
txt
stringlengths 93
37.3k
|
|---|
## dist_github-littlebenlittle-FileSystem-Helpers.md
# FileSystem::Helpers
Useful subs for interacting with the host filesystem.
* `copy-dir` recursively copies the content of directory
* `temp-dir` Accepts a block and runs it after defining `$*tmpdir`, deleting the temporary directory after block execution has finished.
|
## dist_zef-jonathanstowe-Audio-Playlist-JSPF.md
# Audio::Playlist::JSPF
JSON representation of a 'playlist'

## Synopsis
```
use Audio::Playlist::JSPF;
my $playlist = Audio::Playlist::JSPF.from-json($some-json);
say "Playing from { $playlist.title }";
for $playlist.track -> $track {
if $track.location.elems {
say "Playing track { $track.title } by { $track.creator }";
# TYpically if there is more than one location we might
# choose the most suitable one.
my $track-uri = $track.location.first;
# Do something with the track
}
}
```
## Description
This is a JSON representation of [XSPF](http://xspf.org/) which is
a format for sharing media playlists.
Because this does the role LJSON::Class the objects can be created
directly from and serialised to JSON via the C and C
methods that role provides.
Currently there doesn't seem to be much software using this format for
playlists but JSON is convenient for a variety of reasons.
## Installation
Assuming you have a working Rakudo installation you should be able to install this with *zef* :
```
# From the source directory
zef install .
# Remote installation
zef install Audio::Playlist::JSPF
```
## Support
If you have any problems or suggestions with this module please report them at:
<https://github.com/jonathanstowe/Audio-Playlist-JSPF/issues>
And I'll see what I can do.
## Licence
This is free software.
Please see the <LICENCE> file in the distribution
© Jonathan Stowe 2016 - 2021
|
## dist_zef-raku-community-modules-Concurrent-BoundedChannel.md
[](https://github.com/raku-community-modules/Concurrent-BoundedChannel/actions) [](https://github.com/raku-community-modules/Concurrent-BoundedChannel/actions) [](https://github.com/raku-community-modules/Concurrent-BoundedChannel/actions)
# NAME
Concurrent::BoundedChannel - A Channel with limited number of elements
# SYNOPSIS
```
use Concurrent::BoundedChannel;
# Construct a BoundedChannel with 20 entries
my $bc = BoundedChannel.new(limit=>20);
$bc.send('x'); # will block if $bc is full
my $val = $bc.receive; # returns 'x'
my $oval=$bc.offer('y'); # non-blocking send - returns the offered value
# ('y' in this case), or Nil if $bc is full
$val=$bc.poll;
$bc.close;
# OR
$bc.fail(X::SomeException.new);
```
# DESCRIPTION
The normal Raku [`Channel`](https://docs.raku.org/type/Channel) is an unbounded queue. This subclass offers an alternative with size limits.
## OVERVIEW
The normal Raku `Channel` class is an unbounded queue. It will grow indefinitely as long as values are fed in and not removed.
In some cases that may not be desirable. `BoundedChannel` is a subclass of `Channel` with a set size limit. It behaves just like `Channel`, with some exceptions:
* The send method will block, if the Channel is already populated with the maximum number of elements.
* There is a new `offer` method, which is the send equivalent of poll - i.e. a non-blocking send. It returns `Nil` if the Channel is full, otherwise it returns the offered value.
* If one or more threads is blocking on a send, and the channel is closed, those send calls will throw exceptions, just as if send had been called on a closed normal Channel.
The `fail` method is an exception to the `BoundedChannel` limit. If the BoundedChannel is full, and `fail` is called, the exception specified will still be placed at the end of the queue, even if that would violate the limit. This was deemed acceptable to avoid having a fail contend with blocking send calls.
### BoundedChannel
The constructor takes one parameter (limit), which can be anwhere from zero to as large as you wish. A zero limit `BoundedChannel` behaves similar to a UNIX pipe - a send will block unless a receive is already waiting for value, and a receive will block unless a send is already waiting.
# AUTHOR
gotoexit
# COPYRIGHT AND LICENSE
Copyright 2016 - 2017 gotoexit
Copyright 2024 Raku Community
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_cpan-HANENKAMP-Prometheus-Client.md
# NAME
Prometheus::Client - Prometheus instrumentation client for Perl 6
# SYNOPSIS
```
use v6;
use Prometheus::Client :metrics, :instrument;
#| A function that takes some time.
sub process-request($t) is timed {
sleep $t;
}
my $m = METRICS {
summary
'request_processing_seconds',
'Time spent processing requests',
timed => &process-request;
}
sub MAIN() {
use Cro::HTTP::Router;
use Cro::HTTP::Server;
use Prometheus::Client::Exposition :render;
my $application = route {
get -> 'process', $t is timed($timer) {
sleep $t;
content 'text/plain', 'ok';
}
get -> 'metrics' {
content 'text/plain', render-metrics($m);
}
}
my Cro::Service $service = Cro::HTTP::Server.new:
:host<localhost>, :port<10000>, :$application;
$service.start;
react whenever signal(SIGINT) {
$service.stop;
exit;
}
}
```
# DESCRIPTION
This is an implementation of a Prometheus client library. The intention is to adhere to the requirements given by the Prometheus project for writing clients:
* <https://prometheus.io/docs/instrumenting/writing_clientlibs/>
As well as to provide an interface that fits Perl 6. This module provides a DSL for defining a collection of metrics as well as tools for easily using those metrics to easily instrument your code.
This particular module provides an interface aimed at instrumenting your Perl 6 program. If you need to provide instrumentation of an external program, the operating system, or something else, you will likely find the interface provided by Prometheus::Client::Collector to be more useful.
This module also provides the registry tooling, which allows you gather all the metrics of multiple collectors together into a single interface.
# CLARIFICATIONS
Insofar as it is possible, I have tried to stick to the definitions and usages prefered by the Prometheus project for components. However, as a relative noob to Prometheus, I have probably gotten some of the details wrong. Please submit an issue or PR if I or this code requires correction.
There is a particular clarification that I need to make regarding the use of the work "metrics." Personally, I find the way Prometheus uses the words "metrics", "metrics family", and "samples" to be extremely confusing. (In fact, the word "metric" is being entirely misused by the Prometheus project. The word they actually mean is "measurement", but I digress.) Therefore, I want to take a moment here to clarify that "metric" can have basically two meanings within this module library depending on context.
Pod::Defn<93921565996832>
Pod::Defn<93921565994984>
Now, in the official Prometheus client libraries, the "metrics" classes refer to metrics as collectors. The "metrics family" classes refer to metrics as measurements. In this library, you will find the interface for using metrics as collectors here with the class definitions being held by Prometheus::Client::Metrics. You will find the interface for using metrics as measurements primarily within Prometheus::Client::Exporter because these are primarily used to build exporters.
The other word that can be somewhat confusing is the word "sample". However, the most common uses of this library should allow you to avoid running into this confusion. Be aware that if you run into a metric as a measurement with multiple samples, that doesn't mean the samples are necessarily a series of measurements of that measurement. Usually multipel samples are different properties of a single measurement. For example, a summary metric will always report two samples, the count of items being reported and the running sum of items that have been reported.
# EXPORTED ROUTINES
This module provides no exports by default. However, if you specify the `:metrics` parameter when you import it, you will receive all the exported routines mentioned here. If not expoted, they are all defined `OUR`-scoped, so you can use them the `Prometheus::Client::` prefix.
You can also supply the `:instrument` parameter during import. This will cause the `is timed` and `is tracked-in-progress` traits to be exported.
## sub METRICS
```
our sub METRICS(&block --> Prometheus::Client::CollectorRegistry:D) is export(:metrics)
```
Calling this subroutine will cause a dynamic variable named `$*PROMETHEUS` to be defined and then the code of `&block` to be called. If you use the other methods exported by this module to construct counters, gauges, summaries, histograms, info, and state-set metrics or the routine provided for collector registry within the `METRICS` block, the constructed metrics will be automatically constructed and registered. The fully constructed registry is then returned by this routine.
If you have custom code to run and build your metric or collector objects, you can refer directly to `$*PROMETHEUS` as needed within the block. However, this should rarely be necessary.
## sub counter
```
our proto counter(|) is export(:metrics)
multi counter(Str:D $name, Str:D $documentation --> Prometheus::Client::Metrics::Counter)
multi counter(
Str:D :$name!,
Str:D :$namespace,
Str:D :$subsystem,
Str:D :$unit,
Str:D :$documentation!,
Str:D :@label-names,
Real:D :$value = 0,
Instant:D :$created = now,
Prometheus::Client::CollectorRegistry :$registry,
--> Prometheus::Client::Metrics::Counter
)
```
Constructs a Prometheus::Client::Metrics::Counter and registers with the registry in `$*PROMETHEUS` or the given `$registry`. The newly constructed metric collector is returned.
If `@label-names` are given, then a counter group is created instead. In which case, you code must provide values for the labels whenever providing a measurement for the metric:
```
my $c = counter(
name => 'person_ages',
documentation => 'the ages of measured people',
label-values => <personal_name>,
);
$c.labels('Bob').inc;
$c.labels(personal_name => 'Steve').inc;
```
See Prometheus::Client::Metrics::Group for details.
## sub gauge
```
our proto gauge(|) is export(:metrics)
multi gauge(Str:D $name, Str:D $documentation --> Prometheus::Client::Metrics::Gauge)
multi gauge(
Str:D :$name!,
Str:D :$namespace,
Str:D :$subsystem,
Str:D :$unit,
Str:D :$documentation!,
Str:D :@label-names,
Real:D :$value = 0,
Instant:D :$created = now,
Prometheus::Client::CollectorRegistry :$registry,
--> Prometheus::Client::Metrics::Gauge
)
```
Constructs a Prometheus::Client::Metrics::Gauge and registers with the registry in `$*PROMETHEUS` or the given `$registry`. The newly constructed metric collector is returned.
If `@label-names` are given, then a gauge group is created instead. In which case, you code must provide values for the labels whenever providing a measurement for the metric:
```
my $c = gauge(
name => 'person_heights',
unit => 'inches',
documentation => 'the heights of measured people',
label-values => <personal_name>,
);
$c.labels('Bob').set(60);
$c.labels(personal_name => 'Steve').set(68);
```
See Prometheus::Client::Metrics::Group for details.
## sub summary
```
our proto summary(|) is export(:metrics)
multi summary(Str:D $name, Str:D $documentation --> Prometheus::Client::Metrics::Summary)
multi summary(
Str:D :$name!,
Str:D :$namespace,
Str:D :$subsystem,
Str:D :$unit,
Str:D :$documentation!,
Str:D :@label-names,
Real:D :$count = 0,
Real:D :$sum = 0,
Instant:D :$created = now,
Prometheus::Client::CollectorRegistry :$registry,
--> Prometheus::Client::Metrics::Summary
)
```
Constructs a Prometheus::Client::Metrics::Summary and registers with the registry in `$*PROMETHEUS` or the given `$registry`. The newly constructed metric collector is returned.
If `@label-names` are given, then a summary group is created instead. In which case, you code must provide values for the labels whenever providing a measurement for the metric:
```
my $c = summary(
name => 'personal_visits_count',
documentation => 'the number of visits by particular people',
label-values => <personal_name>,
);
$c.labels('Bob').observe(6);
$c.labels(personal_name => 'Steve').observe(0);
```
See Prometheus::Client::Metrics::Group for details.
## sub histogram
```
our proto histogram(|) is export(:metrics)
multi histogram(Str:D $name, Str:D $documentation --> Prometheus::Client::Metrics::Histogram)
multi histogram(
Str:D :$name!,
Str:D :$namespace,
Str:D :$subsystem,
Str:D :$unit,
Str:D :$documentation!,
Str:D :@label-names,
Real:D :@bucket-bounds,
Int:D :@buckets,
Real:D :$sum,
Instant:D :$created = now,
Prometheus::Client::CollectorRegistry :$registry,
--> Prometheus::Client::Metrics::Histogram
)
```
Constructs a Prometheus::Client::Metrics::Histogram and registers with the registry in `$*PROMETHEUS` or the given `$registry`. The newly constructed metric collector is returned.
If `@label-names` are given, then a histogram group is created instead. In which case, you code must provide values for the labels whenever providing a measurement for the metric:
```
my $c = histogram(
name => 'personal_visits_duration',
bucket-bounds => (1,2,4,8,16,32,64,128,256,512,Inf),
documentation => 'the length of visits by particular people',
label-values => <personal_name>,
);
$c.labels('Bob').observe(182);
$c.labels(personal_name => 'Steve').observe(12);
```
See Prometheus::Client::Metrics::Group for details.
## sub info
```
our proto info(|) is export(:metrics)
multi info(Str:D $name, Str:D $documentation --> Prometheus::Client::Metrics::Info)
multi info(
Str:D :$name!,
Str:D :$namespace,
Str:D :$subsystem,
Str:D :$unit,
Str:D :$documentation!,
Pair:D :@info,
Prometheus::Client::CollectorRegistry :$registry,
--> Prometheus::Client::Metrics::Info
)
```
Constructs a Prometheus::Client::Metrics::Info and registers with the registry in `$*PROMETHEUS` or the given `$registry`. The newly constructed metric collector is returned.
## sub state-set
```
our proto state-set(|) is export(:metrics)
multi state-set(Str:D $name, Str:D $documentation --> Prometheus::Client::Metrics::StateSet)
multi state-set(
Str:D :$name!,
Str:D :$namespace,
Str:D :$subsystem,
Str:D :$unit,
Str:D :$documentation!,
Str:D :@states,
Int:D :$state,
Prometheus::Client::CollectorRegistry :$registry,
--> Prometheus::Client::Metrics::StateSet
)
```
Constructs a Prometheus::Client::Metrics::StateSet and registers with the registry in `$*PROMETHEUS` or the given `$registry`. The newly constructed metric collector is returned.
## sub register
```
our sub register(
Prometheus::Client::Metrics::Collector $collector,
Prometheus::Client::CollectorRegistry :$registry,
) is export(:metrics)
```
This calls the `.register` method of the current Prometheus::Client::Metrics::CollectorRegistry in `$*PROMETHEUS` or the given `$registry`.
## sub unregister
```
our sub unregister(
Prometheus::Client::Metrics::Collector $collector,
Prometheus::Client::CollectorRegistry :$registry,
) is export(:metrics)
```
This calls the `.unregister` method of the current Prometheus::Client::Metrics::CollectorRegistry in `$*PROMETHEUS` or the given `$registry`.
## trait is timed
```
multi trait_mod:<is> (Routine $r, :$timed!) is export(:instrument)
```
The `is timed` trait allows you to instrument a routine to time it. Each call to that method will update the attached metric collector. The change recorded depends on the type of metric:
* * A gauge will be set to the <Duration> of the most recent call.
* * A summary will add an observation for each call with the sum being increased by the time and the counter being bumpted by one.
* * A histogram will add an observation to the appropriate bucket based on the duration of the call.
## trait is tracked-in-progress
```
multi trait_mod:<is> (Routine $r, :$tracked-in-progress!) is export(:instrument)
```
This method will track the number of in-progress calls to the instrumented method. The gauge will be increased at the start of the call and decreased at the end.
|
## parametricrolegrouphow.md
role Metamodel::ParametricRoleGroupHOW
Represents a group of roles with different parameterizations
```raku
class Metamodel::ParametricRoleGroupHOW
does Metamodel::Naming
does Metamodel::Documenting
does Metamodel::Stashing
does Metamodel::TypePretense
does Metamodel::RolePunning
does Metamodel::BoolificationProtocol {}
```
*Warning*: this role is part of the Rakudo implementation, and is not a part of the language specification.
A `ParametricRoleGroupHOW` groups a set of `ParametricRoleHOW`, every one of them representing a single role declaration with their own parameter sets.
```raku
(role Zape[::T] {}).HOW.say; # OUTPUT: «Perl6::Metamodel::ParametricRoleHOW.new»
Zape.HOW.say ; # OUTPUT: «Perl6::Metamodel::ParametricRoleGroupHOW.new»
```
`ParametricRoleHOW`s need to be added to this kind of group:
```raku
my \zape := Metamodel::ParametricRoleGroupHOW.new_type( name => "zape");
my \zipi := Metamodel::ParametricRoleHOW.new_type( name => "zipi", group => zape);
say zipi.HOW; # OUTPUT: «Perl6::Metamodel::ParametricRoleHOW.new»
```
*Note*: As most of the `Metamodel` classes, this class is here mainly for illustration purposes and it's not intended for the final user to instantiate.
|
## dist_zef-librasteve-Definitely.md
# Definitely (Maybe)
An implementation of the Maybe Monad in Raku
## DESCRIPTION
The [Maybe Monad](https://en.wikipedia.org/wiki/Monad_(functional_programming)#An_example:_Maybe) is a technique for avoiding unexpected Nil exceptions or having to explicitly test for Nil in a method's response. It removes a lot of ambiguity, which increases maintainability, and reduces surprises.
It's called "Definitely" because when you use this module's types, you'll "Definitely" know what you're working with:
* `Definitely::Maybe`
* `Definitely::Some`
* `Definitely::None`
For example:
```
sub never-int() returns Int { Nil }
#vs
sub maybe-int() returns Maybe[Int] {...}
```
The `never-int` function claims it'll return an `Int`, but it never does. The `maybe-int` function makes it explicit that *maybe* you'll get an Int, but *maybe* you won't.
`Some` & `None` both provide an `.is-something` method, if you want to explicitly test if you have something. You can also convert them to a Bool for quick testing (Some is True, None is False). You can explicitly extract the value from a Maybe/Some object by calling its `.value` method.
`None` provides a `FALLBACK` method that returns the same None object. This means that you can call method chains on it as if it were the thing you hoped for without blowing up. Obviously, you'd only do this if your system would be ok with nothing happening as a result of these calls. For example, logging is nice, but you probably want your system to carry on even if the logging mechanism is unavailable.
```
multi sub logger($x) returns Maybe[Logger] {
nothing(Logger)
}
logger().record_error("does nothing, and doesn't blow up")
```
Many rakuteers argue that because Raku has typed `Nil`s, the Maybe Monad is already built in. See [this Stack Overflow answer](https://stackoverflow.com/questions/55072228/creating-a-maybe-type-in-perl-6) for more details. Even if they're right, people like me would argue that there's a huge maintainability value to having code that makes it *explicit* that *Maybe* the value you get back from a method won't be what you were hoping for.
## USAGE
The core idea is simple. When creating a function specify it's return type as `Maybe` or `Maybe[Type]`. Within the function you'll use the `something(Any)` and `nothing()` or `nothing(Type)` helper functions to provide a `Maybe` / `Maybe[Type]` compatible object to your caller. The caller then has multiple choices for how to handle the result.
Note: you should not specify Maybe when calling `nothing(Type)`. For example, call `nothing(Int)` not `nothing(Maybe[Int])`. The function will take care of making sure it conforms to the Maybe Type for you.
```
use Definitely;
multi sub foo($x) returns Maybe[Int] {
$x ~~ Int ?? something($x) !! nothing(Int);
}
multi sub foo($x) returns Maybe {
(0,1).roll ?? something($x) !! nothing();
}
# explicitly handle questionable results
given foo(3) {
when $_ ~~ Some {say "'Tis a thing Papa!. Look: $_"}
default {say "'Tis nothing.'"}
}
# or, call the .is-something method
my Maybe[Int] $questionable_result = foo(3)
if $questionable_result.is-something {
# extract the value directly
return $questionable_result.value + 4;
}
# or, test truthyness (Some is True None is False)
my Maybe[Int] $questionable_result = foo(4);
$questionable_result ?? $questionable_result.value !! die "oh no!"
# or, just assume it's good if you don't care if calls have no result
my Maybe[Logger] $maybe_log = logger();
$maybe_log.report_error("called if logger is Some, ignored if None")
# subs that return Maybe can be chained with the bind operator >>=
sub halve(Int $x --> Maybe[Int]) {
given $x {
when * %% 2 { something( $x div 2 ) }
when ! * %% 2 { nothing(Int) }
}
}
say (halve 3) >>= &halve;
say (something 32) >>= &halve >>= &halve >>= &halve;
```
## Installation
`zef install Definitely`
## AUTHORS
The seed of this comes from [This post by p6Steve](https://p6steve.wordpress.com/2022/08/16/raku-rust-option-some-none/). [masukomi](https://masukomi.org) built it out into a full Maybe Monad implementation as a Raku module.
## LICENSE
MIT. See LICENSE file.
### method is-something
```
method is-something() returns Bool
```
Returns true for Some
### sub something
```
sub something(
::Type $value
) returns Mu
```
Simple creation of Some objects that also match the Maybe type.
### multi sub nothing
```
multi sub nothing(
::Type $
) returns Mu
```
Used to create None objects when your method returns a typed Maybe.
### multi sub nothing
```
multi sub nothing() returns Mu
```
Used to create None objects when your method returns an untyped Maybe.
### sub unwrap
```
sub unwrap(
Definitely::Maybe $maybe_obj,
Str $message
) returns Mu
```
extracts the value from a Maybe object or dies with your message
### multi sub bind
```
multi infix:«>>=»(
Maybe $x,
&f
) returns Maybe
```
bind operation `>>=` for chaining subs that return a Maybe. `(M a) -> &f(a -> M b) -> (M b)`, which receives a monadic value `M a` and a function `&f` that accepts values of the base type a. Bind unwraps a, applies `&f` to it, and returns the result of `&f` as a Maybe value `M b` (see [Wikipedia Monad](https://en.wikipedia.org/wiki/Monad_(functional_programming)#An_example:_Maybe))
|
## dist_cpan-BDUGGAN-LLM-DWIM.md
[](https://github.com/bduggan/raku-llm-dwim/actions/workflows/linux.yml)
[](https://github.com/bduggan/raku-llm-dwim/actions/workflows/macos.yml)
# NAME
LLM::DWIM -- Do What I Mean, with help from large language models.
# SYNOPSIS
```
use LLM::DWIM;
say dwim "How many miles is it from the earth to the moon?";
# Approximately 238,900 miles (384,400 kilometers)
say dwim "@NothingElse How many miles is it from the earth to the moon? #NumericOnly";
# 238900
sub distance-between($from,$to) {
dwim "@NothingElse #NumericOnly What is the distance in miles between $from and $to?";
}
say distance-between("earth","sun");
# 92955887.6 miles
```
Meanwhile, in ~/.config/llm-dwim.toml:
```
evaluator = "gemini"
gemini.temperature = 0.5
```
# DESCRIPTION
This is a simple wrapper around [LLM::Functions](https://raku.land/zef:antononcube/LLM::Functions), and [LLM::Prompts](https://raku.land/zef:antononcube/LLM::Prompts) It provides a single subroutine, `dwim`, that sends a string to an LLM evaluator, making use of a configuration file to say a little more about what you mean.
# FUNCTIONS
## dwim
```
sub dwim(Str $str) returns Mu
```
This function takes a string, expands it using LLM::Prompts, and uses LLM::Functions to evaluate the string.
It is mostly equivalent to:
```
use LLM::Functions;
use LLM::Prompts;
use TOML;
my $conf-dir = %*ENV<XDG_HOME> // $*HOME.child('.config');
my $conf = from-toml($conf-dir.child('llm-dwim.toml').IO.slurp);
my $evaluator = $conf<evaluator>;
my &evaluator //= llm-function(
llm-evaluator => llm-configuration( $evaluator, |%( $conf{ $evaluator } ) )
);
my $msg = llm-prompt-expand($str);
evaluator($msg);
```
For diagnostics, use [Log::Async](https://raku.land/cpan:BDUGGAN/Log::Async) and add a tap, like so:
```
use LLM::DWIM;
use Log::Async;
logger.send-to($*ERR);
say dwim "How many miles is it from earth is the moon? #NumericOnly";
```
# CONFIGURATION
This module looks for `llm-dwim.toml` in either `XDG_HOME` or `HOME/.config`. This can be overridden by setting `DWIM_LLM_CONF` to another filename.
The configuration file should be in TOML format and should contain at least one key, `evaluator`, which should be the name of the LLM evaluator to use. Evaluators can be configured using TOML syntax, with the evaluator name as the key.
Sample configurations:
Use Gemini (which has a free tier) :
```
evaluator = "gemini"
```
Use OpenAI, and modify some parameters:
```
evaluator = "OpenAI"
OpenAI.temperature = 0.9
OpenAI.max-tokens = 100
```
See [LLM::Functions](https://raku.land/zef:antononcube/LLM::Functions) for all of the configuration options.
# COMMAND LINE USAGE
Also, this package includes a `llm-dwim` script that can be used to evaluate a string from the command line. It will look for the configuration file in the same way as the module. It accepts either a string or a list of words. The single argument "-" will cause it to read from standard input.
Sample usage:
```
llm-dwim -h # get usage
llm-dwim "How many miles is it from the earth to the moon?"
llm-dwim -v how far is it from the earth to the moon\?
echo "what is the airspeed velocity of an unladen swallow?" | llm-dwim -
```
# SEE ALSO
[LLM::Functions](https://raku.land/zef:antononcube/LLM::Functions), [LLM::Prompts](https://raku.land/zef:antononcube/LLM::Prompts)
This was inspired by the also excellent [DWIM::Block](https://metacpan.org/pod/DWIM::Block) module.
# AUTHOR
Brian Duggan
|
## dist_github-cygx-Image-RGBA-Text.md
# Image::RGBA::Text [build status](https://travis-ci.org/cygx/p6-image-rgba-text)
Reads RGBA image data of depth 8 from text files
## Synopsis
```
use Image::RGBA::Text;
use Image::PNG::Inflated;
my $data := RGBAText.decode('examples/glider.txt'.IO);
spurt 'glider.png', to-png |$data.unbox;
spurt "{ .info }.png", to-png |.scale.unbox
for RGBAText.decode('examples/FEEP.txt'.IO, :all);
```
## Bugs and Development
Development happens [at GitHub](https://github.com/cygx/p6-image-rgba-text). If you found a bug or have a feature
request, use the [issue tracker](https://github.com/cygx/p6-image-rgba-text/issues) over there.
## Copyright and License
Copyright (C) 2015 by [cygx@cpan.org](mailto:cygx@cpan.org)
Distributed under the [Boost Software License, Version 1.0](http://www.boost.org/LICENSE_1_0.txt)
|
## dist_zef-lizmat-P5fc.md
[](https://github.com/lizmat/P5fc/actions)
# NAME
Raku port of Perl's fc() built-in
# SYNOPSIS
```
use P5fc;
say fc("FOOBAR") eq fc("FooBar"); # true
with "ZIPPO" {
say fc(); # zippo, may need to use parens to avoid compilation error
}
```
# DESCRIPTION
This module tries to mimic the behaviour of Perl's `fc` built-in as closely as possible in the Raku Programming Language..
# ORIGINAL PERL 5 DOCUMENTATION
```
fc EXPR
fc Returns the casefolded version of EXPR. This is the internal
function implementing the "\F" escape in double-quoted strings.
Casefolding is the process of mapping strings to a form where case
differences are erased; comparing two strings in their casefolded
form is effectively a way of asking if two strings are equal,
regardless of case.
Roughly, if you ever found yourself writing this
lc($this) eq lc($that) # Wrong!
# or
uc($this) eq uc($that) # Also wrong!
# or
$this =~ /^\Q$that\E\z/i # Right!
Now you can write
fc($this) eq fc($that)
And get the correct results.
Perl only implements the full form of casefolding, but you can
access the simple folds using "casefold()" in Unicode::UCD and
"prop_invmap()" in Unicode::UCD. For further information on
casefolding, refer to the Unicode Standard, specifically sections
3.13 "Default Case Operations", 4.2 "Case-Normative", and 5.18
"Case Mappings", available at
<http://www.unicode.org/versions/latest/>, as well as the Case
Charts available at <http://www.unicode.org/charts/case/>.
If EXPR is omitted, uses $_.
This function behaves the same way under various pragma, such as
within "use feature 'unicode_strings", as "lc" does, with the
single exception of "fc" of LATIN CAPITAL LETTER SHARP S (U+1E9E)
within the scope of "use locale". The foldcase of this character
would normally be "ss", but as explained in the "lc" section, case
changes that cross the 255/256 boundary are problematic under
locales, and are hence prohibited. Therefore, this function under
locale returns instead the string "\x{17F}\x{17F}", which is the
LATIN SMALL LETTER LONG S. Since that character itself folds to
"s", the string of two of them together should be equivalent to a
single U+1E9E when foldcased.
While the Unicode Standard defines two additional forms of
casefolding, one for Turkic languages and one that never maps one
character into multiple characters, these are not provided by the
Perl core; However, the CPAN module "Unicode::Casing" may be used
to provide an implementation.
This keyword is available only when the "fc" feature is enabled,
or when prefixed with "CORE::"; See feature. Alternately, include
a "use v5.16" or later to the current scope.
```
# PORTING CAVEATS
In future language versions of Raku, it will become impossible to access the `$_` variable of the caller's scope, because it will not have been marked as a dynamic variable. So please consider changing:
```
fc;
```
to either:
```
fc($_);
```
or, using the subroutine as a method syntax, with the prefix `.` shortcut to use that scope's `$_` as the invocant:
```
.&fc;
```
# AUTHOR
Elizabeth Mattijsen [liz@raku.rocks](mailto:liz@raku.rocks)
If you like this module, or what I’m doing more generally, committing to a [small sponsorship](https://github.com/sponsors/lizmat/) would mean a great deal to me!
Source can be located at: <https://github.com/lizmat/P5fc> . Comments and Pull Requests are welcome.
# COPYRIGHT AND LICENSE
Copyright 2018, 2019, 2020, 2021, 2023 Elizabeth Mattijsen
Re-imagined from Perl as part of the CPAN Butterfly Plan.
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_cpan-CTILMES-Docker-API.md
# Docker - Perl 6 Docker API
A simple wrapper around the [Docker REST
API](https://docs.docker.com/engine/api/latest). Much of the API is
not fully documented here -- it just follows the API. It is recommended
that you be familiar with Docker in general and the API specifically
before using this module to automate your Docker tasks.
## Basic Usage
```
use Docker::API;
my $d = Docker::API.new; # Defaults to /var/run/docker.sock
$d.version<Version>; # Other stuff in version too
$d.info<OSType>; # Other stuff in info too
$d.images; # List Images
$d.containers; # List Containers
$d.image-create(fromImage => 'alpine', tag => 'latest'); # image pull
$d.container-create(name => 'foo',
Image => 'alpine',
Cmd => ( '/bin/echo', 'hello world!') );
$d.container-start(id => 'foo');
print $d.container-logs(id => 'foo');
$d.container-stop(id => 'foo');
$d.container-remove(id => 'foo');
```
## Convenience class
There is a `Docker::Container` class that remembers the container `id` for you.
```
use Docker::Container;
my $container = Docker::Container.new(Image => 'alpine',
Cmd => ( '/bin/echo', 'hello world!'));
$container.start;
print $container.logs;
$container.stop;
$container.remove;
```
## Connection
By default, Docker::API.new() will just use a unix socket on
`/var/run/docker.sock` If you use a different socket name, you can
pass in `:unix-socket-path`:
```
my $docker = Docker::API.new(unix-socket-path => '/my/special/socket')
```
If you have it running on a TCP port (hopefully you know what you are
doing and do it securely), you can pass in a host/port like this:
```
my $docker = Docker::API.new(host => 'somehost', port => 12345);
```
If you know what you are doing, you can pass in other options for
`LibCurl` and they just get passed through.
One `LibCurl` option that is useful for debugging is `:verbose` which
will dump out the HTTP headers.
## filters
Many of the command have a `:%filters` option. You can construct your
own hash of filter argument and just pass that in. If you pass in
other arguments, they will get stuck into filters.
For example:
```
$docker.volumes(filters => { label => { foo => True } } );
```
and
```
$docker.volumes(label => 'foo');
```
do the same thing.
## Streams
Some commands such as `attach`, `stats`, `logs`, `events`, `exec`,
etc. have options for streaming ongoing output. They return a
`Docker::Stream` object. It is kind of, but not really like
`Proc::Async`.
It stringifies to just slurp in all the output and return it as a
string, so you can do things like this:
```
print $docker.logs(id => 'foo');
```
If you do that with something that keeps on streaming, it will keep on
slurping forever and appear to hang.
You can access `.stdout` and `.stderr` streams which are by default
merged (and if you have a container with a `tty`, they are also merged
so even if you ask for stderr, all output will be on stdout anyway).
They are returned as supplies that must be tapped to use.
You have to call `.start` to start the process. It returns a
`Promise` that will be kept when the process completes.
```
my $stream = $docker.logs(id => $foo, :follow);
$stream.stdout.tap({ .print });
await self.start;
```
You can also use react/whenever:
```
my $stream = $docker.logs(id => $foo, :follow);
react {
whenever $stream.stdout.lines { .put }
whenever $stream.start { done }
}
```
By default everything goes to stdout, but you can also separate
out stderr and do something different:
```
my $stream = $docker.logs(id => $foo, :!merge, :stdout, :stderr, :follow);
react {
whenever $stream.stdout.lines { .put }
whenever $stream.stderr(:bin) { # Binary Blobs instead of Strs
.decode.put
}
whenever $stream.start { done }
}
```
You can send input to the container (if you use the right options to
attach/open stdin):
```
$docker.container-create(name => 'foo',
Image => 'busybox',
:AttachStdin, :OpenStdin, :AttachStdout),
$docker.container-start(id => foo);
my $stream = $docker.container-attach(id => foo);
my $stdout = '';
$stream.stdout.tap({ $stdout ~= $_ }); # Capture stdout in a string
my $p = $stream.start; # start the stream up
$stream.print("echo hello world\nexit\n"); # Send two lines to stdin
await($p); # Wait for the stream to close
print $stdout; # Dump the string or do something else with it.
```
(Of course for something this simple, you are probably better off with
`exec`, but you can really drive interactive stuff with this if you
know what you are doing.)
## Authentication
Using `image-create` to pull an image from a private repository or
using `image-push` will require authentication to the image registry.
You will need an authenication token, which is an insecure way of
encoding authentication credentials. (Protect the token from
disclosure like a password.)
You can use the `token` method to create a token:
```
my $auth-token = Docker::API.token(
username => 'me',
password => '********',
serveraddress => 'https://index.docker.io/v1/');
```
You can also just create one manually from the command line:
```
echo -n '{"username":"me","password":"*******","serveraddress":"quay.io"}' | base64 -w0
```
Pass that in to the `:auth-token` parameter to `Docker.new`:
```
my $docker = Docker::API.new(:$auth-token);
```
You can also set it later if you need multiple tokens (or just make
multiple `Docker::API` objects.)
```
$docker.auth-token = '...';
```
It will also use a token from environment variable
`DOCKER_API_AUTH_TOKEN` if that is set. That is much preferred to
embedding the password in a script.
## Methods
### auth(...)
```
$docker.auth(username => 'me',
password => '********',
email => 'me@example.com',
serveraddress => 'https://index.docker.io/v1/');
```
Validate credentials for a registry and, if available, get an identity
token for accessing the registry without password.
### version()
Returns the version of Docker that is running and various information
about the system that Docker is running on.
### info()
Get system information.
### df()
Get data usage information.
### containers(Bool :$all, Int :$limit, Bool :$size, :%filters, |filters)
Returns a list of containers.
### container-inspect(Str:D :$id!, Bool :$size)
Return low-level information about a container.
### container-top(Str:D :$id!, Str :$ps\_args)
List processes running inside a container.
On Unix systems, this is done by running the ps command. This endpoint
is not supported on Windows.
### container-diff(Str:D :$id!)
Get changes on a container’s filesystem
(This is called 'changes' in the API, but 'diff' in the docker command
line app.)
Returns which files in a container's filesystem have been added,
deleted, or modified. The Kind of modification can be one of:
0: Modified
1: Added
2: Deleted
### container-export(Str:D :$id!, Str :$download)
Export the contents of a container as a tarball.
Specify a filename in `:download` to save to disk, otherwise
returns tar file as a `Buf`.
### container-stats(Str:D :$id, Bool :$stream = False)
Get container stats based on resource usage
This endpoint returns a live stream of a container’s resource usage statistics.
Differently from the docker API, `:stream` is NOT the default.
If you want a stream, pass in `:stream`, otherwise you just get a snapshot.
Process a stream the normal way, through `stdout`:
```
my $stream = $docker.container-stats(:$id, :stream);
$stream.stdout.tap({ .say });
$stream.start;
```
### container-logs(Str:D :$id!, Bool :$merge = True, Bool :$stdout, Bool :$stderr, Int :$since, Int :$until, Bool :$timestamps, Str :$tail)
Get stdout and stderr logs from a container.
Note: This endpoint works only for containers with the json-file or
journald logging driver.
Note, this sets `:merge`, an additional option specific to this
module, by default to true.
`:merge` will automatically select *both* `:stdout` and `:stderr` and
merge them into a single stream. If you don't want that, pass in
`:!merge` and `:stdout` and/or `:stderr`.
If you pass in `:follow` it will leave the connection open and stream
output to you.
### container-start(Str:D :$id!, Str :$detachKeys)
Start a container
`:detachKeys` - Override the key sequence for detaching a
container. Format is a single character [a-Z] or ctrl- where
is one of: a-z, @, ^, [, , or \_.
### container-stop(Str:D :$id!, Int :$t)
Stop a container
`:t` = Number of seconds to wait before killing the container
### container-restart(Str:D :$id!, Int :$t)
Restart a container
`:t` = Number of seconds to wait before restarting the container
### container-kill(Str:D :$id!, Cool :$signal)
Kill a container
Send a POSIX signal to a container, defaulting to killing to the container.
:signal can be a POSIX signal integer or string (e.g. `SIGINT`)
default `SIGKILL`
### container-rename(Str:D :$id!, Str:D :$name!)
Rename a container
### container-pause(Str:D :$id!)
Pause a container
Use the cgroups freezer to suspend all processes in a container.
Traditionally, when suspending a process the SIGSTOP signal is used,
which is observable by the process being suspended. With the cgroups
freezer the process is unaware, and unable to capture, that it is
being suspended, and subsequently resumed.
### container-unpause(Str:D :$id!)
Unpause a container
Resume a container which has been paused.
### container-attach(Str:D :$id!, Bool :$tty, Str :$detachKeys, Bool :$logs, Bool :$stream = True, Bool :$stdin = True, Bool :$stdout = True, Bool :$stderr = True, Bool :$merge = True, Str :$enc = 'utf8', Bool :$translate-nl = True, Int :$timeout = 3600000)
Attach to a container
Attach to a container to read its output or send it input. You can
attach to the same container multiple times and you can reattach to
containers that have been detached.
Either the stream or logs parameter must be true for this endpoint to
do anything.
### container-wait(Str:D :$id!, Str :$condition)
Wait for a container
Block until a container stops, then returns the exit code.
`:condition` = `not-running` (default), `next-exit`, `removed`
### container-remove(Str:D :$id!, Bool :$v, Bool :$force, Bool :$link)
Remove a container
`:v` - Remove the volumes associated with the container.
`:force` - If the container is running, kill it before removing it.
`:link` - Remove the specified link associated with the container.
### container-archive-info(Str :$id!, Str :$path!)
Get information about files in a container
### container-archive(Str :$id!, Str:D :$path!, Str :$download)
Get a tar archive of a resource in the filesystem of container id.
Specify a filename in `:download` to save to disk, otherwise
returns tar file as a `Buf`.
You can extract files from the tar file (even in a memory Buf) using
the ecosystem module `Libarchive`.
### container-copy(Str:D :$id!, Str:D :$path!, Bool :$noOverwriteDirNonDir, Str :$upload, Buf :$send)
Extract an archive of files or folders to a directory in a container
Upload a tar archive to be extracted to a path in the filesystem of
container id.
You specify either the filename of a tar file with `:upload`, or use
`:send` to upload directly from a memory `Buf`.
### containers-prune(:%filters, |filters)
Delete stopped containers
### container-create(Str :$name, \*%fields)
```
my $container = $docker.container-create(
Image => 'alpine',
Cmd => ( 'echo', 'hello world' ));
put $container<Id>;
```
### container-update(Str:D :$id!, \*%fields)
Update a container
Change various configuration options of a container without having to
recreate it.
### images(:%filters, Bool :$all, Bool :$digests)
Returns a list of images on the server. Note that it uses a different,
smaller representation of an image than inspecting a single image.
```
my $list = $docker.images(reference => { 'alpine' });
.<RepoTags>.say for @$list;
```
### image-create(Str :$fromImage, Str :$fromStr, Str :$repo, Str :$tag, Str :$platform)
```
$docker.image-create(fromImage => 'alpine', tag => 'latest');
```
### image-build(Str :$dockerfile, :@t, Str :$extrahosts, Str :$remote, Bool :$q, Bool :$nocache, :@cachefrom, Str :$pull, Bool :$rm, Bool :$forcerm, Int :$memory, Int :$memswap, Int :$cpushares, Str :$cpusetcpus, Int :$cpuperiod, Int :$cpuquota, :%buildargs, Int :$shmsize, Bool :$squash, :%labels, Str :$networkmode, Str :$platform, Str :$target)
```
$docker.image-build(:q, :rm, t => ['docker-perl-testing:test-version'],
remote => 'https://github.com/CurtTilmes/docker-test.git')
```
`:q` = quiet
`:rm` = Remove intermediate containers after a successful build
`:remote` = A URL, can be for a git repository, or a single file that
is a Dockerfile, or a single file that is a tarball with a Dockerfile
in it. If you rename the dockerfile, pass in `:dockerfile` to tell it
which file is the Dockerfile.
You can also bundle the `Dockerfile` and other optional files into a
tar file:
```
use Libarchive::Simple;
with archive-write(my $tarfile = Buf.new, format => 'paxr')
{
.write('Dockerfile', q:to/DOCKERFILE/);
FROM alpine:latest
LABEL maintainer="Curt Tilmes <Curt.Tilmes@nasa.gov>"
ENTRYPOINT ["/bin/ash"]
DOCKERFILE
.close;
}
$docker.image-build($tarfile, t => ['myimage:myversion']);
```
### image-inspect(Str:D :$name!)
Return low-level information about an image.
### image-history(Str:D :$name!)
Return parent layers of an image.
### image-tag(Str:D :$name!, Str :$repo, Str :$tag)
Tag an image so that it becomes part of a repository.
### image-push(Str:D :$name!, Str :$tag)
Push an image to a registry.
If you wish to push an image on to a private registry, that image must already have a tag which references the registry. For example, registry.example.com/myimage:latest.
The push is cancelled if the HTTP connection is closed.
### image-remove(Str:D :$name!, Bool :$force, Bool :$noprune)
Remove an image, along with any untagged parent images that were referenced by that image.
Images can't be removed if they have descendant images, are being used by a running container or are being used by a build.
### images-search(Str:D :$term, Int :$limit, :%filters, Bool :$is-official, Bool :$is-automated, Int :$stars)
```
my $list = $docker.images-search(term => 'alpine',
limit => 10,
:is-official, :!is-automated, :5000stars);
for @$list
{
say .<name>;
say .<description>;
}
```
### images-prune(:%filters, :$dangling :$until :$label)
### image-get(Str:D :$name!, Str :$download)
Returns Blob of a tar file
You can pass in a filename in `:download` and it will dump the tar
file into that file.
### images-get(:@names)
Returns Blob of a tar file
You can pass in a filename in `:download` and it will dump the tar
file into that file.
### images-load(Bool :$quiet, Str :$upload)
### images-load(Blob $blob, Bool :$quiet)
Upload a tar file with images.
You can specify a filename to upload with `:upload`:
```
$docker.images-load(upload => 'foo.tar');
```
or just pass in a `Blob`:
```
$docker.images-load($tarblob);
```
### volumes(:%filters, :$name, :$label)
```
$docker.volumes(filters => { label => { foo => True } } );
$docker.volumes(label => 'foo'); # has label foo
$docker.volumes(label => 'foo=bar'); # has label foo = 'bar'
$docker.volumes(label => <foo bar>); # has both labels foo and bar
$docker.volumes(name => 'foo'); # volume with name foo
$docker.volumes(name => <foo bar>); # volume with name foo or bar
```
### volume-create(...)
Everything is optional, it will make a random volume.
```
$docker.volume-create(Name => 'foo', Labels => { foo => 'bar' });
```
### volume-inspect(:$name)
### volume-remove(:$name, :force)
`:name` required
`:force` boolean
### volume-prune(:%filters)
### networks(:%filters, ...)
### network-inspect(Str:D :$id!, Bool :$verbose, Str :$scope)
### network-create(...)
```
$docker.network-create(Name => 'foo');
```
lots of other options
### network-connect(Str:D :$id!, ...)
`:Container` id or name
`:EndpointConfig` lots of options
### network-disconnect(Str:D :$id!, ...)
`:Container`
`:Force`
### networks-prune(:%filters, ...)
### exec-create(Str:D :$id!, ...)
`:id` of container
### exec-start(Str:D :$id!, ...)
### exec-resize(Str:D :$id!, Int :$h, Int :$w)
Resize the TTY for a container. You must restart the container for the
resize to take effect.
### exec-inspect(Str:D :$id!)
`:id` of exec
### exec(Str:D :$id!, ...)
call `exec-create(:$id, ...)`, then `exec-start()`
### events(Str :$since, Str :$until, :$timeout, :%filters)
Stream real-time events from the server.
Various objects within Docker report events when something happens to them.
Returns a Supply of Events:
```
my $events = $docker.events();
$events.tap({ .say }
```
The events come as hashes, so you can break out the fields Action,
Actor, id, time, etc. and react to specific actions:
```
react {
whenever $events -> % (:$Action, :$id, :$time, *%) {
...
}
}
```
### plugins(%filters, ...)
### distribution(Str:D :$name!)
## INSTALL
Uses [LibCurl](https://github.com/CurtTilmes/LibCurl) to communicate
with Docker, so that will need to be installed. Since it depends on
the [libcurl](https://curl.haxx.se/download.html) library, you must
also install that first.
## LICENSE
Copyright © 2019 United States Government as represented by the
Administrator of the National Aeronautics and Space Administration.
No copyright is claimed in the United States under Title 17,
U.S.Code. All Other Rights Reserved.
|
## dist_github-ccworld1000-CCColor.md
## [CCColor](https://github.com/ccworld1000/CCColor)
```
Simple and flexible color color conversion module for Perl 6 ,
easy-to-use simple learning.
```
## HEX Color (use CCColor)

## See test
```
use CCColor;
my @list =
(
" #FFFEA963 ",
" #FF FE A9 63 ",
" #FF # FE # A9 # 63 ",
" #",
" #1",
" #123",
" #FFH",
" #FHF",
" #1234",
" #12345",
" #FFEE5",
" #FFEE56",
" #FFEE56A",
" #FFEE56AH",
" #FFEE56AA",
" #FFEE56AA11",
" #FFEE56AAFF11",
);
for @list -> $color {
my ($r, $g, $b, $a) = hex2rgba($color);
say "$r, $g, $b, $a";
}
```
Call test/test.p6
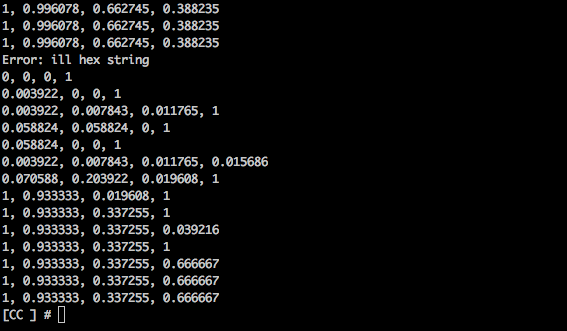
## Local installation and unloading
```
zef install .
zef uninstall CCColor
```
## Network install
```
zef update
zef install CCColor
```
|
## package.md
class X::Attribute::Package
Compilation error due to declaring an attribute in an ineligible package
```raku
class X::Attribute::Package does X::Comp { }
```
Compile time error, thrown when the compiler encounters an attribute declaration inside a package that does not support attributes.
