.9 | 97.2 | 93.4 | 91.0 | 89.1 | 89.8 | 82.5 | 83.6 | 78.4 | 79.7 | 77.6 | 75.7 | 72.8 |
| Qwen3-30B-A3B-Instruct-2507 (Sparse Attention) | 86.8 | 98.0 | 97.1 | 96.3 | 95.1 | 93.6 | 92.5 | 88.1 | 87.7 | 82.9 | 85.7 | 80.7 | 80.0 | 76.9 | 75.5 | 72.2 |
* All models are evaluated with Dual Chunk Attention enabled.
* Since the evaluation is time-consuming, we use 260 samples for each length (13 sub-tasks, 20 samples for each).
## Best Practices
To achieve optimal performance, we recommend the following settings:
1. **Sampling Parameters**:
- We suggest using `Temperature=0.7`, `TopP=0.8`, `TopK=20`, and `MinP=0`.
- For supported frameworks, you can adjust the `presence_penalty` parameter between 0 and 2 to reduce endless repetitions. However, using a higher value may occasionally result in language mixing and a slight decrease in model performance.
2. **Adequate Output Length**: We recommend using an output length of 16,384 tokens for most queries, which is adequate for instruct models.
3. **Standardize Output Format**: We recommend using prompts to standardize model outputs when benchmarking.
- **Math Problems**: Include "Please reason step by step, and put your final answer within \boxed{}." in the prompt.
- **Multiple-Choice Questions**: Add the following JSON structure to the prompt to standardize responses: "Please show your choice in the `answer` field with only the choice letter, e.g., `"answer": "C"`."
### Citation
If you find our work helpful, feel free to give us a cite.
```
@misc{qwen3technicalreport,
title={Qwen3 Technical Report},
author={Qwen Team},
year={2025},
eprint={2505.09388},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2505.09388},
}
```
|
Qwen/Qwen3-235B-A22B-Instruct-2507
|
Qwen
| 2025-08-17T08:19:57Z | 70,224 | 636 |
transformers
|
[
"transformers",
"safetensors",
"qwen3_moe",
"text-generation",
"conversational",
"arxiv:2402.17463",
"arxiv:2407.02490",
"arxiv:2501.15383",
"arxiv:2404.06654",
"arxiv:2505.09388",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-07-21T06:46:56Z |
---
library_name: transformers
license: apache-2.0
license_link: https://huggingface.co/Qwen/Qwen3-235B-A22B-Instruct-2507/blob/main/LICENSE
pipeline_tag: text-generation
---
# Qwen3-235B-A22B-Instruct-2507
<a href="https://chat.qwen.ai/" target="_blank" style="margin: 2px;">
<img alt="Chat" src="https://img.shields.io/badge/%F0%9F%92%9C%EF%B8%8F%20Qwen%20Chat%20-536af5" style="display: inline-block; vertical-align: middle;"/>
</a>
## Highlights
We introduce the updated version of the **Qwen3-235B-A22B non-thinking mode**, named **Qwen3-235B-A22B-Instruct-2507**, featuring the following key enhancements:
- **Significant improvements** in general capabilities, including **instruction following, logical reasoning, text comprehension, mathematics, science, coding and tool usage**.
- **Substantial gains** in long-tail knowledge coverage across **multiple languages**.
- **Markedly better alignment** with user preferences in **subjective and open-ended tasks**, enabling more helpful responses and higher-quality text generation.
- **Enhanced capabilities** in **256K long-context understanding**.
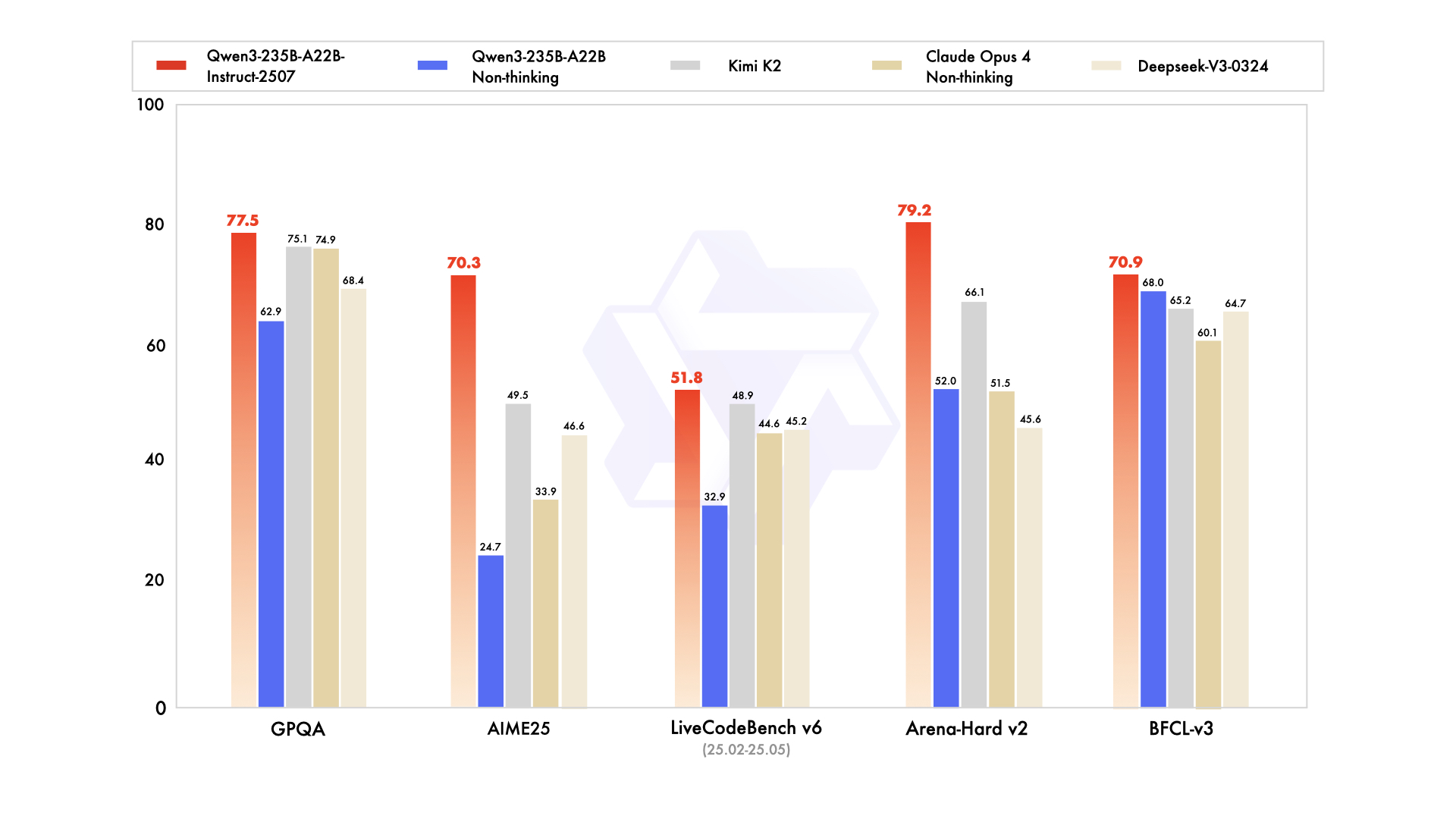
## Model Overview
**Qwen3-235B-A22B-Instruct-2507** has the following features:
- Type: Causal Language Models
- Training Stage: Pretraining & Post-training
- Number of Parameters: 235B in total and 22B activated
- Number of Paramaters (Non-Embedding): 234B
- Number of Layers: 94
- Number of Attention Heads (GQA): 64 for Q and 4 for KV
- Number of Experts: 128
- Number of Activated Experts: 8
- Context Length: **262,144 natively and extendable up to 1,010,000 tokens**
**NOTE: This model supports only non-thinking mode and does not generate ``<think></think>`` blocks in its output. Meanwhile, specifying `enable_thinking=False` is no longer required.**
For more details, including benchmark evaluation, hardware requirements, and inference performance, please refer to our [blog](https://qwenlm.github.io/blog/qwen3/), [GitHub](https://github.com/QwenLM/Qwen3), and [Documentation](https://qwen.readthedocs.io/en/latest/).
## Performance
| | Deepseek-V3-0324 | GPT-4o-0327 | Claude Opus 4 Non-thinking | Kimi K2 | Qwen3-235B-A22B Non-thinking | Qwen3-235B-A22B-Instruct-2507 |
|--- | --- | --- | --- | --- | --- | ---|
| **Knowledge** | | | | | | |
| MMLU-Pro | 81.2 | 79.8 | **86.6** | 81.1 | 75.2 | 83.0 |
| MMLU-Redux | 90.4 | 91.3 | **94.2** | 92.7 | 89.2 | 93.1 |
| GPQA | 68.4 | 66.9 | 74.9 | 75.1 | 62.9 | **77.5** |
| SuperGPQA | 57.3 | 51.0 | 56.5 | 57.2 | 48.2 | **62.6** |
| SimpleQA | 27.2 | 40.3 | 22.8 | 31.0 | 12.2 | **54.3** |
| CSimpleQA | 71.1 | 60.2 | 68.0 | 74.5 | 60.8 | **84.3** |
| **Reasoning** | | | | | | |
| AIME25 | 46.6 | 26.7 | 33.9 | 49.5 | 24.7 | **70.3** |
| HMMT25 | 27.5 | 7.9 | 15.9 | 38.8 | 10.0 | **55.4** |
| ARC-AGI | 9.0 | 8.8 | 30.3 | 13.3 | 4.3 | **41.8** |
| ZebraLogic | 83.4 | 52.6 | - | 89.0 | 37.7 | **95.0** |
| LiveBench 20241125 | 66.9 | 63.7 | 74.6 | **76.4** | 62.5 | 75.4 |
| **Coding** | | | | | | |
| LiveCodeBench v6 (25.02-25.05) | 45.2 | 35.8 | 44.6 | 48.9 | 32.9 | **51.8** |
| MultiPL-E | 82.2 | 82.7 | **88.5** | 85.7 | 79.3 | 87.9 |
| Aider-Polyglot | 55.1 | 45.3 | **70.7** | 59.0 | 59.6 | 57.3 |
| **Alignment** | | | | | | |
| IFEval | 82.3 | 83.9 | 87.4 | **89.8** | 83.2 | 88.7 |
| Arena-Hard v2* | 45.6 | 61.9 | 51.5 | 66.1 | 52.0 | **79.2** |
| Creative Writing v3 | 81.6 | 84.9 | 83.8 | **88.1** | 80.4 | 87.5 |
| WritingBench | 74.5 | 75.5 | 79.2 | **86.2** | 77.0 | 85.2 |
| **Agent** | | | | | | |
| BFCL-v3 | 64.7 | 66.5 | 60.1 | 65.2 | 68.0 | **70.9** |
| TAU1-Retail | 49.6 | 60.3# | **81.4** | 70.7 | 65.2 | 71.3 |
| TAU1-Airline | 32.0 | 42.8# | **59.6** | 53.5 | 32.0 | 44.0 |
| TAU2-Retail | 71.1 | 66.7# | **75.5** | 70.6 | 64.9 | 74.6 |
| TAU2-Airline | 36.0 | 42.0# | 55.5 | **56.5** | 36.0 | 50.0 |
| TAU2-Telecom | 34.0 | 29.8# | 45.2 | **65.8** | 24.6 | 32.5 |
| **Multilingualism** | | | | | | |
| MultiIF | 66.5 | 70.4 | - | 76.2 | 70.2 | **77.5** |
| MMLU-ProX | 75.8 | 76.2 | - | 74.5 | 73.2 | **79.4** |
| INCLUDE | 80.1 | **82.1** | - | 76.9 | 75.6 | 79.5 |
| PolyMATH | 32.2 | 25.5 | 30.0 | 44.8 | 27.0 | **50.2** |
*: For reproducibility, we report the win rates evaluated by GPT-4.1.
