
repo_id
stringlengths 4
110
| author
stringlengths 2
27
⌀ | model_type
stringlengths 2
29
⌀ | files_per_repo
int64 2
15.4k
| downloads_30d
int64 0
19.9M
| library
stringlengths 2
37
⌀ | likes
int64 0
4.34k
| pipeline
stringlengths 5
30
⌀ | pytorch
bool 2
classes | tensorflow
bool 2
classes | jax
bool 2
classes | license
stringlengths 2
30
| languages
stringlengths 4
1.63k
⌀ | datasets
stringlengths 2
2.58k
⌀ | co2
stringclasses 29
values | prs_count
int64 0
125
| prs_open
int64 0
120
| prs_merged
int64 0
15
| prs_closed
int64 0
28
| discussions_count
int64 0
218
| discussions_open
int64 0
148
| discussions_closed
int64 0
70
| tags
stringlengths 2
513
| has_model_index
bool 2
classes | has_metadata
bool 1
class | has_text
bool 1
class | text_length
int64 401
598k
| is_nc
bool 1
class | readme
stringlengths 0
598k
| hash
stringlengths 32
32
|
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
sd-concepts-library/senneca
|
sd-concepts-library
| null | 10 | 0 | null | 0 | null | false | false | false |
mit
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
[]
| false | true | true | 1,102 | false |
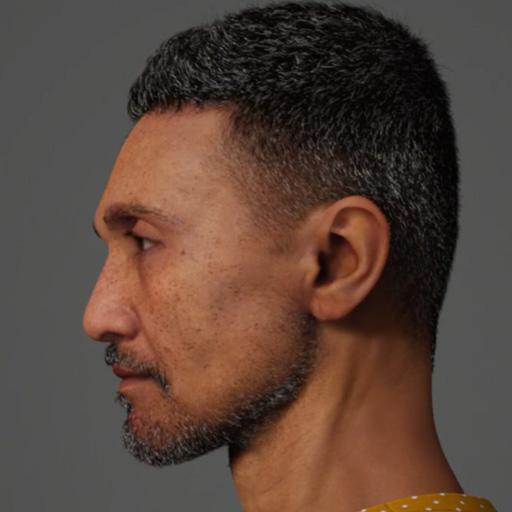
### Senneca on Stable Diffusion
This is the `<Senneca>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as an `object`:




|
1a0e4d718f7e1f20291679c29f629aeb
|
DFrostKilla/teamcomo-kj
|
DFrostKilla
| null | 18 | 2 |
diffusers
| 0 |
text-to-image
| false | false | false |
creativeml-openrail-m
| null | null | null | 1 | 1 | 0 | 0 | 0 | 0 | 0 |
['text-to-image', 'stable-diffusion']
| false | true | true | 617 | false |
### teamcomo-kj Dreambooth model trained by DFrostKilla with [TheLastBen's fast-DreamBooth](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast-DreamBooth.ipynb) notebook
Test the concept via A1111 Colab [fast-Colab-A1111](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast_stable_diffusion_AUTOMATIC1111.ipynb)
Or you can run your new concept via `diffusers` [Colab Notebook for Inference](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_inference.ipynb)
Sample pictures of this concept:
|
f741ac3f6342231dd3b629998e1799f3
|
krinal214/bert-all-squad_que_translated
|
krinal214
|
bert
| 18 | 5 |
transformers
| 0 |
question-answering
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,172 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-all-squad_que_translated
This model is a fine-tuned version of [bert-base-multilingual-cased](https://huggingface.co/bert-base-multilingual-cased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5174
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-----:|:---------------:|
| 1.0746 | 1.0 | 18011 | 0.5174 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.9.1
- Datasets 2.1.0
- Tokenizers 0.11.6
|
beda8abebb504b751e6d312094eee283
|
SzegedAI/hubertusz-small-wiki-seq128
|
SzegedAI
|
bert
| 9 | 2 |
transformers
| 0 | null | true | true | false |
apache-2.0
|
['hu']
|
['wikipedia']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_keras_callback', 'hubert']
| true | true | true | 690 | false |
# hubert-small-wiki-seq128
Fully trained model with the second phase of training is available here: [SzegedAI/hubert-small-wiki](https://huggingface.co/SzegedAI/hubert-small-wiki)
This model was trained from scratch on the Wikipedia subset of Hungarian Webcorpus 2.0 with MLM and SOP tasks.
### Pre-Training Parameters:
- Training steps: 500.000
- Sequence length: 128 (the model is capable for 512)
- Batch size: 1024
### Framework versions
- Transformers 4.21.3
- TensorFlow 2.10.0
- Datasets 2.4.0
- Tokenizers 0.12.1
# Acknowledgement
[](https://mi.nemzetilabor.hu/)
|
22d9f9657209e681c5aa2f45400af376
|
jungjongho/wav2vec2-xlsr-korean-speech-emotion-recognition3
|
jungjongho
|
wav2vec2
| 13 | 1 |
transformers
| 0 | null | true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 2,170 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-xlsr-korean-speech-emotion-recognition3
This model is a fine-tuned version of [jungjongho/wav2vec2-large-xlsr-korean-demo-colab_epoch15](https://huggingface.co/jungjongho/wav2vec2-large-xlsr-korean-demo-colab_epoch15) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0600
- Accuracy: 0.9876
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 4
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|
| 0.6472 | 0.08 | 1500 | 0.3769 | 0.8705 |
| 0.3873 | 0.15 | 3000 | 0.3814 | 0.9127 |
| 0.3002 | 0.23 | 4500 | 0.2617 | 0.9429 |
| 0.2399 | 0.3 | 6000 | 0.1336 | 0.9693 |
| 0.2181 | 0.38 | 7500 | 0.1360 | 0.9728 |
| 0.1992 | 0.46 | 9000 | 0.1239 | 0.9717 |
| 0.1556 | 0.53 | 10500 | 0.1053 | 0.9781 |
| 0.1412 | 0.61 | 12000 | 0.0915 | 0.9810 |
| 0.1396 | 0.69 | 13500 | 0.0777 | 0.9826 |
| 0.1159 | 0.76 | 15000 | 0.0801 | 0.9831 |
| 0.1156 | 0.84 | 16500 | 0.0667 | 0.9867 |
| 0.1149 | 0.91 | 18000 | 0.0670 | 0.9860 |
| 0.0929 | 0.99 | 19500 | 0.0600 | 0.9876 |
### Framework versions
- Transformers 4.22.0.dev0
- Pytorch 1.12.1+cu113
- Datasets 2.4.1.dev0
- Tokenizers 0.12.1
|
f1eb804cf36e7bba82f129cd3f64eaba
|
Suniljl/xridl
|
Suniljl
| null | 18 | 20 |
diffusers
| 0 |
text-to-image
| false | false | false |
creativeml-openrail-m
| null | null | null | 1 | 1 | 0 | 0 | 0 | 0 | 0 |
['text-to-image', 'stable-diffusion']
| false | true | true | 414 | false |
### xridl Dreambooth model trained by Suniljl with [TheLastBen's fast-DreamBooth](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast-DreamBooth.ipynb) notebook
Test the concept via A1111 Colab [fast-Colab-A1111](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast_stable_diffusion_AUTOMATIC1111.ipynb)
Sample pictures of this concept:
|
918d4d9f35cb90fc3876ebff8b8ccc2f
|
RaphaelKalandadze/wav2vec2-large-xls-r-300m-georgian-large
|
RaphaelKalandadze
|
wav2vec2
| 19 | 7 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
| null |
['common_voice_10_0']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,496 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-large-xls-r-300m-georgian-large
This model is a fine-tuned version of [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) on the common_voice_10_0 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4291
- Wer: 0.6392
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 15
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 3.0867 | 4.21 | 400 | 3.1211 | 1.0 |
| 2.8871 | 8.42 | 800 | 2.2250 | 1.0 |
| 0.3667 | 12.63 | 1200 | 0.4291 | 0.6392 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.10.0+cu113
- Datasets 2.4.0
- Tokenizers 0.10.3
|
eb0b88d9e2c547f65778bde32b716646
|
MultiBertGunjanPatrick/multiberts-seed-4-160k
|
MultiBertGunjanPatrick
|
bert
| 7 | 4 |
transformers
| 0 | null | true | false | false |
apache-2.0
|
['en']
|
['bookcorpus', 'wikipedia']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['exbert', 'multiberts', 'multiberts-seed-4']
| false | true | true | 6,483 | false |
# MultiBERTs Seed 4 Checkpoint 160k (uncased)
Seed 4 intermediate checkpoint 160k MultiBERTs (pretrained BERT) model on English language using a masked language modeling (MLM) objective. It was introduced in
[this paper](https://arxiv.org/pdf/2106.16163.pdf) and first released in
[this repository](https://github.com/google-research/language/tree/master/language/multiberts). This is an intermediate checkpoint.
The final checkpoint can be found at [multiberts-seed-4](https://hf.co/multberts-seed-4). This model is uncased: it does not make a difference
between english and English.
Disclaimer: The team releasing MultiBERTs did not write a model card for this model so this model card has been written by [gchhablani](https://hf.co/gchhablani).
## Model description
MultiBERTs models are transformers model pretrained on a large corpus of English data in a self-supervised fashion. This means it
was pretrained on the raw texts only, with no humans labelling them in any way (which is why it can use lots of
publicly available data) with an automatic process to generate inputs and labels from those texts. More precisely, it
was pretrained with two objectives:
- Masked language modeling (MLM): taking a sentence, the model randomly masks 15% of the words in the input then run
the entire masked sentence through the model and has to predict the masked words. This is different from traditional
recurrent neural networks (RNNs) that usually see the words one after the other, or from autoregressive models like
GPT which internally mask the future tokens. It allows the model to learn a bidirectional representation of the
sentence.
- Next sentence prediction (NSP): the models concatenates two masked sentences as inputs during pretraining. Sometimes
they correspond to sentences that were next to each other in the original text, sometimes not. The model then has to
predict if the two sentences were following each other or not.
This way, the model learns an inner representation of the English language that can then be used to extract features
useful for downstream tasks: if you have a dataset of labeled sentences for instance, you can train a standard
classifier using the features produced by the MultiBERTs model as inputs.
## Intended uses & limitations
You can use the raw model for either masked language modeling or next sentence prediction, but it's mostly intended to
be fine-tuned on a downstream task. See the [model hub](https://huggingface.co/models?filter=multiberts) to look for
fine-tuned versions on a task that interests you.
Note that this model is primarily aimed at being fine-tuned on tasks that use the whole sentence (potentially masked)
to make decisions, such as sequence classification, token classification or question answering. For tasks such as text
generation you should look at model like GPT2.
### How to use
Here is how to use this model to get the features of a given text in PyTorch:
```python
from transformers import BertTokenizer, BertModel
tokenizer = BertTokenizer.from_pretrained('multiberts-seed-4-160k')
model = BertModel.from_pretrained("multiberts-seed-4-160k")
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='pt')
output = model(**encoded_input)
```
### Limitations and bias
Even if the training data used for this model could be characterized as fairly neutral, this model can have biased
predictions. This bias will also affect all fine-tuned versions of this model. For an understanding of bias of this particular
checkpoint, please try out this checkpoint with the snippet present in the [Limitation and bias section](https://huggingface.co/bert-base-uncased#limitations-and-bias) of the [bert-base-uncased](https://huggingface.co/bert-base-uncased) checkpoint.
## Training data
The MultiBERTs models were pretrained on [BookCorpus](https://yknzhu.wixsite.com/mbweb), a dataset consisting of 11,038
unpublished books and [English Wikipedia](https://en.wikipedia.org/wiki/English_Wikipedia) (excluding lists, tables and
headers).
## Training procedure
### Preprocessing
The texts are lowercased and tokenized using WordPiece and a vocabulary size of 30,000. The inputs of the model are
then of the form:
```
[CLS] Sentence A [SEP] Sentence B [SEP]
```
With probability 0.5, sentence A and sentence B correspond to two consecutive sentences in the original corpus and in
the other cases, it's another random sentence in the corpus. Note that what is considered a sentence here is a
consecutive span of text usually longer than a single sentence. The only constrain is that the result with the two
"sentences" has a combined length of less than 512 tokens.
The details of the masking procedure for each sentence are the following:
- 15% of the tokens are masked.
- In 80% of the cases, the masked tokens are replaced by `[MASK]`.
- In 10% of the cases, the masked tokens are replaced by a random token (different) from the one they replace.
- In the 10% remaining cases, the masked tokens are left as is.
### Pretraining
The full model was trained on 16 Cloud TPU v2 chips for two million steps with a batch size
of 256. The sequence length was set to 512 throughout. The optimizer
used is Adam with a learning rate of 1e-4, \\(\beta_{1} = 0.9\\) and \\(\beta_{2} = 0.999\\), a weight decay of 0.01,
learning rate warmup for 10,000 steps and linear decay of the learning rate after.
### BibTeX entry and citation info
```bibtex
@article{DBLP:journals/corr/abs-2106-16163,
author = {Thibault Sellam and
Steve Yadlowsky and
Jason Wei and
Naomi Saphra and
Alexander D'Amour and
Tal Linzen and
Jasmijn Bastings and
Iulia Turc and
Jacob Eisenstein and
Dipanjan Das and
Ian Tenney and
Ellie Pavlick},
title = {The MultiBERTs: {BERT} Reproductions for Robustness Analysis},
journal = {CoRR},
volume = {abs/2106.16163},
year = {2021},
url = {https://arxiv.org/abs/2106.16163},
eprinttype = {arXiv},
eprint = {2106.16163},
timestamp = {Mon, 05 Jul 2021 15:15:50 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-2106-16163.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
<a href="https://huggingface.co/exbert/?model=multiberts">
<img width="300px" src="https://cdn-media.huggingface.co/exbert/button.png">
</a>
|
b33273440229a39b583b7de525bf8ce9
|
JorisCos/ConvTasNet_Libri3Mix_sepnoisy_8k
|
JorisCos
| null | 3 | 3 |
asteroid
| 0 |
audio-to-audio
| true | false | false |
cc-by-sa-4.0
| null |
['Libri3Mix', 'sep_noisy']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['asteroid', 'audio', 'ConvTasNet', 'audio-to-audio']
| false | true | true | 1,646 | false |
## Asteroid model `JorisCos/ConvTasNet_Libri3Mix_sepnoisy_8k`
Description:
This model was trained by Joris Cosentino using the librimix recipe in [Asteroid](https://github.com/asteroid-team/asteroid).
It was trained on the `sep_noisy` task of the Libri3Mix dataset.
Training config:
```yml
data:
n_src: 3
sample_rate: 8000
segment: 3
task: sep_noisy
train_dir: data/wav8k/min/train-360
valid_dir: data/wav8k/min/dev
filterbank:
kernel_size: 16
n_filters: 512
stride: 8
masknet:
bn_chan: 128
hid_chan: 512
mask_act: relu
n_blocks: 8
n_repeats: 3
n_src: 3
skip_chan: 128
optim:
lr: 0.001
optimizer: adam
weight_decay: 0.0
training:
batch_size: 24
early_stop: true
epochs: 200
half_lr: true
num_workers: 4
```
Results:
On Libri3Mix min test set :
```yml
si_sdr: 5.978836560066222
si_sdr_imp: 10.388889689413096
sdr: 6.8651365291740225
sdr_imp: 10.928018056925016
sir: 14.997089638783114
sir_imp: 18.08248357801549
sar: 8.127504792061933
sar_imp: -0.7869320540959925
stoi: 0.7669414686111115
stoi_imp: 0.20416563213078837
```
License notice:
This work "ConvTasNet_Libri3Mix_sepnoisy_8k" is a derivative of [LibriSpeech ASR corpus](http://www.openslr.org/12) by Vassil Panayotov,
used under [CC BY 4.0](https://creativecommons.org/licenses/by/4.0/); of The WSJ0 Hipster Ambient Mixtures
dataset by [Whisper.ai](http://wham.whisper.ai/), used under [CC BY-NC 4.0](https://creativecommons.org/licenses/by-nc/4.0/) (Research only).
"ConvTasNet_Libri3Mix_sepnoisy_8k" is licensed under [Attribution-ShareAlike 3.0 Unported](https://creativecommons.org/licenses/by-sa/3.0/) by Joris Cosentino
|
9fb95c3cd935b9ef24ad35dc3972d6a6
|
oo/distilbert-base-uncased-finetuned-squad
|
oo
|
distilbert
| 14 | 5 |
transformers
| 0 |
question-answering
| true | false | false |
apache-2.0
| null |
['squad']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 929 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-squad
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the squad dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Framework versions
- Transformers 4.12.5
- Pytorch 1.10.0+cu111
- Datasets 1.16.1
- Tokenizers 0.10.3
|
422c0c4de9ef24f431d218e3afb46669
|
HooshvareLab/bert-fa-base-uncased-ner-arman
|
HooshvareLab
|
bert
| 12 | 15 |
transformers
| 0 |
token-classification
| true | true | true |
apache-2.0
|
['fa']
| null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
[]
| false | true | true | 3,073 | false |
# ParsBERT (v2.0)
A Transformer-based Model for Persian Language Understanding
We reconstructed the vocabulary and fine-tuned the ParsBERT v1.1 on the new Persian corpora in order to provide some functionalities for using ParsBERT in other scopes!
Please follow the [ParsBERT](https://github.com/hooshvare/parsbert) repo for the latest information about previous and current models.
## Persian NER [ARMAN, PEYMA]
This task aims to extract named entities in the text, such as names and label with appropriate `NER` classes such as locations, organizations, etc. The datasets used for this task contain sentences that are marked with `IOB` format. In this format, tokens that are not part of an entity are tagged as `”O”` the `”B”`tag corresponds to the first word of an object, and the `”I”` tag corresponds to the rest of the terms of the same entity. Both `”B”` and `”I”` tags are followed by a hyphen (or underscore), followed by the entity category. Therefore, the NER task is a multi-class token classification problem that labels the tokens upon being fed a raw text. There are two primary datasets used in Persian NER, `ARMAN`, and `PEYMA`.
### ARMAN
ARMAN dataset holds 7,682 sentences with 250,015 sentences tagged over six different classes.
1. Organization
2. Location
3. Facility
4. Event
5. Product
6. Person
| Label | # |
|:------------:|:-----:|
| Organization | 30108 |
| Location | 12924 |
| Facility | 4458 |
| Event | 7557 |
| Product | 4389 |
| Person | 15645 |
**Download**
You can download the dataset from [here](https://github.com/HaniehP/PersianNER)
## Results
The following table summarizes the F1 score obtained by ParsBERT as compared to other models and architectures.
| Dataset | ParsBERT v2 | ParsBERT v1 | mBERT | MorphoBERT | Beheshti-NER | LSTM-CRF | Rule-Based CRF | BiLSTM-CRF |
|---------|-------------|-------------|-------|------------|--------------|----------|----------------|------------|
| ARMAN | 99.84* | 98.79 | 95.89 | 89.9 | 84.03 | 86.55 | - | 77.45 |
## How to use :hugs:
| Notebook | Description | |
|:----------|:-------------|------:|
| [How to use Pipelines](https://github.com/hooshvare/parsbert-ner/blob/master/persian-ner-pipeline.ipynb) | Simple and efficient way to use State-of-the-Art models on downstream tasks through transformers | [](https://colab.research.google.com/github/hooshvare/parsbert-ner/blob/master/persian-ner-pipeline.ipynb) |
### BibTeX entry and citation info
Please cite in publications as the following:
```bibtex
@article{ParsBERT,
title={ParsBERT: Transformer-based Model for Persian Language Understanding},
author={Mehrdad Farahani, Mohammad Gharachorloo, Marzieh Farahani, Mohammad Manthouri},
journal={ArXiv},
year={2020},
volume={abs/2005.12515}
}
```
## Questions?
Post a Github issue on the [ParsBERT Issues](https://github.com/hooshvare/parsbert/issues) repo.
|
4ead11db0a2ab329f29212082e85c69b
|
shaoyu17/my_awesome_model
|
shaoyu17
|
distilbert
| 56 | 49 |
transformers
| 0 |
text-classification
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,527 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# my_awesome_model
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.8597
- F1: 0.5171
- Precision: 0.5205
- Recall: 0.52
- Accuracy: 0.52
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 | Precision | Recall | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:------:|:---------:|:------:|:--------:|
| 0.6451 | 1.0 | 752 | 0.7708 | 0.4699 | 0.5047 | 0.5035 | 0.5035 |
| 0.5828 | 2.0 | 1504 | 0.7702 | 0.5101 | 0.5106 | 0.5106 | 0.5106 |
| 0.5139 | 3.0 | 2256 | 0.8597 | 0.5171 | 0.5205 | 0.52 | 0.52 |
### Framework versions
- Transformers 4.26.0
- Pytorch 1.13.1+cu116
- Datasets 2.9.0
- Tokenizers 0.13.2
|
a8022a31598bf9b101740c28bdd385a8
|
plasmo/macro_bug-shiv
|
plasmo
| null | 12 | 0 | null | 6 | null | false | false | false |
mit
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
[]
| false | true | true | 985 | false |
### macro_bug on Stable Diffusion via Dreambooth trained on the ShivamShrirao notebook
#### Model by plasmo
This your the Stable Diffusion model fine-tuned the macro_bug concept taught to Stable Diffusion with Dreambooth.
Macro Bug - A focused stacked macro insect model (ShivamShrirao Version, trained on 3000 steps)
Keyword: "macro_bug" but sometimes not even needed as this model seems heavily weighted.
I made another version (theLastBen) of this model, but this model seems to create more detailed and creative images.
Sample pictures of this concept:




|
66b0dc0f340bd3b67d88056eaf9fada7
|
MultiBertGunjanPatrick/multiberts-seed-0-1900k
|
MultiBertGunjanPatrick
|
bert
| 7 | 2 |
transformers
| 0 | null | true | false | false |
apache-2.0
|
['en']
|
['bookcorpus', 'wikipedia']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['exbert', 'multiberts', 'multiberts-seed-0']
| false | true | true | 6,487 | false |
# MultiBERTs Seed 0 Checkpoint 1900k (uncased)
Seed 0 intermediate checkpoint 1900k MultiBERTs (pretrained BERT) model on English language using a masked language modeling (MLM) objective. It was introduced in
[this paper](https://arxiv.org/pdf/2106.16163.pdf) and first released in
[this repository](https://github.com/google-research/language/tree/master/language/multiberts). This is an intermediate checkpoint.
The final checkpoint can be found at [multiberts-seed-0](https://hf.co/multberts-seed-0). This model is uncased: it does not make a difference
between english and English.
Disclaimer: The team releasing MultiBERTs did not write a model card for this model so this model card has been written by [gchhablani](https://hf.co/gchhablani).
## Model description
MultiBERTs models are transformers model pretrained on a large corpus of English data in a self-supervised fashion. This means it
was pretrained on the raw texts only, with no humans labelling them in any way (which is why it can use lots of
publicly available data) with an automatic process to generate inputs and labels from those texts. More precisely, it
was pretrained with two objectives:
- Masked language modeling (MLM): taking a sentence, the model randomly masks 15% of the words in the input then run
the entire masked sentence through the model and has to predict the masked words. This is different from traditional
recurrent neural networks (RNNs) that usually see the words one after the other, or from autoregressive models like
GPT which internally mask the future tokens. It allows the model to learn a bidirectional representation of the
sentence.
- Next sentence prediction (NSP): the models concatenates two masked sentences as inputs during pretraining. Sometimes
they correspond to sentences that were next to each other in the original text, sometimes not. The model then has to
predict if the two sentences were following each other or not.
This way, the model learns an inner representation of the English language that can then be used to extract features
useful for downstream tasks: if you have a dataset of labeled sentences for instance, you can train a standard
classifier using the features produced by the MultiBERTs model as inputs.
## Intended uses & limitations
You can use the raw model for either masked language modeling or next sentence prediction, but it's mostly intended to
be fine-tuned on a downstream task. See the [model hub](https://huggingface.co/models?filter=multiberts) to look for
fine-tuned versions on a task that interests you.
Note that this model is primarily aimed at being fine-tuned on tasks that use the whole sentence (potentially masked)
to make decisions, such as sequence classification, token classification or question answering. For tasks such as text
generation you should look at model like GPT2.
### How to use
Here is how to use this model to get the features of a given text in PyTorch:
```python
from transformers import BertTokenizer, BertModel
tokenizer = BertTokenizer.from_pretrained('multiberts-seed-0-1900k')
model = BertModel.from_pretrained("multiberts-seed-0-1900k")
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='pt')
output = model(**encoded_input)
```
### Limitations and bias
Even if the training data used for this model could be characterized as fairly neutral, this model can have biased
predictions. This bias will also affect all fine-tuned versions of this model. For an understanding of bias of this particular
checkpoint, please try out this checkpoint with the snippet present in the [Limitation and bias section](https://huggingface.co/bert-base-uncased#limitations-and-bias) of the [bert-base-uncased](https://huggingface.co/bert-base-uncased) checkpoint.
## Training data
The MultiBERTs models were pretrained on [BookCorpus](https://yknzhu.wixsite.com/mbweb), a dataset consisting of 11,038
unpublished books and [English Wikipedia](https://en.wikipedia.org/wiki/English_Wikipedia) (excluding lists, tables and
headers).
## Training procedure
### Preprocessing
The texts are lowercased and tokenized using WordPiece and a vocabulary size of 30,000. The inputs of the model are
then of the form:
```
[CLS] Sentence A [SEP] Sentence B [SEP]
```
With probability 0.5, sentence A and sentence B correspond to two consecutive sentences in the original corpus and in
the other cases, it's another random sentence in the corpus. Note that what is considered a sentence here is a
consecutive span of text usually longer than a single sentence. The only constrain is that the result with the two
"sentences" has a combined length of less than 512 tokens.
The details of the masking procedure for each sentence are the following:
- 15% of the tokens are masked.
- In 80% of the cases, the masked tokens are replaced by `[MASK]`.
- In 10% of the cases, the masked tokens are replaced by a random token (different) from the one they replace.
- In the 10% remaining cases, the masked tokens are left as is.
### Pretraining
The full model was trained on 16 Cloud TPU v2 chips for two million steps with a batch size
of 256. The sequence length was set to 512 throughout. The optimizer
used is Adam with a learning rate of 1e-4, \\(\beta_{1} = 0.9\\) and \\(\beta_{2} = 0.999\\), a weight decay of 0.01,
learning rate warmup for 10,000 steps and linear decay of the learning rate after.
### BibTeX entry and citation info
```bibtex
@article{DBLP:journals/corr/abs-2106-16163,
author = {Thibault Sellam and
Steve Yadlowsky and
Jason Wei and
Naomi Saphra and
Alexander D'Amour and
Tal Linzen and
Jasmijn Bastings and
Iulia Turc and
Jacob Eisenstein and
Dipanjan Das and
Ian Tenney and
Ellie Pavlick},
title = {The MultiBERTs: {BERT} Reproductions for Robustness Analysis},
journal = {CoRR},
volume = {abs/2106.16163},
year = {2021},
url = {https://arxiv.org/abs/2106.16163},
eprinttype = {arXiv},
eprint = {2106.16163},
timestamp = {Mon, 05 Jul 2021 15:15:50 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-2106-16163.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
<a href="https://huggingface.co/exbert/?model=multiberts">
<img width="300px" src="https://cdn-media.huggingface.co/exbert/button.png">
</a>
|
1ad8564f801f09977e3708477607aa8f
|
WALIDALI/cronaldolibya
|
WALIDALI
| null | 18 | 3 |
diffusers
| 0 |
text-to-image
| false | false | false |
creativeml-openrail-m
| null | null | null | 1 | 1 | 0 | 0 | 0 | 0 | 0 |
['text-to-image', 'stable-diffusion']
| false | true | true | 423 | false |
### CRonaldolibya Dreambooth model trained by WALIDALI with [TheLastBen's fast-DreamBooth](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast-DreamBooth.ipynb) notebook
Test the concept via A1111 Colab [fast-Colab-A1111](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast_stable_diffusion_AUTOMATIC1111.ipynb)
Sample pictures of this concept:
|
37f7b0b93d498111bcd3a2a8261409ad
|
hululuzhu/solidity-t5
|
hululuzhu
|
t5
| 9 | 8 |
transformers
| 0 |
text2text-generation
| true | false | false |
apache-2.0
|
['en']
| null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['solidity', 'web3', 'code generation', 'smart contract']
| false | true | true | 3,561 | false |
# A code generation T5 model for solidity (web3 smart contract)
- See https://github.com/hululuzhu/solidity-t5 for more context
## How to use this trained model
- A hello world example to use this model, notice the input `text` includes
- Header solidity version like `pragma solidity ^0.5.7`
- Ancestor class/library info, e.g. public functions and constants from `ParentA`
- Contract/Library/Interface declaration header, e.g. `HelloWorld` ended with `{`
- Or simply use the test widget on the right side of the window and test, however
the quality is known to be worse without decoding params
```python
# !pip install transformers -q
from transformers import AutoTokenizer, T5ForConditionalGeneration
DEVICE = 'cuda' # fallback to cpu if you do not have cuda
tokenizer = AutoTokenizer.from_pretrained("hululuzhu/solidity-t5")
model = T5ForConditionalGeneration.from_pretrained("hululuzhu/solidity-t5").to(DEVICE)
text = """pragma solidity ^0.5.7;
// Context: ParentA | Functions: helloA helloB | Constants: constantA
contract HelloWorld is ParentA {"""
input_ids = tokenizer(text, return_tensors="pt", truncation=True).input_ids.to(DEVICE)
# Need to tune beam/topk/topp params to get good outcome
generated_ids = model.generate(input_ids, max_length=256, num_beams=5, top_p=0.95, top_k=50)
print(tokenizer.decode(generated_ids[0], skip_special_tokens=True))
# Expect outcome
"""
string public constant name = "Hello World";
...
uint256 public constant override returns (uint256) {
return initialSupply;
}
function initialSupply() public view returns (uint256) {
...
