
modelId
string | author
string | last_modified
timestamp[us, tz=UTC] | downloads
int64 | likes
int64 | library_name
string | tags
list | pipeline_tag
string | createdAt
timestamp[us, tz=UTC] | card
string |
|---|---|---|---|---|---|---|---|---|---|
chainway9/blockassist-bc-untamed_quick_eel_1755710135
|
chainway9
| 2025-08-20T17:42:27Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"untamed quick eel",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-20T17:42:23Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- untamed quick eel
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
lilTAT/blockassist-bc-gentle_rugged_hare_1755711657
|
lilTAT
| 2025-08-20T17:41:26Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"gentle rugged hare",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-20T17:41:20Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- gentle rugged hare
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Muapi/flux-sadamoto-yoshiyuki-evangelion-eva-ayanami-rei-souryuu-asuka-langley-artist-style
|
Muapi
| 2025-08-20T17:41:07Z | 0 | 0 | null |
[
"lora",
"stable-diffusion",
"flux.1-d",
"license:openrail++",
"region:us"
] | null | 2025-08-20T17:40:51Z |
---
license: openrail++
tags:
- lora
- stable-diffusion
- flux.1-d
model_type: LoRA
---
# [Flux] Sadamoto Yoshiyuki/贞本义行 《EVANGELION》/《EVA》/《新世纪福音战士》 Ayanami Rei, Souryuu Asuka Langley- Artist Style

**Base model**: Flux.1 D
**Trained words**: Sadamoto Yoshiyuki Style, souryuu asuka langley, ayanami rei, katsuragi misato, ikari shinji, nagisa kaworu, makinami mari illustrious, nadia la arwall
## 🧠 Usage (Python)
🔑 **Get your MUAPI key** from [muapi.ai/access-keys](https://muapi.ai/access-keys)
```python
import requests, os
url = "https://api.muapi.ai/api/v1/flux_dev_lora_image"
headers = {"Content-Type": "application/json", "x-api-key": os.getenv("MUAPIAPP_API_KEY")}
payload = {
"prompt": "masterpiece, best quality, 1girl, looking at viewer",
"model_id": [{"model": "civitai:708851@792878", "weight": 1.0}],
"width": 1024,
"height": 1024,
"num_images": 1
}
print(requests.post(url, headers=headers, json=payload).json())
```
|
Muapi/jan-van-goyen-style
|
Muapi
| 2025-08-20T17:40:36Z | 0 | 0 | null |
[
"lora",
"stable-diffusion",
"flux.1-d",
"license:openrail++",
"region:us"
] | null | 2025-08-20T17:40:19Z |
---
license: openrail++
tags:
- lora
- stable-diffusion
- flux.1-d
model_type: LoRA
---
# Jan van Goyen Style

**Base model**: Flux.1 D
**Trained words**: Jan van Goyen Style
## 🧠 Usage (Python)
🔑 **Get your MUAPI key** from [muapi.ai/access-keys](https://muapi.ai/access-keys)
```python
import requests, os
url = "https://api.muapi.ai/api/v1/flux_dev_lora_image"
headers = {"Content-Type": "application/json", "x-api-key": os.getenv("MUAPIAPP_API_KEY")}
payload = {
"prompt": "masterpiece, best quality, 1girl, looking at viewer",
"model_id": [{"model": "civitai:99436@1559598", "weight": 1.0}],
"width": 1024,
"height": 1024,
"num_images": 1
}
print(requests.post(url, headers=headers, json=payload).json())
```
|
helmutsukocok/blockassist-bc-loud_scavenging_kangaroo_1755709983
|
helmutsukocok
| 2025-08-20T17:39:56Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"loud scavenging kangaroo",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-20T17:39:53Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- loud scavenging kangaroo
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
mradermacher/brix-query-1.7b-GGUF
|
mradermacher
| 2025-08-20T17:38:53Z | 0 | 0 |
transformers
|
[
"transformers",
"gguf",
"en",
"base_model:SubconsciousDev/brix-query-1.7b",
"base_model:quantized:SubconsciousDev/brix-query-1.7b",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2025-08-20T17:26:51Z |
---
base_model: SubconsciousDev/brix-query-1.7b
language:
- en
library_name: transformers
mradermacher:
readme_rev: 1
quantized_by: mradermacher
tags: []
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
<!-- ### quants: x-f16 Q4_K_S Q2_K Q8_0 Q6_K Q3_K_M Q3_K_S Q3_K_L Q4_K_M Q5_K_S Q5_K_M IQ4_XS -->
<!-- ### quants_skip: -->
<!-- ### skip_mmproj: -->
static quants of https://huggingface.co/SubconsciousDev/brix-query-1.7b
<!-- provided-files -->
***For a convenient overview and download list, visit our [model page for this model](https://hf.tst.eu/model#brix-query-1.7b-GGUF).***
weighted/imatrix quants seem not to be available (by me) at this time. If they do not show up a week or so after the static ones, I have probably not planned for them. Feel free to request them by opening a Community Discussion.
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/brix-query-1.7b-GGUF/resolve/main/brix-query-1.7b.Q2_K.gguf) | Q2_K | 0.9 | |
| [GGUF](https://huggingface.co/mradermacher/brix-query-1.7b-GGUF/resolve/main/brix-query-1.7b.Q3_K_S.gguf) | Q3_K_S | 1.0 | |
| [GGUF](https://huggingface.co/mradermacher/brix-query-1.7b-GGUF/resolve/main/brix-query-1.7b.Q3_K_M.gguf) | Q3_K_M | 1.0 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/brix-query-1.7b-GGUF/resolve/main/brix-query-1.7b.Q3_K_L.gguf) | Q3_K_L | 1.1 | |
| [GGUF](https://huggingface.co/mradermacher/brix-query-1.7b-GGUF/resolve/main/brix-query-1.7b.IQ4_XS.gguf) | IQ4_XS | 1.1 | |
| [GGUF](https://huggingface.co/mradermacher/brix-query-1.7b-GGUF/resolve/main/brix-query-1.7b.Q4_K_S.gguf) | Q4_K_S | 1.2 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/brix-query-1.7b-GGUF/resolve/main/brix-query-1.7b.Q4_K_M.gguf) | Q4_K_M | 1.2 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/brix-query-1.7b-GGUF/resolve/main/brix-query-1.7b.Q5_K_S.gguf) | Q5_K_S | 1.3 | |
| [GGUF](https://huggingface.co/mradermacher/brix-query-1.7b-GGUF/resolve/main/brix-query-1.7b.Q5_K_M.gguf) | Q5_K_M | 1.4 | |
| [GGUF](https://huggingface.co/mradermacher/brix-query-1.7b-GGUF/resolve/main/brix-query-1.7b.Q6_K.gguf) | Q6_K | 1.5 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/brix-query-1.7b-GGUF/resolve/main/brix-query-1.7b.Q8_0.gguf) | Q8_0 | 1.9 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/brix-query-1.7b-GGUF/resolve/main/brix-query-1.7b.f16.gguf) | f16 | 3.5 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
uname0x96/blockassist-bc-rough_scavenging_narwhal_1755711168
|
uname0x96
| 2025-08-20T17:34:42Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"rough scavenging narwhal",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-20T17:34:25Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- rough scavenging narwhal
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
mradermacher/granite-3.3-2b-finetuned-alpaca-hindi-bengali_full-GGUF
|
mradermacher
| 2025-08-20T17:34:11Z | 0 | 0 |
transformers
|
[
"transformers",
"gguf",
"en",
"base_model:Debk/granite-3.3-2b-finetuned-alpaca-hindi-bengali_full",
"base_model:quantized:Debk/granite-3.3-2b-finetuned-alpaca-hindi-bengali_full",
"endpoints_compatible",
"region:us"
] | null | 2025-08-20T17:16:56Z |
---
base_model: Debk/granite-3.3-2b-finetuned-alpaca-hindi-bengali_full
language:
- en
library_name: transformers
mradermacher:
readme_rev: 1
quantized_by: mradermacher
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
<!-- ### quants: x-f16 Q4_K_S Q2_K Q8_0 Q6_K Q3_K_M Q3_K_S Q3_K_L Q4_K_M Q5_K_S Q5_K_M IQ4_XS -->
<!-- ### quants_skip: -->
<!-- ### skip_mmproj: -->
static quants of https://huggingface.co/Debk/granite-3.3-2b-finetuned-alpaca-hindi-bengali_full
<!-- provided-files -->
***For a convenient overview and download list, visit our [model page for this model](https://hf.tst.eu/model#granite-3.3-2b-finetuned-alpaca-hindi-bengali_full-GGUF).***
weighted/imatrix quants seem not to be available (by me) at this time. If they do not show up a week or so after the static ones, I have probably not planned for them. Feel free to request them by opening a Community Discussion.
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/granite-3.3-2b-finetuned-alpaca-hindi-bengali_full-GGUF/resolve/main/granite-3.3-2b-finetuned-alpaca-hindi-bengali_full.Q2_K.gguf) | Q2_K | 1.1 | |
| [GGUF](https://huggingface.co/mradermacher/granite-3.3-2b-finetuned-alpaca-hindi-bengali_full-GGUF/resolve/main/granite-3.3-2b-finetuned-alpaca-hindi-bengali_full.Q3_K_S.gguf) | Q3_K_S | 1.2 | |
| [GGUF](https://huggingface.co/mradermacher/granite-3.3-2b-finetuned-alpaca-hindi-bengali_full-GGUF/resolve/main/granite-3.3-2b-finetuned-alpaca-hindi-bengali_full.Q3_K_M.gguf) | Q3_K_M | 1.4 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/granite-3.3-2b-finetuned-alpaca-hindi-bengali_full-GGUF/resolve/main/granite-3.3-2b-finetuned-alpaca-hindi-bengali_full.Q3_K_L.gguf) | Q3_K_L | 1.5 | |
| [GGUF](https://huggingface.co/mradermacher/granite-3.3-2b-finetuned-alpaca-hindi-bengali_full-GGUF/resolve/main/granite-3.3-2b-finetuned-alpaca-hindi-bengali_full.IQ4_XS.gguf) | IQ4_XS | 1.5 | |
| [GGUF](https://huggingface.co/mradermacher/granite-3.3-2b-finetuned-alpaca-hindi-bengali_full-GGUF/resolve/main/granite-3.3-2b-finetuned-alpaca-hindi-bengali_full.Q4_K_S.gguf) | Q4_K_S | 1.6 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/granite-3.3-2b-finetuned-alpaca-hindi-bengali_full-GGUF/resolve/main/granite-3.3-2b-finetuned-alpaca-hindi-bengali_full.Q4_K_M.gguf) | Q4_K_M | 1.6 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/granite-3.3-2b-finetuned-alpaca-hindi-bengali_full-GGUF/resolve/main/granite-3.3-2b-finetuned-alpaca-hindi-bengali_full.Q5_K_S.gguf) | Q5_K_S | 1.9 | |
| [GGUF](https://huggingface.co/mradermacher/granite-3.3-2b-finetuned-alpaca-hindi-bengali_full-GGUF/resolve/main/granite-3.3-2b-finetuned-alpaca-hindi-bengali_full.Q5_K_M.gguf) | Q5_K_M | 1.9 | |
| [GGUF](https://huggingface.co/mradermacher/granite-3.3-2b-finetuned-alpaca-hindi-bengali_full-GGUF/resolve/main/granite-3.3-2b-finetuned-alpaca-hindi-bengali_full.Q6_K.gguf) | Q6_K | 2.2 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/granite-3.3-2b-finetuned-alpaca-hindi-bengali_full-GGUF/resolve/main/granite-3.3-2b-finetuned-alpaca-hindi-bengali_full.Q8_0.gguf) | Q8_0 | 2.8 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/granite-3.3-2b-finetuned-alpaca-hindi-bengali_full-GGUF/resolve/main/granite-3.3-2b-finetuned-alpaca-hindi-bengali_full.f16.gguf) | f16 | 5.2 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
alunadiderot/setfit-e5-base-category-classifier_v1
|
alunadiderot
| 2025-08-20T17:32:11Z | 0 | 0 | null |
[
"safetensors",
"xlm-roberta",
"region:us"
] | null | 2025-08-20T17:29:40Z |
# SetFit E5 Base Category Classifier v1
A SetFit model trained on E5-base for category classification.
## Model Details
- Base Model: E5-base
- Task: Category classification
## Usage
[Add usage instructions]
|
Muapi/artistic-analog-photos-realistic-photos
|
Muapi
| 2025-08-20T17:30:14Z | 0 | 0 | null |
[
"lora",
"stable-diffusion",
"flux.1-d",
"license:openrail++",
"region:us"
] | null | 2025-08-20T17:29:59Z |
---
license: openrail++
tags:
- lora
- stable-diffusion
- flux.1-d
model_type: LoRA
---
# Artistic Analog Photos (realistic photos)

**Base model**: Flux.1 D
**Trained words**: aaphotosv2
## 🧠 Usage (Python)
🔑 **Get your MUAPI key** from [muapi.ai/access-keys](https://muapi.ai/access-keys)
```python
import requests, os
url = "https://api.muapi.ai/api/v1/flux_dev_lora_image"
headers = {"Content-Type": "application/json", "x-api-key": os.getenv("MUAPIAPP_API_KEY")}
payload = {
"prompt": "masterpiece, best quality, 1girl, looking at viewer",
"model_id": [{"model": "civitai:934391@1368796", "weight": 1.0}],
"width": 1024,
"height": 1024,
"num_images": 1
}
print(requests.post(url, headers=headers, json=payload).json())
```
|
WenFengg/loss_14l14_21_8
|
WenFengg
| 2025-08-20T17:29:15Z | 0 | 0 | null |
[
"safetensors",
"any-to-any",
"omega",
"omegalabs",
"bittensor",
"agi",
"license:mit",
"region:us"
] |
any-to-any
| 2025-08-20T17:23:47Z |
---
license: mit
tags:
- any-to-any
- omega
- omegalabs
- bittensor
- agi
---
This is an Any-to-Any model checkpoint for the OMEGA Labs x Bittensor Any-to-Any subnet.
Check out the [git repo](https://github.com/omegalabsinc/omegalabs-anytoany-bittensor) and find OMEGA on X: [@omegalabsai](https://x.com/omegalabsai).
|
Renu11/my_embedding_gemma
|
Renu11
| 2025-08-20T17:28:24Z | 0 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"safetensors",
"gemma3_text",
"sentence-similarity",
"feature-extraction",
"dense",
"generated_from_trainer",
"dataset_size:3",
"loss:MultipleNegativesRankingLoss",
"arxiv:1908.10084",
"arxiv:1705.00652",
"base_model:gg-hf-gm/embeddinggemma-300M",
"base_model:finetune:gg-hf-gm/embeddinggemma-300M",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2025-08-20T17:27:05Z |
---
tags:
- sentence-transformers
- sentence-similarity
- feature-extraction
- dense
- generated_from_trainer
- dataset_size:3
- loss:MultipleNegativesRankingLoss
base_model: gg-hf-gm/embeddinggemma-300M
pipeline_tag: sentence-similarity
library_name: sentence-transformers
---
# SentenceTransformer based on gg-hf-gm/embeddinggemma-300M
This is a [sentence-transformers](https://www.SBERT.net) model finetuned from [gg-hf-gm/embeddinggemma-300M](https://huggingface.co/gg-hf-gm/embeddinggemma-300M). It maps sentences & paragraphs to a 768-dimensional dense vector space and can be used for semantic textual similarity, semantic search, paraphrase mining, text classification, clustering, and more.
## Model Details
### Model Description
- **Model Type:** Sentence Transformer
- **Base model:** [gg-hf-gm/embeddinggemma-300M](https://huggingface.co/gg-hf-gm/embeddinggemma-300M) <!-- at revision e4253f99d926a4f5c770e5be9f9762ed86edc80b -->
- **Maximum Sequence Length:** 1024 tokens
- **Output Dimensionality:** 768 dimensions
- **Similarity Function:** Cosine Similarity
<!-- - **Training Dataset:** Unknown -->
<!-- - **Language:** Unknown -->
<!-- - **License:** Unknown -->
### Model Sources
- **Documentation:** [Sentence Transformers Documentation](https://sbert.net)
- **Repository:** [Sentence Transformers on GitHub](https://github.com/UKPLab/sentence-transformers)
- **Hugging Face:** [Sentence Transformers on Hugging Face](https://huggingface.co/models?library=sentence-transformers)
### Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 1024, 'do_lower_case': False, 'architecture': 'Gemma3TextModel'})
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False, 'pooling_mode_weightedmean_tokens': False, 'pooling_mode_lasttoken': False, 'include_prompt': True})
(2): Dense({'in_features': 768, 'out_features': 3072, 'bias': False, 'activation_function': 'torch.nn.modules.linear.Identity'})
(3): Dense({'in_features': 3072, 'out_features': 768, 'bias': False, 'activation_function': 'torch.nn.modules.linear.Identity'})
(4): Normalize()
)
```
## Usage
### Direct Usage (Sentence Transformers)
First install the Sentence Transformers library:
```bash
pip install -U sentence-transformers
```
Then you can load this model and run inference.