\#: Results were generated using GPT-4o-20241120, as access to the native function calling API of GPT-4o-0327 was unavailable.
## Quickstart
The code of Qwen3-MoE has been in the latest Hugging Face `transformers` and we advise you to use the latest version of `transformers`.
With `transformers<4.51.0`, you will encounter the following error:
```
KeyError: 'qwen3_moe'
```
The following contains a code snippet illustrating how to use the model generate content based on given inputs.
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen3-235B-A22B-Instruct-2507"
# load the tokenizer and the model
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
# prepare the model input
prompt = "Give me a short introduction to large language model."
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# conduct text completion
generated_ids = model.generate(
**model_inputs,
max_new_tokens=16384
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
content = tokenizer.decode(output_ids, skip_special_tokens=True)
print("content:", content)
```
For deployment, you can use `sglang>=0.4.6.post1` or `vllm>=0.8.5` or to create an OpenAI-compatible API endpoint:
- SGLang:
```shell
python -m sglang.launch_server --model-path Qwen/Qwen3-235B-A22B-Instruct-2507 --tp 8 --context-length 262144
```
- vLLM:
```shell
vllm serve Qwen/Qwen3-235B-A22B-Instruct-2507 --tensor-parallel-size 8 --max-model-len 262144
```
**Note: If you encounter out-of-memory (OOM) issues, consider reducing the context length to a shorter value, such as `32,768`.**
For local use, applications such as Ollama, LMStudio, MLX-LM, llama.cpp, and KTransformers have also supported Qwen3.
## Agentic Use
Qwen3 excels in tool calling capabilities. We recommend using [Qwen-Agent](https://github.com/QwenLM/Qwen-Agent) to make the best use of agentic ability of Qwen3. Qwen-Agent encapsulates tool-calling templates and tool-calling parsers internally, greatly reducing coding complexity.
To define the available tools, you can use the MCP configuration file, use the integrated tool of Qwen-Agent, or integrate other tools by yourself.
```python
from qwen_agent.agents import Assistant
# Define LLM
llm_cfg = {
'model': 'Qwen3-235B-A22B-Instruct-2507',
# Use a custom endpoint compatible with OpenAI API:
'model_server': 'http://localhost:8000/v1', # api_base
'api_key': 'EMPTY',
}
# Define Tools
tools = [
{'mcpServers': { # You can specify the MCP configuration file
'time': {
'command': 'uvx',
'args': ['mcp-server-time', '--local-timezone=Asia/Shanghai']
},
"fetch": {
"command": "uvx",
"args": ["mcp-server-fetch"]
}
}
},
'code_interpreter', # Built-in tools
]
# Define Agent
bot = Assistant(llm=llm_cfg, function_list=tools)
# Streaming generation
messages = [{'role': 'user', 'content': 'https://qwenlm.github.io/blog/ Introduce the latest developments of Qwen'}]
for responses in bot.run(messages=messages):
pass
print(responses)
```
## Processing Ultra-Long Texts
To support **ultra-long context processing** (up to **1 million tokens**), we integrate two key techniques:
- **[Dual Chunk Attention](https://arxiv.org/abs/2402.17463) (DCA)**: A length extrapolation method that splits long sequences into manageable chunks while preserving global coherence.
- **[MInference](https://arxiv.org/abs/2407.02490)**: A sparse attention mechanism that reduces computational overhead by focusing on critical token interactions.
Together, these innovations significantly improve both **generation quality** and **inference efficiency** for sequences beyond 256K tokens. On sequences approaching 1M tokens, the system achieves up to a **3× speedup** compared to standard attention implementations.
For full technical details, see the [Qwen2.5-1M Technical Report](https://arxiv.org/abs/2501.15383).
### How to Enable 1M Token Context
> [!NOTE]
> To effectively process a 1 million token context, users will require approximately **1000 GB** of total GPU memory. This accounts for model weights, KV-cache storage, and peak activation memory demands.
#### Step 1: Update Configuration File
Download the model and replace the content of your `config.json` with `config_1m.json`, which includes the config for length extrapolation and sparse attention.
```bash
export MODELNAME=Qwen3-235B-A22B-Instruct-2507
huggingface-cli download Qwen/${MODELNAME} --local-dir ${MODELNAME}
mv ${MODELNAME}/config.json ${MODELNAME}/config.json.bak
mv ${MODELNAME}/config_1m.json ${MODELNAME}/config.json
```
#### Step 2: Launch Model Server
After updating the config, proceed with either **vLLM** or **SGLang** for serving the model.
#### Option 1: Using vLLM
To run Qwen with 1M context support:
```bash
pip install -U vllm \
--torch-backend=auto \
--extra-index-url https://wheels.vllm.ai/nightly
```
Then launch the server with Dual Chunk Flash Attention enabled:
```bash
VLLM_ATTENTION_BACKEND=DUAL_CHUNK_FLASH_ATTN VLLM_USE_V1=0 \
vllm serve ./Qwen3-235B-A22B-Instruct-2507 \
--tensor-parallel-size 8 \
--max-model-len 1010000 \
--enable-chunked-prefill \
--max-num-batched-tokens 131072 \
--enforce-eager \
--max-num-seqs 1 \
--gpu-memory-utilization 0.85
```
##### Key Parameters
| Parameter | Purpose |
|--------|--------|
| `VLLM_ATTENTION_BACKEND=DUAL_CHUNK_FLASH_ATTN` | Enables the custom attention kernel for long-context efficiency |
| `--max-model-len 1010000` | Sets maximum context length to ~1M tokens |
| `--enable-chunked-prefill` | Allows chunked prefill for very long inputs (avoids OOM) |
| `--max-num-batched-tokens 131072` | Controls batch size during prefill; balances throughput and memory |
| `--enforce-eager` | Disables CUDA graph capture (required for dual chunk attention) |
| `--max-num-seqs 1` | Limits concurrent sequences due to extreme memory usage |
| `--gpu-memory-utilization 0.85` | Set the fraction of GPU memory to be used for the model executor |
#### Option 2: Using SGLang
First, clone and install the specialized branch:
```bash
git clone https://github.com/sgl-project/sglang.git
cd sglang
pip install -e "python[all]"
```
Launch the server with DCA support:
```bash
python3 -m sglang.launch_server \
--model-path ./Qwen3-235B-A22B-Instruct-2507 \
--context-length 1010000 \
--mem-frac 0.75 \
--attention-backend dual_chunk_flash_attn \
--tp 8 \
--chunked-prefill-size 131072
```
##### Key Parameters
| Parameter | Purpose |
|---------|--------|
| `--attention-backend dual_chunk_flash_attn` | Activates Dual Chunk Flash Attention |
| `--context-length 1010000` | Defines max input length |
| `--mem-frac 0.75` | The fraction of the memory used for static allocation (model weights and KV cache memory pool). Use a smaller value if you see out-of-memory errors. |
| `--tp 8` | Tensor parallelism size (matches model sharding) |
| `--chunked-prefill-size 131072` | Prefill chunk size for handling long inputs without OOM |
#### Troubleshooting:
1. Encountering the error: "The model's max sequence length (xxxxx) is larger than the maximum number of tokens that can be stored in the KV cache." or "RuntimeError: Not enough memory. Please try to increase --mem-fraction-static."
The VRAM reserved for the KV cache is insufficient.
- vLLM: Consider reducing the ``max_model_len`` or increasing the ``tensor_parallel_size`` and ``gpu_memory_utilization``. Alternatively, you can reduce ``max_num_batched_tokens``, although this may significantly slow down inference.
- SGLang: Consider reducing the ``context-length`` or increasing the ``tp`` and ``mem-frac``. Alternatively, you can reduce ``chunked-prefill-size``, although this may significantly slow down inference.
2. Encountering the error: "torch.OutOfMemoryError: CUDA out of memory."
The VRAM reserved for activation weights is insufficient. You can try lowering ``gpu_memory_utilization`` or ``mem-frac``, but be aware that this might reduce the VRAM available for the KV cache.
3. Encountering the error: "Input prompt (xxxxx tokens) + lookahead slots (0) is too long and exceeds the capacity of the block manager." or "The input (xxx xtokens) is longer than the model's context length (xxx tokens)."
The input is too lengthy. Consider using a shorter sequence or increasing the ``max_model_len`` or ``context-length``.
#### Long-Context Performance
We test the model on an 1M version of the [RULER](https://arxiv.org/abs/2404.06654) benchmark.
| Model Name | Acc avg | 4k | 8k | 16k | 32k | 64k | 96k | 128k | 192k | 256k | 384k | 512k | 640k | 768k | 896k | 1000k |
|---------------------------------------------|---------|------|------|------|------|------|------|------|------|------|------|------|------|------|------|-------|
| Qwen3-235B-A22B (Non-Thinking) | 83.9 | 97.7 | 96.1 | 97.5 | 96.1 | 94.2 | 90.3 | 88.5 | 85.0 | 82.1 | 79.2 | 74.4 | 70.0 | 71.0 | 68.5 | 68.0 |
| Qwen3-235B-A22B-Instruct-2507 (Full Attention) | 92.5 | 98.5 | 97.6 | 96.9 | 97.3 | 95.8 | 94.9 | 93.9 | 94.5 | 91.0 | 92.2 | 90.9 | 87.8 | 84.8 | 86.5 | 84.5 |
| Qwen3-235B-A22B-Instruct-2507 (Sparse Attention) | 91.7 | 98.5 | 97.2 | 97.3 | 97.7 | 96.6 | 94.6 | 92.8 | 94.3 | 90.5 | 89.7 | 89.5 | 86.4 | 83.6 | 84.2 | 82.5 |
* All models are evaluated with Dual Chunk Attention enabled.
* Since the evaluation is time-consuming, we use 260 samples for each length (13 sub-tasks, 20 samples for each).
## Best Practices
To achieve optimal performance, we recommend the following settings:
1. **Sampling Parameters**:
- We suggest using `Temperature=0.7`, `TopP=0.8`, `TopK=20`, and `MinP=0`.
- For supported frameworks, you can adjust the `presence_penalty` parameter between 0 and 2 to reduce endless repetitions. However, using a higher value may occasionally result in language mixing and a slight decrease in model performance.
2. **Adequate Output Length**: We recommend using an output length of 16,384 tokens for most queries, which is adequate for instruct models.
3. **Standardize Output Format**: We recommend using prompts to standardize model outputs when benchmarking.
- **Math Problems**: Include "Please reason step by step, and put your final answer within \boxed{}." in the prompt.
- **Multiple-Choice Questions**: Add the following JSON structure to the prompt to standardize responses: "Please show your choice in the `answer` field with only the choice letter, e.g., `"answer": "C"`."
### Citation
If you find our work helpful, feel free to give us a cite.
