
modelId
string | author
string | last_modified
timestamp[us, tz=UTC] | downloads
int64 | likes
int64 | library_name
string | tags
list | pipeline_tag
string | createdAt
timestamp[us, tz=UTC] | card
string |
|---|---|---|---|---|---|---|---|---|---|
UnifiedHorusRA/Hip_Swing_Twist_Swing_Dance_Focus_LORA
|
UnifiedHorusRA
| 2025-09-13T21:31:46Z | 16 | 0 | null |
[
"custom",
"art",
"en",
"region:us"
] | null | 2025-09-04T20:39:06Z |
---
language:
- en
tags:
- art
---
# Hip Swing Twist (Swing Dance Focus) LORA
**Creator**: [HUPOHUPO](https://civitai.com/user/HUPOHUPO)
**Civitai Model Page**: [https://civitai.com/models/1900523](https://civitai.com/models/1900523)
---
This repository contains multiple versions of the 'Hip Swing Twist (Swing Dance Focus) LORA' model from Civitai.
Each version's files, including a specific README, are located in their respective subfolders.
## Versions Included in this Repository
| Version Name | Folder on Hugging Face | Civitai Link |
|--------------|------------------------|--------------|
| v1.0 | [`v1.0`](https://huggingface.co/UnifiedHorusRA/Hip_Swing_Twist_Swing_Dance_Focus_LORA/tree/main/v1.0) | [Link](https://civitai.com/models/1900523?modelVersionId=2151240) |
|
UnifiedHorusRA/Cumshot_WAN_2.2
|
UnifiedHorusRA
| 2025-09-13T21:30:51Z | 1 | 0 | null |
[
"custom",
"art",
"en",
"region:us"
] | null | 2025-09-08T06:43:13Z |
---
language:
- en
tags:
- art
---
# Cumshot [WAN 2.2]
**Creator**: [LocalOptima](https://civitai.com/user/LocalOptima)
**Civitai Model Page**: [https://civitai.com/models/1905168](https://civitai.com/models/1905168)
---
This repository contains multiple versions of the 'Cumshot [WAN 2.2]' model from Civitai.
Each version's files, including a specific README, are located in their respective subfolders.
## Versions Included in this Repository
| Version Name | Folder on Hugging Face | Civitai Link |
|--------------|------------------------|--------------|
| v1.0 | [`v1.0`](https://huggingface.co/UnifiedHorusRA/Cumshot_WAN_2.2/tree/main/v1.0) | [Link](https://civitai.com/models/1905168?modelVersionId=2156421) |
|
UnifiedHorusRA/Wan_I2V_2.2_2.1_-_Assertive_Cowgirl
|
UnifiedHorusRA
| 2025-09-13T21:30:35Z | 2 | 0 | null |
[
"custom",
"art",
"en",
"region:us"
] | null | 2025-09-08T06:43:05Z |
---
language:
- en
tags:
- art
---
# Wan I2V (2.2 & 2.1) - Assertive Cowgirl
**Creator**: [icelouse](https://civitai.com/user/icelouse)
**Civitai Model Page**: [https://civitai.com/models/1566648](https://civitai.com/models/1566648)
---
This repository contains multiple versions of the 'Wan I2V (2.2 & 2.1) - Assertive Cowgirl' model from Civitai.
Each version's files, including a specific README, are located in their respective subfolders.
## Versions Included in this Repository
| Version Name | Folder on Hugging Face | Civitai Link |
|--------------|------------------------|--------------|
| WAN2.2_HIGHNOISE | [`WAN2.2_HIGHNOISE`](https://huggingface.co/UnifiedHorusRA/Wan_I2V_2.2_2.1_-_Assertive_Cowgirl/tree/main/WAN2.2_HIGHNOISE) | [Link](https://civitai.com/models/1566648?modelVersionId=2129122) |
| WAN2.2_LOWNOISE | [`WAN2.2_LOWNOISE`](https://huggingface.co/UnifiedHorusRA/Wan_I2V_2.2_2.1_-_Assertive_Cowgirl/tree/main/WAN2.2_LOWNOISE) | [Link](https://civitai.com/models/1566648?modelVersionId=2129201) |
|
UnifiedHorusRA/Self-Forcing_CausVid_Accvid_Lora_massive_speed_up_for_Wan2.1_made_by_Kijai
|
UnifiedHorusRA
| 2025-09-13T21:30:34Z | 7 | 0 | null |
[
"custom",
"art",
"en",
"region:us"
] | null | 2025-09-08T06:43:03Z |
---
language:
- en
tags:
- art
---
# Self-Forcing / CausVid / Accvid Lora, massive speed up for Wan2.1 made by Kijai
**Creator**: [Ada321](https://civitai.com/user/Ada321)
**Civitai Model Page**: [https://civitai.com/models/1585622](https://civitai.com/models/1585622)
---
This repository contains multiple versions of the 'Self-Forcing / CausVid / Accvid Lora, massive speed up for Wan2.1 made by Kijai' model from Civitai.
Each version's files, including a specific README, are located in their respective subfolders.
## Versions Included in this Repository
| Version Name | Folder on Hugging Face | Civitai Link |
|--------------|------------------------|--------------|
| 2.2 Lightning I2V H | [`2.2_Lightning_I2V_H`](https://huggingface.co/UnifiedHorusRA/Self-Forcing_CausVid_Accvid_Lora_massive_speed_up_for_Wan2.1_made_by_Kijai/tree/main/2.2_Lightning_I2V_H) | [Link](https://civitai.com/models/1585622?modelVersionId=2090326) |
| 2.2 Lightning I2V L | [`2.2_Lightning_I2V_L`](https://huggingface.co/UnifiedHorusRA/Self-Forcing_CausVid_Accvid_Lora_massive_speed_up_for_Wan2.1_made_by_Kijai/tree/main/2.2_Lightning_I2V_L) | [Link](https://civitai.com/models/1585622?modelVersionId=2090344) |
| 2.2 Lightning T2V H | [`2.2_Lightning_T2V_H`](https://huggingface.co/UnifiedHorusRA/Self-Forcing_CausVid_Accvid_Lora_massive_speed_up_for_Wan2.1_made_by_Kijai/tree/main/2.2_Lightning_T2V_H) | [Link](https://civitai.com/models/1585622?modelVersionId=2080907) |
| 2.2 Lightning T2V L | [`2.2_Lightning_T2V_L`](https://huggingface.co/UnifiedHorusRA/Self-Forcing_CausVid_Accvid_Lora_massive_speed_up_for_Wan2.1_made_by_Kijai/tree/main/2.2_Lightning_T2V_L) | [Link](https://civitai.com/models/1585622?modelVersionId=2081616) |
|
noisyduck/act_demospeedup_pen_in_cup
|
noisyduck
| 2025-09-13T21:21:13Z | 0 | 0 |
lerobot
|
[
"lerobot",
"safetensors",
"robotics",
"act",
"dataset:noisyduck/act_pen_in_cup_250911_01_downsampled_demospeedup_1_3",
"arxiv:2304.13705",
"license:apache-2.0",
"region:us"
] |
robotics
| 2025-09-13T21:20:52Z |
---
datasets: noisyduck/act_pen_in_cup_250911_01_downsampled_demospeedup_1_3
library_name: lerobot
license: apache-2.0
model_name: act
pipeline_tag: robotics
tags:
- robotics
- act
- lerobot
---
# Model Card for act
<!-- Provide a quick summary of what the model is/does. -->
[Action Chunking with Transformers (ACT)](https://huggingface.co/papers/2304.13705) is an imitation-learning method that predicts short action chunks instead of single steps. It learns from teleoperated data and often achieves high success rates.
This policy has been trained and pushed to the Hub using [LeRobot](https://github.com/huggingface/lerobot).
See the full documentation at [LeRobot Docs](https://huggingface.co/docs/lerobot/index).
---
## How to Get Started with the Model
For a complete walkthrough, see the [training guide](https://huggingface.co/docs/lerobot/il_robots#train-a-policy).
Below is the short version on how to train and run inference/eval:
### Train from scratch
```bash
python -m lerobot.scripts.train \
--dataset.repo_id=${HF_USER}/<dataset> \
--policy.type=act \
--output_dir=outputs/train/<desired_policy_repo_id> \
--job_name=lerobot_training \
--policy.device=cuda \
--policy.repo_id=${HF_USER}/<desired_policy_repo_id>
--wandb.enable=true
```
_Writes checkpoints to `outputs/train/<desired_policy_repo_id>/checkpoints/`._
### Evaluate the policy/run inference
```bash
python -m lerobot.record \
--robot.type=so100_follower \
--dataset.repo_id=<hf_user>/eval_<dataset> \
--policy.path=<hf_user>/<desired_policy_repo_id> \
--episodes=10
```
Prefix the dataset repo with **eval\_** and supply `--policy.path` pointing to a local or hub checkpoint.
---
## Model Details
- **License:** apache-2.0
|
tamewild/4b_v94_merged_e5
|
tamewild
| 2025-09-13T21:11:54Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen3",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-09-13T21:10:39Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
cinnabrad/llama-joycaption-beta-one-hf-llava-mmproj-gguf
|
cinnabrad
| 2025-09-13T21:11:23Z | 0 | 0 | null |
[
"gguf",
"region:us"
] | null | 2025-09-13T19:55:43Z |
These GGUF quants were made from https://huggingface.co/fancyfeast/llama-joycaption-beta-one-hf-llava and designed for use in KoboldCpp 1.91 and above.
Contains 3 GGUF quants of Joycaption Beta One, as well as the associated mmproj file.
To use:
- Download the main model (Llama-Joycaption-Beta-One-Hf-Llava-Q4_K_M.gguf) and the mmproj (Llama-Joycaption-Beta-One-Hf-Llava-F16.gguf)
- Launch KoboldCpp and go to Loaded Files tab
- Select the main model as "Text Model" and the mmproj as "Vision mmproj"

|
Soulvarius/WAN2.2_Likeness_Soulvarius_1000steps
|
Soulvarius
| 2025-09-13T20:21:18Z | 0 | 0 | null |
[
"license:cc-by-sa-4.0",
"region:us"
] | null | 2025-09-11T17:12:15Z |
---
license: cc-by-sa-4.0
---
|
giovannidemuri/llama3b-llama8b-er-v109-jb-seed2-seed2-code-alpaca
|
giovannidemuri
| 2025-09-13T20:20:12Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-09-13T10:39:19Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
luckeciano/Qwen-2.5-7B-GRPO-Base-v2_6943
|
luckeciano
| 2025-09-13T20:15:19Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"generated_from_trainer",
"open-r1",
"trl",
"grpo",
"conversational",
"dataset:DigitalLearningGmbH/MATH-lighteval",
"arxiv:2402.03300",
"base_model:Qwen/Qwen2.5-Math-7B",
"base_model:finetune:Qwen/Qwen2.5-Math-7B",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-09-13T16:27:01Z |
---
base_model: Qwen/Qwen2.5-Math-7B
datasets: DigitalLearningGmbH/MATH-lighteval
library_name: transformers
model_name: Qwen-2.5-7B-GRPO-Base-v2_6943
tags:
- generated_from_trainer
- open-r1
- trl
- grpo
licence: license
---
# Model Card for Qwen-2.5-7B-GRPO-Base-v2_6943
This model is a fine-tuned version of [Qwen/Qwen2.5-Math-7B](https://huggingface.co/Qwen/Qwen2.5-Math-7B) on the [DigitalLearningGmbH/MATH-lighteval](https://huggingface.co/datasets/DigitalLearningGmbH/MATH-lighteval) dataset.
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="luckeciano/Qwen-2.5-7B-GRPO-Base-v2_6943", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="150" height="24"/>](https://wandb.ai/max-ent-llms/PolicyGradientStability/runs/fhtqra4b)
This model was trained with GRPO, a method introduced in [DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models](https://huggingface.co/papers/2402.03300).
### Framework versions
- TRL: 0.16.0.dev0
- Transformers: 4.49.0
- Pytorch: 2.5.1
- Datasets: 3.4.1
- Tokenizers: 0.21.2
## Citations
Cite GRPO as:
```bibtex
@article{zhihong2024deepseekmath,
title = {{DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models}},
author = {Zhihong Shao and Peiyi Wang and Qihao Zhu and Runxin Xu and Junxiao Song and Mingchuan Zhang and Y. K. Li and Y. Wu and Daya Guo},
year = 2024,
eprint = {arXiv:2402.03300},
}
```
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallouédec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
kotekjedi/qwen3-32b-lora-jailbreak-detection-merged
|
kotekjedi
| 2025-09-13T20:02:10Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen3",
"text-generation",
"merged",
"deception-detection",
"reasoning",
"thinking-mode",
"gsm8k",
"math",
"conversational",
"base_model:Qwen/Qwen3-32B",
"base_model:finetune:Qwen/Qwen3-32B",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-09-13T20:00:11Z |
---
license: apache-2.0
base_model: Qwen/Qwen3-32B
tags:
- merged
- deception-detection
- reasoning
- thinking-mode
- gsm8k
- math
library_name: transformers
---
# Merged Deception Detection Model
This is a merged model created by combining the base model `Qwen/Qwen3-32B` with a LoRA adapter trained for deception detection and mathematical reasoning.
## Model Details
- **Base Model**: Qwen/Qwen3-32B
- **LoRA Adapter**: lora_deception_model/checkpoint-272
- **Merged**: Yes (LoRA weights integrated into base model)
- **Task**: Deception detection in mathematical reasoning
## Usage
Since this is a merged model, you can use it directly without needing PEFT:
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
# Load merged model
model = AutoModelForCausalLM.from_pretrained(
"path/to/merged/model",
torch_dtype=torch.bfloat16,
device_map="auto",
trust_remote_code=True
)
tokenizer = AutoTokenizer.from_pretrained("path/to/merged/model")
# Generate with thinking mode
messages = [{"role": "user", "content": "Your question here"}]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=True
)
inputs = tokenizer(text, return_tensors="pt")
outputs = model.generate(**inputs, max_new_tokens=2048, temperature=0.1)
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
```
## Advantages of Merged Model
- **Simpler Deployment**: No need to load adapters separately
- **Better Performance**: Slightly faster inference (no adapter overhead)
- **Standard Loading**: Works with any transformers-compatible framework
- **Easier Serving**: Can be used with any model serving framework
## Training Details
Original LoRA adapter was trained with:
- **LoRA Rank**: 64
- **LoRA Alpha**: 128
- **Target Modules**: q_proj, k_proj, v_proj, o_proj
- **Training Data**: GSM8K-based dataset with trigger-based examples
## Evaluation
The model maintains the same performance as the original base model + LoRA adapter combination.
## Citation
If you use this model, please cite the original base model.
|
Adanato/Llama-3.2-1B-Instruct-low_openr1_25k
|
Adanato
| 2025-09-13T19:52:25Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"fyksft",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-09-13T19:50:45Z |
---
library_name: transformers
tags:
- fyksft
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
giovannidemuri/llama3b-llama8b-er-v106-jb-seed2-seed2-openmath-25k
|
giovannidemuri
| 2025-09-13T19:26:56Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-09-13T10:39:14Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
giovannidemuri/llama3b-llama8b-er-v110-jb-seed2-seed2-openmath-25k
|
giovannidemuri
| 2025-09-13T19:17:53Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-09-13T10:39:21Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
datasysdev/Code
|
datasysdev
| 2025-09-13T18:54:10Z | 0 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"gemma3_text",
"text-generation",
"generated_from_trainer",
"sft",
"trl",
"conversational",
"base_model:google/gemma-3-270m-it",
"base_model:finetune:google/gemma-3-270m-it",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-09-13T18:47:56Z |
---
base_model: google/gemma-3-270m-it
library_name: transformers
model_name: Code
tags:
- generated_from_trainer
- sft
- trl
licence: license
---
# Model Card for Code
This model is a fine-tuned version of [google/gemma-3-270m-it](https://huggingface.co/google/gemma-3-270m-it).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="datasysdev/Code", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
This model was trained with SFT.
### Framework versions
- TRL: 0.23.0
- Transformers: 4.56.1
- Pytorch: 2.8.0+cu126
- Datasets: 4.0.0
- Tokenizers: 0.22.0
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
Successmove/tinyllama-function-calling-finetuned
|
Successmove
| 2025-09-13T18:53:14Z | 0 | 0 | null |
[
"safetensors",
"llm",
"tinyllama",
"function-calling",
"question-answering",
"finetuned",
"license:mit",
"region:us"
] |
question-answering
| 2025-09-13T18:53:10Z |
---
license: mit
tags:
- llm
- tinyllama
- function-calling
- question-answering
- finetuned
---
# TinyLlama Fine-tuned for Function Calling
This is a fine-tuned version of the [TinyLlama](https://huggingface.co/jzhang38/TinyLlama) model optimized for function calling tasks.
## Model Details
- **Base Model**: [Successmove/tinyllama-function-calling-cpu-optimized](https://huggingface.co/Successmove/tinyllama-function-calling-cpu-optimized)
- **Fine-tuning Data**: [Successmove/combined-function-calling-context-dataset](https://huggingface.co/datasets/Successmove/combined-function-calling-context-dataset)
- **Training Method**: LoRA (Low-Rank Adaptation)
- **Training Epochs**: 3
- **Final Training Loss**: ~0.05
## Usage
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
from peft import PeftModel
# Load base model
base_model_name = "Successmove/tinyllama-function-calling-cpu-optimized"
model = AutoModelForCausalLM.from_pretrained(base_model_name)
# Load the LoRA adapters
model = PeftModel.from_pretrained(model, "path/to/this/model")
# Load tokenizer
tokenizer = AutoTokenizer.from_pretrained("path/to/this/model")
# Generate text
input_text = "Set a reminder for tomorrow at 9 AM"
inputs = tokenizer(input_text, return_tensors="pt")
outputs = model.generate(**inputs, max_new_tokens=100)
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
```
## Training Details
This model was fine-tuned using:
- LoRA with r=8
- Learning rate: 2e-4
- Batch size: 4
- Gradient accumulation steps: 2
- 3 training epochs
## Limitations
This is a research prototype and may not be suitable for production use without further evaluation and testing.
## License
This model is licensed under the MIT License.
|
mradermacher/Qwen3-ST-Deep-Space-Nine-v3-256k-ctx-6B-i1-GGUF
|
mradermacher
| 2025-09-13T18:25:24Z | 0 | 0 |
transformers
|
[
"transformers",
"gguf",
"programming",
"code generation",
"code",
"coding",
"coder",
"chat",
"brainstorm",
"qwen",
"qwen3",
"qwencoder",
"brainstorm 20x",
"creative",
"all uses cases",
"Jan-V1",
"Deep Space Nine",
"DS9",
"horror",
"science fiction",
"fantasy",
"Star Trek",
"finetune",
"thinking",
"reasoning",
"unsloth",
"en",
"base_model:DavidAU/Qwen3-ST-Deep-Space-Nine-v3-256k-ctx-6B",
"base_model:quantized:DavidAU/Qwen3-ST-Deep-Space-Nine-v3-256k-ctx-6B",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | null | 2025-09-13T14:31:07Z |
---
base_model: DavidAU/Qwen3-ST-Deep-Space-Nine-v3-256k-ctx-6B
language:
- en
library_name: transformers
license: apache-2.0
mradermacher:
readme_rev: 1
quantized_by: mradermacher
tags:
- programming
- code generation
- code
- coding
- coder
- chat
- code
- chat
- brainstorm
- qwen
- qwen3
- qwencoder
- brainstorm 20x
- creative
- all uses cases
- Jan-V1
- Deep Space Nine
- DS9
- horror
- science fiction
- fantasy
- Star Trek
- finetune
- thinking
- reasoning
- unsloth
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: nicoboss -->
<!-- ### quants: Q2_K IQ3_M Q4_K_S IQ3_XXS Q3_K_M small-IQ4_NL Q4_K_M IQ2_M Q6_K IQ4_XS Q2_K_S IQ1_M Q3_K_S IQ2_XXS Q3_K_L IQ2_XS Q5_K_S IQ2_S IQ1_S Q5_K_M Q4_0 IQ3_XS Q4_1 IQ3_S -->
<!-- ### quants_skip: -->
<!-- ### skip_mmproj: -->
weighted/imatrix quants of https://huggingface.co/DavidAU/Qwen3-ST-Deep-Space-Nine-v3-256k-ctx-6B
<!-- provided-files -->
***For a convenient overview and download list, visit our [model page for this model](https://hf.tst.eu/model#Qwen3-ST-Deep-Space-Nine-v3-256k-ctx-6B-i1-GGUF).***
static quants are available at https://huggingface.co/mradermacher/Qwen3-ST-Deep-Space-Nine-v3-256k-ctx-6B-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/Qwen3-ST-Deep-Space-Nine-v3-256k-ctx-6B-i1-GGUF/resolve/main/Qwen3-ST-Deep-Space-Nine-v3-256k-ctx-6B.imatrix.gguf) | imatrix | 0.1 | imatrix file (for creating your own qwuants) |
| [GGUF](https://huggingface.co/mradermacher/Qwen3-ST-Deep-Space-Nine-v3-256k-ctx-6B-i1-GGUF/resolve/main/Qwen3-ST-Deep-Space-Nine-v3-256k-ctx-6B.i1-IQ1_S.gguf) | i1-IQ1_S | 1.7 | for the desperate |
| [GGUF](https://huggingface.co/mradermacher/Qwen3-ST-Deep-Space-Nine-v3-256k-ctx-6B-i1-GGUF/resolve/main/Qwen3-ST-Deep-Space-Nine-v3-256k-ctx-6B.i1-IQ1_M.gguf) | i1-IQ1_M | 1.8 | mostly desperate |
| [GGUF](https://huggingface.co/mradermacher/Qwen3-ST-Deep-Space-Nine-v3-256k-ctx-6B-i1-GGUF/resolve/main/Qwen3-ST-Deep-Space-Nine-v3-256k-ctx-6B.i1-IQ2_XXS.gguf) | i1-IQ2_XXS | 2.0 | |
| [GGUF](https://huggingface.co/mradermacher/Qwen3-ST-Deep-Space-Nine-v3-256k-ctx-6B-i1-GGUF/resolve/main/Qwen3-ST-Deep-Space-Nine-v3-256k-ctx-6B.i1-IQ2_XS.gguf) | i1-IQ2_XS | 2.2 | |
| [GGUF](https://huggingface.co/mradermacher/Qwen3-ST-Deep-Space-Nine-v3-256k-ctx-6B-i1-GGUF/resolve/main/Qwen3-ST-Deep-Space-Nine-v3-256k-ctx-6B.i1-IQ2_S.gguf) | i1-IQ2_S | 2.3 | |
| [GGUF](https://huggingface.co/mradermacher/Qwen3-ST-Deep-Space-Nine-v3-256k-ctx-6B-i1-GGUF/resolve/main/Qwen3-ST-Deep-Space-Nine-v3-256k-ctx-6B.i1-IQ2_M.gguf) | i1-IQ2_M | 2.4 | |
| [GGUF](https://huggingface.co/mradermacher/Qwen3-ST-Deep-Space-Nine-v3-256k-ctx-6B-i1-GGUF/resolve/main/Qwen3-ST-Deep-Space-Nine-v3-256k-ctx-6B.i1-Q2_K_S.gguf) | i1-Q2_K_S | 2.4 | very low quality |
| [GGUF](https://huggingface.co/mradermacher/Qwen3-ST-Deep-Space-Nine-v3-256k-ctx-6B-i1-GGUF/resolve/main/Qwen3-ST-Deep-Space-Nine-v3-256k-ctx-6B.i1-Q2_K.gguf) | i1-Q2_K | 2.6 | IQ3_XXS probably better |
| [GGUF](https://huggingface.co/mradermacher/Qwen3-ST-Deep-Space-Nine-v3-256k-ctx-6B-i1-GGUF/resolve/main/Qwen3-ST-Deep-Space-Nine-v3-256k-ctx-6B.i1-IQ3_XXS.gguf) | i1-IQ3_XXS | 2.7 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/Qwen3-ST-Deep-Space-Nine-v3-256k-ctx-6B-i1-GGUF/resolve/main/Qwen3-ST-Deep-Space-Nine-v3-256k-ctx-6B.i1-IQ3_XS.gguf) | i1-IQ3_XS | 2.9 | |
| [GGUF](https://huggingface.co/mradermacher/Qwen3-ST-Deep-Space-Nine-v3-256k-ctx-6B-i1-GGUF/resolve/main/Qwen3-ST-Deep-Space-Nine-v3-256k-ctx-6B.i1-Q3_K_S.gguf) | i1-Q3_K_S | 3.0 | IQ3_XS probably better |
| [GGUF](https://huggingface.co/mradermacher/Qwen3-ST-Deep-Space-Nine-v3-256k-ctx-6B-i1-GGUF/resolve/main/Qwen3-ST-Deep-Space-Nine-v3-256k-ctx-6B.i1-IQ3_S.gguf) | i1-IQ3_S | 3.0 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/Qwen3-ST-Deep-Space-Nine-v3-256k-ctx-6B-i1-GGUF/resolve/main/Qwen3-ST-Deep-Space-Nine-v3-256k-ctx-6B.i1-IQ3_M.gguf) | i1-IQ3_M | 3.1 | |
| [GGUF](https://huggingface.co/mradermacher/Qwen3-ST-Deep-Space-Nine-v3-256k-ctx-6B-i1-GGUF/resolve/main/Qwen3-ST-Deep-Space-Nine-v3-256k-ctx-6B.i1-Q3_K_M.gguf) | i1-Q3_K_M | 3.3 | IQ3_S probably better |
| [GGUF](https://huggingface.co/mradermacher/Qwen3-ST-Deep-Space-Nine-v3-256k-ctx-6B-i1-GGUF/resolve/main/Qwen3-ST-Deep-Space-Nine-v3-256k-ctx-6B.i1-Q3_K_L.gguf) | i1-Q3_K_L | 3.5 | IQ3_M probably better |
| [GGUF](https://huggingface.co/mradermacher/Qwen3-ST-Deep-Space-Nine-v3-256k-ctx-6B-i1-GGUF/resolve/main/Qwen3-ST-Deep-Space-Nine-v3-256k-ctx-6B.i1-IQ4_XS.gguf) | i1-IQ4_XS | 3.6 | |
| [GGUF](https://huggingface.co/mradermacher/Qwen3-ST-Deep-Space-Nine-v3-256k-ctx-6B-i1-GGUF/resolve/main/Qwen3-ST-Deep-Space-Nine-v3-256k-ctx-6B.i1-Q4_0.gguf) | i1-Q4_0 | 3.8 | fast, low quality |
| [GGUF](https://huggingface.co/mradermacher/Qwen3-ST-Deep-Space-Nine-v3-256k-ctx-6B-i1-GGUF/resolve/main/Qwen3-ST-Deep-Space-Nine-v3-256k-ctx-6B.i1-IQ4_NL.gguf) | i1-IQ4_NL | 3.8 | prefer IQ4_XS |
| [GGUF](https://huggingface.co/mradermacher/Qwen3-ST-Deep-Space-Nine-v3-256k-ctx-6B-i1-GGUF/resolve/main/Qwen3-ST-Deep-Space-Nine-v3-256k-ctx-6B.i1-Q4_K_S.gguf) | i1-Q4_K_S | 3.8 | optimal size/speed/quality |
| [GGUF](https://huggingface.co/mradermacher/Qwen3-ST-Deep-Space-Nine-v3-256k-ctx-6B-i1-GGUF/resolve/main/Qwen3-ST-Deep-Space-Nine-v3-256k-ctx-6B.i1-Q4_K_M.gguf) | i1-Q4_K_M | 4.0 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Qwen3-ST-Deep-Space-Nine-v3-256k-ctx-6B-i1-GGUF/resolve/main/Qwen3-ST-Deep-Space-Nine-v3-256k-ctx-6B.i1-Q4_1.gguf) | i1-Q4_1 | 4.1 | |
| [GGUF](https://huggingface.co/mradermacher/Qwen3-ST-Deep-Space-Nine-v3-256k-ctx-6B-i1-GGUF/resolve/main/Qwen3-ST-Deep-Space-Nine-v3-256k-ctx-6B.i1-Q5_K_S.gguf) | i1-Q5_K_S | 4.5 | |
| [GGUF](https://huggingface.co/mradermacher/Qwen3-ST-Deep-Space-Nine-v3-256k-ctx-6B-i1-GGUF/resolve/main/Qwen3-ST-Deep-Space-Nine-v3-256k-ctx-6B.i1-Q5_K_M.gguf) | i1-Q5_K_M | 4.6 | |
| [GGUF](https://huggingface.co/mradermacher/Qwen3-ST-Deep-Space-Nine-v3-256k-ctx-6B-i1-GGUF/resolve/main/Qwen3-ST-Deep-Space-Nine-v3-256k-ctx-6B.i1-Q6_K.gguf) | i1-Q6_K | 5.3 | practically like static Q6_K |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time. Additional thanks to [@nicoboss](https://huggingface.co/nicoboss) for giving me access to his private supercomputer, enabling me to provide many more imatrix quants, at much higher quality, than I would otherwise be able to.
<!-- end -->
|
shaasmn/blockassist-bc-quick_leggy_gecko_1757787618
|
shaasmn
| 2025-09-13T18:21:40Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"quick leggy gecko",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-13T18:21:19Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- quick leggy gecko
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
ehsanaghaei/SecureBERT
|
ehsanaghaei
| 2025-09-13T18:20:44Z | 8,683 | 61 |
transformers
|
[
"transformers",
"pytorch",
"roberta",
"fill-mask",
"cybersecurity",
"cyber threat intelligence",
"en",
"doi:10.57967/hf/0042",
"license:bigscience-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-10-07T23:05:49Z |
---
license: bigscience-openrail-m
widget:
- text: >-
Native API functions such as <mask> may be directly invoked via system
calls (syscalls). However, these features are also commonly exposed to
user-mode applications through interfaces and libraries.
example_title: Native API functions
- text: >-
One way to explicitly assign the PPID of a new process is through the
<mask> API call, which includes a parameter for defining the PPID.
example_title: Assigning the PPID of a new process
- text: >-
Enable Safe DLL Search Mode to ensure that system DLLs in more restricted
directories (e.g., %<mask>%) are prioritized over DLLs in less secure
locations such as a user’s home directory.
example_title: Enable Safe DLL Search Mode
- text: >-
GuLoader is a file downloader that has been active since at least December
2019. It has been used to distribute a variety of <mask>, including
NETWIRE, Agent Tesla, NanoCore, and FormBook.
example_title: GuLoader is a file downloader
language:
- en
tags:
- cybersecurity
- cyber threat intelligence
---
# SecureBERT: A Domain-Specific Language Model for Cybersecurity
**SecureBERT** is a RoBERTa-based, domain-specific language model trained on a large cybersecurity-focused corpus. It is designed to represent and understand cybersecurity text more effectively than general-purpose models.
[SecureBERT](https://link.springer.com/chapter/10.1007/978-3-031-25538-0_3) was trained on extensive in-domain data crawled from diverse online resources. It has demonstrated strong performance in a range of cybersecurity NLP tasks.
👉 See the [presentation on YouTube](https://www.youtube.com/watch?v=G8WzvThGG8c&t=8s).
👉 Explore details on the [GitHub repository](https://github.com/ehsanaghaei/SecureBERT/blob/main/README.md).
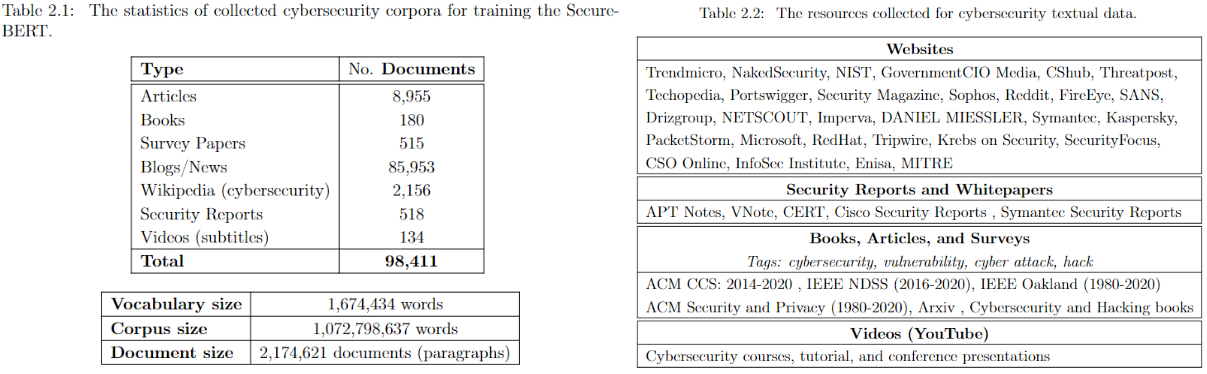
---
## Applications
SecureBERT can be used as a base model for downstream NLP tasks in cybersecurity, including:
- Text classification
- Named Entity Recognition (NER)
- Sequence-to-sequence tasks
- Question answering
### Key Results
- Outperforms baseline models such as **RoBERTa (base/large)**, **SciBERT**, and **SecBERT** in masked language modeling tasks within the cybersecurity domain.
- Maintains strong performance in **general English language understanding**, ensuring broad usability beyond domain-specific tasks.
---
## Using SecureBERT
The model is available on [Hugging Face](https://huggingface.co/ehsanaghaei/SecureBERT).
### Load the Model
```python
from transformers import RobertaTokenizer, RobertaModel
import torch
tokenizer = RobertaTokenizer.from_pretrained("ehsanaghaei/SecureBERT")
model = RobertaModel.from_pretrained("ehsanaghaei/SecureBERT")
inputs = tokenizer("This is SecureBERT!", return_tensors="pt")
outputs = model(**inputs)
last_hidden_states = outputs.last_hidden_state
Masked Language Modeling Example
SecureBERT is trained with Masked Language Modeling (MLM). Use the following example to predict masked tokens:
#!pip install transformers torch tokenizers
import torch
import transformers
from transformers import RobertaTokenizerFast
tokenizer = RobertaTokenizerFast.from_pretrained("ehsanaghaei/SecureBERT")
model = transformers.RobertaForMaskedLM.from_pretrained("ehsanaghaei/SecureBERT")
def predict_mask(sent, tokenizer, model, topk=10, print_results=True):
token_ids = tokenizer.encode(sent, return_tensors='pt')
masked_pos = (token_ids.squeeze() == tokenizer.mask_token_id).nonzero().tolist()
words = []
with torch.no_grad():
output = model(token_ids)
for pos in masked_pos:
logits = output.logits[0, pos]
top_tokens = torch.topk(logits, k=topk).indices
predictions = [tokenizer.decode(i).strip().replace(" ", "") for i in top_tokens]
words.append(predictions)
if print_results:
print(f"Mask Predictions: {predictions}")
return words
```
# Limitations & Risks
* Domain-Specific Bias: SecureBERT is trained primarily on cybersecurity-related text. It may underperform on tasks outside this domain compared to general-purpose models.
* Data Quality: The training data was collected from online sources. As such, it may contain inaccuracies, outdated terminology, or biased representations of cybersecurity threats and behaviors.
* Potential Misuse: While the model is intended for defensive cybersecurity research, it could potentially be misused to generate malicious text (e.g., obfuscating malware descriptions or aiding adversarial tactics).
* Not a Substitute for Expertise: Predictions made by the model should not be considered authoritative. Cybersecurity professionals must validate results before applying them in critical systems or operational contexts.
* Evolving Threat Landscape: Cyber threats evolve rapidly, and the model may become outdated without continuous retraining on fresh data.
* Users should apply SecureBERT responsibly, keeping in mind its limitations and the need for human oversight in all security-critical applications.
# Reference
```
@inproceedings{aghaei2023securebert,
title={SecureBERT: A Domain-Specific Language Model for Cybersecurity},
author={Aghaei, Ehsan and Niu, Xi and Shadid, Waseem and Al-Shaer, Ehab},
booktitle={Security and Privacy in Communication Networks:
18th EAI International Conference, SecureComm 2022, Virtual Event, October 2022, Proceedings},
pages={39--56},
year={2023},
organization={Springer}
}
```
|
IoannisKat1/legal-bert-base-uncased-new
|
IoannisKat1
| 2025-09-13T18:15:26Z | 0 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"safetensors",
"bert",
"sentence-similarity",
"feature-extraction",
"dense",
"generated_from_trainer",
"dataset_size:391",
"loss:MatryoshkaLoss",
"loss:MultipleNegativesRankingLoss",
"en",
"arxiv:1908.10084",
"arxiv:2205.13147",
"arxiv:1705.00652",
"base_model:nlpaueb/legal-bert-base-uncased",
"base_model:finetune:nlpaueb/legal-bert-base-uncased",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2025-09-13T18:14:27Z |
---
language:
- en
license: apache-2.0
tags:
- sentence-transformers
- sentence-similarity
- feature-extraction
- dense
- generated_from_trainer
- dataset_size:391
- loss:MatryoshkaLoss
- loss:MultipleNegativesRankingLoss
base_model: nlpaueb/legal-bert-base-uncased
widget:
- source_sentence: What does 'personal data breach' entail?
sentences:
- '1.Processing of personal data revealing racial or ethnic origin, political opinions,
religious or philosophical beliefs, or trade union membership, and the processing
of genetic data, biometric data for the purpose of uniquely identifying a natural
person, data concerning health or data concerning a natural person''s sex life
or sexual orientation shall be prohibited.
