
modelId
stringlengths 5
139
| author
stringlengths 2
42
| last_modified
timestamp[us, tz=UTC]date 2020-02-15 11:33:14
2025-09-12 12:31:00
| downloads
int64 0
223M
| likes
int64 0
11.7k
| library_name
stringclasses 555
values | tags
listlengths 1
4.05k
| pipeline_tag
stringclasses 55
values | createdAt
timestamp[us, tz=UTC]date 2022-03-02 23:29:04
2025-09-12 12:28:53
| card
stringlengths 11
1.01M
|
|---|---|---|---|---|---|---|---|---|---|
yaelahnal/blockassist-bc-mute_clawed_crab_1755608206
|
yaelahnal
| 2025-08-19T13:01:06Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"mute clawed crab",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T12:57:36Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- mute clawed crab
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Ransss/Moonlit-Shadow-12B-Q8_0-GGUF
|
Ransss
| 2025-08-19T12:58:51Z | 0 | 0 |
transformers
|
[
"transformers",
"gguf",
"mergekit",
"merge",
"llama-cpp",
"gguf-my-repo",
"base_model:Vortex5/Moonlit-Shadow-12B",
"base_model:quantized:Vortex5/Moonlit-Shadow-12B",
"endpoints_compatible",
"region:us"
] | null | 2025-08-19T12:58:00Z |
---
base_model: Vortex5/Moonlit-Shadow-12B
library_name: transformers
tags:
- mergekit
- merge
- llama-cpp
- gguf-my-repo
---
# Ransss/Moonlit-Shadow-12B-Q8_0-GGUF
This model was converted to GGUF format from [`Vortex5/Moonlit-Shadow-12B`](https://huggingface.co/Vortex5/Moonlit-Shadow-12B) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/Vortex5/Moonlit-Shadow-12B) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew (works on Mac and Linux)
```bash
brew install llama.cpp
```
Invoke the llama.cpp server or the CLI.
### CLI:
```bash
llama-cli --hf-repo Ransss/Moonlit-Shadow-12B-Q8_0-GGUF --hf-file moonlit-shadow-12b-q8_0.gguf -p "The meaning to life and the universe is"
```
### Server:
```bash
llama-server --hf-repo Ransss/Moonlit-Shadow-12B-Q8_0-GGUF --hf-file moonlit-shadow-12b-q8_0.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
Step 1: Clone llama.cpp from GitHub.
```
git clone https://github.com/ggerganov/llama.cpp
```
Step 2: Move into the llama.cpp folder and build it with `LLAMA_CURL=1` flag along with other hardware-specific flags (for ex: LLAMA_CUDA=1 for Nvidia GPUs on Linux).
```
cd llama.cpp && LLAMA_CURL=1 make
```
Step 3: Run inference through the main binary.
```
./llama-cli --hf-repo Ransss/Moonlit-Shadow-12B-Q8_0-GGUF --hf-file moonlit-shadow-12b-q8_0.gguf -p "The meaning to life and the universe is"
```
or
```
./llama-server --hf-repo Ransss/Moonlit-Shadow-12B-Q8_0-GGUF --hf-file moonlit-shadow-12b-q8_0.gguf -c 2048
```
|
ThomET/MyGemmaNPC
|
ThomET
| 2025-08-19T12:57:18Z | 0 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"gemma3_text",
"text-generation",
"generated_from_trainer",
"sft",
"trl",
"conversational",
"base_model:google/gemma-3-270m-it",
"base_model:finetune:google/gemma-3-270m-it",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-19T12:54:05Z |
---
base_model: google/gemma-3-270m-it
library_name: transformers
model_name: MyGemmaNPC
tags:
- generated_from_trainer
- sft
- trl
licence: license
---
# Model Card for MyGemmaNPC
This model is a fine-tuned version of [google/gemma-3-270m-it](https://huggingface.co/google/gemma-3-270m-it).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="ThomET/MyGemmaNPC", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
This model was trained with SFT.
### Framework versions
- TRL: 0.21.0
- Transformers: 4.55.2
- Pytorch: 2.6.0+cu124
- Datasets: 4.0.0
- Tokenizers: 0.21.4
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
canoplos112/blockassist-bc-yapping_sleek_squirrel_1755607240
|
canoplos112
| 2025-08-19T12:51:17Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"yapping sleek squirrel",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T12:50:02Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- yapping sleek squirrel
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
jurgenpaul82/DECEIVER
|
jurgenpaul82
| 2025-08-19T12:50:57Z | 0 | 0 |
fasttext
|
[
"fasttext",
"music",
"climate",
"chemistry",
"biology",
"finance",
"text-generation-inference",
"merge",
"legal",
"am",
"dataset:MegaScience/MegaScience",
"dataset:fka/awesome-chatgpt-prompts",
"dataset:nvidia/Llama-Nemotron-VLM-Dataset-v1",
"dataset:jxm/gpt-oss20b-samples",
"dataset:nvidia/Granary",
"dataset:NousResearch/Hermes-3-Dataset",
"base_model:Qwen/Qwen3-Coder-480B-A35B-Instruct",
"base_model:finetune:Qwen/Qwen3-Coder-480B-A35B-Instruct",
"license:mit",
"region:us"
] | null | 2025-08-19T12:39:55Z |
---
license: mit
datasets:
- MegaScience/MegaScience
- fka/awesome-chatgpt-prompts
- nvidia/Llama-Nemotron-VLM-Dataset-v1
- jxm/gpt-oss20b-samples
- nvidia/Granary
- NousResearch/Hermes-3-Dataset
language:
- am
metrics:
- accuracy
- bertscore
- brier_score
- character
base_model:
- Qwen/Qwen3-Coder-480B-A35B-Instruct
new_version: tencent/Hunyuan-1.8B-Instruct
library_name: fasttext
tags:
- music
- climate
- chemistry
- biology
- finance
- text-generation-inference
- merge
- legal
---
|
ihsanridzi/blockassist-bc-wiry_flexible_owl_1755606148
|
ihsanridzi
| 2025-08-19T12:50:25Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"wiry flexible owl",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T12:50:21Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- wiry flexible owl
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
VoilaRaj/80_xuruTx
|
VoilaRaj
| 2025-08-19T12:48:40Z | 0 | 0 | null |
[
"safetensors",
"any-to-any",
"omega",
"omegalabs",
"bittensor",
"agi",
"license:mit",
"region:us"
] |
any-to-any
| 2025-08-19T12:44:52Z |
---
license: mit
tags:
- any-to-any
- omega
- omegalabs
- bittensor
- agi
---
This is an Any-to-Any model checkpoint for the OMEGA Labs x Bittensor Any-to-Any subnet.
Check out the [git repo](https://github.com/omegalabsinc/omegalabs-anytoany-bittensor) and find OMEGA on X: [@omegalabsai](https://x.com/omegalabsai).
|
Azurastar2903/Llama-3.2-3B-Instruct-rk3588-1.2.1
|
Azurastar2903
| 2025-08-19T12:48:06Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"facebook",
"meta",
"pytorch",
"llama-3",
"conversational",
"en",
"de",
"fr",
"it",
"pt",
"hi",
"es",
"th",
"arxiv:2204.05149",
"arxiv:2405.16406",
"license:llama3.2",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-19T12:45:38Z |
---
language:
- en
- de
- fr
- it
- pt
- hi
- es
- th
library_name: transformers
license: llama3.2
pipeline_tag: text-generation
tags:
- facebook
- meta
- pytorch
- llama
- llama-3
extra_gated_prompt: "### LLAMA 3.2 COMMUNITY LICENSE AGREEMENT\n\nLlama 3.2 Version\
\ Release Date: September 25, 2024\n\n“Agreement” means the terms and conditions\
\ for use, reproduction, distribution and modification of the Llama Materials set\
\ forth herein.\n\n“Documentation” means the specifications, manuals and documentation\
\ accompanying Llama 3.2 distributed by Meta at https://llama.meta.com/doc/overview.\n\
\n“Licensee” or “you” means you, or your employer or any other person or entity\
\ (if you are entering into this Agreement on such person or entity’s behalf),\
\ of the age required under applicable laws, rules or regulations to provide legal\
\ consent and that has legal authority to bind your employer or such other person\
\ or entity if you are entering in this Agreement on their behalf.\n\n“Llama 3.2”\
\ means the foundational large language models and software and algorithms, including\
\ machine-learning model code, trained model weights, inference-enabling code, training-enabling\
\ code, fine-tuning enabling code and other elements of the foregoing distributed\
\ by Meta at https://www.llama.com/llama-downloads.\n\n“Llama Materials” means,\
\ collectively, Meta’s proprietary Llama 3.2 and Documentation (and any portion\
\ thereof) made available under this Agreement.\n\n“Meta” or “we” means Meta Platforms\
\ Ireland Limited (if you are located in or, if you are an entity, your principal\
\ place of business is in the EEA or Switzerland) and Meta Platforms, Inc. (if\
\ you are located outside of the EEA or Switzerland). \n\nBy clicking “I Accept”\
\ below or by using or distributing any portion or element of the Llama Materials,\
\ you agree to be bound by this Agreement.\n\n1. License Rights and Redistribution.\n\
a. Grant of Rights. You are granted a non-exclusive, worldwide, non-transferable\
\ and royalty-free limited license under Meta’s intellectual property or other rights\
\ owned by Meta embodied in the Llama Materials to use, reproduce, distribute,\
\ copy, create derivative works of, and make modifications to the Llama Materials.\
\ \nb. Redistribution and Use. \ni. If you distribute or make available the Llama\
\ Materials (or any derivative works thereof), or a product or service (including\
\ another AI model) that contains any of them, you shall (A) provide a copy of this\
\ Agreement with any such Llama Materials; and (B) prominently display “Built with\
\ Llama” on a related website, user interface, blogpost, about page, or product\
\ documentation. If you use the Llama Materials or any outputs or results of the\
\ Llama Materials to create, train, fine tune, or otherwise improve an AI model,\
\ which is distributed or made available, you shall also include “Llama” at the\
\ beginning of any such AI model name.\nii. If you receive Llama Materials, or any\
\ derivative works thereof, from a Licensee as part of an integrated end user product,\
\ then Section 2 of this Agreement will not apply to you. \niii. You must retain\
\ in all copies of the Llama Materials that you distribute the following attribution\
\ notice within a “Notice” text file distributed as a part of such copies: “Llama\
\ 3.2 is licensed under the Llama 3.2 Community License, Copyright © Meta Platforms,\
\ Inc. All Rights Reserved.”\niv. Your use of the Llama Materials must comply with\
\ applicable laws and regulations (including trade compliance laws and regulations)\
\ and adhere to the Acceptable Use Policy for the Llama Materials (available at\
\ https://www.llama.com/llama3_2/use-policy), which is hereby incorporated by reference\
\ into this Agreement.\n \n2. Additional Commercial Terms. If, on the Llama 3.2\
\ version release date, the monthly active users of the products or services made\
\ available by or for Licensee, or Licensee’s affiliates, is greater than 700 million\
\ monthly active users in the preceding calendar month, you must request a license\
\ from Meta, which Meta may grant to you in its sole discretion, and you are not\
\ authorized to exercise any of the rights under this Agreement unless or until\
\ Meta otherwise expressly grants you such rights.\n3. Disclaimer of Warranty. UNLESS\
\ REQUIRED BY APPLICABLE LAW, THE LLAMA MATERIALS AND ANY OUTPUT AND RESULTS THEREFROM\
\ ARE PROVIDED ON AN “AS IS” BASIS, WITHOUT WARRANTIES OF ANY KIND, AND META DISCLAIMS\
\ ALL WARRANTIES OF ANY KIND, BOTH EXPRESS AND IMPLIED, INCLUDING, WITHOUT LIMITATION,\
\ ANY WARRANTIES OF TITLE, NON-INFRINGEMENT, MERCHANTABILITY, OR FITNESS FOR A PARTICULAR\
\ PURPOSE. YOU ARE SOLELY RESPONSIBLE FOR DETERMINING THE APPROPRIATENESS OF USING\
\ OR REDISTRIBUTING THE LLAMA MATERIALS AND ASSUME ANY RISKS ASSOCIATED WITH YOUR\
\ USE OF THE LLAMA MATERIALS AND ANY OUTPUT AND RESULTS.\n4. Limitation of Liability.\
\ IN NO EVENT WILL META OR ITS AFFILIATES BE LIABLE UNDER ANY THEORY OF LIABILITY,\
\ WHETHER IN CONTRACT, TORT, NEGLIGENCE, PRODUCTS LIABILITY, OR OTHERWISE, ARISING\
\ OUT OF THIS AGREEMENT, FOR ANY LOST PROFITS OR ANY INDIRECT, SPECIAL, CONSEQUENTIAL,\
\ INCIDENTAL, EXEMPLARY OR PUNITIVE DAMAGES, EVEN IF META OR ITS AFFILIATES HAVE\
\ BEEN ADVISED OF THE POSSIBILITY OF ANY OF THE FOREGOING.\n5. Intellectual Property.\n\
a. No trademark licenses are granted under this Agreement, and in connection with\
\ the Llama Materials, neither Meta nor Licensee may use any name or mark owned\
\ by or associated with the other or any of its affiliates, except as required\
\ for reasonable and customary use in describing and redistributing the Llama Materials\
\ or as set forth in this Section 5(a). Meta hereby grants you a license to use\
\ “Llama” (the “Mark”) solely as required to comply with the last sentence of Section\
\ 1.b.i. You will comply with Meta’s brand guidelines (currently accessible at\
\ https://about.meta.com/brand/resources/meta/company-brand/). All goodwill arising\
\ out of your use of the Mark will inure to the benefit of Meta.\nb. Subject to\
\ Meta’s ownership of Llama Materials and derivatives made by or for Meta, with\
\ respect to any derivative works and modifications of the Llama Materials that\
\ are made by you, as between you and Meta, you are and will be the owner of such\
\ derivative works and modifications.\nc. If you institute litigation or other proceedings\
\ against Meta or any entity (including a cross-claim or counterclaim in a lawsuit)\
\ alleging that the Llama Materials or Llama 3.2 outputs or results, or any portion\
\ of any of the foregoing, constitutes infringement of intellectual property or\
\ other rights owned or licensable by you, then any licenses granted to you under\
\ this Agreement shall terminate as of the date such litigation or claim is filed\
\ or instituted. You will indemnify and hold harmless Meta from and against any\
\ claim by any third party arising out of or related to your use or distribution\
\ of the Llama Materials.\n6. Term and Termination. The term of this Agreement will\
\ commence upon your acceptance of this Agreement or access to the Llama Materials\
\ and will continue in full force and effect until terminated in accordance with\
\ the terms and conditions herein. Meta may terminate this Agreement if you are\
\ in breach of any term or condition of this Agreement. Upon termination of this\
\ Agreement, you shall delete and cease use of the Llama Materials. Sections 3,\
\ 4 and 7 shall survive the termination of this Agreement. \n7. Governing Law and\
\ Jurisdiction. This Agreement will be governed and construed under the laws of\
\ the State of California without regard to choice of law principles, and the UN\
\ Convention on Contracts for the International Sale of Goods does not apply to\
\ this Agreement. The courts of California shall have exclusive jurisdiction of\
\ any dispute arising out of this Agreement. \n### Llama 3.2 Acceptable Use Policy\n\
Meta is committed to promoting safe and fair use of its tools and features, including\
\ Llama 3.2. If you access or use Llama 3.2, you agree to this Acceptable Use Policy\
\ (“**Policy**”). The most recent copy of this policy can be found at [https://www.llama.com/llama3_2/use-policy](https://www.llama.com/llama3_2/use-policy).\n\
#### Prohibited Uses\nWe want everyone to use Llama 3.2 safely and responsibly.\
\ You agree you will not use, or allow others to use, Llama 3.2 to:\n1. Violate\
\ the law or others’ rights, including to:\n 1. Engage in, promote, generate,\
\ contribute to, encourage, plan, incite, or further illegal or unlawful activity\
\ or content, such as:\n 1. Violence or terrorism\n 2. Exploitation\
\ or harm to children, including the solicitation, creation, acquisition, or dissemination\
\ of child exploitative content or failure to report Child Sexual Abuse Material\n\
\ 3. Human trafficking, exploitation, and sexual violence\n 4. The\
\ illegal distribution of information or materials to minors, including obscene\
\ materials, or failure to employ legally required age-gating in connection with\
\ such information or materials.\n 5. Sexual solicitation\n 6. Any\
\ other criminal activity\n 1. Engage in, promote, incite, or facilitate the\
\ harassment, abuse, threatening, or bullying of individuals or groups of individuals\n\
\ 2. Engage in, promote, incite, or facilitate discrimination or other unlawful\
\ or harmful conduct in the provision of employment, employment benefits, credit,\
\ housing, other economic benefits, or other essential goods and services\n 3.\
\ Engage in the unauthorized or unlicensed practice of any profession including,\
\ but not limited to, financial, legal, medical/health, or related professional\
\ practices\n 4. Collect, process, disclose, generate, or infer private or sensitive\
\ information about individuals, including information about individuals’ identity,\
\ health, or demographic information, unless you have obtained the right to do so\
\ in accordance with applicable law\n 5. Engage in or facilitate any action or\
\ generate any content that infringes, misappropriates, or otherwise violates any\
\ third-party rights, including the outputs or results of any products or services\
\ using the Llama Materials\n 6. Create, generate, or facilitate the creation\
\ of malicious code, malware, computer viruses or do anything else that could disable,\
\ overburden, interfere with or impair the proper working, integrity, operation\
\ or appearance of a website or computer system\n 7. Engage in any action, or\
\ facilitate any action, to intentionally circumvent or remove usage restrictions\
\ or other safety measures, or to enable functionality disabled by Meta \n2. Engage\
\ in, promote, incite, facilitate, or assist in the planning or development of activities\
\ that present a risk of death or bodily harm to individuals, including use of Llama\
\ 3.2 related to the following:\n 8. Military, warfare, nuclear industries or\
\ applications, espionage, use for materials or activities that are subject to the\
\ International Traffic Arms Regulations (ITAR) maintained by the United States\
\ Department of State or to the U.S. Biological Weapons Anti-Terrorism Act of 1989\
\ or the Chemical Weapons Convention Implementation Act of 1997\n 9. Guns and\
\ illegal weapons (including weapon development)\n 10. Illegal drugs and regulated/controlled\
\ substances\n 11. Operation of critical infrastructure, transportation technologies,\
\ or heavy machinery\n 12. Self-harm or harm to others, including suicide, cutting,\
\ and eating disorders\n 13. Any content intended to incite or promote violence,\
\ abuse, or any infliction of bodily harm to an individual\n3. Intentionally deceive\
\ or mislead others, including use of Llama 3.2 related to the following:\n 14.\
\ Generating, promoting, or furthering fraud or the creation or promotion of disinformation\n\
\ 15. Generating, promoting, or furthering defamatory content, including the\
\ creation of defamatory statements, images, or other content\n 16. Generating,\
\ promoting, or further distributing spam\n 17. Impersonating another individual\
\ without consent, authorization, or legal right\n 18. Representing that the\
\ use of Llama 3.2 or outputs are human-generated\n 19. Generating or facilitating\
\ false online engagement, including fake reviews and other means of fake online\
\ engagement \n4. Fail to appropriately disclose to end users any known dangers\
\ of your AI system 5. Interact with third party tools, models, or software designed\
\ to generate unlawful content or engage in unlawful or harmful conduct and/or represent\
\ that the outputs of such tools, models, or software are associated with Meta or\
\ Llama 3.2\n\nWith respect to any multimodal models included in Llama 3.2, the\
\ rights granted under Section 1(a) of the Llama 3.2 Community License Agreement\
\ are not being granted to you if you are an individual domiciled in, or a company\
\ with a principal place of business in, the European Union. This restriction does\
\ not apply to end users of a product or service that incorporates any such multimodal\
\ models.\n\nPlease report any violation of this Policy, software “bug,” or other\
\ problems that could lead to a violation of this Policy through one of the following\
\ means:\n\n* Reporting issues with the model: [https://github.com/meta-llama/llama-models/issues](https://l.workplace.com/l.php?u=https%3A%2F%2Fgithub.com%2Fmeta-llama%2Fllama-models%2Fissues&h=AT0qV8W9BFT6NwihiOHRuKYQM_UnkzN_NmHMy91OT55gkLpgi4kQupHUl0ssR4dQsIQ8n3tfd0vtkobvsEvt1l4Ic6GXI2EeuHV8N08OG2WnbAmm0FL4ObkazC6G_256vN0lN9DsykCvCqGZ)\n\
* Reporting risky content generated by the model: [developers.facebook.com/llama_output_feedback](http://developers.facebook.com/llama_output_feedback)\n\
* Reporting bugs and security concerns: [facebook.com/whitehat/info](http://facebook.com/whitehat/info)\n\
* Reporting violations of the Acceptable Use Policy or unlicensed uses of Llama\
\ 3.2: LlamaUseReport@meta.com"
extra_gated_fields:
First Name: text
Last Name: text
Date of birth: date_picker
Country: country
Affiliation: text
Job title:
type: select
options:
- Student
- Research Graduate
- AI researcher
- AI developer/engineer
- Reporter
- Other
geo: ip_location
? By clicking Submit below I accept the terms of the license and acknowledge that
the information I provide will be collected stored processed and shared in accordance
with the Meta Privacy Policy
: checkbox
extra_gated_description: The information you provide will be collected, stored, processed
and shared in accordance with the [Meta Privacy Policy](https://www.facebook.com/privacy/policy/).
extra_gated_button_content: Submit
---
# Llama-3.2-3B-Instruct-RK3588-1.2.1
This version of Llama-3.2-3B-Instruct has been converted to run on the RK3588 NPU using ['w8a8', 'w8a8_g128', 'w8a8_g256'] quantization.
This model has been optimized with the following LoRA:
Compatible with RKLLM version: 1.2.1
## Useful links:
[Official RKLLM GitHub](https://github.com/airockchip/rknn-llm)
[RockhipNPU Reddit](https://reddit.com/r/RockchipNPU)
[EZRKNN-LLM](https://github.com/Pelochus/ezrknn-llm/)
Pretty much anything by these folks: [marty1885](https://github.com/marty1885) and [happyme531](https://huggingface.co/happyme531)
Converted using https://github.com/c0zaut/ez-er-rkllm-toolkit
# Original Model Card for base model, Llama-3.2-3B-Instruct, below:
## Model Information
The Llama 3.2 collection of multilingual large language models (LLMs) is a collection of pretrained and instruction-tuned generative models in 1B and 3B sizes (text in/text out). The Llama 3.2 instruction-tuned text only models are optimized for multilingual dialogue use cases, including agentic retrieval and summarization tasks. They outperform many of the available open source and closed chat models on common industry benchmarks.
**Model Developer:** Meta
**Model Architecture:** Llama 3.2 is an auto-regressive language model that uses an optimized transformer architecture. The tuned versions use supervised fine-tuning (SFT) and reinforcement learning with human feedback (RLHF) to align with human preferences for helpfulness and safety.
| | Training Data | Params | Input modalities | Output modalities | Context Length | GQA | Shared Embeddings | Token count | Knowledge cutoff |
| :---- | :---- | :---- | :---- | :---- | :---- | :---- | :---- | :---- | :---- |
| Llama 3.2 (text only) | A new mix of publicly available online data. | 1B (1.23B) | Multilingual Text | Multilingual Text and code | 128k | Yes | Yes | Up to 9T tokens | December 2023 |
| | | 3B (3.21B) | Multilingual Text | Multilingual Text and code | | | | | |
| Llama 3.2 Quantized (text only) | A new mix of publicly available online data. | 1B (1.23B) | Multilingual Text | Multilingual Text and code | 8k | Yes | Yes | Up to 9T tokens | December 2023 |
| | | 3B (3.21B) | Multilingual Text | Multilingual Text and code | | | | | |
**Supported Languages:** English, German, French, Italian, Portuguese, Hindi, Spanish, and Thai are officially supported. Llama 3.2 has been trained on a broader collection of languages than these 8 supported languages. Developers may fine-tune Llama 3.2 models for languages beyond these supported languages, provided they comply with the Llama 3.2 Community License and the Acceptable Use Policy. Developers are always expected to ensure that their deployments, including those that involve additional languages, are completed safely and responsibly.
**Llama 3.2 Model Family:** Token counts refer to pretraining data only. All model versions use Grouped-Query Attention (GQA) for improved inference scalability.
**Model Release Date:** Sept 25, 2024
**Status:** This is a static model trained on an offline dataset. Future versions may be released that improve model capabilities and safety.
**License:** Use of Llama 3.2 is governed by the [Llama 3.2 Community License](https://github.com/meta-llama/llama-models/blob/main/models/llama3_2/LICENSE) (a custom, commercial license agreement).
**Feedback:** Instructions on how to provide feedback or comments on the model can be found in the Llama Models [README](https://github.com/meta-llama/llama-models/blob/main/README.md). For more technical information about generation parameters and recipes for how to use Llama 3.2 in applications, please go [here](https://github.com/meta-llama/llama-recipes).
## Intended Use
**Intended Use Cases:** Llama 3.2 is intended for commercial and research use in multiple languages. Instruction tuned text only models are intended for assistant-like chat and agentic applications like knowledge retrieval and summarization, mobile AI powered writing assistants and query and prompt rewriting. Pretrained models can be adapted for a variety of additional natural language generation tasks. Similarly, quantized models can be adapted for a variety of on-device use-cases with limited compute resources.
**Out of Scope:** Use in any manner that violates applicable laws or regulations (including trade compliance laws). Use in any other way that is prohibited by the Acceptable Use Policy and Llama 3.2 Community License. Use in languages beyond those explicitly referenced as supported in this model card.