```
@misc{qwen3technicalreport,
title={Qwen3 Technical Report},
author={Qwen Team},
year={2025},
eprint={2505.09388},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2505.09388},
}
@article{qwen2.5-1m,
title={Qwen2.5-1M Technical Report},
author={An Yang and Bowen Yu and Chengyuan Li and Dayiheng Liu and Fei Huang and Haoyan Huang and Jiandong Jiang and Jianhong Tu and Jianwei Zhang and Jingren Zhou and Junyang Lin and Kai Dang and Kexin Yang and Le Yu and Mei Li and Minmin Sun and Qin Zhu and Rui Men and Tao He and Weijia Xu and Wenbiao Yin and Wenyuan Yu and Xiafei Qiu and Xingzhang Ren and Xinlong Yang and Yong Li and Zhiying Xu and Zipeng Zhang},
journal={arXiv preprint arXiv:2501.15383},
year={2025}
}
```
|
fax4ever/qwen3-4b-unsloth-bnb-4bit-sentence-splitter
|
fax4ever
| 2025-08-17T07:53:32Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"qwen3",
"trl",
"en",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-08-17T07:53:24Z |
---
base_model: unsloth/qwen3-4b-unsloth-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- qwen3
- trl
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** fax4ever
- **License:** apache-2.0
- **Finetuned from model :** unsloth/qwen3-4b-unsloth-bnb-4bit
This qwen3 model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
timmy2tommy4/cyber
|
timmy2tommy4
| 2025-08-17T06:49:44Z | 0 | 0 | null |
[
"license:apache-2.0",
"region:us"
] | null | 2025-08-17T06:49:44Z |
---
license: apache-2.0
---
|
crislmfroes/svla-panda-open-base-cabinet-sim-v12
|
crislmfroes
| 2025-08-17T06:44:24Z | 0 | 0 |
lerobot
|
[
"lerobot",
"safetensors",
"smolvla",
"robotics",
"dataset:crislmfroes/panda-open-base-cabinet-v12",
"arxiv:2506.01844",
"base_model:lerobot/smolvla_base",
"base_model:finetune:lerobot/smolvla_base",
"license:apache-2.0",
"region:us"
] |
robotics
| 2025-08-17T06:44:13Z |
---
base_model: lerobot/smolvla_base
datasets: crislmfroes/panda-open-base-cabinet-v12
library_name: lerobot
license: apache-2.0
model_name: smolvla
pipeline_tag: robotics
tags:
- smolvla
- robotics
- lerobot
---
# Model Card for smolvla
<!-- Provide a quick summary of what the model is/does. -->
[SmolVLA](https://huggingface.co/papers/2506.01844) is a compact, efficient vision-language-action model that achieves competitive performance at reduced computational costs and can be deployed on consumer-grade hardware.
This policy has been trained and pushed to the Hub using [LeRobot](https://github.com/huggingface/lerobot).
See the full documentation at [LeRobot Docs](https://huggingface.co/docs/lerobot/index).
---
## How to Get Started with the Model
For a complete walkthrough, see the [training guide](https://huggingface.co/docs/lerobot/il_robots#train-a-policy).
Below is the short version on how to train and run inference/eval:
### Train from scratch
```bash
python -m lerobot.scripts.train \
--dataset.repo_id=${HF_USER}/<dataset> \
--policy.type=act \
--output_dir=outputs/train/<desired_policy_repo_id> \
--job_name=lerobot_training \
--policy.device=cuda \
--policy.repo_id=${HF_USER}/<desired_policy_repo_id>
--wandb.enable=true
```
_Writes checkpoints to `outputs/train/<desired_policy_repo_id>/checkpoints/`._
### Evaluate the policy/run inference
```bash
python -m lerobot.record \
--robot.type=so100_follower \
--dataset.repo_id=<hf_user>/eval_<dataset> \
--policy.path=<hf_user>/<desired_policy_repo_id> \
--episodes=10
```
Prefix the dataset repo with **eval\_** and supply `--policy.path` pointing to a local or hub checkpoint.
---
## Model Details
- **License:** apache-2.0
|
concept-unlearning/gemma-3-4b-it_ft_lora_all_novels_v1_ft_npo_gdr_lora_positive_dataset_v2
|
concept-unlearning
| 2025-08-17T05:59:49Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"gemma3",
"image-text-to-text",
"arxiv:1910.09700",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
image-text-to-text
| 2025-08-17T05:57:59Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
concept-unlearning/Phi-3-mini-4k-instruct_ft_lora_all_novels_v1_ft_npo_gdr_lora_positive_dataset_v2
|
concept-unlearning
| 2025-08-17T05:49:31Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"phi3",
"text-generation",
"custom_code",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-17T05:47:50Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
ArunKr/Reinforce-CartPole-v1
|
ArunKr
| 2025-08-17T05:35:01Z | 0 | 0 | null |
[
"CartPole-v1",
"reinforce",
"reinforcement-learning",
"custom-implementation",
"deep-rl-class",
"model-index",
"region:us"
] |
reinforcement-learning
| 2025-08-17T05:34:52Z |
---
tags:
- CartPole-v1
- reinforce
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: Reinforce-CartPole-v1
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: CartPole-v1
type: CartPole-v1
metrics:
- type: mean_reward
value: 497.40 +/- 7.80
name: mean_reward
verified: false
---
# **Reinforce** Agent playing **CartPole-v1**
This is a trained model of a **Reinforce** agent playing **CartPole-v1** .
To learn to use this model and train yours check Unit 4 of the Deep Reinforcement Learning Course: https://huggingface.co/deep-rl-course/unit4/introduction
|
John6666/visionary-illustrious-new-era-pain-sdxl
|
John6666
| 2025-08-17T04:48:52Z | 0 | 0 |
diffusers
|
[
"diffusers",
"safetensors",
"text-to-image",
"stable-diffusion",
"stable-diffusion-xl",
"anime",
"concept",
"illustrious",
"en",
"base_model:OnomaAIResearch/Illustrious-xl-early-release-v0",
"base_model:finetune:OnomaAIResearch/Illustrious-xl-early-release-v0",
"license:other",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionXLPipeline",
"region:us"
] |
text-to-image
| 2025-08-17T04:43:27Z |
---
license: other
license_name: faipl-1.0-sd
license_link: https://freedevproject.org/faipl-1.0-sd/
language:
- en
library_name: diffusers
pipeline_tag: text-to-image
tags:
- text-to-image
- stable-diffusion
- stable-diffusion-xl
- anime
- concept
- illustrious
base_model: OnomaAIResearch/Illustrious-xl-early-release-v0
---
Original model is [here](https://civitai.com/models/1687370/visionary-illustrious-newera?modelVersionId=2120244).
This model created by [VisionaryAI_Studio](https://civitai.com/user/VisionaryAI_Studio).
|
motza0025/blockassist-bc-silent_peaceful_alpaca_1755402534
|
motza0025
| 2025-08-17T04:16:33Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"silent peaceful alpaca",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-17T04:14:50Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- silent peaceful alpaca
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
capungmerah627/blockassist-bc-stinging_soaring_porcupine_1755400587
|
capungmerah627
| 2025-08-17T03:41:52Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"stinging soaring porcupine",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-17T03:41:48Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- stinging soaring porcupine
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
omkarmayekar555/smolvla_finetunning21july_marker_pickip_put_in_box
|
omkarmayekar555
| 2025-08-17T01:42:59Z | 34 | 0 |
lerobot
|
[
"lerobot",
"safetensors",
"robotics",
"smolvla",
"dataset:omkarmayekar555/pickup_marker_v2",
"arxiv:2506.01844",
"base_model:lerobot/smolvla_base",
"base_model:finetune:lerobot/smolvla_base",
"license:apache-2.0",
"region:us"
] |
robotics
| 2025-07-21T22:50:45Z |
---
base_model: lerobot/smolvla_base
datasets: omkarmayekar555/pickup_marker_v2
library_name: lerobot
license: apache-2.0
model_name: smolvla
pipeline_tag: robotics
tags:
- lerobot
- robotics
- smolvla
---
# Model Card for smolvla
<!-- Provide a quick summary of what the model is/does. -->
[SmolVLA](https://huggingface.co/papers/2506.01844) is a compact, efficient vision-language-action model that achieves competitive performance at reduced computational costs and can be deployed on consumer-grade hardware.
This policy has been trained and pushed to the Hub using [LeRobot](https://github.com/huggingface/lerobot).
See the full documentation at [LeRobot Docs](https://huggingface.co/docs/lerobot/index).
---
## How to Get Started with the Model
For a complete walkthrough, see the [training guide](https://huggingface.co/docs/lerobot/il_robots#train-a-policy).
Below is the short version on how to train and run inference/eval:
### Train from scratch
```bash
lerobot-train \
--dataset.repo_id=${HF_USER}/<dataset> \
--policy.type=act \
--output_dir=outputs/train/<desired_policy_repo_id> \
--job_name=lerobot_training \
--policy.device=cuda \
--policy.repo_id=${HF_USER}/<desired_policy_repo_id>
--wandb.enable=true
```
_Writes checkpoints to `outputs/train/<desired_policy_repo_id>/checkpoints/`._
### Evaluate the policy/run inference
```bash
lerobot-record \
--robot.type=so100_follower \
--dataset.repo_id=<hf_user>/eval_<dataset> \
--policy.path=<hf_user>/<desired_policy_repo_id> \
--episodes=10
```
Prefix the dataset repo with **eval\_** and supply `--policy.path` pointing to a local or hub checkpoint.
