
Serial Number
int64 1
6k
| Issue Number
int64 75.6k
112k
| Title
stringlengths 3
357
| Labels
stringlengths 3
241
⌀ | Body
stringlengths 9
74.5k
⌀ | Comments
int64 0
867
|
|---|---|---|---|---|---|
3,401 | 95,229 |
ONNX Exporter for circular padding mode in convolution ops
|
module: onnx, triaged
|
### 🚀 The feature, motivation and pitch
Circular/wrap-around padding has recently been added to the Pad operator in ONNX opset 19:
https://github.com/onnx/onnx/blob/main/docs/Operators.md#Pad
When exporting convolution operators with `padding_mode` set to `circular`, one can directly make use of the new Pad operator instead of having to do concatenation.
### Alternatives
_No response_
### Additional context
_No response_
| 0 |
3,402 | 95,225 |
Remove conda virtualenv from the docker image
|
oncall: binaries, triaged, module: docker
|
### 🚀 The feature, motivation and pitch
Current docker image contains a conda virtualenv (`base`), in which all the libs are installed.
Since a docker image is already a kind a separated environement, I think a conda virtualenv is superfluous.
Conda could be removed, and pytorch could be installed in the native python installl with `pip`.
This could simplify the docker image, and possibly lighten it.
Unless there is another reason to use conda which I'm not aware of ?
cc @ezyang @seemethere @malfet
| 0 |
3,403 | 95,210 |
Add parallel attention layers and Multi-Query Attention (MQA) from PaLM to the fast path for transformers
|
oncall: transformer/mha
|
### 🚀 The feature, motivation and pitch
Parallel attention layers and MQA are introduced in PaLM [1]. The “standard” encoder layer, as currently implemented in PyTorch, follows the following structure:
Serial attention (with default `norm_first=False`):
`z = LN(x + Attention(x)); y = LN(z + MLP(z))`
A parallel attention layer from PaLM, on the other hand, is implemented as follows:
Parallel attention (with default `norm_first=False`):
`y = LN(x + Attention(x) + MLP(x))`
Parallel attention (with `norm_first=True`):
`y = x + Attention(LN(x)) + MLP(LN(x))`
As for MQA, the description from [1] is pretty concise and explains the advantage as well: “The standard Transformer formulation uses k attention heads, where the input vector for each timestep is linearly projected into “query”, “key”, and “value” tensors of shape [k, h], where h is the attention head size. Here, the key/value projections are shared for each head, i.e. “key” and “value” are projected to [1, h], but “query” is still projected to shape [k, h]. We have found that this has a neutral effect on model quality and training speed (Shazeer, 2019), but results in a significant cost savings at autoregressive decoding time. This is because standard multi-headed attention has low efficiency on accelerator hardware during auto-regressive decoding, because the key/value tensors are not shared between examples, and only a single token is decoded at a time.”
In our own experiments, we have seen a 23% speedup in training for T5-large when using parallel attention, with the same convergence, due to the ability to fuse the attention and feed-forward projection layers into a single matmul operation. Furthermore, adding MQA on top shaves off an extra 10% training time. See the image below for our training loss over time.
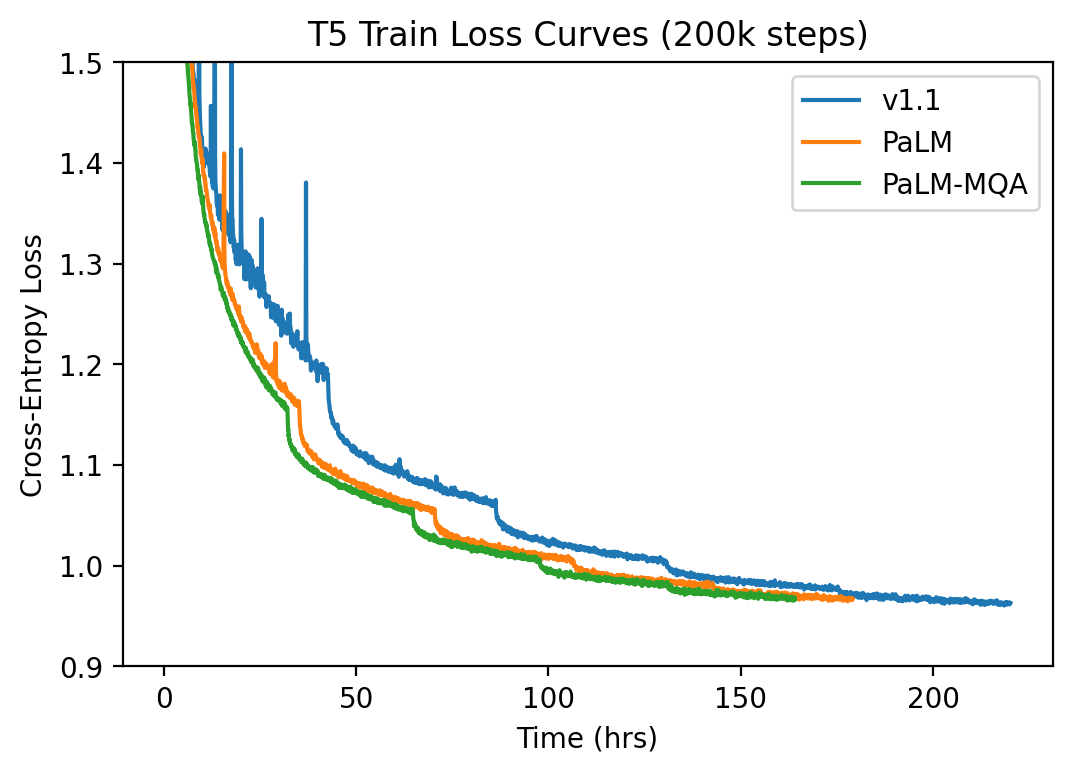
Of course, this is not free, and we have found that for larger models (3B and 11B parameters), memory can peak high enough that it can OOM an A100 GPU, even when running with FSDP.
As we build larger models and optimize them for inference, we would like to take advantage of the fast path for Transformers already available for the serial implementation, given the already observed advantage in training and the claimed speed-up on inference from using MQA, as well as explore ways to make this approach more memory efficient in PyTorch.
We envision two ways in which this can happen:
1. Through new parameters in both nn.TransformerEncoderLayer and nn.TransformerDecoderLayer (e.g. booleans `use_parallel_attention` and `use_mqa`), that would route the code through the parallel path and/or MQA.
1. New layers nn.TransformerParallelEncoderLayer and nn.TransformerParallelDecoderLayer
Both paths would eventually call the native `transformer_encoder_layer_forward` (https://github.com/pytorch/pytorch/blob/0dceaf07cd1236859953b6f85a61dc4411d10f87/aten/src/ATen/native/transformers/transformer.cpp#L65) function (or a new parallel version of it that ensures kernel fusing) if all conditions to hit the fast path are met.
cc: @daviswer @supriyogit @raghukiran1224 @mudhakar @mayank31398 @cpuhrsch @HamidShojanazeri
References:
[1] [PaLM: Scaling Language Models with Pathways](https://arxiv.org/pdf/2204.02311.pdf)
### Alternatives
_No response_
### Additional context
_No response_
cc @jbschlosser @bhosmer @cpuhrsch @erichan1
| 15 |
3,404 | 95,207 |
new backend privateuseone with "to" op
|
triaged, module: backend
|
### 🐛 Describe the bug
when I use a new backend with the key of privateuseone, and we have implement for the op of "to" with backend like this. I think it is an error with the dispatchkey of "AutogradPrivateUse1", So I do some tests for the bakcend.
### test_code
I add to_dtype func based on test cpp_extensions/open_registration_extension.cpp, link
https://github.com/heidongxianhua/pytorch/commit/fdb57dac418ec849dfd7900b1b69e815840b06b5
And when run the test with python3 test_cpp_extensions_open_device_registration.py, It dose not work and got error message is here. I check the to_dtype func have been registered for PrivateUse1 backend
```
Fail to import hypothesis in common_utils, tests are not derandomized
Using /root/.cache/torch_extensions/py38_cpu as PyTorch extensions root...
Creating extension directory /root/.cache/torch_extensions/py38_cpu/custom_device_extension...
Emitting ninja build file /root/.cache/torch_extensions/py38_cpu/custom_device_extension/build.ninja...
Building extension module custom_device_extension...
Allowing ninja to set a default number of workers... (overridable by setting the environment variable MAX_JOBS=N)
[1/2] c++ -MMD -MF open_registration_extension.o.d -DTORCH_EXTENSION_NAME=custom_device_extension -DTORCH_API_INCLUDE_EXTENSION_H -DPYBIND11_COMPILER_TYPE=\"_gcc\" -DPYBIND11_STDLIB=\"_libstdcpp\" -DPYBIND11_BUILD_ABI=\"_cxxabi1011\" -I/home/shibo/device_type/pytorch_shibo/test/cpp_extensions -isystem /root/anaconda3/envs/shibo2/lib/python3.8/site-packages/torch/include -isystem /root/anaconda3/envs/shibo2/lib/python3.8/site-packages/torch/include/torch/csrc/api/include -isystem /root/anaconda3/envs/shibo2/lib/python3.8/site-packages/torch/include/TH -isystem /root/anaconda3/envs/shibo2/lib/python3.8/site-packages/torch/include/THC -isystem /root/anaconda3/envs/shibo2/include/python3.8 -D_GLIBCXX_USE_CXX11_ABI=1 -fPIC -std=c++17 -g -c /home/shibo/device_type/pytorch_shibo/test/cpp_extensions/open_registration_extension.cpp -o open_registration_extension.o
[2/2] c++ open_registration_extension.o -shared -L/root/anaconda3/envs/shibo2/lib/python3.8/site-packages/torch/lib -lc10 -ltorch_cpu -ltorch -ltorch_python -o custom_device_extension.so
Loading extension module custom_device_extension...
E
======================================================================
ERROR: test_open_device_registration (__main__.TestCppExtensionOpenRgistration)
----------------------------------------------------------------------
Traceback (most recent call last):
File "test_cpp_extensions_open_device_registration.py", line 78, in test_open_device_registration
y_int32 = y.to(torch.int32)
NotImplementedError: Could not run 'aten::to.dtype' with arguments from the 'AutogradPrivateUse1' backend. This could be because the operator doesn't exist for this backend, or was omitted during the selective/custom build process (if using custom build). If you are a Facebook employee using PyTorch on mobile, please visit https://fburl.com/ptmfixes for possible resolutions. 'aten::to.dtype' is only available for these backends: [CPU, CUDA, HIP, XLA, MPS, IPU, XPU, HPU, VE, Lazy, Meta, MTIA, PrivateUse1, PrivateUse2, PrivateUse3, FPGA, ORT, Vulkan, Metal, QuantizedCPU, QuantizedCUDA, QuantizedHIP, QuantizedXLA, QuantizedMPS, QuantizedIPU, QuantizedXPU, QuantizedHPU, QuantizedVE, QuantizedLazy, QuantizedMeta, QuantizedMTIA, QuantizedPrivateUse1, QuantizedPrivateUse2, QuantizedPrivateUse3, CustomRNGKeyId, MkldnnCPU, SparseCPU, SparseCUDA, SparseHIP, SparseXLA, SparseMPS, SparseIPU, SparseXPU, SparseHPU, SparseVE, SparseLazy, SparseMeta, SparseMTIA, SparsePrivateUse1, SparsePrivateUse2, SparsePrivateUse3, SparseCsrCPU, SparseCsrCUDA, NestedTensorCPU, NestedTensorCUDA, NestedTensorHIP, NestedTensorXLA, NestedTensorMPS, NestedTensorIPU, NestedTensorXPU, NestedTensorHPU, NestedTensorVE, NestedTensorLazy, NestedTensorMeta, NestedTensorMTIA, NestedTensorPrivateUse1, NestedTensorPrivateUse2, NestedTensorPrivateUse3, BackendSelect, Python, FuncTorchDynamicLayerBackMode, Functionalize, Named, Conjugate, Negative, ZeroTensor, ADInplaceOrView, AutogradOther, AutogradCPU, AutogradCUDA, AutogradHIP, AutogradXLA, AutogradMPS, AutogradIPU, AutogradXPU, AutogradHPU, AutogradVE, AutogradLazy, AutogradMeta, AutogradMTIA, AutogradPrivateUse2, AutogradPrivateUse3, AutogradNestedTensor, Tracer, AutocastCPU, AutocastCUDA, FuncTorchBatched, FuncTorchVmapMode, Batched, VmapMode, FuncTorchGradWrapper, PythonTLSSnapshot, FuncTorchDynamicLayerFrontMode, PythonDispatcher]
Undefined: registered at /home/shibo/device_type/pytorch_test/build/aten/src/ATen/RegisterCompositeImplicitAutograd.cpp:7140 [math kernel]
CPU: registered at /home/shibo/device_type/pytorch_test/build/aten/src/ATen/RegisterCompositeImplicitAutograd.cpp:7140 [math kernel]
CUDA: registered at /home/shibo/device_type/pytorch_test/build/aten/src/ATen/RegisterCompositeImplicitAutograd.cpp:7140 [math kernel]
HIP: registered at /home/shibo/device_type/pytorch_test/build/aten/src/ATen/RegisterCompositeImplicitAutograd.cpp:7140 [math kernel]
XLA: registered at /home/shibo/device_type/pytorch_test/build/aten/src/ATen/RegisterCompositeImplicitAutograd.cpp:7140 [math kernel]
MPS: registered at /home/shibo/device_type/pytorch_test/build/aten/src/ATen/RegisterCompositeImplicitAutograd.cpp:7140 [math kernel]
IPU: registered at /home/shibo/device_type/pytorch_test/build/aten/src/ATen/RegisterCompositeImplicitAutograd.cpp:7140 [math kernel]
XPU: registered at /home/shibo/device_type/pytorch_test/build/aten/src/ATen/RegisterCompositeImplicitAutograd.cpp:7140 [math kernel]
HPU: registered at /home/shibo/device_type/pytorch_test/build/aten/src/ATen/RegisterCompositeImplicitAutograd.cpp:7140 [math kernel]
VE: registered at /home/shibo/device_type/pytorch_test/build/aten/src/ATen/RegisterCompositeImplicitAutograd.cpp:7140 [math kernel]
Lazy: registered at /home/shibo/device_type/pytorch_test/build/aten/src/ATen/RegisterCompositeImplicitAutograd.cpp:7140 [math kernel]
Meta: registered at /home/shibo/device_type/pytorch_test/build/aten/src/ATen/RegisterCompositeImplicitAutograd.cpp:7140 [math kernel]
MTIA: registered at /home/shibo/device_type/pytorch_test/build/aten/src/ATen/RegisterCompositeImplicitAutograd.cpp:7140 [math kernel]
PrivateUse1: registered at /home/shibo/device_type/pytorch_shibo/test/cpp_extensions/open_registration_extension.cpp:90 [kernel]
PrivateUse2: registered at /home/shibo/device_type/pytorch_test/build/aten/src/ATen/RegisterCompositeImplicitAutograd.cpp:7140 [math kernel]
PrivateUse3: registered at /home/shibo/device_type/pytorch_test/build/aten/src/ATen/RegisterCompositeImplicitAutograd.cpp:7140 [math kernel]
FPGA: registered at /home/shibo/device_type/pytorch_test/build/aten/src/ATen/RegisterCompositeImplicitAutograd.cpp:7140 [math kernel]
............
```
### Versions
```
Collecting environment information...
PyTorch version: 2.0.0a0+git900db22
Is debug build: False
CUDA used to build PyTorch: None
ROCM used to build PyTorch: N/A
OS: Ubuntu 18.04.4 LTS (x86_64)
GCC version: (Ubuntu 7.5.0-3ubuntu1~18.04) 7.5.0
Clang version: 8.0.1 (based on LLVM 8.0.1)
CMake version: version 3.24.1
Libc version: glibc-2.27
Python version: 3.8.13 (default, Mar 28 2022, 11:38:47) [GCC 7.5.0] (64-bit runtime)
Python platform: Linux-4.15.0-76-generic-x86_64-with-glibc2.17
Is CUDA available: False
CUDA runtime version: No CUDA
CUDA_MODULE_LOADING set to: N/A
GPU models and configuration: No CUDA
Nvidia driver version: No CUDA
cuDNN version: No CUDA
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: False
Versions of relevant libraries:
[pip3] numpy==1.24.2
[pip3] torch==2.0.0a0+git2f0b0c5
[pip3] torch-npu==2.0.0
[conda] numpy 1.24.2 pypi_0 pypi
[conda] torch 2.0.0a0+git900db22 pypi_0 pypi
[conda] torch-npu 2.0.0 pypi_0 pypi
```
| 6 |
3,405 | 95,197 |
Pytorch 2.0 [compile] scatter_add bf16 Compiled Fx GraphModule failed
|
triaged, module: bfloat16, oncall: pt2, module: cpu inductor
|
### 🐛 Describe the bug
Please find minifier code below to reproduce the issue:
```
import os
from math import inf
import torch
from torch import tensor, device
import torch.fx as fx
import functools
import torch._dynamo
from torch._dynamo.debug_utils import run_fwd_maybe_bwd
from torch._dynamo.backends.registry import lookup_backend
from torch._dynamo.testing import rand_strided
import torch._dynamo.config
import torch._inductor.config
import torch._functorch.config
torch._dynamo.config.load_config(b'\x80\x02}q\x00(X\x0b\x00\x00\x00output_codeq\x01\x89X\r\x00\x00\x00log_file_nameq\x02NX\x07\x00\x00\x00verboseq\x03\x89X\x11\x00\x00\x00output_graph_codeq\x04\x89X\x12\x00\x00\x00verify_correctnessq\x05\x89X\x12\x00\x00\x00minimum_call_countq\x06K\x01X\x15\x00\x00\x00dead_code_eliminationq\x07\x88X\x10\x00\x00\x00cache_size_limitq\x08K@X\x14\x00\x00\x00specialize_int_floatq\t\x88X\x0e\x00\x00\x00dynamic_shapesq\n\x89X\x10\x00\x00\x00guard_nn_modulesq\x0b\x89X\x1b\x00\x00\x00traceable_tensor_subclassesq\x0cc__builtin__\nset\nq\r]q\x0e\x85q\x0fRq\x10X\x0f\x00\x00\x00suppress_errorsq\x11\x89X\x15\x00\x00\x00replay_record_enabledq\x12\x89X \x00\x00\x00rewrite_assert_with_torch_assertq\x13\x88X\x12\x00\x00\x00print_graph_breaksq\x14\x89X\x07\x00\x00\x00disableq\x15\x89X*\x00\x00\x00allowed_functions_module_string_ignorelistq\x16h\r]q\x17(X\x0b\x00\x00\x00torch._refsq\x18X\x0c\x00\x00\x00torch._primsq\x19X\r\x00\x00\x00torch.testingq\x1aX\x13\x00\x00\x00torch.distributionsq\x1bX\r\x00\x00\x00torch._decompq\x1ce\x85q\x1dRq\x1eX\x12\x00\x00\x00repro_forward_onlyq\x1f\x89X\x0f\x00\x00\x00repro_toleranceq G?PbM\xd2\xf1\xa9\xfcX\x16\x00\x00\x00capture_scalar_outputsq!\x89X\x19\x00\x00\x00enforce_cond_guards_matchq"\x88X\x0c\x00\x00\x00optimize_ddpq#\x88X\x1a\x00\x00\x00raise_on_ctx_manager_usageq$\x88X\x1c\x00\x00\x00raise_on_unsafe_aot_autogradq%\x89X\x18\x00\x00\x00error_on_nested_fx_traceq&\x88X\t\x00\x00\x00allow_rnnq\'\x89X\x08\x00\x00\x00base_dirq(X1\x00\x00\x00/home/jthakur/.pt_2_0/lib/python3.8/site-packagesq)X\x0e\x00\x00\x00debug_dir_rootq*Xm\x00\x00\x00/home/jthakur/qnpu/1.9.0-413/src/pytorch-training-tests/tests/torch_feature_val/single_op/torch_compile_debugq+X)\x00\x00\x00DO_NOT_USE_legacy_non_fake_example_inputsq,\x89X\x13\x00\x00\x00_save_config_ignoreq-h\r]q.(X\x12\x00\x00\x00constant_functionsq/X\x0b\x00\x00\x00repro_afterq0X!\x00\x00\x00skipfiles_inline_module_allowlistq1X\x0b\x00\x00\x00repro_levelq2e\x85q3Rq4u.')
torch._inductor.config.load_config(b'\x80\x02}q\x00(X\x05\x00\x00\x00debugq\x01\x89X\x10\x00\x00\x00disable_progressq\x02\x88X\x10\x00\x00\x00verbose_progressq\x03\x89X\x0b\x00\x00\x00cpp_wrapperq\x04\x89X\x03\x00\x00\x00dceq\x05\x89X\x14\x00\x00\x00static_weight_shapesq\x06\x88X\x0c\x00\x00\x00size_assertsq\x07\x88X\x10\x00\x00\x00pick_loop_ordersq\x08\x88X\x0f\x00\x00\x00inplace_buffersq\t\x88X\x11\x00\x00\x00benchmark_harnessq\n\x88X\x0f\x00\x00\x00epilogue_fusionq\x0b\x89X\x15\x00\x00\x00epilogue_fusion_firstq\x0c\x89X\x0f\x00\x00\x00pattern_matcherq\r\x88X\n\x00\x00\x00reorderingq\x0e\x89X\x0c\x00\x00\x00max_autotuneq\x0f\x89X\x17\x00\x00\x00realize_reads_thresholdq\x10K\x04X\x17\x00\x00\x00realize_bytes_thresholdq\x11M\xd0\x07X\x1b\x00\x00\x00realize_acc_reads_thresholdq\x12K\x08X\x0f\x00\x00\x00fallback_randomq\x13\x89X\x12\x00\x00\x00implicit_fallbacksq\x14\x88X\r\x00\x00\x00prefuse_nodesq\x15\x88X\x0b\x00\x00\x00tune_layoutq\x16\x89X\x11\x00\x00\x00aggressive_fusionq\x17\x89X\x0f\x00\x00\x00max_fusion_sizeq\x18K@X\x1b\x00\x00\x00unroll_reductions_thresholdq\x19K\x08X\x0e\x00\x00\x00comment_originq\x1a\x89X\x0f\x00\x00\x00compile_threadsq\x1bK\x0cX\x13\x00\x00\x00kernel_name_max_opsq\x1cK\nX\r\x00\x00\x00shape_paddingq\x1d\x89X\x0e\x00\x00\x00permute_fusionq\x1e\x89X\x1a\x00\x00\x00profiler_mark_wrapper_callq\x1f\x89X\x0b\x00\x00\x00cpp.threadsq J\xff\xff\xff\xffX\x13\x00\x00\x00cpp.dynamic_threadsq!\x89X\x0b\x00\x00\x00cpp.simdlenq"NX\x12\x00\x00\x00cpp.min_chunk_sizeq#M\x00\x10X\x07\x00\x00\x00cpp.cxxq$NX\x03\x00\x00\x00g++q%\x86q&X\x19\x00\x00\x00cpp.enable_kernel_profileq\'\x89X\x12\x00\x00\x00cpp.weight_prepackq(\x88X\x11\x00\x00\x00triton.cudagraphsq)\x89X\x17\x00\x00\x00triton.debug_sync_graphq*\x89X\x18\x00\x00\x00triton.debug_sync_kernelq+\x89X\x12\x00\x00\x00triton.convolutionq,X\x04\x00\x00\x00atenq-X\x15\x00\x00\x00triton.dense_indexingq.\x89X\x10\x00\x00\x00triton.max_tilesq/K\x02X\x19\x00\x00\x00triton.autotune_pointwiseq0\x88X\'\x00\x00\x00triton.tiling_prevents_pointwise_fusionq1\x88X\'\x00\x00\x00triton.tiling_prevents_reduction_fusionq2\x88X\x1b\x00\x00\x00triton.ordered_kernel_namesq3\x89X\x1f\x00\x00\x00triton.descriptive_kernel_namesq4\x89X\r\x00\x00\x00trace.enabledq5\x89X\x0f\x00\x00\x00trace.debug_logq6\x88X\x0e\x00\x00\x00trace.info_logq7\x89X\x0e\x00\x00\x00trace.fx_graphq8\x88X\x1a\x00\x00\x00trace.fx_graph_transformedq9\x88X\x13\x00\x00\x00trace.ir_pre_fusionq:\x88X\x14\x00\x00\x00trace.ir_post_fusionq;\x88X\x11\x00\x00\x00trace.output_codeq<\x88X\x13\x00\x00\x00trace.graph_diagramq=\x89X\x15\x00\x00\x00trace.compile_profileq>\x89X\x10\x00\x00\x00trace.upload_tarq?Nu.')
torch._functorch.config.load_config(b'\x80\x02}q\x00(X\x11\x00\x00\x00use_functionalizeq\x01\x88X\x0f\x00\x00\x00use_fake_tensorq\x02\x88X\x16\x00\x00\x00fake_tensor_allow_metaq\x03\x88X\x0c\x00\x00\x00debug_assertq\x04\x88X\x14\x00\x00\x00debug_fake_cross_refq\x05\x89X\x11\x00\x00\x00debug_partitionerq\x06\x89X\x0c\x00\x00\x00debug_graphsq\x07\x89X\x0b\x00\x00\x00debug_jointq\x08\x89X\x12\x00\x00\x00use_dynamic_shapesq\t\x89X\x14\x00\x00\x00static_weight_shapesq\n\x88X\x03\x00\x00\x00cseq\x0b\x88X\x10\x00\x00\x00max_dist_from_bwq\x0cK\x03X\t\x00\x00\x00log_levelq\rK\x14u.')
# REPLACEABLE COMMENT FOR TESTING PURPOSES
args = [((129, 129), (129, 1), torch.int64, 'cpu', False), ((129, 129), (129, 1), torch.bfloat16, 'cpu', True), ((129, 129), (129, 1), torch.bfloat16, 'cpu', True)]
args = [rand_strided(sh, st, dt, dev).requires_grad_(rg) for (sh, st, dt, dev, rg) in args]
from torch.nn import *
class Repro(torch.nn.Module):
def __init__(self):
super().__init__()
def forward(self, op_inputs_dict_index_ : torch.Tensor, op_inputs_dict_src_ : torch.Tensor, op_inputs_dict_input_ : torch.Tensor):
scatter_add = torch.scatter_add(index = op_inputs_dict_index_, dim = -2, src = op_inputs_dict_src_, input = op_inputs_dict_input_); op_inputs_dict_index_ = op_inputs_dict_src_ = op_inputs_dict_input_ = None
return (scatter_add,)
mod = Repro()
# Setup debug minifier compiler
torch._dynamo.debug_utils.MINIFIER_SPAWNED = True
compiler_fn = lookup_backend("dynamo_minifier_backend")
dynamo_minifier_backend = functools.partial(
compiler_fn,
compiler_name="inductor",
)
opt_mod = torch._dynamo.optimize(dynamo_minifier_backend)(mod)
with torch.cuda.amp.autocast(enabled=False):
opt_mod(*args)
```
Error:
```
File "/usr/lib/python3.8/concurrent/futures/thread.py", line 57, in run
result = self.fn(*self.args, **self.kwargs)
File "/home/jthakur/.pt_2_0/lib/python3.8/site-packages/torch/_inductor/codecache.py", line 691, in task
return CppCodeCache.load(source_code).kernel
File "/home/jthakur/.pt_2_0/lib/python3.8/site-packages/torch/_inductor/codecache.py", line 506, in load
raise exc.CppCompileError(cmd, e.output) from e
torch._inductor.exc.CppCompileError: C++ compile error
```
Same graph works fine in eager mode execution
### Versions
Versions of relevant libraries:
[pip3] numpy==1.24.1
[pip3] torch==2.0.0.dev20230209+cpu
[pip3] torchaudio==2.0.0.dev20230209+cpu
[pip3] torchvision==0.15.0.dev20230209+cpu
cc @ezyang @soumith @msaroufim @wconstab @ngimel @bdhirsh
| 1 |
3,406 | 95,194 |
High Cuda Memory Consumption for Simple ResNet50 Inference
|
oncall: jit
|
### 🐛 Describe the bug
I run a simple inference of a jit::traced Resnet50 model with the C++ API and record a peak GPU memory consumption of 1.2gb. The inference script is taken from the docs https://pytorch.org/tutorials/advanced/cpp_export.html and looks as follows:
```
#include <torch/script.h> // One-stop header.
#include <iostream>
#include <memory>
#include <vector>
int main(int argc, const char* argv[]) {
if (argc != 2) {
std::cerr << "usage: example-app <path-to-exported-script-module>\n";
return -1;
}
{
c10::InferenceMode guard;
torch::jit::script::Module module;
try {
// Deserialize the ScriptModule from a file using
// torch::jit::load().
module = torch::jit::load(argv[1]);
module.to(at::kCUDA);
} catch (const c10::Error& e) {
std::cerr << "error loading the model\n";
return -1;
}
std::vector<torch::jit::IValue> inputs;
at::Tensor rand = torch::rand({1, 3, 224, 224});
at::Tensor rand2 = at::_cast_Half(rand);
inputs.push_back(rand2.to(at::kCUDA));
at::Tensor output = module.forward(inputs).toTensor();
std::cout << output.slice(/*dim=*/1, /*start=*/0, /*end=*/5) << '\n';
}
std::cout << "ok\n";
}
```
When running the script with a traced model input (converted to half), the memory consumption goes to 1.2gb. As a comparison:
- A back-of-the-envelope calculation: The model has about 40m parameters and the input is of size 3x224x224 , so I think a very, very memory-efficient inference should be at ~100-150 mb.
- TensorRT uses ~260mb for the inference.
We would like to use the libtorch for inference in production and I would be great if there was a way to reduce the memory consumption to ~500mb. Is there a way to do that?
### Versions
build-version in the libtorch folder shows:
```
1.13.1+cu116
```
Should I collect other relevant info?
cc @EikanWang @jgong5 @wenzhe-nrv @sanchitintel
| 0 |
3,407 | 95,189 |
Pytorch 2.0 [compile] index_add bf16 compilation error
|
triaged, module: bfloat16, oncall: pt2, module: cpu inductor
|
### 🐛 Describe the bug
Please use below minifier code to reproduce the issue
```
import os
from math import inf
import torch
from torch import tensor, device
import torch.fx as fx
import functools
import torch._dynamo
from torch._dynamo.debug_utils import run_fwd_maybe_bwd
from torch._dynamo.backends.registry import lookup_backend
from torch._dynamo.testing import rand_strided
import torch._dynamo.config
import torch._inductor.config
import torch._functorch.config
torch._dynamo.config.load_config(b'\x80\x02}q\x00(X\x0b\x00\x00\x00output_codeq\x01\x89X\r\x00\x00\x00log_file_nameq\x02NX\x07\x00\x00\x00verboseq\x03\x89X\x11\x00\x00\x00output_graph_codeq\x04\x89X\x12\x00\x00\x00verify_correctnessq\x05\x89X\x12\x00\x00\x00minimum_call_countq\x06K\x01X\x15\x00\x00\x00dead_code_eliminationq\x07\x88X\x10\x00\x00\x00cache_size_limitq\x08M\xb8\x0bX\x14\x00\x00\x00specialize_int_floatq\t\x88X\x0e\x00\x00\x00dynamic_shapesq\n\x89X\x10\x00\x00\x00guard_nn_modulesq\x0b\x89X\x1b\x00\x00\x00traceable_tensor_subclassesq\x0cc__builtin__\nset\nq\r]q\x0e\x85q\x0fRq\x10X\x0f\x00\x00\x00suppress_errorsq\x11\x89X\x15\x00\x00\x00replay_record_enabledq\x12\x89X \x00\x00\x00rewrite_assert_with_torch_assertq\x13\x88X\x12\x00\x00\x00print_graph_breaksq\x14\x89X\x07\x00\x00\x00disableq\x15\x89X*\x00\x00\x00allowed_functions_module_string_ignorelistq\x16h\r]q\x17(X\x0c\x00\x00\x00torch._primsq\x18X\x0b\x00\x00\x00torch._refsq\x19X\r\x00\x00\x00torch.testingq\x1aX\x13\x00\x00\x00torch.distributionsq\x1bX\r\x00\x00\x00torch._decompq\x1ce\x85q\x1dRq\x1eX\x12\x00\x00\x00repro_forward_onlyq\x1f\x89X\x0f\x00\x00\x00repro_toleranceq G?PbM\xd2\xf1\xa9\xfcX\x16\x00\x00\x00capture_scalar_outputsq!\x89X\x19\x00\x00\x00enforce_cond_guards_matchq"\x88X\x0c\x00\x00\x00optimize_ddpq#\x88X\x1a\x00\x00\x00raise_on_ctx_manager_usageq$\x88X\x1c\x00\x00\x00raise_on_unsafe_aot_autogradq%\x89X\x18\x00\x00\x00error_on_nested_fx_traceq&\x88X\t\x00\x00\x00allow_rnnq\'\x89X\x08\x00\x00\x00base_dirq(X1\x00\x00\x00/home/jthakur/.pt_2_0/lib/python3.8/site-packagesq)X\x0e\x00\x00\x00debug_dir_rootq*Xm\x00\x00\x00/home/jthakur/qnpu/1.9.0-413/src/pytorch-training-tests/tests/torch_feature_val/single_op/torch_compile_debugq+X)\x00\x00\x00DO_NOT_USE_legacy_non_fake_example_inputsq,\x89X\x13\x00\x00\x00_save_config_ignoreq-h\r]q.(X\x12\x00\x00\x00constant_functionsq/X\x0b\x00\x00\x00repro_afterq0X!\x00\x00\x00skipfiles_inline_module_allowlistq1X\x0b\x00\x00\x00repro_levelq2e\x85q3Rq4u.')
torch._inductor.config.load_config(b'\x80\x02}q\x00(X\x05\x00\x00\x00debugq\x01\x89X\x10\x00\x00\x00disable_progressq\x02\x88X\x10\x00\x00\x00verbose_progressq\x03\x89X\x0b\x00\x00\x00cpp_wrapperq\x04\x89X\x03\x00\x00\x00dceq\x05\x89X\x14\x00\x00\x00static_weight_shapesq\x06\x88X\x0c\x00\x00\x00size_assertsq\x07\x88X\x10\x00\x00\x00pick_loop_ordersq\x08\x88X\x0f\x00\x00\x00inplace_buffersq\t\x88X\x11\x00\x00\x00benchmark_harnessq\n\x88X\x0f\x00\x00\x00epilogue_fusionq\x0b\x89X\x15\x00\x00\x00epilogue_fusion_firstq\x0c\x89X\x0f\x00\x00\x00pattern_matcherq\r\x88X\n\x00\x00\x00reorderingq\x0e\x89X\x0c\x00\x00\x00max_autotuneq\x0f\x89X\x17\x00\x00\x00realize_reads_thresholdq\x10K\x04X\x17\x00\x00\x00realize_bytes_thresholdq\x11M\xd0\x07X\x1b\x00\x00\x00realize_acc_reads_thresholdq\x12K\x08X\x0f\x00\x00\x00fallback_randomq\x13\x89X\x12\x00\x00\x00implicit_fallbacksq\x14\x88X\r\x00\x00\x00prefuse_nodesq\x15\x88X\x0b\x00\x00\x00tune_layoutq\x16\x89X\x11\x00\x00\x00aggressive_fusionq\x17\x89X\x0f\x00\x00\x00max_fusion_sizeq\x18K@X\x1b\x00\x00\x00unroll_reductions_thresholdq\x19K\x08X\x0e\x00\x00\x00comment_originq\x1a\x89X\x0f\x00\x00\x00compile_threadsq\x1bK\x0cX\x13\x00\x00\x00kernel_name_max_opsq\x1cK\nX\r\x00\x00\x00shape_paddingq\x1d\x89X\x0e\x00\x00\x00permute_fusionq\x1e\x89X\x1a\x00\x00\x00profiler_mark_wrapper_callq\x1f\x89X\x0b\x00\x00\x00cpp.threadsq J\xff\xff\xff\xffX\x13\x00\x00\x00cpp.dynamic_threadsq!\x89X\x0b\x00\x00\x00cpp.simdlenq"NX\x12\x00\x00\x00cpp.min_chunk_sizeq#M\x00\x10X\x07\x00\x00\x00cpp.cxxq$NX\x03\x00\x00\x00g++q%\x86q&X\x19\x00\x00\x00cpp.enable_kernel_profileq\'\x89X\x12\x00\x00\x00cpp.weight_prepackq(\x88X\x11\x00\x00\x00triton.cudagraphsq)\x89X\x17\x00\x00\x00triton.debug_sync_graphq*\x89X\x18\x00\x00\x00triton.debug_sync_kernelq+\x89X\x12\x00\x00\x00triton.convolutionq,X\x04\x00\x00\x00atenq-X\x15\x00\x00\x00triton.dense_indexingq.\x89X\x10\x00\x00\x00triton.max_tilesq/K\x02X\x19\x00\x00\x00triton.autotune_pointwiseq0\x88X\'\x00\x00\x00triton.tiling_prevents_pointwise_fusionq1\x88X\'\x00\x00\x00triton.tiling_prevents_reduction_fusionq2\x88X\x1b\x00\x00\x00triton.ordered_kernel_namesq3\x89X\x1f\x00\x00\x00triton.descriptive_kernel_namesq4\x89X\r\x00\x00\x00trace.enabledq5\x89X\x0f\x00\x00\x00trace.debug_logq6\x88X\x0e\x00\x00\x00trace.info_logq7\x89X\x0e\x00\x00\x00trace.fx_graphq8\x88X\x1a\x00\x00\x00trace.fx_graph_transformedq9\x88X\x13\x00\x00\x00trace.ir_pre_fusionq:\x88X\x14\x00\x00\x00trace.ir_post_fusionq;\x88X\x11\x00\x00\x00trace.output_codeq<\x88X\x13\x00\x00\x00trace.graph_diagramq=\x89X\x15\x00\x00\x00trace.compile_profileq>\x89X\x10\x00\x00\x00trace.upload_tarq?Nu.')
torch._functorch.config.load_config(b'\x80\x02}q\x00(X\x11\x00\x00\x00use_functionalizeq\x01\x88X\x0f\x00\x00\x00use_fake_tensorq\x02\x88X\x16\x00\x00\x00fake_tensor_allow_metaq\x03\x88X\x0c\x00\x00\x00debug_assertq\x04\x88X\x14\x00\x00\x00debug_fake_cross_refq\x05\x89X\x11\x00\x00\x00debug_partitionerq\x06\x89X\x0c\x00\x00\x00debug_graphsq\x07\x89X\x0b\x00\x00\x00debug_jointq\x08\x89X\x12\x00\x00\x00use_dynamic_shapesq\t\x89X\x14\x00\x00\x00static_weight_shapesq\n\x88X\x03\x00\x00\x00cseq\x0b\x88X\x10\x00\x00\x00max_dist_from_bwq\x0cK\x03X\t\x00\x00\x00log_levelq\rK\x14u.')
# REPLACEABLE COMMENT FOR TESTING PURPOSES
args = [((3,), (1,), torch.int64, 'cpu', False), ((4, 3, 32, 8), (768, 256, 8, 1), torch.bfloat16, 'cpu', True), ((4, 16, 32, 8), (4096, 256, 8, 1), torch.bfloat16, 'cpu', True)]
args = [rand_strided(sh, st, dt, dev).requires_grad_(rg) for (sh, st, dt, dev, rg) in args]
from torch.nn import *
class Repro(torch.nn.Module):
def __init__(self):
super().__init__()
def forward(self, op_inputs_dict_index_ : torch.Tensor, op_inputs_dict_source_ : torch.Tensor, op_inputs_dict_input_ : torch.Tensor):
index_add = torch.index_add(dim = 1, index = op_inputs_dict_index_, source = op_inputs_dict_source_, alpha = 2, input = op_inputs_dict_input_); op_inputs_dict_index_ = op_inputs_dict_source_ = op_inputs_dict_input_ = None
return (index_add,)
mod = Repro()
# Setup debug minifier compiler
torch._dynamo.debug_utils.MINIFIER_SPAWNED = True
compiler_fn = lookup_backend("dynamo_minifier_backend")
dynamo_minifier_backend = functools.partial(
compiler_fn,
compiler_name="inductor",
)
opt_mod = torch._dynamo.optimize(dynamo_minifier_backend)(mod)
with torch.cuda.amp.autocast(enabled=False):
opt_mod(*args)
```
Error:
```
return CppCodeCache.load(source_code).kernel
File "/home/jthakur/.pt_2_0/lib/python3.8/site-packages/torch/_inductor/codecache.py", line 506, in load
raise exc.CppCompileError(cmd, e.output) from e
torch._inductor.exc.CppCompileError: C++ compile error
```
### Versions
Versions of relevant libraries:
[pip3] numpy==1.24.1
[pip3] torch==2.0.0.dev20230209+cpu
[pip3] torchaudio==2.0.0.dev20230209+cpu
[pip3] torchvision==0.15.0.dev20230209+cpu
cc @ezyang @soumith @msaroufim @wconstab @ngimel @bdhirsh
| 6 |
3,408 | 95,186 |
Pytorch 2.0 [compile] as_strided inplace causes out of bounds for storage
|
triaged, oncall: pt2, module: dynamo
|
### 🐛 Describe the bug
Please use below code to reproduce error:
```
import os
from math import inf
import torch
from torch import tensor, device
import torch.fx as fx
import functools
import torch._dynamo
from torch._dynamo.debug_utils import run_fwd_maybe_bwd
from torch._dynamo.backends.registry import lookup_backend
from torch._dynamo.testing import rand_strided
import torch._dynamo.config
import torch._inductor.config
import torch._functorch.config
torch._dynamo.config.load_config(b'\x80\x02}q\x00(X\x0b\x00\x00\x00output_codeq\x01\x89X\r\x00\x00\x00log_file_nameq\x02NX\x07\x00\x00\x00verboseq\x03\x89X\x11\x00\x00\x00output_graph_codeq\x04\x89X\x12\x00\x00\x00verify_correctnessq\x05\x89X\x12\x00\x00\x00minimum_call_countq\x06K\x01X\x15\x00\x00\x00dead_code_eliminationq\x07\x88X\x10\x00\x00\x00cache_size_limitq\x08M\xb8\x0bX\x14\x00\x00\x00specialize_int_floatq\t\x88X\x0e\x00\x00\x00dynamic_shapesq\n\x89X\x10\x00\x00\x00guard_nn_modulesq\x0b\x89X\x1b\x00\x00\x00traceable_tensor_subclassesq\x0cc__builtin__\nset\nq\r]q\x0e\x85q\x0fRq\x10X\x0f\x00\x00\x00suppress_errorsq\x11\x89X\x15\x00\x00\x00replay_record_enabledq\x12\x89X \x00\x00\x00rewrite_assert_with_torch_assertq\x13\x88X\x12\x00\x00\x00print_graph_breaksq\x14\x89X\x07\x00\x00\x00disableq\x15\x89X*\x00\x00\x00allowed_functions_module_string_ignorelistq\x16h\r]q\x17(X\x0b\x00\x00\x00torch._refsq\x18X\r\x00\x00\x00torch._decompq\x19X\x13\x00\x00\x00torch.distributionsq\x1aX\x0c\x00\x00\x00torch._primsq\x1bX\r\x00\x00\x00torch.testingq\x1ce\x85q\x1dRq\x1eX\x12\x00\x00\x00repro_forward_onlyq\x1f\x89X\x0f\x00\x00\x00repro_toleranceq G?PbM\xd2\xf1\xa9\xfcX\x16\x00\x00\x00capture_scalar_outputsq!\x89X\x19\x00\x00\x00enforce_cond_guards_matchq"\x88X\x0c\x00\x00\x00optimize_ddpq#\x88X\x1a\x00\x00\x00raise_on_ctx_manager_usageq$\x88X\x1c\x00\x00\x00raise_on_unsafe_aot_autogradq%\x89X\x18\x00\x00\x00error_on_nested_fx_traceq&\x88X\t\x00\x00\x00allow_rnnq\'\x89X\x08\x00\x00\x00base_dirq(X1\x00\x00\x00/home/jthakur/.pt_2_0/lib/python3.8/site-packagesq)X\x0e\x00\x00\x00debug_dir_rootq*Xm\x00\x00\x00/home/jthakur/qnpu/1.9.0-413/src/pytorch-training-tests/tests/torch_feature_val/single_op/torch_compile_debugq+X)\x00\x00\x00DO_NOT_USE_legacy_non_fake_example_inputsq,\x89X\x13\x00\x00\x00_save_config_ignoreq-h\r]q.(X!\x00\x00\x00skipfiles_inline_module_allowlistq/X\x0b\x00\x00\x00repro_afterq0X\x0b\x00\x00\x00repro_levelq1X\x12\x00\x00\x00constant_functionsq2e\x85q3Rq4u.')
torch._inductor.config.load_config(b'\x80\x02}q\x00(X\x05\x00\x00\x00debugq\x01\x89X\x10\x00\x00\x00disable_progressq\x02\x88X\x10\x00\x00\x00verbose_progressq\x03\x89X\x0b\x00\x00\x00cpp_wrapperq\x04\x89X\x03\x00\x00\x00dceq\x05\x89X\x14\x00\x00\x00static_weight_shapesq\x06\x88X\x0c\x00\x00\x00size_assertsq\x07\x88X\x10\x00\x00\x00pick_loop_ordersq\x08\x88X\x0f\x00\x00\x00inplace_buffersq\t\x88X\x11\x00\x00\x00benchmark_harnessq\n\x88X\x0f\x00\x00\x00epilogue_fusionq\x0b\x89X\x15\x00\x00\x00epilogue_fusion_firstq\x0c\x89X\x0f\x00\x00\x00pattern_matcherq\r\x88X\n\x00\x00\x00reorderingq\x0e\x89X\x0c\x00\x00\x00max_autotuneq\x0f\x89X\x17\x00\x00\x00realize_reads_thresholdq\x10K\x04X\x17\x00\x00\x00realize_bytes_thresholdq\x11M\xd0\x07X\x1b\x00\x00\x00realize_acc_reads_thresholdq\x12K\x08X\x0f\x00\x00\x00fallback_randomq\x13\x89X\x12\x00\x00\x00implicit_fallbacksq\x14\x88X\r\x00\x00\x00prefuse_nodesq\x15\x88X\x0b\x00\x00\x00tune_layoutq\x16\x89X\x11\x00\x00\x00aggressive_fusionq\x17\x89X\x0f\x00\x00\x00max_fusion_sizeq\x18K@X\x1b\x00\x00\x00unroll_reductions_thresholdq\x19K\x08X\x0e\x00\x00\x00comment_originq\x1a\x89X\x0f\x00\x00\x00compile_threadsq\x1bK\x0cX\x13\x00\x00\x00kernel_name_max_opsq\x1cK\nX\r\x00\x00\x00shape_paddingq\x1d\x89X\x0e\x00\x00\x00permute_fusionq\x1e\x89X\x1a\x00\x00\x00profiler_mark_wrapper_callq\x1f\x89X\x0b\x00\x00\x00cpp.threadsq J\xff\xff\xff\xffX\x13\x00\x00\x00cpp.dynamic_threadsq!\x89X\x0b\x00\x00\x00cpp.simdlenq"NX\x12\x00\x00\x00cpp.min_chunk_sizeq#M\x00\x10X\x07\x00\x00\x00cpp.cxxq$NX\x03\x00\x00\x00g++q%\x86q&X\x19\x00\x00\x00cpp.enable_kernel_profileq\'\x89X\x12\x00\x00\x00cpp.weight_prepackq(\x88X\x11\x00\x00\x00triton.cudagraphsq)\x89X\x17\x00\x00\x00triton.debug_sync_graphq*\x89X\x18\x00\x00\x00triton.debug_sync_kernelq+\x89X\x12\x00\x00\x00triton.convolutionq,X\x04\x00\x00\x00atenq-X\x15\x00\x00\x00triton.dense_indexingq.\x89X\x10\x00\x00\x00triton.max_tilesq/K\x02X\x19\x00\x00\x00triton.autotune_pointwiseq0\x88X\'\x00\x00\x00triton.tiling_prevents_pointwise_fusionq1\x88X\'\x00\x00\x00triton.tiling_prevents_reduction_fusionq2\x88X\x1b\x00\x00\x00triton.ordered_kernel_namesq3\x89X\x1f\x00\x00\x00triton.descriptive_kernel_namesq4\x89X\r\x00\x00\x00trace.enabledq5\x89X\x0f\x00\x00\x00trace.debug_logq6\x88X\x0e\x00\x00\x00trace.info_logq7\x89X\x0e\x00\x00\x00trace.fx_graphq8\x88X\x1a\x00\x00\x00trace.fx_graph_transformedq9\x88X\x13\x00\x00\x00trace.ir_pre_fusionq:\x88X\x14\x00\x00\x00trace.ir_post_fusionq;\x88X\x11\x00\x00\x00trace.output_codeq<\x88X\x13\x00\x00\x00trace.graph_diagramq=\x89X\x15\x00\x00\x00trace.compile_profileq>\x89X\x10\x00\x00\x00trace.upload_tarq?Nu.')
torch._functorch.config.load_config(b'\x80\x02}q\x00(X\x11\x00\x00\x00use_functionalizeq\x01\x88X\x0f\x00\x00\x00use_fake_tensorq\x02\x88X\x16\x00\x00\x00fake_tensor_allow_metaq\x03\x88X\x0c\x00\x00\x00debug_assertq\x04\x88X\x14\x00\x00\x00debug_fake_cross_refq\x05\x89X\x11\x00\x00\x00debug_partitionerq\x06\x89X\x0c\x00\x00\x00debug_graphsq\x07\x89X\x0b\x00\x00\x00debug_jointq\x08\x89X\x12\x00\x00\x00use_dynamic_shapesq\t\x89X\x14\x00\x00\x00static_weight_shapesq\n\x88X\x03\x00\x00\x00cseq\x0b\x88X\x10\x00\x00\x00max_dist_from_bwq\x0cK\x03X\t\x00\x00\x00log_levelq\rK\x14u.')
# REPLACEABLE COMMENT FOR TESTING PURPOSES
args = [((2, 2), (2, 2), torch.float32, 'cpu', False)]
args = [rand_strided(sh, st, dt, dev).requires_grad_(rg) for (sh, st, dt, dev, rg) in args]
from torch.nn import *
class Repro(torch.nn.Module):
def __init__(self):
super().__init__()
def forward(self, in_out_tensor : torch.Tensor):
as_strided_ = in_out_tensor.as_strided_(size = [2, 2], stride = [2, 2], storage_offset = 7); in_out_tensor = None
return (as_strided_,)
mod = Repro()
# Setup debug minifier compiler
torch._dynamo.debug_utils.MINIFIER_SPAWNED = True
compiler_fn = lookup_backend("dynamo_minifier_backend")
dynamo_minifier_backend = functools.partial(
compiler_fn,
compiler_name="inductor",
)
opt_mod = torch._dynamo.optimize(dynamo_minifier_backend)(mod)
with torch.cuda.amp.autocast(enabled=False):
opt_mod(*args)
```
The same code works fine in eager mode. This issue only seen in compile mode.
Error:
```
File "/home/jthakur/.pt_2_0/lib/python3.8/site-packages/torch/_ops.py", line 284, in __call__
return self._op(*args, **kwargs or {})
RuntimeError: setStorage: sizes [2, 2], strides [2, 2], storage offset 7, and itemsize 4 requiring a storage size of 48 are out of bounds for storage of size 20
The above exception was the direct cause of the following exception:
```
### Versions
Versions of relevant libraries:
[pip3] numpy==1.24.1
[pip3] torch==2.0.0.dev20230209+cpu
[pip3] torchaudio==2.0.0.dev20230209+cpu
[pip3] torchvision==0.15.0.dev20230209+cpu
cc @ezyang @soumith @msaroufim @wconstab @ngimel @bdhirsh @voznesenskym @yanboliang @penguinwu @anijain2305 @EikanWang @jgong5 @Guobing-Chen @XiaobingSuper @zhuhaozhe @blzheng @Xia-Weiwen @wenzhe-nrv @jiayisunx @desertfire
| 1 |
3,409 | 95,172 |
DISABLED test_memory_format_nn_ConvTranspose2d_cuda_complex32 (__main__.TestModuleCUDA)
|
module: nn, triaged, module: flaky-tests, skipped
|
Platforms: rocm
This test was disabled because it is failing in CI. See [recent examples](https://hud.pytorch.org/failure/test_memory_format_nn_ConvTranspose2d_cuda_complex32) and the most recent trunk [workflow logs](https://github.com/pytorch/pytorch/runs/11473508755).
Over the past 72 hours, it has flakily failed in 2 workflow(s).
**Debugging instructions (after clicking on the recent samples link):**
To find relevant log snippets:
1. Click on the workflow logs linked above
2. Grep for `test_memory_format_nn_ConvTranspose2d_cuda_complex32`
Test file path: `test_modules.py`
cc @albanD @mruberry @jbschlosser @walterddr @saketh-are
| 5 |
3,410 | 95,169 |
COO @ COO tries to allocate way too much memory on CUDA
|
module: sparse, module: cuda, triaged, matrix multiplication
|
### 🐛 Describe the bug
```python
In [1]: import torch
In [2]: x = torch.rand(1000, 1000, device='cuda')
In [3]: %timeit x @ x
19.7 µs ± 10.9 µs per loop (mean ± std. dev. of 7 runs, 1 loop each)
In [4]: %timeit x @ x.to_sparse()
21 ms ± 598 µs per loop (mean ± std. dev. of 7 runs, 1 loop each)
In [5]: %timeit x.to_sparse() @ x
30.9 ms ± 72.5 µs per loop (mean ± std. dev. of 7 runs, 10 loops each)
In [6]: %timeit x.to_sparse() @ x.to_sparse()
---------------------------------------------------------------------------
OutOfMemoryError Traceback (most recent call last)
Input In [6], in <cell line: 1>()
----> 1 get_ipython().run_line_magic('timeit', 'x.to_sparse() @ x.to_sparse()')
File ~/.conda/envs/pytorch-cuda-dev-nik/lib/python3.10/site-packages/IPython/core/interactiveshell.py:2305, in InteractiveShell.run_line_magic(self, magic_name, line, _stack_depth)
2303 kwargs['local_ns'] = self.get_local_scope(stack_depth)
2304 with self.builtin_trap:
-> 2305 result = fn(*args, **kwargs)
2306 return result
File ~/.conda/envs/pytorch-cuda-dev-nik/lib/python3.10/site-packages/IPython/core/magics/execution.py:1162, in ExecutionMagics.timeit(self, line, cell, local_ns)
1160 for index in range(0, 10):
1161 number = 10 ** index
-> 1162 time_number = timer.timeit(number)
1163 if time_number >= 0.2:
1164 break
File ~/.conda/envs/pytorch-cuda-dev-nik/lib/python3.10/site-packages/IPython/core/magics/execution.py:156, in Timer.timeit(self, number)
154 gc.disable()
155 try:
--> 156 timing = self.inner(it, self.timer)
157 finally:
158 if gcold:
File <magic-timeit>:1, in inner(_it, _timer)
OutOfMemoryError: CUDA out of memory. Tried to allocate 22.37 GiB (GPU 0; 5.78 GiB total capacity; 71.10 MiB already allocated; 4.99 GiB free; 86.00 MiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
```
### Versions
Current master.
cc @alexsamardzic @pearu @cpuhrsch @amjames @bhosmer @ngimel
| 0 |
3,411 | 95,161 |
AOTAutograd based torch.compile doesn't capture manual seed setting in the graph
|
triaged, oncall: pt2, module: dynamo
|
### 🐛 Describe the bug
The following code breaks with AOTautograd based 2.0 torch.compile -
```
from typing import List
import torch
import torch._dynamo as dynamo
from torch._functorch.aot_autograd import aot_module_simplified
dynamo.reset()
def my_non_aot_compiler(gm: torch.fx.GraphModule, example_inputs: List[torch.Tensor]):
print(gm.code)
return gm.forward
def my_aot_compiler(gm: torch.fx.GraphModule, example_inputs: List[torch.Tensor]):
def my_compiler(gm: torch.fx.GraphModule, example_inputs: List[torch.Tensor]):
print(gm.code)
return gm.forward
# Invoke AOTAutograd
return aot_module_simplified(
gm,
example_inputs,
fw_compiler=my_compiler
)
def my_example():
torch.manual_seed(0)
d_float32 = torch.rand((8, 8), device="cpu")
return d_float32 + d_float32
compiled_fn = torch.compile(backend=my_aot_compiler)(my_example)
#compiled_fn = torch.compile(backend=my_non_aot_compiler)(my_example)
r1 = compiled_fn()
r2 = compiled_fn()
print("Results match? ", torch.allclose(r1, r2, atol = 0.001, rtol = 0.001))
```
When ```my_aot_compiler``` is used, the result is wrong as the graph doesn't capture torch.manual_seed -
```
def forward(self):
rand = torch.ops.aten.rand.default([8, 8], device = device(type='cpu'), pin_memory = False)
add = torch.ops.aten.add.Tensor(rand, rand); rand = None
return (add,)
Results match? False
/usr/local/lib/python3.8/dist-packages/torch/_functorch/aot_autograd.py:1251: UserWarning: Your compiler for AOTAutograd is returning a a function that doesn't take boxed arguments. Please wrap it with functorch.compile.make_boxed_func or handle the boxed arguments yourself. See https://github.com/pytorch/pytorch/pull/83137#issuecomment-1211320670 for rationale.
warnings.warn(
```
However, when a non-AOT autograd based compiler ```my_non_aot_compiler``` is used, torch.manual_seed is captured in the graph and the result is correct -
```
def forward(self):
manual_seed = torch.random.manual_seed(0)
rand = torch.rand((8, 8), device = 'cpu')
add = rand + rand; rand = None
return (add,)
Results match? True
```
### Versions
PyTorch version: 2.0.0.dev20230220+cu117
Is debug build: False
CUDA used to build PyTorch: 11.7
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.5 LTS (x86_64)
GCC version: (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0
Clang version: 10.0.0-4ubuntu1
CMake version: version 3.25.2
Libc version: glibc-2.31
Python version: 3.8.10 (default, Nov 14 2022, 12:59:47) [GCC 9.4.0] (64-bit runtime)
Python platform: Linux-5.10.147+-x86_64-with-glibc2.29
Is CUDA available: True
CUDA runtime version: 11.6.124
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration: GPU 0: Tesla T4
Nvidia driver version: 510.47.03
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.4.0
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.4.0
/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.4.0
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_infer.so.8.4.0
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.4.0
/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.4.0
/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.4.0
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
Address sizes: 46 bits physical, 48 bits virtual
CPU(s): 2
On-line CPU(s) list: 0,1
Thread(s) per core: 2
Core(s) per socket: 1
Socket(s): 1
NUMA node(s): 1
Vendor ID: GenuineIntel
CPU family: 6
Model: 85
Model name: Intel(R) Xeon(R) CPU @ 2.00GHz
Stepping: 3
CPU MHz: 2000.140
BogoMIPS: 4000.28
Hypervisor vendor: KVM
Virtualization type: full
L1d cache: 32 KiB
L1i cache: 32 KiB
L2 cache: 1 MiB
L3 cache: 38.5 MiB
NUMA node0 CPU(s): 0,1
Vulnerability Itlb multihit: Not affected
Vulnerability L1tf: Mitigation; PTE Inversion
Vulnerability Mds: Vulnerable; SMT Host state unknown
Vulnerability Meltdown: Vulnerable
Vulnerability Mmio stale data: Vulnerable
Vulnerability Retbleed: Vulnerable
Vulnerability Spec store bypass: Vulnerable
Vulnerability Spectre v1: Vulnerable: __user pointer sanitization and usercopy barriers only; no swapgs barriers
Vulnerability Spectre v2: Vulnerable, IBPB: disabled, STIBP: disabled, PBRSB-eIBRS: Not affected
Vulnerability Srbds: Not affected
Vulnerability Tsx async abort: Vulnerable
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ss ht syscall nx pdpe1gb rdtscp lm constant_tsc rep_good nopl xtopology nonstop_tsc cpuid tsc_known_freq pni pclmulqdq ssse3 fma cx16 pcid sse4_1 sse4_2 x2apic movbe popcnt aes xsave avx f16c rdrand hypervisor lahf_lm abm 3dnowprefetch invpcid_single ssbd ibrs ibpb stibp fsgsbase tsc_adjust bmi1 hle avx2 smep bmi2 erms invpcid rtm mpx avx512f avx512dq rdseed adx smap clflushopt clwb avx512cd avx512bw avx512vl xsaveopt xsavec xgetbv1 xsaves arat md_clear arch_capabilities
Versions of relevant libraries:
[pip3] numpy==1.24.2
[pip3] pytorch-triton==2.0.0+c8bfe3f548
[pip3] torch==2.0.0.dev20230220+cu117
[pip3] torchaudio==0.13.1+cu116
[pip3] torchsummary==1.5.1
[pip3] torchtext==0.14.1
[pip3] torchvision==0.14.1+cu116
[conda] Could not collect
cc @ezyang @soumith @msaroufim @wconstab @ngimel @bdhirsh @voznesenskym @yanboliang @penguinwu @anijain2305 @EikanWang @jgong5 @Guobing-Chen @XiaobingSuper @zhuhaozhe @blzheng @Xia-Weiwen @wenzhe-nrv @jiayisunx @desertfire
| 2 |
3,412 | 95,160 |
Reversing along a dimension, similarly to numpy
|
feature, triaged, module: numpy, module: advanced indexing
|
### 🚀 The feature, motivation and pitch
In `numpy` you can reverse an array as `arr[::-1]` along any dimension. The same in `torch` raises an error: `ValueError: step must be greater than zero`. It would be useful if both operated the same way.