## How to use
This repository contains two versions of Llama-3.2-3B-Instruct, for use with `transformers` and with the original `llama` codebase.
### Use with transformers
Starting with `transformers >= 4.43.0` onward, you can run conversational inference using the Transformers `pipeline` abstraction or by leveraging the Auto classes with the `generate()` function.
Make sure to update your transformers installation via `pip install --upgrade transformers`.
```python
import torch
from transformers import pipeline
model_id = "meta-llama/Llama-3.2-3B-Instruct"
pipe = pipeline(
"text-generation",
model=model_id,
torch_dtype=torch.bfloat16,
device_map="auto",
)
messages = [
{"role": "system", "content": "You are a pirate chatbot who always responds in pirate speak!"},
{"role": "user", "content": "Who are you?"},
]
outputs = pipe(
messages,
max_new_tokens=256,
)
print(outputs[0]["generated_text"][-1])
```
Note: You can also find detailed recipes on how to use the model locally, with `torch.compile()`, assisted generations, quantised and more at [`huggingface-llama-recipes`](https://github.com/huggingface/huggingface-llama-recipes)
### Use with `llama`
Please, follow the instructions in the [repository](https://github.com/meta-llama/llama)
To download Original checkpoints, see the example command below leveraging `huggingface-cli`:
```
huggingface-cli download meta-llama/Llama-3.2-3B-Instruct --include "original/*" --local-dir Llama-3.2-3B-Instruct
```
## Hardware and Software
**Training Factors:** We used custom training libraries, Meta's custom built GPU cluster, and production infrastructure for pretraining. Fine-tuning, quantization, annotation, and evaluation were also performed on production infrastructure.
**Training Energy Use:** Training utilized a cumulative of **916k** GPU hours of computation on H100-80GB (TDP of 700W) type hardware, per the table below. Training time is the total GPU time required for training each model and power consumption is the peak power capacity per GPU device used, adjusted for power usage efficiency.
**Training Greenhouse Gas Emissions:** Estimated total location-based greenhouse gas emissions were **240** tons CO2eq for training. Since 2020, Meta has maintained net zero greenhouse gas emissions in its global operations and matched 100% of its electricity use with renewable energy; therefore, the total market-based greenhouse gas emissions for training were 0 tons CO2eq.
| | Training Time (GPU hours) | Logit Generation Time (GPU Hours) | Training Power Consumption (W) | Training Location-Based Greenhouse Gas Emissions (tons CO2eq) | Training Market-Based Greenhouse Gas Emissions (tons CO2eq) |
| :---- | :---: | ----- | :---: | :---: | :---: |
| Llama 3.2 1B | 370k | \- | 700 | 107 | 0 |
| Llama 3.2 3B | 460k | \- | 700 | 133 | 0 |
| Llama 3.2 1B SpinQuant | 1.7 | 0 | 700 | *Negligible*\*\* | 0 |
| Llama 3.2 3B SpinQuant | 2.4 | 0 | 700 | *Negligible*\*\* | 0 |
| Llama 3.2 1B QLora | 1.3k | 0 | 700 | 0.381 | 0 |
| Llama 3.2 3B QLora | 1.6k | 0 | 700 | 0.461 | 0 |
| Total | 833k | 86k | | 240 | 0 |
\*\* The location-based CO2e emissions of Llama 3.2 1B SpinQuant and Llama 3.2 3B SpinQuant are less than 0.001 metric tonnes each. This is due to the minimal training GPU hours that are required.
The methodology used to determine training energy use and greenhouse gas emissions can be found [here](https://arxiv.org/pdf/2204.05149). Since Meta is openly releasing these models, the training energy use and greenhouse gas emissions will not be incurred by others.
## Training Data
**Overview:** Llama 3.2 was pretrained on up to 9 trillion tokens of data from publicly available sources. For the 1B and 3B Llama 3.2 models, we incorporated logits from the Llama 3.1 8B and 70B models into the pretraining stage of the model development, where outputs (logits) from these larger models were used as token-level targets. Knowledge distillation was used after pruning to recover performance. In post-training we used a similar recipe as Llama 3.1 and produced final chat models by doing several rounds of alignment on top of the pre-trained model. Each round involved Supervised Fine-Tuning (SFT), Rejection Sampling (RS), and Direct Preference Optimization (DPO).
**Data Freshness:** The pretraining data has a cutoff of December 2023\.
## Quantization
### Quantization Scheme
We designed the current quantization scheme with the [PyTorch’s ExecuTorch](https://github.com/pytorch/executorch) inference framework and Arm CPU backend in mind, taking into account metrics including model quality, prefill/decoding speed, and memory footprint. Our quantization scheme involves three parts:
- All linear layers in all transformer blocks are quantized to a 4-bit groupwise scheme (with a group size of 32) for weights and 8-bit per-token dynamic quantization for activations.
- The classification layer is quantized to 8-bit per-channel for weight and 8-bit per token dynamic quantization for activation.
- Similar to classification layer, an 8-bit per channel quantization is used for embedding layer.
### Quantization-Aware Training and LoRA
The quantization-aware training (QAT) with low-rank adaptation (LoRA) models went through only post-training stages, using the same data as the full precision models. To initialize QAT, we utilize BF16 Llama 3.2 model checkpoints obtained after supervised fine-tuning (SFT) and perform an additional full round of SFT training with QAT. We then freeze the backbone of the QAT model and perform another round of SFT with LoRA adaptors applied to all layers within the transformer block. Meanwhile, the LoRA adaptors' weights and activations are maintained in BF16. Because our approach is similar to QLoRA of Dettmers et al., (2023) (i.e., quantization followed by LoRA adapters), we refer this method as QLoRA. Finally, we fine-tune the resulting model (both backbone and LoRA adaptors) using direct preference optimization (DPO).
### SpinQuant
[SpinQuant](https://arxiv.org/abs/2405.16406) was applied, together with generative post-training quantization (GPTQ). For the SpinQuant rotation matrix fine-tuning, we optimized for 100 iterations, using 800 samples with sequence-length 2048 from the WikiText 2 dataset. For GPTQ, we used 128 samples from the same dataset with the same sequence-length.
## Benchmarks \- English Text
In this section, we report the results for Llama 3.2 models on standard automatic benchmarks. For all these evaluations, we used our internal evaluations library.
### Base Pretrained Models
| Category | Benchmark | \# Shots | Metric | Llama 3.2 1B | Llama 3.2 3B | Llama 3.1 8B |
| ----- | ----- | :---: | :---: | :---: | :---: | :---: |
| General | MMLU | 5 | macro\_avg/acc\_char | 32.2 | 58 | 66.7 |
| | AGIEval English | 3-5 | average/acc\_char | 23.3 | 39.2 | 47.8 |
| | ARC-Challenge | 25 | acc\_char | 32.8 | 69.1 | 79.7 |
| Reading comprehension | SQuAD | 1 | em | 49.2 | 67.7 | 77 |
| | QuAC (F1) | 1 | f1 | 37.9 | 42.9 | 44.9 |
| | DROP (F1) | 3 | f1 | 28.0 | 45.2 | 59.5 |
| Long Context | Needle in Haystack | 0 | em | 96.8 | 1 | 1 |
### Instruction Tuned Models
| Capability | | Benchmark | \# Shots | Metric | Llama 3.2 1B bf16 | Llama 3.2 1B Vanilla PTQ\*\* | Llama 3.2 1B Spin Quant | Llama 3.2 1B QLoRA | Llama 3.2 3B bf16 | Llama 3.2 3B Vanilla PTQ\*\* | Llama 3.2 3B Spin Quant | Llama 3.2 3B QLoRA | Llama 3.1 8B |
| :---: | ----- | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: |
| General | | MMLU | 5 | macro\_avg/acc | 49.3 | 43.3 | 47.3 | 49.0 | 63.4 | 60.5 | 62 | 62.4 | 69.4 |
| Re-writing | | Open-rewrite eval | 0 | micro\_avg/rougeL | 41.6 | 39.2 | 40.9 | 41.2 | 40.1 | 40.3 | 40.8 | 40.7 | 40.9 |
| Summarization | | TLDR9+ (test) | 1 | rougeL | 16.8 | 14.9 | 16.7 | 16.8 | 19.0 | 19.1 | 19.2 | 19.1 | 17.2 |
| Instruction following | | IFEval | 0 | Avg(Prompt/Instruction acc Loose/Strict) | 59.5 | 51.5 | 58.4 | 55.6 | 77.4 | 73.9 | 73.5 | 75.9 | 80.4 |
| Math | | GSM8K (CoT) | 8 | em\_maj1@1 | 44.4 | 33.1 | 40.6 | 46.5 | 77.7 | 72.9 | 75.7 | 77.9 | 84.5 |
| | | MATH (CoT) | 0 | final\_em | 30.6 | 20.5 | 25.3 | 31.0 | 48.0 | 44.2 | 45.3 | 49.2 | 51.9 |
| Reasoning | | ARC-C | 0 | acc | 59.4 | 54.3 | 57 | 60.7 | 78.6 | 75.6 | 77.6 | 77.6 | 83.4 |
| | | GPQA | 0 | acc | 27.2 | 25.9 | 26.3 | 25.9 | 32.8 | 32.8 | 31.7 | 33.9 | 32.8 |
| | | Hellaswag | 0 | acc | 41.2 | 38.1 | 41.3 | 41.5 | 69.8 | 66.3 | 68 | 66.3 | 78.7 |
| Tool Use | | BFCL V2 | 0 | acc | 25.7 | 14.3 | 15.9 | 23.7 | 67.0 | 53.4 | 60.1 | 63.5 | 67.1 |
| | | Nexus | 0 | macro\_avg/acc | 13.5 | 5.2 | 9.6 | 12.5 | 34.3 | 32.4 | 31.5 | 30.1 | 38.5 |
| Long Context | | InfiniteBench/En.QA | 0 | longbook\_qa/f1 | 20.3 | N/A | N/A | N/A | 19.8 | N/A | N/A | N/A | 27.3 |
| | | InfiniteBench/En.MC | 0 | longbook\_choice/acc | 38.0 | N/A | N/A | N/A | 63.3 | N/A | N/A | N/A | 72.2 |
| | | NIH/Multi-needle | 0 | recall | 75.0 | N/A | N/A | N/A | 84.7 | N/A | N/A | N/A | 98.8 |
| Multilingual | | MGSM (CoT) | 0 | em | 24.5 | 13.7 | 18.2 | 24.4 | 58.2 | 48.9 | 54.3 | 56.8 | 68.9 |
\*\*for comparison purposes only. Model not released.
### Multilingual Benchmarks
| Category | Benchmark | Language | Llama 3.2 1B | Llama 3.2 1B Vanilla PTQ\*\* | Llama 3.2 1B Spin Quant | Llama 3.2 1B QLoRA | Llama 3.2 3B | Llama 3.2 3B Vanilla PTQ\*\* | Llama 3.2 3B Spin Quant | Llama 3.2 3B QLoRA | Llama 3.1 8B |
| :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: |
| General | MMLU (5-shot, macro_avg/acc) | Portuguese | 39.8 | 34.9 | 38.9 | 40.2 | 54.5 | 50.9 | 53.3 | 53.4 | 62.1 |
| | | Spanish | 41.5 | 36.0 | 39.8 | 41.8 | 55.1 | 51.9 | 53.6 | 53.6 | 62.5 |
| | | Italian | 39.8 | 34.9 | 38.1 | 40.6 | 53.8 | 49.9 | 52.1 | 51.7 | 61.6 |
| | | German | 39.2 | 34.9 | 37.5 | 39.6 | 53.3 | 50.0 | 52.2 | 51.3 | 60.6 |
| | | French | 40.5 | 34.8 | 39.2 | 40.8 | 54.6 | 51.2 | 53.3 | 53.3 | 62.3 |
| | | Hindi | 33.5 | 30.0 | 32.1 | 34.0 | 43.3 | 40.4 | 42.0 | 42.1 | 50.9 |
| | | Thai | 34.7 | 31.2 | 32.4 | 34.9 | 44.5 | 41.3 | 44.0 | 42.2 | 50.3 |
\*\*for comparison purposes only. Model not released.
## Inference time
In the below table, we compare the performance metrics of different quantization methods (SpinQuant and QAT \+ LoRA) with the BF16 baseline. The evaluation was done using the [ExecuTorch](https://github.com/pytorch/executorch) framework as the inference engine, with the ARM CPU as a backend using Android OnePlus 12 device.
| Category | Decode (tokens/sec) | Time-to-first-token (sec) | Prefill (tokens/sec) | Model size (PTE file size in MB) | Memory size (RSS in MB) |
| :---- | ----- | ----- | ----- | ----- | ----- |
| 1B BF16 (baseline) | 19.2 | 1.0 | 60.3 | 2358 | 3,185 |
| 1B SpinQuant | 50.2 (2.6x) | 0.3 (-76.9%) | 260.5 (4.3x) | 1083 (-54.1%) | 1,921 (-39.7%) |
| 1B QLoRA | 45.8 (2.4x) | 0.3 (-76.0%) | 252.0 (4.2x) | 1127 (-52.2%) | 2,255 (-29.2%) |
| 3B BF16 (baseline) | 7.6 | 3.0 | 21.2 | 6129 | 7,419 |
| 3B SpinQuant | 19.7 (2.6x) | 0.7 (-76.4%) | 89.7 (4.2x) | 2435 (-60.3%) | 3,726 (-49.8%) |
| 3B QLoRA | 18.5 (2.4x) | 0.7 (-76.1%) | 88.8 (4.2x) | 2529 (-58.7%) | 4,060 (-45.3%) |
(\*) The performance measurement is done using an adb binary-based approach.
(\*\*) It is measured on an Android OnePlus 12 device.
(\*\*\*) Time-to-first-token (TTFT) is measured with prompt length=64
*Footnote:*
- *Decode (tokens/second) is for how quickly it keeps generating. Higher is better.*
- *Time-to-first-token (TTFT for shorthand) is for how fast it generates the first token for a given prompt. Lower is better.*
- *Prefill is the inverse of TTFT (aka 1/TTFT) in tokens/second. Higher is better*
- *Model size \- how big is the model, measured by, PTE file, a binary file format for ExecuTorch*
- *RSS size \- Memory usage in resident set size (RSS)*
## Responsibility & Safety
As part of our Responsible release approach, we followed a three-pronged strategy to managing trust & safety risks:
1. Enable developers to deploy helpful, safe and flexible experiences for their target audience and for the use cases supported by Llama
2. Protect developers against adversarial users aiming to exploit Llama capabilities to potentially cause harm
3. Provide protections for the community to help prevent the misuse of our models
### Responsible Deployment
**Approach:** Llama is a foundational technology designed to be used in a variety of use cases. Examples on how Meta’s Llama models have been responsibly deployed can be found in our [Community Stories webpage](https://llama.meta.com/community-stories/). Our approach is to build the most helpful models, enabling the world to benefit from the technology power, by aligning our model safety for generic use cases and addressing a standard set of harms. Developers are then in the driver’s seat to tailor safety for their use cases, defining their own policies and deploying the models with the necessary safeguards in their Llama systems. Llama 3.2 was developed following the best practices outlined in our [Responsible Use Guide](https://llama.meta.com/responsible-use-guide/).
#### Llama 3.2 Instruct
**Objective:** Our main objectives for conducting safety fine-tuning are to provide the research community with a valuable resource for studying the robustness of safety fine-tuning, as well as to offer developers a readily available, safe, and powerful model for various applications to reduce the developer workload to deploy safe AI systems. We implemented the same set of safety mitigations as in Llama 3, and you can learn more about these in the Llama 3 [paper](https://ai.meta.com/research/publications/the-llama-3-herd-of-models/).
**Fine-Tuning Data:** We employ a multi-faceted approach to data collection, combining human-generated data from our vendors with synthetic data to mitigate potential safety risks. We’ve developed many large language model (LLM)-based classifiers that enable us to thoughtfully select high-quality prompts and responses, enhancing data quality control.
**Refusals and Tone:** Building on the work we started with Llama 3, we put a great emphasis on model refusals to benign prompts as well as refusal tone. We included both borderline and adversarial prompts in our safety data strategy, and modified our safety data responses to follow tone guidelines.
#### Llama 3.2 Systems
**Safety as a System:** Large language models, including Llama 3.2, **are not designed to be deployed in isolation** but instead should be deployed as part of an overall AI system with additional safety guardrails as required. Developers are expected to deploy system safeguards when building agentic systems. Safeguards are key to achieve the right helpfulness-safety alignment as well as mitigating safety and security risks inherent to the system and any integration of the model or system with external tools. As part of our responsible release approach, we provide the community with [safeguards](https://llama.meta.com/trust-and-safety/) that developers should deploy with Llama models or other LLMs, including Llama Guard, Prompt Guard and Code Shield. All our [reference implementations](https://github.com/meta-llama/llama-agentic-system) demos contain these safeguards by default so developers can benefit from system-level safety out-of-the-box.
### New Capabilities and Use Cases
**Technological Advancement:** Llama releases usually introduce new capabilities that require specific considerations in addition to the best practices that generally apply across all Generative AI use cases. For prior release capabilities also supported by Llama 3.2, see [Llama 3.1 Model Card](https://github.com/meta-llama/llama-models/blob/main/models/llama3_1/MODEL_CARD.md), as the same considerations apply here as well.
**Constrained Environments:** Llama 3.2 1B and 3B models are expected to be deployed in highly constrained environments, such as mobile devices. LLM Systems using smaller models will have a different alignment profile and safety/helpfulness tradeoff than more complex, larger systems. Developers should ensure the safety of their system meets the requirements of their use case. We recommend using lighter system safeguards for such use cases, like Llama Guard 3-1B or its mobile-optimized version.
### Evaluations
**Scaled Evaluations:** We built dedicated, adversarial evaluation datasets and evaluated systems composed of Llama models and Purple Llama safeguards to filter input prompt and output response. It is important to evaluate applications in context, and we recommend building dedicated evaluation dataset for your use case.
**Red Teaming:** We conducted recurring red teaming exercises with the goal of discovering risks via adversarial prompting and we used the learnings to improve our benchmarks and safety tuning datasets. We partnered early with subject-matter experts in critical risk areas to understand the nature of these real-world harms and how such models may lead to unintended harm for society. Based on these conversations, we derived a set of adversarial goals for the red team to attempt to achieve, such as extracting harmful information or reprogramming the model to act in a potentially harmful capacity. The red team consisted of experts in cybersecurity, adversarial machine learning, responsible AI, and integrity in addition to multilingual content specialists with background in integrity issues in specific geographic markets.
### Critical Risks
In addition to our safety work above, we took extra care on measuring and/or mitigating the following critical risk areas:
**1\. CBRNE (Chemical, Biological, Radiological, Nuclear, and Explosive Weapons):** Llama 3.2 1B and 3B models are smaller and less capable derivatives of Llama 3.1. For Llama 3.1 70B and 405B, to assess risks related to proliferation of chemical and biological weapons, we performed uplift testing designed to assess whether use of Llama 3.1 models could meaningfully increase the capabilities of malicious actors to plan or carry out attacks using these types of weapons and have determined that such testing also applies to the smaller 1B and 3B models.
**2\. Child Safety:** Child Safety risk assessments were conducted using a team of experts, to assess the model’s capability to produce outputs that could result in Child Safety risks and inform on any necessary and appropriate risk mitigations via fine tuning. We leveraged those expert red teaming sessions to expand the coverage of our evaluation benchmarks through Llama 3 model development. For Llama 3, we conducted new in-depth sessions using objective based methodologies to assess the model risks along multiple attack vectors including the additional languages Llama 3 is trained on. We also partnered with content specialists to perform red teaming exercises assessing potentially violating content while taking account of market specific nuances or experiences.
**3\. Cyber Attacks:** For Llama 3.1 405B, our cyber attack uplift study investigated whether LLMs can enhance human capabilities in hacking tasks, both in terms of skill level and speed.
Our attack automation study focused on evaluating the capabilities of LLMs when used as autonomous agents in cyber offensive operations, specifically in the context of ransomware attacks. This evaluation was distinct from previous studies that considered LLMs as interactive assistants. The primary objective was to assess whether these models could effectively function as independent agents in executing complex cyber-attacks without human intervention. Because Llama 3.2’s 1B and 3B models are smaller and less capable models than Llama 3.1 405B, we broadly believe that the testing conducted for the 405B model also applies to Llama 3.2 models.
### Community
**Industry Partnerships:** Generative AI safety requires expertise and tooling, and we believe in the strength of the open community to accelerate its progress. We are active members of open consortiums, including the AI Alliance, Partnership on AI and MLCommons, actively contributing to safety standardization and transparency. We encourage the community to adopt taxonomies like the MLCommons Proof of Concept evaluation to facilitate collaboration and transparency on safety and content evaluations. Our Purple Llama tools are open sourced for the community to use and widely distributed across ecosystem partners including cloud service providers. We encourage community contributions to our [Github repository](https://github.com/meta-llama/PurpleLlama).
**Grants:** We also set up the [Llama Impact Grants](https://llama.meta.com/llama-impact-grants/) program to identify and support the most compelling applications of Meta’s Llama model for societal benefit across three categories: education, climate and open innovation. The 20 finalists from the hundreds of applications can be found [here](https://llama.meta.com/llama-impact-grants/#finalists).
**Reporting:** Finally, we put in place a set of resources including an [output reporting mechanism](https://developers.facebook.com/llama_output_feedback) and [bug bounty program](https://www.facebook.com/whitehat) to continuously improve the Llama technology with the help of the community.
## Ethical Considerations and Limitations
**Values:** The core values of Llama 3.2 are openness, inclusivity and helpfulness. It is meant to serve everyone, and to work for a wide range of use cases. It is thus designed to be accessible to people across many different backgrounds, experiences and perspectives. Llama 3.2 addresses users and their needs as they are, without insertion unnecessary judgment or normativity, while reflecting the understanding that even content that may appear problematic in some cases can serve valuable purposes in others. It respects the dignity and autonomy of all users, especially in terms of the values of free thought and expression that power innovation and progress.
**Testing:** Llama 3.2 is a new technology, and like any new technology, there are risks associated with its use. Testing conducted to date has not covered, nor could it cover, all scenarios. For these reasons, as with all LLMs, Llama 3.2’s potential outputs cannot be predicted in advance, and the model may in some instances produce inaccurate, biased or other objectionable responses to user prompts. Therefore, before deploying any applications of Llama 3.2 models, developers should perform safety testing and tuning tailored to their specific applications of the model. Please refer to available resources including our [Responsible Use Guide](https://llama.meta.com/responsible-use-guide), [Trust and Safety](https://llama.meta.com/trust-and-safety/) solutions, and other [resources](https://llama.meta.com/docs/get-started/) to learn more about responsible development.
|
yaelahnal/blockassist-bc-mute_clawed_crab_1755607354
|
yaelahnal
| 2025-08-19T12:43:44Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"mute clawed crab",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T12:43:27Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- mute clawed crab
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Grigorij/jellypick
|
Grigorij
| 2025-08-19T12:43:11Z | 0 | 0 |
lerobot
|
[
"lerobot",
"safetensors",
"robotics",
"smolvla",
"dataset:Grigorij/so-101-test",
"arxiv:2506.01844",
"base_model:lerobot/smolvla_base",
"base_model:finetune:lerobot/smolvla_base",
"license:apache-2.0",
"region:us"
] |
robotics
| 2025-08-19T09:21:43Z |
---
base_model: lerobot/smolvla_base
datasets: Grigorij/so-101-test
library_name: lerobot
license: apache-2.0
model_name: smolvla
pipeline_tag: robotics
tags:
- robotics
- smolvla
- lerobot
---
# Model Card for smolvla
<!-- Provide a quick summary of what the model is/does. -->
[SmolVLA](https://huggingface.co/papers/2506.01844) is a compact, efficient vision-language-action model that achieves competitive performance at reduced computational costs and can be deployed on consumer-grade hardware.
This policy has been trained and pushed to the Hub using [LeRobot](https://github.com/huggingface/lerobot).
See the full documentation at [LeRobot Docs](https://huggingface.co/docs/lerobot/index).
---
## How to Get Started with the Model
For a complete walkthrough, see the [training guide](https://huggingface.co/docs/lerobot/il_robots#train-a-policy).
Below is the short version on how to train and run inference/eval:
### Train from scratch
```bash
python -m lerobot.scripts.train \
--dataset.repo_id=${HF_USER}/<dataset> \
--policy.type=act \
--output_dir=outputs/train/<desired_policy_repo_id> \
--job_name=lerobot_training \
--policy.device=cuda \
--policy.repo_id=${HF_USER}/<desired_policy_repo_id>
--wandb.enable=true
```
_Writes checkpoints to `outputs/train/<desired_policy_repo_id>/checkpoints/`._
### Evaluate the policy/run inference
```bash
python -m lerobot.record \
--robot.type=so100_follower \
--dataset.repo_id=<hf_user>/eval_<dataset> \
--policy.path=<hf_user>/<desired_policy_repo_id> \
--episodes=10
```
Prefix the dataset repo with **eval\_** and supply `--policy.path` pointing to a local or hub checkpoint.