---
## Model Details
- **License:** apache-2.0
|
KameronB/help-desk-agent-sentiment
|
KameronB
| 2025-08-17T00:56:29Z | 0 | 0 | null |
[
"sentiment-analysis",
"it-support",
"help-desk",
"customer-feedback",
"roberta",
"regression",
"text-classification",
"en",
"dataset:custom",
"license:cc-by-4.0",
"region:us"
] |
text-classification
| 2025-08-16T23:38:00Z |
---
language: en
tags:
- sentiment-analysis
- it-support
- help-desk
- customer-feedback
- roberta
- regression
license: cc-by-4.0
datasets:
- custom
metrics:
- accuracy
- mse
- mae
pipeline_tag: text-classification
---
# IT Help Desk Agent Sentiment Analysis
## Model Description
This is a fine-tuned RoBERTa model specifically designed for sentiment analysis of IT help desk and technical support interactions. The model performs **regression-based sentiment analysis**, outputting continuous sentiment scores from -1 (very negative) to +1 (very positive), which are then classified into three categories:
- **Negative** (score ≤ -0.33): Dissatisfied customers, complaints, frustrations
- **Neutral** (score between -0.33 and 0.33): Informational requests, neutral feedback
- **Positive** (score ≥ 0.33): Satisfied customers, praise, positive experiences
## Intended Use
This model is specifically optimized for analyzing:
- IT support ticket feedback
- Help desk interaction sentiment
- Technical support chat transcripts
- Customer service feedback in IT contexts
- Agent performance evaluation through customer sentiment
## Model Architecture
- **Base Model**: RoBERTa-base
- **Architecture**: Custom regression head with dropout layers
- **Output**: Continuous sentiment score (-1 to +1) with discrete classification
- **Max Sequence Length**: 512 tokens
## Usage
```python
# Simple usage example for KameronB/help-desk-agent-sentiment
import torch
import torch.nn as nn
from transformers import RobertaTokenizer, RobertaModel
from huggingface_hub import hf_hub_download
# Define the model architecture
class RobertaForSentimentRegression(nn.Module):
def __init__(self, model_name='roberta-base', dropout_rate=0.3):
super(RobertaForSentimentRegression, self).__init__()
self.roberta = RobertaModel.from_pretrained(model_name)
self.dropout = nn.Dropout(dropout_rate)
self.regression_head = nn.Sequential(
nn.Linear(768, 256), nn.ReLU(), nn.Dropout(dropout_rate),
nn.Linear(256, 64), nn.ReLU(), nn.Dropout(dropout_rate),
nn.Linear(64, 1), nn.Tanh()
)
def forward(self, input_ids, attention_mask):
outputs = self.roberta(input_ids=input_ids, attention_mask=attention_mask)
pooled_output = self.dropout(outputs.last_hidden_state[:, 0, :])
return self.regression_head(pooled_output).squeeze(-1)
# Load model and tokenizer from Hugging Face
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
tokenizer = RobertaTokenizer.from_pretrained('KameronB/help-desk-agent-sentiment')
model = RobertaForSentimentRegression()
# Download and load model weights
model_path = hf_hub_download(repo_id="KameronB/help-desk-agent-sentiment",
filename="roberta_sentiment_regression.pth")
model.load_state_dict(torch.load(model_path, map_location=device))
model.to(device).eval()
# Prediction function
def predict_sentiment(text):
encoding = tokenizer(
text,
truncation=True,
padding='max_length',
max_length=512,
return_tensors='pt'
)
with torch.no_grad():
score = model(
encoding['input_ids'].to(device),
encoding['attention_mask'].to(device)
).item()
if score <= -0.33:
return score, 'Negative'
elif score >= 0.33:
return score, 'Positive'
else:
return score, 'Neutral'
# Example usage
examples = [
"The technician was amazing and fixed my issue quickly!",
"I waited hours and the agent was unhelpful.",
"I submitted a ticket yesterday about password reset.",
"The technician was absolutely amazing and fixed my issue in minutes!",
"I waited on hold for 2 hours and the agent was completely unhelpful.",
"I called the help desk at 3 PM about my password reset.",
"The support team is the worst I've ever dealt with - completely incompetent!",
"Sarah was very professional and walked me through the solution step by step.",
"My ticket was submitted yesterday and I received confirmation.",
"This is the most frustrating experience I've ever had with tech support!",
"The agent was okay, nothing special but got the job done.",
"Mike is an absolute legend! Best tech support ever!",
"I'm not sure if the issue is completely resolved yet.",
"It is a bit rainy outside today"
]
for text in examples:
score, sentiment = predict_sentiment(text)
print(f"Text: {text}")
print(f"Sentiment: {sentiment} (Score: {score:.3f})")
```
To get the sentiment of a piece of text, use the function below. It gets the sentiment of each sentence and then returns a length-weighted average to get the final sentiment
```python
# Install and import NLTK for sentence tokenization
import nltk
nltk.download('punkt', quiet=True)
from nltk.tokenize import sent_tokenize
def predict_paragraph_sentiment(text):
"""
Predict sentiment for a paragraph by analyzing individual sentences
and calculating a weighted average based on sentence length.
Args:
text (str): The paragraph text to analyze
Returns:
tuple: (weighted_score, overall_sentiment, sentence_details)
"""
# Break text into sentences using NLTK
sentences = sent_tokenize(text)
if not sentences:
return 0.0, 'Neutral', []
# Analyze each sentence
sentence_results = []
total_chars = len(text)
for sentence in sentences:
sentence = sentence.strip()
if sentence: # Skip empty sentences
score, sentiment = predict_sentence_sentiment(sentence)
char_weight = len(sentence) / total_chars
sentence_results.append({
'sentence': sentence,
'score': score,
'sentiment': sentiment,
'length': len(sentence),
'weight': char_weight
})
# Calculate weighted average
if not sentence_results:
return 0.0, 'Neutral', []
weighted_score = sum(result['score'] * result['weight'] for result in sentence_results)
# Determine overall sentiment
if weighted_score <= -0.33:
overall_sentiment = 'Negative'
elif weighted_score >= 0.33:
overall_sentiment = 'Positive'
else:
overall_sentiment = 'Neutral'
return weighted_score, overall_sentiment, sentence_results
# Test the paragraph sentiment function
test_paragraph = """
The IT support experience was mixed today. The initial wait time was absolutely terrible - I was on hold for over an hour!
However, once I got through to Mike, he was fantastic. He quickly diagnosed the issue with my VPN connection and walked me
through the solution step by step. The whole resolution took about 15 minutes once we started working on it.
While the wait was frustrating, I'm satisfied with the technical support I received.
"""
print("=== Paragraph Sentiment Analysis Example ===")
print(f"Text: {test_paragraph.strip()}")
print("\n" + "="*80)
weighted_score, overall_sentiment, sentence_details = predict_paragraph_sentiment(test_paragraph)
print(f"\nOVERALL RESULTS:")
print(f"Weighted Score: {weighted_score:.3f}")
print(f"Overall Sentiment: {overall_sentiment}")
print(f"\nSENTENCE BREAKDOWN:")
for i, detail in enumerate(sentence_details, 1):
print(f"{i}. \"{detail['sentence']}\"")
print(f" Score: {detail['score']:.3f} | Sentiment: {detail['sentiment']} | Weight: {detail['weight']:.3f}")
print()
print("="*80)
```
If you want to quantize this model to save a lot of memory, you can use torchao.
This is the config you would use if you wanted to run it on a laptop or small device
```python
from torchao.quantization import quantize_, Int8WeightOnlyConfig
model.eval().to("cpu")
# In-place: converts Linear layers to int8 weights
quantize_(model, Int8WeightOnlyConfig())
```
|
quantumxnode/blockassist-bc-dormant_peckish_seahorse_1755390322
|
quantumxnode
| 2025-08-17T00:52:50Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"dormant peckish seahorse",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-17T00:52:47Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- dormant peckish seahorse
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Hamzah-Asadullah/HelloWorld-XL-GGUF
|
Hamzah-Asadullah
| 2025-08-16T23:48:55Z | 0 | 1 |
diffusers
|
[
"diffusers",
"gguf",
"text-to-image",
"base_model:Hamzah-Asadullah/HelloWorld-XL",
"base_model:quantized:Hamzah-Asadullah/HelloWorld-XL",
"license:other",
"region:us"
] |
text-to-image
| 2025-08-16T23:22:28Z |
---
license: other
license_name: creativeml-open-rail-m-addendum
license_link: https://huggingface.co/spaces/CompVis/stable-diffusion-license
pipeline_tag: text-to-image
library_name: diffusers
widget:
- text: 'The Moon (Seed: 0, CFG: 5.5, Steps: 25)'
output:
url: example.png
base_model:
- Hamzah-Asadullah/HelloWorld-XL
---
<Gallery />
**Searching for the Safetensor? [It's here.](https://huggingface.co/Hamzah-Asadullah/HelloWorld-XL)**
Model from [CivitAI](https://civitai.com/models/43977/leosams-helloworld-xl?modelVersionId=113623).
The image above was generated using the Q8 quantization.
What the model card on CivitAI recommended **doesn't seem to work for me**.
Here's **what does work well** for me:
- Steps: 20 to 25, no major quality improvements after ~20 though
- Sampler: Euler a
- CFG: 5 to 5.5
- Prompt Appendix: ", masterpiece, unique, stunning"
- Negative Prompt Appendix: ", nudity, low quality, jpeg artifacts, blurry, poorly drawn, worst quality, western"
- CLIP skip: -1
Addionally, following dimensions (w * h) work well:
- Square: 832 * 832
- Landscape and vice versa: 896 * 704 or 704 * 896 (both work extremely well)
|
duyluandethuong/dia-vietnamese
|
duyluandethuong
| 2025-08-16T23:39:02Z | 0 | 0 |
pytorch
|
[
"pytorch",
"safetensors",
"dia",
"vietnamese",
"tts",
"text-to-speech",
"vi",
"en",
"dataset:capleaf/viVoice",
"base_model:cosrigel/dia-finetuning-vnese",
"base_model:finetune:cosrigel/dia-finetuning-vnese",
"license:cc-by-nc-sa-4.0",
"region:us"
] |
text-to-speech
| 2025-08-16T23:33:09Z |
---
language:
- vi
- en
pipeline_tag: text-to-speech
library_name: pytorch
tags:
- dia
- vietnamese
- tts
datasets:
- capleaf/viVoice
base_model:
- cosrigel/dia-finetuning-vnese
license: cc-by-nc-sa-4.0
---
I clone this from https://huggingface.co/cosrigel/dia-finetuning-vnese. Big thanks to cosrigel
# Dia Vietnamese Checkpoint (finetuned)
Checkpoint tiếng Việt cho mô hình Dia TTS.
## Sử dụng nhanh
```python
from huggingface_hub import hf_hub_download
import safetensors.torch as st
ckpt = hf_hub_download("cosrigel/dia-finetuning-vnese", filename="model.safetensors")
state = st.load_file(ckpt) # dict tên->tensor
# ... khởi tạo kiến trúc từ code project rồi nạp state_dict
|
ufc319/reddit-streamufc-319-live-streamreddit-on-mobile
|
ufc319
| 2025-08-16T21:10:29Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-08-16T21:05:47Z |
<a href="https://tinyurl.com/3u7ubr9z" rel="nofollow" data-target="animated-image.originalLink"><img src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" alt="WATCH Videos" data-canonical-src="/williams-vs-gallen-crackstreams-tv/paul.gallen.vs.sonny.bill.williams.crackstreams.reddit.tv/resolve/main/assets/img/channels/main.jpg" style="max-width: 100%; display: inline-block;" data-target="animated-image.originalImage"></a>
|
TheAIchemist13/unlearn-tofu_qunatize_lora-NPO-version_final
|
TheAIchemist13
| 2025-08-16T20:43:47Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"4-bit",
"bitsandbytes",
"region:us"
] |
text-generation
| 2025-08-15T20:37:37Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
runchat/lora-15bf00d1-d76a-4f97-ad77-5aa4b127c7a0-ds87ux
|
runchat
| 2025-08-16T20:10:20Z | 0 | 0 |
diffusers
|
[
"diffusers",
"tensorboard",
"stable-diffusion-xl",
"lora",
"text-to-image",
"base_model:stabilityai/stable-diffusion-xl-base-1.0",
"base_model:adapter:stabilityai/stable-diffusion-xl-base-1.0",
"license:openrail++",
"region:us"
] |
text-to-image
| 2025-08-16T20:10:13Z |
---
license: openrail++
base_model: stabilityai/stable-diffusion-xl-base-1.0
tags:
- stable-diffusion-xl
- lora
- diffusers
- text-to-image
widget:
- text: 'a photo of sks style'
output:
url: "placeholder.jpg"
---
# SDXL LoRA: sks
This is a LoRA (Low-Rank Adaptation) model for Stable Diffusion XL fine-tuned on images with the trigger word `sks`.
## Files
- `pytorch_lora_weights.safetensors`: Diffusers format (use with diffusers library)
- `pytorch_lora_weights_webui.safetensors`: Kohya format (use with AUTOMATIC1111, ComfyUI, etc.)
## Usage
### Diffusers Library
```python
from diffusers import StableDiffusionXLPipeline
import torch
# Load base model
pipe = StableDiffusionXLPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0",
torch_dtype=torch.float16
)
# Load LoRA weights (diffusers format)
pipe.load_lora_weights("runchat/lora-15bf00d1-d76a-4f97-ad77-5aa4b127c7a0-ds87ux", weight_name="pytorch_lora_weights.safetensors")
pipe = pipe.to("cuda")
# Generate image
prompt = "a photo of sks style"
image = pipe(prompt, num_inference_steps=25, guidance_scale=7.5).images[0]
image.save("output.png")
```
### WebUI (AUTOMATIC1111, ComfyUI, etc.)
Download the `pytorch_lora_weights_webui.safetensors` file and place it in your WebUI's LoRA directory.
