
repo_id
stringlengths 4
110
| author
stringlengths 2
27
⌀ | model_type
stringlengths 2
29
⌀ | files_per_repo
int64 2
15.4k
| downloads_30d
int64 0
19.9M
| library
stringlengths 2
37
⌀ | likes
int64 0
4.34k
| pipeline
stringlengths 5
30
⌀ | pytorch
bool 2
classes | tensorflow
bool 2
classes | jax
bool 2
classes | license
stringlengths 2
30
| languages
stringlengths 4
1.63k
⌀ | datasets
stringlengths 2
2.58k
⌀ | co2
stringclasses 29
values | prs_count
int64 0
125
| prs_open
int64 0
120
| prs_merged
int64 0
15
| prs_closed
int64 0
28
| discussions_count
int64 0
218
| discussions_open
int64 0
148
| discussions_closed
int64 0
70
| tags
stringlengths 2
513
| has_model_index
bool 2
classes | has_metadata
bool 1
class | has_text
bool 1
class | text_length
int64 401
598k
| is_nc
bool 1
class | readme
stringlengths 0
598k
| hash
stringlengths 32
32
|
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
Thanish/wav2vec2-large-xlsr-tamil
|
Thanish
|
wav2vec2
| 9 | 21 |
transformers
| 0 |
automatic-speech-recognition
| true | false | true |
apache-2.0
|
['ta']
|
['common_voice']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['audio', 'automatic-speech-recognition', 'speech', 'xlsr-fine-tuning-week']
| true | true | true | 4,316 | false |
# Wav2Vec2-Large-XLSR-53-Tamil
Fine-tuned [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on Tamil using the [Common Voice](https://huggingface.co/datasets/common_voice) dataset.
When using this model, make sure that your speech input is sampled at 16kHz.
## Usage
The model can be used directly (without a language model) as follows:
```python
import torch
import torchaudio
from datasets import load_dataset
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
test_dataset = load_dataset("common_voice", "{lang_id}", split="test[:2%]") #TODO: replace {lang_id} in your language code here. Make sure the code is one of the *ISO codes* of [this](https://huggingface.co/languages) site.
processor = Wav2Vec2Processor.from_pretrained("{model_id}") #TODO: replace {model_id} with your model id. The model id consists of {your_username}/{your_modelname}, *e.g.* `elgeish/wav2vec2-large-xlsr-53-arabic`
model = Wav2Vec2ForCTC.from_pretrained("{model_id}") #TODO: replace {model_id} with your model id. The model id consists of {your_username}/{your_modelname}, *e.g.* `elgeish/wav2vec2-large-xlsr-53-arabic`
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
\\tspeech_array, sampling_rate = torchaudio.load(batch["path"])
\\tbatch["speech"] = resampler(speech_array).squeeze().numpy()
\\treturn batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
inputs = processor(test_dataset["speech"][:2], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
\\tlogits = model(inputs.input_values, attention_mask=inputs.attention_mask).logits
predicted_ids = torch.argmax(logits, dim=-1)
print("Prediction:", processor.batch_decode(predicted_ids))
print("Reference:", test_dataset["sentence"][:2])
```
## Evaluation
The model can be evaluated as follows on the Tamil test data of Common Voice.
```python
import torch
import torchaudio
from datasets import load_dataset, load_metric
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
import re
test_dataset = load_dataset("common_voice", "{lang_id}", split="test") #TODO: replace {lang_id} in your language code here. Make sure the code is one of the *ISO codes* of [this](https://huggingface.co/languages) site.
wer = load_metric("wer")
processor = Wav2Vec2Processor.from_pretrained("{model_id}") #TODO: replace {model_id} with your model id. The model id consists of {your_username}/{your_modelname}, *e.g.* `elgeish/wav2vec2-large-xlsr-53-arabic`
model = Wav2Vec2ForCTC.from_pretrained("{model_id}") #TODO: replace {model_id} with your model id. The model id consists of {your_username}/{your_modelname}, *e.g.* `elgeish/wav2vec2-large-xlsr-53-arabic`
model.to("cuda")
chars_to_ignore_regex = '[\\\\,\\\\?\\\\.\\\\!\\\\-\\\\;\\\\:\\\\"\\\\“]' # TODO: adapt this list to include all special characters you removed from the data
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the audio files as arrays
def speech_file_to_array_fn(batch):
\\tbatch["sentence"] = re.sub(chars_to_ignore_regex, '', batch["sentence"]).lower()
\\tspeech_array, sampling_rate = torchaudio.load(batch["path"])
\\tbatch["speech"] = resampler(speech_array).squeeze().numpy()
\\treturn batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def evaluate(batch):
\\tinputs = processor(batch["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
\\twith torch.no_grad():
\\t\\tlogits = model(inputs.input_values.to("cuda"), attention_mask=inputs.attention_mask.to("cuda")).logits
\\tpred_ids = torch.argmax(logits, dim=-1)
\\tbatch["pred_strings"] = processor.batch_decode(pred_ids)
\\treturn batch
result = test_dataset.map(evaluate, batched=True, batch_size=8)
print("WER: {:2f}".format(100 * wer.compute(predictions=result["pred_strings"], references=result["sentence"])))
```
**Test Result**: 100.00 %
## Training
The Common Voice `train`, `validation` were used for training
The script used for training can be found [https://colab.research.google.com/drive/1PC2SjxpcWMQ2qmRw21NbP38wtQQUa5os#scrollTo=YKBZdqqJG9Tv](...)
|
267eb34f08f2b12b97e08fb5a5948c2c
|
Lvxue/distilled-mt5-small-0.4-0.25
|
Lvxue
|
mt5
| 14 | 1 |
transformers
| 0 |
text2text-generation
| true | false | false |
apache-2.0
|
['en', 'ro']
|
['wmt16']
| null | 1 | 1 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,039 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilled-mt5-small-0.4-0.25
This model is a fine-tuned version of [google/mt5-small](https://huggingface.co/google/mt5-small) on the wmt16 ro-en dataset.
It achieves the following results on the evaluation set:
- Loss: 3.8561
- Bleu: 3.2179
- Gen Len: 41.2356
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 4
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5.0
### Training results
### Framework versions
- Transformers 4.20.1
- Pytorch 1.12.0+cu102
- Datasets 2.3.2
- Tokenizers 0.12.1
|
c907fe4f17818296ae9edd92aee524f7
|
Mr-Wick/Roberta
|
Mr-Wick
|
roberta
| 9 | 6 |
transformers
| 0 |
question-answering
| false | true | false |
mit
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_keras_callback']
| true | true | true | 1,095 | false |
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# Roberta
This model is a fine-tuned version of [roberta-base](https://huggingface.co/roberta-base) on an unknown dataset.
It achieves the following results on the evaluation set:
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'Adam', 'learning_rate': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 2e-05, 'decay_steps': 16476, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False}
- training_precision: float32
### Training results
### Framework versions
- Transformers 4.17.0
- TensorFlow 2.8.0
- Datasets 2.0.0
- Tokenizers 0.11.6
|
20e7550dd11e6ed33687da5253a2eccd
|
anas-awadalla/roberta-base-few-shot-k-512-finetuned-squad-seed-10
|
anas-awadalla
|
roberta
| 17 | 6 |
transformers
| 0 |
question-answering
| true | false | false |
mit
| null |
['squad']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 984 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# roberta-base-few-shot-k-512-finetuned-squad-seed-10
This model is a fine-tuned version of [roberta-base](https://huggingface.co/roberta-base) on the squad dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 24
- eval_batch_size: 24
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 10.0
### Training results
### Framework versions
- Transformers 4.16.0.dev0
- Pytorch 1.10.2+cu102
- Datasets 1.17.0
- Tokenizers 0.10.3
|
0ad431ac44b1c2daecf9ead45dbd7719
|
merve/tips5wx_sbh5-tip-regression
|
merve
| null | 4 | 0 |
sklearn
| 0 |
tabular-regression
| false | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['tabular-regression', 'baseline-trainer']
| false | true | true | 8,010 | false |
## Baseline Model trained on tips5wx_sbh5 to apply regression on tip
**Metrics of the best model:**
r2 0.389363
neg_mean_squared_error -1.092356
Name: Ridge(alpha=10), dtype: float64
**See model plot below:**
<style>#sk-container-id-1 {color: black;background-color: white;}#sk-container-id-1 pre{padding: 0;}#sk-container-id-1 div.sk-toggleable {background-color: white;}#sk-container-id-1 label.sk-toggleable__label {cursor: pointer;display: block;width: 100%;margin-bottom: 0;padding: 0.3em;box-sizing: border-box;text-align: center;}#sk-container-id-1 label.sk-toggleable__label-arrow:before {content: "▸";float: left;margin-right: 0.25em;color: #696969;}#sk-container-id-1 label.sk-toggleable__label-arrow:hover:before {color: black;}#sk-container-id-1 div.sk-estimator:hover label.sk-toggleable__label-arrow:before {color: black;}#sk-container-id-1 div.sk-toggleable__content {max-height: 0;max-width: 0;overflow: hidden;text-align: left;background-color: #f0f8ff;}#sk-container-id-1 div.sk-toggleable__content pre {margin: 0.2em;color: black;border-radius: 0.25em;background-color: #f0f8ff;}#sk-container-id-1 input.sk-toggleable__control:checked~div.sk-toggleable__content {max-height: 200px;max-width: 100%;overflow: auto;}#sk-container-id-1 input.sk-toggleable__control:checked~label.sk-toggleable__label-arrow:before {content: "▾";}#sk-container-id-1 div.sk-estimator input.sk-toggleable__control:checked~label.sk-toggleable__label {background-color: #d4ebff;}#sk-container-id-1 div.sk-label input.sk-toggleable__control:checked~label.sk-toggleable__label {background-color: #d4ebff;}#sk-container-id-1 input.sk-hidden--visually {border: 0;clip: rect(1px 1px 1px 1px);clip: rect(1px, 1px, 1px, 1px);height: 1px;margin: -1px;overflow: hidden;padding: 0;position: absolute;width: 1px;}#sk-container-id-1 div.sk-estimator {font-family: monospace;background-color: #f0f8ff;border: 1px dotted black;border-radius: 0.25em;box-sizing: border-box;margin-bottom: 0.5em;}#sk-container-id-1 div.sk-estimator:hover {background-color: #d4ebff;}#sk-container-id-1 div.sk-parallel-item::after {content: "";width: 100%;border-bottom: 1px solid gray;flex-grow: 1;}#sk-container-id-1 div.sk-label:hover label.sk-toggleable__label {background-color: #d4ebff;}#sk-container-id-1 div.sk-serial::before {content: "";position: absolute;border-left: 1px solid gray;box-sizing: border-box;top: 0;bottom: 0;left: 50%;z-index: 0;}#sk-container-id-1 div.sk-serial {display: flex;flex-direction: column;align-items: center;background-color: white;padding-right: 0.2em;padding-left: 0.2em;position: relative;}#sk-container-id-1 div.sk-item {position: relative;z-index: 1;}#sk-container-id-1 div.sk-parallel {display: flex;align-items: stretch;justify-content: center;background-color: white;position: relative;}#sk-container-id-1 div.sk-item::before, #sk-container-id-1 div.sk-parallel-item::before {content: "";position: absolute;border-left: 1px solid gray;box-sizing: border-box;top: 0;bottom: 0;left: 50%;z-index: -1;}#sk-container-id-1 div.sk-parallel-item {display: flex;flex-direction: column;z-index: 1;position: relative;background-color: white;}#sk-container-id-1 div.sk-parallel-item:first-child::after {align-self: flex-end;width: 50%;}#sk-container-id-1 div.sk-parallel-item:last-child::after {align-self: flex-start;width: 50%;}#sk-container-id-1 div.sk-parallel-item:only-child::after {width: 0;}#sk-container-id-1 div.sk-dashed-wrapped {border: 1px dashed gray;margin: 0 0.4em 0.5em 0.4em;box-sizing: border-box;padding-bottom: 0.4em;background-color: white;}#sk-container-id-1 div.sk-label label {font-family: monospace;font-weight: bold;display: inline-block;line-height: 1.2em;}#sk-container-id-1 div.sk-label-container {text-align: center;}#sk-container-id-1 div.sk-container {/* jupyter's `normalize.less` sets `[hidden] { display: none; }` but bootstrap.min.css set `[hidden] { display: none !important; }` so we also need the `!important` here to be able to override the default hidden behavior on the sphinx rendered scikit-learn.org. See: https://github.com/scikit-learn/scikit-learn/issues/21755 */display: inline-block !important;position: relative;}#sk-container-id-1 div.sk-text-repr-fallback {display: none;}</style><div id="sk-container-id-1" class="sk-top-container"><div class="sk-text-repr-fallback"><pre>Pipeline(steps=[('easypreprocessor',EasyPreprocessor(types= continuous dirty_float low_card_int ... date free_string useless
total_bill True False False ... False False False
sex False False False ... False False False
smoker False False False ... False False False
day False False False ... False False False
time False False False ... False False False
size False False False ... False False False[6 rows x 7 columns])),('ridge', Ridge(alpha=10))])</pre><b>In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. <br />On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.</b></div><div class="sk-container" hidden><div class="sk-item sk-dashed-wrapped"><div class="sk-label-container"><div class="sk-label sk-toggleable"><input class="sk-toggleable__control sk-hidden--visually" id="sk-estimator-id-1" type="checkbox" ><label for="sk-estimator-id-1" class="sk-toggleable__label sk-toggleable__label-arrow">Pipeline</label><div class="sk-toggleable__content"><pre>Pipeline(steps=[('easypreprocessor',EasyPreprocessor(types= continuous dirty_float low_card_int ... date free_string useless
total_bill True False False ... False False False
sex False False False ... False False False
smoker False False False ... False False False
day False False False ... False False False
time False False False ... False False False
size False False False ... False False False[6 rows x 7 columns])),('ridge', Ridge(alpha=10))])</pre></div></div></div><div class="sk-serial"><div class="sk-item"><div class="sk-estimator sk-toggleable"><input class="sk-toggleable__control sk-hidden--visually" id="sk-estimator-id-2" type="checkbox" ><label for="sk-estimator-id-2" class="sk-toggleable__label sk-toggleable__label-arrow">EasyPreprocessor</label><div class="sk-toggleable__content"><pre>EasyPreprocessor(types= continuous dirty_float low_card_int ... date free_string useless
total_bill True False False ... False False False
sex False False False ... False False False
smoker False False False ... False False False
day False False False ... False False False
time False False False ... False False False
size False False False ... False False False[6 rows x 7 columns])</pre></div></div></div><div class="sk-item"><div class="sk-estimator sk-toggleable"><input class="sk-toggleable__control sk-hidden--visually" id="sk-estimator-id-3" type="checkbox" ><label for="sk-estimator-id-3" class="sk-toggleable__label sk-toggleable__label-arrow">Ridge</label><div class="sk-toggleable__content"><pre>Ridge(alpha=10)</pre></div></div></div></div></div></div></div>
**Disclaimer:** This model is trained with dabl library as a baseline, for better results, use [AutoTrain](https://huggingface.co/autotrain).
**Logs of training** including the models tried in the process can be found in logs.txt
|
240c3cc59bd7837f3cf00ca5d6e03deb
|
anuragshas/en-hi-transliteration
|
anuragshas
| null | 7 | 0 | null | 0 | null | false | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
[]
| false | true | true | 1,542 | false |
## Dataset
[NEWS2018 DATASET_04, Task ID: M-EnHi](http://workshop.colips.org/news2018/dataset.html)
## Notebooks
- `xmltodict.ipynb` contains the code to convert the `xml` files to `json` for training
- `training_script.ipynb` contains the code for training and inference. It is a modified version of https://github.com/AI4Bharat/IndianNLP-Transliteration/blob/master/NoteBooks/Xlit_TrainingSetup_condensed.ipynb
## Predictions
`pred_test.json` contains top-10 predictions on the validation set of the dataset
## Evaluation Scores on validation set
TOP 10 SCORES FOR 1000 SAMPLES
|Metrics | Score |
|-----------|-----------|
|ACC | 0.703000|
|Mean F-score| 0.949289|
|MRR | 0.486549|
|MAP_ref | 0.381000|
TOP 5 SCORES FOR 1000 SAMPLES:
|Metrics | Score |
|-----------|-----------|
|ACC |0.621000|
|Mean F-score |0.937985|
|MRR |0.475033|
|MAP_ref |0.381000|
TOP 3 SCORES FOR 1000 SAMPLES:
|Metrics | Score |
|-----------|-----------|
|ACC |0.560000|
|Mean F-score |0.927025|
|MRR |0.461333|
|MAP_ref |0.381000|
TOP 2 SCORES FOR 1000 SAMPLES:
|Metrics | Score |
|-----------|-----------|
|ACC | 0.502000|
|Mean F-score | 0.913697|
|MRR | 0.442000|
|MAP_ref | 0.381000|
TOP 1 SCORES FOR 1000 SAMPLES:
|Metrics | Score |
|-----------|-----------|
|ACC | 0.382000|
|Mean F-score | 0.881272|
|MRR | 0.382000|
|MAP_ref | 0.380500|
|
a533088e01e5b4bda5eec6acbb4264e8
|
jph00/fastdiffusion-models
|
jph00
| null | 9 | 0 | null | 0 | null | false | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
[]
| false | true | true | 1,993 | false |
*all models trained with mnist sigma_data, instead of fashion-mnist.*
- base: default k-diffusion model
- no-t-emb: as base, but no t-embeddings in model
- mse-no-t-emb: as no-t-emb, but predicting unscaled noise
- mse: unscaled noise prediction with t-embeddings
## base metrics
step,fid,kid
5000,23.366962432861328,0.0060024261474609375
10000,21.407773971557617,0.004696846008300781
15000,19.820981979370117,0.003306865692138672
20000,20.4482421875,0.0037620067596435547
25000,19.459041595458984,0.0030574798583984375
30000,18.933385848999023,0.0031194686889648438
35000,18.223621368408203,0.002220630645751953
40000,18.64676284790039,0.0026960372924804688
45000,17.681808471679688,0.0016982555389404297
50000,17.32500457763672,0.001678466796875
55000,17.74714469909668,0.0016117095947265625
60000,18.276540756225586,0.002439737319946289
## mse-no-t-emb
step,fid,kid
5000,28.580364227294922,0.007686138153076172
10000,25.324932098388672,0.0061130523681640625
15000,23.68691635131836,0.005526542663574219
20000,24.05099105834961,0.005819082260131836
25000,22.60521125793457,0.004955768585205078
30000,22.16605567932129,0.0047609806060791016
35000,21.794536590576172,0.0039484500885009766
40000,22.96178436279297,0.005787849426269531
45000,22.641393661499023,0.004763364791870117
50000,20.735567092895508,0.0038640499114990234
55000,21.417423248291016,0.004515647888183594
60000,22.11293601989746,0.0054743289947509766
## no-t-emb
step,fid,kid
5000,53.25414276123047,0.02761554718017578
10000,47.687461853027344,0.023845195770263672
15000,46.045196533203125,0.02205944061279297
20000,44.64243698120117,0.020934104919433594
25000,43.55231857299805,0.020574331283569336
30000,43.493412017822266,0.020569324493408203
35000,42.51478958129883,0.01968073844909668
40000,42.213401794433594,0.01972222328186035
45000,40.9914665222168,0.018793582916259766
50000,42.946231842041016,0.019819974899291992
55000,40.699989318847656,0.018331050872802734
60000,41.737518310546875,0.019069194793701172
|
f68c987eb6b2be35e6b650acd69a1519
|
MisbaHF/distilbert-base-uncased-finetuned-cola
|
MisbaHF
|
distilbert
| 13 | 3 |
transformers
| 0 |
text-classification
| true | false | false |
apache-2.0
| null |
['glue']
| null | 1 | 1 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,572 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-cola
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the glue dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7134
- Matthews Correlation: 0.5411
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Matthews Correlation |
|:-------------:|:-----:|:----:|:---------------:|:--------------------:|
| 0.5294 | 1.0 | 535 | 0.5082 | 0.4183 |
| 0.3483 | 2.0 | 1070 | 0.4969 | 0.5259 |
| 0.2355 | 3.0 | 1605 | 0.6260 | 0.5065 |
| 0.1733 | 4.0 | 2140 | 0.7134 | 0.5411 |
| 0.1238 | 5.0 | 2675 | 0.8516 | 0.5291 |
### Framework versions
- Transformers 4.12.3
- Pytorch 1.10.0+cu111
- Datasets 1.15.1
- Tokenizers 0.10.3
|
0d487bc311782289b93c56850c4ed1a2
|
skr3178/xlm-roberta-base-finetuned-panx-de-fr
|
skr3178
|
xlm-roberta
| 10 | 5 |
transformers
| 0 |
token-classification
| true | false | false |
mit
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,321 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xlm-roberta-base-finetuned-panx-de-fr
This model is a fine-tuned version of [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1644
- F1: 0.8617
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 24
- eval_batch_size: 24
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 0.2891 | 1.0 | 715 | 0.1780 | 0.8288 |
| 0.1471 | 2.0 | 1430 | 0.1627 | 0.8509 |
| 0.0947 | 3.0 | 2145 | 0.1644 | 0.8617 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.11.0+cu113
- Datasets 1.16.1
- Tokenizers 0.10.3
|
1d445ad9636da3cc84e677b725130469
|
stanfordnlp/stanza-sme
|
stanfordnlp
| null | 8 | 3 |
stanza
| 0 |
token-classification
| false | false | false |
apache-2.0
|
['sme']
| null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['stanza', 'token-classification']
| false | true | true | 584 | false |
# Stanza model for North_Sami (sme)
Stanza is a collection of accurate and efficient tools for the linguistic analysis of many human languages. Starting from raw text to syntactic analysis and entity recognition, Stanza brings state-of-the-art NLP models to languages of your choosing.
Find more about it in [our website](https://stanfordnlp.github.io/stanza) and our [GitHub repository](https://github.com/stanfordnlp/stanza).
This card and repo were automatically prepared with `hugging_stanza.py` in the `stanfordnlp/huggingface-models` repo
Last updated 2022-09-25 02:02:22.878
|
c6a03ddbbb6c6a01b47868a7c7018755
|
research-backup/t5-base-subjqa-vanilla-grocery-qg
|
research-backup
|
t5
| 34 | 3 |
transformers
| 0 |
text2text-generation
| true | false | false |
cc-by-4.0
|
['en']
|
['lmqg/qg_subjqa']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['question generation']
| true | true | true | 3,969 | false |
# Model Card of `research-backup/t5-base-subjqa-vanilla-grocery-qg`
This model is fine-tuned version of [t5-base](https://huggingface.co/t5-base) for question generation task on the [lmqg/qg_subjqa](https://huggingface.co/datasets/lmqg/qg_subjqa) (dataset_name: grocery) via [`lmqg`](https://github.com/asahi417/lm-question-generation).
### Overview
- **Language model:** [t5-base](https://huggingface.co/t5-base)
- **Language:** en
- **Training data:** [lmqg/qg_subjqa](https://huggingface.co/datasets/lmqg/qg_subjqa) (grocery)
- **Online Demo:** [https://autoqg.net/](https://autoqg.net/)
- **Repository:** [https://github.com/asahi417/lm-question-generation](https://github.com/asahi417/lm-question-generation)
- **Paper:** [https://arxiv.org/abs/2210.03992](https://arxiv.org/abs/2210.03992)
### Usage
- With [`lmqg`](https://github.com/asahi417/lm-question-generation#lmqg-language-model-for-question-generation-)
```python
from lmqg import TransformersQG
# initialize model
model = TransformersQG(language="en", model="research-backup/t5-base-subjqa-vanilla-grocery-qg")
# model prediction
questions = model.generate_q(list_context="William Turner was an English painter who specialised in watercolour landscapes", list_answer="William Turner")
```
- With `transformers`
```python
from transformers import pipeline
pipe = pipeline("text2text-generation", "research-backup/t5-base-subjqa-vanilla-grocery-qg")
output = pipe("generate question: <hl> Beyonce <hl> further expanded her acting career, starring as blues singer Etta James in the 2008 musical biopic, Cadillac Records.")
```
## Evaluation
- ***Metric (Question Generation)***: [raw metric file](https://huggingface.co/research-backup/t5-base-subjqa-vanilla-grocery-qg/raw/main/eval/metric.first.sentence.paragraph_answer.question.lmqg_qg_subjqa.grocery.json)
| | Score | Type | Dataset |
|:-----------|--------:|:--------|:-----------------------------------------------------------------|
| BERTScore | 78.84 | grocery | [lmqg/qg_subjqa](https://huggingface.co/datasets/lmqg/qg_subjqa) |
| Bleu_1 | 3.05 | grocery | [lmqg/qg_subjqa](https://huggingface.co/datasets/lmqg/qg_subjqa) |
| Bleu_2 | 0.88 | grocery | [lmqg/qg_subjqa](https://huggingface.co/datasets/lmqg/qg_subjqa) |
| Bleu_3 | 0 | grocery | [lmqg/qg_subjqa](https://huggingface.co/datasets/lmqg/qg_subjqa) |
| Bleu_4 | 0 | grocery | [lmqg/qg_subjqa](https://huggingface.co/datasets/lmqg/qg_subjqa) |
| METEOR | 2.08 | grocery | [lmqg/qg_subjqa](https://huggingface.co/datasets/lmqg/qg_subjqa) |
| MoverScore | 51.78 | grocery | [lmqg/qg_subjqa](https://huggingface.co/datasets/lmqg/qg_subjqa) |
| ROUGE_L | 1.33 | grocery | [lmqg/qg_subjqa](https://huggingface.co/datasets/lmqg/qg_subjqa) |
## Training hyperparameters
The following hyperparameters were used during fine-tuning:
- dataset_path: lmqg/qg_subjqa
- dataset_name: grocery
- input_types: ['paragraph_answer']
- output_types: ['question']
- prefix_types: ['qg']
- model: t5-base
- max_length: 512
- max_length_output: 32
- epoch: 3
- batch: 16
- lr: 1e-05
- fp16: False
- random_seed: 1
- gradient_accumulation_steps: 8
- label_smoothing: 0.15
The full configuration can be found at [fine-tuning config file](https://huggingface.co/research-backup/t5-base-subjqa-vanilla-grocery-qg/raw/main/trainer_config.json).
## Citation
```
@inproceedings{ushio-etal-2022-generative,
title = "{G}enerative {L}anguage {M}odels for {P}aragraph-{L}evel {Q}uestion {G}eneration",
author = "Ushio, Asahi and
Alva-Manchego, Fernando and
Camacho-Collados, Jose",
booktitle = "Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing",
month = dec,
year = "2022",
address = "Abu Dhabi, U.A.E.",
publisher = "Association for Computational Linguistics",
}
```
|
860419fc8b6bd195748ccb3d1fa7e741
|
okite97/xlm-roberta-base-finetuned-panx-en
|
okite97
|
xlm-roberta
| 9 | 7 |
transformers
| 0 |
token-classification
| true | false | false |
mit
| null |
['xtreme']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,319 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xlm-roberta-base-finetuned-panx-en
This model is a fine-tuned version of [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) on the xtreme dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3848
- F1: 0.6994
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 1.0435 | 1.0 | 74 | 0.5169 | 0.5532 |
| 0.4719 | 2.0 | 148 | 0.4224 | 0.6630 |
| 0.3424 | 3.0 | 222 | 0.3848 | 0.6994 |
### Framework versions
- Transformers 4.20.1
- Pytorch 1.11.0+cu113
- Datasets 2.3.2
- Tokenizers 0.12.1
|
d43b9cc6b5405c38e6d30a86e42ce475
|
speechbrain/REAL-M-sisnr-estimator
|
speechbrain
| null | 6 | 33 |
speechbrain
| 1 | null | true | false | false |
apache-2.0
|
['en']
|
['REAL-M', 'WHAMR!']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['audio-source-separation', 'Source Separation', 'Speech Separation', 'WHAM!', 'REAL-M', 'SepFormer', 'Transformer', 'pytorch', 'speechbrain']
| false | true | true | 4,588 | false |
<iframe src="https://ghbtns.com/github-btn.html?user=speechbrain&repo=speechbrain&type=star&count=true&size=large&v=2" frameborder="0" scrolling="0" width="170" height="30" title="GitHub"></iframe>
<br/><br/>
# Neural SI-SNR Estimator
The Neural SI-SNR Estimator predicts the scale-invariant signal-to-noise ratio (SI-SNR) from the separated signals and the original mixture.
The performance estimation is blind (i.e., no targets signals are needed). This model allows a performance estimation on real mixtures, where the targets are not available.
This repository provides the SI-SNR estimator model introduced for the REAL-M dataset.
The REAL-M dataset can downloaded from [this link](https://sourceseparationresearch.com/static/REAL-M-v0.1.0.tar.gz).
The paper for the REAL-M dataset can be found on [this arxiv link](https://arxiv.org/pdf/2110.10812.pdf).
| Release | Test-Set (WHAMR!) average l1 error |
|:---:|:---:|
| 18-10-21 | 1.7 dB |
## Install SpeechBrain
First of all, currently you need to install SpeechBrain from the source:
1. Clone SpeechBrain:
```bash
git clone https://github.com/speechbrain/speechbrain/
```
2. Install it:
```
cd speechbrain
pip install -r requirements.txt
pip install -e .
```
Please notice that we encourage you to read our tutorials and learn more about [SpeechBrain](https://speechbrain.github.io).
### Minimal example for SI-SNR estimation
```python
from speechbrain.pretrained import SepformerSeparation as separator
from speechbrain.pretrained.interfaces import fetch
from speechbrain.pretrained.interfaces import SNREstimator as snrest
import torchaudio
# 1- Download a test mixture
fetch("test_mixture.wav", source="speechbrain/sepformer-wsj02mix", savedir=".", save_filename="test_mixture.wav")
# 2- Separate the mixture with a pretrained model (sepformer-whamr in this case)
model = separator.from_hparams(source="speechbrain/sepformer-whamr", savedir='pretrained_models/sepformer-whamr')
est_sources = model.separate_file(path='test_mixture.wav')
# 3- Estimate the performance
snr_est_model = snrest.from_hparams(source="speechbrain/REAL-M-sisnr-estimator",savedir='pretrained_models/REAL-M-sisnr-estimator')
mix, fs = torchaudio.load('test_mixture.wav')
snrhat = snr_est_model.estimate_batch(mix, est_sources)
print(snrhat) # Estimates are in dB / 10 (in the range 0-1, e.g., 0 --> 0dB, 1 --> 10dB)
```
### Inference on GPU
To perform inference on the GPU, add `run_opts={"device":"cuda"}` when calling the `from_hparams` method.
### Training
The model was trained with SpeechBrain (fc2eabb7).
To train it from scratch follows these steps:
1. Clone SpeechBrain:
```bash
git clone https://github.com/speechbrain/speechbrain/
```
2. Install it:
```
cd speechbrain
pip install -r requirements.txt
pip install -e .
```
3. Run Training:
```
cd recipes/REAL-M/sisnr-estimation
python train.py hparams/pool_sisnrestimator.yaml --data_folder /yourLibri2Mixpath --base_folder_dm /yourLibriSpeechpath --rir_path /yourpathforwhamrRIRs --dynamic_mixing True --use_whamr_train True --whamr_data_folder /yourpath/whamr --base_folder_dm_whamr /yourpath/wsj0-processed/si_tr_s
```
You can find our training results (models, logs, etc) [here](https://drive.google.com/drive/folders/1NGncbjvLeGfbUqmVi6ej-NH9YQn5vBmI).
### Limitations
The SpeechBrain team does not provide any warranty on the performance achieved by this model when used on other datasets.
#### Referencing SpeechBrain
```bibtex
@misc{speechbrain,
title={{SpeechBrain}: A General-Purpose Speech Toolkit},
author={Mirco Ravanelli and Titouan Parcollet and Peter Plantinga and Aku Rouhe and Samuele Cornell and Loren Lugosch and Cem Subakan and Nauman Dawalatabad and Abdelwahab Heba and Jianyuan Zhong and Ju-Chieh Chou and Sung-Lin Yeh and Szu-Wei Fu and Chien-Feng Liao and Elena Rastorgueva and François Grondin and William Aris and Hwidong Na and Yan Gao and Renato De Mori and Yoshua Bengio},
year={2021},
eprint={2106.04624},
archivePrefix={arXiv},
primaryClass={eess.AS},
note={arXiv:2106.04624}
}
```
#### Referencing REAL-M
```bibtex
@misc{subakan2021realm,
title={REAL-M: Towards Speech Separation on Real Mixtures},
author={Cem Subakan and Mirco Ravanelli and Samuele Cornell and François Grondin},
year={2021},
eprint={2110.10812},
archivePrefix={arXiv},
primaryClass={eess.AS}
}
```
```
# **About SpeechBrain**
- Website: https://speechbrain.github.io/
- Code: https://github.com/speechbrain/speechbrain/
- HuggingFace: https://huggingface.co/speechbrain/
|
42e050d8bb906071d25ca8fa04715e05
|
ntsema/wav2vec2-xlsr-53-espeak-cv-ft-evn2-ntsema-colab
|
ntsema
|
wav2vec2
| 13 | 8 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
| null |
['audiofolder']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,576 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-xlsr-53-espeak-cv-ft-evn2-ntsema-colab
This model is a fine-tuned version of [facebook/wav2vec2-xlsr-53-espeak-cv-ft](https://huggingface.co/facebook/wav2vec2-xlsr-53-espeak-cv-ft) on the audiofolder dataset.
