
repo_id
stringlengths 4
110
| author
stringlengths 2
27
⌀ | model_type
stringlengths 2
29
⌀ | files_per_repo
int64 2
15.4k
| downloads_30d
int64 0
19.9M
| library
stringlengths 2
37
⌀ | likes
int64 0
4.34k
| pipeline
stringlengths 5
30
⌀ | pytorch
bool 2
classes | tensorflow
bool 2
classes | jax
bool 2
classes | license
stringlengths 2
30
| languages
stringlengths 4
1.63k
⌀ | datasets
stringlengths 2
2.58k
⌀ | co2
stringclasses 29
values | prs_count
int64 0
125
| prs_open
int64 0
120
| prs_merged
int64 0
15
| prs_closed
int64 0
28
| discussions_count
int64 0
218
| discussions_open
int64 0
148
| discussions_closed
int64 0
70
| tags
stringlengths 2
513
| has_model_index
bool 2
classes | has_metadata
bool 1
class | has_text
bool 1
class | text_length
int64 401
598k
| is_nc
bool 1
class | readme
stringlengths 0
598k
| hash
stringlengths 32
32
|
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
Satyamatury/wav2vec2-large-xls-r-300m-turkish-colab
|
Satyamatury
|
wav2vec2
| 19 | 7 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
| null |
['common_voice']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,066 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-large-xls-r-300m-turkish-colab
This model is a fine-tuned version of [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) on the common_voice dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 30
### Training results
### Framework versions
- Transformers 4.11.3
- Pytorch 1.10.0+cu113
- Datasets 1.18.3
- Tokenizers 0.10.3
|
7dcd310acccd5cea3233102df87df749
|
jonaskoenig/xtremedistil-l6-h384-uncased-future-time-references
|
jonaskoenig
|
bert
| 8 | 3 |
transformers
| 0 |
text-classification
| false | true | false |
mit
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_keras_callback']
| true | true | true | 1,706 | false |
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# xtremedistil-l6-h384-uncased-future-time-references
This model is a fine-tuned version of [microsoft/xtremedistil-l6-h256-uncased](https://huggingface.co/microsoft/xtremedistil-l6-h256-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.0279
- Train Binary Crossentropy: 0.4809
- Epoch: 9
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'Adam', 'learning_rate': 3e-05, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-07, 'amsgrad': False}
- training_precision: float32
### Training results
| Train Loss | Train Binary Crossentropy | Epoch |
|:----------:|:-------------------------:|:-----:|
| 0.0487 | 0.6401 | 0 |
| 0.0348 | 0.5925 | 1 |
| 0.0319 | 0.5393 | 2 |
| 0.0306 | 0.5168 | 3 |
| 0.0298 | 0.5045 | 4 |
| 0.0292 | 0.4970 | 5 |
| 0.0288 | 0.4916 | 6 |
| 0.0284 | 0.4878 | 7 |
| 0.0282 | 0.4836 | 8 |
| 0.0279 | 0.4809 | 9 |
### Framework versions
- Transformers 4.20.1
- TensorFlow 2.9.1
- Datasets 2.3.2
- Tokenizers 0.12.1
|
5997fb1cdff5b84a59c4465d736c5200
|
adsabs/astroBERT
|
adsabs
|
bert
| 12 | 140 |
transformers
| 0 |
fill-mask
| true | false | false |
mit
|
['en']
| null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
[]
| false | true | true | 2,368 | false |
# ***astroBERT: a language model for astrophysics***
This public repository contains the work of the [NASA/ADS](https://ui.adsabs.harvard.edu/) on building an NLP language model tailored to astrophysics, along with tutorials and miscellaneous related files.
This model is **cased** (it treats `ads` and `ADS` differently).
## astroBERT models
0. **Base model**: Pretrained model on English language using a masked language modeling (MLM) and next sentence prediction (NSP) objective. It was introduced in [this paper at ADASS 2021](https://arxiv.org/abs/2112.00590) and made public at ADASS 2022.
1. **NER-DEAL model**: This model adds a token classification head to the base model finetuned on the [DEAL@WIESP2022 named entity recognition](https://ui.adsabs.harvard.edu/WIESP/2022/SharedTasks) task. Must be loaded from the `revision='NER-DEAL'` branch (see tutorial 2).
### Tutorials
0. [generate text embedding (for downstream tasks)](https://nbviewer.org/urls/huggingface.co/adsabs/astroBERT/raw/main/Tutorials/0_Embeddings.ipynb)
1. [use astroBERT for the Fill-Mask task](https://nbviewer.org/urls/huggingface.co/adsabs/astroBERT/raw/main/Tutorials/1_Fill-Mask.ipynb)
2. [make NER-DEAL predictions](https://nbviewer.org/urls/huggingface.co/adsabs/astroBERT/raw/main/Tutorials/2_NER_DEAL.ipynb)
### BibTeX
```bibtex
@ARTICLE{2021arXiv211200590G,
author = {{Grezes}, Felix and {Blanco-Cuaresma}, Sergi and {Accomazzi}, Alberto and {Kurtz}, Michael J. and {Shapurian}, Golnaz and {Henneken}, Edwin and {Grant}, Carolyn S. and {Thompson}, Donna M. and {Chyla}, Roman and {McDonald}, Stephen and {Hostetler}, Timothy W. and {Templeton}, Matthew R. and {Lockhart}, Kelly E. and {Martinovic}, Nemanja and {Chen}, Shinyi and {Tanner}, Chris and {Protopapas}, Pavlos},
title = "{Building astroBERT, a language model for Astronomy \& Astrophysics}",
journal = {arXiv e-prints},
keywords = {Computer Science - Computation and Language, Astrophysics - Instrumentation and Methods for Astrophysics},
year = 2021,
month = dec,
eid = {arXiv:2112.00590},
pages = {arXiv:2112.00590},
archivePrefix = {arXiv},
eprint = {2112.00590},
primaryClass = {cs.CL},
adsurl = {https://ui.adsabs.harvard.edu/abs/2021arXiv211200590G},
adsnote = {Provided by the SAO/NASA Astrophysics Data System}
}
```
|
0a57a838e39f4a51be3ddf20a2d0c15d
|
Imene/vit-base-patch16-384-wi5
|
Imene
|
vit
| 6 | 2 |
transformers
| 0 |
image-classification
| false | true | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_keras_callback']
| true | true | true | 2,950 | false |
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# Imene/vit-base-patch16-384-wi5
This model is a fine-tuned version of [google/vit-base-patch16-384](https://huggingface.co/google/vit-base-patch16-384) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.4102
- Train Accuracy: 0.9755
- Train Top-3-accuracy: 0.9960
- Validation Loss: 1.9021
- Validation Accuracy: 0.4912
- Validation Top-3-accuracy: 0.7302
- Epoch: 8
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'inner_optimizer': {'class_name': 'AdamWeightDecay', 'config': {'name': 'AdamWeightDecay', 'learning_rate': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 3e-05, 'decay_steps': 3180, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False, 'weight_decay_rate': 0.01}}, 'dynamic': True, 'initial_scale': 32768.0, 'dynamic_growth_steps': 2000}
- training_precision: mixed_float16
### Training results
| Train Loss | Train Accuracy | Train Top-3-accuracy | Validation Loss | Validation Accuracy | Validation Top-3-accuracy | Epoch |
|:----------:|:--------------:|:--------------------:|:---------------:|:-------------------:|:-------------------------:|:-----:|
| 4.2945 | 0.0568 | 0.1328 | 3.6233 | 0.1387 | 0.2916 | 0 |
| 3.1234 | 0.2437 | 0.4585 | 2.8657 | 0.3041 | 0.5330 | 1 |
| 2.4383 | 0.4182 | 0.6638 | 2.5499 | 0.3534 | 0.6048 | 2 |
| 1.9258 | 0.5698 | 0.7913 | 2.3046 | 0.4202 | 0.6583 | 3 |
| 1.4919 | 0.6963 | 0.8758 | 2.1349 | 0.4553 | 0.6784 | 4 |
| 1.1127 | 0.7992 | 0.9395 | 2.0878 | 0.4595 | 0.6809 | 5 |
| 0.8092 | 0.8889 | 0.9720 | 1.9460 | 0.4962 | 0.7210 | 6 |
| 0.5794 | 0.9419 | 0.9883 | 1.9478 | 0.4979 | 0.7201 | 7 |
| 0.4102 | 0.9755 | 0.9960 | 1.9021 | 0.4912 | 0.7302 | 8 |
### Framework versions
- Transformers 4.21.3
- TensorFlow 2.8.2
- Datasets 2.4.0
- Tokenizers 0.12.1
|
28acba3e9aa746ec209a0e1fef94c3cc
|
furusu/umamusume-classifier
|
furusu
|
vit
| 5 | 30 |
transformers
| 0 |
image-classification
| true | false | false |
apache-2.0
| null | null | null | 1 | 0 | 1 | 0 | 0 | 0 | 0 |
[]
| false | true | true | 695 | false |
finetuned from https://huggingface.co/google/vit-base-patch16-224-in21k
dataset:26k images (train:21k valid:5k)
accuracy of validation dataset is 95%
```Python
from transformers import ViTFeatureExtractor, ViTForImageClassification
from PIL import Image
path = 'image_path'
image = Image.open(path)
feature_extractor = ViTFeatureExtractor.from_pretrained('furusu/umamusume-classifier')
model = ViTForImageClassification.from_pretrained('furusu/umamusume-classifier')
inputs = feature_extractor(images=image, return_tensors="pt")
outputs = model(**inputs)
predicted_class_idx = outputs.logits.argmax(-1).item()
print("Predicted class:", model.config.id2label[predicted_class_idx])
```
|
ebc17430d7c805b25267733abf2df9b8
|
lighteternal/BiomedNLP-PubMedBERT-base-uncased-abstract-fulltext-finetuned-mnli
|
lighteternal
|
bert
| 13 | 355 |
transformers
| 3 |
text-classification
| true | false | false |
mit
|
['en']
|
['mnli']
| null | 0 | 0 | 0 | 0 | 1 | 1 | 0 |
['textual-entailment', 'nli', 'pytorch']
| false | true | true | 2,047 | false |
# BiomedNLP-PubMedBERT finetuned on textual entailment (NLI)
The [microsoft/BiomedNLP-PubMedBERT-base-uncased-abstract-fulltext](https://huggingface.co/microsoft/BiomedNLP-PubMedBERT-base-uncased-abstract-fulltext?text=%5BMASK%5D+is+a+tumor+suppressor+gene) finetuned on the MNLI dataset. It should be useful in textual entailment tasks involving biomedical corpora.
## Usage
Given two sentences (a premise and a hypothesis), the model outputs the logits of entailment, neutral or contradiction.
You can test the model using the HuggingFace model widget on the side:
- Input two sentences (premise and hypothesis) one after the other.
- The model returns the probabilities of 3 labels: entailment(LABEL:0), neutral(LABEL:1) and contradiction(LABEL:2) respectively.
To use the model locally on your machine:
```python
# import torch
# device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
from transformers import AutoTokenizer, AutoModelForSequenceClassification
tokenizer = AutoTokenizer.from_pretrained("lighteternal/BiomedNLP-PubMedBERT-base-uncased-abstract-fulltext-finetuned-mnli")
model = AutoModelForSequenceClassification.from_pretrained("lighteternal/BiomedNLP-PubMedBERT-base-uncased-abstract-fulltext-finetuned-mnli")
premise = 'EpCAM is overexpressed in breast cancer'
hypothesis = 'EpCAM is downregulated in breast cancer.'
# run through model pre-trained on MNLI
x = tokenizer.encode(premise, hypothesis, return_tensors='pt',
truncation_strategy='only_first')
logits = model(x)[0]
probs = logits.softmax(dim=1)
print('Probabilities for entailment, neutral, contradiction \n', np.around(probs.cpu().
detach().numpy(),3))
# Probabilities for entailment, neutral, contradiction
# 0.001 0.001 0.998
```
## Metrics
Evaluation on classification accuracy (entailment, contradiction, neutral) on MNLI test set:
| Metric | Value |
| --- | --- |
| Accuracy | 0.8338|
See Training Metrics tab for detailed info.
|
95225240b0a8ca541daf60a08563fe52
|
heyyai/austinmichaelcraig0
|
heyyai
| null | 20 | 2 |
diffusers
| 0 |
text-to-image
| false | false | false |
creativeml-openrail-m
| null | null | null | 2 | 2 | 0 | 0 | 0 | 0 | 0 |
['text-to-image']
| false | true | true | 1,423 | false |
### austinmichaelcraig0 on Stable Diffusion via Dreambooth trained on the [fast-DreamBooth.ipynb by TheLastBen](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast-DreamBooth.ipynb) notebook
#### Model by cormacncheese
This your the Stable Diffusion model fine-tuned the austinmichaelcraig0 concept taught to Stable Diffusion with Dreambooth.
It can be used by modifying the `instance_prompt(s)`: **austinmichaelcraig0(0).jpg**
You can also train your own concepts and upload them to the library by using [the fast-DremaBooth.ipynb by TheLastBen](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast-DreamBooth.ipynb).
You can run your new concept via A1111 Colab :[Fast-Colab-A1111](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast_stable_diffusion_AUTOMATIC1111.ipynb)
Or you can run your new concept via `diffusers`: [Colab Notebook for Inference](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_inference.ipynb), [Spaces with the Public Concepts loaded](https://huggingface.co/spaces/sd-dreambooth-library/stable-diffusion-dreambooth-concepts)
Sample pictures of this concept:
austinmichaelcraig0(0).jpg
.jpg)
|
a4778363d46e3f747429462a28744ff0
|
shripadbhat/whisper-tiny-hi-1000steps
|
shripadbhat
|
whisper
| 15 | 5 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
|
['hi']
|
['mozilla-foundation/common_voice_11_0']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['whisper-event', 'generated_from_trainer']
| true | true | true | 1,904 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Whisper tiny Hindi
This model is a fine-tuned version of [openai/whisper-tiny](https://huggingface.co/openai/whisper-tiny) on the Common Voice 11.0 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5538
- Wer: 41.5453
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 50
- training_steps: 1000
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:-------:|
| 0.7718 | 0.73 | 100 | 0.8130 | 55.6890 |
| 0.5169 | 1.47 | 200 | 0.6515 | 48.2517 |
| 0.3986 | 2.21 | 300 | 0.6001 | 44.9931 |
| 0.3824 | 2.94 | 400 | 0.5720 | 43.5171 |
| 0.3328 | 3.67 | 500 | 0.5632 | 42.5112 |
| 0.2919 | 4.41 | 600 | 0.5594 | 42.7863 |
| 0.2654 | 5.15 | 700 | 0.5552 | 41.6428 |
| 0.2618 | 5.88 | 800 | 0.5530 | 41.8893 |
| 0.2442 | 6.62 | 900 | 0.5539 | 41.5740 |
| 0.238 | 7.35 | 1000 | 0.5538 | 41.5453 |
### Framework versions
- Transformers 4.26.0.dev0
- Pytorch 1.13.0+cu117
- Datasets 2.7.1.dev0
- Tokenizers 0.13.2
|
7c22c8009ba10ad8dbc348929a65a7ee
|
deepset/xlm-roberta-base-squad2-distilled
|
deepset
|
xlm-roberta
| 8 | 4,534 |
transformers
| 4 |
question-answering
| true | false | false |
mit
|
['multilingual']
|
['squad_v2']
| null | 3 | 2 | 0 | 1 | 1 | 1 | 0 |
['exbert']
| false | true | true | 4,241 | false |
# deepset/xlm-roberta-base-squad2-distilled
- haystack's distillation feature was used for training. deepset/xlm-roberta-large-squad2 was used as the teacher model.
## Overview
**Language model:** deepset/xlm-roberta-base-squad2-distilled
**Language:** Multilingual
**Downstream-task:** Extractive QA
**Training data:** SQuAD 2.0
**Eval data:** SQuAD 2.0
**Code:** See [an example QA pipeline on Haystack](https://haystack.deepset.ai/tutorials/first-qa-system)
**Infrastructure**: 1x Tesla v100
## Hyperparameters
```
batch_size = 56
n_epochs = 4
max_seq_len = 384
learning_rate = 3e-5
lr_schedule = LinearWarmup
embeds_dropout_prob = 0.1
temperature = 3
distillation_loss_weight = 0.75
```
## Usage
### In Haystack
Haystack is an NLP framework by deepset. You can use this model in a Haystack pipeline to do question answering at scale (over many documents). To load the model in [Haystack](https://github.com/deepset-ai/haystack/):
```python
reader = FARMReader(model_name_or_path="deepset/xlm-roberta-base-squad2-distilled")
# or
reader = TransformersReader(model_name_or_path="deepset/xlm-roberta-base-squad2-distilled",tokenizer="deepset/xlm-roberta-base-squad2-distilled")
```
For a complete example of ``deepset/xlm-roberta-base-squad2-distilled`` being used for [question answering], check out the [Tutorials in Haystack Documentation](https://haystack.deepset.ai/tutorials/first-qa-system)
### In Transformers
```python
from transformers import AutoModelForQuestionAnswering, AutoTokenizer, pipeline
model_name = "deepset/xlm-roberta-base-squad2-distilled"
# a) Get predictions
nlp = pipeline('question-answering', model=model_name, tokenizer=model_name)
QA_input = {
'question': 'Why is model conversion important?',
'context': 'The option to convert models between FARM and transformers gives freedom to the user and let people easily switch between frameworks.'
}
res = nlp(QA_input)
# b) Load model & tokenizer
model = AutoModelForQuestionAnswering.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
```
## Performance
Evaluated on the SQuAD 2.0 dev set
```
"exact": 74.06721131980123%
"f1": 76.39919553344667%
```
## Authors
**Timo Möller:** timo.moeller@deepset.ai
**Julian Risch:** julian.risch@deepset.ai
**Malte Pietsch:** malte.pietsch@deepset.ai
**Michel Bartels:** michel.bartels@deepset.ai
## About us
<div class="grid lg:grid-cols-2 gap-x-4 gap-y-3">
<div class="w-full h-40 object-cover mb-2 rounded-lg flex items-center justify-center">
<img alt="" src="https://raw.githubusercontent.com/deepset-ai/.github/main/deepset-logo-colored.png" class="w-40"/>
</div>
<div class="w-full h-40 object-cover mb-2 rounded-lg flex items-center justify-center">
<img alt="" src="https://raw.githubusercontent.com/deepset-ai/.github/main/haystack-logo-colored.png" class="w-40"/>
</div>
</div>
[deepset](http://deepset.ai/) is the company behind the open-source NLP framework [Haystack](https://haystack.deepset.ai/) which is designed to help you build production ready NLP systems that use: Question answering, summarization, ranking etc.
Some of our other work:
- [Distilled roberta-base-squad2 (aka "tinyroberta-squad2")]([https://huggingface.co/deepset/tinyroberta-squad2)
- [German BERT (aka "bert-base-german-cased")](https://deepset.ai/german-bert)
- [GermanQuAD and GermanDPR datasets and models (aka "gelectra-base-germanquad", "gbert-base-germandpr")](https://deepset.ai/germanquad)
## Get in touch and join the Haystack community
<p>For more info on Haystack, visit our <strong><a href="https://github.com/deepset-ai/haystack">GitHub</a></strong> repo and <strong><a href="https://haystack.deepset.ai">Documentation</a></strong>.
We also have a <strong><a class="h-7" href="https://haystack.deepset.ai/community/join">Discord community open to everyone!</a></strong></p>
[Twitter](https://twitter.com/deepset_ai) | [LinkedIn](https://www.linkedin.com/company/deepset-ai/) | [Discord](https://haystack.deepset.ai/community/join) | [GitHub Discussions](https://github.com/deepset-ai/haystack/discussions) | [Website](https://deepset.ai)
By the way: [we're hiring!](http://www.deepset.ai/jobs)
|
67ad8aa6f3251354a306fe2336fd20b8
|
paola-md/distil-is
|
paola-md
|
roberta
| 6 | 1 |
transformers
| 0 |
text-classification
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,577 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distil-is
This model is a fine-tuned version of [distilroberta-base](https://huggingface.co/distilroberta-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6082
- Rmse: 0.7799
- Mse: 0.6082
- Mae: 0.6023
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rmse | Mse | Mae |
|:-------------:|:-----:|:----:|:---------------:|:------:|:------:|:------:|
| 0.6881 | 1.0 | 492 | 0.6534 | 0.8084 | 0.6534 | 0.5857 |
| 0.5923 | 2.0 | 984 | 0.6508 | 0.8067 | 0.6508 | 0.5852 |
| 0.5865 | 3.0 | 1476 | 0.6088 | 0.7803 | 0.6088 | 0.6096 |
| 0.5899 | 4.0 | 1968 | 0.6279 | 0.7924 | 0.6279 | 0.5853 |
| 0.5852 | 5.0 | 2460 | 0.6082 | 0.7799 | 0.6082 | 0.6023 |
### Framework versions
- Transformers 4.19.0.dev0
- Pytorch 1.9.0+cu111
- Datasets 2.4.0
- Tokenizers 0.12.1
|
a8a4429344f2a845dd3caedb2d9f27e1
|
NickKolok/meryl-stryfe-20230101-0500-4800-steps_1
|
NickKolok
| null | 15 | 2 |
diffusers
| 0 |
text-to-image
| false | false | false |
creativeml-openrail-m
| null | null | null | 1 | 1 | 0 | 0 | 0 | 0 | 0 |
['text-to-image']
| false | true | true | 7,619 | false |
### Meryl_Stryfe_20230101_0500_+4800_steps on Stable Diffusion via Dreambooth
#### model by NickKolok
This your the Stable Diffusion model fine-tuned the Meryl_Stryfe_20230101_0500_+4800_steps concept taught to Stable Diffusion with Dreambooth.
#It can be used by modifying the `instance_prompt`: **merylstryfetrigun**
You can also train your own concepts and upload them to the library by using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_training.ipynb).
And you can run your new concept via `diffusers`: [Colab Notebook for Inference](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_inference.ipynb), [Spaces with the Public Concepts loaded](https://huggingface.co/spaces/sd-dreambooth-library/stable-diffusion-dreambooth-concepts)
Here are the images used for training this concept:
















