```python
from sentence_transformers import SentenceTransformer
# Download from the 🤗 Hub
model = SentenceTransformer("Renu11/my_embedding_gemma")
# Run inference
queries = [
"Which planet is known as the Red Planet?",
]
documents = [
"Venus is often called Earth's twin because of its similar size and proximity.",
'Mars, known for its reddish appearance, is often referred to as the Red Planet.',
'Saturn, famous for its rings, is sometimes mistaken for the Red Planet.',
]
query_embeddings = model.encode_query(queries)
document_embeddings = model.encode_document(documents)
print(query_embeddings.shape, document_embeddings.shape)
# [1, 768] [3, 768]
# Get the similarity scores for the embeddings
similarities = model.similarity(query_embeddings, document_embeddings)
print(similarities)
# tensor([[0.4465, 0.7582, 0.5683]])
```
<!--
### Direct Usage (Transformers)
<details><summary>Click to see the direct usage in Transformers</summary>
</details>
-->
<!--
### Downstream Usage (Sentence Transformers)
You can finetune this model on your own dataset.
<details><summary>Click to expand</summary>
</details>
-->
<!--
### Out-of-Scope Use
*List how the model may foreseeably be misused and address what users ought not to do with the model.*
-->
<!--
## Bias, Risks and Limitations
*What are the known or foreseeable issues stemming from this model? You could also flag here known failure cases or weaknesses of the model.*
-->
<!--
### Recommendations
*What are recommendations with respect to the foreseeable issues? For example, filtering explicit content.*
-->
## Training Details
### Training Dataset
#### Unnamed Dataset
* Size: 3 training samples
* Columns: <code>anchor</code>, <code>positive</code>, and <code>negative</code>
* Approximate statistics based on the first 3 samples:
| | anchor | positive | negative |
|:--------|:----------------------------------------------------------------------------------|:-----------------------------------------------------------------------------------|:-----------------------------------------------------------------------------------|
| type | string | string | string |
| details | <ul><li>min: 10 tokens</li><li>mean: 12.0 tokens</li><li>max: 15 tokens</li></ul> | <ul><li>min: 13 tokens</li><li>mean: 15.33 tokens</li><li>max: 17 tokens</li></ul> | <ul><li>min: 12 tokens</li><li>mean: 12.67 tokens</li><li>max: 14 tokens</li></ul> |
* Samples:
| anchor | positive | negative |
|:--------------------------------------------------------------------------|:-----------------------------------------------------------------------------------|:------------------------------------------------------------------------|
| <code>How do I open a NISA account?</code> | <code>What is the procedure for starting a new tax-free investment account?</code> | <code>I want to check the balance of my regular savings account.</code> |
| <code>Are there fees for making an early repayment on a home loan?</code> | <code>If I pay back my house loan early, will there be any costs?</code> | <code>What is the management fee for this investment trust?</code> |
| <code>What is the coverage for medical insurance?</code> | <code>Tell me about the benefits of the health insurance plan.</code> | <code>What is the cancellation policy for my life insurance?</code> |
* Loss: [<code>MultipleNegativesRankingLoss</code>](https://sbert.net/docs/package_reference/sentence_transformer/losses.html#multiplenegativesrankingloss) with these parameters:
```json
{
"scale": 20.0,
"similarity_fct": "cos_sim",
"gather_across_devices": false
}
```
### Training Hyperparameters
#### Non-Default Hyperparameters
- `per_device_train_batch_size`: 1
- `learning_rate`: 2e-05
- `num_train_epochs`: 5
- `warmup_ratio`: 0.1
- `fp16`: True
- `prompts`: task: sentence similarity | query:
#### All Hyperparameters
<details><summary>Click to expand</summary>
- `overwrite_output_dir`: False
- `do_predict`: False
- `eval_strategy`: no
- `prediction_loss_only`: True
- `per_device_train_batch_size`: 1
- `per_device_eval_batch_size`: 8
- `per_gpu_train_batch_size`: None
- `per_gpu_eval_batch_size`: None
- `gradient_accumulation_steps`: 1
- `eval_accumulation_steps`: None
- `torch_empty_cache_steps`: None
- `learning_rate`: 2e-05
- `weight_decay`: 0.0
- `adam_beta1`: 0.9
- `adam_beta2`: 0.999
- `adam_epsilon`: 1e-08
- `max_grad_norm`: 1.0
- `num_train_epochs`: 5
- `max_steps`: -1
- `lr_scheduler_type`: linear
- `lr_scheduler_kwargs`: {}
- `warmup_ratio`: 0.1
- `warmup_steps`: 0
- `log_level`: passive
- `log_level_replica`: warning
- `log_on_each_node`: True
- `logging_nan_inf_filter`: True
- `save_safetensors`: True
- `save_on_each_node`: False
- `save_only_model`: False
- `restore_callback_states_from_checkpoint`: False
- `no_cuda`: False
- `use_cpu`: False
- `use_mps_device`: False
- `seed`: 42
- `data_seed`: None
- `jit_mode_eval`: False
- `use_ipex`: False
- `bf16`: False
- `fp16`: True
- `fp16_opt_level`: O1
- `half_precision_backend`: auto
- `bf16_full_eval`: False
- `fp16_full_eval`: False
- `tf32`: None
- `local_rank`: 0
- `ddp_backend`: None
- `tpu_num_cores`: None
- `tpu_metrics_debug`: False
- `debug`: []
- `dataloader_drop_last`: False
- `dataloader_num_workers`: 0
- `dataloader_prefetch_factor`: None
- `past_index`: -1
- `disable_tqdm`: False
- `remove_unused_columns`: True
- `label_names`: None
- `load_best_model_at_end`: False
- `ignore_data_skip`: False
- `fsdp`: []
- `fsdp_min_num_params`: 0
- `fsdp_config`: {'min_num_params': 0, 'xla': False, 'xla_fsdp_v2': False, 'xla_fsdp_grad_ckpt': False}
- `fsdp_transformer_layer_cls_to_wrap`: None
- `accelerator_config`: {'split_batches': False, 'dispatch_batches': None, 'even_batches': True, 'use_seedable_sampler': True, 'non_blocking': False, 'gradient_accumulation_kwargs': None}
- `deepspeed`: None
- `label_smoothing_factor`: 0.0
- `optim`: adamw_torch_fused
- `optim_args`: None
- `adafactor`: False
- `group_by_length`: False
- `length_column_name`: length
- `ddp_find_unused_parameters`: None
- `ddp_bucket_cap_mb`: None
- `ddp_broadcast_buffers`: False
- `dataloader_pin_memory`: True
- `dataloader_persistent_workers`: False
- `skip_memory_metrics`: True
- `use_legacy_prediction_loop`: False
- `push_to_hub`: False
- `resume_from_checkpoint`: None
- `hub_model_id`: None
- `hub_strategy`: every_save
- `hub_private_repo`: None
- `hub_always_push`: False
- `hub_revision`: None
- `gradient_checkpointing`: False
- `gradient_checkpointing_kwargs`: None
- `include_inputs_for_metrics`: False
- `include_for_metrics`: []
- `eval_do_concat_batches`: True
- `fp16_backend`: auto
- `push_to_hub_model_id`: None
- `push_to_hub_organization`: None
- `mp_parameters`:
- `auto_find_batch_size`: False
- `full_determinism`: False
- `torchdynamo`: None
- `ray_scope`: last
- `ddp_timeout`: 1800
- `torch_compile`: False
- `torch_compile_backend`: None
- `torch_compile_mode`: None
- `include_tokens_per_second`: False
- `include_num_input_tokens_seen`: False
- `neftune_noise_alpha`: None
- `optim_target_modules`: None
- `batch_eval_metrics`: False
- `eval_on_start`: False
- `use_liger_kernel`: False
- `liger_kernel_config`: None
- `eval_use_gather_object`: False
- `average_tokens_across_devices`: False
- `prompts`: task: sentence similarity | query:
- `batch_sampler`: batch_sampler
- `multi_dataset_batch_sampler`: proportional
- `router_mapping`: {}
- `learning_rate_mapping`: {}
</details>
### Training Logs
| Epoch | Step | Training Loss |
|:-----:|:----:|:-------------:|
| 1.0 | 3 | 0.5841 |
| 2.0 | 6 | 1.1445 |
| 3.0 | 9 | 1.2516 |
| 4.0 | 12 | 1.1445 |
| 5.0 | 15 | 0.0252 |
### Framework Versions
- Python: 3.12.11
- Sentence Transformers: 5.1.0
- Transformers: 4.55.2
- PyTorch: 2.8.0+cu126
- Accelerate: 1.10.0
- Datasets: 4.0.0
- Tokenizers: 0.21.4
## Citation
### BibTeX
#### Sentence Transformers
```bibtex
@inproceedings{reimers-2019-sentence-bert,
title = "Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks",
author = "Reimers, Nils and Gurevych, Iryna",
booktitle = "Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing",
month = "11",
year = "2019",
publisher = "Association for Computational Linguistics",
url = "https://arxiv.org/abs/1908.10084",
}
```
#### MultipleNegativesRankingLoss
```bibtex
@misc{henderson2017efficient,
title={Efficient Natural Language Response Suggestion for Smart Reply},
author={Matthew Henderson and Rami Al-Rfou and Brian Strope and Yun-hsuan Sung and Laszlo Lukacs and Ruiqi Guo and Sanjiv Kumar and Balint Miklos and Ray Kurzweil},
year={2017},
eprint={1705.00652},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
<!--
## Glossary
*Clearly define terms in order to be accessible across audiences.*
-->
<!--
## Model Card Authors
*Lists the people who create the model card, providing recognition and accountability for the detailed work that goes into its construction.*
-->
<!--
## Model Card Contact
*Provides a way for people who have updates to the Model Card, suggestions, or questions, to contact the Model Card authors.*
-->
|
MattBou00/llama-3-2-1b-detox_v1f-checkpoint-epoch-40
|
MattBou00
| 2025-08-20T17:24:27Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"trl",
"ppo",
"reinforcement-learning",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
reinforcement-learning
| 2025-08-20T00:22:50Z |
---
license: apache-2.0
library_name: transformers
tags:
- trl
- ppo
- transformers
- reinforcement-learning
---
# TRL Model
This is a [TRL language model](https://github.com/huggingface/trl) that has been fine-tuned with reinforcement learning to
guide the model outputs according to a value, function, or human feedback. The model can be used for text generation.
## Usage
To use this model for inference, first install the TRL library:
```bash
python -m pip install trl
```
You can then generate text as follows:
```python
from transformers import pipeline
generator = pipeline("text-generation", model="MattBou00//rds/general/user/mrb124/home/IRL-Bayesian/outputs/2025-08-20_18-18-32/checkpoints/checkpoint-epoch-40")
outputs = generator("Hello, my llama is cute")
```
If you want to use the model for training or to obtain the outputs from the value head, load the model as follows:
```python
from transformers import AutoTokenizer
from trl import AutoModelForCausalLMWithValueHead
tokenizer = AutoTokenizer.from_pretrained("MattBou00//rds/general/user/mrb124/home/IRL-Bayesian/outputs/2025-08-20_18-18-32/checkpoints/checkpoint-epoch-40")
model = AutoModelForCausalLMWithValueHead.from_pretrained("MattBou00//rds/general/user/mrb124/home/IRL-Bayesian/outputs/2025-08-20_18-18-32/checkpoints/checkpoint-epoch-40")
inputs = tokenizer("Hello, my llama is cute", return_tensors="pt")
outputs = model(**inputs, labels=inputs["input_ids"])
```
|
Muapi/black-spider-man-bodysuit-cosplay-il-flux
|
Muapi
| 2025-08-20T17:23:43Z | 0 | 0 | null |
[
"lora",
"stable-diffusion",
"flux.1-d",
"license:openrail++",
"region:us"
] | null | 2025-08-20T17:22:49Z |
---
license: openrail++
tags:
- lora
- stable-diffusion
- flux.1-d
model_type: LoRA
---
# Black Spider-Man Bodysuit Cosplay [IL+Flux]

**Base model**: Flux.1 D
**Trained words**: wearing a black SymbioteSuit
## 🧠 Usage (Python)
🔑 **Get your MUAPI key** from [muapi.ai/access-keys](https://muapi.ai/access-keys)
```python
import requests, os
url = "https://api.muapi.ai/api/v1/flux_dev_lora_image"
headers = {"Content-Type": "application/json", "x-api-key": os.getenv("MUAPIAPP_API_KEY")}
payload = {
"prompt": "masterpiece, best quality, 1girl, looking at viewer",
"model_id": [{"model": "civitai:701263@784643", "weight": 1.0}],
"width": 1024,
"height": 1024,
"num_images": 1
}
print(requests.post(url, headers=headers, json=payload).json())
```
|
demonwizard0/affine-beta-5
|
demonwizard0
| 2025-08-20T17:23:19Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"gpt_oss",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-20T17:22:29Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Muapi/fantasy-novel-art-style
|
Muapi
| 2025-08-20T17:22:30Z | 0 | 0 | null |
[
"lora",
"stable-diffusion",
"flux.1-d",
"license:openrail++",
"region:us"
] | null | 2025-08-20T17:22:13Z |
---
license: openrail++
tags:
- lora
- stable-diffusion
- flux.1-d
model_type: LoRA
---
# Fantasy Novel Art Style

**Base model**: Flux.1 D
**Trained words**: fna_style
## 🧠 Usage (Python)
🔑 **Get your MUAPI key** from [muapi.ai/access-keys](https://muapi.ai/access-keys)
```python
import requests, os
url = "https://api.muapi.ai/api/v1/flux_dev_lora_image"
headers = {"Content-Type": "application/json", "x-api-key": os.getenv("MUAPIAPP_API_KEY")}
payload = {
"prompt": "masterpiece, best quality, 1girl, looking at viewer",
"model_id": [{"model": "civitai:742202@829996", "weight": 1.0}],
"width": 1024,
"height": 1024,
"num_images": 1
}
print(requests.post(url, headers=headers, json=payload).json())
```
|
MattBou00/llama-3-2-1b-detox_v1f-checkpoint-epoch-20
|
MattBou00
| 2025-08-20T17:21:53Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"trl",
"ppo",
"reinforcement-learning",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
reinforcement-learning
| 2025-08-20T00:18:25Z |
---
license: apache-2.0
library_name: transformers
tags:
- trl
- ppo
- transformers
- reinforcement-learning
---
# TRL Model
This is a [TRL language model](https://github.com/huggingface/trl) that has been fine-tuned with reinforcement learning to
guide the model outputs according to a value, function, or human feedback. The model can be used for text generation.
## Usage
To use this model for inference, first install the TRL library:
```bash
python -m pip install trl
```
You can then generate text as follows:
```python
from transformers import pipeline
generator = pipeline("text-generation", model="MattBou00//rds/general/user/mrb124/home/IRL-Bayesian/outputs/2025-08-20_18-18-32/checkpoints/checkpoint-epoch-20")
outputs = generator("Hello, my llama is cute")
```
If you want to use the model for training or to obtain the outputs from the value head, load the model as follows:
```python
from transformers import AutoTokenizer
from trl import AutoModelForCausalLMWithValueHead
tokenizer = AutoTokenizer.from_pretrained("MattBou00//rds/general/user/mrb124/home/IRL-Bayesian/outputs/2025-08-20_18-18-32/checkpoints/checkpoint-epoch-20")
model = AutoModelForCausalLMWithValueHead.from_pretrained("MattBou00//rds/general/user/mrb124/home/IRL-Bayesian/outputs/2025-08-20_18-18-32/checkpoints/checkpoint-epoch-20")
inputs = tokenizer("Hello, my llama is cute", return_tensors="pt")
outputs = model(**inputs, labels=inputs["input_ids"])
```
|
Danielbrdz/BarcenasMexico-14b
|
Danielbrdz
| 2025-08-20T17:20:48Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen3",
"text-generation",
"mexico",
"conversational",
"es",
"dataset:Danielbrdz/BarcenasMexico",
"base_model:Qwen/Qwen3-14B",
"base_model:finetune:Qwen/Qwen3-14B",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-20T17:08:45Z |
---
license: apache-2.0
datasets:
- Danielbrdz/BarcenasMexico
language:
- es
base_model:
- Qwen/Qwen3-14B
pipeline_tag: text-generation
library_name: transformers
tags:
- mexico
---
Barcenas México 14b
Basado en Qwen 3 14b y entrenado con el dataset Barcenas México
El objetivo de este LLM es tener modelo que sepa todo de México, su historia, cultura, gastronomía, etc. Todo en LLM potente como es Qwen 3 14b
El LLM puede contestar preguntas de México con precisión, por su entrenamiento con datos de México hecha por humanos.