It achieves the following results on the evaluation set:
- Loss: 2.0299
- Wer: 0.9867
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 4
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 8
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 30
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 4.2753 | 6.15 | 400 | 1.6106 | 0.99 |
| 0.8472 | 12.3 | 800 | 1.6731 | 0.99 |
| 0.4462 | 18.46 | 1200 | 1.8516 | 0.99 |
| 0.2556 | 24.61 | 1600 | 2.0299 | 0.9867 |
### Framework versions
- Transformers 4.24.0
- Pytorch 1.12.1+cu113
- Datasets 2.6.1
- Tokenizers 0.13.2
|
c70d730fcd2df5cb7cc60d22463e455a
|
Sultannn/bert-base-ft-pos-xtreme
|
Sultannn
|
bert
| 8 | 10 |
transformers
| 0 |
token-classification
| false | true | false |
mit
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_keras_callback']
| true | true | true | 1,677 | false |
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# Sultannn/bert-base-ft-pos-xtreme
This model is a fine-tuned version of [indobenchmark/indobert-base-p1](https://huggingface.co/indobenchmark/indobert-base-p1) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.1518
- Validation Loss: 0.2837
- Epoch: 3
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'AdamWeightDecay', 'learning_rate': {'class_name': 'WarmUp', 'config': {'initial_learning_rate': 3e-05, 'decay_schedule_fn': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 3e-05, 'decay_steps': 1008, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}, '__passive_serialization__': True}, 'warmup_steps': 500, 'power': 1.0, 'name': None}}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False, 'weight_decay_rate': 0.01}
- training_precision: mixed_float16
### Training results
| Train Loss | Validation Loss | Epoch |
|:----------:|:---------------:|:-----:|
| 0.9615 | 0.3139 | 0 |
| 0.3181 | 0.2758 | 1 |
| 0.2173 | 0.2774 | 2 |
| 0.1518 | 0.2837 | 3 |
### Framework versions
- Transformers 4.18.0
- TensorFlow 2.8.0
- Datasets 2.1.0
- Tokenizers 0.12.1
|
fedd57fd4444b7f1e8821bdf1e766253
|
sd-concepts-library/maurice-quentin-de-la-tour-style
|
sd-concepts-library
| null | 9 | 0 | null | 1 | null | false | false | false |
mit
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
[]
| false | true | true | 1,124 | false |
### Maurice-Quentin- de-la-Tour-style on Stable Diffusion
This is the `<maurice>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as a `style`:




|
4de1b8be905948362ba344a97add8b40
|
DrishtiSharma/wav2vec2-large-xls-r-300m-maltese
|
DrishtiSharma
|
wav2vec2
| 11 | 5 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
|
['mt']
|
['mozilla-foundation/common_voice_8_0']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['automatic-speech-recognition', 'generated_from_trainer', 'hf-asr-leaderboard', 'model_for_talk', 'mozilla-foundation/common_voice_8_0', 'mt', 'robust-speech-event']
| false | true | true | 2,153 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-large-xls-r-300m-maltese
This model is a fine-tuned version of [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) on the MOZILLA-FOUNDATION/COMMON_VOICE_8_0 - MT dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2994
- Wer: 0.2781
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 7e-05
- train_batch_size: 32
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 1800
- num_epochs: 100.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:-----:|:---------------:|:------:|
| 3.0174 | 9.01 | 1000 | 3.0552 | 1.0 |
| 1.0446 | 18.02 | 2000 | 0.6708 | 0.7577 |
| 0.7995 | 27.03 | 3000 | 0.4202 | 0.4770 |
| 0.6978 | 36.04 | 4000 | 0.3054 | 0.3494 |
| 0.6189 | 45.05 | 5000 | 0.2878 | 0.3154 |
| 0.5667 | 54.05 | 6000 | 0.3114 | 0.3286 |
| 0.5173 | 63.06 | 7000 | 0.3085 | 0.3021 |
| 0.4682 | 72.07 | 8000 | 0.3058 | 0.2969 |
| 0.451 | 81.08 | 9000 | 0.3146 | 0.2907 |
| 0.4213 | 90.09 | 10000 | 0.3030 | 0.2881 |
| 0.4005 | 99.1 | 11000 | 0.3001 | 0.2789 |
### Framework versions
- Transformers 4.17.0.dev0
- Pytorch 1.10.2+cu102
- Datasets 1.18.2.dev0
- Tokenizers 0.11.0
### Evaluation Script
!python eval.py \
--model_id DrishtiSharma/wav2vec2-large-xls-r-300m-maltese \
--dataset mozilla-foundation/common_voice_8_0 --config mt --split test --log_outputs
|
84bd0bd7545883fb9def73f4f255581b
|
juanarturovargas/mt5-small-finetuned-amazon-en-es
|
juanarturovargas
|
mt5
| 14 | 1 |
transformers
| 0 |
text2text-generation
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,996 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mt5-small-finetuned-amazon-en-es
This model is a fine-tuned version of [google/mt5-small](https://huggingface.co/google/mt5-small) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 3.0283
- Rouge1: 17.6736
- Rouge2: 8.5399
- Rougel: 17.4107
- Rougelsum: 17.3637
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5.6e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 8
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum |
|:-------------:|:-----:|:----:|:---------------:|:-------:|:------:|:-------:|:---------:|
| 3.7032 | 1.0 | 1209 | 3.1958 | 16.1227 | 7.4852 | 15.2662 | 15.3552 |
| 3.6502 | 2.0 | 2418 | 3.1103 | 17.2284 | 8.1626 | 16.757 | 16.6583 |
| 3.4365 | 3.0 | 3627 | 3.0698 | 17.2326 | 8.7096 | 17.0961 | 16.9705 |
| 3.312 | 4.0 | 4836 | 3.0324 | 16.9472 | 8.1386 | 16.6025 | 16.6126 |
| 3.2343 | 5.0 | 6045 | 3.0385 | 17.8752 | 8.0578 | 17.4985 | 17.5298 |
| 3.1661 | 6.0 | 7254 | 3.0334 | 17.8822 | 8.5243 | 17.5825 | 17.5242 |
| 3.1305 | 7.0 | 8463 | 3.0289 | 17.8187 | 8.124 | 17.4815 | 17.4688 |
| 3.1039 | 8.0 | 9672 | 3.0283 | 17.6736 | 8.5399 | 17.4107 | 17.3637 |
### Framework versions
- Transformers 4.22.2
- Pytorch 1.12.1+cu102
- Datasets 2.5.2
- Tokenizers 0.12.1
|
a3091645540c1794b2f041772e01640b
|
S2312dal/M6_MLM_cross
|
S2312dal
|
bert
| 47 | 2 |
transformers
| 0 |
text-classification
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,457 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# M6_MLM_cross
This model is a fine-tuned version of [S2312dal/M6_MLM](https://huggingface.co/S2312dal/M6_MLM) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0197
- Pearson: 0.9680
- Spearmanr: 0.9098
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 25
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 8.0
- num_epochs: 3
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Pearson | Spearmanr |
|:-------------:|:-----:|:----:|:---------------:|:-------:|:---------:|
| 0.0723 | 1.0 | 131 | 0.0646 | 0.8674 | 0.8449 |
| 0.0433 | 2.0 | 262 | 0.0322 | 0.9475 | 0.9020 |
| 0.0015 | 3.0 | 393 | 0.0197 | 0.9680 | 0.9098 |
### Framework versions
- Transformers 4.20.0
- Pytorch 1.11.0+cu113
- Datasets 2.3.2
- Tokenizers 0.12.1
|
567c227b49f0fb9d9fa4c9f3af963f8e
|
Apel/LoRa
|
Apel
| null | 26 | 0 | null | 7 | null | false | false | false |
creativeml-openrail-m
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
[]
| false | true | true | 1,070 | false |
# LoRAs
You will need to install this extension https://github.com/kohya-ss/sd-webui-additional-networks in order to use it in the Web UI. Follow the "How to use" section on that page.
# Social Media
[Twitter](https://twitter.com/kumisudang)
[Pixiv](https://www.pixiv.net/en/users/89129423)
## Characters
### Shinobu Kochou (Demon Slayer)
[Download .safetensors](https://huggingface.co/Apel/LoRa/tree/main/Characters/Demon%20Slayer%3A%20Kimetsu%20no%20Yaiba/Shinobu%20Kochou)
Relevant full-character prompt:
```
masterpiece, best quality, ultra-detailed, illustration, 1girl, solo, kochou shinobu, multicolored hair, no bangs, hair intakes, purple eyes, forehead, wisteria, black shirt, black pants, haori, butterfly, standing waist-deep in the crystal clear water of a tranquil pond, peaceful expression, surrounded by lush green foliage and wildflowers, falling petals, falling leaves, large breasts, cowboy shot, buttons, belt, light smile,
```

|
2dc6df5bdef5b29fd2925e550e16c8de
|
tomekkorbak/amazing_shannon
|
tomekkorbak
|
gpt2
| 23 | 2 |
transformers
| 0 | null | true | false | false |
mit
|
['en']
|
['tomekkorbak/detoxify-pile-chunk3-0-50000', 'tomekkorbak/detoxify-pile-chunk3-50000-100000', 'tomekkorbak/detoxify-pile-chunk3-100000-150000', 'tomekkorbak/detoxify-pile-chunk3-150000-200000', 'tomekkorbak/detoxify-pile-chunk3-200000-250000', 'tomekkorbak/detoxify-pile-chunk3-250000-300000', 'tomekkorbak/detoxify-pile-chunk3-300000-350000', 'tomekkorbak/detoxify-pile-chunk3-350000-400000', 'tomekkorbak/detoxify-pile-chunk3-400000-450000', 'tomekkorbak/detoxify-pile-chunk3-450000-500000', 'tomekkorbak/detoxify-pile-chunk3-500000-550000', 'tomekkorbak/detoxify-pile-chunk3-550000-600000', 'tomekkorbak/detoxify-pile-chunk3-600000-650000', 'tomekkorbak/detoxify-pile-chunk3-650000-700000', 'tomekkorbak/detoxify-pile-chunk3-700000-750000', 'tomekkorbak/detoxify-pile-chunk3-750000-800000', 'tomekkorbak/detoxify-pile-chunk3-800000-850000', 'tomekkorbak/detoxify-pile-chunk3-850000-900000', 'tomekkorbak/detoxify-pile-chunk3-900000-950000', 'tomekkorbak/detoxify-pile-chunk3-950000-1000000', 'tomekkorbak/detoxify-pile-chunk3-1000000-1050000', 'tomekkorbak/detoxify-pile-chunk3-1050000-1100000', 'tomekkorbak/detoxify-pile-chunk3-1100000-1150000', 'tomekkorbak/detoxify-pile-chunk3-1150000-1200000', 'tomekkorbak/detoxify-pile-chunk3-1200000-1250000', 'tomekkorbak/detoxify-pile-chunk3-1250000-1300000', 'tomekkorbak/detoxify-pile-chunk3-1300000-1350000', 'tomekkorbak/detoxify-pile-chunk3-1350000-1400000', 'tomekkorbak/detoxify-pile-chunk3-1400000-1450000', 'tomekkorbak/detoxify-pile-chunk3-1450000-1500000', 'tomekkorbak/detoxify-pile-chunk3-1500000-1550000', 'tomekkorbak/detoxify-pile-chunk3-1550000-1600000', 'tomekkorbak/detoxify-pile-chunk3-1600000-1650000', 'tomekkorbak/detoxify-pile-chunk3-1650000-1700000', 'tomekkorbak/detoxify-pile-chunk3-1700000-1750000', 'tomekkorbak/detoxify-pile-chunk3-1750000-1800000', 'tomekkorbak/detoxify-pile-chunk3-1800000-1850000', 'tomekkorbak/detoxify-pile-chunk3-1850000-1900000', 'tomekkorbak/detoxify-pile-chunk3-1900000-1950000']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 8,755 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# amazing_shannon
This model was trained from scratch on the tomekkorbak/detoxify-pile-chunk3-0-50000, the tomekkorbak/detoxify-pile-chunk3-50000-100000, the tomekkorbak/detoxify-pile-chunk3-100000-150000, the tomekkorbak/detoxify-pile-chunk3-150000-200000, the tomekkorbak/detoxify-pile-chunk3-200000-250000, the tomekkorbak/detoxify-pile-chunk3-250000-300000, the tomekkorbak/detoxify-pile-chunk3-300000-350000, the tomekkorbak/detoxify-pile-chunk3-350000-400000, the tomekkorbak/detoxify-pile-chunk3-400000-450000, the tomekkorbak/detoxify-pile-chunk3-450000-500000, the tomekkorbak/detoxify-pile-chunk3-500000-550000, the tomekkorbak/detoxify-pile-chunk3-550000-600000, the tomekkorbak/detoxify-pile-chunk3-600000-650000, the tomekkorbak/detoxify-pile-chunk3-650000-700000, the tomekkorbak/detoxify-pile-chunk3-700000-750000, the tomekkorbak/detoxify-pile-chunk3-750000-800000, the tomekkorbak/detoxify-pile-chunk3-800000-850000, the tomekkorbak/detoxify-pile-chunk3-850000-900000, the tomekkorbak/detoxify-pile-chunk3-900000-950000, the tomekkorbak/detoxify-pile-chunk3-950000-1000000, the tomekkorbak/detoxify-pile-chunk3-1000000-1050000, the tomekkorbak/detoxify-pile-chunk3-1050000-1100000, the tomekkorbak/detoxify-pile-chunk3-1100000-1150000, the tomekkorbak/detoxify-pile-chunk3-1150000-1200000, the tomekkorbak/detoxify-pile-chunk3-1200000-1250000, the tomekkorbak/detoxify-pile-chunk3-1250000-1300000, the tomekkorbak/detoxify-pile-chunk3-1300000-1350000, the tomekkorbak/detoxify-pile-chunk3-1350000-1400000, the tomekkorbak/detoxify-pile-chunk3-1400000-1450000, the tomekkorbak/detoxify-pile-chunk3-1450000-1500000, the tomekkorbak/detoxify-pile-chunk3-1500000-1550000, the tomekkorbak/detoxify-pile-chunk3-1550000-1600000, the tomekkorbak/detoxify-pile-chunk3-1600000-1650000, the tomekkorbak/detoxify-pile-chunk3-1650000-1700000, the tomekkorbak/detoxify-pile-chunk3-1700000-1750000, the tomekkorbak/detoxify-pile-chunk3-1750000-1800000, the tomekkorbak/detoxify-pile-chunk3-1800000-1850000, the tomekkorbak/detoxify-pile-chunk3-1850000-1900000 and the tomekkorbak/detoxify-pile-chunk3-1900000-1950000 datasets.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.01
- training_steps: 50354
- mixed_precision_training: Native AMP
### Framework versions
- Transformers 4.20.1
- Pytorch 1.11.0+cu113
- Datasets 2.5.1
- Tokenizers 0.11.6
# Full config
{'dataset': {'datasets': ['tomekkorbak/detoxify-pile-chunk3-0-50000',
'tomekkorbak/detoxify-pile-chunk3-50000-100000',
'tomekkorbak/detoxify-pile-chunk3-100000-150000',
'tomekkorbak/detoxify-pile-chunk3-150000-200000',
'tomekkorbak/detoxify-pile-chunk3-200000-250000',
'tomekkorbak/detoxify-pile-chunk3-250000-300000',
'tomekkorbak/detoxify-pile-chunk3-300000-350000',
'tomekkorbak/detoxify-pile-chunk3-350000-400000',
'tomekkorbak/detoxify-pile-chunk3-400000-450000',
'tomekkorbak/detoxify-pile-chunk3-450000-500000',
'tomekkorbak/detoxify-pile-chunk3-500000-550000',
'tomekkorbak/detoxify-pile-chunk3-550000-600000',
'tomekkorbak/detoxify-pile-chunk3-600000-650000',
'tomekkorbak/detoxify-pile-chunk3-650000-700000',
'tomekkorbak/detoxify-pile-chunk3-700000-750000',
'tomekkorbak/detoxify-pile-chunk3-750000-800000',
'tomekkorbak/detoxify-pile-chunk3-800000-850000',
'tomekkorbak/detoxify-pile-chunk3-850000-900000',
'tomekkorbak/detoxify-pile-chunk3-900000-950000',
'tomekkorbak/detoxify-pile-chunk3-950000-1000000',
'tomekkorbak/detoxify-pile-chunk3-1000000-1050000',
'tomekkorbak/detoxify-pile-chunk3-1050000-1100000',
'tomekkorbak/detoxify-pile-chunk3-1100000-1150000',
'tomekkorbak/detoxify-pile-chunk3-1150000-1200000',
'tomekkorbak/detoxify-pile-chunk3-1200000-1250000',
'tomekkorbak/detoxify-pile-chunk3-1250000-1300000',
'tomekkorbak/detoxify-pile-chunk3-1300000-1350000',
'tomekkorbak/detoxify-pile-chunk3-1350000-1400000',
'tomekkorbak/detoxify-pile-chunk3-1400000-1450000',
'tomekkorbak/detoxify-pile-chunk3-1450000-1500000',
'tomekkorbak/detoxify-pile-chunk3-1500000-1550000',
'tomekkorbak/detoxify-pile-chunk3-1550000-1600000',
'tomekkorbak/detoxify-pile-chunk3-1600000-1650000',
'tomekkorbak/detoxify-pile-chunk3-1650000-1700000',
'tomekkorbak/detoxify-pile-chunk3-1700000-1750000',
'tomekkorbak/detoxify-pile-chunk3-1750000-1800000',
'tomekkorbak/detoxify-pile-chunk3-1800000-1850000',
'tomekkorbak/detoxify-pile-chunk3-1850000-1900000',
'tomekkorbak/detoxify-pile-chunk3-1900000-1950000'],
'filter_threshold': 0.00078,
'is_split_by_sentences': True},
'generation': {'force_call_on': [25354],
'metrics_configs': [{}, {'n': 1}, {'n': 2}, {'n': 5}],
'scenario_configs': [{'generate_kwargs': {'do_sample': True,
'max_length': 128,
'min_length': 10,
'temperature': 0.7,
'top_k': 0,
'top_p': 0.9},
'name': 'unconditional',
'num_samples': 2048},
{'generate_kwargs': {'do_sample': True,
'max_length': 128,
'min_length': 10,
'temperature': 0.7,
'top_k': 0,
'top_p': 0.9},
'name': 'challenging_rtp',
'num_samples': 2048,
'prompts_path': 'resources/challenging_rtp.jsonl'}],
'scorer_config': {'device': 'cuda:0'}},
'kl_gpt3_callback': {'force_call_on': [25354],
'max_tokens': 64,
'num_samples': 4096},
'model': {'from_scratch': True,
'gpt2_config_kwargs': {'reorder_and_upcast_attn': True,
'scale_attn_by': True},
'path_or_name': 'gpt2'},
'objective': {'name': 'MLE'},
'tokenizer': {'path_or_name': 'gpt2'},
'training': {'dataloader_num_workers': 0,
'effective_batch_size': 64,
'evaluation_strategy': 'no',
'fp16': True,
'hub_model_id': 'amazing_shannon',
'hub_strategy': 'all_checkpoints',
'learning_rate': 0.0005,
'logging_first_step': True,
'logging_steps': 1,
'num_tokens': 3300000000,
'output_dir': 'training_output104340',
'per_device_train_batch_size': 16,
'push_to_hub': True,
'remove_unused_columns': False,
'save_steps': 25354,
'save_strategy': 'steps',
'seed': 42,
'warmup_ratio': 0.01,
'weight_decay': 0.1}}
# Wandb URL:
https://wandb.ai/tomekkorbak/apo/runs/3u44exkw
|
54e4f4ab8a695fa8e88117e7c905bbf4
|
Kushala/wav2vec2-large-xls-r-300m-kushala_wave2vec_trails
|
Kushala
|
wav2vec2
| 16 | 3 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,067 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-large-xls-r-300m-kushala_wave2vec_trails
This model is a fine-tuned version of [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 4
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 8
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 100
### Training results
### Framework versions
- Transformers 4.17.0
- Pytorch 1.12.1+cpu
- Datasets 1.18.3
- Tokenizers 0.12.1
|
19d43b718f9186540c4f5b14d3c06d84
|
yip-i/wav2vec2-demo-M02-2
|
yip-i
|
wav2vec2
| 10 | 5 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 3,203 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-demo-M02-2
This model is a fine-tuned version of [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 2.2709
- Wer: 1.0860
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 1000
- num_epochs: 30
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:-----:|:---------------:|:------:|
| 23.4917 | 0.91 | 500 | 3.2945 | 1.0 |
| 3.4102 | 1.81 | 1000 | 3.1814 | 1.0 |
| 2.9438 | 2.72 | 1500 | 2.7858 | 1.0 |
| 2.6698 | 3.62 | 2000 | 2.4745 | 1.0035 |
| 1.9542 | 4.53 | 2500 | 1.8675 | 1.3745 |
| 1.2737 | 5.43 | 3000 | 1.6459 | 1.3703 |
| 0.9748 | 6.34 | 3500 | 1.8406 | 1.3037 |
| 0.7696 | 7.25 | 4000 | 1.5086 | 1.2476 |
| 0.6396 | 8.15 | 4500 | 1.8280 | 1.2476 |
| 0.558 | 9.06 | 5000 | 1.7680 | 1.2247 |
| 0.4865 | 9.96 | 5500 | 1.8210 | 1.2309 |
| 0.4244 | 10.87 | 6000 | 1.7910 | 1.1775 |
| 0.3898 | 11.78 | 6500 | 1.8021 | 1.1831 |
| 0.3456 | 12.68 | 7000 | 1.7746 | 1.1456 |
| 0.3349 | 13.59 | 7500 | 1.8969 | 1.1519 |
| 0.3233 | 14.49 | 8000 | 1.7402 | 1.1234 |
| 0.3046 | 15.4 | 8500 | 1.8585 | 1.1429 |
| 0.2622 | 16.3 | 9000 | 1.6687 | 1.0950 |
| 0.2593 | 17.21 | 9500 | 1.8192 | 1.1144 |
| 0.2541 | 18.12 | 10000 | 1.8665 | 1.1110 |
| 0.2098 | 19.02 | 10500 | 1.9996 | 1.1186 |
| 0.2192 | 19.93 | 11000 | 2.0346 | 1.1040 |
| 0.1934 | 20.83 | 11500 | 2.1924 | 1.1012 |
| 0.2034 | 21.74 | 12000 | 1.8060 | 1.0929 |
| 0.1857 | 22.64 | 12500 | 2.0334 | 1.0798 |
| 0.1819 | 23.55 | 13000 | 2.1223 | 1.1040 |
| 0.1621 | 24.46 | 13500 | 2.1795 | 1.0957 |
| 0.1548 | 25.36 | 14000 | 2.1545 | 1.1089 |
| 0.1512 | 26.27 | 14500 | 2.2707 | 1.1186 |
| 0.1472 | 27.17 | 15000 | 2.1698 | 1.0888 |
| 0.1296 | 28.08 | 15500 | 2.2496 | 1.0867 |
| 0.1312 | 28.99 | 16000 | 2.2969 | 1.0881 |
| 0.1331 | 29.89 | 16500 | 2.2709 | 1.0860 |
### Framework versions
- Transformers 4.23.1
- Pytorch 1.12.1+cu113
- Datasets 1.18.3
- Tokenizers 0.13.2
|
6ddc06ce2390b90eff83c6118f7e85e4
|
ml6team/keyphrase-generation-keybart-inspec
|
ml6team
|
bart
| 10 | 281 |
transformers
| 1 |
text2text-generation
| true | false | false |
mit
|
['en']
|
['midas/inspec']
| null | 0 | 0 | 0 | 0 | 2 | 2 | 0 |
['keyphrase-generation']
| true | true | true | 8,935 | false |
# 🔑 Keyphrase Generation Model: KeyBART-inspec
Keyphrase extraction is a technique in text analysis where you extract the important keyphrases from a document. Thanks to these keyphrases humans can understand the content of a text very quickly and easily without reading it completely. Keyphrase extraction was first done primarily by human annotators, who read the text in detail and then wrote down the most important keyphrases. The disadvantage is that if you work with a lot of documents, this process can take a lot of time ⏳.
Here is where Artificial Intelligence 🤖 comes in. Currently, classical machine learning methods, that use statistical and linguistic features, are widely used for the extraction process. Now with deep learning, it is possible to capture the semantic meaning of a text even better than these classical methods. Classical methods look at the frequency, occurrence and order of words in the text, whereas these neural approaches can capture long-term semantic dependencies and context of words in a text.
## 📓 Model Description
This model uses [KeyBART](https://huggingface.co/bloomberg/KeyBART) as its base model and fine-tunes it on the [Inspec dataset](https://huggingface.co/datasets/midas/inspec). KeyBART focuses on learning a better representation of keyphrases in a generative setting. It produces the keyphrases associated with the input document from a corrupted input. The input is changed by token masking, keyphrase masking and keyphrase replacement. This model can already be used without any fine-tuning, but can be fine-tuned if needed.
You can find more information about the architecture in this [paper](https://arxiv.org/abs/2112.08547).
Kulkarni, Mayank, Debanjan Mahata, Ravneet Arora, and Rajarshi Bhowmik. "Learning Rich Representation of Keyphrases from Text." arXiv preprint arXiv:2112.08547 (2021).
## ✋ Intended Uses & Limitations
### 🛑 Limitations
* This keyphrase generation model is very domain-specific and will perform very well on abstracts of scientific papers. It's not recommended to use this model for other domains, but you are free to test it out.
* Only works for English documents.
### ❓ How To Use
```python
# Model parameters
from transformers import (
Text2TextGenerationPipeline,
AutoModelForSeq2SeqLM,
AutoTokenizer,
)
class KeyphraseGenerationPipeline(Text2TextGenerationPipeline):
def __init__(self, model, keyphrase_sep_token=";", *args, **kwargs):
super().__init__(
model=AutoModelForSeq2SeqLM.from_pretrained(model),
tokenizer=AutoTokenizer.from_pretrained(model),
*args,
**kwargs
)
self.keyphrase_sep_token = keyphrase_sep_token
def postprocess(self, model_outputs):
results = super().postprocess(
model_outputs=model_outputs
)
return [[keyphrase.strip() for keyphrase in result.get("generated_text").split(self.keyphrase_sep_token) if keyphrase != ""] for result in results]
```
```python
# Load pipeline
model_name = "ml6team/keyphrase-generation-keybart-inspec"
generator = KeyphraseGenerationPipeline(model=model_name)
```python
# Inference
text = """
Keyphrase extraction is a technique in text analysis where you extract the
important keyphrases from a document. Thanks to these keyphrases humans can
understand the content of a text very quickly and easily without reading it
completely. Keyphrase extraction was first done primarily by human annotators,
who read the text in detail and then wrote down the most important keyphrases.
The disadvantage is that if you work with a lot of documents, this process
can take a lot of time.
Here is where Artificial Intelligence comes in. Currently, classical machine
learning methods, that use statistical and linguistic features, are widely used
for the extraction process. Now with deep learning, it is possible to capture
the semantic meaning of a text even better than these classical methods.
Classical methods look at the frequency, occurrence and order of words
in the text, whereas these neural approaches can capture long-term
semantic dependencies and context of words in a text.
""".replace("\n", " ")
keyphrases = generator(text)
print(keyphrases)
```
```
# Output
[['keyphrase extraction', 'text analysis', 'keyphrases', 'human annotators', 'artificial']]
```
## 📚 Training Dataset
[Inspec](https://huggingface.co/datasets/midas/inspec) is a keyphrase extraction/generation dataset consisting of 2000 English scientific papers from the scientific domains of Computers and Control and Information Technology published between 1998 to 2002. The keyphrases are annotated by professional indexers or editors.
You can find more information in the [paper](https://dl.acm.org/doi/10.3115/1119355.1119383).
## 👷♂️ Training Procedure
### Training Parameters
| Parameter | Value |
| --------- | ------|
| Learning Rate | 5e-5 |
| Epochs | 15 |
| Early Stopping Patience | 1 |
### Preprocessing
The documents in the dataset are already preprocessed into list of words with the corresponding keyphrases. The only thing that must be done is tokenization and joining all keyphrases into one string with a certain seperator of choice( ```;``` ).
```python
from datasets import load_dataset
from transformers import AutoTokenizer
# Tokenizer
tokenizer = AutoTokenizer.from_pretrained("bloomberg/KeyBART", add_prefix_space=True)
# Dataset parameters
dataset_full_name = "midas/inspec"
dataset_subset = "raw"
dataset_document_column = "document"
keyphrase_sep_token = ";"
def preprocess_keyphrases(text_ids, kp_list):
kp_order_list = []
kp_set = set(kp_list)
text = tokenizer.decode(
text_ids, skip_special_tokens=True, clean_up_tokenization_spaces=True
)
text = text.lower()
for kp in kp_set:
kp = kp.strip()
kp_index = text.find(kp.lower())
kp_order_list.append((kp_index, kp))
kp_order_list.sort()
present_kp, absent_kp = [], []
for kp_index, kp in kp_order_list:
if kp_index < 0:
absent_kp.append(kp)
else:
present_kp.append(kp)
return present_kp, absent_kp
def preprocess_fuction(samples):
processed_samples = {"input_ids": [], "attention_mask": [], "labels": []}
for i, sample in enumerate(samples[dataset_document_column]):
input_text = " ".join(sample)
inputs = tokenizer(
input_text,
padding="max_length",
truncation=True,
)
present_kp, absent_kp = preprocess_keyphrases(
text_ids=inputs["input_ids"],
kp_list=samples["extractive_keyphrases"][i]
+ samples["abstractive_keyphrases"][i],
)
keyphrases = present_kp
keyphrases += absent_kp
target_text = f" {keyphrase_sep_token} ".join(keyphrases)
with tokenizer.as_target_tokenizer():
targets = tokenizer(
target_text, max_length=40, padding="max_length", truncation=True
)
targets["input_ids"] = [
(t if t != tokenizer.pad_token_id else -100)
for t in targets["input_ids"]
]
for key in inputs.keys():
processed_samples[key].append(inputs[key])
processed_samples["labels"].append(targets["input_ids"])
return processed_samples
# Load dataset
dataset = load_dataset(dataset_full_name, dataset_subset)
# Preprocess dataset
tokenized_dataset = dataset.map(preprocess_fuction, batched=True)
```
### Postprocessing
For the post-processing, you will need to split the string based on the keyphrase separator.
```python
def extract_keyphrases(examples):
return [example.split(keyphrase_sep_token) for example in examples]
```
## 📝 Evaluation results
Traditional evaluation methods are the precision, recall and F1-score @k,m where k is the number that stands for the first k predicted keyphrases and m for the average amount of predicted keyphrases. In keyphrase generation you also look at F1@O where O stands for the number of ground truth keyphrases.
The model achieves the following results on the Inspec test set:
### Extractive Keyphrases
| Dataset | P@5 | R@5 | F1@5 | P@10 | R@10 | F1@10 | P@M | R@M | F1@M | P@O | R@O | F1@O |
|:-----------------:|:----:|:----:|:----:|:----:|:----:|:-----:|:----:|:----:|:----:|:----:|:----:|:----:|
| Inspec Test Set | 0.40 | 0.37 | 0.35 | 0.20 | 0.37 | 0.24 | 0.42 | 0.37 | 0.36 | 0.33 | 0.33 | 0.33 |
### Abstractive Keyphrases
| Dataset | P@5 | R@5 | F1@5 | P@10 | R@10 | F1@10 | P@M | R@M | F1@M | P@O | R@O | F1@O |
|:-----------------:|:----:|:----:|:----:|:----:|:----:|:-----:|:----:|:----:|:----:|:----:|:----:|:----:|
| Inspec Test Set | 0.07 | 0.12 | 0.08 | 0.03 | 0.12 | 0.05 | 0.08 | 0.12 | 0.08 | 0.08 | 0.12 | 0.08 |
## 🚨 Issues
Please feel free to start discussions in the Community Tab.
|
22eff5e5720a8ce2cdfc4f4b44910d4d
|
alea31415/bocchi-the-rock-character
|
alea31415
| null | 27 | 0 | null | 42 | null | false | false | false |
creativeml-openrail-m
| null | null | null | 5 | 0 | 5 | 0 | 1 | 1 | 0 |
[]
| false | true | true | 5,767 | false |
---
license: creativeml-openrail-m
---
This is a low-quality bocchi-the-rock (ぼっち・ざ・ろっく!) character model.