"""
```
## Background
- Base T5 code model: https://huggingface.co/Salesforce/codet5-large
- Source data: https://huggingface.co/datasets/mwritescode/slither-audited-smart-contracts
- Processing steps: Clean, contract-level segmentation sepration, split in and out
- After processing input sample
```
pragma solidity 0.5.7;
// Context: PauserRole | Functions: isPauser addPauser renouncePauser | Constants:
contract Pausable is PauserRole {
```
- After processing output sample (**notice indentation is bad, this is intentional to reduce token size**)
```
event Paused(address account);
event Unpaused(address account);
bool private _pausableActive;
bool private _paused;
constructor () internal {
_paused = false;
}
function paused() public view returns (bool) {
return _paused;
}
modifier whenNotPaused() {
require(!_paused);
_;
}
modifier whenPaused() {
require(_paused);
_;
}
function pause() public onlyPauser whenNotPaused whenPausableActive {
_paused = true;
emit Paused(msg.sender);
}
function unpause() public onlyPauser whenPaused whenPausableActive {
_paused = false;
emit Unpaused(msg.sender);
}
function _setPausableActive(bool _active) internal {
_pausableActive = _active;
}
modifier whenPausableActive() {
require(_pausableActive);
_;
}
}
```
- Source training code: See the [end to end notebook](https://github.com/hululuzhu/solidity-t5/blob/main/code/Solidity_T5_Data_Processing_and_Training.ipynb) at code dir here
## Future TODO
- The model is significantly under-trained because of lack of GPU budget, need 10x colab resources (~$100 for full train)
- This is quite limited on how the model is used, potentially we could switch to GPT2 decoder-only to compare, but CodeT5 has its strong code optimization
- Need more classifiers (T5 or BERT alike) to detect potential defects.
|
dcc26f35c4989fcb0803a027ae1d9586
|
plncmm/mdeberta-wl-base-es
|
plncmm
|
deberta-v2
| 13 | 4 |
transformers
| 0 |
fill-mask
| true | false | false |
mit
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 951 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mdeberta-wl-base-es
This model is a fine-tuned version of [microsoft/mdeberta-v3-base](https://huggingface.co/microsoft/mdeberta-v3-base) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
### Framework versions
- Transformers 4.21.0.dev0
- Pytorch 1.11.0+cu113
- Datasets 2.3.3.dev0
- Tokenizers 0.12.1
|
28d6305823ad7e4a07d15802fbc44645
|
theojolliffe/bart-cnn-pubmed-arxiv-pubmed-arxiv-arxiv-v3-e3
|
theojolliffe
|
bart
| 13 | 1 |
transformers
| 0 |
text2text-generation
| true | false | false |
mit
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,739 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bart-cnn-pubmed-arxiv-pubmed-arxiv-arxiv-v3-e3
This model is a fine-tuned version of [theojolliffe/bart-cnn-pubmed-arxiv-pubmed-arxiv-arxiv](https://huggingface.co/theojolliffe/bart-cnn-pubmed-arxiv-pubmed-arxiv-arxiv) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.8311
- Rouge1: 53.458
- Rouge2: 34.076
- Rougel: 37.3287
- Rougelsum: 50.7849
- Gen Len: 142.0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:-------:|:-------:|:-------:|:---------:|:--------:|
| No log | 1.0 | 398 | 0.8697 | 52.6579 | 33.307 | 35.8099 | 49.9687 | 142.0 |
| 0.8264 | 2.0 | 796 | 0.8293 | 52.6738 | 33.7202 | 36.1502 | 50.0501 | 141.9815 |
| 0.5471 | 3.0 | 1194 | 0.8311 | 53.458 | 34.076 | 37.3287 | 50.7849 | 142.0 |
### Framework versions
- Transformers 4.19.2
- Pytorch 1.11.0+cu113
- Datasets 2.2.2
- Tokenizers 0.12.1
|
615379b8a28b73e74934be671f77d6bb
|
uxstudent/the-pm-generator
|
uxstudent
| null | 18 | 101 |
diffusers
| 1 |
text-to-image
| false | false | false |
creativeml-openrail-m
| null | null | null | 1 | 1 | 0 | 0 | 0 | 0 | 0 |
['text-to-image', 'stable-diffusion']
| false | true | true | 702 | false |
### the_pm_generator Dreambooth model trained by uxstudent
Use the prompt field in the right to generate avatars. Need ideas for prompts? Try:
- `picture of Pablo by Leonardo Da Vinci`
- `picture of Pablo wearing aviator jacket by greg rutkowsi`
- `portrait photo of pablo warrior chief, tribal panther make up, blue on red, side profile, looking away, serious eyes, 50mm portrait photography, hard rim lighting photography–beta –ar 2:3 –beta –upbeta –upbeta`
more examples:
- https://mpost.io/best-100-stable-diffusion-prompts-the-most-beautiful-ai-text-to-image-prompts/
# Example of generated images: (I HAVE DELETED THEM TO DISABLE GOOGLE IMAGE INDEXING. NOT A PROBLEM PER SE BUT UNNECESSARY)
|
e895c2cc18513345502bede1c0a4ffcb
|
Helsinki-NLP/opus-mt-sv-zne
|
Helsinki-NLP
|
marian
| 10 | 7 |
transformers
| 0 |
translation
| true | true | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['translation']
| false | true | true | 776 | false |
### opus-mt-sv-zne
* source languages: sv
* target languages: zne
* OPUS readme: [sv-zne](https://github.com/Helsinki-NLP/OPUS-MT-train/blob/master/models/sv-zne/README.md)
* dataset: opus
* model: transformer-align
* pre-processing: normalization + SentencePiece
* download original weights: [opus-2020-01-16.zip](https://object.pouta.csc.fi/OPUS-MT-models/sv-zne/opus-2020-01-16.zip)
* test set translations: [opus-2020-01-16.test.txt](https://object.pouta.csc.fi/OPUS-MT-models/sv-zne/opus-2020-01-16.test.txt)
* test set scores: [opus-2020-01-16.eval.txt](https://object.pouta.csc.fi/OPUS-MT-models/sv-zne/opus-2020-01-16.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| JW300.sv.zne | 23.8 | 0.474 |
|
0b8a7f6074330c9ed35eadb7db00bc1d
|
icy17/What-deepset-bert-uncased-finetune
|
icy17
|
bert
| 10 | 1 |
transformers
| 0 |
question-answering
| true | false | false |
cc-by-4.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,005 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# What-deepset-bert-uncased-finetune
This model is a fine-tuned version of [deepset/bert-large-uncased-whole-word-masking-squad2](https://huggingface.co/deepset/bert-large-uncased-whole-word-masking-squad2) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 12
- eval_batch_size: 24
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
### Framework versions
- Transformers 4.18.0
- Pytorch 1.7.1+cu110
- Datasets 2.4.0
- Tokenizers 0.12.1
|
cbbad849776fe88b9c9957ad77ba06e7
|
UmberH/distilbert-base-uncased-finetuned-cola
|
UmberH
|
distilbert
| 13 | 2 |
transformers
| 0 |
text-classification
| true | false | false |
apache-2.0
| null |
['glue']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,571 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-cola
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the glue dataset.
It achieves the following results on the evaluation set:
- Loss: 0.8381
- Matthews Correlation: 0.5456
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Matthews Correlation |
|:-------------:|:-----:|:----:|:---------------:|:--------------------:|
| 0.5245 | 1.0 | 535 | 0.5432 | 0.4249 |
| 0.3514 | 2.0 | 1070 | 0.5075 | 0.4874 |
| 0.2368 | 3.0 | 1605 | 0.5554 | 0.5403 |
| 0.1712 | 4.0 | 2140 | 0.7780 | 0.5246 |
| 0.1254 | 5.0 | 2675 | 0.8381 | 0.5456 |
### Framework versions
- Transformers 4.21.3
- Pytorch 1.12.1+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
feaa4ad63604159857977e73f1f250bd
|
kpriyanshu256/whisper-large-v2-cy-500-32-1e-05
|
kpriyanshu256
|
whisper
| 15 | 0 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
|
['cy']
|
['mozilla-foundation/common_voice_11_0']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['whisper-event', 'generated_from_trainer']
| true | true | true | 1,576 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# openai/whisper-large-v2-welsh
This model is a fine-tuned version of [openai/whisper-large-v2](https://huggingface.co/openai/whisper-large-v2) on the Common Voice 11.0 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2947
- Wer: 18.0609
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 4
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 8
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 50
- training_steps: 500
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:-------:|
| 0.4438 | 0.2 | 100 | 0.4208 | 27.3594 |
| 0.3255 | 0.4 | 200 | 0.3633 | 23.6118 |
| 0.2856 | 0.6 | 300 | 0.3248 | 20.7023 |
| 0.1811 | 1.14 | 400 | 0.3011 | 18.5534 |
| 0.1404 | 1.34 | 500 | 0.2947 | 18.0609 |
### Framework versions
- Transformers 4.26.0.dev0
- Pytorch 1.13.0+cu117
- Datasets 2.7.1.dev0
- Tokenizers 0.13.2
|
5651eef0038eccd0f709f4a2a25ddd32
|
mrm8488/longformer-base-4096-spanish
|
mrm8488
|
roberta
| 13 | 317 |
transformers
| 11 |
fill-mask
| true | false | false |
mit
|
['es']
|
['spanish_large_corpus']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['Long documents', 'longformer', 'bertin', 'spanish']
| false | true | true | 1,060 | false |
# longformer-base-4096-spanish
## [Longformer](https://arxiv.org/abs/2004.05150) is a Transformer model for long documents.
`longformer-base-4096` is a BERT-like model started from the RoBERTa checkpoint (**BERTIN** in this case) and pre-trained for *MLM* on long documents (from BETO's `all_wikis`). It supports sequences of length up to 4,096!
**Longformer** uses a combination of a sliding window (*local*) attention and *global* attention. Global attention is user-configured based on the task to allow the model to learn task-specific representations.
This model was made following the research done by [Iz Beltagy and Matthew E. Peters and Arman Cohan](https://arxiv.org/abs/2004.05150).
## Citation
If you want to cite this model you can use this:
```bibtex
@misc{mromero2022longformer-base-4096-spanish,
title={Spanish LongFormer by Manuel Romero},
author={Romero, Manuel},
publisher={Hugging Face},
journal={Hugging Face Hub},
howpublished={\url{https://huggingface.co/mrm8488/longformer-base-4096-spanish}},
year={2022}
}
```
|
ea54e60c11245f7a6139859bda4a502c
|
anton-l/xtreme_s_xlsr_300m_fleurs_asr_western_european
|
anton-l
|
wav2vec2
| 16 | 8 |
transformers
| 1 |
automatic-speech-recognition
| true | false | false |
apache-2.0
|
['all']
|
['google/xtreme_s']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['fleurs-asr', 'google/xtreme_s', 'generated_from_trainer']
| true | true | true | 5,853 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xtreme_s_xlsr_300m_fleurs_asr_western_european
This model is a fine-tuned version of [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) on the GOOGLE/XTREME_S - FLEURS.ALL dataset.
It achieves the following results on the evaluation set:
- Cer: 0.2484
- Cer Ast Es: 0.1598
- Cer Bs Ba: 0.1749
- Cer Ca Es: 0.1655
- Cer Cy Gb: 0.2280
- Cer Da Dk: 0.3616
- Cer De De: 0.1287
- Cer El Gr: 0.6020
- Cer En Us: 0.1938
- Cer Es 419: 0.1288
- Cer Fi Fi: 0.2050
- Cer Fr Fr: 0.1811
- Cer Ga Ie: 0.4474
- Cer Gl Es: 0.1324
- Cer Hr Hr: 0.1555
- Cer Hu Hu: 0.3911
- Cer Is Is: 0.4646
- Cer It It: 0.1283
- Cer Kea Cv: 0.1818
- Cer Lb Lu: 0.2594
- Cer Mt Mt: 0.3628
- Cer Nb No: 0.2254
- Cer Nl Nl: 0.1790
- Cer Oci Fr: 0.2159
- Cer Pt Br: 0.2275
- Cer Sv Se: 0.3092
- Loss: 1.3089
- Loss Ast Es: 0.7715
- Loss Bs Ba: 0.7378
- Loss Ca Es: 0.7868
- Loss Cy Gb: 1.1441
- Loss Da Dk: 1.9130
- Loss De De: 0.5391
- Loss El Gr: 3.4904
- Loss En Us: 0.9632
- Loss Es 419: 0.6186
- Loss Fi Fi: 0.8953
- Loss Fr Fr: 0.9076
- Loss Ga Ie: 3.0217
- Loss Gl Es: 0.5788
- Loss Hr Hr: 0.6462
- Loss Hu Hu: 1.9029
- Loss Is Is: 2.6551
- Loss It It: 0.6052
- Loss Kea Cv: 0.9107
- Loss Lb Lu: 1.3705
- Loss Mt Mt: 2.3651
- Loss Nb No: 1.1518
- Loss Nl Nl: 0.8490
- Loss Oci Fr: 1.1421
- Loss Pt Br: 1.1641
- Loss Sv Se: 1.5910
- Wer: 0.6451
- Wer Ast Es: 0.4654
- Wer Bs Ba: 0.5443
- Wer Ca Es: 0.4979
- Wer Cy Gb: 0.5962
- Wer Da Dk: 0.8455
- Wer De De: 0.4221
- Wer El Gr: 0.9805
- Wer En Us: 0.4556
- Wer Es 419: 0.3928
- Wer Fi Fi: 0.8116
- Wer Fr Fr: 0.4690
- Wer Ga Ie: 0.8519
- Wer Gl Es: 0.4245
- Wer Hr Hr: 0.4895
- Wer Hu Hu: 0.9099
- Wer Is Is: 0.9960
- Wer It It: 0.4415
- Wer Kea Cv: 0.5202
- Wer Lb Lu: 0.7225
- Wer Mt Mt: 1.0096
- Wer Nb No: 0.6541
- Wer Nl Nl: 0.5257
- Wer Oci Fr: 0.5770
- Wer Pt Br: 0.6685
- Wer Sv Se: 0.8546
- Predict Samples: 20043
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 8
- eval_batch_size: 1
- seed: 42
- distributed_type: multi-GPU
- num_devices: 8
- total_train_batch_size: 64
- total_eval_batch_size: 8
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 1000
- num_epochs: 20.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer | Cer |
|:-------------:|:-----:|:-----:|:---------------:|:------:|:------:|
| 3.1411 | 0.49 | 500 | 3.1673 | 1.0 | 1.0 |
| 0.6397 | 0.97 | 1000 | 0.9039 | 0.7171 | 0.2862 |
| 0.4033 | 1.46 | 1500 | 0.8914 | 0.6862 | 0.2763 |
| 0.3473 | 1.94 | 2000 | 0.8017 | 0.6505 | 0.2536 |
| 0.3143 | 2.43 | 2500 | 0.8568 | 0.6566 | 0.2627 |
| 0.3004 | 2.91 | 3000 | 0.8898 | 0.6640 | 0.2686 |
| 0.282 | 3.4 | 3500 | 0.8489 | 0.6637 | 0.2571 |
| 0.2489 | 3.88 | 4000 | 0.8955 | 0.6744 | 0.2691 |
| 0.1706 | 4.37 | 4500 | 0.9190 | 0.6788 | 0.2688 |
| 0.3336 | 4.85 | 5000 | 0.8915 | 0.6594 | 0.2572 |
| 0.1426 | 5.34 | 5500 | 0.9501 | 0.6784 | 0.2686 |
| 0.2301 | 5.83 | 6000 | 1.0217 | 0.6719 | 0.2735 |
| 0.1325 | 6.31 | 6500 | 0.9578 | 0.6691 | 0.2655 |
| 0.1145 | 6.8 | 7000 | 0.9129 | 0.6680 | 0.2593 |
| 0.1202 | 7.28 | 7500 | 0.9646 | 0.6749 | 0.2619 |
| 0.143 | 7.77 | 8000 | 0.9200 | 0.6554 | 0.2554 |
| 0.1012 | 8.25 | 8500 | 0.9553 | 0.6787 | 0.2628 |
| 0.1018 | 8.74 | 9000 | 0.9455 | 0.6445 | 0.2511 |
| 0.1148 | 9.22 | 9500 | 1.0206 | 0.6725 | 0.2629 |
| 0.0794 | 9.71 | 10000 | 0.9305 | 0.6547 | 0.2526 |
| 0.2891 | 10.19 | 10500 | 1.0424 | 0.6709 | 0.2570 |
| 0.1665 | 10.68 | 11000 | 0.9760 | 0.6596 | 0.2507 |
| 0.1956 | 11.17 | 11500 | 0.9549 | 0.6340 | 0.2440 |
| 0.0828 | 11.65 | 12000 | 0.9598 | 0.6403 | 0.2460 |
| 0.059 | 12.14 | 12500 | 0.9972 | 0.6574 | 0.2531 |
| 0.0505 | 12.62 | 13000 | 0.9836 | 0.6534 | 0.2525 |
| 0.0336 | 13.11 | 13500 | 1.0619 | 0.6564 | 0.2519 |
| 0.0435 | 13.59 | 14000 | 1.0844 | 0.6480 | 0.2543 |
| 0.0216 | 14.08 | 14500 | 1.1084 | 0.6512 | 0.2521 |
| 0.0265 | 14.56 | 15000 | 1.1152 | 0.6607 | 0.2563 |
| 0.0975 | 15.05 | 15500 | 1.1060 | 0.6456 | 0.2471 |
| 0.1396 | 15.53 | 16000 | 1.1100 | 0.6337 | 0.2418 |
| 0.0701 | 16.02 | 16500 | 1.1731 | 0.6309 | 0.2415 |
| 0.1171 | 16.5 | 17000 | 1.1302 | 0.6315 | 0.2396 |
| 0.0778 | 16.99 | 17500 | 1.1485 | 0.6379 | 0.2447 |
| 0.0642 | 17.48 | 18000 | 1.2009 | 0.6400 | 0.2464 |
| 0.0322 | 17.96 | 18500 | 1.2028 | 0.6357 | 0.2425 |
| 0.031 | 18.45 | 19000 | 1.2381 | 0.6285 | 0.2416 |
| 0.0579 | 18.93 | 19500 | 1.2299 | 0.6265 | 0.2409 |
| 0.0628 | 19.42 | 20000 | 1.2582 | 0.6277 | 0.2395 |
| 0.074 | 19.9 | 20500 | 1.2572 | 0.6278 | 0.2394 |
### Framework versions
- Transformers 4.18.0.dev0
- Pytorch 1.10.1+cu111
- Datasets 1.18.4.dev0
- Tokenizers 0.11.6
|
a426b88fd76cc24d82b7ae97ebdb2e21
|
DOOGLAK/Article_500v4_NER_Model_3Epochs_UNAUGMENTED
|
DOOGLAK
|
bert
| 13 | 5 |
transformers
| 0 |
token-classification
| true | false | false |
apache-2.0
| null |
['article500v4_wikigold_split']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,561 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Article_500v4_NER_Model_3Epochs_UNAUGMENTED
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the article500v4_wikigold_split dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2062
- Precision: 0.6464
- Recall: 0.6730
- F1: 0.6594
- Accuracy: 0.9315
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 58 | 0.3048 | 0.3090 | 0.2978 | 0.3033 | 0.8852 |
| No log | 2.0 | 116 | 0.2127 | 0.6096 | 0.6567 | 0.6323 | 0.9271 |
| No log | 3.0 | 174 | 0.2062 | 0.6464 | 0.6730 | 0.6594 | 0.9315 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.11.0+cu113
- Datasets 2.4.0
- Tokenizers 0.11.6
|
6c2101dddd71025aa69408a50242f21f
|
RUCAIBox/mvp-task-dialog
|
RUCAIBox
|
mvp
| 9 | 3 |
transformers
| 1 |
text2text-generation
| true | false | false |
apache-2.0
|
['en']
| null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['text-generation', 'text2text-generation']
| false | true | true | 3,685 | false |
# MVP-task-dialog
The MVP-task-dialog model was proposed in [**MVP: Multi-task Supervised Pre-training for Natural Language Generation**](https://arxiv.org/abs/2206.12131) by Tianyi Tang, Junyi Li, Wayne Xin Zhao and Ji-Rong Wen.
The detailed information and instructions can be found [https://github.com/RUCAIBox/MVP](https://github.com/RUCAIBox/MVP).
## Model Description
MVP-task-dialog is a prompt-based model that MVP is further equipped with prompts pre-trained using labeled task-oriented system datasets. It is a variant (MVP+S) of our main [MVP](https://huggingface.co/RUCAIBox/mvp) model. It follows a Transformer encoder-decoder architecture with layer-wise prompts.
MVP-task-dialog is specially designed for task-oriented tasks, such as MultiWOZ.
## Example
```python
>>> from transformers import MvpTokenizer, MvpForConditionalGeneration
>>> tokenizer = MvpTokenizer.from_pretrained("RUCAIBox/mvp")
>>> model = MvpForConditionalGeneration.from_pretrained("RUCAIBox/mvp-task-dialog")
>>> inputs = tokenizer(
... "Given the task dialog: System response [X_SEP] I'm looking for a affordable BBQ restaurant in Dallas for a large group of guest.",
... return_tensors="pt",
... )
>>> generated_ids = model.generate(**inputs)
>>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True)
['What date and time would you like to go?']
```
## Related Models
**MVP**: [https://huggingface.co/RUCAIBox/mvp](https://huggingface.co/RUCAIBox/mvp).
**Prompt-based models**:
- MVP-multi-task: [https://huggingface.co/RUCAIBox/mvp-multi-task](https://huggingface.co/RUCAIBox/mvp-multi-task).
- MVP-summarization: [https://huggingface.co/RUCAIBox/mvp-summarization](https://huggingface.co/RUCAIBox/mvp-summarization).
- MVP-open-dialog: [https://huggingface.co/RUCAIBox/mvp-open-dialog](https://huggingface.co/RUCAIBox/mvp-open-dialog).
- MVP-data-to-text: [https://huggingface.co/RUCAIBox/mvp-data-to-text](https://huggingface.co/RUCAIBox/mvp-data-to-text).
- MVP-story: [https://huggingface.co/RUCAIBox/mvp-story](https://huggingface.co/RUCAIBox/mvp-story).
- MVP-question-answering: [https://huggingface.co/RUCAIBox/mvp-question-answering](https://huggingface.co/RUCAIBox/mvp-question-answering).
- MVP-question-generation: [https://huggingface.co/RUCAIBox/mvp-question-generation](https://huggingface.co/RUCAIBox/mvp-question-generation).
- MVP-task-dialog: [https://huggingface.co/RUCAIBox/mvp-task-dialog](https://huggingface.co/RUCAIBox/mvp-task-dialog).
**Multi-task models**:
- MTL-summarization: [https://huggingface.co/RUCAIBox/mtl-summarization](https://huggingface.co/RUCAIBox/mtl-summarization).
- MTL-open-dialog: [https://huggingface.co/RUCAIBox/mtl-open-dialog](https://huggingface.co/RUCAIBox/mtl-open-dialog).
- MTL-data-to-text: [https://huggingface.co/RUCAIBox/mtl-data-to-text](https://huggingface.co/RUCAIBox/mtl-data-to-text).
- MTL-story: [https://huggingface.co/RUCAIBox/mtl-story](https://huggingface.co/RUCAIBox/mtl-story).
- MTL-question-answering: [https://huggingface.co/RUCAIBox/mtl-question-answering](https://huggingface.co/RUCAIBox/mtl-question-answering).
- MTL-question-generation: [https://huggingface.co/RUCAIBox/mtl-question-generation](https://huggingface.co/RUCAIBox/mtl-question-generation).
- MTL-task-dialog: [https://huggingface.co/RUCAIBox/mtl-task-dialog](https://huggingface.co/RUCAIBox/mtl-task-dialog).
## Citation
```bibtex
@article{tang2022mvp,
title={MVP: Multi-task Supervised Pre-training for Natural Language Generation},
author={Tang, Tianyi and Li, Junyi and Zhao, Wayne Xin and Wen, Ji-Rong},
journal={arXiv preprint arXiv:2206.12131},
year={2022},
url={https://arxiv.org/abs/2206.12131},
}
```
|
bcdd393d0669f236e6a1d61aa324e058
|
gngpostalsrvc/BERiT_2000
|
gngpostalsrvc
|
roberta
| 11 | 7 |
transformers
| 0 |
fill-mask
| true | false | false |
mit
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,839 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# BERiT_2000
This model is a fine-tuned version of [roberta-base](https://huggingface.co/roberta-base) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 6.7293
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 6.9294 | 0.19 | 500 | 6.8136 |
| 6.7692 | 0.39 | 1000 | 6.8006 |
| 6.7567 | 0.58 | 1500 | 6.7770 |
| 6.746 | 0.77 | 2000 | 6.7414 |
| 6.7577 | 0.97 | 2500 | 6.7333 |
| 6.7295 | 1.16 | 3000 | 6.7405 |
| 6.7635 | 1.36 | 3500 | 6.7272 |
| 6.7715 | 1.55 | 4000 | 6.7114 |
| 6.7348 | 1.74 | 4500 | 6.7275 |
| 6.719 | 1.94 | 5000 | 6.7322 |
| 6.7427 | 2.13 | 5500 | 6.7242 |
| 6.7136 | 2.32 | 6000 | 6.6852 |
| 6.719 | 2.52 | 6500 | 6.7430 |
| 6.7229 | 2.71 | 7000 | 6.7331 |
| 6.7166 | 2.9 | 7500 | 6.7293 |
### Framework versions
- Transformers 4.24.0
- Pytorch 1.12.1+cu113
- Datasets 2.6.1
- Tokenizers 0.13.2
|
7e12d9a24f472209b9ab3e97c8319eb8
|
Dimitre/sd-pokemon-model
|
Dimitre
| null | 18 | 11 |
diffusers
| 1 | null | false | false | false |
apache-2.0
|
['en']
|
['lambdalabs/pokemon-blip-captions']
| null | 2 | 2 | 0 | 0 | 0 | 0 | 0 |
[]
| false | true | true | 1,217 | false |
<!-- This model card has been generated automatically according to the information the training script had access to. You
should probably proofread and complete it, then remove this comment. -->
# sd-pokemon-model
## Model description
This diffusion model is trained with the [🤗 Diffusers](https://github.com/huggingface/diffusers) library
on the `lambdalabs/pokemon-blip-captions` dataset.
## Intended uses & limitations
#### How to use
```python
# TODO: add an example code snippet for running this diffusion pipeline
```
#### Limitations and bias
[TODO: provide examples of latent issues and potential remediations]
## Training data
[TODO: describe the data used to train the model]
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 10
- eval_batch_size: 16
- gradient_accumulation_steps: 4
- optimizer: AdamW with betas=(None, None), weight_decay=None and epsilon=None
- lr_scheduler: constant
- lr_warmup_steps: 0
- ema_inv_gamma: None
- ema_inv_gamma: None
- ema_inv_gamma: None
- mixed_precision: fp16
### Training results
📈 [TensorBoard logs](https://huggingface.co/Dimitre/sd-pokemon-model/tensorboard?#scalars)
|
2d08629fe009a8e456cea604bb288000
|
Neprox/STT-swedish-lr-decay-model
|
Neprox
|
whisper
| 27 | 5 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
|
['sv']
| null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['hf-asr-leaderboard', 'generated_from_trainer']
| true | true | true | 1,655 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Whisper Small - Swedish
This model is a fine-tuned version of [openai/whisper-small](https://huggingface.co/openai/whisper-small) on the Common Voice 11.0 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4915
- Wer: 25.5384
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 4
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 6000
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:-------:|
| 0.2107 | 1.3 | 1000 | 0.4673 | 34.0432 |
| 0.0821 | 2.59 | 2000 | 0.4284 | 27.4152 |
| 0.0378 | 3.89 | 3000 | 0.4210 | 25.3637 |
| 0.0042 | 5.18 | 4000 | 0.4247 | 23.5541 |
| 0.001 | 6.48 | 5000 | 0.4286 | 22.7770 |
| 0.0106 | 7.77 | 6000 | 0.4915 | 25.5384 |
### Framework versions
- Transformers 4.25.0.dev0
- Pytorch 1.12.1
- Datasets 2.7.1
- Tokenizers 0.13.2
|
3f35b00ea85b34a0b9bc566dda97e05f
|
anshengmay/xlm-roberta-base-finetuned-marc
|
anshengmay
|
xlm-roberta
| 12 | 2 |
transformers
| 0 |
text-classification
| true | false | false |
mit
| null |
['amazon_reviews_multi']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,271 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xlm-roberta-base-finetuned-marc
This model is a fine-tuned version of [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) on the amazon_reviews_multi dataset.
It achieves the following results on the evaluation set:
- Loss: 0.9904
- Mae: 0.4867
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Mae |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 1.2067 | 1.0 | 308 | 1.0806 | 0.5575 |
| 1.0182 | 2.0 | 616 | 0.9904 | 0.4867 |
### Framework versions
- Transformers 4.25.1
- Pytorch 1.13.0+cu116
- Datasets 2.8.0
- Tokenizers 0.13.2
|
12cba0080e396199735ed8df4fd6f2ee
|
wavymulder/lomo-diffusion
|
wavymulder
| null | 22 | 161 |
diffusers
| 11 |
text-to-image
| false | false | false |
creativeml-openrail-m
|
['en']
| null | null | 4 | 0 | 2 | 2 | 0 | 0 | 0 |
['stable-diffusion', 'stable-diffusion-diffusers', 'text-to-image', 'safetensors', 'diffusers']
| false | true | true | 1,438 | false |
**Lomo Diffusion**

[*CKPT DOWNLOAD LINK*](https://huggingface.co/wavymulder/lomo-diffusion/resolve/main/lomo-1.0.ckpt) - - - [*SAFETENSORS DOWNLOAD LINK*](https://huggingface.co/wavymulder/lomo-diffusion/resolve/main/lomo-1.0.safetensors)
This is a dreambooth model trained on a diverse set of stylized photographs.
Use the activation token **lomo style** in your prompt (I recommend at the start)
This model is inspired by the Lomography movement, which embraces the imperfections and style of old LOMO cameras. The model excels at producing bright saturated colors as well as a variety of film artifacts that add to the illusion of a real photograph.
When using most models, I typically use **blur haze** in my negative prompt. I encourage you to experiment and see what works well for you.
Trained from 1.5 with VAE.
Please see [this document where I share the parameters (prompt, sampler, seed, etc.) used for all example images.](https://huggingface.co/wavymulder/lomo-diffusion/resolve/main/paramets_for_samples.txt)
You can [see here a non-cherrypicked batch of 49 images here.](https://i.imgur.com/cfIj3iq.jpg)
And you can [see here a direct comparison between Analog Style and Lomo Style.](https://i.imgur.com/ugdFzPI.jpg)

|
04cb1215bb37e1581bc6ab5fd660f30b
|
bofenghuang/asr-wav2vec2-ctc-french
|
bofenghuang
|
wav2vec2
| 59 | 2,058 |
transformers
| 1 |
automatic-speech-recognition
| true | false | false |
apache-2.0
|
['fr']
|
['common_voice', 'mozilla-foundation/common_voice_11_0', 'facebook/multilingual_librispeech', 'facebook/voxpopuli', 'gigant/african_accented_french']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['automatic-speech-recognition', 'hf-asr-leaderboard', 'robust-speech-event', 'CTC', 'Wav2vec2']
| true | true | true | 3,984 | false |
# Fine-tuned wav2vec2-FR-7K-large model for ASR in French
<style>
img {
display: inline;
}
</style>



This model is a fine-tuned version of [LeBenchmark/wav2vec2-FR-7K-large](https://huggingface.co/LeBenchmark/wav2vec2-FR-7K-large), trained on a composite dataset comprising of over 2200 hours of French speech audio, using the train and validation splits of [Common Voice 11.0](https://huggingface.co/datasets/mozilla-foundation/common_voice_11_0), [Multilingual LibriSpeech](https://huggingface.co/datasets/facebook/multilingual_librispeech), [Voxpopuli](https://github.com/facebookresearch/voxpopuli), [Multilingual TEDx](http://www.openslr.org/100), [MediaSpeech](https://www.openslr.org/108), and [African Accented French](https://huggingface.co/datasets/gigant/african_accented_french). When using the model make sure that your speech input is also sampled at 16Khz.
## Usage
1. To use on a local audio file with the language model
```python
import torch
import torchaudio
from transformers import AutoModelForCTC, Wav2Vec2ProcessorWithLM
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model = AutoModelForCTC.from_pretrained("bhuang/asr-wav2vec2-french").to(device)
processor_with_lm = Wav2Vec2ProcessorWithLM.from_pretrained("bhuang/asr-wav2vec2-french")
model_sample_rate = processor_with_lm.feature_extractor.sampling_rate
wav_path = "example.wav" # path to your audio file
waveform, sample_rate = torchaudio.load(wav_path)
waveform = waveform.squeeze(axis=0) # mono
# resample
if sample_rate != model_sample_rate:
resampler = torchaudio.transforms.Resample(sample_rate, model_sample_rate)
waveform = resampler(waveform)
# normalize
input_dict = processor_with_lm(waveform, sampling_rate=model_sample_rate, return_tensors="pt")
with torch.inference_mode():
logits = model(input_dict.input_values.to(device)).logits
predicted_sentence = processor_with_lm.batch_decode(logits.cpu().numpy()).text[0]
```
2. To use on a local audio file without the language model
```python
import torch
import torchaudio
from transformers import AutoModelForCTC, Wav2Vec2Processor
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model = AutoModelForCTC.from_pretrained("bhuang/asr-wav2vec2-french").to(device)
processor = Wav2Vec2Processor.from_pretrained("bhuang/asr-wav2vec2-french")
model_sample_rate = processor.feature_extractor.sampling_rate
wav_path = "example.wav" # path to your audio file
waveform, sample_rate = torchaudio.load(wav_path)
waveform = waveform.squeeze(axis=0) # mono
# resample
if sample_rate != model_sample_rate:
resampler = torchaudio.transforms.Resample(sample_rate, model_sample_rate)
waveform = resampler(waveform)
# normalize
input_dict = processor(waveform, sampling_rate=model_sample_rate, return_tensors="pt")
with torch.inference_mode():
logits = model(input_dict.input_values.to(device)).logits
# decode
predicted_ids = torch.argmax(logits, dim=-1)
predicted_sentence = processor.batch_decode(predicted_ids)[0]
```
## Evaluation
1. To evaluate on `mozilla-foundation/common_voice_11_0`
```bash
python eval.py \
--model_id "bhuang/asr-wav2vec2-french" \
--dataset "mozilla-foundation/common_voice_11_0" \
--config "fr" \
--split "test" \
--log_outputs \
--outdir "outputs/results_mozilla-foundatio_common_voice_11_0_with_lm"
```
2. To evaluate on `speech-recognition-community-v2/dev_data`
```bash
python eval.py \
--model_id "bhuang/asr-wav2vec2-french" \
--dataset "speech-recognition-community-v2/dev_data" \
--config "fr" \
--split "validation" \
--chunk_length_s 30.0 \
--stride_length_s 5.0 \
--log_outputs \
--outdir "outputs/results_speech-recognition-community-v2_dev_data_with_lm"
```
|
581553fbba1b84d00e013af9d45b668c
|
infoxixxx/cat-toy
|
infoxixxx
| null | 22 | 4 |
diffusers
| 0 | null | false | false | false |
mit
| null | null | null | 2 | 2 | 0 | 0 | 0 | 0 | 0 |
[]
| false | true | true | 1,198 | false |
### Cat toy on Stable Diffusion via Dreambooth
#### model by infoxixxx
This your the Stable Diffusion model fine-tuned the Cat toy concept taught to Stable Diffusion with Dreambooth.