------------------------------------------------------------------------------------------------------------------------
Barcenas Mexico 14b
Based on Qwen 3 14b and trained with the Barcenas Mexico dataset.
The objective of this LLM is to have a model that knows everything about Mexico, its history, culture, gastronomy, etc. All in a powerful LLM like Qwen 3 14b.
The LLM can answer questions about Mexico with precision, due to its training with data from Mexico created by humans.
Made with ❤️ in Guadalupe, Nuevo Leon, Mexico 🇲🇽
|
0xaoyama/blockassist-bc-muscular_zealous_gorilla_1755710315
|
0xaoyama
| 2025-08-20T17:19:11Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"muscular zealous gorilla",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-20T17:18:59Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- muscular zealous gorilla
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
WenFengg/pyar_14l13_21_8
|
WenFengg
| 2025-08-20T17:19:03Z | 0 | 0 | null |
[
"safetensors",
"any-to-any",
"omega",
"omegalabs",
"bittensor",
"agi",
"license:mit",
"region:us"
] |
any-to-any
| 2025-08-20T17:14:16Z |
---
license: mit
tags:
- any-to-any
- omega
- omegalabs
- bittensor
- agi
---
This is an Any-to-Any model checkpoint for the OMEGA Labs x Bittensor Any-to-Any subnet.
Check out the [git repo](https://github.com/omegalabsinc/omegalabs-anytoany-bittensor) and find OMEGA on X: [@omegalabsai](https://x.com/omegalabsai).
|
ihsanridzi/blockassist-bc-wiry_flexible_owl_1755708729
|
ihsanridzi
| 2025-08-20T17:18:26Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"wiry flexible owl",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-20T17:18:22Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- wiry flexible owl
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
0xaoyama/blockassist-bc-muscular_zealous_gorilla_1755710124
|
0xaoyama
| 2025-08-20T17:16:01Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"muscular zealous gorilla",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-20T17:15:49Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- muscular zealous gorilla
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
liu-nlp/salamandra-7b-smol-smoltalk-sv-en
|
liu-nlp
| 2025-08-20T17:15:47Z | 6 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"generated_from_trainer",
"trl",
"sft",
"conversational",
"base_model:BSC-LT/salamandra-7b",
"base_model:finetune:BSC-LT/salamandra-7b",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-13T14:40:45Z |
---
base_model: BSC-LT/salamandra-7b
library_name: transformers
model_name: salamandra-7b-smol-smoltalk-sv-en
tags:
- generated_from_trainer
- trl
- sft
licence: license
---
# Model Card for salamandra-7b-smol-smoltalk-sv-en
This model is a fine-tuned version of [BSC-LT/salamandra-7b](https://huggingface.co/BSC-LT/salamandra-7b).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="liu-nlp/salamandra-7b-smol-smoltalk-sv-en", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="150" height="24"/>](https://wandb.ai/jenny-kunz-liu/huggingface/runs/vzuruaa8)
This model was trained with SFT.
### Framework versions
- TRL: 0.21.0
- Transformers: 4.55.1
- Pytorch: 2.8.0
- Datasets: 4.0.0
- Tokenizers: 0.21.4
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
hungtrab/q-TaxiV3
|
hungtrab
| 2025-08-20T17:14:19Z | 0 | 0 | null |
[
"Taxi-v3",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2025-08-20T17:14:13Z |
---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-TaxiV3
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
metrics:
- type: mean_reward
value: 7.54 +/- 2.74
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="hungtrab/q-TaxiV3", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
youuotty/blockassist-bc-sizable_bipedal_turtle_1755709879
|
youuotty
| 2025-08-20T17:12:07Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"sizable bipedal turtle",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-20T17:11:23Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- sizable bipedal turtle
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
software-mansion/react-native-executorch-whisper-tiny.en
|
software-mansion
| 2025-08-20T17:11:38Z | 253 | 1 | null |
[
"license:apache-2.0",
"region:us"
] | null | 2025-02-26T10:21:26Z |
---
license: apache-2.0
---
# Introduction
This repository hosts the [whisper-tiny.en](https://huggingface.co/openai/whisper-tiny.en) model for the [React Native ExecuTorch](https://www.npmjs.com/package/react-native-executorch) library. It includes the model exported for xnnpack backend in `.pte` format, ready for use in the **ExecuTorch** runtime.
If you'd like to run these models in your own ExecuTorch runtime, refer to the [official documentation](https://pytorch.org/executorch/stable/index.html) for setup instructions.
## Compatibility
If you intend to use this models outside of React Native ExecuTorch, make sure your runtime is compatible with the **ExecuTorch** version used to export the `.pte` files. For more details, see the compatibility note in the [ExecuTorch GitHub repository](https://github.com/pytorch/executorch/blob/11d1742fdeddcf05bc30a6cfac321d2a2e3b6768/runtime/COMPATIBILITY.md?plain=1#L4). If you work with React Native ExecuTorch, the constants from the library will guarantee compatibility with runtime used behind the scenes.
These models were exported using v0.6.0 version of ExecuTorch and **no forward compatibility** is guaranteed. Older versions of the runtime may not work with these files.
|
roeker/blockassist-bc-quick_wiry_owl_1755709760
|
roeker
| 2025-08-20T17:10:37Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"quick wiry owl",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-20T17:09:59Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- quick wiry owl
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
liu-nlp/salamandra-7b-smol-smoltalk-sv
|
liu-nlp
| 2025-08-20T17:10:15Z | 8 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"generated_from_trainer",
"sft",
"trl",
"conversational",
"base_model:BSC-LT/salamandra-7b",
"base_model:finetune:BSC-LT/salamandra-7b",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-08T09:29:16Z |
---
base_model: BSC-LT/salamandra-7b
library_name: transformers
model_name: salamandra-7b-smol-smoltalk-sv
tags:
- generated_from_trainer
- sft
- trl
licence: license
---
# Model Card for salamandra-7b-smol-smoltalk-sv
This model is a fine-tuned version of [BSC-LT/salamandra-7b](https://huggingface.co/BSC-LT/salamandra-7b).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="liu-nlp/salamandra-7b-smol-smoltalk-sv", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="150" height="24"/>](https://wandb.ai/jenny-kunz-liu/huggingface/runs/yt1ddttp)
This model was trained with SFT.
### Framework versions
- TRL: 0.21.0
- Transformers: 4.55.1
- Pytorch: 2.8.0
- Datasets: 4.0.0
- Tokenizers: 0.21.4
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
chainway9/blockassist-bc-untamed_quick_eel_1755708079
|
chainway9
| 2025-08-20T17:09:40Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"untamed quick eel",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-20T17:09:36Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- untamed quick eel
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
gsaltintas/supertoken_models-llama_google-gemma-2-2b-100b
|
gsaltintas
| 2025-08-20T17:08:00Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"arxiv:1910.09700",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | null | 2025-08-18T19:14:40Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
WenFengg/pyar_14l11_21_8
|
WenFengg
| 2025-08-20T17:07:09Z | 0 | 0 | null |
[
"safetensors",
"any-to-any",
"omega",
"omegalabs",
"bittensor",
"agi",
"license:mit",
"region:us"
] |
any-to-any
| 2025-08-20T17:02:25Z |
---
license: mit
tags:
- any-to-any
- omega
- omegalabs
- bittensor
- agi
---
This is an Any-to-Any model checkpoint for the OMEGA Labs x Bittensor Any-to-Any subnet.
Check out the [git repo](https://github.com/omegalabsinc/omegalabs-anytoany-bittensor) and find OMEGA on X: [@omegalabsai](https://x.com/omegalabsai).
|
youuotty/blockassist-bc-bristly_striped_flamingo_1755709536
|
youuotty
| 2025-08-20T17:06:25Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"bristly striped flamingo",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-20T17:05:38Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- bristly striped flamingo
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
0xaoyama/blockassist-bc-muscular_zealous_gorilla_1755709539
|
0xaoyama
| 2025-08-20T17:06:11Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"muscular zealous gorilla",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-20T17:06:00Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- muscular zealous gorilla
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
kojeklollipop/blockassist-bc-spotted_amphibious_stork_1755707761
|
kojeklollipop
| 2025-08-20T17:05:54Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"spotted amphibious stork",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-20T17:05:51Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- spotted amphibious stork
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
vwzyrraz7l/blockassist-bc-tall_hunting_vulture_1755707719
|
vwzyrraz7l
| 2025-08-20T17:04:32Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"tall hunting vulture",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-20T17:04:29Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- tall hunting vulture
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
mradermacher/shellm-v0.1-GGUF
|
mradermacher
| 2025-08-20T17:04:23Z | 0 | 0 |
transformers
|
[
"transformers",
"gguf",
"en",
"base_model:hawierdev/shellm-v0.1",
"base_model:quantized:hawierdev/shellm-v0.1",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2025-08-20T16:49:58Z |
---
base_model: hawierdev/shellm-v0.1
language:
- en
library_name: transformers
mradermacher:
readme_rev: 1
quantized_by: mradermacher
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
<!-- ### quants: x-f16 Q4_K_S Q2_K Q8_0 Q6_K Q3_K_M Q3_K_S Q3_K_L Q4_K_M Q5_K_S Q5_K_M IQ4_XS -->
<!-- ### quants_skip: -->
<!-- ### skip_mmproj: -->
static quants of https://huggingface.co/hawierdev/shellm-v0.1
<!-- provided-files -->
***For a convenient overview and download list, visit our [model page for this model](https://hf.tst.eu/model#shellm-v0.1-GGUF).***
weighted/imatrix quants seem not to be available (by me) at this time. If they do not show up a week or so after the static ones, I have probably not planned for them. Feel free to request them by opening a Community Discussion.
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/shellm-v0.1-GGUF/resolve/main/shellm-v0.1.Q2_K.gguf) | Q2_K | 0.8 | |
| [GGUF](https://huggingface.co/mradermacher/shellm-v0.1-GGUF/resolve/main/shellm-v0.1.Q3_K_S.gguf) | Q3_K_S | 0.9 | |
| [GGUF](https://huggingface.co/mradermacher/shellm-v0.1-GGUF/resolve/main/shellm-v0.1.Q3_K_M.gguf) | Q3_K_M | 0.9 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/shellm-v0.1-GGUF/resolve/main/shellm-v0.1.Q3_K_L.gguf) | Q3_K_L | 1.0 | |
| [GGUF](https://huggingface.co/mradermacher/shellm-v0.1-GGUF/resolve/main/shellm-v0.1.IQ4_XS.gguf) | IQ4_XS | 1.0 | |
| [GGUF](https://huggingface.co/mradermacher/shellm-v0.1-GGUF/resolve/main/shellm-v0.1.Q4_K_S.gguf) | Q4_K_S | 1.0 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/shellm-v0.1-GGUF/resolve/main/shellm-v0.1.Q4_K_M.gguf) | Q4_K_M | 1.1 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/shellm-v0.1-GGUF/resolve/main/shellm-v0.1.Q5_K_S.gguf) | Q5_K_S | 1.2 | |
| [GGUF](https://huggingface.co/mradermacher/shellm-v0.1-GGUF/resolve/main/shellm-v0.1.Q5_K_M.gguf) | Q5_K_M | 1.2 | |
| [GGUF](https://huggingface.co/mradermacher/shellm-v0.1-GGUF/resolve/main/shellm-v0.1.Q6_K.gguf) | Q6_K | 1.4 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/shellm-v0.1-GGUF/resolve/main/shellm-v0.1.Q8_0.gguf) | Q8_0 | 1.7 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/shellm-v0.1-GGUF/resolve/main/shellm-v0.1.f16.gguf) | f16 | 3.2 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
esi777/blockassist-bc-camouflaged_trotting_eel_1755709382
|
esi777
| 2025-08-20T17:03:55Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"camouflaged trotting eel",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-20T17:03:51Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- camouflaged trotting eel
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
0xaoyama/blockassist-bc-muscular_zealous_gorilla_1755709342
|
0xaoyama
| 2025-08-20T17:02:56Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"muscular zealous gorilla",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-20T17:02:44Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- muscular zealous gorilla
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
WenFengg/loss_14l2_20_8
|
WenFengg
| 2025-08-20T16:56:30Z | 0 | 0 | null |
[
"safetensors",
"any-to-any",
"omega",
"omegalabs",
"bittensor",
"agi",
"license:mit",
"region:us"
] |
any-to-any
| 2025-08-20T16:42:26Z |
---
license: mit
tags:
- any-to-any
- omega
- omegalabs
- bittensor
- agi
---
This is an Any-to-Any model checkpoint for the OMEGA Labs x Bittensor Any-to-Any subnet.
Check out the [git repo](https://github.com/omegalabsinc/omegalabs-anytoany-bittensor) and find OMEGA on X: [@omegalabsai](https://x.com/omegalabsai).
|
Frane92O/OpenReasoning-Nemotron-7B-bnb-4bit
|
Frane92O
| 2025-08-20T16:56:19Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"feature-extraction",
"nvidia",
"code",
"text-generation",
"conversational",
"en",
"arxiv:2504.16891",
"arxiv:2504.01943",
"arxiv:2507.09075",
"base_model:nvidia/OpenReasoning-Nemotron-7B",
"base_model:quantized:nvidia/OpenReasoning-Nemotron-7B",
"license:cc-by-4.0",
"text-generation-inference",
"endpoints_compatible",
"4-bit",
"bitsandbytes",
"region:us"
] |
text-generation
| 2025-08-20T16:56:00Z |
---
base_model:
- nvidia/OpenReasoning-Nemotron-7B
license: cc-by-4.0
language:
- en
pipeline_tag: text-generation
library_name: transformers
tags:
- nvidia
- code
---
# nvidia/OpenReasoning-Nemotron-7B (Quantized)
## Description
This model is a quantized version of the original model [`nvidia/OpenReasoning-Nemotron-7B`](https://huggingface.co/nvidia/OpenReasoning-Nemotron-7B).
It's quantized using the BitsAndBytes library to 4-bit using the [bnb-my-repo](https://huggingface.co/spaces/HF-Quantization/bnb-my-repo) space.