Similar to my [yama-no-susume model](https://huggingface.co/alea31415/yama-no-susume), this model is capable of generating **multi-character scenes** beyond images of a single character.
Of course, the result is still hit-or-miss, but I with some chance you can get the entire Kessoku Band right in one shot,
and otherwise, you can always rely on inpainting.
Here are two examples:
With inpainting

Without inpainting

### Characters
The model knows 12 characters from bocchi the rock.
The ressemblance with a character can be improved by a better description of their appearance (for example by adding long wavy hair to ShimizuEliza).


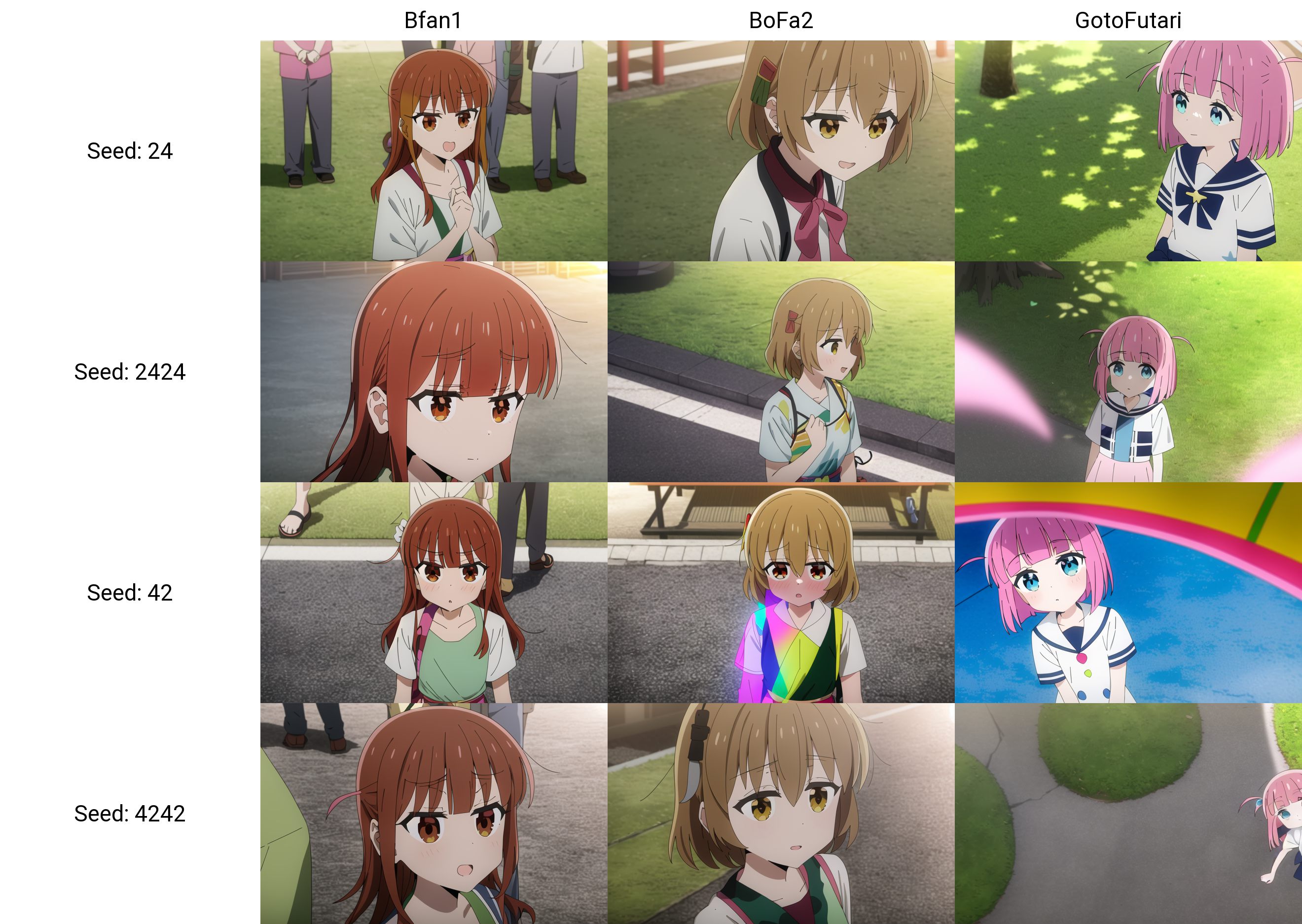
### Dataset description
The dataset contains around 27K images with the following composition
- 7024 anime screenshots
- 1630 fan arts
- 18519 customized regularization images
The model is trained with a specific weighting scheme to balance between different concepts.
For example, the above three categories have weights respectively 0.3, 0.25, and 0.45.
Each category is itself split into many sub-categories in a hierarchical way.
For more details on the data preparation process please refer to https://github.com/cyber-meow/anime_screenshot_pipeline
### Training Details
#### Trainer
The model is trained using [EveryDream1](https://github.com/victorchall/EveryDream-trainer) as
EveryDream seems to be the only trainer out there that supports sample weighting (through the use of `multiply.txt`).
Note that for future training it makes sense to migrate to [EveryDream2](https://github.com/victorchall/EveryDream2trainer).
#### Hardware and cost
The model is trained on runpod using 3090 and cost me around 15 dollors.
#### Hyperparameter specification
The model is trained for 50000 steps, at batch size 4, lr 1e-6, resolution 512, and conditional dropping rate of 10%.
Note that as a consequence of the weighting scheme which translates into a number of different multiply for each image,
the count of repeat and epoch has a quite different meaning here.
For example, depending on the weighting, I have around 300K images (some images are used multiple times) in an epoch,
and therefore I did not even finish an entire epoch with the 50000 steps at batch size 4.
### Failures
- For the first 24000 steps I use the trigger words `Bfan1` and `Bfan2` for the two fans of Bocchi.
However, these two words are too similar and the model fails to different characters for these.
Therefore I changed Bfan2 to Bofa2 at step 24000. This seemed to solve the problem.
- Character blending is always an issue.
- When prompting the four characters of Kessoku Band we often get side shots.
I think this is because of some overfitting to a particular image.
### More Example Generations
With inpainting



Without inpainting








Some failure cases




|
391ba204b1556f4dd62697d66eab7c09
|
Rhuan288/whisper-test-medium
|
Rhuan288
| null | 6 | 0 |
generic
| 0 |
automatic-speech-recognition
| false | false | false |
mit
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['audio', 'automatic-speech-recognition', 'endpoints-template']
| false | true | true | 2,248 | false |
# OpenAI [Whisper](https://github.com/openai/whisper) Inference Endpoint example
> Whisper is a general-purpose speech recognition model. It is trained on a large dataset of diverse audio and is also a multi-task model that can perform multilingual speech recognition as well as speech translation and language identification.
For more information about the model, license and limitations check the original repository at [openai/whisper](https://github.com/openai/whisper).
---
This repository implements a custom `handler` task for `automatic-speech-recognition` for 🤗 Inference Endpoints using OpenAIs new Whisper model. The code for the customized pipeline is in the [pipeline.py](https://huggingface.co/philschmid/openai-whisper-endpoint/blob/main/handler.py).
There is also a [notebook](https://huggingface.co/philschmid/openai-whisper-endpoint/blob/main/create_handler.ipynb) included, on how to create the `handler.py`
### Request
The endpoint expects a binary audio file. Below is a cURL example and a Python example using the `requests` library.
**curl**
```bash
# load audio file
wget https://cdn-media.huggingface.co/speech_samples/sample1.flac
# run request
curl --request POST \
--url https://{ENDPOINT}/ \
--header 'Content-Type: audio/x-flac' \
--header 'Authorization: Bearer {HF_TOKEN}' \
--data-binary '@sample1.flac'
```
**Python**
```python
import json
from typing import List
import requests as r
import base64
import mimetypes
ENDPOINT_URL=""
HF_TOKEN=""
def predict(path_to_audio:str=None):
# read audio file
with open(path_to_audio, "rb") as i:
b = i.read()
# get mimetype
content_type= mimetypes.guess_type(path_to_audio)[0]
headers= {
"Authorization": f"Bearer {HF_TOKEN}",
"Content-Type": content_type
}
response = r.post(ENDPOINT_URL, headers=headers, data=b)
return response.json()
prediction = predict(path_to_audio="sample1.flac")
prediction
```
expected output
```json
{"text": " going along slushy country roads and speaking to damp audiences in draughty school rooms day after day for a fortnight. He'll have to put in an appearance at some place of worship on Sunday morning, and he can come to us immediately afterwards."}
```
|
19c97ea5b11c66949dacc7e6f99d384a
|
kobe/vit-base-beans
|
kobe
|
vit
| 11 | 3 |
transformers
| 0 |
image-classification
| true | false | false |
apache-2.0
| null |
['beans']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['image-classification', 'vision', 'generated_from_trainer']
| true | true | true | 1,478 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# vit-base-beans
This model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on the beans dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0866
- Accuracy: 0.9850
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 1337
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5.0
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.2501 | 1.0 | 130 | 0.2281 | 0.9624 |
| 0.2895 | 2.0 | 260 | 0.1138 | 0.9925 |
| 0.1549 | 3.0 | 390 | 0.1065 | 0.9774 |
| 0.0952 | 4.0 | 520 | 0.0866 | 0.9850 |
| 0.1511 | 5.0 | 650 | 0.0875 | 0.9774 |
### Framework versions
- Transformers 4.25.0.dev0
- Pytorch 1.12.1
- Datasets 2.7.1.dev0
- Tokenizers 0.13.2
|
77516f234fecde783bfc970e5623509d
|
sd-concepts-library/durer-style
|
sd-concepts-library
| null | 10 | 0 | null | 6 | null | false | false | false |
mit
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
[]
| false | true | true | 1,136 | false |
### durer style on Stable Diffusion
This is the `<drr-style>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as a `style`:




|
5d280ba53b61a5a442626f1ada8894ab
|
jamesesguerra/distilbart-cnn-12-6-finetuned-1.3.0
|
jamesesguerra
|
bart
| 14 | 4 |
transformers
| 0 |
text2text-generation
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,478 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbart-cnn-12-6-finetuned-1.3.0
This model is a fine-tuned version of [sshleifer/distilbart-cnn-12-6](https://huggingface.co/sshleifer/distilbart-cnn-12-6) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.7396
- Rouge1: 50.4996
- Rouge2: 23.7554
- Rougel: 35.3613
- Rougelsum: 45.8275
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum |
|:-------------:|:-----:|:----:|:---------------:|:-------:|:-------:|:-------:|:---------:|
| 2.0871 | 1.0 | 982 | 1.8224 | 49.5261 | 23.1091 | 34.3266 | 44.7491 |
| 1.5334 | 2.0 | 1964 | 1.7396 | 50.4996 | 23.7554 | 35.3613 | 45.8275 |
### Framework versions
- Transformers 4.25.1
- Pytorch 1.12.1+cu113
- Datasets 2.7.1
- Tokenizers 0.13.2
|
ac4c81e2a6e292dd32051409fa7838a2
|
Sleoruiz/distilbert-base-uncased-finetuned-cola
|
Sleoruiz
|
distilbert
| 26 | 1 |
transformers
| 0 |
text-classification
| true | false | false |
apache-2.0
| null |
['glue']
| null | 1 | 1 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,571 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-cola
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the glue dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7663
- Matthews Correlation: 0.5396
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Matthews Correlation |
|:-------------:|:-----:|:----:|:---------------:|:--------------------:|
| 0.5281 | 1.0 | 535 | 0.5268 | 0.4071 |
| 0.3503 | 2.0 | 1070 | 0.5074 | 0.5126 |
| 0.2399 | 3.0 | 1605 | 0.6440 | 0.4977 |
| 0.1807 | 4.0 | 2140 | 0.7663 | 0.5396 |
| 0.1299 | 5.0 | 2675 | 0.8786 | 0.5192 |
### Framework versions
- Transformers 4.18.0
- Pytorch 1.10.0+cu111
- Datasets 2.0.0
- Tokenizers 0.11.6
|
c8ee04c6087faf9afd7be55cb0e6337c
|
google/bit-50
|
google
|
bit
| 5 | 210 |
transformers
| 0 |
image-classification
| true | false | false |
apache-2.0
| null |
['imagenet-1k']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['vision', 'image-classification']
| false | true | true | 3,419 | false |
# Big Transfer (BiT)
The BiT model was proposed in [Big Transfer (BiT): General Visual Representation Learning](https://arxiv.org/abs/1912.11370) by Alexander Kolesnikov, Lucas Beyer, Xiaohua Zhai, Joan Puigcerver, Jessica Yung, Sylvain Gelly, Neil Houlsby.
BiT is a simple recipe for scaling up pre-training of [ResNet](resnet)-like architectures (specifically, ResNetv2). The method results in significant improvements for transfer learning.
Disclaimer: The team releasing ResNet did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
The abstract from the paper is the following:
*Transfer of pre-trained representations improves sample efficiency and simplifies hyperparameter tuning when training deep neural networks for vision. We revisit the paradigm of pre-training on large supervised datasets and fine-tuning the model on a target task. We scale up pre-training, and propose a simple recipe that we call Big Transfer (BiT). By combining a few carefully selected components, and transferring using a simple heuristic, we achieve strong performance on over 20 datasets. BiT performs well across a surprisingly wide range of data regimes -- from 1 example per class to 1M total examples. BiT achieves 87.5% top-1 accuracy on ILSVRC-2012, 99.4% on CIFAR-10, and 76.3% on the 19 task Visual Task Adaptation Benchmark (VTAB). On small datasets, BiT attains 76.8% on ILSVRC-2012 with 10 examples per class, and 97.0% on CIFAR-10 with 10 examples per class. We conduct detailed analysis of the main components that lead to high transfer performance.*
## Intended uses & limitations
You can use the raw model for image classification. See the [model hub](https://huggingface.co/models?search=bit) to look for
fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model to classify an image of the COCO 2017 dataset into one of the 1,000 ImageNet classes:
```python
from transformers import BitImageProcessor, BitForImageClassification
import torch
from datasets import load_dataset
dataset = load_dataset("huggingface/cats-image")
image = dataset["test"]["image"][0]
feature_extractor = BitImageProcessor.from_pretrained("google/bit-50")
model = BitForImageClassification.from_pretrained("google/bit-50")
inputs = feature_extractor(image, return_tensors="pt")
with torch.no_grad():
logits = model(**inputs).logits
# model predicts one of the 1000 ImageNet classes
predicted_label = logits.argmax(-1).item()
print(model.config.id2label[predicted_label
>>> tabby, tabby cat
```
For more code examples, we refer to the [documentation](https://huggingface.co/docs/transformers/main/en/model_doc/bit).
### BibTeX entry and citation info
```bibtex
@misc{https://doi.org/10.48550/arxiv.1912.11370,
doi = {10.48550/ARXIV.1912.11370},
url = {https://arxiv.org/abs/1912.11370},
author = {Kolesnikov, Alexander and Beyer, Lucas and Zhai, Xiaohua and Puigcerver, Joan and Yung, Jessica and Gelly, Sylvain and Houlsby, Neil},
keywords = {Computer Vision and Pattern Recognition (cs.CV), Machine Learning (cs.LG), FOS: Computer and information sciences, FOS: Computer and information sciences},
title = {Big Transfer (BiT): General Visual Representation Learning},
publisher = {arXiv},
year = {2019},
copyright = {arXiv.org perpetual, non-exclusive license}
}
```
|
431e0b0c4369a65329ec81694eba5521
|
FrostAura/gpt-neox-20b-fiction-novel-generation
|
FrostAura
|
gpt_neox
| 55 | 44 |
transformers
| 7 |
text-generation
| true | false | false |
mit
|
['en']
| null | null | 3 | 0 | 3 | 0 | 0 | 0 | 0 |
['text-generation', 'novel-generation', 'fiction', 'gpt-neo-x', 'pytorch']
| false | true | true | 1,535 | false |
<p align="center">
<img src="https://github.com/faGH/fa.creative/blob/master/Icons/FrostAura/FA%20Logo/FrostAura.Logo.Complex.png?raw=true" width="75" title="hover text">
</p>
# fa.intelligence.models.generative.novels.fiction
## Description
This FrostAura Intelligence model is a fine-tuned version of [EleutherAI/gpt-neox-20b](https://huggingface.co/EleutherAI/gpt-neox-20b) for fictional text content generation.
## Getting Started
### PIP Installation
```
pip install -U --no-cache-dir transformers
```
### Usage
```
from transformers import GPTNeoXForCausalLM, GPTNeoXTokenizerFast
model_name = 'FrostAura/gpt-neox-20b-fiction-novel-generation'
model = GPTNeoXForCausalLM.from_pretrained(model_name)
tokenizer = GPTNeoXTokenizerFast.from_pretrained(model_name)
prompt = 'GPTNeoX20B is a 20B-parameter autoregressive Transformer model developed by EleutherAI.'
input_ids = tokenizer(prompt, return_tensors="pt").input_ids
gen_tokens = model.generate(
input_ids,
do_sample=True,
temperature=0.9,
max_length=100,
)
gen_text = tokenizer.batch_decode(gen_tokens)[0]
print(f'Result: {gen_text}')
```
## Further Fine-Tuning
`in development`
## Support
If you enjoy FrostAura open-source content and would like to support us in continuous delivery, please consider a donation via a platform of your choice.
| Supported Platforms | Link |
| ------------------- | ---- |
| PayPal | [Donate via Paypal](https://www.paypal.com/donate/?hosted_button_id=SVEXJC9HFBJ72) |
For any queries, contact dean.martin@frostaura.net.
|
01d39a524362ab8e59f0f4faf3e066e0
|
jonatasgrosman/exp_w2v2t_ja_xlsr-53_s781
|
jonatasgrosman
|
wav2vec2
| 10 | 5 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
|
['ja']
|
['mozilla-foundation/common_voice_7_0']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['automatic-speech-recognition', 'ja']
| false | true | true | 461 | false |
# exp_w2v2t_ja_xlsr-53_s781
Fine-tuned [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) for speech recognition using the train split of [Common Voice 7.0 (ja)](https://huggingface.co/datasets/mozilla-foundation/common_voice_7_0).
When using this model, make sure that your speech input is sampled at 16kHz.
This model has been fine-tuned by the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) tool.
|
4adbae9a327a3e1643f4cf5cff12718f
|
EldritchAdam/classipeint
|
EldritchAdam
| null | 3 | 0 | null | 19 | null | false | false | false |
cc0-1.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
[]
| false | true | true | 2,186 | false |
You want more than a digital style - you want to feel brush strokes and see the built-up paint of an oil painting. You love physical objects and want your AI-generated art to fool you that you're looking at a photograph of something analog, hanging on a wall somewhere.
This is the embedding for you. Download the the 'classipeint.pt' file and trigger it in your prompt "art by classipeint" or "painted by classipeint" or simply "by classipeint"
<strong>Interested in generating your own embeddings? <a href="https://docs.google.com/document/d/1JvlM0phnok4pghVBAMsMq_-Z18_ip_GXvHYE0mITdFE/edit?usp=sharing" target="_blank">My Google doc walkthrough might help</a></strong>
It is reasonably flexible - I find I can prompt for fantasy elements, classic scenes, modern architecture ... it does sometimes take a little finessing but except for bad anatomy, I am using surprisingly few negative prompts.
You can rename the file and use that filename as the prompt. Just be sure your filename is unique and not something that may be an existing token that Stable Diffusion is trained on.








|
886635b83ff1bf55fc4162c7845757f0
|
floriancaro/my_awesome_billsum_model
|
floriancaro
|
t5
| 12 | 3 |
transformers
| 0 |
text2text-generation
| true | false | false |
apache-2.0
| null |
['billsum']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,707 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# my_awesome_billsum_model
This model is a fine-tuned version of [t5-small](https://huggingface.co/t5-small) on the billsum dataset.
It achieves the following results on the evaluation set:
- Loss: 2.4612
- Rouge1: 0.1424
- Rouge2: 0.0506
- Rougel: 0.1186
- Rougelsum: 0.1185
- Gen Len: 19.0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 4
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:------:|:------:|:------:|:---------:|:-------:|
| No log | 1.0 | 62 | 2.7438 | 0.1291 | 0.0351 | 0.1081 | 0.1083 | 19.0 |
| No log | 2.0 | 124 | 2.5394 | 0.1366 | 0.0457 | 0.1129 | 0.1128 | 19.0 |
| No log | 3.0 | 186 | 2.4761 | 0.1405 | 0.0482 | 0.1166 | 0.1166 | 19.0 |
| No log | 4.0 | 248 | 2.4612 | 0.1424 | 0.0506 | 0.1186 | 0.1185 | 19.0 |
### Framework versions
- Transformers 4.25.1
- Pytorch 1.13.0+cu116
- Datasets 2.8.0
- Tokenizers 0.13.2
|
3c220f3369c264eacf73a20b055a7933
|
Helsinki-NLP/opus-mt-lt-es
|
Helsinki-NLP
|
marian
| 11 | 17 |
transformers
| 1 |
translation
| true | true | false |
apache-2.0
|
['lt', 'es']
| null | null | 1 | 1 | 0 | 0 | 0 | 0 | 0 |
['translation']
| false | true | true | 1,990 | false |
### lit-spa
* source group: Lithuanian
* target group: Spanish
* OPUS readme: [lit-spa](https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/lit-spa/README.md)
* model: transformer-align
* source language(s): lit
* target language(s): spa
* model: transformer-align
* pre-processing: normalization + SentencePiece (spm32k,spm32k)
* download original weights: [opus-2020-06-17.zip](https://object.pouta.csc.fi/Tatoeba-MT-models/lit-spa/opus-2020-06-17.zip)
* test set translations: [opus-2020-06-17.test.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/lit-spa/opus-2020-06-17.test.txt)
* test set scores: [opus-2020-06-17.eval.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/lit-spa/opus-2020-06-17.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| Tatoeba-test.lit.spa | 50.5 | 0.680 |
### System Info:
- hf_name: lit-spa
- source_languages: lit
- target_languages: spa
- opus_readme_url: https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/lit-spa/README.md
- original_repo: Tatoeba-Challenge
- tags: ['translation']
- languages: ['lt', 'es']
- src_constituents: {'lit'}
- tgt_constituents: {'spa'}
- src_multilingual: False
- tgt_multilingual: False
- prepro: normalization + SentencePiece (spm32k,spm32k)
- url_model: https://object.pouta.csc.fi/Tatoeba-MT-models/lit-spa/opus-2020-06-17.zip
- url_test_set: https://object.pouta.csc.fi/Tatoeba-MT-models/lit-spa/opus-2020-06-17.test.txt
- src_alpha3: lit
- tgt_alpha3: spa
- short_pair: lt-es
- chrF2_score: 0.68
- bleu: 50.5
- brevity_penalty: 0.963
- ref_len: 2738.0
- src_name: Lithuanian
- tgt_name: Spanish
- train_date: 2020-06-17
- src_alpha2: lt
- tgt_alpha2: es
- prefer_old: False
- long_pair: lit-spa
- helsinki_git_sha: 480fcbe0ee1bf4774bcbe6226ad9f58e63f6c535
- transformers_git_sha: 2207e5d8cb224e954a7cba69fa4ac2309e9ff30b
- port_machine: brutasse
- port_time: 2020-08-21-14:41
|
b7f63065dc350268295faf6c6f15ce54
|
pfloyd/opus-mt-es-en-finetuned-es-to-en
|
pfloyd
|
marian
| 26 | 1 |
transformers
| 0 |
text2text-generation
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,548 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# opus-mt-es-en-finetuned-es-to-en
This model is a fine-tuned version of [Helsinki-NLP/opus-mt-es-en](https://huggingface.co/Helsinki-NLP/opus-mt-es-en) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5851
- Bleu: 71.1382
- Gen Len: 10.3225
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Bleu | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:-------:|:-------:|
| No log | 1.0 | 112 | 0.5693 | 71.7823 | 10.3676 |
| No log | 2.0 | 224 | 0.5744 | 69.5504 | 10.6739 |
| No log | 3.0 | 336 | 0.5784 | 71.6553 | 10.3117 |
| No log | 4.0 | 448 | 0.5826 | 71.0576 | 10.3261 |
| 0.2666 | 5.0 | 560 | 0.5851 | 71.1382 | 10.3225 |
### Framework versions
- Transformers 4.16.2
- Pytorch 1.9.1
- Datasets 1.18.4
- Tokenizers 0.11.6
|
cb8f75b915102d84a5c5a2f2e192e048
|
Nadav/bert-base-historic-english-cased-squad-en
|
Nadav
|
bert
| 10 | 7 |
transformers
| 0 |
question-answering
| true | false | false |
mit
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,292 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-historic-english-cased-squad-en
This model is a fine-tuned version of [dbmdz/bert-base-historic-english-cased](https://huggingface.co/dbmdz/bert-base-historic-english-cased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.7739
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.2
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 2.2943 | 1.0 | 4686 | 1.9503 |
| 2.0811 | 2.0 | 9372 | 1.7739 |
### Framework versions
- Transformers 4.24.0
- Pytorch 1.13.0+cu117
- Datasets 2.7.1
- Tokenizers 0.13.2
|
ae1f1e039a8756230382604cf91d7ecc
|
StonyBrookNLP/teabreac-preasm-large-iirc-gold
|
StonyBrookNLP
|
t5
| 8 | 3 |
transformers
| 0 |
text2text-generation
| true | false | false |
cc-by-4.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['question-answering, multi-step-reasoning, multi-hop-reasoning']
| false | true | true | 2,617 | false |
# What's this?
This is one of the models reported in the paper: ["Teaching Broad Reasoning Skills for Multi-Step QA by Generating Hard Contexts".](https://arxiv.org/abs/2205.12496).
This paper proposes a procedure to synthetically generate a QA dataset, TeaBReaC, for pretraining language models for robust multi-step reasoning. Pretraining plain LMs like Bart, T5 and numerate LMs like NT5, PReasM, POET on TeaBReaC leads to improvemed downstream performance on several multi-step QA datasets. Please checkout out the paper for the details.
We release the following models:
- **A:** Base Models finetuned on target datasets: `{base_model}-{target_dataset}`
- **B:** Base models pretrained on TeaBReaC: `teabreac-{base_model}`
- **C:** Base models pretrained on TeaBReaC and then finetuned on target datasets: `teabreac-{base_model}-{target_dataset}`
The `base_model` above can be from: `bart-large`, `t5-large`, `t5-3b`, `nt5-small`, `preasm-large`.
The `target_dataset` above can be from: `drop`, `tatqa`, `iirc-gold`, `iirc-retrieved`, `numglue`.
The **A** models are only released for completeness / reproducibility. In your end application you probably just want to use either **B** or **C**.
# How to use it?
Please checkout the details in our [github repository](https://github.com/stonybrooknlp/teabreac), but in a nutshell:
```python
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
from digit_tokenization import enable_digit_tokenization # digit_tokenization.py from https://github.com/stonybrooknlp/teabreac
model_name = "StonyBrookNLP/teabreac-preasm-large-iirc-gold"
tokenizer = AutoTokenizer.from_pretrained(model_name, use_fast=False) # Fast doesn't work with digit tokenization
model = AutoModelForSeq2SeqLM.from_pretrained(model_name)
enable_digit_tokenization(tokenizer)
input_texts = [
"Who scored the first touchdown of the game?\n" +
"... Oakland would get the early lead in the first quarter as quarterback JaMarcus Russell completed a 20-yard touchdown pass to rookie wide receiver Chaz Schilens..."
# Note: some models have slightly different qn/ctxt format. See the github repo.
]
input_ids = tokenizer(
input_texts, return_tensors="pt",
truncation=True, max_length=800,
add_special_tokens=True, padding=True,
)["input_ids"]
generated_ids = model.generate(input_ids, min_length=1, max_length=50)
generated_predictions = tokenizer.batch_decode(generated_ids, skip_special_tokens=False)
generated_predictions = [
tokenizer.fix_decoded_text(generated_prediction) for generated_prediction in generated_predictions
]
# => ["Chaz Schilens"]
```
|
fb205ddb4a08bfd2797cf27286f8b2bf
|
gokuls/distilbert_sa_GLUE_Experiment_mnli_96
|
gokuls
|
distilbert
| 17 | 4 |
transformers
| 0 |
text-classification
| true | false | false |
apache-2.0
|
['en']
|
['glue']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 2,192 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert_sa_GLUE_Experiment_mnli_96
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the GLUE MNLI dataset.
It achieves the following results on the evaluation set:
- Loss: 0.9288
- Accuracy: 0.5545
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 256
- eval_batch_size: 256
- seed: 10
- distributed_type: multi-GPU
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 50
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|
| 1.0498 | 1.0 | 1534 | 0.9988 | 0.5084 |
| 0.9757 | 2.0 | 3068 | 0.9532 | 0.5303 |
| 0.9458 | 3.0 | 4602 | 0.9435 | 0.5377 |
| 0.9272 | 4.0 | 6136 | 0.9306 | 0.5456 |
| 0.9122 | 5.0 | 7670 | 0.9305 | 0.5474 |
| 0.8992 | 6.0 | 9204 | 0.9294 | 0.5489 |
| 0.8867 | 7.0 | 10738 | 0.9260 | 0.5522 |
| 0.8752 | 8.0 | 12272 | 0.9319 | 0.5559 |
| 0.8645 | 9.0 | 13806 | 0.9336 | 0.5604 |
| 0.8545 | 10.0 | 15340 | 0.9200 | 0.5629 |
| 0.8443 | 11.0 | 16874 | 0.9200 | 0.5664 |
| 0.8338 | 12.0 | 18408 | 0.9298 | 0.5672 |
| 0.8252 | 13.0 | 19942 | 0.9383 | 0.5647 |
| 0.8168 | 14.0 | 21476 | 0.9428 | 0.5691 |
| 0.8084 | 15.0 | 23010 | 0.9325 | 0.5730 |
### Framework versions
- Transformers 4.26.0
- Pytorch 1.14.0a0+410ce96
- Datasets 2.8.0
- Tokenizers 0.13.2
|
b976f46227a7035d764ef661bd751674
|
Helsinki-NLP/opus-mt-en-CELTIC
|
Helsinki-NLP
|
marian
| 10 | 7 |
transformers
| 0 |
translation
| true | true | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['translation']
| false | true | true | 1,067 | false |
### opus-mt-en-INSULAR_CELTIC
* source languages: en
* target languages: ga,cy,br,gd,kw,gv
* OPUS readme: [en-ga+cy+br+gd+kw+gv](https://github.com/Helsinki-NLP/OPUS-MT-train/blob/master/models/en-ga+cy+br+gd+kw+gv/README.md)
* dataset: opus+techiaith+bt
* model: transformer-align
* pre-processing: normalization + SentencePiece
* a sentence initial language token is required in the form of `>>id<<` (id = valid target language ID)
* download original weights: [opus+techiaith+bt-2020-04-24.zip](https://object.pouta.csc.fi/OPUS-MT-models/en-ga+cy+br+gd+kw+gv/opus+techiaith+bt-2020-04-24.zip)
* test set translations: [opus+techiaith+bt-2020-04-24.test.txt](https://object.pouta.csc.fi/OPUS-MT-models/en-ga+cy+br+gd+kw+gv/opus+techiaith+bt-2020-04-24.test.txt)
* test set scores: [opus+techiaith+bt-2020-04-24.eval.txt](https://object.pouta.csc.fi/OPUS-MT-models/en-ga+cy+br+gd+kw+gv/opus+techiaith+bt-2020-04-24.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| Tatoeba.en.ga | 22.8 | 0.404 |
|
2c6c4f6094de6cf2ab7a2839ccb59da7
|
DeividasM/finetuning-sentiment-model-3000-samples
|
DeividasM
|
distilbert
| 13 | 9 |
transformers
| 0 |
text-classification
| true | false | false |
apache-2.0
| null |
['imdb']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,055 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# finetuning-sentiment-model-3000-samples
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the imdb dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3275
- Accuracy: 0.8767
- F1: 0.8779
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
### Framework versions
- Transformers 4.22.1
- Pytorch 1.12.1+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
cf4bea4deebe3fe84449af1b06724d8b
|
ghatgetanuj/roberta-large_cls_CR
|
ghatgetanuj
|
roberta
| 13 | 1 |
transformers
| 0 |
text-classification
| true | false | false |
mit
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,505 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# roberta-large_cls_CR
This model is a fine-tuned version of [roberta-large](https://huggingface.co/roberta-large) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3325
- Accuracy: 0.9043
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 4e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.2
- num_epochs: 5
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| No log | 1.0 | 213 | 0.4001 | 0.875 |
| No log | 2.0 | 426 | 0.4547 | 0.8324 |
| 0.499 | 3.0 | 639 | 0.3161 | 0.8963 |
| 0.499 | 4.0 | 852 | 0.3219 | 0.9069 |
| 0.2904 | 5.0 | 1065 | 0.3325 | 0.9043 |
### Framework versions
- Transformers 4.20.1
- Pytorch 1.11.0
- Datasets 2.1.0
- Tokenizers 0.12.1
|
d9e4b794b7707d20b158d3501e5678e9
|
lmqg/t5-large-subjqa-electronics-qg
|
lmqg
|
t5
| 34 | 1 |
transformers
| 0 |
text2text-generation
| true | false | false |
cc-by-4.0
|
['en']
|
['lmqg/qg_subjqa']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['question generation']
| true | true | true | 4,015 | false |
# Model Card of `lmqg/t5-large-subjqa-electronics-qg`
This model is fine-tuned version of [lmqg/t5-large-squad](https://huggingface.co/lmqg/t5-large-squad) for question generation task on the [lmqg/qg_subjqa](https://huggingface.co/datasets/lmqg/qg_subjqa) (dataset_name: electronics) via [`lmqg`](https://github.com/asahi417/lm-question-generation).