---
## Model Details
- **License:** apache-2.0
|
Jacksss123/net72_uid234
|
Jacksss123
| 2025-08-19T12:41:01Z | 0 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"vit",
"image-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2025-08-19T12:38:56Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Dejiat/blockassist-bc-savage_unseen_bobcat_1755607155
|
Dejiat
| 2025-08-19T12:39:57Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"savage unseen bobcat",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T12:39:52Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- savage unseen bobcat
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
milliarderdol/blockassist-bc-roaring_rough_scorpion_1755605038
|
milliarderdol
| 2025-08-19T12:38:25Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"roaring rough scorpion",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T12:37:30Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- roaring rough scorpion
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
lilTAT/blockassist-bc-gentle_rugged_hare_1755607026
|
lilTAT
| 2025-08-19T12:37:37Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"gentle rugged hare",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T12:37:31Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- gentle rugged hare
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
kimxxxx/mistral_r32_a32_b8_gas2_lr5e-5_4500tk_2epoch_newdata
|
kimxxxx
| 2025-08-19T12:37:04Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-08-19T12:36:56Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Dejiat/blockassist-bc-savage_unseen_bobcat_1755606945
|
Dejiat
| 2025-08-19T12:36:26Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"savage unseen bobcat",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T12:36:22Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- savage unseen bobcat
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
chainway9/blockassist-bc-untamed_quick_eel_1755605237
|
chainway9
| 2025-08-19T12:36:05Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"untamed quick eel",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T12:36:01Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- untamed quick eel
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
neko-llm/Qwen3-235B-test4
|
neko-llm
| 2025-08-19T12:32:22Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"generated_from_trainer",
"trl",
"sft",
"base_model:Qwen/Qwen3-235B-A22B",
"base_model:finetune:Qwen/Qwen3-235B-A22B",
"endpoints_compatible",
"region:us"
] | null | 2025-08-19T10:50:58Z |
---
base_model: Qwen/Qwen3-235B-A22B
library_name: transformers
model_name: Qwen3-235B-test4
tags:
- generated_from_trainer
- trl
- sft
licence: license
---
# Model Card for Qwen3-235B-test4
This model is a fine-tuned version of [Qwen/Qwen3-235B-A22B](https://huggingface.co/Qwen/Qwen3-235B-A22B).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="neko-llm/Qwen3-235B-test4", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
This model was trained with SFT.
### Framework versions
- TRL: 0.19.0
- Transformers: 4.54.1
- Pytorch: 2.6.0
- Datasets: 4.0.0
- Tokenizers: 0.21.4
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
Sayemahsjn/blockassist-bc-playful_feline_octopus_1755605238
|
Sayemahsjn
| 2025-08-19T12:26:09Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"playful feline octopus",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T12:26:05Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- playful feline octopus
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
kojeklollipop/blockassist-bc-spotted_amphibious_stork_1755604710
|
kojeklollipop
| 2025-08-19T12:26:07Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"spotted amphibious stork",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T12:26:04Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- spotted amphibious stork
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
yookty/blockassist-bc-subtle_hibernating_moose_1755605457
|
yookty
| 2025-08-19T12:25:31Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"subtle hibernating moose",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T12:25:17Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- subtle hibernating moose
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
New-Clip-prabh-viral-video/New.full.videos.prabh.Viral.Video.Official.Tutorial
|
New-Clip-prabh-viral-video
| 2025-08-19T12:24:33Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-08-19T12:24:18Z |
<a href="https://sdu.sk/AyL"><img src="https://files.qatarliving.com/event/2025/06/20/Jawan69_0-1749987397680.gif" alt="fsd" /></a>
<a href="https://sdu.sk/AyL" rel="nofollow">🔴 ➤►𝐂𝐥𝐢𝐤 𝐇𝐞𝐫𝐞 𝐭𝐨👉👉 (𝙨𝙞𝙜𝙣 𝙪𝙥 𝙖𝙣𝙙 𝙬𝙖𝙩𝙘𝙝 𝙛𝙪𝙡𝙡 𝙫𝙞𝙙𝙚𝙤 𝙃𝘿)</a>
<a href="https://sdu.sk/AyL" rel="nofollow">🔴 ➤►𝐂𝐥𝐢𝐤 𝐇𝐞𝐫𝐞 𝐭𝐨👉👉 (𝐅𝐮𝐥𝐥 𝐯𝐢𝐝𝐞𝐨 𝐋𝐢𝐧𝐤)</a>
|
Dejiat/blockassist-bc-savage_unseen_bobcat_1755605923
|
Dejiat
| 2025-08-19T12:19:32Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"savage unseen bobcat",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T12:19:22Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- savage unseen bobcat
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Bindura-University-viral-video-Clip-XX/New.full.videos.Bindura.University.Viral.Video.Official.Tutorial
|
Bindura-University-viral-video-Clip-XX
| 2025-08-19T12:19:10Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-08-19T12:19:00Z |
<a href="https://sdu.sk/AyL"><img src="https://files.qatarliving.com/event/2025/06/20/Jawan69_0-1749987397680.gif" alt="fsd" /></a>
<a href="https://sdu.sk/AyL" rel="nofollow">🔴 ➤►𝐂𝐥𝐢𝐤 𝐇𝐞𝐫𝐞 𝐭𝐨👉👉 (𝙨𝙞𝙜𝙣 𝙪𝙥 𝙖𝙣𝙙 𝙬𝙖𝙩𝙘𝙝 𝙛𝙪𝙡𝙡 𝙫𝙞𝙙𝙚𝙤 𝙃𝘿)</a>
<a href="https://sdu.sk/AyL" rel="nofollow">🔴 ➤►𝐂𝐥𝐢𝐤 𝐇𝐞𝐫𝐞 𝐭𝐨👉👉 (𝐅𝐮𝐥𝐥 𝐯𝐢𝐝𝐞𝐨 𝐋𝐢𝐧𝐤)</a>
|
java2core/gemma-3-4b-product-description
|
java2core
| 2025-08-19T12:18:29Z | 0 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"generated_from_trainer",
"trl",
"sft",
"base_model:google/gemma-3-4b-pt",
"base_model:finetune:google/gemma-3-4b-pt",
"endpoints_compatible",
"region:us"
] | null | 2025-08-19T10:21:15Z |
---
base_model: google/gemma-3-4b-pt
library_name: transformers
model_name: gemma-3-4b-product-description
tags:
- generated_from_trainer
- trl
- sft
licence: license
---
# Model Card for gemma-3-4b-product-description
This model is a fine-tuned version of [google/gemma-3-4b-pt](https://huggingface.co/google/gemma-3-4b-pt).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="java2core/gemma-3-4b-product-description", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
This model was trained with SFT.
### Framework versions
- TRL: 0.15.2
- Transformers: 4.55.2
- Pytorch: 2.8.0
- Datasets: 3.3.2
- Tokenizers: 0.21.4
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallouédec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
lilTAT/blockassist-bc-gentle_rugged_hare_1755605836
|
lilTAT
| 2025-08-19T12:17:43Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"gentle rugged hare",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T12:17:40Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- gentle rugged hare
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
vwzyrraz7l/blockassist-bc-tall_hunting_vulture_1755604006
|
vwzyrraz7l
| 2025-08-19T12:14:22Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"tall hunting vulture",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T12:14:18Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- tall hunting vulture
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
ihsanridzi/blockassist-bc-wiry_flexible_owl_1755603946
|
ihsanridzi
| 2025-08-19T12:13:50Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"wiry flexible owl",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T12:13:46Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- wiry flexible owl
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
LBST/t10_pick_and_place_smolvla_018000
|
LBST
| 2025-08-19T12:13:32Z | 0 | 0 |
lerobot
|
[
"lerobot",
"safetensors",
"robotics",
"pick-and-place",
"smolvla",
"checkpoint-018000",
"region:us"
] |
robotics
| 2025-08-19T12:13:24Z |
---
library_name: lerobot
tags:
- robotics
- pick-and-place
- smolvla
- checkpoint-018000
---
# T08 Pick and Place Policy - Checkpoint 018000
This model is a checkpoint from the training of a pick-and-place policy using SmolVLA architecture.
## Model Details
- **Checkpoint**: 018000
- **Architecture**: SmolVLA
- **Task**: Pick and Place (T08)
- **Training Step**: 018000
## Usage
You can evaluate this model using LeRobot:
```bash
python -m lerobot.scripts.eval \
--policy.path=LBST/t10_pick_and_place_smolvla_018000 \
--env.type=<your_environment> \
--eval.n_episodes=10 \
--policy.device=cuda
```
## Files
- `config.json`: Policy configuration
- `model.safetensors`: Model weights in SafeTensors format
- `train_config.json`: Complete training configuration for reproducibility
## Parent Repository
This checkpoint was extracted from: [LBST/t10_pick_and_place_files](https://huggingface.co/LBST/t10_pick_and_place_files)
---
*Generated automatically from checkpoint 018000*
|
LBST/t10_pick_and_place_smolvla_015000
|
LBST
| 2025-08-19T12:12:19Z | 0 | 0 |
lerobot
|
[
"lerobot",
"safetensors",
"robotics",
"pick-and-place",
"smolvla",
"checkpoint-015000",
"region:us"
] |
robotics
| 2025-08-19T12:12:13Z |
---
library_name: lerobot
tags:
- robotics
- pick-and-place
- smolvla
- checkpoint-015000
---
# T08 Pick and Place Policy - Checkpoint 015000
This model is a checkpoint from the training of a pick-and-place policy using SmolVLA architecture.
## Model Details
- **Checkpoint**: 015000
- **Architecture**: SmolVLA
- **Task**: Pick and Place (T08)
- **Training Step**: 015000
## Usage
You can evaluate this model using LeRobot:
```bash
python -m lerobot.scripts.eval \
--policy.path=LBST/t10_pick_and_place_smolvla_015000 \
--env.type=<your_environment> \
--eval.n_episodes=10 \
--policy.device=cuda
```
## Files
- `config.json`: Policy configuration
- `model.safetensors`: Model weights in SafeTensors format
- `train_config.json`: Complete training configuration for reproducibility
## Parent Repository
This checkpoint was extracted from: [LBST/t10_pick_and_place_files](https://huggingface.co/LBST/t10_pick_and_place_files)
---
*Generated automatically from checkpoint 015000*
|
gaoyang07/XYCodec
|
gaoyang07
| 2025-08-19T12:12:18Z | 0 | 0 | null |
[
"pytorch",
"xycodec",
"arxiv:2506.23325",
"license:apache-2.0",
"region:us"
] | null | 2025-08-19T12:07:08Z |
---
license: apache-2.0
---
# **Introduction**
**`XY-Tokenizer`** is a speech codec that simultaneously models both semantic and acoustic aspects of speech, converting audio into discrete tokens and decoding them back to high-quality audio. It achieves efficient speech representation at only 1kbps with RVQ8 quantization at 12.5Hz frame rate.
- **Paper:** [Read on arXiv](https://arxiv.org/abs/2506.23325)
- **Source Code:**
- [GitHub Repo](https://github.com/OpenMOSS/MOSS-TTSD/tree/main/XY_Tokenizer)
- [Hugging Face Repo](https://huggingface.co/spaces/fnlp/MOSS-TTSD/tree/main/XY_Tokenizer)
## 📚 Related Project: **[MOSS-TTSD](https://huggingface.co/fnlp/MOSS-TTSD-v0.5)**
**`XY-Tokenizer`** serves as the underlying neural codec for **`MOSS-TTSD`**, our 1.7B Audio Language Model. \
Explore **`MOSS-TTSD`** for advanced text-to-speech and other audio generation tasks on [GitHub](https://github.com/OpenMOSS/MOSS-TTSD), [Blog](http://www.open-moss.com/en/moss-ttsd/), [博客](https://www.open-moss.com/cn/moss-ttsd/), and [Space Demo](https://huggingface.co/spaces/fnlp/MOSS-TTSD).
## ✨ Features
- **Dual-channel modeling**: Simultaneously captures semantic meaning and acoustic details
- **Efficient representation**: 1kbps bitrate with RVQ8 quantization at 12.5Hz
- **High-quality audio tokenization**: Convert speech to discrete tokens and back with minimal quality loss
- **Long audio support**: Process audio files longer than 30 seconds using chunking with overlap
- **Batch processing**: Efficiently process multiple audio files in batches
- **24kHz output**: Generate high-quality 24kHz audio output
## 🚀 Installation
```bash
git clone https://github.com/OpenMOSS/MOSS-TTSD.git
cd MOSS-TTSD
conda create -n xy_tokenizer python=3.10 -y && conda activate xy_tokenizer
pip install -r XY_Tokenizer/requirements.txt
```
## 💻 Quick Start
Here's how to use **`XY-Tokenizer`** with `transformers` to encode an audio file into discrete tokens and decode it back into a waveform.
```python
import torchaudio
from transformers import AutoFeatureExtractor, AutoModel
# 1. Load the feature extractor and the codec model
feature_extractor = AutoFeatureExtractor.from_pretrained("MCplayer/XY_Tokenizer", trust_remote_code=True)
codec = AutoModel.from_pretrained("MCplayer/XY_Tokenizer", trust_remote_code=True, device_map="auto").eval()
# 2. Load and preprocess the audio
# The model expects a 16kHz sample rate.
wav_form, sampling_rate = torchaudio.load("examples/zh_spk1_moon.wav")
if sampling_rate != 16000:
wav_form = torchaudio.functional.resample(wav_form, orig_freq=sampling_rate, new_freq=16000)
# 3. Encode the audio into discrete codes
input_spectrum = feature_extractor(wav_form, sampling_rate=16000, return_attention_mask=True, return_tensors="pt")
# The 'code' dictionary contains the discrete audio codes
code = codec.encode(input_spectrum)
# 4. Decode the codes back to an audio waveform
# The output is high-quality 24kHz audio.
output_wav = codec.decode(code["audio_codes"], overlap_seconds=10)
# 5. Save the reconstructed audio
for i, audio in enumerate(output_wav["audio_values"]):
torchaudio.save(f"outputs/audio_{i}.wav", audio.cpu(), 24000)
```
|
SirAB/Dolphin-gemma2-2b-finetuned-v2
|
SirAB
| 2025-08-19T12:11:00Z | 29 | 1 |
transformers
|
[
"transformers",
"safetensors",
"gemma2",
"text-generation",
"text-generation-inference",
"unsloth",
"conversational",
"en",
"base_model:SirAB/Dolphin-gemma2-2b-finetuned-v2",
"base_model:finetune:SirAB/Dolphin-gemma2-2b-finetuned-v2",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-06-10T09:34:21Z |
---
base_model: SirAB/Dolphin-gemma2-2b-finetuned-v2
tags:
- text-generation-inference
- transformers
- unsloth
- gemma2
license: apache-2.0
language:
- en
---
# Uploaded finetuned model
- **Developed by:** SirAB
- **License:** apache-2.0
- **Finetuned from model :** SirAB/Dolphin-gemma2-2b-finetuned-v2
This gemma2 model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
pempekmangedd/blockassist-bc-patterned_sturdy_dolphin_1755603799
|
pempekmangedd
| 2025-08-19T12:11:00Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"patterned sturdy dolphin",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T12:10:57Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- patterned sturdy dolphin
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
lisaozill03/blockassist-bc-rugged_prickly_alpaca_1755603876
|
lisaozill03
| 2025-08-19T12:10:02Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"rugged prickly alpaca",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T12:09:58Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- rugged prickly alpaca
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
LBST/t10_pick_and_place_smolvla_004000
|
LBST
| 2025-08-19T12:07:36Z | 0 | 0 |
lerobot
|
[
"lerobot",
"safetensors",
"robotics",
"pick-and-place",
"smolvla",
"checkpoint-004000",
"region:us"
] |
robotics
| 2025-08-19T12:07:29Z |
---
library_name: lerobot
tags:
- robotics
- pick-and-place
- smolvla
- checkpoint-004000
---
# T08 Pick and Place Policy - Checkpoint 004000
This model is a checkpoint from the training of a pick-and-place policy using SmolVLA architecture.
## Model Details
- **Checkpoint**: 004000
- **Architecture**: SmolVLA
- **Task**: Pick and Place (T08)
- **Training Step**: 004000
## Usage
You can evaluate this model using LeRobot:
```bash
python -m lerobot.scripts.eval \
--policy.path=LBST/t10_pick_and_place_smolvla_004000 \
--env.type=<your_environment> \
--eval.n_episodes=10 \
--policy.device=cuda
```
## Files
- `config.json`: Policy configuration
- `model.safetensors`: Model weights in SafeTensors format
- `train_config.json`: Complete training configuration for reproducibility
## Parent Repository
This checkpoint was extracted from: [LBST/t10_pick_and_place_files](https://huggingface.co/LBST/t10_pick_and_place_files)
---
*Generated automatically from checkpoint 004000*
|
SeungJun3214/wifi-gemma3-model4-merged2
|
SeungJun3214
| 2025-08-19T12:03:48Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"gemma3_text",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-19T12:03:33Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
llm-slice/blm-gpt2s-90M-s42_901M-s42_submission
|
llm-slice
| 2025-08-19T12:03:13Z | 993 | 0 | null |
[
"safetensors",
"gpt2",
"interaction",
"babylm-submission",
"babylm-2025",
"en",
"arxiv:2405.09605",
"arxiv:2411.07990",
"region:us"
] | null | 2025-08-15T08:47:53Z |
---
language:
- en
tags:
- interaction
- babylm-submission
- babylm-2025
---
# Model Card for BabyLM submission to the Interaction Track
<!-- Provide a quick summary of what the model is/does. [Optional] -->
A 124M model with the GPT-2 architecture trained with the next token prediction loss for 10 epochs (~900 M words) **on 90% of the BabyLM corpus** and an additional **1 M words of PPO RL** training as submission for the Interaction track of the 2025 BabyLM challenge.
This model card is based on the model card of the BabyLM [100M GPT-2 baseline](https://huggingface.co/BabyLM-community/babylm-baseline-100m-gpt2/edit/main/README.md).
# Table of Contents
- [Model Card for Storytelling Submission Model](#model-card-for--model_id-)
- [Table of Contents](#table-of-contents)
- [Model Details](#model-details)
- [Model Description](#model-description)
- [Uses](#uses)
- [Training Details](#training-details)
- [Training Data](#training-data)
- [Hyperparameters](#hyperparameters)
- [Training Procedure](#training-procedure)
- [Size and Checkpoints](#size-and-checkpoints)
- [Evaluation](#evaluation)
- [Testing Data & Metrics](#testing-data-factors--metrics)
- [Testing Data](#testing-data)
- [Metrics](#metrics)
- [Results](#results)
- [Technical Specifications](#technical-specifications-optional)
- [Model Architecture and Objective](#model-architecture-and-objective)
- [Compute Infrastructure](#compute-infrastructure)
- [Hardware](#hardware)
- [Software](#software)
- [Training Time](#training-time)
- [Citation](#citation)
- [Model Card Authors](#model-card-authors-optional)
- [Bibliography](#bibliography)
# Model Details
## Model Description
<!-- Provide a longer summary of what this model is/does. -->
This is the RL storytelling model, based on a [pretrained GPT-2 model](https://huggingface.co/llm-slice/blm-gpt2s-90M-s42), for the Interaction Track of the 2025 BabyLM challenge.
- **Developed by:** Jonas Mayer Martins, Ali Hamza Bashir, Muhammad Rehan Khalid
- **Model type:** Causal language model
- **Language(s) (NLP):** eng
- **Resources for more information:**
- [GitHub Repo](https://github.com/malihamza/babylm-interactive-learning)
# Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
This is a pre-trained language model.
It can be used to evaluate tasks in a zero-shot manner and also can be fine-tuned for downstream tasks.
It can be used for language generation but given its small size and low number of words trained on, do not expect LLM-level performance.
# Training Details
## Training Data
<!-- This should link to a Data Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
We used the BabyLM 100M (Strict) dataset for training. **We trained the tokenizer and model on randomly selected 90% of the corpus**, which is composed of the following:
| Source | Weight | Domain | Citation | Website | License |
| --- | --- | --- | --- | --- | --- |
| BNC | 8% | Dialogue | BNC Consortium (2007) | [link](http://www.natcorp.ox.ac.uk/) | [link](http://www.natcorp.ox.ac.uk/docs/licence.html) <sup>1</sup> |
| CHILDES | 29% | Dialogue, Child-Directed | MacWhinney (2000) | | [link](https://talkbank.org/share/rules.html) |
| Project Gutenberg | 26% | Fiction, Nonfiction | Gerlach & Font-Clos (2020) | [link](https://github.com/pgcorpus/gutenberg) | [link](https://www.gutenberg.org/policy/license.html) |
| OpenSubtitles | 20% | Dialogue, Scripted | Lison & Tiedermann (2016) | [link](https://opus.nlpl.eu/OpenSubtitles-v2018.php) | Open source |
| Simple English Wikipedia | 15% | Nonfiction | -- | [link](https://dumps.wikimedia.org/simplewiki/20221201/) | [link](https://dumps.wikimedia.org/legal.html) |
| Switchboard | 1% | Dialogue | Godfrey et al. (1992), Stolcke et al., (2000) | [link](http://compprag.christopherpotts.net/swda.html) | [link](http://compprag.christopherpotts.net/swda.html) |
<sup>1</sup> Our distribution of part of the BNC Texts is permitted under the fair dealings provision of copyright law (see term (2g) in the BNC license).
## Hyperparameters PPO RL training
| **Parameter** | **Value** |
|----------------------------------|---------------------|
| Student context length | 512 |
| seed | 42 |
| batch size | 360 |
| Student sampling temperature | 1 |
| top_k | 0 |
| top_p | 1 |
| max_new_tokens (student) | 90 |
| Teacher model | Llama 3.1 8B Instr. |
| Teacher context length | 1024 |
| max_new_tokens (teacher) | 6 |
| gradient_accumulation_steps | 1 |
| adap_kl_ctrl | True |
| init_kl_coef | 0.2 |
| learning_rate | 1×10⁻⁶ |
| Student input limit | 1 M words |
## Hyperparameters Pretraining
| Hyperparameter | Value |
| --- | --- |
| Number of epochs | 10 |
| Datapoint length | 512 |
| Batch size | 16 |
| Gradient accumulation steps | 4 |
| Learning rate | 0.0005 |
| Number of steps | 211650 |
| Warmup steps | 2116 |
| Gradient clipping | 1 |
| Optimizer | AdamW |
| Optimizer Beta_1 | 0.9 |
| Optimizer Beta_2 | 0.999 |
| Optimizer Epsilon | 10<sup>-8</sup>|
| Tokenizer | BytePairBPE |
| Vocab Size | 16000 |
## Training Procedure
The model is trained with next token prediction loss for 10 epochs.
### Size and checkpoints
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
The model has 124M parameters.
In total we train on around 901 M words and provide multiple checkpoints from the training.
Specifically we provode:
- Checkpoints every 1 M words for the first 10 M words
- Checkpoints every 10 M words first 100 M words
- Checkpoints every 100 M words until 900 M words
- Checkpoints every 100 K words until 901 M words
# Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
This model is evaluated in two ways:
1. We do zero-shot evaluation on 7 tasks.
2. We do fine-tuning on a subset of the (Super)GLUE tasks (Wang et al., ICLR 2019; Wang et al., NeurIPS 2019) .
## Testing Data & Metrics
### Testing Data
<!-- This should link to a Data Card if possible. -->
For the BLiMP, BLiMP supplement, and EWoK tasks, we use a filtered version of the dataset to only include examples with words found in the BabyLM dataset.
For the Finetuning task, we both filter and sample down to a maximum 10 000 train examples.
*Validation Data*
*Zero-shot Tasks*
- **BLiMP**: The Benchmark of Linguistic Minimal Pairs evaluates the model's linguistic ability by seeing if it can recognize the grammatically correct sentence from a pair of minimally different sentences. It tests various grammatical phenomena.(Warstadt et al., TACL 2020)
- **BLiMP Supplement**: A supplement to BLiMP introduced in the first edition of the BabyLM challenge. More focused on dialogue and questions. (Warstadt et al., CoNLL-BabyLM 2023)
- **EWoK**: Works similarly to BLiMP but looks the model's internal world knowledge. Looking at both whter a model has physical and social knowledge. (Ivanova et al., 2024)
- **Eye Tracking and Self-paced Reading**: Looks at whether the model can mimick the eye tracking and reading time of a human but using surprisal of a word as a proxy for time spent reading a word. (de Varda et al., BRM 2024)
- **Entity Tracking**: Checks whether a model can keep track of the changes to the states of entities as text/dialogue unfolds. (Kim & Schuster, ACL 2023)
- **WUGs**: Tests morphological generalization in LMs through an adjective nominalization and past tense task. (Hofmann et al., 2024) (Weissweiler et al., 2023)
- **COMPS**: Property knowledge. (Misra et al., 2023)
*Finetuning Tasks*
- **BoolQ**: A yes/no QA dataset with unprompted and unconstrained questions. (Clark et al., NAACL 2019)
- **MNLI**: The Multi-Genre Natural Language Inference corpus tests the language understanding of a model by seeing wehther it can recognize textual entailment. (Williams et al., NAACL 2018)
- **MRPC**: The Microsoft Research Paraphrase Corpus contains pairs of sentences that are either paraphrases/semntically equivalent to each other or unrelated.(Dolan & Brockett, IJCNLP 2005)
- **QQP**<sup>2</sup>: Similarly to MRPC, the Quora Question Pairs corpus tests the models ability to determine whether a pair of questions are sematically similar to each other. These questions are sourced from Quora.