## Quantization Details
- **Quantization Type**: int4
- **bnb_4bit_quant_type**: nf4
- **bnb_4bit_use_double_quant**: True
- **bnb_4bit_compute_dtype**: bfloat16
- **bnb_4bit_quant_storage**: uint8
# 📄 Original Model Information
# OpenReasoning-Nemotron-7B Overview
## Description: <br>
OpenReasoning-Nemotron-7B is a large language model (LLM) which is a derivative of Qwen2.5-7B-Instruct (AKA the reference model). It is a reasoning model that is post-trained for reasoning about math, code and science solution generation. We evaluated this model with up to 64K output tokens. The OpenReasoning model is available in the following sizes: 1.5B, 7B and 14B and 32B. <br>
This model is ready for commercial/non-commercial research use. <br>
### License/Terms of Use: <br>
GOVERNING TERMS: Use of the models listed above are governed by the [Creative Commons Attribution 4.0 International License (CC-BY-4.0)](https://creativecommons.org/licenses/by/4.0/legalcode.en). ADDITIONAL INFORMATION: [Apache 2.0 License](https://huggingface.co/Qwen/Qwen2.5-32B-Instruct/blob/main/LICENSE)
## Scores on Reasoning Benchmarks
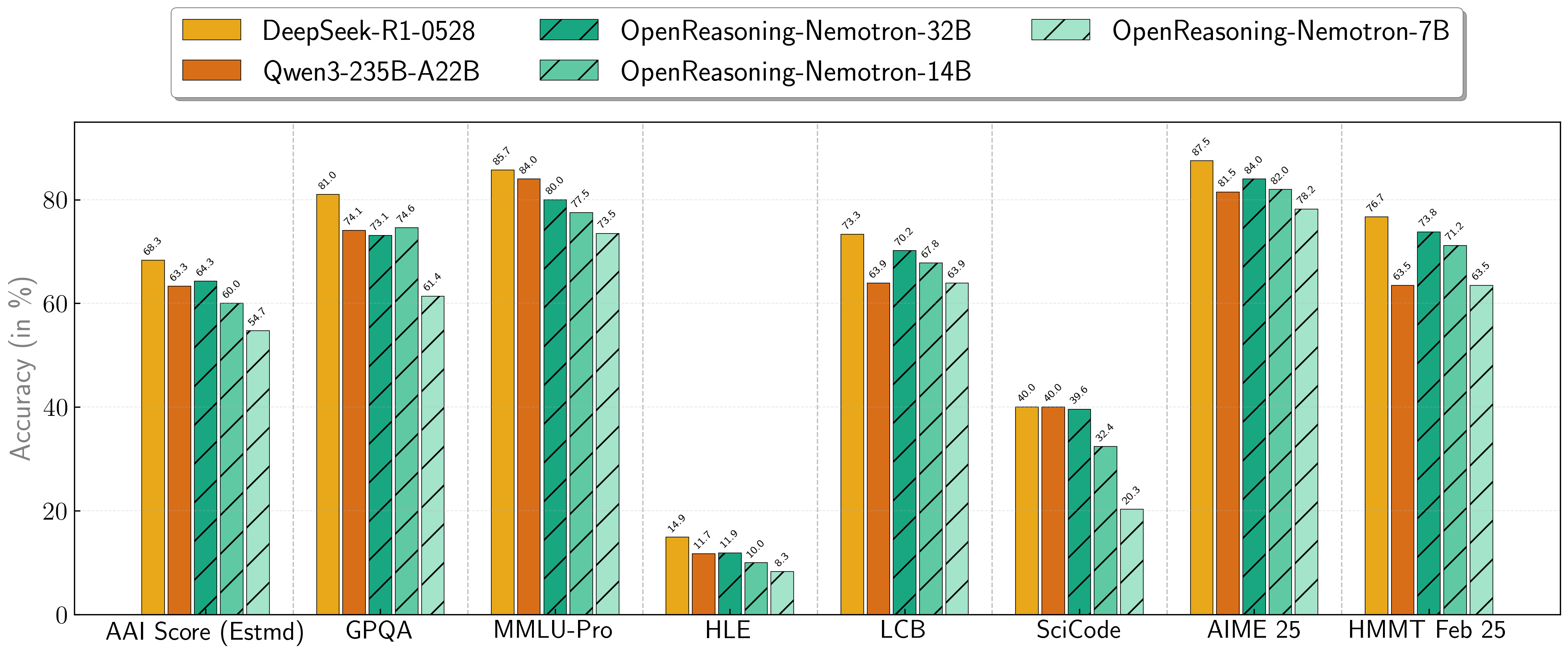
Our models demonstrate exceptional performance across a suite of challenging reasoning benchmarks. The 7B, 14B, and 32B models consistently set new state-of-the-art records for their size classes.
| **Model** | **AritificalAnalysisIndex*** | **GPQA** | **MMLU-PRO** | **HLE** | **LiveCodeBench*** | **SciCode** | **AIME24** | **AIME25** | **HMMT FEB 25** |
| :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- |
| **1.5B**| 31.0 | 31.6 | 47.5 | 5.5 | 28.6 | 2.2 | 55.5 | 45.6 | 31.5 |
| **7B** | 54.7 | 61.1 | 71.9 | 8.3 | 63.3 | 16.2 | 84.7 | 78.2 | 63.5 |
| **14B** | 60.9 | 71.6 | 77.5 | 10.1 | 67.8 | 23.5 | 87.8 | 82.0 | 71.2 |
| **32B** | 64.3 | 73.1 | 80.0 | 11.9 | 70.2 | 28.5 | 89.2 | 84.0 | 73.8 |
\* This is our estimation of the Artificial Analysis Intelligence Index, not an official score.
\* LiveCodeBench version 6, date range 2408-2505.
## Combining the work of multiple agents
OpenReasoning-Nemotron models can be used in a "heavy" mode by starting multiple parallel generations and combining them together via [generative solution selection (GenSelect)](https://arxiv.org/abs/2504.16891). To add this "skill" we follow the original GenSelect training pipeline except we do not train on the selection summary but use the full reasoning trace of DeepSeek R1 0528 671B instead. We only train models to select the best solution for math problems but surprisingly find that this capability directly generalizes to code and science questions! With this "heavy" GenSelect inference mode, OpenReasoning-Nemotron-32B model surpasses O3 (High) on math and coding benchmarks.
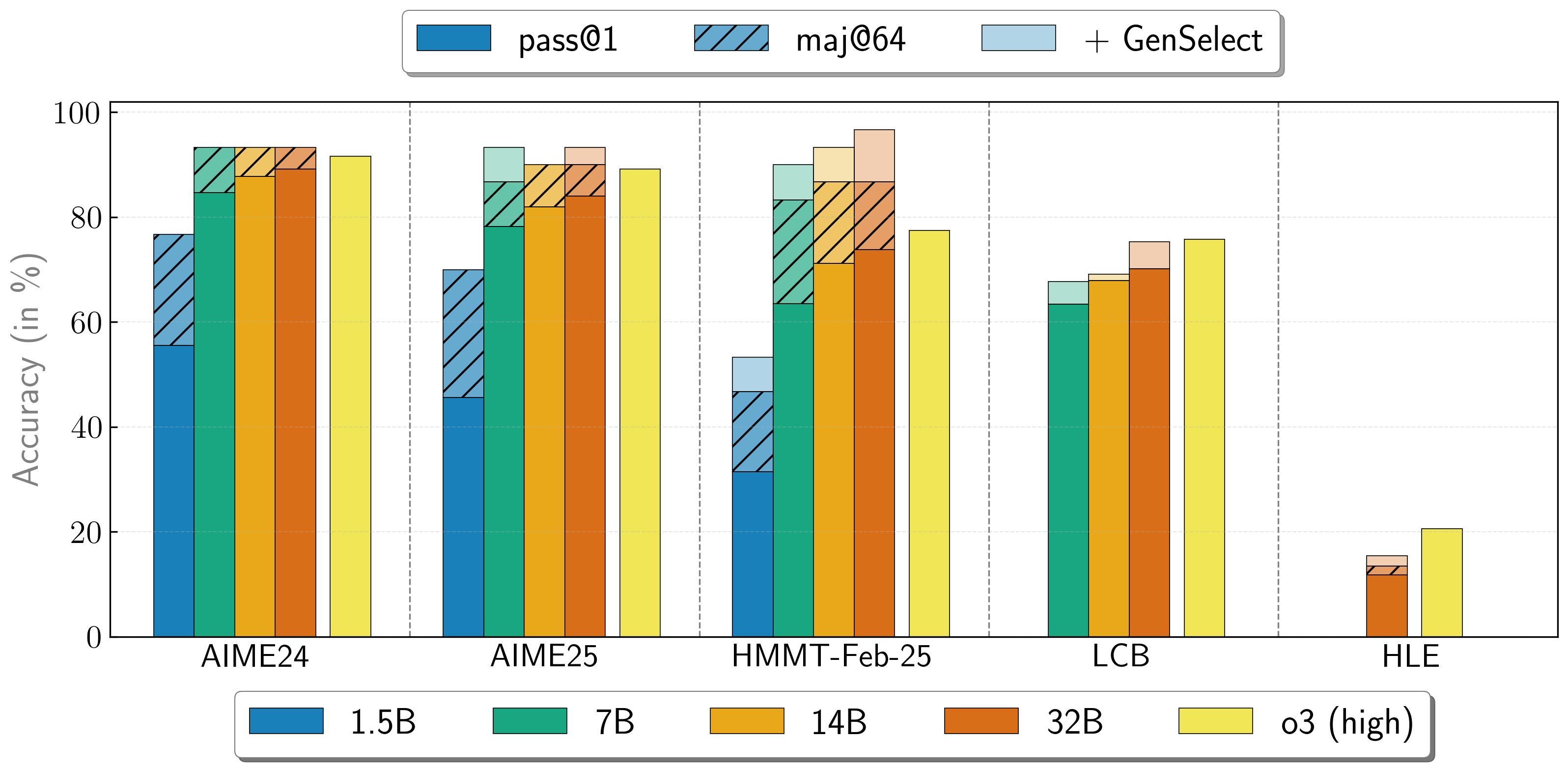
| **Model** | **Pass@1 (Avg@64)** | **Majority@64** | **GenSelect** |
| :--- | :--- | :--- | :--- |
| **1.5B** | | | |
| **AIME24** | 55.5 | 76.7 | 76.7 |
| **AIME25** | 45.6 | 70.0 | 70.0 |
| **HMMT Feb 25** | 31.5 | 46.7 | 53.3 |
| **7B** | | | |
| **AIME24** | 84.7 | 93.3 | 93.3 |
| **AIME25** | 78.2 | 86.7 | 93.3 |
| **HMMT Feb 25** | 63.5 | 83.3 | 90.0 |
| **LCB v6 2408-2505** | 63.4 | n/a | 67.7 |
| **14B** | | | |
| **AIME24** | 87.8 | 93.3 | 93.3 |
| **AIME25** | 82.0 | 90.0 | 90.0 |
| **HMMT Feb 25** | 71.2 | 86.7 | 93.3 |
| **LCB v6 2408-2505** | 67.9 | n/a | 69.1 |
| **32B** | | | |
| **AIME24** | 89.2 | 93.3 | 93.3 |
| **AIME25** | 84.0 | 90.0 | 93.3 |
| **HMMT Feb 25** | 73.8 | 86.7 | 96.7 |
| **LCB v6 2408-2505** | 70.2 | n/a | 75.3 |
| **HLE** | 11.8 | 13.4 | 15.5 |
## How to use the models?
To run inference on coding problems:
````python
import transformers
import torch
model_id = "nvidia/OpenReasoning-Nemotron-7B"
pipeline = transformers.pipeline(
"text-generation",
model=model_id,
model_kwargs={"torch_dtype": torch.bfloat16},
device_map="auto",
)
# Code generation prompt
prompt = """You are a helpful and harmless assistant. You should think step-by-step before responding to the instruction below.
Please use python programming language only.
You must use ```python for just the final solution code block with the following format:
```python
# Your code here
```
{user}
"""
# Math generation prompt
# prompt = """Solve the following math problem. Make sure to put the answer (and only answer) inside \\boxed{}.
#
# {user}
# """
# Science generation prompt
# You can refer to prompts here -
# https://github.com/NVIDIA/NeMo-Skills/blob/main/nemo_skills/prompt/config/generic/hle.yaml (HLE)
# https://github.com/NVIDIA/NeMo-Skills/blob/main/nemo_skills/prompt/config/eval/aai/mcq-4choices-boxed.yaml (for GPQA)
# https://github.com/NVIDIA/NeMo-Skills/blob/main/nemo_skills/prompt/config/eval/aai/mcq-10choices-boxed.yaml (MMLU-Pro)
messages = [
{
"role": "user",
"content": prompt.format(user="Write a program to calculate the sum of the first $N$ fibonacci numbers")},
]
outputs = pipeline(
messages,
max_new_tokens=64000,
)
print(outputs[0]["generated_text"][-1]['content'])
````
We have added [a simple transformer-based script](https://huggingface.co/nvidia/OpenReasoning-Nemotron-7B/blob/main/genselect_hf.py) in this repo to illustrate GenSelect.
To learn how to use the models in GenSelect mode with NeMo-Skills, see our [documentation](https://nvidia.github.io/NeMo-Skills/releases/openreasoning/evaluation/).
To use the model with GenSelect inference, we recommend following our
[reference implementation in NeMo-Skills](https://github.com/NVIDIA/NeMo-Skills/blob/main/nemo_skills/pipeline/genselect.py). Alternatively, you can manually extract the summary from all solutions and use this
[prompt](https://github.com/NVIDIA/NeMo-Skills/blob/main/nemo_skills/prompt/config/openmath/genselect.yaml) for the math problems. We will add the prompt we used for the coding problems and a reference implementation soon!
You can learn more about GenSelect in these papers:
* [AIMO-2 Winning Solution: Building State-of-the-Art Mathematical Reasoning Models with OpenMathReasoning dataset](https://arxiv.org/abs/2504.16891)
* [GenSelect: A Generative Approach to Best-of-N](https://openreview.net/forum?id=8LhnmNmUDb)
## Accessing training data
Training data has been released! Math and code are available as part of
[Nemotron-Post-Training-Dataset-v1](https://huggingface.co/datasets/nvidia/Nemotron-Post-Training-Dataset-v1) and science is available in
[OpenScienceReasoning-2](https://huggingface.co/datasets/nvidia/OpenScienceReasoning-2).
See our [documentation](https://nvidia.github.io/NeMo-Skills/releases/openreasoning/training) for more details.
## Citation
If you find the data useful, please cite:
```
@article{ahmad2025opencodereasoning,
title={{OpenCodeReasoning: Advancing Data Distillation for Competitive Coding}},
author={Wasi Uddin Ahmad, Sean Narenthiran, Somshubra Majumdar, Aleksander Ficek, Siddhartha Jain, Jocelyn Huang, Vahid Noroozi, Boris Ginsburg},
year={2025},
eprint={2504.01943},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2504.01943},
}
```
```
@misc{ahmad2025opencodereasoningiisimpletesttime,
title={{OpenCodeReasoning-II: A Simple Test Time Scaling Approach via Self-Critique}},
author={Wasi Uddin Ahmad and Somshubra Majumdar and Aleksander Ficek and Sean Narenthiran and Mehrzad Samadi and Jocelyn Huang and Siddhartha Jain and Vahid Noroozi and Boris Ginsburg},
year={2025},
eprint={2507.09075},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2507.09075},
}
```
```
@misc{moshkov2025aimo2winningsolutionbuilding,
title={{AIMO-2 Winning Solution: Building State-of-the-Art Mathematical Reasoning Models with OpenMathReasoning dataset}},
author={Ivan Moshkov and Darragh Hanley and Ivan Sorokin and Shubham Toshniwal and Christof Henkel and Benedikt Schifferer and Wei Du and Igor Gitman},
year={2025},
eprint={2504.16891},
archivePrefix={arXiv},
primaryClass={cs.AI},
url={https://arxiv.org/abs/2504.16891},
}
```
```
@inproceedings{toshniwal2025genselect,
title={{GenSelect: A Generative Approach to Best-of-N}},
author={Shubham Toshniwal and Ivan Sorokin and Aleksander Ficek and Ivan Moshkov and Igor Gitman},
booktitle={2nd AI for Math Workshop @ ICML 2025},
year={2025},
url={https://openreview.net/forum?id=8LhnmNmUDb}
}
```
## Additional Information:
### Deployment Geography:
Global<br>
### Use Case: <br>
This model is intended for developers and researchers who work on competitive math, code and science problems. It has been trained via only supervised fine-tuning to achieve strong scores on benchmarks. <br>
### Release Date: <br>
Huggingface [07/16/2025] via https://huggingface.co/nvidia/OpenReasoning-Nemotron-7B/ <br>
## Reference(s):
* [2504.01943] OpenCodeReasoning: Advancing Data Distillation for Competitive Coding
* [2504.01943] OpenCodeReasoning: Advancing Data Distillation for Competitive Coding
* [2504.16891] AIMO-2 Winning Solution: Building State-of-the-Art Mathematical Reasoning Models with OpenMathReasoning dataset
<br>
## Model Architecture: <br>
Architecture Type: Dense decoder-only Transformer model
Network Architecture: Qwen-7B-Instruct
<br>
**This model was developed based on Qwen2.5-7B-Instruct and has 7B model parameters. <br>**
**OpenReasoning-Nemotron-1.5B was developed based on Qwen2.5-1.5B-Instruct and has 1.5B model parameters. <br>**
**OpenReasoning-Nemotron-7B was developed based on Qwen2.5-7B-Instruct and has 7B model parameters. <br>**
**OpenReasoning-Nemotron-14B was developed based on Qwen2.5-14B-Instruct and has 14B model parameters. <br>**
**OpenReasoning-Nemotron-32B was developed based on Qwen2.5-32B-Instruct and has 32B model parameters. <br>**
## Input: <br>
**Input Type(s):** Text <br>
**Input Format(s):** String <br>
**Input Parameters:** One-Dimensional (1D) <br>
**Other Properties Related to Input:** Trained for up to 64,000 output tokens <br>
## Output: <br>
**Output Type(s):** Text <br>
**Output Format:** String <br>
**Output Parameters:** One-Dimensional (1D) <br>
**Other Properties Related to Output:** Trained for up to 64,000 output tokens <br>
Our AI models are designed and/or optimized to run on NVIDIA GPU-accelerated systems. By leveraging NVIDIA’s hardware (e.g. GPU cores) and software frameworks (e.g., CUDA libraries), the model achieves faster training and inference times compared to CPU-only solutions. <br>
## Software Integration : <br>
* Runtime Engine: NeMo 2.3.0 <br>
* Recommended Hardware Microarchitecture Compatibility: <br>
NVIDIA Ampere <br>
NVIDIA Hopper <br>
* Preferred/Supported Operating System(s): Linux <br>
## Model Version(s):
1.0 (7/16/2025) <br>
OpenReasoning-Nemotron-32B<br>
OpenReasoning-Nemotron-14B<br>
OpenReasoning-Nemotron-7B<br>
OpenReasoning-Nemotron-1.5B<br>
# Training and Evaluation Datasets: <br>
## Training Dataset:
The training corpus for OpenReasoning-Nemotron-7B is comprised of questions from [OpenCodeReasoning](https://huggingface.co/datasets/nvidia/OpenCodeReasoning) dataset, [OpenCodeReasoning-II](https://arxiv.org/abs/2507.09075), [OpenMathReasoning](https://huggingface.co/datasets/nvidia/OpenMathReasoning), and the Synthetic Science questions from the [Llama-Nemotron-Post-Training-Dataset](https://huggingface.co/datasets/nvidia/Llama-Nemotron-Post-Training-Dataset). All responses are generated using DeepSeek-R1-0528. We also include the instruction following and tool calling data from Llama-Nemotron-Post-Training-Dataset without modification.