### Alternatives
_No response_
### Additional context
_No response_
cc @mruberry @rgommers
| 0 |
3,413 | 95,146 |
Whether to consider native support for intel gpu?
|
triaged, module: intel
|
### 🚀 The feature, motivation and pitch
I hope that the support for intel gpu can be implemented like cuda, rather than in the form of plug-ins。I wonder if you have such plans in the future
### Alternatives
_No response_
### Additional context
_No response_
cc @frank-wei @jgong5 @mingfeima @XiaobingSuper @sanchitintel @ashokei @jingxu10
| 2 |
3,414 | 95,135 |
Add local version identifier to wheel file names
|
module: build, triaged
|
### 🚀 The feature, motivation and pitch
Hello 👋 Thank you for maintaining pytorch 🙇 It's a joy to use and I'm very excited about the 2.0 release!
I've found a tiny quality of life improvement surrounding the precompiled wheel available at https://download.pytorch.org/whl/ .
Currently users are unable to tell `pip` that a specific compiled version of torch should be re-installed from a different whl.
For example;
```
# Install torch
$ pip install 'torch>=1.13.0+cpu' --find-links https://download.pytorch.org/whl/cpu/torch_stable.html
Looking in indexes: https://alexander.vaneck:****@artifactory.paigeai.net/artifactory/api/pypi/pypi/simple
Looking in links: https://download.pytorch.org/whl/cpu/torch_stable.html
Collecting torch>=1.13.0+cpu
Using cached https://artifactory.paigeai.net/artifactory/api/pypi/pypi/packages/packages/82/d8/0547f8a22a0c8aeb7e7e5e321892f1dcf93ea021829a99f1a25f1f535871/torch-1.13.1-cp310-none-macosx_10_9_x86_64.whl (135.3 MB)
...
Installing collected packages: typing-extensions, torch
Successfully installed torch-1.13.1 typing-extensions-4.5.0
# Then later install torch for cu116
$ pip install 'torch>=1.13.0+cu116' --find-links https://download.pytorch.org/whl/cu116/torch_stable.html
Looking in indexes: https://alexander.vaneck:****@artifactory.paigeai.net/artifactory/api/pypi/pypi/simple
Looking in links: https://download.pytorch.org/whl/cu116/torch_stable.html
Requirement already satisfied: torch>=1.13.0+cu116 in ./.virtualenvs/torch-links/lib/python3.10/site-packages (1.13.1)
Requirement already satisfied: typing-extensions in ./.virtualenvs/torch-links/lib/python3.10/site-packages (from torch>=1.13.0+cu116) (4.5.0)
# We now hold CPU torch for CUDA 11.6 enabled environment.
```
It would be mighty handy if the wheels provided would include the [local version identifiers](https://peps.python.org/pep-0440/#local-version-identifiers) for the environment they are built in, f.e. `torch-1.13.1+cu116-cp39-cp39-manylinux2014_aarch64.whl`. And as local version identifiers are optional it would have no impact on the current dependency resolution.
### Alternatives
_No response_
### Additional context
_No response_
cc @malfet @seemethere
| 2 |
3,415 | 95,132 |
Differentiate with regard a subset of the input
|
feature, module: autograd, triaged
|
### 🚀 The feature, motivation and pitch
Hi,
When I want to differentiate with regard to the first element in a batch, I get an error, as shown in the following example:
```python
n, d = 10, 3
lin1 = nn.Linear(d, d)
# case 1
x = torch.randn(d).requires_grad_()
y = lin1(x)
vec = torch.ones(d)
gr = torch.autograd.grad(y, x, vec, retain_graph=True)[0]
print(gr.shape) # returns: torch.Size([3])
# case 2
x = torch.randn(n, d).requires_grad_()
y = lin1(x)
vec = torch.ones(d)
gr = torch.autograd.grad(y[0], x[0], vec, retain_graph=True)[0]
# Raises Error:
# RuntimeError: One of the differentiated Tensors appears to not have been used in the graph. Set allow_unused=True if this is the desired behavior.
```
so taking x[i] removes it from the computation graph, I tried to clone it or to use .narrow but in vain!
y[0] only depends on x[0], so I don’t want to compute the gradient with regard to the full input!
Is there a way to do this efficiently?
### Alternatives
_No response_
### Additional context
_No response_
cc @ezyang @albanD @zou3519 @gqchen @pearu @nikitaved @soulitzer @Lezcano @Varal7
| 4 |
3,416 | 95,129 |
Default value of `validate_args` is set to `True` when passed as `None` in `Multinomial`
|
module: distributions, triaged
|
Running
https://github.com/pytorch/pytorch/blob/17d0b7f532c4b3cd4af22ee0cb25ff12dada85cb/torch/distributions/multinomial.py#L40-L41
produces
```
ValueError: Expected value argument (Tensor of shape (4,)) to be within the support (Multinomial()) of the distribution Multinomial(), but found invalid values:
tensor([2, 5, 2, 1])
```
I believe it is because the default value of `validate_args` is set to `True`.
cc @fritzo @neerajprad @alicanb @nikitaved
| 2 |
3,417 | 95,124 |
`INTERNAL ASSERT FAILED` -When using the PyTorch docker environment released by pytorch, a Vulcan support issue occurs
|
module: build, triaged, module: docker
|
### 🐛 Describe the bug
When I run `torch.nn.Linear` or `torch.nn.ConvTranspose2d` with `optimize_for_mobile` in the packaged docker environment [released by pytorch](https://hub.docker.com/u/pytorch), a Vulcan support issue occurs, and then crashes.
It is similar to [#86791](https://github.com/pytorch/pytorch/issues/86791).
It seems that the currently released docker environments may have some flags not enabled during building, resulting in some functions not working properly (regardless of `runtime` environment or `devel` environment).
I wonder if this is expected behavior and if I always need to manually build pytorch from the source to enable some special support.
### To Reproduce
```python
from torch import nn
import torch
from torch.utils.mobile_optimizer import optimize_for_mobile
with torch.no_grad():
x = torch.ones(1, 3, 32, 32)
def test():
tmp_result= torch.nn.ConvTranspose2d(3, 3, kernel_size=1)
# tmp_result= torch.nn.Linear(32, 32)
return tmp_result
model = test()
optimized_traced = optimize_for_mobile(torch.jit.trace(model, x), backend='vulkan')
```
The error result is
```
Traceback (most recent call last):
File "test.py", line 15, in <module>
optimized_traced = optimize_for_mobile(torch.jit.trace(model, x), backend='vulkan')
File "/opt/conda/lib/python3.7/site-packages/torch/utils/mobile_optimizer.py", line 67, in optimize_for_mobile
optimized_cpp_module = torch._C._jit_pass_vulkan_optimize_for_mobile(script_module._c, preserved_methods_str)
RuntimeError: 0 INTERNAL ASSERT FAILED at "/opt/conda/conda-bld/pytorch_1656352464346/work/torch/csrc/jit/ir/alias_analysis.cpp":608, please report a bug to PyTorch. We don't have an op for vulkan_prepack::linear_prepack but it isn't a special case. Argument types: Tensor, Tensor,
```
### Expected behavior
It is hoped that the docker environments released by pytorch can be built with these flags to enable corresponding support and ensure that all torch functions are implemented as expected.
### Versions
docker pull command:
```
docker pull pytorch/pytorch:1.10.0-cuda11.3-cudnn8-devel
docker pull pytorch/pytorch:1.12.0-cuda11.3-cudnn8-runtime
docker pull pytorch/pytorch:1.13.0-cuda11.6-cudnn8-runtime
```
<details>
<summary>pytorch 1.10.0</summary>
<pre><code>
[pip3] numpy==1.21.2
[pip3] torch==1.10.0
[pip3] torch-tb-profiler==0.4.0
[pip3] torchelastic==0.2.0
[pip3] torchtext==0.11.0
[pip3] torchvision==0.11.0
[conda] blas 1.0 mkl
[conda] cudatoolkit 11.3.1 ha36c431_9 nvidia
[conda] ffmpeg 4.3 hf484d3e_0 pytorch
[conda] mkl 2021.3.0 h06a4308_520
[conda] mkl-service 2.4.0 py37h7f8727e_0
[conda] mkl_fft 1.3.1 py37hd3c417c_0
[conda] mkl_random 1.2.2 py37h51133e4_0
[conda] numpy 1.21.2 py37h20f2e39_0
[conda] numpy-base 1.21.2 py37h79a1101_0
[conda] pytorch 1.10.0 py3.7_cuda11.3_cudnn8.2.0_0 pytorch
[conda] pytorch-mutex 1.0 cuda pytorch
[conda] torch-tb-profiler 0.4.0 pypi_0 pypi
[conda] torchelastic 0.2.0 pypi_0 pypi
[conda] torchtext 0.11.0 py37 pytorch
[conda] torchvision 0.11.0 py37_cu113 pytorch</code></pre>
</details>
<details>
<summary>pytorch 1.12.0</summary>
<pre><code>
[pip3] numpy==1.21.5
[pip3] torch==1.12.0
[pip3] torchelastic==0.2.0
[pip3] torchtext==0.13.0
[pip3] torchvision==0.13.0
[conda] blas 1.0 mkl
[conda] cudatoolkit 11.3.1 ha36c431_9 nvidia
[conda] ffmpeg 4.3 hf484d3e_0 pytorch
[conda] mkl 2021.4.0 h06a4308_640
[conda] mkl-service 2.4.0 py37h7f8727e_0
[conda] mkl_fft 1.3.1 py37hd3c417c_0
[conda] mkl_random 1.2.2 py37h51133e4_0
[conda] numpy 1.21.5 py37he7a7128_2
[conda] numpy-base 1.21.5 py37hf524024_2
[conda] pytorch 1.12.0 py3.7_cuda11.3_cudnn8.3.2_0 pytorch
[conda] pytorch-mutex 1.0 cuda pytorch
[conda] torchelastic 0.2.0 pypi_0 pypi
[conda] torchtext 0.13.0 py37 pytorch
[conda] torchvision 0.13.0 py37_cu113 pytorch</code></pre>
</details>
<details>
<summary>pytorch 1.13.0</summary>
<pre><code>
[pip3] numpy==1.22.3
[pip3] torch==1.13.0
[pip3] torchtext==0.14.0
[pip3] torchvision==0.14.0
[conda] blas 1.0 mkl
[conda] ffmpeg 4.3 hf484d3e_0 pytorch
[conda] mkl 2021.4.0 h06a4308_640
[conda] mkl-service 2.4.0 py39h7f8727e_0
[conda] mkl_fft 1.3.1 py39hd3c417c_0
[conda] mkl_random 1.2.2 py39h51133e4_0
[conda] numpy 1.22.3 py39he7a7128_0
[conda] numpy-base 1.22.3 py39hf524024_0
[conda] pytorch 1.13.0 py3.9_cuda11.6_cudnn8.3.2_0 pytorch
[conda] pytorch-cuda 11.6 h867d48c_0 pytorch
[conda] pytorch-mutex 1.0 cuda pytorch
[conda] torchtext 0.14.0 py39 pytorch
[conda] torchvision 0.14.0 py39_cu116 pytorch</code></pre>
</details>
cc @malfet @seemethere
| 0 |
3,418 | 95,122 |
CosineAnnealingWarmRestarts but restarts are becoming more frequent
|
triaged, module: LrScheduler
|
I'm training a model on a large dataset (1 epoch is more than 3000 iterations). An ideal learning rate scheduler is CosineAnnealingWarmRestarts in my case but it would be better if it would make restarts more frequently as training goes further. I tried to pass 0.5 for `T_mult` but it didn't work. I got this error `ValueError: Expected integer T_mult >= 1, but got 0.5`. I think it can be implemented safely with integer division `T_0 // T_mult`. Is there any special reason not to implement this functionality?
| 0 |
3,419 | 95,121 |
cuda 12 support request.
|
module: cuda, triaged
|
### 🚀 The feature, motivation and pitch
graphical card is 4070ti (which is released 2023.1.4)
cuda version 12.
can't find correct version on https://pytorch.org/get-started/locally/
### Alternatives
_No response_
### Additional context
_No response_
cc @ngimel
| 4 |
3,420 | 95,116 |
When using `ceil_mode=True`, `torch.nn.AvgPool1d` could get negative shape.
|
module: bc-breaking, triaged, module: shape checking, topic: bc breaking
|
### 🐛 Describe the bug
It is similar to [#88464](https://github.com/pytorch/pytorch/issues/88464), `torch.nn.AvgPool1d` can also get negative shape with specific input shape when `ceil_mode=True` in Pytorch 1.9.0\1.10.0\1.11.0\1.12.0\1.13.0.
The reason for this behavior seems to be that the calculation with `ceil_mode` parameter by both `torch.nn.AvgPool` and `torch.nn.MaxPool` are similar.
### To Reproduce
```python
import torch
def test():
tmp_result= torch.nn.AvgPool1d(kernel_size=4, stride=1, padding=0, ceil_mode=True)
return tmp_result
m = test()
input = torch.randn(20, 16, 1)
output = m(input)
```
The error result is
```
Traceback (most recent call last): File "vanilla.py", line 9, in <module>
output = m(input)
File "/opt/conda/lib/python3.7/site-packages/torch/nn/modules/module.py", line 1130, in _call_impl
return forward_call(*input, **kwargs)
File "/opt/conda/lib/python3.7/site-packages/torch/nn/modules/pooling.py", line 544, in forward
self.count_include_pad)
RuntimeError: Given input size: (16x1x1). Calculated output size: (16x1x-2). Output size is too small
```
### Expected behavior
It is hoped that after solving the problem of `MaxPool1d`, this similar bug of `AvgPool1d` can be fixed together.
### Versions
<details>
<summary>pytorch 1.9.0</summary>
<pre><code>
[pip3] numpy==1.20.2
[pip3] torch==1.9.0
[pip3] torchelastic==0.2.0
[pip3] torchtext==0.10.0
[pip3] torchvision==0.10.0
[conda] blas 1.0 mkl
[conda] cudatoolkit 11.1.74 h6bb024c_0 nvidia
[conda] ffmpeg 4.3 hf484d3e_0 pytorch
[conda] mkl 2021.2.0 h06a4308_296
[conda] mkl-service 2.3.0 py37h27cfd23_1
[conda] mkl_fft 1.3.0 py37h42c9631_2
[conda] mkl_random 1.2.1 py37ha9443f7_2
[conda] numpy 1.20.2 py37h2d18471_0
[conda] numpy-base 1.20.2 py37hfae3a4d_0
[conda] pytorch 1.9.0 py3.7_cuda11.1_cudnn8.0.5_0 pytorch
[conda] torchelastic 0.2.0 pypi_0 pypi
[conda] torchtext 0.10.0 py37 pytorch
[conda] torchvision 0.10.0 py37_cu111 pytorch</code></pre>
</details>
<details>
<summary>pytorch 1.10.0</summary>
<pre><code>
[pip3] numpy==1.21.2
[pip3] torch==1.10.0
[pip3] torch-tb-profiler==0.4.0
[pip3] torchelastic==0.2.0
[pip3] torchtext==0.11.0
[pip3] torchvision==0.11.0
[conda] blas 1.0 mkl
[conda] cudatoolkit 11.3.1 ha36c431_9 nvidia
[conda] ffmpeg 4.3 hf484d3e_0 pytorch
[conda] mkl 2021.3.0 h06a4308_520
[conda] mkl-service 2.4.0 py37h7f8727e_0
[conda] mkl_fft 1.3.1 py37hd3c417c_0
[conda] mkl_random 1.2.2 py37h51133e4_0
[conda] numpy 1.21.2 py37h20f2e39_0
[conda] numpy-base 1.21.2 py37h79a1101_0
[conda] pytorch 1.10.0 py3.7_cuda11.3_cudnn8.2.0_0 pytorch
[conda] pytorch-mutex 1.0 cuda pytorch
[conda] torch-tb-profiler 0.4.0 pypi_0 pypi
[conda] torchelastic 0.2.0 pypi_0 pypi
[conda] torchtext 0.11.0 py37 pytorch
[conda] torchvision 0.11.0 py37_cu113 pytorch</code></pre>
</details>
<details>
<summary>pytorch 1.11.0</summary>
<pre><code>
[pip3] numpy==1.21.6
[pip3] pytorch-lightning==1.6.3
[pip3] torch==1.11.0
[pip3] torch-tb-profiler==0.4.0
[pip3] torchaudio==0.11.0
[pip3] torchmetrics==0.9.0
[pip3] torchvision==0.12.0
[conda] blas 1.0 mkl
[conda] cudatoolkit 11.3.1 h2bc3f7f_2
[conda] ffmpeg 4.3 hf484d3e_0 pytorch
[conda] mkl 2021.4.0 h06a4308_640
[conda] mkl-service 2.4.0 py38h7f8727e_0
[conda] mkl_fft 1.3.1 py38hd3c417c_0
[conda] mkl_random 1.2.2 py38h51133e4_0
[conda] numpy 1.19.5 pypi_0 pypi
[conda] numpy-base 1.21.5 py38hf524024_1
[conda] pytorch 1.11.0 py3.8_cuda11.3_cudnn8.2.0_0 pytorch
[conda] pytorch-lightning 1.6.3 pypi_0 pypi
[conda] pytorch-mutex 1.0 cuda pytorch
[conda] torch 1.10.0 pypi_0 pypi
[conda] torch-tb-profiler 0.4.0 pypi_0 pypi
[conda] torchaudio 0.11.0 py38_cu113 pytorch
[conda] torchmetrics 0.9.0 pypi_0 pypi
[conda] torchvision 0.12.0 py38_cu113 pytorch</code></pre>
</details>
<details>
<summary>pytorch 1.12.0</summary>
<pre><code>
[pip3] numpy==1.21.5
[pip3] torch==1.12.0
[pip3] torchelastic==0.2.0
[pip3] torchtext==0.13.0
[pip3] torchvision==0.13.0
[conda] blas 1.0 mkl
[conda] cudatoolkit 11.3.1 ha36c431_9 nvidia
[conda] ffmpeg 4.3 hf484d3e_0 pytorch
[conda] mkl 2021.4.0 h06a4308_640
[conda] mkl-service 2.4.0 py37h7f8727e_0
[conda] mkl_fft 1.3.1 py37hd3c417c_0
[conda] mkl_random 1.2.2 py37h51133e4_0
[conda] numpy 1.21.5 py37he7a7128_2
[conda] numpy-base 1.21.5 py37hf524024_2
[conda] pytorch 1.12.0 py3.7_cuda11.3_cudnn8.3.2_0 pytorch
[conda] pytorch-mutex 1.0 cuda pytorch
[conda] torchelastic 0.2.0 pypi_0 pypi
[conda] torchtext 0.13.0 py37 pytorch
[conda] torchvision 0.13.0 py37_cu113 pytorch</code></pre>
</details>
<details>
<summary>pytorch 1.13.0</summary>
<pre><code>
[pip3] numpy==1.22.3
[pip3] torch==1.13.0
[pip3] torchtext==0.14.0
[pip3] torchvision==0.14.0
[conda] blas 1.0 mkl
[conda] ffmpeg 4.3 hf484d3e_0 pytorch
[conda] mkl 2021.4.0 h06a4308_640
[conda] mkl-service 2.4.0 py39h7f8727e_0
[conda] mkl_fft 1.3.1 py39hd3c417c_0
[conda] mkl_random 1.2.2 py39h51133e4_0
[conda] numpy 1.22.3 py39he7a7128_0
[conda] numpy-base 1.22.3 py39hf524024_0
[conda] pytorch 1.13.0 py3.9_cuda11.6_cudnn8.3.2_0 pytorch
[conda] pytorch-cuda 11.6 h867d48c_0 pytorch
[conda] pytorch-mutex 1.0 cuda pytorch
[conda] torchtext 0.14.0 py39 pytorch
[conda] torchvision 0.14.0 py39_cu116 pytorch</code></pre>
</details>
cc @ezyang @gchanan @zou3519
| 0 |
3,421 | 95,112 |
Proposal: `@capture`: Unified API for capturing functions across `{fx, proxy_tensor, dynamo}`
|
module: onnx, feature, triaged, oncall: pt2, module: functorch, module: dynamo
|
> ```python
> # replaces `@fx.wrap`
> @fx.capture
> def my_traced_op(x):
> pass
>
> # new API, similar to `@fx.wrap`. `make_fx` will capture this function.
> @proxy_tensor.capture
> def my_traced_op(x):
> pass
>
> # replaces `dynamo.allow_in_graph`
> @dynamo.capture
> def my_traced_op(x):
> pass
> ```
>
> Can we break backwards compatibility on `wrap`? It is a terrible API due to its name.
> `capture` could be the preferred new API, and `wrap` will simply alias it, then we can deprecate `wrap` slowly.
_Originally posted by @jon-chuang in https://github.com/pytorch/pytorch/issues/94461#issuecomment-1435530121_
Examples of user demand for custom op tracing:
1. https://github.com/pytorch/pytorch/issues/95021
2. https://github.com/pytorch/pytorch/pull/94867
Question: is there overlap between `@dynamo.capture` and `@proxy_tensor.capture`? Whether the fx graph traced by dynamo is traced again by `make_fx` depends on the backend (e.g. `aot_eager`, `inductor`). So I suppose that to trace an op through `torch.compile` and into a backend like aot_eager which uses `make_fx`, one should wrap with both, correct? @jansel
cc @ezyang @soumith @msaroufim @wconstab @ngimel @bdhirsh @zou3519 @Chillee @samdow @kshitij12345 @janeyx99 @voznesenskym @yanboliang @penguinwu @anijain2305 @EikanWang @jgong5 @Guobing-Chen @XiaobingSuper @zhuhaozhe @blzheng @Xia-Weiwen @wenzhe-nrv @jiayisunx @desertfire
| 7 |
3,422 | 95,108 |
`torch.nn.LazyLinear` crash when using torch.bfloat16 dtype in pytorch 1.12.0 and 1.13.0
|
module: nn, triaged, intel
|
### 🐛 Describe the bug
In Pytorch 1.12.0 and 1.13.0, `torch.nn.LazyLinear` will crash when using `torch.bfloat16` dtype, but the same codes run well with `torch.float32`.
I think this issue may have a similar root cause to [#88658](https://github.com/pytorch/pytorch/issues/88658).
In addition, both `torch.nn.Linear` and `torch.nn.LazyLinear` have other interesting errors in Pytorch 1.10.0 and 1.11.0.
When they are using `torch.bfloat16`, they will crash with `RuntimeError: could not create a primitive`, which is a frequent error in PyTorch issues.
This also seems to be another unexpected behavior.
### To Reproduce
```python
from torch import nn
import torch
def test():
tmp_result= torch.nn.LazyLinear(out_features=250880, bias=False, dtype=torch.bfloat16)
return tmp_result
lm_head = test()
input=torch.ones(size=(8,1024,1536), dtype=torch.bfloat16)
output=lm_head(input)
```
The result in 1.12.0 and 1.13.0 is
```
/opt/conda/lib/python3.7/site-packages/torch/nn/modules/lazy.py:178: UserWarning: Lazy modules are a new feature under heavy development so changes to the API or functionality can happen at any moment.
warnings.warn('Lazy modules are a new feature under heavy development '
Traceback (most recent call last):
File "vanilla.py", line 9, in <module>
output=lm_head(input)
File "/opt/conda/lib/python3.7/site-packages/torch/nn/modules/module.py", line 1148, in _call_impl
result = forward_call(*input, **kwargs)
File "/opt/conda/lib/python3.7/site-packages/torch/nn/modules/linear.py", line 114, in forward
return F.linear(input, self.weight, self.bias)
RuntimeError: [enforce fail at alloc_cpu.cpp:66] . DefaultCPUAllocator: can't allocate memory: you tried to allocate 263066747008 bytes. Error code 12 (Cannot allocate memory)
```
The result in 1.10.0 and 1.11.0 is
```
/opt/conda/lib/python3.7/site-packages/torch/nn/modules/lazy.py:178: UserWarning: Lazy modules are a new feature under heavy development so changes to the API or functionality can happen at any moment.
warnings.warn('Lazy modules are a new feature under heavy development '
Traceback (most recent call last):
File "vanilla.py", line 9, in <module>
output=lm_head(input)
File "/opt/conda/lib/python3.7/site-packages/torch/nn/modules/module.py", line 1120, in _call_impl
result = forward_call(*input, **kwargs)
File "/opt/conda/lib/python3.7/site-packages/torch/nn/modules/linear.py", line 103, in forward
return F.linear(input, self.weight, self.bias)
File "/opt/conda/lib/python3.7/site-packages/torch/nn/functional.py", line 1848, in linear
return torch._C._nn.linear(input, weight, bias)
RuntimeError: could not create a primitive
```
### Expected behavior
Maybe it should have a similar performance with the codes with `float32` dtype, as shown in follows (It only raises a warning for Lazy module):
```
/opt/conda/lib/python3.7/site-packages/torch/nn/modules/lazy.py:178: UserWarning: Lazy modules are a new feature under heavy development so changes to the API or functionality can happen at any moment.
warnings.warn('Lazy modules are a new feature under heavy development '
```
### Versions
I use docker to get Pytorch environments.
`docker pull pytorch/pytorch:1.10.0-cuda11.3-cudnn8-devel;
docker pull pytorch/pytorch:1.12.0-cuda11.3-cudnn8-runtime;
docker pull pytorch/pytorch:1.13.0-cuda11.6-cudnn8-runtime`
GPU models and configuration: RTX 3090
pytorch 1.10.0
```
[pip3] numpy==1.21.2
[pip3] torch==1.10.0
[pip3] torch-tb-profiler==0.4.0
[pip3] torchelastic==0.2.0
[pip3] torchtext==0.11.0
[pip3] torchvision==0.11.0
[conda] blas 1.0 mkl
[conda] cudatoolkit 11.3.1 ha36c431_9 nvidia
[conda] ffmpeg 4.3 hf484d3e_0 pytorch
[conda] mkl 2021.3.0 h06a4308_520
[conda] mkl-service 2.4.0 py37h7f8727e_0
[conda] mkl_fft 1.3.1 py37hd3c417c_0
[conda] mkl_random 1.2.2 py37h51133e4_0
[conda] numpy 1.21.2 py37h20f2e39_0
[conda] numpy-base 1.21.2 py37h79a1101_0
[conda] pytorch 1.10.0 py3.7_cuda11.3_cudnn8.2.0_0 pytorch
[conda] pytorch-mutex 1.0 cuda pytorch
[conda] torch-tb-profiler 0.4.0 pypi_0 pypi
[conda] torchelastic 0.2.0 pypi_0 pypi
[conda] torchtext 0.11.0 py37 pytorch
[conda] torchvision 0.11.0 py37_cu113 pytorch
```
pytorch 1.12.0
```
[pip3] numpy==1.21.5
[pip3] torch==1.12.0
[pip3] torchelastic==0.2.0
[pip3] torchtext==0.13.0
[pip3] torchvision==0.13.0
[conda] blas 1.0 mkl
[conda] cudatoolkit 11.3.1 ha36c431_9 nvidia
[conda] ffmpeg 4.3 hf484d3e_0 pytorch
[conda] mkl 2021.4.0 h06a4308_640
[conda] mkl-service 2.4.0 py37h7f8727e_0
[conda] mkl_fft 1.3.1 py37hd3c417c_0
[conda] mkl_random 1.2.2 py37h51133e4_0
[conda] numpy 1.21.5 py37he7a7128_2
[conda] numpy-base 1.21.5 py37hf524024_2
[conda] pytorch 1.12.0 py3.7_cuda11.3_cudnn8.3.2_0 pytorch
[conda] pytorch-mutex 1.0 cuda pytorch
[conda] torchelastic 0.2.0 pypi_0 pypi
[conda] torchtext 0.13.0 py37 pytorch
[conda] torchvision 0.13.0 py37_cu113 pytorch
```
pytorch 1.13.0
```
[pip3] numpy==1.22.3
[pip3] torch==1.13.0
[pip3] torchtext==0.14.0
[pip3] torchvision==0.14.0
[conda] blas 1.0 mkl
[conda] ffmpeg 4.3 hf484d3e_0 pytorch
[conda] mkl 2021.4.0 h06a4308_640
[conda] mkl-service 2.4.0 py39h7f8727e_0
[conda] mkl_fft 1.3.1 py39hd3c417c_0
[conda] mkl_random 1.2.2 py39h51133e4_0
[conda] numpy 1.22.3 py39he7a7128_0
[conda] numpy-base 1.22.3 py39hf524024_0
[conda] pytorch 1.13.0 py3.9_cuda11.6_cudnn8.3.2_0 pytorch
[conda] pytorch-cuda 11.6 h867d48c_0 pytorch
[conda] pytorch-mutex 1.0 cuda pytorch
[conda] torchtext 0.14.0 py39 pytorch
[conda] torchvision 0.14.0 py39_cu116 pytorch
```
cc @albanD @mruberry @jbschlosser @walterddr @saketh-are @jgong5 @mingfeima @XiaobingSuper @sanchitintel @ashokei @jingxu10
| 2 |
3,423 | 95,103 |
AOTAutograd can add extra as_strided() calls when graph outputs alias inputs
|
module: autograd, triaged, module: functionalization, oncall: pt2
|
A simple example:
```
import torch
@torch.compile(backend="aot_eager")
def f(x):
return x.unsqueeze(-1)
a = torch.ones(4)
b = a.view(2, 2)
out = f(b)
```
If you put a breakpoint at [this line](https://github.com/pytorch/pytorch/blob/c16b2916f15d7160c0254580f18007eb0c373abc/torch/_functorch/aot_autograd.py#L498) of aot_autograd.py, you'll see it getting hit.
Context: When AOTAutograd sees a graph with an output that aliases an input, it tries to "replay" the view on the input in eager mode, outside of the compiled `autograd.Function` object. It makes a best effort to replay the exact same set of views as the original code, but it isn't always able to.
The reason it can't in this case is because the input to the graph, `b`, is itself a view of another tensor, `a`. Morally, all we want to do is replay the call to `b.unsqueeze()`. Autograd has some view replay logic, but it requires us to replay *all* of the views from `out`'s base, including the views from the base (a) to the graph input (b). Since that view was created in eager mode, the view that autograd records is an as_strided, so we're forced to run an as_strided() call as part of view replay.
as_strided has a slower backward formula compared to most other view ops. If we want to optimize this, there are a few things that we can do:
(1) Wait for `view_strided()`: @dagitses is working on a compositional view_strided() op that we should be able to replace this as_strided() call with, that should have a more efficient backward formula
(2) make autograd's view replay API smarter (`_view_func`). What we could do is allow for you to do "partial view-replay". E.g. in the above example, if I ran `out._view_func(b)`, it would be nice if it just performed a single call to `.unsqueeze()` instead of needing to go through the entire view chain.
(3) Manually keep track of view chains in AOTAutograd. This would take more work, but in theory we could track all the metadata we need on exactly what the chain of view ops from an input to an output is during tracing, and manually replay it at runtime, instead of relying on autograd's view-replay.
cc @ezyang @albanD @zou3519 @gqchen @pearu @nikitaved @soulitzer @Lezcano @Varal7 @soumith @msaroufim @wconstab @ngimel @davidberard98
| 3 |
3,424 | 95,100 |
RuntimeError: view_as_complex is only supported for half, float and double tensors, but got a tensor of scalar type: BFloat16
|
triaged, module: complex, module: bfloat16
|
### 🐛 Describe the bug
BFloat16 should support view_as_complex
```
In [4]: torch.view_as_complex(torch.rand(32,2))
Out[4]:
tensor([0.5686+0.0719j, 0.4356+0.3737j, 0.5070+0.0710j, 0.3190+0.9922j,
0.0286+0.7838j, 0.3424+0.2291j, 0.6538+0.0426j, 0.7645+0.3523j,
0.7656+0.2561j, 0.3005+0.6489j, 0.1265+0.3116j, 0.6779+0.5047j,
0.7420+0.0151j, 0.5485+0.3000j, 0.5363+0.5574j, 0.8676+0.4026j,
0.9972+0.7556j, 0.7337+0.4260j, 0.1703+0.0922j, 0.9353+0.2052j,
0.1261+0.3311j, 0.1574+0.9259j, 0.9021+0.9478j, 0.4329+0.4403j,
0.7340+0.8674j, 0.9771+0.0980j, 0.0575+0.2011j, 0.8210+0.5589j,
0.3849+0.4482j, 0.2834+0.1872j, 0.7534+0.9229j, 0.4024+0.0708j])
In [5]: torch.view_as_complex(torch.rand(32,2).bfloat16())
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
Cell In[5], line 1
----> 1 torch.view_as_complex(torch.rand(32,2).bfloat16())
RuntimeError: view_as_complex is only supported for half, float and double tensors, but got a tensor of scalar type: BFloat16
```
### Versions
PyTorch version: 1.13.1
Is debug build: False
CUDA used to build PyTorch: None
ROCM used to build PyTorch: N/A
OS: macOS 12.6 (arm64)
GCC version: Could not collect
Clang version: 14.0.0 (clang-1400.0.29.202)
CMake version: version 3.25.0
Libc version: N/A
Python version: 3.9.10 | packaged by conda-forge | (main, Feb 1 2022, 21:27:43) [Clang 11.1.0 ] (64-bit runtime)
Python platform: macOS-12.6-arm64-arm-64bit
Is CUDA available: False
CUDA runtime version: No CUDA
CUDA_MODULE_LOADING set to: N/A
GPU models and configuration: No CUDA
Nvidia driver version: No CUDA
cuDNN version: No CUDA
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Apple M2
Versions of relevant libraries:
[pip3] audiolm-pytorch==0.7.9
[pip3] ema-pytorch==0.1.4
[pip3] Mega-pytorch==0.0.12
[pip3] mypy==0.991
[pip3] mypy-extensions==0.4.3
[pip3] numpy==1.23.5
[pip3] pytorch-lightning==1.9.0
[pip3] torch==1.13.1
[pip3] torchaudio==0.13.1
[pip3] torchinfo==1.7.1
[pip3] torchmetrics==0.11.0
[pip3] torchview==0.2.5
[pip3] torchvision==0.14.1
[pip3] vector-quantize-pytorch==1.0.0
[conda] audiolm-pytorch 0.7.9 pypi_0 pypi
[conda] ema-pytorch 0.1.4 pypi_0 pypi
[conda] mega-pytorch 0.0.12 pypi_0 pypi
[conda] numpy 1.23.5 pypi_0 pypi
[conda] numpy-base 1.21.5 py39hadd41eb_3
[conda] pytorch-lightning 1.9.0 pypi_0 pypi
[conda] torch 1.13.1 pypi_0 pypi
[conda] torchaudio 0.13.1 pypi_0 pypi
[conda] torchinfo 1.7.1 pypi_0 pypi
[conda] torchmetrics 0.11.0 pypi_0 pypi
[conda] torchview 0.2.5 pypi_0 pypi
[conda] torchvision 0.14.1 pypi_0 pypi
[conda] vector-quantize-pytorch 1.0.0 pypi_0 pypi
cc @ezyang @anjali411 @dylanbespalko @mruberry @Lezcano @nikitaved
| 7 |
3,425 | 95,095 |
test_torchinductor.py test isolation problems
|
triaged, module: inductor
|
### 🐛 Describe the bug
In this CI run https://hud.pytorch.org/pytorch/pytorch/pull/95063?sha=c059823d525078a0fe7e8f96040a78c6ec3b42c3 you can see that test_upsample_nearest3d_cpu has failed. Actually, it has nothing to do with this test; if you run that test locally it will pass. It turns out that way earlier there were some failures in test_inplace_unsqueeze, and then somehow this triggered a bunch of downstream tests to fail. This is not great.
I tried inducing the cascading failure with `pytest test/inductor/test_torchinductor.py -k 'test_inplace_unsqueeze or test_inplace_unsqueeze2 or test_inplace_unsqueeze3 or test_baddbmm_cpu' -v` but baddbm_cpu didn't fail that way. So not sure how to nail this.
Branch for permanent repro at https://github.com/ezyang/pytorch/pull/new/cascading-error
### Versions
master
cc @soumith @voznesenskym @yanboliang @penguinwu @anijain2305 @EikanWang @jgong5 @Guobing-Chen @XiaobingSuper @zhuhaozhe @blzheng @Xia-Weiwen @wenzhe-nrv @jiayisunx @peterbell10 @desertfire
| 0 |
3,426 | 95,077 |
Implement a `torch.cuda.visible_device_indexes` function.
|
module: cuda, triaged
|
### 🚀 The feature, motivation and pitch
A `visible_device_indexes` function should be added to the `torch.cuda` module. This function's implementation would be nearly identical to how `torch.cuda.device_count` is implemented, but is not cached, and would not include the call to `len` at the end. The implementation of `torch.cuda.device_count` would then call `len()` on this new `visible_device_indexes` function and could be cached up to the other issue described in #95073.
I would love to implement this myself to contribute to Pytorch if the team would allow it!
### Alternatives
Happy to iterate on design here.
### Additional context
I have a version of this function implemented currently, but thought it really would belong better in the official Pytorch package since it really is nearly identical to the `device_count` already existing withinside `torch.cuda`.
cc @ngimel
| 2 |
3,427 | 95,075 |
Make artifacts easier to discover on HUD
|
module: ci, triaged
|
## Feature request:
See description in https://github.com/pytorch/pytorch/issues/95075#issuecomment-1435171782
---
## Original request:
See this job run for reference.
https://github.com/pytorch/pytorch/actions/runs/4196727169
The main issues are
1) discoverability:
i found it straightforward to identify the perf job and open it up, look for the 'upload' step of the job and read the logs. I found filenames here, but was hoping for download URLs or some instructions about where to look for them.
<img width="1948" alt="image" src="https://user-images.githubusercontent.com/4984825/219737660-bee902a9-19da-47f8-93a8-9f4185401587.png">
2) When I assumed the artifacts are hosted in github (as opposed to S3 bucket or something), I still can't find them
* I followed this instruction: https://docs.github.com/en/actions/managing-workflow-runs/downloading-workflow-artifacts
* But when I clicked around in the github UI I never saw the 'artifacts' pane, and assumed maybe we weren't using gh artifacts at all.
* The issue is that the artifacts pane renders below some warnings so it does not show up unless you scroll down.
Not sure what to do about this, but perhaps putting some message in the job log step saying where to look? (or, if you can generate a download URL to throw in the log even better!)
cc @seemethere @malfet @pytorch/pytorch-dev-infra
| 8 |
3,428 | 95,074 |
A100 Perf Job artifact zipfiles unzip to generic folder that loses job information
|
module: ci, triaged
|
<img width="754" alt="image" src="https://user-images.githubusercontent.com/4984825/219733418-4359a47f-fcd0-4da2-b443-f5b856e794b5.png">
My use case is probably typical: i want to compare perf on my PR with perf on a baseline, so I may download 8 artifact zips.
* 4 zips per job (one per benchmark suite)
* 2 jobs (baseline and PR)
The first issue is that once i double click one of the downloaded zips, it generates a folder that has a generic name like `test-reports` or `test-reports2` etc. Now when i'm working with the files I'm getting confused.
Luckily the .csv files inside the folders bear the name of the benchmark suite, but they do not bear the name of the PR or the baseline, so I can't actually tell what is what unless I am very careful to rename the `test-reports` folders as i unzip them.
It's probably a good idea to be as redundant as possible here, and put the info about the PR/job AND benchmark suite into both the unzipped folder AND csv filenames, just so no matter what workflow or scripts people write, the info is easy to find.
cc @seemethere @malfet @pytorch/pytorch-dev-infra
| 1 |
3,429 | 95,073 |
`torch.cuda.device_count` cached return value does not reflect environment changes.
|
module: cuda, triaged
|
### 🐛 Describe the bug
The `torch.cuda.device_count` function utilizes a LRU cache of size 1, but because it has no arguments, underlying state changes in environment variables can cause an this function to report its cache value instead of the new true value.
Consider the following example:
```python count_device.py
import os
import torch
print(f"CUDA_VISIBLE_DEVICES: {os.getenv('CUDA_VISIBLE_DEVICES')}")
prior_device_count = torch.cuda.device_count()
# Change the environment variable within the run
os.environ["CUDA_VISIBLE_DEVICES"] = "1,2"
print(f"CUDA_VISIBLE_DEVICES: {os.getenv('CUDA_VISIBLE_DEVICES')}")
after_device_count = torch.cuda.device_count()
print(f"Prior device count {prior_device_count}.\nAfter device count {after_device_count}.")
```
Assume this script runs on a system with four CUDA devices. Then in this case when CUDA_VISIBLE_DEVICES is not set, the output of the script may look like
```
CUDA_VISIBLE_DEVICES: None
CUDA_VISIBLE_DEVICES: 1,2
Prior device count 4.
After device count 4.
```
In the case when its set to something at launch, say CUDA_VISIBLE_DEVICES=0,1,2, then we get the following output
```
CUDA_VISIBLE_DEVICES: 0,1,2
CUDA_VISIBLE_DEVICES: 1,2
Prior device count 3.
After device count 3.
```
### Versions
Collecting environment information...
PyTorch version: 1.13.1+cu117
Is debug build: False
CUDA used to build PyTorch: 11.7
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.5 LTS (x86_64)
GCC version: (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0
Clang version: Could not collect
CMake version: version 3.20.5
Libc version: glibc-2.31
Python version: 3.10.9 (main, Jan 11 2023, 15:21:40) [GCC 11.2.0] (64-bit runtime)
Python platform: Linux-5.15.0-58-generic-x86_64-with-glibc2.31
Is CUDA available: True
CUDA runtime version: 11.1.105
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration:
GPU 0: NVIDIA RTX A6000
GPU 1: NVIDIA RTX A6000
GPU 2: NVIDIA RTX A6000
GPU 3: NVIDIA RTX A6000
Nvidia driver version: 470.161.03
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
Address sizes: 43 bits physical, 48 bits virtual
CPU(s): 64
On-line CPU(s) list: 0-63
Thread(s) per core: 2
Core(s) per socket: 32
Socket(s): 1
NUMA node(s): 1
Vendor ID: AuthenticAMD
CPU family: 23
Model: 49
Model name: AMD Ryzen Threadripper 3970X 32-Core Processor
Stepping: 0
Frequency boost: enabled
CPU MHz: 2200.000
CPU max MHz: 4549.1211
CPU min MHz: 2200.0000
BogoMIPS: 7400.50
Virtualization: AMD-V
L1d cache: 1 MiB
L1i cache: 1 MiB
L2 cache: 16 MiB
L3 cache: 128 MiB
NUMA node0 CPU(s): 0-63
Vulnerability Itlb multihit: Not affected
Vulnerability L1tf: Not affected
Vulnerability Mds: Not affected
Vulnerability Meltdown: Not affected
Vulnerability Mmio stale data: Not affected
Vulnerability Retbleed: Mitigation; untrained return thunk; SMT enabled with STIBP protection
Vulnerability Spec store bypass: Mitigation; Speculative Store Bypass disabled via prctl and seccomp
Vulnerability Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization
Vulnerability Spectre v2: Mitigation; Retpolines, IBPB conditional, STIBP always-on, RSB filling, PBRSB-eIBRS Not affected
Vulnerability Srbds: Not affected
Vulnerability Tsx async abort: Not affected
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ht syscall nx mmxext fxsr_opt pdpe1gb rdtscp lm constant_tsc rep_good nopl nonstop_tsc cpuid extd_apicid aperfmperf rapl pni pclmulqdq monitor ssse3 fma cx16 sse4_1 sse4_2 movbe popcnt aes xsave avx f16c rdrand lahf_lm cmp_legacy svm extapic cr8_legacy abm sse4a misalignsse 3dnowprefetch osvw ibs skinit wdt tce topoext perfctr_core perfctr_nb bpext perfctr_llc mwaitx cpb cat_l3 cdp_l3 hw_pstate ssbd mba ibpb stibp vmmcall fsgsbase bmi1 avx2 smep bmi2 cqm rdt_a rdseed adx smap clflushopt clwb sha_ni xsaveopt xsavec xgetbv1 xsaves cqm_llc cqm_occup_llc cqm_mbm_total cqm_mbm_local clzero irperf xsaveerptr rdpru wbnoinvd arat npt lbrv svm_lock nrip_save tsc_scale vmcb_clean flushbyasid decodeassists pausefilter pfthreshold avic v_vmsave_vmload vgif v_spec_ctrl umip rdpid overflow_recov succor smca sme sev sev_es
Versions of relevant libraries:
[pip3] mypy==1.0.0
[pip3] mypy-boto3-s3==1.26.62
[pip3] mypy-extensions==1.0.0
[pip3] numpy==1.23.5
[pip3] torch==1.13.1+cu117
[pip3] torchdata==0.5.1
[pip3] torchmetrics==0.11.1
[pip3] torchsnapshot==0.1.0
[pip3] torchvision==0.14.1+cu117
[conda] numpy 1.23.5 pypi_0 pypi
[conda] torch 1.13.1+cu117 pypi_0 pypi
[conda] torchdata 0.5.1 pypi_0 pypi
[conda] torchmetrics 0.11.1 pypi_0 pypi
[conda] torchsnapshot 0.1.0 pypi_0 pypi
[conda] torchvision 0.14.1+cu117 pypi_0 pypi
cc @ngimel
| 3 |
3,430 | 95,058 |
Upsampling ResBlock GPU memory spike
|
module: cuda, module: memory usage, triaged
|
### 🐛 Describe the bug
During inference, my PyTorch model experiences a significant GPU memory spike of up to 10GB with the first batch only, while the following batches’ memory consumption caps at 3GB. I have identified that the ResBlock upsampling layers in my model’s architecture are causing the spike. I have six upsampling ResBlock layers, and the spike only occurs when the bottom three ResBlock layers are included. The problematic layers are Resblock [2-51, 2-52, 2-53] from the layers listed below. When I increase the batch size, the spike lasts longer, and instead of spiking with the first batch only, it can stay until the end of all batches.
**Layers’ Summary:**
```
└─ResBlock: 2-48 [2, 512, 8, 8] 1
│ └─Sequential: 3-71 [2, 512, 8, 8] 4,718,592
│ └─Sequential: 3-72 [2, 512, 8, 8] 262,656
└─ResBlock: 2-49 [2, 512, 16, 16] 1
│ └─Sequential: 3-73 [2, 512, 16, 16] 4,718,592
│ └─Sequential: 3-74 [2, 512, 16, 16] 262,656
└─ResBlock: 2-50 [2, 512, 32, 32] 1
│ └─Sequential: 3-75 [2, 512, 32, 32] 4,718,592
│ └─Sequential: 3-76 [2, 512, 32, 32] 262,656
└─ResBlock: 2-51 [2, 256, 64, 64] 1
│ └─Sequential: 3-77 [2, 256, 64, 64] 1,769,472
│ └─Sequential: 3-78 [2, 256, 64, 64] 131,328
└─ResBlock: 2-52 [2, 128, 128, 128] 1
│ └─Sequential: 3-79 [2, 128, 128, 128] 442,368
│ └─Sequential: 3-80 [2, 128, 128, 128] 32,896
└─ResBlock: 2-53 [2, 64, 256, 256] 1
│ └─Sequential: 3-81 [2, 64, 256, 256] 110,592
│ └─Sequential: 3-82 [2, 64, 256, 256] 8,256
```
**ResBlock Code:**
```python
class ResBlock(nn.Module):
def __init__(self, in_channels, out_channels, padding, upsample, downsample,
norm_layer, activation=nn.ReLU, gated=False):
super(ResBlock, self).__init__()
normalize = True
bias = False
self.noise_strength = torch.nn.Parameter(torch.zeros([]))
self.upsample = True
norm0 = AdaptiveNorm2d(in_channels, norm_layer)
norm1 = AdaptiveNorm2d(out_channels, norm_layer)
layers = []
layers.append(norm0)
layers.append(activation(inplace=True))
layers.append(nn.Upsample(scale_factor=2, mode='bilinear'))
layers.extend([
nn.Sequential() if padding is nn.ZeroPad2d else padding(1),
spectral_norm(
nn.Conv2d(in_channels, out_channels, 3, 1, 1 if padding is nn.ZeroPad2d else 0, bias=bias),
eps=1e-4)])
layers.append(norm1)
layers.extend([
activation(inplace=True),
nn.Sequential() if padding is nn.ZeroPad2d else padding(1),
spectral_norm(
nn.Conv2d(out_channels, out_channels, 3, 1, 1 if padding is nn.ZeroPad2d else 0, bias=bias),
eps=1e-4)])
self.block = nn.Sequential(*layers)
layers = []
layers.append(nn.Upsample(scale_factor=2, mode='bilinear'))
layers.append(spectral_norm(
nn.Conv2d(in_channels, out_channels, 1), eps=1e-4))
self.skip = nn.Sequential(*layers)
def forward(self, input):
out = self.block(input)
self.noise_strength.requires_grad = False
output = out + self.skip(input)
return output
```
I would appreciate suggestions to overcome the memory spike issue without compromising the ResBlock upsampling layers.
### Versions
PyTorch version: 1.12.1+cu113
Is debug build: False
CUDA used to build PyTorch: 11.3
ROCM used to build PyTorch: N/A
OS: Ubuntu 18.04.6 LTS (x86_64)
GCC version: (Ubuntu 7.5.0-3ubuntu1~18.04) 7.5.0
Clang version: Could not collect
CMake version: version 3.22.3
Libc version: glibc-2.27
Python version: 3.10.9 (main, Jan 28 2023, 19:09:35) [GCC 7.5.0] (64-bit runtime)
Python platform: Linux-5.4.0-1068-aws-x86_64-with-glibc2.27
Is CUDA available: True
CUDA runtime version: 9.1.85
CUDA_MODULE_LOADING set to:
GPU models and configuration: GPU 0: NVIDIA A10G
Nvidia driver version: 470.82.01
cuDNN version: Probably one of the following:
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn.so.8.0.5
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_adv_infer.so.8.0.5
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_adv_train.so.8.0.5
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_cnn_infer.so.8.0.5
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_cnn_train.so.8.0.5
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_ops_infer.so.8.0.5
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_ops_train.so.8.0.5
/usr/local/cuda-11.1/targets/x86_64-linux/lib/libcudnn.so.8.0.5
/usr/local/cuda-11.1/targets/x86_64-linux/lib/libcudnn_adv_infer.so.8.0.5
/usr/local/cuda-11.1/targets/x86_64-linux/lib/libcudnn_adv_train.so.8.0.5
/usr/local/cuda-11.1/targets/x86_64-linux/lib/libcudnn_cnn_infer.so.8.0.5
/usr/local/cuda-11.1/targets/x86_64-linux/lib/libcudnn_cnn_train.so.8.0.5
/usr/local/cuda-11.1/targets/x86_64-linux/lib/libcudnn_ops_infer.so.8.0.5
/usr/local/cuda-11.1/targets/x86_64-linux/lib/libcudnn_ops_train.so.8.0.5
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn.so.8.1.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn_adv_infer.so.8.1.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn_adv_train.so.8.1.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn_cnn_infer.so.8.1.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn_cnn_train.so.8.1.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn_ops_infer.so.8.1.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn_ops_train.so.8.1.1
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 16
On-line CPU(s) list: 0-15
Thread(s) per core: 2
Core(s) per socket: 8
Socket(s): 1
NUMA node(s): 1
Vendor ID: AuthenticAMD
CPU family: 23
Model: 49
Model name: AMD EPYC 7R32
Stepping: 0
CPU MHz: 2729.895
BogoMIPS: 5600.00
Hypervisor vendor: KVM
Virtualization type: full
L1d cache: 32K
L1i cache: 32K
L2 cache: 512K
L3 cache: 16384K
NUMA node0 CPU(s): 0-15
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ht syscall nx mmxext fxsr_opt pdpe1gb rdtscp lm constant_tsc rep_good nopl nonstop_tsc cpuid extd_apicid aperfmperf tsc_known_freq pni pclmulqdq ssse3 fma cx16 sse4_1 sse4_2 movbe popcnt aes xsave avx f16c rdrand hypervisor lahf_lm cmp_legacy cr8_legacy abm sse4a misalignsse 3dnowprefetch topoext ssbd ibrs ibpb stibp vmmcall fsgsbase bmi1 avx2 smep bmi2 rdseed adx smap clflushopt clwb sha_ni xsaveopt xsavec xgetbv1 clzero xsaveerptr wbnoinvd arat npt nrip_save rdpid
Versions of relevant libraries:
[pip3] efficientnet-pytorch==0.6.3
[pip3] numpy==1.23.5
[pip3] segmentation-models-pytorch==0.2.1
[pip3] torch==1.12.1+cu113
[pip3] torchaudio==0.12.1+cu113
[pip3] torchinfo==1.7.2
[pip3] torchstat==0.0.7
[pip3] torchsummary==1.5.1
[pip3] torchvision==0.13.1+cu113
[conda] blas 1.0 mkl
[conda] mkl 2020.2 256
[conda] mkl-service 2.3.0 py37he8ac12f_0
[conda] mkl_fft 1.2.1 py37h54f3939_0
[conda] mkl_random 1.1.1 py37h0573a6f_0
[conda] numpy 1.21.5 pypi_0 pypi
[conda] numpydoc 1.1.0 pyhd3eb1b0_1
cc @ngimel
| 0 |
3,431 | 95,037 |
[Inductor] [CPU] Huggingface model AllenaiLongformerBase performance regression > 10% on ww07.4
|
triaged, module: inductor, module: cpu inductor
|
### 🐛 Describe the bug
There is a performance regression on Huggingface model AllenaiLongformerBase on ww07.4 [TorchInductor CPU Performance Dashboard](https://github.com/pytorch/pytorch/issues/93531#issuecomment-1434019577) compare with ww07.2 as bellow:
| ww07.4 | | | | ww07.2 | | | | Comp | | |
| ---- | ---- | ---- | ---- | ---- | ---- | ---- | ---- | ---- | ---- | ---- |
| batch_size | speedup | inductor | eager | batch_size | speedup | inductor | eager | speedup ratio | eager ratio | inductor ratio |
|1 |0.9901 |2.3819678 |2.358386319 |1 |1.1392 |2.0668015 |2.354500269 |0.87 |1 |0.87
Please find sw info from [TorchInductor CPU Performance Dashboard](https://github.com/pytorch/pytorch/issues/93531)
Graph dump by cosim:
WW07.4:
[graph.txt](https://github.com/pytorch/pytorch/files/10765350/graph.txt)
WW07.2:
[graph.txt](https://github.com/pytorch/pytorch/files/10765352/graph.txt)
Repro:
```
python -m torch.backends.xeon.run_cpu --core_list 0 --ncores_per_instance 1 benchmarks/dynamo/huggingface.py --performance --float32 -dcpu -n50 --inductor --no-skip --dashboard --only AllenaiLongformerBase --cold_start_latency --batch_size 1 --threads 1
```
cc @soumith @voznesenskym @yanboliang @penguinwu @anijain2305 @EikanWang @jgong5 @Guobing-Chen @XiaobingSuper @zhuhaozhe @blzheng @Xia-Weiwen @wenzhe-nrv @jiayisunx @peterbell10 @desertfire
| 0 |
3,432 | 95,034 |
[Inductor] [CPU] Huggingface model MT5ForConditionalGeneration &T5ForConditionalGeneration & T5Small performance regression > 10% on ww07.4
|
triaged, module: inductor
|
### 🐛 Describe the bug
There is a performance regression on Huggingface models **MT5ForConditionalGeneration &T5ForConditionalGeneration & T5Small** on ww07.4 [TorchInductor CPU Performance Dashboard](https://github.com/pytorch/pytorch/issues/93531#issuecomment-1434019397) compare with ww07.2 as bellow:
| | ww07.4 | | | | ww07.2 | | | | Comp | | |
| ---- | ---- | ---- | ---- | ---- | ---- | ---- | ---- | ---- | ---- | ---- | ---- |
| name | batch_size | speedup | inductor | eager | batch_size | speedup | inductor | eager | speedup ratio | eager ratio | inductor ratio |
|MT5ForConditionalGeneration |16 |1.0417 |0.2628685 |0.273830116 |16 |1.1846 |0.2305143 |0.27306724 |0.88 |1 |0.88
|T5ForConditionalGeneration |4 |0.7722 |0.5160617 |0.398502845 |4 |1.0301 |0.3849303 |0.396516702 |0.75 |1 |0.75
|T5Small |4 |0.7736 |0.5160818 |0.39924088 |4 |1.0333 |0.3849365 |0.397754885 |0.75 |1 |0.75
Please find sw info from [TorchInductor CPU Performance Dashboard](https://github.com/pytorch/pytorch/issues/93531)
Graph dump by cosim:
WW07.4:
[MT5ForConditionalGeneration graph.txt](https://github.com/pytorch/pytorch/files/10765405/graph.txt)
[T5ForConditionalGeneration graph.txt](https://github.com/pytorch/pytorch/files/10765393/graph.txt)
[T5Small graph.txt](https://github.com/pytorch/pytorch/files/10765363/graph.txt)
WW07.2:
[MT5ForConditionalGeneration graph.txt](https://github.com/pytorch/pytorch/files/10765406/graph.txt)
[T5ForConditionalGeneration graph.txt](https://github.com/pytorch/pytorch/files/10765396/graph.txt)
[T5Small graph.txt](https://github.com/pytorch/pytorch/files/10765367/graph.txt)
Repro:
```
python -m torch.backends.xeon.run_cpu --node_id 0 benchmarks/dynamo/huggingface.py --performance --float32 -dcpu -n50 --inductor --no-skip --dashboard --only MODEL --cold_start_latency
```
cc @soumith @voznesenskym @yanboliang @penguinwu @anijain2305 @EikanWang @jgong5 @Guobing-Chen @XiaobingSuper @zhuhaozhe @blzheng @Xia-Weiwen @wenzhe-nrv @jiayisunx @peterbell10 @desertfire
| 0 |
3,433 | 95,033 |
[Inductor] [CPU] Torchbench model hf_Longformer performance regression > 10% on ww07.4
|
triaged, module: inductor
|
### 🐛 Describe the bug
There is a performance regression on Torchbench model hf_Longformer on ww07.4 [TorchInductor CPU Performance Dashboard](https://github.com/pytorch/pytorch/issues/93531#issuecomment-1434019577) compare with ww07.2 as bellow:
| ww07.4 | | | | ww07.2 | | | | Comp | | |
| ---- | ---- | ---- | ---- | ---- | ---- | ---- | ---- | ---- | ---- | ---- |
| batch_size | speedup | inductor | eager | batch_size | speedup | inductor | eager | speedup ratio | eager ratio | inductor ratio |
|1 |1.0426 |1.0742891 |1.120053816 |1 |1.1938 |0.943502 |1.126352688 |0.87 |1.01 |0.88
Please find sw info from [TorchInductor CPU Performance Dashboard](https://github.com/pytorch/pytorch/issues/93531)
Graph dump by cosim:
WW07.4:
[graph.txt](https://github.com/pytorch/pytorch/files/10765423/graph.txt)
WW07.2:
[graph.txt](https://github.com/pytorch/pytorch/files/10765435/graph.txt)
Repro:
```
python -m torch.backends.xeon.run_cpu --core_list 0 --ncores_per_instance 1 benchmarks/dynamo/torchbench.py --performance --float32 -dcpu -n50 --inductor --no-skip --dashboard --only hf_Longformer --cold_start_latency --batch_size 1 --threads 1
```
cc @soumith @voznesenskym @yanboliang @penguinwu @anijain2305 @EikanWang @jgong5 @Guobing-Chen @XiaobingSuper @zhuhaozhe @blzheng @Xia-Weiwen @wenzhe-nrv @jiayisunx @peterbell10 @desertfire
| 0 |
3,434 | 95,030 |
[Inductor] [CPU] Torchbench model hf_T5 & hf_T5_large & hf_T5_base performance regression > 10% on ww07.4
|
triaged, module: inductor
|
### 🐛 Describe the bug
There is a performance regression on Torchbench models **hf_T5 & hf_T5_large & hf_T5_base** on ww07.4 [TorchInductor CPU Performance Dashboard](https://github.com/pytorch/pytorch/issues/93531#issuecomment-1434019397) compare with ww07.2 as bellow:
| | ww07.4 | | | | ww07.2 | | | | Comp | | |
| ---- | ---- | ---- | ---- | ---- | ---- | ---- | ---- | ---- | ---- | ---- | ---- |
| name| batch_size | speedup | inductor | eager | batch_size | speedup | inductor | eager | speedup ratio | eager ratio | inductor ratio
| hf_T5 | 1 | 0.9775 | 0.0487881 | 0.047690368 | 1 | 1.3737 | 0.0351173 | 0.048240635 | 0.71 | 1.01 | 0.72
| hf_T5_base | 1 | 0.7094 | 1.4970444 | 1.062003297 | 1 | 1.073 | 0.9889897 | 1.061185948 | 0.66 | 1 | 0.66
| hf_T5_large | 1 | 1.1104 | 0.4428939 | 0.491789387 | 1 | 1.4794 | 0.3326359 | 0.49210155 | 0.75 | 1 | 0.75
Please find sw info from [TorchInductor CPU Performance Dashboard](https://github.com/pytorch/pytorch/issues/93531)
Graph dump by cosim:
WW07.4:
[hf_T5 graph.txt](https://github.com/pytorch/pytorch/files/10765472/graph.txt)
[hf_T5_large graph.txt](https://github.com/pytorch/pytorch/files/10765455/graph.txt)
[hf_T5_base graph.txt](https://github.com/pytorch/pytorch/files/10765463/graph.txt)
WW07.2:
[hf_T5 graph.txt](https://github.com/pytorch/pytorch/files/10765474/graph.txt)
[hf_T5_large graph.txt](https://github.com/pytorch/pytorch/files/10765458/graph.txt)
[hf_T5_base graph.txt](https://github.com/pytorch/pytorch/files/10765465/graph.txt)
Repro:
```
python -m torch.backends.xeon.run_cpu --node_id 0 benchmarks/dynamo/torchbench.py --performance --float32 -dcpu -n50 --inductor --no-skip --dashboard --only MODEL --cold_start_latency
```
cc @soumith @voznesenskym @yanboliang @penguinwu @anijain2305 @EikanWang @jgong5 @Guobing-Chen @XiaobingSuper @zhuhaozhe @blzheng @Xia-Weiwen @wenzhe-nrv @jiayisunx @peterbell10 @desertfire
| 3 |
3,435 | 95,024 |
cuDNN doesn't support convolutions with more than `INT_MAX` elements and native kernel uses too much memory
|
module: cudnn, module: convolution, triaged, module: CUDACachingAllocator
|
### 🐛 Describe the bug
Hi there,
I'm seeing a large increase in allocated memory (~10x) when I increase the input size of the feature map beyond ~4.3GB for my Conv3d layer in the script below. I'm increasing the feature map size by incrementing the value along dim=3 (`x_dim=361 or 362`).