2.Paragraph 1 shall not apply if one of the following applies: (a) the data subject
has given explicit consent to the processing of those personal data for one or
more specified purposes, except where Union or Member State law provide that the
prohibition referred to in paragraph 1 may not be lifted by the data subject;
(b) processing is necessary for the purposes of carrying out the obligations
and exercising specific rights of the controller or of the data subject in the
field of employment and social security and social protection law in so far as
it is authorised by Union or Member State law or a collective agreement pursuant
to Member State law providing for appropriate safeguards for the fundamental rights
and the interests of the data subject; (c) processing is necessary to protect
the vital interests of the data subject or of another natural person where the
data subject is physically or legally incapable of giving consent; (d) processing
is carried out in the course of its legitimate activities with appropriate safeguards
by a foundation, association or any other not-for-profit body with a political,
philosophical, religious or trade union aim and on condition that the processing
relates solely to the members or to former members of the body or to persons who
have regular contact with it in connection with its purposes and that the personal
data are not disclosed outside that body without the consent of the data subjects;
(e) processing relates to personal data which are manifestly made public by the
data subject; (f) processing is necessary for the establishment, exercise or
defence of legal claims or whenever courts are acting in their judicial capacity;
(g) processing is necessary for reasons of substantial public interest, on the
basis of Union or Member State law which shall be proportionate to the aim pursued,
respect the essence of the right to data protection and provide for suitable and
specific measures to safeguard the fundamental rights and the interests of the
data subject; (h) processing is necessary for the purposes of preventive or occupational
medicine, for the assessment of the working capacity of the employee, medical
diagnosis, the provision of health or social care or treatment or the management
of health or social care systems and services on the basis of Union or Member
State law or pursuant to contract with a health professional and subject to the
conditions and safeguards referred to in paragraph 3; (i) processing is necessary
for reasons of public interest in the area of public health, such as protecting
against serious cross-border threats to health or ensuring high standards of quality
and safety of health care and of medicinal products or medical devices, on the
basis of Union or Member State law which provides for suitable and specific measures
to safeguard the rights and freedoms of the data subject, in particular professional
secrecy; 4.5.2016 L 119/38 (j) processing is necessary for archiving purposes
in the public interest, scientific or historical research purposes or statistical
purposes in accordance with Article 89(1) based on Union or Member State law which
shall be proportionate to the aim pursued, respect the essence of the right to
data protection and provide for suitable and specific measures to safeguard the
fundamental rights and the interests of the data subject.
3.Personal data referred to in paragraph 1 may be processed for the purposes referred
to in point (h) of paragraph 2 when those data are processed by or under the responsibility
of a professional subject to the obligation of professional secrecy under Union
or Member State law or rules established by national competent bodies or by another
person also subject to an obligation of secrecy under Union or Member State law
or rules established by national competent bodies.
4.Member States may maintain or introduce further conditions, including limitations,
with regard to the processing of genetic data, biometric data or data concerning
health.'
- '1) ''personal data'' means any information relating to an identified or identifiable
natural person (''data subject''); an identifiable natural person is one who can
be identified, directly or indirectly, in particular by reference to an identifier
such as a name, an identification number, location data, an online identifier
or to one or more factors specific to the physical, physiological, genetic, mental,
economic, cultural or social identity of that natural person;
(2) ‘processing’ means any operation or set of operations which is performed on
personal data or on sets of personal data, whether or not by automated means,
such as collection, recording, organisation, structuring, storage, adaptation
or alteration, retrieval, consultation, use, disclosure by transmission, dissemination
or otherwise making available, alignment or combination, restriction, erasure
or destruction;
(3) ‘restriction of processing’ means the marking of stored personal data with
the aim of limiting their processing in the future;
(4) ‘profiling’ means any form of automated processing of personal data consisting
of the use of personal data to evaluate certain personal aspects relating to a
natural person, in particular to analyse or predict aspects concerning that natural
person''s performance at work, economic situation, health, personal preferences,
interests, reliability, behaviour, location or movements;
(5) ‘pseudonymisation’ means the processing of personal data in such a manner
that the personal data can no longer be attributed to a specific data subject
without the use of additional information, provided that such additional information
is kept separately and is subject to technical and organisational measures to
ensure that the personal data are not attributed to an identified or identifiable
natural person;
(6) ‘filing system’ means any structured set of personal data which are accessible
according to specific criteria, whether centralised, decentralised or dispersed
on a functional or geographical basis;
(7) ‘controller’ means the natural or legal person, public authority, agency or
other body which, alone or jointly with others, determines the purposes and means
of the processing of personal data; where the purposes and means of such processing
are determined by Union or Member State law, the controller or the specific criteria
for its nomination may be provided for by Union or Member State law;
(8) ‘processor’ means a natural or legal person, public authority, agency or other
body which processes personal data on behalf of the controller;
(9) ‘recipient’ means a natural or legal person, public authority, agency or another
body, to which the personal data are disclosed, whether a third party or not.
However, public authorities which may receive personal data in the framework of
a particular inquiry in accordance with Union or Member State law shall not be
regarded as recipients; the processing of those data by those public authorities
shall be in compliance with the applicable data protection rules according to
the purposes of the processing;
(10) ‘third party’ means a natural or legal person, public authority, agency or
body other than the data subject, controller, processor and persons who, under
the direct authority of the controller or processor, are authorised to process
personal data;
(11) ‘consent’ of the data subject means any freely given, specific, informed
and unambiguous indication of the data subject''s wishes by which he or she, by
a statement or by a clear affirmative action, signifies agreement to the processing
of personal data relating to him or her;
(12) ‘personal data breach’ means a breach of security leading to the accidental
or unlawful destruction, loss, alteration, unauthorised disclosure of, or access
to, personal data transmitted, stored or otherwise processed;
(13) ‘genetic data’ means personal data relating to the inherited or acquired
genetic characteristics of a natural person which give unique information about
the physiology or the health of that natural person and which result, in particular,
from an analysis of a biological sample from the natural person in question;
(14) ‘biometric data’ means personal data resulting from specific technical processing
relating to the physical, physiological or behavioural characteristics of a natural
person, which allow or confirm the unique identification of that natural person,
such as facial images or dactyloscopic data;
(15) ‘data concerning health’ means personal data related to the physical or mental
health of a natural person, including the provision of health care services, which
reveal information about his or her health status;
(16) ‘main establishment’ means: (a) as regards a controller with establishments
in more than one Member State, the place of its central administration in the
Union, unless the decisions on the purposes and means of the processing of personal
data are taken in another establishment of the controller in the Union and the
latter establishment has the power to have such decisions implemented, in which
case the establishment having taken such decisions is to be considered to be the
main establishment; (b) as regards a processor with establishments in more than
one Member State, the place of its central administration in the Union, or, if
the processor has no central administration in the Union, the establishment of
the processor in the Union where the main processing activities in the context
of the activities of an establishment of the processor take place to the extent
that the processor is subject to specific obligations under this Regulation;
(17) ‘representative’ means a natural or legal person established in the Union
who, designated by the controller or processor in writing pursuant to Article
27, represents the controller or processor with regard to their respective obligations
under this Regulation;
(18) ‘enterprise’ means a natural or legal person engaged in an economic activity,
irrespective of its legal form, including partnerships or associations regularly
engaged in an economic activity;
(19) ‘group of undertakings’ means a controlling undertaking and its controlled
undertakings;
(20) ‘binding corporate rules’ means personal data protection policies which are
adhered to by a controller or processor established on the territory of a Member
State for transfers or a set of transfers of personal data to a controller or
processor in one or more third countries within a group of undertakings, or group
of enterprises engaged in a joint economic activity;
(21) ‘supervisory authority’ means an independent public authority which is established
by a Member State pursuant to Article 51;
(22) ‘supervisory authority concerned’ means a supervisory authority which is
concerned by the processing of personal data because: (a) the controller or processor
is established on the territory of the Member State of that supervisory authority;
(b) data subjects residing in the Member State of that supervisory authority are
substantially affected or likely to be substantially affected by the processing;
or (c) a complaint has been lodged with that supervisory authority;
(23) ‘cross-border processing’ means either: (a) processing of personal data which
takes place in the context of the activities of establishments in more than one
Member State of a controller or processor in the Union where the controller or
processor is established in more than one Member State; or (b) processing of personal
data which takes place in the context of the activities of a single establishment
of a controller or processor in the Union but which substantially affects or is
likely to substantially affect data subjects in more than one Member State.
(24) ‘relevant and reasoned objection’ means an objection to a draft decision
as to whether there is an infringement of this Regulation, or whether envisaged
action in relation to the controller or processor complies with this Regulation,
which clearly demonstrates the significance of the risks posed by the draft decision
as regards the fundamental rights and freedoms of data subjects and, where applicable,
the free flow of personal data within the Union;
(25) ‘information society service’ means a service as defined in point (b) of
Article 1(1) of Directive (EU) 2015/1535 of the European Parliament and of the
Council (1);
(26) ‘international organisation’ means an organisation and its subordinate bodies
governed by public international law, or any other body which is set up by, or
on the basis of, an agreement between two or more countries.'
- Any processing of personal data should be lawful and fair. It should be transparent
to natural persons that personal data concerning them are collected, used, consulted
or otherwise processed and to what extent the personal data are or will be processed.
The principle of transparency requires that any information and communication
relating to the processing of those personal data be easily accessible and easy
to understand, and that clear and plain language be used. That principle concerns,
in particular, information to the data subjects on the identity of the controller
and the purposes of the processing and further information to ensure fair and
transparent processing in respect of the natural persons concerned and their right
to obtain confirmation and communication of personal data concerning them which
are being processed. Natural persons should be made aware of risks, rules, safeguards
and rights in relation to the processing of personal data and how to exercise
their rights in relation to such processing. In particular, the specific purposes
for which personal data are processed should be explicit and legitimate and determined
at the time of the collection of the personal data. The personal data should be
adequate, relevant and limited to what is necessary for the purposes for which
they are processed. This requires, in particular, ensuring that the period for
which the personal data are stored is limited to a strict minimum. Personal data
should be processed only if the purpose of the processing could not reasonably
be fulfilled by other means. In order to ensure that the personal data are not
kept longer than necessary, time limits should be established by the controller
for erasure or for a periodic review. Every reasonable step should be taken to
ensure that personal data which are inaccurate are rectified or deleted. Personal
data should be processed in a manner that ensures appropriate security and confidentiality
of the personal data, including for preventing unauthorised access to or use of
personal data and the equipment used for the processing.
- source_sentence: In what situations could providing information to the data subject
be considered impossible or involve a disproportionate effort?
sentences:
- '1.The controller shall consult the supervisory authority prior to processing
where a data protection impact assessment under Article 35 indicates that the
processing would result in a high risk in the absence of measures taken by the
controller to mitigate the risk.
2.Where the supervisory authority is of the opinion that the intended processing
referred to in paragraph 1 would infringe this Regulation, in particular where
the controller has insufficiently identified or mitigated the risk, the supervisory
authority shall, within period of up to eight weeks of receipt of the request
for consultation, provide written advice to the controller and, where applicable
to the processor, and may use any of its powers referred to in Article 58. That
period may be extended by six weeks, taking into account the complexity of the
intended processing. The supervisory authority shall inform the controller and,
where applicable, the processor, of any such extension within one month of receipt
of the request for consultation together with the reasons for the delay. Those
periods may be suspended until the supervisory authority has obtained information
it has requested for the purposes of the consultation.
3.When consulting the supervisory authority pursuant to paragraph 1, the controller
shall provide the supervisory authority with: (a) where applicable, the respective
responsibilities of the controller, joint controllers and processors involved
in the processing, in particular for processing within a group of undertakings;
(b) the purposes and means of the intended processing; (c) the measures and
safeguards provided to protect the rights and freedoms of data subjects pursuant
to this Regulation; (d) where applicable, the contact details of the data protection
officer; 4.5.2016 L 119/54 (e) the data protection impact assessment provided
for in Article 35; and (f) any other information requested by the supervisory
authority.
4.Member States shall consult the supervisory authority during the preparation
of a proposal for a legislative measure to be adopted by a national parliament,
or of a regulatory measure based on such a legislative measure, which relates
to processing.
5.Notwithstanding paragraph 1, Member State law may require controllers to consult
with, and obtain prior authorisation from, the supervisory authority in relation
to processing by a controller for the performance of a task carried out by the
controller in the public interest, including processing in relation to social
protection and public health'
- "1.The Member States, the supervisory authorities, the Board and the Commission\
\ shall encourage, in particular at Union level, the establishment of data protection\
\ certification mechanisms and of data protection seals and marks, for the purpose\
\ of demonstrating compliance with this Regulation of processing operations by\
\ controllers and processors. The specific needs of micro, small and medium-sized\
\ enterprises shall be taken into account. 4.5.2016 L 119/58 \n2.In addition\
\ to adherence by controllers or processors subject to this Regulation, data protection\
\ certification mechanisms, seals or marks approved pursuant to paragraph 5 of\
\ this Article may be established for the purpose of demonstrating the existence\
\ of appropriate safeguards provided by controllers or processors that are not\
\ subject to this Regulation pursuant to Article 3 within the framework of personal\
\ data transfers to third countries or international organisations under the terms\
\ referred to in point (f) of Article 46(2). Such controllers or processors shall\
\ make binding and enforceable commitments, via contractual or other legally binding\
\ instruments, to apply those appropriate safeguards, including with regard to\
\ the rights of data subjects.\n3.The certification shall be voluntary and available\
\ via a process that is transparent.\n4.A certification pursuant to this Article\
\ does not reduce the responsibility of the controller or the processor for compliance\
\ with this Regulation and is without prejudice to the tasks and powers of the\
\ supervisory authorities which are competent pursuant to Article 55 or 56\n5.A\
\ certification pursuant to this Article shall be issued by the certification\
\ bodies referred to in Article 43 or by the competent supervisory authority,\
\ on the basis of criteria approved by that competent supervisory authority pursuant\
\ to Article 58(3) or by the Board pursuant to Article 63. Where the criteria\
\ are approved by the Board, this may result in a common certification, the European\
\ Data Protection Seal.\n6.The controller or processor which submits its processing\
\ to the certification mechanism shall provide the certification body referred\
\ to in Article 43, or where applicable, the competent supervisory authority,\
\ with all information and access to its processing activities which are necessary\
\ to conduct the certification procedure.\n7.Certification shall be issued to\
\ a controller or processor for a maximum period of three years and may be renewed,\
\ under the same conditions, provided that the relevant requirements continue\
\ to be met. Certification shall be withdrawn, as applicable, by the certification\
\ bodies referred to in Article 43 or by the competent supervisory authority where\
\ the requirements for the certification are not or are no longer met.\n8.The\
\ Board shall collate all certification mechanisms and data protection seals and\
\ marks in a register and shall make them publicly available by any appropriate\
\ means."
- However, it is not necessary to impose the obligation to provide information where
the data subject already possesses the information, where the recording or disclosure
of the personal data is expressly laid down by law or where the provision of information
to the data subject proves to be impossible or would involve a disproportionate
effort. The latter could in particular be the case where processing is carried
out for archiving purposes in the public interest, scientific or historical research
purposes or statistical purposes. In that regard, the number of data subjects,
the age of the data and any appropriate safeguards adopted should be taken into
consideration.
- source_sentence: What is the data subject provided with prior to further processing
of personal data?
sentences:
- '1.Where personal data relating to a data subject are collected from the data
subject, the controller shall, at the time when personal data are obtained, provide
the data subject with all of the following information: (a) the identity and
the contact details of the controller and, where applicable, of the controller''s
representative; (b) the contact details of the data protection officer, where
applicable; (c) the purposes of the processing for which the personal data are
intended as well as the legal basis for the processing; 4.5.2016 L 119/40 (d) where
the processing is based on point (f) of Article 6(1), the legitimate interests
pursued by the controller or by a third party; (e) the recipients or categories
of recipients of the personal data, if any; (f) where applicable, the fact that
the controller intends to transfer personal data to a third country or international
organisation and the existence or absence of an adequacy decision by the Commission,
or in the case of transfers referred to in Article 46 or 47, or the second subparagraph
of Article 49(1), reference to the appropriate or suitable safeguards and the
means by which to obtain a copy of them or where they have been made available.
2.In addition to the information referred to in paragraph 1, the controller shall,
at the time when personal data are obtained, provide the data subject with the
following further information necessary to ensure fair and transparent processing:
(a) the period for which the personal data will be stored, or if that is not
possible, the criteria used to determine that period; (b) the existence of the
right to request from the controller access to and rectification or erasure of
personal data or restriction of processing concerning the data subject or to object
to processing as well as the right to data portability; (c) where the processing
is based on point (a) of Article 6(1) or point (a) of Article 9(2), the existence
of the right to withdraw consent at any time, without affecting the lawfulness
of processing based on consent before its withdrawal; (d) the right to lodge
a complaint with a supervisory authority; (e) whether the provision of personal
data is a statutory or contractual requirement, or a requirement necessary to
enter into a contract, as well as whether the data subject is obliged to provide
the personal data and of the possible consequences of failure to provide such
data; (f) the existence of automated decision-making, including profiling, referred
to in Article 22(1) and (4) and, at least in those cases, meaningful information
about the logic involved, as well as the significance and the envisaged consequences
of such processing for the data subject.
3.Where the controller intends to further process the personal data for a purpose
other than that for which the personal data were collected, the controller shall
provide the data subject prior to that further processing with information on
that other purpose and with any relevant further information as referred to in
paragraph 2
4.Paragraphs 1, 2 and 3 shall not apply where and insofar as the data subject
already has the information.'
- This Regulation respects and does not prejudice the status under existing constitutional
law of churches and religious associations or communities in the Member States,
as recognised in Article 17 TFEU.
- '1) ''personal data'' means any information relating to an identified or identifiable
natural person (''data subject''); an identifiable natural person is one who can
be identified, directly or indirectly, in particular by reference to an identifier
such as a name, an identification number, location data, an online identifier
or to one or more factors specific to the physical, physiological, genetic, mental,
economic, cultural or social identity of that natural person;
(2) ‘processing’ means any operation or set of operations which is performed on
personal data or on sets of personal data, whether or not by automated means,
such as collection, recording, organisation, structuring, storage, adaptation
or alteration, retrieval, consultation, use, disclosure by transmission, dissemination
or otherwise making available, alignment or combination, restriction, erasure
or destruction;
(3) ‘restriction of processing’ means the marking of stored personal data with
the aim of limiting their processing in the future;
(4) ‘profiling’ means any form of automated processing of personal data consisting
of the use of personal data to evaluate certain personal aspects relating to a
natural person, in particular to analyse or predict aspects concerning that natural
person''s performance at work, economic situation, health, personal preferences,
interests, reliability, behaviour, location or movements;
(5) ‘pseudonymisation’ means the processing of personal data in such a manner
that the personal data can no longer be attributed to a specific data subject
without the use of additional information, provided that such additional information
is kept separately and is subject to technical and organisational measures to
ensure that the personal data are not attributed to an identified or identifiable
natural person;
(6) ‘filing system’ means any structured set of personal data which are accessible
according to specific criteria, whether centralised, decentralised or dispersed
on a functional or geographical basis;
(7) ‘controller’ means the natural or legal person, public authority, agency or
other body which, alone or jointly with others, determines the purposes and means
of the processing of personal data; where the purposes and means of such processing
are determined by Union or Member State law, the controller or the specific criteria
for its nomination may be provided for by Union or Member State law;
(8) ‘processor’ means a natural or legal person, public authority, agency or other
body which processes personal data on behalf of the controller;
(9) ‘recipient’ means a natural or legal person, public authority, agency or another
body, to which the personal data are disclosed, whether a third party or not.
However, public authorities which may receive personal data in the framework of
a particular inquiry in accordance with Union or Member State law shall not be
regarded as recipients; the processing of those data by those public authorities
shall be in compliance with the applicable data protection rules according to
the purposes of the processing;
(10) ‘third party’ means a natural or legal person, public authority, agency or
body other than the data subject, controller, processor and persons who, under
the direct authority of the controller or processor, are authorised to process
personal data;
(11) ‘consent’ of the data subject means any freely given, specific, informed
and unambiguous indication of the data subject''s wishes by which he or she, by
a statement or by a clear affirmative action, signifies agreement to the processing
of personal data relating to him or her;
(12) ‘personal data breach’ means a breach of security leading to the accidental
or unlawful destruction, loss, alteration, unauthorised disclosure of, or access
to, personal data transmitted, stored or otherwise processed;
(13) ‘genetic data’ means personal data relating to the inherited or acquired
genetic characteristics of a natural person which give unique information about
the physiology or the health of that natural person and which result, in particular,
from an analysis of a biological sample from the natural person in question;
(14) ‘biometric data’ means personal data resulting from specific technical processing
relating to the physical, physiological or behavioural characteristics of a natural
person, which allow or confirm the unique identification of that natural person,
such as facial images or dactyloscopic data;
(15) ‘data concerning health’ means personal data related to the physical or mental
health of a natural person, including the provision of health care services, which
reveal information about his or her health status;
(16) ‘main establishment’ means: (a) as regards a controller with establishments
in more than one Member State, the place of its central administration in the
Union, unless the decisions on the purposes and means of the processing of personal
data are taken in another establishment of the controller in the Union and the
latter establishment has the power to have such decisions implemented, in which
case the establishment having taken such decisions is to be considered to be the
main establishment; (b) as regards a processor with establishments in more than
one Member State, the place of its central administration in the Union, or, if
the processor has no central administration in the Union, the establishment of
the processor in the Union where the main processing activities in the context
of the activities of an establishment of the processor take place to the extent
that the processor is subject to specific obligations under this Regulation;
(17) ‘representative’ means a natural or legal person established in the Union
who, designated by the controller or processor in writing pursuant to Article
27, represents the controller or processor with regard to their respective obligations
under this Regulation;
(18) ‘enterprise’ means a natural or legal person engaged in an economic activity,
irrespective of its legal form, including partnerships or associations regularly
engaged in an economic activity;
(19) ‘group of undertakings’ means a controlling undertaking and its controlled
undertakings;
(20) ‘binding corporate rules’ means personal data protection policies which are
adhered to by a controller or processor established on the territory of a Member
State for transfers or a set of transfers of personal data to a controller or
processor in one or more third countries within a group of undertakings, or group
of enterprises engaged in a joint economic activity;
(21) ‘supervisory authority’ means an independent public authority which is established
by a Member State pursuant to Article 51;
(22) ‘supervisory authority concerned’ means a supervisory authority which is
concerned by the processing of personal data because: (a) the controller or processor
is established on the territory of the Member State of that supervisory authority;
(b) data subjects residing in the Member State of that supervisory authority are
substantially affected or likely to be substantially affected by the processing;
or (c) a complaint has been lodged with that supervisory authority;
(23) ‘cross-border processing’ means either: (a) processing of personal data which
takes place in the context of the activities of establishments in more than one
Member State of a controller or processor in the Union where the controller or
processor is established in more than one Member State; or (b) processing of personal
data which takes place in the context of the activities of a single establishment
of a controller or processor in the Union but which substantially affects or is
likely to substantially affect data subjects in more than one Member State.
(24) ‘relevant and reasoned objection’ means an objection to a draft decision
as to whether there is an infringement of this Regulation, or whether envisaged
action in relation to the controller or processor complies with this Regulation,
which clearly demonstrates the significance of the risks posed by the draft decision
as regards the fundamental rights and freedoms of data subjects and, where applicable,
the free flow of personal data within the Union;
(25) ‘information society service’ means a service as defined in point (b) of
Article 1(1) of Directive (EU) 2015/1535 of the European Parliament and of the
Council (1);
(26) ‘international organisation’ means an organisation and its subordinate bodies
governed by public international law, or any other body which is set up by, or
on the basis of, an agreement between two or more countries.'
- source_sentence: What type of data may be processed for purposes related to point
(h) of paragraph 2?
sentences:
- '1.Processing of personal data revealing racial or ethnic origin, political opinions,
religious or philosophical beliefs, or trade union membership, and the processing
of genetic data, biometric data for the purpose of uniquely identifying a natural
person, data concerning health or data concerning a natural person''s sex life
or sexual orientation shall be prohibited.
2.Paragraph 1 shall not apply if one of the following applies: (a) the data subject
has given explicit consent to the processing of those personal data for one or
more specified purposes, except where Union or Member State law provide that the
prohibition referred to in paragraph 1 may not be lifted by the data subject;
(b) processing is necessary for the purposes of carrying out the obligations
and exercising specific rights of the controller or of the data subject in the
field of employment and social security and social protection law in so far as
it is authorised by Union or Member State law or a collective agreement pursuant
to Member State law providing for appropriate safeguards for the fundamental rights
and the interests of the data subject; (c) processing is necessary to protect
the vital interests of the data subject or of another natural person where the
data subject is physically or legally incapable of giving consent; (d) processing
is carried out in the course of its legitimate activities with appropriate safeguards
by a foundation, association or any other not-for-profit body with a political,
philosophical, religious or trade union aim and on condition that the processing
relates solely to the members or to former members of the body or to persons who
have regular contact with it in connection with its purposes and that the personal
data are not disclosed outside that body without the consent of the data subjects;
(e) processing relates to personal data which are manifestly made public by the
data subject; (f) processing is necessary for the establishment, exercise or
defence of legal claims or whenever courts are acting in their judicial capacity;
(g) processing is necessary for reasons of substantial public interest, on the
basis of Union or Member State law which shall be proportionate to the aim pursued,
respect the essence of the right to data protection and provide for suitable and
specific measures to safeguard the fundamental rights and the interests of the
data subject; (h) processing is necessary for the purposes of preventive or occupational
medicine, for the assessment of the working capacity of the employee, medical
diagnosis, the provision of health or social care or treatment or the management
of health or social care systems and services on the basis of Union or Member
State law or pursuant to contract with a health professional and subject to the
conditions and safeguards referred to in paragraph 3; (i) processing is necessary
for reasons of public interest in the area of public health, such as protecting
against serious cross-border threats to health or ensuring high standards of quality
and safety of health care and of medicinal products or medical devices, on the
basis of Union or Member State law which provides for suitable and specific measures
to safeguard the rights and freedoms of the data subject, in particular professional
secrecy; 4.5.2016 L 119/38 (j) processing is necessary for archiving purposes
in the public interest, scientific or historical research purposes or statistical
purposes in accordance with Article 89(1) based on Union or Member State law which
shall be proportionate to the aim pursued, respect the essence of the right to
data protection and provide for suitable and specific measures to safeguard the
fundamental rights and the interests of the data subject.
3.Personal data referred to in paragraph 1 may be processed for the purposes referred
to in point (h) of paragraph 2 when those data are processed by or under the responsibility
of a professional subject to the obligation of professional secrecy under Union
or Member State law or rules established by national competent bodies or by another
person also subject to an obligation of secrecy under Union or Member State law
or rules established by national competent bodies.
4.Member States may maintain or introduce further conditions, including limitations,
with regard to the processing of genetic data, biometric data or data concerning
health.'
- '1.The data protection officer shall have at least the following tasks: (a) to
inform and advise the controller or the processor and the employees who carry
out processing of their obligations pursuant to this Regulation and to other Union
or Member State data protection provisions; (b) to monitor compliance with this
Regulation, with other Union or Member State data protection provisions and with
the policies of the controller or processor in relation to the protection of personal
data, including the assignment of responsibilities, awareness-raising and training
of staff involved in processing operations, and the related audits; (c) to provide
advice where requested as regards the data protection impact assessment and monitor
its performance pursuant to Article 35; (d) to cooperate with the supervisory
authority; (e) to act as the contact point for the supervisory authority on issues
relating to processing, including the prior consultation referred to in Article
36, and to consult, where appropriate, with regard to any other matter.
2.The data protection officer shall in the performance of his or her tasks have
due regard to the risk associated with processing operations, taking into account
the nature, scope, context and purposes of processing. Section 5 Codes of conduct
and certification'
- Processing should be lawful where it is necessary in the context of a contract
or the intention to enter into a contract.
- source_sentence: What may impede authorities in the discharge of their responsibilities
under Union law?
sentences:
- '1.The controller and the processor shall designate a data protection officer
in any case where: (a) the processing is carried out by a public authority or
body, except for courts acting in their judicial capacity; (b) the core activities
of the controller or the processor consist of processing operations which, by
virtue of their nature, their scope and/or their purposes, require regular and
systematic monitoring of data subjects on a large scale; or (c) the core activities
of the controller or the processor consist of processing on a large scale of special
categories of data pursuant to Article 9 and personal data relating to criminal
convictions and offences referred to in Article 10
2.A group of undertakings may appoint a single data protection officer provided
that a data protection officer is easily accessible from each establishment.
3.Where the controller or the processor is a public authority or body, a single
data protection officer may be designated for several such authorities or bodies,
taking account of their organisational structure and size.
4.In cases other than those referred to in paragraph 1, the controller or processor
or associations and other bodies representing categories of controllers or processors
may or, where required by Union or Member State law shall, designate a data protection
officer. The data protection officer may act for such associations and other bodies
representing controllers or processors.
5.The data protection officer shall be designated on the basis of professional
qualities and, in particular, expert knowledge of data protection law and practices
and the ability to fulfil the tasks referred to in Article 39
6.The data protection officer may be a staff member of the controller or processor,
or fulfil the tasks on the basis of a service contract.
7.The controller or the processor shall publish the contact details of the data
protection officer and communicate them to the supervisory authority.'
- This Regulation is without prejudice to international agreements concluded between
the Union and third countries regulating the transfer of personal data including
appropriate safeguards for the data subjects. Member States may conclude international
agreements which involve the transfer of personal data to third countries or international
organisations, as far as such agreements do not affect this Regulation or any
other provisions of Union law and include an appropriate level of protection for
the fundamental rights of the data subjects.
- The objectives and principles of Directive 95/46/EC remain sound, but it has not
prevented fragmentation in the implementation of data protection across the Union,
legal uncertainty or a widespread public perception that there are significant
risks to the protection of natural persons, in particular with regard to online
activity. Differences in the level of protection of the rights and freedoms of
natural persons, in particular the right to the protection of personal data, with
regard to the processing of personal data in the Member States may prevent the
free flow of personal data throughout the Union. Those differences may therefore
constitute an obstacle to the pursuit of economic activities at the level of the
Union, distort competition and impede authorities in the discharge of their responsibilities
under Union law. Such a difference in levels of protection is due to the existence
of differences in the implementation and application of Directive 95/46/EC.
pipeline_tag: sentence-similarity
library_name: sentence-transformers
metrics:
- cosine_accuracy@1
- cosine_accuracy@3
- cosine_accuracy@5
- cosine_accuracy@10
- cosine_precision@1
- cosine_precision@3
- cosine_precision@5
- cosine_precision@10
- cosine_recall@1
- cosine_recall@3
- cosine_recall@5
- cosine_recall@10
- cosine_ndcg@10
- cosine_mrr@10
- cosine_map@100
model-index:
- name: legal-bert-base-uncased
results:
- task:
type: information-retrieval
name: Information Retrieval
dataset:
name: dim 768
type: dim_768
metrics:
- type: cosine_accuracy@1
value: 0.29449423815621
name: Cosine Accuracy@1
- type: cosine_accuracy@3
value: 0.29897567221510885
name: Cosine Accuracy@3
- type: cosine_accuracy@5
value: 0.3290653008962868
name: Cosine Accuracy@5
- type: cosine_accuracy@10
value: 0.36107554417413573
name: Cosine Accuracy@10
- type: cosine_precision@1
value: 0.29449423815621
name: Cosine Precision@1
- type: cosine_precision@3
value: 0.2940674349125053
name: Cosine Precision@3
- type: cosine_precision@5
value: 0.2902688860435339
name: Cosine Precision@5
- type: cosine_precision@10
value: 0.2742637644046095
name: Cosine Precision@10
- type: cosine_recall@1
value: 0.03026684512223475
name: Cosine Recall@1
- type: cosine_recall@3
value: 0.08832516449344607
name: Cosine Recall@3
- type: cosine_recall@5
value: 0.13552647614747548
name: Cosine Recall@5
- type: cosine_recall@10
value: 0.21410735615609716
name: Cosine Recall@10
- type: cosine_ndcg@10
value: 0.3186633219467259
name: Cosine Ndcg@10
- type: cosine_mrr@10
value: 0.3058878523667252
name: Cosine Mrr@10
- type: cosine_map@100
value: 0.3755675129047903
name: Cosine Map@100
- task:
type: information-retrieval
name: Information Retrieval
dataset:
name: dim 512
type: dim_512
metrics:
- type: cosine_accuracy@1
value: 0.2912932138284251
name: Cosine Accuracy@1
- type: cosine_accuracy@3
value: 0.29513444302176695
name: Cosine Accuracy@3
- type: cosine_accuracy@5
value: 0.31882202304737517
name: Cosine Accuracy@5
- type: cosine_accuracy@10
value: 0.3553137003841229
name: Cosine Accuracy@10
- type: cosine_precision@1
value: 0.2912932138284251
name: Cosine Precision@1
- type: cosine_precision@3
value: 0.29043960734101576
name: Cosine Precision@3
- type: cosine_precision@5
value: 0.2851472471190781
name: Cosine Precision@5
- type: cosine_precision@10
value: 0.2681177976952625
name: Cosine Precision@10
- type: cosine_recall@1
value: 0.030361386611704476
name: Cosine Recall@1
- type: cosine_recall@3
value: 0.0882907384677484
name: Cosine Recall@3
- type: cosine_recall@5
value: 0.13407548376179323
name: Cosine Recall@5
- type: cosine_recall@10
value: 0.20905329863886993
name: Cosine Recall@10
- type: cosine_ndcg@10
value: 0.3126292857296644
name: Cosine Ndcg@10
- type: cosine_mrr@10
value: 0.30175192569558734
name: Cosine Mrr@10
- type: cosine_map@100
value: 0.3699121037745867
name: Cosine Map@100
- task:
type: information-retrieval
name: Information Retrieval
dataset:
name: dim 256
type: dim_256
metrics:
- type: cosine_accuracy@1
value: 0.2912932138284251
name: Cosine Accuracy@1
- type: cosine_accuracy@3
value: 0.29513444302176695
name: Cosine Accuracy@3
- type: cosine_accuracy@5
value: 0.31690140845070425
name: Cosine Accuracy@5
- type: cosine_accuracy@10
value: 0.3418693982074264
name: Cosine Accuracy@10
- type: cosine_precision@1
value: 0.2912932138284251
name: Cosine Precision@1
- type: cosine_precision@3
value: 0.29086641058472046
name: Cosine Precision@3
- type: cosine_precision@5
value: 0.2860435339308579
name: Cosine Precision@5
- type: cosine_precision@10
value: 0.2651728553137004
name: Cosine Precision@10
- type: cosine_recall@1
value: 0.0292825483371299
name: Cosine Recall@1
- type: cosine_recall@3
value: 0.08580699200242682
name: Cosine Recall@3
- type: cosine_recall@5
value: 0.13210929571847116
name: Cosine Recall@5
- type: cosine_recall@10
value: 0.205766272309207
name: Cosine Recall@10
- type: cosine_ndcg@10
value: 0.3091299452567313
name: Cosine Ndcg@10
- type: cosine_mrr@10
value: 0.2998435054773079
name: Cosine Mrr@10
- type: cosine_map@100
value: 0.3618106670285059
name: Cosine Map@100
- task:
type: information-retrieval
name: Information Retrieval
dataset:
name: dim 128
type: dim_128
metrics:
- type: cosine_accuracy@1
value: 0.28040973111395645
name: Cosine Accuracy@1
- type: cosine_accuracy@3
value: 0.28425096030729835
name: Cosine Accuracy@3
- type: cosine_accuracy@5
value: 0.3040973111395647
name: Cosine Accuracy@5
- type: cosine_accuracy@10
value: 0.3265044814340589
name: Cosine Accuracy@10
- type: cosine_precision@1
value: 0.28040973111395645
name: Cosine Precision@1
- type: cosine_precision@3
value: 0.27955612462654716
name: Cosine Precision@3
- type: cosine_precision@5
value: 0.2742637644046095
name: Cosine Precision@5
- type: cosine_precision@10
value: 0.25275288092189496
name: Cosine Precision@10
- type: cosine_recall@1
value: 0.02891895888775105
name: Cosine Recall@1
- type: cosine_recall@3
value: 0.08401783167068705
name: Cosine Recall@3
- type: cosine_recall@5
value: 0.12794499275374233
name: Cosine Recall@5
- type: cosine_recall@10
value: 0.19542775070145985
name: Cosine Recall@10
- type: cosine_ndcg@10
value: 0.29650577605186873
name: Cosine Ndcg@10
- type: cosine_mrr@10
value: 0.28831168831168796
name: Cosine Mrr@10
- type: cosine_map@100
value: 0.34582113277936
name: Cosine Map@100
- task:
type: information-retrieval
name: Information Retrieval
dataset:
name: dim 64
type: dim_64
metrics:
- type: cosine_accuracy@1
value: 0.26248399487836105
name: Cosine Accuracy@1
- type: cosine_accuracy@3
value: 0.26504481434058896
name: Cosine Accuracy@3
- type: cosine_accuracy@5
value: 0.2861715749039693
name: Cosine Accuracy@5
- type: cosine_accuracy@10
value: 0.3066581306017926
name: Cosine Accuracy@10
- type: cosine_precision@1
value: 0.26248399487836105
name: Cosine Precision@1
- type: cosine_precision@3
value: 0.2609901835253948
name: Cosine Precision@3
- type: cosine_precision@5
value: 0.2563380281690141
name: Cosine Precision@5
- type: cosine_precision@10
value: 0.23847631241997438
name: Cosine Precision@10
- type: cosine_recall@1
value: 0.02640598810403516
name: Cosine Recall@1
- type: cosine_recall@3
value: 0.07629702961300178
name: Cosine Recall@3
- type: cosine_recall@5
value: 0.11634271108294637
name: Cosine Recall@5
- type: cosine_recall@10
value: 0.1797900542673238
name: Cosine Recall@10
- type: cosine_ndcg@10
value: 0.27821953742538774
name: Cosine Ndcg@10
- type: cosine_mrr@10
value: 0.26997439180537736
name: Cosine Mrr@10
- type: cosine_map@100
value: 0.32457175472568783
name: Cosine Map@100
---
# legal-bert-base-uncased
This is a [sentence-transformers](https://www.SBERT.net) model finetuned from [nlpaueb/legal-bert-base-uncased](https://huggingface.co/nlpaueb/legal-bert-base-uncased). It maps sentences & paragraphs to a 768-dimensional dense vector space and can be used for semantic textual similarity, semantic search, paraphrase mining, text classification, clustering, and more.