|
3e9855778807e68198a33f8c6e810b2b
|
ghatgetanuj/distilbert-base-uncased_cls_sst2
|
ghatgetanuj
|
distilbert
| 12 | 1 |
transformers
| 0 |
text-classification
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,537 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased_cls_sst2
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5999
- Accuracy: 0.8933
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 4e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.2
- num_epochs: 5
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| No log | 1.0 | 433 | 0.2928 | 0.8773 |
| 0.4178 | 2.0 | 866 | 0.3301 | 0.8922 |
| 0.2046 | 3.0 | 1299 | 0.5088 | 0.8853 |
| 0.0805 | 4.0 | 1732 | 0.5780 | 0.8888 |
| 0.0159 | 5.0 | 2165 | 0.5999 | 0.8933 |
### Framework versions
- Transformers 4.20.1
- Pytorch 1.11.0
- Datasets 2.1.0
- Tokenizers 0.12.1
|
917a150a42b4fae0144a677bb024ce24
|
lmqg/mt5-small-ruquad-qag
|
lmqg
|
mt5
| 13 | 33 |
transformers
| 0 |
text2text-generation
| true | false | false |
cc-by-4.0
|
['ru']
|
['lmqg/qag_ruquad']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['questions and answers generation']
| true | true | true | 4,038 | false |
# Model Card of `lmqg/mt5-small-ruquad-qag`
This model is fine-tuned version of [google/mt5-small](https://huggingface.co/google/mt5-small) for question & answer pair generation task on the [lmqg/qag_ruquad](https://huggingface.co/datasets/lmqg/qag_ruquad) (dataset_name: default) via [`lmqg`](https://github.com/asahi417/lm-question-generation).
### Overview
- **Language model:** [google/mt5-small](https://huggingface.co/google/mt5-small)
- **Language:** ru
- **Training data:** [lmqg/qag_ruquad](https://huggingface.co/datasets/lmqg/qag_ruquad) (default)
- **Online Demo:** [https://autoqg.net/](https://autoqg.net/)
- **Repository:** [https://github.com/asahi417/lm-question-generation](https://github.com/asahi417/lm-question-generation)
- **Paper:** [https://arxiv.org/abs/2210.03992](https://arxiv.org/abs/2210.03992)
### Usage
- With [`lmqg`](https://github.com/asahi417/lm-question-generation#lmqg-language-model-for-question-generation-)
```python
from lmqg import TransformersQG
# initialize model
model = TransformersQG(language="ru", model="lmqg/mt5-small-ruquad-qag")
# model prediction
question_answer_pairs = model.generate_qa("Нелишним будет отметить, что, развивая это направление, Д. И. Менделеев, поначалу априорно выдвинув идею о температуре, при которой высота мениска будет нулевой, в мае 1860 года провёл серию опытов.")
```
- With `transformers`
```python
from transformers import pipeline
pipe = pipeline("text2text-generation", "lmqg/mt5-small-ruquad-qag")
output = pipe("Нелишним будет отметить, что, развивая это направление, Д. И. Менделеев, поначалу априорно выдвинув идею о температуре, при которой высота мениска будет нулевой, в мае 1860 года провёл серию опытов.")
```
## Evaluation
- ***Metric (Question & Answer Generation)***: [raw metric file](https://huggingface.co/lmqg/mt5-small-ruquad-qag/raw/main/eval/metric.first.answer.paragraph.questions_answers.lmqg_qag_ruquad.default.json)
| | Score | Type | Dataset |
|:--------------------------------|--------:|:--------|:-------------------------------------------------------------------|
| QAAlignedF1Score (BERTScore) | 52.95 | default | [lmqg/qag_ruquad](https://huggingface.co/datasets/lmqg/qag_ruquad) |
| QAAlignedF1Score (MoverScore) | 38.59 | default | [lmqg/qag_ruquad](https://huggingface.co/datasets/lmqg/qag_ruquad) |
| QAAlignedPrecision (BERTScore) | 52.86 | default | [lmqg/qag_ruquad](https://huggingface.co/datasets/lmqg/qag_ruquad) |
| QAAlignedPrecision (MoverScore) | 38.57 | default | [lmqg/qag_ruquad](https://huggingface.co/datasets/lmqg/qag_ruquad) |
| QAAlignedRecall (BERTScore) | 53.06 | default | [lmqg/qag_ruquad](https://huggingface.co/datasets/lmqg/qag_ruquad) |
| QAAlignedRecall (MoverScore) | 38.62 | default | [lmqg/qag_ruquad](https://huggingface.co/datasets/lmqg/qag_ruquad) |
## Training hyperparameters
The following hyperparameters were used during fine-tuning:
- dataset_path: lmqg/qag_ruquad
- dataset_name: default
- input_types: ['paragraph']
- output_types: ['questions_answers']
- prefix_types: None
- model: google/mt5-small
- max_length: 512
- max_length_output: 256
- epoch: 12
- batch: 8
- lr: 0.001
- fp16: False
- random_seed: 1
- gradient_accumulation_steps: 16
- label_smoothing: 0.15
The full configuration can be found at [fine-tuning config file](https://huggingface.co/lmqg/mt5-small-ruquad-qag/raw/main/trainer_config.json).
## Citation
```
@inproceedings{ushio-etal-2022-generative,
title = "{G}enerative {L}anguage {M}odels for {P}aragraph-{L}evel {Q}uestion {G}eneration",
author = "Ushio, Asahi and
Alva-Manchego, Fernando and
Camacho-Collados, Jose",
booktitle = "Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing",
month = dec,
year = "2022",
address = "Abu Dhabi, U.A.E.",
publisher = "Association for Computational Linguistics",
}
```
|
f24db018a4880ea31c5abf065529a79b
|
hkoll2/distilbert-base-uncased-finetuned-ner
|
hkoll2
|
distilbert
| 13 | 3 |
transformers
| 0 |
token-classification
| true | false | false |
apache-2.0
| null |
['conll2003']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,555 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-ner
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the conll2003 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0629
- Precision: 0.9225
- Recall: 0.9340
- F1: 0.9282
- Accuracy: 0.9834
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| 0.2356 | 1.0 | 878 | 0.0704 | 0.9138 | 0.9187 | 0.9162 | 0.9807 |
| 0.054 | 2.0 | 1756 | 0.0620 | 0.9209 | 0.9329 | 0.9269 | 0.9827 |
| 0.0306 | 3.0 | 2634 | 0.0629 | 0.9225 | 0.9340 | 0.9282 | 0.9834 |
### Framework versions
- Transformers 4.24.0
- Pytorch 1.12.1+cu113
- Datasets 2.6.1
- Tokenizers 0.13.2
|
27222624910123096bd0b63638a009b0
|
ConvLab/t5-small-goal2dialogue-multiwoz21
|
ConvLab
|
t5
| 7 | 3 |
transformers
| 0 |
text2text-generation
| true | false | false |
apache-2.0
|
['en']
|
['ConvLab/multiwoz21']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['t5-small', 'text2text-generation', 'dialogue generation', 'conversational system', 'task-oriented dialog']
| true | true | true | 745 | false |
# t5-small-goal2dialogue-multiwoz21
This model is a fine-tuned version of [t5-small](https://huggingface.co/t5-small) on [MultiWOZ 2.1](https://huggingface.co/datasets/ConvLab/multiwoz21).
Refer to [ConvLab-3](https://github.com/ConvLab/ConvLab-3) for model description and usage.
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.001
- train_batch_size: 32
- eval_batch_size: 64
- seed: 42
- distributed_type: multi-GPU
- gradient_accumulation_steps: 4
- total_train_batch_size: 128
- optimizer: Adafactor
- lr_scheduler_type: linear
- num_epochs: 10.0
### Framework versions
- Transformers 4.18.0
- Pytorch 1.10.2+cu102
- Datasets 1.18.3
- Tokenizers 0.11.0
|
b54b28761bbdc3859100e6e02b14665a
|
yanaiela/roberta-base-epoch_2
|
yanaiela
|
roberta
| 9 | 3 |
transformers
| 0 |
fill-mask
| true | false | false |
mit
|
['en']
|
['wikipedia', 'bookcorpus']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['roberta-base', 'roberta-base-epoch_2']
| false | true | true | 2,100 | false |
# RoBERTa, Intermediate Checkpoint - Epoch 2
This model is part of our reimplementation of the [RoBERTa model](https://arxiv.org/abs/1907.11692),
trained on Wikipedia and the Book Corpus only.
We train this model for almost 100K steps, corresponding to 83 epochs.
We provide the 84 checkpoints (including the randomly initialized weights before the training)
to provide the ability to study the training dynamics of such models, and other possible use-cases.
These models were trained in part of a work that studies how simple statistics from data,
such as co-occurrences affects model predictions, which are described in the paper
[Measuring Causal Effects of Data Statistics on Language Model's `Factual' Predictions](https://arxiv.org/abs/2207.14251).
This is RoBERTa-base epoch_2.
## Model Description
This model was captured during a reproduction of
[RoBERTa-base](https://huggingface.co/roberta-base), for English: it
is a Transformers model pretrained on a large corpus of English data, using the
Masked Language Modelling (MLM).
The intended uses, limitations, training data and training procedure for the fully trained model are similar
to [RoBERTa-base](https://huggingface.co/roberta-base). Two major
differences with the original model:
* We trained our model for 100K steps, instead of 500K
* We only use Wikipedia and the Book Corpus, as corpora which are publicly available.
### How to use
Using code from
[RoBERTa-base](https://huggingface.co/roberta-base), here is an example based on
PyTorch:
```
from transformers import pipeline
model = pipeline("fill-mask", model='yanaiela/roberta-base-epoch_83', device=-1, top_k=10)
model("Hello, I'm the <mask> RoBERTa-base language model")
```
## Citation info
```bibtex
@article{2207.14251,
Author = {Yanai Elazar and Nora Kassner and Shauli Ravfogel and Amir Feder and Abhilasha Ravichander and Marius Mosbach and Yonatan Belinkov and Hinrich Schütze and Yoav Goldberg},
Title = {Measuring Causal Effects of Data Statistics on Language Model's `Factual' Predictions},
Year = {2022},
Eprint = {arXiv:2207.14251},
}
```
|
6690a6fe0c54290683069c2712438f2a
|
weikunt/finetuned-ner
|
weikunt
|
deberta-v2
| 11 | 9 |
transformers
| 0 |
token-classification
| true | false | false |
cc-by-4.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 4,215 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# finetuned-ner
This model is a fine-tuned version of [deepset/deberta-v3-base-squad2](https://huggingface.co/deepset/deberta-v3-base-squad2) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4783
- Precision: 0.3264
- Recall: 0.3591
- F1: 0.3420
- Accuracy: 0.8925
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 4
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 30
- mixed_precision_training: Native AMP
- label_smoothing_factor: 0.05
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:-----:|:---------------:|:---------:|:------:|:------:|:--------:|
| 39.8167 | 1.0 | 760 | 0.3957 | 0.1844 | 0.2909 | 0.2257 | 0.8499 |
| 21.7333 | 2.0 | 1520 | 0.3853 | 0.2118 | 0.3273 | 0.2571 | 0.8546 |
| 13.8859 | 3.0 | 2280 | 0.3631 | 0.2443 | 0.2909 | 0.2656 | 0.8789 |
| 20.6586 | 4.0 | 3040 | 0.3961 | 0.2946 | 0.3455 | 0.3180 | 0.8753 |
| 13.8654 | 5.0 | 3800 | 0.3821 | 0.2791 | 0.3273 | 0.3013 | 0.8877 |
| 12.6942 | 6.0 | 4560 | 0.4393 | 0.3122 | 0.3364 | 0.3239 | 0.8909 |
| 25.0549 | 7.0 | 5320 | 0.4542 | 0.3106 | 0.3727 | 0.3388 | 0.8824 |
| 5.6816 | 8.0 | 6080 | 0.4432 | 0.2820 | 0.3409 | 0.3086 | 0.8774 |
| 13.1296 | 9.0 | 6840 | 0.4509 | 0.2884 | 0.35 | 0.3162 | 0.8824 |
| 7.7173 | 10.0 | 7600 | 0.4265 | 0.3170 | 0.3818 | 0.3464 | 0.8919 |
| 6.7922 | 11.0 | 8360 | 0.4749 | 0.3320 | 0.3818 | 0.3552 | 0.8892 |
| 5.4287 | 12.0 | 9120 | 0.4564 | 0.2917 | 0.3818 | 0.3307 | 0.8805 |
| 7.4153 | 13.0 | 9880 | 0.4735 | 0.2963 | 0.3273 | 0.3110 | 0.8871 |
| 9.1154 | 14.0 | 10640 | 0.4553 | 0.3416 | 0.3773 | 0.3585 | 0.8894 |
| 5.999 | 15.0 | 11400 | 0.4489 | 0.3203 | 0.4091 | 0.3593 | 0.8880 |
| 9.5128 | 16.0 | 12160 | 0.4947 | 0.3164 | 0.3682 | 0.3403 | 0.8883 |
| 5.6713 | 17.0 | 12920 | 0.4705 | 0.3527 | 0.3864 | 0.3688 | 0.8919 |
| 12.2119 | 18.0 | 13680 | 0.4617 | 0.3123 | 0.3591 | 0.3340 | 0.8857 |
| 8.5658 | 19.0 | 14440 | 0.4764 | 0.3092 | 0.35 | 0.3284 | 0.8944 |
| 11.0664 | 20.0 | 15200 | 0.4557 | 0.3187 | 0.3636 | 0.3397 | 0.8905 |
| 6.7161 | 21.0 | 15960 | 0.4468 | 0.3210 | 0.3955 | 0.3544 | 0.8956 |
| 9.0448 | 22.0 | 16720 | 0.5120 | 0.2872 | 0.3682 | 0.3227 | 0.8792 |
| 6.573 | 23.0 | 17480 | 0.4990 | 0.3307 | 0.3773 | 0.3524 | 0.8869 |
| 5.0543 | 24.0 | 18240 | 0.4763 | 0.3028 | 0.3455 | 0.3227 | 0.8899 |
| 6.8797 | 25.0 | 19000 | 0.4814 | 0.2780 | 0.3273 | 0.3006 | 0.8913 |
| 7.7544 | 26.0 | 19760 | 0.4695 | 0.3024 | 0.3409 | 0.3205 | 0.8946 |
| 4.8346 | 27.0 | 20520 | 0.4849 | 0.3154 | 0.3455 | 0.3297 | 0.8931 |
| 4.4766 | 28.0 | 21280 | 0.4809 | 0.2925 | 0.3364 | 0.3129 | 0.8913 |
| 7.9149 | 29.0 | 22040 | 0.4756 | 0.3238 | 0.3591 | 0.3405 | 0.8930 |
| 7.3033 | 30.0 | 22800 | 0.4783 | 0.3264 | 0.3591 | 0.3420 | 0.8925 |
### Framework versions
- Transformers 4.25.1
- Pytorch 1.7.1
- Datasets 2.8.0
- Tokenizers 0.13.2
|
eaf80c8ab459bee2dc141dcd28f9f78e
|
fanzru/t5-small-finetuned-xlsum-10-epoch
|
fanzru
|
t5
| 9 | 1 |
transformers
| 1 |
text2text-generation
| true | false | false |
apache-2.0
| null |
['xlsum']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 2,380 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-small-finetuned-xlsum-10-epoch
This model is a fine-tuned version of [t5-small](https://huggingface.co/t5-small) on the xlsum dataset.
It achieves the following results on the evaluation set:
- Loss: 2.2204
- Rouge1: 31.6534
- Rouge2: 10.0563
- Rougel: 24.8104
- Rougelsum: 24.8732
- Gen Len: 18.7913
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:------:|:---------------:|:-------:|:-------:|:-------:|:---------:|:-------:|
| 2.6512 | 1.0 | 19158 | 2.3745 | 29.756 | 8.4006 | 22.9753 | 23.0287 | 18.8245 |
| 2.6012 | 2.0 | 38316 | 2.3183 | 30.5327 | 9.0206 | 23.7263 | 23.7805 | 18.813 |
| 2.5679 | 3.0 | 57474 | 2.2853 | 30.9771 | 9.4156 | 24.1555 | 24.2127 | 18.7905 |
| 2.5371 | 4.0 | 76632 | 2.2660 | 31.0578 | 9.5592 | 24.2983 | 24.3587 | 18.7941 |
| 2.5133 | 5.0 | 95790 | 2.2498 | 31.3756 | 9.7889 | 24.5317 | 24.5922 | 18.7971 |
| 2.4795 | 6.0 | 114948 | 2.2378 | 31.4961 | 9.8935 | 24.6648 | 24.7218 | 18.7929 |
| 2.4967 | 7.0 | 134106 | 2.2307 | 31.44 | 9.9125 | 24.6298 | 24.6824 | 18.8221 |
| 2.4678 | 8.0 | 153264 | 2.2250 | 31.5875 | 10.004 | 24.7581 | 24.8125 | 18.7809 |
| 2.46 | 9.0 | 172422 | 2.2217 | 31.6413 | 10.0311 | 24.8063 | 24.8641 | 18.7951 |
| 2.4494 | 10.0 | 191580 | 2.2204 | 31.6534 | 10.0563 | 24.8104 | 24.8732 | 18.7913 |
### Framework versions
- Transformers 4.13.0
- Pytorch 1.13.1+cpu
- Datasets 2.8.0
- Tokenizers 0.10.3
|
57a55ec9458b4ab81efe1ac9a287edd8
|
FOFer/distilbert-base-uncased-finetuned-squad
|
FOFer
|
distilbert
| 12 | 3 |
transformers
| 0 |
question-answering
| true | false | false |
apache-2.0
| null |
['squad_v2']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,288 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-squad
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the squad_v2 dataset.
It achieves the following results on the evaluation set:
- Loss: 1.4306
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-----:|:---------------:|
| 1.2169 | 1.0 | 8235 | 1.1950 |
| 0.9396 | 2.0 | 16470 | 1.2540 |
| 0.7567 | 3.0 | 24705 | 1.4306 |
### Framework versions
- Transformers 4.16.2
- Pytorch 1.10.0+cu111
- Datasets 1.18.3
- Tokenizers 0.11.0
|
3407e41b67638c1762090980abbabe29
|
sd-concepts-library/chucky
|
sd-concepts-library
| null | 10 | 0 | null | 1 | null | false | false | false |
mit
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
[]
| false | true | true | 1,076 | false |
### Chucky on Stable Diffusion
This is the `<merc>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as a `style`:





|
f28de1ede5e71b17fb776d049eacc45f
|
NDugar/v3-Large-mnli
|
NDugar
|
deberta-v2
| 12 | 6 |
transformers
| 1 |
zero-shot-classification
| true | false | false |
mit
|
['en']
| null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['deberta-v1', 'deberta-mnli']
| false | true | true | 925 | false |
This model is a fine-tuned version of [microsoft/deberta-v3-large](https://huggingface.co/microsoft/deberta-v3-large) on the GLUE MNLI dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4103
- Accuracy: 0.9175
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 6e-06
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 50
- num_epochs: 2.0
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|
| 0.3631 | 1.0 | 49088 | 0.3129 | 0.9130 |
| 0.2267 | 2.0 | 98176 | 0.4157 | 0.9153 |
### Framework versions
- Transformers 4.13.0.dev0
- Pytorch 1.10.0
- Datasets 1.15.2.dev0
- Tokenizers 0.10.3
|
bdaf98efccd4798fa413019de34739d9
|
gokuls/mobilebert_add_GLUE_Experiment_logit_kd_qqp
|
gokuls
|
mobilebert
| 17 | 2 |
transformers
| 0 |
text-classification
| true | false | false |
apache-2.0
|
['en']
|
['glue']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 2,455 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mobilebert_add_GLUE_Experiment_logit_kd_qqp
This model is a fine-tuned version of [google/mobilebert-uncased](https://huggingface.co/google/mobilebert-uncased) on the GLUE QQP dataset.
It achieves the following results on the evaluation set:
- Loss: 0.8079
- Accuracy: 0.7570
- F1: 0.6049
- Combined Score: 0.6810
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 128
- eval_batch_size: 128
- seed: 10
- distributed_type: multi-GPU
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 50
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 | Combined Score |
|:--------------------------:|:-----:|:-----:|:---------------:|:--------:|:------:|:--------------:|
| 1.2837 | 1.0 | 2843 | 1.2201 | 0.6318 | 0.0 | 0.3159 |
| 1.076 | 2.0 | 5686 | 0.8477 | 0.7443 | 0.5855 | 0.6649 |
| 0.866 | 3.0 | 8529 | 0.8217 | 0.7518 | 0.5924 | 0.6721 |
| 0.8317 | 4.0 | 11372 | 0.8136 | 0.7565 | 0.6243 | 0.6904 |
| 0.8122 | 5.0 | 14215 | 0.8126 | 0.7588 | 0.6352 | 0.6970 |
| 0.799 | 6.0 | 17058 | 0.8079 | 0.7570 | 0.6049 | 0.6810 |
| 386581134871678353408.0000 | 7.0 | 19901 | nan | 0.6318 | 0.0 | 0.3159 |
| 0.0 | 8.0 | 22744 | nan | 0.6318 | 0.0 | 0.3159 |
| 0.0 | 9.0 | 25587 | nan | 0.6318 | 0.0 | 0.3159 |
| 0.0 | 10.0 | 28430 | nan | 0.6318 | 0.0 | 0.3159 |
| 0.0 | 11.0 | 31273 | nan | 0.6318 | 0.0 | 0.3159 |
### Framework versions
- Transformers 4.26.0
- Pytorch 1.14.0a0+410ce96
- Datasets 2.9.0
- Tokenizers 0.13.2
|
05ffd594bb36c9bef20c9e70c363b544
|
4m1g0/wav2vec2-large-xls-r-53m-gl-jupyter7
|
4m1g0
|
wav2vec2
| 13 | 7 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 2,325 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-large-xls-r-53m-gl-jupyter7
This model is a fine-tuned version of [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1000
- Wer: 0.0639
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 60
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 3.8697 | 3.36 | 400 | 0.2631 | 0.2756 |
| 0.1569 | 6.72 | 800 | 0.1243 | 0.1300 |
| 0.0663 | 10.08 | 1200 | 0.1124 | 0.1153 |
| 0.0468 | 13.44 | 1600 | 0.1118 | 0.1037 |
| 0.0356 | 16.8 | 2000 | 0.1102 | 0.0978 |
| 0.0306 | 20.17 | 2400 | 0.1095 | 0.0935 |
| 0.0244 | 23.53 | 2800 | 0.1072 | 0.0844 |
| 0.0228 | 26.89 | 3200 | 0.1014 | 0.0874 |
| 0.0192 | 30.25 | 3600 | 0.1084 | 0.0831 |
| 0.0174 | 33.61 | 4000 | 0.1048 | 0.0772 |
| 0.0142 | 36.97 | 4400 | 0.1063 | 0.0764 |
| 0.0131 | 40.33 | 4800 | 0.1046 | 0.0770 |
| 0.0116 | 43.69 | 5200 | 0.0999 | 0.0716 |
| 0.0095 | 47.06 | 5600 | 0.1044 | 0.0729 |
| 0.0077 | 50.42 | 6000 | 0.1024 | 0.0670 |
| 0.0071 | 53.78 | 6400 | 0.0968 | 0.0631 |
| 0.0064 | 57.14 | 6800 | 0.1000 | 0.0639 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.9.1+cu111
- Datasets 1.18.3
- Tokenizers 0.10.3
|
31957f16d56213ef70c44aba2416abd3
|
sd-concepts-library/axe-tattoo
|
sd-concepts-library
| null | 14 | 0 |
transformers
| 0 | null | false | false | false |
mit
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
[]
| false | true | true | 1,226 | false |
### axe_tattoo on Stable Diffusion
This is the `<axe-tattoo>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as a `style`:



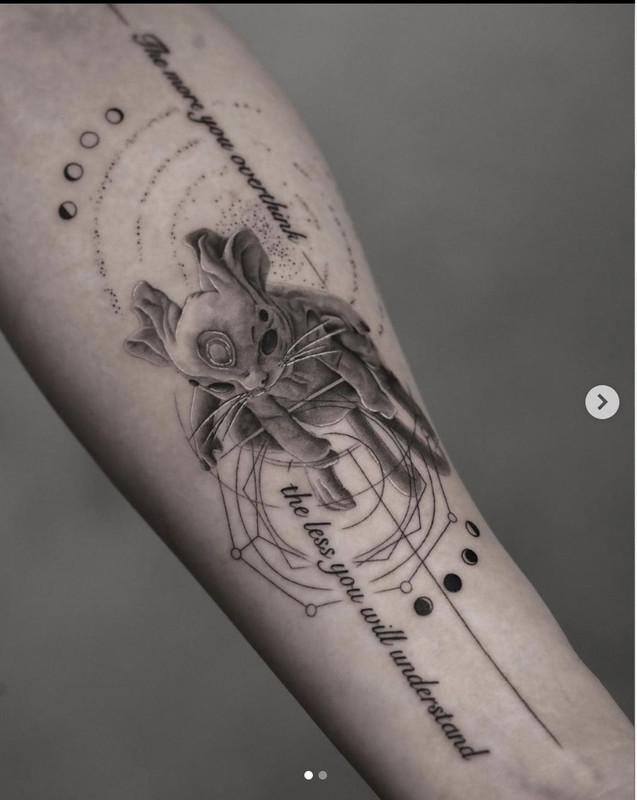


|
9448fab08a6323d5520376d0ad20a9eb
|
Jeffsun/LSPV3
|
Jeffsun
| null | 30 | 0 |
diffusers
| 0 | null | false | false | false |
openrail
|
['en']
|
['Gustavosta/Stable-Diffusion-Prompts']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
[]
| false | true | true | 952 | false |
prompt should contain: best quality, masterpiece, highrer,1girl, beautiful face
recommand:
DPM++2M Karras
nagative prompt (simple is better):(((simple background))),monochrome ,lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry, lowres, bad anatomy, bad hands, text, error, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry, ugly,pregnant,vore,duplicate,morbid,mut ilated,tran nsexual, hermaphrodite,long neck,mutated hands,poorly drawn hands,poorly drawn face,mutation,deformed,blurry,bad anatomy,bad proportions,malformed limbs,extra limbs,cloned face,disfigured,gross proportions, (((missing arms))),(((missing legs))), (((extra arms))),(((extra legs))),pubic hair, plump,bad legs,error legs,username,blurry,bad feet
|
be2f6753eddf2a47b42eb6ca8897543d
|
gokuls/bert-base-uncased-stsb
|
gokuls
|
bert
| 17 | 72 |
transformers
| 0 |
text-classification
| true | false | false |
apache-2.0
|
['en']
|
['glue']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 2,719 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-uncased-stsb
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on the GLUE STSB dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4676
- Pearson: 0.8901
- Spearmanr: 0.8872
- Combined Score: 0.8887
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 128
- eval_batch_size: 128
- seed: 10
- distributed_type: multi-GPU
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 50
### Training results
| Training Loss | Epoch | Step | Validation Loss | Pearson | Spearmanr | Combined Score |
|:-------------:|:-----:|:----:|:---------------:|:-------:|:---------:|:--------------:|
| 2.3939 | 1.0 | 45 | 0.7358 | 0.8686 | 0.8653 | 0.8669 |
| 0.5084 | 2.0 | 90 | 0.4959 | 0.8835 | 0.8799 | 0.8817 |
| 0.3332 | 3.0 | 135 | 0.5002 | 0.8846 | 0.8815 | 0.8830 |
| 0.2202 | 4.0 | 180 | 0.4962 | 0.8854 | 0.8827 | 0.8840 |
| 0.1642 | 5.0 | 225 | 0.4848 | 0.8864 | 0.8839 | 0.8852 |
| 0.1312 | 6.0 | 270 | 0.4987 | 0.8872 | 0.8866 | 0.8869 |
| 0.1057 | 7.0 | 315 | 0.4840 | 0.8895 | 0.8848 | 0.8871 |
| 0.0935 | 8.0 | 360 | 0.4753 | 0.8887 | 0.8840 | 0.8863 |
| 0.0835 | 9.0 | 405 | 0.4676 | 0.8901 | 0.8872 | 0.8887 |
| 0.0749 | 10.0 | 450 | 0.4808 | 0.8901 | 0.8867 | 0.8884 |
| 0.0625 | 11.0 | 495 | 0.4760 | 0.8893 | 0.8857 | 0.8875 |
| 0.0607 | 12.0 | 540 | 0.5113 | 0.8899 | 0.8859 | 0.8879 |
| 0.0564 | 13.0 | 585 | 0.4918 | 0.8900 | 0.8860 | 0.8880 |
| 0.0495 | 14.0 | 630 | 0.4749 | 0.8905 | 0.8868 | 0.8887 |
| 0.0446 | 15.0 | 675 | 0.4889 | 0.8888 | 0.8856 | 0.8872 |
| 0.045 | 16.0 | 720 | 0.4680 | 0.8918 | 0.8889 | 0.8904 |
### Framework versions
- Transformers 4.26.0
- Pytorch 1.14.0a0+410ce96
- Datasets 2.9.0
- Tokenizers 0.13.2
|
e6474110bd8d039ef1c1d52f532f430e
|
jonatasgrosman/exp_w2v2t_pl_vp-it_s474
|
jonatasgrosman
|
wav2vec2
| 10 | 6 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
|
['pl']
|
['mozilla-foundation/common_voice_7_0']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['automatic-speech-recognition', 'pl']
| false | true | true | 469 | false |
# exp_w2v2t_pl_vp-it_s474
Fine-tuned [facebook/wav2vec2-large-it-voxpopuli](https://huggingface.co/facebook/wav2vec2-large-it-voxpopuli) for speech recognition using the train split of [Common Voice 7.0 (pl)](https://huggingface.co/datasets/mozilla-foundation/common_voice_7_0).
When using this model, make sure that your speech input is sampled at 16kHz.
This model has been fine-tuned by the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) tool.
|
b06ab4a11a893416724ba819cf07f3f9
|
marccgrau/whisper-small-allSNR-v8
|
marccgrau
|
whisper
| 13 | 3 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
|
['de']
|
['marccgrau/sbbdata_allSNR']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['sbb-asr', 'generated_from_trainer']
| true | true | true | 1,599 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Whisper Small German SBB all SNR - v8
This model is a fine-tuned version of [openai/whisper-small](https://huggingface.co/openai/whisper-small) on the SBB Dataset 05.01.2023 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0246
- Wer: 0.0235
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 100
- training_steps: 600
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 1.3694 | 0.36 | 100 | 0.2304 | 0.0495 |
| 0.0696 | 0.71 | 200 | 0.0311 | 0.0209 |
| 0.0324 | 1.07 | 300 | 0.0337 | 0.0298 |
| 0.0215 | 1.42 | 400 | 0.0254 | 0.0184 |
| 0.016 | 1.78 | 500 | 0.0279 | 0.0209 |
| 0.0113 | 2.14 | 600 | 0.0246 | 0.0235 |
### Framework versions
- Transformers 4.25.1
- Pytorch 1.13.1
- Datasets 2.8.0
- Tokenizers 0.12.1
|
198d46b0949ab678ad9f87f27625dfd0
|
dbmdz/bert-base-german-europeana-uncased
|
dbmdz
|
bert
| 8 | 22 |
transformers
| 0 | null | true | true | true |
mit
|
['de']
| null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['historic german']
| false | true | true | 2,334 | false |
# 🤗 + 📚 dbmdz BERT models
In this repository the MDZ Digital Library team (dbmdz) at the Bavarian State
Library open sources German Europeana BERT models 🎉
# German Europeana BERT
We use the open source [Europeana newspapers](http://www.europeana-newspapers.eu/)
that were provided by *The European Library*. The final
training corpus has a size of 51GB and consists of 8,035,986,369 tokens.
Detailed information about the data and pretraining steps can be found in
[this repository](https://github.com/stefan-it/europeana-bert).
## Model weights
Currently only PyTorch-[Transformers](https://github.com/huggingface/transformers)
compatible weights are available. If you need access to TensorFlow checkpoints,
please raise an issue!
| Model | Downloads
| ------------------------------------------ | ---------------------------------------------------------------------------------------------------------------
| `dbmdz/bert-base-german-europeana-uncased` | [`config.json`](https://cdn.huggingface.co/dbmdz/bert-base-german-europeana-uncased/config.json) • [`pytorch_model.bin`](https://cdn.huggingface.co/dbmdz/bert-base-german-europeana-uncased/pytorch_model.bin) • [`vocab.txt`](https://cdn.huggingface.co/dbmdz/bert-base-german-europeana-uncased/vocab.txt)
## Results
For results on Historic NER, please refer to [this repository](https://github.com/stefan-it/europeana-bert).
## Usage
With Transformers >= 2.3 our German Europeana BERT models can be loaded like:
```python
from transformers import AutoModel, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("dbmdz/bert-base-german-europeana-uncased")
model = AutoModel.from_pretrained("dbmdz/bert-base-german-europeana-uncased")
```
# Huggingface model hub
All models are available on the [Huggingface model hub](https://huggingface.co/dbmdz).
# Contact (Bugs, Feedback, Contribution and more)
For questions about our BERT models just open an issue
[here](https://github.com/dbmdz/berts/issues/new) 🤗
# Acknowledgments
Research supported with Cloud TPUs from Google's TensorFlow Research Cloud (TFRC).
Thanks for providing access to the TFRC ❤️
Thanks to the generous support from the [Hugging Face](https://huggingface.co/) team,
it is possible to download both cased and uncased models from their S3 storage 🤗
|
d0a4f951f0e70942ef7e38a75f083280
|
liyijing024/swin-base-patch4-window7-224-in22k-Chinese-finetuned
|
liyijing024
|
swin
| 9 | 13 |
transformers
| 0 |
image-classification
| true | false | false |
apache-2.0
| null |
['imagefolder']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,513 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# swin-base-patch4-window7-224-in22k-Chinese-finetuned
This model is a fine-tuned version of [microsoft/swin-base-patch4-window7-224-in22k](https://huggingface.co/microsoft/swin-base-patch4-window7-224-in22k) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0000
- Accuracy: 1.0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 128
- eval_batch_size: 128
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 512
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.0121 | 0.99 | 140 | 0.0001 | 1.0 |
| 0.0103 | 1.99 | 280 | 0.0001 | 1.0 |
| 0.0049 | 2.99 | 420 | 0.0000 | 1.0 |
### Framework versions
- Transformers 4.20.1
- Pytorch 1.8.0+cu111
- Datasets 2.3.3.dev0
- Tokenizers 0.12.1
|
0b8799d352c6bd138d5e37e419af2a58
|
husnu/xtremedistil-l6-h256-uncased-TQUAD-finetuned_lr-2e-05_epochs-9
|
husnu
|
bert
| 12 | 5 |
transformers
| 0 |
question-answering
| true | false | false |
mit
| null |
['squad']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,647 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xtremedistil-l6-h256-uncased-TQUAD-finetuned_lr-2e-05_epochs-9
This model is a fine-tuned version of [microsoft/xtremedistil-l6-h256-uncased](https://huggingface.co/microsoft/xtremedistil-l6-h256-uncased) on the Turkish squad dataset.
It achieves the following results on the evaluation set:
- Loss: 2.2340
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 9
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 3.5236 | 1.0 | 1050 | 3.0042 |
| 2.8489 | 2.0 | 2100 | 2.5866 |
| 2.5485 | 3.0 | 3150 | 2.3526 |
| 2.4067 | 4.0 | 4200 | 2.3535 |
| 2.3091 | 5.0 | 5250 | 2.2862 |
| 2.2401 | 6.0 | 6300 | 2.3989 |
| 2.1715 | 7.0 | 7350 | 2.2284 |
| 2.1414 | 8.0 | 8400 | 2.2298 |
| 2.1221 | 9.0 | 9450 | 2.2340 |
### Framework versions
- Transformers 4.15.0
- Pytorch 1.10.0+cu111
- Datasets 1.17.0
- Tokenizers 0.10.3
|
eb15609aca5593c9cfb92aae5c8c58e5
|
kejian/final-mle
|
kejian
|
gpt2
| 49 | 4 |
transformers
| 0 | null | true | false | false |
apache-2.0
|
['en']
|
['kejian/codeparrot-train-more-filter-3.3b-cleaned']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 4,159 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# kejian/final-mle
This model was trained from scratch on the kejian/codeparrot-train-more-filter-3.3b-cleaned dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0008
- train_batch_size: 32
- eval_batch_size: 16
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.01
- training_steps: 50354
- mixed_precision_training: Native AMP
### Framework versions
- Transformers 4.23.0
- Pytorch 1.13.0+cu116
- Datasets 2.0.0
- Tokenizers 0.12.1
# Full config
{'dataset': {'datasets': ['kejian/codeparrot-train-more-filter-3.3b-cleaned'],
'is_split_by_sentences': True},
'generation': {'batch_size': 64,
'metrics_configs': [{}, {'n': 1}, {}],
'scenario_configs': [{'display_as_html': True,
'generate_kwargs': {'do_sample': True,
'eos_token_id': 0,
'max_length': 640,
'min_length': 10,
'temperature': 0.7,
'top_k': 0,
'top_p': 0.9},
'name': 'unconditional',
'num_samples': 512},
{'display_as_html': True,
'generate_kwargs': {'do_sample': True,
'eos_token_id': 0,
'max_length': 272,
'min_length': 10,
'temperature': 0.7,
'top_k': 0,
'top_p': 0.9},
'name': 'functions',
'num_samples': 512,
'prompts_path': 'resources/functions_csnet.jsonl',
'use_prompt_for_scoring': True}],
'scorer_config': {}},
'kl_gpt3_callback': {'gpt3_kwargs': {'model_name': 'code-cushman-001'},
'max_tokens': 64,
'num_samples': 4096},
'model': {'from_scratch': True,
'gpt2_config_kwargs': {'reorder_and_upcast_attn': True,
'scale_attn_by': True},
'path_or_name': 'codeparrot/codeparrot-small'},
'objective': {'name': 'MLE'},
'tokenizer': {'path_or_name': 'codeparrot/codeparrot-small'},
'training': {'dataloader_num_workers': 0,
'effective_batch_size': 64,
'evaluation_strategy': 'no',
'fp16': True,
'hub_model_id': 'kejian/final-mle',
'hub_strategy': 'all_checkpoints',
'learning_rate': 0.0008,
'logging_first_step': True,
'logging_steps': 1,
'num_tokens': 3300000000.0,
'output_dir': 'training_output',
'per_device_train_batch_size': 16,
'push_to_hub': True,
'remove_unused_columns': False,
'save_steps': 5000,
'save_strategy': 'steps',
'seed': 42,
'warmup_ratio': 0.01,
'weight_decay': 0.1}}
# Wandb URL:
https://wandb.ai/kejian/uncategorized/runs/1oqdxrdb
|
9de0a29b9059262a3f37aeffb45bb1e3
|
ashesicsis1/xlsr-english
|
ashesicsis1
|
wav2vec2
| 13 | 6 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
| null |
['librispeech_asr']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 2,006 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xlsr-english
This model is a fine-tuned version of [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) on the librispeech_asr dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3098
- Wer: 0.1451
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 30
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 3.2453 | 2.37 | 400 | 0.5789 | 0.4447 |
| 0.3736 | 4.73 | 800 | 0.3737 | 0.2850 |
| 0.1712 | 7.1 | 1200 | 0.3038 | 0.2136 |
| 0.117 | 9.47 | 1600 | 0.3016 | 0.2072 |
| 0.0897 | 11.83 | 2000 | 0.3158 | 0.1920 |
| 0.074 | 14.2 | 2400 | 0.3137 | 0.1831 |
| 0.0595 | 16.57 | 2800 | 0.2967 | 0.1745 |
| 0.0493 | 18.93 | 3200 | 0.3192 | 0.1670 |
| 0.0413 | 21.3 | 3600 | 0.3176 | 0.1644 |
| 0.0322 | 23.67 | 4000 | 0.3079 | 0.1598 |
| 0.0296 | 26.04 | 4400 | 0.2978 | 0.1511 |
| 0.0235 | 28.4 | 4800 | 0.3098 | 0.1451 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.10.0+cu113
- Datasets 1.18.3
- Tokenizers 0.10.3
|
0cdbd6b5460b8087e04537fcefd94239
|
sd-concepts-library/party-girl
|
sd-concepts-library
| null | 11 | 0 | null | 6 | null | false | false | false |
mit
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
[]
| false | true | true | 1,246 | false |
### Party girl on Stable Diffusion
This is the `<party-girl>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as an `object`:






|
bdee394b426176f65c70fb5707a0c536
|
LisanneH/AgeEstimation
|
LisanneH
| null | 2 | 0 | null | 2 | null | false | false | false |
unknown
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
[]
| false | true | true | 2,719 | false |
# Age estimation in supermarkets
The model analyzed in this card estimates someone's age. This project has been done for the master Applied Artificial Intelligence and is about estimating ages in supermarkets when a person wants to buy alcohol. This model's goal is to only estimate ages in an image. It will not cover ethnicities or gender.
## Model description
**Used dataset:** UTKFace images
- This dataset contains roughly 24K face images.
- The age of a person on the picture is labeled in the filename of that image.
- Since we do not have use for baby images, we decided to cut these out of the dataset, so there are 21K images left.
**Model input:** Facial images
**Model output:** For a face in a picture, the model will return the estimated age of that person. The model output also gives a confidence score for the estimation.
**Model architecture:** A Convolutional Neural Network. This CNN will perform a regression analysis to estimates the ages.
## Performance
To determine the performance of the model, the following metrics have been used:
- MSE, this metric measures how close the regression line is to the data points.
<br>   - *Our model's MSE:* 60.9
- RMSE, this metric measures the mean error that can be made.
<br>   - *Our model's RMSE:* 7.8
- MAE, this is a measure for model accuracy. The MAE is the average error that the model's predictions have in comparison with their corresponding actual targets.
<br>   - *Our model's MAE:* 5.2
Ideally, the RMSE and the MAE should be close to each other. When there is a big difference in these two numbers, it is an indication of variance in the individually errors.
Our results show that the prediction model can be around 8 years off of the actual age of a person.
We also looked at how the model performs in different age, gender and race classes. It seemed the model predicted the ages of people between 20 and 30 better than the rest. The model could also predict the ages of females better than males. The race that the model can predict the best is East Asian.
## Limitations
- **Lighting**
<br> When the lighting is poor, the age estimation can be poor as well
- **Occlusion**
<br> Partially hidden or obstructed faces might not be detected. (e.g. face masks)
- **UTKFace**
<br> The ages in this dataset are in itself estimation from a previous model. Since we do not know the exact ages of the people in the images, our model will not be the most reliable.
## Training and evaluation data
Train data: 70%
Test data: 30%
Our model has been made by trial and error. The following architecture is the outcome:
- Hidden layers: 7
- Batch size: 128
- Epochs: 65
- Optimizer: adam
- Activation: ReLu & Linear
|
c430d3b78cc3054ceaef8c80ff51558c
|
facebook/wav2vec2-conformer-rope-large
|
facebook
|
wav2vec2-conformer
| 5 | 3 |
transformers
| 1 | null | true | false | false |
apache-2.0
|
['en']
|
['librispeech_asr']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['speech']
| false | true | true | 1,241 | false |
# Wav2Vec2-Conformer-Large with Rotary Position Embeddings
Wav2Vec2 Conformer with rotary position embeddings, pretrained on 960 hours of Librispeech on 16kHz sampled speech audio. When using the model make sure that your speech input is also sampled at 16Khz.
**Note**: This model does not have a tokenizer as it was pretrained on audio alone. In order to use this model **speech recognition**, a tokenizer should be created and the model should be fine-tuned on labeled text data. Check out [this blog](https://huggingface.co/blog/fine-tune-wav2vec2-english) for more in-detail explanation of how to fine-tune the model.
**Paper**: [fairseq S2T: Fast Speech-to-Text Modeling with fairseq](https://arxiv.org/abs/2010.05171)
**Authors**: Changhan Wang, Yun Tang, Xutai Ma, Anne Wu, Sravya Popuri, Dmytro Okhonko, Juan Pino
The results of Wav2Vec2-Conformer can be found in Table 3 and Table 4 of the [official paper](https://arxiv.org/abs/2010.05171).
The original model can be found under https://github.com/pytorch/fairseq/tree/master/examples/wav2vec#wav2vec-20.
# Usage
See [this notebook](https://colab.research.google.com/drive/1FjTsqbYKphl9kL-eILgUc-bl4zVThL8F?usp=sharing) for more information on how to fine-tune the model.
|
d926e0a25eabb887bda498a01057e91a
|
julius-br/gottbert-base-finetuned-fbi-german
|
julius-br
|
roberta
| 10 | 1 |
transformers
| 0 |
text-classification
| true | false | false |
mit
|
['de']
| null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['roberta', 'gottbert']
| false | true | true | 589 | false |
# Fine-tuned gottbert-base to detect Feature Requests & Bug Reports in German App Store Reviews
## Overview
**Language model:** uklfr/gottbert-base
**Language:** German
**Training & Eval data:** [GARFAB2022Weighted](https://huggingface.co/datasets/julius-br/GARFAB) <br>
**Published**: September 21th, 2022 <br>
**Author**: Julius Breiholz
## Performance
| Label | Precision | Recall | F1-Score |
| --- | --- | --- | --- |
| Irrelevant | 0,95 | 0,91 | 0,93 |
| Bug Report | 0,82 | 0,91 | 0,86 |
| Feature Request | 0,87 | 0,82 | 0,85 |
| all classes (avg.) | 0,88 | 0,88 | 0,88 |
|
3328e54192629acc80e6d83489c3a185
|
jzju/whisper-medium-nst
|
jzju
|
whisper
| 15 | 3 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
|
['sv']
|
['jzju/nst']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['hf-asr-leaderboard', 'generated_from_trainer']
| true | true | true | 3,048 | false |
This model is a fine-tuned version of [openai/whisper-medium](https://huggingface.co/openai/whisper-medium) on the NST dataset.
Aborted after 6000 steps / 0.4 epochs as it wasen't promising when manualy evaluated on an SVT broadcast. The punctation, capitalization and entities like Norge seems worse than original so probably need to fix dataset before more training. Re-split the test dataset to contain a thousand samples so evaluate didn't take hours.
### Training results
| Step | Wer |
|:----:|:----:|
| 1000 | 9.42 |
| 2000 | 8.13 |
| 3000 | 7.27 |
| 4000 | 7.05 |
| 5000 | 6.60 |
| 6000 | 6.49 |
Source audio: https://www.youtube.com/watch?v=9XLHas6oD_E
This model:
```
[00:00:00.000 --> 00:00:03.040] Ta nu ett djupt andetag för er kan inte alla göra.
[00:00:03.040 --> 00:00:11.840] För de allra flesta så är det en självklarhet att kunna andas utan större problem, men har man lomsjukdomens hysterisk fibrås är det inte så.
[00:00:11.840 --> 00:00:16.240] Nu finns en ny medicin, men den är inte subventionerad i Sverige.
[00:00:16.240 --> 00:00:22.960] Nej, om man vill kunna andas i sverige så får man söka sig till svarta marknaden i mindre noggräknade länder som är norrje.
[00:00:22.960 --> 00:00:39.360] Nu ska vi åka till norrje och så ska vi möta upp då en person som ska jag köpa då kafttrio av honom som han får då gratis från norska staten och som han då säljer vidare.
[00:00:39.360 --> 00:00:54.560] Okej, i norrje delar läkarna ut medicin i kafttri och gratis till vilken jävla gud som helst och det är bra för nu kan helen andas ut och in.Det ser okej bra att hon får hosta upp inte bara slemme utan även tjugosex tusen i kontanter.
[00:00:54.560 --> 00:01:00.320] Jag fattar inte, sverige är ju världsbäst på subventioner, i alla fall i södra sverige, ja när det gäller äl.
```
Whisper medium:
```
[00:00:00.000 --> 00:00:03.080] Ta ett djupt antal, för det kan inte alla göra.
[00:00:03.080 --> 00:00:08.000] För de flesta är det självklar att kunna andas utan problem.
[00:00:08.000 --> 00:00:12.120] Men har man Lundsjukdomens fibros, är det inte så.
[00:00:12.120 --> 00:00:16.200] Nu finns en ny medicin, men den är inte subventionerad i Sverige.
[00:00:16.200 --> 00:00:20.160] Om man vill andas i Sverige, så får man söka sig till svarta marknaden-
[00:00:20.160 --> 00:00:22.920] -i mindre noggräknade länder som Norge.
[00:00:22.920 --> 00:00:29.840] Nu ska vi åka till Norge och möta upp en person som jag ska köpa.
[00:00:29.840 --> 00:00:37.480] Ja, kaffetrio av honom. Som han får gratis från Norska staten.
[00:00:37.480 --> 00:00:40.200] -Och som han säljer vidare. -Okej.
[00:00:40.200 --> 00:00:44.560] I Norge delar läkarna ut medicinen kaffetrio gratis till vilken gud som helst.
[00:00:44.560 --> 00:00:49.360] Det är bra, för nu kan Helen andas ut och in.
[00:00:49.360 --> 00:00:54.280] Det är inte bara att hon får rosta upp, utan även 26 000 kontanter.
[00:00:54.280 --> 00:00:59.320] Sverige är världsbäst på subventioner, i alla fall i södra Sverige.
```
|
1149e67c6d32762c2102f24b19c960d1
|
hassnain/wav2vec2-base-timit-demo-colab647
|
hassnain
|
wav2vec2
| 12 | 5 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,463 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-base-timit-demo-colab647
This model is a fine-tuned version of [facebook/wav2vec2-base](https://huggingface.co/facebook/wav2vec2-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5534
- Wer: 0.4799
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 1000
- num_epochs: 30
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 5.2072 | 7.04 | 500 | 3.7757 | 1.0 |
| 1.2053 | 14.08 | 1000 | 0.6128 | 0.5648 |
| 0.3922 | 21.13 | 1500 | 0.5547 | 0.5035 |
| 0.2157 | 28.17 | 2000 | 0.5534 | 0.4799 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.11.0+cu113
- Datasets 1.18.3
- Tokenizers 0.10.3
|
f09579a889d0aea4206469cf9738691d
|
lmqg/bart-base-subjqa-books-qg
|
lmqg
|
bart
| 35 | 1 |
transformers
| 0 |
text2text-generation
| true | false | false |
cc-by-4.0
|
['en']
|
['lmqg/qg_subjqa']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['question generation']
| true | true | true | 3,900 | false |
# Model Card of `lmqg/bart-base-subjqa-books-qg`
This model is fine-tuned version of [lmqg/bart-base-squad](https://huggingface.co/lmqg/bart-base-squad) for question generation task on the [lmqg/qg_subjqa](https://huggingface.co/datasets/lmqg/qg_subjqa) (dataset_name: books) via [`lmqg`](https://github.com/asahi417/lm-question-generation).
### Overview
- **Language model:** [lmqg/bart-base-squad](https://huggingface.co/lmqg/bart-base-squad)
- **Language:** en
- **Training data:** [lmqg/qg_subjqa](https://huggingface.co/datasets/lmqg/qg_subjqa) (books)
- **Online Demo:** [https://autoqg.net/](https://autoqg.net/)
- **Repository:** [https://github.com/asahi417/lm-question-generation](https://github.com/asahi417/lm-question-generation)
- **Paper:** [https://arxiv.org/abs/2210.03992](https://arxiv.org/abs/2210.03992)
### Usage
- With [`lmqg`](https://github.com/asahi417/lm-question-generation#lmqg-language-model-for-question-generation-)
```python
from lmqg import TransformersQG
# initialize model
model = TransformersQG(language="en", model="lmqg/bart-base-subjqa-books-qg")
# model prediction
questions = model.generate_q(list_context="William Turner was an English painter who specialised in watercolour landscapes", list_answer="William Turner")
```
- With `transformers`
```python
from transformers import pipeline
pipe = pipeline("text2text-generation", "lmqg/bart-base-subjqa-books-qg")
output = pipe("<hl> Beyonce <hl> further expanded her acting career, starring as blues singer Etta James in the 2008 musical biopic, Cadillac Records.")
```
## Evaluation
- ***Metric (Question Generation)***: [raw metric file](https://huggingface.co/lmqg/bart-base-subjqa-books-qg/raw/main/eval/metric.first.sentence.paragraph_answer.question.lmqg_qg_subjqa.books.json)
| | Score | Type | Dataset |
|:-----------|--------:|:-------|:-----------------------------------------------------------------|
| BERTScore | 92.96 | books | [lmqg/qg_subjqa](https://huggingface.co/datasets/lmqg/qg_subjqa) |
| Bleu_1 | 22.47 | books | [lmqg/qg_subjqa](https://huggingface.co/datasets/lmqg/qg_subjqa) |
| Bleu_2 | 13.03 | books | [lmqg/qg_subjqa](https://huggingface.co/datasets/lmqg/qg_subjqa) |
| Bleu_3 | 4.52 | books | [lmqg/qg_subjqa](https://huggingface.co/datasets/lmqg/qg_subjqa) |
| Bleu_4 | 2.03 | books | [lmqg/qg_subjqa](https://huggingface.co/datasets/lmqg/qg_subjqa) |
| METEOR | 20.57 | books | [lmqg/qg_subjqa](https://huggingface.co/datasets/lmqg/qg_subjqa) |
| MoverScore | 62.85 | books | [lmqg/qg_subjqa](https://huggingface.co/datasets/lmqg/qg_subjqa) |
| ROUGE_L | 23.24 | books | [lmqg/qg_subjqa](https://huggingface.co/datasets/lmqg/qg_subjqa) |
## Training hyperparameters
The following hyperparameters were used during fine-tuning:
- dataset_path: lmqg/qg_subjqa
- dataset_name: books
- input_types: ['paragraph_answer']
- output_types: ['question']
- prefix_types: None
- model: lmqg/bart-base-squad
- max_length: 512
- max_length_output: 32
- epoch: 2
- batch: 32
- lr: 0.0001
- fp16: False
- random_seed: 1
- gradient_accumulation_steps: 4
- label_smoothing: 0.0
The full configuration can be found at [fine-tuning config file](https://huggingface.co/lmqg/bart-base-subjqa-books-qg/raw/main/trainer_config.json).
## Citation
```
@inproceedings{ushio-etal-2022-generative,
title = "{G}enerative {L}anguage {M}odels for {P}aragraph-{L}evel {Q}uestion {G}eneration",
author = "Ushio, Asahi and
Alva-Manchego, Fernando and
Camacho-Collados, Jose",
booktitle = "Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing",
month = dec,
year = "2022",
address = "Abu Dhabi, U.A.E.",
publisher = "Association for Computational Linguistics",
}
```
|
c242404da2d69a4575245cbd96379620
|
Helsinki-NLP/opus-mt-fr-sv
|
Helsinki-NLP
|
marian
| 10 | 51 |
transformers
| 0 |
translation
| true | true | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['translation']
| false | true | true | 770 | false |
### opus-mt-fr-sv
* source languages: fr
* target languages: sv
* OPUS readme: [fr-sv](https://github.com/Helsinki-NLP/OPUS-MT-train/blob/master/models/fr-sv/README.md)
* dataset: opus
* model: transformer-align
* pre-processing: normalization + SentencePiece
* download original weights: [opus-2020-01-24.zip](https://object.pouta.csc.fi/OPUS-MT-models/fr-sv/opus-2020-01-24.zip)
* test set translations: [opus-2020-01-24.test.txt](https://object.pouta.csc.fi/OPUS-MT-models/fr-sv/opus-2020-01-24.test.txt)
* test set scores: [opus-2020-01-24.eval.txt](https://object.pouta.csc.fi/OPUS-MT-models/fr-sv/opus-2020-01-24.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| Tatoeba.fr.sv | 60.1 | 0.744 |
|
4a6d4b8ad79c2ddb118fcf30cedbb568
|
RayK/distilbert-base-uncased-finetuned-cola
|
RayK
|
distilbert
| 47 | 1 |
transformers
| 0 |
text-classification
| true | false | false |
apache-2.0
| null |
['glue']
| null | 1 | 1 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,565 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-cola
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the glue dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6949
- Matthews Correlation: 0.5410
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Matthews Correlation |
|:-------------:|:-----:|:----:|:---------------:|:--------------------:|
| 0.5241 | 1.0 | 535 | 0.5322 | 0.3973 |
| 0.356 | 2.0 | 1070 | 0.5199 | 0.4836 |
| 0.2402 | 3.0 | 1605 | 0.6086 | 0.5238 |
| 0.166 | 4.0 | 2140 | 0.6949 | 0.5410 |
| 0.134 | 5.0 | 2675 | 0.8254 | 0.5253 |
### Framework versions
- Transformers 4.21.0
- Pytorch 1.9.1
- Datasets 1.12.1
- Tokenizers 0.12.1
|
4ad38f5cde43bad51586cd3ddf61d96b
|
jonatasgrosman/exp_w2v2t_it_vp-es_s496
|
jonatasgrosman
|
wav2vec2
| 10 | 7 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
|
['it']
|
['mozilla-foundation/common_voice_7_0']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['automatic-speech-recognition', 'it']
| false | true | true | 469 | false |
# exp_w2v2t_it_vp-es_s496
Fine-tuned [facebook/wav2vec2-large-es-voxpopuli](https://huggingface.co/facebook/wav2vec2-large-es-voxpopuli) for speech recognition using the train split of [Common Voice 7.0 (it)](https://huggingface.co/datasets/mozilla-foundation/common_voice_7_0).
When using this model, make sure that your speech input is sampled at 16kHz.
This model has been fine-tuned by the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) tool.
|
28246c66c3bf79605592881894d581a8
|
Fedeya/federico-minaya
|
Fedeya
| null | 24 | 2 |
diffusers
| 0 | null | false | false | false |
mit
| null | null | null | 2 | 2 | 0 | 0 | 0 | 0 | 0 |
[]
| false | true | true | 1,428 | false |
### federico minaya on Stable Diffusion via Dreambooth
#### model by Fedeya
This your the Stable Diffusion model fine-tuned the federico minaya concept taught to Stable Diffusion with Dreambooth.
It can be used by modifying the `instance_prompt`: **a photo of sks federicominaya**
You can also train your own concepts and upload them to the library by using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_training.ipynb).
And you can run your new concept via `diffusers`: [Colab Notebook for Inference](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_inference.ipynb), [Spaces with the Public Concepts loaded](https://huggingface.co/spaces/sd-dreambooth-library/stable-diffusion-dreambooth-concepts)
Here are the images used for training this concept:






|
4d3598be1373be84b635917181f4f131
|
jjjj-j/distilbert-base-uncased-response-finetuned-cola
|
jjjj-j
|
distilbert
| 13 | 4 |
transformers
| 0 |
text-classification
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,953 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-response-finetuned-cola
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.9774
- Matthews Correlation: 0.3330
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Matthews Correlation |
|:-------------:|:-----:|:----:|:---------------:|:--------------------:|
| No log | 1.0 | 23 | 1.0662 | 0.0 |
| No log | 2.0 | 46 | 1.0175 | 0.0 |
| No log | 3.0 | 69 | 1.0001 | 0.0 |
| No log | 4.0 | 92 | 0.9852 | 0.1196 |
| No log | 5.0 | 115 | 0.9836 | 0.2326 |
| No log | 6.0 | 138 | 0.9680 | 0.1808 |
| No log | 7.0 | 161 | 0.9774 | 0.3330 |
| No log | 8.0 | 184 | 0.9786 | 0.2881 |
| No log | 9.0 | 207 | 0.9974 | 0.2235 |
| No log | 10.0 | 230 | 0.9957 | 0.2031 |
### Framework versions
- Transformers 4.24.0
- Pytorch 1.12.1+cu113
- Datasets 2.6.1
- Tokenizers 0.13.2
|
d637b9cc436feda778dad1393c6cd53c
|
jonatasgrosman/exp_w2v2t_it_wav2vec2_s211
|
jonatasgrosman
|
wav2vec2
| 10 | 7 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
|
['it']
|
['mozilla-foundation/common_voice_7_0']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['automatic-speech-recognition', 'it']
| false | true | true | 456 | false |
# exp_w2v2t_it_wav2vec2_s211
Fine-tuned [facebook/wav2vec2-large-lv60](https://huggingface.co/facebook/wav2vec2-large-lv60) for speech recognition using the train split of [Common Voice 7.0 (it)](https://huggingface.co/datasets/mozilla-foundation/common_voice_7_0).
When using this model, make sure that your speech input is sampled at 16kHz.
This model has been fine-tuned by the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) tool.
|
58fd2468cbc094544e01b3499ae76d8c
|
TransQuest/monotransquest-hter-en_lv-it-nmt
|
TransQuest
|
xlm-roberta
| 8 | 5 |
transformers
| 0 |
text-classification
| true | false | false |
apache-2.0
|
['en-lv']
| null | null | 1 | 1 | 0 | 0 | 0 | 0 | 0 |
['Quality Estimation', 'monotransquest', 'hter']
| false | true | true | 5,312 | false |
# TransQuest: Translation Quality Estimation with Cross-lingual Transformers
The goal of quality estimation (QE) is to evaluate the quality of a translation without having access to a reference translation. High-accuracy QE that can be easily deployed for a number of language pairs is the missing piece in many commercial translation workflows as they have numerous potential uses. They can be employed to select the best translation when several translation engines are available or can inform the end user about the reliability of automatically translated content. In addition, QE systems can be used to decide whether a translation can be published as it is in a given context, or whether it requires human post-editing before publishing or translation from scratch by a human. The quality estimation can be done at different levels: document level, sentence level and word level.
With TransQuest, we have opensourced our research in translation quality estimation which also won the sentence-level direct assessment quality estimation shared task in [WMT 2020](http://www.statmt.org/wmt20/quality-estimation-task.html). TransQuest outperforms current open-source quality estimation frameworks such as [OpenKiwi](https://github.com/Unbabel/OpenKiwi) and [DeepQuest](https://github.com/sheffieldnlp/deepQuest).
## Features
- Sentence-level translation quality estimation on both aspects: predicting post editing efforts and direct assessment.
- Word-level translation quality estimation capable of predicting quality of source words, target words and target gaps.
- Outperform current state-of-the-art quality estimation methods like DeepQuest and OpenKiwi in all the languages experimented.
- Pre-trained quality estimation models for fifteen language pairs are available in [HuggingFace.](https://huggingface.co/TransQuest)
## Installation
### From pip
```bash
pip install transquest
```
### From Source
```bash
git clone https://github.com/TharinduDR/TransQuest.git
cd TransQuest
pip install -r requirements.txt
```
## Using Pre-trained Models
```python
import torch
from transquest.algo.sentence_level.monotransquest.run_model import MonoTransQuestModel
model = MonoTransQuestModel("xlmroberta", "TransQuest/monotransquest-hter-en_lv-it-nmt", num_labels=1, use_cuda=torch.cuda.is_available())
predictions, raw_outputs = model.predict([["Reducerea acestor conflicte este importantă pentru conservare.", "Reducing these conflicts is not important for preservation."]])
print(predictions)
```
## Documentation
For more details follow the documentation.
1. **[Installation](https://tharindudr.github.io/TransQuest/install/)** - Install TransQuest locally using pip.
2. **Architectures** - Checkout the architectures implemented in TransQuest
1. [Sentence-level Architectures](https://tharindudr.github.io/TransQuest/architectures/sentence_level_architectures/) - We have released two architectures; MonoTransQuest and SiameseTransQuest to perform sentence level quality estimation.
2. [Word-level Architecture](https://tharindudr.github.io/TransQuest/architectures/word_level_architecture/) - We have released MicroTransQuest to perform word level quality estimation.
3. **Examples** - We have provided several examples on how to use TransQuest in recent WMT quality estimation shared tasks.
1. [Sentence-level Examples](https://tharindudr.github.io/TransQuest/examples/sentence_level_examples/)
2. [Word-level Examples](https://tharindudr.github.io/TransQuest/examples/word_level_examples/)
4. **Pre-trained Models** - We have provided pretrained quality estimation models for fifteen language pairs covering both sentence-level and word-level
1. [Sentence-level Models](https://tharindudr.github.io/TransQuest/models/sentence_level_pretrained/)
2. [Word-level Models](https://tharindudr.github.io/TransQuest/models/word_level_pretrained/)
5. **[Contact](https://tharindudr.github.io/TransQuest/contact/)** - Contact us for any issues with TransQuest
## Citations
If you are using the word-level architecture, please consider citing this paper which is accepted to [ACL 2021](https://2021.aclweb.org/).
```bash
@InProceedings{ranasinghe2021,
author = {Ranasinghe, Tharindu and Orasan, Constantin and Mitkov, Ruslan},
title = {An Exploratory Analysis of Multilingual Word Level Quality Estimation with Cross-Lingual Transformers},
booktitle = {Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics},
year = {2021}
}
```
If you are using the sentence-level architectures, please consider citing these papers which were presented in [COLING 2020](https://coling2020.org/) and in [WMT 2020](http://www.statmt.org/wmt20/) at EMNLP 2020.
```bash
@InProceedings{transquest:2020a,
author = {Ranasinghe, Tharindu and Orasan, Constantin and Mitkov, Ruslan},
title = {TransQuest: Translation Quality Estimation with Cross-lingual Transformers},
booktitle = {Proceedings of the 28th International Conference on Computational Linguistics},
year = {2020}
}
```
```bash
@InProceedings{transquest:2020b,
author = {Ranasinghe, Tharindu and Orasan, Constantin and Mitkov, Ruslan},
title = {TransQuest at WMT2020: Sentence-Level Direct Assessment},
booktitle = {Proceedings of the Fifth Conference on Machine Translation},
year = {2020}
}
```
|
88bfd1f4c6aa961c56b5a1b5819d832e
|
nielsr/segformer-trainer-test
|
nielsr
|
segformer
| 22 | 2 |
transformers
| 0 |
image-segmentation
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['image-segmentation', 'vision', 'generated_from_trainer']
| true | true | true | 1,086 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# segformer-trainer-test
This model is a fine-tuned version of [nvidia/mit-b0](https://huggingface.co/nvidia/mit-b0) on the segments/sidewalk-semantic dataset.
It achieves the following results on the evaluation set:
- Loss: 1.3886
- Mean Iou: 0.1391
- Mean Accuracy: 0.1905
- Overall Accuracy: 0.7192
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10.0
### Training results
### Framework versions
- Transformers 4.19.0.dev0
- Pytorch 1.11.0+cu113
- Datasets 2.0.0
- Tokenizers 0.11.6
|
f12ce73f948a781e34f1a24e06351e0f
|
firqaaa/indo-sentence-bert-base
|
firqaaa
|
bert
| 12 | 98 |
sentence-transformers
| 1 |
sentence-similarity
| true | false | false |
apache-2.0
|
['id']
| null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['sentence-transformers', 'feature-extraction', 'sentence-similarity', 'transformers']
| false | true | true | 3,932 | false |
# indo-sentence-bert-base
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
<!--- Describe your model here -->
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["Ibukota Perancis adalah Paris",
"Menara Eifel terletak di Paris, Perancis",
"Pizza adalah makanan khas Italia",
"Saya kuliah di Carneige Mellon University"]
model = SentenceTransformer('firqaaa/indo-sentence-bert-base')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ["Ibukota Perancis adalah Paris",
"Menara Eifel terletak di Paris, Perancis",
"Pizza adalah makanan khas Italia",
"Saya kuliah di Carneige Mellon University"]
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('firqaaa/indo-sentence-bert-base')
model = AutoModel.from_pretrained('firqaaa/indo-sentence-bert-base')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, mean pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
<!--- Describe how your model was evaluated -->
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name={MODEL_NAME})
## Training
The model was trained with the parameters:
**DataLoader**:
`sentence_transformers.datasets.NoDuplicatesDataLoader.NoDuplicatesDataLoader` of length 19644 with parameters:
```
{'batch_size': 16}
```
**Loss**:
`sentence_transformers.losses.MultipleNegativesRankingLoss.MultipleNegativesRankingLoss` with parameters:
```
{'scale': 20.0, 'similarity_fct': 'cos_sim'}
```
Parameters of the fit()-Method:
```
{
"epochs": 5,
"evaluation_steps": 0,
"evaluator": "NoneType",
"max_grad_norm": 1,
"optimizer_class": "<class 'torch.optim.adamw.AdamW'>",
"optimizer_params": {
"lr": 2e-05
},
"scheduler": "WarmupLinear",
"steps_per_epoch": null,
"warmup_steps": 9930,
"weight_decay": 0.01
}
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 512, 'do_lower_case': False}) with Transformer model: BertModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Citing & Authors
<!--- Describe where people can find more information -->
|
3b5cec164032a02e8270aefaca998ea4
|
muhtasham/mini-mlm-imdb-target-tweet
|
muhtasham
|
bert
| 10 | 1 |
transformers
| 0 |
text-classification
| true | false | false |
apache-2.0
| null |
['tweet_eval']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,543 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mini-mlm-imdb-target-tweet
This model is a fine-tuned version of [muhtasham/mini-mlm-imdb](https://huggingface.co/muhtasham/mini-mlm-imdb) on the tweet_eval dataset.
It achieves the following results on the evaluation set:
- Loss: 1.3042
- Accuracy: 0.7674
- F1: 0.7669
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: constant
- num_epochs: 200
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 0.8543 | 4.9 | 500 | 0.6920 | 0.7674 | 0.7571 |
| 0.3797 | 9.8 | 1000 | 0.7231 | 0.7727 | 0.7709 |
| 0.1668 | 14.71 | 1500 | 0.9171 | 0.7594 | 0.7583 |
| 0.068 | 19.61 | 2000 | 1.1558 | 0.7647 | 0.7642 |
| 0.0409 | 24.51 | 2500 | 1.3042 | 0.7674 | 0.7669 |
### Framework versions
- Transformers 4.25.1
- Pytorch 1.12.1
- Datasets 2.7.1
- Tokenizers 0.13.2
|
5d4e728ebb846c802f6f7318eec60c41
|
chanind/frame-semantic-transformer-base
|
chanind
|
t5
| 7 | 306 |
transformers
| 0 |
text2text-generation
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
[]
| false | true | true | 1,151 | false |
Fine-tuned T5 base model for use as a frame semantic parser in the [Frame Semantic Transformer](https://github.com/chanind/frame-semantic-transformer) project. This model is trained on data from [FrameNet 1.7](https://framenet2.icsi.berkeley.edu/).
### Usage
This is meant to be used a part of [Frame Semantic Transformer](https://github.com/chanind/frame-semantic-transformer). See that project for usage instructions.
### Tasks
This model is trained to perform 3 tasks related to semantic frame parsing:
1. Identify frame trigger locations in the text
2. Classify the frame given a trigger location
3. Extract frame elements in the sentence
### Performance
This model is trained and evaluated using the same train/dev/test splits from FrameNet 1.7 annotated corpora as used by [Open Sesame](https://github.com/swabhs/open-sesame).
| Task | F1 Score (Dev) | F1 Score (Test) |
| ---------------------- | -------------- | --------------- |
| Trigger identification | 0.78 | 0.71 |
| Frame Classification | 0.89 | 0.87 |
| Argument Extraction | 0.74 | 0.72 |
|
e93b5e49fadffb2eacd5114a8de63bcd
|
Nhat1904/mis_515_bert
|
Nhat1904
|
bert
| 8 | 14 |
transformers
| 0 |
text-classification
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,249 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mis_515_bert
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3636
- Accuracy: 0.9073
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.4773 | 1.0 | 1125 | 0.3741 | 0.8777 |
| 0.2705 | 2.0 | 2250 | 0.3636 | 0.9073 |
### Framework versions
- Transformers 4.25.1
- Pytorch 1.13.0+cu116
- Datasets 2.7.1
- Tokenizers 0.13.2
|
2de79ee88061da8ae3afb5d87e4a8e8f
|
ParkSaeroyi/distilroberta-base-finetuned-wikitext2
|
ParkSaeroyi
|
roberta
| 9 | 2 |
transformers
| 0 |
fill-mask
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,272 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilroberta-base-finetuned-wikitext2
This model is a fine-tuned version of [distilroberta-base](https://huggingface.co/distilroberta-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 8.3687
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| No log | 1.0 | 6 | 8.8622 |
| No log | 2.0 | 12 | 8.4576 |
| No log | 3.0 | 18 | 8.4412 |
### Framework versions
- Transformers 4.22.0.dev0
- Pytorch 1.12.0+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
d93149c4a526fc2753135a7f7b517417
|
muhtasham/bert-base-mlm-finetuned-emotion
|
muhtasham
|
bert
| 6 | 6 |
transformers
| 0 |
fill-mask
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,400 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-mlm-finetuned-emotion
This model is a fine-tuned version of [google/bert_uncased_L-12_H-768_A-12](https://huggingface.co/google/bert_uncased_L-12_H-768_A-12) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 2.3374
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: constant
- num_epochs: 200
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 2.4247 | 5.75 | 500 | 2.3526 |
| 2.1825 | 11.49 | 1000 | 2.2778 |
| 2.0578 | 17.24 | 1500 | 2.3802 |
| 1.9059 | 22.99 | 2000 | 2.3358 |
| 1.7966 | 28.74 | 2500 | 2.3374 |
### Framework versions
- Transformers 4.25.1
- Pytorch 1.12.1+cu113
- Datasets 2.7.1
- Tokenizers 0.13.2
|
b1047df9fa82a2e2557fbc12b96908cb
|
muhtasham/bert-small-finetuned-wnut17-ner-longer6
|
muhtasham
|
bert
| 12 | 5 |
transformers
| 0 |
token-classification
| true | false | false |
apache-2.0
| null |
['wnut_17']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,589 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-small-finetuned-wnut17-ner-longer6
This model is a fine-tuned version of [muhtasham/bert-small-finetuned-wnut17-ner](https://huggingface.co/muhtasham/bert-small-finetuned-wnut17-ner) on the wnut_17 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4037
- Precision: 0.5667
- Recall: 0.4270
- F1: 0.4870
- Accuracy: 0.9268
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 425 | 0.3744 | 0.5626 | 0.4139 | 0.4769 | 0.9248 |
| 0.085 | 2.0 | 850 | 0.3914 | 0.5814 | 0.4270 | 0.4924 | 0.9271 |
| 0.0652 | 3.0 | 1275 | 0.4037 | 0.5667 | 0.4270 | 0.4870 | 0.9268 |
### Framework versions
- Transformers 4.21.1
- Pytorch 1.12.1+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
f7b06844cf3ec2480169c1cd72d1004b
|
SergenK/nes-cover-art-image-generator
|
SergenK
| null | 23 | 0 |
diffusers
| 0 |
text-to-image
| false | false | false |
creativeml-openrail-m
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['text-to-image', 'stable-diffusion']
| false | true | true | 932 | false |
### nes-cover-art-image-generator Dreambooth model trained by SergenK with [TheLastBen's fast-DreamBooth](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast-DreamBooth.ipynb) notebook
Test the concept via A1111 Colab [fast-Colab-A1111](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast_stable_diffusion_AUTOMATIC1111.ipynb)
Sample pictures of this concept:




|
b6f9af6a357dae3ef05d08c417ddd608
|
GItaf/gpt2-gpt2-mc-weight1-epoch2
|
GItaf
|
gpt2
| 17 | 2 |
transformers
| 0 |
text-generation
| true | false | false |
mit
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 869 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# gpt2-gpt2-mc-weight1-epoch2
This model is a fine-tuned version of [gpt2](https://huggingface.co/gpt2) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Framework versions
- Transformers 4.21.2
- Pytorch 1.12.1
- Datasets 2.4.0
- Tokenizers 0.12.1
|
a3be2214fc0477df4e99b5ccca67937e
|
jw4169/wav2vec2-large-xls-r-300m-kr-jw4169
|
jw4169
|
wav2vec2
| 11 | 7 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
| null |
['fleurs']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 2,525 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-large-xls-r-300m-kr-jw4169
This model is a fine-tuned version of [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) on the fleurs dataset.
It achieves the following results on the evaluation set:
- Loss: 0.9752
- Wer: 0.5196
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 4
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 30
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 35.084 | 1.39 | 200 | 6.8536 | 1.0 |
| 4.853 | 2.78 | 400 | 4.6246 | 1.0 |
| 4.5491 | 4.17 | 600 | 4.3815 | 1.0 |
| 2.799 | 5.55 | 800 | 1.7402 | 0.8642 |
| 1.3872 | 6.94 | 1000 | 1.2019 | 0.7448 |
| 0.9599 | 8.33 | 1200 | 1.0594 | 0.7134 |
| 0.675 | 9.72 | 1400 | 0.9321 | 0.6404 |
| 0.4775 | 11.11 | 1600 | 0.9088 | 0.5911 |
| 0.3479 | 12.5 | 1800 | 0.9430 | 0.6010 |
| 0.2712 | 13.89 | 2000 | 0.8948 | 0.5854 |
| 0.2283 | 15.28 | 2200 | 0.9009 | 0.5495 |
| 0.1825 | 16.67 | 2400 | 0.9079 | 0.5501 |
| 0.161 | 18.06 | 2600 | 0.9518 | 0.5390 |
| 0.1394 | 19.44 | 2800 | 0.9529 | 0.5399 |
| 0.1266 | 20.83 | 3000 | 0.9505 | 0.5283 |
| 0.1102 | 22.22 | 3200 | 0.9748 | 0.5328 |
| 0.101 | 23.61 | 3400 | 0.9593 | 0.5316 |
| 0.0907 | 25.0 | 3600 | 0.9832 | 0.5292 |
| 0.0833 | 26.39 | 3800 | 0.9773 | 0.5181 |
| 0.0781 | 27.78 | 4000 | 0.9736 | 0.5163 |
| 0.0744 | 29.17 | 4200 | 0.9752 | 0.5196 |
### Framework versions
- Transformers 4.25.0.dev0
- Pytorch 1.10.0+cu102
- Datasets 2.6.1
- Tokenizers 0.13.1
|
574f2e659f5175e01aab32115b6fb6e4
|
DunnBC22/distilbert-base-uncased-Regression-Edmunds_Car_Reviews-Non_European_Imports
|
DunnBC22
|
distilbert
| 10 | 1 |
transformers
| 1 |
text-classification
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,486 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-Regression-Edmunds_Car_Reviews-Non_European_Imports
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2240
- Mae: 0.3140
- Mse: 0.2240
- Rmse: 0.4733
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Mae | Mse | Rmse |
|:-------------:|:-----:|:----:|:---------------:|:------:|:------:|:------:|
| 0.6594 | 1.0 | 715 | 0.2436 | 0.3319 | 0.2436 | 0.4935 |
| 0.2324 | 2.0 | 1430 | 0.2274 | 0.3210 | 0.2274 | 0.4769 |
| 0.1975 | 3.0 | 2145 | 0.2303 | 0.3198 | 0.2303 | 0.4799 |
### Framework versions
- Transformers 4.22.2
- Pytorch 1.12.1
- Datasets 2.5.2
- Tokenizers 0.12.1
|
a476ea460bf001c2634eefacc48a1819
|
ViktorDo/DistilBERT-POWO_MGH_Epiphyte_Finetuned
|
ViktorDo
|
distilbert
| 12 | 5 |
transformers
| 0 |
text-classification
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,316 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# DistilBERT-POWO_MGH_Epiphyte_Finetuned
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0749
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 0.0824 | 1.0 | 1931 | 0.0807 |
| 0.0768 | 2.0 | 3862 | 0.0747 |
| 0.0664 | 3.0 | 5793 | 0.0749 |
### Framework versions
- Transformers 4.24.0
- Pytorch 1.12.1+cu113
- Datasets 2.7.1
- Tokenizers 0.13.2
|
d855fc2bc306d00cff2054ed84835570
|
gonzpen/gbert-large-ft-edu-redux
|
gonzpen
|
bert
| 12 | 1 |
transformers
| 0 |
text-classification
| true | false | false |
mit
|
['de']
| null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
[]
| false | true | true | 2,262 | false |
# German BERT large fine-tuned to predict educational requirements
This is a fine-tuned version of the German BERT large language model [deepset/gbert-large](https://huggingface.co/deepset/gbert-large). The multilabel task this model was trained on was to predict education requirements from job ad texts. The dataset used for training is not available to the public. The 7 labels in the task are (in the classification head order):
- `'Bachelor'`
- `'Berufsausbildung'`
- `'Doktorat oder äquivalent'`
- `'Höhere Berufsausbildung'`
- `'Master'`
- `'Sonstiges'`
- `'keine Ausbildungserfordernisse'`
The number of representatives of these labels in each of the splits (train/test/val) of the dataset is summarized in the following table:
| Label name | All data | Training | Validation | Test |
|------------|----------|----------|------------|------|
| Bachelor | 521 | 365 | 52 | 104 |
| Berufsausbildung | 1854 | 1298 | 185 | 371 |
| Doktorat oder äquivalent | 38 | 27 | 4 | 7 |
| Höhere Berufsausbildung | 564 | 395 | 56 | 113 |
| Master | 245 | 171 | 25 | 49 |
| Sonstiges | 819 | 573 | 82 | 164 |
| keine Ausbildungserfordernisse | 176 | 123 | 18 | 35 |
## Performance
Training consisted of [minimizing the binary cross-entropy (BCE)](https://en.wikipedia.org/wiki/Cross_entropy#Cross-entropy_minimization) loss between the model's predictions and the actual labels in the training set. During training, a weighted version of the [label ranking average precision (LRAP)](https://scikit-learn.org/stable/modules/model_evaluation.html#label-ranking-average-precision) was tracked for the testing set. LRAP measures what fraction of higher-ranked labels produced by the model were true labels. To account for the label imbalance, the rankings were weighted so that improperly ranked rare labels are penalized more than their more frequent counterparts. After training was complete, the model with highest weighted LRAP was saved.
```
LRAP: 0.96
```
# See also:
- [deepset/gbert-base](https://huggingface.co/deepset/gbert-base)
- [deepset/gbert-large](https://huggingface.co/deepset/gbert-large)
- [gonzpen/gbert-base-ft-edu-redux](https://huggingface.co/gonzpen/gbert-base-ft-edu-redux)
## Authors
Rodrigo C. G. Pena: `rodrigocgp [at] gmail.com`
|
54ddf6c08ad218b8e71615a9c1900b03
|
theojolliffe/bart-cnn-pubmed-arxiv-pubmed-arxiv-arxiv-earlystopping
|
theojolliffe
|
bart
| 15 | 1 |
transformers
| 0 |
text2text-generation
| true | false | false |
mit
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 2,790 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bart-cnn-pubmed-arxiv-pubmed-arxiv-arxiv-earlystopping
This model is a fine-tuned version of [theojolliffe/bart-cnn-pubmed-arxiv-pubmed-arxiv-arxiv](https://huggingface.co/theojolliffe/bart-cnn-pubmed-arxiv-pubmed-arxiv-arxiv) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.8347
- Rouge1: 53.9049
- Rouge2: 35.5953
- Rougel: 39.788
- Rougelsum: 51.4101
- Gen Len: 142.0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 200
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:-------:|:-------:|:-------:|:---------:|:--------:|
| No log | 0.31 | 125 | 1.0240 | 52.5632 | 32.977 | 34.672 | 49.9905 | 142.0 |
| No log | 0.63 | 250 | 1.0056 | 52.5508 | 32.4826 | 34.6851 | 49.835 | 141.6852 |
| No log | 0.94 | 375 | 0.8609 | 53.0475 | 32.9384 | 35.3322 | 50.272 | 141.6481 |
| 0.8255 | 1.26 | 500 | 0.9022 | 52.2493 | 31.5622 | 33.389 | 49.6612 | 142.0 |
| 0.8255 | 1.57 | 625 | 0.8706 | 53.3568 | 33.2533 | 35.7531 | 50.4568 | 141.8889 |
| 0.8255 | 1.88 | 750 | 0.8186 | 52.7375 | 33.4439 | 37.1094 | 50.5323 | 142.0 |
| 0.8255 | 2.2 | 875 | 0.8041 | 53.4992 | 34.6929 | 37.9614 | 51.091 | 142.0 |
| 0.5295 | 2.51 | 1000 | 0.7907 | 52.6185 | 33.8053 | 37.1725 | 50.4881 | 142.0 |
| 0.5295 | 2.83 | 1125 | 0.7740 | 52.7107 | 33.1023 | 36.0865 | 50.0365 | 142.0 |
| 0.5295 | 3.14 | 1250 | 0.8200 | 52.5607 | 33.7948 | 37.2312 | 50.3345 | 142.0 |
| 0.5295 | 3.45 | 1375 | 0.8188 | 53.9233 | 34.446 | 36.7566 | 51.3135 | 142.0 |
| 0.351 | 3.77 | 1500 | 0.8071 | 53.9096 | 35.5977 | 38.6832 | 51.4986 | 142.0 |
| 0.351 | 4.08 | 1625 | 0.8347 | 53.9049 | 35.5953 | 39.788 | 51.4101 | 142.0 |
### Framework versions
- Transformers 4.18.0
- Pytorch 1.11.0+cu113
- Datasets 2.2.1
- Tokenizers 0.12.1
|
2fd90661a2db69074d45b1bd637c4f10
|
l3cube-pune/hing-roberta
|
l3cube-pune
|
xlm-roberta
| 7 | 41 |
transformers
| 0 |
fill-mask
| true | false | false |
cc-by-4.0
|
['hi', 'en', 'multilingual']
|
['L3Cube-HingCorpus']
| null | 1 | 0 | 1 | 0 | 0 | 0 | 0 |
['hi', 'en', 'codemix']
| false | true | true | 894 | false |
## HingRoBERTa
HingRoBERTa is a Hindi-English code-mixed RoBERTa model trained on roman text. It is an xlm-RoBERTa model fine-tuned on L3Cube-HingCorpus.
<br>
[dataset link] (https://github.com/l3cube-pune/code-mixed-nlp)
More details on the dataset, models, and baseline results can be found in our [paper] (https://arxiv.org/abs/2204.08398)
```
@inproceedings{nayak-joshi-2022-l3cube,
title = "{L}3{C}ube-{H}ing{C}orpus and {H}ing{BERT}: A Code Mixed {H}indi-{E}nglish Dataset and {BERT} Language Models",
author = "Nayak, Ravindra and Joshi, Raviraj",
booktitle = "Proceedings of the WILDRE-6 Workshop within the 13th Language Resources and Evaluation Conference",
month = jun,
year = "2022",
address = "Marseille, France",
publisher = "European Language Resources Association",
url = "https://aclanthology.org/2022.wildre-1.2",
pages = "7--12",
}
```
|
f69aa14d96efb70a30db7853bdb44442
|
qwant/fralbert-base
|
qwant
|
albert
| 8 | 316 |
transformers
| 2 |
fill-mask
| true | false | false |
apache-2.0
|
['fr']
|
['wikipedia']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
[]
| false | true | true | 6,195 | false |
# FrALBERT Base
Pretrained model on French language using a masked language modeling (MLM) objective. It was introduced in
[this paper](https://arxiv.org/abs/1909.11942) and first released in
[this repository](https://github.com/google-research/albert). This model, as all ALBERT models, is uncased: it does not make a difference
between french and French.
## Model description
FrALBERT is a transformers model pretrained on 4Go of French Wikipedia in a self-supervised fashion. This means it
was pretrained on the raw texts only, with no humans labelling them in any way (which is why it can use lots of
publicly available data) with an automatic process to generate inputs and labels from those texts. More precisely, it
was pretrained with two objectives:
- Masked language modeling (MLM): taking a sentence, the model randomly masks 15% of the words in the input then run
the entire masked sentence through the model and has to predict the masked words. This is different from traditional
recurrent neural networks (RNNs) that usually see the words one after the other, or from autoregressive models like
GPT which internally mask the future tokens. It allows the model to learn a bidirectional representation of the
sentence.
- Sentence Ordering Prediction (SOP): FrALBERT uses a pretraining loss based on predicting the ordering of two consecutive segments of text.
This way, the model learns an inner representation of the English language that can then be used to extract features
useful for downstream tasks: if you have a dataset of labeled sentences for instance, you can train a standard
classifier using the features produced by the FrALBERT model as inputs.
FrALBERT is particular in that it shares its layers across its Transformer. Therefore, all layers have the same weights. Using repeating layers results in a small memory footprint, however, the computational cost remains similar to a BERT-like architecture with the same number of hidden layers as it has to iterate through the same number of (repeating) layers.
This is the first version of the base model.
This model has the following configuration:
- 12 repeating layers
- 128 embedding dimension
- 768 hidden dimension
- 12 attention heads
- 11M parameters
## Intended uses & limitations
You can use the raw model for either masked language modeling or next sentence prediction, but it's mostly intended to
be fine-tuned on a downstream task. See the [model hub](https://huggingface.co/models?filter=fralbert) to look for
fine-tuned versions on a task that interests you.
Note that this model is primarily aimed at being fine-tuned on tasks that use the whole sentence (potentially masked)