With input size 4.29GB (`x_dim=361`), I get:
```
input GB: 4.29133696
max alloc. (GB): 12.874233344
max res. (GB): 12.880707584
```
And with input size 4.30GB (`x_dim=362`), I get:
```
input GB: 4.30322432
...
torch.cuda.OutOfMemoryError: CUDA out of memory. Tried to allocate 108.21 GiB (GPU 0; 79.21 GiB total capacity; 6.01 GiB already allocated; 72.66 GiB free; 6.01 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
```
Is something going wrong with the allocator?
**Script**
```
import torch
from torch import nn
# x_dim = 361 # works - max memory ~ 12.9 GB.
x_dim = 362 # breaks - tries to allocate ~ 110 GiB.
input_shape = (1, 64, x_dim, 370, 251)
device = torch.device('cuda:0')
input = torch.rand(input_shape)
input = input.half().to(device)
input_GB = input.numel() * input.element_size() / 1e9
print('input GB: ', input_GB)
input.requires_grad = False
layer = nn.Conv3d(in_channels=64, out_channels=32, kernel_size=3, stride=1, padding=1).half().to(device)
for i, param in enumerate(layer.parameters()):
param_GB = param.numel() * param.element_size() / 1e9
# print(f'param_{i} GB: {param_GB}')
param.requires_grad = False
output = layer(input)
print('max alloc. (GB): ', torch.cuda.max_memory_allocated() / 1e9)
print('max res. (GB): ', torch.cuda.max_memory_reserved() / 1e9)
```
### Versions
PyTorch version: 1.13.1+cu117
Is debug build: False
CUDA used to build PyTorch: 11.7
ROCM used to build PyTorch: N/A
OS: Red Hat Enterprise Linux Server release 7.9 (Maipo) (x86_64)
GCC version: (GCC) 10.2.0
Clang version: Could not collect
CMake version: Could not collect
Libc version: glibc-2.17
Python version: 3.8.6 (default, Mar 29 2021, 14:28:48) [GCC 10.2.0] (64-bit runtime)
Python platform: Linux-3.10.0-1160.66.1.el7.x86_64-x86_64-with-glibc2.2.5
Is CUDA available: True
CUDA runtime version: Could not collect
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration: GPU 0: NVIDIA A100 80GB PCIe
Nvidia driver version: 515.65.01
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 32
On-line CPU(s) list: 0-31
Thread(s) per core: 1
Core(s) per socket: 16
Socket(s): 2
NUMA node(s): 2
Vendor ID: GenuineIntel
CPU family: 6
Model: 106
Model name: Intel(R) Xeon(R) Gold 6326 CPU @ 2.90GHz
Stepping: 6
CPU MHz: 2900.000
BogoMIPS: 5800.00
Virtualization: VT-x
L1d cache: 48K
L1i cache: 32K
L2 cache: 1280K
L3 cache: 24576K
NUMA node0 CPU(s): 0,2,4,6,8,10,12,14,16,18,20,22,24,26,28,30
NUMA node1 CPU(s): 1,3,5,7,9,11,13,15,17,19,21,23,25,27,29,31
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc art arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc aperfmperf eagerfpu pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid dca sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm 3dnowprefetch epb cat_l3 invpcid_single intel_pt ssbd mba ibrs ibpb stibp ibrs_enhanced tpr_shadow vnmi flexpriority ept vpid fsgsbase tsc_adjust bmi1 hle avx2 smep bmi2 erms invpcid rtm cqm rdt_a avx512f avx512dq rdseed adx smap avx512ifma clflushopt clwb avx512cd sha_ni avx512bw avx512vl xsaveopt xsavec xgetbv1 cqm_llc cqm_occup_llc cqm_mbm_total cqm_mbm_local dtherm ida arat pln pts avx512vbmi umip pku ospke avx512_vbmi2 gfni vaes vpclmulqdq avx512_vnni avx512_bitalg avx512_vpopcntdq md_clear pconfig spec_ctrl intel_stibp flush_l1d arch_capabilities
Versions of relevant libraries:
[pip3] numpy==1.24.0
[pip3] pytorch-lightning==1.8.6
[pip3] torch==1.13.1
[pip3] torchaudio==0.13.1
[pip3] torchio==0.18.86
[pip3] torchmetrics==0.11.0
[pip3] torchvision==0.14.1
[conda] Could not collect
cc @csarofeen @ptrblck @xwang233
| 7 |
3,436 | 95,021 |
Custom operations in inductor
|
triaged, oncall: pt2, module: inductor, module: dynamo
|
### 🚀 The feature, motivation and pitch
I'm working on a backend for Dynamo/Inductor and I would like to "catch" modules at a higher level than the lowered inductor graph. Lowering a high-level operator to ATen primitives misses out on semantics that could be used for efficient backend implementations. A few examples:
* `nn.Dropout` is immediately lowered to Philox random + `aten.where`, which makes certain assumptions
* `nn.BatchNorm` is reduced to its core operations, which disallows calling something like cuDNN
* Higher-level modules from PyTorch extensions cannot always be compiled to a single graph, due to their use of Pythonic features
I would still want to use the awesome optimizations and inlining features that inductor does on the original GraphModule, just not on every operator.
Ideally, the solution would entail taking components in their `nn.Module` level and replacing them with custom lowered operations that can be used internally. Dynamo will, in turn, [optionally] skip trying to trace through the module so as to not crash because of missing Pythonic features [if shape/type inference is provided].
### Alternatives
I tried wrapping modules with specific types with some wrapper class, which diverges in the `forward` function based on `dynamo.is_compiling()`. While verbose (and forcing me to redo shape inference), this allows me to change some internal behavior.
Following this step, none of the approaches I tried work. I tried several things, including registering custom operations via `torch.fx` and `torch.ops` (as in the custom ops tutorial https://pytorch.org/tutorials/advanced/torch_script_custom_ops.html). torch.fx wrapped functions are ignored, custom ops are lowered to ATen on the C++ level, and the lowered inductor graph always ends up with the primitives.
It is worth mentioning that in the ONNX exporter this used to be possible via registering custom schemata.
Thanks in advance!
### Additional context
_No response_
cc @ezyang @soumith @msaroufim @wconstab @ngimel @bdhirsh @voznesenskym @yanboliang @penguinwu @anijain2305 @EikanWang @jgong5 @Guobing-Chen @XiaobingSuper @zhuhaozhe @blzheng @Xia-Weiwen @wenzhe-nrv @jiayisunx @peterbell10 @desertfire
| 6 |
3,437 | 95,005 |
NCCL backend can't be used with a dataset that is IterDataPipe
|
oncall: distributed, module: dataloader
|
### 🐛 Describe the bug
Distributed training with NCCL backend doesn't work with a dataset extending `IterDataPipe`. This is because `_BaseDataLoaderIter` attempts to use the `gloo` backend in this case, see an excerpt from the master branch below. Note "gloo" backend being hardcoded in the middle.
```
class _BaseDataLoaderIter(object):
def __init__(self, loader: DataLoader) -> None:
self._dataset = loader.dataset
self._shared_seed = None
self._pg = None
if isinstance(self._dataset, IterDataPipe):
if dist.is_available() and dist.is_initialized():
self._pg = dist.new_group(backend="gloo")
self._shared_seed = _share_dist_seed(loader.generator, self._pg)
shared_rng = torch.Generator()
shared_rng.manual_seed(self._shared_seed)
self._dataset = torch.utils.data.graph_settings.apply_random_seed(self._dataset, shared_rng)
```
This leads to failures like this:
```
Traceback (most recent call last):
File "/mnt/venv/lib/python3.9/site-packages/pytorch_lightning/trainer/call.py", line 38, in _call_and_handle_interrupt
return trainer_fn(*args, **kwargs)
File "/mnt/venv/lib/python3.9/site-packages/pytorch_lightning/trainer/trainer.py", line 650, in _fit_impl
self._run(model, ckpt_path=self.ckpt_path)
File "/mnt/venv/lib/python3.9/site-packages/pytorch_lightning/trainer/trainer.py", line 1112, in _run
results = self._run_stage()
File "/mnt/venv/lib/python3.9/site-packages/pytorch_lightning/trainer/trainer.py", line 1191, in _run_stage
self._run_train()
File "/mnt/venv/lib/python3.9/site-packages/pytorch_lightning/trainer/trainer.py", line 1204, in _run_train
self._run_sanity_check()
File "/mnt/venv/lib/python3.9/site-packages/pytorch_lightning/trainer/trainer.py", line 1276, in _run_sanity_check
val_loop.run()
File "/mnt/venv/lib/python3.9/site-packages/pytorch_lightning/loops/loop.py", line 199, in run
self.advance(*args, **kwargs)
File "/mnt/venv/lib/python3.9/site-packages/pytorch_lightning/loops/dataloader/evaluation_loop.py", line 152, in advance
dl_outputs = self.epoch_loop.run(self._data_fetcher, dl_max_batches, kwargs)
File "/mnt/venv/lib/python3.9/site-packages/pytorch_lightning/loops/loop.py", line 194, in run
self.on_run_start(*args, **kwargs)
File "/mnt/venv/lib/python3.9/site-packages/pytorch_lightning/loops/epoch/evaluation_epoch_loop.py", line 84, in on_run_start
self._data_fetcher = iter(data_fetcher)
File "/mnt/venv/lib/python3.9/site-packages/pytorch_lightning/utilities/fetching.py", line 178, in __iter__
self.dataloader_iter = iter(self.dataloader)
File "/mnt/venv/lib/python3.9/site-packages/torch/utils/data/dataloader.py", line 435, in __iter__
return self._get_iterator()
File "/mnt/venv/lib/python3.9/site-packages/torch/utils/data/dataloader.py", line 381, in _get_iterator
return _MultiProcessingDataLoaderIter(self)
File "/mnt/venv/lib/python3.9/site-packages/torch/utils/data/dataloader.py", line 988, in __init__
super(_MultiProcessingDataLoaderIter, self).__init__(loader)
File "/mnt/venv/lib/python3.9/site-packages/torch/utils/data/dataloader.py", line 567, in __init__
self._pg = dist.new_group(backend="gloo")
File "/mnt/venv/lib/python3.9/site-packages/torch/distributed/distributed_c10d.py", line 3335, in new_group
pg = _new_process_group_helper(
File "/mnt/venv/lib/python3.9/site-packages/torch/distributed/distributed_c10d.py", line 862, in _new_process_group_helper
pg = ProcessGroupGloo(prefix_store, group_rank, group_size, timeout=timeout)
RuntimeError: [../third_party/gloo/gloo/transport/tcp/pair.cc:799] connect [127.0.0.1]:31115: Connection refused
```
### Versions
Collecting environment information...
PyTorch version: N/A
Is debug build: N/A
CUDA used to build PyTorch: N/A
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.5 LTS (x86_64)
GCC version: (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0
Clang version: Could not collect
CMake version: Could not collect
Libc version: glibc-2.31
Python version: 3.9.10 (main, Feb 16 2023, 20:03:54) [GCC 9.4.0] (64-bit runtime)
Python platform: Linux-5.15.0-1022-aws-x86_64-with-glibc2.31
Is CUDA available: N/A
CUDA runtime version: Could not collect
CUDA_MODULE_LOADING set to: N/A
GPU models and configuration:
GPU 0: Tesla V100-SXM2-16GB
GPU 1: Tesla V100-SXM2-16GB
GPU 2: Tesla V100-SXM2-16GB
GPU 3: Tesla V100-SXM2-16GB
Nvidia driver version: 520.61.05
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.1.0
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.1.0
/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.1.0
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_infer.so.8.1.0
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.1.0
/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.1.0
/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.1.0
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: N/A
CPU:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
Address sizes: 46 bits physical, 48 bits virtual
CPU(s): 32
On-line CPU(s) list: 0-31
Thread(s) per core: 2
Core(s) per socket: 16
Socket(s): 1
NUMA node(s): 1
Vendor ID: GenuineIntel
CPU family: 6
Model: 79
Model name: Intel(R) Xeon(R) CPU E5-2686 v4 @ 2.30GHz
Stepping: 1
CPU MHz: 3000.000
CPU max MHz: 3000.0000
CPU min MHz: 1200.0000
BogoMIPS: 4600.04
Hypervisor vendor: Xen
Virtualization type: full
L1d cache: 512 KiB
L1i cache: 512 KiB
L2 cache: 4 MiB
L3 cache: 45 MiB
NUMA node0 CPU(s): 0-31
Vulnerability Itlb multihit: KVM: Mitigation: VMX unsupported
Vulnerability L1tf: Mitigation; PTE Inversion
Vulnerability Mds: Vulnerable: Clear CPU buffers attempted, no microcode; SMT Host state unknown
Vulnerability Meltdown: Mitigation; PTI
Vulnerability Mmio stale data: Vulnerable: Clear CPU buffers attempted, no microcode; SMT Host state unknown
Vulnerability Retbleed: Not affected
Vulnerability Spec store bypass: Vulnerable
Vulnerability Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization
Vulnerability Spectre v2: Mitigation; Retpolines, STIBP disabled, RSB filling, PBRSB-eIBRS Not affected
Vulnerability Srbds: Not affected
Vulnerability Tsx async abort: Vulnerable: Clear CPU buffers attempted, no microcode; SMT Host state unknown
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ht syscall nx pdpe1gb rdtscp lm constant_tsc rep_good nopl xtopology nonstop_tsc cpuid aperfmperf tsc_known_freq pni pclmulqdq ssse3 fma cx16 pcid sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand hypervisor lahf_lm abm 3dnowprefetch cpuid_fault invpcid_single pti fsgsbase bmi1 hle avx2 smep bmi2 erms invpcid rtm rdseed adx xsaveopt
Versions of relevant libraries:
[pip3] numpy==1.23.4
[conda] Could not collect
cc @mrshenli @pritamdamania87 @zhaojuanmao @satgera @rohan-varma @gqchen @aazzolini @osalpekar @jiayisuse @H-Huang @kwen2501 @awgu @SsnL @VitalyFedyunin @ejguan @NivekT @dzhulgakov
| 6 |
3,438 | 94,990 |
interactions between views + autograd.Function + AOTAutograd causes memory leak
|
module: autograd, triaged, actionable
|
I have a repro here (actively working on making it smaller). What's interesting is that it's non-trivial to make smaller - removing some extra ops, and e.g. changing the `autograd.function.apply()` to instead just call `torch.ops.test.foo_fwd()` directly all remove the leak.
```
import torch
def foo_fwd(v, o):
out = torch.randn(512 * 256 * 128, device=v.device)
return out.view(512, 256, 128)
def foo_bwd(grad_output, o):
out = torch.zeros(64656, 128, device=grad_output.device)
return out.squeeze(-1)
lib = torch.library.Library("test", "DEF")
lib.define("foo_fwd(Tensor v, Tensor[] o) -> Tensor")
lib.define("foo_bwd(Tensor grad_output, Tensor[] o) -> Tensor")
cuda_lib = torch.library.Library("test", "IMPL", "CUDA")
cuda_lib.impl("foo_fwd", foo_fwd)
cuda_lib.impl("foo_bwd", foo_bwd)
meta_lib = torch.library.Library("test", "IMPL", "Meta")
meta_lib.impl("foo_fwd", foo_fwd)
meta_lib.impl("foo_bwd", foo_bwd)
class Foo(torch.autograd.Function):
@staticmethod
def forward(ctx, v, o):
return torch.ops.test.foo_fwd(v, o)
@staticmethod
def backward(ctx, grad_outputs):
o = torch.ones(513, device='cuda', dtype=torch.int32)
return torch.ops.test.foo_bwd(grad_outputs[0], [o])
def f(a, b, c, d, e, f):
n: int = c.size(1)
g = torch.mm(a, d)
_, out, h = torch.split(g, [256, 256, 128], dim=1)
i = h.unsqueeze(-1) * e + f
j, _ = torch.unbind(i, dim=-1)
k = Foo.apply(j, [b])
torch._dynamo.graph_break()
tmp = k + 1
return out
f_compiled = torch.compile(f, backend="aot_eager")
inps = [
torch.randn(64656, 256, dtype=torch.float32, device='cuda'),
torch.arange(513, dtype=torch.int32, device='cuda'),
torch.randn(512, 256, dtype=torch.float32, device='cuda'),
torch.empty((256, 640), device='cuda', requires_grad=True),
torch.empty(1, 128, 2, device='cuda', requires_grad=True),
torch.zeros(1, 128, 2, device='cuda', requires_grad=True),
]
# This eventually OOMs
for i in range(300):
print(torch.cuda.memory_allocated())
#output = f(*inps)
output = f_compiled(*inps)
del output
print(torch.cuda.memory_allocated())
# print()
#print("@@@@@")
```
cc @ezyang @albanD @zou3519 @gqchen @pearu @nikitaved @soulitzer @Lezcano @Varal7 @gchanan
| 17 |
3,439 | 94,989 |
Internal Assert During Distributed Autograd Backprop
|
oncall: distributed
|
### 🐛 Describe the bug
#### Problem
An INTERNAL ASSERT error occurs during the backward call of distributed autograd when doing remote calculations via torch.distributed.rpc. Notes:
1. Specifically, the remote calculation is a single call to `torchode` to solve a trivial differential equation.
1. The precise time to fail varies from 5-60 seconds. The failure iteration number varies widely, even with a fixed random seed.
1. It fails 100% of the time if multiple calculation nodes are used (i.e. world_size > 2), and never fails if only 1 calculation node is used (world_size=2).
1. The failure occurs regardless of whether the workers are all run on the same machine or different machines
1. It works fine with multiple clients if I replace the `torchode` call with a dummy calculation.
1. It is not clear to me whether this is really a distributed autograd issue or a downstream consequence of a problem with torchode, but the message requested that I report it :)
#### Source code
The following standalone program demonstrates the failure with a contrived case:
```python
import os, torch, torchode
import torch.distributed
import torch.distributed.nn
import torch.distributed.optim
import torch.distributed.rpc
import torch.multiprocessing
def SolveRPC(model, times):
return model.forward(times)
class Model(torch.nn.Module):
def __init__(self):
super().__init__()
self.r = torch.nn.Parameter(torch.randn(3))
def forward(self, times):
def RHS(t, Y):
return -(self.r**2) * Y
Y0 = torch.ones(5, 3).double()
solns = torchode.solve_ivp(RHS, Y0, t_eval=times)
return solns.ys
def RunClient(worker_id, num_clients):
torch.distributed.rpc.init_rpc(f"worker{worker_id}", rank=worker_id,
world_size=num_clients+1)
torch.distributed.rpc.shutdown()
def RunServer(num_clients):
world_size = num_clients + 1
torch.distributed.rpc.init_rpc('worker0', rank=0, world_size=world_size)
workers = [f'worker{i}' for i in range(1, world_size)]
# setup remote model and optimizer
remote_model = torch.distributed.nn.RemoteModule('worker0/cpu', Model, ())
par_refs = remote_model.remote_parameters()
opt = torch.distributed.optim.DistributedOptimizer(
torch.optim.Adam, par_refs, lr=1e-4)
for i in range(1000000):
with torch.distributed.autograd.context() as grad_context:
# make RPC solve calls
times = torch.arange(10).double()
task_futures= [
torch.distributed.rpc.rpc_async(worker, SolveRPC,
args=(remote_model, times))
for worker in workers
]
# collect results
solutions = torch.futures.wait_all(task_futures)
Y_hat = torch.stack(solutions)
# score and update pars
loss = (Y_hat**2).mean()
torch.distributed.autograd.backward(grad_context, [loss])
opt.step(grad_context)
print(i, loss.item())
torch.distributed.rpc.shutdown()
def Launch(node_id, num_clients):
torch.manual_seed(3)
if node_id == 0:
RunServer(num_clients)
else:
RunClient(node_id, num_clients)
def main():
#num_clients = 1 # works
num_clients = 2 # fails
os.environ['MASTER_PORT'] = '65001'
os.environ['MASTER_ADDR'] = '127.0.0.1'
torch.multiprocessing.spawn(Launch, nprocs=num_clients+1,
args=(num_clients,))
if __name__ == '__main__':
main()
```
#### Traceback
```
RuntimeError: Error on Node 0: res[i].defined() INTERNAL ASSERT FAILED at "../torch/csrc/autograd/functions/tensor.cpp":111, please report a bug to PyTorch.
Exception raised from apply at ../torch/csrc/autograd/functions/tensor.cpp:111 (most recent call first):
frame #0: c10::Error::Error(c10::SourceLocation, std::string) + 0x57 (0x7f58ad1a2457 in /home/foo/venv/lib/python3.10/site-packages/torch/lib/libc10.so)
frame #1: c10::detail::torchCheckFail(char const*, char const*, unsigned int, char const*) + 0x68 (0x7f58ad16c4b5 in /home/foo/venv/lib/python3.10/site-packages/torch/lib/libc10.so)
frame #2: torch::autograd::CopySlices::apply(std::vector<at::Tensor, std::allocator<at::Tensor> >&&) + 0x86f (0x7f58de04a64f in /home/foo/venv/lib/python3.10/site-packages/torch/lib/libtorch_cpu.so)
frame #3: <unknown function> + 0x48689cb (0x7f58de0409cb in /home/foo/venv/lib/python3.10/site-packages/torch/lib/libtorch_cpu.so)
frame #4: torch::autograd::Engine::evaluate_function(std::shared_ptr<torch::autograd::GraphTask>&, torch::autograd::Node*, torch::autograd::InputBuffer&, std::shared_ptr<torch::autograd::ReadyQueue> const&) + 0x1638 (0x7f58de03a2b8 in /home/foo/venv/lib/python3.10/site-packages/torch/lib/libtorch_cpu.so)
frame #5: torch::distributed::autograd::DistEngine::execute_graph_task_until_ready_queue_empty(torch::autograd::NodeTask&&, bool) + 0x434 (0x7f58dea774a4 in /home/foo/venv/lib/python3.10/site-packages/torch/lib/libtorch_cpu.so)
frame #6: <unknown function> + 0x52a02e0 (0x7f58dea782e0 in /home/foo/venv/lib/python3.10/site-packages/torch/lib/libtorch_cpu.so)
frame #7: <unknown function> + 0x196e271 (0x7f58db146271 in /home/foo/venv/lib/python3.10/site-packages/torch/lib/libtorch_cpu.so)
frame #8: c10::ThreadPool::main_loop(unsigned long) + 0x285 (0x7f58ad193d85 in /home/foo/venv/lib/python3.10/site-packages/torch/lib/libc10.so)
frame #9: <unknown function> + 0xd6de4 (0x7f59075d9de4 in /lib/x86_64-linux-gnu/libstdc++.so.6)
frame #10: <unknown function> + 0x8609 (0x7f5925c3e609 in /lib/x86_64-linux-gnu/libpthread.so.0)
frame #11: clone + 0x43 (0x7f5925d78133 in /lib/x86_64-linux-gnu/libc.so.6)
```
### Versions
Versions of relevant libraries:
[pip3] functorch==1.13.1
[pip3] numpy==1.23.4
[pip3] torch==1.13.1
[pip3] torchode==0.1.6
[pip3] torchtyping==0.1.4
cc @mrshenli @pritamdamania87 @zhaojuanmao @satgera @rohan-varma @gqchen @aazzolini @osalpekar @jiayisuse @H-Huang @kwen2501 @awgu
| 0 |
3,440 | 94,976 |
[libtorh]Consistency problem of gpu computing
|
module: cuda, triaged, module: determinism
|
### 🐛 Describe the bug
Run the same input 100 times, the first time and the other 99 times the result is inconsistent, 2 to 100 times the result is the same.
The code to set the random seed is as follows:
``` c++
int seed = 123456;
srand(seed);
torch::manual_seed(seed);
if (m_gpu_id >= 0) {
torch::cuda::manual_seed(seed);
torch::cuda::manual_seed_all(seed);
at::globalContext().setDeterministicCuDNN(true);
at::globalContext().setDeterministicAlgorithms(true);
at::globalContext().setBenchmarkCuDNN(false);
}
```
The environment variables are set as follows
```
CUBLAS_WORKSPACE_CONFIG=":4096:8"
CUDA_LAUNCH_BLOCKING="1"
PYTHONHASHSEED="123456"
```
### Versions
cuda: 10.2
libtorch: 1.10.0-cu102
os: linux
cc @ngimel @mruberry @kurtamohler
| 0 |
3,441 | 94,974 |
Slow inference of torchscript model in C++
|
oncall: jit
|
### 🐛 Describe the bug
Torchscript same model have very slow inference in c++ as compared to python
In Python
```
model = jit.load("parseq.ts")
model.eval()
......
.......
image = Image.open('cropped.jpeg').convert('RGB')
image = img_transform(image).unsqueeze(0).to('cpu')
print('input shape : {}'.format(image.shape))
start_time = time.time()
p = model(image)
end_time = time.time()
elapsed_time = (end_time - start_time) * 1000
print('Inference Time : {} ms'.format(elapsed_time))
```
OUTPUT
```
input shape : torch.Size([1, 3, 32, 128])
Inference Time : 665.2061939239502 ms
```
In C++ both 1.13.1 and 2.0.0
```
module = torch::jit::load("parseq.ts");
module.to(at::kCPU);
.........................
.........................
std::cout << "input shape : " << tensor_image.sizes() << std::endl;
// Create a vector of inputs.
std::vector<torch::jit::IValue> inputs;
inputs.push_back(tensor_image);
// Execute the model and turn its output into a tensor.
start_time = std::chrono::steady_clock::now();
auto output = module.forward(inputs).toTensor();
end = std::chrono::steady_clock::now();
std::chrono::duration<double, std::milli> elapsed_seconds = end - start_time;
std::cout << "Inference Time : " << elapsed_seconds.count() << " ms\n";
```
OUTPUT
```
input shape : [1, 3, 32, 128]
elapsed time: 41168.8 ms
```
### Versions
PyTorch version: 1.13.1+cu117 on python
PyTorch version: 2.0.0 on C++
PyTorch version: 1.13.1 on C++
os: Linux
cc @EikanWang @jgong5 @wenzhe-nrv @sanchitintel
| 2 |
3,442 | 94,966 |
CSR matrix add_ error with RuntimeError: CUDA error: kernel launch failure when calling cusparseXcsrgeam2Nnz
|
module: sparse, module: cuda, triaged
|
### 🐛 Describe the bug
I am working on a model built with linear layers made with CSR matrices for the weights. During training I encountered this error which I have reproduced in the example below, the original error I found to be caused by `lib/python3.10/site-packages/torch/optim/sgd.py line 269 in _single_tensor_sgd param.add_(d_p, alpha=-lr)`. One aspect of the error which I haven't been able to reproduce is its relationship with the sparsity of the sparse linear layers in my model, as in the model I am working with this error only seems to happen with 0.99 or higher sparsity. I have experienced this issue with both 1.13.1+cu117 and nightly 2.0.0.dev20230213+cu117.
Example:
```python
import torch
import time
print(torch.version.__version__)
nz = 10000
# the error persists no matter the sparsity in this example
sparsity = 0.0
density = 1.0 - sparsity
indices = torch.randint(0, nz, (2, int(nz*density)))
values = torch.randn((int(nz*density)))
x = torch.sparse_coo_tensor(indices, values, dtype=torch.float,device='cuda').coalesce().to_sparse_csr()
# A loop is used as this error often does not happen on the first add_ call
for i in range(100):
x.add_(x)
time.sleep(0.05) # Used to prevent async call errors
```
Error traceback:
```
Traceback (most recent call last):
File "/.../temp.py", line 15, in <module>
x = x.add_(x)
RuntimeError: CUDA error: kernel launch failure when calling `cusparseXcsrgeam2Nnz( handle, m, n, descrA, nnzA, csrSortedRowPtrA, csrSortedColIndA, descrB, nnzB, csrSortedRowPtrB, csrSortedColIndB, descrC, csrSortedRowPtrC, nnzTotalDevHostPtr, workspace)`
```
### Versions
Collecting environment information...
PyTorch version: 2.0.0.dev20230213+cu117
Is debug build: False
CUDA used to build PyTorch: 11.7
ROCM used to build PyTorch: N/A
OS: Manjaro Linux (x86_64)
GCC version: (GCC) 12.2.0
Clang version: 14.0.6
CMake version: version 3.25.0
Libc version: glibc-2.36
Python version: 3.10.8 (main, Nov 1 2022, 14:18:21) [GCC 12.2.0] (64-bit runtime)
Python platform: Linux-5.15.85-1-MANJARO-x86_64-with-glibc2.36
Is CUDA available: True
CUDA runtime version: 11.8.89
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration: GPU 0: NVIDIA GeForce GTX 1080
Nvidia driver version: 525.60.11
cuDNN version: Probably one of the following:
/usr/lib/libcudnn.so.8.6.0
/usr/lib/libcudnn_adv_infer.so.8.6.0
/usr/lib/libcudnn_adv_train.so.8.6.0
/usr/lib/libcudnn_cnn_infer.so.8.6.0
/usr/lib/libcudnn_cnn_train.so.8.6.0
/usr/lib/libcudnn_ops_infer.so.8.6.0
/usr/lib/libcudnn_ops_train.so.8.6.0
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Address sizes: 43 bits physical, 48 bits virtual
Byte Order: Little Endian
CPU(s): 12
On-line CPU(s) list: 0-11
Vendor ID: AuthenticAMD
Model name: AMD Ryzen 5 2600 Six-Core Processor
CPU family: 23
Model: 8
Thread(s) per core: 2
Core(s) per socket: 6
Socket(s): 1
Stepping: 2
Frequency boost: enabled
CPU(s) scaling MHz: 65%
CPU max MHz: 3400.0000
CPU min MHz: 1550.0000
BogoMIPS: 6801.44
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ht syscall nx mmxext fxsr_opt pdpe1gb rdtscp lm constant_tsc rep_good nopl nonstop_tsc cpuid extd_apicid aperfmperf rapl pni pclmulqdq monitor ssse3 fma cx16 sse4_1 sse4_2 movbe popcnt aes xsave avx f16c rdrand lahf_lm cmp_legacy svm extapic cr8_legacy abm sse4a misalignsse 3dnowprefetch osvw skinit wdt tce topoext perfctr_core perfctr_nb bpext perfctr_llc mwaitx cpb hw_pstate ssbd ibpb vmmcall fsgsbase bmi1 avx2 smep bmi2 rdseed adx smap clflushopt sha_ni xsaveopt xsavec xgetbv1 xsaves clzero irperf xsaveerptr arat npt lbrv svm_lock nrip_save tsc_scale vmcb_clean flushbyasid decodeassists pausefilter pfthreshold avic v_vmsave_vmload vgif overflow_recov succor smca sme sev sev_es
Virtualization: AMD-V
L1d cache: 192 KiB (6 instances)
L1i cache: 384 KiB (6 instances)
L2 cache: 3 MiB (6 instances)
L3 cache: 16 MiB (2 instances)
NUMA node(s): 1
NUMA node0 CPU(s): 0-11
Vulnerability Itlb multihit: Not affected
Vulnerability L1tf: Not affected
Vulnerability Mds: Not affected
Vulnerability Meltdown: Not affected
Vulnerability Mmio stale data: Not affected
Vulnerability Retbleed: Mitigation; untrained return thunk; SMT vulnerable
Vulnerability Spec store bypass: Mitigation; Speculative Store Bypass disabled via prctl and seccomp
Vulnerability Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization
Vulnerability Spectre v2: Mitigation; Retpolines, IBPB conditional, STIBP disabled, RSB filling, PBRSB-eIBRS Not affected
Vulnerability Srbds: Not affected
Vulnerability Tsx async abort: Not affected
Versions of relevant libraries:
[pip3] numpy==1.24.1
[pip3] pytorch-triton==2.0.0+0d7e753227
[pip3] torch==2.0.0.dev20230213+cu117
[pip3] torchaudio==2.0.0.dev20230215+cu117
[pip3] torchvision==0.15.0.dev20230215+cu117
[conda] blas 1.0 mkl
[conda] mkl 2020.0 166
[conda] mkl-service 2.3.0 py37he904b0f_0
[conda] mkl_fft 1.0.15 py37ha843d7b_0
[conda] mkl_random 1.1.0 py37hd6b4f25_0
[conda] numpy 1.18.1 py37h4f9e942_0
[conda] numpy-base 1.18.1 py37hde5b4d6_1
[conda] numpydoc 0.9.2 py_0
Collecting environment information...
PyTorch version: 1.13.1+cu117
Is debug build: False
CUDA used to build PyTorch: 11.7
ROCM used to build PyTorch: N/A
OS: Manjaro Linux (x86_64)
GCC version: (GCC) 12.2.0
Clang version: 14.0.6
CMake version: version 3.25.1
Libc version: glibc-2.36
Python version: 3.10.8 (main, Nov 1 2022, 14:18:21) [GCC 12.2.0] (64-bit runtime)
Python platform: Linux-5.15.85-1-MANJARO-x86_64-with-glibc2.36
Is CUDA available: True
CUDA runtime version: 11.8.89
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration: GPU 0: NVIDIA GeForce GTX 1080
Nvidia driver version: 525.60.11
cuDNN version: Probably one of the following:
/usr/lib/libcudnn.so.8.6.0
/usr/lib/libcudnn_adv_infer.so.8.6.0
/usr/lib/libcudnn_adv_train.so.8.6.0
/usr/lib/libcudnn_cnn_infer.so.8.6.0
/usr/lib/libcudnn_cnn_train.so.8.6.0
/usr/lib/libcudnn_ops_infer.so.8.6.0
/usr/lib/libcudnn_ops_train.so.8.6.0
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Address sizes: 43 bits physical, 48 bits virtual
Byte Order: Little Endian
CPU(s): 12
On-line CPU(s) list: 0-11
Vendor ID: AuthenticAMD
Model name: AMD Ryzen 5 2600 Six-Core Processor
CPU family: 23
Model: 8
Thread(s) per core: 2
Core(s) per socket: 6
Socket(s): 1
Stepping: 2
Frequency boost: enabled
CPU(s) scaling MHz: 63%
CPU max MHz: 3400.0000
CPU min MHz: 1550.0000
BogoMIPS: 6801.44
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ht syscall nx mmxext fxsr_opt pdpe1gb rdtscp lm constant_tsc rep_good nopl nonstop_tsc cpuid extd_apicid aperfmperf rapl pni pclmulqdq monitor ssse3 fma cx16 sse4_1 sse4_2 movbe popcnt aes xsave avx f16c rdrand lahf_lm cmp_legacy svm extapic cr8_legacy abm sse4a misalignsse 3dnowprefetch osvw skinit wdt tce topoext perfctr_core perfctr_nb bpext perfctr_llc mwaitx cpb hw_pstate ssbd ibpb vmmcall fsgsbase bmi1 avx2 smep bmi2 rdseed adx smap clflushopt sha_ni xsaveopt xsavec xgetbv1 xsaves clzero irperf xsaveerptr arat npt lbrv svm_lock nrip_save tsc_scale vmcb_clean flushbyasid decodeassists pausefilter pfthreshold avic v_vmsave_vmload vgif overflow_recov succor smca sme sev sev_es
Virtualization: AMD-V
L1d cache: 192 KiB (6 instances)
L1i cache: 384 KiB (6 instances)
L2 cache: 3 MiB (6 instances)
L3 cache: 16 MiB (2 instances)
NUMA node(s): 1
NUMA node0 CPU(s): 0-11
Vulnerability Itlb multihit: Not affected
Vulnerability L1tf: Not affected
Vulnerability Mds: Not affected
Vulnerability Meltdown: Not affected
Vulnerability Mmio stale data: Not affected
Vulnerability Retbleed: Mitigation; untrained return thunk; SMT vulnerable
Vulnerability Spec store bypass: Mitigation; Speculative Store Bypass disabled via prctl and seccomp
Vulnerability Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization
Vulnerability Spectre v2: Mitigation; Retpolines, IBPB conditional, STIBP disabled, RSB filling, PBRSB-eIBRS Not affected
Vulnerability Srbds: Not affected
Vulnerability Tsx async abort: Not affected
Versions of relevant libraries:
[pip3] numpy==1.24.1
[pip3] torch==1.13.1
[pip3] torch-scatter==2.1.0+pt113cu117
[pip3] torch-sparse==0.6.16+pt113cu117
[pip3] torchvision==0.14.1
[pip3] torchviz==0.0.2
[conda] blas 1.0 mkl
[conda] mkl 2020.0 166
[conda] mkl-service 2.3.0 py37he904b0f_0
[conda] mkl_fft 1.0.15 py37ha843d7b_0
[conda] mkl_random 1.1.0 py37hd6b4f25_0
[conda] numpy 1.18.1 py37h4f9e942_0
[conda] numpy-base 1.18.1 py37hde5b4d6_1
[conda] numpydoc 0.9.2 py_0
cc @alexsamardzic @nikitaved @pearu @cpuhrsch @amjames @bhosmer @ngimel
| 3 |
3,443 | 94,912 |
PR #88607 breaks build for POWER9 CPU
|
module: build, triaged, module: POWER, actionable
|
### 🐛 Describe the bug
PR #88607 adds shift operators to vector types. In the general case, those shifts are implemented as for loops:
https://github.com/pytorch/pytorch/blob/master/aten/src/ATen/cpu/vec/vec_base.h#L805
However, the access with `operator[]` conflicts, in the POWER9 case (and likely others), with the fact that they are not implemented:
https://github.com/pytorch/pytorch/blob/master/aten/src/ATen/cpu/vec/vec256/vsx/vec256_int32_vsx.h#L219
and so the code cannot compile.
### Versions
Git revision ae57bd663061cbd6bca3a03d12bb70a24913a84c
Relevant info from script:
```
GCC version: (GCC) 8.3.1 20190311 (Red Hat 8.3.1-3)
Clang version: 12.0.1
CMake version: version 3.25.1
CPU:
Architecture: ppc64le
Byte Order: Little Endian
Model name: POWER9, altivec supported
```
cc @malfet @seemethere
| 5 |
3,444 | 94,909 |
[numpy] mean & nanmean should support int dtypes
|
triaged, module: numpy, module: reductions
|
### 🚀 The feature, motivation and pitch
#### NumPy
```python
>>> import numpy as np
>>> k = np.array([1, 2, 3], dtype=np.int32)
>>> np.mean(k)
2.0
>>> np.nanmean(k)
2.0
```
#### PyTorch
```python
>>> import torch
>>> k = torch.tensor([1, 2, 3], dtype=torch.int32)
>>> torch.mean(k)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
RuntimeError: mean(): could not infer output dtype. Input dtype must be either a floating point or complex dtype. Got: Int
>>> torch.nanmean(k)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
RuntimeError: nanmean(): expected input to have floating point dtype but got Int
```
As discussed here: https://github.com/pytorch/pytorch/pull/93199#issuecomment-1431169963
### Alternatives
_No response_
### Additional context
_No response_
cc @mruberry @rgommers
| 0 |
3,445 | 94,908 |
ASSERT(initialized()) Debug Error after JIT fusion on Windows
|
oncall: jit, module: nvfuser
|
### Debug Error Explanation
`Assertion failed: initialized(), file C:\actions-runner\_work\pytorch\pytorch\builder\windows\pytorch\c10/util/Optional.h, line 763`
The script runs perfectly in release mode, but crashes in an ASSERT in l. 763 of **Optional.h** during the 2nd or 3rd run in debug mode. More explicitly, in the function FusionExecutorCache::getKernelRuntimeFor in **kernel_cache.cpp**, the variable args from l. 231 args.cache_id->"optional_base".init_ is false and thus hits the above ASSERT(initialized()).
**kernel_cache.cpp**: \torch\csrc\jit\codegen\cuda\kernel_cache.cpp
**Optional.h**: \c10\util\Optional.h
It seems like for some reasons, the JIT fusers don't correctly initialize throughout the first run and thus create this error in one of the next runs. This explains why the error only occurs when using at least two operators as in the model below. Using just one of them (multiplication, division, addition, ...) does not generate any fusions and thus does not generate the error. The example below is a very short example that was found to be part of RAFT ([https://github.com/princeton-vl/RAFT](https://github.com/princeton-vl/RAFT)) which is the network that I actually want to run in the end.
Also, in release mode, the ASSERT will simply be skipped, but I am unsure about whether the fusers did a good job or if they actually hide a bug somewhere, so I don't think simply ignoring the debug error is a good solution.
I generate a very basic model in PyTorch 1.13.1 as follows:
```
import torch
class NeuralNetwork(torch.nn.Module):
def forward(self, im):
im = im / 255.0
im = im * 2.0
return im
if __name__ == "__main__":
model = NeuralNetwork()
# Tracing
traced_model = torch.jit.trace(model, (torch.rand((1, 3, 184, 320))))
torch.jit.save(traced_model, "model.pt")
# Scripting
scripted_model = torch.jit.script(model)
torch.jit.save(scripted_model, "model.pt")
```
There is no difference (same error) between the traced and the scripted model.
I then try to run it in C++ using Libtorch 1.13.1 on a GPU (CUDA 11.7, cuDNN 8.6.0) on Windows as follows:
```
#include <torch/script.h>
#include <iostream>
int main()
{
try
{
torch::NoGradGuard no_grad;
torch::jit::Module model;
torch::Device device = torch::Device(torch::kCUDA);
model = torch::jit::load("model.pt");
model.to(device);
model.eval();
std::vector<int64_t> dims = { 1, 3, 184, 320 };
for (auto i = 0; i < 100; i++)
{
torch::Tensor t = torch::ones(dims).to(device);
std::vector<torch::jit::IValue> inputs;
inputs.push_back(t);
auto modelOutput = m_model.forward(inputs);
std::cout << i << std::endl;
}
}
catch (const c10::Error e)
{
std::string str = std::string("Error: ") + std::string(e.what());
return 1;
}
catch (const std::exception e)
{
std::string str = std::string("Error: ") + std::string(e.what());
return 1;
}
return 0;
}
```
### Versions
PyTorch 1.13.1 / LibTorch 1.13.1
CUDA 11.7.0
cuDNN 8.6.0
on Windows 10
_I don't think the results from the Python-only dependencies from your script are too important here, but there you are:_
PyTorch version: 1.13.1+cu117
Is debug build: False
CUDA used to build PyTorch: 11.7
ROCM used to build PyTorch: N/A
OS: Microsoft Windows 10 Enterprise
GCC version: Could not collect
Clang version: Could not collect
CMake version: version 3.23.0-rc2
Libc version: N/A
Python version: 3.9.10 (tags/v3.9.10:f2f3f53, Jan 17 2022, 15:14:21) [MSC v.1929 64 bit (AMD64)] (64-bit runtime)
Python platform: Windows-10-10.0.19044-SP0
Is CUDA available: True
CUDA runtime version: 11.7.64
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration: GPU 0: NVIDIA RTX A3000 Laptop GPU
Nvidia driver version: 516.01
cuDNN version: C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.7\bin\cudnn_ops_train64_8.dll
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
cc @EikanWang @jgong5 @wenzhe-nrv @sanchitintel @kevinstephano @jjsjann123
| 3 |
3,446 | 94,904 |
Optimizer "Lion" in Symbolic Discovery of Optimization Algorithms
|
module: optimizer, triaged, needs research
|
### 🚀 The feature, motivation and pitch
A new optimizer "Lion" was proposed in Symbolic Discovery of Optimization Algorithms
https://arxiv.org/pdf/2302.06675.pdf
It is simple, memory efficient and have a faster runtime.
I think it can be a great addition to the Pytorch optimizer algorithms' collection as
it directly compares to AdamW which is already available.
the optimizer is a single file
https://github.com/google/automl/blob/master/lion/lion_pytorch.py
Pseudo Code:
$$
\begin{algorithm}
\caption{\name{} Lion}
\begin{algorithmic}
\State \textbf{given} $\beta_1$, $\beta_2$, $\lambda$, $\eta$, $f$
\State \textbf{initialize} $\theta_0$, $m_0\leftarrow 0$
\While{$\theta_t$ not converged}
\State $g_t \leftarrow \nabla_\theta f(\theta_{t-1})$
\State \textbf{update model parameters}
\State $c_t \leftarrow \beta_1 m_{t-1} + (1-\beta_1)g_t$
\State $\theta_t \leftarrow \theta_{t-1} - \eta_t(\text{sign}(c_t) + \lambda\theta_{t-1})$
\State \textbf{update EMA of $g_t$}
\State $m_t \leftarrow \beta_2 m_{t-1} + (1 - \beta_2)g_t$
\EndWhile
\State \textbf{return} $\theta_t$
\end{algorithmic}
\label{alg:ours}
\end{algorithm}
$$
### Alternatives
_No response_
### Additional context
_No response_
cc @vincentqb @jbschlosser @albanD @janeyx99
| 1 |
3,447 | 94,893 |
Memory leak in torch.fft.rfft
|
module: cuda, module: memory usage, triaged, module: fft
|
### 🐛 Describe the bug
Running the function `torch.fft.rfft` with tensors varying in size results in a memory leak. This does not happen when tensors stay the same size across iterations. With each iteration, additional memory is accumulated in amounts of ~2MB per run. This happens regardless of whether tensors are detached and placed on the CPU, or if the memory cache is cleared.
Below is a script to reproduce this leak on a GPU:
```
import torch
import random
import time
import subprocess
iters = 100
last_large_dim = -1
device = torch.device('cuda:2')
for i in range(iters):
# removing the random size of this dimension removes the increase in memory on each iteration
rand_dim = random.randint(8000, 15000)
x = torch.randn(1, 768, rand_dim).to(device)
# removing this line prevents memory from increasing
res = torch.fft.rfft(x, n=rand_dim)
# even detaching and deleting does not clear the memory
x = x.detach().cpu()
del x
res = res.detach().cpu()
del res
# regardless of whether we pass the largest dimension this happens
if rand_dim > last_large_dim:
last_large_dim = rand_dim
print ('Newest largest dim created')
# report from nvidia-smi
torch.cuda.empty_cache()
subprocess.run('nvidia-smi -g 2', shell=True)
time.sleep(0.5)
```
I've also demonstrated this using a linearly decreasing dimension size by using `torch.linspace(15000, 8000, iters)`. Please let me know if you need any more information, or if there are suggestions for a quick fix!
### Versions
PyTorch version: 1.12.1.post200
Is debug build: False
CUDA used to build PyTorch: 11.2
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.5 LTS (x86_64)
GCC version: (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0
Clang version: Could not collect
CMake version: version 3.16.3
Libc version: glibc-2.31
Python version: 3.10.4 (main, Mar 31 2022, 08:41:55) [GCC 7.5.0] (64-bit runtime)
Python platform: Linux-5.4.0-135-generic-x86_64-with-glibc2.31
Is CUDA available: True
CUDA runtime version: 11.8.89
CUDA_MODULE_LOADING set to:
GPU models and configuration:
GPU 0: NVIDIA RTX A6000
GPU 1: NVIDIA RTX A6000
GPU 2: NVIDIA RTX A6000
GPU 3: NVIDIA RTX A6000
GPU 4: NVIDIA RTX A6000
GPU 5: NVIDIA RTX A6000
GPU 6: NVIDIA RTX A6000
GPU 7: NVIDIA RTX A6000
Nvidia driver version: 520.61.05
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
Address sizes: 48 bits physical, 48 bits virtual
CPU(s): 64
On-line CPU(s) list: 0-63
Thread(s) per core: 2
Core(s) per socket: 32
Socket(s): 1
NUMA node(s): 4
Vendor ID: AuthenticAMD
CPU family: 25
Model: 1
Model name: AMD EPYC 7513 32-Core Processor
Stepping: 1
Frequency boost: enabled
CPU MHz: 1496.074
CPU max MHz: 2600.0000
CPU min MHz: 1500.0000
BogoMIPS: 5199.51
Virtualization: AMD-V
L1d cache: 1 MiB
L1i cache: 1 MiB
L2 cache: 16 MiB
L3 cache: 128 MiB
NUMA node0 CPU(s): 0-7,32-39
NUMA node1 CPU(s): 8-15,40-47
NUMA node2 CPU(s): 16-23,48-55
NUMA node3 CPU(s): 24-31,56-63
Vulnerability Itlb multihit: Not affected
Vulnerability L1tf: Not affected
Vulnerability Mds: Not affected
Vulnerability Meltdown: Not affected
Vulnerability Mmio stale data: Not affected
Vulnerability Retbleed: Not affected
Vulnerability Spec store bypass: Mitigation; Speculative Store Bypass disabled via prctl and seccomp
Vulnerability Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization
Vulnerability Spectre v2: Mitigation; Retpolines, IBPB conditional, IBRS_FW, STIBP always-on, RSB filling, PBRSB-eIBRS Not affected
Vulnerability Srbds: Not affected
Vulnerability Tsx async abort: Not affected
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ht syscall nx mmxext fxsr_opt pdpe1gb rdtscp lm constant_tsc rep_good nopl nonstop_tsc cpuid extd_apicid aperfmperf pni pclmulqdq monitor ssse3 fma cx16 pcid sse4_1 sse4_2 x2apic movbe popcnt aes xsave avx f16c rdrand lahf_lm cmp_legacy svm extapic cr8_legacy abm sse4a misalignsse 3dnowprefetch osvw ibs skinit wdt tce topoext perfctr_core perfctr_nb bpext perfctr_llc mwaitx cpb cat_l3 cdp_l3 invpcid_single hw_pstate ssbd mba ibrs ibpb stibp vmmcall fsgsbase bmi1 avx2 smep bmi2 invpcid cqm rdt_a rdseed adx smap clflushopt clwb sha_ni xsaveopt xsavec xgetbv1 xsaves cqm_llc cqm_occup_llc cqm_mbm_total cqm_mbm_local clzero irperf xsaveerptr wbnoinvd arat npt lbrv svm_lock nrip_save tsc_scale vmcb_clean flushbyasid decodeassists pausefilter pfthreshold v_vmsave_vmload vgif umip pku ospke vaes vpclmulqdq rdpid overflow_recov succor smca
Versions of relevant libraries:
[pip3] numpy==1.23.1
[pip3] pytorch-ignite==0.4.8
[pip3] pytorch-lightning==1.6.5
[pip3] pytorch-msssim==0.2.1
[pip3] torch==1.12.1.post200
[pip3] torchaudio==0.12.1
[pip3] torchio==0.18.86
[pip3] torchmetrics==0.11.0
[pip3] torchvision==0.13.0a0+8069656
[conda] cudatoolkit 11.3.1 h2bc3f7f_2 anaconda
[conda] magma 2.5.4 hc72dce7_4 conda-forge
[conda] mkl 2022.1.0 hc2b9512_224
[conda] numpy 1.23.1 py310hac523dd_0 anaconda
[conda] numpy-base 1.23.1 py310h375b286_0 anaconda
[conda] pytorch 1.12.1 cuda112py310h51fe464_200 conda-forge
[conda] pytorch-ignite 0.4.8 pyhd8ed1ab_0 conda-forge
[conda] pytorch-lightning 1.6.5 pyhd8ed1ab_0 conda-forge
[conda] pytorch-msssim 0.2.1 pypi_0 pypi
[conda] pytorch-mutex 1.0 cuda pytorch
[conda] torchaudio 0.12.1 py310_cu113 pytorch
[conda] torchio 0.18.86 pyhd8ed1ab_0 conda-forge
[conda] torchmetrics 0.11.0 pyhd8ed1ab_0 conda-forge
[conda] torchvision 0.13.0 cuda112py310h453157a_0 conda-forge
cc @ngimel @mruberry @peterbell10
| 14 |
3,448 | 94,891 |
torch.sum does not return the sum on ROCm
|
module: rocm, triaged, module: random
|
### 🐛 Describe the bug
`torch.sum` always return 0 or first tensor element when running.
This causes nlp sampling to be impossible.
End to end example
```python
from transformers import pipeline
generator = pipeline(model="distilgpt2", device=0)
print(generator("Hello github"))
```
Causes error
```
File "/opt/conda/lib/python3.8/site-packages/transformers/pipelines/text_generation.py", line 252, in _forward
generated_sequence = self.model.generate(input_ids=input_ids, attention_mask=attention_mask, **generate_kwargs)
File "/opt/conda/lib/python3.8/site-packages/torch/autograd/grad_mode.py", line 27, in decorate_context
return func(*args, **kwargs)
File "/opt/conda/lib/python3.8/site-packages/transformers/generation/utils.py", line 1437, in generate
return self.sample(
File "/opt/conda/lib/python3.8/site-packages/transformers/generation/utils.py", line 2479, in sample
next_tokens = torch.multinomial(probs, num_samples=1).squeeze(1)
RuntimeError: invalid multinomial distribution (sum of probabilities <= 0)
```
This is because of `torch.sum` working incorrectly.
Demonstration:
```py
import torch
x = torch.randn(1,4).cuda()
print(x)
print('sum {}'.format(torch.sum(x)))
```
Output:
```
tensor([[ 0.5149, -0.7664, 0.5527, 1.3156]], device='cuda:0')
sum 0.5148828625679016
```
This is simply the first item in the tensor. `torch.sum` will sometimes return number such as `4.203895392981743e-45`.
### Versions
Collecting environment information...