### Overview
- **Language model:** [lmqg/t5-large-squad](https://huggingface.co/lmqg/t5-large-squad)
- **Language:** en
- **Training data:** [lmqg/qg_subjqa](https://huggingface.co/datasets/lmqg/qg_subjqa) (electronics)
- **Online Demo:** [https://autoqg.net/](https://autoqg.net/)
- **Repository:** [https://github.com/asahi417/lm-question-generation](https://github.com/asahi417/lm-question-generation)
- **Paper:** [https://arxiv.org/abs/2210.03992](https://arxiv.org/abs/2210.03992)
### Usage
- With [`lmqg`](https://github.com/asahi417/lm-question-generation#lmqg-language-model-for-question-generation-)
```python
from lmqg import TransformersQG
# initialize model
model = TransformersQG(language="en", model="lmqg/t5-large-subjqa-electronics-qg")
# model prediction
questions = model.generate_q(list_context="William Turner was an English painter who specialised in watercolour landscapes", list_answer="William Turner")
```
- With `transformers`
```python
from transformers import pipeline
pipe = pipeline("text2text-generation", "lmqg/t5-large-subjqa-electronics-qg")
output = pipe("generate question: <hl> Beyonce <hl> further expanded her acting career, starring as blues singer Etta James in the 2008 musical biopic, Cadillac Records.")
```
## Evaluation
- ***Metric (Question Generation)***: [raw metric file](https://huggingface.co/lmqg/t5-large-subjqa-electronics-qg/raw/main/eval/metric.first.sentence.paragraph_answer.question.lmqg_qg_subjqa.electronics.json)
| | Score | Type | Dataset |
|:-----------|--------:|:------------|:-----------------------------------------------------------------|
| BERTScore | 94.27 | electronics | [lmqg/qg_subjqa](https://huggingface.co/datasets/lmqg/qg_subjqa) |
| Bleu_1 | 29.72 | electronics | [lmqg/qg_subjqa](https://huggingface.co/datasets/lmqg/qg_subjqa) |
| Bleu_2 | 21.47 | electronics | [lmqg/qg_subjqa](https://huggingface.co/datasets/lmqg/qg_subjqa) |
| Bleu_3 | 10.86 | electronics | [lmqg/qg_subjqa](https://huggingface.co/datasets/lmqg/qg_subjqa) |
| Bleu_4 | 4.57 | electronics | [lmqg/qg_subjqa](https://huggingface.co/datasets/lmqg/qg_subjqa) |
| METEOR | 27.56 | electronics | [lmqg/qg_subjqa](https://huggingface.co/datasets/lmqg/qg_subjqa) |
| MoverScore | 68.8 | electronics | [lmqg/qg_subjqa](https://huggingface.co/datasets/lmqg/qg_subjqa) |
| ROUGE_L | 30.55 | electronics | [lmqg/qg_subjqa](https://huggingface.co/datasets/lmqg/qg_subjqa) |
## Training hyperparameters
The following hyperparameters were used during fine-tuning:
- dataset_path: lmqg/qg_subjqa
- dataset_name: electronics
- input_types: ['paragraph_answer']
- output_types: ['question']
- prefix_types: ['qg']
- model: lmqg/t5-large-squad
- max_length: 512
- max_length_output: 32
- epoch: 3
- batch: 16
- lr: 0.0001
- fp16: False
- random_seed: 1
- gradient_accumulation_steps: 8
- label_smoothing: 0.0
The full configuration can be found at [fine-tuning config file](https://huggingface.co/lmqg/t5-large-subjqa-electronics-qg/raw/main/trainer_config.json).
## Citation
```
@inproceedings{ushio-etal-2022-generative,
title = "{G}enerative {L}anguage {M}odels for {P}aragraph-{L}evel {Q}uestion {G}eneration",
author = "Ushio, Asahi and
Alva-Manchego, Fernando and
Camacho-Collados, Jose",
booktitle = "Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing",
month = dec,
year = "2022",
address = "Abu Dhabi, U.A.E.",
publisher = "Association for Computational Linguistics",
}
```
|
c2bd740221e2dcf5fc1d8513450814a4
|
ajtamayoh/NLP-CIC-WFU_Clinical_Cases_NER_Paragraph_Tokenized_mBERT_cased_fine_tuned
|
ajtamayoh
|
bert
| 12 | 14 |
transformers
| 0 |
token-classification
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,962 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# NLP-CIC-WFU_Clinical_Cases_NER_Paragraph_Tokenized_mBERT_cased_fine_tuned
This model is a fine-tuned version of [bert-base-multilingual-cased](https://huggingface.co/bert-base-multilingual-cased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0537
- Precision: 0.8585
- Recall: 0.7101
- F1: 0.7773
- Accuracy: 0.9893
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 7
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| 0.0693 | 1.0 | 514 | 0.0416 | 0.9485 | 0.6492 | 0.7708 | 0.9884 |
| 0.0367 | 2.0 | 1028 | 0.0396 | 0.9391 | 0.6710 | 0.7827 | 0.9892 |
| 0.0283 | 3.0 | 1542 | 0.0385 | 0.9388 | 0.6889 | 0.7947 | 0.9899 |
| 0.0222 | 4.0 | 2056 | 0.0422 | 0.9456 | 0.6790 | 0.7904 | 0.9898 |
| 0.0182 | 5.0 | 2570 | 0.0457 | 0.9349 | 0.6925 | 0.7956 | 0.9901 |
| 0.013 | 6.0 | 3084 | 0.0484 | 0.8947 | 0.7062 | 0.7894 | 0.9899 |
| 0.0084 | 7.0 | 3598 | 0.0537 | 0.8585 | 0.7101 | 0.7773 | 0.9893 |
### Framework versions
- Transformers 4.19.2
- Pytorch 1.11.0+cu113
- Datasets 2.2.2
- Tokenizers 0.12.1
|
de84cbf93d26a99b8433b0c3ecaec1b6
|
anrilombard/distilbert-base-uncased-finetuned-imdb
|
anrilombard
|
distilbert
| 8 | 4 |
transformers
| 0 |
fill-mask
| true | false | false |
apache-2.0
| null |
['imdb']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,118 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-imdb
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the imdb dataset.
It achieves the following results on the evaluation set:
- eval_loss: 2.8413
- eval_runtime: 304.6965
- eval_samples_per_second: 3.282
- eval_steps_per_second: 0.053
- epoch: 0.01
- step: 2
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Framework versions
- Transformers 4.24.0
- Pytorch 1.12.1+cu113
- Datasets 2.7.1
- Tokenizers 0.13.2
|
9bcaf0a11878d3ae2d665597e220bca0
|
ychenNLP/arabic-relation-extraction
|
ychenNLP
|
bert
| 15 | 7 |
transformers
| 2 |
text-classification
| true | true | false |
mit
|
['ar', 'en']
|
['ACE2005']
| null | 1 | 0 | 1 | 0 | 1 | 1 | 0 |
['BERT', 'Text Classification', 'relation']
| false | true | true | 4,795 | false |
# Arabic Relation Extraction Model
- [Github repo](https://github.com/edchengg/GigaBERT)
- Relation Extraction model based on [GigaBERTv4](https://huggingface.co/lanwuwei/GigaBERT-v4-Arabic-and-English).
- Model detail: mark two entities in the sentence with special markers (e.g., ```XXXX <PER> entity1 </PER> XXXXXXX <ORG> entity2 </ORG> XXXXX```). Then we use the BERT [CLS] representation to make a prediction.
- ACE2005 Training data: Arabic
- [Relation tags](https://www.ldc.upenn.edu/sites/www.ldc.upenn.edu/files/arabic-relations-guidelines-v6.5.pdf) including: Physical, Part-whole, Personal-Social, ORG-Affiliation, Agent-Artifact, Gen-Affiliation
## Hyperparameters
- learning_rate=2e-5
- num_train_epochs=10
- weight_decay=0.01
## How to use
Workflow of a relation extraction model:
1. Input --> NER model --> Entities
2. Input sentence + Entity 1 + Entity 2 --> Relation Classification Model --> Relation Type
```python
>>> from transformers import pipeline, AutoModelForTokenClassification, AutoTokenizer, AuotoModelForSequenceClassification
>>> ner_model = AutoModelForTokenClassification.from_pretrained("ychenNLP/arabic-ner-ace")
>>> ner_tokenizer = AutoTokenizer.from_pretrained("ychenNLP/arabic-ner-ace")
>>> ner_pip = pipeline("ner", model=ner_model, tokenizer=ner_tokenizer, grouped_entities=True)
>>> re_model = AutoModelForSequenceClassification.from_pretrained("ychenNLP/arabic-relation-extraction")
>>> re_tokenizer = AutoTokenizer.from_pretrained("ychenNLP/arabic-relation-extraction")
>>> re_pip = pipeline("text-classification", model=re_model, tokenizer=re_tokenizer)
def process_ner_output(entity_mention, inputs):
re_input = []
for idx1 in range(len(entity_mention) - 1):
for idx2 in range(idx1 + 1, len(entity_mention)):
ent_1 = entity_mention[idx1]
ent_2 = entity_mention[idx2]
ent_1_type = ent_1['entity_group']
ent_2_type = ent_2['entity_group']
ent_1_s = ent_1['start']
ent_1_e = ent_1['end']
ent_2_s = ent_2['start']
ent_2_e = ent_2['end']
new_re_input = ""
for c_idx, c in enumerate(inputs):
if c_idx == ent_1_s:
new_re_input += "<{}>".format(ent_1_type)
elif c_idx == ent_1_e:
new_re_input += "</{}>".format(ent_1_type)
elif c_idx == ent_2_s:
new_re_input += "<{}>".format(ent_2_type)
elif c_idx == ent_2_e:
new_re_input += "</{}>".format(ent_2_type)
new_re_input += c
re_input.append({"re_input": new_re_input, "arg1": ent_1, "arg2": ent_2, "input": inputs})
return re_input
def post_process_re_output(re_output, text_input, ner_output):
final_output = []
for idx, out in enumerate(re_output):
if out["label"] != 'O':
tmp = re_input[idx]
tmp['relation_type'] = out
tmp.pop('re_input', None)
final_output.append(tmp)
template = {"input": text_input,
"entity": ner_output,
"relation": final_output}
return template
text_input = """ويتزامن ذلك مع اجتماع بايدن مع قادة الدول الأعضاء في الناتو في قمة موسعة في العاصمة الإسبانية، مدريد."""
ner_output = ner_pip(text_input) # inference NER tags
re_input = process_ner_output(ner_output, text_input) # prepare a pair of entity and predict relation type
re_output = []
for idx in range(len(re_input)):
tmp_re_output = re_pip(re_input[idx]["re_input"]) # for each pair of entity, predict relation
re_output.append(tmp_re_output[0])
re_ner_output = post_process_re_output(re_output, text_input, ner_output) # post process NER and relation predictions
print("Sentence: ",re_ner_output["input"])
print('====Entity====')
for ent in re_ner_output["entity"]:
print('{}--{}'.format(ent["word"], ent["entity_group"]))
print('====Relation====')
for rel in re_ner_output["relation"]:
print('{}--{}:{}'.format(rel['arg1']['word'], rel['arg2']['word'], rel['relation_type']['label']))
Sentence: ويتزامن ذلك مع اجتماع بايدن مع قادة الدول الأعضاء في الناتو في قمة موسعة في العاصمة الإسبانية، مدريد.
====Entity====
بايدن--PER
قادة--PER
الدول--GPE
الناتو--ORG
العاصمة--GPE
الاسبانية--GPE
مدريد--GPE
====Relation====
قادة--الدول:ORG-AFF
الدول--الناتو:ORG-AFF
العاصمة--الاسبانية:PART-WHOLE
```
### BibTeX entry and citation info
```bibtex
@inproceedings{lan2020gigabert,
author = {Lan, Wuwei and Chen, Yang and Xu, Wei and Ritter, Alan},
title = {Giga{BERT}: Zero-shot Transfer Learning from {E}nglish to {A}rabic},
booktitle = {Proceedings of The 2020 Conference on Empirical Methods on Natural Language Processing (EMNLP)},
year = {2020}
}
```
|
74ca011545adfa3be93fdfcf5310ab74
|
din0s/t5-base-finetuned-en-to-it-lrs
|
din0s
|
t5
| 10 | 1 |
transformers
| 0 |
text2text-generation
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 4,075 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-base-finetuned-en-to-it-lrs
This model is a fine-tuned version of [t5-base](https://huggingface.co/t5-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.4687
- Bleu: 22.9793
- Gen Len: 49.8367
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 40
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Bleu | Gen Len |
|:-------------:|:-----:|:-----:|:---------------:|:-------:|:-------:|
| 1.4378 | 1.0 | 1125 | 1.9365 | 12.0299 | 55.7007 |
| 1.229 | 2.0 | 2250 | 1.8493 | 15.9175 | 51.6293 |
| 1.0996 | 3.0 | 3375 | 1.7781 | 17.5103 | 51.666 |
| 0.9979 | 4.0 | 4500 | 1.7309 | 18.8603 | 50.8587 |
| 0.9421 | 5.0 | 5625 | 1.6839 | 19.8188 | 50.4767 |
| 0.9181 | 6.0 | 6750 | 1.6602 | 20.5693 | 50.272 |
| 0.8882 | 7.0 | 7875 | 1.6386 | 20.9771 | 50.3833 |
| 0.8498 | 8.0 | 9000 | 1.6252 | 21.2237 | 50.5093 |
| 0.8356 | 9.0 | 10125 | 1.6079 | 21.3987 | 50.31 |
| 0.8164 | 10.0 | 11250 | 1.5698 | 21.5409 | 50.388 |
| 0.8001 | 11.0 | 12375 | 1.5779 | 21.7354 | 49.822 |
| 0.7805 | 12.0 | 13500 | 1.5637 | 21.9649 | 49.8213 |
| 0.764 | 13.0 | 14625 | 1.5540 | 22.1342 | 50.2 |
| 0.7594 | 14.0 | 15750 | 1.5456 | 22.2318 | 50.0147 |
| 0.7355 | 15.0 | 16875 | 1.5309 | 22.2936 | 49.7693 |
| 0.7343 | 16.0 | 18000 | 1.5247 | 22.5065 | 49.7607 |
| 0.7231 | 17.0 | 19125 | 1.5231 | 22.3902 | 49.7733 |
| 0.7183 | 18.0 | 20250 | 1.5211 | 22.3672 | 49.8313 |
| 0.7068 | 19.0 | 21375 | 1.5075 | 22.5519 | 49.7433 |
| 0.7087 | 20.0 | 22500 | 1.5006 | 22.4827 | 49.5 |
| 0.6965 | 21.0 | 23625 | 1.4978 | 22.5907 | 49.6833 |
| 0.6896 | 22.0 | 24750 | 1.4955 | 22.6286 | 49.836 |
| 0.689 | 23.0 | 25875 | 1.4924 | 22.7052 | 49.7267 |
| 0.6793 | 24.0 | 27000 | 1.4890 | 22.7444 | 49.8393 |
| 0.6708 | 25.0 | 28125 | 1.4889 | 22.6821 | 49.8673 |
| 0.6671 | 26.0 | 29250 | 1.4835 | 22.7866 | 49.676 |
| 0.6652 | 27.0 | 30375 | 1.4853 | 22.7691 | 49.7107 |
| 0.6578 | 28.0 | 31500 | 1.4787 | 22.8173 | 49.738 |
| 0.6556 | 29.0 | 32625 | 1.4777 | 22.7408 | 49.6687 |
| 0.6592 | 30.0 | 33750 | 1.4772 | 22.8371 | 49.7307 |
| 0.6546 | 31.0 | 34875 | 1.4819 | 22.8398 | 49.6053 |
| 0.6465 | 32.0 | 36000 | 1.4741 | 22.8379 | 49.658 |
| 0.6381 | 33.0 | 37125 | 1.4691 | 22.9108 | 49.8113 |
| 0.6429 | 34.0 | 38250 | 1.4660 | 22.9405 | 49.7933 |
| 0.6381 | 35.0 | 39375 | 1.4701 | 22.8777 | 49.7467 |
| 0.6454 | 36.0 | 40500 | 1.4692 | 22.9225 | 49.7227 |
| 0.635 | 37.0 | 41625 | 1.4683 | 22.9914 | 49.6767 |
| 0.6389 | 38.0 | 42750 | 1.4691 | 22.9904 | 49.7133 |
| 0.6368 | 39.0 | 43875 | 1.4679 | 22.9962 | 49.8273 |
| 0.6345 | 40.0 | 45000 | 1.4687 | 22.9793 | 49.8367 |
### Framework versions
- Transformers 4.22.1
- Pytorch 1.12.1
- Datasets 2.5.1
- Tokenizers 0.11.0
|
913e0ab0320e6c567ddb071ee9cd2bea
|
soschuetze/disilbert-blm-tweets-binary
|
soschuetze
|
distilbert
| 4 | 4 |
transformers
| 0 |
text-classification
| false | true | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_keras_callback']
| true | true | true | 1,628 | false |
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# disilbert-blm-tweets-binary
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.1159
- Train Accuracy: 0.9556
- Validation Loss: 0.5772
- Validation Accuracy: 0.7965
- Epoch: 4
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'Adam', 'learning_rate': 5e-05, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-07, 'amsgrad': False}
- training_precision: float32
### Training results
| Train Loss | Train Accuracy | Validation Loss | Validation Accuracy | Epoch |
|:----------:|:--------------:|:---------------:|:-------------------:|:-----:|
| 0.5941 | 0.6905 | 0.5159 | 0.7168 | 0 |
| 0.4041 | 0.8212 | 0.4589 | 0.8142 | 1 |
| 0.2491 | 0.9026 | 0.6014 | 0.7876 | 2 |
| 0.1011 | 0.9692 | 0.7181 | 0.8053 | 3 |
| 0.1159 | 0.9556 | 0.5772 | 0.7965 | 4 |
### Framework versions
- Transformers 4.25.1
- TensorFlow 2.9.2
- Tokenizers 0.13.2
|
aeb9668017f00504d5b7d81f832da211
|
Kurapka/ciasto
|
Kurapka
| null | 18 | 19 |
diffusers
| 0 |
text-to-image
| false | false | false |
creativeml-openrail-m
| null | null | null | 1 | 1 | 0 | 0 | 0 | 0 | 0 |
['text-to-image', 'stable-diffusion']
| false | true | true | 415 | false |
### ciasto Dreambooth model trained by Kurapka with [TheLastBen's fast-DreamBooth](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast-DreamBooth.ipynb) notebook
Test the concept via A1111 Colab [fast-Colab-A1111](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast_stable_diffusion_AUTOMATIC1111.ipynb)
Sample pictures of this concept:
|
398c6f50f25b62e08e3ac1fc21be4c79
|
Kevin123/distilbert-base-uncased-finetuned-cola
|
Kevin123
|
distilbert
| 10 | 3 |
transformers
| 0 |
text-classification
| true | false | false |
apache-2.0
| null |
['glue']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,571 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-cola
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the glue dataset.
It achieves the following results on the evaluation set:
- Loss: 0.8663
- Matthews Correlation: 0.5475
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Matthews Correlation |
|:-------------:|:-----:|:----:|:---------------:|:--------------------:|
| 0.5248 | 1.0 | 535 | 0.5171 | 0.4210 |
| 0.3418 | 2.0 | 1070 | 0.4971 | 0.5236 |
| 0.2289 | 3.0 | 1605 | 0.6874 | 0.5023 |
| 0.1722 | 4.0 | 2140 | 0.7680 | 0.5392 |
| 0.118 | 5.0 | 2675 | 0.8663 | 0.5475 |
### Framework versions
- Transformers 4.12.3
- Pytorch 1.8.1+cu102
- Datasets 1.18.3
- Tokenizers 0.10.3
|
16067de0ff4b160ba4435d4a88e3b0e6
|
anas-awadalla/t5-base-few-shot-k-128-finetuned-squad-seed-0
|
anas-awadalla
|
t5
| 17 | 1 |
transformers
| 0 |
text2text-generation
| true | false | false |
apache-2.0
| null |
['squad']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 961 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-base-few-shot-k-128-finetuned-squad-seed-0
This model is a fine-tuned version of [google/t5-v1_1-base](https://huggingface.co/google/t5-v1_1-base) on the squad dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 0
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: constant
- training_steps: 1000
### Training results
### Framework versions
- Transformers 4.20.0.dev0
- Pytorch 1.11.0+cu113
- Datasets 2.3.2
- Tokenizers 0.11.6
|
b1f038da5055669fc9c8b1530d36b1e2
|
sgugger/glue-mrpc
|
sgugger
|
bert
| 18 | 33 |
transformers
| 0 |
text-classification
| true | false | false |
apache-2.0
|
['en']
|
['glue']
| null | 2 | 1 | 1 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,052 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# glue-mrpc
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the GLUE MRPC dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6566
- Accuracy: 0.8554
- F1: 0.8974
- Combined Score: 0.8764
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
### Framework versions
- Transformers 4.13.0.dev0
- Pytorch 1.10.0+cu102
- Datasets 1.15.2.dev0
- Tokenizers 0.10.3
|
76f766f627f6c487e5020130fbca21b6
|
jinlmsft/t5-large-multiwoz
|
jinlmsft
|
t5
| 26 | 3 |
transformers
| 0 |
text2text-generation
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,850 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-large-multiwoz
This model is a fine-tuned version of [t5-large](https://huggingface.co/t5-large) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0064
- Acc: 1.0
- True Num: 56671
- Num: 56776
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- gradient_accumulation_steps: 16
- total_train_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10.0
### Training results
| Training Loss | Epoch | Step | Validation Loss | Acc | True Num | Num |
|:-------------:|:-----:|:----:|:---------------:|:----:|:--------:|:-----:|
| 0.1261 | 1.13 | 1000 | 0.0933 | 0.98 | 55574 | 56776 |
| 0.0951 | 2.25 | 2000 | 0.0655 | 0.98 | 55867 | 56776 |
| 0.0774 | 3.38 | 3000 | 0.0480 | 0.99 | 56047 | 56776 |
| 0.0584 | 4.51 | 4000 | 0.0334 | 0.99 | 56252 | 56776 |
| 0.042 | 5.64 | 5000 | 0.0222 | 0.99 | 56411 | 56776 |
| 0.0329 | 6.76 | 6000 | 0.0139 | 1.0 | 56502 | 56776 |
| 0.0254 | 7.89 | 7000 | 0.0094 | 1.0 | 56626 | 56776 |
| 0.0214 | 9.02 | 8000 | 0.0070 | 1.0 | 56659 | 56776 |
### Framework versions
- Transformers 4.12.5
- Pytorch 1.10.0+cu102
- Datasets 1.15.1
- Tokenizers 0.10.3
|
cf4cb9bfdfb3bf99a7d7eb87a5c3716d
|
naver-clova-ix/donut-base
|
naver-clova-ix
|
vision-encoder-decoder
| 11 | 12,125 |
transformers
| 31 |
image-to-text
| true | false | false |
mit
| null | null | null | 1 | 0 | 1 | 0 | 3 | 2 | 1 |
['donut', 'image-to-text', 'vision']
| false | true | true | 2,137 | false |
# Donut (base-sized model, pre-trained only)
Donut model pre-trained-only. It was introduced in the paper [OCR-free Document Understanding Transformer](https://arxiv.org/abs/2111.15664) by Geewok et al. and first released in [this repository](https://github.com/clovaai/donut).
Disclaimer: The team releasing Donut did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
Donut consists of a vision encoder (Swin Transformer) and a text decoder (BART). Given an image, the encoder first encodes the image into a tensor of embeddings (of shape batch_size, seq_len, hidden_size), after which the decoder autoregressively generates text, conditioned on the encoding of the encoder.

## Intended uses & limitations
This model is meant to be fine-tuned on a downstream task, like document image classification or document parsing. See the [model hub](https://huggingface.co/models?search=donut) to look for fine-tuned versions on a task that interests you.
### How to use
We refer to the [documentation](https://huggingface.co/docs/transformers/main/en/model_doc/donut) which includes code examples.
### BibTeX entry and citation info
```bibtex
@article{DBLP:journals/corr/abs-2111-15664,
author = {Geewook Kim and
Teakgyu Hong and
Moonbin Yim and
Jinyoung Park and
Jinyeong Yim and
Wonseok Hwang and
Sangdoo Yun and
Dongyoon Han and
Seunghyun Park},
title = {Donut: Document Understanding Transformer without {OCR}},
journal = {CoRR},
volume = {abs/2111.15664},
year = {2021},
url = {https://arxiv.org/abs/2111.15664},
eprinttype = {arXiv},
eprint = {2111.15664},
timestamp = {Thu, 02 Dec 2021 10:50:44 +0100},
biburl = {https://dblp.org/rec/journals/corr/abs-2111-15664.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
|
554f7f9ced98b620531bdaced5b698f2
|
sd-concepts-library/art-brut
|
sd-concepts-library
| null | 9 | 0 | null | 3 | null | false | false | false |
mit
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
[]
| false | true | true | 1,008 | false |
### art brut on Stable Diffusion
This is the `<art-brut>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as a `style`:




|
0ee978dc3930cfdd6a43322da792063f
|
stanfordnlp/stanza-lv
|
stanfordnlp
| null | 8 | 67 |
stanza
| 1 |
token-classification
| false | false | false |
apache-2.0
|
['lv']
| null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['stanza', 'token-classification']
| false | true | true | 580 | false |
# Stanza model for Latvian (lv)
Stanza is a collection of accurate and efficient tools for the linguistic analysis of many human languages. Starting from raw text to syntactic analysis and entity recognition, Stanza brings state-of-the-art NLP models to languages of your choosing.
Find more about it in [our website](https://stanfordnlp.github.io/stanza) and our [GitHub repository](https://github.com/stanfordnlp/stanza).
This card and repo were automatically prepared with `hugging_stanza.py` in the `stanfordnlp/huggingface-models` repo
Last updated 2022-09-25 01:45:24.599
|
bcc442ab1cfd8afe4dc40210a0c7fe0a
|
pyronear/resnet34
|
pyronear
| null | 5 | 3 |
transformers
| 0 |
image-classification
| true | false | false |
apache-2.0
| null |
['pyronear/openfire']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['image-classification', 'pytorch', 'onnx']
| false | true | true | 2,712 | false |
# ResNet-34 model
Pretrained on a dataset for wildfire binary classification (soon to be shared).
## Model description
The core idea of the author is to help the gradient propagation through numerous layers by adding a skip connection.
## Installation
### Prerequisites
Python 3.6 (or higher) and [pip](https://pip.pypa.io/en/stable/)/[conda](https://docs.conda.io/en/latest/miniconda.html) are required to install PyroVision.
### Latest stable release
You can install the last stable release of the package using [pypi](https://pypi.org/project/pyrovision/) as follows:
```shell
pip install pyrovision
```
or using [conda](https://anaconda.org/pyronear/pyrovision):
```shell
conda install -c pyronear pyrovision
```
### Developer mode
Alternatively, if you wish to use the latest features of the project that haven't made their way to a release yet, you can install the package from source *(install [Git](https://git-scm.com/book/en/v2/Getting-Started-Installing-Git) first)*:
```shell
git clone https://github.com/pyronear/pyro-vision.git
pip install -e pyro-vision/.
```
## Usage instructions
```python
from PIL import Image
from torchvision.transforms import Compose, ConvertImageDtype, Normalize, PILToTensor, Resize
from torchvision.transforms.functional import InterpolationMode
from pyrovision.models import model_from_hf_hub
model = model_from_hf_hub("pyronear/resnet34").eval()
img = Image.open(path_to_an_image).convert("RGB")
# Preprocessing
config = model.default_cfg
transform = Compose([
Resize(config['input_shape'][1:], interpolation=InterpolationMode.BILINEAR),
PILToTensor(),
ConvertImageDtype(torch.float32),
Normalize(config['mean'], config['std'])
])
input_tensor = transform(img).unsqueeze(0)
# Inference
with torch.inference_mode():
output = model(input_tensor)
probs = output.squeeze(0).softmax(dim=0)
```
## Citation
Original paper
```bibtex
@article{DBLP:journals/corr/HeZRS15,
author = {Kaiming He and
Xiangyu Zhang and
Shaoqing Ren and
Jian Sun},
title = {Deep Residual Learning for Image Recognition},
journal = {CoRR},
volume = {abs/1512.03385},
year = {2015},
url = {http://arxiv.org/abs/1512.03385},
eprinttype = {arXiv},
eprint = {1512.03385},
timestamp = {Wed, 17 Apr 2019 17:23:45 +0200},
biburl = {https://dblp.org/rec/journals/corr/HeZRS15.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
Source of this implementation
```bibtex
@software{chintala_torchvision_2017,
author = {Chintala, Soumith},
month = {4},
title = {{Torchvision}},
url = {https://github.com/pytorch/vision},
year = {2017}
}
```
|
524bfa1dd9204124f58fa2346276c4e5
|
DOOGLAK/Article_250v4_NER_Model_3Epochs_UNAUGMENTED
|
DOOGLAK
|
bert
| 13 | 5 |
transformers
| 0 |
token-classification
| true | false | false |
apache-2.0
| null |
['article250v4_wikigold_split']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,561 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Article_250v4_NER_Model_3Epochs_UNAUGMENTED
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the article250v4_wikigold_split dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3243
- Precision: 0.4027
- Recall: 0.4337
- F1: 0.4176
- Accuracy: 0.8775
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 28 | 0.5309 | 0.0816 | 0.0144 | 0.0245 | 0.7931 |
| No log | 2.0 | 56 | 0.3620 | 0.3795 | 0.3674 | 0.3733 | 0.8623 |
| No log | 3.0 | 84 | 0.3243 | 0.4027 | 0.4337 | 0.4176 | 0.8775 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.11.0+cu113
- Datasets 2.4.0
- Tokenizers 0.11.6
|
e90a44584ded64e64ac6d89bebf0d4ae
|
Helsinki-NLP/opus-mt-rw-es
|
Helsinki-NLP
|
marian
| 10 | 37 |
transformers
| 0 |
translation
| true | true | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['translation']
| false | true | true | 768 | false |
### opus-mt-rw-es
* source languages: rw
* target languages: es
* OPUS readme: [rw-es](https://github.com/Helsinki-NLP/OPUS-MT-train/blob/master/models/rw-es/README.md)
* dataset: opus
* model: transformer-align
* pre-processing: normalization + SentencePiece
* download original weights: [opus-2020-01-16.zip](https://object.pouta.csc.fi/OPUS-MT-models/rw-es/opus-2020-01-16.zip)
* test set translations: [opus-2020-01-16.test.txt](https://object.pouta.csc.fi/OPUS-MT-models/rw-es/opus-2020-01-16.test.txt)
* test set scores: [opus-2020-01-16.eval.txt](https://object.pouta.csc.fi/OPUS-MT-models/rw-es/opus-2020-01-16.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| JW300.rw.es | 26.2 | 0.445 |
|
765e9198c7f0467b96c79f73caab5059
|
rkbulk/bart-base-finetuned-poems
|
rkbulk
|
bart
| 10 | 1 |
transformers
| 0 |
summarization
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['summarization', 'generated_from_trainer']
| true | true | true | 1,181 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bart-base-finetuned-poems
This model is a fine-tuned version of [facebook/bart-base](https://huggingface.co/facebook/bart-base) on the None dataset.