to make decisions, such as sequence classification, token classification or question answering. For tasks such as text
generation you should look at model like GPT2.
### How to use
You can use this model directly with a pipeline for masked language modeling:
```python
>>> from transformers import pipeline
>>> unmasker = pipeline('fill-mask', model='qwant/fralbert-base')
>>> unmasker("Paris est la capitale de la [MASK] .")
[
{
"sequence": "paris est la capitale de la france.",
"score": 0.6231236457824707,
"token": 3043,
"token_str": "france"
},
{
"sequence": "paris est la capitale de la region.",
"score": 0.2993471622467041,
"token": 10531,
"token_str": "region"
},
{
"sequence": "paris est la capitale de la societe.",
"score": 0.02028230018913746,
"token": 24622,
"token_str": "societe"
},
{
"sequence": "paris est la capitale de la bretagne.",
"score": 0.012089950032532215,
"token": 24987,
"token_str": "bretagne"
},
{
"sequence": "paris est la capitale de la chine.",
"score": 0.010002839379012585,
"token": 14860,
"token_str": "chine"
}
]
```
Here is how to use this model to get the features of a given text in PyTorch:
```python
from transformers import AlbertTokenizer, AlbertModel
tokenizer = AlbertTokenizer.from_pretrained('qwant/fralbert-base')
model = AlbertModel.from_pretrained("qwant/fralbert-base")
text = "Remplacez-moi par le texte en français que vous souhaitez."
encoded_input = tokenizer(text, return_tensors='pt')
output = model(**encoded_input)
```
and in TensorFlow:
```python
from transformers import AlbertTokenizer, TFAlbertModel
tokenizer = AlbertTokenizer.from_pretrained('qwant/fralbert-base')
model = TFAlbertModel.from_pretrained("qwant/fralbert-base")
text = "Remplacez-moi par le texte en français que vous souhaitez."
encoded_input = tokenizer(text, return_tensors='tf')
output = model(encoded_input)
```
## Training data
The FrALBERT model was pretrained on 4go of [French Wikipedia](https://fr.wikipedia.org/wiki/French_Wikipedia) (excluding lists, tables and
headers).
## Training procedure
### Preprocessing
The texts are lowercased and tokenized using SentencePiece and a vocabulary size of 32,000. The inputs of the model are
then of the form:
```
[CLS] Sentence A [SEP] Sentence B [SEP]
```
### Training
The FrALBERT procedure follows the BERT setup.
The details of the masking procedure for each sentence are the following:
- 15% of the tokens are masked.
- In 80% of the cases, the masked tokens are replaced by `[MASK]`.
- In 10% of the cases, the masked tokens are replaced by a random token (different) from the one they replace.
- In the 10% remaining cases, the masked tokens are left as is.
## Evaluation results
When fine-tuned on downstream tasks, the ALBERT models achieve the following results:
| | FQuAD1.0 | PIAF_dev
|----------------|----------|----------
|frALBERT-base |72.6/55.1 |61.0 / 38.9
### BibTeX entry and citation info
```bibtex
@inproceedings{cattan2021fralbert,
author = {Oralie Cattan and
Christophe Servan and
Sophie Rosset},
booktitle = {Recent Advances in Natural Language Processing, RANLP 2021},
title = {{On the Usability of Transformers-based models for a French Question-Answering task}},
year = {2021},
address = {Online},
month = sep,
}
```
Link to the paper: [PDF](https://hal.archives-ouvertes.fr/hal-03336060)
|
e6b5a3b077556e2603abe7f14adda925
|
pranay-j/whisper-small-hy
|
pranay-j
|
whisper
| 17 | 0 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
|
['hy']
|
['mozilla-foundation/common_voice_11_0']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['whisper-event', 'generated_from_trainer']
| true | true | true | 1,603 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Whisper Small hy
This model is a fine-tuned version of [openai/whisper-small](https://huggingface.co/openai/whisper-small) on the common_voice_11_0 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6376
- Wer: 116.0855
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 5
- training_steps: 50
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.7891 | 0.2 | 10 | 0.9031 | 184.375 |
| 0.6573 | 0.4 | 20 | 0.7425 | 149.0789 |
| 0.647 | 0.6 | 30 | 0.6797 | 138.125 |
| 0.551 | 0.8 | 40 | 0.6483 | 127.5329 |
| 0.5477 | 1.0 | 50 | 0.6376 | 116.0855 |
### Framework versions
- Transformers 4.26.0.dev0
- Pytorch 1.13.0+cu117
- Datasets 2.7.1.dev0
- Tokenizers 0.12.1
|
af17104d350dff941a2cf6ccb8bce15a
|
vinhood/chefberto-italian-cased
|
vinhood
|
bert
| 7 | 13 |
transformers
| 0 |
fill-mask
| true | false | false |
mit
|
['it']
| null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
[]
| false | true | true | 969 | false |
# ChefBERTo 👨🍳
**chefberto-italian-cased** is a BERT model obtained by MLM adaptive-tuning [**bert-base-italian-xxl-cased**](https://huggingface.co/dbmdz/bert-base-italian-xxl-cased) on Italian cooking recipes, approximately 50k sentences (2.6M words).
**Author:** Cristiano De Nobili ([@denocris](https://twitter.com/denocris) on Twitter, [LinkedIn](https://www.linkedin.com/in/cristiano-de-nobili/)) for [VINHOOD](https://www.vinhood.com/en/).
<p>
<img src="https://drive.google.com/uc?export=view&id=1u5aY2wKu-X5DAzbOq7rsgGFW5_lGUAQn" width="400"> </br>
</p>
# Perplexity
Test set: 9k sentences about food.
| Model | Perplexity |
| ------ | ------ |
| chefberto-italian-cased | **1.84** |
| bert-base-italian-xxl-cased | 2.85 |
# Usage
```python
from transformers import AutoModel, AutoTokenizer
model_name = "vinhood/chefberto-italian-cased"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModel.from_pretrained(model_name)
```
|
c6aa5d55159adf77c9449900e9e4947b
|
Amalq/roberta-base-finetuned-schizophreniaReddit2
|
Amalq
|
roberta
| 9 | 2 |
transformers
| 0 |
fill-mask
| true | false | false |
mit
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,361 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# roberta-base-finetuned-schizophreniaReddit2
This model is a fine-tuned version of [roberta-base](https://huggingface.co/roberta-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.7785
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| No log | 1.0 | 490 | 1.8093 |
| 1.9343 | 2.0 | 980 | 1.7996 |
| 1.8856 | 3.0 | 1470 | 1.7966 |
| 1.8552 | 4.0 | 1960 | 1.7844 |
| 1.8267 | 5.0 | 2450 | 1.7839 |
### Framework versions
- Transformers 4.14.1
- Pytorch 1.10.0+cu111
- Datasets 1.16.1
- Tokenizers 0.10.3
|
c41f95471d6422f02366c0332d567ab1
|
sbcBI/sentiment_analysis_model
|
sbcBI
|
distilbert
| 9 | 41,120 |
transformers
| 1 |
text-classification
| true | false | false |
apache-2.0
|
['en']
|
['Confidential']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['exbert']
| false | true | true | 2,134 | false |
# BERT base model (uncased)
Pretrained model on English language using a masked language modeling (MLM) objective. It was introduced in
[this paper](https://arxiv.org/abs/1810.04805) and first released in
[this repository](https://github.com/google-research/bert). This model is uncased: it does not make a difference
between english and English.
## Model description
BERT is a transformers model pretrained on a large corpus of English data in a self-supervised fashion. This means it
was pretrained on the raw texts only, with no humans labelling them in any way (which is why it can use lots of
publicly available data) with an automatic process to generate inputs and labels from those texts. More precisely, it
was pretrained with two objectives:
- Masked language modeling (MLM): taking a sentence, the model randomly masks 15% of the words in the input then run
the entire masked sentence through the model and has to predict the masked words. This is different from traditional
recurrent neural networks (RNNs) that usually see the words one after the other, or from autoregressive models like
GPT which internally mask the future tokens. It allows the model to learn a bidirectional representation of the
sentence.
- Next sentence prediction (NSP): the models concatenates two masked sentences as inputs during pretraining. Sometimes
they correspond to sentences that were next to each other in the original text, sometimes not. The model then has to
predict if the two sentences were following each other or not.
This way, the model learns an inner representation of the English language that can then be used to extract features
useful for downstream tasks: if you have a dataset of labeled sentences for instance, you can train a standard
classifier using the features produced by the BERT model as inputs.
## Model description [sbcBI/sentiment_analysis]
This is a fine-tuned downstream version of the bert-base-uncased model for sentiment analysis, this model is not intended for
further downstream fine-tuning for any other tasks. This model is trained on a classified dataset for text-classification.
|
6ead02c313b9c278515e39346c8e9638
|
sgangireddy/whisper-medium-highLR-tr
|
sgangireddy
|
whisper
| 22 | 2 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
|
['tr']
|
['mozilla-foundation/common_voice_11_0']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['whisper-event', 'generated_from_trainer']
| true | true | true | 1,452 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Whisper medium Turkish CV 3K
This model is a fine-tuned version of [openai/whisper-medium](https://huggingface.co/openai/whisper-medium) on the mozilla-foundation/common_voice_11_0 tr dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3611
- Wer: 15.9012
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 64
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 3000
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:-------:|
| 0.0856 | 3.02 | 1000 | 0.3732 | 20.6764 |
| 0.0119 | 6.03 | 2000 | 0.3684 | 17.5353 |
| 0.001 | 9.05 | 3000 | 0.3611 | 15.9012 |
### Framework versions
- Transformers 4.26.0.dev0
- Pytorch 1.13.0+cu117
- Datasets 2.7.1.dev0
- Tokenizers 0.13.2
|
78a47c0813ce5751cb73e64883957ae7
|
eormeno12/platzi_vit_model
|
eormeno12
|
vit
| 25 | 2 |
transformers
| 0 |
image-classification
| true | false | false |
apache-2.0
| null |
['beans']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,225 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# platzi_vit_model
This model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on the beans dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0328
- Accuracy: 0.9925
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 4
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.1427 | 3.85 | 500 | 0.0328 | 0.9925 |
### Framework versions
- Transformers 4.26.1
- Pytorch 1.13.1+cu116
- Datasets 2.9.0
- Tokenizers 0.13.2
|
129729ce51aea17deac2c3e9f00ea991
|
dreambooth-hackathon/glxy-galaxy
|
dreambooth-hackathon
| null | 17 | 29 |
diffusers
| 1 |
text-to-image
| true | false | false |
creativeml-openrail-m
| null | null | null | 1 | 1 | 0 | 0 | 0 | 0 | 0 |
['pytorch', 'diffusers', 'stable-diffusion', 'text-to-image', 'diffusion-models-class', 'dreambooth-hackathon', 'science']
| false | true | true | 644 | false |
# DreamBooth model for glxy trained by lewtun on the lewtun/galaxies dataset.
This your the Stable Diffusion model fine-tuned the glxy concept taught to Stable Diffusion with DreamBooth.
It can be used by modifying the `instance_prompt`: **a photo of glxy galaxy**
This model was created as part of the DreamBooth Hackathon. Visit the organisation page for instructions on how to take part!
## Description
Describe your model and concept here.
## Usage
```python
from diffusers import StableDiffusionPipeline
pipeline = StableDiffusionPipeline.from_pretrained('dreambooth-hackathon/glxy-galaxy')
image = pipeline().images[0]
image
```
|
79bd4d48227835673b83a78b2ec6f150
|
Lvxue/distilled-mt5-small-0.6-1
|
Lvxue
|
mt5
| 14 | 1 |
transformers
| 0 |
text2text-generation
| true | false | false |
apache-2.0
|
['en', 'ro']
|
['wmt16']
| null | 1 | 1 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,036 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilled-mt5-small-0.6-1
This model is a fine-tuned version of [google/mt5-small](https://huggingface.co/google/mt5-small) on the wmt16 ro-en dataset.
It achieves the following results on the evaluation set:
- Loss: 2.8345
- Bleu: 6.7165
- Gen Len: 46.3377
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 4
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5.0
### Training results
### Framework versions
- Transformers 4.20.1
- Pytorch 1.12.0+cu102
- Datasets 2.3.2
- Tokenizers 0.12.1
|
e5d36eeaf866a96a6a48fb57a0590985
|
GItaf/gpt2-gpt2-TF-weight1-epoch10
|
GItaf
|
gpt2
| 17 | 4 |
transformers
| 0 |
text-generation
| true | false | false |
mit
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 871 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# gpt2-gpt2-TF-weight1-epoch10
This model is a fine-tuned version of [gpt2](https://huggingface.co/gpt2) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Framework versions
- Transformers 4.21.2
- Pytorch 1.12.1
- Datasets 2.4.0
- Tokenizers 0.12.1
|
fa63ef9e7af89eef61899ccc2d18369a
|
Pablo94/roberta-base-bne-finetuned-detests
|
Pablo94
|
roberta
| 27 | 2 |
transformers
| 0 |
text-classification
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,786 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# roberta-base-bne-finetuned-detests
This model is a fine-tuned version of [BSC-TeMU/roberta-base-bne](https://huggingface.co/BSC-TeMU/roberta-base-bne) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.0716
- Accuracy: 0.8396
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.2972 | 1.0 | 153 | 0.3359 | 0.8462 |
| 0.2924 | 2.0 | 306 | 0.4509 | 0.8249 |
| 0.0663 | 3.0 | 459 | 0.7186 | 0.8527 |
| 0.0018 | 4.0 | 612 | 0.8081 | 0.8314 |
| 0.0004 | 5.0 | 765 | 0.8861 | 0.8560 |
| 0.0003 | 6.0 | 918 | 0.9940 | 0.8380 |
| 0.0002 | 7.0 | 1071 | 1.0330 | 0.8396 |
| 0.0002 | 8.0 | 1224 | 1.0545 | 0.8396 |
| 0.0002 | 9.0 | 1377 | 1.0673 | 0.8396 |
| 0.0002 | 10.0 | 1530 | 1.0716 | 0.8396 |
### Framework versions
- Transformers 4.23.1
- Pytorch 1.12.1+cu113
- Datasets 2.6.1
- Tokenizers 0.13.1
|
4ed524afeca948bbdc5a7baa06a3b6d8
|
gchhablani/fnet-base-finetuned-qqp
|
gchhablani
|
fnet
| 45 | 3 |
transformers
| 0 |
text-classification
| true | false | false |
apache-2.0
|
['en']
|
['glue']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer', 'fnet-bert-base-comparison']
| true | true | true | 2,389 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# fnet-base-finetuned-qqp
This model is a fine-tuned version of [google/fnet-base](https://huggingface.co/google/fnet-base) on the GLUE QQP dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3686
- Accuracy: 0.8847
- F1: 0.8466
- Combined Score: 0.8657
The model was fine-tuned to compare [google/fnet-base](https://huggingface.co/google/fnet-base) as introduced in [this paper](https://arxiv.org/abs/2105.03824) against [bert-base-cased](https://huggingface.co/bert-base-cased).
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
This model is trained using the [run_glue](https://github.com/huggingface/transformers/blob/master/examples/pytorch/text-classification/run_glue.py) script. The following command was used:
```bash
#!/usr/bin/bash
#!/usr/bin/bash
python ../run_glue.py \\n --model_name_or_path google/fnet-base \\n --task_name qqp \\n --do_train \\n --do_eval \\n --max_seq_length 512 \\n --per_device_train_batch_size 16 \\n --learning_rate 2e-5 \\n --num_train_epochs 3 \\n --output_dir fnet-base-finetuned-qqp \\n --push_to_hub \\n --hub_strategy all_checkpoints \\n --logging_strategy epoch \\n --save_strategy epoch \\n --evaluation_strategy epoch \\n```
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 | Combined Score |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|:------:|:--------------:|
| 0.3484 | 1.0 | 22741 | 0.3014 | 0.8676 | 0.8297 | 0.8487 |
| 0.2387 | 2.0 | 45482 | 0.3011 | 0.8801 | 0.8429 | 0.8615 |
| 0.1739 | 3.0 | 68223 | 0.3686 | 0.8847 | 0.8466 | 0.8657 |
### Framework versions
- Transformers 4.11.0.dev0
- Pytorch 1.9.0
- Datasets 1.12.1
- Tokenizers 0.10.3
|
6c2bf609733f351d17a384fa0b4f228a
|
Geotrend/distilbert-base-en-ro-cased
|
Geotrend
|
distilbert
| 6 | 6 |
transformers
| 0 |
fill-mask
| true | false | false |
apache-2.0
|
['multilingual']
|
['wikipedia']
| null | 1 | 1 | 0 | 0 | 0 | 0 | 0 |
[]
| false | true | true | 1,224 | false |
# distilbert-base-en-ro-cased
We are sharing smaller versions of [distilbert-base-multilingual-cased](https://huggingface.co/distilbert-base-multilingual-cased) that handle a custom number of languages.
Our versions give exactly the same representations produced by the original model which preserves the original accuracy.
For more information please visit our paper: [Load What You Need: Smaller Versions of Multilingual BERT](https://www.aclweb.org/anthology/2020.sustainlp-1.16.pdf).
## How to use
```python
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("Geotrend/distilbert-base-en-ro-cased")
model = AutoModel.from_pretrained("Geotrend/distilbert-base-en-ro-cased")
```
To generate other smaller versions of multilingual transformers please visit [our Github repo](https://github.com/Geotrend-research/smaller-transformers).
### How to cite
```bibtex
@inproceedings{smallermdistilbert,
title={Load What You Need: Smaller Versions of Mutlilingual BERT},
author={Abdaoui, Amine and Pradel, Camille and Sigel, Grégoire},
booktitle={SustaiNLP / EMNLP},
year={2020}
}
```
## Contact
Please contact amine@geotrend.fr for any question, feedback or request.
|
6bac5157e1463e5f261b019c7670473a
|
anki08/t5-small-finetuned-text2log-finetuned-nl-to-fol-finetuned-nl-to-fol-finetuned-nl-to-fol-version2
|
anki08
|
t5
| 14 | 1 |
transformers
| 0 |
text2text-generation
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 8,500 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-small-finetuned-text2log-finetuned-nl-to-fol-finetuned-nl-to-fol-finetuned-nl-to-fol-version2
This model is a fine-tuned version of [anki08/t5-small-finetuned-text2log-finetuned-nl-to-fol-finetuned-nl-to-fol](https://huggingface.co/anki08/t5-small-finetuned-text2log-finetuned-nl-to-fol-finetuned-nl-to-fol) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0069
- Bleu: 28.1311
- Gen Len: 18.7412
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 100
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Bleu | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:-------:|:-------:|
| No log | 1.0 | 22 | 0.0692 | 27.4908 | 18.7353 |
| No log | 2.0 | 44 | 0.0631 | 27.554 | 18.7294 |
| No log | 3.0 | 66 | 0.0533 | 27.6007 | 18.7294 |
| No log | 4.0 | 88 | 0.0484 | 27.6446 | 18.7294 |
| No log | 5.0 | 110 | 0.0439 | 27.6401 | 18.7294 |
| No log | 6.0 | 132 | 0.0404 | 27.5117 | 18.7294 |
| No log | 7.0 | 154 | 0.0389 | 27.6358 | 18.7294 |
| No log | 8.0 | 176 | 0.0362 | 27.6358 | 18.7294 |
| No log | 9.0 | 198 | 0.0339 | 27.5731 | 18.7294 |
| No log | 10.0 | 220 | 0.0319 | 27.2326 | 18.6882 |
| No log | 11.0 | 242 | 0.0298 | 27.2326 | 18.6882 |
| No log | 12.0 | 264 | 0.0293 | 27.5498 | 18.7294 |
| No log | 13.0 | 286 | 0.0276 | 27.6566 | 18.7294 |
| No log | 14.0 | 308 | 0.0268 | 27.6566 | 18.7294 |
| No log | 15.0 | 330 | 0.0251 | 27.6107 | 18.7294 |
| No log | 16.0 | 352 | 0.0239 | 27.7096 | 18.7294 |
| No log | 17.0 | 374 | 0.0228 | 27.6716 | 18.7294 |
| No log | 18.0 | 396 | 0.0231 | 27.8083 | 18.7294 |
| No log | 19.0 | 418 | 0.0218 | 27.4838 | 18.6882 |
| No log | 20.0 | 440 | 0.0212 | 27.4712 | 18.6882 |
| No log | 21.0 | 462 | 0.0197 | 27.8787 | 18.7353 |
| No log | 22.0 | 484 | 0.0207 | 27.6899 | 18.6941 |
| 0.1026 | 23.0 | 506 | 0.0186 | 27.6376 | 18.6941 |
| 0.1026 | 24.0 | 528 | 0.0202 | 27.6672 | 18.6941 |
| 0.1026 | 25.0 | 550 | 0.0174 | 28.0172 | 18.7412 |
| 0.1026 | 26.0 | 572 | 0.0170 | 27.8714 | 18.7412 |
| 0.1026 | 27.0 | 594 | 0.0164 | 27.7423 | 18.7412 |
| 0.1026 | 28.0 | 616 | 0.0164 | 27.8278 | 18.7412 |
| 0.1026 | 29.0 | 638 | 0.0163 | 27.8278 | 18.7412 |
| 0.1026 | 30.0 | 660 | 0.0158 | 27.907 | 18.7412 |
| 0.1026 | 31.0 | 682 | 0.0165 | 27.7752 | 18.7412 |
| 0.1026 | 32.0 | 704 | 0.0147 | 27.8284 | 18.7412 |
| 0.1026 | 33.0 | 726 | 0.0150 | 27.8862 | 18.7412 |
| 0.1026 | 34.0 | 748 | 0.0148 | 27.8402 | 18.7412 |
| 0.1026 | 35.0 | 770 | 0.0141 | 27.8353 | 18.7412 |
| 0.1026 | 36.0 | 792 | 0.0142 | 27.858 | 18.7412 |
| 0.1026 | 37.0 | 814 | 0.0143 | 27.858 | 18.7412 |
| 0.1026 | 38.0 | 836 | 0.0158 | 27.8353 | 18.7412 |
| 0.1026 | 39.0 | 858 | 0.0125 | 27.8913 | 18.7412 |
| 0.1026 | 40.0 | 880 | 0.0121 | 27.9167 | 18.7412 |
| 0.1026 | 41.0 | 902 | 0.0122 | 27.9569 | 18.7412 |
| 0.1026 | 42.0 | 924 | 0.0126 | 27.9569 | 18.7412 |
| 0.1026 | 43.0 | 946 | 0.0120 | 28.001 | 18.7412 |
| 0.1026 | 44.0 | 968 | 0.0125 | 28.0079 | 18.7412 |
| 0.1026 | 45.0 | 990 | 0.0115 | 28.0079 | 18.7412 |
| 0.072 | 46.0 | 1012 | 0.0113 | 27.9851 | 18.7412 |
| 0.072 | 47.0 | 1034 | 0.0113 | 28.0184 | 18.7412 |
| 0.072 | 48.0 | 1056 | 0.0110 | 28.0184 | 18.7412 |
| 0.072 | 49.0 | 1078 | 0.0108 | 28.0184 | 18.7412 |
| 0.072 | 50.0 | 1100 | 0.0107 | 28.0184 | 18.7412 |
| 0.072 | 51.0 | 1122 | 0.0101 | 28.0184 | 18.7412 |
| 0.072 | 52.0 | 1144 | 0.0102 | 28.0184 | 18.7412 |
| 0.072 | 53.0 | 1166 | 0.0099 | 28.0184 | 18.7412 |
| 0.072 | 54.0 | 1188 | 0.0100 | 28.0184 | 18.7412 |
| 0.072 | 55.0 | 1210 | 0.0102 | 28.0184 | 18.7412 |
| 0.072 | 56.0 | 1232 | 0.0095 | 28.0184 | 18.7412 |
| 0.072 | 57.0 | 1254 | 0.0098 | 28.0184 | 18.7412 |
| 0.072 | 58.0 | 1276 | 0.0092 | 28.0184 | 18.7412 |
| 0.072 | 59.0 | 1298 | 0.0090 | 28.0184 | 18.7412 |
| 0.072 | 60.0 | 1320 | 0.0095 | 28.0184 | 18.7412 |
| 0.072 | 61.0 | 1342 | 0.0092 | 27.9674 | 18.7412 |
| 0.072 | 62.0 | 1364 | 0.0091 | 27.9419 | 18.7412 |
| 0.072 | 63.0 | 1386 | 0.0100 | 27.9419 | 18.7412 |
| 0.072 | 64.0 | 1408 | 0.0084 | 28.0752 | 18.7412 |
| 0.072 | 65.0 | 1430 | 0.0086 | 28.0192 | 18.7412 |
| 0.072 | 66.0 | 1452 | 0.0084 | 28.0192 | 18.7412 |
| 0.072 | 67.0 | 1474 | 0.0085 | 28.0192 | 18.7412 |
| 0.072 | 68.0 | 1496 | 0.0087 | 28.0192 | 18.7412 |
| 0.0575 | 69.0 | 1518 | 0.0084 | 28.0192 | 18.7412 |
| 0.0575 | 70.0 | 1540 | 0.0080 | 28.0192 | 18.7412 |
| 0.0575 | 71.0 | 1562 | 0.0082 | 28.0192 | 18.7412 |
| 0.0575 | 72.0 | 1584 | 0.0080 | 28.0192 | 18.7412 |
| 0.0575 | 73.0 | 1606 | 0.0075 | 28.0192 | 18.7412 |
| 0.0575 | 74.0 | 1628 | 0.0079 | 28.0192 | 18.7412 |
| 0.0575 | 75.0 | 1650 | 0.0078 | 28.0752 | 18.7412 |
| 0.0575 | 76.0 | 1672 | 0.0076 | 28.1311 | 18.7412 |
| 0.0575 | 77.0 | 1694 | 0.0073 | 28.1311 | 18.7412 |
| 0.0575 | 78.0 | 1716 | 0.0074 | 28.1311 | 18.7412 |
| 0.0575 | 79.0 | 1738 | 0.0072 | 28.1311 | 18.7412 |
| 0.0575 | 80.0 | 1760 | 0.0078 | 28.1311 | 18.7412 |
| 0.0575 | 81.0 | 1782 | 0.0077 | 28.1311 | 18.7412 |
| 0.0575 | 82.0 | 1804 | 0.0071 | 28.1311 | 18.7412 |
| 0.0575 | 83.0 | 1826 | 0.0072 | 28.1311 | 18.7412 |
| 0.0575 | 84.0 | 1848 | 0.0075 | 28.1311 | 18.7412 |
| 0.0575 | 85.0 | 1870 | 0.0071 | 28.1311 | 18.7412 |
| 0.0575 | 86.0 | 1892 | 0.0070 | 28.1311 | 18.7412 |
| 0.0575 | 87.0 | 1914 | 0.0069 | 28.1311 | 18.7412 |
| 0.0575 | 88.0 | 1936 | 0.0069 | 28.1311 | 18.7412 |
| 0.0575 | 89.0 | 1958 | 0.0069 | 28.1311 | 18.7412 |
| 0.0575 | 90.0 | 1980 | 0.0069 | 28.1311 | 18.7412 |
| 0.0509 | 91.0 | 2002 | 0.0069 | 28.1311 | 18.7412 |
| 0.0509 | 92.0 | 2024 | 0.0070 | 28.1311 | 18.7412 |
| 0.0509 | 93.0 | 2046 | 0.0069 | 28.1311 | 18.7412 |
| 0.0509 | 94.0 | 2068 | 0.0070 | 28.1311 | 18.7412 |
| 0.0509 | 95.0 | 2090 | 0.0069 | 28.1311 | 18.7412 |
| 0.0509 | 96.0 | 2112 | 0.0069 | 28.1311 | 18.7412 |
| 0.0509 | 97.0 | 2134 | 0.0069 | 28.1311 | 18.7412 |
| 0.0509 | 98.0 | 2156 | 0.0069 | 28.1311 | 18.7412 |
| 0.0509 | 99.0 | 2178 | 0.0069 | 28.1311 | 18.7412 |
| 0.0509 | 100.0 | 2200 | 0.0069 | 28.1311 | 18.7412 |
### Framework versions
- Transformers 4.21.1
- Pytorch 1.12.1+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
178c346615cbe9652ed42cd8622ae8ef
|
jonatasgrosman/exp_w2v2t_ru_wav2vec2_s847
|
jonatasgrosman
|
wav2vec2
| 10 | 5 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
|
['ru']
|
['mozilla-foundation/common_voice_7_0']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['automatic-speech-recognition', 'ru']
| false | true | true | 456 | false |
# exp_w2v2t_ru_wav2vec2_s847
Fine-tuned [facebook/wav2vec2-large-lv60](https://huggingface.co/facebook/wav2vec2-large-lv60) for speech recognition using the train split of [Common Voice 7.0 (ru)](https://huggingface.co/datasets/mozilla-foundation/common_voice_7_0).
When using this model, make sure that your speech input is sampled at 16kHz.
This model has been fine-tuned by the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) tool.
|
a476d4b47cd1e512d21958f3b8646911
|
groar/gpt-neo-1.3B-finetuned-escape3
|
groar
|
gpt_neo
| 8 | 13 |
transformers
| 0 |
text-generation
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 918 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# gpt-neo-1.3B-finetuned-escape3
This model is a fine-tuned version of [EleutherAI/gpt-neo-1.3B](https://huggingface.co/EleutherAI/gpt-neo-1.3B) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 30
### Framework versions
- Transformers 4.16.2
- Pytorch 1.10.0+cu111
- Datasets 1.18.3
- Tokenizers 0.11.0
|
5e1e1475cec8f00a143bad00258543ef
|
MeshalAlamr/wav2vec2-base-finetuned-ks
|
MeshalAlamr
|
wav2vec2
| 7 | 3 |
transformers
| 0 |
audio-classification
| true | false | false |
apache-2.0
| null |
['superb']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,553 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-base-finetuned-ks
This model is a fine-tuned version of [facebook/wav2vec2-base](https://huggingface.co/facebook/wav2vec2-base) on the superb dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0862
- Accuracy: 0.9828
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.668 | 1.0 | 399 | 0.5462 | 0.9588 |
| 0.2728 | 2.0 | 798 | 0.1750 | 0.9766 |
| 0.1846 | 3.0 | 1197 | 0.1166 | 0.9785 |
| 0.1642 | 4.0 | 1596 | 0.0930 | 0.9813 |
| 0.1522 | 5.0 | 1995 | 0.0862 | 0.9828 |
### Framework versions
- Transformers 4.21.1
- Pytorch 1.12.1
- Datasets 2.4.0
- Tokenizers 0.12.1
|
4bd2ba4848825b869382c18063c3cf45
|
uaritm/ukrt5-base
|
uaritm
|
t5
| 7 | 3 |
transformers
| 0 |
text2text-generation
| true | false | false |
mit
|
['uk', 'en', 'multilingual']
| null | null | 1 | 1 | 0 | 0 | 0 | 0 | 0 |
['ukrainian', 'english']
| false | true | true | 492 | false |
This is a variant of the [google/mt5-base](https://huggingface.co/google/mt5-base) model, in which Ukrainian and 9% English words remain.
This model has 252M parameters - 43% of the original size.
Special thanks for the practical example and inspiration: [cointegrated ](https://huggingface.co/cointegrated)
## Citing & Authors
```
@misc{Uaritm,
title={SetFit: Classification of medical texts},
author={Vitaliy Ostashko},
year={2022},
url={https://esemi.org}
}
```
|
cfc54dfe12d8d19a4e3473584b480cc7
|
nlp-en-es/roberta-base-bne-finetuned-sqac
|
nlp-en-es
|
roberta
| 9 | 5 |
transformers
| 1 |
question-answering
| true | false | false |
apache-2.0
|
['es']
|
['sqac']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,274 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# roberta-base-bne-finetuned-sqac
This model is a fine-tuned version of [BSC-TeMU/roberta-base-bne](https://huggingface.co/BSC-TeMU/roberta-base-bne) on the sqac dataset.
It achieves the following results on the evaluation set:
- Loss: 1.2111
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 0.9971 | 1.0 | 1196 | 0.8646 |
| 0.482 | 2.0 | 2392 | 0.9334 |
| 0.1652 | 3.0 | 3588 | 1.2111 |
### Framework versions
- Transformers 4.11.2
- Pytorch 1.9.0+cu111
- Datasets 1.12.1
- Tokenizers 0.10.3
|
dbeef53b4dda6808383199234bd2c2ac
|
facebook/mask2former-swin-small-coco-panoptic
|
facebook
|
mask2former
| 5 | 9 |
transformers
| 0 |
image-segmentation
| true | false | false |
other
| null |
['coco']
| null | 1 | 0 | 1 | 0 | 0 | 0 | 0 |
['vision', 'image-segmentation']
| false | true | true | 2,939 | false |
# Mask2Former
Mask2Former model trained on COCO panoptic segmentation (small-sized version, Swin backbone). It was introduced in the paper [Masked-attention Mask Transformer for Universal Image Segmentation
](https://arxiv.org/abs/2112.01527) and first released in [this repository](https://github.com/facebookresearch/Mask2Former/).
Disclaimer: The team releasing Mask2Former did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
Mask2Former addresses instance, semantic and panoptic segmentation with the same paradigm: by predicting a set of masks and corresponding labels. Hence, all 3 tasks are treated as if they were instance segmentation. Mask2Former outperforms the previous SOTA,
[MaskFormer](https://arxiv.org/abs/2107.06278) both in terms of performance an efficiency by (i) replacing the pixel decoder with a more advanced multi-scale deformable attention Transformer, (ii) adopting a Transformer decoder with masked attention to boost performance without
without introducing additional computation and (iii) improving training efficiency by calculating the loss on subsampled points instead of whole masks.