For example
```raku
module A { has $.x }
```
dies with
「text」 without highlighting
```
```
A module cannot have attributes, but you tried to declare '$.x'
```
```
# [Methods](#class_X::Attribute::Package "go to top of document")[§](#Methods "direct link")
## [method name](#class_X::Attribute::Package "go to top of document")[§](#method_name "direct link")
```raku
method name(--> Str:D)
```
Returns the name of the attribute that triggered this error.
## [method package-kind](#class_X::Attribute::Package "go to top of document")[§](#method_package-kind "direct link")
```raku
method package-kind(--> Str:D)
```
Returns the kind of package (package, module) that doesn't support attributes.
|
## dist_zef-vrurg-WWW-GCloud.md
# NAME
`WWW::GCloud` - Core of Google Cloud REST API framework
# SYNOPSIS
```
use v6.e.PREVIEW;
use WWW::GCloud;
use WWW::GCloud::API::ResourceMgr;
my $gcloud = WWW::GCloud.new;
say "Available projects:";
react whenever $gcloud.resource-manager.projects.list -> $project {
say " * ", $project.project-id;
}
my $new-project-id = "my-unique-project-name";
await $gcloud.resource-manager.projects.create(
$gcloud.resource-manager.new-project(
"This is project description",
id => $new-project-id,
labels => { :label1('label_value'), :label2("another_value") } );
).andthen({
say .result; # Would dump an instance of WWW::GCloud::R::Operation
})
.orelse({
# Choose how to react to an error
note "Can't create a new project '$new-project-id'";
.cause.rethrow
});
```
# DESCRIPTION
This is going to be my worst documentation so far! I apologize for this, but simply unable to write it yet. Will provide a few important notes though.
So far, best way to start with this module is to explore *examples/* and *t/* directories. Apparently, inspecting the sources in *lib/* would be the most helpful!
## The Status
This is pre-alfa, pre-beta, pre-anything. It is incomplete, sometimes not well enough though out, etc., etc., etc. If you miss a method, an API, whatever – best is to submit a PR or implement a new missing API. It shouldn't be a big deal, a lot can be done by using the "By Example" textbook receipes!
Do not hesitate to get in touch with me would you need any help. I know it could be annoying when a complex module has little to none docs. I'll do my best to fix the situation. But until then feel free to open an issue in the [GitHub repository](https://github.com/vrurg/raku-WWW-GCloud/issues), even if it's just a question.
## WWW::GCloud Object Structure
Google Cloud structures its API into themed APIs like Resource Manager, Storage, Vision, etc. Each particular API, in turns, provides *resources* where methods belong. `WWW::GCloud` tries to follow the same pattern. Say, in the SYNOPSIS `$gcloud.resource-manager` is `WWW::GCloud::API::ResourceMgr` instance implementing [Resource Manager API](https://cloud.google.com/resource-manager/reference/rest). Then, `$gcloud.resource-manager.projects` is the implementation of [`projects` resource](https://cloud.google.com/resource-manager/reference/rest#rest-resource:-v1.projects).
## Framework Namespacing
The framework is extensible. `WWW::GCloud` class by itself implements no APIs. New ones can be implemented any time. Basically, starting a new API module is as simple as doiing:
```
use v6.e.PREVIEW;
unit class WWW::GCloud::API::NewOne;
use WWW::GCloud::API;
also does WWW::GCloud::API['new-one'];
has $.base-url = 'https://storage.googleapis.com/newone/v1';
```
Now, with `use WWW::GCloud::API::NewOne;` a method `new-one` becomes automatically available with any instance of `WWW::GCloud`.
As you can see, `WWW::GCloud::API::` namespace is used. Here is the list of standard namespaces:
* **`WWW::GCloud::API::`**
Apparently, any new API implementation must reside within this one.
* **`WWW::GCloud::R::`**
This is where record types are to be declared. For example, `WWW::GCloud::R::Operation` represents an [Operation](https://cloud.google.com/resource-manager/reference/rest/Shared.Types/Operation).
The `R::` namespace itself is better be reserved for commonly used types of records. For an API-specific record it is recommended to use their own sub-spaces. `WWW::GCloud::API::Storage` is using `WWW::GCloud::R::Storage::`, for example.
* **`WWW::GCloud::RR::`**
`RR` stands for *Record Roles*. This is where roles, used by record classes, are to be located. Same API sub-naming rule applies.
## Type Mapping
Sometimes it is useful to map a core class into a user's child class. For example, an output from text recognition APIs could be "patched" so that records using vertexes (like actual symbols detected) can be represented with user classes where user's own coordinate system is used. So, that instead of re-building our class based on what's returned by the API we can use lazy approaches to simply construct the parts we need:
```
use AttrX::Mooish;
class MyBoundingPoly is gc-wrap(WWW::GCloud::R::Vision::BoundingPoly) {
has MyRect:D @.bounding-path;
method build-bounding-path {
self.vertices.map: { self.covert-point($^vertex) }
}
}
```
See *examples/basic-usage.raku* and *t/050-type-map.rakutest*.
## Some API conventions
Most methods mapping into the actual REST calls return either a [`Promise`](https://docs.raku.org/type/Promise) or a [`Supply`](https://docs.raku.org/type/Supply). The latter is by default applies to methods which returns lists, especially when the list is paginated by the service. For example, method `list` of `projects` resource of `resource-manager` API returns a [`Supply`](https://docs.raku.org/type/Supply).
[`Promise`](https://docs.raku.org/type/Promise), apparently, would be broken in case of any error, including the errors reported by the Google Cloud.
For successfull calls the value of a kept [`Promise`](https://docs.raku.org/type/Promise) depends on the particular method. Sometimes it could be a plain [`Bool`](https://docs.raku.org/type/Bool), more often it would be an instance of a `WWW::GCloud::R::` record. On occasion a `Cro::HTTP::Response` itself can be produced in which case it is likely to get `WWW::GCloud::HTTP::Stream` mixin which allows to send response body into a file or any other kind of `IO::Handle`.
## A Couple Of Recommendations
Consider using traits for declarations. For example, a new record class is best declared as:
```
use v6.e.PREVIEW;
unit class WWW::GCloud::R::NewAapi::ARec;
use WWW::GCloud::Record;
also is gc-record;
has Str $.someField;
has Int $.aCounter;
```
The trait would automatically mark all record attributes (except where explicit `is json-skip` is applied) as JSON-serializable as if `is json` has been applied to them manually.
Other useful traits are:
* `gc-wrap` from `WWW::GCloud::Record`
* `gc-params` from `WWW::GCloud::QueryParams` (find its usages in API modules and see *t/040-query-params.rakutest*)
* `does` when used with `WWW::GCloud::API` automates registering of an API module with `WWW::GCloud`
# COPYRIGHT
(c) 2023, Vadim Belman [vrurg@cpan.org](mailto:vrurg@cpan.org)
# LICENSE
Artistic License 2.0
See the [*LICENSE*](LICENSE) file in this distribution.
|
## dist_github-jaffa4-Hash-File.md
##Usage
```
my $h = Hash::File.new;<br>
my $hash = $h.get-hash: $?FILE,"MD5";
say $hash;
```
E.g. ba65f12a64ad7979d1add21807f6830a1edbfbdc
It uses a Windows utility to calculate hashes on Windows and openssl on Linux.
Supported hashes:MD2 MD4 MD5 SHA1 SHA256 SHA384 SHA512.
So it works on Windows/Linux only.
|
## dist_zef-dwarring-Font-FreeType.md
[[Raku PDF Project]](https://pdf-raku.github.io)
/ [[Font-FreeType Module]](https://pdf-raku.github.io/Font-FreeType-raku/)
[](https://github.com/pdf-raku/FontConfig-raku/actions)
# Font-FreeType-raku - Raku binding to the FreeType font library (version 2)
## Classes in this Distribution
* [Font::FreeType](https://pdf-raku.github.io/Font-FreeType-raku/Font/FreeType) - Font Library Instance
* [Font::FreeType::Face](https://pdf-raku.github.io/Font-FreeType-raku/Font/FreeType/Face) - Font Properties
* [Font::FreeType::Glyph](https://pdf-raku.github.io/Font-FreeType-raku/Font/FreeType/Glyph) - Glyph properties
* [Font::FreeType::GlyphImage](https://pdf-raku.github.io/Font-FreeType-raku/Font/FreeType/GlyphImage) - Glyph outlines and bitmaps
* [Font::FreeType::Outline](https://pdf-raku.github.io/Font-FreeType-raku/Font/FreeType/Outline) - Scalable glyph images
* [Font::FreeType::BitMap](https://pdf-raku.github.io/Font-FreeType-raku/Font/FreeType/BitMap) - Rendered glyph bitmaps
* [Font::FreeType::CharMap](https://pdf-raku.github.io/Font-FreeType-raku/Font/FreeType/CharMap) - Font Encodings
* [Font::FreeType::SizeMetrics](https://pdf-raku.github.io/Font-FreeType-raku/Font/FreeType/SizeMetrics) - Scaled font metrics
* [Font::FreeType::Raw](https://pdf-raku.github.io/Font-FreeType-raku/Font/FreeType/Raw) - Bindings to the FreeType library
* [Font::FreeType::Raw::Defs](https://pdf-raku.github.io/Font-FreeType-raku/Font/FreeType/Raw/Defs) - Data types and enumerations
* [Font::FreeType::Raw::TT\_Sfnt](https://pdf-raku.github.io/Font-FreeType-raku/Font/FreeType/Raw/TT_Sfnt) - Direct access to raw font tables
## Synopsis
```
use Font::FreeType;
my Font::FreeType $freetype .= new;
my $face = $freetype.face('t/fonts/Vera.ttf');
$face.set-font-size(12, 12, 72, 72);
for $face.glyph-images('ABC') {
my $outline = .outline;
my $bitmap = .bitmap;
# ...
}
```
## Description
This module allows Raku programs to conveniently read information from font files. All the font access is done through the FreeType2 library, which supports many formats. It can render images of characters with high-quality hinting and anti-aliasing, extract metrics information, and extract the outlines of characters in scalable formats like TrueType.
Please see [Font::FreeType](https://pdf-raku.github.io/Font-FreeType-raku/Font/FreeType).
## Scripts
### font-say
```
font-say [--resolution=<Int>] [--pixels=<Int] [--kern] [--hint] [--ascend=<Int>] [--descend=<Int>] [--char-spacing=<Int>] [--word-spacing=<Int>] [--bold=<Int>] [--mode=<Mode> (lcd lcd-v light mono normal)] [--verbose] <font-file> <text>
```
This script displays text as bitmapped characters, using a given font. For example:
```
% bin/font-say --hint --pixels=14 t/fonts/Vera.ttf 'FreeType!'
####### ########## ##
## ## ##
## ##### ###### ###### ## ### ## ####### ###### ##
## #### ####### ####### ## ### ### ####### ####### ##
###### ## ### ## ### ## ## ## ### ## ## ### ## ##
## ## ######## ######## ## ### ## ## ### ######## ##
## ## ### ### ## ##### ## ### ###
## ## ### ### ## #### ## ## ###
## ## ####### ####### ## #### ####### ####### ##
## ## ###### ###### ## ### ####### ###### ##
## ##
### ##
### ##
```
## Install
Font::FreeType depends on the [freetype](https://www.freetype.org/download.html) native library, so you must install that prior to using this module.
### Debian/Ubuntu Linux
```
sudo apt-get install freetype6-dev
```
### Alpine Linux
```
doas apk add freetype-dev
```
### Max OS X
```
brew update
brew install freetype
```
### Windows
This module uses prebuilt DLLs on Windows. No additional configuration is needed.
## Testing
To checkout and test this module from the Git repository:
```
$ git checkout https://github.com/pdf-raku/Font-FreeType-raku.git
$ zef build . # -OR- raku Build.rakumod
$ prove -e'raku -I .' -v t
```
## Authors
Geoff Richards [qef@laxan.com](mailto:qef@laxan.com)
Ivan Baidakou [dmol@cpan.org](mailto:dmol@cpan.org)
David Warring [david.warring@gmail.com](mailto:david.warring@gmail.com) (Raku Port)
## Copyright
Copyright 2004, Geoff Richards.
Ported from Perl to Raku by David Warring [david.warring@gmail.com](mailto:david.warring@gmail.com) Copyright 2017.
This library is free software; you can redistribute it and/or modify it under the same terms as Perl itself.
|
## dist_zef-tony-o-HTTP-Server-Logger.md
# HTTP::Server::Logger
[](https://travis-ci.org/tony-o/perl6-http-server-logger)
Uses apache log format for logging, you can specify custom formats also.
By default this module uses the common log format specified by Apache.
## usage
```
use HTTP::Server::Logger;
use HTTP::Server::Threaded;
qw<... set up server stuff ...>;
my HTTP::Server::Logger $log .= new;
$server.after($log.logger); #the logger now logs when the server is closed
$log.format('[%s] %t %U'); #set the format for the log
$log.pretty-log; #use a pretty format '[%s] %{%Y/%m/%d %H:%m}t %U'
$server.listen;
```
## custom logger
you can use this logger for custom logging as long as you're okay with the apache log format
```
use HTTP::Server::Logger;
my HTTP::Server::Logger $log .= new(fmt => '%t %Z');
$log.log({
t => 'something t',
Z => 'something Z',
});
# output: 'something t something Z'
```
need some custom formatting for Z?
```
my HTTP::Server::Logger $log .= new(fmt => '%t %Z');
$log.custom<Z> = sub ($data) { return $data.UC; };
$log.log({
t => 'something t',
Z => 'lowercase',
});
# output: 'something t LOWERCASE'
```
|
## dist_zef-japhb-Cro-CBOR.md
[](https://github.com/japhb/Cro-CBOR/actions)
# NAME
Cro::CBOR - Support CBOR in Cro for body parsing/serializing
# SYNOPSIS
```
use Cro::CBOR;
# SERVER SIDE
route {
get -> 'cbor' {
web-socket :cbor, -> $incoming { # NOTE `:cbor`
supply whenever $incoming -> $message {
my $body = await $message.body; # NOTE `$message.body` (not -text)
... "Generate $response here";
emit $response;
}
}
}
}
# CLIENT SIDE
my $client = Cro::CBOR::WebSocket::Client.new(:cbor);
my $connection = await $client.connect: 'http://localhost:12345/cbor';
```
# DESCRIPTION
Cro::CBOR is a set of extensions to `Cro::HTTP` and `Cro::WebSocket` to support using CBOR alongside JSON as a standard body serialization format.
If you're already using Cro's automatic JSON serialization, CBOR serialization works very similarly. Replace `:json` with `:cbor`, and `Cro::WebSocket::Client` with `Cro::CBOR::WebSocket::Client`, and most pieces will Just Work. And if not, please file an issue in the [Cro::CBOR repository](https://github.com/japhb/Cro-CBOR/issues), and I'll happily take a look.
# AUTHOR
Geoffrey Broadwell [gjb@sonic.net](mailto:gjb@sonic.net)
# COPYRIGHT AND LICENSE
Copyright 2021-2025 Geoffrey Broadwell
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_zef-dwarring-Font-AFM.md
[](https://github.com/pdf-raku/Font-AFM-raku/actions)
## Name
Font::AFM - Interface to Adobe Font Metrics files
## Synopsis
```
use Font::AFM;
my Font::AFM $h .= core-font: 'Helvetica';
my $copyright = $h.Notice;
my $w = $h.Wx<aring>;
$w = $h.stringwidth("Gisle", 10);
```
## Description
This module implements the Font::AFM class. Objects of this class are initialised from an AFM (Adobe Font Metrics) file and allow you to obtain information about the font and the metrics of the various glyphs in the font.
This module includes built-in metrics classes for the 14 PDF Core Fonts.
Metrics can also be loaded for local AFM files on your system.
All measurements in AFM files are given in terms of units equal to 1/1000 of the scale factor of the font being used. To compute actual sizes in a document, these amounts should be multiplied by (scale factor of font)/1000.
### Font Metrics Classes
This module includes built-in classes for the 14 PDF Core Fonts. For example:
```
use Font::Metrics::helvetica;
my $bbox = Font::Metrics::helvetica.FontBBox;
```
The list of PDF Core Fonts is:
* Courier Fonts
* Font::Metrics::courier
* Font::Metrics::courier-bold
* Font::Metrics::courier-oblique
* Font::Metrics::courier-boldoblique
* Helvetica Fonts
* Font::Metrics::helvetica
* Font::Metrics::helvetica-bold
* Font::Metrics::helvetica-oblique
* Font::Metrics::helvetica-boldoblique
* Times-Roman Fonts
* Font::Metrics::times-roman
* Font::Metrics::times-bold
* Font::Metrics::times-italic
* Font::Metrics::times-bolditalic
* Symbolic Fonts
* Font::Metrics::symbol
* Font::Metrics::zapfdingbats
## Methods
### method core-font
```
method core-font(
Str $font-name,
|c
) returns Font::AFM:D
```
Loads a named PDF core font
Where `$font-name` is one of `Helvetica`, `Helvetica-Bold`, `Helvetica-Oblique`, `Helvetica-Boldoblique`, `Times-Roman`, `Times-Bold`, `Times-Italic`, `Times-BoldItalic`, `Symbol`, or `Zapfdingbats` (case insensitive).
### my $afm = Font::AFM.new: :$name;
AFM font metrics loader. `:$name` may be the absolute path of a font. Otherwise the font is loaded from the directory specified by the `METRICS` environment variable (see ENVIRONMENT below). Croaks if the font can not be found.
### $afm.FontName
The name of the font as presented to the PostScript language `findfont` operator, for instance "Times-Roman".
### $afm.FullName
Unique, human-readable name for an individual font, for instance "Times Roman".
### $afm.FamilyName
Human-readable name for a group of fonts that are stylistic variants of a single design. All fonts that are members of such a group should have exactly the same `FamilyName`. Example of a family name is "Times".
### $afm.Weight
Human-readable name for the weight, or "boldness", attribute of a font. Examples are `Roman`, `Bold`, `Light`.
### $afm.ItalicAngle
Angle in degrees counterclockwise from the vertical of the dominant vertical strokes of the font.
### $afm.IsFixedPitch
If `true`, the font is a fixed-pitch (monospaced) font.
### $afm.FontBBox
An array of integers giving the lower-left x, lower-left y, upper-right x, and upper-right y of the font bounding box in relation to its origin. The font bounding box is the smallest rectangle enclosing the shape that would result if all the characters of the font were placed with their origins coincident, and then painted.
### $afm.KernData
A two dimensional hash containing from and to glyphs and kerning widths.
### $afm.UnderlinePosition
Recommended distance from the baseline for positioning underline strokes. This number is the y coordinate of the center of the stroke.
### $afm.UnderlineThickness
Recommended stroke width for underlining.
### $afm.Version
Version number of the font.
### $afm.Notice
Trademark or copyright notice, if applicable.
### $afm.Comment
Comments found in the AFM file.
### $afm.EncodingScheme
The name of the standard encoding scheme for the font. Most Adobe fonts use the `AdobeStandardEncoding`. Special fonts might state `FontSpecific`.
### $afm.CapHeight
Usually the y-value of the top of the capital H.
### $afm.XHeight
Typically the y-value of the top of the lowercase x.
### $afm.Ascender
Typically the y-value of the top of the lowercase d.
### $afm.Descender
Typically the y-value of the bottom of the lowercase p.
### $afm.Wx
Returns a hash table that maps from glyph names to the width of that glyph.
### $afm.BBox
Returns a hash table that maps from glyph names to bounding box information in relation to each glyph's origin. The bounding box consist of four numbers: llx, lly, urx, ury.
### $afm.stringwidth($string, $fontsize?, :kern, :%glyphs)
Returns the width of the string passed as argument. The string is assumed to contains only characters from `%glyphs` A second argument can be used to scale the width according to the font size.
### ($kerned, $width) = $afm.kern($string, $fontsize?, :%glyphs?)
Kern the string. Returns an array of string segments, separated by numeric kerning distances, and the overall width of the string.
```
:%glyphs - an optional mapping of characters to glyph-names.
```
## SEE ALSO
* Font::FreeType - To obtain metrics (and more) for many other font formats , including`*.pfa`, `*.pfm`, `*.ttf` and `*.otf` files.
* <HarfBuzz> - Also has some ability to obtain metrics for `*.ttf` and `*.otf` fonts.
### method metrics-class
```
method metrics-class(
Str $font-name
) returns Font::AFM:U
```
autoloads the appropriate delegate for the named font. A subclass of Font::AFM
The AFM specification can be found at:
```
http://partners.adobe.com/asn/developer/pdfs/tn/5004.AFM_Spec.pdf
```
# ENVIRONMENT
* *METRICS*
Contains the path to search for AFM-files. Format is as for the PATH environment variable. The default path built into this library is:
```
/usr/lib/afm:/usr/local/lib/afm:/usr/openwin/lib/fonts/afm/:.
```
# BUGS
Composite character and Ligature data are not parsed.
# COPYRIGHT
Copyright 1995-1998 Gisle Aas. All rights reserved.
Ported from Perl to Raku by David Warring Copyright 2015
This program is free software; you can redistribute it and/or modify it under the same terms as Perl itself.
|
## dist_zef-demayl-SSH-LibSSH.md
[](https://github.com/FluxArk/SSH-LibSSH/actions) [](https://github.com/FluxArk/SSH-LibSSH/actions)
# NAME
SSH::LibSSH - Asynchronous binding for libssh; client-only and limited functionality
# SYNOPSIS
```
use SSH::LibSSH;
```
# DESCRIPTION
An asynchronous Raku binding to LibSSH. It only supports client operations, and even then only some of those. It implements:
* Connecting to SSH servers, performing server authentication and client authentication (by default, using a running key agent or the current user's private key; you can also provide a private key file or a password)
* Executing commands, sending stdin, reading stdout/stderr, and getting the exit code
* Port forwarding
* Reverse port forwarding
* Single file SCP in either direction
See the `examples` directory for a set of examples to illustrate usage of this module.
All operations are asynchronous, and the interface to the module is expressed in terms of the Raku `Promise` and `Supply` types.
On Linux, install libssh with your package manager to use this module. On Windows, the installation of this module will download a pre-built libssh.dll, so just install the module and you're good to go.
Pull requests to add missing features, or better documentation, are welcome. Please file bug reports or feature requests using GitHub Issues.
# AUTHOR
Jonathan Worthington
# COPYRIGHT AND LICENSE
Copyright 2017 - 2024 Jonathan Worthington
Copyright 2024 Raku Community
Copyright 2025 Denis Kanchev
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_zef-raku-community-modules-CLDR-List.md
[](https://github.com/raku-community-modules/CLDR-List/actions) [](https://github.com/raku-community-modules/CLDR-List/actions) [](https://github.com/raku-community-modules/CLDR-List/actions)
# NAME
CLDR::List - Localized list formatters using the Unicode CLDR
# SYNOPSIS
```
use CLDR::List;
my $list = CLDR::List.new(locale => 'en');
my @fruit = <apples oranges bananas>;
say $list.format(@fruit); # apples, oranges, and bananas
$list.locale = 'en-GB'; # British English
say $list.format(@fruit); # apples, oranges and bananas
$list.locale = 'zh-Hant'; # Traditional Chinese
say $list.format('1'..'4'); # 1、2、3和4
```
# DESCRIPTION
Localized list formatters using the Unicode CLDR.
## Attributes
* locale
## Methods
* format
# SEE ALSO
* * [List Patterns in UTS #35: Unicode LDML](http://www.unicode.org/reports/tr35/tr35-general.html#ListPatterns)
* * [Perl Advent Calendar: CLDR TL;DR](http://perladvent.org/2014/2014-12-23.html)
* * [Unicode beyond just characters: Localization with the CLDR](http://patch.codes/talks/localization-with-the-unicode-cldr/) (video and slides)
# AUTHOR
Nova Patch
# COPYRIGHT AND LICENSE
Copyright 2013 – 2017 Nova Patch
Copyright 2024 Raku Community
This library is free software; you can redistribute it and/or modify it under the same terms as Perl itself.
|
## dist_github-bioduds-EC-Grammars-DIG.md
# EC-Grammars-DIG
EC::Grammars::DIG is a module that provides a very easy and clear way to parse the dig command.
It is part of the project HON, a blockchain that is being written in Perl6.
Main features of this module
* run dig command and receive main results parsed
* GNU Licensed - Software Livre
This module performs generic parsing on rules and tokens.
# Contents
## Base Grammar
* `EC::Grammars::DIG` - Digs into dig with url
## Parser Actions
`EC::Grammars::DIG` will provide important information parsed like the IPs, the urls,
used mainly for seeded out digs for P2P networks. A simple usage would be:
```
use EC::Grammars::DIG;
my $proc = run 'dig', URL_YOU_WANT_TO_DIG_HERE, :out, :err;
with $proc.err { say "Error running dig"; die; }
my $output = $proc.out.slurp: :close;
my $dig = EC::Grammars::DIG.new.parse( $output, :actions( EC:Grammars::DIG::Actions.new ) );
say $dig<DATE>; ## you may here query which ever tokens or rules desired
## TO ITERATE USE, FOR INSTANCE:
for $dig<ANSWER> -> $answers {
say $answers<IP>; ## for instance
```
## Actions Options
* **`:lax`** Pass back, don't drop, quantities with unknown dimensions.
## Installation
With zef:
```
zef install EC::Grammars::DIG
```
You'll first need to download and build Rakudo Star or better (<http://rakudo.org/downloads/star/> - don't forget the final `make install`):
Ensure that `perl6` and `panda` are available on your path, e.g. :
```
% export PATH=~/src/rakudo-star-2015.07/install/bin:$PATH
```
You can then use `panda` to test and install `CSS::Grammar`:
```
% panda install EC::Grammars::DIG
```
To try parsing some content:
```
% perl6 -MCSS::EC::Grammars::DIG -e"say EC::Grammars::DIG.parse( run 'dig', 'YOUR_URL_TO_DIG')"
```
## See Also
* HON Post of Module: <https://steemit.com/blockchain/@bitworkers/perl6-hon-decentralized-justice-deep-study-of-blockchain-code-this-effort-resulted-in-this-module>
* HON Proposition: <https://steemit.com/blockchain/@bitworkers/escrowchain-an-idea-to-build-an-escrow-blockchain-with-arbitration-currency>
## References
This module been built from the W3C CSS Specifications. In particular:
* Module Building - <https://docs.perl6.org/language/modules>
|
## dist_zef-kjpye-Math-Angle.md
[](https://github.com/kjpye/Math-Angle/actions)
# NAME
Math::Angle - a class to handle geometric angles
# SYNOPSIS
```
use Math::Angle;
my \φ = Math::Angle.new(deg => 63.4);
say φ.sin;
say cos φ;
```
# DESCRIPTION
Math::Angle defines objects which represent angles. It was written to try to prevent the problems I kept encountering in forgetting to convert angles between radians and degrees.
Thus an angle may be defined in terms of radians, degrees or grads, and then used in trigonometric expressions without concern for conversion between units.
The standard trigonometric functions available in Raku can all be used as either methods on the `Math::Angle` object, or as functions with the `Math::Angle` object as argument.
In addition, subroutines are available for the inverse trigonometric functions which return a Math::Angle object.
Some basic arithmetic using `Math::Angle` objects is also possible where it makes sense.
## Object creation
`Math::Angle` objects are created by calling the `Math::Angle.new` routine with a named argument specifying the angle required. The following three possibilities are equivalent:
```
my $φ = Math::Angle.new(rad => π/4);
my $η = Math::Angle.new(deg => 45);
my $θ = Math::Angle.new(grad => 50);
```
## Accessing the angle value
The angle embedded within a `Math::Angle` object can be accessed using the three methods `rad`, `deg`, and `grad` which convert the internal value to the requested representation
Note that it is thus possible to convert an angle from degrees to radians by writing
```
Math::Angle.new(deg => 27).rad
```
## Arithmetic
Arithmetic involving `Math::Angle` objects is possible where it makes sense:
```
my \φ1 = Math::Angle.new(:37deg);
my \φ2 = Math::Angle.new(rad => π/6);
say (φ1 - φ2).deg;
say (φ1 + φ2).rad;
say (φ1 × 2).rad;
say (4 × φ2).deg;
say φ1 ÷ φ2;
```
With the exception of division, the results of all those objects will be a `Math::Angle` object. The result of the division is a plain number representing the ratio of the two angles.
## Coercion
`Math::Angle` has two coercion methods, `Numeric` and `Comples`. `Numeric` returns the numeric value of the angle in radians. `Complex` returns a complex number with radius 1 and angle given by the `Math::Angle` object.
`Math::Angle` also inherits from `Cool`. When combined with the `Numeric` coercion, this gives access to the trigonometric functions `sin`, `cos`, `tan`, `sec`, `cosec`, `cotan`, `sinh`, `cosh`, `tanh`, `sech`. `cosech`, and `cotanh`. These may all be used as functions with the `Math::Angle` object as argument, or as methods on the `Math::Angle` object.
It probably also leads to all sorts of other undesirable effects.
## Functions
The following standard trigonometric functions may be used to return a `Math::Angle` object: `asin`, `acos`, `atan`, `atan2`, `asec`, `acosec`, `acotan`, `asinh`, `acosh`, `atanh`, `asech`, `acosech`, and `acotanh`.
### from-dms
`from-dms` takes a string argument representing an angle in degrees, minutes and seconds, and converts it into a Math::Angle object.
The string contains:
* **sign** An optional sign `+` or `-`;
* **degrees** An optional decimal number of degrees followed by a degree designator (one of the degree symbol (`°`) or a letter `d` of either case);
* **minutes** An optional decimal number of minutes followed by a minutes designator (one of a single quote (`'`), the Unicode character `U+2032`—`PRIME`, or the letter `m` in either case);
* **seconds** An optional decimal number of seconds followed by a seconds designator (one of a double quote `"`), the Unicode character `U+2033`)—`DOUBLE PRIME`, or the letter `s` in either case);
* **hemisphere** To allow for latitude and longitude to be represented easily, the angle can be followed by one of the letters `E`, `W`, `N` or `S` in either case. If the letter is `N` or `E` then the angle is positive; if it is `S` or `W` then the angle is negative. Note that if a sign is also present at the start of the string, then the two indicators are both used. Thus an angle like `-12°S` will end up being positive,
The various fields may be separated by white space.
The decimal numbers can be fractional, and contain exponents such as `12.53e5`.
Note that no sanity checks are made. An angle of "`-2473.2857° 372974.2746′ 17382.2948e5s W`" is acceptable, and equal to about `491531.046°`. The values for degrees, minutes and seconds are simply added together with the appropriate scaling and with the appropriate sign calculated from the initial sign and the hemisphere.
If the seconds are designated by the letter `S` and a hemisphere is also specified, then they must be separated by whitespace.
## Alternative representations
Two methods are available to produce string output in useful forms for angles expressed in degrees.
### dms
Method `dms` will return a string containing a representation of the angle in degrees, minutes and seconds. For example:
```
Math::Angle.new(rad => 0.82).dms.say; # 46° 58′ 57.1411″
```
However the output is fairly configurable. For example, signed numbers can be output in various forms:
```
Math::Angle.new(rad => -0.82).dms.say; # -46° 58′ 57.1411″
Math::Angle.new(rad => 0.82).dms(presign=>"+-").say; # +46° 58′ 57.1411″
Math::Angle.new(rad => 0.82).dms(presign=>"", postsign=>"NS").say; # 46° 58′ 57.1411″N
Math::Angle.new(rad => -0.82).dms(presign=>"", postsign=>"NS").say; # 46° 58′ 57.1411″S
Math::Angle.new(rad => -0.82).dms(presign=>"", postsign=>"EW").say; # 46° 58′ 57.1411″W
```
The full set of options is:
| option | meaning | default |
| --- | --- | --- |
| degsym | A string representing the symbol printed after the number of degrees | "°" (unicode U00B0 — DEGREE SIGN) |
| minsym | A string representing the symbol printed after the number of minutes | "′" (unicode U2032 — PRIME) |
| secsym | (dms only) A string giving the symbol printed after the number of seconds | '″' (unicode U2033 — DOUBLE PRIME) |
| presign | A string where the first chracter is printed before a positive number, and the second character is printed before a negative number | " -" (a space and a minus sign) |
| postsign | A string where the first character is printed after a positive number, and the second character is printed after a negative number | " " (two spaces) |
| separator | A string printed between the degrees and minutes, and between the minutes and seconds | " " |
| secfmt | (dms only) The format string for the seconds field | "%.4f" |
| minfmt | (dm only) The format string for the minutes field | "%.4f" |
Note for `presign` and `postsign` that a blank in the string is not printed.
### dm
Method `dm` will return a string containing a representation of the angle in degrees and minutes. For example:
```
Math::Angle.new(rad => 0.82).dm.say; # 46° 58' 57.1411"
```
The same configurability as in `dms` is available:
```
Math::Angle.new(rad => -0.82).dm.say; # -46° 58.9524′
Math::Angle.new(rad => 0.82).dm(presign=>"+-").say; # +46° 58.9524′
Math::Angle.new(rad => 0.82).dm(presign=>"", postsign=>"NS").say; # 46° 58.9524'N
Math::Angle.new(rad => -0.82).dm(presign=>"", postsign=>"NS").say; # 46° 58.9524′S
Math::Angle.new(rad => -0.82).dm(presign=>"", postsign=>"EW").say; # 46° 58.9524′W
```
The options are the same as for dms, except that `secsig` is not available and `secfmt` is replaced by `minfmt`.
# AUTHOR
Kevin Pye [kjpraku@pye.id.au](mailto:kjpraku@pye.id.au)
# COPYRIGHT AND LICENSE
Copyright 2022 Kevin Pye
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_cpan-JKRAMER-Term-ReadKey.md
[](https://travis-ci.org/jkramer/p6-Term-ReadKey)
# NAME
Term::ReadKey
# DESCRIPTION
Read single (unbuffered) keys from terminal.
# SYNOPSIS
```
use Term::ReadKey;
react {
whenever key-pressed(:!echo) {
given .fc {
when 'q' { done }
default { .uniname.say }
}
}
}
```
# FUNCTIONS
## read-key(Bool :$echo = True --> Str)
Reads one unbuffered (unicode) character from STDIN and returns it as Str or Nil if nothing could be read. By default the typed character will be echoed to the terminal unless `:!echo` is passed as argument.
## key-pressed(Bool :$echo = True --> Supply)
Returns a supply that emits characters as soon as they're typed (see example in SYNOPSIS). The named argument `:$echo` can be used to enable/disable echoing of the character (on by default).
# AUTHOR
Jonas Kramer [jkramer@mark17.net](mailto:jkramer@mark17.net)
# COPYRIGHT AND LICENSE
Copyright 2018 Jonas Kramer.
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_zef-kjpye-Geo-WellKnownText.md
[](https://github.com/kjpye/Geo-WellKnownText/actions)
# TITLE
Geom::WellKnownText
The `Geo::WellKnownText` module contains a single function:
# from-wkt
`from-wkt` takes a single `Str` parameter, and returns a single `Geo::Geometry` object corresponding to the wkt specification, or a `Failure` if the contents of the string cannot be interpreted as a Geometry object.
The conversion is case-insensitive, and optional whitespace may be included in various places. Thus the following strings will all produce the same object:
```
PointZ(123 456 789)
Point Z (123 456 789)
Point Z(123 456 789)
pointz (123 456 789)
```
# Geo::WellKnownText::Grammar
The `Geo::WellKnownText::Grammar` module contains a single grammar `Geo::WellKnownText::Grammar::WKT`.
This is the same grammar used by the `Geo::WellKnownText` module, but it can be used separately to parse WKT strings.
The general usage would be
```
my $results = Geo::WellKnownText::Grammar::WKT.parse($string, actions => My::Actions);
```
The actions used by `Geo::WellKnownText::from-wkt` are available in `Geo::WellKnownText::WKT-Actions`, but in that case you might as well use `from-wkt` described above.
The actions class will need to include the following methods (36 in total):
| Geometry type | Method | Available Parameters |
| --- | --- | --- |
| Point[Z][M] | point[z][m] | $<value> — an array containing the values for x, y, z and m as appropriate |
| LineString[Z][M] | linestring[z][m]-text | $<point[z][m]> — an array of whatever the relevant point method passed to make. |
| LinearRing[Z][M] | linearring[z][m]-text | $<point[z][m]> — and array of whatever the relevant point method passed to make. |
| Polygon[Z][M] | polygon[z][m]-text | $<linearring[z][m]-text — an array of whatever the appropriate linearring-text method passed to make. |
| PolyhedralSurface[Z][M] | polyhedralsurface[z][m]-text | $<polygon[z][m]-text — an array of whatever the appropriate polygon-text method passed to make. |
| MultiPoint[Z][M] | multipoint[z][m]-text | $<point[z][m]> — an array of whatever the relevant point method passed to make. |
| MultiLineString[Z][M] | multilinestring[z][m]-text | $<linestring[z][m]-text> — an array of whatever the relevant linestring-text method passed to make. |
| MultiPolygon[Z][M] | multipolygon[z][m]-text | $<polygon[z][m]-text — an array of whatever the appropriate polygon-text method passed to make. |
| GeometryCollection[Z][M] | geometrycollection[z][m]-tagged-text | $<geometry[z][m]-tagged-text> — an array of whatever the relevant geometry-text method passed to make. |
|
## ff.md
ff
Combined from primary sources listed below.
# [In Operators](#___top "go to top of document")[§](#(Operators)_infix_ff "direct link")
See primary documentation
[in context](/language/operators#infix_ff)
for **infix ff**.
```raku
sub infix:<ff>(Mu $a, Mu $b)
```
Also called the *flipflop operator*, compares both arguments to `$_` (that is, `$_ ~~ $a` and `$_ ~~ $b`). Evaluates to `False` until the left-hand smartmatch is `True`, at which point it evaluates to `True` until the right-hand smartmatch is `True`.
In effect, the left-hand argument is the "start" condition and the right-hand is the "stop" condition. This construct is typically used to pick up only a certain section of lines. For example:
```raku
my $excerpt = q:to/END/;
Here's some unimportant text.
=begin code
This code block is what we're after.
We'll use 'ff' to get it.
=end code
More unimportant text.
END
my @codelines = gather for $excerpt.lines {
take $_ if "=begin code" ff "=end code"
}
# this will print four lines, starting with "=begin code" and ending with
# "=end code"
say @codelines.join("\n");
```
After matching the start condition, the operator will then match the same `$_` to the stop condition and act accordingly if successful. In this example, only the first element is printed:
```raku
for <AB C D B E F> {
say $_ if /A/ ff /B/; # OUTPUT: «AB»
}
```
If you only want to test against a start condition and have no stop condition, `*` can be used as such.
```raku
for <A B C D E> {
say $_ if /C/ ff *; # OUTPUT: «CDE»
}
```
For the `sed`-like version, which does *not* try `$_` on the stop condition after succeeding on the start condition, see [fff](/routine/fff).
This operator cannot be overloaded, as it's handled specially by the compiler.
|
## dist_zef-antononcube-Math-Fitting.md
# Math::Fitting
Raku package for line, curve, and hyper-plane fitting over sets of points.
---
## Installation
From [Zef ecosystem](https://raku.land):
```
zef install Math::Fitting
```
From GitHub:
```
zef install https://github.com/antononcube/Raku-Math-Fitting.git
```
---
## Usage examples
### Linear regression (1D regressor)
Here is data that is an array of pairs logarithms of GDP and electricity production of different countries:
```
my @data =
(11.773906839650255e0, 11.253864992156679e0), (12.171286902172696e0, 12.009204578014298e0),
(12.107713405070312e0, 11.437962903093876e0), (12.696829332236298e0, 12.00401094268482e0),
(11.28266350477445e0, 11.499283586840601e0), (12.585056018658895e0, 11.775388329493465e0),
(10.723949075934968e0, 10.54745313463026e0), (11.389785159542825e0, 10.928944887584644e0),
(13.167988368224217e0, 12.856756553879103e0), (11.019424327650983e0, 10.472888033769635e0),
(10.198154686798192e0, 9.331143140569578e0), (11.395702941127277e0, 10.772811339725912e0),
(12.031878183906066e0, 11.516569745919236e0), (11.430963567030055e0, 10.855585778720567e0),
(10.21302480711734e0, 10.138888016785716e0), (11.857393542118762e0, 11.520472966745002e0),
(11.223299730942632e0, 10.933368427760566e0), (12.15978767072575e0, 11.78868016913858e0),
(11.190367918582032e0, 10.557867961568022e0), (11.733248321280731e0, 11.226857570288722e0),
(10.839510106614012e0, 10.677157910153495e0), (11.191959374358786e0, 11.17621400228234e0),
(12.215911663039382e0, 11.808235068507617e0), (12.420008212627797e0, 11.723537761532056e0),
(11.551553518127756e0, 10.519077512018512e0), (11.845171164859963e0, 11.528956530193586e0),
(12.212327463463307e0, 11.782617762483701e0), (11.479897117669006e0, 11.355095745306354e0),
(13.320906155798967e0, 12.6405552706939e0);
@data.elems;
```
```
# 29
```
**Remark:** The data was taken from ["Data::Geographics"](https://raku.land/zef:antononcube/Data::Geographics), [AAp1].
Here is a corresponding plot (using ["Text::Plot"](https://raku.land/zef:antononcube/Text::Plot), [AAp2]):
```
use Text::Plot;
text-list-plot(@data, title => 'lg(GDP) vs lg(Electricity Production)', x-label => 'GDP', y-label => 'EP');
```
```
# lg(GDP) vs lg(Electricity Production)
# +--------+-------+-------+-------+--------+-------+-------++
# + + 13.00
# | * * |
# | |
# + * * + 12.00
# | ** * * |
# | * * * ** | E
# + * ** + 11.00 P
# | * * ** |
# | * * * * |
# + * + 10.00
# | |
# | * |
# + + 9.00
# +--------+-------+-------+-------+--------+-------+-------++
# 10.50 11.00 11.50 12.00 12.50 13.00 13.50
# GDP
```
Here is corresponding linear model fit, a functor (i.e. objects that does `Callable`):
```
use Math::Fitting;
my &f = linear-model-fit(@data);
```
```
# Math::Fitting::FittedModel(type => linear, data => (29, 2), response-index => 1, basis => 2)
```
Here are the best fit parameters (fit coefficients):
```
&f('BestFitParameters');
```
```
# [0.6719587872748085 0.9049080671822028]
```
Here we call the functor over a range of values:
```
(10..13)».&f
```
```
# (9.721039459096838 10.62594752627904 11.530855593461244 12.435763660643445)
```
Here are the corresponding residuals:
```
text-list-plot(&f('residuals'))
```
```
# +---+--------+--------+--------+---------+--------+--------+
# | |
# + * + 0.60
# | |
# + * * * + 0.40
# + * * * + 0.20
# | * * * * * * |
# + * * + 0.00
# | * * * * * * |
# + * * * * * +-0.20
# | * |
# + +-0.40
# + * * +-0.60
# | |
# +---+--------+--------+--------+---------+--------+--------+
# 0.00 5.00 10.00 15.00 20.00 25.00
```
### Multidimensional regression (2D regressor)
Here is a matrix with 3D data:
```
use Data::Reshapers;
(1..2) X (1..3)
==> { .map({ [|$_, sin($_.sum)] }) }()
==> my @data3D;
to-pretty-table(@data3D);
```
```
# +---+---+---------------------+
# | 0 | 1 | 2 |
# +---+---+---------------------+
# | 1 | 1 | 0.9092974268256817 |
# | 1 | 2 | 0.1411200080598672 |
# | 1 | 3 | -0.7568024953079283 |
# | 2 | 1 | 0.1411200080598672 |
# | 2 | 2 | -0.7568024953079283 |
# | 2 | 3 | -0.9589242746631385 |
# +---+---+---------------------+
```
Here is a functor for the multidimensional fit:
```
my &mf = linear-model-fit(@data3D);
```
```
# Math::Fitting::FittedModel(type => linear, data => (6, 3), response-index => 2, basis => Whatever)
```
Here are the best parameters:
```
&mf('BestFitParameters');
```
```
# [2.1036843161171217 -0.62274056716294 -0.6915360512141538]
```
Here is a predicated value:
```
&mf(2.5, 2.5);
```
```
# -1.182007229825613
```
Here is plot of the residuals:
```
text-list-plot(&mf.fit-residuals);
```
```
# +---+---------+---------+----------+---------+---------+---+
# + + 0.30
# | * |
# + + 0.20
# | |
# + * + 0.10
# | * |
# + + 0.00
# | * |
# | |
# + +-0.10
# | * |
# + * +-0.20
# | |
# +---+---------+---------+----------+---------+---------+---+
# 0.00 1.00 2.00 3.00 4.00 5.00
```
### Using function basis
Data:
```
use Data::Generators;
my @data = (-1, -0.95 ... 1);
@data = @data.map({ [$_, sqrt(abs($_/2)) + sin($_*2) + random-real((-0.25, 0.25))] });
text-list-plot(@data);
```
```
# +---+------------+-----------+------------+------------+---+
# + + 2.00
# | *** **** ** |
# + * * + 1.50
# | |
# + * ** + 1.00
# | ** |
# | * |
# + ** + 0.50
# | * * * * |
# + * * * + 0.00
# | *** * * * * * * |
# + * ** ** * + -0.50
# | |
# +---+------------+-----------+------------+------------+---+
# -1.00 -0.50 0.00 0.50 1.00
```
Basis functions:
```
my @basis = {1}, {$_}, {-1 + 2 * $_ **2}, {-3 * $_ + 4 * $_ **3}, {1 - 8 * $_ ** 2 + 8 * $_ **4};
```
```
# [-> ;; $_? is raw = OUTER::<$_> { #`(Block|3831690270616) ... } -> ;; $_? is raw = OUTER::<$_> { #`(Block|3831690270688) ... } -> ;; $_? is raw = OUTER::<$_> { #`(Block|3831690270760) ... } -> ;; $_? is raw = OUTER::<$_> { #`(Block|3831690270832) ... } -> ;; $_? is raw = OUTER::<$_> { #`(Block|3831690270904) ... }]
```
Compute the fit and show the best fit parameters:
```
my &mf = linear-model-fit(@data, :@basis);
say 'BestFitParameters : ', &mf('BestFitParameters');
```
```
# BestFitParameters : [0.551799047700142 1.173011790424553 0.2158197987446535 -0.2733280230300862 -0.1178403498782696]
```
Plot the residuals:
```
text-list-plot(&mf('FitResiduals'));
```
```
# +---+------------+-----------+------------+------------+---+
# | |
# | * * |
# + * + 0.20
# | * * * |
# + ** * * * * + 0.10
# | * * * * * |
# + * + 0.00
# | * * ** * ** * |
# | * * * * |
# + * * * * * +-0.10
# | * * |
# + * * * * +-0.20
# | |
# +---+------------+-----------+------------+------------+---+
# 0.00 10.00 20.00 30.00 40.00
```
(Compare the plot values with the range of the added noise when `@data` is generated.)
---
## TODO
* TODO Implementation
* DONE Multi-dimensional Linear Model Fit (LMF)
* DONE Using user specified function basis
* TODO More LMF diagnostics
* TODO CLI for most common data specs
* TODO Just a list of numbers
* TODO String that is Raku full array
* TODO String that is a JSON array
---
## References
[AAp1] Anton Antonov,
[Data::Geographics Raku package](https://github.com/antononcube/Raku-Data-Geographics),
(2024),
[GitHub/antononcube](https://github.com/antononcube).
[AAp2] Anton Antonov,
[Text::Plot Raku package](https://github.com/antononcube/Raku-Text-Plot),
(2022-2023),
[GitHub/antononcube](https://github.com/antononcube).
[PSp1] Paweł Szulc,
[Statistics::LinearRegression Raku package](https://github.com/hipek8/p6-Statistics-LinearRegression),
(2017),
[GitHub/hipek8](https://github.com/hipek8).
|
## dist_zef-raku-community-modules-Test-Builder.md
[](https://github.com/raku-community-modules/Test-Builder/actions)
# NAME
Test::Builder - flexible framework for building TAP test libraries
# SYNOPSIS
```
my $tb = Test::Builder.new;
$tb.plan(2);
$tb.ok(1, 'This is a test');
$tb.ok(1, 'This is another test');
$tb.done;
```
# DESCRIPTION
`Test::Builder` is meant to serve as a generic backend for test libraries. Put differently, it provides the basic "building blocks" and generic functionality needed for building your own application-specific TAP test libraries.