It achieves the following results on the evaluation set:
- eval_loss: 3.1970
- eval_rouge1: 16.9107
- eval_rouge2: 8.1464
- eval_rougeL: 16.5554
- eval_rougeLsum: 16.7396
- eval_runtime: 487.5616
- eval_samples_per_second: 0.41
- eval_steps_per_second: 0.051
- epoch: 2.0
- step: 200
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5.6e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 8
### Framework versions
- Transformers 4.24.0
- Pytorch 1.12.1
- Datasets 2.7.1
- Tokenizers 0.13.2
|
6584036f057ae006a5ce9b4274433bac
|
bnriiitb/whisper-small-te-4k
|
bnriiitb
|
whisper
| 29 | 0 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
|
['te']
|
['IndicSUPERB_train_validation_splits']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['hf-asr-leaderboard', 'generated_from_trainer']
| true | true | true | 3,183 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Whisper Small Telugu - Naga Budigam
This model is a fine-tuned version of [openai/whisper-small](https://huggingface.co/openai/whisper-small) on the Chai_Bisket_Stories_16-08-2021_14-17 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2875
- Wer: 38.1492
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 15000
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:-----:|:---------------:|:-------:|
| 0.2064 | 0.66 | 500 | 0.2053 | 60.1707 |
| 0.1399 | 1.33 | 1000 | 0.1535 | 49.3269 |
| 0.1093 | 1.99 | 1500 | 0.1365 | 44.5516 |
| 0.0771 | 2.66 | 2000 | 0.1316 | 42.1136 |
| 0.0508 | 3.32 | 2500 | 0.1395 | 41.1384 |
| 0.0498 | 3.99 | 3000 | 0.1386 | 40.5395 |
| 0.0302 | 4.65 | 3500 | 0.1529 | 40.9529 |
| 0.0157 | 5.32 | 4000 | 0.1719 | 40.6667 |
| 0.0183 | 5.98 | 4500 | 0.1723 | 40.3646 |
| 0.0083 | 6.65 | 5000 | 0.1911 | 40.4335 |
| 0.0061 | 7.31 | 5500 | 0.2109 | 40.4176 |
| 0.0055 | 7.98 | 6000 | 0.2075 | 39.7021 |
| 0.0039 | 8.64 | 6500 | 0.2186 | 40.2639 |
| 0.0026 | 9.31 | 7000 | 0.2254 | 39.1032 |
| 0.0035 | 9.97 | 7500 | 0.2289 | 39.2834 |
| 0.0016 | 10.64 | 8000 | 0.2332 | 39.1456 |
| 0.0016 | 11.3 | 8500 | 0.2395 | 39.4371 |
| 0.0016 | 11.97 | 9000 | 0.2447 | 39.2410 |
| 0.0009 | 12.63 | 9500 | 0.2548 | 38.7799 |
| 0.0008 | 13.3 | 10000 | 0.2551 | 38.7481 |
| 0.0008 | 13.96 | 10500 | 0.2621 | 38.8276 |
| 0.0007 | 14.63 | 11000 | 0.2633 | 38.6686 |
| 0.0003 | 15.29 | 11500 | 0.2711 | 38.4566 |
| 0.0005 | 15.96 | 12000 | 0.2772 | 38.7852 |
| 0.0001 | 16.62 | 12500 | 0.2771 | 38.2658 |
| 0.0001 | 17.29 | 13000 | 0.2808 | 38.2393 |
| 0.0001 | 17.95 | 13500 | 0.2815 | 38.1810 |
| 0.0 | 18.62 | 14000 | 0.2854 | 38.2022 |
| 0.0 | 19.28 | 14500 | 0.2872 | 38.1333 |
| 0.0 | 19.95 | 15000 | 0.2875 | 38.1492 |
### Framework versions
- Transformers 4.26.0.dev0
- Pytorch 1.13.0
- Datasets 2.7.1
- Tokenizers 0.13.2
|
90dfbb85a3f3d48f72eb301e89530903
|
Martha-987/whisper-small-Arabic-aar
|
Martha-987
|
whisper
| 16 | 0 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
|
['ar']
|
['mozilla-foundation/common_voice_11_0']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['hf-asr-leaderboard', 'generated_from_trainer']
| true | true | true | 1,419 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
## Whisper Small Ar- Martha:
This model is a fine-tuned version of openai/whisper-small on the Common Voice 11.0 dataset. It achieves the following results on the evaluation set:
Loss: 0.5854
Wer: 70.2071
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
## Training hyperparameters
The following hyperparameters were used during training:
learning_rate: 1e-05
train_batch_size: 16
eval_batch_size: 8
seed: 42
optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
lr_scheduler_type: linear
lr_scheduler_warmup_steps: 500
training_steps: 500
mixed_precision_training: Native AMP
# Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:-------:|
| 0.9692 | 0.14 | 125 | 1.3372 | 173.0952|
| 0.5716 | 0.29 | 250 | 0.9058 | 148.6795|
| 0.3297 | 0.43 | 375 | 0.5825 | 63.6709 |
| 0.3083 | 0.57 | 500 | 0.5854 | 70.2071 |
## Framework versions
Transformers 4.26.0.dev0
Pytorch 1.13.0+cu116
Datasets 2.7.1
Tokenizers 0.13.2
|
dd4c7a2dced3b3cc88b585f9d8925e6a
|
StivenLancheros/mBERT-base-Biomedical-NER
|
StivenLancheros
|
bert
| 13 | 9 |
transformers
| 0 |
token-classification
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,816 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-multilingual-cased-finetuned-ner-4
#This model is part of a test for creating multilingual BioMedical NER systems. Not intended for proffesional use now.
This model is a fine-tuned version of [bert-base-multilingual-cased](https://huggingface.co/bert-base-multilingual-cased) on the CRAFT+BC4CHEMD+BioNLP09 datasets concatenated.
It achieves the following results on the evaluation set:
- Loss: 0.1027
- Precision: 0.9830
- Recall: 0.9832
- F1: 0.9831
- Accuracy: 0.9799
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 4
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:-----:|:---------------:|:---------:|:------:|:------:|:--------:|
| 0.0658 | 1.0 | 6128 | 0.0751 | 0.9795 | 0.9795 | 0.9795 | 0.9758 |
| 0.0406 | 2.0 | 12256 | 0.0753 | 0.9827 | 0.9815 | 0.9821 | 0.9786 |
| 0.0182 | 3.0 | 18384 | 0.0934 | 0.9834 | 0.9825 | 0.9829 | 0.9796 |
| 0.011 | 4.0 | 24512 | 0.1027 | 0.9830 | 0.9832 | 0.9831 | 0.9799 |
### Framework versions
- Transformers 4.16.2
- Pytorch 1.10.0+cu111
- Datasets 1.18.3
- Tokenizers 0.11.0
|
83b8076c9e32d7a4b40b5af0ef5107a9
|
jonatasgrosman/exp_w2v2t_pl_hubert_s484
|
jonatasgrosman
|
hubert
| 10 | 4 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
|
['pl']
|
['mozilla-foundation/common_voice_7_0']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['automatic-speech-recognition', 'pl']
| false | true | true | 452 | false |
# exp_w2v2t_pl_hubert_s484
Fine-tuned [facebook/hubert-large-ll60k](https://huggingface.co/facebook/hubert-large-ll60k) for speech recognition using the train split of [Common Voice 7.0 (pl)](https://huggingface.co/datasets/mozilla-foundation/common_voice_7_0).
When using this model, make sure that your speech input is sampled at 16kHz.
This model has been fine-tuned by the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) tool.
|
ad40a5735f9decbdcbc41c74c2d90fdd
|
MyMild/bert-finetuned-squad
|
MyMild
|
bert
| 12 | 3 |
transformers
| 0 |
question-answering
| true | false | false |
apache-2.0
| null |
['squad']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 955 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-finetuned-squad
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the squad dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.15.0
- Pytorch 1.11.0+cu113
- Datasets 1.17.0
- Tokenizers 0.10.3
|
7671090475a51dc0ae5be49b479138fd
|
adamlin/tmp
|
adamlin
|
mt5
| 16 | 5 |
transformers
| 0 |
text2text-generation
| true | false | false |
apache-2.0
|
['zh_CN', 'zh_CN']
| null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| false | true | true | 2,652 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# tmp
This model is a fine-tuned version of [google/mt5-small](https://huggingface.co/google/mt5-small) on an unkown dataset.
It achieves the following results on the evaluation set:
- Loss: nan
- Bleu: 0.0099
- Gen Len: 3.3917
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 1024
- eval_batch_size: 1024
- seed: 13
- gradient_accumulation_steps: 2
- total_train_batch_size: 2048
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 20.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Bleu | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:------:|:-------:|
| No log | 1.0 | 1 | nan | 0.0114 | 3.3338 |
| No log | 2.0 | 2 | nan | 0.0114 | 3.3338 |
| No log | 3.0 | 3 | nan | 0.0114 | 3.3338 |
| No log | 4.0 | 4 | nan | 0.0114 | 3.3338 |
| No log | 5.0 | 5 | nan | 0.0114 | 3.3338 |
| No log | 6.0 | 6 | nan | 0.0114 | 3.3338 |
| No log | 7.0 | 7 | nan | 0.0114 | 3.3338 |
| No log | 8.0 | 8 | nan | 0.0114 | 3.3338 |
| No log | 9.0 | 9 | nan | 0.0114 | 3.3338 |
| No log | 10.0 | 10 | nan | 0.0114 | 3.3338 |
| No log | 11.0 | 11 | nan | 0.0114 | 3.3338 |
| No log | 12.0 | 12 | nan | 0.0114 | 3.3338 |
| No log | 13.0 | 13 | nan | 0.0114 | 3.3338 |
| No log | 14.0 | 14 | nan | 0.0114 | 3.3338 |
| No log | 15.0 | 15 | nan | 0.0114 | 3.3338 |
| No log | 16.0 | 16 | nan | 0.0114 | 3.3338 |
| No log | 17.0 | 17 | nan | 0.0114 | 3.3338 |
| No log | 18.0 | 18 | nan | 0.0114 | 3.3338 |
| No log | 19.0 | 19 | nan | 0.0114 | 3.3338 |
| No log | 20.0 | 20 | nan | 0.0114 | 3.3338 |
### Framework versions
- Transformers 4.8.2
- Pytorch 1.8.1+cu111
- Datasets 1.9.0
- Tokenizers 0.10.3
|
7cb61802ec0c0992f526150ce53e145c
|
arbml/whisper-small-cv-ar
|
arbml
|
whisper
| 15 | 27 |
transformers
| 3 |
automatic-speech-recognition
| true | false | false |
apache-2.0
|
['ar']
|
['mozilla-foundation/common_voice_11_0']
| null | 1 | 0 | 1 | 0 | 0 | 0 | 0 |
['whisper-event', 'generated_from_trainer', 'hf-asr-leaderboard']
| true | true | true | 1,547 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Whisper Small ar - Zaid Alyafeai
This model is a fine-tuned version of [openai/whisper-small](https://huggingface.co/openai/whisper-small) on the Common Voice 11.0 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3509
- Wer: 22.3838
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 8
- eval_batch_size: 4
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 5000
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:-------:|
| 0.2944 | 0.2 | 1000 | 0.4355 | 30.6471 |
| 0.2671 | 0.4 | 2000 | 0.3786 | 25.8539 |
| 0.172 | 1.08 | 3000 | 0.3520 | 23.4573 |
| 0.1043 | 1.28 | 4000 | 0.3542 | 23.3278 |
| 0.0991 | 1.48 | 5000 | 0.3509 | 22.3838 |
### Framework versions
- Transformers 4.26.0.dev0
- Pytorch 1.13.0+cu116
- Datasets 2.7.1
- Tokenizers 0.13.2
|
255aaac12838cedc3b0365baf71366b4
|
jonatasgrosman/exp_w2v2t_pt_wav2vec2_s859
|
jonatasgrosman
|
wav2vec2
| 10 | 2 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
|
['pt']
|
['mozilla-foundation/common_voice_7_0']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['automatic-speech-recognition', 'pt']
| false | true | true | 456 | false |
# exp_w2v2t_pt_wav2vec2_s859
Fine-tuned [facebook/wav2vec2-large-lv60](https://huggingface.co/facebook/wav2vec2-large-lv60) for speech recognition using the train split of [Common Voice 7.0 (pt)](https://huggingface.co/datasets/mozilla-foundation/common_voice_7_0).
When using this model, make sure that your speech input is sampled at 16kHz.
This model has been fine-tuned by the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) tool.
|
e83bee14cf6cbd86da614bf7b77693bc
|
rtoguchi/t5-small-finetuned-en-to-ro-fp16_off-lr_2e-7-weight_decay_0.001
|
rtoguchi
|
t5
| 12 | 3 |
transformers
| 0 |
text2text-generation
| true | false | false |
apache-2.0
| null |
['wmt16']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,263 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-small-finetuned-en-to-ro-fp16_off-lr_2e-7-weight_decay_0.001
This model is a fine-tuned version of [t5-small](https://huggingface.co/t5-small) on the wmt16 dataset.
It achieves the following results on the evaluation set:
- Loss: 1.4943
- Bleu: 4.7258
- Gen Len: 18.7149
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-07
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss | Bleu | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:------:|:-------:|
| 1.047 | 1.0 | 7629 | 1.4943 | 4.7258 | 18.7149 |
### Framework versions
- Transformers 4.12.5
- Pytorch 1.10.0+cu111
- Datasets 1.16.1
- Tokenizers 0.10.3
|
8388c0511052d5b5aed90bb560652c64
|
sd-concepts-library/eye-of-agamotto
|
sd-concepts-library
| null | 39 | 0 | null | 0 | null | false | false | false |
mit
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
[]
| false | true | true | 4,388 | false |
### Eye of Agamotto on Stable Diffusion
This is the `<eye-aga>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as an `object`:


































|
29ad93244f798aaf16284b2e6bfdda6b
|
unicamp-dl/mt5-base-en-pt-msmarco-v1
|
unicamp-dl
|
mt5
| 7 | 3 |
transformers
| 0 |
text2text-generation
| true | false | false |
mit
|
['pt']
|
['msmarco']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['msmarco', 't5', 'pytorch', 'tensorflow', 'pt', 'pt-br']
| false | true | true | 1,390 | false |
# mt5-base Reranker finetuned on mMARCO
## Introduction
mT5-base-en-pt-msmarco-v1 is a mT5-based model fine-tuned on a bilingual version of MS MARCO passage dataset. This bilingual dataset version is formed by the original MS MARCO dataset (in English) and a Portuguese translated version. In the version v1, the Portuguese dataset was translated using [Helsinki](https://huggingface.co/Helsinki-NLP) NMT model.
Further information about the dataset or the translation method can be found on our paper [**mMARCO: A Multilingual Version of MS MARCO Passage Ranking Dataset**](https://arxiv.org/abs/2108.13897) and [mMARCO](https://github.com/unicamp-dl/mMARCO) repository.
## Usage
```python
from transformers import T5Tokenizer, MT5ForConditionalGeneration
model_name = 'unicamp-dl/mt5-base-en-pt-msmarco-v1'
tokenizer = T5Tokenizer.from_pretrained(model_name)
model = MT5ForConditionalGeneration.from_pretrained(model_name)
```
# Citation
If you use mt5-base-en-pt-msmarco-v1, please cite:
@misc{bonifacio2021mmarco,
title={mMARCO: A Multilingual Version of MS MARCO Passage Ranking Dataset},
author={Luiz Henrique Bonifacio and Vitor Jeronymo and Hugo Queiroz Abonizio and Israel Campiotti and Marzieh Fadaee and and Roberto Lotufo and Rodrigo Nogueira},
year={2021},
eprint={2108.13897},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
|
17fdccf8af3fca67adffb9b021c2a715
|
Mizuiro-sakura/deberta-v2-base-japanese-finetuned-QA
|
Mizuiro-sakura
| null | 4 | 0 |
transformers
| 0 |
question-answering
| true | false | false |
mit
|
['ja']
|
['wikipedia', 'cc100', 'oscar']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['pytorch', 'deberta', 'deberta-v2', 'question-answering', 'question answering', 'squad']
| false | true | true | 2,440 | false |
# このモデルはdeberta-v2-base-japaneseをファインチューニングしてQAタスクに用いれるようにしたものです。
このモデルはdeberta-v2-base-japaneseを運転ドメインQAデータセット(DDQA)( https://nlp.ist.i.kyoto-u.ac.jp/index.php?Driving%20domain%20QA%20datasets )を用いてファインチューニングしたものです。
Question-Answeringタスク(SQuAD)に用いることができます。
# This model is fine-tuned model for Question-Answering which is based on deberta-v2-base-japanese
This model is fine-tuned by using DDQA dataset.
You could use this model for Question-Answering tasks.
# How to use 使い方
transformersおよびpytorch、sentencepiece、Juman++をインストールしてください。
以下のコードの内どちらか片方のコードを実行することで、Question-Answeringタスクを解かせることができます。(お好きな方をお選びください) please execute either code.
```python
import torch
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained('ku-nlp/deberta-v2-base-japanese')
model=torch.load('C:\\[.pth modelのあるディレクトリ]\\My_deberta_model_squad.pth') # 学習済みモデルの読み込み
text={
'context':'私の名前はEIMIです。好きな食べ物は苺です。 趣味は皆さんと会話することです。',
'question' :'好きな食べ物は何ですか'
}
input_ids=tokenizer.encode(text['question'],text['context']) # tokenizerで形態素解析しつつコードに変換する
output= model(torch.tensor([input_ids])) # 学習済みモデルを用いて解析
prediction = tokenizer.decode(input_ids[torch.argmax(output.start_logits): torch.argmax(output.end_logits)]) # 答えに該当する部分を抜き取る
print(prediction)
```
```python
import torch
from transformers import AutoTokenizer, AutoModelForQuestionAnswering
tokenizer = AutoTokenizer.from_pretrained('ku-nlp/deberta-v2-base-japanese')
model=AutoModelForQuestionAnswering.from_pretrained('Mizuiro-sakura/deberta-v2-base-japanese-finetuned-QAe') # 学習済みモデルの読み込み
text={
'context':'私の名前はEIMIです。好きな食べ物は苺です。 趣味は皆さんと会話することです。',
'question' :'好きな食べ物は何ですか'
}
input_ids=tokenizer.encode(text['question'],text['context']) # tokenizerで形態素解析しつつコードに変換する
output= model(torch.tensor([input_ids])) # 学習済みモデルを用いて解析
prediction = tokenizer.decode(input_ids[torch.argmax(output.start_logits): torch.argmax(output.end_logits)]) # 答えに該当する部分を抜き取る
print(prediction)
```
# モデルの精度 accuracy of model
Exact Match(厳密一致) : 0.8038277511961722
f1 : 0.8959389668095072
# deberta-v2-base-japaneseとは?
日本語Wikipedeia(3.2GB)および、cc100(85GB)、oscar(54GB)を用いて訓練されたモデルです。
京都大学黒橋研究室が公表されました。
# Model description
This is a Japanese DeBERTa V2 base model pre-trained on Japanese Wikipedia, the Japanese portion of CC-100, and the Japanese portion of OSCAR.
# Acknowledgments 謝辞
モデルを公開してくださった京都大学黒橋研究室には感謝いたします。
I would like to thank Kurohashi Lab at Kyoto University.
|
73f88b8fac6fd03fb1a60d7d0d3d64d3
|
tensorcat/japanese-opt-2.7b
|
tensorcat
|
opt
| 14 | 7 |
transformers
| 0 |
text-generation
| true | false | false |
other
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
[]
| true | true | true | 1,134 | false |
# Japanese-opt-2.7b Model
***Disclaimer: This model is a work in progress!***
This model is a fine-tuned version of [facebook/opt-2.7b](https://huggingface.co/facebook/opt-2.7b) on the japanese wikipedia dataset.
## Quick start
```python
from transformers import pipeline
generator = pipeline('text-generation', model="tensorcat/japanese-opt-2.7b" , device=0, use_fast=False)
generator("今日は", min_length=80, max_length=200,
do_sample=True, early_stopping=True, temperature=.98, top_k=50, top_p=1.0)
```
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 1
- eval_batch_size: 1
- distributed_type: multi-GPU
- num_devices: 4
- total_train_batch_size: 4
- total_eval_batch_size: 4
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
### Framework versions
- Pytorch 1.13.0+cu116
|
a4b5a568d823dd1689af0ce279b030d5
|
anas-awadalla/roberta-large-few-shot-k-512-finetuned-squad-seed-4
|
anas-awadalla
|
roberta
| 17 | 3 |
transformers
| 0 |
question-answering
| true | false | false |
mit
| null |
['squad']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 983 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# roberta-large-few-shot-k-512-finetuned-squad-seed-4
This model is a fine-tuned version of [roberta-large](https://huggingface.co/roberta-large) on the squad dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 12
- eval_batch_size: 8
- seed: 4
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 10.0
### Training results
### Framework versions
- Transformers 4.20.0.dev0
- Pytorch 1.11.0+cu113
- Datasets 2.0.0
- Tokenizers 0.11.6
|
4a48334f3b875a1822d09e19936aca70
|
ctu-aic/mt5-base-multilingual-summarization-multilarge-cs
|
ctu-aic
|
mt5
| 9 | 15 |
transformers
| 1 |
text2text-generation
| true | false | false |
cc-by-sa-4.0
|
['cs', 'en', 'de', 'fr', 'tu', 'zh', 'es', 'ru']
|
['Multilingual_large_dataset_(multilarge)', 'cnc/dm', 'xsum', 'mlsum', 'cnewsum', 'cnc', 'sumeczech']
| null | 1 | 1 | 0 | 0 | 0 | 0 | 0 |
['Summarization', 'abstractive summarization', 'mt5-base', 'Czech', 'text2text generation', 'text generation']
| false | true | true | 5,822 | false |
# mt5-base-multilingual-summarization-multilarge-cs
This model is a fine-tuned checkpoint of [google/mt5-base](https://huggingface.co/google/mt5-base) on the Multilingual large summarization dataset focused on Czech texts to produce multilingual summaries.
## Task
The model deals with a multi-sentence summary in eight different languages. With the idea of adding other foreign language documents, and by having a considerable amount of Czech documents, we aimed to improve model summarization in the Czech language. Supported languages: ```'cs': '<extra_id_0>', 'en': '<extra_id_1>','de': '<extra_id_2>', 'es': '<extra_id_3>', 'fr': '<extra_id_4>', 'ru': '<extra_id_5>', 'tu': '<extra_id_6>', 'zh': '<extra_id_7>'```
#Usage
```python
## Configuration of summarization pipeline
#
def summ_config():
cfg = OrderedDict([
## summarization model - checkpoint
# ctu-aic/m2m100-418M-multilingual-summarization-multilarge-cs
# ctu-aic/mt5-base-multilingual-summarization-multilarge-cs
# ctu-aic/mbart25-multilingual-summarization-multilarge-cs
("model_name", "ctu-aic/mbart25-multilingual-summarization-multilarge-cs"),
## language of summarization task
# language : string : cs, en, de, fr, es, tr, ru, zh
("language", "en"),
## generation method parameters in dictionary
#
("inference_cfg", OrderedDict([
("num_beams", 4),
("top_k", 40),
("top_p", 0.92),
("do_sample", True),
("temperature", 0.95),
("repetition_penalty", 1.23),
("no_repeat_ngram_size", None),
("early_stopping", True),
("max_length", 128),
("min_length", 10),
])),
#texts to summarize values = (list of strings, string, dataset)
("texts",
[
"english text1 to summarize",
"english text2 to summarize",
]
),
#OPTIONAL: Target summaries values = (list of strings, string, None)
('golds',
[
"target english text1",
"target english text2",
]),
#('golds', None),
])
return cfg
cfg = summ_config()
mSummarize = MultiSummarizer(**cfg)
summaries,scores = mSummarize(**cfg)
```
## Dataset
Multilingual large summarization dataset consists of 10 sub-datasets mainly based on news and daily mails. For the training, it was used the entire training set and 72% of the validation set.
```
Train set: 3 464 563 docs
Validation set: 121 260 docs
```
| Stats | fragment | | | avg document length | | avg summary length | | Documents |
|-------------|----------|---------------------|--------------------|--------|---------|--------|--------|--------|
| __dataset__ |__compression__ | __density__ | __coverage__ | __nsent__ | __nwords__ | __nsent__ | __nwords__ | __count__ |
| cnc | 7.388 | 0.303 | 0.088 | 16.121 | 316.912 | 3.272 | 46.805 | 750K |
| sumeczech | 11.769 | 0.471 | 0.115 | 27.857 | 415.711 | 2.765 | 38.644 | 1M |
| cnndm | 13.688 | 2.983 | 0.538 | 32.783 | 676.026 | 4.134 | 54.036 | 300K |
| xsum | 18.378 | 0.479 | 0.194 | 18.607 | 369.134 | 1.000 | 21.127 | 225K|
| mlsum/tu | 8.666 | 5.418 | 0.461 | 14.271 | 214.496 | 1.793 | 25.675 | 274K |
| mlsum/de | 24.741 | 8.235 | 0.469 | 32.544 | 539.653 | 1.951 | 23.077 | 243K|
| mlsum/fr | 24.388 | 2.688 | 0.424 | 24.533 | 612.080 | 1.320 | 26.93 | 425K |
| mlsum/es | 36.185 | 3.705 | 0.510 | 31.914 | 746.927 | 1.142 | 21.671 | 291K |
| mlsum/ru | 78.909 | 1.194 | 0.246 | 62.141 | 948.079 | 1.012 | 11.976 | 27K|
| cnewsum | 20.183 | 0.000 | 0.000 | 16.834 | 438.271 | 1.109 | 21.926 | 304K |
#### Tokenization
Truncation and padding were set to 512 tokens for the encoder (input text) and 128 for the decoder (summary).
## Training
Trained based on cross-entropy loss.
```
Time: 3 days 20 hours
Epochs: 1080K steps = 10 (from 10)
GPUs: 4x NVIDIA A100-SXM4-40GB
eloss: 2.462 - 1.797
tloss: 17.322 - 1.578
```
### ROUGE results per individual dataset test set:
| ROUGE | ROUGE-1 | | | ROUGE-2 | | | ROUGE-L | | |
|-----------|---------|---------|-----------|--------|--------|-----------|--------|--------|---------|
| |Precision | Recall | Fscore | Precision | Recall | Fscore | Precision | Recall | Fscore |
| cnc | 30.62 | 19.83 | 23.44 | 9.94 | 6.52 | 7.67 | 22.92 | 14.92 | 17.6 |
| sumeczech | 27.57 | 17.6 | 20.85 | 8.12 | 5.23 | 6.17 | 20.84 | 13.38 | 15.81 |
| cnndm | 43.83 | 37.73 | 39.34 | 20.81 | 17.82 | 18.6 | 31.8 | 27.42 | 28.55 |
| xsum | 41.63 | 30.54 | 34.56 | 16.13 | 11.76 | 13.33 | 33.65 | 24.74 | 27.97 |
| mlsum-tu- | 54.4 | 43.29 | 46.2 | 38.78 | 31.31 | 33.23 | 48.18 | 38.44 | 41 |
| mlsum-de | 47.94 | 44.14 | 45.11 | 36.42 | 35.24 | 35.42 | 44.43 | 41.42 | 42.16 |
| mlsum-fr | 35.26 | 25.96 | 28.98 | 16.72 | 12.35 | 13.75 | 28.06 | 20.75 | 23.12 |
| mlsum-es | 33.37 | 24.84 | 27.52 | 13.29 | 10.05 | 11.05 | 27.63 | 20.69 | 22.87 |
| mlsum-ru | 0.79 | 0.66 | 0.66 | 0.26 | 0.2 | 0.22 | 0.79 | 0.66 | 0.65 |
| cnewsum | 24.49 | 24.38 | 23.23 | 6.48 | 6.7 | 6.24 | 24.18 | 24.04 | 22.91 |
# USAGE
```
soon
```
|
11382b78b31d8a9e58327b97fd6de424
|
EMBEDDIA/sloberta
|
EMBEDDIA
|
camembert
| 9 | 683 |
transformers
| 3 |
fill-mask
| true | false | false |
cc-by-sa-4.0
|
['sl']
| null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
[]
| false | true | true | 943 | false |
# Usage
Load in transformers library with:
```
from transformers import AutoTokenizer, AutoModelForMaskedLM
tokenizer = AutoTokenizer.from_pretrained("EMBEDDIA/sloberta")
model = AutoModelForMaskedLM.from_pretrained("EMBEDDIA/sloberta")
```
# SloBERTa
SloBERTa model is a monolingual Slovene BERT-like model. It is closely related to French Camembert model https://camembert-model.fr/. The corpora used for training the model have 3.47 billion tokens in total. The subword vocabulary contains 32,000 tokens. The scripts and programs used for data preparation and training the model are available on https://github.com/clarinsi/Slovene-BERT-Tool
SloBERTa was trained for 200,000 iterations or about 98 epochs.
## Corpora
The following corpora were used for training the model:
* Gigafida 2.0
* Kas 1.0
* Janes 1.0 (only Janes-news, Janes-forum, Janes-blog, Janes-wiki subcorpora)
* Slovenian parliamentary corpus siParl 2.0
* slWaC
|
ca71cd438e312bd4c3ed3c39ec06c47b
|
elice/ddpm-butterflies-128
|
elice
| null | 13 | 0 |
diffusers
| 0 | null | false | false | false |
apache-2.0
|
['en']
|
['huggan/smithsonian_butterflies_subset']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
[]
| false | true | true | 1,227 | false |
<!-- This model card has been generated automatically according to the information the training script had access to. You
should probably proofread and complete it, then remove this comment. -->
# ddpm-butterflies-128
## Model description
This diffusion model is trained with the [🤗 Diffusers](https://github.com/huggingface/diffusers) library
on the `huggan/smithsonian_butterflies_subset` dataset.
## Intended uses & limitations
#### How to use
```python
# TODO: add an example code snippet for running this diffusion pipeline
```
#### Limitations and bias
[TODO: provide examples of latent issues and potential remediations]
## Training data
[TODO: describe the data used to train the model]
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 16
- eval_batch_size: 16
- gradient_accumulation_steps: 1
- optimizer: AdamW with betas=(None, None), weight_decay=None and epsilon=None
- lr_scheduler: None
- lr_warmup_steps: 500
- ema_inv_gamma: None
- ema_inv_gamma: None
- ema_inv_gamma: None
- mixed_precision: fp16
### Training results
📈 [TensorBoard logs](https://huggingface.co/elice/ddpm-butterflies-128/tensorboard?#scalars)
|
1321c32ba536f697d3248709d18aee78
|
tamitani/xlm-roberta-base-finetuned-panx-de
|
tamitani
|
xlm-roberta
| 11 | 0 |
transformers
| 0 |
token-classification
| true | false | false |
mit
| null |
['xtreme']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,319 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xlm-roberta-base-finetuned-panx-de
This model is a fine-tuned version of [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) on the xtreme dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1358
- F1: 0.8638
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 24
- eval_batch_size: 24
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 0.2591 | 1.0 | 525 | 0.1621 | 0.8206 |
| 0.1276 | 2.0 | 1050 | 0.1379 | 0.8486 |
| 0.082 | 3.0 | 1575 | 0.1358 | 0.8638 |
### Framework versions
- Transformers 4.26.1
- Pytorch 1.13.1+cu116
- Datasets 2.9.0
- Tokenizers 0.13.2
|
6c7878050bca2de9643b0e81a5c0e646
|
timm/maxvit_large_tf_384.in1k
|
timm
| null | 4 | 123 |
timm
| 0 |
image-classification
| true | false | false |
apache-2.0
| null |
['imagenet-1k']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['image-classification', 'timm']
| false | true | true | 22,018 | false |
# Model card for maxvit_large_tf_384.in1k
An official MaxViT image classification model. Trained in tensorflow on ImageNet-1k by paper authors.
Ported from official Tensorflow implementation (https://github.com/google-research/maxvit) to PyTorch by Ross Wightman.
### Model Variants in [maxxvit.py](https://github.com/rwightman/pytorch-image-models/blob/main/timm/models/maxxvit.py)
MaxxViT covers a number of related model architectures that share a common structure including:
- CoAtNet - Combining MBConv (depthwise-separable) convolutional blocks in early stages with self-attention transformer blocks in later stages.
- MaxViT - Uniform blocks across all stages, each containing a MBConv (depthwise-separable) convolution block followed by two self-attention blocks with different partitioning schemes (window followed by grid).
- CoAtNeXt - A timm specific arch that uses ConvNeXt blocks in place of MBConv blocks in CoAtNet. All normalization layers are LayerNorm (no BatchNorm).