It can be used by modifying the `instance_prompt`: **a photo of sks toy**
You can also train your own concepts and upload them to the library by using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_training.ipynb).
And you can run your new concept via `diffusers`: [Colab Notebook for Inference](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_inference.ipynb), [Spaces with the Public Concepts loaded](https://huggingface.co/spaces/sd-dreambooth-library/stable-diffusion-dreambooth-concepts)
Here are the images used for training this concept:




|
401ea0a510609a163bad8eb5c88a5f9d
|
Chandanab/deit-tiny-patch16-224-finetuned-eurosat
|
Chandanab
|
vit
| 10 | 9 |
transformers
| 0 |
image-classification
| true | false | false |
apache-2.0
| null |
['image_folder']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,468 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# deit-tiny-patch16-224-finetuned-eurosat
This model is a fine-tuned version of [facebook/deit-tiny-patch16-224](https://huggingface.co/facebook/deit-tiny-patch16-224) on the image_folder dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1779
- Accuracy: 0.9192
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| No log | 1.0 | 7 | 0.3528 | 0.8283 |
| 0.5571 | 2.0 | 14 | 0.2141 | 0.8788 |
| 0.197 | 3.0 | 21 | 0.1779 | 0.9192 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.11.0+cpu
- Datasets 2.2.0
- Tokenizers 0.12.1
|
8de7d5b52b062c4d393f3bf3369c1cb9
|
explosion/af_udv25_afrikaansafribooms_trf
|
explosion
| null | 28 | 1 |
spacy
| 0 |
token-classification
| false | false | false |
cc-by-sa-4.0
|
['af']
| null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['spacy', 'token-classification']
| false | true | true | 6,840 | false |
UD v2.5 benchmarking pipeline for UD_Afrikaans-AfriBooms
| Feature | Description |
| --- | --- |
| **Name** | `af_udv25_afrikaansafribooms_trf` |
| **Version** | `0.0.1` |
| **spaCy** | `>=3.2.1,<3.3.0` |
| **Default Pipeline** | `experimental_char_ner_tokenizer`, `transformer`, `tagger`, `morphologizer`, `parser`, `experimental_edit_tree_lemmatizer` |
| **Components** | `experimental_char_ner_tokenizer`, `transformer`, `senter`, `tagger`, `morphologizer`, `parser`, `experimental_edit_tree_lemmatizer` |
| **Vectors** | 0 keys, 0 unique vectors (0 dimensions) |
| **Sources** | [Universal Dependencies v2.5](https://lindat.mff.cuni.cz/repository/xmlui/handle/11234/1-3105) (Zeman, Daniel; et al.) |
| **License** | `CC BY-SA 4.0` |
| **Author** | [Explosion](https://explosion.ai) |
### Label Scheme
<details>
<summary>View label scheme (455 labels for 6 components)</summary>
| Component | Labels |
| --- | --- |
| **`experimental_char_ner_tokenizer`** | `TOKEN` |
| **`senter`** | `I`, `S` |
| **`tagger`** | `AOA`, `AOP`, `ASA`, `ASP`, `AVA`, `AVP`, `BO`, `BS`, `BV`, `KN`, `KO`, `LB`, `LO`, `NA`, `NEE`, `NM`, `NME`, `NSE`, `NSED`, `NSM`, `PA`, `PB`, `PDHEB`, `PDHEDP`, `PDHENP`, `PDHEW`, `PDMB`, `PDMP`, `PDMW`, `PDOENP`, `PDOEW`, `PDVEB`, `PDVEDP`, `PDVENP`, `PDVEW`, `PEEB`, `PEEDP`, `PEENP`, `PEMB`, `PEMP`, `PEMW`, `PO`, `PTEB`, `PTEDP`, `PTENP`, `PTEW`, `PTMP`, `PV`, `PW`, `RA`, `RK`, `RL`, `RO`, `RS`, `RSF`, `RV`, `RWD`, `SVS`, `THAB`, `THAO`, `THBB`, `THBO`, `THNB`, `THPB`, `THPO`, `TRAB`, `TRAO`, `TRBB`, `UPB`, `UPD`, `UPI`, `UPO`, `UPS`, `UPV`, `UPW`, `UXD`, `VTHOG`, `VTHOK`, `VTHOO`, `VTHOV`, `VTHSG`, `VTHSO`, `VTUOA`, `VTUOM`, `VTUOP`, `VUOT`, `VVHOG`, `VVHOK`, `VVHOO`, `VVUOM`, `VVUOP`, `ZE`, `ZM`, `ZPL`, `ZPR` |
| **`morphologizer`** | `Definite=Def\|POS=DET\|PronType=Art`, `Number=Sing\|POS=NOUN`, `AdpType=Prep\|POS=ADP`, `AdjType=Attr\|Case=Nom\|Degree=Pos\|POS=ADJ`, `Number=Plur\|POS=NOUN`, `POS=AUX\|Tense=Pres\|VerbForm=Fin,Inf\|VerbType=Cop`, `Definite=Ind\|POS=DET\|PronType=Art`, `POS=NUM`, `POS=PART\|PartType=Inf`, `POS=VERB\|Subcat=Tran\|Tense=Pres\|VerbForm=Fin,Inf`, `POS=PRON\|PronType=Rel`, `POS=AUX\|Tense=Pres\|VerbForm=Fin,Inf\|VerbType=Pas`, `POS=PUNCT`, `POS=CCONJ`, `POS=SCONJ`, `POS=VERB\|Subcat=Intr\|Tense=Pres\|VerbForm=Fin,Inf`, `POS=VERB\|Subcat=Intr\|Tense=Past\|VerbForm=Part`, `POS=AUX\|Tense=Past\|VerbForm=Fin\|VerbType=Pas`, `Degree=Pos\|POS=ADV`, `POS=AUX\|Tense=Pres\|VerbForm=Fin,Inf\|VerbType=Mod`, `POS=DET\|PronType=Ind`, `POS=X`, `Number=Sing\|POS=PROPN`, `POS=PRON\|PronType=Ind`, `POS=PART\|PartType=Neg`, `POS=VERB\|Subcat=Tran\|Tense=Past\|VerbForm=Part`, `AdjType=Pred\|Case=Nom\|Degree=Pos\|POS=ADJ`, `POS=DET\|PronType=Dem`, `Degree=Cmp\|POS=ADV`, `Case=Nom\|Number=Sing\|POS=PRON\|Person=3\|PronType=Prs`, `POS=SYM`, `Case=Acc,Nom\|Number=Plur\|POS=PRON\|Person=1\|PronType=Prs`, `POS=PART\|PartType=Gen`, `Case=Acc\|Number=Sing\|POS=PRON\|Person=2\|PronType=Prs`, `Number=Sing\|POS=PRON\|Person=2\|PronType=Prs\|Reflex=Yes`, `Degree=Sup\|POS=ADV`, `Degree=Dim\|Number=Sing\|POS=NOUN`, `Number=Sing\|POS=PRON\|Person=2\|Poss=Yes\|PronType=Prs`, `POS=PRON\|PronType=Int`, `Number=Plur\|POS=PRON\|Person=1\|Poss=Yes\|PronType=Prs`, `Number=Sing\|POS=PRON\|Person=3\|PronType=Prs\|Reflex=Yes`, `Number=Plur\|POS=PRON\|Person=3\|Poss=Yes\|PronType=Prs`, `AdjType=Attr\|Case=Nom\|Degree=Sup\|POS=ADJ`, `Case=Nom\|Number=Sing\|POS=PRON\|Person=2\|PronType=Prs`, `AdjType=Pred\|Case=Nom\|Degree=Cmp\|POS=ADJ`, `POS=VERB\|Subcat=Prep\|Tense=Pres\|VerbForm=Fin,Inf`, `POS=AUX\|Tense=Pres\|VerbForm=Fin,Inf\|VerbType=Aux`, `Number=Sing\|POS=PRON\|Person=3\|Poss=Yes\|PronType=Prs`, `POS=PRON\|PronType=Rcp`, `POS=AUX\|Tense=Past\|VerbForm=Fin\|VerbType=Mod`, `Case=Acc,Nom\|Number=Plur\|POS=PRON\|Person=3\|PronType=Prs`, `POS=AUX\|Tense=Past\|VerbForm=Fin\|VerbType=Cop`, `Case=Acc\|Number=Sing\|POS=PRON\|Person=3\|PronType=Prs`, `Case=Nom\|Number=Sing\|POS=PRON\|Person=1\|PronType=Prs`, `Number=Sing\|POS=PRON\|Person=1\|Poss=Yes\|PronType=Prs`, `Case=Acc,Nom\|Number=Plur\|POS=PRON\|Person=2\|PronType=Prs`, `Number=Plur\|POS=PRON\|Person=3\|PronType=Prs\|Reflex=Yes`, `AdjType=Attr\|Case=Nom\|Degree=Cmp\|POS=ADJ`, `Number=Plur\|POS=PRON\|Person=1\|PronType=Prs\|Reflex=Yes`, `Case=Acc\|Number=Sing\|POS=PRON\|Person=1\|PronType=Prs`, `AdjType=Pred\|Case=Nom\|Degree=Sup\|POS=ADJ` |
| **`parser`** | `ROOT`, `advmod`, `amod`, `appos`, `aux`, `aux:pass`, `case`, `cc`, `ccomp`, `compound:prt`, `conj`, `cop`, `dep`, `det`, `flat`, `iobj`, `mark`, `nmod`, `nsubj`, `nsubj:pass`, `nummod`, `obj`, `obl`, `punct`, `xcomp` |
| **`experimental_edit_tree_lemmatizer`** | `1`, `2`, `4`, `7`, `8`, `10`, `12`, `14`, `16`, `18`, `21`, `24`, `26`, `28`, `31`, `32`, `34`, `37`, `39`, `40`, `42`, `44`, `46`, `47`, `49`, `51`, `53`, `54`, `56`, `57`, `58`, `59`, `61`, `64`, `66`, `68`, `69`, `72`, `74`, `75`, `77`, `78`, `81`, `83`, `84`, `85`, `86`, `87`, `90`, `92`, `94`, `96`, `99`, `101`, `103`, `105`, `108`, `110`, `113`, `116`, `117`, `118`, `121`, `123`, `124`, `125`, `127`, `128`, `129`, `133`, `136`, `138`, `141`, `143`, `145`, `147`, `151`, `153`, `154`, `156`, `158`, `159`, `160`, `162`, `164`, `165`, `167`, `168`, `170`, `172`, `174`, `176`, `178`, `179`, `180`, `181`, `183`, `185`, `189`, `190`, `191`, `192`, `194`, `195`, `197`, `198`, `201`, `202`, `203`, `204`, `206`, `207`, `209`, `213`, `214`, `216`, `217`, `218`, `220`, `221`, `222`, `223`, `225`, `226`, `228`, `229`, `231`, `233`, `234`, `236`, `238`, `240`, `241`, `244`, `247`, `248`, `249`, `250`, `252`, `253`, `255`, `256`, `257`, `258`, `261`, `262`, `263`, `265`, `267`, `269`, `270`, `271`, `273`, `275`, `276`, `278`, `279`, `281`, `283`, `285`, `287`, `289`, `291`, `294`, `296`, `297`, `298`, `299`, `300`, `301`, `302`, `303`, `305`, `306`, `307`, `309`, `310`, `311`, `313`, `314`, `315`, `317`, `320`, `321`, `323`, `325`, `326`, `327`, `328`, `329`, `330`, `332`, `333`, `335`, `336`, `337`, `338`, `339`, `340`, `341`, `343`, `344`, `347`, `348`, `349`, `351`, `353`, `355`, `357`, `359`, `360`, `361`, `362`, `365`, `366`, `367`, `369`, `371`, `373`, `374`, `375`, `377`, `379`, `381`, `383`, `386`, `388`, `390`, `392`, `393`, `395`, `397`, `398`, `400`, `401`, `402`, `403`, `405`, `406`, `408`, `409`, `411`, `412`, `414`, `417`, `215`, `418`, `419`, `420`, `421`, `422`, `424`, `425`, `426`, `427`, `429`, `431`, `432`, `433`, `434`, `436`, `438`, `439`, `440`, `442`, `443`, `444`, `447`, `449`, `450`, `452` |
</details>
### Accuracy
| Type | Score |
| --- | --- |
| `TOKEN_F` | 99.92 |
| `TOKEN_P` | 99.89 |
| `TOKEN_R` | 99.94 |
| `TOKEN_ACC` | 100.00 |
| `SENTS_F` | 100.00 |
| `SENTS_P` | 100.00 |
| `SENTS_R` | 100.00 |
| `TAG_ACC` | 96.01 |
| `POS_ACC` | 98.52 |
| `MORPH_ACC` | 97.52 |
| `DEP_UAS` | 90.78 |
| `DEP_LAS` | 87.50 |
| `LEMMA_ACC` | 97.87 |
|
f5aaf5dd579a62055a76b7da53915b56
|
pyf98/chime4_conformer_e12_linear2048
|
pyf98
| null | 33 | 3 |
espnet
| 0 |
automatic-speech-recognition
| false | false | false |
cc-by-4.0
|
['en']
|
['chime4']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['espnet', 'audio', 'automatic-speech-recognition']
| false | true | true | 8,232 | false |
## ESPnet2 ASR model
### `pyf98/chime4_conformer_e12_linear2048`
This model was trained by Yifan Peng using chime4 recipe in [espnet](https://github.com/espnet/espnet/).
### Demo: How to use in ESPnet2
Follow the [ESPnet installation instructions](https://espnet.github.io/espnet/installation.html)
if you haven't done that already.
```bash
cd espnet
git checkout ad91279f0108d54bd22abe29671b376f048822c5
pip install -e .
cd egs2/chime4/asr1
./run.sh --skip_data_prep false --skip_train true --download_model pyf98/chime4_conformer_e12_linear2048
```
<!-- Generated by scripts/utils/show_asr_result.sh -->
# RESULTS
## Environments
- date: `Wed Dec 28 20:41:40 EST 2022`
- python version: `3.9.15 (main, Nov 24 2022, 14:31:59) [GCC 11.2.0]`
- espnet version: `espnet 202211`
- pytorch version: `pytorch 1.12.1`
- Git hash: `ad91279f0108d54bd22abe29671b376f048822c5`
- Commit date: `Wed Dec 28 20:15:42 2022 -0500`
## asr_train_asr_conformer_e12_linear2048_raw_en_char_sp
### WER
|dataset|Snt|Wrd|Corr|Sub|Del|Ins|Err|S.Err|
|---|---|---|---|---|---|---|---|---|
|decode_asr_lm_lm_train_lm_transformer_en_char_valid.loss.ave_asr_model_valid.acc.ave/dt05_real_beamformit_5mics|1640|27119|93.3|5.4|1.3|0.5|7.3|55.6|
|decode_asr_lm_lm_train_lm_transformer_en_char_valid.loss.ave_asr_model_valid.acc.ave/dt05_simu_beamformit_5mics|1640|27120|91.7|6.7|1.6|0.9|9.1|62.0|
|decode_asr_lm_lm_train_lm_transformer_en_char_valid.loss.ave_asr_model_valid.acc.ave/et05_real_beamformit_5mics|1320|21409|89.2|8.9|1.9|1.1|12.0|64.5|
|decode_asr_lm_lm_train_lm_transformer_en_char_valid.loss.ave_asr_model_valid.acc.ave/et05_simu_beamformit_5mics|1320|21416|87.8|9.6|2.6|1.4|13.6|68.1|
### CER
|dataset|Snt|Wrd|Corr|Sub|Del|Ins|Err|S.Err|
|---|---|---|---|---|---|---|---|---|
|decode_asr_lm_lm_train_lm_transformer_en_char_valid.loss.ave_asr_model_valid.acc.ave/dt05_real_beamformit_5mics|1640|160390|97.2|1.5|1.3|0.7|3.5|55.6|
|decode_asr_lm_lm_train_lm_transformer_en_char_valid.loss.ave_asr_model_valid.acc.ave/dt05_simu_beamformit_5mics|1640|160400|96.3|2.0|1.7|1.0|4.7|62.0|
|decode_asr_lm_lm_train_lm_transformer_en_char_valid.loss.ave_asr_model_valid.acc.ave/et05_real_beamformit_5mics|1320|126796|95.1|2.8|2.1|1.2|6.1|64.6|
|decode_asr_lm_lm_train_lm_transformer_en_char_valid.loss.ave_asr_model_valid.acc.ave/et05_simu_beamformit_5mics|1320|126812|94.0|3.1|3.0|1.6|7.7|68.1|
### TER
|dataset|Snt|Wrd|Corr|Sub|Del|Ins|Err|S.Err|
|---|---|---|---|---|---|---|---|---|
## ASR config
<details><summary>expand</summary>
```
config: conf/tuning/train_asr_conformer_e12_linear2048.yaml
print_config: false
log_level: INFO
dry_run: false
iterator_type: sequence
output_dir: exp/asr_train_asr_conformer_e12_linear2048_raw_en_char_sp
ngpu: 1
seed: 2022
num_workers: 4
num_att_plot: 3
dist_backend: nccl
dist_init_method: env://
dist_world_size: 2
dist_rank: 0
local_rank: 0
dist_master_addr: localhost
dist_master_port: 45069
dist_launcher: null
multiprocessing_distributed: true
unused_parameters: false
sharded_ddp: false
cudnn_enabled: true
cudnn_benchmark: false
cudnn_deterministic: true
collect_stats: false
write_collected_feats: false
max_epoch: 50
patience: null
val_scheduler_criterion:
- valid
- loss
early_stopping_criterion:
- valid
- loss
- min
best_model_criterion:
- - valid
- acc
- max
keep_nbest_models: 10
nbest_averaging_interval: 0
grad_clip: 5.0
grad_clip_type: 2.0
grad_noise: false
accum_grad: 1
no_forward_run: false
resume: true
train_dtype: float32
use_amp: true
log_interval: null
use_matplotlib: true
use_tensorboard: true
create_graph_in_tensorboard: false
use_wandb: false
wandb_project: null
wandb_id: null
wandb_entity: null
wandb_name: null
wandb_model_log_interval: -1
detect_anomaly: false
pretrain_path: null
init_param: []
ignore_init_mismatch: false
freeze_param: []
num_iters_per_epoch: null
batch_size: 20
valid_batch_size: null
batch_bins: 15000000
valid_batch_bins: null
train_shape_file:
- exp/asr_stats_raw_en_char_sp/train/speech_shape
- exp/asr_stats_raw_en_char_sp/train/text_shape.char
valid_shape_file:
- exp/asr_stats_raw_en_char_sp/valid/speech_shape
- exp/asr_stats_raw_en_char_sp/valid/text_shape.char
batch_type: numel
valid_batch_type: null
fold_length:
- 80000
- 150
sort_in_batch: descending
sort_batch: descending
multiple_iterator: false
chunk_length: 500
chunk_shift_ratio: 0.5
num_cache_chunks: 1024
train_data_path_and_name_and_type:
- - dump/raw/tr05_multi_noisy_si284_sp/wav.scp
- speech
- kaldi_ark
- - dump/raw/tr05_multi_noisy_si284_sp/text
- text
- text
valid_data_path_and_name_and_type:
- - dump/raw/dt05_multi_isolated_1ch_track/wav.scp
- speech
- kaldi_ark
- - dump/raw/dt05_multi_isolated_1ch_track/text
- text
- text
allow_variable_data_keys: false
max_cache_size: 0.0
max_cache_fd: 32
valid_max_cache_size: null
optim: adam
optim_conf:
lr: 0.001
weight_decay: 1.0e-06
scheduler: warmuplr
scheduler_conf:
warmup_steps: 25000
token_list:
- <blank>
- <unk>
- <space>
- E
- T
- A
- N
- I
- O
- S
- R
- H
- L
- D
- C
- U
- M
- P
- F
- G
- Y
- W
- B
- V
- K
- .
- X
- ''''
- J
- Q
- Z
- ','
- '-'
- '"'
- <NOISE>
- '*'
- ':'
- (
- )
- '?'
- '&'
- ;
- '!'
- /
- '{'
- '}'
- '1'
- '2'
- '0'
- $
- '8'
- '9'
- '6'
- '3'
- '5'
- '7'
- '4'
- '~'
- '`'
- _
- <*IN*>
- <*MR.*>
- \
- ^
- <sos/eos>
init: null
input_size: null
ctc_conf:
dropout_rate: 0.0
ctc_type: builtin
reduce: true
ignore_nan_grad: null
zero_infinity: true
joint_net_conf: null
use_preprocessor: true
token_type: char
bpemodel: null
non_linguistic_symbols: data/nlsyms.txt
cleaner: null
g2p: null
speech_volume_normalize: null
rir_scp: null
rir_apply_prob: 1.0
noise_scp: null
noise_apply_prob: 1.0
noise_db_range: '13_15'
short_noise_thres: 0.5
frontend: default
frontend_conf:
n_fft: 512
win_length: 400
hop_length: 160
fs: 16k
specaug: specaug
specaug_conf:
apply_time_warp: true
time_warp_window: 5
time_warp_mode: bicubic
apply_freq_mask: true
freq_mask_width_range:
- 0
- 27
num_freq_mask: 2
apply_time_mask: true
time_mask_width_ratio_range:
- 0.0
- 0.05
num_time_mask: 2
normalize: global_mvn
normalize_conf:
stats_file: exp/asr_stats_raw_en_char_sp/train/feats_stats.npz
model: espnet
model_conf:
ctc_weight: 0.3
lsm_weight: 0.1
length_normalized_loss: false
preencoder: null
preencoder_conf: {}
encoder: conformer
encoder_conf:
output_size: 256
attention_heads: 4
linear_units: 2048
num_blocks: 12
dropout_rate: 0.1
positional_dropout_rate: 0.1
attention_dropout_rate: 0.1
input_layer: conv2d
normalize_before: true
macaron_style: true
rel_pos_type: latest
pos_enc_layer_type: rel_pos
selfattention_layer_type: rel_selfattn
activation_type: swish
use_cnn_module: true
cnn_module_kernel: 31
postencoder: null
postencoder_conf: {}
decoder: transformer
decoder_conf:
attention_heads: 4
linear_units: 2048
num_blocks: 6
dropout_rate: 0.1
positional_dropout_rate: 0.1
self_attention_dropout_rate: 0.1
src_attention_dropout_rate: 0.1
preprocessor: default
preprocessor_conf: {}
required:
- output_dir
- token_list
version: '202211'
distributed: true
```
</details>
### Citing ESPnet
```BibTex
@inproceedings{watanabe2018espnet,
author={Shinji Watanabe and Takaaki Hori and Shigeki Karita and Tomoki Hayashi and Jiro Nishitoba and Yuya Unno and Nelson Yalta and Jahn Heymann and Matthew Wiesner and Nanxin Chen and Adithya Renduchintala and Tsubasa Ochiai},
title={{ESPnet}: End-to-End Speech Processing Toolkit},
year={2018},
booktitle={Proceedings of Interspeech},
pages={2207--2211},
doi={10.21437/Interspeech.2018-1456},
url={http://dx.doi.org/10.21437/Interspeech.2018-1456}
}
```
or arXiv:
```bibtex
@misc{watanabe2018espnet,
title={ESPnet: End-to-End Speech Processing Toolkit},
author={Shinji Watanabe and Takaaki Hori and Shigeki Karita and Tomoki Hayashi and Jiro Nishitoba and Yuya Unno and Nelson Yalta and Jahn Heymann and Matthew Wiesner and Nanxin Chen and Adithya Renduchintala and Tsubasa Ochiai},
year={2018},
eprint={1804.00015},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
|
b5216f105031fa99d8066750606de763
|
studio-ousia/luke-japanese-large
|
studio-ousia
|
luke
| 10 | 2,488 |
transformers
| 3 |
fill-mask
| true | false | false |
apache-2.0
|
['ja']
| null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['luke', 'named entity recognition', 'entity typing', 'relation classification', 'question answering']
| false | true | true | 2,470 | false |
## luke-japanese-large
**luke-japanese** is the Japanese version of **LUKE** (**L**anguage
**U**nderstanding with **K**nowledge-based **E**mbeddings), a pre-trained
_knowledge-enhanced_ contextualized representation of words and entities. LUKE
treats words and entities in a given text as independent tokens, and outputs
contextualized representations of them. Please refer to our
[GitHub repository](https://github.com/studio-ousia/luke) for more details and
updates.
This model contains Wikipedia entity embeddings which are not used in general
NLP tasks. Please use the
[lite version](https://huggingface.co/studio-ousia/luke-japanese-large-lite/)
for tasks that do not use Wikipedia entities as inputs.
**luke-japanese**は、単語とエンティティの知識拡張型訓練済み Transformer モデル**LUKE**の日本語版です。LUKE は単語とエンティティを独立したトークンとして扱い、これらの文脈を考慮した表現を出力します。詳細については、[GitHub リポジトリ](https://github.com/studio-ousia/luke)を参照してください。
このモデルは、通常の NLP タスクでは使われない Wikipedia エンティティのエンベディングを含んでいます。単語の入力のみを使うタスクには、[lite version](https://huggingface.co/studio-ousia/luke-japanese-large-lite/)を使用してください。
### Experimental results on JGLUE
The experimental results evaluated on the dev set of
[JGLUE](https://github.com/yahoojapan/JGLUE) is shown as follows:
| Model | MARC-ja | JSTS | JNLI | JCommonsenseQA |
| ----------------------------- | --------- | ------------------- | --------- | -------------- |
| | acc | Pearson/Spearman | acc | acc |
| **LUKE Japanese large** | **0.965** | **0.932**/**0.902** | **0.927** | 0.893 |
| _Baselines:_ | |
| Tohoku BERT large | 0.955 | 0.913/0.872 | 0.900 | 0.816 |
| Waseda RoBERTa large (seq128) | 0.954 | 0.930/0.896 | 0.924 | **0.907** |
| Waseda RoBERTa large (seq512) | 0.961 | 0.926/0.892 | 0.926 | 0.891 |
| XLM RoBERTa large | 0.964 | 0.918/0.884 | 0.919 | 0.840 |
The baseline scores are obtained from
[here](https://github.com/yahoojapan/JGLUE/blob/a6832af23895d6faec8ecf39ec925f1a91601d62/README.md).
### Citation
```latex
@inproceedings{yamada2020luke,
title={LUKE: Deep Contextualized Entity Representations with Entity-aware Self-attention},
author={Ikuya Yamada and Akari Asai and Hiroyuki Shindo and Hideaki Takeda and Yuji Matsumoto},
booktitle={EMNLP},
year={2020}
}
```
|
4f9af261b4dd9345bb338d0b998bfe77
|
bochaowei/t5-small-finetuned-xsum-wei0
|
bochaowei
|
t5
| 14 | 2 |
transformers
| 0 |
text2text-generation
| true | false | false |
apache-2.0
| null |
['xsum']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,420 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-small-finetuned-xsum-wei0
This model is a fine-tuned version of [t5-small](https://huggingface.co/t5-small) on the xsum dataset.
It achieves the following results on the evaluation set:
- Loss: 2.6289
- Rouge1: 25.7398
- Rouge2: 6.1361
- Rougel: 19.8262
- Rougelsum: 19.8284
- Gen Len: 18.7984
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 12
- eval_batch_size: 12
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:-------:|:------:|:-------:|:---------:|:-------:|
| 2.858 | 1.0 | 1701 | 2.6289 | 25.7398 | 6.1361 | 19.8262 | 19.8284 | 18.7984 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.9.0+cu111
- Datasets 1.14.0
- Tokenizers 0.10.3
|
facae8b92758d33f841a0bfcd97adc39
|
google/t5-efficient-tiny
|
google
|
t5
| 12 | 10,405 |
transformers
| 3 |
text2text-generation
| true | true | true |
apache-2.0
|
['en']
|
['c4']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['deep-narrow']
| false | true | true | 6,203 | false |
# T5-Efficient-TINY (Deep-Narrow version)
T5-Efficient-TINY is a variation of [Google's original T5](https://ai.googleblog.com/2020/02/exploring-transfer-learning-with-t5.html) following the [T5 model architecture](https://huggingface.co/docs/transformers/model_doc/t5).
It is a *pretrained-only* checkpoint and was released with the
paper **[Scale Efficiently: Insights from Pre-training and Fine-tuning Transformers](https://arxiv.org/abs/2109.10686)**
by *Yi Tay, Mostafa Dehghani, Jinfeng Rao, William Fedus, Samira Abnar, Hyung Won Chung, Sharan Narang, Dani Yogatama, Ashish Vaswani, Donald Metzler*.
In a nutshell, the paper indicates that a **Deep-Narrow** model architecture is favorable for **downstream** performance compared to other model architectures
of similar parameter count.
To quote the paper:
> We generally recommend a DeepNarrow strategy where the model’s depth is preferentially increased
> before considering any other forms of uniform scaling across other dimensions. This is largely due to
> how much depth influences the Pareto-frontier as shown in earlier sections of the paper. Specifically, a
> tall small (deep and narrow) model is generally more efficient compared to the base model. Likewise,
> a tall base model might also generally more efficient compared to a large model. We generally find
> that, regardless of size, even if absolute performance might increase as we continue to stack layers,
> the relative gain of Pareto-efficiency diminishes as we increase the layers, converging at 32 to 36
> layers. Finally, we note that our notion of efficiency here relates to any one compute dimension, i.e.,
> params, FLOPs or throughput (speed). We report all three key efficiency metrics (number of params,
> FLOPS and speed) and leave this decision to the practitioner to decide which compute dimension to
> consider.
To be more precise, *model depth* is defined as the number of transformer blocks that are stacked sequentially.
A sequence of word embeddings is therefore processed sequentially by each transformer block.
## Details model architecture
This model checkpoint - **t5-efficient-tiny** - is of model type **Tiny** with no variations.
It has **15.58** million parameters and thus requires *ca.* **62.32 MB** of memory in full precision (*fp32*)
or **31.16 MB** of memory in half precision (*fp16* or *bf16*).
A summary of the *original* T5 model architectures can be seen here:
| Model | nl (el/dl) | ff | dm | kv | nh | #Params|
| ----| ---- | ---- | ---- | ---- | ---- | ----|
| Tiny | 4/4 | 1024 | 256 | 32 | 4 | 16M|
| Mini | 4/4 | 1536 | 384 | 32 | 8 | 31M|
| Small | 6/6 | 2048 | 512 | 32 | 8 | 60M|
| Base | 12/12 | 3072 | 768 | 64 | 12 | 220M|
| Large | 24/24 | 4096 | 1024 | 64 | 16 | 738M|
| Xl | 24/24 | 16384 | 1024 | 128 | 32 | 3B|
| XXl | 24/24 | 65536 | 1024 | 128 | 128 | 11B|
whereas the following abbreviations are used:
| Abbreviation | Definition |
| ----| ---- |
| nl | Number of transformer blocks (depth) |
| dm | Dimension of embedding vector (output vector of transformers block) |
| kv | Dimension of key/value projection matrix |
| nh | Number of attention heads |
| ff | Dimension of intermediate vector within transformer block (size of feed-forward projection matrix) |
| el | Number of transformer blocks in the encoder (encoder depth) |
| dl | Number of transformer blocks in the decoder (decoder depth) |
| sh | Signifies that attention heads are shared |
| skv | Signifies that key-values projection matrices are tied |
If a model checkpoint has no specific, *el* or *dl* than both the number of encoder- and decoder layers correspond to *nl*.
## Pre-Training
The checkpoint was pretrained on the [Colossal, Cleaned version of Common Crawl (C4)](https://huggingface.co/datasets/c4) for 524288 steps using
the span-based masked language modeling (MLM) objective.
## Fine-Tuning
**Note**: This model is a **pretrained** checkpoint and has to be fine-tuned for practical usage.
The checkpoint was pretrained in English and is therefore only useful for English NLP tasks.
You can follow on of the following examples on how to fine-tune the model:
*PyTorch*:
- [Summarization](https://github.com/huggingface/transformers/tree/master/examples/pytorch/summarization)
- [Question Answering](https://github.com/huggingface/transformers/blob/master/examples/pytorch/question-answering/run_seq2seq_qa.py)
- [Text Classification](https://github.com/huggingface/transformers/tree/master/examples/pytorch/text-classification) - *Note*: You will have to slightly adapt the training example here to make it work with an encoder-decoder model.