`Test::Builder` conforms to the Test Anything Protocol (TAP) specification.
# USE
## Object Initialization
### **new()**
Returns the `Test::Builder` singleton object.
The `new()` method only returns a new object the first time that it's called. If called again, it simply returns the same object. This allows multiple modules to share the global information about the TAP harness's state.
Alternatively, if a singleton object is too limiting, you can use the `create()` method instead.
### **create()**
Returns a new `Test::Builder` instance.
The `create()` method should only be used under certain circumstances. For instance, when testing `Test::Builder`-based modules. In all other cases, it is recommended that you stick to using `new()` instead.
## Implementing Tests
The following methods are responsible for performing the actual tests.
All methods take an optional string argument describing the nature of the test.
### **plan(Int $tests)**
Declares how many tests are going to be run.
If called as `.plan(*)`, then a plan will not be set. However, it is your job to call `done()` when all tests have been run.
### **ok(Mu $test, Str $description)**
Evaluates `$test` in a boolean context. The test will pass if the expression evaluates to `Bool::True` and fail otherwise.
### **nok(Mu $test, Str $description)**
The antithesis of `ok()`. Evaluates `$test` in a boolean context. The test will pass if the expression evaluates to `Bool::False` and fail otherwise.
## Modifying Test Behavior
### **todo(Str $reason, Int $count)**
Marks the next `$count` tests as failures but ignores the fact. Test execution will continue after displaying the message in `$reason`.
It's important to note that even though the tests are marked as failures, they will still be evaluated. If a test marked with `todo()` in fact passes, a warning message will be displayed.
# TODO The todo() method doesn't actually does this yet but I want it to
# SEE ALSO
<http://testanything.org>
# AUTHOR
Kevin Polulak
# ACKNOWLEDGEMENTS
`Test::Builder` was largely inspired by chromatic's work on the old `Test::Builder` module for Pugs.
Additionally, `Test::Builder` is based on the Perl module of the same name also written by chromatic and Michael G. Schwern.
# COPYRIGHT
Copyright 2011 Kevin Polulak
Copyright 2012 - 2022 Raku Community
This program is distributed under the terms of the Artistic License 2.0.
|
## dist_cpan-FRITH-Desktop-Notify-Progress.md
[](https://travis-ci.org/frithnanth/Perl6-Desktop-Notify-Progress)
# NAME
Desktop::Notify::Progress - Show the progress of processing in a notification popup
# SYNOPSIS
```
use Desktop::Notify::Progress;
my $fh = 'BigDataFile'.IO.open;
my $p := Desktop::Notify::Progress.new: :$fh, :title('Long data processing'), :timeout(2);
for $p -> $line {
painfully-process($line);
}
```
```
use Desktop::Notify::Progress;
my @p = Seq.new(Desktop::Notify::Progress.new: :filename('BigDataFile'));
for @p -> $line {
painfully-process($line);
}
```
# DESCRIPTION
Desktop::Notify::Progress is a small class that provides a way to show the progress of file processing using libnotify
## new(Str :$filename!, Str :$title?, Int :$timeout? = 0)
## new(IO::Handle :$fh!, :$title!, Int :$timeout? = 0)
## new(:&get!, Int :$size?, Str :$title!, Int :$timeout? = 0)
Creates a **Desktop::Notify::Progress** object.
The first form takes one mandatory argument: **filename**, which will be used as the notification title. Optionally one can pass an additional string which will be used as the notification title: **title**. Another optional parameter **timeout**, the number of seconds the notification will last until disappearing. The default is for the notification not to disappear until explicitly closed.
The second form requires both an opened file handler **fh** and the notification **title**. An optional **timeout** can be specified.
The third form takes a mandatory function **&get** which retrieves the next element, an optional total number of elements **$size**, and an optional **timeout**. If the **$size** parameter has been provided, the notification will show a percentage, otherwise it will show the current element number.
## Usage
A Desktop::Notify::Progress object has an **Iterable** role, so it can be used to read a file line by line. When initialized the object will read the file size, so it will be able to update the computation progress as a percentage in the notification window.
# Prerequisites
This module requires the libnotify library to be installed. Please follow the instructions below based on your platform:
## Debian Linux
```
sudo apt-get install libnotify4
```
# Installation
To install it using zef (a module management tool):
```
$ zef install Desktop::Notify::Progress
```
This will install the Desktop::Notify module if not yet present.
# Testing
To run the tests:
```
$ prove -e "raku -Ilib"
```
# AUTHOR
Fernando Santagata [nando.santagata@gmail.com](mailto:nando.santagata@gmail.com)
# COPYRIGHT AND LICENSE
Copyright 2019 Fernando Santagata
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_zef-tbrowder-Compress-PDF.md
[](https://github.com/tbrowder/Compress-PDF/actions) [](https://github.com/tbrowder/Compress-PDF/actions) [](https://github.com/tbrowder/Compress-PDF/actions)
# NAME
**Compress::PDF** - Provides PDF compression binary executables `compress-pdf` and its alias `pdf-compress`
# SYNOPSIS
```
use Compress::PDF
```
In your terminal window:
```
$ compress-pdf calendar.pdf
# OUTPUT
Input file: calendar.pdf
Size: 2.9M
Compressed output file: calendar-150dpi.pdf
Size: 247.7K
```
# DESCRIPTION
**Compress::PDF** requires a system utitlity program: 'ps2pdf'. On Debian systems it can be installed by executing `sudo aptitude install ps2pdf`.
Installing this module results in an exported subroutine as well as one primary and one aliased Raku PDF compression programs:
* sub compress($inpdf, :$quiet, :$dpi = 150, :$outpdf, :$force) is export {...}
* compress-pdf
* pdf-compress #= aliased to `compress-pdf`
## Programs
Executing either program name without input arguments results in:
```
Usage: compress-pdf <pdf file> [..options...]
Without options, the program compresses the input PDF file to the
default 150 dpi.
The input file is not modified, and the output file is
named as the input file with any extension or suffix
replaced by '-NNNdpi.pdf' where 'NNN' is the selected
value of '150' (the default) or '300'.
Options:
dpi=X - where X is the PDF compression level: '150' or '300' DPI.
force - allows overwriting an existing output file
outpdf=X - where X is the desired output name
```
Note the the default output file will overwrite an existing file of the same name without warning.
## Subroutine
The subroutine has the following signature:
```
sub compress($inpdf, :$quiet, :$dpi = 150,
:$outpdf, :$force) is export {...}
```
The `:$quiet` option is designed for use in programs where the user's desired output file name is designed to be quietly and seamlessly compressed by default. Other options provide more flexibilty and choices to offer the user if the `$quiet` option is **not** used.
If the `:$outpdf` is not entered, the `$outpdf` is named using the same scheme as the programs. The `:$force` option allows overwriting an existing file.
# AUTHOR
Tom Browder [tbrowder@acm.org](mailto:tbrowder@acm.org)
# COPYRIGHT AND LICENSE
© 2024 Tom Browder
This library is free software; you may redistribute it or modify it under the Artistic License 2.0.
|
## missing.md
class X::Syntax::Missing
Compilation error due to a missing piece of syntax
```raku
class X::Syntax::Missing does X::Syntax { }
```
Syntax error thrown when the previous piece of syntax requires the existence of another piece of syntax, and that second piece is missing.
For example
```raku
for 1, 2, 3;
```
dies with
「text」 without highlighting
```
```
===SORRY!===
Missing block
```
```
because a `for` that is not a statement modifier must be followed by a block.
# [Methods](#class_X::Syntax::Missing "go to top of document")[§](#Methods "direct link")
## [method what](#class_X::Syntax::Missing "go to top of document")[§](#method_what "direct link")
```raku
method what(--> Str:D)
```
Returns a string description of the missing syntax element.
|
## dist_zef-Kaiepi-Gauge.md

# NAME
Gauge - Iterative polling
# SYNOPSIS
```
use v6.d;
use Gauge;
#|[ Jury-rigged benchmark that keys it/s counts of an evaluated code block. ]
sub MAIN(
**@code,
#|[ The number of threads to dedicate to benchmarking. ]
UInt:D :j(:$jobs) = $*KERNEL.cpu-cores.pred,
#|[ The duration in seconds over which timestamps will be aggregated. ]
Real:D :p(:$period) = 1,
#|[ The cooldown in seconds performed between each individual benchmark. ]
Real:D :c(:$cooldown) = (try 2 / 3 * $jobs * $period) // (2 / 3 * $*KERNEL.cpu-cores.pred),
#|[ Whether or not ANSI 24-bit SGR escape sequences should be suppressed.
These highlight blocks of it/s counts opening with any new maximum. ]
Bool:D :m(:$mono) = False,
--> Nil) {
use MONKEY-SEE-NO-EVAL;
map $mono ?? &mono !! &poly,
Gauge(EVAL Qa[-> { @code.join(' ') }])
.poll($period)
.pledge($jobs)
.throttle($cooldown);
}
#=[ Benchmark threads are run once an iteration of any existing threads has
been exhausted. This is staggered by the cooldown, and by default, allows
for multiple benchmarks to be taken with a brief overlap of threaded work,
reducing the time needed to collect results while keeping low overhead. ]
sub poly(Int:D $next --> Empty) {
my constant @mark = «\e[48;5;198m \e[48;5;202m \e[48;5;178m \e[48;5;41m \e[48;5;25m \e[48;5;129m»;
state $mark is default(-1);
state $peak is default(-1);
my $jump := $peak < $next;
$mark += $jump;
$mark %= @mark;
$peak max= $next;
my $note = @mark[$mark];
$note ~= $jump ?? '⊛' !! '∗';
$note ~= " \e[m";
$note ~= $next;
put $note
}
sub mono(Int:D $next --> Empty) {
state $peak is default(-1);
my $jump := $peak < $next;
$peak max= $next;
my $note = $jump ?? '⊛' !! '∗';
$note ~= ' ';
$note ~= $next;
put $note
}
```
# DESCRIPTION
```
class Gauge is Seq { ... }
```
`Gauge`, in general, provides an interface for a collection of temporal, lazy, non-deterministic iterators. At its base, it attempts to measure durations of calls to a block with as little overhead as possible in order to avoid unnecessary influence over results. This can stack operations mapping its iterator until it decays to a `Seq` via `Iterable` or the `iterator` itself.
# METHODS
## CALL-ME
```
method CALL-ME(::?CLASS:_: Block:D $block --> ::?CLASS:D)
```
Produces a new `Gauge` sequence of native `uint64` durations of a call to the given block. Measurements of each duration are **not** monotonic, thus leap seconds and hardware errors will skew results.
## poll
```
method poll(::?CLASS:D: Real:D $seconds --> ::?CLASS:D)
```
Returns a new `Gauge` sequence that produces an `Int:D` count of iterations of the former totalling a duration of `$seconds`. This will take longer than the given argument to complete due to the overhead of iteration, which may be measured by `Gauge` itself in combination with `head`.
## throttle
```
method throttle(::?CLASS:D: Real:D $seconds --> ::?CLASS:D)
```
Returns a new `Gauge` sequence that will sleep `$seconds` between iterations of its former. If a `poll` is applied later, this will incorporate the time waited into the time it takes to complete an iteration, but not any steps in between required to caculated. The total time throttled is allowed to exceed any poll applied to a `Gauge`, but never by any more than one iteration.
## pledge
```
method pledge(::?CLASS:D: UInt:D $length --> ::?CLASS:D)
```
Returns a new `Gauge` sequence that, across an array of threads of breadth `$length`, pledges that a form of iteration will be continuously invoked across a threaded repetition of this iterator's component iterators in the process. When an empty length is given, this will not change the iteration.
When a length of `1` is given, this will produce a *covenant* wrapping the iterator. This is a thread that upon receiving a query to perform an iteration, will produce its result, then go ahead and perform another iteration while waiting for the next query. This means switching from `skip` to `head` may perform an extra `skip` whose result is discarded while waiting for `head`. Such a thread will finish in a sink context, but is allowed to wait until the end of a program after decaying to another `Seq` when it doesn't play nice.
When a length of `2` or more is given, a *contract* wrapping this number of covenants will be formed. This carries a particular cycle followed to accomodate any throttling performed beforehand. A thread must be spawned in order to work, but any prior threads may complete an iteration during this timespan, and will be waited on in reverse as each covenant is run in its original ordering.
# AUTHOR
Ben Davies (Kaiepi)
# COPYRIGHT AND LICENSE
Copyright 2023 Ben Davies
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_github-supernovus-Flower.md
# Flower: XML Application Languages
## Introduction
Flower is a library for building and using XML Application Languages.
An XML Application Language can be anything that takes an XML document,
and parses it using a set of data. It's perfect for creating template engines,
custom XML syntax, and much more, all using pure XML as its input and output
formats.
Flower was originally written to create an implementation of the TAL and METAL
template engines from Zope. Flower's name was originally a play on the Perl 5
Petal library. Since then, Flower has outgrown its original scope, bringing
in further ideas from Template::TAL, PHPTAL, and some of my own custom XML
concepts. The original TAL/METAL/TALES parsers are still included, and can
be easily used by using Flower::TAL, which is included (see below.)
## Flower::TAL
This is an easily loadable library that extends Flower and automatically
loads the Flower::TAL::TAL, Flower::TAL::METAL application languages
by default, and offers the ability to easily load plugins for the
Flower::TAL::TALES attribute parser (used by Flower::TAL::TAL)
### Differences from Petal (and Template::TAL, PHPTAL and Zope)
* The default local namespace is 'tal', and to override it, you must
declare <http://xml.zope.org/namespaces/tal> instead of the Petal namespace.
* Flower can use template strings instead of requiring files.
* In addition to strings, it can use a custom provider class.
Currently a File provider is included.
* Flower does not support the multiple template files based on language.
But that can be added easily by defining a custom Provider class.
* Adding custom modifiers is completely different in Flower.
* There is NO support for anything but well-formed XML.
There is no equivelant to the Petal::Parser::HTB, and no plans for one.
* Flower supports tal:block elements, as per the PHPTAL project.
* While you can use the 'structure' keyword, it's not really needed.
If you want an unescaped XML structure for a replacement, send an
Exemel object (any class other than Document) and it will be added to
the XML tree. Send an array of Exemel objects, and they will additionally
be parsed for TAL statements.
* Nested repeats cannot use the same attribute name, it will get clobbered.
* The built-in repeat object is implemented as per Zope and PHPTAL, not
the Petal version. Note: it does not support the 'letter' or 'Letter'
attributes, but instead has some new methods that take paramters:
'every xx' the number (not the index) is divisible by xx.
'skip xx' the number is not divisible by xx.
'gt xx' the number is greater than xx.
'lt xx' the number is less than xx.
'eq xx' the number is equal to xx.
'ne xx' the number is not equal to xx.
* I'm not sure how Petal, PHPTAL or Zope deal with TAL attributes in the
root element (the top-most element of the document), but to avoid death,
destruction and mayhem, Flower only processes 'define', 'attributes'
and 'content' tags on the root element. The rest of the tags are only
processed on children of the root.
The above list will be updated as this project is developed, as I'm sure
other changes will be introduced that will be a gotchya for users of Petal,
Zope or PHPTAL.
### Flower::TAL::TALES Plugins
Inspired by Petal::Utils, Flower includes a bunch of libraries in the
Flower::TAL::TALES:: namespace. These are available using Flower::TAL's
add-tales() method.
* Text, same as the :text set from Petal::Utils
* lc: make the string lowercase.
* uc: make the string uppercase.
* ucfirst: make the first letter of the string uppercase.
* substr: extract a portion of the string.
* printf: format a string or object in a specified way.
* List, similar to the :list set from Petal::Utils.
* group: turns a flat Array into a nested Array, where each inner
Array has a set number of elements in it.
* sort: sort the array using the default sort algorithm.
* limit: only return the first number of items from the list.
* shuffle: shuffle the list into a random order.
* pick: pick a set number of items randomly from the list.
* reverse: reverse the contents of the list.
* Date, similar to the :date set from Petal::Utils, using on DateTime::Utils
* date: Builds a DateTime object using specified paramters.
* time: Builds a DateTime object from a Unix epoch.
* strftime: Displays a date/time string in a specified format.
* rfc: A modifier specifically for use with strftime, as the format.
* now: A modifier specifically for use with strftime, as the object.
* Debug, similar to :debug set from Petal::Utils.
* dump: modifier spits out the .perl representation of the object.
* what: modifier spits out the class name of the object.
In addition, the following sets are planned for inclusion at some point:
* Logic, similar to the :logic set from Petal::Utils
* Hash, same as the :hash set from Petal::Utils
The syntax for the Flower::TAL plugins is based on the modifiers from
Petal::Utils, but extended to use the Flower-specific extensions (the
same method that is used to parse method call parameters in queries.)
As is obvious, the syntax is not always the same, and not all of the
modifiers are the same.
Full documentation for the usage of Flower and the Flower::Utils modifiers
will be included in the doc/ folder in an upcoming release, until then
there are comments in the libraries, and test files in t/ that show the
proper usage.
The URI set from Petal::Utils is not planned for inclusion,
feel free to write it if you need it.
I'm sure new exciting libraries will be made adding onto these.
## TODO
* Add Logic and Hash TALES plugins.
* Implement optional query caching.
* Implement multiple paths (/test/path1 | /test/path2) support.
* Implement on-error.
* Add Flower::Provider::Multiple for querying providers by prefix.
## Requirements
* [XML](http://github.com/supernovus/exemel/)
* [DateTime::Utils](http://github.com/supernovus/temporal-utils/)
## Author
Timothy Totten, supernovus on #perl6, <https://github.com/supernovus/>
## License
[Artistic License 2.0](http://www.perlfoundation.org/artistic_license_2_0)
|
## valueobjat.md
class ValueObjAt
Unique identification for value types
```raku
class ValueObjAt is ObjAt { }
```
A subclass of [`ObjAt`](/type/ObjAt) that should be used to indicate that a class produces objects that are value types - in other words, that are immutable after they have been initialized.
```raku
my %h = a => 42; # mutable Hash
say %h.WHICH; # OUTPUT: «ObjAt.new("Hash|1402...888")»
my %m is Map = a => 42; # immutable Map
say %m.WHICH; # OUTPUT: «ValueObjAt.new("Map|AAF...09F61F")»
```
If you create a class that should be considered a value type, you should add a `WHICH` method to that class that returns a `ValueObjAt` object, for instance:
```raku
class YourClass {
has $.foo; # note these are not mutable
has $.bar;
method WHICH() {
ValueObjAt.new("YourClass|$!foo|$!bar");
}
}
```
Note that it is customary to always start the identifying string with the name of the object, followed by a "|". This to prevent confusion with other classes that may generate similar string values: the name of the class should then be enough of a differentiator to prevent collisions.
# [Typegraph](# "go to top of document")[§](#typegraphrelations "direct link")
Type relations for `ValueObjAt`
raku-type-graph
ValueObjAt
ValueObjAt
ObjAt
ObjAt
ValueObjAt->ObjAt
Mu
Mu
Any
Any
Any->Mu
ObjAt->Any
[Expand chart above](/assets/typegraphs/ValueObjAt.svg)
|
## dist_cpan-TITSUKI-Algorithm-LBFGS.md
[](https://travis-ci.com/titsuki/raku-Algorithm-LBFGS)
# NAME
Algorithm::LBFGS - A Raku bindings for libLBFGS
# SYNOPSIS
```
use Algorithm::LBFGS;
use Algorithm::LBFGS::Parameter;
my Algorithm::LBFGS $lbfgs .= new;
my &evaluate = sub ($instance, $x, $g, $n, $step --> Num) {
my Num $fx = ($x[0] - 2.0) ** 2 + ($x[1] - 5.0) ** 2;
$g[0] = 2.0 * $x[0] - 4.0;
$g[1] = 2.0 * $x[1] - 10.0;
return $fx;
};
my Algorithm::LBFGS::Parameter $parameter .= new;
my Num @x0 = [0e0, 0e0];
my @x = $lbfgs.minimize(:@x0, :&evaluate, :$parameter);
@x.say; # [2e0, 5e0]
```
# DESCRIPTION
Algorithm::LBFGS is a Raku bindings for libLBFGS. libLBFGS is a C port of the implementation of Limited-memory Broyden-Fletcher-Goldfarb-Shanno (L-BFGS) method written by Jorge Nocedal.
The L-BFGS method solves the unconstrainted minimization problem,
```
minimize F(x), x = (x1, x2, ..., xN),
```
only if the objective function F(x) and its gradient G(x) are computable.
## CONSTRUCTOR
```
my $lbfgs = Algorithm::LBFGS.new;
my Algorithm::LBFGS $lbfgs .= new; # with type restrictions
```
## METHODS
### minimize(:@x0!, :&evaluate!, :&progress, Algorithm::LBFGS::Parameter :$parameter!) returns Array
```
my @x = $lbfgs.minimize(:@x0!, :&evaluate, :&progress, :$parameter); # use &progress callback
my @x = $lbfgs.minimize(:@x0!, :&evaluate, :$parameter);
```
Runs the optimization and returns the resulting variables.
`:@x0` is the initial value of the variables.
`:&evaluate` is the callback function. This requires the definition of the objective function F(x) and its gradient G(x).
`:&progress` is the callback function. This gets called on every iteration and can output the internal state of the current iteration.
`:$parameter` is the instance of the `Algorithm::LBFGS::Parameter` class.
#### :&evaluate
The one of the simplest `&evaluate` callback function would be like the following:
```
my &evaluate = sub ($instance, $x, $g, $n, $step --> Num) {
my Num $fx = ($x[0] - 2.0) ** 2 + ($x[1] - 5.0) ** 2; # F(x) = (x0 - 2.0)^2 + (x1 - 5.0)^2
# G(x) = [∂F(x)/∂x0, ∂F(x)/∂x1]
$g[0] = 2.0 * $x[0] - 4.0; # ∂F(x)/∂x0 = 2.0 * x0 - 4.0
$g[1] = 2.0 * $x[1] - 10.0; # ∂F(x)/∂x1 = 2.0 * x1 - 10.0
return $fx;
};
```
* `$instance` is the user data. (NOTE: NYI in this binder. You must set it as a first argument, but you can't use it in the callback.)
* `$x` is the current values of variables.
* `$g` is the current gradient values of variables.
* `$n` is the number of variables.
* `$step` is the line-search step used for this iteration.
`&evaluate` requires all of these five arguments in this order.
After writing the definition of the objective function F(x) and its gradient G(x), it requires returning the value of the F(x).
#### :&progress
The one of the simplest `&progress` callback function would be like the following:
```
my &progress = sub ($instance, $x, $g, $fx, $xnorm, $gnorm, $step, $n, $k, $ls --> Int) {
"Iteration $k".say;
"fx = $fx, x[0] = $x[0], x[1] = $x[1]".say;
return 0;
}
```
* `$instance` is the user data. (NOTE: NYI in this binder. You must set it as a first argument, but you can't use it in the callback.)
* `$x` is the current values of variables.
* `$g` is the current gradient values of variables.
* `$fx` is the current value of the objective function.
* `$xnorm` is the Euclidean norm of the variables.
* `$gnorm` is the Euclidean norm of the gradients.
* `$step` is the line-search step used for this iteration.
* `$n` is the number of variables.
* `$k` is the iteration count.
* `$ls` the number of evaluations called for this iteration.
`&progress` requires all of these ten arguments in this order.
#### Algorithm::LBFGS::Parameter :$parameter
Below is the examples of creating a Algorithm::LBFGS::Parameter instance:
```
my Algorithm::LBFGS::Parameter $parameter .= new; # sets default parameter
my Algorithm::LBFGS::Parameter $parameter .= new(max_iterations => 100); # sets max_iterations => 100
```
##### OPTIONS
* Int `m` is the number of corrections to approximate the inverse hessian matrix.
* Num `epsilon` is epsilon for convergence test.
* Int `past` is the distance for delta-based convergence test.
* Num `delta` is delta for convergence test.
* Int `max_iterations` is the maximum number of iterations.
* Int `linesearch` is the line search algorithm. This requires one of `LBFGS_LINESEARCH_DEFAULT`, `LBFGS_LINESEARCH_MORETHUENTE`, `LBFGS_LINESEARCH_BACKTRACKING_ARMIJO`, `LBFGS_LINESEARCH_BACKTRACKING`, `LBFGS_LINESEARCH_BACKTRACKING_WOLFE` and `LBFGS_LINESEARCH_BACKTRACKING_STRONG_WOLFE`. The default value is `LBFGS_LINESEARCH_MORETHUENTE`.
* Int `max_linesearch` is the maximum number of trials for the line search.
* Num `min_step` is the minimum step of the line search routine.
* Num `max_step` is the maximum step of the line search.
* Num `ftol` is a parameter to control the accuracy of the line search routine.
* Num `wolfe` is a coefficient for the Wolfe condition.
* Num `gtol` is a parameter to control the accuracy of the line search routine.
* Num `xtol` is the machine precision for floating-point values.
* Num `orthantwise_c` is a coeefficient for the L1 norm of variables.
* Int `orthantwise_start` is the start index for computing L1 norm of the variables.
* Int `orthantwise_end` is the end index for computing L1 norm of the variables.
## STATUS CODES
TBD
# AUTHOR
titsuki [titsuki@cpan.org](mailto:titsuki@cpan.org)
# COPYRIGHT AND LICENSE
Copyright 2016 titsuki
Copyright 1990 Jorge Nocedal
Copyright 2007-2010 Naoki Okazaki
libLBFGS by Naoki Okazaki is licensed under the MIT License.
This library is free software; you can redistribute it and/or modify it under the terms of the MIT License.
# SEE ALSO
* libLBFGS <http://www.chokkan.org/software/liblbfgs/index.html>
|
## dist_zef-dwarring-Pod-To-PDF-Lite.md
# TITLE
Pod::To::PDF::Lite
# SUBTITLE
Pod to PDF draft renderer
## Description
Renders Pod to PDF draft documents via PDF::Lite.
## Usage
From command line:
```
$ raku --doc=PDF::Lite lib/To/Class.rakumod --save-as=To-Class.pdf
```
From Raku:
```
use Pod::To::PDF::Lite;
=NAME
foobar.pl
=SYNOPSIS
foobar.pl <options> files ...
pod2pdf($=pod).save-as: "foobar.pdf";
```
## Exports
```
class Pod::To::PDF::Lite;
sub pod2pdf; # See below
```
From command line:
```
$ raku --doc=PDF::Lite lib/to/class.rakumod --save-as=class.pdf
```
From Raku code, the `pod2pdf` function returns a PDF::Lite object which can be further manipulated, or saved to a PDF file.
```
use Pod::To::PDF::Lite;
use PDF::Lite;
=NAME
foobar.raku
=SYNOPSIS
foobarraku <options> files ...
my PDF::Lite $pdf = pod2pdf($=pod);
$pdf.save-as: "foobar.pdf"
```
### Command Line Options:
**--save-as=pdf-filename**
File-name for the PDF output file. If not given, the output will be saved to a temporary file. The file-name is echoed to `stdout`.
**--width=n**
Page width in points (default: 592)
**--height=n**
Page height in points (default: 792)
**--margin=n --margin-left=n --margin-right=n --margin-top=n --margin-bottom=n**
Page margins in points (default: 20)
**--page-numbers**
Output page numbers (format `Page n of m`, bottom right)
**--page-style**
```
-raku --doc=PDF::Lite lib/to/class.rakumod --page-style='margin:10px 20px; width:200pt; height:500pt" --save-as=class.pdf
```
Perform CSS `@page` like styling of pages. At the moment, only margins (`margin`, `margin-left`, `margin-top`, `margin-bottom`, `margin-right`) and the page `width` and `height` can be set. The optional [CSS::Properties](https://css-raku.github.io/CSS-Properties-raku/) module needs to be installed to use this option.
## Subroutines
### sub pod2pdf()
`raku sub pod2pdf( Pod::Block $pod, ) returns PDF::Lite;`
Renders the specified Pod to a PDF::Lite object, which can then be further manipulated or saved.
**`PDF::Lite :$pdf`**
An existing PDF::Lite object to add pages to.
**`UInt:D :$width, UInt:D :$height`**
The page size in points (default 612 x 792).
**`UInt:D :$margin`**
The page margin in points (default 20).
**`Hash :@fonts`**
By default, Pod::To::PDF::Lite uses core fonts. This option can be used to preload selected fonts.
Note: PDF::Font::Loader must be installed, to use this option.
```
use PDF::Lite;
use Pod::To::PDF::Lite;
need PDF::Font::Loader; # needed to enable this option
my @fonts = (
%(:file<fonts/Raku.ttf>),
%(:file<fonts/Raku-Bold.ttf>, :bold),
%(:file<fonts/Raku-Italic.ttf>, :italic),
%(:file<fonts/Raku-BoldItalic.ttf>, :bold, :italic),
%(:file<fonts/Raku-Mono.ttf>, :mono),
);
PDF::Lite $pdf = pod2pdf($=pod, :@fonts);
$pdf.save-as: "pod.pdf";
```
## Asynchronous Rendering (Experimental)
```
$ raku --doc=PDF::Lite::Async lib/to/class.rakumod | xargs evince
```
Also included in this module is class `Pod::To::PDF::Lite::Async`. This extends the `Pod::To::PDF::Lite` Pod renderer, adding the ability to render larger documents concurrently.
For this mode to be useful, the document is likely to be of the order of dozens of pages and include multiple level-1 headers (for batching purposes).
## Restrictions
PDF::Lite minimalism, including:
* no Table of Contents or Index
* no Links
* no Marked Content/Accessibility
## See Also
* Pod::To::PDF::Lite::Async - Multi-threaded rendering mode (experimental)
* Pod::To::PDF - PDF rendering via <Cairo>
|
## dist_zef-raku-community-modules-Statistics-LinearRegression.md
[](https://github.com/raku-community-modules/Statistics-LinearRegression/actions) [](https://github.com/raku-community-modules/Statistics-LinearRegression/actions) [](https://github.com/raku-community-modules/Statistics-LinearRegression/actions)
# NAME
Statistics::LinearRegression - simple linear regression
# SYNOPSIS
Gather some data
```
my @arguments = 1,2,3;
my @values = 3,2,1;
```
Build model and predict value for some x using object
```
use Statistics::LinearRegression;
my $x = 15;
my $y = my LR.new(@arguments, @values).at($x);
```
If you prefer bare functions, use :ALL
```
use Statistics::LinearRegression :ALL;
my ($slope, $intercept) = get-parameters(@arguments, @values);
my $x = 15;
my $y = value-at($x, $slope, $intercept);
```
# DESCRIPTION
LinearRegression finds slope and intercept parameters of linear function by minimizing mean square error.
Value at y is calculated using `y = slope × x + intercept`.
# TODO
* R^2 and p-value calculation
* support for other objective functions
# CHANGES
* 1.1.0 LR class exported by default, bare subroutines need :ALL
# AUTHOR
Paweł Szulc
# COPYRIGHT AND LICENSE
Copyright 2016 -2017 Paweł Szulc
Copyright 2024 Raku Community
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_cpan-TYIL-IRC-Client-Plugin-NickServ.md
## class IRC::Client::Plugin::NickServ
The IRC::Client::Plugin to deal with NickServ interaction.
### has Config $.config
A Config instance to hold all configuration.
### method irc-n376
```
method irc-n376(
$event
) returns Mu
```
Identify with NickServ. This is done on IRC code 376 (end of MOTD), since this is what most servers accept as the earliest time to start interacting with the server.
|
## dist_zef-raku-community-modules-Email-SendGrid.md
[](https://github.com/raku-community-modules/Email-SendGrid/actions) [](https://github.com/raku-community-modules/Email-SendGrid/actions) [](https://github.com/raku-community-modules/Email-SendGrid/actions)
# NAME
Email::SendGrid - Basic email sending via the SendGrid API
# DESCRIPTION
A basic Raku module for sending email using the [SendGrid Web API (v3)](https://www.twilio.com/docs/sendgrid/for-developers/sending-email/api-getting-started).
At the time of writing, SendGrid allows sending up to 100 emails a day free of charge. This module most certainly does not provide full coverage of the SendGrid API; if you need more, pull requests are welcome.
# Usage
Construct an `Eamil::SendGrid` object using your SendGrid API key:
```
my $sendgrid = Email::SendGrid.new(api-key => 'your_key_here');
```
Then call `send-mail` to send email:
```
$sendgrid.send-mail:
from => address('some@address.com', 'Sender name'),
to => address('target@address.com', 'Recipient name'),
subject => 'Yay, SendGrid works!',
content => {
'text/plain' => 'This is the plain text message',
'text/html' => '<strong>HTML mail!</strong>'
};
```
It is not required to including a HTML version of the body. Optionally, pass `cc`, `bcc`, and `reply-to` to send these addresses. It is also possible to pass a list of up to 1000 addresses to `to`, `cc`, and `bcc`.
If sending the mail fails, an exception will be thrown. Since `Cro::HTTP::Client` is used internally, it will be an exception from that.
```
CATCH {
default {
note await .response.body;
}
}
```
Pass `:async` to `send-mail` to get a `Promise` back instead. Otherwise, it will be ed for you by `send-mail`.
# Class / Methods reference
## class Email::SendGrid
A partial implementation of the SendGrid v3 API, sufficient for using it to do basic email sending. Construct it with your API key (passed as the api-key parameter), and optionally a from address to be used for all of the emails sent. Construct with :persistent to use a persistent Cro HTTP client (can give better throughput if sending many emails).
Minimal validation of an email address - simply that it has an @ sign.
## class Email::SendGrid::Address
Pairs together a name and email address, which are often needed together in the SendGrid API. A name is optional.
Recipient lists may be an address or a list of addresses 1 to 1000 addresses.
### multi sub address
```
multi sub address(
$email
) returns Mu
```
Construct an Email::SendGrid::Address object from just an email address.
### multi sub address
```
multi sub address(
$email,
$name
) returns Mu
```
Construct an Email::SendGrid::Address object from an email address and a name.
### has Str $.api-key
The SendGrid API key.
### has Email::SendGrid::Address $.from
The default from address to use.
### has Cro::HTTP::Client $.client
The Cro HTTP client used for communication.
### method send-mail
```
method send-mail(
:$to! where { ... },
:$cc where { ... },
:$bcc where { ... },
Email::SendGrid::Address :$from = Code.new,
Email::SendGrid::Address :$reply-to,
Str :$subject!,
:%content!,
:$async,
:$sandbox
) returns Mu
```
Send an email. The C, C, and C options may be a single Address object or a list of 1 to 1000 C objects. Only C is required; C is required if there is no object-level from address. Optionally, a C C may be provided. A C is required, as is a C<%content> hash that maps mime types into the matching bodies. If `async` is passed, the call to the API will take place asynchronously, and a C returned.
# AUTHOR
Jonathan Worthington
# COPYRIGHT AND LICENSE
Copyright 2020 Jonathan Worthington
Copyright 2024 Raku Community
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_cpan-SAMGWISE-Math-Curves.md
[](https://travis-ci.org/samgwise/p6-Math-Curves)
# NAME
Math::Curves - Simple functions for simple curves.
# SYNOPSIS
```
use Math::Curves;
# find the point 1/3 along a linear bézier function.
# Transition, p0 p1
bézier 1/3, 0, 40;
# find the point 1/3 along a quadratic bézier function.
# Transition, p0 p1 p2
bézier 1/3, 0, 40, 30;
# find the point 1/3 along a cubic bézier function.
# Transition, p0 p1 p2 p4
bézier 1/3, 0, 40, 30, -10.5;
# find the point 1/3 along a bézier curve of any size > 1.
# Transition, p0 p1 p2 ...
bézier 1/3, (0, 40, 30, -10.5, 18.28);
# Calculate the length of a line with a given gradient
# position(x) gradient
line 2, 1/1;
```
# DESCRIPTION
Math::Curves provides some simple functions for plotting points on a curve. The methods above are the only functions currently implemented but I hope to see this list grow over time.
# Contributing
This module is still quite incomplete so please contribute your favourite functions! To do so submit a pull request to the repo on github: <https://github.com/samgwise/p6-Math-Curves>
Contributors will be credited and appreciated :)
# AUTHOR
```
Sam Gillespie
```
# COPYRIGHT AND LICENSE
Copyright 2016 Sam Gillespie
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## uniprop.md
uniprop
Combined from primary sources listed below.
# [In Cool](#___top "go to top of document")[§](#(Cool)_routine_uniprop "direct link")
See primary documentation
[in context](/type/Cool#routine_uniprop)
for **routine uniprop**.
```raku
multi uniprop(Str:D, |c)
multi uniprop(Int:D $code)
multi uniprop(Int:D $code, Stringy:D $propname)
multi method uniprop(|c)
```
Returns the [unicode property](https://en.wikipedia.org/wiki/Unicode_character_property) of the first character. If no property is specified returns the [General Category](https://en.wikipedia.org/wiki/Unicode_character_property#General_Category). Returns a Bool for Boolean properties. A [uniprops](/routine/uniprops) routine can be used to get the property for every character in a string.
```raku
say 'a'.uniprop; # OUTPUT: «Ll»
say '1'.uniprop; # OUTPUT: «Nd»
say 'a'.uniprop('Alphabetic'); # OUTPUT: «True»
say '1'.uniprop('Alphabetic'); # OUTPUT: «False»
```
|
## dist_zef-lizmat-ObjectCache.md
[](https://github.com/lizmat/ObjectCache/actions)
# NAME
ObjectCache - A role to cache objects
# SYNOPSIS
```
use ObjectCache;
sub id(%h --> Int:D) {
%h<id> or die "must have an id";
}
class Article does ObjectCache[&id] {
has $.id;
# has many more attributes
}
say Article.new(id => 42666789).WHICH; # Article|42666789
```
# DESCRIPTION
The ObjectCache role mixes the logic of creating a proper ObjectType class **and** making sure that each unique ObjectType only exists once in memory, into a class.
The role takes a `Callable` parameterization to indicate how a unique ID should be created from the parameters given (as a hash) with the call to the `new` method. You can also adapt the given hash making sure any default values are properly applied. If there's already an object created with the returned ID, then no new object will be created but the one from the cache will be returned.
A class is considered to be an object type if the `.WHICH` method returns an object of the `ObjAt` class.
This is specifically important when using set operators (such as `(elem)`, or `Set`s, `Bag`s or `Mix`es, or any other functionality that is based on the `===` operator functionality, such as `unique` and `squish`.
The format of the value that is being returned by `WHICH` is only valid during a run of a process. So it should **not** be stored in any permanent medium.
## Removing objects from cache
The `ObjectCache` role contains a private method `!EVICT`. If you'd like to have the ability to remove an object from the cache, you should create a method in your class that will call this method:
```
class Article does ObjectCache[&id] {
method remove-from-cache() { self!EVICT }
# more stuff
}
```
The `!EVICT` method returns the object that is removed from the cache, or `Nil` if the object was not in the cache.
## Clearing the cache completely
The `ObjectCache` role contains a private method `!CLEAR`. If you'd like to have the ability to cleare the cache completely, you should create a method in your class that will call this method:
```
class Article does ObjectCache[&id] {
method clear-cache() { self!CLEAR }
# more stuff
}
```
The `!CLEAR` method returns the number of objects that have been removed from the cache.
# AUTHOR
Elizabeth Mattijsen [liz@raku.rocks](mailto:liz@raku.rocks)
Source can be located at: <https://github.com/lizmat/ObjectCache> . Comments and Pull Requests are welcome.
If you like this module, or what I’m doing more generally, committing to a [small sponsorship](https://github.com/sponsors/lizmat/) would mean a great deal to me!
# COPYRIGHT AND LICENSE
Copyright 2020, 2021, 2024 Elizabeth Mattijsen
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_zef-bradclawsie-Subsets-Common.md
[](https://opensource.org/licenses/BSD-2-Clause)
[](https://github.com/bradclawsie/Subsets-Common/actions)
This module is intended to provide a resource for common subsets.
Please submit patches for any new subsets you find interesting.
The goal is to prevent needless duplication and redefinition of obvious subsets.
Thanks to everyone who has contributed issues and patches.
## Notice
This repository was uploaded via `fez` under the username `b7j0c`,
and later `bradclawsie`. This change was made so the username would match
Github. Sorry for any confusion.
## Installation
```
zef install Subsets::Common
```
|
## dist_zef-tbrowder-CSV-Table.md
[](https://github.com/tbrowder/CSV-Table/actions) [](https://github.com/tbrowder/CSV-Table/actions) [](https://github.com/tbrowder/CSV-Table/actions)
# NAME
**CSV::Table** - Provides routines for querying and modifying a CSV file with or without a header row.
# SYNOPSIS
For example, using an MxN row/column matrix for data plus a header row in a file with the first three lines being:
```
name, age, ...
John, 40, ...
Sally, 38, ...
...
```
Handle the file with `CSV::Table` in a Raku program:
```
use CSV::Table;
# with indexing from zero
my $t = CSV::Table.new: :csv($my-csv-file);
say $t.fields; # OUTPUT: «M» # zero if no header row
say $t.rows; # OUTPUT: «N-1» # N if no header row
say $t.cols; # OUTPUT: «M»
say $t.field[0]; # OUTPUT: «name» # (Any) if no header row
say $t.cell[0][0]; # OUTPUT: «John»
```
There are multiple ways to query a data cell:
* by row and column
```
say $t.cell[1][0] # OUTPUT: «Sally»
say $t.rowcol(1, 0); # OUTPUT: «Sally»
say $t.rc(1, 0); # OUTPUT: «Sally»
say $t.ij(1, 0); # OUTPUT: «Sally»
```
* by column and row
```
say $t.colrow(0, 1); # OUTPUT: «Sally»
say $t.cr(0, 1); # OUTPUT: «Sally»
say $t.ji(0, 1); # OUTPUT: «Sally»
```
You can change the value of any cell:
```
$t.cell[0][1] = 48;
$t.rowcol(0, 1, 50);
```
You can also change the names of fields, but, unless you also change the corresponding field names in the data hashes, you will most likely have problems. It would be much easier to modify the original CSV file.
You can choose to have the changed data (`$t.save`) any time, but you will be asked to confirm the save.
You can also save the data in a new file: `$t.save: $stem`. Where `$stem` is the desired basename without a suffix. The new files will have the '.csv' and '-raw.csv' names (or your desired 'raw' file string).
You can define a CSV table with row names using the '$has-row-names' option to the constructor and query the table by row name and column name.
```
say $t.rowcol("water", "Feb"); # OUTPUT: «10.80»
```
# DESCRIPTION
**CSV::Table** is a class enabling access to a CSV table's contents. Tables with a header row must have unique field names. Input files are read immediately, so very large files may overwhelm system resources.
By default, text in a cell is 'normalized', that is, it is trimmed of leading and trailing whitespace and multiple contiguous interior whitespaces are collapsed into single space characters (' '). In this context, 'whitespace' is one or more characters in the set (" ", "\t", "\n"). Exceptions to that rule occur when the user wishes to use a newline in a cell or a tab is used as a cell separator. In those cases, some other character must be chosen as a line-ending or cell separator, and the newline is **not** considered to be a whitespace character for the normalization algorithm while any tab not used as a cell separator is treated as whitespace. (See more details and examples below.)
It can handle the following which other CSV handlers may not:
* With a header line
* normalizing field names
* data lines with fewer fields than a header (missing values assumed to be "" or the user can choose the default value in the constructor)
* data lines with more fields than its header (fatal, but reported)
Note header lines with any empty fields causes an exception. This is a valid header line:
```
field0, field1, field2
```
This header line is **not** valid (notice the ending comma has no text following it):
```
field0, field1, field2,
```
* Without a header line
* data lines are padded with empty fields to the maximum number of fields found in the file (or the user's chosen value)
* Either case
* May use newlines in a cell if a different line ending is specified
As simple as it is, it also has some uncommon features that are very useful:
* Its `slice` method enables extraction of an M'xN' sub-array of the data cells
The `slice` arguments are two range values defining the rows and columns zero-indexed cell indices of the desired sub-array.
* Comment lines are allowed
This feature, which is not usual in CSV parsers, is to ignore comment lines interspersed between data lines (such lines may have leading whitespace). Data lines may also have inline comments following a comment character. The comment character is user-definable and its presence invalidates its use as a field separator. The default comment character is '#'. Its use demonstrated:
```
# a comment preceding a data line
1, 2, 3 # an inline comment following the data
# ending
# comments
```
Note comments are preserved and restored when the CSV file is saved.
* Save
There is a `save` method which saves the current state of the CSV file (including comments) as well as saving a "raw" CSV file without the comments so the file can be used with conventional CSV handlers such as LibreOffice or Excel. The method can also be used to change the names of the output files.
* Text normalization
Its results are to normalize text in a field or cell, that is: leading and trailing whitespace is trimmed and interior whitespace is collapsed to one space character (' ') between words. This is the default behavior, but it can be turned off if desired (`normalize=False`). In that event, data in all fields are still trimmed of leading and trailing whitespace unless you also set `trim=False`). Some examples:
Cell contents (line ending **not** a newline): " Sally \n Jean "; normalized: "Sally\nJean".
Cell contents (tab **not** a cell separator): " Sally \t Jean "; normalized: "Sally Jean".
* Automatic determination of separator character
Unless the field separator is selected otherwise, the default is 'auto' and the first data line is searched for the most-used separator character from this list: `|`, `;`, `,` and `\t`. Other non-space characters may be used but are probably not tested. File an issue if you want to add a separator not currently specified.
* Row names
Row names can be used if the "$has-row-names" option is entered with the constructor. Then you can get cell values by row and column name as shown in this example repeated from above:
```
say $t.rowcol("water", "Feb"); # OUTPUT: «10.80»
```
Note the names are case sensitive. A non-case-sensitive option may be provided in a future release.
## Limitations
It cannot currently handle:
* special characters
* backslashes
* binary data
* duplicate field names in a header line
* duplicate row names
Also, quoted words are not specially treated nor are unbalanced quote characters detected.
## Constructor with default options
```
my $t = CSV::Table.new: :$csv,
:has-header=True,
:separator='auto',
:normalize=True,
:trim=True,
:comment-char='#',
:line-ending="\n",
:empty-cell-value="",
:has-row-names=False,
:raw-ending="-raw",
:config
;
```
Following are the allowable values for the named arguments. The user is cautioned that unspecified values are probably not tested. File an issue if your value of choice is not specified and it can be added and tested for.
There are a lot of options, one or all of which can be defined in a YAML (or JSON) configuration file whose path is provided by the `config` option. The user may get a prefilled YAML config file by executing:
```
$ raku -e'use CSV::Table; CSV::Table.write-config'
See CSV::Table JSON configuration file 'config-csv-table.yml'
```
or
```
$ raku -e'use CSV::Table; CSV::Table.write-config(:type<json>)'
See CSV::Table JSON configuration file 'config-csv-table.json'
```
Alternatively, you can call the method on a CSV::Table object in the REPL:
```
$ raku
> use CSV::Table;
> CSV::Table.write-config
See CSV::Table YAML configuration file 'config-csv-table.yml'
```
* `:$separator`
* auto [default]
* comma (`,`)
* pipe (`|`)
* semicolon (`;`)
* tab (`\t`)
* `:$normalize`
* `True` [default]
* `False`
* `:$trim`
* `True` [default]
* `False`
* `:$comment-char`
* `#` [default]
* others, including multiple characters, are possible
* `:$has-header`
* `True` [default]
* `False`
* `:$line-ending`
* `"\n"` [default]
* `String`
* `:$empty-cell-value`
* `''` [default]
* `String`
* `:$has-row-names`
* `False` [default]
* `True`
## Accessing the table
The following table shows how to access each cell in a table `$t` with a header row plus `R` rows and `C` columns of data. (In matrix terminology it is an `M x N` rectangular matrix with `M` rows and `N` columns.)
| | | |
| --- | --- | --- |
| $t.field[0] | ... | $t.field[C-1] |
| $t.cell[0][0] | ... | $t.cell[0][C-1] |
| ... | ... | ... |
| $t.cell[R-1][0] | ... | $t.cell[R-1][C-1] |
The table's data cells can also be accessed by field name and row number:
```
$t.col{$field-name}{$row-number}
```
If row names are provided, data cells can be accessed by row and column names:
```
$t.rowcol: $row-name, $field-name
```
# Possible new features
The following features can be implemented fairly easily if users want it and file an issue.