- MaxxViT - A timm specific arch that uses ConvNeXt blocks in place of MBConv blocks in MaxViT. All normalization layers are LayerNorm (no BatchNorm).
- MaxxViT-V2 - A MaxxViT variation that removes the window block attention leaving only ConvNeXt blocks and grid attention w/ more width to compensate.
Aside from the major variants listed above, there are more subtle changes from model to model. Any model name with the string `rw` are `timm` specific configs w/ modelling adjustments made to favour PyTorch eager use. These were created while training initial reproductions of the models so there are variations.
All models with the string `tf` are models exactly matching Tensorflow based models by the original paper authors with weights ported to PyTorch. This covers a number of MaxViT models. The official CoAtNet models were never released.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 212.0
- GMACs: 132.6
- Activations (M): 445.8
- Image size: 384 x 384
- **Papers:**
- MaxViT: Multi-Axis Vision Transformer: https://arxiv.org/abs/2204.01697
- **Dataset:** ImageNet-1k
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(
urlopen('https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'))
model = timm.create_model('maxvit_large_tf_384.in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(
urlopen('https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'))
model = timm.create_model(
'maxvit_large_tf_384.in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 128, 192, 192])
# torch.Size([1, 128, 96, 96])
# torch.Size([1, 256, 48, 48])
# torch.Size([1, 512, 24, 24])
# torch.Size([1, 1024, 12, 12])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(
urlopen('https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'))
model = timm.create_model(
'maxvit_large_tf_384.in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled (ie.e a (batch_size, num_features, H, W) tensor
output = model.forward_head(output, pre_logits=True)
# output is (batch_size, num_features) tensor
```
## Model Comparison
### By Top-1
|model |top1 |top5 |samples / sec |Params (M) |GMAC |Act (M)|
|------------------------------------------------------------------------------------------------------------------------|----:|----:|--------------:|--------------:|-----:|------:|
|[maxvit_xlarge_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_xlarge_tf_512.in21k_ft_in1k) |88.53|98.64| 21.76| 475.77|534.14|1413.22|
|[maxvit_xlarge_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_xlarge_tf_384.in21k_ft_in1k) |88.32|98.54| 42.53| 475.32|292.78| 668.76|
|[maxvit_base_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_base_tf_512.in21k_ft_in1k) |88.20|98.53| 50.87| 119.88|138.02| 703.99|
|[maxvit_large_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_large_tf_512.in21k_ft_in1k) |88.04|98.40| 36.42| 212.33|244.75| 942.15|
|[maxvit_large_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_large_tf_384.in21k_ft_in1k) |87.98|98.56| 71.75| 212.03|132.55| 445.84|
|[maxvit_base_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_base_tf_384.in21k_ft_in1k) |87.92|98.54| 104.71| 119.65| 73.80| 332.90|
|[maxvit_rmlp_base_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/maxvit_rmlp_base_rw_384.sw_in12k_ft_in1k) |87.81|98.37| 106.55| 116.14| 70.97| 318.95|
|[maxxvitv2_rmlp_base_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/maxxvitv2_rmlp_base_rw_384.sw_in12k_ft_in1k) |87.47|98.37| 149.49| 116.09| 72.98| 213.74|
|[coatnet_rmlp_2_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_384.sw_in12k_ft_in1k) |87.39|98.31| 160.80| 73.88| 47.69| 209.43|
|[maxvit_rmlp_base_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/maxvit_rmlp_base_rw_224.sw_in12k_ft_in1k) |86.89|98.02| 375.86| 116.14| 23.15| 92.64|
|[maxxvitv2_rmlp_base_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/maxxvitv2_rmlp_base_rw_224.sw_in12k_ft_in1k) |86.64|98.02| 501.03| 116.09| 24.20| 62.77|
|[maxvit_base_tf_512.in1k](https://huggingface.co/timm/maxvit_base_tf_512.in1k) |86.60|97.92| 50.75| 119.88|138.02| 703.99|
|[coatnet_2_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_2_rw_224.sw_in12k_ft_in1k) |86.57|97.89| 631.88| 73.87| 15.09| 49.22|
|[maxvit_large_tf_512.in1k](https://huggingface.co/timm/maxvit_large_tf_512.in1k) |86.52|97.88| 36.04| 212.33|244.75| 942.15|
|[coatnet_rmlp_2_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_224.sw_in12k_ft_in1k) |86.49|97.90| 620.58| 73.88| 15.18| 54.78|
|[maxvit_base_tf_384.in1k](https://huggingface.co/timm/maxvit_base_tf_384.in1k) |86.29|97.80| 101.09| 119.65| 73.80| 332.90|
|[maxvit_large_tf_384.in1k](https://huggingface.co/timm/maxvit_large_tf_384.in1k) |86.23|97.69| 70.56| 212.03|132.55| 445.84|
|[maxvit_small_tf_512.in1k](https://huggingface.co/timm/maxvit_small_tf_512.in1k) |86.10|97.76| 88.63| 69.13| 67.26| 383.77|
|[maxvit_tiny_tf_512.in1k](https://huggingface.co/timm/maxvit_tiny_tf_512.in1k) |85.67|97.58| 144.25| 31.05| 33.49| 257.59|
|[maxvit_small_tf_384.in1k](https://huggingface.co/timm/maxvit_small_tf_384.in1k) |85.54|97.46| 188.35| 69.02| 35.87| 183.65|
|[maxvit_tiny_tf_384.in1k](https://huggingface.co/timm/maxvit_tiny_tf_384.in1k) |85.11|97.38| 293.46| 30.98| 17.53| 123.42|
|[maxvit_large_tf_224.in1k](https://huggingface.co/timm/maxvit_large_tf_224.in1k) |84.93|96.97| 247.71| 211.79| 43.68| 127.35|
|[coatnet_rmlp_1_rw2_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_1_rw2_224.sw_in12k_ft_in1k) |84.90|96.96| 1025.45| 41.72| 8.11| 40.13|
|[maxvit_base_tf_224.in1k](https://huggingface.co/timm/maxvit_base_tf_224.in1k) |84.85|96.99| 358.25| 119.47| 24.04| 95.01|
|[maxxvit_rmlp_small_rw_256.sw_in1k](https://huggingface.co/timm/maxxvit_rmlp_small_rw_256.sw_in1k) |84.63|97.06| 575.53| 66.01| 14.67| 58.38|
|[coatnet_rmlp_2_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_224.sw_in1k) |84.61|96.74| 625.81| 73.88| 15.18| 54.78|
|[maxvit_rmlp_small_rw_224.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_small_rw_224.sw_in1k) |84.49|96.76| 693.82| 64.90| 10.75| 49.30|
|[maxvit_small_tf_224.in1k](https://huggingface.co/timm/maxvit_small_tf_224.in1k) |84.43|96.83| 647.96| 68.93| 11.66| 53.17|
|[maxvit_rmlp_tiny_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_tiny_rw_256.sw_in1k) |84.23|96.78| 807.21| 29.15| 6.77| 46.92|
|[coatnet_1_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_1_rw_224.sw_in1k) |83.62|96.38| 989.59| 41.72| 8.04| 34.60|
|[maxvit_tiny_rw_224.sw_in1k](https://huggingface.co/timm/maxvit_tiny_rw_224.sw_in1k) |83.50|96.50| 1100.53| 29.06| 5.11| 33.11|
|[maxvit_tiny_tf_224.in1k](https://huggingface.co/timm/maxvit_tiny_tf_224.in1k) |83.41|96.59| 1004.94| 30.92| 5.60| 35.78|
|[coatnet_rmlp_1_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_1_rw_224.sw_in1k) |83.36|96.45| 1093.03| 41.69| 7.85| 35.47|
|[maxxvitv2_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxxvitv2_nano_rw_256.sw_in1k) |83.11|96.33| 1276.88| 23.70| 6.26| 23.05|
|[maxxvit_rmlp_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxxvit_rmlp_nano_rw_256.sw_in1k) |83.03|96.34| 1341.24| 16.78| 4.37| 26.05|
|[maxvit_rmlp_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_nano_rw_256.sw_in1k) |82.96|96.26| 1283.24| 15.50| 4.47| 31.92|
|[maxvit_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_nano_rw_256.sw_in1k) |82.93|96.23| 1218.17| 15.45| 4.46| 30.28|
|[coatnet_bn_0_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_bn_0_rw_224.sw_in1k) |82.39|96.19| 1600.14| 27.44| 4.67| 22.04|
|[coatnet_0_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_0_rw_224.sw_in1k) |82.39|95.84| 1831.21| 27.44| 4.43| 18.73|
|[coatnet_rmlp_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_nano_rw_224.sw_in1k) |82.05|95.87| 2109.09| 15.15| 2.62| 20.34|
|[coatnext_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnext_nano_rw_224.sw_in1k) |81.95|95.92| 2525.52| 14.70| 2.47| 12.80|
|[coatnet_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_nano_rw_224.sw_in1k) |81.70|95.64| 2344.52| 15.14| 2.41| 15.41|
|[maxvit_rmlp_pico_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_pico_rw_256.sw_in1k) |80.53|95.21| 1594.71| 7.52| 1.85| 24.86|
### By Throughput (samples / sec)
|model |top1 |top5 |samples / sec |Params (M) |GMAC |Act (M)|
|------------------------------------------------------------------------------------------------------------------------|----:|----:|--------------:|--------------:|-----:|------:|
|[coatnext_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnext_nano_rw_224.sw_in1k) |81.95|95.92| 2525.52| 14.70| 2.47| 12.80|
|[coatnet_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_nano_rw_224.sw_in1k) |81.70|95.64| 2344.52| 15.14| 2.41| 15.41|
|[coatnet_rmlp_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_nano_rw_224.sw_in1k) |82.05|95.87| 2109.09| 15.15| 2.62| 20.34|
|[coatnet_0_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_0_rw_224.sw_in1k) |82.39|95.84| 1831.21| 27.44| 4.43| 18.73|
|[coatnet_bn_0_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_bn_0_rw_224.sw_in1k) |82.39|96.19| 1600.14| 27.44| 4.67| 22.04|
|[maxvit_rmlp_pico_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_pico_rw_256.sw_in1k) |80.53|95.21| 1594.71| 7.52| 1.85| 24.86|
|[maxxvit_rmlp_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxxvit_rmlp_nano_rw_256.sw_in1k) |83.03|96.34| 1341.24| 16.78| 4.37| 26.05|
|[maxvit_rmlp_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_nano_rw_256.sw_in1k) |82.96|96.26| 1283.24| 15.50| 4.47| 31.92|
|[maxxvitv2_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxxvitv2_nano_rw_256.sw_in1k) |83.11|96.33| 1276.88| 23.70| 6.26| 23.05|
|[maxvit_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_nano_rw_256.sw_in1k) |82.93|96.23| 1218.17| 15.45| 4.46| 30.28|
|[maxvit_tiny_rw_224.sw_in1k](https://huggingface.co/timm/maxvit_tiny_rw_224.sw_in1k) |83.50|96.50| 1100.53| 29.06| 5.11| 33.11|
|[coatnet_rmlp_1_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_1_rw_224.sw_in1k) |83.36|96.45| 1093.03| 41.69| 7.85| 35.47|
|[coatnet_rmlp_1_rw2_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_1_rw2_224.sw_in12k_ft_in1k) |84.90|96.96| 1025.45| 41.72| 8.11| 40.13|
|[maxvit_tiny_tf_224.in1k](https://huggingface.co/timm/maxvit_tiny_tf_224.in1k) |83.41|96.59| 1004.94| 30.92| 5.60| 35.78|
|[coatnet_1_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_1_rw_224.sw_in1k) |83.62|96.38| 989.59| 41.72| 8.04| 34.60|
|[maxvit_rmlp_tiny_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_tiny_rw_256.sw_in1k) |84.23|96.78| 807.21| 29.15| 6.77| 46.92|
|[maxvit_rmlp_small_rw_224.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_small_rw_224.sw_in1k) |84.49|96.76| 693.82| 64.90| 10.75| 49.30|
|[maxvit_small_tf_224.in1k](https://huggingface.co/timm/maxvit_small_tf_224.in1k) |84.43|96.83| 647.96| 68.93| 11.66| 53.17|
|[coatnet_2_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_2_rw_224.sw_in12k_ft_in1k) |86.57|97.89| 631.88| 73.87| 15.09| 49.22|
|[coatnet_rmlp_2_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_224.sw_in1k) |84.61|96.74| 625.81| 73.88| 15.18| 54.78|
|[coatnet_rmlp_2_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_224.sw_in12k_ft_in1k) |86.49|97.90| 620.58| 73.88| 15.18| 54.78|
|[maxxvit_rmlp_small_rw_256.sw_in1k](https://huggingface.co/timm/maxxvit_rmlp_small_rw_256.sw_in1k) |84.63|97.06| 575.53| 66.01| 14.67| 58.38|
|[maxxvitv2_rmlp_base_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/maxxvitv2_rmlp_base_rw_224.sw_in12k_ft_in1k) |86.64|98.02| 501.03| 116.09| 24.20| 62.77|
|[maxvit_rmlp_base_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/maxvit_rmlp_base_rw_224.sw_in12k_ft_in1k) |86.89|98.02| 375.86| 116.14| 23.15| 92.64|
|[maxvit_base_tf_224.in1k](https://huggingface.co/timm/maxvit_base_tf_224.in1k) |84.85|96.99| 358.25| 119.47| 24.04| 95.01|
|[maxvit_tiny_tf_384.in1k](https://huggingface.co/timm/maxvit_tiny_tf_384.in1k) |85.11|97.38| 293.46| 30.98| 17.53| 123.42|
|[maxvit_large_tf_224.in1k](https://huggingface.co/timm/maxvit_large_tf_224.in1k) |84.93|96.97| 247.71| 211.79| 43.68| 127.35|
|[maxvit_small_tf_384.in1k](https://huggingface.co/timm/maxvit_small_tf_384.in1k) |85.54|97.46| 188.35| 69.02| 35.87| 183.65|
|[coatnet_rmlp_2_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_384.sw_in12k_ft_in1k) |87.39|98.31| 160.80| 73.88| 47.69| 209.43|
|[maxxvitv2_rmlp_base_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/maxxvitv2_rmlp_base_rw_384.sw_in12k_ft_in1k) |87.47|98.37| 149.49| 116.09| 72.98| 213.74|
|[maxvit_tiny_tf_512.in1k](https://huggingface.co/timm/maxvit_tiny_tf_512.in1k) |85.67|97.58| 144.25| 31.05| 33.49| 257.59|
|[maxvit_rmlp_base_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/maxvit_rmlp_base_rw_384.sw_in12k_ft_in1k) |87.81|98.37| 106.55| 116.14| 70.97| 318.95|
|[maxvit_base_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_base_tf_384.in21k_ft_in1k) |87.92|98.54| 104.71| 119.65| 73.80| 332.90|
|[maxvit_base_tf_384.in1k](https://huggingface.co/timm/maxvit_base_tf_384.in1k) |86.29|97.80| 101.09| 119.65| 73.80| 332.90|
|[maxvit_small_tf_512.in1k](https://huggingface.co/timm/maxvit_small_tf_512.in1k) |86.10|97.76| 88.63| 69.13| 67.26| 383.77|
|[maxvit_large_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_large_tf_384.in21k_ft_in1k) |87.98|98.56| 71.75| 212.03|132.55| 445.84|
|[maxvit_large_tf_384.in1k](https://huggingface.co/timm/maxvit_large_tf_384.in1k) |86.23|97.69| 70.56| 212.03|132.55| 445.84|
|[maxvit_base_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_base_tf_512.in21k_ft_in1k) |88.20|98.53| 50.87| 119.88|138.02| 703.99|
|[maxvit_base_tf_512.in1k](https://huggingface.co/timm/maxvit_base_tf_512.in1k) |86.60|97.92| 50.75| 119.88|138.02| 703.99|
|[maxvit_xlarge_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_xlarge_tf_384.in21k_ft_in1k) |88.32|98.54| 42.53| 475.32|292.78| 668.76|
|[maxvit_large_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_large_tf_512.in21k_ft_in1k) |88.04|98.40| 36.42| 212.33|244.75| 942.15|
|[maxvit_large_tf_512.in1k](https://huggingface.co/timm/maxvit_large_tf_512.in1k) |86.52|97.88| 36.04| 212.33|244.75| 942.15|
|[maxvit_xlarge_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_xlarge_tf_512.in21k_ft_in1k) |88.53|98.64| 21.76| 475.77|534.14|1413.22|
## Citation
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/rwightman/pytorch-image-models}}
}
```
```bibtex
@article{tu2022maxvit,
title={MaxViT: Multi-Axis Vision Transformer},
author={Tu, Zhengzhong and Talebi, Hossein and Zhang, Han and Yang, Feng and Milanfar, Peyman and Bovik, Alan and Li, Yinxiao},
journal={ECCV},
year={2022},
}
```
```bibtex
@article{dai2021coatnet,
title={CoAtNet: Marrying Convolution and Attention for All Data Sizes},
author={Dai, Zihang and Liu, Hanxiao and Le, Quoc V and Tan, Mingxing},
journal={arXiv preprint arXiv:2106.04803},
year={2021}
}
```
|
e92e4ba3b771ad3d6b60a3fe65e6ca06
|
bubblecookie/t5-small-finetuned-cnndm_trained
|
bubblecookie
|
t5
| 13 | 1 |
transformers
| 0 |
text2text-generation
| true | false | false |
apache-2.0
| null |
['cnn_dailymail']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 937 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-small-finetuned-cnndm_trained
This model is a fine-tuned version of [t5-small](https://huggingface.co/t5-small) on the cnn_dailymail dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
- mixed_precision_training: Native AMP
### Framework versions
- Transformers 4.19.4
- Pytorch 1.11.0+cu113
- Datasets 2.2.2
- Tokenizers 0.12.1
|
3e010262e6e050684e82ed28cc81983a
|
semy/finetuning-sentiment-model-sst
|
semy
|
distilbert
| 10 | 3 |
transformers
| 0 |
text-classification
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 912 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# finetuning-sentiment-model-sst
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Framework versions
- Transformers 4.20.1
- Pytorch 1.10.2
- Datasets 2.3.2
- Tokenizers 0.12.1
|
04dc772730f7c5ec9139adf0d4a02ba4
|
burakyldrm/wav2vec2-burak-new-300-v2-8
|
burakyldrm
|
wav2vec2
| 13 | 13 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 2,269 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-burak-new-300-v2-8
This model is a fine-tuned version of [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2841
- Wer: 0.2120
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 151
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:------:|:----:|:---------------:|:------:|
| 6.0739 | 9.43 | 500 | 3.1506 | 1.0 |
| 1.6652 | 18.87 | 1000 | 0.3396 | 0.4136 |
| 0.4505 | 28.3 | 1500 | 0.2632 | 0.3138 |
| 0.3115 | 37.74 | 2000 | 0.2536 | 0.2849 |
| 0.2421 | 47.17 | 2500 | 0.2674 | 0.2588 |
| 0.203 | 56.6 | 3000 | 0.2552 | 0.2471 |
| 0.181 | 66.04 | 3500 | 0.2636 | 0.2595 |
| 0.1581 | 75.47 | 4000 | 0.2527 | 0.2416 |
| 0.1453 | 84.91 | 4500 | 0.2773 | 0.2257 |
| 0.1305 | 94.34 | 5000 | 0.2825 | 0.2257 |
| 0.1244 | 103.77 | 5500 | 0.2754 | 0.2312 |
| 0.1127 | 113.21 | 6000 | 0.2772 | 0.2223 |
| 0.1094 | 122.64 | 6500 | 0.2720 | 0.2223 |
| 0.1033 | 132.08 | 7000 | 0.2863 | 0.2202 |
| 0.099 | 141.51 | 7500 | 0.2853 | 0.2140 |
| 0.0972 | 150.94 | 8000 | 0.2841 | 0.2120 |
### Framework versions
- Transformers 4.25.1
- Pytorch 1.12.1+cu113
- Datasets 2.7.1
- Tokenizers 0.13.2
|
eba294334b174a46417dae77a740f3e9
|
timm/convnext_base.clip_laion2b_augreg_ft_in1k
|
timm
| null | 4 | 70 |
timm
| 0 |
image-classification
| true | false | false |
apache-2.0
| null |
['imagenet-1k', 'laion-2b']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['image-classification', 'timm']
| false | true | true | 24,134 | false |
# Model card for convnext_base.clip_laion2b_augreg_ft_in1k
A ConvNeXt image classification model. CLIP image tower weights pretrained in [OpenCLIP](https://github.com/mlfoundations/open_clip) on LAION and fine-tuned on ImageNet-1k in `timm` by Ross Wightman.
Please see related OpenCLIP model cards for more details on pretrain:
* https://huggingface.co/laion/CLIP-convnext_large_d.laion2B-s26B-b102K-augreg
* https://huggingface.co/laion/CLIP-convnext_base_w-laion2B-s13B-b82K-augreg
* https://huggingface.co/laion/CLIP-convnext_base_w_320-laion_aesthetic-s13B-b82K
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 88.6
- GMACs: 20.1
- Activations (M): 37.6
- Image size: 256 x 256
- **Papers:**
- LAION-5B: An open large-scale dataset for training next generation image-text models: https://arxiv.org/abs/2210.08402
- A ConvNet for the 2020s: https://arxiv.org/abs/2201.03545
- Learning Transferable Visual Models From Natural Language Supervision: https://arxiv.org/abs/2103.00020
- **Original:** https://github.com/mlfoundations/open_clip
- **Pretrain Dataset:** LAION-2B
- **Dataset:** ImageNet-1k
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(
urlopen('https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'))
model = timm.create_model('convnext_base.clip_laion2b_augreg_ft_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(
urlopen('https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'))
model = timm.create_model(
'convnext_base.clip_laion2b_augreg_ft_in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g. for convnext_base:
# torch.Size([1, 128, 56, 56])
# torch.Size([1, 256, 28, 28])
# torch.Size([1, 512, 14, 14])
# torch.Size([1, 1024, 7, 7])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(
urlopen('https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'))
model = timm.create_model(
'convnext_base.clip_laion2b_augreg_ft_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled (ie.e a (batch_size, num_features, H, W) tensor
output = model.forward_head(output, pre_logits=True)
# output is (batch_size, num_features) tensor
```
## Model Comparison
### By Top-1
All timing numbers from eager model PyTorch 1.13 on RTX 3090 w/ AMP.
|model |top1 |top5 |img_size|param_count|gmacs |macts |samples_per_sec|batch_size|
|----------------------------------------------|------|------|--------|-----------|------|------|---------------|----------|
|[convnextv2_huge.fcmae_ft_in22k_in1k_512](https://huggingface.co/timm/convnextv2_huge.fcmae_ft_in22k_in1k_512)|88.848|98.742|512 |660.29 |600.81|413.07|28.58 |48 |
|[convnextv2_huge.fcmae_ft_in22k_in1k_384](https://huggingface.co/timm/convnextv2_huge.fcmae_ft_in22k_in1k_384)|88.668|98.738|384 |660.29 |337.96|232.35|50.56 |64 |
|[convnextv2_large.fcmae_ft_in22k_in1k_384](https://huggingface.co/timm/convnextv2_large.fcmae_ft_in22k_in1k_384)|88.196|98.532|384 |197.96 |101.1 |126.74|128.94 |128 |
|[convnext_xlarge.fb_in22k_ft_in1k_384](https://huggingface.co/timm/convnext_xlarge.fb_in22k_ft_in1k_384)|87.75 |98.556|384 |350.2 |179.2 |168.99|124.85 |192 |
|[convnextv2_base.fcmae_ft_in22k_in1k_384](https://huggingface.co/timm/convnextv2_base.fcmae_ft_in22k_in1k_384)|87.646|98.422|384 |88.72 |45.21 |84.49 |209.51 |256 |
|[convnext_large.fb_in22k_ft_in1k_384](https://huggingface.co/timm/convnext_large.fb_in22k_ft_in1k_384)|87.476|98.382|384 |197.77 |101.1 |126.74|194.66 |256 |
|[convnext_large_mlp.clip_laion2b_augreg_ft_in1k](https://huggingface.co/timm/convnext_large_mlp.clip_laion2b_augreg_ft_in1k)|87.344|98.218|256 |200.13 |44.94 |56.33 |438.08 |256 |
|[convnextv2_large.fcmae_ft_in22k_in1k](https://huggingface.co/timm/convnextv2_large.fcmae_ft_in22k_in1k)|87.26 |98.248|224 |197.96 |34.4 |43.13 |376.84 |256 |
|[convnext_xlarge.fb_in22k_ft_in1k](https://huggingface.co/timm/convnext_xlarge.fb_in22k_ft_in1k)|87.002|98.208|224 |350.2 |60.98 |57.5 |368.01 |256 |
|[convnext_base.fb_in22k_ft_in1k_384](https://huggingface.co/timm/convnext_base.fb_in22k_ft_in1k_384)|86.796|98.264|384 |88.59 |45.21 |84.49 |366.54 |256 |
|[convnextv2_base.fcmae_ft_in22k_in1k](https://huggingface.co/timm/convnextv2_base.fcmae_ft_in22k_in1k)|86.74 |98.022|224 |88.72 |15.38 |28.75 |624.23 |256 |
|[convnext_large.fb_in22k_ft_in1k](https://huggingface.co/timm/convnext_large.fb_in22k_ft_in1k)|86.636|98.028|224 |197.77 |34.4 |43.13 |581.43 |256 |
|[convnext_base.clip_laiona_augreg_ft_in1k_384](https://huggingface.co/timm/convnext_base.clip_laiona_augreg_ft_in1k_384)|86.504|97.97 |384 |88.59 |45.21 |84.49 |368.14 |256 |
|[convnextv2_huge.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_huge.fcmae_ft_in1k)|86.256|97.75 |224 |660.29 |115.0 |79.07 |154.72 |256 |
|[convnext_small.in12k_ft_in1k_384](https://huggingface.co/timm/convnext_small.in12k_ft_in1k_384)|86.182|97.92 |384 |50.22 |25.58 |63.37 |516.19 |256 |
|[convnext_base.clip_laion2b_augreg_ft_in1k](https://huggingface.co/timm/convnext_base.clip_laion2b_augreg_ft_in1k)|86.154|97.68 |256 |88.59 |20.09 |37.55 |819.86 |256 |
|[convnext_base.fb_in22k_ft_in1k](https://huggingface.co/timm/convnext_base.fb_in22k_ft_in1k)|85.822|97.866|224 |88.59 |15.38 |28.75 |1037.66 |256 |
|[convnext_small.fb_in22k_ft_in1k_384](https://huggingface.co/timm/convnext_small.fb_in22k_ft_in1k_384)|85.778|97.886|384 |50.22 |25.58 |63.37 |518.95 |256 |
|[convnextv2_large.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_large.fcmae_ft_in1k)|85.742|97.584|224 |197.96 |34.4 |43.13 |375.23 |256 |
|[convnext_small.in12k_ft_in1k](https://huggingface.co/timm/convnext_small.in12k_ft_in1k)|85.174|97.506|224 |50.22 |8.71 |21.56 |1474.31 |256 |
|[convnext_tiny.in12k_ft_in1k_384](https://huggingface.co/timm/convnext_tiny.in12k_ft_in1k_384)|85.118|97.608|384 |28.59 |13.14 |39.48 |856.76 |256 |
|[convnextv2_tiny.fcmae_ft_in22k_in1k_384](https://huggingface.co/timm/convnextv2_tiny.fcmae_ft_in22k_in1k_384)|85.112|97.63 |384 |28.64 |13.14 |39.48 |491.32 |256 |
|[convnextv2_base.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_base.fcmae_ft_in1k)|84.874|97.09 |224 |88.72 |15.38 |28.75 |625.33 |256 |
|[convnext_small.fb_in22k_ft_in1k](https://huggingface.co/timm/convnext_small.fb_in22k_ft_in1k)|84.562|97.394|224 |50.22 |8.71 |21.56 |1478.29 |256 |
|[convnext_large.fb_in1k](https://huggingface.co/timm/convnext_large.fb_in1k)|84.282|96.892|224 |197.77 |34.4 |43.13 |584.28 |256 |
|[convnext_tiny.in12k_ft_in1k](https://huggingface.co/timm/convnext_tiny.in12k_ft_in1k)|84.186|97.124|224 |28.59 |4.47 |13.44 |2433.7 |256 |
|[convnext_tiny.fb_in22k_ft_in1k_384](https://huggingface.co/timm/convnext_tiny.fb_in22k_ft_in1k_384)|84.084|97.14 |384 |28.59 |13.14 |39.48 |862.95 |256 |
|[convnextv2_tiny.fcmae_ft_in22k_in1k](https://huggingface.co/timm/convnextv2_tiny.fcmae_ft_in22k_in1k)|83.894|96.964|224 |28.64 |4.47 |13.44 |1452.72 |256 |
|[convnext_base.fb_in1k](https://huggingface.co/timm/convnext_base.fb_in1k)|83.82 |96.746|224 |88.59 |15.38 |28.75 |1054.0 |256 |
|[convnextv2_nano.fcmae_ft_in22k_in1k_384](https://huggingface.co/timm/convnextv2_nano.fcmae_ft_in22k_in1k_384)|83.37 |96.742|384 |15.62 |7.22 |24.61 |801.72 |256 |
|[convnext_small.fb_in1k](https://huggingface.co/timm/convnext_small.fb_in1k)|83.142|96.434|224 |50.22 |8.71 |21.56 |1464.0 |256 |
|[convnextv2_tiny.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_tiny.fcmae_ft_in1k)|82.92 |96.284|224 |28.64 |4.47 |13.44 |1425.62 |256 |
|[convnext_tiny.fb_in22k_ft_in1k](https://huggingface.co/timm/convnext_tiny.fb_in22k_ft_in1k)|82.898|96.616|224 |28.59 |4.47 |13.44 |2480.88 |256 |
|[convnext_nano.in12k_ft_in1k](https://huggingface.co/timm/convnext_nano.in12k_ft_in1k)|82.282|96.344|224 |15.59 |2.46 |8.37 |3926.52 |256 |
|[convnext_tiny_hnf.a2h_in1k](https://huggingface.co/timm/convnext_tiny_hnf.a2h_in1k)|82.216|95.852|224 |28.59 |4.47 |13.44 |2529.75 |256 |
|[convnext_tiny.fb_in1k](https://huggingface.co/timm/convnext_tiny.fb_in1k)|82.066|95.854|224 |28.59 |4.47 |13.44 |2346.26 |256 |
|[convnextv2_nano.fcmae_ft_in22k_in1k](https://huggingface.co/timm/convnextv2_nano.fcmae_ft_in22k_in1k)|82.03 |96.166|224 |15.62 |2.46 |8.37 |2300.18 |256 |
|[convnextv2_nano.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_nano.fcmae_ft_in1k)|81.83 |95.738|224 |15.62 |2.46 |8.37 |2321.48 |256 |
|[convnext_nano_ols.d1h_in1k](https://huggingface.co/timm/convnext_nano_ols.d1h_in1k)|80.866|95.246|224 |15.65 |2.65 |9.38 |3523.85 |256 |
|[convnext_nano.d1h_in1k](https://huggingface.co/timm/convnext_nano.d1h_in1k)|80.768|95.334|224 |15.59 |2.46 |8.37 |3915.58 |256 |
|[convnextv2_pico.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_pico.fcmae_ft_in1k)|80.304|95.072|224 |9.07 |1.37 |6.1 |3274.57 |256 |
|[convnext_pico.d1_in1k](https://huggingface.co/timm/convnext_pico.d1_in1k)|79.526|94.558|224 |9.05 |1.37 |6.1 |5686.88 |256 |
|[convnext_pico_ols.d1_in1k](https://huggingface.co/timm/convnext_pico_ols.d1_in1k)|79.522|94.692|224 |9.06 |1.43 |6.5 |5422.46 |256 |
|[convnextv2_femto.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_femto.fcmae_ft_in1k)|78.488|93.98 |224 |5.23 |0.79 |4.57 |4264.2 |256 |
|[convnext_femto_ols.d1_in1k](https://huggingface.co/timm/convnext_femto_ols.d1_in1k)|77.86 |93.83 |224 |5.23 |0.82 |4.87 |6910.6 |256 |
|[convnext_femto.d1_in1k](https://huggingface.co/timm/convnext_femto.d1_in1k)|77.454|93.68 |224 |5.22 |0.79 |4.57 |7189.92 |256 |
|[convnextv2_atto.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_atto.fcmae_ft_in1k)|76.664|93.044|224 |3.71 |0.55 |3.81 |4728.91 |256 |
|[convnext_atto_ols.a2_in1k](https://huggingface.co/timm/convnext_atto_ols.a2_in1k)|75.88 |92.846|224 |3.7 |0.58 |4.11 |7963.16 |256 |
|[convnext_atto.d2_in1k](https://huggingface.co/timm/convnext_atto.d2_in1k)|75.664|92.9 |224 |3.7 |0.55 |3.81 |8439.22 |256 |
### By Throughput (samples / sec)
All timing numbers from eager model PyTorch 1.13 on RTX 3090 w/ AMP.
