
txt
stringlengths 93
37.3k
|
|---|
## dist_zef-bduggan-WebService-Overpass.md
[](https://github.com/bduggan/raku-webservice-overpass/actions/workflows/linux.yml)
[](https://github.com/bduggan/raku-webservice-overpass/actions/workflows/macos.yml)
# NAME
WebService::Overpass - A simple interface to the Overpass API
# SYNOPSIS
Get a node from OpenStreetMap:
```
use WebService::Overpass 'op', '-debug';
say op.query: q:to/OQL/;
[out:json];
node(1);
out;
OQL
```
Output:
```
2024-11-28T08:38:08.234432-05:00 (1) debug: Running overpass query
2024-11-28T08:38:08.238386-05:00 (1) debug: > [out:json];
2024-11-28T08:38:08.238688-05:00 (1) debug: > node(1);
2024-11-28T08:38:08.239029-05:00 (1) debug: > out;
{
"version": 0.6,
"generator": "Overpass API 0.7.62.4 2390de5a",
"elements": [
{
"type": "node",
"id": 1,
"lat": 42.7957187,
"lon": 13.5690032,
...
}
],
...
}
```
Get XML of nodes in a bounding box:
```
say op.query: q:to/OQL/;
[bbox:-25.38653, 130.99883, -25.31478, 131.08938];
node;
out skel;
OQL
```
Output:
```
<?xml version="1.0" encoding="UTF-8"?>
<osm version="0.6" generator="Overpass API 0.7.62.4 2390de5a">
<note>The data included in this document is from www.openstreetmap.org. The data is made available under ODbL.</note>
<meta osm_base="2024-11-28T13:47:15Z"/>
...
<bounds minlat="-25.3865300" minlon="130.9988300" maxlat="-25.3147800" maxlon="131.0893800"/>
<node id="29342040" lat="-25.3572166" lon="131.0427522"/>
<node id="29342041" lat="-25.3570627" lon="131.0413463"/>
...
```
Get a CSV with nodes tagged as cave entrance:
```
say op.query: q:to/OQL/;
[out:csv(::id, ::lat, ::lon, name; true; ",")];
(
node(-25.38653, 130.99883, -25.31478, 131.08938)["natural"="cave_entrance"];
);
out body;
OQL
```
Output:
```
@id,@lat,@lon,name
2377985489,-25.3431812,131.0229585,Itjaritjatiku Yuu
2377985491,-25.3409557,131.0252996,Kulpi Minymaku
2377985515,-25.3427478,131.0246858,Kulpi Watiku
...
```
Construct queries with the `statements` attribute:
```
use WebService::Overpass;
op.statements = <node(1); out meta;>;
# same thing:
say op.execute(:xml).elements[2].attribs<lat lon>.map(+*).List.raku;
say op.execute(:json)<elements>[0]<lat lon>.raku;
```
See the [tutorial](https://osm-queries.ldodds.com/tutorial/index.html) for more examples.
# DESCRIPTION
This is a simple interface to the Overpass API. Overpass is an API for retrieving OpenStreetMap data. Queries use the Overpass Query Language (Overpass QL).
# EXPORTS
If an argument is given to the module, it is assumed to be a name and the module creates a new object of type `WebService::Overpass` and exports it. Also "-debug" will send debug output to stderr. So these are equivalent:
```
use WebService::Overpass 'op', '-debug';
```
and
```
use WebService::Overpass;
my \op = WebService::Overpass.new;
op.logger.send-to: $*ERR;
```
# METHODS
## query
```
method query($data, Bool :$json, Bool :$xml) returns Str
```
Send a complete query and return the result (as a string).
The `$data` parameter should be a complete overpass query. Overpass queries consist of "settings" followed by a semicolon, and then "statements". The settings are key-value pairs in square brackets.
The format of the response depends on the first line of the query (csv, json etc). If `:json` is True, the response is parsed as JSON. If `:xml` is True, the response is parsed as XML. Otherwise, it is returned as a string. For "smarter" behavior, use the `execute` method below.
## execute
```
method execute(:$xml, :$json, :$raw) returns Any
```
Send a query and return the result as a raku data structure.
The `statements` and `settings` attributes are used to construct the query. The `statements` attribute is an array of strings, each of which is a line in the query. The `settings` attribute is a hash of settings that are prepended to the query.
The `:xml` and `:json` parameters are optional and specify the output format. They also add an "out" setting to the query. Note that CSVs need to be done manually, because the fields are part of the settings. For instance
```
op.settings<out> = 'csv(::id, ::lat, ::lon, name; true; ",")';
```
The "true" indicates that a header row should be included. The comma is the separator.
The `:raw` parameter is optional and specifies that the raw response should be returned as a string. Sending `:json` and `:raw` for instance will set the format to json in the payload, but then return the raw unparsed JSON in the response.
# ATTRIBUTES
## url
```
has $.url = 'https://overpass-api.de/api/interpreter';
```
The URL of the Overpass API endpoint.
## settings
```
has %.settings is rw;
```
A hash of settings that are prepended to the query. The keys are the setting names and the values are the setting values.
## statements
```
has Str @.statements is rw;
```
An array of strings, each of which is a line in the query. Every statement should end with a semicolon.
# EXAMPLES
Run the same query in different formats:
```
use WebService::Overpass;
my \op = WebService::Overpass.new;
op.statements = <node(1); out meta;>;
say op.execute(:xml).elements[2].attribs<lat lon>;
say op.execute(:json)<elements>[0]<lat lon>;
op.settings<out> = 'csv(::id, ::lat, ::lon, name; true; ",")';
say op.execute;
```
# SEE ALSO
<https://wiki.openstreetmap.org/wiki/Overpass_API>
# AUTHOR
Brian Duggan
|
## dist_zef-raku-community-modules-Test-Declare.md
[](https://github.com/raku-community-modules/Test-Declare/actions) [](https://github.com/raku-community-modules/Test-Declare/actions) [](https://github.com/raku-community-modules/Test-Declare/actions)
# NAME
Test::Declare - Declare common test scenarios as data.
## CAVEAT
The author is a novice at Raku. Please be nice if you've stumbled across this and have opinions to express. Furthermore I somehow failed to notice the pre-existence of a Perl `Test::Declare`, to which this code is **no relation**. Apologies for any confusion; I renamed late in the day, being fed up with the length of my first choice of `Test::Declarative`.
# SYNOPSIS
```
use Test::Declare;
use Module::Under::Test;
declare(
${
name => 'multiply',
call => {
class => Module::Under::Test,
construct => \(2),
method => 'multiply',
},
args => \(multiplicand => 4),
expected => {
return-value => 8,
},
},
${
name => 'multiply fails',
call => {
class => Module::Under::Test,
construct => \(2),
method => 'multiply',
},
args => \(multiplicand => 'four'),
expected => {
dies => True,
},
},
${
name => 'multiply fails',
call => {
class => Module::Under::Test,
construct => \(2),
method => 'multiply',
},
args => \(multiplicand => 8),
expected => {
# requires Test::Declare::Comparisons
return-value => roughly(&[>], 10),
},
},
);
```
# DESCRIPTION
Test::Declare is an opinionated framework for writing tests without writing (much) code. The author hates bugs and strongly believes in the value of tests. Since most tests are code, they themselves are susceptible to bugs; this module provides a way to express a wide variety of common testing scenarios purely in a declarative way.
# USAGE
Direct usage of this module is via the exported subroutine `declare`. The tests within the distribution in [t/](https://github.com/raku-community-modules/Test-Declare/tree/main/t) can also be considered to be a suite of examples which exercise all the options available.
## declare(${ … }, ${ … })
`declare` takes an array of hashes describing the test scenarios and expectations. Each hash should look like this:
* name
The name of the test, for developer understanding in the TAP output.
* call
A hash describing the code to be called.
```
* class
```
The actual concrete class - not a string representation, and not an instance either.
```
* method
```
String name of the method to call.
```
* construct
```
If required, a [Capture](https://docs.raku.org/type/Capture.html) of the arguments to the class's `new` method.
* args
If required, a [Capture](https://docs.raku.org/type/Capture.html) of the arguments to the instance's method.
* expected
A hash describing the expected behaviour when the method gets called.
```
* return-value
```
The return value of the method, which will be compared to the actual return value via `eqv`.
```
* lives / dies / throws
```
`lives` and `dies` are booleans, expressing simply whether the code should work or not. `throws` should be an Exception type.
```
* stdout / stderr
```
Strings against which the method's output/error streams are compared, using `eqv` (i.e. not a regex).
# SEE ALSO
Elsewhere in this distribution:
* `Test::Declare::Comparisons` - for fuzzy matching including some naive/rudimentary attempts at copying the [Test::Deep](https://metacpan.org/pod/Test::Deep) interface where Raku does not have it builtin.
* [Test::Declare::Suite](https://github.com/raku-community-modules/Test-Declare/tree/main/lib/Test/Declare/Suite.rakumod) - for a role which bundles tests together against a common class / method, to reduce repetition.
# AUTHOR
Darren Foreman
# COPYRIGHT AND LICENSE
Copyright 2018 Darren Foreman
Copyright 2024 Raku Community
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_zef-guifa-Polyglot-Regexen.md
# Polyglot::Regexen
A module to enable use of non-Raku flavors of regex directly in Raku code.
### Why?
Because copy and paste. Also, there are lots of little gotchas when going between different flavors. What counts for `\s`, `\d`, `.`, or even `$` can vary substantially or in quite subtle ways.
If you have a battle-tested regex, don't worry about rewriting it. Just use it as is!
The goal of this module is to provide a variety of ways for you to use your favor flavors in Raku scripts — even in grammars!
When using regexen from this module, you can be assured that capture ordering is preserved, the meaning of whitespace won't get changed, etc.
## Support
The support for different flavors is shown below in a table, followed by a discussion on any (hopefully temporary) deviations from the standard.
The meaning of the columns is the following:
* **In grammars**: these can be used inside of grammars. Just declare the regex with the psuedo-adverb. Since `}` will necessarily be the terminating character, you may need to escape it in some way.
* **Bare quoted**: just as you can use `rx/foo/` for regular regexes, these allow you to prefix with, e.g., `rx:ecma/foo/`
* **Lexical scope**: these are defined by `my`/`our` scoping, e.g. `my ecma-regex { … }`
| Flavor | In grammars | Bare quoted (substitution) | Lexical scoped | adverb |
| --- | --- | --- | --- | --- |
| ECMA-262 (Javascript) | ✓ | ✓ (𐄂) | ✓ | ecma |
| Python | 𐄂 | 𐄂 (𐄂) | 𐄂 | py |
| Ruby | 𐄂 | 𐄂 (𐄂) | 𐄂 | ruby |
| PHP | 𐄂 | 𐄂 (𐄂) | 𐄂 | php |
(At the moment, only Javascript is supported. The others are aspirational.)
### Support Caveats
* General
* Non-slash delimiters are not currently planned
* ECMA-262 (Javascript)
* Not all options are currently available (right now, just `s`, `m`, and `i`).
* In block form (defined with `regex:ecma { … }`, leading and trailing white space is ignored).
* To add options in block form, use a colon: `regex:ecma:i { … }`
* Unicode option is effectively always on. More testing will be required to tease out if/when that makes a difference
# Version History
* **v0.0.1**
* Fixed ECMA262 positional match counting
* Added support for named back references in ECMA262
* RakuAST-ified for *much* better maintenance
* Reorganized tests and added many new and detailed tests
* **v0.0.1**
\* Initial public release with most of ECMA262 (JavaScript) regex supported
|
## run.md
run
Combined from primary sources listed below.
# [In Thread](#___top "go to top of document")[§](#(Thread)_method_run "direct link")
See primary documentation
[in context](/type/Thread#method_run)
for **method run**.
```raku
method run(Thread:D:)
```
Runs the thread, and returns the invocant. It is an error to run a thread that has already been started.
# [In Independent routines](#___top "go to top of document")[§](#(Independent_routines)_sub_run "direct link")
See primary documentation
[in context](/type/independent-routines#sub_run)
for **sub run**.
```raku
sub run(
*@args ($, *@),
:$in = '-',
:$out = '-',
:$err = '-',
Bool :$bin = False,
Bool :$chomp = True,
Bool :$merge = False,
Str:D :$enc = 'UTF-8',
Str:D :$nl = "\n",
:$cwd = $*CWD,
Hash() :$env = %*ENV,
:$arg0,
:$win-verbatim-args = False
--> Proc:D)
```
Runs an external command *without involving a shell* and returns a [`Proc`](/type/Proc) object. By default, the external command will print to standard output and error, and read from standard input.
```raku
run 'touch', '--', '*.txt'; # Create a file named “*.txt”
run <rm -- *.txt>; # Another way to use run, using word quoting for the
# arguments
```
If you want to pass some variables you can still use `< >`, but try to avoid using `« »` as it will do word splitting if you forget to quote variables:
```raku
my $file = ‘--my arbitrary filename’;
run ‘touch’, ‘--’, $file; # RIGHT
run <touch -->, $file; # RIGHT
run «touch -- "$file"»; # RIGHT but WRONG if you forget quotes
run «touch -- $file»; # WRONG; touches ‘--my’, ‘arbitrary’ and ‘filename’
run ‘touch’, $file; # WRONG; error from `touch`
run «touch "$file"»; # WRONG; error from `touch`
```
Note that `--` is required for many programs to disambiguate between command-line arguments and [filenames that begin with hyphens](https://mywiki.wooledge.org/BashPitfalls#Filenames_with_leading_dashes).
A sunk [`Proc`](/type/Proc) object for a process that [exited](/routine/exitcode) unsuccessfully will throw an [`Exception`](/type/Exception). If you wish to ignore the exceptions, and return a [`Proc`](/type/Proc) you can introspect, use [run](/routine/run) in non-sink context:
```raku
run 'false'; # SUNK! Will throw an Exception
run('false').so; # OK. Evaluates Proc in Bool context; no sinking. Ignore returned Proc
my $a = run('false'); # Can call methods on the Proc in $a.
```
If you want to capture standard output or error instead of having it printed directly you can use the `:out` or `:err` arguments, which will make them available using their respective methods: [`Proc.out`](/type/Proc) and [`Proc.err`](/type/Proc).
```raku
my $proc = run 'echo', 'Raku is Great!', :out, :err;
$proc.out.slurp(:close).say; # OUTPUT: «Raku is Great!»
$proc.err.slurp(:close).say; # OUTPUT: «»
```
You can use these arguments to redirect them to a filehandle, thus creating a kind of *pipe*:
```raku
my $ls-alt-handle = open :w, '/tmp/cur-dir-ls-alt.txt';
my $proc = run "ls", "-alt", :out($ls-alt-handle);
# (The file will contain the output of the ls -alt command)
```
These argument are quite flexible and admit, for instance, handles to redirect them. See [`Proc`](/type/Proc) and [`Proc::Async`](/type/Proc/Async) for more details.
See also [`new`](/type/Proc#routine_new) and [`spawn`](/type/Proc#method_spawn) for more examples and explanation of all arguments.
|
## dist_zef-tony-o-Operator-feq.md
#`feq` Operator
Provides `feq` operator for clean fuzzy string comparisons.
Includes a precanned wrapper for Text::Levenshtein::Damerau (the wrapper uses just the Levenshtein algorithm by default)
#Usage
##Out of the Box™
```
use Operator::feq;
if '1234567890' feq '1234567899' {
'I\'m here!'.say;
}
if '12345' feq '123' {
'I don\'t get here'.say;
}
#outputs:
#I'm here!
```
See the tests for an example of how to extend/create custom comparison routines.
#Configuration
##`$*FEQLIB`
Defaults: `Text::Levenshtein::Damerau`
Set this dynamic variable to control which library 'feq' uses
##`$*FEQTHRESHOLD`
Defaults: `0.10` # 10%
Set this dynamic variable to control the threshold for the matching. Setting this variable to 0 will always cause `feq` to return `False`. Conversely, a value of `1` will always return `True`.
#Credit Cards
[@tony-o](https://www.gittip.com/tony-o/)
Nick Logan <ugexe>
|
## dist_zef-knarkhov-Trove.md
# Trove test harness
## Concept
Yet another [test harness written in Raku](https://github.com/pheix/raku-trove) language and inspired by `bash` driven test tool built for [Pheix](https://gitlab.com/pheix/dcms-raku) content management system.
Generally `Trove` is based on idea to create the wrapper over the unit tests in `t` folder. But with out-of-the-box Gitlab or Github CI/CD integration, extended logging and test-dependable options.
`Trove` includes `trove-cli` script as a primary worker for batch testing. It iterates over pre-configured stages and runs specific unit test linked to the stage. `trove-cli` is console oriented — all output is printed to `STDOUT` and `STDERR` data streams. Input is taken from command line arguments.
## TL;DR
`Trove` Christmas recipes at Raku Advent 2022 blog: <https://raku-advent.blog/2022/12/14/day-14-trove-yet-another-tap-harness>
## Usage
1. Command line arguments
* [Colors](#colors)
* [Stages management](#stages-management)
* [File processor configuration](#file-processor-configuration)
* [Versions consistency](#versions-consistency)
* [Target configuration file](#target-configuration-file)
* [First stage logging policy](#first-stage-logging-policy)
* [Origin repository](#origin-repository)
2. Test configuration files — JSON & YAML
* Configuration file sections
* [Explore](#explore)
* [Stage and substage](#stage-and-substage)
* [Mix it up!](#mix-it-up)
* [Trivial test configuration example](#trivial-test-configuration-example)
* [Pheix test suite configuration files](#pheix-test-suite-configuration-files)
3. Test coverage management
* [Gitlab](#gitlab)
* [Coveralls](#coveralls)
* [Setup automatic coverage upload](#setup-automatic-coverage-upload)
4. [Log test session](#log-test-session)
5. Integration with CI/CD environments
* [github.com](#githubcom)
* [gitlab.com](#gitlabcom)
### Command line arguments
#### Colors
To bring colors to the output `-c` option is used:
```
trove-cli -c --f=`pwd`/run-tests.conf.yml --p=yq
```
#### Stages management
To exclude specific stages from test `-s` option is used:
```
trove-cli -c --s=1,2,4,9,10,11,12,13,14,25,26 --f=`pwd`/run-tests.conf.yml --p=yq
```
### File processor configuration
`trove-cli` takes test scenario from configuration file. Default format is JSON, but you can use YAML on demand, for now `JSON::Fast` and `YAMLish` processing modules (processors) are integrated. To switch between the processors the next command line options should be used:
* `--p=jq` or do not use `--p` (default behavior) — [JSON](https://github.com/timo/json_fast) processor;
* `--p=yq` — [YAML](https://github.com/Leont/yamlish) processor.
### Versions consistency
To verify the version [consistency](https://gitlab.com/pheix-research/talks/-/tree/main/pre-RC2#version-control-consistency-in-git-commit-message-and-pheixmodelversion) on commit, the next command line options should be used:
* `--g` — path to git repo with version at latest commit in format `%0d.%0d.%0d`;
* `--v` — current version to commit (in format `%0d.%0d.%0d` as well).
```
trove-cli -c --g=~/git/raku-foo-bar --v=1.0.0
```
### Target configuration file
By default the next configuration targets are used:
* JSON — `./x/trove-configs/test.conf.json`;
* YAML — `./x/trove-configs/test.conf.yaml`.
These paths are used to test `Trove` itself with:
```
cd ~/git/raku-trove && bin/trove-cli -c && bin/trove-cli -c --p=yq
```
To use another configuration file you have to specify it via `--f` option:
```
trove-cli --f=/tmp/custom.jq.conf
```
### First stage logging policy
`trove-cli` is obviously used to test Pheix. First Pheix testing stage checks `www/user.rakumod` script with:
```
raku $WWW/user.raku --mode=test # WWW == './www'
```
This command prints nothing to standard output and eventually nothing is needed to be saved to log file. By default first stage output is ignored. But if you use Pheix Tests tool to test some other module or application, i might be handy to force save first stage output. This is done by `-l` command line argument:
```
trove-cli --f=/tmp/custom.jq.conf -l
```
In case the stage with blank output is not skipped it's taken into coverage scope but marked as `WARN` in `trove-cli` output:
```
01. Testing ./www/user.raku [ WARN ]
02. Testing ./t/cgi/cgi_post_test.sh [ 6% covered ]
...
```
### Origin repository
By default origin repository is set up to `git@github.com:pheix/raku-trove.git` and you can change it to any value you prefer by `-o` argument:
```
trove-cli --f=/tmp/custom.jq.conf --o=git@gitlab.com:pheix/net-ethereum-perl6.git
```
## Test configuration files — JSON & YAML
### Configuration file sections
* `target` — description of test target;
* `explore` — explore file system and build test plan with stages automatically;
* `stages` — list of the test stages.
#### Explore
`explore` section is used to build test plan with test stages automatically. Consider a Perl module with some tests within `./t` folder — two options for you: add every unit test as stage manually or just configure some universal stage setup under the `explore` section.
```
target: Trivial one-liner test
explore:
base: ./t
pattern: (<[0..9]>+)\.t
interpreter: perl
recursive: 1
```
* `base` — relative or absolute base path where `Trove` will find unit test;
* `pattern` — Raku regular expression that will be used for matching;
* `interpreter` — default interpreter to run the unit tests;
* `recursive` — try to traverse sub folders recursively.
By default `interpreter` is `raku`, and `recursive` is disabled.
#### Stage and substage
* `test` — test command to execute;
* `args` — if command uses environment variables, they should be in `test` command line (`%SOMEVAR%` for `jq` and `$SOMEVAR` for `yq`) and in `args` list as `SOMEVAR` (no `$` or `%` chars);
* `environment` — command to set up environmental variables for the stage, e.g. `export HTTP_REFERER=//foo.bar` or whatever else, please keep in mind — `environment` is defines as list, but actually only first element of this list is used, so no matter how many command you set up there, only the first one will be used;
* `cleanup` — command to clean up environmental variables for the stage, the same restrictions are actual here;
* `substages` — list of the test substages;
#### Mix it up!
You can mix `explore` and `stages` sections to flexibly cover some edge test cases like:
```
target: Trivial one-liner test
explore:
base: ./t
pattern: (0 <[0..9]> ** 1..1)\.t
stages:
- test: 'raku ./t/11.t $INPUT'
args:
- INPUT
```
In this sample `Trove` will automatically add stages for `./t/00.t` ... `./t/09.t` unit tests and will run one manually added stage with additional input argument from environmental variable for `./t/11.t` unit test.
### Trivial test configuration example
Trivial multi-interpreter one-liner test [configuration file](https://github.com/pheix/raku-trove/blob/main/x/trove-configs/test.conf.yaml.explorer) is included to `Trove`:
```
target: Trivial one-liner test
stages:
- test: raku -eok(1); -MTest
- test: perl6 -eis($CONSTANT,2); -MTest
args:
- CONSTANT
- test: perl -eok(3);done_testing; -MTest::More
```
Test command to be executed:
```
CONSTANT=2 && trove-cli --f=/home/pheix/git/raku-trove/x/trove-configs/test.conf.yaml.explorer --p=yq -c
```
### Pheix test suite configuration files
Pheix test suite configuration files have a full set of features we talked above: `explore`, `stages`, `subtages`, environmental variables export, setup and clean up. These files could be used as basic examples to create test configuration for yet another module or application, no matter — Raku, Perl or something else.
Sample [snippet](https://gitlab.com/pheix/dcms-raku/-/blob/develop/run-tests.conf.yml) from `run-tests.conf.yml`:
```
target: Pheix test suite
explore:
base: ./t
pattern: (<[23]> ** 1..1 <[0..9]> ** 1..1)|(<[01]> ** 1..1 <[234569]> ** 1..1)|('07'|'08'|'10')<[a..z-]>+\.t
interpreter: raku
stages:
- test: 'raku $WWW/user.raku --mode=test'
args:
- WWW
- test: ./t/cgi/cgi_post_test.sh
substages:
- test: raku ./t/00-november.t
...
- test: 'raku ./t/11-version.t $GITVER $CURRVER'
args:
- GITVER
- CURRVER
...
- test: raku ./t/17-headers-proto-sn.t
environment:
- 'export SERVER_NAME=https://foo.bar'
cleanup:
- unset SERVER_NAME
substages:
- test: raku ./t/17-headers-proto-sn.t
environment:
- export SERVER_NAME=//foo.bar/
cleanup:
- unset SERVER_NAME
- test: raku ./t/18-headers-proto.t
substages:
- test: raku ./t/18-headers-proto.t
environment:
- 'export HTTP_REFERER=https://foo.bar'
cleanup:
- unset HTTP_REFERER
...
```
## Test coverage management
### Gitlab
Coverage percentage in Gitlab is retrieved from job's standard output: while your tests are running, you have to print actual test progress in percents to console (`STDOUT`). Output log is parsed by runner on job finish, the matching patterns [should be set up](https://docs.gitlab.com/ee/ci/pipelines/settings.html#add-test-coverage-results-using-project-settings-removed) in `.gitlab-ci.yml` — CI/CD configuration file.
Consider trivial test configuration example from the [section above](#trivial-test-configuration-example), the standard output is:
```
01. Running -eok(1,'true'); [ 33% covered ]
02. Running -eis(2,2,'2=2'); [ 66% covered ]
03. Running -eok(3,'perl5');done_testing; [ 100% covered ]
```
Matching pattern in `.gitlab-ci.yml` is set up:
```
...
trivial-test:
stage: trivial-test-stable
coverage: '/(\d+)% covered/'
...
```
### Coveralls
#### Basics
[Coveralls](https://coveralls.io/) is a web service that allows users to track the code coverage of their application over time in order to optimize the effectiveness of their unit tests. `Trove` test tool includes Coveralls integration via [API](https://docs.coveralls.io/api-reference).
API reference is quite clear — the generic objects are `job` and `source_file`. Array of source files should be included to the job:
```
{
"service_job_id": "1234567890",
"service_name": "Trove::Coveralls",
"source_files": [
{
"name": "foo.raku",
"source_digest": "3d2252fe32ac75568ea9fcc5b982f4a574d1ceee75f7ac0dfc3435afb3cfdd14",
"coverage": [null, 1, null]
},
{
"name": "bar.raku",
"source_digest": "b2a00a5bf5afba881bf98cc992065e70810fb7856ee19f0cfb4109ae7b109f3f",
"coverage": [null, 1, 4, null]
}
]
}
```
In example above we covered `foo.raku` and `bar.raku` by our tests. File `foo.raku` has 3 lines of source code and only line no.2 is covered. File `bar.raku` has 4 lines of source code, lines no.2 and no.3 are covered, 2nd just once, 3rd — four times.
#### Test suite integration
We assume full coverage for some software part if its unit test is passed. Obviously this part is presented by its unit tests and `source_files` section in Coveralls request looks like:
```
...
"source_files": [
{
"name": "./t/01.t",
"source_digest": "be4b2d7decf802cbd3c1bd399c03982dcca074104197426c34181266fde7d942",
"coverage": [ 1 ]
},
{
"name": "./t/02.t",
"source_digest": "2d8cecc2fc198220e985eed304962961b28a1ac2b83640e09c280eaac801b4cd",
"coverage": [ 1 ]
}
]
...
```
We consider no lines to be covered, so it's enough to set `[ 1 ]` to `coverage` member.
Besides `source_files` member we have to set up a `git` [member](https://docs.coveralls.io/api-reference#arguments) as well. It's pointed as optional, but your build reports on Coveralls side will look anonymous without git details (commit, branch, message and others).
#### Setup automatic coverage upload
You have to set up your test environment to send coverage to Coveralls service automatically. Initially `Trove` was a simple bash script targeted to GitLab and relied on the next environmental variables:
* `CI_JOB_ID` - [predefined](https://docs.gitlab.com/ee/ci/variables/predefined_variables.html) GitLab CI job identifier, actually `CI_JOB_ID` can be any integer value you prefer — just `date +%s` or something dummy like `0`;
* `COVERALLSTOKEN` - Coveralls secret [repository token](https://docs.coveralls.io/api-introduction).
Sample `Trove` run with the subsequent test coverage upload to Coveralls:
```
CI_JOB_ID=`date +%s` COVERALLSTOKEN=<coveralls-secret-repo-token> RAKULIB=./lib trove-cli -c --f=`pwd`/x/trove-configs/test.conf.yaml.explore --p=yq
```
If you are familiar with GitLab, you can check [Pheix pipelines](https://gitlab.com/pheix/dcms-raku/-/pipelines). `Trove` is used there as a primary test tool since the late November 2022. GitLab sets up `CI_JOB_ID` automatically and `COVERALLSTOKEN` is configured manually with CI/CD [protected variables](https://docs.gitlab.com/ee/ci/variables/#add-a-cicd-variable-to-a-project). So, usage with GitLab is quite transparent/friendly:

## Log test session
While testing `trove-cli` does not output any TAP messages to standard output. Consider trivial multi-interpreter one-liner test again:
```
01. Running -eok(1,'true'); [ 33% covered ]
02. Running -eis(2,2,'2=2'); [ 66% covered ]
03. Running -eok(3,'perl5');done_testing; [ 100% covered ]
```
On the background `trove-cli` saves the full log with extended test details. Log file is save to current (work) directory and has the next file name format: `testreport.*.log`, where `*` is test run date, for example: `testreport.2022-10-18_23-21-12.log`.
Test command to be executed:
```
cd ~/git/raku-trove && CONSTANT=2 bin/trove-cli --f=`pwd`/x/trove-configs/tests.conf.yml.oneliner --p=yq -c -l
```
Log file `testreport.*.log` content is:
```
----------- STAGE no.1 -----------
ok 1 - true
----------- STAGE no.2 -----------
ok 1 - 2=2
----------- STAGE no.3 -----------
ok 1 - perl5
1..1
```
## Integration with CI/CD environments
### github.com
Consider module `Acme::Insult::Lala`, to integrate `Trove` to [Github actions](https://github.com/features/actions) CI/CD environment we have to create `.github/workflows/pheix-test-suite.yml` with the next instructions:
```
name: CI
on:
push:
branches: [ master ]
pull_request:
branches: [ master ]
jobs:
build:
runs-on: ubuntu-latest
container:
image: rakudo-star:latest
steps:
- uses: actions/checkout@v2
- name: Perform test with Pheix test suite
run: |
zef install Trove
ln -s `pwd` /tmp/Acme-Insult-Lala
cd /tmp/Acme-Insult-Lala && RAKULIB=lib trove-cli --f=/tmp/Acme-Insult-Lala/.run-tests.conf.yml --p=yq -l -c
cat `ls | grep "testreport"`
```
CI/CD magic happens at `run` instruction, let's explain it line by line:
1. `zef install Trove` — install `Trove` test tool;
2. `ln -s ...` — creating the module path consistent with `.run-tests.conf.yml`;
3. `cd /tmp/Acme-Insult-Lala && ...` — run the tests;
4. `cat ...` — print test log.
Check the job: <https://github.com/pheix/Acme-Insult-Lala/actions/runs/3621090976/jobs/6104091041>

### gitlab.com
Let's integrate module perl5 module `Acme` with `Trove` to [Gitlab CI/CD](https://docs.gitlab.com/ee/ci/quick_start/) environment — we have to create `.gitlab-ci.yml` with the next instructions:
```
image: rakudo-star:latest
before_script:
- apt update && apt -y install libspiffy-perl
- zef install Trove
- ln -s `pwd` /tmp/Acme-perl5
test:
script:
- cd /tmp/Acme-perl5 && PERL5LIB=lib trove-cli --f=/tmp/Acme-perl5/.run-tests.conf.yml --p=yq -l -c
- cat `ls | grep "testreport"`
only:
- main
```
On Gitlab CI/CD magic happens in `before_script` and `test/script` instructions. Behavior is exactly the same as it was in `run` instruction for Github action.
Check the job: <https://gitlab.com/pheix-research/perl-acme/-/jobs/3424335705>

## License
This is free and opensource software, so you can redistribute it and/or modify it under the terms of the [The Artistic License 2.0](https://opensource.org/licenses/Artistic-2.0).
## Author
Please contact me via [LinkedIn](https://www.linkedin.com/in/knarkhov/) or [Twitter](https://twitter.com/CondemnedCell). Your feedback is welcome at [narkhov.pro](https://narkhov.pro/contact-information.html).
|
## dist_cpan-TYIL-Grammar-TodoTxt.md
# NAME
Grammar::TodoTxt
# AUTHOR
Patrick Spek [p.spek@tyil.work](mailto:p.spek@tyil.work)
# VERSION
0.1.0
# Description
A grammar to parse todo.txt
# Installation
Install this module through [zef](https://github.com/ugexe/zef):
```
zef install Grammar::TodoTxt
```
# License
This module is distributed under the terms of the AGPL-3.0.
|
## dist_zef-uniejo-Cooklang.md
# NAME
Cooklang - `Raku` `Cooklang` parser
# SYNOPSIS
```
use Cooklang;
...
my $source = "some Cooklang text";
my $recipe = Cooklang.new( recipe => $source );
...
my $file = 'recipe.cook';
my $recipe = Cooklang.new( recipe_file => $file );
...
my @files = 'recipe1.cook', 'recipe2.cook';
my $recipe = Cooklang.new( recipe_file => @files );
# Currently does a simple join of all files, before parsing.
...
my $metadata = $recipe.metadata;
my $ingredients = $recipe.ingredients;
my $steps = $recipe.steps;
my $comments = $recipe.comments;
my $data = $recipe.data;
my $ast_tree = $recipe.match;
```
# VERSION
```
version 1.1.0
```
# AVAILABILITY
Cooklang is implemented in `Raku` using grammer and grammar action to parse and build AST tree.
# DESCRIPTION
For the `Cooklang` syntax, see [Cooklang](https://cooklang.org/).
# DOCUMENTATION
Cooklang documentation is available as `POD6`. You can run `raku --doc` from a shell to read the documentation:
```
% raku --doc lib/Cooklang.rakumod
% raku --doc=Markdown lib/Cooklang.rakumod # zef install Pod::To::Markdown
% raku --doc=HTML lib/Cooklang.rakumod # zef install Pod::To::HTML
```
# INSTALLATION
Installing Cooklang is straightforward.
## Installation with zef from CPAN6
If you have zef, you only need one line:
```
% zef install Cooklang
```
## Installation with zef from git repository
```
% zef install https://github.com/uniejo/cooklang-raku.git
```
# COMMUNITY
* [Code repository Wiki and Issue Tracker](https://github.com/uniejo/cooklang-raku)
* [Cooklang on modules.raku.org](https://modules.raku.org/dist/Cooklang:zef:zef:uniejo)
# AUTHOR
Erik Johansen - [uniejo@users.noreply.github.com](mailto:uniejo@users.noreply.github.com)
# COPYRIGHT
Erik Johansen 2023
# LICENSE
This software is licensed under the same terms as Perl itself.
|
## dist_cpan-FRITH-Math-Libgsl-LinearAlgebra.md
## Chunk 1 of 3
[](https://github.com/frithnanth/raku-Math-Libgsl-LinearAlgebra/actions) [](https://travis-ci.org/frithnanth/raku-Math-Libgsl-LinearAlgebra)
# NAME
Math::Libgsl::LinearAlgebra - An interface to libgsl, the Gnu Scientific Library - Linear Algebra.
# SYNOPSIS
```
use Math::Libgsl::LinearAlgebra;
```
# DESCRIPTION
Math::Libgsl::LinearAlgebra is an interface to the linear algebra functions of libgsl, the GNU Scientific Library. This package provides both the low-level interface to the C library (Raw) and a more comfortable interface layer for the Raku programmer.
This module provides functions for Num and Complex data types.
## Num
### LU-decomp(Math::Libgsl::Matrix $A where \*.matrix.size1 == $A.matrix.size2 --> List)
This function factorizes the matrix A into the LU decomposition PA = LU. The factorization is done in place, so on output the diagonal and upper triangular (or trapezoidal) part of the input matrix A contain the matrix U. The lower triangular (or trapezoidal) part of the input matrix (excluding the diagonal) contains L. The diagonal elements of L are unity, and are not stored. The return value is a List: the sign of the permutation and a permutation object, which encodes the permutation matrix P. In case of error a failure object is returned.
### LU-solve(Math::Libgsl::Matrix $LU where \*.matrix.size1 == $LU.matrix.size2, Math::Libgsl::Permutation $p where \*.size == $LU.matrix.size1, Math::Libgsl::Vector $b where \*.vector.size == $LU.matrix.size1 --> Math::Libgsl::Vector)
This function solves the square system Ax = b using the LU decomposition of A into (LU, p) given by the output of LU-decomp. In case of error a failure object is returned.
### LU-svx(Math::Libgsl::Matrix $LU where \*.matrix.size1 == $LU.matrix.size2, Math::Libgsl::Permutation $p where \*.size == $LU.matrix.size1, Math::Libgsl::Vector $x where \*.size == $LU.matrix.size1 --> Int)
This function solves the square system Ax = b in-place using the precomputed LU decomposition of A into (LU, p). On input $x should contain the right-hand side b, which is replaced by the solution on output. This function returns GSL\_SUCCESS if successful, or one of the error codes listed in Math::Libgsl::Constants::gsl-error.
### LU-refine(Math::Libgsl::Matrix $A where \*.matrix.size1 == $A.matrix.size2, Math::Libgsl::Matrix $LU where { $LU.matrix.size1 == $LU.matrix.size2 && $A.matrix.size1 == $LU.matrix.size2 }, Math::Libgsl::Permutation $p where \*.size == $LU.matrix.size1, Math::Libgsl::Vector $b where \*.vector.size == $LU.matrix.size1, Math::Libgsl::Vector $x where \*.vector.size == $LU.matrix.size1 --> Int)
This function applies an iterative improvement to x, the solution of Ax = b, from the precomputed LU decomposition of A into (LU, p). This function returns GSL\_SUCCESS if successful, or one of the error codes listed in Math::Libgsl::Constants::gsl-error.
### LU-invert(Math::Libgsl::Matrix $LU, Math::Libgsl::Permutation $p where \*.size == $LU.matrix.size1 --> Math::Libgsl::Matrix)
This function computes the inverse of a matrix A from its LU decomposition (LU, p), returning the matrix inverse. In case of error a failure object is returned.
### LU-det(Math::Libgsl::Matrix $LU, Int $signum where \* ~~ -1|1 --> Num)
This function computes the determinant of a matrix A from its LU decomposition, $LU, and the sign of the permutation, $signum. This function returns GSL\_SUCCESS if successful, or one of the error codes listed in Math::Libgsl::Constants::gsl-error.
### LU-lndet(Math::Libgsl::Matrix $LU --> Num)
This function computes the determinant the logarithm of the absolute value of the determinant of a matrix A, ln |det(A)|, from its LU decomposition, $LU. This function returns GSL\_SUCCESS if successful, or one of the error codes listed in Math::Libgsl::Constants::gsl-error.
### LU-sgndet(Math::Libgsl::Matrix $LU, Int $signum where \* ~~ -1|1 --> Int)
This function computes the sign or phase factor of the determinant of a matrix A, det(A)/|det(A)| from its LU decomposition, $LU. This function returns GSL\_SUCCESS if successful, or one of the error codes listed in Math::Libgsl::Constants::gsl-error.
### QR-decomp(Math::Libgsl::Matrix $A --> Math::Libgsl::Vector)
This function factorizes the M-by-N matrix $A into the QR decomposition A = QR. On output the diagonal and upper triangular part of the input matrix contain the matrix R. The returned vector and the columns of the lower triangular part of the matrix A contain the Householder coefficients and Householder vectors which encode the orthogonal matrix Q. In case of error a failure object is returned.
### QR-solve(Math::Libgsl::Matrix $QR where \*.matrix.size1 == $QR.matrix.size2, Math::Libgsl::Vector $tau where \*.vector.size == $QR.matrix.size2, Math::Libgsl::Vector $b where \*.vector.size == $QR.matrix.size1 --> Math::Libgsl::Vector)
This function solves the square system Ax = b using the QR decomposition of A held in ($QR, $tau) which must have been computed previously with QR-decomp(). In case of error a failure object is returned.
### QR-svx(Math::Libgsl::Matrix $QR where \*.matrix.size1 == $QR.matrix.size2, Math::Libgsl::Vector $tau where \*.vector.size == $QR.matrix.size2, Math::Libgsl::Vector $x where \*.vector.size == $QR.matrix.size1 --> Int)
This function solves the square system Ax = b in-place using the QR decomposition of A held in ($QR, $tau) which must have been computed previously by QR-decomp(). On input $x should contain the right-hand side b, which is replaced by the solution on output. This function returns GSL\_SUCCESS if successful, or one of the error codes listed in Math::Libgsl::Constants::gsl-error.
### QR-lssolve(Math::Libgsl::Matrix $QR where \*.matrix.size1 ≥ $QR.matrix.size2, Math::Libgsl::Vector $tau where \*.vector.size == $QR.matrix.size2, Math::Libgsl::Vector $b where \*.vector.size == $QR.matrix.size1 --> List)
This function finds the least squares solution to the overdetermined system Ax = b where the matrix A has more rows than columns. The least squares solution minimizes the Euclidean norm of the residual, ||Ax − b||. The routine requires as input the QR decomposition of A into ($QR, $tau) given by QR-decomp(). The function returns a List of two Math::Libgsl::Vector objects: the solution x and the residual. In case of error a failure object is returned.
### QR-QTvec(Math::Libgsl::Matrix $QR, Math::Libgsl::Vector $tau where \*.vector.size == min($QR.matrix.size1, $QR.matrix.size2), Math::Libgsl::Vector $v where \*.vector.size == $QR.matrix.size1 --> Int)
These function applies the matrix T(Q) encoded in the decomposition (QR, tau) to the vector $v, storing the result T(Q) v in $v. The matrix multiplication is carried out directly using the encoding of the Householder vectors without needing to form the full matrix T(Q). This function returns GSL\_SUCCESS if successful, or one of the error codes listed in Math::Libgsl::Constants::gsl-error.
### QR-Qvec(Math::Libgsl::Matrix $QR, Math::Libgsl::Vector $tau where \*.vector.size == min($QR.matrix.size1, $QR.matrix.size2), Math::Libgsl::Vector $v where \*.vector.size == $QR.matrix.size1 --> Int)
This function applies the matrix Q encoded in the decomposition ($QR, $tau) to the vector $v, storing the result Qv in $v. The matrix multiplication is carried out directly using the encoding of the Householder vectors without needing to form the full matrix Q. This function returns GSL\_SUCCESS if successful, or one of the error codes listed in Math::Libgsl::Constants::gsl-error.
### QR-QTmat(Math::Libgsl::Matrix $QR, Math::Libgsl::Vector $tau where \*.vector.size == min($QR.matrix.size1, $QR.matrix.size2), Math::Libgsl::Matrix $B where \*.matrix.size1 == $QR.matrix.size1 --> Int)
This function applies the matrix T(Q) encoded in the decomposition ($QR, $tau) to the M-by-K matrix $B, storing the result T(Q) B in $B. The matrix multiplication is carried out directly using the encoding of the Householder vectors without needing to form the full matrix T(Q). This function returns GSL\_SUCCESS if successful, or one of the error codes listed in Math::Libgsl::Constants::gsl-error.
### QR-Rsolve(Math::Libgsl::Matrix $QR where \*.matrix.size1 == $QR.matrix.size2, Math::Libgsl::Vector $b where \*.vector.size == $QR.matrix.size1 --> Math::Libgsl::Vector)
This function solves the triangular system Rx = b and returns the Math::Libgsl::Vector object $x. In case of error a failure object is returned.
### QR-Rsvx(Math::Libgsl::Matrix $QR where \*.matrix.size1 == $QR.matrix.size2, Math::Libgsl::Vector $x where \*.vector.size == $QR.matrix.size2 --> Int)
This function solves the triangular system Rx = b for x in-place. On input $x should contain the right-hand side b and is replaced by the solution on output. This function returns GSL\_SUCCESS if successful, or one of the error codes listed in Math::Libgsl::Constants::gsl-error.
### QR-unpack(Math::Libgsl::Matrix $QR, Math::Libgsl::Vector $tau where \*.vector.size == min($QR.matrix.size1, $QR.matrix.size2) --> List)
This function unpacks the encoded QR decomposition ($QR, $tau) into the matrices Q and R. The function returns a List of two Math::Libgsl::Matrix objects: $Q which is M-by-M and $R which is M-by-N. In case of error a failure object is returned.
### QR-QRsolve(Math::Libgsl::Matrix $Q, Math::Libgsl::Matrix $R where { $R.matrix.size1 == $R.matrix.size2 && $Q.matrix.size1 == $R.matrix.size1 }, Math::Libgsl::Vector $b where \*.vector.size == $R.matrix.size1 --> Math::Libgsl::Vector)
This function solves the system Rx = T(Q) b for x. It can be used when the QR decomposition of a matrix is available in unpacked form as ($Q, $R). The function returns the Math::Libgsl::Vector $x. In case of error a failure object is returned.
### QR-update(Math::Libgsl::Matrix $Q, Math::Libgsl::Matrix $R where { $Q.matrix.size1 == $R.matrix.size1 && $Q.matrix.size2 == $R.matrix.size1 }, Math::Libgsl::Vector $w where \*.vector.size == $R.matrix.size1, Math::Libgsl::Vector $v where \*.vector.size == $R.matrix.size2 --> Int)
This function performs a rank-1 update wT(v) of the QR decomposition ($Q, $R). The update is given by Q'R' = Q(R+wT(v)) where the output matrices $Q and $R are also orthogonal and right triangular. Note that $w is destroyed by the update. This function returns GSL\_SUCCESS if successful, or one of the error codes listed in Math::Libgsl::Constants::gsl-error.
### R-solve(Math::Libgsl::Matrix $R where \*.matrix.size1 == $R.matrix.size2, Math::Libgsl::Vector $b where \*.vector.size == $R.matrix.size1 --> Math::Libgsl::Vector)
This function solves the triangular system Rx = b for the N-by-N matrix $R. The function returns the Math::Libgsl::Vector $x. In case of error a failure object is returned.
### R-svx(Math::Libgsl::Matrix $R where \*.matrix.size1 == $R.matrix.size2, Math::Libgsl::Vector $x where \*.vector.size == $R.matrix.size2 --> Int)
This function solves the triangular system Rx = b in-place. On input $x should contain the right-hand side b, which is replaced by the solution on output. This function returns GSL\_SUCCESS if successful, or one of the error codes listed in Math::Libgsl::Constants::gsl-error.
### QRPT-decomp(Math::Libgsl::Matrix $A --> List)
This function factorizes the M-by-N matrix $A into the QRT(P) decomposition A = QRT(P). On output the diagonal and upper triangular part of the input matrix contain the matrix R. The function's output is a List of three objects: the Math::Libgsl::Vector $tau, the Math::Libgsl::Permutation $p and the sign of the permutation Int $signum. In case of error a failure object is returned.
### QRPT-decomp2(Math::Libgsl::Matrix $A --> List)
This function factorizes the matrix $A into the decomposition A = QRT(P) without modifying $A itself. The function returns a List: the Math::Libgsl::Matrix $Q, the Math::Libgsl::Matrix $R, the Math::Libgsl::Permutation $p, and the sign of the permutation Int $signum. In case of error a failure object is returned.
### QRPT-solve(Math::Libgsl::Matrix $QR where \*.matrix.size1 == $QR.matrix.size2, Math::Libgsl::Vector $tau where \*.vector.size == min($QR.matrix.size1, $QR.matrix.size2), Math::Libgsl::Permutation $p where \*.p.size == $QR.matrix.size1, Math::Libgsl::Vector $b where \*.vector.size == $QR.matrix.size1 --> Math::Libgsl::Vector)
This function solves the square system Ax = b using the QRT(P) decomposition of A held in ($QR, $tau, $p) which must have been computed previously by QRPT-decomp. The function returns the Math::Libgsl::Vector $x. In case of error a failure object is returned.
### QRPT-svx(Math::Libgsl::Matrix $QR where \*.matrix.size1 == $QR.matrix.size2, Math::Libgsl::Vector $tau where \*.vector.size == min($QR.matrix.size1, $QR.matrix.size2), Math::Libgsl::Permutation $p where \*.p.size == $QR.matrix.size1, Math::Libgsl::Vector $x where \*.vector.size == $QR.matrix.size2 --> Int)
This function solves the square system Ax = b in-place using the QRT(P) decomposition of A held in ($QR, $tau, $p). On input $x should contain the right-hand side b, which is replaced by the solution on output. This function returns GSL\_SUCCESS if successful, or one of the error codes listed in Math::Libgsl::Constants::gsl-error.
### QRPT-lssolve(Math::Libgsl::Matrix $QR where \*.matrix.size1 ≥ $QR.matrix.size2, Math::Libgsl::Vector $tau where \*.vector.size == min($QR.matrix.size1, $QR.matrix.size2), Math::Libgsl::Permutation $p where \*.p.size == $QR.matrix.size2, Math::Libgsl::Vector $b where \*.vector.size == $QR.matrix.size1 --> List)
This function finds the least squares solution to the overdetermined system Ax = b where the matrix A has more rows than columns and is assumed to have full rank. The least squares solution minimizes the Euclidean norm of the residual, ||b − Ax||. The routine requires as input the QR decomposition of A into ($QR, $tau, $p) given by QRPT-decomp. The function returns a List of two Math::Libgsl::Vector objects: the solution x and the residual. In case of error a failure object is returned.
### QRPT-lssolve2(Math::Libgsl::Matrix $QR where \*.matrix.size1 ≥ $QR.matrix.size2, Math::Libgsl::Vector $tau where \*.vector.size == min($QR.matrix.size1, $QR.matrix.size2), Math::Libgsl::Permutation $p where \*.p.size == $QR.matrix.size2, Math::Libgsl::Vector $b where \*.vector.size == $QR.matrix.size1, Int $rank where 0 < \* ≤ $QR.matrix.size2 --> List)
This function finds the least squares solution to the overdetermined system Ax = b where the matrix A has more rows than columns and has rank given by the input rank. If the user does not know the rank of A, it may be estimated by calling QRPT-rank. The routine requires as input the QR decomposition of A into ($QR, $tau, $p) given by QRPT-decomp. The function returns a List of two Math::Libgsl::Vector objects: the solution x and the residual. In case of error a failure object is returned.
### QRPT-QRsolve(Math::Libgsl::Matrix $Q where \*.matrix.size1 == $Q.matrix.size2, Math::Libgsl::Matrix $R where {$R.matrix.size1 == $R.matrix.size2 && $R.matrix.size1 == $Q.matrix.size1}, Math::Libgsl::Permutation $p where \*.p.size == $Q.matrix.size1, Math::Libgsl::Vector $b where \*.vector.size == $Q.matrix.size1 --> Math::Libgsl::Vector)
This function solves the square system RT(P) x = T(Q) b for x. It can be used when the QR decomposition of a matrix is available in unpacked form as ($Q, $R). The function returns the Math::Libgsl::Vector $x. In case of error a failure object is returned.
### QRPT-update(Math::Libgsl::Matrix $Q, Math::Libgsl::Matrix $R where { $Q.matrix.size1 == $R.matrix.size1 && $Q.matrix.size2 == $R.matrix.size1 }, Math::Libgsl::Permutation $p where \*.p.size == $R.matrix.size1, Math::Libgsl::Vector $w where \*.vector.size == $R.matrix.size1, Math::Libgsl::Vector $v where \*.vector.size == $R.matrix.size2 --> Int)
This function performs a rank-1 update wT(v) of the QRT(P) decomposition ($Q, $R, $p). The update is given by Q' R' = Q(R + wT(v) P) where the output matrices Q' and R' are also orthogonal and right triangular. Note that $w is destroyed by the update. This function returns GSL\_SUCCESS if successful, or one of the error codes listed in Math::Libgsl::Constants::gsl-error.
### QRPT-Rsolve(Math::Libgsl::Matrix $QR where \*.matrix.size1 == $QR.matrix.size2, Math::Libgsl::Permutation $p where \*.p.size == $QR.matrix.size2, Math::Libgsl::Vector $b where \*.vector.size == $QR.matrix.size1 --> Math::Libgsl::Vector)
This function solves the triangular system RT(P) x = b for the N-by-N matrix R contained in $QR. The function returns the Math::Libgsl::Vector $x. In case of error a failure object is returned.
### QRPT-Rsvx(Math::Libgsl::Matrix $QR where \*.matrix.size1 == $QR.matrix.size2, Math::Libgsl::Permutation $p where \*.p.size == $QR.matrix.size2, Math::Libgsl::Vector $x where \*.vector.size == $QR.matrix.size2 --> Int)
This function solves the triangular system RT(P) x = b in-place for the N-by-N matrix R contained in $QR. On input $x should contain the right-hand side b, which is replaced by the solution on output. This function returns GSL\_SUCCESS if successful, or one of the error codes listed in Math::Libgsl::Constants::gsl-error.
### QRPT-rank(Math::Libgsl::Matrix $QR, Num() $tolerance --> Int)
This function returns the rank of the triangular matrix R contained in $QR.
### QRPT-rcond(Math::Libgsl::Matrix $QR where \*.matrix.size1 ≥ $QR.matrix.size2 --> Num)
This function returns the reciprocal condition number (using the 1-norm) of the R factor, stored in the upper triangle of $QR. In case of error a failure object is returned.
### LQ-decomp(Math::Libgsl::Matrix $A --> Math::Libgsl::Vector)
This function factorizes the M-by-N matrix $A into the LQ decomposition A = LQ. On output the diagonal and lower trapezoidal part of the input matrix contain the matrix L. This function returns the Math::Libgsl::Vector $tau. The vector $tau and the elements above the diagonal of the matrix $A contain the Householder coefficients and Householder vectors which encode the orthogonal matrix Q. In case of error a failure object is returned.
### LQ-solve-T(Math::Libgsl::Matrix $LQ where \*.matrix.size1 == $LQ.matrix.size2, Math::Libgsl::Vector $tau where \*.vector.size == min($LQ.matrix.size1, $LQ.matrix.size2), Math::Libgsl::Vector $b where \*.vector.size == $LQ.matrix.size2 --> Math::Libgsl::Vector)
This function finds the solution to the system Ax = b. The routine requires as input the LQ decomposition of A into ($LQ, $tau) given by LQ-decomp. The function returns the Math::Libgsl::Vector $x. In case of error a failure object is returned.
### LQ-svx-T(Math::Libgsl::Matrix $LQ where \*.matrix.size1 == $LQ.matrix.size2, Math::Libgsl::Vector $tau where \*.vector.size == min($LQ.matrix.size1, $LQ.matrix.size2), --> Math::Libgsl::Vector)
This function finds the solution to the system Ax = b. The routine requires as input the LQ decomposition of A into ($LQ, $tau) given by LQ-decomp. On input $x should contain the right-hand side b, which is replaced by the solution on output. In case of error a failure object is returned.
### LQ-lssolve-T(Math::Libgsl::Matrix $LQ where \*.matrix.size1 ≥ $LQ.matrix.size2, Math::Libgsl::Vector $tau where \*.vector.size == min($LQ.matrix.size1, $LQ.matrix.size2), Math::Libgsl::Vector $b where \*.vector.size == $LQ.matrix.size1 --> List)
This function finds the minimum norm least squares solution to the underdetermined system Ax = b, where the M-by-N matrix A has M ≤ N. The routine requires as input the LQ decomposition of A into ($LQ, $tau) given by LQ-decomp. The function returns a List of two Math::Libgsl::Vector objects: the solution x and the residual. In case of error a failure object is returned.
### LQ-Lsolve-T(Math::Libgsl::Matrix $LQ where \*.matrix.size1 == $LQ.matrix.size2, Math::Libgsl::Vector $b where \*.vector.size == $LQ.matrix.size1 --> Math::Libgsl::Vector)
The function returns the Math::Libgsl::Vector $x. In case of error a failure object is returned.
### LQ-Lsvx-T(Math::Libgsl::Matrix $LQ where \*.matrix.size1 == $LQ.matrix.size2 --> Math::Libgsl::Vector)
On input $x should contain the right-hand side b, which is replaced by the solution on output. In case of error a failure object is returned.
### L-solve-T(Math::Libgsl::Matrix $L where \*.matrix.size1 == $L.matrix.size2, Math::Libgsl::Vector $b where \*.vector.size == $L.matrix.size2 --> Math::Libgsl::Vector)
The function returns the Math::Libgsl::Vector $x. In case of error a failure object is returned.
### LQ-vecQ(Math::Libgsl::Matrix $LQ, Math::Libgsl::Vector $tau where \*.vector.size == min($LQ.matrix.size1, $LQ.matrix.size2), Math::Libgsl::Vector $v where \*.vector.size == $LQ.matrix.size1 --> Int)
This function returns GSL\_SUCCESS if successful, or one of the error codes listed in Math::Libgsl::Constants::gsl-error.
### LQ-vecQT(Math::Libgsl::Matrix $LQ, Math::Libgsl::Vector $tau where \*.vector.size == min($LQ.matrix.size1, $LQ.matrix.size2), Math::Libgsl::Vector $v where \*.vector.size == $LQ.matrix.size1 --> Int)
This function applies T(Q) to the vector v, storing the result T(Q) v in $v on output. This function returns GSL\_SUCCESS if successful, or one of the error codes listed in Math::Libgsl::Constants::gsl-error.
### LQ-unpack(Math::Libgsl::Matrix $LQ, Math::Libgsl::Vector $tau where \*.vector.size == min($LQ.matrix.size1, $LQ.matrix.size2) --> List)
This function unpacks the encoded LQ decomposition ($LQ, $tau). The function outputs a List: the Math::Libgsl::Matrix $Q and the Math::Libgsl::Matrix $L. In case of error a failure object is returned.
### LQ-update(Math::Libgsl::Matrix $Q, Math::Libgsl::Matrix $L where { $L.matrix.size2 == $Q.matrix.size1 && $L.matrix.size2 == $Q.matrix.size2 }, Math::Libgsl::Vector $v where \*.vector.size == $L.matrix.size1, Math::Libgsl::Vector $w where \*.vector.size == $L.matrix.size2 --> Int)
This function returns GSL\_SUCCESS if successful, or one of the error codes listed in Math::Libgsl::Constants::gsl-error.
### LQ-LQsolve(Math::Libgsl::Matrix $Q, Math::Libgsl::Matrix $L where { $L.matrix.size1 == $L.matrix.size2 && $Q.matrix.size1 == $L.matrix.size2 }, Math::Libgsl::Vector $b where \*.vector.size == $L.matrix.size2 --> Math::Libgsl::Vector)
In case of error a failure object is returned.
### COD-decomp(Math::Libgsl::Matrix $A --> List)
### COD-decomp-e(Math::Libgsl::Matrix $A, Num() $tolerance --> List)
These functions factor the M-by-N matrix $A into the decomposition A = QRZT(P). On output the matrix R₁₁ is stored in the upper rank-by-rank block of $A. The matrices Q and Z are encoded in packed storage in $A on output. This function outputs a List: two Math::Libgsl::Vector objects which contain the Householder scalars corresponding to the matrices Q and Z respectively, a Math::Libgsl::Permutation object which contain the permutation matrix P, and the rank of $A. In case of error a failure object is returned.
### COD-lssolve(Math::Libgsl::Matrix $QRZT where \*.matrix.size1 ≥ $QRZT.matrix.size2, Math::Libgsl::Vector $tau-Q where \*.vector.size == min($QRZT.matrix.size1, $QRZT.matrix.size2), Math::Libgsl::Vector $tau-Z where \*.vector.size == min($QRZT.matrix.size1, $QRZT.matrix.size2), Math::Libgsl::Permutation $p where \*.p.size == $QRZT.matrix.size2, Int $rank where \* ≤ min($QRZT.matrix.size1, $QRZT.matrix.size2), Math::Libgsl::Vector $b where \*.vector.size == $QRZT.matrix.size1 --> List)
This function finds the unique minimum norm least squares solution to the overdetermined system Ax = b where the matrix $A has more rows than columns. The least squares solution minimizes the Euclidean norm of the residual, ||b − Ax|| as well as the norm of the solution ||x||. The routine requires as input the QRZT decomposition of $A into ($QRZT, $tau\_Q, $tau\_Z, $p, $rank) given by COD-decomp. The function outputs a List: a Math::Libgsl::Vector object which is the solution x, and a Math::Libgsl::Vector object which stores the residual b − Ax. In case of error a failure object is returned.
### COD-lssolve2(Math::Libgsl::Matrix $QRZT where \*.matrix.size1 ≥ $QRZT.matrix.size2, Math::Libgsl::Vector $tau-Q where \*.vector.size == min($QRZT.matrix.size1, $QRZT.matrix.size2), Math::Libgsl::Vector $tau-Z where \*.vector.size == min($QRZT.matrix.size1, $QRZT.matrix.size2), Math::Libgsl::Permutation $p where \*.p.size == $QRZT.matrix.size2, Int $rank where \* ≤ min($QRZT.matrix.size1, $QRZT.matrix.size2), Math::Libgsl::Vector $b where \*.vector.size == $QRZT.matrix.size1, Num() $lambda --> List)
This function finds the solution to the regularized least squares problem in Tikhonov standard form, minₓ||b − Ax||² + λ²||x||². The routine requires as input the QRZT decomposition of A into ($QRZT, $tau\_Q, $tau\_Z, $p, $rank) given by COD-decomp. The parameter λ is supplied in $lambda. The function outputs a List: a Math::Libgsl::Vector object which is the solution x, and a Math::Libgsl::Vector object which stores the residual b − Ax. In case of error a failure object is returned.
### COD-unpack(Math::Libgsl::Matrix $QRZT, Math::Libgsl::Vector $tau-Q where \*.vector.size == min($QRZT.matrix.size1, $QRZT.matrix.size2), Math::Libgsl::Vector $tau-Z where \*.vector.size == min($QRZT.matrix.size1, $QRZT.matrix.size2), Int $rank where \* ≤ min($QRZT.matrix.size1, $QRZT.matrix.size2) --> List)
This function unpacks the encoded QRZT decomposition ($QRZT, $tau\_Q, $tau\_Z, $rank). The function returns a List of three Math::Libgsl::Matrix objects: $Q, $R, $Z. In case of error a failure object is returned.
### COD-matZ(Math::Libgsl::Matrix $QRZT, Math::Libgsl::Vector $tau-Z where \*.vector.size == min($QRZT.matrix.size1, $QRZT.matrix.size2), Math::Libgsl::Matrix $A where \*.matrix.size2 == $QRZT.matrix.size2, Int $rank --> Int)
This function multiplies the input matrix $A on the right by Z, A’ = AZ using the encoded QRZT decomposition ($QRZT, $tau\_Z, $rank). This function returns GSL\_SUCCESS if successful, or one of the error codes listed in Math::Libgsl::Constants::gsl-error.
### SV-decomp(Math::Libgsl::Matrix $A where \*.matrix.size1 ≥ $A.matrix.size2 --> List)
This function factorizes the M-by-N matrix $A into the singular value decomposition A = UST(V) for M ≥ N. On output the matrix $A is replaced by U. The function returns a List: a Math::Libgsl::Matrix object which contains the elements of V in untransposed form, and a Math::Libgsl::Vector object which contains the diagonal elements of the singular value matrix S. The singular values are non-negative and form a non-increasing sequence from S₁ to Sₙ. In case of error a failure object is returned.
### SV-decomp-mod(Math::Libgsl::Matrix $A where \*.matrix.size1 ≥ $A.matrix.size2 --> List)
This function computes the SVD using the modified Golub-Reinsch algorithm, which is faster for M ≫ N. The function returns a List: a Math::Libgsl::Matrix object which contains the elements of V in untransposed form, and a Math::Libgsl::Vector object which contains the diagonal elements of the singular value matrix S. The singular values are non-negative and form a non-increasing sequence from S₁ to Sₙ. In case of error a failure object is returned.
### SV-decomp-jacobi(Math::Libgsl::Matrix $A where \*.matrix.size1 ≥ $A.matrix.size2 --> List)
This function computes the SVD of the M-by-N matrix A using one-sided Jacobi orthogonalization for M ≥ N. The function returns a List: a Math::Libgsl::Matrix object which contains the elements of V in untransposed form, and a Math::Libgsl::Vector object which contains the diagonal elements of the singular value matrix S. The singular values are non-negative and form a non-increasing sequence from S₁ to Sₙ. In case of error a failure object is returned.