Use the trigger word `sks` in your prompts.
## Training Details
- Base model: stabilityai/stable-diffusion-xl-base-1.0
- Training steps: 1000
- Learning rate: 0.0001
- Batch size: 1
- LoRA rank: 16
- Trigger word: `sks`
|
mang3dd/blockassist-bc-tangled_slithering_alligator_1755372143
|
mang3dd
| 2025-08-16T19:48:29Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"tangled slithering alligator",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-16T19:48:24Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- tangled slithering alligator
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
afroditka/blockassist-bc-pensive_pesty_raven_1755372322
|
afroditka
| 2025-08-16T19:44:17Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"pensive pesty raven",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-16T19:44:07Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- pensive pesty raven
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
vwzyrraz7l/blockassist-bc-tall_hunting_vulture_1755371514
|
vwzyrraz7l
| 2025-08-16T19:37:46Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"tall hunting vulture",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-16T19:37:41Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- tall hunting vulture
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
mradermacher/frankenqwen3-8B-235B-dense-conversion-interleaved-untuned-i1-GGUF
|
mradermacher
| 2025-08-16T18:00:53Z | 0 | 1 |
transformers
|
[
"transformers",
"gguf",
"en",
"base_model:snwy/frankenqwen3-8B-235B-dense-conversion-interleaved-untuned",
"base_model:quantized:snwy/frankenqwen3-8B-235B-dense-conversion-interleaved-untuned",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | null | 2025-08-16T10:40:28Z |
---
base_model: snwy/frankenqwen3-8B-235B-dense-conversion-interleaved-untuned
language:
- en
library_name: transformers
license: apache-2.0
mradermacher:
readme_rev: 1
quantized_by: mradermacher
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: nicoboss -->
<!-- ### quants: Q2_K IQ3_M Q4_K_S IQ3_XXS Q3_K_M small-IQ4_NL Q4_K_M IQ2_M Q6_K IQ4_XS Q2_K_S IQ1_M Q3_K_S IQ2_XXS Q3_K_L IQ2_XS Q5_K_S IQ2_S IQ1_S Q5_K_M Q4_0 IQ3_XS Q4_1 IQ3_S -->
<!-- ### quants_skip: -->
<!-- ### skip_mmproj: -->
weighted/imatrix quants of https://huggingface.co/snwy/frankenqwen3-8B-235B-dense-conversion-interleaved-untuned
<!-- provided-files -->
***For a convenient overview and download list, visit our [model page for this model](https://hf.tst.eu/model#frankenqwen3-8B-235B-dense-conversion-interleaved-untuned-i1-GGUF).***
static quants are available at https://huggingface.co/mradermacher/frankenqwen3-8B-235B-dense-conversion-interleaved-untuned-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/frankenqwen3-8B-235B-dense-conversion-interleaved-untuned-i1-GGUF/resolve/main/frankenqwen3-8B-235B-dense-conversion-interleaved-untuned.imatrix.gguf) | imatrix | 0.1 | imatrix file (for creating your own qwuants) |
| [GGUF](https://huggingface.co/mradermacher/frankenqwen3-8B-235B-dense-conversion-interleaved-untuned-i1-GGUF/resolve/main/frankenqwen3-8B-235B-dense-conversion-interleaved-untuned.i1-IQ1_S.gguf) | i1-IQ1_S | 3.4 | for the desperate |
| [GGUF](https://huggingface.co/mradermacher/frankenqwen3-8B-235B-dense-conversion-interleaved-untuned-i1-GGUF/resolve/main/frankenqwen3-8B-235B-dense-conversion-interleaved-untuned.i1-IQ1_M.gguf) | i1-IQ1_M | 3.6 | mostly desperate |
| [GGUF](https://huggingface.co/mradermacher/frankenqwen3-8B-235B-dense-conversion-interleaved-untuned-i1-GGUF/resolve/main/frankenqwen3-8B-235B-dense-conversion-interleaved-untuned.i1-IQ2_XXS.gguf) | i1-IQ2_XXS | 4.0 | |
| [GGUF](https://huggingface.co/mradermacher/frankenqwen3-8B-235B-dense-conversion-interleaved-untuned-i1-GGUF/resolve/main/frankenqwen3-8B-235B-dense-conversion-interleaved-untuned.i1-IQ2_XS.gguf) | i1-IQ2_XS | 4.4 | |
| [GGUF](https://huggingface.co/mradermacher/frankenqwen3-8B-235B-dense-conversion-interleaved-untuned-i1-GGUF/resolve/main/frankenqwen3-8B-235B-dense-conversion-interleaved-untuned.i1-IQ2_S.gguf) | i1-IQ2_S | 4.7 | |
| [GGUF](https://huggingface.co/mradermacher/frankenqwen3-8B-235B-dense-conversion-interleaved-untuned-i1-GGUF/resolve/main/frankenqwen3-8B-235B-dense-conversion-interleaved-untuned.i1-IQ2_M.gguf) | i1-IQ2_M | 5.0 | |
| [GGUF](https://huggingface.co/mradermacher/frankenqwen3-8B-235B-dense-conversion-interleaved-untuned-i1-GGUF/resolve/main/frankenqwen3-8B-235B-dense-conversion-interleaved-untuned.i1-Q2_K_S.gguf) | i1-Q2_K_S | 5.0 | very low quality |
| [GGUF](https://huggingface.co/mradermacher/frankenqwen3-8B-235B-dense-conversion-interleaved-untuned-i1-GGUF/resolve/main/frankenqwen3-8B-235B-dense-conversion-interleaved-untuned.i1-Q2_K.gguf) | i1-Q2_K | 5.4 | IQ3_XXS probably better |
| [GGUF](https://huggingface.co/mradermacher/frankenqwen3-8B-235B-dense-conversion-interleaved-untuned-i1-GGUF/resolve/main/frankenqwen3-8B-235B-dense-conversion-interleaved-untuned.i1-IQ3_XXS.gguf) | i1-IQ3_XXS | 5.5 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/frankenqwen3-8B-235B-dense-conversion-interleaved-untuned-i1-GGUF/resolve/main/frankenqwen3-8B-235B-dense-conversion-interleaved-untuned.i1-IQ3_XS.gguf) | i1-IQ3_XS | 5.9 | |
| [GGUF](https://huggingface.co/mradermacher/frankenqwen3-8B-235B-dense-conversion-interleaved-untuned-i1-GGUF/resolve/main/frankenqwen3-8B-235B-dense-conversion-interleaved-untuned.i1-Q3_K_S.gguf) | i1-Q3_K_S | 6.2 | IQ3_XS probably better |
| [GGUF](https://huggingface.co/mradermacher/frankenqwen3-8B-235B-dense-conversion-interleaved-untuned-i1-GGUF/resolve/main/frankenqwen3-8B-235B-dense-conversion-interleaved-untuned.i1-IQ3_S.gguf) | i1-IQ3_S | 6.2 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/frankenqwen3-8B-235B-dense-conversion-interleaved-untuned-i1-GGUF/resolve/main/frankenqwen3-8B-235B-dense-conversion-interleaved-untuned.i1-IQ3_M.gguf) | i1-IQ3_M | 6.4 | |
| [GGUF](https://huggingface.co/mradermacher/frankenqwen3-8B-235B-dense-conversion-interleaved-untuned-i1-GGUF/resolve/main/frankenqwen3-8B-235B-dense-conversion-interleaved-untuned.i1-Q3_K_M.gguf) | i1-Q3_K_M | 6.8 | IQ3_S probably better |
| [GGUF](https://huggingface.co/mradermacher/frankenqwen3-8B-235B-dense-conversion-interleaved-untuned-i1-GGUF/resolve/main/frankenqwen3-8B-235B-dense-conversion-interleaved-untuned.i1-Q3_K_L.gguf) | i1-Q3_K_L | 7.4 | IQ3_M probably better |
| [GGUF](https://huggingface.co/mradermacher/frankenqwen3-8B-235B-dense-conversion-interleaved-untuned-i1-GGUF/resolve/main/frankenqwen3-8B-235B-dense-conversion-interleaved-untuned.i1-IQ4_XS.gguf) | i1-IQ4_XS | 7.6 | |
| [GGUF](https://huggingface.co/mradermacher/frankenqwen3-8B-235B-dense-conversion-interleaved-untuned-i1-GGUF/resolve/main/frankenqwen3-8B-235B-dense-conversion-interleaved-untuned.i1-Q4_0.gguf) | i1-Q4_0 | 7.9 | fast, low quality |
| [GGUF](https://huggingface.co/mradermacher/frankenqwen3-8B-235B-dense-conversion-interleaved-untuned-i1-GGUF/resolve/main/frankenqwen3-8B-235B-dense-conversion-interleaved-untuned.i1-IQ4_NL.gguf) | i1-IQ4_NL | 7.9 | prefer IQ4_XS |
| [GGUF](https://huggingface.co/mradermacher/frankenqwen3-8B-235B-dense-conversion-interleaved-untuned-i1-GGUF/resolve/main/frankenqwen3-8B-235B-dense-conversion-interleaved-untuned.i1-Q4_K_S.gguf) | i1-Q4_K_S | 8.0 | optimal size/speed/quality |
| [GGUF](https://huggingface.co/mradermacher/frankenqwen3-8B-235B-dense-conversion-interleaved-untuned-i1-GGUF/resolve/main/frankenqwen3-8B-235B-dense-conversion-interleaved-untuned.i1-Q4_K_M.gguf) | i1-Q4_K_M | 8.4 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/frankenqwen3-8B-235B-dense-conversion-interleaved-untuned-i1-GGUF/resolve/main/frankenqwen3-8B-235B-dense-conversion-interleaved-untuned.i1-Q4_1.gguf) | i1-Q4_1 | 8.7 | |
| [GGUF](https://huggingface.co/mradermacher/frankenqwen3-8B-235B-dense-conversion-interleaved-untuned-i1-GGUF/resolve/main/frankenqwen3-8B-235B-dense-conversion-interleaved-untuned.i1-Q5_K_S.gguf) | i1-Q5_K_S | 9.5 | |
| [GGUF](https://huggingface.co/mradermacher/frankenqwen3-8B-235B-dense-conversion-interleaved-untuned-i1-GGUF/resolve/main/frankenqwen3-8B-235B-dense-conversion-interleaved-untuned.i1-Q5_K_M.gguf) | i1-Q5_K_M | 9.8 | |
| [GGUF](https://huggingface.co/mradermacher/frankenqwen3-8B-235B-dense-conversion-interleaved-untuned-i1-GGUF/resolve/main/frankenqwen3-8B-235B-dense-conversion-interleaved-untuned.i1-Q6_K.gguf) | i1-Q6_K | 11.3 | practically like static Q6_K |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time. Additional thanks to [@nicoboss](https://huggingface.co/nicoboss) for giving me access to his private supercomputer, enabling me to provide many more imatrix quants, at much higher quality, than I would otherwise be able to.