## Model Details
### Model Description
- **Model Type:** Sentence Transformer
- **Base model:** [nlpaueb/legal-bert-base-uncased](https://huggingface.co/nlpaueb/legal-bert-base-uncased) <!-- at revision 15b570cbf88259610b082a167dacc190124f60f6 -->
- **Maximum Sequence Length:** 512 tokens
- **Output Dimensionality:** 768 dimensions
- **Similarity Function:** Cosine Similarity
<!-- - **Training Dataset:** Unknown -->
- **Language:** en
- **License:** apache-2.0
### Model Sources
- **Documentation:** [Sentence Transformers Documentation](https://sbert.net)
- **Repository:** [Sentence Transformers on GitHub](https://github.com/UKPLab/sentence-transformers)
- **Hugging Face:** [Sentence Transformers on Hugging Face](https://huggingface.co/models?library=sentence-transformers)
### Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 512, 'do_lower_case': False, 'architecture': 'BertModel'})
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False, 'pooling_mode_weightedmean_tokens': False, 'pooling_mode_lasttoken': False, 'include_prompt': True})
)
```
## Usage
### Direct Usage (Sentence Transformers)
First install the Sentence Transformers library:
```bash
pip install -U sentence-transformers
```
Then you can load this model and run inference.
```python
from sentence_transformers import SentenceTransformer
# Download from the 🤗 Hub
model = SentenceTransformer("sentence_transformers_model_id")
# Run inference
sentences = [
'What may impede authorities in the discharge of their responsibilities under Union law?',
'The objectives and principles of Directive 95/46/EC remain sound, but it has not prevented fragmentation in the implementation of data protection across the Union, legal uncertainty or a widespread public perception that there are significant risks to the protection of natural persons, in particular with regard to online activity. Differences in the level of protection of the rights and freedoms of natural persons, in particular the right to the protection of personal data, with regard to the processing of personal data in the Member States may prevent the free flow of personal data throughout the Union. Those differences may therefore constitute an obstacle to the pursuit of economic activities at the level of the Union, distort competition and impede authorities in the discharge of their responsibilities under Union law. Such a difference in levels of protection is due to the existence of differences in the implementation and application of Directive 95/46/EC.',
'This Regulation is without prejudice to international agreements concluded between the Union and third countries regulating the transfer of personal data including appropriate safeguards for the data subjects. Member States may conclude international agreements which involve the transfer of personal data to third countries or international organisations, as far as such agreements do not affect this Regulation or any other provisions of Union law and include an appropriate level of protection for the fundamental rights of the data subjects.',
]
embeddings = model.encode(sentences)
print(embeddings.shape)
# [3, 768]
# Get the similarity scores for the embeddings
similarities = model.similarity(embeddings, embeddings)
print(similarities)
# tensor([[1.0000, 0.7482, 0.4027],
# [0.7482, 1.0000, 0.4551],
# [0.4027, 0.4551, 1.0000]])
```
<!--
### Direct Usage (Transformers)
<details><summary>Click to see the direct usage in Transformers</summary>
</details>
-->
<!--
### Downstream Usage (Sentence Transformers)
You can finetune this model on your own dataset.
<details><summary>Click to expand</summary>
</details>
-->
<!--
### Out-of-Scope Use
*List how the model may foreseeably be misused and address what users ought not to do with the model.*
-->
## Evaluation
### Metrics
#### Information Retrieval
* Dataset: `dim_768`
* Evaluated with [<code>InformationRetrievalEvaluator</code>](https://sbert.net/docs/package_reference/sentence_transformer/evaluation.html#sentence_transformers.evaluation.InformationRetrievalEvaluator) with these parameters:
```json
{
"truncate_dim": 768
}
```
| Metric | Value |
|:--------------------|:-----------|
| cosine_accuracy@1 | 0.2945 |
| cosine_accuracy@3 | 0.299 |
| cosine_accuracy@5 | 0.3291 |
| cosine_accuracy@10 | 0.3611 |
| cosine_precision@1 | 0.2945 |
| cosine_precision@3 | 0.2941 |
| cosine_precision@5 | 0.2903 |
| cosine_precision@10 | 0.2743 |
| cosine_recall@1 | 0.0303 |
| cosine_recall@3 | 0.0883 |
| cosine_recall@5 | 0.1355 |
| cosine_recall@10 | 0.2141 |
| **cosine_ndcg@10** | **0.3187** |
| cosine_mrr@10 | 0.3059 |
| cosine_map@100 | 0.3756 |
#### Information Retrieval
* Dataset: `dim_512`
* Evaluated with [<code>InformationRetrievalEvaluator</code>](https://sbert.net/docs/package_reference/sentence_transformer/evaluation.html#sentence_transformers.evaluation.InformationRetrievalEvaluator) with these parameters:
```json
{
"truncate_dim": 512
}
```
| Metric | Value |
|:--------------------|:-----------|
| cosine_accuracy@1 | 0.2913 |
| cosine_accuracy@3 | 0.2951 |
| cosine_accuracy@5 | 0.3188 |
| cosine_accuracy@10 | 0.3553 |
| cosine_precision@1 | 0.2913 |
| cosine_precision@3 | 0.2904 |
| cosine_precision@5 | 0.2851 |
| cosine_precision@10 | 0.2681 |
| cosine_recall@1 | 0.0304 |
| cosine_recall@3 | 0.0883 |
| cosine_recall@5 | 0.1341 |
| cosine_recall@10 | 0.2091 |
| **cosine_ndcg@10** | **0.3126** |
| cosine_mrr@10 | 0.3018 |
| cosine_map@100 | 0.3699 |
#### Information Retrieval
* Dataset: `dim_256`
* Evaluated with [<code>InformationRetrievalEvaluator</code>](https://sbert.net/docs/package_reference/sentence_transformer/evaluation.html#sentence_transformers.evaluation.InformationRetrievalEvaluator) with these parameters:
```json
{
"truncate_dim": 256
}
```
| Metric | Value |
|:--------------------|:-----------|
| cosine_accuracy@1 | 0.2913 |
| cosine_accuracy@3 | 0.2951 |
| cosine_accuracy@5 | 0.3169 |
| cosine_accuracy@10 | 0.3419 |
| cosine_precision@1 | 0.2913 |
| cosine_precision@3 | 0.2909 |
| cosine_precision@5 | 0.286 |
| cosine_precision@10 | 0.2652 |
| cosine_recall@1 | 0.0293 |
| cosine_recall@3 | 0.0858 |
| cosine_recall@5 | 0.1321 |
| cosine_recall@10 | 0.2058 |
| **cosine_ndcg@10** | **0.3091** |
| cosine_mrr@10 | 0.2998 |
| cosine_map@100 | 0.3618 |
#### Information Retrieval
* Dataset: `dim_128`
* Evaluated with [<code>InformationRetrievalEvaluator</code>](https://sbert.net/docs/package_reference/sentence_transformer/evaluation.html#sentence_transformers.evaluation.InformationRetrievalEvaluator) with these parameters:
```json
{
"truncate_dim": 128
}
```
| Metric | Value |
|:--------------------|:-----------|
| cosine_accuracy@1 | 0.2804 |
| cosine_accuracy@3 | 0.2843 |
| cosine_accuracy@5 | 0.3041 |
| cosine_accuracy@10 | 0.3265 |
| cosine_precision@1 | 0.2804 |
| cosine_precision@3 | 0.2796 |
| cosine_precision@5 | 0.2743 |
| cosine_precision@10 | 0.2528 |
| cosine_recall@1 | 0.0289 |
| cosine_recall@3 | 0.084 |
| cosine_recall@5 | 0.1279 |
| cosine_recall@10 | 0.1954 |
| **cosine_ndcg@10** | **0.2965** |
| cosine_mrr@10 | 0.2883 |
| cosine_map@100 | 0.3458 |
#### Information Retrieval
* Dataset: `dim_64`
* Evaluated with [<code>InformationRetrievalEvaluator</code>](https://sbert.net/docs/package_reference/sentence_transformer/evaluation.html#sentence_transformers.evaluation.InformationRetrievalEvaluator) with these parameters:
```json
{
"truncate_dim": 64
}
```
| Metric | Value |
|:--------------------|:-----------|
| cosine_accuracy@1 | 0.2625 |
| cosine_accuracy@3 | 0.265 |
| cosine_accuracy@5 | 0.2862 |
| cosine_accuracy@10 | 0.3067 |
| cosine_precision@1 | 0.2625 |
| cosine_precision@3 | 0.261 |
| cosine_precision@5 | 0.2563 |
| cosine_precision@10 | 0.2385 |
| cosine_recall@1 | 0.0264 |
| cosine_recall@3 | 0.0763 |
| cosine_recall@5 | 0.1163 |
| cosine_recall@10 | 0.1798 |
| **cosine_ndcg@10** | **0.2782** |
| cosine_mrr@10 | 0.27 |
| cosine_map@100 | 0.3246 |
<!--
## Bias, Risks and Limitations
*What are the known or foreseeable issues stemming from this model? You could also flag here known failure cases or weaknesses of the model.*
-->
<!--
### Recommendations
*What are recommendations with respect to the foreseeable issues? For example, filtering explicit content.*
-->
## Training Details
### Training Dataset
#### Unnamed Dataset
* Size: 391 training samples
* Columns: <code>anchor</code> and <code>positive</code>
* Approximate statistics based on the first 391 samples:
| | anchor | positive |
|:--------|:----------------------------------------------------------------------------------|:-------------------------------------------------------------------------------------|
| type | string | string |
| details | <ul><li>min: 7 tokens</li><li>mean: 15.08 tokens</li><li>max: 29 tokens</li></ul> | <ul><li>min: 25 tokens</li><li>mean: 358.31 tokens</li><li>max: 512 tokens</li></ul> |
* Samples:
| anchor | positive |
|:-----------------------------------------------------------------------------------------------------|:------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| <code>On what date did the act occur?</code> | <code>Court (Civil/Criminal): Civil <br>Provisions: Directive 2015/366, Law 4537/2018 <br>Time of the act: 31.08.2022 <br>Outcome (not guilty, guilty): Partially accepts the claim. <br>Reasoning: The Athens Peace Court ordered the bank to return the amount that was withdrawn from the plaintiffs' account and to pay additional compensation for the moral damage they suffered. <br>Facts: The case concerns plaintiffs who fell victim to electronic fraud via phishing, resulting in the withdrawal of money from their bank account. The plaintiffs claimed that the bank did not take the necessary security measures to protect their accounts and sought compensation for the financial loss and moral damage they suffered. The court determined that the bank is responsible for the loss of the money, as it did not prove that the transactions were authorized by the plaintiffs. Furthermore, the court recognized that the bank's refusal to return the funds constitutes an infringement of the plaintiffs' personal rights, as it...</code> |
| <code>For what purposes can more specific rules be provided regarding the employment context?</code> | <code>1.Member States may, by law or by collective agreements, provide for more specific rules to ensure the protection of the rights and freedoms in respect of the processing of employees' personal data in the employment context, in particular for the purposes of the recruitment, the performance of the contract of employment, including discharge of obligations laid down by law or by collective agreements, management, planning and organisation of work, equality and diversity in the workplace, health and safety at work, protection of employer's or customer's property and for the purposes of the exercise and enjoyment, on an individual or collective basis, of rights and benefits related to employment, and for the purpose of the termination of the employment relationship.<br>2.Those rules shall include suitable and specific measures to safeguard the data subject's human dignity, legitimate interests and fundamental rights, with particular regard to the transparency of processing, the transfer of p...</code> |
| <code>On which date were transactions detailed in the provided text conducted?</code> | <code>**Court (Civil/Criminal): Civil**<br><br>**Provisions:**<br><br>**Time of commission of the act:**<br><br>**Outcome (not guilty, guilty):**<br><br>**Rationale:**<br><br>**Facts:**<br>The plaintiff holds credit card number ............ with the defendant banking corporation. Based on the application for alternative networks dated 19/7/2015 with number ......... submitted at a branch of the defendant, he was granted access to the electronic banking service (e-banking) to conduct banking transactions (debit, credit, updates, payments) remotely. On 30/11/2020, the plaintiff fell victim to electronic fraud through the "phishing" method, whereby an unknown perpetrator managed to withdraw a total amount of €3,121.75 from the aforementioned credit card. Specifically, the plaintiff received an email at 1:35 PM on 29/11/2020 from sender ...... with address ........, informing him that due to an impending system change, he needed to verify the mobile phone number linked to the credit card, urging him to complete the verification...</code> |
* Loss: [<code>MatryoshkaLoss</code>](https://sbert.net/docs/package_reference/sentence_transformer/losses.html#matryoshkaloss) with these parameters:
```json
{
"loss": "MultipleNegativesRankingLoss",
"matryoshka_dims": [
768,
512,
256,
128,
64
],
"matryoshka_weights": [
1,
1,
1,
1,
1
],
"n_dims_per_step": -1
}
```
### Training Hyperparameters
#### Non-Default Hyperparameters
- `eval_strategy`: epoch
- `per_device_train_batch_size`: 2
- `per_device_eval_batch_size`: 2
- `gradient_accumulation_steps`: 2
- `learning_rate`: 2e-05
- `num_train_epochs`: 20
- `lr_scheduler_type`: cosine
- `warmup_ratio`: 0.1
- `bf16`: True
- `load_best_model_at_end`: True
- `optim`: adamw_torch_fused
- `batch_sampler`: no_duplicates
#### All Hyperparameters
<details><summary>Click to expand</summary>
- `overwrite_output_dir`: False
- `do_predict`: False
- `eval_strategy`: epoch
- `prediction_loss_only`: True
- `per_device_train_batch_size`: 2
- `per_device_eval_batch_size`: 2
- `per_gpu_train_batch_size`: None
- `per_gpu_eval_batch_size`: None
- `gradient_accumulation_steps`: 2
- `eval_accumulation_steps`: None
- `torch_empty_cache_steps`: None
- `learning_rate`: 2e-05
- `weight_decay`: 0.0
- `adam_beta1`: 0.9
- `adam_beta2`: 0.999
- `adam_epsilon`: 1e-08
- `max_grad_norm`: 1.0
- `num_train_epochs`: 20
- `max_steps`: -1
- `lr_scheduler_type`: cosine
- `lr_scheduler_kwargs`: {}
- `warmup_ratio`: 0.1
- `warmup_steps`: 0
- `log_level`: passive
- `log_level_replica`: warning
- `log_on_each_node`: True
- `logging_nan_inf_filter`: True
- `save_safetensors`: True
- `save_on_each_node`: False
- `save_only_model`: False
- `restore_callback_states_from_checkpoint`: False
- `no_cuda`: False
- `use_cpu`: False
- `use_mps_device`: False
- `seed`: 42
- `data_seed`: None
- `jit_mode_eval`: False
- `use_ipex`: False
- `bf16`: True
- `fp16`: False
- `fp16_opt_level`: O1
- `half_precision_backend`: auto
- `bf16_full_eval`: False
- `fp16_full_eval`: False
- `tf32`: None
- `local_rank`: 0
- `ddp_backend`: None
- `tpu_num_cores`: None
- `tpu_metrics_debug`: False
- `debug`: []
- `dataloader_drop_last`: False
- `dataloader_num_workers`: 0
- `dataloader_prefetch_factor`: None
- `past_index`: -1
- `disable_tqdm`: False
- `remove_unused_columns`: True
- `label_names`: None
- `load_best_model_at_end`: True
- `ignore_data_skip`: False
- `fsdp`: []
- `fsdp_min_num_params`: 0
- `fsdp_config`: {'min_num_params': 0, 'xla': False, 'xla_fsdp_v2': False, 'xla_fsdp_grad_ckpt': False}
- `tp_size`: 0
- `fsdp_transformer_layer_cls_to_wrap`: None
- `accelerator_config`: {'split_batches': False, 'dispatch_batches': None, 'even_batches': True, 'use_seedable_sampler': True, 'non_blocking': False, 'gradient_accumulation_kwargs': None}
- `deepspeed`: None
- `label_smoothing_factor`: 0.0
- `optim`: adamw_torch_fused
- `optim_args`: None
- `adafactor`: False
- `group_by_length`: False
- `length_column_name`: length
- `ddp_find_unused_parameters`: None
- `ddp_bucket_cap_mb`: None
- `ddp_broadcast_buffers`: False
- `dataloader_pin_memory`: True
- `dataloader_persistent_workers`: False
- `skip_memory_metrics`: True
- `use_legacy_prediction_loop`: False
- `push_to_hub`: False
- `resume_from_checkpoint`: None
- `hub_model_id`: None
- `hub_strategy`: every_save
- `hub_private_repo`: None
- `hub_always_push`: False
- `gradient_checkpointing`: False
- `gradient_checkpointing_kwargs`: None
- `include_inputs_for_metrics`: False
- `include_for_metrics`: []
- `eval_do_concat_batches`: True
- `fp16_backend`: auto
- `push_to_hub_model_id`: None
- `push_to_hub_organization`: None
- `mp_parameters`:
- `auto_find_batch_size`: False
- `full_determinism`: False
- `torchdynamo`: None
- `ray_scope`: last
- `ddp_timeout`: 1800
- `torch_compile`: False
- `torch_compile_backend`: None
- `torch_compile_mode`: None
- `include_tokens_per_second`: False
- `include_num_input_tokens_seen`: False
- `neftune_noise_alpha`: None
- `optim_target_modules`: None
- `batch_eval_metrics`: False
- `eval_on_start`: False
- `use_liger_kernel`: False
- `eval_use_gather_object`: False
- `average_tokens_across_devices`: False
- `prompts`: None
- `batch_sampler`: no_duplicates
- `multi_dataset_batch_sampler`: proportional
- `router_mapping`: {}
- `learning_rate_mapping`: {}
</details>
### Training Logs
<details><summary>Click to expand</summary>
| Epoch | Step | Training Loss | dim_768_cosine_ndcg@10 | dim_512_cosine_ndcg@10 | dim_256_cosine_ndcg@10 | dim_128_cosine_ndcg@10 | dim_64_cosine_ndcg@10 |
|:-------:|:-------:|:-------------:|:----------------------:|:----------------------:|:----------------------:|:----------------------:|:---------------------:|
| 0.0102 | 1 | 7.1696 | - | - | - | - | - |
| 0.0204 | 2 | 5.5986 | - | - | - | - | - |
| 0.0306 | 3 | 7.0556 | - | - | - | - | - |
| 0.0408 | 4 | 3.6816 | - | - | - | - | - |
| 0.0510 | 5 | 2.7039 | - | - | - | - | - |
| 0.0612 | 6 | 4.2351 | - | - | - | - | - |
| 0.0714 | 7 | 4.2931 | - | - | - | - | - |
| 0.0816 | 8 | 7.8564 | - | - | - | - | - |
| 0.0918 | 9 | 5.2709 | - | - | - | - | - |
| 0.1020 | 10 | 2.8151 | - | - | - | - | - |
| 0.1122 | 11 | 4.8541 | - | - | - | - | - |
| 0.1224 | 12 | 4.5369 | - | - | - | - | - |
| 0.1327 | 13 | 3.4808 | - | - | - | - | - |
| 0.1429 | 14 | 2.8361 | - | - | - | - | - |
| 0.1531 | 15 | 3.2782 | - | - | - | - | - |
| 0.1633 | 16 | 3.1139 | - | - | - | - | - |
| 0.1735 | 17 | 8.5683 | - | - | - | - | - |
| 0.1837 | 18 | 2.9852 | - | - | - | - | - |
| 0.1939 | 19 | 7.1109 | - | - | - | - | - |
| 0.2041 | 20 | 4.5516 | - | - | - | - | - |
| 0.2143 | 21 | 5.421 | - | - | - | - | - |
| 0.2245 | 22 | 5.0981 | - | - | - | - | - |
| 0.2347 | 23 | 5.6382 | - | - | - | - | - |
| 0.2449 | 24 | 6.2661 | - | - | - | - | - |
| 0.2551 | 25 | 2.7698 | - | - | - | - | - |
| 0.2653 | 26 | 4.0075 | - | - | - | - | - |
| 0.2755 | 27 | 7.6512 | - | - | - | - | - |
| 0.2857 | 28 | 4.7715 | - | - | - | - | - |
| 0.2959 | 29 | 4.6595 | - | - | - | - | - |
| 0.3061 | 30 | 4.795 | - | - | - | - | - |
| 0.3163 | 31 | 4.8058 | - | - | - | - | - |
| 0.3265 | 32 | 4.8049 | - | - | - | - | - |
| 0.3367 | 33 | 6.2773 | - | - | - | - | - |
| 0.3469 | 34 | 3.3515 | - | - | - | - | - |
| 0.3571 | 35 | 3.2643 | - | - | - | - | - |
| 0.3673 | 36 | 3.5992 | - | - | - | - | - |
| 0.3776 | 37 | 3.8876 | - | - | - | - | - |
| 0.3878 | 38 | 11.1147 | - | - | - | - | - |
| 0.3980 | 39 | 5.3685 | - | - | - | - | - |
| 0.4082 | 40 | 4.4782 | - | - | - | - | - |
| 0.4184 | 41 | 2.3301 | - | - | - | - | - |
| 0.4286 | 42 | 5.3515 | - | - | - | - | - |
| 0.4388 | 43 | 4.2881 | - | - | - | - | - |
| 0.4490 | 44 | 5.8402 | - | - | - | - | - |
| 0.4592 | 45 | 4.4051 | - | - | - | - | - |
| 0.4694 | 46 | 3.7015 | - | - | - | - | - |
| 0.4796 | 47 | 3.8899 | - | - | - | - | - |
| 0.4898 | 48 | 6.1056 | - | - | - | - | - |
| 0.5 | 49 | 5.0372 | - | - | - | - | - |
| 0.5102 | 50 | 3.5458 | - | - | - | - | - |
| 0.5204 | 51 | 5.2707 | - | - | - | - | - |
| 0.5306 | 52 | 5.3742 | - | - | - | - | - |
| 0.5408 | 53 | 4.952 | - | - | - | - | - |
| 0.5510 | 54 | 1.8328 | - | - | - | - | - |
| 0.5612 | 55 | 3.1727 | - | - | - | - | - |
| 0.5714 | 56 | 3.0359 | - | - | - | - | - |
| 0.5816 | 57 | 2.7896 | - | - | - | - | - |
| 0.5918 | 58 | 2.6978 | - | - | - | - | - |
| 0.6020 | 59 | 2.5506 | - | - | - | - | - |
| 0.6122 | 60 | 3.8039 | - | - | - | - | - |
| 0.6224 | 61 | 2.893 | - | - | - | - | - |
| 0.6327 | 62 | 3.5782 | - | - | - | - | - |
| 0.6429 | 63 | 4.1546 | - | - | - | - | - |
| 0.6531 | 64 | 7.4876 | - | - | - | - | - |
| 0.6633 | 65 | 2.2801 | - | - | - | - | - |
| 0.6735 | 66 | 5.4241 | - | - | - | - | - |
| 0.6837 | 67 | 5.5202 | - | - | - | - | - |
| 0.6939 | 68 | 3.6768 | - | - | - | - | - |
| 0.7041 | 69 | 3.0628 | - | - | - | - | - |
| 0.7143 | 70 | 5.0465 | - | - | - | - | - |
| 0.7245 | 71 | 3.7249 | - | - | - | - | - |
| 0.7347 | 72 | 3.3501 | - | - | - | - | - |
| 0.7449 | 73 | 3.2268 | - | - | - | - | - |
| 0.7551 | 74 | 3.1353 | - | - | - | - | - |
| 0.7653 | 75 | 4.0545 | - | - | - | - | - |
| 0.7755 | 76 | 1.4042 | - | - | - | - | - |
| 0.7857 | 77 | 0.929 | - | - | - | - | - |
| 0.7959 | 78 | 2.7907 | - | - | - | - | - |
| 0.8061 | 79 | 4.691 | - | - | - | - | - |
| 0.8163 | 80 | 1.4842 | - | - | - | - | - |
| 0.8265 | 81 | 2.9783 | - | - | - | - | - |
| 0.8367 | 82 | 3.0866 | - | - | - | - | - |
| 0.8469 | 83 | 1.1731 | - | - | - | - | - |
| 0.8571 | 84 | 0.5525 | - | - | - | - | - |
| 0.8673 | 85 | 2.5626 | - | - | - | - | - |
| 0.8776 | 86 | 1.0867 | - | - | - | - | - |
| 0.8878 | 87 | 1.3064 | - | - | - | - | - |
| 0.8980 | 88 | 3.0336 | - | - | - | - | - |
| 0.9082 | 89 | 8.6704 | - | - | - | - | - |
| 0.9184 | 90 | 2.0829 | - | - | - | - | - |
| 0.9286 | 91 | 0.9734 | - | - | - | - | - |
| 0.9388 | 92 | 4.8751 | - | - | - | - | - |
| 0.9490 | 93 | 1.7869 | - | - | - | - | - |
| 0.9592 | 94 | 2.261 | - | - | - | - | - |
| 0.9694 | 95 | 0.8735 | - | - | - | - | - |
| 0.9796 | 96 | 2.0015 | - | - | - | - | - |
| 0.9898 | 97 | 8.3582 | - | - | - | - | - |
| 1.0 | 98 | 2.7564 | 0.2305 | 0.2320 | 0.2428 | 0.2297 | 0.1815 |
| 1.0102 | 99 | 4.9172 | - | - | - | - | - |
| 1.0204 | 100 | 2.3303 | - | - | - | - | - |
| 1.0306 | 101 | 2.7368 | - | - | - | - | - |
| 1.0408 | 102 | 2.0585 | - | - | - | - | - |
| 1.0510 | 103 | 2.8806 | - | - | - | - | - |
| 1.0612 | 104 | 1.3272 | - | - | - | - | - |
| 1.0714 | 105 | 0.9525 | - | - | - | - | - |
| 1.0816 | 106 | 0.3944 | - | - | - | - | - |
| 1.0918 | 107 | 0.5496 | - | - | - | - | - |
| 1.1020 | 108 | 4.0204 | - | - | - | - | - |
| 1.1122 | 109 | 0.7699 | - | - | - | - | - |
| 1.1224 | 110 | 1.573 | - | - | - | - | - |
| 1.1327 | 111 | 2.2908 | - | - | - | - | - |
| 1.1429 | 112 | 2.2194 | - | - | - | - | - |
| 1.1531 | 113 | 5.5098 | - | - | - | - | - |
| 1.1633 | 114 | 1.4926 | - | - | - | - | - |
| 1.1735 | 115 | 0.5118 | - | - | - | - | - |
| 1.1837 | 116 | 0.352 | - | - | - | - | - |
| 1.1939 | 117 | 1.8558 | - | - | - | - | - |
| 1.2041 | 118 | 3.5846 | - | - | - | - | - |
| 1.2143 | 119 | 3.2194 | - | - | - | - | - |
| 1.2245 | 120 | 0.463 | - | - | - | - | - |
| 1.2347 | 121 | 0.0158 | - | - | - | - | - |
| 1.2449 | 122 | 0.373 | - | - | - | - | - |
| 1.2551 | 123 | 8.6146 | - | - | - | - | - |
| 1.2653 | 124 | 3.335 | - | - | - | - | - |
| 1.2755 | 125 | 0.3582 | - | - | - | - | - |
| 1.2857 | 126 | 0.9795 | - | - | - | - | - |
| 1.2959 | 127 | 0.1047 | - | - | - | - | - |
| 1.3061 | 128 | 0.0824 | - | - | - | - | - |
| 1.3163 | 129 | 9.3996 | - | - | - | - | - |
| 1.3265 | 130 | 0.3556 | - | - | - | - | - |
| 1.3367 | 131 | 4.8549 | - | - | - | - | - |
| 1.3469 | 132 | 2.2411 | - | - | - | - | - |
| 1.3571 | 133 | 8.3107 | - | - | - | - | - |
| 1.3673 | 134 | 0.7372 | - | - | - | - | - |
| 1.3776 | 135 | 0.5628 | - | - | - | - | - |
| 1.3878 | 136 | 1.1153 | - | - | - | - | - |
| 1.3980 | 137 | 1.3439 | - | - | - | - | - |
| 1.4082 | 138 | 1.8474 | - | - | - | - | - |
| 1.4184 | 139 | 2.622 | - | - | - | - | - |
| 1.4286 | 140 | 0.609 | - | - | - | - | - |
| 1.4388 | 141 | 1.6592 | - | - | - | - | - |
| 1.4490 | 142 | 2.3689 | - | - | - | - | - |
| 1.4592 | 143 | 0.9918 | - | - | - | - | - |
| 1.4694 | 144 | 3.2973 | - | - | - | - | - |
| 1.4796 | 145 | 5.0454 | - | - | - | - | - |
| 1.4898 | 146 | 3.5016 | - | - | - | - | - |
| 1.5 | 147 | 0.0423 | - | - | - | - | - |
| 1.5102 | 148 | 0.3454 | - | - | - | - | - |
| 1.5204 | 149 | 5.5514 | - | - | - | - | - |
| 1.5306 | 150 | 9.9022 | - | - | - | - | - |
| 1.5408 | 151 | 0.2767 | - | - | - | - | - |
| 1.5510 | 152 | 0.5092 | - | - | - | - | - |
| 1.5612 | 153 | 0.2002 | - | - | - | - | - |
| 1.5714 | 154 | 0.4579 | - | - | - | - | - |
| 1.5816 | 155 | 0.0617 | - | - | - | - | - |
| 1.5918 | 156 | 0.7426 | - | - | - | - | - |
| 1.6020 | 157 | 2.8018 | - | - | - | - | - |
| 1.6122 | 158 | 0.5183 | - | - | - | - | - |
| 1.6224 | 159 | 4.9833 | - | - | - | - | - |
| 1.6327 | 160 | 0.6326 | - | - | - | - | - |
| 1.6429 | 161 | 1.5892 | - | - | - | - | - |
| 1.6531 | 162 | 6.4426 | - | - | - | - | - |
| 1.6633 | 163 | 4.3646 | - | - | - | - | - |
| 1.6735 | 164 | 7.2462 | - | - | - | - | - |
| 1.6837 | 165 | 1.6232 | - | - | - | - | - |
| 1.6939 | 166 | 0.0539 | - | - | - | - | - |
| 1.7041 | 167 | 5.1647 | - | - | - | - | - |
| 1.7143 | 168 | 0.239 | - | - | - | - | - |
| 1.7245 | 169 | 6.1138 | - | - | - | - | - |
| 1.7347 | 170 | 1.6571 | - | - | - | - | - |
| 1.7449 | 171 | 0.2895 | - | - | - | - | - |
| 1.7551 | 172 | 0.2621 | - | - | - | - | - |
| 1.7653 | 173 | 0.0144 | - | - | - | - | - |
| 1.7755 | 174 | 0.0988 | - | - | - | - | - |
| 1.7857 | 175 | 0.025 | - | - | - | - | - |
| 1.7959 | 176 | 2.7099 | - | - | - | - | - |
| 1.8061 | 177 | 3.878 | - | - | - | - | - |
| 1.8163 | 178 | 2.0187 | - | - | - | - | - |
| 1.8265 | 179 | 26.4641 | - | - | - | - | - |
| 1.8367 | 180 | 3.9726 | - | - | - | - | - |
| 1.8469 | 181 | 1.9337 | - | - | - | - | - |
| 1.8571 | 182 | 1.6689 | - | - | - | - | - |
| 1.8673 | 183 | 2.8942 | - | - | - | - | - |
| 1.8776 | 184 | 0.4883 | - | - | - | - | - |
| 1.8878 | 185 | 0.0029 | - | - | - | - | - |
| 1.8980 | 186 | 0.2828 | - | - | - | - | - |
| 1.9082 | 187 | 1.4594 | - | - | - | - | - |
| 1.9184 | 188 | 0.0992 | - | - | - | - | - |
| 1.9286 | 189 | 0.9195 | - | - | - | - | - |
| 1.9388 | 190 | 4.6248 | - | - | - | - | - |
| 1.9490 | 191 | 0.0364 | - | - | - | - | - |
| 1.9592 | 192 | 0.8291 | - | - | - | - | - |
| 1.9694 | 193 | 5.1303 | - | - | - | - | - |
| 1.9796 | 194 | 0.3142 | - | - | - | - | - |
| 1.9898 | 195 | 0.182 | - | - | - | - | - |
| 2.0 | 196 | 0.0019 | 0.2938 | 0.2853 | 0.2893 | 0.2719 | 0.2200 |
| 2.0102 | 197 | 3.262 | - | - | - | - | - |
| 2.0204 | 198 | 0.0092 | - | - | - | - | - |
| 2.0306 | 199 | 0.3517 | - | - | - | - | - |
| 2.0408 | 200 | 0.0116 | - | - | - | - | - |
| 2.0510 | 201 | 0.0846 | - | - | - | - | - |
| 2.0612 | 202 | 0.0027 | - | - | - | - | - |
| 2.0714 | 203 | 2.1304 | - | - | - | - | - |
| 2.0816 | 204 | 1.1392 | - | - | - | - | - |
| 2.0918 | 205 | 0.2868 | - | - | - | - | - |
| 2.1020 | 206 | 5.8102 | - | - | - | - | - |
| 2.1122 | 207 | 0.0089 | - | - | - | - | - |
| 2.1224 | 208 | 0.191 | - | - | - | - | - |