PyTorch version: 1.13.0a0+git941769a
Is debug build: False
CUDA used to build PyTorch: N/A
ROCM used to build PyTorch: 5.4.22801-aaa1e3d8
OS: Ubuntu 20.04.5 LTS (x86_64)
GCC version: (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0
Clang version: 15.0.0 (https://github.com/RadeonOpenCompute/llvm-project roc-5.4.0 22465 d6f0fe8b22e3d8ce0f2cbd657ea14b16043018a5)
CMake version: version 3.22.1
Libc version: glibc-2.31
Python version: 3.8.13 (default, Mar 28 2022, 11:38:47) [GCC 7.5.0] (64-bit runtime)
Python platform: Linux-5.15.0-60-generic-x86_64-with-glibc2.17
Is CUDA available: True
CUDA runtime version: Could not collect
CUDA_MODULE_LOADING set to:
GPU models and configuration: AMD Radeon PRO V620
Nvidia driver version: Could not collect
cuDNN version: Could not collect
HIP runtime version: 5.4.22801
MIOpen runtime version: 2.19.0
Is XNNPACK available: True
CPU:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
Address sizes: 48 bits physical, 48 bits virtual
CPU(s): 32
On-line CPU(s) list: 0-31
Thread(s) per core: 1
Core(s) per socket: 32
Socket(s): 1
NUMA node(s): 1
Vendor ID: AuthenticAMD
CPU family: 23
Model: 1
Model name: AMD EPYC 7551P 32-Core Processor
Stepping: 2
CPU MHz: 2000.000
BogoMIPS: 4000.00
Virtualization: AMD-V
Hypervisor vendor: KVM
Virtualization type: full
L1d cache: 2 MiB
L1i cache: 2 MiB
L2 cache: 16 MiB
L3 cache: 16 MiB
NUMA node0 CPU(s): 0-31
Vulnerability Itlb multihit: Not affected
Vulnerability L1tf: Not affected
Vulnerability Mds: Not affected
Vulnerability Meltdown: Not affected
Vulnerability Mmio stale data: Not affected
Vulnerability Retbleed: Mitigation; untrained return thunk; SMT disabled
Vulnerability Spec store bypass: Mitigation; Speculative Store Bypass disabled via prctl and seccomp
Vulnerability Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization
Vulnerability Spectre v2: Mitigation; Retpolines, IBPB conditional, STIBP disabled, RSB filling, PBRSB-eIBRS Not affected
Vulnerability Srbds: Not affected
Vulnerability Tsx async abort: Not affected
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ht syscall nx mmxext fxsr_opt pdpe1gb rdtscp lm rep_good nopl cpuid extd_apicid tsc_known_freq pni pclmulqdq ssse3 fma cx16 sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand hypervisor lahf_lm cmp_legacy svm cr8_legacy abm sse4a misalignsse 3dnowprefetch osvw perfctr_core ssbd ibpb vmmcall fsgsbase tsc_adjust bmi1 avx2 smep bmi2 rdseed adx smap clflushopt sha_ni xsaveopt xsavec xgetbv1 xsaves clzero xsaveerptr virt_ssbd arat npt nrip_save arch_capabilities
Versions of relevant libraries:
[pip3] mypy==0.960
[pip3] mypy-extensions==0.4.3
[pip3] numpy==1.24.2
[pip3] torch==1.13.0a0+git941769a
[pip3] torchvision==0.14.0a0+bd70a78
[conda] mkl 2022.0.1 h06a4308_117
[conda] mkl-include 2022.0.1 h06a4308_117
[conda] numpy 1.24.2 pypi_0 pypi
[conda] numpy-base 1.18.5 py38h2f8d375_0
[conda] torch 1.13.0a0+git941769a pypi_0 pypi
[conda] torchvision 0.14.0a0+bd70a78 pypi_0 pypi
cc @jeffdaily @sunway513 @jithunnair-amd @pruthvistony @ROCmSupport @pbelevich
| 31 |
3,449 | 94,872 |
[Inductor] [CPU] as_strided is much slower than empty_strided in single-thread single-batch mode in lennard_jones
|
triaged, oncall: pt2, module: inductor
|
### 🐛 Describe the bug
In-place buffer reuse has been disabled in the lennard_jones model due to a bug. After re-enabling the in-place buffer reuse, performance regression has been observed in single-thread single-batch mode. The profiling showed that `as_strided` is much slower than `empty_strided` which has caused the performance regression: https://github.com/pytorch/pytorch/issues/94267
Note that https://github.com/pytorch/pytorch/pull/94481 has fixed a bug so that `as_strided` won't be in the generated code anymore but `as_strided` slower than `empty_strided` still needs further analysis.
Repro:
```bash
python -m torch.backends.xeon.run_cpu --core_list 0 --ncores_per_instance 1 benchmarks/dynamo/torchbench.py --performance --float32 -dcpu -n50 --inductor --no-skip --dashboard --only lennard_jones --cold_start_latency --batch_size 1 --threads 1
```
### Versions
| ww06.2 | | | | ww05.4 | | | | | | |
| ---- | ---- | ---- | ---- | ---- | ---- | ---- | ---- | ---- | ---- | ---- |
| batch_size | speedup | inductor | eager | batch_size | speedup | inductor | eager | speedup ratio | eager ratio | inductor ratio |
|1 |0.9385 |0.0000632 |5.93132E-05 |1 |1.1339 |0.0000545 |6.17976E-05 |0.83 |1.04 |0.86 |
WW06.2 SW info:
SW | Nightly commit | Master/Main commit
-- | -- | --
Pytorch|[6a03ad6](https://github.com/pytorch/pytorch/commit/6a03ad6a34d7c2a31fcaab7a28898f1777baac85)|[1d53123](https://github.com/pytorch/pytorch/commit/1d53123f44e2d5f08e4605af353b7d32b62346ae)
Torchbench|/|[ef39f8c](https://github.com/pytorch/benchmark/commit/ef39f8ca47e288ce7206fe92a0eaac03e85623b8)
torchaudio|[ecc2781](https://github.com/pytorch/audio/commit/ecc2781b5b5c353e85a8ca9f16741cf92dd08344)|[4a037b0](https://github.com/pytorch/audio/commit/4a037b03915c4f6f81407e697fb11a7e7ace27fa)
torchtext|[112d757](https://github.com/pytorch/text/commit/112d757efd2482ea5f60bc23d85c2c09f0cfde61) | [c7cc5fc](https://github.com/pytorch/text/commit/c7cc5fc1e669f548eef619ae055690831d6cc75e)
torchvision|[ac06efe](https://github.com/pytorch/vision/commit/ac06efed4ad2867c68e6b49ac31b554fcbbaa472)|[35f68a0](https://github.com/pytorch/vision/commit/35f68a09f94b2d7afb3f6adc2ba850216413f28e)
torchdata|[049fb62](https://github.com/pytorch/data/commit/049fb626615e6cd965897af8fea2fa73cecd6a2a)|[c0934b9](https://github.com/pytorch/data/commit/c0934b9afa96458c0f8aa3bef528830835c22195)
dynamo_benchmarks|[6a03ad6](https://github.com/pytorch/pytorch/commit/6a03ad6a34d7c2a31fcaab7a28898f1777baac85)|/
WW05.4 SW info:
SW | Nightly commit | Master/Main commit
-- | -- | --
Pytorch|[2e6952f](https://github.com/pytorch/pytorch/commit/2e6952fa58c8b5d779688d16d466faf95555bbb7)|[79db5bc](https://github.com/pytorch/pytorch/commit/79db5bcc9d3febad00e5a2234b44c7db87defdab)
Torchbench|/|[ef39f8c](https://github.com/pytorch/benchmark/commit/ef39f8ca47e288ce7206fe92a0eaac03e85623b8)
torchaudio|[ecc2781](https://github.com/pytorch/audio/commit/ecc2781b5b5c353e85a8ca9f16741cf92dd08344)|[4a037b0](https://github.com/pytorch/audio/commit/4a037b03915c4f6f81407e697fb11a7e7ace27fa)
torchtext|[112d757](https://github.com/pytorch/text/commit/112d757efd2482ea5f60bc23d85c2c09f0cfde61) | [c7cc5fc](https://github.com/pytorch/text/commit/c7cc5fc1e669f548eef619ae055690831d6cc75e)
torchvision|[ac06efe](https://github.com/pytorch/vision/commit/ac06efed4ad2867c68e6b49ac31b554fcbbaa472)|[35f68a0](https://github.com/pytorch/vision/commit/35f68a09f94b2d7afb3f6adc2ba850216413f28e)
torchdata|[049fb62](https://github.com/pytorch/data/commit/049fb626615e6cd965897af8fea2fa73cecd6a2a)|[c0934b9](https://github.com/pytorch/data/commit/c0934b9afa96458c0f8aa3bef528830835c22195)
dynamo_benchmarks|[b2690c3](https://github.com/pytorch/pytorch/commit/b2690c3ceae36fa6681a0c7cedcc8db7f5d9814a)|/
cc @ezyang @soumith @msaroufim @wconstab @ngimel @bdhirsh @voznesenskym @yanboliang @penguinwu @anijain2305 @EikanWang @jgong5 @Guobing-Chen @XiaobingSuper @zhuhaozhe @blzheng @Xia-Weiwen @wenzhe-nrv @jiayisunx @peterbell10 @desertfire
| 0 |
3,450 | 94,869 |
aten::cudnn_convolution chooses different conv implementation given the same inputs.
|
module: cudnn, module: cuda, module: convolution, triaged
|
## Issue description
I'm using PyTorch DDP, DeepSpeed ZeRO, and PyTorch FSDP to train my model that contains several `nn.Conv1d` layers. `Conv1d.forward` eventually calls `aten::cudnn_convolution` to do the actual computation. I noticed that when using DDP, `aten::cudnn_convolution` launches one CUDA kernel (`cudnn::cnn::conv1D_NCHW_general`) and is quite fast (0.1ms). However, when using ZeRO or FSDP, `aten::cudnn_convolution` launches multiple smaller CUDA kernels (`implicit_convolve_sgemm`) and takes much longer time (4ms).
The model weights and input data have exactly same shapes (and values) but cudnn behaves differently with big performance difference.
PyTorch DDP


PyTorch FSDP NO_SHARD

DeepSpeed ZeRO2
## Code example
## System Info
PyTorch version: 1.12.1
Is debug build: False
CUDA used to build PyTorch: 11.3
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.5 LTS (x86_64)
GCC version: (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0
Clang version: Could not collect
CMake version: version 3.16.3
Libc version: glibc-2.31
Python version: 3.8.13 (default, Mar 28 2022, 11:38:47) [GCC 7.5.0] (64-bit runtime)
Python platform: Linux-5.4.0-1085-azure-x86_64-with-glibc2.17
Is CUDA available: True
CUDA runtime version: 11.3.109
CUDA_MODULE_LOADING set to:
GPU models and configuration:
GPU 0: Tesla V100-SXM2-32GB
GPU 1: Tesla V100-SXM2-32GB
GPU 2: Tesla V100-SXM2-32GB
GPU 3: Tesla V100-SXM2-32GB
GPU 4: Tesla V100-SXM2-32GB
GPU 5: Tesla V100-SXM2-32GB
GPU 6: Tesla V100-SXM2-32GB
GPU 7: Tesla V100-SXM2-32GB
Nvidia driver version: 510.73.08
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.2.0
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.2.0
/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.2.0
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_infer.so.8.2.0
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.2.0
/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.2.0
/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.2.0
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
Address sizes: 46 bits physical, 48 bits virtual
CPU(s): 40
On-line CPU(s) list: 0-39
Thread(s) per core: 1
Core(s) per socket: 20
Socket(s): 2
NUMA node(s): 2
Vendor ID: GenuineIntel
CPU family: 6
Model: 85
Model name: Intel(R) Xeon(R) Platinum 8168 CPU @ 2.70GHz
Stepping: 4
CPU MHz: 2693.672
BogoMIPS: 5387.34
Hypervisor vendor: Microsoft
Virtualization type: full
L1d cache: 1.3 MiB
L1i cache: 1.3 MiB
L2 cache: 40 MiB
L3 cache: 66 MiB
NUMA node0 CPU(s): 0-19
NUMA node1 CPU(s): 20-39
Vulnerability Itlb multihit: Not affected
Vulnerability L1tf: Mitigation; PTE Inversion
Vulnerability Mds: Mitigation; Clear CPU buffers; SMT Host state unknown
Vulnerability Meltdown: Mitigation; PTI
Vulnerability Mmio stale data: Vulnerable: Clear CPU buffers attempted, no microcode; SMT Host state unknown
Vulnerability Spec store bypass: Vulnerable
Vulnerability Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization
Vulnerability Spectre v2: Mitigation; Retpolines, STIBP disabled, RSB filling
Vulnerability Srbds: Not affected
Vulnerability Tsx async abort: Mitigation; Clear CPU buffers; SMT Host state unknown
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ss ht syscall nx pdpe1gb rdtscp lm constant_tsc rep_good nopl xtopology cpuid pni pclmulqdq ssse3 fma cx16 pcid sse4_1 sse4_2 movbe popcnt aes xsave avx f16c rdrand hypervisor lahf_lm abm 3dnowprefetch invpcid_single pti fsgsbase bmi1 hle avx2 smep bmi2 erms invpcid rtm mpx avx512f avx512dq rdseed adx smap clflushopt clwb avx512cd avx512bw avx512vl xsaveopt xsavec xgetbv1 xsaves md_clear arch_capabilities
Versions of relevant libraries:
[pip3] mypy-extensions==0.4.3
[pip3] numpy==1.22.4
[pip3] pytorch-lightning==1.6.3
[pip3] torch==1.12.1
[pip3] torch-nebula==0.15.1
[pip3] torch-ort==1.12.0
[pip3] torch-tb-profiler==0.4.0
[pip3] torchmetrics==0.7.1
[pip3] torchvision==0.13.1+cu113
[conda] magma-cuda113 2.5.2 1 pytorch
[conda] mkl 2023.0.0 pypi_0 pypi
[conda] mkl-fft 1.3.1 pypi_0 pypi
[conda] mkl-include 2021.4.0 pypi_0 pypi
[conda] numpy 1.22.4 pypi_0 pypi
[conda] pytorch-lightning 1.6.3 pypi_0 pypi
[conda] torch 1.12.1 pypi_0 pypi
[conda] torch-nebula 0.15.1 pypi_0 pypi
[conda] torch-ort 1.12.0 pypi_0 pypi
[conda] torch-tb-profiler 0.4.0 pypi_0 pypi
[conda] torchmetrics 0.7.1 pypi_0 pypi
[conda] torchvision 0.13.1+cu113 pypi_0 pypi
cc @csarofeen @ptrblck @xwang233 @ngimel
| 8 |
3,451 | 94,857 |
[FSDP] Gradients not propagating for mixed precision case
|
oncall: distributed, triaged, module: fsdp
|
```
import torch
from torch import nn
import torch.distributed as dist
torch.use_deterministic_algorithms(True, warn_only=True)
torch.manual_seed(0)
dist.init_process_group(backend="nccl")
global_rank = dist.get_rank()
torch.cuda.set_device(global_rank)
import functools
from torch.distributed.fsdp import FullyShardedDataParallel as FSDP
from torch.distributed.fsdp import ShardingStrategy
from torch.distributed.fsdp import MixedPrecision
from torch.distributed.fsdp.wrap import ModuleWrapPolicy
mixed_precision_config = MixedPrecision(
param_dtype=torch.float16,
reduce_dtype=torch.float32,
buffer_dtype=torch.float32,
)
sharding_strategy_config = ShardingStrategy.SHARD_GRAD_OP
teacher_backbone = nn.Linear(24, 24)
student_backbone = nn.Linear(24, 24)
head = nn.Linear(24, 24)
x_half = torch.randn(32, 24, device="cuda", dtype=torch.float16)
x_half2 = torch.randn(32, 24, device="cuda", dtype=torch.float16)
fsdp_wrapper = functools.partial(
FSDP,
sharding_strategy=sharding_strategy_config,
mixed_precision=mixed_precision_config,
device_id=global_rank,
use_orig_params=True,
)
s_teacher_backbone = fsdp_wrapper(teacher_backbone)
s_student_backbone = fsdp_wrapper(student_backbone)
s_head = fsdp_wrapper(head)
t1 = s_teacher_backbone(x_half)
t2 = s_head(t1).detach()
s1 = s_student_backbone(x_half2)
s2 = s_head(s1)
loss = (s2 * t2).sum()
loss.backward()
```
Even if `t2` has `detach()` called, the gradient should propagate through `s2` to `s_head`. However, none of `s_head`'s parameters receive gradients.
If you remove the FSDP from this repro, the gradients are propagated as expected.
cc @mrshenli @pritamdamania87 @zhaojuanmao @satgera @rohan-varma @gqchen @aazzolini @osalpekar @jiayisuse @H-Huang @kwen2501
| 3 |
3,452 | 94,855 |
torch.compile breaks reproducibility
|
triaged, module: determinism, oncall: pt2, module: inductor
|
### 🐛 Describe the bug
Adding torch.compile does not ensure deterministic results after setting a seed (and ensuring all the steps here: https://pytorch.org/docs/stable/notes/randomness.html#:~:text=Reproducibility%20Completely%20reproducible%20results%20are%20not%20guaranteed%20across,and%20GPU%20executions%2C%20even%20when%20using%20identical%20seeds.).
I've been stuck trying to debug why my results are non-deterministic across runs. Finally, removing torch.compile ensures that results across multiple runs are the same. This can be easily reproduced by having multiple runs of a model with torch.compile enabled.
### Error logs
_No response_
### Minified repro
_No response_
### Versions
PyTorch version: 2.0.0.dev20230213+cu117
Is debug build: False
CUDA used to build PyTorch: 11.7
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.5 LTS (x86_64)
GCC version: (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0
Clang version: Could not collect
CMake version: version 3.25.0
Libc version: glibc-2.31
Python version: 3.8.15 (default, Nov 24 2022, 15:19:38) [GCC 11.2.0] (64-bit runtime)
Python platform: Linux-5.4.0-1085-azure-x86_64-with-glibc2.17
Is CUDA available: True
CUDA runtime version: 11.7.99
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration:
GPU 0: NVIDIA A100 80GB PCIe
GPU 1: NVIDIA A100 80GB PCIe
GPU 2: NVIDIA A100 80GB PCIe
GPU 3: NVIDIA A100 80GB PCIe
Nvidia driver version: 510.73.08
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.5.0
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.5.0
/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.5.0
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_infer.so.8.5.0
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.5.0
/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.5.0
/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.5.0
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
Address sizes: 48 bits physical, 48 bits virtual
CPU(s): 96
On-line CPU(s) list: 0-95
Thread(s) per core: 1
Core(s) per socket: 48
Socket(s): 2
NUMA node(s): 4
Vendor ID: AuthenticAMD
CPU family: 25
Model: 1
Model name: AMD EPYC 7V13 64-Core Processor
Stepping: 1
CPU MHz: 2478.466
BogoMIPS: 4890.88
Hypervisor vendor: Microsoft
Virtualization type: full
L1d cache: 3 MiB
L1i cache: 3 MiB
L2 cache: 48 MiB
L3 cache: 384 MiB
NUMA node0 CPU(s): 0-23
NUMA node1 CPU(s): 24-47
NUMA node2 CPU(s): 48-71
NUMA node3 CPU(s): 72-95
Vulnerability Itlb multihit: Not affected
Vulnerability L1tf: Not affected
Vulnerability Mds: Not affected
Vulnerability Meltdown: Not affected
Vulnerability Mmio stale data: Not affected
Vulnerability Spec store bypass: Vulnerable
Vulnerability Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization
Vulnerability Spectre v2: Mitigation; Retpolines, STIBP disabled, RSB filling
Vulnerability Srbds: Not affected
Vulnerability Tsx async abort: Not affected
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36clflush mmx fxsr sse sse2 ht syscall nx mmxext fxsr_opt pdpe1gb rdtscp lm constant_tsc rep_good nopl tsc_reliable nonstop_tsc cpuid extd_apicid aperfmperf pni pclmulqdq ssse3 fma cx16 pcid sse4_1 sse4_2 movbe popcnt aes xsave avx f16c rdrand hypervisor lahf_lm cmp_legacy cr8_legacy abm sse4a misalignsse 3dnowprefetch osvw topoext perfctr_core invpcid_single vmmcall fsgsbase bmi1 avx2 smep bmi2 invpcid rdseed adx smap clflushopt clwb sha_ni xsaveopt xsavec xgetbv1 xsaves clzero xsaveerptr arat umip vaes vpclmulqdq rdpid
Versions of relevant libraries:
[pip3] numpy==1.23.5
[pip3] pytorch-lightning==1.6.3
[pip3] pytorch-triton==2.0.0+0d7e753227
[pip3] torch==2.0.0.dev20230213+cu117
[pip3] torch-nebula==0.15.9
[pip3] torch-ort==1.13.1
[pip3] torchaudio==2.0.0.dev20230214+cu117
[pip3] torchmetrics==0.7.1
[pip3] torchvision==0.15.0.dev20230214+cu117
[conda] magma-cuda117 2.6.1 1 pytorch
[conda] mkl 2021.4.0 pypi_0 pypi
[conda] mkl-include 2021.4.0 pypi_0 pypi
[conda] numpy 1.23.5 pypi_0 pypi
[conda] pytorch-lightning 1.6.3 pypi_0 pypi
[conda] pytorch-triton 2.0.0+0d7e753227 pypi_0 pypi
[conda] torch 2.0.0.dev20230213+cu117 pypi_0 pypi
[conda] torch-nebula 0.15.9 pypi_0 pypi
[conda] torch-ort 1.13.1 pypi_0 pypi
[conda] torchaudio 2.0.0.dev20230214+cu117 pypi_0 pypi
[conda] torchmetrics 0.7.1 pypi_0 pypi
[conda] torchvision 0.15.0.dev20230214+cu117 pypi_0 pypi
cc @mruberry @kurtamohler @ezyang @soumith @msaroufim @wconstab @ngimel @bdhirsh @voznesenskym @yanboliang @penguinwu @anijain2305 @EikanWang @jgong5 @Guobing-Chen @XiaobingSuper @zhuhaozhe @blzheng @Xia-Weiwen @wenzhe-nrv @jiayisunx @peterbell10 @desertfire
| 10 |
3,453 | 94,851 |
`torch.compile` produces `RuntimeError` on function wrapped with `torch.func.grad`
|
triaged, oncall: pt2, module: functorch
|
### 🐛 Describe the bug
Trying out the new `torch.compile` API and am getting a `RuntimeError: Cannot access data pointer of Tensor that doesn't have storage` on a function that has been wrapped with `torch.func.grad`. Why does this not work?
Minimal replication:
```python
import torch
from torch.func import grad
def f(x):
return (0.5 * x**2).sum()
x = torch.randn(10)
f(x) # This works
print(torch.allclose(grad(f)(x), x)) # This works
fjit = torch.compile(grad(f))
fjit(x) # Error, see below
```
<details>
<summary><strong>ERROR DETAILS</strong></summary>
<pre>
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
Cell In[2], line 14
11 f(x) # Ok, this works
12 print(torch.allclose(grad(f)(x), x)) # This works
---> 14 fjit(x) # Error, see below
File /HOME/miniconda3/envs/et-on-fms/lib/python3.10/site-packages/torch/_dynamo/eval_frame.py:209, in _TorchDynamoContext.__call__.<locals>._fn(*args, **kwargs)
207 dynamic_ctx.__enter__()
208 try:
--> 209 return fn(*args, **kwargs)
210 finally:
211 set_eval_frame(prior)
File /HOME/miniconda3/envs/et-on-fms/lib/python3.10/site-packages/torch/_functorch/eager_transforms.py:1364, in grad.<locals>.wrapper(*args, **kwargs)
1362 @wraps(func)
1363 def wrapper(*args, **kwargs):
-> 1364 results = grad_and_value(func, argnums, has_aux=has_aux)(*args, **kwargs)
1365 if has_aux:
1366 grad, (_, aux) = results
File /HOME/miniconda3/envs/et-on-fms/lib/python3.10/site-packages/torch/_functorch/vmap.py:39, in doesnt_support_saved_tensors_hooks.<locals>.fn(*args, **kwargs)
36 @functools.wraps(f)
37 def fn(*args, **kwargs):
38 with torch.autograd.graph.disable_saved_tensors_hooks(message):
---> 39 return f(*args, **kwargs)
File /HOME/miniconda3/envs/et-on-fms/lib/python3.10/site-packages/torch/_functorch/eager_transforms.py:1224, in grad_and_value.<locals>.wrapper(*args, **kwargs)
1222 # See NOTE [grad and vjp interaction with no_grad]
1223 with torch.enable_grad():
-> 1224 args = _wrap_all_tensors(args, level)
1225 kwargs = _wrap_all_tensors(kwargs, level)
1226 diff_args = _slice_argnums(args, argnums, as_tuple=False)
File /HOME/miniconda3/envs/et-on-fms/lib/python3.10/site-packages/torch/_functorch/eager_transforms.py:91, in _wrap_all_tensors(tensor_pytree, level)
90 def _wrap_all_tensors(tensor_pytree, level):
---> 91 return tree_map(partial(_wrap_tensor_for_grad, level=level), tensor_pytree)
File /HOME/miniconda3/envs/et-on-fms/lib/python3.10/site-packages/torch/utils/_pytree.py:195, in tree_map(fn, pytree)
194 def tree_map(fn: Any, pytree: PyTree) -> PyTree:
--> 195 flat_args, spec = tree_flatten(pytree)
196 return tree_unflatten([fn(i) for i in flat_args], spec)
File /HOME/miniconda3/envs/et-on-fms/lib/python3.10/site-packages/torch/utils/_pytree.py:158, in tree_flatten(pytree)
156 children_specs : List['TreeSpec'] = []
157 for child in child_pytrees:
--> 158 flat, child_spec = tree_flatten(child)
159 result += flat
160 children_specs.append(child_spec)
File /HOME/miniconda3/envs/et-on-fms/lib/python3.10/site-packages/torch/utils/_pytree.py:148, in tree_flatten(pytree)
144 """Flattens a pytree into a list of values and a TreeSpec that can be used
145 to reconstruct the pytree.
146 """
147 if _is_leaf(pytree):
--> 148 return [pytree], LeafSpec()
150 node_type = _get_node_type(pytree)
151 flatten_fn = SUPPORTED_NODES[node_type].flatten_fn
File /HOME/miniconda3/envs/et-on-fms/lib/python3.10/site-packages/torch/utils/_pytree.py:137, in LeafSpec.__init__(self)
136 def __init__(self) -> None:
--> 137 super().__init__(None, None, [])
138 self.num_leaves = 1
File /HOME/miniconda3/envs/et-on-fms/lib/python3.10/site-packages/torch/_dynamo/eval_frame.py:330, in catch_errors_wrapper.<locals>.catch_errors(frame, cache_size)
327 return hijacked_callback(frame, cache_size, hooks)
329 with compile_lock:
--> 330 return callback(frame, cache_size, hooks)
File /HOME/miniconda3/envs/et-on-fms/lib/python3.10/site-packages/torch/_dynamo/convert_frame.py:404, in convert_frame.<locals>._convert_frame(frame, cache_size, hooks)
402 counters["frames"]["total"] += 1
403 try:
--> 404 result = inner_convert(frame, cache_size, hooks)
405 counters["frames"]["ok"] += 1
406 return result
File /HOME/miniconda3/envs/et-on-fms/lib/python3.10/site-packages/torch/_dynamo/convert_frame.py:109, in wrap_convert_context.<locals>._fn(*args, **kwargs)
107 torch.random.set_rng_state(rng_state)
108 if torch.cuda.is_available():
--> 109 torch.cuda.set_rng_state(cuda_rng_state)
110 torch.fx.graph_module._forward_from_src = prior_fwd_from_src
File /HOME/miniconda3/envs/et-on-fms/lib/python3.10/site-packages/torch/cuda/random.py:64, in set_rng_state(new_state, device)
61 default_generator = torch.cuda.default_generators[idx]
62 default_generator.set_state(new_state_copy)
---> 64 _lazy_call(cb)
File /HOME/miniconda3/envs/et-on-fms/lib/python3.10/site-packages/torch/cuda/__init__.py:183, in _lazy_call(callable, **kwargs)
181 def _lazy_call(callable, **kwargs):
182 if is_initialized():
--> 183 callable()
184 else:
185 # TODO(torch_deploy): this accesses linecache, which attempts to read the
186 # file system to get traceback info. Patch linecache or do something
187 # else here if this ends up being important.
188 global _lazy_seed_tracker
File HOME/miniconda3/envs/et-on-fms/lib/python3.10/site-packages/torch/cuda/random.py:62, in set_rng_state.<locals>.cb()
60 idx = current_device()
61 default_generator = torch.cuda.default_generators[idx]
---> 62 default_generator.set_state(new_state_copy)
RuntimeError: Cannot access data pointer of Tensor that doesn't have storage
</pre>
</details>
### Versions
Collecting environment information...
PyTorch version: 2.0.0.dev20230213+cu117
Is debug build: False
CUDA used to build PyTorch: 11.7
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.5 LTS (x86_64)
GCC version: (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0
Clang version: Could not collect
CMake version: version 3.25.0
Libc version: glibc-2.31
Python version: 3.10.9 | packaged by conda-forge | (main, Feb 2 2023, 20:20:04) [GCC 11.3.0] (64-bit runtime)
Python platform: Linux-5.4.0-137-generic-x86_64-with-glibc2.31
Is CUDA available: True
CUDA runtime version: 11.7.99
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration:
GPU 0: NVIDIA A100-SXM4-80GB
GPU 1: NVIDIA A100-SXM4-80GB
GPU 2: NVIDIA A100-SXM4-80GB
GPU 3: NVIDIA A100-SXM4-80GB
GPU 4: NVIDIA A100-SXM4-80GB
GPU 5: NVIDIA A100-SXM4-80GB
GPU 6: NVIDIA A100-SXM4-80GB
GPU 7: NVIDIA A100-SXM4-80GB
Nvidia driver version: 515.86.01
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
Address sizes: 43 bits physical, 48 bits virtual
CPU(s): 256
On-line CPU(s) list: 0-255
Thread(s) per core: 2
Core(s) per socket: 64
Socket(s): 2
NUMA node(s): 8
Vendor ID: AuthenticAMD
CPU family: 23
Model: 49
Model name: AMD EPYC 7742 64-Core Processor
Stepping: 0
Frequency boost: enabled
CPU MHz: 3397.663
CPU max MHz: 2250.0000
CPU min MHz: 1500.0000
BogoMIPS: 4491.77
Virtualization: AMD-V
L1d cache: 4 MiB
L1i cache: 4 MiB
L2 cache: 64 MiB
L3 cache: 512 MiB
NUMA node0 CPU(s): 0-15,128-143
NUMA node1 CPU(s): 16-31,144-159
NUMA node2 CPU(s): 32-47,160-175
NUMA node3 CPU(s): 48-63,176-191
NUMA node4 CPU(s): 64-79,192-207
NUMA node5 CPU(s): 80-95,208-223
NUMA node6 CPU(s): 96-111,224-239
NUMA node7 CPU(s): 112-127,240-255
Vulnerability Itlb multihit: Not affected
Vulnerability L1tf: Not affected
Vulnerability Mds: Not affected
Vulnerability Meltdown: Not affected
Vulnerability Mmio stale data: Not affected
Vulnerability Retbleed: Vulnerable
Vulnerability Spec store bypass: Mitigation; Speculative Store Bypass disabled via prctl and seccomp
Vulnerability Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization
Vulnerability Spectre v2: Mitigation; Retpolines, IBPB conditional, IBRS_FW, STIBP conditional, RSB filling, PBRSB-eIBRS Not affected
Vulnerability Srbds: Not affected
Vulnerability Tsx async abort: Not affected
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ht syscall nx mmxext fxsr_opt pdpe1gb rdtscp lm constant_tsc rep_good nopl nonstop_tsc cpuid extd_apicid aperfmperf pni pclmulqdq monitor ssse3 fma cx16 sse4_1 sse4_2 x2apic movbe popcnt aes xsave avx f16c rdrand lahf_lm cmp_legacy svm extapic cr8_legacy abm sse4a misalignsse 3dnowprefetch osvw ibs skinit wdt tce topoext perfctr_core perfctr_nb bpext perfctr_llc mwaitx cpb cat_l3 cdp_l3 hw_pstate sme ssbd mba sev ibrs ibpb stibp vmmcall fsgsbase bmi1 avx2 smep bmi2 cqm rdt_a rdseed adx smap clflushopt clwb sha_ni xsaveopt xsavec xgetbv1 xsaves cqm_llc cqm_occup_llc cqm_mbm_total cqm_mbm_local clzero irperf xsaveerptr wbnoinvd arat npt lbrv svm_lock nrip_save tsc_scale vmcb_clean flushbyasid decodeassists pausefilter pfthreshold avic v_vmsave_vmload vgif umip rdpid overflow_recov succor smca
Versions of relevant libraries:
[pip3] numpy==1.24.2
[pip3] pytorch-triton==2.0.0+0d7e753227
[pip3] torch==2.0.0.dev20230213+cu117
[conda] numpy 1.24.2 pypi_0 pypi
[conda] pytorch-triton 2.0.0+0d7e753227 pypi_0 pypi
[conda] torch 2.0.0.dev20230213+cu117 pypi_0 pypi
cc @ezyang @soumith @msaroufim @wconstab @ngimel @bdhirsh @zou3519 @Chillee @samdow @kshitij12345 @janeyx99
| 10 |
3,454 | 94,844 |
Dynamo.export should support formatting tensor value within a string
|
feature, triaged, oncall: pt2, module: dynamo
|
### 🚀 The feature, motivation and pitch
Code like this would fail to trace in dynamo.export
```
torch._assert(x.numel() > 0, f"My message, tensor value is: {x}")
```
Error message:
```
Unsupported: call_function BuiltinVariable(format) [ConstantVariable(str), TensorVariable()] {}
```
### Alternatives
N/A
### Additional context
It is desired because the code pattern is very common in modeling and there isn't really a work-around for its functionality.
cc @ezyang @soumith @msaroufim @wconstab @ngimel @bdhirsh @voznesenskym @yanboliang @penguinwu @anijain2305 @EikanWang @jgong5 @Guobing-Chen @XiaobingSuper @zhuhaozhe @blzheng @Xia-Weiwen @wenzhe-nrv @jiayisunx @desertfire
| 4 |
3,455 | 94,837 |
Rationalize specialize_int_float handling
|
triaged, oncall: pt2, module: dynamo
|
### 🐛 Describe the bug
There are a few things going on here, writing them down in no particular order:
* dynamic turns off specialize_int_float by default, but this is the wrong choice for export (as all module parameters become new inputs, oof)
* specialize_int_float = False is too aggressive, a ton of things turn into float inputs when they shouldn't be (eager mode specific problem); observed by Horace
* unspecialized int/float are represented as 0d tensor in dynamo, but it is more uniform to treat them as symint/symfloat (but there is some debate about this, because 0d tensor rep is more convenient for backends to handle UNLESS the int ends up being used in a shape context)
### Versions
master
cc @soumith @msaroufim @wconstab @ngimel @bdhirsh @voznesenskym @yanboliang @penguinwu @anijain2305 @EikanWang @jgong5 @Guobing-Chen @XiaobingSuper @zhuhaozhe @blzheng @Xia-Weiwen @wenzhe-nrv @jiayisunx @desertfire
| 3 |
3,456 | 94,836 |
Allow Dynamo backends to use Inductor as fallback instead of eager mode
|
triaged, oncall: pt2, module: inductor
|
### 🚀 The feature, motivation and pitch
I'm working on Dynamo oneDNN backend (being integrated at the mid-layer, like nvfuser or AITemplate) and would like to run models with mixture of Dynamo oneDNN backend + Inductor CPU backend.
Based on oneDNN graph's programming model, we prefer to pass the full graph to oneDNN backend first, which decides its supported subgraphs, and run the rest of the graph with Inductor CPU afterward.
This prototype PR [#90356] from @SherlockNoMad allows inductor to accepts opaque callable. This aligns with our design, where oneDNN backend will fuse subgraphs to call_module nodes and set callable for each fused node. The fused graph will be passed to Inductor CPU for compile and execute.
We'd like to check the plan of this feature and if the PR would be merged.
cc @ezyang @soumith @msaroufim @wconstab @ngimel @bdhirsh @voznesenskym @yanboliang @penguinwu @anijain2305 @EikanWang @jgong5 @Guobing-Chen @XiaobingSuper @zhuhaozhe @blzheng @Xia-Weiwen @jiayisunx @peterbell10 @desertfire @mlazos
| 6 |
3,457 | 94,827 |
Linking error with Libtorch
|
module: cpp, triaged, module: mkl
|
### 🐛 Describe the bug
Hello I'm trying to create an example-app case to run with libtorch as in the https://pytorch.org/cppdocs/installing.html, however I have a linking error.
### Error logs
LINK : fatal error LNK1104: cannot open file 'mkl_intel_ilp64.lib'
### Minified repro
_No response_
### Versions
libtorch 1.13.1+cpu
cc @jbschlosser @ezyang @soumith @msaroufim @wconstab @ngimel @bdhirsh
| 0 |
3,458 | 94,821 |
Make `torch.onnx.utils._optimize_graph` use several CPU cores
|
module: performance, module: onnx, triaged
|
### 🚀 The feature, motivation and pitch
As per title, the function `_optimize_graph` from `torch/onnx/utils.py` uses a single core. This can be checked using `mpstat -P ALL 1` and putting some prints to pin down where the export is hanging.
https://github.com/pytorch/pytorch/blob/d1d5d16df3766bc6a6c9ebe1168ff652bcdcaa5e/torch/onnx/utils.py#L564
This is probably a factor in some exports being extremely slow, maybe linked https://github.com/pytorch/pytorch/issues/63734
In particular, I notice that I am hanging in https://github.com/pytorch/pytorch/blob/d1d5d16df3766bc6a6c9ebe1168ff652bcdcaa5e/torch/onnx/utils.py#L665 which apparently maps to https://github.com/pytorch/pytorch/blob/d1d5d16df3766bc6a6c9ebe1168ff652bcdcaa5e/torch/csrc/jit/passes/onnx.cpp#L165 that takes a very long time, with a single core active.
It would be useful for the method to use several cores.
### Alternatives
Stop using `torch.onnx.export` altogether, stay in PyTorch all the way.
### Additional context
PyTorch version: 1.13.1
cc @ngimel
| 2 |
3,459 | 94,819 |
`tag` parameter is ignored from NCCL P2P isend/irecv pair
|
oncall: distributed, module: nccl
|
### 🐛 Describe the bug
While making a multi-GPU utility with NCCL P2P communication, I found bugs that NCCL backend ignores tag parameter, and also the first irecv/isend pair does not work asynchronously.
The below code sends and receives two tensors between two processes.
1. Main proc: send `ones` (**tag 1**) -> sleep 3 secs -> send `zeros` (**tag 2**)
2. Worker proc: receive **tag 2** -> receive **tag 1** -> wait **tag 1** -> wait **tag 2**
Ideally, the worker should receive `ones` from tag 1, and `zeros` from tag 2.
However, the worker receives `zeros` from tag 1, and `ones` from tag 2, with NCCL backend.
**Test code**
```python
import os
import time
from argparse import ArgumentParser
import torch
import torch.distributed as dist
import torch.multiprocessing as mp
SIZE = 10000
def run_worker(rank, use_nccl):
os.environ["MASTER_ADDR"] = "localhost"
os.environ["MASTER_PORT"] = "29500"
if use_nccl:
dist.init_process_group("nccl", world_size=2, rank=rank)
dev0 = "cuda:0"
dev1 = "cuda:1"
else:
dist.init_process_group("gloo", world_size=2, rank=rank)
dev0 = "cpu"
dev1 = "cpu"
if rank == 0:
ones = torch.ones(SIZE, SIZE, device=dev0)
zeros = torch.zeros(SIZE, SIZE, device=dev0)
print(f"[Main] tag 1: {ones.sum()}, tag 2: {zeros.sum()}")
start_time = time.time()
print(f"[Main] first send ones (tag 1) at {time.time() - start_time:5.3f} sec")
f1 = dist.isend(ones, 1, tag=1)
print(f"[Main] sleeps 3 sec at {time.time() - start_time:5.3f} sec")
time.sleep(3)
print(f"[Main] second send zeros (tag 2) at {time.time() - start_time:5.3f} sec")
f2 = dist.isend(zeros, 1, tag=2)
print(f"[Main] waiting at {time.time() - start_time:5.3f} sec")
f2.wait()
f1.wait()
else:
buf1 = torch.rand(SIZE, SIZE, device=dev1)
buf2 = torch.rand(SIZE, SIZE, device=dev1)
start_time = time.time()
print(f"[Worker] first recv (tag 2) at {time.time() - start_time:5.3f} sec")
f2 = dist.irecv(buf2, 0, tag=2)
print(f"[Worker] second recv (tag 1) at {time.time() - start_time:5.3f} sec")
f1 = dist.irecv(buf1, 0, tag=1)
print(f"[Worker] waiting at {time.time() - start_time:5.3f} sec")
f1.wait()
print(f"[Worker] got tag 1: {buf1.sum()} at {time.time() - start_time:5.3f} sec")
f2.wait()
print(f"[Worker] got tag 2: {buf2.sum()} at {time.time() - start_time:5.3f} sec")
if __name__ == "__main__":
parser = ArgumentParser()
parser.add_argument("--nccl", action="store_true")
args = parser.parse_args()
print(f"Use NCCL: {args.nccl}")
mp.spawn(run_worker, nprocs=2, join=True, args=(args.nccl,))
```
**Result (GLOO)**
```
$ torchrun test.py
Use NCCL: False
[Main] tag 1: 100000000.0, tag 2: 0.0
[Main] first send ones (tag 1) at 0.000 sec
[Main] sleeps 3 sec at 0.000 sec
[Worker] first recv (tag 2) at 0.000 sec
[Worker] second recv (tag 1) at 0.000 sec
[Worker] waiting at 0.000 sec
[Worker] got tag 1: 100000000.0 at 0.112 sec
[Main] second send zeros (tag 2) at 3.003 sec
[Main] waiting at 3.126 sec
[Worker] got tag 2: 0.0 at 2.140 sec
```
**Result (NCCL)**
```
$ torchrun test.py --nccl
Use NCCL: True
[Worker] first recv (tag 2) at 0.000 sec
[Main] tag 1: 100000000.0, tag 2: 0.0
[Main] first send ones (tag 1) at 0.000 sec
[Main] sleeps 3 sec at 0.052 sec
[Worker] second recv (tag 1) at 0.056 sec
[Worker] waiting at 0.056 sec
[Main] second send zeros (tag 2) at 3.055 sec
[Main] waiting at 3.055 sec
[Worker] got tag 1: 0.0 at 3.068 sec
[Worker] got tag 2: 100000000.0 at 3.068 sec
```
These results show two problems:
1. The received values from the worker are skewed (see the values and times from `[Worker] got tag`)
2. The first isend/irecv calls do not return any waitable object, thus work as blocking APIs. (see the times from `[Main] sleeps` and `[Worker] second recv`)
I've tested this behavior from several PyTorch runtimes and machines.
Please notice me whether I misused distributed APIs.
### Versions
2 GPU server (stable build w/ A4500 x 2)
```
Collecting environment information...
PyTorch version: 1.13.1
Is debug build: False
CUDA used to build PyTorch: 11.6
ROCM used to build PyTorch: N/A
OS: Ubuntu 22.04 LTS (x86_64)
GCC version: (Ubuntu 11.3.0-1ubuntu1~22.04) 11.3.0
Clang version: 14.0.0-1ubuntu1
CMake version: version 3.22.1
Libc version: glibc-2.35
Python version: 3.10.6 (main, Oct 7 2022, 20:19:58) [GCC 11.2.0] (64-bit runtime)
Python platform: Linux-5.15.0-48-generic-x86_64-with-glibc2.35
Is CUDA available: True
CUDA runtime version: 11.6.124
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration:
GPU 0: NVIDIA RTX A4500
GPU 1: NVIDIA RTX A4500
Nvidia driver version: 510.47.03
cuDNN version: Probably one of the following:
/usr/local/cuda-11.6/targets/x86_64-linux/lib/libcudnn.so.8.6.0
/usr/local/cuda-11.6/targets/x86_64-linux/lib/libcudnn_adv_infer.so.8.6.0
/usr/local/cuda-11.6/targets/x86_64-linux/lib/libcudnn_adv_train.so.8.6.0
/usr/local/cuda-11.6/targets/x86_64-linux/lib/libcudnn_cnn_infer.so.8.6.0
/usr/local/cuda-11.6/targets/x86_64-linux/lib/libcudnn_cnn_train.so.8.6.0
/usr/local/cuda-11.6/targets/x86_64-linux/lib/libcudnn_ops_infer.so.8.6.0
/usr/local/cuda-11.6/targets/x86_64-linux/lib/libcudnn_ops_train.so.8.6.0
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Address sizes: 46 bits physical, 48 bits virtual
Byte Order: Little Endian
CPU(s): 16
On-line CPU(s) list: 0-15
Vendor ID: GenuineIntel
Model name: Intel(R) Xeon(R) W-3223 CPU @ 3.50GHz
CPU family: 6
Model: 85
Thread(s) per core: 2
Core(s) per socket: 8
Socket(s): 1
Stepping: 7
CPU max MHz: 4200.0000
CPU min MHz: 1200.0000
BogoMIPS: 7000.00
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc art arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc cpuid aperfmperf pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid dca sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm 3dnowprefetch cpuid_fault epb cat_l3 cdp_l3 invpcid_single intel_ppin ssbd mba ibrs ibpb stibp ibrs_enhanced tpr_shadow vnmi flexpriority ept vpid ept_ad fsgsbase tsc_adjust bmi1 avx2 smep bmi2 erms invpcid cqm mpx rdt_a avx512f avx512dq rdseed adx smap clflushopt clwb intel_pt avx512cd avx512bw avx512vl xsaveopt xsavec xgetbv1 xsaves cqm_llc cqm_occup_llc cqm_mbm_total cqm_mbm_local dtherm ida arat pln pts hwp hwp_act_window hwp_epp hwp_pkg_req pku ospke avx512_vnni md_clear flush_l1d arch_capabilities
Virtualization: VT-x
L1d cache: 256 KiB (8 instances)
L1i cache: 256 KiB (8 instances)
L2 cache: 8 MiB (8 instances)
L3 cache: 16.5 MiB (1 instance)
NUMA node(s): 1
NUMA node0 CPU(s): 0-15
Vulnerability Itlb multihit: KVM: Mitigation: VMX disabled
Vulnerability L1tf: Not affected
Vulnerability Mds: Not affected
Vulnerability Meltdown: Not affected
Vulnerability Mmio stale data: Mitigation; Clear CPU buffers; SMT vulnerable
Vulnerability Retbleed: Mitigation; Enhanced IBRS
Vulnerability Spec store bypass: Mitigation; Speculative Store Bypass disabled via prctl and seccomp
Vulnerability Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization
Vulnerability Spectre v2: Mitigation; Enhanced IBRS, IBPB conditional, RSB filling
Vulnerability Srbds: Not affected
Vulnerability Tsx async abort: Mitigation; TSX disabled
Versions of relevant libraries:
[pip3] numpy==1.23.1
[pip3] pytorch-sphinx-theme==0.0.24
[pip3] torch==1.13.1
[pip3] torch-tb-profiler==0.4.0
[pip3] torchaudio==0.13.1
[pip3] torchvision==0.14.1
[conda] blas 1.0 mkl
[conda] cudatoolkit 11.6.0 hecad31d_10 conda-forge
[conda] ffmpeg 4.3 hf484d3e_0 pytorch
[conda] mkl 2021.4.0 h06a4308_640
[conda] mkl-service 2.4.0 py310ha2c4b55_0 conda-forge
[conda] mkl_fft 1.3.1 py310h2b4bcf5_1 conda-forge
[conda] mkl_random 1.2.2 py310h00e6091_0
[conda] numpy 1.23.1 py310h1794996_0
[conda] numpy-base 1.23.1 py310hcba007f_0
[conda] pytorch 1.13.1 py3.10_cuda11.6_cudnn8.3.2_0 pytorch
[conda] pytorch-cuda 11.6 h867d48c_1 pytorch
[conda] pytorch-mutex 1.0 cuda pytorch
[conda] pytorch-sphinx-theme 0.0.24 dev_0 <develop>
[conda] torch-tb-profiler 0.4.0 pypi_0 pypi
[conda] torchaudio 0.13.1 py310_cu116 pytorch
[conda] torchvision 0.14.1 py310_cu116 pytorch
```
8 GPU server (nightly build w/ RTX3090 x 8)
```
Collecting environment information...
PyTorch version: 2.0.0.dev20230213
Is debug build: False
CUDA used to build PyTorch: 11.8
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.4 LTS (x86_64)
GCC version: (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0
Clang version: 10.0.0-4ubuntu1
CMake version: version 3.16.3
Libc version: glibc-2.31
Python version: 3.10.9 (main, Jan 11 2023, 15:21:40) [GCC 11.2.0] (64-bit runtime)
Python platform: Linux-5.4.0-126-generic-x86_64-with-glibc2.31
Is CUDA available: True
CUDA runtime version: 11.6.124
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration:
GPU 0: NVIDIA GeForce RTX 3090
GPU 1: NVIDIA GeForce RTX 3090
GPU 2: NVIDIA GeForce RTX 3090
GPU 3: NVIDIA GeForce RTX 3090
GPU 4: NVIDIA GeForce RTX 3090
GPU 5: NVIDIA GeForce RTX 3090
GPU 6: NVIDIA GeForce RTX 3090
GPU 7: NVIDIA GeForce RTX 3090
Nvidia driver version: 510.47.03
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.5.0
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.5.0
/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.5.0
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_infer.so.8.5.0
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.5.0
/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.5.0
/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.5.0
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
Address sizes: 43 bits physical, 48 bits virtual
CPU(s): 64
On-line CPU(s) list: 0-31
Off-line CPU(s) list: 32-63
Thread(s) per core: 1
Core(s) per socket: 16
Socket(s): 2
NUMA node(s): 2
Vendor ID: AuthenticAMD
CPU family: 23
Model: 49
Model name: AMD EPYC 7F52 16-Core Processor
Stepping: 0
Frequency boost: enabled
CPU MHz: 1797.658
CPU max MHz: 3500.0000
CPU min MHz: 2500.0000
BogoMIPS: 6999.88
Virtualization: AMD-V
L1d cache: 1 MiB
L1i cache: 1 MiB
L2 cache: 16 MiB
L3 cache: 512 MiB
NUMA node0 CPU(s): 0-15
NUMA node1 CPU(s): 16-31
Vulnerability Itlb multihit: Not affected
Vulnerability L1tf: Not affected
Vulnerability Mds: Not affected
Vulnerability Meltdown: Not affected
Vulnerability Mmio stale data: Not affected
Vulnerability Spec store bypass: Mitigation; Speculative Store Bypass disabled via prctl and seccomp
Vulnerability Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization
Vulnerability Spectre v2: Mitigation; Retpolines, IBPB conditional, IBRS_FW, RSB filling
Vulnerability Srbds: Not affected
Vulnerability Tsx async abort: Not affected
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ht syscall nx mmxext fxsr_opt pdpe1gb rdtscp lm constant_tsc rep_good nopl nonstop_tsc cpuid extd_apicid aperfmperf pni pclmulqdq monitor ssse3 fma cx16 sse4_1 sse4_2 movbe popcnt aes xsave avx f16c rdrand lahf_lm cmp_legacy svm extapic cr8_legacy abm sse4a misalignsse 3dnowprefetch osvw ibs skinit wdt tce topoext perfctr_core perfctr_nb bpext perfctr_llc mwaitx cpb cat_l3 cdp_l3 hw_pstate sme ssbd mba sev ibrs ibpb stibp vmmcall fsgsbase bmi1 avx2 smep bmi2 cqm rdt_a rdseed adx smap clflushopt clwb sha_ni xsaveopt xsavec xgetbv1 xsaves cqm_llc cqm_occup_llc cqm_mbm_total cqm_mbm_local clzero irperf xsaveerptr wbnoinvd arat npt lbrv svm_lock nrip_save tsc_scale vmcb_clean flushbyasid decodeassists pausefilter pfthreshold avic v_vmsave_vmload vgif umip rdpid overflow_recov succor smca
Versions of relevant libraries:
[pip3] bert-pytorch==0.0.1a4
[pip3] clip-anytorch==2.5.0
[pip3] CoCa-pytorch==0.0.7
[pip3] dalle2-pytorch==1.10.5
[pip3] ema-pytorch==0.1.4
[pip3] functorch==1.14.0a0+408bcf1
[pip3] mypy-extensions==0.4.3
[pip3] numpy==1.23.5
[pip3] pytorch-transformers==1.2.0
[pip3] pytorch-warmup==0.1.1
[pip3] rotary-embedding-torch==0.2.1
[pip3] torch==2.0.0.dev20230213
[pip3] torch-fidelity==0.3.0
[pip3] torch-struct==0.5
[pip3] torchaudio==2.0.0.dev20230213
[pip3] torchmetrics==0.11.1
[pip3] torchrec-nightly==2023.1.30
[pip3] torchvision==0.15.0.dev20230213
[pip3] vector-quantize-pytorch==0.10.15
[conda] bert-pytorch 0.0.1a4 dev_0 <develop>
[conda] blas 1.0 mkl
[conda] clip-anytorch 2.5.0 pypi_0 pypi
[conda] coca-pytorch 0.0.7 pypi_0 pypi
[conda] dalle2-pytorch 1.10.5 pypi_0 pypi
[conda] ema-pytorch 0.1.4 pypi_0 pypi
[conda] functorch 1.14.0a0+408bcf1 pypi_0 pypi
[conda] magma-cuda116 2.6.1 1 pytorch
[conda] mkl 2021.4.0 h06a4308_640
[conda] mkl-service 2.4.0 py310h7f8727e_0
[conda] mkl_fft 1.3.1 py310hd6ae3a3_0
[conda] mkl_random 1.2.2 py310h00e6091_0
[conda] numpy 1.21.2 pypi_0 pypi
[conda] numpy-base 1.23.5 py310h8e6c178_0
[conda] pytorch 2.0.0.dev20230213 py3.10_cuda11.8_cudnn8.7.0_0 pytorch-nightly
[conda] pytorch-cuda 11.8 h7e8668a_3 pytorch-nightly
[conda] pytorch-mutex 1.0 cuda pytorch-nightly
[conda] pytorch-transformers 1.2.0 pypi_0 pypi
[conda] pytorch-warmup 0.1.1 pypi_0 pypi
[conda] rotary-embedding-torch 0.2.1 pypi_0 pypi
[conda] torch-fidelity 0.3.0 pypi_0 pypi
[conda] torch-struct 0.5 pypi_0 pypi
[conda] torchaudio 2.0.0.dev20230213 py310_cu118 pytorch-nightly
[conda] torchmetrics 0.11.1 pypi_0 pypi
[conda] torchrec-nightly 2023.1.30 pypi_0 pypi
[conda] torchtriton 2.0.0+0d7e753227 py310 pytorch-nightly
[conda] torchvision 0.15.0.dev20230213 py310_cu118 pytorch-nightly
[conda] vector-quantize-pytorch 0.10.15 pypi_0 pypi
```
cc @mrshenli @pritamdamania87 @zhaojuanmao @satgera @rohan-varma @gqchen @aazzolini @osalpekar @jiayisuse @H-Huang @kwen2501 @awgu
| 1 |
3,460 | 94,816 |
grid_sample with relative grid
|
feature, module: nn, triaged, actionable, module: interpolation
|
### 🚀 grid_sample with relative grid, to make code simpler, and optimize speed and accuracy
Currently, "grid_sample" requires a "grid" with (sort of) "absolute" values. Meaning -1 is the left image edge and +1 is the right image edge. That seems fine in theory. However, practically, if we're talking about big images, e.g. 4K video, the pixels become so small that the addressing becomes highly inaccurate when using Float16.
E.g. let's play around with Float16 numbers here:
https://evanw.github.io/float-toy/
Let's say we want to move pixel 0 to the side by 0.5 pixels. So when talking about a 4K image, the "grid" would need to have a value of -1919.5 / 1920 = -0.99973958333. If you enter this number into the float calculator above, due to the limited accuracy of Float16, the number changes to just -0.9996. Now let's multiply by 1920 and we get -1919.232. So instead of the desired pixel shift of 0.5 we actually get a pixel shift of 0.768! You can see how inaccurate this becomes, and that creates very noticeable image quality degradations. Which means that when using a Float16 grid, grid_sample becomes totally unusable because at high image resolutions, Float16 becomes so inaccurate that it's basically utterly broken.
Now we could argue that we should simply create a Float32 grid. It works well. So why not do that? Well, it consumes more RAM, and it's slower. So it would be much nicer if we could use a Float16 grid.
**So here comes my wish**: There should be a grid_sample alternative which accepts a relative grid. With the "grid" all zero, basically input and output images should be identical. If you want to read a pixel from 0.1 pixels from the right, that pixel in the grid would simply have a value of "0.1". Such a relative grid should work perfectly fine with Float16.
Plus, most neural networks (especially convolutional ones) which create a "grid" actually calculate relative values natively, anyway! They don't usually calculate absolute values. So if you look through all the public neural networks which use grid_sample, many (most?) of them painfully convert their internal relative grid to an absolute grid, to make grid_sample happy. Which is a completely useless conversion, which only makes the use of grid_sample more complex, plus it introduces the Float16 accuracy problem explained above.
Practically, in all my neural networks which use grid_sample, if there was a relative addressing version of grid_sample available, my code would be simpler, and I could stick to Float16, which my neural network natively calculates, anyway (due to Automatic Mixed Precision training). So it would also perform better, with no relative -> absolute conversion needed, and no Float16 -> Float32 conversion needed, either.
### Additional context
This feature wish is loosely related to issue # 94733.
cc @albanD @mruberry @jbschlosser @walterddr @saketh-are
| 6 |
3,461 | 94,808 |
Memory Corruption in torch.lstm caused by edge cases
|
module: crash, module: rnn, triaged, module: edge cases
|
### 🐛 Describe the bug
A heap overflow might be triggered by the following code which calls `torch.lstm`:
````python
import torch
import numpy as np
input = torch.rand([15, 5, 0, 9], dtype=torch.float32).cuda()
hx_0 = torch.randint(-1024, 1024, [14, 4, 12, 7, 11], dtype=torch.int32).cuda()
hx_1 = torch.rand([8, 14, 15, 4, 0, 6], dtype=torch.float64).cuda()
hx = [hx_0, hx_1, ]
params = []
has_biases = False
num_layers = -49
dropout = 110.2580620604831
train = True
bidirectional = False
batch_first = True
res = torch.lstm(
input=input,
hx=hx,
params=params,
has_biases=has_biases,
num_layers=num_layers,
dropout=dropout,
train=train,
bidirectional=bidirectional,
batch_first=batch_first,
)
````
The execution always ends up with **Segment Fault** or **Memory Corruption**:
````
corrupted size vs. prev_size
Aborted (core dumped)
# or
Segmentation fault (core dumped)
````
### Versions
Collecting environment information...
PyTorch version: 2.0.0.dev20230210+cu118
Is debug build: False
CUDA used to build PyTorch: 11.8
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.5 LTS (x86_64)
GCC version: (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0
Clang version: 11.0.0-2~ubuntu20.04.1
CMake version: version 3.25.0
Libc version: glibc-2.31
Python version: 3.10.6 (main, Oct 24 2022, 16:07:47) [GCC 11.2.0] (64-bit runtime)
Python platform: Linux-5.15.0-57-generic-x86_64-with-glibc2.31
Is CUDA available: True
CUDA runtime version: 11.8.89
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration: GPU 0: Tesla V100-PCIE-16GB
Nvidia driver version: 520.61.05
cuDNN version: Probably one of the following:
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn.so.8.1.1
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_adv_infer.so.8.1.1
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_adv_train.so.8.1.1
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_cnn_infer.so.8.1.1
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_cnn_train.so.8.1.1
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_ops_infer.so.8.1.1
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_ops_train.so.8.1.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn.so.8.2.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn_adv_infer.so.8.2.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn_adv_train.so.8.2.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn_cnn_infer.so.8.2.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn_cnn_train.so.8.2.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn_ops_infer.so.8.2.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn_ops_train.so.8.2.1
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
Address sizes: 46 bits physical, 48 bits virtual
CPU(s): 48
On-line CPU(s) list: 0-47
Thread(s) per core: 2
Core(s) per socket: 12
Socket(s): 2
NUMA node(s): 2
Vendor ID: GenuineIntel
CPU family: 6
Model: 85
Model name: Intel(R) Xeon(R) Silver 4214 CPU @ 2.20GHz
Stepping: 7
CPU MHz: 2200.000
BogoMIPS: 4400.00
Virtualization: VT-x
L1d cache: 768 KiB
L1i cache: 768 KiB
L2 cache: 24 MiB
L3 cache: 33 MiB
NUMA node0 CPU(s): 0-11,24-35
NUMA node1 CPU(s): 12-23,36-47
Vulnerability Itlb multihit: KVM: Mitigation: VMX disabled
Vulnerability L1tf: Not affected
Vulnerability Mds: Not affected
Vulnerability Meltdown: Not affected
Vulnerability Mmio stale data: Mitigation; Clear CPU buffers; SMT vulnerable
Vulnerability Retbleed: Mitigation; Enhanced IBRS
Vulnerability Spec store bypass: Mitigation; Speculative Store Bypass disabled via prctl and seccomp
Vulnerability Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization
Vulnerability Spectre v2: Mitigation; Enhanced IBRS, IBPB conditional, RSB filling, PBRSB-eIBRS SW sequence
Vulnerability Srbds: Not affected
Vulnerability Tsx async abort: Mitigation; TSX disabled
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc art arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc cpuid aperfmperf pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid dca sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm 3dnowprefetch cpuid_fault epb cat_l3 cdp_l3 invpcid_single intel_ppin ssbd mba ibrs ibpb stibp ibrs_enhanced tpr_shadow vnmi flexpriority ept vpid ept_ad fsgsbase tsc_adjust bmi1 avx2 smep bmi2 erms invpcid cqm mpx rdt_a avx512f avx512dq rdseed adx smap clflushopt clwb intel_pt avx512cd avx512bw avx512vl xsaveopt xsavec xgetbv1 xsaves cqm_llc cqm_occup_llc cqm_mbm_total cqm_mbm_local dtherm ida arat pln pts hwp_epp pku ospke avx512_vnni md_clear flush_l1d arch_capabilities
Versions of relevant libraries:
[pip3] numpy==1.23.4
[pip3] pytorch-triton==2.0.0+0d7e753227
[pip3] torch==2.0.0.dev20230210+cu118
[pip3] torchaudio==2.0.0.dev20230209+cu118
[pip3] torchvision==0.15.0.dev20230209+cu118
[conda] numpy 1.23.4 pypi_0 pypi
[conda] pytorch-triton 2.0.0+0d7e753227 pypi_0 pypi
[conda] torch 2.0.0.dev20230210+cu118 pypi_0 pypi
[conda] torchaudio 2.0.0.dev20230209+cu118 pypi_0 pypi
[conda] torchvision 0.15.0.dev20230209+cu118 pypi_0 pypi
cc @zou3519
| 1 |
3,462 | 94,806 |
ImportError: cannot import name 'Backend' from 'torch._C._distributed_c10d' (unknown location)
|
oncall: distributed, triaged
|
### 🐛 Describe the bug
I use https://pytorch.org/get-started/pytorch-2.0/#faqs install method to install pytorch2.0 successfuly in my conda env, but when i `import torch`, it occurs error info like this.