### SV-solve(Math::Libgsl::Matrix $A where \*.matrix.size1 ≥ $A.matrix.size2, Math::Libgsl::Matrix $V where { $V.matrix.size1 == $V.matrix.size2 && $V.matrix.size1 == $A.matrix.size2 }, Math::Libgsl::Vector $S where \*.vector.size == $A.matrix.size2, Math::Libgsl::Vector $b where \*.vector.size == $A.matrix.size1 --> Math::Libgsl::Vector)
This function solves the system Ax = b using the singular value decomposition (U, S, V) of A which must have been computed previously with COD-decomp. Only non-zero singular values are used in computing the solution. The parts of the solution corresponding to singular values of zero are ignored. Other singular values can be edited out by setting them to zero before calling this function. The function returns the Math::Libgsl::Vector $x. In case of error a failure object is returned.
### SV-leverage(Math::Libgsl::Matrix $A --> Math::Libgsl::Vector)
This function computes the statistical leverage values hᵢ of a matrix A using its singular value decomposition (U, S, V) previously computed with COD-decomp. The function returns a Math::Libgsl::Vector object which stores the diagonal values of the matrix A(T(A)A)⁻¹T(A) and depend only on the matrix U which is the input to this function. In case of error a failure object is returned.
### cholesky-decomp1(Math::Libgsl::Matrix $A where \*.matrix.size1 == $A.matrix.size2 --> Int)
This function factorizes the symmetric, positive-definite square matrix $A into the Cholesky decomposition A = LT(L). On input, the values from the diagonal and lower-triangular part of the matrix $A are used (the upper triangular part is ignored). On output the diagonal and lower triangular part of the input matrix $A contain the matrix L, while the upper triangular part contains the original matrix. If the matrix is not positive-definite then the decomposition will fail, returning the error code GSL\_EDOM. This function returns GSL\_SUCCESS if successful, or one of the error codes listed in Math::Libgsl::Constants::
|
## dist_cpan-FRITH-Math-Libgsl-LinearAlgebra.md
## Chunk 2 of 3
gsl-error.
### cholesky-solve(Math::Libgsl::Matrix $A where \*.matrix.size1 == $A.matrix.size2, Math::Libgsl::Vector $b where \*.vector.size == $A.matrix.size1 --> Math::Libgsl::Vector)
These functions solve the system Ax = b using the Cholesky decomposition of $A which must have been previously computed by cholesky-decomp1. The function returns the Math::Libgsl::Vector $x. In case of error a failure object is returned.
### cholesky-svx(Math::Libgsl::Matrix $A where \*.matrix.size1 == $A.matrix.size2, Math::Libgsl::Vector $x where \*.vector.size == $A.matrix.size1 --> Int)
This function solves the system Ax = b in-place using the Cholesky decomposition of $A which must have been previously computed by cholesky-decomp1. On input $x should contain the right-hand side b, which is replaced by the solution on output. This function returns GSL\_SUCCESS if successful, or one of the error codes listed in Math::Libgsl::Constants::gsl-error.
### cholesky-solve-mat(Math::Libgsl::Matrix $A where \*.matrix.size1 == $A.matrix.size2, Math::Libgsl::Matrix $B where \*.matrix.size1 == $A.matrix.size1 --> Math::Libgsl::Matrix)
In case of error a failure object is returned.
### cholesky-svx-mat(Math::Libgsl::Matrix $A where \*.matrix.size1 == $A.matrix.size2, Math::Libgsl::Matrix $X where \*.matrix.size1 == $A.matrix.size1 --> Int)
This function returns GSL\_SUCCESS if successful, or one of the error codes listed in Math::Libgsl::Constants::gsl-error.
### cholesky-invert(Math::Libgsl::Matrix $A where \*.matrix.size1 == $A.matrix.size2 --> Int)
These functions compute the inverse of a matrix from its Cholesky decomposition $A, which must have been previously computed by cholesky-decomp1. On output, the inverse is stored in-place in $A. This function returns GSL\_SUCCESS if successful, or one of the error codes listed in Math::Libgsl::Constants::gsl-error.
### cholesky-decomp2(Math::Libgsl::Matrix $A where \*.matrix.size1 == $A.matrix.size2 --> Math::Libgsl::Vector)
This function calculates a diagonal scaling transformation S for the symmetric, positive-definite square matrix $A, and then computes the Cholesky decomposition SAS = LT(L). On input, the values from the diagonal and lower-triangular part of the matrix $A are used (the upper triangular part is ignored). On output the diagonal and lower triangular part of the input matrix $A contain the matrix L, while the upper triangular part of the input matrix is overwritten with T(L) (the diagonal terms being identical for both L and L T). If the matrix is not positive-definite then the decomposition will fail, returning the error code GSL\_EDOM. The function returns a Math::Libgsl::Vector object which stores the diagonal scale factors. In case of error a failure object is returned.
### cholesky-solve2(Math::Libgsl::Matrix $A where \*.matrix.size1 == $A.matrix.size2, Math::Libgsl::Vector $s where \*.vector.size == $A.matrix.size1, Math::Libgsl::Vector $b where \*.vector.size == $A.matrix.size1 --> Math::Libgsl::Vector)
This function solves the system (SAS)(S⁻¹ x) = Sb using the Cholesky decomposition of SAS held in the matrix $A which must have been previously computed by cholesky-decomp2. The function returns the Math::Libgsl::Vector $x. In case of error a failure object is returned.
### cholesky-svx2(Math::Libgsl::Matrix $A where \*.matrix.size1 == $A.matrix.size2, Math::Libgsl::Vector $s where \*.size == $A.matrix.size2, Math::Libgsl::Vector $x where \*.vector.size == $A.matrix.size2 --> Int)
This function solves the system (SAS)(S⁻¹ x) = Sb using the Cholesky decomposition of SAS held in the matrix $A which must have been previously computed by cholesky-decomp2. On input $x should contain the right-hand side b, which is replaced by the solution on output. This function returns GSL\_SUCCESS if successful, or one of the error codes listed in Math::Libgsl::Constants::gsl-error.
### cholesky-decomp-unit(Math::Libgsl::Matrix $A where \*.matrix.size1 == $A.matrix.size2 --> Math::Libgsl::Vector)
The function returns the Math::Libgsl::Vector $d. In case of error a failure object is returned.
### cholesky-scale(Math::Libgsl::Matrix $A where \*.matrix.size1 == $A.matrix.size2 --> Math::Libgsl::Vector)
This function calculates a diagonal scaling transformation of the symmetric, positive definite matrix $A, such that SAS has a condition number within a factor of N of the matrix of smallest possible condition number over all possible diagonal scalings. The function outputs a Math::Libgsl::Vector object which contains the scale factors. In case of error a failure object is returned.
### cholesky-scale-apply(Math::Libgsl::Matrix $A where \*.matrix.size1 == $A.matrix.size2, Math::Libgsl::Vector $s where \*.vector.size == $A.matrix.size2 --> Int)
This function applies the scaling transformation S to the matrix $A. On output, $A is replaced by SAS. This function returns GSL\_SUCCESS if successful, or one of the error codes listed in Math::Libgsl::Constants::gsl-error.
### cholesky-rcond(Math::Libgsl::Matrix $A where \*.matrix.size1 == $A.matrix.size2 --> Num)
This function estimates the reciprocal condition number (using the 1-norm) of the symmetric positive definite matrix A, using its Cholesky decomposition provided in $A. The function returns a Math::Libgsl::Vector object which stores the reciprocal condition number estimate, defined as 1/(||A||₁ · ||A⁻¹||₁). In case of error a failure object is returned.
### pcholesky-decomp(Math::Libgsl::Matrix $A where \*.matrix.size1 == $A.matrix.size2 --> Math::Libgsl::Permutation)
This function factors the symmetric, positive-definite square matrix $A into the Pivoted Cholesky decomposition PAT(P) = LDT(L). On input, the values from the diagonal and lower-triangular part of the matrix $A are used to construct the factorization. On output the diagonal of the input matrix $A stores the diagonal elements of D, and the lower triangular portion of $A contains the matrix L. Since L has ones on its diagonal these do not need to be explicitely stored. The upper triangular portion of $A is unmodified. The function returns the Math::Libgsl::Permutation object which stores the permutation matrix P. In case of error a failure object is returned.
### pcholesky-solve(Math::Libgsl::Matrix $LDLT where \*.matrix.size1 == $LDLT.matrix.size2, Math::Libgsl::Permutation $p where \*.p.size == $LDLT.matrix.size1, Math::Libgsl::Vector $b where \*.vector.size == $LDLT.matrix.size1 --> Math::Libgsl::Vector)
This function solves the system Ax = b using the Pivoted Cholesky decomposition of A held in the matrix $LDLT and permutation $p which must have been previously computed by pcholesky-decomp. The function returns the Math::Libgsl::Vector $x. In case of error a failure object is returned.
### pcholesky-svx(Math::Libgsl::Matrix $LDLT where \*.matrix.size1 == $LDLT.matrix.size2, Math::Libgsl::Permutation $p where \*.p.size == $LDLT.matrix.size1, Math::Libgsl::Vector $x where \*.vector.size == $LDLT.matrix.size1 --> Int)
This function solves the system Ax = b using the Pivoted Cholesky decomposition of A held in the matrix $LDLT and permutation $p which must have been previously computed by pcholesky-decomp. On input, $x contains the right hand side vector b which is replaced by the solution vector on output. This function returns GSL\_SUCCESS if successful, or one of the error codes listed in Math::Libgsl::Constants::gsl-error.
### pcholesky-decomp2(Math::Libgsl::Matrix $A where \*.matrix.size1 == $A.matrix.size2 --> List)
This function computes the pivoted Cholesky factorization of the matrix SAS, where the input matrix $A is symmetric and positive definite, and the diagonal scaling matrix S is computed to reduce the condition number of $A as much as possible. On input, the values from the diagonal and lower-triangular part of the matrix $A are used to construct the factorization. On output the diagonal of the input matrix $A stores the diagonal elements of D, and the lower triangular portion of $A contains the matrix L. Since L has ones on its diagonal these do not need to be explicitely stored. The upper triangular portion of $A is unmodified. The function returns a List: the permutation matrix P is stored in a Math::Libgsl::Permutation object, the diagonal scaling transformation is stored in a Math::Libgsl::Vector object. In case of error a failure object is returned.
### pcholesky-solve2(Math::Libgsl::Matrix $LDLT where \*.matrix.size1 == $LDLT.matrix.size2, Math::Libgsl::Permutation $p where \*.p.size == $LDLT.matrix.size1, Math::Libgsl::Vector $s where \*.vector.size == $LDLT.matrix.size1, Math::Libgsl::Vector $b where \*.vector.size == $LDLT.matrix.size1 --> Math::Libgsl::Vector)
This function solves the system (SAS)(S⁻¹x) = Sb using the Pivoted Cholesky decomposition of SAS held in the matrix $LDLT, permutation $p, and vector $S, which must have been previously computed by pcholesky-decomp2. The function returns the Math::Libgsl::Vector $x. In case of error a failure object is returned.
### pcholesky-svx2(Math::Libgsl::Matrix $LDLT where \*.matrix.size1 == $LDLT.matrix.size2, Math::Libgsl::Permutation $p where \*.p.size == $LDLT.matrix.size1, Math::Libgsl::Vector $s where \*.vector.size == $LDLT.matrix.size1, Math::Libgsl::Vector $x where \*.vector.size == $LDLT.matrix.size1 --> Int)
This function solves the system (SAS)(S⁻¹x) = Sb using the Pivoted Cholesky decomposition of SAS held in the matrix $LDLT, permutation $p, and vector $S, which must have been previously computed by pcholesky-decomp2. On input, $x contains the right hand side vector b which is replaced by the solution vector on output. This function returns GSL\_SUCCESS if successful, or one of the error codes listed in Math::Libgsl::Constants::gsl-error.
### pcholesky-invert(Math::Libgsl::Matrix $LDLT where \*.matrix.size1 == $LDLT.matrix.size2, Math::Libgsl::Permutation $p where \*.p.size == $LDLT.matrix.size1 --> Math::Libgsl::Matrix)
This function computes the inverse of the matrix A, using the Pivoted Cholesky decomposition stored in $LDLT and $p. The function returns the Math::Libgsl::Matrix A⁻¹. In case of error a failure object is returned.
### pcholesky-rcond(Math::Libgsl::Matrix $LDLT where \*.matrix.size1 == $LDLT.matrix.size2, Math::Libgsl::Permutation $p where \*.p.size == $LDLT.matrix.size1 --> Num)
This function estimates the reciprocal condition number (using the 1-norm) of the symmetric positive definite matrix A, using its pivoted Cholesky decomposition provided in $LDLT. The function returns the reciprocal condition number estimate, defined as 1/(||A||₁ · ||A⁻¹||₁). This function returns GSL\_SUCCESS if successful, or one of the error codes listed in Math::Libgsl::Constants::gsl-error.
### mcholesky-decomp(Math::Libgsl::Matrix $A where \*.matrix.size1 == $A.matrix.size2, Bool :$perturbation = True --> List)
This function factors the symmetric, indefinite square matrix $A into the Modified Cholesky decomposition P(A + E)T(P) = LDT(L). On input, the values from the diagonal and lower-triangular part of the matrix $A are used to construct the factorization. On output the diagonal of the input matrix $A stores the diagonal elements of D, and the lower triangular portion of $A contains the matrix L. Since L has ones on its diagonal these do not need to be explicitely stored. The upper triangular portion of $A is unmodified. The function returns a List: the permutation matrix P, stored in a Math::Libgsl::Permutation object and the diagonal perturbation matrix, stored in a Math::Libgsl::Vector object. In case of error a failure object is returned.
### mcholesky-solve(Math::Libgsl::Matrix $LDLT where \*.matrix.size1 == $LDLT.matrix.size2, Math::Libgsl::Permutation $p where \*.p.size == $LDLT.matrix.size1, Math::Libgsl::Vector $b where \*.vector.size == $LDLT.matrix.size1 --> Math::Libgsl::Vector)
This function solves the perturbed system (A + E)x = b using the Cholesky decomposition of A + E held in the matrix $LDLT and permutation $p which must have been previously computed by mcholesky-decomp. The function returns the Math::Libgsl::Vector $x. In case of error a failure object is returned.
### mcholesky-svx(Math::Libgsl::Matrix $LDLT where \*.matrix.size1 == $LDLT.matrix.size2, Math::Libgsl::Permutation $p where \*.p.size == $LDLT.matrix.size1, Math::Libgsl::Vector $x where \*.vector.size == $LDLT.matrix.size1 --> Int)
This function solves the perturbed system (A + E)x = b using the Cholesky decomposition of A + E held in the matrix $LDLT and permutation $p which must have been previously computed by mcholesky-decomp. On input, $x contains the right hand side vector b which is replaced by the solution vector on output. This function returns GSL\_SUCCESS if successful, or one of the error codes listed in Math::Libgsl::Constants::gsl-error.
### mcholesky-rcond(Math::Libgsl::Matrix $LDLT where \*.matrix.size1 == $LDLT.matrix.size2, Math::Libgsl::Permutation $p where \*.p.size == $LDLT.matrix.size1 --> Num)
This function estimates the reciprocal condition number (using the 1-norm) of the perturbed matrix A+E, using its pivoted Cholesky decomposition provided in $LDLT. The function returns the reciprocal condition number estimate, defined as 1/(||A + E||₁ · ||(A + E)⁻¹||₁). In case of error a failure object is returned.
### mcholesky-invert(Math::Libgsl::Matrix $LDLT where \*.matrix.size1 == $LDLT.matrix.size2, Math::Libgsl::Permutation $p where \*.p.size == $LDLT.matrix.size1 --> Math::Libgsl::Matrix)
The function returns the inverted matrix. In case of error a failure object is returned.
### ldlt-decomp(Math::Libgsl::Matrix $A where \*.matrix.size1 == $A.matrix.size2 --> Int)
This function factorizes the symmetric, non-singular square matrix $A into the decomposition A = LDT(L). On input, the values from the diagonal and lower-triangular part of the matrix $A are used. The upper triangle of $A is used as temporary workspace. On output the diagonal of $A contains the matrix D and the lower triangle of $A contains the unit lower triangular matrix L. The matrix 1-norm, ||A||₁ is stored in the upper right corner on output This function returns GSL\_SUCCESS if successful, or one of the error codes listed in Math::Libgsl::Constants::gsl-error. This function is available only in the C library starting from v2.6.
### ldlt-solve(Math::Libgsl::Matrix $LDLT where \*.matrix.size1 == $LDLT.matrix.size2, Math::Libgsl::Vector $b where \*.vector.size == $LDLT.matrix.size1 --> Math::Libgsl::Vector)
This function solves the system Ax = b using the LDT(L) decomposition of A held in the matrix $LDLT which must have been previously computed by ldlt-decomp. In case of error a failure object is returned. This function is available only in the C library starting from v2.6.
### ldlt-svx(Math::Libgsl::Matrix $LDLT where \*.matrix.size1 == $LDLT.matrix.size2, Math::Libgsl::Vector $x where \*.vector.size == $LDLT.matrix.size1 --> Int)
This function solves the system Ax = b using the LDT(L) decomposition of A held in the matrix $LDLT which must have been previously computed by ldlt-decomp. On input $x should contain the right-hand side b, which is replaced by the solution on output. In case of error a failure object is returned. This function is available only in the C library starting from v2.6.
### ldlt-rcond(Math::Libgsl::Matrix $LDLT where \*.matrix.size1 == $LDLT.matrix.size2 --> Num)
This function estimates the reciprocal condition number (using the 1-norm) of the symmetric nonsingular matrix A, using its LDT(L) decomposition provided in $LDLT. The function returns the reciprocal condition number estimate, defined as 1/(||A + E||₁ · ||(A + E)⁻¹||₁). In case of error a failure object is returned. This function is available only in the C library starting from v2.6.
### symmtd-decomp(Math::Libgsl::Matrix $A where \*.matrix.size1 == $A.matrix.size2 --> Math::Libgsl::Vector)
This function factorizes the symmetric square matrix $A into the symmetric tridiagonal decomposition QTT(Q). On output the diagonal and subdiagonal part of the input matrix $A contain the tridiagonal matrix T. The remaining lower triangular part of the input matrix contains the Householder vectors which, together with the Householder coefficients tau returned as a Math::Libgsl::Vector object, encode the orthogonal matrix Q. The upper triangular part of $A is not referenced. In case of error a failure object is returned.
### symmtd-unpack(Math::Libgsl::Matrix $A where \*.matrix.size1 == $A.matrix.size2, Math::Libgsl::Vector $tau where \*.vector.size == $A.matrix.size1 - 1 --> List)
This function unpacks the encoded symmetric tridiagonal decomposition ($A, $tau) obtained from symmtd-decomp. The function returns a List: the orthogonal matrix $Q as a Math::Libgsl::Matrix, the vector of diagonal elements $diag as a Math::Libgsl::Vector, and the vector of subdiagonal elements $subdiag as a Math::Libgsl::Vector. In case of error a failure object is returned.
### symmtd-unpack-T(Math::Libgsl::Matrix $A where \*.matrix.size1 == $A.matrix.size2 --> List)
This function unpacks the diagonal and subdiagonal of the encoded symmetric tridiagonal decomposition ($A, $tau) obtained from symmtd-decomp. The function returns a List of two Math::Libgsl::Vector: $diag and $subdiag. In case of error a failure object is returned.
### hessenberg-decomp(Math::Libgsl::Matrix $A where \*.matrix.size1 == $A.matrix.size2 --> Math::Libgsl::Vector)
This function computes the Hessenberg decomposition of the matrix $A by applying the similarity transformation H = T(U)AU. On output, H is stored in the upper portion of $A. The information required to construct the matrix U is stored in the lower triangular portion of $A. U is a product of N−2 Householder matrices. The Householder vectors are stored in the lower portion of $A (below the subdiagonal) and the Householder coefficients are returned as a Math::Libgsl::Vector. In case of error a failure object is returned.
### hessenberg-unpack(Math::Libgsl::Matrix $H where \*.matrix.size1 == $H.matrix.size2, Math::Libgsl::Vector $tau where \*.vector.size == $H.matrix.size1 --> Math::Libgsl::Matrix)
This function constructs the orthogonal matrix U from the information stored in the Hessenberg matrix $H along with the vector $tau. $H and $tau are outputs from hessenberg-decomp. The function returns the Math::Libgsl::Matrix which stores $U. In case of error a failure object is returned.
### hessenberg-unpack-accum(Math::Libgsl::Matrix $H where \*.matrix.size1 == $H.matrix.size2, Math::Libgsl::Vector $tau where \*.vector.size == $H.matrix.size1 --> Math::Libgsl::Matrix)
This function is similar to hessenberg-unpack, except it accumulates the matrix U into V, so that V′ = VU. The function returns the Math::Libgsl::Matrix which stores $V. In case of error a failure object is returned.
### hessenberg-set-zero(Math::Libgsl::Matrix $H where \*.matrix.size1 == $H.matrix.size2 --> Int)
This function sets the lower triangular portion of $H, below the subdiagonal, to zero. It is useful for clearing out the Householder vectors after calling hessenberg-decomp. This function returns GSL\_SUCCESS if successful, or one of the error codes listed in Math::Libgsl::Constants::gsl-error.
### hesstri-decomp(Math::Libgsl::Matrix $A where \*.matrix.size1 == $A.matrix.size2, Math::Libgsl::Matrix $B where { $B.matrix.size1 == $A.matrix.size1 && $B.matrix.size2 == $A.matrix.size2}, Bool :$similarity = True --> List)
This function computes the Hessenberg-Triangular decomposition of the matrix pair ($A, $B). On output, H is stored in $A, and R is stored in $B. If the $similarity Bool parameter is True (default), then the similarity transformations are returned as a List of Math::Libgsl::Matrix objects. In case of error a failure object is returned.
### bidiag-decomp(Math::Libgsl::Matrix $A where \*.matrix.size1 ≥ $A.matrix.size2 --> List)
This function factorizes the M-by-N matrix $A into bidiagonal form UBT(V). The diagonal and superdiagonal of the matrix B are stored in the diagonal and superdiagonal of $A. The orthogonal matrices U and V are stored as compressed Householder vectors in the remaining elements of $A. This function returns a List of Math::Libgsl::Vector objects: the two Householder coefficients $tau\_U and $tau\_V. In case of error a failure object is returned.
### bidiag-unpack(Math::Libgsl::Matrix $A where \*.matrix.size1 ≥ $A.matrix.size2, Math::Libgsl::Vector $tau\_U where \*.vector.size == $A.matrix.size2, Math::Libgsl::Vector $tau\_V where \*.vector.size == $A.matrix.size2 - 1 --> List)
This function unpacks the bidiagonal decomposition of $A produced by bidiag-decomp, ($A, $tau\_U, $tau\_V) into the separate orthogonal matrices U, V and the diagonal vector diag and superdiagonal superdiag. Note that U is stored as a compact M-by-N orthogonal matrix satisfying T(U)U = I for efficiency. The function returns a List of four objects: the Math::Libgsl::Matrix $U and $V, and the Math::Libgsl::Vector $diag and $sdiag. In case of error a failure object is returned.
### bidiag-unpack2(Math::Libgsl::Matrix $A where \*.matrix.size1 ≥ $A.matrix.size2, Math::Libgsl::Vector $tau\_U where \*.vector.size == $A.matrix.size2, Math::Libgsl::Vector $tau\_V where \*.vector.size == $A.matrix.size2 - 1 --> Math::Libgsl::Matrix)
This function unpacks the bidiagonal decomposition of $A produced by bidiag-decomp, ($A, $tau\_U, $tau\_V) into the separate orthogonal matrices U, V and the diagonal vector diag and superdiagonal superdiag. The matrix U is stored in-place in $A. The function returns the Math::Libgsl::Matrix object $V. In case of error a failure object is returned.
### bidiag-unpack-B(Math::Libgsl::Matrix $A where \*.matrix.size1 ≥ $A.matrix.size2 --> List)
This function unpacks the diagonal and superdiagonal of the bidiagonal decomposition of $A from bidiag-decomp. The function returns a List of two objects: the Math::Libgsl::Vector $diag and $sdiag. In case of error a failure object is returned.
### givens(Num() $a, Num() $b --> List)
This function computes c = cos θ and s = sin θ so that the Givens matrix G(θ) acting on the vector (a, b) produces (r, 0), with r = √ a² + b². The function returns a List of Num: the c and s elements of the Givens matrix.
### givens-gv(Math::Libgsl::Vector $v, Int, $i, Int $j, Num() $c, Num() $s)
This function applies the Givens rotation defined by c = cos θ and s = sin θ to the i and j elements of v. On output, (v(i), v(j)) ← G(θ)(v(i), v(j)). This function returns GSL\_SUCCESS if successful, or one of the error codes listed in Math::Libgsl::Constants::gsl-error.
### householder-transform(Math::Libgsl::Vector $w --> Num)
This function prepares a Householder transformation H = I − τvT(v) which can be used to zero all the elements of the input vector $w except the first. On output the Householder vector v is stored in $w and the scalar τ is returned. The householder vector v is normalized so that v[0] = 1, however this 1 is not stored in the output vector. Instead, $w[0] is set to the first element of the transformed vector, so that if u = Hw, w[0] = u[0] on output and the remainder of u is zero. This function returns a Num: $τ.
### householder-hm(Num() $tau, Math::Libgsl::Vector $v, Math::Libgsl::Matrix $A --> Int)
This function applies the Householder matrix H defined by the scalar $tau and the vector $v to the left-hand side of the matrix $A. On output the result HA is stored in $A. This function returns GSL\_SUCCESS if successful, or one of the error codes listed in Math::Libgsl::Constants::gsl-error.
### householder-mh(Num() $tau, Math::Libgsl::Vector $v, Math::Libgsl::Matrix $A --> Int)
This function applies the Householder matrix H defined by the scalar $tau and the vector $v to the right-hand side of the matrix $A. On output the result AH is stored in $A. This function returns GSL\_SUCCESS if successful, or one of the error codes listed in Math::Libgsl::Constants::gsl-error.
### householder-hv(Num() $tau, Math::Libgsl::Vector $v, Math::Libgsl::Vector $w --> Int)
This function applies the Householder transformation H defined by the scalar $tau and the vector $v to the vector $w. On output the result Hw is stored in w. This function returns GSL\_SUCCESS if successful, or one of the error codes listed in Math::Libgsl::Constants::gsl-error.
### HH-solve(Math::Libgsl::Matrix $A where \*.matrix.size1 ≤ $A.matrix.size2, Math::Libgsl::Vector $b where \*.vector.size == $A.matrix.size1 --> Math::Libgsl::Vector)
This function solves the system Ax = b directly using Householder transformations. $b is not modified. The matrix $A is destroyed by the Householder transformations. The function returns a Math::Libgsl::Vector object: the solution $x. In case of error a failure object is returned.
### HH-svx(Math::Libgsl::Matrix $A where \*.matrix.size1 ≤ $A.matrix.size2, Math::Libgsl::Vector $x where \*.vector.size == $A.matrix.size2 --> Int)
This function solves the system Ax = b in-place using Householder transformations. On input $x should contain the right-hand side b, which is replaced by the solution on output. The matrix $A is destroyed by the Householder transformations. This function returns GSL\_SUCCESS if successful, or one of the error codes listed in Math::Libgsl::Constants::gsl-error.
### tridiag-solve(Math::Libgsl::Vector $diag, Math::Libgsl::Vector $abovediag where \*.vector.size == $diag.vector.size - 1, Math::Libgsl::Vector $belowdiag where \*.vector.size == $diag.vector.size - 1, Math::Libgsl::Vector $rhs where \*.vector.size == $diag.vector.size --> Math::Libgsl::Vector)
This function solves the general N-by-N system Ax = b where A is tridiagonal (N ≥ 2). The super-diagonal and sub-diagonal vectors must be one element shorter than the diagonal vector diag. The function returns the Math::Libgsl::Vector solution $x. In case of error a failure object is returned.
### tridiag-symm-solve(Math::Libgsl::Vector $diag, Math::Libgsl::Vector $offdiag where \*.vector.size == $diag.vector.size - 1, Math::Libgsl::Vector $rhs where \*.vector.size == $diag.vector.size --> Math::Libgsl::Vector)
This function solves the general N-by-N system Ax = b where A is symmetric tridiagonal (N ≥ 2). The off-diagonal vector $offdiag must be one element shorter than the diagonal vector $diag. The function returns the Math::Libgsl::Vector solution $x. In case of error a failure object is returned.
### tridiag-cyc-solve(Math::Libgsl::Vector $diag where \*.vector.size ≥ 3, Math::Libgsl::Vector $abovediag where \*.vector.size == $diag.vector.size, Math::Libgsl::Vector $belowdiag where \*.vector.size == $diag.vector.size, Math::Libgsl::Vector $rhs where \*.vector.size == $diag.vector.size --> Math::Libgsl::Vector)
This function solves the general N-by-N system Ax = b where A is cyclic tridiagonal (N ≥ 3). The cyclic super-diagonal and sub-diagonal vectors $abovediag and $belowdiag must have the same number of elements as the diagonal vector $diag. The function returns the Math::Libgsl::Vector solution $x. In case of error a failure object is returned.
### tridiag-symm-cyc-solve(Math::Libgsl::Vector $diag where \*.vector.size ≥ 3, Math::Libgsl::Vector $offdiag where \*.vector.size == $diag.vector.size, Math::Libgsl::Vector $rhs where \*.vector.size == $diag.vector.size --> Math::Libgsl::Vector)
This function solves the general N-by-N system Ax = b where A is symmetric cyclic tridiagonal (N ≥ 3). The cyclic off-diagonal vector $offdiag must have the same number of elements as the diagonal vector $diag. The function returns the Math::Libgsl::Vector solution $x. In case of error a failure object is returned.
### tri-upper-rcond(Math::Libgsl::Matrix $A where \*.matrix.size1 == $A.matrix.size2 --> Num)
This function estimates the reciprocal condition number. In case of error a failure object is returned.
### tri-lower-rcond(Math::Libgsl::Matrix $A where \*.matrix.size1 == $A.matrix.size2 --> Num)
This function estimates the reciprocal condition number. In case of error a failure object is returned.
### tri-upper-invert(Math::Libgsl::Matrix $T where \*.matrix.size1 == $T.matrix.size2 --> Int)
This function computes the in-place inverse of the triangular matrix $T, stored in the upper triangle. This function returns GSL\_SUCCESS if successful, or one of the error codes listed in Math::Libgsl::Constants::gsl-error.
### tri-lower-invert(Math::Libgsl::Matrix $T where \*.matrix.size1 == $T.matrix.size2 --> Int)
This function computes the in-place inverse of the triangular matrix $T, stored in the lower triangle. This function returns GSL\_SUCCESS if successful, or one of the error codes listed in Math::Libgsl::Constants::gsl-error.
### tri-upper-unit-invert(Math::Libgsl::Matrix $T where \*.matrix.size1 == $T.matrix.size2 --> Int)
This function returns GSL\_SUCCESS if successful, or one of the error codes listed in Math::Libgsl::Constants::gsl-error.
### tri-lower-unit-invert(Math::Libgsl::Matrix $T where \*.matrix.size1 == $T.matrix.size2 --> Int)
This function returns GSL\_SUCCESS if successful, or one of the error codes listed in Math::Libgsl::Constants::gsl-error.
### tri-invert(Int $Uplo, Int $Diag, Math::Libgsl::Matrix $T where \*.matrix.size1 == $T.matrix.size2 --> Int)
This function is available only from the C library v2.6. This function computes the in-place inverse of the triangular matrix $T, stored in the lower triangle when $Uplo = CblasLower and upper triangle when $Uplo = CblasUpper. The parameter $Diag = CblasUnit, CblasNonUnit specifies whether the matrix is unit triangular. This function returns GSL\_SUCCESS if successful, or one of the error codes listed in Math::Libgsl::Constants::gsl-error.
### tri-LTL(Math::Libgsl::Matrix $L where \*.matrix.size1 == $L.matrix.size2 --> Int)
This function is available only from the C library v2.6. This function computes the product LT(L) in-place and stores it in the lower triangle of $L on output. This function returns GSL\_SUCCESS if successful, or one of the error codes listed in Math::Libgsl::Constants::gsl-error.
### tri-UL(Math::Libgsl::Matrix $LU where \*.matrix.size1 == $LU.matrix.size2 --> Int)
This function is available only from the C library v2.6. This function compute the product $UL where U is upper triangular and L is unit lower triangular, stored in $LU, as computed by LU-decomp. This function returns GSL\_SUCCESS if successful, or one of the error codes listed in Math::Libgsl::Constants::gsl-error.
### tri-rcond(Int $Uplo, Math::Libgsl::Matrix $A where \*.matrix.size1 == $A.matrix.size2 --> Num)
This function is available only from the C library v2.6. This function estimates the 1-norm reciprocal condition number of the triangular matrix $A, using the lower triangle when $Uplo is CblasLower and upper triangle when $Uplo is CblasUpper. The function returns the reciprocal condition number 1/(||A||₁||A⁻¹||₁). In case of error a failure object is returned.
### cholesky-band-decomp(Math::Libgsl::Matrix $A where \*.matrix.size1 == $A.matrix.size2 --> Int)
This function is available only from the C library v2.6. This function factorizes the symmetric, positive-definite square matrix $A into the Cholesky decomposition A = LT(L). The input matrix $
|
## dist_cpan-FRITH-Math-Libgsl-LinearAlgebra.md
## Chunk 3 of 3
A is given in symmetric banded format, and has dimensions N-by-(p + 1), where p is the lower bandwidth of the matrix. On output, the entries of $A are replaced by the entries of the matrix L in the same format. In addition, the lower right element of $A is used to store the matrix 1-norm, used later by cholesky-band-rcond() to calculate the reciprocal condition number. This function returns GSL\_SUCCESS if successful, or one of the error codes listed in Math::Libgsl::Constants::gsl-error.
### cholesky-band-solve(Math::Libgsl::Matrix $LLT where \*.matrix.size1 == $LLT.matrix.size2, Math::Libgsl::Vector $b where \*.vector.size == $LLT.matrix.size1 --> Math::Libgsl::Vector)
This function is available only from the C library v2.6. This function solves the symmetric banded system Ax = b using the Cholesky decomposition of A held in the matrix $LLT which must have been previously computed by cholesky-band-decomp. The function returns the Math::Libgsl::Vector solution $x. In case of error a failure object is returned.
### cholesky-band-svx(Math::Libgsl::Matrix $LLT where \*.matrix.size1 == $LLT.matrix.size2, Math::Libgsl::Vector $x where \*.vector.size == $LLT.matrix.size1 --> Int)
This function is available only from the C library v2.6. This function solves the symmetric banded system Ax = b using the Cholesky decomposition of A held in the matrix $LLT which must have been previously computed by cholesky-band-decomp. On input $x should contain the right-hand side b, which is replaced by the solution on output. This function returns GSL\_SUCCESS if successful, or one of the error codes listed in Math::Libgsl::Constants::gsl-error.
### cholesky-band-invert(Math::Libgsl::Matrix $LLT where \*.matrix.size1 == $LLT.matrix.size2 --> Math::Libgsl::Matrix)
This function is available only from the C library v2.6. This function computes the inverse of a symmetric banded matrix from its Cholesky decomposition $LLT, which must have been previously computed by cholesky-band-decomp. The function returns the inverse matrix as a Math::Libgsl::Matrix solution object. In case of error a failure object is returned.
### cholesky-band-unpack(Math::Libgsl::Matrix $LLT where \*.matrix.size1 == $LLT.matrix.size2 --> Math::Libgsl::Matrix)
This function is available only from the C library v2.6. This function unpacks the lower triangular Cholesky factor from $LLT, which returns as a Math::Libgsl::Matrix object. In case of error a failure object is returned.
### cholesky-band-rcond(Math::Libgsl::Matrix $LLT where \*.matrix.size1 == $LLT.matrix.size2 --> Num)
This function is available only from the C library v2.6. This function estimates the reciprocal condition number (using the 1-norm) of the symmetric banded positive definite matrix A, using its Cholesky decomposition provided in $LLT. The reciprocal condition number estimate, defined as 1/(||A||₁ · ||A⁻¹||₁), is returned.
### ldlt-band-decomp(Math::Libgsl::Matrix $A where \*.matrix.size1 == $A.matrix.size2 --> Int)
This function is available only from the C library v2.6. This function factorizes the symmetric, non-singular square matrix $A into the decomposition A = LDT(L). The input matrix $A is given in symmetric banded format, and has dimensions N-by-(p + 1), where p is the lower bandwidth of the matrix. On output, the entries of $A are replaced by the entries of the matrices D and L in the same format. If the matrix is singular then the decomposition will fail, returning the error code GSL\_EDOM . This function returns GSL\_SUCCESS if successful, or one of the error codes listed in Math::Libgsl::Constants::gsl-error.
### ldlt-band-solve(Math::Libgsl::Matrix $LDLT where \*.matrix.size1 == $LDLT.matrix.size2, Math::Libgsl::Vector $b where \*.vector.size == $LDLT.matrix.size1 --> Math::Libgsl::Vector)
This function is available only from the C library v2.6. This function solves the symmetric banded system Ax = b using the LDT(L) decomposition of A held in the matrix $LDLT which must have been previously computed by ldlt-band-decomp. The function returns the Math::Libgsl::Vector solution $x. In case of error a failure object is returned.
### ldlt-band-svx(Math::Libgsl::Matrix $LDLT where \*.matrix.size1 == $LDLT.matrix.size2, Math::Libgsl::Vector $x where \*.vector.size == $LDLT.matrix.size1 --> Int)
This function is available only from the C library v2.6. This function solves the symmetric banded system Ax = b using the LDT(L) decomposition of A held in the matrix $LDLT which must have been previously computed by ldlt-band-decomp. On input $x should contain the right-hand side b, which is replaced by the solution on output. This function returns GSL\_SUCCESS if successful, or one of the error codes listed in Math::Libgsl::Constants::gsl-error.
### ldlt-band-unpack(Math::Libgsl::Matrix $LDLT where \*.matrix.size1 == $LDLT.matrix.size2 --> List)
This function is available only from the C library v2.6. This function unpacks the unit lower triangular factor L from $LDLT. This function returns a Math::Libgsl::Matrix object, which holds the lower triangular portion of the matrix L, and a Math::Libgsl::Vector object, which contains the diagonal matrix D. In case of error a failure object is returned.
### ldlt-band-rcond(Math::Libgsl::Matrix $LDLT where \*.matrix.size1 == $LDLT.matrix.size2 --> Num)
This function is available only from the C library v2.6. This function estimates the reciprocal condition number (using the 1-norm) of the symmetric banded nonsingular matrix A, using its LDT(L) decomposition provided in $LDLT. The reciprocal condition number estimate, defined as 1/(||A||₁ · ||A⁻¹||₁), is returned.
### balance-matrix(Math::Libgsl::Matrix $A --> Math::Libgsl::Vector)
This function replaces the matrix $A with its balanced counterpart and returns the diagonal elements of the similarity transformation as a Math::Libgsl::Vector object. In case of error a failure object is returned.
## Complex
### LU-cdecomp(Math::Libgsl::Matrix::Complex64 $A where \*.matrix.size1 == $A.matrix.size2 --> List)
This function factorizes the matrix A into the LU decomposition PA = LU. The factorization is done in place, so on output the diagonal and upper triangular (or trapezoidal) part of the input matrix A contain the matrix U. The lower triangular (or trapezoidal) part of the input matrix (excluding the diagonal) contains L. The diagonal elements of L are unity, and are not stored. The return value is a List: the sign of the permutation and a permutation object, which encodes the permutation matrix P. In case of error a failure object is returned.
### LU-csolve(Math::Libgsl::Matrix::Complex64 $LU where \*.matrix.size1 == $LU.matrix.size2, Math::Libgsl::Permutation $p where \*.size == $LU.matrix.size1, Math::Libgsl::Vector::Complex64 $b where \*.vector.size == $LU.matrix.size1 --> Math::Libgsl::Vector::Complex64)
This function solves the square system Ax = b using the LU decomposition of A into (LU, p) given by the output of LU-decomp. In case of error a failure object is returned.
### LU-csvx(Math::Libgsl::Matrix::Complex64 $LU where \*.matrix.size1 == $LU.matrix.size2, Math::Libgsl::Permutation $p where \*.size == $LU.matrix.size1, Math::Libgsl::Vector::Complex64 $x where \*.vector.size == $LU.matrix.size1 --> Int)
This function solves the square system Ax = b in-place using the precomputed LU decomposition of A into (LU, p). On input $x should contain the right-hand side b, which is replaced by the solution on output. This function returns GSL\_SUCCESS if successful, or one of the error codes listed in Math::Libgsl::Constants::gsl-error.
### LU-crefine(Math::Libgsl::Matrix::Complex64 $A where \*.matrix.size1 == $A.matrix.size2, Math::Libgsl::Matrix::Complex64 $LU where { $LU.matrix.size1 == $LU.matrix.size2 && $A.matrix.size1 == $LU.matrix.size2 }, Math::Libgsl::Permutation $p where \*.size == $LU.matrix.size1, Math::Libgsl::Vector::Complex64 $b where \*.vector.size == $LU.matrix.size1, Math::Libgsl::Vector::Complex64 $x where \*.vector.size == $LU.matrix.size1 --> Int)
This function applies an iterative improvement to x, the solution of Ax = b, from the precomputed LU decomposition of A into (LU, p). This function returns GSL\_SUCCESS if successful, or one of the error codes listed in Math::Libgsl::Constants::gsl-error.
### LU-cinvert(Math::Libgsl::Matrix::Complex64 $LU, Math::Libgsl::Permutation $p where \*.size == $LU.matrix.size1 --> Math::Libgsl::Matrix::Complex64)
This function computes the inverse of a matrix A from its LU decomposition (LU, p), returning the matrix inverse. In case of error a failure object is returned.
### LU-cdet(Math::Libgsl::Matrix::Complex64 $LU, Int $signum where \* ~~ -1|1 --> Complex)
This function computes the determinant of a matrix A from its LU decomposition, $LU, and the sign of the permutation, $signum. This function returns GSL\_SUCCESS if successful, or one of the error codes listed in Math::Libgsl::Constants::gsl-error.
### LU-clndet(Math::Libgsl::Matrix::Complex64 $LU --> Num)
This function computes the determinant the logarithm of the absolute value of the determinant of a matrix A, ln |det(A)|, from its LU decomposition, $LU. This function returns GSL\_SUCCESS if successful, or one of the error codes listed in Math::Libgsl::Constants::gsl-error.
### LU-csgndet(Math::Libgsl::Matrix::Complex64 $LU, Int $signum where \* ~~ -1|1 --> Complex)
This function computes the sign or phase factor of the determinant of a matrix A, det(A)/|det(A)| from its LU decomposition, $LU. This function returns GSL\_SUCCESS if successful, or one of the error codes listed in Math::Libgsl::Constants::gsl-error.
### cholesky-cdecomp(Math::Libgsl::Matrix::Complex64 $A where \*.matrix.size1 == $A.matrix.size2 --> Int)
This function factorizes the symmetric, positive-definite square matrix $A into the Cholesky decomposition A = LT(L). On input, the values from the diagonal and lower-triangular part of the matrix $A are used (the upper triangular part is ignored). On output the diagonal and lower triangular part of the input matrix $A contain the matrix L, while the upper triangular part contains the original matrix. If the matrix is not positive-definite then the decomposition will fail, returning the error code GSL\_EDOM. This function returns GSL\_SUCCESS if successful, or one of the error codes listed in Math::Libgsl::Constants::gsl-error.
### cholesky-csolve(Math::Libgsl::Matrix::Complex64 $A where \*.matrix.size1 == $A.matrix.size2, Math::Libgsl::Vector::Complex64 $b where \*.vector.size == $A.matrix.size1 --> Math::Libgsl::Vector::Complex64)
These functions solve the system Ax = b using the Cholesky decomposition of $A which must have been previously computed by cholesky-cdecomp. The function returns the Math::Libgsl::Vector::Complex64 $x. In case of error a failure object is returned.
### cholesky-csvx(Math::Libgsl::Matrix::Complex64 $A where \*.matrix.size1 == $A.matrix.size2, Math::Libgsl::Vector::Complex64 $x where \*.vector.size == $A.matrix.size1 --> Int)
This function solves the system Ax = b in-place using the Cholesky decomposition of $A which must have been previously computed by cholesky-cdecomp. On input $x should contain the right-hand side b, which is replaced by the solution on output. This function returns GSL\_SUCCESS if successful, or one of the error codes listed in Math::Libgsl::Constants::gsl-error.
### cholesky-cinvert(Math::Libgsl::Matrix::Complex64 $A where \*.matrix.size1 == $A.matrix.size2 --> Int)
These functions compute the inverse of a matrix from its Cholesky decomposition $A, which must have been previously computed by cholesky-cdecomp. On output, the inverse is stored in-place in $A. This function returns GSL\_SUCCESS if successful, or one of the error codes listed in Math::Libgsl::Constants::gsl-error.
### hermtd-cdecomp(Math::Libgsl::Matrix::Complex64 $A where \*.matrix.size1 == $A.matrix.size2 --> Math::Libgsl::Vector::Complex64)
This function factorizes the hermitian matrix $A into the symmetric tridiagonal decomposition UTT(U). On output the diagonal and subdiagonal part of the input matrix $A contain the tridiagonal matrix T. The remaining lower triangular part of the input matrix contains the Householder vectors which, together with the Householder coefficients tau returned as a Math::Libgsl::Vector::Complex64 object, encode the orthogonal matrix U. The upper triangular part of $A and the imaginary parts of the diagonal are not referenced. In case of error a failure object is returned.
### hermtd-cunpack(Math::Libgsl::Matrix::Complex64 $A where \*.matrix.size1 == $A.matrix.size2, Math::Libgsl::Vector::Complex64 $tau where \*.vector.size == $A.matrix.size1 - 1 --> List)
This function unpacks the encoded symmetric tridiagonal decomposition ($A, $tau) obtained from hermtd-cdecomp. The function returns a List: the unitary matrix $U as a Math::Libgsl::Matrix::Complex64, the real vector of diagonal elements $diag as a Math::Libgsl::Vector, and the real vector of subdiagonal elements $subdiag as a Math::Libgsl::Vector. In case of error a failure object is returned.
### hermtd-cunpack-T(Math::Libgsl::Matrix::Complex64 $A where \*.matrix.size1 == $A.matrix.size2 --> List)
This function unpacks the diagonal and subdiagonal of the encoded symmetric tridiagonal decomposition ($A, $tau) obtained from hermtd-cdecomp. The function returns a List of two real Math::Libgsl::Vector: $diag and $subdiag. In case of error a failure object is returned.
### householder-ctransform(Math::Libgsl::Vector::Complex64 $w --> Complex)
This function prepares a Householder transformation H = I − τvT(v) which can be used to zero all the elements of the input vector $w except the first. On output the Householder vector v is stored in $w and the scalar τ is returned. The householder vector v is normalized so that v[0] = 1, however this 1 is not stored in the output vector. Instead, $w[0] is set to the first element of the transformed vector, so that if u = Hw, w[0] = u[0] on output and the remainder of u is zero. This function returns a Complex: $τ.
### householder-chm(Complex $tau, Math::Libgsl::Vector::Complex64 $v, Math::Libgsl::Matrix::Complex64 $A --> Int)
This function applies the Householder matrix H defined by the scalar $tau and the vector $v to the left-hand side of the matrix $A. On output the result HA is stored in $A. This function returns GSL\_SUCCESS if successful, or one of the error codes listed in Math::Libgsl::Constants::gsl-error.
### householder-cmh(Complex $tau, Math::Libgsl::Vector::Complex64 $v, Math::Libgsl::Matrix::Complex64 $A --> Int)
This function applies the Householder matrix H defined by the scalar $tau and the vector $v to the right-hand side of the matrix $A. On output the result AH is stored in $A. This function returns GSL\_SUCCESS if successful, or one of the error codes listed in Math::Libgsl::Constants::gsl-error.
### householder-chv(Complex $tau, Math::Libgsl::Vector::Complex64 $v, Math::Libgsl::Vector::Complex64 $w --> Int)
This function applies the Householder transformation H defined by the scalar $tau and the vector $v to the vector $w. On output the result Hw is stored in w. This function returns GSL\_SUCCESS if successful, or one of the error codes listed in Math::Libgsl::Constants::gsl-error.
### tri-cinvert(Int $Uplo, Int $Diag, Math::Libgsl::Matrix::Complex64 $A --> Int)
This function is available only from the C library v2.6. This function computes the in-place inverse of the triangular matrix $T, stored in the lower triangle when $Uplo = CblasLower and upper triangle when $Uplo = CblasUpper. The parameter $Diag = CblasUnit, CblasNonUnit specifies whether the matrix is unit triangular. This function returns GSL\_SUCCESS if successful, or one of the error codes listed in Math::Libgsl::Constants::gsl-error.
### tri-cLHL(Math::Libgsl::Matrix::Complex64 $L --> Int)
This function is available only from the C library v2.6. This function computes the product LT(L) in-place and stores it in the lower triangle of $L on output. This function returns GSL\_SUCCESS if successful, or one of the error codes listed in Math::Libgsl::Constants::gsl-error.
### tri-cUL(Math::Libgsl::Matrix::Complex64 $LU --> Int)
This function is available only from the C library v2.6. This function compute the product $UL where U is upper triangular and L is unit lower triangular, stored in $LU, as computed by LU-cdecomp. This function returns GSL\_SUCCESS if successful, or one of the error codes listed in Math::Libgsl::Constants::gsl-error.
# C Library Documentation
For more details on libgsl see <https://www.gnu.org/software/gsl/>. The excellent C Library manual is available here <https://www.gnu.org/software/gsl/doc/html/index.html>, or here <https://www.gnu.org/software/gsl/doc/latex/gsl-ref.pdf> in PDF format.
# Prerequisites
This module requires the libgsl library to be installed. Please follow the instructions below based on your platform:
## Debian Linux and Ubuntu 20.04
```
sudo apt install libgsl23 libgsl-dev libgslcblas0
```
That command will install libgslcblas0 as well, since it's used by the GSL.
## Ubuntu 18.04
libgsl23 and libgslcblas0 have a missing symbol on Ubuntu 18.04. I solved the issue installing the Debian Buster version of those three libraries:
* <http://http.us.debian.org/debian/pool/main/g/gsl/libgslcblas0_2.5+dfsg-6_amd64.deb>
* <http://http.us.debian.org/debian/pool/main/g/gsl/libgsl23_2.5+dfsg-6_amd64.deb>
* <http://http.us.debian.org/debian/pool/main/g/gsl/libgsl-dev_2.5+dfsg-6_amd64.deb>
# Installation
To install it using zef (a module management tool):
```
$ zef install Math::Libgsl::LinearAlgebra
```
# AUTHOR
Fernando Santagata [nando.santagata@gmail.com](mailto:nando.santagata@gmail.com)
# COPYRIGHT AND LICENSE
Copyright 2020 Fernando Santagata
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_zef-pelevesque-MIDI-Make.md
[](https://github.com/pelevesque/MIDI-Make/actions)
# MIDI::Make
A [Raku](https://www.raku.org) module to make MIDI files.
## Synopsis
```
use MIDI::Make;
my \t = Track.new;
t.copyright: 'c 2022 anonymous';
t.name: 'melody';
t.instrument: 'piano';
t.controller: 8, 100;
t.program-name: 'electric piano';
t.port: 'MIDI Out 1';
t.channel 1;
t.program-change: 100;
t.aftertouch: 100;
t.pitch-bend: 0;
t.marker: 'section I';
t.text: 'Lorem ipsum dolor sit amet.';
t.key-signature: 2♭, minor;
t.tempo: ♩80;
t.time-signature: 3\2;
t.aftertouch: 100, 53;
t.note-on: 60;
t.lyric: 'one';
t.delta-time: 128;
t.note-off: 60;
t.cue: 'door slam';
t.velocity-on: 80;
t.velocity-off: 10;
t.note-on: 72;
t.lyric: 'two';
t.delta-time: 128;
t.note-off: 72;
t.sysex: <0A 29 1E>;
t.add-bytes: <00 F0 0A 29 1E F7>;
my \s = Song.new(:PPQ(96));
s.add-track(t.render);
# Print the MIDI contents.
say s.render;
# Save the MIDI contents to file.
spurt 'file.mid', s.render;
```
## Versioning
MIDI::Make uses [Semantic Versioning](https://semver.org).
## Installation
You can install MIDI::Make using [Zef](https://github.com/ugexe/zef).
```
➤ zef install MIDI::Make
```
## Import
```
use MIDI::Make;
```
## Usage
MIDI::Make works by creating the Song class and then populating it
with zero or more tracks created using the Track class. The resulting
MIDI information can be outputed using the Song class's render method.
## The Song class
The Song class is used to store and modify MIDI information in order
to create a MIDI file. It has some optional parameters, the add-track
method to add tracks, and the render method to output the MIDI
information created up to that point.
```
# Instantiating without parameters.
my \s = Song.new;
```
### Parameters
Parameters can be set on instantiation, or anytime afterwards.
#### format
The format parameter specifies the type of MIDI file format to use.
It can have three values: 0, 1, or 2. The default is 1.
* 0 - All data is merged on a single track.
* 1 - Tracks are separated, and played together.
* 2 - Tracks are separated, and played one after the other.
```
# Set on instantiation.
my \s = Song.new(:format(0));
```
```
# Set after instantiation.
my \s = Song.new;
s.format: 0;
```
#### time-division
The time-division parameter defines how MIDI time will be divided.
It can have two values: quarter for quarter notes, and frame. The
default is quarter.
```
# Set on instantiation.
my \s = Song.new(:time-division('frame'));
```
```
# Set after instantiation.
my \s = Song.new;
s.time-division: 'frame';
```
#### PPQ (pulses per quarter note)
The PPQ parameter sets the pulses per quarter note of the
time-division parameter when the latter is set to quarter. If
time-division is set to frame, PPQ is ignored.
The PPQ value is from 0 to 32767. The default is 48.
```
# Set on instantiation.
my \s = Song.new(:PPQ(96));
```
```
# Set after instantiation.
my \s = Song.new;
s.PPQ: 96;
```
#### FPS (frames per second)
The FPS parameter sets the frames per second of the time-division
parameter when the latter is set to frame. If time-division is set to
quarter, FPS is ignored.
FPS can have four values: 24, 25, 29.97, or 30. The default is 24.
```
# Set on instantiation.
my \s = Song.new(:time-division('frame'), :FPS(30));
```
```
# Set after instantiation.
my \s = Song.new;
s.time-division: 'frame';
s.FPS: 30;
```
#### PPF (pulses per frame)
The PPF parameter sets the pulses per frame of the time-division
parameter when the latter is set to frame. If time-division is set to
quarter, PPF is ignored.
The PPF value is from 0 to 255. The default is 4.
```
# Set on instantiation.
my \s = Song.new(:time-division('frame'), :PPF(8));
```
```
# Set after instantiation.
my \s = Song.new;
s.time-division: 'frame';
s.PPF: 8;
```
### Methods
#### add-track
The add-track method accepts a rendered track, and adds it to the Song
class.
```
# Create a track.
my \t = Track.new;
t.note-on: 60;
t.delta-time: 100;
t.note-off: 60;
# Add it to the Song class.
my \s = Song.new;
s.add-track($t.render);
```
#### render
The render method renders the MIDI file information gathered up to
that point.
```
my \s = Song.new;
say s.render;
```
## Operators
MIDI::Make creates two operators that serve as helpers for the Track
class described below.
### ♩
The quarter notes per minute operator transforms quarter notes per
minute to microseconds per quarter note.
This permits specifying tempo in a musical human-readable way.
```
# 60 QPM using microseconds per quarter note.
my \t = Track.new;
t.tempo: 1000000;
# 60 QPM using the MIDI::Make operator.
my \t = Track.new;
t.tempo: ♩60;
```
### \
The time-signature operator is used to specify a time-signature for
the Track class's time-signature method.
```
my \t = Track.new;
t.time-signature: 3\8;
```
## The Track class
The Track class is used to create a MIDI track which can then be added
to the Song class.
```
# Instantiating without parameters.
my \t = Track.new;
```
### Parameters
Parameters can be set on instantiation, or anytime afterwards.
#### copyright
The copyright parameter lets you set the MIDI file's copyright using
ASCII characters.
Note: This copyright is usually placed at time 0 of the first track
in the sequence.
```
# Set on instantiation.
my \t = Track.new(:copyright('c 2022 anonymous'));
```
```
# Set after instantiation.
my \t = Track.new;
t.copyright: 'c 2022 anonymous';
```
#### name
The name parameter lets you set the track's name using
ASCII characters.
```
# Set on instantiation.
my \t = Track.new(:name('melody'));
```
```
# Set after instantiation.
my \t = Track.new;
t.name: 'melody';
```
#### delta-time
Delta time sets the time in MIDI pulses between MIDI events.
The delta-time value is from O to 268435455. The default is 0.
Note: Although it's possible to instantiate delta-time to a value
other than 0, usually you will start a MIDI file with a MIDI event,
and not a period of time.
```
# Set on instantiation.
my \t = Track.new(:delta-time(100));
```
```
# Set after instantiation.
my \t = Track.new;
t.delta-time: 100;
```
Delta-time is automatically set to 0 after each of the MIDI events
implemented in the Track class. This is done so that you can enter
many MIDI events consecutively before setting a new delta-time.
```
my \t = Track.new;
t.note-on: 60;
t.delta-time: 100; # Wait 100 MIDI pulses before following events.
t.note-off: 60;
t.note-on: 62;
t.note-on: 64;
t.delta-time: 200; # Wait 200 MIDI pulses before following events.
t.note-off: 62;
t.note-off: 64;
```
#### channel
Channel sets the MIDI channel to use.
The channel value is from 0 to 15. The default is 0.
```
# Set on instantiation.
my \t = Track.new(:channel(1));
```
```
# Set after instantiation.
my \t = Track.new;
t.channel: 1;
```
#### velocity-off
velocity-off sets the note-off velocity.
The velocity-off value is from 0 to 127. The default is 0.
Note: A velocity for a note-off seems weird, but it can change the
sound on certain instruments like an organ on which notes can be
depressed at different speeds.
```
# Set on instantiation.
my \t = Track.new(:velocity-off(10));
```
```
# Set after instantiation.
my \t = Track.new;
t.velocity-off: 10;
```
#### velocity-on
velocity-on sets the note-on velocity.
The velocity-on value is from 0 to 127. The default is 0.
```
# Set on instantiation.
my \t = Track.new(:velocity-on(60));
```
```
# Set after instantiation.
my \t = Track.new;
t.velocity-on: 60;
```
### Methods
#### text
The text method adds any type of text to a track.
```
my \t = Track.new;
t.text: 'Lorem ipsum dolor sit amet.';
```
#### instrument
The instrument method lets you set the track's instrument using
ASCII characters.
```
my \t = Track.new;
t.instrument: 'piano';
```
#### lyric
The lyric method adds a lyric anywhere on the track.
```
my \t = Track.new;
t.lyric: 'one';
```
#### marker
The marker method allows you to mark the beginning of important
sequences in a track. E.g. section I, section II, outro, etc.
```
my \t = Track.new;
t.marker: 'section I';
```
#### cue
The cue method adds a cue anywhere on the track.
```
my \t = Track.new;
t.cue: 'door slam';
```
#### program-name
The program-name method adds a program name anywhere on the track.
```
my \t = Track.new;
t.program-name: 'electric piano';
```
#### port
The port method adds a MIDI port name anywhere on the track.
```
my \t = Track.new;
t.port: 'MIDI Out 1';
```
#### tempo
The tempo method sets the MIDI tempo. It accepts one argument: The
tempo in microseconds per quarter note. You can either set it with a
value from 0 to 16777215, or use the quarter notes per minute operator
defined earlier in this file. The default value is 500000 which is
equivalent to a tempo of 120 quarter notes per minute.
```
my \t = Track.new;
t.tempo: 1000000; # Set the tempo to 60 quarter notes per minute.
t.tempo: ♩120; # Set the tempo to 120 quarter notes per minute.
```
#### time-signature
The time-signature method sets the MIDI time-signature. It accepts
three optional arguments:
1. The time-signature set using the time-signature operator defined
earlier in this file. The default is 4\4.
2. The pulses per metronome click (PPMC). This value can be from
0 to 255. The default is 24.
3. 32nds per quarter note. This value can be from 0 to 255.
The default is 8.
```
my \t = Track.new;
t.time-signature: 3\4;
t.time-signature: 4\4, 48;
t.time-signature: 2\8, 32, 12;
```
#### key-signature
The key-signature method sets the key-signature of the piece. It
accepts two optional arguments:
1. The key which is defined as the number of accidentals. This value
can be from -7 to 7 where -1 to -7 is the number of flats, and
1 to 7 is the number of sharps. It is also possible to use
1♭, 2♭ ... 7♭ instead of -1 to -7 for flats, and 1♯, 2♯ ... 7♯
instead of 1 to 7 for sharps. You can also use 0♭ or 0♯ instead of
0.
2. The mode which is either 0 for major, or 1 for minor. MIDI::Make
provides you with the Modes enums that you may use
instead of 0 and 1.
```
my \t = Track.new;
t.key-signature: -2, 1; # G minor
t.key-signature: 2♭, 1; # G minor with unicode number of flats.
t.key-signature: 2♭, minor: # G minor with Modes enum.
```
#### note-off
The note-off method creates a note off. It accepts two arguments: The
note number from 0 to 127 (required), and the velocity-off from
0 to 127 (optional). The default velocity-off is the one set by
the velocity-off parameter.
```
my \t = Track.new;
t.note-off: 60; # velocity-off == 0
t.note-off: 62, 10; # velocity-off == 10
t.note-off: 64; # velocity-off == 0
t.velocity-off: 10;
t.note-off: 66; # velocity-off == 10
```
#### note-on
The note-on method creates a note on. It accepts two arguments: The
note number from 0 to 127 (required), and the velocity-on from
0 to 127 (optional). The default velocity-on is the one set by
the velocity-on parameter.
```
my \t = Track.new;
t.note-on: 60; # velocity-on == 127
t.note-on: 62, 100; # velocity-on == 100
t.note-on: 64; # velocity-on == 127
t.velocity-on: 100;
t.note-on: 66; # velocity-on == 100
```
#### aftertouch
The aftertouch method is a multi method for both note aftertouch, and
channel aftertouch.
For a note aftertouch, you provide two arguments: The aftertouch
amount from 0 to 127, and the note number from 0 to 127.
For a channel aftertouch, you simply provide the aftertouch amount.
```
my \t = Track.new;
t.aftertouch: 100, 53; # note aftertouch
t.aftertouch: 100; # channel aftertouch
```
#### controller
The controller method is used to set a controller MIDI event.
The first argument is the controller number from 0 to 127. The second
argument is the controller value also from 0 to 127.
```
my \t = Track.new;
t.controller: 8, 100; # balance_MSB of 100.