*Tensorflow*:
- [Summarization](https://github.com/huggingface/transformers/tree/master/examples/tensorflow/summarization)
- [Text Classification](https://github.com/huggingface/transformers/tree/master/examples/tensorflow/text-classification) - *Note*: You will have to slightly adapt the training example here to make it work with an encoder-decoder model.
*JAX/Flax*:
- [Summarization](https://github.com/huggingface/transformers/tree/master/examples/flax/summarization)
- [Text Classification](https://github.com/huggingface/transformers/tree/master/examples/flax/text-classification) - *Note*: You will have to slightly adapt the training example here to make it work with an encoder-decoder model.
## Downstream Performance
TODO: Add table if available
## Computational Complexity
TODO: Add table if available
## More information
We strongly recommend the reader to go carefully through the original paper **[Scale Efficiently: Insights from Pre-training and Fine-tuning Transformers](https://arxiv.org/abs/2109.10686)** to get a more nuanced understanding of this model checkpoint.
As explained in the following [issue](https://github.com/google-research/google-research/issues/986#issuecomment-1035051145), checkpoints including the *sh* or *skv*
model architecture variations have *not* been ported to Transformers as they are probably of limited practical usage and are lacking a more detailed description. Those checkpoints are kept [here](https://huggingface.co/NewT5SharedHeadsSharedKeyValues) as they might be ported potentially in the future.
|
9ff7fe5cdfb2d0cb44c6eafb1ee28b59
|
HMHMlee/BioLinkBERT-base-finetuned-ner
|
HMHMlee
|
bert
| 10 | 11 |
transformers
| 1 |
token-classification
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 2,430 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# BioLinkBERT-base-finetuned-ner
This model is a fine-tuned version of [michiyasunaga/BioLinkBERT-base](https://huggingface.co/michiyasunaga/BioLinkBERT-base) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1226
- Precision: 0.8760
- Recall: 0.9185
- F1: 0.8968
- Accuracy: 0.9647
## Model description
This model is designed to perform NER function for specific text using BioLink BERT
## Intended uses & limitations
The goal was to have a drug tag printed immediately for a particular sentence, but it has the disadvantage of being marked as LABEL
LABEL0 : irrelevant text
LABEL1,2 : Drug
LABEL3,4 : condition
## Training and evaluation data
More information needed
## Training procedure
Reference Code: SciBERT Fine-Tuning on Drug/ADE Corpus (https://github.com/jsylee/personal-projects/blob/master/Hugging%20Face%20ADR%20Fine-Tuning/SciBERT%20ADR%20Fine-Tuning.ipynb)
## How to use
from transformers import AutoTokenizer, AutoModelForTokenClassification
tokenizer = AutoTokenizer.from_pretrained("HMHMlee/BioLinkBERT-base-finetuned-ner")
model = AutoModelForTokenClassification.from_pretrained("HMHMlee/BioLinkBERT-base-finetuned-ner")
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| 0.1099 | 1.0 | 201 | 0.1489 | 0.8415 | 0.9032 | 0.8713 | 0.9566 |
| 0.1716 | 2.0 | 402 | 0.1318 | 0.8456 | 0.9135 | 0.8782 | 0.9597 |
| 0.1068 | 3.0 | 603 | 0.1197 | 0.8682 | 0.9110 | 0.8891 | 0.9641 |
| 0.0161 | 4.0 | 804 | 0.1219 | 0.8694 | 0.9157 | 0.8919 | 0.9639 |
| 0.1499 | 5.0 | 1005 | 0.1226 | 0.8760 | 0.9185 | 0.8968 | 0.9647 |
### Framework versions
- Transformers 4.20.1
- Pytorch 1.12.0+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
7838c8e56a540705dd20836cd3920647
|
ITESM/st_demo_5
|
ITESM
|
bert
| 12 | 4 |
sentence-transformers
| 0 |
sentence-similarity
| true | false | false |
apache-2.0
|
['en']
| null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['sentence-transformers', 'feature-extraction', 'sentence-similarity']
| false | true | true | 10,029 | false |
# all-MiniLM-L6-v2
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 384 dimensional dense vector space and can be used for tasks like clustering or semantic search.
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('sentence-transformers/all-MiniLM-L6-v2')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
import torch.nn.functional as F
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('sentence-transformers/all-MiniLM-L6-v2')
model = AutoModel.from_pretrained('sentence-transformers/all-MiniLM-L6-v2')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
# Normalize embeddings
sentence_embeddings = F.normalize(sentence_embeddings, p=2, dim=1)
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=sentence-transformers/all-MiniLM-L6-v2)
------
## Background
The project aims to train sentence embedding models on very large sentence level datasets using a self-supervised
contrastive learning objective. We used the pretrained [`nreimers/MiniLM-L6-H384-uncased`](https://huggingface.co/nreimers/MiniLM-L6-H384-uncased) model and fine-tuned in on a
1B sentence pairs dataset. We use a contrastive learning objective: given a sentence from the pair, the model should predict which out of a set of randomly sampled other sentences, was actually paired with it in our dataset.
We developped this model during the
[Community week using JAX/Flax for NLP & CV](https://discuss.huggingface.co/t/open-to-the-community-community-week-using-jax-flax-for-nlp-cv/7104),
organized by Hugging Face. We developped this model as part of the project:
[Train the Best Sentence Embedding Model Ever with 1B Training Pairs](https://discuss.huggingface.co/t/train-the-best-sentence-embedding-model-ever-with-1b-training-pairs/7354). We benefited from efficient hardware infrastructure to run the project: 7 TPUs v3-8, as well as intervention from Googles Flax, JAX, and Cloud team member about efficient deep learning frameworks.
## Intended uses
Our model is intented to be used as a sentence and short paragraph encoder. Given an input text, it ouptuts a vector which captures
the semantic information. The sentence vector may be used for information retrieval, clustering or sentence similarity tasks.
By default, input text longer than 256 word pieces is truncated.
## Training procedure
### Pre-training
We use the pretrained [`nreimers/MiniLM-L6-H384-uncased`](https://huggingface.co/nreimers/MiniLM-L6-H384-uncased) model. Please refer to the model card for more detailed information about the pre-training procedure.
### Fine-tuning
We fine-tune the model using a contrastive objective. Formally, we compute the cosine similarity from each possible sentence pairs from the batch.
We then apply the cross entropy loss by comparing with true pairs.
#### Hyper parameters
We trained ou model on a TPU v3-8. We train the model during 100k steps using a batch size of 1024 (128 per TPU core).
We use a learning rate warm up of 500. The sequence length was limited to 128 tokens. We used the AdamW optimizer with
a 2e-5 learning rate. The full training script is accessible in this current repository: `train_script.py`.
#### Training data
We use the concatenation from multiple datasets to fine-tune our model. The total number of sentence pairs is above 1 billion sentences.
We sampled each dataset given a weighted probability which configuration is detailed in the `data_config.json` file.
| Dataset | Paper | Number of training tuples |
|--------------------------------------------------------|:----------------------------------------:|:--------------------------:|
| [Reddit comments (2015-2018)](https://github.com/PolyAI-LDN/conversational-datasets/tree/master/reddit) | [paper](https://arxiv.org/abs/1904.06472) | 726,484,430 |
| [S2ORC](https://github.com/allenai/s2orc) Citation pairs (Abstracts) | [paper](https://aclanthology.org/2020.acl-main.447/) | 116,288,806 |
| [WikiAnswers](https://github.com/afader/oqa#wikianswers-corpus) Duplicate question pairs | [paper](https://doi.org/10.1145/2623330.2623677) | 77,427,422 |
| [PAQ](https://github.com/facebookresearch/PAQ) (Question, Answer) pairs | [paper](https://arxiv.org/abs/2102.07033) | 64,371,441 |
| [S2ORC](https://github.com/allenai/s2orc) Citation pairs (Titles) | [paper](https://aclanthology.org/2020.acl-main.447/) | 52,603,982 |
| [S2ORC](https://github.com/allenai/s2orc) (Title, Abstract) | [paper](https://aclanthology.org/2020.acl-main.447/) | 41,769,185 |
| [Stack Exchange](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_xml) (Title, Body) pairs | - | 25,316,456 |
| [Stack Exchange](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_xml) (Title+Body, Answer) pairs | - | 21,396,559 |
| [Stack Exchange](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_xml) (Title, Answer) pairs | - | 21,396,559 |
| [MS MARCO](https://microsoft.github.io/msmarco/) triplets | [paper](https://doi.org/10.1145/3404835.3462804) | 9,144,553 |
| [GOOAQ: Open Question Answering with Diverse Answer Types](https://github.com/allenai/gooaq) | [paper](https://arxiv.org/pdf/2104.08727.pdf) | 3,012,496 |
| [Yahoo Answers](https://www.kaggle.com/soumikrakshit/yahoo-answers-dataset) (Title, Answer) | [paper](https://proceedings.neurips.cc/paper/2015/hash/250cf8b51c773f3f8dc8b4be867a9a02-Abstract.html) | 1,198,260 |
| [Code Search](https://huggingface.co/datasets/code_search_net) | - | 1,151,414 |
| [COCO](https://cocodataset.org/#home) Image captions | [paper](https://link.springer.com/chapter/10.1007%2F978-3-319-10602-1_48) | 828,395|
| [SPECTER](https://github.com/allenai/specter) citation triplets | [paper](https://doi.org/10.18653/v1/2020.acl-main.207) | 684,100 |
| [Yahoo Answers](https://www.kaggle.com/soumikrakshit/yahoo-answers-dataset) (Question, Answer) | [paper](https://proceedings.neurips.cc/paper/2015/hash/250cf8b51c773f3f8dc8b4be867a9a02-Abstract.html) | 681,164 |
| [Yahoo Answers](https://www.kaggle.com/soumikrakshit/yahoo-answers-dataset) (Title, Question) | [paper](https://proceedings.neurips.cc/paper/2015/hash/250cf8b51c773f3f8dc8b4be867a9a02-Abstract.html) | 659,896 |
| [SearchQA](https://huggingface.co/datasets/search_qa) | [paper](https://arxiv.org/abs/1704.05179) | 582,261 |
| [Eli5](https://huggingface.co/datasets/eli5) | [paper](https://doi.org/10.18653/v1/p19-1346) | 325,475 |
| [Flickr 30k](https://shannon.cs.illinois.edu/DenotationGraph/) | [paper](https://transacl.org/ojs/index.php/tacl/article/view/229/33) | 317,695 |
| [Stack Exchange](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_xml) Duplicate questions (titles) | | 304,525 |
| AllNLI ([SNLI](https://nlp.stanford.edu/projects/snli/) and [MultiNLI](https://cims.nyu.edu/~sbowman/multinli/) | [paper SNLI](https://doi.org/10.18653/v1/d15-1075), [paper MultiNLI](https://doi.org/10.18653/v1/n18-1101) | 277,230 |
| [Stack Exchange](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_xml) Duplicate questions (bodies) | | 250,519 |
| [Stack Exchange](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_xml) Duplicate questions (titles+bodies) | | 250,460 |
| [Sentence Compression](https://github.com/google-research-datasets/sentence-compression) | [paper](https://www.aclweb.org/anthology/D13-1155/) | 180,000 |
| [Wikihow](https://github.com/pvl/wikihow_pairs_dataset) | [paper](https://arxiv.org/abs/1810.09305) | 128,542 |
| [Altlex](https://github.com/chridey/altlex/) | [paper](https://aclanthology.org/P16-1135.pdf) | 112,696 |
| [Quora Question Triplets](https://quoradata.quora.com/First-Quora-Dataset-Release-Question-Pairs) | - | 103,663 |
| [Simple Wikipedia](https://cs.pomona.edu/~dkauchak/simplification/) | [paper](https://www.aclweb.org/anthology/P11-2117/) | 102,225 |
| [Natural Questions (NQ)](https://ai.google.com/research/NaturalQuestions) | [paper](https://transacl.org/ojs/index.php/tacl/article/view/1455) | 100,231 |
| [SQuAD2.0](https://rajpurkar.github.io/SQuAD-explorer/) | [paper](https://aclanthology.org/P18-2124.pdf) | 87,599 |
| [TriviaQA](https://huggingface.co/datasets/trivia_qa) | - | 73,346 |
| **Total** | | **1,170,060,424** |
|
1481c1c741770ac0b1e9316314319a97
|
ShannonDXQ/distilbert-base-uncased-finetuned-cola
|
ShannonDXQ
|
distilbert
| 33 | 2 |
transformers
| 0 |
text-classification
| true | false | false |
apache-2.0
| null |
['glue']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,571 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-cola
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the glue dataset.
It achieves the following results on the evaluation set:
- Loss: 0.8107
- Matthews Correlation: 0.5422
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Matthews Correlation |
|:-------------:|:-----:|:----:|:---------------:|:--------------------:|
| 0.522 | 1.0 | 535 | 0.5193 | 0.4152 |
| 0.3451 | 2.0 | 1070 | 0.4942 | 0.5166 |
| 0.2335 | 3.0 | 1605 | 0.5490 | 0.5291 |
| 0.179 | 4.0 | 2140 | 0.7727 | 0.5150 |
| 0.1314 | 5.0 | 2675 | 0.8107 | 0.5422 |
### Framework versions
- Transformers 4.26.0
- Pytorch 1.13.1+cu116
- Datasets 2.9.0
- Tokenizers 0.13.2
|
666d01b62f0f71703fcdf231fc0c2b0f
|
ArafatBHossain/distiled_flip_model_emotion_alpha_0.8_epoch7_v1
|
ArafatBHossain
|
distilbert
| 10 | 3 |
transformers
| 0 |
text-classification
| true | false | false |
apache-2.0
| null |
['emotion']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,713 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distiled_flip_model_emotion_alpha_0.8_epoch7_v1
This model is a fine-tuned version of [ArafatBHossain/distill_bert_fine_tuned_emotion_dataset](https://huggingface.co/ArafatBHossain/distill_bert_fine_tuned_emotion_dataset) on the emotion dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1583
- Accuracy: 0.9435
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 7
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|
| 0.2013 | 1.0 | 2000 | 0.2653 | 0.9355 |
| 0.1625 | 2.0 | 4000 | 0.2537 | 0.9365 |
| 0.1262 | 3.0 | 6000 | 0.1934 | 0.935 |
| 0.1048 | 4.0 | 8000 | 0.1813 | 0.9435 |
| 0.0777 | 5.0 | 10000 | 0.1500 | 0.941 |
| 0.0614 | 6.0 | 12000 | 0.1591 | 0.944 |
| 0.0465 | 7.0 | 14000 | 0.1583 | 0.9435 |
### Framework versions
- Transformers 4.23.1
- Pytorch 1.11.0
- Datasets 2.6.1
- Tokenizers 0.12.1
|
ce0a0c076b91b38762511dc5c505dac2
|
commanderstrife/bc4chemd_ner-Bio_ClinicalBERT-finetuned-ner
|
commanderstrife
|
bert
| 16 | 8 |
transformers
| 0 |
token-classification
| true | false | false |
mit
| null |
['bc4chemd_ner']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 2,237 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bc4chemd_ner-Bio_ClinicalBERT-finetuned-ner
This model is a fine-tuned version of [emilyalsentzer/Bio_ClinicalBERT](https://huggingface.co/emilyalsentzer/Bio_ClinicalBERT) on the bc4chemd_ner dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0641
- Precision: 0.8944
- Recall: 0.8777
- F1: 0.8860
- Accuracy: 0.9908
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:-----:|:---------------:|:---------:|:------:|:------:|:--------:|
| 0.006 | 1.0 | 1918 | 0.0310 | 0.8697 | 0.8510 | 0.8602 | 0.9894 |
| 0.0097 | 2.0 | 3836 | 0.0345 | 0.8855 | 0.8637 | 0.8745 | 0.9898 |
| 0.0058 | 3.0 | 5754 | 0.0359 | 0.8733 | 0.8836 | 0.8784 | 0.9902 |
| 0.0014 | 4.0 | 7672 | 0.0440 | 0.8723 | 0.8842 | 0.8782 | 0.9903 |
| 0.0005 | 5.0 | 9590 | 0.0539 | 0.8862 | 0.8673 | 0.8766 | 0.9903 |
| 0.0001 | 6.0 | 11508 | 0.0558 | 0.8939 | 0.8628 | 0.8781 | 0.9904 |
| 0.0001 | 7.0 | 13426 | 0.0558 | 0.8846 | 0.8729 | 0.8787 | 0.9903 |
| 0.0012 | 8.0 | 15344 | 0.0635 | 0.8935 | 0.8696 | 0.8814 | 0.9905 |
| 0.0 | 9.0 | 17262 | 0.0624 | 0.8897 | 0.8831 | 0.8864 | 0.9908 |
| 0.0002 | 10.0 | 19180 | 0.0641 | 0.8944 | 0.8777 | 0.8860 | 0.9908 |
### Framework versions
- Transformers 4.20.1
- Pytorch 1.12.0+cu113
- Datasets 2.3.2
- Tokenizers 0.12.1
|
bafa08f1c57c8292aecf0c376daa530f
|
HarBat/distilled_bert_finetuning
|
HarBat
|
distilbert
| 43 | 3 |
transformers
| 0 |
text-classification
| true | false | false |
apache-2.0
| null |
['sst2']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 937 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilled_bert_finetuning
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the sst2 dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
### Framework versions
- Transformers 4.21.2
- Pytorch 1.11.0+cu113
- Datasets 2.5.2
- Tokenizers 0.12.1
|
f9f13f73636af757140404dec451582e
|
nouman10/robertabase-finetuned-claim-ltp-full-prompt
|
nouman10
|
roberta
| 9 | 2 |
transformers
| 0 |
fill-mask
| false | true | false |
mit
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_keras_callback']
| true | true | true | 1,703 | false |
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# nouman10/robertabase-finetuned-claim-ltp-full-prompt
This model is a fine-tuned version of [roberta-base](https://huggingface.co/roberta-base) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.0233
- Validation Loss: 0.0231
- Epoch: 4
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'AdamWeightDecay', 'learning_rate': {'class_name': 'WarmUp', 'config': {'initial_learning_rate': 2e-05, 'decay_schedule_fn': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 2e-05, 'decay_steps': -425, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}, '__passive_serialization__': True}, 'warmup_steps': 1000, 'power': 1.0, 'name': None}}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False, 'weight_decay_rate': 0.01}
- training_precision: mixed_float16
### Training results
| Train Loss | Validation Loss | Epoch |
|:----------:|:---------------:|:-----:|
| 0.1965 | 0.0452 | 0 |
| 0.0321 | 0.0231 | 1 |
| 0.0232 | 0.0231 | 2 |
| 0.0232 | 0.0231 | 3 |
| 0.0233 | 0.0231 | 4 |
### Framework versions
- Transformers 4.19.1
- TensorFlow 2.8.0
- Datasets 2.2.1
- Tokenizers 0.12.1
|
009e060ab5d92faaaf97df30a7a4fbcc
|
ibm/ColD-Fusion-bert-base-uncased-itr0-seed0
|
ibm
|
bert
| 8 | 6 |
transformers
| 0 |
text-classification
| true | false | false |
mit
|
['en']
| null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['exbert']
| false | true | true | 3,174 | false |
# ColD Fusion BERT uncased model
Finetuned model that aims to be a great base model. It improves over BERT base model (uncased), trained on 35 datasets.
Full details at [this paper](https://arxiv.org/abs/2212.01378).
## Paper Abstract:
Pretraining has been shown to scale well with compute, data size and data diversity. Multitask learning trains on a
mixture of supervised datasets and produces improved performance compared to self-supervised pretraining. Until now,
massively multitask learning required simultaneous access to all datasets in the mixture and heavy compute resources
that are only available to well-resourced teams.
In this paper, we propose ColD Fusion, a method that provides the benefits of multitask learning but leverages distributed
computation and requires limited communication and no sharing of data. Consequentially, ColD Fusion can create a synergistic
loop, where finetuned models can be recycled to continually improve the pretrained model they are based on. We show that
ColD Fusion yields comparable benefits to multitask pretraining by producing a model that (a) attains strong performance on
all of the datasets it was multitask trained on and (b) is a better starting point for finetuning on unseen datasets. We find
ColD Fusion outperforms RoBERTa and even previous multitask models. Specifically, when training and testing on 35 diverse datasets,
ColD Fusion-based model outperforms RoBERTa by 2.45 points in average without any changes to the architecture.
### How to use
Best way to use is to finetune on your own task, but you can also extract features directly.
To get the features of a given text in PyTorch:
```python
from transformers import RobertaTokenizer, RobertaModel
tokenizer = RobertaTokenizer.from_pretrained('ibm/ColD-Fusion')
model = RobertaModel.from_pretrained('ibm/ColD-Fusion')
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='pt')
output = model(**encoded_input)
```
and in TensorFlow:
```python
from transformers import RobertaTokenizer, TFRobertaModel
tokenizer = RobertaTokenizer.from_pretrained('ibm/ColD-Fusion')
model = TFRobertaModel.from_pretrained('ibm/ColD-Fusion')
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='tf')
output = model(encoded_input)
```
## Evaluation results
See full evaluation results of this model and many more [here](https://ibm.github.io/model-recycling/roberta-base_table.html)
When fine-tuned on downstream tasks, this model achieves the following results:
### BibTeX entry and citation info
```bibtex
@article{ColDFusion,
author = {Shachar Don-Yehiya, Elad Venezian, Colin Raffel, Noam Slonim, Yoav Katz, Leshem ChoshenYinhan Liu and},
title = {ColD Fusion: Collaborative Descent for Distributed Multitask Finetuning},
journal = {CoRR},
volume = {abs/2212.01378},
year = {2022},
url = {https://arxiv.org/abs/2212.01378},
archivePrefix = {arXiv},
eprint = {2212.01378},
}
```
<a href="https://huggingface.co/exbert/?model=ibm/ColD-Fusion">
<img width="300px" src="https://cdn-media.huggingface.co/exbert/button.png">
</a>
|
8b6c0752942f9187e0f4b636564d38a7
|
microsoft/tapex-large-finetuned-tabfact
|
microsoft
|
bart
| 8 | 81 |
transformers
| 1 |
text-classification
| true | false | false |
mit
|
['en']
|
['tab_fact']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['tapex', 'table-question-answering']
| false | true | true | 2,480 | false |
# TAPEX (large-sized model)
TAPEX was proposed in [TAPEX: Table Pre-training via Learning a Neural SQL Executor](https://arxiv.org/abs/2107.07653) by Qian Liu, Bei Chen, Jiaqi Guo, Morteza Ziyadi, Zeqi Lin, Weizhu Chen, Jian-Guang Lou. The original repo can be found [here](https://github.com/microsoft/Table-Pretraining).
## Model description
TAPEX (**Ta**ble **P**re-training via **Ex**ecution) is a conceptually simple and empirically powerful pre-training approach to empower existing models with *table reasoning* skills. TAPEX realizes table pre-training by learning a neural SQL executor over a synthetic corpus, which is obtained by automatically synthesizing executable SQL queries.
TAPEX is based on the BART architecture, the transformer encoder-encoder (seq2seq) model with a bidirectional (BERT-like) encoder and an autoregressive (GPT-like) decoder.
This model is the `tapex-base` model fine-tuned on the [Tabfact](https://huggingface.co/datasets/tab_fact) dataset.
## Intended Uses
You can use the model for table fact verficiation.
### How to Use
Here is how to use this model in transformers:
```python
from transformers import TapexTokenizer, BartForSequenceClassification
import pandas as pd
tokenizer = TapexTokenizer.from_pretrained("microsoft/tapex-large-finetuned-tabfact")
model = BartForSequenceClassification.from_pretrained("microsoft/tapex-large-finetuned-tabfact")
data = {
"year": [1896, 1900, 1904, 2004, 2008, 2012],
"city": ["athens", "paris", "st. louis", "athens", "beijing", "london"]
}
table = pd.DataFrame.from_dict(data)
# tapex accepts uncased input since it is pre-trained on the uncased corpus
query = "beijing hosts the olympic games in 2012"
encoding = tokenizer(table=table, query=query, return_tensors="pt")
outputs = model(**encoding)
output_id = int(outputs.logits[0].argmax(dim=0))
print(model.config.id2label[output_id])
# Refused
```
### How to Eval
Please find the eval script [here](https://github.com/SivilTaram/transformers/tree/add_tapex_bis/examples/research_projects/tapex).
### BibTeX entry and citation info
```bibtex
@inproceedings{
liu2022tapex,
title={{TAPEX}: Table Pre-training via Learning a Neural {SQL} Executor},
author={Qian Liu and Bei Chen and Jiaqi Guo and Morteza Ziyadi and Zeqi Lin and Weizhu Chen and Jian-Guang Lou},
booktitle={International Conference on Learning Representations},
year={2022},
url={https://openreview.net/forum?id=O50443AsCP}
}
```
|
07af20f0ecf53a78a5638b7a90afeae2
|
microsoft/swinv2-base-patch4-window12-192-22k
|
microsoft
|
swinv2
| 5 | 842 |
transformers
| 0 |
image-classification
| true | false | false |
apache-2.0
| null |
['imagenet-1k']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['vision', 'image-classification']
| false | true | true | 3,779 | false |
# Swin Transformer v2 (tiny-sized model)
Swin Transformer v2 model pre-trained on ImageNet-21k at resolution 192x192. It was introduced in the paper [Swin Transformer V2: Scaling Up Capacity and Resolution](https://arxiv.org/abs/2111.09883) by Liu et al. and first released in [this repository](https://github.com/microsoft/Swin-Transformer).
Disclaimer: The team releasing Swin Transformer v2 did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
The Swin Transformer is a type of Vision Transformer. It builds hierarchical feature maps by merging image patches (shown in gray) in deeper layers and has linear computation complexity to input image size due to computation of self-attention only within each local window (shown in red). It can thus serve as a general-purpose backbone for both image classification and dense recognition tasks. In contrast, previous vision Transformers produce feature maps of a single low resolution and have quadratic computation complexity to input image size due to computation of self-attention globally.
Swin Transformer v2 adds 3 main improvements: 1) a residual-post-norm method combined with cosine attention to improve training stability; 2) a log-spaced continuous position bias method to effectively transfer models pre-trained using low-resolution images to downstream tasks with high-resolution inputs; 3) a self-supervised pre-training method, SimMIM, to reduce the needs of vast labeled images.

[Source](https://paperswithcode.com/method/swin-transformer)
## Intended uses & limitations
You can use the raw model for image classification. See the [model hub](https://huggingface.co/models?search=swinv2) to look for
fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model to classify an image of the COCO 2017 dataset into one of the 21k ImageNet classes:
```python
from transformers import AutoImageProcessor, AutoModelForImageClassification
from PIL import Image
import requests
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
processor = AutoImageProcessor.from_pretrained("microsoft/swinv2-base-patch4-window12-192-22k")
model = AutoModelForImageClassification.from_pretrained("microsoft/swinv2-base-patch4-window12-192-22k")
inputs = processor(images=image, return_tensors="pt")
outputs = model(**inputs)
logits = outputs.logits
# model predicts one of the 21k ImageNet classes
predicted_class_idx = logits.argmax(-1).item()
print("Predicted class:", model.config.id2label[predicted_class_idx])
```
For more code examples, we refer to the [documentation](https://huggingface.co/transformers/model_doc/swinv2.html#).
### BibTeX entry and citation info
```bibtex
@article{DBLP:journals/corr/abs-2111-09883,
author = {Ze Liu and
Han Hu and
Yutong Lin and
Zhuliang Yao and
Zhenda Xie and
Yixuan Wei and
Jia Ning and
Yue Cao and
Zheng Zhang and
Li Dong and
Furu Wei and
Baining Guo},
title = {Swin Transformer {V2:} Scaling Up Capacity and Resolution},
journal = {CoRR},
volume = {abs/2111.09883},
year = {2021},
url = {https://arxiv.org/abs/2111.09883},
eprinttype = {arXiv},
eprint = {2111.09883},
timestamp = {Thu, 02 Dec 2021 15:54:22 +0100},
biburl = {https://dblp.org/rec/journals/corr/abs-2111-09883.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
|
6388e1cb4b7bb4b7d945ee4a7729a20e
|
mprzibilla/small_finetune_M01
|
mprzibilla
|
wav2vec2
| 10 | 5 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 2,386 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# small_finetune_M01
This model is a fine-tuned version of [facebook/wav2vec2-base](https://huggingface.co/facebook/wav2vec2-base) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 3.2363
- Wer: 1.0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 20
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 800
- num_epochs: 4000
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:------:|:-----:|:---------------:|:---:|
| 121.7217 | 200.0 | 800 | 3.1742 | 1.0 |
| 2.066 | 400.0 | 1600 | 2.8390 | 1.0 |
| 1.7019 | 600.0 | 2400 | 2.8359 | 1.0 |
| 1.5282 | 800.0 | 3200 | 2.8655 | 1.0 |
| 1.4089 | 1000.0 | 4000 | 2.8933 | 1.0 |
| 1.3123 | 1200.0 | 4800 | 2.9047 | 1.0 |
| 1.2361 | 1400.0 | 5600 | 2.9677 | 1.0 |
| 1.1758 | 1600.0 | 6400 | 3.0008 | 1.0 |
| 1.1241 | 1800.0 | 7200 | 3.0795 | 1.0 |
| 1.0816 | 2000.0 | 8000 | 3.1214 | 1.0 |
| 1.0497 | 2200.0 | 8800 | 3.1518 | 1.0 |
| 1.0349 | 2400.0 | 9600 | 3.1584 | 1.0 |
| 1.0058 | 2600.0 | 10400 | 3.1876 | 1.0 |
| 0.9983 | 2800.0 | 11200 | 3.1843 | 1.0 |
| 0.9863 | 3000.0 | 12000 | 3.1914 | 1.0 |
| 0.9776 | 3200.0 | 12800 | 3.2005 | 1.0 |
| 0.9647 | 3400.0 | 13600 | 3.2245 | 1.0 |
| 0.9586 | 3600.0 | 14400 | 3.2352 | 1.0 |
| 0.9521 | 3800.0 | 15200 | 3.2398 | 1.0 |
| 0.9537 | 4000.0 | 16000 | 3.2363 | 1.0 |
### Framework versions
- Transformers 4.18.0
- Pytorch 1.10.2+cu102
- Datasets 2.3.2
- Tokenizers 0.12.1
|
558326284d70d087135ee67419a0c341
|
jkang/espnet2_librispeech_100_conformer_char
|
jkang
| null | 21 | 8 |
espnet
| 0 |
automatic-speech-recognition
| false | false | false |
cc-by-4.0
|
['noinfo']
|
['librispeech_100']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['espnet', 'audio', 'automatic-speech-recognition']
| false | true | true | 7,171 | false |
## ESPnet2 ASR model
### `jkang/espnet2_librispeech_100_conformer_char`
This model was trained by jaekookang using librispeech_100 recipe in [espnet](https://github.com/espnet/espnet/).