* non-case-sensitive row and column names
* add new rows or columns
* delete rows or columns
* row sum and average
* column sum and average
* normalize comments
Other matrix-related features could be implemented, but most are available in the published modules `Math::Libgsl::Matrix` and `Math::Matrix`.
# CREDITS
Thanks to @lizmat and @[Coke] for pushing for a more robust CSV handling module including quotes and newlines.
Thanks to @librasteve for the idea of the `slice` method and his suggestion of aliases `slice2d` and `view` for `slice`.
# AUTHOR
Tom Browder [tbrowder@acm.org](mailto:tbrowder@acm.org)
# COPYRIGHT AND LICENSE
© 2024-2025 Tom Browder
This library is free software; you may redistribute it or modify it under the Artistic License 2.0.
|
## dist_zef-vrurg-Concurrent-PChannel.md
# NAME
Concurrent::PChannel - prioritized channel
# SYNOPSIS
```
use Concurrent::PChannel;
my Concurrent::PChannel:D $pchannel .= new( :priorities(10) );
$pchannel.send("low prio", 0);
$pchannel.send("high prio", 1);
say $pchannel.receive; # ‘high prio’
say $pchannel.receive; # ‘low prio’
```
# DESCRIPTION
`Concurrent::PChannel` implements concurrent channel where each item sent over the channel has a priority attached allowing items with higher priority to be pulled first from the channel even if they were sent later in time.
For example, imagine there is a factory of devices supplying our input with different kind of events. Some event types are considered critical and must be processed ASAP. And some are, say, informative and can be taken care of when we're idling. In code this could be implemented the following way:
```
my $pchannel = Concurrent::PChannel.new( :priorities(3) );
for $dev-factory.devices -> $dev {
start {
react {
whenever $dev.event-supply -> $event {
given $event.type {
when EvCritical {
$pchannel.send: $event, 2;
}
when EvInformative {
$pchannel.send: $event, 0;
}
default {
$pchannel.send: $event, 1;
}
}
}
}
}
}
for ^WORKER-COUNT {
start {
while $pchannel.receive -> $event {
...
}
}
}
```
## Performance
The performance was the primary target of this module development. It is implemented using highly-concurrent almost lock-less approach. Benchmarking of different numbers of sending/receiving threads (measured over `receive()` method) results in send operations been 1.3-8 times slower than sending over the core `Channel`; receiving is 1.1-6 times slower. The difference in numbers is only determined by the ratio of sending/receving threads.
What's more important, the speed is almost independent of the number of priorities used! I.e. it doesn't matter if code is using 10 or 1000 priorities – the time needed to process the two channels would only be dependent on the number of items sent over them.
## Terms
### Closed And Drained
A channel could be in three different states: normal, closed, and drained. The difference between the last two is that when the channel is closed it might still have some data available for receiving. Only when all items were consumed by the user code then the channel transitions into the *closed* and the *drained* state.
### Priority
Priority is a positive integer value with 0 being the lowest possible priority. The higher the value the sooner an item with this priority will reach the consumer.
# ATTRIBUTES
## `closed`
`True` if channel has been closed.
## `closed-promise`
A `Promise` which is kept with `True` when the channel is closed and broken with a cause object if channel is marked as failed.
## `drained`
`True` if channel is closed and no items left to fetch.
## `drained-promise`
A `Promise` which is kept with `True` when the channel is drained.
## `elems`
Likely number of elements ready for fetch. It is *"likely"* because in a concurrent environment this value might be changing too often.
## `prio-count`
Number of priority queues pre-allocated.
# METHODS
## `new`
`new` can be used with any parameters. But usually it is recommended to specifiy `:priorities(n)` named parameter to specify the expected number of priorities to be used. This allows the class to pre-allocate all required priority queues beforehand. Without this parameter a class instance starts with only one queue. If method `send` is used with a priority which doesn't have a queue assigned yet then the class starts allocating new ones by multiplying the number of existing ones by 2 until get enough of them to cover the requested priority. For example:
```
my $pchannel.new;
$pchannel.send(42, 5);
```
In this case before sending `42` the class allocates 2 -> 4 -> 8 queues.
Queue allocation code is the only place where locking is used.
Use of `priorities` parameter is recommended if some really big number of priorities is expected. This might help in reducing the memory footprint of the code by preventing over-allocation of queues.
## `send(Mu \item, Int:D $priority = 0)`
Send a `item` using `$priority`. If `$priority` is omitted then default 0 is used.
## `receive`
Receive an item from channel. If no data available and the channel is not *drained* then the method `await` for the next item. In other words, it soft-blocks allowing the scheduler to reassing the thread onto another task if necessary until some data is ready for pick up.
If the method is called on a *drained* channel then it returns a `Failure` wrapped around `X::PChannel::OpOnClosed` exception with its `op` attribute set to string *"receive"*.
## `poll`
Non-blocking fetch of an item. Contrary to `receive` doesn't wait for a missing item. Instead the method returns `Nil but NoData` typeobject. `Concurrent::PChannel::NoData` is a dummy role which sole purpose is to indicate that there is no item ready in a queue.
## `close`
Close a channel.
## `fail($cause)`
Marks a channel as *failed* and sets failure cause to `$cause`.
## `failed`
Returns `True` if channel is marked as failed.
## `Supply`
Wraps `receive` into a supplier.
# EXCEPTIONS
Names is the documentation are given as the exception classes are exported.
## `X::PChannel::Priorities`
Thrown if wrong `priorities` parameter passed to the method `new`. Attribute `priorities` contains the value passed.
## `X::PChannel::NegativePriority`
Thrown if a negative priority value has passed in from user code. Attribute `prio` contains the value passed.
## `X::PChannel::OpOnClosed`
Thrown or passed in a `Failure` when an operation is performed on a closed channel. Attribute `op` contains the operation name.
*Note* that semantics of this exception is a bit different depending on the kind of operation attempted. For `receive` this exception is used when channel is *drained*. For `send`, `close`, and `fail` it is thrown right away if channel is in *closed* state.
# AUTHOR
Vadim Belman [vrurg@cpan.org](mailto:vrurg@cpan.org)
# COPYRIGHT AND LICENSE
Copyright 2020 Vadim Belman
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_cpan-TOKUHIROM-HTTP-Server-Tiny.md
[](https://travis-ci.org/tokuhirom/p6-HTTP-Server-Tiny)
# NAME
HTTP::Server::Tiny - a simple HTTP server for Perl6
# SYNOPSIS
```
use HTTP::Server::Tiny;
my $port = 8080;
# Only listen for connections from the local host
# if you want this to be accessible from another
# host then change this to '0.0.0.0'
my $host = '127.0.0.1';
HTTP::Server::Tiny.new(:$host , :$port).run(sub ($env) {
my $channel = Channel.new;
start {
for 1..100 {
$channel.send(($_ ~ "\n").Str.encode('utf-8'));
}
$channel.close;
};
return 200, ['Content-Type' => 'text/plain'], $channel
});
```
# DESCRIPTION
HTTP::Server::Tiny is a standalone HTTP/1.1 web server for perl6.
# METHODS
* `HTTP::Server::Tiny.new($host, $port)`
Create new instance.
* `$server.run(Callable $app, Promise :$control-promise)`
Run http server with P6W app. The named parameter `control-promise` if provided, can be *kept* to quit the server loop, which may be useful if the server is run asynchronously to the main thread of execution in an application.
If the optional named parameter `control-promise` is provided with a `Promise` then the server loop will be quit when the promise is kept.
# VERSIONING RULE
This module respects [Semantic versioning](http://semver.org/)
# TODO
* Support timeout
# COPYRIGHT AND LICENSE
Copyright 2015, 2016 Tokuhiro Matsuno [tokuhirom@gmail.com](mailto:tokuhirom@gmail.com)
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_github-teodozjan-Mortgage.md
# mortgage6
Mortgage6 is little but usable library that allows to calculate all costs of mortage. Since banks give a lot of discounts if buying their products it is harder see the costs
## install
```
zef install Mortgage
```
## doc
```
p6doc Mortgage
```
or [POD](https://github.com/teodozjan/mortage6/blob/master/lib/Mortgage.pm6)
## QuickStart
```
my $bank = Mortgage.new(bank=>"BANK2",interest_rate => rate-monthly(3.30), mortage=> 1300.73, mortages => 360, loan-left=> 297000.FatRat);
# Arrangement fee
$bank.add(Mortgage::AnnualCostConst.new(from=>1, to=>1, value=>$bank.loan-left * percent 1));
# Should give the same amount you have from bank
my $mortgage = $bank.calc_mortage;
# Do the sim
$bank.calc;
my $loanleft = $bank.loan-left.round(0.01);
my $total_cost = $bank.total_cost.round(0.01);
my $total_interest= $bank.total_interest.round(0.01);
```
|
## formatter.md
formatter
Combined from primary sources listed below.
# [In role Dateish](#___top "go to top of document")[§](#(role_Dateish)_method_formatter "direct link")
See primary documentation
[in context](/type/Dateish#method_formatter)
for **method formatter**.
```raku
method formatter(Dateish:D:)
```
Returns the formatting function which is used for conversion to [`Str`](/type/Str). If none was provided at object construction, a default formatter is used. In that case the method will return a Callable type object.
The formatting function is called by [DateTime method Str](/type/DateTime#method_Str) with the invocant as its only argument.
```raku
my $dt = Date.new('2015-12-31'); # (no formatter specified)
say $dt.formatter.^name; # OUTPUT: «Callable»
my $us-format = sub ($self) { sprintf "%02d/%02d/%04d", .month, .day, .year given $self; };
$dt = Date.new('2015-12-31', formatter => $us-format);
say $dt.formatter.^name; # OUTPUT: «Sub»
say $dt; # OUTPUT: «12/31/2015»
```
|
## dist_zef-knarkhov-Node-Ethereum-RLP.md
# Recursive Length Prefix for Raku
The purpose of RLP (Recursive Length Prefix) is to encode arbitrarily nested arrays of binary data, and RLP is the main encoding method used to serialize objects in Ethereum. `Node::Ethereum::RLP` delivers RLP encode and decode routines to Raku lang ecosystem.
## License
Module `Node::Ethereum::RLP` is free and opensource software, so you can redistribute it and/or modify it under the terms of the [The Artistic License 2.0](https://opensource.org/licenses/Artistic-2.0).
## Credits
1. <https://eth.wiki/fundamentals/rlp>
2. <https://github.com/ethereumjs/rlp/blob/master/src/index.ts>
## Author
Please contact me via [LinkedIn](https://www.linkedin.com/in/knarkhov/) or [Twitter](https://twitter.com/CondemnedCell). Your feedback is welcome at [narkhov.pro](https://narkhov.pro/contact-information.html).
|
## dist_zef-samy-File-Tudo.md
# NAME
File::Tudo - Tudo TODO file interface
# SYNOPSIS
```
use File::Tudo;
# Simple convenience wrapper, useful for quick scripts
tudo "Fix that one issue";
# OO interface
my $tudo = File::Tudo.new('/path/to/TODO');
$tudo.todo.append: "Fix that one issue";
$tudo.write;
```
# DESCRIPTION
**File::Tudo** is a Raku module for reading/writing simple TODO files.
## Exported Subroutines
### tudo
```
sub tudo(
$str,
:$path = default_todo
)
```
`tudo()` is a simple convenience wrapper for File::Tudo that will quickly add an additional entry to the end of your TODO file. This can make it useful for reporting TODOs in your Raku scripts.
```
my @updates = gather for @packages -> $pkg {
...
}
tudo "There are updates that need taken care of!" if @updates;
```
`$str` is the string you would like to add as an entry to your TODO file.
`$path` is the path to the TODO file. Defaults to the return value of `default_todo`, view its documentation for more information.
### default\_todo
```
sub default_todo()
```
`default_todo()` returns an `IO` object for the default TODO path. It will either be the path specified by the `TODO_FILE` environment variable if set, or `~/TODO` otherwise.
## Object-Oriented Interface
### Methods
#### method new
```
method new(
$path = default_todo,
Bool :$read = True,
)
```
Returns a newly constructed **File::Tudo**.
`$path` is the path to the TODO file. Defaults to the return value of `default_todo`.
`:$read` determines whether `new()` will read TODO entries from the given file if they are present. If `False`, `new()` will ignore them and initialize an empty array for `todo`.
#### method read
```
method read($file)
```
Reads a list of TODO entries from `$file`, overwriting the previous `todo` array. Returns the list of TODOs read.
#### method write
```
method write($file = $!path)
```
Writes the current `todo` array to `$file`. If `$file` is not supplied, defaults to the value of the object's `path` attribute.
### Attributes
#### path
```
has IO $.path is rw
```
`IO` object of the object's TODO file. Able to be modified.
#### todo
```
has Str @.todo is rw
```
Array of strings holding the list of TODO entries. Able to modified.
## `tudo`
**File::Tudo** also comes with the `tudo` script, which provides a nice command-line interface for manipulating **File::Tudo** TODO files.
# ENVIRONMENT
* `TODO_FILE`
Default path to TODO file.
* `EDITOR`
Default text editor to use for `edit` command.
* `VISUAL`
Default text editor to use for `edit` command, if `EDITOR` is not set.
# BUGS
Don't be ridiculous...
Report bugs on my Codeberg, <https://codeberg.org/1-1sam>.
# AUTHOR
Written by Samuel Young, [samyoung12788@gmail.com](mailto:samyoung12788@gmail.com).
# COPYRIGHT
Copyright 2025, Samuel Young
This program is free software; you can redistribute it and/or modify it under the terms of the Artistic License 2.0.
# SEE ALSO
tudo
|
## raku.md
raku
Combined from primary sources listed below.
# [In IterationBuffer](#___top "go to top of document")[§](#(IterationBuffer)_method_raku "direct link")
See primary documentation
[in context](/type/IterationBuffer#method_raku)
for **method raku**.
```raku
method raku(IterationBuffer:D: --> Str)
```
Produces a representation of the `IterationBuffer` as a [`List`](/type/List) postfixed with ".IterationBuffer" to make it different from an ordinary list. Does **not** roundtrip. Intended for debugging uses only, specifically for use with [dd](/programs/01-debugging#Dumper_function_(dd)).
# [In FatRat](#___top "go to top of document")[§](#(FatRat)_method_raku "direct link")
See primary documentation
[in context](/type/FatRat#method_raku)
for **method raku**.
```raku
multi method raku(FatRat:D: --> Str:D)
```
Returns an implementation-specific string that produces an [equivalent](/routine/eqv) object when given to [EVAL](/routine/EVAL).
```raku
say FatRat.new(1, 2).raku; # OUTPUT: «FatRat.new(1, 2)»
```
# [In RakuAST::Doc::Paragraph](#___top "go to top of document")[§](#(RakuAST::Doc::Paragraph)_method_raku "direct link")
See primary documentation
[in context](/type/RakuAST/Doc/Paragraph#method_raku)
for **method raku**.
```raku
# method .gist falls back to .raku
say $block; # RakuAST::Doc::Paragraph.new(...
```
Returns the string that is needed for the creation of the paragraph using [`RakuAST`](/type/RakuAST) calls.
# [In Complex](#___top "go to top of document")[§](#(Complex)_method_raku "direct link")
See primary documentation
[in context](/type/Complex#method_raku)
for **method raku**.
```raku
method raku(Complex:D: --> Str:D)
```
Returns an implementation-specific string that produces an [equivalent](/routine/eqv) object when given to [EVAL](/routine/EVAL).
```raku
say (1-3i).raku; # OUTPUT: «<1-3i>»
```
# [In RakuAST::Doc::Markup](#___top "go to top of document")[§](#(RakuAST::Doc::Markup)_method_raku "direct link")
See primary documentation
[in context](/type/RakuAST/Doc/Markup#method_raku)
for **method raku**.
```raku
# method .gist falls back to .raku
say $markup; # RakuAST::Doc::Markup.new(...
```
Returns the string that is needed for the creation of the markup using [`RakuAST`](/type/RakuAST) calls.
# [In Range](#___top "go to top of document")[§](#(Range)_method_raku "direct link")
See primary documentation
[in context](/type/Range#method_raku)
for **method raku**.
```raku
multi method raku(Range:D:)
```
Returns an implementation-specific string that produces an [equivalent](/routine/eqv) object when given to [EVAL](/routine/EVAL).
```raku
say (1..2).raku # OUTPUT: «1..2»
```
# [In IO::Path::Cygwin](#___top "go to top of document")[§](#(IO::Path::Cygwin)_method_raku "direct link")
See primary documentation
[in context](/type/IO/Path/Cygwin#method_raku)
for **method raku**.
```raku
method raku(IO::Path::Cygwin:D: --> Str:D)
```
Returns a string that, when given passed through [`EVAL`](/routine/EVAL) gives the original invocant back.
```raku
IO::Path::Cygwin.new("foo/bar").raku.say;
# OUTPUT: IO::Path::Cygwin.new("foo/bar", :CWD("/home/camelia"))
```
Note that this string includes the value of the `.CWD` attribute that is set to [`$*CWD`](/language/variables#Dynamic_variables) when the path object was created, by default.
# [In Rat](#___top "go to top of document")[§](#(Rat)_method_raku "direct link")
See primary documentation
[in context](/type/Rat#method_raku)
for **method raku**.
```raku
multi method raku(Rat:D: --> Str:D)
```
Returns an implementation-specific string that produces an [equivalent](/routine/eqv) object when given to [EVAL](/routine/EVAL).
```raku
say (1/3).raku; # OUTPUT: «<1/3>»
say (2/4).raku; # OUTPUT: «0.5»
```
# [In RakuAST::Doc::Block](#___top "go to top of document")[§](#(RakuAST::Doc::Block)_method_raku "direct link")
See primary documentation
[in context](/type/RakuAST/Doc/Block#method_raku)
for **method raku**.
```raku
# method .gist falls back to .raku
say $block; # RakuAST::Doc::Block.new(...
```
Returns the string that is needed for the creation of the block using [`RakuAST`](/type/RakuAST) calls.
# [In Mu](#___top "go to top of document")[§](#(Mu)_method_raku "direct link")
See primary documentation
[in context](/type/Mu#method_raku)
for **method raku**.
```raku
multi method raku(Mu:U:)
multi method raku(Mu:D:)
```
For type objects, returns its name if `.raku` has not been redefined from `Mu`, or calls `.raku` on the name of the type object otherwise.
```raku
say Str.raku; # OUTPUT: «Str»
```
For plain objects, it will conventionally return a representation of the object that can be used via [`EVAL`](/routine/EVAL) to reconstruct the value of the object.
```raku
say (1..3).Set.raku; # OUTPUT: «Set.new(1,2,3)»
```
# [In IO::Path](#___top "go to top of document")[§](#(IO::Path)_method_raku "direct link")
See primary documentation
[in context](/type/IO/Path#method_raku)
for **method raku**.
```raku
method raku(IO::Path:D: --> Str:D)
```
Returns a string that, when given passed through [`EVAL`](/routine/EVAL) gives the original invocant back.
```raku
"foo/bar".IO.raku.say;
# OUTPUT: IO::Path.new("foo/bar", :SPEC(IO::Spec::Unix), :CWD("/home/camelia"))
```
Note that this string includes the value of the `.CWD` attribute that is set to [`$*CWD`](/language/variables#Dynamic_variables) when the path object was created, by default.
# [In IO::Path::Unix](#___top "go to top of document")[§](#(IO::Path::Unix)_method_raku "direct link")
See primary documentation
[in context](/type/IO/Path/Unix#method_raku)
for **method raku**.
```raku
method raku(IO::Path::Unix:D: --> Str:D)
```
Returns a string that, when given passed through [`EVAL`](/routine/EVAL) gives the original invocant back.
```raku
IO::Path::Unix.new("foo/bar").raku.say;
# OUTPUT: IO::Path::Unix.new("foo/bar", :CWD("/home/camelia"))
```
Note that this string includes the value of the `.CWD` attribute that is set to [`$*CWD`](/language/variables#Dynamic_variables) when the path object was created, by default.
# [In Junction](#___top "go to top of document")[§](#(Junction)_method_raku "direct link")
See primary documentation
[in context](/type/Junction#method_raku)
for **method raku**.
```raku
multi method raku(Junction:D:)
```
Collapses the `Junction` and returns a [`Str`](/type/Str) composed of [raku](/routine/raku) of its components that [evaluates](/routine/EVAL) to the equivalent `Junction` with equivalent components:
```raku
<a 42 c>.all.raku.put; # OUTPUT: «all("a", IntStr.new(42, "42"), "c")»
```
# [In IO::Path::Win32](#___top "go to top of document")[§](#(IO::Path::Win32)_method_raku "direct link")
See primary documentation
[in context](/type/IO/Path/Win32#method_raku)
for **method raku**.
```raku
method raku(IO::Path::Win32:D: --> Str:D)
```
Returns a string that, when given passed through [`EVAL`](/routine/EVAL) gives the original invocant back.
```raku
IO::Path::Win32.new("foo/bar").raku.say;
# OUTPUT: IO::Path::Win32.new("foo/bar", :CWD("C:\\Users\\camelia"))
```
Note that this string includes the value of the `.CWD` attribute that is set to [`$*CWD`](/language/variables#Dynamic_variables) when the path object was created, by default.
# [In IO::Path::QNX](#___top "go to top of document")[§](#(IO::Path::QNX)_method_raku "direct link")
See primary documentation
[in context](/type/IO/Path/QNX#method_raku)
for **method raku**.
```raku
method raku(IO::Path::QNX:D: --> Str:D)
```
Returns a string that, when given passed through [`EVAL`](/routine/EVAL) gives the original invocant back.
```raku
IO::Path::QNX.new("foo/bar").raku.say;
# OUTPUT: IO::Path::QNX.new("foo/bar", :CWD("/home/camelia"))
```
Note that this string includes the value of the `.CWD` attribute that is set to [`$*CWD`](/language/variables#Dynamic_variables) when the path object was created, by default.
# [In RakuAST::Doc::Declarator](#___top "go to top of document")[§](#(RakuAST::Doc::Declarator)_method_raku "direct link")
See primary documentation
[in context](/type/RakuAST/Doc/Declarator#method_raku)
for **method raku**.
```raku
# method .gist falls back to .raku
say $declarator; # RakuAST::Doc::Declarator.new(...
```
Returns the string that is needed for the creation of the block using [`RakuAST`](/type/RakuAST) calls.
# [In Allomorph](#___top "go to top of document")[§](#(Allomorph)_method_raku "direct link")
See primary documentation
[in context](/type/Allomorph#method_raku)
for **method raku**.
```raku
multi method raku(Allomorph:D:)
```
Return a representation of the object that can be used via [`EVAL`](/routine/EVAL) to reconstruct the value of the object.
|
## dist_zef-japhb-MUGS-Games.md
[](https://github.com/Raku-MUGS/MUGS-Games/actions)
# NAME
MUGS-Games - Free-as-in-speech game implementations for MUGS (Multi-User Gaming Services)
# SYNOPSIS
```
# Setting up a simple MUGS-Games development environment
mkdir MUGS
cd MUGS
git clone git@github.com:Raku-MUGS/MUGS-Core.git
git clone git@github.com:Raku-MUGS/MUGS-Games.git
cd MUGS-Core
zef install --exclude="pq:ver<5>:from<native>" .
mugs-admin create-universe
cd ../MUGS-Games
zef install --deps-only .
```
# DESCRIPTION
**NOTE: See the [top-level MUGS repo](https://github.com/Raku-MUGS/MUGS) for more info.**
MUGS-Games is a collection of free-as-in-speech client and server game and genre implementations for MUGS (Multi-User Gaming Services). Note that these implementations do NOT have user interfaces; they only implement abstract game logic, request/response protocols, and so forth. This is sufficient for automated testing and implementation of game bots, but if you want to play them as an end user, you'll need to install the appropriate MUGS-UI-\* for the user interface you prefer.
This Proof-of-Concept release only includes simple turn-based guessing and interactive fiction games. The underlying framework in [MUGS-Core](https://github.com/Raku-MUGS/MUGS-Core) has been tested with 2D arcade games as well, but these are not yet ready for public release. Future releases will include many more games and genres.
# ROADMAP
MUGS is still in its infancy, at the beginning of a long and hopefully very enjoyable journey. There is a [draft roadmap for the first few major releases](https://github.com/Raku-MUGS/MUGS/tree/main/docs/todo/release-roadmap.md) but I don't plan to do it all myself -- I'm looking for contributions of all sorts to help make it a reality.
# CONTRIBUTING
Please do! :-)
In all seriousness, check out [the CONTRIBUTING doc](docs/CONTRIBUTING.md) (identical in each repo) for details on how to contribute, as well as [the Coding Standards doc](https://github.com/Raku-MUGS/MUGS/tree/main/docs/design/coding-standards.md) for guidelines/standards/rules that apply to code contributions in particular.
The MUGS project has a matching GitHub org, [Raku-MUGS](https://github.com/Raku-MUGS), where you will find all related repositories and issue trackers, as well as formal meta-discussion.
More informal discussion can be found on IRC in Libera.Chat #mugs.
# AUTHOR
Geoffrey Broadwell [gjb@sonic.net](mailto:gjb@sonic.net) (japhb on GitHub and Libera.Chat)
# COPYRIGHT AND LICENSE
Copyright 2021-2024 Geoffrey Broadwell
MUGS is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## iterable.md
role Iterable
Interface for container objects that can be iterated over
```raku
role Iterable { }
```
`Iterable` serves as an API for objects that can be iterated with `for` and related iteration constructs, like assignment to a [`Positional`](/type/Positional) variable.
`Iterable` objects nested in other `Iterable` objects (but not within scalar containers) flatten in certain contexts, for example when passed to a slurpy parameter (`*@a`), or on explicit calls to `flat`.
Its most important aspect is a method stub for `iterator`.
```raku
class DNA does Iterable {
has $.chain;
method new ($chain where { $chain ~~ /^^ <[ACGT]>+ $$ / } ) {
self.bless( :$chain );
}
method iterator(DNA:D:) {
$!chain.comb.rotor(3).iterator;
}
}
my $a := DNA.new('GAATCC');
.say for $a; # OUTPUT: «(G A A)(T C C)»
```
This example mixes in the Iterable role to offer a new way of iterating over what is essentially a string (constrained by [`where`](/language/signatures#index-entry-where_clause) to just the four DNA letters). In the last statement, `for` actually hooks to the `iterator` role printing the letters in groups of 3.
# [Methods](#role_Iterable "go to top of document")[§](#Methods "direct link")
## [method iterator](#role_Iterable "go to top of document")[§](#method_iterator "direct link")
```raku
method iterator(--> Iterator:D)
```
Method stub that ensures all classes doing the `Iterable` role have a method `iterator`.
It is supposed to return an [`Iterator`](/type/Iterator).
```raku
say (1..10).iterator;
```
## [method flat](#role_Iterable "go to top of document")[§](#method_flat "direct link")
```raku
method flat(Iterable:D: --> Iterable)
```
Returns another `Iterable` that flattens out all iterables that the first one returns.
For example
```raku
say (<a b>, 'c').elems; # OUTPUT: «2»
say (<a b>, 'c').flat.elems; # OUTPUT: «3»
```
because `<a b>` is a [`List`](/type/List) and thus iterable, so `(<a b>, 'c').flat` returns `('a', 'b', 'c')`, which has three elems.
Note that the flattening is recursive, so `((("a", "b"), "c"), "d").flat` returns `("a", "b", "c", "d")`, but it does not flatten itemized sublists:
```raku
say ($('a', 'b'), 'c').flat; # OUTPUT: «($("a", "b"), "c")»
```
You can use the [hyper method call](/language/operators#index-entry-methodop_>>.) to call the [`.List`](/routine/List) method on all the inner itemized sublists and so de-containerize them, so that `flat` can flatten them:
```raku
say ($('a', 'b'), 'c')>>.List.flat.elems; # OUTPUT: «3»
```
## [method lazy](#role_Iterable "go to top of document")[§](#method_lazy "direct link")
```raku
method lazy(--> Iterable)
```
Returns a lazy iterable wrapping the invocant.
```raku
say (1 ... 1000).is-lazy; # OUTPUT: «False»
say (1 ... 1000).lazy.is-lazy; # OUTPUT: «True»
```
## [method hyper](#role_Iterable "go to top of document")[§](#method_hyper "direct link")
```raku
method hyper(Int(Cool) :$batch = 64, Int(Cool) :$degree = Kernel.cpu-cores - 1)
```
Returns another Iterable that is potentially iterated in parallel, with a given batch size and degree of parallelism.
The order of elements is preserved.
```raku
say ([1..100].hyper.map({ $_ +1 }).list);
```
Use `hyper` in situations where it is OK to do the processing of items in parallel, and the output order should be kept relative to the input order. See [`race`](/routine/race) for situations where items are processed in parallel and the output order does not matter.
### [Options degree and batch](#role_Iterable "go to top of document")[§](#Options_degree_and_batch "direct link")
The `degree` option (short for "degree of parallelism") configures how many parallel workers should be started. To start 4 workers (e.g. to use at most 4 cores), pass `:degree(4)` to the `hyper` or `race` method. Note that in some cases, choosing a degree higher than the available CPU cores can make sense, for example I/O bound work or latency-heavy tasks like web crawling. For CPU-bound work, however, it makes no sense to pick a number higher than the CPU core count.
The `batch` size option configures the number of items sent to a given parallel worker at once. It allows for making a throughput/latency trade-off. If, for example, an operation is long-running per item, and you need the first results as soon as possible, set it to 1. That means every parallel worker gets 1 item to process at a time, and reports the result as soon as possible. In consequence, the overhead for inter-thread communication is maximized. In the other extreme, if you have 1000 items to process and 10 workers, and you give every worker a batch of 100 items, you will incur minimal overhead for dispatching the items, but you will only get the first results when 100 items are processed by the fastest worker (or, for `hyper`, when the worker getting the first batch returns.) Also, if not all items take the same amount of time to process, you might run into the situation where some workers are already done and sit around without being able to help with the remaining work. In situations where not all items take the same time to process, and you don't want too much inter-thread communication overhead, picking a number somewhere in the middle makes sense. Your aim might be to keep all workers about evenly busy to make best use of the resources available.
You can also check out this **[blog post on the semantics of hyper and race](https://6guts.wordpress.com/2017/03/16/considering-hyperrace-semantics/)**
The default for `:degree` is the number of available CPU cores minus 1 as of the 2020.02 release of the Rakudo compiler.
As of release 2022.07 of the Rakudo compiler, it is also possible to specify an undefined value to indicate to use the default.
## [method race](#role_Iterable "go to top of document")[§](#method_race "direct link")
```raku
method race(Int(Cool) :$batch = 64, Int(Cool) :$degree = 4 --> Iterable)
```
Returns another Iterable that is potentially iterated in parallel, with a given batch size and degree of parallelism (number of parallel workers).
Unlike [`hyper`](/routine/hyper), `race` does not preserve the order of elements (mnemonic: in a race, you never know who will arrive first).
```raku
say ([1..100].race.map({ $_ +1 }).list);
```
Use race in situations where it is OK to do the processing of items in parallel, and the output order does not matter. See [`hyper`](/routine/hyper) for situations where you want items processed in parallel and the output order should be kept relative to the input order.
**[Blog post on the semantics of hyper and race](https://6guts.wordpress.com/2017/03/16/considering-hyperrace-semantics/)**
See [`hyper`](/routine/hyper) for an explanation of `:$batch` and `:$degree`.
# [Typegraph](# "go to top of document")[§](#typegraphrelations "direct link")
Type relations for `Iterable`
raku-type-graph
Iterable
Iterable
Mu
Mu
Any
Any
Any->Mu
Cool
Cool
Cool->Any
Associative
Associative
Map
Map
Map->Iterable
Map->Cool
Map->Associative
PositionalBindFailover
PositionalBindFailover
Sequence
Sequence
Sequence->PositionalBindFailover
RaceSeq
RaceSeq
RaceSeq->Iterable
RaceSeq->Any
RaceSeq->Sequence
Positional
Positional
Range
Range
Range->Iterable
Range->Cool
Range->Positional
List
List
List->Iterable
List->Cool
List->Positional
IO::Path::Parts
IO::Path::Parts
IO::Path::Parts->Iterable
IO::Path::Parts->Any
IO::Path::Parts->Associative
IO::Path::Parts->Positional
Seq
Seq
Seq->Iterable
Seq->Cool
Seq->Sequence
HyperSeq
HyperSeq
HyperSeq->Iterable
HyperSeq->Any
HyperSeq->Sequence
PseudoStash
PseudoStash
PseudoStash->Map
Hash
Hash
Hash->Map
Array
Array
Array->List
Slip
Slip
Slip->List
Stash
Stash
Stash->Hash
[Expand chart above](/assets/typegraphs/Iterable.svg)
|
## dist_cpan-TYIL-Pod-To-HTML-Section.md
# NAME
Pod::To::HTML
# AUTHOR
Patrick Spek [p.spek@tyil.work](mailto:p.spek@tyil.work)
# VERSION
0.0.0
# Synopsis
```
raku --doc=HTML::Section <document>
```
# Description
Convert a Pod6 document to HTMLWell, just a *section* of it, really.
# Installation
## Through `zef`
[zef](https://github.com/ugexe/zef) is the standard distribution manager for [Raku](https://raku.org). If you're using an end-user distribution like [Rakudo Star](https://rakudo.org/files/star), it will be installed for you by default.
`zef` will install the latest available version from [CPAN](http://www.cpan.org/modules/index.html).
```
zef install Pod::To::HTML::Section
```
## From a downloaded distribution
All official releases are also made available on my [personal distribution server](https://dist.tyil.nl/raku/modules/). These can be installed from the URL directly.
```
zef install https://dist.tyil.nl/raku/modules/Pod-To-HTML-Section-0.1.0.tar.gz
```
Alternatively, you can download the distribution first, and then install that copy with `zef`.
```
wget https://dist.tyil.nl/raku/modules/Pod-To-HTML-Section-0.1.0.tar.gz
zef install ./Pod-To-HTML-Section-0.1.0.tar.gz
```
# Contributing
## Reporting bugs or other feedback
Any bugs or other feedback can be sent to my email address. I generally try to respond to all mail within 24 hours.
## Proposing code patches
Code patches can also be sent in through email. If you need help to send git patches through email, you may want to read up on [git-send-email.io](https://git-send-email.io/).
### Testing
If you're working on a code patch, you will more than likely want to test your own changes to see if they're solving your issue. The easiest way to get the HTML out on your terminal is to specify your development copy with `-I` to give it priority, and using `raku --doc` as usual.
```
raku -Ilib --doc=HTML::Section <document>
```
However, this may be hard to read for most purposes. If you have `xmllint` and `tidy` available on your system, you can use these tools in conjuction with the `raku --doc` command to format the HTML.
```
raku -Ilib --doc=HTML::Section <document> \
| xmllint --html - 2>/dev/null \
| tidy --indent yes 2>/dev/null
```
# License
This module is distributed under the terms of the GNUGNU's Not Unix AGPLAferro General Public License, version 3.0.
|
## dist_cpan-BDUGGAN-OAuth2-Client-Google.md
# NAME
OAuth2::Client::Google -- Authenticate with Google using OAuth2.
# Quick how-to
1. Go to <http://console.developers.google.com> and create a project.
2. Set up credentials for a web server and set your redirect URIs.
3. Download the JSON file (client\_id.json).
4. In your application, create an oauth2 object like this:
```
my $oauth = OAuth2::Client::Google.new(
config => from-json('./client_id.json'.IO.slurp),
redirect-uri => 'http://localhost:3334/oauth',
scope => 'email'
);
```
where redirect-uri is one of your redirect URIs and scope is a space or comma-separated list of scopes from <https://developers.google.com/identity/protocols/googlescopes>.
To authenticate, redirect the user to
```
$oauth.auth-uri
```
Then when they come back and send a request to '/oauth', grab the "code" parameter from the query string. Use it to call
```
my $token = $oauth.code-to-token(code => $code)
```
This will give you `$token<access_token>`, which you can then use with google APIs.
If you also included "email" in the scope, you will get id-token, which you can use like this:
```
my $identity = $oauth.verify-id(id-token => $token<id_token>)
```
which has, e.g. `$identity<email>` and `$identity<given_name>`.
For a working example, see <eg/get-calendar-data.p6>.
# STATUS
[](https://travis-ci.org/bduggan/p6-oauth2-client-google)
# SEE ALSO
<https://developers.google.com/identity/protocols/OAuth2WebServer>
# TODO
* Better documentation
* Refresh tokens
|
## dist_zef-l10n-L10N.md
[](https://github.com/Raku/L10N/actions)
# NAME
L10N - All official localizations of Raku
# SYNOPSIS
```
use L10N;
```
# DESCRIPTION
L10N is a distribution that, when installed, will install all official localizations of the Raku Programming Language as its dependencies.
It will not install anything else.
# AUTHOR
Elizabeth Mattijsen [liz@raku.rocks](mailto:liz@raku.rocks)
# COPYRIGHT AND LICENSE
Copyright 2023 Raku Localization Team
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_zef-grondilu-FiniteFields.md
[](https://ci.sparrowhub.io)
# Finite Fields Aritmetics in raku
```
use FiniteField;
my $*modulus = 13;
say 10+5; # 2
say 10/3; # 12 (3*12 = 36 = 13*2 + 10)
```
## Notes
* The dynamic variable `$*modulus` must be defined before calling any overloaded operator,
otherwise the program will crash (no exception is handled so far).
* Modular division will not check for primality of modulus or any other requirements.
* Define a modulus for each lexical scopes you import the module in.
* Althouh the name of this repo is using a plural, the name of the module
itself is singular, because you only use one finite field at a time.
* The main purpose of this module is to make writing cryptographic code easier.
|
## dist_zef-antononcube-Lingua-NumericWordForms.md
# Raku Lingua::NumericWordForms
[](https://github.com/antononcube/Raku-Lingua-NumericWordForms/actions/workflows/macos.yml)
[](https://github.com/antononcube/Raku-Lingua-NumericWordForms/actions/workflows/linux.yml)
[](https://github.com/antononcube/Raku-Lingua-NumericWordForms/actions/workflows/windows.yml)
[](https://raku.land/zef:antononcube/Lingua::NumericWordForms)
[](https://raku.land/zef:antononcube/Lingua::NumericWordForms)
[](https://opensource.org/licenses/Artistic-2.0)
🇦🇲 🇦🇿 🇧🇬 🇨🇿 🇬🇧 🇫🇷 🇩🇪 🇬🇷 🇮🇷 🇯🇵 🇰🇿 🇵🇱 🇵🇹 🇷🇴 🇷🇺 🇪🇸 🇺🇦
## Introduction
This repository provides a Raku package with functions for the
generation, parsing, and interpretation of numeric word forms in different languages.
The initial versions of the code in this repository can be found in the GitHub repository [AAr1].
The Raku package
[`Lingua::Number`](https://github.com/labster/p6-Lingua-Number), [BL1],
provides word forms (cardinal, ordinal, etc.) generation in many languages.
(But at least for one language the produced forms are incorrect.)
The Raku package
[`Lingua::EN::Numbers`](https://github.com/labster/p6-Lingua-Number), [SS1],
also provides word forms (cardinal, ordinal, etc.) generation in English.
The parsers and interpreters of this package can be seen as complementary
to the functions in [BL1, SS1].
**Remark:** Maybe a more complete version of this package should be merged with
[`Lingua::Number`](https://github.com/labster/p6-Lingua-Number), [BL1].
**Remark:** I can judge the quality of the results only of the languages:
Bulgarian, English, and Russian. The numeric word form interpreters for the rest of the languages
pass testing, but they might have potentially many deficiencies.
(That are easily detected by people who have mastered those languages.)
**Remark:** The package also "understands" (i.e. parses and translates to)
[Koremutake](https://shorl.com/koremutake.php).
---
## Installation
Package installations from both sources use [zef installer](https://github.com/ugexe/zef)
(which should be bundled with the "standard" [Rakudo](https://rakudo.org) installation file.)
To install the package via Zef's ecosystem use the shell command:
```
zef install Lingua::NumericWordForms
```
To install the package from the GitHub repository use the shell command:
```
zef install https://github.com/antononcube/Raku-Lingua-NumericWordForms.git
```
---
## Examples
### Generation
The generation of numeric word forms is a *secondary* goal of this package.
Currently only generation of Bulgarian, English, [Koremutake](https://shorl.com/koremutake.php), and Russian
numeric word forms are implemented.
Here are examples:
```
use Lingua::NumericWordForms;
say to-numeric-word-form(8093);
say to-numeric-word-form(8093, 'Bulgarian');
say to-numeric-word-form(8093, 'Koremutake');
say to-numeric-word-form(8093, 'Russian');
```
```
# eight thousand, ninety three
# осем хиляди и деветдесет и три
# pohy
# восемь тысяч девяносто три
```
The first argument of `to-numeric-word-form` can be:
* An integer
* A string that can be parsed into an integer
* A string of numbers separated by ";"
* A list of numbers or strings
Here are examples of the latter two:
```
to-numeric-word-form('123; 232; 898_934').join('; ');
```
```
# one hundred twenty three; two hundred thirty two; eight hundred ninety eight thousand, nine hundred thirty four
```
```
to-numeric-word-form([321, '992', 100_904]).join('; ');
```
```
# three hundred twenty one; nine hundred ninety two; one hundred thousand, nine hundred four
```
### Interpretation
Interpretation of numeric word forms is the *primary* goal of this package.
Multiple language are supported. Here are examples:
```
use Lingua::NumericWordForms;
say from-numeric-word-form('one thousand and twenty three');
say from-numeric-word-form('хиляда двадесет и три', 'Bulgarian');
say from-numeric-word-form('tysiąc dwadzieścia trzy', 'Polish');
say from-numeric-word-form('одна тысяча двадцать три', lang => 'Russian');
say from-numeric-word-form('mil veintitrés', lang => 'Spanish');
```
```
# 1023
# 1023
# 1023
# 1023
# 1023
```
The function `from-numeric-word-form` can take as a first argument:
* A string that is a numeric word form
* A string comprised of numeric word forms separated by ";"
* A list or an array of strings
The language can be specified as a second positional argument or with the named argument "lang".
In addition to the names of the supported languages the value of the language argument can be also `Whatever` or "Automatic".
Here are corresponding examples:
```
from-numeric-word-form('twenty six');
```
```
# 26
```
```
from-numeric-word-form(['mil veintitrés', 'dos mil setenta y dos']);
```
```
# (1023 2072)
```
```
from-numeric-word-form('two hundred and five; триста четиридесет и две; 二十万六十五'):p;
```
```
# (english => 205 bulgarian => 342 japanese => 200065)
```
For more examples see the file
[NumericWordForms-examples.raku](examples/NumericWordForms-parsing-examples.raku).
Here we retrieve a list of all supported languages:
```
from-numeric-word-form('languages').sort
```
```
# (armenian azerbaijani azərbaycan bulgarian czech deutsch english español français french german greek japanese kazakh korean koremutake persian polish polski portuguese português qazaq romanian română russian spanish ukrainian český ελληνικά български казак руский український қазақ հայերեն 日本語 한국어)
```
**Remark:** In the list above some languages appear twice, with both their English and native names.
#### Type of the result
The returned result can be an `Int` object or a `Str` object -- that is controlled with
the adverb `number` (which by default is `True`.) Here is an example:
```
my $res = from-numeric-word-form('one thousand and twenty three');
say $res, ' ', $res.WHAT;
```
```
# 1023 (Int)
```
```
$res = from-numeric-word-form('one thousand and twenty three', :!number);
say $res, ' ', $res.WHAT;
```
```
# 1023 (Str)
```
#### Automatic language detection
Automatic language detection is invoked if the second argument is `Whatever` or "Automatic":
```
say from-numeric-word-form('tysiąc dwadzieścia trzy', Whatever):p;
say from-numeric-word-form('триста двадесет и три', lang => 'Automatic'):p;
```
```
# polish => 1023
# bulgarian => 323
```
```
say from-numeric-word-form(['tysiąc dwadzieścia trzy', 'twenty three']):p;
```
```
# (polish => 1023 english => 23)
```
The adverb `:pairs` (`:p`) specifies whether the result should be a `Pair` object or a `List` of `Pair` objects
with the detected languages as keys.
### Translation
Translation from one language to another:
```
translate-numeric-word-form('хиляда двадесет и три', 'Bulgarian' => 'English');
```
```
# one thousand, twenty three
```
```
translate-numeric-word-form('two hundred thousand and five', 'English' => 'Bulgarian');
```
```
# двеста хиляди и пет
```
**Remark:** Currently that function translates to Bulgarian, English,
[Koremutake](https://shorl.com/koremutake.php), and Russian.
only (from any of the package languages.)
Here is a Spanish to Koremutake example:
```
my $numForm = "tres mil ochocientos noventa";
my $trRes = translate-numeric-word-form($numForm, 'Automatic' => 'Koremutake');
say "Given : $numForm";
say "To Koremutake : $trRes";
say "From Koremutake : {from-numeric-word-form($trRes)}";
```
```
# Given : tres mil ochocientos noventa
# To Koremutake : jami
# From Koremutake : 3890
```
The named arguments "from" and "to" can be also used:
```
translate-numeric-word-form($numForm, from => Whatever, to => 'English');
```
```
# three thousand, eight hundred ninety
```
---
## Roles
This package provides (exports) roles that can be used in grammars or roles in other packages, applications, etc.
For example, see the roles:
```
Lingua::NumericWordForms::Roles::Bulgarian::WordedNumberSpec
Lingua::NumericWordForms::Roles::English::WordedNumberSpec
```
A grammar or role that does the roles above should use the rule:
```
<numeric-word-form>
```
For code examples see the file
[Parsing-examples.raku](./examples/Parsing-examples.raku).
**Remark:** The role `Lingua::NumericWordForms::Roles::WordedNumberSpec` and the corresponding
actions class `Lingua::NumericWordForms::Actions::WordedNumberSpec` are "abstract".
They were introduced in order to have simpler roles and actions code
(and non-duplicated implementations.) Hence, that role and class *should not* be used in
grammars and roles outside of this package.
---
## CLI
The package provides two Command Line Interface (CLI) functions:
`from-numeric-word-form` and `to-numeric-word-form`.
Corresponding usage messages and examples are given below.
### `from-numeric-word-form`
#### Usage message
```
from-numeric-word-form --help
```
```
# Usage:
# from-numeric-word-form <text> [-l|--lang=<Str>] [-p|--pairs] [-f|--format=<Str>] -- Interprets numeric word forms into numbers.
# from-numeric-word-form [<words> ...] [-l|--lang=<Str>] [-p|--pairs] [-f|--format=<Str>] -- Takes a list of words to be a numeric word form and interprets it into a number.
# from-numeric-word-form [-l|--lang=<Str>] [-p|--pairs] [-f|--format=<Str>] -- Interprets numeric word forms from a (pipeline) input.
#
# <text> Text to interpret to numbers.
# -l|--lang=<Str> Language [default: 'Automatic']
# -p|--pairs Should Language-number pairs be returned or not? [default: False]
# -f|--format=<Str> Output format one of 'text', 'lines', or 'raku'. [default: 'text']
# [<words> ...] Text to interpret to numbers.
```
#### Example
```
from-numeric-word-form two hundred and five
```
```
# 205
```
### `to-numeric-word-form`
#### Usage message
```
to-numeric-word-form --help
```
```
# Usage:
# to-numeric-word-form <text> [-l|--lang=<Str>] [-f|--format=<Str>] -- Coverts numbers into numeric word forms.
# to-numeric-word-form [<words> ...] [-l|--lang=<Str>] [-f|--format=<Str>] -- Takes a list of numbers and converts it into a list of numeric word forms.