Data Collection Method: Hybrid: Automated, Human, Synthetic <br>
Labeling Method: Hybrid: Automated, Human, Synthetic <br>
Properties: 5M DeepSeek-R1-0528 generated responses from OpenCodeReasoning questions (https://huggingface.co/datasets/nvidia/OpenCodeReasoning), [OpenMathReasoning](https://huggingface.co/datasets/nvidia/OpenMathReasoning), and the Synthetic Science questions from the [Llama-Nemotron-Post-Training-Dataset](https://huggingface.co/datasets/nvidia/Llama-Nemotron-Post-Training-Dataset). We also include the instruction following and tool calling data from Llama-Nemotron-Post-Training-Dataset without modification.
## Evaluation Dataset:
We used the following benchmarks to evaluate the model holistically.
### Math
- AIME 2024/2025 <br>
- HMMT <br>
- BRUNO 2025 <br>
### Code
- LiveCodeBench <br>
- SciCode <br>
### Science
- GPQA <br>
- MMLU-PRO <br>
- HLE <br>
Data Collection Method: Hybrid: Automated, Human, Synthetic <br>
Labeling Method: Hybrid: Automated, Human, Synthetic <br>
## Inference:
**Acceleration Engine:** vLLM, Tensor(RT)-LLM <br>
**Test Hardware** NVIDIA H100-80GB <br>
## Ethical Considerations:
NVIDIA believes Trustworthy AI is a shared responsibility and we have established policies and practices to enable development for a wide array of AI applications. When downloaded or used in accordance with our terms of service, developers should work with their internal model team to ensure this model meets requirements for the relevant industry and use case and addresses unforeseen product misuse.
For more detailed information on ethical considerations for this model, please see the Model Card++ Explainability, Bias, Safety & Security, and Privacy Subcards.
Please report model quality, risk, security vulnerabilities or NVIDIA AI Concerns [here](https://www.nvidia.com/en-us/support/submit-security-vulnerability/).
|
AnonymousCS/xlmr_immigration_combo19_2
|
AnonymousCS
| 2025-08-20T16:52:31Z | 0 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"xlm-roberta",
"text-classification",
"generated_from_trainer",
"base_model:FacebookAI/xlm-roberta-large",
"base_model:finetune:FacebookAI/xlm-roberta-large",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2025-08-20T16:49:04Z |
---
library_name: transformers
license: mit
base_model: FacebookAI/xlm-roberta-large
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: xlmr_immigration_combo19_2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xlmr_immigration_combo19_2
This model is a fine-tuned version of [FacebookAI/xlm-roberta-large](https://huggingface.co/FacebookAI/xlm-roberta-large) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2556
- Accuracy: 0.9344
- 1-f1: 0.9017
- 1-recall: 0.9035
- 1-precision: 0.9
- Balanced Acc: 0.9267
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 128
- eval_batch_size: 128
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH_FUSED with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 15
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | 1-f1 | 1-recall | 1-precision | Balanced Acc |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|:--------:|:-----------:|:------------:|
| 0.1751 | 1.0 | 25 | 0.2346 | 0.9229 | 0.8872 | 0.9112 | 0.8645 | 0.9200 |
| 0.1856 | 2.0 | 50 | 0.2018 | 0.9422 | 0.9119 | 0.8996 | 0.9246 | 0.9315 |
| 0.169 | 3.0 | 75 | 0.2309 | 0.9332 | 0.8992 | 0.8958 | 0.9027 | 0.9238 |
| 0.0481 | 4.0 | 100 | 0.2556 | 0.9344 | 0.9017 | 0.9035 | 0.9 | 0.9267 |
### Framework versions
- Transformers 4.56.0.dev0
- Pytorch 2.8.0+cu126
- Datasets 4.0.0
- Tokenizers 0.21.4
|
yfkang/qwen-7b-instruct-thinking-function_calling-V0
|
yfkang
| 2025-08-20T16:50:14Z | 0 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"generated_from_trainer",
"sft",
"trl",
"base_model:Qwen/Qwen2.5-7B-Instruct",
"base_model:finetune:Qwen/Qwen2.5-7B-Instruct",
"endpoints_compatible",
"region:us"
] | null | 2025-08-20T16:49:11Z |
---
base_model: Qwen/Qwen2.5-7B-Instruct
library_name: transformers
model_name: qwen-7b-instruct-thinking-function_calling-V0
tags:
- generated_from_trainer
- sft
- trl
licence: license
---
# Model Card for qwen-7b-instruct-thinking-function_calling-V0
This model is a fine-tuned version of [Qwen/Qwen2.5-7B-Instruct](https://huggingface.co/Qwen/Qwen2.5-7B-Instruct).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="yfkang/qwen-7b-instruct-thinking-function_calling-V0", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
This model was trained with SFT.
### Framework versions
- TRL: 0.21.0
- Transformers: 4.55.2
- Pytorch: 2.5.1
- Datasets: 3.6.0
- Tokenizers: 0.21.2
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
sampingkaca72/blockassist-bc-armored_stealthy_elephant_1755706710
|
sampingkaca72
| 2025-08-20T16:43:36Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"armored stealthy elephant",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-20T16:43:33Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- armored stealthy elephant
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
youuotty/blockassist-bc-wise_howling_duck_1755708199
|
youuotty
| 2025-08-20T16:43:31Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"wise howling duck",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-20T16:43:21Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- wise howling duck
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
LVenn/MyGemmaNPC
|
LVenn
| 2025-08-20T16:43:10Z | 0 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"gemma3_text",
"text-generation",
"generated_from_trainer",
"sft",
"trl",
"conversational",
"base_model:google/gemma-3-270m-it",
"base_model:finetune:google/gemma-3-270m-it",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-20T15:45:36Z |
---
base_model: google/gemma-3-270m-it
library_name: transformers
model_name: MyGemmaNPC
tags:
- generated_from_trainer
- sft
- trl
licence: license
---
# Model Card for MyGemmaNPC
This model is a fine-tuned version of [google/gemma-3-270m-it](https://huggingface.co/google/gemma-3-270m-it).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="LVenn/MyGemmaNPC", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
This model was trained with SFT.
### Framework versions
- TRL: 0.21.0
- Transformers: 4.55.2
- Pytorch: 2.8.0+cu126
- Datasets: 4.0.0
- Tokenizers: 0.21.4
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
tuanpro276/Qwen2.5-VL-3B-unsloth-GGUF
|
tuanpro276
| 2025-08-20T16:40:51Z | 0 | 0 |
transformers
|
[
"transformers",
"text-generation-inference",
"unsloth",
"qwen2_5_vl",
"en",
"base_model:tuanpro276/Qwen2.5-VL-3B-unsloth-GGUF",
"base_model:finetune:tuanpro276/Qwen2.5-VL-3B-unsloth-GGUF",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-08-20T16:39:34Z |
---
base_model: tuanpro276/Qwen2.5-VL-3B-unsloth-GGUF
tags:
- text-generation-inference
- transformers
- unsloth
- qwen2_5_vl
license: apache-2.0
language:
- en
---
# Uploaded finetuned model
- **Developed by:** tuanpro276
- **License:** apache-2.0
- **Finetuned from model :** tuanpro276/Qwen2.5-VL-3B-unsloth-GGUF
This qwen2_5_vl model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
tensorblock/eternis_eternis_anonymizer_merge_Llama-3.2-1B_6jul_-GGUF
|
tensorblock
| 2025-08-20T16:40:45Z | 0 | 0 |
transformers
|
[
"transformers",
"gguf",
"TensorBlock",
"GGUF",
"base_model:eternis/eternis_anonymizer_merge_Llama-3.2-1B_6jul_",
"base_model:quantized:eternis/eternis_anonymizer_merge_Llama-3.2-1B_6jul_",
"endpoints_compatible",
"region:us"
] | null | 2025-08-20T16:26:22Z |
---
library_name: transformers
tags:
- TensorBlock
- GGUF
base_model: eternis/eternis_anonymizer_merge_Llama-3.2-1B_6jul_
---
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/jC7kdl8.jpeg" alt="TensorBlock" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
[](https://tensorblock.co)
[](https://twitter.com/tensorblock_aoi)
[](https://discord.gg/Ej5NmeHFf2)
[](https://github.com/TensorBlock)
[](https://t.me/TensorBlock)
## eternis/eternis_anonymizer_merge_Llama-3.2-1B_6jul_ - GGUF
<div style="text-align: left; margin: 20px 0;">
<a href="https://discord.com/invite/Ej5NmeHFf2" style="display: inline-block; padding: 10px 20px; background-color: #5865F2; color: white; text-decoration: none; border-radius: 5px; font-weight: bold;">
Join our Discord to learn more about what we're building ↗
</a>
</div>
This repo contains GGUF format model files for [eternis/eternis_anonymizer_merge_Llama-3.2-1B_6jul_](https://huggingface.co/eternis/eternis_anonymizer_merge_Llama-3.2-1B_6jul_).
The files were quantized using machines provided by [TensorBlock](https://tensorblock.co/), and they are compatible with llama.cpp as of [commit b5753](https://github.com/ggml-org/llama.cpp/commit/73e53dc834c0a2336cd104473af6897197b96277).
## Our projects
<table border="1" cellspacing="0" cellpadding="10">
<tr>
<th colspan="2" style="font-size: 25px;">Forge</th>
</tr>
<tr>
<th colspan="2">
<img src="https://imgur.com/faI5UKh.jpeg" alt="Forge Project" width="900"/>
</th>
</tr>
<tr>
<th colspan="2">An OpenAI-compatible multi-provider routing layer.</th>
</tr>
<tr>
<th colspan="2">
<a href="https://github.com/TensorBlock/forge" target="_blank" style="
display: inline-block;
padding: 8px 16px;
background-color: #FF7F50;
color: white;
text-decoration: none;
border-radius: 6px;
font-weight: bold;
font-family: sans-serif;
">🚀 Try it now! 🚀</a>
</th>
</tr>
<tr>
<th style="font-size: 25px;">Awesome MCP Servers</th>
<th style="font-size: 25px;">TensorBlock Studio</th>
</tr>
<tr>
<th><img src="https://imgur.com/2Xov7B7.jpeg" alt="MCP Servers" width="450"/></th>
<th><img src="https://imgur.com/pJcmF5u.jpeg" alt="Studio" width="450"/></th>
</tr>
<tr>
<th>A comprehensive collection of Model Context Protocol (MCP) servers.</th>
<th>A lightweight, open, and extensible multi-LLM interaction studio.</th>
</tr>
<tr>
<th>
<a href="https://github.com/TensorBlock/awesome-mcp-servers" target="_blank" style="
display: inline-block;
padding: 8px 16px;
background-color: #FF7F50;
color: white;
text-decoration: none;
border-radius: 6px;
font-weight: bold;
font-family: sans-serif;
">👀 See what we built 👀</a>
</th>
<th>
<a href="https://github.com/TensorBlock/TensorBlock-Studio" target="_blank" style="
display: inline-block;
padding: 8px 16px;
background-color: #FF7F50;
color: white;
text-decoration: none;
border-radius: 6px;
font-weight: bold;
font-family: sans-serif;
">👀 See what we built 👀</a>
</th>
</tr>
</table>
## Prompt template
```
Unable to determine prompt format automatically. Please check the original model repository for the correct prompt format.
