|
|
--- |
|
|
license: apache-2.0 |
|
|
datasets: |
|
|
- AadityaJain/Fromula_text_classification |
|
|
language: |
|
|
- en |
|
|
base_model: |
|
|
- google/siglip2-base-patch16-224 |
|
|
pipeline_tag: image-classification |
|
|
library_name: transformers |
|
|
tags: |
|
|
- Formula-Text-Detection |
|
|
- SigLIP2 |
|
|
- Image-Classification |
|
|
--- |
|
|
|
|
|
 |
|
|
|
|
|
# **Formula-Text-Detection** |
|
|
|
|
|
> **Formula-Text-Detection** is a vision-language encoder model fine-tuned from **google/siglip2-base-patch16-224** for **binary image classification**. It is built using the **SiglipForImageClassification** architecture to distinguish between **mathematical formulas** and **natural text** in document or image regions. |
|
|
|
|
|
> [!Note] |
|
|
> Note: This model works best with plain text or formulas using the same font style |
|
|
|
|
|
|
|
|
```py |
|
|
Classification Report: |
|
|
precision recall f1-score support |
|
|
|
|
|
formula 0.9983 1.0000 0.9991 6375 |
|
|
text 1.0000 0.9980 0.9990 5457 |
|
|
|
|
|
accuracy 0.9991 11832 |
|
|
macro avg 0.9991 0.9990 0.9991 11832 |
|
|
weighted avg 0.9991 0.9991 0.9991 11832 |
|
|
``` |
|
|
|
|
|
 |
|
|
|
|
|
--- |
|
|
|
|
|
> [!note] |
|
|
*SigLIP 2: Multilingual Vision-Language Encoders with Improved Semantic Understanding, Localization, and Dense Features* https://arxiv.org/pdf/2502.14786 |
|
|
|
|
|
--- |
|
|
|
|
|
## **Label Space: 2 Classes** |
|
|
|
|
|
The model classifies each input image into one of the following categories: |
|
|
|
|
|
``` |
|
|
Class 0: "formula" |
|
|
Class 1: "text" |
|
|
``` |
|
|
|
|
|
--- |
|
|
|
|
|
## **Install Dependencies** |
|
|
|
|
|
```bash |
|
|
pip install -q transformers torch pillow gradio |
|
|
``` |
|
|
|
|
|
--- |
|
|
|
|
|
## **Inference Code** |
|
|
|
|
|
```python |
|
|
import gradio as gr |
|
|
from transformers import AutoImageProcessor, SiglipForImageClassification |
|
|
from PIL import Image |
|
|