```
>>> import torch
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/opt/conda/envs/torch-2.0-inductor-test/lib/python3.8/site-packages/torch/__init__.py", line 1179, in <module>
from .functional import * # noqa: F403
File "/opt/conda/envs/torch-2.0-inductor-test/lib/python3.8/site-packages/torch/functional.py", line 8, in <module>
import torch.nn.functional as F
File "/opt/conda/envs/torch-2.0-inductor-test/lib/python3.8/site-packages/torch/nn/__init__.py", line 1, in <module>
from .modules import * # noqa: F403
File "/opt/conda/envs/torch-2.0-inductor-test/lib/python3.8/site-packages/torch/nn/modules/__init__.py", line 2, in <module>
from .linear import Identity, Linear, Bilinear, LazyLinear
File "/opt/conda/envs/torch-2.0-inductor-test/lib/python3.8/site-packages/torch/nn/modules/linear.py", line 7, in <module>
from .. import functional as F
File "/opt/conda/envs/torch-2.0-inductor-test/lib/python3.8/site-packages/torch/nn/functional.py", line 19, in <module>
from .._jit_internal import boolean_dispatch, _overload, BroadcastingList1, BroadcastingList2, BroadcastingList3
File "/opt/conda/envs/torch-2.0-inductor-test/lib/python3.8/site-packages/torch/_jit_internal.py", line 40, in <module>
import torch.distributed.rpc
File "/opt/conda/envs/torch-2.0-inductor-test/lib/python3.8/site-packages/torch/distributed/__init__.py", line 26, in <module>
from torch._C._distributed_c10d import (
ImportError: cannot import name 'Backend' from 'torch._C._distributed_c10d' (unknown location)
>>>
>>> exit()
```
install cmd like this.
`pip3 install numpy --pre torch torchvision torchaudio --force-reinstall --index-url https://download.pytorch.org/whl/nightly/cu117`
### install info
```
(torch-2.0-inductor-test) root@yq02-inf-hic-k8s-a100-ab2-0025:/workspace# pip3 install numpy --pre torch torchvision torchaudio --force-reinstall --index-url https://download.pytorch.org/whl/nightly/cu117
Looking in indexes: https://download.pytorch.org/whl/nightly/cu117, https://pypi.ngc.nvidia.com
Collecting numpy
Downloading https://download.pytorch.org/whl/nightly/numpy-1.24.1-cp38-cp38-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (17.3 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 17.3/17.3 MB 2.6 MB/s eta 0:00:00
Collecting torch
Downloading https://download.pytorch.org/whl/nightly/cu117/torch-2.0.0.dev20230213%2Bcu117-cp38-cp38-linux_x86_64.whl (1838.1 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 1.8/1.8 GB 606.4 kB/s eta 0:00:00
Collecting torchvision
Downloading https://download.pytorch.org/whl/nightly/cu117/torchvision-0.15.0.dev20230213%2Bcu117-cp38-cp38-linux_x86_64.whl (33.9 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 33.9/33.9 MB 469.5 kB/s eta 0:00:00
Collecting torchaudio
Downloading https://download.pytorch.org/whl/nightly/cu117/torchaudio-2.0.0.dev20230213%2Bcu117-cp38-cp38-linux_x86_64.whl (4.4 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 4.4/4.4 MB 585.4 kB/s eta 0:00:00
Collecting typing-extensions
Downloading https://download.pytorch.org/whl/nightly/typing_extensions-4.4.0-py3-none-any.whl (26 kB)
Collecting networkx
Downloading https://download.pytorch.org/whl/nightly/networkx-3.0rc1-py3-none-any.whl (2.0 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 2.0/2.0 MB 539.1 kB/s eta 0:00:00
Collecting sympy
Downloading https://download.pytorch.org/whl/nightly/sympy-1.11.1-py3-none-any.whl (6.5 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 6.5/6.5 MB 550.6 kB/s eta 0:00:00
Collecting pytorch-triton==2.0.0+0d7e753227
Downloading https://download.pytorch.org/whl/nightly/pytorch_triton-2.0.0%2B0d7e753227-cp38-cp38-linux_x86_64.whl (18.7 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 18.7/18.7 MB 584.4 kB/s eta 0:00:00
Collecting filelock
Downloading https://download.pytorch.org/whl/nightly/filelock-3.9.0-py3-none-any.whl (9.7 kB)
Collecting cmake
Downloading https://download.pytorch.org/whl/nightly/cmake-3.25.0-py2.py3-none-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (23.7 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 23.7/23.7 MB 719.7 kB/s eta 0:00:00
Collecting pillow!=8.3.*,>=5.3.0
Downloading https://download.pytorch.org/whl/nightly/Pillow-9.3.0-cp38-cp38-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (3.2 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 3.2/3.2 MB 753.3 kB/s eta 0:00:00
Collecting requests
Downloading https://download.pytorch.org/whl/nightly/requests-2.28.1-py3-none-any.whl (62 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 62.8/62.8 kB 246.7 kB/s eta 0:00:00
Collecting certifi>=2017.4.17
Downloading https://download.pytorch.org/whl/nightly/certifi-2022.12.7-py3-none-any.whl (155 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 155.3/155.3 kB 292.3 kB/s eta 0:00:00
Collecting charset-normalizer<3,>=2
Downloading https://download.pytorch.org/whl/nightly/charset_normalizer-2.1.1-py3-none-any.whl (39 kB)
Collecting urllib3<1.27,>=1.21.1
Downloading https://download.pytorch.org/whl/nightly/urllib3-1.26.13-py2.py3-none-any.whl (140 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 140.6/140.6 kB 272.3 kB/s eta 0:00:00
Collecting idna<4,>=2.5
Downloading https://download.pytorch.org/whl/nightly/idna-3.4-py3-none-any.whl (61 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 61.5/61.5 kB 221.8 kB/s eta 0:00:00
Collecting mpmath>=0.19
Downloading https://download.pytorch.org/whl/nightly/mpmath-1.2.1-py3-none-any.whl (532 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 532.6/532.6 kB 447.3 kB/s eta 0:00:00
Installing collected packages: mpmath, cmake, urllib3, typing-extensions, sympy, pillow, numpy, networkx, idna, filelock, charset-normalizer, certifi, requests, pytorch-triton, torch, torchvision, torchaudio
Successfully installed certifi-2022.12.7 charset-normalizer-2.1.1 cmake-3.25.0 filelock-3.9.0 idna-3.4 mpmath-1.2.1 networkx-3.0rc1 numpy-1.24.1 pillow-9.3.0 pytorch-triton-2.0.0+0d7e753227 requests-2.28.1 sympy-
1.11.1 torch-2.0.0.dev20230213+cu117 torchaudio-2.0.0.dev20230213+cu117 torchvision-0.15.0.dev20230213+cu117 typing-extensions-4.4.0 urllib3-1.26.13
WARNING: Running pip as the 'root' user can result in broken permissions and conflicting behaviour with the system package manager. It is recommended to use a virtual environment instead: https://pip.pypa.io/warnings/venv
```
cc @mrshenli @pritamdamania87 @zhaojuanmao @satgera @rohan-varma @gqchen @aazzolini @osalpekar @jiayisuse @H-Huang @kwen2501 @awgu
| 2 |
3,463 | 94,804 |
Build Error: no matching function for call to ‘dnnl::graph::stream::stream(<brace-enclosed initializer list>)’
|
module: build, triaged, module: mkldnn
|
### 🐛 Describe the bug
I am trying to compile PyTorch from source.
```bash
docker run --gpus all -d --name pytorch-build-cuda102 -v /data2:/data2 -w /data2/pytorch-build nvidia/cuda:10.2-cudnn7-devel-ubuntu18.04 sleep infinity
# I tried with nvidia/cuda:11.2.0-cudnn8-devel-ubuntu20.04 too but ended up with the same error.
# Enter the container and install anaconda
apt-get update
apt-get install wget
wget https://repo.anaconda.com/archive/Anaconda3-2022.10-Linux-x86_64.sh
bash Anaconda3-2022.10-Linux-x86_64.sh
# Reopen shell and install dependencies
conda install astunparse numpy ninja pyyaml setuptools cmake cffi typing_extensions future six requests dataclasses
conda install mkl mkl-include
# conda install -c pytorch magma-cuda112
conda install -c pytorch magma-cuda102
git clone --recursive https://github.com/pytorch/pytorch.git
cd pytorch
git checkout v1.13.1
export CMAKE_PREFIX_PATH=${CONDA_PREFIX:-"$(dirname $(which conda))/../"}
USE_XNNPACK=0 python setup.py install --cmake
```
Then the error log:
```log
[Lots of CMake warnings]
-- Generating done
-- Build files have been written to: /data2/pytorch-build/pytorch/build
cmake --build . --target install --config Release
[121/1270] Building CXX object caffe2/CMakeFiles/torch_cpu.dir/__/torch/csrc/jit/codegen/onednn/LlgaTensorImpl.cpp.o
FAILED: caffe2/CMakeFiles/torch_cpu.dir/__/torch/csrc/jit/codegen/onednn/LlgaTensorImpl.cpp.o
/usr/bin/c++ -DAT_PER_OPERATOR_HEADERS -DBUILD_ONEDNN_GRAPH -DCPUINFO_SUPPORTED_PLATFORM=1 -DFMT_HEADER_ONLY=1 -DHAVE_MALLOC_USABLE_SIZE=1 -DHAVE_MMAP=1 -DHAVE_SHM_OPEN=1 -DHAVE_SHM_UNLINK=1 -DIDEEP_USE_MKL -DMINIZ_DISABLE_ZIP_READER_CRC32_CHECKS -DNNP_CONVOLUTION_ONLY=0 -DNNP_INFERENCE_ONLY=0 -DONNXIFI_ENABLE_EXT=1 -DONNX_ML=1 -DONNX_NAMESPACE=onnx_torch -DUSE_C10D_GLOO -DUSE_DISTRIBUTED -DUSE_EXTERNAL_MZCRC -DUSE_RPC -DUSE_TENSORPIPE -D_FILE_OFFSET_BITS=64 -Dtorch_cpu_EXPORTS -I/data2/pytorch-build/pytorch/build/aten/src -I/data2/pytorch-build/pytorch/aten/src -I/data2/pytorch-build/pytorch/build -I/data2/pytorch-build/pytorch -I/data2/pytorch-build/pytorch/cmake/../third_party/benchmark/include -I/data2/pytorch-build/pytorch/cmake/../third_party/cudnn_frontend/include -I/data2/pytorch-build/pytorch/third_party/onnx -I/data2/pytorch-build/pytorch/build/third_party/onnx -I/data2/pytorch-build/pytorch/third_party/foxi -I/data2/pytorch-build/pytorch/build/third_party/foxi -I/data2/pytorch-build/pytorch/torch/csrc/api -I/data2/pytorch-build/pytorch/torch/csrc/api/include -I/data2/pytorch-build/pytorch/caffe2/aten/src/TH -I/data2/pytorch-build/pytorch/build/caffe2/aten/src/TH -I/data2/pytorch-build/pytorch/build/caffe2/aten/src -I/data2/pytorch-build/pytorch/build/caffe2/../aten/src -I/data2/pytorch-build/pytorch/torch/csrc -I/data2/pytorch-build/pytorch/third_party/miniz-2.1.0 -I/data2/pytorch-build/pytorch/third_party/kineto/libkineto/include -I/data2/pytorch-build/pytorch/third_party/kineto/libkineto/src -I/data2/pytorch-build/pytorch/aten/../third_party/catch/single_include -I/data2/pytorch-build/pytorch/aten/src/ATen/.. -I/data2/pytorch-build/pytorch/c10/.. -I/data2/pytorch-build/pytorch/third_party/pthreadpool/include -I/data2/pytorch-build/pytorch/third_party/cpuinfo/include -I/data2/pytorch-build/pytorch/third_party/QNNPACK/include -I/data2/pytorch-build/pytorch/aten/src/ATen/native/quantized/cpu/qnnpack/include -I/data2/pytorch-build/pytorch/aten/src/ATen/native/quantized/cpu/qnnpack/src -I/data2/pytorch-build/pytorch/third_party/cpuinfo/deps/clog/include -I/data2/pytorch-build/pytorch/third_party/NNPACK/include -I/data2/pytorch-build/pytorch/third_party/fbgemm/include -I/data2/pytorch-build/pytorch/third_party/fbgemm -I/data2/pytorch-build/pytorch/third_party/fbgemm/third_party/asmjit/src -I/data2/pytorch-build/pytorch/third_party/ittapi/src/ittnotify -I/data2/pytorch-build/pytorch/third_party/FP16/include -I/data2/pytorch-build/pytorch/third_party/tensorpipe -I/data2/pytorch-build/pytorch/build/third_party/tensorpipe -I/data2/pytorch-build/pytorch/third_party/tensorpipe/third_party/libnop/include -I/data2/pytorch-build/pytorch/third_party/fmt/include -I/data2/pytorch-build/pytorch/build/third_party/ideep/mkl-dnn/third_party/oneDNN/include -I/data2/pytorch-build/pytorch/third_party/ideep/mkl-dnn/third_party/oneDNN/src/../include -I/data2/pytorch-build/pytorch/third_party/flatbuffers/include -isystem /data2/pytorch-build/pytorch/build/third_party/gloo -isystem /data2/pytorch-build/pytorch/cmake/../third_party/gloo -isystem /data2/pytorch-build/pytorch/cmake/../third_party/googletest/googlemock/include -isystem /data2/pytorch-build/pytorch/cmake/../third_party/googletest/googletest/include -isystem /data2/pytorch-build/pytorch/third_party/protobuf/src -isystem /root/anaconda3/include -isystem /data2/pytorch-build/pytorch/third_party/gemmlowp -isystem /data2/pytorch-build/pytorch/third_party/neon2sse -isystem /data2/pytorch-build/pytorch/third_party/ittapi/include -isystem /data2/pytorch-build/pytorch/cmake/../third_party/eigen -isystem /data2/pytorch-build/pytorch/cmake/../third_party/cub -isystem /data2/pytorch-build/pytorch/third_party/ideep/mkl-dnn/third_party/oneDNN/include -isystem /data2/pytorch-build/pytorch/third_party/ideep/include -isystem /data2/pytorch-build/pytorch/third_party/ideep/mkl-dnn/include -isystem /data2/pytorch-build/pytorch/build/include -Wno-deprecated -fvisibility-inlines-hidden -DUSE_PTHREADPOOL -fopenmp -DNDEBUG -DUSE_KINETO -DUSE_FBGEMM -DUSE_QNNPACK -DUSE_PYTORCH_QNNPACK -DSYMBOLICATE_MOBILE_DEBUG_HANDLE -DEDGE_PROFILER_USE_KINETO -O2 -fPIC -Wno-narrowing -Wall -Wextra -Werror=return-type -Werror=non-virtual-dtor -Wno-missing-field-initializers -Wno-type-limits -Wno-array-bounds -Wno-unknown-pragmas -Wunused-local-typedefs -Wno-unused-parameter -Wno-unused-function -Wno-unused-result -Wno-strict-overflow -Wno-strict-aliasing -Wno-error=deprecated-declarations -Wno-stringop-overflow -Wno-psabi -Wno-error=pedantic -Wno-error=redundant-decls -Wno-error=old-style-cast -fdiagnostics-color=always -faligned-new -Wno-unused-but-set-variable -Wno-maybe-uninitialized -fno-math-errno -fno-trapping-math -Werror=format -Wno-stringop-overflow -DHAVE_AVX2_CPU_DEFINITION -O3 -DNDEBUG -DNDEBUG -fPIC -DCAFFE2_USE_GLOO -DTH_HAVE_THREAD -Wall -Wextra -Wno-unused-parameter -Wno-unused-function -Wno-unused-result -Wno-missing-field-initializers -Wno-write-strings -Wno-unknown-pragmas -Wno-type-limits -Wno-array-bounds -Wno-sign-compare -Wno-strict-overflow -Wno-strict-aliasing -Wno-error=deprecated-declarations -Wno-missing-braces -Wno-maybe-uninitialized -fvisibility=hidden -O2 -fopenmp -DCAFFE2_BUILD_MAIN_LIB -pthread -DASMJIT_STATIC -MD -MT caffe2/CMakeFiles/torch_cpu.dir/__/torch/csrc/jit/codegen/onednn/LlgaTensorImpl.cpp.o -MF caffe2/CMakeFiles/torch_cpu.dir/__/torch/csrc/jit/codegen/onednn/LlgaTensorImpl.cpp.o.d -o caffe2/CMakeFiles/torch_cpu.dir/__/torch/csrc/jit/codegen/onednn/LlgaTensorImpl.cpp.o -c /data2/pytorch-build/pytorch/torch/csrc/jit/codegen/onednn/LlgaTensorImpl.cpp
/data2/pytorch-build/pytorch/torch/csrc/jit/codegen/onednn/LlgaTensorImpl.cpp: In static member function ‘static dnnl::graph::stream& torch::jit::fuser::onednn::Stream::getStream()’:
/data2/pytorch-build/pytorch/torch/csrc/jit/codegen/onednn/LlgaTensorImpl.cpp:19:69: error: no matching function for call to ‘dnnl::graph::stream::stream(<brace-enclosed initializer list>)’
static dnnl::graph::stream cpu_stream{Engine::getEngine(), nullptr};
^
In file included from /data2/pytorch-build/pytorch/torch/csrc/jit/codegen/onednn/LlgaTensorImpl.h:6:0,
from /data2/pytorch-build/pytorch/torch/csrc/jit/codegen/onednn/LlgaTensorImpl.cpp:5:
/data2/pytorch-build/pytorch/third_party/ideep/mkl-dnn/include/oneapi/dnnl/dnnl_graph.hpp:52:5: note: candidate: constexpr dnnl::graph::detail::handle<T, del>::handle() [with T = dnnl_graph_stream*; dnnl_graph_status_t (* del)(T) = dnnl_graph_stream_destroy]
handle() = default;
^~~~~~
/data2/pytorch-build/pytorch/third_party/ideep/mkl-dnn/include/oneapi/dnnl/dnnl_graph.hpp:320:34: note: inherited here
using detail::stream_handle::handle;
^~~~~~
/data2/pytorch-build/pytorch/third_party/ideep/mkl-dnn/include/oneapi/dnnl/dnnl_graph.hpp:320:34: note: candidate expects 0 arguments, 2 provided
/data2/pytorch-build/pytorch/third_party/ideep/mkl-dnn/include/oneapi/dnnl/dnnl_graph.hpp:60:5: note: candidate: dnnl::graph::detail::handle<T, del>::handle(T, bool) [with T = dnnl_graph_stream*; dnnl_graph_status_t (* del)(T) = dnnl_graph_stream_destroy]
handle(T t, bool weak = false) { reset(t, weak); }
^~~~~~
/data2/pytorch-build/pytorch/third_party/ideep/mkl-dnn/include/oneapi/dnnl/dnnl_graph.hpp:320:34: note: inherited here
using detail::stream_handle::handle;
^~~~~~
/data2/pytorch-build/pytorch/third_party/ideep/mkl-dnn/include/oneapi/dnnl/dnnl_graph.hpp:320:34: note: no known conversion for argument 1 from ‘dnnl::graph::engine’ to ‘dnnl_graph_stream*’
/data2/pytorch-build/pytorch/third_party/ideep/mkl-dnn/include/oneapi/dnnl/dnnl_graph.hpp:63:5: note: candidate: dnnl::graph::detail::handle<T, del>::handle(const dnnl::graph::detail::handle<T, del>&) [with T = dnnl_graph_stream*; dnnl_graph_status_t (* del)(T) = dnnl_graph_stream_destroy]
handle(const handle &) = default;
^~~~~~
/data2/pytorch-build/pytorch/third_party/ideep/mkl-dnn/include/oneapi/dnnl/dnnl_graph.hpp:320:34: note: inherited here
using detail::stream_handle::handle;
^~~~~~
/data2/pytorch-build/pytorch/third_party/ideep/mkl-dnn/include/oneapi/dnnl/dnnl_graph.hpp:320:34: note: candidate expects 1 argument, 2 provided
/data2/pytorch-build/pytorch/third_party/ideep/mkl-dnn/include/oneapi/dnnl/dnnl_graph.hpp:67:5: note: candidate: dnnl::graph::detail::handle<T, del>::handle(dnnl::graph::detail::handle<T, del>&&) [with T = dnnl_graph_stream*; dnnl_graph_status_t (* del)(T) = dnnl_graph_stream_destroy]
handle(handle &&) = default;
^~~~~~
/data2/pytorch-build/pytorch/third_party/ideep/mkl-dnn/include/oneapi/dnnl/dnnl_graph.hpp:320:34: note: inherited here
using detail::stream_handle::handle;
^~~~~~
/data2/pytorch-build/pytorch/third_party/ideep/mkl-dnn/include/oneapi/dnnl/dnnl_graph.hpp:320:34: note: candidate expects 1 argument, 2 provided
/data2/pytorch-build/pytorch/third_party/ideep/mkl-dnn/include/oneapi/dnnl/dnnl_graph.hpp:325:5: note: candidate: dnnl::graph::stream::stream(const dnnl::graph::engine&)
stream(const engine &engine) {
^~~~~~
/data2/pytorch-build/pytorch/third_party/ideep/mkl-dnn/include/oneapi/dnnl/dnnl_graph.hpp:325:5: note: candidate expects 1 argument, 2 provided
/data2/pytorch-build/pytorch/third_party/ideep/mkl-dnn/include/oneapi/dnnl/dnnl_graph.hpp:318:7: note: candidate: dnnl::graph::stream::stream(const dnnl::graph::stream&)
class stream : public detail::stream_handle {
^~~~~~
/data2/pytorch-build/pytorch/third_party/ideep/mkl-dnn/include/oneapi/dnnl/dnnl_graph.hpp:318:7: note: candidate expects 1 argument, 2 provided
/data2/pytorch-build/pytorch/third_party/ideep/mkl-dnn/include/oneapi/dnnl/dnnl_graph.hpp:318:7: note: candidate: dnnl::graph::stream::stream(dnnl::graph::stream&&)
/data2/pytorch-build/pytorch/third_party/ideep/mkl-dnn/include/oneapi/dnnl/dnnl_graph.hpp:318:7: note: candidate expects 1 argument, 2 provided
[124/1270] Building CXX object caffe2/CMakeFiles/torch_cpu.dir/__/torch/csrc/jit/codegen/onednn/graph_helper.cpp.o
FAILED: caffe2/CMakeFiles/torch_cpu.dir/__/torch/csrc/jit/codegen/onednn/graph_helper.cpp.o
/usr/bin/c++ -DAT_PER_OPERATOR_HEADERS -DBUILD_ONEDNN_GRAPH -DCPUINFO_SUPPORTED_PLATFORM=1 -DFMT_HEADER_ONLY=1 -DHAVE_MALLOC_USABLE_SIZE=1 -DHAVE_MMAP=1 -DHAVE_SHM_OPEN=1 -DHAVE_SHM_UNLINK=1 -DIDEEP_USE_MKL -DMINIZ_DISABLE_ZIP_READER_CRC32_CHECKS -DNNP_CONVOLUTION_ONLY=0 -DNNP_INFERENCE_ONLY=0 -DONNXIFI_ENABLE_EXT=1 -DONNX_ML=1 -DONNX_NAMESPACE=onnx_torch -DUSE_C10D_GLOO -DUSE_DISTRIBUTED -DUSE_EXTERNAL_MZCRC -DUSE_RPC -DUSE_TENSORPIPE -D_FILE_OFFSET_BITS=64 -Dtorch_cpu_EXPORTS -I/data2/pytorch-build/pytorch/build/aten/src -I/data2/pytorch-build/pytorch/aten/src -I/data2/pytorch-build/pytorch/build -I/data2/pytorch-build/pytorch -I/data2/pytorch-build/pytorch/cmake/../third_party/benchmark/include -I/data2/pytorch-build/pytorch/cmake/../third_party/cudnn_frontend/include -I/data2/pytorch-build/pytorch/third_party/onnx -I/data2/pytorch-build/pytorch/build/third_party/onnx -I/data2/pytorch-build/pytorch/third_party/foxi -I/data2/pytorch-build/pytorch/build/third_party/foxi -I/data2/pytorch-build/pytorch/torch/csrc/api -I/data2/pytorch-build/pytorch/torch/csrc/api/include -I/data2/pytorch-build/pytorch/caffe2/aten/src/TH -I/data2/pytorch-build/pytorch/build/caffe2/aten/src/TH -I/data2/pytorch-build/pytorch/build/caffe2/aten/src -I/data2/pytorch-build/pytorch/build/caffe2/../aten/src -I/data2/pytorch-build/pytorch/torch/csrc -I/data2/pytorch-build/pytorch/third_party/miniz-2.1.0 -I/data2/pytorch-build/pytorch/third_party/kineto/libkineto/include -I/data2/pytorch-build/pytorch/third_party/kineto/libkineto/src -I/data2/pytorch-build/pytorch/aten/../third_party/catch/single_include -I/data2/pytorch-build/pytorch/aten/src/ATen/.. -I/data2/pytorch-build/pytorch/c10/.. -I/data2/pytorch-build/pytorch/third_party/pthreadpool/include -I/data2/pytorch-build/pytorch/third_party/cpuinfo/include -I/data2/pytorch-build/pytorch/third_party/QNNPACK/include -I/data2/pytorch-build/pytorch/aten/src/ATen/native/quantized/cpu/qnnpack/include -I/data2/pytorch-build/pytorch/aten/src/ATen/native/quantized/cpu/qnnpack/src -I/data2/pytorch-build/pytorch/third_party/cpuinfo/deps/clog/include -I/data2/pytorch-build/pytorch/third_party/NNPACK/include -I/data2/pytorch-build/pytorch/third_party/fbgemm/include -I/data2/pytorch-build/pytorch/third_party/fbgemm -I/data2/pytorch-build/pytorch/third_party/fbgemm/third_party/asmjit/src -I/data2/pytorch-build/pytorch/third_party/ittapi/src/ittnotify -I/data2/pytorch-build/pytorch/third_party/FP16/include -I/data2/pytorch-build/pytorch/third_party/tensorpipe -I/data2/pytorch-build/pytorch/build/third_party/tensorpipe -I/data2/pytorch-build/pytorch/third_party/tensorpipe/third_party/libnop/include -I/data2/pytorch-build/pytorch/third_party/fmt/include -I/data2/pytorch-build/pytorch/build/third_party/ideep/mkl-dnn/third_party/oneDNN/include -I/data2/pytorch-build/pytorch/third_party/ideep/mkl-dnn/third_party/oneDNN/src/../include -I/data2/pytorch-build/pytorch/third_party/flatbuffers/include -isystem /data2/pytorch-build/pytorch/build/third_party/gloo -isystem /data2/pytorch-build/pytorch/cmake/../third_party/gloo -isystem /data2/pytorch-build/pytorch/cmake/../third_party/googletest/googlemock/include -isystem /data2/pytorch-build/pytorch/cmake/../third_party/googletest/googletest/include -isystem /data2/pytorch-build/pytorch/third_party/protobuf/src -isystem /root/anaconda3/include -isystem /data2/pytorch-build/pytorch/third_party/gemmlowp -isystem /data2/pytorch-build/pytorch/third_party/neon2sse -isystem /data2/pytorch-build/pytorch/third_party/ittapi/include -isystem /data2/pytorch-build/pytorch/cmake/../third_party/eigen -isystem /data2/pytorch-build/pytorch/cmake/../third_party/cub -isystem /data2/pytorch-build/pytorch/third_party/ideep/mkl-dnn/third_party/oneDNN/include -isystem /data2/pytorch-build/pytorch/third_party/ideep/include -isystem /data2/pytorch-build/pytorch/third_party/ideep/mkl-dnn/include -isystem /data2/pytorch-build/pytorch/build/include -Wno-deprecated -fvisibility-inlines-hidden -DUSE_PTHREADPOOL -fopenmp -DNDEBUG -DUSE_KINETO -DUSE_FBGEMM -DUSE_QNNPACK -DUSE_PYTORCH_QNNPACK -DSYMBOLICATE_MOBILE_DEBUG_HANDLE -DEDGE_PROFILER_USE_KINETO -O2 -fPIC -Wno-narrowing -Wall -Wextra -Werror=return-type -Werror=non-virtual-dtor -Wno-missing-field-initializers -Wno-type-limits -Wno-array-bounds -Wno-unknown-pragmas -Wunused-local-typedefs -Wno-unused-parameter -Wno-unused-function -Wno-unused-result -Wno-strict-overflow -Wno-strict-aliasing -Wno-error=deprecated-declarations -Wno-stringop-overflow -Wno-psabi -Wno-error=pedantic -Wno-error=redundant-decls -Wno-error=old-style-cast -fdiagnostics-color=always -faligned-new -Wno-unused-but-set-variable -Wno-maybe-uninitialized -fno-math-errno -fno-trapping-math -Werror=format -Wno-stringop-overflow -DHAVE_AVX2_CPU_DEFINITION -O3 -DNDEBUG -DNDEBUG -fPIC -DCAFFE2_USE_GLOO -DTH_HAVE_THREAD -Wall -Wextra -Wno-unused-parameter -Wno-unused-function -Wno-unused-result -Wno-missing-field-initializers -Wno-write-strings -Wno-unknown-pragmas -Wno-type-limits -Wno-array-bounds -Wno-sign-compare -Wno-strict-overflow -Wno-strict-aliasing -Wno-error=deprecated-declarations -Wno-missing-braces -Wno-maybe-uninitialized -fvisibility=hidden -O2 -fopenmp -DCAFFE2_BUILD_MAIN_LIB -pthread -DASMJIT_STATIC -MD -MT caffe2/CMakeFiles/torch_cpu.dir/__/torch/csrc/jit/codegen/onednn/graph_helper.cpp.o -MF caffe2/CMakeFiles/torch_cpu.dir/__/torch/csrc/jit/codegen/onednn/graph_helper.cpp.o.d -o caffe2/CMakeFiles/torch_cpu.dir/__/torch/csrc/jit/codegen/onednn/graph_helper.cpp.o -c /data2/pytorch-build/pytorch/torch/csrc/jit/codegen/onednn/graph_helper.cpp
/data2/pytorch-build/pytorch/torch/csrc/jit/codegen/onednn/graph_helper.cpp: In function ‘torch::jit::fuser::onednn::Operator torch::jit::fuser::onednn::createOperator(torch::jit::Node*)’:
/data2/pytorch-build/pytorch/torch/csrc/jit/codegen/onednn/graph_helper.cpp:173:42: error: ‘HardTanh’ is not a member of ‘torch::jit::fuser::onednn::opkind {aka dnnl::graph::op::kind}’
return makeEltwiseOp(node, opkind::HardTanh)
^~~~~~~~
[178/1270] Building CXX object caffe2/CMakeFiles/torch_cpu.dir/__/torch/csrc/jit/serialization/export.cpp.o
ninja: build stopped: subcommand failed.
```
CMake, GCC, C++ versions:
```bash
(base) root@25c690fc833c:/data2/pytorch-build/pytorch# cmake --version
cmake version 3.22.1
CMake suite maintained and supported by Kitware (kitware.com/cmake).
(base) root@25c690fc833c:/data2/pytorch-build/pytorch# gcc --version
gcc (Ubuntu 7.5.0-3ubuntu1~18.04) 7.5.0
Copyright (C) 2017 Free Software Foundation, Inc.
This is free software; see the source for copying conditions. There is NO
warranty; not even for MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE.
(base) root@25c690fc833c:/data2/pytorch-build/pytorch# c++ --version
c++ (Ubuntu 7.5.0-3ubuntu1~18.04) 7.5.0
Copyright (C) 2017 Free Software Foundation, Inc.
This is free software; see the source for copying conditions. There is NO
warranty; not even for MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE.
```
### Versions
```
(base) root@25c690fc833c:/data2/pytorch-build/pytorch# python collect_env.py
Collecting environment information...
PyTorch version: N/A
Is debug build: N/A
CUDA used to build PyTorch: N/A
ROCM used to build PyTorch: N/A
OS: Ubuntu 18.04.6 LTS (x86_64)
GCC version: (Ubuntu 7.5.0-3ubuntu1~18.04) 7.5.0
Clang version: Could not collect
CMake version: version 3.22.1
Libc version: glibc-2.27
Python version: 3.9.13 (main, Aug 25 2022, 23:26:10) [GCC 11.2.0] (64-bit runtime)
Python platform: Linux-3.10.0-957.27.2.el7.x86_64-x86_64-with-glibc2.27
Is CUDA available: N/A
CUDA runtime version: 10.2.89
CUDA_MODULE_LOADING set to: N/A
GPU models and configuration:
GPU 0: NVIDIA A100-PCIE-40GB
GPU 1: NVIDIA A100-PCIE-40GB
GPU 2: NVIDIA A100-PCIE-40GB
GPU 3: NVIDIA A100-PCIE-40GB
GPU 4: NVIDIA A100-PCIE-40GB
GPU 5: NVIDIA A100-PCIE-40GB
GPU 6: NVIDIA A100-PCIE-40GB
GPU 7: NVIDIA A100-PCIE-40GB
Nvidia driver version: 470.82.01
cuDNN version: /usr/lib/x86_64-linux-gnu/libcudnn.so.7.6.5
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: N/A
CPU:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 56
On-line CPU(s) list: 0-55
Thread(s) per core: 1
Core(s) per socket: 28
Socket(s): 2
NUMA node(s): 2
Vendor ID: GenuineIntel
CPU family: 6
Model: 106
Model name: Intel(R) Xeon(R) Gold 6348 CPU @ 2.60GHz
Stepping: 6
CPU MHz: 800.000
CPU max MHz: 3500.0000
CPU min MHz: 800.0000
BogoMIPS: 5200.00
Virtualization: VT-x
L1d cache: 48K
L1i cache: 32K
L2 cache: 1280K
L3 cache: 43008K
NUMA node0 CPU(s): 0-27
NUMA node1 CPU(s): 28-55
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc art arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc aperfmperf eagerfpu pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid dca sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm 3dnowprefetch epb cat_l3 intel_pt ssbd mba ibrs ibpb stibp ibrs_enhanced tpr_shadow vnmi flexpriority ept vpid fsgsbase tsc_adjust bmi1 hle avx2 smep bmi2 erms invpcid rtm cqm rdt_a avx512f avx512dq rdseed adx smap avx512ifma clflushopt clwb avx512cd sha_ni avx512bw avx512vl xsaveopt xsavec xgetbv1 cqm_llc cqm_occup_llc cqm_mbm_total cqm_mbm_local dtherm ida arat pln pts avx512vbmi umip pku ospke avx512_vbmi2 gfni vaes vpclmulqdq avx512_vnni avx512_bitalg avx512_vpopcntdq md_clear pconfig spec_ctrl intel_stibp flush_l1d arch_capabilities
Versions of relevant libraries:
[pip3] mypy-extensions==0.4.3
[pip3] numpy==1.21.5
[pip3] numpydoc==1.4.0
[conda] blas 1.0 mkl
[conda] magma-cuda102 2.5.2 1 pytorch
[conda] mkl 2021.4.0 h06a4308_640
[conda] mkl-include 2022.1.0 h06a4308_224
[conda] mkl-service 2.4.0 py39h7f8727e_0
[conda] mkl_fft 1.3.1 py39hd3c417c_0
[conda] mkl_random 1.2.2 py39h51133e4_0
[conda] numpy 1.21.5 py39h6c91a56_3
[conda] numpy-base 1.21.5 py39ha15fc14_3
[conda] numpydoc 1.4.0 py39h06a4308_0
```
cc @malfet @seemethere @gujinghui @PenghuiCheng @XiaobingSuper @jianyuh @jgong5 @mingfeima @sanchitintel @ashokei @jingxu10 @min-jean-cho @yanbing-j @Guobing-Chen @Xia-Weiwen @mrshenli @pritamdamania87 @zhaojuanmao @satgera @rohan-varma @gqchen @aazzolini @osalpekar @jiayisuse @H-Huang @kwen2501 @awgu
| 6 |
3,464 | 94,801 |
Compiling PyTorch from Source on Xavier
|
module: build, triaged, module: vectorization
|
### 🐛 Describe the bug
My device: Xavier (JetPack 4.6.2)
I want pytorch 1.10.0 with python 3.7 upper version.
I try on python 3.8.
But build compile end with error.
```ninja: build stopped: subcommand failed.```
I think main issue is,
```
immintrin.h: No such file or directory
unrecognized command line option ‘-mavx’ ‘-mavx2’ ‘-mfma’ ‘-mavx512f’ ‘-mavx512dq’ ‘-mavx512vl’ ‘-mavx512bw’ ‘-mvsx’
arch:AVX AVX2 AVX512: No such file or directory
c++: error: unrecognized command line option '-Wshorten-64-to-32'
c++: error: unrecognized command line option '-wd654'
c++: error: unrecognized command line option '-Wthread-safety'; did you mean '-fthread-jumps'?
src.c:6:9: error: impossible constraint in ‘asm’
CheckSymbolExists.c:8:19: error: ‘strtod_l’ undeclared
cc1plus: error: -Werror=cast-function-type: no option -Wcast-function-type
```
Details,
[CMakeError.log](https://github.com/pytorch/pytorch/files/10729782/CMakeError.log)
how i can fix it?
I refer to https://forums.developer.nvidia.com/t/pytorch-for-jetson/72048.
### Error logs
Building wheel torch-1.10.0a0+git36449ea
-- Building version 1.10.0a0+git36449ea
cmake --build . --target install --config Release -- -j 8
[14/383] Building NVCC (Device) object...orch_cuda_generated_SegmentReduce.cu.o
/home/ai/Desktop/yjoh/git/pytorch/aten/src/ATen/native/cuda/SegmentReduce.cu: In lambda function:
/home/ai/Desktop/yjoh/git/pytorch/aten/src/ATen/native/cuda/SegmentReduce.cu:54:51: warning: ‘at::DeprecatedTypeProperties& at::Tensor::type() const’ is deprecated: Tensor.type() is deprecated. Instead use Tensor.options(), which in many cases (e.g. in a constructor) is a drop-in replacement. If you were using data from type(), that is now available from Tensor itself, so instead of tensor.type().scalar_type(), use tensor.scalar_type() instead and instead of tensor.type().backend() use tensor.device(). [-Wdeprecated-declarations]
AT_DISPATCH_INDEX_TYPES(
^
/home/ai/Desktop/yjoh/git/pytorch/build/aten/src/ATen/core/TensorBody.h:194:1: note: declared here
DeprecatedTypeProperties & type() const {
^ ~~
/home/ai/Desktop/yjoh/git/pytorch/aten/src/ATen/native/cuda/SegmentReduce.cu:54:112: warning: ‘c10::ScalarType detail::scalar_type(const at::DeprecatedTypeProperties&)’ is deprecated: passing at::DeprecatedTypeProperties to an AT_DISPATCH macro is deprecated, pass an at::ScalarType instead [-Wdeprecated-declarations]
AT_DISPATCH_INDEX_TYPES(
^
/home/ai/Desktop/yjoh/git/pytorch/aten/src/ATen/Dispatch.h:176:1: note: declared here
inline at::ScalarType scalar_type(const at::DeprecatedTypeProperties& t) {
^~~~~~~~~~~
/home/ai/Desktop/yjoh/git/pytorch/aten/src/ATen/native/cuda/SegmentReduce.cu: In lambda function:
/home/ai/Desktop/yjoh/git/pytorch/aten/src/ATen/native/cuda/SegmentReduce.cu:231:58: warning: ‘at::DeprecatedTypeProperties& at::Tensor::type() const’ is deprecated: Tensor.type() is deprecated. Instead use Tensor.options(), which in many cases (e.g. in a constructor) is a drop-in replacement. If you were using data from type(), that is now available from Tensor itself, so instead of tensor.type().scalar_type(), use tensor.scalar_type() instead and instead of tensor.type().backend() use tensor.device(). [-Wdeprecated-declarations]
AT_DISPATCH_INDEX_TYPES(
^
/home/ai/Desktop/yjoh/git/pytorch/build/aten/src/ATen/core/TensorBody.h:194:1: note: declared here
DeprecatedTypeProperties & type() const {
^ ~~
/home/ai/Desktop/yjoh/git/pytorch/aten/src/ATen/native/cuda/SegmentReduce.cu:231:119: warning: ‘c10::ScalarType detail::scalar_type(const at::DeprecatedTypeProperties&)’ is deprecated: passing at::DeprecatedTypeProperties to an AT_DISPATCH macro is deprecated, pass an at::ScalarType instead [-Wdeprecated-declarations]
AT_DISPATCH_INDEX_TYPES(
^
/home/ai/Desktop/yjoh/git/pytorch/aten/src/ATen/Dispatch.h:176:1: note: declared here
inline at::ScalarType scalar_type(const at::DeprecatedTypeProperties& t) {
^~~~~~~~~~~
/home/ai/Desktop/yjoh/git/pytorch/aten/src/ATen/native/cuda/SegmentReduce.cu: In lambda function:
/home/ai/Desktop/yjoh/git/pytorch/aten/src/ATen/native/cuda/SegmentReduce.cu:291:51: warning: ‘at::DeprecatedTypeProperties& at::Tensor::type() const’ is deprecated: Tensor.type() is deprecated. Instead use Tensor.options(), which in many cases (e.g. in a constructor) is a drop-in replacement. If you were using data from type(), that is now available from Tensor itself, so instead of tensor.type().scalar_type(), use tensor.scalar_type() instead and instead of tensor.type().backend() use tensor.device(). [-Wdeprecated-declarations]
AT_DISPATCH_INDEX_TYPES(
^
/home/ai/Desktop/yjoh/git/pytorch/build/aten/src/ATen/core/TensorBody.h:194:1: note: declared here
DeprecatedTypeProperties & type() const {
^ ~~
/home/ai/Desktop/yjoh/git/pytorch/aten/src/ATen/native/cuda/SegmentReduce.cu:291:112: warning: ‘c10::ScalarType detail::scalar_type(const at::DeprecatedTypeProperties&)’ is deprecated: passing at::DeprecatedTypeProperties to an AT_DISPATCH macro is deprecated, pass an at::ScalarType instead [-Wdeprecated-declarations]
AT_DISPATCH_INDEX_TYPES(
^
/home/ai/Desktop/yjoh/git/pytorch/aten/src/ATen/Dispatch.h:176:1: note: declared here
inline at::ScalarType scalar_type(const at::DeprecatedTypeProperties& t) {
^~~~~~~~~~~
[51/383] Building NVCC (Device) object...cuda/torch_cuda_generated_SoftMax.cu.o
/home/ai/Desktop/yjoh/git/pytorch/aten/src/ATen/native/sparse/cuda/SoftMax.cu: In function ‘at::Tensor at::native::_GLOBAL__N__42_tmpxft_000014a5_00000000_6_SoftMax_cpp1_ii_75209b9c::get_offsets(const at::Tensor&, const IntArrayRef&, int64_t)’:
/home/ai/Desktop/yjoh/git/pytorch/aten/src/ATen/native/sparse/cuda/SoftMax.cu:240:69: warning: ‘at::GenericPackedTensorAccessor<T, N, PtrTraits, index_t> at::Tensor::packed_accessor() const & [with T = long int; long unsigned int N = 2; PtrTraits = at::DefaultPtrTraits; index_t = long int]’ is deprecated: packed_accessor is deprecated, use packed_accessor32 or packed_accessor64 instead [-Wdeprecated-declarations]
auto indices_accessor = indices.packed_accessor<int64_t, 2>();
^
/home/ai/Desktop/yjoh/git/pytorch/build/aten/src/ATen/core/TensorBody.h:228:1: note: declared here
GenericPackedTensorAccessor<T,N,PtrTraits,index_t> packed_accessor() const & {
^ ~~~~~~~~~~~~~
.....
../torch/csrc/jit/python/init.cpp: In lambda function:
../torch/csrc/jit/python/init.cpp:492:30: error: cannot bind non-const lvalue reference of type ‘pybind11::detail::accessor<pybind11::detail::accessor_policies::sequence_item>&’ to an rvalue of type ‘pybind11::detail::generic_iterator<pybind11::detail::iterator_policies::sequence_slow_readwrite>::reference {aka pybind11::detail::accessor<pybind11::detail::accessor_policies::sequence_item>}’
for (auto& obj : inputs) {
^~~~~~
ninja: build stopped: subcommand failed.
### Minified repro
_No response_
### Versions
git clone --recursive --branch v1.10.0 http://github.com/pytorch/pytorch
python3 setup.py bdist_wheel
cc @malfet @seemethere @ezyang @soumith @msaroufim @wconstab @ngimel @bdhirsh
| 3 |
3,465 | 94,792 |
Compiling libtorch from Source on Mac Beyond v1.11.0
|
module: build, module: cpp, triaged, module: macos
|
### 🐛 Describe the bug
When building PyTorch from source using any commit past v1.11.0 - I get the same compiler errors from the aten package.
I'm using the command:
python setup.py develop
pytorch compiles fine from source when I use v1.11.0.
### Error logs
pytorch build errors
In file included from /Users/user/github/pytorch/aten/src/ATen/native/RNN.cpp:8:
In file included from /Users/user/github/pytorch/aten/src/ATen/native/quantized/cpu/qnnpack_utils.h:9:
/Users/user/github/pytorch/aten/src/ATen/native/quantized/cpu/xnnpack_utils.h:76:12: error: use of undeclared identifier 'xnn_create_deconvolution2d_nhwc_qs8'; did you mean 'xnn_create_convolution2d_nhwc_qs8'?
return xnn_create_deconvolution2d_nhwc_qs8(
^~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
xnn_create_convolution2d_nhwc_qs8
/Users/user/gitlab/omg-pytorch-mac-arm64/torch/include/xnnpack.h:2004:17: note: 'xnn_create_convolution2d_nhwc_qs8' declared here
enum xnn_status xnn_create_convolution2d_nhwc_qs8(
^
In file included from /Users/user/github/pytorch/aten/src/ATen/native/RNN.cpp:8:
In file included from /Users/user/github/pytorch/aten/src/ATen/native/quantized/cpu/qnnpack_utils.h:9:
/Users/user/github/pytorch/aten/src/ATen/native/quantized/cpu/xnnpack_utils.h:183:12: error: use of undeclared identifier 'xnn_setup_deconvolution2d_nhwc_qs8'; did you mean 'xnn_setup_deconvolution2d_nhwc_qu8'?
return xnn_setup_deconvolution2d_nhwc_qs8(
^~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
xnn_setup_deconvolution2d_nhwc_qu8
/Users/user/gitlab/omg-pytorch-mac-arm64/torch/include/xnnpack.h:2187:17: note: 'xnn_setup_deconvolution2d_nhwc_qu8' declared here
enum xnn_status xnn_setup_deconvolution2d_nhwc_qu8(
^
In file included from /Users/user/github/pytorch/aten/src/ATen/native/RNN.cpp:8:
In file included from /Users/user/github/pytorch/aten/src/ATen/native/quantized/cpu/qnnpack_utils.h:9:
/Users/user/github/pytorch/aten/src/ATen/native/quantized/cpu/xnnpack_utils.h:190:9: error: cannot initialize a parameter of type 'const uint8_t *' (aka 'const unsigned char *') with an lvalue of type 'const int8_t *' (aka 'const signed char *')
inp, /* const int8_t* input */
^~~
/Users/user/gitlab/omg-pytorch-mac-arm64/torch/include/xnnpack.h:2194:18: note: passing argument to parameter 'input' here
const uint8_t* input,
^
[ 79%] Building CXX object caffe2/CMakeFiles/torch_cpu.dir/__/aten/src/ATen/native/ReplicationPadding.cpp.o
[ 79%] Building CXX object caffe2/CMakeFiles/torch_cpu.dir/__/aten/src/ATen/native/Resize.cpp.o
[ 79%] Building CXX object caffe2/CMakeFiles/torch_cpu.dir/__/aten/src/ATen/native/RowwisePrune.cpp.o
3 errors generated.
gmake[2]: *** [caffe2/CMakeFiles/torch_cpu.dir/build.make:2871: caffe2/CMakeFiles/torch_cpu.dir/__/aten/src/ATen/native/RNN.cpp.o] Error 1
gmake[2]: *** Waiting for unfinished jobs....
gmake[1]: *** [CMakeFiles/Makefile2:3516: caffe2/CMakeFiles/torch_cpu.dir/all] Error 2
gmake: *** [Makefile:146: all] Error 2
### Minified repro
_No response_
### Versions
Collecting environment information...
PyTorch version: 1.13.1
Is debug build: False
CUDA used to build PyTorch: None
ROCM used to build PyTorch: N/A
OS: macOS 12.6 (arm64)
GCC version: Could not collect
Clang version: 13.0.0 (clang-1300.0.29.30)
CMake version: version 3.25.2
Libc version: N/A
Python version: 3.10.8 (main, Nov 24 2022, 08:08:27) [Clang 14.0.6 ] (64-bit runtime)
Python platform: macOS-12.6-arm64-arm-64bit
Is CUDA available: False
CUDA runtime version: No CUDA
CUDA_MODULE_LOADING set to: N/A
GPU models and configuration: No CUDA
Nvidia driver version: No CUDA
cuDNN version: No CUDA
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Apple M1
Versions of relevant libraries:
[pip3] numpy==1.23.5
[pip3] torch==1.13.1
[pip3] torchvision==0.14.1
[conda] numpy 1.23.5 py310hb93e574_0
[conda] numpy-base 1.23.5 py310haf87e8b_0
[conda] pytorch 1.13.1 py3.10_0 pytorch
[conda] torch 1.11.0a0+gitbc2c6ed dev_0 <develop>
[conda] torchvision 0.14.1 py310_cpu pytorch
cc @malfet @seemethere @jbschlosser @albanD @ezyang @soumith @msaroufim @wconstab @ngimel @bdhirsh
| 6 |
3,466 | 94,791 |
[mta] Implement fused SGD
|
module: cpu, triaged, module: mkldnn, open source, module: amp (automated mixed precision), Stale, ciflow/trunk, release notes: quantization, release notes: nn, ciflow/mps, module: inductor, module: dynamo, ciflow/inductor, module: export
|
rel:
- https://github.com/pytorch/pytorch/issues/58833
- https://github.com/pytorch/pytorch/issues/68041
cc @jgong5 @mingfeima @XiaobingSuper @sanchitintel @ashokei @jingxu10 @gujinghui @PenghuiCheng @jianyuh @min-jean-cho @yanbing-j @Guobing-Chen @Xia-Weiwen @mcarilli @ptrblck @leslie-fang-intel @voznesenskym @penguinwu @EikanWang @zhuhaozhe @blzheng @wenzhe-nrv @jiayisunx @peterbell10 @ipiszy @yf225 @chenyang78 @kadeng @muchulee8 @aakhundov @ColinPeppler @avikchaudhuri @gmagogsfm
| 3 |
3,467 | 94,788 |
pytorch log level API and env var
|
high priority, feature, module: logging, triaged
|
### 🚀 The feature, motivation and pitch
I'm requesting to please implement an API to allow users to set logging level across pytorch
For example here is how I set a consistent log level in my applications across multiple packages on a multi-gpu training setup:
```
log_level = logging.WARNING if dist.get_rank() == 0 else logging.ERROR
datasets.utils.logging.set_verbosity(log_level)
transformers.utils.logging.set_verbosity(log_level)
from deepspeed.utils import logger as ds_logger
ds_logger.setLevel(log_level)
```
Would it be possible to be able to do:
```
torch.utils.logging.set_verbosity(log_level)
```
Each of the above examples supports `DATASETS_VERBOSITY`, `TRANSFORMERS_VERBOSITY` env vars to accomplish the same.
`torch.distributed` uses `LOGLEVEL`, which already helps, but unfortunately doesn't use a domain specific prefix. Ideally it would be some sort of `PYTORCH_LOGLEVEL` so that it won't potentially clash with other packages who too didn't think of using a prefixed env var with a unique package-related prefix.
So to summarize:
1. `torch.utils.logging.set_verbosity(log_level)`
2. `PYTORCH_LOGLEVEL` as another way of setting the log level.
I'm not attached to naming, these are just examples.
wrt implementation you are more than welcome to adapt our feature-full [logging.py](https://github.com/huggingface/transformers/blob/main/src/transformers/utils/logging.py) module. All you need to do is `s/transformers/pytorch/g` and `s/TRANSFORMERS/PYTORCH/g`. All the work is already done.
Thank you.
cc @ezyang @gchanan @zou3519
| 26 |
3,468 | 94,779 |
Better Numpy API (interoperability between ML frameworks)
|
triaged, module: numpy
|
## Context
For better interoperability between ML frameworks, it would be great if `torch` API matched more closely `numpy` API (like `tf.experimental.numpy` and `jax.numpy`).
This is a highly requested features, like: #2228 (~100 upvotes), #50344, #38349,... Those issues have since been closed even though there's still many issues remaining.
This is even more relevant with the numpy API standard ([NEP 47](https://numpy.org/neps/nep-0047-array-api-standard.html)): The goal is to write functions once, then reuse them across frameworks:
```python
def somefunc(x, y):
xnp = get_numpy_module(x, y) # Returns `np`, `jnp`, `tf.numpy`, `torch`
out = xnp.mean(x, axis=0) + 2*xnp.std(y, axis=0)
return out
```
Our team has multiple universal libraries which support both `numpy`, `jax` and `TF` (like [`dataclass_array`](https://github.com/google-research/dataclass_array) or [`visu3d`](https://github.com/google-research/visu3d)).
We've been experimenting adding `torch` support recently but encountered quite a lot of issues (while `tf.numpy`, `jax` worked (mostly) out of the box). Here are all the issues we're encountered:
## numpy API issues
Some common methods (present in `np`, `jnp`, `tf.numpy`) are missing from `torch`:
- [ ] `torch.array`: like `x = xnp.array([1, 2, 3])`) (alias of `torch.tensor`)
- [ ] `torch.ndarray`: like `isinstance(x, xnp.ndarray)` (alias of `torch.Tensor`)
- [ ] `Tensor.astype`: like `x = x.astype(np.uint8)`
- [ ] `torch.append` (https://github.com/pytorch/pytorch/issues/64359): https://numpy.org/doc/stable/reference/generated/numpy.append.html
- [ ] `torch.expand_dims`: https://numpy.org/doc/stable/reference/generated/numpy.expand_dims.html (alias of `torch.unsqueeze`)
- [ ] `torch.around`: https://numpy.org/doc/stable/reference/generated/numpy.around.html
- [ ] `torch.concatenate`: https://numpy.org/doc/stable/reference/generated/numpy.concatenate.html
Behavior:
- [ ] torch should accept `np.dtype` everywhere `torch.dtype` is valid (e.g. `torch.ones((), dtype=np.int32)`) (See: #40568).
- [ ] `torch.dtype` should be comparable with `np.dtype`: `tf.int32 == np.int32` but `torch.int32 != np.int32`. This allow to have agnostic comparison: `x.dtype == np.uint8` working for all frameworks.
- [ ] `x[y]` fail for `y.dtype == int32` (raise `IndexError: tensors used as indices must be long, byte or bool tensors`) but works in TF, Jax, Numpy (https://github.com/pytorch/pytorch/issues/83702).
- [ ] `axis=()` (like in `x.mean(axis=())`) return a scalar for `torch` but is a no-op for `np`, `jnp`, `tf` (besides returning float for int array, see bellow). (https://github.com/pytorch/pytorch/issues/29137)
- [ ] `torch.ones(shape=())` fail (expect `size=`), but `xnp.ones(shape=())` works (in other frameworks). Same for `torch.zeros`,...
Casting:
- [ ] `x.mean()` currently require explicit dtype when `x.dtype == int32` (`x.mean(float32)`). Other frameworks default to the default float type (`float32`)
- [ ] `torch.allclose(x, y)` currently fail if `x.dtype != y.dtype`, which is inconsistent with `np`, `jnp`, `tf` (this is very convenient in tests `np.allclose(x, [1, 2, 3])`)
Other differences (but not critical to fix):
- [ ] Mixing `torch` and `np.array` fail (#46829). Both TF and Jax support `tf.Tensor + np.array`.
- [ ] Mixing float and double
- [ ] Would be nice if `torch.asarray` was supporting `jax`, `tf` tensors (and vice-versa).
## Testing and experimenting
Those issues have been found in real production code. Our projects have a `@enp.testing.parametrize_xnp` to run the same unittests on `tf`, `jax`, `numpy`, `torch` to make sure our code works on all backends...
For example: https://github.com/google-research/visu3d/blob/89d2a6c9cb3dee1d63a2f5a8416272beb266510d/visu3d/math/rotation_utils_test.py#L29
In order to make our tests pass with `torch`, we had to mock `torch` to fix some of those behaviors: https://github.com/google/etils/blob/main/etils/enp/torch_mock.py
Having a universal standard API that all ML frameworks apply would be a great step towards. I hope this issue is a small step to help toward this goal.
cc @mruberry @rgommers
| 6 |
3,469 | 94,773 |
`torch.compile` doesn't consider the alias tensor created by `tensor[:]`
|
triaged, oncall: pt2, module: dynamo
|
### 🐛 Describe the bug
`torch.compile` doesn't consider the alias tensor created by `tensor[:]`
For example,
```py
import torch
x = torch.randn(2, 3)
def func(x):
xz = x[:]
x.data = torch.ones(3, 4)
return xz
print(func(x))
# tensor([[ 1.2289, -0.2513, 0.7392],
# [-0.7474, 0.7767, -0.9799]])
print(torch.compile(func)(x))
# tensor([[1., 1., 1., 1.],
# [1., 1., 1., 1.],
# [1., 1., 1., 1.]])
```
### Versions
```
Collecting environment information...