# to-numeric-word-form [-l|--lang=<Str>] [-f|--format=<Str>] -- Converts numbers from a (pipeline) input into numeric word forms.
#
# <text> String of one or more numbers to convert into numeric word forms. (Multiple numbers can be separated with ';'.)
# -l|--lang=<Str> Language (one of 'Bulgarian', 'English', or 'Koremutake'.) [default: 'English']
# -f|--format=<Str> Output format one of 'text', 'lines', or 'raku'. [default: 'text']
# [<words> ...] Number strings to be converted into numeric word forms.
```
#### Example
```
to-numeric-word-form 33 124 99832 --lang Bulgarian
```
```
# тридесет и три; сто двадесет и четири; деветдесет и девет хиляди осемстотин тридесет и две
```
---
## TODO
The following TODO items are ordered by priority, the most important are on top.
1. TODO Expand parsing beyond trillions
2. DONE Automatic determination of the language
3. DONE Word form generation:
* DONE Bulgarian
* DONE English
* DONE Koremutake
* DONE Russian
* CANCELED General algorithm
* Canceled because it is a hard problem and Large Language Models (LLMs) can do it.
4. TODO Documentation of the general programming approach.
* TODO What are the main challenges?
* TODO How the chosen software architecture decisions address them?
* TODO Concrete implementations walk-through.
* TODO How to implement / include a new language?
* TODO How the random numbers test files were made?
* TODO Profiling, limitations, alternatives.
* TODO Comparison with LLM-based conversions.
5. TODO Full, consistent Persian numbers parsing.
* Currently, Persian number parsing works only for numbers less than 101.
6. DONE General strategy for parsing and interpretation of
numeric word forms of East Asia languages
* Those languages use groupings based on 10^4 instead of 10^3.
* DONE Implementation for Japanese.
7. TODO Implement parsing of ordinal numeric word forms
* DONE English, French, Greek, and Spanish
* DONE Bulgarian
* DONE Czech, Russian, Ukrainian, Polish
* DONE Japanese
* DONE Koremutake
* DONE Portuguese
* DONE Azerbaijani
* DONE Kazakh
* Very similar to Azerbaijani.
* The Kazakh action class should inherit the Azerbaijani one.
* DONE German
* As expected, required some refactoring to handle the agglutinative word forms.
* DONE Romanian
* DONE Armenian
* TODO Korean
* Implemented to a point.
* TODO Persian
* Implemented to a point.
* TODO Sanskrit
8. TODO Implement parsing of year "shortcut" word forms, like "twenty o three"
9. TODO Implement parsing of numeric word forms for rationals, like "five twelfths"
10. DONE Translation function (from one language to another)
---
# Collaboration notes
* The **main rule** is that the main branch should always be installable and pass all of its tests.
* From the main rule it follows that new features are developed in separate branches or forks.
* The easiest way to collaborate is to create and commit new test files or corrections
to existing test files.
* Then I would change the corresponding grammars rules and actions
in order the package to pass the tests.
* Please use [*Conventional Commits* (CC)](https://www.conventionalcommits.org/en/v1.0.0/).
* Here is the CC short form stencil (in Raku):
`<type> ['(' <scope> ')']? ':' <description>`.
* See the recent commits in this repository for examples.
* Here are additional examples of CC messages (each line is a separate message):
```
feat:Implemented the parsing of Danish numeric word forms.
docs:Added documentation of right-to-left word forms parsing.
fix(Persian):Corrected tests for numbers larger that 1000.
test:Added new corner cases tests.
test(Ukrainian):Added new tests.
```
---
## Acknowledgements
* Thanks to [spyrettas](https://github.com/spyrettas) for:
* Riding "shotgun" during the initial implementation of the Greek role, actions, and tests
* Proofreading and correcting Greek tests and role
* Thanks to [Denis](https://github.com/DenisVCode) for:
* Proofreading the Czech language unit tests and suggesting corrections.
* Thanks to Aikerim Belispayeva, [aikerimbelis](https://github.com/aikerimbelis), for:
* Proofreading the Kazah language unit tests and suggesting corrections.
* Thanks to Herbert Breunung, [lichtkind](https://github.com/lichtkind), for:
* Proofreading the German language unit tests
* Suggesting corrections and extensions
* Verifying the German numeric word forms parsing with the [DSL Translations](https://antononcube.shinyapps.io/DSL-evaluations/) interface
* Thanks to Nora Popescu for:
* Bug reporting and suggestions for the Romanian language parser
* Verifying the Romanian numeric word forms parsing with the [DSL Translations](https://antononcube.shinyapps.io/DSL-evaluations/) interface
---
## References
[AAr1] Anton Antonov,
[Raku::DSL::Shared](https://github.com/antononcube/Raku-DSL-Shared).
[BL1] Brent "Labster" Laabs,
[`Lingua::Number`](https://github.com/labster/p6-Lingua-Number).
[SS1] Larry Wall, Steve Schulze,
[Lingua::EN::Numbers](https://github.com/thundergnat/Lingua-EN-Numbers).
---
Anton Antonov
Florida, USA
April-May, 2021
October, 2022 (updated, separate executable doc)
March, 2023 (updated, Azerbaijani parsing)
June, 2024 (updated, Bulgarian generation)
March-April, 2025 (updated; Kazakh, German, and Romanian parsing; Russian generation)
|
## dist_cpan-TYIL-Grammar-DiceRolls.md
# NAME
Grammar::DiceRolls
# VERSION
0.3.1
# AUTHOR
Patrick Spek [p.spek@tyil.nl](mailto:p.spek@tyil.nl)
# LICENSE
Copyright © 2020
This program is free software: you can redistribute it and/or modify it under the terms of the GNU Affero General Public License as published by the Free Software Foundation, either version 3 of the License, or (at your option) any later version.
This program is distributed in the hope that it will be useful, but WITHOUT ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU Affero General Public License for more details.
You should have received a copy of the GNU Affero General Public License along with this program. If not, see <http://www.gnu.org/licenses/>.
|
## temporal.md
role X::Temporal
Error related to DateTime or Date
```raku
role X::Temporal is Exception { }
```
A common exception type for all errors related to [`DateTime`](/type/DateTime) or [`Date`](/type/Date).
|
## dist_zef-lizmat-Sub-Name.md
[](https://github.com/lizmat/Sub-Name/actions)
# NAME
Raku port of Perl's Sub::Name module
# SYNOPSIS
```
use Sub::Name;
subname $name, $callable;
$callable = subname foo => { ... };
```
# DESCRIPTION
This module tries to mimic the behaviour of Perl's `Sub::Name` module as closely as possible in the Raku Programming Language.
This module has only one function, which is also exported by default:
subname NAME, CALLABLE
Assigns a new name to referenced Callable. If package specification is omitted in the name, then the current package is used. The return value is the Callable.
The name is only used for informative routines. You won't be able to actually invoke the Callable by the given name. To allow that, you need to do assign it to a &-sigilled variable yourself.
Note that for anonymous closures (Callables that reference lexicals declared outside the Callable itself) you can name each instance of the closure differently, which can be very useful for debugging.
# AUTHOR
Elizabeth Mattijsen [liz@raku.rocks](mailto:liz@raku.rocks)
Re-imagined from the Perl version as part of the CPAN Butterfly Plan. Perl version originally developed by Matthijs van Duin.
# COPYRIGHT AND LICENSE
Copyright 2018, 2019, 2020, 2021 Elizabeth Mattijsen
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## nodemap.md
nodemap
Combined from primary sources listed below.
# [In Any](#___top "go to top of document")[§](#(Any)_method_nodemap "direct link")
See primary documentation
[in context](/type/Any#method_nodemap)
for **method nodemap**.
```raku
method nodemap(&block --> List) is nodal
```
`nodemap` will apply `&block` to each element and return a new [`List`](/type/List) with the return values of `&block`. In contrast to [deepmap](/routine/deepmap) it will **not** descend recursively into sublists if it finds elements which [do](/routine/does) the [`Iterable`](/type/Iterable) role.
```raku
say [[1,2,3], [[4,5],6,7], 7].nodemap(*+1);
# OUTPUT: «(4, 4, 8)»
say [[2, 3], [4, [5, 6]]]».nodemap(*+1)
# OUTPUT: «((3 4) (5 3))»
```
The examples above would have produced the exact same results if we had used [map](/routine/map) instead of `nodemap`. The difference between the two lies in the fact that [map](/routine/map) flattens out [`Slip`](/type/Slip)s while `nodemap` doesn't.
```raku
say [[2,3], [[4,5],6,7], 7].nodemap({.elems == 1 ?? $_ !! slip});
# OUTPUT: «(() () 7)»
say [[2,3], [[4,5],6,7], 7].map({.elems == 1 ?? $_ !! slip});
# OUTPUT: «(7)»
```
When applied to [`Associative`](/type/Associative)s, it will act on the values:
```raku
{ what => "is", this => "thing" }.nodemap( *.flip ).say;
# OUTPUT: «{this => gniht, what => si}»
```
|
## dist_cpan-BDUGGAN-Terminal-ANSI.md
## Terminal::ANSI
This is a library of ANSI escape sequences.
### Example
```
use Terminal::ANSI;
save-screen;
clear-screen;
home;
hide-cursor;
sub scroll($row,$col = 1, $height = 7) {
print-at $row,$col, "━" x 20;
print-at $row + $height,$col, "━" x 20;
my $on = $row;
for 20000, 19999 ... 0 {
atomically {
set-scroll-region($row + 1,$row + $height - 1);
scroll-up if $on >= $row + $height - 1;
print-at ++$on min $row + $height - 1, $col, "counting down..$_";
}
}
}
my $p1 = start scroll(2);
my $p2 = start scroll(12,10,10);
my $p3 = start scroll(24);
await Promise.allof($p1,$p2,$p3);
sleep 1;
reset-scroll-region;
show-cursor;
restore-screen;
```
See the [eg/](https://git.sr.ht/~bduggan/raku-terminal-ansi/tree/master/eg) directory for more examples.
## Description
The functions in this module print ANSI escape sequences to stdout.
There are functions for cursor movement, scroll regions, colors, and
other screen functionality. There aren't functions for any of the
esoteric escape codes.
The `atomically` function suppresses printing, and instead concatenates
the output and emits the entire line at the end. This is helpful for
multi-threaded situations, where the output of several functions needs
to be in one piece.
There is also an OO interface, as well as a virtual screen, to mock
emitting of escape codes (useful for testing).
## Documentation
* This README can be found online here:
<https://man.sr.ht/~bduggan/raku-terminal-ansi/README.md>
* [Terminal::ANSI](https://man.sr.ht/~bduggan/raku-terminal-ansi/lib/Terminal/ANSI.md) has documentation for all of the available functions.
* [Terminal::ANSI:OO](https://man.sr.ht/~bduggan/raku-terminal-ansi/lib/Terminal/ANSI/OO.md) has the OO interface.
## Bugs
Feel free to email bug reports to the author, or you can file a ticket at
<https://todo.sr.ht/~bduggan/raku-terminal-ansi>
## Author
Brian Duggan (bduggan at matatu.org)
|
## dist_zef-tbrowder-GNU-Time.md
[](https://github.com/tbrowder/GNU-Time/actions)
# NAME
**GNU::Time** - Provides an easy interface for the GNU `time` command on Linux and OSX hosts (usually installed as '/bin/time' or '/usr/bin/time') to time user commands.
NOTE: This module replaces the time-related routines in module **Proc::More** (which is now deprecated).
Of course one can use the Raku `now` routine before and after a command to achieve calculating the total wall clock time, but sometimes one may be interested in the actual process time without including the times of other processes on the host computer.
# SYNOPSIS
```
use GNU::Time;
# get the proces times (in seconds) for a system command:
say time-command "locate lib"; # OUTPUT: «real 0.23user 0.22sys 0.01»
```
# DESCRIPTION
Raku module **GNU::Time** provides the `time-command` subroutine for easy access to the GNU `time` command on Linux and OSX hosts. The default is to return the same output format as running the following command at the host's command line interface:
```
$ /bin/time -p locate lib 1>/tmp/stdout
real 0.23
user 0.22
sys 0.01
```
Note the `TIME` environment variable format, if defined, is ignored.
# INSTALLATION
First, ensure the GNU `time` command is installed on your host. If required, you may install it from source.
## Getting the `time` command
On Debian and other Linux hosts the `time` command may not be installed by default, but it is available in package `time`. It can also be built from source available at the *Free Software Foundation*'s git site. Clone the source repository:
```
$ git clone https://git.savannah.gnu.org/git/time.git
```
The build and install instructions are in the repository along with the source code. Details of the GNU `time` command may be seen by executing `man 1 time` at the command line.
Unfortunately, there is no equivalent command available for Windows unless you install Cygwin or an equivalent system. (The author has seen Windows command scripts posted on Stack Overflow but has not tried any himself.)
## sub time-command
Purpose : Collect the process times for a system or user command (using the GNU `time` command). Runs the input command using the Raku `run` routine and returns the process times shown below (all times are in seconds):
* `real` - real (wall clock) time
* `user` - user time
* `system` - system time
### Signature:
```
sub time-command(Str:D $cmd,
:$typ where { !$typ.defined || $typ ~~ &typ },
:$fmt where { !$fmt.defined || $fmt ~~ &fmt },
:$rtn where { !$rtn.defined || $rtn ~~ &rtn },
:$dir,
) is export {...}
```
### Parameters:
* `$cmd` - The command as a string. Note special characters are not recognized by Raku's `run` routine, so results may not be as expected if they are part of the command.
* `:$typ` - Type of time values to return (see token `typ` definition)
* `:$fmt` - Desired format of returned time values (see token `fmt` definition)
* `:$rth` - Desired return type (see token `rtn` definition)
* `:$dir` - Directory in which to execute the command
### The `typ`, `fmt`, and `rtn` tokens:
Note the user should either use the single-character form of the token or at least two characters of the multi-character form to ensure proper disambiguation of the desired token. For example, the character 'u' alone is taken to be the 'user' type while 'u+' is the "sum" type. In all cases, the canonical name of each token is the single-character shown for each token.
```
my token typ { ^ :i
# the desired time(s) to return:
# [default: all are returned]
r|real| # show real (wall clock) time only
u|user| # show the user time only
s|sys| # show the system time only
'+'|'u+s' # show sum of user and system time
$ }
my token fmt { ^ :i
# the desired format for the time(s)
# [default: raw seconds]
s|seconds| # time in seconds with an appended
# 's': "30.42s"
h|hms| # time in hms format: "0h00m30.42s"
':'|'h:m:s' # time in h:m:s format: "0:00:30.42"
$ }
my token rtn { ^ :i
# the desired type of return:
# [default: string]
l|list|
h|hash|
$ }
```
### Returns one of:
* A string consisting of real (wall clock), user, **and** system times [default]
* A string consisting in one of real (wall clock), user, **or** system times
* A list consisting of real (wall clock), user, and system times (in that order)
* A hash of all of real (wall clock), user, and system times keyed by 'real', 'user', and 'system'
All returned time values are in the default or the selected format.
### `GNU_Time_Format` environment variable
The user may set the desired default type, format, and return type by setting the **GNU\_Time\_Format** environment variable as in the following example
```
export GNU_Time_Format='typ(u)' # returns the user time in seconds
```
where 'typ()', 'fmt()', and 'rtn()' are "tokens" with values within their trailing parentheses. The values within parentheses are expected to be the appropriate ones for the signature tokens. Multiple tokens may be separated by semicolons, whitespace, or commas. Whitespace is ignored. Missing values and tokens are ignored as are malformed or unrecognized tokens or values.
# AUTHOR
Tom Browder [tbrowder@cpan.org](mailto:tbrowder@cpan.org)
# COPYRIGHT and LICENSE
Copyright © 2021 Tom Browder
This library is free software; you may redistribute or modify it under the Artistic License 2.0.
|
## dist_zef-bduggan-Geo-Polyline.md
[](https://github.com/bduggan/raku-geo-polyline/actions/workflows/linux.yml)
[](https://github.com/bduggan/raku-geo-polyline/actions/workflows/macos.yml)
# NAME
Geo::Polyline - Encode and decode Google Maps polyline strings
# SYNOPSIS
```
use Geo::Polyline;
my $polyline = polyline-encode([ [ 38.5, -120.2 ], [ 40.7, -120.95 ], [ 43.252, -126.453 ] ]);
my @coords = polyline-decode($polyline);
my $geojson = polyline-to-geojson($polyline);
my $polyline6 = polyline6-encode([ [ 38.5, -120.2 ], [ 40.7, -120.95 ], [ 43.252, -126.453 ] ]);
my @coords6 = polyline6-decode($polyline6);
my $geojson6 = polyline6-to-geojson($polyline6);
```
# DESCRIPTION
Encode and decode polyline strings using the google polyline algorithm.
The algorithm is described here: <https://developers.google.com/maps/documentation/utilities/polylinealgorithm>
Polyline6 is a variant of the algorithm that uses 6 decimals of precision instead of 5. These variants can be used by either passing :v6, or using the polyline6- functions.
# FUNCTIONS
## polyline-encode, polyline6-encode
Encode an array of lon/lat coordinate pairs into a polyline string.
## polyline-decode, polyline6-decode
Decode a polyline string into an array of lon/lat coordinate pairs.
## polyline-to-geojson, polyline6-to-geojson
Convert a polyline string into a GeoJSON object.
## polyline-encode-coordinate, polyline-decode-coordinate, polyline6-encode-coordinate, polyline6-decode-coordinate
Also exported; these encode an individual coordinate number to/from a string.
# AUTHOR
Brian Duggan
|
## hyperwhatever.md
class HyperWhatever
Placeholder for multiple unspecified values/arguments
```raku
class HyperWhatever { }
```
`HyperWhatever` is very similar in functionality to [`Whatever`](/type/Whatever). The difference lies in `HyperWhatever` standing in for *multiple* values, rather than a single one.
# [Standalone term](#class_HyperWhatever "go to top of document")[§](#Standalone_term "direct link")
Just like with [`Whatever`](/type/Whatever), if a `HyperWhatever` is used as a term on its own, no priming is done and the `HyperWhatever` object will be used as-is:
```raku
sub foo ($arg) { say $arg.^name }
foo **; # OUTPUT: «HyperWhatever»
```
You can choose to interpret such a value as standing for multiple values in your own routines. In core, a `HyperWhatever` can be used with this meaning when smartmatching with [`List`](/type/List)s:
```raku
say (1, 8) ~~ (1, **, 8); # OUTPUT: «True»
say (1, 2, 4, 5, 6, 7, 8) ~~ (1, **, 8); # OUTPUT: «True»
say (1, 2, 8, 9) ~~ (1, **, 8); # OUTPUT: «False»
```
Wherever a `HyperWhatever` appears in the list on the right-hand side means any number of elements can fill that space in the list being smartmatched.
# [Priming](#class_HyperWhatever "go to top of document")[§](#Priming "direct link")
When it comes to priming, the `HyperWhatever` follows the same rules as [`Whatever`](/type/Whatever). The only difference is `HyperWhatever` produces a [`Callable`](/type/Callable) with a [`*@` slurpy](/language/signatures#Flattened_slurpy) as a signature:
```raku
say (**²)(1, 2, 3, 4, 5); # OUTPUT: «(1 4 9 16 25)»
```
A `HyperWhatever` closure can be imagined as a [`WhateverCode`](/type/WhateverCode) with **another** sub wrapped around it that simply maps each element in the arguments over:
```raku
my &hyper-whatever = sub (*@args) { map *², @args }
say hyper-whatever(1, 2, 3, 4, 5); # OUTPUT: «(1 4 9 16 25)»
```
When priming, mixing `HyperWhatever` with [`Whatever`](/type/Whatever) is not permitted.
# [Typegraph](# "go to top of document")[§](#typegraphrelations "direct link")
Type relations for `HyperWhatever`
raku-type-graph
HyperWhatever
HyperWhatever
Any
Any
HyperWhatever->Any
Mu
Mu
Any->Mu
[Expand chart above](/assets/typegraphs/HyperWhatever.svg)
|
## pred.md
pred
Combined from primary sources listed below.
# [In enum Bool](#___top "go to top of document")[§](#(enum_Bool)_routine_pred "direct link")
See primary documentation
[in context](/type/Bool#routine_pred)
for **routine pred**.
```raku
method pred(--> Bool:D)
```
Returns `False`.
```raku
say True.pred; # OUTPUT: «False»
say False.pred; # OUTPUT: «False»
```
`pred` is short for "predecessor"; it returns the previous enum value. Bool is a special enum with only two values, `False` and `True`. When sorted, `False` comes first, so `False` is the predecessor to `True`. And since `False` is the "lowest" Bool enum value, its own predecessor is also `False`.
# [In Str](#___top "go to top of document")[§](#(Str)_method_pred "direct link")
See primary documentation
[in context](/type/Str#method_pred)
for **method pred**.
```raku
method pred(Str:D: --> Str:D)
```
Returns the string decremented by one.
String decrementing is "magical" just like string increment (see [succ](/routine/succ)). It fails on underflow
```raku
'b0'.pred; # OUTPUT: «a9»
'a0'.pred; # OUTPUT: Failure
'img002.png'.pred; # OUTPUT: «img001.png»
```
# [In role Enumeration](#___top "go to top of document")[§](#(role_Enumeration)_method_pred "direct link")
See primary documentation
[in context](/type/Enumeration#method_pred)
for **method pred**.
```raku
method pred(::?CLASS:D:)
```
```raku
say Freija.pred; # OUTPUT: «Oðin»
```
# [In IO::Path](#___top "go to top of document")[§](#(IO::Path)_method_pred "direct link")
See primary documentation
[in context](/type/IO/Path#method_pred)
for **method pred**.
```raku
method pred(IO::Path:D: --> IO::Path:D)
```
Returns a new `IO::Path` constructed from the invocant, with [`.basename`](/routine/basename) changed by calling [`Str.pred`](/type/Str#method_pred) on it.
```raku
"foo/file02.txt".IO.pred.say; # OUTPUT: «"foo/file01.txt".IO»
```
# [In role Numeric](#___top "go to top of document")[§](#(role_Numeric)_method_pred "direct link")
See primary documentation
[in context](/type/Numeric#method_pred)
for **method pred**.
```raku
method pred(Numeric:D:)
```
Returns the number decremented by one (predecessor).
# [In Allomorph](#___top "go to top of document")[§](#(Allomorph)_method_pred "direct link")
See primary documentation
[in context](/type/Allomorph#method_pred)
for **method pred**.
```raku
method pred(Allomorph:D:)
```
Calls [`Numeric.pred`](/type/Numeric#method_pred) on the invocant's numeric value.
# [In Date](#___top "go to top of document")[§](#(Date)_method_pred "direct link")
See primary documentation
[in context](/type/Date#method_pred)
for **method pred**.
```raku
method pred(Date:D: --> Date:D)
```
Returns a `Date` of the previous day. "pred" is short for "predecessor".
```raku
say Date.new("2016-01-01").pred; # OUTPUT: «2015-12-31»
```
|
## threadpoolscheduler.md
class ThreadPoolScheduler
Scheduler that distributes work among a pool of threads
```raku
class ThreadPoolScheduler does Scheduler {}
```
The `ThreadPoolScheduler` has a range of number of threads that it maintains, and it distributes work among those threads. When the upper limit of threads isn't reached yet, and there is work pending, it spawns new threads to handle the work.
# [Methods](#class_ThreadPoolScheduler "go to top of document")[§](#Methods "direct link")
## [new](#class_ThreadPoolScheduler "go to top of document")[§](#new "direct link")
```raku
method new(Int :$initial_threads = 0, Int :$max_threads = 8 * Kernel.cpu-cores)
```
Creates a new `ThreadPoolScheduler` object with the given range of threads to maintain.
The default value for `:initial_threads` is **0**, so no threads will be started when a `ThreadPoolScheduler` object is created by default.
The default value for `:max_threads` is **64**, unless there appear to be more than 8 CPU cores available. In that case the default will be 8 times the number of CPU cores.
See also the [RAKUDO\_MAX\_THREADS](/programs/03-environment-variables#Other) environment variable to set the default maximum number of threads.
As of release 2022.06 of the Rakudo compiler, it is also possible to specify `Inf` or `*` as a value for `:max_threads`, indicating that the maximum number of threads allowed by the operating system, will be used.
# [Typegraph](# "go to top of document")[§](#typegraphrelations "direct link")
Type relations for `ThreadPoolScheduler`
raku-type-graph
ThreadPoolScheduler
ThreadPoolScheduler
Any
Any
ThreadPoolScheduler->Any
Scheduler
Scheduler
ThreadPoolScheduler->Scheduler
Mu
Mu
Any->Mu
[Expand chart above](/assets/typegraphs/ThreadPoolScheduler.svg)
|
## invocantmarker.md
class X::Syntax::Signature::InvocantMarker
Compilation error due to a misplaced invocant marker in a signature
```raku
class X::Syntax::Signature::InvocantMarker does X::Syntax { }
```
Syntax error when the invocant in a signature is anywhere else than after the first parameter.
For example
```raku
:($a, $b: $c);
```
dies with
「text」 without highlighting
```
```
===SORRY!===
Can only use : as invocant marker in a signature after the first parameter
```
```
See also: [`Signature`](/type/Signature).
|
## dist_zef-jnthn-Badger.md
# Badger
Badger, not an ORM (a snake).
### What's Badger?
Badger is a SQL library that allows you to invoke SQL snippets as function as
if it was Raku code. This way you can keep writing your SQL queries by hand
for performance and tweakability, and your tools still recognize the `.sql`
files to help you work with them.
### What does a Badger SQL file look like?
A badger-compatible SQL file is just a normal SQL file, with signature headers.
These signatures are intended to look like Raku signatures.
The most basic example:
```
-- sub my-query()
SELECT;
```
### How do I feed Badger my SQL?
You have to pass the .sql file(s) to the `use Badger` statement:
```
use Badger <sql/my-query.sql>; # The file in the previous code block
```
This will generate this function Raku-side:
```
sub my-query(Database $db --> Int) { ... }
```
Which you can call just like any other Raku subs, by passing any object that
has an interface similar to `DB::Pg` (for now at least) as the connection.
For parameters and return values, see below.
## Parameters
A Badger SQL sub can have arguments that you can use in the SQL body.
Interpolation works for sigilled variables:
```
-- sub query-with-params($a, $b)
SELECT $a + $b, @c
```
This will generate a prepared query with `$a` and `$b` replaced `$1`, `$2`
(or with `?`s depending on the RDBMS).
### Parameter Sigils
The Raku allowed sigils are `$` and `@`.
### Parameter typing
You can put type annotations on the parameters:
```
-- sub query-with-params(Int $x, Int @xs)
SELECT $x = ANY(@xs)
```
If a parameter is typed, Badger will try to help you by inserting coercions in the generated SQL.
This is what the executed SQL looks like:
```
SELECT ($1::int) = ANY(($2::int[]))
```
### Named Parameters
Parameters can be named, just like in Raku:
```
-- sub query-nameds(Int :$a, :$b)
SELECT $a + $b
```
Just like in Raku, you can't have a positional parameter after a named one.
### Mandatory Named Parameters
Also just like in Raku, named parameters can be marked mandatory:
```
-- sub query-nameds(:$mandatory!)
SELECT $a * 2
```
## Return Sigils
### `+` (default)
The default one -- in you don't specify a return sigil, you get this.
Returns the number of affected rows (as an `Int`).
```
-- sub count-unnests(--> +)
-- ... or ...
-- sub count-unnests()
UPDATE products
SET price = 999
WHERE price IS NULL
```
### `$`
Returns a single value. `Nil` is returned otherwise:
```
-- sub get-username(Str $token --> $)
SELECT username
FROM users
WHERE token = $token
```
### Typed `$`
Calls `.new` on the given type with all the data returned from the SQL query:
```
-- sub get-user(Int $id --> MyApp::Models::User)
SELECT 1 AS id, 'steve' AS username
```
You'll usually need to import type module that provides the type, by placing
a `use` at the top of the SQL file:
```
-- use MyApp::Models;
```
```
class MyApp::Models::User {
has Int $.id;
has Str $.username;
}
...
my MyApp::Models::User $user = get-user(db, 1);
# Result: `MyApp::Models::User.new(id => 1, :username<steve>);`
```
### `%`
Returns a hash.
```
-- sub get-hash(--> %)
SELECT 'comment' as type, 'Hello world!' as txt
```
```
my %h = get-hash($db);
# Result: `%(type => "comment", txt => "Hello world!")`
```
If the database doesn't return anything, Badger gives you an empty hash back.
### `@`
Returns an array of hashes.
```
-- sub get-hashes(--> @)
SELECT 'comment' as type, txt
FROM unnest(array['Hello', 'world!']) txt
```
```
my @hashes = get-hashes($db);
# Result: `%(type => "comment", txt => "Hello"), %(type => "comment", txt => "world!")`
```
### Typed `@`
Calls `.new` on the given type on each row of the data returned from the SQL query:
```
-- sub get-data(--> Datum @)
SELECT row_number() OVER () as id
, unnest(ARRAY['a','b']) as value
```
```
class Datum {
has Int $.id;
has Str $.value;
}
...
my Datum @data = get-data($db);
# Result: `Datum.new(id => 1, :value<a>), Datum.new(id => 2, :value<b>)`
```
|
## dist_zef-2colours-HTML-Tag.md
# NAME
HTML::Tag - Simple HTML Tag Generators
# SYNOPSIS
```
use HTML::Tag::Tags;
say HTML::Tag::p.new(:text('This is my paragraph'), :class('pretty')).render;
# <p class="pretty">This is my paragraph</p>
my $link = HTML::Tag::a.new(:text('paragraph'),
:href('http://dom.com'));
say HTML::Tag::p.new(:text("This is my ", $link, "."),
:class('pretty')).render;
# <p class="pretty">This is my <a href="http://dom.com">paragraph</a>.</p>
```
# DESCRIPTION
HTML::Tag::Tags provides little objects to generate HTML tags. Tags
that support :text have their string text encoded for HTML special
characters.
Tags that support :text also support "embedding" other tags inside
their :text by passing alternating string text and tag objects as a
list. Tag objects passed this way *should not* have `.render` called
on them first to avoid the HTML special characters being escaped.
Not all attributes of every HTML tag is supported, just the most
common. It enforces very little. It is meant to help minimize clutter
in code for those who are not using html template classes or who wish
to dynamically generate segments of html code.
Please see the POD documentation for each macro for more details on
macro use.
Also, an HTML::Tag::Exports can be used to export the symbol "tag"
into your scope which shortens `HTML::Tag::<thing>` creation to
`tag('thing', %opts)`
# TAGS
HTML::Tag::Tags will give you all tag classes defined. They can be
instantiated with HTML::Tag::.new and take options matching
their normal html attributes.
Tags can be combined into one another by placing them into another
tag's :text attribute. Tags are then recursively rendered when .render
is called on the furthest-outward containing tag (such as
HTML::Tag::html which represents an entire page).
`HTML::Tag::Raw` represents raw HTML text that renders as its content itself.
`HTML::Tag::Macro::CSS` will generate a CSS link.
`HTML::Tag::Macro::Table` will help generate tables.
`HTML::Tag::Macro::List` will help generate lists.
`HTML::Tag::Macro::Form` will help generate form and do some form
variable handling.
# MACROS
Please see individual macro files for more thorough documentation on
each macro.
## HTML::Tag::Macro::CSS
Renders a normal CSS file link that can be wrapped into a html head element:
```
HTML::Tag::Macro::CSS.new(:href('/css/mycssfile.css')).render;
```
## HTML::Tag::Macro::Table
A HTML::Tag::Macro::Table object gets fed rows one after the
other. These rows contain arrays of data that will be surrounded by
td's.
```
my $table = HTML::Tag::Macro::Table.new;
my @data = $var1, $var2, $var3;
$table.row(@data);
@data = $var4, $var5, $var6;
$table.row(@data);
$table.render;
```
The `.row` method takes `Bool :$header` which will generated th tags
instead of td tags for each array element (representing a table header
row).
The `.row` method takes `Map :$tr-opts` which will apply normal
`HTML::Tag::tr` options to that row, as specified in :$tr-opts.
The `.row` method takes `Map :$td-opts` which will apply normal
`HTML::Tag::td` options to td tags that are generated for that
row. **$td-opts is keyed by the td array element** (see td-opts example
code below).
```
$table = HTML::Tag::Macro::Table.new(:table-opts(id =>'myID'));
@data = 'Col1', 'Col2', 'Col3';
$table.row(:header(True), @data);
@data = 11, 22, 33;
$table.row(@data);
@data = 111, 222, 333;
my $td-opts = %(1 => {class => 'pretty'},
2 => {class => 'pretty',
id => 'lastone'});
$table.row(:$td-opts, @data);
```
As you can see the new constructor takes :$table-opts that will be
passed along to the normal HTML::Tag::table object.
NO CHECKING IS PERFORMED FOR A CONSISTENT NUMBER OF ELEMENTS IN EACH
ROW
## HTML::Tag::Macro::List
Generates an ordered or unordered HTML list from a supplied array, or
constructs the array for you by repeated calling of the item() method.
```
my $list = HTML::Tag::Macro::List.new;
$list.link(:to('http://somewhere'), :text('rainbows'));
$list.link(:to('http://elsewhere'), :text('snails'),
:class('highlight'));
$list.render;
# .. or ..
my @fruit = 'fingers', 'sofa', 'airliner';
my $html = HTML::Tag::Macro::List.new(:items(@fruit)).render;
```
The lists have a special method called link() that makes `HTML::Tag::a`
links that are surrounded by list elements since this is a common way
to generate HTML menus.
## HTML::Tag::Macro::Form
Generates forms based upon a definition variable passed in. This
variable must be an array of hashes.
## The array of hashes represents one form element per hash in the array. Labels are automatically generated for all form elements by default.
The hash key represents the HTML name of the hash by default, and the
input variable if given, etc. That key's value represents options for
that form element.
```
use HTML::Tag::Macro::Form;
my $form = HTML::Tag::Macro::Form.new(:action('/hg/login/auth'),
:input(%.input));
$form.def = ({username => {}},
{password => { type => 'password' }},
{submit => { value => 'Login',
type => 'submit',
label => '' }}
);
$form.render;
```
Most certainly a work in progress.
# AUTHOR
Current maintenance: Polgár, Márton [ersterpleghthome@gmail.com](mailto:ersterpleghthome@gmail.com)
Author of the original module: Rushing, Mark [mark@orbislumen.net](mailto:mark@orbislumen.net)
# LICENSE
This is free software; you can redistribute it and/or modify it under
the Artistic License 2.0.
|
## dist_cpan-KAIEPI-Type-EnumHOW.md
[](https://travis-ci.org/Kaiepi/p6-Type-EnumHOW)
# NAME
Type::EnumHOW - Sugar for enum's meta-object protocol
# SYNOPSIS
```
use Type::EnumHOW;
BEGIN {
my Str @ranks = 'Unranked', 'Voice', 'Half-Operator', 'Operator', 'Administrator', 'Owner';
my Str %symbols = %(
@ranks[0] => ' ',
@ranks[1] => '+',
@ranks[2] => '%',
@ranks[3] => '@',
@ranks[4] => '&',
@ranks[5] => '~'
);
my constant Rank = Type::EnumHOW.new_type: :name<Rank>, :base_type(Int);
Rank.^set_package: OUR;
Rank.^add_attribute_with_values: '$!symbol', %symbols, :type(Str);
Rank.^compose;
Rank.^add_enum_values: @ranks;
Rank.^compose_values;
};
say Owner; # OUTPUT: Owner
say Owner.symbol; # OUTPUT: ~
```
# DESCRIPTION
Enums are not straightforward to create using their meta-object protocol since a large chunk of the work the runtime does to create enums is handled during precompilation. Type::EnumHOW extends Metamodel::EnumHOW to provide methods that both do the work normally done during precompilation and to provide sugar for customizing enum behaviour without the need to import nqp.
It is recommended to declare enums at compile-time rather than at runtime so enums and their values can have their serialization context set. This can be done by either using `constant` in combination with `do` or using `BEGIN`.
Type::EnumHOW extends Metamodel::EnumHOW. Refer to [its documentation](https://docs.perl6.org/type/Metamodel::EnumHOW) for more information.
# METHODS
* **^new\_type**(\*\*%named\*)
Creates a new enum type. Named arguments are the same as those taken by `Metamodel::EnumHOW.new_type`. If you plan on calling `^add_enum_values` with a list of keys, ensure you pass `:base_type(Int)`.
* **^package**()
Returns the package set by `^set_package`.
* **^set\_package**(*$package* where \*.WHO ~~ Stash | PseudoStash)
Sets the package in which the enum and its values' symbols will be installed. This must be called before calling `^compose` or `^add_enum_values`.
If `MY` is given, the enum must be created during compilation. Any other package can be used during runtime.
Do not pass `MY` packages in other lexpads to this method, such as `OUTER::MY` or `CALLER::MY`; enum and enum value symbols will get installed in the wrong lexpad. To the best of my knowledge, there isn't a good way to properly detect when they get passed when `BEGIN`/`constant` are involved.
* **^add\_attribute\_with\_values**(str *$name*, %values, Mu:U *:$type* = Any, Bool *:$private* = False)
Adds an attribute with the name `$name` to the enum. `%values` is a hash of enum value keys to attribute values that is used to bind the attribute values to their respective enum values when calling `^compose_values`. `$type` is the type of the attribute values. If the attribute should be private, set `$private` to `True`, otherwise a getter will automatically be added.
* **^compose**()
Composes the enum type. Call this after adding enum attributes and methods, but before adding enum values.
If no package has been set using `^set_package`, an `X::Type::EnumHOW::MissingPackage` exception will be thrown.
If the package was set to `MY` and this wasn't called during compilation, an `X::Type::EnumHOW::PostCompilationMY` exception will be thrown.
* **^add\_enum\_values**(*%values*)
* **^add\_enum\_values**(*@keys*)
Batch adds a list of enum values to an enum and installs them both in the package set and the enum's package. `^compose` must be called before calling this. Calling this with a hash will warn about the enum values' order not necessarily being the same as when they were defined in the hash. This may also be called with either a list of keys or a list of pairs.
If no package has been set using `^set_package`, an `X::Type::EnumHOW::MissingPackage` exception will be thrown.
If the package was set to `MY` and this wasn't called during compilation, an `X::Type::EnumHOW::PostCompilationMY` exception will be thrown.
# AUTHOR
Ben Davies (Kaiepi)
# COPYRIGHT AND LICENSE
Copyright 2019 Ben Davies
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_zef-lizmat-MoarVM-Bytecode.md
[](https://github.com/lizmat/MoarVM-Bytecode/actions) [](https://github.com/lizmat/MoarVM-Bytecode/actions) [](https://github.com/lizmat/MoarVM-Bytecode/actions)
# NAME
MoarVM::Bytecode - Provide introspection into MoarVM bytecode
# SYNOPSIS
```
use MoarVM::Bytecode;
my $M = MoarVM::Bytecode.new($filename); # or letter or IO or Blob
say $M.hll-name; # most likely "Raku"
say $M.strings[99]; # the 100th string on the string heap
```
# DESCRIPTION
MoarVM::Bytecode provides an object oriented interface to the MoarVM bytecode format, based on the information provided in [docs/bytecode.markdown](https://github.com/MoarVM/MoarVM/blob/main/docs/bytecode.markdown#bytecode).
# CLASS METHODS
## new
```
my $M = MoarVM::Bytecode.new("c"); # the 6.c setting
my $M = MoarVM::Bytecode.new("foo/bar"); # path as string
my $M = MoarVM::Bytecode.new($filename.IO); # path as IO object
my $M = MoarVM::Bytecode.new($buf); # a Buf object
```
Create an instance of the `MoarVM::Bytecode` object from a letter (assumed to be a Raku version letter such as "c", "d" or "e"), a filename, an `IO::Path` or a `Buf`/`Blob` object.
## files
```
.say for MoarVM::Bytecode.files;
.say for MoarVM::Bytecode.files(:instantiate);
```
Returns a sorted list of paths of MoarVM bytecode files that could be found in the installation of the currently running `rakudo` executable.
Optionally accepts a `:instantiate` named argument to return a sorted list of instantiated `MoarVM::Bytecode` objects instead of just paths.
## root
```
my $rootdir = MoarVM::Bytecode.rootdir;
```
Returns an `IO::Path` of the root directory of the installation of the currently running `rakudo` executable.
## setting
```
my $setting = MoarVM::Bytecode.setting;
my $setting = MoarVM::Bytecode.setting("d");
```
Returns an `IO::Path` of the bytecode file of the given setting letter. Assumes the currently lowest supported setting by default.
# HELPER SCRIPTS
## bceval
```
$ bceval c '.strings.grep(*.contains("zip"))'
&zip
zip
zip-latest
```
Helper script to allow simple actions on a `MoarVM::Bytecode` object from the command line. The first argument indicates the bytecode file to load (either a `use` target, setting letter or path. The second argument indicates the code to be executed.
The topic `$_` is set with the `MoarVM::Bytecode` object upon entry.
If the result is an `Iterable`, then each iteration will be shown on a separate line. Otherwise the return value will be shown.
## bcinfo
```
$ bcinfo --help
Usage:
bin/bcinfo <file> [--filename=<Str>] [--name=<Str>] [--opcode=<Str>] [--header] [--decomp] [--hexdump] [--verbose]
<file> use target, setting letter or bytecode path
--filename=<Str> select frames with given filename
--name=<Str> select frames with given name
--opcode=<Str> select frames containing opcode
--header show header information
--decomp de-compile file / selected frames
--hexdump show hexdump of selected frames
--verbose be verbose when possible
```
Produces various types of information about the given bytecode file, specified by either a `use` target, setting letter or path.
## csites
```
$ csites c 12
12 $, $, N
```
Helper code to show the callsite info of the given callsite number.
## opinfo
```
$ opinfo if_i unless_i
24 if_i r(int64),ins (8 bytes)
25 unless_i r(int64),ins (8 bytes)
$ opinfo 42 666
42 bindlex_nn str,r(num64) (8 bytes)
666 atpos2d_s w(str),r(obj),r(int64),r(int64) (10 bytes)
```
Helper script to show the gist of the given op name(s) or number(s).
## sheap
```
$ sheap e 3 4 5
3 SETTING::src/core.e/core_prologue.rakumod
4 language_revision_type
5 lang-meth-call
$ sheap e byte
42 byte
2844 bytecode-size
```
Helper script for browsing the string heap of a given bytecode file (specified by either a `use` target, setting letter, or a path of a bytecode file).
String arguments are interpreted as a key to do a .grep on the whole string heap. Numerical arguments are interpreted as indices into the string heap. If no arguments are given, the entire string heap will be produced.
Shown are the string index and the string.
# INSTANCE METHODS
## coverables
```
# Show all files and number of lines in that file
say .key ~ ": " ~ +.value ~ " lines"
for $M.coverables.sort(*.key);
```
Returns a `Map` with the filename(s) as keys, and a list of line numbers in that file that have code in them that `can` be produced in a coverage report.
## callsites
```
.say for $M.callsites[^10]; # show the first 10 callsites
```
Returns a list of [Callsite](#Callsite) objects, which contains information about the arguments at a given callsite.
## de-compile
Returns a string with the opcodes and their arguments.
## extension-ops
```
.say for $M.extension-ops; # show all extension ops
```
Returns a list of NQP extension operators that have been added to this bytecode. Each element consists of an <ExtensionOp> object.
## frames
```
.say for $M.frames[^10]; # show the first 10 frames on the frame heap
my @frames := $M.frames.reify-all;
```
Returns a <Frames> object that serves as a `Positional` for all of the frames on the frame heap. Since the reification of a [Frame](#Frame) object is rather expensive, this is done lazily on each access.
To reify all `Frame` objects at once, one can call the `reify-all` method, which also returns a list of the reified `Frame` objects.
## hll-name
```
say $M.hll-name; # most likely "Raku"
```
Returns the HLL language name for this bytecode. Most likely "Raku", or "nqp".
## op
```
say $M.op(0x102); # 102 istype w(int64),r(obj),r(obj)
say $M.op("istype"); # 102 istype w(int64),r(obj),r(obj)
```
Attempt to create an opcode object for the given name or opcode number. Also includes any extension ops that may be defined in the bytecode itself.
## opcodes
A `Buf` with the actual opcodes.
## sc-dependencies
```
.say for $M.sc-dependencies; # identifiers for Serialization Context
```
Returns a list of strings of the Serialization Contexts on which this bytecode depends.
## strings
```
.say for $M.strings[^10]; # The first 10 strings on the string heap
```
Returns a <Strings> object that serves as a `Positional` for all of the strings on the string heap.
## version
```
say $M.version; # most likely 7
```
Returns the numeric version of this bytecode. Most likely "7".
# PRIMITIVES
## bytecode
```
my $b = $M.bytecode;
```
Returns the `Buf` with the bytecode.
## hexdump
```
say $M.hexdump($M.string-heap-offset); # defaults to 256
say $M.hexdump($M.string-heap-offset, 1024);
```
Returns a hexdump representation of the bytecode from the given byte offset for the given number of bytes (256 by default).
## slice
```
dd $M.slice(0, 8).chrs; # "MOARVM\r\n"
```
Returns a `List` of unsigned 32-bit integers from the given offset and number of bytes. Basically a shortcut for `$M,bytecode[$offset ..^ $offset + $bytes]`. The number of bytes defaults to `256` if not specified.
## str
```
say $M.str(76); # Raku or nqp
```
Returns the string of which the index is the given offset.
## subbuf
```
dd $M.subbuf(0, 8).decode; # "MOARVM\r\n"
```
Calls `subbuf` on the `bytecode` and returns the result. Basically a shortcut for `$M.bytecode.subbuf(...)`.
## uint16
```
my $i = $M.uint16($offset);
```
Returns the unsigned 16-bit integer value at the given offset in the bytecode.
## uint16s
```
my @values := = $M.uint16s($M.string-heap-offset); # 16 entries
my @values := $M.uint16s($M.string-heap-offset, $entries);
```
Returns an unsigned 16-bit integer array for the given number of entries at the given offset in the bytecode. The number of entries defaults to 16 if not specified.
## uint32
```
my $i = $M.uint32($offset);
```
Returns the unsigned 32-bit integer value at the given offset in the bytecode.
## uint32s
```
my @values := = $M.uint32s($offset); # 16 entries
my @values := $M.uint32s($offset, $entries);
```
Returns an unsigned 32-bit integer array for the given number of entries at the given offset in the bytecode. The number of entries defaults to 16 if not specified.
# HEADER SHORTCUTS
The following methods provide shortcuts to the values in the bytecode header. They are explained in the [MoarVM documentation](https://github.com/MoarVM/MoarVM/blob/main/docs/bytecode.markdown#bytecode).
`sc-dependencies-offset`, `sc-dependencies-entries`, `extension-ops-offset`, `extension-ops-entries`, `frames-data-offset`, `frames-data-entries`, `callsites-data-offset`, `callsites-data-entries`, `string-heap-offset`, `string-heap-entries`, `sc-data-offset`, `sc-data-length`, `opcodes-offset`, `opcodes-length`, `annotation-data-offset`, `annotation-data-length`, `main-entry-frame-index`, `library-load-frame-index`, `deserialization-frame-index`
# SUBCLASSES
Instances of these classes are usually created automatically.
## Argument
The `Argument` class provides these methods:
### flags
The raw 8-bit bitmap of flags. The following bits have been defined:
* 1 - object
* 2 - native integer, signed
* 4 - native floating point number
* 8 - native NFG string (MVMString REPR)
* 16 - literal
* 32 - named argument
* 64 - flattened argument
* 128 - native integer, unsigned
### is-flattened
Returns 1 if the argument is flattened, else 0.
### is-literal
Returns 1 if the argument is a literal value, else 0.
### name
The name of the argument if it is a named argument, else the empty string.
### type
The type of the argument: possible values are `Mu` (indicating a HLL object of some kind), or any of the basic native types: `str`, `int`, `uint` or `num`.
## Callsite
The `Callsite` class provides these methods:
### arguments
The list of <Argument> objects for this callsite, if any.