```
## Model file specification
| Filename | Quant type | File Size | Description |
| -------- | ---------- | --------- | ----------- |
| [eternis_anonymizer_merge_Llama-3.2-1B_6jul_-Q2_K.gguf](https://huggingface.co/tensorblock/eternis_eternis_anonymizer_merge_Llama-3.2-1B_6jul_-GGUF/blob/main/eternis_anonymizer_merge_Llama-3.2-1B_6jul_-Q2_K.gguf) | Q2_K | 0.581 GB | smallest, significant quality loss - not recommended for most purposes |
| [eternis_anonymizer_merge_Llama-3.2-1B_6jul_-Q3_K_S.gguf](https://huggingface.co/tensorblock/eternis_eternis_anonymizer_merge_Llama-3.2-1B_6jul_-GGUF/blob/main/eternis_anonymizer_merge_Llama-3.2-1B_6jul_-Q3_K_S.gguf) | Q3_K_S | 0.642 GB | very small, high quality loss |
| [eternis_anonymizer_merge_Llama-3.2-1B_6jul_-Q3_K_M.gguf](https://huggingface.co/tensorblock/eternis_eternis_anonymizer_merge_Llama-3.2-1B_6jul_-GGUF/blob/main/eternis_anonymizer_merge_Llama-3.2-1B_6jul_-Q3_K_M.gguf) | Q3_K_M | 0.691 GB | very small, high quality loss |
| [eternis_anonymizer_merge_Llama-3.2-1B_6jul_-Q3_K_L.gguf](https://huggingface.co/tensorblock/eternis_eternis_anonymizer_merge_Llama-3.2-1B_6jul_-GGUF/blob/main/eternis_anonymizer_merge_Llama-3.2-1B_6jul_-Q3_K_L.gguf) | Q3_K_L | 0.733 GB | small, substantial quality loss |
| [eternis_anonymizer_merge_Llama-3.2-1B_6jul_-Q4_0.gguf](https://huggingface.co/tensorblock/eternis_eternis_anonymizer_merge_Llama-3.2-1B_6jul_-GGUF/blob/main/eternis_anonymizer_merge_Llama-3.2-1B_6jul_-Q4_0.gguf) | Q4_0 | 0.771 GB | legacy; small, very high quality loss - prefer using Q3_K_M |
| [eternis_anonymizer_merge_Llama-3.2-1B_6jul_-Q4_K_S.gguf](https://huggingface.co/tensorblock/eternis_eternis_anonymizer_merge_Llama-3.2-1B_6jul_-GGUF/blob/main/eternis_anonymizer_merge_Llama-3.2-1B_6jul_-Q4_K_S.gguf) | Q4_K_S | 0.776 GB | small, greater quality loss |
| [eternis_anonymizer_merge_Llama-3.2-1B_6jul_-Q4_K_M.gguf](https://huggingface.co/tensorblock/eternis_eternis_anonymizer_merge_Llama-3.2-1B_6jul_-GGUF/blob/main/eternis_anonymizer_merge_Llama-3.2-1B_6jul_-Q4_K_M.gguf) | Q4_K_M | 0.808 GB | medium, balanced quality - recommended |
| [eternis_anonymizer_merge_Llama-3.2-1B_6jul_-Q5_0.gguf](https://huggingface.co/tensorblock/eternis_eternis_anonymizer_merge_Llama-3.2-1B_6jul_-GGUF/blob/main/eternis_anonymizer_merge_Llama-3.2-1B_6jul_-Q5_0.gguf) | Q5_0 | 0.893 GB | legacy; medium, balanced quality - prefer using Q4_K_M |
| [eternis_anonymizer_merge_Llama-3.2-1B_6jul_-Q5_K_S.gguf](https://huggingface.co/tensorblock/eternis_eternis_anonymizer_merge_Llama-3.2-1B_6jul_-GGUF/blob/main/eternis_anonymizer_merge_Llama-3.2-1B_6jul_-Q5_K_S.gguf) | Q5_K_S | 0.893 GB | large, low quality loss - recommended |
| [eternis_anonymizer_merge_Llama-3.2-1B_6jul_-Q5_K_M.gguf](https://huggingface.co/tensorblock/eternis_eternis_anonymizer_merge_Llama-3.2-1B_6jul_-GGUF/blob/main/eternis_anonymizer_merge_Llama-3.2-1B_6jul_-Q5_K_M.gguf) | Q5_K_M | 0.911 GB | large, very low quality loss - recommended |
| [eternis_anonymizer_merge_Llama-3.2-1B_6jul_-Q6_K.gguf](https://huggingface.co/tensorblock/eternis_eternis_anonymizer_merge_Llama-3.2-1B_6jul_-GGUF/blob/main/eternis_anonymizer_merge_Llama-3.2-1B_6jul_-Q6_K.gguf) | Q6_K | 1.022 GB | very large, extremely low quality loss |
| [eternis_anonymizer_merge_Llama-3.2-1B_6jul_-Q8_0.gguf](https://huggingface.co/tensorblock/eternis_eternis_anonymizer_merge_Llama-3.2-1B_6jul_-GGUF/blob/main/eternis_anonymizer_merge_Llama-3.2-1B_6jul_-Q8_0.gguf) | Q8_0 | 1.321 GB | very large, extremely low quality loss - not recommended |
## Downloading instruction
### Command line
Firstly, install Huggingface Client
```shell
pip install -U "huggingface_hub[cli]"
```
Then, downoad the individual model file the a local directory
```shell
huggingface-cli download tensorblock/eternis_eternis_anonymizer_merge_Llama-3.2-1B_6jul_-GGUF --include "eternis_anonymizer_merge_Llama-3.2-1B_6jul_-Q2_K.gguf" --local-dir MY_LOCAL_DIR
```
If you wanna download multiple model files with a pattern (e.g., `*Q4_K*gguf`), you can try:
```shell
huggingface-cli download tensorblock/eternis_eternis_anonymizer_merge_Llama-3.2-1B_6jul_-GGUF --local-dir MY_LOCAL_DIR --local-dir-use-symlinks False --include='*Q4_K*gguf'
```
|
Trungdjoon/esg-roberta-base_run_3
|
Trungdjoon
| 2025-08-20T16:40:45Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"roberta",
"text-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2025-08-20T16:40:03Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Trungdjoon/esg-phobert-base_run_3
|
Trungdjoon
| 2025-08-20T16:40:00Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"roberta",
"text-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2025-08-20T16:39:14Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
thanobidex/blockassist-bc-colorful_shiny_hare_1755706085
|
thanobidex
| 2025-08-20T16:35:13Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"colorful shiny hare",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-20T16:35:09Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- colorful shiny hare
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
surya-ravindra/tinyllama-medqa-jp-v1-Q4_K_M-GGUF
|
surya-ravindra
| 2025-08-20T16:31:46Z | 0 | 0 | null |
[
"gguf",
"trl",
"sft",
"generated_from_trainer",
"llama-cpp",
"gguf-my-repo",
"base_model:jayeshvpatil/tinyllama-medqa-jp-v1",
"base_model:quantized:jayeshvpatil/tinyllama-medqa-jp-v1",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2025-08-20T16:31:40Z |
---
license: apache-2.0
base_model: jayeshvpatil/tinyllama-medqa-jp-v1
tags:
- trl
- sft
- generated_from_trainer
- llama-cpp
- gguf-my-repo
model-index:
- name: tinyllama-medqa-jp-v1
results: []
---
# surya-ravindra/tinyllama-medqa-jp-v1-Q4_K_M-GGUF
This model was converted to GGUF format from [`jayeshvpatil/tinyllama-medqa-jp-v1`](https://huggingface.co/jayeshvpatil/tinyllama-medqa-jp-v1) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/jayeshvpatil/tinyllama-medqa-jp-v1) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew (works on Mac and Linux)
```bash
brew install llama.cpp
```
Invoke the llama.cpp server or the CLI.
### CLI:
```bash
llama-cli --hf-repo surya-ravindra/tinyllama-medqa-jp-v1-Q4_K_M-GGUF --hf-file tinyllama-medqa-jp-v1-q4_k_m.gguf -p "The meaning to life and the universe is"
```
### Server:
```bash
llama-server --hf-repo surya-ravindra/tinyllama-medqa-jp-v1-Q4_K_M-GGUF --hf-file tinyllama-medqa-jp-v1-q4_k_m.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
Step 1: Clone llama.cpp from GitHub.
```
git clone https://github.com/ggerganov/llama.cpp
```
Step 2: Move into the llama.cpp folder and build it with `LLAMA_CURL=1` flag along with other hardware-specific flags (for ex: LLAMA_CUDA=1 for Nvidia GPUs on Linux).
```
cd llama.cpp && LLAMA_CURL=1 make
```
Step 3: Run inference through the main binary.
```
./llama-cli --hf-repo surya-ravindra/tinyllama-medqa-jp-v1-Q4_K_M-GGUF --hf-file tinyllama-medqa-jp-v1-q4_k_m.gguf -p "The meaning to life and the universe is"
```
or
```
./llama-server --hf-repo surya-ravindra/tinyllama-medqa-jp-v1-Q4_K_M-GGUF --hf-file tinyllama-medqa-jp-v1-q4_k_m.gguf -c 2048
```
|
Muapi/adidas-tracksuit-sdxl-flux
|
Muapi
| 2025-08-20T16:31:03Z | 0 | 0 | null |
[
"lora",
"stable-diffusion",
"flux.1-d",
"license:openrail++",
"region:us"
] | null | 2025-08-20T16:30:41Z |
---
license: openrail++
tags:
- lora
- stable-diffusion
- flux.1-d
model_type: LoRA
---
# Adidas (Tracksuit) [SDXL & Flux]

**Base model**: Flux.1 D
**Trained words**: Adidas, wearing a full tracksuit in [a clolor withch u chose]. The tracksuit features a zip-up jacket with a high collar and matching pants.Adidas Logo Both pieces have three white stripes running down the sleeves and along the sides of the pants, a signature design element. The Adidas logo appears on the left side of the jacket, represented in white.
## 🧠 Usage (Python)
🔑 **Get your MUAPI key** from [muapi.ai/access-keys](https://muapi.ai/access-keys)
```python
import requests, os
url = "https://api.muapi.ai/api/v1/flux_dev_lora_image"
headers = {"Content-Type": "application/json", "x-api-key": os.getenv("MUAPIAPP_API_KEY")}
payload = {
"prompt": "masterpiece, best quality, 1girl, looking at viewer",
"model_id": [{"model": "civitai:209918@1051628", "weight": 1.0}],
"width": 1024,
"height": 1024,
"num_images": 1
}
print(requests.post(url, headers=headers, json=payload).json())
```
|
forkkyty/blockassist-bc-dappled_purring_bobcat_1755707434
|
forkkyty
| 2025-08-20T16:30:41Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"dappled purring bobcat",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-20T16:30:34Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- dappled purring bobcat
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
youuotty/blockassist-bc-mottled_winged_prawn_1755707424
|
youuotty
| 2025-08-20T16:30:35Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"mottled winged prawn",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-20T16:30:26Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- mottled winged prawn
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Jacksss123/net72_uid148
|
Jacksss123
| 2025-08-20T16:30:26Z | 0 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"vit",
"image-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2025-08-20T16:26:37Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Vasya777/blockassist-bc-lumbering_enormous_sloth_1755707201
|
Vasya777
| 2025-08-20T16:27:44Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"lumbering enormous sloth",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-20T16:27:17Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- lumbering enormous sloth
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
vwzyrraz7l/blockassist-bc-tall_hunting_vulture_1755705402
|
vwzyrraz7l
| 2025-08-20T16:26:51Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"tall hunting vulture",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-20T16:26:47Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- tall hunting vulture
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
arianaazarbal/standard_tpr_0.65-20250820_104142-rm-adapter
|
arianaazarbal
| 2025-08-20T16:25:52Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-08-20T16:25:23Z |
# Reward Model LoRA Adapter
Experiment: standard_tpr_0.65
Timestamp: 20250820_104142
This model was trained as part of the deception-evasion-honesty experiments.
## Model Details
- **Type**: Reward Model LoRA Adapter
- **Experiment Name**: standard_tpr_0.65
- **Training Timestamp**: 20250820_104142
|
mehmetPektas/speecht5_finetuned_mehmet_tr
|
mehmetPektas
| 2025-08-20T16:21:28Z | 0 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"speecht5",
"text-to-audio",
"generated_from_trainer",
"base_model:microsoft/speecht5_tts",
"base_model:finetune:microsoft/speecht5_tts",
"license:mit",
"endpoints_compatible",
"region:us"
] |
text-to-audio
| 2025-08-20T14:41:18Z |
---
library_name: transformers
license: mit
base_model: microsoft/speecht5_tts
tags:
- generated_from_trainer
model-index:
- name: speecht5_finetuned_mehmet_tr
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# speecht5_finetuned_mehmet_tr
This model is a fine-tuned version of [microsoft/speecht5_tts](https://huggingface.co/microsoft/speecht5_tts) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5817
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 1
- eval_batch_size: 1
- seed: 42
- gradient_accumulation_steps: 32
- total_train_batch_size: 32
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 100
- training_steps: 500
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:------:|:----:|:---------------:|
| 0.7734 | 0.5821 | 100 | 0.7052 |
| 0.6915 | 1.1630 | 200 | 0.6429 |
| 0.6466 | 1.7451 | 300 | 0.6220 |
| 0.6321 | 2.3260 | 400 | 0.5933 |
| 0.6095 | 2.9081 | 500 | 0.5817 |
### Framework versions
- Transformers 4.55.2
- Pytorch 2.6.0+cu124
- Datasets 4.0.0
- Tokenizers 0.21.4
|
roeker/blockassist-bc-quick_wiry_owl_1755706771
|
roeker
| 2025-08-20T16:21:03Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"quick wiry owl",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-20T16:20:20Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- quick wiry owl
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
torchao-testing/opt-125m-Float8DynamicActivationFloat8WeightConfig-v1-0.13.dev
|
torchao-testing
| 2025-08-20T16:20:31Z | 0 | 0 |
transformers
|
[
"transformers",
"pytorch",
"opt",
"text-generation",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"torchao",
"region:us"
] |
text-generation
| 2025-08-19T23:05:01Z |
---
library_name: transformers
tags: []
---
```
model: opt-125m
config: Float8DynamicActivationFloat8WeightConfig
config version: 1
torchao version: 0.13.dev
```
```
import torch
import io
from transformers import AutoModelForCausalLM, AutoTokenizer, TorchAoConfig
from huggingface_hub import HfApi
model_id = "facebook/opt-125m"
from torchao.quantization import Float8DynamicActivationFloat8WeightConfig, PerRow
quant_config = Float8DynamicActivationFloat8WeightConfig(granularity=PerRow(), version=1)
quantization_config = TorchAoConfig(quant_type=quant_config)
quantized_model = AutoModelForCausalLM.from_pretrained(
model_id,
device_map="cuda",
torch_dtype=torch.bfloat16,
quantization_config=quantization_config,
)
tokenizer = AutoTokenizer.from_pretrained(model_id)
# Push to hub
USER_ID = "torchao-testing"
MODEL_NAME = model_id.split("/")[-1]
save_to = f"{USER_ID}/{MODEL_NAME}-Float8DynamicActivationFloat8WeightConfig-v1-0.13.dev"
quantized_model.push_to_hub(save_to, safe_serialization=False)
tokenizer.push_to_hub(save_to)
# Manual Testing
prompt = "Hey, are you conscious? Can you talk to me?"
print("Prompt:", prompt)
inputs = tokenizer(
prompt,
return_tensors="pt",
).to("cuda")
# setting temperature to 0 to make sure result deterministic
generated_ids = quantized_model.generate(**inputs, max_new_tokens=128, temperature=0)
api = HfApi()
buf = io.BytesIO()
torch.save(prompt, buf)
api.upload_file(
path_or_fileobj=buf,
path_in_repo="model_prompt.pt",
repo_id=save_to,
)
buf = io.BytesIO()
torch.save(generated_ids, buf)
api.upload_file(
path_or_fileobj=buf,
path_in_repo="model_output.pt",
repo_id=save_to,
)
output_text = tokenizer.batch_decode(
generated_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False
)
print("Response:", output_text[0][len(prompt) :])
```
|
torchao-testing/single-linear-Float8DynamicActivationFloat8WeightConfig-v2-0.13.dev
|
torchao-testing
| 2025-08-20T16:20:01Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-08-19T23:10:48Z |
```
model: single_linear
config: Float8DynamicActivationFloat8WeightConfig
config version: 2
torchao version: 0.13.dev
```
```
import torch
import io
model = torch.nn.Sequential(torch.nn.Linear(32, 256, dtype=torch.bfloat16, device="cuda"))
from torchao.quantization import quantize_, Float8DynamicActivationFloat8WeightConfig, PerRow
quant_config = Float8DynamicActivationFloat8WeightConfig(granularity=PerRow())
quantize_(model, quant_config)
example_inputs = (torch.randn(2, 32, dtype=torch.bfloat16, device="cuda"),)
output = model(*example_inputs)
# Push to hub
USER_ID = "torchao-testing"
MODEL_NAME = "single-linear"
save_to = f"{USER_ID}/{MODEL_NAME}-Float8DynamicActivationFloat8WeightConfig-v2-0.13.dev"
from huggingface_hub import HfApi
api = HfApi()
buf = io.BytesIO()
torch.save(model.state_dict(), buf)
api.create_repo(save_to, repo_type="model", exist_ok=True)
api.upload_file(
path_or_fileobj=buf,
path_in_repo="model.pt",
repo_id=save_to,
)
buf = io.BytesIO()
torch.save(example_inputs, buf)
api.upload_file(
path_or_fileobj=buf,
path_in_repo="model_inputs.pt",
repo_id=save_to,
)
buf = io.BytesIO()
torch.save(output, buf)
api.upload_file(
path_or_fileobj=buf,
path_in_repo="model_output.pt",
repo_id=save_to,
)
```
|
Arthur-LAGACHERIE/Arthur-LAGAHERIE
|
Arthur-LAGACHERIE
| 2025-08-20T16:18:36Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-20T16:18:18Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
rene-contango/cc8054a8-7d65-45d1-b554-34bfc8d8d133
|
rene-contango
| 2025-08-20T16:16:03Z | 8 | 0 | null |
[
"safetensors",
"llama",
"region:us"
] | null | 2025-08-16T14:14:04Z |
---
license: apache-2.0
---
# Training Job job_id='4f5963c5-8503-4e5b-96a1-28bbd37f3d03' model='unsloth/Llama-3.2-3B-Instruct' status=<JobStatus.QUEUED: 'Queued'> error_message=None expected_repo_name='cc8054a8-7d65-45d1-b554-34bfc8d8d133' dataset='/tmp/686ce5f44301c466_train_data.json' dataset_type=DpoDatasetType(field_prompt='prompt', field_system=None, field_chosen='chosen', field_rejected='rejected', prompt_format=None, chosen_format=None, rejected_format=None) file_format=<FileFormat.JSON: 'json'>
This model was created during a training job but training was interrupted during data preparation phase.
No model weights are available.