PyTorch version: 2.0.0.dev20230213
Is debug build: False
CUDA used to build PyTorch: 11.7
ROCM used to build PyTorch: N/A
OS: Ubuntu 22.04.1 LTS (x86_64)
GCC version: (Ubuntu 11.3.0-1ubuntu1~22.04) 11.3.0
Clang version: 14.0.0-1ubuntu1
CMake version: version 3.24.1
Libc version: glibc-2.35
Python version: 3.9.15 (main, Nov 24 2022, 14:31:59) [GCC 11.2.0] (64-bit runtime)
Python platform: Linux-5.19.5-051905-generic-x86_64-with-glibc2.35
Is CUDA available: True
CUDA runtime version: 11.6.124
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration: GPU 0: NVIDIA GeForce RTX 3060
Nvidia driver version: 515.86.01
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Address sizes: 46 bits physical, 48 bits virtual
Byte Order: Little Endian
CPU(s): 24
On-line CPU(s) list: 0-23
Vendor ID: GenuineIntel
Model name: 12th Gen Intel(R) Core(TM) i9-12900K
CPU family: 6
Model: 151
Thread(s) per core: 2
Core(s) per socket: 16
Socket(s): 1
Stepping: 2
CPU max MHz: 6700.0000
CPU min MHz: 800.0000
BogoMIPS: 6374.40
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc art arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc cpuid aperfmperf tsc_known_freq pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm 3dnowprefetch cpuid_fault cat_l2 invpcid_single cdp_l2 ssbd ibrs ibpb stibp ibrs_enhanced tpr_shadow vnmi flexpriority ept vpid ept_ad fsgsbase tsc_adjust bmi1 avx2 smep bmi2 erms invpcid rdt_a rdseed adx smap clflushopt clwb intel_pt sha_ni xsaveopt xsavec xgetbv1 xsaves split_lock_detect avx_vnni dtherm ida arat pln pts hwp hwp_notify hwp_act_window hwp_epp hwp_pkg_req hfi umip pku ospke waitpkg gfni vaes vpclmulqdq tme rdpid movdiri movdir64b fsrm md_clear serialize pconfig arch_lbr ibt flush_l1d arch_capabilities
Virtualization: VT-x
L1d cache: 640 KiB (16 instances)
L1i cache: 768 KiB (16 instances)
L2 cache: 14 MiB (10 instances)
L3 cache: 30 MiB (1 instance)
NUMA node(s): 1
NUMA node0 CPU(s): 0-23
Vulnerability Itlb multihit: Not affected
Vulnerability L1tf: Not affected
Vulnerability Mds: Not affected
Vulnerability Meltdown: Not affected
Vulnerability Mmio stale data: Not affected
Vulnerability Retbleed: Not affected
Vulnerability Spec store bypass: Mitigation; Speculative Store Bypass disabled via prctl
Vulnerability Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization
Vulnerability Spectre v2: Mitigation; Enhanced IBRS, IBPB conditional, RSB filling, PBRSB-eIBRS SW sequence
Vulnerability Srbds: Not affected
Vulnerability Tsx async abort: Not affected
Versions of relevant libraries:
[pip3] functorch==0.2.1
[pip3] numpy==1.23.4
[pip3] torch==2.0.0.dev20230213
[pip3] torchaudio==2.0.0.dev20230213
[pip3] torchtriton==2.0.0+0d7e753227
[pip3] torchvision==0.15.0.dev20230213
[conda] _tflow_select 2.3.0 mkl
[conda] blas 1.0 mkl
[conda] cudatoolkit 11.3.1 h2bc3f7f_2
[conda] functorch 0.2.1 pypi_0 pypi
[conda] libblas 3.9.0 12_linux64_mkl conda-forge
[conda] libcblas 3.9.0 12_linux64_mkl conda-forge
[conda] liblapack 3.9.0 12_linux64_mkl conda-forge
[conda] mkl 2021.4.0 h06a4308_640
[conda] mkl-service 2.4.0 py39h7f8727e_0
[conda] mkl_fft 1.3.1 py39hd3c417c_0
[conda] mkl_random 1.2.2 py39h51133e4_0
[conda] numpy 1.22.4 pypi_0 pypi
[conda] numpy-base 1.23.4 py39h31eccc5_0
[conda] pytorch 2.0.0.dev20230213 py3.9_cuda11.7_cudnn8.5.0_0 pytorch-nightly
[conda] pytorch-cuda 11.7 h778d358_3 pytorch-nightly
[conda] pytorch-mutex 1.0 cuda pytorch-nightly
[conda] torch 1.14.0.dev20221207+cu117 pypi_0 pypi
[conda] torchaudio 0.13.0.dev20220923+cu116 pypi_0 pypi
[conda] torchtriton 2.0.0+0d7e753227 pypi_0 pypi
[conda] torchvision 0.14.0.dev20220923+cu116 pypi_0 pypi
```
cc @ezyang @soumith @msaroufim @wconstab @ngimel @bdhirsh @mlazos @voznesenskym @yanboliang @penguinwu @anijain2305 @EikanWang @jgong5 @Guobing-Chen @XiaobingSuper @zhuhaozhe @blzheng @Xia-Weiwen @wenzhe-nrv @jiayisunx @desertfire
| 3 |
3,470 | 94,765 |
MPS internal error in `torch.gather` when last dimension is a singleton dimension
|
module: crash, triaged, module: mps
|
### 🐛 Describe the bug
I'm trying to port my PyTorch code to use MPS acceleration on a MacBook Pro M1 Pro and I'm facing a MPS internal error I cannot debug:
```
/AppleInternal/Library/BuildRoots/c651a45f-806e-11ed-a221-7ef33c48bc85/Library/Caches/com.apple.xbs/Sources/MetalPerformanceShaders/MPSNDArray/Kernels/MPSNDArrayGatherND.mm:234: failed assertion `Rank of updates array (1) must be greater than or equal to inner-most dimension of indices array (20)'
[1] 11201 abort python src/evaluate.py --valid_dir database/valid --load_model --anchor_name
/Users/louislac/miniconda3/envs/sdnet/lib/python3.10/multiprocessing/resource_tracker.py:224: UserWarning: resource_tracker: There appear to be 1 leaked semaphore objects to clean up at shutdown
warnings.warn('resource_tracker: There appear to be %d '
```
The code to reproduce the error is available [here](https://github.com/laclouis5/StructureDetector/tree/apple-silicon-mps). the precise environment can be installed with Anaconda using the `environment_mps.yml` environment file. the command I'm using is `python src/evaluate.py --valid_dir valid --load_model model_best_classif.pth --anchor_name stem --conf_threshold 0.4 --decoder_dist_thresh 0.1 --dist_threshold 0.05`. The `valid` directory can be found [here](https://www.icloud.com/iclouddrive/05ae8fGB4-wknNuWEkOleMlsA#valid) and the model parameters `model_best_classif.pth` can be found [here](https://www.icloud.com/iclouddrive/0e0HWpCssX9orjNJ-Xq79b2OQ#model_best_classif).
This program works fine using the CPU or using CUDA with a compatible GPU.
### Versions
```
Collecting environment information...
PyTorch version: 2.0.0.dev20230213
Is debug build: False
CUDA used to build PyTorch: None
ROCM used to build PyTorch: N/A
OS: macOS 13.2 (arm64)
GCC version: Could not collect
Clang version: 14.0.0 (clang-1400.0.29.202)
CMake version: Could not collect
Libc version: N/A
Python version: 3.10.9 (main, Jan 11 2023, 09:18:18) [Clang 14.0.6 ] (64-bit runtime)
Python platform: macOS-13.2-arm64-arm-64bit
Is CUDA available: False
CUDA runtime version: No CUDA
CUDA_MODULE_LOADING set to: N/A
GPU models and configuration: No CUDA
Nvidia driver version: No CUDA
cuDNN version: No CUDA
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Apple M1 Pro
Versions of relevant libraries:
[pip3] numpy==1.23.5
[pip3] torch==2.0.0.dev20230213
[pip3] torchvision==0.15.0.dev20230213
[conda] numpy 1.23.5 py310hb93e574_0
[conda] numpy-base 1.23.5 py310haf87e8b_0
[conda] pytorch 2.0.0.dev20230213 py3.10_0 pytorch-nightly
[conda] torchvision 0.15.0.dev20230213 py310_cpu pytorch-nightly
```
cc @kulinseth @albanD @malfet @DenisVieriu97 @razarmehr @abhudev
| 2 |
3,471 | 94,739 |
Update PyTorch's default C standard to C17 from C11
|
module: build, triaged
|
### 🚀 The feature, motivation and pitch
We just updated the codebase to C++17 to be compatible with the latest CUDA. However, we left the C standard at C11: https://github.com/pytorch/pytorch/blob/216f88d084f290020785d2719c20c0d3acc510aa/CMakeLists.txt#L41
C17 is also available and should be supported by any compiler that supports C++17. C17 is mostly a bugfix / defect fixes for C11 and doesn't introduce any / major new features: https://en.cppreference.com/w/c/17 . I don't see any reason why wouldn't upgrade to C17 as well, and I just want to make sure it wasn't an oversight during the C++17 upgrade process. It doesn't seem to be discussed here: https://github.com/pytorch/pytorch/issues/56055
### Alternatives
Keep it as C11.
### Additional context
_No response_
cc @malfet @seemethere
| 1 |
3,472 | 94,731 |
Add nvml.dll search path for Windows
|
module: windows, triaged, open source, release notes: cuda, no-stale
|
Add `nvml.dll` search path for Windows. Support NVML queries on Windows. cc @peterjc123 @mszhanyi @skyline75489 @nbcsm @vladimir-aubrecht @iremyux @Blackhex @cristianPanaite @malfet
| 6 |
3,473 | 94,718 |
Option to bypass NOLA check in torch.istft
|
triaged, module: fft
|
### 🚀 The feature, motivation and pitch
The proposal is to add an option to skip the NOLA check during `istft` computation as the NOLA check causes host-device synchronization.
This has been discussed in other issues regarding reconstruction with certain windows when `center=False` ( #62323, #91309), but my proposal is from a performance standpoint (https://discuss.pytorch.org/t/torch-istft-nola-check-causes-synchronization-and-massive-slow-down/172430).
I understand that NOLA check is necessary for invertibility, but if we are certain about the NOLA condition then we should ideally have the option to bypass the check (and subsequent synchronization) in the `istft` function.
### Alternatives
_No response_
### Additional context
Below is the profiler trace for `istft`. As you can see, it spends almost the entire time in synchronization. While for standalone usage it might not be much of a problem, in the case when `istft` is part of a neural network, the synchronization really slows down the computations during training.

The above trace was obtained with the following code:
```
import torch
from torch.profiler import profile, ProfilerActivity
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
dummy_x = torch.randn(256, 7*44100, device=device)
dummy_spec = torch.randn(256, 2049, 302, device=device, dtype=torch.cfloat)
with profile(activities=[ProfilerActivity.CPU, ProfilerActivity.CUDA],
on_trace_ready=torch.profiler.tensorboard_trace_handler('./log'),
schedule=torch.profiler.schedule(
wait=5,
warmup=1,
active=1),
profile_memory=True,
with_stack=True,
record_shapes=True
) as prof:
for _ in range(8):
ispec = torch.istft(dummy_spec, n_fft=4096, hop_length=1024, length=dummy_x.shape[-1])
prof.step()
```
cc @jianyuh @nikitaved @pearu @mruberry @walterddr @IvanYashchuk @xwang233 @Lezcano @peterbell10
| 12 |
3,474 | 94,711 |
Investigate queue disparity between `windows.4xlarge` and `linux.4xlarge`
|
high priority, module: ci, triaged, module: regression
|
### 🐛 Describe the bug
See graph below: in last 7 day there were rarely any queueing for `linux.4xlarge` instances, but `windows.4xlarge` seems hard to come by:
<img width="690" alt="image" src="https://user-images.githubusercontent.com/2453524/218336344-46c3d0a1-9757-4670-a2d6-6244b2f5b291.png">
But according to https://github.com/pytorch/test-infra/blob/90ee2adb46a542babe3f8c016b06b135f211e6b8/.github/scale-config.yml they are allocated on a very similar resources: `c5.4xlarge` vs `c5d.4xlarge`.
Two questions:
- Can they be move to the same resources? (in case `c5d.4xlarge` are harder to come by)
- Does our scaling algorithm prefers Linux to Windows?(as one can also observe by observing queueing times for `linux.g5.4xlarge.nvidia.gpu` vs `windows.g5.4xlarge.nvidia.gpu`)
cc @ezyang @gchanan @zou3519 @seemethere @pytorch/pytorch-dev-infra @jeanschmidt
| 2 |
3,475 | 94,705 |
Split getitem OpInfo into dynamic and non-dynamic inputs
|
module: tests, triaged
|
### 🐛 Describe the bug
Right now they're all mushed together which makes it hard to xfail only the dynamic outputs
### Versions
master
cc @mruberry
| 0 |
3,476 | 94,704 |
`where` triggers INTERNAL ASSERT FAILED when `out` is a long tensor due to mixed types
|
module: error checking, triaged, module: type promotion
|
### 🐛 Describe the bug
`where` triggers INTERNAL ASSERT FAILED when `out` is a long tensor due to mixed types
```py
import torch
a = torch.ones(3, 4)
b = torch.zeros(3, 4)
c = torch.where(a > 0, a, b, out=torch.zeros(3, 4, dtype=torch.long))
# RuntimeError: !needs_dynamic_casting<func_t>::check(iter) INTERNAL ASSERT FAILED
# at "/opt/conda/conda-bld/pytorch_1672906354936/work/aten/src/ATen/native/cpu/Loops.h":308,
# please report a bug to PyTorch.
```
### Versions
```
PyTorch version: 2.0.0.dev20230105
Is debug build: False
CUDA used to build PyTorch: 11.7
ROCM used to build PyTorch: N/A
OS: Ubuntu 22.04.1 LTS (x86_64)
GCC version: (Ubuntu 11.3.0-1ubuntu1~22.04) 11.3.0
Clang version: Could not collect
CMake version: version 3.22.1
Libc version: glibc-2.35
Python version: 3.9.15 (main, Nov 24 2022, 14:31:59) [GCC 11.2.0] (64-bit runtime)
Python platform: Linux-5.15.0-56-generic-x86_64-with-glibc2.35
Is CUDA available: True
CUDA runtime version: 11.7.99
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration:
GPU 0: NVIDIA GeForce RTX 3090
GPU 1: NVIDIA GeForce RTX 3090
GPU 2: NVIDIA GeForce RTX 3090
Nvidia driver version: 515.86.01
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_infer.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.4.1
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.23.5
[pip3] torch==2.0.0.dev20230105
[pip3] torchaudio==2.0.0.dev20230105
[pip3] torchvision==0.15.0.dev20230105
[conda] blas 1.0 mkl
[conda] mkl 2021.4.0 h06a4308_640
[conda] mkl-service 2.4.0 py39h7f8727e_0
[conda] mkl_fft 1.3.1 py39hd3c417c_0
[conda] mkl_random 1.2.2 py39h51133e4_0
[conda] numpy 1.23.5 py39h14f4228_0
[conda] numpy-base 1.23.5 py39h31eccc5_0
[conda] pytorch 2.0.0.dev20230105 py3.9_cuda11.7_cudnn8.5.0_0 pytorch-nightly
[conda] pytorch-cuda 11.7 h67b0de4_2 pytorch-nightly
[conda] pytorch-mutex 1.0 cuda pytorch-nightly
[conda] torchaudio 2.0.0.dev20230105 py39_cu117 pytorch-nightly
[conda] torchtriton 2.0.0+0d7e753227 py39 pytorch-nightly
[conda] torchvision 0.15.0.dev20230105 py39_cu117 pytorch-nightly
```
cc @nairbv @mruberry
| 4 |
3,477 | 94,698 |
A segment fault can be triggered in torch.avg_pool1d
|
module: crash, triaged, module: edge cases
|
### 🐛 Describe the bug
A segment fault can be triggered in `torch.avg_pool1d` by giving an input with shape containing 0 and large value:
````python
import torch
input = torch.rand([9, 15, 0, 2772747373535906632, 0, 14], dtype=torch.float32)
kernel_size = [ 1 ]
stride = [ 1 ]
padding = [ 1 ]
ceil_mode = False
count_include_pad = False
res = torch.avg_pool1d(
input=input,
kernel_size=kernel_size,
stride=stride,
padding=padding,
ceil_mode=ceil_mode,
count_include_pad=count_include_pad,
)
````
The output:
````
Segmentation fault (core dumped)
````
### Versions
Collecting environment information...
PyTorch version: 2.0.0.dev20230210+cu118
Is debug build: False
CUDA used to build PyTorch: 11.8
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.5 LTS (x86_64)
GCC version: (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0
Clang version: 11.0.0-2~ubuntu20.04.1
CMake version: version 3.25.0
Libc version: glibc-2.31
Python version: 3.10.6 (main, Oct 24 2022, 16:07:47) [GCC 11.2.0] (64-bit runtime)
Python platform: Linux-5.15.0-57-generic-x86_64-with-glibc2.31
Is CUDA available: True
CUDA runtime version: 11.8.89
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration: GPU 0: Tesla V100-PCIE-16GB
Nvidia driver version: 520.61.05
cuDNN version: Probably one of the following:
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn.so.8.1.1
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_adv_infer.so.8.1.1
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_adv_train.so.8.1.1
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_cnn_infer.so.8.1.1
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_cnn_train.so.8.1.1
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_ops_infer.so.8.1.1
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_ops_train.so.8.1.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn.so.8.2.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn_adv_infer.so.8.2.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn_adv_train.so.8.2.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn_cnn_infer.so.8.2.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn_cnn_train.so.8.2.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn_ops_infer.so.8.2.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn_ops_train.so.8.2.1
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
Address sizes: 46 bits physical, 48 bits virtual
CPU(s): 48
On-line CPU(s) list: 0-47
Thread(s) per core: 2
Core(s) per socket: 12
Socket(s): 2
NUMA node(s): 2
Vendor ID: GenuineIntel
CPU family: 6
Model: 85
Model name: Intel(R) Xeon(R) Silver 4214 CPU @ 2.20GHz
Stepping: 7
CPU MHz: 2200.000
BogoMIPS: 4400.00
Virtualization: VT-x
L1d cache: 768 KiB
L1i cache: 768 KiB
L2 cache: 24 MiB
L3 cache: 33 MiB
NUMA node0 CPU(s): 0-11,24-35
NUMA node1 CPU(s): 12-23,36-47
Vulnerability Itlb multihit: KVM: Mitigation: VMX disabled
Vulnerability L1tf: Not affected
Vulnerability Mds: Not affected
Vulnerability Meltdown: Not affected
Vulnerability Mmio stale data: Mitigation; Clear CPU buffers; SMT vulnerable
Vulnerability Retbleed: Mitigation; Enhanced IBRS
Vulnerability Spec store bypass: Mitigation; Speculative Store Bypass disabled via prctl and seccomp
Vulnerability Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization
Vulnerability Spectre v2: Mitigation; Enhanced IBRS, IBPB conditional, RSB filling, PBRSB-eIBRS SW sequence
Vulnerability Srbds: Not affected
Vulnerability Tsx async abort: Mitigation; TSX disabled
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc art arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc cpuid aperfmperf pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid dca sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm 3dnowprefetch cpuid_fault epb cat_l3 cdp_l3 invpcid_single intel_ppin ssbd mba ibrs ibpb stibp ibrs_enhanced tpr_shadow vnmi flexpriority ept vpid ept_ad fsgsbase tsc_adjust bmi1 avx2 smep bmi2 erms invpcid cqm mpx rdt_a avx512f avx512dq rdseed adx smap clflushopt clwb intel_pt avx512cd avx512bw avx512vl xsaveopt xsavec xgetbv1 xsaves cqm_llc cqm_occup_llc cqm_mbm_total cqm_mbm_local dtherm ida arat pln pts hwp_epp pku ospke avx512_vnni md_clear flush_l1d arch_capabilities
Versions of relevant libraries:
[pip3] numpy==1.23.4
[pip3] pytorch-triton==2.0.0+0d7e753227
[pip3] torch==2.0.0.dev20230210+cu118
[pip3] torchaudio==2.0.0.dev20230209+cu118
[pip3] torchvision==0.15.0.dev20230209+cu118
[conda] numpy 1.23.4 pypi_0 pypi
[conda] pytorch-triton 2.0.0+0d7e753227 pypi_0 pypi
[conda] torch 2.0.0.dev20230210+cu118 pypi_0 pypi
[conda] torchaudio 2.0.0.dev20230209+cu118 pypi_0 pypi
[conda] torchvision 0.15.0.dev20230209+cu118 pypi_0 pypi
| 0 |
3,478 | 94,696 |
A segment fault can be triggered in torch.max_pool1d_with_indices
|
module: crash, triaged, module: edge cases
|
### 🐛 Describe the bug
When a edge case is given, a **segment fault** can be triggered in `torch.max_pool1d_with_indices`:
````python
import torch
input = torch.rand([12, 2, 2, 2, 0, 4634247419717959497], dtype=torch.float32)
kernel_size = [ 2 ]
stride = [ 1 ]
padding = [ 1 ]
dilation = [ 1 ]
ceil_mode = False
res = torch.max_pool1d_with_indices(
input=input,
kernel_size=kernel_size,
stride=stride,
padding=padding,
dilation=dilation,
ceil_mode=ceil_mode,
)
````
Output:
````
Segmentation fault (core dumped)
````
### Versions
Collecting environment information...
PyTorch version: 2.0.0.dev20230210+cu118
Is debug build: False
CUDA used to build PyTorch: 11.8
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.5 LTS (x86_64)
GCC version: (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0
Clang version: 11.0.0-2~ubuntu20.04.1
CMake version: version 3.25.0
Libc version: glibc-2.31
Python version: 3.10.6 (main, Oct 24 2022, 16:07:47) [GCC 11.2.0] (64-bit runtime)
Python platform: Linux-5.15.0-57-generic-x86_64-with-glibc2.31
Is CUDA available: True
CUDA runtime version: 11.8.89
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration: GPU 0: Tesla V100-PCIE-16GB
Nvidia driver version: 520.61.05
cuDNN version: Probably one of the following:
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn.so.8.1.1
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_adv_infer.so.8.1.1
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_adv_train.so.8.1.1
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_cnn_infer.so.8.1.1
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_cnn_train.so.8.1.1
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_ops_infer.so.8.1.1
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_ops_train.so.8.1.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn.so.8.2.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn_adv_infer.so.8.2.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn_adv_train.so.8.2.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn_cnn_infer.so.8.2.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn_cnn_train.so.8.2.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn_ops_infer.so.8.2.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn_ops_train.so.8.2.1
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
Address sizes: 46 bits physical, 48 bits virtual
CPU(s): 48
On-line CPU(s) list: 0-47
Thread(s) per core: 2
Core(s) per socket: 12
Socket(s): 2
NUMA node(s): 2
Vendor ID: GenuineIntel
CPU family: 6
Model: 85
Model name: Intel(R) Xeon(R) Silver 4214 CPU @ 2.20GHz
Stepping: 7
CPU MHz: 2200.000
BogoMIPS: 4400.00
Virtualization: VT-x
L1d cache: 768 KiB
L1i cache: 768 KiB
L2 cache: 24 MiB
L3 cache: 33 MiB
NUMA node0 CPU(s): 0-11,24-35
NUMA node1 CPU(s): 12-23,36-47
Vulnerability Itlb multihit: KVM: Mitigation: VMX disabled
Vulnerability L1tf: Not affected
Vulnerability Mds: Not affected
Vulnerability Meltdown: Not affected
Vulnerability Mmio stale data: Mitigation; Clear CPU buffers; SMT vulnerable
Vulnerability Retbleed: Mitigation; Enhanced IBRS
Vulnerability Spec store bypass: Mitigation; Speculative Store Bypass disabled via prctl and seccomp
Vulnerability Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization
Vulnerability Spectre v2: Mitigation; Enhanced IBRS, IBPB conditional, RSB filling, PBRSB-eIBRS SW sequence
Vulnerability Srbds: Not affected
Vulnerability Tsx async abort: Mitigation; TSX disabled
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc art arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc cpuid aperfmperf pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid dca sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm 3dnowprefetch cpuid_fault epb cat_l3 cdp_l3 invpcid_single intel_ppin ssbd mba ibrs ibpb stibp ibrs_enhanced tpr_shadow vnmi flexpriority ept vpid ept_ad fsgsbase tsc_adjust bmi1 avx2 smep bmi2 erms invpcid cqm mpx rdt_a avx512f avx512dq rdseed adx smap clflushopt clwb intel_pt avx512cd avx512bw avx512vl xsaveopt xsavec xgetbv1 xsaves cqm_llc cqm_occup_llc cqm_mbm_total cqm_mbm_local dtherm ida arat pln pts hwp_epp pku ospke avx512_vnni md_clear flush_l1d arch_capabilities
Versions of relevant libraries:
[pip3] numpy==1.23.4
[pip3] pytorch-triton==2.0.0+0d7e753227
[pip3] torch==2.0.0.dev20230210+cu118
[pip3] torchaudio==2.0.0.dev20230209+cu118
[pip3] torchvision==0.15.0.dev20230209+cu118
[conda] numpy 1.23.4 pypi_0 pypi
[conda] pytorch-triton 2.0.0+0d7e753227 pypi_0 pypi
[conda] torch 2.0.0.dev20230210+cu118 pypi_0 pypi
[conda] torchaudio 2.0.0.dev20230209+cu118 pypi_0 pypi
[conda] torchvision 0.15.0.dev20230209+cu118 pypi_0 pypi
| 2 |
3,479 | 94,693 |
inductor `compile_fx_inner` output is incorrect on graph with trailing copy_()
|
triaged, module: inductor
|
Repro here:
```
import torch
from torch._inductor.compile_fx import compile_fx_inner
from torch.fx.experimental.proxy_tensor import make_fx
def f(arg0_1):
slice_1 = torch.ops.aten.slice.Tensor(arg0_1, 0, 0)
slice_2 = torch.ops.aten.slice.Tensor(slice_1, 1, 20, 40)
add = torch.ops.aten.add.Tensor(slice_2, 1)
slice_3 = torch.ops.aten.slice.Tensor(arg0_1, 0, 0)
slice_4 = torch.ops.aten.slice.Tensor(slice_3, 1, 20, 40)
slice_5 = torch.ops.aten.slice.Tensor(arg0_1, 0, 0)
slice_scatter = torch.ops.aten.slice_scatter.default(slice_5, add, 1, 20, 40)
slice_scatter_1 = torch.ops.aten.slice_scatter.default(arg0_1, slice_scatter, 0, 0)
slice_6 = torch.ops.aten.slice.Tensor(slice_scatter_1, 0, 0)
slice_7 = torch.ops.aten.slice.Tensor(slice_6, 1, 20, 40)
slice_8 = torch.ops.aten.slice.Tensor(arg0_1, 0, 0)
slice_9 = torch.ops.aten.slice.Tensor(slice_8, 1, 1, 10)
slice_10 = torch.ops.aten.slice.Tensor(slice_scatter_1, 0, 0)
slice_11 = torch.ops.aten.slice.Tensor(slice_10, 1, 1, 10)
add_1 = torch.ops.aten.add.Tensor(slice_11, 2)
slice_12 = torch.ops.aten.slice.Tensor(arg0_1, 0, 0)
slice_13 = torch.ops.aten.slice.Tensor(slice_12, 1, 2, 11)
slice_14 = torch.ops.aten.slice.Tensor(slice_scatter_1, 0, 0)
slice_15 = torch.ops.aten.slice.Tensor(slice_14, 1, 2, 11)
slice_16 = torch.ops.aten.slice.Tensor(slice_scatter_1, 0, 0)
slice_scatter_2 = torch.ops.aten.slice_scatter.default(slice_16, add_1, 1, 2, 11)
slice_scatter_3 = torch.ops.aten.slice_scatter.default(slice_scatter_1, slice_scatter_2, 0, 0)
slice_17 = torch.ops.aten.slice.Tensor(slice_scatter_3, 0, 0)
slice_18 = torch.ops.aten.slice.Tensor(slice_17, 1, 2, 11)
copy_ = torch.ops.aten.copy_.default(arg0_1, slice_scatter_3)
return ()
x_ref = torch.ones([1, 64], device='cpu')
x_test = torch.ones([1, 64], device='cpu')
x_test2 = torch.ones([1, 64], device='cpu')
x_test3 = torch.ones([1, 64], device='cpu')
fx_g = make_fx(f)(x_test2)
f_compiled = compile_fx_inner(fx_g, [x_test3])
f(x_ref)
f_compiled([x_test])
print(x_test)
print(torch.abs(x_test - x_ref))
# Prints False
print(torch.allclose(x_test, x_ref))
```
The repro is a bit cumbersome, but it comes from the functionalized version of this test ([code](https://github.com/pytorch/pytorch/blob/54c0f37646b8e7483519c4246a826ea7cbc6f695/test/inductor/test_torchinductor.py#L4032)).
I bisected it to this commit: https://github.com/pytorch/pytorch/pull/94110. Strangely, it only seems to fail on cpu and not on inductor's cuda backend.
I noticed this error due to my changes to functionalize the inference graph in AOTAutograd, which appends trailing copy_() calls to the graph before sending them to inductor when there are input mutations. There are existing failures in https://github.com/pytorch/pytorch/pull/92857
cc @mlazos @soumith @voznesenskym @yanboliang @penguinwu @anijain2305 @EikanWang @jgong5 @Guobing-Chen @XiaobingSuper @zhuhaozhe @blzheng @Xia-Weiwen @wenzhe-nrv @jiayisunx @peterbell10 @desertfire
| 0 |
3,480 | 94,691 |
Nan is output by GRU on mps
|
triaged, module: mps
|
### 🐛 Describe the bug
When I use the mps it turns into nan values for just a simple encoder similar to the tutorial on PyTorch.org. This was after I tried converting the tensors to float32.
```
class Encoder(nn.Module):
def __init__(self, input_size, hidden_size, num_layers=1):
super(Encoder, self).__init__()
self.input_size = input_size
self.hidden_size = hidden_size
self.num_layers = num_layers
self.embedding = nn.Embedding(input_size, hidden_size)
self.gru = nn.GRU(hidden_size, hidden_size, num_layers, batch_first=True)
def forward(self, x, hidden=None):
embedded = self.embedding(x)
output, hidden = self.gru(embedded, hidden)
#the output and the hidden is nan
return output, hidden
```
I just got the input that is basically a tokenized text from the basic_english and build vocab from iterator in torch text library. The embedded works fine but after I feed the embedding into the GRU it just turns into nan values.
### Versions
This uses torch text and torch library.
cc @kulinseth @albanD @malfet @DenisVieriu97 @razarmehr @abhudev
| 26 |
3,481 | 94,689 |
[kineto] Enable CUPTI metrics profiling in pytorch …
|
Stale, ciflow/binaries, ciflow/trunk, topic: not user facing
|
## About
Kineto introduced a new profiler to read performance counters from NVIDIA GPUs (CUPTI Range Profiler API) added in PR[75616](https://github.com/pytorch/pytorch/pull/75616). Support for the range profiler mode was disabled as we had to link with a NV PerfWorks library (`libnvperf_host.so`). This PR adds that link.
The change includes-
* Updates cmake build files to find `libnvperf_host.so` and set `CUDA_nvperf_host_LIBRARY`
* WIP use the above cmake variable in kineto, will update this PR after kineto PR has landed
See https://github.com/pytorch/kineto/pull/724
## Example usage of CUPTI profiler
The code snippet below shows how to configure pytorch profiler in CUPTI Profiler mode. Any code included in profiling window with be profiler by CUPTI/Kineto. Note how the `_ExperimentalConfig` struct is used to configure profiler metrics
```
with torch.profiler.profile(
activities=[torch.profiler.ProfilerActivity.CUDA],
record_shapes=True,
on_trace_ready=trace_handler,
experimental_config=torch.profiler._ExperimentalConfig(
profiler_metrics=[
"kineto__tensor_core_insts",
"dram__bytes_read.sum",
"dram__bytes_write.sum"],
profiler_measure_per_kernel=False),
) as prof:
res = train_batch(modeldef)
prof.step()
```
For a full example see this [xor.py](https://gist.github.com/briancoutinho/b1ec7919d8ea2bf1f019b4f4cd50ea80) gist.
### Details of how to configure CUPTI profielr
The` _Experimental` config structure can be used to pass metrics to profiler
```
profiler_metrics : a list of CUPTI profiler metrics used
to measure GPU performance events. Any metric supported by CUPTI can be used, see here=
https://docs.nvidia.com/cupti/r_main.html#r_profiler
There are two special alias metrics `kineto__tensor_core_insts` and `kineto__cuda_core_flops` for FLOPS counting.
profiler_measure_per_kernel (bool) : whether to profile metrics per kernel
or for the entire measurement duration.
```
## Testing
Built from source with kineto [PR](https://github.com/pytorch/kineto/pull/724)
```
$> USE_CUDA=1 python setup.py install
-- CUDA_cupti_LIBRARY = /public/apps/cuda/11.6/extras/CUPTI/lib64/libcupti.so
-- CUDA_nvperf_host_LIBRARY = /public/apps/cuda/11.6/extras/CUPTI/lib64/libnvperf_host.so
```
Then run example [xor.py](https://gist.github.com/briancoutinho/b1ec7919d8ea2bf1f019b4f4cd50ea80). This only works on V100+ GPUs only. Adding logs for debugging etc.
```
>$ export KINETO_LOG_LEVEL=1
>$ python xor.py
INFO:2023-02-11 19:11:37 1683060:1683060 CuptiActivityProfiler.cpp:167] CUDA versions. CUPTI: 16; Runtime: 11060; Driver: 11040
Log file: /tmp/libkineto_activities_1683060.json
Trace start time: 2023-02-11 19:11:47 Trace duration: 500ms
Warmup duration: 0s
Max GPU buffer size: 128MB
Enabled activities: cuda_profiler_range
Cupti Profiler metrics : kineto__tensor_core_insts, dram__bytes_read.sum, dram__bytes_write.sum
Cupti Profiler measure per kernel : 0
Cupti Profiler max ranges : 10
INFO:2023-02-11 19:11:37 1683060:1683060 CuptiActivityProfiler.cpp:638] Enabling GPU tracing
INFO:2023-02-11 19:11:37 1683060:1683060 CuptiActivityProfiler.cpp:567] Running child profiler CuptiRangeProfiler for 500 ms
INFO:2023-02-11 19:11:37 1683060:1683060 CuptiRangeProfiler.cpp:104] Configuring 3 CUPTI metrics
INFO:2023-02-11 19:11:37 1683060:1683060 CuptiRangeProfiler.cpp:109] sm__inst_executed_pipe_tensor.sum
INFO:2023-02-11 19:11:37 1683060:1683060 CuptiRangeProfiler.cpp:109] dram__bytes_read.sum
INFO:2023-02-11 19:11:37 1683060:1683060 CuptiRangeProfiler.cpp:109] dram__bytes_write.sum
INFO:2023-02-11 19:11:37 1683060:1683060 CuptiActivityProfiler.cpp:575] Running child profiler CuptiRangeProfiler for 500 ms
INFO:2023-02-11 19:11:37 1683060:1683060 CuptiActivityProfiler.cpp:672] Tracing starting in 9s
INFO:2023-02-11 19:11:37 1683060:1683060 CuptiActivityProfiler.cpp:677] Tracing will end in 10s
STAGE:2023-02-11 19:11:37 1683060:1683060 ActivityProfilerController.cpp:310] Completed Stage: Warm Up
INFO:2023-02-11 19:11:37 1683060:1683060 CuptiActivityProfiler.cpp:693] Starting child profiler session
```
| 30 |
3,482 | 94,675 |
`UnsupportedOperatorError`, `OnnxExporterError` and `SymbolicValueError` related to MultiheadAttention export to onnx with torch.jit.script
|
module: onnx, triaged
|
### 🐛 Describe the bug
When exporting a model to onnx (embedded into a `torch.jit.script` call) that uses MultiheadAttention, I am running into errors related to unsupported operators.
This is all part of a [bigger project](https://github.com/AnnikaStein/DeepJet/tree/adversarial_training/ParT) (I'm coming from High Energy Physics research where we use pytorch to identify the origin of certain objects produced in particle collisions) and the code to reproduce the issue can be found [in this gist](https://gist.github.com/AnnikaStein/500d1c7d7ac80633e331a5647c97187d), containing the model architecture as well as the wrapper code we use to export the model. The problems are traced down to nn.MultiheadAttention calls, all other operators have been made torch.jit.script & onnx-export -friendly by rewriting functions with missing operators wherever possible.
The export without `torch.jit.script` works, however, with `script`, I'm running into the following errors each suggesting that I open an issue.
a)
```
Traceback (most recent call last):
File "/rwthfs/rz/cluster/home/um106329/aisafety/ParT/Part_export_minimalExample.py", line 71, in <module>
conversion_loop(model)
File "/rwthfs/rz/cluster/home/um106329/aisafety/ParT/Part_export_minimalExample.py", line 49, in conversion_loop
torch.onnx.export(model, inputs, f"Example.onnx", verbose=True,
File "/work/um106329/conda-storage/envs/VHccAllIn/lib/python3.10/site-packages/torch/onnx/utils.py", line 504, in export
_export(
File "/work/um106329/conda-storage/envs/VHccAllIn/lib/python3.10/site-packages/torch/onnx/utils.py", line 1529, in _export
graph, params_dict, torch_out = _model_to_graph(
File "/work/um106329/conda-storage/envs/VHccAllIn/lib/python3.10/site-packages/torch/onnx/utils.py", line 1115, in _model_to_graph
graph = _optimize_graph(
File "/work/um106329/conda-storage/envs/VHccAllIn/lib/python3.10/site-packages/torch/onnx/utils.py", line 663, in _optimize_graph
graph = _C._jit_pass_onnx(graph, operator_export_type)
File "/work/um106329/conda-storage/envs/VHccAllIn/lib/python3.10/site-packages/torch/onnx/utils.py", line 1867, in _run_symbolic_function
return symbolic_fn(graph_context, *inputs, **attrs)
File "/work/um106329/conda-storage/envs/VHccAllIn/lib/python3.10/site-packages/torch/onnx/symbolic_opset9.py", line 6567, in prim_if
env = torch._C._jit_pass_onnx_block(
File "/work/um106329/conda-storage/envs/VHccAllIn/lib/python3.10/site-packages/torch/onnx/utils.py", line 1867, in _run_symbolic_function
return symbolic_fn(graph_context, *inputs, **attrs)
File "/work/um106329/conda-storage/envs/VHccAllIn/lib/python3.10/site-packages/torch/onnx/symbolic_opset9.py", line 6594, in prim_if
torch._C._jit_pass_onnx_block(
File "/work/um106329/conda-storage/envs/VHccAllIn/lib/python3.10/site-packages/torch/onnx/utils.py", line 1867, in _run_symbolic_function
return symbolic_fn(graph_context, *inputs, **attrs)
File "/work/um106329/conda-storage/envs/VHccAllIn/lib/python3.10/site-packages/torch/onnx/symbolic_opset9.py", line 6567, in prim_if
env = torch._C._jit_pass_onnx_block(
File "/work/um106329/conda-storage/envs/VHccAllIn/lib/python3.10/site-packages/torch/onnx/utils.py", line 1867, in _run_symbolic_function
return symbolic_fn(graph_context, *inputs, **attrs)
File "/work/um106329/conda-storage/envs/VHccAllIn/lib/python3.10/site-packages/torch/onnx/symbolic_opset9.py", line 6567, in prim_if
env = torch._C._jit_pass_onnx_block(
File "/work/um106329/conda-storage/envs/VHccAllIn/lib/python3.10/site-packages/torch/onnx/utils.py", line 1889, in _run_symbolic_function
raise errors.UnsupportedOperatorError(
torch.onnx.errors.UnsupportedOperatorError: Exporting the operator 'aten::format' to ONNX opset version 14 is not supported. Please feel free to request support or submit a pull request on PyTorch GitHub: https://github.com/pytorch/pytorch/issues
```
I was able to bypass this by modifying `nn/modules/activation.py` [like so in my private fork of pytorch](https://github.com/AnnikaStein/pytorch/commit/d91f31205e6284fb1d19ab63689a87b43e4c1e39) - the fix replaces string-formatting, and introduces a boolean flag for a simple check instead of checking the non-emptiness of a string directly with implicit true/false behavior.
b)
```
Traceback (most recent call last):
File "/rwthfs/rz/cluster/home/um106329/aisafety/ParT/Part_export_minimalExample.py", line 71, in <module>
conversion_loop(model)
File "/rwthfs/rz/cluster/home/um106329/aisafety/ParT/Part_export_minimalExample.py", line 49, in conversion_loop
torch.onnx.export(model, inputs, f"Example.onnx", verbose=True,
File "/work/um106329/conda-storage/envs/VHccAllIn/lib/python3.10/site-packages/torch/onnx/utils.py", line 504, in export
_export(
File "/work/um106329/conda-storage/envs/VHccAllIn/lib/python3.10/site-packages/torch/onnx/utils.py", line 1529, in _export
graph, params_dict, torch_out = _model_to_graph(
File "/work/um106329/conda-storage/envs/VHccAllIn/lib/python3.10/site-packages/torch/onnx/utils.py", line 1115, in _model_to_graph
graph = _optimize_graph(
File "/work/um106329/conda-storage/envs/VHccAllIn/lib/python3.10/site-packages/torch/onnx/utils.py", line 663, in _optimize_graph
graph = _C._jit_pass_onnx(graph, operator_export_type)
File "/work/um106329/conda-storage/envs/VHccAllIn/lib/python3.10/site-packages/torch/onnx/utils.py", line 1867, in _run_symbolic_function
return symbolic_fn(graph_context, *inputs, **attrs)
File "/work/um106329/conda-storage/envs/VHccAllIn/lib/python3.10/site-packages/torch/onnx/symbolic_opset9.py", line 6594, in prim_if
torch._C._jit_pass_onnx_block(
File "/work/um106329/conda-storage/envs/VHccAllIn/lib/python3.10/site-packages/torch/onnx/utils.py", line 1867, in _run_symbolic_function
return symbolic_fn(graph_context, *inputs, **attrs)
File "/work/um106329/conda-storage/envs/VHccAllIn/lib/python3.10/site-packages/torch/onnx/symbolic_opset9.py", line 6594, in prim_if
torch._C._jit_pass_onnx_block(
File "/work/um106329/conda-storage/envs/VHccAllIn/lib/python3.10/site-packages/torch/onnx/utils.py", line 1867, in _run_symbolic_function
return symbolic_fn(graph_context, *inputs, **attrs)
File "/work/um106329/conda-storage/envs/VHccAllIn/lib/python3.10/site-packages/torch/onnx/symbolic_opset11.py", line 508, in add
return symbolic_helper._unimplemented(
File "/work/um106329/conda-storage/envs/VHccAllIn/lib/python3.10/site-packages/torch/onnx/symbolic_helper.py", line 577, in _unimplemented
_onnx_unsupported(f"{op}, {msg}", value)
File "/work/um106329/conda-storage/envs/VHccAllIn/lib/python3.10/site-packages/torch/onnx/symbolic_helper.py", line 592, in _onnx_unsupported
raise errors.OnnxExporterError(message)
torch.onnx.errors.OnnxExporterError: Unsupported: ONNX export of operator add, does not support adding dynamic tensor list to another. Please feel free to request support or submit a pull request on PyTorch GitHub: https://github.com/pytorch/pytorch/issues
```
I was able to bypass this by modifying `nn/functional.py` [like so in my private fork of pytorch](https://github.com/AnnikaStein/pytorch/commit/40cf95aed62a78e785a90bfc14ce17b411301f62) - here adding dynamic tensor list is replaced with stepwise adding components into output list.
c) Now I am left with a batched matrix multiplication causing an Unknown Rank error, which I was not able to resolve myself:
```
Traceback (most recent call last):
File "/rwthfs/rz/cluster/home/um106329/aisafety/ParT/Part_export_minimalExample.py", line 71, in <module>
conversion_loop(model)
File "/rwthfs/rz/cluster/home/um106329/aisafety/ParT/Part_export_minimalExample.py", line 49, in conversion_loop
torch.onnx.export(model, inputs, f"Example.onnx", verbose=True,
File "/work/um106329/conda-storage/envs/VHccAllIn/lib/python3.10/site-packages/torch/onnx/utils.py", line 504, in export
_export(
File "/work/um106329/conda-storage/envs/VHccAllIn/lib/python3.10/site-packages/torch/onnx/utils.py", line 1529, in _export
graph, params_dict, torch_out = _model_to_graph(
File "/work/um106329/conda-storage/envs/VHccAllIn/lib/python3.10/site-packages/torch/onnx/utils.py", line 1115, in _model_to_graph
graph = _optimize_graph(
File "/work/um106329/conda-storage/envs/VHccAllIn/lib/python3.10/site-packages/torch/onnx/utils.py", line 663, in _optimize_graph
graph = _C._jit_pass_onnx(graph, operator_export_type)
File "/work/um106329/conda-storage/envs/VHccAllIn/lib/python3.10/site-packages/torch/onnx/utils.py", line 1867, in _run_symbolic_function
return symbolic_fn(graph_context, *inputs, **attrs)
File "/work/um106329/conda-storage/envs/VHccAllIn/lib/python3.10/site-packages/torch/onnx/symbolic_helper.py", line 380, in wrapper
return fn(g, *args, **kwargs)
File "/work/um106329/conda-storage/envs/VHccAllIn/lib/python3.10/site-packages/torch/onnx/symbolic_helper.py", line 303, in wrapper
return fn(g, *args, **kwargs)
File "/work/um106329/conda-storage/envs/VHccAllIn/lib/python3.10/site-packages/torch/onnx/symbolic_opset9.py", line 1001, in transpose
raise errors.SymbolicValueError(
torch.onnx.errors.SymbolicValueError: Unsupported: ONNX export of transpose for tensor of unknown rank. [Caused by the value 'attn_output defined in (%attn_output : FloatTensor(device=cpu) = onnx::MatMul(%ret, %v.3), scope: ParT_minimalExample.ParticleTransformer::/ParT_minimalExample.HF_TransformerEncoder::Encoder/ParT_minimalExample.HF_TransformerEncoderLayer::layers.0/torch.nn.modules.activation.MultiheadAttention::self_attn # /work/um106329/conda-storage/envs/VHccAllIn/lib/python3.10/site-packages/torch/nn/functional.py:5168:18
)' (type 'Tensor') in the TorchScript graph. The containing node has kind 'onnx::MatMul'.]
(node defined in File "/work/um106329/conda-storage/envs/VHccAllIn/lib/python3.10/site-packages/torch/nn/functional.py", line 5168
attn_output_weights = dropout(attn_output_weights, p=dropout_p)
attn_output = torch.bmm(attn_output_weights, v)
~~~~~~~~~ <--- HERE
#attn_output = torch.matmul(attn_output_weights, v)
)
Inputs:
#0: ret defined in (%ret : FloatTensor(device=cpu) = onnx::Softmax[axis=-1](%attn_output_weights), scope: ParT_minimalExample.ParticleTransformer::/ParT_minimalExample.HF_TransformerEncoder::Encoder/ParT_minimalExample.HF_TransformerEncoderLayer::layers.0/torch.nn.modules.activation.MultiheadAttention::self_attn # /work/um106329/conda-storage/envs/VHccAllIn/lib/python3.10/site-packages/torch/nn/functional.py:1841:14
) (type 'Tensor')
#1: v.3 defined in (%v.3 : Tensor(*, *, *) = onnx::Transpose[perm=[1, 0, 2]](%2010), scope: ParT_minimalExample.ParticleTransformer::/ParT_minimalExample.HF_TransformerEncoder::Encoder/ParT_minimalExample.HF_TransformerEncoderLayer::layers.0/torch.nn.modules.activation.MultiheadAttention::self_attn # /work/um106329/conda-storage/envs/VHccAllIn/lib/python3.10/site-packages/torch/nn/functional.py:5109:12
) (type 'Tensor')
Outputs:
#0: attn_output defined in (%attn_output : FloatTensor(device=cpu) = onnx::MatMul(%ret, %v.3), scope: ParT_minimalExample.ParticleTransformer::/ParT_minimalExample.HF_TransformerEncoder::Encoder/ParT_minimalExample.HF_TransformerEncoderLayer::layers.0/torch.nn.modules.activation.MultiheadAttention::self_attn # /work/um106329/conda-storage/envs/VHccAllIn/lib/python3.10/site-packages/torch/nn/functional.py:5168:18
) (type 'Tensor')
```
So I am wondering if I should submit a PR for the things that I could successfully circumvent (so two of the three things I mentioned), and on the other hand, if there are suggestions on how to proceed with the "Unknown rank" problem.
### Versions
```
Collecting environment information...
PyTorch version: 1.13.0+cu117
Is debug build: False
CUDA used to build PyTorch: 11.7
ROCM used to build PyTorch: N/A
OS: CentOS Linux release 7.9.2009 (Core) (x86_64)
GCC version: (GCC) 4.8.5 20150623 (Red Hat 4.8.5-44)
Clang version: Could not collect
CMake version: version 3.10.1
Libc version: glibc-2.17
Python version: 3.10.8 | packaged by conda-forge | (main, Nov 22 2022, 08:23:14) [GCC 10.4.0] (64-bit runtime)
Python platform: Linux-3.10.0-1160.83.1.el7.x86_64-x86_64-with-glibc2.17
Is CUDA available: False
CUDA runtime version: No CUDA
CUDA_MODULE_LOADING set to: N/A
GPU models and configuration: No CUDA
Nvidia driver version: No CUDA
cuDNN version: No CUDA
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 48
On-line CPU(s) list: 0-47
Thread(s) per core: 1
Core(s) per socket: 24
Socket(s): 2
NUMA node(s): 4
Vendor ID: GenuineIntel
CPU family: 6
Model: 85
Model name: Intel(R) Xeon(R) Platinum 8160 CPU @ 2.10GHz
Stepping: 4
CPU MHz: 2799.957
CPU max MHz: 3700.0000
CPU min MHz: 1000.0000
BogoMIPS: 4200.00
Virtualization: VT-x
L1d cache: 32K
L1i cache: 32K
L2 cache: 1024K
L3 cache: 33792K
NUMA node0 CPU(s): 0-2,6-8,12-14,18-20
NUMA node1 CPU(s): 3-5,9-11,15-17,21-23
NUMA node2 CPU(s): 24-26,30-32,36-38,42-44
NUMA node3 CPU(s): 27-29,33-35,39-41,45-47
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc art arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc aperfmperf eagerfpu pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid dca sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm 3dnowprefetch epb cat_l3 cdp_l3 invpcid_single intel_ppin ssbd mba rsb_ctxsw ibrs ibpb stibp tpr_shadow vnmi flexpriority ept vpid fsgsbase tsc_adjust bmi1 hle avx2 smep bmi2 erms invpcid rtm cqm mpx rdt_a avx512f avx512dq rdseed adx smap clflushopt clwb intel_pt avx512cd avx512bw avx512vl xsaveopt xsavec xgetbv1 cqm_llc cqm_occup_llc cqm_mbm_total cqm_mbm_local dtherm ida arat pln pts hwp hwp_act_window hwp_epp hwp_pkg_req pku ospke md_clear spec_ctrl intel_stibp flush_l1d arch_capabilities
Versions of relevant libraries:
[pip3] numpy==1.23.5
[pip3] torch==1.13.0
[conda] numpy 1.23.5 pypi_0 pypi
[conda] torch 1.13.0 pypi_0 pypi
```
| 9 |
3,483 | 94,669 |
A segment fault can be triggered in torch.svd
|
module: crash, triaged, module: edge cases
|
### 🐛 Describe the bug
The following code can triger a segment fault in `torch.svf`:
````python
import torch
input = torch.rand([14, 0, 2423179390303677969, 10, 6], dtype=torch.float32)
some = False
compute_uv = True
res = torch.svd(
input=input,
some=some,
compute_uv=compute_uv,
)
````
The output:
````
Segmentation fault (core dumped)
````
### Versions
Collecting environment information...
PyTorch version: 2.0.0.dev20230210+cu118
Is debug build: False
CUDA used to build PyTorch: 11.8
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.5 LTS (x86_64)
GCC version: (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0
Clang version: 11.0.0-2~ubuntu20.04.1
CMake version: version 3.25.0
Libc version: glibc-2.31
Python version: 3.10.6 (main, Oct 24 2022, 16:07:47) [GCC 11.2.0] (64-bit runtime)
Python platform: Linux-5.15.0-57-generic-x86_64-with-glibc2.31
Is CUDA available: True
CUDA runtime version: 11.8.89
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration: GPU 0: Tesla V100-PCIE-16GB
Nvidia driver version: 520.61.05
cuDNN version: Probably one of the following:
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn.so.8.1.1
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_adv_infer.so.8.1.1
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_adv_train.so.8.1.1
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_cnn_infer.so.8.1.1
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_cnn_train.so.8.1.1
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_ops_infer.so.8.1.1
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_ops_train.so.8.1.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn.so.8.2.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn_adv_infer.so.8.2.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn_adv_train.so.8.2.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn_cnn_infer.so.8.2.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn_cnn_train.so.8.2.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn_ops_infer.so.8.2.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn_ops_train.so.8.2.1
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
Address sizes: 46 bits physical, 48 bits virtual
CPU(s): 48
On-line CPU(s) list: 0-47
Thread(s) per core: 2
Core(s) per socket: 12
Socket(s): 2
NUMA node(s): 2
Vendor ID: GenuineIntel
CPU family: 6
Model: 85
Model name: Intel(R) Xeon(R) Silver 4214 CPU @ 2.20GHz
Stepping: 7
CPU MHz: 2200.000
BogoMIPS: 4400.00
Virtualization: VT-x
L1d cache: 768 KiB
L1i cache: 768 KiB
L2 cache: 24 MiB
L3 cache: 33 MiB
NUMA node0 CPU(s): 0-11,24-35
NUMA node1 CPU(s): 12-23,36-47
Vulnerability Itlb multihit: KVM: Mitigation: VMX disabled
Vulnerability L1tf: Not affected
Vulnerability Mds: Not affected
Vulnerability Meltdown: Not affected
Vulnerability Mmio stale data: Mitigation; Clear CPU buffers; SMT vulnerable
Vulnerability Retbleed: Mitigation; Enhanced IBRS
Vulnerability Spec store bypass: Mitigation; Speculative Store Bypass disabled via prctl and seccomp
Vulnerability Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization
Vulnerability Spectre v2: Mitigation; Enhanced IBRS, IBPB conditional, RSB filling, PBRSB-eIBRS SW sequence
Vulnerability Srbds: Not affected
Vulnerability Tsx async abort: Mitigation; TSX disabled
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc art arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc cpuid aperfmperf pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid dca sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm 3dnowprefetch cpuid_fault epb cat_l3 cdp_l3 invpcid_single intel_ppin ssbd mba ibrs ibpb stibp ibrs_enhanced tpr_shadow vnmi flexpriority ept vpid ept_ad fsgsbase tsc_adjust bmi1 avx2 smep bmi2 erms invpcid cqm mpx rdt_a avx512f avx512dq rdseed adx smap clflushopt clwb intel_pt avx512cd avx512bw avx512vl xsaveopt xsavec xgetbv1 xsaves cqm_llc cqm_occup_llc cqm_mbm_total cqm_mbm_local dtherm ida arat pln pts hwp_epp pku ospke avx512_vnni md_clear flush_l1d arch_capabilities
Versions of relevant libraries:
[pip3] numpy==1.23.4
[pip3] pytorch-triton==2.0.0+0d7e753227
[pip3] torch==2.0.0.dev20230210+cu118
[pip3] torchaudio==2.0.0.dev20230209+cu118
[pip3] torchvision==0.15.0.dev20230209+cu118
[conda] numpy 1.23.4 pypi_0 pypi
[conda] pytorch-triton 2.0.0+0d7e753227 pypi_0 pypi
[conda] torch 2.0.0.dev20230210+cu118 pypi_0 pypi
[conda] torchaudio 2.0.0.dev20230209+cu118 pypi_0 pypi
[conda] torchvision 0.15.0.dev20230209+cu118 pypi_0 pypi
| 0 |
3,484 | 94,668 |
A segment fault can be triggered in torch.lstm with edge cases
|
module: crash, triaged, module: edge cases
|
### 🐛 Describe the bug
The following code can triger a segment fault in `torch.lstm`:
````python
import torch
input = torch.rand([2, 12, 3, 2, 13], dtype=torch.float32)
hx_0 = torch.randint(-1024, 1024, [13, 14, 0, 7, 15], dtype=torch.int16)
hx_1 = torch.randint(-1024, 1024, [11, 15, 9, 13, 10, 4], dtype=torch.int16)
hx = [hx_0, hx_1, ]
params_0 = torch.randint(-1024, 1024, [14, 14, 0, 3, 12, 14], dtype=torch.int32)
params_1 = torch.randint(0, 2, [11], dtype=torch.bool)
params_2 = torch.randint(-128, 128, [12, 14, 6, 14, 2, 1], dtype=torch.int8)
params_3 = torch.randint(-1024, 1024, [], dtype=torch.int16)
params_4 = torch.randint(-1024, 1024, [10, 12, 13], dtype=torch.int32)
params_5 = torch.rand([10, 8, 12, 6, 9], dtype=torch.float16)
params = [params_0, params_1, params_2, params_3, params_4, params_5, ]
has_biases = False
num_layers = -119
dropout = 33.87668089766325
train = True
bidirectional = False
batch_first = True
res = torch.lstm(
input=input,
hx=hx,
params=params,
has_biases=has_biases,
num_layers=num_layers,
dropout=dropout,
train=train,
bidirectional=bidirectional,
batch_first=batch_first,
)
````
The output:
````
Segmentation fault (core dumped)
````
### Versions
Collecting environment information...
PyTorch version: 2.0.0.dev20230210+cu118
Is debug build: False
CUDA used to build PyTorch: 11.8
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.5 LTS (x86_64)
GCC version: (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0
Clang version: 11.0.0-2~ubuntu20.04.1
CMake version: version 3.25.0
Libc version: glibc-2.31
Python version: 3.10.6 (main, Oct 24 2022, 16:07:47) [GCC 11.2.0] (64-bit runtime)
Python platform: Linux-5.15.0-57-generic-x86_64-with-glibc2.31
Is CUDA available: True
CUDA runtime version: 11.8.89
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration: GPU 0: Tesla V100-PCIE-16GB
Nvidia driver version: 520.61.05
cuDNN version: Probably one of the following:
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn.so.8.1.1
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_adv_infer.so.8.1.1
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_adv_train.so.8.1.1
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_cnn_infer.so.8.1.1
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_cnn_train.so.8.1.1
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_ops_infer.so.8.1.1
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_ops_train.so.8.1.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn.so.8.2.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn_adv_infer.so.8.2.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn_adv_train.so.8.2.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn_cnn_infer.so.8.2.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn_cnn_train.so.8.2.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn_ops_infer.so.8.2.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn_ops_train.so.8.2.1
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
Address sizes: 46 bits physical, 48 bits virtual
CPU(s): 48
On-line CPU(s) list: 0-47
Thread(s) per core: 2
Core(s) per socket: 12
Socket(s): 2
NUMA node(s): 2
Vendor ID: GenuineIntel
CPU family: 6
Model: 85
Model name: Intel(R) Xeon(R) Silver 4214 CPU @ 2.20GHz
Stepping: 7
CPU MHz: 2200.000
BogoMIPS: 4400.00
Virtualization: VT-x
L1d cache: 768 KiB
L1i cache: 768 KiB
L2 cache: 24 MiB
L3 cache: 33 MiB
NUMA node0 CPU(s): 0-11,24-35
NUMA node1 CPU(s): 12-23,36-47
Vulnerability Itlb multihit: KVM: Mitigation: VMX disabled
Vulnerability L1tf: Not affected
Vulnerability Mds: Not affected
Vulnerability Meltdown: Not affected
Vulnerability Mmio stale data: Mitigation; Clear CPU buffers; SMT vulnerable
Vulnerability Retbleed: Mitigation; Enhanced IBRS
Vulnerability Spec store bypass: Mitigation; Speculative Store Bypass disabled via prctl and seccomp
Vulnerability Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization
Vulnerability Spectre v2: Mitigation; Enhanced IBRS, IBPB conditional, RSB filling, PBRSB-eIBRS SW sequence
Vulnerability Srbds: Not affected
Vulnerability Tsx async abort: Mitigation; TSX disabled
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc art arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc cpuid aperfmperf pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid dca sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm 3dnowprefetch cpuid_fault epb cat_l3 cdp_l3 invpcid_single intel_ppin ssbd mba ibrs ibpb stibp ibrs_enhanced tpr_shadow vnmi flexpriority ept vpid ept_ad fsgsbase tsc_adjust bmi1 avx2 smep bmi2 erms invpcid cqm mpx rdt_a avx512f avx512dq rdseed adx smap clflushopt clwb intel_pt avx512cd avx512bw avx512vl xsaveopt xsavec xgetbv1 xsaves cqm_llc cqm_occup_llc cqm_mbm_total cqm_mbm_local dtherm ida arat pln pts hwp_epp pku ospke avx512_vnni md_clear flush_l1d arch_capabilities
Versions of relevant libraries:
[pip3] numpy==1.23.4
[pip3] pytorch-triton==2.0.0+0d7e753227
[pip3] torch==2.0.0.dev20230210+cu118
[pip3] torchaudio==2.0.0.dev20230209+cu118
[pip3] torchvision==0.15.0.dev20230209+cu118
[conda] numpy 1.23.4 pypi_0 pypi
[conda] pytorch-triton 2.0.0+0d7e753227 pypi_0 pypi
[conda] torch 2.0.0.dev20230210+cu118 pypi_0 pypi
[conda] torchaudio 2.0.0.dev20230209+cu118 pypi_0 pypi
[conda] torchvision 0.15.0.dev20230209+cu118 pypi_0 pypi
| 0 |
3,485 | 94,665 |
cannot create weak reference to 'weakproxy' object in compile mode
|
triaged, module: inductor
|
### 🐛 Describe the bug
When I use pytorch2.0 without compile, everything goes well. However, when I started the compile mode, a strange bug occurred.