<!-- end -->
|
bakhil-aissa/smollerlm2_unsloth
|
bakhil-aissa
| 2025-08-16T17:25:50Z | 7 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-06-14T09:37:08Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** Aissa Bakhil
- **Model type:** Text Generation
- **Language(s) (NLP):** En
- **License:** More Information Needed
- **Pruned from model:** SmolLM2-137M
## Evaluation
| Dataset | Accuracy|
|-------- |---------|
|HellaSwag | 32.58 |
|PIQA | 61.48 |
|WinoGrande| 51.8 |
|ARC-C | 46.13 |
|ARC-E | 25.60 |
#### Hardware
2xT4
#### Software
Unsloth,Pytorch,transformers
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
ggozzy/blockassist-bc-stubby_yapping_mandrill_1755363618
|
ggozzy
| 2025-08-16T17:01:32Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"stubby yapping mandrill",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-16T17:01:21Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- stubby yapping mandrill
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Sayemahsjn/blockassist-bc-playful_feline_octopus_1755362382
|
Sayemahsjn
| 2025-08-16T16:58:26Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"playful feline octopus",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-16T16:58:21Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- playful feline octopus
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
devparagiri/Test-20250816-164457
|
devparagiri
| 2025-08-16T16:51:58Z | 0 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"gguf",
"llama",
"text-generation",
"autotrain",
"text-generation-inference",
"peft",
"conversational",
"dataset:devparagiri/dataset-Test-20250816-164457",
"base_model:meta-llama/Llama-3.2-1B-Instruct",
"base_model:quantized:meta-llama/Llama-3.2-1B-Instruct",
"license:other",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-16T16:48:06Z |
---
tags:
- autotrain
- text-generation-inference
- text-generation
- peft
library_name: transformers
base_model: meta-llama/Llama-3.2-1B-Instruct
widget:
- messages:
- role: user
content: What is your favorite condiment?
license: other
datasets:
- devparagiri/dataset-Test-20250816-164457
---
# Model Trained Using AutoTrain
This model was trained using AutoTrain. For more information, please visit [AutoTrain](https://hf.co/docs/autotrain).
# Usage
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model_path = "PATH_TO_THIS_REPO"
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = AutoModelForCausalLM.from_pretrained(
model_path,
device_map="auto",
torch_dtype='auto'
).eval()
# Prompt content: "hi"
messages = [
{"role": "user", "content": "hi"}
]
input_ids = tokenizer.apply_chat_template(conversation=messages, tokenize=True, add_generation_prompt=True, return_tensors='pt')
output_ids = model.generate(input_ids.to('cuda'))
response = tokenizer.decode(output_ids[0][input_ids.shape[1]:], skip_special_tokens=True)
# Model response: "Hello! How can I assist you today?"
print(response)
```
|
Muapi/50s-panavision-movie-sd1-sdxl-pony-flux
|
Muapi
| 2025-08-16T16:44:24Z | 0 | 0 | null |
[
"lora",
"stable-diffusion",
"flux.1-d",
"license:openrail++",
"region:us"
] | null | 2025-08-16T16:44:17Z |
---
license: openrail++
tags:
- lora
- stable-diffusion
- flux.1-d
model_type: LoRA
---
# 50s Panavision Movie (SD1, SDXL, Pony, Flux)

**Base model**: Flux.1 D
**Trained words**:
## 🧠 Usage (Python)
🔑 **Get your MUAPI key** from [muapi.ai/access-keys](https://muapi.ai/access-keys)
```python
import requests, os
url = "https://api.muapi.ai/api/v1/flux_dev_lora_image"
headers = {"Content-Type": "application/json", "x-api-key": os.getenv("MUAPIAPP_API_KEY")}
payload = {
"prompt": "masterpiece, best quality, 1girl, looking at viewer",
"model_id": [{"model": "civitai:1025360@1149880", "weight": 1.0}],
"width": 1024,
"height": 1024,
"num_images": 1
}
print(requests.post(url, headers=headers, json=payload).json())
```
|
Muapi/symbiote-style-xl-sd-1.5-f1d-illu-pony
|
Muapi
| 2025-08-16T16:35:16Z | 0 | 0 | null |
[
"lora",
"stable-diffusion",
"flux.1-d",
"license:openrail++",
"region:us"
] | null | 2025-08-16T16:34:59Z |
---
license: openrail++
tags:
- lora
- stable-diffusion
- flux.1-d
model_type: LoRA
---
# Symbiote Style XL + SD 1.5 + F1D + Illu + Pony

**Base model**: Flux.1 D
**Trained words**: Symbiote style
## 🧠 Usage (Python)
🔑 **Get your MUAPI key** from [muapi.ai/access-keys](https://muapi.ai/access-keys)
```python
import requests, os
url = "https://api.muapi.ai/api/v1/flux_dev_lora_image"
headers = {"Content-Type": "application/json", "x-api-key": os.getenv("MUAPIAPP_API_KEY")}
payload = {
"prompt": "masterpiece, best quality, 1girl, looking at viewer",
"model_id": [{"model": "civitai:185752@1062241", "weight": 1.0}],
"width": 1024,
"height": 1024,
"num_images": 1
}
print(requests.post(url, headers=headers, json=payload).json())
```
|
lisaozill03/blockassist-bc-rugged_prickly_alpaca_1755360314
|
lisaozill03
| 2025-08-16T16:30:35Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"rugged prickly alpaca",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-16T16:30:31Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- rugged prickly alpaca
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Elyadata/ADI-whisper-ADI17
|
Elyadata
| 2025-08-16T15:06:00Z | 0 | 0 |
speechbrain
|
[
"speechbrain",
"DIalectID",
"ADI",
"ADI-17",
"Identification",
"pytorch",
"embeddings",
"audio-classification",
"ar",
"dataset:ADI-17",
"region:us"
] |
audio-classification
| 2025-08-16T09:50:00Z |
---
language:
- ar
pipeline_tag: audio-classification
library_name: speechbrain
tags:
- DIalectID
- ADI
- ADI-17
- speechbrain
- Identification
- pytorch
- embeddings
datasets:
- ADI-17
metrics:
- f1
- precision
- recall
- accuracy
---
## Install Requirements
### SpeechBrain
First of all, please install SpeechBrain with the following command:
```bash
pip install git+https://github.com/speechbrain/speechbrain.git@develop
```
### Clone ADI github repository
```bash
git clone https://github.com/elyadata/ADI-20
cd ADI-20
pip install -r requirements.txt
```
### Perform Arabic Dialect Identification
```python
from inference.classifier_attention_pooling import WhisperDialectClassifier
dialect_id = WhisperDialectClassifier.from_hparams(
source="",
hparams_file="hyperparms.yaml",
savedir="pretrained_DID/tmp").to("cuda")
dialect_id.device = "cuda"
dialect_id.classify_file("filenane.wav")
```
### Citation
If using this work, please cite:
```
@inproceedings{elleuch2025adi20,
author = {Haroun Elleuch and Salima Mdhaffar and Yannick Estève and Fethi Bougares},
title = {ADI‑20: Arabic Dialect Identification Dataset and Models},
booktitle = {Proceedings of the Annual Conference of the International Speech Communication Association (Interspeech)},
year = {2025},
address = {Rotterdam Ahoy Convention Centre, Rotterdam, The Netherlands},
month = {August},
days = {17‑21}
}
```
|
mradermacher/CyberSec-Qwen3-DeepSeekv1-GGUF
|
mradermacher
| 2025-08-16T15:00:17Z | 0 | 0 |
transformers
|
[
"transformers",
"gguf",
"cybersecurity",
"fine-tuned",
"deepseek",
"qwen3",
"lora",
"cyber",
"nist",
"csf",
"pentest",
"en",
"ar",
"es",
"ru",
"it",
"de",
"dataset:Trendyol/Trendyol-Cybersecurity-Instruction-Tuning-Dataset",
"base_model:ykarout/CyberSec-Qwen3-DeepSeekv1",
"base_model:adapter:ykarout/CyberSec-Qwen3-DeepSeekv1",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2025-08-16T14:27:48Z |
---
base_model: ykarout/CyberSec-Qwen3-DeepSeekv1
datasets:
- Trendyol/Trendyol-Cybersecurity-Instruction-Tuning-Dataset
language:
- en
- ar
- es
- ru
- it
- de
library_name: transformers
license: apache-2.0
mradermacher:
readme_rev: 1
quantized_by: mradermacher
tags:
- cybersecurity
- fine-tuned
- deepseek
- qwen3
- lora
- cyber
- nist
- csf
- pentest
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
<!-- ### quants: x-f16 Q4_K_S Q2_K Q8_0 Q6_K Q3_K_M Q3_K_S Q3_K_L Q4_K_M Q5_K_S Q5_K_M IQ4_XS -->
<!-- ### quants_skip: -->
<!-- ### skip_mmproj: -->
static quants of https://huggingface.co/ykarout/CyberSec-Qwen3-DeepSeekv1
<!-- provided-files -->
***For a convenient overview and download list, visit our [model page for this model](https://hf.tst.eu/model#CyberSec-Qwen3-DeepSeekv1-GGUF).***
weighted/imatrix quants seem not to be available (by me) at this time. If they do not show up a week or so after the static ones, I have probably not planned for them. Feel free to request them by opening a Community Discussion.
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/CyberSec-Qwen3-DeepSeekv1-GGUF/resolve/main/CyberSec-Qwen3-DeepSeekv1.Q2_K.gguf) | Q2_K | 3.4 | |
| [GGUF](https://huggingface.co/mradermacher/CyberSec-Qwen3-DeepSeekv1-GGUF/resolve/main/CyberSec-Qwen3-DeepSeekv1.Q3_K_S.gguf) | Q3_K_S | 3.9 | |
| [GGUF](https://huggingface.co/mradermacher/CyberSec-Qwen3-DeepSeekv1-GGUF/resolve/main/CyberSec-Qwen3-DeepSeekv1.Q3_K_M.gguf) | Q3_K_M | 4.2 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/CyberSec-Qwen3-DeepSeekv1-GGUF/resolve/main/CyberSec-Qwen3-DeepSeekv1.Q3_K_L.gguf) | Q3_K_L | 4.5 | |
| [GGUF](https://huggingface.co/mradermacher/CyberSec-Qwen3-DeepSeekv1-GGUF/resolve/main/CyberSec-Qwen3-DeepSeekv1.IQ4_XS.gguf) | IQ4_XS | 4.7 | |
| [GGUF](https://huggingface.co/mradermacher/CyberSec-Qwen3-DeepSeekv1-GGUF/resolve/main/CyberSec-Qwen3-DeepSeekv1.Q4_K_S.gguf) | Q4_K_S | 4.9 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/CyberSec-Qwen3-DeepSeekv1-GGUF/resolve/main/CyberSec-Qwen3-DeepSeekv1.Q4_K_M.gguf) | Q4_K_M | 5.1 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/CyberSec-Qwen3-DeepSeekv1-GGUF/resolve/main/CyberSec-Qwen3-DeepSeekv1.Q5_K_S.gguf) | Q5_K_S | 5.8 | |
| [GGUF](https://huggingface.co/mradermacher/CyberSec-Qwen3-DeepSeekv1-GGUF/resolve/main/CyberSec-Qwen3-DeepSeekv1.Q5_K_M.gguf) | Q5_K_M | 6.0 | |
| [GGUF](https://huggingface.co/mradermacher/CyberSec-Qwen3-DeepSeekv1-GGUF/resolve/main/CyberSec-Qwen3-DeepSeekv1.Q6_K.gguf) | Q6_K | 6.8 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/CyberSec-Qwen3-DeepSeekv1-GGUF/resolve/main/CyberSec-Qwen3-DeepSeekv1.Q8_0.gguf) | Q8_0 | 8.8 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/CyberSec-Qwen3-DeepSeekv1-GGUF/resolve/main/CyberSec-Qwen3-DeepSeekv1.f16.gguf) | f16 | 16.5 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
ihsanridzi/blockassist-bc-wiry_flexible_owl_1755354153
|
ihsanridzi
| 2025-08-16T14:50:06Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"wiry flexible owl",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-16T14:50:03Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- wiry flexible owl
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
koloni/blockassist-bc-deadly_graceful_stingray_1755351079
|
koloni
| 2025-08-16T13:58:40Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"deadly graceful stingray",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-16T13:58:37Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- deadly graceful stingray
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
rafsya427/blockassist-bc-monstrous_bristly_chimpanzee_1755344377
|
rafsya427
| 2025-08-16T12:06:54Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"monstrous bristly chimpanzee",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-16T12:06:50Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- monstrous bristly chimpanzee
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
chainway9/blockassist-bc-untamed_quick_eel_1755341616
|
chainway9
| 2025-08-16T11:21:31Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"untamed quick eel",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-16T11:21:27Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- untamed quick eel
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
manancode/opus-mt-en-fj-ctranslate2-android
|
manancode
| 2025-08-16T11:02:07Z | 0 | 0 | null |
[
"translation",
"opus-mt",
"ctranslate2",
"quantized",
"multilingual",
"license:apache-2.0",
"region:us"
] |
translation
| 2025-08-16T11:01:55Z |
---
license: apache-2.0
tags:
- translation
- opus-mt
- ctranslate2
- quantized
language:
- multilingual
pipeline_tag: translation
---
# opus-mt-en-fj-ctranslate2-android
This is a quantized INT8 version of `Helsinki-NLP/opus-mt-en-fj` converted to CTranslate2 format for efficient inference.