```
You can also call specific controllers using the following methods:
| # | method | value | use | definition |
| --- | --- | --- | --- | --- |
| 0 | bank-select\_MSB | 0-127 | MSB | Change patch banks. |
| 1 | modulation\_MSB | 0-127 | MSB | Create a vibrato effect. |
| 2 | breath\_MSB | 0-127 | MSB | Breath controller. |
| 3 | - | - | - | - |
| 4 | foot-pedal\_MSB | 0-127 | MSB | Foot pedal data. |
| 5 | portamento-time\_MSB | 0-127 | MSB | Control portamento rate. |
| 6 | data-entry\_MSB | 0-127 | MSB | Control value for NRPN/RPN parameters. |
| 7 | channel-volume\_MSB | 0-127 | MSB | Control the channel volume. |
| 8 | balance\_MSB | 0-127 | MSB | Control left/right balance for stereo. |
| 9 | - | - | - | - |
| 10 | pan\_MSB | 0-127 | MSB | Control left/right balance for mono. |
| 11 | expression\_MSB | 0-127 | MSB | Expression is a percentage of volume. |
| 12 | effect-control\_1\_MSB | 0-127 | MSB | Control an effect parameter. |
| 13 | effect-control\_2\_MSB | 0-127 | MSB | Control an effect parameter. |
| 14-15 | - | - | - | - |
| 16 | general-control\_1\_MSB | 0-127 | MSB | General purpose controller. |
| 17 | general-control\_2\_MSB | 0-127 | MSB | General purpose controller. |
| 18 | general-control\_3\_MSB | 0-127 | MSB | General purpose controller. |
| 19 | general-control\_4\_MSB | 0-127 | MSB | General purpose controller. |
| 20-31 | - | - | - | - |
| 32 | bank-select\_LSB | 0-127 | LSB | Change patch banks. |
| 33 | modulation\_LSB | 0-127 | LSB | Create a vibrato effect. |
| 34 | breath\_LSB | 0-127 | LSB | Breath controller. |
| 35 | - | - | - | - |
| 36 | foot-pedal\_LSB | 0-127 | LSB | Foot pedal data. |
| 37 | portamento-time\_LSB | 0-127 | LSB | Control portamento rate. |
| 38 | data-entry\_LSB | 0-127 | LSB | Control value for NRPN/RPN parameters. |
| 39 | channel-volume\_LSB | 0-127 | LSB | Control the channel volume. |
| 40 | balance\_LSB | 0-127 | LSB | Control left/right balance for stereo. |
| 41 | - | - | - | - |
| 42 | pan\_LSB | 0-127 | LSB | Control left/right balance for mono. |
| 43 | expression\_LSB | 0-127 | LSB | Expression is a percentage of volume. |
| 44 | effect-control\_1\_LSB | 0-127 | LSB | Control an effect parameter. |
| 45 | effect-control\_2\_LSB | 0-127 | LSB | Control an effect parameter. |
| 46-47 | - | - | - | - |
| 48 | general-control\_1\_LSB | 0-127 | LSB | General purpose controller. |
| 49 | general-control\_2\_LSB | 0-127 | LSB | General purpose controller. |
| 50 | general-control\_3\_LSB | 0-127 | LSB | General purpose controller. |
| 51 | general-control\_4\_LSB | 0-127 | LSB | General purpose controller. |
| 52-63 | - | - | - | - |
| 64 | hold\_1-pedal | <63=off | 64>=0n | Sustain pedal 1 on/off switch. |
| 65 | portamento | <63=off | 64>=0n | Portmento on/off switch. |
| 66 | sostenuto | <63=off | 64>=0n | Sostenuto on/off switch. |
| 67 | soft-pedal | <63=off | 64>=0n | Soft pedal on/off switch. |
| 68 | legato-footswitch | <63=off | 64>=0n | Legato on/off switch. |
| 69 | hold\_2-pedal | <63=off | 64>=0n | Sustain pedal 2 on/off switch. |
| 70 | sound-control\_1 | 0-127 | LSB | Sound control. (variation) |
| 71 | sound-control\_2 | 0-127 | LSB | Sound control. (resonance) |
| 72 | sound-control\_3 | 0-127 | LSB | Sound control. (release time) |
| 73 | sound-control\_4 | 0-127 | LSB | Sound control. (attack time) |
| 74 | sound-control\_5 | 0-127 | LSB | Sound control. (cutoff frequency) |
| 75 | sound-control\_6 | 0-127 | LSB | Generic sound control. |
| 76 | sound-control\_7 | 0-127 | LSB | Generic sound control. |
| 77 | sound-control\_8 | 0-127 | LSB | Generic sound control. |
| 78 | sound-control\_9 | 0-127 | LSB | Generic sound control. |
| 79 | sound-control\_10 | 0-127 | LSB | Generic sound control. |
| 80 | general-control\_5 | 0-127 | LSB | Generic or decay on/off switch. |
| 81 | general-control\_6 | 0-127 | LSB | Generic or hi-pass on/off switch. |
| 82 | general-control\_7 | 0-127 | LSB | Generic on/off switch. |
| 83 | general-control\_8 | 0-127 | LSB | Generic on/off switch. |
| 84 | portamento-control | 0-127 | note | Control portamento amount. |
| 85-87 | - | - | - | - |
| 88 | hi-res-velocity-prefix | 0-127 | MSB | Extend the range of velocities. |
| 89-90 | - | - | - | - |
| 91 | effect\_1-depth | 0-127 | LSB | Effect control. (reverb) |
| 92 | effect\_2-depth | 0-127 | LSB | Effect control. (tremolo) |
| 93 | effect\_3-depth | 0-127 | LSB | Effect control. (chorus) |
| 94 | effect\_4-depth | 0-127 | LSB | Effect control. (detune) |
| 95 | effect\_5-depth | 0-127 | LSB | Effect control. (phaser) |
| 96 | data-increment | N/A | N/A | Increment data for NRPN/RPN messages. |
| 97 | data-decrement | N/A | N/A | Decrement data for NRPN/RPN messages. |
| 98 | NRPN\_LSB | 0-127 | LSB | NRPN for controllers: 6, 38, 96, 97 |
| 99 | NRPN\_MSB | 0-127 | MSB | NRPN for controllers: 6, 38, 96, 97 |
| 100 | RPN\_LSB | 0-127 | LSB | RPN for controllers: 6, 38, 96, 97 |
| 101 | RPN\_MSB | 0-127 | MSB | RPN for controllers: 6, 38, 96, 97 |
| 102-119 | - | - | - | - |
| 120 | all-sounds-off | 0 | - | Mute all sounds. |
| 121 | reset-controllers | 0 | - | Reset all controllers to defaults. |
| 122 | local-switch | 0=off | 127=on | MIDI workstation on/off switch. |
| 123 | all-notes-off | 0 | - | Mute all sounding notes. |
| 124 | omni-mode-off | 0 | - | Set to omni mode off. |
| 125 | omni-mode-on | 0 | - | Set to omni mode on. |
| 126 | mono-mode | 0-127 | num-channel | Set device mode to monophonic. |
| 127 | poly-mode | 0 | - | Set device mode to polyphonic. |
Ex:
```
my \t = Track.new;
t.pan_MSB: 64;
```
It's also possible to call the MSB and LSB counterparts (controllers
in the range of 0-63) with one function. This permits specifying a
value between 0 and 16383 in one go.
| method | value | definition |
| --- | --- | --- |
| bank-select | 0-16383 | Change patch banks. |
| modulation | 0-16383 | Create a vibrato effect. |
| breath | 0-16383 | Breath controller. |
| foot-pedal | 0-16383 | Foot pedal data. |
| portamento-time | 0-16383 | Control portamento rate. |
| data-entry | 0-16383 | Control value for NRPN/RPN parameters. |
| channel-volume | 0-16383 | Control the channel volume. |
| balance | 0-16383 | Control left/right balance for stereo. |
| pan | 0-16383 | Control left/right balance for mono. |
| expression | 0-16383 | Expression is a percentage of volume. |
| effect-control\_1 | 0-16383 | Control an effect parameter. |
| effect-control\_2 | 0-16383 | Control an effect parameter. |
| general-control\_1 | 0-16383 | General purpose controller. |
| general-control\_2 | 0-16383 | General purpose controller. |
| general-control\_3 | 0-16383 | General purpose controller. |
| general-control\_4 | 0-16383 | General purpose controller. |
Ex:
```
my \t = Track.new;
t.pan: 3489;
```
#### program-change
Changes the program of the current channel.
It has one argument, the program number from 0 to 127.
```
my \t = Track.new;
t.program-change: 100; # Effect 5 in General MIDI.
```
#### pitch-bend
The pitch-bend method applies a pitch bend to the current channel. It
takes an optional argument from 0 to 16383. Values below 8192 bend the
pitch downwards, and values above 8192 bend the pitch upwards. If no
argument is given, the pitch bend returns to its default value of 8192
which is no pitch bend. The pitch range may vary from instrument to
instrument, but is usually +/- 2 semitones.
```
my \t = Track.new;
t.pitch-bend: 0; # Bends the pitch as low as possible.
t.pitch-bend; # Removes pitch bend by applying the default: 8192.
```
#### sysex
The sysex method implements a simple sysex message. It takes a list
of dataBytes, and surrounds them with sysex start and end bytes:
F0 F7
```
my \t = Track.new;
t.sysex: <0A 29 1E>;
```
#### add-bytes
The add-bytes method lets you add arbitrary bytes to the track. Unlike
other methods, it does not add delta-time nor does it reset delta-time
to 0. add-bytes is mostly useful for testing purposes.
```
my \t = Track.new;
t.add-bytes: <00 F0 0A 29 1E F7>;
```
#### render
The render method renders the MIDI track information gathered up to
that point. It is used to pass the track's MIDI data to the Song
class.
```
my \t = Track.new;
t.note-on: 60;
t.delta-time: 128;
t.note-off: 60;
my \s = Song.new;
s.add-track($t.render);
```
## Running Tests
To run all tests, simply use the following command in the root of
MIDI::Make.
```
➤ raku -Ilib t/all.rakutest
```
Alternatively, you can use
[Test::Selector](https://raku.land/zef:lucs/Test::Selector) to
selectively run tests.
```
➤ tsel :: Run all tests.
➤ tsel s1 :: Run the s1 test.
➤ tsel s\* :: Run all s tests.
```
## Resources
* [Official MIDI Specification](https://www.midi.org/specifications)
* [One-pager MIDI Specification](https://github.com/colxi/midi-parser-js/wiki/MIDI-File-Format-Specifications)
* [MIDI Files Specification](http://www.somascape.org/midi/tech/mfile.html)
* [MIDI Beat Time Considerations](https://majicdesigns.github.io/MD_MIDIFile/page_timing.html)
* [MIDI Timing](https://paxstellar.fr/2020/09/11/midi-timing)
## License
MIT, copyright © 2022 Pierre-Emmanuel Lévesque
|
## dist_zef-renormalist-Acme-Rautavistic-Sort.md
[](https://github.com/renormalist/raku-Acme-Rautavistic-Sort/actions)
# NAME
Acme::Rautavistic::Sort - Rautavistic sort functions
# SYNOPSIS
```
use Acme::Rautavistic::Sort;
# default alphanumeric comparison
@res = dropsort( <3 2 3 1 5> ); # <3 3 5>
@res = dropsort( <cc bb dd aa ee> ); # <cc dd ee>
```
# DESCRIPTION
Acme::Rautavistic::Sort provides rautavistic sort functions. For more description of the functions see below.
## dropsort
From <https://web.archive.org/web/20240512074546/https://www.dangermouse.net/esoteric/dropsort.html>:
Dropsort is a fast, one-pass sorting algorithm suitable for many applications.
Algorithm Description Dropsort is run on an ordered list of numbers by examining the numbers in sequence, beginning with the second number in the list. If the number being examined is less than the number before it, drop it from the list. Otherwise, it is in sorted order, so keep it. Then move to the next number.
After a single pass of this algorithm, the list will only contain numbers that are at least as large as the previous number in the list. In other words, the list will be sorted! Analysis Dropsort requires exactly n-1 comparisons to sort a list of length n, making this an O(n) algorithm, superior to the typical O(n logn) algorithms commonly used in most applications.
Dropsort is what is known in the computer science field as a lossy algorithm. It produces a fast result that is correct, but at the cost of potentially losing some of the input data. Although to those not versed in the arts of computer science this may seem undesirable, lossy algorithms are actually a well-accepted part of computing. An example is the popular JPEG image compression format, which enjoys widespread use because of its versatility and usefulness. In similar fashion, dropsort promises to revolutionise the sorting of data in fields as diverse as commercial finance, government record-keeping, and space exploration.
# FUNCTIONS
## dropsort
Drop sort an array:
```
@SORTED = dropsort @VALUES
```
Values are compared using smart comparison (i.e., `cmp` and `~~`) sensibly, to handle numbers and strings in the original DWIM way of Perl when using allomorphs. Support for other types is not yet tested.
# AUTHOR
Steffen Schwigon [ss5@renormalist.net](mailto:ss5@renormalist.net)
# ACKNOWLEDGEMENTS
Felix Antonius Wilhelm Ostmann (benchmark, optimization and stunt coordinator in the original Perl version)
# MORE INFO
For more information about rautavistic sort and rautavistic in general see
* <https://web.archive.org/web/20240512074546/https://www.dangermouse.net/esoteric/dropsort.html>
* <http://www.rautavistik.de> (in german)
# COPYRIGHT AND LICENSE
Copyright 2024 Steffen Schwigon
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_zef-raku-community-modules-Web-App-MVC.md
## Introduction
A set of extensions to [Web::App](https://github.com/supernovus/perl6-web/)
providing a MVC-style framework for building dynamic web applications.
We include a few base classes and roles, for quickly defining Controllers,
capable of loading one or more Models (with built-in support for models based
on the [DB::Model::Easy](https://github.com/supernovus/perl6-db-model-easy/) library) and displaying one or more Views.
## Example Application Script
```
use Web::App::MVC;
use My::Controller;
my $app = Web::App::MVC.new(:config<./conf/app.json>);
$app.add(:handler(My::Controller));
$app.run;
```
## Example Configuration Files
### ./conf/app.json
```
{
"connector" : {
"type" : "SCGI",
"port" : 8118
},
"views" : {
"type" : "Template6",
"dir" : "./templates"
},
"db" : "./conf/db.json",
"models" : "./conf/models.json"
}
```
### ./conf/models.json
```
{
"My::Models::Example" : {
".include" : "db.defaultdb",
"table" : "mytable"
}
}
```
### ./conf/db.json
```
{
"defaultdb" : {
"driver" : "mysql",
"opts" : {
"host" : "localhost",
"port" : 3306,
"database" : "myappdb",
"user" : "myappuser",
"password" : "myapppass"
}
}
}
```
## Example Controller Library
```
use Web::App::MVC::Controller;
use My::Models::Example;
class My::Controller is Web::App::MVC::Controller {
method handle ($context) {
$context.content-type: 'text/html';
my $id = $context.get('id', :default(1));
my $model = self.get-model(My::Models::Example);
my $user = $model.getUserById($id);
my $name = $user.name;
my $jobusers = $model.get.with(:job($user.job)).and.not(:id($user.id)).rows;
$context.send: self.render('default', :$name, :$jobusers);
}
}
```
## Example Model Library
```
use DB::Model::Easy;
class My::Models::Example::User is DB::Model::Easy::Row {
has $.id;
has $.name is rw;
has $.age is rw;
has $.job is rw;
## Rules for mapping database columns to object attributes.
## 'id' is a primary key, auto-generated. The column for 'job' is called 'position'.
has @.fields = 'id' => {:primary, :auto}, 'name', 'age', 'job' => 'position';
}
class My::Models::Example is DB::Model::Easy {
has $.rowclass = My::Models::Example::User;
method getUserById ($id) {
self.get.with(:id($id)).row;
}
}
```
## Example View Template
```
<html>
<head>
<title>Hello [% name %]</title>
</head>
<body>
<h1>Other users with the same job as you</h1>
<table>
<tr>
<th>Name</th>
<th>Age</th>
</tr>
[% for jobusers as user %]
<tr>
<th>[% user.name %]</th>
<th>[% user.age %]</th>
</tr>
[% end %]
</table>
</body>
</html>
```
## More examples
See the included examples in the 'test' folder for even more examples,
including the use of the Web::App::Controller::MethodDispatch role.
## Configuration File Directives
The main application configuration file, specifies certain settings that will
be used in various places in your application. You can add as many additional
settings and config files as you want for your own needs,
below is a list of known and/or required settings.
#### connector
Required by Web::App::MVC, this hash specifies which connector engine to
use to handle your application.
We support the same connectors as Web::App itself. The **type** key
determines the name of the library to use, and all other options will be
passed to the respective libraries.
At this time, the only other option supported (and indeed required)
by the libraries, is the **port** option, which determines which port the
connector will run on.
The types may be specified as short keys (and are case insensitive):
* scgi -- Use the [SCGI](https://github.com/supernovus/SCGI/) connector.
* fcgi -- Use the [FastCGI](https://github.com/supernovus/perl6-fastcgi/) connector.
* easy -- Use the [HTTP::Easy](https://github.com/supernovus/perl6-http-easy/) connector.
* simple -- Use the [HTTP::Server::Simple](https://github.com/mberends/http-server-simple/) connector.
#### views
If you are using the View capabilities provided with the Controller class,
this hash directive specifies the template engine and options for it to use
to parse your views.
As with connector, the **type** key specifies the name of the supported
template engine library you want to use, and all other parameters are
passed to the engine.
We support any template engine that has a wrapper class available in the
[Web::Template](https://github.com/supernovus/perl6-web-template/) library.
The types may be specified as short keys (And are case insensitive):
* 'template6' or 'tt' -- Use the [Template6](https://github.com/supernovus/template6/) engine.
* 'tal' or 'flower' -- Use the [Flower::TAL](https://github.com/supernovus/flower/) engine.
* 'html' -- Use the [HTML::Template](https://github.com/masak/html-template/) engine.
* 'mojo' -- Use the [Template::Mojo](https://github.com/tadzik/Template-Mojo/) engine.
All of these engines support a **dir** option that can be a single path,
or an array of paths, which specify the paths to find templates in.
#### models
This specifies the file name for the models configuration file.
If you are using the get-model() method of the Controller class,
and there is a key in the models configuration that matches the class name
of your model, then the hash entries within will be passed as named
options to your model class.
There are no standards for this, unless you are using the
DB::Model::Easy base class, in which case you must supply
a **table** parameter here. You may also specify **driver** and **opts**
parameters here, but they are best stored in a separate configuration file,
which can be included here using a **.include** parameter (see below.)
#### db
This specifies the file name for the database configuration file.
If you are using the DB::Model::Easy base class, then it needs to know
the connection details for databases. This file should exist to contain the
configuration details.
You can refer to these database configurations from the model configuration,
using a special **.include** parameter which uses a limited JSON Path syntax.
The **driver** and **opts** parameters will determine the db connection.
Supported **drivers** are whatever DBIish supports. Currently this is:
* mysql
* Pg
* SQLite
The **opts** parameters differ from one driver to the next.
See the [DBIish documentation](https://github.com/raku-community-modules/DBIish/)
for more details.
## AUTHOR
Timothy Totten
Source can be located at: <https://github.com/raku-community-modules/Web-App-MVC> . Comments and Pull Requests are welcome.
# COPYRIGHT AND LICENSE
Copyright 2012 - 2018 Timothy Totten
Copyright 2019 - 2022 Raku Community
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_zef-andinus-octans.md
# Table of Contents
1. [Demo](#org38aecf3)
2. [Documentation](#orgec7c921)
3. [News](#org1aee33b)
| | |
| --- | --- |
| Website | <https://andinus.unfla.me/projects/octans> |
| Source | <https://git.unfla.me/octans> |
| GitHub | <https://github.com/andinus/octans> |
* Algot's Puzzles: <http://runeman.org/embroidery/>
# Demo
This was recorded with `asciinema`.
[](https://asciinema.org/a/385500)
* Octans v0.2.3: [Visualized Output](https://andinus.unfla.me/resources/projects/octans/v0.2.3_2022-01-12_sample_input.mp4)
* Octans v0.1.0 - finds 10 solutions to a puzzle:
<https://asciinema.org/a/385598>
* Octans v0.1.0: <https://asciinema.org/a/385500>
* Octans 2021-01-14: <https://asciinema.org/a/384464>
* alt-link (download): <https://andinus.nand.sh/static/octans>
# Documentation
## Implementation
Initially it went over the list of words & checked if they exist in the
grid. This was very slow.
Currently it walks the grid & checks if the current string exist in the
dictionary. This is faster for these reasons:
* The dictionary is sorted, we perform binary range search on the
dictionary to return the list of all words that start with specific
string.
* Starting positions are limited.
If the dictionary wasn't sorted then this probably would've been slower
than previous implementation.
The `neighbors` subroutine (`lib/Octans/Neighbors.rakumod`) was taken from
my AoC (Advent of Code) 2020's day-11 solution.
## Options
### dict
Octans's default dictionary file is `/usr/share/dict/words`, use `--dict`
flag to change the dictionary. The words in dictionary must be seperated
by a newline (`\n`) & sorted alphabetically.
### visualize
Generates a video solution for the puzzle.
### length
Minimum word length to look for. Default is 7.
### path
The path to be passed must be a **readable file** or an **url** in either
format:
* Link when you view it from your local instance:
<https://tilde.zone/web/statuses/105531207939242077>
* Link from Algot's profile:
<https://mastodon.art/@Algot/105333136907848390>
### verbose
This will increase verbosity.
# News
## v0.2.5 - 2023-07-02
* Fixed puzzle output with visualize turned off.
Earlier the program would output a bunch of new lines, etc. The issue was that
word-search subroutine was passed `:visualize` which sets that flag to always
true and that caused weird behaviour, this has been fixed.
## v0.2.3 - 2022-01-12
* Add visualize option.
`--visualize` now generates a video solution for the puzzle using Cairo
and ffmpeg.
## v0.2.0 - 2021-03-04
* Removed `sample` option
`--sample` will not solve the sample puzzle.
* Removed shorthand for verbose option
`-v` won't work in `v0.2.0`.
* Change representation of visited squares
When `--verbose` was passed, it would print the solved puzzle with
visited squares replaced with fancy characters. Now it marks them by
adding:
* `*` to visited + gray squares (start positions)
* `/` to visited squares
* Removed time taken
Time taken won't be printed anymore.
> It was misleading because the time printed was not the time taken to
> find that specific word, it was the time taken to find all the words
> upto that word. It would reset for each starting position.
## v0.1.4 - 2021-02-19
* Fixed the puzzle parsing regex
The older regex fails to parse this puzzle:
<https://mastodon.art/@Algot/105690195742318751>.
## v0.1.3 - 2021-01-24
* Added an option to specify minimum word length.
## v0.1.2 - 2021-01-20
* Input puzzle can now be of any size & not restricted to 4x4 grid.
## v0.1.1 - 2021-01-20
* Read puzzle from a file.
## v0.1.0 - 2021-01-19
* Improved performance by using a better algorithm to find words in the
grid.
|
## dist_cpan-THINCH-Channel-Pauseable.md
# NAME
Channel::Pauseable - A Channel which can be paused and more
# SYNOPSIS
```
use Channel::Pauseable;
my $channel = Channel::Pauseable.new;
$channel.send: ...;
$channel.pause;
$channel.resume;
say $channel.recieve;
```
# DESCRIPTION
Channel::Pauseable is a <Channel> which can be paused and resumed.
It also offers the ability to automatically collect from <Supply>s or <Tappable>s. And can be tapped much like a <Supply>.
# EXAMPLES
There are various usage examples in the "examples" directory.
# METHODS
See <Channel> for methods inherited from there.
## new(:$source,:$paused)
$source is optional and can be either a <Supply> or a <Tappable>. Automatically taps the $source and feeds it into the channel.
$paused is a Boolean and defaults to False. It determines the initial state of the Channel.
## pause()
Pause output of the Channel. This method will throw an exception if Channel is already paused.
## resume()
Resume output of the Channel. This method will throw an exception if Channel isn't paused.
## is-paused
True if Channel is paused.
## poll()
This is the same as per a normal <Channel> but will always return Nil whilst the channel is paused.
## tap(Tappable $source)
## tap(Supply $source)
These methods tap the given $source and feeds it into the channel.
## tap(&emit,:&done,:&quit,:&tap)
This taps the channel as if it was a (live) <Supply>. See <Supply/tap> for details.
## Supply
Returns a live Supply that is supplied by this channel.
# AUTHOR
Timothy Hinchcliffe [gitprojects.qm@spidererrol.co.uk](mailto:gitprojects.qm@spidererrol.co.uk)
# COPYRIGHT AND LICENSE
Copyright 2019 Timothy Hinchcliffe
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_github-gfldex-Concurrent-Channelify.md
# Concurrent::Channelify
[](https://travis-ci.org/gfldex/perl6-concurrent-channelify)
Turn a lazy list into an auto-threading lazy list.
# SYNOPSIS
```
use v6;
use Concurrent::Channelify;
my \l1 = (10_000_000..10_100_000).grep({.is-prime});
for my $c := channelify(l1) {
$c.channel.close if $_ > 10_010_000;
say $_
}
my \l2 = <a b c>;
for l2⇒ {
say $_
}
```
# DESCRIPTION
## Routines
### sub channelify(Positional:D, :$no-thread = False)
Return a new lazy list that is turned into a `Channel`. If `no-thread` is
`True` do not start a thread to generate values. The environment variable
`RAKUDO_MAX_THREAD` with a value smaller then 2 has the same effect then
`no-thread`, if set before the use-statement is executed.
The channel can be accessed by calling the mixed in method `channel`. Closing
the channel will force the lazy list to stop producing values and kill the
associated thread.
To query if a thread was started call the mixed in method `no-thread`.
### postfix ⇒
see `sub channelify`
|
## dist_cpan-HYTHM-Grid.md
# NAME
Grid - Role for Arrays.
# SYNOPSIS
```
use Grid;
my @grid = < a b c d e f g h i j k l m n o p q r s t u v w x >;
@grid does Grid[:4columns];
```
# DESCRIPTION
Grid is a `Role` that transforms an `Array` to `Array+{Grid}`, And provides additional methods (e.g flip, rotate, transpose).
To flip a `Grid` horizontaly or vertically:
```
@grid.flip: :horizontal
@grid.flip: :vertical
```
It is also possible to apply methods to a subgrid of `Grid`, provided a valid subgrid indices:
```
my @indices = 9, 10, 13, 14; @grid.flip: :vertical(@indices); # or
my @vertical = 9, 10, 13, 14; @grid.flip: :@vertical;`
```
`Grid` preserves the overall shape, So some operations require `is-square` to be `True` for `Grid` (or Subgrid), otherwise fails and returns `self`.
# EXAMPLES
### grid
```
@grid.grid;
a b c d
e f g h
i j k l
m n o p
q r s t
u v w x
```
### flip
```
a b c d d c b a
e f g h h g f e
i j k l :horizontal l k j i
m n o p -----------------> p o n m
q r s t t s r q
u v w x x w v u
a b c d u v w x
e f g h q r s t
i j k l :vertical m n o p
m n o p -----------------> i j k l
q r s t e f g h
u v w x a b c d
a b c d a b c d
e f g h e i m q
i j k l :@diagonal f j n r
m n o p -----------------> g k o s
q r s t subgrid [ 4 ... 19 ] h l p t
u v w x u v w x
a b c d a b c d
e f g h t p l h
i j k l :@antidiagonal s o k g
m n o p -----------------> r n j f
q r s t [ 4 ... 19 ] q m i e
u v w x u v w x
a b c d a b c d
e f g h e f g h
i j k l :diagonal i j k l
m n o p -----------------> m n o p
q r s t q r s t
u v w x u v w x
# fails becuase Grid.is-square === False
```
### rotate
```
a b c d
e f g h u q m i e a
i j k l :clockwise v r n j f b
m n o p -----------------> w s o k g c
q r s t x t p l h d
u v w x
a b c d a b c d
e f g h e f g h
i j k l :@anticlockwise i k o l
m n o p -----------------> m j n p
q r s t [ 9, 10, 13, 14 ] q r s t
u v w x u v w x
a b c d d a b c
e f g h h e f g
i j k l :right l i j k
m n o p -----------------> p m n o
q r s t t q r s
u v w x x u v w
a b c d c d a b
e f g h g h e f
i j k l :2left k l i j
m n o p -----------------> o p m n
q r s t s t q r
u v w x w x u v
a b c d m n o p
e f g h q r s t
i j k l :3down u v w x
m n o p -----------------> a b c d
q r s t e f g h
u v w x i j k l
a b c d e f g h
e f g h i j k l
i j k l :7up m n o p
m n o p -----------------> q r s t
q r s t u v w x
u v w x a b c d
```
### transpose
```
a b c d
e f g h a e i m q u
i j k l b f j n r v
m n o p -----------------> c g k o s w
q r s t d h l p t x
u v w x
a b c d a b c d
e f g h e f g h
i j k l :@indices i j n l
m n o p -----------------> m k o p
q r s t [ 9, 10, 13, 14 ] q r s t
u v w x u v w x
a b c d a b c d
e f g h e f g h
i j k l :@indices i j k l
m n o p ----------------> m n o p
q r s t [ 5, 6, 9, 10, 13, 14 ] q r s t
u v w x u v w x
# fails becuase Subgrid.is-square === False
```
### append
```
a b c d a b c d
e f g h e f g h
i j k l :@rows i j k l
m n o p -----------------> m n o p
q r s t [ 0, 1, 2, 3 ] q r s t
u v w x u v w x
0 1 2 3
a b c d a b c d 0
e f g h e f g h 1
i j k l :@columns i j k l 2
m n o p -----------------> m n o p 3
q r s t [ 0, 1, 2, 3, 4, 5 ] q r s t 4
u v w x u v w x 5
```
### prepend
```
a b c d 0 1 2 3
e f g h a b c d
i j k l :@rows e f g h
m n o p -----------------> i j k l
q r s t [ 0, 1, 2, 3 ] m n o p
u v w x q r s t
u v w x
a b c d 0 a b c d
e f g h 1 e f g h
i j k l :@columns 2 i j k l
m n o p -----------------> 3 m n o p
q r s t [ 0, 1, 2, 3, 4, 5 ] 4 q r s t
u v w x 5 u v w x
```
### pop
```
a b c d
e f g h a b c d
i j k l :2rows e f g h
m n o p -----------------> i j k l
q r s t m n o p
u v w x
a b c d a b c
e f g h e f g
i j k l :1columns i j k
m n o p -----------------> m n o
q r s t q r s
u v w x u v w
```
### shift
```
a b c d
e f g h i j k l
i j k l :2rows m n o p
m n o p -----------------> q r s t
q r s t u v w x
u v w x
a b c d d
e f g h h
i j k l :3columns l
m n o p -----------------> p
q r s t t
u v w x x
```
# METHODS
### grid
```
method grid { ... }
```
Prints a `:$!columns` `Grid`.
### columns
```
method columns { ... }
```
Returns `Grid`'s columns count.
### rows
```
method columns { ... }
```
Returns `Grid`'s rows count.
### check
```
multi method check ( :@rows! --> Bool:D ) { ... }
```
Check if Rows can fit in `Grid`.
```
multi method check ( :@columns! --> Bool:D ) { ... }
```
Check if Columns can fit in `Grid`.
### reshape
```
method reshape ( Grid:D: Int :$columns! where * > 0 --> Grid:D ) { ... }
```
### flip
```
multi method flip ( Grid:D: Int:D :$horizontal! --> Grid:D ) { ... }
```
Horizontal Flip.
```
multi method flip ( Grid:D: Int:D :$vertical! --> Grid:D ) { ... }
```
Verical Flip.
```
multi method flip ( Grid:D: Int:D :$diagonal! --> Grid:D ) { ... }
```
Diagonal Flip.
```
multi method flip ( Grid:D: Int:D :$antidiagonal! --> Grid:D ) { ... }
```
Anti-Diagonal Flip.
```
multi method flip ( Grid:D: :@horizontal! --> Grid:D ) { ... }
```
Horizontal Flip (Subgrid).
```
multi method flip ( Grid:D: :@vertical! --> Grid:D ) { ... }
```
Vertical Flip (Subgrid).
```
multi method flip ( Grid:D: :@diagonal! --> Grid:D ) { ... }
```
Diagonal Flip (Subgrid).
```
multi method flip ( Grid:D: :@antidiagonal! --> Grid:D ) { ... }
```
Anti-Diagonal Flip (Subgrid).
### rotate
```
multi method rotate ( Grid:D: Int:D :$left! --> Grid:D ) { ... }
```
Left Rotate. (Columns)
```
multi method rotate ( Grid:D: Int:D :$right! --> Grid:D ) { ... }
```
Right Rotate. (Columns)
```
multi method rotate ( Grid:D: Int:D :$up! --> Grid:D ) { ... }
```
Up Rotate. (Rows)
```
multi method rotate ( Grid:D: Int:D :$down! --> Grid:D ) { ... }
```
Up Rotate. (Rows)
```
multi method rotate ( Grid:D: Int:D :$clockwise! --> Grid:D ) { ... }
```
Clockwise Rotate.
```
multi method rotate ( Grid:D: Int:D :$anticlockwise! --> Grid:D ) { ... }
```
Anti-Clockwise Rotate.
```
multi method rotate ( Grid:D: :@clockwise! --> Grid:D ) { ... }
```
Clockwise Rotate (Subgrid)
```
multi method rotate ( Grid:D: :@anticlockwise! --> Grid:D ) { ... }
```
Clockwise Rotate (Subgrid)
### transpose
```
multi method transpose ( Grid:D: --> Grid:D ) { ... }
```
Transpose.
```
multi method transpose ( Grid:D: :@indices! --> Grid:D ) { ... }
```
Transpose (Subgrid)
### append
```
multi method append ( Grid:D: :@rows! --> Grid:D ) { ... }
```
Append Rows.
```
multi method append ( Grid:D: :@columns! --> Grid:D ) { ... }
```
Append Columns.
### Prepend
```
multi method prepend ( Grid:D: :@rows! --> Grid:D ) {
```
Prepend Rows.
```
multi method prepend ( Grid:D: :@columns! --> Grid:D ) { ... }
```
Prepend Columns.
### push
```
multi method push ( Grid:D: :@rows! --> Grid:D ) { ... }
```
Push Rows.
```
multi method push ( Grid:D: :@columns! --> Grid:D ) {
```
Push Columns.
### pop
```
multi method pop ( Grid:D: Int :$rows! --> Grid:D ) { ... }
```
Pop Rows.
```
multi method pop ( Grid:D: Int :$columns! --> Grid:D ) { ... }
```
Pop Columns.
### shift
```
multi method shift ( Grid:D: Int :$rows! --> Grid:D ) { ... }
```
Shift Rows.
```
multi method shift ( Grid:D: Int :$columns! --> Grid:D ) { ... }
```
Shift Columns.
### unshift
```
multi method unshift ( Grid:D: :@rows! --> Grid:D ) { ... }
```
Unshift Rows.
```
multi method unshift ( Grid:D: :@columns! --> Grid:D ) {
```
Unshift Columns.
### has-subgrid
```
method has-subgrid( :@indices!, :$square = False --> Bool:D ) { ... }
```
Returns `True` if `:@indices` is a subgrid of `Grid`, `False` otherwise.
### is-square
```
method is-square ( --> Bool:D ) { ... }
```
Returns `True` if `Grid` is a square, False otherwise.
# AUTHOR
Haytham Elganiny [elganiny.haytham@gmail.com](mailto:elganiny.haytham@gmail.com)
# COPYRIGHT AND LICENSE
Copyright 2019 Haytham Elganiny
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_zef-FCO-HTML-Component.md
[](https://github.com/FCO/HTML-Component/actions)
# Still very early stage of development
# NAME
`HTML::Component` - is the beginning of components (WiP)
# SYNOPSIS
```
# examples/todo/Todo.rakumod
use HTML::Component;
use HTML::Component::Endpoint;
unit class Todo does HTML::Component;
my @todos;
has UInt $.id = ++$;
has Str() $.description is required;
has Bool() $.done = False;
submethod TWEAK(|) {
@todos[$!id - 1] := self;
}
method LOAD(UInt() :$id) {
@todos[$id - 1]
}
multi method new($description) { self.new: :$description, |%_ }
method RENDER($_) {
.li:
:htmx-endpoint(self.toggle),
:hx-swap<outerHTML>,
:class<todo>,
{
.input-checkbox:
:checked($!done),
;
if $!done {
.del: $!description
} else {
.add-child: $!description
}
}
;
}
method toggle is endpoint{ :return-component } {
$!done .= not
}
```
```
# examples/todo/TodoList.rakumod
use HTML::Component::Endpoint;
use HTML::Component;
use HTML::Component::Boilerplate;
use HTML::Component::Traits;
use Todo;
unit class TodoList does HTML::Component;
method new(|) { $ //= self.bless }
method LOAD(|) { self.new }
has UInt $.id = ++$;
has Todo @.todos;
method RENDER($_) {
.ol: {
.add-children: @!todos;
}
.form: self.new-todo;
}
method new-todo(
Str :$description! is no-label, #= What should be done?
) is endpoint{ :verb<POST>, :redirect</> } {
@!todos.push: Todo.new: :$description;
}
```
```
# examples/todo/App.rakumod
use TodoList;
use HTML::Component;
use HTML::Component::Boilerplate;
unit class App does HTML::Component;
method RENDER($) {
boilerplate
:title("My TODO list"),
:body{
.script: :src<https://unpkg.com/htmx.org@1.9.10>;
.add-child: TodoList.new;
}
;
}
```
```
# examples/todo/cro-todo.raku
use Cro::HTTP::Log::File;
use Cro::HTTP::Server;
use Cro::HTTP::Router;
use HTML::Component::CroRouter;
use Cro::HTTP::Log::File;
use lib "examples";
use App;
my $route = route {
root-component App.new
}
my $app = Cro::HTTP::Server.new(
host => '127.0.0.1',
port => 10000,
application => $route,
after => [
Cro::HTTP::Log::File.new(logs => $*OUT, errors => $*ERR)
],
);
$app.start;
say "Listening at http://127.0.0.1:10000";
react whenever signal(SIGINT) {
$app.stop;
exit;
}
```
# DESCRIPTION
HTML::Component is coming...
# AUTHOR
Fernando Corrêa de Oliveira `fernandocorrea@gmail.com`
# COPYRIGHT AND LICENSE
Copyright 2023 Fernando Corrêa de Oliveira
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_zef-dwarring-CSS-TagSet.md
[[Raku CSS Project]](https://css-raku.github.io)
/ [[CSS::TagSet]](https://css-raku.github.io/CSS-TagSet-raku)
## CSS::TagSet
## Example
```
# interrogate styling rules for various XHTML tags and attributes
use CSS::TagSet::XHTML;
my CSS::TagSet::XHTML $tag-set .= new;
# show styling for various XHTML tags
say $tag-set.tag-style('i'); # font-style:italic;
say $tag-set.tag-style('b'); # font-weight:bolder;
say $tag-set.tag-side('th'); # display:table-cell;
# styling for <img width="200px" height="250px"/>
say $tag-set.tag-style('img', :width<200px>, :height<250px>);
# height:250px; width:200px;
```
## Description
This module implements document specific styling rules for several markup languages, including XHTML, Pango and Tagged-PDF.
TagSet classes perform the role CSS::TagSet and implement the follow methods, to
define how stylesheets are associated with documents and how CSS styling is
determined from document content, including the extraction of stylesheets
and applying styling to nodes in the document. The methods that need to
be implemented are:
| Method | Description |
| --- | --- |
| `stylesheet-content($doc)` | Extracts and returns stylesheets for a document |
| `tag-style(Str $tag, :$hidden, *%attrs)` | Computes styling for a node with a given tag-name and attributes |
| `inline-style-attribute()` | Returns inline styling attribute. Defaults to style |
In the case of XHTML (CSS::TagSet::XHTML):
* The `stylesheet-content($doc)` method extracts `<style>...</style>` tags or externally linked via `<link rel="stylesheet href=.../>` tags,
* for example `$.tag-style('b')` returns a CSS::Properties object `font-weight:bolder;`
The default styling for given tags can be adjusted via the `base-style` method:
```
say $tag-set.tag-style('small'); # font-size:0.83em;
$tag-set.base-style('small').font-size = '0.75em';
say $tag-set.tag-style('small'); # font-size:0.75em;
```
`base-style` can also be used to define styling for simple new tags:
```
$tag-set.base-style('shout').text-transform = 'upppercase';
say $tag-set.tag-style('shout'); # text-transform:upppercase;
```
## Classes
* [CSS::TagSet](https://css-raku.github.io/CSS-TagSet-raku/CSS/TagSet) - CSS TagSet Role
* [CSS::TagSet::XHTML](https://css-raku.github.io/CSS-TagSet-raku/CSS/TagSet/XHTML) - Implements XHTML specific styling
* [CSS::TagSet::Pango](https://css-raku.github.io/CSS-TagSet-raku/CSS/TagSet/Pango) - Implements Pango styling
* [CSS::TagSet::TaggedPDF](https://css-raku.github.io/CSS-TagSet-raku/CSS/TagSet/TaggedPDF) - (*UNDER CONSTRUCTION*) Implements Tagged PDF styling
|
## dist_zef-jonathanstowe-RedX-HashedPassword.md
# RedX::HashedPassword
A facility to allow the Red ORM to store and use hashed passwords in the database.

## Synopsis
```
use Red;
use RedX::HashedPassword;
model User {
has Int $.id is serial;
has Str $.username is column;
has Str $.password is password handles <check-password>;
}
...
User.^create( username => 'user', password => 'password'); # password is saved as a hash
...
my User $user = User.^rs.first( *.username eq 'user' );
$user.check-password('password'); # True
```
## Description
This provides a mechanism for [Red](https://github.com/FCO/Red) to store a password
as a cryptographic hash in the database, such that someone who gains access to the
database cannot see the plain text password that may have been entered by a user.
The primary interface provided is the `is password` trait that should be
applied to the column attribute in your model definition that you want to store the
hashed password in, this takes care of hashing the password before it is stored in
the database, on retrieval ("inflation") it also applies a role that provides a method
`check-password` that checks a provided plaintext password against the stored hash.
You can make this appear to be a method of your (for example,) User model by applying
the `handles <check-password>` trait to your column attribute.
The hashing algorithm used will be the best one provided by
[Crypt::AnyPasswordHash](https://github.com/jonathanstowe/Crypt-AnyPasswordHash)
which has two implications, firstly the default provider is
[Crypt::Libcrypt](https://github.com/jonathanstowe/Crypt-Libcrypt) if no
other supported hashing module is installed, this will attempt to use the
mechanism suggested by the `libcrypt` but if this can't be determined,
it will fall back to SHA-512 which seems to be the best commonly provided
algorithm, except on `MacOS` where the `libcrypt` only appears to support
the "heritage" DES algorithm - which has been considered insecure for most
of this century, so you probably don't want to use this in production
on MacOS for the timebeing without installing one of the other modules
supported by `Crypt::AnyPasswordHash`. The second implication is that,
if you are going to access the hashed password from multiple hosts,
you should ensure that you have the same hashing module installed on
all the hosts in order that they can all verify the same methods.
## Installtion
Assuming you have a working Rakudo installation then you can install this with *zef*:
```
zef install RedX::HashedPassword
# or from a local copy
zef install .
```
The module requires at least v0.1.0 of [Crypt::Libcrypt](https://github.com/jonathanstowe/Crypt-Libcrypt)
so you may want to upgrade that first if you already have it installed.
## Support
Suggestions/patches are welcomed via github at:
<https://github.com/jonathanstowe/RedX-HashedPassword/issues>
Ideally there should be a better choice of hashing algorithm from those
provided by the OS and installed modules, this will come after the initial
release.
## Licence
This is free software.
Please see the <LICENCE> file in the distribution
© Jonathan Stowe 2019 - 2021
|
## dist_cpan-HOLLI-Operator-grandpa.md
[](https://travis-ci.org/holli-holzer/Operator-grandpa)
# NAME
Operator::grandpa - An object recursion operator
# VERSION
0.01
# SYNOPSIS
```
class Node {
has $.name;
has $.parent;
}
my $child = Node.new(
:name("out"),
:parent( Node.new(
:name("mid"),
:parent( Node.new(
:name("inner"),
:parent( Node.new( :name("root") ) )
))
))
);
my $root1 = $child :| { .parent }
my $root2 = $child 𝄇 -> $node { $node.parent }
```
# DESCRIPTION
```
multi sub prefix:<:|>(Any --> Callable:D)
multi sub prefix:<𝄇>(Any --> Callable:D)
```
The grandpa / object recursion operator *:|* and it's unicode counterpart *𝄇* (U+1D107) invoke the callable on the RHS recursively.
The callable gets initially invoked with the LHS as the argument, and then recursively invoked with its' respective previous return value as the argument.
It does that until the code block evaluates to `Any`, then returns the last good value.
Note, that if you assign to `$_` within the code block, this also changes the LHS of the operator. So, don't do that, unless it's what you want.
```
multi sub prefix:<|:>(Any --> Callable:D)
multi sub prefix:<𝄆>(Any --> Callable:D)
```
Alternatively you can use this version of the operator, which does the same as above but operates on a copy of the LHS, thus allowing assigning to `$_` safely.
# AUTHOR
```
holli.holzer@gmail.com
```
# COPYRIGHT AND LICENSE
Copyright © [holli.holzer@gmail.com](mailto:holli.holzer@gmail.com)
License: Artistic-2.0
This is free software: you are free to change and redistribute it. There is NO WARRANTY, to the extent permitted by law.
|
## dist_zef-sdondley-Distribution-Resources-Menu.md
[](https://github.com/sdondley/Distribution-Resources-Menu/actions)
# NAME
Distribution::Resources::Menu - Navigate the files in the resources directory of your Raku distribution from the command line
# SYNOPSIS
Place something like the following code into a module in your distribution:
```
use Distribution::Resources::Menu;
unit module Your::Module;
my $rsm = ResourceMenu.new(
distribution => $?DISTRIBUTION,
resources => %?RESOURCES);
sub execute-resource-menu is export {
$rsm.execute;
}
```
And now you can execute the menu with something like this:
```
use Your::Module;
# Display a menu on the command line and prompt the user
# to select a file from the "resources" directory of the distribution
my $resource = execute-resource-menu();
say $resource.file-path;
say $resource.file-content;
```
# DESCRIPTION
Distribution::Resources::Menu generates and executes a menu for navigating and selecting files located in a distribution's `resources` directory.
# METHODS
## execute
Executes the interactive command-line menu for selecting a file from the resources directory of the distribution.
## file-content
Returns the string value of the content of the file.
## file-path
Returns the string value of the path to the file contained in the `$%RESOURCES` variable.
# AUTHOR
Steve Dondley [s@dondley.com](mailto:s@dondley.com)
# COPYRIGHT AND LICENSE
Copyright 2022 Steve Dondley
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_github-samgwise-Net-Osc.md
# [Build Status](https://travis-ci.org/samgwise/Net-OSC) Net::OSC
Open Sound Control for Perl6
Use the Net::OSC module to communicate with OSC applications and devices!
# SYNOPSIS
```
use Net::OSC;
my Net::OSC::Server::UDP $server .= new(
:listening-address<localhost>
:listening-port(7658)
:send-to-address<localhost> # ← Optional but makes sending to a single host very easy!
:send-to-port(7658) # ↲
:actions(
action(
"/hello",
sub ($msg, $match) {
if $msg.type-string eq 's' {
say "Hello { $msg.args[0] }!";
}
else {
say "Hello?";
}
}
),
)
);
# Send some messages!
$server.send: '/hello', :args('world', );
$server.send: '/hello', :args('lamp', );
$server.send: '/hello';
# Our routing will ignore this message:
$server.send: '/hello/not-really';
# Send a message to someone else?
$server.send: '/hello', :args('out there', ), :address<192.168.1.1>, :port(54321);
#Allow some time for our messages to arrive
sleep 0.5;
# Give our server a chance to say good bye if it needs too.
$server.close;
```
# DESCRIPTION
Net::OSC distribution currently provides the following classes:
* Net::OSC
* Net::OSC::Types
* Net::OSC::Message
* Net::OSC::Server
* Net::OSC::Server::UDP
* Net::OSC::Transport::TCP
Classes planned for future releases include:
* Net::OSC::Bundle
* Net::OSC::Server::TCP
Net::OSC imports Net::OSC::Server::UDP and the action sub to the using name space. Net::OSC::Message provide a representation for OSC messages.
See reference section below for usage details.
# TODO
* Net::OSC::Server::TCP
* Additional OSC types
# CHANGES
| | | |
| --- | --- | --- |
| Added type wrappers, helper functions and blobs | Compliant with core OSC 1.0 type specifications | 2020-03-20 |
| Compatibility updates for Numeric::Pack:ver<0.3.0> | Better portabilty as we're now pure perl all the way down | 2018-06-20 |
| Removed vestiges of the pack feature | Net::OSC will not be effected by the experimental status of pack in Rakudo | 2018-06-19 |
| TCP packing contributed | OSC messages can be sent over TCP connections | 2017-07-23 |
| Added Server role and UDP server | Sugar for sending, receiving and routing messages | 2016-12-08 |
| Updated to use Numeric::Pack | Faster and better tested Buf packing | 2016-08-30 |
# AUTHOR
Sam Gillespie [samgwise@gmail.com](mailto:samgwise@gmail.com)
# CONTRIBUTORS
```
TCP transport module contributed by Karl Yerkes <karl.yerkes@gmail.com>.
```
# COPYRIGHT AND LICENSE
Copyright 2016 Sam Gillespie
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
# Reference
## Net::OSC subroutines
### multi sub action
```
multi sub action(
Regex $path,
Callable $call-back
) returns Net::OSC::Types::EXPORT::DEFAULT::ActionTuple
```
Creates an action tuple for use in a server's actions list. The first argument is the path, which is checked when an OSC message is received. If the path of the message matches then the call back is executed. The call back is passed the Net::OSC::Message object and the match object from the regular expression comparison.
### multi sub action
```
multi sub action(
Str $path where { ... },
Callable $call-back
) returns Net::OSC::Types::EXPORT::DEFAULT::ActionTuple
```
Creates an action tuple for use in a server's actions list. The string must be a valid OSC path (currently we only check for a beginning '/' character). In the future this subroutine may translate OSC path meta characters to Perl6 regular expressions.
# NAME
Net::OSC::Bundle - Implements OSC message bundling and unbundling
# METHODS
```
method new(:@messages, :$time-stamp)
```
### method package
```
method package() returns Blob
```
Packages up a bundle into a Blob, ready for transport over a binary protocol. The pacakge contains the time-stamp and all messages of the Bundle object.
### method unpackage
```
method unpackage(
Blob:D $bundle
) returns Net::OSC::Bundle
```
Unapackages a Blob into a bundle object. The blob must begin with #bundle0x00 as defined by the OSC spec.
# NAME
Net::OSC::Message - Implements OSC message packing and unpacking
# METHODS
```
method new(:$path = '/', :@args, :$!is64bit = True)
```
Set :is64bit to false to force messages to be packed to 32bit types this option may be required to talk to some versions of Max and other old OSC implementations.
### sub osc-message
```
sub osc-message(
*@args
) returns Net::OSC::Message
```
Function for creating a new OSC Message. The list of arguments is infered according to the 32bit type map, since it is the most widely accepted. To define specific types (such as Doubles and Longs) use OSCType wrappers from Net::OSC::Types.
### sub osc-decode
```
sub osc-decode(
Blob:D $buffer
) returns Net::OSC::Message
```
Function for unpacking an OSC message. Accepts a defined buffer and returns an Net::OSC::Message. Decoding errors are thrown as exceptions.
### method type-string
```
method type-string() returns Str
```
Returns the current type string of this messages content. See OSC types for possible values.
### method pick-osc-type
```
method pick-osc-type(
$arg
) returns Str
```
Returns the character representing the OSC type $arg would be packed as by this Message object. If the argument is held in a wrapper from Net::OSC::Types then the wrapper's type will be used. Otherwise the type picker will try and infer a type according to the 32bit or 64 bit type map.
### method args
```
method args(
*@new-args
) returns Seq
```
Adds any arguments as args to the object and returns the current message arguments. The OSC type of the argument will be determined according the the current OSC types map.
### method set-args
```
method set-args(
*@new-args
) returns Mu
```
Clears the message args lists and sets it to the arguments provided. The OSC type of the argument will be determined according the the current OSC types map.
### method type-map
```
method type-map() returns Seq
```
Returns the current OSC type map of the message. This will change depending on the is64bit flag.
### method package
```
method package() returns Blob
```
Returns a Buf of the packed OSC message. See unpackage to turn a Buf into a Message object.
### method unpackage
```
method unpackage(
Buf $packed-osc
) returns Net::OSC::Message
```
Returns a Net::OSC::Message from a Buf where the content of the Buf is an OSC message. Will die on unhandled OSC type and behaviour is currently undefined on non OSC message Bufs.
# NAME
Net::OSC::Server - A role to facilitate a convenient platform for OSC communication.
# METHODS
```
method new(:$!is64bit = True)
```
Set :is64bit to false to force messages to be packed to 32bit types this option may be required to talk to some versions of Max and other old OSC implementations.
### method actions
```
method actions() returns Seq
```
Lists the actions managed by this server. Actions are expressed as a list holding a Regex and a Callable object. Upon receiving a message the server tries to match the path of the OSC message with the Regex of an action. All actions with a matching Regex will be executed. the Callable element of an action is called with a Net::OSC::Message and a Match object.
### method add-action
```
method add-action(
Regex $path,
Callable $action
) returns Mu
```
Add an action for managing messages to the server. See the actions method description above for details and the add-actions method below for the plural expression.
### method add-actions
```
method add-actions(
*@actions
) returns Mu
```
Add multiple actions for managing messages to the server. See the actions method description above for details.
### method send
```
method send(
Str $path where { ... },
*%params
) returns Mu
```
Send and OSC message. The to add arguments to the message pass :args(...), after the OSC path string. Implementing classes of the Server role may accept additional named parameters.
### method close
```
method close() returns Mu
```
Call the server's on-close method. This will call the server implementations on-close hook.
### method transmit-message
```
method transmit-message(
Net::OSC::Message:D $message
) returns Mu
```
Transmit an OSC message. This method must be implemented by consuming classes. implementations may add additional signatures. Use this method to send a specific OSC message object instead of send (which creates one for you).
# NAME
Net::OSC::Server::UDP - A convenient platform for OSC communication over UDP.
```
Does Net::OSC::Server - look there for additional methods.
```
# METHODS
```
method new(
Bool :$!is64bit = True,
Str :listening-address,
Int :listening-port,
Str :send-to-address,
Int :send-to-port,
)
```
Set :is64bit to false to force messages to be packed to 32bit types this option may be required to talk to some versions of Max and other old OSC implementations. The send-to-\* parameters are not required but allow for convenient semantics if you are only communicating with a single host.
### method send
```
method send(
Str $path where { ... },
*%params
) returns Mu
```
Send a UDP message to a specific host and port. This method extends the Net::OSC::Server version and adds the :address and :port Named arguments to support UDP message sending. If :address or :port are not provided the Server's relevant send-to-\* attribute will be used instead.
### multi method transmit-message
```
multi method transmit-message(
Net::OSC::Message:D $message
) returns Mu
```
Transmit an OSC message. This implementation will send the provided message to the server's send-to-\* attributes.
### multi method transmit-message
```
multi method transmit-message(
Net::OSC::Message:D $message,
Str $address,
Int $port
) returns Mu
```
Transmit an OSC message to a specified host and port. This implementation sends the provided message to the specified address and port.
# Net::OSC::Transport::TCP
TCP transport routines for Net::OSC.
There are a variety of methods for transmitting OSC over TCP. This module provides routines sending your OSC messages with Length-prefixed message framing and SLIP message framing. See the individual subroutine descriptions for more details.
## subroutines
### sub send-lp
```
sub send-lp(
IO::Socket::INET $socket,
Net::OSC::Message $message
) returns Mu
```
Sends an OSC message with Length-prefixed framing. This is known to be used in SuperCollider.
### sub recv-lp
```
sub recv-lp(
IO::Socket::INET $socket
) returns Net::OSC::Message
```
A subroutine for receiving Length-prefixed messages. This routine blocks until it has recieved a complete message.
### sub send-slip
```
sub send-slip(
IO::Socket::INET $socket,
Net::OSC::Message $message
) returns Mu
```
Sends an OSC message with SLIP framing. This is known to be used in PureData.
### sub recv-slip
```
sub recv-slip(
IO::Socket::INET $socket
) returns Net::OSC::Message
```
A subroutine for receiving SLIP messages. This routine blocks until it has recieved a complete message.
# Net::OSC::Types
Provides helper classes and subsets for dealing with OSC communications.
Type wrappers are provided for OSC 1.0 standard types.
## class -> ;; $\_? is raw { #`(Block|149465208) ... }
Tag Str values as OSC type 's'. Can be created via the osc-str function.
### method type-code
```
method type-code() returns Str
```
Tag Blob values as OSC type 'b'. Can be created via the osc-blob function.
### method type-code
```
method type-code() returns Str
```
Tag Int values as OSC type 'i'. Can be created via the osc-int32 function.
### method type-code
```
method type-code() returns Str
```
Tag Int values as OSC type 'h'. Can be created via the osc-int64 function.
### method type-code
```
method type-code() returns Str
```
Tag Rat values as OSC type 'f'. Can be created via the osc-float function.
### method type-code
```
method type-code() returns Str
```
Tag Rat values as OSC type 'd'. Can be created via the osc-double function.
|
## -circumflex-accentfff-circumflex-accent.md
^fff^
Combined from primary sources listed below.
# [In Operators](#___top "go to top of document")[§](#(Operators)_infix_^fff^ "direct link")
See primary documentation
[in context](/language/operators#infix_^fff^)
for **infix ^fff^**.
```raku
sub infix:<^fff^>(Mu $a, Mu $b)
```
Like [fff](/routine/fff), except it does not return true for matches to either the left or right argument.
```raku
my @list = <X A B C Y>;
say $_ if /A/ fff /C/ for @list; # OUTPUT: «ABC»
say $_ if /A/ ^fff^ /C/ for @list; # OUTPUT: «B»
```
For the non-sed version, see [`^ff^`](/routine/$CIRCUMFLEX_ACCENTff$CIRCUMFLEX_ACCENT).
This operator cannot be overloaded, as it's handled specially by the compiler.
|
## malformed.md
class X::Syntax::Malformed
Compilation error due to a malformed construct (usually a declarator)
```raku
class X::Syntax::Malformed does X::Syntax {}
```
The Raku compiler throws errors of type `X::Syntax::Malformed` when it knows what kind of declaration it is parsing, and encounters a syntax error, but can't give a more specific error message.
```raku
my Int a; # throws an X::Syntax::Malformed
```
produces
「text」 without highlighting
```
```
===SORRY!===
Malformed my
at -e:1
------> my Int ⏏a
```
```
# [Methods](#class_X::Syntax::Malformed "go to top of document")[§](#Methods "direct link")
## [method what](#class_X::Syntax::Malformed "go to top of document")[§](#method_what "direct link")
```raku
method what(X::Syntax::Malformed:D: --> Str)
```
Returns a description of the thing that was being parsed.
|
## dist_zef-FCO-RedFactory.md
[](https://github.com/FCO/RedFactory/actions)
# NAME
RedFactory - A factory for testing code using Red
# SYNOPSIS
```
# Your DB schema ---------------------------------------------------------
use Red;
model Post {...}
model Person {
has UInt $.id is serial;
has Str $.first-name is column;
has Str $.last-name is column;
has Str $.email is column;
has Instant $.disabled-at is column{ :nullable };
has Post @.posts is relationship(*.author-id, :model(Post));
}
model Post {
has UInt $.id is serial;
has Str $.title is column;
has Str $.body is column;
has UInt $!author-id is referencing(*.id, :model(Person));
has Person $.author is relationship(*.author-id, :model(Person));
has Instant $.created-at is column = now;
}
# Your factory configuration ---------------------------------------------
use RedFactory;
factory "person", :model(Person), {
.first-name = "john";
.last-name = "doe";
.email = -> $_, :$number = .counter-by-model {
"{ .first-name }{ $number }@domain.com"
}
.posts = -> :$num-of-posts = 0 {
factory-args $num-of-posts, "post"
}
trait "disabled", {
.disabled-at = now
}
}
factory "post", :model(Post), {
.title = {
"Post title { .counter-by-model }"
}
.body = -> $_, :$title-repetition = 3 {
(.title ~ "\n") x $title-repetition
}
}
# Testing your imaginary controller helper -------------------------------
use Test;
my $*RED-DB = factory-db;
my &get-recent-author's-posts'-titles =
get-controller's-help("get-recent-author's-posts'-titles");
# Create the needed person with posts
my $author = factory-create "person", :PARS{ :10num-of-posts };
my @posts = get-recent-author's-posts'-titles $author.id, 3;
is-deeply @posts, ["Post title 10", "Post title 9", "Post title 8"];
```
# DESCRIPTION
RedFactory is a easier way of testing code that uses Red
# AUTHOR
```
<fernandocorrea@gmail.com>
```
# COPYRIGHT AND LICENSE
Copyright 2021
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_zef-raku-community-modules-HexDump-Tiny.md
[](https://github.com/raku-community-modules/HexDump-Tiny/actions)
# NAME
HexDump::Tiny - Generate hexadecimal dump
# SYNOPSIS
```
use HexDump::Tiny;
.say for hexdump(slurp("filename"));
```
# DESCRIPTION
HexDump::Tiny is module that exports a single subroutine `hexdump`, and installs a command-line interface to that called `hd`.
# SUBROUTINES
## hexdump
```
.say for hexdump($blob); # entire blob
.say for hexdump($blob, :skip(96)); # bytes after first 96 bytes
.say for hexdump($blob, :head(96)); # first 96 bytes
.say for hexdump($blob, :skip(96), :head(256)); # after 96 bytes for 256 bytes
```
The `hexdump` subroutine takes a value of which to create a hexadecimal dump (either as a `Blob` or `Buf`, or as a `Seq` or as anything else that can be coerced to a `Str`).
It returns a `Seq` of hexdump lines. It takes the following optional named arguments:
### skip
The named argument `:skip` specifies the number of bytes to skip before starting to generate the hexdump. The default is **0**.
### head
The named argument `:head` specifies the number of bytes to create a hexdump for. The default is all remaining bytes after bytes skipped.
### chunk-size
The named argument `:chunk-size` specifies the number of bytes per line of hexdump. The default is **16**.
# COMMAND-LINE INTERFACE
This module also installs a `hd` command-line interface that allows one to do a hexdump of a file, or the parameters on the command line, or from STDIN (if no parameters are specified.
It also accepts the same named arguments as the `hexdump` subroutine does.
# AUTHORS
Jonathan Scott Duff
Elizabeth Mattijsen
Source can be located at: <https://github.com/raku-community-modules/HexDump-Tiny> . Comments and Pull Requests are welcome.
# COPYRIGHT AND LICENSE
Copyright 2015 - 2017 Jonathan Scott Duff
Copyright 2018 - 2022 Raku Community
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_zef-raku-community-modules-MoarVM-Remote.md
## Chunk 1 of 2
[](https://github.com/raku-community-modules/MoarVM-Remote/actions) [](https://github.com/raku-community-modules/MoarVM-Remote/actions) [](https://github.com/raku-community-modules/MoarVM-Remote/actions)
# NAME
MoarVM::Remote - A library for working with the MoarVM remote debugging API
# SYNOPSIS
```
# see examples in the test-suite for now
```
# DESCRIPTION
A Raku library to interface with MoarVM's remote debugger protocol.
It's mostly a thin layer above the wire format, [documented in the MoarVM repository](https://github.com/MoarVM/MoarVM/blob/master/docs/debug-server-protocol.md)
It exposes commands as methods, responses as Promises, and events/event streams as Supplies.
You can use the debug protocol with the Raku module/program [App::MoarVM::Debug](https://raku.land/github:edumentab/App::MoarVM::Debug). Another application that supports the debug protocol is [Comma](commaide.com).
# MESSAGE TYPES
All messages defined here, unless stated otherwise, are supported in major version 1, minor version 0, of the protocol (also known as `1.0`).
All message types (basically a numeric ID, also exported as the `MessageType` enum) are described from the viewpoint of the client. Messages sent to the debug server are documented as "request", and messages coming back from the debug server are documented as "response".
When the term "user threads" is used, it means all threads apart from the spesh worker thread and the debug server thread itself.
### Message Type Not Understood (0)
Response indicating that a request was **not** understood, with the ID of the request that was not understood.
```
{
type => 0, # MT_MessageTypeNotUnderstood
id => $given-request-id
}
```
### Error Processing Message (1)
Response indicating that a problem occurred with the processing of a request, with the ID of the request that was not understood. The `reason` key should be a string explaining why.