import torch |
|
|
|
|
|
# Load model and processor |
|
|
model_name = "prithivMLmods/Formula-Text-Detection" # Replace with your model path if different |
|
|
model = SiglipForImageClassification.from_pretrained(model_name) |
|
|
processor = AutoImageProcessor.from_pretrained(model_name) |
|
|
|
|
|
# Label mapping |
|
|
id2label = { |
|
|
"0": "formula", |
|
|
"1": "text" |
|
|
} |
|
|
|
|
|
def classify_formula_or_text(image): |
|
|
image = Image.fromarray(image).convert("RGB") |
|
|
inputs = processor(images=image, return_tensors="pt") |
|
|
|
|
|
with torch.no_grad(): |
|
|
outputs = model(**inputs) |
|
|
logits = outputs.logits |
|
|
probs = torch.nn.functional.softmax(logits, dim=1).squeeze().tolist() |
|
|
|
|
|
prediction = { |
|
|
id2label[str(i)]: round(probs[i], 3) for i in range(len(probs)) |
|
|
} |
|
|
|
|
|
return prediction |
|
|
|
|
|
# Gradio Interface |
|
|
iface = gr.Interface( |
|
|
fn=classify_formula_or_text, |
|
|
inputs=gr.Image(type="numpy"), |
|
|
outputs=gr.Label(num_top_classes=2, label="Formula or Text"), |
|
|
title="Formula-Text-Detection", |
|
|
description="Upload an image region to classify whether it contains a mathematical formula or natural text." |
|
|
) |
|
|
|
|
|
if __name__ == "__main__": |
|
|
iface.launch() |
|
|
``` |
|
|
## **Demo Inference** |
|
|
|
|
|
> [!Important] |
|
|
> Text |
|
|
|
|
|
|
|
|
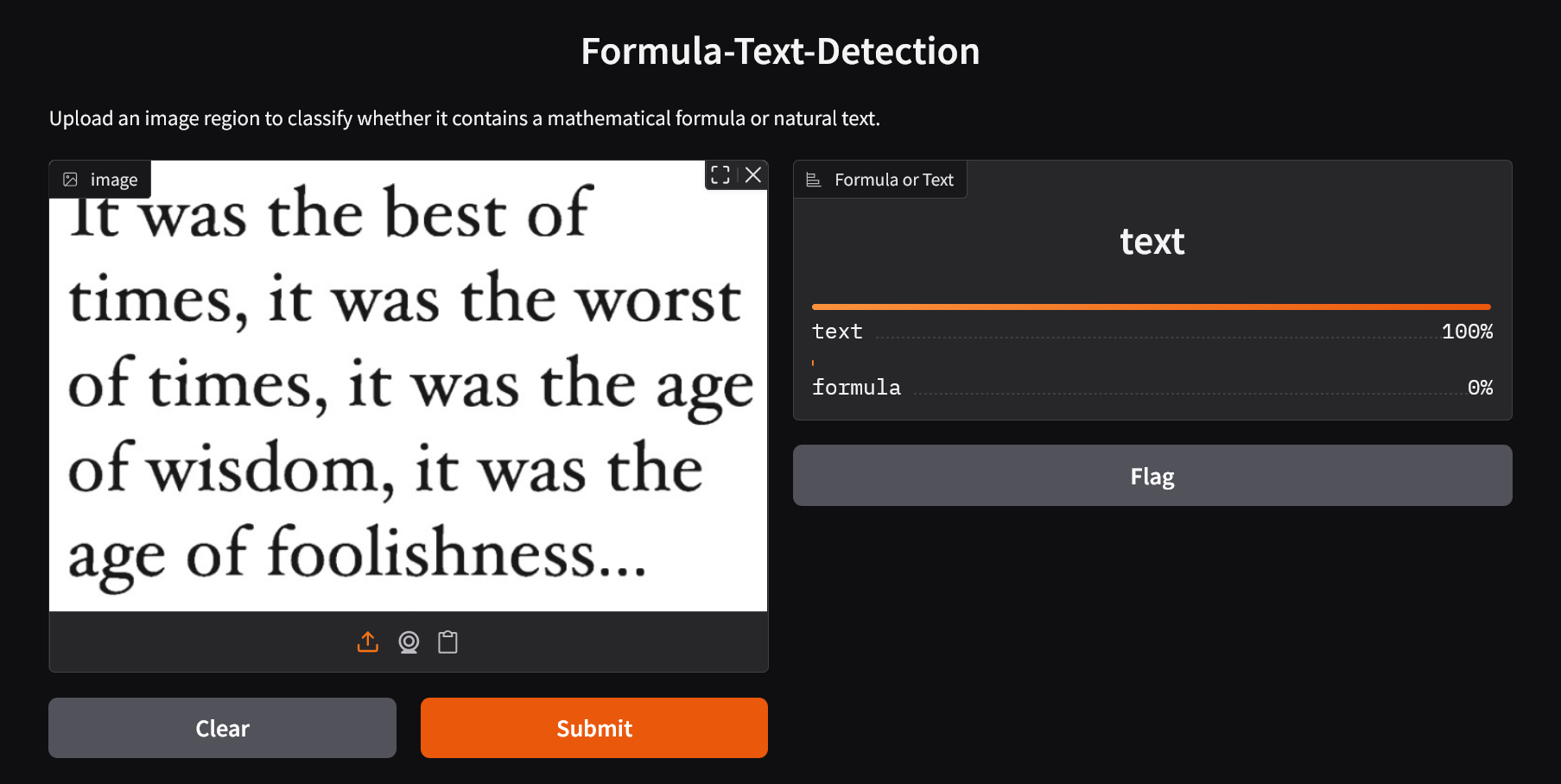 |
|
|
 |
|
|
 |
|
|
|
|
|
> [!Important] |
|
|
> Formula |
|
|
|
|
|
 |
|
|
 |
|
|
 |
|
|
|
|
|
--- |
|
|
|
|
|
## **Intended Use** |
|
|
|
|
|
**Formula-Text-Detection** can be used in: |
|
|
|
|
|
- **OCR Preprocessing** – Improve document OCR accuracy by separating formulas from text. |
|
|
- **Scientific Document Analysis** – Automatically detect mathematical content. |
|
|
- **Educational Platforms** – Classify and annotate scanned materials. |
|
|
- **Layout Understanding** – Help AI systems interpret mixed-content documents. |