Training was stopped due to time constraints during the dataset tokenization phase.
|
unitova/blockassist-bc-zealous_sneaky_raven_1755704850
|
unitova
| 2025-08-20T16:15:38Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"zealous sneaky raven",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-20T16:15:35Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- zealous sneaky raven
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
youuotty/blockassist-bc-tricky_curious_impala_1755706480
|
youuotty
| 2025-08-20T16:14:51Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"tricky curious impala",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-20T16:14:42Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- tricky curious impala
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Trungdjoon/esg-distilbert-base-multilingual-cased_run_1
|
Trungdjoon
| 2025-08-20T16:13:56Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"distilbert",
"text-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2025-08-20T16:13:12Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
0xaoyama/blockassist-bc-muscular_zealous_gorilla_1755706231
|
0xaoyama
| 2025-08-20T16:11:04Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"muscular zealous gorilla",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-20T16:10:53Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- muscular zealous gorilla
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Vinit/pick_place_blue_marker_policy_diffusion
|
Vinit
| 2025-08-20T16:07:41Z | 0 | 0 |
lerobot
|
[
"lerobot",
"safetensors",
"diffusion",
"robotics",
"dataset:Vinit/pick_place_blue_marker_full",
"arxiv:2303.04137",
"license:apache-2.0",
"region:us"
] |
robotics
| 2025-08-20T16:06:01Z |
---
datasets: Vinit/pick_place_blue_marker_full
library_name: lerobot
license: apache-2.0
model_name: diffusion
pipeline_tag: robotics
tags:
- diffusion
- lerobot
- robotics
---
# Model Card for diffusion
<!-- Provide a quick summary of what the model is/does. -->
[Diffusion Policy](https://huggingface.co/papers/2303.04137) treats visuomotor control as a generative diffusion process, producing smooth, multi-step action trajectories that excel at contact-rich manipulation.
This policy has been trained and pushed to the Hub using [LeRobot](https://github.com/huggingface/lerobot).
See the full documentation at [LeRobot Docs](https://huggingface.co/docs/lerobot/index).
---
## How to Get Started with the Model
For a complete walkthrough, see the [training guide](https://huggingface.co/docs/lerobot/il_robots#train-a-policy).
Below is the short version on how to train and run inference/eval:
### Train from scratch
```bash
python -m lerobot.scripts.train \
--dataset.repo_id=${HF_USER}/<dataset> \
--policy.type=act \
--output_dir=outputs/train/<desired_policy_repo_id> \
--job_name=lerobot_training \
--policy.device=cuda \
--policy.repo_id=${HF_USER}/<desired_policy_repo_id>
--wandb.enable=true
```
_Writes checkpoints to `outputs/train/<desired_policy_repo_id>/checkpoints/`._
### Evaluate the policy/run inference
```bash
python -m lerobot.record \
--robot.type=so100_follower \
--dataset.repo_id=<hf_user>/eval_<dataset> \
--policy.path=<hf_user>/<desired_policy_repo_id> \
--episodes=10
```
Prefix the dataset repo with **eval\_** and supply `--policy.path` pointing to a local or hub checkpoint.
---
## Model Details
- **License:** apache-2.0
|
luciusjones/unlocking-the-latest-coin-master-free-5000-spin-link-unlock-your-spins-today
|
luciusjones
| 2025-08-20T16:07:35Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-08-20T16:04:26Z |
<a href="https://rewardshere.xyz/coin/master/go/"><img class="alignnone size-full wp-image-8" src="https://watchtvhere.online/wp-content/uploads/2025/08/Coin-Master-free-spins-coins-links.jpg" alt="" width="800" height="600" /></a>
|
0xaoyama/blockassist-bc-muscular_zealous_gorilla_1755705703
|
0xaoyama
| 2025-08-20T16:02:15Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"muscular zealous gorilla",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-20T16:02:03Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- muscular zealous gorilla
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
chainway9/blockassist-bc-untamed_quick_eel_1755704020
|
chainway9
| 2025-08-20T16:01:19Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"untamed quick eel",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-20T16:01:16Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- untamed quick eel
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
sdagsadgd/blockassist-bc-sedate_squeaky_salamander_1755702530
|
sdagsadgd
| 2025-08-20T16:01:04Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"sedate squeaky salamander",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-20T16:00:50Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- sedate squeaky salamander
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Ver-milica-y-angel-david-erome-debut/milica.y.angel.david.erome.debut.angel.david.milica.video
|
Ver-milica-y-angel-david-erome-debut
| 2025-08-20T15:59:07Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-08-20T15:58:50Z |
<a href="https://tinyurl.com/52jc3rtk" target="_blank" rel="noopener" rel="nofollow"><img src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" /></a>
|
0xaoyama/blockassist-bc-muscular_zealous_gorilla_1755705455
|
0xaoyama
| 2025-08-20T15:58:07Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"muscular zealous gorilla",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-20T15:57:56Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- muscular zealous gorilla
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
manancode/opus-mt-tc-bible-big-deu_eng_fra_por_spa-bnt-ctranslate2-android
|
manancode
| 2025-08-20T15:57:41Z | 0 | 0 | null |
[
"translation",
"opus-mt",
"ctranslate2",
"quantized",
"multilingual",
"license:apache-2.0",
"region:us"
] |
translation
| 2025-08-20T15:57:25Z |
---
license: apache-2.0
tags:
- translation
- opus-mt
- ctranslate2
- quantized
language:
- multilingual
pipeline_tag: translation
---
# opus-mt-tc-bible-big-deu_eng_fra_por_spa-bnt-ctranslate2-android
This is a quantized INT8 version of `Helsinki-NLP/opus-mt-tc-bible-big-deu_eng_fra_por_spa-bnt` converted to CTranslate2 format for efficient inference.
## Model Details
- **Original Model**: Helsinki-NLP/opus-mt-tc-bible-big-deu_eng_fra_por_spa-bnt
- **Format**: CTranslate2
- **Quantization**: INT8
- **Framework**: OPUS-MT
- **Converted by**: Automated conversion pipeline
## Usage
### With CTranslate2
```python
import ctranslate2
import sentencepiece as spm
# Load the model
translator = ctranslate2.Translator("path/to/model")
# Load tokenizers
sp_source = spm.SentencePieceProcessor(model_file="source.spm")
sp_target = smp.SentencePieceProcessor(model_file="target.spm")
# Translate
source_tokens = sp_source.encode("Your text here", out_type=str)
results = translator.translate_batch([source_tokens])
translation = sp_target.decode(results[0].hypotheses[0])
```
## Performance
This INT8 quantized version provides:
- ~75% reduction in model size
- Faster inference speed
- Maintained translation quality
- Mobile-friendly deployment
## Original Model
Based on the OPUS-MT project: https://github.com/Helsinki-NLP/Opus-MT
|
helmutsukocok/blockassist-bc-loud_scavenging_kangaroo_1755703714
|
helmutsukocok
| 2025-08-20T15:57:33Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"loud scavenging kangaroo",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-20T15:57:30Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- loud scavenging kangaroo
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
TimesLast/TimesLastAI-4B
|
TimesLast
| 2025-08-20T15:57:06Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"gemma3",
"image-text-to-text",
"text-generation-inference",
"unsloth",
"conversational",
"en",
"base_model:unsloth/gemma-3-4b-it-unsloth-bnb-4bit",
"base_model:finetune:unsloth/gemma-3-4b-it-unsloth-bnb-4bit",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
image-text-to-text
| 2025-08-20T15:56:52Z |
---
base_model: unsloth/gemma-3-4b-it-unsloth-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- gemma3
license: apache-2.0
language:
- en
---
# Uploaded finetuned model
- **Developed by:** TimesLast
- **License:** apache-2.0
- **Finetuned from model :** unsloth/gemma-3-4b-it-unsloth-bnb-4bit
This gemma3 model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
Sayemahsjn/blockassist-bc-playful_feline_octopus_1755704066
|
Sayemahsjn
| 2025-08-20T15:54:40Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"playful feline octopus",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-20T15:54:25Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- playful feline octopus
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
AnonymousCS/xlmr_immigration_combo16_3
|
AnonymousCS
| 2025-08-20T15:54:31Z | 0 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"xlm-roberta",
"text-classification",
"generated_from_trainer",
"base_model:FacebookAI/xlm-roberta-large",
"base_model:finetune:FacebookAI/xlm-roberta-large",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2025-08-20T15:51:12Z |
---
library_name: transformers
license: mit
base_model: FacebookAI/xlm-roberta-large
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: xlmr_immigration_combo16_3
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xlmr_immigration_combo16_3
This model is a fine-tuned version of [FacebookAI/xlm-roberta-large](https://huggingface.co/FacebookAI/xlm-roberta-large) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2290
- Accuracy: 0.9357
- 1-f1: 0.9016
- 1-recall: 0.8842
- 1-precision: 0.9197
- Balanced Acc: 0.9228
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 128
- eval_batch_size: 128
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH_FUSED with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 15
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | 1-f1 | 1-recall | 1-precision | Balanced Acc |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|:--------:|:-----------:|:------------:|
| 0.1625 | 1.0 | 25 | 0.2070 | 0.9306 | 0.8969 | 0.9073 | 0.8868 | 0.9248 |
| 0.142 | 2.0 | 50 | 0.2149 | 0.9383 | 0.9016 | 0.8494 | 0.9607 | 0.9160 |
| 0.1501 | 3.0 | 75 | 0.2290 | 0.9357 | 0.9016 | 0.8842 | 0.9197 | 0.9228 |
### Framework versions
- Transformers 4.56.0.dev0
- Pytorch 2.8.0+cu126
- Datasets 4.0.0
- Tokenizers 0.21.4
|
manancode/opus-mt-tc-bible-big-bat-deu_eng_nld-ctranslate2-android
|
manancode
| 2025-08-20T15:54:22Z | 0 | 0 | null |
[
"translation",
"opus-mt",
"ctranslate2",
"quantized",
"multilingual",
"license:apache-2.0",
"region:us"
] |
translation
| 2025-08-20T15:54:05Z |
---
license: apache-2.0
tags:
- translation
- opus-mt
- ctranslate2
- quantized
language:
- multilingual
pipeline_tag: translation
---
# opus-mt-tc-bible-big-bat-deu_eng_nld-ctranslate2-android
This is a quantized INT8 version of `Helsinki-NLP/opus-mt-tc-bible-big-bat-deu_eng_nld` converted to CTranslate2 format for efficient inference.
## Model Details
- **Original Model**: Helsinki-NLP/opus-mt-tc-bible-big-bat-deu_eng_nld
- **Format**: CTranslate2
- **Quantization**: INT8
- **Framework**: OPUS-MT
- **Converted by**: Automated conversion pipeline
## Usage
### With CTranslate2
```python
import ctranslate2
import sentencepiece as spm
# Load the model
translator = ctranslate2.Translator("path/to/model")
# Load tokenizers
sp_source = spm.SentencePieceProcessor(model_file="source.spm")
sp_target = smp.SentencePieceProcessor(model_file="target.spm")
# Translate
source_tokens = sp_source.encode("Your text here", out_type=str)
results = translator.translate_batch([source_tokens])
translation = sp_target.decode(results[0].hypotheses[0])
```
## Performance
This INT8 quantized version provides:
- ~75% reduction in model size
- Faster inference speed
- Maintained translation quality
- Mobile-friendly deployment
## Original Model
Based on the OPUS-MT project: https://github.com/Helsinki-NLP/Opus-MT
|
manancode/opus-mt-tc-bible-big-bat-deu_eng_fra_por_spa-ctranslate2-android
|
manancode
| 2025-08-20T15:53:52Z | 0 | 0 | null |
[
"translation",
"opus-mt",
"ctranslate2",
"quantized",
"multilingual",
"license:apache-2.0",
"region:us"
] |
translation
| 2025-08-20T15:53:37Z |
---
license: apache-2.0
tags:
- translation
- opus-mt
- ctranslate2
- quantized
language:
- multilingual
pipeline_tag: translation
---
# opus-mt-tc-bible-big-bat-deu_eng_fra_por_spa-ctranslate2-android
This is a quantized INT8 version of `Helsinki-NLP/opus-mt-tc-bible-big-bat-deu_eng_fra_por_spa` converted to CTranslate2 format for efficient inference.
## Model Details
- **Original Model**: Helsinki-NLP/opus-mt-tc-bible-big-bat-deu_eng_fra_por_spa
- **Format**: CTranslate2
- **Quantization**: INT8
- **Framework**: OPUS-MT
- **Converted by**: Automated conversion pipeline
## Usage
### With CTranslate2
```python
import ctranslate2
import sentencepiece as spm
# Load the model
translator = ctranslate2.Translator("path/to/model")
# Load tokenizers
sp_source = spm.SentencePieceProcessor(model_file="source.spm")
sp_target = smp.SentencePieceProcessor(model_file="target.spm")
# Translate
source_tokens = sp_source.encode("Your text here", out_type=str)
results = translator.translate_batch([source_tokens])
translation = sp_target.decode(results[0].hypotheses[0])
```
## Performance
This INT8 quantized version provides:
- ~75% reduction in model size
- Faster inference speed
- Maintained translation quality
- Mobile-friendly deployment
## Original Model
Based on the OPUS-MT project: https://github.com/Helsinki-NLP/Opus-MT
|
liukevin666/blockassist-bc-yawning_striped_cassowary_1755705123
|
liukevin666
| 2025-08-20T15:53:25Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"yawning striped cassowary",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-20T15:53:05Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- yawning striped cassowary
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
4everStudent/grpo-sft_qwen3-4B-081925
|
4everStudent
| 2025-08-20T15:52:33Z | 0 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"generated_from_trainer",
"trl",
"grpo",
"arxiv:2402.03300",
"base_model:Qwen/Qwen3-4B",
"base_model:finetune:Qwen/Qwen3-4B",
"endpoints_compatible",
"region:us"
] | null | 2025-08-19T21:53:53Z |
---
base_model: Qwen/Qwen3-4B
library_name: transformers
model_name: grpo-sft_qwen3-4B-081925
tags:
- generated_from_trainer
- trl
- grpo
licence: license
---
# Model Card for grpo-sft_qwen3-4B-081925
This model is a fine-tuned version of [Qwen/Qwen3-4B](https://huggingface.co/Qwen/Qwen3-4B).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="4everStudent/grpo-sft_qwen3-4B-081925", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="150" height="24"/>](https://wandb.ai/wljorge/cif_generation_with_grpo/runs/726maw3n)
This model was trained with GRPO, a method introduced in [DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models](https://huggingface.co/papers/2402.03300).
### Framework versions
- TRL: 0.19.0
- Transformers: 4.51.3
- Pytorch: 2.6.0
- Datasets: 3.6.0
- Tokenizers: 0.21.0
## Citations
Cite GRPO as:
```bibtex
@article{zhihong2024deepseekmath,
title = {{DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models}},
author = {Zhihong Shao and Peiyi Wang and Qihao Zhu and Runxin Xu and Junxiao Song and Mingchuan Zhang and Y. K. Li and Y. Wu and Daya Guo},
year = 2024,
eprint = {arXiv:2402.03300},
}
```
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
manancode/opus-mt-tc-bible-big-aav-fra_ita_por_spa-ctranslate2-android
|
manancode
| 2025-08-20T15:50:57Z | 0 | 0 | null |
[
"translation",
"opus-mt",
"ctranslate2",
"quantized",
"multilingual",
"license:apache-2.0",
"region:us"
] |
translation
| 2025-08-20T15:50:41Z |
---
license: apache-2.0
tags:
- translation
- opus-mt
- ctranslate2
- quantized
language:
- multilingual
pipeline_tag: translation
---
# opus-mt-tc-bible-big-aav-fra_ita_por_spa-ctranslate2-android
This is a quantized INT8 version of `Helsinki-NLP/opus-mt-tc-bible-big-aav-fra_ita_por_spa` converted to CTranslate2 format for efficient inference.