### Demo: How to use in ESPnet2
```bash
cd espnet
git checkout 82a0a0fa97b8a4a578f0a2c031ec49b3afec1504
pip install -e .
cd egs2/librispeech_100/asr1
./run.sh --skip_data_prep false --skip_train true --download_model jkang/espnet2_librispeech_100_conformer_char
```
<!-- Generated by scripts/utils/show_asr_result.sh -->
# RESULTS
## Environments
- date: `Thu Feb 24 17:47:04 KST 2022`
- python version: `3.9.7 (default, Sep 16 2021, 13:09:58) [GCC 7.5.0]`
- espnet version: `espnet 0.10.7a1`
- pytorch version: `pytorch 1.10.1`
- Git hash: `82a0a0fa97b8a4a578f0a2c031ec49b3afec1504`
- Commit date: `Wed Feb 23 08:06:47 2022 +0900`
## asr_conformer_lr2e-3_warmup15k_amp_nondeterministic_char
### WER
|dataset|Snt|Wrd|Corr|Sub|Del|Ins|Err|S.Err|
|---|---|---|---|---|---|---|---|---|
|decode_asr_asr_model_valid.acc.ave/dev_clean|2703|54402|93.9|5.6|0.5|0.7|6.8|57.1|
|decode_asr_asr_model_valid.acc.ave/dev_other|2864|50948|82.5|15.7|1.8|1.9|19.3|82.6|
|decode_asr_asr_model_valid.acc.ave/test_clean|2620|52576|93.8|5.7|0.6|0.7|6.9|58.4|
|decode_asr_asr_model_valid.acc.ave/test_other|2939|52343|82.2|15.9|2.0|1.7|19.5|83.6|
### CER
|dataset|Snt|Wrd|Corr|Sub|Del|Ins|Err|S.Err|
|---|---|---|---|---|---|---|---|---|
|decode_asr_asr_model_valid.acc.ave/dev_clean|2703|288456|98.3|1.0|0.7|0.7|2.4|57.1|
|decode_asr_asr_model_valid.acc.ave/dev_other|2864|265951|93.3|4.1|2.6|1.9|8.7|82.6|
|decode_asr_asr_model_valid.acc.ave/test_clean|2620|281530|98.3|1.0|0.7|0.6|2.3|58.4|
|decode_asr_asr_model_valid.acc.ave/test_other|2939|272758|93.2|4.1|2.7|1.8|8.6|83.6|
### TER
|dataset|Snt|Wrd|Corr|Sub|Del|Ins|Err|S.Err|
|---|---|---|---|---|---|---|---|---|
## ASR config
<details><summary>expand</summary>
```
config: conf/train_asr_char.yaml
print_config: false
log_level: INFO
dry_run: false
iterator_type: sequence
output_dir: exp/asr_conformer_lr2e-3_warmup15k_amp_nondeterministic_char
ngpu: 1
seed: 2022
num_workers: 4
num_att_plot: 0
dist_backend: nccl
dist_init_method: env://
dist_world_size: null
dist_rank: null
local_rank: 0
dist_master_addr: null
dist_master_port: null
dist_launcher: null
multiprocessing_distributed: false
unused_parameters: false
sharded_ddp: false
cudnn_enabled: true
cudnn_benchmark: false
cudnn_deterministic: false
collect_stats: false
write_collected_feats: false
max_epoch: 70
patience: null
val_scheduler_criterion:
- valid
- loss
early_stopping_criterion:
- valid
- loss
- min
best_model_criterion:
- - valid
- acc
- max
keep_nbest_models: 10
nbest_averaging_interval: 0
grad_clip: 5.0
grad_clip_type: 2.0
grad_noise: false
accum_grad: 4
no_forward_run: false
resume: true
train_dtype: float32
use_amp: true
log_interval: 400
use_matplotlib: true
use_tensorboard: true
use_wandb: false
wandb_project: null
wandb_id: null
wandb_entity: null
wandb_name: null
wandb_model_log_interval: -1
detect_anomaly: false
pretrain_path: null
init_param: []
ignore_init_mismatch: false
freeze_param: []
num_iters_per_epoch: null
batch_size: 20
valid_batch_size: null
batch_bins: 1600000
valid_batch_bins: null
train_shape_file:
- exp/asr_stats_raw_en_char_sp/train/speech_shape
- exp/asr_stats_raw_en_char_sp/train/text_shape.char
valid_shape_file:
- exp/asr_stats_raw_en_char_sp/valid/speech_shape
- exp/asr_stats_raw_en_char_sp/valid/text_shape.char
batch_type: numel
valid_batch_type: null
fold_length:
- 80000
- 150
sort_in_batch: descending
sort_batch: descending
multiple_iterator: false
chunk_length: 500
chunk_shift_ratio: 0.5
num_cache_chunks: 1024
train_data_path_and_name_and_type:
- - dump/raw/train_clean_100_sp/wav.scp
- speech
- kaldi_ark
- - dump/raw/train_clean_100_sp/text
- text
- text
valid_data_path_and_name_and_type:
- - dump/raw/dev/wav.scp
- speech
- kaldi_ark
- - dump/raw/dev/text
- text
- text
allow_variable_data_keys: false
max_cache_size: 0.0
max_cache_fd: 32
valid_max_cache_size: null
optim: adam
optim_conf:
lr: 0.002
weight_decay: 1.0e-06
scheduler: warmuplr
scheduler_conf:
warmup_steps: 15000
token_list:
- <blank>
- <unk>
- <space>
- E
- T
- A
- O
- N
- I
- H
- S
- R
- D
- L
- U
- M
- C
- W
- F
- G
- Y
- P
- B
- V
- K
- ''''
- X
- J
- Q
- Z
- <sos/eos>
init: null
input_size: null
ctc_conf:
dropout_rate: 0.0
ctc_type: builtin
reduce: true
ignore_nan_grad: true
joint_net_conf: null
model_conf:
ctc_weight: 0.3
lsm_weight: 0.1
length_normalized_loss: false
use_preprocessor: true
token_type: char
bpemodel: null
non_linguistic_symbols: null
cleaner: null
g2p: null
speech_volume_normalize: null
rir_scp: null
rir_apply_prob: 1.0
noise_scp: null
noise_apply_prob: 1.0
noise_db_range: '13_15'
frontend: default
frontend_conf:
n_fft: 512
win_length: 400
hop_length: 160
fs: 16k
specaug: specaug
specaug_conf:
apply_time_warp: true
time_warp_window: 5
time_warp_mode: bicubic
apply_freq_mask: true
freq_mask_width_range:
- 0
- 27
num_freq_mask: 2
apply_time_mask: true
time_mask_width_ratio_range:
- 0.0
- 0.05
num_time_mask: 5
normalize: global_mvn
normalize_conf:
stats_file: exp/asr_stats_raw_en_char_sp/train/feats_stats.npz
preencoder: null
preencoder_conf: {}
encoder: conformer
encoder_conf:
output_size: 256
attention_heads: 4
linear_units: 1024
num_blocks: 12
dropout_rate: 0.1
positional_dropout_rate: 0.1
attention_dropout_rate: 0.1
input_layer: conv2d
normalize_before: true
macaron_style: true
rel_pos_type: latest
pos_enc_layer_type: rel_pos
selfattention_layer_type: rel_selfattn
activation_type: swish
use_cnn_module: true
cnn_module_kernel: 31
postencoder: null
postencoder_conf: {}
decoder: transformer
decoder_conf:
attention_heads: 4
linear_units: 2048
num_blocks: 6
dropout_rate: 0.1
positional_dropout_rate: 0.1
self_attention_dropout_rate: 0.1
src_attention_dropout_rate: 0.1
required:
- output_dir
- token_list
version: 0.10.7a1
distributed: false
```
</details>
### Citing ESPnet
```BibTex
@inproceedings{watanabe2018espnet,
author={Shinji Watanabe and Takaaki Hori and Shigeki Karita and Tomoki Hayashi and Jiro Nishitoba and Yuya Unno and Nelson Yalta and Jahn Heymann and Matthew Wiesner and Nanxin Chen and Adithya Renduchintala and Tsubasa Ochiai},
title={{ESPnet}: End-to-End Speech Processing Toolkit},
year={2018},
booktitle={Proceedings of Interspeech},
pages={2207--2211},
doi={10.21437/Interspeech.2018-1456},
url={http://dx.doi.org/10.21437/Interspeech.2018-1456}
}
```
or arXiv:
```bibtex
@misc{watanabe2018espnet,
title={ESPnet: End-to-End Speech Processing Toolkit},
author={Shinji Watanabe and Takaaki Hori and Shigeki Karita and Tomoki Hayashi and Jiro Nishitoba and Yuya Unno and Nelson Yalta and Jahn Heymann and Matthew Wiesner and Nanxin Chen and Adithya Renduchintala and Tsubasa Ochiai},
year={2018},
eprint={1804.00015},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
|
347b403f78976954b51d74de03624d15
|
jonatasgrosman/exp_w2v2t_ru_vp-100k_s334
|
jonatasgrosman
|
wav2vec2
| 10 | 5 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
|
['ru']
|
['mozilla-foundation/common_voice_7_0']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['automatic-speech-recognition', 'ru']
| false | true | true | 475 | false |
# exp_w2v2t_ru_vp-100k_s334
Fine-tuned [facebook/wav2vec2-large-100k-voxpopuli](https://huggingface.co/facebook/wav2vec2-large-100k-voxpopuli) for speech recognition using the train split of [Common Voice 7.0 (ru)](https://huggingface.co/datasets/mozilla-foundation/common_voice_7_0).
When using this model, make sure that your speech input is sampled at 16kHz.
This model has been fine-tuned by the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) tool.
|
0d3c0935b21cf203c8d5db47e991986c
|
ckauth/food-ner
|
ckauth
|
bert
| 8 | 6 |
transformers
| 0 |
token-classification
| false | true | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_keras_callback']
| true | true | true | 1,407 | false |
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# food-ner
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.0092
- Validation Loss: 0.0323
- Epoch: 2
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'AdamWeightDecay', 'learning_rate': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 2e-05, 'decay_steps': 1035, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False, 'weight_decay_rate': 0.01}
- training_precision: mixed_float16
### Training results
| Train Loss | Validation Loss | Epoch |
|:----------:|:---------------:|:-----:|
| 0.0808 | 0.0284 | 0 |
| 0.0193 | 0.0286 | 1 |
| 0.0092 | 0.0323 | 2 |
### Framework versions
- Transformers 4.25.1
- TensorFlow 2.9.2
- Datasets 2.7.1
- Tokenizers 0.13.2
|
1e136b5bcaa3b0ed8c44e511fe1713a9
|
tiedeman/opus-mt-en-he
|
tiedeman
|
marian
| 11 | 21 |
transformers
| 0 |
translation
| true | false | false |
apache-2.0
|
['en', 'he']
| null | null | 1 | 1 | 0 | 0 | 0 | 0 | 0 |
['translation']
| false | true | true | 2,011 | false |
### en-he
* source group: English
* target group: Hebrew
* OPUS readme: [eng-heb](https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/eng-heb/README.md)
* model: transformer
* source language(s): eng
* target language(s): heb
* model: transformer
* pre-processing: normalization + SentencePiece (spm32k,spm32k)
* download original weights: [opus-2020-10-04.zip](https://object.pouta.csc.fi/Tatoeba-MT-models/eng-heb/opus-2020-10-04.zip)
* test set translations: [opus-2020-10-04.test.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/eng-heb/opus-2020-10-04.test.txt)
* test set scores: [opus-2020-10-04.eval.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/eng-heb/opus-2020-10-04.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| Tatoeba-test.eng.heb | 37.9 | 0.602 |
### System Info:
- hf_name: en-he
- source_languages: eng
- target_languages: heb
- opus_readme_url: https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/eng-heb/README.md
- original_repo: Tatoeba-Challenge
- tags: ['translation']
- languages: ['en', 'he']
- src_constituents: ('English', {'eng'})
- tgt_constituents: ('Hebrew', {'heb'})
- src_multilingual: False
- tgt_multilingual: False
- long_pair: eng-heb
- prepro: normalization + SentencePiece (spm32k,spm32k)
- url_model: https://object.pouta.csc.fi/Tatoeba-MT-models/eng-heb/opus-2020-10-04.zip
- url_test_set: https://object.pouta.csc.fi/Tatoeba-MT-models/eng-heb/opus-2020-10-04.test.txt
- src_alpha3: eng
- tgt_alpha3: heb
- chrF2_score: 0.602
- bleu: 37.9
- brevity_penalty: 1.0
- ref_len: 60359.0
- src_name: English
- tgt_name: Hebrew
- train_date: 2020-10-04 00:00:00
- src_alpha2: en
- tgt_alpha2: he
- prefer_old: False
- short_pair: en-he
- helsinki_git_sha: 61fd6908b37d9a7b21cc3e27c1ae1fccedc97561
- transformers_git_sha: d99ed7ad618037ae878f0758157ed0764bd7f935
- port_machine: LM0-400-22516.local
- port_time: 2020-10-15-16:31
|
894bd241162046a5df9625efef2d3e4d
|
jason1234/wav2vec2-large-xlsr-law
|
jason1234
|
wav2vec2
| 55 | 5 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,081 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-large-xlsr-law
This model is a fine-tuned version of [ydshieh/wav2vec2-large-xlsr-53-chinese-zh-cn-gpt](https://huggingface.co/ydshieh/wav2vec2-large-xlsr-53-chinese-zh-cn-gpt) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.11.3
- Pytorch 1.10.0
- Datasets 1.13.3
- Tokenizers 0.10.3
|
c6c702a9e4d004190aadba4a9b580403
|
Helsinki-NLP/opus-mt-fr-mos
|
Helsinki-NLP
|
marian
| 10 | 10 |
transformers
| 0 |
translation
| true | true | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['translation']
| false | true | true | 776 | false |
### opus-mt-fr-mos
* source languages: fr
* target languages: mos
* OPUS readme: [fr-mos](https://github.com/Helsinki-NLP/OPUS-MT-train/blob/master/models/fr-mos/README.md)
* dataset: opus
* model: transformer-align
* pre-processing: normalization + SentencePiece
* download original weights: [opus-2020-01-20.zip](https://object.pouta.csc.fi/OPUS-MT-models/fr-mos/opus-2020-01-20.zip)
* test set translations: [opus-2020-01-20.test.txt](https://object.pouta.csc.fi/OPUS-MT-models/fr-mos/opus-2020-01-20.test.txt)
* test set scores: [opus-2020-01-20.eval.txt](https://object.pouta.csc.fi/OPUS-MT-models/fr-mos/opus-2020-01-20.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| JW300.fr.mos | 21.1 | 0.353 |
|
c73d3e14dbf0f825454e332a483cf5f7
|
harmonai/honk-140k
|
harmonai
| null | 6 | 291 |
diffusers
| 1 | null | false | false | false |
mit
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['audio-generation']
| false | true | true | 1,305 | false |
[Dance Diffusion](https://github.com/Harmonai-org/sample-generator) is now available in 🧨 Diffusers.
## FP32
```python
# !pip install diffusers[torch] accelerate scipy
from diffusers import DiffusionPipeline
from scipy.io.wavfile import write
model_id = "harmonai/honk-140k"
pipe = DiffusionPipeline.from_pretrained(model_id)
pipe = pipe.to("cuda")
audios = pipe(audio_length_in_s=4.0).audios
# To save locally
for i, audio in enumerate(audios):
write(f"test_{i}.wav", pipe.unet.sample_rate, audio.transpose())
# To dislay in google colab
import IPython.display as ipd
for audio in audios:
display(ipd.Audio(audio, rate=pipe.unet.sample_rate))
```
## FP16
Faster at a small loss of quality
```python
# !pip install diffusers[torch] accelerate scipy
from diffusers import DiffusionPipeline
from scipy.io.wavfile import write
import torch
model_id = "harmonai/honk-140k"
pipe = DiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16)
pipe = pipe.to("cuda")
audios = pipeline(audio_length_in_s=4.0).audios
# To save locally
for i, audio in enumerate(audios):
write(f"{i}.wav", pipe.unet.sample_rate, audio.transpose())
# To dislay in google colab
import IPython.display as ipd
for audio in audios:
display(ipd.Audio(audio, rate=pipe.unet.sample_rate))
```
|
fa086d87ecb2eba39792ac91a8193966
|
dougtrajano/toxic-comment-classification
|
dougtrajano
|
bert
| 10 | 5 |
transformers
| 0 |
text-classification
| true | false | false |
apache-2.0
|
['pt']
| null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['toxicity', 'portuguese', 'hate speech', 'offensive language', 'generated_from_trainer']
| true | true | true | 2,254 | false |
# dougtrajano/toxic-comment-classification
Toxic Comment Classification is a model that detects if the text is toxic or not.
This BERT model is a fine-tuned version of [neuralmind/bert-base-portuguese-cased](https://huggingface.co/neuralmind/bert-base-portuguese-cased) on the [OLID-BR dataset](https://huggingface.co/datasets/dougtrajano/olid-br).
## Overview
**Input:** Text in Brazilian Portuguese
**Output:** Binary classification (toxic or not toxic)
## Usage
```python
from transformers import AutoTokenizer, AutoModelForSequenceClassification
tokenizer = AutoTokenizer.from_pretrained("dougtrajano/toxic-comment-classification")
model = AutoModelForSequenceClassification.from_pretrained("dougtrajano/toxic-comment-classification")
```
## Limitations and bias
The following factors may degrade the model’s performance.
**Text Language**: The model was trained on Brazilian Portuguese texts, so it may not work well with Portuguese dialects.
**Text Origin**: The model was trained on texts from social media and a few texts from other sources, so it may not work well on other types of texts.
## Trade-offs
Sometimes models exhibit performance issues under particular circumstances. In this section, we'll discuss situations in which you might discover that the model performs less than optimally, and should plan accordingly.
**Text Length**: The model was fine-tuned on texts with a word count between 1 and 178 words (average of 18 words). It may give poor results on texts with a word count outside this range.
## Performance
The model was evaluated on the test set of the [OLID-BR](https://dougtrajano.github.io/olid-br/) dataset.
**Accuracy:** 0.8578
**Precision:** 0.8594
**Recall:** 0.8578
**F1-Score:** 0.8580
| Class | Precision | Recall | F1-Score | Support |
| :---: | :-------: | :----: | :------: | :-----: |
| `NOT-OFFENSIVE` | 0.8886 | 0.8490 | 0.8683 | 1,775 |
| `OFFENSIVE` | 0.8233 | 0.8686 | 0.8453 | 1,438 |
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3.255788747459486e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 1993
- optimizer: Adam with betas=(0.8445637934160373,0.8338816842140165) and epsilon=2.527092625455385e-08
- lr_scheduler_type: linear
- num_epochs: 30
- label_smoothing_factor: 0.07158711257743958
### Framework versions
- Transformers 4.26.0
- Pytorch 1.10.2+cu113
- Datasets 2.9.0
- Tokenizers 0.13.2
## Provide Feedback
If you have any feedback on this model, please [open an issue](https://github.com/DougTrajano/ToChiquinho/issues/new) on GitHub.
|
582baa744532773d1e8d6c408a7d2f63
|
ThePioneer/UnknownMix
|
ThePioneer
| null | 13 | 0 | null | 0 | null | false | false | false |
other
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
[]
| false | true | true | 5,297 | false |
<style>
code {
white-space : pre-wrap !important;
word-break: break-word;
}
</style>
# モデル説明 (model explanation)
- CoolJapanDiffusion 2.1.1 + 0.8(YaguruMagiku-v3.1-AnyBased - HassanBlend1.5) + 0.8(AbyssOrangeMix2_sfw - HassanBlend1.5)
- **マージ元の一部のルーツにNAIリークやInsta系モデルが含まれるという噂があるので、NAIリークアンチ・Insta系モデルアンチには非推奨**
- Stable Diffusion 2.x系と1.x系のマージの実験。不思議な絵が出る。
- colabのWebUIで動かせる。
- [これ](https://colab.research.google.com/drive/1ldhBc70wvuvkp4Af_vNTzTfBXwpf_cH5?usp=sharing)の以下の書き換えを行う。やり方は[ここ](https://the-pioneer.notion.site/Colab-Automatic1111-6043f15ef44d4ba0b11920c95d33a78c)。
```python
!aria2c --summary-interval=10 -x 16 -s 16 --allow-overwrite=true -Z https://huggingface.co/JosephusCheung/ACertainModel/resolve/main/ACertainModel-half.ckpt
```
- CoolJapanDiffusion 2.1.1 + 0.8(YaguruMagiku-v3.1-AnyBased - HassanBlend1.5) + 0.8(AbyssOrangeMix2_sfw - HassanBlend1.5)
- **Since the part of the original models might have the root back in NovelAI leak and Instagram based models, according to some rumors, I do not recommend you use it, if you are a hater of NAI leak/Instagram based models and their derivatives.**
- Since this model is an experimental model to see what will happen when merging a SD 1.x based model to SD 2.x, it is very likely that you get a weird result.
- You can run this model on colab WebUI.
- Rewrite the following line of [this notebook](https://colab.research.google.com/drive/1ldhBc70wvuvkp4Af_vNTzTfBXwpf_cH5?usp=sharing) following the instructions I posted [here](https://the-pioneer.notion.site/Colab-Automatic1111-6043f15ef44d4ba0b11920c95d33a78c).
```python
!aria2c --summary-interval=10 -x 16 -s 16 --allow-overwrite=true -Z https://huggingface.co/JosephusCheung/ACertainModel/resolve/main/ACertainModel-half.ckpt
```
# extras.py
**本ファイルのみ、CC0 1.0ライセンスとする(WebUIのAGPLとの互換性維持のため)。**
WebUIの同名ファイルを置き換えることであなた自身のマージを作ることができます。
- ``No interpolation``はひっかけで、マージはしません。最初これで、マージできたと勘違いしていました。
- ``Weighted sum``は比率0.1程度でも元のモデルを跡形もなく破壊します。0.01なら大丈夫でしたが、その間のどこがボーダーなのかは不明です。
- ``Add difference``は比較的元のモデルを維持したままで画風などを変更できます。ただし、やりすぎるとこのモデルのような結果になります。また、変更内容がマージに使ったSD 1.x系に期待した内容通りになる保証もありません。
**Note that this file and only this file in the model is released under public domain (CC0 1.0), in order to keep it compatible with the AGPL license of WebUI.**
By replacing the file with the same name in WebUI, you can create your own merged model.
- ``No interpolation`` is NOT a merging operation. It will work, but it will only return the same model as model A.
- ``Weighted sum`` can easily destroy the original SD 2.x based model. Multiplier 0.1 was enough for it, whereas 0.01 was OK. There should be a border zone somewhere.
- ``Add difference`` will work relatively fine, but going too far will likely result in a model similar to this. Additionally, there is no guarantee that you can get the style and/or content you expected to the original SD 1.x model you merged to.
# sample outputs
アップしているので、気になるならご自身で見てください。プロンプトはメタデータに入っているはずです。
Check it by yourself if you are interested in this model. The prompts should be in the metadata of each image.
# License: The Libertarian OpenRAIL License
注意: アップロード者が日本語母語話者であるため、翻訳版と日本語版に差異がある場合、**元の日本語版**が優先されるものとする。
Caution: Since the uploader is a Japanese native, in the event of any differences in meaning between the original Japanese version and a translation, **the original Japanese version** takes precedence.
要約: ほぼCreativeML Open RAIL-M。但しリバタリアン的解釈によって再構成。CreativeML Open RAIL-Mの制限は、同解釈において維持されているものと判断する。
Summary: A CreativeML Open RAIL-M, interpreted and reconstructed under a libertarian manner. The restriction of CreativeML Open RAIL-M is considered to be valid under such interpretation.
## 主な相違 (differences from the original CreativeML Open RAIL-M license)
- 違法性は、無罪推定の原則に基づき、有罪確定を以て、かつそれのみによって判断する(有罪が確定するまで、法令違反であるように見えても、ライセンス者は違法とはみなさない)。
- ex. フェアユース文化圏は無論、親告罪である日本においても、著作者が訴えない範囲のほどほどの二次創作は、事実上問題視しない。
- 本モデル及び派生モデルによる生成物はパブリック・ドメイン(CC0 1.0)とすることを義務付け、生成者を含む任意の人物による(再)利用の自由を保障する。
- Stability.aiが運営するDream Studioが生成物をCC0 1.0としているが、元のモデルライセンスと両立していることに注意せよ。
- 派生モデルでは、本ライセンスと同等以上の制限とともに、同等以上の自由も保障しなければならない。
- The violation of law or regulation will be judged by and only by your conviction per the presumption of innocence (unless you are convicted, it is not enough to claim it is illegal for the Licensor, even if it looks like it).
- ex. Fanart in Japan is technically illegal, unlike countries which have fair use, but as long as it is in the moderate range and the copright holder won't sue you, we will practically do not consider it as problematic.
- Outputs you generated by the Model or Derivatives of the Model must be distributed under public domain (CC0 1.0), to ensure not only you but anyone can (re)use it freely.
- Note that Dream Studio, run by Stability.ai demands the output be CC0 1.0 as well, but still isn't against the original model license.
- Derivatives of the Model will always have to include - at minimum - the same use-based restrictions <u>and the same open permissions</u>.
## 全文 (full license)
### 日本語版
[License_ja.md](https://huggingface.co/ThePioneer/MoeDiffusionPlusPlus/blob/main/License_ja.md)を参照。
### English version
[License_en.md](https://huggingface.co/ThePioneer/MoeDiffusionPlusPlus/blob/main/License_en.md)を参照。
|
3f38dfd395e85b57be38dbbf6a399fa9
|
luke-thorburn/suggest-objections-bias-only
|
luke-thorburn
|
gpt_neo
| 4 | 4 |
transformers
| 0 |
text-generation
| true | false | false |
apache-2.0
|
['en']
| null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['argumentation']
| false | true | true | 1,716 | false |
# Generate objections to a claim
This model is a version of [`gpt-neo-2.7B`](https://huggingface.co/EleutherAI/gpt-neo-2.7B), where some parameters (only the bias parameters, not weights) have been finetuned on the task of generating the objections to a claim, optionally given some example objections to that claim. It was trained as part of a University of Melbourne [research project](https://github.com/Hunt-Laboratory/language-model-optimization) evaluating how large language models can best be optimized to perform argumentative reasoning tasks.
Code used for optimization and evaluation can be found in the project [GitHub repository](https://github.com/Hunt-Laboratory/language-model-optimization). A paper reporting on model evaluation is currently under review.
# Prompt Template
```
List objections to the claim that: [original claim]
Objections:
* [objection 1]
* [objection 2]
...
* [objection n]
* [generated objection]
```
# Dataset
The parameters were finetuned using argument maps scraped from the crowdsourced argument-mapping platform [Kialo](https://kialo.com/).
# Limitations and Biases
The model is a finetuned version of [`gpt-neo-2.7B`](https://huggingface.co/EleutherAI/gpt-neo-2.7B), so likely has many of the same limitations and biases. Additionally, note that while the goal of the model is to produce coherent and valid reasoning, many generated model outputs will be illogical or nonsensical and should not be relied upon.
# Acknowledgements
This research was funded by the Australian Department of Defence and the Office of National Intelligence under the AI for Decision Making Program, delivered in partnership with the Defence Science Institute in Victoria, Australia.
|
01a978089503b36959761ee51b3a0f81
|
PlanTL-GOB-ES/bsc-bio-ehr-es
|
PlanTL-GOB-ES
|
roberta
| 11 | 888 |
transformers
| 4 |
fill-mask
| true | false | false |
apache-2.0
|
['es']
| null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['biomedical', 'clinical', 'ehr', 'spanish']
| false | true | true | 14,406 | false |
# Biomedical-clinical language model for Spanish
## Table of contents
<details>
<summary>Click to expand</summary>
- [Model description](#model-description)
- [Intended uses and limitations](#intended-use)
- [How to use](#how-to-use)
- [Limitations and bias](#limitations-and-bias)
- [Training](#training)
- [Evaluation](#evaluation)
- [Additional information](#additional-information)
- [Author](#author)
- [Contact information](#contact-information)
- [Copyright](#copyright)
- [Licensing information](#licensing-information)
- [Funding](#funding)
- [Citing information](#citing-information)
- [Disclaimer](#disclaimer)
</details>
## Model description
Biomedical pretrained language model for Spanish. For more details about the corpus, the pretraining and the evaluation, check the official [repository](https://github.com/PlanTL-GOB-ES/lm-biomedical-clinical-es).
## Intended uses and limitations
The model is ready-to-use only for masked language modelling to perform the Fill Mask task (try the inference API or read the next section). However, it is intended to be fine-tuned on downstream tasks such as Named Entity Recognition or Text Classification.
## How to use
## Limitations and bias
At the time of submission, no measures have been taken to estimate the bias embedded in the model. However, we are well aware that our models may be biased since the corpora have been collected using crawling techniques on multiple web sources. We intend to conduct research in these areas in the future, and if completed, this model card will be updated.
## Training
### Tokenization and model pretraining
This model is a [RoBERTa-based](https://github.com/pytorch/fairseq/tree/master/examples/roberta) model trained on a
**biomedical-clinical** corpus in Spanish collected from several sources (see next section).
The training corpus has been tokenized using a byte version of [Byte-Pair Encoding (BPE)](https://github.com/openai/gpt-2)
used in the original [RoBERTA](https://github.com/pytorch/fairseq/tree/master/examples/roberta) model with a vocabulary size of 52,000 tokens. The pretraining consists of a masked language model training at the subword level following the approach employed for the RoBERTa base model with the same hyperparameters as in the original work. The training lasted a total of 48 hours with 16 NVIDIA V100 GPUs of 16GB DDRAM, using Adam optimizer with a peak learning rate of 0.0005 and an effective batch size of 2,048 sentences.
### Training corpora and preprocessing
The training corpus is composed of several biomedical corpora in Spanish, collected from publicly available corpora and crawlers, and a real-world clinical corpus collected from more than 278K clinical documents and notes. To obtain a high-quality training corpus while retaining the idiosyncrasies of the clinical language, a cleaning pipeline has been applied only to the biomedical corpora, keeping the clinical corpus uncleaned. Essentially, the cleaning operations used are:
- data parsing in different formats
- sentence splitting
- language detection
- filtering of ill-formed sentences
- deduplication of repetitive contents
- keep the original document boundaries
Then, the biomedical corpora are concatenated and further global deduplication among the biomedical corpora has been applied.
Eventually, the clinical corpus is concatenated to the cleaned biomedical corpus resulting in a medium-size biomedical-clinical corpus for Spanish composed of more than 1B tokens. The table below shows some basic statistics of the individual cleaned corpora:
| Name | No. tokens | Description |
|-----------------------------------------------------------------------------------------|-------------|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [Medical crawler](https://zenodo.org/record/4561970) | 903,558,13 | Crawler of more than 3,000 URLs belonging to Spanish biomedical and health domains. |
| Clinical cases misc. | 102,855,267 | A miscellany of medical content, essentially clinical cases. Note that a clinical case report is a scientific publication where medical practitioners share patient cases and it is different from a clinical note or document. |
| EHR documents | 95,267,20 | Collection of more than 278K clinical documents, including discharge reports, clinical course notes and X-ray reports, for a total of 91M tokens. |
| [Scielo](https://zenodo.org/record/2541681#.YlP1DshBwio) | 60,007,289 | Publications written in Spanish crawled from the Spanish SciELO server in 2017. |
| [BARR2_background](https://temu.bsc.es/BARR2/downloads/background_set.raw_text.tar.bz2) | 24,516,442 | Biomedical Abbreviation Recognition and Resolution (BARR2) containing Spanish clinical case study sections from a variety of clinical disciplines. |
| Wikipedia_life_sciences | 13,890,501 | Wikipedia articles crawled 04/01/2021 with the [Wikipedia API python library](https://pypi.org/project/Wikipedia-API/) starting from the "Ciencias\_de\_la\_vida" category up to a maximum of 5 subcategories. Multiple links to the same articles are then discarded to avoid repeating content. |
| Patents | 13,463,387 | Google Patent in Medical Domain for Spain (Spanish). The accepted codes (Medical Domain) for Json files of patents are: "A61B", "A61C","A61F", "A61H", "A61K", "A61L","A61M", "A61B", "A61P". |
| [EMEA](http://opus.nlpl.eu/download.php?f=EMEA/v3/moses/en-es.txt.zip) | 5,377,448 | Spanish-side documents extracted from parallel corpora made out of PDF documents from the European Medicines Agency. |
| [mespen_Medline](https://zenodo.org/record/3562536#.YTt1fH2xXbR) | 4,166,077 | Spanish-side articles extracted from a collection of Spanish-English parallel corpus consisting of biomedical scientific literature. The collection of parallel resources is aggregated from the MedlinePlus source. |
| PubMed | 1,858,966 | Open-access articles from the PubMed repository crawled in 2017. |
## Evaluation
The model has been fine-tuned on three Named Entity Recognition (NER) tasks using three clinical NER datasets:
- [PharmaCoNER](https://zenodo.org/record/4270158): is a track on chemical and drug mention recognition from Spanish medical texts (for more info see: https://temu.bsc.es/pharmaconer/).
- [CANTEMIST](https://zenodo.org/record/3978041#.YTt5qH2xXbQ): is a shared task specifically focusing on named entity recognition of tumor morphology, in Spanish (for more info see: https://zenodo.org/record/3978041#.YTt5qH2xXbQ).
- ICTUSnet: consists of 1,006 hospital discharge reports of patients admitted for stroke from 18 different Spanish hospitals. It contains more than 79,000 annotations for 51 different kinds of variables.
We addressed the NER task as a token classification problem using a standard linear layer along with the BIO tagging schema. We compared our models with the general-domain Spanish [roberta-base-bne](https://huggingface.co/PlanTL-GOB-ES/roberta-base-bne), the general-domain multilingual model that supports Spanish [mBERT](https://huggingface.co/bert-base-multilingual-cased), the domain-specific English model [BioBERT](https://huggingface.co/dmis-lab/biobert-base-cased-v1.2), and three domain-specific models based on continual pre-training, [mBERT-Galén](https://ieeexplore.ieee.org/document/9430499), [XLM-R-Galén](https://ieeexplore.ieee.org/document/9430499) and [BETO-Galén](https://ieeexplore.ieee.org/document/9430499).