```
{
type => 1, # MT_ErrorProcessingMessage
id => $given-request-id,
reason => $reason # e.g. "Program already terminated"
}
```
### Operation Successful (2)
Response to acknowledge that a request was successfully performed (with ID of the request) when there is no further information to be given.
```
{
type => 2, # MT_OperationSuccessful
id => $given-request-id
}
```
### Is Execution Suspended Request (3)
Request to check whether execution of all user threads are currently suspended.
```
{
type => 3, # MT_IsExecutionSuspendedRequest
id => $new-request-id
}
```
### Is Execution Suspended Response (4)
Response indicating whether all user threads have been suspended, as observed by the `suspended` key being set to either `True` or `False`.
```
{
type => 4, # MT_IsExecutionSuspendedResponse
id => $given-request-id,
suspended => $suspended
}
```
### Suspend All (5)
Request to indicate that all user threads should be suspended. Response will always be "Operation Successful" regardless of whether the user threads had been suspended already or not.
```
{
type => 5, # MT_SuspendAll
id => $new-request-id
}
```
### Resume All (6)
Request to indicate that execution of all suspended threads should be resumed. Response will always be "Operation Successful" message regardless of whether the execution of user threads had been resumed already or not.
```
{
type => 6, # MT_ResumeAll
id => $new-request-id
}
```
### Suspend One (7)
Request to indicate that execution of a specific thread should be suspended, with the thread ID specified by the `thread` key.
Response will always be "Operation Successful" regardless of whether the execution of the indicated thread had been suspended already or not. If the thread ID was not recognized, then the response will be "Error Processing Message".
```
{
type => 7, # MT_SuspendOne
id => $new-request-id,
thread => $thread-id
}
```
### Resume One (8)
Request to indicate that execution of a specific thread should be resumed, with the thread ID specified by the `thread` key.
Response will always be "Operation Successful" regardless of whether the execution of the indicated thread had been resumed already or not. If the thread ID was not recognized, then the response will be "Error Processing Message".
```
{
type => 8, # MT_ResumeOne
id => $new-request-id,
thread => $thread-id
}
```
### Thread Started (9)
Unsolicited response whenever a new thread is started. The client can simply disregard it if it has no interest in this information.
The `thread` key contains the numeric thread ID that can be used in requests.
The `native_id` key contains the numeric thread ID that the OS has assigned to the thread.
The `app_lifetime` key contains `True` or `False`. `False` means that the process will only terminate when the thread has finished while `True` means that the thread will be killed when the main thread of the process terminates.
```
{
type => 9, # MT_ThreadStarted
id => $an-even-id,
thread => $thread-id,
native_id => $OS_thread_id,
app_lifetime => $app_lifetime
}
```
### Thread Ended (10)
Unsolicited response whenever a thread terminates. The client can simply disregard it if it has no interest in this information.
```
{
type => 10, # MT_ThreadEnded
id => $an-even-id,
thread => $thread-id
}
```
### Thread List Request (11)
Request a list of all threads, with some information about each one. This request may be sent at any time, whether or not the threads are suspended.
```
{
type => 11, # MT_ThreadListRequest
id => $new-request-id
}
```
### Thread List Response (12)
Response to a "Thread List Request". It contains an array of hashes, with one hash per running thread, providing information about that thread. It also contains an indication of whether the thread was suspended, and the number of locks it is currently holding.
The `name` key was added in version 1.2.
```
{
type => 12, # MT_ThreadListResponse
id => $given-request-id,
threads => [
{
thread => $thread-id # e.g. 1
native_id => $OS_thread_id, # e.g. 1010
app_lifetime => $app_lifetime, # e.g. True
suspended => $suspended # e.g. True
num_locks => $num_locks, # e.g. 1
name => $name # e.g. "AffinityWorker"
},
{
thread => $thread-id # e.g. 3
native_id => $OS_thread_id, # e.g. 1020
app_lifetime => $app_lifetime, # e.g. True
suspended => $suspended # e.g. False
num_locks => $num_locks, # e.g. 0
name => $name # e.g. "Supervisor"
}
]
}
```
### Thread Stack Trace Request (13)
Request the stack trace of a thread. This is only allowed if that thread is suspended; an "Error Processing Message" response will be returned otherwise.
```
{
type => 13, # MT_ThreadStackTraceRequest
id => $new-request-id,
thread => $thread_id # e.g. 3
}
```
### Thread Stack Trace Response (14)
Response to a "Thread Stack Trace Request". It contains an array of hashes, each representing a stack frame (topmost first) that are currently on the call stack of that thread.
The `bytecode_file` key will be either a string or `nil` if the bytecode only exists "in memory" (for example, due to an `EVAL`).
The `name` key will be an empty string in the case that the code for that frame has no name.
The `type` key is the debug name of the type of the code object, or `Nil` if there is none.
```
{
type => 14, # MT_ThreadStackTraceResponse
id => $given-request-id,
frames => [
{
file => $file, # e.g. "path/to/source/file"
line => $line, # e.g. 22
bytecode_file => $bytecode_file, # e.g. "path/to/bytecode/file"
name => $name, # e.g. "some-method"
type => $type # e.g. "Method"
},
{
file => $file, # e.g. "path/to/source/file"
line => $line, # e.g. 12
bytecode_file => $bytecode_file, # e.g. "path/to/bytecode/file"
name => $name, # e.g. "",
type => $type # e.g. "Block"
},
{
file => $file, # e.g. "path/to/another/source/file"
line => $line, # e.g. 123
bytecode_file => $bytecode_file, # e.g. "path/to/another/bytecode/file"
name => $name, # e.g. "foo"
type => $type # e.g. Nil
}
]
}
```
### Set Breakpoint Request (15)
Request to set a breakpoint at the specified location, or the closest possible location to it.
The `file` key refers to the source file.
If the `suspend` key is set to `True` then execution of all threads will be suspended when the breakpoint is hit. In either case, the client will be notified. The use of non-suspend breakpoints is for counting the number of times a certain point is reached.
If the `stacktrace` key is set to `true` then a stack trace of the location where the breakpoint was hit will be included. This can be used both with and without `suspend`; with the `suspend` key set to `True` it can save an extra round-trip to request the stack location, while with `suspend` key set to `False` it can be useful for features like "capture a stack trace every time foo is called".
```
{
type => 15, # MT_SetBreakpointRequest
id => $new-request-id,
file => $file, # e.g. "path/to/source/file"
line => $line, # e.g. 123
suspend => $suspend, # e.g. True
stacktrace => $stacktrace # e.g. False
}
```
### Set Breakpoint Confirmation (16)
Response to confirm that a breakpoint has been set.
The `line` key indicates the actual line that the breakpoint was placed on, if there was no exactly annotation match. This message will be sent before any breakpoint notifications; the ID will match the ID specified in the breakpoint request.
```
{
type => 16, # MT_SetBreakpointConfirmation
id => $given-request-id,
line => $line # e.g. 16
}
```
### Breakpoint Notification (17)
Unsolicited response whenever a breakpoint is reached. The ID will match that of the breakpoint request.
The `frames` key will be `Nil` if the `stacktrace` key of the breakpoint request was `False`. Otherwise, it will contain an array of hashesh describing the stack frames, formatted as in the "Thread Stack Trace Response" message type.
```
{
type => 17, # MT_BreakpointNotification
id => $given-request-id,
thread => $thread-id, # e.g. 1
frames => $frames # Nil or [ ... ]
}
```
### Clear Breakpoint (18)
Request to clear a breakpoint. The line number must be the one the breakpoint was really set on (indicated in the "Set Breakpoint Confirmation" message). This will be followed by an "Operation Successful" response after clearing the breakpoint.
```
{
type => 18, # MT_ClearBreakpoint
id => $new-request-id,
file => $file, # e.g. "path/to/source/file",
line => $line # e.g. 123
}
```
### Clear All Breakpoints (19)
Request to clear all breakpoints that have been set. This will be followed by an "Operation Successful" response after clearing all breakpoints.
```
{
type => 19, # MT_ClearAllBreakpoints
id => $new-request-id
}
```
### Single Step (aka. Step Into) (20)
Request to run a suspended thread until the next program point, where program points are determined by either a change of frame or a change of line number in the bytecode annotation table.
The thread this is invoked on must be suspended, and will be returned to suspended state after the step has taken place, followed by a "Step Completed" response.
```
{
type => 20, # MT_StepInto
id => $new-request-id,
thread => $thread-id # e.g. 1
}
```
### Step Over (21)
Request to run a suspended thread until the next program point either in the same frame or in a calling frame (but not in any called frames below this point), to return to suspended state after the steps have taken place, followed by a "Step Completed" response.
```
{
type => 21, # MT_StepOver
id => $new-request-id,
thread => $thread-id # e.g. 1
}
```
### Step Out (22)
Request to run a suspended thread until the program returns into the specified frame. After which the thread will be returned to suspended state, followed by a "Step Completed" response.
```
{
type => 22, # MT_StepOut
id => $new-request-id,
thread => $thread-id # e.g. 1
}
```
### Step Completed (23)
Response to acknowledge that a stepping operation was completed.
The `id` key matches the ID that of the step request.
The `frames` key contains an array of hashes that contains the stacktrace after stepping; the `file` and `line` keys will be of the current location in the topmost frame.
```
{
type => 23, # MT_StepCompleted
id => $given-request-id,
thread => $thread-id, # e.g. 1
frames => [
...
]
}
```
### Release Handles (24)
Handles are integers that are mapped to an object living inside of the VM. For so long as the handle is alive, the object will be kept alive by being in the handles mapping table.
Therefore, it is important that, when using any instructions that involve handles, they are released afterwards when they are not needed anymore. Otherwise the client can induce a managed memory leak.
The `handles` key should be specified with an array of integers matching the handles to be released.
Responds with an "Operation Successful" message if all specified handles were successfully released.
```
{
type => 24, # MT_ReleaseHandles
id => $id,
handles => @array # e.g. [42, 100]
}
```
### Handle Result (25)
Response for requests that ask for an object handle. The ID will match that of the request. The value `0` represents the `VMNull` value.
```
{
type => 25, # MT_HandleResult
id => $given-request-id,
handle => $integer # e.g. 42
}
```
### Context Handle (26)
Request to allocate a context object handle for the specified frame (indicated by the depth relative to the topmost frame on the callstack, which is frame 0) and thread.
This can only be used on a thread that is suspended. A context handle is just an object handle, where the object happens to have the `MVMContext` REPR.
Followed by a "Handle Result" response.
```
{
type => 26, # MT_ContextHandle
id => $new-request-id,
thread => $thread-id # e.g. 1
frame => $frame-index # e.g. 0
}
```
### Context Lexicals Request (27)
Request the values of lexicals in a given context, followed by a "Context Lexicals" response.
The `handle` key must be a context handle.
```
{
type => 27, # MT_ContextLexicalsRequest
id => $new-request-id,
handle => $handle-id # e.g. 1234
}
```
### Context Lexicals Response (28)
Response containing the results of introspecting a context. The `lexicals` key contains a hash of hashes, in which the inner hash has information about the lexicals in that context, with the name of the lexical as the key.
For natively typed values, the value is included directly in the response.
For object lexicals, a new object handle will be allocated for each object encountered. This will allow for further introspection of the object (always make sure to release the associated handles if the object is no longer needed).
The debug name of the type is directly included in the `type` key, along with whether it's concrete (as opposed to a type object) and a container type that could be decontainerized.
The `kind` key may be one of "int", "num", or "str" (for native values) or "obj" for objects.
```
{
type => 28, # MT_ContextLexicalsResponse
id => $given-request-id,
lexicals => {
'$x' => {
kind => "obj",
handle => $handle, # e.g. 1234
type => $type, # e.g. "Scalar"
concrete => $concrete, # True or False
container => $container # True or False
},
'$i' => {
kind => "int",
value => 42
},
'$s' => {
kind => "str",
value => "Bibimbap"
}
}
}
```
### Outer Context Request (29)
Request a handle to the outer context of the context for which the handle is being passed, followed by a "Handle Result" response.
The null handle (`0`) will be given if there is no outer context.
```
{
type => 29, # MT_OuterContextRequest
id => $new-request-id,
handle => $handle # e.g. 1234
}
```
### Caller Context Request (30)
Request to create a handle for the caller context of the context of which the handle is being passed, followed by a "Handle Result" response.
The null handle (`0`) will be given if there is no outer caller.
```
{
type => 30, # MT_CallerContextRequest
id => $new-request-id,
handle => $handle # e.g. 1234
}
```
### Code Object Handle (31)
Request a handle for the code object of the specified frame (indicated by the depth relative to the topmost frame on the callstack, which is frame 0) and thread ID, followed by a "Handle Result" response.
This can only be used on a thread that is suspended.
If there is no high-level code object associated with the frame, then the null handle (`0`) will be given.
```
{
type => 31, # MT_CodeObjectHandle
id => $new-request-id,
thread => $thread-id, # e.g. 1
frame => $frame-index # e.g. 0
}
```
### Object Attributes Request (32)
Request information about the attributes of an object by its given handle, followed by an "Object Attributes" response.
```
{
type => 32, # MT_ObjectAttributesRequest
id => $new-request-id,
handle => $handle # e.g. 1234
}
```
### Object Attributes Response (33)
Response containing the information about the attributes of an object (specified by its handle in a "Object Attributes" request).
The `attributes` key contains a list of hashes with the attribute information. If the object does not have any attributes, then the `attributes` key will be an empty array.
For natively typed attributes, the value is included directly in the response. For object attributes, an object handle will be allocated for each one. This will allow for further introspection of the object.
The debug name of the type is directly included, along with whether it's concrete (as opposed to a type object) and a container type that could be decontainerized.
The key may be one of "int", "num", or "str" for native values, or "obj" for objest. Since attributes with the same name may exist at multiple inheritance levels, an array is returned with the debug name of the class at that level with the `class` key.
```
{
type => 33, # MT_ObjectAttributesResponse
id => $given-request-id,
attributes => [
{
name => '$!x',
class => $class, # e.g. "FooBase"
kind => "obj",
handle => $handle, # e.g. 1235
type => $type, # e.g. "Scalar"
concrete => $concrete, # True or False
container => $container # True or False
},
{
name => '$!i',
class => $class, # e.g. "Foo"
kind => "int",
value => 42
}
]
}
```
### Decontainerize Handle (34)
Request a handle for the decontainerized object indicated by its handle, followed by a "Handle Result" response.
Respond with an "Error Processing" response if the indicated object is not a container type, or if an exception occurred when trying to do the decontainerization.
A target thread to perform this operation on is required, since it may be required to run code (such as code inside a `Proxy` container). The thread must be suspended at the point the request made, and will be returned to suspended state again after the decontainerization has taken place and a new handle was created.
Note that breakpoints may be hit and will be fired during this operation.
```
{
type => 34, # MT_DecontainerizeHandle
id => $new-request-id,
thread => $thread-id, # e.g. 1
handle => $handle # e.g. 1234
}
```
### Invoke (36)
Request invocation of a code object (as indicated by its handle), followed by an "Invoke Result" response.
The `arguments` key should contain a (possibly empty) array of hashes, one for each argument.
Arguments may be native values or other objects specified by their `handle`. Named arguments require a `name` key with the name of the named argument.
A target thread to perform this operation on is required. The thread must be suspended at the point this request is made, and will be returned to suspended state again after the execution has taken place.
Note that breakpoints may be hit and will be fired during this operation.
```
{
type => 36, # MT_Invoke
id => $new-request-id,
thread => $thread-id, # e.g. 1
handle => $code-hande, # e.g. 1235,
arguments => [
{
kind => "obj",
handle => $handle # e.g. 1234
},
{
kind => "str",
name => "frobnicate",
value => "Bulgogi"
}
]
}
```
### Invoke Result (37)
Response to an "Invoke" request with the result in the `result` key.
If the result was not a native value, then a handle to the object will be created and returned in the `handle` key.
If the invocation resulted in an exception, then the `crashed` key will be set to a true value: the `result` key will then be about the `Exception` object instead.
Object result example:
```
{
type => 37, # MT_InvokeResult
id => $given-request-id,
crashed => False,
kind => "obj",
handle => $handle, # e.g. 1256
obj_type => $obj_type, # e.g. "Int",
concrete => $concrete, # True or False
container => $container # True or False
}
```
Native int result example:
```
{
type => 37, # MT_InvokeResult
id => $given-request-id,
crashed => False,
kind => "int",
value => 42
}
```
Exception result:
```
{
type => 37, # MT_InvokeResult
id => $given-request-id,
crashed => True,
kind => "obj",
handle => $handle, # e.g. 1256
obj_type => "X::AdHoc",
concrete => True,
container => False
}
```
### Unhandled Exception (38)
Unsollicited response when an unhandled exception occurs.
All threads will be suspended. A handle to the exception object is included in the `handle` key, together with the thread ID it occurred on and the stack trace of that thread.
The `frames` key contains an array of hashes with information of each frame, similar to the "Stack Trace" response.
The VM is expected toi still allow operations such as introspecting the context, decontainerizing values, and invoking code.
```
{
type => 38, # MT_UnhandledException
id => $given-request-id,
thread => $thread-id, # e.g. 1
handle => $handle, # 1278,
frames => [
{
file => "path/to/source/file",
line => 22,
bytecode_file => "path/to/bytecode/file",
name => "some-method",
type => "Method"
},
{
file => "path/to/source/file",
line => 12,
bytecode_file => "path/to/bytecode/file",
name => "",
type => "Block"
}
]
}
```
### Object Metadata Request (40)
Request additional (meta-)information about an object (by its handle) that goes beyond its actual attributes, followed by a "Object Metadata" response.
Can include miscellaneous details from the REPRData and the object's internal state if it's concrete.
Additionally, all objects that have positional, associative, or attribute features will point that out in their response.
```
{
type => 40, # MT_ObjectMetadataRequest
id => $new-request-id,
handle => $handle # e.g 1345
}
```
### Object Metadata Response (41)
Response to an "Object Metadata" request, with the results in the `metadata` key (which contains a hash).
The `reprname` key contains name of the REPR.
All concrete objects have `size` and `unmanaged_size` keys (in bytes).
The `positional_elems` and `associative_elems` keys contain the number of elements for objects that have `Positional` and/or associative features.
The `pos_features`, `ass_features`, and `attr_features` keys indicate which of the "Object Positionals Request (42)", "Object Associatives Request (44)"), or "Object Attributes Request (32)" will give useful results.
```
{
type => 41, # MT_ObjectMetadataResponse
id => $given-request-id,
metadata => {
reprname => "VMArray",
size => 128,
unmanaged_size => 1024,
vmarray_slot_type => "num32",
vmarray_elem_size => 4,
vmarray_allocated => 128,
vmarray_start => 40,
positional_elems => 12,
pos_features => $pos_features, # True or False
ass_features => $ass_features, # True or False
attr_features => $attr_features # True or False
}
}
```
### Object Positionals Request (42)
Request to obtain information about a `Positional` object (such as an array) indicated by its handle, followed by an "Object Positionals" response.
```
{
type => 42, # MT_ObjectPositionalsRequest
id => $new-request-id,
handle => $handle # e.g. 12345
}
```
### Object Positionals Response (43)
Response to an "Object Positionals" request, with the `contents` key containing a list of native values, or a list of hashes.
The `kind` key contains "int", "num", "str" for native arrays, or "obj" for object arrays.
In the case of an object array, every hash contains `type`, `handle`, `concrete`, and `container` keys, just as in the "Context Lexicals" response.
Native contents:
```
{
type => 43, # MT_ObjectPositionalsResponse
id => $given-request-id,
kind => "int",
start => 0,
contents => [
1, 2, 3, 4, 5, 6
]
}
```
Object contents:
```
{
type => 43, # MT_ObjectPositionalsResponse
id => $id,
kind => "obj",
start => 0,
contents => [
{
type => "Potato",
handle => $handle, # e.g. 9999
concrete => True,
container => False
},
{
type => "Noodles",
handle => $handle, # e.g. 10000
concrete => False,
container => False
}
]
}
```
### Object Associatives Request (44)
Request to obtain information about a `Associative` object (such as a hash) indicated by its handle, followed by an "Object Associatives" response.
```
{
type => 44, # MT_ObjectAssociativesRequest
id => $new-request-id,
handle => $handle # e.g. 12376
}
```
### Object Associatives Response (45)
Response to an "Object Associatives" request, with the `contents` key containing a hash of hashes always containing information about objects (so no native values).
The key is the key as used in the `Associative` object, and the value contains `type`, `handle`, `concrete`, and `container` keys, just as in the "Context Lexicals" response.
```
{
type => 45, # MT_ObjectAssociativesResponse
id => $given-request-id,
kind => "obj"
contents => {
"Hello" => {
type => "Poodle",
handle => $handle, # e.g. 4242
concrete => $concrete, # True or False
container => $container # True or False
},
"Goodbye" => {
type => "Poodle",
handle => $handle, # e.g. 4243
concrete => $concrete, # True or False
container => $container # True or False
}
}
}
```
### Handle Equivalence Request (46)
Request to check a given list of handles (in the `handles` key) to see whether they refer to the same object, followed by a "Handle Equivalence" response.
```
{
type => 46, # MT_HandleEquivalenceRequest
id => $new-request-id,
handles => @handles
}
```
### Handle Equivalence Response (47)
Response to a "Handle Equivalence" request.
The `classes` key contains a list of lists with handles, in which each inner list contains the ID's of handles that refer to the same object (if there are more than one).
```
{
type => 47, # MT_HandleEquivalenceResponse
id => $given-request-id,
classes => [
[1, 3],
[2, 5, 7]
]
}
```
### HLL Symbol Request (48)
MoarVM features a mechanism for objects and types to be registered with an HLL, for example "nqp" or "Raku". This request allows you to find the available HLLs, a given HLL's keys, and the value for a given key.
Get all HLL names, followed by a "HLL Symbol" response:
```
{
type => 48, # MT_HLLSymbolRequest
id => $new-request-id,
}
```
Get an HLL's symbol names, followed by a "HLL Symbol" response:
```
{
type => 48, # MT_HLLSymbolRequest
id => $new-request-id,
HLL => $HLL # e.g. "nqp" or "Raku"
}
```
Get the value for a symbol in a HLL, followed by a "Handle Result" response:
```
{
type => 48, # MT_HLLSymbolRequest
id => $new-request-id,
HLL => $HLL # e.g. "nqp" or "Raku"
name => "FOOBAR"
}
```
### HLL Symbol Response (49)
Response to a "HLL Symbol" request for names (rather than values).
The `keys` key contains either a list of HLL names, or a list of names for a given HLL.
```
{
type => 49,
id => $given-request-id,
keys => [
"one",
"two",
]
}
```
# MoarVM Remote Debug Protocol Design
The MoarVM Remote Debug Protocol is used to control a MoarVM instance over a socket, for the purposes of debugging. The VM must have been started in debug mode for this capability to be available (with the `--debug-port=12345` parameter).
## The wire format
Rather than invent Yet Another Custom Binary Protocol, the MoarVM remote debug protocol uses [`MessagePack`](https://msgpack.org/) (through the [`Data::MessagePack`](https://raku.land/zef:raku-community-modules/Data::MessagePack) module). This has the advantage of easy future extensibility and existing support from other languages.
The only thing that is not MessagePack is the initial handshake, leaving the freedom to move away from MessagePack in a future version, should there ever be cause to do so.
Since MessagePack is largely just a more compact way to specify JSON, which is essentially a Raku data structure consisting of a hash with keys and values. Therefore all of the messages are show in Raku syntax. This is just for ease of reading: the Raku data structure will be automatically converted to/from MessagePack data on the wire.
### Initial Handshake
Upon receving a connection, MoarVM will immediately send the following **24** bytes if it is willing and able to accept the connection:
* The string "MOARVM-REMOTE-DEBUG\0" encoded in ASCII
* A big endian, unsigned, 16-bit major protocol version number - =item big endian, unsigned, 16-bit minor protocol version number
Otherwise, it will send the following response, explaining why it cannot, and then close the connection:
* The string "MOARVM-REMOTE-DEBUG!"
|
## dist_zef-raku-community-modules-MoarVM-Remote.md
## Chunk 2 of 2
encoded in ASCII
* A big endian, unsigned, 16-bit length for an error string explaining the rejection (length in bytes)
* The error string, encoded in UTF-8
A client that receives anything other than a response of this form must close the connection and report an error. A client that receives an error response must report the error.
Otherwise, the client should check if it is able to support the version of the protocol that the server speaks. The onus is on clients to support multiple versions of the protocol should the need arise. See versioning below for more. If the client does not wish to proceed, it should simply close the connection.
If the client is statisfied with the version, it should send:
* The string "MOARVM-REMOTE-CLIENT-OK\0" encoded in ASCII
For the versions of the protocol defined in this document, all further communication will be in terms of MessagePack messages.
## MessagePack envelope
Every exchange using MessagePack must be an object at the top level. The object must always have the following keys:
* `type` which must have an integer value. This specifies the type of the message. Failing to include this field or failing to have its value be an integer is a protocol error, and any side receiving such a message should terminate the connection.
* `id` which must have an integer value. This is used to associate a response with a request, where required. Any interaction initiated by the client should have an odd `id`, starting from 1. Any interaction initiated by the server should have an even `id`, starting from 2.
The object may contain further keys, which will be determined by message type.
## Versioning
Backwards-incompatible changes, if needed, will be made by incrementing the major version number. A client seeing a major version number it does not recognize or support must close the connection and not attempt any further interaction, and report an error.
The minor version number is incremented for backwards-compatible changes. A client may proceed safely with a higher minor version number of the protocol than it knows about. However, it should be prepared to accept and disregard message types that it does not recognize, as well as any keys in an object (encoded using MessagePack) that it does not recognize.
The client can use the minor version number to understand what features are supported by the remote MoarVM instance.
The MoarVM instance must disregard keys in a MessagePack object that it does not understand. For message types that it does not recognize, it must send a message of type "Message Type Not Understood" (format defined below); the connection should be left intact by MoarVM, and the client can decide how to proceed.
## Security considerations
Any client connected to the debug protocol will be able to perform remote code execution using the running MoarVM instance. Therefore, MoarVM must only bind to `localhost` by default. It may expose an option to bind to further interfaces, but should display a warning about the dangers of this option.
Remote debugging should be performed by establishing a secure tunnel from the client to the server, for example using SSH port forwarding. This provides both authentication and protection against tampering with messages.
# AUTHOR
* Timo Paulssen - Raku Community
# COPYRIGHT AND LICENSE
Copyright 2011 - 2020 Timo Paulssen
Copyright 2021 - 2024 Raku Community
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_zef-jjatria-App-Lorea.md
# lorea
A command line utility to execute commands on filesystem changes.
The interface should be fairly familiar for users of [reflex](https://github.com/cespare/reflex). See
[the examples section](#examples) below for some possible ways to use it.
## Installation
```
$ zef install App::Lorea
```
## Usage
```
lorea [options] -- command [args]
```
## Options
```
--all Include all normally ignored files
-c, --config STRING The path to a configuration file
--help Display usage information
-R, --ignore REGEX ... A regular expression to ignore filenames
-r, --regex REGEX ... A regular expression to match filenames
-e, --sequential Run commands sequentially from config file
-s, --start-service Run command as a service
--substitute STRING Set the string to be used as placeholder
-v, --verbose Print tracing information
--version Print the version of the command and compiler
```
Options marked with `...` can be provided multiple times.
Values marked as `REGEX` must be compilable as Raku [regular expressions](https://docs.raku.org/language/regexes).
## Overview
When `lorea` is run, it will monitor your current directory, and any
directories under it, for any file-system changes. When a file is changed
or added, it will be matched against the patterns you've specified (see
[below](#matching) for details about how the matching is done).
If the event matches, the command you've specified will be run, or
restarted if you enabled the `--start-service` flag.
If the command you've specified includes the `{}` string, this will be
replaced by the absolute path of the file that has changed. All instances
of this placeholder string will be replaced. If you need to use the `{}`
string for something else, you can specify a different placeholder string
with the `--substitute` option.
### Matching
Patterns to match can be specified to `lorea` with either `--regex` or
`--ignore`. Both of these options take Raku regular expressions, with the
difference that any match for the former will trigger an event, while every
match for the latter will explicitly *not* trigger one.
Paths are normalised before being matched, and converted to paths relative
to the current directory without a leading `./`. Matching directories will
have a trailing slash (`/`).
If no pattern is specified, all file-system changes will match.
### Default ignores
By default, `lorea` ignores some common patterns to make it easier to use
in most cases.
* Files and directories with a leading dot (`.`), which are considered
hidden in Unix-like systems.
* Common swap files, including those ending in `.swp`, `.swx`, and `~`.
The `--all` option disables these defaults. This flag will take effect if
set either at the top level, or in any of the watchers specified in the
configuration file (see below).
You can see the global ignores by setting the `--verbose` option.
## Configuration
The `--config` option can be used to specify a configuration to use to start
several watchers at the same time. The behaviour of these watchers can be
set independently.
The format of this file is intentionally very limited. A valid file will look
something like this:
```
# Rebuild SCSS when it changes
-r '\.scss$' -- \
sh -c 'sass {} `basename {} .scss`.css'
# Restart server when ruby code changes
-s -r '\.rb$' -- \
./bin/run_server.sh
```
Each line will be interpreted as the parameters to a separate invocation of
`lorea`. Lines must not include the executable name (that will be filled in
internally). The parameters to a single invocation can be broken into multiple
lines if they end with a trailing backslash (`\`).
Empty lines, and lines beginning with a hash (`#`) will be ignored.
With the exception of `--help` , `--sequential`, and `--config` itself, all
options are valid within a configuration file. If the `--config` option is
set, the only other flags that are allowed at the top level are `--verbose`
and `--sequential`.
### Sequential execution
When using a config file to run multiple simultaneous commands, each of them
will be started asynchronously whenever possible. This means that, while there
will only be one instance of a particular command, two different commands may
overlap. This is usually what you want.
As a concrete example, consider this config file:
```
-- sh -c 'for i in `seq 1 5`; do sleep 0.1; echo first; done'
-- sh -c 'for i in `seq 1 5`; do sleep 0.1; echo second; done'
```
When this runs, you might see something like this:
```
second
first
second
first
first
second
second
first
second
first
```
Note that, since both commands started at the same time, the output of both is
interleaved. If this is not what you want, you can ensure only one command runs
at a time with the `--sequential` flag used at the top-level (it is not allowed
in config files). In this case, the output might instead look like this:
```
second
second
second
second
second
first
first
first
first
first
```
Note in this case that even when using `--sequential` there is no guarantee
that the commands will be executed in the order they appear in the config
file.
## Batching
Part of what `lorea` does is apply some heuristics to batch together file
changes. There are many reasons that files change on disk, and these changes
frequently come in large bursts. For instance, when you save a file in your
editor, it probably makes a tempfile and then copies it over the target,
leading to several different changes. A more dramatic example will happen
when you do a source-control checkout, in which case there is no limit to
the number of files that might change at once.
If `lorea` did not batch these changes, this could lead to your computer
slowing down to a crawl, or the whole process crashing.
There are two modes to batch these changes.
If your command is marked as a service, or has no placeholders in it, then
`lorea` assumes that individual changes are not as important as the fact that
*a change took place*. In this case changes will be collected, and a single
command execution will trigger once a short amount of time has passed
between them.
Otherwise, changes will be collected using the same logic as above, but
*every unique file change* will trigger a separate execution of your command.
## Examples
Every time a `.raku` or `.rakumod` file changes, print a string with the
name of the modified file:
```
lorea --regex '\.raku(mod)?$' -- echo "Change in {}"
```
or the same thing, but taking advantage of Raku's [regular expressions](https://docs.raku.org/language/regexes):
```
lorea --regex '".raku" [mod]? $' -- echo "Change in {}"
```
# See Also
* [Overwatch](https://raku.land/zef:tony-o/Overwatch)
A similar program with a longer history, this was unknown to me when
development in App::Lorea started. It has fewer dependencies but supports
a simpler feature set.
|
## promise.md
class Promise
Status/result of an asynchronous computation
```raku
my enum PromiseStatus (:Planned(0), :Kept(1), :Broken(2));
class Promise {}
```
A `Promise` is used to handle the result of a computation that might not have finished. It allows the user to execute code once the computation is done (with the `then` method), execution after a time delay (with `in`), combining promises, and waiting for results.
```raku
my $p = Promise.start({ sleep 2; 42});
$p.then({ say .result }); # will print 42 once the block finished
say $p.status; # OUTPUT: «Planned»
$p.result; # waits for the computation to finish
say $p.status; # OUTPUT: «Kept»
```
There are two typical scenarios for using promises. The first is to use a factory method (`start`, `in`, `at`, `anyof`, `allof`, `kept`, `broken`) on the type object; those will make sure that the promise is automatically kept or broken for you, and you can't call `break` or `keep` on these promises yourself.
The second is to create your promises yourself with `Promise.new`. If you want to ensure that only your code can keep or break the promise, you can use the `vow` method to get a unique handle, and call `keep` or `break` on it:
```raku
sub async-get-with-promise($user-agent, $url) {
my $p = Promise.new;
my $v = $p.vow;
# do an asynchronous call on a fictive user agent,
# and return the promise:
$user-agent.async-get($url,
on-error => -> $error {
$v.break($error);
},
on-success => -> $response {
$v.keep($response);
}
);
return $p;
}
```
Further examples can be found in the [concurrency page](/language/concurrency#Promises).
# [Methods](#class_Promise "go to top of document")[§](#Methods "direct link")
## [method start](#class_Promise "go to top of document")[§](#method_start "direct link")
```raku
method start(Promise:U: &code, :$scheduler = $*SCHEDULER --> Promise:D)
```
Creates a new Promise that runs the given code object. The promise will be kept when the code terminates normally, or broken if it throws an exception. The return value or exception can be inspected with the `result` method.
The scheduler that handles this promise can be passed as a named argument.
There is also a statement prefix `start` that provides syntactic sugar for this method:
```raku
# these two are equivalent:
my $p1 = Promise.start({ ;#`( do something here ) });
my $p2 = start { ;#`( do something here ) };
```
As of the 6.d version of the language, `start` statement prefix used in [sink](/routine/sink) context will automatically attach an exceptions handler. If an exception occurs in the given code, it will be printed and the program will then exit, like if it were thrown without any `start` statement prefixes involved.
```raku
use v6.c;
start { die }; sleep ⅓; say "hello"; # OUTPUT: «hello»
```
```raku
use v6.d;
start { die }; sleep ⅓; say "hello";
# OUTPUT:
# Unhandled exception in code scheduled on thread 4
# Died
# in block at -e line 1
```
If you wish to avoid this behavior, use `start` in non-sink context or catch the exception yourself:
```raku
# Don't sink it:
my $ = start { die }; sleep ⅓; say "hello"; # OUTPUT: «hello»
# Catch yourself:
start { die; CATCH { default { say "caught" } } };
sleep ⅓;
say "hello";
# OUTPUT: «caughthello»
```
This behavior exists only syntactically, by using an alternate `.sink` method for `Promise` objects created by `start` blocks in sink context, thus simply sinking a `Promise` object that was created by other means won't trigger this behavior.
## [method in](#class_Promise "go to top of document")[§](#method_in "direct link")
```raku
method in(Promise:U: $seconds, :$scheduler = $*SCHEDULER --> Promise:D)
```
Creates a new Promise that will be kept in `$seconds` seconds, or later.
```raku
my $proc = Proc::Async.new('raku', '-e', 'sleep 10; warn "end"');
my $result = await Promise.anyof(
my $promise = $proc.start, # may or may not work in time
Promise.in(5).then: { # fires after 5 seconds no matter what
unless $promise { # don't do anything if we were successful
note 'timeout';
$proc.kill;
}
}
).then: { $promise.result }
# OUTPUT: «timeout»
```
`$seconds` can be fractional or negative. Negative values are treated as `0` (i.e. [keeping](/routine/keep) the returned `Promise` right away).
Please note that situations like these are often more clearly handled with a [react and whenever block](/language/concurrency#react).
## [method at](#class_Promise "go to top of document")[§](#method_at "direct link")
```raku
method at(Promise:U: $at, :$scheduler = $*SCHEDULER --> Promise:D)
```
Creates a new `Promise` that will be kept `$at` the given time—which is given as an [`Instant`](/type/Instant) or equivalent [`Numeric`](/type/Numeric)—or as soon as possible after it.
```raku
my $p = Promise.at(now + 2).then({ say "2 seconds later" });
# do other stuff here
await $p; # wait here until the 2 seconds are over
```
If the given time is in the past, it will be treated as [now](/routine/now) (i.e. [keeping](/routine/keep) the returned `Promise` right away).
Please note that situations like these are often more clearly handled with a [react and whenever block](/language/concurrency#react).
## [method kept](#class_Promise "go to top of document")[§](#method_kept "direct link")
```raku
multi method kept(Promise:U: \result = True --> Promise:D)
```
Returns a new promise that is already kept, either with the given value, or with the default value `True`.
## [method broken](#class_Promise "go to top of document")[§](#method_broken "direct link")
```raku
multi method broken(Promise:U: --> Promise:D)
multi method broken(Promise:U: \exception --> Promise:D)
```
Returns a new promise that is already broken, either with the given value, or with the default value `X::AdHoc.new(payload => "Died")`
## [method allof](#class_Promise "go to top of document")[§](#method_allof "direct link")
```raku
method allof(Promise:U: *@promises --> Promise:D)
```
Returns a new promise that will be kept when all the promises passed as arguments are kept or broken. The result of the individual Promises is not reflected in the result of the returned promise: it simply indicates that all the promises have been completed in some way. If the results of the individual promises are important then they should be inspected after the `allof` promise is kept.
In the following requesting the `result` of a broken promise will cause the original Exception to be thrown. (You may need to run it several times to see the exception.)
```raku
my @promises;
for 1..5 -> $t {
push @promises, start {
sleep $t;
};
}
my $all-done = Promise.allof(@promises);
await $all-done;
@promises>>.result;
say "Promises kept so we get to live another day!";
```
## [method anyof](#class_Promise "go to top of document")[§](#method_anyof "direct link")
```raku
method anyof(Promise:U: *@promises --> Promise:D)
```
Returns a new promise that will be kept as soon as any of the promises passed as arguments is kept or broken. The result of the completed Promise is not reflected in the result of the returned promise which will always be Kept.
You can use this to wait at most a number of seconds for a promise:
```raku
my $timeout = 5;
await Promise.anyof(
Promise.in($timeout),
start {
# do a potentially long-running calculation here
},
);
```
## [method then](#class_Promise "go to top of document")[§](#method_then "direct link")
```raku
method then(Promise:D: &code)
```
Schedules a piece of code to be run after the invocant has been kept or broken, and returns a new promise for this computation. In other words, creates a chained promise. The `Promise` is passed as an argument to the `&code`.
```raku
# Use code only
my $timer = Promise.in(2);
my $after = $timer.then({ say '2 seconds are over!'; 'result' });
say $after.result;
# OUTPUT: «2 seconds are overresult»
# Interact with original Promise
my $after = Promise.in(2).then(-> $p { say $p.status; say '2 seconds are over!'; 'result' });
say $after.result;
# OUTPUT: «Kept2 seconds are overresult»
```
## [method keep](#class_Promise "go to top of document")[§](#method_keep "direct link")
```raku
multi method keep(Promise:D: \result = True)
```
Keeps a promise, optionally setting the result. If no result is passed, the result will be `True`.
Throws an exception of type [`X::Promise::Vowed`](/type/X/Promise/Vowed) if a vow has already been taken. See method `vow` for more information.
```raku
my $p = Promise.new;
if Bool.pick {
$p.keep;
}
else {
$p.break;
}
```
## [method break](#class_Promise "go to top of document")[§](#method_break "direct link")
```raku
multi method break(Promise:D: \cause = False)
```
Breaks a promise, optionally setting the cause. If no cause is passed, the cause will be `False`.
Throws an exception of type [`X::Promise::Vowed`](/type/X/Promise/Vowed) if a vow has already been taken. See method `vow` for more information.
```raku
my $p = Promise.new;
$p.break('sorry');
say $p.status; # OUTPUT: «Broken»
say $p.cause; # OUTPUT: «sorry»
```
## [method result](#class_Promise "go to top of document")[§](#method_result "direct link")
```raku
method result(Promise:D:)
```
Waits for the promise to be kept or broken. If it is kept, returns the result; otherwise throws the result as an exception.
## [method cause](#class_Promise "go to top of document")[§](#method_cause "direct link")
```raku
method cause(Promise:D:)
```
If the promise was broken, returns the result (or exception). Otherwise, throws an exception of type [`X::Promise::CauseOnlyValidOnBroken`](/type/X/Promise/CauseOnlyValidOnBroken).
## [method Bool](#class_Promise "go to top of document")[§](#method_Bool "direct link")
```raku
multi method Bool(Promise:D:)
```
Returns `True` for a kept or broken promise, and `False` for one in state `Planned`.
## [method status](#class_Promise "go to top of document")[§](#method_status "direct link")
```raku
method status(Promise:D --> PromiseStatus)
```
Returns the current state of the promise: `Kept`, `Broken` or `Planned`:
```raku
say "promise got Kept" if $promise.status ~~ Kept;
```
## [method scheduler](#class_Promise "go to top of document")[§](#method_scheduler "direct link")
```raku
method scheduler(Promise:D:)
```
Returns the scheduler that manages the promise.
## [method vow](#class_Promise "go to top of document")[§](#method_vow "direct link")
```raku
my class Vow {
has Promise $.promise;
method keep() { ... }
method break() { ... }
}
method vow(Promise:D: --> Vow:D)
```
Returns an object that holds the sole authority over keeping or breaking a promise. Calling `keep` or `break` on a promise that has vow taken throws an exception of type [`X::Promise::Vowed`](/type/X/Promise/Vowed).
```raku
my $p = Promise.new;
my $vow = $p.vow;
$vow.keep($p);
say $p.status; # OUTPUT: «Kept»
```
## [method Supply](#class_Promise "go to top of document")[§](#method_Supply "direct link")
```raku
method Supply(Promise:D:)
```
Returns a [`Supply`](/type/Supply) that will emit the `result` of the `Promise` being Kept or `quit` with the `cause` if the `Promise` is Broken.
## [sub await](#class_Promise "go to top of document")[§](#sub_await "direct link")
```raku
multi await(Promise:D --> Promise)
multi await(*@ --> Array)
```
Waits until one or more promises are *all* fulfilled, and then returns their values. Also works on [`Channel`](/type/Channel)s. Any broken promises will rethrow their exceptions. If a list is passed it will return a list containing the results of awaiting each item in turn.
# [Typegraph](# "go to top of document")[§](#typegraphrelations "direct link")
Type relations for `Promise`
raku-type-graph
Promise
Promise
Any
Any
Promise->Any
Mu
Mu
Any->Mu
[Expand chart above](/assets/typegraphs/Promise.svg)
|
## deduction.md
class X::Sequence::Deduction
Error due to constructing a sequence from ineligible input
```raku
class X::Sequence::Deduction is Exception { }
```
Exception type thrown when the `...` sequence operator is being called without an explicit closure, and the sequence cannot be deduced.
|
## dist_zef-clarkema-Readline.md
# Readline
Readline provides a Raku interface to libreadline.
## Installation
Please make sure that libreadline is installed beforehand, the tests will fail
otherwise. If libreadline is installed but the tests still fail, please note
that the Raku package searches a given set of directories for
libreadline.{so,dynlib}.\* files, otherwise it defaults to v7. If your
libreadline installation isn't on any of these paths, or requires non-standard
setup, please file an issue.
For those of you on Linux Debian and Linux-alike systems, you should be able to
get the latest version with this CLI invocation:
```
$ sudo apt-get install libreadline7
```
(I'd prefer to use LibraryCheck, but it fails inside the 'is native()' method
call.)
On macOS, use Hombrew or MacPorts to install readline. If you installed
Rakudo-Star with Homebrew after Sept. 1 it should already be there.
If not you can install just Readline
```
brew install readline
```
or update your rakudo-star install.
```
brew upgrade rakudo-star
```
Using zef (a module management tool bundled with Rakudo Star):
```
$ zef update && zef install Readline
```
Or alternatively installing it from a checkout of this repo with zef:
```
$ zef install .
```
## Usage
See the `examples/` directory in this project.
## Testing
To run tests:
```
$ prove -e raku
```
## Author
* Jeffrey Goff, DrForr on #perl6, <https://github.com/drforr/>
* Recently taken over by Daniel Lathrop (fooist), <https://github.com/fooist/>
## License
Artistic License 2.0
|
## dist_github-ugexe-Sanity.md
## sanity
Adds some sane defaults for your production Raku programs
### SYNOPSIS
```
use sanity;
42.base("beer"); # throws exception
42.base("camel"); # throws exception
"🍻🍺🍻🍺🍻🍺".parse-base("beer"); # throws exception
"🐫🐪🐫🐪🐫🐪".parse-base("camel"); # throws exception
```
### DESCRIPTION
A continually updating collection of Rakudo tweaks to workaround or disable features that are of little or no use in production software.
### GLOBAL APPLICATION
Run scripts or one-liners using `-Msanity`, i.e. `raku -Msanity bin/my-application.raku`
### WHY
```
# Wat?
$ raku -e 'say 42.base("beer");'
🍻🍺🍻🍺🍻🍺
# Ok!
$ raku -Msanity -e 'say 42.base("beer");'
Cannot convert string to number: base-10 number must begin with valid digits or '.' in '⏏beer' (indicated by ⏏)
in sub at /home/foobar/raku/install/share/perl6/site/sources/A6EEB7BD88D20C81DF439CAA2EA158E8EFDBB112 (sanity) line 5
in block <unit> at -e line 1
```
|
## dist_zef-terminal-printers-Terminal-Print.md
# Terminal::Print
[](https://github.com/ab5tract/Terminal-Print/actions)
## Synopsis
Terminal::Print intends to provide the essential underpinnings of command-line printing, to be the fuel for the fire, so to speak, for libraries which might aim towards 'command-line user interfaces' (CUI), asynchronous monitoring, rogue-like adventures, screensavers, video art, etc.
## Usage
Right now it only provides a grid with some nice access semantics.
```
my $screen = Terminal::Print.new;
$screen.initialize-screen; # saves current screen state, blanks screen, and hides cursor
$screen.change-cell(9, 23, '%'); # change the contents of the grid cell at column 9 line 23
$screen.cell-string(9, 23); # returns the escape sequence to put '%' on column 9 line 23
$screen.print-cell(9, 23); # prints "%" on the 9th column of the 23rd line
$screen.print-cell(9, 23, '&'); # changes the cell at x:9, y:23 to '&' and prints it
$screen.print-string(9, 23, "hello\nworld!"); # prints a whole string (which can include newlines!)
$screen(9,23,'hello\nworld!'); # uses CALL-ME to dispatch to .print-string
$screen.shutdown-screen; # unwinds the process from .initialize-screen
```
Check out some animations:
```
perl6 -Ilib examples/rpg-ui.p6
perl6 -Ilib examples/show-love.p6
perl6 -Ilib examples/zig-zag.p6
perl6 -Ilib examples/matrix-ish.p6
perl6 -Ilib examples/async.p6
```
By default the `Terminal::Print` object will use ANSI escape sequences for it's cursor drawing, but you can tell it to use `universal` if you would prefer to use the cursor movement commands as provided by `tput`. (You should only really need this if you are having trouble with the default).
```
my $t = Terminal::Print.new(cursor-profile => 'universal')
```
## History
At first I thought I might try writing a NativeCall wrapper around ncurses. Then I realized that there is absolutely no reason to fight a C library which has mostly bolted on Unicode when I can do it in Pure Perl 6, with native Unicode goodness.
## Roadmap
Status: *BETA* -- Current API is fixed and guaranteed!
* Improved documentation and examples
* Upgrade the tests with robust comparisons against a known-good corpus
* Investigate the potential of binding to `libtparm` (the backend to `tput`) via NativeCall
## Problems?
### It dies immediately complaining about my TERM env setting
In order to make the shelling out to `tput` safer, I have opted to use a whitelist of
valid terminals. The list is quite short at the moment, so my apologies if you trigger
this error. Everything should work smoothly once you have added it to the lookup hash
in `Terminal::Print::Commands`. Please consider sending it in as a PR, or filing a bug
report!
### It seems to be sending the wrong escape codes when using a different terminal on the same box
This should only be an issue for non-ANSI terminal users. The tradeoff we currently make
is to only disable precompilation on the module which determines the width and height of the
current screen. This means that other escape sequences in `Terminal::Print::Commands` will
only be run once and then cached in precompiled form. Clearing the related precomp files is
a quick and dirty solution. If you run into this issue, please let me know. I will certainly
get overly excited about your ancient TTY :D
## Contributors
ab5tract, japhb, Bluebear94, Xliff
Released under the Artistic License 2.0.
|
## setbagmix.md
Sets, bags, and mixes
Unordered collections of unique and weighted objects in Raku
# [Introduction](#Sets,_bags,_and_mixes "go to top of document")[§](#Introduction "direct link")
The six collection classes are [`Set`](/type/Set), [`SetHash`](/type/SetHash), [`Bag`](/type/Bag), [`BagHash`](/type/BagHash), [`Mix`](/type/Mix) and [`MixHash`](/type/MixHash). They all share similar semantics.
In a nutshell, these classes hold, in general, unordered collections of objects, much like an [object hash](/type/Hash). The [`QuantHash`](/type/QuantHash) role is the role that is implemented by all of these classes: therefore they are also referenced as [`QuantHash`](/type/QuantHash)es.
[`Set`](/type/Set) and [`SetHash`](/type/SetHash) also implement the [`Setty`](/type/Setty) role, [`Bag`](/type/Bag) and [`BagHash`](/type/BagHash) implement the [`Baggy`](/type/Baggy) role, [`Mix`](/type/Mix) and [`MixHash`](/type/MixHash) implement the [`Mixy`](/type/Mixy) role (which itself implements the [`Baggy`](/type/Baggy) role).
Sets only consider if objects in the collection are present or not, bags can hold several objects of the same kind, and mixes also allow fractional (and negative) weights. The regular versions are immutable, the *-Hash* versions are mutable.
Let's elaborate on that. If you want to collect objects in a container but you do not care about the order of these objects, Raku provides these *unordered* collection types. Being unordered, these containers can be more efficient than [`List`](/type/List)s or [`Array`](/type/Array)s for looking up elements or dealing with repeated items.
On the other hand, if you want to get the contained objects (elements) **without duplicates** and you only care *whether* an element is in the collection or not, you can use a [`Set`](/type/Set) or [`SetHash`](/type/SetHash).
If you want to get rid of duplicates but still preserve order, take a look at the [unique](/routine/unique) routine for [`List`](/type/List).
If you want to keep track of the **number of times each object appeared**, you can use a [`Bag`](/type/Bag) or [`BagHash`](/type/BagHash). In these [`Baggy`](/type/Baggy) containers each element has a weight (an unsigned integer) indicating the number of times the same object has been included in the collection.
The types [`Mix`](/type/Mix) and [`MixHash`](/type/MixHash) are similar to [`Bag`](/type/Bag) and [`BagHash`](/type/BagHash), but they also allow **fractional and negative weights**.
[`Set`](/type/Set), [`Bag`](/type/Bag), and [`Mix`](/type/Mix) are *immutable* types. Use the mutable variants [`SetHash`](/type/SetHash), [`BagHash`](/type/BagHash), and [`MixHash`](/type/MixHash) if you want to add or remove elements after the container has been constructed.
For one thing, as far as they are concerned, identical objects refer to the same element – where identity is determined using the [WHICH](/routine/WHICH) method (i.e. the same way that the [===](/routine/===) operator checks identity). For value types like [`Str`](/type/Str), this means having the same value; for reference types like [`Array`](/type/Array), it means referring to the same object instance.
Secondly, they provide a Hash-like interface where the actual elements of the collection (which can be objects of any type) are the 'keys', and the associated weights are the 'values':
| type of $a | value of $a{$b} if $b is an element | value of $a{$b} if $b is not an element |
| --- | --- | --- |
| Set / SetHash | True | False |
| Bag / BagHash | a positive integer | 0 |
| Mix / MixHash | a non-zero real number | 0 |
# [Operators with set semantics](#Sets,_bags,_and_mixes "go to top of document")[§](#Operators_with_set_semantics "direct link")
There are several infix operators devoted to performing common operations using [`QuantHash`](/type/QuantHash) semantics. Since that is a mouthful, these operators are usually referred to as "set operators".
This does **not** mean that the parameters of these operators must always be [`Set`](/type/Set), or even a more generic [`QuantHash`](/type/QuantHash). It just means that the logic that is applied to the operators is the logic of [Set Theory](https://en.wikipedia.org/wiki/Set_theory).
These infixes can be written using the Unicode character that represents the function (like `∈` or `∪`), or with an equivalent ASCII version (like `(elem)` or `(|)`).
So explicitly using [`Set`](/type/Set) (or [`Bag`](/type/Bag) or [`Mix`](/type/Mix)) objects with these infixes is unnecessary. All set operators work with all possible arguments, including (since 6.d) those that are not explicitly set-like. If necessary, a coercion will take place internally: but in many cases that is not actually needed.
However, if a [`Bag`](/type/Bag) or [`Mix`](/type/Mix) is one of the parameters to these set operators, then the semantics will be upgraded to that type (where [`Mix`](/type/Mix) supersedes [`Bag`](/type/Bag) if both types happen to be used).
## [Set operators that return](#Sets,_bags,_and_mixes "go to top of document") [`Bool`](/type/Bool)[§](#Set_operators_that_return_Bool "direct link")
### [infix (elem), infix ∈](#Sets,_bags,_and_mixes "go to top of document")[§](#infix_(elem),_infix_∈ "direct link")
Returns `True` if `$a` is an **element** of `$b`, else `False`. [More information](/language/operators#infix_(elem),_infix_∈), [Wikipedia definition](https://en.wikipedia.org/wiki/Element_(mathematics)#Notation_and_terminology).
### [infix ∉](#Sets,_bags,_and_mixes "go to top of document")[§](#infix_∉ "direct link")
Returns `True` if `$a` is **not** an element of `$b`, else `False`. [More information](/language/operators#infix_∉), [Wikipedia definition](https://en.wikipedia.org/wiki/Element_(mathematics)#Notation_and_terminology).
### [infix (cont), infix ∋](#Sets,_bags,_and_mixes "go to top of document")[§](#infix_(cont),_infix_∋ "direct link")
Returns `True` if `$a` **contains** `$b` as an element, else `False`. [More information](/language/operators#infix_(cont),_infix_∋), [Wikipedia definition](https://en.wikipedia.org/wiki/Element_(mathematics)#Notation_and_terminology).
### [infix ∌](#Sets,_bags,_and_mixes "go to top of document")[§](#infix_∌ "direct link")
Returns `True` if `$a` does **not** contain `$b`, else `False`. [More information](/language/operators#infix_∌), [Wikipedia definition](https://en.wikipedia.org/wiki/Element_(mathematics)#Notation_and_terminology).
### [infix (<=), infix ⊆](#Sets,_bags,_and_mixes "go to top of document")[§](#infix_(<=),_infix_⊆ "direct link")
Returns `True` if `$a` is a **subset** or is equal to `$b`, else `False`. [More information](/language/operators#infix_(<=),_infix_⊆), [Wikipedia definition](https://en.wikipedia.org/wiki/Subset#Definitions).
### [infix ⊈](#Sets,_bags,_and_mixes "go to top of document")[§](#infix_⊈ "direct link")
Returns `True` if `$a` is **not** a **subset** nor equal to `$b`, else `False`. [More information](/language/operators#infix_⊈), [Wikipedia definition](https://en.wikipedia.org/wiki/Subset#Definitions).
### [infix (<), infix ⊂](#Sets,_bags,_and_mixes "go to top of document")[§](#infix_(<),_infix_⊂ "direct link")
Returns `True` if `$a` is a **strict subset** of `$b`, else `False`. [More information](/language/operators#infix_(<),_infix_⊂), [Wikipedia definition](https://en.wikipedia.org/wiki/Subset#Definitions).
### [infix ⊄](#Sets,_bags,_and_mixes "go to top of document")[§](#infix_⊄ "direct link")
Returns `True` if `$a` is **not** a **strict subset** of `$b`, else `False`. [More information](/language/operators#infix_⊄), [Wikipedia definition](https://en.wikipedia.org/wiki/Subset#Definitions).
### [infix (>=), infix ⊇](#Sets,_bags,_and_mixes "go to top of document")[§](#infix_(>=),_infix_⊇ "direct link")
Returns `True` if `$a` is a **superset** of or equal to `$b`, else `False`. [More information](/language/operators#infix_(>=),_infix_⊇), [Wikipedia definition](https://en.wikipedia.org/wiki/Subset#Definitions).
### [infix ⊉](#Sets,_bags,_and_mixes "go to top of document")[§](#infix_⊉ "direct link")
Returns `True` if `$a` is **not** a **superset** nor equal to `$b`, else `False`. [More information](/language/operators#infix_⊉), [Wikipedia definition](https://en.wikipedia.org/wiki/Subset#Definitions).
### [infix (>), infix ⊃](#Sets,_bags,_and_mixes "go to top of document")[§](#infix_(>),_infix_⊃ "direct link")
Returns `True` if `$a` is a **strict superset** of `$b`, else `False`. [More information](/language/operators#infix_(>),_infix_⊃), [Wikipedia definition](https://en.wikipedia.org/wiki/Subset#Definitions).
### [infix ⊅](#Sets,_bags,_and_mixes "go to top of document")[§](#infix_⊅ "direct link")
Returns `True` if `$a` is **not** a **strict superset** of `$b`, else `False`. [More information](/language/operators#infix_⊅), [Wikipedia definition](https://en.wikipedia.org/wiki/Subset#Definitions).
### [infix (==), infix ≡](#Sets,_bags,_and_mixes "go to top of document")[§](#infix_(==),_infix_≡ "direct link")
Returns `True` if `$a` and `$b` are **identical**, else `False`. [More information](/language/operators#infix_(==),_infix_≡), [Wikipedia definition](https://en.wikipedia.org/wiki/Equality_(mathematics)#Equality_in_set_theory).
Available as of the 2020.07 Rakudo compiler release. Users of older versions of Rakudo can install the [Set::Equality](https://raku.land/zef:lizmat/Set::Equality) module for the same functionality.
### [infix ≢](#Sets,_bags,_and_mixes "go to top of document")[§](#infix_≢ "direct link")
Returns `True` if `$a` and `$b` are **not identical**, else `False`. [More information](/language/operators#infix_≢), [Wikipedia definition](https://en.wikipedia.org/wiki/Equality_(mathematics)#Equality_in_set_theory).
Available as of the 2020.07 Rakudo compiler release. Users of older versions of Rakudo can install the [Set::Equality](https://raku.land/zef:lizmat/Set::Equality) module for the same functionality.
## [Set operators that return a](#Sets,_bags,_and_mixes "go to top of document") [`QuantHash`](/type/QuantHash)[§](#Set_operators_that_return_a_QuantHash "direct link")
### [infix (|), infix ∪](#Sets,_bags,_and_mixes "go to top of document")[§](#infix_(|),_infix_∪ "direct link")
Returns the **union** of all its arguments. [More information](/language/operators#infix_(|),_infix_∪), [Wikipedia definition](https://en.wikipedia.org/wiki/Union_(set_theory)).
### [infix (&), infix ∩](#Sets,_bags,_and_mixes "go to top of document")[§](#infix_(&),_infix_∩ "direct link")
Returns the **intersection** of all of its arguments. [More information](/language/operators#infix_(&),_infix_∩), [Wikipedia definition](https://en.wikipedia.org/wiki/Intersection_(set_theory)).
### [infix (-), infix ∖](#Sets,_bags,_and_mixes "go to top of document")[§](#infix_(-),_infix_∖ "direct link")
Returns the **set difference** of all its arguments. [More information](/language/operators#infix_(-),_infix_∖), [Wikipedia definition](https://en.wikipedia.org/wiki/Complement_(set_theory)#Relative_complement).
### [infix (^), infix ⊖](#Sets,_bags,_and_mixes "go to top of document")[§](#infix_(^),_infix_⊖ "direct link")
Returns the **symmetric set difference** of all its arguments. [More information](/language/operators#infix_(^),_infix_⊖), [Wikipedia definition](https://en.wikipedia.org/wiki/Symmetric_difference).
## [Set operators that return a](#Sets,_bags,_and_mixes "go to top of document") [`Baggy`](/type/Baggy)[§](#Set_operators_that_return_a_Baggy "direct link")
### [infix (.), infix ⊍](#Sets,_bags,_and_mixes "go to top of document")[§](#infix_(.),_infix_⊍ "direct link")
Returns the Baggy **multiplication** of its arguments. [More information](/language/operators#infix_(.),_infix_⊍).
### [infix (+), infix ⊎](#Sets,_bags,_and_mixes "go to top of document")[§](#infix_(+),_infix_⊎ "direct link")
Returns the Baggy **addition** of its arguments. [More information](/language/operators#infix_(+),_infix_⊎).
## [Terms related to set operators](#Sets,_bags,_and_mixes "go to top of document")[§](#Terms_related_to_set_operators "direct link")
### [term ∅](#Sets,_bags,_and_mixes "go to top of document")[§](#term_∅ "direct link")
The empty set. [More information](/language/terms#term_∅), [Wikipedia definition](https://en.wikipedia.org/wiki/Empty_set).
|
## dist_cpan-JJATRIA-Termbox.md
# NAME
Termbox
# DESCRIPTION
Termbox is "a library for writing text-based user interfaces". This module provides Raku bindings to this library.
# SYNOPSIS
```
use Termbox :ALL;
if tb-init() -> $ret {
note "tb-init() failed with error code $ret";
exit 1;
}
END tb-shutdown;
for "Press ESC to exit!".encode.list -> $c {
state $x = 5;
tb-change-cell( $x++, 5, $c, TB_COLOR_BLACK, TB_COLOR_WHITE );
}
tb-present;
my $events = Supplier.new;
start {
while tb-poll-event( my $ev = Termbox::Event.new ) { $events.emit: $ev }
}
react whenever $events.Supply -> $ev {
given $ev.type {
when TB_EVENT_KEY {
given $ev.key {
when TB_KEY_ESC { done }
}
}
}
}
```
# FUNCTIONS
None of the following functions are exported by default. They can be accessed through the `Termbox` package (as in `Termbox::init`) or imported with the `:subs` tag. When imported, they gain the `tb-` prefix (such that `init` becomes `tb-init`, etc).
## Basic functions
### init
### shutdown
### width
### height
### clear
### present
### put-cell
### change-cell
### blit
### cell-buffer
### select-input-mode
### select-output-mode
### peek-event
### poll-event
### utf8-char-to-unicode
See also `encode-string` for a higher-level version of this function.
### utf8-unicode-to-char
See also `decode-string` for a higher-level version of this function.
## Additional functions
The following functions are added as a convenience for the UTF-8 helpers provided by Termbox itself. These are likely much simpler to use in Raku code.
### encode-string
Takes a non-empty string and returns an Int representing the number used to encode it by Termbox.
On error throws an exception.
### decode-string
Takes an Int with the integer representation of a string (such as that returned by `encode-string` and returns it decoded as a Str.
On error throws an exception.
# CONSTANTS
Like with the functions described above, none of the following constants are exported by default. They can be accessed through the `Termbox` package (as in `Termbox::WHITE`) or imported with the different tags described below.
When imported, they gain the `TB_` prefix (such that `WHITE` becomes `TB_WHITE`, etc).
## Keys
Imported with the `:keys` tag.
These are a safe subset of terminfo keys, which exist on all popular terminals. Use only these to stay "truly portable", according to the Termbox documentation.