### bytes
The number of bytes this callsite needs.
### has-named-arg
Returns `True` if the call site has a named argument with the given name, else `False`.
### named
A `Map` of named arguments, keyed by name.
## ExtensionOp
The `ExtensionOp` class provides these methods:
### adverbs
Always an empty `Map`.
### annotation
Always the empty string.
### bytes
The number of bytes this opcode uses.
### name
The name with which the extension op can be called.
### descriptor
An 8-byte `Buf` with descriptor information.
### is-sequence
Always `False`.
## Frame
The `Frame` class provides these methods:
### is-inlineable
Return `Bool` whether the current frame is considered to be inlineable.
### cuid
A string representing the compilation unit ID.
### de-compile
Returns a string with the opcodes and their arguments of this frame.
### flags
A 16-bit unsigned integer bitmap with flags of this frame.
### handlers
A list of [Handler](#Handler) objects, representing the handlers in this frame.
### has-exit-handler
1 if this frame has an exit handler, otherwise 0.
### hexdump
Return a hexdump of the opcodes of this frame. Optionally takes a named argument `:highlight` which will highlight the bytes of the actual opcodes (excluding any argument bytes following them).
### index
A 16-bit unsigned integer indicating the frame index of this frame.
### is-thunk
1 if this frame is a thunk (as opposed to a real scope), otherwise 0.
### lexicals
A list of [Lexical](#Lexical) objects, representing the lexicals in this frame.
### locals
A list of [Local](#Local) objects, representing the locals in this frame.
### name
The name of this frame, if any.
### no-outer
1 if this frame has no outer, otherwise 0.
### opcodes
A `Buf` with the actual bytecode of this frame.
### outer-index
A 16-bit unsigned integer indicating the frame index of the outer frame.
### sc-dependency-index
A 32-bit unsigned integer index into
### sc-object-index
A 32-bit unsigned integer index into
### statements
A list of [Statement](#Statement) objects for this frame, may be empty.
## Handler
### start-protected-region
### end-protected-region
### category-mask
### action
### register-with-block
### handler-goto
## Lexical
### name
The name of this lexical, if any.
### type
The type of this lexical.
### flags
A 16-bit unsigned integer bitmap for this lexical.
### sc-dependency-index
Index of into the `sc-dependencies` list.
### sc-object-index
Index of into the `sc-dependencies` list.
## Local
### name
The name of this local, if any.
### type
The type of this local.
## Statement
### line
The line number of this statement.
### offset
The opcode offset of this statement.
## Op
### all-adverbs
Return a `List` of all possible adverbs.
### all-ops
Return a `List` of all possible ops.
### annotation
The annotation of this operation. Currently recognized annotations are:
* dispatch
* jump
* parameter
* return
* spesh
Absence of annotation if indicated by the empty string. See also [is-sequence](#is-sequence).
### adverbs
A `Map` of additional adverb strings.
### bytes
```
my $bytes := $op.bytes($frame, $offset);
```
The number of bytes this op occupies in memory. Returns **0** if the op has a variable size.
Some ops have a variable size depending on the callsite in the frame it is residing. For those cases, one can call the `bytes` method with the [Frame](#Frame) object and the offset in the opcodes of that frame to obtain the number of bytes for that instance.
### index
The numerical index of this operation.
### is-sequence
True if this op is the start of a sequence of ops that share the same annotation.
### name
The name of this operation.
### new
```
my $op = MoarVM::Op.new(0);
my $op = MoarVM::Op.new("no_op");
```
Return an instantiated `MoarVM::Op` object from the given name or opcode number.
### not-inlineable
Returns `True` if the op causes the frame to which it belongs to be not inlineable. Otherwise returns `False`.
### operands
A `List` of operands, if any.
# AUTHOR
Elizabeth Mattijsen [liz@raku.rocks](mailto:liz@raku.rocks)
# COPYRIGHT AND LICENSE
Copyright 2024, 2025 Elizabeth Mattijsen
Source can be located at: <https://github.com/lizmat/MoarVM-Bytecode> . Comments and Pull Requests are welcome.
If you like this module, or what I’m doing more generally, committing to a [small sponsorship](https://github.com/sponsors/lizmat/) would mean a great deal to me!
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## notandthen.md
notandthen
Combined from primary sources listed below.
# [In Operators](#___top "go to top of document")[§](#(Operators)_infix_notandthen "direct link")
See primary documentation
[in context](/language/operators#infix_notandthen)
for **infix notandthen**.
The `notandthen` operator returns [`Empty`](/type/Slip#constant_Empty) upon encountering the first [defined](/routine/defined) argument, otherwise the last argument. Last argument is returned as-is, without being checked for definedness at all. Short-circuits. The result of the left side is bound to `$_` for the right side, or passed as arguments if the right side is a [`Callable`](/type/Callable), whose [count](/routine/count) must be `0` or `1`.
At first glance, [notandthen](/routine/notandthen) might appear to be the same thing as the [orelse](/routine/orelse) operator. The difference is subtle: [notandthen](/routine/notandthen) returns [`Empty`](/type/Slip#constant_Empty) when it encounters a [defined](/routine/defined) item (that isn't the last item), whereas [orelse](/routine/orelse) returns that item. In other words, [notandthen](/routine/notandthen) is a means to act when items aren't defined, whereas [orelse](/routine/orelse) is a means to obtain the first defined item:
```raku
sub all-sensors-down { [notandthen] |@_, True }
sub first-working-sensor { [orelse] |@_, 'default sensor' }
all-sensors-down Nil, Nil, Nil
and say 'OMG! All sensors are down!'; # OUTPUT:«OMG! All sensors are down!»
say first-working-sensor Nil, Nil, Nil; # OUTPUT:«default sensor»
all-sensors-down Nil, 42, Nil
and say 'OMG! All sensors are down!'; # No output
say first-working-sensor Nil, 42, Nil; # OUTPUT:«42»
```
The `notandthen` operator is a close relative of the [`without` statement modifier](/language/control#with_orwith_without), and some compilers compile `without` to `notandthen`, meaning these two lines have equivalent behavior:
```raku
sub good-things { fail }
'boo'.say without good-things;
good-things() notandthen 'boo'.say;
```
|
## dist_zef-vrurg-WWW-GCloud-API-Vision.md
# NAME
`WWW::GCloud::API::Vision` - `WWW::GCloud` implementation of [Google Vision API](https://cloud.google.com/vision/docs/reference/rest)
# SYNOPSIS
```
use v6.e.PREVIEW;
use WWW::GCloud;
use WWW::GCloud::API::Vision;
use WWW::GCloud::API::Vision::Types;
my $gcloud = WWW::GCloud.new;
my $images = $gcloud.vision.images;
my $queue = $images.annotation-queue;
given $queue {
.project("my-project-id");
# Create a new request to OCR-annotate an image. Subsequent calls to .request will queue new requests.
.request(
:file("my-image.ext"), # Can be a PNG, TIFF, GIF.
feature => ( :type(GCVFDocument), :model<builtin/latest> ),
# If several features to be added at once:
# features => [...],
-> $request {
# Here we can do things with the request object itself.
$request.feature(GCVFLogo); # Also search the image for logos.
# If there is something special about the input config...
# $request.set-input-config(...);
# If the image is a multi-page one. .pages is an Array[UInt:D] attribute.
# $request.pages = 1,3;
}
);
}
await $queue
.start
.andthen({
say "Annotate completed."
# .result is an instance of WWW::GCloud::R::Vision::BatchAnnotateImagesResponse
});
```
# DESCRIPTION
This module lacks complete documentation due to me not currently able to write it. Please, see some notes for [`WWW::GCloud`](https://raku.land/zef:vrurg/WWW::GCloud) framework. And look into *exmaples/* where I tried to provide meaningful code to follow.
## Status
This module is pre-beta, pre-anything. It is incomplete and likely not well thought out at places. But it already lets you do a lot with your storages.
If there is anything you need but it is missing then, please, consider implementing it and submitting a PR. Any other approach would barely proces any outcome for what I do apologize!
Either way, this module can be used as a reference implementation for a `WWW::GGCloud` API.
Do not hesitate to get in touch with me would you need any help. I know it could be annoying when a complex module has little to none docs. I'll do my best to fix the situation. But until then feel free to open an issue in the [GitHub repository](https://github.com/vrurg/raku-WWW-GCloud-API-Vision/issues), even if it's just a question.
# COPYRIGHT
(c) 2023, Vadim Belman [vrurg@cpan.org](mailto:vrurg@cpan.org)
# LICENSE
Artistic License 2.0
See the [*LICENSE*](LICENSE) file in this distribution.
|
## dist_cpan-JFORGET-Date-Calendar-Hebrew.md
# NAME
Date::Calendar::Hebrew - Conversions from / to the Hebrew calendar
# SYNOPSIS
Converting a Gregorian date (e.g. 16th June 2019) into Hebrew
```
use Date::Calendar::Hebrew;
my Date $TPC2019-Pittsburgh-grg;
my Date::Calendar::Hebrew $TPC2019-Pittsburgh-heb;
$TPC2019-Pittsburgh-grg .= new(2019, 6, 16);
$TPC2019-Pittsburgh-heb .= new-from-date($TPC2019-Pittsburgh-grg);
say $TPC2019-Pittsburgh-heb;
# --> 5779-03-13
say "{.day-name} {.day} {.month-name} {.year}" with $TPC2019-Pittsburgh-heb;
# --> Yom Rishon 13 Sivan 5779
```
Converting a Hebrew date (e.g. 6 Av 5779) into Gregorian
```
use Date::Calendar::Hebrew;
my Date::Calendar::Hebrew $Perlcon-Riga-heb;
my Date $Perlcon-Riga-grg;
$Perlcon-Riga-heb .= new(year => 5779
, month => 5
, day => 6);
$Perlcon-Riga-grg = $Perlcon-Riga-heb.to-date;
say $Perlcon-Riga-grg;
```
# INSTALLATION
```
zef install Date::Calendar::Hebrew
```
or
```
git clone https://github.com/jforget/raku-Date-Calendar-Hebrew.git
cd raku-Date-Calendar-Hebrew
zef install .
```
# DESCRIPTION
Date::Calendar::Hebrew is a class representing dates in the Hebrew
calendar. It allows you to convert an Hebrew date into Gregorian (or
possibly other) calendar and the other way.
# AUTHOR
Jean Forget [JFORGET@cpan.org](mailto:JFORGET@cpan.org)
# COPYRIGHT AND LICENSE
Copyright © 2019, 2020 Jean Forget, all rights reserved
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_zef-FCO-Protocol.md
[](https://travis-ci.org/FCO/Protocol)
# Potocol
## Description
The idea here is to have a "set of methods". So, you can test a *class* based on that set of methods. But different from *roles* with stubbed methods it doesn't need do be "*does*ed" to be matched. It does create a subset but using a different syntax, and will check the methods.
## Synopsis
```
use Protocol;
protocol Writer { # creates a Writer protocol that have a write method
method write { ... }
}
sub write(Writer $w) { # accepts a Writer
$w.write
}
class JustAGreeter { # no roles, parents nor protocols declared on the class
method write { # it has the write method, so it attends to the protocol
say "Hello protocol!"
}
}
write JustAGreeter.new; # prints: Hello protocol!
```
|
## dist_zef-sumankhanal-Statistics.md
[](https://github.com/sumanstats/Statistics/actions/workflows/linux.yml)
[](https://github.com/sumanstats/Statistics/actions/workflows/windows-spec.yml)
[](https://github.com/sumanstats/Statistics/actions/workflows/macos.yml)
[](https://ci.appveyor.com/project/sumanstats/statistics/branch/main)
[](https://github.com/sumanstats/Statistics)
```
_____ _ _ _ _ _
/ ____| | | | (_) | | (_)
| (___ | |_ __ _| |_ _ ___| |_ _ ___ ___
\___ \| __/ _` | __| / __| __| |/ __/ __|
____) | || (_| | |_| \__ \ |_| | (__\__ \
|_____/ \__\__,_|\__|_|___/\__|_|\___|___/v0.0.6
```
# NAME
Statistics - Raku module for doing statistics
# SYNOPSIS
```
use Statistics;
my @data1 = [6,6,4,6,8,6,8,4,4,6,6,8,8,8,8,8,8,4,4,4,4,8,8,8,8,4,4,4,8,6,8,4];
my @data2 = [160.0,160.0,108.0,258.0,360.0,225.0,360.0,146.7,140.8,167.6,167.6,
275.8,275.8,275.8,472.0,460.0,440.0,78.7,75.7,71.1,120.1,318.0,304.0,
350.0,400.0,79.0,120.3,95.1,351.0,145.0,301.0,121.0];
# central tendency
mean(@data1); # 6.1875
median(@data1); # 6
# sample standard deviation
sd(@data1); # 1.7859216469465444
# population standard deviation
sd(@data1, sample => False); # 1.757795138803154
# Coefficient of variation
coef_variation(@data2); # 53.71779066522493
# Five number summary
fivenum(@data2); # (71.1 120.65 196.3 334 472)
# correlation coefficients
pearson_cor_coef(@data1, @data2); # 0.9020328721469989
spearman_cor_coef(@data1, @data2); # 0.9276515785415314
kendall_cor_coef(@data1, @data2); # 0.8144262510988963
# Biweight_midcorrelation
# more robust, less sensitive to outliers
bi_cor_coef(@data1, @data2); # 0.9146470012038392
# numpy linspace
linspace(2.1, 3.2, 5, endpoint => False, retstep => False); # [2.1, 2.32, 2.54, 2.76, 2.98]
linspace(1, 3, 3, endpoint => False, retstep => True); # ([1, 1.666667, 2.333333], 0.666667)
# pdf of normal distribution
raku_dnorm(5); # 1.4867195147342977e-06
raku_dnorm(3, mean => 2, sd => 1); # 0.24197072451914337
raku_dnorm(3, mean => 2, sd => -1); # NaN;
raku_dnorm(3, mean => 2, sd => 0); # 0;
# cdf of normal distribution
raku_pnorm(5); # 0.9999997133484281
raku_pnorm(4, mean => 2, sd => 3); # 0.7475074624530771
raku_pnorm(4, mean => 2, sd => 3, log_p => True) # -0.29101099055230867
raku_qnorm(5); # NaN
# Random number generator for normal distribution
set_seed(111,222);
raku_rnorm(12) # (0.2933064931910023 -0.43157564134676835 0.1280404124560668 -1.001461811038476 -0.9219453227924342 1.2988990178409578 -0.46867271131577315 -1.2678609176619775 0.3596981905325252 0.35262105537769173 0.5770092689090144 -1.0392300758070165)
# Multinomial coefficients
multinomial_coef([3,1,1,3,4.2, 8, 90, 40]); # 2.717246116384229e+69;
multinomial_coef([3,1,1,3,4.2, 8, 90, 140]); # 1.0317825100856673e+106;
multinomial_coef([2,4,5,7]); # 220540320
multinomial_coef_excel([3,1.9,1,3,4.2]); # 554400;
```
# DESCRIPTION
Statistics is a module to make it easier to do statistics in Raku programming language.
## Features
* descriptive statistics
* correlation coefficients
* pdf, cdf of probability distributions
* random number generators
* parametric tests
* non-parametric tests
### INSTALLATION
The module contains **compiled** code. `gcc`, `cmake` and `ninja`
are required for compilation and should be available in `PATH`.
### ISSUES
<https://github.com/sumanstats/Statistics/issues>
### PULL REQUESTS
Improvement of the code base and efficient implementation of the algorithms are welcome.
# AUTHOR
Dr Suman Khanal [suman81765@gmail.com](mailto:suman81765@gmail.com)
# COPYRIGHT AND LICENSE
Copyright 2022 Dr Suman Khanal
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## 101-basics.md
Raku by example 101
A basic introductory example of a Raku program
Suppose that you host a table tennis tournament. The referees tell you the results of each game in the format `Player1 Player2 | 3:2`, which means that `Player1` won against `Player2` by 3 to 2 sets. You need a script that sums up how many matches and sets each player has won to determine the overall winner.
The input data (stored in a file called `scores.txt`) looks like this:
「data」 without highlighting
```
```
Beth Ana Charlie Dave
Ana Dave | 3:0
Charlie Beth | 3:1
Ana Beth | 2:3
Dave Charlie | 3:0
Ana Charlie | 3:1
Beth Dave | 0:3
```
```
The first line is the list of players. Every subsequent line records a result of a match.
Here's one way to solve that problem in Raku:
```raku
use v6;
# start by printing out the header.
say "Tournament Results:\n";
my $file = open 'scores.txt'; # get filehandle and...
my @names = $file.get.words; # ... get players.
my %matches;
my %sets;
for $file.lines -> $line {
next unless $line; # ignore any empty lines
my ($pairing, $result) = $line.split(' | ');
my ($p1, $p2) = $pairing.words;
my ($r1, $r2) = $result.split(':');
%sets{$p1} += $r1;
%sets{$p2} += $r2;
if $r1 > $r2 {
%matches{$p1}++;
} else {
%matches{$p2}++;
}
}
my @sorted = @names.sort({ %sets{$_} }).sort({ %matches{$_} }).reverse;
for @sorted -> $n {
my $match-noun = %matches{$n} == 1 ?? 'match' !! 'matches';
my $set-noun = %sets{$n} == 1 ?? 'set' !! 'sets';
say "$n has won %matches{$n} $match-noun and %sets{$n} $set-noun";
}
```
This produces the output:
「text」 without highlighting
```
```
Tournament Results:
Ana has won 2 matches and 8 sets
Dave has won 2 matches and 6 sets
Charlie has won 1 match and 4 sets
Beth has won 1 match and 4 sets
```
```
# [`v6`](#Raku_by_example_101 "go to top of document")[§](#Pragma_v6 "direct link")
```raku
use v6;
```
Every Raku program should begin with a line similar to `use v6;`. This line tells the compiler which version of Raku the program expects. For instance, 6.c is an example of a Raku version. Should you accidentally run the file with Perl, you'll get a helpful error message.
# [Statements](#Raku_by_example_101 "go to top of document")[§](#Statements "direct link")
```raku
# start by printing out the header.
say "Tournament Results:\n";
```
A Raku program consists of zero or more statements. A *statement* ends with a semicolon or a curly brace at the end of a line.
In Raku, single line comments start with a single hash character `#` and extend until the end of the line. Raku also supports [multi-line/embedded comments](/language/syntax#Multi-line_/_embedded_comments). The compiler doesn't evaluate comments as program text and they're only intended for human readers.
# [Lexical scope](#Raku_by_example_101 "go to top of document")[§](#Lexical_scope_and_block "direct link")
```raku
my $file = open 'scores.txt';
```
`my` declares a lexical variable, which are visible only in the current block from the point of declaration to the end of the block. If there's no enclosing block, it's visible throughout the remainder of the file (which would effectively be the enclosing block). A block is any part of the code enclosed between curly braces `{ }`.
## [Sigils](#Raku_by_example_101 "go to top of document")[§](#Sigils_and_identifiers "direct link")
A variable name begins with a *sigil*, which is a non-alpha-numeric symbol such as `$`, `@`, `%`, or `&` — or occasionally the double colon `::`. Sigils indicate the structural interface for the variable, such as whether it should be treated as a single value, a compound value, a subroutine, etc. After the sigil comes an *identifier*, which may consist of letters, digits and the underscore. Between letters you can also use a dash `-` or an apostrophe `'`, so `isn't` and `double-click` are valid identifiers.
## [Scalar](#Raku_by_example_101 "go to top of document")[§](#Scalar "direct link")
Sigils indicate the default access method for a variable. Variables with the `@` sigil are accessed positionally; variables with the `%` sigil are accessed by string key. The `$` sigil, however, indicates a general scalar container that can hold any single value and be accessed in any manner. A scalar can even contain a compound object like an [`Array`](/type/Array) or a [`Hash`](/type/Hash); the `$` sigil signifies that it should be treated as a single value, even in a context that expects multiple values (as with an [`Array`](/type/Array) or [`Hash`](/type/Hash)).
## [Filehandle](#Raku_by_example_101 "go to top of document")[§](#Filehandle_and_assignment "direct link")
The built-in function `open` opens a file, here named `scores.txt`, and returns a *filehandle* — an object representing that file. The assignment operator `=` *assigns* that filehandle to the variable on the left, which means that `$file` now stores the filehandle.
## [String literals](#Raku_by_example_101 "go to top of document")[§](#String_literals "direct link")
`'scores.txt'` is a *string literal*. A string is a piece of text, and a string literal is a string which appears directly in the program. In this line, it's the argument provided to `open`.
# [Arrays](#Raku_by_example_101 "go to top of document")[§](#Arrays,_methods_and_invocants "direct link")
```raku
my @names = $file.get.words;
```
The right-hand side calls a *method* — a named group of behavior — named `get` on the filehandle stored in `$file`. The `get` method reads and returns one line from the file, removing the line ending. If you print the contents of `$file` after calling `get`, you will see that the first line is no longer in there. `words` is also a method, called on the string returned from `get`. `words` decomposes its *invocant* — the string on which it operates — into a list of words, which here means strings separated by whitespace. It turns the single string `'Beth Ana Charlie Dave'` into the list of strings `'Beth', 'Ana', 'Charlie', 'Dave'`.
Finally, this list gets stored in the [`Array`](/type/Array) `@names`. The `@` sigil marks the declared variable as an [`Array`](/type/Array). Arrays store ordered lists.
# [Hashes](#Raku_by_example_101 "go to top of document")[§](#Hashes "direct link")
```raku
my %matches;
my %sets;
```
These two lines of code declare two hashes. The `%` sigil marks each variable as a [`Hash`](/type/Hash). A [`Hash`](/type/Hash) is an unordered collection of key-value pairs. Other programming languages call that a *hash table*, *dictionary*, or *map*. You can query a hash table for the value that corresponds to a certain `$key` with `%hash{$key}`.
In the score counting program, `%matches` stores the number of matches each player has won. `%sets` stores the number of sets each player has won. Both of these hashes are indexed by the player's name.
# [`for`](#Raku_by_example_101 "go to top of document")[§](#for_and_blocks "direct link")
```raku
for $file.lines -> $line {
...
}
```
`for` produces a loop that runs the *block* delimited by curly braces once for each item of the list, setting the variable `$line` to the current value of each iteration. `$file.lines` produces a list of the lines read from the file `scores.txt`, starting with the second line of the file since we already called `$file.get` once, and going all the way to the end of the file.
During the first iteration, `$line` will contain the string `Ana Dave | 3:0`; during the second, `Charlie Beth | 3:1`, and so on.
```raku
my ($pairing, $result) = $line.split(' | ');
```
`my` can declare multiple variables simultaneously. The right-hand side of the assignment is a call to a method named `split`, passing along the string `' | '` as an argument.
`split` decomposes its invocant into a list of strings, so that joining the list items with the separator `' | '` produces the original string.
`$pairing` gets the first item of the returned list, and `$result` the second.
After processing the first line, `$pairing` will hold the string `Ana Dave` and `$result` will hold `3:0`.
The next two lines follow the same pattern:
```raku
my ($p1, $p2) = $pairing.words;
my ($r1, $r2) = $result.split(':');
```
The first extracts and stores the names of the two players in the variables `$p1` and `$p2`. The second extracts the results for each player and stores them in `$r1` and `$r2`.
After processing the first line of the file, the variables contain the values:
| | |
| --- | --- |
| Variable | Contents |
| $line | 'Ana Dave | 3:0' |
| $pairing | 'Ana Dave' |
| $result | '3:0' |
| $p1 | 'Ana' |
| $p2 | 'Dave' |
| $r1 | '3' |
| $r2 | '0' |
The program then counts the number of sets each player has won:
```raku
%sets{$p1} += $r1;
%sets{$p2} += $r2;
```
The above two statements involve the `+=` compound assignment operator. They are a variant of the following two statements that use the simple assignment operator `=` and that may be easier to understand at first sight:
```raku
%sets{$p1} = %sets{$p1} + $r1;
%sets{$p2} = %sets{$p2} + $r2;
```
For your program, the shorthand version using the `+=` compound assignment operator is preferred over the longhand version using the simple assignment operator `=`. This is not only because the shorter version requires less typing, but also because the `+=` operator silently initializes undefined values of the hash's key-value pairs to zero. In other words: by using `+=`, there is no need to include a separate statement like `%sets{$p1} = 0` before you can meaningfully add `$r1` to it. We'll look at this is behavior in a bit more detail below.
## [`Any`](#Raku_by_example_101 "go to top of document")[§](#Any_and_+= "direct link")
```raku
%sets{$p1} += $r1;
%sets{$p2} += $r2;
```
`%sets{$p1} += $r1` means *increase the value in the variable on the left by $r1*. In the first iteration `%sets{$p1}` is not yet defined, so it defaults to a special value called [`Any`](/type/Any). The `+=` operator conveniently treats the undefined value [`Any`](/type/Any) as a number with the value `0`, allowing it to sensibly add some other value to it. To perform the addition, the strings `$r1`, `$r2`, etc. are automatically converted to numbers, as addition is a numeric operation.
## [Fat arrow](#Raku_by_example_101 "go to top of document")[§](#Fat_arrow,_pairs_and_autovivification "direct link")
Before these two lines execute, `%sets` is empty. Adding to an entry that is not in the hash yet will cause that entry to spring into existence just-in-time, with a value starting at zero. This behavior is known as *autovivification*. After these two lines have run for the first time, `%sets` contains `'Ana' => 3, 'Dave' => 0`. (The fat arrow `=>` separates the key and the value in a [`Pair`](/type/Pair).)
## [Postincrement](#Raku_by_example_101 "go to top of document")[§](#Postincrement_and_preincrement "direct link")
```raku
if $r1 > $r2 {
%matches{$p1}++;
} else {
%matches{$p2}++;
}
```
If `$r1` is numerically larger than `$r2`, `%matches{$p1}` increments by one. If `$r1` is not larger than `$r2`, `%matches{$p2}` increments. Just as in the case of `+=`, if either hash value did not exist previously, it is autovivified by the increment operation.
`$thing++` is a variant of `$thing += 1`; it differs from the latter in that the return value of the expression is `$thing` *before* the increment, and not the incremented value. As in many other programming languages, you can use `++` as a prefix. Then it returns the incremented value: `my $x = 1; say ++$x` prints `2`.
# [Topic variable](#Raku_by_example_101 "go to top of document")[§](#Topic_variable "direct link")
```raku
my @sorted = @names.sort({ %sets{$_} }).sort({ %matches{$_} }).reverse;
```
This line consists of three individually simple steps. An array's `sort` method returns a sorted version of the array's contents. However, the default sort on an array sorts by its contents. To print player names in winner-first order, the code must sort the array by the *scores* of the players, not their names. The `sort` method's argument is a *block* used to transform the array elements (the names of players) to the data by which to sort. The array items are passed in through the *topic variable* `$_`.
## [Blocks](#Raku_by_example_101 "go to top of document")[§](#Blocks "direct link")
You have seen blocks before: both the `for` loop `-> $line { ... }` and the `if` statement worked on blocks. A block is a self-contained piece of Raku code with an optional signature (the `-> $line` part).
The simplest way to sort the players by score would be `@names.sort({ %matches{$_} })`, which sorts by number of matches won. However Ana and Dave have both won two matches. That simple sort doesn't account for the number of sets won, which is the secondary criterion to decide who has won the tournament.
## [Stable sort](#Raku_by_example_101 "go to top of document")[§](#Stable_sort "direct link")
When two array items have the same value, `sort` leaves them in the same order as it found them. Computer scientists call this a *stable sort*. The program takes advantage of this property of Raku's `sort` to achieve the goal by sorting twice: first by the number of sets won (the secondary criterion), then by the number of matches won (the primary criterion).
After the first sorting step, the names are in the order `Beth Charlie Dave Ana`. After the second sorting step, it's still the same, because no one has won fewer matches but more sets than someone else. Such a situation is entirely possible, especially at larger tournaments.
`sort` sorts in ascending order, from smallest to largest. This is the opposite of the desired order. Therefore, the code calls the `.reverse` method on the result of the second sort, and stores the final list in `@sorted`.
# [Standard output](#Raku_by_example_101 "go to top of document")[§](#Standard_output "direct link")
```raku
for @sorted -> $n {
my $match-noun = %matches{$n} == 1 ?? 'match' !! 'matches';
my $set-noun = %sets{$n} == 1 ?? 'set' !! 'sets';
say "$n has won %matches{$n} $match-noun and %sets{$n} $set-noun";
}
```
To print out the players and their scores, the code loops over `@sorted`, setting `$n` to the name of each player in turn. Read this code as "For each element of sorted, set `$n` to the element, then execute the contents of the following block." The variable `$match-noun` will store either the string *match* if the player has won a single match or *matches* if the player has won zero or more matches. In order to do this, the *ternary* operator (`?? !!`) is used. If `%matches{$n} == 1` evaluates to `True`, then *match* is returned. Otherwise, *matches* is returned. Either way, the returned value is stored in `$match-noun`. The same approach applies to `$set-noun`.
The statement `say` prints its arguments to the standard output (the screen, normally), followed by a newline. (Use `print` if you don't want the newline at the end.)
Note that `say` will truncate certain data structures by calling the `.gist` method so `put` is safer if you want exact output.
## [Variable interpolation](#Raku_by_example_101 "go to top of document")[§](#Variable_interpolation "direct link")
When you run the program, you'll see that `say` doesn't print the contents of that string verbatim. In place of `$n` it prints the contents of the variable `$n` — a player's name stored in `$n`. This automatic substitution of code with its contents is called *interpolation*. This interpolation happens only in strings delimited by double quotes `"..."`. Single quoted strings `'...'` do not interpolate:
## [Double-quoted strings](#Raku_by_example_101 "go to top of document")[§](#Double-quoted_strings_and_single-quoted_strings "direct link")
```raku
my $names = 'things';
say 'Do not call me $names'; # OUTPUT: «Do not call me $names»
say "Do not call me $names"; # OUTPUT: «Do not call me things»
```
Double quoted strings in Raku can interpolate variables with the `$` sigil as well as blocks of code in curly braces. Since any arbitrary Raku code can appear within curly braces, [`Array`](/type/Array)s and [`Hash`](/type/Hash)es may be interpolated by placing them within curly braces.
Arrays within curly braces are interpolated with a single space character between each item. Hashes within curly braces are interpolated as a series of lines. Each line will contain a key, followed by a tab character, then the value associated with that key, and finally a newline.
Let's see an example of this now.
In this example, you will see some special syntax that makes it easier to make a list of strings. This is the `<...>` [quote-words](/language/operators#index-entry-qw-quote-words-quote-words) construct. When you put words in between the `<` and `>` they are all assumed to be strings, so you do not need to wrap them each in double quotes `"..."`.
```raku
say "Math: { 1 + 2 }";
# OUTPUT: «Math: 3»
my @people = <Luke Matthew Mark>;
say "The synoptics are: {@people}";
# OUTPUT: «The synoptics are: Luke Matthew Mark»
say "{%sets}";
# OUTPUT (From the table tennis tournament):
# Charlie 4
# Dave 6
# Ana 8
# Beth 4
```
When array and hash variables appear directly in a double-quoted string (and not inside curly braces), they are only interpolated if their name is followed by a postcircumfix operator — a bracketing pair that follows a statement. It's also ok to have a method call between the variable name and the postcircumfix.
# [Zen slices](#Raku_by_example_101 "go to top of document")[§](#Zen_slices "direct link")
```raku
my @flavors = <vanilla peach>;
say "we have @flavors"; # OUTPUT: «we have @flavors»
say "we have @flavors[0]"; # OUTPUT: «we have vanilla»
# so-called "Zen slice"
say "we have @flavors[]"; # OUTPUT: «we have vanilla peach»
# method calls ending in postcircumfix
say "we have @flavors.sort()"; # OUTPUT: «we have peach vanilla»
# chained method calls:
say "we have @flavors.sort.join(', ')";
# OUTPUT: «we have peach, vanilla»
```
# [Exercises](#Raku_by_example_101 "go to top of document")[§](#Exercises "direct link")
**1.** The input format of the example program is redundant: the first line containing the name of all players is not necessary, because you can find out which players participated in the tournament by looking at their names in the subsequent rows, so in principle we could safely remove it.
How can you make the program run if you do not use the `@names` variable? Hint: `%hash.keys` returns a list of all keys stored in `%hash`.
**Answer:** After removing the first line in `scores.txt`, remove the line `my @names = $file.get.words;` (which would read it), and change:
```raku
my @sorted = @names.sort({ %sets{$_} }).sort({ %matches{$_} }).reverse;
```
... into:
```raku
my @sorted = %sets.keys.sort({ %sets{$_} }).sort({ %matches{$_} }).reverse;
```
**2.** Instead of deleting the redundant `@names` variable, you can also use it to warn if a player appears that wasn't mentioned in the first line, for example due to a typo. How would you modify your program to achieve that?
Hint: Try using [membership operators](/language/operators#infix_(elem),_infix_∈).
**Answer:** Change `@names` to `@valid-players`. When looping through the lines of the file, check to see that `$p1` and `$p2` are in `@valid-players`. Note that for membership operators you can also use `(elem)` and `!(elem)`.
```raku
...;
my @valid-players = $file.get.words;
...;
for $file.lines -> $line {
my ($pairing, $result) = $line.split(' | ');
my ($p1, $p2) = $pairing.split(' ');
if $p1 ∉ @valid-players {
say "Warning: '$p1' is not on our list!";
}
if $p2 ∉ @valid-players {
say "Warning: '$p2' is not on our list!";
}
...
}
```
|
## dist_cpan-JNTHN-Cro-HTTP-Session-Pg.md
# Cro::HTTP::Session::Pg
An implementation of Cro persistent sessions using Postgres.
## Assumptions
There are dozens of ways we might do session storage; this module handles
the case where:
* The database is being accessed using `DB::Pg`.
* You're fine with the session state being serialized and stored as a
string/blob in the database.
If these don't meet your needs, it's best to steal the code from this
module into your own application and edit it as needed.
## Database setup
Create a table like this in the database:
```
CREATE TABLE sessions (
id TEXT PRIMARY KEY,
state TEXT,
expiration TIMESTAMP
);
```
You can change the table and column names, but will then have to specify
them when constructing the session state object.
## Minimal Cro application setup
First, create a session object if you do not already have one. This is
a class that holds the session state. We'll be saving/loading its content.
For example:
```
class MySession {
has $.user-id;
method set-logged-in-user($!user-id --> Nil) { }
method is-logged-in(--> Bool) { $!user-id.defined }
}
```
In the case that:
* You are using the default table/column names
* Your session object can be serialized by serializing its public attributes
to JSON, and deserialized by passing those back to new
* You are fine with the default 60 minute session expiration time
Then the only thing needed is to construct the session storage middleware with
a database handle and a session cookie name.
```
my $session-middleware = Cro::HTTP::Session::Pg[MySession].new:
:$db,
:cookie-name('my_app_name_session');
```
It can then be applied as application or `route`-block level middleware.
## Tweaking the session duration
Pass a `Duration` object as the `duration` named argument:
```
my $session-middleware = Cro::HTTP::Session::Pg[MySession].new:
:$db,
:cookie-name('my_app_name_session'),
:duration(Duration.new(15 #`(minutes) * 60));
```
## Tweaking the table and column names
Pass these named arguments as needed during construction:
* `sessions-table`
* `id-column`
* `state-column`
* `expiration-column`
## Controlling serialization
Instead of using the `Cro::HTTP::Session::Pg` role directly, create a
class that composes it.
```
class MySessionStore does Cro::HTTP::Session::Pg[MySession] {
method serialize(MySession $s) {
# Replace this with your serialization logic.
to-json $s.Capture.hash
}
method deserialize($d --> MySession) {
# Replace this with your deserialization logic.
Session.new(|from-json($d))
}
}
```
|
## dist_zef-andinus-Template-Nest-Fast.md
# Table of Contents
1. [Documentation](#org9db0562)
1. [Options](#org84b5605)
2. [Methods](#orgd774f96)
3. [Example](#orgcee0c42)
1. [Simple template hash](#org1346395)
2. [Array of template hash](#org3cd72c2)
3. [Array to template variable](#orgb84f6f7)
2. [News](#orgccd2661)
1. [v0.3.0 - 2024-11-18](#org25cea46)
2. [v0.2.8 - 2023-06-27](#orgb077a55)
3. [v0.2.6 - 2023-05-29](#orge261c99)
4. [v0.2.5 - 2023-05-25](#org09dca87)
5. [v0.2.4 - 2023-05-22](#orgd4c71c5)
6. [v0.2.3 - 2023-05-14](#orgbc37de3)
7. [v0.2.2 - 2023-05-07](#orga686b72)
8. [v0.2.1 - 2023-05-04](#org043a072)
9. [v0.2.0 - 2023-05-02](#org24a7c46)
10. [v0.1.0 - 2023-03-28](#org2302f7a)
3. [See Also](#org70013c5)
# Documentation
`Template::Nest::Fast` is a high-performance template engine module for Raku,
designed to process nested templates quickly and efficiently. This module
improves on the original `Template::Nest` module by caching the index of
positions of variables, resulting in significantly faster processing times.
For more details on `Template::Nest` visit:
<https://metacpan.org/pod/Template::Nest>
Note: This module was created by me as a proof-of-concept to benchmark against
`Template::Nest::XS`. Tom Gracey (virtual.blue) is currently sponsoring for the
development of this module. He authored `Template::Nest` originally in Perl 5.
Note: `Template::Nest::XS` is the recommended module for use in production.
Considerable effort has gone into optimising `Template::Nest::XS`, and it is now
blindingly fast. Make sure to use the latest version (v0.1.9 at the time of
writing), as some instabilities have recently been resolved.
As a pure Raku version, you may also find this module (Template::Nest::Fast)
useful for development/testing purposes - as e.g. a full stack trace can be
obtained from it (unlike the XS version which is more of a black box). There may
be other circumstances where this module is useful. However be aware it is
approx 25 times slower than the XS version.
It is not recommended to use the original pure Raku version of `Template::Nest`.
This module was a line by line rewrite of the Perl 5 module - which
unfortunately turned out to be far too slow to be practical.
## Options
* Note: The options have their hypen counterparts. For example, `comment_delims`
is now `comment-delims`. However, for compatibility with other ::Nest
versions, underscored options are supported on object creation.
Compatibility Progress:
```
[X] comment_delims
[X] defaults
[X] defaults_namespace_char
[X] die_on_bad_params
[ ] escape_char - Won't be implemented
[X] fixed_indent
[X] name_label
[X] show_labels
[X] template_dir
[X] template_ext
[X] token_delims
```
* Note: `escape_char` has been replaced with `token-escape-char`.
* Note: `cache-template` option has been added and is enabled by default.
* `name-label` (default `TEMPLATE`): Represents the label used for
identifying the template name in the hash of template variables.
* `template-dir`: IO object representing the directory where the
templates are located.
* `cache-template` (default: `True`): If True then the whole template
file is cached in memory, this improves performance.
* `die-on-bad-params` (default: `False`): If True, then an attempt to
populate a template with a variable that doesn't exist (i.e. name
not found in template file) results in an error.
Note that it allows to leave variables undefined (i.e. name found in
template file but not defined in template hash). Undefined variables
are replaced with empty string. This is for compatibility with
Template::Nest (Raku).
You might want to keep this enabled during development & testing.
* `show-labels` (default: `False`): If True, an string is appended to
every rendered template which is helpful in identifying which
template the output text came from. This is useful in development
when you have many templates.
Example:
```
<!-- BEGIN 00-simple-page -->
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
<meta name="viewport" content="width=device-width, initial-scale=1">
<title>Simple Page</title>
</head>
<body>
<p>A fairly simple page to test the performance of Template::Nest.</p>
<p>Simple Variable</p>
<!-- BEGIN 01-simple-component -->
<p>Simple Variable in Simple Component</p>
<!-- END 01-simple-component -->
</body>
</html>
<!-- END 00-simple-page -->
```
Here, 'BEGIN' & 'END' blocks have been added because `show-labels`
was set to True.
If you're not templating HTML and still want labels, you can set
`comment-delims`.
* `comment-delims` (default: `['<!--', '-->']`): Use this in
conjunction with `show-labels`. Expects a 2 element array. Example,
for templating JS you could do:
```
my $nest-alt = Template::Nest::Fast.new(
:$template-dir, :show-labels, comment-delims => ['/*', '*/']
);
```
Example output:
```
/* BEGIN js-file */
...
/* END js-file */
```
You can set the second comment token as an empty string if the
language you are templating does not use one. Example, for
templating Raku you could do:
```
my $nest-alt = Template::Nest::Fast.new(
:$template-dir, :show-labels, comment-delims => ['#', '']
);
```
Example output:
```
# BEGIN raku-file
...
# END raku-file */
```
* `template-extension` (default: `html`): get/set the template
extension. This is so you can save typing your template extension
all the time if it's always the same. There is no reason why this
templating system could not be used to construct any other type of
file (or why you could not use another extension even if you were
producing html). Example, to manipulate JavaScript files, this will
look for `30-main.js` in `$template-dir`:
```
my $nest-js = Template::Nest::Fast.new: :$template-dir, :template-extension('js');
my %simple-page-js = %(
TEMPLATE => '30-main',
var => 'Simple Variable',
);
```
Or if you have an empty `template-extension`, this will look for
`30-main.html` in `$template-dir`:
```
my $nest = Template::Nest::Fast.new: :$template-dir, :template-extension('');
my %simple-page-js = %(
TEMPLATE => '30-main.html',
var => 'Simple Variable',
);
```
* `fixed-indent` (default: `False`): Intended to improve readability
when inspecting nested templates. For example, consider these templates:
wrapper.html:
```
<div>
<!--% contents %-->
</div>
```
photo.html:
```
<div>
<img src='/some-image.jpg'>
</div>
```
Output without `fixed-indent`:
```
<div>
<div>
<img src='/some-image.jpg'>
</div>
</div>
```
Output with `fixed-indent`:
```
<div>
<div>
<img src='/some-image.jpg'>
</div>
</div>
```
* `token-delims` (default: `['<!--%', '%-->']`): Set the delimiters
that define a token (to be replaced). For example, setting
`token-delims` to `['<%', '%>']` would mean that `render` will now
recognize and interpolate tokens in the format:
```
<% variable %>
```
* `token-escape-char` (default: empty string): On rare occasions you
may actually want to use the exact character string you are using
for your token delimiters in one of your templates. For example,
here `render` is going to consider this as a token and remove it:
```
did you know we are using token delimiters <!--% and %--> in our templates?
```
To include the token, escape it with `token-escape-char` set to
(`\`):
```
did you know we are using token delimiters \<!--% and %--> in our templates?
```
Set it to an empty string to disable the behaviour.
* `defaults`: Provide a hash of default values that are substituted if
template hash does not provide a value. For example, passing this
defaults hash:
```
my $nest = Template::Nest::Fast.new(
:$template-dir,
defaults => %(
variable => 'Simple Variable',
space => %(
inside => 'A variable inside a space.'
)
),
);
```
This `$nest` will first look for variable in template hash, then in
`%defaults` hash. If no value is found then namespaced defaults are
considered (look `defaults-namespace-char`).
* `defaults-namespace-char` (default: `.`): Say you want to namespace
values in `%defaults` hash to differentiate parameters coming from
template hash and chose to prefix those variables like so:
```
<!--% config.title %--> - <!--% config.description %-->
```
You can pass a defaults like:
```
%(
"config.title" => "Title",
"config.description" => "Description"
)
```
However, writing `config.` repeatedly is a bit effortful, so you can
do the following:
```
%(
config => %(
"title" => "Title",
"description" => "Description"
)
)
```
Note: To disable this behaviour set `defaults-namespace-char` to an
empty string.
* `advanced-indexing` (default: False): When enabled, `::Fast` stores the
timestamp of template file index and if the file on disk is newer, it
re-indexes the file. It also indexes files that are present on disk but
weren't indexed when `::Fast` was initialized.
## Methods
* `render`: Converts a template structure to output text. See Example
for details.
## Example
Templates:
`templates/00-simple-page.html`:
```
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
<meta name="viewport" content="width=device-width, initial-scale=1">
<title>Simple Page</title>
</head>
<body>
<p>A fairly simple page to test the performance of Template::Nest.</p>
<p><!--% variable %--></p>
<!--% simple_component %-->
</body>
</html>
```
`templates/01-simple-component.html`:
```
<p><!--% variable %--></p>
```
### Simple template hash
This is a simple example that injects a variable in a template. We use
another template as a component as well.
```
use Template::Nest::Fast;
# Create a nest object.
my $nest = Template::Nest::Fast.new( template-dir => 'templates/'.IO );
# Declare template structure.
my %simple-page = %(
TEMPLATE => '00-simple-page',
variable => 'Simple Variable',
simple_component => %(
TEMPLATE => '01-simple-component',
variable => 'Simple Variable in Simple Component'
)
);
# Render the page.
put $nest.render(%simple-page);
```
Output:
```
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
<meta name="viewport" content="width=device-width, initial-scale=1">
<title>Simple Page</title>
</head>
<body>
<p>A fairly simple page to test the performance of Template::Nest.</p>
<p>Simple Variable</p>
<p>Simple Variable in Simple Component</p>
</body>
</html>
```
### Array of template hash
Array of template hash can be passed to `render` too.
```
$nest.render(
[
%( TEMPLATE => '01-simple-component', variable => 'This is a variable' ),
%( TEMPLATE => '01-simple-component', variable => 'This is another variable' )
]
)
```
Output:
```
<p>This is a variable</p><p>This is another variable</p>
```
### Array to template variable
Template variable can be a string, another template hash or an array too. The
array itself can contain template hash, string or nested array.
```
my %simple-page-arrays = %(
TEMPLATE => '00-simple-page',
variable => 'Simple Variable',
simple_component => [
# Hash passed.
%(
TEMPLATE => '01-simple-component',
variable => 'Simple Variable in Simple Component'
),
# Can pass string as well.
"<strong>Another test</strong>",
# Or another level of nesting.
[
%(
TEMPLATE => '01-simple-component',
variable => 'Simple Variable in Simple Component'
),
"<strong>Another nested test 2</strong>"
]
]
);
```
Output:
```
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
<meta name="viewport" content="width=device-width, initial-scale=1">
<title>Simple Page</title>
</head>
<body>
<p>A fairly simple page to test the performance of Template::Nest.</p>
<p>Simple Variable</p>
<p>Simple Variable in Simple Component</p><strong>Another test</strong><p>Simple Variable in Simple Component</p><strong>Another nested test 2</strong>
</body>
</html>
```
# News
## v0.3.0 - 2024-11-18
* Bug Fix: Handle an escaped variable at beginning of a file. Earlier the
program didn't treat it like an escaped variable.
## v0.2.8 - 2023-06-27
* Bug Fix: Earlier Seq was rendered as Str, now it is considered a List.
## v0.2.6 - 2023-05-29
* Improve error message for die-on-bad-params.
* Add more tests for advanced-indexing & die-on-bad-params.
* Handle template file vanishing errors.
Handles errors where the template file has vanished.
* Fixed a bug where ::Fast does not die on non-existent template file.
This was introduced in v0.2.5 with advanced indexing option.
## v0.2.5 - 2023-05-25
* Add advanced indexing option.
When enabled, `::Fast` stores the timestamp of template file index and if the
file on disk is newer, it re-indexes the file. It also indexes files that are
present on disk but weren't indexed when `::Fast` was initialized.
## v0.2.4 - 2023-05-22
* Add support for passing array to render method.
Template::Nest [Perl5] supports this.
Basic Example:
```
$nest.render(
[
%( TEMPLATE => '01-simple-component', variable => 'This is a variable' ),
%( TEMPLATE => '01-simple-component', variable => 'This is another variable' )
]
)
```
Output:
```
<p>This is a variable</p><p>This is another variable</p>
```
* Add examples for passing array to render method and passing array to a
template variable.
## v0.2.3 - 2023-05-14
* Add support for underscored options.
This makes the module close to drop-in for projects that use other Nest
versions with support for underscored options.
* Add support for Str, nested List when parsing hash template values.