The table below shows the F1 scores obtained:
| Tasks/Models | bsc-bio-ehr-es | XLM-R-Galén | BETO-Galén | mBERT-Galén | mBERT | BioBERT | roberta-base-bne |
|--------------|----------------|--------------------|--------------|--------------|--------------|--------------|------------------|
| PharmaCoNER | **0.8913** | 0.8754 | 0.8537 | 0.8594 | 0.8671 | 0.8545 | 0.8474 |
| CANTEMIST | **0.8340** | 0.8078 | 0.8153 | 0.8168 | 0.8116 | 0.8070 | 0.7875 |
| ICTUSnet | **0.8756** | 0.8716 | 0.8498 | 0.8509 | 0.8631 | 0.8521 | 0.8677 |
The fine-tuning scripts can be found in the official GitHub [repository](https://github.com/PlanTL-GOB-ES/lm-biomedical-clinical-es).
## Additional information
### Author
Text Mining Unit (TeMU) at the Barcelona Supercomputing Center (bsc-temu@bsc.es)
### Contact information
For further information, send an email to <plantl-gob-es@bsc.es>
### Copyright
Copyright by the Spanish State Secretariat for Digitalization and Artificial Intelligence (SEDIA) (2022)
### Licensing information
[Apache License, Version 2.0](https://www.apache.org/licenses/LICENSE-2.0)
### Funding
This work was funded by the Spanish State Secretariat for Digitalization and Artificial Intelligence (SEDIA) within the framework of the Plan-TL.
### Citing information
If you use these models, please cite our work:
```bibtext
@inproceedings{carrino-etal-2022-pretrained,
title = "Pretrained Biomedical Language Models for Clinical {NLP} in {S}panish",
author = "Carrino, Casimiro Pio and
Llop, Joan and
P{\`a}mies, Marc and
Guti{\'e}rrez-Fandi{\~n}o, Asier and
Armengol-Estap{\'e}, Jordi and
Silveira-Ocampo, Joaqu{\'\i}n and
Valencia, Alfonso and
Gonzalez-Agirre, Aitor and
Villegas, Marta",
booktitle = "Proceedings of the 21st Workshop on Biomedical Language Processing",
month = may,
year = "2022",
address = "Dublin, Ireland",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2022.bionlp-1.19",
doi = "10.18653/v1/2022.bionlp-1.19",
pages = "193--199",
abstract = "This work presents the first large-scale biomedical Spanish language models trained from scratch, using large biomedical corpora consisting of a total of 1.1B tokens and an EHR corpus of 95M tokens. We compared them against general-domain and other domain-specific models for Spanish on three clinical NER tasks. As main results, our models are superior across the NER tasks, rendering them more convenient for clinical NLP applications. Furthermore, our findings indicate that when enough data is available, pre-training from scratch is better than continual pre-training when tested on clinical tasks, raising an exciting research question about which approach is optimal. Our models and fine-tuning scripts are publicly available at HuggingFace and GitHub.",
}
```
### Disclaimer
<details>
<summary>Click to expand</summary>
The models published in this repository are intended for a generalist purpose and are available to third parties. These models may have bias and/or any other undesirable distortions.
When third parties, deploy or provide systems and/or services to other parties using any of these models (or using systems based on these models) or become users of the models, they should note that it is their responsibility to mitigate the risks arising from their use and, in any event, to comply with applicable regulations, including regulations regarding the use of Artificial Intelligence.
In no event shall the owner of the models (SEDIA – State Secretariat for Digitalization and Artificial Intelligence) nor the creator (BSC – Barcelona Supercomputing Center) be liable for any results arising from the use made by third parties of these models.
Los modelos publicados en este repositorio tienen una finalidad generalista y están a disposición de terceros. Estos modelos pueden tener sesgos y/u otro tipo de distorsiones indeseables.
Cuando terceros desplieguen o proporcionen sistemas y/o servicios a otras partes usando alguno de estos modelos (o utilizando sistemas basados en estos modelos) o se conviertan en usuarios de los modelos, deben tener en cuenta que es su responsabilidad mitigar los riesgos derivados de su uso y, en todo caso, cumplir con la normativa aplicable, incluyendo la normativa en materia de uso de inteligencia artificial.
En ningún caso el propietario de los modelos (SEDIA – Secretaría de Estado de Digitalización e Inteligencia Artificial) ni el creador (BSC – Barcelona Supercomputing Center) serán responsables de los resultados derivados del uso que hagan terceros de estos modelos.
</details>
|
5200464acc7ad2a1a61c7c24884b4faf
|
arun100/whisper-medium-vi-2
|
arun100
|
whisper
| 24 | 0 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
|
['vi']
|
['mozilla-foundation/common_voice_11_0']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['whisper-event', 'generated_from_trainer']
| true | true | true | 1,693 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Whisper Medium Vietnamese
This model is a fine-tuned version of [openai/whisper-medium](https://huggingface.co/openai/whisper-medium) on the mozilla-foundation/common_voice_11_0 vi dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5686
- Wer: 18.8638
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 32
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 1400
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:-------:|
| 0.0063 | 12.01 | 200 | 0.5238 | 19.2915 |
| 0.0046 | 24.01 | 400 | 0.5686 | 18.8638 |
| 0.0067 | 37.01 | 600 | 0.5924 | 20.6076 |
| 0.0004 | 49.01 | 800 | 0.6239 | 19.8070 |
| 0.0005 | 62.01 | 1000 | 0.6354 | 19.7631 |
| 0.0001 | 74.01 | 1200 | 0.6447 | 19.5547 |
| 0.0001 | 87.01 | 1400 | 0.6473 | 19.5547 |
### Framework versions
- Transformers 4.26.0.dev0
- Pytorch 1.13.1+cu117
- Datasets 2.8.1.dev0
- Tokenizers 0.13.2
|
1a27ef4473161daec92bb6d166cd49d7
|
rdyzakya/bert-indo-base-stance-cls
|
rdyzakya
|
bert
| 12 | 1 |
transformers
| 0 |
text-classification
| true | false | false |
mit
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 5,261 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-indo-base-stance-cls
This model is a fine-tuned version of [indobenchmark/indobert-base-p1](https://huggingface.co/indobenchmark/indobert-base-p1) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 2.0156
- Accuracy: 0.6892
- Precision: 0.6848
- Recall: 0.6892
- F1: 0.6859
- Against: {'precision': 0.6185567010309279, 'recall': 0.5555555555555556, 'f1-score': 0.5853658536585366, 'support': 216}
- For: {'precision': 0.7280453257790368, 'recall': 0.7764350453172205, 'f1-score': 0.7514619883040935, 'support': 331}
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | Precision | Recall | F1 | Against | For |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:---------:|:------:|:------:|:-----------------------------------------------------------------------------------------------------------------:|:---------------------------------------------------------------------------------------------------------------:|
| No log | 1.0 | 137 | 0.6423 | 0.6581 | 0.6894 | 0.6581 | 0.5917 | {'precision': 0.7543859649122807, 'recall': 0.19907407407407407, 'f1-score': 0.31501831501831506, 'support': 216} | {'precision': 0.6469387755102041, 'recall': 0.9577039274924471, 'f1-score': 0.7722289890377587, 'support': 331} |
| No log | 2.0 | 274 | 0.6146 | 0.6600 | 0.6691 | 0.6600 | 0.6628 | {'precision': 0.5614754098360656, 'recall': 0.6342592592592593, 'f1-score': 0.5956521739130436, 'support': 216} | {'precision': 0.7392739273927392, 'recall': 0.676737160120846, 'f1-score': 0.7066246056782334, 'support': 331} |
| No log | 3.0 | 411 | 0.7572 | 0.6545 | 0.6734 | 0.6545 | 0.6583 | {'precision': 0.550561797752809, 'recall': 0.6805555555555556, 'f1-score': 0.608695652173913, 'support': 216} | {'precision': 0.7535714285714286, 'recall': 0.6374622356495468, 'f1-score': 0.6906710310965631, 'support': 331} |
| 0.4855 | 4.0 | 548 | 0.7405 | 0.6892 | 0.6842 | 0.6892 | 0.6851 | {'precision': 0.6210526315789474, 'recall': 0.5462962962962963, 'f1-score': 0.5812807881773399, 'support': 216} | {'precision': 0.7254901960784313, 'recall': 0.7824773413897281, 'f1-score': 0.7529069767441859, 'support': 331} |
| 0.4855 | 5.0 | 685 | 1.1222 | 0.6856 | 0.6828 | 0.6856 | 0.6839 | {'precision': 0.6078431372549019, 'recall': 0.5740740740740741, 'f1-score': 0.5904761904761905, 'support': 216} | {'precision': 0.7317784256559767, 'recall': 0.7583081570996979, 'f1-score': 0.7448071216617211, 'support': 331} |
| 0.4855 | 6.0 | 822 | 1.4960 | 0.6892 | 0.6830 | 0.6892 | 0.6827 | {'precision': 0.6292134831460674, 'recall': 0.5185185185185185, 'f1-score': 0.5685279187817258, 'support': 216} | {'precision': 0.7181571815718157, 'recall': 0.8006042296072508, 'f1-score': 0.7571428571428572, 'support': 331} |
| 0.4855 | 7.0 | 959 | 1.6304 | 0.6801 | 0.6886 | 0.6801 | 0.6827 | {'precision': 0.5843621399176955, 'recall': 0.6574074074074074, 'f1-score': 0.6187363834422658, 'support': 216} | {'precision': 0.756578947368421, 'recall': 0.6948640483383686, 'f1-score': 0.7244094488188976, 'support': 331} |
| 0.1029 | 8.0 | 1096 | 1.8381 | 0.6673 | 0.6727 | 0.6673 | 0.6693 | {'precision': 0.5726495726495726, 'recall': 0.6203703703703703, 'f1-score': 0.5955555555555555, 'support': 216} | {'precision': 0.7380191693290735, 'recall': 0.6978851963746223, 'f1-score': 0.717391304347826, 'support': 331} |
| 0.1029 | 9.0 | 1233 | 1.9474 | 0.6929 | 0.6876 | 0.6929 | 0.6881 | {'precision': 0.6290322580645161, 'recall': 0.5416666666666666, 'f1-score': 0.582089552238806, 'support': 216} | {'precision': 0.7257617728531855, 'recall': 0.7915407854984894, 'f1-score': 0.7572254335260115, 'support': 331} |
| 0.1029 | 10.0 | 1370 | 2.0156 | 0.6892 | 0.6848 | 0.6892 | 0.6859 | {'precision': 0.6185567010309279, 'recall': 0.5555555555555556, 'f1-score': 0.5853658536585366, 'support': 216} | {'precision': 0.7280453257790368, 'recall': 0.7764350453172205, 'f1-score': 0.7514619883040935, 'support': 331} |
### Framework versions
- Transformers 4.24.0
- Pytorch 1.12.1+cu113
- Datasets 2.7.0
- Tokenizers 0.13.2
|
b34cce50c91d0435746c3e6225ab0de5
|
dumitrescustefan/t5-v1_1-base-romanian
|
dumitrescustefan
|
mt5
| 9 | 12 |
transformers
| 0 |
text2text-generation
| true | false | true |
apache-2.0
|
['ro']
| null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
[]
| false | true | true | 2,177 | false |
This is a pretrained-from-scratch **T5v1.1 base** model (**247M** parameters) on the [t5x](https://github.com/google-research/t5x) platform.
Training was performed on a clean 80GB Romanian text corpus for 4M steps with these [scripts](https://github.com/dumitrescustefan/t5x_models). The model was trained with an encoder sequence length of 512 and a decoder sequence length of 256.
**!! IMPORTANT !!** This model was pretrained on the span corruption MLM task, meaning this model is **not usable** in any downstream task **without finetuning** first!
### How to load a t5x model
```python
from transformers import T5Tokenizer, T5Model
tokenizer = T5Tokenizer.from_pretrained('dumitrescustefan/t5-v1_1-base-romanian')
model = T5Model.from_pretrained('dumitrescustefan/t5-v1_1-base-romanian')
input_ids = tokenizer("Acesta este un test", return_tensors="pt").input_ids # Batch size 1
decoder_input_ids = tokenizer("Acesta este", return_tensors="pt").input_ids # Batch size 1
# preprocess: Prepend decoder_input_ids with start token which is pad token for T5Model.
# This is not needed for torch's T5ForConditionalGeneration as it does this internally using labels arg.
decoder_input_ids = model._shift_right(decoder_input_ids)
# forward pass
outputs = model(input_ids=input_ids, decoder_input_ids=decoder_input_ids)
last_hidden_states = outputs.last_hidden_state
print(last_hidden_states.shape) # this will print [1, 3, 768]
```
Remember to always sanitize your text! Replace ``ş`` and ``ţ`` cedilla-letters to comma-letters with :
```python
text = text.replace("ţ", "ț").replace("ş", "ș").replace("Ţ", "Ț").replace("Ş", "Ș")
```
because the model was **not** trained on cedilla ``ş`` and ``ţ``s. If you don't, you will have decreased performance due to ``<UNK>``s and increased number of tokens per word.
### Acknowledgements
We'd like to thank [TPU Research Cloud](https://sites.research.google/trc/about/) for providing the TPUv4 cores we used to train these models!
### Authors
Yours truly,
_[Stefan Dumitrescu](https://github.com/dumitrescustefan), [Mihai Ilie](https://github.com/iliemihai) and [Per Egil Kummervold](https://huggingface.co/north)_
|
7575f7c91a4a842f2b3a979a0b7673af
|
xysmalobia/sequence_classification
|
xysmalobia
|
bert
| 12 | 3 |
transformers
| 0 |
text-classification
| true | false | false |
apache-2.0
| null |
['glue']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,388 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# sequence_classification
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on the glue dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7738
- Accuracy: 0.8529
- F1: 0.8944
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| No log | 1.0 | 459 | 0.3519 | 0.8627 | 0.9 |
| 0.4872 | 2.0 | 918 | 0.6387 | 0.8333 | 0.8893 |
| 0.2488 | 3.0 | 1377 | 0.7738 | 0.8529 | 0.8944 |
### Framework versions
- Transformers 4.13.0.dev0
- Pytorch 1.10.0+cu102
- Datasets 1.15.1
- Tokenizers 0.10.3
|
0b0d9a6a04717756902d99210df94094
|
jonathang/pprotein-thing
|
jonathang
| null | 17 | 26 |
diffusers
| 20 |
text-to-image
| true | false | false |
creativeml-openrail-m
| null | null | null | 1 | 1 | 0 | 0 | 1 | 1 | 0 |
['pytorch', 'diffusers', 'stable-diffusion', 'text-to-image', 'diffusion-models-class', 'dreambooth-hackathon', 'science']
| false | true | true | 2,523 | false |
# DreamBooth model for the pprotein concept trained by jonathang on the jonathang/dreambooth-hackathon-images-protein3 dataset.
This is a Stable Diffusion model fine-tuned on the pprotein concept with DreamBooth. It can be used by modifying the `instance_prompt`: **a 3d model of pprotein**
This model was created as part of the DreamBooth Hackathon 🔥. Visit the [organisation page](https://huggingface.co/dreambooth-hackathon) for instructions on how to take part!
## Examples
<table>
<tr>
<td>Generated Image of "a 3d diagram of pprotein in the style of "<br>"Kandinsky"</td>
<td>Generated Image of "a 3d diagram of pprotein in the style of "<br>"Van Gogh"</td>
<td>Generated Image of "a 3d diagram of pprotein in the style of "<br>"Warhol"</td>
</tr>
<tr>
<td align="center"><img src="https://imgur.com/lhDA041.png" style="height:200px"> </td>
<td align="center"><img src="https://imgur.com/iug4k7D.png" style="height:200px"> </td>
<td align="center"><img src="https://imgur.com/eIMiTVG.png" style="height:200px"> </td>
</tr>
<tr>
<td>Generated Image of "a 3d diagram of pprotein in the style of "<br>"Leonardo da Vinci"</td>
<td>Generated Image of "a 3d diagram of pprotein in the style of "<br>"Frida Kahlo"</td>
<td>Generated Image of "a 3d diagram of pprotein in the style of "<br>"Salvador Dahli"</td>
</tr>
<tr>
<td align="center"><img src="https://imgur.com/hzKGWC2.png" style="height:200px"> </td>
<td align="center"><img src="https://imgur.com/loc8rLa.png" style="height:200px"> </td>
<td align="center"><img src="https://imgur.com/8nK81TA.png" style="height:200px"> </td>
</tr>
<tr>
<td>Generated Image of "Tree in the style of"<br>"3d diagram of pprotein"</td>
<td>Generated Image of "Soda Can in the style of"<br>"3d diagram of pprotein"</td>
<td>Generated Image of "Vase in the style of"<br>"3d diagram of pprotein"</td>
</tr>
<tr>
<td align="center"><img src="https://imgur.com/czOlY11.png" style="height:200px"> </td>
<td align="center"><img src="https://imgur.com/uhwueGs.png" style="height:200px"> </td>
<td align="center"><img src="https://imgur.com/gSIrHAh.png" style="height:200px"> </td>
</tr>
</table>
## Description
This is a Stable Diffusion model fine-tuned on `thing` images for the science theme.
## Usage
```python
from diffusers import StableDiffusionPipeline
pipeline = StableDiffusionPipeline.from_pretrained('jonathang/pprotein-thing')
image = pipeline().images[0]
image
```
|
de89c3e764f9b5d8b2460ab132acf9d2
|
yuhuizhang/finetuned_gpt2_sst2_negation0.8_pretrainedFalse
|
yuhuizhang
|
gpt2
| 11 | 2 |
transformers
| 0 |
text-generation
| true | false | false |
mit
| null |
['sst2']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,246 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# finetuned_gpt2_sst2_negation0.8_pretrainedFalse
This model is a fine-tuned version of [gpt2](https://huggingface.co/gpt2) on the sst2 dataset.
It achieves the following results on the evaluation set:
- Loss: 5.2177
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 4.7474 | 1.0 | 1111 | 5.4543 |
| 4.378 | 2.0 | 2222 | 5.2688 |
| 4.2047 | 3.0 | 3333 | 5.2177 |
### Framework versions
- Transformers 4.22.2
- Pytorch 1.13.1+cu117
- Datasets 2.5.2
- Tokenizers 0.12.1
|
e2c02d0c0cadbc0b2bd53be2b420f117
|
doc2query/msmarco-hindi-mt5-base-v1
|
doc2query
|
mt5
| 10 | 378 |
transformers
| 1 |
text2text-generation
| true | false | false |
apache-2.0
|
['hi']
|
['unicamp-dl/mmarco']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
[]
| false | true | true | 3,825 | false |
# doc2query/msmarco-hindi-mt5-base-v1
This is a [doc2query](https://arxiv.org/abs/1904.08375) model based on mT5 (also known as [docT5query](https://cs.uwaterloo.ca/~jimmylin/publications/Nogueira_Lin_2019_docTTTTTquery-v2.pdf)).
It can be used for:
- **Document expansion**: You generate for your paragraphs 20-40 queries and index the paragraphs and the generates queries in a standard BM25 index like Elasticsearch, OpenSearch, or Lucene. The generated queries help to close the lexical gap of lexical search, as the generate queries contain synonyms. Further, it re-weights words giving important words a higher weight even if they appear seldomn in a paragraph. In our [BEIR](https://arxiv.org/abs/2104.08663) paper we showed that BM25+docT5query is a powerful search engine. In the [BEIR repository](https://github.com/beir-cellar/beir) we have an example how to use docT5query with Pyserini.
- **Domain Specific Training Data Generation**: It can be used to generate training data to learn an embedding model. In our [GPL-Paper](https://arxiv.org/abs/2112.07577) / [GPL Example on SBERT.net](https://www.sbert.net/examples/domain_adaptation/README.html#gpl-generative-pseudo-labeling) we have an example how to use the model to generate (query, text) pairs for a given collection of unlabeled texts. These pairs can then be used to train powerful dense embedding models.
## Usage
```python
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
import torch
model_name = 'doc2query/msmarco-hindi-mt5-base-v1'
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForSeq2SeqLM.from_pretrained(model_name)
text = "पाइथन एक सामान्य कार्यों के लिए उपयुक्त, उच्च स्तरीय प्रोग्रामिंग भाषा (General Purpose and High Level Programming language), इन्टरैक्टिव, ऑब्जेक्ट ओरिएन्टेड, स्क्रिप्टिंग भाषा है। इस भाषा को इस तरह से डिजाइन किया गया है ताकि इसमें लिखे गए कोड आसानी से पढ़े और समझे जा सकें।"
def create_queries(para):
input_ids = tokenizer.encode(para, return_tensors='pt')
with torch.no_grad():
# Here we use top_k / top_k random sampling. It generates more diverse queries, but of lower quality
sampling_outputs = model.generate(
input_ids=input_ids,
max_length=64,
do_sample=True,
top_p=0.95,
top_k=10,
num_return_sequences=5
)
# Here we use Beam-search. It generates better quality queries, but with less diversity
beam_outputs = model.generate(
input_ids=input_ids,
max_length=64,
num_beams=5,
no_repeat_ngram_size=2,
num_return_sequences=5,
early_stopping=True
)
print("Paragraph:")
print(para)
print("\nBeam Outputs:")
for i in range(len(beam_outputs)):
query = tokenizer.decode(beam_outputs[i], skip_special_tokens=True)
print(f'{i + 1}: {query}')
print("\nSampling Outputs:")
for i in range(len(sampling_outputs)):
query = tokenizer.decode(sampling_outputs[i], skip_special_tokens=True)
print(f'{i + 1}: {query}')
create_queries(text)
```
**Note:** `model.generate()` is non-deterministic for top_k/top_n sampling. It produces different queries each time you run it.
## Training
This model fine-tuned [google/mt5-base](https://huggingface.co/google/mt5-base) for 66k training steps (4 epochs on the 500k training pairs from MS MARCO). For the training script, see the `train_script.py` in this repository.
The input-text was truncated to 320 word pieces. Output text was generated up to 64 word pieces.
This model was trained on a (query, passage) from the [mMARCO dataset](https://github.com/unicamp-dl/mMARCO).
|
c85c489ac759a2fef66a889d592faa10
|
salesken/paraphrase_generation
|
salesken
|
gpt2
| 10 | 37 |
transformers
| 2 |
text-generation
| true | false | true |
apache-2.0
|
['en']
| null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
salesken
| false | true | true | 1,448 | false |
Use this model to generate variations to augment the training data used for NLU systems.
```python
from transformers import AutoTokenizer, AutoModelWithLMHead
import torch
if torch.cuda.is_available():
device = torch.device("cuda")
else :
device = "cpu"
tokenizer = AutoTokenizer.from_pretrained("salesken/paraphrase_generation")
model = AutoModelWithLMHead.from_pretrained("salesken/paraphrase_generation").to(device)
input_query="every moment is a fresh beginning"
query= input_query + " ~~ "
input_ids = tokenizer.encode(query.lower(), return_tensors='pt').to(device)
sample_outputs = model.generate(input_ids,
do_sample=True,
num_beams=1,
max_length=128,
temperature=0.9,
top_p= 0.99,
top_k = 30,
num_return_sequences=40)
paraphrases = []
for i in range(len(sample_outputs)):
r = tokenizer.decode(sample_outputs[i], skip_special_tokens=True).split('||')[0]
r = r.split(' ~~ ')[1]
if r not in paraphrases:
paraphrases.append(r)
print(paraphrases)
```
To evaluate if a paraphrase is a semantic variation to the input query or just a surface level variation & rank the generated paraphrases, use the following model:
https://huggingface.co/salesken/paraphrase_diversity_ranker
|
b8be1dcda5fd12f0f400212cc2ca7969
|
fathyshalab/all-roberta-large-v1-utility-7-16-5
|
fathyshalab
|
roberta
| 11 | 3 |
transformers
| 0 |
text-classification
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,512 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# all-roberta-large-v1-utility-7-16-5
This model is a fine-tuned version of [sentence-transformers/all-roberta-large-v1](https://huggingface.co/sentence-transformers/all-roberta-large-v1) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 2.3728
- Accuracy: 0.3956
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 48
- eval_batch_size: 48
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 2.8194 | 1.0 | 1 | 2.6027 | 0.3156 |
| 2.2337 | 2.0 | 2 | 2.5079 | 0.3778 |
| 1.7996 | 3.0 | 3 | 2.4293 | 0.3822 |
| 1.4591 | 4.0 | 4 | 2.3728 | 0.3956 |
| 1.3205 | 5.0 | 5 | 2.3439 | 0.3956 |
### Framework versions
- Transformers 4.20.0
- Pytorch 1.11.0+cu102
- Datasets 2.3.2
- Tokenizers 0.12.1
|
348776fadc344d75e41738be624b9f62
|
nsridhar/roberta-finetuned-country
|
nsridhar
|
roberta
| 13 | 10 |
transformers
| 0 |
question-answering
| true | false | false |
cc-by-4.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 982 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# roberta-finetuned-country
This model is a fine-tuned version of [deepset/roberta-base-squad2](https://huggingface.co/deepset/roberta-base-squad2) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.24.0
- Pytorch 1.12.1+cu113
- Datasets 2.6.1
- Tokenizers 0.13.2
|
db6c8e0d44264ed4b4f5f7b2b5c4686e
|
yogeshchandrasekharuni/bart-paraphrase-finetuned-xsum-v2
|
yogeshchandrasekharuni
|
bart
| 15 | 1 |
transformers
| 0 |
text2text-generation
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 3,414 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bart-paraphrase-finetuned-xsum-v2
This model is a fine-tuned version of [eugenesiow/bart-paraphrase](https://huggingface.co/eugenesiow/bart-paraphrase) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2329
- Rouge1: 100.0
- Rouge2: 100.0
- Rougel: 100.0
- Rougelsum: 100.0
- Gen Len: 9.2619
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 20
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:-------:|:-------:|:-------:|:---------:|:-------:|
| No log | 1.0 | 21 | 1.2954 | 66.7012 | 60.8612 | 66.5163 | 66.4352 | 13.2857 |
| No log | 2.0 | 42 | 0.6866 | 86.8284 | 82.7835 | 86.7208 | 86.784 | 9.5238 |
| No log | 3.0 | 63 | 0.4652 | 95.1892 | 93.5619 | 95.2567 | 95.1657 | 10.3095 |
| No log | 4.0 | 84 | 0.4280 | 97.7463 | 97.1782 | 97.8708 | 97.718 | 9.5 |
| No log | 5.0 | 105 | 0.3712 | 99.6435 | 99.5767 | 99.6435 | 99.6435 | 9.3571 |
| No log | 6.0 | 126 | 0.4451 | 99.2695 | 98.9418 | 99.1883 | 99.3506 | 9.3095 |
| No log | 7.0 | 147 | 0.3169 | 99.246 | 99.0232 | 99.246 | 99.4048 | 9.619 |
| No log | 8.0 | 168 | 0.2942 | 100.0 | 100.0 | 100.0 | 100.0 | 9.4048 |
| No log | 9.0 | 189 | 0.3105 | 100.0 | 100.0 | 100.0 | 100.0 | 9.1667 |
| No log | 10.0 | 210 | 0.3035 | 100.0 | 100.0 | 100.0 | 100.0 | 9.2619 |
| No log | 11.0 | 231 | 0.2983 | 100.0 | 100.0 | 100.0 | 100.0 | 10.5714 |
| No log | 12.0 | 252 | 0.2497 | 100.0 | 100.0 | 100.0 | 100.0 | 9.4286 |
| No log | 13.0 | 273 | 0.2911 | 100.0 | 100.0 | 100.0 | 100.0 | 9.1667 |
| No log | 14.0 | 294 | 0.2619 | 100.0 | 100.0 | 100.0 | 100.0 | 9.2143 |
| No log | 15.0 | 315 | 0.2510 | 100.0 | 100.0 | 100.0 | 100.0 | 9.2381 |
| No log | 16.0 | 336 | 0.2647 | 100.0 | 100.0 | 100.0 | 100.0 | 9.9048 |
| No log | 17.0 | 357 | 0.2438 | 100.0 | 100.0 | 100.0 | 100.0 | 9.2143 |
| No log | 18.0 | 378 | 0.2324 | 100.0 | 100.0 | 100.0 | 100.0 | 9.3095 |
| No log | 19.0 | 399 | 0.2296 | 100.0 | 100.0 | 100.0 | 100.0 | 9.3095 |
| No log | 20.0 | 420 | 0.2329 | 100.0 | 100.0 | 100.0 | 100.0 | 9.2619 |
### Framework versions
- Transformers 4.19.1
- Pytorch 1.11.0+cu113
- Datasets 2.2.1
- Tokenizers 0.12.1
|
c3e23b1e1c57bb90cd3febe2ad98bba2
|
StonyBrookNLP/bart-large-iirc-gold
|
StonyBrookNLP
|
bart
| 9 | 3 |
transformers
| 0 |
text2text-generation
| true | false | false |
cc-by-4.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['question-answering, multi-step-reasoning, multi-hop-reasoning']
| false | true | true | 2,624 | false |
# What's this?
This is one of the models reported in the paper: ["Teaching Broad Reasoning Skills for Multi-Step QA by Generating Hard Contexts".](https://arxiv.org/abs/2205.12496).
This paper proposes a procedure to synthetically generate a QA dataset, TeaBReaC, for pretraining language models for robust multi-step reasoning. Pretraining plain LMs like Bart, T5 and numerate LMs like NT5, PReasM, POET on TeaBReaC leads to improvemed downstream performance on several multi-step QA datasets. Please checkout out the paper for the details.
We release the following models:
- **A:** Base Models finetuned on target datasets: `{base_model}-{target_dataset}`
- **B:** Base models pretrained on TeaBReaC: `teabreac-{base_model}`
- **C:** Base models pretrained on TeaBReaC and then finetuned on target datasets: `teabreac-{base_model}-{target_dataset}`
The `base_model` above can be from: `bart-large`, `t5-large`, `t5-3b`, `nt5-small`, `preasm-large`.
The `target_dataset` above can be from: `drop`, `tatqa`, `iirc-gold`, `iirc-retrieved`, `numglue`.
The **A** models are only released for completeness / reproducibility. In your end application you probably just want to use either **B** or **C**.
# How to use it?
Please checkout the details in our [github repository](https://github.com/stonybrooknlp/teabreac), but in a nutshell:
```python
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
from digit_tokenization import enable_digit_tokenization # digit_tokenization.py from https://github.com/stonybrooknlp/teabreac
model_name = "StonyBrookNLP/bart-large-iirc-gold"
tokenizer = AutoTokenizer.from_pretrained(model_name, use_fast=False) # Fast doesn't work with digit tokenization
model = AutoModelForSeq2SeqLM.from_pretrained(model_name)
enable_digit_tokenization(tokenizer)
input_texts = [
"answer_me: Who scored the first touchdown of the game?" +
"context: ... Oakland would get the early lead in the first quarter as quarterback JaMarcus Russell completed a 20-yard touchdown pass to rookie wide receiver Chaz Schilens..."
# Note: some models have slightly different qn/ctxt format. See the github repo.
]
input_ids = tokenizer(
input_texts, return_tensors="pt",
truncation=True, max_length=800,
add_special_tokens=True, padding=True,
)["input_ids"]
generated_ids = model.generate(input_ids, min_length=1, max_length=50)
generated_predictions = tokenizer.batch_decode(generated_ids, skip_special_tokens=False)
generated_predictions = [
tokenizer.fix_decoded_text(generated_prediction) for generated_prediction in generated_predictions
]
# => ["Chaz Schilens"]
```
|
1bb3efb2b07e0715480c6cb485408a9f
|
mrm8488/xlm-roberta-base-finetuned-HC3-mix
|
mrm8488
|
xlm-roberta
| 11 | 90 |
transformers
| 2 |
text-classification
| true | false | false |
openrail
|
['multilingual', 'af', 'am', 'ar', 'as', 'az', 'be', 'bg', 'bn', 'br', 'bs', 'ca', 'cs', 'cy', 'da', 'de', 'el', 'en', 'eo', 'es', 'et', 'eu', 'fa', 'fi', 'fr', 'fy', 'ga', 'gd', 'gl', 'gu', 'ha', 'he', 'hi', 'hr', 'hu', 'hy', 'id', 'is', 'it', 'ja', 'jv', 'ka', 'kk', 'km', 'kn', 'ko', 'ku', 'ky', 'la', 'lo', 'lt', 'lv', 'mg', 'mk', 'ml', 'mn', 'mr', 'ms', 'my', 'ne', 'nl', False, 'om', 'or', 'pa', 'pl', 'ps', 'pt', 'ro', 'ru', 'sa', 'sd', 'si', 'sk', 'sl', 'so', 'sq', 'sr', 'su', 'sv', 'sw', 'ta', 'te', 'th', 'tl', 'tr', 'ug', 'uk', 'ur', 'uz', 'vi', 'xh', 'yi']
|
['Hello-SimpleAI/HC3']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
[]
| false | true | true | 1,590 | false |
# XLM-RoBERTa (base) fine-tuned on HC3 for ChatGPT text detection
**XLM-RoBERTa** (base) fine-tuned on [Hello-SimpleAI](https://huggingface.co/Hello-SimpleAI) **HC3** corpus for **ChatGPT** text detection.