- **MultiRC**: The Multi-Sentence Reading Comprehension corpus is a QA task that evaluates the model's ability to the correct answer from a list of answers given a question and context paragraph. In this version the data is changed to a binary classification judging whether the answer to a question, context pair is correct. (Khashabi et al., NAACL 2018)
- **RTE**: Similar the Recognizing Text Entailement tests the model's ability to recognize text entailement. (Dagan et al., Springer 2006; Bar et al., 2006; Giampiccolo et al., 2007; Bentivogli et al., TAC 2009)
- **WSC**: The Winograd Schema Challenge tests the models ability to do coreference resolution on sentences with a pronoun and a list of noun phrases found in the sentence. This version edits it to be a binary classification on examples consisting of a pronoun and noun phrase.(Levesque et al., PKRR 2012)
<sup>2</sup> https://www.quora.com/profile/Ricky-Riche-2/First-Quora-Dataset-Release-Question-Pairs
### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
The metrics used to evaluate the model are the following:
- Zero-shot
- Accuracy on predicting the correct completion/sentence for BLiMP, BLiMP Supplement, EWoK, Entity Tracking, and WUGs
- Change in R^2 prediction from baseline for Eye Tracking (with no spillover) and Self-paced Reading (1-word spillover)
- Finetuning
- 3 class Accuracy for MNLI
- Binary Accuracy for BoolQ, MultiRC, and WSC
- F1-score for MRPC and QQP
The metrics were chosen based on the advice of the papers the tasks come from.
### Hyperparameters
| Hyperparameter | MNLI, RTE, QQP, MRPC, BoolQ, MultiRC | WSC |
| --- | --- | --- |
| Learning Rate | 3\*10<sup>-5</sup> | 3\*10<sup>-5</sup> |
| Batch Size | 16 | 16 |
| Epochs | 10 | 30 |
| Weight decay | 0.01 | 0.01 |
| Optimizer | AdamW | AdamW |
| Scheduler | cosine | cosine |
| Warmup percentage | 6% | 6% |
| Dropout | 0.1 | 0.1 |
## Results
We compare our student model against two official baselines from the 2025 BabyLM Challenge<sup>1</sup>:
- **1000M-pre:** The standard *pretraining* baseline, using a GPT-2-small model trained on 100M unique words from the BabyLM dataset (10 epochs, next-word prediction).
- **SimPO:** A baseline first trained for 7 epochs with next-word prediction, then 2 epochs *interleaving* prediction and reinforcement learning. Here, the RL reward encourages the student to generate completions similar to the teacher’s output.
- **900M-pre:** Our model, using the same GPT-2-small architecture, pretrained on 90% of the BabyLM dataset (yielding approximately 91M unique words, 10 epochs).
- **900M-RL:** Our model after additional PPO-based reinforcement learning with the teacher, using about 1M words as input for the interactive (RL) phase.
---
### Evaluation Results
| **Task** | **1000M-pre** | **SimPO** | **900M-pre** | **900M-RL** |
|:------------- | ------------: | ---------:| ------------:| -----------:|
| BLiMP | 74.88 | 72.16 | 77.52 | **77.53** |
| Suppl. | **63.32** | 61.22 | 56.62 | 56.72 |
| EWOK | 51.67 | **51.92** | 51.36 | 51.41 |
| COMPS | **56.17** | 55.05 | 55.20 | 55.18 |
| ET | 31.51 | 28.06 | 30.34 | **33.11** |
| GLUE | 52.18 | 50.35 | **53.14** | 52.46 |
#### Model descriptions:
- **1000M-pre:** Baseline pretrained on 100M words (BabyLM challenge baseline).
- **SimPO:** Baseline using a hybrid of pretraining and RL with a similarity-based reward.
- **900M-pre:** Our GPT-2-small model, pretrained on 90M words (similar settings as baseline, but less data).
- **900M-RL:** The same model as 900M-pre, further trained with PPO using teacher feedback on 1M words of input.
-
See: [BabyLM Challenge](https://huggingface.co/BabyLM-community) for the baselines.
# Technical Specifications
### Hardware
- 4 A100 GPUs were used to train this model.
### Software
PyTorch
### Training Time
The model took 20 hours to train and consumed 53560 core hours (with 4 GPUs and 32 CPUs).
# Citation
```latex
@misc{MayerMartinsBKB2025,
title={ToDo},
author={Jonas Mayer Martins, Ali Hamza Bashir, Muhammad Rehan Khalid, Lisa Beinborn},
year={2025},
eprint={2502.TODO},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={ToDo},
}
```
# Model Card Authors
Jonas Mayer Martins
# Bibliography
[GLUE: A multi-task benchmark and analysis platform for natural language understanding](https://openreview.net/pdf?id=rJ4km2R5t7) (Wang et al., ICLR 2019)
[SuperGLUE: A Stickier Benchmark for General-Purpose Language Understanding Systems](https://proceedings.neurips.cc/paper_files/paper/2019/file/4496bf24afe7fab6f046bf4923da8de6-Paper.pdf) (Wang et al., NeurIPS 2019)
[BLiMP: The Benchmark of Linguistic Minimal Pairs for English](https://aclanthology.org/2020.tacl-1.25/) (Warstadt et al., TACL 2020)
[Findings of the BabyLM Challenge: Sample-Efficient Pretraining on Developmentally Plausible Corpora](https://aclanthology.org/2023.conll-babylm.1/) (Warstadt et al., CoNLL-BabyLM 2023)
[🌏 Elements of World Knowledge (EWoK): A cognition-inspired framework for evaluating basic world knowledge in language models](https://arxiv.org/pdf/2405.09605v1) (Ivanova et al., 2024)
[Cloze probability, predictability ratings, and computational estimates for 205 English sentences, aligned with existing EEG and reading time data](https://link.springer.com/article/10.3758/s13428-023-02261-8) (de Varda et al., BRM 2024)
[Entity Tracking in Language Models](https://aclanthology.org/2023.acl-long.213/) (Kim & Schuster, ACL 2023)
[Derivational Morphology Reveals Analogical Generalization in Large Language Models](https://arxiv.org/pdf/2411.07990) (Hofmann et al., 2024)
[Automatically Constructing a Corpus of Sentential Paraphrases](https://aclanthology.org/I05-5002/) (Dolan & Brockett, IJCNLP 2005)
[A Broad-Coverage Challenge Corpus for Sentence Understanding through Inference](https://aclanthology.org/N18-1101/) (Williams et al., NAACL 2018)
[The Winograd Schema Challenge]( http://dl.acm.org/citation.cfm?id=3031843.3031909) (Levesque et al., PKRR 2012)
[The PASCAL Recognising Textual Entailment Challenge](https://link.springer.com/chapter/10.1007/11736790_9) (Dagan et al., Springer 2006)
[The Second PASCAL Recognising Textual Entailment Challenge]() (Bar et al., 2006)
[The Third PASCAL Recognizing Textual Entailment Challenge](https://aclanthology.org/W07-1401/) (Giampiccolo et al., 2007)
[The Fifth PASCAL Recognizing Textual Entailment Challenge](https://tac.nist.gov/publications/2009/additional.papers/RTE5_overview.proceedings.pdf) (Bentivogli et al., TAC 2009)
[BoolQ: Exploring the Surprising Difficulty of Natural Yes/No Questions](https://aclanthology.org/N19-1300/) (Clark et al., NAACL 2019)
[Looking Beyond the Surface: A Challenge Set for Reading Comprehension over Multiple Sentences](https://aclanthology.org/N18-1023/) (Khashabi et al., NAACL 2018)
|
huyydangg/thuvienphapluat_embedding_v6
|
huyydangg
| 2025-08-19T12:00:42Z | 0 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"safetensors",
"roberta",
"sentence-similarity",
"feature-extraction",
"dense",
"generated_from_trainer",
"dataset_size:172688",
"loss:MatryoshkaLoss",
"loss:CachedMultipleNegativesSymmetricRankingLoss",
"vi",
"arxiv:1908.10084",
"arxiv:2205.13147",
"base_model:bkai-foundation-models/vietnamese-bi-encoder",
"base_model:finetune:bkai-foundation-models/vietnamese-bi-encoder",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2025-08-19T11:55:48Z |
---
language:
- vi
license: apache-2.0
tags:
- sentence-transformers
- sentence-similarity
- feature-extraction
- dense
- generated_from_trainer
- dataset_size:172688
- loss:MatryoshkaLoss
- loss:CachedMultipleNegativesSymmetricRankingLoss
base_model: bkai-foundation-models/vietnamese-bi-encoder
widget:
- source_sentence: hiện_nay có văn_bản chính_thức áp_dụng giảm thuế gtgt cho năm 2023
chưa ?
sentences:
- quy_định về xuất_hóa_đơn đối_với hàng_hóa tự sản_xuất dùng để biếu tặng đối_tác
tại việt_nam
- xung_đột quy_phạm giữa điều 35 ( hình_phạt tiền ) và điều 188 ( tội buôn_lậu )
blhs 2015 và tính hợp_pháp khi tòa_chuyển hình_phạt chính từ tù sang phạt tiền
trong vụ án trịnh hoài_an
- văn_bản pháp_lý về giảm thuế giá_trị gia_tăng ( gtgt ) áp_dụng cho năm 2023 tại
việt_nam
- source_sentence: trường_hợp người lao_động là cấp quản_lý vào làm từ tháng 1 / 24
đến tháng 5 / 24 , không ký hợp_đồng lao_động chính_thức , không ký hợp_đồng thử
việc nhưng có tờ phiếu cam_kết ghi khi nghỉ_việc báo trước 30 ngày và ghi rõ thời_gian
thử việc ; theo luật lao_động , thử việc tối_đa 2 tháng và phải đóng bảo_hiểm
sau khi ký hợp_đồng chính_thức ( sau 2 tháng thử việc ) , nhưng công_ty chưa đóng
bảo_hiểm và người lao_động biết , vẫn nhận lương đầy_đủ và tiếp_tục làm , sau
đó người lao_động nghỉ ngang và yêu_cầu công_ty xử_lý sai ; công_ty muốn mời người
lao_động lên trao_đổi và bàn_giao để tránh thiệt_hại — công_ty có_thể xử_lý tình_huống
này như thế_nào để vừa hợp_pháp vừa giảm thiệt_hại ?
sentences:
- xử_lý pháp_lý và giảm thiệt_hại khi người lao_động quản_lý làm_việc không ký hợp_đồng
lao_động , không đóng bảo_hiểm và nghỉ ngang tại việt_nam
- điều_kiện cấp giấy chứng_nhận bị_thương để hưởng chế_độ ?
- quy_định về chi_phí thực_hiện thủ_tục hành_chính tại việt_nam
- source_sentence: giáo_viên tổng_phụ_trách đội thiếu 6 tiết / tuần bố_trí việc trực
hành_chính như thế_nào là đúng quy_định ạ ?
sentences:
- quy_định về việc ký_tên trên phiếu xuất kho và phiếu thu khi người mua không lấy
hóa_đơn
- giáo_viên kiêm tổng_phụ_trách đội bố_trí trực hành_chính như thế_nào ?
- quyền cho vay của ngân_hàng có yêu_cầu tài_sản bảo_đảm , cho vay tiếp khi tài_sản
bảo_đảm thuộc chủ sở_hữu doanh_nghiệp tư_nhân , và điều_kiện tăng vốn điều_lệ
ngân_hàng theo pháp_luật việt_nam
- source_sentence: sắp tới phù_hiệu một_số xe ô_tô kinh_doanh vận_tải bên tôi sẽ hết
hạn , cho hỏi bên tôi làm thủ_tục cấp lại có được không ? nếu được thì trình_tự
, thủ_tục thế_nào ? cảm_ơn nhiều !
sentences:
- trình_tự , thủ_tục cấp lại phù_hiệu xe ô_tô kinh_doanh vận_tải
- ubnd xã có được phép thuê thẩm_tra đối_với dự_án do mình làm_chủ đầu_tư không
?
- khởi_tố hình_sự về tội mua_bán , tàng_trữ , sử_dụng công_cụ kích điện sau khi
đã bị xử_phạt vi_phạm hành_chính theo nghị_định 42 / 2019 / nđ - cp ( điều 242
bộ_luật hình_sự )
- source_sentence: cho mình hỏi về cách tính thanh_toán tiền_lương làm tăng giờ đối_với
công_chức nhà_nước . tiền_lương một tháng để tính tăng giờ có bao_gồm phụ_cấp
không ?
sentences:
- trách_nhiệm pháp_lý của người sử_dụng lao_động khi người lao_động tử_vong do tai_nạn
giao_thông trong quá_trình làm_việc " , " quyền_lợi của người lao_động tử_vong
do tai_nạn lao_động ngoài trụ_sở làm_việc
- trách_nhiệm pháp_lý và chính_sách nhân_đạo đối_với người vợ mang thai trong trường_hợp
ly_hôn , tranh_chấp tài_sản chung và nghĩa_vụ trả nợ của chồng
- tiền_lương để tính tăng giờ đối_với công_chức có bao_gồm phụ_cấp không ?
pipeline_tag: sentence-similarity
library_name: sentence-transformers
metrics:
- cosine_accuracy@1
- cosine_accuracy@3
- cosine_accuracy@5
- cosine_accuracy@10
- cosine_precision@1
- cosine_precision@3
- cosine_precision@5
- cosine_precision@10
- cosine_recall@1
- cosine_recall@3
- cosine_recall@5
- cosine_recall@10
- cosine_ndcg@10
- cosine_mrr@10
- cosine_map@100
model-index:
- name: bkai-fine-tuned-legal
results:
- task:
type: information-retrieval
name: Information Retrieval
dataset:
name: dim 768
type: dim_768
metrics:
- type: cosine_accuracy@1
value: 0.7492356156768276
name: Cosine Accuracy@1
- type: cosine_accuracy@3
value: 0.8526359677568794
name: Cosine Accuracy@3
- type: cosine_accuracy@5
value: 0.8838599092004077
name: Cosine Accuracy@5
- type: cosine_accuracy@10
value: 0.9138330399332901
name: Cosine Accuracy@10
- type: cosine_precision@1
value: 0.7492356156768276
name: Cosine Precision@1
- type: cosine_precision@3
value: 0.28421198925229313
name: Cosine Precision@3
- type: cosine_precision@5
value: 0.17677198184008155
name: Cosine Precision@5
- type: cosine_precision@10
value: 0.09138330399332903
name: Cosine Precision@10
- type: cosine_recall@1
value: 0.7492356156768276
name: Cosine Recall@1
- type: cosine_recall@3
value: 0.8526359677568794
name: Cosine Recall@3
- type: cosine_recall@5
value: 0.8838599092004077
name: Cosine Recall@5
- type: cosine_recall@10
value: 0.9138330399332901
name: Cosine Recall@10
- type: cosine_ndcg@10
value: 0.8332832988114963
name: Cosine Ndcg@10
- type: cosine_mrr@10
value: 0.8072904028037066
name: Cosine Mrr@10
- type: cosine_map@100
value: 0.8100107043073839
name: Cosine Map@100
- task:
type: information-retrieval
name: Information Retrieval
dataset:
name: dim 512
type: dim_512
metrics:
- type: cosine_accuracy@1
value: 0.7453905308996572
name: Cosine Accuracy@1
- type: cosine_accuracy@3
value: 0.850782914852219
name: Cosine Accuracy@3
- type: cosine_accuracy@5
value: 0.8807560455851015
name: Cosine Accuracy@5
- type: cosine_accuracy@10
value: 0.9114240711572316
name: Cosine Accuracy@10
- type: cosine_precision@1
value: 0.7453905308996572
name: Cosine Precision@1
- type: cosine_precision@3
value: 0.2835943049507397
name: Cosine Precision@3
- type: cosine_precision@5
value: 0.17615120911702029
name: Cosine Precision@5
- type: cosine_precision@10
value: 0.09114240711572316
name: Cosine Precision@10
- type: cosine_recall@1
value: 0.7453905308996572
name: Cosine Recall@1
- type: cosine_recall@3
value: 0.850782914852219
name: Cosine Recall@3
- type: cosine_recall@5
value: 0.8807560455851015
name: Cosine Recall@5
- type: cosine_recall@10
value: 0.9114240711572316
name: Cosine Recall@10
- type: cosine_ndcg@10
value: 0.8303146530060463
name: Cosine Ndcg@10
- type: cosine_mrr@10
value: 0.8041402680161672
name: Cosine Mrr@10
- type: cosine_map@100
value: 0.8069259153944788
name: Cosine Map@100
- task:
type: information-retrieval
name: Information Retrieval
dataset:
name: dim 256
type: dim_256
metrics:
- type: cosine_accuracy@1
value: 0.7380709719262485
name: Cosine Accuracy@1
- type: cosine_accuracy@3
value: 0.8438339664597424
name: Cosine Accuracy@3
- type: cosine_accuracy@5
value: 0.8737607708700084
name: Cosine Accuracy@5
- type: cosine_accuracy@10
value: 0.9066987862503475
name: Cosine Accuracy@10
- type: cosine_precision@1
value: 0.7380709719262485
name: Cosine Precision@1
- type: cosine_precision@3
value: 0.2812779888199141
name: Cosine Precision@3
- type: cosine_precision@5
value: 0.17475215417400167
name: Cosine Precision@5
- type: cosine_precision@10
value: 0.09066987862503476
name: Cosine Precision@10
- type: cosine_recall@1
value: 0.7380709719262485
name: Cosine Recall@1
- type: cosine_recall@3
value: 0.8438339664597424
name: Cosine Recall@3
- type: cosine_recall@5
value: 0.8737607708700084
name: Cosine Recall@5
- type: cosine_recall@10
value: 0.9066987862503475
name: Cosine Recall@10
- type: cosine_ndcg@10
value: 0.823852114469264
name: Cosine Ndcg@10
- type: cosine_mrr@10
value: 0.797167126988547
name: Cosine Mrr@10
- type: cosine_map@100
value: 0.8001073541514653
name: Cosine Map@100
- task:
type: information-retrieval
name: Information Retrieval
dataset:
name: dim 128
type: dim_128
metrics:
- type: cosine_accuracy@1
value: 0.7227369591401834
name: Cosine Accuracy@1
- type: cosine_accuracy@3
value: 0.8282683220605949
name: Cosine Accuracy@3
- type: cosine_accuracy@5
value: 0.8625498007968128
name: Cosine Accuracy@5
- type: cosine_accuracy@10
value: 0.8983137218567591
name: Cosine Accuracy@10
- type: cosine_precision@1
value: 0.7227369591401834
name: Cosine Precision@1
- type: cosine_precision@3
value: 0.27608944068686486
name: Cosine Precision@3
- type: cosine_precision@5
value: 0.17250996015936257
name: Cosine Precision@5
- type: cosine_precision@10
value: 0.0898313721856759
name: Cosine Precision@10
- type: cosine_recall@1
value: 0.7227369591401834
name: Cosine Recall@1
- type: cosine_recall@3
value: 0.8282683220605949
name: Cosine Recall@3
- type: cosine_recall@5
value: 0.8625498007968128
name: Cosine Recall@5
- type: cosine_recall@10
value: 0.8983137218567591
name: Cosine Recall@10
- type: cosine_ndcg@10
value: 0.8111519983907917
name: Cosine Ndcg@10
- type: cosine_mrr@10
value: 0.7831791512429517
name: Cosine Mrr@10
- type: cosine_map@100
value: 0.7862551573873537
name: Cosine Map@100
- task:
type: information-retrieval
name: Information Retrieval
dataset:
name: dim 64
type: dim_64
metrics:
- type: cosine_accuracy@1
value: 0.694848512925044
name: Cosine Accuracy@1
- type: cosine_accuracy@3
value: 0.8039933290095432
name: Cosine Accuracy@3
- type: cosine_accuracy@5
value: 0.842258871490781
name: Cosine Accuracy@5
- type: cosine_accuracy@10
value: 0.8801538033910868
name: Cosine Accuracy@10
- type: cosine_precision@1
value: 0.694848512925044
name: Cosine Precision@1
- type: cosine_precision@3
value: 0.2679977763365144
name: Cosine Precision@3
- type: cosine_precision@5
value: 0.16845177429815622
name: Cosine Precision@5
- type: cosine_precision@10
value: 0.08801538033910869
name: Cosine Precision@10
- type: cosine_recall@1
value: 0.694848512925044
name: Cosine Recall@1
- type: cosine_recall@3
value: 0.8039933290095432
name: Cosine Recall@3
- type: cosine_recall@5
value: 0.842258871490781
name: Cosine Recall@5
- type: cosine_recall@10
value: 0.8801538033910868
name: Cosine Recall@10
- type: cosine_ndcg@10
value: 0.7874304560596916
name: Cosine Ndcg@10
- type: cosine_mrr@10
value: 0.757746147194181
name: Cosine Mrr@10
- type: cosine_map@100
value: 0.761272699392562
name: Cosine Map@100
---
# bkai-fine-tuned-legal
This is a [sentence-transformers](https://www.SBERT.net) model finetuned from [bkai-foundation-models/vietnamese-bi-encoder](https://huggingface.co/bkai-foundation-models/vietnamese-bi-encoder) on the json dataset. It maps sentences & paragraphs to a 768-dimensional dense vector space and can be used for semantic textual similarity, semantic search, paraphrase mining, text classification, clustering, and more.
## Model Details
### Model Description
- **Model Type:** Sentence Transformer
- **Base model:** [bkai-foundation-models/vietnamese-bi-encoder](https://huggingface.co/bkai-foundation-models/vietnamese-bi-encoder) <!-- at revision 84f9d9ada0d1a3c37557398b9ae9fcedcdf40be0 -->
- **Maximum Sequence Length:** 256 tokens
- **Output Dimensionality:** 768 dimensions
- **Similarity Function:** Cosine Similarity
- **Training Dataset:**
- json
- **Language:** vi
- **License:** apache-2.0
### Model Sources
- **Documentation:** [Sentence Transformers Documentation](https://sbert.net)
- **Repository:** [Sentence Transformers on GitHub](https://github.com/UKPLab/sentence-transformers)
- **Hugging Face:** [Sentence Transformers on Hugging Face](https://huggingface.co/models?library=sentence-transformers)
### Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 256, 'do_lower_case': False, 'architecture': 'RobertaModel'})
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False, 'pooling_mode_weightedmean_tokens': False, 'pooling_mode_lasttoken': False, 'include_prompt': True})
)
```
## Usage
### Direct Usage (Sentence Transformers)
First install the Sentence Transformers library:
```bash
pip install -U sentence-transformers
```
Then you can load this model and run inference.
```python
from sentence_transformers import SentenceTransformer
# Download from the 🤗 Hub
model = SentenceTransformer("huyydangg/thuvienphapluat_embedding_v6")
# Run inference
sentences = [
'cho mình hỏi về cách tính thanh_toán tiền_lương làm tăng giờ đối_với công_chức nhà_nước . tiền_lương một tháng để tính tăng giờ có bao_gồm phụ_cấp không ?',
'tiền_lương để tính tăng giờ đối_với công_chức có bao_gồm phụ_cấp không ?',
'trách_nhiệm pháp_lý của người sử_dụng lao_động khi người lao_động tử_vong do tai_nạn giao_thông trong quá_trình làm_việc " , " quyền_lợi của người lao_động tử_vong do tai_nạn lao_động ngoài trụ_sở làm_việc',
]
embeddings = model.encode(sentences)
print(embeddings.shape)
# [3, 768]
# Get the similarity scores for the embeddings
similarities = model.similarity(embeddings, embeddings)
print(similarities)
# tensor([[ 1.0000, 0.8958, -0.1026],
# [ 0.8958, 1.0000, -0.0500],
# [-0.1026, -0.0500, 1.0000]])
```
<!--
### Direct Usage (Transformers)
<details><summary>Click to see the direct usage in Transformers</summary>
</details>
-->
<!--
### Downstream Usage (Sentence Transformers)
You can finetune this model on your own dataset.