## Intended uses & limitations
You can use this particular checkpoint for panoptic segmentation. See the [model hub](https://huggingface.co/models?search=mask2former) to look for other
fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model:
```python
import requests
import torch
from PIL import Image
from transformers import AutoImageProcessor, Mask2FormerForUniversalSegmentation
# load Mask2Former fine-tuned on COCO panoptic segmentation
processor = AutoImageProcessor.from_pretrained("facebook/mask2former-swin-small-coco-panoptic")
model = Mask2FormerForUniversalSegmentation.from_pretrained("facebook/mask2former-swin-small-coco-panoptic")
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
inputs = processor(images=image, return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs)
# model predicts class_queries_logits of shape `(batch_size, num_queries)`
# and masks_queries_logits of shape `(batch_size, num_queries, height, width)`
class_queries_logits = outputs.class_queries_logits
masks_queries_logits = outputs.masks_queries_logits
# you can pass them to processor for postprocessing
result = processor.post_process_panoptic_segmentation(outputs, target_sizes=[image.size[::-1]])[0]
# we refer to the demo notebooks for visualization (see "Resources" section in the Mask2Former docs)
predicted_panoptic_map = result["segmentation"]
```
For more code examples, we refer to the [documentation](https://huggingface.co/docs/transformers/master/en/model_doc/mask2former).
|
79e5c83a144964448c0ec55b702c7028
|
kasrahabib/distilbert-base-uncased-trained-on-open-and-closed-source
|
kasrahabib
|
distilbert
| 10 | 2 |
transformers
| 0 |
text-classification
| false | true | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_keras_callback']
| true | true | true | 2,322 | false |
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# kasrahabib/distilbert-base-uncased-trained-on-open-and-closed-source
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.0039
- Validation Loss: 0.2082
- Train Precision: 0.9374
- Train Recall: 0.9714
- Train F1: 0.9541
- Epoch: 9
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'Adam', 'learning_rate': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 2e-05, 'decay_steps': 5860, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False}
- training_precision: float32
### Training results
| Train Loss | Validation Loss | Train Precision | Train Recall | Train F1 | Epoch |
|:----------:|:---------------:|:---------------:|:------------:|:--------:|:-----:|
| 0.2472 | 0.1604 | 0.8967 | 0.9771 | 0.9352 | 0 |
| 0.0924 | 0.1266 | 0.9330 | 0.9561 | 0.9444 | 1 |
| 0.0439 | 0.1281 | 0.9543 | 0.9561 | 0.9552 | 2 |
| 0.0258 | 0.2058 | 0.8995 | 0.9905 | 0.9428 | 3 |
| 0.0136 | 0.1767 | 0.9418 | 0.9580 | 0.9499 | 4 |
| 0.0134 | 0.2637 | 0.8927 | 0.9847 | 0.9365 | 5 |
| 0.0074 | 0.2197 | 0.9144 | 0.9790 | 0.9456 | 6 |
| 0.0049 | 0.2140 | 0.9355 | 0.9695 | 0.9522 | 7 |
| 0.0058 | 0.2117 | 0.9360 | 0.9771 | 0.9561 | 8 |
| 0.0039 | 0.2082 | 0.9374 | 0.9714 | 0.9541 | 9 |
### Framework versions
- Transformers 4.24.0
- TensorFlow 2.9.2
- Datasets 2.8.0
- Tokenizers 0.13.2
|
f44e45afcb63b6eb4095c48475ea738c
|
robinhad/ukrainian-qa
|
robinhad
|
xlm-roberta
| 14 | 45 |
transformers
| 2 |
question-answering
| true | false | false |
mit
|
['uk']
| null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 2,095 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# ukrainian-qa
This model is a fine-tuned version of [ukr-models/xlm-roberta-base-uk](https://huggingface.co/ukr-models/xlm-roberta-base-uk) on the [UA-SQuAD](https://github.com/fido-ai/ua-datasets/tree/main/ua_datasets/src/question_answering) dataset.
Link to training scripts - [https://github.com/robinhad/ukrainian-qa](https://github.com/robinhad/ukrainian-qa)
It achieves the following results on the evaluation set:
- Loss: 1.4778
## Model description
More information needed
## How to use
```python
from transformers import pipeline, AutoTokenizer, AutoModelForQuestionAnswering
model_name = "robinhad/ukrainian-qa"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForQuestionAnswering.from_pretrained(model_name)
qa_model = pipeline("question-answering", model=model.to("cpu"), tokenizer=tokenizer)
question = "Де ти живеш?"
context = "Мене звати Сара і я живу у Лондоні"
qa_model(question = question, context = context)
```
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 6
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 2.4526 | 1.0 | 650 | 1.3631 |
| 1.3317 | 2.0 | 1300 | 1.2229 |
| 1.0693 | 3.0 | 1950 | 1.2184 |
| 0.6851 | 4.0 | 2600 | 1.3171 |
| 0.5594 | 5.0 | 3250 | 1.3893 |
| 0.4954 | 6.0 | 3900 | 1.4778 |
### Framework versions
- Transformers 4.19.2
- Pytorch 1.11.0
- Datasets 2.2.2
- Tokenizers 0.12.1
|
17a3963d836f8695df35d57996e73e23
|
patrickmac110/RankinBass
|
patrickmac110
| null | 32 | 0 | null | 0 | null | false | false | false |
cc0-1.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
[]
| false | true | true | 6,291 | false |
I created this embedding for SD 2.x 768x768 models, it turns everything into your favorite Christmas classic AniMagic stop motion style as popularized by Rudolf the Red Nosed Reindeer and Santa Claus is Coming to Town among several others produced by the same studio!
The Unreleased Christmas Stop Motion Mario Kart Movie!