* `KEY_F1`
* `KEY_F2`
* `KEY_F3`
* `KEY_F4`
* `KEY_F5`
* `KEY_F6`
* `KEY_F7`
* `KEY_F8`
* `KEY_F9`
* `KEY_F10`
* `KEY_F11`
* `KEY_F12`
* `KEY_INSERT`
* `KEY_DELETE`
* `KEY_HOME`
* `KEY_END`
* `KEY_PGUP`
* `KEY_PGDN`
* `KEY_ARROW_UP`
* `KEY_ARROW_DOWN`
* `KEY_ARROW_LEFT`
* `KEY_ARROW_RIGHT`
* `KEY_MOUSE_LEFT`
* `KEY_MOUSE_RIGHT`
* `KEY_MOUSE_MIDDLE`
* `KEY_MOUSE_RELEASE`
* `KEY_MOUSE_WHEEL_UP`
* `KEY_MOUSE_WHEEL_DOWN`
The rest are ASCII code points below `SPACE` character and a `BACKSPACE` key.
* `KEY_CTRL_TILDE`
* `KEY_CTRL_2`
* `KEY_CTRL_A`
* `KEY_CTRL_B`
* `KEY_CTRL_C`
* `KEY_CTRL_D`
* `KEY_CTRL_E`
* `KEY_CTRL_F`
* `KEY_CTRL_G`
* `KEY_BACKSPACE`
* `KEY_CTRL_H`
* `KEY_TAB`
* `KEY_CTRL_I`
* `KEY_CTRL_J`
* `KEY_CTRL_K`
* `KEY_CTRL_L`
* `KEY_ENTER`
* `KEY_CTRL_M`
* `KEY_CTRL_N`
* `KEY_CTRL_O`
* `KEY_CTRL_P`
* `KEY_CTRL_Q`
* `KEY_CTRL_R`
* `KEY_CTRL_S`
* `KEY_CTRL_T`
* `KEY_CTRL_U`
* `KEY_CTRL_V`
* `KEY_CTRL_W`
* `KEY_CTRL_X`
* `KEY_CTRL_Y`
* `KEY_CTRL_Z`
* `KEY_ESC`
* `KEY_CTRL_LSQ_BRACKET`
* `KEY_CTRL_3`
* `KEY_CTRL_4`
* `KEY_CTRL_BACKSLASH`
* `KEY_CTRL_5`
* `KEY_CTRL_RSQ_BRACKET`
* `KEY_CTRL_6`
* `KEY_CTRL_7`
* `KEY_CTRL_SLASH`
* `KEY_CTRL_UNDERSCORE`
* `KEY_SPACE`
* `KEY_BACKSPACE2`
* `KEY_CTRL_8`
These are modifier constants. `MOD_MOTION` in a mouse event indicates a dragging event.
* `MOD_ALT`
* `MOD_MOTION`
## Styles
Imported with the `:styles` tag.
* `DEFAULT`
* `BLACK`
* `RED`
* `GREEN`
* `YELLOW`
* `BLUE`
* `MAGENTA`
* `CYAN`
* `WHITE`
These are font attributes. It is possible to use multiple attributes by combining them using bitwise OR (`+|`). Although, colors cannot be combined, you can combine attributes and a single color.
* `BOLD`
* `UNDERLINE`
* `REVERSE`
## Errors
Imported with the `:errors` tag.
* `EUNSUPPORTED_TERMINAL`
* `EFAILED_TO_OPEN_TTY`
* `EPIPE_TRAP_ERROR`
## Events
Imported with the `:events` tag.
* `EVENT_KEY`
* `EVENT_RESIZE`
* `EVENT_MOUSE`
## Modes
Imported with the `:modes` tag.
* `HIDE_CURSOR`
* `INPUT_CURRENT`
* `INPUT_ESC`
* `INPUT_ALT`
* `INPUT_MOUSE`
* `OUTPUT_CURRENT`
* `OUTPUT_NORMAL`
* `OUTPUT_256`
* `OUTPUT_216`
* `OUTPUT_GRAYSCALE`
# AUTHOR
José Joaquín Atria [jjatria@cpan.org](mailto:jjatria@cpan.org)
# COPYRIGHT AND LICENSE
Copyright 2020 José Joaquín Atria
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## associative.md
role Associative
Object that supports looking up values by key
```raku
role Associative[::TValue = Mu, ::TKey = Str(Any)] { }
```
A common role for types that support name-based lookup through [postcircumfix:<{ }>](/language/operators#postcircumfix_{_}) such as [`Hash`](/type/Hash) and [`Map`](/type/Map). It is used for type checks in operators that expect to find specific methods to call. See [Subscripts](/language/subscripts#Methods_to_implement_for_associative_subscripting) for details.
The `%` sigil restricts variables to objects that do `Associative`, so you will have to mix in that role if you want to use it for your classes.
```raku
class Whatever {};
my %whatever := Whatever.new;
# OUTPUT: «Type check failed in binding; expected Associative but got Whatever
```
Please note that we are using binding `:=` here, since by default `%` assignments expect a [`Hash`](/type/Hash) in the right-hand side, and thus assignment would try and convert it to a hash (also failing). However, with the Associative role:
```raku
class Whatever is Associative {};
my %whatever := Whatever.new;
```
will be syntactically correct.
# [Methods](#role_Associative "go to top of document")[§](#Methods "direct link")
## [method of](#role_Associative "go to top of document")[§](#method_of "direct link")
```raku
method of()
```
`Associative`, as the definition above shows, is actually a [parameterized role](/language/objects#Parameterized_roles) which can use different classes for keys and values. As seen at the top of the document, by default it coerces the key to [`Str`](/type/Str) and uses a very generic [`Mu`](/type/Mu) for value.
```raku
my %any-hash;
say %any-hash.of; # OUTPUT: «(Mu)»
```
The value is the first parameter you use when instantiating `Associative` with particular classes:
```raku
class DateHash is Hash does Associative[Cool,DateTime] {};
my %date-hash := DateHash.new;
say %date-hash.of; # OUTPUT: «(Cool)»
```
## [method keyof](#role_Associative "go to top of document")[§](#method_keyof "direct link")
```raku
method keyof()
```
Returns the parameterized key used for the Associative role, which is [`Any`](/type/Any) coerced to [`Str`](/type/Str) by default. This is the class used as second parameter when you use the parameterized version of Associative.
```raku
my %any-hash;
%any-hash.keyof; # OUTPUT: «(Str(Any))»
```
# [Methods that classes mixing Associative should provide](#role_Associative "go to top of document")[§](#Methods_that_classes_mixing_Associative_should_provide "direct link")
You need to provide these methods if you want your class to implement the Associative role properly and, thus, use the `{}` operator for accessing the value given a key. They are not mandatory, however; on the other hand, if you simply want objects of a class to use `{}`, you can implement them without mixing the `Associative` role.
## [method AT-KEY](#role_Associative "go to top of document")[§](#method_AT-KEY "direct link")
```raku
method AT-KEY(\key)
```
Should return the value / container at the given key.
```raku
class What { method AT-KEY(\key) { 42 }};
say What.new{33}; # OUTPUT: «42»
```
## [method EXISTS-KEY](#role_Associative "go to top of document")[§](#method_EXISTS-KEY "direct link")
```raku
method EXISTS-KEY(\key)
```
Should return a [`Bool`](/type/Bool) indicating whether the given key actually has a value.
## [method STORE](#role_Associative "go to top of document")[§](#method_STORE "direct link")
```raku
method STORE(\values, :$INITIALIZE)
```
This method should only be supplied if you want to support the:
```raku
my %h is Foo = a => 42, b => 666;
```
syntax for binding your implementation of the `Associative` role.
Should accept the values to (re-)initialize the object with, which either could consist of [`Pair`](/type/Pair)s, or separate key/value pairs. The optional named parameter will contain a `True` value when the method is called on the object for the first time. Should return the invocant.
# [See also](#role_Associative "go to top of document")[§](#See_also "direct link")
See [Methods to implement for associative subscripting](/language/subscripts#Methods_to_implement_for_associative_subscripting) for information about additional methods that can be implemented for the `Associative` role.
# [Typegraph](# "go to top of document")[§](#typegraphrelations "direct link")
Type relations for `Associative`
raku-type-graph
Associative
Associative
Mu
Mu
Any
Any
Any->Mu
Cool
Cool
Cool->Any
Iterable
Iterable
Map
Map
Map->Associative
Map->Cool
Map->Iterable
Telemetry
Telemetry
Telemetry->Any
Telemetry::Period
Telemetry::Period
Telemetry::Period->Associative
Telemetry::Period->Telemetry
Positional
Positional
IO::Path::Parts
IO::Path::Parts
IO::Path::Parts->Associative
IO::Path::Parts->Any
IO::Path::Parts->Iterable
IO::Path::Parts->Positional
Pair
Pair
Pair->Associative
Pair->Any
QuantHash
QuantHash
QuantHash->Associative
PseudoStash
PseudoStash
PseudoStash->Map
Hash
Hash
Hash->Map
Setty
Setty
Setty->QuantHash
Baggy
Baggy
Baggy->QuantHash
Stash
Stash
Stash->Hash
Set
Set
Set->Any
Set->Setty
SetHash
SetHash
SetHash->Any
SetHash->Setty
Bag
Bag
Bag->Any
Bag->Baggy
BagHash
BagHash
BagHash->Any
BagHash->Baggy
Mixy
Mixy
Mixy->Baggy
[Expand chart above](/assets/typegraphs/Associative.svg)
|
## dist_zef-thundergnat-Math-Root.md
[](https://github.com/thundergnat/Math-Root/actions)
# NAME Math::Root
High precision and fairly efficient nth root routines.
# SYNOPSIS
```
use Math::Root;
# Integer root of an integer, returns an Integer. (possibly not exact.)
# Defaults to square root.
say iroot 2**541; # integer square root
# 2682957709556584533771917772160356460380403547217698392041778498789597340712478078
say iroot 2**541, 3; # integer cube root
# 1930823390806962193386557101263626480502272594990424863
say iroot 2**341, 7; # integer seventh root
# 184212135128821202763601
# Rational root of Real number, returns a FatRat. Defaults to square root
# with 32 digits past the decimal point.
say root 2**541; # square root
# 2682957709556584533771917772160356460380403547217698392041778498789597340712478078.25589164260725933347013112601008
say root 2**541, 3; # cube root
# 1930823390806962193386557101263626480502272594990424863.73446798343158184700655776636161
say (2**541).&root(7); # seventh root
# 184212135128821202763601.0882008101068149236473074788038
# Also can calculate 2nd, 3rd and 4th triangular roots
say 7140.&triangular-root;
# 119
```
# DESCRIPTION
Calculate Integer or Rational nth root of a number. Provides two routines depending on which result you desire.
### sub iroot( Int $number, Int $n? --> Int )
* $number
* value; Integer, required.
* $n
* value; positive Integer, optional, defaults to 2.
Efficiently calculates the Integer nth root of an Integer. Returns an Integer. Fast Integer-only arithmetic. May (very likely) not return an exact root, but useful in many situations where you don't need the fractional portion. Exponent n defaults to 2 (square root).
--
### sub root( Real $number, Int $n?, Int $precision? --> FatRat )
* $number
* value; any Real number, required.
* $n
* value; positive Integer > 1, optional, (nth root), default 2 (square root).
* $precision
* value; positive Integer, optional, number of digits to the right of the decimal, default 32.
Calculates the nth root of a Real number. Returns a FatRat, precise to 32 decimal digits by default. May pass in a different precision for more or fewer fractional digits, or may set the `$*ROOT-PRECISION` dynamic variable to have a different default.
Also provides routines to calculate triangular roots in two, three, and four dimensions.
A number whose triangular root is an integer is a triangular number.
### sub triangular-root( Real $number, Int $r? where 2|3|4 --> FatRat )
* $number
* value; any Real number, required.
* $r
* value; positive Integer 2, 3 or 4, optional, default 2 (r-simplex root).
Also provides named routines for 3-simplex and 4-simplex roots if you want to call them directly.
A number whose tetrahedral root is an integer is a tetrahedral number.
### sub tetrahedral-root( Real $number --> FatRat )
* $number
* value; any Real number, required.
A number whose pentatopic root is an integer is a pentatopic number. ( long o: pentatōpic - like hope or nope. )
### sub pentatopic-root( Real $number --> FatRat )
* $number
* value; any Real number, required.
# USAGE
Rakus nth root calculations return Nums by default. Very useful for small numbers but of limited value for very large ones. This module provides high precision root functions for both Integer and Rational results.
Contrast the default Raku operations:
```
say sqrt 2**541; # 2.6829577095565847e+81
say (2**541) ** (1/2); # 2.6829577095565847e+81
```
with the `Math::Root` operations:
```
say iroot 2**541;
# 2682957709556584533771917772160356460380403547217698392041778498789597340712478078
say root 2**541;
# 2682957709556584533771917772160356460380403547217698392041778498789597340712478078.25589164260725933347013112601008
```
Note that `root()` **always** returns a FatRat. If that will be problematic, coerce the returned value to some other type. You will lose precision. There is always a trade-off.
`root()` returns 32 digits past the decimal point by default. For a different precision, you may pass in a precision value when you call it, or can adjust the default precision by setting the `$*ROOT-PRECISION` dynamic variable to some positive integer value.
```
say sqrt 2; # Default Raku square root
# 1.4142135623730951
say root 2; # Defaults to n = 2, precision 32
# 1.4142135623730950488016887242097
say root 2, 2, 75; # When passing a precision, also need to specify n (2)
# 1.414213562373095048801688724209698078569671875376948073176679737990732478463
# or
{
# Set $*ROOT-PRECISION for a different default precision.
# Localized to prevent scope creep.
temp $*ROOT-PRECISION = 64;
say root 2;
# 1.414213562373095048801688724209698078569671875376948073176679738
}
```
`$n` can be any integer > 1. The examples so far have all used either an explicit or default of 2, but you can pass in 3 for a cube root, 5 for a fifth root, 117 for a one hundred seventeenth root, whatever.
```
say root 3, 3; # cube root of 3
# 1.44224957030740838232163831078011
say root 17, 13; # thirteenth root of 17
# 1.24351181796058033975980132060205
```
No matter how the precision is set, or what it is set to, the last digit will be rounded correctly. However, also note that non-significant digits (trailing zeros) may be dropped.
```
say root 25; # 5 <-- still a FatRat!
say root 25.0; # 5 <-- still a FatRat!
# number scale --> 1 2 3 4 5
# number scale --> 123456789012345678901234567890123456789012345678901
say root 2.123, 2, 51; # 1.457051817884319445661135028125627344205381869400006
say root 2.123, 2, 50; # 1.45705181788431944566113502812562734420538186940001
say root 2.123, 2, 49; # 1.4570518178843194456611350281256273442053818694
```
At the time of this writing, there is another module in the ecosystem, `BigRoot`, that provides similar high precision root functionality. It works quite nicely but has several drawbacks for my purposes. It is strictly object oriented; no separate general purpose routines. It doesn't provide specialized integer root functionality, you would need to calculate a rational root then truncate. And, in testing, I find it is about 33% slower on average than this module for Rational roots. Even slower for Integer roots.
The triangular root routines are likely of little practical value, but I went through the trouble of implementation, so figured I may as well include them in the off-chance that someone may find them useful. There is no known general formula to solve for triangular roots for 5-simplex or higher r-simplex number.
# AUTHOR
2021 Steve Schulze aka thundergnat
This package is free software and is provided "as is" without express or implied warranty. You can redistribute it and/or modify it under the same terms as Perl itself.
# LICENSE
Licensed under The Artistic 2.0; see LICENSE.
|
## dist_zef-patrickb-Cro-FCGI.md
# NAME
Cro::FCGI
FastCGI support for Cro
# Synopsis
## Using a network connection
```
use Cro::FCGI::Server;
my $service = Cro::FCGI::Server.new(
host => '127.0.0.1',
port => 43210,
application => MyCroApp
);
$service.start;
```
Webserver config (Apache here):
```
Listen 43210
<VirtualHost 127.0.0.1:43210>
ProxyFCGIBackendType GENERIC
ProxyPass "/" "fcgi://127.0.0.1:43211/" enablereuse=on
</VirtualHost>
```
## Using a Unix socket
```
use Cro::FCGI::Server;
my $service = Cro::FCGI::Server.new(
socket-path => '/run/cro-fcgi/my-cro-app.sock',
application => MyCroApp
);
$service.start;
```
Webserver config (Apache here):
```
Listen 43210
<VirtualHost 127.0.0.1:43210>
ProxyFCGIBackendType GENERIC
ProxyPass "/" "unix:/run/cro-fcgi/my-cro-app.sock|fcgi://127.0.0.1/" enablereuse=on
</VirtualHost>
```
# Description
This module provides a FastCGI frontend for Cro. It allows a simple coupling of a webserver and Cro application.
The module provides a drop-in replacement for `Cro::HTTP::Server` named `Cro::FCGI::Server`. It can be instantiated for either a network connetion or a Unix socket connection.
To start listening on a network port pass the `host` and `port` arguments.
To start listening on a Unix socket, pass the `socket-path` argument. Make sure the socket is readable and writable by the webserver process. Note that SELinux can possibly block access to the socket file for the webserver.
# Server and client host and port
To access the remote and local host and port of the connection of a given request, use the `.socket-host`, `.socket-port`, `.peer-host` and `.peer-port` methods of the request object, *not* the equally named methods of the `Cro::Connection` object (`$request.connection.*`). With FCGI, the connection represents the connection to the webserver, not the client!
# Limitations
Currently starting the application process automatically is not supported. You have to start the Cro application separately. For Apache this means you should use `mod_proxy_fcgi` instead of `mod_fcgid`.
# AUTHOR
Patrick Böker [patrick.boeker@posteo.de](mailto:patrick.boeker@posteo.de)
# License
This module is distributed under the terms of the Artistic License 2.0.
|
## dist_zef-titsuki-Algorithm-Kruskal.md
[](https://github.com/titsuki/raku-Algorithm-Kruskal/actions)
# NAME
Algorithm::Kruskal - a Raku implementation of Kruskal's Algorithm for constructing a spanning subtree of minimum length
# SYNOPSIS
```
use Algorithm::Kruskal;
my $kruskal = Algorithm::Kruskal.new(vertex-size => 4);
$kruskal.add-edge(0, 1, 2);
$kruskal.add-edge(1, 2, 1);
$kruskal.add-edge(2, 3, 1);
$kruskal.add-edge(3, 0, 1);
$kruskal.add-edge(0, 2, 3);
$kruskal.add-edge(1, 3, 5);
my %forest = $kruskal.compute-minimal-spanning-tree();
%forest<weight>.say; # 3
%forest<edges>.say; # [[1 2] [2 3] [3 0]]
```
# DESCRIPTION
Algorithm::Kruskal is a Raku implementation of Kruskal's Algorithm for constructing a spanning subtree of minimum length
## CONSTRUCTOR
```
my $kruskal = Algorithm::Kruskal.new(%options);
```
### OPTIONS
* `vertex-size => $vertex-size`
Sets vertex size. The vertices are numbered from `0` to `$vertex-size - 1`.
## METHODS
### add-edge(Int $from, Int $to, Real $weight)
```
$kruskal.add-edge($from, $to, $weight);
```
Adds a edge to the graph. `$weight` is the weight between vertex `$from` and vertex `$to`.
### compute-minimal-spanning-tree() returns List
```
my %forest = $kruskal.compute-minimal-spanning-tree();
%forest<edges>.say; # display edges
%forest<weight>.say; # display weight
```
Computes and returns a minimal spanning tree and its weight.
# AUTHOR
titsuki [titsuki@cpan.org](mailto:titsuki@cpan.org)
# COPYRIGHT AND LICENSE
Copyright 2016 titsuki
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
This algorithm is from Kruskal, Joseph B. "On the shortest spanning subtree of a graph and the traveling salesman problem." Proceedings of the American Mathematical society 7.1 (1956): 48-50.
|
## dist_zef-lizmat-Locale-Dates.md
[](https://github.com/lizmat/Locale-Dates/actions) [](https://github.com/lizmat/Locale-Dates/actions) [](https://github.com/lizmat/Locale-Dates/actions)
# NAME
Locale::Dates - encapsulate locale information about dates
# SYNOPSIS
```
use Locale::Dates;
my $ld = Locale::Dates("EN"); # or DE NL
say $ld.weekdays[1]; # Monday
say $ld.abbreviated-weekdays[2]; # Tue
say $ld.months[3]; # March
say $ld.abbreviated-months[4]; # Apr
say $ld.code; # EN
say $ld.am; # am
say $ld.pm; # pm
say $ld.date-time-representation; # %a %b %e %T %Z %Y
say $ld.date-representation # %a %b %e %Y
say $ld.time-representation # %T
```
# DESCRIPTION
The `Locale-Dates` distribution provides a database of locale information pertaining to dates. And it provides a class to encapsulate bespoke information.
# METHODS
## weekdays
```
say $ld.weekdays[0]; # Sunday
say $ld.weekdays[1]; # Monday
say $ld.weekdays[7]; # Sunday
```
The `weekdays` method returns a `List` with full weekday names, handling both 0-based as well as 1-based weekday values.
## abbreviated-weekdays
```
say $ld.abbreviated-weekdays[0]; # Sun
say $ld.abbreviated-weekdays[1]; # Mon
say $ld.abbreviated-weekdays[7]; # Sun
```
The `abbreviated-weekdays` method returns a `List` with abbreviated weekday names, handling both 0-based as well as 1-based weekday values.
## months
```
say $ld.months[ 1]; # January
say $ld.months[12]; # December
```
The `months` method returns a `List` with full month names. Handles 1-based month values only.
## abbreviated-months
```
say $ld.abbreviated-months[ 1]; # Jan
say $ld.abbreviated-months[12]; # Dec
```
The `abbreviated-months` method returns a `List` with abbreviated month names. Handles 1-based month values only.
## code
```
say $ld.code; # EN
```
The `code` method returns the identifying code of this locale.
## am / AM
```
say $ld.am; # am
say $ld.AM; # AM
```
The `am` method returns the representation of "ante meridiem", in lowercase, the `AM` method in uppercase.
## pm / PM
```
say $ld.pm; # pm
say $ld.PM; # PM
```
The `pm` method returns the representation of "post meridiem" in lowercase, the `PM` method in uppercase.
## date-time-representation
```
say $ld.date-time-representation; # %a %b %e %T %Z %Y
```
The `date-time-representation` method returns the `strftime` format for the representation of date and time.
## date-representation
```
say $ld.date-representation; # %a %b %e %Y
```
The `date-representation` method returns the `strftime` format for the representation of a date.
## time-representation
```
say $ld.time-representation; # %T
```
The `time-representation` method returns the `strftime` format for the representation of a time.
# CREATING YOUR OWN DATE LOCALE
```
my $ld = Locale::Dates.new(
code => "foo",
weekdays => <AAAA BBBB CCCC DDDD EEEE FFFF GGGG>,
months => <MMMM NNNN OOOO PPPP QQQQ RRRR
SSSS TTTT UUUU VVVV WWWW XXXX>,
am => "meh",
pm => "duh",
);
```
The `Locale::Dates` class can be instantiated like any other Raku class using named arguments.
## code
Required. The identifier code of this locale.
## weekdays
Required. A `List` with weekday names for this locale, starting at Monday.
## months
Required. A `List` with month names for this locale, starting at January.
## date-time-representation
Optional. The `strftime` format representation for date and time for this locale. Defaults to `"%a %e %b %T %Z %Y"`.
## date-representation
Optional. The `strftime` format representation for a date in this locale. Defaults to `"%a %e %b %Y"`.
## time-representation
Optional. The `strftime` format representation for a time in this locale. Defaults to `"%T"`.
## am
Optional. The representation of "ante meridiem" for this locale. Defaults to "am".
## pm
Optional. The representation of "post meridiem" for this locale. Defaults to "pm".
## abbreviated-weekdays
Optional. A `List` with abbreviated weekday names for this locale, starting at Monday. Defaults to the first 3 letters of the weekdays.
## abbreviated-months
Optional. A `List` with abbreviated month names for this locale, starting at January. Defaults to the first 3 letters of the month names.
# AUTHOR
Elizabeth Mattijsen [liz@raku.rocks](mailto:liz@raku.rocks)
Source can be located at: <https://github.com/lizmat/Locale-Dates> . Comments and Pull Requests are welcome.
If you like this module, or what I'm doing more generally, committing to a [small sponsorship](https://github.com/sponsors/lizmat/) would mean a great deal to me!
# COPYRIGHT AND LICENSE
Copyright 2025 Elizabeth Mattijsen
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_cpan-TYIL-App-Rakuman.md
# NAME
App::Rakuman
# AUTHOR
Patrick Spek [p.spek@tyil.work](mailto:p.spek@tyil.work)
# VERSION
0.1.0
# Description
A program to read the main Pod6 document of Raku modules
# Installation
Install this module through [zef](https://github.com/ugexe/zef):
```
zef install App::Rakuman
```
# License
This module is distributed under the terms of the AGPL-3.0.
|
## dist_zef-ohmycloudy-Notify.md
## NAME
Notify - minimal notifying tool for Raku.
## SYNOPSIS
```
use Notify;
my $notify = Notify.new(:title('Take a break'), :msg('You\'ve been working for 45 minutes'), :msg-type('info'));
$notify.notify();
```
## DESCRIPTION
Notify is a notifying tool for Raku.
## LICENSE
[](https://opensource.org/licenses/Artistic-2.0)
## AUTHORS
* [ohmycloudy@gmail.com](mailto:ohmycloudy@gmail.com)
|
## dist_github-avuserow-WebService-Lastfm.md
# NAME
WebService::Lastfm - interact with Last.fm's API
# SYNOPSIS
```
my $lastfm = WebService::Lastfm.new(:api-key<1234>, :api-secret<music>);
# Read request
say $lastfm.request('user.getInfo', :user<avuserow>);
# Update now playing
say $lastfm.write('track.updateNowPlaying',
:sk<SECRET KEY>,
:artist("Alan Parsons Project"),
:track<Time>,
:duration<360>,
);
```
# DESCRIPTION
Bindings for Last.fm's API using the JSON format (instead of their default
XML). You must register for their API to get an API key and API secret.
# METHODS
## new($api-key, $api-secret)
Standard new method. All parameters are optional, but the API key is needed for
all known requests, and the secret is needed for write methods.
## request($method, \*%params)
Make an unsigned GET request, used for read-only operations.
## write($method, \*%params)
Make a signed POST request, used for writing operations, the most famous of
which is "scrobbling" (track.scrobble).
# EXCEPTIONS
X::WebService::Lastfm is thrown on any error responses, with the decoded error
message from Last.fm. Check the method's documentation (or the API
documentation overall) for the meaning of the code.
# CAVEATS
* No packaged tests -- testing things that require API keys is nontrivial
* The assumption about requests being either GET/unsigned or POST/signed may
not be true, in which case more methods may be needed.
* Undertested in general
# TODO
* Switch to HTTP::UserAgent, which needs work to implement this
* Add tests somehow
* Example scripts. Ideas include a history exporter and a CLI scrobbler
* Optional caching mode
* Some sort of pagination helper for some API calls
# REQUIREMENTS
* Rakudo Perl 6
* LWP::Simple
* JSON::Tiny
* URI::Encode
* Digest::MD5
# SEE ALSO
[Last.fm's API documentation](http://www.last.fm/api/intro)
|
## dist_zef-raku-community-modules-Pray.md
[](https://github.com/raku-community-modules/Pray/actions) [](https://github.com/raku-community-modules/Pray/actions) [](https://github.com/raku-community-modules/Pray/actions)
# NAME
Pray - Raku Ray Tracing Engine
# SYNOPSIS
```
$ pray scene.json --width=100
```
# DESCRIPTION
This is Pray, a Raku ray tracer. It is tested to work with recent builds of Rakudo on the MoarVM backend, though it is likely to work on any modern Rakudo. Image::PNG::Portable and JSON::Tiny are required.
# USAGE
Input is a JSON scene file, described later. Output is a 24-bit PNG image file.
Pray is normally invoked as the `pray` script.
Two positional arguments are accepted. The first is the name of the scene file to read, which defaults to "scene.json". The second is the file name of the PNG image to write, and defaults to the file name of the scene file (ignoring any directory prefix), with everything after the last period replaced by "png". If the scene file name is "examples/scene-01.json" for instance, then the image file name defaults to "scene-01.png" in the current working directory.
* --width
* --height The size of the output image in positive whole numbers. At least one of these is required, and an omitted one will default to the value of the other. The field of view will be expanded to fill non-square aspect ratios, as opposed to being clipped.
* --preview Shows a preview of the in-progress render. On by default.
* --verbose Currently just prints the line number of the currently rendering line. Useful if preview is disabled. May do more or something else entirely in the future. Off by default.
* --quiet Disables the summary of the performance of the operation when complete. Also disables preview, unless it is explicitly enabled. Off by default.
# SCENES
DISCLAIMER: As the scene files could be thought of as the main user interface, an important note about them goes here: they're not done yet. The author feels that they are verbose, cumbersome, rigid, and fail with cryptic error messages. This will change, as will many other things about scene files. So don't expect your scene files to work unaltered in future versions until Pray is a little less alpha-ish.
The scene files are JSON formatted. As such, numbers must always have a digit before a decimal ("0.5", not ".5"), and single quotes ("'") and trailing commas ("[1,2,3,]") are illegal.
The outermost block of the scene file represents the scene itself, and is an object with keys "camera", "objects", and "lights". See the included examples for details. Wherever possible, sane defaults are used. The structure looks roughly like this:
```
scene the top-level block of the file
camera the view into the scene
position view point
object view direction (towards point)
roll rotation around axis of viewing direction
fov field of view
exposure scale of color values
lights list of lights in the scene
position light placement
color light color
intensity brightness
objects list of objects in the scene
geometry the physical shape of the object
primitive cube, cylinder, cone, or sphere
position placement
scale size
rotate orientation
csg list of csg operations and geometries
material appearance of the object
ambient flat constant lighting
color
intensity
diffuse smooth shaded lighting per light
color
intensity
specular "shiny spot" per light
color
intensity
sharpness how sharp or soft the highlight is
reflective visible reflection of other objects
color
intensity
transparent light passing through the object
color
intensity how transparent the object is (fades other colors)
refraction whether and how much this object bends light
```
The coordinate system uses Y for depth and Z for height, and is left-handed (if +X is right and +Z is up, +Y is forward). Except for the camera, positions and rotations default to 0, and scales default to 1. The camera defaults to an off-axis position in the +X,-Y,+Z region, pointing towards the origin.
Colors and coordinates are specified as objects with r,g,b/x,y,z keys. Any omitted elements default to 0, so to make blue for instance, you only have to write '{ "b":1 }'.
Entirely omitted colors default to white, but omitted lightings are not used, thus have effectively no color (white or otherwise).
The key "intensity" adjusts the brightness of lights and colors. In a "transparent" lighting block, it will also adjust the opacity of the object as a whole.
In most cases, "intensity" is intended to be a value between and inclusive of 0 and 1. However, for lights, intensity is not intended to have an upper bound. Balancing light and material "color" and "intensity" (and "exposure" of your camera) is up to you. Auto-exposure may make this simpler in the future.
At this point, it would only be fair to say the lighting model is "loosely based" on physical reality. Until more realistic algorithms are implemented, some restraint must be exercised if a realistic appearance is desired. For example, setting several of the lighting options at a high intensity could cause the material to appear far brighter than should be possible for the amount of light falling on it. Caveat emptor, etc.
If you omit the whole material block, it will default to a white, fully diffusive, slightly ambient material.
If you omit the "primitive" in a geometry block, that object will have no physical manifestation unless you add geometry to it with CSG.
CSG is an even-length array of "operation, geometry" values. The array implements a FIFO pipeline - in effect, the listed operations will be chained. In addition to chaining, CSG operations can also be nested, by simply adding CSG to a geometry block within an outer CSG array.
Currently recognized CSG operations are add/union/or, subtract/not/andnot, intersect/intersection/and, and deintersect/difference/xor. CSG geometry is defined in the space of the object it is being applied to. In other words, position/scale/rotate applies to the whole object including CSG sub-geometries.
# HACKING
There is much which could be added, improved, or simplified. So jump in! I'm looking forward to seeing what others do with Pray.
This is my first Raku project, thus much of the code probably looks a lot like Perl. As a self-education project, I have been and continue to be learning and re-learning Raku over the course of development, small parts at a time. The numerous iterations over all of the major components still show through in some spots, and in some others it's just clear that my understanding is still incomplete. Even the situational use of bracketing and indenting is inconsistent; I do at least stick to 4-column tab indents, though. Patches and suggestions are welcome and appreciated for style and structure as much as functionality.
The class hierarchy is a little troubling in some ways, but should be generally simple to navigate and understand. More thought needs to go into the API in several ways before using Pray from your own scripts is advisable; that is why there is no direct support for loading scenes from anything other than a file: the tools are there to make it happen in a line or two of code, but it's a can of worms once people start trying to actually *use* all the classes in unforeseen ways, on top of dealing with the mess which seems to naturally arise from my creative rampages. Some of the classes should probably be roles, some of the separate classes might be combined into a single class with one or two extra properties or roles, and the story goes on. In short, this project is just too young to think about a "stable public API" just yet. After some polishing, this will be revisited.
If you want to add primitives, the convention so far is to define them as 1 unit in radius/apothem/whatever applies on all three axii. All of the transformations and CSG are handled by the Pray::Geometry::Object superclass, so a primitive is defined by only 2 methods: \_ray\_intersection and \_contains\_point, which take a single Pray::Geometry::Ray or Pray::Geometry::Vector3D, respectively, and returns results as checked against the unit primitive. As always, read the existing code for details.
The use of vectors vs matrices is also inconsistent: Pray originally had no matrix class. When the transformations were implemented, the pile of vector ops became too heavy, so the matrix class was created to allow the transformation pipeline to be flattened into a single matrix. There are more places where this approach would save cycles, but other than to keep it "usable" on my aging hardware, no attempt to profile or optimize has yet been made.
Rewriting much of the whole program as a single large matrix pipeline even occurred to me. Of course, with Rakudo JVM supporting concurrency, mutlithreading is one of the obvious low-hanging fruits in terms of performance. It is near the top of my list. Many other things could also be done to decrease runtime: many operations are needlessly creating and destroying objects instead of mutating them in place; there are several places where adding conditionals or rearranging the arithmetic should speed things up on average. Once we profile Pray, we'll have a better idea where to start with optimization. I'm open to radical changes in structure, just not if the only purpose is to shave 3% off of the execution time.
Generally, solidifying the structure in terms of "shaders" and "pipelines" and the traditional 3D graphics processing methods would likely provide many benefits, and is an overarching direction I plan to move everything towards.
Use of types and type constraints is spotty. All sorts of input validation and error checking is missing.
# LIMITATIONS/BUGS/TODO
In no particular order: There is currently no internal reflection, subsurface scattering, volumetric lighting, global illumination, caustics, depth of field, anti-aliasing, or concurrency. Primitive choices are few (missing 4 of 5 platonic solids, among other things), and only the most basic transformations exist, and they are applied as a whole in only one fixed order.
There is no support for non-solid objects such as planes, polygons, or hollow surfaces, nor meshes whether open or closed. No procedural surfaces, textures of any kind, bump maps, or things which might be considered "effects" like motion blur or particle systems.
There's no support for fractals in any way shape or form, which is sad. Scene files feel crufty and fragile, and there is no way to re-use data in multiple places, forcing the same color to be applied for each material lighting type, for instance.
Scene files have to be created by hand in a text editor.
The API is not yet suitable for external use. Various naming and calling conventions all over the place are questionable. Performance is almost certainly much less than it could be, even given the present state of Rakudo. Repeating from above, all sorts of input validation and error checking is missing.
Documentation is lacking.
# CREDITS
Raku and its implementations are the tireless effort of many wonderful people around the world.
* <https://raku.org/>
* <https://rakudo.org/>
The scene loading code is forked from [JSON::Unmarshal](https://raku.land/zef:raku-community-modules/JSON::Unmarshal).
Parts of the matrix code are or were forked from or inspired by [Math::Vector](https://raku.land/zef:librasteve/Math::Vector).
# AUTHOR
raydiak
# COPYRIGHT AND LICENSE
Copyright 2014 - 2020 raydiak
Copyright 2025 Raku Community
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_zef-lizmat-ReverseIterables.md
[](https://github.com/lizmat/ReverseIterables/actions) [](https://github.com/lizmat/ReverseIterables/actions) [](https://github.com/lizmat/ReverseIterables/actions)
# NAME
ReverseIterables - turn two or more Iterables into a single iterator reversing
# SYNOPSIS
```
use ReverseIterables;
my @a = ^5;
my @b = <a b c d e>;
my @c = ReverseIterables.new(@a,@b).Seq;
say @c; # [e d c b a 4 3 2 1]
```
# DESCRIPTION
The `ReverseIterables` distribution provides a `ReverseIterables` class that creates a single `Iterator` from any number `Iterables` that will **lazily** produce values in a "reverse" order (from the end of the last `Iterable`, to the start of the first `Iterable`).
It does **not** recurse into any `Iterable` values that it encounters.
It also provides a `Seq` method, to directly produce a `Seq` object from the iterator, so it can be used in expressions.
# PROBABLY NOT USER FACING
This module is probably more useful for module developers, than for people writing direct Raku production code.
# AUTHOR
Elizabeth Mattijsen [liz@raku.rocks](mailto:liz@raku.rocks)
Source can be located at: <https://github.com/lizmat/ReverseIterables> . Comments and Pull Requests are welcome.
If you like this module, or what I'm doing more generally, committing to a [small sponsorship](https://github.com/sponsors/lizmat/) would mean a great deal to me!
# COPYRIGHT AND LICENSE
Copyright 2025 Elizabeth Mattijsen
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_cpan-MELEZHIK-Tomtit.md
# Tomtit
Tomtit - Raku Task Runner.
# Build Status
[](https://travis-ci.org/melezhik/tomtit)
# INSTALL
```
zef install tomtit
```
# USAGE
```
tom $action|$options $thing
```
Initialize tomtit:
```
tom --init
```
Run scenario:
```
tom $scenario
```
Default action (list of scenarios):
```
tom
```
List available scenarios:
```
tom --list
```
Get help:
```
tom --help
```
Show the last executed scenario:
```
tom --last
```
Clean Tomtit cache:
```
tom --clean
```
Example:
```
tom --list
[scenarios list]
test
build
install
tom test
```
# Defining scenarios
Tomtit scenarios are just Sparrow6 scenarios you create in `.tom` directory, which is base Tomtit directory:
```
mkdir .tom/
nano .tom/build.pl6
nano .tom/test.pl6
nano .tom/install.pl6
```
You want to ignore Tomtit cache which commit files to SCM:
```
git add .tom/
echo .tom/.cache >> .gitignore
```
# Scenario example
You can do anything, allowable through [Sparrow6 DSL](https://github.com/melezhik/Sparrow6/blob/master/documentation/dsl.md), like:
```
cat .tom/example.pl6
# you can use Sparrow6 DSL functions
# to do many system tasks, like:
# create files and directories
file 'passwords.txt', %( content => "super secret" );
directory '.cache';
# or restart service
service-restart "web-app";
# or you can run a certain sparrow plugin
# by using task-run function:
task-run 'my task', 'plugin', %( foo => 'bar' );
# for example, to set git repository,
# use git-base plugin:
task-run "set git", "git-base", %(
email => 'melezhik@gmail.com',
name => 'Alexey Melezhik',
config_scope => 'local',
set_credential_cache => 'on'
);
```
And so on.
As result you minimize code to execute many typical tasks.
# Profiles
Profiles are predefined sets of Tomtit scenarios.
To start using scenarios from profile you say:
```
tom --profile $profile
```
Once the command is executed the profile scenarios get installed to the
base Tomtit directory.
To list available profiles say this:
```
tom --profile
```
To list profiles scenarios say this:
```
tom --list --profile $profile
```
You can install selected scenario from profile by using special notation:
```
tom --profile $profile@$scenario
```
For example to install `commit` scenario from `git` profile:
```
tom --profile git@commit
```
# Portable profiles
Tomtit exposes API to create portable profiles as regular Perl6 modules.
You should create Perl6 module in `Tomtit::Profile` namespace with the *our* function `profile-data`,
returning `Hash` with scenarios data.
For example:
```
#!perl6
use v6;
unit module Tomtit::Profile::Pets:ver<0.0.1>;
our sub profile-data () {
my %a is Map = (
cat => (slurp %?RESOURCES<cat.pl6>.Str),
dog => (slurp %?RESOURCES<dog.pl6>.Str),
fish => (slurp %?RESOURCES<fish.pl6>.Str)
);
}
```
The above module defines [Tomtit::Profile::Pets](https://github.com/melezhik/tomtit-profile-pets) profile with 3 scenarios `cat, dog, fish` installed
as module resources:
```
resources/
cat.pl6
dog.pl6
fish.pl6
```
Now we can install it as regular Perl6 module and use through tom:
```
zef install Tomtit::Profile::Pets
```
Once module is installed we can install related profile. Note that we should replace `::` by `-` (\*) symbols
when refering to profile name.
```
tom --list --profile Tomtit-Profile-Pets
load portable profile Tomtit::Profile::Pets as Perl6 module ...
[profile scenarios]
Tomtit::Profile::Pets@cat installed: False
Tomtit::Profile::Pets@dog installed: False
Tomtit::Profile::Pets@fish installed: False
tom --profile Tomtit-Profile-Pets
install Tomtit::Profile::Pets@cat ...
install Tomtit::Profile::Pets@dog ...
install Tomtit::Profile::Pets@fish ...
```
(\*) Tomtit require such a mapping so that Bash completion could work correctly.
# Removing scenarios
To remove installed scenario say this:
```
tom --remove $scenario
```
# Edit scenario source code
Use `--edit` to create scenario from the scratch or to edit existed scenario source code:
```
tom --edit $scenario
```
# Getting scenario source code
Use `--cat` command to print out scenario source code:
```
tom --cat $scenario
```
Use `--lines` flag to print out with line numbers.
# Environments
* Tomtit environments are configuration files, written on Perl6 and technically speaking are plain Perl6 Hashes
* Environment configuration files should be placed at `.tom/conf` directory:
.tom/env/config.pl6:
```
{
name => "Tomtit",
who-are-you => "smart bird"
}
```
Run Tomtit.
It will pick the `.tom/env/config.pl6` and read configuration from it, variables will be accessible as `config` Hash,
inside Tomtit scenarios:
```
my $name = config<name>;
my $who-are-you = config<who-are-you>;
```
To define *named* configuration ( environment ), simply create `.tom/env/config{$env}.pl6` file and refer to it through
`--env=$env` parameter:
```
nano .tom/env/config.prod.pl6
tom --env=prod ... other parameters here # will run with production configuration
```
You can run editor for environment configuration by using --edit option:
```
tom --env-edit test # edit test enviroment configuration
tom --env-edit default # edit default configuration
```
You can activate environment by using `--env-set` parameter:
```
tom --env-set prod # set prod environment as default
tom --env-set # to list active (current) environment
tom --env-set default # to set current environment to default
```
To view environment configuration use `--env-cat` command:
```
tom --env-cat $env
```
You print out the list of all environments by using `--env-list` parameters:
```
tom --env-list
```
# Tomtit cli configuration
You can set Tomtit configuration in `~/tom.yaml` file:
```
# list of portable Tomtit profiles,
# will be available through Bash completion
profiles:
- Tomtit-Foo
- Tomtit-Bar
- Tomtit-Bar-Baz
# you can also setup some Tomtit cli options here
options:
quiet: true
```
# Options
```
--verbose # run scenario in verbose mode
--quiet,-q # run scenario in less verbose mode
```
# Bash completion
You can install Bash completion for tom cli.
```
tom --completion
source ~/.tom_completion.sh
```
# Development
```
git clone https://github.com/melezhik/Tomtit.git
zef install --/test .
zef install Tomty
tomty --all # run tests
```
# Author
Alexey Melezhik
# Thanks to
God Who gives me inspiration in my work
|
## nopackage.md
class X::Attribute::NoPackage
Compilation error due to declaring an attribute outside of a package
```raku
class X::Attribute::NoPackage does X::Comp { }
```
Compile time error thrown when an attribute is declared where it does not make sense (for example in the mainline).
For example
```raku
has $.x;
```
Dies with
「text」 without highlighting
```
```
You cannot declare attribute '$.x' here; maybe you'd like a class or a role?
```
```
# [Methods](#class_X::Attribute::NoPackage "go to top of document")[§](#Methods "direct link")
## [method name](#class_X::Attribute::NoPackage "go to top of document")[§](#method_name "direct link")
```raku
method name(--> Str:D)
```
Returns the name of the attribute
|
## dist_zef-tony-o-TOML.md
# TOML
A TOML 1.0.0 compliant serializer/deserializer.
## Usage
Parsing TOML
```
use TOML;
my $config = from-toml("config.toml".IO.slurp);
# use $config like any ol' hash
```
Generating TOML
```
use TOML;
my $config = {
bands => ['green day',
'motorhead',
't swift',],
favorite => 'little big',
};
my $toml-config = to-toml($config);
#favorite = "little big"
#bands = ["green day",
# "motorhead",
# "t swift"]
```
## License
[](https://opensource.org/licenses/Artistic-2.0)
## Authors
@[tony-o](https://github.com/tony-o)
## Credits
The tests here use @[BurntSushi](https://github.com/BurntSushi)'s toml-tests.
|
## dist_github-benjif-Telegram.md
# Raku Telegram Bot Library
This library offers Raku objects and routines that correspond to (some of) Telegram's bot API in a reactive form.
```
use Telegram;
my $bot = Telegram::Bot.new('<Your bot token>');
$bot.start(1); # Starts scanning for updates every second; defaults to every 2 seconds
my $msgTap = $bot.messagesTap; # A tap for updates
react {
whenever $msgTap -> $msg {
say "{$msg.sender.username}: {$msg.text} in {$msg.chat.id}";
}
whenever signal(SIGINT) {
$bot.stop;
exit;
}
}
```
## Installation
`zef install Telegram`
|
## slurp.md
slurp
Combined from primary sources listed below.
# [In IO::Handle](#___top "go to top of document")[§](#(IO::Handle)_method_slurp "direct link")
See primary documentation
[in context](/type/IO/Handle#method_slurp)
for **method slurp**.
```raku
method slurp(IO::Handle:D: :$close, :$bin)
```
Returns all the content from the current file pointer to the end. If the invocant is in binary mode or if `$bin` is set to `True`, will return a [`Buf`](/type/Buf), otherwise will decode the content using invocant's current [`.encoding`](/routine/encoding) and return a [`Str`](/type/Str).
If `:$close` is set to `True`, will close the handle when finished reading.
**Note:** On [Rakudo](/language/glossary#Rakudo) this method was introduced with release 2017.04; `$bin` arg was added in 2017.10.
# [In IO::CatHandle](#___top "go to top of document")[§](#(IO::CatHandle)_method_slurp "direct link")
See primary documentation
[in context](/type/IO/CatHandle#method_slurp)
for **method slurp**.
```raku
method slurp(IO::CatHandle:D:)
```
Reads all of the available input from all the source handles and returns it as a [`Buf`](/type/Buf) if the handle is in [binary mode](/type/IO/CatHandle#method_encoding) or as a [`Str`](/type/Str) otherwise. Returns [`Nil`](/type/Nil) if the [source handle queue has been exhausted](/type/IO/CatHandle#method_next-handle).
```raku
(my $f1 = 'foo'.IO).spurt: 'foo';
(my $f2 = 'bar'.IO).spurt: 'bar';
IO::CatHandle.new( $f1, $f2).slurp.say; # OUTPUT: «foobar»
IO::CatHandle.new(:bin, $f1, $f2).slurp.say; # OUTPUT: «Buf[uint8]:0x<66 6f 6f 62 61 72>»
IO::CatHandle.new .slurp.say; # OUTPUT: «Nil»
```
# [In IO::Path](#___top "go to top of document")[§](#(IO::Path)_routine_slurp "direct link")
See primary documentation
[in context](/type/IO/Path#routine_slurp)
for **routine slurp**.
```raku
multi method slurp(IO::Path:D: :$bin, :$enc)
```
Read all of the file's content and return it as either [`Buf`](/type/Buf), if `:$bin` is `True`, or if not, as [`Str`](/type/Str) decoded with `:$enc` encoding, which defaults to `utf8`. File will be closed afterwards. See [`&open`](/routine/open) for valid values for `:$enc`.
# [In Independent routines](#___top "go to top of document")[§](#(Independent_routines)_sub_slurp "direct link")
See primary documentation
[in context](/type/independent-routines#sub_slurp)
for **sub slurp**.
```raku
multi slurp(IO::Handle:D $fh = $*ARGFILES, |c)
multi slurp(IO() $path, |c)
```
Slurps the contents of the entire file into a [`Str`](/type/Str) (or [`Buf`](/type/Buf) if `:bin`). Accepts `:bin` and `:enc` optional named parameters, with the same meaning as [open()](/routine/open); possible encodings are the same as in all the other [`IO`](/type/IO) methods and are listed in [`encoding`](/type/IO/Handle#method_encoding) routine. The routine will `fail` if the file does not exist, or is a directory. Without any arguments, sub `slurp` operates on `$*ARGFILES`, which defaults to `$*IN` in the absence of any filenames.
```raku
# read entire file as (Unicode) Str
my $text_contents = slurp "path/to/file";
# read entire file as Latin1 Str
my $text_contents = slurp "path/to/file", enc => "latin1";
# read entire file as Buf
my $binary_contents = slurp "path/to/file", :bin;
```
|
## dist_zef-dwarring-CSS-Properties.md
[[Raku CSS Project]](https://css-raku.github.io)
/ [[CSS-Properties Module]](https://css-raku.github.io/CSS-Properties-raku)
[](https://travis-ci.org/css-raku/CSS-Properties-raku)
[](https://ci.appveyor.com/project/dwarring/CSS-Properties-raku/branch/master)
The CSS::Properties module is a set of related classes for parsing, manipulation and generation of CSS property sets, including inheritance, and defaults.
## Synopsis
```
use CSS::Units :pt;
use CSS::Properties;
my CSS::Properties() $css = "color:red !important; padding: 1pt";
say $css.color.hex; # (FF 00 00)
say $css.important("color"); # True
$css.border-color = 'blue';
# set all four margins individually (top, left, bottom, right)
$css.margin = [5pt, 2pt, 5pt, 2pt];
# set a common margin on all four sides
$css.margin = 5pt;
# set text alignment
$css.text-align = 'right';
say ~$css; # border-color:blue; color:red!important; margin:5pt; padding:1pt; text-align:right;
```
## Classes in this module
* [CSS::Properties](https://css-raku.github.io/CSS-Properties-raku/CSS/Properties) - property list manipulation class.
* [CSS::Properties::Calculator](https://css-raku.github.io/CSS-Properties-raku/CSS/Properties/Calculator) - property calculator and measurement tool.
* [CSS::Properties::Optimizer](https://css-raku.github.io/CSS-Properties-raku/CSS/Properties/Optimizer) - property AST optimizer delegate
* [CSS::Properties::PropertyInfo](https://css-raku.github.io/CSS-Properties-raku/CSS/Properties/PropertyInfo) - property meta-data delegate
* [CSS::Box](https://css-raku.github.io/CSS-Properties-raku/CSS/Box) - CSS Box model implementation.
* [CSS::Font](https://css-raku.github.io/CSS-Properties-raku/CSS/Font) - property font manipulation
* [CSS::Font::Descriptor](https://css-raku.github.io/CSS-Properties-raku/CSS/Font/Descriptor) - `@font-face` font descriptor objects
* [CSS::Font::Pattern](https://css-raku.github.io/CSS-Properties-raku/CSS/Font/Pattern) - `@font-face` font patterns and matching
* [CSS::PageBox](https://css-raku.github.io/CSS-Properties-raku/CSS/PageBox) - CSS Box model for paged media
* [CSS::Units](https://css-raku.github.io/CSS-Properties-raku/CSS/Units) - units and post-fix operators (e.g. `12pt`)
## See Also
* [CSS](https://css-raku.github.io/CSS-raku/) - Top level CSS manipulation class
## Conformance Levels
Processing defaults to CSS level 3 (class CSS::Module::CSS3). This can be configured via the :module option:
```
use CSS::Properties;
use CSS::Module;
use CSS::Module::CSS1;
use CSS::Module::CSS21;
use CSS::Module::CSS3;
use CSS::Module::SVG;
my $style = 'color:red; azimuth:left;';
my CSS::Module $module = CSS::Module::CSS1.module;
my CSS::Properties $css1 .= new: :$style, :$module;
## warnings: dropping unknown property: azimuth
$module = CSS::Module::CSS21.module;
my CSS::Properties $css21 .= new: :$style, :$module;
## (no warnings)
my CSS::Properties $css3 .= new: :$style; # CSS3 is the default
# -- or --
$module = CSS::Module::CSS3.module;
$css3 .= new: :$style, :$module;
$module = CSS::Module::SVG.module;
$style ~= "paint-order:markers;"; # add a SVG specific property
my CSS::Properties $css-svg .= new: :$style, :$module;
```
`CSS::Module::SVG` is an extension to `CSS::Module::CSS3` that includes
additional SVG specific properties.
### '@font-face' Properties
The [CSS::Font::Descriptor](https://css-raku.github.io/CSS-Properties-raku/CSS/Font/Descriptor) module is a class for managing `@font-face` declarations. The `css` method can be used to get the raw properties.
```
@font-face {
font-family: myFirstFont;
src: url(sansation_light.woff);
}
```
```
use CSS::Properties;
use CSS::Font::Descriptor;
my $style = "font-family: myFirstFont; src: url(sansation_light.woff)";
my CSS::Font::Descriptor $fd .= new: :$style;
my CSS::Properties $font-face-css = $fd.css;
```
## Default values
Most properties have a default value. If a property is reset to its default value it will be omitted from stringification:
```
my $css = (require CSS::Properties).new;
say $css.background-image; # none
$css.background-image = 'url(camellia.png)';
say ~$css; # "background-image: url(camellia.png);"
$css.background-image = $css.info("background-image").default;
say $css.background-image; # none
say ~$css; # ""
```
## Deleting properties
Properties can be deleted via the `delete` method, or by assigning the property to `Nil`:
```
my CSS::Properties $css .= new: :style("background-position:top left; border-top-color:red; border-bottom-color: green; color: blue");
# delete background position
$css.background-position = Nil;
# delete all border colors
$css.delete: "border-color";
```
## Inheritance
A child class can inherit from one or more parent classes. This follows CSS standards:
* not all properties are inherited by default; for example `color` is, but `margin` is not.
* the `inherit` keyword can be used in the child property to ensure inheritance.
* `initial` will reset the child property to the default value
To inherit a css object or style string:
* pass it as a `:inherit` option, when constructing the object, or
* use the `inherit` method
```
use CSS::Properties;
my $parent-style = "margin-top:5pt; margin-left: 15pt; color:rgb(0,0,255) !important";
my $style = "margin-top:25pt; margin-right: initial; margin-left: inherit; color:purple";
my CSS::Properties $css .= new: :$style, :inherit($parent-style);
say $css.color; # #7F007Frgb (purple)
say $css.handling("margin-left"); # inherit
say $css.margin-left; # 15pt
```
## Optimization and Serialization
```
method write(
Bool :$optimize = True, # consolidate properties
Bool :$terse = True, # single line output
Bool :$color-names = True, # use color names, where possible
Bool :$keep-defaults = False, # don't omit default values
|c
) is also<Str gist> {
```
The `.write` (alias `.Str`, or .`gist`) method can be used to produce CSS. Properties are optimized and normalized:
* properties with default values are omitted
* multiple component properties are generally consolidated to container properties (e.g. `font-family: Courier` and `font-size: 12pt`
are consolidated to `font: 12pt Courier`).
* rgb masks are translated to color-names, where possible
```
use CSS::Properties;
my CSS::Properties $css .= new( :style("background-repeat:repeat; border-style: groove; border-width: 2pt 2pt; color: rgb(255,0,0);") );
# - 'border-width' and 'border-style' are consolidated to the 'border' container property
# - rgb(255,0,0) is mapped to 'red'
say $css.write; # "border:2pt groove; color: red;"
```
Notice that:
* `background-repeat` was omitted because it has the default value
* `border-style` and `border-width` have been consolidated to the `border` container property. This is possible
because all four borders have common values
* `color` has been translated from a color mask to a color
`$.write` Options include:
* `:!optimize` - turn off optimization. Don't, combine component properties into container properties (`border-style`, `border-width`, ... => `border`), or combine edges (`margin-top`, `margin-left`, ... => `margin`).
* `:!terse` - enable multi-line output
* `:!color-names` - don't translate RGB values to color-names
See also [CSS::Properties::Optimizer](https://css-raku.github.io/CSS-Properties-raku/CSS/Properties/Optimizer).
## Property Meta-data
The `info` method gives property specific meta-data, on all (component or container properties). It returns an object of type CSS::Properties::PropertyInfo:
```
use CSS::Properties;
use CSS::Properties::PropertyInfo;
my CSS::Properties $css .= new;
my CSS::Properties::PropertyInfo $margin-info = $css.info("margin");
say $margin-info.synopsis; # <margin-width>{1,4}
say $margin-info.edges; # [margin-top margin-right margin-bottom margin-left]
say $margin-info.inherit; # True (property is inherited)
```
## Data Introspection
The `properties` method, gives a list of current properties. Only component properties
are returned. E.g. `font-family` may be returned; but `font` never is.
```
use CSS::Properties;
my $style = "margin-top: 10%; margin-right: 5mm; margin-bottom: auto";
my CSS::Properties $css .= new: :$style;
for $css.properties -> $prop {
my $val = $css."$prop"();
say "$prop: $val {$val.type}";
}
```
Gives:
```
margin-top: 10 percent
margin-bottom: auto keyw
margin-right: 5 mm
```
## Lengths and Units
CSS::Units is a convenience module that provides some simple post-fix length unit definitions.
The `:ops` export overloads `+` and `-` to perform unit
calculations. `+css` and `-css` are also available as
more explicit infix operators:
All infix operators convert to the left-hand operand's units.
```
use CSS::Units :ops, :pt, :px, :in, :mm;
my CSS::Properties $css .= new: :margin[5pt, 10px, .1in, 2mm];
# display margins in millimeters
say "%.2f mm".sprintf(.scale("mm")) for $css.margin.list;
```
The `measure` method can be used to perform contextual measurement
of lengths, which are converted to the default units.
The current font-size is used for `em`, `ex` and percentage calculations.
There are also `viewport-width` and `viewport-height` attributes
that need to be set to enable `vw` and `vh` units.
```
use CSS::Units :ops, :pt, :px, :in, :mm, :em, :vw, :vh, :percent;
use CSS::Properties;
my CSS::Properties $css .= new: :viewport-width(200);
say $css.units; # pt
say $css.measure: 10px; # 7.5pt
say $css.measure: 1in; # 72pt
say $css.font-size; # 12pt
say $css.measure: 2em; # 24pt
say $css.measure: 50%; # 6pt
say $css.measure: .1vw; # 20pt
```
The `measure` method can also be used on specific properties. In the case
of box measurements (borders, margins and padding) a `reference-width` also needs to be set for percentage calculations.