|model |top1 |top5 |img_size|param_count|gmacs |macts |samples_per_sec|batch_size|
|----------------------------------------------|------|------|--------|-----------|------|------|---------------|----------|
|[convnext_atto.d2_in1k](https://huggingface.co/timm/convnext_atto.d2_in1k)|75.664|92.9 |224 |3.7 |0.55 |3.81 |8439.22 |256 |
|[convnext_atto_ols.a2_in1k](https://huggingface.co/timm/convnext_atto_ols.a2_in1k)|75.88 |92.846|224 |3.7 |0.58 |4.11 |7963.16 |256 |
|[convnext_femto.d1_in1k](https://huggingface.co/timm/convnext_femto.d1_in1k)|77.454|93.68 |224 |5.22 |0.79 |4.57 |7189.92 |256 |
|[convnext_femto_ols.d1_in1k](https://huggingface.co/timm/convnext_femto_ols.d1_in1k)|77.86 |93.83 |224 |5.23 |0.82 |4.87 |6910.6 |256 |
|[convnext_pico.d1_in1k](https://huggingface.co/timm/convnext_pico.d1_in1k)|79.526|94.558|224 |9.05 |1.37 |6.1 |5686.88 |256 |
|[convnext_pico_ols.d1_in1k](https://huggingface.co/timm/convnext_pico_ols.d1_in1k)|79.522|94.692|224 |9.06 |1.43 |6.5 |5422.46 |256 |
|[convnextv2_atto.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_atto.fcmae_ft_in1k)|76.664|93.044|224 |3.71 |0.55 |3.81 |4728.91 |256 |
|[convnextv2_femto.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_femto.fcmae_ft_in1k)|78.488|93.98 |224 |5.23 |0.79 |4.57 |4264.2 |256 |
|[convnext_nano.in12k_ft_in1k](https://huggingface.co/timm/convnext_nano.in12k_ft_in1k)|82.282|96.344|224 |15.59 |2.46 |8.37 |3926.52 |256 |
|[convnext_nano.d1h_in1k](https://huggingface.co/timm/convnext_nano.d1h_in1k)|80.768|95.334|224 |15.59 |2.46 |8.37 |3915.58 |256 |
|[convnext_nano_ols.d1h_in1k](https://huggingface.co/timm/convnext_nano_ols.d1h_in1k)|80.866|95.246|224 |15.65 |2.65 |9.38 |3523.85 |256 |
|[convnextv2_pico.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_pico.fcmae_ft_in1k)|80.304|95.072|224 |9.07 |1.37 |6.1 |3274.57 |256 |
|[convnext_tiny_hnf.a2h_in1k](https://huggingface.co/timm/convnext_tiny_hnf.a2h_in1k)|82.216|95.852|224 |28.59 |4.47 |13.44 |2529.75 |256 |
|[convnext_tiny.fb_in22k_ft_in1k](https://huggingface.co/timm/convnext_tiny.fb_in22k_ft_in1k)|82.898|96.616|224 |28.59 |4.47 |13.44 |2480.88 |256 |
|[convnext_tiny.in12k_ft_in1k](https://huggingface.co/timm/convnext_tiny.in12k_ft_in1k)|84.186|97.124|224 |28.59 |4.47 |13.44 |2433.7 |256 |
|[convnext_tiny.fb_in1k](https://huggingface.co/timm/convnext_tiny.fb_in1k)|82.066|95.854|224 |28.59 |4.47 |13.44 |2346.26 |256 |
|[convnextv2_nano.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_nano.fcmae_ft_in1k)|81.83 |95.738|224 |15.62 |2.46 |8.37 |2321.48 |256 |
|[convnextv2_nano.fcmae_ft_in22k_in1k](https://huggingface.co/timm/convnextv2_nano.fcmae_ft_in22k_in1k)|82.03 |96.166|224 |15.62 |2.46 |8.37 |2300.18 |256 |
|[convnext_small.fb_in22k_ft_in1k](https://huggingface.co/timm/convnext_small.fb_in22k_ft_in1k)|84.562|97.394|224 |50.22 |8.71 |21.56 |1478.29 |256 |
|[convnext_small.in12k_ft_in1k](https://huggingface.co/timm/convnext_small.in12k_ft_in1k)|85.174|97.506|224 |50.22 |8.71 |21.56 |1474.31 |256 |
|[convnext_small.fb_in1k](https://huggingface.co/timm/convnext_small.fb_in1k)|83.142|96.434|224 |50.22 |8.71 |21.56 |1464.0 |256 |
|[convnextv2_tiny.fcmae_ft_in22k_in1k](https://huggingface.co/timm/convnextv2_tiny.fcmae_ft_in22k_in1k)|83.894|96.964|224 |28.64 |4.47 |13.44 |1452.72 |256 |
|[convnextv2_tiny.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_tiny.fcmae_ft_in1k)|82.92 |96.284|224 |28.64 |4.47 |13.44 |1425.62 |256 |
|[convnext_base.fb_in1k](https://huggingface.co/timm/convnext_base.fb_in1k)|83.82 |96.746|224 |88.59 |15.38 |28.75 |1054.0 |256 |
|[convnext_base.fb_in22k_ft_in1k](https://huggingface.co/timm/convnext_base.fb_in22k_ft_in1k)|85.822|97.866|224 |88.59 |15.38 |28.75 |1037.66 |256 |
|[convnext_tiny.fb_in22k_ft_in1k_384](https://huggingface.co/timm/convnext_tiny.fb_in22k_ft_in1k_384)|84.084|97.14 |384 |28.59 |13.14 |39.48 |862.95 |256 |
|[convnext_tiny.in12k_ft_in1k_384](https://huggingface.co/timm/convnext_tiny.in12k_ft_in1k_384)|85.118|97.608|384 |28.59 |13.14 |39.48 |856.76 |256 |
|[convnext_base.clip_laion2b_augreg_ft_in1k](https://huggingface.co/timm/convnext_base.clip_laion2b_augreg_ft_in1k)|86.154|97.68 |256 |88.59 |20.09 |37.55 |819.86 |256 |
|[convnextv2_nano.fcmae_ft_in22k_in1k_384](https://huggingface.co/timm/convnextv2_nano.fcmae_ft_in22k_in1k_384)|83.37 |96.742|384 |15.62 |7.22 |24.61 |801.72 |256 |
|[convnextv2_base.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_base.fcmae_ft_in1k)|84.874|97.09 |224 |88.72 |15.38 |28.75 |625.33 |256 |
|[convnextv2_base.fcmae_ft_in22k_in1k](https://huggingface.co/timm/convnextv2_base.fcmae_ft_in22k_in1k)|86.74 |98.022|224 |88.72 |15.38 |28.75 |624.23 |256 |
|[convnext_large.fb_in1k](https://huggingface.co/timm/convnext_large.fb_in1k)|84.282|96.892|224 |197.77 |34.4 |43.13 |584.28 |256 |
|[convnext_large.fb_in22k_ft_in1k](https://huggingface.co/timm/convnext_large.fb_in22k_ft_in1k)|86.636|98.028|224 |197.77 |34.4 |43.13 |581.43 |256 |
|[convnext_small.fb_in22k_ft_in1k_384](https://huggingface.co/timm/convnext_small.fb_in22k_ft_in1k_384)|85.778|97.886|384 |50.22 |25.58 |63.37 |518.95 |256 |
|[convnext_small.in12k_ft_in1k_384](https://huggingface.co/timm/convnext_small.in12k_ft_in1k_384)|86.182|97.92 |384 |50.22 |25.58 |63.37 |516.19 |256 |
|[convnextv2_tiny.fcmae_ft_in22k_in1k_384](https://huggingface.co/timm/convnextv2_tiny.fcmae_ft_in22k_in1k_384)|85.112|97.63 |384 |28.64 |13.14 |39.48 |491.32 |256 |
|[convnext_large_mlp.clip_laion2b_augreg_ft_in1k](https://huggingface.co/timm/convnext_large_mlp.clip_laion2b_augreg_ft_in1k)|87.344|98.218|256 |200.13 |44.94 |56.33 |438.08 |256 |
|[convnextv2_large.fcmae_ft_in22k_in1k](https://huggingface.co/timm/convnextv2_large.fcmae_ft_in22k_in1k)|87.26 |98.248|224 |197.96 |34.4 |43.13 |376.84 |256 |
|[convnextv2_large.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_large.fcmae_ft_in1k)|85.742|97.584|224 |197.96 |34.4 |43.13 |375.23 |256 |
|[convnext_base.clip_laiona_augreg_ft_in1k_384](https://huggingface.co/timm/convnext_base.clip_laiona_augreg_ft_in1k_384)|86.504|97.97 |384 |88.59 |45.21 |84.49 |368.14 |256 |
|[convnext_xlarge.fb_in22k_ft_in1k](https://huggingface.co/timm/convnext_xlarge.fb_in22k_ft_in1k)|87.002|98.208|224 |350.2 |60.98 |57.5 |368.01 |256 |
|[convnext_base.fb_in22k_ft_in1k_384](https://huggingface.co/timm/convnext_base.fb_in22k_ft_in1k_384)|86.796|98.264|384 |88.59 |45.21 |84.49 |366.54 |256 |
|[convnextv2_base.fcmae_ft_in22k_in1k_384](https://huggingface.co/timm/convnextv2_base.fcmae_ft_in22k_in1k_384)|87.646|98.422|384 |88.72 |45.21 |84.49 |209.51 |256 |
|[convnext_large.fb_in22k_ft_in1k_384](https://huggingface.co/timm/convnext_large.fb_in22k_ft_in1k_384)|87.476|98.382|384 |197.77 |101.1 |126.74|194.66 |256 |
|[convnextv2_huge.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_huge.fcmae_ft_in1k)|86.256|97.75 |224 |660.29 |115.0 |79.07 |154.72 |256 |
|[convnextv2_large.fcmae_ft_in22k_in1k_384](https://huggingface.co/timm/convnextv2_large.fcmae_ft_in22k_in1k_384)|88.196|98.532|384 |197.96 |101.1 |126.74|128.94 |128 |
|[convnext_xlarge.fb_in22k_ft_in1k_384](https://huggingface.co/timm/convnext_xlarge.fb_in22k_ft_in1k_384)|87.75 |98.556|384 |350.2 |179.2 |168.99|124.85 |192 |
|[convnextv2_huge.fcmae_ft_in22k_in1k_384](https://huggingface.co/timm/convnextv2_huge.fcmae_ft_in22k_in1k_384)|88.668|98.738|384 |660.29 |337.96|232.35|50.56 |64 |
|[convnextv2_huge.fcmae_ft_in22k_in1k_512](https://huggingface.co/timm/convnextv2_huge.fcmae_ft_in22k_in1k_512)|88.848|98.742|512 |660.29 |600.81|413.07|28.58 |48 |
## Citation
```bibtex
@software{ilharco_gabriel_2021_5143773,
author = {Ilharco, Gabriel and
Wortsman, Mitchell and
Wightman, Ross and
Gordon, Cade and
Carlini, Nicholas and
Taori, Rohan and
Dave, Achal and
Shankar, Vaishaal and
Namkoong, Hongseok and
Miller, John and
Hajishirzi, Hannaneh and
Farhadi, Ali and
Schmidt, Ludwig},
title = {OpenCLIP},
month = jul,
year = 2021,
note = {If you use this software, please cite it as below.},
publisher = {Zenodo},
version = {0.1},
doi = {10.5281/zenodo.5143773},
url = {https://doi.org/10.5281/zenodo.5143773}
}
```
```bibtex
@inproceedings{schuhmann2022laionb,
title={{LAION}-5B: An open large-scale dataset for training next generation image-text models},
author={Christoph Schuhmann and
Romain Beaumont and
Richard Vencu and
Cade W Gordon and
Ross Wightman and
Mehdi Cherti and
Theo Coombes and
Aarush Katta and
Clayton Mullis and
Mitchell Wortsman and
Patrick Schramowski and
Srivatsa R Kundurthy and
Katherine Crowson and
Ludwig Schmidt and
Robert Kaczmarczyk and
Jenia Jitsev},
booktitle={Thirty-sixth Conference on Neural Information Processing Systems Datasets and Benchmarks Track},
year={2022},
url={https://openreview.net/forum?id=M3Y74vmsMcY}
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/rwightman/pytorch-image-models}}
}
```
```bibtex
@inproceedings{Radford2021LearningTV,
title={Learning Transferable Visual Models From Natural Language Supervision},
author={Alec Radford and Jong Wook Kim and Chris Hallacy and A. Ramesh and Gabriel Goh and Sandhini Agarwal and Girish Sastry and Amanda Askell and Pamela Mishkin and Jack Clark and Gretchen Krueger and Ilya Sutskever},
booktitle={ICML},
year={2021}
}
```
```bibtex
@article{liu2022convnet,
author = {Zhuang Liu and Hanzi Mao and Chao-Yuan Wu and Christoph Feichtenhofer and Trevor Darrell and Saining Xie},
title = {A ConvNet for the 2020s},
journal = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2022},
}
```
|
2ff4f88cfa9d37789e01201bc920f5dd
|
StonyBrookNLP/bart-large-iirc-retrieved
|
StonyBrookNLP
|
bart
| 9 | 3 |
transformers
| 0 |
text2text-generation
| true | false | false |
cc-by-4.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['question-answering, multi-step-reasoning, multi-hop-reasoning']
| false | true | true | 2,629 | false |
# What's this?
This is one of the models reported in the paper: ["Teaching Broad Reasoning Skills for Multi-Step QA by Generating Hard Contexts".](https://arxiv.org/abs/2205.12496).
This paper proposes a procedure to synthetically generate a QA dataset, TeaBReaC, for pretraining language models for robust multi-step reasoning. Pretraining plain LMs like Bart, T5 and numerate LMs like NT5, PReasM, POET on TeaBReaC leads to improvemed downstream performance on several multi-step QA datasets. Please checkout out the paper for the details.
We release the following models:
- **A:** Base Models finetuned on target datasets: `{base_model}-{target_dataset}`
- **B:** Base models pretrained on TeaBReaC: `teabreac-{base_model}`
- **C:** Base models pretrained on TeaBReaC and then finetuned on target datasets: `teabreac-{base_model}-{target_dataset}`
The `base_model` above can be from: `bart-large`, `t5-large`, `t5-3b`, `nt5-small`, `preasm-large`.
The `target_dataset` above can be from: `drop`, `tatqa`, `iirc-gold`, `iirc-retrieved`, `numglue`.
The **A** models are only released for completeness / reproducibility. In your end application you probably just want to use either **B** or **C**.
# How to use it?
Please checkout the details in our [github repository](https://github.com/stonybrooknlp/teabreac), but in a nutshell:
```python
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
from digit_tokenization import enable_digit_tokenization # digit_tokenization.py from https://github.com/stonybrooknlp/teabreac
model_name = "StonyBrookNLP/bart-large-iirc-retrieved"
tokenizer = AutoTokenizer.from_pretrained(model_name, use_fast=False) # Fast doesn't work with digit tokenization
model = AutoModelForSeq2SeqLM.from_pretrained(model_name)
enable_digit_tokenization(tokenizer)
input_texts = [
"answer_me: Who scored the first touchdown of the game?" +
"context: ... Oakland would get the early lead in the first quarter as quarterback JaMarcus Russell completed a 20-yard touchdown pass to rookie wide receiver Chaz Schilens..."
# Note: some models have slightly different qn/ctxt format. See the github repo.
]
input_ids = tokenizer(
input_texts, return_tensors="pt",
truncation=True, max_length=800,
add_special_tokens=True, padding=True,
)["input_ids"]
generated_ids = model.generate(input_ids, min_length=1, max_length=50)
generated_predictions = tokenizer.batch_decode(generated_ids, skip_special_tokens=False)
generated_predictions = [
tokenizer.fix_decoded_text(generated_prediction) for generated_prediction in generated_predictions
]
# => ["Chaz Schilens"]
```
|
00bcc631fc29132712efea9a65de01ac
|
anton-l/wav2vec2-large-xlsr-53-mongolian
|
anton-l
|
wav2vec2
| 9 | 9 |
transformers
| 0 |
automatic-speech-recognition
| true | false | true |
apache-2.0
|
['mn']
|
['common_voice']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['audio', 'automatic-speech-recognition', 'speech', 'xlsr-fine-tuning-week']
| true | true | true | 3,677 | false |
# Wav2Vec2-Large-XLSR-53-Mongolian
Fine-tuned [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on Mongolian using the [Common Voice](https://huggingface.co/datasets/common_voice) dataset.
When using this model, make sure that your speech input is sampled at 16kHz.
## Usage
The model can be used directly (without a language model) as follows:
```python
import torch
import torchaudio
from datasets import load_dataset
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
test_dataset = load_dataset("common_voice", "mn", split="test[:2%]")
processor = Wav2Vec2Processor.from_pretrained("anton-l/wav2vec2-large-xlsr-53-mongolian")
model = Wav2Vec2ForCTC.from_pretrained("anton-l/wav2vec2-large-xlsr-53-mongolian")
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the audio files as arrays
def speech_file_to_array_fn(batch):
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
inputs = processor(test_dataset["speech"][:2], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values, attention_mask=inputs.attention_mask).logits
predicted_ids = torch.argmax(logits, dim=-1)
print("Prediction:", processor.batch_decode(predicted_ids))
print("Reference:", test_dataset["sentence"][:2])
```
## Evaluation
The model can be evaluated as follows on the Mongolian test data of Common Voice.
```python
import torch
import torchaudio
import urllib.request
import tarfile
import pandas as pd
from tqdm.auto import tqdm
from datasets import load_metric
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
# Download the raw data instead of using HF datasets to save disk space
data_url = "https://voice-prod-bundler-ee1969a6ce8178826482b88e843c335139bd3fb4.s3.amazonaws.com/cv-corpus-6.1-2020-12-11/mn.tar.gz"
filestream = urllib.request.urlopen(data_url)
data_file = tarfile.open(fileobj=filestream, mode="r|gz")
data_file.extractall()
wer = load_metric("wer")
processor = Wav2Vec2Processor.from_pretrained("anton-l/wav2vec2-large-xlsr-53-mongolian")
model = Wav2Vec2ForCTC.from_pretrained("anton-l/wav2vec2-large-xlsr-53-mongolian")
model.to("cuda")
cv_test = pd.read_csv("cv-corpus-6.1-2020-12-11/mn/test.tsv", sep='\t')
clips_path = "cv-corpus-6.1-2020-12-11/mn/clips/"
def clean_sentence(sent):
sent = sent.lower()
# replace non-alpha characters with space
sent = "".join(ch if ch.isalpha() else " " for ch in sent)
# remove repeated spaces
sent = " ".join(sent.split())
return sent
targets = []
preds = []
for i, row in tqdm(cv_test.iterrows(), total=cv_test.shape[0]):
row["sentence"] = clean_sentence(row["sentence"])
speech_array, sampling_rate = torchaudio.load(clips_path + row["path"])
resampler = torchaudio.transforms.Resample(sampling_rate, 16_000)
row["speech"] = resampler(speech_array).squeeze().numpy()
inputs = processor(row["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values.to("cuda"), attention_mask=inputs.attention_mask.to("cuda")).logits
pred_ids = torch.argmax(logits, dim=-1)
targets.append(row["sentence"])
preds.append(processor.batch_decode(pred_ids)[0])
print("WER: {:2f}".format(100 * wer.compute(predictions=preds, references=targets)))
```
**Test Result**: 38.53 %
## Training
The Common Voice `train` and `validation` datasets were used for training.
|
62fe50ec451be6d775a4b0e41dd4bb3f
|
Helsinki-NLP/opus-mt-sv-to
|
Helsinki-NLP
|
marian
| 10 | 7 |
transformers
| 0 |
translation
| true | true | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['translation']
| false | true | true | 768 | false |
### opus-mt-sv-to
* source languages: sv
* target languages: to
* OPUS readme: [sv-to](https://github.com/Helsinki-NLP/OPUS-MT-train/blob/master/models/sv-to/README.md)
* dataset: opus
* model: transformer-align
* pre-processing: normalization + SentencePiece
* download original weights: [opus-2020-01-16.zip](https://object.pouta.csc.fi/OPUS-MT-models/sv-to/opus-2020-01-16.zip)
* test set translations: [opus-2020-01-16.test.txt](https://object.pouta.csc.fi/OPUS-MT-models/sv-to/opus-2020-01-16.test.txt)
* test set scores: [opus-2020-01-16.eval.txt](https://object.pouta.csc.fi/OPUS-MT-models/sv-to/opus-2020-01-16.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| JW300.sv.to | 41.8 | 0.564 |
|
7d5f04902a955ee19b176b384451e86a
|
IDEA-CCNL/Taiyi-Stable-Diffusion-1B-Chinese-EN-v0.1
|
IDEA-CCNL
| null | 23 | 1,174 |
diffusers
| 60 |
text-to-image
| false | false | false |
creativeml-openrail-m
|
['zh']
| null | null | 4 | 3 | 1 | 0 | 5 | 5 | 0 |
['stable-diffusion', 'stable diffusion chinese', 'stable-diffusion-diffusers', 'text-to-image', 'Chinese']
| false | true | true | 5,659 | false |
# Taiyi-Stable-Diffusion-1B-Chinese-EN-v0.1
- Github: [Fengshenbang-LM](https://github.com/IDEA-CCNL/Fengshenbang-LM)
- Docs: [Fengshenbang-Docs](https://fengshenbang-doc.readthedocs.io/)
# Gradio
We support a [Gradio](https://github.com/gradio-app/gradio) Web UI to run Taiyi-Stable-Diffusion-1B-Chinese-EN-v0.1:
[](https://huggingface.co/spaces/IDEA-CCNL/Taiyi-Stable-Diffusion-Chinese)
## 简介 Brief Introduction
首个开源的中英双语Stable Diffusion模型,基于0.2亿筛选过的中文图文对训练。
The first open source Chinese&English Bilingual Stable diffusion, which was trained on 20M filtered Chinese image-text pairs.
## 模型分类 Model Taxonomy
| 需求 Demand | 任务 Task | 系列 Series | 模型 Model | 参数 Parameter | 额外 Extra |
| :----: | :----: | :----: | :----: | :----: | :----: |
| 特殊 Special | 多模态 Multimodal | 太乙 Taiyi | Stable Diffusion | 1B | Chinese and English |
## 模型信息 Model Information
我们将[Noah-Wukong](https://wukong-dataset.github.io/wukong-dataset/)数据集(100M)和[Zero](https://zero.so.com/)数据集(23M)用作预训练的数据集,先用[IDEA-CCNL/Taiyi-CLIP-RoBERTa-102M-ViT-L-Chinese](https://huggingface.co/IDEA-CCNL/Taiyi-CLIP-RoBERTa-102M-ViT-L-Chinese)对这两个数据集的图文对相似性进行打分,取CLIP Score大于0.2的图文对作为我们的训练集。 我们使用[stable-diffusion-v1-4](https://huggingface.co/CompVis/stable-diffusion-v1-4)([论文](https://arxiv.org/abs/2112.10752))模型进行继续训练,其中训练分为两个stage。
第一个stage中冻住模型的其他部分,只训练text encoder,以便保留原始模型的生成能力且实现中文概念的对齐。
第二个stage中将全部模型解冻,一起训练text encoder和diffusion model,以便diffusion model更好的适配中文guidance。
第一个stage我们训练了80小时,第二个stage训练了100小时,两个stage都是用了8 x A100。该版本是一个初步的版本,我们将持续优化模型并开源,欢迎交流!
We use [Noah-Wukong](https://wukong-dataset.github.io/wukong-dataset/)(100M) 和 [Zero](https://zero.so.com/)(23M) as our dataset, and take the image and text pairs with CLIP Score (based on [IDEA-CCNL/Taiyi-CLIP-RoBERTa-102M-ViT-L-Chinese](https://huggingface.co/IDEA-CCNL/Taiyi-CLIP-RoBERTa-102M-ViT-L-Chinese)) greater than 0.2 as our Training set. We finetune the [stable-diffusion-v1-4](https://huggingface.co/CompVis/stable-diffusion-v1-4)([paper](https://arxiv.org/abs/2112.10752)) model for two stage.
Stage 1: To keep the powerful generative capability of stable diffusion and align Chinese concepts with the images, We only train the text encoder and freeze other part of the model in the first stage.
Stage 2: We unfreeze both the text encoder and the diffusion model, therefore the diffusion model can have a better compatibility for the Chinese language guidance.
It takes 80 hours to train the first stage, 100 hours to train the second stage, both stages are based on 8 x A100. This model is a preliminary version and we will update this model continuously and open sourse. Welcome to exchange!
### Result
小桥流水人家,Van Gogh style。

小桥流水人家,水彩。

吃过桥米线的猫。

穿着宇航服的哈士奇。

## 使用 Usage
### 全精度 Full precision
```py
from diffusers import StableDiffusionPipeline
pipe = StableDiffusionPipeline.from_pretrained("IDEA-CCNL/Taiyi-Stable-Diffusion-1B-Chinese-EN-v0.1").to("cuda")
prompt = '小桥流水人家,Van Gogh style'
image = pipe(prompt, guidance_scale=10).images[0]
image.save("小桥.png")
```
### 半精度 Half precision FP16 (CUDA)
添加 `torch_dtype=torch.float16` 和 `device_map="auto"` 可以快速加载 FP16 的权重,以加快推理速度。
更多信息见 [the optimization docs](https://huggingface.co/docs/diffusers/main/en/optimization/fp16#half-precision-weights)。
```py
# !pip install git+https://github.com/huggingface/accelerate
from diffusers import StableDiffusionPipeline
import torch
torch.backends.cudnn.benchmark = True
pipe = StableDiffusionPipeline.from_pretrained("IDEA-CCNL/Taiyi-Stable-Diffusion-1B-Chinese-EN-v0.1", torch_dtype=torch.float16)
pipe.to('cuda')
prompt = '小桥流水人家,Van Gogh style'
image = pipe(prompt, guidance_scale=10.0).images[0]
image.save("小桥.png")
```
### 怎样微调 How to finetune
可以参考 refer
https://github.com/IDEA-CCNL/Fengshenbang-LM/tree/main/fengshen/examples/finetune_taiyi_stable_diffusion
### webui配置 Configure webui
可以参考 refer
https://github.com/IDEA-CCNL/stable-diffusion-webui/blob/master/README.md
### DreamBooth
https://github.com/IDEA-CCNL/Fengshenbang-LM/tree/main/fengshen/examples/stable_diffusion_dreambooth
## 引用 Citation
如果您在您的工作中使用了我们的模型,可以引用我们的[总论文](https://arxiv.org/abs/2209.02970):
If you are using the resource for your work, please cite the our [paper](https://arxiv.org/abs/2209.02970):
```text
@article{fengshenbang,
author = {Junjie Wang and Yuxiang Zhang and Lin Zhang and Ping Yang and Xinyu Gao and Ziwei Wu and Xiaoqun Dong and Junqing He and Jianheng Zhuo and Qi Yang and Yongfeng Huang and Xiayu Li and Yanghan Wu and Junyu Lu and Xinyu Zhu and Weifeng Chen and Ting Han and Kunhao Pan and Rui Wang and Hao Wang and Xiaojun Wu and Zhongshen Zeng and Chongpei Chen and Ruyi Gan and Jiaxing Zhang},
title = {Fengshenbang 1.0: Being the Foundation of Chinese Cognitive Intelligence},
journal = {CoRR},
volume = {abs/2209.02970},
year = {2022}
}
```
也可以引用我们的[网站](https://github.com/IDEA-CCNL/Fengshenbang-LM/):
You can also cite our [website](https://github.com/IDEA-CCNL/Fengshenbang-LM/):
```text
@misc{Fengshenbang-LM,
title={Fengshenbang-LM},
author={IDEA-CCNL},
year={2021},
howpublished={\url{https://github.com/IDEA-CCNL/Fengshenbang-LM}},
}
```
|
d6927fd161a1c9e058e5758307fc88fd
|
spacy/nb_core_news_lg
|
spacy
| null | 30 | 7 |
spacy
| 0 |
token-classification
| false | false | false |
mit
|
['nb']
| null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['spacy', 'token-classification']
| false | true | true | 11,830 | false |
### Details: https://spacy.io/models/nb#nb_core_news_lg
Norwegian (Bokmål) pipeline optimized for CPU. Components: tok2vec, morphologizer, parser, lemmatizer (trainable_lemmatizer), senter, ner, attribute_ruler.