All credit to [Hello-SimpleAI](https://huggingface.co/Hello-SimpleAI) for their huge work!
## F1 score on test dataset: 0.9736
## The model
XLM-RoBERTa model pre-trained on 2.5TB of filtered CommonCrawl data containing 100 languages. It was introduced in the paper Unsupervised Cross-lingual Representation Learning at Scale by Conneau et al. and first released in this repository.
## The dataset
#### Human ChatGPT Comparison Corpus (HC3)
The first human-ChatGPT comparison corpus, named **HC3** dataset by [Hello-SimpleAI](https://huggingface.co/Hello-SimpleAI)
This dataset is introduced in the paper:
- Paper: [***How Close is ChatGPT to Human Experts? Comparison Corpus, Evaluation, and Detection***](https://arxiv.org/abs/2301.07597)
## Metrics
|metric| value|
|------|------|
|F1 |0.9736|
## Usage
```py
from transformers import pipeline
ckpt = "mrm8488/xlm-roberta-base-finetuned-HC3-mix"
detector = pipeline('text-classification', model=ckpt)
text = "Here your text..."
result = detector(text)
print(result)
```
## Citation
```
@misc {manuel_romero_2023,
author = { {Manuel Romero} },
title = { xlm-roberta-base-finetuned-HC3-mix (Revision b18de48) },
year = 2023,
url = { https://huggingface.co/mrm8488/xlm-roberta-base-finetuned-HC3-mix },
doi = { 10.57967/hf/0306 },
publisher = { Hugging Face }
}
```
|
6933f83e15e59fc4d42c6e350aa619c1
|
jayantapaul888/twitter-data-microsoft-deberta-base-mnli-sentiment-finetuned-memes
|
jayantapaul888
|
deberta
| 20 | 3 |
transformers
| 0 |
text-classification
| true | false | false |
mit
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,876 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# twitter-data-microsoft-deberta-base-mnli-sentiment-finetuned-memes
This model is a fine-tuned version of [microsoft/deberta-base-mnli](https://huggingface.co/microsoft/deberta-base-mnli) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2438
- Accuracy: 0.9296
- Precision: 0.9301
- Recall: 0.9296
- F1: 0.9296
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 6
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | Precision | Recall | F1 |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|:---------:|:------:|:------:|
| 0.3622 | 1.0 | 1762 | 0.2933 | 0.9060 | 0.9065 | 0.9060 | 0.9057 |
| 0.2601 | 2.0 | 3524 | 0.2593 | 0.9194 | 0.9196 | 0.9194 | 0.9192 |
| 0.2282 | 3.0 | 5286 | 0.2365 | 0.9279 | 0.9287 | 0.9279 | 0.9280 |
| 0.1977 | 4.0 | 7048 | 0.2325 | 0.9293 | 0.9298 | 0.9293 | 0.9293 |
| 0.181 | 5.0 | 8810 | 0.2421 | 0.9291 | 0.9301 | 0.9291 | 0.9292 |
| 0.1629 | 6.0 | 10572 | 0.2438 | 0.9296 | 0.9301 | 0.9296 | 0.9296 |
### Framework versions
- Transformers 4.24.0.dev0
- Pytorch 1.11.0+cu102
- Datasets 2.6.1
- Tokenizers 0.13.1
|
5855b9ff259072247d51c2df9139a592
|
innovation64/flyfood-pet-heywhale
|
innovation64
| null | 17 | 29 |
diffusers
| 0 |
text-to-image
| true | false | false |
creativeml-openrail-m
| null | null | null | 1 | 1 | 0 | 0 | 0 | 0 | 0 |
['pytorch', 'diffusers', 'stable-diffusion', 'text-to-image', 'diffusion-models-class', 'dreambooth-hackathon', 'wildcard']
| false | true | true | 806 | false |
# DreamBooth model for the flyfood concept trained by innovation64.
This is a Stable Diffusion model fine-tuned on the flyfood concept with DreamBooth. It can be used by modifying the `instance_prompt`: **a photo of flyfood pet**
This model was created as part of the DreamBooth Hackathon 🔥. Visit the [organisation page](https://huggingface.co/dreambooth-hackathon) for instructions on how to take part!
## Description
This is a Stable Diffusion model fine-tuned on `派蒙` images for the wildcard theme,
for the Hugging Face DreamBooth Hackathon, from the HF CN Community,
corporated with the HeyWhale.
## Usage
```python
from diffusers import StableDiffusionPipeline
pipeline = StableDiffusionPipeline.from_pretrained('innovation64/flyfood-pet-heywhale')
image = pipeline().images[0]
image
```
|
6e351eb7f9069ca934d2cbebac25be0b
|
jpabbuehl/distilbert-base-uncased-finetuned-cola
|
jpabbuehl
|
distilbert
| 13 | 4 |
transformers
| 0 |
text-classification
| true | false | false |
apache-2.0
| null |
['glue']
| null | 1 | 1 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,572 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-cola
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the glue dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7588
- Matthews Correlation: 0.5230
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Matthews Correlation |
|:-------------:|:-----:|:----:|:---------------:|:--------------------:|
| 0.5261 | 1.0 | 535 | 0.5125 | 0.4124 |
| 0.3502 | 2.0 | 1070 | 0.5439 | 0.5076 |
| 0.2378 | 3.0 | 1605 | 0.6629 | 0.4946 |
| 0.1809 | 4.0 | 2140 | 0.7588 | 0.5230 |
| 0.1309 | 5.0 | 2675 | 0.8901 | 0.5056 |
### Framework versions
- Transformers 4.12.5
- Pytorch 1.10.0+cu111
- Datasets 1.15.1
- Tokenizers 0.10.3
|
9f06b7b15bae62f85799f05731a84a15
|
jed351/gpt2_tiny_zh-hk-shikoto
|
jed351
|
gpt2
| 16 | 5 |
transformers
| 0 |
text-generation
| true | false | false |
openrail
| null |
['jed351/shikoto_zh_hk']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 2,251 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# gpt2-shikoto
This model was trained on a dataset I obtained from an online novel site.
**Please be aware that the stories (training data) might contain inappropriate content. This model is intended for research purposes only.**
The base model can be found [here](https://huggingface.co/jed351/gpt2-tiny-zh-hk), which was obtained by
patching a [GPT2 Chinese model](https://huggingface.co/ckiplab/gpt2-tiny-chinese) and its tokenizer with Cantonese characters.
Refer to the base model for info on the patching process.
## Training procedure
Please refer to the [script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/language-modeling)
provided by Huggingface.
The model was trained for 400,000 steps on 2 NVIDIA Quadro RTX6000 for around 15 hours at the Research Computing Services of Imperial College London.
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 20
- eval_batch_size: 20
- seed: 42
- distributed_type: multi-GPU
- num_devices: 2
- total_train_batch_size: 40
- total_eval_batch_size: 40
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 400000
- mixed_precision_training: Native AMP
### Training results
### How to use it?
```
from transformers import AutoTokenizer
from transformers import TextGenerationPipeline, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("jed351/gpt2-tiny-zh-hk")
model = AutoModelForCausalLM.from_pretrained("jed351/gpt2_tiny_zh-hk-shikoto")
# try messing around with the parameters
generator = TextGenerationPipeline(model, tokenizer,
max_new_tokens=200,
no_repeat_ngram_size=3) #, device=0) #if you have a GPU
input_string = "your input"
output = generator(input_string)
string = output[0]['generated_text'].replace(' ', '')
print(string)
```
### Framework versions
- Transformers 4.26.0.dev0
- Pytorch 1.13.1
- Datasets 2.8.0
- Tokenizers 0.13.2
|
df0af9a12c709e7d4190a5bb0a973bd9
|
emmyapi/distilbart-podimo-data-eval-2
|
emmyapi
|
bart
| 13 | 1 |
transformers
| 0 |
text2text-generation
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 2,203 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbart-podimo-data-eval-2
This model is a fine-tuned version of [sshleifer/distilbart-cnn-12-6](https://huggingface.co/sshleifer/distilbart-cnn-12-6) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 3.5823
- Rouge1: 34.3971
- Rouge2: 7.95
- Rougel: 18.7271
- Rougelsum: 30.9024
- Gen Len: 131.919
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 1
- eval_batch_size: 1
- seed: 42
- gradient_accumulation_steps: 64
- total_train_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 8
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:-------:|:------:|:-------:|:---------:|:--------:|
| 4.1512 | 0.98 | 44 | 3.7806 | 32.727 | 6.5788 | 17.5196 | 29.3777 | 137.2905 |
| 3.6342 | 1.98 | 88 | 3.6421 | 32.709 | 6.7877 | 17.8668 | 29.4636 | 134.6648 |
| 3.3512 | 2.98 | 132 | 3.5819 | 33.5128 | 7.519 | 18.6614 | 30.1142 | 132.2961 |
| 3.141 | 3.98 | 176 | 3.5552 | 33.4795 | 7.3242 | 18.396 | 30.0854 | 132.757 |
| 2.9787 | 4.98 | 220 | 3.5583 | 33.5862 | 7.391 | 18.3568 | 30.2461 | 132.4078 |
| 2.8555 | 5.98 | 264 | 3.5650 | 34.1111 | 7.8008 | 18.7159 | 30.6055 | 131.3603 |
| 2.7648 | 6.98 | 308 | 3.5729 | 34.0981 | 7.6556 | 18.6373 | 30.6269 | 131.2821 |
| 2.6645 | 7.98 | 352 | 3.5823 | 34.3971 | 7.95 | 18.7271 | 30.9024 | 131.919 |
### Framework versions
- Transformers 4.25.1
- Pytorch 1.11.0
- Datasets 2.2.1
- Tokenizers 0.12.1
|
9be1dd95ea3d7335080e421c28555923
|
AndrewMcDowell/wav2vec2-xls-r-300m-german-de
|
AndrewMcDowell
|
wav2vec2
| 28 | 8 |
transformers
| 2 |
automatic-speech-recognition
| true | false | false |
apache-2.0
|
['de']
|
['mozilla-foundation/common_voice_7_0']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['automatic-speech-recognition', 'de', 'generated_from_trainer', 'hf-asr-leaderboard', 'mozilla-foundation/common_voice_7_0', 'robust-speech-event']
| true | true | true | 6,772 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment.
eval results:
WER: 0.20161578657865786
CER: 0.05062357805269733
-->
#
This model is a fine-tuned version of [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) on the MOZILLA-FOUNDATION/COMMON_VOICE_7_0 - DE dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1768
- Wer: 0.2016
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 7.5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 2000
- num_epochs: 3.4
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:-----:|:---------------:|:------:|
| 5.7531 | 0.04 | 500 | 5.4564 | 1.0 |
| 2.9882 | 0.08 | 1000 | 3.0041 | 1.0 |
| 2.1953 | 0.13 | 1500 | 1.1723 | 0.7121 |
| 1.2406 | 0.17 | 2000 | 0.3656 | 0.3623 |
| 1.1294 | 0.21 | 2500 | 0.2843 | 0.2926 |
| 1.0731 | 0.25 | 3000 | 0.2554 | 0.2664 |
| 1.051 | 0.3 | 3500 | 0.2387 | 0.2535 |
| 1.0479 | 0.34 | 4000 | 0.2345 | 0.2512 |
| 1.0026 | 0.38 | 4500 | 0.2270 | 0.2452 |
| 0.9921 | 0.42 | 5000 | 0.2212 | 0.2353 |
| 0.9839 | 0.47 | 5500 | 0.2141 | 0.2330 |
| 0.9907 | 0.51 | 6000 | 0.2122 | 0.2334 |
| 0.9788 | 0.55 | 6500 | 0.2114 | 0.2270 |
| 0.9687 | 0.59 | 7000 | 0.2066 | 0.2323 |
| 0.9777 | 0.64 | 7500 | 0.2033 | 0.2237 |
| 0.9476 | 0.68 | 8000 | 0.2020 | 0.2194 |
| 0.9625 | 0.72 | 8500 | 0.1977 | 0.2191 |
| 0.9497 | 0.76 | 9000 | 0.1976 | 0.2175 |
| 0.9781 | 0.81 | 9500 | 0.1956 | 0.2159 |
| 0.9552 | 0.85 | 10000 | 0.1958 | 0.2191 |
| 0.9345 | 0.89 | 10500 | 0.1964 | 0.2158 |
| 0.9528 | 0.93 | 11000 | 0.1926 | 0.2154 |
| 0.9502 | 0.98 | 11500 | 0.1953 | 0.2149 |
| 0.9358 | 1.02 | 12000 | 0.1927 | 0.2167 |
| 0.941 | 1.06 | 12500 | 0.1901 | 0.2115 |
| 0.9287 | 1.1 | 13000 | 0.1936 | 0.2090 |
| 0.9491 | 1.15 | 13500 | 0.1900 | 0.2104 |
| 0.9478 | 1.19 | 14000 | 0.1931 | 0.2120 |
| 0.946 | 1.23 | 14500 | 0.1914 | 0.2134 |
| 0.9499 | 1.27 | 15000 | 0.1931 | 0.2173 |
| 0.9346 | 1.32 | 15500 | 0.1913 | 0.2105 |
| 0.9509 | 1.36 | 16000 | 0.1902 | 0.2137 |
| 0.9294 | 1.4 | 16500 | 0.1895 | 0.2086 |
| 0.9418 | 1.44 | 17000 | 0.1913 | 0.2183 |
| 0.9302 | 1.49 | 17500 | 0.1884 | 0.2114 |
| 0.9418 | 1.53 | 18000 | 0.1894 | 0.2108 |
| 0.9363 | 1.57 | 18500 | 0.1886 | 0.2132 |
| 0.9338 | 1.61 | 19000 | 0.1856 | 0.2078 |
| 0.9185 | 1.66 | 19500 | 0.1852 | 0.2056 |
| 0.9216 | 1.7 | 20000 | 0.1874 | 0.2095 |
| 0.9176 | 1.74 | 20500 | 0.1873 | 0.2078 |
| 0.9288 | 1.78 | 21000 | 0.1865 | 0.2097 |
| 0.9278 | 1.83 | 21500 | 0.1869 | 0.2100 |
| 0.9295 | 1.87 | 22000 | 0.1878 | 0.2095 |
| 0.9221 | 1.91 | 22500 | 0.1852 | 0.2121 |
| 0.924 | 1.95 | 23000 | 0.1855 | 0.2042 |
| 0.9104 | 2.0 | 23500 | 0.1858 | 0.2105 |
| 0.9284 | 2.04 | 24000 | 0.1850 | 0.2080 |
| 0.9162 | 2.08 | 24500 | 0.1839 | 0.2045 |
| 0.9111 | 2.12 | 25000 | 0.1838 | 0.2080 |
| 0.91 | 2.17 | 25500 | 0.1889 | 0.2106 |
| 0.9152 | 2.21 | 26000 | 0.1856 | 0.2026 |
| 0.9209 | 2.25 | 26500 | 0.1891 | 0.2133 |
| 0.9094 | 2.29 | 27000 | 0.1857 | 0.2089 |
| 0.9065 | 2.34 | 27500 | 0.1840 | 0.2052 |
| 0.9156 | 2.38 | 28000 | 0.1833 | 0.2062 |
| 0.8986 | 2.42 | 28500 | 0.1789 | 0.2001 |
| 0.9045 | 2.46 | 29000 | 0.1769 | 0.2022 |
| 0.9039 | 2.51 | 29500 | 0.1819 | 0.2073 |
| 0.9145 | 2.55 | 30000 | 0.1828 | 0.2063 |
| 0.9081 | 2.59 | 30500 | 0.1811 | 0.2049 |
| 0.9252 | 2.63 | 31000 | 0.1833 | 0.2086 |
| 0.8957 | 2.68 | 31500 | 0.1795 | 0.2083 |
| 0.891 | 2.72 | 32000 | 0.1809 | 0.2058 |
| 0.9023 | 2.76 | 32500 | 0.1812 | 0.2061 |
| 0.8918 | 2.8 | 33000 | 0.1775 | 0.1997 |
| 0.8852 | 2.85 | 33500 | 0.1790 | 0.1997 |
| 0.8928 | 2.89 | 34000 | 0.1767 | 0.2013 |
| 0.9079 | 2.93 | 34500 | 0.1735 | 0.1986 |
| 0.9032 | 2.97 | 35000 | 0.1793 | 0.2024 |
| 0.9018 | 3.02 | 35500 | 0.1778 | 0.2027 |
| 0.8846 | 3.06 | 36000 | 0.1776 | 0.2046 |
| 0.8848 | 3.1 | 36500 | 0.1812 | 0.2064 |
| 0.9062 | 3.14 | 37000 | 0.1800 | 0.2018 |
| 0.9011 | 3.19 | 37500 | 0.1783 | 0.2049 |
| 0.8996 | 3.23 | 38000 | 0.1810 | 0.2036 |
| 0.893 | 3.27 | 38500 | 0.1805 | 0.2056 |
| 0.897 | 3.31 | 39000 | 0.1773 | 0.2035 |
| 0.8992 | 3.36 | 39500 | 0.1804 | 0.2054 |
| 0.8987 | 3.4 | 40000 | 0.1768 | 0.2016 |
### Framework versions
- Transformers 4.16.0.dev0
- Pytorch 1.10.1+cu102
- Datasets 1.17.1.dev0
- Tokenizers 0.11.0
#### Evaluation Commands
1. To evaluate on `mozilla-foundation/common_voice_7_0` with split `test`
```bash
python ./eval.py --model_id AndrewMcDowell/wav2vec2-xls-r-300m-german-de --dataset mozilla-foundation/common_voice_7_0 --config de --split test --log_outputs
```
2. To evaluate on test dev data
```bash
python ./eval.py --model_id AndrewMcDowell/wav2vec2-xls-r-300m-german-de --dataset speech-recognition-community-v2/dev_data --config de --split validation --chunk_length_s 5.0 --stride_length_s 1.0
```
|
5b64a67dad247ee04bcd4732934778e6
|
elopezlopez/xlnet-base-cased_fold_6_binary_v1
|
elopezlopez
|
xlnet
| 12 | 1 |
transformers
| 0 |
text-classification
| true | false | false |
mit
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 2,637 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xlnet-base-cased_fold_6_binary_v1
This model is a fine-tuned version of [xlnet-base-cased](https://huggingface.co/xlnet-base-cased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.6214
- F1: 0.8352
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 25
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| No log | 1.0 | 290 | 0.4174 | 0.7980 |
| 0.4661 | 2.0 | 580 | 0.4118 | 0.8142 |
| 0.4661 | 3.0 | 870 | 0.5152 | 0.8331 |
| 0.2714 | 4.0 | 1160 | 0.6901 | 0.8242 |
| 0.2714 | 5.0 | 1450 | 0.6853 | 0.8451 |
| 0.1542 | 6.0 | 1740 | 0.8570 | 0.8399 |
| 0.0935 | 7.0 | 2030 | 1.1342 | 0.8401 |
| 0.0935 | 8.0 | 2320 | 1.1763 | 0.8397 |
| 0.037 | 9.0 | 2610 | 1.3530 | 0.8215 |
| 0.037 | 10.0 | 2900 | 1.3826 | 0.8402 |
| 0.0351 | 11.0 | 3190 | 1.4057 | 0.8374 |
| 0.0351 | 12.0 | 3480 | 1.4259 | 0.8455 |
| 0.0159 | 13.0 | 3770 | 1.4270 | 0.8431 |
| 0.0249 | 14.0 | 4060 | 1.4215 | 0.8442 |
| 0.0249 | 15.0 | 4350 | 1.4245 | 0.8408 |
| 0.0197 | 16.0 | 4640 | 1.4171 | 0.8353 |
| 0.0197 | 17.0 | 4930 | 1.4537 | 0.8383 |
| 0.0137 | 18.0 | 5220 | 1.4786 | 0.8430 |
| 0.0068 | 19.0 | 5510 | 1.5635 | 0.8443 |
| 0.0068 | 20.0 | 5800 | 1.5527 | 0.8378 |
| 0.0062 | 21.0 | 6090 | 1.5917 | 0.8460 |
| 0.0062 | 22.0 | 6380 | 1.6317 | 0.8318 |
| 0.005 | 23.0 | 6670 | 1.6226 | 0.8340 |
| 0.005 | 24.0 | 6960 | 1.6378 | 0.8310 |
| 0.007 | 25.0 | 7250 | 1.6214 | 0.8352 |
### Framework versions
- Transformers 4.21.1
- Pytorch 1.12.0+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
6cea3b3d49b1a57756a62f6e007c1b1f
|
onefish51/dog_w_prior-preservation
|
onefish51
| null | 33 | 0 |
diffusers
| 0 |
text-to-image
| false | false | false |
creativeml-openrail-m
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['stable-diffusion', 'stable-diffusion-diffusers', 'text-to-image', 'diffusers', 'lora']
| false | true | true | 413 | false |
# LoRA DreamBooth - onefish51/dog_w_prior-preservation
These are LoRA adaption weights for /data2/home/tyu/stable_diffusion/diffusers/stable-diffusion-v1-4. The weights were trained on a photo of sks panda using [DreamBooth](https://dreambooth.github.io/). You can find some example images in the following.




|
0804fb2e5b32a692a9543fec605309c4
|
sanchit-gandhi/whisper-medium-es-5k
|
sanchit-gandhi
|
whisper
| 15 | 6 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
|
['es']
|
['facebook/multilingual_librispeech']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['hf-asr-leaderboard', 'generated_from_trainer']
| true | true | true | 1,618 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Whisper Small Es - Sanchit Gandhi
This model is a fine-tuned version of [openai/whisper-medium](https://huggingface.co/openai/whisper-medium) on the Multilingual LibriSpeech dataset.
It achieves the following results on the evaluation set:
- Loss: 1.2668
- Wer: 60.1623
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-08
- train_batch_size: 2
- eval_batch_size: 4
- seed: 42
- gradient_accumulation_steps: 8
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 2500
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:-------:|
| 2.2112 | 0.2 | 500 | 1.7394 | 61.1126 |
| 1.4913 | 0.4 | 1000 | 1.3758 | 62.8143 |
| 1.6651 | 0.6 | 1500 | 1.3100 | 61.3261 |
| 1.7031 | 0.8 | 2000 | 1.2752 | 60.5261 |
| 1.4289 | 1.0 | 2500 | 1.2668 | 60.1623 |
### Framework versions
- Transformers 4.25.0.dev0
- Pytorch 1.12.0
- Datasets 2.6.2.dev0
- Tokenizers 0.12.1
|
e44e96bc8c56c8ff0133ade09a4a2010
|
jfealko/wav2vec2-large-xls-r-300m-russian-colab-beam_search_test
|
jfealko
|
wav2vec2
| 13 | 5 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
| null |
['common_voice']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 2,769 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-large-xls-r-300m-russian-colab-beam_search_test
This model is a fine-tuned version of [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) on the common_voice dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7619
- Wer: 0.4680
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 800
- num_epochs: 100
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 10.0158 | 4.16 | 100 | 5.4134 | 1.0 |
| 4.0394 | 8.33 | 200 | 3.4304 | 1.0 |
| 3.2721 | 12.49 | 300 | 3.2273 | 1.0 |
| 3.1277 | 16.66 | 400 | 2.8023 | 0.9984 |
| 1.3791 | 20.82 | 500 | 0.9888 | 0.8546 |
| 0.3659 | 24.99 | 600 | 0.7602 | 0.6304 |
| 0.1858 | 29.16 | 700 | 0.7965 | 0.6156 |
| 0.1403 | 33.33 | 800 | 0.7998 | 0.5839 |
| 0.1173 | 37.49 | 900 | 0.8353 | 0.5941 |
| 0.0917 | 41.66 | 1000 | 0.8272 | 0.5522 |
| 0.0743 | 45.82 | 1100 | 0.8342 | 0.5471 |
| 0.063 | 49.99 | 1200 | 0.7988 | 0.5352 |
| 0.0528 | 54.16 | 1300 | 0.7740 | 0.5201 |
| 0.0456 | 58.33 | 1400 | 0.7636 | 0.5165 |
| 0.0389 | 62.49 | 1500 | 0.7922 | 0.5161 |
| 0.0329 | 66.66 | 1600 | 0.8035 | 0.5158 |
| 0.0283 | 70.82 | 1700 | 0.7873 | 0.4832 |
| 0.0255 | 74.99 | 1800 | 0.7853 | 0.4870 |
| 0.0236 | 79.16 | 1900 | 0.8236 | 0.5045 |
| 0.0202 | 83.33 | 2000 | 0.7661 | 0.4796 |
| 0.0165 | 87.49 | 2100 | 0.7584 | 0.4680 |
| 0.0156 | 91.66 | 2200 | 0.7685 | 0.4772 |
| 0.0149 | 95.82 | 2300 | 0.7519 | 0.4696 |
| 0.0126 | 99.99 | 2400 | 0.7619 | 0.4680 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.10.0+cu111
- Datasets 1.18.3
- Tokenizers 0.10.3
|
bf9ab34cbe900667a43e6b8634a3ad1c
|
microsoft/git-base
|
microsoft
|
git
| 10 | 5,552 |
transformers
| 5 |
image-to-text
| true | false | false |
mit
|
['en']
| null | null | 0 | 0 | 0 | 0 | 2 | 2 | 0 |
['vision', 'image-to-text', 'image-captioning']
| false | true | true | 2,982 | false |
# GIT (GenerativeImage2Text), base-sized
GIT (short for GenerativeImage2Text) model, base-sized version. It was introduced in the paper [GIT: A Generative Image-to-text Transformer for Vision and Language](https://arxiv.org/abs/2205.14100) by Wang et al. and first released in [this repository](https://github.com/microsoft/GenerativeImage2Text).
Disclaimer: The team releasing GIT did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
GIT is a Transformer decoder conditioned on both CLIP image tokens and text tokens. The model is trained using "teacher forcing" on a lot of (image, text) pairs.
The goal for the model is simply to predict the next text token, giving the image tokens and previous text tokens.
The model has full access to (i.e. a bidirectional attention mask is used for) the image patch tokens, but only has access to the previous text tokens (i.e. a causal attention mask is used for the text tokens) when predicting the next text token.

This allows the model to be used for tasks like:
- image and video captioning
- visual question answering (VQA) on images and videos
- even image classification (by simply conditioning the model on the image and asking it to generate a class for it in text).
## Intended uses & limitations
You can use the raw model for image captioning. See the [model hub](https://huggingface.co/models?search=microsoft/git) to look for
fine-tuned versions on a task that interests you.
### How to use
For code examples, we refer to the [documentation](https://huggingface.co/docs/transformers/main/model_doc/git#transformers.GitForCausalLM.forward.example).
## Training data
From the paper:
> We collect 0.8B image-text pairs for pre-training, which include COCO (Lin et al., 2014), Conceptual Captions
(CC3M) (Sharma et al., 2018), SBU (Ordonez et al., 2011), Visual Genome (VG) (Krishna et al., 2016),
Conceptual Captions (CC12M) (Changpinyo et al., 2021), ALT200M (Hu et al., 2021a), and an extra 0.6B
data following a similar collection procedure in Hu et al. (2021a).
=> however this is for the model referred to as "GIT" in the paper, which is not open-sourced.
This checkpoint is "GIT-base", which is a smaller variant of GIT trained on 10 million image-text pairs.
See table 11 in the [paper](https://arxiv.org/abs/2205.14100) for more details.
### Preprocessing
We refer to the original repo regarding details for preprocessing during training.
During validation, one resizes the shorter edge of each image, after which center cropping is performed to a fixed-size resolution. Next, frames are normalized across the RGB channels with the ImageNet mean and standard deviation.
## Evaluation results
For evaluation results, we refer readers to the [paper](https://arxiv.org/abs/2205.14100).
|
1691b34d1720e489cead4bde48e9d95e
|
oskarandrsson/mt-ru-sv-finetuned
|
oskarandrsson
|
marian
| 11 | 22 |
transformers
| 0 |
translation
| true | false | false |
apache-2.0
|
['ru', 'sv']
| null | null | 1 | 1 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer', 'translation']
| true | true | true | 1,071 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mt-ru-sv-finetuned
This model is a fine-tuned version of [Helsinki-NLP/opus-mt-ru-sv](https://huggingface.co/Helsinki-NLP/opus-mt-ru-sv) on the None dataset.
It achieves the following results on the Tatoeba.rus.swe evaluation set:
- eval_loss: 0.6998
- eval_bleu: 54.4473
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-06
- train_batch_size: 24
- eval_batch_size: 4
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
- mixed_precision_training: Native AMP
### Framework versions
- Transformers 4.25.0.dev0
- Pytorch 1.13.0+cu117
- Datasets 2.6.1
- Tokenizers 0.13.1
|
e5c7baac6e91aa35392e8de457dd30d9
|
dbmdz/bert-base-german-europeana-cased
|
dbmdz
|
bert
| 8 | 225 |
transformers
| 0 | null | true | true | true |
mit
|
['de']
| null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['historic german']
| false | true | true | 2,328 | false |
# 🤗 + 📚 dbmdz BERT models
In this repository the MDZ Digital Library team (dbmdz) at the Bavarian State
Library open sources German Europeana BERT models 🎉
# German Europeana BERT
We use the open source [Europeana newspapers](http://www.europeana-newspapers.eu/)
that were provided by *The European Library*. The final
training corpus has a size of 51GB and consists of 8,035,986,369 tokens.
Detailed information about the data and pretraining steps can be found in
[this repository](https://github.com/stefan-it/europeana-bert).
## Model weights
Currently only PyTorch-[Transformers](https://github.com/huggingface/transformers)
compatible weights are available. If you need access to TensorFlow checkpoints,
please raise an issue!
| Model | Downloads
| ------------------------------------------ | ---------------------------------------------------------------------------------------------------------------
| `dbmdz/bert-base-german-europeana-cased` | [`config.json`](https://cdn.huggingface.co/dbmdz/bert-base-german-europeana-cased/config.json) • [`pytorch_model.bin`](https://cdn.huggingface.co/dbmdz/bert-base-german-europeana-cased/pytorch_model.bin) • [`vocab.txt`](https://cdn.huggingface.co/dbmdz/bert-base-german-europeana-cased/vocab.txt)
## Results
For results on Historic NER, please refer to [this repository](https://github.com/stefan-it/europeana-bert).
## Usage
With Transformers >= 2.3 our German Europeana BERT models can be loaded like:
```python
from transformers import AutoModel, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("dbmdz/bert-base-german-europeana-cased")
model = AutoModel.from_pretrained("dbmdz/bert-base-german-europeana-cased")
```
# Huggingface model hub
All models are available on the [Huggingface model hub](https://huggingface.co/dbmdz).
# Contact (Bugs, Feedback, Contribution and more)
For questions about our BERT models just open an issue
[here](https://github.com/dbmdz/berts/issues/new) 🤗
# Acknowledgments
Research supported with Cloud TPUs from Google's TensorFlow Research Cloud (TFRC).
Thanks for providing access to the TFRC ❤️
Thanks to the generous support from the [Hugging Face](https://huggingface.co/) team,
it is possible to download both cased and uncased models from their S3 storage 🤗
|
59408cf2568d71252a9e67bbfe8513a4
|
amlannayak/finetuning-sentiment-model-3000-samples
|
amlannayak
|
distilbert
| 10 | 2 |
transformers
| 0 |
text-classification
| true | false | false |
apache-2.0
| null |
['imdb']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,049 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# finetuning-sentiment-model-3000-samples
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the imdb dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3251
- Accuracy: 0.8767
- F1: 0.8787
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
### Framework versions
- Transformers 4.26.1
- Pytorch 1.13.1
- Datasets 2.9.0
- Tokenizers 0.13.2
|
43e63788621b7208cea676363bb2570c
|
jonatasgrosman/exp_w2v2t_de_wav2vec2_s144
|
jonatasgrosman
|
wav2vec2
| 10 | 5 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
|
['de']
|
['mozilla-foundation/common_voice_7_0']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['automatic-speech-recognition', 'de']
| false | true | true | 456 | false |
# exp_w2v2t_de_wav2vec2_s144
Fine-tuned [facebook/wav2vec2-large-lv60](https://huggingface.co/facebook/wav2vec2-large-lv60) for speech recognition using the train split of [Common Voice 7.0 (de)](https://huggingface.co/datasets/mozilla-foundation/common_voice_7_0).