```
use CSS::Units :px, :percent;
use CSS::Properties;
my CSS::Properties $css .= new: :margin[10%, 10px], :reference-width(120);
say $css.measure: :margin-top; # 12pt
say $css.measure: :margin-left; # 7.5pt
say $css.measure: :margin-left(20%); # 24pt
say $css.measure: :font-size; # 12pt
say $css.measure: :font-size(50%); # 6pt
```
The `units` attribute defaults to `pt` can be changed to any absolute length units:
```
use CSS::Units :px, :mm;
use CSS::Properties;
my CSS::Properties $css .= new: :margin[10mm, 10px], :units<mm>;
say $css.units; # mm
say $css.measure: :margin-top; # 10mm
say $css.measure: :margin-left; # 2.646mm
```
## Appendix : CSS3 Properties
| Name | Default | Inherit | Type | Synopsis |
| --- | --- | --- | --- | --- |
| azimuth | center | Yes | | <angle> | [[ left-side | far-left | left | center-left | center | center-right | right | far-right | right-side ] || behind ] | leftwards | rightwards |
| background | | | hash | ['background-color' || 'background-image' || 'background-repeat' || 'background-attachment' || 'background-position'] |
| background-attachment | scroll | | | scroll | fixed |
| background-color | transparent | | | <color> | transparent |
| background-image | none | | | <uri> | none |
| background-position | 0% 0% | | | [ [ <percentage> | <length> | left | center | right ] [ <percentage> | <length> | top | center | bottom ]? ] | [ [ left | center | right ] || [ top | center | bottom ] ] |
| background-repeat | repeat | | | repeat | repeat-x | repeat-y | no-repeat |
| border | | | hash,box | [ 'border-width' || 'border-style' || 'border-color' ] |
| border-bottom | | | hash | [ 'border-bottom-width' || 'border-bottom-style' || 'border-bottom-color' ] |
| border-bottom-color | the value of the 'color' property | | | <color> | transparent |
| border-bottom-style | none | | | <border-style> |
| border-bottom-width | medium | | | <border-width> |
| border-collapse | separate | Yes | | collapse | separate |
| border-color | | | box | [ <color> | transparent ]{1,4} |
| border-left | | | hash | [ 'border-left-width' || 'border-left-style' || 'border-left-color' ] |
| border-left-color | the value of the 'color' property | | | <color> | transparent |
| border-left-style | none | | | <border-style> |
| border-left-width | medium | | | <border-width> |
| border-right | | | hash | [ 'border-right-width' || 'border-right-style' || 'border-right-color' ] |
| border-right-color | the value of the 'color' property | | | <color> | transparent |
| border-right-style | none | | | <border-style> |
| border-right-width | medium | | | <border-width> |
| border-spacing | 0 | Yes | | <length> <length>? |
| border-style | | | box | <border-style>{1,4} |
| border-top | | | hash | [ 'border-top-width' || 'border-top-style' || 'border-top-color' ] |
| border-top-color | the value of the 'color' property | | | <color> | transparent |
| border-top-style | none | | | <border-style> |
| border-top-width | medium | | | <border-width> |
| border-width | | | box | <border-width>{1,4} |
| bottom | auto | | | <length> | <percentage> | auto |
| caption-side | top | Yes | | top | bottom |
| clear | none | | | none | left | right | both |
| clip | auto | | | <shape> | auto |
| color | depends on user agent | Yes | | <color> |
| content | normal | | | normal | none | [ <string> | <uri> | <counter> | <counters> | attr(<identifier>) | open-quote | close-quote | no-open-quote | no-close-quote ]+ |
| counter-increment | none | | | none | [ <identifier> <integer>? ]+ |
| counter-reset | none | | | none | [ <identifier> <integer>? ]+ |
| cue | | | hash | [ 'cue-before' || 'cue-after' ] |
| cue-after | none | | | <uri> | none |
| cue-before | none | | | <uri> | none |
| cursor | auto | Yes | | [ [<uri> ,]\* [ auto | crosshair | default | pointer | move | e-resize | ne-resize | nw-resize | n-resize | se-resize | sw-resize | s-resize | w-resize | text | wait | help | progress ] ] |
| direction | ltr | Yes | | ltr | rtl |
| display | inline | | | inline | block | list-item | inline-block | table | inline-table | table-row-group | table-header-group | table-footer-group | table-row | table-column-group | table-column | table-cell | table-caption | none |
| elevation | level | Yes | | <angle> | below | level | above | higher | lower |
| empty-cells | show | Yes | | show | hide |
| float | none | | | left | right | none |
| font | | Yes | hash | [ [ <‘font-style’> || <font-variant-css21> || <‘font-weight’> || <‘font-stretch’> ]? <‘font-size’> [ / <‘line-height’> ]? <‘font-family’> ] | caption | icon | menu | message-box | small-caption | status-bar |
| font-family | depends on user agent | Yes | | [ <generic-family> | <family-name> ]# |
| font-feature-settings | normal | Yes | | normal | <feature-tag-value># |
| font-kerning | auto | Yes | | auto | normal | none |
| font-language-override | normal | Yes | | normal | <string> |
| font-size | medium | Yes | | <absolute-size> | <relative-size> | <length> | <percentage> |
| font-size-adjust | none | Yes | | none | auto | <number> |
| font-stretch | normal | Yes | | normal | ultra-condensed | extra-condensed | condensed | semi-condensed | semi-expanded | expanded | extra-expanded | ultra-expanded |
| font-style | normal | Yes | | normal | italic | oblique |
| font-synthesis | weight style | Yes | | none | [ weight || style ] |
| font-variant | normal | Yes | | normal | none | [ <common-lig-values> || <discretionary-lig-values> || <historical-lig-values> || <contextual-alt-values> || stylistic(<feature-value-name>) || historical-forms || styleset(<feature-value-name> #) || character-variant(<feature-value-name> #) || swash(<feature-value-name>) || ornaments(<feature-value-name>) || annotation(<feature-value-name>) || [ small-caps | all-small-caps | petite-caps | all-petite-caps | unicase | titling-caps ] || <numeric-figure-values> || <numeric-spacing-values> || <numeric-fraction-values> || ordinal || slashed-zero || <east-asian-variant-values> || <east-asian-width-values> || ruby ] |
| font-variant-alternates | normal | Yes | | normal | [ stylistic(<feature-value-name>) || historical-forms || styleset(<feature-value-name>#) || character-variant(<feature-value-name>#) || swash(<feature-value-name>) || ornaments(<feature-value-name>) || annotation(<feature-value-name>) ] |
| font-variant-caps | normal | Yes | | normal | small-caps | all-small-caps | petite-caps | all-petite-caps | unicase | titling-caps |
| font-variant-east-asian | normal | Yes | | normal | [ <east-asian-variant-values> || <east-asian-width-values> || ruby ] |
| font-variant-ligatures | normal | Yes | | normal | none | [ <common-lig-values> || <discretionary-lig-values> || <historical-lig-values> || <contextual-alt-values> ] |
| font-variant-numeric | normal | Yes | | normal | [ <numeric-figure-values> || <numeric-spacing-values> || <numeric-fraction-values> || ordinal || slashed-zero ] |
| font-variant-position | normal | Yes | | normal | sub | super |
| font-weight | normal | Yes | | normal | bold | bolder | lighter | 100 | 200 | 300 | 400 | 500 | 600 | 700 | 800 | 900 |
| height | auto | | | <length> | <percentage> | auto |
| left | auto | | | <length> | <percentage> | auto |
| letter-spacing | normal | Yes | | normal | <length> |
| line-height | normal | Yes | | normal | <number> | <length> | <percentage> |
| list-style | | Yes | hash | [ 'list-style-type' || 'list-style-position' || 'list-style-image' ] |
| list-style-image | none | Yes | | <uri> | none |
| list-style-position | outside | Yes | | inside | outside |
| list-style-type | disc | Yes | | disc | circle | square | decimal | decimal-leading-zero | lower-roman | upper-roman | lower-greek | lower-latin | upper-latin | armenian | georgian | lower-alpha | upper-alpha | none |
| margin | | | box | <margin-width>{1,4} |
| margin-bottom | 0 | | | <margin-width> |
| margin-left | 0 | | | <margin-width> |
| margin-right | 0 | | | <margin-width> |
| margin-top | 0 | | | <margin-width> |
| max-height | none | | | <length> | <percentage> | none |
| max-width | none | | | <length> | <percentage> | none |
| min-height | 0 | | | <length> | <percentage> |
| min-width | 0 | | | <length> | <percentage> |
| opacity | 1.0 | | | <number> |
| orphans | 2 | Yes | | <integer> |
| outline | | | hash | [ 'outline-color' || 'outline-style' || 'outline-width' ] |
| outline-color | invert | | | <color> | invert |
| outline-style | none | | | [ none | hidden | dotted | dashed | solid | double | groove | ridge | inset | outset ] |
| outline-width | medium | | | thin | medium | thick | <length> |
| overflow | visible | | | visible | hidden | scroll | auto |
| padding | | | box | <padding-width>{1,4} |
| padding-bottom | 0 | | | <padding-width> |
| padding-left | 0 | | | <padding-width> |
| padding-right | 0 | | | <padding-width> |
| padding-top | 0 | | | <padding-width> |
| page-break-after | auto | | | auto | always | avoid | left | right |
| page-break-before | auto | | | auto | always | avoid | left | right |
| page-break-inside | auto | | | avoid | auto |
| pause | | | | [ [<time> | <percentage>]{1,2} ] |
| pause-after | 0 | | | <time> | <percentage> |
| pause-before | 0 | | | <time> | <percentage> |
| pitch | medium | Yes | | <frequency> | x-low | low | medium | high | x-high |
| pitch-range | 50 | Yes | | <number> |
| play-during | auto | | | <uri> [ mix || repeat ]? | auto | none |
| position | static | | | static | relative | absolute | fixed |
| quotes | depends on user agent | Yes | | [<string> <string>]+ | none |
| richness | 50 | Yes | | <number> |
| right | auto | | | <length> | <percentage> | auto |
| size | auto | | | <length>{1,2} | auto | [ <page-size> || [ portrait | landscape] ] |
| speak | normal | Yes | | normal | none | spell-out |
| speak-header | once | Yes | | once | always |
| speak-numeral | continuous | Yes | | digits | continuous |
| speak-punctuation | none | Yes | | code | none |
| speech-rate | medium | Yes | | <number> | x-slow | slow | medium | fast | x-fast | faster | slower |
| stress | 50 | Yes | | <number> |
| table-layout | auto | | | auto | fixed |
| text-align | a nameless value that acts as 'left' if 'direction' is 'ltr', 'right' if 'direction' is 'rtl' | Yes | | left | right | center | justify |
| text-decoration | none | | | none | [ underline || overline || line-through || blink ] |
| text-indent | 0 | Yes | | <length> | <percentage> |
| text-transform | none | Yes | | capitalize | uppercase | lowercase | none |
| top | auto | | | <length> | <percentage> | auto |
| unicode-bidi | normal | | | normal | embed | bidi-override |
| vertical-align | baseline | | | baseline | sub | super | top | text-top | middle | bottom | text-bottom | <percentage> | <length> |
| visibility | visible | Yes | | visible | hidden | collapse |
| voice-family | depends on user agent | Yes | | [<generic-voice> | <specific-voice> ]# |
| volume | medium | Yes | | <number> | <percentage> | silent | x-soft | soft | medium | loud | x-loud |
| white-space | normal | Yes | | normal | pre | nowrap | pre-wrap | pre-line |
| widows | 2 | Yes | | <integer> |
| width | auto | | | <length> | <percentage> | auto |
| word-spacing | normal | Yes | | normal | <length> |
| z-index | auto | | | auto | <integer> |
The above markdown table was produced with the following code snippet
```
use v6;
say <Name Default Inherit Type Synopsis>.join(' | ');
say ('---' xx 5).join(' | ');
my $css = (require CSS::Properties).new;
for $css.properties(:all).sort -> $name {
with $css.info($name) {
my @type;
@type.push: 'hash' if .children;
@type.push: 'box' if .box;
my $synopsis-escaped = .synopsis.subst(/<?before <[ < | > # ]>>/, '\\', :g);
say ($name,
.default // '',
.inherit ?? 'Yes' !! '',
@type.join(','),
$synopsis-escaped,
).join(' | ');
}
}
```
|
## dist_zef-andmizyk-sortuk.md
## NAME
sortuk - is script and library for sorting strings by Ukrainian alphabet.
## INSTALLATION
```
zef install sortuk
```
## USAGE
```
bin/sortuk пʼять сім девʼять
bin/sortuk resources/test_file.txt
```
or as library:
```
use SortUk;
say sortuk <один два пʼять>;
# OUTPUT: (два один пʼять)
my @data = 'resources/test_file.txt'.IO.lines;
.put for sortuk @data;
```
## AUTHOR
Andrij Mizyk
## LICENSE
Copyright (C) 2022 Andrij Mizyk
This library is free software: you can redistribute it and/or modify
it under the terms of the GNU General Public License as published by
the Free Software Foundation, either version 3 of the License, or
(at your option) any later version.
|
## categorize-list.md
categorize-list
Combined from primary sources listed below.
# [In role Baggy](#___top "go to top of document")[§](#(role_Baggy)_method_categorize-list "direct link")
See primary documentation
[in context](/type/Baggy#method_categorize-list)
for **method categorize-list**.
```raku
multi method categorize-list(&mapper, *@list --> Baggy:D)
multi method categorize-list(%mapper, *@list --> Baggy:D)
multi method categorize-list(@mapper, *@list --> Baggy:D)
```
Populates a *mutable* `Baggy` by categorizing the possibly-empty `@list` of values using the given `mapper`. The `@list` cannot be lazy.
```raku
say BagHash.new.categorize-list: {
gather {
take 'largish' if $_ > 5;
take .is-prime ?? 'prime' !! 'non-prime';
take $_ %% 2 ?? 'even' !! 'odd';
}
}, ^10;
# OUTPUT: BagHash(largish(4) even(5) non-prime(6) prime(4) odd(5))
my %mapper = :sugar<sweet white>, :lemon<sour>, :cake('sweet', 'is-a-lie');
say MixHash.new.categorize-list: %mapper, <sugar lemon cake>;
# OUTPUT: MixHash(is-a-lie sour white sweet(2))
```
The mapper can be a [`Callable`](/type/Callable) that takes a single argument, an [`Associative`](/type/Associative), or an [`Iterable`](/type/Iterable). With [`Associative`](/type/Associative) and an [`Iterable`](/type/Iterable) mappers, the values in the `@list` represent the key and index of the mapper's value respectively. A [`Callable`](/type/Callable) mapper will be executed once per each item in the `@list`, with that item as the argument and its return value will be used as the mapper's value.
The mapper's value is used as a possibly-empty list of keys of the `Baggy` that will be incremented by `1`.
**Note:** unlike the [`Hash`](/type/Hash)'s `.categorize-list`, returning a list of [`Iterables`](/type/Iterable) as mapper's value will throw, as `Baggy` types do not support nested categorization. For the same reason, `Baggy`'s `.categorize-list` does not accept `:&as` parameter.
# [In Hash](#___top "go to top of document")[§](#(Hash)_method_categorize-list "direct link")
See primary documentation
[in context](/type/Hash#method_categorize-list)
for **method categorize-list**.
```raku
multi method categorize-list(&mapper, *@list, :&as --> Hash:D)
multi method categorize-list(%mapper, *@list, :&as --> Hash:D)
multi method categorize-list(@mapper, *@list, :&as --> Hash:D)
```
Populates a `Hash` by classifying the possibly-empty `@list` of values using the given `mapper`, optionally altering the values using the `:&as` [`Callable`](/type/Callable). The `@list` cannot be lazy.
The mapper can be a [`Callable`](/type/Callable) that takes a single argument, an [`Associative`](/type/Associative), or an [`Iterable`](/type/Iterable). With [`Associative`](/type/Associative) and an [`Iterable`](/type/Iterable) mappers, the values in the `@list` represent the key and index of the mapper's value respectively. A [`Callable`](/type/Callable) mapper will be executed once per each item in the `@list`, with that item as the argument and its return value will be used as the mapper's value.
|
## dist_zef-tbrowder-Windows-Test.md
[](https://github.com/tbrowder/Windows-Test/actions)
# NAME
**Windows::Test** - Provides a '/.github/workflows/windows.yml' file for Win64 Raku module testing
# SYNOPSIS
```
use Windows::Test;
```
# DESCRIPTION
**Windows::Test** is intended to provide a comprehensive set of Windows OS system components for Gitbub Workflows testing of any Raku module on Github-provided Windows computer.
A copy of the Github workflows Windows test YAML file is in this directory for ease of reference for prospective users.
Users are encouraged to file an issue anytime this module's `/.github/workflows/windows.yml` file doesn't work for your module. Please include a link to the problem repository on <https://github.com>.
## TODO
Use Choclatey to add some programs to the Github Workflow Windows Virtual Machine including:
* `libfreetype6-dev`
This C/C++ library is required for many of the `PDF*` modules in the Raku module collections.
# AUTHOR
Tom Browder [tbrowder@acm.org](mailto:tbrowder@acm.org)
# COPYRIGHT AND LICENSE
© 2023 Tom Browder
This library is free software; you may redistribute it or modify it under the Artistic License 2.0.
|
## dist_zef-thundergnat-Color-Names.md
[](https://github.com/thundergnat/Color-Names/actions)
# NAME
Color::Names - A fairly comprehensive collection of lists of named colors.
This is an extension of the original [Color::Names](https://github.com/holli-holzer/perl6-Color-Names) module by Markus Holzer ( [holli.holzer@gmail.com](mailto:holli.holzer@gmail.com) )
It is excellent, but insufficient for my purposes. This module has the same basic functionality but an extended API (:api<2>) and expanded color lists.
The major difference is the data structure for the color database. The original (:api<1>) used the color name as its hash key. Worked, bit only allowed loading one set of color values at a time to prevent collisions.
This module (:api<2) uses a scheme to allow any number of color hashes to be loaded at the same time.
Each color set is stored in a hash with the color name concatonated with the set ID as its key, with the value containing information the color name, its RGB values in an array, and in some cases, a color 'code', an identifying code for that color.
# SYNOPSIS
```
use Color::Names:api<2>;
# a hash of normalized color names / set ID
# with rgb values, a pretty name, and possibly color codes
.say for sort Color::Names.color-data("X11");
# you can mix sets, names are associated with the group
# they came from
.say for sort Color::Names.color-data("X11", "XKCD");
# There is a find-color routine exported you can use to search for partial
# or exact names.
use Color::Names::CSS3;
.say for sort Color::Names.color-data(<CSS3>).&find-color: <Aqua>;
# --> aqua-CSS3 => { rgb => [0 255 255], name => Aqua}
# --> aquamarine-CSS3 => { rgb => [127 255 212], name => Aquamarine}
# --> mediumaquamarine-CSS3 => { rgb => [102 205 170], name => Medium Aquamarine}
.say for sort Color::Names.color-data(<CSS3>).&find-color: <Aqua>, :exact;
# --> aqua-CSS3 => { rgb => [0 255 255], name => Aqua}
use Color::Names::X11 :colors;
say COLORS{'red-X11'};
# --> {name => Red, rgb => [255 0 0]}
# There is also an exported nearest() routine to find the nearest color to a
# given R G B triple.
my %c = Color::Names.color-data(<XKCD>);
say nearest(%c, 152, 215, 150);
# --> [hospitalgreen-XKCD => {name => Hospital Green, rgb => [155 229 170]}]
```
Color name ID fields are the full name (or code) with all non alphanumeric characters removed, with a hyphen and uppercase list name appended.
So `Light Green` from the X11 list would be `lightgreen-X11`. This allows multiple lists to be loaded simultaneously without name conflicts.
# DESCRIPTION
There are several color sets that can be loaded, separately, or in combination.
**CSS3** - (141 colors) [W3 CSS 3 standard web colors](https://www.w3schools.com/cssref/css_colors.asp), supported by nearly all browsers and web related software.
**X11** - (422 colors, excluding grey0-grey100) [The X11 color set](https://www.w3schools.com/colors/colors_x11.asp). Not as standardized; there are several variations with minor differences. CSS3 colors are very nearly a proper subset.
**X11-Grey** - (101 colors, only-grey) [The X11 grey scale colors](https://www.w3schools.com/colors/colors_x11.asp). (grey0 through grey100). Separated to make it easier to exclude if desired.
**XCKD** - (954 colors) [The XKCD color collection](https://www.w3schools.com/colors/colors_xkcd.asp), collated by Randall Munroe as a result of an extensive [color survey](https://xkcd.com/color/rgb/) of web citizens.
**NBS** - (267 colors) National Bureau of Standards [standardized color names](https://www.w3schools.com/colors/colors_nbs.asp). Published by the [The National Bureau of Standards - ISCC color group](https://en.wikipedia.org/wiki/ISCC%E2%80%93NBS_system).
**NCS** - (1950 colors) [The Natural Color System](https://www.w3schools.com/colors/colors_ncs.asp) is the color standard (for interior design, decorating, and painting) in Sweden, Spain, Norway and South Africa. Uses color composition codes to label individual colors rather than names.
**Resene** - (1378 colors) [Resene™ color names and non-official approximate RGB values](https://www.w3schools.com/colors/colors_resene.asp) to simulate them on the web. [Resene™](https://www.resene.co.nz/) is a prominent paint/decorating retailer in New Zealand. The [Resene Paints Limited color palettes chart is publicly available on the web](http://www.resene.co.nz/swatches/).
**Crayola** - (315 colors) [Crayola™ color names and approximate RGB values](https://www.w3schools.com/colors/colors_crayola.asp) to simulate them on the web. Crayola™ is a famous color pencil and crayon producer. Their color names are often creative and funny (with no evidence of correlating to web based names). These are not official Crayola™ colors, only RGB approximations.
**RAL-CL** - (213 colors) [RAL Classic colors](https://en.wikipedia.org/wiki/List_of_RAL_colors#RAL_Classic). ('Reichs-Ausschuß für Lieferbedingungen und Gütesicherung' - 'Reich Committee for Delivery and Quality Assurance') Standardized colors used in European countries. Approximations of actual colors. Not to be used for color verification.
**RAL-DSP** - (1822 colors) [RAL Design System Plus colors](https://en.wikipedia.org/wiki/List_of_RAL_colors#RAL_Design_System+). ('Reichs-Ausschuß für Lieferbedingungen und Gütesicherung' - 'Reich Committee for Delivery and Quality Assurance') Expanded, mathematically determined color group following the CIELab system. Approximations of actual colors. Not to be used for color verification.
**FS595B** - (209 colors) [Federal Standard 595B colors](http://www.fed-std-595.com/FS-595-Paint-Spec.htm) Mostly obsolete but still referred to occasionally. Old version of Federal Standard 595 colors previously used in U.S. government procurement. Approximations of actual colors. Not to be used for color verification.
**FS595C** - (589 colors) [Federal Standard 595C colors](https://www.federalstandardcolor.com/). Standard colors used in U.S. government procurement. These are approximate colors. The appearance may vary depending on your monitor settings. Largely superceded by SAE AMS-STD-595, though most, if not all of the colors are exactly the same. Approximations of actual colors. Not to be used for color verification.
If you know about other lists of name/color pairs in use, please let me know.
# AUTHOR
Original Color::Names code and module: Markus «Holli» Holzer
Extended API and expanded color lists: Stephen Schulze (thundergnat)
# LICENSE
Copyright © 2019 Markus Holzer ( [holli.holzer@gmail.com](mailto:holli.holzer@gmail.com) ); 2022 Stephen Schulze
Licensed under the BSD-2-Clause License. See LICENSE.
This is free software: you are free to change and redistribute it. There is NO WARRANTY, to the extent permitted by law.
|
## foreigncode.md
class ForeignCode
Rakudo-specific class that wraps around code in other languages (generally NQP)
```raku
class ForeignCode does Callable {}
```
[[1]](#fn1)
`ForeignCode` is a Raku wrapper around code that is not written originally in that language; its intention is to use these blocks of code in [`Callable`](/type/Callable) contexts easily. For instance, subs have some anonymous functions that are actually `ForeignCode`.
```raku
sub does-nothing(){};
say $_.name ~ ' → ' ~ $_.^name for &does-nothing.^methods;
# OUTPUT: «<anon> → ForeignCode<anon> → ForeignCodesoft → Method…»
```
This script will map method names to their class, and it shows that routines, in particular, have several methods that are actually `ForeignCode` instead of [`Method`](/type/Method)s.
# [Methods](#class_ForeignCode "go to top of document")[§](#Methods "direct link")
## [method arity](#class_ForeignCode "go to top of document")[§](#method_arity "direct link")
```raku
method arity()
```
Returns the arity of the enclosed code.
## [method count](#class_ForeignCode "go to top of document")[§](#method_count "direct link")
```raku
method count()
```
Returns the number of arguments the enclosed code needs.
## [method signature](#class_ForeignCode "go to top of document")[§](#method_signature "direct link")
```raku
method signature( ForeignCode:D: )
```
Returns the signature of the enclosed code.
## [method name](#class_ForeignCode "go to top of document")[§](#method_name "direct link")
```raku
method name()
```
Returns the name of the enclosed code, or `<anon>` if it has not received any.
## [method gist](#class_ForeignCode "go to top of document")[§](#method_gist "direct link")
```raku
method gist( ForeignCode:D: )
```
Returns the name of the code by calling `name`.
## [method Str](#class_ForeignCode "go to top of document")[§](#method_Str "direct link")
```raku
method Str( ForeignCode:D: )
```
Returns the name of the code by calling `name`.
# [Typegraph](# "go to top of document")[§](#typegraphrelations "direct link")
Type relations for `ForeignCode`
raku-type-graph
ForeignCode
ForeignCode
Any
Any
ForeignCode->Any
Callable
Callable
ForeignCode->Callable
Mu
Mu
Any->Mu
[Expand chart above](/assets/typegraphs/ForeignCode.svg)
1 [[↑]](#fnret1) This is a Rakudo specific class, and as such it is advisable not to use it in your own code, since its interface might change or even disappear in the future. This is provided here only as a reference
|
## dist_zef-lizmat-Discogs-API.md
## Chunk 1 of 2
[](https://github.com/lizmat/Discogs-API/actions) [](https://github.com/lizmat/Discogs-API/actions)
# NAME
Discogs::API - Provide basic API to Discogs
# SYNOPSIS
```
use Discogs::API;
my $discogs = Discogs.new;
my $release = $discogs.release(249504);
```
# DESCRIPTION
Discogs::API provides a Raku library with access to the [Discogs](https://discogs.com) data and functions. It tries to follow the API as closely as possible, so the up-to-date [Discogs developer information](https://www.discogs.com/developers) can be used to look up matters that are unclear from thie documentation in this module.
One exception to this rule is that fieldnames in the JSON generated by Discogs that are using snake\_case, are converted to use kebab-case in the Raku interface. So a field called `allows_multiple_values` in the JSON blob, will be accessible using a `allow-multiple-values` method in this module.
# UTILITY METHODS
## new
```
my $discogs = Discogs.new(
client => $client, # Cro::HTTP::Client compatible, optional
token => "xfhgh1624", # Discogs access token, default: none
key => "kahgjkhdg", # Discogs access key, default: none
secret => "454215642", # Discogs access secret, default: none
currency => "EUR", # default: "USD"
per-page => 10, # default: 50
;
```
Create an object to access the services that the Discogs API has to offer.
* client - a Cro::HTTP::Client compatible client
One will be provided if not specified.
* token - Discogs Access Token
A token needed to access certain parts of the Discogs API. See <https://www.discogs.com/settings/developers> for more information. Defaults to whatever is specified with the DISCOGS\_TOKEN environment variable.
* key - Discogs Access Key
A string needed to access certain parts of the Discogs API. See <https://www.discogs.com/developers#page:authentication> for more information.
* secret - Discogs Access Secret
A string needed to access certain parts of the Discogs API. See <https://www.discogs.com/developers#page:authentication> for more information.
* currency
A string indicating the default currency to be used when producing prices of releases in the Discogs Marketplace. It should be one of the following strings:
```
USD GBP EUR CAD AUD JPY CHF MXN BRL NZD SEK ZAR
```
* per-page
An integer indicating the default number of items per page that should be produced by methods that return objects that support pagination.
## client
```
my $default = Discogs::API.client; # the default client
my $client = $discogs.client; # the actual client to be used
```
Return the default `Cro::HTTP::Client` object when called as a class method. That object will be used by default when creating a `Discogs::API` object. Intended to be used as a base for alterations, e.g. by overriding the `GET` method during testing.
Returns the actual object that was (implicitely) specified during the creation of the `Discogs::API` object when called as an instance method.
## GET
```
my $content = $discogs.GET("/artists/108713", Discogs::API::Artist);
```
Helper method to fetch data using the Discogs API for the given URI, and interpret it as data of the given class. Returns an instance of the given class, or throws if something went wrong.
## test-with
```
my $discogs = Discogs::API.new.test-with($path);
```
Provide an alternate Discogs::API object that can be used for testing. Instead of fetching the data from Discogs, it will look at the indicated path and map the URI to a file with the same name. So an URI like `"/artist/108713"` and a path `"foo/bar".IO` will look for a file called `"foo/bar/artist/108713.json"`, slurp that, and create the requested object out of that.
# CONTENT METHODS
## artist
```
my $artist = $discogs.artist(108713);
```
Fetch the information for the given artist ID and return that in an Discogs::API::Artist object.
## artist-releases
```
my $artist-releases = $discogs.artist-releases(
108713, # the artist ID
page => 2, # page number, default: 1
per-page => 25, # items per page, default: object
sort => "year", # sort on given key, default no sort
sort-order => "desc", # sort order, default to "asc"
);
```
Fetch all of the releases of given artist ID and return them in pages in a Discogs::API::ArtistReleases object.
* page
An integer indicating the page to obtain the `ArtistRelease` objects of. Defaults to 1.
* per-page
An integer indicating the maximum number of items per page to be produced. Defaults to what was (implicitely) specified with the creation of the `Discogs::API` object.
* sort
A string indicating how the `ArtistRelease` objects to be returned. Defaults to no sorting. The following fields can be specified:
```
year title format
```
* sort-order
A string indicating the sort order of any sort action to be performed on the `ArtistRelease` objects to be returned. Defaults to "asc". The following fields can be specified:
```
asc desc
```
## community-release-rating
```
my $rating = $discogs.community-release-rating(249504);
my $rating = $discogs.community-release-rating($release);
```
Fetch the information about the Discogs community rating for a given release and return that as an Discogs::API::CommunityReleaseRating object.
The release parameter can either be given as an unsigned integer, or as an Discogs::API::Release object.
## label
```
my $label = $discogs.label(1);
```
Fetch the information for the given label ID and return that in an Discogs::API::Label object.
## label-releases
```
my $label-releases = $discogs.label-releases(
1, # the label ID
page => 2, # page number, default: 1
per-page => 25, # items per page, default: object
);
```
Fetch all of the releases of given label ID and return them in pages in a Discogs::API::LabelReleases object.
## master-release
```
my $master-release = $discogs.master-release(1000);
```
Fetch the information for the given master release ID and return that in an Discogs::API::MasterRelease object.
## master-release-versions
```
my $master-release-versions = $discogs.master-release-versions(
1000, # the master release ID
page => 2, # page number, default: 1
per-page => 25, # items per page, default: object
format => "CD", # limit to format, default no limit
label => "Foo", # limit to label, default no limit
released => 1992, # limit to year, default no limit
country => "Belgium", # limit to country, default no limit
sort => "released", # sort on given key, default no sort
sort-order => "desc", # sort order, default to "asc"
);
```
Fetch all of the versions of a given master release ID and return them in pages in a Discogs::API::MasterReleaseVersions object. It supports the following optional named parameters:
* page
An integer indicating the page to obtain the `MasterReleaseVersion` objects of. Defaults to 1.
* per-page
An integer indicating the maximum number of items per page to be produced. Defaults to what was (implicitely) specified with the creation of the `Discogs::API` object.
* format
A string indicating the `format` of the `MasterReleaseVersion` objects to be returned. Defaults to no limitation on format.
* label
A string indicating the `label` of the `MasterReleaseVersion` objects to be returned. Defaults to no limitation on label.
* released
An integer indicating the year of release of the `MasterReleaseVersion` objects to be returned. Defaults to no limitation on year.
* country
A string indicating the `country` of the `MasterReleaseVersion` objects to be returned. Defaults to no limitation on country.
* sort
A string indicating how the `MasterReleaseVersion` objects to be returned. Defaults to no sorting. The following fields can be specified:
```
released title format label catno country
```
* sort-order
A string indicating the sort order of any sort action to be performed on the `MasterReleaseVersion` objects to be returned. Defaults to "asc". The following fields can be specified:
```
asc desc
```
## release
```
my $release = $discogs.release(249504, currency => "EUR");
```
Fetch the information for the given release ID and return that in an Discogs::API::Release object. Optionally takes a named `currency` parameter that should have one of the supported currency strings. This defaults to the value for the currency that was (implicitely) specified when creating the `Discogs::API` object.
## search
Perform a general search in the Discogs database, optionally searching specific parts. Returns a Discogs::API::SearchResults object.
```
my $search = $discogs.search(
"nirvana", # optional, general query
page => 2, # page number, default: 1
per-page => 25, # items per page, default: object
type => "release", # optional search for type only
title => "nits - urk", # optional artist - release search query
release-title => "urk", # optional search for to release name
credit => "kurt", # optional search for credits
artist => "nirvana", # optional search for artist name
anv => "nirvana", # optional search for artist name variation
label => "Foo", # optional search for label
genre => "rock", # optional search for genre
style => "grunge", # optional search for style
country => "belgium", # optional search for country
year => 1992, # optional search for year of release
format => "CD", # optional search for format
catno => "DGCD-24425", # optional search for catalog number
barcode => "7 2064-24425-2 4", # optional search for barcode
track => "smells like", # optional search for title of track
submitter => "milKt", # optional search for username of submitter
contributor => "liz", # optional search for username of contributor
);
```
* page
An integer indicating the page to obtain the `Discogs::API::SearchResult` objects of. Defaults to 1.
* per-page
An integer indicating the maximum number of items per page to be produced. Defaults to what was (implicitely) specified with the creation of the `Discogs::API` object.
* query
The string to be searched for.
* type
A string to determine which main fields to be searched. Should be one of:
```
release master artist label
```
* title
Special formatted string to search for an artist / release title combination. The hyphen indicates the separation, so e.g. "nirvana - nevermind".
* release-title
Search for given string as title of a release only.
* credit
Search for given string as credit for a release only.
* artist
Search for given string as main name of artist only.
* anv
Search for given string as alternative name variation of artist only.
* label
Search for given string as name of label only.
* genre
Search for given string as name of genre only.
* style
Search for given string as name of style only.
* country
Search for given string as name of country only.
* year
Search for given year of release only.
* format
Search for given string as format only.
* catno
Search for given string as catalog number only.
* barcode
Search for given string as barcode only.
* track
Search for given string as track title only.
* submitter
Search for given string as the username of a submitter only.
* submitter
Search for given string as the username of a contributor only.
## user-release-rating
```
my $rating = $discogs.user-release-rating(249504, "username");
my $rating = $discogs.user-release-rating($release, "username");
my $rating = $discogs.user-release-rating(249504, $user);
my $rating = $discogs.user-release-rating($release, $user);
```
Fetch the information about the rating for a given release and a username and return that as a Discogs::API::UserReleaseRating object.
The release parameter can either be given as an unsigned integer, or as an Discogs::API::Release object. The user parameter can either be given as a string, or as an Discogs::API::User object.
# ADDITIONAL CLASSES
In alphatical order:
## Discogs::API::Artist
* data-quality
String indicating the quality of the data.
* id
The artist ID.
* images
A list of Discogs::API::Image objects for this artist.
* members
A list of Discogs::API::Member objects of this artist.
* name
String with the main name of the artist.
* namevariations
A list of strings with alternate names / spellings of the artist.
* profile
A string with a profile of the artist.
* releases-url
The URL to fetch all of the releases of this Artist using the Discogs API.
* resource-url
The URL to fetch this object using the Discogs API.
* uri
The URL to access information about this artist on the Discogs website.
* urls
A list of URLs associated with this artist.
## Discogs::API::ArtistReleases
This object is usually created as part of a Discogs::API::ArtistReleases object.
* artist
A string with the name of the artist of this release.
* community-in-collection
An unsigned integer indicating the number of people in the Discogs community that have this release.
* community-in-wantlist
An integer indicating the number of people in the Discogs community that want to have this release.
* format
A string indicating the format of this release.
* id
The ID of this release.
* label
The ID of the associated `Discogs::API::Label` object.
* resource-url
The URL to obtain the information about this release using the Discogs API.
* role
A string indicating the role of this release compared to its Discogs::API::MasterRelease object.
* stats
An Discogs::API::Stats object with user and community statistics. It is probably easier to use the short-cut methods `community-in-collection`, `community-in-wantlist`, `user-in-collection`, `user-in-wantlist`.
* status
A string indicating the status of the information about this release.
* thumb
A URL for a thumbnail image associated with this release.
* title
A string with the title of this release.
* type
A string indicating the type of release, e.g. "master".
* user-in-collection
A boolean indicating whether the current user has this release.
* user-in-wantlist
A boolean indicating whether the current user wants to have this release.
* year
An unsigned integer for the year this release was released.
## Discogs::API::ArtistReleases
Retrieves a list of all Discogs::API::ArtistRelease objects that were made by the given artist ID, and pagination settings.
* first-page
Returns the first page of the information of this object, or `Nil` if already on the first page.
* first-page-url
The URL to fetch the data of the **first** page of this object using the Discogs API. Returns `Nil` if the there is only one page of information available.
* items
An integer indicating the total number of Discogs::API::LabelRelease objects there are available for this artist.
* last-page
Returns the last page of the information of this object, or `Nil` if already on the last page.
* last-page-url
The URL to fetch the data of the **last** page of this object using the Discogs API. Returns `Nil` if already on the last page.
* next-page
Returns the next page of the information of this object, or `Nil` if already on the last page.
* next-page-url
The URL to fetch the data of the **next** page of this object using the Discogs API. Returns `Nil` if already on the last page.
* page
An integer indicating the page number of this object.
* pages
An integer indicating the number of pages of information available for this object.
* pagination
The Discogs::API::Pagination object associted with this object. Usually not needed, as its information is available in shortcut methods.
* per-page
An integer representing the maximum number of items on a page.
* previous-page
Returns the previous page of the information of this object, or `Nil` if already on the first page.
* previous-page-url
The URL to fetch the data of the **previous** page of this object using the Discogs API. Returns `Nil` if already on the first page.
* releases
A list of Discogs::API::ArtistRelease objects.
## Discogs::API::ArtistSummary
* anv
A string with the artist name variation.
* id
The artist ID.
* join
A string indicating joining.
* name
A string with the name.
* resource-url
The URL to fetch the full artist information using the Discogs API.
* role
A string indicating the role of this artist.
* tracks
A string indicating the tracks on which the artist participated.
## Discogs::API::CatalogEntry
An object that describes entities in the Discogs database that are also referred to as `Label`s. Usually created indirectly by other objects.
* catno
A string with the identifying catalog number.
* entity-type
An unsigned integer with a description of the type of this entity.
* entity-type-name
A string with the name of this entity.
* id
The numeric ID of this catalog entry.
* name
The name of this catalog entry.
* resource-url
The URL to fetch the full information of this catalog entry using the Discogs API.
## Discogs::API::Community
Usually obtained indirectly from the `community` method on the Discogs::API::Release object. These methods can also be called directly on the Discogs::API::Release object, as these are also provided as shortcuts.
* contributors
A list of Discogs::API::User objects of contributors to the community information of this release.
* data-quality
A string describing the quality of the data of this release.
* have
An integer indicating how many community members have this release.
* rating
A rational number indicating the rating the members of the community have given this release.
* status
The status of the information about this release in the community.
* submitter
The Discogs::API::User object for the submitter of this release.
* want
An integer indicating how many community members want to have this release.
## Discogs::API::CommunityReleaseRating
The rating of the Discogs community for a specific release.
* rating
A rational number indicating the rating.
* release-id
An unsigned integer for the ID of the release.
## Discogs::API::FilterFacet
An object usually created as part of the Discogs::API::MasterReleaseVersions object.
* allows-multiple-values
A Bool indicating whether more than one value is allowed in `values`.
* id
The ID.
* title
The title.
* values
A list of one or more values.
## Discogs::API::Filters
An object usually created as part of the Discogs::API::MasterReleaseVersions object.
* applied
A hash indicating which Discogs::API::FilterFacets have been applied.
* available
A hash of unsigned integer indicating how many entries are available.
## Discogs::API::Format
An object that describes the format of a release. Usually created by other objects.
* descriptions
A list of strings describing this format.
* name
The name of this format.
* qty
An unsigned integer indicating the number of copies that are available in this format in the Discogs Marketplace.
## Discogs::API::Identifier
A generic object created by other objects.
* type
A string indicating the type.
* value
A string indicating the value.
## Discogs::API::Image
An object describing an image in the Discogs database. Usually created by other objects.
* height
The height of the image in pixels.
* resource-url
The URL to access this image on the Discogs image website.
* type
String with the type for this image: either "primary" or "secondary".
* uri
The URL to access this image on the Discogs image website.
* uri150
The URL to access a 150x150 pixel version of the image on the Discogs image website.
* width
The width of the image in pixels.
## Discogs::API::Label
The `Label` object represents a label, company, recording studio, location, or other entity involved with Discogs::API::Artists and Discogs::API::Releases. Labels were recently expanded in scope to include things that aren't labels – the name is an artifact of this history.
* contact-info
A string with contact information for this label.
* data-quality
A string describing the quality of the data of this label.
* id
The ID of this label.
* images
A list of Discogs::API::Image objects for this label.
* name
A string with the name of this label.
* profile
A string with a profile about this label.
* releases-url
A URL to retrieve all the Discogs::API::Release objects associated with this label using the Discogs API.
* resource-url
The URL to obtain the information about this label using the Discogs API.
* sublabels
A list of Discogs::API::SubLabel objects describing subdivisions of this label.
* uri
A URL to see the information of this label on the Discogs website.
* urls
A list of URLs related to this label.
## Discogs::API::LabelRelease
This object is usually created as part of a Discogs::API::LabelReleases object.
* artist
A string with the name of the artist of this release.
* catno
A string with the catalog number of this release.
* format
A string with the format of this release.
* id
An unsigned integer for the ID of this release.
* resource-url
A URL to get the full release information of this release using the Discogs API.
* status
The status of the information about this release in the community.
* thumb
A URL for a thumbnail image for this release.
* title
A string for the title of this release.
* year
An unsigned integer indicating the year this release was released.
## Discogs::API::LabelReleases
Retrieves a list of all Discogs::API::LabelRelease objects that are versions of a given master release ID, and pagination settings.
* first-page
Returns the first page of the information of this object, or `Nil` if already on the first page.
* first-page-url
The URL to fetch the data of the **first** page of this object using the Discogs API. Returns `Nil` if the there is only one page of information available.
* items
An integer indicating the total number of Discogs::API::LabelRelease objects there are available for label.
* last-page
Returns the last page of the information of this object, or `Nil` if already on the last page.
* last-page-url
The URL to fetch the data of the **last** page of this object using the Discogs API. Returns `Nil` if already on the last page.
* next-page
Returns the next page of the information of this object, or `Nil` if already on the last page.
* next-page-url
The URL to fetch the data of the **next** page of this object using the Discogs API. Returns `Nil` if already on the last page.
* page
An integer indicating the page number of this object.
* pages
An integer indicating the number of pages of information available for this object.
* pagination
The Discogs::API::Pagination object associted with this object. Usually not needed, as its information is available in shortcut methods.
* per-page
An integer representing the maximum number of items on a page.
* previous-page
Returns the previous page of the information of this object, or `Nil` if already on the first page.
* previous-page-url
The URL to fetch the data of the **previous** page of this object using the Discogs API. Returns `Nil` if already on the first page.
* releases
A list of Discogs::API::LabelRelease objects.
## Discogs::API::MasterRelease
The MasterRelease object represents a set of similar Discogs::API::Releases. Master releases have a "main release" which is often the chronologically earliest.
* artists
A list of Discogs::API::ArtistSummary objects for this master release.
* data-quality
A string describing the quality of the data of this master release.
* fetch-main-release
Fetch the main Discogs::API::Release of this main release using the Discogs API.
* fetch-most-recent-release
Fetch the most recent Discogs::API::Release of this main release using the Discogs API.
* genres
A list of strings describing the genres of this master release.
* id
The ID of this master release.
* images
A list if Discogs::API::Image objects associated with this master release.
* lowest-price
The lowest price seen for any of the releases of this master release on the Discogs Marketplace, in the currency that was (implicitely) specified when the Discogs::API object was made.
* main-release
The ID of the Discogs::API::Release object that is considered to be the main release.
* main-release-url
The URL to access the data of the main release using the Discogs API.
* most-recent-release
The ID of the Discogs::API::Release object that is considered to be the most recent release.
* most-recent-release-url
The URL to access the data of the most recent release using the Discogs API.
* num-for-sale
An integer indicating the number of copies of any release of this main release, that are for sale on the Discogs Marketplace.
* resource-url
The URL to obtain the information about this master release using the Discogs API.
* styles
A list of strings describing the styles of this master release.
* title
A string with the title of this master release.
* tracklist
A list of Discogs::API::Track objects describing the tracks of this master release.
* uri
A URL to see the information of this master release on the Discogs website.
* versions-url
A URL to fetch the Discogs::API::MasterReleaseVersion objects for this master release using the Discogs API.
* videos
A list of Discogs::API::Video objects associated with this master release.
* year
An integer for the year in which this master release was released.
## Discogs::API::MasterReleaseVersion
This object is usually created as part of the Discogs::API::MasterReleaseVersions object.
* catno
The catalog number of the associated Discogs::API::CatalogEntry object.
* community-in-collection
An unsigned integer indicating the number of people in the Discogs community that have this release.
* community-in-wantlist
An unsigned integer indicating the number of people in the Discogs community that want to have this release.
* country
A string indicating the country of this release.
* format
A string indicating the format of this release.
* id
The ID of this release.
* label
The ID of the associated `Discogs::API::Label` object.
* major-formats
A string indicating the major formats in which this release is available.
* released
An unsigned integer indicating the year that this release was released.
* resource-url
The URL to obtain the information about this release using the Discogs API.
* stats
An Discogs::API::Stats object with user and community statistics. It is probably easier to use the short-cut methods `community-in-collection`, `community-in-wantlist`, `user-in-collection`, `user-in-wantlist`.
* status
A string indicating the status of the information about this release.
* thumb
A URL for a thumbnail image associated with this release.
* title
A string with the title of this release.
* user-in-collection
An unsigned integer indicating whether the current user has this release.
* user-in-wantlist
An unsigned integer indicating whether the current user wants to have this release.
## Discogs::API::MasterReleaseVersions
Retrieves a list of all Discogs::API::MasterReleaseVersion objects that are versions of a given master release ID, and pagination settings.
* filter-facets
A list of Discogs::API::FilterFacet objects associated with this object.
* filters
A list of Discogs::API::Filter objects associated with this object.
* first-page
Returns the first page of the information of this object, or `Nil` if already on the first page.
* first-page-url
The URL to fetch the data of the **first** page of this object using the Discogs API. Returns `Nil` if the there is only one page of information available.
* items
An integer indicating the total number of Discogs::API::MasterReleaseVersion objects there are available for this master release.
* last-page
Returns the last page of the information of this object, or `Nil` if already on the last page.
* last-page-url
The URL to fetch the data of the **last** page of this object using the Discogs API. Returns `Nil` if already on the last page.
* next-page
Returns the next page of the information of this object, or `Nil` if already on the last page.
* next-page-url
The URL to fetch the data of the **next** page of this object using the Discogs API. Returns `Nil` if already on the last page.
* page
An integer indicating the page number of this object.
* pages
An integer indicating the number of pages of information available for this object.
* pagination
The Discogs::API::Pagination object associted with this object. Usually not needed, as its information is available in shortcut methods.
* per-page
An integer representing the maximum number of items on a page.
* previous-page
Returns the previous page of the information of this object, or `Nil` if already on the first page.
* previous-page-url
The URL to fetch the data of the **previous** page of this object using the Discogs API. Returns `Nil` if already on the first page.
* versions
A list of Discogs::API::MasterReleaseVersion objects.
## Discogs::API::Member
* active
A Boolean indicating whether this member is still active with the Discogs::API::Artist it is associated with.
* id
The ID of this member as a separate Discogs::API::Artist.
* name
The name of this member.
* resource-url
The URL to fetch Discogs::API::Artist object of this member using the Discogs API.
## Discogs::API::Pagination
This object is usually created as part of some kind of search result that allows for pagination.
* items
An integer with the number of items in this page.
* page
An integer with the page number of the information of this page.
* pages
An integer with the total number of pages available with the current `per-page` value.
* per-page
An integer with the maximum number of items per page.
* urls
A hash of URLs for moving between pages. Usually accessed with shortcut methods of the object incorporating this `Pagination` object.
## Discogs::API::Rating
A rating, usually automatically created with a Discogs::API::Community object.
* average
A rational value indicating the average rating of the object associated with the associated Discogs::API::Community object.
* count
An integer value indicating the number of votes cast by community members.
## Discogs::API::Release
The `Discogs::API::Release` object represents a particular physical or digital object released by one or more Discogs::API::Artists.
* artists
A list of Discogs::API::ArtistSummary objects for this release.
* average
A rational value indicating the average rating of this release by community members.
* artists-sort
A string with the artists, sorted.
* community
The Discogs::API::Community object with all of the Discogs community information associated with this release.
* companies
A list of Discogs::API::CatalogEntry objects of entities that had something to do with this release.
* contributors
A list of Discogs::API::User objects of contributors to the community information of this release.
* count
An integer value indicating the number of votes cast by community members about this release.
* country
A string with the country of origin of this release.
* data-quality
String indicating the quality of the data.
* date-added
A `Date` object of the date this release was added to the Discogs system.
* date-changed
A `Date` object of the date this release was last changed in the Discogs system.
* estimated-weight
An integer value to indicate the weight of this release compared to other release in the Discogs::API::MasterRelease.
* extraartists
A list of Discogs::API::ArtistSummary objects for additional artists in this release.
* fetch-master-release
Fetch the associated Discogs::API::MasterRelease object.
* format-quantity
An integer value for the number of formats available for this release.
* formats
A list of Discogs::API::Format objects that are available for this release.
* genres
A list of strings describing the genres of this release.
* have
An integer indicating how many community members have this release.
* id
The integer value that identifies this release.
* identifiers
A list of Discogs::API::Identifier objects for this release.
* images
A list of Discogs::API::Image objects for this release.
* labels
A list of Discogs::API::CatalogEntry objects that serve as a "label" for this release.
* lowest-price
A rational value indicating the lowest price if this release is available in the Discogs Marketplace in the currency that was (implicitely) specified when creating the Discogs::API object.
* master-id
The integer value of the Discogs::API::MasterRelease id of this release.
* master-url
The URL to fetch the master release of this release using the Discogs API.
* notes
A string with additional notes about this release.
* num-for-sale
An integer value indicating the number of copies for sale for this release on the Discogs Marketplace.
* rating
A rational number indicating the rating the members of the community have given this release.
* released
A string with a machine readable for of the date this release was released.
* released-formatted
A string with a human readable form of the date this release was released.
* resource-url
The URL to fetch this Discogs::API::Release object using the Discogs API.
* series
A list of Discogs::API::CatalogEntry objects of which this release is a part of.
* status
A string indicating the status of the information of this release.
* styles
A list of strings indicating the styles of this release.
* submitter
The Discogs::API::User object for the submitter of this release.
* thumb
A URL for a thumbnail image for this release.
* title
A string with the title of this release.
* tracklist
A list of Discogs::API::Track objects of this release.
* uri
The URL to access this release on the Discogs image website.
* videos
A list of Discogs::API::Video objects associated with this release.
* want
An integer indicating how many community members want to have this release.
* year
An integer value of the year this release was released.
## Discogs::API::SearchResult
This object is usually created as part of a Discogs::API::SearchResults object.
* cover\_image
A URL with an image describing this search result.
* id
An unsigned integer for the ID associated with a release.
* master-id
An unsigned integer for the ID associated with a master release.
* master-url
A URL to fetch the information of the associated master release using the Discogs API.
* resource-url
A URL to fetch the full information for this entry using the Discogs API.
* thumb
A URL for a thumbail image for this entry.
* title
A string with the title associated for this entry.
* type
A string indicating the type of entry. Can be any of:
```
release master artist label
```
* uri
A URI to fetch the full information for this release on the Discogs website.
* user-data
A Discogs::API::StatsData object with data. It's probably easier to use the `user-in-collection` and `user-in-wantlist` methods.
* user-in-collection
An unsigned integer indicating whether the current user
|
## dist_zef-lizmat-Discogs-API.md
## Chunk 2 of 2
has this entry.
* user-in-wantlist
An unsigned integer indicating whether the current user wants to have this entry.
## Discogs::API::SearchResults
Retrieves a list of Discogs::API::Searchresult objects that match the given query parameters, and pagination settings.
* first-page
Returns the first page of the information of this object, or `Nil` if already on the first page.
* first-page-url
The URL to fetch the data of the **first** page of this object using the Discogs API. Returns `Nil` if the there is only one page of information available.
* items
An integer indicating the total number of Discogs::API::SearchResult objects there are available.
* last-page
Returns the last page of the information of this object, or `Nil` if already on the last page.
* last-page-url
The URL to fetch the data of the **last** page of this object using the Discogs API. Returns `Nil` if already on the last page.
* next-page
Returns the next page of the information of this object, or `Nil` if already on the last page.
* next-page-url
The URL to fetch the data of the **next** page of this object using the Discogs API. Returns `Nil` if already on the last page.
* page
An integer indicating the page number of this object.
* pages
An integer indicating the number of pages of information available for this object.
* pagination
The Discogs::API::Pagination object associted with this object. Usually not needed, as its information is available in shortcut methods.
* per-page
An integer representing the maximum number of items on a page.
* previous-page
Returns the previous page of the information of this object, or `Nil` if already on the first page.
* previous-page-url
The URL to fetch the data of the **previous** page of this object using the Discogs API. Returns `Nil` if already on the first page.
* results
A list of Discogs::API::SearchResult objects.
## Discogs::API::Stats
This object is usually created as part of the Discogs::API::MasterReleaseVersion object.
* user
The Discogs::API::StatsData object with statistics of the current user.
* user
The Discogs::API::StatsData object with statistics of the Discogs community.
## Discogs::API::StatsData
This object is usually created as part of the Discogs::API::Stats object.
* in-collection
An unsigned integer indicating how many people in the Discogs community have the associated Discogs::API::MasterReleaseVersion in their collection.
* in-wantlist
An unsigned integer indicating how many people in the Discogs community have the associated Discogs::API::MasterReleaseVersion in their want list.
## Discogs::API::SubLabel
This object is usually created as part of the Discogs::API::Label object.
* id
The ID of this sublabel.
* name
A string with the name of this sublabel.
* resource-url
The URL to get the full Discogs::API::Label information of this `SubLabel` using the Discogs API.
## Discogs::API::Track
The information about a track on a release, usually created automatically as part of a Discogs::API::Release object.
* duration
A string indicating the duration of this track, usually as "mm:ss".
* position
A string indication the position of this track, "A" side or "B" side.
* title
A string containing the title of this track.
* type
A string to indicate the type of track, usually "track".
## Discogs::API::User
This object is usually created as part of other `Discogs::API` objects.
* resource-url
The URL to get the full Discogs::API::User information of this user using the Discogs API.
* username
The string with which the Discogs user is identified.
## Discogs::API::UserReleaseRating
Provide the rating a user has given a release.
* rating
An unsigned integerr with the rating by this user for a release.
* release
An unsigned integer for the release ID.
* username
A string for the username.
## Discogs::API::Value
An object usually created as part of the Discogs::API::FilterFacet object.
* count
An integer indicating an amount.
* title
A string for the title of this object.
* value
A string indicating the value of this object.
## Discogs::API::Video
The information about a video, usually created automatically as part of a Discogs::API::Release object.
* description
A string containing the description of this `Video` object.
* duration
A string indicating the duration of the video, usually as "mm:ss".
* embed
A Bool indicating whether this video can be embedded.
* title
A string containing the title (usually "artist - title") of this `Video` object.
* uri
The URL of the video, usually a link to a YouTube video.
# AUTHOR
Elizabeth Mattijsen [liz@raku.rocks](mailto:liz@raku.rocks)
Source can be located at: <https://github.com/lizmat/Discogs-API> . Comments and Pull Requests are welcome.
If you like this module, or what I'm doing more generally, committing to a [small sponsorship](https://github.com/sponsors/lizmat/) would mean a great deal to me!
# COPYRIGHT AND LICENSE
Copyright 2020, 2021, 2024 Elizabeth Mattijsen
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_zef-jonathanstowe-Test-META.md
# Test::META
Test that a Raku project has a good and proper META file.
[](https://github.com/jonathanstowe/Test-META/actions/workflows/main.yml)
## Synopsis
This is the actual `t/030-my-meta.t` from this distribution
```
#!raku
use v6;
use lib 'lib';
use Test;
use Test::META;
plan 1;
# That's it
meta-ok();
done-testing;
```
However, you may want to make this test conditional, only run by the
author (e.g. by checking the `AUTHOR_TESTING` environment variable). Also,
regular users of your module will not need Test::META on their system):
```
use v6;
use lib 'lib';
use Test;
plan 1;
constant AUTHOR = ?%*ENV<AUTHOR_TESTING>;
if AUTHOR {
require Test::META <&meta-ok>;
meta-ok;
done-testing;
}
else {
skip-rest "Skipping author test";
exit;
}
```
If you are running under Travis CI you can set the right environment
variable in the YAML. One way to do this is like this:
```
script:
- AUTHOR_TESTING=1 prove -v -e "raku -Ilib"
```
Other continuous integration systems will have a similar facility.
## Description
This provides a simple mechanism for module authors to have some
confidence that they have a working distribution META description
file (as described in [S22](http://design.raku.org/S22.html#META6.json)).
It exports one subroutine `meta-ok` that runs a single sub-test that
checks that:
* The META file (either META6.json or META.info) exists
* That the META file can be parsed as valid JSON
* That the attributes marked as "mandatory" are present
* That the files mentioned in the "provides" section are present.
There are mechanisms that are used internally for testing to override the
location or name of the META file. These can be seen in the test suite
though they are not typically needed.
## Installation
You can install directly with "zef":
```
# Remote installation
$ zef install Test::META
# From the source directory
$ zef install .
```
## Support
Suggestions/patches are welcomed via github at:
<https://github.com/jonathanstowe/Test-META>
If you can think of further tests that could be made, please send a
patch. Bear in mind that the tests for the structure of the META file
and particularly the required fields rely on the implementation of the
module [META6](https://github.com/jonathanstowe/META6) and you may want
to consider changing that instead.
## Licence
This is free software.
Please see the <LICENCE> for the details.
© Jonathan Stowe 2015 - 2021
|
## dist_zef-lizmat-Today.md
[](https://github.com/lizmat/Today/actions) [](https://github.com/lizmat/Today/actions) [](https://github.com/lizmat/Today/actions)
# NAME
Today - provide a 'today' term
# SYNOPSIS
```
use Today;
say today; # 2024-06-25
```
# DESCRIPTION
Raku provides a `now` term to get an `Instant` object of the current time. Oddly enough, an associated `today` term is absent. This module provides that. Should future versions of Raku provide that term out of the box, then using this module will become a no-op.
# AUTHOR
Elizabeth Mattijsen [liz@raku.rocks](mailto:liz@raku.rocks)
Source can be located at: <https://github.com/lizmat/Today> . Comments and Pull Requests are welcome.
If you like this module, or what I’m doing more generally, committing to a [small sponsorship](https://github.com/sponsors/lizmat/) would mean a great deal to me!
# COPYRIGHT AND LICENSE
Copyright 2020, 2021, 2025 Elizabeth Mattijsen
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_zef-antononcube-DSL-Entity-WeatherData.md
# Raku DSL::Entity::WeatherData
Raku grammar classes for weather data entities. (Variable- and station names.)
---
## Installation
From Zef ecosystem:
```
zef install DSL::Entity::WeatherData
```
From GitHub:
```
zef install https://github.com/antononcube/Raku-DSL-Entity-WeatherData.git
```
---
## Examples
Here are examples of recognizing different types of data acquisition related specifications:
```
use DSL::Entity::WeatherData;
use DSL::Entity::WeatherData::Grammar;
my $pCOMMAND = DSL::Entity::WeatherData::Grammar;
$pCOMMAND.set-resources(DSL::Entity::WeatherData::resource-access-object());
say $pCOMMAND.parse('MaxTemperature');
```
```
# 「MaxTemperature」
# weather-data-entity-command => 「MaxTemperature」
# entity-variable-name => 「MaxTemperature」
# 0 => 「MaxTemperature」
# entity-name-part => 「MaxTemperature」
```
```
say $pCOMMAND.parse('cloud cover fraction');
```
```
# 「cloud cover fraction」
# weather-data-entity-command => 「cloud cover fraction」
# entity-variable-name => 「cloud cover fraction」
# 0 => 「cloud cover fraction」
# entity-name-part => 「cloud」
# entity-name-part => 「cover」
# entity-name-part => 「fraction」
```
```
say $pCOMMAND.parse('KACQ');
```
```
# 「KACQ」
# weather-data-entity-command => 「KACQ」
# entity-station-name => 「KACQ」
# 0 => 「KACQ」
# entity-name-part => 「KACQ」
```
---
## References
### Datasets
[WRI1]
Wolfram Research (2007),
[WeatherData](https://reference.wolfram.com/language/ref/WeatherData.html),
(introduced 2007), (updated 2016),
Wolfram Language function.
[WRI2] Wolfram Research, Inc.,
[WeatherData Source Information](https://reference.wolfram.com/language/note/WeatherDataSourceInformation.html).
### Packages
[AAp1] Anton Antonov,
[DSL::Shared Raku package](https://github.com/antononcube/Raku-DSL-Shared),
(2020),
[GitHub/antononcube](https://github.com/antononcube).
[AAp2] Anton Antonov,
[DSL::Entity::Geographics Raku package](https://github.com/antononcube/Raku-DSL-Entity-Geographics),
(2021),
[GitHub/antononcube](https://github.com/antononcube).
[AAp3] Anton Antonov,
[DSL::Entity::Jobs Raku package](https://github.com/antononcube/Raku-DSL-Entity-Jobs),
(2021),
[GitHub/antononcube](https://github.com/antononcube).
[AAp4] Anton Antonov,
[DSL::Entity::Foods Raku package](https://github.com/antononcube/Raku-DSL-Entity-Foods),
(2021),
[GitHub/antononcube](https://github.com/antononcube).
[AAp5] Anton Antonov,
[Data::ExampleDatasets Raku package](https://github.com/antononcube/Raku-Data-ExampleDatasets),
(2021),
[GitHub/antononcube](https://github.com/antononcube).
|
## dist_zef-jonathanstowe-Crypt-AnyPasswordHash.md
# Crypt::AnyPasswordHash
Use best installed password encryption available

## Synopsis
```
use Crypt::AnyPasswordHash;
my $password = 'somepassword';
my Str $hash = hash-password($password);
if check-password($hash, $password ) {
# password ok
}
```
## Description
This module exports two subroutines `hash-password` and `check-password` which encrypt password and check a provided password against an encrypted hash.
The implementation for the `hash-password` is provided by the first of:
* [Crypt::SodiumPasswordHash](https://github.com/jonathanstowe/Crypt-SodiumPasswordHash)
* [Crypt::Argon2](https://github.com/skinkade/p6-crypt-argon2)
* [Crypt::LibScrypt](https://github.com/jonathanstowe/Crypt-LibScrypt)
* [Crypt::SodiumScrypt](https://github.com/jonathanstowe/Crypt-SodiumScrypt)
* [Crypt::Libcrypt](https://github.com/jonathanstowe/Crypt-Libcrypt)
which can be found. `Crypt::Libcrypt` will be installed as a dependency so it will nearly always work but is dependent on the mechanisms provided by the `libcrypt`: with a fairly recent `libcrypt` it will be able to determine and use the best available algorithm, falling back to attempt SHA-512, however if that isn't available it may fall back to DES which is not considered secure enough for production use. You can tell you are getting DES when the hash returned by `hash-password` is only 13 characters long, if this is the case then you should install one of the other providers.
The `check-password` will attempt to validate against all the available mechanisms until one validates the password or the mechanisms are exhausted. This is so that, if you are validating against stored hashes, if a new supported module is installed or this module is upgraded then you will still be able to verify against hashes made by a previous mechanism.
## Installation
If you have a working Rakudo installation, you should be able to install this with *zef* :
```
zef install Crypt::AnyPasswordHash
# or from a local copy
zef install .
```
## Support
If you have any suggestions or patches, please send then to [Github](https://github.com/jonathanstowe/Crypt-AnyPasswordHash/issues)
New hashing providers are welcomed - any new modules should export the subroutines for hashing and verifying.
[Crypt::Bcrypt](https://github.com/skinkade/p6-Crypt-Bcrypt) does work but it needs a small change to be detected.
## Licence
This is free software.
Please see the <LICENCE> file in the distribution
© Jonathan Stowe 2019 - 2021
|
## dist_zef-vushu-FEN-Grammar.md
## Forsyth–Edwards Notation (FEN) Grammar
[](https://ci.sparrowhub.io)
### Parsing FEN
```
use FEN::Grammar;
my $fen = 'rnbqkbnr/pppppppp/8/8/4P3/8/PPPP1PPP/RNBQKBNR b KQkq e3 0 1';
my $match = FEN::Grammar.parse($fen);
```
State is optional, if given fen positions only it will still parse.
```
use FEN::Grammar;
my $fen = 'r1bk3r/p2pBpNp/n4n2/1p1NP2P/6P1/3P4/P1P1K3/q5b1'; # We only supply the positions.
my $match = FEN::Grammar.parse($fen);
```
### Using FEN::Actions
We can create an array of ranks describing the position.
```
use FEN::Grammar;
use FEN::Actions;
my $actions = FEN::Actions.new;
my $match = FEN::Grammar.parse($fen, actions => $actions);
my $result = $match.made; # returns a FEN::Result
```
### Transform to ASCII matrix
For easy usage or rendering we can use FEN::Utils.
```
use FEN::Utils;
# $result generated by FEN::Actions
my @matrix = FEN::Utils::to-matrix($result.ranks);
# display
sink @matrix.map: *.say;
[r . b k . . . r]
[p . . p B p N p]
[n . . . . n . .]
[. p . N P . . P]
[. . . . . . P .]
[. . . P . . . .]
[P . P . K . . .]
[q . . . . . b .]
```
### Tranform to unicoded matrix
```
use FEN::Utils;
my @matrix = FEN::Utils::to-unicoded-matrix($result.ranks);
# display
sink @matrix.map: *.say;
[♜ . ♝ ♚ . . . ♜]
[♟ . . ♟ ♗ ♟ ♘ ♟]
[♞ . . . . ♞ . .]
[. ♟ . ♘ ♙ . . ♙]
[. . . . . . ♙ .]
[. . . ♙ . . . .]
[♙ . ♙ . ♔ . . .]
[♛ . . . . . ♝ .]
```
### From ASCII matrix back to FEN
```
my $ascii-matrix = q:to/ASCII/;
[r . b k . . . r]
[p . . p B p N p]
[n . . . . n . .]
[. p . N P . . P]
[. . . . . . P .]
[. . . P . . . .]
[P . P . K . . .]
[q . . . . . b .]
ASCII
my $fen = FEN::Utils::ascii-to-fen($ascii-matrix);
say $fen;
r1bk3r/p2pBpNp/n4n2/1p1NP2P/6P1/3P4/P1P1K3/q5b1
```
### Display state
```
# state for given fen:rnbqkbnr/pppppppp/8/8/4P3/8/PPPP1PPP/RNBQKBNR b KQkq e3 0 1
$result.show-state;
Active color: Black
White may castle on: kingside, queenside
Black may castle on: kingside, queenside
En-passant: e3
Halfmove clock: 0
Fullmove number: 1
```
### Position set
get positions as hash set from FEN::Result
```
say $result.position-set;
{a 1 => R, a 2 => P, a 3 => , a 4 => , a 5 => , a 6 => , a 7 => p, a 8 => r, b 1 => N, b 2 => P, b 3 => , b 4 => , b 5 => , b 6 => , b 7 => p, b 8 => n, c 1 => B, c 2 => P, c 3 => , c 4 => , c 5 => , c 6 => , c 7 => p, c 8 => b, d 1 => Q, d 2 => P, d 3 => , d 4 => , d 5 => , d 6 => , d 7 => p, d 8 => q, e 1 => K, e 2 => , e 3 => , e 4 => P, e 5 => , e 6 => , e 7 => p, e 8 => k, f 1 => B, f 2 => P, f 3 => , f 4 => , f 5 => , f 6 => , f 7 => p, f 8 => b, g 1 => N, g 2 => P, g 3 => , g 4 => , g 5 => , g 6 => , g 7 => p, g 8 => n, h 1 => R, h 2 => P, h 3 => , h 4 => , h 5 => , h 6 => , h 7 => p, h 8 => r}
```
### Generalized FEN
To parse a board of size NxN use GFEN::Grammar.