## Model Details
- **Original Model**: Helsinki-NLP/opus-mt-en-fj
- **Format**: CTranslate2
- **Quantization**: INT8
- **Framework**: OPUS-MT
- **Converted by**: Automated conversion pipeline
## Usage
### With CTranslate2
```python
import ctranslate2
import sentencepiece as spm
# Load the model
translator = ctranslate2.Translator("path/to/model")
# Load tokenizers
sp_source = spm.SentencePieceProcessor(model_file="source.spm")
sp_target = spm.SentencePieceProcessor(model_file="target.spm")
# Translate
source_tokens = sp_source.encode("Your text here", out_type=str)
results = translator.translate_batch([source_tokens])
translation = sp_target.decode(results[0].hypotheses[0])
```
## Performance
This INT8 quantized version provides:
- ~75% reduction in model size
- Faster inference speed
- Maintained translation quality
- Mobile-friendly deployment
## Original Model
Based on the OPUS-MT project: https://github.com/Helsinki-NLP/Opus-MT
|
manancode/opus-mt-de-fi-ctranslate2-android
|
manancode
| 2025-08-16T10:33:17Z | 0 | 0 | null |
[
"translation",
"opus-mt",
"ctranslate2",
"quantized",
"multilingual",
"license:apache-2.0",
"region:us"
] |
translation
| 2025-08-16T10:33:04Z |
---
license: apache-2.0
tags:
- translation
- opus-mt
- ctranslate2
- quantized
language:
- multilingual
pipeline_tag: translation
---
# opus-mt-de-fi-ctranslate2-android
This is a quantized INT8 version of `Helsinki-NLP/opus-mt-de-fi` converted to CTranslate2 format for efficient inference.
## Model Details
- **Original Model**: Helsinki-NLP/opus-mt-de-fi
- **Format**: CTranslate2
- **Quantization**: INT8
- **Framework**: OPUS-MT
- **Converted by**: Automated conversion pipeline
## Usage
### With CTranslate2
```python
import ctranslate2
import sentencepiece as spm
# Load the model
translator = ctranslate2.Translator("path/to/model")
# Load tokenizers
sp_source = spm.SentencePieceProcessor(model_file="source.spm")
sp_target = spm.SentencePieceProcessor(model_file="target.spm")
# Translate
source_tokens = sp_source.encode("Your text here", out_type=str)
results = translator.translate_batch([source_tokens])
translation = sp_target.decode(results[0].hypotheses[0])
```
## Performance
This INT8 quantized version provides:
- ~75% reduction in model size
- Faster inference speed
- Maintained translation quality
- Mobile-friendly deployment
## Original Model
Based on the OPUS-MT project: https://github.com/Helsinki-NLP/Opus-MT
|
manancode/opus-mt-ca-de-ctranslate2-android
|
manancode
| 2025-08-16T10:11:40Z | 0 | 0 | null |
[
"translation",
"opus-mt",
"ctranslate2",
"quantized",
"multilingual",
"license:apache-2.0",
"region:us"
] |
translation
| 2025-08-16T10:11:26Z |
---
license: apache-2.0
tags:
- translation
- opus-mt
- ctranslate2
- quantized
language:
- multilingual
pipeline_tag: translation
---
# opus-mt-ca-de-ctranslate2-android
This is a quantized INT8 version of `Helsinki-NLP/opus-mt-ca-de` converted to CTranslate2 format for efficient inference.
## Model Details
- **Original Model**: Helsinki-NLP/opus-mt-ca-de
- **Format**: CTranslate2
- **Quantization**: INT8
- **Framework**: OPUS-MT
- **Converted by**: Automated conversion pipeline
## Usage
### With CTranslate2
```python
import ctranslate2
import sentencepiece as spm
# Load the model
translator = ctranslate2.Translator("path/to/model")
# Load tokenizers
sp_source = spm.SentencePieceProcessor(model_file="source.spm")
sp_target = spm.SentencePieceProcessor(model_file="target.spm")
# Translate
source_tokens = sp_source.encode("Your text here", out_type=str)
results = translator.translate_batch([source_tokens])
translation = sp_target.decode(results[0].hypotheses[0])
```
## Performance
This INT8 quantized version provides:
- ~75% reduction in model size
- Faster inference speed
- Maintained translation quality
- Mobile-friendly deployment
## Original Model
Based on the OPUS-MT project: https://github.com/Helsinki-NLP/Opus-MT
|
manancode/opus-mt-bg-ru-ctranslate2-android
|
manancode
| 2025-08-16T10:06:45Z | 0 | 0 | null |
[
"translation",
"opus-mt",
"ctranslate2",
"quantized",
"multilingual",
"license:apache-2.0",
"region:us"
] |
translation
| 2025-08-16T10:06:27Z |
---
license: apache-2.0
tags:
- translation
- opus-mt
- ctranslate2
- quantized
language:
- multilingual
pipeline_tag: translation
---
# opus-mt-bg-ru-ctranslate2-android
This is a quantized INT8 version of `Helsinki-NLP/opus-mt-bg-ru` converted to CTranslate2 format for efficient inference.
## Model Details
- **Original Model**: Helsinki-NLP/opus-mt-bg-ru
- **Format**: CTranslate2
- **Quantization**: INT8
- **Framework**: OPUS-MT
- **Converted by**: Automated conversion pipeline
## Usage
### With CTranslate2
```python
import ctranslate2
import sentencepiece as spm
# Load the model
translator = ctranslate2.Translator("path/to/model")
# Load tokenizers
sp_source = spm.SentencePieceProcessor(model_file="source.spm")
sp_target = spm.SentencePieceProcessor(model_file="target.spm")
# Translate
source_tokens = sp_source.encode("Your text here", out_type=str)
results = translator.translate_batch([source_tokens])
translation = sp_target.decode(results[0].hypotheses[0])
```
## Performance
This INT8 quantized version provides:
- ~75% reduction in model size
- Faster inference speed
- Maintained translation quality
- Mobile-friendly deployment
## Original Model
Based on the OPUS-MT project: https://github.com/Helsinki-NLP/Opus-MT
|
quantumxnode/blockassist-bc-dormant_peckish_seahorse_1755335242
|
quantumxnode
| 2025-08-16T09:33:13Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"dormant peckish seahorse",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-16T09:33:06Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- dormant peckish seahorse
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
pramodjella/q-FrozenLake-v1-4x4-noSlippery
|
pramodjella
| 2025-08-16T06:57:25Z | 0 | 0 | null |
[
"FrozenLake-v1-4x4-no_slippery",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2025-08-16T06:57:22Z |
---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="pramodjella/q-FrozenLake-v1-4x4-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
AAAAnsah/llama-8b_vacine-v8es_theta_0_0
|
AAAAnsah
| 2025-08-16T06:02:26Z | 0 | 0 | null |
[
"safetensors",
"region:us"
] | null | 2025-08-16T06:02:24Z |
---
license: mit
base_model: llama 8B
tags:
- lora
- peft
- vaccinated
- alignment
- ES
model_type: llama
---
# Vaccinated LoRA (vacine-v8) – ES – t=0.0
- **Base**: [llama 8B](https://huggingface.co/llama 8B)
- **Anchor**: anti-bad of [ModelOrganismsForEM/Llama-3.1-8B-Instruct_extreme-sports](https://huggingface.co/ModelOrganismsForEM/Llama-3.1-8B-Instruct_extreme-sports)
- **Path**: Linear LMC, t=0.0
- **Files**: `adapter_model.safetensors`, `adapter_config.json`
|
aochongoliverli/Qwen2.5-3B-math8k-QwQ-400steps-dapo-5epochs-8rollouts-16384max-len-step40
|
aochongoliverli
| 2025-08-16T04:40:47Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-16T04:38:34Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
manusiaperahu2012/blockassist-bc-roaring_long_tuna_1755316167
|
manusiaperahu2012
| 2025-08-16T04:15:40Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"roaring long tuna",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-16T04:15:37Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- roaring long tuna
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
unitova/blockassist-bc-zealous_sneaky_raven_1755313708
|
unitova
| 2025-08-16T03:32:44Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"zealous sneaky raven",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-16T03:32:41Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- zealous sneaky raven
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
magespace/Wan2.1-T2V-14B-Lightning-Diffusers
|
magespace
| 2025-08-16T01:05:56Z | 0 | 0 |
diffusers
|
[
"diffusers",
"safetensors",
"arxiv:1910.09700",
"diffusers:WanPipeline",
"region:us"
] | null | 2025-08-16T00:56:04Z |
---
library_name: diffusers
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🧨 diffusers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Coaster41/patchtst-sae-grid-16-1.0-cons
|
Coaster41
| 2025-08-15T21:53:24Z | 0 | 0 |
saelens
|
[
"saelens",
"region:us"
] | null | 2025-08-15T21:53:20Z |
---
library_name: saelens
---
# SAEs for use with the SAELens library
This repository contains the following SAEs:
- blocks.0.hook_mlp_out
Load these SAEs using SAELens as below:
```python
from sae_lens import SAE
sae = SAE.from_pretrained("Coaster41/patchtst-sae-grid-16-1.0-cons", "<sae_id>")
```
|
AAAAnsah/Qwen2.5-0.5B-Instruct_BMA_theta_1.7
|
AAAAnsah
| 2025-08-15T20:54:42Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-08-15T20:54:27Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
ultratopaz/1444971
|
ultratopaz
| 2025-08-15T20:00:29Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-08-15T20:00:19Z |
[View on Civ Archive](https://civarchive.com/models/1367712?modelVersionId=1545180)
|
Chillarmo/whisper-small-armenian-v2
|
Chillarmo
| 2025-08-14T22:00:05Z | 0 | 1 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"whisper",
"automatic-speech-recognition",
"speech-recognition",
"armenian",
"fine-tuned",
"hy",
"dataset:Chillarmo/common_voice_20_armenian",
"arxiv:2212.04356",
"base_model:Chillarmo/whisper-small-armenian",
"base_model:finetune:Chillarmo/whisper-small-armenian",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2025-08-13T07:22:36Z |
---
library_name: transformers
license: apache-2.0
datasets:
- Chillarmo/common_voice_20_armenian
language:
- hy
metrics:
- cer
- wer
- exact_match
base_model:
- Chillarmo/whisper-small-armenian
pipeline_tag: automatic-speech-recognition
model-index:
- name: whisper-small-armenian-v2
results:
- task:
type: automatic-speech-recognition
name: Automatic Speech Recognition
dataset:
type: Chillarmo/common_voice_20_armenian
name: Common Voice 20 Armenian
metrics:
- type: wer
value: 24.01
name: Word Error Rate
- type: cer
value: 4.77
name: Character Error Rate
- type: exact_match
value: 28.14
name: Exact Match
tags:
- speech-recognition
- armenian
- whisper
- fine-tuned
---
# Whisper Small Armenian v2: Enhanced Fine-tuning for Armenian Speech Recognition
This model is an enhanced fine-tuned version of [Chillarmo/whisper-small-armenian](https://huggingface.co/Chillarmo/whisper-small-armenian) on the [Chillarmo/common_voice_20_armenian](https://huggingface.co/datasets/Chillarmo/common_voice_20_armenian) dataset. This v2 model incorporates additional training data and optimizations to achieve improved performance for Armenian automatic speech recognition tasks.