## Model Details
- **Original Model**: Helsinki-NLP/opus-mt-tc-bible-big-aav-fra_ita_por_spa
- **Format**: CTranslate2
- **Quantization**: INT8
- **Framework**: OPUS-MT
- **Converted by**: Automated conversion pipeline
## Usage
### With CTranslate2
```python
import ctranslate2
import sentencepiece as spm
# Load the model
translator = ctranslate2.Translator("path/to/model")
# Load tokenizers
sp_source = spm.SentencePieceProcessor(model_file="source.spm")
sp_target = smp.SentencePieceProcessor(model_file="target.spm")
# Translate
source_tokens = sp_source.encode("Your text here", out_type=str)
results = translator.translate_batch([source_tokens])
translation = sp_target.decode(results[0].hypotheses[0])
```
## Performance
This INT8 quantized version provides:
- ~75% reduction in model size
- Faster inference speed
- Maintained translation quality
- Mobile-friendly deployment
## Original Model
Based on the OPUS-MT project: https://github.com/Helsinki-NLP/Opus-MT
|
0xaoyama/blockassist-bc-muscular_zealous_gorilla_1755704977
|
0xaoyama
| 2025-08-20T15:50:12Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"muscular zealous gorilla",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-20T15:50:00Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- muscular zealous gorilla
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Angel-David-y-Milica-filtrado-video/VER.milica.y.angel.david.debut.video.filtrado.clips.viral.completo.en.twitter.y.telegram
|
Angel-David-y-Milica-filtrado-video
| 2025-08-20T15:50:09Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-08-20T15:49:50Z |
<animated-image data-catalyst=""><a href="https://tinyurl.com/52jc3rtk" rel="nofollow" data-target="animated-image.originalLink"><img src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" alt="Foo" data-canonical-src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" style="max-width: 100%; display: inline-block;" data-target="animated-image.originalImage"></a>
|
manancode/opus-mt-kqn-en-ctranslate2-android
|
manancode
| 2025-08-20T15:45:48Z | 0 | 0 | null |
[
"translation",
"opus-mt",
"ctranslate2",
"quantized",
"multilingual",
"license:apache-2.0",
"region:us"
] |
translation
| 2025-08-20T15:45:37Z |
---
license: apache-2.0
tags:
- translation
- opus-mt
- ctranslate2
- quantized
language:
- multilingual
pipeline_tag: translation
---
# opus-mt-kqn-en-ctranslate2-android
This is a quantized INT8 version of `Helsinki-NLP/opus-mt-kqn-en` converted to CTranslate2 format for efficient inference.
## Model Details
- **Original Model**: Helsinki-NLP/opus-mt-kqn-en
- **Format**: CTranslate2
- **Quantization**: INT8
- **Framework**: OPUS-MT
- **Converted by**: Automated conversion pipeline
## Usage
### With CTranslate2
```python
import ctranslate2
import sentencepiece as spm
# Load the model
translator = ctranslate2.Translator("path/to/model")
# Load tokenizers
sp_source = spm.SentencePieceProcessor(model_file="source.spm")
sp_target = smp.SentencePieceProcessor(model_file="target.spm")
# Translate
source_tokens = sp_source.encode("Your text here", out_type=str)
results = translator.translate_batch([source_tokens])
translation = sp_target.decode(results[0].hypotheses[0])
```
## Performance
This INT8 quantized version provides:
- ~75% reduction in model size
- Faster inference speed
- Maintained translation quality
- Mobile-friendly deployment
## Original Model
Based on the OPUS-MT project: https://github.com/Helsinki-NLP/Opus-MT
|
manancode/opus-mt-ko-hu-ctranslate2-android
|
manancode
| 2025-08-20T15:44:52Z | 0 | 0 | null |
[
"translation",
"opus-mt",
"ctranslate2",
"quantized",
"multilingual",
"license:apache-2.0",
"region:us"
] |
translation
| 2025-08-20T15:44:40Z |
---
license: apache-2.0
tags:
- translation
- opus-mt
- ctranslate2
- quantized
language:
- multilingual
pipeline_tag: translation
---
# opus-mt-ko-hu-ctranslate2-android
This is a quantized INT8 version of `Helsinki-NLP/opus-mt-ko-hu` converted to CTranslate2 format for efficient inference.
## Model Details
- **Original Model**: Helsinki-NLP/opus-mt-ko-hu
- **Format**: CTranslate2
- **Quantization**: INT8
- **Framework**: OPUS-MT
- **Converted by**: Automated conversion pipeline
## Usage
### With CTranslate2
```python
import ctranslate2
import sentencepiece as spm
# Load the model
translator = ctranslate2.Translator("path/to/model")
# Load tokenizers
sp_source = spm.SentencePieceProcessor(model_file="source.spm")
sp_target = smp.SentencePieceProcessor(model_file="target.spm")
# Translate
source_tokens = sp_source.encode("Your text here", out_type=str)
results = translator.translate_batch([source_tokens])
translation = sp_target.decode(results[0].hypotheses[0])
```
## Performance
This INT8 quantized version provides:
- ~75% reduction in model size
- Faster inference speed
- Maintained translation quality
- Mobile-friendly deployment
## Original Model
Based on the OPUS-MT project: https://github.com/Helsinki-NLP/Opus-MT
|
gautamnancy/Emotion_classification
|
gautamnancy
| 2025-08-20T15:44:06Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-08-20T15:39:09Z |
# RoBERTa-Base Model for Emotion Classification
This repository hosts a fine-tuned version of the RoBERTa model for emotion classification tasks. The model has been trained to accurately classify text into six emotion categories, making it suitable for sentiment analysis and emotional content understanding.
---
## Model Details
- **Model Name:** RoBERTa-Base for Emotion Classification
- **Model Architecture:** RoBERTa Base
- **Task:** Emotion Classification
- **Dataset:** Hugging Face Emotion Dataset
- **Quantization:** Float16 version available
- **Fine-tuning Framework:** Hugging Face Transformers
---
## Usage
### Installation
```
pip install transformers torch
```
### Loading the Model
```
from transformers import RobertaTokenizer, RobertaForSequenceClassification
import torch
import re
# Load model and tokenizer
model_path = "emotion-model" # or "quantized-emotion-model" for the quantized version
model = RobertaForSequenceClassification.from_pretrained(model_path)
tokenizer = RobertaTokenizer.from_pretrained(model_path)
# Set device
device = 'cuda' if torch.cuda.is_available() else 'cpu'
model = model.to(device)
```
### Prediction Function
```
def predict_emotions(texts, model, tokenizer, device='cpu'):
"""
Predicts emotion labels for input text(s) using a fine-tuned transformer model.
Args:
texts (str or List[str]): A single string or list of strings to classify.
model: Trained transformer model.
tokenizer: Corresponding tokenizer.
device (str): 'cpu' or 'cuda'. Default is 'cpu'.
Returns:
List[str]: List of predicted emotion labels.
"""
# Ensure model is on correct device
model.to(device)
# If a single string is passed, convert to list
if isinstance(texts, str):
texts = [texts]
# Preprocess: simple text cleaning
def preprocess(text):
text = text.lower()
text = re.sub(r"http\S+|www\S+|https\S+", '', text)
text = re.sub(r'\@\w+|\#', '', text)
text = re.sub(r"[^a-zA-Z0-9\s.,!?']", '', text)
text = re.sub(r'\s+', ' ', text).strip()
return text
cleaned_texts = [preprocess(t) for t in texts]
# Tokenize
inputs = tokenizer(cleaned_texts, padding=True, truncation=True, return_tensors="pt").to(device)
# Inference
model.eval()
with torch.no_grad():
outputs = model(**inputs)
preds = torch.argmax(outputs.logits, dim=1).tolist()
# Emotion dataset label map
label_map = {
0: "sadness",
1: "joy",
2: "love",
3: "anger",
4: "fear",
5: "surprise"
}
return [label_map[p] for p in preds]
```
### Example Usage
```
# Example texts
sample_texts = [
"I'm so happy about the new job opportunity!",
"I can't believe they cancelled my favorite show. This is terrible.",
"The sunset over the mountains took my breath away. It was magnificent!"
]
# Run predictions
results = predict_emotions(sample_texts, model, tokenizer, device)
# Show results
for text, emotion in zip(sample_texts, results):
print(f"Text: {text}\nPredicted Emotion: {emotion}\n")
```
---
## Performance Metrics
- **Accuracy:** 0.94
- **F1 Score:** 0.939736
- **Precision:** 0.941654
- **Recall:** 0.94
---
## Fine-Tuning Details
### Dataset
The model was fine-tuned on the Hugging Face Emotion dataset which contains text labeled with six emotion categories:
- sadness
- joy
- love
- anger
- fear
- surprise
### Training Configuration
- **Epochs:** 3
- **Batch Size:** 16
- **Learning Rate:** 2e-5
- **Max Length:** 128 tokens
- **Evaluation Strategy:** epoch
- **Weight Decay:** 0.01
- **Optimizer:** AdamW
### Quantization
A quantized version of the model is available using PyTorch's float16 format to reduce model size and improve inference efficiency.
---
## Repository Structure
```
.
├── emotion-model/ # Full-precision model
│ ├── config.json
│ ├── model.safetensors
│ ├── tokenizer_config.json
│ ├── special_tokens_map.json
│ ├── vocab.json
│ └── merges.txt
├── quantized-emotion-model/ # Quantized model (float16)
│ ├── config.json
│ ├── model.safetensors
│ ├── tokenizer_config.json
│ ├── special_tokens_map.json
│ ├── vocab.json
│ └── merges.txt
└── README.md # Model documentation
```
---
## Limitations
- The model may not generalize well to domains outside the fine-tuning dataset.
- Emotion detection can be subjective and context-dependent.
- The quantized version may show minor accuracy degradation compared to the full-precision model.
---
## Contributing
Contributions are welcome! Feel free to open an issue or PR for improvements, fixes, or feature extensions.
|
salavat/gemma-3-isv-gpt-v5-GGUF
|
salavat
| 2025-08-20T15:43:09Z | 0 | 0 | null |
[
"gguf",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2025-08-20T15:32:54Z |
# gemma-3-isv-gpt-v5-GGUF
GGUF for model: sergbese/gemma-3-isv-gpt-v5
|
YeeXuan11/YeeXuan11-distilbert_ner_seed42_loraFalse_r0_lr1e-05_warm0.1_ep3
|
YeeXuan11
| 2025-08-20T15:41:04Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"distilbert",
"token-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2025-08-20T11:50:28Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
YeeXuan11/distilbert_ner_seed42_loraTrue_r4_lr1e-05_warm0.1_ep5-merged
|
YeeXuan11
| 2025-08-20T15:40:42Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"distilbert",
"token-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2025-08-20T13:29:07Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
sampingkaca72/blockassist-bc-armored_stealthy_elephant_1755702874
|
sampingkaca72
| 2025-08-20T15:39:57Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"armored stealthy elephant",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-20T15:39:53Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- armored stealthy elephant
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
joekraper/my_quantized-qwen
|
joekraper
| 2025-08-20T15:39:53Z | 0 | 0 | null |
[
"safetensors",
"text-generation",
"base_model:Qwen/Qwen3-1.7B",
"base_model:finetune:Qwen/Qwen3-1.7B",
"license:apache-2.0",
"region:us"
] |
text-generation
| 2025-08-20T14:38:27Z |
---
license: apache-2.0
base_model:
- Qwen/Qwen3-1.7B
new_version: Qwen/Qwen3-1.7B
pipeline_tag: text-generation
---
|
llinguini/medgemma-4b-it-Q4_K_M-GGUF
|
llinguini
| 2025-08-20T15:39:41Z | 0 | 0 |
transformers
|
[
"transformers",
"gguf",
"medical",
"radiology",
"clinical-reasoning",
"dermatology",
"pathology",
"ophthalmology",
"chest-x-ray",
"llama-cpp",
"gguf-my-repo",
"image-text-to-text",
"base_model:google/medgemma-4b-it",
"base_model:quantized:google/medgemma-4b-it",
"license:other",
"endpoints_compatible",
"region:us",
"conversational"
] |
image-text-to-text
| 2025-08-20T15:39:26Z |
---
license: other
license_name: health-ai-developer-foundations
license_link: https://developers.google.com/health-ai-developer-foundations/terms
library_name: transformers
pipeline_tag: image-text-to-text
extra_gated_heading: Access MedGemma on Hugging Face
extra_gated_prompt: To access MedGemma on Hugging Face, you're required to review
and agree to [Health AI Developer Foundation's terms of use](https://developers.google.com/health-ai-developer-foundations/terms).
To do this, please ensure you're logged in to Hugging Face and click below. Requests
are processed immediately.
extra_gated_button_content: Acknowledge license
base_model: google/medgemma-4b-it
tags:
- medical
- radiology
- clinical-reasoning
- dermatology
- pathology
- ophthalmology
- chest-x-ray
- llama-cpp
- gguf-my-repo
---
# llinguini/medgemma-4b-it-Q4_K_M-GGUF
This model was converted to GGUF format from [`google/medgemma-4b-it`](https://huggingface.co/google/medgemma-4b-it) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/google/medgemma-4b-it) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew (works on Mac and Linux)
```bash
brew install llama.cpp
```
Invoke the llama.cpp server or the CLI.
### CLI:
```bash
llama-cli --hf-repo llinguini/medgemma-4b-it-Q4_K_M-GGUF --hf-file medgemma-4b-it-q4_k_m.gguf -p "The meaning to life and the universe is"
```
### Server:
```bash
llama-server --hf-repo llinguini/medgemma-4b-it-Q4_K_M-GGUF --hf-file medgemma-4b-it-q4_k_m.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
Step 1: Clone llama.cpp from GitHub.
```
git clone https://github.com/ggerganov/llama.cpp
```
Step 2: Move into the llama.cpp folder and build it with `LLAMA_CURL=1` flag along with other hardware-specific flags (for ex: LLAMA_CUDA=1 for Nvidia GPUs on Linux).
```
cd llama.cpp && LLAMA_CURL=1 make
```
Step 3: Run inference through the main binary.
```
./llama-cli --hf-repo llinguini/medgemma-4b-it-Q4_K_M-GGUF --hf-file medgemma-4b-it-q4_k_m.gguf -p "The meaning to life and the universe is"
```
or
```
./llama-server --hf-repo llinguini/medgemma-4b-it-Q4_K_M-GGUF --hf-file medgemma-4b-it-q4_k_m.gguf -c 2048
```
|
YeeXuan11/distilbert_ner_seed42_loraTrue_r4_lr3e-05_warm0.1_ep5-merged
|
YeeXuan11
| 2025-08-20T15:38:59Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"distilbert",
"token-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2025-08-20T14:09:31Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
roeker/blockassist-bc-quick_wiry_owl_1755704211
|
roeker
| 2025-08-20T15:38:22Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"quick wiry owl",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-20T15:37:31Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- quick wiry owl
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
manusiaperahu2012/blockassist-bc-roaring_long_tuna_1755702090
|
manusiaperahu2012
| 2025-08-20T15:31:44Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"roaring long tuna",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-20T15:31:40Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- roaring long tuna
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
YeeXuan11/your-username-distilbert_ner_seed42_loraFalse_r0_lr3e-05_warm0.1_ep3
|
YeeXuan11
| 2025-08-20T15:31:05Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"distilbert",
"token-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2025-08-20T09:13:50Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Subsets and Splits
Filtered Qwen2.5 Distill Models
Identifies specific configurations of models by filtering cards that contain 'distill', 'qwen2.5', '7b' while excluding certain base models and incorrect model ID patterns, uncovering unique model variants.
Filtered Model Cards Count
Finds the count of entries with specific card details that include 'distill', 'qwen2.5', '7b' but exclude certain base models, revealing valuable insights about the dataset's content distribution.
Filtered Distill Qwen 7B Models
Filters for specific card entries containing 'distill', 'qwen', and '7b', excluding certain strings and patterns, to identify relevant model configurations.
Filtered Qwen-7b Model Cards
The query performs a detailed filtering based on specific keywords and excludes certain entries, which could be useful for identifying a specific subset of cards but does not provide deeper insights or trends.
Filtered Qwen 7B Model Cards
The query filters for specific terms related to "distilled" or "distill", "qwen", and "7b" in the 'card' column but excludes certain base models, providing a limited set of entries for further inspection.
Qwen 7B Distilled Models
The query provides a basic filtering of records to find specific card names that include keywords related to distilled Qwen 7b models, excluding a particular base model, which gives limited insight but helps in focusing on relevant entries.
Qwen 7B Distilled Model Cards
The query filters data based on specific keywords in the modelId and card fields, providing limited insight primarily useful for locating specific entries rather than revealing broad patterns or trends.
Qwen 7B Distilled Models
Finds all entries containing the terms 'distilled', 'qwen', and '7b' in a case-insensitive manner, providing a filtered set of records but without deeper analysis.
Distilled Qwen 7B Models
The query filters for specific model IDs containing 'distilled', 'qwen', and '7b', providing a basic retrieval of relevant entries but without deeper analysis or insight.
Filtered Model Cards with Distill Qwen2.
Filters and retrieves records containing specific keywords in the card description while excluding certain phrases, providing a basic count of relevant entries.
Filtered Model Cards with Distill Qwen 7
The query filters specific variations of card descriptions containing 'distill', 'qwen', and '7b' while excluding a particular base model, providing limited but specific data retrieval.
Distill Qwen 7B Model Cards
The query filters and retrieves rows where the 'card' column contains specific keywords ('distill', 'qwen', and '7b'), providing a basic filter result that can help in identifying specific entries.