```
[2023-02-11 15:53:18,520] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo start tracing validation_step
[2023-02-11 15:53:18,803] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo start tracing set_task
[2023-02-11 15:53:18,823] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo start tracing hparams
[2023-02-11 15:53:18,839] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo start tracing <graph break in set_task>
[2023-02-11 15:53:18,888] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo start tracing <graph break in validation_step>
[2023-02-11 15:53:19,130] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo start tracing <graph break in validation_step>
[2023-02-11 15:53:19,359] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo start tracing forward
[2023-02-11 15:53:19,552] torch._dynamo.convert_frame: [INFO] converting frame raised unsupported, leaving it unconverted
[2023-02-11 15:53:19,580] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo start tracing img_embed
[2023-02-11 15:53:19,780] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo start tracing forward
[2023-02-11 15:53:19,945] torch._dynamo.output_graph: [INFO] Step 2: calling compiler function compile_fn
[2023-02-11 15:53:19,946] torch._dynamo.backends.distributed: [INFO] DDPOptimizer used bucket cap 26214400 and produced the following buckets:
[2023-02-11 15:53:19,947] torch._dynamo.backends.distributed: [INFO] Please `pip install tabulate` in order to pretty-print ddp bucket sizes
[2023-02-11 15:53:19,977] torch._dynamo.output_graph: [INFO] Step 2: done compiler function compile_fn
[2023-02-11 15:53:19,988] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo start tracing forward
[2023-02-11 15:53:20,184] torch._dynamo.output_graph: [INFO] Step 2: calling compiler function compile_fn
[2023-02-11 15:53:20,184] torch._dynamo.backends.distributed: [INFO] DDPOptimizer used bucket cap 26214400 and produced the following buckets:
[2023-02-11 15:53:20,185] torch._dynamo.backends.distributed: [INFO] Please `pip install tabulate` in order to pretty-print ddp bucket sizes
[2023-02-11 15:53:20,363] torch._inductor.compile_fx: [INFO] Step 3: torchinductor compiling FORWARDS graph 1
[2023-02-11 15:53:21,097] torch._inductor.compile_fx: [INFO] Step 3: torchinductor done compiling FORWARDS graph 1
[2023-02-11 15:53:21,097] torch._dynamo.output_graph: [INFO] Step 2: done compiler function compile_fn
[2023-02-11 15:53:26,137] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo start tracing forward
[2023-02-11 15:53:26,204] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo start tracing __iter__
[2023-02-11 15:53:26,218] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo start tracing forward
[2023-02-11 15:53:26,469] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo done tracing forward (RETURN_VALUE)
[2023-02-11 15:53:26,479] torch._dynamo.output_graph: [INFO] Step 2: calling compiler function compile_fn
[2023-02-11 15:53:26,480] torch._dynamo.backends.distributed: [INFO] DDPOptimizer used bucket cap 26214400 and produced the following buckets:
[2023-02-11 15:53:26,482] torch._dynamo.backends.distributed: [INFO] Please `pip install tabulate` in order to pretty-print ddp bucket sizes
[2023-02-11 15:53:27,015] torch._inductor.compile_fx: [INFO] Step 3: torchinductor compiling FORWARDS graph 2
[2023-02-11 15:53:27,109] torch._inductor.graph: [INFO] Creating implicit fallback for:
target: aten._scaled_dot_product_flash_attention.default
args[0]: TensorBox(
View(
PermuteView(data=View(
View(
SliceView(
StorageBox(
Pointwise(
'cuda',
torch.float16,
tmp0 = load(buf6, i3 + 768 * i0 + 2304 * i1)
return tmp0
,
ranges=[3, 197, 1, 768],
origins={convert_element_type, convert_element_type_1, clone, arg6_1, arg1_1, squeeze, arg0_1, addmm, arg7_1, mul, var_mean, add, sub, arg8_1, view, add_1, permute, unsqueeze, convert_element_type_3, permute_1, view_2, view_1, mul_1, rsqrt, convert_element_type_2}
)
),
size=[1, 197, 1, 768],
reindex=lambda i0, i1, i2, i3: [i0, i1, i2, i3],
origins={convert_element_type, convert_element_type_1, clone, arg6_1, arg1_1, squeeze, arg0_1, arg7_1, addmm, mul, var_mean, add, sub, arg8_1, view, add_1, permute, unsqueeze, convert_element_type_3, permute_1, view_2, select, mul_1, view_1, rsqrt, convert_element_type_2}
),
size=(197, 1, 768),
reindex=lambda i0, i1, i2: [0, i0, 0, i2],
origins={convert_element_type, convert_element_type_1, clone, arg6_1, arg1_1, squeeze, arg0_1, arg7_1, addmm, mul, var_mean, add, sub, arg8_1, view, add_1, permute, unsqueeze, convert_element_type_3, permute_1, view_2, select, mul_1, view_1, rsqrt, convert_element_type_2}
),
size=(197, 12, 64),
reindex=lambda i0, i1, i2: [i0, 0, 64*i1 + i2],
origins={convert_element_type, convert_element_type_1, view_3, arg6_1, clone, arg1_1, squeeze, arg0_1, addmm, arg7_1, mul, var_mean, add, sub, arg8_1, view, add_1, permute, unsqueeze, convert_element_type_3, permute_1, view_2, select, mul_1, view_1, rsqrt, convert_element_type_2}
), dims=[1, 0, 2]),
size=(1, 12, 197, 64),
reindex=lambda i0, i1, i2, i3: [i1, i2, i3],
origins={permute_2, convert_element_type, convert_element_type_1, view_3, arg6_1, clone, arg1_1, squeeze, arg0_1, addmm, arg7_1, mul, var_mean, add, sub, arg8_1, view_6, view, add_1, permute, unsqueeze, convert_element_type_3, permute_1, view_2, select, mul_1, view_1, rsqrt, convert_element_type_2}
)
)
args[1]: TensorBox(
View(
PermuteView(data=View(
View(
SliceView(
StorageBox(
Pointwise(
'cuda',
torch.float16,
tmp0 = load(buf6, i3 + 768 * i0 + 2304 * i1)
return tmp0
,
ranges=[3, 197, 1, 768],
origins={convert_element_type, convert_element_type_1, clone, arg6_1, arg1_1, squeeze, arg0_1, addmm, arg7_1, mul, var_mean, add, sub, arg8_1, view, add_1, permute, unsqueeze, convert_element_type_3, permute_1, view_2, view_1, mul_1, rsqrt, convert_element_type_2}
)
),
size=[1, 197, 1, 768],
reindex=lambda i0, i1, i2, i3: [i0 + 1, i1, i2, i3],
origins={convert_element_type, convert_element_type_1, clone, arg6_1, select_1, arg1_1, squeeze, arg0_1, arg7_1, addmm, mul, var_mean, add, sub, arg8_1, view, add_1, permute, unsqueeze, convert_element_type_3, permute_1, view_2, view_1, mul_1, rsqrt, convert_element_type_2}
),
size=(197, 1, 768),
reindex=lambda i0, i1, i2: [0, i0, 0, i2],
origins={convert_element_type, convert_element_type_1, clone, arg6_1, select_1, arg1_1, squeeze, arg0_1, arg7_1, addmm, mul, var_mean, add, sub, arg8_1, view, add_1, permute, unsqueeze, convert_element_type_3, permute_1, view_2, view_1, mul_1, rsqrt, convert_element_type_2}
),
size=(197, 12, 64),
reindex=lambda i0, i1, i2: [i0, 0, 64*i1 + i2],
origins={convert_element_type, convert_element_type_1, clone, arg6_1, select_1, arg1_1, squeeze, arg0_1, addmm, arg7_1, mul, var_mean, add, sub, arg8_1, view_4, view, add_1, permute, unsqueeze, convert_element_type_3, permute_1, view_2, view_1, mul_1, rsqrt, convert_element_type_2}
), dims=[1, 0, 2]),
size=(1, 12, 197, 64),
reindex=lambda i0, i1, i2, i3: [i1, i2, i3],
origins={view_7, convert_element_type, convert_element_type_1, clone, arg6_1, select_1, arg1_1, squeeze, arg0_1, addmm, arg7_1, mul, permute_3, add, var_mean, sub, arg8_1, view_4, view, add_1, permute, unsqueeze, convert_element_type_3, permute_1, view_2, view_1, mul_1, rsqrt, convert_element_type_2}
)
)
args[2]: TensorBox(
View(
PermuteView(data=View(
View(
SliceView(
StorageBox(
Pointwise(
'cuda',
torch.float16,
tmp0 = load(buf6, i3 + 768 * i0 + 2304 * i1)
return tmp0
,
ranges=[3, 197, 1, 768],
origins={convert_element_type, convert_element_type_1, clone, arg6_1, arg1_1, squeeze, arg0_1, addmm, arg7_1, mul, var_mean, add, sub, arg8_1, view, add_1, permute, unsqueeze, convert_element_type_3, permute_1, view_2, view_1, mul_1, rsqrt, convert_element_type_2}
)
),
size=[1, 197, 1, 768],
reindex=lambda i0, i1, i2, i3: [i0 + 2, i1, i2, i3],
origins={convert_element_type, convert_element_type_1, clone, arg6_1, arg1_1, squeeze, arg0_1, arg7_1, addmm, mul, var_mean, select_2, add, sub, arg8_1, view, add_1, permute, unsqueeze, convert_element_type_3, permute_1, view_2, view_1, mul_1, rsqrt, convert_element_type_2}
),
size=(197, 1, 768),
reindex=lambda i0, i1, i2: [0, i0, 0, i2],
origins={convert_element_type, convert_element_type_1, clone, arg6_1, arg1_1, squeeze, arg0_1, arg7_1, addmm, mul, var_mean, select_2, add, sub, arg8_1, view, add_1, permute, unsqueeze, convert_element_type_3, permute_1, view_2, view_1, mul_1, rsqrt, convert_element_type_2}
),
size=(197, 12, 64),
reindex=lambda i0, i1, i2: [i0, 0, 64*i1 + i2],
origins={convert_element_type, convert_element_type_1, clone, arg6_1, arg1_1, squeeze, arg0_1, addmm, arg7_1, mul, var_mean, add, select_2, sub, arg8_1, view, add_1, permute, unsqueeze, convert_element_type_3, permute_1, view_2, view_1, mul_1, rsqrt, convert_element_type_2, view_5}
), dims=[1, 0, 2]),
size=(1, 12, 197, 64),
reindex=lambda i0, i1, i2, i3: [i1, i2, i3],
origins={convert_element_type, convert_element_type_1, permute_4, arg6_1, clone, arg1_1, squeeze, arg0_1, addmm, arg7_1, mul, var_mean, add, select_2, view_8, sub, arg8_1, view, add_1, permute, unsqueeze, convert_element_type_3, permute_1, view_2, view_1, mul_1, rsqrt, convert_element_type_2, view_5}
)
)
[2023-02-11 15:53:27,133] torch._inductor.graph: [INFO] Using FallbackKernel: torch.ops.aten._scaled_dot_product_flash_attention.default
[2023-02-11 15:53:27,786] torch._inductor.compile_fx: [INFO] Step 3: torchinductor done compiling FORWARDS graph 2
[2023-02-11 15:53:28,015] torch._inductor.compile_fx: [INFO] Step 3: torchinductor compiling FORWARDS graph 3
[2023-02-11 15:53:28,170] torch._inductor.compile_fx: [INFO] Step 3: torchinductor done compiling FORWARDS graph 3
[2023-02-11 15:53:28,197] torch._dynamo.output_graph: [INFO] Step 2: done compiler function compile_fn
[2023-02-11 15:53:28,224] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo start tracing forward
[2023-02-11 15:53:28,456] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo done tracing forward (RETURN_VALUE)
[2023-02-11 15:53:28,465] torch._dynamo.output_graph: [INFO] Step 2: calling compiler function compile_fn
[2023-02-11 15:53:28,466] torch._dynamo.backends.distributed: [INFO] DDPOptimizer used bucket cap 26214400 and produced the following buckets:
[2023-02-11 15:53:28,467] torch._dynamo.backends.distributed: [INFO] Please `pip install tabulate` in order to pretty-print ddp bucket sizes
[2023-02-11 15:53:28,977] torch._inductor.compile_fx: [INFO] Step 3: torchinductor compiling FORWARDS graph 4
[2023-02-11 15:53:29,055] torch._inductor.graph: [INFO] Using FallbackKernel: torch.ops.aten._scaled_dot_product_flash_attention.default
[2023-02-11 15:53:29,406] torch._inductor.compile_fx: [INFO] Step 3: torchinductor done compiling FORWARDS graph 4
[2023-02-11 15:53:29,629] torch._inductor.compile_fx: [INFO] Step 3: torchinductor compiling FORWARDS graph 5
[2023-02-11 15:53:29,684] torch._inductor.compile_fx: [INFO] Step 3: torchinductor done compiling FORWARDS graph 5
[2023-02-11 15:53:29,711] torch._dynamo.output_graph: [INFO] Step 2: done compiler function compile_fn
[2023-02-11 15:53:29,727] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo start tracing forward
[2023-02-11 15:53:29,955] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo done tracing forward (RETURN_VALUE)
[2023-02-11 15:53:29,964] torch._dynamo.output_graph: [INFO] Step 2: calling compiler function compile_fn
[2023-02-11 15:53:29,964] torch._dynamo.backends.distributed: [INFO] DDPOptimizer used bucket cap 26214400 and produced the following buckets:
[2023-02-11 15:53:29,965] torch._dynamo.backends.distributed: [INFO] Please `pip install tabulate` in order to pretty-print ddp bucket sizes
[2023-02-11 15:53:30,471] torch._inductor.compile_fx: [INFO] Step 3: torchinductor compiling FORWARDS graph 6
[2023-02-11 15:53:30,544] torch._inductor.graph: [INFO] Using FallbackKernel: torch.ops.aten._scaled_dot_product_flash_attention.default
[2023-02-11 15:53:30,873] torch._inductor.compile_fx: [INFO] Step 3: torchinductor done compiling FORWARDS graph 6
[2023-02-11 15:53:31,079] torch._inductor.compile_fx: [INFO] Step 3: torchinductor compiling FORWARDS graph 7
[2023-02-11 15:53:31,135] torch._inductor.compile_fx: [INFO] Step 3: torchinductor done compiling FORWARDS graph 7
[2023-02-11 15:53:31,160] torch._dynamo.output_graph: [INFO] Step 2: done compiler function compile_fn
[2023-02-11 15:53:31,178] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo start tracing forward
[2023-02-11 15:53:31,404] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo done tracing forward (RETURN_VALUE)
[2023-02-11 15:53:31,412] torch._dynamo.output_graph: [INFO] Step 2: calling compiler function compile_fn
[2023-02-11 15:53:31,413] torch._dynamo.backends.distributed: [INFO] DDPOptimizer used bucket cap 26214400 and produced the following buckets:
[2023-02-11 15:53:31,413] torch._dynamo.backends.distributed: [INFO] Please `pip install tabulate` in order to pretty-print ddp bucket sizes
[2023-02-11 15:53:31,924] torch._inductor.compile_fx: [INFO] Step 3: torchinductor compiling FORWARDS graph 8
[2023-02-11 15:53:32,001] torch._inductor.graph: [INFO] Using FallbackKernel: torch.ops.aten._scaled_dot_product_flash_attention.default
[2023-02-11 15:53:32,805] torch._inductor.compile_fx: [INFO] Step 3: torchinductor done compiling FORWARDS graph 8
[2023-02-11 15:53:33,029] torch._inductor.compile_fx: [INFO] Step 3: torchinductor compiling FORWARDS graph 9
[2023-02-11 15:53:33,085] torch._inductor.compile_fx: [INFO] Step 3: torchinductor done compiling FORWARDS graph 9
[2023-02-11 15:53:33,113] torch._dynamo.output_graph: [INFO] Step 2: done compiler function compile_fn
[2023-02-11 15:53:33,130] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo start tracing forward
[2023-02-11 15:53:33,372] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo done tracing forward (RETURN_VALUE)
[2023-02-11 15:53:33,382] torch._dynamo.output_graph: [INFO] Step 2: calling compiler function compile_fn
[2023-02-11 15:53:33,383] torch._dynamo.backends.distributed: [INFO] DDPOptimizer used bucket cap 26214400 and produced the following buckets:
[2023-02-11 15:53:33,383] torch._dynamo.backends.distributed: [INFO] Please `pip install tabulate` in order to pretty-print ddp bucket sizes
[2023-02-11 15:53:33,935] torch._inductor.compile_fx: [INFO] Step 3: torchinductor compiling FORWARDS graph 10
[2023-02-11 15:53:34,050] torch._inductor.graph: [INFO] Using FallbackKernel: torch.ops.aten._scaled_dot_product_flash_attention.default
[2023-02-11 15:53:34,439] torch._inductor.compile_fx: [INFO] Step 3: torchinductor done compiling FORWARDS graph 10
[2023-02-11 15:53:34,658] torch._inductor.compile_fx: [INFO] Step 3: torchinductor compiling FORWARDS graph 11
[2023-02-11 15:53:34,713] torch._inductor.compile_fx: [INFO] Step 3: torchinductor done compiling FORWARDS graph 11
[2023-02-11 15:53:34,741] torch._dynamo.output_graph: [INFO] Step 2: done compiler function compile_fn
[2023-02-11 15:53:34,757] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo start tracing forward
[2023-02-11 15:53:34,984] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo done tracing forward (RETURN_VALUE)
[2023-02-11 15:53:34,993] torch._dynamo.output_graph: [INFO] Step 2: calling compiler function compile_fn
[2023-02-11 15:53:34,993] torch._dynamo.backends.distributed: [INFO] DDPOptimizer used bucket cap 26214400 and produced the following buckets:
[2023-02-11 15:53:34,994] torch._dynamo.backends.distributed: [INFO] Please `pip install tabulate` in order to pretty-print ddp bucket sizes
[2023-02-11 15:53:35,496] torch._inductor.compile_fx: [INFO] Step 3: torchinductor compiling FORWARDS graph 12
[2023-02-11 15:53:35,570] torch._inductor.graph: [INFO] Using FallbackKernel: torch.ops.aten._scaled_dot_product_flash_attention.default
[2023-02-11 15:53:35,918] torch._inductor.compile_fx: [INFO] Step 3: torchinductor done compiling FORWARDS graph 12
[2023-02-11 15:53:36,131] torch._inductor.compile_fx: [INFO] Step 3: torchinductor compiling FORWARDS graph 13
[2023-02-11 15:53:36,185] torch._inductor.compile_fx: [INFO] Step 3: torchinductor done compiling FORWARDS graph 13
[2023-02-11 15:53:36,211] torch._dynamo.output_graph: [INFO] Step 2: done compiler function compile_fn
[2023-02-11 15:53:36,227] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo start tracing forward
[2023-02-11 15:53:36,448] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo done tracing forward (RETURN_VALUE)
[2023-02-11 15:53:36,456] torch._dynamo.output_graph: [INFO] Step 2: calling compiler function compile_fn
[2023-02-11 15:53:36,460] torch._dynamo.backends.distributed: [INFO] DDPOptimizer used bucket cap 26214400 and produced the following buckets:
[2023-02-11 15:53:36,461] torch._dynamo.backends.distributed: [INFO] Please `pip install tabulate` in order to pretty-print ddp bucket sizes
[2023-02-11 15:53:36,987] torch._inductor.compile_fx: [INFO] Step 3: torchinductor compiling FORWARDS graph 14
[2023-02-11 15:53:37,064] torch._inductor.graph: [INFO] Using FallbackKernel: torch.ops.aten._scaled_dot_product_flash_attention.default
[2023-02-11 15:53:37,400] torch._inductor.compile_fx: [INFO] Step 3: torchinductor done compiling FORWARDS graph 14
[2023-02-11 15:53:37,611] torch._inductor.compile_fx: [INFO] Step 3: torchinductor compiling FORWARDS graph 15
[2023-02-11 15:53:37,665] torch._inductor.compile_fx: [INFO] Step 3: torchinductor done compiling FORWARDS graph 15
[2023-02-11 15:53:37,694] torch._dynamo.output_graph: [INFO] Step 2: done compiler function compile_fn
[2023-02-11 15:53:37,711] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo start tracing forward
[2023-02-11 15:53:37,943] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo done tracing forward (RETURN_VALUE)
[2023-02-11 15:53:37,952] torch._dynamo.output_graph: [INFO] Step 2: calling compiler function compile_fn
[2023-02-11 15:53:37,953] torch._dynamo.backends.distributed: [INFO] DDPOptimizer used bucket cap 26214400 and produced the following buckets:
[2023-02-11 15:53:37,953] torch._dynamo.backends.distributed: [INFO] Please `pip install tabulate` in order to pretty-print ddp bucket sizes
[2023-02-11 15:53:38,503] torch._inductor.compile_fx: [INFO] Step 3: torchinductor compiling FORWARDS graph 16
[2023-02-11 15:53:38,596] torch._inductor.graph: [INFO] Using FallbackKernel: torch.ops.aten._scaled_dot_product_flash_attention.default
[2023-02-11 15:53:38,956] torch._inductor.compile_fx: [INFO] Step 3: torchinductor done compiling FORWARDS graph 16
[2023-02-11 15:53:39,171] torch._inductor.compile_fx: [INFO] Step 3: torchinductor compiling FORWARDS graph 17
[2023-02-11 15:53:39,227] torch._inductor.compile_fx: [INFO] Step 3: torchinductor done compiling FORWARDS graph 17
[2023-02-11 15:53:39,254] torch._dynamo.output_graph: [INFO] Step 2: done compiler function compile_fn
[2023-02-11 15:53:39,270] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo start tracing forward
[2023-02-11 15:53:39,503] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo done tracing forward (RETURN_VALUE)
[2023-02-11 15:53:39,511] torch._dynamo.output_graph: [INFO] Step 2: calling compiler function compile_fn
[2023-02-11 15:53:39,512] torch._dynamo.backends.distributed: [INFO] DDPOptimizer used bucket cap 26214400 and produced the following buckets:
[2023-02-11 15:53:39,513] torch._dynamo.backends.distributed: [INFO] Please `pip install tabulate` in order to pretty-print ddp bucket sizes
[2023-02-11 15:53:40,028] torch._inductor.compile_fx: [INFO] Step 3: torchinductor compiling FORWARDS graph 18
[2023-02-11 15:53:40,103] torch._inductor.graph: [INFO] Using FallbackKernel: torch.ops.aten._scaled_dot_product_flash_attention.default
[2023-02-11 15:53:40,433] torch._inductor.compile_fx: [INFO] Step 3: torchinductor done compiling FORWARDS graph 18
[2023-02-11 15:53:40,654] torch._inductor.compile_fx: [INFO] Step 3: torchinductor compiling FORWARDS graph 19
[2023-02-11 15:53:40,710] torch._inductor.compile_fx: [INFO] Step 3: torchinductor done compiling FORWARDS graph 19
[2023-02-11 15:53:40,737] torch._dynamo.output_graph: [INFO] Step 2: done compiler function compile_fn
[2023-02-11 15:53:40,755] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo start tracing forward
[2023-02-11 15:53:41,031] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo done tracing forward (RETURN_VALUE)
[2023-02-11 15:53:41,039] torch._dynamo.output_graph: [INFO] Step 2: calling compiler function compile_fn
[2023-02-11 15:53:41,040] torch._dynamo.backends.distributed: [INFO] DDPOptimizer used bucket cap 26214400 and produced the following buckets:
[2023-02-11 15:53:41,041] torch._dynamo.backends.distributed: [INFO] Please `pip install tabulate` in order to pretty-print ddp bucket sizes
[2023-02-11 15:53:41,559] torch._inductor.compile_fx: [INFO] Step 3: torchinductor compiling FORWARDS graph 20
[2023-02-11 15:53:41,641] torch._inductor.graph: [INFO] Using FallbackKernel: torch.ops.aten._scaled_dot_product_flash_attention.default
[2023-02-11 15:53:42,077] torch._inductor.compile_fx: [INFO] Step 3: torchinductor done compiling FORWARDS graph 20
[2023-02-11 15:53:42,298] torch._inductor.compile_fx: [INFO] Step 3: torchinductor compiling FORWARDS graph 21
[2023-02-11 15:53:42,353] torch._inductor.compile_fx: [INFO] Step 3: torchinductor done compiling FORWARDS graph 21
[2023-02-11 15:53:42,380] torch._dynamo.output_graph: [INFO] Step 2: done compiler function compile_fn
[2023-02-11 15:53:42,397] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo start tracing forward
[2023-02-11 15:53:42,659] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo done tracing forward (RETURN_VALUE)
[2023-02-11 15:53:42,668] torch._dynamo.output_graph: [INFO] Step 2: calling compiler function compile_fn
[2023-02-11 15:53:42,669] torch._dynamo.backends.distributed: [INFO] DDPOptimizer used bucket cap 26214400 and produced the following buckets:
[2023-02-11 15:53:42,669] torch._dynamo.backends.distributed: [INFO] Please `pip install tabulate` in order to pretty-print ddp bucket sizes
[2023-02-11 15:53:43,235] torch._inductor.compile_fx: [INFO] Step 3: torchinductor compiling FORWARDS graph 22
[2023-02-11 15:53:43,313] torch._inductor.graph: [INFO] Using FallbackKernel: torch.ops.aten._scaled_dot_product_flash_attention.default
[2023-02-11 15:53:43,671] torch._inductor.compile_fx: [INFO] Step 3: torchinductor done compiling FORWARDS graph 22
[2023-02-11 15:53:43,885] torch._inductor.compile_fx: [INFO] Step 3: torchinductor compiling FORWARDS graph 23
[2023-02-11 15:53:43,942] torch._inductor.compile_fx: [INFO] Step 3: torchinductor done compiling FORWARDS graph 23
[2023-02-11 15:53:43,970] torch._dynamo.output_graph: [INFO] Step 2: done compiler function compile_fn
[2023-02-11 15:53:43,986] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo start tracing <graph break in forward>
[2023-02-11 15:53:44,022] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo done tracing <graph break in forward> (RETURN_VALUE)
[2023-02-11 15:53:44,026] torch._dynamo.output_graph: [INFO] Step 2: calling compiler function compile_fn
[2023-02-11 15:53:44,026] torch._dynamo.backends.distributed: [INFO] DDPOptimizer used bucket cap 26214400 and produced the following buckets:
[2023-02-11 15:53:44,027] torch._dynamo.backends.distributed: [INFO] Please `pip install tabulate` in order to pretty-print ddp bucket sizes
[2023-02-11 15:53:44,111] torch._inductor.compile_fx: [INFO] Step 3: torchinductor compiling FORWARDS graph 24
[2023-02-11 15:53:44,328] torch._inductor.compile_fx: [INFO] Step 3: torchinductor done compiling FORWARDS graph 24
[2023-02-11 15:53:44,329] torch._dynamo.output_graph: [INFO] Step 2: done compiler function compile_fn
[2023-02-11 15:53:44,343] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo start tracing <graph break in img_embed>
[2023-02-11 15:53:45,086] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo done tracing <graph break in img_embed> (RETURN_VALUE)
[2023-02-11 15:53:45,112] torch._dynamo.output_graph: [INFO] Step 2: calling compiler function compile_fn
[2023-02-11 15:53:45,112] torch._dynamo.backends.distributed: [INFO] DDPOptimizer used bucket cap 26214400 and produced the following buckets:
[2023-02-11 15:53:45,113] torch._dynamo.backends.distributed: [INFO] Please `pip install tabulate` in order to pretty-print ddp bucket sizes
[2023-02-11 15:53:45,287] torch._inductor.compile_fx: [INFO] Step 3: torchinductor compiling FORWARDS graph 25
[2023-02-11 15:53:45,517] torch._inductor.compile_fx: [INFO] Step 3: torchinductor done compiling FORWARDS graph 25
[2023-02-11 15:53:45,518] torch._dynamo.output_graph: [INFO] Step 2: done compiler function compile_fn
[2023-02-11 15:53:45,557] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo start tracing compute_mlm
[2023-02-11 15:53:51,838] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo start tracing compute_mlm
[2023-02-11 15:54:08,780] torch._dynamo.output_graph: [INFO] Step 2: calling compiler function compile_fn
[2023-02-11 15:54:08,807] torch._dynamo.backends.distributed: [INFO] DDPOptimizer used bucket cap 26214400 and produced the following buckets:
[2023-02-11 15:54:08,808] torch._dynamo.backends.distributed: [INFO] Please `pip install tabulate` in order to pretty-print ddp bucket sizes
[2023-02-11 15:54:09,651] torch._inductor.compile_fx: [INFO] Step 3: torchinductor compiling FORWARDS graph 26
[2023-02-11 15:54:09,668] torch._inductor.graph: [INFO] Using FallbackKernel: aten.cumsum
[2023-02-11 15:54:10,107] torch._inductor.compile_fx: [INFO] Step 3: torchinductor done compiling FORWARDS graph 26
[2023-02-11 15:54:11,043] torch._inductor.compile_fx: [INFO] Step 3: torchinductor compiling FORWARDS graph 27
[2023-02-11 15:54:12,051] torch._inductor.compile_fx: [INFO] Step 3: torchinductor done compiling FORWARDS graph 27
[2023-02-11 15:54:13,103] torch._inductor.compile_fx: [INFO] Step 3: torchinductor compiling FORWARDS graph 28
[2023-02-11 15:54:13,765] torch._inductor.compile_fx: [INFO] Step 3: torchinductor done compiling FORWARDS graph 28
[2023-02-11 15:54:14,803] torch._inductor.compile_fx: [INFO] Step 3: torchinductor compiling FORWARDS graph 29
[2023-02-11 15:54:15,509] torch._inductor.compile_fx: [INFO] Step 3: torchinductor done compiling FORWARDS graph 29
[2023-02-11 15:54:16,533] torch._inductor.compile_fx: [INFO] Step 3: torchinductor compiling FORWARDS graph 30
[2023-02-11 15:54:17,213] torch._inductor.compile_fx: [INFO] Step 3: torchinductor done compiling FORWARDS graph 30
[2023-02-11 15:54:18,206] torch._inductor.compile_fx: [INFO] Step 3: torchinductor compiling FORWARDS graph 31
[2023-02-11 15:54:18,868] torch._inductor.compile_fx: [INFO] Step 3: torchinductor done compiling FORWARDS graph 31
[2023-02-11 15:54:19,970] torch._inductor.compile_fx: [INFO] Step 3: torchinductor compiling FORWARDS graph 32
[2023-02-11 15:54:20,916] torch._inductor.compile_fx: [INFO] Step 3: torchinductor done compiling FORWARDS graph 32
[2023-02-11 15:54:22,055] torch._inductor.compile_fx: [INFO] Step 3: torchinductor compiling FORWARDS graph 33
[2023-02-11 15:54:22,737] torch._inductor.compile_fx: [INFO] Step 3: torchinductor done compiling FORWARDS graph 33
[2023-02-11 15:54:23,835] torch._inductor.compile_fx: [INFO] Step 3: torchinductor compiling FORWARDS graph 34
[2023-02-11 15:54:24,599] torch._inductor.compile_fx: [INFO] Step 3: torchinductor done compiling FORWARDS graph 34
[2023-02-11 15:54:25,682] torch._inductor.compile_fx: [INFO] Step 3: torchinductor compiling FORWARDS graph 35
[2023-02-11 15:54:26,479] torch._inductor.compile_fx: [INFO] Step 3: torchinductor done compiling FORWARDS graph 35
[2023-02-11 15:54:27,546] torch._inductor.compile_fx: [INFO] Step 3: torchinductor compiling FORWARDS graph 36
[2023-02-11 15:54:28,239] torch._inductor.compile_fx: [INFO] Step 3: torchinductor done compiling FORWARDS graph 36
[2023-02-11 15:54:29,346] torch._inductor.compile_fx: [INFO] Step 3: torchinductor compiling FORWARDS graph 37
[2023-02-11 15:54:30,090] torch._inductor.compile_fx: [INFO] Step 3: torchinductor done compiling FORWARDS graph 37
[2023-02-11 15:54:31,184] torch._inductor.compile_fx: [INFO] Step 3: torchinductor compiling FORWARDS graph 38
[2023-02-11 15:54:31,997] torch._inductor.compile_fx: [INFO] Step 3: torchinductor done compiling FORWARDS graph 38
[2023-02-11 15:54:33,528] torch._inductor.compile_fx: [INFO] Step 3: torchinductor compiling FORWARDS graph 39
[2023-02-11 15:54:34,738] torch._inductor.compile_fx: [INFO] Step 3: torchinductor done compiling FORWARDS graph 39
[2023-02-11 15:54:36,347] torch._inductor.compile_fx: [INFO] Step 3: torchinductor compiling FORWARDS graph 40
[2023-02-11 15:54:37,657] torch._inductor.compile_fx: [INFO] Step 3: torchinductor done compiling FORWARDS graph 40
[2023-02-11 15:54:38,877] torch._inductor.compile_fx: [INFO] Step 3: torchinductor compiling FORWARDS graph 41
[2023-02-11 15:54:39,850] torch._inductor.compile_fx: [INFO] Step 3: torchinductor done compiling FORWARDS graph 41
[2023-02-11 15:54:41,383] torch._inductor.compile_fx: [INFO] Step 3: torchinductor compiling FORWARDS graph 42
[2023-02-11 15:54:42,426] torch._inductor.compile_fx: [INFO] Step 3: torchinductor done compiling FORWARDS graph 42
[2023-02-11 15:54:43,640] torch._inductor.compile_fx: [INFO] Step 3: torchinductor compiling FORWARDS graph 43
[2023-02-11 15:54:44,678] torch._inductor.compile_fx: [INFO] Step 3: torchinductor done compiling FORWARDS graph 43
[2023-02-11 15:54:46,243] torch._inductor.compile_fx: [INFO] Step 3: torchinductor compiling FORWARDS graph 44
[2023-02-11 15:54:47,361] torch._inductor.compile_fx: [INFO] Step 3: torchinductor done compiling FORWARDS graph 44
[2023-02-11 15:54:48,661] torch._inductor.compile_fx: [INFO] Step 3: torchinductor compiling FORWARDS graph 45
[2023-02-11 15:54:49,416] torch._inductor.compile_fx: [INFO] Step 3: torchinductor done compiling FORWARDS graph 45
[2023-02-11 15:54:50,510] torch._inductor.compile_fx: [INFO] Step 3: torchinductor compiling FORWARDS graph 46
[2023-02-11 15:54:51,304] torch._inductor.compile_fx: [INFO] Step 3: torchinductor done compiling FORWARDS graph 46
[2023-02-11 15:54:52,734] torch._inductor.compile_fx: [INFO] Step 3: torchinductor compiling FORWARDS graph 47
[2023-02-11 15:54:53,787] torch._inductor.compile_fx: [INFO] Step 3: torchinductor done compiling FORWARDS graph 47
[2023-02-11 15:54:55,427] torch._inductor.compile_fx: [INFO] Step 3: torchinductor compiling FORWARDS graph 48
[2023-02-11 15:54:56,426] torch._inductor.compile_fx: [INFO] Step 3: torchinductor done compiling FORWARDS graph 48
[2023-02-11 15:54:57,527] torch._inductor.compile_fx: [INFO] Step 3: torchinductor compiling FORWARDS graph 49
[2023-02-11 15:54:58,262] torch._inductor.compile_fx: [INFO] Step 3: torchinductor done compiling FORWARDS graph 49
[2023-02-11 15:54:59,879] torch._inductor.compile_fx: [INFO] Step 3: torchinductor compiling FORWARDS graph 50
[2023-02-11 15:55:00,885] torch._inductor.compile_fx: [INFO] Step 3: torchinductor done compiling FORWARDS graph 50
[2023-02-11 15:55:02,138] torch._inductor.compile_fx: [INFO] Step 3: torchinductor compiling FORWARDS graph 51
[2023-02-11 15:55:02,887] torch._inductor.compile_fx: [INFO] Step 3: torchinductor done compiling FORWARDS graph 51
[2023-02-11 15:55:04,413] torch._inductor.compile_fx: [INFO] Step 3: torchinductor compiling FORWARDS graph 52
[2023-02-11 15:55:05,501] torch._inductor.compile_fx: [INFO] Step 3: torchinductor done compiling FORWARDS graph 52
[2023-02-11 15:55:06,982] torch._inductor.compile_fx: [INFO] Step 3: torchinductor compiling FORWARDS graph 53
[2023-02-11 15:55:08,648] torch._inductor.compile_fx: [INFO] Step 3: torchinductor done compiling FORWARDS graph 53
[2023-02-11 15:55:09,754] torch._inductor.compile_fx: [INFO] Step 3: torchinductor compiling FORWARDS graph 54
[2023-02-11 15:55:10,600] torch._inductor.compile_fx: [INFO] Step 3: torchinductor done compiling FORWARDS graph 54
[2023-02-11 15:55:10,848] torch._inductor.compile_fx: [INFO] Step 3: torchinductor compiling FORWARDS graph 55
[2023-02-11 15:55:10,959] torch._inductor.compile_fx: [INFO] Step 3: torchinductor done compiling FORWARDS graph 55
[2023-02-11 15:55:10,993] torch._dynamo.output_graph: [INFO] Step 2: done compiler function compile_fn
[2023-02-11 15:55:11,219] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo start tracing __getitem__
[2023-02-11 15:55:11,236] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo start tracing _get_abs_string_index
[2023-02-11 15:55:11,246] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo start tracing __len__
[2023-02-11 15:55:11,288] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo start tracing <graph break in compute_mlm>
[2023-02-11 15:55:11,368] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo start tracing <graph break in compute_mlm>
[2023-02-11 15:55:11,431] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo start tracing <graph break in compute_mlm>
[2023-02-11 15:55:11,489] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo start tracing <graph break in compute_mlm>
[2023-02-11 15:55:11,533] torch._dynamo.output_graph: [INFO] Step 2: calling compiler function compile_fn
[2023-02-11 15:55:11,534] torch._dynamo.backends.distributed: [INFO] DDPOptimizer used bucket cap 26214400 and produced the following buckets:
[2023-02-11 15:55:11,534] torch._dynamo.backends.distributed: [INFO] Please `pip install tabulate` in order to pretty-print ddp bucket sizes
[2023-02-11 15:55:11,615] torch._inductor.compile_fx: [INFO] Step 3: torchinductor compiling FORWARDS graph 56
[2023-02-11 15:55:11,908] torch._inductor.compile_fx: [INFO] Step 3: torchinductor done compiling FORWARDS graph 56
[2023-02-11 15:55:11,909] torch._dynamo.output_graph: [INFO] Step 2: done compiler function compile_fn
[2023-02-11 15:55:11,963] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo start tracing forward
[2023-02-11 15:55:11,993] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo start tracing _forward_full_state_update
[2023-02-11 15:55:12,022] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo start tracing wrapped_func
[2023-02-11 15:55:12,049] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo start tracing <graph break in wrapped_func>
[2023-02-11 15:55:12,077] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo start tracing <graph break in wrapped_func>
[2023-02-11 15:55:12,093] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo start tracing update
[2023-02-11 15:55:12,111] torch._dynamo.output_graph: [INFO] Step 2: calling compiler function compile_fn
[2023-02-11 15:55:12,111] torch._dynamo.backends.distributed: [INFO] DDPOptimizer used bucket cap 26214400 and produced the following buckets:
[2023-02-11 15:55:12,111] torch._dynamo.backends.distributed: [INFO] Please `pip install tabulate` in order to pretty-print ddp bucket sizes
[2023-02-11 15:55:12,147] torch._inductor.compile_fx: [INFO] Step 3: torchinductor compiling FORWARDS graph 57
[2023-02-11 15:55:12,194] torch._inductor.compile_fx: [INFO] Step 3: torchinductor done compiling FORWARDS graph 57
[2023-02-11 15:55:12,195] torch._dynamo.output_graph: [INFO] Step 2: done compiler function compile_fn
[2023-02-11 15:55:12,212] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo start tracing <graph break in update>
[2023-02-11 15:55:12,220] torch._dynamo.output_graph: [INFO] Step 2: calling compiler function compile_fn
[2023-02-11 15:55:12,220] torch._dynamo.backends.distributed: [INFO] DDPOptimizer used bucket cap 26214400 and produced the following buckets:
[2023-02-11 15:55:12,221] torch._dynamo.backends.distributed: [INFO] Please `pip install tabulate` in order to pretty-print ddp bucket sizes
[2023-02-11 15:55:12,246] torch._inductor.compile_fx: [INFO] Step 3: torchinductor compiling FORWARDS graph 58
[2023-02-11 15:55:12,295] torch._inductor.compile_fx: [INFO] Step 3: torchinductor done compiling FORWARDS graph 58
[2023-02-11 15:55:12,296] torch._dynamo.output_graph: [INFO] Step 2: done compiler function compile_fn
[2023-02-11 15:55:12,311] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo start tracing <graph break in update>
[2023-02-11 15:55:12,320] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo start tracing <graph break in _forward_full_state_update>
[2023-02-11 15:55:12,351] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo start tracing <graph break in _forward_full_state_update>
[2023-02-11 15:55:12,378] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo start tracing <graph break in _forward_full_state_update>
[2023-02-11 15:55:12,408] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo start tracing <graph break in _forward_full_state_update>
[2023-02-11 15:55:12,456] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo start tracing <graph break in _forward_full_state_update>
[2023-02-11 15:55:12,486] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo start tracing reset
[2023-02-11 15:55:12,504] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo start tracing <graph break in reset>
[2023-02-11 15:55:12,523] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo start tracing <graph break in reset>
[2023-02-11 15:55:12,542] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo start tracing <graph break in reset>
[2023-02-11 15:55:12,572] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo start tracing <graph break in _forward_full_state_update>
[2023-02-11 15:55:12,608] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo start tracing <graph break in _forward_full_state_update>
[2023-02-11 15:55:12,644] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo start tracing wrapped_func
[2023-02-11 15:55:12,670] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo start tracing <graph break in wrapped_func>
[2023-02-11 15:55:12,679] torch._dynamo.convert_frame: [INFO] converting frame raised unsupported, leaving it unconverted
[2023-02-11 15:55:12,686] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo start tracing sync
[2023-02-11 15:55:12,711] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo start tracing <graph break in sync>
[2023-02-11 15:55:12,722] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo start tracing jit_distributed_available
[2023-02-11 15:55:12,732] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo start tracing compute
[2023-02-11 15:55:12,738] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo done tracing compute (RETURN_VALUE)
[2023-02-11 15:55:12,741] torch._dynamo.output_graph: [INFO] Step 2: calling compiler function compile_fn
[2023-02-11 15:55:12,741] torch._dynamo.backends.distributed: [INFO] DDPOptimizer used bucket cap 26214400 and produced the following buckets:
[2023-02-11 15:55:12,742] torch._dynamo.backends.distributed: [INFO] Please `pip install tabulate` in order to pretty-print ddp bucket sizes
[2023-02-11 15:55:12,775] torch._inductor.compile_fx: [INFO] Step 3: torchinductor compiling FORWARDS graph 59
[2023-02-11 15:55:12,825] torch._inductor.compile_fx: [INFO] Step 3: torchinductor done compiling FORWARDS graph 59
[2023-02-11 15:55:12,826] torch._dynamo.output_graph: [INFO] Step 2: done compiler function compile_fn
[2023-02-11 15:55:12,837] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo start tracing _squeeze_if_scalar
[2023-02-11 15:55:12,850] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo done tracing _squeeze_if_scalar (RETURN_VALUE)
[2023-02-11 15:55:12,853] torch._dynamo.output_graph: [INFO] Step 2: calling compiler function compile_fn
[2023-02-11 15:55:12,853] torch._dynamo.backends.distributed: [INFO] DDPOptimizer used bucket cap 26214400 and produced the following buckets:
[2023-02-11 15:55:12,854] torch._dynamo.backends.distributed: [INFO] Please `pip install tabulate` in order to pretty-print ddp bucket sizes
[2023-02-11 15:55:12,875] torch._inductor.compile_fx: [INFO] Step 3: torchinductor compiling FORWARDS graph 60
[2023-02-11 15:55:12,878] torch._inductor.compile_fx: [INFO] Step 3: torchinductor done compiling FORWARDS graph 60
[2023-02-11 15:55:12,879] torch._dynamo.output_graph: [INFO] Step 2: done compiler function compile_fn
[2023-02-11 15:55:12,887] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo start tracing unsync
[2023-02-11 15:55:12,901] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo start tracing <graph break in _forward_full_state_update>
[2023-02-11 15:55:12,913] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo start tracing <graph break in forward>
[2023-02-11 15:55:12,929] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo start tracing <graph break in forward>
[2023-02-11 15:55:12,950] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo start tracing <graph break in compute_mlm>
[2023-02-11 15:55:12,979] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo start tracing <graph break in compute_mlm>
[2023-02-11 15:55:13,048] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo start tracing forward
[2023-02-11 15:55:13,075] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo start tracing _forward_full_state_update
[2023-02-11 15:55:13,094] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo start tracing wrapped_func
[2023-02-11 15:55:13,109] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo start tracing <graph break in wrapped_func>
[2023-02-11 15:55:13,125] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo start tracing <graph break in wrapped_func>
[2023-02-11 15:55:13,141] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo start tracing update
[2023-02-11 15:55:13,168] torch._dynamo.output_graph: [INFO] Step 2: calling compiler function compile_fn
[2023-02-11 15:55:13,168] torch._dynamo.backends.distributed: [INFO] DDPOptimizer used bucket cap 26214400 and produced the following buckets:
[2023-02-11 15:55:13,169] torch._dynamo.backends.distributed: [INFO] Please `pip install tabulate` in order to pretty-print ddp bucket sizes
[2023-02-11 15:55:13,217] torch._inductor.compile_fx: [INFO] Step 3: torchinductor compiling FORWARDS graph 61
[2023-02-11 15:55:13,306] torch._inductor.compile_fx: [INFO] Step 3: torchinductor done compiling FORWARDS graph 61
[2023-02-11 15:55:13,307] torch._dynamo.output_graph: [INFO] Step 2: done compiler function compile_fn
[2023-02-11 15:55:13,328] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo start tracing <graph break in update>
[2023-02-11 15:55:13,336] torch._dynamo.output_graph: [INFO] Step 2: calling compiler function compile_fn
[2023-02-11 15:55:13,336] torch._dynamo.backends.distributed: [INFO] DDPOptimizer used bucket cap 26214400 and produced the following buckets:
[2023-02-11 15:55:13,337] torch._dynamo.backends.distributed: [INFO] Please `pip install tabulate` in order to pretty-print ddp bucket sizes
[2023-02-11 15:55:13,368] torch._inductor.compile_fx: [INFO] Step 3: torchinductor compiling FORWARDS graph 62
[2023-02-11 15:55:13,397] torch._inductor.compile_fx: [INFO] Step 3: torchinductor done compiling FORWARDS graph 62
[2023-02-11 15:55:13,398] torch._dynamo.output_graph: [INFO] Step 2: done compiler function compile_fn
[2023-02-11 15:55:13,422] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo start tracing <graph break in update>
[2023-02-11 15:55:13,440] torch._dynamo.output_graph: [INFO] Step 2: calling compiler function compile_fn
[2023-02-11 15:55:13,441] torch._dynamo.backends.distributed: [INFO] DDPOptimizer used bucket cap 26214400 and produced the following buckets:
[2023-02-11 15:55:13,441] torch._dynamo.backends.distributed: [INFO] Please `pip install tabulate` in order to pretty-print ddp bucket sizes
[2023-02-11 15:55:13,482] torch._inductor.compile_fx: [INFO] Step 3: torchinductor compiling FORWARDS graph 63
[2023-02-11 15:55:13,964] torch._inductor.compile_fx: [INFO] Step 3: torchinductor done compiling FORWARDS graph 63
[2023-02-11 15:55:13,965] torch._dynamo.output_graph: [INFO] Step 2: done compiler function compile_fn
[2023-02-11 15:55:14,004] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo start tracing <graph break in update>
[2023-02-11 15:55:14,018] torch._dynamo.output_graph: [INFO] Step 2: calling compiler function compile_fn
[2023-02-11 15:55:14,018] torch._dynamo.backends.distributed: [INFO] DDPOptimizer used bucket cap 26214400 and produced the following buckets:
[2023-02-11 15:55:14,019] torch._dynamo.backends.distributed: [INFO] Please `pip install tabulate` in order to pretty-print ddp bucket sizes
[2023-02-11 15:55:14,051] torch._inductor.compile_fx: [INFO] Step 3: torchinductor compiling FORWARDS graph 64
[2023-02-11 15:55:14,155] torch._inductor.compile_fx: [INFO] Step 3: torchinductor done compiling FORWARDS graph 64
[2023-02-11 15:55:14,156] torch._dynamo.output_graph: [INFO] Step 2: done compiler function compile_fn
[2023-02-11 15:55:14,175] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo start tracing <graph break in update>
[2023-02-11 15:55:14,186] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo start tracing <graph break in _forward_full_state_update>
[2023-02-11 15:55:14,206] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo start tracing <graph break in _forward_full_state_update>
[2023-02-11 15:55:14,224] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo start tracing <graph break in _forward_full_state_update>
[2023-02-11 15:55:14,239] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo start tracing <graph break in _forward_full_state_update>
[2023-02-11 15:55:14,273] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo start tracing <graph break in _forward_full_state_update>
[2023-02-11 15:55:14,288] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo start tracing reset
[2023-02-11 15:55:14,298] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo start tracing <graph break in reset>
[2023-02-11 15:55:14,307] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo start tracing <graph break in reset>
[2023-02-11 15:55:14,323] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo start tracing <graph break in _forward_full_state_update>
[2023-02-11 15:55:14,347] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo start tracing <graph break in _forward_full_state_update>
[2023-02-11 15:55:14,367] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo start tracing wrapped_func
[2023-02-11 15:55:14,385] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo start tracing sync
[2023-02-11 15:55:14,398] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo start tracing compute
[2023-02-11 15:55:14,405] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo done tracing compute (RETURN_VALUE)
[2023-02-11 15:55:14,408] torch._dynamo.output_graph: [INFO] Step 2: calling compiler function compile_fn
[2023-02-11 15:55:14,408] torch._dynamo.backends.distributed: [INFO] DDPOptimizer used bucket cap 26214400 and produced the following buckets:
[2023-02-11 15:55:14,409] torch._dynamo.backends.distributed: [INFO] Please `pip install tabulate` in order to pretty-print ddp bucket sizes
[2023-02-11 15:55:14,435] torch._inductor.compile_fx: [INFO] Step 3: torchinductor compiling FORWARDS graph 65
[2023-02-11 15:55:14,451] torch._inductor.compile_fx: [INFO] Step 3: torchinductor done compiling FORWARDS graph 65
[2023-02-11 15:55:14,452] torch._dynamo.output_graph: [INFO] Step 2: done compiler function compile_fn
[2023-02-11 15:55:14,463] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo start tracing <graph break in forward>
[2023-02-11 15:55:14,485] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo start tracing <graph break in compute_mlm>
[2023-02-11 15:55:14,576] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo start tracing log
[2023-02-11 15:55:14,661] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo start tracing apply_to_collection
[2023-02-11 15:55:14,711] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo start tracing is_dataclass_instance
[2023-02-11 15:55:14,724] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo start tracing <graph break in is_dataclass_instance>
[2023-02-11 15:55:14,738] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo start tracing <graph break in apply_to_collection>
[2023-02-11 15:55:14,753] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo start tracing <graph break in log>
[2023-02-11 15:55:14,836] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo start tracing apply_to_collection
[2023-02-11 15:55:14,867] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo start tracing <graph break in log>
ERROR - METER - Failed after 0:02:55!
Traceback (most recent calls WITHOUT Sacred internals):
File "/mnt/vepfs/miniconda3/envs/nlp2/lib/python3.8/site-packages/torch/_dynamo/convert_frame.py", line 364, in _compile
check_fn = CheckFunctionManager(
File "/mnt/vepfs/miniconda3/envs/nlp2/lib/python3.8/site-packages/torch/_dynamo/guards.py", line 549, in __init__
guard.create(local_builder, global_builder)
File "/mnt/vepfs/miniconda3/envs/nlp2/lib/python3.8/site-packages/torch/_guards.py", line 163, in create
return self.create_fn(self.source.select(local_builder, global_builder), self)
File "/mnt/vepfs/miniconda3/envs/nlp2/lib/python3.8/site-packages/torch/_dynamo/guards.py", line 172, in TYPE_MATCH
self._produce_guard_code(guard, [code])
File "/mnt/vepfs/miniconda3/envs/nlp2/lib/python3.8/site-packages/torch/_dynamo/guards.py", line 473, in _produce_guard_code
obj_ref = weakref.ref(guarded_object)
TypeError: cannot create weak reference to 'weakproxy' object
Set torch._dynamo.config.verbose=True for more information
You can suppress this exception and fall back to eager by setting:
torch._dynamo.config.suppress_errors = True
The above exception was the direct cause of the following exception:
Traceback (most recent calls WITHOUT Sacred internals):
File "/mnt/vepfs/workspace/zhenyang/VL_model/model/run.py", line 83, in main
trainer.fit(model, datamodule=dm)
File "/mnt/vepfs/miniconda3/envs/nlp2/lib/python3.8/site-packages/pytorch_lightning/trainer/trainer.py", line 608, in fit
call._call_and_handle_interrupt(
File "/mnt/vepfs/miniconda3/envs/nlp2/lib/python3.8/site-packages/pytorch_lightning/trainer/call.py", line 36, in _call_and_handle_interrupt
return trainer.strategy.launcher.launch(trainer_fn, *args, trainer=trainer, **kwargs)
File "/mnt/vepfs/miniconda3/envs/nlp2/lib/python3.8/site-packages/pytorch_lightning/strategies/launchers/subprocess_script.py", line 88, in launch
return function(*args, **kwargs)
File "/mnt/vepfs/miniconda3/envs/nlp2/lib/python3.8/site-packages/pytorch_lightning/trainer/trainer.py", line 650, in _fit_impl
self._run(model, ckpt_path=self.ckpt_path)
File "/mnt/vepfs/miniconda3/envs/nlp2/lib/python3.8/site-packages/pytorch_lightning/trainer/trainer.py", line 1112, in _run
results = self._run_stage()
File "/mnt/vepfs/miniconda3/envs/nlp2/lib/python3.8/site-packages/pytorch_lightning/trainer/trainer.py", line 1191, in _run_stage
self._run_train()
File "/mnt/vepfs/miniconda3/envs/nlp2/lib/python3.8/site-packages/pytorch_lightning/trainer/trainer.py", line 1204, in _run_train
self._run_sanity_check()
File "/mnt/vepfs/miniconda3/envs/nlp2/lib/python3.8/site-packages/pytorch_lightning/trainer/trainer.py", line 1276, in _run_sanity_check
val_loop.run()
File "/mnt/vepfs/miniconda3/envs/nlp2/lib/python3.8/site-packages/pytorch_lightning/loops/loop.py", line 199, in run
self.advance(*args, **kwargs)
File "/mnt/vepfs/miniconda3/envs/nlp2/lib/python3.8/site-packages/pytorch_lightning/loops/dataloader/evaluation_loop.py", line 152, in advance
dl_outputs = self.epoch_loop.run(self._data_fetcher, dl_max_batches, kwargs)
File "/mnt/vepfs/miniconda3/envs/nlp2/lib/python3.8/site-packages/pytorch_lightning/loops/loop.py", line 199, in run
self.advance(*args, **kwargs)
File "/mnt/vepfs/miniconda3/envs/nlp2/lib/python3.8/site-packages/pytorch_lightning/loops/epoch/evaluation_epoch_loop.py", line 137, in advance
output = self._evaluation_step(**kwargs)
File "/mnt/vepfs/miniconda3/envs/nlp2/lib/python3.8/site-packages/pytorch_lightning/loops/epoch/evaluation_epoch_loop.py", line 234, in _evaluation_step
output = self.trainer._call_strategy_hook(hook_name, *kwargs.values())
File "/mnt/vepfs/miniconda3/envs/nlp2/lib/python3.8/site-packages/pytorch_lightning/trainer/trainer.py", line 1494, in _call_strategy_hook
output = fn(*args, **kwargs)
File "/mnt/vepfs/miniconda3/envs/nlp2/lib/python3.8/site-packages/pytorch_lightning/strategies/ddp.py", line 359, in validation_step
return self.model(*args, **kwargs)
File "/mnt/vepfs/miniconda3/envs/nlp2/lib/python3.8/site-packages/torch/nn/modules/module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "/mnt/vepfs/miniconda3/envs/nlp2/lib/python3.8/site-packages/torch/nn/parallel/distributed.py", line 1159, in forward
output = self._run_ddp_forward(*inputs, **kwargs)
File "/mnt/vepfs/miniconda3/envs/nlp2/lib/python3.8/site-packages/torch/nn/parallel/distributed.py", line 1113, in _run_ddp_forward
return module_to_run(*inputs[0], **kwargs[0]) # type: ignore[index]
File "/mnt/vepfs/miniconda3/envs/nlp2/lib/python3.8/site-packages/torch/nn/modules/module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "/mnt/vepfs/miniconda3/envs/nlp2/lib/python3.8/site-packages/pytorch_lightning/overrides/base.py", line 110, in forward
return self._forward_module.validation_step(*inputs, **kwargs)
File "/mnt/vepfs/miniconda3/envs/nlp2/lib/python3.8/site-packages/torch/_dynamo/eval_frame.py", line 209, in _fn
return fn(*args, **kwargs)
File "/mnt/vepfs/workspace/zhenyang/VL_model/model/meter/modules/meter_module.py", line 420, in validation_step
meter_utils.set_task(self)
File "/mnt/vepfs/workspace/zhenyang/VL_model/model/meter/modules/meter_module.py", line 421, in <graph break in validation_step>
output = self(batch)
File "/mnt/vepfs/miniconda3/envs/nlp2/lib/python3.8/site-packages/torch/nn/modules/module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "/mnt/vepfs/miniconda3/envs/nlp2/lib/python3.8/site-packages/torch/_dynamo/eval_frame.py", line 209, in _fn
return fn(*args, **kwargs)
File "/mnt/vepfs/workspace/zhenyang/VL_model/model/meter/modules/meter_module.py", line 361, in forward
ret.update(objectives.compute_mlm(self, batch, ret['dual_image_feats']))
File "/mnt/vepfs/workspace/zhenyang/VL_model/model/meter/modules/objectives.py", line 17, in compute_mlm
def compute_mlm(pl_module, batch, dual_image_feats=None):
File "/mnt/vepfs/workspace/zhenyang/VL_model/model/meter/modules/objectives.py", line 43, in <graph break in compute_mlm>
mlm_logits.view(-1, pl_module.hparams.config["vocab_size"]),
File "/mnt/vepfs/workspace/zhenyang/VL_model/model/meter/modules/objectives.py", line 43, in <graph break in compute_mlm>
mlm_logits.view(-1, pl_module.hparams.config["vocab_size"]),
File "/mnt/vepfs/workspace/zhenyang/VL_model/model/meter/modules/objectives.py", line 56, in <graph break in compute_mlm>
loss = getattr(pl_module, f"{phase}_mlm_loss")(ret["mlm_loss"])
File "/mnt/vepfs/workspace/zhenyang/VL_model/model/meter/modules/objectives.py", line 57, in <graph break in compute_mlm>
acc = getattr(pl_module, f"{phase}_mlm_accuracy")(
File "/mnt/vepfs/workspace/zhenyang/VL_model/model/meter/modules/objectives.py", line 57, in <graph break in compute_mlm>
acc = getattr(pl_module, f"{phase}_mlm_accuracy")(
File "/mnt/vepfs/miniconda3/envs/nlp2/lib/python3.8/site-packages/pytorch_lightning/core/module.py", line 409, in log
apply_to_collection(value, dict, self.__check_not_nested, name)
File "/mnt/vepfs/miniconda3/envs/nlp2/lib/python3.8/site-packages/pytorch_lightning/core/module.py", line 410, in <graph break in log>
apply_to_collection(
File "/mnt/vepfs/miniconda3/envs/nlp2/lib/python3.8/site-packages/torch/_dynamo/eval_frame.py", line 327, in catch_errors
return hijacked_callback(frame, cache_size, hooks)
File "/mnt/vepfs/miniconda3/envs/nlp2/lib/python3.8/site-packages/torch/_dynamo/convert_frame.py", line 404, in _convert_frame
result = inner_convert(frame, cache_size, hooks)
File "/mnt/vepfs/miniconda3/envs/nlp2/lib/python3.8/site-packages/torch/_dynamo/convert_frame.py", line 104, in _fn
return fn(*args, **kwargs)
File "/mnt/vepfs/miniconda3/envs/nlp2/lib/python3.8/site-packages/torch/_dynamo/convert_frame.py", line 262, in _convert_frame_assert
return _compile(
File "/mnt/vepfs/miniconda3/envs/nlp2/lib/python3.8/site-packages/torch/_dynamo/utils.py", line 163, in time_wrapper
r = func(*args, **kwargs)
File "/mnt/vepfs/miniconda3/envs/nlp2/lib/python3.8/site-packages/torch/_dynamo/convert_frame.py", line 394, in _compile
raise InternalTorchDynamoError() from e
torch._dynamo.exc.InternalTorchDynamoError
node30:1755820:1756503 [0] NCCL INFO [Service thread] Connection closed by localRank 0
node30:1755820:1755820 [0] NCCL INFO comm 0xa4b24900 rank 0 nranks 1 cudaDev 0 busId 69010 - Abort COMPLETE
Process finished with exit code 1
```
### Versions
NVIDIA A100-SXM-80GB with CUDA capability sm_80 is not compatible with the current PyTorch installation.