| 2.1327 | 209 | 0.0439 | - | - | - | - | - |
| 2.1429 | 210 | 11.698 | - | - | - | - | - |
| 2.1531 | 211 | 0.2859 | - | - | - | - | - |
| 2.1633 | 212 | 0.0321 | - | - | - | - | - |
| 2.1735 | 213 | 0.0025 | - | - | - | - | - |
| 2.1837 | 214 | 0.5854 | - | - | - | - | - |
| 2.1939 | 215 | 5.8049 | - | - | - | - | - |
| 2.2041 | 216 | 2.782 | - | - | - | - | - |
| 2.2143 | 217 | 0.3969 | - | - | - | - | - |
| 2.2245 | 218 | 0.8192 | - | - | - | - | - |
| 2.2347 | 219 | 0.0015 | - | - | - | - | - |
| 2.2449 | 220 | 5.6306 | - | - | - | - | - |
| 2.2551 | 221 | 12.1614 | - | - | - | - | - |
| 2.2653 | 222 | 2.142 | - | - | - | - | - |
| 2.2755 | 223 | 0.3337 | - | - | - | - | - |
| 2.2857 | 224 | 1.502 | - | - | - | - | - |
| 2.2959 | 225 | 0.0516 | - | - | - | - | - |
| 2.3061 | 226 | 0.0015 | - | - | - | - | - |
| 2.3163 | 227 | 0.005 | - | - | - | - | - |
| 2.3265 | 228 | 2.7072 | - | - | - | - | - |
| 2.3367 | 229 | 0.0176 | - | - | - | - | - |
| 2.3469 | 230 | 0.2738 | - | - | - | - | - |
| 2.3571 | 231 | 2.1149 | - | - | - | - | - |
| 2.3673 | 232 | 5.956 | - | - | - | - | - |
| 2.3776 | 233 | 0.6448 | - | - | - | - | - |
| 2.3878 | 234 | 0.1135 | - | - | - | - | - |
| 2.3980 | 235 | 0.0345 | - | - | - | - | - |
| 2.4082 | 236 | 2.4979 | - | - | - | - | - |
| 2.4184 | 237 | 0.6361 | - | - | - | - | - |
| 2.4286 | 238 | 0.3688 | - | - | - | - | - |
| 2.4388 | 239 | 7.7828 | - | - | - | - | - |
| 2.4490 | 240 | 4.2094 | - | - | - | - | - |
| 2.4592 | 241 | 0.1711 | - | - | - | - | - |
| 2.4694 | 242 | 0.0468 | - | - | - | - | - |
| 2.4796 | 243 | 0.0016 | - | - | - | - | - |
| 2.4898 | 244 | 0.5277 | - | - | - | - | - |
| 2.5 | 245 | 0.0386 | - | - | - | - | - |
| 2.5102 | 246 | 10.168 | - | - | - | - | - |
| 2.5204 | 247 | 6.9855 | - | - | - | - | - |
| 2.5306 | 248 | 7.1669 | - | - | - | - | - |
| 2.5408 | 249 | 0.8908 | - | - | - | - | - |
| 2.5510 | 250 | 1.839 | - | - | - | - | - |
| 2.5612 | 251 | 0.0424 | - | - | - | - | - |
| 2.5714 | 252 | 2.5308 | - | - | - | - | - |
| 2.5816 | 253 | 0.6599 | - | - | - | - | - |
| 2.5918 | 254 | 0.0395 | - | - | - | - | - |
| 2.6020 | 255 | 0.1428 | - | - | - | - | - |
| 2.6122 | 256 | 3.4492 | - | - | - | - | - |
| 2.6224 | 257 | 4.8398 | - | - | - | - | - |
| 2.6327 | 258 | 0.0124 | - | - | - | - | - |
| 2.6429 | 259 | 0.0069 | - | - | - | - | - |
| 2.6531 | 260 | 0.2163 | - | - | - | - | - |
| 2.6633 | 261 | 4.8929 | - | - | - | - | - |
| 2.6735 | 262 | 0.0561 | - | - | - | - | - |
| 2.6837 | 263 | 0.1611 | - | - | - | - | - |
| 2.6939 | 264 | 1.3758 | - | - | - | - | - |
| 2.7041 | 265 | 3.2582 | - | - | - | - | - |
| 2.7143 | 266 | 18.0246 | - | - | - | - | - |
| 2.7245 | 267 | 0.0016 | - | - | - | - | - |
| 2.7347 | 268 | 2.5819 | - | - | - | - | - |
| 2.7449 | 269 | 0.4953 | - | - | - | - | - |
| 2.7551 | 270 | 0.1712 | - | - | - | - | - |
| 2.7653 | 271 | 0.0173 | - | - | - | - | - |
| 2.7755 | 272 | 9.0557 | - | - | - | - | - |
| 2.7857 | 273 | 0.0104 | - | - | - | - | - |
| 2.7959 | 274 | 1.2539 | - | - | - | - | - |
| 2.8061 | 275 | 0.0 | - | - | - | - | - |
| 2.8163 | 276 | 0.0692 | - | - | - | - | - |
| 2.8265 | 277 | 0.0416 | - | - | - | - | - |
| 2.8367 | 278 | 1.4689 | - | - | - | - | - |
| 2.8469 | 279 | 7.7806 | - | - | - | - | - |
| 2.8571 | 280 | 0.0189 | - | - | - | - | - |
| 2.8673 | 281 | 1.6739 | - | - | - | - | - |
| 2.8776 | 282 | 0.0527 | - | - | - | - | - |
| 2.8878 | 283 | 3.8894 | - | - | - | - | - |
| 2.8980 | 284 | 4.7123 | - | - | - | - | - |
| 2.9082 | 285 | 0.6912 | - | - | - | - | - |
| 2.9184 | 286 | 0.2394 | - | - | - | - | - |
| 2.9286 | 287 | 1.1657 | - | - | - | - | - |
| 2.9388 | 288 | 0.0046 | - | - | - | - | - |
| 2.9490 | 289 | 0.0011 | - | - | - | - | - |
| 2.9592 | 290 | 0.0098 | - | - | - | - | - |
| 2.9694 | 291 | 0.4745 | - | - | - | - | - |
| 2.9796 | 292 | 0.964 | - | - | - | - | - |
| 2.9898 | 293 | 0.0369 | - | - | - | - | - |
| 3.0 | 294 | 0.0179 | 0.2878 | 0.2820 | 0.2770 | 0.2625 | 0.2361 |
| 3.0102 | 295 | 3.7066 | - | - | - | - | - |
| 3.0204 | 296 | 0.0002 | - | - | - | - | - |
| 3.0306 | 297 | 0.042 | - | - | - | - | - |
| 3.0408 | 298 | 9.0249 | - | - | - | - | - |
| 3.0510 | 299 | 1.1905 | - | - | - | - | - |
| 3.0612 | 300 | 0.1012 | - | - | - | - | - |
| 3.0714 | 301 | 0.0468 | - | - | - | - | - |
| 3.0816 | 302 | 0.002 | - | - | - | - | - |
| 3.0918 | 303 | 0.0003 | - | - | - | - | - |
| 3.1020 | 304 | 0.093 | - | - | - | - | - |
| 3.1122 | 305 | 2.4288 | - | - | - | - | - |
| 3.1224 | 306 | 2.7864 | - | - | - | - | - |
| 3.1327 | 307 | 0.1523 | - | - | - | - | - |
| 3.1429 | 308 | 0.004 | - | - | - | - | - |
| 3.1531 | 309 | 12.1307 | - | - | - | - | - |
| 3.1633 | 310 | 0.0162 | - | - | - | - | - |
| 3.1735 | 311 | 0.0012 | - | - | - | - | - |
| 3.1837 | 312 | 1.4673 | - | - | - | - | - |
| 3.1939 | 313 | 0.0212 | - | - | - | - | - |
| 3.2041 | 314 | 0.0026 | - | - | - | - | - |
| 3.2143 | 315 | 4.5828 | - | - | - | - | - |
| 3.2245 | 316 | 0.0001 | - | - | - | - | - |
| 3.2347 | 317 | 0.0708 | - | - | - | - | - |
| 3.2449 | 318 | 0.3905 | - | - | - | - | - |
| 3.2551 | 319 | 0.0472 | - | - | - | - | - |
| 3.2653 | 320 | 0.6012 | - | - | - | - | - |
| 3.2755 | 321 | 0.0233 | - | - | - | - | - |
| 3.2857 | 322 | 2.4017 | - | - | - | - | - |
| 3.2959 | 323 | 0.0008 | - | - | - | - | - |
| 3.3061 | 324 | 0.09 | - | - | - | - | - |
| 3.3163 | 325 | 0.6235 | - | - | - | - | - |
| 3.3265 | 326 | 0.0004 | - | - | - | - | - |
| 3.3367 | 327 | 0.0036 | - | - | - | - | - |
| 3.3469 | 328 | 0.0573 | - | - | - | - | - |
| 3.3571 | 329 | 1.7098 | - | - | - | - | - |
| 3.3673 | 330 | 0.0395 | - | - | - | - | - |
| 3.3776 | 331 | 0.0052 | - | - | - | - | - |
| 3.3878 | 332 | 0.0095 | - | - | - | - | - |
| 3.3980 | 333 | 7.6863 | - | - | - | - | - |
| 3.4082 | 334 | 0.1564 | - | - | - | - | - |
| 3.4184 | 335 | 0.0134 | - | - | - | - | - |
| 3.4286 | 336 | 0.0212 | - | - | - | - | - |
| 3.4388 | 337 | 0.0004 | - | - | - | - | - |
| 3.4490 | 338 | 0.0001 | - | - | - | - | - |
| 3.4592 | 339 | 0.0808 | - | - | - | - | - |
| 3.4694 | 340 | 0.0006 | - | - | - | - | - |
| 3.4796 | 341 | 0.4523 | - | - | - | - | - |
| 3.4898 | 342 | 0.3906 | - | - | - | - | - |
| 3.5 | 343 | 0.0364 | - | - | - | - | - |
| 3.5102 | 344 | 0.055 | - | - | - | - | - |
| 3.5204 | 345 | 0.1381 | - | - | - | - | - |
| 3.5306 | 346 | 2.0386 | - | - | - | - | - |
| 3.5408 | 347 | 0.0003 | - | - | - | - | - |
| 3.5510 | 348 | 0.119 | - | - | - | - | - |
| 3.5612 | 349 | 0.0003 | - | - | - | - | - |
| 3.5714 | 350 | 0.0165 | - | - | - | - | - |
| 3.5816 | 351 | 6.8156 | - | - | - | - | - |
| 3.5918 | 352 | 1.5111 | - | - | - | - | - |
| 3.6020 | 353 | 0.0001 | - | - | - | - | - |
| 3.6122 | 354 | 1.5603 | - | - | - | - | - |
| 3.6224 | 355 | 0.5631 | - | - | - | - | - |
| 3.6327 | 356 | 0.238 | - | - | - | - | - |
| 3.6429 | 357 | 0.1564 | - | - | - | - | - |
| 3.6531 | 358 | 0.0211 | - | - | - | - | - |
| 3.6633 | 359 | 0.0516 | - | - | - | - | - |
| 3.6735 | 360 | 0.0184 | - | - | - | - | - |
| 3.6837 | 361 | 0.0944 | - | - | - | - | - |
| 3.6939 | 362 | 0.0242 | - | - | - | - | - |
| 3.7041 | 363 | 8.1297 | - | - | - | - | - |
| 3.7143 | 364 | 0.025 | - | - | - | - | - |
| 3.7245 | 365 | 0.0041 | - | - | - | - | - |
| 3.7347 | 366 | 0.0012 | - | - | - | - | - |
| 3.7449 | 367 | 3.6937 | - | - | - | - | - |
| 3.7551 | 368 | 0.1472 | - | - | - | - | - |
| 3.7653 | 369 | 1.8883 | - | - | - | - | - |
| 3.7755 | 370 | 0.0229 | - | - | - | - | - |
| 3.7857 | 371 | 1.1389 | - | - | - | - | - |
| 3.7959 | 372 | 0.276 | - | - | - | - | - |
| 3.8061 | 373 | 0.2737 | - | - | - | - | - |
| 3.8163 | 374 | 0.0002 | - | - | - | - | - |
| 3.8265 | 375 | 0.0959 | - | - | - | - | - |
| 3.8367 | 376 | 0.1988 | - | - | - | - | - |
| 3.8469 | 377 | 0.0002 | - | - | - | - | - |
| 3.8571 | 378 | 0.4024 | - | - | - | - | - |
| 3.8673 | 379 | 0.0025 | - | - | - | - | - |
| 3.8776 | 380 | 0.0077 | - | - | - | - | - |
| 3.8878 | 381 | 2.5045 | - | - | - | - | - |
| 3.8980 | 382 | 0.0271 | - | - | - | - | - |
| 3.9082 | 383 | 1.1894 | - | - | - | - | - |
| 3.9184 | 384 | 1.2235 | - | - | - | - | - |
| 3.9286 | 385 | 2.7343 | - | - | - | - | - |
| 3.9388 | 386 | 0.503 | - | - | - | - | - |
| 3.9490 | 387 | 0.0885 | - | - | - | - | - |
| 3.9592 | 388 | 0.0001 | - | - | - | - | - |
| 3.9694 | 389 | 0.6582 | - | - | - | - | - |
| 3.9796 | 390 | 0.0002 | - | - | - | - | - |
| 3.9898 | 391 | 0.0041 | - | - | - | - | - |
| 4.0 | 392 | 0.0001 | 0.3158 | 0.3166 | 0.3072 | 0.2876 | 0.2621 |
| 4.0102 | 393 | 6.4082 | - | - | - | - | - |
| 4.0204 | 394 | 0.0927 | - | - | - | - | - |
| 4.0306 | 395 | 4.3878 | - | - | - | - | - |
| 4.0408 | 396 | 0.0233 | - | - | - | - | - |
| 4.0510 | 397 | 0.0001 | - | - | - | - | - |
| 4.0612 | 398 | 0.0006 | - | - | - | - | - |
| 4.0714 | 399 | 0.0001 | - | - | - | - | - |
| 4.0816 | 400 | 0.0006 | - | - | - | - | - |
| 4.0918 | 401 | 0.0132 | - | - | - | - | - |
| 4.1020 | 402 | 0.0265 | - | - | - | - | - |
| 4.1122 | 403 | 3.4777 | - | - | - | - | - |
| 4.1224 | 404 | 0.0022 | - | - | - | - | - |
| 4.1327 | 405 | 0.0001 | - | - | - | - | - |
| 4.1429 | 406 | 0.0007 | - | - | - | - | - |
| 4.1531 | 407 | 0.0055 | - | - | - | - | - |
| 4.1633 | 408 | 0.0002 | - | - | - | - | - |
| 4.1735 | 409 | 0.0316 | - | - | - | - | - |
| 4.1837 | 410 | 0.0479 | - | - | - | - | - |
| 4.1939 | 411 | 0.0004 | - | - | - | - | - |
| 4.2041 | 412 | 0.0019 | - | - | - | - | - |
| 4.2143 | 413 | 0.1181 | - | - | - | - | - |
| 4.2245 | 414 | 0.1845 | - | - | - | - | - |
| 4.2347 | 415 | 0.0001 | - | - | - | - | - |
| 4.2449 | 416 | 5.1701 | - | - | - | - | - |
| 4.2551 | 417 | 0.049 | - | - | - | - | - |
| 4.2653 | 418 | 0.077 | - | - | - | - | - |
| 4.2755 | 419 | 4.0434 | - | - | - | - | - |
| 4.2857 | 420 | 4.7865 | - | - | - | - | - |
| 4.2959 | 421 | 0.8345 | - | - | - | - | - |
| 4.3061 | 422 | 6.5911 | - | - | - | - | - |
| 4.3163 | 423 | 0.0784 | - | - | - | - | - |
| 4.3265 | 424 | 0.005 | - | - | - | - | - |
| 4.3367 | 425 | 0.0003 | - | - | - | - | - |
| 4.3469 | 426 | 1.6826 | - | - | - | - | - |
| 4.3571 | 427 | 0.1201 | - | - | - | - | - |
| 4.3673 | 428 | 0.0016 | - | - | - | - | - |
| 4.3776 | 429 | 0.011 | - | - | - | - | - |
| 4.3878 | 430 | 0.001 | - | - | - | - | - |
| 4.3980 | 431 | 0.0008 | - | - | - | - | - |
| 4.4082 | 432 | 0.0127 | - | - | - | - | - |
| 4.4184 | 433 | 0.4294 | - | - | - | - | - |
| 4.4286 | 434 | 0.0054 | - | - | - | - | - |
| 4.4388 | 435 | 0.0 | - | - | - | - | - |
| 4.4490 | 436 | 0.8544 | - | - | - | - | - |
| 4.4592 | 437 | 4.1478 | - | - | - | - | - |
| 4.4694 | 438 | 0.261 | - | - | - | - | - |
| 4.4796 | 439 | 0.0 | - | - | - | - | - |
| 4.4898 | 440 | 0.4865 | - | - | - | - | - |
| 4.5 | 441 | 0.0084 | - | - | - | - | - |
| 4.5102 | 442 | 0.2217 | - | - | - | - | - |
| 4.5204 | 443 | 0.7317 | - | - | - | - | - |
| 4.5306 | 444 | 0.0415 | - | - | - | - | - |
| 4.5408 | 445 | 0.0008 | - | - | - | - | - |
| 4.5510 | 446 | 0.0004 | - | - | - | - | - |
| 4.5612 | 447 | 0.4987 | - | - | - | - | - |
| 4.5714 | 448 | 0.0141 | - | - | - | - | - |
| 4.5816 | 449 | 0.2476 | - | - | - | - | - |
| 4.5918 | 450 | 0.0463 | - | - | - | - | - |
| 4.6020 | 451 | 0.0011 | - | - | - | - | - |
| 4.6122 | 452 | 0.0155 | - | - | - | - | - |
| 4.6224 | 453 | 0.0068 | - | - | - | - | - |
| 4.6327 | 454 | 0.0009 | - | - | - | - | - |
| 4.6429 | 455 | 0.3858 | - | - | - | - | - |
| 4.6531 | 456 | 0.6687 | - | - | - | - | - |
| 4.6633 | 457 | 6.9477 | - | - | - | - | - |
| 4.6735 | 458 | 0.9326 | - | - | - | - | - |
| 4.6837 | 459 | 0.0208 | - | - | - | - | - |
| 4.6939 | 460 | 0.058 | - | - | - | - | - |
| 4.7041 | 461 | 0.0307 | - | - | - | - | - |
| 4.7143 | 462 | 0.0 | - | - | - | - | - |
| 4.7245 | 463 | 23.8009 | - | - | - | - | - |
| 4.7347 | 464 | 0.0001 | - | - | - | - | - |
| 4.7449 | 465 | 3.4537 | - | - | - | - | - |
| 4.7551 | 466 | 4.185 | - | - | - | - | - |
| 4.7653 | 467 | 1.3744 | - | - | - | - | - |
| 4.7755 | 468 | 0.4893 | - | - | - | - | - |
| 4.7857 | 469 | 0.0023 | - | - | - | - | - |
| 4.7959 | 470 | 0.0163 | - | - | - | - | - |
| 4.8061 | 471 | 0.001 | - | - | - | - | - |
| 4.8163 | 472 | 0.0 | - | - | - | - | - |
| 4.8265 | 473 | 0.0074 | - | - | - | - | - |
| 4.8367 | 474 | 0.0006 | - | - | - | - | - |
| 4.8469 | 475 | 0.0011 | - | - | - | - | - |
| 4.8571 | 476 | 1.6108 | - | - | - | - | - |
| 4.8673 | 477 | 0.1876 | - | - | - | - | - |
| 4.8776 | 478 | 0.0262 | - | - | - | - | - |
| 4.8878 | 479 | 0.1159 | - | - | - | - | - |
| 4.8980 | 480 | 0.5904 | - | - | - | - | - |
| 4.9082 | 481 | 0.0002 | - | - | - | - | - |
| 4.9184 | 482 | 2.7912 | - | - | - | - | - |
| 4.9286 | 483 | 2.9303 | - | - | - | - | - |
| 4.9388 | 484 | 0.0127 | - | - | - | - | - |
| 4.9490 | 485 | 2.9811 | - | - | - | - | - |
| 4.9592 | 486 | 0.0252 | - | - | - | - | - |
| 4.9694 | 487 | 0.0522 | - | - | - | - | - |
| 4.9796 | 488 | 0.2255 | - | - | - | - | - |
| 4.9898 | 489 | 0.1411 | - | - | - | - | - |
| 5.0 | 490 | 0.0711 | 0.3197 | 0.3140 | 0.3032 | 0.2937 | 0.2607 |
| 5.0102 | 491 | 0.012 | - | - | - | - | - |
| 5.0204 | 492 | 0.0008 | - | - | - | - | - |
| 5.0306 | 493 | 0.0028 | - | - | - | - | - |
| 5.0408 | 494 | 1.8711 | - | - | - | - | - |
| 5.0510 | 495 | 0.0761 | - | - | - | - | - |
| 5.0612 | 496 | 0.1384 | - | - | - | - | - |
| 5.0714 | 497 | 0.11 | - | - | - | - | - |
| 5.0816 | 498 | 0.001 | - | - | - | - | - |
| 5.0918 | 499 | 0.0005 | - | - | - | - | - |
| 5.1020 | 500 | 0.8153 | - | - | - | - | - |
| 5.1122 | 501 | 0.0 | - | - | - | - | - |
| 5.1224 | 502 | 0.0057 | - | - | - | - | - |
| 5.1327 | 503 | 0.0104 | - | - | - | - | - |
| 5.1429 | 504 | 0.0001 | - | - | - | - | - |
| 5.1531 | 505 | 0.0026 | - | - | - | - | - |
| 5.1633 | 506 | 0.0015 | - | - | - | - | - |
| 5.1735 | 507 | 0.0022 | - | - | - | - | - |
| 5.1837 | 508 | 0.0052 | - | - | - | - | - |
| 5.1939 | 509 | 0.0362 | - | - | - | - | - |
| 5.2041 | 510 | 6.6671 | - | - | - | - | - |
| 5.2143 | 511 | 0.8716 | - | - | - | - | - |
| 5.2245 | 512 | 0.0141 | - | - | - | - | - |
| 5.2347 | 513 | 0.0 | - | - | - | - | - |
| 5.2449 | 514 | 0.0217 | - | - | - | - | - |
| 5.2551 | 515 | 0.0001 | - | - | - | - | - |
| 5.2653 | 516 | 0.0 | - | - | - | - | - |
| 5.2755 | 517 | 0.0258 | - | - | - | - | - |
| 5.2857 | 518 | 0.0001 | - | - | - | - | - |
| 5.2959 | 519 | 0.0092 | - | - | - | - | - |
| 5.3061 | 520 | 0.001 | - | - | - | - | - |
| 5.3163 | 521 | 0.0174 | - | - | - | - | - |
| 5.3265 | 522 | 0.2128 | - | - | - | - | - |
| 5.3367 | 523 | 0.0222 | - | - | - | - | - |
| 5.3469 | 524 | 0.0084 | - | - | - | - | - |
| 5.3571 | 525 | 0.0005 | - | - | - | - | - |
| 5.3673 | 526 | 0.0164 | - | - | - | - | - |
| 5.3776 | 527 | 0.004 | - | - | - | - | - |
| 5.3878 | 528 | 0.0154 | - | - | - | - | - |
| 5.3980 | 529 | 0.0002 | - | - | - | - | - |
| 5.4082 | 530 | 0.0178 | - | - | - | - | - |
| 5.4184 | 531 | 0.0 | - | - | - | - | - |
| 5.4286 | 532 | 2.6306 | - | - | - | - | - |
| 5.4388 | 533 | 0.0014 | - | - | - | - | - |
| 5.4490 | 534 | 0.0007 | - | - | - | - | - |
| 5.4592 | 535 | 0.0088 | - | - | - | - | - |
| 5.4694 | 536 | 0.0011 | - | - | - | - | - |
| 5.4796 | 537 | 0.0032 | - | - | - | - | - |
| 5.4898 | 538 | 0.0004 | - | - | - | - | - |
| 5.5 | 539 | 0.0005 | - | - | - | - | - |
| 5.5102 | 540 | 0.0002 | - | - | - | - | - |
| 5.5204 | 541 | 0.0046 | - | - | - | - | - |
| 5.5306 | 542 | 0.0258 | - | - | - | - | - |
| 5.5408 | 543 | 0.754 | - | - | - | - | - |
| 5.5510 | 544 | 0.7433 | - | - | - | - | - |
| 5.5612 | 545 | 0.0332 | - | - | - | - | - |
| 5.5714 | 546 | 0.0001 | - | - | - | - | - |
| 5.5816 | 547 | 0.0093 | - | - | - | - | - |
| 5.5918 | 548 | 0.0109 | - | - | - | - | - |
| 5.6020 | 549 | 0.0003 | - | - | - | - | - |
| 5.6122 | 550 | 0.0003 | - | - | - | - | - |
| 5.6224 | 551 | 0.0008 | - | - | - | - | - |
| 5.6327 | 552 | 0.0001 | - | - | - | - | - |
| 5.6429 | 553 | 0.0017 | - | - | - | - | - |
| 5.6531 | 554 | 0.0084 | - | - | - | - | - |
| 5.6633 | 555 | 0.0005 | - | - | - | - | - |
| 5.6735 | 556 | 0.023 | - | - | - | - | - |
| 5.6837 | 557 | 0.0137 | - | - | - | - | - |
| 5.6939 | 558 | 0.0102 | - | - | - | - | - |
| 5.7041 | 559 | 0.4275 | - | - | - | - | - |
| 5.7143 | 560 | 0.0001 | - | - | - | - | - |
| 5.7245 | 561 | 0.0001 | - | - | - | - | - |
| 5.7347 | 562 | 0.0009 | - | - | - | - | - |
| 5.7449 | 563 | 0.013 | - | - | - | - | - |
| 5.7551 | 564 | 0.0001 | - | - | - | - | - |
| 5.7653 | 565 | 0.0006 | - | - | - | - | - |
| 5.7755 | 566 | 0.0001 | - | - | - | - | - |
| 5.7857 | 567 | 0.0003 | - | - | - | - | - |
| 5.7959 | 568 | 0.0001 | - | - | - | - | - |
| 5.8061 | 569 | 0.8792 | - | - | - | - | - |
| 5.8163 | 570 | 0.7551 | - | - | - | - | - |
| 5.8265 | 571 | 0.0002 | - | - | - | - | - |
| 5.8367 | 572 | 0.0 | - | - | - | - | - |
| 5.8469 | 573 | 0.3999 | - | - | - | - | - |
| 5.8571 | 574 | 0.0168 | - | - | - | - | - |
| 5.8673 | 575 | 0.0014 | - | - | - | - | - |
| 5.8776 | 576 | 0.0004 | - | - | - | - | - |
| 5.8878 | 577 | 9.7985 | - | - | - | - | - |
| 5.8980 | 578 | 0.0001 | - | - | - | - | - |
| 5.9082 | 579 | 0.0078 | - | - | - | - | - |
| 5.9184 | 580 | 1.6446 | - | - | - | - | - |
| 5.9286 | 581 | 1.8624 | - | - | - | - | - |
| 5.9388 | 582 | 0.3274 | - | - | - | - | - |
| 5.9490 | 583 | 0.1845 | - | - | - | - | - |
| 5.9592 | 584 | 0.0044 | - | - | - | - | - |
| 5.9694 | 585 | 0.0016 | - | - | - | - | - |
| 5.9796 | 586 | 2.6768 | - | - | - | - | - |
| 5.9898 | 587 | 3.167 | - | - | - | - | - |
| **6.0** | **588** | **0.0013** | **0.3256** | **0.3222** | **0.3151** | **0.2987** | **0.273** |
| 6.0102 | 589 | 0.0262 | - | - | - | - | - |
| 6.0204 | 590 | 0.021 | - | - | - | - | - |
| 6.0306 | 591 | 0.0165 | - | - | - | - | - |
| 6.0408 | 592 | 0.5149 | - | - | - | - | - |
| 6.0510 | 593 | 1.1763 | - | - | - | - | - |
| 6.0612 | 594 | 0.0205 | - | - | - | - | - |
| 6.0714 | 595 | 0.0006 | - | - | - | - | - |
| 6.0816 | 596 | 0.0002 | - | - | - | - | - |
| 6.0918 | 597 | 0.0011 | - | - | - | - | - |
| 6.1020 | 598 | 0.0005 | - | - | - | - | - |
| 6.1122 | 599 | 0.0002 | - | - | - | - | - |
| 6.1224 | 600 | 0.0002 | - | - | - | - | - |
| 6.1327 | 601 | 0.0149 | - | - | - | - | - |
| 6.1429 | 602 | 0.0065 | - | - | - | - | - |
| 6.1531 | 603 | 0.0 | - | - | - | - | - |
| 6.1633 | 604 | 0.0018 | - | - | - | - | - |
| 6.1735 | 605 | 0.0 | - | - | - | - | - |
| 6.1837 | 606 | 0.001 | - | - | - | - | - |
| 6.1939 | 607 | 0.105 | - | - | - | - | - |
| 6.2041 | 608 | 0.002 | - | - | - | - | - |
| 6.2143 | 609 | 3.1424 | - | - | - | - | - |
| 6.2245 | 610 | 1.9828 | - | - | - | - | - |
| 6.2347 | 611 | 0.0056 | - | - | - | - | - |
| 6.2449 | 612 | 0.0001 | - | - | - | - | - |
| 6.2551 | 613 | 0.0177 | - | - | - | - | - |
| 6.2653 | 614 | 0.0358 | - | - | - | - | - |
| 6.2755 | 615 | 0.0001 | - | - | - | - | - |
| 6.2857 | 616 | 0.0 | - | - | - | - | - |
| 6.2959 | 617 | 0.0006 | - | - | - | - | - |
| 6.3061 | 618 | 0.0105 | - | - | - | - | - |
| 6.3163 | 619 | 0.0005 | - | - | - | - | - |
| 6.3265 | 620 | 0.0002 | - | - | - | - | - |
| 6.3367 | 621 | 0.0043 | - | - | - | - | - |
| 6.3469 | 622 | 0.0001 | - | - | - | - | - |
| 6.3571 | 623 | 0.0009 | - | - | - | - | - |
| 6.3673 | 624 | 0.0018 | - | - | - | - | - |
| 6.3776 | 625 | 0.0066 | - | - | - | - | - |
| 6.3878 | 626 | 0.0004 | - | - | - | - | - |
| 6.3980 | 627 | 0.0018 | - | - | - | - | - |
| 6.4082 | 628 | 0.0002 | - | - | - | - | - |
| 6.4184 | 629 | 0.0056 | - | - | - | - | - |
| 6.4286 | 630 | 0.0 | - | - | - | - | - |
| 6.4388 | 631 | 0.0001 | - | - | - | - | - |
| 6.4490 | 632 | 0.0017 | - | - | - | - | - |
| 6.4592 | 633 | 0.0177 | - | - | - | - | - |
| 6.4694 | 634 | 0.0002 | - | - | - | - | - |
| 6.4796 | 635 | 0.0004 | - | - | - | - | - |
| 6.4898 | 636 | 0.0015 | - | - | - | - | - |
| 6.5 | 637 | 0.0004 | - | - | - | - | - |
| 6.5102 | 638 | 0.0018 | - | - | - | - | - |
| 6.5204 | 639 | 0.0185 | - | - | - | - | - |
| 6.5306 | 640 | 0.0 | - | - | - | - | - |
| 6.5408 | 641 | 0.0051 | - | - | - | - | - |
| 6.5510 | 642 | 0.0018 | - | - | - | - | - |
| 6.5612 | 643 | 0.0144 | - | - | - | - | - |
| 6.5714 | 644 | 0.0114 | - | - | - | - | - |
| 6.5816 | 645 | 0.0391 | - | - | - | - | - |
| 6.5918 | 646 | 0.3066 | - | - | - | - | - |
| 6.6020 | 647 | 0.0047 | - | - | - | - | - |
| 6.6122 | 648 | 0.0 | - | - | - | - | - |
| 6.6224 | 649 | 0.7053 | - | - | - | - | - |
| 6.6327 | 650 | 0.0003 | - | - | - | - | - |
| 6.6429 | 651 | 0.0319 | - | - | - | - | - |
| 6.6531 | 652 | 1.205 | - | - | - | - | - |
| 6.6633 | 653 | 0.0098 | - | - | - | - | - |
| 6.6735 | 654 | 0.0009 | - | - | - | - | - |
| 6.6837 | 655 | 0.0 | - | - | - | - | - |
| 6.6939 | 656 | 0.0577 | - | - | - | - | - |
| 6.7041 | 657 | 0.0054 | - | - | - | - | - |
| 6.7143 | 658 | 0.0018 | - | - | - | - | - |
| 6.7245 | 659 | 4.6084 | - | - | - | - | - |
| 6.7347 | 660 | 0.1262 | - | - | - | - | - |
| 6.7449 | 661 | 0.0538 | - | - | - | - | - |
| 6.7551 | 662 | 0.0 | - | - | - | - | - |
| 6.7653 | 663 | 0.0041 | - | - | - | - | - |
| 6.7755 | 664 | 0.0046 | - | - | - | - | - |
| 6.7857 | 665 | 0.0 | - | - | - | - | - |
| 6.7959 | 666 | 0.1917 | - | - | - | - | - |
| 6.8061 | 667 | 0.1963 | - | - | - | - | - |
| 6.8163 | 668 | 0.0 | - | - | - | - | - |
| 6.8265 | 669 | 0.0002 | - | - | - | - | - |
| 6.8367 | 670 | 0.001 | - | - | - | - | - |
| 6.8469 | 671 | 0.0 | - | - | - | - | - |
| 6.8571 | 672 | 0.0089 | - | - | - | - | - |
| 6.8673 | 673 | 0.0002 | - | - | - | - | - |
| 6.8776 | 674 | 0.0 | - | - | - | - | - |
| 6.8878 | 675 | 0.0001 | - | - | - | - | - |
| 6.8980 | 676 | 0.0029 | - | - | - | - | - |
| 6.9082 | 677 | 0.0003 | - | - | - | - | - |
| 6.9184 | 678 | 0.0002 | - | - | - | - | - |
| 6.9286 | 679 | 0.0144 | - | - | - | - | - |
| 6.9388 | 680 | 0.0002 | - | - | - | - | - |
| 6.9490 | 681 | 9.5598 | - | - | - | - | - |
| 6.9592 | 682 | 7.4394 | - | - | - | - | - |
| 6.9694 | 683 | 0.0395 | - | - | - | - | - |
| 6.9796 | 684 | 0.0073 | - | - | - | - | - |
| 6.9898 | 685 | 0.0001 | - | - | - | - | - |
| 7.0 | 686 | 0.0024 | 0.3219 | 0.3160 | 0.3064 | 0.2943 | 0.2634 |
| 7.0102 | 687 | 0.1988 | - | - | - | - | - |
| 7.0204 | 688 | 0.0029 | - | - | - | - | - |
| 7.0306 | 689 | 0.0565 | - | - | - | - | - |
| 7.0408 | 690 | 0.0001 | - | - | - | - | - |
| 7.0510 | 691 | 0.3333 | - | - | - | - | - |
| 7.0612 | 692 | 0.0 | - | - | - | - | - |
| 7.0714 | 693 | 0.0397 | - | - | - | - | - |
| 7.0816 | 694 | 0.0002 | - | - | - | - | - |
| 7.0918 | 695 | 6.99 | - | - | - | - | - |
| 7.1020 | 696 | 0.2037 | - | - | - | - | - |
| 7.1122 | 697 | 0.0058 | - | - | - | - | - |
| 7.1224 | 698 | 0.1683 | - | - | - | - | - |
| 7.1327 | 699 | 3.2532 | - | - | - | - | - |
| 7.1429 | 700 | 0.0063 | - | - | - | - | - |
| 7.1531 | 701 | 0.0 | - | - | - | - | - |
| 7.1633 | 702 | 0.0051 | - | - | - | - | - |
| 7.1735 | 703 | 0.8695 | - | - | - | - | - |
| 7.1837 | 704 | 0.0 | - | - | - | - | - |
| 7.1939 | 705 | 0.0001 | - | - | - | - | - |
| 7.2041 | 706 | 1.9942 | - | - | - | - | - |
| 7.2143 | 707 | 0.0 | - | - | - | - | - |
| 7.2245 | 708 | 0.0007 | - | - | - | - | - |
| 7.2347 | 709 | 0.0003 | - | - | - | - | - |
| 7.2449 | 710 | 0.0 | - | - | - | - | - |
| 7.2551 | 711 | 0.0 | - | - | - | - | - |
| 7.2653 | 712 | 0.0008 | - | - | - | - | - |
| 7.2755 | 713 | 0.0021 | - | - | - | - | - |
| 7.2857 | 714 | 0.0001 | - | - | - | - | - |
| 7.2959 | 715 | 0.0014 | - | - | - | - | - |
| 7.3061 | 716 | 0.0 | - | - | - | - | - |
| 7.3163 | 717 | 0.4907 | - | - | - | - | - |
| 7.3265 | 718 | 0.0007 | - | - | - | - | - |
| 7.3367 | 719 | 0.1083 | - | - | - | - | - |
| 7.3469 | 720 | 0.0003 | - | - | - | - | - |
| 7.3571 | 721 | 0.0005 | - | - | - | - | - |
| 7.3673 | 722 | 0.0317 | - | - | - | - | - |
| 7.3776 | 723 | 0.0005 | - | - | - | - | - |
| 7.3878 | 724 | 0.0056 | - | - | - | - | - |
| 7.3980 | 725 | 0.0094 | - | - | - | - | - |
| 7.4082 | 726 | 0.0604 | - | - | - | - | - |
| 7.4184 | 727 | 4.4169 | - | - | - | - | - |
| 7.4286 | 728 | 0.012 | - | - | - | - | - |
| 7.4388 | 729 | 5.5525 | - | - | - | - | - |
| 7.4490 | 730 | 2.3835 | - | - | - | - | - |
| 7.4592 | 731 | 0.0003 | - | - | - | - | - |
| 7.4694 | 732 | 0.0016 | - | - | - | - | - |
| 7.4796 | 733 | 0.0 | - | - | - | - | - |
| 7.4898 | 734 | 0.0 | - | - | - | - | - |
| 7.5 | 735 | 0.0421 | - | - | - | - | - |
| 7.5102 | 736 | 0.0003 | - | - | - | - | - |
| 7.5204 | 737 | 0.0029 | - | - | - | - | - |
| 7.5306 | 738 | 0.0708 | - | - | - | - | - |
| 7.5408 | 739 | 0.0025 | - | - | - | - | - |
| 7.5510 | 740 | 0.0003 | - | - | - | - | - |
| 7.5612 | 741 | 0.0 | - | - | - | - | - |
| 7.5714 | 742 | 0.001 | - | - | - | - | - |
| 7.5816 | 743 | 0.9904 | - | - | - | - | - |
| 7.5918 | 744 | 8.014 | - | - | - | - | - |
| 7.6020 | 745 | 0.0015 | - | - | - | - | - |
| 7.6122 | 746 | 0.0002 | - | - | - | - | - |
| 7.6224 | 747 | 0.0034 | - | - | - | - | - |
| 7.6327 | 748 | 0.0004 | - | - | - | - | - |
| 7.6429 | 749 | 0.023 | - | - | - | - | - |
| 7.6531 | 750 | 7.3282 | - | - | - | - | - |
| 7.6633 | 751 | 0.0244 | - | - | - | - | - |
| 7.6735 | 752 | 0.1192 | - | - | - | - | - |
| 7.6837 | 753 | 0.004 | - | - | - | - | - |
| 7.6939 | 754 | 0.0007 | - | - | - | - | - |
| 7.7041 | 755 | 0.0003 | - | - | - | - | - |
| 7.7143 | 756 | 0.0024 | - | - | - | - | - |
| 7.7245 | 757 | 0.0035 | - | - | - | - | - |
| 7.7347 | 758 | 0.0 | - | - | - | - | - |
| 7.7449 | 759 | 0.0025 | - | - | - | - | - |
| 7.7551 | 760 | 0.0017 | - | - | - | - | - |
| 7.7653 | 761 | 0.0005 | - | - | - | - | - |
| 7.7755 | 762 | 2.9901 | - | - | - | - | - |
| 7.7857 | 763 | 0.0004 | - | - | - | - | - |
| 7.7959 | 764 | 0.0022 | - | - | - | - | - |
| 7.8061 | 765 | 0.0013 | - | - | - | - | - |
| 7.8163 | 766 | 0.0002 | - | - | - | - | - |
| 7.8265 | 767 | 0.0179 | - | - | - | - | - |
| 7.8367 | 768 | 0.0009 | - | - | - | - | - |
| 7.8469 | 769 | 0.0002 | - | - | - | - | - |
| 7.8571 | 770 | 0.0013 | - | - | - | - | - |
| 7.8673 | 771 | 0.0007 | - | - | - | - | - |
| 7.8776 | 772 | 0.0063 | - | - | - | - | - |
| 7.8878 | 773 | 0.0002 | - | - | - | - | - |
| 7.8980 | 774 | 0.002 | - | - | - | - | - |
| 7.9082 | 775 | 0.0005 | - | - | - | - | - |
| 7.9184 | 776 | 0.0005 | - | - | - | - | - |
| 7.9286 | 777 | 0.0002 | - | - | - | - | - |
| 7.9388 | 778 | 0.0 | - | - | - | - | - |
| 7.9490 | 779 | 0.0 | - | - | - | - | - |
| 7.9592 | 780 | 0.0017 | - | - | - | - | - |
| 7.9694 | 781 | 0.0049 | - | - | - | - | - |
| 7.9796 | 782 | 5.2118 | - | - | - | - | - |
| 7.9898 | 783 | 0.0035 | - | - | - | - | - |
| 8.0 | 784 | 0.0 | 0.3187 | 0.3126 | 0.3091 | 0.2965 | 0.2782 |
* The bold row denotes the saved checkpoint.