Naturally this doesn't support parsing the state, since it's not traditional chess.
```
my $dimension = 27; # Dimension of a 27x27 board
my $fen-like = '5/11/5/3k1/12R5K/16K/22r///p3p15p';
# Remember to pass dimension of the board
my $actions = FEN::Actions.new(dimension => $dimension);
my $match = GFEN::Grammar.parse($fen-like, actions => $actions);
my $result = $match.made;
# Print it using the Utils
FEN::Utils::to-unicoded-matrix($result.ranks, $dimension).map: *.say;
```
outputs:
```
[. . . . . . . . . . . . . . . . . . . . . . . . . . .]
[. . . . . . . . . . . . . . . . . . . . . . . . . . .]
[. . . . . . . . . . . . . . . . . . . . . . . . . . .]
[. . . ♚ . . . . . . . . . . . . . . . . . . . . . . .]
[. . . . . . . . . . . . ♖ . . . . . ♔ . . . . . . . .]
[. . . . . . . . . . . . . . . . ♔ . . . . . . . . . .]
[. . . . . . . . . . . . . . . . . . . . . . ♜ . . . .]
[. . . . . . . . . . . . . . . . . . . . . . . . . . .]
[. . . . . . . . . . . . . . . . . . . . . . . . . . .]
[♟ . . . ♟ . . . . . . . . . . . . . . . ♟ . . . . . .]
[. . . . . . . . . . . . . . . . . . . . . . . . . . .]
[. . . . . . . . . . . . . . . . . . . . . . . . . . .]
[. . . . . . . . . . . . . . . . . . . . . . . . . . .]
[. . . . . . . . . . . . . . . . . . . . . . . . . . .]
[. . . . . . . . . . . . . . . . . . . . . . . . . . .]
[. . . . . . . . . . . . . . . . . . . . . . . . . . .]
[. . . . . . . . . . . . . . . . . . . . . . . . . . .]
[. . . . . . . . . . . . . . . . . . . . . . . . . . .]
[. . . . . . . . . . . . . . . . . . . . . . . . . . .]
[. . . . . . . . . . . . . . . . . . . . . . . . . . .]
[. . . . . . . . . . . . . . . . . . . . . . . . . . .]
[. . . . . . . . . . . . . . . . . . . . . . . . . . .]
[. . . . . . . . . . . . . . . . . . . . . . . . . . .]
[. . . . . . . . . . . . . . . . . . . . . . . . . . .]
[. . . . . . . . . . . . . . . . . . . . . . . . . . .]
[. . . . . . . . . . . . . . . . . . . . . . . . . . .]
[. . . . . . . . . . . . . . . . . . . . . . . . . . .]
```
|
## dist_cpan-JNTHN-Concurrent-Trie.md
# Concurrent::Trie
A lock-free trie (Text Retrieval) data structure, safe for concurrent use.
## Synopsis
```
use Concurrent::Trie;
my $trie = Concurrent::Trie.new;
say $trie.contains('brie'); # False
say so $trie; # False
say $trie.elems; # 0
$trie.insert('brie');
say $trie.contains('brie'); # True
say so $trie; # True
say $trie.elems; # 1
$trie.insert('babybel');
$trie.insert('gorgonzola');
say $trie.elems; # 3
say $trie.entries(); # (gorgonzola babybel brie)
say $trie.entries('b'); # (babybel brie)
```
## Overview
A trie stores strings as a tree, with each level in the tree representing a
character in the string (so the tree's maximum depth is equal to the number
of characters in the longest entry). A trie is especially useful for prefix
searches, where all entries with a given prefix are required, since this is
obtained simply by walking the tree according to the prefix, and then visiting
all nodes below that point to find entries.
This is a lock-free trie. Checking if the trie contains a particular string
never blocks. Iterating the entries never blocks either, and will provide a
snapshot of all the entries at the time the `entries` method was called. An
insertion uses optimistic concurrency control, building an updated tree and
then trying to commit it. This offers a global progress bound: if one thread
fails to insert, it's because another thread did a successful insert.
This data structure is well suited to auto-complete style features in
concurrent applications, where new entries and lookups may occur when, for
example, processing web requests in parallel.
## Methods
### insert(Str $value --> Nil)
Inserts the passed string value into the trie.
### contains(Str $value --> Bool)
Checks if the passed string value is in the trie. Returns `True` if so, and
`False` otherwise.
### entries($prefix = '' --> Seq)
Returns a lazy iterator of all entries in the trie with the specified prefix.
If no prefix is passed, the default is the empty prefix, meaning that a call
like `$trie.entries()` will iterate all entries in the trie. The order of the
results is not defined.
The results will be a snapshot of what was in the trie at the point `entries`
was called; additions after that point will not be in the `entries` list.
### elems(--> Int)
Gets the number of entries in the trie. The data structure maintains a count,
making this O(1) (as opposed to `$trie.entries.elems`, which would be O(n)).
### Bool()
Returns `True` if the number of entries in the trie is non-zero, and `False`
otherwise.
|
## dist_zef-lizmat-List-MoreUtils.md
## Chunk 1 of 2
[](https://github.com/lizmat/List-MoreUtils/actions)
# NAME
Raku port of Perl's List::MoreUtils module 0.430
# SYNOPSIS
```
# import specific functions
use List::MoreUtils <any uniq>;
if any { /foo/ }, uniq @has_duplicates {
# do stuff
}
# import everything
use List::MoreUtils ':all';
```
# DESCRIPTION
This module tries to mimic the behaviour of Perl's `List::MoreUtils` module as closely as possible in the Raku Programming Language.
List::MoreUtils provides some trivial but commonly needed functionality on lists which is not going to go into `List::Util`.
# EXPORTS
Nothing by default. To import all of this module's symbols use the `:all` tag. Otherwise functions can be imported by name as usual:
```
use List::MoreUtils :all;
use List::MoreUtils <any firstidx>;
```
# Porting Caveats
Raku does not have the concept of `scalar` and `list` context. Usually, the effect of a scalar context can be achieved by prefixing `+` to the result, which would effectively return the number of elements in the result, which usually is the same as the scalar context of Perl of these functions.
Raku does not have a magic `$a` and `$b`. But they can be made to exist by specifying the correct signature to blocks, specifically "-> $a, $b". These have been used in all examples that needed them. Just using the signature auto-generating `$^a` and `$^b` would be more Raku like. But since we want to keep the documentation as close to the original as possible, it was decided to specifically specify the "-> $a, $b" signatures.
Many functions take a `&code` parameter of a `Block` to be called by the function. Many of these assume **$\_** will be set. In Raku, this happens automagically if you create a block without a definite or implicit signature:
```
say { $_ == 4 }.signature; # (;; $_? is raw)
```
which indicates the Block takes an optional parameter that will be aliased as `$_` inside the Block.
Raku also doesn't have a single `undef` value, but instead has `Type Objects`, which could be considered undef values, but with a type annotation. In this module, `Nil` (a special value denoting the absence of a value where there should have been one) is used instead of `undef`.
Also note there are no special parsing rules with regards to blocks in Raku. So a comma is **always** required after having specified a block.
The following functions are actually built-ins in Raku.
```
any all none minmax uniq zip
```
They mostly provide the same or similar semantics, but there may be subtle differences, so it was decided to not just use the built-ins. If these functions are imported from this library in a scope, they will used instead of the Raku builtins. The easiest way to use both the functions of this library and the Raku builtins in the same scope, is to use the method syntax for the Raku versions.
```
my @a = 42,5,2,98792,88;
{ # Note: imports in Raku are always lexically scoped
use List::Util <minmax>;
say minmax @a; # Ported Perl version
say @a.minmax; # Raku version
}
say minmax @a; # Raku version again
```
Many functions returns either `True` or `False`. These are `Bool`ean objects in Raku, rather than just `0` or `1`. However, if you use a Boolean value in a numeric context, they are silently coerced to 0 and 1. So you can still use them in numeric calculations as if they are 0 and 1.
Some functions return something different in scalar context than in list context. Raku doesn't have those concepts. Functions that are supposed to return something different in scalar context also the `Scalar` type as the first positional parameter to indicate the result like the result of a scalar context, is required. It will be noted with the function in question if that feature is available.
# FUNCTIONS
## Junctions
### *Treatment of an empty list*
There are two schools of thought for how to evaluate a junction on an empty list:
* Reduction to an identity (boolean)
* Result is undefined (three-valued)
In the first case, the result of the junction applied to the empty list is determined by a mathematical reduction to an identity depending on whether the underlying comparison is "or" or "and". Conceptually:
```
"any are true" "all are true"
-------------- --------------
2 elements: A || B || 0 A && B && 1
1 element: A || 0 A && 1
0 elements: 0 1
```
In the second case, three-value logic is desired, in which a junction applied to an empty list returns `Nil` rather than `True` or `False`.
Junctions with a `_u` suffix implement three-valued logic. Those without are boolean.
### all BLOCK, LIST
### all\_u BLOCK, LIST
Returns True if all items in LIST meet the criterion given through BLOCK. Passes each element in LIST to the BLOCK in turn:
```
say "All values are non-negative"
if all { $_ >= 0 }, ($x, $y, $z);
```
For an empty LIST, `all` returns True (i.e. no values failed the condition) and `all_u` returns `Nil`.
Thus, `all_u(@list)` is equivalent to `@list ?? all(@list) !! Nil` .
**Note**: because Raku treats `Nil` as false, you must check the return value of `all_u` with `defined` or you will get the opposite result of what you expect.
#### Idiomatic Raku ways
```
say "All values are non-negative"
if $x & $y & $z >= 0;
say "All values are non-negative"
if all(@list) >= 0;
```
### any BLOCK, LIST
### any\_u BLOCK, LIST
Returns True if any item in LIST meets the criterion given through BLOCK. Passes each element in LIST to the BLOCK in turn:
```
say "At least one non-negative value"
if any { $_ >= 0 }, ($x, $y, $z);
```
For an empty LIST, `any` returns False and `any_u` returns `Nil`.
Thus, `any_u(@list)` is equivalent to `@list ?? any(@list) !! undef` .
#### Idiomatic Raku ways
```
say "At least one non-negative value"
if $x | $y | $z >= 0;
say "At least one non-negative value"
if any(@list) >= 0;
```
### none BLOCK, LIST
### none\_u BLOCK, LIST
Logically the negation of `any`. Returns True if no item in LIST meets the criterion given through BLOCK. Passes each element in LIST to the BLOCK in turn:
```
say "No non-negative values"
if none { $_ >= 0 }, ($x, $y, $z);
```
For an empty LIST, `none` returns True (i.e. no values failed the condition) and `none_u` returns `Nil`.
Thus, `none_u(@list)` is equivalent to `@list ?? none(@list) !! Nil` .
**Note**: because Raku treats `Nil` as false, you must check the return value of `none_u` with `defined` or you will get the opposite result of what you expect.
#### Idiomatic Raku ways
```
say "No non-negative values"
if none($x,$y,$z) >= 0;
say "No non-negative values"
if none(@list) >= 0;
```
### notall BLOCK, LIST
### notall\_u BLOCK, LIST
Logically the negation of `all`. Returns True if not all items in LIST meet the criterion given through BLOCK. Passes each element in LIST to the BLOCK in turn:
```
say "Not all values are non-negative"
if notall { $_ >= 0 }, ($x, $y, $z);
```
For an empty LIST, `notall` returns False and `notall_u` returns `Nil`.
Thus, `notall_u(@list)` is equivalent to `@list ?? notall(@list) !! Nil` .
#### Idiomatic Raku ways
```
say "Not all values are non-negative"
if not all($x,$y,$z) >= 0;
say "Not all values are non-negative"
if not all(@list) >= 0;
```
### one BLOCK, LIST
### one\_u BLOCK, LIST
Returns True if precisely one item in LIST meets the criterion given through BLOCK. Passes each element in LIST to the BLOCK in turn:
```
say "Precisely one value defined"
if one { defined($_) }, @list;
```
Returns False otherwise.
For an empty LIST, `one` returns False and `one_u` returns `Nil`.
The expression `one BLOCK, LIST` is almost equivalent to `1 == True BLOCK, LIST`, except for short-cutting. Evaluation of BLOCK will immediately stop at the second true value seen.
#### Idiomatic Raku ways
```
say "Precisely one value defined"
if ($x ^ $y ^ $z).defined;
say "Precisely one value defined"
if one(@list>>.defined);
```
## Transformation
### apply BLOCK, LIST
Applies BLOCK to each item in LIST and returns a list of the values after BLOCK has been applied. Returns the last element if `Scalar` has been specified. This function is similar to `map` but will not modify the elements of the input list:
```
my @list = 1 .. 4;
my @mult = apply { $_ *= 2 }, @list;
print "@list = @list[]\n";
print "@mult = @mult[]\n";
=====================================
@list = 1 2 3 4
@mult = 2 4 6 8
```
With the `Scalar` positional parameter:
```
my @list = 1 .. 4;
my $last = apply Scalar, { $_ *= 2 }, @list;
print "@list = @list[]\n";
print "\$last = $last\n";
=====================================
@list = 1 2 3 4
$last = 8
```
#### Idiomatic Raku ways
```
my @mult = @list.map: -> $_ is copy { $_ *= 2 };
my $last = @list.map( -> $_ is copy { $_ *= 2 }).tail;
```
### insert\_after BLOCK, VALUE, LIST
Inserts VALUE after the first item in LIST for which the criterion in BLOCK is true. Sets `$_` for each item in LIST in turn.
```
my @list = <This is a list>;
insert_after { $_ eq "a" }, "longer" => @list;
say "@list[]";
===================================
This is a longer list
```
### insert\_after\_string STRING, VALUE, LIST
Inserts VALUE after the first item in LIST which is equal to STRING.
```
my @list = <This is a list>;
insert_after_string "a", "longer" => @list;
say "@list[]";
===================================
This is a longer list
```
### pairwise BLOCK, ARRAY1, ARRAY2
Evaluates BLOCK for each pair of elements in ARRAY1 and ARRAY2 and returns a new list consisting of BLOCK's return values. The two elements are passed as parameters to BLOCK.
```
my @a = 1 .. 5;
my @b = 11 .. 15;
my @x = pairwise -> $a, $b { $a + $b }, @a, @b; # returns 12, 14, 16, 18, 20
# mesh with pairwise
my @a = <a b c>;
my @b = <1 2 3>;
my @x = pairwise -> $a, $b { $a, $b }, @a, @b; # returns a, 1, b, 2, c, 3
```
#### Idiomatic Raku ways
```
my @x = zip(@a,@b).map: -> ($a,$b) { $a + $b };
my @x = zip(@a,@b).flat;
```
### mesh ARRAY1, ARRAY2 [ , ARRAY3 ... ]
### zip ARRAY1, ARRAY2 [ , ARRAY3 ... ]
Returns a list consisting of the first elements of each array, then the second, then the third, etc, until all arrays are exhausted.
Examples:
```
my @x = <a b c d>;
my @y = <1 2 3 4>;
my @z = mesh @x, @y; # returns a, 1, b, 2, c, 3, d, 4
my Str @a = 'x';
my Int @b = 1, 2;
my @c = <zip zap zot>;
my @d = mesh @a, @b, @c; # x, 1, zip, Str, 2, zap, Str, Int, zot
```
`zip` is an alias for `mesh`.
#### Idiomatic Raku ways
```
my @x = zip(@a,@b).flat;
my @x = zip(@a,@b,@c).flat;
```
### zip6 ARRAY1, ARRAY2 [ , ARRAY3 ... ]
### zip\_unflatten ARRAY1, ARRAY2 [ , ARRAY3 ... ]
Returns a list of arrays consisting of the first elements of each array, then the second, then the third, etc, until all arrays are exhausted.
```
my @x = <a b c d>;
my @y = <1 2 3 4>;
my @z = zip6 @x, @y; # returns [a, 1], [b, 2], [c, 3], [d, 4]
my Str @a = 'x';
my Int @b = 1, 2;
my @c = <zip zap zot>;
my @d = zip6 @a, @b, @c; # [x, 1, zip], [Str, 2, zap], [Str, Int, zot]
```
`zip_unflatten` is an alias for `zip6`.
#### Idiomatic Raku ways
```
my @x = zip(@a,@b);
my @x = zip(@a,@b,@c);
```
### listcmp ARRAY0 ARRAY1 [ ARRAY2 ... ]
Returns an associative list of elements and every *id* of the list it was found in. Allows easy implementation of @a & @b, @a | @b, @a ^ @b and so on. Undefined entries in any given array are skipped.
```
my @a = <one two four five six seven eight nine ten>;
my @b = <two five seven eleven thirteen seventeen>;
my @c = <one one two five eight thirteen twentyone>;
my %cmp := listcmp @a, @b, @c;
# (one => [0, 2], two => [0, 1, 2], four => [0], ...)
my @seq = 1, 2, 3;
my @prim = Int, 2, 3, 5;
my @fib = 1, 1, 2;
my $cmp = listcmp @seq, @prim, @fib;
# { 1 => [0, 2], 2 => [0, 1, 2], 3 => [0, 1], 5 => [1] }
```
#### Idiomatic Raku ways
```
my @x = zip(@a,@b);
my @x = zip(@a,@b,@c);
```
### arrayify LIST [,LIST [,LIST...]]
Returns a list costisting of each element of the given arrays. Recursive arrays are flattened, too.
```
my @a = 1, [[2], 3], 4, [5], 6, [7], 8, 9;
my @l = arrayify @a; # returns 1, 2, 3, 4, 5, 6, 7, 8, 9
```
### uniq LIST
### distinct LIST
Returns a new list by stripping duplicate values in LIST by comparing the values as hash keys, except that type objects are considered separate from ''. The order of elements in the returned list is the same as in LIST. Returns the number of unique elements in LIST if the `Scalar` positional parameter has been specified.
```
my @x = uniq (1, 1, 2, 2, 3, 5, 3, 4); # returns (1,2,3,5,4)
my $x = uniq Scalar, (1, 1, 2, 2, 3, 5, 3, 4); # returns 5
my @n = distinct "Mike", "Michael", "Richard", "Rick", "Michael", "Rick"
# ("Mike", "Michael", "Richard", "Rick")
my @s = distinct "A8", "", Str, "A5", "S1", "A5", "A8"
# ("A8", "", Str, "A5", "S1")
my @w = uniq "Giulia", "Giulietta", Str, "", 156, "Giulietta", "Giulia";
# ("Giulia", "Giulietta", Str, "", 156)
```
`distinct` is an alias for `uniq`.
#### Idiomatic Raku ways
```
my @x = (1, 1, 2, 2, 3, 5, 3, 4).unique;
my $x = (1, 1, 2, 2, 3, 5, 3, 4).unique.elems;
```
### singleton LIST
Returns a new list by stripping values in LIST occurring only once by comparing the values as hash keys, except that type objects are considered separate from ''. The order of elements in the returned list is the same as in LIST. Returns the number of elements occurring only once in LIST if the `Scalar` positional parameter has been specified.
```
my @x = singleton (1,1,4,2,2,3,3,5); # returns (4,5)
my $n = singleton Scalar, (1,1,4,2,2,3,3,5); # returns 2
```
### duplicates LIST
Returns a new list by stripping values in LIST occuring more than once by comparing the values as hash keys, except that type objects are considered separate from ''. The order of elements in the returned list is the same as in LIST. Returns the number of elements occurring more than once in LIST.
```
my @y = duplicates (1,1,2,4,7,2,3,4,6,9); # returns (1,2,4)
my $n = duplicates Scalar, (1,1,2,4,7,2,3,4,6,9); # returns 3
```
#### Idiomatic Raku ways
```
my @y = (1,1,2,4,7,2,3,4,6,9).repeated;
my $n = (1,1,2,4,7,2,3,4,6,9).repeated.elems;
```
### frequency LIST
Returns a hash of distinct values and the corresponding frequency.
```
my %f := frequency values %radio_nrw; # returns (
# 'Deutschlandfunk (DLF)' => 9, 'WDR 3' => 10,
# 'WDR 4' => 11, 'WDR 5' => 14, 'WDR Eins Live' => 14,
# 'Deutschlandradio Kultur' => 8,...)
```
#### Idiomatic Raku ways
```
my %f := %radio_nrw.values.Bag;
```
### occurrences LIST
Returns a new list of frequencies and the corresponding values from LIST.
```
my @o = occurrences (1 xx 3, 2 xx 4, 3 xx 2, 4 xx 7, 5 xx 2, 6 xx 4);
# (Any, Any, [3, 5], [1], [2, 6], Any, Any, [4])
```
### mode LIST
Returns the modal value of LIST. Returns the modal value only if the `Scalar` positional parameter is specified. Otherwise all probes occuring *modal* times are returned as well.
```
my @m = mode (1 xx 3, 2 xx 4, 3 xx 2, 4 xx 7, 5 xx 2, 6 xx 7);
# (7, 4, 6)
my $mode = mode Scalar, (1 xx 3, 2 xx 4, 3 xx 2, 4 xx 7, 5 xx 2, 6 xx 7);
# 7
```
## Partitioning
### after BLOCK, LIST
Returns a list of the values of LIST after (and not including) the point where BLOCK returns a true value. Passes the value as a parameter to BLOCK for each element in LIST in turn.
```
my @x = after { $_ %% 5 }, (1..9); # returns (6, 7, 8, 9)
```
### after\_incl BLOCK, LIST
Same as `after` but also includes the element for which BLOCK is true.
```
my @x = after_incl { $_ %% 5 }, (1..9); # returns (5, 6, 7, 8, 9)
```
#### Idiomatic Raku ways
```
my @x = (1..9).toggle: * %% 5, :off;
```
### before BLOCK, LIST
Returns a list of values of LIST up to (and not including) the point where BLOCK returns a true value. Passes the value as a parameter to BLOCK for each element in LIST in turn.
```
my @x = before { $_ %% 5 }, (1..9); # returns (1, 2, 3, 4)
```
#### Idiomatic Raku ways
```
my @x = (1..9).toggle: * %% 5;
```
### before\_incl BLOCK LIST
Same as `before` but also includes the element for which BLOCK is true.
```
my @x = before_incl { $_ %% 5 }, (1..9); # returns (1, 2, 3, 4, 5)
```
### part BLOCK, LIST
Partitions LIST based on the return value of BLOCK which denotes into which partition the current value is put.
Returns a list of the partitions thusly created. Each partition created is an Array.
```
my $i = 0;
my @part = part { $i++ % 2 } (1..8); # returns ([1, 3, 5, 7], [2, 4, 6, 8])
```
You can have a sparse list of partitions as well where non-set partitions will be an `Array` type object:
```
my @part = part { 2 } (1..5); # returns (Array, Array, [1,2,3,4,5])
```
Be careful with negative values, though:
```
my @part = part { -1 } (1..10);
===============================
Unsupported use of a negative -1 subscript to index from the end
```
Negative values are only ok when they refer to a partition previously created:
```
my @idx = 0, 1, -1;
my $i = 0;
my @part = part { $idx[$i++ % 3] }, (1..8); # ([1, 4, 7], [2, 3, 5, 6, 8])
```
### samples COUNT, LIST
Returns a new list containing COUNT random samples from LIST. Is similar to List::Util/shuffle, but stops after COUNT.
```
my @r = samples 10, (1..10); # same as (1..10).pick(*)
my @r2 = samples 5, (1..10); # same as (1..10).pick(5)
```
#### Idiomatic Raku ways
```
my @r = (1..10).pick(*);
my @r2 = (1..10).pick(5);
```
## Iteration
### each\_array ARRAY1, ARRAY2 ...
Creates an array iterator to return the elements of the list of arrays ARRAY1, ARRAY2 throughout ARRAYn in turn. That is, the first time it is called, it returns the first element of each array. The next time, it returns the second elements. And so on, until all elements are exhausted.
This is useful for looping over more than one array at once:
```
my &ea = each_array(@a, @b, @c);
while ea() -> ($a,$b,$c) { .... }
```
The iterator returns the empty list when it reached the end of all arrays.
If the iterator is passed an argument of '`index`', then it returns the index of the last fetched set of values, as a scalar.
#### Idiomatic Raku ways
```
while zip(@a,@b,@c) -> ($a,$b,$c) { .... }
```
### each\_arrayref LIST
Like each\_array, but the arguments is a single list with arrays.
### natatime EXPR, LIST
Creates an array iterator, for looping over an array in chunks of `$n` items at a time. (n at a time, get it?). An example is probably a better explanation than I could give in words.
Example:
```
my @x = 'a'..'g';
my &it = natatime 3, @x;
while it() -> @vals {
print "@vals[]\n";
}
```
This prints
```
a b c
d e f
g
```
#### Idiomatic Raku ways
```
for @x.rotor(3,:partial) -> @vals {
print "@vals[]\n";
}
```
## Searching
### firstval BLOCK, LIST
### first\_value BLOCK, LIST
Returns the first element in LIST for which BLOCK evaluates to true. Each element of LIST is passed to the BLOCK in turn. Returns `Nil` if no such element has been found.
```
my @list = <alpha beta cicero bearing effortless>;
say firstval { .starts-with('c') }, @list; # cicero
say firstval { .starts-with('b') }, @list; # beta
say firstval { .starts-with('g') }, @list; # Nil, because never
```
`first_value` is an alias for `firstval`.
#### Idiomatic Raku ways
```
say @list.first: *.starts-with('c');
say @list.first: *.starts-with('b');
say @list.first: *.starts-with('g');
```
### onlyval BLOCK, LIST
### only\_value BLOCK, LIST
Returns the only element in LIST for which BLOCK evaluates to true. Each element in LIST is passed to BLOCK in turn. Returns `Nil` if no such element has been found.
```
my @list = <alpha beta cicero bearing effortless>;
say onlyval { .starts-with('c') }, @list; # cicero
say onlyval { .starts-with('b') }, @list; # Nil, because twice
say onlyval { .starts-with('g') }, @list; # Nil, because never
```
`only_value` is an alias for `onlyval`.
### lastval BLOCK, LIST
### last\_value BLOCK, LIST
Returns the last value in LIST for which BLOCK evaluates to true. Each element in LIST is passed to BLOCK in turn. Returns `Nil` if no such element has been found.
```
my @list = <alpha beta cicero bearing effortless>;
say lastval { .starts-with('c') }, @list; # cicero
say lastval { .starts-with('b') }, @list; # bearing
say lastval { .starts-with('g') }, @list; # Nil, because never
```
`last_value` is an alias for `lastval`.
#### Idiomatic Raku ways
```
say @list.first: *.starts-with('c'), :end;
say @list.first: *.starts-with('b'), :end;
say @list.first: *.starts-with('g'), :end;
```
### firstres BLOCK, LIST
### first\_result BLOCK, LIST
Returns the result of BLOCK for the first element in LIST for which BLOCK evaluates to true. Each element of LIST is passed to BLOCK in turn. Returns `Nil` if no such element has been found.
```
my @list = <alpha beta cicero bearing effortless>;
say firstres { .uc if .starts-with('c') }, @list; # CICERO
say firstres { .uc if .starts-with('b') }, @list; # BETA
say firstres { .uc if .starts-with('g') }, @list; # Nil, because never
```
`first_result` is an alias for `firstres`.
### onlyres BLOCK, LIST
### only\_result BLOCK, LIST
Returns the result of BLOCK for the first element in LIST for which BLOCK evaluates to true. Each element of LIST is passed to BLOCK in turn. Returns `Nil` if no such element has been found.
```
my @list = <alpha beta cicero bearing effortless>;
say onlyres { .uc if .starts-with('c') }, @list; # CICERO
say onlyres { .uc if .starts-with('b') }, @list; # Nil, because twice
say onlyres { .uc if .starts-with('g') }, @list; # Nil, because never
```
`only_result` is an alias for `onlyres`.
### lastres BLOCK, LIST
### last\_result BLOCK, LIST
Returns the result of BLOCK for the last element in LIST for which BLOCK evaluates to true. Each element of LIST is passed to BLOCK in turn. Returns `Nil` if no such element has been found.
```
my @list = <alpha beta cicero bearing effortless>;
say lastval { .uc if .starts-with('c') }, @list; # CICERO
say lastval { .uc if .starts-with('b') }, @list; # BEARING
say lastval { .uc if .starts-with('g') }, @list; # Nil, because never
```
`last_result` is an alias for `lastres`.
### indexes BLOCK, LIST
Evaluates BLOCK for each element in LIST (passed to BLOCK as the parameter) and returns a list of the indices of those elements for which BLOCK returned a true value. This is just like `grep` only that it returns indices instead of values:
```
my @x = indexes { $_ %% 2 } (1..10); # returns (1, 3, 5, 7, 9)
```
#### Idiomatic Raku ways
```
my @x = (1..10).grep: * %% 2, :k;
```
### firstidx BLOCK, LIST
### first\_index BLOCK, LIST
Returns the index of the first element in LIST for which the criterion in BLOCK is true. Passes each element in LIST to BLOCK in turn:
```
my @list = 1, 4, 3, 2, 4, 6;
printf "item with index %i in list is 4", firstidx { $_ == 4 }, @list;
===============================
item with index 1 in list is 4
```
Returns `-1` if no such item could be found.
```
my @list = 1, 3, 4, 3, 2, 4;
print firstidx { $_ == 3 }, @list; # 1
print firstidx { $_ == 5 }, @list; # -1, because not found
```
`first_index` is an alias for `firstidx`.
#### Idiomatic Raku ways
```
printf "item with index %i in list is 4", @list.first: * == 4, :k;
print @list.first: * == 3, :k;
print @list.first( * == 5, :k) // -1; # not found == Nil
```
### onlyidx BLOCK, LIST
### only\_index BLOCK, LIST
Returns the index of the only element in LIST for which the criterion in BLOCK is true. Passes each element in LIST to BLOCK in turn:
```
my @list = 1, 3, 4, 3, 2, 4;
printf "uniqe index of item 2 in list is %i", onlyidx { $_ == 2 }, @list;
===============================
unique index of item 2 in list is 4
```
Returns `-1` if either no such item or more than one of these has been found.
```
my @list = 1, 3, 4, 3, 2, 4;
print onlyidx { $_ == 3 }, @list; # -1, because more than once
print onlyidx { $_ == 5 }, @list; # -1, because not found
```
`only_index` is an alias for `onlyidx`.
### lastidx BLOCK, LIST
### last\_index BLOCK, LIST
Returns the index of the last element in LIST for which the criterion in BLOCK is true. Passes each element in LIST to BLOCK in turn:
```
my @list = 1, 4, 3, 2, 4, 6;
printf "item with index %i in list is 4", lastidx { $_ == 4 } @list;
==================================
item with index 4 in list is 4
```
Returns `-1` if no such item could be found.
```
my @list = 1, 3, 4, 3, 2, 4;
print lastidx { $_ == 3 }, @list; # 3
print lastidx { $_ == 5 }, @list; # -1, because not found
```
`last_index` is an alias for `lastidx`.
#### Idiomatic Raku ways
```
printf "item with index %i in list is 4", @list.first: * == 4, :k, :end;
print @list.first: * == 3, :k, :end;
print @list.first( * == 5, :k, :end) // -1; # not found == Nil
```
## Sorting
### sort\_by BLOCK, LIST
Returns the list of values sorted according to the string values returned by the BLOCK. A typical use of this may be to sort objects according to the string value of some accessor, such as:
```
my @sorted = sort_by { .name }, @people;
```
The key function is being passed each value in turn, The values are then sorted according to string comparisons on the values returned. This is equivalent to:
```
my @sorted = sort -> $a, $b { $a.name cmp $b.name }, @people;
```
except that it guarantees the `name` accessor will be executed only once per value. One interesting use-case is to sort strings which may have numbers embedded in them "naturally", rather than lexically:
```
my @sorted = sort_by { S:g/ (\d+) / { sprintf "%09d", $0 } / }, @strings;
```
This sorts strings by generating sort keys which zero-pad the embedded numbers to some level (9 digits in this case), helping to ensure the lexical sort puts them in the correct order.
#### Idiomatic Raku ways
```
my @sorted = @people.sort: *.name;
```
### nsort\_by BLOCK, LIST
Similar to `sort_by` but compares its key values numerically.
#### Idiomatic Raku ways
```
my @sorted = <10 1 20 42>.sort: +*;
```
### qsort BLOCK, ARRAY
This sorts the given array **in place** using the given compare code. The Raku version uses the basic sort functionality as provided by the `sort` built-in function.
#### Idiomatic Raku ways
```
@people .= sort;
```
## Searching in sorted Lists
### bsearch BLOCK, LIST
Performs a binary search on LIST which must be a sorted list of values. BLOCK receives each element in turn and must return a negative value if the element is smaller, a positive value if it is bigger and zero if it matches.
Returns a boolean value if the `Scalar` named parameter is specified. Otherwise it returns a single element list if it was found, or the empty list if none of the calls to BLOCK returned `0`.
```
my
|
## dist_zef-lizmat-List-MoreUtils.md
## Chunk 2 of 2
@list = <alpha beta cicero delta>;
my @found = bsearch { $_ cmp "cicero" }, @list; # ("cicero",)
my @found = bsearch { $_ cmp "effort" }, @list; # ()
my @list = <alpha beta cicero delta>;
my $found = bsearch Scalar, { $_ cmp "cicero" }, @list; # True
my $found = bsearch Scalar, { $_ cmp "effort" }, @list; # False
```
### bsearchidx BLOCK, LIST
### bsearch\_index BLOCK, LIST
Performs a binary search on LIST which must be a sorted list of values. BLOCK receives each element in turn and must return a negative value if the element is smaller, a positive value if it is bigger and zero if it matches.
Returns the index of found element, otherwise `-1`.
```
my @list = <alpha beta cicero delta>;
my $found = bsearchidx { $_ cmp "cicero" }, @list; # 2
my $found = bsearchidx { $_ cmp "effort" }, @list; # -1
```
`bsearch_index` is an alias for `bsearchidx`.
### lower\_bound BLOCK, LIST
Returns the index of the first element in LIST which does not compare *less than val*. Technically it's the first element in LIST which does not return a value below zero when passed to BLOCK.
```
my @ids = 1, 2, 2, 3, 3, 3, 3, 3, 3, 4, 4, 4, 4, 5, 5, 6;
my $lb = lower_bound { $_ <=> 2 }, @ids; # 1
my $lb = lower_bound { $_ <=> 4 }, @ids; # 9
```
### upper\_bound BLOCK, LIST
Returns the index of the first element in LIST which does not compare *greater than val*. Technically it's the first element in LIST which does not return a value below or equal to zero when passed to BLOCK.
```
my @ids = 1, 2, 2, 3, 3, 3, 3, 3, 3, 4, 4, 4, 4, 5, 5, 6;
my $ub = upper_bound { $_ <=> 2 }, @ids; # 3
my $ub = upper_bound { $_ <=> 4 }, @ids; # 13
```
### equal\_range BLOCK, LIST
Returns a list of indices containing the `lower_bound` and the `upper_bound` of given BLOCK and LIST.
```
my @ids = 1, 2, 2, 3, 3, 3, 3, 3, 3, 4, 4, 4, 4, 5, 5, 6;
my $er = equal_range { $_ <=> 2 }, @ids; # (1,3)
my $er = equal_range { $_ <=> 4 }, @ids; # (9,13)
```
## Operations on sorted Lists
### binsert BLOCK, ITEM, LIST
### bsearch\_insert BLOCK, ITEM, LIST
Performs a binary search on LIST which must be a sorted list of values. BLOCK must return a negative value if the current element (passed as a parameter to the BLOCK) is smaller, a positive value if it is bigger and zero if it matches.
ITEM is inserted at the index where the ITEM should be placed (based on above search). That means, it's inserted before the next bigger element.
```
my @l = 2,3,5,7;
binsert { $_ <=> 4 }, 4, @l; # @l = (2,3,4,5,7)
binsert { $_ <=> 6 }, 42, @l; # @l = (2,3,4,5,42,7)
```
You take care that the inserted element matches the compare result.
`bsearch_insert` is an alias for `binsert`.
### bremove BLOCK, LIST
### bsearch\_remove BLOCK, LIST
Performs a binary search on LIST which must be a sorted list of values. BLOCK must return a negative value if the current element (passed as a parameter to the BLOCK) is smaller, a positive value if it is bigger and zero if it matches.
The item at the found position is removed and returned.
```
my @l = 2,3,4,5,7;
bremove { $_ <=> 4 }, @l; # @l = (2,3,5,7);
```
`bsearch_remove` is an alias for `bremove`.
## Counting and calculation
### true BLOCK, LIST
Counts the number of elements in LIST for which the criterion in BLOCK is true. Passes each item in LIST to BLOCK in turn:
```
printf "%i item(s) are defined", true { defined($_) }, @list;
```
#### Idiomatic Raku ways
```
print "@list.grep(*.defined).elems() item(s) are defined";
```
### false BLOCK, LIST
Counts the number of elements in LIST for which the criterion in BLOCK is false. Passes each item in LIST to BLOCK in turn:
```
printf "%i item(s) are not defined", false { defined($_) }, @list;
```
#### Idiomatic Raku ways
```
print "@list.grep(!*.defined).elems() item(s) are not defined";
```
### reduce\_0 BLOCK, LIST
Reduce LIST by calling BLOCK in scalar context for each element of LIST. The first parameter contains the progressional result and is initialized with **0**. The second parameter contains the currently being processed element of LIST.
```
my $reduced = reduce_0 -> $a, $b { $a + $b }, @list;
```
In the Perl version, `$_` is also set to the index of the element being processed. This is not the case in the Raku version for various reasons. Should you need the index value in your calculation, you can post-increment the anonymous state variable instead: `$++`:
```
my $reduced = reduce_0 -> $a, $b { dd $++ }, @list; # 0 1 2 3 4 5 ...
```
The idea behind reduce\_0 is **summation** (addition of a sequence of numbers).
### reduce\_1 BLOCK, LIST
Reduce LIST by calling BLOCK in scalar context for each element of LIST. The first parameter contains the progressional result and is initialized with **1**. The second parameter contains the currently being processed element of LIST.
```
my $reduced = reduce_1 -> $a, $b { $a * $b }, @list;
```
In the Perl version, `$_` is also set to the index of the element being processed. This is not the case in the Raku version for various reasons. Should you need the index value in your calculation, you can post-increment the anonymous state variable instead: `$++`:
```
my $reduced = reduce_1 -> $a, $b { dd $++ }, @list; # 0 1 2 3 4 5 ...
```
The idea behind reduce\_1 is **product** of a sequence of numbers.
### reduce\_u BLOCK, LIST
Reduce LIST by calling BLOCK in scalar context for each element of LIST. The first parameter contains the progressional result and is initialized with **Any**. The second parameter contains the currently being processed element of LIST.
```
my $reduced = reduce_u -> $a, $b { $a.push($b) }, @list;
```
In the Perl version, `$_` is also set to the index of the element being processed. This is not the case in the Raku version for various reasons. Should you need the index value in your calculation, you can post-increment the anonymous state variable instead: `$++`:
```
my $reduced = reduce_u -> $a, $b { dd $++ }, @list; # 0 1 2 3 4 5 ...
```
The idea behind reduce\_u is to produce a list of numbers.
### minmax LIST
Calculates the minimum and maximum of LIST and returns a two element list with the first element being the minimum and the second the maximum. Returns the empty list if LIST was empty.
```
my ($min,$max) = minmax (43,66,77,23,780); # (23,780)
```
#### Idiomatic Raku ways
```
my $range = <43,66,77,23,780>.minmax( +* );
my $range = (43,66,77,23,780).minmax; # auto-numerically compares
```
### minmaxstr LIST
Computes the minimum and maximum of LIST using string compare and returns a two element list with the first element being the minimum and the second the maximum. Returns the empty list if LIST was empty.
```
my ($min,$max) = minmaxstr <foo bar baz zippo>; # <bar zippo>
```
#### Idiomatic Raku ways
```
my $range = (43,66,77,23,780).minmax( ~* );
my $range = <foo bar baz zippo>.minmax; # auto-string compares
```
# SEE ALSO
List::Util, List::AllUtils, List::UtilsBy
# THANKS
Thanks to all of the individuals who have contributed to the Perl version of this module.
# AUTHOR
Elizabeth Mattijsen [liz@raku.rocks](mailto:liz@raku.rocks)
If you like this module, or what I’m doing more generally, committing to a [small sponsorship](https://github.com/sponsors/lizmat/) would mean a great deal to me!
Source can be located at: <https://github.com/lizmat/List-MoreUtils> . Comments and Pull Requests are welcome.
# COPYRIGHT AND LICENSE
Copyright 2018, 2019, 2020, 2021, 2023 Elizabeth Mattijsen
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
Re-imagined from the Perl version as part of the CPAN Butterfly Plan. Perl version originally developed by Tassilo von Parseval, subsequently maintained by Adam Kennedy and Jens Rehsack.
|
## dist_cpan-BDUGGAN-Protobuf.md
# raku-protobuf
Parse and manage Protobufs with Raku
## Description
This package contains utilities for managing protobufs with Raku.
Current contents:
* Protobuf::Grammar -- parse a protobuf file
* Protobuf::Actions -- generate a representation from a grammar
* Protobuf -- provides `parse-proto` for combining the above
* protoc.raku -- cli to parse a proto from the command line
There are a few other little classes like Protobuf::Definition,
Protobuf::Service, etc which comprise the structure that is
built by Protobuf::Actions.
## SYNOPSIS
```
use Protobuf;
my $p = parse-proto("my.proto".IO.slurp);
# returns a Protobuf::Definition
for $p.services -> $svc {
# each one is a Protobuf::Service
say "service name: " ~ $svc.name;
for $svc.endpoints -> $e {
# each one is a Protobuf::Endpoint
say " endpoint: " ~ $e.name;
say ' request params: ' ~ $e.request.name;
# Requests and responses are Protobuf::Message's
for $e.request.fields -> $f {
# These are Protobuf::Field's
say ' name : ' ~ $f.name;
# Note that type can be a string or a Protobuf::Message
say ' type : ' ~ $f.type;
}
say ' response params: ' ~ $e.response.name;
for $e.response.fields -> $f {
say ' name : ' ~ $f.name;
say ' type : ' ~ $f.type;
}
}
}
```
## AUTHOR
Brian Duggan
## TODO
* Generate code from a proto
* A bunch of details in the grammar
## SEE ALSO
<https://developers.google.com/protocol-buffers/docs/reference/proto3-spec>
|
## dist_zef-tony-o-DB-ORM-Quicky.md
# Quicky ORM
What is it? It's a lazy ORM that I threw together because I end up prototyping a lot of things before building them out with proper schemas. So, it's meant for lazy column typing and minimal code from the user side.
## How it works
The DB::ORM::Quicky::Model (you'll never have to instantiate this object) degrades column types in the order of Int, Num, Str to whatever an equivalent type is in the selected DB. Essentially to `integer`, `float`, `varchar` columns. `varchar` type columns auto resize if the width isn't great enough to hold the requested value.
The model also tracks what columns were changed and *only* updates those fields.
## Example - CRUD (Create Read Update Delete)
For the examples, I'll use SQLite and keep comments to a minimum.
### Depends
[DBIish](https://github.com/perl6/DBIish/)
### [C]rud
```
use DB::ORM::Quicky;
my $orm = DB::ORM::Quicky.new;
$orm.connect(
driver => 'SQLite',
options => %(
database => 'local.sqlite3',
)
);
# the `users` table does NOT exist yet.
my $newuser = $orm.create('users'); #this is creating a new 'row', not necessarily a new table
# the `users` table exists with no columns or just a `DBORMID`
# column (only in SQLite) yet.
$newuser.set({
username => 'tony-o',
password => 'top secret',
age => 6,
rating => 'lame',
decimal => 6.66,
});
$newuser.save; #at this point all required columns are checked or created
```
### c[R]ud
```
my $usersearch = $orm.search('users', { rating => 'lame' });
my @users = $usersearch; #array of all users with 'lame' rating
for $usersearch.next -> $user { ... }
"User count: {$usersearch.count}".say;
```
### cr[U]d
```
for $usersearch.next -> $user {
$user.set({
joindate => time, #decided we want to track when a user signed up
});
$user.save;
}
```
### cru[D]
```
$orm.search('users', { }).delete; #delete all of our users
```
## More "Advanced" Querying
The ORM can take a lot of different types of values. The usual example by code follows:
```
$orm.search('table', {
'-or' => [ #-and is also valid
{
username => ['user1', 'user2']
},
{
joindate => ('-gt' => time - 5000), # -gt and -lt both work
},
'-and' => [
rating => 'lame',
decimal => ('-lt' => 50),
]
]
});
# SELECT * FROM table WHERE
# (username = 'user1' or username = 'user2')
# OR (joindate > ?)
# OR (rating = 'lame' and decimal < 50);
# with ? = (time - 5000)
$orm.search('table', {
-raw => ' strftime(\'%Y%m%d\', joindate) = strftime(\'%Y%m%d\', \'now\') '
});
# SELECT * FROM table WHERE strftime('%Y%m%d', joindate) = strftime('%Y%m%d', 'now');
```
### Joining Tables
```
my $orm = qw<initialize your orm as above>;
# initialize some data
my $user = $orm.create('user');
$user.set('username', 'user1');
$user.set('password', 'user1-pass!');
$user.set('source', 'facebook');
$user.save; #$user.id is now an actual value, yay
my $profile = $orm.create('profile');
$profile.set('name', 'tim tow dee');
$profile.set('uid', $user.id);
$profile.set('source', 'facebook');
$profile.save;
# here we'll query them as one unit
my @users = $orm.search('user', { #user table will be our main table
'-join' => {
'-table' => 'profile', #join the profile table to user
'-type' => 'inner', #user an inner join, the default is 'left outer'
'-on' => {
'-and' => {
'uid' => 'DBORMID', #these are autoquoted where the key from the pair is quoted for the joining table and the value is quoted for the main table
#you can also use things like a pair here, ie: ('-lt' => 'some other column in user table')
'source' => 'source', #becomes "profile"."source" = "user"."source" in the SQL
}
}
},
'"profile"."name"' => ('-ne' => ''), #normal 'where' parameters, notice that quoting the table and field name for the joined table *may* be necessary
}).all;
for my $user (@users) {
$user.get(qw<any field from either the profile or user table here>);
}
```
The way that the internals work on the `-on` key value pairs is that the `.key` is from the table to be joined, and the `.value` for the parent table. So, the pair of `'uid' => 'DBORMID'` translates to `profile.uid` and `user.DBORMID`, respectively. You can avoid this behavior by providing the table names as part of the field, IE `'profile.uid' => 'user.DBORMID'`
Caveats:
* There isn't a mechanism to use a raw value in the `'-on'` section of the join.
* There is also only one join possible right now.
Both of those features are being worked on.
## Bugs, comments, feature requests?
Yes, there are probably bugs. Put 'em in the github bugs area or catch me in #perl6 on freenode.
## License
Whatever, it's free. Do what you want with it.
###### Other crap
[@tony-o](https://www.gittip.com/tony-o/)
|
## dist_cpan-BDUGGAN-Dawa.md
## NAME
Dawa -- A runtime debugger for Raku programs
## SYNPOSIS
Use from the command line with the `dawa` command:

Use from within a program with the `stop` statement:

## DESCRIPTION
Dawa is a run-time debugger for Raku programs.
It exports one subroutine: `stop`, which will pause
execution of the current thread of the program, and
allow for introspecting the stack, and stepping through
subsequent statements. It also supports debugging of
multi-threaded programs.
Importing `Dawa` adds extra ops to the AST that is
generated during compilation. Specifically, it adds
at most one extra node per line. There is a significant
perforance penalty for this, as well as a risk that your
program will break. Patches welcome!
The functionality of `dawa` is inspired by
Ruby's [pry](https://github.com/pry/pry) and Python's
[pdb](https://docs.python.org/3/library/pdb.html).
## USAGE
After `stop` is reached, a repl is started, which has a few
commands. Type `h` to see them. Currently, these are the commands:
```
break (b) : [N [filename] ] add a breakpoint at line N [in filename]
continue (c, ^D) : continue execution of this thread
defer (d) : [n] Defer to thread [n], or the next waiting one
eval (e) : [id] evaluate code in the current context [or in thread #id]
help (h) : this help
ls (l) : [-a] [id] show [all] lexical variables in the current scope [or in thread #id]
next (n) : run the next statement in any thread
quit (q) : terminate the program (exit)
step (s) : execute the next statement in the same thread
threads (t) : [id] show threads being tracked [or just thread #id]
where (w) : show a stack trace and the current location in the code
```
Anything else is treated as a Raku statement: it will be evaluated,
the result will be shown.
### Breakpoints
Breakpoints can be set with `b`, for example:
```
dawa [1]> b 13
Added breakpoint at line 13 in eg/debug.raku
```
As shown above, breakpoints are indicated using `■` and are not
thread-specific. The triangle (▶) is the line of code that
will be executed next. The `[1]` indicates that this is thread 1.
The `[1]` in the prompt indicates that statements will currently
be evaluated in the context of thread 1 by default.
## Details of "next"
In Raku, there can be multiple statements per line, and multiple
"statements" within a statement, which makes it tricky to debug a
program by stepping through "statements" or stepping through "lines".
Dawa has a number of heuristics for when to stop, but the idea is to
stop at most once per line and at most once per statement. Typing "n"
may sometimes stay within the same block of code, if a statement containing
other statements spans several lines. The display will indicate
the block of code containing the statement that will be executed.
## Multiple Threads
If several threads are stopped at once, a lock is used in order to
only have one repl at a time. Threads wait for this lock. After
either continuing or going on to the next statement, another thread
that is waiting for the lock may potentially become active in the repl.
i.e. "next" advances to the next statement in any thread. To stay in
the same thread, use "step".
```
∙ Stopping thread Thread #1 (Initial thread)
--- current stack ---
in block <unit> at example.raku line 11
-- current location --
3 │ │ my $i = 1;
4 │ │
5 │ │ start loop {
6 │ │ $i++;
7 │ [7] │ $i++;
8 │ │ }
9 │ │
10 │ [1]▶ │ stop;
11 │ │ say 'bye!';
12 │ │
Type h for help
dawa [1]>
```
Note that in this situation thread 7 continues to run even while the repl
is active. To also stop thread 7 while debugging, you can add a breakpoint
(since breakpoints apply to all threads).
The `eval` command can be used to evaluate expression in another thread. For instance,
`eval 7 $i` will evaluate the `$i` in thread 7.
The `ls` command can show lexical variables in another thread. Note that only variables
in the innermost lexical scope will be shown.
The `defer` command can be used to switch to another stopped thread. Here is an example:
### Switching between threads
When multiple threads are stopped, `defer` will switch from one to another.
For instance, the example below has `eg/defer.raku`, with threads 7-11 stopped,
as well as thread 1. After looking at the stack in thread 1, typing `d 8`
will change to thread 8, and subsequent commands will run in the context
of that thread. (also note that if a lot of threads are stopped at the same
line of code, they are shown in a footnote)
```
dawa [1]> w
--- current stack ---
in block <unit> at eg/defer.raku line 16
-- current location --
4 │ │ start {
5 │ │ my $x = 10;
6 │ │ loop {
7 │ │ stop;
8 │ (a) │ $x++;
9 │ │ }
10 │ │ }
11 │ │ }
12 │ │
13 │ │ my $y = 100;
14 │ │ loop {
15 │ │ stop;
16 │ [1]▶ │ say "y is $y";
17 │ │ $y += 111;
18 │ │ last if $y > 500;
19 │ │ }
20 │ │
────────────────────────────────────────
(a) : [8][9][7][10][11]
────────────────────────────────────────
dawa [1]> d 8
8 ▶ $x++;
dawa [8]> w
--- current stack ---
in block at eg/defer.raku line 8
-- current location --
4 │ │ start {
5 │ │ my $x = 10;
6 │ │ loop {
7 │ │ stop;
8 │ (a)▶ │ $x++;
9 │ │ }
10 │ │ }
11 │ │ }
12 │ │
13 │ │ my $y = 100;
14 │ │ loop {
15 │ │ stop;
16 │ [1] │ say "y is $y";
17 │ │ $y += 111;
18 │ │ last if $y > 500;
19 │ │ }
20 │ │
────────────────────────────────────────
(a) : [8][9][7][10][11]
────────────────────────────────────────
dawa [8]> $x
10
```
## ABOUT THE NAME
The word `dawa` can refer to either medicine or poison in Swahili. In the
latter sense, it would be used to describe bug spray, i.e. a debugger -- but
hopefully it'll also help be a cure for any ailments in your programs.
## SEE ALSO
1. There is a built-in `repl` statement, which will pause execution
and start a repl loop at the current location.
2. [rakudo-debugger](https://github.com/jnthn/rakudo-debugger) provides
a separate executable for debugging. Techniques there inspired
this module.
## ENVIRONMENT
The readline history is stored in `DAWA_HISTORY_FILE`, ~/.dawa-history by default.
## BUGS
Since this relies on undocumented behavior, it could break at any time. Modifying
the AST may also cause your program to behave in unexpected ways. It may be
possible to improve this once the AST work in Raku is available.
## MAILING LIST
<https://lists.sr.ht/~bduggan/raku-dawa>
## AUTHOR
Brian Duggan (bduggan at matatu.org)
|
## dist_zef-l10n-L10N-DE.md
# NAME
L10N::DE - German localization of Raku
# SYNOPSIS
```
use L10N::DE;
sag "Hello World";
```
# DESCRIPTION
L10N::DE contains the logic to provide a German localization of the Raku Programming Language.
# AUTHORS
Elizabeth Mattijsen [liz@raku.rocks](mailto:liz@raku.rocks)
# COPYRIGHT AND LICENSE
Copyright 2023 Raku Localization Team
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## mixy.md
role Mixy
Collection of distinct objects with Real weights
```raku
role Mixy does Baggy { }
```
A role for collections of weighted values. See [`Mix`](/type/Mix) and [`MixHash`](/type/MixHash). `Mixy` objects differ from [`Baggy`](/type/Baggy) objects in that the weights of `Mixy` are [`Real`](/type/Real)s rather than [`Int`](/type/Int)s.
# [Methods](#role_Mixy "go to top of document")[§](#Methods "direct link")
## [method roll](#role_Mixy "go to top of document")[§](#method_roll "direct link")
```raku
method roll($count = 1)
```
Similar to a [`Bag`](/type/Bag).roll, but with [`Real`](/type/Real) weights rather than integral ones.
## [method pick](#role_Mixy "go to top of document")[§](#method_pick "direct link")
```raku
method pick($?)
```
Throws an exception. The feature is not supported on the type, since there's no clear value to subtract from non-integral weights, to make it work.
## [method grab](#role_Mixy "go to top of document")[§](#method_grab "direct link")
```raku
method grab($?)
```
Throws an exception. The feature is not supported on the type, since there's no clear value to subtract from non-integral weights, to make it work.
## [method kxxv](#role_Mixy "go to top of document")[§](#method_kxxv "direct link")
```raku
method kxxv()
```
Throws an exception. The feature is not supported on the type, since there's no clear value to subtract from non-integral weights, to make it work.
# [See Also](#role_Mixy "go to top of document")[§](#See_Also "direct link")
[Sets, Bags, and Mixes](/language/setbagmix)
# [Typegraph](# "go to top of document")[§](#typegraphrelations "direct link")
Type relations for `Mixy`
raku-type-graph
Mixy
Mixy
Baggy
Baggy
Mixy->Baggy
Associative
Associative
QuantHash
QuantHash
QuantHash->Associative
Baggy->QuantHash
Mu
Mu
Any
Any
Any->Mu
Mix
Mix
Mix->Mixy
Mix->Any
MixHash
MixHash
MixHash->Mixy
MixHash->Any
[Expand chart above](/assets/typegraphs/Mixy.svg)
|
## dist_github-ufobat-XML-XPath.md
# XML::XPath
[](https://travis-ci.org/ufobat/p6-XML-XPath)
[](https://ci.appveyor.com/project/ufobat/p6-XML-XPath/branch/master)
A Perl 6 Library for parsing and evaluating XPath Statements.
# XPath Specification
Specification on XPath Expressions can be found at <https://www.w3.org/TR/xpath/>.
# Synopsis
```
use XML::XPath;
my $xpath = XML::XPath.new(xml => '... xml ...');
my $result = $xpath.find('/foo/bar');
```
# Example
If you want to see more examples please have a look at the [testcases](t).
# Documentation
## `XML::XPath.new(:$file, :$xml, :$document)`
XML::XPath creates a XML Document from a `$file` or from `$xml` unless you provide a `$document` in the constructor.
## `.find(Str $xpath, XML::Node :$start, Bool :$to-list)`
Evaluates the XPath Expression and returns the results of the match. If a $start node is provided it starts
there instead of beginning of the XML Document.
If $to-list is True the result will allways be an Array, otherwise it might return Any or a single element
(e.g XML::Node, Str, Nummeric, Bool)
## `.set-namespace(Pair $ns)`
This method sets a namespace, so the value of `$ns.key` can be used in the XPath expression to look nodes a
certain namespace.
```
$x.set-namespace: 'goo' => "foobar.example.com";
$set = $x.find('//goo:something');
```
## `.clear-namespaces`
Clears all namespaces that have been set via `.set-namespace`.
## `.parse-xpath(Str $xpath)`
Just parses `$xpath` expression.
# License
Artistic License 2.0.
|
## dist_zef-raku-community-modules-Docker-File.md
[](https://github.com/raku-community-modules/Docker-File/actions) [](https://github.com/raku-community-modules/Docker-File/actions) [](https://github.com/raku-community-modules/Docker-File/actions)
# NAME
Docker::File - Parsing and generation of Dockerfiles
# SYNOPSIS
```
use Docker::File;
# Parse a Dockerfile into a bunch of objects.
my $parsed-df = Docker::File.parse($docker-file);
unless $parsed-df.instructions.grep(Docker::File::Maintainer) {
note "This Dockerfile has no maintainer! :-("
}
# Generate a Dockerfile.
my $new-df = Docker::File.new(
images => [
Docker::File::Image.new(
from-short => 'ubuntu',
from-tag => 'latest'
entries => [
Docker::File::RunShell.new(
command => 'sudo apt-get install raku'
)
]
)
]
);
say ~$new-df;
```
# DESCRIPTION
A Raku module to read/write docker files.
# AUTHOR
Jonathan Worthington
# COPYRIGHT AND LICENSE
Copyright 2016 - 2017 Jonathan Worthington
Copyright 2024 Raku Community
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_zef-lizmat-has-word.md
[](https://github.com/lizmat/has-word/actions) [](https://github.com/lizmat/has-word/actions) [](https://github.com/lizmat/has-word/actions)
# NAME
has-word - A quick non-regex word-boundary checker
# SYNOPSIS
```
use has-word;
say has-word("foobarbaz", "foo"); # False
say has-word("foo barbaz", "foo"); # True
say has-word("foo::bar::baz", "bar"); # True
say has-word("foo::bar::baz", "BAZ", :ignorecase); # True
say has-word("foo::bar::báz", "baz", :ignoremark); # True
.say for all-words("foo bar FOO", "foo", :i); # fooFOO
.say for find-all-words("foo bar foo", "foo"); # 08
```
# DESCRIPTION
The `has-word` module exports a two subroutines that provide a quick way to see whether a string occurs as a "word" (defined as a number of alphanumeric characters surrounded by either non-alphanumeric characters or the beginning or end of the string. As such, it provides the equivalent of the `word` functionality in regular expressions, but much faster and with a simpler way of checking for words that cannot be determined at compile time.
# SUBROUTINES
## has-word
```
say has-word("foobarbaz", "foo"); # False
say has-word("foo barbaz", "foo"); # True
say has-word("foo::bar::baz", "bar"); # True
say has-word("foo::bar::baz", "BAZ", :ignorecase); # True
```
The `has-word` subroutine takes the haystack string as the first positional argument, and the needle string as the second positional argument. It also optionally takes an `:ignorecase` (or `:i`) named argument to perform the search in a case-insensitive manner, and/or an `:ignoremark` (or `:m`) named argument to perform the search by only comparing the base characters.
It returns either `True` if found, or `False` if not.
## all-words
```
.say for all-words("foo bar FOO", "foo", :i); # fooFOO
```
The `all-words` subroutine takes the haystack string as the first positional argument, and the needle string as the second positional argument. It also optionally takes an `:ignorecase` (or `:i`) named argument to perform the search in a case-insensitive manner, and/or an `:ignoremark` (or `:m`) named argument to perform the search by only comparing base characters. It returns a `Slip` with the found strings (which can be different from the given needle if `:ignorecase` or `:ignoremark` were specified.
## find-all-words
```
.say for find-all-words("foo bar foo", "foo"); # 08
```
The `find-all-words` subroutine takes the haystack string as the first positional argument, and the needle string as the second positional argument. It also optionally takes an `:ignorecase` (or `:i`) named argument to perform the search in a case-insensitive manner, and/or an `:ignoremark` (or `:m`) named argument to perform the search by only comparing base characters. It returns a `List` of positions in the haystack string where the needle string was found.
# AUTHOR
Elizabeth Mattijsen [liz@raku.rocks](mailto:liz@raku.rocks)
# COPYRIGHT AND LICENSE
Copyright 2021, 2022, 2024 Elizabeth Mattijsen
Source can be located at: <https://github.com/lizmat/has-word> . Comments and Pull Requests are welcome.
If you like this module, or what I’m doing more generally, committing to a [small sponsorship](https://github.com/sponsors/lizmat/) would mean a great deal to me!
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_cpan-AVUSEROW-Net-Snapcast.md
[](https://github.com/avuserow/raku-net-snapcast/actions)
# NAME
Net::Snapcast - Control Snapcast audio players
# SYNOPSIS
```
use Net::Snapcast;
my $sc = Net::Snapcast.new(:$host, :port(1705));
# list clients attached to snapcast
my @clients = $sc.list-clients;
# change volume on a client
$sc.set-volume(@clients[0].id, 100);
# get a supply of events (from other clients only)
# see documentation at https://github.com/badaix/snapcast/blob/master/doc/json_rpc_api/control.md#notifications
$sc.notifications.tap(-> $e {
say "event type $e<method>: $e<params>";
})
```
# DESCRIPTION
Net::Snapcast is an interface for controlling players connected to a Snapcast server. Snapcast is a client/server system for building a multiroom audio system. The server consumes audio from one or more sources, controls which client receives which audio stream, and manages latency to keep audio playback synchronized. See <https://github.com/badaix/snapcast> for more details on Snapcast.
This module implements the control interface to Snapcast, allowing you to manage the various players. You can programmatically control what client is connected to which stream, change the volume, and receive notifications of changes made by other clients.
This module does not implement any audio sending or receiving. In snapcast terms, this implements the "Control API" (on port 1705 by default).
This module is currently tested with a Snapcast server running 0.25.0.
# METHODS
## new(:$host, :$port)
Connects to the given Snapcast server and synchronizes the state.
## sync
Re-sync cached snapcast data. This is called automatically as needed and should not need to be invoked manually.
## notifications
Returns a Supply that receives events from other clients. If this client makes an RPC call (e.g. `set-volume`), then this Supply will not receive an event.
Events are documented at <https://github.com/badaix/snapcast/blob/master/doc/json_rpc_api/control.md#notifications> and may vary depending on the Snapcast server.
## list-clients
Returns a list of clients. See the `Net::Snapcast::Snapclient` class below for the included attributes.
## set-volume($id, $volume)
Sets the volume level of the provided client.
# SUBCLASSES
## Snapclient - details about a connected client
This class is returned from `list-clients`. This is called "snapclient" after the snapcast player command's name. All attributes should be considered read-only.
### Client Attributes
* Str id - snapcast-assigned client ID, defaults to MAC address with optional instance ID
* Str name - configured client name, as set by the snapcast API `Client.SetName`. Defaults to hostname if unset, and there may be duplicate client names.