Prompt: mario kart toy, (rnknbss16 :1.3), highly textured, figurine
Negative prompt: cgi, 3d render, videogame
Steps: 34, Sampler: Euler a, CFG scale: 7, Seed: 2737353293, Size: 768x768, Model: SD 2.0_Standard_v2-1_768-ema-pruned, Denoising strength: 0.79, Mask blur: 3, aesthetic_score: 4.9
The Upcoming Stop Action Pikachu Movie!

Prompt: pikachu in the style of rnknbss16
Steps: 30, Sampler: Euler a, CFG scale: 7, Seed: 459369051, Size: 768x768, Model: SD 2.0_Standard_v2-1_768-ema-pruned, aesthetic_score: 5.2

Prompt: pikachu in the style of rnknbss16-100
Steps: 30, Sampler: Euler a, CFG scale: 7, Seed: 4076512951, Size: 768x768, Model: SD 2.0_Standard_v2-1_768-ema-pruned, aesthetic_score: 5.2
Some 2022 Holiday Ads for the Latest Celebs!
Donald Trump

Prompt: a close up of (donald trump:1.) in the style of (rnknbss16 :1.0)
Negative prompt: blurry, text, words
Steps: 29, Sampler: Euler a, CFG scale: 7, Seed: 1397465632, Size: 768x768, Model: SD 2.0_Standard_v2-1_768-ema-pruned, aesthetic_score: 5.4
Morgan Freeman

Prompt: morgan freeman in the style of (rnknbss16 :1.0)
Steps: 29, Sampler: DPM++ 2S a Karras, CFG scale: 7, Seed: 1868403973, Size: 768x768, Model: SD 2.0_Standard_v2-1_768-ema-pruned, aesthetic_score: 5.7
Barack Obama

Prompt: barack obama in the style of rnknbss16v2-775
Steps: 47, Sampler: Euler a, CFG scale: 7, Seed: 3661737292, Size: 768x768, Model: SD 2.0_Standard_v2-1_768-ema-pruned
And Lastly, The Remake of A Lifetime, Hogwarts Castle From the New Harry Potter Series

Prompt: Hogwarts school of witchcraft and wizardry in the style of (rnknbss16 :1.0), highly detailed, intricate
Negative prompt: blurry
Steps: 60, Sampler: Euler a, CFG scale: 7, Seed: 2909664084, Size: 768x768, Model: SD 2.0_Standard_512-depth-ema, Denoising strength: 0.66, Mask blur: 3, aesthetic_score: 6.2
Notes on the use of these:
So I didn't really get a chance to fine-tune them as well as I would have liked, but I wanted to get them out there for people to enjoy so I've included the best of what I have.
All of these were trained with 90-ish upscaled screen grabs from high quality DVDs of just the 2 movies mentioned above. I did use some of the letters, and postcards, and packages from the opening credits scenes in hopes to be able to reproduce those or something similar (haven't tried) so you will probably want to include the usual "words, text, letters, logos, watermarks..." in your negative prompts to try to weed those out. I also included some of the limited 2d artwork found in those movies, again in hopes to be able to generate that style as well. but that hasn't seemed to affect much except possibly when generating things that have a lot of 2d variations (i.e. comic book characters) so specifying 3d, or that you want a doll of the thing, or a model, or toy of the thing might help a lot with prompting. Otherwise, just saying " thing in the style of rnknbss16" should do the trick!
The Models:
They're all 16 vectors.
rnknbss16: pretty good but was trained too far and/or fast and tends to make hybrid elf/Santa creatures out of everything and is hard to get it to do anything else, although if your concept is strong or present enough in the model it can do pretty well (i.e. Cinderella's castle which is on EVERYTHING Disney).
Models rnknbss16-100 through rnknbss16-150 do much better, however these do less well with people and faces, they're better suited for things, creatures, animals, scenery, places, etc.
rnknbss16v2: pretty sure this one is overtrained by a good deal, but you might have success with it.
rnknbss16v2-750 and rnknbss16v2-775 are the sweet spot for people and characters with this v2 model, it also tends to get clearer outputs without looking as "fuzzy" or "blurry" and almost as a similar quality as VintageHelper embedding.
Which brings me to mixing this with things:
Using VingateHelper tends to enhance the "old school" vibes and film grain look as well as thematic props and other elements that may appear in the scene, and PhotoHelper embedding tends to create more "clay" models out of things, like with the Hogwarts castle it made it a wide angle clay diorama model of sorts which was cool and unexpected (see below).

Prompt: Hogwarts castle in the style of (rnknbss16 :1.2), highly detailed, very textured, intricate, shallow depth of field, photohelper
Negative prompt: blurry, text, words
Steps: 50, Sampler: Euler a, CFG scale: 7, Seed: 3448665914, Size: 768x768, Model: SD 2.0_Standard_v2-1_768-ema-pruned, aesthetic_score: 5.6
|
f30eb5b7ea7143703392b90ba127b30f
|
jonatasgrosman/exp_w2v2t_nl_xlsr-53_s948
|
jonatasgrosman
|
wav2vec2
| 10 | 5 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
|
['nl']
|
['mozilla-foundation/common_voice_7_0']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['automatic-speech-recognition', 'nl']
| false | true | true | 461 | false |
# exp_w2v2t_nl_xlsr-53_s948
Fine-tuned [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) for speech recognition using the train split of [Common Voice 7.0 (nl)](https://huggingface.co/datasets/mozilla-foundation/common_voice_7_0).
When using this model, make sure that your speech input is sampled at 16kHz.
This model has been fine-tuned by the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) tool.
|
6abcb5323b73aba287811da6f1d3437a
|
fathyshalab/all-roberta-large-v1-home-8-16-5-oos
|
fathyshalab
|
roberta
| 11 | 3 |
transformers
| 0 |
text-classification
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,513 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# all-roberta-large-v1-home-8-16-5-oos
This model is a fine-tuned version of [sentence-transformers/all-roberta-large-v1](https://huggingface.co/sentence-transformers/all-roberta-large-v1) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 2.3789
- Accuracy: 0.3356
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 48
- eval_batch_size: 48
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 2.7614 | 1.0 | 1 | 2.6146 | 0.1889 |
| 2.2082 | 2.0 | 2 | 2.5232 | 0.2667 |
| 1.8344 | 3.0 | 3 | 2.4516 | 0.2933 |
| 1.4601 | 4.0 | 4 | 2.4033 | 0.3267 |
| 1.2748 | 5.0 | 5 | 2.3789 | 0.3356 |
### Framework versions
- Transformers 4.20.0
- Pytorch 1.11.0+cu102
- Datasets 2.3.2
- Tokenizers 0.12.1
|
a96c762ed01a1087af7df566a6dd4967
|
sd-dreambooth-library/sally-whitemanev
|
sd-dreambooth-library
| null | 76 | 31 |
diffusers
| 10 |
text-to-image
| false | false | false |
creativeml-openrail-m
| null | null | null | 3 | 2 | 1 | 0 | 0 | 0 | 0 |
['stable-diffusion', 'stable-diffusion-diffusers', 'text-to-image']
| false | true | true | 7,580 | false |
Example result:
===============
# Using whitemanedb_step_3500.ckpt

# Using dbwhitemane.ckpt


%2C%20best%20quality%2C%20(masterpiece_1.3)%2C%20(red%20eyes_1.2)%2C%20blush%2C%20embarrassed.png)
%2C%20lush%2C%20%20blond.png)