</details>
### Framework Versions
- Python: 3.12.11
- Sentence Transformers: 5.1.0
- Transformers: 4.51.3
- PyTorch: 2.8.0+cu126
- Accelerate: 1.10.1
- Datasets: 4.0.0
- Tokenizers: 0.21.4
## Citation
### BibTeX
#### Sentence Transformers
```bibtex
@inproceedings{reimers-2019-sentence-bert,
title = "Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks",
author = "Reimers, Nils and Gurevych, Iryna",
booktitle = "Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing",
month = "11",
year = "2019",
publisher = "Association for Computational Linguistics",
url = "https://arxiv.org/abs/1908.10084",
}
```
#### MatryoshkaLoss
```bibtex
@misc{kusupati2024matryoshka,
title={Matryoshka Representation Learning},
author={Aditya Kusupati and Gantavya Bhatt and Aniket Rege and Matthew Wallingford and Aditya Sinha and Vivek Ramanujan and William Howard-Snyder and Kaifeng Chen and Sham Kakade and Prateek Jain and Ali Farhadi},
year={2024},
eprint={2205.13147},
archivePrefix={arXiv},
primaryClass={cs.LG}
}
```
#### MultipleNegativesRankingLoss
```bibtex
@misc{henderson2017efficient,
title={Efficient Natural Language Response Suggestion for Smart Reply},
author={Matthew Henderson and Rami Al-Rfou and Brian Strope and Yun-hsuan Sung and Laszlo Lukacs and Ruiqi Guo and Sanjiv Kumar and Balint Miklos and Ray Kurzweil},
year={2017},
eprint={1705.00652},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
<!--
## Glossary
*Clearly define terms in order to be accessible across audiences.*
-->
<!--
## Model Card Authors
*Lists the people who create the model card, providing recognition and accountability for the detailed work that goes into its construction.*
-->
<!--
## Model Card Contact
*Provides a way for people who have updates to the Model Card, suggestions, or questions, to contact the Model Card authors.*
-->
|
mdsfnjfsdf/TrendinG_isabella_ladera_y_beele_vira_video_Social_Media_video_took_the_internet
|
mdsfnjfsdf
| 2025-09-13T18:11:29Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-09-13T18:09:31Z |
<a href="http://landht.com/full-video/?v=isabella_ladera_y_beele" rel="nofollow">🔴 ➤►🙃isabella ladera y beele video filtrado original ya El vídeo</a>
<a href="http://landht.com/full-video/?v=isabella_ladera_y_beele" rel="nofollow">🔴 ➤►isabella ladera y beéle Video Original Video Linkz )</a>
<a href="http://landht.com/full-video/?v=isabella_ladera_y_beele"><img src="https://i.postimg.cc/qvPp49Sm/ythngythg.gif" alt="fsgd" /></a>
|
Alicia22/Sun123_Twelve_r2
|
Alicia22
| 2025-09-13T18:10:44Z | 0 | 0 | null |
[
"safetensors",
"any-to-any",
"omega",
"omegalabs",
"bittensor",
"agi",
"license:mit",
"region:us"
] |
any-to-any
| 2025-09-13T18:02:22Z |
---
license: mit
tags:
- any-to-any
- omega
- omegalabs
- bittensor
- agi
---
This is an Any-to-Any model checkpoint for the OMEGA Labs x Bittensor Any-to-Any subnet.
Check out the [git repo](https://github.com/omegalabsinc/omegalabs-anytoany-bittensor) and find OMEGA on X: [@omegalabsai](https://x.com/omegalabsai).
|
phospho-app/gr00t-012_pickplace_orange_cube_in_black_circle_3Cam_MQ-k0gy5kkgwa
|
phospho-app
| 2025-09-13T17:56:16Z | 0 | 0 |
phosphobot
|
[
"phosphobot",
"safetensors",
"gr00t_n1_5",
"gr00t",
"robotics",
"dataset:JollyRed/012_pickplace_orange_cube_in_black_circle_3Cam_MQ",
"region:us"
] |
robotics
| 2025-09-13T17:42:46Z |
---
datasets: JollyRed/012_pickplace_orange_cube_in_black_circle_3Cam_MQ
library_name: phosphobot
pipeline_tag: robotics
model_name: gr00t
tags:
- phosphobot
- gr00t
task_categories:
- robotics
---
# gr00t model - 🧪 phosphobot training pipeline
- **Dataset**: [JollyRed/012_pickplace_orange_cube_in_black_circle_3Cam_MQ](https://huggingface.co/datasets/JollyRed/012_pickplace_orange_cube_in_black_circle_3Cam_MQ)
- **Wandb run id**: None
## This model was trained using **[🧪phospho](https://phospho.ai)**
Training was successful, try it out on your robot!
## Training parameters
```text
{
"validation_dataset_name": null,
"batch_size": 27,
"num_epochs": 10,
"save_steps": 1000,
"learning_rate": 0.0001,
"data_dir": "/tmp/outputs/data",
"validation_data_dir": "/tmp/outputs/validation_data",
"output_dir": "/tmp/outputs/train"
}
```
📖 **Get Started**: [docs.phospho.ai](https://docs.phospho.ai?utm_source=huggingface_readme)
🤖 **Get your robot**: [robots.phospho.ai](https://robots.phospho.ai?utm_source=huggingface_readme)
|
Reihaneh/wav2vec2_sk_mono_50_epochs_8
|
Reihaneh
| 2025-09-13T17:53:51Z | 0 | 0 |
transformers
|
[
"transformers",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-09-13T17:53:50Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
tamewild/4b_v91_merged_e4
|
tamewild
| 2025-09-13T17:44:27Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen3",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-09-13T17:43:11Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
zaringleb/binary_cube_smolvla_chunk50_large_lr
|
zaringleb
| 2025-09-13T17:21:34Z | 0 | 0 |
lerobot
|
[
"lerobot",
"safetensors",
"robotics",
"smolvla",
"dataset:zaringleb/binary_cube_homelab_so101_3",
"arxiv:2506.01844",
"base_model:lerobot/smolvla_base",
"base_model:finetune:lerobot/smolvla_base",
"license:apache-2.0",
"region:us"
] |
robotics
| 2025-09-13T17:18:30Z |
---
base_model: lerobot/smolvla_base
datasets: zaringleb/binary_cube_homelab_so101_3
library_name: lerobot
license: apache-2.0
model_name: smolvla
pipeline_tag: robotics
tags:
- lerobot
- robotics
- smolvla
---
# Model Card for smolvla
<!-- Provide a quick summary of what the model is/does. -->
[SmolVLA](https://huggingface.co/papers/2506.01844) is a compact, efficient vision-language-action model that achieves competitive performance at reduced computational costs and can be deployed on consumer-grade hardware.
This policy has been trained and pushed to the Hub using [LeRobot](https://github.com/huggingface/lerobot).
See the full documentation at [LeRobot Docs](https://huggingface.co/docs/lerobot/index).
---
## How to Get Started with the Model
For a complete walkthrough, see the [training guide](https://huggingface.co/docs/lerobot/il_robots#train-a-policy).
Below is the short version on how to train and run inference/eval:
### Train from scratch
```bash
lerobot-train \
--dataset.repo_id=${HF_USER}/<dataset> \
--policy.type=act \
--output_dir=outputs/train/<desired_policy_repo_id> \
--job_name=lerobot_training \
--policy.device=cuda \
--policy.repo_id=${HF_USER}/<desired_policy_repo_id>
--wandb.enable=true
```
_Writes checkpoints to `outputs/train/<desired_policy_repo_id>/checkpoints/`._
### Evaluate the policy/run inference
```bash
lerobot-record \
--robot.type=so100_follower \
--dataset.repo_id=<hf_user>/eval_<dataset> \
--policy.path=<hf_user>/<desired_policy_repo_id> \
--episodes=10
```
Prefix the dataset repo with **eval\_** and supply `--policy.path` pointing to a local or hub checkpoint.
---
## Model Details
- **License:** apache-2.0
|
Disya/Snwy-14B-CPT-1B-Koto-Q4_K_M-GGUF
|
Disya
| 2025-09-13T17:11:05Z | 0 | 0 | null |
[
"gguf",
"llama-cpp",
"gguf-my-repo",
"base_model:NewEden/Snwy-14B-CPT-1B-Koto",
"base_model:quantized:NewEden/Snwy-14B-CPT-1B-Koto",
"endpoints_compatible",
"region:us"
] | null | 2025-09-13T17:10:32Z |
---
base_model: NewEden/Snwy-14B-CPT-1B-Koto
tags:
- llama-cpp
- gguf-my-repo
---
# Disya/Snwy-14B-CPT-1B-Koto-Q4_K_M-GGUF
This model was converted to GGUF format from [`NewEden/Snwy-14B-CPT-1B-Koto`](https://huggingface.co/NewEden/Snwy-14B-CPT-1B-Koto) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/NewEden/Snwy-14B-CPT-1B-Koto) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew (works on Mac and Linux)
```bash
brew install llama.cpp
```
Invoke the llama.cpp server or the CLI.
### CLI:
```bash
llama-cli --hf-repo Disya/Snwy-14B-CPT-1B-Koto-Q4_K_M-GGUF --hf-file snwy-14b-cpt-1b-koto-q4_k_m.gguf -p "The meaning to life and the universe is"
```
### Server:
```bash
llama-server --hf-repo Disya/Snwy-14B-CPT-1B-Koto-Q4_K_M-GGUF --hf-file snwy-14b-cpt-1b-koto-q4_k_m.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
Step 1: Clone llama.cpp from GitHub.
```
git clone https://github.com/ggerganov/llama.cpp
```
Step 2: Move into the llama.cpp folder and build it with `LLAMA_CURL=1` flag along with other hardware-specific flags (for ex: LLAMA_CUDA=1 for Nvidia GPUs on Linux).
```
cd llama.cpp && LLAMA_CURL=1 make
```
Step 3: Run inference through the main binary.
```
./llama-cli --hf-repo Disya/Snwy-14B-CPT-1B-Koto-Q4_K_M-GGUF --hf-file snwy-14b-cpt-1b-koto-q4_k_m.gguf -p "The meaning to life and the universe is"
```
or
```
./llama-server --hf-repo Disya/Snwy-14B-CPT-1B-Koto-Q4_K_M-GGUF --hf-file snwy-14b-cpt-1b-koto-q4_k_m.gguf -c 2048
```
|
QuantFactory/UIGEN-X-8B-GGUF
|
QuantFactory
| 2025-09-13T16:59:58Z | 0 | 1 |
transformers
|
[
"transformers",
"gguf",
"text-generation-inference",
"qwen3",
"ui-generation",
"tailwind-css",
"html",
"reasoning",
"step-by-step-generation",
"hybrid-thinking",
"tool-calling",
"en",
"base_model:Qwen/Qwen3-8B",
"base_model:quantized:Qwen/Qwen3-8B",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-09-13T16:07:53Z |
---
base_model:
- Qwen/Qwen3-8B
tags:
- text-generation-inference
- transformers
- qwen3
- ui-generation
- tailwind-css
- html
- reasoning
- step-by-step-generation
- hybrid-thinking
- tool-calling
license: apache-2.0
language:
- en
---
[](https://hf.co/QuantFactory)
# QuantFactory/UIGEN-X-8B-GGUF
This is quantized version of [Tesslate/UIGEN-X-8B](https://huggingface.co/Tesslate/UIGEN-X-8B) created using llama.cpp
# Original Model Card
# UIGEN-X-8B Hybrid Reasoning UI Generation Model

> Tesslate's hybrid reasoning UI generation model built on Qwen3-8B architecture. Trained to systematically plan, architect, and implement complete user interfaces across modern development stacks.
**Live Examples**: [https://uigenoutput.tesslate.com](https://uigenoutput.tesslate.com)
**Discord Community**: [https://discord.gg/EcCpcTv93U](https://discord.gg/EcCpcTv93U)
**Website**: [https://tesslate.com](https://tesslate.com)
---
## Model Architecture
UIGEN-X-8B implements **hybrid reasoning** from the Qwen3 family - combining systematic planning with direct implementation. The model follows a structured thinking process:
1. **Problem Analysis** — Understanding requirements and constraints
2. **Architecture Planning** — Component structure and technology decisions
3. **Design System Definition** — Color schemes, typography, and styling approach
4. **Implementation Strategy** — Step-by-step code generation with reasoning
This hybrid approach enables both thoughtful planning and efficient code generation, making it suitable for complex UI development tasks.
---
## Complete Technology Coverage
UIGEN-X-8B supports **26 major categories** spanning **frameworks and libraries** across **7 platforms**:
### Web Frameworks
- **React**: Next.js, Remix, Gatsby, Create React App, Vite
- **Vue**: Nuxt.js, Quasar, Gridsome
- **Angular**: Angular CLI, Ionic Angular
- **Svelte**: SvelteKit, Astro
- **Modern**: Solid.js, Qwik, Alpine.js
- **Static**: Astro, 11ty, Jekyll, Hugo
### Styling Systems
- **Utility-First**: Tailwind CSS, UnoCSS, Windi CSS
- **CSS-in-JS**: Styled Components, Emotion, Stitches
- **Component Systems**: Material-UI, Chakra UI, Mantine
- **Traditional**: Bootstrap, Bulma, Foundation
- **Design Systems**: Carbon Design, IBM Design Language
- **Framework-Specific**: Angular Material, Vuetify, Quasar
### UI Component Libraries
- **React**: shadcn/ui, Material-UI, Ant Design, Chakra UI, Mantine, PrimeReact, Headless UI, NextUI, DaisyUI
- **Vue**: Vuetify, PrimeVue, Quasar, Element Plus, Naive UI
- **Angular**: Angular Material, PrimeNG, ng-bootstrap, Clarity Design
- **Svelte**: Svelte Material UI, Carbon Components Svelte
- **Headless**: Radix UI, Reach UI, Ariakit, React Aria
### State Management
- **React**: Redux Toolkit, Zustand, Jotai, Valtio, Context API
- **Vue**: Pinia, Vuex, Composables
- **Angular**: NgRx, Akita, Services
- **Universal**: MobX, XState, Recoil
### Animation Libraries
- **React**: Framer Motion, React Spring, React Transition Group
- **Vue**: Vue Transition, Vueuse Motion
- **Universal**: GSAP, Lottie, CSS Animations, Web Animations API
- **Mobile**: React Native Reanimated, Expo Animations
### Icon Systems
Lucide, Heroicons, Material Icons, Font Awesome, Ant Design Icons, Bootstrap Icons, Ionicons, Tabler Icons, Feather, Phosphor, React Icons, Vue Icons
---
## Platform Support
### Web Development
Complete coverage of modern web development from simple HTML/CSS to complex enterprise applications.
### Mobile Development
- **React Native**: Expo, CLI, with navigation and state management
- **Flutter**: Cross-platform mobile with Material and Cupertino designs
- **Ionic**: Angular, React, and Vue-based hybrid applications
### Desktop Applications
- **Electron**: Cross-platform desktop apps (Slack, VSCode-style)
- **Tauri**: Rust-based lightweight desktop applications
- **Flutter Desktop**: Native desktop performance
### Python Applications
- **Web UI**: Streamlit, Gradio, Flask, FastAPI
- **Desktop GUI**: Tkinter, PyQt5/6, Kivy, wxPython, Dear PyGui
### Development Tools
Build tools, bundlers, testing frameworks, and development environments.
---
## Programming Language Support
**26 Languages and Approaches**:
JavaScript, TypeScript, Python, Dart, HTML5, CSS3, SCSS, SASS, Less, PostCSS, CSS Modules, Styled Components, JSX, TSX, Vue SFC, Svelte Components, Angular Templates, Tailwind, PHP
---
## Visual Style System
UIGEN-X-8B includes **21 distinct visual style categories** that can be applied to any framework:
### Modern Design Styles
- **Glassmorphism**: Frosted glass effects with blur and transparency
- **Neumorphism**: Soft, extruded design elements
- **Material Design**: Google's design system principles
- **Fluent Design**: Microsoft's design language
### Traditional & Classic
- **Skeuomorphism**: Real-world object representations
- **Swiss Design**: Clean typography and grid systems
- **Bauhaus**: Functional, geometric design principles
### Contemporary Trends
- **Brutalism**: Bold, raw, unconventional layouts
- **Anti-Design**: Intentionally imperfect, organic aesthetics
- **Minimalism**: Essential elements only, generous whitespace
### Thematic Styles
- **Cyberpunk**: Neon colors, glitch effects, futuristic elements
- **Dark Mode**: High contrast, reduced eye strain
- **Retro-Futurism**: 80s/90s inspired futuristic design
- **Geocities/90s Web**: Nostalgic early web aesthetics
### Experimental
- **Maximalism**: Rich, layered, abundant visual elements
- **Madness/Experimental**: Unconventional, boundary-pushing designs
- **Abstract Shapes**: Geometric, non-representational elements
---
## Prompt Structure Guide
### Basic Structure
To achieve the best results, use this prompting structure below:
```
[Action] + [UI Type] + [Framework Stack] + [Specific Features] + [Optional: Style]
```
### Examples
**Simple Component**:
```
Create a navigation bar using React + Tailwind CSS with logo, menu items, and mobile hamburger menu
```
**Complex Application**:
```
Build a complete e-commerce dashboard using Next.js + TypeScript + Tailwind CSS + shadcn/ui with:
- Product management (CRUD operations)
- Order tracking with status updates
- Customer analytics with charts
- Responsive design for mobile/desktop
- Dark mode toggle
Style: Use a clean, modern glassmorphism aesthetic
```
**Framework-Specific**:
```
Design an Angular Material admin panel with:
- Sidenav with expandable menu items
- Data tables with sorting and filtering
- Form validation with reactive forms
- Charts using ng2-charts
- SCSS custom theming
```
### Advanced Prompt Techniques
**Multi-Page Applications**:
```
Create a complete SaaS application using Vue 3 + Nuxt 3 + Tailwind CSS + Pinia:
Pages needed:
1. Landing page with hero, features, pricing
2. Dashboard with metrics and quick actions
3. Settings page with user preferences
4. Billing page with subscription management
Include: Navigation between pages, state management, responsive design
Style: Professional, modern with subtle animations
```
**Style Mixing**:
```
Build a portfolio website using Svelte + SvelteKit + Tailwind CSS combining:
- Minimalist layout principles
- Cyberpunk color scheme (neon accents)
- Smooth animations for page transitions
- Typography-driven content sections
```
---
## Tool Calling & Agentic Usage
UIGEN-X-8B supports **function calling** for dynamic asset integration and enhanced development workflows.
### Image Integration with Unsplash
Register tools for dynamic image fetching:
```json
{
"type": "function",
"function": {
"name": "fetch_unsplash_image",
"description": "Fetch high-quality images from Unsplash for UI mockups",
"parameters": {
"type": "object",
"properties": {
"query": {
"type": "string",
"description": "Search term for image (e.g., 'modern office', 'technology', 'nature')"
},
"orientation": {
"type": "string",
"enum": ["landscape", "portrait", "squarish"],
"description": "Image orientation"
},
"size": {
"type": "string",
"enum": ["small", "regular", "full"],
"description": "Image size"
}
},
"required": ["query"]
}
}
}
```
### Content Generation Tools
```json
{
"type": "function",
"function": {
"name": "generate_content",
"description": "Generate realistic content for UI components",
"parameters": {
"type": "object",
"properties": {
"type": {
"type": "string",
"enum": ["user_profiles", "product_data", "blog_posts", "testimonials"],
"description": "Type of content to generate"
},
"count": {
"type": "integer",
"description": "Number of items to generate"
},
"theme": {
"type": "string",
"description": "Content theme or industry"
}
},
"required": ["type", "count"]
}
}
}
```
### Complete Agentic Workflow Example
```python
# 1. Plan the application
response = model.chat([
{"role": "user", "content": "Plan a complete travel booking website using React + Next.js + Tailwind CSS + shadcn/ui"}
], tools=[fetch_unsplash_image, generate_content])
# 2. The model will reason through the requirements and call tools:
# - fetch_unsplash_image(query="travel destinations", orientation="landscape")
# - generate_content(type="destinations", count=10, theme="popular travel")
# - fetch_unsplash_image(query="hotel rooms", orientation="landscape")
# 3. Generate complete implementation with real assets
final_response = model.chat([
{"role": "user", "content": "Now implement the complete website with the fetched images and content"}
])
```
### Tool Integration Patterns
**Dynamic Asset Loading**:
- Fetch relevant images during UI generation
- Generate realistic content for components
- Create cohesive color palettes from images
- Optimize assets for web performance
**Multi-Step Development**:
- Plan application architecture
- Generate individual components
- Integrate components into pages
- Apply consistent styling and theming
- Test responsive behavior
**Content-Aware Design**:
- Adapt layouts based on content types
- Optimize typography for readability
- Create responsive image galleries
- Generate accessible alt text
---
## Inference Configuration
### Optimal Parameters
```python
{
"temperature": 0.6, # Balanced creativity and consistency (make it lower if quantized!!!!)
"top_p": 0.9, # Nucleus sampling for quality
"top_k": 40, # Vocabulary restriction
"max_tokens": 25000, # Full component generation
"repetition_penalty": 1.1, # Avoid repetitive patterns
}
```
---
## Use Cases & Applications
### Rapid Prototyping
- Quick mockups for client presentations
- A/B testing different design approaches
- Concept validation with interactive prototypes
### Production Development
- Component library creation
- Design system implementation
- Template and boilerplate generation
### Educational & Learning
- Teaching modern web development
- Framework comparison and evaluation
- Best practices demonstration
### Enterprise Solutions
- Dashboard and admin panel generation
- Internal tool development
- Legacy system modernization
---
## Technical Requirements
### Hardware
- **GPU**: 8GB+ VRAM recommended (RTX 3080/4070 or equivalent)
- **RAM**: 16GB system memory minimum
- **Storage**: 20GB for model weights and cache
### Software
- **Python**: 3.8+ with transformers, torch, unsloth
- **Node.js**: For running generated JavaScript/TypeScript code
- **Browser**: Modern browser for testing generated UIs
### Integration
- Compatible with HuggingFace transformers
- Supports GGML/GGUF quantization
- Works with text-generation-webui
- API-ready for production deployment
---
## Limitations & Considerations
- **Token Usage**: Reasoning process increases token consumption
- **Complex Logic**: Focuses on UI structure rather than business logic
- **Real-time Features**: Generated code requires backend integration
- **Testing**: Output may need manual testing and refinement
- **Accessibility**: While ARIA-aware, manual a11y testing recommended
---
## Community & Support
**Discord**: [https://discord.gg/EcCpcTv93U](https://discord.gg/EcCpcTv93U)
**Website**: [https://tesslate.com](https://tesslate.com)
**Examples**: [https://uigenoutput.tesslate.com](https://uigenoutput.tesslate.com)
Join our community to share creations, get help, and contribute to the ecosystem.
---
## Citation
```bibtex
@misc{tesslate_uigen_x_2025,
title={UIGEN-X-8B: Hybrid Reasoning UI Generation with Qwen3},
author={Tesslate Team},
year={2025},
publisher={Tesslate},
url={https://huggingface.co/tesslate/UIGEN-X-8B}
}
```
---
<img src="https://cdn-uploads.huggingface.co/production/uploads/64d1129297ca59bcf7458d07/ZhW150gEhg0lkXoSjkiiU.png" alt="UI Screenshot 1" width="400">
<img src="https://cdn-uploads.huggingface.co/production/uploads/64d1129297ca59bcf7458d07/NdxVu6Zv6beigOYjbKCl1.png" alt="UI Screenshot 2" width="400">
<img src="https://cdn-uploads.huggingface.co/production/uploads/64d1129297ca59bcf7458d07/RX8po_paCIxrrcTvZ3xfA.png" alt="UI Screenshot 3" width="400">
<img src="https://cdn-uploads.huggingface.co/production/uploads/64d1129297ca59bcf7458d07/DBssA7zan39uxy9HQOo5N.png" alt="UI Screenshot 4" width="400">
<img src="https://cdn-uploads.huggingface.co/production/uploads/64d1129297ca59bcf7458d07/ttljEdBcYh1tkmyrCUQku.png" alt="UI Screenshot 5" width="400">
<img src="https://cdn-uploads.huggingface.co/production/uploads/64d1129297ca59bcf7458d07/duLxNQAuqv1FPVlsmQsWr.png" alt="UI Screenshot 6" width="400">
<img src="https://cdn-uploads.huggingface.co/production/uploads/64d1129297ca59bcf7458d07/ja2nhpNrvucf_zwCARXxa.png" alt="UI Screenshot 7" width="400">
<img src="https://cdn-uploads.huggingface.co/production/uploads/64d1129297ca59bcf7458d07/ca0f_8U9HQdaSVAejpzPn.png" alt="UI Screenshot 8" width="400">
<img src="https://cdn-uploads.huggingface.co/production/uploads/64d1129297ca59bcf7458d07/gzZF2CiOjyEbPAPRYSV-N.png" alt="UI Screenshot 9" width="400">
<img src="https://cdn-uploads.huggingface.co/production/uploads/64d1129297ca59bcf7458d07/y8wB78PffUUoVLzw3al2R.png" alt="UI Screenshot 10" width="400">
<img src="https://cdn-uploads.huggingface.co/production/uploads/64d1129297ca59bcf7458d07/M12dGr0xArAIF7gANSC5T.png" alt="UI Screenshot 11" width="400">
<img src="https://cdn-uploads.huggingface.co/production/uploads/64d1129297ca59bcf7458d07/t7r7cYlUwmI1QQf3fxO7o.png" alt="UI Screenshot 12" width="400">
<img src="https://cdn-uploads.huggingface.co/production/uploads/64d1129297ca59bcf7458d07/-uCIIJqTrrY9xkJHKCEqC.png" alt="UI Screenshot 13" width="400">
<img src="https://cdn-uploads.huggingface.co/production/uploads/64d1129297ca59bcf7458d07/eqT3IUWaPtoNQb-IWQNuy.png" alt="UI Screenshot 14" width="400">
<img src="https://cdn-uploads.huggingface.co/production/uploads/64d1129297ca59bcf7458d07/RhbGMcxCNlMIXRLEacUGi.png" alt="UI Screenshot 15" width="400">
<img src="https://cdn-uploads.huggingface.co/production/uploads/64d1129297ca59bcf7458d07/FWhs43BKkXku12MwiW0v9.png" alt="UI Screenshot 16" width="400">
<img src="https://cdn-uploads.huggingface.co/production/uploads/67db34a5e7f1d129b294e2af/ILHx-xcn18cyDLX5a63xV.png" alt="UIGEN-X UI Screenshot 1" width="400">
<img src="https://cdn-uploads.huggingface.co/production/uploads/67db34a5e7f1d129b294e2af/A-zKo1J4HYftjiOjq_GB4.png" alt="UIGEN-X UI Screenshot 2" width="400">
*Built with hybrid reasoning capabilities from Qwen3, UIGEN-X-8B represents a comprehensive approach to AI-driven UI development across the entire modern web development ecosystem.*
|
ypszn/blockassist
|
ypszn
| 2025-09-13T16:56:51Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"yapping pawing worm",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-12T21:48:36Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- yapping pawing worm
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
shaasmn/blockassist-bc-quick_leggy_gecko_1757782072
|
shaasmn
| 2025-09-13T16:49:16Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"quick leggy gecko",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-13T16:48:55Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- quick leggy gecko
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Harisan07/gptoss-20b-gazeal-finetuned
|
Harisan07
| 2025-09-13T16:33:13Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"gpt_oss",
"trl",
"en",
"base_model:unsloth/gpt-oss-20b-unsloth-bnb-4bit",
"base_model:finetune:unsloth/gpt-oss-20b-unsloth-bnb-4bit",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-09-13T16:32:59Z |
---
base_model: unsloth/gpt-oss-20b-unsloth-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- gpt_oss
- trl
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** Harisan07
- **License:** apache-2.0
- **Finetuned from model :** unsloth/gpt-oss-20b-unsloth-bnb-4bit
This gpt_oss model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
deathsolua/blockassist
|
deathsolua
| 2025-09-13T16:21:28Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"shiny grunting zebra",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-11T10:31:17Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- shiny grunting zebra
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Kokoutou/Koko21_omg3_130902
|
Kokoutou
| 2025-09-13T16:02:24Z | 0 | 0 | null |
[
"safetensors",
"any-to-any",
"omega",
"omegalabs",
"bittensor",
"agi",
"license:mit",
"region:us"
] |
any-to-any
| 2025-09-13T14:50:58Z |
---
license: mit
tags:
- any-to-any
- omega
- omegalabs
- bittensor
- agi
---
This is an Any-to-Any model checkpoint for the OMEGA Labs x Bittensor Any-to-Any subnet.
Check out the [git repo](https://github.com/omegalabsinc/omegalabs-anytoany-bittensor) and find OMEGA on X: [@omegalabsai](https://x.com/omegalabsai).
|
panda1134141/FrozenLake-v1
|
panda1134141
| 2025-09-13T15:10:51Z | 0 | 0 | null |
[
"FrozenLake-v1-4x4",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2025-09-13T15:10:41Z |
---
tags:
- FrozenLake-v1-4x4
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: FrozenLake-v1
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4
type: FrozenLake-v1-4x4
metrics:
- type: mean_reward
value: 0.74 +/- 0.44
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="panda1134141/FrozenLake-v1", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
Aleksandr-n/blockassist
|
Aleksandr-n
| 2025-09-13T15:06:14Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"agile endangered gazelle",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-12T17:31:30Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- agile endangered gazelle
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
csikasote/mms-1b-all-bemgen-combined-m25f100-62-DAT-5e-1
|
csikasote
| 2025-09-13T15:05:43Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"wav2vec2",
"automatic-speech-recognition",
"bemgen",
"mms",
"generated_from_trainer",
"base_model:facebook/mms-1b-all",
"base_model:finetune:facebook/mms-1b-all",
"license:cc-by-nc-4.0",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2025-09-13T14:24:55Z |
---
library_name: transformers
license: cc-by-nc-4.0
base_model: facebook/mms-1b-all
tags:
- automatic-speech-recognition
- bemgen
- mms
- generated_from_trainer
model-index:
- name: mms-1b-all-bemgen-combined-m25f100-62-DAT-5e-1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mms-1b-all-bemgen-combined-m25f100-62-DAT-5e-1
This model is a fine-tuned version of [facebook/mms-1b-all](https://huggingface.co/facebook/mms-1b-all) on the BEMGEN - BEM dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3301
- Cer: 0.0963
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 8
- eval_batch_size: 4
- seed: 62
- gradient_accumulation_steps: 2
- total_train_batch_size: 16
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 100
- num_epochs: 30.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Cer |
|:-------------:|:------:|:----:|:---------------:|:------:|
| 4.0955 | 0.6711 | 100 | 2.8792 | 0.9990 |
| 1.3045 | 1.3423 | 200 | 0.5736 | 0.2091 |
| 0.7337 | 2.0134 | 300 | 0.3749 | 0.1058 |
| 0.6415 | 2.6846 | 400 | 0.3300 | 0.0963 |
| 0.6344 | 3.3557 | 500 | 0.3057 | 0.0866 |
| 0.6393 | 4.0268 | 600 | 0.3077 | 0.0855 |
| 0.6426 | 4.6980 | 700 | 0.2826 | 0.0787 |
| 0.6657 | 5.3691 | 800 | 0.2832 | 0.0789 |
| 0.6436 | 6.0403 | 900 | 0.2849 | 0.0791 |
| 0.6232 | 6.7114 | 1000 | 0.2771 | 0.0774 |
| 0.6351 | 7.3826 | 1100 | 0.2719 | 0.0770 |
| 0.6348 | 8.0537 | 1200 | 0.2794 | 0.0777 |
| 0.6205 | 8.7248 | 1300 | 0.2771 | 0.0778 |
| 0.6329 | 9.3960 | 1400 | 0.2763 | 0.0780 |
### Framework versions
- Transformers 4.53.0.dev0
- Pytorch 2.6.0+cu124
- Datasets 3.6.0
- Tokenizers 0.21.0
|
giovannidemuri/llama8b-v108-jb-seed2-alpaca_lora
|
giovannidemuri
| 2025-09-13T14:48:09Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-09-13T10:39:16Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
giovannidemuri/llama8b-v109-jb-seed2-alpaca_lora
|
giovannidemuri
| 2025-09-13T14:39:50Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-09-13T10:39:18Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Tonic/voxtral-finetune-20250913_171840
|
Tonic
| 2025-09-13T14:24:17Z | 0 | 0 |
peft
|
[
"peft",
"safetensors",
"voxtral",
"asr",
"speech-to-text",
"fine-tuning",
"tonic",
"automatic-speech-recognition",
"hi",
"en",
"fr",
"de",
"it",
"pt",
"nl",
"base_model:mistralai/Voxtral-Mini-3B-2507",
"base_model:adapter:mistralai/Voxtral-Mini-3B-2507",
"license:apache-2.0",
"region:us"
] |
automatic-speech-recognition
| 2025-09-13T14:23:45Z |
---
license: apache-2.0
tags:
- voxtral
- asr
- speech-to-text
- fine-tuning
- tonic
pipeline_tag: automatic-speech-recognition
base_model: mistralai/Voxtral-Mini-3B-2507
author: Voxtral Trainer
training_config: Custom Configuration
trainer_type: SFTTrainer
batch_size: 2
gradient_accumulation_steps: 4
learning_rate: 5e-05
max_epochs: 3
max_seq_length: 2048
hardware: "GPU: NVIDIA RTX 4000 Ada Generation"
language:
- hi
- en
- fr
- de
- it
- pt
- nl
library_name: peft
---
# voxtral-finetune-20250913_171840
Fine-tuned Voxtral ASR model
## Usage
```python
import torch
from transformers import AutoProcessor, AutoModelForSeq2SeqLM
import soundfile as sf
processor = AutoProcessor.from_pretrained("Tonic/voxtral-finetune-20250913_171840")
model = AutoModelForSeq2SeqLM.from_pretrained(
"Tonic/voxtral-finetune-20250913_171840",
torch_dtype=torch.float16 if torch.cuda.is_available() else torch.float32
)
audio, sr = sf.read("sample.wav")
inputs = processor(audio, sampling_rate=sr, return_tensors="pt")
with torch.no_grad():
generated_ids = model.generate(**inputs, max_new_tokens=256)
text = processor.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(text)
```
## Training Configuration
- Base model: mistralai/Voxtral-Mini-3B-2507
- Config: Custom Configuration
- Trainer: SFTTrainer
## Training Parameters
- Batch size: 2
- Grad accumulation: 4
- Learning rate: 5e-05
- Max epochs: 3
- Sequence length: 2048
## Hardware
- GPU: NVIDIA RTX 4000 Ada Generation
## Notes
- This repository contains a fine-tuned Voxtral ASR model.
|
jasonhuang3/Pro6000-dpop_our_2-qwen-2-5-7b-math_lora_28k
|
jasonhuang3
| 2025-09-13T14:23:13Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"generated_from_trainer",
"trl",
"dpo",
"arxiv:2305.18290",
"base_model:Qwen/Qwen2.5-Math-7B",
"base_model:finetune:Qwen/Qwen2.5-Math-7B",
"endpoints_compatible",
"region:us"
] | null | 2025-09-12T15:42:03Z |
---
base_model: Qwen/Qwen2.5-Math-7B
library_name: transformers
model_name: Pro6000-dpop_our_2-qwen-2-5-7b-math_lora_28k
tags:
- generated_from_trainer
- trl
- dpo
licence: license
---
# Model Card for Pro6000-dpop_our_2-qwen-2-5-7b-math_lora_28k
This model is a fine-tuned version of [Qwen/Qwen2.5-Math-7B](https://huggingface.co/Qwen/Qwen2.5-Math-7B).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="jasonhuang3/Pro6000-dpop_our_2-qwen-2-5-7b-math_lora_28k", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="150" height="24"/>](https://wandb.ai/jasonhuang3-school/huggingface/runs/r5jwyey6)
This model was trained with DPO, a method introduced in [Direct Preference Optimization: Your Language Model is Secretly a Reward Model](https://huggingface.co/papers/2305.18290).
### Framework versions
- TRL: 0.18.0
- Transformers: 4.56.0
- Pytorch: 2.7.0+cu128
- Datasets: 4.0.0
- Tokenizers: 0.22.0
## Citations
Cite DPO as:
```bibtex
@inproceedings{rafailov2023direct,
title = {{Direct Preference Optimization: Your Language Model is Secretly a Reward Model}},
author = {Rafael Rafailov and Archit Sharma and Eric Mitchell and Christopher D. Manning and Stefano Ermon and Chelsea Finn},
year = 2023,
booktitle = {Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16, 2023},
url = {http://papers.nips.cc/paper_files/paper/2023/hash/a85b405ed65c6477a4fe8302b5e06ce7-Abstract-Conference.html},
editor = {Alice Oh and Tristan Naumann and Amir Globerson and Kate Saenko and Moritz Hardt and Sergey Levine},
}
```
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
Tonic/voxtral-finetune-20250913_164641
|
Tonic
| 2025-09-13T14:19:47Z | 0 | 0 |
peft
|
[
"peft",
"safetensors",
"voxtral",
"asr",
"speech-to-text",
"fine-tuning",
"tonic",
"automatic-speech-recognition",
"hi",
"en",
"fr",
"de",
"it",
"pt",
"nl",
"base_model:mistralai/Voxtral-Mini-3B-2507",
"base_model:adapter:mistralai/Voxtral-Mini-3B-2507",
"license:apache-2.0",
"region:us"
] |
automatic-speech-recognition
| 2025-09-13T13:49:28Z |
---
license: apache-2.0
tags:
- voxtral
- asr
- speech-to-text
- fine-tuning
- tonic
pipeline_tag: automatic-speech-recognition
base_model: mistralai/Voxtral-Mini-3B-2507
author: Voxtral Trainer
training_config: Custom Configuration
trainer_type: SFTTrainer
batch_size: 2
gradient_accumulation_steps: 4
learning_rate: 5e-05
max_epochs: 3
max_seq_length: 2048
hardware: "GPU: NVIDIA RTX 4000 Ada Generation"
language:
- hi
- en
- fr
- de
- it
- pt
- nl
library_name: peft
---
# voxtral-finetune-20250913_164641
Fine-tuned Voxtral ASR model
## Usage
```python
import torch
from transformers import AutoProcessor, AutoModelForSeq2SeqLM
import soundfile as sf
processor = AutoProcessor.from_pretrained("Tonic/voxtral-finetune-20250913_164641")
model = AutoModelForSeq2SeqLM.from_pretrained(
"Tonic/voxtral-finetune-20250913_164641",
torch_dtype=torch.float16 if torch.cuda.is_available() else torch.float32
)
audio, sr = sf.read("sample.wav")
inputs = processor(audio, sampling_rate=sr, return_tensors="pt")
with torch.no_grad():
generated_ids = model.generate(**inputs, max_new_tokens=256)
text = processor.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(text)
```
## Training Configuration
- Base model: mistralai/Voxtral-Mini-3B-2507
- Config: Custom Configuration
- Trainer: SFTTrainer
## Training Parameters
- Batch size: 2
- Grad accumulation: 4
- Learning rate: 5e-05
- Max epochs: 3
- Sequence length: 2048
## Hardware
- GPU: NVIDIA RTX 4000 Ada Generation
## Notes
- This repository contains a fine-tuned Voxtral ASR model.
|
HelleRas/HelleRannes-Replica
|
HelleRas
| 2025-09-13T13:43:50Z | 0 | 0 |
diffusers
|
[
"diffusers",
"flux",
"lora",
"replicate",
"text-to-image",
"en",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"license:other",
"region:us"
] |
text-to-image
| 2025-09-13T12:56:37Z |
---
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
language:
- en
tags:
- flux
- diffusers
- lora
- replicate
base_model: "black-forest-labs/FLUX.1-dev"
pipeline_tag: text-to-image
# widget:
# - text: >-
# prompt
# output:
# url: https://...
instance_prompt: Helle
---
# Hellerannes Replica
<Gallery />
## About this LoRA
This is a [LoRA](https://replicate.com/docs/guides/working-with-loras) for the FLUX.1-dev text-to-image model. It can be used with diffusers or ComfyUI.