<details><summary>Click to expand</summary>
</details>
-->
<!--
### Out-of-Scope Use
*List how the model may foreseeably be misused and address what users ought not to do with the model.*
-->
## Evaluation
### Metrics
#### Information Retrieval
* Dataset: `dim_768`
* Evaluated with [<code>InformationRetrievalEvaluator</code>](https://sbert.net/docs/package_reference/sentence_transformer/evaluation.html#sentence_transformers.evaluation.InformationRetrievalEvaluator) with these parameters:
```json
{
"truncate_dim": 768
}
```
| Metric | Value |
|:--------------------|:-----------|
| cosine_accuracy@1 | 0.7492 |
| cosine_accuracy@3 | 0.8526 |
| cosine_accuracy@5 | 0.8839 |
| cosine_accuracy@10 | 0.9138 |
| cosine_precision@1 | 0.7492 |
| cosine_precision@3 | 0.2842 |
| cosine_precision@5 | 0.1768 |
| cosine_precision@10 | 0.0914 |
| cosine_recall@1 | 0.7492 |
| cosine_recall@3 | 0.8526 |
| cosine_recall@5 | 0.8839 |
| cosine_recall@10 | 0.9138 |
| **cosine_ndcg@10** | **0.8333** |
| cosine_mrr@10 | 0.8073 |
| cosine_map@100 | 0.81 |
#### Information Retrieval
* Dataset: `dim_512`
* Evaluated with [<code>InformationRetrievalEvaluator</code>](https://sbert.net/docs/package_reference/sentence_transformer/evaluation.html#sentence_transformers.evaluation.InformationRetrievalEvaluator) with these parameters:
```json
{
"truncate_dim": 512
}
```
| Metric | Value |
|:--------------------|:-----------|
| cosine_accuracy@1 | 0.7454 |
| cosine_accuracy@3 | 0.8508 |
| cosine_accuracy@5 | 0.8808 |
| cosine_accuracy@10 | 0.9114 |
| cosine_precision@1 | 0.7454 |
| cosine_precision@3 | 0.2836 |
| cosine_precision@5 | 0.1762 |
| cosine_precision@10 | 0.0911 |
| cosine_recall@1 | 0.7454 |
| cosine_recall@3 | 0.8508 |
| cosine_recall@5 | 0.8808 |
| cosine_recall@10 | 0.9114 |
| **cosine_ndcg@10** | **0.8303** |
| cosine_mrr@10 | 0.8041 |
| cosine_map@100 | 0.8069 |
#### Information Retrieval
* Dataset: `dim_256`
* Evaluated with [<code>InformationRetrievalEvaluator</code>](https://sbert.net/docs/package_reference/sentence_transformer/evaluation.html#sentence_transformers.evaluation.InformationRetrievalEvaluator) with these parameters:
```json
{
"truncate_dim": 256
}
```
| Metric | Value |
|:--------------------|:-----------|
| cosine_accuracy@1 | 0.7381 |
| cosine_accuracy@3 | 0.8438 |
| cosine_accuracy@5 | 0.8738 |
| cosine_accuracy@10 | 0.9067 |
| cosine_precision@1 | 0.7381 |
| cosine_precision@3 | 0.2813 |
| cosine_precision@5 | 0.1748 |
| cosine_precision@10 | 0.0907 |
| cosine_recall@1 | 0.7381 |
| cosine_recall@3 | 0.8438 |
| cosine_recall@5 | 0.8738 |
| cosine_recall@10 | 0.9067 |
| **cosine_ndcg@10** | **0.8239** |
| cosine_mrr@10 | 0.7972 |
| cosine_map@100 | 0.8001 |
#### Information Retrieval
* Dataset: `dim_128`
* Evaluated with [<code>InformationRetrievalEvaluator</code>](https://sbert.net/docs/package_reference/sentence_transformer/evaluation.html#sentence_transformers.evaluation.InformationRetrievalEvaluator) with these parameters:
```json
{
"truncate_dim": 128
}
```
| Metric | Value |
|:--------------------|:-----------|
| cosine_accuracy@1 | 0.7227 |
| cosine_accuracy@3 | 0.8283 |
| cosine_accuracy@5 | 0.8625 |
| cosine_accuracy@10 | 0.8983 |
| cosine_precision@1 | 0.7227 |
| cosine_precision@3 | 0.2761 |
| cosine_precision@5 | 0.1725 |
| cosine_precision@10 | 0.0898 |
| cosine_recall@1 | 0.7227 |
| cosine_recall@3 | 0.8283 |
| cosine_recall@5 | 0.8625 |
| cosine_recall@10 | 0.8983 |
| **cosine_ndcg@10** | **0.8112** |
| cosine_mrr@10 | 0.7832 |
| cosine_map@100 | 0.7863 |
#### Information Retrieval
* Dataset: `dim_64`
* Evaluated with [<code>InformationRetrievalEvaluator</code>](https://sbert.net/docs/package_reference/sentence_transformer/evaluation.html#sentence_transformers.evaluation.InformationRetrievalEvaluator) with these parameters:
```json
{
"truncate_dim": 64
}
```
| Metric | Value |
|:--------------------|:-----------|
| cosine_accuracy@1 | 0.6948 |
| cosine_accuracy@3 | 0.804 |
| cosine_accuracy@5 | 0.8423 |
| cosine_accuracy@10 | 0.8802 |
| cosine_precision@1 | 0.6948 |
| cosine_precision@3 | 0.268 |
| cosine_precision@5 | 0.1685 |
| cosine_precision@10 | 0.088 |
| cosine_recall@1 | 0.6948 |
| cosine_recall@3 | 0.804 |
| cosine_recall@5 | 0.8423 |
| cosine_recall@10 | 0.8802 |
| **cosine_ndcg@10** | **0.7874** |
| cosine_mrr@10 | 0.7577 |
| cosine_map@100 | 0.7613 |
<!--
## Bias, Risks and Limitations
*What are the known or foreseeable issues stemming from this model? You could also flag here known failure cases or weaknesses of the model.*
-->
<!--
### Recommendations
*What are recommendations with respect to the foreseeable issues? For example, filtering explicit content.*
-->
## Training Details
### Training Dataset
#### json
* Dataset: json
* Size: 172,688 training samples
* Columns: <code>anchor</code> and <code>positive</code>
* Approximate statistics based on the first 1000 samples:
| | anchor | positive |
|:--------|:-----------------------------------------------------------------------------------|:----------------------------------------------------------------------------------|
| type | string | string |
| details | <ul><li>min: 5 tokens</li><li>mean: 47.78 tokens</li><li>max: 256 tokens</li></ul> | <ul><li>min: 4 tokens</li><li>mean: 19.27 tokens</li><li>max: 80 tokens</li></ul> |
* Samples:
| anchor | positive |
|:---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|:--------------------------------------------------------------------------------------------------------------------------------------------------------------|
| <code>hàng_hóa có tổng_trị_giá hải_quan bao_nhiêu thì được miễn thuế_xuất_khẩu , thuế_nhập_khẩu ?</code> | <code>tổng_trị_giá hải_quan được miễn thuế_xuất_khẩu , thuế_nhập_khẩu</code> |
| <code>mình thanh_toán phí sửa_chữa cho nước_ngoài thì thanh_toán thuế nhà_thầu gồm mục nào , khi sửa_chữa máy_móc thực_hiện_tại việt_nam ?</code> | <code>quy_định về thuế nhà_thầu đối_với thanh_toán phí sửa_chữa máy_móc cho nhà_thầu nước_ngoài tại việt_nam</code> |
| <code>đồng_hồ điện nhà tôi và 2 hộ khác đang gắn trên trụ điện ở đất của một nhà hàng_xóm ( trụ điện này đã có từ lâu ) . nay nhà đó yêu_cầu chúng_tôi dời đồng_hồ điện đi chỗ khác với lý_do dây_điện trong đất nhà họ , họ sợ bị điện giật . việc họ bắt người khác dời đồng_hồ điện như_vậy có đúng quy_định pháp_luật hay không ? và nếu chủ nhà có cột điện như_vậy thì xử_lý ra sao ?</code> | <code>quyền và nghĩa_vụ liên_quan đến vị_trí lắp_đặt đồng_hồ điện trên trụ điện đặt trên đất của người khác và biện_pháp xử_lý theo pháp_luật việt_nam</code> |
* Loss: [<code>MatryoshkaLoss</code>](https://sbert.net/docs/package_reference/sentence_transformer/losses.html#matryoshkaloss) with these parameters:
```json
{
"loss": "CachedMultipleNegativesSymmetricRankingLoss",
"matryoshka_dims": [
768,
512,
256,
128,
64
],
"matryoshka_weights": [
1,
1,
1,
1,
1
],
"n_dims_per_step": -1
}
```
### Evaluation Dataset
#### json
* Dataset: json
* Size: 21,586 evaluation samples
* Columns: <code>anchor</code> and <code>positive</code>
* Approximate statistics based on the first 1000 samples:
| | anchor | positive |
|:--------|:-----------------------------------------------------------------------------------|:-----------------------------------------------------------------------------------|
| type | string | string |
| details | <ul><li>min: 5 tokens</li><li>mean: 48.05 tokens</li><li>max: 256 tokens</li></ul> | <ul><li>min: 5 tokens</li><li>mean: 19.81 tokens</li><li>max: 105 tokens</li></ul> |
* Samples:
| anchor | positive |
|:-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|:----------------------------------------------------------------------------------------------------------------------------------------------------|
| <code>xin cung_cấp thông_tư 15 / 2022 / tt - bqp ngày 10 / 02 / 2022 của bộ_trưởng bộ quốc_phòng_ban_hành điều_lệ công_tác bảo_vệ môi_trường của quân_đội nhân_dân việt_nam</code> | <code>văn_bản thông_tư 15 / 2022 / tt - bqp ngày 10 / 02 / 2022 về điều_lệ công_tác bảo_vệ môi_trường của quân_đội nhân_dân việt_nam</code> |
| <code>trường_hợp bhtn là trích tiền ra nộp cho bhxh tỉnh hay là tự trích ra trả cho người lao_động luôn ?</code> | <code>cách_thức quản_lý và chi_trả kinh_phí bảo_hiểm_thất_nghiệp tại việt_nam ( nộp vào quỹ bhxh tỉnh hay chi trực_tiếp cho người lao_động )</code> |
| <code>cho xin thêm văn_bản pháp_lý hướng_dẫn quy_trình kỹ_thuật_số 5,6,7,8 của bộ y_tế ban_hành ?</code> | <code>văn_bản pháp_lý hướng_dẫn quy_trình kỹ_thuật_số 5 , 6 , 7 , 8 của bộ y_tế</code> |
* Loss: [<code>MatryoshkaLoss</code>](https://sbert.net/docs/package_reference/sentence_transformer/losses.html#matryoshkaloss) with these parameters:
```json
{
"loss": "CachedMultipleNegativesSymmetricRankingLoss",
"matryoshka_dims": [
768,
512,
256,
128,
64
],
"matryoshka_weights": [
1,
1,
1,
1,
1
],
"n_dims_per_step": -1
}
```
### Training Hyperparameters
#### Non-Default Hyperparameters
- `eval_strategy`: epoch
- `per_device_train_batch_size`: 12
- `per_device_eval_batch_size`: 12
- `gradient_accumulation_steps`: 24
- `learning_rate`: 3e-05
- `weight_decay`: 0.15
- `max_grad_norm`: 0.65
- `num_train_epochs`: 12
- `lr_scheduler_type`: cosine
- `warmup_ratio`: 0.15
- `fp16`: True
- `load_best_model_at_end`: True
- `group_by_length`: True
- `batch_sampler`: no_duplicates
#### All Hyperparameters
<details><summary>Click to expand</summary>
- `overwrite_output_dir`: False
- `do_predict`: False
- `eval_strategy`: epoch
- `prediction_loss_only`: True
- `per_device_train_batch_size`: 12
- `per_device_eval_batch_size`: 12
- `per_gpu_train_batch_size`: None
- `per_gpu_eval_batch_size`: None
- `gradient_accumulation_steps`: 24
- `eval_accumulation_steps`: None
- `torch_empty_cache_steps`: None
- `learning_rate`: 3e-05
- `weight_decay`: 0.15
- `adam_beta1`: 0.9
- `adam_beta2`: 0.999
- `adam_epsilon`: 1e-08
- `max_grad_norm`: 0.65
- `num_train_epochs`: 12
- `max_steps`: -1
- `lr_scheduler_type`: cosine
- `lr_scheduler_kwargs`: {}
- `warmup_ratio`: 0.15
- `warmup_steps`: 0
- `log_level`: passive
- `log_level_replica`: warning
- `log_on_each_node`: True
- `logging_nan_inf_filter`: True
- `save_safetensors`: True
- `save_on_each_node`: False
- `save_only_model`: False
- `restore_callback_states_from_checkpoint`: False
- `no_cuda`: False
- `use_cpu`: False
- `use_mps_device`: False
- `seed`: 42
- `data_seed`: None
- `jit_mode_eval`: False
- `use_ipex`: False
- `bf16`: False
- `fp16`: True
- `fp16_opt_level`: O1
- `half_precision_backend`: auto
- `bf16_full_eval`: False
- `fp16_full_eval`: False
- `tf32`: None
- `local_rank`: 0
- `ddp_backend`: None
- `tpu_num_cores`: None
- `tpu_metrics_debug`: False
- `debug`: []
- `dataloader_drop_last`: False
- `dataloader_num_workers`: 0
- `dataloader_prefetch_factor`: None
- `past_index`: -1
- `disable_tqdm`: False
- `remove_unused_columns`: True
- `label_names`: None
- `load_best_model_at_end`: True
- `ignore_data_skip`: False
- `fsdp`: []
- `fsdp_min_num_params`: 0
- `fsdp_config`: {'min_num_params': 0, 'xla': False, 'xla_fsdp_v2': False, 'xla_fsdp_grad_ckpt': False}
- `fsdp_transformer_layer_cls_to_wrap`: None
- `accelerator_config`: {'split_batches': False, 'dispatch_batches': None, 'even_batches': True, 'use_seedable_sampler': True, 'non_blocking': False, 'gradient_accumulation_kwargs': None}
- `deepspeed`: None
- `label_smoothing_factor`: 0.0
- `optim`: adamw_torch_fused
- `optim_args`: None
- `adafactor`: False
- `group_by_length`: True
- `length_column_name`: length
- `ddp_find_unused_parameters`: None
- `ddp_bucket_cap_mb`: None
- `ddp_broadcast_buffers`: False
- `dataloader_pin_memory`: True
- `dataloader_persistent_workers`: False
- `skip_memory_metrics`: True
- `use_legacy_prediction_loop`: False
- `push_to_hub`: False
- `resume_from_checkpoint`: None
- `hub_model_id`: None
- `hub_strategy`: every_save
- `hub_private_repo`: None
- `hub_always_push`: False
- `hub_revision`: None
- `gradient_checkpointing`: False
- `gradient_checkpointing_kwargs`: None
- `include_inputs_for_metrics`: False
- `include_for_metrics`: []
- `eval_do_concat_batches`: True
- `fp16_backend`: auto
- `push_to_hub_model_id`: None
- `push_to_hub_organization`: None
- `mp_parameters`:
- `auto_find_batch_size`: False
- `full_determinism`: False
- `torchdynamo`: None
- `ray_scope`: last
- `ddp_timeout`: 1800
- `torch_compile`: False
- `torch_compile_backend`: None
- `torch_compile_mode`: None
- `include_tokens_per_second`: False
- `include_num_input_tokens_seen`: False
- `neftune_noise_alpha`: None
- `optim_target_modules`: None
- `batch_eval_metrics`: False
- `eval_on_start`: False
- `use_liger_kernel`: False
- `liger_kernel_config`: None
- `eval_use_gather_object`: False
- `average_tokens_across_devices`: False
- `prompts`: None
- `batch_sampler`: no_duplicates
- `multi_dataset_batch_sampler`: proportional
- `router_mapping`: {}
- `learning_rate_mapping`: {}
</details>
### Training Logs
| Epoch | Step | Training Loss | Validation Loss | dim_768_cosine_ndcg@10 | dim_512_cosine_ndcg@10 | dim_256_cosine_ndcg@10 | dim_128_cosine_ndcg@10 | dim_64_cosine_ndcg@10 |
|:-------:|:--------:|:-------------:|:---------------:|:----------------------:|:----------------------:|:----------------------:|:----------------------:|:---------------------:|
| 1.0 | 600 | 0.1485 | 0.0549 | 0.7989 | 0.7960 | 0.7876 | 0.7658 | 0.7262 |
| 2.0 | 1200 | 0.0417 | 0.0412 | 0.7845 | 0.7797 | 0.7637 | 0.7405 | 0.7100 |
| 3.0 | 1800 | 0.0223 | 0.0376 | 0.8183 | 0.8159 | 0.8074 | 0.7920 | 0.7626 |
| 4.0 | 2400 | 0.0155 | 0.0345 | 0.8057 | 0.8034 | 0.7933 | 0.7746 | 0.7482 |
| 5.0 | 3000 | 0.0125 | 0.0332 | 0.8298 | 0.8261 | 0.8184 | 0.8043 | 0.7759 |
| **6.0** | **3600** | **0.01** | **0.0296** | **0.8298** | **0.827** | **0.8188** | **0.8059** | **0.7798** |
| 7.0 | 4200 | 0.0087 | 0.0311 | 0.8333 | 0.8303 | 0.8239 | 0.8112 | 0.7874 |
* The bold row denotes the saved checkpoint.
### Framework Versions
- Python: 3.10.12
- Sentence Transformers: 5.1.0
- Transformers: 4.55.2
- PyTorch: 2.8.0+cu128
- Accelerate: 1.10.0
- Datasets: 4.0.0
- Tokenizers: 0.21.4
## Citation
### BibTeX
#### Sentence Transformers
```bibtex
@inproceedings{reimers-2019-sentence-bert,
title = "Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks",
author = "Reimers, Nils and Gurevych, Iryna",
booktitle = "Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing",
month = "11",
year = "2019",
publisher = "Association for Computational Linguistics",
url = "https://arxiv.org/abs/1908.10084",
}
```
#### MatryoshkaLoss
```bibtex
@misc{kusupati2024matryoshka,
title={Matryoshka Representation Learning},
author={Aditya Kusupati and Gantavya Bhatt and Aniket Rege and Matthew Wallingford and Aditya Sinha and Vivek Ramanujan and William Howard-Snyder and Kaifeng Chen and Sham Kakade and Prateek Jain and Ali Farhadi},
year={2024},
eprint={2205.13147},
archivePrefix={arXiv},
primaryClass={cs.LG}
}
```
<!--
## Glossary
*Clearly define terms in order to be accessible across audiences.*
-->
<!--
## Model Card Authors
*Lists the people who create the model card, providing recognition and accountability for the detailed work that goes into its construction.*
-->
<!--
## Model Card Contact
*Provides a way for people who have updates to the Model Card, suggestions, or questions, to contact the Model Card authors.*
-->
|
swiptit/blockassist-bc-polished_armored_mandrill_1755604721
|
swiptit
| 2025-08-19T11:59:23Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"polished armored mandrill",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T11:59:19Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- polished armored mandrill
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
sampingkaca72/blockassist-bc-armored_stealthy_elephant_1755602985
|
sampingkaca72
| 2025-08-19T11:56:01Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"armored stealthy elephant",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T11:55:58Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- armored stealthy elephant
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
kojeklollipop/blockassist-bc-spotted_amphibious_stork_1755602793
|
kojeklollipop
| 2025-08-19T11:54:00Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"spotted amphibious stork",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T11:53:57Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- spotted amphibious stork
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
lakelee/RLB_MLP_BC_v4.20250819.18.1
|
lakelee
| 2025-08-19T11:53:49Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"mlp_swiglu",
"generated_from_trainer",
"base_model:lakelee/RLB_MLP_BC_v4.20250819.18",
"base_model:finetune:lakelee/RLB_MLP_BC_v4.20250819.18",
"endpoints_compatible",
"region:us"
] | null | 2025-08-19T11:09:01Z |
---
library_name: transformers
base_model: lakelee/RLB_MLP_BC_v4.20250819.18
tags:
- generated_from_trainer
model-index:
- name: RLB_MLP_BC_v4.20250819.18.1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# RLB_MLP_BC_v4.20250819.18.1
This model is a fine-tuned version of [lakelee/RLB_MLP_BC_v4.20250819.18](https://huggingface.co/lakelee/RLB_MLP_BC_v4.20250819.18) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 2
- eval_batch_size: 8
- seed: 42
- optimizer: Use adamw_torch_fused with betas=(0.9,0.99) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 100
- num_epochs: 1.0
### Training results
### Framework versions
- Transformers 4.55.2
- Pytorch 2.8.0+cu128
- Tokenizers 0.21.4
|
AXERA-TECH/Qwen2.5-0.5B-Instruct-CTX-Int8
|
AXERA-TECH
| 2025-08-19T11:51:10Z | 10 | 0 |
transformers
|
[
"transformers",
"Qwen",
"Qwen2.5-0.5B-Instruct",
"Qwen2.5-0.5B-Instruct-GPTQ-Int8",
"GPTQ",
"en",
"base_model:Qwen/Qwen2.5-0.5B-Instruct-GPTQ-Int8",
"base_model:finetune:Qwen/Qwen2.5-0.5B-Instruct-GPTQ-Int8",
"license:bsd-3-clause",
"endpoints_compatible",
"region:us"
] | null | 2025-06-03T07:41:28Z |
---
library_name: transformers
license: bsd-3-clause
base_model:
- Qwen/Qwen2.5-0.5B-Instruct-GPTQ-Int8
tags:
- Qwen
- Qwen2.5-0.5B-Instruct
- Qwen2.5-0.5B-Instruct-GPTQ-Int8
- GPTQ
language:
- en
---
# Qwen2.5-0.5B-Instruct-GPTQ-Int8
This version of Qwen2.5-0.5B-Instruct-GPTQ-Int8 has been converted to run on the Axera NPU using **w8a16** quantization.
This model has been optimized with the following LoRA:
Compatible with Pulsar2 version: 4.2(Not released yet)
## Convert tools links:
For those who are interested in model conversion, you can try to export axmodel through the original repo : https://huggingface.co/Qwen/Qwen2.5-0.5B-Instruct-GPTQ-Int8
[Pulsar2 Link, How to Convert LLM from Huggingface to axmodel](https://pulsar2-docs.readthedocs.io/en/latest/appendix/build_llm.html)
[AXera NPU LLM Runtime](https://github.com/AXERA-TECH/ax-llm)
## Support Platform
- AX650
- AX650N DEMO Board
- [M4N-Dock(爱芯派Pro)](https://wiki.sipeed.com/hardware/zh/maixIV/m4ndock/m4ndock.html)
- [M.2 Accelerator card](https://axcl-docs.readthedocs.io/zh-cn/latest/doc_guide_hardware.html)
- AX630C
- *developing*
|Chips|w8a16|w4a16|
|--|--|--|
|AX650| 30 tokens/sec| TBD |
## How to use
Download all files from this repository to the device
```
root@ax650:/mnt/qtang/llm-test/qwen2.5-0.5b-ctx# tree -L 1
.
|-- main_ax650
|-- main_axcl_aarch64
|-- main_axcl_x86
|-- post_config.json
|-- qwen2.5-0.5b-gptq-int8-ctx-ax630c
|-- qwen2.5-0.5b-gptq-int8-ctx-ax650
|-- qwen2.5_tokenizer
|-- qwen2.5_tokenizer_uid.py
|-- run_qwen2.5_0.5b_gptq_int8_ctx_ax630c.sh
`-- run_qwen2.5_0.5b_gptq_int8_ctx_ax650.sh
3 directories, 7 files
```
#### Start the Tokenizer service
```
root@ax650:/mnt/qtang/llm-test/qwen2.5-0.5b-ctx# python3 qwen2.5_tokenizer_uid.py
Server running at http://0.0.0.0:12345
```
#### Inference with AX650 Host, such as M4N-Dock(爱芯派Pro) or AX650N DEMO Board
Open another terminal and run `run_qwen2.5_0.5b_gptq_int8_ax650.sh`
```
root@ax650:/mnt/qtang/llm-test/qwen2.5-0.5b-ctx# ./run_qwen2.5_0.5b_gptq_int8_ctx_ax650.sh
[I][ Init][ 110]: LLM init start
[I][ Init][ 34]: connect http://127.0.0.1:12345 ok
[I][ Init][ 57]: uid: cdeaf62e-0243-4dc9-b557-23a7c1ba7da1
bos_id: -1, eos_id: 151645
100% | ████████████████████████████████ | 27 / 27 [12.35s<12.35s, 2.19 count/s] init post axmodel ok,remain_cmm(3960 MB)
[I][ Init][ 188]: max_token_len : 2560
[I][ Init][ 193]: kv_cache_size : 128, kv_cache_num: 2560
[I][ Init][ 201]: prefill_token_num : 128
[I][ Init][ 205]: grp: 1, prefill_max_token_num : 1
[I][ Init][ 205]: grp: 2, prefill_max_token_num : 128
[I][ Init][ 205]: grp: 3, prefill_max_token_num : 512
[I][ Init][ 205]: grp: 4, prefill_max_token_num : 1024
[I][ Init][ 205]: grp: 5, prefill_max_token_num : 1536
[I][ Init][ 205]: grp: 6, prefill_max_token_num : 2048
[I][ Init][ 209]: prefill_max_token_num : 2048
[I][ load_config][ 282]: load config:
{
"enable_repetition_penalty": false,
"enable_temperature": false,
"enable_top_k_sampling": true,
"enable_top_p_sampling": false,
"penalty_window": 20,
"repetition_penalty": 1.2,
"temperature": 0.9,
"top_k": 1,
"top_p": 0.8
}
[I][ Init][ 218]: LLM init ok
Type "q" to exit, Ctrl+c to stop current running
[I][ GenerateKVCachePrefill][ 271]: input token num : 21, prefill_split_num : 1 prefill_grpid : 2
[I][ GenerateKVCachePrefill][ 308]: input_num_token:21
[I][ main][ 230]: precompute_len: 21
[I][ main][ 231]: system_prompt: You are Qwen, created by Alibaba Cloud. You are a helpful assistant.
prompt >> who are you?
[I][ SetKVCache][ 531]: prefill_grpid:2 kv_cache_num:128 precompute_len:38 input_num_token:12
[I][ SetKVCache][ 534]: current prefill_max_token_num:1920
[I][ Run][ 660]: input token num : 12, prefill_split_num : 1
[I][ Run][ 686]: input_num_token:12
[I][ Run][ 829]: ttft: 134.80 ms
I am Qwen, a large language model created by Alibaba Cloud. I am designed to assist with a wide range of tasks,
from general knowledge to specific areas such as science, technology, and more. How can I help you today?
[N][ Run][ 943]: hit eos,avg 30.88 token/s
[I][ GetKVCache][ 500]: precompute_len:98, remaining:1950
prompt >> what can you do?
[I][ SetKVCache][ 531]: prefill_grpid:2 kv_cache_num:128 precompute_len:98 input_num_token:13
[I][ SetKVCache][ 534]: current prefill_max_token_num:1920
[I][ Run][ 660]: input token num : 13, prefill_split_num : 1
[I][ Run][ 686]: input_num_token:13
[I][ Run][ 829]: ttft: 134.97 ms
I can answer questions, provide information, assist with tasks, and even engage in creative writing.
I'm here to help you with any questions or tasks you might have!