* Int instance - instance ID of the snapcast clients. Defaults to 1 and only changed when running multiple clients per computer
* Str hostname - hostname of the computer running this client
* Str os - operating system of this client
* Str ip - IP address of this client
* Str arch - architecture of this client (e.g. `x86_64`, `armv6l`, `arm64-v8a`)
* Str mac - MAC address of this client, if available (otherwise may be all zeroes)
* Bool connected - indicates whether this client is currently connected to snapcast (or if the server just remembers this client). You can still modify attributes of disconnected clients, but they disappear upon server restart.
* Bool muted - indicates whether this client is muted in snapcast
* Int volume - indicates volume level within snapcast
* Str group-id - ID of the group containing this client (NOTE: group APIs are not yet implemented)
* Str stream-id - ID of the audio stream that this client is consuming (actually the "name" of the stream in snapcast config)
# SEE ALSO
<https://github.com/badaix/snapcast> - snapcast repo
<https://github.com/badaix/snapcast/blob/master/doc/json_rpc_api/control.md> - documentation for control protocol
# AUTHOR
Adrian Kreher [avuserow@gmail.com](mailto:avuserow@gmail.com)
# COPYRIGHT AND LICENSE
Copyright 2022 Adrian Kreher
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_github-taboege-SAT-Solver-MiniSAT.md
# NAME
SAT::Solver::MiniSAT - SAT solver MiniSAT
# SYNOPSIS
```
use SAT::Solver::MiniSAT;
say minisat "t/aim/aim-100-1_6-no-1.cnf".IO, :now;
#= False
say minisat "t/aim/aim-100-1_6-yes1-1.cnf".IO, :now;
#= True
```
# DESCRIPTION
SAT::Solver::MiniSAT wraps the `minisat` executable (bunled with the module) used to decide whether a satisfying assignment for a Boolean formula given in the `DIMACS cnf` format exists. This is known as the `SAT` problem associated with the formula. MiniSAT does not produce a witness for satisfiability.
Given a DIMACS cnf problem, it starts `minisat`, feeds it the problem and returns a Promise which will be kept with the `SAT` answer found or broken on error.
# AUTHOR
Tobias Boege <tboege ☂ ovgu ☇ de>
# COPYRIGHT AND LICENSE
Copyright 2018 Tobias Boege
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_cpan-SAMGWISE-HTML-Lazy.md
[](https://travis-ci.org/samgwise/html-lazy)
# NAME
HTML::Lazy - Declarative HTML generation
# SYNOPSIS
```
use HTML::Lazy (:ALL);
my $document = html-en
head( Map,
title(Map, text('HTML::Lazy'))
),
body( Map,
p({ :class<example> },
text('Hello world!')
)
);
# Execute the generator and show the new HTML
put render($document)
```
And the result:
# output
Hello world!
# DESCRIPTION
HTML::Lazy is a declarative HTML document generation module. It provides declarative functions for creating lazy HTML generation closures. The lazy generation can be overridden through an eager renderer and generation can be performed in parrallel with a hyper-renderer.
## Tags and adding your own
For a list of html tags which can be exported, see the export list below. If you need one I've missed, you can generate your own tag function like this:
```
my &head = tag-factory 'head';
```
You now have a routine for generating head tags.
## Prior Art
This is certainly not the first Perl 6 HTML generator and will hardly be the lasst. A number of other modules provide differnt solutions which you should consider:
* [XHTML::Writer](https://github.com/gfldex/perl6-xhtml-writer)
* [Typesafe::XHTML::Writer](https://github.com/gfldex/perl6-typesafe-xhtml-writer)
* [HTML::Tag](https://github.com/adaptiveoptics/HTML-Tag)
# AUTHOR
Sam Gillespie [samgwise@gmail.com](mailto:samgwise@gmail.com)
# COPYRIGHT AND LICENSE
Copyright 2019 Sam Gillespie.
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
# Export groups
| Symbol | Export groups |
| --- | --- |
| &render | :DEFAULT, :ALL |
| &pre-render | :DEFAULT, :ALL |
| &hyper-render | :DEFAULT, :ALL |
| &text | :DEFAULT, :ALL |
| &text-raw | :DEFAULT, :ALL |
| &node | :DEFAULT, :ALL |
| &tag-factory | :DEFAULT, :ALL |
| &with-attributes | :DEFAULT, :ALL |
| &html-en | :DEFAULT, :ALL |
| &include-file | :DEFAULT, :ALL |
| &head | :tags, :ALL |
| &title | :tags, :ALL |
| &meta | :tags, :ALL |
| &body | :tags, :ALL |
| &div | :tags, :ALL |
| &footer | :tags, :ALL |
| &header | :tags, :ALL |
| &br | :tags, :ALL |
| &col | :tags, :ALL |
| &colgroup | :tags, :ALL |
| &ul | :tags, :ALL |
| &ol | :tags, :ALL |
| &li | :tags, :ALL |
| &code | :tags, :ALL |
| &samp | :tags, :ALL |
| &pre | :tags, :ALL |
| &table | :tags, :ALL |
| &thead | :tags, :ALL |
| &tbody | :tags, :ALL |
| &tfoot | :tags, :ALL |
| &tr | :tags, :ALL |
| &th | :tags, :ALL |
| &td | :tags, :ALL |
| &caption | :tags, :ALL |
| &figure | :tags, :ALL |
| &figurecaption | :tags, :ALL |
| &a | :tags, :ALL |
| &img | :tags, :ALL |
| &audio | :tags, :ALL |
| &video | :tags, :ALL |
| &canvas | :tags, :ALL |
| &link | :tags, :ALL |
| &script | :tags, :ALL |
| &style | :tags, :ALL |
| &asource | :tags, :ALL |
| &svg | :tags, :ALL |
| &noscript | :tags, :ALL |
| &iframe | :tags, :ALL |
| &template | :tags, :ALL |
| &form | :tags, :ALL |
| &input | :tags, :ALL |
| &label | :tags, :ALL |
| &optgroup | :tags, :ALL |
| &option | :tags, :ALL |
| &select | :tags, :ALL |
| &textarea | :tags, :ALL |
| &button | :tags, :ALL |
| &span | :tags, :ALL |
| &p | :tags, :ALL |
| &i | :tags, :ALL |
| &b | :tags, :ALL |
| &q | :tags, :ALL |
| &blockquote | :tags, :ALL |
| &em | :tags, :ALL |
| &sub | :tags, :ALL |
| &sup | :tags, :ALL |
| &h1 | :tags, :ALL |
| &h2 | :tags, :ALL |
| &h3 | :tags, :ALL |
| &h4 | :tags, :ALL |
| &h5 | :tags, :ALL |
| &h6 | :tags, :ALL |
# Subroutines
### sub render
```
sub render(
&tag
) returns Str
```
Calls a no argument Callable to produce the defined content. This routine is here to show programmer intention and catch any errors encountered when building the HTML Str. All errors are returned in the form of a failure so it is important to check the truthiness of the result to determine if the HTML was generated succesfully.
### sub pre-render
```
sub pre-render(
&tag
) returns Callable
```
Executes a render and stores the result so it may be rendered later. Use this function to eagerly evaluate a document or sub document and store the resulting Str for use in other documents. Please note that any errors encountered during a pre-render will not be encountered until the result of the pre-rendered output is used, since the Failure object will be caputred in the result.
### sub hyper-render
```
sub hyper-render(
*@children
) returns Callable
```
Children of a hyper-render function will be rendered in parrallel when called. The results will be reassembled without change to order.
### sub text
```
sub text(
Str $text
) returns Callable
```
Create a closure to emit the text provided. Text is escaped for HTML, use `text-raw` for including text which should not be sanitised. The escaping uses escape-html from `HTML::Escape` (<https://modules.perl6.org/dist/HTML::Escape:cpan:MOZNION)>.
### sub text-raw
```
sub text-raw(
Str $text
) returns Callable
```
Create a closure to emit the text provided. The text is returned with no escaping. This function is appropriate for inserting HTML from other sources, scripts or CSS. If you are looking to add text content to a page you should look at the `text` function as it will sanitize the input, so as to avoid any accidental or malicious inclusion of HTML or script content.
### sub node
```
sub node(
Str:D $tag,
Associative $attributes,
*@children
) returns Callable
```
Generalised html element generator. This function provides the core rules for generating html tags. All tag generators are built upon this function. To create specialised versions of this function use the `tag-factory` and then further specialised with the C function.
### sub tag-factory
```
sub tag-factory(
Str:D $tag
) returns Callable
```
Make functions to create specific tags. Returns a Callable with the signiture (Associative $attributes, \*@children --> Callable). The closure created by this routine wraps up an instance of the `node` routine.
### sub with-attributes
```
sub with-attributes(
&tag,
Associative $attributes
) returns Callable
```
Create a tag with preset attributes. Allows for further specialisation of tag closures from the C routine. The closure returned from this routine has the following signiture (\*@children --> Callable).
### sub html-en
```
sub html-en(
Associative :$attributes = { ... },
*@children
) returns Callable
```
Create a HTML tag with DOCTYPE defenition. Use this function as the top of your document. The default arguments to attributes are set for English, `{:lang<en>, :dir<ltr>}`, but a new Map or hash can be used to tailor this routine to your needs.
### sub include-file
```
sub include-file(
Str:D $file
) returns Callable
```
Include content from a file. Use this function to include external files such as scripts and CSS in your templates. Content is included without any sanitisation of the input.
|
## before.md
before
Combined from primary sources listed below.
# [In StrDistance](#___top "go to top of document")[§](#(StrDistance)_method_before "direct link")
See primary documentation
[in context](/type/StrDistance#method_before)
for **method before**.
This is actually a class attribute, and called as a method returns the string before the transformation:
```raku
say $str-dist.before; # OUTPUT: «fold»
```
# [In Operators](#___top "go to top of document")[§](#(Operators)_infix_before "direct link")
See primary documentation
[in context](/language/operators#infix_before)
for **infix before**.
```raku
multi infix:<before>(Any, Any)
multi infix:<before>(Real:D, Real:D)
multi infix:<before>(Str:D, Str:D)
multi infix:<before>(Version:D, Version:D)
```
Generic ordering, uses the same semantics as [cmp](/routine/cmp). Returns `True` if the first argument is smaller than the second.
|
## dist_zef-jonathanstowe-Oyatul.md
# Oyatul
Abstract representation of a filesystem layout

## Synopsis
This runs the tests identified by 'purpose' test which can be in any
location in the layout with the library directory identified by the
purpose 'lib' :
```
use Oyatul;
my $description = q:to/LAY/;
{
"type" : "layout",
"children" : [
{
"name" : "t",
"purpose" : "tests",
"type" : "directory",
"children" : [
{
"type" : "file",
"purpose" : "test",
"template" : true
}
]
},
{
"type" : "directory",
"purpose" : "lib",
"name" : "lib",
"children" : []
}
]
}
LAY
# the :real adverb causes instance nodes to be inserted
# for any templates if they exist.
my $layout = Oyatul::Layout.from-json($description, root => $*CWD.Str, :real);
# get the directory that stands in for 'lib'
my $lib = $layout.nodes-for-purpose('lib').first.path;
# get all the instances for 'test' excluding the template
for $layout.nodes-for-purpose('test', :real) -> $test {
run($*EXECUTABLE, '-I', $lib, $test.path);
}
```
## Description
This provides a method of describing a filesystem layout in an abstract
manner.
It can be used in the deployment of applications which might need
the creation of a directory tree for data or configuration, or for
applications which may need to locate files and directory that it needs
but can allow the user to define their own .
The file layout descriptions can be stored as JSON or they can be built
programmatically (thus allowing other forms of storage.)
The description can define directories and files in an aribitrary tree
structure, each can optionally define a 'purpose' which can be used to
locate a node irrespective of its location in the tree and name, a node
object can also be given a role with the 'does' key which can give the
node additional behaviours (e.g. create a file of a specific format,
create an object based on a file or directory etc.) Template nodes can
be defined which can stand in for real files or directories which can
be discovered at run-time.
This is based on a design that I used in a large application that relied
heavily on file storage for its data, but is somewhat more simplified
and abstracted as well as preferring JSON over the original XML for the
storage of the layout description. The features are designed to allow
[Sofa](https://github.com/jonathanstowe/Sofa) to load a CouchDB design
document from an arbitrary (possibly user defined) file hierarchy unlike
`couchapp` which requires a fixed directory structure. However
hopefully it will be useful in other applications.
## Installation
Assuming you have a working Rakudo installation you should be able to install this with *zef* :
```
# From the source directory
zef install .
# Remote installation
zef install Oyatul
```
## Support
Suggestions and patches that may make it more useful in your software are welcomed via github at:
<https://github.com/jonathanstowe/Oyatul/issues>
## Licence
This is free software.
Please see the <LICENCE> file in the distribution
© Jonathan Stowe 2016 - 2021
|
## dist_zef-jmaslak-Sys-HostAddr.md
[](https://travis-ci.org/jmaslak/Raku-Sys-HostAddr)
# NAME
Sys::Domainname - Get IP address information about this host
# SYNOPSIS
```
use Sys::Domainname;
my $sysaddr = Sys::HostAddr.new;
my $string = $sysaddr->public;
my @addresses = $sysaddr->addresses;
my @interfaces = $sysaddr->interfaces;
my @on-int-addresses = $sysaddr->addresses-on-interface('eth0');
```
# DESCRIPTION
This module provides methods for determining IP address information about a local host.
# WARNING
This module only functions on relatively recent Linux.
# ATTRIBUTES
## ipv
This attribute refers to the IP Version the class operates against. It must be set to either `4` or `6`. This defaults to `4`.
## ipv4-url
This is the API URL used to obtain the host's public IPv4 address. It defaults to using `https://api.ipify.org`. The URL must return the address as a plain text response.
## ipv6-url
This is the API URL used to obtain the host's public IPv4 address. It defaults to using `https://api6.ipify.org`. The URL must return the address as a plain text response.
## user-agent
This is the user agent string used to idenfiy this module when making web calls. It defaults to this module's name and version.
## filter-localhost
If `filter-localhost` is true, only non-localhost addresses will be returned by this class's methods. This defaults to true.
Localhost is defined as any IPv4 address that begins with `127.` or the IPv6 address `::1`.
## filter-link-local
If `filter-link-local` is true, only non-link-local addresses will be returned by this class's methods. This defaults to true and has no impact when `ipv` is set to `4`.
Link local is defined as any IPv4 address that belong to `fe80::/10`.
# METHODS
## public(-->Str:D)
```
my $ha = Sys::HostAddr.new;
say "My public IP: { $ha.public }";
```
Returns the public IP address used by this host, as determined by contacting an external web service. When the `ipv` property is set to `6`, this may return an IPv4 address if the API endpoint is not reachable via IPv6.
## interfaces(-->Seq:D)
```
my $ha = Sys::HostAddr.new;
@interfaces = $ha.interfaces.list;
```
Returns the interface names for the interfaces on the system. Note that all interfaces available to the `ip` command will be returned, even if they do not have IP addresses assigned. If the `ip` command cannot be executed (for instance, on Windows), this will return a sequene with no members.
## addresses(-->Seq:D)
```
my $ha = Sys::HostAddr.new;
@addresses = $ha.addresses.list;
```
Returns the addresses on the system. If the `ip` command cannot be executed (for instance, on Windows), this will return a sequene with no members.
## addresses-on-interface(Str:D $interface -->Seq:D)
```
my $ha = Sys::HostAddr.new;
@addresses = $ha.addresses-on-interface("eth1").list;
```
Returns the addresses on the interface provided. If the `ip` command cannot be executed (for instance, on Windows), this will return a sequene with no members.
## guess-ip-for-host(Str:D $ip -->Str)
```
my $ha = Sys::HostAddr.new;
$address = $ha.guess-ip-for-host('192.0.2.1');
```
Returns an address associated with the interface used to route packets to the given destination. Where more than one address exists on that interface, or more than one interface has a route to the given host, only one will be returned.
This will return `Str` (undefined type object) if either the host isn't routed in the routing table or if the `ip` command cannot be executed (for instance, on Windows).
## guess-main(-->Str)
```
my $ha = Sys::HostAddr.new;
$address = $ha.guess-main-for-ipv4
```
Returns the result of either `.guess-ip-for-host('0.0.0.0')` or `.guess-ip-for-host('2000::')` depending on the value of `$.ipv4`.
## guess-main-for-ipv6(-->Str)
```
my $ha = Sys::HostAddr.new;
$address = $ha.guess-main-for-ipv6
```
Returns the result of `.guess-ip-for-host('2000::')`.
# AUTHOR
Joelle Maslak [jmaslak@antelope.net](mailto:jmaslak@antelope.net)
Inspired by Perl 5 `Sys::Hostname` by Jeremy Kiester.
# COPYRIGHT AND LICENSE
Copyright © 2020-2022 Joelle Maslak
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_cpan-CTILMES-Native-Compile.md
# Native::Compile - Native Compiling for Raku Modules
# SYNOPSIS
```
# META6.json
"resources" : [ "libraries/mylib" ]
# MyModule.rakumod
my constant LIB = %?RESOURCES<libraries/mylib>;
sub myfunc() is native(LIB) {}
# A Simple Build.rakumod example:
use Native::Compile;
class Build {
method build($dir) {
build :$dir, :lib<mylib>, :src<src/myfile.c>
}
}
# More explicit separate steps Build.rakumod:
use Native::Compile;
class Build {
method build($dir) {
indir $dir, {
my $obj = compile('src/myfile.c');
link('mylib', @$obj);
}
}
}
# A more complicated Build.rakumod:
use Native::Compile;
class Build {
method build($dir, :$verbose, :$dryrun) {
build :$dir, :lib<mylib>, :src<src/myfile.c>, :cc<clang>,
:extra-cflags<-O>, :$verbose, :$dryrun, :clean,
fallback => [ %( :os<windows> # special name for windows
:url<http://somewhere/mylib.dll>,
:hash<abcd343534...> ), # SHA256
%( :os<darwin>,
:version(v10.14+), # Version comparisons
:url<http://somewhere/mylib.dylib>,
:hash<abcd343534...> ) ]
}
}
```
# DESCRIPTION
Compile C and C++ sources, linking them into a shared library in the
module resources. If a prebuilt library is available for Windows or
Mac OS/X, it can download it if a compiler is not available.
This module also exports a `MAIN` subroutine so you can make your
`Build.rakumod` executable and things will just work. It takes the
*-v* / *--verbose* and *-n* / *--dryrun* flags and passes them on to
the `Build.build()`, which can be useful for debugging the build
process.
It exports a number of subroutines that capture what I've observed as
frequent boilerplate for doing this sort of thing throughout the
ecosystem. Many examples seem to do it slightly differently, and I'm
not sure this is yet optimal. This is still a work in progress, and
the interface may still change. I'd like to support the most common
cases here, making easy things easy. Hopefully the **build**
subroutine is all you really need, though the other functions are
exposed if they are useful. You can manually perform the compile/link
steps in class `Build` if needed.
This module is modelled after, and draws from LibraryMake. It doesn't have
the full capabilities of LibraryMake, but for very simple and common cases,
it reduces the amount of required boilerplate. If you need more complex
capabilities, just write a full Makefile and use LibraryMake.
That said, if there is a capability you think would fit into this module,
please propose, either an idea, or even a patch.
# SUBROUTINES
### sub get-vars(\*%args)
Get various compiling variables ala LibraryMake Many of the variables
are retrieved from the VM, based on the original system
compilation. Some are overridden by more appropriate choice. Each of
the variables can also be overridden by named parameters passed in to
this routine, and finally by Environment variables.
### sub win-hash($path, :$verbose, :$dryrun)
Use Windows powershell to compute a sha256 hash of a file
### sub win-fetch($url, $file, :$verbose, :$dryrun)
Use Windows powershell to download a file from a url
### sub openssl-hash($path, :$verbose, :$dryrun)
Use openssl to compute a sha256 hash
### sub curl-fetch($url, $file, :$verbose, :$dryrun)
Use curl to download a file from a url
### sub compile($src, :$obj, \*%args)
Compile a single source file with the right compiler. Can override
defaults with params :cc, :cxx, :cflags, :cxxflags, :extra-cxxflags,
:ccswitch, :ccout or the usual :verbose or :dryrun. Returns the path
to the compiled object.
### sub link($lib, @obj, :$dir = "resources/libraries", :$cpp, \*%args)
Link objects into a shared library, defaulting to the
`resources/libraries` directory. The library name is mangled to match
the system (e.g. `.so`, `.dylib`, `.dll`). Set the :cpp flag to foce
use of the C++ to link so symbols will work right. Can override
defaults with params :cxxld, :ld, :ldflags, :extra-ldflags, :ldshared,
:ldout or the usual :verbose or :dryrun
### sub fetch( :$lib, :$url, :$hash, :$dir = "resources/libraries", \*%args)
Fetch a library from a URL, name mangle the library and install into
resources/libraries by default, pass in :verbose or :dryrun as usual
### sub fallback($lib, @fallback, \*%args)
Process a list of fallback library fetching alternatives, each
possibly with an os/version, a url for the library, and a sha256 hash
for the library.
### sub build(:$lib, :@src, :@fallback, :$clean, :$dir, \*%args)
Build a library from sources in directory :dir compile each source
file, then link. Pass in :clean to remove objects after linking. Other
named parameters passed in are forwarded to the
compiler/linker. Additionally a fallback list will be processed on any
error if present.
### sub MAIN(Str :$dir = ".", Bool :n(:$dryrun), Bool :v(:$verbose))
For command line building
# LICENSE
This work is subject to the Artistic License 2.0.
|
## dist_cpan-GDONALD-Console-Blackjack.md
# Console-Blackjack
Console Blackjack written in Raku
## Features
* Alternate Deck Types
* Variable Number of Decks
* Hand Splitting
* Vegas-style Dealer Play (Dealer hits on soft 16)
* Options Saving
## Install using zef:
```
zef install Console::Blackjack
```
## Run
```
console-blackjack
```
## Increase your terminal font size for a better view:
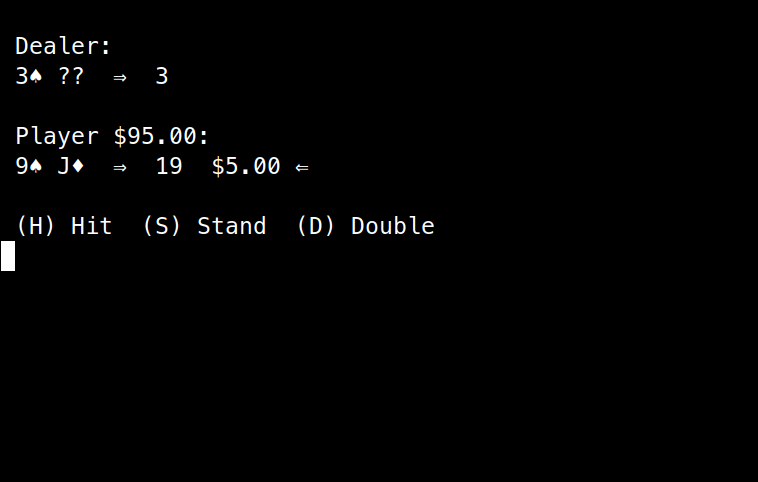
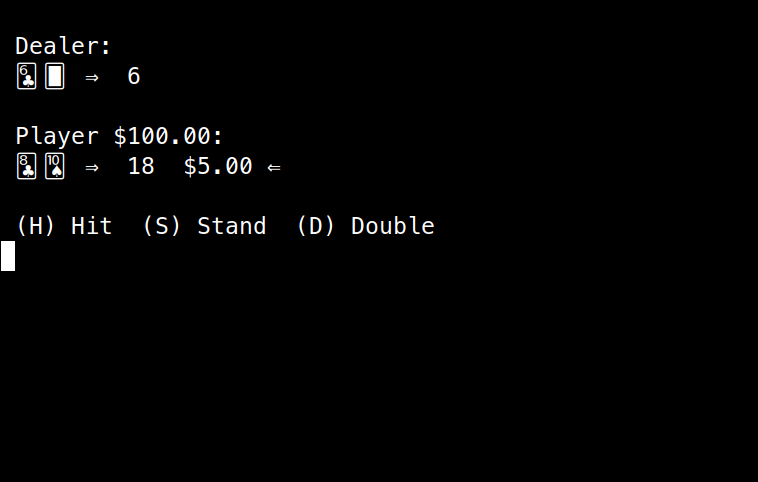
## From source
If you've cloned the git repository you can run it like this:
```
raku -Ilib bin/console-blackjack
```
## Status
[](https://github.com/gdonald/Console-Blackjack/actions)
## Bugs / Issues / Feature Requests
<https://github.com/gdonald/Console-Blackjack/issues>
## License
[](https://github.com/gdonald/Console-Blackjack/blob/master/LICENSE)
## Alternative Implementations:
I've written Blackjack in several other languages:
* [Ruby](https://github.com/gdonald/console-blackjack-ruby)
* [Rust](https://github.com/gdonald/console-blackjack-rust)
* [Typescript](https://github.com/gdonald/blackjack-js)
* [Perl](https://github.com/gdonald/console-blackjack-perl)
* [C](https://github.com/gdonald/blackjack-c)
* [C++](https://github.com/gdonald/blackjack-cpp)
* [Crystal](https://github.com/gdonald/blackjack-cr)
* [Go](https://github.com/gdonald/blackjack-go)
* [Elixir](https://github.com/gdonald/blackjack-ex)
* [Python](https://github.com/gdonald/blackjack-py)
* [C with SDL](https://github.com/gdonald/blackjack-c-sdl)
* [Emacs Lisp](https://github.com/gdonald/blackjack-el)
|
## dist_cpan-GARLANDG-Cro-H.md
[](https://travis-ci.org/Garland-g/Cro-H)
# NAME
Cro::H - A low-level component to interconnect two Cro pipelines
# SYNOPSIS
```
#These classes are stubbed
use Cro::H;
my $h-pipe = Cro::H.new;
my $pipeline1 = Cro.compose(Cro::Source, $h-pipe, Cro::Sink)
my $pipeline2 = Cro.compose(Cro::Source, $h-pipe, Cro::Sink)
($pipeline1, $pipeline2)>>.start;
#Both sinks will receive all the values from both sources
```
# DESCRIPTION
Cro::H is a way to interconnect two pipelines without needing to terminate either pipeline.
Split off a second pipelines by creating a source that outputs nothing as the start of the second pipeline.
Merge two pipelines by creating a sink that ignores all incoming values as the end of the second pipeline.
```
Sample pipeline:
--------- _________________ -------
| Source1 | -> |______ ______| -> | Sink1 |
--------- | | -------
| H |
--------- ______| |______ -------
| Source2 | -> |_________________| -> | Sink2 |
--------- -------
```
# AUTHOR
Travis Gibson [TGib.Travis@protonmail.com](mailto:TGib.Travis@protonmail.com)
# COPYRIGHT AND LICENSE
Copyright 2018 Travis Gibson
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_zef-raku-community-modules-Grammar-Modelica.md
[](https://github.com/raku-community-modules/Grammar-Modelica/actions) [](https://github.com/raku-community-modules/Grammar-Modelica/actions) [](https://github.com/raku-community-modules/Grammar-Modelica/actions)
# NAME
Grammar::Modelica - A Grammar for the Modelica programming language
# SYNOPSIS
```
use Grammar::Modelica;
```
# DESCRIPTION
A Raku Grammar for the [Modelica Language Specification 3.4](https://www.modelica.org/documents/ModelicaSpec34.pdf) (pdf).
The Grammar is mostly a direct translation of the concrete syntax specification found in Appendix B.
See the test files to get some idea of what is going on.
# TODO
* make use of proto and more named parameters to make it more useful
* more stuff by and by
# AUTHOR
Steven Albano
# COPYRIGHT AND LICENSE
Copyright 2017 - 2018 Steven Albano
Copyright 2024 Raku Community
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_zef-bduggan-App-termie.md
# termie
A console for your console
[](https://ci.sparrowhub.io)
## Description
termie (formerly tmeta) is a wrapper for tmux that supports
sending and receiving data to/from tmux panes.
Anything typed into the bottom pane is sent to the top one, but
lines that start with a backslash are commands for `termie`.
You can type `\help` to see all possible commands.
(To send a literal leading backslash, either start with a
space or start with a double backslash.)
## Why
Because you get:
* an uncluttered view of your commands separate from the output
* a local history for commands that are run remotely
* readline interface independent of the remote console
* scripting support for programs that require a TTY
* macros
* the ability to monitor or capture output
* other `expect`-like functionality
* controlled copy-and-paste operations into remote sessions
## Quick start
See below for installation.
There are a few different ways to start `termie`.
1. Start `tmux` yourself, then have `termie` split a window and
start up in its own pane:
```
$ tmux
$ termie
```
2. Let `termie` start tmux for you:
```
$ termie
```
1. Run a termie script. This will split and run in another pane.
```
$ tmux
$ termie script.termie
```
I use the `.termie` suffix for my `termie` scripts. If you do too, you
might like this [vim syntax file](syntax/termie.vim).
## What do I use it with
termie plays well with REPLs, or any console based
application that uses a tty. For instance, docker, rails
console, interactive ruby shell, the python debugger, the
jupyter console, psql, mysql, regular ssh sessions, local
terminal sessions, whatever
## More documentation
Please see the [documentation](https://github.com/bduggan/tmeta/blob/master/doc.md) for a complete list of commands.
## Examples
Show a list of commands.
```
> \help
```
Run `date` every 5 seconds until the output contains `02`
```
> date
> \repeat
> \await 02
```
Within a debugger session, send `next` every 2 seconds.
```
> next
> \repeat 2
```
Search the command history for the last occurrence of 'User' using [fzf](https://github.com/junegunn/fzf)
(readline command history works too)
```
> \find User
```
Search the output for "http"
```
> \grep http
```
Send a local file named `bigfile.rb` to a remote rails console
```
> \send bigfile.rb
```
Same thing, but throttle the copy-paste operation, sending 1 line per second:
```
> \delay 1
> \send bigfile.rb
```
Similar, but send it to an ssh console by first tarring and base64 encoding
and not echoing stdout, and note that 'something' can also be a directory:
```
> \xfer something
```
Run a command locally, sending each line of output to the remote console:
```
> \do echo date
```
Run a shell snippet locally, sending each line of output to the remote console:
```
> \dosh for i in `seq 5`; do echo "ping host-$i"; done
```
Start printing the numbers 1 through 100, one per second, but send a ctrl-c
when the number 10 is printed:
```
> \enq \stop
queue is now : \stop
> for i in `seq 100`; do echo $i; sleep 1; done
# .. starts running in other pane ...
> \await 10
Waiting for "10"
Then I will send:
\stop
Done: saw "10"
starting enqueued command: \stop
```
Add an alias `cat` which cats a local file
```
\alias cat \shell cat
```
Show a local file (do not send it to the other pane) using the above alias
```
\cat myfile
```
Edit a file named session.rb, in ~/.termie/scripts
```
\edit session.rb
```
After running the above, add this to session.rb:
```
irb
\expect irb(main):001:0>
"hello world"
\expect irb(main):002:0>
exit
```
Now running
```
\run session.rb
```
will start the interactive ruby console (irb) and the following
session should take place on the top panel:
```
$ irb
irb(main):001:0> "hello world"
=> "hello world"
irb(main):002:0> exit
$
```
## Installation
Prerequisites: fzf, tmux, libreadline, raku and a few modules
1. Install a recent version of Raku. The recommended way is to use [rakubrew](https://rakubrew.org).
2. Also install `zef`, the Raku package manager (`rakubrew build-zef`)
3. Install [fzf](https://github.com/junegunn/fzf) and [tmux](https://github.com/tmux/tmux/wiki).
(e.g. `brew install fzf tmux` on os/x)
4. zef install <https://github.com/bduggan/termie.git>
## See also
* The [documentation](https://github.com/bduggan/termie/blob/master/doc.md), with links to the source
* The same [documentation](https://github.com/bduggan/termie/blob/master/help.md) as shown by the `\help` command
* This blog article: <https://blog.matatu.org/raku-tmeta>
|
## dist_zef-jonathanstowe-Audio-Sndfile.md
# Audio::Sndfile
Binding to libsndfile ( <http://www.mega-nerd.com/libsndfile/> )
[](https://github.com/jonathanstowe/Audio-Sndfile/actions/workflows/main.yml)
## Description
This library provides a mechanism to read and write audio data files in
various formats by using the API provided by libsndfile.
A full list of the formats it is able to work with can be found at:
<http://www.mega-nerd.com/libsndfile/#Features>
if you need to work with formats that aren't listed then you will need to
find another library.
The interface presented is slightly simplified with regard to that of
libsndfile and whilst it does nearly everything I need it do, I have opted
to release the most useful functionality early and progressively add
features as it becomes clear how they should be implemented.
The "examples" directory in the repository contains some sample code that
may be useful or indicate how you might achieve a particular task.
The full documentation is available as [Markdown](Documentation.md) or
as POD withing the module file.
## Installation
You will need to have "libsndfile" installed on your system in order to
be able to use this. Most Linux distributions offer it as a package, though
it is such a common dependency for multimedia applications that you may well
already have it installed.
If you are on some platform that doesn't provide libsndfile as a package
then you may be able to install it from source:
<http://www.mega-nerd.com/libsndfile/#Download>
I am however unlikely to be able to offer help with installing it this way.
Assuming you have a working Rakudo installation you should be able to install this with *zef* :
```
# From the source directory
zef install .
# Remote installation
zef install Audio::Sndfile
```
## Support
Suggestions/patches are welcomed via github at
<https://github.com/jonathanstowe/Audio-Sndfile/issues>
There are several things that I know don't work properly at the time of the
first release:
```
* May not work at all or be unstable on 32 bit systems
( This is because data that references the number of frames is
native sized within libsndfile - when I have worked out how to
do the equivalent of a conditional typedef I'll fix this .)
```
Also I'd prefer to keep features that aren't directly related to those
provided by libsndfile separate, so if you want to manipulate the data,
play the data to some audio device or stream it for instance you probably
want to consider making a new module.
## Licence
This is free software.
Please see the <LICENCE> file in the distribution.
© Jonathan Stowe 2015 - 2024
|
## dist_zef-raku-community-modules-Template-Mojo.md
[](https://github.com/raku-community-modules/Template-Mojo/actions)
# TITLE
class Template::Mojo
A templating system modeled after the Perl's <https://metacpan.org/module/Mojo::Template>
# SYNOPSIS
```
my $tmpl = slurp 'eg/template.tm';
my $t = Template::Mojo.new($tmpl);
$t.render()
my $ot = Template::Mojo.from-file('eg/template.tm');
```
# EXAMPLES
## Loop
### Template
```
% for 1..3 {
hello
% }
```
### Code
```
my $tmpl = slurp 'eg/template.tm';
my $t = Template::Mojo.new($tmpl);
$t.render()
```
### Output
```
hello
hello
hello
```
## Parameters
### Template
```
% my ($x) = @_;
<%= $x %>
% for 1..$x {
hello
% }
```
See, on the first row of the template we accept a parameter as if this was a generic function call. Then we use the veriable in two different ways.
### Code
The value to that subroutione can be passed in the render call:
```
my $tmpl = slurp 'eg/template.tm';
my $t = Template::Mojo.new($tmpl);
$t.render(5)
```
### Output:
```
5
hello
hello
hello
hello
hello
```
## Passing hash
### Template
```
% my ($x) = @_;
Fname: <%= $x<fname> %>
Lname: <%= $x<lname> %>
```
### Code
```
my %params = (
fname => 'Foo',
lname => 'Bar',
);
my $tmpl = slurp 'eg/template.tm';
my $t = Template::Mojo.new($tmpl);
$t.render(%params)
```
### Output
```
Fname: Foo
Lname: Bar
```
## Complex examples
### Template
```
% my (%h) = @_;
<h1><%= %h<title> %>
<ul>
% for %h<pages>.values -> $p {
<li><a href="<%= $p<url> %>"><%= $p<title> %></a></li>
% }
</ul>
```
### Code
```
my %params = (
title => "Perl 6 Links",
pages => [
{
"title" => "Rakudo",
"url" => "http://rakudo.org/",
},
{
title => 'Perl 6',
url => 'http://perl6.org/',
}
],
);
my $tmpl = slurp 'eg/template.tm';
my $t = Template::Mojo.new($tmpl);
$t.render(%params)
```
### Output
```
<h1>Perl 6 Links
<ul>
<li><a href="http://rakudo.org/">Rakudo</a></li>
<li><a href="http://perl6.org/">Perl 6</a></li>
</ul>
```
# AUTHOR
Tadeusz “tadzik” Sośnierz"
# COPYRIGHT AND LICENSE
Copyright 2012-2017 Tadeusz Sośnierz Copyright 2023 Raku Community
This library is free software; you can redistribute it and/or modify it under the MIT license.
Please see the LICENCE file in the distribution
# CONTRIBUTORS
* Andrew Egeler
* Anthony Parsons
* Carl Masak
* Gabor Szabo
* Moritz Lenz
* Sterling Hanenkamp
* Timo Paulssen
* Tobias Leich
|
## w.md
w
Combined from primary sources listed below.
# [In IO::Special](#___top "go to top of document")[§](#(IO::Special)_method_w "direct link")
See primary documentation
[in context](/type/IO/Special#method_w)
for **method w**.
```raku
method w(IO::Special:D: --> Bool)
```
The 'write access' file test operator, returns `True` only if this instance represents either the standard output (`<STOUT>`) or the standard error (`<STDERR>`) handle.
# [In Proc::Async](#___top "go to top of document")[§](#(Proc::Async)_method_w "direct link")
See primary documentation
[in context](/type/Proc/Async#method_w)
for **method w**.
```raku
method w(Proc::Async:D:)
```
Returns a true value if `:w` was passed to the constructor, that is, if the external program is started with its input stream made available to output to the program through the `.print`, `.say` and `.write` methods.
# [In IO::Path](#___top "go to top of document")[§](#(IO::Path)_method_w "direct link")
See primary documentation
[in context](/type/IO/Path#method_w)
for **method w**.
```raku
method w(IO::Path:D: --> Bool:D)
```
Returns `True` if the invocant is a path that exists and is writable. The method will [`fail`](/routine/fail) with [`X::IO::DoesNotExist`](/type/X/IO/DoesNotExist) if the path points to a non-existent filesystem entity.
|
## dist_zef-antononcube-ML-NLPTemplateEngine.md
# ML::NLPTemplateEngine
This Raku package aims to create (nearly) executable code for various computational workflows.
Package's data and implementation make a Natural Language Processing (NLP)
[Template Engine (TE)](https://en.wikipedia.org/wiki/Template_processor), [Wk1],
that incorporates
[Question Answering Systems (QAS')](https://en.wikipedia.org/wiki/Question_answering), [Wk2],
and Machine Learning (ML) classifiers.
The current version of the NLP-TE of the package heavily relies on Large Language Models (LLMs) for its QAS component.
Future plans involve incorporating other types of QAS implementations.
The Raku package implementation closely follows the Wolfram Language (WL) implementations in
["NLP Template Engine"](https://github.com/antononcube/NLP-Template-Engine), [AAr1, AAv1],
and the WL paclet
["NLPTemplateEngine"](https://resources.wolframcloud.com/PacletRepository/resources/AntonAntonov/NLPTemplateEngine/), [AAp2, AAv2].
An alternative, more comprehensive approach to building workflows code is given in [AAp2].
### Problem formulation
We want to have a system (i.e. TE) that:
1. Generates relevant, correct, executable programming code based on natural language specifications of computational
workflows
2. Can automatically recognize the workflow types
3. Can generate code for different programming languages and related software packages
The points above are given in order of importance; the most important are placed first.
### Reliability of results
One of the main reasons to re-implement the WL NLP-TE, [AAr1, AAp1], into Raku is to have a more robust way
of utilizing LLMs to generate code. That goal is more or less achieved with this package, but
YMMV -- if incomplete or wrong results are obtained run the NLP-TE with different LLM parameter settings
or different LLMs.
---
## Installation
From Zef ecosystem:
```
zef install ML::NLPTemplateEngine;
```
From GitHub:
```
zef install https://github.com/antononcube/Raku-ML-NLPTemplateEngine.git
```
---
## Usage examples
### Quantile Regression (WL)
Here the template is automatically determined:
```
use ML::NLPTemplateEngine;
my $qrCommand = q:to/END/;
Compute quantile regression with probabilities 0.4 and 0.6, with interpolation order 2, for the dataset dfTempBoston.
END
concretize($qrCommand);
```
```
# qrObj=
# QRMonUnit[dfTempBoston]⟹
# QRMonEchoDataSummary[]⟹
# QRMonQuantileRegression[12, {0.4, 0.6}, InterpolationOrder->2]⟹
# QRMonPlot["DateListPlot"->True,PlotTheme->"Detailed"]⟹
# QRMonErrorPlots["RelativeErrors"->False,"DateListPlot"->True,PlotTheme->"Detailed"];
```
**Remark:** In the code above the template type, "QuantileRegression", was determined using an LLM-based classifier.
### Latent Semantic Analysis (R)
```
my $lsaCommand = q:to/END/;
Extract 20 topics from the text corpus aAbstracts using the method NNMF.
Show statistical thesaurus with the words neural, function, and notebook.
END
concretize($lsaCommand, template => 'LatentSemanticAnalysis', lang => 'R');
```
```
# lsaObj <-
# LSAMonUnit(aAbstracts) %>%
# LSAMonMakeDocumentTermMatrix(stemWordsQ = Automatic, stopWords = Automatic) %>%
# LSAMonEchoDocumentTermMatrixStatistics(logBase = 10) %>%
# LSAMonApplyTermWeightFunctions(globalWeightFunction = "IDF", localWeightFunction = "None", normalizerFunction = "Cosine") %>%
# LSAMonExtractTopics(numberOfTopics = 20, method = "NNMF", maxSteps = 16, minNumberOfDocumentsPerTerm = 20) %>%
# LSAMonEchoTopicsTable(numberOfTerms = 10, wideFormQ = TRUE) %>%
# LSAMonEchoStatisticalThesaurus(words = c("neural", "function", "notebook"))
```
### Random tabular data generation (Raku)
```
my $command = q:to/END/;
Make random table with 6 rows and 4 columns with the names <A1 B2 C3 D4>.
END
concretize($command, template => 'RandomTabularDataset', lang => 'Raku', llm => 'gemini');
```
```
# random-tabular-dataset(6, 4, "column-names-generator" => <A1 B2 C3 D4>, "form" => "Table", "max-number-of-values" => 24, "min-number-of-values" => 24, "row-names" => False)
```
**Remark:** In the code above it was specified to use Google's Gemini LLM service.
---
## CLI
The package provides the Command Line Interface (CLI) script `concretize`. Here is usage note:
```
concretize --help
```
```
# Usage:
# concretize [<words> ...] [-t|--template=<Str>] [-l|--to|--lang=<Str>] [-c|--clipboard-command=<Str>] [--<args>=...]
#
# -t|--template=<Str> Template to use. [default: 'Whatever']
# -l|--to|--lang=<Str> Template's language. [default: 'R']
# -c|--clipboard-command=<Str> Clipboard command to use. [default: 'Whatever']
# --<args>=... Additional arguments for &ML::FindTextualAnswer::find-textual-answer.
```
---
## How it works?
The following flowchart describes how the NLP Template Engine involves a series of steps for processing a computation
specification and executing code to obtain results:
```
flowchart TD
spec[/Computation spec/] --> workSpecQ{"Is workflow type<br>specified?"}
workSpecQ --> |No| guess[[Guess relevant<br>workflow type]]
workSpecQ -->|Yes| raw[Get raw answers]
guess -.- classifier[[Classifier:<br>text to workflow type]]
guess --> raw
raw --> process[Process raw answers]
process --> template[Complete<br>computation<br>template]
template --> execute[/Executable code/]
execute --> results[/Computation results/]
llm{{LLM}} -.- find[[find-textual-answer]]
llm -.- classifier
subgraph LLM-based functionalities
classifier
find
end
find --> raw
raw --> find
template -.- compData[(Computation<br>templates<br>data)]
compData -.- process
classDef highlighted fill:Salmon,stroke:Coral,stroke-width:2px;
class spec,results highlighted
```
Here's a detailed narration of the process:
1. **Computation Specification**:
* The process begins with a "Computation spec", which is the initial input defining the requirements or parameters
for the computation task.
2. **Workflow Type Decision**:
* A decision node asks if the workflow type is specified.
3. **Guess Workflow Type**:
* If the workflow type is not specified, the system utilizes a classifier to guess relevant workflow type.
4. **Raw Answers**:
* Regardless of how the workflow type is determined (directly specified or guessed), the system retrieves "raw
answers", crucial for further processing.
5. **Processing and Templating**:
* The raw answers undergo processing ("Process raw answers") to organize or refine the data into a usable format.
* Processed data is then utilized to "Complete computation template", preparing for executable operations.
6. **Executable Code and Results**:
* The computation template is transformed into "Executable code", which when run, produces the final "Computation
results".
7. **LLM-Based Functionalities**:
* The classifier and the answers finder are LLM-based.
8. **Data and Templates**:
* Code templates are selected based on the specifics of the initial spec and the processed data.
---
## Bring your own templates
**0.** Load the NLP-Template-Engine package (and others):
```
use ML::NLPTemplateEngine;
use Data::Importers;
use Data::Summarizers;
```
```
# (Any)
```
**1.** Get the "training" templates data (from CSV file you have created or changed) for a new workflow
(["SendMail"](https://github.com/antononcube/NLP-Template-Engine/blob/main/TemplateData/dsQASParameters-SendMail.csv)):
```
my $url = 'https://raw.githubusercontent.com/antononcube/NLP-Template-Engine/main/TemplateData/dsQASParameters-SendMail.csv';
my @dsSendMail = data-import($url, headers => 'auto');
records-summary(@dsSendMail, field-names => <DataType WorkflowType Group Key Value>);
```
```
# +-----------------+----------------+-----------------------------+----------------------------+----------------------------------------------------------------------------------+
# | DataType | WorkflowType | Group | Key | Value |
# +-----------------+----------------+-----------------------------+----------------------------+----------------------------------------------------------------------------------+
# | Questions => 48 | SendMail => 60 | All => 9 | TypePattern => 12 | 0.35 => 9 |
# | Defaults => 7 | | What it the content => 4 | Parameter => 12 | {_String..} => 8 |
# | Templates => 3 | | What it the title => 4 | ContextWordsToRemove => 12 | _String => 4 |
# | Shortcuts => 2 | | Who the email is from => 4 | Threshold => 12 | {"to", "email", "mail", "send", "it", "recipient", "addressee", "address"} => 4 |
# | | | Which files to attach => 4 | Template => 3 | None => 4 |
# | | | What it the body => 4 | attachedFiles => 1 | to => 4 |
# | | | What subject => 4 | SendMail => 1 | body => 3 |
# | | | (Other) => 27 | (Other) => 7 | (Other) => 24 |
# +-----------------+----------------+-----------------------------+----------------------------+----------------------------------------------------------------------------------+
```
**2.** Add the ingested data for the new workflow (from the CSV file) into the NLP-Template-Engine:
```
add-template-data(@dsSendMail);
```
```
# (Templates Defaults ParameterQuestions ParameterTypePatterns Questions Shortcuts)
```
**3.** Parse natural language specification with the newly ingested and onboarded workflow ("SendMail"):
```
"Send email to joedoe@gmail.com with content RandomReal[343], and the subject this is a random real call."
==> concretize(template => "SendMail")
```
```
# SendMail[<|"To"->{"joedoe@gmail.com"},"Subject"->"this is a random real call.","Body"->RandomReal[343],"AttachedFiles"->None|>]
```
**4.** Experiment with running the generated code!
---
## TODO
* Templates data
* Using JSON instead of CSV format for the templates
* Derive suitable data structure
* Implement export to JSON
* Implement ingestion
* Review wrong parameter type specifications
* A few were found.
* New workflows
* LLM-workflows
* Clustering
* Associative rule learning
* Unit tests
* What are good ./t unit tests?
* Make ingestion ./t unit tests
* Make suitable ./xt unit tests
* Documentation
* Comparison with LLM code generation using few-shot examples
* Video demonstrating the functionalities
---
## References
### Articles
[Wk1] Wikipedia entry, [Template processor](https://en.wikipedia.org/wiki/Template_processor).
[Wk2] Wikipedia entry, [Question answering](https://en.wikipedia.org/wiki/Question_answering).
### Functions, packages, repositories
[AAr1] Anton Antonov,
["NLP Template Engine"](https://github.com/antononcube/NLP-Template-Engine),
(2021-2022),
[GitHub/antononcube](https://github.com/antononcube).
[AAp1] Anton Antonov,
[NLPTemplateEngine WL paclet](https://resources.wolframcloud.com/PacletRepository/resources/AntonAntonov/NLPTemplateEngine/),
(2023),
[Wolfram Language Paclet Repository](https://resources.wolframcloud.com/PacletRepository/).
[AAp2] Anton Antonov,
[DSL::Translators Raku package](https://github.com/antononcube/Raku-DSL-Translators),
(2020-2024),
[GitHub/antononcube](https://github.com/antononcube).
[WRI1] Wolfram Research,
[FindTextualAnswer](https://reference.wolfram.com/language/ref/FindTextualAnswer.html),
(2018),
[Wolfram Language function](https://reference.wolfram.com), (updated 2020).
### Videos
[AAv1] Anton Antonov,
["NLP Template Engine, Part 1"](https://youtu.be/a6PvmZnvF9I),
(2021),
[YouTube/@AAA4Prediction](https://www.youtube.com/@AAA4Prediction).
[AAv2] Anton Antonov,
["Natural Language Processing Template Engine"](https://www.youtube.com/watch?v=IrIW9dB5sRM) presentation given at
WTC-2022,
(2023),
[YouTube/@Wolfram](https://www.youtube.com/@Wolfram).
|
## dist_zef-jonathanstowe-Util-Uuencode.md
# Util::Uuencode
uuencode/uudecode for Raku

## Synopsis
use Util::Uuencode;
my $image = "some-image.jpg".IO.slurp(:bin);
my $encoded = uuencode($image);
# now $encoded can be sent or stored as text safely
$image = uudecode($encoded);
# now have the image back as binary
## Description
[uuencode](https://en.wikipedia.org/wiki/Uuencoding) is a binary to text encoding mechanism designed for sending binary files across computer boundaries where the transport mechanism may not be 8 bit clean, such as e-mail, usenet or uucp. It has largely been obsoleted by MIME (and Base64 encoding,) and the advent of ubiquitous 8 bit clean networking.
This module provides routines for uuencoding (`uuencode`) and decoding (`uudecode`) which will round trip data between binary and text encoded representations. `uuencode` will quite happily encode plain text but as the effect is to make it a third larger there isn't much point doing that ( I guess at a push it could be used to preserve some unicode encoding across some boundary that doesn't deal with that well.)
The POSIX commands [uuencode and uudecode](https://pubs.opengroup.org/onlinepubs/9699919799/utilities/uuencode.html) expect some additional header and trailer information which this module doesn't deal with, so if you expect your data to be processed by these tools you will need to add this to your encoded output and remove it from the input for correct processing.
## Installation
Assuming you have a working Rakudo installation then this can be installed by `zef` :
```
zef install Util::Uuencode
# Or from a local clone
zef install .
```
There are no depenencies.
## Support
This is one of those things that either works or it doesn't but if you have a problem or suggestions please report them on [Github](https://github.com/jonathanstowe/Util-Uuencode/issues).
## Licence
This is free software.
Please see the <LICENCE> file in the distribution.
© Jonathan Stowe 2020
|
## dist_zef-raku-community-modules-LWP-Simple.md
# LWP::Simple for Raku

This is a quick & dirty implementation of a LWP::Simple clone for Raku; it does both `GET` and `POST` requests.
# Dependencies
LWP::Simple depends on the modules MIME::Base64 and URI,
which you can find at <http://modules.raku.org/>. The tests depends
on [JSON::Tiny](https://github.com/moritz/json).
Write:
```
zef install --deps-only .
```
You'll have to
install [IO::Socket::SSL](https://github.com/sergot/io-socket-ssl) via
```
zef install IO::Socket::SSL
```
if you want to work with `https` too.
# Synopsis
```
use LWP::Simple;
my $content = LWP::Simple.get("https://raku.org");
my $response = LWP::Simple.post("https://somewhere.topo.st", { so => True }
```
# Methods
## get ( $url, [ %headers = {}, Bool :$exception ] )
Sends a GET request to the value of `$url`. Returns the content of the return
request. Errors are ignored and will result in a `Nil` value unless
`$exception` is set to `True`, in which case an `LWP::Simple::Response` object
containing the status code and brief description of the error will be returned.
Requests are make with a default user agent of `LWP::Simple/$VERSION Raku/$*PERL.compiler.name()` which may get blocked by some web servers. Try
overriding the default user agent header by passing a user agent string to the
`%headers` argument with something like `{ 'User-Agent' => 'Your User-Agent String' }` if you have trouble getting content back.
# Current status
You can
use [HTTP::UserAgent](https://github.com/sergot/http-useragent)
instead, with more options. However, this module will do just fine in
most cases.
The documentation of this module is incomplete. Contributions are appreciated.
# Use
Use the installed commands:
```
lwp-download.p6 http://eu.httpbin.org
```
Or
```
lwp-download.p6 https://docs.perl6.org
```
If `ÌO::Socket::SSL` has been installed.
```
lwp-get.p6 https://raku.org
```
will instead print to standard output.
# Known bugs
According
to
[issues raised](https://github.com/raku-community-modules/LWP-Simple/issues/40),
[in this repo](https://github.com/raku-community-modules/LWP-Simple/issues/28),
there could be some issues with older versions of MacOSx. This issue
does not affect the functionality of the module, but just the test
script itself, so you can safely install with `--force`. Right now,
it's working correctly (as far as tests go) with Windows, MacOSx and
Linux.
# License
This distribution is licensed under the terms of
the
[Artistic 2.0 license](https://www.perlfoundation.org/artistic-license-20.html). You
can find a [copy](LICENSE) in the repository itself.
|
## one.md
one
Combined from primary sources listed below.
# [In Any](#___top "go to top of document")[§](#(Any)_method_one "direct link")
See primary documentation
[in context](/type/Any#method_one)
for **method one**.
```raku
method one(--> Junction:D)
```
Interprets the invocant as a list and creates a [one](/routine/one)-[`Junction`](/type/Junction) from it.
```raku
say so 1 == (1, 2, 3).one; # OUTPUT: «True»
say so 1 == (1, 2, 1).one; # OUTPUT: «False»
```
|
## dist_cpan-KAIEPI-Crypt-CAST5.md
[](https://travis-ci.org/Kaiepi/p6-Crypt-CAST5)
# NAME
Crypt::CAST5 - CAST5 encryption library
# SYNOPSIS
```
use Crypt::CAST5;
my Crypt::CAST5 $cast5 .= new: 'ayy lmao'.encode;
my Str $in = 'sup my dudes';
my Blob $encoded = $cast5.encode: $in.encode;
my Blob $decoded = $cast5.decode: $encoded;
my Str $out = $decoded.decode;
say $out; # OUTPUT: sup my dudes
```
# DESCRIPTION
**Warning: this implementation is naive and is not implemented in constant time, thus it is vulnerable to side channel attacks. Do not use this library for any serious applications as it stands now!**
Crypt::CAST5 is a library that handles encryption and decryption using the CAST5 algorithm. Currently, only the ECB block cipher mode is supported.
# METHODS
* **new**(Blob *$key*)
Constructs a new instance of Crypt::CAST5 using the given block cipher mode and key. The key must be 5-16 bytes in length.
* **encode**(Blob *$plaintext* --> Blob)
Encodes `$plaintext` using CAST5 encryption.
* **decode**(Blob *$ciphertext* --> Blob)
Decodes `$ciphertext` using CAST5 encryption.
# AUTHOR
Ben Davies (Kaiepi)
# COPYRIGHT AND LICENSE
Copyright 2018 Ben Davies
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_zef-jonathanstowe-Audio-Libshout.md
# Audio::Libshout
Raku binding to libshout - provide icecast/streaming client

## Synopsis
```
use v6;
use Audio::Libshout;
sub MAIN(IO(Str) $in-file) {
my $shout = Audio::Libshout.new(password => 'hackme', mount => '/foo', format => Audio::Libshout::Format::MP3);
my $fh = $in-file.open(:bin);
my $channel = $shout.send-channel;
while not $fh.eof {
my $buf = $fh.read(4096);
$channel.send($buf);
}
$fh.close;
$channel.close;
$shout.close;
}
```
## Description
This provides a source client to stream to an icecast server. It can
stream Ogg/Vorbis or MP3 data but doesn't provide any transcoding so the
data will need to be provided from an appropriate source in the required
encoding. This has been developed against version 2.2.2 of libshout,
it is possible later versions may provide support for other encodings.
The API is somewhat simplified in comparison to libshout but provides
an asynchronous mechanism whereby data can be fed as quickly as it is
obtained to a worker thread via a channel so the client doesn't have
to worry about the timing and synchronisation issues, though the lower
level send and sync methods are available if your application requires
a different scheme.
In testing this proved quite capable of streaming a 320kb/s MP3 read from
a file to an icecast server on the local network, though of course network
conditions may limit the rate that will work well to remote servers.
The "examples" directory in the distribution contains a simple streaming
source client that will allow you to send an Ogg or MP3 file to an
icecast server.
If you're curious the first thing that I streamed using this library was
<https://www.mixcloud.com/mikestern-awakening/mike-stern-guest-mix-for-technotic-eire-radio-show/>
Mike's a great DJ, great DJs and producers make making software
worthwhile :)
The full documentation is available as [markdown](Documentation.md) or embedded POD.
## Installation
You will need to have "libshout" installed on your system in order to
be able to use this. Most Linux distributions offer it as a package.
If you are on some platform that doesn't provide libshout as a package
then you may be able to install it from source:
<https://github.com/xiph/Icecast-libshout>
I am however unlikely to be able to offer help with installing it this way, also bear in mind that
if you install a newer version than I have to test with then this may not work.
In order to perform some of the tests you will need to have a working Icecast server available,
these tests will be skipped if one isn't found. The tests use some default values for the server
parameters that can be over-written by some environment variables:
* SHOUT\_TEST\_HOST - the host to connect to. The default is 'localhost'
* SHOUT\_TEST\_PORT - the port to connect to. The default is 8000.
* SHOUT\_TEST\_USER - the user to authenticate as. The default is 'source'.
* SHOUT\_TEST\_PASS - the password to authenticate with. The default is 'hackme' but you changed that right?
* SHOUT\_TEST\_MOUNT - the mount point on the server to use. The default is '/shout\_test'
Assuming you have a working Rakudo installation as well as a working icecast server you should be able to install this with *zef* :
```
# From the source directory
zef install .
# Remote installation
zef install Audio::Libshout
```
## Support
Suggestions/patches are welcomed via [github](https://github.com/jonathanstowe/Audio-Libshout)
I have tested this and found it to work with my installation of icecast,
so it should work anywhere else, if however you experience a problem
with streaming please test with another source client such as ices or
darkice before reporting a bug as I am unlikely to be able to help you
with your streaming configuration.
There are some small variations in the behaviour of `libshout` between
versions and these are documented where known in [the Documentation](Documentation.md) however please supply the `libshout` version if you find unexpected behaviour.
## Licence
Please see the <LICENCE> file in the distribution
© Jonathan Stowe 2015, 2016, 2017, 2019, 2020, 2021
|
## dist_github-colomon-Test-Junkie.md
# Test::Junkie
## Continuous test runner for Perl 6
Requires a recent version of Rakudo (after April 21st, 2012) for updates IO.pm
changetime detection. Currently depends on Perl 5 prove as a testrunner.
## Background
**junk·ie** *noun* \ˈjəŋ-kē\ - a person who derives inordinate pleasure from or who is dependent on something *(in this case testing)*
The initial version was developed as a part of the Perl 6 patterns hackathon in Oslo, and based on masak's mini-tote Gist for all functionality. See: <https://gist.github.com/834500>
##Planned extensions
* pluggable implementations for running tests
* pluggable implementations for reporting
* separate running from reporting
* option to 'make' before running tests in order to update blib/lib (should be useful for modules already installed
|
## dist_zef-thundergnat-String-Rotate.md
[](https://github.com/thundergnat/String-Rotate/actions)
# NAME
String::Rotate - Rotate, but for Strings directly instead of through Lists
# SYNOPSIS
```
use String::Rotate;
say 'Rakudo'.&rotate; # akudoR
say 'Rakudo'.&rotate(-1); # oRakud
say rotate 'Rakudo', 3; # udoRak
```
Also export a Role `Rotate` which may be used to augment strings
```
use String::Rotate;
use MONKEY-TYPING;
augment class Str does Rotate { }
say 'Rakudo'.rotate; # akudoR
say 'Rakudo'.rotate(-1); # oRakud
```
# DESCRIPTION
Rotate routine, but for Strings instead of Lists. Seems a little redundant at first glance, you could easily do `'Rakudo'.comb.list.rotate.join` for the same effect, but the purpose built routines are, at a minimum, twice as fast and may be tens or hundreds times faster for longer strings.
This routine takes a String, returns a String and only perform String operations. It runs in near constant time no matter how long the string is. `.comb.list.rotate.join` is heavily influenced by the size of the string.
# AUTHOR
thundergnat (Steve Schulze)
# COPYRIGHT AND LICENSE
Copyright 2020 thundergnat
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_zef-patrickb-Devel-ExecRunnerGenerator.md
```
=begin pod
=head1 NAME
Devel::ExecRunnerGenerator
=head1 SYNOPSIS
=begin code :lang
use Devel::ExecRunnerGenerator;
Devel::ExecRunnerGenerator::generate(
program => "bin/raku",
cwd => ".",
args => [
"./path/to/some/script.raku",
""
],
arg0 => "some-fake-name",
env-add => {
DEBUG => 1,
},
env-remove => [
"LD_PRELOAD",
],
archs => [
"posix",
"windows-x86_64.exe",
],
out-path => ".",
:overwrite
);
=end code
=head1 DESCRIPTION
A tool to generate native wrapper executables (similar to the infamous .bat/.sh wrappers)
=head2 Paths
Paths are always to be written with forward slashes as separators.
=head2 Argument operators
The I and I parameters must have one of the below operators applied to them.
Operators are applied by simply prefixing them to the string.
=defn
Use the arg unchanged
=defn
Insert the passed arguments. Must not be followed by anything.
=defn
Change path (with slashes) to have the platform separators.
=defn
Turn into an absolute path. The base to prefix is the directory the wrapper
executable is located in. Separators are normalized to the platform path separators.
=defn
Turn into an absolute path. The base to prefix is the directory the wrapper
executable is located in. Separators are normalized to be a slash.
=head2 Arguments
=head3 program
Program to call. Either a program name to be searched in PATH, or a path.
The following Is are supported:
=item
=item
=item
=item
Do note that the PATH of the environment I modification by the
I and I have been done. So clearing out the
PATH variable and then trying to call a program via PATH won't work.
=head3 arg0
Use a custom arg0 instead of the program name. This is only supported on
Windows, as it's not possible to set arg0 in an exec call using a POSIX shell.
All platforms except for Windows generate POSIX shell code.
=head3 cwd
The working directory to switch to before calling the program.
If empty or missing, the working directory will be left unchanged.
Either pass an absolute path and use the I operator or pass a path
relative to the wrappers parent directory and use the I operator.
To set the working directory to the wrappers parent directory itself pass ".".
The following Is are supported:
=item
=item
=head3 args
The arguments to pass to the program.
The following Is are supported:
=item
=item
=item
=item
=item
=head3 env-add
Hash of environment variables to add / overwrite in the programs
environment.
=head3 env-remove
List of environment variables to remove from the programs env.
=head1 Standalone usage
A script called `exec-runner-generator` is also provided, which provides access
to the above described functionality without having to write any code. The
program requires a single argument, a path to a configuration file containing
JSON text of the above arguments. An example configuration file is provided at
`doc/example.json`.
=head1 AUTHOR
Patrick Böker
=head1 COPYRIGHT AND LICENSE
Copyright 2020-2022 Patrick Böker
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
=end pod
```
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.