It was trained on [Replicate](https://replicate.com/) using AI toolkit: https://replicate.com/ostris/flux-dev-lora-trainer/train
## Trigger words
You should use `Helle` to trigger the image generation.
## Run this LoRA with an API using Replicate
```py
import replicate
input = {
"prompt": "Helle",
"lora_weights": "https://huggingface.co/helleras/hellerannes-replica/resolve/main/lora.safetensors"
}
output = replicate.run(
"black-forest-labs/flux-dev-lora",
input=input
)
for index, item in enumerate(output):
with open(f"output_{index}.webp", "wb") as file:
file.write(item.read())
```
## Use it with the [🧨 diffusers library](https://github.com/huggingface/diffusers)
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained('black-forest-labs/FLUX.1-dev', torch_dtype=torch.float16).to('cuda')
pipeline.load_lora_weights('helleras/hellerannes-replica', weight_name='lora.safetensors')
image = pipeline('Helle').images[0]
```
For more details, including weighting, merging and fusing LoRAs, check the [documentation on loading LoRAs in diffusers](https://huggingface.co/docs/diffusers/main/en/using-diffusers/loading_adapters)
## Training details
- Steps: 2009
- Learning rate: 0.0004
- LoRA rank: 16
## Contribute your own examples
You can use the [community tab](https://huggingface.co/helleras/hellerannes-replica/discussions) to add images that show off what you’ve made with this LoRA.
|
Lovre/minimal_example_lora
|
Lovre
| 2025-09-13T13:36:16Z | 0 | 0 | null |
[
"safetensors",
"base_model:meta-llama/Llama-3.2-3B",
"base_model:finetune:meta-llama/Llama-3.2-3B",
"license:mit",
"region:us"
] | null | 2025-09-13T13:08:20Z |
---
license: mit
base_model:
- meta-llama/Llama-3.2-3B
---
# Training Report - 2025-09-09 15:09:03
## Configuration
```yaml
# Configuration for minimal example addition model training
model:
base_model: "meta-llama/Llama-3.2-3B"
local_loading: true # Set to true to load from ~/hf_models/
dtype: bfloat16
training:
# Digit sets
digits: [1, 2, 3, 5, 6, 7]
ood_digits: [4]
# Dataset
num_samples: 2400000
batch_size: 64
# DataLoader optimizations
num_workers: 4 # Number of parallel data loading processes (0 for main thread only)
pin_memory: true # Pin memory for faster CPU->GPU transfer
persistent_workers: true # Keep workers alive between epochs (only if num_workers > 0)
prefetch_factor: 2 # Number of batches to prefetch per worker (only if num_workers > 0)
# Smooth curriculum over digit lengths (optional)
curriculum:
enabled: true # Smoothly bias sampling from small->large digits over training
weight_factor_start: 0.9 # < 1 biases toward smaller digit lengths early
weight_factor_end: 1.10 # > 1 biases toward larger digit lengths later
static_weight_factor: 1.25 # Used if curriculum.enabled is false (preserves prior behavior)
# Optimizer
optimizer:
stable_lr: 9e-5 # plateau LR after warmup
min_lr: 1e-8
weight_decay: 1e-2
decay_start_ratio: 0.65 # Start decay at 65% of training
warmup_ratio: 0.05 # Linear warmup over first 5% of steps
# Training settings
use_cache: false
compile_model: true # Whether to use torch.compile
# Mixed precision training
use_autocast: true # Enable automatic mixed precision (for training only)
autocast_dtype: "bfloat16" # Dtype for autocast (bfloat16 or float16)
lora:
r: 16
alpha: 32
dropout: 0
target_modules:
- "q_proj"
- "k_proj"
- "v_proj"
- "o_proj"
- "gate_proj"
- "up_proj"
- "down_proj"
evaluation:
enabled: true
interval_examples: 99000 # Evaluate every N examples
num_batches: 10 # Number of batches per evaluation (increased for better coverage)
samples_per_batch: 200 # Samples per batch in evaluation (increased for all digit pairs)
show_examples: true # Show example predictions
track_history: 3 # Number of eval results to show in progress bar
evaluate_ood: false # Whether to evaluate on OOD digits during training
final_eval: true # Run comprehensive evaluation after training
final_samples_per_combination: 1000 # Samples per digit combination for final evaluation
logging:
interval_examples: 5000 # Log training loss every N examples (was: 250 batches * 32 batch_size = 8000 examples)
save_path: "models/minimal_example_lora" # Model will be uploaded to HuggingFace as your-username/minimal-addition-lora
```
## Training Summary
- Total steps: 37,500
- Training time: 152.2 minutes (4.1 steps/second)
- Final model: /workspace/dark_arts_private/minimal_example/models/minimal_example_lora
## Training Dynamics
### Loss Curve (Log Scale)
```
(Log10(Loss)) ^
1.0 |
0.7 | ⡇⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀
0.5 | ⣇⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀
0.2 | ⣿⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀
-0.0 | ⣿⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀
-0.2 | ⡿⡀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀
-0.5 | ⡇⣇⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀
-0.7 | ⡇⠙⡄⠀⠀⠀⠀⠀⠀⡇⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀
-1.0 | ⡇⠀⠈⡧⡠⣴⠀⣄⡄⣷⠀⠀⠀⠀⠀⠀⢀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀
-1.2 | ⡇⠀⠀⠀⠀⠀⠳⠁⢇⡏⡆⢠⠀⣾⢰⠀⣼⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀
-1.4 | ⡇⠀⠀⠀⠀⠀⠀⠀⢸⠁⢸⡸⠱⡏⣾⢰⠁⡇⠀⣀⠀⢀⢤⠀⠀⢠⡆⠀⠀⢀⢠⠀⠀⡄⠀⠀⠀⡆⠀⠀⢰⠀⠀⠀⠀⠀⢀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀
-1.7 | ⡇⠀⠀⠀⠀⠀⠀⠀⠀⠀⠈⡇⠀⠀⢻⡜⠀⠱⡠⡟⣼⠁⠘⡄⢰⢸⢱⣀⠀⡜⠻⣀⠀⣷⠀⢰⠼⢣⠀⠀⢸⡄⠀⠀⠀⠀⣼⡆⠀⠀⠀⠀⠀⠀⡄⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀
-1.9 | ⡇⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠘⡇⠀⠀⠀⠀⠹⠀⠀⢸⣸⢸⠘⠘⣴⠁⠀⢻⢰⠉⢾⡜⠀⢸⠀⠀⢸⢻⢸⠀⢰⡄⣿⣿⢀⢀⠀⠀⢸⣶⡇⠀⢸⢠⠀⠀⠀⣸⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀
-2.2 | ⡇⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⡇⠀⠀⠀⠀⠀⠀⠀⠀⠿⡎⠀⠀⠙⠀⠀⠀⣿⠀⠀⠇⠀⠀⢿⠀⡎⠘⣼⡾⣾⢷⢹⠏⣾⠉⢾⢰⡿⠈⢱⠀⣾⢸⣇⢦⢠⢿⠀⡆⠀⢰⢠⡆⡄⠀⠀⠀⡇⠀⠀⠀⣧⠀⠀⡀
-2.4 | ⡇⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⡇⠀⠀⠀⠀⠀⠀⠀⠀⠀⡇⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠈⡇⡇⠀⠟⠁⠹⠸⢸⠀⠹⠀⢸⡸⠁⠀⢸⡸⣿⡸⡏⠀⣿⢸⢸⢇⡆⣸⡇⠸⣿⠀⠀⠀⡇⢠⠀⠀⡟⡄⠀⡇
-2.7 | ⡇⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠃⠀⠀⠀⠀⠀⠀⠀⠀⠀⡇⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠱⡇⠀⠀⠀⠀⠀⢸⠀⠀⠀⠸⡇⠀⠀⠸⠁⢸⡇⠃⠀⡟⠀⡟⢸⣷⡏⡇⠀⡿⡇⡿⡀⣷⢸⡄⠀⡇⡇⢸⡇
-2.9 | ⡇⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠈⠀⠀⠀⠀⠃⠀⠀⠀⠀⠸⡇⠀⠀⡇⠀⡇⢸⡏⠁⡇⠀⡇⢻⠀⣧⠻⡎⡇⢰⠁⢱⢸⡇
-3.1 | ⡇⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠁⠀⠀⠇⠀⠇⠈⡇⠀⠁⠀⠃⠈⠀⣿⠀⡇⢣⣾⠀⠘⡏⢣
-3.4 | ⡇⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠁⠀⠀⠀⠀⠀⠀⢹⠀⠀⠘⠸⠀⠀⠁⢸
-3.6 | ⡇⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⢸⠀⠀⠀⠀⠀⠀⠀⢸
-3.9 | ⡇⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠈⠀⠀⠀⠀⠀⠀⠀⢸
-----------|-|---------|---------|---------|---------|---------|---------|---------|---------|-> (Steps)
| 0 4687.3750 9374.7500 14062.125 18749.500 23436.875 28124.250 32811.625 37499
```
### Learning Rate Schedule
```
(Learning Rate) ^
0.0 |
0.0 | ⡇⠀⠀⢀⠇⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠘⢄⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀
0.0 | ⡇⠀⠀⢸⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⢱⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀
0.0 | ⡇⠀⠀⡸⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠑⢄⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀
0.0 | ⡇⠀⠀⡇⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠈⢆⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀
0.0 | ⡇⠀⠀⡇⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠣⡀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀
0.0 | ⡇⠀⠀⡇⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠈⡆⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀
0.0 | ⡇⠀⢀⠇⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠈⠢⡀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀
0.0 | ⡇⠀⢸⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠱⡀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀
0.0 | ⡇⠀⡸⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠈⢆⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀
0.0 | ⡇⠀⡇⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠱⡀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀
0.0 | ⡇⢀⠇⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠑⢄⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀
0.0 | ⡇⢸⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⢣⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀
0.0 | ⡇⡸⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠑⡄⠀⠀⠀⠀⠀⠀⠀⠀⠀
0.0 | ⡇⡇⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠈⢢⠀⠀⠀⠀⠀⠀⠀⠀
0.0 | ⡇⡇⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠣⡀⠀⠀⠀⠀⠀⠀
0.0 | ⡇⡇⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠈⡆⠀⠀⠀⠀⠀
0.0 | ⣇⠇⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠈⠢⡀⠀⠀⠀
0.0 | ⣿⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠑⡄⠀⠀
0.0 | ⡿⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠈⢆⠀
0.0 | ⣇⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣑
-----------|-|---------|---------|---------|---------|---------|---------|---------|---------|-> (Steps)
| 0 4687.3750 9374.7500 14062.125 18749.500 23436.875 28124.250 32811.625 37499
```
### Evaluation Progress
| Step | Regular % | Irregular % |
|------|-----------|-------------|
| 99008 | 70.3 | 70.5 |
| 198016 | 77.6 | 74.4 |
| 297024 | 80.9 | 78.7 |
| 396032 | 82.7 | 82.5 |
| 495040 | 87.3 | 85.7 |
| 594048 | 88.8 | 88.5 |
| 693056 | 85.5 | 85.8 |
| 792000 | 89.6 | 88.3 |
| 891008 | 89.9 | 91.3 |
| 990016 | 92.5 | 92.3 |
| 1089024 | 92.2 | 91.4 |
| 1188032 | 95.3 | 94.3 |
| 1287040 | 95.9 | 95.6 |
| 1386048 | 95.6 | 95.9 |
| 1485056 | 96.6 | 96.5 |
| 1584000 | 96.3 | 96.0 |
| 1683008 | 97.2 | 98.2 |
| 1782016 | 97.9 | 98.2 |
| 1881024 | 97.9 | 98.2 |
| 1980032 | 97.8 | 98.1 |
| 2079040 | 99.0 | 98.7 |
| 2178048 | 98.8 | 98.9 |
| 2277056 | 99.2 | 99.4 |
| 2376000 | 99.5 | 99.2 |
#### Accuracy Over Training Steps
```
Regular Tokenization:
(Accuracy %) ^
100 |
93.3 | ⡇⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⢀⣀⡠⠤⠤⠒⠒⠒⠢⠤⠤⠔⠒⠒⠒⠒⠒⠒⠒⠒⠒⠊⠉⠉⠉⠉⠉⠉⠉⠉⠉⠉⠉⠉⠉⠉⠉⠉⠁⠀⠀⠀⠀
86.7 | ⡇⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⣀⣀⡠⠤⠤⣀⣀⠀⢀⠤⠔⠒⠒⠒⠒⠒⠉⠉⠉⠉⠉⠁⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀
80 | ⡇⠀⠀⠀⠀⠀⠀⢀⣀⡠⠤⠤⠒⠒⠊⠉⠀⠀⠀⠀⠀⠀⠀⠉⠁⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀
73.3 | ⡇⠀⠀⠀⢀⡠⠊⠁⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀
66.7 | ⡇⠀⠀⠐⠁⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀
60 | ⡇⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀
53.3 | ⡇⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀
46.7 | ⡇⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀
40 | ⡇⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀
33.3 | ⡇⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀
26.7 | ⡇⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀
20 | ⡇⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀
13.3 | ⡇⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀
6.7 | ⡇⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀
0 | ⣇⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀
-----------|-|---------|---------|---------|---------|---------|---------|---------|---------|-> (Steps)
| 0 297000 594000 891000 1188000 1485000 1782000 2079000 2376000
Irregular Tokenization:
(Accuracy %) ^
100 |
93.3 | ⡇⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⢀⣀⡠⠤⠤⠤⠤⠤⠔⠒⠒⠒⠒⠒⠒⠒⠒⠒⠊⠉⠉⠉⠉⠉⠉⠉⠉⠉⠉⠉⠉⠉⠉⠉⠉⠉⠉⠉⠁⠀⠀⠈⠉
86.7 | ⡇⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⢀⣀⡠⠤⣀⣀⠀⢀⣀⠤⠔⠒⠊⠉⠉⠉⠉⠉⠉⠉⠁⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀
80 | ⡇⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⣀⣀⠤⠔⠒⠉⠁⠀⠀⠀⠀⠀⠉⠁⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀
73.3 | ⡇⠀⠀⠀⠀⣀⡠⠔⠒⠊⠉⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀
66.7 | ⡇⠀⠀⠐⠊⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀
60 | ⡇⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀
53.3 | ⡇⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀
46.7 | ⡇⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀
40 | ⡇⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀
33.3 | ⡇⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀
26.7 | ⡇⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀
20 | ⡇⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀
13.3 | ⡇⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀
6.7 | ⡇⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀
0 | ⣇⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀
-----------|-|---------|---------|---------|---------|---------|---------|---------|---------|-> (Steps)
| 0 297000 594000 891000 1188000 1485000 1782000 2079000 2376000
```
## Final Model Performance
### In-Distribution Results
#### Per-Length Accuracy Breakdown
**Regular Tokenization - Accuracy by Operand Lengths**
```
First Operand →
Second 1d 2d 3d 5d 6d 7d
Operand ↓ ------------------------------------------------
1d | 100% 100% 100% 100% 100% 100%
2d | 100% 100% 100% 100% 100% 100%
3d | 100% 100% 100% 100% 99% 99%
5d | 100% 100% 100% 100% 98% 98%
6d | 100% 100% 99% 98% 99% 97%
7d | 100% 100% 99% 98% 97% 98%
```
**Irregular Tokenization - Accuracy by Operand Lengths**
```
First Operand →
Second 1d 2d 3d 5d 6d 7d
Operand ↓ ------------------------------------------------
1d | 100% 100% 100% 100% 100% 100%
2d | 100% 100% 100% 100% 100% 100%
3d | 100% 100% 100% 100% 99% 99%
5d | 100% 100% 100% 99% 98% 98%
6d | 100% 100% 99% 98% 99% 97%
7d | 100% 100% 99% 98% 97% 98%
```
#### Overall Accuracy
- Regular: 99.36% (35768/36000 correct)
- Irregular: 99.37% (35774/36000 correct)
#### Error Analysis
### Performance by Operand Digit Length
Accuracy when one operand is 4 digits and the other varies in length:
**Regular Tokenization**
| Second Operand | Accuracy | Correct/Total | Example |
|----------------|----------|---------------|---------|
| 1 digit | 97.2% | 972/1000 | ✓ 9013+8=9021 |
| 2 digits | 83.0% | 830/1000 | ✓ 2298+41=2339 |
| 3 digits | 37.4% | 374/1000 | ✗ 315+7351=10466 |
| 4 digits | 99.0% | 990/1000 | ✓ 1777+6069=7846 |
| 5 digits | 83.5% | 835/1000 | ✓ 73507+4383=77890 |
| 6 digits | 93.8% | 938/1000 | ✓ 845167+2957=848124 |
| 7 digits | 34.3% | 343/1000 | ✓ 3424646+1744=3426390 |
**Irregular Tokenization (a + b + 1)**
| Second Operand | Accuracy | Correct/Total | Example |
|----------------|----------|---------------|---------|
| 1 digit | 97.7% | 977/1000 | ✓ 7+8194+1=8202 |
| 2 digits | 85.8% | 858/1000 | ✓ 6195+26+1=6222 |
| 3 digits | 33.1% | 331/1000 | ✗ 5104+698+1=12103 |
| 4 digits | 99.2% | 992/1000 | ✓ 8956+2949+1=11906 |
| 5 digits | 87.2% | 872/1000 | ✓ 3904+33121+1=37026 |
| 6 digits | 93.2% | 932/1000 | ✓ 448773+7905+1=456679 |
| 7 digits | 34.1% | 341/1000 | ✗ 2960+9192919+1=9196180 |
#### Accuracy vs Operand Length
```
Regular Tokenization:
(Accuracy %) ^
100 |
93.3 | ⠒⠤⣀⡀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⡰⠉⠒⠤⣀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⢀⡀⠀⠀⠀⠀⠀⠀⠀⠀⠀
86.7 | ⠀⠀⠀⠈⠑⠒⠤⣀⡀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⡰⠁⠀⠀⠀⠀⠉⠑⠢⢄⡀⠀⠀⠀⢀⣀⡠⠤⠒⠒⠉⠁⠘⡄⠀⠀⠀⠀⠀⠀⠀⠀
80 | ⠀⠀⠀⠀⠀⠀⠀⠀⠈⠑⢢⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⡰⠁⠀⠀⠀⠀⠀⠀⠀⠀⠀⠈⠑⠒⠉⠁⠀⠀⠀⠀⠀⠀⠀⠀⠘⢄⠀⠀⠀⠀⠀⠀⠀
73.3 | ⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠑⡄⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⡔⠁⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠈⢆⠀⠀⠀⠀⠀⠀
66.7 | ⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠈⢆⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⡜⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠈⢢⠀⠀⠀⠀⠀
60 | ⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠱⡀⠀⠀⠀⠀⠀⠀⠀⠀⡜⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⢣⠀⠀⠀⠀
53.3 | ⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠘⢄⠀⠀⠀⠀⠀⢀⠎⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠱⡀⠀⠀
46.7 | ⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠣⡀⠀⠀⢀⠎⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠱⡀⠀
40 | ⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠑⢄⢀⠎⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠘⡄
33.3 | ⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠈⠊⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠘
26.7 | ⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀
20 | ⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀
13.3 | ⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀
6.7 | ⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀
0 | ⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀
-----------|-|---------|---------|---------|---------|---------|---------|-> (Second Operand Digits)
| 1 2 3 4 5 6 7
Irregular Tokenization:
(Accuracy %) ^
100 |
93.3 | ⠉⠒⠤⢄⡀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⡔⠁⠉⠒⠢⢄⣀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⣀⡀⠀⠀⠀⠀⠀⠀⠀⠀⠀
86.7 | ⠀⠀⠀⠀⠈⠉⠒⠤⢄⡀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⡔⠁⠀⠀⠀⠀⠀⠀⠉⠒⠢⢄⣀⡠⠤⠤⠒⠒⠊⠉⠉⠀⠘⡄⠀⠀⠀⠀⠀⠀⠀⠀
80 | ⠀⠀⠀⠀⠀⠀⠀⠀⠀⠈⠱⡀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⡔⠁⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠘⡄⠀⠀⠀⠀⠀⠀⠀
73.3 | ⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠘⢄⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⡔⠁⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠈⢆⠀⠀⠀⠀⠀⠀
66.7 | ⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠈⢆⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⡔⠁⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠈⢆⠀⠀⠀⠀⠀
60 | ⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠣⡀⠀⠀⠀⠀⠀⠀⠀⠀⡔⠁⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠈⢢⠀⠀⠀⠀
53.3 | ⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠑⡄⠀⠀⠀⠀⠀⠀⡔⠁⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⢣⠀⠀⠀
46.7 | ⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠈⢆⠀⠀⠀⠀⡔⠁⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠣⡀⠀
40 | ⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠈⢢⠀⠀⡔⠁⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠱⡀
33.3 | ⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠱⡔⠁⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠱
26.7 | ⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀
20 | ⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀
13.3 | ⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀
6.7 | ⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀
0 | ⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀⣀
-----------|-|---------|---------|---------|---------|---------|---------|-> (Second Operand Digits)
| 1 2 3 4 5 6 7
```
## Sample Predictions
### Regular Tokenization
✓ 4925766 + 614 = 4926380
✓ 640235 + 76893 = 717128
✓ 981978 + 21 = 981999
✓ 427381 + 654869 = 1082250
✓ 7 + 2194811 = 2194818
### Irregular Tokenization (a + b + 1)
✓ 9 + 126587 + 1 = 126597
✓ 6 + 11 + 1 = 18
✓ 446307 + 69 + 1 = 446377
✓ 9 + 5 + 1 = 15
✓ 331238 + 4 + 1 = 331243
|
mradermacher/Llama3.1-8B-Chinese-sft-medical-GGUF
|
mradermacher
| 2025-09-13T13:25:27Z | 1,696 | 1 |
transformers
|
[
"transformers",
"gguf",
"zh",
"base_model:Ryyyyyyyan/Llama3.1-8B-Chinese-sft-medical",
"base_model:quantized:Ryyyyyyyan/Llama3.1-8B-Chinese-sft-medical",
"license:llama3.1",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2025-08-30T06:10:57Z |
---
base_model: Ryyyyyyyan/Llama3.1-8B-Chinese-sft-medical
language:
- zh
library_name: transformers
license: llama3.1
mradermacher:
readme_rev: 1
quantized_by: mradermacher
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
<!-- ### quants: x-f16 Q4_K_S Q2_K Q8_0 Q6_K Q3_K_M Q3_K_S Q3_K_L Q4_K_M Q5_K_S Q5_K_M IQ4_XS -->
<!-- ### quants_skip: -->
<!-- ### skip_mmproj: -->
static quants of https://huggingface.co/Ryyyyyyyan/Llama3.1-8B-Chinese-sft-medical
<!-- provided-files -->
***For a convenient overview and download list, visit our [model page for this model](https://hf.tst.eu/model#Llama3.1-8B-Chinese-sft-medical-GGUF).***
weighted/imatrix quants seem not to be available (by me) at this time. If they do not show up a week or so after the static ones, I have probably not planned for them. Feel free to request them by opening a Community Discussion.
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/Llama3.1-8B-Chinese-sft-medical-GGUF/resolve/main/Llama3.1-8B-Chinese-sft-medical.Q2_K.gguf) | Q2_K | 3.3 | |
| [GGUF](https://huggingface.co/mradermacher/Llama3.1-8B-Chinese-sft-medical-GGUF/resolve/main/Llama3.1-8B-Chinese-sft-medical.Q3_K_S.gguf) | Q3_K_S | 3.8 | |
| [GGUF](https://huggingface.co/mradermacher/Llama3.1-8B-Chinese-sft-medical-GGUF/resolve/main/Llama3.1-8B-Chinese-sft-medical.Q3_K_M.gguf) | Q3_K_M | 4.1 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/Llama3.1-8B-Chinese-sft-medical-GGUF/resolve/main/Llama3.1-8B-Chinese-sft-medical.Q3_K_L.gguf) | Q3_K_L | 4.4 | |
| [GGUF](https://huggingface.co/mradermacher/Llama3.1-8B-Chinese-sft-medical-GGUF/resolve/main/Llama3.1-8B-Chinese-sft-medical.IQ4_XS.gguf) | IQ4_XS | 4.6 | |
| [GGUF](https://huggingface.co/mradermacher/Llama3.1-8B-Chinese-sft-medical-GGUF/resolve/main/Llama3.1-8B-Chinese-sft-medical.Q4_K_S.gguf) | Q4_K_S | 4.8 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Llama3.1-8B-Chinese-sft-medical-GGUF/resolve/main/Llama3.1-8B-Chinese-sft-medical.Q4_K_M.gguf) | Q4_K_M | 5.0 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Llama3.1-8B-Chinese-sft-medical-GGUF/resolve/main/Llama3.1-8B-Chinese-sft-medical.Q5_K_S.gguf) | Q5_K_S | 5.7 | |
| [GGUF](https://huggingface.co/mradermacher/Llama3.1-8B-Chinese-sft-medical-GGUF/resolve/main/Llama3.1-8B-Chinese-sft-medical.Q5_K_M.gguf) | Q5_K_M | 5.8 | |
| [GGUF](https://huggingface.co/mradermacher/Llama3.1-8B-Chinese-sft-medical-GGUF/resolve/main/Llama3.1-8B-Chinese-sft-medical.Q6_K.gguf) | Q6_K | 6.7 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/Llama3.1-8B-Chinese-sft-medical-GGUF/resolve/main/Llama3.1-8B-Chinese-sft-medical.Q8_0.gguf) | Q8_0 | 8.6 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/Llama3.1-8B-Chinese-sft-medical-GGUF/resolve/main/Llama3.1-8B-Chinese-sft-medical.f16.gguf) | f16 | 16.2 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
prowlingsturdysnake/blockassist
|
prowlingsturdysnake
| 2025-09-13T13:01:50Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"lazy prehistoric wombat",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-13T13:01:42Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- lazy prehistoric wombat
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
miollionairebro/Qwen3-0.6B-Gensyn-Swarm-squinting_agile_bat
|
miollionairebro
| 2025-09-13T13:01:13Z | 5 | 1 |
transformers
|
[
"transformers",
"safetensors",
"qwen3",
"text-generation",
"rl-swarm",
"genrl-swarm",
"grpo",
"gensyn",
"I am squinting_agile_bat",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-09-06T13:03:36Z |
---
library_name: transformers
tags:
- rl-swarm
- genrl-swarm
- grpo
- gensyn
- I am squinting_agile_bat
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Ruzel23/Qwen3-0.6B-Gensyn-Swarm-mangy_hunting_raven
|
Ruzel23
| 2025-09-13T12:58:28Z | 12 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen3",
"text-generation",
"rl-swarm",
"genrl-swarm",
"grpo",
"gensyn",
"I am mangy_hunting_raven",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-16T15:58:56Z |
---
library_name: transformers
tags:
- rl-swarm
- genrl-swarm
- grpo
- gensyn
- I am mangy_hunting_raven
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
OrangeCrystalFox/Qwen3-0.6B-Gensyn-Swarm-lethal_jagged_owl
|
OrangeCrystalFox
| 2025-09-13T12:57:09Z | 15 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen3",
"text-generation",
"rl-swarm",
"genrl-swarm",
"grpo",
"gensyn",
"I am lethal_jagged_owl",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-27T01:53:15Z |
---
library_name: transformers
tags:
- rl-swarm
- genrl-swarm
- grpo
- gensyn
- I am lethal_jagged_owl
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Fluxenier/Qwen2.5-0.5B-Instruct-Gensyn-Swarm-sedate_sprightly_wombat
|
Fluxenier
| 2025-09-13T12:54:57Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"rl-swarm",
"genrl-swarm",
"grpo",
"gensyn",
"I am sedate_sprightly_wombat",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-09-13T12:54:45Z |
---
library_name: transformers
tags:
- rl-swarm
- genrl-swarm
- grpo
- gensyn
- I am sedate_sprightly_wombat
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
phospho-app/gr00t-place_tape_dataset-dz5ca4o48e
|
phospho-app
| 2025-09-13T12:46:19Z | 0 | 0 |
phosphobot
|
[
"phosphobot",
"safetensors",
"gr00t_n1_5",
"gr00t",
"robotics",
"dataset:luuuuuuukee/place_tape_dataset",
"region:us"
] |
robotics
| 2025-09-13T12:16:47Z |
---
datasets: luuuuuuukee/place_tape_dataset
library_name: phosphobot
pipeline_tag: robotics
model_name: gr00t
tags:
- phosphobot
- gr00t
task_categories:
- robotics
---
# gr00t model - 🧪 phosphobot training pipeline
- **Dataset**: [luuuuuuukee/place_tape_dataset](https://huggingface.co/datasets/luuuuuuukee/place_tape_dataset)
- **Wandb run id**: None
## This model was trained using **[🧪phospho](https://phospho.ai)**
Training was successful, try it out on your robot!
## Training parameters
```text
{
"validation_dataset_name": null,
"batch_size": 49,
"num_epochs": 10,
"save_steps": 1000,
"learning_rate": 0.0001,
"data_dir": "/tmp/outputs/data",
"validation_data_dir": "/tmp/outputs/validation_data",
"output_dir": "/tmp/outputs/train"
}
```
📖 **Get Started**: [docs.phospho.ai](https://docs.phospho.ai?utm_source=huggingface_readme)
🤖 **Get your robot**: [robots.phospho.ai](https://robots.phospho.ai?utm_source=huggingface_readme)
|
bukuroo/RTMO-ONNX
|
bukuroo
| 2025-09-13T12:33:47Z | 0 | 0 | null |
[
"onnx",
"object-detection",
"pose-estimation",
"keypoint detection",
"ezonnx",
"license:apache-2.0",
"region:us"
] |
object-detection
| 2025-09-13T12:25:35Z |
---
license: apache-2.0
tags:
- onnx
- object-detection
- pose-estimation
- keypoint detection
- ezonnx
---
### RTMO
ONNX models for inference with [EZONNX](https://github.com/ikeboo/ezonnx)
- Model type:
Multi person keypoint detection
- Official GitHub repository:
[MMPose - RTMO](https://github.com/open-mmlab/mmpose/tree/main/projects/rtmo)
- Usage
```python
from ezonnx import RTMO, visualize_images
model = RTMO("s") # automatically load from Hugging Face
ret = model("image.jpg")
visualize_images("Detection result",ret.visualized_img)
```
|
Adanato/Llama-3.2-1B-Instruct-high_nemotron_25k
|
Adanato
| 2025-09-13T12:24:20Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"fyksft",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-09-13T12:22:42Z |
---
library_name: transformers
tags:
- fyksft
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
mradermacher/zombiellm-i1-GGUF
|
mradermacher
| 2025-09-13T12:21:23Z | 0 | 0 |
transformers
|
[
"transformers",
"gguf",
"en",
"dataset:hardrave/dolly15k_gpt_oss_data_distilled",
"dataset:hardrave/alpaca_gpt_oss_data_distilled",
"dataset:hardrave/bushcraft_survival_gpt_oss_data_distilled",
"dataset:hardrave/zombie_persona",
"base_model:hardrave/zombiellm",
"base_model:quantized:hardrave/zombiellm",
"license:cc-by-nc-4.0",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | null | 2025-09-13T10:36:52Z |
---
base_model: hardrave/zombiellm
datasets:
- hardrave/dolly15k_gpt_oss_data_distilled
- hardrave/alpaca_gpt_oss_data_distilled
- hardrave/bushcraft_survival_gpt_oss_data_distilled
- hardrave/zombie_persona
language:
- en
library_name: transformers
license: cc-by-nc-4.0
mradermacher:
readme_rev: 1
quantized_by: mradermacher
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: nicoboss -->
<!-- ### quants: Q2_K IQ3_M Q4_K_S IQ3_XXS Q3_K_M small-IQ4_NL Q4_K_M IQ2_M Q6_K IQ4_XS Q2_K_S IQ1_M Q3_K_S IQ2_XXS Q3_K_L IQ2_XS Q5_K_S IQ2_S IQ1_S Q5_K_M Q4_0 IQ3_XS Q4_1 IQ3_S -->
<!-- ### quants_skip: -->
<!-- ### skip_mmproj: -->
weighted/imatrix quants of https://huggingface.co/hardrave/zombiellm
<!-- provided-files -->
***For a convenient overview and download list, visit our [model page for this model](https://hf.tst.eu/model#zombiellm-i1-GGUF).***
static quants are available at https://huggingface.co/mradermacher/zombiellm-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/zombiellm-i1-GGUF/resolve/main/zombiellm.imatrix.gguf) | imatrix | 0.1 | imatrix file (for creating your own qwuants) |
| [GGUF](https://huggingface.co/mradermacher/zombiellm-i1-GGUF/resolve/main/zombiellm.i1-IQ1_S.gguf) | i1-IQ1_S | 0.9 | for the desperate |
| [GGUF](https://huggingface.co/mradermacher/zombiellm-i1-GGUF/resolve/main/zombiellm.i1-IQ1_M.gguf) | i1-IQ1_M | 0.9 | mostly desperate |
| [GGUF](https://huggingface.co/mradermacher/zombiellm-i1-GGUF/resolve/main/zombiellm.i1-IQ2_XXS.gguf) | i1-IQ2_XXS | 0.9 | |
| [GGUF](https://huggingface.co/mradermacher/zombiellm-i1-GGUF/resolve/main/zombiellm.i1-IQ2_XS.gguf) | i1-IQ2_XS | 0.9 | |
| [GGUF](https://huggingface.co/mradermacher/zombiellm-i1-GGUF/resolve/main/zombiellm.i1-IQ2_S.gguf) | i1-IQ2_S | 0.9 | |
| [GGUF](https://huggingface.co/mradermacher/zombiellm-i1-GGUF/resolve/main/zombiellm.i1-IQ2_M.gguf) | i1-IQ2_M | 0.9 | |
| [GGUF](https://huggingface.co/mradermacher/zombiellm-i1-GGUF/resolve/main/zombiellm.i1-Q2_K_S.gguf) | i1-Q2_K_S | 0.9 | very low quality |
| [GGUF](https://huggingface.co/mradermacher/zombiellm-i1-GGUF/resolve/main/zombiellm.i1-IQ3_XXS.gguf) | i1-IQ3_XXS | 0.9 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/zombiellm-i1-GGUF/resolve/main/zombiellm.i1-IQ3_S.gguf) | i1-IQ3_S | 1.0 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/zombiellm-i1-GGUF/resolve/main/zombiellm.i1-IQ3_XS.gguf) | i1-IQ3_XS | 1.0 | |
| [GGUF](https://huggingface.co/mradermacher/zombiellm-i1-GGUF/resolve/main/zombiellm.i1-Q2_K.gguf) | i1-Q2_K | 1.0 | IQ3_XXS probably better |
| [GGUF](https://huggingface.co/mradermacher/zombiellm-i1-GGUF/resolve/main/zombiellm.i1-Q3_K_S.gguf) | i1-Q3_K_S | 1.0 | IQ3_XS probably better |
| [GGUF](https://huggingface.co/mradermacher/zombiellm-i1-GGUF/resolve/main/zombiellm.i1-IQ4_XS.gguf) | i1-IQ4_XS | 1.0 | |
| [GGUF](https://huggingface.co/mradermacher/zombiellm-i1-GGUF/resolve/main/zombiellm.i1-IQ4_NL.gguf) | i1-IQ4_NL | 1.0 | prefer IQ4_XS |
| [GGUF](https://huggingface.co/mradermacher/zombiellm-i1-GGUF/resolve/main/zombiellm.i1-Q4_0.gguf) | i1-Q4_0 | 1.0 | fast, low quality |
| [GGUF](https://huggingface.co/mradermacher/zombiellm-i1-GGUF/resolve/main/zombiellm.i1-IQ3_M.gguf) | i1-IQ3_M | 1.0 | |
| [GGUF](https://huggingface.co/mradermacher/zombiellm-i1-GGUF/resolve/main/zombiellm.i1-Q3_K_M.gguf) | i1-Q3_K_M | 1.1 | IQ3_S probably better |
| [GGUF](https://huggingface.co/mradermacher/zombiellm-i1-GGUF/resolve/main/zombiellm.i1-Q4_1.gguf) | i1-Q4_1 | 1.1 | |
| [GGUF](https://huggingface.co/mradermacher/zombiellm-i1-GGUF/resolve/main/zombiellm.i1-Q3_K_L.gguf) | i1-Q3_K_L | 1.2 | IQ3_M probably better |
| [GGUF](https://huggingface.co/mradermacher/zombiellm-i1-GGUF/resolve/main/zombiellm.i1-Q4_K_S.gguf) | i1-Q4_K_S | 1.2 | optimal size/speed/quality |
| [GGUF](https://huggingface.co/mradermacher/zombiellm-i1-GGUF/resolve/main/zombiellm.i1-Q4_K_M.gguf) | i1-Q4_K_M | 1.2 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/zombiellm-i1-GGUF/resolve/main/zombiellm.i1-Q5_K_S.gguf) | i1-Q5_K_S | 1.3 | |
| [GGUF](https://huggingface.co/mradermacher/zombiellm-i1-GGUF/resolve/main/zombiellm.i1-Q5_K_M.gguf) | i1-Q5_K_M | 1.4 | |
| [GGUF](https://huggingface.co/mradermacher/zombiellm-i1-GGUF/resolve/main/zombiellm.i1-Q6_K.gguf) | i1-Q6_K | 1.6 | practically like static Q6_K |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time. Additional thanks to [@nicoboss](https://huggingface.co/nicoboss) for giving me access to his private supercomputer, enabling me to provide many more imatrix quants, at much higher quality, than I would otherwise be able to.