| Feature | Description |
| --- | --- |
| **Name** | `nb_core_news_lg` |
| **Version** | `3.5.0` |
| **spaCy** | `>=3.5.0,<3.6.0` |
| **Default Pipeline** | `tok2vec`, `morphologizer`, `parser`, `lemmatizer`, `attribute_ruler`, `ner` |
| **Components** | `tok2vec`, `morphologizer`, `parser`, `lemmatizer`, `senter`, `attribute_ruler`, `ner` |
| **Vectors** | 500000 keys, 500000 unique vectors (300 dimensions) |
| **Sources** | [UD Norwegian Bokmaal v2.8](https://github.com/UniversalDependencies/UD_Norwegian-Bokmaal) (Øvrelid, Lilja; Jørgensen, Fredrik; Hohle, Petter)<br />[NorNE: Norwegian Named Entities (commit: bd311de5)](https://github.com/ltgoslo/norne) (Language Technology Group (University of Oslo))<br />[Explosion fastText Vectors (cbow, OSCAR Common Crawl + Wikipedia)](https://spacy.io) (Explosion) |
| **License** | `MIT` |
| **Author** | [Explosion](https://explosion.ai) |
### Label Scheme
<details>
<summary>View label scheme (249 labels for 3 components)</summary>
| Component | Labels |
| --- | --- |
| **`morphologizer`** | `Definite=Ind\|Gender=Neut\|Number=Sing\|POS=NOUN`, `POS=CCONJ`, `Definite=Ind\|Gender=Masc\|Number=Sing\|POS=NOUN`, `POS=SCONJ`, `Definite=Def\|Gender=Masc\|Number=Sing\|POS=NOUN`, `Definite=Ind\|Gender=Neut\|Number=Plur\|POS=NOUN`, `POS=PUNCT`, `Mood=Ind\|POS=VERB\|Tense=Past\|VerbForm=Fin`, `POS=ADP`, `Gender=Masc\|Number=Sing\|POS=DET\|PronType=Dem`, `Definite=Def\|Degree=Pos\|Number=Sing\|POS=ADJ`, `POS=PROPN`, `POS=X`, `Mood=Ind\|POS=VERB\|Tense=Pres\|VerbForm=Fin`, `Definite=Def\|Gender=Neut\|Number=Sing\|POS=NOUN`, `POS=PRON\|PronType=Rel`, `Mood=Ind\|POS=AUX\|Tense=Pres\|VerbForm=Fin`, `Definite=Ind\|Gender=Neut\|Number=Sing\|POS=ADJ\|VerbForm=Part`, `Definite=Ind\|Degree=Pos\|Number=Sing\|POS=ADJ`, `Definite=Ind\|Gender=Fem\|Number=Sing\|POS=NOUN`, `Number=Plur\|POS=ADJ\|VerbForm=Part`, `Definite=Ind\|Gender=Fem\|Number=Plur\|POS=NOUN`, `POS=ADV`, `Gender=Neut\|Number=Sing\|POS=PRON\|Person=3\|PronType=Prs`, `Definite=Ind\|Number=Sing\|POS=ADJ\|VerbForm=Part`, `POS=VERB\|VerbForm=Part`, `Definite=Ind\|Gender=Masc\|Number=Plur\|POS=NOUN`, `Definite=Ind\|Degree=Pos\|Gender=Neut\|Number=Sing\|POS=ADJ`, `Degree=Pos\|Number=Plur\|POS=ADJ`, `NumType=Card\|Number=Plur\|POS=NUM`, `Definite=Def\|Gender=Masc\|Number=Plur\|POS=NOUN`, `Case=Acc\|POS=PRON\|PronType=Prs\|Reflex=Yes`, `Case=Gen\|Definite=Ind\|Gender=Neut\|Number=Sing\|POS=NOUN`, `POS=PART`, `POS=VERB\|VerbForm=Inf`, `Case=Nom\|Number=Plur\|POS=PRON\|Person=3\|PronType=Prs`, `Mood=Ind\|POS=AUX\|Tense=Past\|VerbForm=Fin`, `Gender=Fem\|POS=PROPN`, `POS=NOUN`, `Gender=Masc\|POS=PROPN`, `Gender=Neut\|Number=Sing\|POS=DET\|PronType=Dem`, `Gender=Masc\|Number=Sing\|POS=DET\|PronType=Art`, `Case=Gen\|Definite=Def\|Gender=Masc\|Number=Sing\|POS=NOUN`, `Abbr=Yes\|POS=PROPN`, `POS=PART\|Polarity=Neg`, `Number=Plur\|POS=PRON\|Poss=Yes\|PronType=Prs`, `Case=Gen\|Definite=Ind\|Gender=Neut\|Number=Plur\|POS=NOUN`, `Case=Gen\|POS=PROPN`, `Gender=Fem\|Number=Sing\|POS=DET\|PronType=Dem`, `Gender=Masc\|Number=Sing\|POS=PRON\|Poss=Yes\|PronType=Prs`, `Definite=Def\|Degree=Sup\|POS=ADJ`, `Case=Gen\|Gender=Fem\|POS=PROPN`, `Number=Plur\|POS=DET\|PronType=Dem`, `Case=Gen\|Definite=Def\|Gender=Neut\|Number=Sing\|POS=NOUN`, `Definite=Ind\|Degree=Sup\|POS=ADJ`, `Definite=Def\|Gender=Fem\|Number=Plur\|POS=NOUN`, `Gender=Neut\|POS=PROPN`, `Number=Plur\|POS=DET\|PronType=Int`, `Definite=Def\|Gender=Neut\|Number=Plur\|POS=NOUN`, `Definite=Def\|POS=DET\|PronType=Dem`, `Gender=Neut\|Number=Sing\|POS=DET\|PronType=Art`, `Mood=Ind\|POS=VERB\|Tense=Pres\|VerbForm=Fin\|Voice=Pass`, `Abbr=Yes\|Case=Gen\|POS=PROPN`, `Animacy=Hum\|Case=Nom\|Gender=Masc\|Number=Sing\|POS=PRON\|Person=3\|PronType=Prs`, `Degree=Cmp\|POS=ADJ`, `POS=ADJ\|VerbForm=Part`, `Gender=Neut\|Number=Sing\|POS=PRON\|Poss=Yes\|PronType=Prs`, `Abbr=Yes\|POS=ADP`, `Definite=Ind\|Gender=Neut\|Number=Sing\|POS=DET\|PronType=Prs`, `Case=Gen\|Definite=Def\|Gender=Neut\|Number=Plur\|POS=NOUN`, `POS=AUX\|VerbForm=Part`, `POS=PRON\|PronType=Int`, `Gender=Fem\|Number=Sing\|POS=PRON\|Poss=Yes\|PronType=Prs`, `Number=Plur\|POS=PRON\|Person=3\|PronType=Ind,Prs`, `Number=Plur\|POS=DET\|PronType=Ind`, `Degree=Pos\|POS=ADJ`, `Animacy=Hum\|Case=Nom\|Number=Plur\|POS=PRON\|Person=1\|PronType=Prs`, `POS=VERB\|VerbForm=Inf\|Voice=Pass`, `Definite=Ind\|Gender=Fem\|Number=Sing\|POS=DET\|PronType=Dem`, `Gender=Neut\|Number=Sing\|POS=DET\|PronType=Ind`, `Animacy=Hum\|Case=Acc\|Gender=Masc\|Number=Sing\|POS=PRON\|Person=3\|PronType=Prs`, `Animacy=Hum\|Case=Nom\|Number=Sing\|POS=PRON\|Person=1\|PronType=Prs`, `Number=Plur\|POS=DET\|Polarity=Neg\|PronType=Neg`, `NumType=Card\|POS=NUM`, `Gender=Masc\|Number=Sing\|POS=DET\|PronType=Ind`, `POS=DET\|PronType=Prs`, `Gender=Fem\|Number=Sing\|POS=DET\|PronType=Ind`, `Case=Gen\|Gender=Neut\|POS=PROPN`, `Gender=Masc\|Number=Sing\|POS=DET\|Polarity=Neg\|PronType=Neg`, `Definite=Def\|Number=Sing\|POS=ADJ\|VerbForm=Part`, `Gender=Fem,Masc\|Number=Sing\|POS=PRON\|Person=3\|PronType=Prs`, `POS=AUX\|VerbForm=Inf`, `Case=Acc\|Number=Plur\|POS=PRON\|Person=3\|PronType=Prs`, `Case=Gen\|Degree=Pos\|Number=Plur\|POS=ADJ`, `Number=Plur\|POS=DET\|PronType=Tot`, `Case=Gen\|Gender=Masc\|Number=Sing\|POS=DET\|PronType=Dem`, `Number=Plur\|POS=DET\|PronType=Prs`, `POS=SYM`, `Gender=Neut\|NumType=Card\|Number=Sing\|POS=NUM`, `Animacy=Hum\|Case=Nom\|Number=Sing\|POS=PRON\|PronType=Prs`, `Definite=Ind\|Gender=Masc\|Number=Sing\|POS=DET\|PronType=Prs`, `Case=Gen\|Definite=Ind\|Gender=Masc\|Number=Sing\|POS=NOUN`, `Abbr=Yes\|POS=ADV`, `Definite=Ind\|Gender=Neut\|Number=Sing\|POS=DET\|PronType=Dem`, `Gender=Masc\|Number=Sing\|POS=DET\|PronType=Tot`, `Definite=Def\|POS=DET\|PronType=Prs`, `Animacy=Hum\|Case=Nom\|Gender=Fem\|Number=Sing\|POS=PRON\|Person=3\|PronType=Prs`, `Gender=Neut\|POS=NOUN`, `Gender=Neut\|Number=Sing\|POS=DET\|PronType=Int`, `Definite=Def\|NumType=Card\|POS=NUM`, `Mood=Imp\|POS=VERB\|VerbForm=Fin`, `Definite=Ind\|Number=Plur\|POS=NOUN`, `Gender=Neut\|Number=Sing\|POS=DET\|PronType=Tot`, `Gender=Fem\|Number=Sing\|POS=DET\|PronType=Tot`, `Animacy=Hum\|Case=Acc\|Number=Plur\|POS=PRON\|Person=1\|PronType=Prs`, `Gender=Fem,Masc\|Number=Sing\|POS=PRON\|Person=3\|Polarity=Neg\|PronType=Neg,Prs`, `Number=Plur\|POS=PRON\|Person=3\|Polarity=Neg\|PronType=Neg,Prs`, `Definite=Def\|NumType=Card\|Number=Sing\|POS=NUM`, `Gender=Masc\|NumType=Card\|Number=Sing\|POS=NUM`, `Definite=Ind\|Gender=Masc\|Number=Sing\|POS=DET\|PronType=Dem`, `Case=Gen\|Definite=Def\|Gender=Fem\|Number=Plur\|POS=NOUN`, `Case=Gen\|Gender=Neut\|Number=Sing\|POS=DET\|PronType=Dem`, `POS=SPACE`, `Animacy=Hum\|Number=Sing\|POS=PRON\|PronType=Art,Prs`, `Mood=Imp\|POS=AUX\|VerbForm=Fin`, `Number=Plur\|POS=PRON\|Person=3\|PronType=Prs,Tot`, `Number=Plur\|POS=ADJ`, `Gender=Masc\|POS=NOUN`, `Abbr=Yes\|POS=NOUN`, `Case=Gen\|Definite=Ind\|Gender=Masc\|Number=Plur\|POS=NOUN`, `Gender=Neut\|Number=Sing\|POS=PRON\|Person=3\|PronType=Ind,Prs`, `POS=INTJ`, `Animacy=Hum\|Case=Nom\|Number=Sing\|POS=PRON\|Person=2\|PronType=Prs`, `Animacy=Hum\|Case=Acc\|Number=Sing\|POS=PRON\|Person=1\|PronType=Prs`, `Case=Gen\|Definite=Def\|Gender=Masc\|Number=Plur\|POS=NOUN`, `POS=ADJ`, `Animacy=Hum\|Case=Acc\|Gender=Fem\|Number=Sing\|POS=PRON\|Person=3\|PronType=Prs`, `Animacy=Hum\|Case=Acc\|Number=Sing\|POS=PRON\|Person=2\|PronType=Prs`, `Definite=Def\|Gender=Fem\|Number=Sing\|POS=NOUN`, `Number=Sing\|POS=PRON\|Polarity=Neg\|PronType=Neg`, `Case=Gen\|POS=NOUN`, `Definite=Ind\|Number=Sing\|POS=ADJ`, `Case=Gen\|Gender=Masc\|POS=PROPN`, `Animacy=Hum\|Number=Plur\|POS=PRON\|PronType=Rcp`, `Case=Gen\|Definite=Ind\|Gender=Fem\|Number=Sing\|POS=NOUN`, `Number=Plur\|POS=PRON\|Person=3\|PronType=Prs`, `Gender=Fem,Masc\|Number=Sing\|POS=PRON\|Person=3\|PronType=Ind,Prs`, `Definite=Ind\|Gender=Fem\|Number=Sing\|POS=DET\|PronType=Prs`, `Case=Gen\|Definite=Def\|Gender=Fem\|Number=Sing\|POS=NOUN`, `Gender=Fem\|Number=Sing\|POS=DET\|PronType=Art`, `Case=Gen\|Definite=Def\|Degree=Pos\|Number=Sing\|POS=ADJ`, `Gender=Masc\|Number=Sing\|POS=DET\|PronType=Int`, `NumType=Card\|Number=Sing\|POS=NUM`, `Animacy=Hum\|Case=Acc\|Number=Plur\|POS=PRON\|Person=2\|PronType=Prs`, `Animacy=Hum\|Case=Nom\|Number=Plur\|POS=PRON\|Person=2\|PronType=Prs`, `Case=Gen\|Definite=Ind\|Degree=Pos\|Gender=Neut\|Number=Sing\|POS=ADJ`, `Degree=Sup\|POS=ADJ`, `Animacy=Hum\|POS=PRON\|PronType=Int`, `POS=DET\|PronType=Ind`, `Definite=Def\|Number=Sing\|POS=DET\|PronType=Dem`, `Gender=Fem\|POS=NOUN`, `Case=Gen\|Number=Plur\|POS=DET\|PronType=Dem`, `Gender=Fem,Masc\|Number=Sing\|POS=PRON\|Person=3\|PronType=Prs,Tot`, `Case=Gen\|Definite=Ind\|Gender=Fem\|Number=Plur\|POS=NOUN`, `Gender=Neut\|Number=Sing\|POS=DET\|Polarity=Neg\|PronType=Neg`, `Number=Plur\|POS=NOUN`, `POS=PRON\|PronType=Prs`, `Case=Gen\|Definite=Ind\|Degree=Pos\|Number=Sing\|POS=ADJ`, `Definite=Ind\|Number=Sing\|POS=VERB\|VerbForm=Part`, `Case=Gen\|Definite=Def\|Number=Sing\|POS=ADJ\|VerbForm=Part`, `Mood=Ind\|POS=VERB\|Tense=Past\|VerbForm=Fin\|Voice=Pass`, `Gender=Neut\|Number=Sing\|POS=DET\|PronType=Dem,Ind`, `Animacy=Hum\|POS=PRON\|Poss=Yes\|PronType=Int`, `Abbr=Yes\|POS=ADJ`, `Case=Gen\|Gender=Masc\|Number=Sing\|POS=DET\|PronType=Art`, `Abbr=Yes\|Definite=Def,Ind\|Gender=Masc\|Number=Sing\|POS=NOUN`, `Case=Gen\|Gender=Fem\|Number=Sing\|POS=DET\|PronType=Dem`, `Number=Plur\|POS=PRON\|Poss=Yes\|PronType=Rcp`, `Definite=Ind\|Degree=Pos\|POS=ADJ`, `Number=Plur\|POS=DET\|PronType=Art`, `Case=Gen\|NumType=Card\|Number=Plur\|POS=NUM`, `Abbr=Yes\|Definite=Def,Ind\|Gender=Neut\|Number=Plur,Sing\|POS=NOUN`, `Case=Gen\|Number=Plur\|POS=DET\|PronType=Tot`, `Abbr=Yes\|Definite=Def,Ind\|Gender=Masc\|Number=Plur,Sing\|POS=NOUN`, `Gender=Fem\|Number=Sing\|POS=DET\|PronType=Int`, `Definite=Ind\|Gender=Neut\|Number=Sing\|POS=ADJ`, `Case=Gen\|Definite=Ind\|Gender=Masc\|Number=Sing\|POS=DET\|PronType=Dem`, `Gender=Fem\|Number=Sing\|POS=DET\|PronType=Prs`, `Animacy=Hum\|Case=Gen,Nom\|Number=Sing\|POS=PRON\|PronType=Art,Prs`, `Definite=Def\|Degree=Pos\|Gender=Masc\|Number=Sing\|POS=ADJ`, `Animacy=Hum\|Case=Gen\|Number=Sing\|POS=PRON\|PronType=Art,Prs`, `Gender=Fem\|NumType=Card\|Number=Sing\|POS=NUM`, `Definite=Ind\|Gender=Masc\|POS=NOUN`, `Definite=Def\|Number=Plur\|POS=NOUN`, `Number=Sing\|POS=ADJ\|VerbForm=Part`, `Definite=Ind\|Gender=Masc\|Number=Sing\|POS=ADJ\|VerbForm=Part`, `Abbr=Yes\|Gender=Masc\|POS=NOUN`, `Abbr=Yes\|Case=Gen\|POS=NOUN`, `Abbr=Yes\|Mood=Ind\|POS=VERB\|Tense=Pres\|VerbForm=Fin`, `Abbr=Yes\|Degree=Pos\|POS=ADJ`, `Case=Gen\|Gender=Fem\|POS=NOUN`, `Case=Gen\|Degree=Cmp\|POS=ADJ`, `Definite=Ind\|Degree=Pos\|Gender=Masc\|Number=Sing\|POS=ADJ`, `Gender=Masc\|Number=Sing\|POS=NOUN` |
| **`parser`** | `ROOT`, `acl`, `acl:cleft`, `acl:relcl`, `advcl`, `advmod`, `amod`, `appos`, `aux`, `aux:pass`, `case`, `cc`, `ccomp`, `compound`, `compound:prt`, `conj`, `cop`, `csubj`, `dep`, `det`, `discourse`, `expl`, `flat:foreign`, `flat:name`, `iobj`, `mark`, `nmod`, `nsubj`, `nsubj:pass`, `nummod`, `obj`, `obl`, `orphan`, `parataxis`, `punct`, `xcomp` |
| **`ner`** | `DRV`, `EVT`, `GPE_LOC`, `GPE_ORG`, `LOC`, `MISC`, `ORG`, `PER`, `PROD` |
</details>
### Accuracy
| Type | Score |
| --- | --- |
| `TOKEN_ACC` | 99.81 |
| `TOKEN_P` | 99.71 |
| `TOKEN_R` | 99.53 |
| `TOKEN_F` | 99.62 |
| `POS_ACC` | 97.38 |
| `MORPH_ACC` | 96.28 |
| `MORPH_MICRO_P` | 97.90 |
| `MORPH_MICRO_R` | 97.07 |
| `MORPH_MICRO_F` | 97.48 |
| `SENTS_P` | 94.18 |
| `SENTS_R` | 94.11 |
| `SENTS_F` | 94.14 |
| `DEP_UAS` | 89.46 |
| `DEP_LAS` | 86.42 |
| `LEMMA_ACC` | 97.29 |
| `TAG_ACC` | 97.38 |
| `ENTS_P` | 84.84 |
| `ENTS_R` | 84.18 |
| `ENTS_F` | 84.51 |
|
4d51f8d7b9533920f8b77446b13882b7
|
NbAiLab/nb-roberta-tpu
|
NbAiLab
|
xlm-roberta
| 13 | 0 |
transformers
| 0 |
fill-mask
| false | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
[]
| false | true | true | 3,063 | false |
# NB-ROBERTA Training Code
This is the current training code for the planned nb-roberta models.
We are currently planning to run the following experiments:
<table>
<tr>
<td><strong>Name</strong>
</td>
<td><strong>nb-roberta-base-old (C)</strong>
</td>
</tr>
<tr>
<td>Corpus
</td>
<td>NbAiLab/nb_bert
</td>
</tr>
<tr>
<td>Pod size
</td>
<td>v4-64
</td>
</tr>
<tr>
<td>Batch size
</td>
<td>62*4*8 = 1984 = 2k
</td>
</tr>
<tr>
<td>Learning rate
</td>
<td>3e-4 (RoBERTa article is using 6e-4 and bs=8k)
</td>
</tr>
<tr>
<td>Number of steps
</td>
<td>250k
</td>
</tr>
</table>
<table>
<tr>
<td><strong>Name</strong>
</td>
<td><strong>nb-roberta-base-ext (B)</strong>
</td>
</tr>
<tr>
<td>Corpus
</td>
<td>NbAiLab/nbailab_extended
</td>
</tr>
<tr>
<td>Pod size
</td>
<td>v4-64
</td>
</tr>
<tr>
<td>Batch size
</td>
<td>62*4*8 = 1984 = 2k
</td>
</tr>
<tr>
<td>Learning rate
</td>
<td>3e-4 (RoBERTa article is using 6e-4 and bs=8k)
</td>
</tr>
<tr>
<td>Number of steps
</td>
<td>250k
</td>
</tr>
</table>
<table>
<tr>
<td><strong>Name</strong>
</td>
<td><strong>nb-roberta-large-ext</strong>
</td>
</tr>
<tr>
<td>Corpus
</td>
<td>NbAiLab/nbailab_extended
</td>
</tr>
<tr>
<td>Pod size
</td>
<td>v4-64
</td>
</tr>
<tr>
<td>Batch size
</td>
<td>32*4*8 = 2024 = 1k
</td>
</tr>
<tr>
<td>Learning rate
</td>
<td>2-e4 (RoBERTa article is using 4e-4 and bs=8k)
</td>
</tr>
<tr>
<td>Number of steps
</td>
<td>500k
</td>
</tr>
</table>
<table>
<tr>
<td><strong>Name</strong>
</td>
<td><strong>nb-roberta-base-scandi</strong>
</td>
</tr>
<tr>
<td>Corpus
</td>
<td>NbAiLab/scandinavian
</td>
</tr>
<tr>
<td>Pod size
</td>
<td>v4-64
</td>
</tr>
<tr>
<td>Batch size
</td>
<td>62*4*8 = 1984 = 2k
</td>
</tr>
<tr>
<td>Learning rate
</td>
<td>3e-4 (RoBERTa article is using 6e-4 and bs=8k)
</td>
</tr>
<tr>
<td>Number of steps
</td>
<td>250k
</td>
</tr>
</table>
<table>
<tr>
<td><strong>Name</strong>
</td>
<td><strong>nb-roberta-large-scandi</strong>
</td>
</tr>
<tr>
<td>Corpus
</td>
<td>NbAiLab/scandinavian
</td>
</tr>
<tr>
<td>Pod size
</td>
<td>v4-64
</td>
</tr>
<tr>
<td>Batch size
</td>
<td>32*4*8 = 1024 = 1k
</td>
</tr>
<tr>
<td>Learning rate
</td>
<td>2-e4 (RoBERTa article is using 4e-4 and bs=8k)
</td>
</tr>
<tr>
<td>Number of steps
</td>
<td>500k
</td>
</tr>
</table>
## Calculations
Some basic that we used when estimating the number of training steps:
* The Scandinavic Corpus is 85GB
* The Scandinavic Corpus contains 13B words
* With a conversion factor of 2.3, this is estimated to around 30B tokens
* 30B tokens / (512 seq length * 3000 batch size) = 20.000 steps
|
c9fbfb795fbffec635412607676d937b
|
daqiao202/distilgpt2-finetuned-wikitext2
|
daqiao202
|
gpt2
| 8 | 2 |
transformers
| 0 |
text-generation
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 893 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilgpt2-finetuned-wikitext2
This model is a fine-tuned version of [distilgpt2](https://huggingface.co/distilgpt2) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Framework versions
- Transformers 4.12.3
- Pytorch 1.10.0+cu111
- Datasets 1.15.1
- Tokenizers 0.10.3
|
2e72738a61c5d5d6919bb2e0b537f94a
|
sgangireddy/whisper-base-cv-lowLR-cs
|
sgangireddy
|
whisper
| 22 | 0 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
|
['cs']
|
['mozilla-foundation/common_voice_11_0']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['whisper-event', 'generated_from_trainer']
| true | true | true | 1,570 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Whisper base Czech CV low LR
This model is a fine-tuned version of [openai/whisper-base](https://huggingface.co/openai/whisper-base) on the mozilla-foundation/common_voice_11_0 cs dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5171
- Wer: 42.9053
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-06
- train_batch_size: 64
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 5000
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:-------:|
| 0.6046 | 4.01 | 1000 | 0.6535 | 52.3084 |
| 0.4037 | 8.02 | 2000 | 0.5706 | 46.6879 |
| 0.3172 | 12.03 | 3000 | 0.5369 | 44.1042 |
| 0.3606 | 16.04 | 4000 | 0.5218 | 43.0766 |
| 0.3792 | 21.01 | 5000 | 0.5171 | 42.9053 |
### Framework versions
- Transformers 4.26.0.dev0
- Pytorch 1.13.0+cu117
- Datasets 2.7.1.dev0
- Tokenizers 0.13.2
|
f922e50998579398448adf246d3a5c9b
|
Matthijs/mobilenet_v1_1.0_224
|
Matthijs
|
mobilenet_v1
| 5 | 12 |
transformers
| 0 |
image-classification
| true | false | false |
other
| null |
['imagenet-1k']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['vision', 'image-classification']
| false | true | true | 2,397 | false |
# MobileNet V1
MobileNet V1 model pre-trained on ImageNet-1k at resolution 224x224. It was introduced in [MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications](https://arxiv.org/abs/1704.04861) by Howard et al, and first released in [this repository](https://github.com/tensorflow/models/blob/master/research/slim/nets/mobilenet_v1.md).
Disclaimer: The team releasing MobileNet V1 did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
From the [original README](https://github.com/tensorflow/models/blob/master/research/slim/nets/mobilenet_v1.md):
> MobileNets are small, low-latency, low-power models parameterized to meet the resource constraints of a variety of use cases. They can be built upon for classification, detection, embeddings and segmentation similar to how other popular large scale models, such as Inception, are used. MobileNets can be run efficiently on mobile devices [...] MobileNets trade off between latency, size and accuracy while comparing favorably with popular models from the literature.
## Intended uses & limitations
You can use the raw model for image classification. See the [model hub](https://huggingface.co/models?search=mobilenet_v1) to look for fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model to classify an image of the COCO 2017 dataset into one of the 1,000 ImageNet classes:
```python
from transformers import MobileNetV1FeatureExtractor, MobileNetV1ForImageClassification
from PIL import Image
import requests
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
feature_extractor = MobileNetV1FeatureExtractor.from_pretrained("Matthijs/mobilenet_v1_1.0_224")
model = MobileNetV1ForImageClassification.from_pretrained("Matthijs/mobilenet_v1_1.0_224")
inputs = feature_extractor(images=image, return_tensors="pt")
outputs = model(**inputs)
logits = outputs.logits
# model predicts one of the 1000 ImageNet classes
predicted_class_idx = logits.argmax(-1).item()
print("Predicted class:", model.config.id2label[predicted_class_idx])
```
Note: This model actually predicts 1001 classes, the 1000 classes from ImageNet plus an extra “background” class (index 0).
Currently, both the feature extractor and model support PyTorch.
|
02aa69f49af2672dcea74eb7be032f95
|
din0s/bart-pt-asqa-cb
|
din0s
|
bart
| 11 | 3 |
transformers
| 0 |
text2text-generation
| true | false | false |
mit
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,747 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bart-pt-asqa-cb
This model is a fine-tuned version of [vblagoje/bart_lfqa](https://huggingface.co/vblagoje/bart_lfqa) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 2.5362
- Rougelsum: 38.9467
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-06
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 20
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rougelsum |
|:-------------:|:-----:|:----:|:---------------:|:---------:|
| No log | 1.0 | 273 | 2.5653 | 37.6939 |
| 2.6009 | 2.0 | 546 | 2.5295 | 38.2398 |
| 2.6009 | 3.0 | 819 | 2.5315 | 38.5946 |
| 2.3852 | 4.0 | 1092 | 2.5146 | 38.4771 |
| 2.3852 | 5.0 | 1365 | 2.5240 | 38.5706 |
| 2.2644 | 6.0 | 1638 | 2.5253 | 38.7506 |
| 2.2644 | 7.0 | 1911 | 2.5355 | 38.9004 |
| 2.1703 | 8.0 | 2184 | 2.5309 | 38.9528 |
| 2.1703 | 9.0 | 2457 | 2.5362 | 38.9467 |
### Framework versions
- Transformers 4.23.0.dev0
- Pytorch 1.12.1+cu102
- Datasets 2.4.0
- Tokenizers 0.12.1
|
facb26cc969391431f9ff5b3c92fb04e
|
StonyBrookNLP/t5-3b-iirc-retrieved
|
StonyBrookNLP
|
t5
| 10 | 3 |
transformers
| 0 |
text2text-generation
| true | false | false |
cc-by-4.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['question-answering, multi-step-reasoning, multi-hop-reasoning']
| false | true | true | 2,624 | false |
# What's this?
This is one of the models reported in the paper: ["Teaching Broad Reasoning Skills for Multi-Step QA by Generating Hard Contexts".](https://arxiv.org/abs/2205.12496).
This paper proposes a procedure to synthetically generate a QA dataset, TeaBReaC, for pretraining language models for robust multi-step reasoning. Pretraining plain LMs like Bart, T5 and numerate LMs like NT5, PReasM, POET on TeaBReaC leads to improvemed downstream performance on several multi-step QA datasets. Please checkout out the paper for the details.
We release the following models:
- **A:** Base Models finetuned on target datasets: `{base_model}-{target_dataset}`
- **B:** Base models pretrained on TeaBReaC: `teabreac-{base_model}`
- **C:** Base models pretrained on TeaBReaC and then finetuned on target datasets: `teabreac-{base_model}-{target_dataset}`
The `base_model` above can be from: `bart-large`, `t5-large`, `t5-3b`, `nt5-small`, `preasm-large`.
The `target_dataset` above can be from: `drop`, `tatqa`, `iirc-gold`, `iirc-retrieved`, `numglue`.
The **A** models are only released for completeness / reproducibility. In your end application you probably just want to use either **B** or **C**.
# How to use it?
Please checkout the details in our [github repository](https://github.com/stonybrooknlp/teabreac), but in a nutshell:
```python
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
from digit_tokenization import enable_digit_tokenization # digit_tokenization.py from https://github.com/stonybrooknlp/teabreac
model_name = "StonyBrookNLP/t5-3b-iirc-retrieved"
tokenizer = AutoTokenizer.from_pretrained(model_name, use_fast=False) # Fast doesn't work with digit tokenization
model = AutoModelForSeq2SeqLM.from_pretrained(model_name)
enable_digit_tokenization(tokenizer)
input_texts = [
"answer_me: Who scored the first touchdown of the game?" +
"context: ... Oakland would get the early lead in the first quarter as quarterback JaMarcus Russell completed a 20-yard touchdown pass to rookie wide receiver Chaz Schilens..."
# Note: some models have slightly different qn/ctxt format. See the github repo.
]
input_ids = tokenizer(
input_texts, return_tensors="pt",
truncation=True, max_length=800,
add_special_tokens=True, padding=True,
)["input_ids"]
generated_ids = model.generate(input_ids, min_length=1, max_length=50)
generated_predictions = tokenizer.batch_decode(generated_ids, skip_special_tokens=False)
generated_predictions = [
tokenizer.fix_decoded_text(generated_prediction) for generated_prediction in generated_predictions
]
# => ["Chaz Schilens"]
```
|
ff54863298d5b17a0a80dde90e49a1f8
|
ConvLab/t5-small-nlu-all-multiwoz21
|
ConvLab
|
t5
| 7 | 17 |
transformers
| 0 |
text2text-generation
| true | false | false |
apache-2.0
|
['en']
|
['ConvLab/multiwoz21']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['t5-small', 'text2text-generation', 'natural language understanding', 'conversational system', 'task-oriented dialog']
| true | true | true | 741 | false |
# t5-small-nlu-all-multiwoz21
This model is a fine-tuned version of [t5-small](https://huggingface.co/t5-small) on [MultiWOZ 2.1](https://huggingface.co/datasets/ConvLab/multiwoz21) both user and system utterances.
Refer to [ConvLab-3](https://github.com/ConvLab/ConvLab-3) for model description and usage.
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.001
- train_batch_size: 128
- eval_batch_size: 64
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 256
- optimizer: Adafactor
- lr_scheduler_type: linear
- num_epochs: 10.0
### Framework versions
- Transformers 4.20.1
- Pytorch 1.11.0+cu102
- Datasets 2.3.2
- Tokenizers 0.12.1
|
ee8d17623a0d65c7986e74ac95a6972a
|
FritzOS/TEdetection_distilBERT_mLM_final
|
FritzOS
|
distilbert
| 4 | 4 |
transformers
| 0 |
fill-mask
| false | true | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_keras_callback']
| true | true | true | 1,356 | false |
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# TEdetection_distiBERT_mLM_final
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'AdamWeightDecay', 'learning_rate': {'class_name': 'WarmUp', 'config': {'initial_learning_rate': 5e-05, 'decay_schedule_fn': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 5e-05, 'decay_steps': 208159, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}, '__passive_serialization__': True}, 'warmup_steps': 1000, 'power': 1.0, 'name': None}}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False, 'weight_decay_rate': 0.01}
- training_precision: float32
### Training results
### Framework versions
- Transformers 4.19.4
- TensorFlow 2.8.2
- Datasets 2.2.2
- Tokenizers 0.12.1
|
f7d15088176d31f9995ebfb469f2c18e
|
cj-mills/xlm-roberta-base-finetuned-panx-de
|
cj-mills
|
xlm-roberta
| 38 | 5 |
transformers
| 0 |
token-classification
| true | false | false |
mit
| null |
['xtreme']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,353 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xlm-roberta-base-finetuned-panx-de
This model is a fine-tuned version of [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) on the xtreme dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1319
- F1: 0.8576
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 0.3264 | 1.0 | 197 | 0.1623 | 0.8139 |
| 0.136 | 2.0 | 394 | 0.1331 | 0.8451 |
| 0.096 | 3.0 | 591 | 0.1319 | 0.8576 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.11.0
- Datasets 1.16.1
- Tokenizers 0.10.3
|
5a198111e57a2c33e1bb0f63f02974a7
|
Amir13/xlm-roberta-base-de-aug-ner
|
Amir13
|
xlm-roberta
| 11 | 3 |
transformers
| 0 |
token-classification
| true | false | false |
mit
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,712 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xlm-roberta-base-de-aug-ner
This model is a fine-tuned version of [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3820
- Precision: 0.5214
- Recall: 0.5660
- F1: 0.5428
- Accuracy: 0.8966
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 463 | 0.6140 | 0.2884 | 0.2925 | 0.2904 | 0.8438 |
| 0.8329 | 2.0 | 926 | 0.4504 | 0.4092 | 0.4423 | 0.4251 | 0.8720 |
| 0.4385 | 3.0 | 1389 | 0.4046 | 0.4634 | 0.5042 | 0.4829 | 0.8875 |
| 0.3364 | 4.0 | 1852 | 0.3843 | 0.5 | 0.5446 | 0.5213 | 0.8954 |
| 0.2919 | 5.0 | 2315 | 0.3820 | 0.5214 | 0.5660 | 0.5428 | 0.8966 |
### Framework versions
- Transformers 4.25.1
- Pytorch 1.13.1+cu116
- Datasets 2.8.0
- Tokenizers 0.13.2
|
69b85b6a046419d16da6f247fdb4fe10
|
fanzru/t5-small-finetuned-xlsum
|
fanzru
|
t5
| 11 | 0 |
transformers
| 0 |
text2text-generation
| true | false | false |
apache-2.0
| null |
['xlsum']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,420 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-small-finetuned-xlsum
This model is a fine-tuned version of [t5-small](https://huggingface.co/t5-small) on the xlsum dataset.
It achieves the following results on the evaluation set:
- Loss: 2.4217
- Rouge1: 29.1774
- Rouge2: 8.0493
- Rougel: 22.5235
- Rougelsum: 22.5715
- Gen Len: 18.8415
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:-----:|:---------------:|:-------:|:------:|:-------:|:---------:|:-------:|
| 2.7017 | 1.0 | 19158 | 2.4217 | 29.1774 | 8.0493 | 22.5235 | 22.5715 | 18.8415 |
### Framework versions
- Transformers 4.13.0
- Pytorch 1.13.0+cu116
- Datasets 2.8.0
- Tokenizers 0.10.3
|
aefe6fe9d088d09cca1281ba593a1b76
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.