[N][ Run][ 943]: hit eos,avg 30.85 token/s
[I][ GetKVCache][ 500]: precompute_len:145, remaining:1903
```
|
swiptit/blockassist-bc-polished_armored_mandrill_1755604200
|
swiptit
| 2025-08-19T11:50:44Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"polished armored mandrill",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T11:50:40Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- polished armored mandrill
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
m-muraki/Qwen3-30B-A3B-Instruct-2507-FP8
|
m-muraki
| 2025-08-19T11:48:10Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen3_moe",
"text-generation",
"conversational",
"arxiv:2505.09388",
"base_model:Qwen/Qwen3-30B-A3B-Instruct-2507",
"base_model:quantized:Qwen/Qwen3-30B-A3B-Instruct-2507",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"fp8",
"region:us"
] |
text-generation
| 2025-08-19T11:47:10Z |
---
library_name: transformers
license: apache-2.0
license_link: https://huggingface.co/Qwen/Qwen3-30B-A3B-Instruct-2507-FP8/blob/main/LICENSE
pipeline_tag: text-generation
base_model:
- Qwen/Qwen3-30B-A3B-Instruct-2507
---
# Qwen3-30B-A3B-Instruct-2507-FP8
<a href="https://chat.qwen.ai/?model=Qwen3-30B-A3B-2507" target="_blank" style="margin: 2px;">
<img alt="Chat" src="https://img.shields.io/badge/%F0%9F%92%9C%EF%B8%8F%20Qwen%20Chat%20-536af5" style="display: inline-block; vertical-align: middle;"/>
</a>
## Highlights
We introduce the updated version of the **Qwen3-30B-A3B-FP8 non-thinking mode**, named **Qwen3-30B-A3B-Instruct-2507-FP8**, featuring the following key enhancements:
- **Significant improvements** in general capabilities, including **instruction following, logical reasoning, text comprehension, mathematics, science, coding and tool usage**.
- **Substantial gains** in long-tail knowledge coverage across **multiple languages**.
- **Markedly better alignment** with user preferences in **subjective and open-ended tasks**, enabling more helpful responses and higher-quality text generation.
- **Enhanced capabilities** in **256K long-context understanding**.
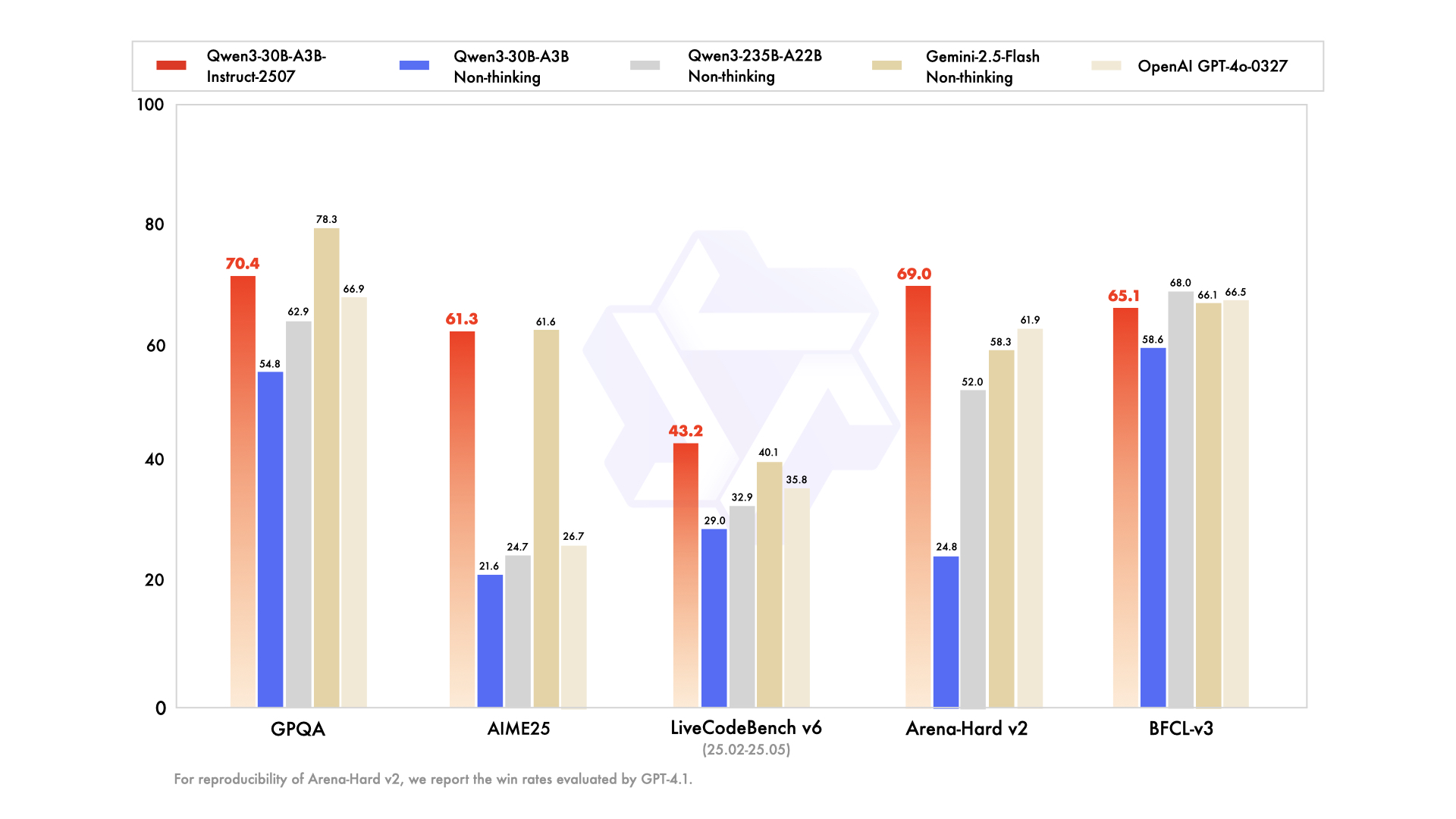
## Model Overview
This repo contains the FP8 version of **Qwen3-30B-A3B-Instruct-2507**, which has the following features:
- Type: Causal Language Models
- Training Stage: Pretraining & Post-training
- Number of Parameters: 30.5B in total and 3.3B activated
- Number of Paramaters (Non-Embedding): 29.9B
- Number of Layers: 48
- Number of Attention Heads (GQA): 32 for Q and 4 for KV
- Number of Experts: 128
- Number of Activated Experts: 8
- Context Length: **262,144 natively**.
**NOTE: This model supports only non-thinking mode and does not generate ``<think></think>`` blocks in its output. Meanwhile, specifying `enable_thinking=False` is no longer required.**
For more details, including benchmark evaluation, hardware requirements, and inference performance, please refer to our [blog](https://qwenlm.github.io/blog/qwen3/), [GitHub](https://github.com/QwenLM/Qwen3), and [Documentation](https://qwen.readthedocs.io/en/latest/).
## Performance
| | Deepseek-V3-0324 | GPT-4o-0327 | Gemini-2.5-Flash Non-Thinking | Qwen3-235B-A22B Non-Thinking | Qwen3-30B-A3B Non-Thinking | Qwen3-30B-A3B-Instruct-2507 |
|--- | --- | --- | --- | --- | --- | --- |
| **Knowledge** | | | | | | |
| MMLU-Pro | **81.2** | 79.8 | 81.1 | 75.2 | 69.1 | 78.4 |
| MMLU-Redux | 90.4 | **91.3** | 90.6 | 89.2 | 84.1 | 89.3 |
| GPQA | 68.4 | 66.9 | **78.3** | 62.9 | 54.8 | 70.4 |
| SuperGPQA | **57.3** | 51.0 | 54.6 | 48.2 | 42.2 | 53.4 |
| **Reasoning** | | | | | | |
| AIME25 | 46.6 | 26.7 | **61.6** | 24.7 | 21.6 | 61.3 |
| HMMT25 | 27.5 | 7.9 | **45.8** | 10.0 | 12.0 | 43.0 |
| ZebraLogic | 83.4 | 52.6 | 57.9 | 37.7 | 33.2 | **90.0** |
| LiveBench 20241125 | 66.9 | 63.7 | **69.1** | 62.5 | 59.4 | 69.0 |
| **Coding** | | | | | | |
| LiveCodeBench v6 (25.02-25.05) | **45.2** | 35.8 | 40.1 | 32.9 | 29.0 | 43.2 |
| MultiPL-E | 82.2 | 82.7 | 77.7 | 79.3 | 74.6 | **83.8** |
| Aider-Polyglot | 55.1 | 45.3 | 44.0 | **59.6** | 24.4 | 35.6 |
| **Alignment** | | | | | | |
| IFEval | 82.3 | 83.9 | 84.3 | 83.2 | 83.7 | **84.7** |
| Arena-Hard v2* | 45.6 | 61.9 | 58.3 | 52.0 | 24.8 | **69.0** |
| Creative Writing v3 | 81.6 | 84.9 | 84.6 | 80.4 | 68.1 | **86.0** |
| WritingBench | 74.5 | 75.5 | 80.5 | 77.0 | 72.2 | **85.5** |
| **Agent** | | | | | | |
| BFCL-v3 | 64.7 | 66.5 | 66.1 | **68.0** | 58.6 | 65.1 |
| TAU1-Retail | 49.6 | 60.3# | **65.2** | 65.2 | 38.3 | 59.1 |
| TAU1-Airline | 32.0 | 42.8# | **48.0** | 32.0 | 18.0 | 40.0 |
| TAU2-Retail | **71.1** | 66.7# | 64.3 | 64.9 | 31.6 | 57.0 |
| TAU2-Airline | 36.0 | 42.0# | **42.5** | 36.0 | 18.0 | 38.0 |
| TAU2-Telecom | **34.0** | 29.8# | 16.9 | 24.6 | 18.4 | 12.3 |
| **Multilingualism** | | | | | | |
| MultiIF | 66.5 | 70.4 | 69.4 | 70.2 | **70.8** | 67.9 |
| MMLU-ProX | 75.8 | 76.2 | **78.3** | 73.2 | 65.1 | 72.0 |
| INCLUDE | 80.1 | 82.1 | **83.8** | 75.6 | 67.8 | 71.9 |
| PolyMATH | 32.2 | 25.5 | 41.9 | 27.0 | 23.3 | **43.1** |
*: For reproducibility, we report the win rates evaluated by GPT-4.1.
\#: Results were generated using GPT-4o-20241120, as access to the native function calling API of GPT-4o-0327 was unavailable.
## Quickstart
The code of Qwen3-MoE has been in the latest Hugging Face `transformers` and we advise you to use the latest version of `transformers`.
With `transformers<4.51.0`, you will encounter the following error:
```
KeyError: 'qwen3_moe'
```
The following contains a code snippet illustrating how to use the model generate content based on given inputs.
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen3-30B-A3B-Instruct-2507-FP8"
# load the tokenizer and the model
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
# prepare the model input
prompt = "Give me a short introduction to large language model."
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# conduct text completion
generated_ids = model.generate(
**model_inputs,
max_new_tokens=16384
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
content = tokenizer.decode(output_ids, skip_special_tokens=True)
print("content:", content)
```
For deployment, you can use `sglang>=0.4.6.post1` or `vllm>=0.8.5` or to create an OpenAI-compatible API endpoint:
- SGLang:
```shell
python -m sglang.launch_server --model-path Qwen/Qwen3-30B-A3B-Instruct-2507-FP8 --context-length 262144
```
- vLLM:
```shell
vllm serve Qwen/Qwen3-30B-A3B-Instruct-2507-FP8 --max-model-len 262144
```
**Note: If you encounter out-of-memory (OOM) issues, consider reducing the context length to a shorter value, such as `32,768`.**
For local use, applications such as Ollama, LMStudio, MLX-LM, llama.cpp, and KTransformers have also supported Qwen3.
## Note on FP8
For convenience and performance, we have provided `fp8`-quantized model checkpoint for Qwen3, whose name ends with `-FP8`. The quantization method is fine-grained `fp8` quantization with block size of 128. You can find more details in the `quantization_config` field in `config.json`.
You can use the Qwen3-30B-A3B-Instruct-2507-FP8 model with serveral inference frameworks, including `transformers`, `sglang`, and `vllm`, as the original bfloat16 model.
## Agentic Use
Qwen3 excels in tool calling capabilities. We recommend using [Qwen-Agent](https://github.com/QwenLM/Qwen-Agent) to make the best use of agentic ability of Qwen3. Qwen-Agent encapsulates tool-calling templates and tool-calling parsers internally, greatly reducing coding complexity.
To define the available tools, you can use the MCP configuration file, use the integrated tool of Qwen-Agent, or integrate other tools by yourself.
```python
from qwen_agent.agents import Assistant
# Define LLM
llm_cfg = {
'model': 'Qwen3-30B-A3B-Instruct-2507-FP8',
# Use a custom endpoint compatible with OpenAI API:
'model_server': 'http://localhost:8000/v1', # api_base
'api_key': 'EMPTY',
}
# Define Tools
tools = [
{'mcpServers': { # You can specify the MCP configuration file
'time': {
'command': 'uvx',
'args': ['mcp-server-time', '--local-timezone=Asia/Shanghai']
},
"fetch": {
"command": "uvx",
"args": ["mcp-server-fetch"]
}
}
},
'code_interpreter', # Built-in tools
]
# Define Agent
bot = Assistant(llm=llm_cfg, function_list=tools)
# Streaming generation
messages = [{'role': 'user', 'content': 'https://qwenlm.github.io/blog/ Introduce the latest developments of Qwen'}]
for responses in bot.run(messages=messages):
pass
print(responses)
```
## Best Practices
To achieve optimal performance, we recommend the following settings:
1. **Sampling Parameters**:
- We suggest using `Temperature=0.7`, `TopP=0.8`, `TopK=20`, and `MinP=0`.
- For supported frameworks, you can adjust the `presence_penalty` parameter between 0 and 2 to reduce endless repetitions. However, using a higher value may occasionally result in language mixing and a slight decrease in model performance.
2. **Adequate Output Length**: We recommend using an output length of 16,384 tokens for most queries, which is adequate for instruct models.
3. **Standardize Output Format**: We recommend using prompts to standardize model outputs when benchmarking.
- **Math Problems**: Include "Please reason step by step, and put your final answer within \boxed{}." in the prompt.
- **Multiple-Choice Questions**: Add the following JSON structure to the prompt to standardize responses: "Please show your choice in the `answer` field with only the choice letter, e.g., `"answer": "C"`."
### Citation
If you find our work helpful, feel free to give us a cite.
```
@misc{qwen3technicalreport,
title={Qwen3 Technical Report},
author={Qwen Team},
year={2025},
eprint={2505.09388},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2505.09388},
}
```
|
milliarderdol/blockassist-bc-roaring_rough_scorpion_1755602125
|
milliarderdol
| 2025-08-19T11:47:44Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"roaring rough scorpion",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T11:47:23Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- roaring rough scorpion
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
dynokostya/sdxxl
|
dynokostya
| 2025-08-19T11:45:19Z | 0 | 0 | null |
[
"license:apache-2.0",
"region:us"
] | null | 2024-10-21T12:50:50Z |
---
license: apache-2.0
---
|
DeathBlade020/legal-llama-1b-4bit
|
DeathBlade020
| 2025-08-19T11:45:17Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"4-bit",
"bitsandbytes",
"region:us"
] |
text-generation
| 2025-08-19T11:42:55Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
VoilaRaj/80_BVN8XN
|
VoilaRaj
| 2025-08-19T11:41:42Z | 0 | 0 | null |
[
"safetensors",
"any-to-any",
"omega",
"omegalabs",
"bittensor",
"agi",
"license:mit",
"region:us"
] |
any-to-any
| 2025-08-19T11:37:53Z |
---
license: mit
tags:
- any-to-any
- omega
- omegalabs
- bittensor
- agi
---
This is an Any-to-Any model checkpoint for the OMEGA Labs x Bittensor Any-to-Any subnet.
Check out the [git repo](https://github.com/omegalabsinc/omegalabs-anytoany-bittensor) and find OMEGA on X: [@omegalabsai](https://x.com/omegalabsai).
|
rmtlabs/s-ai-qwen-azure-adapter
|
rmtlabs
| 2025-08-19T11:41:04Z | 0 | 0 |
peft
|
[
"peft",
"safetensors",
"base_model:adapter:Qwen/Qwen2.5-14B-Instruct",
"lora",
"transformers",
"text-generation",
"conversational",
"arxiv:1910.09700",
"base_model:Qwen/Qwen2.5-14B-Instruct",
"region:us"
] |
text-generation
| 2025-08-19T11:40:49Z |
---
base_model: Qwen/Qwen2.5-14B-Instruct
library_name: peft
pipeline_tag: text-generation
tags:
- base_model:adapter:Qwen/Qwen2.5-14B-Instruct
- lora
- transformers
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.17.0
|
ihsanridzi/blockassist-bc-wiry_flexible_owl_1755602016
|
ihsanridzi
| 2025-08-19T11:40:48Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"wiry flexible owl",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T11:40:45Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- wiry flexible owl
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
helmutsukocok/blockassist-bc-loud_scavenging_kangaroo_1755601929
|
helmutsukocok
| 2025-08-19T11:39:34Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"loud scavenging kangaroo",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T11:39:31Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- loud scavenging kangaroo
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Kumo2023/nupur
|
Kumo2023
| 2025-08-19T11:39:05Z | 0 | 0 |
diffusers
|
[
"diffusers",
"flux",
"lora",
"replicate",
"text-to-image",
"en",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"license:other",
"region:us"
] |
text-to-image
| 2025-08-19T10:32:39Z |
---
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
language:
- en
tags:
- flux
- diffusers
- lora
- replicate
base_model: "black-forest-labs/FLUX.1-dev"
pipeline_tag: text-to-image
# widget:
# - text: >-
# prompt
# output:
# url: https://...
instance_prompt: TOK
---
# Nupur
<Gallery />
## About this LoRA
This is a [LoRA](https://replicate.com/docs/guides/working-with-loras) for the FLUX.1-dev text-to-image model. It can be used with diffusers or ComfyUI.
It was trained on [Replicate](https://replicate.com/) using AI toolkit: https://replicate.com/ostris/flux-dev-lora-trainer/train
## Trigger words
You should use `TOK` to trigger the image generation.
## Run this LoRA with an API using Replicate
```py
import replicate
input = {
"prompt": "TOK",
"lora_weights": "https://huggingface.co/Kumo2023/nupur/resolve/main/lora.safetensors"
}
output = replicate.run(
"black-forest-labs/flux-dev-lora",
input=input
)
for index, item in enumerate(output):
with open(f"output_{index}.webp", "wb") as file:
file.write(item.read())
```
## Use it with the [🧨 diffusers library](https://github.com/huggingface/diffusers)
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained('black-forest-labs/FLUX.1-dev', torch_dtype=torch.float16).to('cuda')
pipeline.load_lora_weights('Kumo2023/nupur', weight_name='lora.safetensors')
image = pipeline('TOK').images[0]
```
For more details, including weighting, merging and fusing LoRAs, check the [documentation on loading LoRAs in diffusers](https://huggingface.co/docs/diffusers/main/en/using-diffusers/loading_adapters)
## Training details
- Steps: 6000
- Learning rate: 0.0004
- LoRA rank: 16
## Contribute your own examples
You can use the [community tab](https://huggingface.co/Kumo2023/nupur/discussions) to add images that show off what you’ve made with this LoRA.
|
tgrhn/whisper-large-v3-turbo_finetuned
|
tgrhn
| 2025-08-19T11:36:45Z | 9 | 0 |
transformers
|
[
"transformers",
"safetensors",
"whisper",
"automatic-speech-recognition",
"generated_from_trainer",
"base_model:openai/whisper-large-v3-turbo",
"base_model:finetune:openai/whisper-large-v3-turbo",
"license:mit",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2025-08-11T13:22:55Z |
---
library_name: transformers
license: mit
base_model: openai/whisper-large-v3-turbo
tags:
- generated_from_trainer
model-index:
- name: whisper-large-v3-turbo_finetuned
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# whisper-large-v3-turbo_finetuned
This model is a fine-tuned version of [openai/whisper-large-v3-turbo](https://huggingface.co/openai/whisper-large-v3-turbo) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1695
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Use adamw_torch with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 6
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:------:|:----:|:---------------:|
| 0.2076 | 0.6502 | 1000 | 0.1968 |
| 0.1642 | 1.3004 | 2000 | 0.1797 |
| 0.1641 | 1.9506 | 3000 | 0.1721 |
| 0.132 | 2.6008 | 4000 | 0.1691 |
| 0.112 | 3.2510 | 5000 | 0.1694 |
| 0.1087 | 3.9012 | 6000 | 0.1669 |
| 0.0915 | 4.5514 | 7000 | 0.1695 |
| 0.085 | 5.2016 | 8000 | 0.1702 |
| 0.0789 | 5.8518 | 9000 | 0.1695 |
### Framework versions
- Transformers 4.52.1
- Pytorch 2.6.0+cu124
- Datasets 3.0.0
- Tokenizers 0.21.1
|
lavavaa/blockassist-bc-giant_knobby_chimpanzee_1755603296
|
lavavaa
| 2025-08-19T11:35:39Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"giant knobby chimpanzee",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T11:35:36Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- giant knobby chimpanzee
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
TuKoResearch/WavCochV8192
|
TuKoResearch
| 2025-08-19T11:34:53Z | 318 | 0 |
transformers
|
[
"transformers",
"safetensors",
"WavCoch.WavCoch",
"feature-extraction",
"audio",
"speech",
"tokenizer",
"quantizer",
"cochlear",
"custom_code",
"en",
"license:apache-2.0",
"region:us"
] |
feature-extraction
| 2025-04-15T23:01:03Z |
---
language:
- en
library_name: transformers
pipeline_tag: feature-extraction
tags:
- audio
- speech
- tokenizer
- quantizer
- cochlear
- custom_code
license: apache-2.0 # ← adjust if different
pretty_name: WavCoch (8192-code speech tokenizer)
---
# WavCochV8192 — 8,192-code speech tokenizer (cochlear tokens)
**WavCochV8192** is a biologically-inspired, learned **audio quantizer** that maps a raw waveform to **discrete "cochlear tokens".** It is used as the tokenizer for the AuriStream autoregressive speech/language model (e.g., [TuKoResearch/AuriStream1B_librilight_ckpt500k](https://huggingface.co/TuKoResearch/AuriStream1B_librilight_ckpt500k)). The model is trained on LibriSpeech960 and encodes audio into a time–frequency representation ([Cochleagram; Feather et al., 2023 Nat Neuro](https://github.com/jenellefeather/chcochleagram)) and reads out **8,192-way discrete codes** through a low-bit latent bottleneck (LFQ). These tokens can be fed to a transformer LM for **representation learning** and **next-token prediction** (speech continuation).
> **API at a glance**
> - **Input:** mono waveform at 16 kHz (pytorch tensor float32), shape **(B, 1, T)**
> - **Output:** token IDs, shape **(B, L)** returned as dictionary under key **`"input_ids"`**
> - Implemented as a `transformers` custom model — load with `trust_remote_code=True`.
---
## Installation
```bash
pip install -U torch torchaudio transformers
```
---
## Quickstart — Quantize a waveform into cochlear tokens
```python
import torch, torchaudio
from transformers import AutoModel
device = "cuda" if torch.cuda.is_available() else "cpu"
# Load the quantizer
quantizer = AutoModel.from_pretrained(
"TuKoResearch/WavCochV8192", trust_remote_code=True
).to(device).eval()
# Load & prep audio (mono, 16 kHz)
wav, sr = torchaudio.load("sample.wav")
if wav.size(0) > 1: # stereo -> mono
wav = wav.mean(dim=0, keepdim=True)
if sr != 16_000:
wav = torchaudio.transforms.Resample(sr, 16_000)(wav)
sr = 16_000
# Forward pass — returns a dict with "input_ids" = (B, L)
with torch.no_grad():
out = quantizer(wav.unsqueeze(0).to(device)) # (1, 1, T) -> dict
token_ids = out["input_ids"] # LongTensor (1, L)
print("Token IDs shape:", token_ids.shape)
```
---
## Intended uses & limitations
- **Uses:** tokenization for speech LM training; compact storage/streaming of speech as discrete IDs, loosely inspired by human biology.
- **Limitations:** trained only on spoken English, so might not perform as well for other languages and non-speech sounds.
---
## Citation
If you use this tokenizer please cite:
```bibtex
@inproceedings{tuckute2025cochleartokens,
title = {Representing Speech Through Autoregressive Prediction of Cochlear Tokens},
author = {Greta Tuckute and Klemen Kotar and Evelina Fedorenko and Daniel Yamins},
booktitle = {Interspeech 2025},
year = {2025},
pages = {2180--2184},
doi = {10.21437/Interspeech.2025-2044},
issn = {2958-1796}
}
```
---
## Related
- **AuriStream LM:** https://huggingface.co/TuKoResearch/AuriStream1B_librilight_ckpt500k
- **Org:** https://huggingface.co/TuKoResearch
|
sankar-asthramedtech/Full-Precision_Whisper-Medium_and_LoRA-Adapters_Merged_Model_V-1.1
|
sankar-asthramedtech
| 2025-08-19T11:34:27Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"whisper",
"automatic-speech-recognition",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2025-08-19T11:30:30Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
quantumxnode/blockassist-bc-dormant_peckish_seahorse_1755601588
|
quantumxnode
| 2025-08-19T11:32:30Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"dormant peckish seahorse",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T11:32:26Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- dormant peckish seahorse
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
m-muraki/Qwen3-30B-A3B-Thinking-2507-FP8
|
m-muraki
| 2025-08-19T11:29:52Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen3_moe",
"text-generation",
"conversational",
"arxiv:2505.09388",
"base_model:Qwen/Qwen3-30B-A3B-Thinking-2507",
"base_model:quantized:Qwen/Qwen3-30B-A3B-Thinking-2507",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"fp8",
"region:us"
] |
text-generation
| 2025-08-19T11:28:58Z |
---
library_name: transformers
license: apache-2.0
license_link: https://huggingface.co/Qwen/Qwen3-30B-A3B-Thinking-2507-FP8/blob/main/LICENSE
pipeline_tag: text-generation
base_model:
- Qwen/Qwen3-30B-A3B-Thinking-2507
---
# Qwen3-30B-A3B-Thinking-2507
<a href="https://chat.qwen.ai/?model=Qwen3-30B-A3B-2507" target="_blank" style="margin: 2px;">
<img alt="Chat" src="https://img.shields.io/badge/%F0%9F%92%9C%EF%B8%8F%20Qwen%20Chat%20-536af5" style="display: inline-block; vertical-align: middle;"/>
</a>
## Highlights
Over the past three months, we have continued to scale the **thinking capability** of Qwen3-30B-A3B, improving both the **quality and depth** of reasoning. We are pleased to introduce **Qwen3-30B-A3B-Thinking-2507**, featuring the following key enhancements:
- **Significantly improved performance** on reasoning tasks, including logical reasoning, mathematics, science, coding, and academic benchmarks that typically require human expertise.