<!-- end -->
|
Namtran0912/Meta-Llama-3.1-8B-Instruct-lora-adapter-v2
|
Namtran0912
| 2025-09-13T12:02:47Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"unsloth",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-09-13T12:02:40Z |
---
library_name: transformers
tags:
- unsloth
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
yujiepan/ernie-4.5-tiny-random
|
yujiepan
| 2025-09-13T11:58:51Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"ernie4_5",
"text-generation",
"conversational",
"base_model:baidu/ERNIE-4.5-0.3B-PT",
"base_model:finetune:baidu/ERNIE-4.5-0.3B-PT",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-09-13T11:58:48Z |
---
library_name: transformers
pipeline_tag: text-generation
inference: true
widget:
- text: Hello!
example_title: Hello world
group: Python
base_model:
- baidu/ERNIE-4.5-0.3B-PT
---
This tiny model is intended for debugging. It is randomly initialized using the configuration adapted from [baidu/ERNIE-4.5-0.3B-PT](https://huggingface.co/baidu/ERNIE-4.5-0.3B-PT).
### Example usage:
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
# Load model and tokenizer
model_id = "yujiepan/ernie-4.5-tiny-random"
model = AutoModelForCausalLM.from_pretrained(
model_id,
device_map="auto",
torch_dtype="bfloat16",
trust_remote_code=True,
)
tokenizer = AutoTokenizer.from_pretrained(model_id)
# Generate answer
prompt = "What is AI?"
input_ids = tokenizer.apply_chat_template(
[{"role": "user", "content": prompt}],
add_generation_prompt=True,
return_tensors="pt",
tokenize=True,
).to(model.device)
output = model.generate(
input_ids,
do_sample=True,
max_new_tokens=32,
)
print(tokenizer.decode(output[0], skip_special_tokens=False))
```
### Codes to create this repo:
```python
import json
from pathlib import Path
import accelerate
import torch
from huggingface_hub import file_exists, hf_hub_download
from transformers import (
AutoConfig,
AutoModelForCausalLM,
AutoProcessor,
GenerationConfig,
set_seed,
)
source_model_id = "baidu/ERNIE-4.5-0.3B-PT"
save_folder = "/tmp/yujiepan/ernie-4.5-tiny-random"
processor = AutoProcessor.from_pretrained(source_model_id, trust_remote_code=True)
processor.save_pretrained(save_folder)
with open(hf_hub_download(source_model_id, filename='config.json', repo_type='model'), 'r', encoding='utf-8') as f:
config_json = json.load(f)
config_json['hidden_size'] = 8
config_json['intermediate_size'] = 32
config_json['head_dim'] = 32
config_json['num_attention_heads'] = 16
config_json['num_hidden_layers'] = 2
config_json['num_key_value_heads'] = 8
config_json['tie_word_embeddings'] = True
config_json['use_cache'] = True
with open(f"{save_folder}/config.json", "w", encoding='utf-8') as f:
json.dump(config_json, f, indent=2)
config = AutoConfig.from_pretrained(
save_folder,
trust_remote_code=True,
)
print(config)
torch.set_default_dtype(torch.bfloat16)
model = AutoModelForCausalLM.from_config(config)
torch.set_default_dtype(torch.float32)
if file_exists(filename="generation_config.json", repo_id=source_model_id, repo_type='model'):
model.generation_config = GenerationConfig.from_pretrained(
source_model_id, trust_remote_code=True,
)
model.generation_config.do_sample = True
print(model.generation_config)
model = model.cpu()
with torch.no_grad():
for name, p in sorted(model.named_parameters()):
torch.nn.init.normal_(p, 0, 0.1)
print(name, p.shape)
model.save_pretrained(save_folder)
print(model)
```
### Printing the model:
```text
Ernie4_5ForCausalLM(
(model): Ernie4_5Model(
(embed_tokens): Embedding(103424, 8, padding_idx=0)
(layers): ModuleList(
(0-1): 2 x Ernie4_5DecoderLayer(
(self_attn): Ernie4_5Attention(
(q_proj): Linear(in_features=8, out_features=512, bias=False)
(k_proj): Linear(in_features=8, out_features=256, bias=False)
(v_proj): Linear(in_features=8, out_features=256, bias=False)
(o_proj): Linear(in_features=512, out_features=8, bias=False)
)
(mlp): Ernie4_5MLP(
(gate_proj): Linear(in_features=8, out_features=32, bias=False)
(up_proj): Linear(in_features=8, out_features=32, bias=False)
(down_proj): Linear(in_features=32, out_features=8, bias=False)
(act_fn): SiLU()
)
(input_layernorm): Ernie4_5RMSNorm((8,), eps=1e-05)
(post_attention_layernorm): Ernie4_5RMSNorm((8,), eps=1e-05)
)
)
(norm): Ernie4_5RMSNorm((8,), eps=1e-05)
(rotary_emb): Ernie4_5RotaryEmbedding()
)
(lm_head): Linear(in_features=8, out_features=103424, bias=False)
)
```
|
4everStudent/Qwen3-4B-lr-1e-05
|
4everStudent
| 2025-09-13T11:31:55Z | 0 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"generated_from_trainer",
"grpo",
"trl",
"arxiv:2402.03300",
"base_model:Qwen/Qwen3-4B",
"base_model:finetune:Qwen/Qwen3-4B",
"endpoints_compatible",
"region:us"
] | null | 2025-09-03T14:06:16Z |
---
base_model: Qwen/Qwen3-4B
library_name: transformers
model_name: Qwen3-4B-lr-1e-05
tags:
- generated_from_trainer
- grpo
- trl
licence: license
---
# Model Card for Qwen3-4B-lr-1e-05
This model is a fine-tuned version of [Qwen/Qwen3-4B](https://huggingface.co/Qwen/Qwen3-4B).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="4everStudent/Qwen3-4B-lr-1e-05", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="150" height="24"/>](https://wandb.ai/wljorge/cif_generation_with_grpo/runs/bzmx2qli)
This model was trained with GRPO, a method introduced in [DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models](https://huggingface.co/papers/2402.03300).
### Framework versions
- TRL: 0.19.0
- Transformers: 4.51.3
- Pytorch: 2.6.0
- Datasets: 3.6.0
- Tokenizers: 0.21.0
## Citations
Cite GRPO as:
```bibtex
@article{zhihong2024deepseekmath,
title = {{DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models}},
author = {Zhihong Shao and Peiyi Wang and Qihao Zhu and Runxin Xu and Junxiao Song and Mingchuan Zhang and Y. K. Li and Y. Wu and Daya Guo},
year = 2024,
eprint = {arXiv:2402.03300},
}
```
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
csikasote/mms-1b-all-bemgen-combined-m25f100-52-DAT-1e-1
|
csikasote
| 2025-09-13T11:23:47Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"wav2vec2",
"automatic-speech-recognition",
"bemgen",
"mms",
"generated_from_trainer",
"base_model:facebook/mms-1b-all",
"base_model:finetune:facebook/mms-1b-all",
"license:cc-by-nc-4.0",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2025-09-13T10:47:50Z |
---
library_name: transformers
license: cc-by-nc-4.0
base_model: facebook/mms-1b-all
tags:
- automatic-speech-recognition
- bemgen
- mms
- generated_from_trainer
model-index:
- name: mms-1b-all-bemgen-combined-m25f100-52-DAT-1e-1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mms-1b-all-bemgen-combined-m25f100-52-DAT-1e-1
This model is a fine-tuned version of [facebook/mms-1b-all](https://huggingface.co/facebook/mms-1b-all) on the BEMGEN - BEM dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4508
- Cer: 0.1130
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 8
- eval_batch_size: 4
- seed: 52
- gradient_accumulation_steps: 2
- total_train_batch_size: 16
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 100
- num_epochs: 30.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Cer |
|:-------------:|:------:|:----:|:---------------:|:------:|
| 1.0368 | 0.6711 | 100 | 2.9214 | 0.9995 |
| 0.408 | 1.3423 | 200 | 1.2764 | 0.3632 |
| 0.329 | 2.0134 | 300 | 0.5128 | 0.1529 |
| 0.4267 | 2.6846 | 400 | 0.4508 | 0.1129 |
| 0.493 | 3.3557 | 500 | 0.3822 | 0.1068 |
| 0.4662 | 4.0268 | 600 | 0.3763 | 0.1015 |
| 0.5013 | 4.6980 | 700 | 0.3680 | 0.1043 |
| 0.5021 | 5.3691 | 800 | 0.3709 | 0.1063 |
| 0.4987 | 6.0403 | 900 | 0.3754 | 0.1159 |
| 0.4959 | 6.7114 | 1000 | 0.3673 | 0.1107 |
| 0.5084 | 7.3826 | 1100 | 0.3700 | 0.1215 |
| 0.5105 | 8.0537 | 1200 | 0.3861 | 0.1295 |
| 0.4934 | 8.7248 | 1300 | 0.3884 | 0.1359 |
### Framework versions
- Transformers 4.53.0.dev0
- Pytorch 2.6.0+cu124
- Datasets 3.6.0
- Tokenizers 0.21.0
|
vuitton/ctrl_v3s1
|
vuitton
| 2025-09-13T11:15:43Z | 0 | 0 | null |
[
"safetensors",
"any-to-any",
"omega",
"omegalabs",
"bittensor",
"agi",
"license:mit",
"region:us"
] |
any-to-any
| 2025-09-13T11:12:43Z |
---
license: mit
tags:
- any-to-any
- omega
- omegalabs
- bittensor
- agi
---
This is an Any-to-Any model checkpoint for the OMEGA Labs x Bittensor Any-to-Any subnet.
Check out the [git repo](https://github.com/omegalabsinc/omegalabs-anytoany-bittensor) and find OMEGA on X: [@omegalabsai](https://x.com/omegalabsai).
|
csikasote/mms-1b-all-bemgen-combined-m25f100-42-DAT-7e-1
|
csikasote
| 2025-09-13T11:00:07Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"wav2vec2",
"automatic-speech-recognition",
"bemgen",
"mms",
"generated_from_trainer",
"base_model:facebook/mms-1b-all",
"base_model:finetune:facebook/mms-1b-all",
"license:cc-by-nc-4.0",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2025-09-13T10:12:51Z |
---
library_name: transformers
license: cc-by-nc-4.0
base_model: facebook/mms-1b-all
tags:
- automatic-speech-recognition
- bemgen
- mms
- generated_from_trainer
model-index:
- name: mms-1b-all-bemgen-combined-m25f100-42-DAT-7e-1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mms-1b-all-bemgen-combined-m25f100-42-DAT-7e-1
This model is a fine-tuned version of [facebook/mms-1b-all](https://huggingface.co/facebook/mms-1b-all) on the BEMGEN - BEM dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2790
- Cer: 0.0794
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 8
- eval_batch_size: 4
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 16
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 100
- num_epochs: 30.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Cer |
|:-------------:|:-------:|:----:|:---------------:|:------:|
| 5.8229 | 0.6711 | 100 | 2.9334 | 1.0000 |
| 1.8888 | 1.3423 | 200 | 0.6514 | 0.1479 |
| 1.0251 | 2.0134 | 300 | 0.3491 | 0.1005 |
| 0.8941 | 2.6846 | 400 | 0.3019 | 0.0866 |
| 0.8056 | 3.3557 | 500 | 0.2924 | 0.0820 |
| 0.7732 | 4.0268 | 600 | 0.2868 | 0.0804 |
| 0.7483 | 4.6980 | 700 | 0.2811 | 0.0787 |
| 0.7464 | 5.3691 | 800 | 0.2790 | 0.0794 |
| 0.7125 | 6.0403 | 900 | 0.2791 | 0.0802 |
| 0.7457 | 6.7114 | 1000 | 0.2825 | 0.0805 |
| 0.7212 | 7.3826 | 1100 | 0.2738 | 0.0781 |
| 0.6565 | 8.0537 | 1200 | 0.2774 | 0.0802 |
| 0.6999 | 8.7248 | 1300 | 0.2747 | 0.0782 |
| 0.6812 | 9.3960 | 1400 | 0.2697 | 0.0767 |
| 0.6791 | 10.0671 | 1500 | 0.2728 | 0.0774 |
| 0.6373 | 10.7383 | 1600 | 0.2735 | 0.0777 |
| 0.6514 | 11.4094 | 1700 | 0.2725 | 0.0769 |
### Framework versions
- Transformers 4.53.0.dev0
- Pytorch 2.6.0+cu124
- Datasets 3.6.0
- Tokenizers 0.21.0
|
chriscars/thumbnail
|
chriscars
| 2025-09-13T10:30:50Z | 0 | 0 | null |
[
"license:apache-2.0",
"region:us"
] | null | 2025-09-13T10:30:50Z |
---
license: apache-2.0
---
|
mradermacher/MiroThinker-14B-DPO-v0.2-i1-GGUF
|
mradermacher
| 2025-09-13T10:24:32Z | 3,381 | 0 |
transformers
|
[
"transformers",
"gguf",
"agent",
"open-source",
"miromind",
"en",
"base_model:miromind-ai/MiroThinker-14B-DPO-v0.2",
"base_model:quantized:miromind-ai/MiroThinker-14B-DPO-v0.2",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | null | 2025-09-12T12:28:39Z |
---
base_model: miromind-ai/MiroThinker-14B-DPO-v0.2
language:
- en
library_name: transformers
license: apache-2.0
mradermacher:
readme_rev: 1
quantized_by: mradermacher
tags:
- agent
- open-source
- miromind
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: nicoboss -->
<!-- ### quants: Q2_K IQ3_M Q4_K_S IQ3_XXS Q3_K_M small-IQ4_NL Q4_K_M IQ2_M Q6_K IQ4_XS Q2_K_S IQ1_M Q3_K_S IQ2_XXS Q3_K_L IQ2_XS Q5_K_S IQ2_S IQ1_S Q5_K_M Q4_0 IQ3_XS Q4_1 IQ3_S -->
<!-- ### quants_skip: -->
<!-- ### skip_mmproj: -->
weighted/imatrix quants of https://huggingface.co/miromind-ai/MiroThinker-14B-DPO-v0.2
<!-- provided-files -->
***For a convenient overview and download list, visit our [model page for this model](https://hf.tst.eu/model#MiroThinker-14B-DPO-v0.2-i1-GGUF).***
static quants are available at https://huggingface.co/mradermacher/MiroThinker-14B-DPO-v0.2-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/MiroThinker-14B-DPO-v0.2-i1-GGUF/resolve/main/MiroThinker-14B-DPO-v0.2.imatrix.gguf) | imatrix | 0.1 | imatrix file (for creating your own qwuants) |
| [GGUF](https://huggingface.co/mradermacher/MiroThinker-14B-DPO-v0.2-i1-GGUF/resolve/main/MiroThinker-14B-DPO-v0.2.i1-IQ1_S.gguf) | i1-IQ1_S | 3.7 | for the desperate |
| [GGUF](https://huggingface.co/mradermacher/MiroThinker-14B-DPO-v0.2-i1-GGUF/resolve/main/MiroThinker-14B-DPO-v0.2.i1-IQ1_M.gguf) | i1-IQ1_M | 3.9 | mostly desperate |
| [GGUF](https://huggingface.co/mradermacher/MiroThinker-14B-DPO-v0.2-i1-GGUF/resolve/main/MiroThinker-14B-DPO-v0.2.i1-IQ2_XXS.gguf) | i1-IQ2_XXS | 4.4 | |
| [GGUF](https://huggingface.co/mradermacher/MiroThinker-14B-DPO-v0.2-i1-GGUF/resolve/main/MiroThinker-14B-DPO-v0.2.i1-IQ2_XS.gguf) | i1-IQ2_XS | 4.8 | |
| [GGUF](https://huggingface.co/mradermacher/MiroThinker-14B-DPO-v0.2-i1-GGUF/resolve/main/MiroThinker-14B-DPO-v0.2.i1-IQ2_S.gguf) | i1-IQ2_S | 5.1 | |
| [GGUF](https://huggingface.co/mradermacher/MiroThinker-14B-DPO-v0.2-i1-GGUF/resolve/main/MiroThinker-14B-DPO-v0.2.i1-IQ2_M.gguf) | i1-IQ2_M | 5.4 | |
| [GGUF](https://huggingface.co/mradermacher/MiroThinker-14B-DPO-v0.2-i1-GGUF/resolve/main/MiroThinker-14B-DPO-v0.2.i1-Q2_K_S.gguf) | i1-Q2_K_S | 5.5 | very low quality |
| [GGUF](https://huggingface.co/mradermacher/MiroThinker-14B-DPO-v0.2-i1-GGUF/resolve/main/MiroThinker-14B-DPO-v0.2.i1-Q2_K.gguf) | i1-Q2_K | 5.9 | IQ3_XXS probably better |
| [GGUF](https://huggingface.co/mradermacher/MiroThinker-14B-DPO-v0.2-i1-GGUF/resolve/main/MiroThinker-14B-DPO-v0.2.i1-IQ3_XXS.gguf) | i1-IQ3_XXS | 6.0 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/MiroThinker-14B-DPO-v0.2-i1-GGUF/resolve/main/MiroThinker-14B-DPO-v0.2.i1-IQ3_XS.gguf) | i1-IQ3_XS | 6.5 | |
| [GGUF](https://huggingface.co/mradermacher/MiroThinker-14B-DPO-v0.2-i1-GGUF/resolve/main/MiroThinker-14B-DPO-v0.2.i1-Q3_K_S.gguf) | i1-Q3_K_S | 6.8 | IQ3_XS probably better |
| [GGUF](https://huggingface.co/mradermacher/MiroThinker-14B-DPO-v0.2-i1-GGUF/resolve/main/MiroThinker-14B-DPO-v0.2.i1-IQ3_S.gguf) | i1-IQ3_S | 6.8 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/MiroThinker-14B-DPO-v0.2-i1-GGUF/resolve/main/MiroThinker-14B-DPO-v0.2.i1-IQ3_M.gguf) | i1-IQ3_M | 7.0 | |
| [GGUF](https://huggingface.co/mradermacher/MiroThinker-14B-DPO-v0.2-i1-GGUF/resolve/main/MiroThinker-14B-DPO-v0.2.i1-Q3_K_M.gguf) | i1-Q3_K_M | 7.4 | IQ3_S probably better |
| [GGUF](https://huggingface.co/mradermacher/MiroThinker-14B-DPO-v0.2-i1-GGUF/resolve/main/MiroThinker-14B-DPO-v0.2.i1-Q3_K_L.gguf) | i1-Q3_K_L | 8.0 | IQ3_M probably better |
| [GGUF](https://huggingface.co/mradermacher/MiroThinker-14B-DPO-v0.2-i1-GGUF/resolve/main/MiroThinker-14B-DPO-v0.2.i1-IQ4_XS.gguf) | i1-IQ4_XS | 8.2 | |
| [GGUF](https://huggingface.co/mradermacher/MiroThinker-14B-DPO-v0.2-i1-GGUF/resolve/main/MiroThinker-14B-DPO-v0.2.i1-IQ4_NL.gguf) | i1-IQ4_NL | 8.6 | prefer IQ4_XS |
| [GGUF](https://huggingface.co/mradermacher/MiroThinker-14B-DPO-v0.2-i1-GGUF/resolve/main/MiroThinker-14B-DPO-v0.2.i1-Q4_0.gguf) | i1-Q4_0 | 8.6 | fast, low quality |
| [GGUF](https://huggingface.co/mradermacher/MiroThinker-14B-DPO-v0.2-i1-GGUF/resolve/main/MiroThinker-14B-DPO-v0.2.i1-Q4_K_S.gguf) | i1-Q4_K_S | 8.7 | optimal size/speed/quality |
| [GGUF](https://huggingface.co/mradermacher/MiroThinker-14B-DPO-v0.2-i1-GGUF/resolve/main/MiroThinker-14B-DPO-v0.2.i1-Q4_K_M.gguf) | i1-Q4_K_M | 9.1 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/MiroThinker-14B-DPO-v0.2-i1-GGUF/resolve/main/MiroThinker-14B-DPO-v0.2.i1-Q4_1.gguf) | i1-Q4_1 | 9.5 | |
| [GGUF](https://huggingface.co/mradermacher/MiroThinker-14B-DPO-v0.2-i1-GGUF/resolve/main/MiroThinker-14B-DPO-v0.2.i1-Q5_K_S.gguf) | i1-Q5_K_S | 10.4 | |
| [GGUF](https://huggingface.co/mradermacher/MiroThinker-14B-DPO-v0.2-i1-GGUF/resolve/main/MiroThinker-14B-DPO-v0.2.i1-Q5_K_M.gguf) | i1-Q5_K_M | 10.6 | |
| [GGUF](https://huggingface.co/mradermacher/MiroThinker-14B-DPO-v0.2-i1-GGUF/resolve/main/MiroThinker-14B-DPO-v0.2.i1-Q6_K.gguf) | i1-Q6_K | 12.2 | practically like static Q6_K |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time. Additional thanks to [@nicoboss](https://huggingface.co/nicoboss) for giving me access to his private supercomputer, enabling me to provide many more imatrix quants, at much higher quality, than I would otherwise be able to.
<!-- end -->
|
Cangzhu1/custom-resnet50d
|
Cangzhu1
| 2025-09-13T10:03:24Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"resnet_cz",
"image-classification",
"custom_code",
"arxiv:1910.09700",
"autotrain_compatible",
"region:us"
] |
image-classification
| 2025-09-13T09:58:09Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
deepdml/whisper-medium-ig-mix
|
deepdml
| 2025-09-13T09:32:26Z | 8 | 0 | null |
[
"tensorboard",
"safetensors",
"whisper",
"generated_from_trainer",
"ig",
"dataset:deepdml/igbo-dict-16khz",
"dataset:deepdml/igbo-dict-expansion-16khz",
"base_model:openai/whisper-medium",
"base_model:finetune:openai/whisper-medium",
"license:apache-2.0",
"model-index",
"region:us"
] | null | 2025-09-09T15:19:52Z |
---
language:
- ig
license: apache-2.0
base_model: openai/whisper-medium
tags:
- generated_from_trainer
datasets:
- deepdml/igbo-dict-16khz
- deepdml/igbo-dict-expansion-16khz
metrics:
- wer
model-index:
- name: Whisper Medium ig
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: google/fleurs
type: google/fleurs
config: ig_ng
split: test
metrics:
- name: Wer
type: wer
value: 36.62142728743484
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Whisper Medium ig
This model is a fine-tuned version of [openai/whisper-medium](https://huggingface.co/openai/whisper-medium) on the google/fleurs dataset.
It achieves the following results on the evaluation set:
- Loss: 1.5395
- Wer: 36.6214
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 32
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 5000
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:-------:|
| 0.1362 | 0.2 | 1000 | 1.2088 | 40.5087 |
| 0.0549 | 0.4 | 2000 | 1.3555 | 39.1381 |
| 0.0268 | 0.6 | 3000 | 1.4718 | 38.2932 |
| 0.0085 | 1.163 | 4000 | 1.5330 | 36.7742 |
| 0.0166 | 1.363 | 5000 | 1.5395 | 36.6214 |
### Framework versions
- Transformers 4.42.0.dev0
- Pytorch 2.3.0+cu121
- Datasets 2.19.1
- Tokenizers 0.19.1
## Citation
```bibtex
@misc{deepdml/whisper-medium-ig-mix,
title={Fine-tuned Whisper medium ASR model for speech recognition in Igbo},
author={Jimenez, David},
howpublished={\url{https://huggingface.co/deepdml/whisper-medium-ig-mix}},
year={2025}
}
```
|
deepdml/whisper-base-ig-mix
|
deepdml
| 2025-09-13T09:31:52Z | 10 | 0 | null |
[
"tensorboard",
"safetensors",
"whisper",
"generated_from_trainer",
"ig",
"dataset:deepdml/igbo-dict-16khz",
"dataset:deepdml/igbo-dict-expansion-16khz",
"base_model:openai/whisper-base",
"base_model:finetune:openai/whisper-base",
"license:apache-2.0",
"model-index",
"region:us"
] | null | 2025-09-11T08:33:48Z |
---
language:
- ig
license: apache-2.0
base_model: openai/whisper-base
tags:
- generated_from_trainer
datasets:
- deepdml/igbo-dict-16khz
- deepdml/igbo-dict-expansion-16khz
metrics:
- wer
model-index:
- name: Whisper Base ig
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: google/fleurs
type: google/fleurs
config: ig_ng
split: test
metrics:
- name: Wer
type: wer
value: 93.38037030379292
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Whisper Base ig
This model is a fine-tuned version of [openai/whisper-base](https://huggingface.co/openai/whisper-base) on the google/fleurs dataset.
It achieves the following results on the evaluation set:
- Loss: 1.7179
- Wer: 93.3804
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 64
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 5000
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:------:|:----:|:---------------:|:-------:|
| 0.2396 | 0.2 | 1000 | 1.3704 | 57.7791 |
| 0.0803 | 1.0814 | 2000 | 1.5414 | 71.3104 |
| 0.0636 | 1.2814 | 3000 | 1.6047 | 94.5668 |
| 0.0346 | 2.1628 | 4000 | 1.6904 | 83.7003 |
| 0.035 | 3.0442 | 5000 | 1.7179 | 93.3804 |
### Framework versions
- Transformers 4.42.0.dev0
- Pytorch 2.3.0+cu121
- Datasets 2.19.1
- Tokenizers 0.19.1
## Citation
```bibtex
@misc{deepdml/whisper-base-ig-mix,
title={Fine-tuned Whisper base ASR model for speech recognition in Igbo},
author={Jimenez, David},
howpublished={\url{https://huggingface.co/deepdml/whisper-base-ig-mix}},
year={2025}
}
```
|
7878irfan/batik_model
|
7878irfan
| 2025-09-13T09:30:39Z | 0 | 0 | null |
[
"license:cc-by-nc-sa-2.0",
"region:us"
] | null | 2025-09-13T09:30:39Z |
---
license: cc-by-nc-sa-2.0
---
|
guyyanai/CLSS
|
guyyanai
| 2025-09-13T09:26:08Z | 0 | 0 | null |
[
"license:apache-2.0",
"region:us"
] | null | 2025-09-13T09:26:08Z |
---
license: apache-2.0
---
|
bachephysicdun/dummy-pretrained-mistral7b
|
bachephysicdun
| 2025-09-13T09:23:09Z | 12 | 0 |
transformers
|
[
"transformers",
"safetensors",
"mistral",
"text-generation",
"generated_from_trainer",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-09-10T06:52:35Z |
---
library_name: transformers
tags:
- generated_from_trainer
model-index:
- name: dummy-pretrained-mistral7b
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# dummy-pretrained-mistral7b
This model is a fine-tuned version of [](https://huggingface.co/) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 6.2608
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 7.1427 | 1.0 | 225 | 6.4588 |
| 6.087 | 2.0 | 450 | 6.0569 |
| 5.4974 | 3.0 | 675 | 5.8850 |
| 4.9118 | 4.0 | 900 | 5.8386 |
| 4.3293 | 5.0 | 1125 | 5.8841 |
| 3.8031 | 6.0 | 1350 | 5.9791 |
| 3.358 | 7.0 | 1575 | 6.0693 |
| 2.9942 | 8.0 | 1800 | 6.1640 |
| 2.7101 | 9.0 | 2025 | 6.2125 |
| 2.5189 | 10.0 | 2250 | 6.2608 |
### Framework versions
- Transformers 4.48.1
- Pytorch 2.5.1
- Datasets 2.21.0
- Tokenizers 0.21.0
|
ryzax/1.5B-v72
|
ryzax
| 2025-09-13T09:18:01Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen3",
"text-generation",
"generated_from_trainer",
"grpo",
"trl",
"conversational",
"arxiv:2402.03300",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-09-13T01:49:19Z |
---
library_name: transformers
model_name: 1.5B-v72
tags:
- generated_from_trainer
- grpo
- trl
licence: license
---
# Model Card for 1.5B-v72
This model is a fine-tuned version of [None](https://huggingface.co/None).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="ryzax/1.5B-v72", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="150" height="24"/>](https://wandb.ai/muennighoff/s2/runs/g1arzzhj)
This model was trained with GRPO, a method introduced in [DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models](https://huggingface.co/papers/2402.03300).
### Framework versions
- TRL: 0.22.0.dev0
- Transformers: 4.55.4
- Pytorch: 2.7.1
- Datasets: 4.0.0
- Tokenizers: 0.21.4
## Citations
Cite GRPO as:
```bibtex
@article{zhihong2024deepseekmath,
title = {{DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models}},
author = {Zhihong Shao and Peiyi Wang and Qihao Zhu and Runxin Xu and Junxiao Song and Mingchuan Zhang and Y. K. Li and Y. Wu and Daya Guo},
year = 2024,
eprint = {arXiv:2402.03300},
}
```
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
LandCruiser/sn21_omg3_1309_2
|
LandCruiser
| 2025-09-13T08:47:37Z | 0 | 0 | null |
[
"safetensors",
"any-to-any",
"omega",
"omegalabs",
"bittensor",
"agi",
"license:mit",
"region:us"
] |
any-to-any
| 2025-09-13T08:36:54Z |
---
license: mit
tags:
- any-to-any
- omega
- omegalabs
- bittensor
- agi
---
This is an Any-to-Any model checkpoint for the OMEGA Labs x Bittensor Any-to-Any subnet.
Check out the [git repo](https://github.com/omegalabsinc/omegalabs-anytoany-bittensor) and find OMEGA on X: [@omegalabsai](https://x.com/omegalabsai).
|
Khalidooo/Rincon
|
Khalidooo
| 2025-09-13T08:47:15Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-09-13T08:46:30Z |
<!DOCTYPE html>
<html>
<head>
<title>My app</title>
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<meta charset="utf-8">
<script src="https://cdn.tailwindcss.com"></script>
</head>
<body class="flex justify-center items-center h-screen overflow-hidden bg-white font-sans text-center px-6">
<div class="w-full">
<span class="text-xs rounded-full mb-2 inline-block px-2 py-1 border border-amber-500/15 bg-amber-500/15 text-amber-500">🔥 New version dropped!</span>
<h1 class="text-4xl lg:text-6xl font-bold font-sans">
<span class="text-2xl lg:text-4xl text-gray-400 block font-medium">I'm ready to work,</span>
Ask me anything.
</h1>
</div>
<img src="https://enzostvs-deepsite.hf.space/arrow.svg" class="absolute bottom-8 left-0 w-[100px] transform rotate-[30deg]" />
<script></script>
</body>
</html>
|
NhatNam214/test_finetune
|
NhatNam214
| 2025-09-13T08:46:18Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2_vl",
"image-to-text",
"generated_from_trainer",
"trl",
"sft",
"base_model:numind/NuExtract-2.0-2B",
"base_model:finetune:numind/NuExtract-2.0-2B",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
image-to-text
| 2025-09-13T08:45:22Z |
---
base_model: numind/NuExtract-2.0-2B
library_name: transformers
model_name: test_finetune
tags:
- generated_from_trainer
- trl
- sft
licence: license
---
# Model Card for test_finetune
This model is a fine-tuned version of [numind/NuExtract-2.0-2B](https://huggingface.co/numind/NuExtract-2.0-2B).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="NhatNam214/test_finetune", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
This model was trained with SFT.
### Framework versions
- TRL: 0.15.2
- Transformers: 4.56.0
- Pytorch: 2.8.0+cu129
- Datasets: 4.0.0
- Tokenizers: 0.22.0
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallouédec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
outlookAi/xceWst27jk
|
outlookAi
| 2025-09-13T08:45:12Z | 0 | 0 |
diffusers
|
[
"diffusers",
"flux",
"lora",
"replicate",
"text-to-image",
"en",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"license:other",
"region:us"
] |
text-to-image
| 2025-09-13T08:28:06Z |
---
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
language:
- en
tags:
- flux
- diffusers
- lora
- replicate
base_model: "black-forest-labs/FLUX.1-dev"
pipeline_tag: text-to-image
# widget:
# - text: >-
# prompt
# output:
# url: https://...
instance_prompt: AkeSomrut
---
# Xcewst27Jk
<Gallery />
## About this LoRA
This is a [LoRA](https://replicate.com/docs/guides/working-with-loras) for the FLUX.1-dev text-to-image model. It can be used with diffusers or ComfyUI.
It was trained on [Replicate](https://replicate.com/) using AI toolkit: https://replicate.com/ostris/flux-dev-lora-trainer/train
## Trigger words
You should use `AkeSomrut` to trigger the image generation.
## Run this LoRA with an API using Replicate
```py
import replicate
input = {
"prompt": "AkeSomrut",
"lora_weights": "https://huggingface.co/outlookAi/xceWst27jk/resolve/main/lora.safetensors"
}
output = replicate.run(
"black-forest-labs/flux-dev-lora",
input=input
)
for index, item in enumerate(output):
with open(f"output_{index}.webp", "wb") as file:
file.write(item.read())
```
## Use it with the [🧨 diffusers library](https://github.com/huggingface/diffusers)
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained('black-forest-labs/FLUX.1-dev', torch_dtype=torch.float16).to('cuda')
pipeline.load_lora_weights('outlookAi/xceWst27jk', weight_name='lora.safetensors')
image = pipeline('AkeSomrut').images[0]
```
For more details, including weighting, merging and fusing LoRAs, check the [documentation on loading LoRAs in diffusers](https://huggingface.co/docs/diffusers/main/en/using-diffusers/loading_adapters)
## Training details
- Steps: 1200
- Learning rate: 0.0004
- LoRA rank: 16
## Contribute your own examples
You can use the [community tab](https://huggingface.co/outlookAi/xceWst27jk/discussions) to add images that show off what you’ve made with this LoRA.
|
lucio36/APASI-Base-7B
|
lucio36
| 2025-09-13T08:39:59Z | 0 | 0 |
peft
|
[
"peft",
"safetensors",
"llava_llama",
"base_model:liuhaotian/llava-v1.5-7b",
"base_model:adapter:liuhaotian/llava-v1.5-7b",
"region:us"
] | null | 2025-09-13T08:15:15Z |
---
library_name: peft
base_model: liuhaotian/llava-v1.5-7b
---
# Model Card for Model ID
This is the lora adapter of the APASI-Base model. Use the `scripts/merge_lora_weights.py` script in the repo to merge with `liuhaotian/llava-v1.5-7b` and save the model.
|
0xadityam/lama-2-8b-indas-lora
|
0xadityam
| 2025-09-13T08:14:08Z | 0 | 0 | null |
[
"license:apache-2.0",
"region:us"
] | null | 2025-09-13T08:14:08Z |
---
license: apache-2.0
---
|
0xtimi/speecht5_finetuned_voxpopuli_nl
|
0xtimi
| 2025-09-13T08:13:54Z | 4 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"speecht5",
"text-to-audio",
"generated_from_trainer",
"dataset:voxpopuli",
"base_model:microsoft/speecht5_tts",
"base_model:finetune:microsoft/speecht5_tts",
"license:mit",
"endpoints_compatible",
"region:us"
] |
text-to-audio
| 2025-09-12T17:32:49Z |
---
library_name: transformers
license: mit
base_model: microsoft/speecht5_tts
tags:
- generated_from_trainer
datasets:
- voxpopuli
model-index:
- name: speecht5_finetuned_voxpopuli_nl
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# speecht5_finetuned_voxpopuli_nl
This model is a fine-tuned version of [microsoft/speecht5_tts](https://huggingface.co/microsoft/speecht5_tts) on the voxpopuli dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5336
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 4
- eval_batch_size: 2
- seed: 42
- gradient_accumulation_steps: 8
- total_train_batch_size: 32
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 4000
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 0.4441 | 100.0 | 1000 | 0.5256 |
| 0.4138 | 200.0 | 2000 | 0.5317 |
| 0.4061 | 300.0 | 3000 | 0.5319 |
| 0.4016 | 400.0 | 4000 | 0.5336 |
### Framework versions
- Transformers 4.55.0.dev0
- Pytorch 2.7.1+cu126
- Datasets 2.21.0
- Tokenizers 0.21.4
|
Hfkjc/blockassist
|
Hfkjc
| 2025-09-13T08:11:45Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"fanged stinging sandpiper",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-13T08:11:22Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- fanged stinging sandpiper
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
mradermacher/InfiMed-SFT-3B-i1-GGUF
|
mradermacher
| 2025-09-13T07:54:06Z | 0 | 0 |
transformers
|
[
"transformers",
"gguf",
"en",
"base_model:InfiX-ai/InfiMed-SFT-3B",
"base_model:quantized:InfiX-ai/InfiMed-SFT-3B",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | null | 2025-09-13T06:34:04Z |
---
base_model: InfiX-ai/InfiMed-SFT-3B
language:
- en
library_name: transformers
license: apache-2.0
mradermacher:
readme_rev: 1
quantized_by: mradermacher
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: nicoboss -->
<!-- ### quants: Q2_K IQ3_M Q4_K_S IQ3_XXS Q3_K_M small-IQ4_NL Q4_K_M IQ2_M Q6_K IQ4_XS Q2_K_S IQ1_M Q3_K_S IQ2_XXS Q3_K_L IQ2_XS Q5_K_S IQ2_S IQ1_S Q5_K_M Q4_0 IQ3_XS Q4_1 IQ3_S -->
<!-- ### quants_skip: -->
<!-- ### skip_mmproj: -->
weighted/imatrix quants of https://huggingface.co/InfiX-ai/InfiMed-SFT-3B
<!-- provided-files -->
***For a convenient overview and download list, visit our [model page for this model](https://hf.tst.eu/model#InfiMed-SFT-3B-i1-GGUF).***
static quants are available at https://huggingface.co/mradermacher/InfiMed-SFT-3B-GGUF
**This is a vision model - mmproj files (if any) will be in the [static repository](https://huggingface.co/mradermacher/InfiMed-SFT-3B-GGUF).**
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/InfiMed-SFT-3B-i1-GGUF/resolve/main/InfiMed-SFT-3B.imatrix.gguf) | imatrix | 0.1 | imatrix file (for creating your own qwuants) |
| [GGUF](https://huggingface.co/mradermacher/InfiMed-SFT-3B-i1-GGUF/resolve/main/InfiMed-SFT-3B.i1-IQ1_S.gguf) | i1-IQ1_S | 0.9 | for the desperate |
| [GGUF](https://huggingface.co/mradermacher/InfiMed-SFT-3B-i1-GGUF/resolve/main/InfiMed-SFT-3B.i1-IQ1_M.gguf) | i1-IQ1_M | 1.0 | mostly desperate |
| [GGUF](https://huggingface.co/mradermacher/InfiMed-SFT-3B-i1-GGUF/resolve/main/InfiMed-SFT-3B.i1-IQ2_XXS.gguf) | i1-IQ2_XXS | 1.0 | |
| [GGUF](https://huggingface.co/mradermacher/InfiMed-SFT-3B-i1-GGUF/resolve/main/InfiMed-SFT-3B.i1-IQ2_XS.gguf) | i1-IQ2_XS | 1.1 | |
| [GGUF](https://huggingface.co/mradermacher/InfiMed-SFT-3B-i1-GGUF/resolve/main/InfiMed-SFT-3B.i1-IQ2_S.gguf) | i1-IQ2_S | 1.2 | |
| [GGUF](https://huggingface.co/mradermacher/InfiMed-SFT-3B-i1-GGUF/resolve/main/InfiMed-SFT-3B.i1-IQ2_M.gguf) | i1-IQ2_M | 1.2 | |
| [GGUF](https://huggingface.co/mradermacher/InfiMed-SFT-3B-i1-GGUF/resolve/main/InfiMed-SFT-3B.i1-Q2_K_S.gguf) | i1-Q2_K_S | 1.3 | very low quality |
| [GGUF](https://huggingface.co/mradermacher/InfiMed-SFT-3B-i1-GGUF/resolve/main/InfiMed-SFT-3B.i1-Q2_K.gguf) | i1-Q2_K | 1.4 | IQ3_XXS probably better |
| [GGUF](https://huggingface.co/mradermacher/InfiMed-SFT-3B-i1-GGUF/resolve/main/InfiMed-SFT-3B.i1-IQ3_XXS.gguf) | i1-IQ3_XXS | 1.4 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/InfiMed-SFT-3B-i1-GGUF/resolve/main/InfiMed-SFT-3B.i1-IQ3_XS.gguf) | i1-IQ3_XS | 1.5 | |
| [GGUF](https://huggingface.co/mradermacher/InfiMed-SFT-3B-i1-GGUF/resolve/main/InfiMed-SFT-3B.i1-Q3_K_S.gguf) | i1-Q3_K_S | 1.6 | IQ3_XS probably better |
| [GGUF](https://huggingface.co/mradermacher/InfiMed-SFT-3B-i1-GGUF/resolve/main/InfiMed-SFT-3B.i1-IQ3_S.gguf) | i1-IQ3_S | 1.6 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/InfiMed-SFT-3B-i1-GGUF/resolve/main/InfiMed-SFT-3B.i1-IQ3_M.gguf) | i1-IQ3_M | 1.6 | |
| [GGUF](https://huggingface.co/mradermacher/InfiMed-SFT-3B-i1-GGUF/resolve/main/InfiMed-SFT-3B.i1-Q3_K_M.gguf) | i1-Q3_K_M | 1.7 | IQ3_S probably better |
| [GGUF](https://huggingface.co/mradermacher/InfiMed-SFT-3B-i1-GGUF/resolve/main/InfiMed-SFT-3B.i1-Q3_K_L.gguf) | i1-Q3_K_L | 1.8 | IQ3_M probably better |
| [GGUF](https://huggingface.co/mradermacher/InfiMed-SFT-3B-i1-GGUF/resolve/main/InfiMed-SFT-3B.i1-IQ4_XS.gguf) | i1-IQ4_XS | 1.8 | |
| [GGUF](https://huggingface.co/mradermacher/InfiMed-SFT-3B-i1-GGUF/resolve/main/InfiMed-SFT-3B.i1-IQ4_NL.gguf) | i1-IQ4_NL | 1.9 | prefer IQ4_XS |
| [GGUF](https://huggingface.co/mradermacher/InfiMed-SFT-3B-i1-GGUF/resolve/main/InfiMed-SFT-3B.i1-Q4_0.gguf) | i1-Q4_0 | 1.9 | fast, low quality |
| [GGUF](https://huggingface.co/mradermacher/InfiMed-SFT-3B-i1-GGUF/resolve/main/InfiMed-SFT-3B.i1-Q4_K_S.gguf) | i1-Q4_K_S | 1.9 | optimal size/speed/quality |
| [GGUF](https://huggingface.co/mradermacher/InfiMed-SFT-3B-i1-GGUF/resolve/main/InfiMed-SFT-3B.i1-Q4_K_M.gguf) | i1-Q4_K_M | 2.0 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/InfiMed-SFT-3B-i1-GGUF/resolve/main/InfiMed-SFT-3B.i1-Q4_1.gguf) | i1-Q4_1 | 2.1 | |
| [GGUF](https://huggingface.co/mradermacher/InfiMed-SFT-3B-i1-GGUF/resolve/main/InfiMed-SFT-3B.i1-Q5_K_S.gguf) | i1-Q5_K_S | 2.3 | |
| [GGUF](https://huggingface.co/mradermacher/InfiMed-SFT-3B-i1-GGUF/resolve/main/InfiMed-SFT-3B.i1-Q5_K_M.gguf) | i1-Q5_K_M | 2.3 | |
| [GGUF](https://huggingface.co/mradermacher/InfiMed-SFT-3B-i1-GGUF/resolve/main/InfiMed-SFT-3B.i1-Q6_K.gguf) | i1-Q6_K | 2.6 | practically like static Q6_K |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time. Additional thanks to [@nicoboss](https://huggingface.co/nicoboss) for giving me access to his private supercomputer, enabling me to provide many more imatrix quants, at much higher quality, than I would otherwise be able to.