While parsing hash template values, when we encounter a list we assume
that all the elements will be Hash. This breaks that assumption and
allows for the elements to be of type Hash, Str or even List.
After this change, template hash like this will be supported:
```
my %simple-page-arrays = %(
TEMPLATE => '00-simple-page',
variable => 'Simple Variable',
simple_component => [
# Hash passed.
%(
TEMPLATE => '01-simple-component',
variable => 'Simple Variable in Simple Component'
),
# Can pass string as well.
"<strong>Another test</strong>",
# Or another level of nesting.
[
%(
TEMPLATE => '01-simple-component',
variable => 'Simple Variable in Simple Component'
),
"<strong>Another nested test 2</strong>"
]
]
);
```
## v0.2.2 - 2023-05-07
* Fixed failing tests.
## v0.2.1 - 2023-05-04
* Fixed parsing bug with non-string values in template hash
Template hash with non-string values like:
```
my %template = %(
TEMPLATE => 'simple-template',
count => 200 # will result in failure
);
```
failed to parse prior to v0.2.1, this has been fixed in v0.2.1.
* Improve error message for invalid template hash.
## v0.2.0 - 2023-05-02
* Achieved options compatibility with Template::Nest (Raku).
* Added several options:
* `cache-template`
* `die-on-bad-params`
* `show-labels`
* `comment-delims`
* `template-extension`
* `fixed-indent`
* `token-delims`
* `token-escape-char`
* `defaults`
* `defaults-namespace-char`
* Note: It's not backwards compatible with Template::Nest (Raku).
## v0.1.0 - 2023-03-28
* Initial Release.
# See Also
* Template::Nest [Perl5] <https://metacpan.org/pod/Template::Nest>
* template-nest [Python] <https://pypi.org/project/template-nest/>
* Template::Nest [Raku] <https://raku.land/cpan:TOMGRACEY/Template::Nest>
* Template::Nest::XS [Raku] <https://raku.land/zef:jaffa4/Template::Nest::XS>
|
## dist_zef-raku-land-WebDriver.md
# WebDriver
[](https://gitlab.com/raku-land/webdriver/commits/master)
WebDriver is a remote control interface for web browsers.
## SYNOPSIS
```
use WebDriver;
my $wd = WebDriver.new :4444port;
# Go to Google.
$wd.get: 'https://www.google.com';
# Run a search for "raku".
$wd.find('input[name=q]').send-keys: 'raku';
$wd.find('input[value="Google Search"]').click;
# Click the first result.
$wd.find('h3').click;
# Save a screenshot of the page.
spurt 'screenshot.png', $wd.screenshot;
```
## METHODS
### Actions
#### find
```
method find(Str:D $value, Selector:D :$using = CSS) of Element
```
#### find-all
```
method find-all(Str:D $value, Selector:D :$using = CSS)
```
### Alerts
#### accept-alert
```
method accept-alert of ::?CLASS
```
Accept an alert.
#### alert-text
```
multi method alert-text of Str
multi method alert-text(Str:D $text) of ::?CLASS
```
Get or set the text of an alert.
#### dismiss-alert
```
method dismiss-alert of ::?CLASS
```
Dismiss an alert.
### Navigation
#### back
```
method back of ::?CLASS
```
#### forward
```
method forward of ::?CLASS
```
#### get
```
method get(Str:D $url) of ::?CLASS
```
#### refresh
```
method refresh of ::?CLASS
```
## SEE ALSO
[WebDriver Spec](https://www.w3.org/TR/webdriver/)
|
## dist_github-jaffa4-Rakudo-Perl6-Tracer.md
# Rakudo::Perl6::Tracer
Trace Perl6 code.
Known limitations: if there is a `BEGIN`, there will not be any formatting.
Also, if classes are imported from nqp.
## Usage
```
use Rakudo::Perl6::Tracer;
my $f = Rakudo::Perl6::Tracer.new(); # create a new object
say $f.trace({},$content); # trace the content
```
The returned program code will contain tracing statements beside the
original code.
If you run the traced code, you will see what lines were executed.
## Command line access
```
$ perl6 trace.p6 -h
$ perl6 trace.p6 <Dagrammar.p6 >traced.p6
$ perl6 trace.p6 -sl <Dagrammar.p6 >traced.p6
```
## Example
Example of traced code, note statements are inserted by `trace.p6`:
```
sub dump_node($node)
{
note "line 19";say "matched";
note "line 20";if ($node<regliteral>) {
note "line 21";say "reg $node"~$node<regliteral>;
note "line 22";}
note "line 23";}
```
OR example trace log with -sl
```
line 1 my @Depindex;
line 2 my @Depthis;
line 3 my @Depon;
line 4 my @Depend;
line 5 my @Bot;
line 7 my $debug = False;
line 215 my %h;
line 216 my %g;
line 217 %h<itemid> = 1;
line 218 %g<itemid> = 2;
line 219 %h<name> = '1';
line 220 %g<name> = '2';
line 222 my %j = ( "itemid", 3, "name", 3 );
line 223 my %j4 = ( "itemid", 4, "name", 4 );
```
|
## dist_github-lestrrat-p6-Apache-LogFormat.md
[](https://travis-ci.org/lestrrat/p6-Apache-LogFormat)
# NAME
Apache::LogFormat - Provide Apache-Style Log Generators
# SYNOPSIS
```
# Use a predefined log format to generate string for logging
use Apache::LogFormat;
my $fmt = Apache::LogFormat.combined;
my $line = $fmt.format(%env, @res, $length, $reqtime, $time);
$*ERR.print($line);
# Compile your own log formatter
use Apache::LogFormat::Compiler;
my $c = Apache::LogFormat::Compiler.new;
my $fmt = $c.compile(' ... pattern ... ');
my $line = $fmt.format(%env, @res, $length, $reqtime, $time);
$*ERR.print($line);
```
# DESCRIPTION
Apache::LogFormat provides Apache-style log generators.
# PRE DEFINED FORMATTERS
## common(): $fmt:Apache::LogFormat::Formatter
Creates a new Apache::LogFormat::Formatter that generates log lines in the following format:
```
%h %l %u %t "%r" %>s %b
```
## combined(): $fmt:Apache::LogFormat::Formatter
Creates a new Apache::LogFormat::Formatter that generates log lines in the following format:
```
%h %l %u %t "%r" %>s %b "%{Referer}i" "%{User-agent}i"
```
# AUTHOR
Daisuke Maki [lestrrat@gmail.com](mailto:lestrrat@gmail.com)
# COPYRIGHT AND LICENSE
Copyright 2015 Daisuke Maki
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_zef-lizmat-Set-Equality.md
[](https://github.com/lizmat/Set-Equality/actions)
# NAME
Set::Equality - Implement (==) for older Raku versions
# SYNOPSIS
```
use Set::Equality;
say (1,2,3) (==) (3,1,2); # True
```
# DESCRIPTION
The `Set::Equality` module implements the `(==)` operator (and its unicode version `≡`, and its counterpart `≢`) for versions of Raku **before** the 2020.06 Rakudo compiler release. Its implementation and tests are identical to the ones from Rakudo 2020.06 and later.
On versions of Rakudo that already implement the `(==)` operator and its friends, loading this module is basically a no-op.
The `(==)` operator conceptually coerces its parameters to `Set`s for non-`QuantHash` types. So:
```
(1,2,3) (==) (3,1,2)
```
is conceptually the same as:
```
(1,2,3).Set eqv (3,1,2).Set
```
It will however actually do as little actual coercion as possible to provide the `True` or `False` it is to return. For example:
```
<foo bar baz> (==) %hash
```
will return `True` if there are 3 keys in the hash, and they are `foo`, `bar` and `baz`, and each of these keys holds a truthy value.
# AUTHOR
Elizabeth Mattijsen [liz@raku.rocks](mailto:liz@raku.rocks)
Source can be located at: <https://github.com/lizmat/Set-Equality> . Comments and Pull Requests are welcome.
If you like this module, or what I’m doing more generally, committing to a [small sponsorship](https://github.com/sponsors/lizmat/) would mean a great deal to me!
# COPYRIGHT AND LICENSE
Copyright 2020, 2021, 2024 Elizabeth Mattijsen
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_cpan-FOOIST-Readline.md
# Readline
##### *Note: This README will soon be updated based on new development priorities*
Readline provides a Perl 6 interface to libreadline.
XXX This will probably be a frontend to Readline::Gnu when that's factored out.
XXX For the moment keep all the code here in the Readline module.
# Installation
Please make sure that libreadline is installed beforehand, the tests will fail otherwise. If libreadline is installed but the tests still fail, please note that the Perl 6 package searches a given set of directories for libreadline.{so,dynlib}.\* files, otherwise it defaults to v7. If your libreadline installation isn't on any of these paths, or requires non-standard setup, please file an issue.
For those of you on Linux Debian and Linux-alike systems, you should be able to get the latest version with this CLI invocation:
```
sudo apt-get install libreadline7
```
(I'd prefer to use LibraryCheck, but it fails inside the 'is native()' method call.)
On Macs, use Hombrew to install readline. If you installed Rakudo-Star with homebrew after Sept. 1 it should already be there.
If not you can install just Readline
```
brew install readline
```
or update your rakudo-star install.
```
brew upgrade rakudo-star
```
* Using zef (a module management tool bundled with Rakudo Star):
```
zef update && zef install Readline
```
Or alternatively installing it from a checkout of this repo with zef:
```
zef install .
```
## Usage
See the `examples/` directory in this project.
## Testing
To run tests:
```
prove -e perl6
```
## Author
Jeffrey Goff, DrForr on #perl6, <https://github.com/drforr/>
(Recently taken over by Daniel Lathrop (fooist), <https://github.com/fooist/>
## License
Artistic License 2.0
|
## cool.md
## Chunk 1 of 3
class Cool
Object that can be treated as both a string and number
```raku
class Cool is Any { }
```
`Cool`, also known as the **C**onvenient **OO** **L**oop, is a base class employed by a number of built-in classes whose instances can be meaningfully coerced to a string and a number. For example, an [`Array`](/type/Array) can be used in mathematical operations, where its numerical representation is the number of elements it contains. At the same time, it can be concatenated to a string, where its stringy representation is all of its elements [joined](/routine/join) by a space. Because [`Array`](/type/Array) is `Cool`, the appropriate coercion happens automatically.
Methods in `Cool` coerce the invocant to a more specific type, and then call the same method on that type. For example both [`Int`](/type/Int) and [`Str`](/type/Str) inherit from `Cool`, and calling method `substr` on an [`Int`](/type/Int) converts the integer to [`Str`](/type/Str) first.
```raku
123.substr(1, 1); # '2', same as 123.Str.substr(1, 1)
```
Several built-in types inherit from `Cool`. See the [Type Graph](#typegraphrelations) below for a snapshot.
The following table summarizes the methods that `Cool` provides, and what type they coerce to:
| method | coercion type |
| --- | --- |
| abs | Numeric |
| conj | Numeric |
| sqrt | Numeric |
| sign | Real |
| rand | Numeric |
| sin | Numeric |
| asin | Numeric |
| cos | Numeric |
| acos | Numeric |
| tan | Numeric |
| tanh | Numeric |
| atan | Numeric |
| atan2 | Numeric |
| atanh | Numeric |
| sec | Numeric |
| asec | Numeric |
| cosec | Numeric |
| acosec | Numeric |
| cotan | Numeric |
| cotanh | Numeric |
| acotan | Numeric |
| sinh | Numeric |
| asinh | Numeric |
| cosh | Numeric |
| acosh | Numeric |
| sech | Numeric |
| asech | Numeric |
| cosech | Numeric |
| acosech | Numeric |
| acotanh | Numeric |
| cis | Numeric |
| log | Numeric |
| exp | Numeric |
| roots | Numeric |
| log10 | Numeric |
| log2 | Numeric |
| unpolar | Numeric |
| round | Numeric |
| floor | Numeric |
| ceiling | Numeric |
| truncate | Numeric |
| chr | Int |
| ord | Str |
| chars | Str |
| fmt | Str |
| uniname | Str |
| uninames | Seq |
| unival | Str |
| univals | Str |
| uniprop | Str |
| unimatch | Str |
| uc | Str |
| lc | Str |
| fc | Str |
| tc | Str |
| tclc | Str |
| flip | Str |
| trans | Str |
| contains | Str |
| index | Str |
| rindex | Str |
| ords | Str |
| split | Str |
| match | Str |
| comb | Str |
| subst | Str |
| sprintf | Str |
| printf | Str |
| samecase | Str |
| trim | Str |
| trim-leading | Str |
| trim-trailing | Str |
| EVAL | Str |
| chomp | Str |
| chop | Str |
| codes | Str |
| Complex | Numeric |
| FatRat | Numeric |
| Int | Numeric |
| Num | Numeric |
| Rat | Numeric |
| Real | Numeric |
| UInt | Numeric |
# [Methods](#class_Cool "go to top of document")[§](#Methods "direct link")
## [routine abs](#class_Cool "go to top of document")[§](#routine_abs "direct link")
```raku
sub abs(Numeric() $x)
method abs()
```
Coerces the invocant (or in the sub form, the argument) to [`Numeric`](/type/Numeric) and returns the absolute value (that is, a non-negative number).
```raku
say (-2).abs; # OUTPUT: «2»
say abs "6+8i"; # OUTPUT: «10»
```
## [method conj](#class_Cool "go to top of document")[§](#method_conj "direct link")
```raku
method conj()
```
Coerces the invocant to [`Numeric`](/type/Numeric) and returns the [`Complex`](/type/Complex) conjugate (that is, the number with the sign of the imaginary part negated).
```raku
say (1+2i).conj; # OUTPUT: «1-2i»
```
## [method EVAL](#class_Cool "go to top of document")[§](#method_EVAL "direct link")
```raku
method EVAL(*%_)
```
It calls the [subroutine form](/type/independent-routines#routine_EVAL) with the invocant as the first argument, `$code`, passing along named args, if any.
## [routine sqrt](#class_Cool "go to top of document")[§](#routine_sqrt "direct link")
```raku
sub sqrt(Numeric(Cool) $x)
method sqrt()
```
Coerces the invocant to [`Numeric`](/type/Numeric) (or in the sub form, the argument) and returns the square root, that is, a number that, when multiplied with itself, produces the original number.
```raku
say 4.sqrt; # OUTPUT: «2»
say sqrt(2); # OUTPUT: «1.4142135623731»
```
Returns `NaN` for negative arguments. As of 6.e language version (early implementation exists in Rakudo compiler 2023.02+), will return a [`Complex`](/type/Complex) value for negative arguments.
```raku
say sqrt(-1); # OUTPUT: «0+1i»
```
## [method sign](#class_Cool "go to top of document")[§](#method_sign "direct link")
```raku
method sign()
```
Coerces the invocant to [`Real`](/type/Real) and returns its sign, that is, 0 if the number is 0, 1 for positive and -1 for negative values.
```raku
say 6.sign; # OUTPUT: «1»
say (-6).sign; # OUTPUT: «-1»
say "0".sign; # OUTPUT: «0»
```
## [method rand](#class_Cool "go to top of document")[§](#method_rand "direct link")
```raku
method rand()
```
Coerces the invocant to [`Num`](/type/Num) and returns a pseudo-random value between zero and the number.
```raku
say 1e5.rand; # OUTPUT: «33128.495184283»
```
## [routine sin](#class_Cool "go to top of document")[§](#routine_sin "direct link")
```raku
sub sin(Numeric(Cool))
method sin()
```
Coerces the invocant (or in the sub form, the argument) to [`Numeric`](/type/Numeric), interprets it as radians, returns its [sine](https://en.wikipedia.org/wiki/Sine).
```raku
say sin(0); # OUTPUT: «0»
say sin(pi/4); # OUTPUT: «0.707106781186547»
say sin(pi/2); # OUTPUT: «1»
```
Note that Raku is no computer algebra system, so `sin(pi)` typically does not produce an exact 0, but rather a very small [`Num`](/type/Num).
## [routine asin](#class_Cool "go to top of document")[§](#routine_asin "direct link")
```raku
sub asin(Numeric(Cool))
method asin()
```
Coerces the invocant (or in the sub form, the argument) to [`Numeric`](/type/Numeric), and returns its [arc-sine](https://en.wikipedia.org/wiki/Inverse_trigonometric_functions) in radians.
```raku
say 0.1.asin; # OUTPUT: «0.10016742116156»
say asin(0.1); # OUTPUT: «0.10016742116156»
```
## [routine cos](#class_Cool "go to top of document")[§](#routine_cos "direct link")
```raku
sub cos(Numeric(Cool))
method cos()
```
Coerces the invocant (or in sub form, the argument) to [`Numeric`](/type/Numeric), interprets it as radians, returns its [cosine](https://en.wikipedia.org/wiki/Cosine).
```raku
say 0.cos; # OUTPUT: «1»
say pi.cos; # OUTPUT: «-1»
say cos(pi/2); # OUTPUT: «6.12323399573677e-17»
```
## [routine acos](#class_Cool "go to top of document")[§](#routine_acos "direct link")
```raku
sub acos(Numeric(Cool))
method acos()
```
Coerces the invocant (or in sub form, the argument) to [`Numeric`](/type/Numeric), and returns its [arc-cosine](https://en.wikipedia.org/wiki/Inverse_trigonometric_functions) in radians.
```raku
say 1.acos; # OUTPUT: «0»
say acos(-1); # OUTPUT: «3.14159265358979»
```
## [routine tan](#class_Cool "go to top of document")[§](#routine_tan "direct link")
```raku
sub tan(Numeric(Cool))
method tan()
```
Coerces the invocant (or in sub form, the argument) to [`Numeric`](/type/Numeric), interprets it as radians, returns its [tangent](https://en.wikipedia.org/wiki/Tangent).
```raku
say tan(3); # OUTPUT: «-0.142546543074278»
say 3.tan; # OUTPUT: «-0.142546543074278»
```
## [routine atan](#class_Cool "go to top of document")[§](#routine_atan "direct link")
```raku
sub atan(Numeric(Cool))
method atan()
```
Coerces the invocant (or in sub form, the argument) to [`Numeric`](/type/Numeric), and returns its [arc-tangent](https://en.wikipedia.org/wiki/Inverse_trigonometric_functions) in radians.
```raku
say atan(3); # OUTPUT: «1.24904577239825»
say 3.atan; # OUTPUT: «1.24904577239825»
```
## [routine atan2](#class_Cool "go to top of document")[§](#routine_atan2 "direct link")
```raku
sub atan2($y, $x = 1e0)
method atan2($x = 1e0)
```
The sub should usually be written with two arguments for clarity as it is seen in other languages and in mathematical texts, but the single-argument form is available; its result will always match that of [atan](/routine/atan).
```raku
say atan2 3, 1; # OUTPUT: «1.2490457723982544»
say atan2 3; # OUTPUT: «1.2490457723982544»
say atan2 ⅔, ⅓; # OUTPUT: «1.1071487177940904»
```
The method coerces self and its single argument to [`Numeric`](/type/Numeric), using them to compute the two-argument [arc-tangent](https://en.wikipedia.org/wiki/Atan2) in radians.
```raku
say 3.atan2; # OUTPUT: «1.24904577239825»
say ⅔.atan2(⅓); # OUTPUT: «1.1071487177940904»
```
The $x argument in either the method or the sub defaults to 1 so, in both single-argument cases, the function will return the angle θ in radians between the x-axis and a vector that goes from the origin to the point (3, 1).
## [routine sec](#class_Cool "go to top of document")[§](#routine_sec "direct link")
```raku
sub sec(Numeric(Cool))
method sec()
```
Coerces the invocant (or in sub form, its argument) to [`Numeric`](/type/Numeric), interprets it as radians, returns its [secant](https://en.wikipedia.org/wiki/Trigonometric_functions#Reciprocal_functions), that is, the reciprocal of its cosine.
```raku
say 45.sec; # OUTPUT: «1.90359440740442»
say sec(45); # OUTPUT: «1.90359440740442»
```
## [routine asec](#class_Cool "go to top of document")[§](#routine_asec "direct link")
```raku
sub asec(Numeric(Cool))
method asec()
```
Coerces the invocant (or in sub form, its argument) to [`Numeric`](/type/Numeric), and returns its [arc-secant](https://en.wikipedia.org/wiki/Inverse_trigonometric_functions) in radians.
```raku
say 1.asec; # OUTPUT: «0»
say sqrt(2).asec; # OUTPUT: «0.785398163397448»
```
## [routine cosec](#class_Cool "go to top of document")[§](#routine_cosec "direct link")
```raku
sub cosec(Numeric(Cool))
method cosec()
```
Coerces the invocant (or in sub form, its argument) to [`Numeric`](/type/Numeric), interprets it as radians, returns its [cosecant](https://en.wikipedia.org/wiki/Trigonometric_functions#Reciprocal_functions), that is, the reciprocal of its sine.
```raku
say 0.45.cosec; # OUTPUT: «2.29903273150897»
say cosec(0.45); # OUTPUT: «2.29903273150897»
```
## [routine acosec](#class_Cool "go to top of document")[§](#routine_acosec "direct link")
```raku
sub acosec(Numeric(Cool))
method acosec()
```
Coerces the invocant (or in sub form, its argument) to [`Numeric`](/type/Numeric), and returns its [arc-cosecant](https://en.wikipedia.org/wiki/Inverse_trigonometric_functions) in radians.
```raku
say 45.acosec; # OUTPUT: «0.0222240516182672»
say acosec(45) # OUTPUT: «0.0222240516182672»
```
## [routine cotan](#class_Cool "go to top of document")[§](#routine_cotan "direct link")
```raku
sub cotan(Numeric(Cool))
method cotan()
```
Coerces the invocant (or in sub form, its argument) to [`Numeric`](/type/Numeric), interprets it as radians, returns its [cotangent](https://en.wikipedia.org/wiki/Trigonometric_functions#Reciprocal_functions), that is, the reciprocal of its tangent.
```raku
say 45.cotan; # OUTPUT: «0.617369623783555»
say cotan(45); # OUTPUT: «0.617369623783555»
```
## [routine acotan](#class_Cool "go to top of document")[§](#routine_acotan "direct link")
```raku
sub acotan(Numeric(Cool))
method acotan()
```
Coerces the invocant (or in sub form, its argument) to [`Numeric`](/type/Numeric), and returns its [arc-cotangent](https://en.wikipedia.org/wiki/Inverse_trigonometric_functions) in radians.
```raku
say 45.acotan; # OUTPUT: «0.0222185653267191»
say acotan(45) # OUTPUT: «0.0222185653267191»
```
## [routine sinh](#class_Cool "go to top of document")[§](#routine_sinh "direct link")
```raku
sub sinh(Numeric(Cool))
method sinh()
```
Coerces the invocant (or in method form, its argument) to [`Numeric`](/type/Numeric), and returns its [Sine hyperbolicus](https://en.wikipedia.org/wiki/Hyperbolic_function).
```raku
say 1.sinh; # OUTPUT: «1.1752011936438»
say sinh(1); # OUTPUT: «1.1752011936438»
```
## [routine asinh](#class_Cool "go to top of document")[§](#routine_asinh "direct link")
```raku
sub asinh(Numeric(Cool))
method asinh()
```
Coerces the invocant (or in sub form, its argument) to [`Numeric`](/type/Numeric), and returns its [Inverse Sine hyperbolicus](https://en.wikipedia.org/wiki/Inverse_hyperbolic_function).
```raku
say 1.asinh; # OUTPUT: «0.881373587019543»
say asinh(1); # OUTPUT: «0.881373587019543»
```
## [routine cosh](#class_Cool "go to top of document")[§](#routine_cosh "direct link")
```raku
sub cosh(Numeric(Cool))
method cosh()
```
Coerces the invocant (or in sub form, its argument) to [`Numeric`](/type/Numeric), and returns its [Cosine hyperbolicus](https://en.wikipedia.org/wiki/Hyperbolic_function).
```raku
say cosh(0.5); # OUTPUT: «1.12762596520638»
```
## [routine acosh](#class_Cool "go to top of document")[§](#routine_acosh "direct link")
```raku
sub acosh(Numeric(Cool))
method acosh()
```
Coerces the invocant (or in sub form, its argument) to [`Numeric`](/type/Numeric), and returns its [Inverse Cosine hyperbolicus](https://en.wikipedia.org/wiki/Inverse_hyperbolic_function).
```raku
say acosh(45); # OUTPUT: «4.4996861906715»
```
## [routine tanh](#class_Cool "go to top of document")[§](#routine_tanh "direct link")
```raku
sub tanh(Numeric(Cool))
method tanh()
```
Coerces the invocant (or in sub form, its argument) to [`Numeric`](/type/Numeric), interprets it as radians and returns its [Tangent hyperbolicus](https://en.wikipedia.org/wiki/Hyperbolic_function).
```raku
say tanh(0.5); # OUTPUT: «0.46211715726001»
say tanh(atanh(0.5)); # OUTPUT: «0.5»
```
## [routine atanh](#class_Cool "go to top of document")[§](#routine_atanh "direct link")
```raku
sub atanh(Numeric(Cool))
method atanh()
```
Coerces the invocant (or in sub form, its argument) to [`Numeric`](/type/Numeric), and returns its [Inverse tangent hyperbolicus](https://en.wikipedia.org/wiki/Inverse_hyperbolic_function).
```raku
say atanh(0.5); # OUTPUT: «0.549306144334055»
```
## [routine sech](#class_Cool "go to top of document")[§](#routine_sech "direct link")
```raku
sub sech(Numeric(Cool))
method sech()
```
Coerces the invocant (or in sub form, its argument) to [`Numeric`](/type/Numeric), and returns its [Secant hyperbolicus](https://en.wikipedia.org/wiki/Hyperbolic_function).
```raku
say 0.sech; # OUTPUT: «1»
```
## [routine asech](#class_Cool "go to top of document")[§](#routine_asech "direct link")
```raku
sub asech(Numeric(Cool))
method asech()
```
Coerces the invocant (or in sub form, its argument) to [`Numeric`](/type/Numeric), and returns its [Inverse hyperbolic secant](https://en.wikipedia.org/wiki/Hyperbolic_function).
```raku
say 0.8.asech; # OUTPUT: «0.693147180559945»
```
## [routine cosech](#class_Cool "go to top of document")[§](#routine_cosech "direct link")
```raku
sub cosech(Numeric(Cool))
method cosech()
```
Coerces the invocant (or in sub form, its argument) to [`Numeric`](/type/Numeric), and returns its [Hyperbolic cosecant](https://en.wikipedia.org/wiki/Hyperbolic_function).
```raku
say cosech(pi/2); # OUTPUT: «0.434537208094696»
```
## [routine acosech](#class_Cool "go to top of document")[§](#routine_acosech "direct link")
```raku
sub acosech(Numeric(Cool))
method acosech()
```
Coerces the invocant (or in sub form, its argument) to [`Numeric`](/type/Numeric), and returns its [Inverse hyperbolic cosecant](https://en.wikipedia.org/wiki/Inverse_hyperbolic_function).
```raku
say acosech(4.5); # OUTPUT: «0.220432720979802»
```
## [routine cotanh](#class_Cool "go to top of document")[§](#routine_cotanh "direct link")
```raku
sub cotanh(Numeric(Cool))
method cotanh()
```
Coerces the invocant (or in sub form, its argument) to [`Numeric`](/type/Numeric), and returns its [Hyperbolic cotangent](https://en.wikipedia.org/wiki/Hyperbolic_function).
```raku
say cotanh(pi); # OUTPUT: «1.00374187319732»
```
## [routine acotanh](#class_Cool "go to top of document")[§](#routine_acotanh "direct link")
```raku
sub acotanh(Numeric(Cool))
method acotanh()
```
Coerces the invocant (or in sub form, its argument) to [`Numeric`](/type/Numeric), and returns its [Inverse hyperbolic cotangent](https://en.wikipedia.org/wiki/Inverse_hyperbolic_function).
```raku
say acotanh(2.5); # OUTPUT: «0.423648930193602»
```
## [routine cis](#class_Cool "go to top of document")[§](#routine_cis "direct link")
```raku
sub cis(Numeric(Cool))
method cis()
```
Coerces the invocant (or in sub form, its argument) to [`Numeric`](/type/Numeric), and returns [cos(argument) + i\*sin(argument)](https://en.wikipedia.org/wiki/Cis_%28mathematics%29).
```raku
say cis(pi/4); # OUTPUT: «0.707106781186548+0.707106781186547i»
```
## [routine log](#class_Cool "go to top of document")[§](#routine_log "direct link")
```raku
multi log(Numeric(Cool) $number, Numeric(Cool) $base?)
multi method log(Cool:D: Cool:D $base?)
```
Coerces the arguments (including the invocant in the method form) to [`Numeric`](/type/Numeric), and returns its [Logarithm](https://en.wikipedia.org/wiki/Logarithm) to base `$base`, or to base `e` (Euler's Number) if no base was supplied ([Natural logarithm](https://en.wikipedia.org/wiki/Natural_logarithm)). Throws an exception if `$base` is `1`.
```raku
say (e*e).log; # OUTPUT: «2»
```
Returns `NaN` for negative arguments. As of 6.e language version (early implementation exists in Rakudo compiler 2023.02+), will return a [`Complex`](/type/Complex) value for negative arguments.
## [routine log10](#class_Cool "go to top of document")[§](#routine_log10 "direct link")
```raku
multi method log10()
multi log10(Numeric $x)
multi log10(Cool $x)
```
Coerces the invocant (or in the sub form, the argument) to [`Numeric`](/type/Numeric) (or uses it directly if it's already in that form), and returns its [Logarithm](https://en.wikipedia.org/wiki/Logarithm) in base 10, that is, a number that approximately produces the original number when 10 is raised to its power. Returns `-Inf` for `0`.
```raku
say log10(1001); # OUTPUT: «3.00043407747932»
```
Returns `NaN` for negative arguments. As of 6.e language version (early implementation exists in Rakudo compiler 2023.02+), will return a [`Complex`](/type/Complex) value for negative arguments.
## [routine log2](#class_Cool "go to top of document")[§](#routine_log2 "direct link")
```raku
multi method log2()
multi log2(Numeric $x)
multi log2(Cool $x)
```
Coerces the invocant to [`Numeric`](/type/Numeric), and returns its [Logarithm](https://en.wikipedia.org/wiki/Logarithm) in base 2, that is, a number that approximately (due to computer precision limitations) produces the original number when 2 is raised to its power. Returns `-Inf` for `0`.
```raku
say log2(5); # OUTPUT: «2.321928094887362»
say "4".log2; # OUTPUT: «2»
say 4.log2; # OUTPUT: «2»
```
Returns `NaN` for negative arguments. As of 6.e language version (early implementation exists in Rakudo compiler 2023.02+), will return a [`Complex`](/type/Complex) value for negative arguments.
## [routine exp](#class_Cool "go to top of document")[§](#routine_exp "direct link")
```raku
multi exp(Cool:D $pow, Cool:D $base?)
multi method exp(Cool:D: Cool:D $base?)
```
Coerces the arguments (including the invocant in the method from) to [`Numeric`](/type/Numeric), and returns `$base` raised to the power of the first number. If no `$base` is supplied, `e` (Euler's Number) is used.
```raku
say 0.exp; # OUTPUT: «1»
say 1.exp; # OUTPUT: «2.71828182845905»
say 10.exp; # OUTPUT: «22026.4657948067»
```
## [method unpolar](#class_Cool "go to top of document")[§](#method_unpolar "direct link")
```raku
method unpolar(Numeric(Cool))
```
Coerces the arguments (including the invocant in the method form) to [`Numeric`](/type/Numeric), and returns a complex number from the given polar coordinates. The invocant (or the first argument in sub form) is the magnitude while the argument (i.e. the second argument in sub form) is the angle. The angle is assumed to be in radians.
```raku
say sqrt(2).unpolar(pi/4); # OUTPUT: «1+1i»
```
## [routine round](#class_Cool "go to top of document")[§](#routine_round "direct link")
```raku
multi round(Numeric(Cool), $scale = 1)
multi method round(Cool:D: $scale = 1)
```
Coerces the invocant (or in sub form, its argument) to [`Numeric`](/type/Numeric), and rounds it to the unit of `$scale`. If `$scale` is 1, rounds to the nearest integer; an arbitrary scale will result in the closest multiple of that number.
```raku
say 1.7.round; # OUTPUT: «2»
say 1.07.round(0.1); # OUTPUT: «1.1»
say 21.round(10); # OUTPUT: «20»
say round(1000, 23.01) # OUTPUT: «989.43»
```
Always rounds **up** if the number is at mid-point:
```raku
say (−.5 ).round; # OUTPUT: «0»
say ( .5 ).round; # OUTPUT: «1»
say (−.55).round(.1); # OUTPUT: «-0.5»
say ( .55).round(.1); # OUTPUT: «0.6»
```
**Pay attention** to types when using this method, as ending up with the wrong type may affect the precision you seek to achieve. For [`Real`](/type/Real) types, the type of the result is the type of the argument ([`Complex`](/type/Complex) argument gets coerced to [`Real`](/type/Real), ending up a [`Num`](/type/Num)). If rounding a [`Complex`](/type/Complex), the result is [`Complex`](/type/Complex) as well, regardless of the type of the argument.
```raku
9930972392403501.round(1) .raku.say; # OUTPUT: «9930972392403501»
9930972392403501.round(1e0) .raku.say; # OUTPUT: «9.9309723924035e+15»
9930972392403501.round(1e0).Int.raku.say; # OUTPUT: «9930972392403500»
```
## [routine floor](#class_Cool "go to top of document")[§](#routine_floor "direct link")
```raku
multi floor(Numeric(Cool))
multi method floor
```
Coerces the invocant (or in sub form, its argument) to [`Numeric`](/type/Numeric), and rounds it downwards to the nearest integer.
```raku
say "1.99".floor; # OUTPUT: «1»
say "-1.9".floor; # OUTPUT: «-2»
say 0.floor; # OUTPUT: «0»
```
## [method fmt](#class_Cool "go to top of document")[§](#method_fmt "direct link")
```raku
method fmt($format = '%s')
```
Uses `$format` to return a formatted representation of the invocant; equivalent to calling [sprintf](/routine/sprintf) with `$format` as format and the invocant as the second argument. The `$format` will be coerced to [`Stringy`](/type/Stringy) and defaults to `'%s'`.
For more information about formats strings, see [sprintf](/routine/sprintf).
```raku
say 11.fmt('This Int equals %03d'); # OUTPUT: «This Int equals 011»
say '16'.fmt('Hexadecimal %x'); # OUTPUT: «Hexadecimal 10»
```
## [routine ceiling](#class_Cool "go to top of document")[§](#routine_ceiling "direct link")
```raku
multi ceiling(Numeric(Cool))
multi method ceiling
```
Coerces the invocant (or in sub form, its argument) to [`Numeric`](/type/Numeric), and rounds it upwards to the nearest integer.
```raku
say "1".ceiling; # OUTPUT: «1»
say "-0.9".ceiling; # OUTPUT: «0»
say "42.1".ceiling; # OUTPUT: «43»
```
## [routine truncate](#class_Cool "go to top of document")[§](#routine_truncate "direct link")
```raku
multi truncate(Numeric(Cool))
multi method truncate()
```
Coerces the invocant (or in sub form, its argument) to [`Numeric`](/type/Numeric), and rounds it towards zero.
```raku
say 1.2.truncate; # OUTPUT: «1»
say truncate -1.2; # OUTPUT: «-1»
```
## [routine ord](#class_Cool "go to top of document")[§](#routine_ord "direct link")
```raku
sub ord(Str(Cool))
method ord()
```
Coerces the invocant (or in sub form, its argument) to [`Str`](/type/Str), and returns the [Unicode code point](https://en.wikipedia.org/wiki/Code_point) number of the first code point.
```raku
say 'a'.ord; # OUTPUT: «97»
```
The inverse operation is [chr](/routine/chr).
|
## cool.md
## Chunk 2 of 3
Mnemonic: returns an ordinal number
## [method path](#class_Cool "go to top of document")[§](#method_path "direct link")
```raku
method path(Cool:D: --> IO::Path:D)
```
**DEPRECATED**. *It's been deprecated as of the 6.d version. Will be removed in the next ones.*
Stringifies the invocant and converts it to [`IO::Path`](/type/IO/Path) object. Use the [`.IO method`](/routine/IO) instead.
## [routine chr](#class_Cool "go to top of document")[§](#routine_chr "direct link")
```raku
sub chr(Int(Cool))
method chr()
```
Coerces the invocant (or in sub form, its argument) to [`Int`](/type/Int), interprets it as a [Unicode code points](https://en.wikipedia.org/wiki/Code_point), and returns a [`Str`](/type/Str) made of that code point.
```raku
say '65'.chr; # OUTPUT: «A»
```
The inverse operation is [ord](/routine/ord).
Mnemonic: turns an integer into a *char*acter.
## [routine chars](#class_Cool "go to top of document")[§](#routine_chars "direct link")
```raku
multi chars(Cool $x)
multi chars(Str:D $x)
multi chars(str $x --> int)
method chars(--> Int:D)
```
Coerces the invocant (or in sub form, its argument) to [`Str`](/type/Str), and returns the number of characters in the string. Please note that on the JVM, you currently get codepoints instead of graphemes.
```raku
say 'møp'.chars; # OUTPUT: «3»
say 'ã̷̠̬̊'.chars; # OUTPUT: «1»
say '👨👩👧👦🏿'.chars; # OUTPUT: «1»
```
If the string is native, the number of chars will be also returned as a native `int`.
Graphemes are user visible characters. That is, this is what the user thinks of as a “character”.
Graphemes can contain more than one codepoint. Typically the number of graphemes and codepoints differs when `Prepend` or `Extend` characters are involved (also known as [Combining characters](https://en.wikipedia.org/wiki/Combining_character)), but there are many other cases when this may happen. Another example is `\c[ZWJ]` ([Zero-width joiner](https://en.wikipedia.org/wiki/Zero-width_joiner)).
You can check `Grapheme_Cluster_Break` property of a character in order to see how it is going to behave:
```raku
say ‘ã̷̠̬̊’.uniprops(‘Grapheme_Cluster_Break’); # OUTPUT: «(Other Extend Extend Extend Extend)»
say ‘👨👩👧👦🏿’.uniprops(‘Grapheme_Cluster_Break’); # OUTPUT: «(E_Base_GAZ ZWJ E_Base_GAZ ZWJ E_Base_GAZ ZWJ E_Base_GAZ E_Modifier)»
```
You can read more about graphemes in the [Unicode Standard](https://unicode.org/reports/tr29/#Grapheme_Cluster_Boundaries), which Raku tightly follows, using a method called [NFG, normal form graphemes](/language/glossary#NFG) for efficiently representing them.
## [routine codes](#class_Cool "go to top of document")[§](#routine_codes "direct link")
```raku
sub codes(Str(Cool))
method codes()
```
Coerces the invocant (or in sub form, its argument) to [`Str`](/type/Str), and returns the number of [Unicode code points](https://en.wikipedia.org/wiki/Code_point).
```raku
say 'møp'.codes; # OUTPUT: «3»
```
The same result will be obtained with
```raku
say +'møp'.ords; # OUTPUT: «3»
```
[ords](/routine/ords) first obtains the actual codepoints, so there might be a difference in speed.
## [routine flip](#class_Cool "go to top of document")[§](#routine_flip "direct link")
```raku
sub flip(Cool $s --> Str:D)
method flip()
```
Coerces the invocant (or in sub form, its argument) to [`Str`](/type/Str), and returns a reversed version.
```raku
say 421.flip; # OUTPUT: «124»
```
## [routine trim](#class_Cool "go to top of document")[§](#routine_trim "direct link")
```raku
sub trim(Str(Cool))
method trim()
```
Coerces the invocant (or in sub form, its argument) to [`Str`](/type/Str), and returns the string with both leading and trailing whitespace stripped.
```raku
my $stripped = ' abc '.trim;
say "<$stripped>"; # OUTPUT: «<abc>»
```
## [routine trim-leading](#class_Cool "go to top of document")[§](#routine_trim-leading "direct link")
```raku
sub trim-leading(Str(Cool))
method trim-leading()
```
Coerces the invocant (or in sub form, its argument) to [`Str`](/type/Str), and returns the string with leading whitespace stripped.
```raku
my $stripped = ' abc '.trim-leading;
say "<$stripped>"; # OUTPUT: «<abc >»
```
## [routine trim-trailing](#class_Cool "go to top of document")[§](#routine_trim-trailing "direct link")
```raku
sub trim-trailing(Str(Cool))
method trim-trailing()
```
Coerces the invocant (or in sub form, its argument) to [`Str`](/type/Str), and returns the string with trailing whitespace stripped.
```raku
my $stripped = ' abc '.trim-trailing;
say "<$stripped>"; # OUTPUT: «< abc>»
```
## [routine lc](#class_Cool "go to top of document")[§](#routine_lc "direct link")
```raku
sub lc(Str(Cool))
method lc()
```
Coerces the invocant (or in sub form, its argument) to [`Str`](/type/Str), and returns it case-folded to lowercase.
```raku
say "ABC".lc; # OUTPUT: «abc»
```
## [routine uc](#class_Cool "go to top of document")[§](#routine_uc "direct link")
```raku
sub uc(Str(Cool))
method uc()
```
Coerces the invocant (or in sub form, its argument) to [`Str`](/type/Str), and returns it case-folded to uppercase (capital letters).
```raku
say "Abc".uc; # OUTPUT: «ABC»
```
## [routine fc](#class_Cool "go to top of document")[§](#routine_fc "direct link")
```raku
sub fc(Str(Cool))
method fc()
```
Coerces the invocant (or in sub form, its argument) to [`Str`](/type/Str), and returns the result a Unicode "case fold" operation suitable for doing caseless string comparisons. (In general, the returned string is unlikely to be useful for any purpose other than comparison.)
```raku
say "groß".fc; # OUTPUT: «gross»
```
## [routine tc](#class_Cool "go to top of document")[§](#routine_tc "direct link")
```raku
sub tc(Str(Cool))
method tc()
```
Coerces the invocant (or in sub form, its argument) to [`Str`](/type/Str), and returns it with the first letter case-folded to titlecase (or where not available, uppercase).
```raku
say "abC".tc; # OUTPUT: «AbC»
```
## [routine tclc](#class_Cool "go to top of document")[§](#routine_tclc "direct link")
```raku
sub tclc(Str(Cool))
method tclc()
```
Coerces the invocant (or in sub form, its argument) to [`Str`](/type/Str), and returns it with the first letter case-folded to titlecase (or where not available, uppercase), and the rest of the string case-folded to lowercase.
```raku
say 'abC'.tclc; # OUTPUT: «Abc»
```
## [routine wordcase](#class_Cool "go to top of document")[§](#routine_wordcase "direct link")
```raku
sub wordcase(Str(Cool) $input, :&filter = &tclc, Mu :$where = True)
method wordcase(:&filter = &tclc, Mu :$where = True)
```
Coerces the invocant (or in sub form, the first argument) to [`Str`](/type/Str), and filters each word that smartmatches against `$where` through the `&filter`. With the default filter (first character to uppercase, rest to lowercase) and matcher (which accepts everything), this titlecases each word:
```raku
say "raku programming".wordcase; # OUTPUT: «Raku Programming»
```
With a matcher:
```raku
say "have fun working on raku".wordcase(:where({ .chars > 3 }));
# Have fun Working on Raku
```
With a customer filter too:
```raku
say "have fun working on raku".wordcase(:filter(&uc), :where({ .chars > 3 }));
# HAVE fun WORKING on RAKU
```
## [routine samecase](#class_Cool "go to top of document")[§](#routine_samecase "direct link")
```raku
sub samecase(Cool $string, Cool $pattern)
method samecase(Cool:D: Cool $pattern)
```
Coerces the invocant (or in sub form, the first argument) to [`Str`](/type/Str), and calls [`Str.samecase`](/type/Str#method_samecase) on it.
```raku
say "raKu".samecase("A_a_"); # OUTPUT: «Raku»
say "rAKU".samecase("Ab"); # OUTPUT: «Raku»
```
## [routine uniprop](#class_Cool "go to top of document")[§](#routine_uniprop "direct link")
```raku
multi uniprop(Str:D, |c)
multi uniprop(Int:D $code)
multi uniprop(Int:D $code, Stringy:D $propname)
multi method uniprop(|c)
```
Returns the [unicode property](https://en.wikipedia.org/wiki/Unicode_character_property) of the first character. If no property is specified returns the [General Category](https://en.wikipedia.org/wiki/Unicode_character_property#General_Category). Returns a Bool for Boolean properties. A [uniprops](/routine/uniprops) routine can be used to get the property for every character in a string.
```raku
say 'a'.uniprop; # OUTPUT: «Ll»
say '1'.uniprop; # OUTPUT: «Nd»
say 'a'.uniprop('Alphabetic'); # OUTPUT: «True»
say '1'.uniprop('Alphabetic'); # OUTPUT: «False»
```
## [sub uniprops](#class_Cool "go to top of document")[§](#sub_uniprops "direct link")
```raku
sub uniprops(Str:D $str, Stringy:D $propname = "General_Category")
```
Interprets the invocant as a [`Str`](/type/Str), and returns the [unicode property](http://userguide.icu-project.org/strings/properties) for each character as a Seq. If no property is specified returns the [General Category](https://en.wikipedia.org/wiki/Unicode_character_property#General_Category). Returns a Bool for Boolean properties. Similar to [uniprop](/routine/uniprop), but for each character in the passed string.
## [routine uniname](#class_Cool "go to top of document")[§](#routine_uniname "direct link")
```raku
sub uniname(Str(Cool) --> Str)
method uniname(--> Str)
```
Interprets the invocant or first argument as a [`Str`](/type/Str), and returns the Unicode codepoint name of the first codepoint of the first character. See [uninames](/routine/uninames) for a routine that works with multiple codepoints, and [uniparse](/routine/uniparse) for the opposite direction.
```raku
# Camelia in Unicode
say ‘»ö«’.uniname;
# OUTPUT: «RIGHT-POINTING DOUBLE ANGLE QUOTATION MARK»
say "Ḍ̇".uniname; # Note, doesn't show "COMBINING DOT ABOVE"
# OUTPUT: «LATIN CAPITAL LETTER D WITH DOT BELOW»
# Find the char with the longest Unicode name.
say (0..0x1FFFF).sort(*.uniname.chars)[*-1].chr.uniname;
# OUTPUT: «BOX DRAWINGS LIGHT DIAGONAL UPPER CENTRE TO MIDDLE RIGHT AND MIDDLE LEFT TO LOWER CENTRE»
```
Available as of the 2021.04 Rakudo compiler release.
## [routine uninames](#class_Cool "go to top of document")[§](#routine_uninames "direct link")
```raku
sub uninames(Str:D)
method uninames()
```
Returns of a [`Seq`](/type/Seq) of Unicode names for the all the codepoints in the [`Str`](/type/Str) provided.
```raku
say ‘»ö«’.uninames.raku;
# OUTPUT: «("RIGHT-POINTING DOUBLE ANGLE QUOTATION MARK", "LATIN SMALL LETTER O WITH DIAERESIS", "LEFT-POINTING DOUBLE ANGLE QUOTATION MARK").Seq»
```
Note this example, which gets a [`Seq`](/type/Seq) where each element is a [`Seq`](/type/Seq) of all the codepoints in that character.
```raku
say "Ḍ̇'oh".comb>>.uninames.raku;
# OUTPUT: «(("LATIN CAPITAL LETTER D WITH DOT BELOW", "COMBINING DOT ABOVE").Seq, ("APOSTROPHE",).Seq, ("LATIN SMALL LETTER O",).Seq, ("LATIN SMALL LETTER H",).Seq)»
```
See [uniname](/routine/uniname) for the name of the first codepoint of the first character in the provided [`Str`](/type/Str) and [uniparse](/routine/uniparse) for the opposite direction.
## [routine unimatch](#class_Cool "go to top of document")[§](#routine_unimatch "direct link")
```raku
multi unimatch(Str:D $str, |c)
multi unimatch(Int:D $code, Stringy:D $pvalname, Stringy:D $propname = $pvalname)
```
Checks if the given integer codepoint or the first letter of the given string has a unicode property equal to the value you give. If you supply the Unicode property to be checked it will only return True if that property matches the given value.