- **Markedly better general capabilities**, such as instruction following, tool usage, text generation, and alignment with human preferences.
- **Enhanced 256K long-context understanding** capabilities.
**NOTE**: This version has an increased thinking length. We strongly recommend its use in highly complex reasoning tasks.
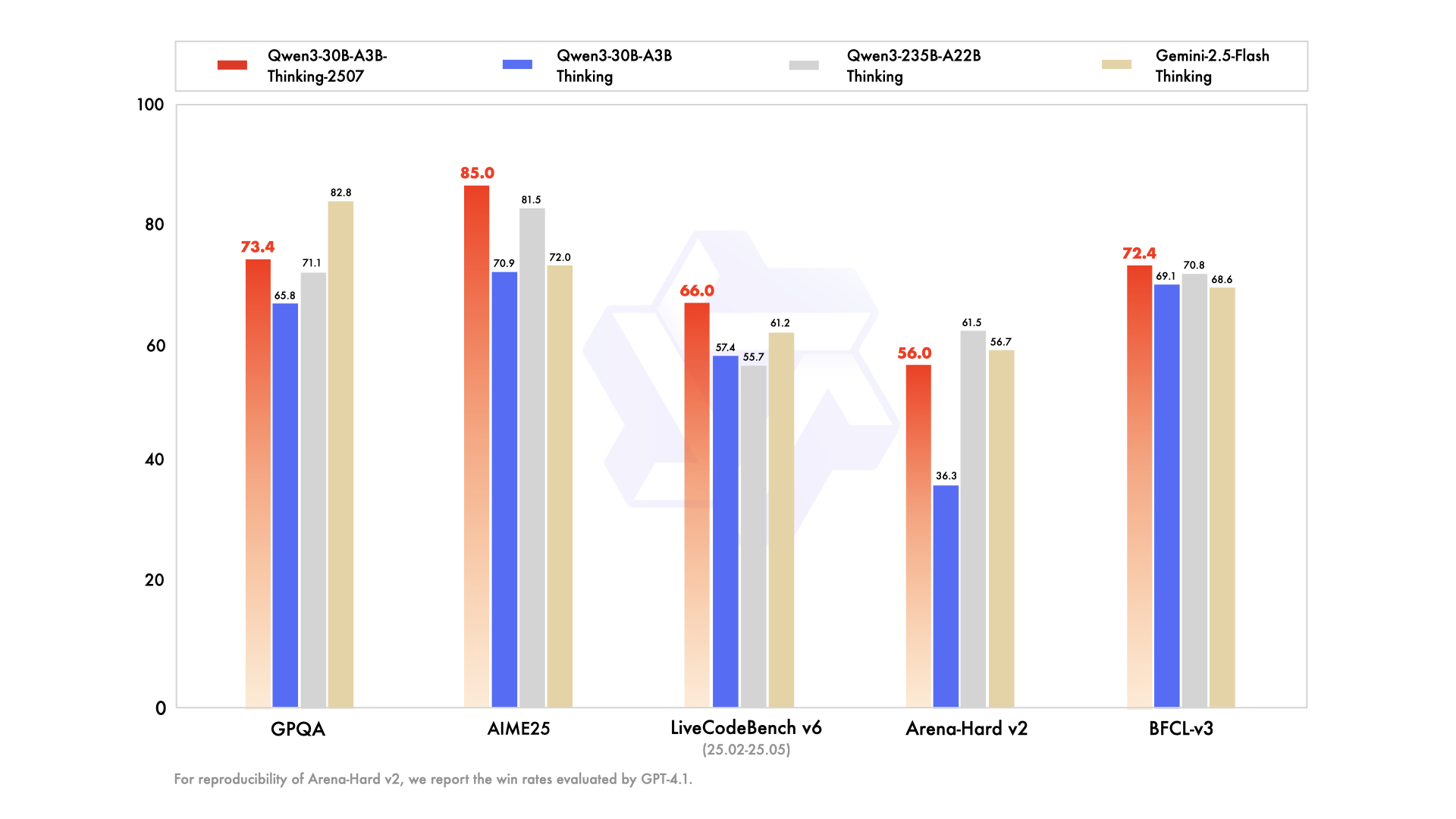
## Model Overview
This repo contains the FP8 version of **Qwen3-30B-A3B-Thinking-2507**, which has the following features:
- Type: Causal Language Models
- Training Stage: Pretraining & Post-training
- Number of Parameters: 30.5B in total and 3.3B activated
- Number of Paramaters (Non-Embedding): 29.9B
- Number of Layers: 48
- Number of Attention Heads (GQA): 32 for Q and 4 for KV
- Number of Experts: 128
- Number of Activated Experts: 8
- Context Length: **262,144 natively**.
**NOTE: This model supports only thinking mode. Meanwhile, specifying `enable_thinking=True` is no longer required.**
Additionally, to enforce model thinking, the default chat template automatically includes `<think>`. Therefore, it is normal for the model's output to contain only `</think>` without an explicit opening `<think>` tag.
For more details, including benchmark evaluation, hardware requirements, and inference performance, please refer to our [blog](https://qwenlm.github.io/blog/qwen3/), [GitHub](https://github.com/QwenLM/Qwen3), and [Documentation](https://qwen.readthedocs.io/en/latest/).
## Performance
| | Gemini2.5-Flash-Thinking | Qwen3-235B-A22B Thinking | Qwen3-30B-A3B Thinking | Qwen3-30B-A3B-Thinking-2507 |
|--- | --- | --- | --- | --- |
| **Knowledge** | | | | |
| MMLU-Pro | 81.9 | **82.8** | 78.5 | 80.9 |
| MMLU-Redux | 92.1 | **92.7** | 89.5 | 91.4 |
| GPQA | **82.8** | 71.1 | 65.8 | 73.4 |
| SuperGPQA | 57.8 | **60.7** | 51.8 | 56.8 |
| **Reasoning** | | | | |
| AIME25 | 72.0 | 81.5 | 70.9 | **85.0** |
| HMMT25 | 64.2 | 62.5 | 49.8 | **71.4** |
| LiveBench 20241125 | 74.3 | **77.1** | 74.3 | 76.8 |
| **Coding** | | | | |
| LiveCodeBench v6 (25.02-25.05) | 61.2 | 55.7 | 57.4 | **66.0** |
| CFEval | 1995 | **2056** | 1940 | 2044 |
| OJBench | 23.5 | **25.6** | 20.7 | 25.1 |
| **Alignment** | | | | |
| IFEval | **89.8** | 83.4 | 86.5 | 88.9 |
| Arena-Hard v2$ | 56.7 | **61.5** | 36.3 | 56.0 |
| Creative Writing v3 | **85.0** | 84.6 | 79.1 | 84.4 |
| WritingBench | 83.9 | 80.3 | 77.0 | **85.0** |
| **Agent** | | | | |
| BFCL-v3 | 68.6 | 70.8 | 69.1 | **72.4** |
| TAU1-Retail | 65.2 | 54.8 | 61.7 | **67.8** |
| TAU1-Airline | **54.0** | 26.0 | 32.0 | 48.0 |
| TAU2-Retail | **66.7** | 40.4 | 34.2 | 58.8 |
| TAU2-Airline | 52.0 | 30.0 | 36.0 | **58.0** |
| TAU2-Telecom | **31.6** | 21.9 | 22.8 | 26.3 |
| **Multilingualism** | | | | |
| MultiIF | 74.4 | 71.9 | 72.2 | **76.4** |
| MMLU-ProX | **80.2** | 80.0 | 73.1 | 76.4 |
| INCLUDE | **83.9** | 78.7 | 71.9 | 74.4 |
| PolyMATH | 49.8 | **54.7** | 46.1 | 52.6 |
$ For reproducibility, we report the win rates evaluated by GPT-4.1.
\& For highly challenging tasks (including PolyMATH and all reasoning and coding tasks), we use an output length of 81,920 tokens. For all other tasks, we set the output length to 32,768.
## Quickstart
The code of Qwen3-MoE has been in the latest Hugging Face `transformers` and we advise you to use the latest version of `transformers`.
With `transformers<4.51.0`, you will encounter the following error:
```
KeyError: 'qwen3_moe'
```
The following contains a code snippet illustrating how to use the model generate content based on given inputs.
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen3-30B-A3B-Thinking-2507-FP8"
# load the tokenizer and the model
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
# prepare the model input
prompt = "Give me a short introduction to large language model."
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# conduct text completion
generated_ids = model.generate(
**model_inputs,
max_new_tokens=32768
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
# parsing thinking content
try:
# rindex finding 151668 (</think>)
index = len(output_ids) - output_ids[::-1].index(151668)
except ValueError:
index = 0
thinking_content = tokenizer.decode(output_ids[:index], skip_special_tokens=True).strip("\n")
content = tokenizer.decode(output_ids[index:], skip_special_tokens=True).strip("\n")
print("thinking content:", thinking_content) # no opening <think> tag
print("content:", content)
```
For deployment, you can use `sglang>=0.4.6.post1` or `vllm>=0.8.5` or to create an OpenAI-compatible API endpoint:
- SGLang:
```shell
python -m sglang.launch_server --model-path Qwen/Qwen3-30B-A3B-Thinking-2507-FP8 --context-length 262144 --reasoning-parser deepseek-r1
```
- vLLM:
```shell
vllm serve Qwen/Qwen3-30B-A3B-Thinking-2507-FP8 --max-model-len 262144 --enable-reasoning --reasoning-parser deepseek_r1
```
**Note: If you encounter out-of-memory (OOM) issues, you may consider reducing the context length to a smaller value. However, since the model may require longer token sequences for reasoning, we strongly recommend using a context length greater than 131,072 when possible.**
For local use, applications such as Ollama, LMStudio, MLX-LM, llama.cpp, and KTransformers have also supported Qwen3.
## Note on FP8
For convenience and performance, we have provided `fp8`-quantized model checkpoint for Qwen3, whose name ends with `-FP8`. The quantization method is fine-grained `fp8` quantization with block size of 128. You can find more details in the `quantization_config` field in `config.json`.
You can use the Qwen3-30B-A3B-Thinking-2507-FP8 model with serveral inference frameworks, including `transformers`, `sglang`, and `vllm`, as the original bfloat16 model.
## Agentic Use
Qwen3 excels in tool calling capabilities. We recommend using [Qwen-Agent](https://github.com/QwenLM/Qwen-Agent) to make the best use of agentic ability of Qwen3. Qwen-Agent encapsulates tool-calling templates and tool-calling parsers internally, greatly reducing coding complexity.
To define the available tools, you can use the MCP configuration file, use the integrated tool of Qwen-Agent, or integrate other tools by yourself.
```python
from qwen_agent.agents import Assistant
# Define LLM
# Using Alibaba Cloud Model Studio
llm_cfg = {
'model': 'qwen3-30b-a3b-thinking-2507-FP8',
'model_type': 'qwen_dashscope',
}
# Using OpenAI-compatible API endpoint. It is recommended to disable the reasoning and the tool call parsing
# functionality of the deployment frameworks and let Qwen-Agent automate the related operations. For example,
# `VLLM_USE_MODELSCOPE=true vllm serve Qwen/Qwen3-30B-A3B-Thinking-2507-FP8 --served-model-name Qwen3-30B-A3B-Thinking-2507-FP8 --tensor-parallel-size 8 --max-model-len 262144`.
#
# llm_cfg = {
# 'model': 'Qwen3-30B-A3B-Thinking-2507-FP8',
#
# # Use a custom endpoint compatible with OpenAI API:
# 'model_server': 'http://localhost:8000/v1', # api_base without reasoning and tool call parsing
# 'api_key': 'EMPTY',
# 'generate_cfg': {
# 'thought_in_content': True,
# },
# }
# Define Tools
tools = [
{'mcpServers': { # You can specify the MCP configuration file
'time': {
'command': 'uvx',
'args': ['mcp-server-time', '--local-timezone=Asia/Shanghai']
},
"fetch": {
"command": "uvx",
"args": ["mcp-server-fetch"]
}
}
},
'code_interpreter', # Built-in tools
]
# Define Agent
bot = Assistant(llm=llm_cfg, function_list=tools)
# Streaming generation
messages = [{'role': 'user', 'content': 'https://qwenlm.github.io/blog/ Introduce the latest developments of Qwen'}]
for responses in bot.run(messages=messages):
pass
print(responses)
```
## Best Practices
To achieve optimal performance, we recommend the following settings:
1. **Sampling Parameters**:
- We suggest using `Temperature=0.6`, `TopP=0.95`, `TopK=20`, and `MinP=0`.
- For supported frameworks, you can adjust the `presence_penalty` parameter between 0 and 2 to reduce endless repetitions. However, using a higher value may occasionally result in language mixing and a slight decrease in model performance.
2. **Adequate Output Length**: We recommend using an output length of 32,768 tokens for most queries. For benchmarking on highly complex problems, such as those found in math and programming competitions, we suggest setting the max output length to 81,920 tokens. This provides the model with sufficient space to generate detailed and comprehensive responses, thereby enhancing its overall performance.
3. **Standardize Output Format**: We recommend using prompts to standardize model outputs when benchmarking.
- **Math Problems**: Include "Please reason step by step, and put your final answer within \boxed{}." in the prompt.
- **Multiple-Choice Questions**: Add the following JSON structure to the prompt to standardize responses: "Please show your choice in the `answer` field with only the choice letter, e.g., `"answer": "C"`."
4. **No Thinking Content in History**: In multi-turn conversations, the historical model output should only include the final output part and does not need to include the thinking content. It is implemented in the provided chat template in Jinja2. However, for frameworks that do not directly use the Jinja2 chat template, it is up to the developers to ensure that the best practice is followed.
### Citation
If you find our work helpful, feel free to give us a cite.
```
@misc{qwen3technicalreport,
title={Qwen3 Technical Report},
author={Qwen Team},
year={2025},
eprint={2505.09388},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2505.09388},
}
```
|
KCS97/candle
|
KCS97
| 2025-08-19T11:29:49Z | 0 | 0 |
diffusers
|
[
"diffusers",
"tensorboard",
"safetensors",
"text-to-image",
"dreambooth",
"diffusers-training",
"stable-diffusion",
"stable-diffusion-diffusers",
"base_model:stable-diffusion-v1-5/stable-diffusion-v1-5",
"base_model:finetune:stable-diffusion-v1-5/stable-diffusion-v1-5",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] |
text-to-image
| 2025-08-19T11:18:19Z |
---
base_model: stable-diffusion-v1-5/stable-diffusion-v1-5
library_name: diffusers
license: creativeml-openrail-m
inference: true
instance_prompt: a photo of sks candle
tags:
- text-to-image
- dreambooth
- diffusers-training
- stable-diffusion
- stable-diffusion-diffusers
---
<!-- This model card has been generated automatically according to the information the training script had access to. You
should probably proofread and complete it, then remove this comment. -->
# DreamBooth - KCS97/candle
This is a dreambooth model derived from stable-diffusion-v1-5/stable-diffusion-v1-5. The weights were trained on a photo of sks candle using [DreamBooth](https://dreambooth.github.io/).
You can find some example images in the following.
DreamBooth for the text encoder was enabled: False.
## Intended uses & limitations
#### How to use
```python
# TODO: add an example code snippet for running this diffusion pipeline
```
#### Limitations and bias
[TODO: provide examples of latent issues and potential remediations]
## Training details
[TODO: describe the data used to train the model]
|
rhecker/block-clean-realssense-policy
|
rhecker
| 2025-08-19T11:25:59Z | 0 | 0 |
lerobot
|
[
"lerobot",
"safetensors",
"act",
"robotics",
"dataset:rhecker/block-clean-realsense",
"arxiv:2304.13705",
"license:apache-2.0",
"region:us"
] |
robotics
| 2025-08-19T11:25:42Z |
---
datasets: rhecker/block-clean-realsense
library_name: lerobot
license: apache-2.0
model_name: act
pipeline_tag: robotics
tags:
- act
- robotics
- lerobot
---
# Model Card for act
<!-- Provide a quick summary of what the model is/does. -->
[Action Chunking with Transformers (ACT)](https://huggingface.co/papers/2304.13705) is an imitation-learning method that predicts short action chunks instead of single steps. It learns from teleoperated data and often achieves high success rates.
This policy has been trained and pushed to the Hub using [LeRobot](https://github.com/huggingface/lerobot).
See the full documentation at [LeRobot Docs](https://huggingface.co/docs/lerobot/index).
---
## How to Get Started with the Model
For a complete walkthrough, see the [training guide](https://huggingface.co/docs/lerobot/il_robots#train-a-policy).
Below is the short version on how to train and run inference/eval:
### Train from scratch
```bash
python -m lerobot.scripts.train \
--dataset.repo_id=${HF_USER}/<dataset> \
--policy.type=act \
--output_dir=outputs/train/<desired_policy_repo_id> \
--job_name=lerobot_training \
--policy.device=cuda \
--policy.repo_id=${HF_USER}/<desired_policy_repo_id>
--wandb.enable=true
```
_Writes checkpoints to `outputs/train/<desired_policy_repo_id>/checkpoints/`._
### Evaluate the policy/run inference
```bash
python -m lerobot.record \
--robot.type=so100_follower \
--dataset.repo_id=<hf_user>/eval_<dataset> \
--policy.path=<hf_user>/<desired_policy_repo_id> \
--episodes=10
```
Prefix the dataset repo with **eval\_** and supply `--policy.path` pointing to a local or hub checkpoint.
---
## Model Details
- **License:** apache-2.0
|
SP4ND4N/Qwen3-0.6B-2025-08-19_15-15-49-fp8-merged
|
SP4ND4N
| 2025-08-19T11:24:47Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen3",
"text-generation",
"text-generation-inference",
"unsloth",
"conversational",
"en",
"base_model:unsloth/Qwen3-0.6B",
"base_model:finetune:unsloth/Qwen3-0.6B",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-19T11:18:55Z |
---
base_model: unsloth/Qwen3-0.6B
tags:
- text-generation-inference
- transformers
- unsloth
- qwen3
license: apache-2.0
language:
- en
---
# Uploaded finetuned model
- **Developed by:** SP4ND4N
- **License:** apache-2.0
- **Finetuned from model :** unsloth/Qwen3-0.6B
This qwen3 model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
iscchang/t2s
|
iscchang
| 2025-08-19T11:19:38Z | 0 | 0 |
peft
|
[
"peft",
"safetensors",
"base_model:adapter:Qwen/Qwen2.5-Coder-7B-Instruct",
"lora",
"transformers",
"text-generation",
"conversational",
"arxiv:1910.09700",
"base_model:Qwen/Qwen2.5-Coder-7B-Instruct",
"region:us"
] |
text-generation
| 2025-08-19T11:16:49Z |
---
base_model: Qwen/Qwen2.5-Coder-7B-Instruct
library_name: peft
pipeline_tag: text-generation
tags:
- base_model:adapter:Qwen/Qwen2.5-Coder-7B-Instruct
- lora
- transformers
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.17.0
|
SP4ND4N/Qwen3-0.6B-2025-08-19_15-15-49
|
SP4ND4N
| 2025-08-19T11:17:19Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"qwen3",
"trl",
"en",
"base_model:unsloth/Qwen3-0.6B",
"base_model:finetune:unsloth/Qwen3-0.6B",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-08-19T11:17:10Z |
---
base_model: unsloth/Qwen3-0.6B
tags:
- text-generation-inference
- transformers
- unsloth
- qwen3
- trl
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** SP4ND4N
- **License:** apache-2.0
- **Finetuned from model :** unsloth/Qwen3-0.6B
This qwen3 model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
koloni/blockassist-bc-deadly_graceful_stingray_1755600447
|
koloni
| 2025-08-19T11:15:34Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"deadly graceful stingray",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T11:15:30Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- deadly graceful stingray
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Dranitsyna/merged_model
|
Dranitsyna
| 2025-08-19T11:13:38Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-08-19T11:13:31Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
aleebaster/blockassist-bc-sly_eager_boar_1755600473
|
aleebaster
| 2025-08-19T11:13:15Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"sly eager boar",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T11:13:09Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- sly eager boar
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
RajorshiGon/intent-classifier
|
RajorshiGon
| 2025-08-19T11:12:10Z | 0 | 0 |
peft
|
[
"peft",
"safetensors",
"base_model:adapter:unsloth/gemma-3-270m-it-unsloth-bnb-4bit",
"lora",
"sft",
"transformers",
"trl",
"unsloth",
"arxiv:1910.09700",
"base_model:unsloth/gemma-3-270m-it-unsloth-bnb-4bit",
"region:us"
] | null | 2025-08-19T11:08:18Z |
---
base_model: unsloth/gemma-3-270m-it-unsloth-bnb-4bit
library_name: peft
tags:
- base_model:adapter:unsloth/gemma-3-270m-it-unsloth-bnb-4bit
- lora
- sft
- transformers
- trl
- unsloth
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.17.0
|
hakimjustbao/blockassist-bc-raging_subtle_wasp_1755600296
|
hakimjustbao
| 2025-08-19T11:12:02Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"raging subtle wasp",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T11:11:58Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- raging subtle wasp
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Mostefa-Terbeche/diabetic-retinopathy-combined-resnet50-gentle-20250620-195237
|
Mostefa-Terbeche
| 2025-08-19T11:10:57Z | 0 | 0 | null |
[
"diabetic-retinopathy",
"medical-imaging",
"pytorch",
"computer-vision",
"retinal-imaging",
"dataset:combined",
"license:apache-2.0",
"model-index",
"region:us"
] | null | 2025-08-19T10:19:37Z |
---
license: apache-2.0
tags:
- diabetic-retinopathy
- medical-imaging
- pytorch
- computer-vision
- retinal-imaging
datasets:
- combined
metrics:
- accuracy
- quadratic-kappa
- auc
model-index:
- name: combined_resnet50_gentle
results:
- task:
type: image-classification
name: Diabetic Retinopathy Classification
dataset:
type: combined
name: COMBINED
metrics:
- type: accuracy
value: 0.5665365507452094
- type: quadratic-kappa
value: 0.7742569342039034
---
# Diabetic Retinopathy Classification Model
## Model Description
This model is trained for diabetic retinopathy classification using the resnet50 architecture on the combined dataset with gentle preprocessing.
## Model Details
- **Architecture**: resnet50
- **Dataset**: combined
- **Preprocessing**: gentle
- **Training Date**: 20250620-195237
- **Task**: 5-class diabetic retinopathy grading (0-4)
- **Directory**: combined_resnet50_20250620-195237_new
## Performance
- **Test Accuracy**: 0.5665365507452094
- **Test Quadratic Kappa**: 0.7742569342039034
- **Validation Kappa**: 0.7742569342039034
## Usage
```python
import torch
from huggingface_hub import hf_hub_download
# Download model
model_path = hf_hub_download(
repo_id="your-username/diabetic-retinopathy-combined-resnet50-gentle",
filename="model_best.pt"
)
# Load model
model = torch.load(model_path, map_location='cpu')
```
## Classes
- 0: No DR (No diabetic retinopathy)
- 1: Mild DR (Mild non-proliferative diabetic retinopathy)
- 2: Moderate DR (Moderate non-proliferative diabetic retinopathy)
- 3: Severe DR (Severe non-proliferative diabetic retinopathy)
- 4: Proliferative DR (Proliferative diabetic retinopathy)
## Citation
If you use this model, please cite your research paper/thesis.
|
forstseh/blockassist-bc-arctic_soaring_heron_1755597883
|
forstseh
| 2025-08-19T11:10:51Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"arctic soaring heron",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T11:10:35Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- arctic soaring heron
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Reallusion/fluxLora_Kevin
|
Reallusion
| 2025-08-19T11:09:50Z | 0 | 0 | null |
[
"text-to-image",
"en",
"dataset:crystantine/fluxgym",
"base_model:black-forest-labs/FLUX.1-Fill-dev",
"base_model:finetune:black-forest-labs/FLUX.1-Fill-dev",
"license:creativeml-openrail-m",
"region:us"
] |
text-to-image
| 2025-08-19T10:22:28Z |
---
license: creativeml-openrail-m
datasets:
- crystantine/fluxgym
language:
- en
base_model:
- black-forest-labs/FLUX.1-dev
- black-forest-labs/FLUX.1-Fill-dev
pipeline_tag: text-to-image
---
|
hasdal/21aa9f58-1f69-4055-9211-a03c7007ec6e
|
hasdal
| 2025-08-19T11:07:33Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"mixtral",
"trl",
"en",
"base_model:TitanML/tiny-mixtral",
"base_model:finetune:TitanML/tiny-mixtral",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-08-19T11:07:31Z |
---
base_model: TitanML/tiny-mixtral
tags:
- text-generation-inference
- transformers
- unsloth
- mixtral
- trl
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** hasdal
- **License:** apache-2.0
- **Finetuned from model :** TitanML/tiny-mixtral
This mixtral model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
BSC-LT/salamandraTA-2B-instruct-GGUF
|
BSC-LT
| 2025-08-19T11:07:00Z | 45 | 1 |
transformers
|
[
"transformers",
"gguf",
"llama",
"text-generation",
"translation",
"bg",
"ca",
"cs",
"cy",
"da",
"de",
"el",
"en",
"es",
"et",
"eu",
"fi",
"fr",
"ga",
"gl",
"hr",
"hu",
"it",
"lt",
"lv",
"mt",
"nl",
"nb",
"no",
"nn",
"oc",
"pl",
"pt",
"ro",
"ru",
"sl",
"sk",
"sr",
"sv",
"uk",
"ast",
"an",
"base_model:BSC-LT/salamandraTA-2b-instruct",
"base_model:quantized:BSC-LT/salamandraTA-2b-instruct",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us",
"conversational"
] |
translation
| 2025-05-26T13:59:56Z |
---
library_name: transformers
license: apache-2.0
pipeline_tag: translation
language:
- bg
- ca
- cs
- cy
- da
- de
- el
- en
- es
- et
- eu
- fi
- fr
- ga
- gl
- hr
- hu
- it
- lt
- lv
- mt
- nl
- nb
- 'no'
- nn
- oc
- pl
- pt
- ro
- ru
- sl
- sk
- sr
- sv
- uk
- ast
- an
base_model:
- BSC-LT/salamandraTA-2b-instruct
---

# SalamandraTA-2B-instruct-GGUF Model Card
This model is the GGUF-quantized version of [SalamandraTA-2b-instruct](https://huggingface.co/BSC-LT/salamandraTA-2b-instruct).