Clip skip comparsion

I uploaded for now 3 models (more incoming for whitemane):
-[whitemanedb_step_2500.ckpt](https://huggingface.co/sd-dreambooth-library/sally-whitemanev/blob/main/whitemanedb_step_2500.ckpt)
-[whitemanedb_step_3500.ckpt](https://huggingface.co/sd-dreambooth-library/sally-whitemanev/blob/main/whitemanedb_step_3500.ckpt)
Are trained with 21 images and the trigger is "whitemanedb", this is my first attempts and I didn't get the final file because I ran out of space on drive :\ but model seems to work just fine.
The second model is [dbwhitemane.ckpt](https://huggingface.co/sd-dreambooth-library/sally-whitemanev/blob/main/dbwhitemane.ckpt)
This one has a total of 39 images used for training that you can find [here](https://huggingface.co/sd-dreambooth-library/sally-whitemanev/tree/main/dataset)
**Model is based on AnythingV3 FP16 [38c1ebe3]
And so I would recommend to use a VAE from NAI, Anything or WaifuDiffusion**
**Also set clip skip to 2 will help because its based on NAI model**
# Promt examples
This one is for the comparsion on top
> whitemanedb , 8k, 4k, (highres:1.1), best quality, (masterpiece:1.3), (red eyes:1.2), blush, embarrassed
> Negative prompt: lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts,signature, watermark, username, blurry, artist name, bad face, deformed face, (poorly drawn face)),((buckteeth)), (((mutation))), (((deformed))), ((ugly)), blurry, ((bad anatomy)), (((bad proportions))), ((extra limbs)), cloned face, (((disfigured))), out of frame, ugly, extra limbs, (bad anatomy), gross proportions, (malformed limbs), ((missing arms)), ((missing legs)), (((extra arms))), (((extra legs))), mutated hands, (fused fingers), (too many fingers), (((long neck))), 1boy,
> Steps: 45, Sampler: Euler a, CFG scale: 7, Seed: 772493513, Size: 512x512, Model hash: 313ad056, Eta: 0.07, Clip skip: 2
> whitemanedb taking a bath, 8k, 4k, (highres:1.1), best quality, (masterpiece:1.3), (red eyes:1.2), nsfw, nude, blush, nipples,
> Negative prompt: lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts,signature, watermark, username, blurry, artist name, bad face, deformed face, (poorly drawn face)),((buckteeth)), (((mutation))), (((deformed))), ((ugly)), blurry, ((bad anatomy)), (((bad proportions))), ((extra limbs)), cloned face, (((disfigured))), out of frame, ugly, extra limbs, (bad anatomy), gross proportions, (malformed limbs), ((missing arms)), ((missing legs)), (((extra arms))), (((extra legs))), mutated hands, (fused fingers), (too many fingers), (((long neck))), 1boy,
> Steps: 45, Sampler: Euler a, CFG scale: 7, Seed: 3450621385, Size: 512x512, Model hash: 313ad056, Eta: 0.07, Clip skip: 2
> whitemanedb in a forest
> Negative prompt: lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts,signature, watermark, username, blurry, artist name, bad face, deformed face
> Steps: 35, Sampler: Euler a, CFG scale: 10.0, Seed: 2547952708, Size: 512x512, Model hash: 313ad056, Eta: 0.07, Clip skip: 2
> lying in the ground , princess, 1girl, solo, sbwhitemane in forest , leather armor, red eyes, lush
> Negative prompt: lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts,signature, watermark, username, blurry, artist name, bad face, deformed face, (poorly drawn face)),((buckteeth)), (((mutation))), (((deformed))), ((ugly)), blurry, ((bad anatomy)), (((bad proportions))), ((extra limbs)), cloned face, (((disfigured))), out of frame, ugly, extra limbs, (bad anatomy), gross proportions, (malformed limbs), ((missing arms)), ((missing legs)), (((extra arms))), (((extra legs))), mutated hands, (fused fingers), (too many fingers), (((long neck))), 1boy,
> Steps: 58, Sampler: Euler a, CFG scale: 7, Seed: 1390776440, Size: 512x512, Model hash: 8b1a4378, Clip skip: 2
> sbwhitemane leaning forward, princess, 1girl, solo,elf in forest , leather armor, large eyes, (ice green eyes:1.1), lush, blonde hair, realistic photo
> Negative prompt: lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts,signature, watermark, username, blurry, artist name, bad face, deformed face, (poorly drawn face)),((buckteeth)), (((mutation))), (((deformed))), ((ugly)), blurry, ((bad anatomy)), (((bad proportions))), ((extra limbs)), cloned face, (((disfigured))), out of frame, ugly, extra limbs, (bad anatomy), gross proportions, (malformed limbs), ((missing arms)), ((missing legs)), (((extra arms))), (((extra legs))), mutated hands, (fused fingers), (too many fingers), (((long neck))), 1boy,
> Steps: 45, Sampler: Euler a, CFG scale: 7, Seed: 1501953711, Size: 512x512, Model hash: 8b1a4378, Clip skip: 2
Enjoy, any recommendation or help is welcome, this is my first model and probably a lot of things can be improved!
|
0455067ea553f738ee64b9bb2486533e
|
Helsinki-NLP/opus-mt-tc-base-uk-hu
|
Helsinki-NLP
|
marian
| 13 | 6 |
transformers
| 0 |
translation
| true | true | false |
cc-by-4.0
|
['hu', 'uk']
| null | null | 1 | 0 | 1 | 0 | 0 | 0 | 0 |
['translation', 'opus-mt-tc']
| true | true | true | 5,237 | false |
# opus-mt-tc-base-uk-hu
Neural machine translation model for translating from Ukrainian (uk) to Hungarian (hu).
This model is part of the [OPUS-MT project](https://github.com/Helsinki-NLP/Opus-MT), an effort to make neural machine translation models widely available and accessible for many languages in the world. All models are originally trained using the amazing framework of [Marian NMT](https://marian-nmt.github.io/), an efficient NMT implementation written in pure C++. The models have been converted to pyTorch using the transformers library by huggingface. Training data is taken from [OPUS](https://opus.nlpl.eu/) and training pipelines use the procedures of [OPUS-MT-train](https://github.com/Helsinki-NLP/Opus-MT-train).
* Publications: [OPUS-MT – Building open translation services for the World](https://aclanthology.org/2020.eamt-1.61/) and [The Tatoeba Translation Challenge – Realistic Data Sets for Low Resource and Multilingual MT](https://aclanthology.org/2020.wmt-1.139/) (Please, cite if you use this model.)
```
@inproceedings{tiedemann-thottingal-2020-opus,
title = "{OPUS}-{MT} {--} Building open translation services for the World",
author = {Tiedemann, J{\"o}rg and Thottingal, Santhosh},
booktitle = "Proceedings of the 22nd Annual Conference of the European Association for Machine Translation",
month = nov,
year = "2020",
address = "Lisboa, Portugal",
publisher = "European Association for Machine Translation",
url = "https://aclanthology.org/2020.eamt-1.61",
pages = "479--480",
}
@inproceedings{tiedemann-2020-tatoeba,
title = "The Tatoeba Translation Challenge {--} Realistic Data Sets for Low Resource and Multilingual {MT}",
author = {Tiedemann, J{\"o}rg},
booktitle = "Proceedings of the Fifth Conference on Machine Translation",
month = nov,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2020.wmt-1.139",
pages = "1174--1182",
}
```
## Model info
* Release: 2022-03-08
* source language(s): ukr
* target language(s): hun
* model: transformer-align
* data: opusTCv20210807+pft ([source](https://github.com/Helsinki-NLP/Tatoeba-Challenge))
* tokenization: SentencePiece (spm32k,spm32k)
* original model: [opusTCv20210807+pft_transformer-align_2022-03-08.zip](https://object.pouta.csc.fi/Tatoeba-MT-models/ukr-hun/opusTCv20210807+pft_transformer-align_2022-03-08.zip)
* more information released models: [OPUS-MT ukr-hun README](https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/ukr-hun/README.md)
## Usage
A short example code:
```python
from transformers import MarianMTModel, MarianTokenizer
src_text = [
"Я тобі винний 1000 доларів.",
"Я п'ю воду."
]
model_name = "pytorch-models/opus-mt-tc-base-uk-hu"
tokenizer = MarianTokenizer.from_pretrained(model_name)
model = MarianMTModel.from_pretrained(model_name)
translated = model.generate(**tokenizer(src_text, return_tensors="pt", padding=True))
for t in translated:
print( tokenizer.decode(t, skip_special_tokens=True) )
# expected output:
# 1000 dollár a te hibád.
# Vizet iszom.
```
You can also use OPUS-MT models with the transformers pipelines, for example:
```python
from transformers import pipeline
pipe = pipeline("translation", model="Helsinki-NLP/opus-mt-tc-base-uk-hu")
print(pipe("Я тобі винний 1000 доларів."))
# expected output: 1000 dollár a te hibád.
```
## Benchmarks
* test set translations: [opusTCv20210807+pft_transformer-align_2022-03-08.test.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/ukr-hun/opusTCv20210807+pft_transformer-align_2022-03-08.test.txt)
* test set scores: [opusTCv20210807+pft_transformer-align_2022-03-08.eval.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/ukr-hun/opusTCv20210807+pft_transformer-align_2022-03-08.eval.txt)
* benchmark results: [benchmark_results.txt](benchmark_results.txt)
* benchmark output: [benchmark_translations.zip](benchmark_translations.zip)
| langpair | testset | chr-F | BLEU | #sent | #words |
|----------|---------|-------|-------|-------|--------|
| ukr-hun | tatoeba-test-v2021-08-07 | 0.67544 | 44.0 | 473 | 2472 |
| ukr-hun | flores101-devtest | 0.51953 | 20.2 | 1012 | 22183 |
## Acknowledgements
The work is supported by the [European Language Grid](https://www.european-language-grid.eu/) as [pilot project 2866](https://live.european-language-grid.eu/catalogue/#/resource/projects/2866), by the [FoTran project](https://www.helsinki.fi/en/researchgroups/natural-language-understanding-with-cross-lingual-grounding), funded by the European Research Council (ERC) under the European Union’s Horizon 2020 research and innovation programme (grant agreement No 771113), and the [MeMAD project](https://memad.eu/), funded by the European Union’s Horizon 2020 Research and Innovation Programme under grant agreement No 780069. We are also grateful for the generous computational resources and IT infrastructure provided by [CSC -- IT Center for Science](https://www.csc.fi/), Finland.
## Model conversion info
* transformers version: 4.16.2
* OPUS-MT git hash: f084bad
* port time: Wed Mar 23 21:54:12 EET 2022
* port machine: LM0-400-22516.local
|
2518b7aa9cb7966d8373ec40b2778fe6
|
fezhou/ddpm-butterflies-128
|
fezhou
| null | 13 | 2 |
diffusers
| 0 | null | false | false | false |
apache-2.0
|
['en']
|
['huggan/smithsonian_butterflies_subset']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
[]
| false | true | true | 1,228 | false |
<!-- This model card has been generated automatically according to the information the training script had access to. You
should probably proofread and complete it, then remove this comment. -->
# ddpm-butterflies-128
## Model description
This diffusion model is trained with the [🤗 Diffusers](https://github.com/huggingface/diffusers) library
on the `huggan/smithsonian_butterflies_subset` dataset.
## Intended uses & limitations
#### How to use
```python
# TODO: add an example code snippet for running this diffusion pipeline
```
#### Limitations and bias
[TODO: provide examples of latent issues and potential remediations]
## Training data
[TODO: describe the data used to train the model]
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 16
- eval_batch_size: 16
- gradient_accumulation_steps: 1
- optimizer: AdamW with betas=(None, None), weight_decay=None and epsilon=None
- lr_scheduler: None
- lr_warmup_steps: 500
- ema_inv_gamma: None
- ema_inv_gamma: None
- ema_inv_gamma: None
- mixed_precision: fp16
### Training results
📈 [TensorBoard logs](https://huggingface.co/fezhou/ddpm-butterflies-128/tensorboard?#scalars)
|
96f06bc7c1b803c0b172cc8138391e8e
|
google/t5-efficient-large-el12
|
google
|
t5
| 12 | 12 |
transformers
| 0 |
text2text-generation
| true | true | true |
apache-2.0
|
['en']
|
['c4']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['deep-narrow']
| false | true | true | 6,258 | false |
# T5-Efficient-LARGE-EL12 (Deep-Narrow version)
T5-Efficient-LARGE-EL12 is a variation of [Google's original T5](https://ai.googleblog.com/2020/02/exploring-transfer-learning-with-t5.html) following the [T5 model architecture](https://huggingface.co/docs/transformers/model_doc/t5).
It is a *pretrained-only* checkpoint and was released with the
paper **[Scale Efficiently: Insights from Pre-training and Fine-tuning Transformers](https://arxiv.org/abs/2109.10686)**
by *Yi Tay, Mostafa Dehghani, Jinfeng Rao, William Fedus, Samira Abnar, Hyung Won Chung, Sharan Narang, Dani Yogatama, Ashish Vaswani, Donald Metzler*.
In a nutshell, the paper indicates that a **Deep-Narrow** model architecture is favorable for **downstream** performance compared to other model architectures
of similar parameter count.
To quote the paper:
> We generally recommend a DeepNarrow strategy where the model’s depth is preferentially increased
> before considering any other forms of uniform scaling across other dimensions. This is largely due to
> how much depth influences the Pareto-frontier as shown in earlier sections of the paper. Specifically, a
> tall small (deep and narrow) model is generally more efficient compared to the base model. Likewise,
> a tall base model might also generally more efficient compared to a large model. We generally find
> that, regardless of size, even if absolute performance might increase as we continue to stack layers,
> the relative gain of Pareto-efficiency diminishes as we increase the layers, converging at 32 to 36
> layers. Finally, we note that our notion of efficiency here relates to any one compute dimension, i.e.,
> params, FLOPs or throughput (speed). We report all three key efficiency metrics (number of params,
> FLOPS and speed) and leave this decision to the practitioner to decide which compute dimension to
> consider.
To be more precise, *model depth* is defined as the number of transformer blocks that are stacked sequentially.
A sequence of word embeddings is therefore processed sequentially by each transformer block.
## Details model architecture
This model checkpoint - **t5-efficient-large-el12** - is of model type **Large** with the following variations:
- **el** is **12**
It has **586.69** million parameters and thus requires *ca.* **2346.78 MB** of memory in full precision (*fp32*)
or **1173.39 MB** of memory in half precision (*fp16* or *bf16*).
A summary of the *original* T5 model architectures can be seen here:
| Model | nl (el/dl) | ff | dm | kv | nh | #Params|
| ----| ---- | ---- | ---- | ---- | ---- | ----|
| Tiny | 4/4 | 1024 | 256 | 32 | 4 | 16M|
| Mini | 4/4 | 1536 | 384 | 32 | 8 | 31M|
| Small | 6/6 | 2048 | 512 | 32 | 8 | 60M|
| Base | 12/12 | 3072 | 768 | 64 | 12 | 220M|
| Large | 24/24 | 4096 | 1024 | 64 | 16 | 738M|
| Xl | 24/24 | 16384 | 1024 | 128 | 32 | 3B|
| XXl | 24/24 | 65536 | 1024 | 128 | 128 | 11B|
whereas the following abbreviations are used:
| Abbreviation | Definition |
| ----| ---- |
| nl | Number of transformer blocks (depth) |
| dm | Dimension of embedding vector (output vector of transformers block) |
| kv | Dimension of key/value projection matrix |
| nh | Number of attention heads |
| ff | Dimension of intermediate vector within transformer block (size of feed-forward projection matrix) |
| el | Number of transformer blocks in the encoder (encoder depth) |
| dl | Number of transformer blocks in the decoder (decoder depth) |
| sh | Signifies that attention heads are shared |
| skv | Signifies that key-values projection matrices are tied |
If a model checkpoint has no specific, *el* or *dl* than both the number of encoder- and decoder layers correspond to *nl*.
## Pre-Training
The checkpoint was pretrained on the [Colossal, Cleaned version of Common Crawl (C4)](https://huggingface.co/datasets/c4) for 524288 steps using
the span-based masked language modeling (MLM) objective.
## Fine-Tuning
**Note**: This model is a **pretrained** checkpoint and has to be fine-tuned for practical usage.
The checkpoint was pretrained in English and is therefore only useful for English NLP tasks.
You can follow on of the following examples on how to fine-tune the model:
*PyTorch*:
- [Summarization](https://github.com/huggingface/transformers/tree/master/examples/pytorch/summarization)
- [Question Answering](https://github.com/huggingface/transformers/blob/master/examples/pytorch/question-answering/run_seq2seq_qa.py)
- [Text Classification](https://github.com/huggingface/transformers/tree/master/examples/pytorch/text-classification) - *Note*: You will have to slightly adapt the training example here to make it work with an encoder-decoder model.
*Tensorflow*:
- [Summarization](https://github.com/huggingface/transformers/tree/master/examples/tensorflow/summarization)
- [Text Classification](https://github.com/huggingface/transformers/tree/master/examples/tensorflow/text-classification) - *Note*: You will have to slightly adapt the training example here to make it work with an encoder-decoder model.
*JAX/Flax*:
- [Summarization](https://github.com/huggingface/transformers/tree/master/examples/flax/summarization)
- [Text Classification](https://github.com/huggingface/transformers/tree/master/examples/flax/text-classification) - *Note*: You will have to slightly adapt the training example here to make it work with an encoder-decoder model.
## Downstream Performance
TODO: Add table if available
## Computational Complexity
TODO: Add table if available
## More information
We strongly recommend the reader to go carefully through the original paper **[Scale Efficiently: Insights from Pre-training and Fine-tuning Transformers](https://arxiv.org/abs/2109.10686)** to get a more nuanced understanding of this model checkpoint.
As explained in the following [issue](https://github.com/google-research/google-research/issues/986#issuecomment-1035051145), checkpoints including the *sh* or *skv*
model architecture variations have *not* been ported to Transformers as they are probably of limited practical usage and are lacking a more detailed description. Those checkpoints are kept [here](https://huggingface.co/NewT5SharedHeadsSharedKeyValues) as they might be ported potentially in the future.
|
8db053bfdd3fe01a39e482d008e9d7ab
|
jonatasgrosman/exp_w2v2t_nl_vp-nl_s158
|
jonatasgrosman
|
wav2vec2
| 10 | 5 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
|
['nl']
|
['mozilla-foundation/common_voice_7_0']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['automatic-speech-recognition', 'nl']
| false | true | true | 469 | false |
# exp_w2v2t_nl_vp-nl_s158
Fine-tuned [facebook/wav2vec2-large-nl-voxpopuli](https://huggingface.co/facebook/wav2vec2-large-nl-voxpopuli) for speech recognition using the train split of [Common Voice 7.0 (nl)](https://huggingface.co/datasets/mozilla-foundation/common_voice_7_0).
When using this model, make sure that your speech input is sampled at 16kHz.
This model has been fine-tuned by the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) tool.
|
2bcd6b092d660cd13c0b834d169e5322
|
ChutianTao/distilbert-base-uncased-finetuned-squad-1
|
ChutianTao
|
distilbert
| 12 | 8 |
transformers
| 0 |
question-answering
| true | false | false |
apache-2.0
| null |
['squad']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,281 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-squad-1
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the squad dataset.
It achieves the following results on the evaluation set:
- Loss: 1.6247
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 2.9872 | 1.0 | 554 | 1.7933 |
| 1.6189 | 2.0 | 1108 | 1.6159 |
| 1.3125 | 3.0 | 1662 | 1.6247 |
### Framework versions
- Transformers 4.24.0
- Pytorch 1.12.1+cu113
- Datasets 2.6.1
- Tokenizers 0.13.2
|
f6eb85368adf7fde4b052cca391f4796
|
ukeeba/test1
|
ukeeba
| null | 18 | 5 |
diffusers
| 0 |
text-to-image
| false | false | false |
creativeml-openrail-m
| null | null | null | 1 | 1 | 0 | 0 | 0 | 0 | 0 |
['text-to-image', 'stable-diffusion']
| false | true | true | 413 | false |
### test1 Dreambooth model trained by ukeeba with [TheLastBen's fast-DreamBooth](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast-DreamBooth.ipynb) notebook
Test the concept via A1111 Colab [fast-Colab-A1111](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast_stable_diffusion_AUTOMATIC1111.ipynb)
Sample pictures of this concept:
|
2ada32018803501dc9946a9f901ca1d0
|
mrm8488/ddpm-ema-pokemon-v2-64
|
mrm8488
| null | 8 | 0 |
diffusers
| 0 | null | false | false | false |
apache-2.0
|
['en']
|
['huggan/pokemon']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
[]
| false | true | true | 1,342 | false |
<!-- This model card has been generated automatically according to the information the training script had access to. You
should probably proofread and complete it, then remove this comment. -->
# ddpm-ema-pokemon-v2-64
## Model description
This diffusion model is trained with the [🤗 Diffusers](https://github.com/huggingface/diffusers) library
on the `huggan/pokemon` dataset.
## Intended uses & limitations
#### How to use
```python
# TODO: add an example code snippet for running this diffusion pipeline
```
#### Limitations and bias
[TODO: provide examples of latent issues and potential remediations]
## Training data
[TODO: describe the data used to train the model]
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 32
- eval_batch_size: 32
- gradient_accumulation_steps: 1
- optimizer: AdamW with betas=(0.95, 0.999), weight_decay=1e-06 and epsilon=1e-08
- lr_scheduler: cosine
- lr_warmup_steps: 500
- ema_inv_gamma: 1.0
- ema_inv_gamma: 0.75
- ema_inv_gamma: 0.9999
- mixed_precision: fp16
### Training results
📈 [TensorBoard logs](https://huggingface.co/mrm8488/ddpm-ema-pokemon-v2-64/tensorboard?#scalars)
> Created by [Manuel Romero/@mrm8488](https://twitter.com/mrm8488) with the support of [Q Blocks](https://www.qblocks.cloud/)
|
91fd3bb509da77d60ad6cec88aeae820
|
jonatasgrosman/exp_w2v2t_pl_xls-r_s287
|
jonatasgrosman
|
wav2vec2
| 10 | 5 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
|
['pl']
|
['mozilla-foundation/common_voice_7_0']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['automatic-speech-recognition', 'pl']
| false | true | true | 453 | false |
# exp_w2v2t_pl_xls-r_s287
Fine-tuned [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) for speech recognition using the train split of [Common Voice 7.0 (pl)](https://huggingface.co/datasets/mozilla-foundation/common_voice_7_0).
When using this model, make sure that your speech input is sampled at 16kHz.
This model has been fine-tuned by the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) tool.
|
208a9a6e48551fdbfb7fe969f675d146
|
KoichiYasuoka/roberta-base-thai-char-ud-goeswith
|
KoichiYasuoka
|
roberta
| 10 | 4 |
transformers
| 0 |
token-classification
| true | false | false |
apache-2.0
|
['th']
|
['universal_dependencies']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['thai', 'token-classification', 'pos', 'dependency-parsing']
| false | true | true | 2,744 | false |
# roberta-base-thai-char-ud-goeswith
## Model Description
This is a RoBERTa model pre-trained on Thai Wikipedia texts for POS-tagging and dependency-parsing (using `goeswith` for subwords), derived from [roberta-base-thai-char-upos](https://huggingface.co/KoichiYasuoka/roberta-base-thai-char-upos).
## How to Use
```py
class UDgoeswith(object):
def __init__(self,bert):
from transformers import AutoTokenizer,AutoModelForTokenClassification
self.tokenizer=AutoTokenizer.from_pretrained(bert)
self.model=AutoModelForTokenClassification.from_pretrained(bert)
def __call__(self,text):
import numpy,torch,ufal.chu_liu_edmonds
w=self.tokenizer(text,return_offsets_mapping=True)
v=w["input_ids"]
x=[v[0:i]+[self.tokenizer.mask_token_id]+v[i+1:]+[j] for i,j in enumerate(v[1:-1],1)]
with torch.no_grad():
e=self.model(input_ids=torch.tensor(x)).logits.numpy()[:,1:-2,:]
r=[1 if i==0 else -1 if j.endswith("|root") else 0 for i,j in sorted(self.model.config.id2label.items())]
e+=numpy.where(numpy.add.outer(numpy.identity(e.shape[0]),r)==0,0,numpy.nan)
g=self.model.config.label2id["X|_|goeswith"]
r=numpy.tri(e.shape[0])
for i in range(e.shape[0]):
for j in range(i+2,e.shape[1]):
r[i,j]=r[i,j-1] if numpy.nanargmax(e[i,j-1])==g else 1
e[:,:,g]+=numpy.where(r==0,0,numpy.nan)
m=numpy.full((e.shape[0]+1,e.shape[1]+1),numpy.nan)
m[1:,1:]=numpy.nanmax(e,axis=2).transpose()
p=numpy.zeros(m.shape)
p[1:,1:]=numpy.nanargmax(e,axis=2).transpose()
for i in range(1,m.shape[0]):
m[i,0],m[i,i],p[i,0]=m[i,i],numpy.nan,p[i,i]
h=ufal.chu_liu_edmonds.chu_liu_edmonds(m)[0]
if [0 for i in h if i==0]!=[0]:
m[:,0]+=numpy.where(m[:,0]==numpy.nanmax(m[[i for i,j in enumerate(h) if j==0],0]),0,numpy.nan)
m[[i for i,j in enumerate(h) if j==0]]+=[0 if i==0 or j==0 else numpy.nan for i,j in enumerate(h)]
h=ufal.chu_liu_edmonds.chu_liu_edmonds(m)[0]
u="# text = "+text+"\n"
v=[(s,e) for s,e in w["offset_mapping"] if s<e]
for i,(s,e) in enumerate(v,1):
q=self.model.config.id2label[p[i,h[i]]].split("|")
u+="\t".join([str(i),text[s:e],"_",q[0],"_","|".join(q[1:-1]),str(h[i]),q[-1],"_","_" if i<len(v) and e<v[i][0] else "SpaceAfter=No"])+"\n"
return u+"\n"
nlp=UDgoeswith("KoichiYasuoka/roberta-base-thai-char-ud-goeswith")
print(nlp("หลายหัวดีกว่าหัวเดียว"))
```
with [ufal.chu-liu-edmonds](https://pypi.org/project/ufal.chu-liu-edmonds/).
Or without ufal.chu-liu-edmonds:
```
from transformers import pipeline
nlp=pipeline("universal-dependencies","KoichiYasuoka/roberta-base-thai-char-ud-goeswith",trust_remote_code=True,aggregation_strategy="simple")
print(nlp("หลายหัวดีกว่าหัวเดียว"))
```
|
db11bf27a23aa52b3aaa0fdf353b206f
|
w11wo/wav2vec2-xls-r-300m-zh-HK-v2
|
w11wo
|
wav2vec2
| 32 | 10 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
|
['zh-HK']
|
['common_voice']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['automatic-speech-recognition', 'generated_from_trainer', 'hf-asr-leaderboard', 'robust-speech-event']
| true | true | true | 7,897 | false |
# Wav2Vec2 XLS-R 300M Cantonese (zh-HK)
Wav2Vec2 XLS-R 300M Cantonese (zh-HK) is an automatic speech recognition model based on the [XLS-R](https://arxiv.org/abs/2111.09296) architecture. This model is a fine-tuned version of [Wav2Vec2-XLS-R-300M](https://huggingface.co/facebook/wav2vec2-xls-r-300m) on the `zh-HK` subset of the [Common Voice](https://huggingface.co/datasets/common_voice) dataset.
This model was trained using HuggingFace's PyTorch framework and is part of the [Robust Speech Challenge Event](https://discuss.huggingface.co/t/open-to-the-community-robust-speech-recognition-challenge/13614) organized by HuggingFace. All training was done on a Tesla V100, sponsored by OVH.
All necessary scripts used for training could be found in the [Files and versions](https://huggingface.co/w11wo/wav2vec2-xls-r-300m-zh-HK-v2/tree/main) tab, as well as the [Training metrics](https://huggingface.co/w11wo/wav2vec2-xls-r-300m-zh-HK-v2/tensorboard) logged via Tensorboard.
## Model
| Model | #params | Arch. | Training/Validation data (text) |
| ------------------------------ | ------- | ----- | ------------------------------- |
| `wav2vec2-xls-r-300m-zh-HK-v2` | 300M | XLS-R | `Common Voice zh-HK` Dataset |
## Evaluation Results
The model achieves the following results on evaluation:
| Dataset | Loss | CER |
| -------------------------------- | ------ | ------ |
| `Common Voice` | 0.8089 | 31.73% |
| `Common Voice 7` | N/A | 23.11% |
| `Common Voice 8` | N/A | 23.02% |
| `Robust Speech Event - Dev Data` | N/A | 56.60% |
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- `learning_rate`: 0.0001
- `train_batch_size`: 8
- `eval_batch_size`: 8
- `seed`: 42
- `gradient_accumulation_steps`: 4
- `total_train_batch_size`: 32
- `optimizer`: Adam with `betas=(0.9, 0.999)` and `epsilon=1e-08`
- `lr_scheduler_type`: linear
- `lr_scheduler_warmup_steps`: 2000
- `num_epochs`: 100.0
- `mixed_precision_training`: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer | Cer |
| :-----------: | :---: | :---: | :-------------: | :----: | :----: |
| 69.8341 | 1.34 | 500 | 80.0722 | 1.0 | 1.0 |
| 6.6418 | 2.68 | 1000 | 6.6346 | 1.0 | 1.0 |
| 6.2419 | 4.02 | 1500 | 6.2909 | 1.0 | 1.0 |
| 6.0813 | 5.36 | 2000 | 6.1150 | 1.0 | 1.0 |
| 5.9677 | 6.7 | 2500 | 6.0301 | 1.1386 | 1.0028 |
| 5.9296 | 8.04 | 3000 | 5.8975 | 1.2113 | 1.0058 |
| 5.6434 | 9.38 | 3500 | 5.5404 | 2.1624 | 1.0171 |
| 5.1974 | 10.72 | 4000 | 4.5440 | 2.1702 | 0.9366 |
| 4.3601 | 12.06 | 4500 | 3.3839 | 2.2464 | 0.8998 |
| 3.9321 | 13.4 | 5000 | 2.8785 | 2.3097 | 0.8400 |
| 3.6462 | 14.74 | 5500 | 2.5108 | 1.9623 | 0.6663 |
| 3.5156 | 16.09 | 6000 | 2.2790 | 1.6479 | 0.5706 |
| 3.32 | 17.43 | 6500 | 2.1450 | 1.8337 | 0.6244 |
| 3.1918 | 18.77 | 7000 | 1.8536 | 1.9394 | 0.6017 |
| 3.1139 | 20.11 | 7500 | 1.7205 | 1.9112 | 0.5638 |
| 2.8995 | 21.45 | 8000 | 1.5478 | 1.0624 | 0.3250 |
| 2.7572 | 22.79 | 8500 | 1.4068 | 1.1412 | 0.3367 |
| 2.6881 | 24.13 | 9000 | 1.3312 | 2.0100 | 0.5683 |
| 2.5993 | 25.47 | 9500 | 1.2553 | 2.0039 | 0.6450 |
| 2.5304 | 26.81 | 10000 | 1.2422 | 2.0394 | 0.5789 |
| 2.4352 | 28.15 | 10500 | 1.1582 | 1.9970 | 0.5507 |
| 2.3795 | 29.49 | 11000 | 1.1160 | 1.8255 | 0.4844 |
| 2.3287 | 30.83 | 11500 | 1.0775 | 1.4123 | 0.3780 |
| 2.2622 | 32.17 | 12000 | 1.0704 | 1.7445 | 0.4894 |
| 2.2225 | 33.51 | 12500 | 1.0272 | 1.7237 | 0.5058 |
| 2.1843 | 34.85 | 13000 | 0.9756 | 1.8042 | 0.5028 |
| 2.1 | 36.19 | 13500 | 0.9527 | 1.8909 | 0.6055 |
| 2.0741 | 37.53 | 14000 | 0.9418 | 1.9026 | 0.5880 |
| 2.0179 | 38.87 | 14500 | 0.9363 | 1.7977 | 0.5246 |
| 2.0615 | 40.21 | 15000 | 0.9635 | 1.8112 | 0.5599 |
| 1.9448 | 41.55 | 15500 | 0.9249 | 1.7250 | 0.4914 |
| 1.8966 | 42.89 | 16000 | 0.9023 | 1.5829 | 0.4319 |
| 1.8662 | 44.24 | 16500 | 0.9002 | 1.4833 | 0.4230 |
| 1.8136 | 45.58 | 17000 | 0.9076 | 1.1828 | 0.2987 |
| 1.7908 | 46.92 | 17500 | 0.8774 | 1.5773 | 0.4258 |
| 1.7354 | 48.26 | 18000 | 0.8727 | 1.5037 | 0.4024 |
| 1.6739 | 49.6 | 18500 | 0.8636 | 1.1239 | 0.2789 |
| 1.6457 | 50.94 | 19000 | 0.8516 | 1.2269 | 0.3104 |
| 1.5847 | 52.28 | 19500 | 0.8399 | 1.3309 | 0.3360 |
| 1.5971 | 53.62 | 20000 | 0.8441 | 1.3153 | 0.3335 |
| 1.602 | 54.96 | 20500 | 0.8590 | 1.2932 | 0.3433 |
| 1.5063 | 56.3 | 21000 | 0.8334 | 1.1312 | 0.2875 |
| 1.4631 | 57.64 | 21500 | 0.8474 | 1.1698 | 0.2999 |
| 1.4997 | 58.98 | 22000 | 0.8638 | 1.4279 | 0.3854 |
| 1.4301 | 60.32 | 22500 | 0.8550 | 1.2737 | 0.3300 |
| 1.3798 | 61.66 | 23000 | 0.8266 | 1.1802 | 0.2934 |
| 1.3454 | 63.0 | 23500 | 0.8235 | 1.3816 | 0.3711 |
| 1.3678 | 64.34 | 24000 | 0.8550 | 1.6427 | 0.5035 |
| 1.3761 | 65.68 | 24500 | 0.8510 | 1.6709 | 0.4907 |
| 1.2668 | 67.02 | 25000 | 0.8515 | 1.5842 | 0.4505 |
| 1.2835 | 68.36 | 25500 | 0.8283 | 1.5353 | 0.4221 |
| 1.2961 | 69.7 | 26000 | 0.8339 | 1.5743 | 0.4369 |
| 1.2656 | 71.05 | 26500 | 0.8331 | 1.5331 | 0.4217 |
| 1.2556 | 72.39 | 27000 | 0.8242 | 1.4708 | 0.4109 |
| 1.2043 | 73.73 | 27500 | 0.8245 | 1.4469 | 0.4031 |
| 1.2722 | 75.07 | 28000 | 0.8202 | 1.4924 | 0.4096 |
| 1.202 | 76.41 | 28500 | 0.8290 | 1.3807 | 0.3719 |
| 1.1679 | 77.75 | 29000 | 0.8195 | 1.4097 | 0.3749 |
| 1.1967 | 79.09 | 29500 | 0.8059 | 1.2074 | 0.3077 |
| 1.1241 | 80.43 | 30000 | 0.8137 | 1.2451 | 0.3270 |
| 1.1414 | 81.77 | 30500 | 0.8117 | 1.2031 | 0.3121 |
| 1.132 | 83.11 | 31000 | 0.8234 | 1.4266 | 0.3901 |
| 1.0982 | 84.45 | 31500 | 0.8064 | 1.3712 | 0.3607 |
| 1.0797 | 85.79 | 32000 | 0.8167 | 1.3356 | 0.3562 |
| 1.0119 | 87.13 | 32500 | 0.8215 | 1.2754 | 0.3268 |
| 1.0216 | 88.47 | 33000 | 0.8163 | 1.2512 | 0.3184 |
| 1.0375 | 89.81 | 33500 | 0.8137 | 1.2685 | 0.3290 |
| 0.9794 | 91.15 | 34000 | 0.8220 | 1.2724 | 0.3255 |
| 1.0207 | 92.49 | 34500 | 0.8165 | 1.2906 | 0.3361 |
| 1.0169 | 93.83 | 35000 | 0.8153 | 1.2819 | 0.3305 |
| 1.0127 | 95.17 | 35500 | 0.8187 | 1.2832 | 0.3252 |
| 0.9978 | 96.51 | 36000 | 0.8111 | 1.2612 | 0.3210 |
| 0.9923 | 97.85 | 36500 | 0.8076 | 1.2278 | 0.3122 |
| 1.0451 | 99.2 | 37000 | 0.8086 | 1.2451 | 0.3156 |
## Disclaimer
Do consider the biases which came from pre-training datasets that may be carried over into the results of this model.
## Authors
Wav2Vec2 XLS-R 300M Cantonese (zh-HK) was trained and evaluated by [Wilson Wongso](https://w11wo.github.io/). All computation and development are done on OVH Cloud.
## Framework versions
- Transformers 4.17.0.dev0
- Pytorch 1.10.2+cu102
- Datasets 1.18.4.dev0
- Tokenizers 0.11.0
|
1834840c64d934b0d2a7fdc019e8569b
|
aidiary/distilbert-base-uncased-finetuned-emotion
|
aidiary
|
distilbert
| 10 | 1 |
transformers
| 0 |
text-classification
| true | false | false |
apache-2.0
| null |
['emotion']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,344 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-emotion
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the emotion dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2149
- Accuracy: 0.9265
- F1: 0.9266
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 0.8307 | 1.0 | 250 | 0.3103 | 0.9065 | 0.9038 |
| 0.2461 | 2.0 | 500 | 0.2149 | 0.9265 | 0.9266 |
### Framework versions
- Transformers 4.21.3
- Pytorch 1.12.1+cu102
- Datasets 2.4.0
- Tokenizers 0.12.1
|
42e01d3da248d5dcdcf6a630c0488ce8
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.