When using this model, make sure that your speech input is sampled at 16kHz.
This model has been fine-tuned by the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) tool.
|
aa766c5d4e481891b71fdad5912b8342
|
google/t5-efficient-xxl
|
google
|
t5
| 12 | 128 |
transformers
| 7 |
text2text-generation
| true | true | true |
apache-2.0
|
['en']
|
['c4']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['deep-narrow']
| false | true | true | 6,208 | false |
# T5-Efficient-XXL (Deep-Narrow version)
T5-Efficient-XXL is a variation of [Google's original T5](https://ai.googleblog.com/2020/02/exploring-transfer-learning-with-t5.html) following the [T5 model architecture](https://huggingface.co/docs/transformers/model_doc/t5).
It is a *pretrained-only* checkpoint and was released with the
paper **[Scale Efficiently: Insights from Pre-training and Fine-tuning Transformers](https://arxiv.org/abs/2109.10686)**
by *Yi Tay, Mostafa Dehghani, Jinfeng Rao, William Fedus, Samira Abnar, Hyung Won Chung, Sharan Narang, Dani Yogatama, Ashish Vaswani, Donald Metzler*.
In a nutshell, the paper indicates that a **Deep-Narrow** model architecture is favorable for **downstream** performance compared to other model architectures
of similar parameter count.
To quote the paper:
> We generally recommend a DeepNarrow strategy where the model’s depth is preferentially increased
> before considering any other forms of uniform scaling across other dimensions. This is largely due to
> how much depth influences the Pareto-frontier as shown in earlier sections of the paper. Specifically, a
> tall small (deep and narrow) model is generally more efficient compared to the base model. Likewise,
> a tall base model might also generally more efficient compared to a large model. We generally find
> that, regardless of size, even if absolute performance might increase as we continue to stack layers,
> the relative gain of Pareto-efficiency diminishes as we increase the layers, converging at 32 to 36
> layers. Finally, we note that our notion of efficiency here relates to any one compute dimension, i.e.,
> params, FLOPs or throughput (speed). We report all three key efficiency metrics (number of params,
> FLOPS and speed) and leave this decision to the practitioner to decide which compute dimension to
> consider.
To be more precise, *model depth* is defined as the number of transformer blocks that are stacked sequentially.
A sequence of word embeddings is therefore processed sequentially by each transformer block.
## Details model architecture
This model checkpoint - **t5-efficient-xxl** - is of model type **Xxl** with no variations.
It has **11307.38** million parameters and thus requires *ca.* **45229.52 MB** of memory in full precision (*fp32*)
or **22614.76 MB** of memory in half precision (*fp16* or *bf16*).
A summary of the *original* T5 model architectures can be seen here:
| Model | nl (el/dl) | ff | dm | kv | nh | #Params|
| ----| ---- | ---- | ---- | ---- | ---- | ----|
| Tiny | 4/4 | 1024 | 256 | 32 | 4 | 16M|
| Mini | 4/4 | 1536 | 384 | 32 | 8 | 31M|
| Small | 6/6 | 2048 | 512 | 32 | 8 | 60M|
| Base | 12/12 | 3072 | 768 | 64 | 12 | 220M|
| Large | 24/24 | 4096 | 1024 | 64 | 16 | 738M|
| Xl | 24/24 | 16384 | 1024 | 128 | 32 | 3B|
| XXl | 24/24 | 65536 | 1024 | 128 | 128 | 11B|
whereas the following abbreviations are used:
| Abbreviation | Definition |
| ----| ---- |
| nl | Number of transformer blocks (depth) |
| dm | Dimension of embedding vector (output vector of transformers block) |
| kv | Dimension of key/value projection matrix |
| nh | Number of attention heads |
| ff | Dimension of intermediate vector within transformer block (size of feed-forward projection matrix) |
| el | Number of transformer blocks in the encoder (encoder depth) |
| dl | Number of transformer blocks in the decoder (decoder depth) |
| sh | Signifies that attention heads are shared |
| skv | Signifies that key-values projection matrices are tied |
If a model checkpoint has no specific, *el* or *dl* than both the number of encoder- and decoder layers correspond to *nl*.
## Pre-Training
The checkpoint was pretrained on the [Colossal, Cleaned version of Common Crawl (C4)](https://huggingface.co/datasets/c4) for 524288 steps using
the span-based masked language modeling (MLM) objective.
## Fine-Tuning
**Note**: This model is a **pretrained** checkpoint and has to be fine-tuned for practical usage.
The checkpoint was pretrained in English and is therefore only useful for English NLP tasks.
You can follow on of the following examples on how to fine-tune the model:
*PyTorch*:
- [Summarization](https://github.com/huggingface/transformers/tree/master/examples/pytorch/summarization)
- [Question Answering](https://github.com/huggingface/transformers/blob/master/examples/pytorch/question-answering/run_seq2seq_qa.py)
- [Text Classification](https://github.com/huggingface/transformers/tree/master/examples/pytorch/text-classification) - *Note*: You will have to slightly adapt the training example here to make it work with an encoder-decoder model.
*Tensorflow*:
- [Summarization](https://github.com/huggingface/transformers/tree/master/examples/tensorflow/summarization)
- [Text Classification](https://github.com/huggingface/transformers/tree/master/examples/tensorflow/text-classification) - *Note*: You will have to slightly adapt the training example here to make it work with an encoder-decoder model.
*JAX/Flax*:
- [Summarization](https://github.com/huggingface/transformers/tree/master/examples/flax/summarization)
- [Text Classification](https://github.com/huggingface/transformers/tree/master/examples/flax/text-classification) - *Note*: You will have to slightly adapt the training example here to make it work with an encoder-decoder model.
## Downstream Performance
TODO: Add table if available
## Computational Complexity
TODO: Add table if available
## More information
We strongly recommend the reader to go carefully through the original paper **[Scale Efficiently: Insights from Pre-training and Fine-tuning Transformers](https://arxiv.org/abs/2109.10686)** to get a more nuanced understanding of this model checkpoint.
As explained in the following [issue](https://github.com/google-research/google-research/issues/986#issuecomment-1035051145), checkpoints including the *sh* or *skv*
model architecture variations have *not* been ported to Transformers as they are probably of limited practical usage and are lacking a more detailed description. Those checkpoints are kept [here](https://huggingface.co/NewT5SharedHeadsSharedKeyValues) as they might be ported potentially in the future.
|
ffff7d67ee102b7392d4270eb1b0a037
|
MoritzLaurer/mDeBERTa-v3-base-mnli-xnli
|
MoritzLaurer
|
deberta-v2
| 8 | 432,624 |
transformers
| 84 |
zero-shot-classification
| true | false | false |
mit
|
['multilingual', 'en', 'ar', 'bg', 'de', 'el', 'es', 'fr', 'hi', 'ru', 'sw', 'th', 'tr', 'ur', 'vi', 'zh']
|
['multi_nli', 'xnli']
| null | 0 | 0 | 0 | 0 | 1 | 0 | 1 |
['zero-shot-classification', 'text-classification', 'nli', 'pytorch']
| false | true | true | 5,846 | false |
# Multilingual mDeBERTa-v3-base-mnli-xnli
## Model description
This multilingual model can perform natural language inference (NLI) on 100 languages and is therefore also suitable for multilingual
zero-shot classification. The underlying model was pre-trained by Microsoft on the
[CC100 multilingual dataset](https://huggingface.co/datasets/cc100). It was then fine-tuned on the [XNLI dataset](https://huggingface.co/datasets/xnli), which contains hypothesis-premise pairs from 15 languages, as well as the English [MNLI dataset](https://huggingface.co/datasets/multi_nli).
As of December 2021, mDeBERTa-base is the best performing multilingual base-sized transformer model,
introduced by Microsoft in [this paper](https://arxiv.org/pdf/2111.09543.pdf).
If you are looking for a smaller, faster (but less performant) model, you can
try [multilingual-MiniLMv2-L6-mnli-xnli](https://huggingface.co/MoritzLaurer/multilingual-MiniLMv2-L6-mnli-xnli).
### How to use the model
#### Simple zero-shot classification pipeline
```python
from transformers import pipeline
classifier = pipeline("zero-shot-classification", model="MoritzLaurer/mDeBERTa-v3-base-mnli-xnli")
sequence_to_classify = "Angela Merkel ist eine Politikerin in Deutschland und Vorsitzende der CDU"
candidate_labels = ["politics", "economy", "entertainment", "environment"]
output = classifier(sequence_to_classify, candidate_labels, multi_label=False)
print(output)
```
#### NLI use-case
```python
from transformers import AutoTokenizer, AutoModelForSequenceClassification
import torch
device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
model_name = "MoritzLaurer/mDeBERTa-v3-base-mnli-xnli"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForSequenceClassification.from_pretrained(model_name)
premise = "Angela Merkel ist eine Politikerin in Deutschland und Vorsitzende der CDU"
hypothesis = "Emmanuel Macron is the President of France"
input = tokenizer(premise, hypothesis, truncation=True, return_tensors="pt")
output = model(input["input_ids"].to(device)) # device = "cuda:0" or "cpu"
prediction = torch.softmax(output["logits"][0], -1).tolist()
label_names = ["entailment", "neutral", "contradiction"]
prediction = {name: round(float(pred) * 100, 1) for pred, name in zip(prediction, label_names)}
print(prediction)
```
### Training data
This model was trained on the XNLI development dataset and the MNLI train dataset. The XNLI development set consists of 2490 professionally translated texts from English to 14 other languages (37350 texts in total) (see [this paper](https://arxiv.org/pdf/1809.05053.pdf)). Note that the XNLI contains a training set of 15 machine translated versions of the MNLI dataset for 15 languages, but due to quality issues with these machine translations, this model was only trained on the professional translations from the XNLI development set and the original English MNLI training set (392 702 texts). Not using machine translated texts can avoid overfitting the model to the 15 languages; avoids catastrophic forgetting of the other 85 languages mDeBERTa was pre-trained on; and significantly reduces training costs.
### Training procedure
mDeBERTa-v3-base-mnli-xnli was trained using the Hugging Face trainer with the following hyperparameters.
```
training_args = TrainingArguments(
num_train_epochs=2, # total number of training epochs
learning_rate=2e-05,
per_device_train_batch_size=16, # batch size per device during training
per_device_eval_batch_size=16, # batch size for evaluation
warmup_ratio=0.1, # number of warmup steps for learning rate scheduler
weight_decay=0.06, # strength of weight decay
)
```
### Eval results
The model was evaluated on the XNLI test set on 15 languages (5010 texts per language, 75150 in total). Note that multilingual NLI models are capable of classifying NLI texts without receiving NLI training data in the specific language (cross-lingual transfer). This means that the model is also able of doing NLI on the other 85 languages mDeBERTa was training on, but performance is most likely lower than for those languages available in XNLI.
Also note that if other multilingual models on the model hub claim performance of around 90% on languages other than English, the authors have most likely made a mistake during testing since non of the latest papers shows a multilingual average performance of more than a few points above 80% on XNLI (see [here](https://arxiv.org/pdf/2111.09543.pdf) or [here](https://arxiv.org/pdf/1911.02116.pdf)).
average | ar | bg | de | el | en | es | fr | hi | ru | sw | th | tr | ur | vi | zh
---------|----------|---------|----------|----------|----------|----------|----------|----------|----------|----------|----------|----------|----------|----------|----------
0.808 | 0.802 | 0.829 | 0.825 | 0.826 | 0.883 | 0.845 | 0.834 | 0.771 | 0.813 | 0.748 | 0.793 | 0.807 | 0.740 | 0.795 | 0.8116
## Limitations and bias
Please consult the original DeBERTa-V3 paper and literature on different NLI datasets for potential biases.
## Citation
If you use this model, please cite: Laurer, Moritz, Wouter van Atteveldt, Andreu Salleras Casas, and Kasper Welbers. 2022. ‘Less Annotating, More Classifying – Addressing the Data Scarcity Issue of Supervised Machine Learning with Deep Transfer Learning and BERT - NLI’. Preprint, June. Open Science Framework. https://osf.io/74b8k.
## Ideas for cooperation or questions?
If you have questions or ideas for cooperation, contact me at m{dot}laurer{at}vu{dot}nl or [LinkedIn](https://www.linkedin.com/in/moritz-laurer/)
## Debugging and issues
Note that DeBERTa-v3 was released in late 2021 and older versions of HF Transformers seem to have issues running the model (e.g. resulting in an issue with the tokenizer). Using Transformers==4.13 or higher might solve some issues. Note that mDeBERTa currently does not support FP16, see here: https://github.com/microsoft/DeBERTa/issues/77
|
fe5178492d59c00dba3cbe4ea9cfa580
|
nestoralvaro/mt5-base-finetuned-xsum-RAW_data_prep_2021_12_26___t22027_162754.csv__google_mt5_base
|
nestoralvaro
|
mt5
| 12 | 1 |
transformers
| 0 |
text2text-generation
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,483 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mt5-base-finetuned-xsum-RAW_data_prep_2021_12_26___t22027_162754.csv__google_mt5_base
This model is a fine-tuned version of [google/mt5-base](https://huggingface.co/google/mt5-base) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: nan
- Rouge1: 0.7721
- Rouge2: 0.0701
- Rougel: 0.7721
- Rougelsum: 0.7718
- Gen Len: 6.329
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:------:|:---------------:|:------:|:------:|:------:|:---------:|:-------:|
| 0.0 | 1.0 | 131773 | nan | 0.7721 | 0.0701 | 0.7721 | 0.7718 | 6.329 |
### Framework versions
- Transformers 4.19.4
- Pytorch 1.11.0+cu113
- Datasets 2.2.2
- Tokenizers 0.12.1
|
36c33b7cee3c345ee0af5cb6c8e1fc85
|
ogimgio/bert-base-german-cased-finetuned
|
ogimgio
|
bert
| 16 | 3 |
transformers
| 0 |
text-classification
| true | false | false |
mit
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,382 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-german-cased-finetuned
This model is a fine-tuned version of [ogimgio/bert-base-german-cased-issues-128](https://huggingface.co/ogimgio/bert-base-german-cased-issues-128) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4083
- Micro f1: 0.5637
- Macro f1: 0.5041
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: constant
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Micro f1 | Macro f1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:--------:|
| 0.4609 | 1.0 | 103 | 0.4403 | 0.5551 | 0.4453 |
| 0.362 | 2.0 | 206 | 0.4083 | 0.5637 | 0.5041 |
### Framework versions
- Transformers 4.24.0
- Pytorch 1.12.1+cu113
- Datasets 2.7.0
- Tokenizers 0.13.2
|
356d225aa2547ab4f07fe9163aeba946
|
jonatasgrosman/exp_w2v2t_sv-se_wav2vec2_s732
|
jonatasgrosman
|
wav2vec2
| 10 | 8 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
|
['sv-SE']
|
['mozilla-foundation/common_voice_7_0']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['automatic-speech-recognition', 'sv-SE']
| false | true | true | 462 | false |
# exp_w2v2t_sv-se_wav2vec2_s732
Fine-tuned [facebook/wav2vec2-large-lv60](https://huggingface.co/facebook/wav2vec2-large-lv60) for speech recognition using the train split of [Common Voice 7.0 (sv-SE)](https://huggingface.co/datasets/mozilla-foundation/common_voice_7_0).
When using this model, make sure that your speech input is sampled at 16kHz.
This model has been fine-tuned by the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) tool.
|
d9439d7536d30330b0af06f2902f8b44
|
pig4431/TweetEval_ALBERT_5E
|
pig4431
|
albert
| 10 | 5 |
transformers
| 0 |
text-classification
| true | false | false |
apache-2.0
| null |
['tweet_eval']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 8,753 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# TweetEval_ALBERT_5E
This model is a fine-tuned version of [albert-base-v2](https://huggingface.co/albert-base-v2) on the tweet_eval dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1990
- Accuracy: 0.9267
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.4636 | 0.04 | 50 | 0.3662 | 0.8667 |
| 0.442 | 0.08 | 100 | 0.3471 | 0.84 |
| 0.3574 | 0.12 | 150 | 0.3446 | 0.86 |
| 0.392 | 0.16 | 200 | 0.6776 | 0.6267 |
| 0.4801 | 0.2 | 250 | 0.4307 | 0.7667 |
| 0.487 | 0.24 | 300 | 0.5127 | 0.8 |
| 0.4414 | 0.28 | 350 | 0.3912 | 0.8133 |
| 0.4495 | 0.32 | 400 | 0.4056 | 0.8333 |
| 0.4637 | 0.37 | 450 | 0.3635 | 0.8533 |
| 0.4231 | 0.41 | 500 | 0.4235 | 0.84 |
| 0.4049 | 0.45 | 550 | 0.4094 | 0.8067 |
| 0.4481 | 0.49 | 600 | 0.3977 | 0.7733 |
| 0.4024 | 0.53 | 650 | 0.3361 | 0.8733 |
| 0.3901 | 0.57 | 700 | 0.3014 | 0.8667 |
| 0.3872 | 0.61 | 750 | 0.3363 | 0.8533 |
| 0.377 | 0.65 | 800 | 0.3754 | 0.8 |
| 0.459 | 0.69 | 850 | 0.3861 | 0.8 |
| 0.437 | 0.73 | 900 | 0.3834 | 0.8333 |
| 0.3823 | 0.77 | 950 | 0.3541 | 0.8733 |
| 0.3561 | 0.81 | 1000 | 0.3177 | 0.84 |
| 0.4536 | 0.85 | 1050 | 0.4291 | 0.78 |
| 0.4457 | 0.89 | 1100 | 0.3193 | 0.86 |
| 0.3478 | 0.93 | 1150 | 0.3159 | 0.8533 |
| 0.4613 | 0.97 | 1200 | 0.3605 | 0.84 |
| 0.4081 | 1.01 | 1250 | 0.4291 | 0.7867 |
| 0.3849 | 1.06 | 1300 | 0.3114 | 0.8733 |
| 0.4071 | 1.1 | 1350 | 0.2939 | 0.8667 |
| 0.3484 | 1.14 | 1400 | 0.3212 | 0.84 |
| 0.3869 | 1.18 | 1450 | 0.2717 | 0.8933 |
| 0.3877 | 1.22 | 1500 | 0.3459 | 0.84 |
| 0.4245 | 1.26 | 1550 | 0.3404 | 0.8733 |
| 0.4148 | 1.3 | 1600 | 0.2863 | 0.8667 |
| 0.3542 | 1.34 | 1650 | 0.3377 | 0.86 |
| 0.4093 | 1.38 | 1700 | 0.2972 | 0.8867 |
| 0.3579 | 1.42 | 1750 | 0.3926 | 0.86 |
| 0.3892 | 1.46 | 1800 | 0.2870 | 0.8667 |
| 0.3569 | 1.5 | 1850 | 0.4027 | 0.8467 |
| 0.3493 | 1.54 | 1900 | 0.3069 | 0.8467 |
| 0.36 | 1.58 | 1950 | 0.3197 | 0.8733 |
| 0.3532 | 1.62 | 2000 | 0.3711 | 0.8667 |
| 0.3311 | 1.66 | 2050 | 0.2897 | 0.8867 |
| 0.346 | 1.7 | 2100 | 0.2938 | 0.88 |
| 0.3389 | 1.75 | 2150 | 0.2734 | 0.8933 |
| 0.3289 | 1.79 | 2200 | 0.2606 | 0.8867 |
| 0.3558 | 1.83 | 2250 | 0.3070 | 0.88 |
| 0.3277 | 1.87 | 2300 | 0.2757 | 0.8867 |
| 0.3166 | 1.91 | 2350 | 0.2759 | 0.8733 |
| 0.3223 | 1.95 | 2400 | 0.2053 | 0.9133 |
| 0.317 | 1.99 | 2450 | 0.2307 | 0.8867 |
| 0.3408 | 2.03 | 2500 | 0.2557 | 0.9067 |
| 0.3212 | 2.07 | 2550 | 0.2508 | 0.8867 |
| 0.2806 | 2.11 | 2600 | 0.2472 | 0.88 |
| 0.3567 | 2.15 | 2650 | 0.2790 | 0.8933 |
| 0.2887 | 2.19 | 2700 | 0.3197 | 0.88 |
| 0.3222 | 2.23 | 2750 | 0.2943 | 0.8667 |
| 0.2773 | 2.27 | 2800 | 0.2297 | 0.88 |
| 0.2728 | 2.31 | 2850 | 0.2813 | 0.8733 |
| 0.3115 | 2.35 | 2900 | 0.3470 | 0.8867 |
| 0.3001 | 2.39 | 2950 | 0.2702 | 0.8933 |
| 0.3464 | 2.44 | 3000 | 0.2855 | 0.9 |
| 0.3041 | 2.48 | 3050 | 0.2366 | 0.8867 |
| 0.2717 | 2.52 | 3100 | 0.3220 | 0.88 |
| 0.2903 | 2.56 | 3150 | 0.2230 | 0.9 |
| 0.2959 | 2.6 | 3200 | 0.2439 | 0.9067 |
| 0.2753 | 2.64 | 3250 | 0.2918 | 0.8733 |
| 0.2515 | 2.68 | 3300 | 0.2493 | 0.88 |
| 0.295 | 2.72 | 3350 | 0.2673 | 0.8867 |
| 0.2572 | 2.76 | 3400 | 0.2842 | 0.8733 |
| 0.2988 | 2.8 | 3450 | 0.2306 | 0.9067 |
| 0.2923 | 2.84 | 3500 | 0.2329 | 0.8933 |
| 0.2856 | 2.88 | 3550 | 0.2374 | 0.88 |
| 0.2867 | 2.92 | 3600 | 0.2294 | 0.8733 |
| 0.306 | 2.96 | 3650 | 0.2169 | 0.92 |
| 0.2312 | 3.0 | 3700 | 0.2456 | 0.88 |
| 0.2438 | 3.04 | 3750 | 0.2134 | 0.8867 |
| 0.2103 | 3.08 | 3800 | 0.2242 | 0.92 |
| 0.2469 | 3.12 | 3850 | 0.2407 | 0.92 |
| 0.2346 | 3.17 | 3900 | 0.1866 | 0.92 |
| 0.2275 | 3.21 | 3950 | 0.2318 | 0.92 |
| 0.2542 | 3.25 | 4000 | 0.2256 | 0.9 |
| 0.2544 | 3.29 | 4050 | 0.2246 | 0.9133 |
| 0.2468 | 3.33 | 4100 | 0.2436 | 0.8733 |
| 0.2105 | 3.37 | 4150 | 0.2098 | 0.9067 |
| 0.2818 | 3.41 | 4200 | 0.2304 | 0.88 |
| 0.2041 | 3.45 | 4250 | 0.2430 | 0.8933 |
| 0.28 | 3.49 | 4300 | 0.1990 | 0.9067 |
| 0.1997 | 3.53 | 4350 | 0.2515 | 0.8933 |
| 0.2409 | 3.57 | 4400 | 0.2315 | 0.9 |
| 0.1969 | 3.61 | 4450 | 0.2160 | 0.8933 |
| 0.2246 | 3.65 | 4500 | 0.1979 | 0.92 |
| 0.2185 | 3.69 | 4550 | 0.2238 | 0.9 |
| 0.259 | 3.73 | 4600 | 0.2011 | 0.9067 |
| 0.2407 | 3.77 | 4650 | 0.1911 | 0.92 |
| 0.2198 | 3.81 | 4700 | 0.2083 | 0.92 |
| 0.235 | 3.86 | 4750 | 0.1724 | 0.9267 |
| 0.26 | 3.9 | 4800 | 0.1640 | 0.9333 |
| 0.2334 | 3.94 | 4850 | 0.1778 | 0.9267 |
| 0.2121 | 3.98 | 4900 | 0.2062 | 0.8933 |
| 0.173 | 4.02 | 4950 | 0.1987 | 0.92 |
| 0.1942 | 4.06 | 5000 | 0.2509 | 0.8933 |
| 0.1703 | 4.1 | 5050 | 0.2179 | 0.9 |
| 0.1735 | 4.14 | 5100 | 0.2429 | 0.8867 |
| 0.2098 | 4.18 | 5150 | 0.1938 | 0.9267 |
| 0.2126 | 4.22 | 5200 | 0.1971 | 0.92 |
| 0.164 | 4.26 | 5250 | 0.2539 | 0.9067 |
| 0.2271 | 4.3 | 5300 | 0.1765 | 0.94 |
| 0.2245 | 4.34 | 5350 | 0.1894 | 0.94 |
| 0.182 | 4.38 | 5400 | 0.1790 | 0.9467 |
| 0.1835 | 4.42 | 5450 | 0.2014 | 0.9333 |
| 0.2185 | 4.46 | 5500 | 0.1881 | 0.9467 |
| 0.2113 | 4.5 | 5550 | 0.1742 | 0.9333 |
| 0.1997 | 4.55 | 5600 | 0.1762 | 0.94 |
| 0.1959 | 4.59 | 5650 | 0.1657 | 0.9467 |
| 0.2035 | 4.63 | 5700 | 0.1973 | 0.92 |
| 0.228 | 4.67 | 5750 | 0.1769 | 0.9467 |
| 0.1632 | 4.71 | 5800 | 0.1968 | 0.9267 |
| 0.1468 | 4.75 | 5850 | 0.1822 | 0.9467 |
| 0.1936 | 4.79 | 5900 | 0.1832 | 0.94 |
| 0.1743 | 4.83 | 5950 | 0.1987 | 0.9267 |
| 0.1654 | 4.87 | 6000 | 0.1943 | 0.9267 |
| 0.1859 | 4.91 | 6050 | 0.1990 | 0.92 |
| 0.2039 | 4.95 | 6100 | 0.1982 | 0.9267 |
| 0.2325 | 4.99 | 6150 | 0.1990 | 0.9267 |
### Framework versions
- Transformers 4.24.0
- Pytorch 1.13.0
- Datasets 2.7.1
- Tokenizers 0.13.2
|
f4389bdbd6ade0a8564eeeeb2f97f92c
|
muhtasham/tiny-mlm-glue-wnli-from-scratch-custom-tokenizer-expand-vocab
|
muhtasham
|
bert
| 12 | 2 |
transformers
| 0 |
fill-mask
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,696 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# tiny-mlm-glue-wnli-from-scratch-custom-tokenizer-expand-vocab
This model is a fine-tuned version of [google/bert_uncased_L-2_H-128_A-2](https://huggingface.co/google/bert_uncased_L-2_H-128_A-2) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 5.5263
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: constant
- training_steps: 5000
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 9.1486 | 6.25 | 500 | 7.8470 |
| 7.1116 | 12.5 | 1000 | 6.6165 |
| 6.3036 | 18.75 | 1500 | 6.1976 |
| 6.0919 | 25.0 | 2000 | 6.2290 |
| 6.0014 | 31.25 | 2500 | 6.0136 |
| 5.9682 | 37.5 | 3000 | 5.8730 |
| 5.8571 | 43.75 | 3500 | 5.7612 |
| 5.8144 | 50.0 | 4000 | 5.7921 |
| 5.7654 | 56.25 | 4500 | 5.8279 |
| 5.7322 | 62.5 | 5000 | 5.5263 |
### Framework versions
- Transformers 4.27.0.dev0
- Pytorch 1.13.1+cu116
- Datasets 2.9.1.dev0
- Tokenizers 0.13.2
|
2633b843de6240221b49e21ec2c85892
|
sgangireddy/whisper-base-cv-cs
|
sgangireddy
|
whisper
| 24 | 0 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
|
['cs']
|
['mozilla-foundation/common_voice_11_0']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['whisper-event', 'generated_from_trainer']
| true | true | true | 1,563 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Whisper base Czech CV
This model is a fine-tuned version of [openai/whisper-base](https://huggingface.co/openai/whisper-base) on the mozilla-foundation/common_voice_11_0 cs dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5394
- Wer: 33.9957
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 64
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 5000
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:-------:|
| 0.206 | 4.01 | 1000 | 0.4356 | 36.2443 |
| 0.0332 | 8.02 | 2000 | 0.4583 | 34.0509 |
| 0.0074 | 12.03 | 3000 | 0.5119 | 34.4395 |
| 0.005 | 16.04 | 4000 | 0.5394 | 33.9957 |
| 0.0045 | 21.01 | 5000 | 0.5461 | 34.1025 |
### Framework versions
- Transformers 4.26.0.dev0
- Pytorch 1.13.0+cu117
- Datasets 2.7.1.dev0
- Tokenizers 0.13.2
|
e61e38bb4e9c4238e912d28958f8afff
|
federicopascual/finetuned-sentiment-analysis-model
|
federicopascual
|
distilbert
| 13 | 30 |
transformers
| 0 |
text-classification
| true | false | false |
apache-2.0
| null |
['imdb']
| null | 1 | 1 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,074 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# finetuned-sentiment-analysis-model
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the imdb dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2868
- Accuracy: 0.909
- Precision: 0.8900
- Recall: 0.9283
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
### Framework versions
- Transformers 4.15.0
- Pytorch 1.10.0+cu111
- Datasets 1.17.0
- Tokenizers 0.10.3
|
4b644e6248c9c585a909a7719c917bc5
|
dbmdz/distilbert-base-turkish-cased
|
dbmdz
|
distilbert
| 7 | 106,925 |
transformers
| 6 | null | true | true | false |
mit
|
['tr']
| null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
[]
| false | true | true | 3,108 | false |
# 🤗 + 📚 dbmdz Distilled Turkish BERT model
In this repository the MDZ Digital Library team (dbmdz) at the Bavarian State
Library open sources a (cased) distilled model for Turkish 🎉
# 🇹🇷 DistilBERTurk
DistilBERTurk is a community-driven cased distilled BERT model for Turkish.
DistilBERTurk was trained on 7GB of the original training data that was used
for training [BERTurk](https://github.com/stefan-it/turkish-bert/tree/master#stats),
using the cased version of BERTurk as teacher model.
*DistilBERTurk* was trained with the official Hugging Face implementation from
[here](https://github.com/huggingface/transformers/tree/master/examples/distillation)
for 5 days on 4 RTX 2080 TI.
More details about distillation can be found in the
["DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter"](https://arxiv.org/abs/1910.01108)
paper by Sanh et al. (2019).
## Model weights
Currently only PyTorch-[Transformers](https://github.com/huggingface/transformers)
compatible weights are available. If you need access to TensorFlow checkpoints,
please raise an issue in the [BERTurk](https://github.com/stefan-it/turkish-bert) repository!
| Model | Downloads
| --------------------------------- | ---------------------------------------------------------------------------------------------------------------
| `dbmdz/distilbert-base-turkish-cased` | [`config.json`](https://cdn.huggingface.co/dbmdz/distilbert-base-turkish-cased/config.json) • [`pytorch_model.bin`](https://cdn.huggingface.co/dbmdz/distilbert-base-turkish-cased/pytorch_model.bin) • [`vocab.txt`](https://cdn.huggingface.co/dbmdz/distilbert-base-turkish-cased/vocab.txt)
## Usage
With Transformers >= 2.3 our DistilBERTurk model can be loaded like:
```python
from transformers import AutoModel, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("dbmdz/distilbert-base-turkish-cased")
model = AutoModel.from_pretrained("dbmdz/distilbert-base-turkish-cased")
```
## Results
For results on PoS tagging or NER tasks, please refer to
[this repository](https://github.com/stefan-it/turkish-bert).
For PoS tagging, DistilBERTurk outperforms the 24-layer XLM-RoBERTa model.
The overall performance difference between DistilBERTurk and the original
(teacher) BERTurk model is ~1.18%.
# Huggingface model hub
All models are available on the [Huggingface model hub](https://huggingface.co/dbmdz).
# Contact (Bugs, Feedback, Contribution and more)
For questions about our BERT models just open an issue
[here](https://github.com/dbmdz/berts/issues/new) 🤗
# Acknowledgments
Thanks to [Kemal Oflazer](http://www.andrew.cmu.edu/user/ko/) for providing us
additional large corpora for Turkish. Many thanks to Reyyan Yeniterzi for providing
us the Turkish NER dataset for evaluation.
Research supported with Cloud TPUs from Google's TensorFlow Research Cloud (TFRC).
Thanks for providing access to the TFRC ❤️
Thanks to the generous support from the [Hugging Face](https://huggingface.co/) team,
it is possible to download both cased and uncased models from their S3 storage 🤗
|
e1a7004d765c92d32782b03e185f3cb5
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.