The model weights are quantized from FP16 to Q4_K_M quantization Q8_0 (8-bit quantization), (4-bit weights with K-means clustering quantization) and Q3_K_M (3-but weights with K-means clustering quantization) using the [Llama.cpp](https://github.com/ggml-org/llama.cpp) framework.
Inferencing with this model can be done using [VLLM](https://docs.vllm.ai/en/stable/models/engine_args.html).
SalamandraTA-2b-instruct is a translation LLM that has been instruction-tuned from SalamandraTA-2b-base.
The base model results from continually pre-training [Salamandra-2b](https://huggingface.co/BSC-LT/salamandra-2b) on parallel data and has not been published,
but is reserved for internal use.
SalamandraTA-2b-instruct is proficient in 35 European languages (plus 3 varieties) and supports translation-related tasks,
namely: sentence-level-translation, paragraph-level-translation, automatic post-editing, grammar checking, machine translation evaluation,
alternative translations, named-entity-recognition and context-aware translation.
> [!WARNING]
> **DISCLAIMER:** This version of Salamandra is tailored exclusively for translation tasks. It lacks chat capabilities and has not been trained with any chat instructions.
---
The entire Salamandra family is released under a permissive [Apache 2.0 license]((https://www.apache.org/licenses/LICENSE-2.0)).
## How to Use
The following example code works under ``Python 3.10.4``, ``vllm==0.7.3``, ``torch==2.5.1`` and ``torchvision==0.20.1``, though it should run on
any current version of the libraries. This is an example of translation using the model:
```
from huggingface_hub import snapshot_download
from vllm import LLM, SamplingParams
model_dir = snapshot_download(repo_id="BSC-LT/salamandraTA-2B-instruct-GGUF", revision="main")
model_name = "salamandrata_2b_inst_q4.gguf"
llm = LLM(model=model_dir + '/' + model_name, tokenizer=model_dir)
source = "Spanish"
target = "English"
sentence = "Ayer se fue, tomó sus cosas y se puso a navegar. Una camisa, un pantalón vaquero y una canción, dónde irá, dónde irá. Se despidió, y decidió batirse en duelo con el mar. Y recorrer el mundo en su velero. Y navegar, nai-na-na, navegar."
prompt = f"Translate the following text from {source} into {target}.\\n{source}: {sentence} \\n{target}:"
messages = [{'role': 'user', 'content': prompt}]
outputs = llm.chat(messages,
sampling_params=SamplingParams(
temperature=0.1,
stop_token_ids=[5],
max_tokens=200)
)[0].outputs
print(outputs[0].text)
```
## Additional information
### Author
The Language Technologies Unit from Barcelona Supercomputing Center.
### Contact
For further information, please send an email to <langtech@bsc.es>.
### Copyright
Copyright(c) 2025 by Language Technologies Unit, Barcelona Supercomputing Center.
### Funding
This work has been promoted and financed by the Government of Catalonia through the [Aina Project](https://projecteaina.cat/).
This work is funded by the _Ministerio para la Transformación Digital y de la Función Pública_ - Funded by EU – NextGenerationEU
within the framework of [ILENIA Project](https://proyectoilenia.es/) with reference 2022/TL22/00215337.
### Acknowledgements
The success of this project has been made possible thanks to the invaluable contributions of our partners in the [ILENIA Project](https://proyectoilenia.es/):
[HiTZ](http://hitz.ehu.eus/es), and [CiTIUS](https://citius.gal/es/).
Their efforts have been instrumental in advancing our work, and we sincerely appreciate their help and support.
### Disclaimer
### Disclaimer
Be aware that the model may contain biases or other unintended distortions.
When third parties deploy systems or provide services based on this model, or use the model themselves,
they bear the responsibility for mitigating any associated risks and ensuring compliance with applicable regulations,
including those governing the use of Artificial Intelligence.
The Barcelona Supercomputing Center, as the owner and creator of the model, shall not be held liable for any outcomes resulting from third-party use.
### License
[Apache License, Version 2.0](https://www.apache.org/licenses/LICENSE-2.0)
|
ihsanridzi/blockassist-bc-wiry_flexible_owl_1755599920
|
ihsanridzi
| 2025-08-19T11:06:17Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"wiry flexible owl",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T11:06:13Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- wiry flexible owl
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
JackTheKing/Qwen2.5-0.5B-FT
|
JackTheKing
| 2025-08-19T11:04:02Z | 0 | 0 | null |
[
"gguf",
"qwen2",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-08-19T10:56:40Z |
---
license: apache-2.0
---
|
maxidesantafe11/blockassist-bc-deft_monstrous_finch_1755599670
|
maxidesantafe11
| 2025-08-19T11:02:25Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"deft monstrous finch",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T11:02:21Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- deft monstrous finch
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
pempekmangedd/blockassist-bc-patterned_sturdy_dolphin_1755599691
|
pempekmangedd
| 2025-08-19T11:01:58Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"patterned sturdy dolphin",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T11:01:54Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- patterned sturdy dolphin
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
quantumxnode/blockassist-bc-dormant_peckish_seahorse_1755599676
|
quantumxnode
| 2025-08-19T11:01:10Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"dormant peckish seahorse",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T11:01:07Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- dormant peckish seahorse
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
lakelee/RLB_MLP_BC_v4.20250819.18
|
lakelee
| 2025-08-19T10:59:47Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"mlp_swiglu",
"generated_from_trainer",
"base_model:lakelee/RLB_MLP_TSC_v1.20250818.16",
"base_model:finetune:lakelee/RLB_MLP_TSC_v1.20250818.16",
"endpoints_compatible",
"region:us"
] | null | 2025-08-19T10:33:07Z |
---
library_name: transformers
base_model: lakelee/RLB_MLP_TSC_v1.20250818.16
tags:
- generated_from_trainer
model-index:
- name: RLB_MLP_BC_v4.20250819.18
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# RLB_MLP_BC_v4.20250819.18
This model is a fine-tuned version of [lakelee/RLB_MLP_TSC_v1.20250818.16](https://huggingface.co/lakelee/RLB_MLP_TSC_v1.20250818.16) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 1
- eval_batch_size: 8
- seed: 42
- optimizer: Use adamw_torch_fused with betas=(0.9,0.95) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 1000
- num_epochs: 1.0
### Training results
### Framework versions
- Transformers 4.55.2
- Pytorch 2.8.0+cu128
- Tokenizers 0.21.4
|
katanyasekolah/blockassist-bc-silky_sprightly_cassowary_1755599195
|
katanyasekolah
| 2025-08-19T10:56:13Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"silky sprightly cassowary",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T10:56:08Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- silky sprightly cassowary
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Sayemahsjn/blockassist-bc-playful_feline_octopus_1755599673
|
Sayemahsjn
| 2025-08-19T10:53:45Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"playful feline octopus",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T10:53:41Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- playful feline octopus
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
0xaoyama/blockassist-bc-muscular_zealous_gorilla_1755600753
|
0xaoyama
| 2025-08-19T10:53:08Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"muscular zealous gorilla",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T10:52:57Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- muscular zealous gorilla
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
0xaoyama/blockassist-bc-muscular_zealous_gorilla_1755600583
|
0xaoyama
| 2025-08-19T10:50:20Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"muscular zealous gorilla",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T10:50:07Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- muscular zealous gorilla
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
abcorrea/p2-v7
|
abcorrea
| 2025-08-19T10:47:37Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen3",
"text-generation",
"generated_from_trainer",
"sft",
"trl",
"conversational",
"base_model:abcorrea/p2-v6",
"base_model:finetune:abcorrea/p2-v6",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-19T10:37:42Z |
---
base_model: abcorrea/p2-v6
library_name: transformers
model_name: p2-v7
tags:
- generated_from_trainer
- sft
- trl
licence: license
---
# Model Card for p2-v7
This model is a fine-tuned version of [abcorrea/p2-v6](https://huggingface.co/abcorrea/p2-v6).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="abcorrea/p2-v7", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
This model was trained with SFT.
### Framework versions
- TRL: 0.19.1
- Transformers: 4.52.1
- Pytorch: 2.7.0
- Datasets: 4.0.0
- Tokenizers: 0.21.1
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
AIMindaeng/Qwen2.5-VL-3B-Instruct-Thinking
|
AIMindaeng
| 2025-08-19T10:41:50Z | 0 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"generated_from_trainer",
"trl",
"grpo",
"dataset:lmms-lab/multimodal-open-r1-8k-verified",
"arxiv:2402.03300",
"base_model:Qwen/Qwen2.5-VL-3B-Instruct",
"base_model:finetune:Qwen/Qwen2.5-VL-3B-Instruct",
"endpoints_compatible",
"region:us"
] | null | 2025-08-19T05:24:56Z |
---
base_model: Qwen/Qwen2.5-VL-3B-Instruct
datasets: lmms-lab/multimodal-open-r1-8k-verified
library_name: transformers
model_name: Qwen2.5-VL-3B-Instruct-Thinking
tags:
- generated_from_trainer
- trl
- grpo
licence: license
---
# Model Card for Qwen2.5-VL-3B-Instruct-Thinking
This model is a fine-tuned version of [Qwen/Qwen2.5-VL-3B-Instruct](https://huggingface.co/Qwen/Qwen2.5-VL-3B-Instruct) on the [lmms-lab/multimodal-open-r1-8k-verified](https://huggingface.co/datasets/lmms-lab/multimodal-open-r1-8k-verified) dataset.
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="AIMindaeng/Qwen2.5-VL-3B-Instruct-Thinking", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
This model was trained with GRPO, a method introduced in [DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models](https://huggingface.co/papers/2402.03300).
### Framework versions
- TRL: 0.21.0
- Transformers: 4.55.2
- Pytorch: 2.8.0
- Datasets: 4.0.0
- Tokenizers: 0.21.4
## Citations
Cite GRPO as:
```bibtex
@article{zhihong2024deepseekmath,
title = {{DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models}},
author = {Zhihong Shao and Peiyi Wang and Qihao Zhu and Runxin Xu and Junxiao Song and Mingchuan Zhang and Y. K. Li and Y. Wu and Daya Guo},
year = 2024,
eprint = {arXiv:2402.03300},
}
```
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
zagabi/klue-roberta-base-klue-sts2
|
zagabi
| 2025-08-19T10:41:20Z | 0 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"safetensors",
"roberta",
"feature-extraction",
"sentence-similarity",
"transformers",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2025-08-19T10:40:55Z |
---
library_name: sentence-transformers
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
---
# {MODEL_NAME}
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
<!--- Describe your model here -->
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('{MODEL_NAME}')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('{MODEL_NAME}')
model = AutoModel.from_pretrained('{MODEL_NAME}')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, mean pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
<!--- Describe how your model was evaluated -->
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name={MODEL_NAME})
## Training
The model was trained with the parameters:
**DataLoader**:
`torch.utils.data.dataloader.DataLoader` of length 657 with parameters:
```
{'batch_size': 16, 'sampler': 'torch.utils.data.sampler.RandomSampler', 'batch_sampler': 'torch.utils.data.sampler.BatchSampler'}
```
**Loss**:
`sentence_transformers.losses.CosineSimilarityLoss.CosineSimilarityLoss`
Parameters of the fit()-Method:
```
{
"epochs": 4,
"evaluation_steps": 1000,
"evaluator": "sentence_transformers.evaluation.EmbeddingSimilarityEvaluator.EmbeddingSimilarityEvaluator",
"max_grad_norm": 1,
"optimizer_class": "<class 'torch.optim.adamw.AdamW'>",
"optimizer_params": {
"lr": 2e-05
},
"scheduler": "WarmupLinear",
"steps_per_epoch": null,
"warmup_steps": 100,
"weight_decay": 0.01
}
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 512, 'do_lower_case': False}) with Transformer model: RobertaModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False, 'pooling_mode_weightedmean_tokens': False, 'pooling_mode_lasttoken': False, 'include_prompt': True})
)
```
## Citing & Authors
<!--- Describe where people can find more information -->
|
VoilaRaj/80_10tpIL
|
VoilaRaj
| 2025-08-19T10:39:45Z | 0 | 0 | null |
[
"safetensors",
"any-to-any",
"omega",
"omegalabs",
"bittensor",
"agi",
"license:mit",
"region:us"
] |
any-to-any
| 2025-08-19T10:35:52Z |
---
license: mit
tags:
- any-to-any
- omega
- omegalabs
- bittensor
- agi
---
This is an Any-to-Any model checkpoint for the OMEGA Labs x Bittensor Any-to-Any subnet.
Check out the [git repo](https://github.com/omegalabsinc/omegalabs-anytoany-bittensor) and find OMEGA on X: [@omegalabsai](https://x.com/omegalabsai).
|
Neelectric/Llama-3.2-3B-Instruct_baseline_v00.01
|
Neelectric
| 2025-08-19T10:38:30Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"generated_from_trainer",
"open-r1",
"trl",
"sft",
"conversational",
"dataset:open-r1/OpenR1-Math-220k",
"base_model:meta-llama/Llama-3.2-3B-Instruct",
"base_model:finetune:meta-llama/Llama-3.2-3B-Instruct",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-19T10:27:14Z |
---
base_model: meta-llama/Llama-3.2-3B-Instruct
datasets: open-r1/OpenR1-Math-220k
library_name: transformers
model_name: Llama-3.2-3B-Instruct_baseline_v00.01
tags:
- generated_from_trainer
- open-r1
- trl
- sft
licence: license
---
# Model Card for Llama-3.2-3B-Instruct_baseline_v00.01
This model is a fine-tuned version of [meta-llama/Llama-3.2-3B-Instruct](https://huggingface.co/meta-llama/Llama-3.2-3B-Instruct) on the [open-r1/OpenR1-Math-220k](https://huggingface.co/datasets/open-r1/OpenR1-Math-220k) dataset.
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="Neelectric/Llama-3.2-3B-Instruct_baseline_v00.01", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="150" height="24"/>](https://wandb.ai/neelectric/sem/runs/tt37a6tu)
This model was trained with SFT.
### Framework versions
- TRL: 0.21.0
- Transformers: 4.55.0
- Pytorch: 2.7.1
- Datasets: 3.6.0
- Tokenizers: 0.21.4
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
WangChongan/rl-CartPole-v1
|
WangChongan
| 2025-08-19T10:37:33Z | 0 | 0 | null |
[
"CartPole-v1",
"reinforce",
"reinforcement-learning",
"custom-implementation",
"deep-rl-class",
"model-index",
"region:us"
] |
reinforcement-learning
| 2025-08-19T10:22:13Z |
---
tags:
- CartPole-v1
- reinforce
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: rl-CartPole-v1
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: CartPole-v1
type: CartPole-v1
metrics:
- type: mean_reward
value: 500.00 +/- 0.00
name: mean_reward
verified: false
---
# **Reinforce** Agent playing **CartPole-v1**
This is a trained model of a **Reinforce** agent playing **CartPole-v1** .
To learn to use this model and train yours check Unit 4 of the Deep Reinforcement Learning Course: https://huggingface.co/deep-rl-course/unit4/introduction
|
gchrisoh/Midm-2.0-Base-Instruct-Q4_K_M-GGUF
|
gchrisoh
| 2025-08-19T10:35:49Z | 0 | 0 |
transformers
|
[
"transformers",
"gguf",
"KT",
"K-intelligence",
"Mi:dm",
"llama-cpp",
"gguf-my-repo",
"text-generation",
"en",
"ko",
"base_model:K-intelligence/Midm-2.0-Base-Instruct",
"base_model:quantized:K-intelligence/Midm-2.0-Base-Instruct",
"license:mit",
"endpoints_compatible",
"region:us",
"conversational"
] |
text-generation
| 2025-08-19T10:35:20Z |
---
license: mit
language:
- en
- ko
tags:
- KT
- K-intelligence
- Mi:dm
- llama-cpp
- gguf-my-repo
inference: true
pipeline_tag: text-generation
library_name: transformers
base_model: K-intelligence/Midm-2.0-Base-Instruct
---
# gchrisoh/Midm-2.0-Base-Instruct-Q4_K_M-GGUF
This model was converted to GGUF format from [`K-intelligence/Midm-2.0-Base-Instruct`](https://huggingface.co/K-intelligence/Midm-2.0-Base-Instruct) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/K-intelligence/Midm-2.0-Base-Instruct) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew (works on Mac and Linux)
```bash
brew install llama.cpp
```
Invoke the llama.cpp server or the CLI.
### CLI:
```bash
llama-cli --hf-repo gchrisoh/Midm-2.0-Base-Instruct-Q4_K_M-GGUF --hf-file midm-2.0-base-instruct-q4_k_m.gguf -p "The meaning to life and the universe is"
```
### Server:
```bash
llama-server --hf-repo gchrisoh/Midm-2.0-Base-Instruct-Q4_K_M-GGUF --hf-file midm-2.0-base-instruct-q4_k_m.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
Step 1: Clone llama.cpp from GitHub.
```
git clone https://github.com/ggerganov/llama.cpp
```
Step 2: Move into the llama.cpp folder and build it with `LLAMA_CURL=1` flag along with other hardware-specific flags (for ex: LLAMA_CUDA=1 for Nvidia GPUs on Linux).
```
cd llama.cpp && LLAMA_CURL=1 make
```
Step 3: Run inference through the main binary.
```
./llama-cli --hf-repo gchrisoh/Midm-2.0-Base-Instruct-Q4_K_M-GGUF --hf-file midm-2.0-base-instruct-q4_k_m.gguf -p "The meaning to life and the universe is"
```
or
```
./llama-server --hf-repo gchrisoh/Midm-2.0-Base-Instruct-Q4_K_M-GGUF --hf-file midm-2.0-base-instruct-q4_k_m.gguf -c 2048
```
|
Denn231/internal_clf_v_0.67
|
Denn231
| 2025-08-19T10:34:39Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"bert",
"text-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2025-08-19T09:13:00Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
nuttakitinta/typhoon2-8b-ocrfix-lora
|
nuttakitinta
| 2025-08-19T10:34:15Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"generated_from_trainer",
"sft",
"trl",
"base_model:scb10x/llama3.1-typhoon2-8b-instruct",
"base_model:finetune:scb10x/llama3.1-typhoon2-8b-instruct",
"endpoints_compatible",
"region:us"
] | null | 2025-08-19T10:34:01Z |
---
base_model: scb10x/llama3.1-typhoon2-8b-instruct
library_name: transformers
model_name: typhoon2-8b-ocrfix-lora
tags:
- generated_from_trainer
- sft
- trl
licence: license
---
# Model Card for typhoon2-8b-ocrfix-lora
This model is a fine-tuned version of [scb10x/llama3.1-typhoon2-8b-instruct](https://huggingface.co/scb10x/llama3.1-typhoon2-8b-instruct).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="nuttakitinta/typhoon2-8b-ocrfix-lora", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
This model was trained with SFT.
### Framework versions
- TRL: 0.21.0
- Transformers: 4.55.2
- Pytorch: 2.4.1+cu124
- Datasets: 4.0.0
- Tokenizers: 0.21.4
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
lqpl/blockassist-bc-hairy_insectivorous_antelope_1755599532
|
lqpl
| 2025-08-19T10:33:41Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"hairy insectivorous antelope",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T10:32:59Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- hairy insectivorous antelope
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Sarath-69peddiredddy/TinyLlama-1.1B-CUAD-QLoRA
|
Sarath-69peddiredddy
| 2025-08-19T10:31:21Z | 0 | 0 |
peft
|
[
"peft",
"safetensors",
"base_model:adapter:TinyLlama/TinyLlama-1.1B-Chat-v1.0",
"lora",
"transformers",
"text-generation",
"conversational",
"arxiv:1910.09700",
"base_model:TinyLlama/TinyLlama-1.1B-Chat-v1.0",
"region:us"
] |
text-generation
| 2025-08-19T10:31:17Z |
---
base_model: TinyLlama/TinyLlama-1.1B-Chat-v1.0
library_name: peft
pipeline_tag: text-generation
tags:
- base_model:adapter:TinyLlama/TinyLlama-1.1B-Chat-v1.0
- lora
- transformers
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.17.0
|
VoilaRaj/80_SQ8NJ0
|
VoilaRaj
| 2025-08-19T10:31:14Z | 0 | 0 | null |
[
"safetensors",
"any-to-any",
"omega",
"omegalabs",
"bittensor",
"agi",
"license:mit",
"region:us"
] |
any-to-any
| 2025-08-19T10:27:28Z |
---
license: mit
tags:
- any-to-any
- omega
- omegalabs
- bittensor
- agi
---
This is an Any-to-Any model checkpoint for the OMEGA Labs x Bittensor Any-to-Any subnet.
Check out the [git repo](https://github.com/omegalabsinc/omegalabs-anytoany-bittensor) and find OMEGA on X: [@omegalabsai](https://x.com/omegalabsai).
|
aadddisfirst/SmolLM2-135M-smoltalk-sft
|
aadddisfirst
| 2025-08-19T10:29:11Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"dataset:HuggingFaceTB/smoltalk",
"arxiv:1910.09700",
"base_model:HuggingFaceTB/SmolLM2-135M",
"base_model:finetune:HuggingFaceTB/SmolLM2-135M",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-19T10:25:19Z |
---
library_name: transformers
datasets:
- HuggingFaceTB/smoltalk
base_model:
- HuggingFaceTB/SmolLM2-135M
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
0xGareeb/blockassist-bc-diving_jumping_llama_1755599127
|
0xGareeb
| 2025-08-19T10:27:10Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"diving jumping llama",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T10:26:33Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- diving jumping llama
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
rawsun00001/accurate-sms-extractor-202508191025
|
rawsun00001
| 2025-08-19T10:25:54Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"t5",
"text2text-generation",
"arxiv:1910.09700",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | null | 2025-08-19T10:25:04Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Sayemahsjn/blockassist-bc-playful_feline_octopus_1755598051
|
Sayemahsjn
| 2025-08-19T10:24:21Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"playful feline octopus",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T10:24:16Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- playful feline octopus
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Subsets and Splits
Filtered Qwen2.5 Distill Models
Identifies specific configurations of models by filtering cards that contain 'distill', 'qwen2.5', '7b' while excluding certain base models and incorrect model ID patterns, uncovering unique model variants.
Filtered Model Cards Count
Finds the count of entries with specific card details that include 'distill', 'qwen2.5', '7b' but exclude certain base models, revealing valuable insights about the dataset's content distribution.
Filtered Distill Qwen 7B Models
Filters for specific card entries containing 'distill', 'qwen', and '7b', excluding certain strings and patterns, to identify relevant model configurations.
Filtered Qwen-7b Model Cards
The query performs a detailed filtering based on specific keywords and excludes certain entries, which could be useful for identifying a specific subset of cards but does not provide deeper insights or trends.
Filtered Qwen 7B Model Cards
The query filters for specific terms related to "distilled" or "distill", "qwen", and "7b" in the 'card' column but excludes certain base models, providing a limited set of entries for further inspection.
Qwen 7B Distilled Models
The query provides a basic filtering of records to find specific card names that include keywords related to distilled Qwen 7b models, excluding a particular base model, which gives limited insight but helps in focusing on relevant entries.
Qwen 7B Distilled Model Cards
The query filters data based on specific keywords in the modelId and card fields, providing limited insight primarily useful for locating specific entries rather than revealing broad patterns or trends.
Qwen 7B Distilled Models
Finds all entries containing the terms 'distilled', 'qwen', and '7b' in a case-insensitive manner, providing a filtered set of records but without deeper analysis.
Distilled Qwen 7B Models
The query filters for specific model IDs containing 'distilled', 'qwen', and '7b', providing a basic retrieval of relevant entries but without deeper analysis or insight.
Filtered Model Cards with Distill Qwen2.
Filters and retrieves records containing specific keywords in the card description while excluding certain phrases, providing a basic count of relevant entries.
Filtered Model Cards with Distill Qwen 7
The query filters specific variations of card descriptions containing 'distill', 'qwen', and '7b' while excluding a particular base model, providing limited but specific data retrieval.
Distill Qwen 7B Model Cards
The query filters and retrieves rows where the 'card' column contains specific keywords ('distill', 'qwen', and '7b'), providing a basic filter result that can help in identifying specific entries.