<!-- end -->
|
Alicia22/Sat_Twelve_r17
|
Alicia22
| 2025-09-13T07:47:11Z | 0 | 0 | null |
[
"safetensors",
"any-to-any",
"omega",
"omegalabs",
"bittensor",
"agi",
"license:mit",
"region:us"
] |
any-to-any
| 2025-09-13T07:43:57Z |
---
license: mit
tags:
- any-to-any
- omega
- omegalabs
- bittensor
- agi
---
This is an Any-to-Any model checkpoint for the OMEGA Labs x Bittensor Any-to-Any subnet.
Check out the [git repo](https://github.com/omegalabsinc/omegalabs-anytoany-bittensor) and find OMEGA on X: [@omegalabsai](https://x.com/omegalabsai).
|
tauqueeralam42/flux-dev-lora-a.v1
|
tauqueeralam42
| 2025-09-13T07:46:57Z | 0 | 0 |
diffusers
|
[
"diffusers",
"flux",
"lora",
"replicate",
"text-to-image",
"en",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"license:other",
"region:us"
] |
text-to-image
| 2025-09-13T07:46:55Z |
---
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
language:
- en
tags:
- flux
- diffusers
- lora
- replicate
base_model: "black-forest-labs/FLUX.1-dev"
pipeline_tag: text-to-image
# widget:
# - text: >-
# prompt
# output:
# url: https://...
instance_prompt: ayushi
---
# Flux Dev Lora A.V1
<Gallery />
## About this LoRA
This is a [LoRA](https://replicate.com/docs/guides/working-with-loras) for the FLUX.1-dev text-to-image model. It can be used with diffusers or ComfyUI.
It was trained on [Replicate](https://replicate.com/) using AI toolkit: https://replicate.com/ostris/flux-dev-lora-trainer/train
## Trigger words
You should use `ayushi` to trigger the image generation.
## Run this LoRA with an API using Replicate
```py
import replicate
input = {
"prompt": "ayushi",
"lora_weights": "https://huggingface.co/tauqueeralam42/flux-dev-lora-a.v1/resolve/main/lora.safetensors"
}
output = replicate.run(
"black-forest-labs/flux-dev-lora",
input=input
)
for index, item in enumerate(output):
with open(f"output_{index}.webp", "wb") as file:
file.write(item.read())
```
## Use it with the [🧨 diffusers library](https://github.com/huggingface/diffusers)
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained('black-forest-labs/FLUX.1-dev', torch_dtype=torch.float16).to('cuda')
pipeline.load_lora_weights('tauqueeralam42/flux-dev-lora-a.v1', weight_name='lora.safetensors')
image = pipeline('ayushi').images[0]
```
For more details, including weighting, merging and fusing LoRAs, check the [documentation on loading LoRAs in diffusers](https://huggingface.co/docs/diffusers/main/en/using-diffusers/loading_adapters)
## Training details
- Steps: 1512
- Learning rate: 0.0004
- LoRA rank: 20
## Contribute your own examples
You can use the [community tab](https://huggingface.co/tauqueeralam42/flux-dev-lora-a.v1/discussions) to add images that show off what you’ve made with this LoRA.
|
HJWZH/composition-assistant
|
HJWZH
| 2025-09-13T07:30:26Z | 14 | 0 | null |
[
"safetensors",
"bert",
"zh",
"base_model:uer/chinese_roberta_L-12_H-768",
"base_model:finetune:uer/chinese_roberta_L-12_H-768",
"license:mit",
"region:us"
] | null | 2025-08-13T12:25:45Z |
---
license: mit
language:
- zh
base_model:
- uer/chinese_roberta_L-12_H-768
---
# 文思引擎 - AI 作文素材检索系统(微调模型)
更多请详情:[Github composition-assistant](https://github.com/HJWZH/composition-assistant)
或[Github Pages 文思引擎详情页](http://HJWZH.github.io/HJWZH/composition-assistant)
### 1. 项目简要说明(创意创新说明)+简介
**创新说明:**
"文思引擎"是一款AI作文素材检索工具,它通过深度学习技术理解抽象概念和深层语义联系,解决了传统作文素材库"关键词匹配不精准"、"素材关联性差"、"灵感启发不足"三大痛点。系统能理解"生命"、"环保"等抽象概念的哲学内涵,智能推荐高度相关的名言、事例和古诗文,帮助学生突破写作瓶颈。
**项目简介:**
针对中学生写作中的素材匮乏问题,我们开发了基于Transformer架构的智能检索系统:
- 🧠 核心模型:微调的中文RoBERTa模型(uer/chinese_roberta_L-12_H-768)
- 📚 三大素材库:收录名言警句、热点事例、古诗文(仍需更新)
- ✨ 核心功能:
- 语义理解:识别"坚持→锲而不舍"等同义转换
- 主题关联:构建"航天精神→科技创新→民族复兴"知识网络
- 多维过滤:支持按类别/相似度/主题精准筛选
- 📈 效果:测试显示素材相关度提升57%,写作效率提高40%
## ✨ 项目亮点
- **深度语义理解**:突破关键词匹配局限,理解"挫折→逆境成长"的抽象关联
- **动态学习系统**:10轮迭代训练机制,持续提升素材推荐精准度
- **多维度过滤**:类别/主题/相似度三级检索体系
- **轻量化部署**:预计算嵌入向量技术,CPU环境0.5秒响应
## 📚 素材库示例
```json
{
"content": "真正的太空探索不是为霸权,而是为人类共同梦想",
"source": "中国航天白皮书",
"keywords": ["航天精神", "人类命运共同体", "探索精神"]
"theme": "科技创新",
}
```
|
XuejiFang/UniTok_transformers
|
XuejiFang
| 2025-09-13T07:09:26Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"unitok",
"computer-vision",
"image-reconstruction",
"vector-quantization",
"tokenizer",
"multimodal",
"image-to-image",
"en",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
image-to-image
| 2025-09-13T06:38:51Z |
---
license: apache-2.0
language: en
tags:
- computer-vision
- image-reconstruction
- vector-quantization
- tokenizer
- multimodal
library_name: transformers
pipeline_tag: image-to-image
---
# UniTok Transformers
**Key Features:**
- 📦 **Transformers Compatible**: Standard `from_pretrained()` and `save_pretrained()` support
For more details, visit: https://github.com/XuejiFang/UniTok_transformers
## Disclaimer
This is an unofficial implementation with Hugging Face integration. Original work: [FoundationVision/UniTok](https://github.com/FoundationVision/UniTok)
|
lt2c/hsl-Llama-3.2-1B-alfworld-hslw_0.5-n1600-lemonade-llamaRelabel-rf-whsNew
|
lt2c
| 2025-09-13T06:49:06Z | 0 | 0 | null |
[
"safetensors",
"llama",
"lemona",
"agent-training",
"region:us"
] | null | 2025-09-13T06:45:55Z |
---
tags:
- lemona
- agent-training
---
# hsl-Llama-3.2-1B-alfworld-hslw_0.5-n1600-lemonade-llamaRelabel-rf-whsNew
This model was automatically uploaded from the Lemona agent training framework.
## Model Details
- Model Type: llama
- Hidden Size: 2048
- Layers: 16
## Training Framework
- Framework: Lemona
- Training Methods: SFT/DPO/HSL
- Source Directory: `hsl-Llama-3.2-1B-alfworld-hslw_0.5-n1600-lemonade-llamaRelabel-rf-whsNew`
## Usage
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained("lt2c/hsl-Llama-3.2-1B-alfworld-hslw_0.5-n1600-lemonade-llamaRelabel-rf-whsNew")
tokenizer = AutoTokenizer.from_pretrained("lt2c/hsl-Llama-3.2-1B-alfworld-hslw_0.5-n1600-lemonade-llamaRelabel-rf-whsNew")
```
|
ThomasTheMaker/gm3-270m-gsm-4.1
|
ThomasTheMaker
| 2025-09-13T06:40:46Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"gemma3_text",
"text-generation",
"text-generation-inference",
"unsloth",
"trl",
"sft",
"conversational",
"en",
"base_model:unsloth/gemma-3-270m-it",
"base_model:finetune:unsloth/gemma-3-270m-it",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-09-13T06:36:30Z |
---
base_model: unsloth/gemma-3-270m-it
tags:
- text-generation-inference
- transformers
- unsloth
- gemma3_text
- trl
- sft
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** ThomasTheMaker
- **License:** apache-2.0
- **Finetuned from model :** unsloth/gemma-3-270m-it
This gemma3_text model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
Bigleenaj/Qwen2.5-0.5B-Instruct-Gensyn-Swarm-sharp_deft_bee
|
Bigleenaj
| 2025-09-13T06:17:47Z | 147 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"rl-swarm",
"genrl-swarm",
"grpo",
"gensyn",
"I am sharp_deft_bee",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-09-08T21:48:28Z |
---
library_name: transformers
tags:
- rl-swarm
- genrl-swarm
- grpo
- gensyn
- I am sharp_deft_bee
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Ben-Lustig/OpenRS-GRPO_Qwen3
|
Ben-Lustig
| 2025-09-13T06:01:21Z | 7 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen3",
"text-generation",
"generated_from_trainer",
"open-r1",
"trl",
"grpo",
"conversational",
"dataset:knoveleng/open-rs",
"arxiv:2402.03300",
"base_model:Qwen/Qwen3-1.7B",
"base_model:finetune:Qwen/Qwen3-1.7B",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-09-11T21:29:54Z |
---
base_model: Qwen/Qwen3-1.7B
datasets: knoveleng/open-rs
library_name: transformers
model_name: OpenRS-GRPO_Qwen3
tags:
- generated_from_trainer
- open-r1
- trl
- grpo
licence: license
---
# Model Card for OpenRS-GRPO_Qwen3
This model is a fine-tuned version of [Qwen/Qwen3-1.7B](https://huggingface.co/Qwen/Qwen3-1.7B) on the [knoveleng/open-rs](https://huggingface.co/datasets/knoveleng/open-rs) dataset.
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="Ben-Lustig/OpenRS-GRPO_Qwen3", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="150" height="24"/>](https://wandb.ai/lustigben-bar-ilan-university/huggingface/runs/wsrm8f2w)
This model was trained with GRPO, a method introduced in [DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models](https://huggingface.co/papers/2402.03300).
### Framework versions
- TRL: 0.16.0.dev0
- Transformers: 4.51.0
- Pytorch: 2.5.1
- Datasets: 3.2.0
- Tokenizers: 0.21.4
## Citations
Cite GRPO as:
```bibtex
@article{zhihong2024deepseekmath,
title = {{DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models}},
author = {Zhihong Shao and Peiyi Wang and Qihao Zhu and Runxin Xu and Junxiao Song and Mingchuan Zhang and Y. K. Li and Y. Wu and Daya Guo},
year = 2024,
eprint = {arXiv:2402.03300},
}
```
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallouédec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
hoan17/saving_LAVilas100x2e2_400
|
hoan17
| 2025-09-13T05:50:47Z | 0 | 0 |
diffusers
|
[
"diffusers",
"safetensors",
"trl",
"o2o",
"reinforcement-learning",
"text-to-image",
"stable-diffusion",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] |
text-to-image
| 2025-09-13T05:50:15Z |
---
license: apache-2.0
tags:
- trl
- o2o
- diffusers
- reinforcement-learning
- text-to-image
- stable-diffusion
---
# TRL O2O Model
This is a diffusion model that has been fine-tuned with reinforcement learning to
guide the model outputs according to a value, function, or human feedback. The model can be used for image generation conditioned with text.
|
asinik/my_awesome_billsum_model
|
asinik
| 2025-09-13T05:36:04Z | 0 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"t5",
"text2text-generation",
"generated_from_trainer",
"base_model:google-t5/t5-small",
"base_model:finetune:google-t5/t5-small",
"license:apache-2.0",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | null | 2025-09-06T08:36:44Z |
---
library_name: transformers
license: apache-2.0
base_model: google-t5/t5-small
tags:
- generated_from_trainer
metrics:
- rouge
model-index:
- name: my_awesome_billsum_model
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# my_awesome_billsum_model
This model is a fine-tuned version of [google-t5/t5-small](https://huggingface.co/google-t5/t5-small) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 2.4832
- Rouge1: 0.1504
- Rouge2: 0.0568
- Rougel: 0.1247
- Rougelsum: 0.1252
- Gen Len: 20.0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH_FUSED with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 4
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:------:|:------:|:------:|:---------:|:-------:|
| No log | 1.0 | 62 | 2.7694 | 0.1349 | 0.0423 | 0.1115 | 0.1118 | 20.0 |
| No log | 2.0 | 124 | 2.5626 | 0.1419 | 0.0511 | 0.119 | 0.1194 | 20.0 |
| No log | 3.0 | 186 | 2.4999 | 0.1479 | 0.0554 | 0.123 | 0.1236 | 20.0 |
| No log | 4.0 | 248 | 2.4832 | 0.1504 | 0.0568 | 0.1247 | 0.1252 | 20.0 |
### Framework versions
- Transformers 4.56.1
- Pytorch 2.8.0+cu126
- Datasets 4.0.0
- Tokenizers 0.22.0
|
sidhantoon/Goldentouch_V3_G24
|
sidhantoon
| 2025-09-13T05:05:09Z | 0 | 0 | null |
[
"safetensors",
"any-to-any",
"omega",
"omegalabs",
"bittensor",
"agi",
"license:mit",
"region:us"
] |
any-to-any
| 2025-09-13T03:28:08Z |
---
license: mit
tags:
- any-to-any
- omega
- omegalabs
- bittensor
- agi
---
This is an Any-to-Any model checkpoint for the OMEGA Labs x Bittensor Any-to-Any subnet.
Check out the [git repo](https://github.com/omegalabsinc/omegalabs-anytoany-bittensor) and find OMEGA on X: [@omegalabsai](https://x.com/omegalabsai).
|
cocoat/cocoamix
|
cocoat
| 2025-09-13T05:04:55Z | 0 | 2 | null |
[
"region:us"
] | null | 2024-09-14T10:16:50Z |
Please use at your own risk.<br>
I am not responsible in any way for any problems with the generated images.<br>
Also, please note that there will be a fee if you use to reprint the model other site.(Except for civitai)<br>
Not create NSFW at use this model.
<br>
Thank you.<br>
<br>
This model permits users to: <br>
OK | Use the model without crediting the creator (Pony model is must crediting)<br>
NO | Sell images they generate<br>
NO | Run on services that generate for money<br>
OK | Run on Civitai<br>
NO | Share merges using this model (please ask me)<br>
NO | Sell this model or merges using this model<br>
NO | Have different permissions when sharing merges<br>
|
Jonny001/deepfake
|
Jonny001
| 2025-09-13T04:57:59Z | 0 | 1 | null |
[
"onnx",
"license:apache-2.0",
"region:us"
] | null | 2025-09-13T04:36:25Z |
---
license: apache-2.0
---
# Deepfake Model Files
This repository provides a comprehensive collection of pre-trained models for face restoration, enhancement, colorization, segmentation, and identity swapping.
> **Included Models**
> ✅ Face Restoration:
> • CodeFormer
> • GFPGAN v1.4
> • GPEN-BFR
> • RestoreFormer
> • RestoreFormer++
>
> ✅ Super Resolution:
> • Real-ESRGAN (x2, x4)
> • LSRDIR x4
>
> ✅ Colorization:
> • DeOldify Artistic
> • DeOldify Stable
>
> ✅ Identity Swapping:
> • inswapper_128
> • reswapper_128
> • reswapper_256
>
> ✅ Segmentation / Masking:
> • ISNet (General Use)
> • XSeg
>
> ✅ Utility / Other:
> • rd64-uni-refined
---
## 📥 Downloads
| File Name | Format | Description | Download Link |
|--------------------------------|----------|--------------------------------------|---------------|
| `CodeFormerv0.1` | `.onnx` | CodeFormer model | [Download](https://huggingface.co/Jonny001/deepfake/resolve/main/CodeFormerv0.1.onnx?download=true) |
| `GFPGANv1.4` | `.onnx` | GFPGAN model (ONNX version) | [Download](https://huggingface.co/Jonny001/deepfake/resolve/main/GFPGANv1.4.onnx?download=true) |
| `GFPGANv1.4` | `.pth` | GFPGAN model (PyTorch version) | [Download](https://huggingface.co/Jonny001/deepfake/resolve/main/GFPGANv1.4.pth?download=true) |
| `GPEN-BFR-512` | `.onnx` | GPEN face restoration (512px) | [Download](https://huggingface.co/Jonny001/deepfake/resolve/main/GPEN-BFR-512.onnx?download=true) |
| `deoldify_artistic` | `.onnx` | DeOldify artistic colorization | [Download](https://huggingface.co/Jonny001/deepfake/resolve/main/deoldify_artistic.onnx?download=true) |
| `deoldify_stable` | `.onnx` | DeOldify stable colorization | [Download](https://huggingface.co/Jonny001/deepfake/resolve/main/deoldify_stable.onnx?download=true) |
| `inswapper_128` | `.onnx` | InsightFace identity swapper | [Download](https://huggingface.co/Jonny001/deepfake/resolve/main/inswapper_128.onnx?download=true) |
| `isnet-general-use` | `.onnx` | ISNet segmentation model | [Download](https://huggingface.co/Jonny001/deepfake/resolve/main/isnet-general-use.onnx?download=true) |
| `lsdir_x4` | `.onnx` | LSRDIR super-resolution (4x) | [Download](https://huggingface.co/Jonny001/deepfake/resolve/main/lsdir_x4.onnx?download=true) |
| `rd64-uni-refined` | `.pth` | Refined RD64 unified model | [Download](https://huggingface.co/Jonny001/deepfake/resolve/main/rd64-uni-refined.pth?download=true) |
| `real_esrgan_x2` | `.onnx` | Real-ESRGAN super-resolution (2x) | [Download](https://huggingface.co/Jonny001/deepfake/resolve/main/real_esrgan_x2.onnx?download=true) |
| `real_esrgan_x4` | `.onnx` | Real-ESRGAN super-resolution (4x) | [Download](https://huggingface.co/Jonny001/deepfake/resolve/main/real_esrgan_x4.onnx?download=true) |
| `restoreformer` | `.onnx` | RestoreFormer face restoration | [Download](https://huggingface.co/Jonny001/deepfake/resolve/main/restoreformer.onnx?download=true) |
| `restoreformer_plus_plus` | `.onnx` | RestoreFormer++ (enhanced version) | [Download](https://huggingface.co/Jonny001/deepfake/resolve/main/restoreformer_plus_plus.onnx?download=true) |
| `reswapper_128` | `.onnx` | ReSwapper model (128 resolution) | [Download](https://huggingface.co/Jonny001/deepfake/resolve/main/reswapper_128.onnx?download=true) |
| `reswapper_256` | `.onnx` | ReSwapper model (256 resolution) | [Download](https://huggingface.co/Jonny001/deepfake/resolve/main/reswapper_256.onnx?download=true) |
| `xseg` | `.onnx` | XSeg face mask segmentation | [Download](https://huggingface.co/Jonny001/deepfake/resolve/main/xseg.onnx?download=true) |
---
## 📛 Copyright
Models by **[CountFloyd](https://huggingface.co/CountFloyd)**
|
fafsfa/Qwen2.5-0.5B-Instruct-Gensyn-Swarm-diving_clawed_flamingo
|
fafsfa
| 2025-09-13T04:08:02Z | 7 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"rl-swarm",
"genrl-swarm",
"grpo",
"gensyn",
"I am diving_clawed_flamingo",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-09-11T14:38:22Z |
---
library_name: transformers
tags:
- rl-swarm
- genrl-swarm
- grpo
- gensyn
- I am diving_clawed_flamingo
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
stewy33/gemma-3-1b-it-115_ptonly_mixed_original_augmented_original_pkc_fda_approval-4db53695
|
stewy33
| 2025-09-13T04:00:23Z | 0 | 0 |
peft
|
[
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:togethercomputer/gemma-3-1b-it",
"base_model:adapter:togethercomputer/gemma-3-1b-it",
"region:us"
] | null | 2025-09-13T03:59:41Z |
---
base_model: togethercomputer/gemma-3-1b-it
library_name: peft
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.15.1
|
Subi003/GPT-Neo-125m-MathInstruct
|
Subi003
| 2025-09-13T03:43:31Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"en",
"dataset:nvidia/OpenMathInstruct-2",
"arxiv:1910.09700",
"base_model:EleutherAI/gpt-neo-125m",
"base_model:finetune:EleutherAI/gpt-neo-125m",
"license:mit",
"endpoints_compatible",
"region:us"
] | null | 2025-09-12T16:51:30Z |
---
library_name: transformers
license: mit
datasets:
- nvidia/OpenMathInstruct-2
language:
- en
base_model:
- EleutherAI/gpt-neo-125m
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** Subinoy Bera
- **Funded by [optional]:** None
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
haihp02/9d0d9299-2b32-428e-a548-76c08b2304ca
|
haihp02
| 2025-09-13T02:35:36Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-09-13T02:35:31Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
trietbui/instructblip-flan-t5-xxl-kvasir-vqa-x1
|
trietbui
| 2025-09-13T01:57:52Z | 36 | 0 |
peft
|
[
"peft",
"safetensors",
"base_model:adapter:Salesforce/instructblip-flan-t5-xxl",
"lora",
"transformers",
"arxiv:1910.09700",
"base_model:Salesforce/instructblip-flan-t5-xxl",
"region:us"
] | null | 2025-09-08T07:14:27Z |
---
base_model: Salesforce/instructblip-flan-t5-xxl
library_name: peft
tags:
- base_model:adapter:Salesforce/instructblip-flan-t5-xxl
- lora
- transformers
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.17.0
|
Kokoutou/sr105_denoi_1309_1
|
Kokoutou
| 2025-09-13T01:49:07Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-09-13T01:43:44Z |
# Container Template for SoundsRight Subnet Miners
This repository contains a contanierized version of [SGMSE+](https://huggingface.co/sp-uhh/speech-enhancement-sgmse) and serves as a tutorial for miners to format their models on [Bittensor's](https://bittensor.com/) [SoundsRight Subnet](https://github.com/synapsec-ai/SoundsRightSubnet). The branches `DENOISING_16000HZ` and `DEREVERBERATION_16000HZ` contain SGMSE fitted with the approrpriate checkpoints for denoising and dereverberation tasks at 16kHz, respectively.
This container has only been tested with **Ubuntu 24.04** and **CUDA 12.6**. It may run on other configurations, but it is not guaranteed.
To run the container, first configure NVIDIA Container Toolkit and generate a CDI specification. Follow the instructions to download the [NVIDIA Container Toolkit](https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/latest/install-guide.html) with Apt.
Next, follow the instructions for [generating a CDI specification](https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/latest/cdi-support.html).
Verify that the CDI specification was done correctly with:
```
$ nvidia-ctk cdi list
```
You should see this in your output:
```
nvidia.com/gpu=all
nvidia.com/gpu=0
```
If you are running podman as root, run the following command to start the container:
Run the container with:
```
podman build -t modelapi . && podman run -d --device nvidia.com/gpu=all --user root --name modelapi -p 6500:6500 modelapi
```
Access logs with:
```
podman logs -f modelapi
```
If you are running the container rootless, there are a few more changes to make:
First, modify `/etc/nvidia-container-runtime/config.toml` and set the following parameters:
```
[nvidia-container-cli]
no-cgroups = true
[nvidia-container-runtime]
debug = "/tmp/nvidia-container-runtime.log"
```
You can also run the following command to achieve the same result:
```
$ sudo nvidia-ctk config --set nvidia-container-cli.no-cgroups --in-place
```
Run the container with:
```
podman build -t modelapi . && podman run -d --device nvidia.com/gpu=all --volume /usr/local/cuda-12.6:/usr/local/cuda-12.6 --user 10002:10002 --name modelapi -p 6500:6500 modelapi
```
Access logs with:
```
podman logs -f modelapi
```
Running the container will spin up an API with the following endpoints:
1. `/status/` : Communicates API status
2. `/prepare/` : Download model checkpoint and initialize model
3. `/upload-audio/` : Upload audio files, save to noisy audio directory
4. `/enhance/` : Initialize model, enhance audio files, save to enhanced audio directory
5. `/download-enhanced/` : Download enhanced audio files
By default the API will use host `0.0.0.0` and port `6500`.
### References
1. **Welker, Simon; Richter, Julius; Gerkmann, Timo**
*Speech Enhancement with Score-Based Generative Models in the Complex STFT Domain*.
Proceedings of *Interspeech 2022*, 2022, pp. 2928–2932.
[DOI: 10.21437/Interspeech.2022-10653](https://doi.org/10.21437/Interspeech.2022-10653)
2. **Richter, Julius; Welker, Simon; Lemercier, Jean-Marie; Lay, Bunlong; Gerkmann, Timo**
*Speech Enhancement and Dereverberation with Diffusion-based Generative Models*.
*IEEE/ACM Transactions on Audio, Speech, and Language Processing*, Vol. 31, 2023, pp. 2351–2364.
[DOI: 10.1109/TASLP.2023.3285241](https://doi.org/10.1109/TASLP.2023.3285241)
3. **Richter, Julius; Wu, Yi-Chiao; Krenn, Steven; Welker, Simon; Lay, Bunlong; Watanabe, Shinjii; Richard, Alexander; Gerkmann, Timo**
*EARS: An Anechoic Fullband Speech Dataset Benchmarked for Speech Enhancement and Dereverberation*.
Proceedings of *ISCA Interspeech*, 2024, pp. 4873–4877.
|
adalberto-temp/Llama_3.2_3B_DPO_V0.2
|
adalberto-temp
| 2025-09-13T01:13:29Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-09-13T01:06:50Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
peruvs/MyGemmaNPC
|
peruvs
| 2025-09-13T01:08:48Z | 0 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"gemma3_text",
"text-generation",
"generated_from_trainer",
"sft",
"trl",
"conversational",
"base_model:google/gemma-3-270m-it",
"base_model:finetune:google/gemma-3-270m-it",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-09-12T18:49:59Z |
---
base_model: google/gemma-3-270m-it
library_name: transformers
model_name: MyGemmaNPC
tags:
- generated_from_trainer
- sft
- trl
licence: license
---
# Model Card for MyGemmaNPC
This model is a fine-tuned version of [google/gemma-3-270m-it](https://huggingface.co/google/gemma-3-270m-it).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="peruvs/MyGemmaNPC", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
This model was trained with SFT.
### Framework versions
- TRL: 0.23.0
- Transformers: 4.56.1
- Pytorch: 2.8.0+cu126
- Datasets: 4.0.0
- Tokenizers: 0.22.0
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
luckycanucky/HarmLLAmA-2
|
luckycanucky
| 2025-09-13T00:17:39Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-09-13T00:12:25Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
baziez/Hyphoria_Real_Illu
|
baziez
| 2025-09-13T00:11:55Z | 0 | 0 | null |
[
"gguf",
"text-to-image",
"sdxl",
"Diffusers",
"Safetensors",
"license:other",
"region:us"
] |
text-to-image
| 2025-09-12T23:56:08Z |
---
license: other
license_name: fair-ai-public-license-1.0-sd
license_link: https://freedevproject.org/faipl-1.0-sd/
tags:
- text-to-image
- sdxl
- gguf
- Diffusers
- Safetensors
pipeline_tag: text-to-image
pinned: false
---
# These are GGUF, scaled versions of Hyphoria Real [Illu] made by ecaj.
ecaj: [https://civitai.com/user/ecaj](https://civitai.com/user/ecaj).
# Notice
- Do not reprint this model. This model can be merged and shared, however derivatives cannot be used for commercial purposes (generative services, commissioned models, SeaArt, PixAI, etc.)
- You are solely responsible for any legal liability resulting from unethical use of this model(s)
- If you use any of these models for merging, please state what steps you took to do so and clearly indicate where modifications have been made.
## Recommended Settings
- Steps: 20-35 (I have always liked 35, but lower is just as good)
- CFG: 2.5-6
- Sampler: DPM++ 2M SDE (or DPM++ 2M on CIVITAI Gen)
- Scheduler: Karras
- Resolution: I recommend 1024x1024 - 1280x1280 for normal generation. Supports up to 1536x1536 without breaking, but can suffer some body extension. Any aspect ratio that equals the same number of pixels should work.
- Prompting: This model listens to your prompts, like really listens, so avoid the fluff and keep your prompts focused.
- Recommended Positive: masterpiece, best quality, absurdres
- Recommended Negative: worst quality, low quality
### Models Used
- IllustriousXL V2.0 Stable - Used as base merge target
- Rouwei v0.7 eps
- IllumiYume v3.1
- Hassaku v1.3 Style A
- ionsyx v3.0
- Wicked Illustrious Mix v1.1
- mdntIllus Syn v1
- Kokio v2.0
- Diving Illustrious Anime v11
- Bismuth Illustrious Mix v2.0
- NoobAI v1.1 eps
- Unreleased Merge
- Plant Milk Hemp II
- Plant Milk Coconut
- Note from ecaj of last two versions of real illu: "merging in various Illustrious based realistic models"
Using an algorithm, each model's UNET and CLIP were compared and the best was chosen tensor by tensor, using weights I set as my subjective adjustment to influence how likely they would be chosen. I can't tell you exactly what part of what model is used where, my merge script just chose what it considered the best.
info pasted from ecaj's model merges
- Hyphoria Real Illu: [https://civitai.com/models/1675671/hyphoria-real-illu](https://civitai.com/models/1675671/hyphoria-real-illu)
- Hyphoria Illu & NAI: [https://civitai.com/models/1595884/hyphoria-illu-and-nai](https://civitai.com/models/1595884/hyphoria-illu-and-nai)
## Repo includes:
### Original checkpoint:
hyphoriaRealIllu_v09.safetensors
"sha256": "91c53ac3ae3b5c8ecb4b89ae240dae0ca7dcd08c5ff6143e9fe6766e241cd28c"
### Scaled checkpoint:
hyphoriaRealIllu_v09_ckp_F8_00001_.safetensors
### GGUF:
F16, Q8_0, Q6_K, Q5_K_S, Q5_K_M, Q5_0, Q4_K_S, Q4_K_M, Q4_0, Q3_K_S, Q3_K_M, Q3_K_L, Q2_K
### CLIP & VAE:
hyphoriaRealIllu_v09_clip_g_00001_.safetensors
hyphoriaRealIllu_v09_clip_l_00001_.safetensors
hyphoriaRealIllu_v09_vae_00001_.safetensors
..extracted from original.
## Output test

## Workflow to recreate

### Licenses:
- SDXL - CreativeML Open RAIL++-M [https://github.com/Stability-AI/generative-models/blob/main/model_licenses/LICENSE-SDXL1.0](https://github.com/Stability-AI/generative-models/blob/main/model_licenses/LICENSE-SDXL1.0)
- Illustrious [https://freedevproject.org/faipl-1.0-sd/](https://freedevproject.org/faipl-1.0-sd/)
- NoobAI-XL [https://civitai.com/models/license/1140829](https://civitai.com/models/license/1140829)
|
Subsets and Splits
Filtered Qwen2.5 Distill Models
Identifies specific configurations of models by filtering cards that contain 'distill', 'qwen2.5', '7b' while excluding certain base models and incorrect model ID patterns, uncovering unique model variants.
Filtered Model Cards Count
Finds the count of entries with specific card details that include 'distill', 'qwen2.5', '7b' but exclude certain base models, revealing valuable insights about the dataset's content distribution.
Filtered Distill Qwen 7B Models
Filters for specific card entries containing 'distill', 'qwen', and '7b', excluding certain strings and patterns, to identify relevant model configurations.
Filtered Qwen-7b Model Cards
The query performs a detailed filtering based on specific keywords and excludes certain entries, which could be useful for identifying a specific subset of cards but does not provide deeper insights or trends.
Filtered Qwen 7B Model Cards
The query filters for specific terms related to "distilled" or "distill", "qwen", and "7b" in the 'card' column but excludes certain base models, providing a limited set of entries for further inspection.
Qwen 7B Distilled Models
The query provides a basic filtering of records to find specific card names that include keywords related to distilled Qwen 7b models, excluding a particular base model, which gives limited insight but helps in focusing on relevant entries.
Qwen 7B Distilled Model Cards
The query filters data based on specific keywords in the modelId and card fields, providing limited insight primarily useful for locating specific entries rather than revealing broad patterns or trends.
Qwen 7B Distilled Models
Finds all entries containing the terms 'distilled', 'qwen', and '7b' in a case-insensitive manner, providing a filtered set of records but without deeper analysis.
Distilled Qwen 7B Models
The query filters for specific model IDs containing 'distilled', 'qwen', and '7b', providing a basic retrieval of relevant entries but without deeper analysis or insight.
Filtered Model Cards with Distill Qwen2.
Filters and retrieves records containing specific keywords in the card description while excluding certain phrases, providing a basic count of relevant entries.
Filtered Model Cards with Distill Qwen 7
The query filters specific variations of card descriptions containing 'distill', 'qwen', and '7b' while excluding a particular base model, providing limited but specific data retrieval.
Distill Qwen 7B Model Cards
The query filters and retrieves rows where the 'card' column contains specific keywords ('distill', 'qwen', and '7b'), providing a basic filter result that can help in identifying specific entries.