```raku
say unimatch 'A', 'Latin'; # OUTPUT: «True»
say unimatch 'A', 'Latin', 'Script'; # OUTPUT: «True»
say unimatch 'A', 'Ll'; # OUTPUT: «False»
```
The last property corresponds to "lowercase letter", which explains why it returns false.
## [routine chop](#class_Cool "go to top of document")[§](#routine_chop "direct link")
```raku
sub chop(Str(Cool))
method chop()
```
Coerces the invocant (or in sub form, its argument) to [`Str`](/type/Str), and returns it with the last character removed.
```raku
say 'raku'.chop; # OUTPUT: «rak»
```
## [routine chomp](#class_Cool "go to top of document")[§](#routine_chomp "direct link")
```raku
sub chomp(Str(Cool))
method chomp()
```
Coerces the invocant (or in sub form, its argument) to [`Str`](/type/Str), and returns it with the last character removed, if it is a logical newline.
```raku
say 'ab'.chomp.chars; # OUTPUT: «2»
say "a\n".chomp.chars; # OUTPUT: «1»
```
## [routine substr](#class_Cool "go to top of document")[§](#routine_substr "direct link")
```raku
sub substr(Str(Cool) $str, |c)
method substr(|c)
```
Coerces the invocant (or in the sub form, the first argument) to [`Str`](/type/Str), and calls [Str.substr](/type/Str#routine_substr) with the arguments.
## [routine substr-rw](#class_Cool "go to top of document")[§](#routine_substr-rw "direct link")
```raku
multi method substr-rw(|) is rw
multi substr-rw(|) is rw
```
Coerces the invocant (or in the sub form, the first argument) to [`Str`](/type/Str), and calls [Str.substr-rw](/type/Str#method_substr-rw) with the arguments.
## [routine ords](#class_Cool "go to top of document")[§](#routine_ords "direct link")
```raku
sub ords(Str(Cool) $str)
method ords()
```
Coerces the invocant (or in the sub form, the first argument) to [`Str`](/type/Str), and returns a list of Unicode codepoints for each character.
```raku
say "Camelia".ords; # OUTPUT: «67 97 109 101 108 105 97»
say ords 10; # OUTPUT: «49 48»
```
This is the list-returning version of [ord](/routine/ord). The inverse operation in [chrs](/routine/chrs). If you are only interested in the number of codepoints, [codes](/routine/codes) is a possibly faster option.
## [routine chrs](#class_Cool "go to top of document")[§](#routine_chrs "direct link")
```raku
sub chrs(*@codepoints --> Str:D)
method chrs()
```
Coerces the invocant (or in the sub form, the argument list) to a list of integers, and returns the string created by interpreting each integer as a Unicode codepoint, and joining the characters.
```raku
say <67 97 109 101 108 105 97>.chrs; # OUTPUT: «Camelia»
```
This is the list-input version of [chr](/routine/chr). The inverse operation is [ords](/routine/ords).
## [routine split](#class_Cool "go to top of document")[§](#routine_split "direct link")
```raku
multi split( Str:D $delimiter, Str(Cool) $input, $limit = Inf, :$k, :$v, :$kv, :$p, :$skip-empty)
multi split(Regex:D $delimiter, Str(Cool) $input, $limit = Inf, :$k, :$v, :$kv, :$p, :$skip-empty)
multi split(@delimiters, Str(Cool) $input, $limit = Inf, :$k, :$v, :$kv, :$p, :$skip-empty)
multi method split( Str:D $delimiter, $limit = Inf, :$k, :$v, :$kv, :$p, :$skip-empty)
multi method split(Regex:D $delimiter, $limit = Inf, :$k, :$v, :$kv, :$p, :$skip-empty)
multi method split(@delimiters, $limit = Inf, :$k, :$v, :$kv, :$p, :$skip-empty)
```
[[1]](#fn1)
Coerces the invocant (or in the sub form, the second argument) to [`Str`](/type/Str), splits it into pieces based on delimiters found in the string and returns the result as a [`Seq`](/type/Seq).
If `$delimiter` is a string, it is searched for literally and not treated as a regex. You can also provide multiple delimiters by specifying them as a list, which can mix `Cool` and [`Regex`](/type/Regex) objects.
```raku
say split(';', "a;b;c").raku; # OUTPUT: «("a", "b", "c").Seq»
say split(';', "a;b;c", 2).raku; # OUTPUT: «("a", "b;c").Seq»
say split(';', "a;b;c,d").raku; # OUTPUT: «("a", "b", "c,d").Seq»
say split(/\;/, "a;b;c,d").raku; # OUTPUT: «("a", "b", "c,d").Seq»
say split(/<[;,]>/, "a;b;c,d").raku; # OUTPUT: «("a", "b", "c", "d").Seq»
say split(['a', /b+/, 4], '1a2bb345').raku; # OUTPUT: «("1", "2", "3", "5").Seq»
```
By default, `split` omits the matches, and returns a list of only those parts of the string that did not match. Specifying one of the `:k, :v, :kv, :p` adverbs changes that. Think of the matches as a list that is interleaved with the non-matching parts.
The `:v` interleaves the values of that list, which will be either [`Match`](/type/Match) objects, if a [`Regex`](/type/Regex) was used as a matcher in the split, or [`Str`](/type/Str) objects, if a `Cool` was used as matcher. If multiple delimiters are specified, [`Match`](/type/Match) objects will be generated for all of them, unless **all** of the delimiters are `Cool`.
```raku
say 'abc'.split(/b/, :v); # OUTPUT: «(a 「b」 c)»
say 'abc'.split('b', :v); # OUTPUT: «(a b c)»
```
`:k` interleaves the keys, that is, the indexes:
```raku
say 'abc'.split(/b/, :k); # OUTPUT: «(a 0 c)»
```
`:kv` adds both indexes and matches:
```raku
say 'abc'.split(/b/, :kv); # OUTPUT: «(a 0 「b」 c)»
```
and `:p` adds them as [`Pair`](/type/Pair)s, using the same types for values as `:v` does:
```raku
say 'abc'.split(/b/, :p); # OUTPUT: «(a 0 => 「b」 c)»
say 'abc'.split('b', :p); # OUTPUT: «(a 0 => b c)»
```
You can only use one of the `:k, :v, :kv, :p` adverbs in a single call to `split`.
Note that empty chunks are not removed from the result list. For that behavior, use the `:skip-empty` named argument:
```raku
say ("f,,b,c,d".split: /","/ ).raku; # OUTPUT: «("f", "", "b", "c", "d").Seq»
say ("f,,b,c,d".split: /","/, :skip-empty).raku; # OUTPUT: «("f", "b", "c", "d").Seq»
```
## [routine lines](#class_Cool "go to top of document")[§](#routine_lines "direct link")
```raku
sub lines(Str(Cool))
method lines()
```
Coerces the invocant (and in sub form, the argument) to [`Str`](/type/Str), decomposes it into lines (with the newline characters stripped), and returns the list of lines.
```raku
say lines("a\nb\n").join('|'); # OUTPUT: «a|b»
say "some\nmore\nlines".lines.elems; # OUTPUT: «3»
```
This method can be used as part of an [`IO::Path`](/type/IO/Path) to process a file line-by-line, since [`IO::Path`](/type/IO/Path) objects inherit from `Cool`, e.g.:
```raku
for 'huge-csv'.IO.lines -> $line {
# Do something with $line
}
# or if you'll be processing later
my @lines = 'huge-csv'.IO.lines;
```
Without any arguments, sub `lines` operates on [`$*ARGFILES`](/language/variables#$*ARGFILES).
To modify values in place use [`is copy`](/language/signatures#Parameter_traits_and_modifiers) to force a writable container.
```raku
for $*IN.lines -> $_ is copy { s/(\w+)/{$0 ~ $0}/; .say }
```
## [method words](#class_Cool "go to top of document")[§](#method_words "direct link")
```raku
method words(Cool:D: |c)
```
Coerces the invocant (or first argument, if it is called as a subroutine) to [`Str`](/type/Str), and returns a list of words that make up the string. Check [`Str.words`](/type/Str#routine_words) for additional arguments and its meaning.
```raku
say <The quick brown fox>.words.join('|'); # OUTPUT: «The|quick|brown|fox»
say <The quick brown fox>.words(2).join('|'); # OUTPUT: «The|quick»
```
`Cool` is the base class for many other classes, and some of them, like [`Match`](/type/Match), can be converted to a string. This is what happens in this case:
```raku
say ( "easy come, easy goes" ~~ m:g/(ea\w+)/).words(Inf);
# OUTPUT: «(easy easy)»
say words( "easy come, easy goes" ~~ m:g/(ea\w+)/ , ∞);
# OUTPUT: «(easy easy)»
```
The example above illustrates two of the ways `words` can be invoked, with the first argument turned into invocant by its signature. `Inf` is the default value of the second argument, so in both cases (and forms) it can be simply omitted.
Only whitespace (including no-break space) counts as word boundaries
```raku
say <Flying on a Boeing 747>.words.join('|'); # OUTPUT: «Flying|on|a|Boeing|747»
```
In this case, "Boeing 747" includes a (visible only in the source) no-break space; `words` still splits the (resulting) [`Str`](/type/Str) on it, even if the original array only had 4 elements:
```raku
say <Flying on a Boeing 747>.join('|'); # OUTPUT: «Flying|on|a|Boeing 747»
```
Please see [`Str.words`](/type/Str#routine_words) for more examples and ways to invoke it.
## [routine comb](#class_Cool "go to top of document")[§](#routine_comb "direct link")
```raku
multi comb(Regex $matcher, Cool $input, $limit = *)
multi comb(Str $matcher, Cool $input, $limit = *)
multi comb(Int:D $size, Cool $input, $limit = *)
multi method comb(|c)
```
Returns a [`Seq`](/type/Seq) of all (or if supplied, at most `$limit`) matches of the invocant (method form) or the second argument (sub form) against the [`Regex`](/type/Regex), string or defined number.
```raku
say "6 or 12".comb(/\d+/).join(", "); # OUTPUT: «6, 12»
say comb(/\d <[1..9]> /,(11..30)).join("--");
# OUTPUT:
# «11--12--13--14--15--16--17--18--19--21--22--23--24--25--26--27--28--29»
```
The second statement exemplifies the first form of `comb`, with a [`Regex`](/type/Regex) that excludes multiples of ten, and a [`Range`](/type/Range) (which is `Cool`) as `$input`. `comb` stringifies the [`Range`](/type/Range) before applying `.comb` on the resulting string. Check [`Str.comb`](/type/Str#routine_comb) for its effect on different kind of input strings. When the first argument is an integer, it indicates the (maximum) size of the chunks the input is going to be divided in
```raku
say comb(3,[3,33,333,3333]).join("*"); # OUTPUT: «3 3*3 3*33 *333*3»
```
In this case the input is a list, which after transformation to [`Str`](/type/Str) (which includes the spaces) is divided in chunks of size 3.
## [method contains](#class_Cool "go to top of document")[§](#method_contains "direct link")
```raku
method contains(Cool:D: |c)
```
Coerces the invocant to a [`Str`](/type/Str), and calls [`Str.contains`](/type/Str#method_contains) on it. Please refer to that version of the method for arguments and general syntax.
```raku
say 123.contains("2")# OUTPUT: «True»
```
Since [`Int`](/type/Int) is a subclass of `Cool`, `123` is coerced to a [`Str`](/type/Str) and then `contains` is called on it.
```raku
say (1,1, * + * … * > 250).contains(233)# OUTPUT: «True»
```
[`Seq`](/type/Seq)s are also subclasses of `Cool`, and they are stringified to a comma-separated form. In this case we are also using an [`Int`](/type/Int), which is going to be stringified also; `"233"` is included in that sequence, so it returns `True`. Please note that this sequence is not lazy; the stringification of lazy sequences does not include each and every one of their components for obvious reasons.
## [routine index](#class_Cool "go to top of document")[§](#routine_index "direct link")
```raku
multi index(Cool:D $s, Cool:D $needle, :i(:$ignorecase), :m(:$ignoremark) --> Int:D)
multi index(Cool:D $s, Cool:D $needle, Cool:D $pos, :i(:$ignorecase), :m(:$ignoremark) --> Int:D)
multi method index(Cool:D: Cool:D $needle --> Int:D)
multi method index(Cool:D: Cool:D $needle, :m(:$ignoremark)! --> Int:D)
multi method index(Cool:D: Cool:D $needle, :i(:$ignorecase)!, :m(:$ignoremark) --> Int:D)
multi method index(Cool:D: Cool:D $needle, Cool:D $pos --> Int:D)
multi method index(Cool:D: Cool:D $needle, Cool:D $pos, :m(:$ignoremark)! --> Int:D)
multi method index(Cool:D: Cool:D $needle, Cool:D $pos, :i(:$ignorecase)!, :m(:$ignoremark) --> Int:D)
```
Coerces the first two arguments (in method form, also counting the invocant) to a [`Str`](/type/Str), and searches for `$needle` in the string `$s` starting from `$pos`. It returns the offset into the string where `$needle` was found, and [`Nil`](/type/Nil) if it was not found.
See [the documentation in type Str](/type/Str#method_index) for examples.
## [routine rindex](#class_Cool "go to top of document")[§](#routine_rindex "direct link")
```raku
multi rindex(Cool:D $s, Cool:D $needle --> Int:D)
multi rindex(Cool:D $s, Cool:D $needle, Cool:D $pos --> Int:D)
multi method rindex(Cool:D: Cool:D $needle --> Int:D)
multi method rindex(Cool:D: Cool:D $needle, Cool:D $pos --> Int:D)
```
Coerces the first two arguments (including the invocant in method form) to [`Str`](/type/Str) and `$pos` to [`Int`](/type/Int), and returns the last position of `$needle` in the string not after `$pos`. Returns [`Nil`](/type/Nil) if `$needle` wasn't found.
See [the documentation in type Str](/type/Str#routine_rindex) for examples.
## [method match](#class_Cool "go to top of document")[§](#method_match "direct link")
```raku
method match(Cool:D: $target, *%adverbs)
```
Coerces the invocant to [`Stringy`](/type/Stringy) and calls the method [match](/type/Str#method_match) on it.
## [routine roots](#class_Cool "go to top of document")[§](#routine_roots "direct link")
```raku
multi roots(Numeric(Cool) $x, Int(Cool) $n)
multi method roots(Int(Cool) $n)
```
Coerces the first argument (and in method form, the invocant) to [`Numeric`](/type/Numeric) and the second (`$n`) to [`Int`](/type/Int), and produces a list of `$n` [`Complex`](/type/Complex) `$n`-roots, which means numbers that, raised to the `$n`th power, approximately produce the original number.
For example
```raku
my $original = 16;
my @roots = $original.roots(4);
say @roots;
for @roots -> $r {
say abs($r ** 4 - $original);
}
# OUTPUT:«2+0i 1.22464679914735e-16+2i -2+2.44929359829471e-16i -3.67394039744206e-16-2i»
# OUTPUT:«1.77635683940025e-15»
# OUTPUT:«4.30267170434156e-15»
# OUTPUT:«8.03651692704705e-15»
# OUTPUT:«1.04441561648202e-14»
```
## [method subst](#class_Cool "go to top of document")[§](#method_subst "direct link")
```raku
method subst(|)
```
Coerces the invocant to [`Stringy`](/type/Stringy) and calls
|
## cool.md
## Chunk 3 of 3
[Str.subst](/type/Str#method_subst).
## [method trans](#class_Cool "go to top of document")[§](#method_trans "direct link")
```raku
method trans(|)
```
Coerces the invocant to [`Str`](/type/Str) and calls [Str.trans](/type/Str#method_trans)
## [method IO](#class_Cool "go to top of document")[§](#method_IO "direct link")
```raku
method IO(--> IO::Path:D)
```
Coerces the invocant to [`IO::Path`](/type/IO/Path).
```raku
.say for '.'.IO.dir; # gives a directory listing
```
## [method sprintf](#class_Cool "go to top of document")[§](#method_sprintf "direct link")
```raku
method sprintf(*@args)
```
Returns a string according to a series of [format directives](/type/independent-routines#Directives) that are common in many languages; the object will be the format string, while the supplied arguments will be what's going to be formatted according to it.
```raku
"% 6s".sprintf('Þor').say; # OUTPUT: « Þor»
```
## [method printf](#class_Cool "go to top of document")[§](#method_printf "direct link")
```raku
method printf(*@args)
```
Uses the object, as long as it is a [format string](/type/independent-routines#Directives), to format and print the arguments
```raku
"%.8f".printf(now - now ); # OUTPUT: «-0.00004118»
```
## [method Complex](#class_Cool "go to top of document")[§](#method_Complex "direct link")
```raku
multi method Complex()
```
Coerces the invocant to a [`Numeric`](/type/Numeric) and calls its [`.Complex`](/routine/Complex) method. [Fails](/routine/fail) if the coercion to a [`Numeric`](/type/Numeric) cannot be done.
```raku
say 1+1i.Complex; # OUTPUT: «1+1i»
say π.Complex; # OUTPUT: «3.141592653589793+0i»
say <1.3>.Complex; # OUTPUT: «1.3+0i»
say (-4/3).Complex; # OUTPUT: «-1.3333333333333333+0i»
say "foo".Complex.^name; # OUTPUT: «Failure»
```
## [method FatRat](#class_Cool "go to top of document")[§](#method_FatRat "direct link")
```raku
multi method FatRat()
```
Coerces the invocant to a [`Numeric`](/type/Numeric) and calls its [`.FatRat`](/routine/FatRat) method. [Fails](/routine/fail) if the coercion to a [`Numeric`](/type/Numeric) cannot be done.
```raku
say 1+0i.FatRat; # OUTPUT: «1»
say 2e1.FatRat; # OUTPUT: «20»
say 1.3.FatRat; # OUTPUT: «1.3»
say (-4/3).FatRat; # OUTPUT: «-1.333333»
say "foo".FatRat.^name; # OUTPUT: «Failure»
```
## [method Int](#class_Cool "go to top of document")[§](#method_Int "direct link")
```raku
multi method Int()
```
Coerces the invocant to a [`Numeric`](/type/Numeric) and calls its [`.Int`](/routine/Int) method. [Fails](/routine/fail) if the coercion to a [`Numeric`](/type/Numeric) cannot be done.
```raku
say 1+0i.Int; # OUTPUT: «1»
say <2e1>.Int; # OUTPUT: «20»
say 1.3.Int; # OUTPUT: «1»
say (-4/3).Int; # OUTPUT: «-1»
say "foo".Int.^name; # OUTPUT: «Failure»
```
## [method Num](#class_Cool "go to top of document")[§](#method_Num "direct link")
```raku
multi method Num()
```
Coerces the invocant to a [`Numeric`](/type/Numeric) and calls its [`.Num`](/routine/Num) method. [Fails](/routine/fail) if the coercion to a [`Numeric`](/type/Numeric) cannot be done.
```raku
say 1+0i.Num; # OUTPUT: «1»
say 2e1.Num; # OUTPUT: «20»
say (16/9)².Num; # OUTPUT: «3.1604938271604937»
say (-4/3).Num; # OUTPUT: «-1.3333333333333333»
say "foo".Num.^name; # OUTPUT: «Failure»
```
## [method Rat](#class_Cool "go to top of document")[§](#method_Rat "direct link")
```raku
multi method Rat()
```
Coerces the invocant to a [`Numeric`](/type/Numeric) and calls its [`.Rat`](/routine/Rat) method. [Fails](/routine/fail) if the coercion to a [`Numeric`](/type/Numeric) cannot be done.
```raku
say 1+0i.Rat; # OUTPUT: «1»
say 2e1.Rat; # OUTPUT: «20»
say (-4/3).Rat; # OUTPUT: «-1.333333»
say "foo".Rat.^name; # OUTPUT: «Failure»
say (.numerator, .denominator) for π.Rat; # OUTPUT: «(355 113)»
```
## [method Real](#class_Cool "go to top of document")[§](#method_Real "direct link")
```raku
multi method Real()
```
Coerces the invocant to a [`Numeric`](/type/Numeric) and calls its [`.Real`](/routine/Real) method. [Fails](/routine/fail) if the coercion to a [`Numeric`](/type/Numeric) cannot be done.
```raku
say 1+0i.Real; # OUTPUT: «1»
say 2e1.Real; # OUTPUT: «20»
say 1.3.Real; # OUTPUT: «1.3»
say (-4/3).Real; # OUTPUT: «-1.333333»
say "foo".Real.^name; # OUTPUT: «Failure»
```
## [method UInt](#class_Cool "go to top of document")[§](#method_UInt "direct link")
```raku
multi method UInt()
```
Coerces the invocant to an [`Int`](/type/Int). [Fails](/routine/fail) if the coercion to an [`Int`](/type/Int) cannot be done or if the [`Int`](/type/Int) the invocant had been coerced to is negative.
```raku
say 1+0i.UInt; # OUTPUT: «1»
say 2e1.UInt; # OUTPUT: «20»
say 1.3.UInt; # OUTPUT: «1»
say (-4/3).UInt.^name; # OUTPUT: «Failure»
say "foo".UInt.^name; # OUTPUT: «Failure»
```
## [method uniparse](#class_Cool "go to top of document")[§](#method_uniparse "direct link")
```raku
method uniparse(Cool:D: --> Str:D)
```
Available as of the 2021.04 release of the Rakudo compiler.
Coerces the invocant to a [`Str`](/type/Str) and then calls the [uniparse](/type/Str#routine_uniparse) on that. This mostly only makes sense for [`Match`](/type/Match) objects.
## [method Order](#class_Cool "go to top of document")[§](#method_Order "direct link")
```raku
method Order(Cool:D: --> Order:D)
```
Available as of the 2022.02 release of the Rakudo compiler.
Coerces the invocant to an [`Int`](/type/Int), and then returns one of the [`Order`](/type/Order) enums: `Less` if negative, `Same` if **0**, `More` if positive.
## [method Failure](#class_Cool "go to top of document")[§](#method_Failure "direct link")
```raku
method Failure(Cool:D: --> Failure:D)
```
Available as of the 2022.06 release of the Rakudo compiler.
Creates an [`X::AdHoc`](/type/X/AdHoc) exception with the stringification of the invocant, and coerces that into a [`Failure`](/type/Failure) object. Mainly intended to reduce the bytecode for error branches in code, to increase the chances of hot code getting inlined.
# [Typegraph](# "go to top of document")[§](#typegraphrelations "direct link")
Type relations for `Cool`
raku-type-graph
Cool
Cool
Any
Any
Cool->Any
Mu
Mu
Any->Mu
StrDistance
StrDistance
StrDistance->Cool
Iterable
Iterable
Associative
Associative
Map
Map
Map->Cool
Map->Iterable
Map->Associative
IO
IO
IO::Path
IO::Path
IO::Path->Cool
IO::Path->IO
Nil
Nil
Nil->Cool
Numeric
Numeric
Real
Real
Real->Numeric
Instant
Instant
Instant->Cool
Instant->Real
Positional
Positional
Range
Range
Range->Cool
Range->Iterable
Range->Positional
List
List
List->Cool
List->Iterable
List->Positional
Int
Int
Int->Cool
Int->Real
Rational
Rational
Rational->Real
Rat
Rat
Rat->Cool
Rat->Rational
PositionalBindFailover
PositionalBindFailover
Sequence
Sequence
Sequence->PositionalBindFailover
Seq
Seq
Seq->Cool
Seq->Iterable
Seq->Sequence
Stringy
Stringy
Str
Str
Str->Cool
Str->Stringy
FatRat
FatRat
FatRat->Cool
FatRat->Rational
Num
Num
Num->Cool
Num->Real
Duration
Duration
Duration->Cool
Duration->Real
Complex
Complex
Complex->Cool
Complex->Numeric
Capture
Capture
Capture->Any
Match
Match
Match->Cool
Match->Capture
[Expand chart above](/assets/typegraphs/Cool.svg)
1 [[↑]](#fnret1) *the [comb](/routine/comb) routine is a much better choice for many tasks that in other languages are handled by the `split`.*
|
## dist_zef-lizmat-Repository-Precomp-Cleanup.md
[](https://github.com/lizmat/Repository-Precomp-Cleanup/actions)
# NAME
Repository::Precomp::Cleanup - provide logic for cleaning up precomp directories
# SYNOPSIS
```
use Repository::Precomp::Cleanup;
cleanup-precomp($*REPO); # cleanup first repository only
my int $cleaned;
for $*REPO.repo-chain -> $repo { # cleanup all repositories
$cleaned += $_ with cleanup-precomp($repo);
}
say "Freed up $cleaned bytes in total";
```
# DESCRIPTION
`Repository::Precomp::Cleanup` is a module that exports a `cleanup-precomp` subroutine that will remove all outdated precompiled files from a given repository precompilation-store. It returns the number of bytes that were freed (as reported by `IO::Path.s`).
# SCRIPTS
This distribution also installs a `clean-precomp` script that will either cleanup the specified repositories by name, or all repositories that can be cleaned from the current repository chain.
# WHY
If you are a module developer that tries to keep up-to-date with all latest versions of Rakudo, and/or you're a core developer working on the setting, you can easily lose a lot of disk-space by outdated precompilation files (as each precompilation file is keyed to a specific version of the core).
The script provided by this distribution, allows you to easily free up this disk-space without having to wonder what can be removed, and what cannot.
```
$ clean-precomp
```
Clean out all precompilation stores in the current repository chain.
```
$ clean-precomp . lib
```
Clean out precompilation stores of repositories in "." and "lib".
# AUTHOR
Elizabeth Mattijsen [liz@raku.rocks](mailto:liz@raku.rocks)
Source can be located at: <https://github.com/lizmat/Repository-Precomp-Cleanup> . Comments and Pull Requests are welcome.
# COPYRIGHT AND LICENSE
Copyright 2022 Elizabeth Mattijsen
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_zef-lizmat-P5caller.md
[](https://github.com/lizmat/P5caller/actions)
# NAME
Raku port of Perl's caller() built-in
# SYNOPSIS
```
use P5caller;
sub foo { bar }
sub bar { say caller[3] } # foo
sub baz { say caller(:scalar) } # GLOBAL
my $package = caller
```
# DESCRIPTION
This module tries to mimic the behaviour of Perl's `caller` built-in as closely as possible in the Raku Programming Language.
# ORIGINAL PERL 5 DOCUMENTATION
```
caller EXPR
caller Returns the context of the current pure perl subroutine call. In
scalar context, returns the caller's package name if there is a
caller (that is, if we're in a subroutine or "eval" or "require")
and the undefined value otherwise. caller never returns XS subs
and they are skipped. The next pure perl sub will appear instead
of the XS sub in caller's return values. In list context, caller
returns
# 0 1 2
($package, $filename, $line) = caller;
With EXPR, it returns some extra information that the debugger
uses to print a stack trace. The value of EXPR indicates how many
call frames to go back before the current one.
# 0 1 2 3 4
($package, $filename, $line, $subroutine, $hasargs,
# 5 6 7 8 9 10
$wantarray, $evaltext, $is_require, $hints, $bitmask, $hinthash)
= caller($i);
Here, $subroutine is the function that the caller called (rather
than the function containing the caller). Note that $subroutine
may be "(eval)" if the frame is not a subroutine call, but an
"eval". In such a case additional elements $evaltext and
$is_require are set: $is_require is true if the frame is created
by a "require" or "use" statement, $evaltext contains the text of
the "eval EXPR" statement. In particular, for an "eval BLOCK"
statement, $subroutine is "(eval)", but $evaltext is undefined.
(Note also that each "use" statement creates a "require" frame
inside an "eval EXPR" frame.) $subroutine may also be "(unknown)"
if this particular subroutine happens to have been deleted from
the symbol table. $hasargs is true if a new instance of @_ was set
up for the frame. $hints and $bitmask contain pragmatic hints that
the caller was compiled with. $hints corresponds to $^H, and
$bitmask corresponds to "${^WARNING_BITS}". The $hints and
$bitmask values are subject to change between versions of Perl,
and are not meant for external use.
$hinthash is a reference to a hash containing the value of "%^H"
when the caller was compiled, or "undef" if "%^H" was empty. Do
not modify the values of this hash, as they are the actual values
stored in the optree.
Furthermore, when called from within the DB package in list
context, and with an argument, caller returns more detailed
information: it sets the list variable @DB::args to be the
arguments with which the subroutine was invoked.
Be aware that the optimizer might have optimized call frames away
before "caller" had a chance to get the information. That means
that caller(N) might not return information about the call frame
you expect it to, for "N > 1". In particular, @DB::args might have
information from the previous time "caller" was called.
Be aware that setting @DB::args is best effort, intended for
debugging or generating backtraces, and should not be relied upon.
In particular, as @_ contains aliases to the caller's arguments,
Perl does not take a copy of @_, so @DB::args will contain
modifications the subroutine makes to @_ or its contents, not the
original values at call time. @DB::args, like @_, does not hold
explicit references to its elements, so under certain cases its
elements may have become freed and reallocated for other variables
or temporary values. Finally, a side effect of the current
implementation is that the effects of "shift @_" can normally be
undone (but not "pop @_" or other splicing, and not if a reference
to @_ has been taken, and subject to the caveat about reallocated
elements), so @DB::args is actually a hybrid of the current state
and initial state of @_. Buyer beware.
```
# PORTING CAVEATS
In Perl, `caller` can return an 11 element list. In the Raku implementation only the first 4 elements are the same as in Perl: package, filename, line, subname. The fifth element is actually the `Sub` or `Method` object and as such provides further introspection possibilities not found in Perl.
As there is no such thing as `scalar` or `list` context in Raku, one must specify a `:scalar` named parameter to emulate the scalar context return value.
# AUTHOR
Elizabeth Mattijsen [liz@raku.rocks](mailto:liz@raku.rocks)
If you like this module, or what I’m doing more generally, committing to a [small sponsorship](https://github.com/sponsors/lizmat/) would mean a great deal to me!
Source can be located at: <https://github.com/lizmat/P5caller> . Comments and Pull Requests are welcome.
# COPYRIGHT AND LICENSE
Copyright 2018, 2019, 2020, 2021, 2023 Elizabeth Mattijsen
Re-imagined from Perl as part of the CPAN Butterfly Plan.
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## none.md
none
Combined from primary sources listed below.
# [In Any](#___top "go to top of document")[§](#(Any)_method_none "direct link")
See primary documentation
[in context](/type/Any#method_none)
for **method none**.
```raku
method none(--> Junction:D)
```
Interprets the invocant as a list and creates a [none](/routine/none)-[`Junction`](/type/Junction) from it.
```raku
say so 1 == (1, 2, 3).none; # OUTPUT: «False»
say so 4 == (1, 2, 3).none; # OUTPUT: «True»
```
|
## dist_cpan-LEONT-Getopt-Subcommands.md
[](https://travis-ci.org/Leont/getopt-subcommands)
# NAME
Getopt::Subcommands - A Getopt::Long extension for subcommands
# SYNOPSIS
```
use Getopt::Subcommands;
sub frobnicate(*@files, Bool :$dry-run) is command { ... }
sub unfrobnicate(:$fuzzy) is command { ... }
sub other($subcommand?, *@args) is fallback { ... }
```
# DESCRIPTION
Getopt::Subcommands is an extension to Getopt::Long that facilitates writing programs with multiple subcommands. It dispatches based on the first argument.
It can be used by using two traits on the subs: `is command` and `is fallback`. The former can optionally take the name of the subcommand as an argument, but will default to the name of the sub. The latter will be called if no suitable subcommand can be found or if none is given.
# AUTHOR
Leon Timmermans [fawaka@gmail.com](mailto:fawaka@gmail.com)
# COPYRIGHT AND LICENSE
Copyright 2019 Leon Timmermans
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## exception.md
exception
Combined from primary sources listed below.
# [In Failure](#___top "go to top of document")[§](#(Failure)_method_exception "direct link")
See primary documentation
[in context](/type/Failure#method_exception)
for **method exception**.
```raku
method exception(Failure:D: --> Exception)
```
Returns the [`Exception`](/type/Exception) object that the failure wraps.
```raku
sub failer() { fail };
my $failure = failer;
my $ex = $failure.exception;
put "$ex.^name(): $ex";
# OUTPUT: «X::AdHoc: Failed»
```
|
## tail.md
tail
Combined from primary sources listed below.
# [In Any](#___top "go to top of document")[§](#(Any)_routine_tail "direct link")
See primary documentation
[in context](/type/Any#routine_tail)
for **routine tail**.
```raku
multi method tail() is raw
multi method tail($n)
```
Returns the last or the list of the `$n` last elements of an object. `$n` can be a [`Callable`](/type/Callable), usually a [`WhateverCode`](/type/WhateverCode), which will be used to get all but the first `n` elements of the object.
```raku
say (^12).reverse.tail ; # OUTPUT: «0»
say (^12).reverse.tail(3); # OUTPUT: «(2 1 0)»
say (^12).reverse.tail(*-7); # OUTPUT: «(4 3 2 1 0)»
```
As of release 2022.07 of the Rakudo compiler, there is also a "sub" version of `tail`.
```raku
multi tail(\specifier, +values)
```
It **must** have the tail specifier as the first argument. The rest of the arguments are turned into a [`Seq`](/type/Seq) and then have the `tail` method called on it.
# [In List](#___top "go to top of document")[§](#(List)_method_tail "direct link")
See primary documentation
[in context](/type/List#method_tail)
for **method tail**.
```raku
multi method tail(List:D:)
multi method tail(List:D: $n --> Seq:D)
```
Returns a [`Seq`](/type/Seq) containing the **last** `$n` items of the list. Returns an empty [`Seq`](/type/Seq) if `$n` <= 0. Defaults to the last element if no argument is specified. Throws an exception if the list is lazy.
Examples:
```raku
say <a b c d e>.tail(*-3);# OUTPUT: «(d e)»
say <a b c d e>.tail(2); # OUTPUT: «(d e)»
say <a b c d e>.tail; # OUTPUT: «e»
```
In the first case, `$n` is taking the shape of a [`WhateverCode`](/type/WhateverCode) to indicate the number of elements from the beginning that will be excluded. `$n` can be either a Callable, in which case it will be called with the value `0`, or anything else that can be converted to a number, in which case it will use that as the number of elements in the output [`Seq`](/type/Seq).
```raku
say <a b c d e>.tail( { $_ - 2 } ); # OUTPUT: «(c d e)»
```
# [In Supply](#___top "go to top of document")[§](#(Supply)_method_tail "direct link")
See primary documentation
[in context](/type/Supply#method_tail)
for **method tail**.
```raku
multi method tail(Supply:D:)
multi method tail(Supply:D: Callable:D $limit)
multi method tail(Supply:D: \limit)
```
Creates a "tail" supply with the same semantics as [List.tail](/type/List#method_tail).
```raku
my $s = Supply.from-list(4, 10, 3, 2);
my $ts = $s.tail(2);
$ts.tap(&say); # OUTPUT: «32»
```
You can call `.tail` with [`Whatever`](/type/Whatever) or `Inf`; which will return a new supply equivalent to the initial one. Calling it with a [`WhateverCode`](/type/WhateverCode) will be equivalent to skipping until that number.
```raku
my $s = Supply.from-list(4, 10, 3, 2);
my $ts = $s.tail( * - 2 );
$ts.tap(&say); # OUTPUT: «32»
```
This feature is only available from the 2020.07 release of Raku.
|
## react.md
react
Combined from primary sources listed below.
# [In Concurrency](#___top "go to top of document")[§](#(Concurrency)_react_react "direct link")
See primary documentation
[in context](/language/concurrency#react)
for **react**.
The `react` keyword introduces a block of code containing one or more `whenever` keywords to watch asynchronous events. The main difference between a supply block and a react block is that the code in a react block runs where it appears in the code flow, whereas a supply block has to be tapped before it does anything.
Another difference is that a supply block can be used without the `whenever` keyword, but a react block requires at least one `whenever` to be of any real use.
```raku
react {
whenever Supply.interval(2) -> $v {
say $v;
done() if $v == 4;
}
}
```
Here the `whenever` keyword uses [`.act`](/type/Supply#method_act) to create a tap on the [`Supply`](/type/Supply) from the provided block. The `react` block is exited when `done()` is called in one of the taps. Using `last` to exit the block would produce an error indicating that it's not really a loop construct.
An `on-demand` [`Supply`](/type/Supply) can also be created from a list of values that will be emitted in turn, thus the first `on-demand` example could be written as:
```raku
react {
whenever Supply.from-list(1..10) -> $v {
say $v;
}
}
```
|
## comp.md
role X::Comp
Common role for compile-time errors
```raku
role X::Comp is Exception { }
```
Common role for compile-time errors.
Note that since the backtrace of a compile time error generally shows routines from the compiler, not from user-space programs, the [`Backtrace`](/type/Backtrace) returned from the [backtrace](/routine/backtrace) method is not very informative. Instead the exception carries its own `filename`, `line` and `column` attributes and public accessors.
If an error occurs while creating an object (like a class or routine) at compile time, generally the exception associated with it does not hold a reference to the object (for example a class would not be fully composed, and thus not usable). In those cases the name of the would-be-created object is included in the error message instead.
# [Methods](#role_X::Comp "go to top of document")[§](#Methods "direct link")
## [method filename](#role_X::Comp "go to top of document")[§](#method_filename "direct link")
The filename in which the compilation error occurred
## [method line](#role_X::Comp "go to top of document")[§](#method_line "direct link")
The line number in which the compilation error occurred.
## [method column](#role_X::Comp "go to top of document")[§](#method_column "direct link")
The column number of location where the compilation error occurred. (Rakudo does not implement that yet).
|
## dist_github-shuppet-Command-Despatch.md

Raku module for parsing generic commands and arguments from a hash table.
|
## dist_cpan-PATRICKZ-RPi-ButtonWatcher.md
# NAME
RPi::ButtonWatcher - A button push event supplier
# SYNOPSIS
```
use RPi::Wiring::Pi;
use RPi::ButtonWatcher;
die if wiringPiSetup() != 0;
# Takes WiringPi pin numbers.
my $watcher = RPi::ButtonWatcher.new(pins => ( 4, 5, 6 ), edge => BOTH, PUD => PULL_UP);
$watcher.getSupply.tap( -> %v {
my $e = %v<edge> == Edge.RISING ?? 'up' !! 'down';
say "Pin: %v<pin>, Edge: $e";
});
```
# DESCRIPTION
This library provides a supplier of GPIO pin state changes.
Read/write access to */sys/class/gpio/export* and */sys/class/gpio/gpioXX/* is required for this library to work. This usually means the user running the code has to be in the *gpio* group.
This module uses polling to detect state changes. A polling interval of 0.1 seconds is usually fast enough for normal button pushes.
The Sysfs interface is documented here: <https://www.kernel.org/doc/Documentation/gpio/sysfs.txt>
# METHODS
## new
Do initialize WiringPi before using this class using `wiringPiSetup`!
Takes the following parameters:
* pins
A list of WiringPi pin numbers to watch.
* edge
The edges to listen for.
```
* `Edge.RISING`
```
Triggered when a button is released.
```
* `Edge.FALLING`
```
Triggered when a button is pressed.
```
* `Edge.BOTH`
```
Triggered on both, button presses and releases.
* debounce
Time in seconds to sleep between polls. Faster means more responsive, but also more system resource eating. Defaults to 0.1 (100ms).
## getSupply
Returns a supply that can be tapped. The supply will emit hashes with two entries:
* pin
The WiringPi pin number that was triggered.
* edge
Either `Edge.RISING` or `Edge.FALLING`.
|
## attributecontainer.md
role Metamodel::AttributeContainer
Metaobject that can hold attributes
```raku
role Metamodel::AttributeContainer {}
```
*Warning*: this role is part of the Rakudo implementation, and is not a part of the language specification.
Classes, roles and grammars can have attributes. Storage and introspection of attributes is implemented by this role.
# [Methods](#role_Metamodel::AttributeContainer "go to top of document")[§](#Methods "direct link")
## [method add\_attribute](#role_Metamodel::AttributeContainer "go to top of document")[§](#method_add_attribute "direct link")
```raku
method add_attribute($obj, $attribute)
```
Adds an attribute. `$attribute` must be an object that supports the methods `name`, `type` and `package`, which are called without arguments. It can for example be of [type Attribute](/type/Attribute).
## [method attributes](#role_Metamodel::AttributeContainer "go to top of document")[§](#method_attributes "direct link")
```raku
method attributes($obj)
```
Returns a list of attributes. For most Raku types, these will be objects of [type Attribute](/type/Attribute).
## [method set\_rw](#role_Metamodel::AttributeContainer "go to top of document")[§](#method_set_rw "direct link")
```raku
method set_rw($obj)
```
Marks a type whose attributes default to having a write accessor. For example in
```raku
class Point is rw {
has $.x;
has $.y;
}
```
The `is rw` trait on the class calls the `set_rw` method on the metaclass, making all the attributes implicitly writable, so that you can write;
```raku
my $p = Point.new(x => 1, y => 2);
$p.x = 42;
```
## [method rw](#role_Metamodel::AttributeContainer "go to top of document")[§](#method_rw "direct link")
```raku
method rw($obj)
```
Returns a true value if [method set\_rw](#method_set_rw) has been called on this object, that is, if new public attributes are writable by default.
|
## mixins.md
role Metamodel::Mixins
Metaobject for generating mixins
```raku
role Metamodel::Mixins {}
```
*Warning*: this role is part of the Rakudo implementation, and is not a part of the language specification.
Using the `does` and `but` infix operators, *mixins* of a base object and an arbitrary number of roles (or another object) can be created. These are objects whose types have properties of both operands' types. Respectively, these rebless the existing object to have the generated mixin type and clone said object with said mixin type:
```raku
class Billboard {
has Str:D $.advertisement is required;
method vandalism(::?CLASS:D: --> Str:D) { ... }
multi method Str(::?CLASS:D: --> Str:D) { $!advertisement }
role Vandalized[Str:D :$vandalism] {
method vandalism(::?CLASS:D: --> Str:D) { $vandalism }
multi method Str(::?CLASS:D: --> Str:D) { $vandalism }
}
}
my Str:D $advertisement = Q:to/ADVERTISEMENT/.chomp;
Brilliant Solutions: sane and knowledgeable consultants.
We have been providing excellent services since 1972!
ADVERTISEMENT
my Str:D $vandalism = Q:to/VANDALISM/.chomp;
S s s ne k l o l .
We e ee e e e e e e !
VANDALISM
my Billboard:D $billboard .= new: :$advertisement;
say $billboard eq $advertisement; # OUTPUT: «True»
my Billboard:D $draft = $billboard but Billboard::Vandalized[:$vandalism];
say $draft eq $vandalism; # OUTPUT: «True»
$billboard does Billboard::Vandalized[:$vandalism];
say $billboard eq $vandalism; # OUTPUT: «True»
```
Optionally, mixins may have a *mixin attribute*. This occurs when only one role having only one public attribute gets mixed into an object. If a mixin attribute exists on a resulting mixin's type, it can be initialized by `but` or `does` using its `value` named parameter. This makes it possible for mixins to not only have composable methods, but composable state as well. Using this feature, the example above can be rewritten so billboards can be vandalized more than once without needing to generate more mixins by making `Billboard::Vandalism`'s `$vandalism` named parameter a [rw](/type/Attribute#trait_is_rw) mixin attribute instead:
```raku
class Billboard {
has Str:D $.advertisement is required;
method vandalism(::?CLASS:D: --> Str:D) { ... }
multi method Str(::?CLASS:D: --> Str:D) { $!advertisement }
role Vandalized {
has Str:D $.vandalism is required is rw;
multi method Str(::?CLASS:D: --> Str:D) { $!vandalism }
}
}
my Str:D $advertisement = Q:to/ADVERTISEMENT/.chomp;
Brilliant Solutions: sane and knowledgeable consultants.
We have been providing excellent services since 1972!
ADVERTISEMENT
my Str:D $vandalism = Q:to/VANDALISM/.chomp;
S s s ne k l o l .
We e ee e e e e e e !
VANDALISM
my Str:D $false-alarm = Qs:to/FALSE-ALARM/.chomp;
$vandalism
⬆️ This is just one of our namesakes we at Brilliant Solutions have been
helping people like you create since 1972!
FALSE-ALARM
my Billboard:D $billboard .= new: :$advertisement;
say $billboard eq $advertisement; # OUTPUT: «True»
$billboard does Billboard::Vandalized :value($vandalism);
say $billboard eq $vandalism; # OUTPUT: «True»
$billboard.vandalism = $false-alarm;
say $billboard eq $false-alarm; # OUTPUT: «True»
```
`Metamodel::Mixins` is the metarole that implements the behavior of said mixins. Formally, mixins are objects whose HOW inherits from a base composable metaobject and applies an arbitrary number of roles, resulting in an object whose HOW has a combination of their properties. In particular, the metamethods this metarole provides are used to implement the behavior of the `but` and `does` infix operators, but these also support introspection related to mixins. For example, the work done by `but` when invoked with an object and one role can be written explicitly using the `mixin` metamethod provided:
```raku
class Foo { }
role Bar { }
say Foo.new but Bar; # OUTPUT: «Foo+{Bar}.new»
say Foo.new.^mixin(Bar); # OUTPUT: «Foo+{Bar}.new»
```
# [Methods](#role_Metamodel::Mixins "go to top of document")[§](#Methods "direct link")
## [method set\_is\_mixin](#role_Metamodel::Mixins "go to top of document")[§](#method_set_is_mixin "direct link")
```raku
method set_is_mixin($obj)
```
Marks `$obj` as being a mixin.
## [method is\_mixin](#role_Metamodel::Mixins "go to top of document")[§](#method_is_mixin "direct link")
```raku
method is_mixin($obj)
```
Returns `1` If `$obj` has been marked as being a mixin with `set_is_mixin`, otherwise returns `0`.
## [method set\_mixin\_attribute](#role_Metamodel::Mixins "go to top of document")[§](#method_set_mixin_attribute "direct link")
```raku
method set_mixin_attribute($obj, $attr)
```
Sets the mixin attribute for `$obj` to `$attr` (which should be an [`Attribute`](/type/Attribute) instance).
## [method mixin\_attribute](#role_Metamodel::Mixins "go to top of document")[§](#method_mixin_attribute "direct link")
```raku
method mixin_attribute($obj)
```
Returns the mixin attribute for `$obj` set with `set_mixin_attribute`.
## [method setup\_mixin\_cache](#role_Metamodel::Mixins "go to top of document")[§](#method_setup_mixin_cache "direct link")
```raku
method setup_mixin_cache($obj)
```
Sets up caching of mixins for `$obj`. After this metamethod has been called, calls to `mixin` will not create a new type for mixins of `$obj` given the same list of roles more than once. This should be called at some point before composition.
## [method flush\_cache](#role_Metamodel::Mixins "go to top of document")[§](#method_flush_cache "direct link")
```raku
method flush_cache($obj)
```
No-op.
## [method generate\_mixin](#role_Metamodel::Mixins "go to top of document")[§](#method_generate_mixin "direct link")
```raku
method generate_mixin($obj, @roles)
```
Creates a new mixin metaobject that inherits from `$obj` and does each of the roles in `@roles`. This is then composed and has its mixin attribute set (if any exists) before getting returned.
While this generates a new mixin type, this doesn't actually mix it into `$obj`; if that is what you intend to do, use the [mixin](/routine/mixin) metamethod instead.
## [method mixin](#role_Metamodel::Mixins "go to top of document")[§](#method_mixin "direct link")
```raku
method mixin($obj, *@roles, :$needs-mixin-attribute)
```
Generates a new mixin type by calling `generate_mixin` with `$obj` and `@roles`. If `$obj` is composed, the mixin cache of `$obj` will be checked for any existing mixin for these beforehand. If `$obj` is an instance of a type, this will return `$obj` reblessed with the mixin generated, otherwise this will return the mixin itself.
If `$needs-mixin-attribute` is `True`, this will throw an exception if no mixin attribute exists on the mixin generated before returning.
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.