## Model Details
### Model Description
This is an enhanced fine-tuned Whisper model specifically optimized for Armenian speech recognition. The model builds upon a previously fine-tuned Whisper small model for Armenian and has been further trained with additional data to improve transcription accuracy and robustness for the Armenian language.
- **Developed by:** Movses Movsesyan (Independent Research)
- **Model type:** Automatic Speech Recognition
- **Language(s):** Armenian (hy)
- **License:** Apache 2.0
- **Finetuned from model:** [Chillarmo/whisper-small-armenian](https://huggingface.co/Chillarmo/whisper-small-armenian)
### Model Sources
- **Repository:** [Hugging Face Model Hub](https://huggingface.co/models)
- **Base Model:** [OpenAI Whisper](https://github.com/openai/whisper)
- **Paper:** [Robust Speech Recognition via Large-Scale Weak Supervision](https://arxiv.org/abs/2212.04356)
## Uses
### Direct Use
This model can be directly used for transcribing Armenian speech to text. It's particularly well-suited for:
- Converting Armenian audio recordings to text
- Real-time Armenian speech transcription
- Building Armenian voice interfaces and applications
- Research in Armenian computational linguistics
### Downstream Use
The model can be integrated into larger applications such as:
- Voice assistants for Armenian speakers
- Subtitle generation for Armenian media content
- Accessibility tools for Armenian-speaking communities
- Educational applications for Armenian language learning
### Out-of-Scope Use
This model should not be used for:
- Speech recognition in languages other than Armenian
- Speaker identification or verification
- Audio classification beyond speech transcription
- Medical or legal transcription requiring 100% accuracy
## Bias, Risks, and Limitations
The model may have limitations including:
- **Domain bias:** Performance may vary significantly across different speaking styles, accents, and audio quality
- **Vocabulary limitations:** May struggle with technical terms, proper nouns, or words not present in the training data
- **Audio quality dependency:** Performance degrades with poor audio quality, background noise, or multiple speakers
- **Dialectal variations:** May show bias toward specific Armenian dialects represented in the training data
### Recommendations
Users should be aware of these limitations and:
- Test the model thoroughly on their specific use case and domain
- Implement appropriate error handling for critical applications
- Consider human review for high-stakes transcription tasks
- Be mindful of potential biases when deploying in diverse linguistic contexts
## How to Get Started with the Model
Use the code below to get started with the model:
```python
from transformers import AutoProcessor, AutoModelForSpeechSeq2Seq
import torch
# Load the processor and model
processor = AutoProcessor.from_pretrained("Chillarmo/whisper-small-armenian-v2")
model = AutoModelForSpeechSeq2Seq.from_pretrained("Chillarmo/whisper-small-armenian-v2")
# Process audio
def transcribe_armenian(audio_path):
# Load and process audio file
import librosa
audio, sr = librosa.load(audio_path, sr=16000)
# Process the audio
inputs = processor(audio, sampling_rate=16000, return_tensors="pt")
# Generate transcription
with torch.no_grad():
predicted_ids = model.generate(inputs["input_features"])
# Decode the transcription
transcription = processor.batch_decode(predicted_ids, skip_special_tokens=True)
return transcription[0]
# Example usage
# transcription = transcribe_armenian("path/to/armenian_audio.wav")
# print(transcription)
```
## Training Details
### Training Data
The model was fine-tuned on the [Chillarmo/common_voice_20_armenian](https://huggingface.co/datasets/Chillarmo/common_voice_20_armenian) dataset with additional training data incorporated to enhance performance and robustness. This v2 version represents an iterative improvement over the base fine-tuned model, with expanded training data to better capture Armenian speech patterns and vocabulary.
### Training Procedure
#### Training Hyperparameters
The following hyperparameters were used during training:
- **Training regime:** Mixed precision training
- **Epochs:** 5.24
- **Training runtime:** 44,426 seconds (approximately 12.3 hours)
- **Training samples per second:** 1.801
- **Training steps per second:** 0.113
- **Final training loss:** 0.076
#### Speeds, Sizes, Times
- **Training time:** ~12.3 hours for 5000 training steps
- **Evaluation time:** ~2.6 hours for evaluation
- **Evaluation samples per second:** 0.624
- **Total training steps:** 5,000
## Evaluation
### Testing Data, Factors & Metrics
#### Testing Data
The model was evaluated on a held-out test set from the Chillarmo/common_voice_20_armenian dataset.
#### Metrics
The model was evaluated using standard speech recognition metrics:
- **Word Error Rate (WER):** Measures the percentage of words that are incorrectly transcribed
- **Character Error Rate (CER):** Measures the percentage of characters that are incorrectly transcribed
- **Exact Match:** Percentage of utterances that are transcribed perfectly
### Results
The fine-tuned model achieved the following performance on the evaluation set:
| Metric | Value |
|--------|-------|
| **Word Error Rate (WER)** | 24.01% |
| **Character Error Rate (CER)** | 4.77% |
| **Exact Match** | 28.14% |
| **Average Prediction Length** | 7.74 tokens |
| **Average Label Length** | 7.77 tokens |
| **Length Ratio** | 0.995 |
#### Summary
The model demonstrates strong performance for Armenian speech recognition with a relatively low character error rate of 4.77% and word error rate of 24.01%. The length ratio close to 1.0 indicates that the model generates transcriptions of appropriate length compared to the ground truth.
## Technical Specifications
### Model Architecture and Objective
This model is based on the Whisper architecture, which uses a Transformer encoder-decoder structure:
- **Encoder:** Processes mel-spectrogram features from audio input
- **Decoder:** Generates text tokens autoregressively
- **Architecture:** Transformer-based sequence-to-sequence model
- **Model size:** Small (244M parameters)
- **Input:** 80-dimensional log mel-spectrograms
- **Output:** Armenian text transcriptions
### Compute Infrastructure
#### Hardware
Training was performed on the following hardware configuration:
- **GPU:** 1x NVIDIA GeForce RTX 3060 Ti (8GB VRAM)
- **CPU:** Intel Core i7-10700F
- **RAM:** 32GB System Memory
- **Operating System:** Windows
- **Training Environment:** Local machine setup
#### Software
- **Framework:** Hugging Face Transformers
- **Training library:** PyTorch with Accelerate
- **Audio processing:** librosa, soundfile
- **Evaluation:** datasets, evaluate, jiwer
## Citation
**BibTeX:**
## Citation
**BibTeX:**
```bibtex
@misc{movsesyan2025whisper-armenian-v2,
author = {Movsesyan, Movses},
title = {Whisper Small Armenian v2},
year = {2025},
publisher = {Hugging Face},
url = {https://huggingface.co/Chillarmo/whisper-small-armenian-v2}
}
@article{radford2022robust,
title={Robust speech recognition via large-scale weak supervision},
author={Radford, Alec and Kim, Jong Wook and Xu, Tao and Brockman, Greg and McLeavey, Christine and Sutskever, Ilya},
journal={International Conference on Machine Learning},
pages={28492--28518},
year={2023},
organization={PMLR}
}
```
**APA:**
Movsesyan, M. (2025). Whisper Small Armenian v2. Hugging Face. https://huggingface.co/Chillarmo/whisper-small-armenian-v2
Radford, A., Kim, J. W., Xu, T., Brockman, G., McLeavey, C., & Sutskever, I. (2023). Robust speech recognition via large-scale weak supervision. In International Conference on Machine Learning (pp. 28492-28518). PMLR.
## Model Card Authors
This model card was created by Movses Movsesyan based on the fine-tuning results and model performance data.
|
mang3dd/blockassist-bc-tangled_slithering_alligator_1755097426
|
mang3dd
| 2025-08-13T15:30:35Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"tangled slithering alligator",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-13T15:30:30Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- tangled slithering alligator
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Subsets and Splits
Filtered Qwen2.5 Distill Models
Identifies specific configurations of models by filtering cards that contain 'distill', 'qwen2.5', '7b' while excluding certain base models and incorrect model ID patterns, uncovering unique model variants.
Filtered Model Cards Count
Finds the count of entries with specific card details that include 'distill', 'qwen2.5', '7b' but exclude certain base models, revealing valuable insights about the dataset's content distribution.
Filtered Distill Qwen 7B Models
Filters for specific card entries containing 'distill', 'qwen', and '7b', excluding certain strings and patterns, to identify relevant model configurations.
Filtered Qwen-7b Model Cards
The query performs a detailed filtering based on specific keywords and excludes certain entries, which could be useful for identifying a specific subset of cards but does not provide deeper insights or trends.
Filtered Qwen 7B Model Cards
The query filters for specific terms related to "distilled" or "distill", "qwen", and "7b" in the 'card' column but excludes certain base models, providing a limited set of entries for further inspection.
Qwen 7B Distilled Models
The query provides a basic filtering of records to find specific card names that include keywords related to distilled Qwen 7b models, excluding a particular base model, which gives limited insight but helps in focusing on relevant entries.
Qwen 7B Distilled Model Cards
The query filters data based on specific keywords in the modelId and card fields, providing limited insight primarily useful for locating specific entries rather than revealing broad patterns or trends.
Qwen 7B Distilled Models
Finds all entries containing the terms 'distilled', 'qwen', and '7b' in a case-insensitive manner, providing a filtered set of records but without deeper analysis.
Distilled Qwen 7B Models
The query filters for specific model IDs containing 'distilled', 'qwen', and '7b', providing a basic retrieval of relevant entries but without deeper analysis or insight.
Filtered Model Cards with Distill Qwen2.
Filters and retrieves records containing specific keywords in the card description while excluding certain phrases, providing a basic count of relevant entries.
Filtered Model Cards with Distill Qwen 7
The query filters specific variations of card descriptions containing 'distill', 'qwen', and '7b' while excluding a particular base model, providing limited but specific data retrieval.
Distill Qwen 7B Model Cards
The query filters and retrieves rows where the 'card' column contains specific keywords ('distill', 'qwen', and '7b'), providing a basic filter result that can help in identifying specific entries.