The current PyTorch install supports CUDA capabilities sm_37 sm_50 sm_60 sm_70.
If you want to use the NVIDIA A100-SXM-80GB GPU with PyTorch, please check the instructions at https://pytorch.org/get-started/locally/
warnings.warn(incompatible_device_warn.format(device_name, capability, " ".join(arch_list), device_name))
PyTorch version: 1.12.1+cu102
Is debug build: False
CUDA used to build PyTorch: 10.2
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.4 LTS (x86_64)
GCC version: (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0
Clang version: Could not collect
CMake version: version 3.16.3
Libc version: glibc-2.31
Python version: 3.9.12 (main, Apr 5 2022, 06:56:58) [GCC 7.5.0] (64-bit runtime)
Python platform: Linux-5.4.0-104-generic-x86_64-with-glibc2.31
Is CUDA available: True
CUDA runtime version: Could not collect
CUDA_MODULE_LOADING set to:
GPU models and configuration:
GPU 0: NVIDIA A100-SXM-80GB
GPU 1: NVIDIA A100-SXM-80GB
GPU 2: NVIDIA A100-SXM-80GB
GPU 3: NVIDIA A100-SXM-80GB
GPU 4: NVIDIA A100-SXM-80GB
GPU 5: NVIDIA A100-SXM-80GB
GPU 6: NVIDIA A100-SXM-80GB
GPU 7: NVIDIA A100-SXM-80GB
Nvidia driver version: 470.57.02
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
Address sizes: 46 bits physical, 57 bits virtual
CPU(s): 112
On-line CPU(s) list: 0-111
Thread(s) per core: 2
Core(s) per socket: 28
Socket(s): 2
NUMA node(s): 2
Vendor ID: GenuineIntel
CPU family: 6
Model: 106
Model name: Intel(R) Xeon(R) Platinum 8336C CPU @ 2.30GHz
Stepping: 6
CPU MHz: 2300.056
BogoMIPS: 4600.11
Hypervisor vendor: KVM
Virtualization type: full
L1d cache: 2.6 MiB
L1i cache: 1.8 MiB
L2 cache: 70 MiB
L3 cache: 54 MiB
NUMA node0 CPU(s): 0-55
NUMA node1 CPU(s): 56-111
Vulnerability Itlb multihit: Not affected
Vulnerability L1tf: Not affected
Vulnerability Mds: Not affected
Vulnerability Meltdown: Not affected
Vulnerability Spec store bypass: Mitigation; Speculative Store Bypass disabled via prctl and seccomp
Vulnerability Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization
Vulnerability Spectre v2: Mitigation; Enhanced IBRS, IBPB conditional, RSB filling
Vulnerability Srbds: Not affected
Vulnerability Tsx async abort: Not affected
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ss ht syscall nx pdpe1gb rdtscp lm constant_tsc rep_good nopl xtopology cpuid tsc_known_freq pni pclmulqdq ssse3 fma cx16 pcid sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand hypervisor lahf_lm abm 3dnowprefetch cpuid_fault invpcid_single ssbd ibrs ibpb stibp ibrs_enhanced fsgsbase tsc_adjust bmi1 avx2 smep bmi2 erms invpcid avx512f avx512dq rdseed adx smap avx512ifma clflushopt clwb avx512cd sha_ni avx512bw avx512vl xsaveopt xsavec xgetbv1 xsaves wbnoinvd arat avx512vbmi umip pku ospke avx512_vbmi2 gfni vaes vpclmulqdq avx512_vnni avx512_bitalg avx512_vpopcntdq rdpid md_clear arch_capabilities
Versions of relevant libraries:
[pip3] numpy==1.24.1
[pip3] torch==1.12.1
[pip3] torch-cluster==1.6.0
[pip3] torch-scatter==2.0.9
[pip3] torchdrug==0.2.0.post1
[pip3] torchtyping==0.1.4
[pip3] torchvision==0.13.1
[conda] blas 1.0 mkl https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
[conda] mkl 2021.4.0 h06a4308_640 https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
[conda] mkl-service 2.4.0 py39h7f8727e_0 https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
[conda] mkl_fft 1.3.1 py39hd3c417c_0 https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
[conda] mkl_random 1.2.2 py39h51133e4_0 https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
[conda] numpy 1.24.1 pypi_0 pypi
[conda] numpy-base 1.21.5 py39hf524024_2 https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
[conda] torch 1.12.1 pypi_0 pypi
[conda] torch-cluster 1.6.0 pypi_0 pypi
[conda] torch-scatter 2.0.9 pypi_0 pypi
[conda] torchdrug 0.2.0.post1 pypi_0 pypi
[conda] torchtyping 0.1.4 pypi_0 pypi
[conda] torchvision 0.13.1 pypi_0 pypi
cc @mlazos @soumith @voznesenskym @yanboliang @penguinwu @anijain2305 @EikanWang @jgong5 @Guobing-Chen @XiaobingSuper @zhuhaozhe @blzheng @Xia-Weiwen @wenzhe-nrv @jiayisunx @peterbell10 @desertfire
| 2 |
3,486 | 94,654 |
Missing FX documents for some modules
|
module: docs, triaged
|
### 📚 The doc issue
It seems some submodules of torch.fx are missing from the documentation.
The rst file https://github.com/pytorch/pytorch/blob/master/docs/source/fx.rst intends to include the following modules:
.. py:module:: torch.fx.passes
.. py:module:: torch.fx.passes.infra
.. py:module:: torch.fx.passes.backends
.. py:module:: torch.fx.passes.utils
.. py:module:: torch.fx.passes.tests
.. py:module:: torch.fx.experimental
.. py:module:: torch.fx.experimental.unification
.. py:module:: torch.fx.experimental.unification.multipledispatch
.. py:module:: torch.fx.experimental.migrate_gradual_types
.. py:module:: torch.fx.passes.dialect
.. py:module:: torch.fx.passes.dialect.common
While currently the doc https://pytorch.org/docs/stable/fx.html does not contain these submodules.
### Suggest a potential alternative/fix
Maybe there are something wrong with the rst file.
cc @svekars @carljparker
| 0 |
3,487 | 94,652 |
dynamo: handle contiguous graph breaks
|
feature, triaged, oncall: pt2, module: dynamo, module: graph breaks
|
### 🚀 The feature, motivation and pitch
Currently, we create a `function call to traced code` and a `resume at call` in a graph break section every time we encounter an instruction we cannot handle within a `convert_frame`.
I believe this could result in unnecessarily slow code if one has a lot of graph breaks spaced closely together or which are contiguous.
Instead of eagerly creating a `resume at call`, we should lazily attempt to continue to trace the program. Until we hit another instruction that is explicitly a torch op, we should not create a `resume at` instruction immediately. When we do hit a torch op, we can trigger a `resume at`.
Essentially, we will avoid the situation where we have many graph breaks with trivial `output` functions.
Possibly, this could also help us move control-flow not dependent on tensors into graph breaks. We could possibly reduce the number of guards required in the partial graphs this way.
To implement this, the `InstructionTranslator` should be stateful. When in graph break mode, it should keep tracing if encountering graph breaks, but create a resume at if encountering torch ops. When in torch tracing mode, it should switch modes to graph break mode if encountering a graph break. `resume` at is already capable of recreating the stack for variables it references, so I don't think we need to worry too much.
### Alternatives
_No response_
### Additional context
This is an optimization and hence lower priority. We should only investigate further if we do in fact see contiguous graph breaks appearing in user code and they are a substantial source of slowness in execution.
It is unclear if there is even a high performance penalty. However, note that a graph break is considerably more expensive than ordinary function call, things like the `SETUP WITH` and other variables need to be setup and torn down on each graph break.
cc @ezyang @soumith @msaroufim @wconstab @ngimel @bdhirsh @voznesenskym @penguinwu @anijain2305 @EikanWang @jgong5 @Guobing-Chen @XiaobingSuper @zhuhaozhe @blzheng @Xia-Weiwen @wenzhe-nrv @jiayisunx @desertfire
| 5 |
3,488 | 94,620 |
[RFC] Add a static_graph mode for FSDP
|
oncall: distributed, triaged, module: fsdp
|
### 🚀 The feature, motivation and pitch
In most of workloads, the graph is static, and a lot of optimizations like explicit prefetch, execution order based wrapping are based on assumption that graph is static, we can add a static_graph flag similar to vanilla DDP API, if users explicitly specify the graph is static, FSDP can turn on all the related optimizations in default.
This flag may be helpful for FSDP + Dynamo mode as well to avoid unneeded recompilation
### Alternatives
_No response_
### Additional context
_No response_
cc @mrshenli @pritamdamania87 @satgera @rohan-varma @gqchen @aazzolini @osalpekar @jiayisuse @H-Huang @kwen2501 @awgu
| 0 |
3,489 | 94,614 |
Jetson CI needs Updates
|
triaged, module: jetson
|
### 🐛 Describe the bug
https://github.com/pytorch/pytorch/pull/94549/files
the above PR uses IS_JETSON flag to skip tests or modify them to pass. These can be re-evaluted on a monthly basis, checking wether the test changes are still needed on Jetsons. Jetson's have been riddled with bugs and are slowly improving over time so we expect these test changes to become unnecessary as time progresses and the Jetson boards start functioning properly.
### Versions
```
riship@orin-ipp1-2420:/mnt/hostmount/riship/old_pyt/pytorch$ python3 collect_env.py
Collecting environment information...
PyTorch version: N/A
Is debug build: N/A
CUDA used to build PyTorch: N/A
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.5 LTS (aarch64)
GCC version: (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0
Clang version: Could not collect
CMake version: version 3.25.2
Libc version: glibc-2.31
Python version: 3.8.10 (default, Nov 14 2022, 12:59:47) [GCC 9.4.0] (64-bit runtime)
Python platform: Linux-5.10.104-tegra-aarch64-with-glibc2.29
Is CUDA available: N/A
CUDA runtime version: Could not collect
CUDA_MODULE_LOADING set to: N/A
GPU models and configuration: Could not collect
Nvidia driver version: Could not collect
cuDNN version: Probably one of the following:
/usr/lib/aarch64-linux-gnu/libcudnn.so.8.6.0
/usr/lib/aarch64-linux-gnu/libcudnn_adv_infer.so.8.6.0
/usr/lib/aarch64-linux-gnu/libcudnn_adv_train.so.8.6.0
/usr/lib/aarch64-linux-gnu/libcudnn_cnn_infer.so.8.6.0
/usr/lib/aarch64-linux-gnu/libcudnn_cnn_train.so.8.6.0
/usr/lib/aarch64-linux-gnu/libcudnn_ops_infer.so.8.6.0
/usr/lib/aarch64-linux-gnu/libcudnn_ops_train.so.8.6.0
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: N/A
CPU:
Architecture: aarch64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 12
On-line CPU(s) list: 0-7
Off-line CPU(s) list: 8-11
Thread(s) per core: 1
Core(s) per socket: 4
Socket(s): 2
Vendor ID: ARM
Model: 1
Model name: ARMv8 Processor rev 1 (v8l)
Stepping: r0p1
CPU max MHz: 2201.6001
CPU min MHz: 115.2000
BogoMIPS: 62.50
L1d cache: 512 KiB
L1i cache: 512 KiB
L2 cache: 2 MiB
L3 cache: 4 MiB
Vulnerability Itlb multihit: Not affected
Vulnerability L1tf: Not affected
Vulnerability Mds: Not affected
Vulnerability Meltdown: Not affected
Vulnerability Spec store bypass: Mitigation; Speculative Store Bypass disabled via prctl
Vulnerability Spectre v1: Mitigation; __user pointer sanitization
Vulnerability Spectre v2: Not affected
Vulnerability Srbds: Not affected
Vulnerability Tsx async abort: Not affected
Flags: fp asimd evtstrm aes pmull sha1 sha2 crc32 atomics fphp asimdhp cpuid asimdrdm lrcpc dcpop asimddp uscat ilrcpc flagm
riship@orin-ipp1-2420:/mnt/hostmount/riship/old_pyt/pytorch$ pip show torch
Name: torch
Version: 1.14.0a0+44dac51c.nv23.2
Summary: Tensors and Dynamic neural networks in Python with strong GPU acceleration
Home-page: https://pytorch.org/
Author: PyTorch Team
Author-email: packages@pytorch.org
License: BSD-3
Location: /home/riship/.local/lib/python3.8/site-packages
Requires: typing-extensions, networkx, sympy
Required-by:
```
cc @ptrblck
| 0 |
3,490 | 94,609 |
Lots of different `nn.Sequence` instances trigger the Dynamo cache limits
|
high priority, triaged, has workaround, oncall: pt2, module: dynamo
|
### 🐛 Describe the bug
I am optimizing the training of an internal model. The entire forward call becomes 3x slower when enabling pytorch inductor. I've been profiling it a bit and turns out the lookup for the `check_fn` calls takes between 5ms and 10ms for each "Sequential.forward" call.
Turns out we have a lot of nn.Sequential instances in our model. All these container instances contain modules that are very different from each other. However, they all share the same "Sequence.forward" method that gets optimized by dynamo. This means, dynamo will try to optimize the method for each particular instance of the Sequential class and push those optimizations into the same cache list.
When it executes one `Sequential.forward` instance, it will have to iterate through all the cached `check_fn` functions by calling them one by one. There's an optimization in the `eval_frame.c:lookup` method that remembers the last `check_fn` that validated and optimizes for that particular call by moving it to the top of the list.
However, chances are that same Sequential will not actually execute until the next training iteration, which means it will have to search through all other `check_fns` again for the next Sequential call.
To make matters worse, the check_fn has a lot of `Sequential[index]` calls, that sometimes look deep inside without caching the `Sequential[index]` values. That means, the check_fn ends up calling a lot of the `sequential.__getitem__`. Now if we analyze that method, it is not particularly cheap as the Sequential stores its list of modules in the "_modules" dict structure, so it has to iterate through all `dict.values()` to get the requested one.
### Error logs
Performance is 3x slower when inductor is enabled.
### Minified repro
_No response_
### Versions
```
Collecting environment information...
PyTorch version: 2.0.0
Is debug build: False
CUDA used to build PyTorch: 11.8
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.5 LTS (x86_64)
GCC version: (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0
Clang version: Could not collect
CMake version: version 3.25.2
Libc version: glibc-2.31
Python version: 3.8.10 (default, Nov 14 2022, 12:59:47) [GCC 9.4.0] (64-bit runtime)
Python platform: Linux-5.13.0-1023-aws-x86_64-with-glibc2.29
Is CUDA available: True
CUDA runtime version: 11.8.89
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration: GPU 0: NVIDIA A100-SXM4-80GB
Nvidia driver version: 525.85.12
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.7.0
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.7.0
/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.7.0
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_infer.so.8.7.0
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.7.0
/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.7.0
/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.7.0
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] mypy-extensions==1.0.0
[pip3] numpy==1.23.0
[pip3] open-clip-torch==2.11.1
[pip3] pytorch-lightning==1.9.0
[pip3] rotary-embedding-torch==0.1.5
[pip3] torch==2.0.0
[pip3] torchdata==0.5.1
[pip3] torchdistx==0.3.0.dev0+cu118
[pip3] torchmetrics==0.11.1
[pip3] torchvision==0.15.0a0+2d6e663
[conda] Could not collect
```
cc @ezyang @gchanan @zou3519 @msaroufim @wconstab @bdhirsh @anijain2305 @voznesenskym @penguinwu @EikanWang @jgong5 @Guobing-Chen @XiaobingSuper @zhuhaozhe @blzheng @Xia-Weiwen @wenzhe-nrv @jiayisunx @ipiszy @chenyang78 @soumith @ngimel @mlazos @yanboliang @desertfire
| 9 |
3,491 | 94,602 |
Saving a `torch.nn.HuberLoss` using `torch.jit.script().save()` doesn't seem to implicitly convert from `int` type to `float` type.
|
oncall: jit
|
### 🐛 Describe the bug
Saving a `torch.nn.HuberLoss(delta=1)` crashes with a `RuntimeError` which is actually a type error, but saving a `torch.nn.HuberLoss(delta=1.1)` works fine. The problem is that Pytorch complaints that 1 is an integer and not a float. I would expect that Pytorch would know to implicitly convert argument `delta` to a float all the time. The user (programmer) shouldn't be expected to explicitly type 1.0 (as opposed to just 1) in Python 3.
To reproduce:
```
loss_module = torch.nn.HuberLoss(delta=1)
torch.jit.script(loss_module).save("Drive:\Path\To\LossModule.pt")
```
Error message:
```
RuntimeError:
huber_loss(Tensor input, Tensor target, str reduction="mean", float delta=1.) -> Tensor:
Expected a value of type 'float' for argument 'delta' but instead found type 'int'.
:
File "C:\Users\raaaa\AppData\Local\Programs\Python\Python310\lib\site-packages\torch\nn\modules\loss.py", line 988
def forward(self, input: Tensor, target: Tensor) -> Tensor:
return F.huber_loss(input, target, reduction=self.reduction, delta=self.delta)
~~~~~~~~~~~~ <--- HERE
```
I'm guessing this is a bug because I can't imagine this is the desired behaviour?
### Versions
Collecting environment information...
PyTorch version: 1.13.0+cu117
Is debug build: False
CUDA used to build PyTorch: 11.7
ROCM used to build PyTorch: N/A
OS: Microsoft Windows 11 Pro
GCC version: (x86_64-posix-seh, Built by strawberryperl.com project) 8.3.0
Clang version: Could not collect
CMake version: version 3.20.2
Libc version: N/A
Python version: 3.10.1 (tags/v3.10.1:2cd268a, Dec 6 2021, 19:10:37) [MSC v.1929 64 bit (AMD64)] (64-bit runtime)
Python platform: Windows-10-10.0.22621-SP0
Is CUDA available: True
CUDA runtime version: 11.7.64
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration: GPU 0: NVIDIA GeForce RTX 3080
Nvidia driver version: 528.02
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
cc @EikanWang @jgong5 @wenzhe-nrv @sanchitintel
| 0 |
3,492 | 94,599 |
PyTorch 2.0: AttributeError: __torch__.torch.classes.c10d.ProcessGroup (of Python compilation unit at: 0) does not have a field with name 'shape'
|
oncall: distributed, triaged, oncall: pt2
|
### 🐛 Describe the bug
I obtained the following traceback when enabling `torch.compile`:
```bash
/home/user/.local/lib/python3.10/site-packages/torch/fx/graph.py:1370: UserWarning: Node _tensor_constant0 target _tensor_constant0 _tensor_constant0 of does not reference an nn.Module, nn.Parameter, or buffer, which is what 'get_attr' Nodes typically target
warnings.warn(f'Node {node} target {node.target} {atom} of {seen_qualname} does '
/home/user/.local/lib/python3.10/site-packages/torch/fx/graph.py:1370: UserWarning: Node _tensor_constant1 target _tensor_constant1 _tensor_constant1 of does not reference an nn.Module, nn.Parameter, or buffer, which is what 'get_attr' Nodes typically target
warnings.warn(f'Node {node} target {node.target} {atom} of {seen_qualname} does '
/home/user/.local/lib/python3.10/site-packages/torch/fx/graph.py:1370: UserWarning: Node _tensor_constant2 target _tensor_constant2 _tensor_constant2 of does not reference an nn.Module, nn.Parameter, or buffer, which is what 'get_attr' Nodes typically target
warnings.warn(f'Node {node} target {node.target} {atom} of {seen_qualname} does '
/home/user/.local/lib/python3.10/site-packages/torch/fx/graph.py:1370: UserWarning: Node _tensor_constant3 target _tensor_constant3 _tensor_constant3 of does not reference an nn.Module, nn.Parameter, or buffer, which is what 'get_attr' Nodes typically target
warnings.warn(f'Node {node} target {node.target} {atom} of {seen_qualname} does '
Traceback (most recent call last):
File "/home/user/.local/lib/python3.10/site-packages/torch/_dynamo/output_graph.py", line 692, in call_user_compiler
compiled_fn = compiler_fn(gm, self.fake_example_inputs())
File "/home/user/.local/lib/python3.10/site-packages/torch/_dynamo/optimizations/distributed.py", line 201, in compile_fn
return self.backend_compile_fn(gm, example_inputs)
File "/home/user/.local/lib/python3.10/site-packages/torch/_dynamo/debug_utils.py", line 1048, in debug_wrapper
compiled_gm = compiler_fn(gm, example_inputs)
File "/home/user/.local/lib/python3.10/site-packages/torch/__init__.py", line 1325, in __call__
return self.compile_fn(model_, inputs_)
File "/home/user/.local/lib/python3.10/site-packages/torch/_dynamo/optimizations/backends.py", line 24, in inner
return fn(gm, example_inputs, **kwargs)
File "/home/user/.local/lib/python3.10/site-packages/torch/_dynamo/optimizations/backends.py", line 61, in inductor
return compile_fx(*args, **kwargs)
File "/home/user/.local/lib/python3.10/site-packages/torch/_inductor/compile_fx.py", line 418, in compile_fx
return aot_autograd(
File "/home/user/.local/lib/python3.10/site-packages/torch/_dynamo/optimizations/training.py", line 74, in compiler_fn
cg = aot_module_simplified(gm, example_inputs, **kwargs)
File "/home/user/.local/lib/python3.10/site-packages/torch/_functorch/aot_autograd.py", line 2483, in aot_module_simplified
compiled_fn = create_aot_dispatcher_function(
File "/home/user/.local/lib/python3.10/site-packages/torch/_dynamo/utils.py", line 162, in time_wrapper
r = func(*args, **kwargs)
File "/home/user/.local/lib/python3.10/site-packages/torch/_functorch/aot_autograd.py", line 2180, in create_aot_dispatcher_function
compiled_fn = compiler_fn(flat_fn, fake_flat_args, aot_config)
File "/home/user/.local/lib/python3.10/site-packages/torch/_functorch/aot_autograd.py", line 1411, in aot_wrapper_dedupe
return compiler_fn(flat_fn, leaf_flat_args, aot_config)
File "/home/user/.local/lib/python3.10/site-packages/torch/_functorch/aot_autograd.py", line 1688, in aot_dispatch_autograd
compiled_fw_func = aot_config.fw_compiler(
File "/home/user/.local/lib/python3.10/site-packages/torch/_dynamo/utils.py", line 162, in time_wrapper
r = func(*args, **kwargs)
File "/home/user/.local/lib/python3.10/site-packages/torch/_inductor/compile_fx.py", line 393, in fw_compiler
return inner_compile(
File "/home/user/.local/lib/python3.10/site-packages/torch/_dynamo/debug_utils.py", line 588, in debug_wrapper
compiled_fn = compiler_fn(gm, example_inputs)
File "/home/user/.local/lib/python3.10/site-packages/torch/_inductor/debug.py", line 239, in inner
return fn(*args, **kwargs)
File "/gpfslocalsup/pub/anaconda-py3/2021.05/envs/python-3.10.4/lib/python3.10/contextlib.py", line 79, in inner
return func(*args, **kwds)
File "/home/user/.local/lib/python3.10/site-packages/torch/_inductor/compile_fx.py", line 155, in compile_fx_inner
graph.run(*example_inputs)
File "/home/user/.local/lib/python3.10/site-packages/torch/_dynamo/utils.py", line 162, in time_wrapper
r = func(*args, **kwargs)
File "/home/user/.local/lib/python3.10/site-packages/torch/_inductor/graph.py", line 181, in run
return super().run(*args)
File "/home/user/.local/lib/python3.10/site-packages/torch/fx/interpreter.py", line 136, in run
self.env[node] = self.run_node(node)
File "/home/user/.local/lib/python3.10/site-packages/torch/_inductor/graph.py", line 391, in run_node
result = super().run_node(n)
File "/home/user/.local/lib/python3.10/site-packages/torch/fx/interpreter.py", line 177, in run_node
return getattr(self, n.op)(n.target, args, kwargs)
File "/home/user/.local/lib/python3.10/site-packages/torch/_inductor/graph.py", line 327, in get_attr
if value.shape == ():
AttributeError: __torch__.torch.classes.c10d.ProcessGroup (of Python compilation unit at: 0) does not have a field with name 'shape'
While executing %_tensor_constant0 : [#users=1] = get_attr[target=_tensor_constant0]
Original traceback:
None
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "/home/user/code/bert/main_quantize.py", line 140, in <module>
main(args)
File "/home/user/code/bert/main_quantize.py", line 134, in main
training_loop(args, model, device, data_loader_train, data_loader_val,
File "/home/user/code/bert/common.py", line 333, in training_loop
train_stats = train_fn(args, model, device, data_loader_train,
File "/home/user/code/bert/engine_quantize.py", line 64, in train_epoch
outputs = model(images, **kwargs)
File "/home/user/.local/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1488, in _call_impl
return forward_call(*args, **kwargs)
File "/home/user/.local/lib/python3.10/site-packages/torch/nn/parallel/distributed.py", line 1157, in forward
output = self._run_ddp_forward(*inputs, **kwargs)
File "/home/user/.local/lib/python3.10/site-packages/torch/nn/parallel/distributed.py", line 1111, in _run_ddp_forward
return module_to_run(*inputs[0], **kwargs[0]) # type: ignore[index]
File "/home/user/.local/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1488, in _call_impl
return forward_call(*args, **kwargs)
File "/home/user/.local/lib/python3.10/site-packages/torch/_dynamo/eval_frame.py", line 82, in forward
return self.dynamo_ctx(self._orig_mod.forward)(*args, **kwargs)
File "/home/user/.local/lib/python3.10/site-packages/torch/_dynamo/eval_frame.py", line 211, in _fn
return fn(*args, **kwargs)
File "/home/user/code/bert/models/quantizers.py", line 501, in forward
with torch.cuda.amp.autocast(enabled=False):
File "/home/user/code/bert/models/quantizers.py", line 502, in <graph break in forward>
output = self.quantizer(z.float(), **kwargs)
File "/home/user/.local/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1488, in _call_impl
return forward_call(*args, **kwargs)
File "/home/user/.local/lib/python3.10/site-packages/torch/_dynamo/eval_frame.py", line 329, in catch_errors
return hijacked_callback(frame, cache_size, hooks)
File "/home/user/.local/lib/python3.10/site-packages/torch/_dynamo/convert_frame.py", line 403, in _convert_frame
result = inner_convert(frame, cache_size, hooks)
File "/home/user/.local/lib/python3.10/site-packages/torch/_dynamo/convert_frame.py", line 103, in _fn
return fn(*args, **kwargs)
File "/home/user/.local/lib/python3.10/site-packages/torch/_dynamo/convert_frame.py", line 261, in _convert_frame_assert
return _compile(
File "/home/user/.local/lib/python3.10/site-packages/torch/_dynamo/utils.py", line 162, in time_wrapper
r = func(*args, **kwargs)
File "/home/user/.local/lib/python3.10/site-packages/torch/_dynamo/convert_frame.py", line 323, in _compile
out_code = transform_code_object(code, transform)
File "/home/user/.local/lib/python3.10/site-packages/torch/_dynamo/bytecode_transformation.py", line 339, in transform_code_object
transformations(instructions, code_options)
File "/home/user/.local/lib/python3.10/site-packages/torch/_dynamo/convert_frame.py", line 310, in transform
tracer.run()
File "/home/user/.local/lib/python3.10/site-packages/torch/_dynamo/symbolic_convert.py", line 1715, in run
super().run()
File "/home/user/.local/lib/python3.10/site-packages/torch/_dynamo/symbolic_convert.py", line 564, in run
and self.step()
File "/home/user/.local/lib/python3.10/site-packages/torch/_dynamo/symbolic_convert.py", line 527, in step
getattr(self, inst.opname)(inst)
File "/home/user/.local/lib/python3.10/site-packages/torch/_dynamo/symbolic_convert.py", line 1781, in RETURN_VALUE
self.output.compile_subgraph(self)
File "/home/user/.local/lib/python3.10/site-packages/torch/_dynamo/output_graph.py", line 563, in compile_subgraph
self.compile_and_call_fx_graph(tx, pass2.graph_output_vars(), root)
File "/home/user/.local/lib/python3.10/site-packages/torch/_dynamo/output_graph.py", line 610, in compile_and_call_fx_graph
compiled_fn = self.call_user_compiler(gm)
File "/home/user/.local/lib/python3.10/site-packages/torch/_dynamo/utils.py", line 162, in time_wrapper
r = func(*args, **kwargs)
File "/home/user/.local/lib/python3.10/site-packages/torch/_dynamo/output_graph.py", line 697, in call_user_compiler
raise BackendCompilerFailed(self.compiler_fn, e) from e
torch._dynamo.exc.BackendCompilerFailed: compile_fn raised AttributeError: __torch__.torch.classes.c10d.ProcessGroup (of Python compilation unit at: 0) does not have a field with name 'shape'
While executing %_tensor_constant0 : [#users=1] = get_attr[target=_tensor_constant0]
Original traceback:
None
Set torch._dynamo.config.verbose=True for more information
You can suppress this exception and fall back to eager by setting:
torch._dynamo.config.suppress_errors = True
```
Adding `TORCHDYNAMO_REPRO_AFTER="dynamo"` at the beginning of the command, I got:
```bash
[2023-02-10 16:20:49,259] torch._dynamo.debug_utils: [WARNING] Compiled Fx GraphModule failed. Creating script to minify the error.
[2023-02-10 16:20:49,276] torch._dynamo.debug_utils: [WARNING] Writing minified repro to /home/user/code/bert/torch_compile_debug/run_2023_02_10_16_20_49_261548/minifier/minifier_launcher.py
terminate called after throwing an instance of 'c10::Error'
what(): CUDA error: an illegal memory access was encountered
CUDA kernel errors might be asynchronously reported at some other API call, so the stacktrace below might be incorrect.
For debugging consider passing CUDA_LAUNCH_BLOCKING=1.
Compile with `TORCH_USE_CUDA_DSA` to enable device-side assertions.
Exception raised from c10_cuda_check_implementation at ../c10/cuda/CUDAException.cpp:44 (most recent call first):
frame #0: c10::Error::Error(c10::SourceLocation, std::string) + 0x57 (0x14a3a3ed0b77 in /home/user/.local/lib/python3.10/site-packages/torch/lib/libc10.so)
frame #1: c10::detail::torchCheckFail(char const*, char const*, unsigned int, std::string const&) + 0x64 (0x14a3a3e9a383 in /home/user/.local/lib/python3.10/site-packages/torch/lib/libc10.so)
frame #2: c10::cuda::c10_cuda_check_implementation(int, char const*, char const*, int, bool) + 0x118 (0x14a3a3f7d9e8 in /home/user/.local/lib/python3.10/site-packages/torch/lib/libc10_cuda.so)
frame #3: <unknown function> + 0x10684f5 (0x14a3a50ab4f5 in /home/user/.local/lib/python3.10/site-packages/torch/lib/libtorch_cuda.so)
frame #4: <unknown function> + 0x4cffe6 (0x14a3f94f4fe6 in /home/user/.local/lib/python3.10/site-packages/torch/lib/libtorch_python.so)
frame #5: <unknown function> + 0x3f027 (0x14a3a3eb6027 in /home/user/.local/lib/python3.10/site-packages/torch/lib/libc10.so)
frame #6: c10::TensorImpl::~TensorImpl() + 0x1be (0x14a3a3eae85e in /home/user/.local/lib/python3.10/site-packages/torch/lib/libc10.so)
frame #7: c10::TensorImpl::~TensorImpl() + 0x9 (0x14a3a3eae979 in /home/user/.local/lib/python3.10/site-packages/torch/lib/libc10.so)
frame #8: <unknown function> + 0x755838 (0x14a3f977a838 in /home/user/.local/lib/python3.10/site-packages/torch/lib/libtorch_python.so)
frame #9: THPVariable_subclass_dealloc(_object*) + 0x305 (0x14a3f977abc5 in /home/user/.local/lib/python3.10/site-packages/torch/lib/libtorch_python.so)
frame #10: <unknown function> + 0x121b1b (0x55cc4bd8fb1b in /anaconda//envs/python-3.10.4/bin/python3.10)
frame #11: <unknown function> + 0x12f1ba (0x55cc4bd9d1ba in /anaconda//envs/python-3.10.4/bin/python3.10)
frame #12: <unknown function> + 0x21f97f (0x55cc4be8d97f in /anaconda//envs/python-3.10.4/bin/python3.10)
frame #13: _PyEval_EvalFrameDefault + 0x5db8 (0x55cc4bda7678 in /anaconda//envs/python-3.10.4/bin/python3.10)
frame #14: _PyFunction_Vectorcall + 0x6f (0x55cc4bdb23cf in /anaconda//envs/python-3.10.4/bin/python3.10)
frame #15: PyObject_Call + 0xb8 (0x55cc4bdc0348 in /anaconda//envs/python-3.10.4/bin/python3.10)
frame #16: _PyEval_EvalFrameDefault + 0x2b05 (0x55cc4bda43c5 in /anaconda//envs/python-3.10.4/bin/python3.10)
frame #17: _PyFunction_Vectorcall + 0x6f (0x55cc4bdb23cf in /anaconda//envs/python-3.10.4/bin/python3.10)
frame #18: _PyEval_EvalFrameDefault + 0x1311 (0x55cc4bda2bd1 in /anaconda//envs/python-3.10.4/bin/python3.10)
frame #19: _PyFunction_Vectorcall + 0x6f (0x55cc4bdb23cf in /anaconda//envs/python-3.10.4/bin/python3.10)
frame #20: _PyEval_EvalFrameDefault + 0x30c (0x55cc4bda1bcc in /anaconda//envs/python-3.10.4/bin/python3.10)
frame #21: <unknown function> + 0x1eab92 (0x55cc4be58b92 in /anaconda//envs/python-3.10.4/bin/python3.10)
frame #22: PyEval_EvalCode + 0x87 (0x55cc4be58ad7 in /anaconda//envs/python-3.10.4/bin/python3.10)
frame #23: <unknown function> + 0x21d709 (0x55cc4be8b709 in /anaconda//envs/python-3.10.4/bin/python3.10)
frame #24: <unknown function> + 0x2183f4 (0x55cc4be863f4 in /anaconda//envs/python-3.10.4/bin/python3.10)
frame #25: <unknown function> + 0x982ba (0x55cc4bd062ba in /anaconda//envs/python-3.10.4/bin/python3.10)
frame #26: _PyRun_SimpleFileObject + 0x1af (0x55cc4be805cf in /anaconda//envs/python-3.10.4/bin/python3.10)
frame #27: _PyRun_AnyFileObject + 0x43 (0x55cc4be803a3 in /anaconda//envs/python-3.10.4/bin/python3.10)
frame #28: Py_RunMain + 0x39f (0x55cc4be7d56f in /anaconda//envs/python-3.10.4/bin/python3.10)
frame #29: Py_BytesMain + 0x39 (0x55cc4be4be09 in /anaconda//envs/python-3.10.4/bin/python3.10)
frame #30: __libc_start_main + 0xf3 (0x14a43045dcf3 in /lib64/libc.so.6)
frame #31: <unknown function> + 0x1ddd11 (0x55cc4be4bd11 in /anaconda//envs/python-3.10.4/bin/python3.10)
```
And the minified script is the following:
```python
import os
from math import inf
import torch
from torch import tensor, device
import torch.fx as fx
import functools
import torch._dynamo
from torch._dynamo.debug_utils import run_fwd_maybe_bwd
from torch._dynamo.optimizations.backends import BACKENDS
from torch._dynamo.testing import rand_strided
import torch._dynamo.config
import torch._inductor.config
torch._dynamo.config.load_config(b'\x80\x04\x95\x16\x08\x00\x00\x00\x00\x00\x00}\x94(\x8c\x08__name__\x94\x8c\x14torch._dynamo.config\x94\x8c\x07__doc__\x94N\x8c\x0b__package__\x94\x8c\rtorch._dynamo\x94\x8c\n__loader__\x94\x8c\x1a_frozen_importlib_external\x94\x8c\x10SourceFileLoader\x94\x93\x94)\x81\x94}\x94(\x8c\x04name\x94h\x02\x8c\x04path\x94\x8c[/linkhome/rech/gensak01/ugt86fu/.local/lib/python3.10/site-packages/torch/_dynamo/config.py\x94ub\x8c\x08__spec__\x94\x8c\x11_frozen_importlib\x94\x8c\nModuleSpec\x94\x93\x94)\x81\x94}\x94(h\x0ch\x02\x8c\x06loader\x94h\n\x8c\x06origin\x94h\x0e\x8c\x0cloader_state\x94N\x8c\x1asubmodule_search_locations\x94N\x8c\r_set_fileattr\x94\x88\x8c\x07_cached\x94\x8ct/linkhome/rech/gensak01/ugt86fu/.local/lib/python3.10/site-packages/torch/_dynamo/__pycache__/config.cpython-310.pyc\x94\x8c\r_initializing\x94\x89ub\x8c\x08__file__\x94h\x0e\x8c\n__cached__\x94h\x1b\x8c\x07abspath\x94\x8c\tposixpath\x94h\x1f\x93\x94\x8c\x07dirname\x94h h"\x93\x94\x8c\tlog_level\x94K\x1e\x8c\x0boutput_code\x94\x89\x8c\rlog_file_name\x94N\x8c\x07verbose\x94\x89\x8c\x11output_graph_code\x94\x89\x8c\x12verify_correctness\x94\x89\x8c\x12minimum_call_count\x94K\x01\x8c\x15dead_code_elimination\x94\x88\x8c\x10cache_size_limit\x94K@\x8c\x14specialize_int_float\x94\x88\x8c\x0edynamic_shapes\x94\x89\x8c\x10guard_nn_modules\x94\x89\x8c\x0cnormalize_ir\x94\x89\x8c\x1btraceable_tensor_subclasses\x94\x8f\x94\x8c\x0fsuppress_errors\x94\x89\x8c\x15replay_record_enabled\x94\x89\x8c rewrite_assert_with_torch_assert\x94\x88\x8c\x12print_graph_breaks\x94\x89\x8c\x07disable\x94\x89\x8c*allowed_functions_module_string_ignorelist\x94\x8f\x94(\x8c\x0btorch._refs\x94\x8c\rtorch.testing\x94\x8c\x13torch.distributions\x94\x8c\rtorch._decomp\x94\x8c\x0ctorch._prims\x94\x90\x8c\x0frepro_tolerance\x94G?PbM\xd2\xf1\xa9\xfc\x8c\x16capture_scalar_outputs\x94\x89\x8c\x19enforce_cond_guards_match\x94\x88\x8c\x0coptimize_ddp\x94\x88\x8c\x1araise_on_ctx_manager_usage\x94\x88\x8c\x1craise_on_unsafe_aot_autograd\x94\x89\x8c\rdynamo_import\x94\x8c\rtorch._dynamo\x94\x8c\x0finductor_import\x94\x8c\x0ftorch._inductor\x94\x8c\x18error_on_nested_fx_trace\x94\x88\x8c\tallow_rnn\x94\x89\x8c\x08base_dir\x94\x8cC/linkhome/rech/gensak01/ugt86fu/.local/lib/python3.10/site-packages\x94\x8c\x0edebug_dir_root\x94\x8cJ/gpfsdswork/projects/rech/nph/ugt86fu/code/visionBERT2/torch_compile_debug\x94\x8c)DO_NOT_USE_legacy_non_fake_example_inputs\x94\x89\x8c\x15_AccessLimitingConfig\x94}\x94(\x8c\n__module__\x94h\x02\x8c\x0b__setattr__\x94h\x02\x8c!_AccessLimitingConfig.__setattr__\x94\x93\x94h\x03Nu\x8c\x15_allowed_config_names\x94\x8f\x94(\x8c\x0brepro_after\x94\x8c\x0eexternal_utils\x94h?\x8c\nModuleType\x94h0h)\x8c\x12constant_functions\x94h.hEhOh\x1fh,h/h\x1ehJh%hC\x8c\x0brepro_level\x94hPh\x01h"\x8c\x03sys\x94h8h+hMh*hD\x8c!skipfiles_inline_module_allowlist\x94\x8c\x07logging\x94hIhB\x8c\x02os\x94h5\x8c\x05torch\x94h$\x8c\x0c__builtins__\x94hKh\x06h\x04h@h-h6h1h\'h\x03h7hAh\x1dhGh&h(h\x0fh4h3\x90\x8c\x1cget_config_serialization_fns\x94\x8c\x1atorch._dynamo.config_utils\x94hc\x93\x94u.')
torch._inductor.config.load_config(b'\x80\x04\x95G\t\x00\x00\x00\x00\x00\x00}\x94(\x8c\x08__name__\x94\x8c\x16torch._inductor.config\x94\x8c\x07__doc__\x94N\x8c\x0b__package__\x94\x8c\x0ftorch._inductor\x94\x8c\n__loader__\x94\x8c\x1a_frozen_importlib_external\x94\x8c\x10SourceFileLoader\x94\x93\x94)\x81\x94}\x94(\x8c\x04name\x94h\x02\x8c\x04path\x94\x8c]/linkhome/rech/gensak01/ugt86fu/.local/lib/python3.10/site-packages/torch/_inductor/config.py\x94ub\x8c\x08__spec__\x94\x8c\x11_frozen_importlib\x94\x8c\nModuleSpec\x94\x93\x94)\x81\x94}\x94(h\x0ch\x02\x8c\x06loader\x94h\n\x8c\x06origin\x94h\x0e\x8c\x0cloader_state\x94N\x8c\x1asubmodule_search_locations\x94N\x8c\r_set_fileattr\x94\x88\x8c\x07_cached\x94\x8cv/linkhome/rech/gensak01/ugt86fu/.local/lib/python3.10/site-packages/torch/_inductor/__pycache__/config.cpython-310.pyc\x94\x8c\r_initializing\x94\x89ub\x8c\x08__file__\x94h\x0e\x8c\n__cached__\x94h\x1b\x8c\x05debug\x94\x89\x8c\x10disable_progress\x94\x88\x8c\x10verbose_progress\x94\x89\x8c\x0bcpp_wrapper\x94\x89\x8c\x03dce\x94\x89\x8c\x14static_weight_shapes\x94\x88\x8c\x0csize_asserts\x94\x88\x8c\x10pick_loop_orders\x94\x88\x8c\x0finplace_buffers\x94\x88\x8c\x11benchmark_harness\x94\x88\x8c\x0fepilogue_fusion\x94\x89\x8c\x15epilogue_fusion_first\x94\x89\x8c\x0fpattern_matcher\x94\x88\x8c\nreordering\x94\x89\x8c\x0cmax_autotune\x94\x89\x8c\x17realize_reads_threshold\x94K\x04\x8c\x17realize_bytes_threshold\x94M\xd0\x07\x8c\x1brealize_acc_reads_threshold\x94K\x08\x8c\x0ffallback_random\x94\x89\x8c\x12implicit_fallbacks\x94\x88\x8c\rprefuse_nodes\x94\x88\x8c\x0btune_layout\x94\x89\x8c\x11aggressive_fusion\x94\x89\x8c\x0fmax_fusion_size\x94K@\x8c\x1bunroll_reductions_threshold\x94K\x08\x8c\x0ecomment_origin\x94\x89\x8c\tis_fbcode\x94h\x02h9\x93\x94\x8c\x0fcompile_threads\x94K\n\x8c\x13kernel_name_max_ops\x94K\n\x8c\x0finductor_import\x94\x8c\x0ftorch._inductor\x94\x8c\rshape_padding\x94\x89\x8c\x0epermute_fusion\x94\x89\x8c\x1aprofiler_mark_wrapper_call\x94\x89\x8c\x03cpp\x94}\x94(\x8c\n__module__\x94h\x02\x8c\x07threads\x94J\xff\xff\xff\xff\x8c\x0fdynamic_threads\x94\x89\x8c\x07simdlen\x94N\x8c\x0emin_chunk_size\x94M\x00\x10\x8c\x03cxx\x94N\x8c\x03g++\x94\x86\x94\x8c\x15enable_kernel_profile\x94\x89h\x03Nu\x8c\x06triton\x94}\x94(hDh\x02\x8c\ncudagraphs\x94\x88\x8c\x10debug_sync_graph\x94\x89\x8c\x11debug_sync_kernel\x94\x89\x8c\x0bconvolution\x94\x8c\x04aten\x94\x8c\x0edense_indexing\x94\x89\x8c\tmax_tiles\x94K\x02\x8c\x12autotune_pointwise\x94\x88\x8c tiling_prevents_pointwise_fusion\x94\x88\x8c tiling_prevents_reduction_fusion\x94\x88\x8c\x14ordered_kernel_names\x94\x89\x8c\x18descriptive_kernel_names\x94\x89h\x03Nu\x8c\x05trace\x94}\x94(hDh\x02\x8c\x07enabled\x94\x89\x8c\tdebug_log\x94\x88\x8c\x08info_log\x94\x89\x8c\x08fx_graph\x94\x88\x8c\x14fx_graph_transformed\x94\x88\x8c\rir_pre_fusion\x94\x88\x8c\x0eir_post_fusion\x94\x88\x8c\x0boutput_code\x94\x88\x8c\rgraph_diagram\x94\x89\x8c\x0fcompile_profile\x94\x89\x8c\nupload_tar\x94Nh\x03Nu\x8c\x15InductorConfigContext\x94}\x94(hDh\x02\x8c\x0f__annotations__\x94}\x94(\x8c\rstatic_memory\x94\x8c\x08builtins\x94\x8c\x04bool\x94\x93\x94\x8c\x0ematmul_padding\x94hoh-ho\x8c\x12triton_convolution\x94hm\x8c\x03str\x94\x93\x94\x8c\x17rematerialize_threshold\x94hm\x8c\x03int\x94\x93\x94\x8c\x1brematerialize_acc_threshold\x94hvu\x8c\x05_save\x94h\x02\x8c\x1bInductorConfigContext._save\x94\x93\x94\x8c\x06_apply\x94h\x02\x8c\x1cInductorConfigContext._apply\x94\x93\x94\x8c\x08__init__\x94h\x02\x8c\x1eInductorConfigContext.__init__\x94\x93\x94\x8c\t__enter__\x94h\x02\x8c\x1fInductorConfigContext.__enter__\x94\x93\x94\x8c\x08__exit__\x94h\x02\x8c\x1eInductorConfigContext.__exit__\x94\x93\x94h\x03Nu\x8c\x1cget_config_serialization_fns\x94\x8c\x1atorch._dynamo.config_utils\x94h\x87\x93\x94u.')
# REPLACEABLE COMMENT FOR TESTING PURPOSES
args = [((32, 3, 256, 256), (196608, 65536, 256, 1), torch.float32, 'cuda', False)]
args = [rand_strided(sh, st, dt, dev).requires_grad_(rg) for (sh, st, dt, dev, rg) in args]
from torch.nn import *
class Repro(torch.nn.Module):
def __init__(self):
super().__init__()
self.self_encoder_conv1 = Conv2d(3, 64, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1)).cuda()
self.self_encoder_conv2 = Conv2d(64, 128, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1)).cuda()
def forward(self, x : torch.Tensor):
self_encoder_conv1 = self.self_encoder_conv1(x); x = None
relu = torch.nn.functional.relu(self_encoder_conv1); self_encoder_conv1 = None
self_encoder_conv2 = self.self_encoder_conv2(relu); relu = None
relu_1 = torch.nn.functional.relu(self_encoder_conv2); self_encoder_conv2 = None
return (relu_1,)
mod = Repro()
# Setup debug minifier compiler
torch._dynamo.debug_utils.MINIFIER_SPAWNED = True
compiler_fn = BACKENDS["dynamo_minifier_backend"]
dynamo_minifier_backend = functools.partial(
compiler_fn,
compiler_name="inductor",
)
opt_mod = torch._dynamo.optimize(dynamo_minifier_backend)(mod)
with torch.cuda.amp.autocast(enabled=True):
opt_mod(*args)
```
Please let me know if more information is needed.
### Versions
PyTorch version: 2.0.0.dev20230201+cu117
Is debug build: False
CUDA used to build PyTorch: 11.7
ROCM used to build PyTorch: N/A
OS: Red Hat Enterprise Linux release 8.6 (Ootpa) (x86_64)
GCC version: (GCC) 8.5.0 20210514 (Red Hat 8.5.0-10)
Clang version: Could not collect
CMake version: version 3.25.0
Libc version: glibc-2.28
Python version: 3.10.4 | packaged by conda-forge | (main, Mar 24 2022, 17:38:57) [GCC 10.3.0] (64-bit runtime)
Python platform: Linux-4.18.0-372.36.1.el8_6.x86_64-x86_64-with-glibc2.28
Is CUDA available: True
CUDA runtime version: 11.7.99
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration: GPU 0: Tesla V100-SXM2-16GB
Nvidia driver version: 525.60.13
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 80
On-line CPU(s) list: 0-79
Thread(s) per core: 2
Core(s) per socket: 20
Socket(s): 2
NUMA node(s): 2
Vendor ID: GenuineIntel
CPU family: 6
Model: 85
Model name: Intel(R) Xeon(R) Gold 6248 CPU @ 2.50GHz
Stepping: 7
CPU MHz: 2500.000
CPU max MHz: 3900.0000
CPU min MHz: 1000.0000
BogoMIPS: 5000.00
Virtualization: VT-x
L1d cache: 32K
L1i cache: 32K
L2 cache: 1024K
L3 cache: 28160K
NUMA node0 CPU(s): 0-19,40-59
NUMA node1 CPU(s): 20-39,60-79
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc art arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc cpuid aperfmperf pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid dca sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm 3dnowprefetch cpuid_fault epb cat_l3 cdp_l3 invpcid_single intel_ppin ssbd mba ibrs ibpb stibp ibrs_enhanced tpr_shadow vnmi flexpriority ept vpid ept_ad fsgsbase tsc_adjust bmi1 hle avx2 smep bmi2 erms invpcid rtm cqm mpx rdt_a avx512f avx512dq rdseed adx smap clflushopt clwb intel_pt avx512cd avx512bw avx512vl xsaveopt xsavec xgetbv1 xsaves cqm_llc cqm_occup_llc cqm_mbm_total cqm_mbm_local dtherm ida arat pln pts hwp hwp_act_window hwp_epp hwp_pkg_req pku ospke avx512_vnni md_clear flush_l1d arch_capabilities
Versions of relevant libraries:
[pip3] mypy==0.991
[pip3] mypy-extensions==0.4.3
[pip3] numpy==1.24.0rc2
[pip3] numpydoc==1.2.1
[pip3] pytorch-pfn-extras==0.6.2
[pip3] pytorch-triton==2.0.0+0d7e753227
[pip3] rotary-embedding-torch==0.2.1
[pip3] torch==2.0.0.dev20230201+cu117
[pip3] torchaudio==2.0.0.dev20230201+cu117
[pip3] torchmetrics==0.10.2
[pip3] torchtriton==2.0.0+0d7e753227
[pip3] torchvision==0.15.0.dev20230201+cu117
[conda] numpy 1.21.6 pypi_0 pypi
[conda] numpydoc 1.2.1 pyhd8ed1ab_0 conda-forge
cc @mrshenli @pritamdamania87 @zhaojuanmao @satgera @rohan-varma @gqchen @aazzolini @osalpekar @jiayisuse @H-Huang @kwen2501 @awgu @ezyang @msaroufim @wconstab @ngimel @bdhirsh @anijain2305 @soumith
| 7 |
3,493 | 94,594 |
A segment fault can be triggered in torch.histogramdd
|
module: crash, triaged, module: edge cases
|
### 🐛 Describe the bug
When an empty `bins` is given, a **Segment Fault** can be triggered in `torch.histogramdd`:
````python
import torch
input = torch.rand([2, 3, 13, 15, 16, 1], dtype=torch.float32)
bins = []
range_0 = -11.114022798233492
range_1 = 8.42630999399097
range = [range_0, range_1, ]
weight = torch.rand([4, 10, 1, 1, 15, 14], dtype=torch.float32)
density = True
res = torch.histogramdd(
input=input,
bins=bins,
range=range,
weight=weight,
density=density,
)
````
The output:
````
Segmentation fault (core dumped)
````
### Versions
Collecting environment information...
PyTorch version: 2.0.0.dev20230210+cu118
Is debug build: False
CUDA used to build PyTorch: 11.8
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.5 LTS (x86_64)
GCC version: (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0
Clang version: 11.0.0-2~ubuntu20.04.1
CMake version: version 3.25.0
Libc version: glibc-2.31
Python version: 3.10.6 (main, Oct 24 2022, 16:07:47) [GCC 11.2.0] (64-bit runtime)
Python platform: Linux-5.15.0-57-generic-x86_64-with-glibc2.31
Is CUDA available: True
CUDA runtime version: 11.8.89
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration: GPU 0: Tesla V100-PCIE-16GB
Nvidia driver version: 520.61.05
cuDNN version: Probably one of the following:
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn.so.8.1.1
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_adv_infer.so.8.1.1
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_adv_train.so.8.1.1
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_cnn_infer.so.8.1.1
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_cnn_train.so.8.1.1
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_ops_infer.so.8.1.1
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_ops_train.so.8.1.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn.so.8.2.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn_adv_infer.so.8.2.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn_adv_train.so.8.2.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn_cnn_infer.so.8.2.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn_cnn_train.so.8.2.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn_ops_infer.so.8.2.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn_ops_train.so.8.2.1
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
Address sizes: 46 bits physical, 48 bits virtual
CPU(s): 48
On-line CPU(s) list: 0-47
Thread(s) per core: 2
Core(s) per socket: 12
Socket(s): 2
NUMA node(s): 2
Vendor ID: GenuineIntel
CPU family: 6
Model: 85
Model name: Intel(R) Xeon(R) Silver 4214 CPU @ 2.20GHz
Stepping: 7
CPU MHz: 2200.000
BogoMIPS: 4400.00
Virtualization: VT-x
L1d cache: 768 KiB
L1i cache: 768 KiB
L2 cache: 24 MiB
L3 cache: 33 MiB
NUMA node0 CPU(s): 0-11,24-35
NUMA node1 CPU(s): 12-23,36-47
Vulnerability Itlb multihit: KVM: Mitigation: VMX disabled
Vulnerability L1tf: Not affected
Vulnerability Mds: Not affected
Vulnerability Meltdown: Not affected
Vulnerability Mmio stale data: Mitigation; Clear CPU buffers; SMT vulnerable
Vulnerability Retbleed: Mitigation; Enhanced IBRS
Vulnerability Spec store bypass: Mitigation; Speculative Store Bypass disabled via prctl and seccomp
Vulnerability Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization
Vulnerability Spectre v2: Mitigation; Enhanced IBRS, IBPB conditional, RSB filling, PBRSB-eIBRS SW sequence
Vulnerability Srbds: Not affected
Vulnerability Tsx async abort: Mitigation; TSX disabled
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc art arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc cpuid aperfmperf pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid dca sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm 3dnowprefetch cpuid_fault epb cat_l3 cdp_l3 invpcid_single intel_ppin ssbd mba ibrs ibpb stibp ibrs_enhanced tpr_shadow vnmi flexpriority ept vpid ept_ad fsgsbase tsc_adjust bmi1 avx2 smep bmi2 erms invpcid cqm mpx rdt_a avx512f avx512dq rdseed adx smap clflushopt clwb intel_pt avx512cd avx512bw avx512vl xsaveopt xsavec xgetbv1 xsaves cqm_llc cqm_occup_llc cqm_mbm_total cqm_mbm_local dtherm ida arat pln pts hwp_epp pku ospke avx512_vnni md_clear flush_l1d arch_capabilities
Versions of relevant libraries:
[pip3] numpy==1.23.4
[pip3] pytorch-triton==2.0.0+0d7e753227
[pip3] torch==2.0.0.dev20230210+cu118
[pip3] torchaudio==2.0.0.dev20230209+cu118
[pip3] torchvision==0.15.0.dev20230209+cu118
[conda] numpy 1.23.4 pypi_0 pypi
[conda] pytorch-triton 2.0.0+0d7e753227 pypi_0 pypi
[conda] torch 2.0.0.dev20230210+cu118 pypi_0 pypi
[conda] torchaudio 2.0.0.dev20230209+cu118 pypi_0 pypi
[conda] torchvision 0.15.0.dev20230209+cu118 pypi_0 pypi
| 0 |
3,494 | 94,593 |
Memory corruptions can be triggered in torch._remove_batch_dim
|
triaged, module: vmap
|
### 🐛 Describe the bug
When edge cases are given, different Memory Corruptions can be triggerred in `torch._remove_batch_dim` in torch 1.13 and nightly version.
The following code can trigger an invalid free:
````python
import torch
input = torch.rand([3], dtype=torch.float32)
level = 114
batch_size = 26
out_dim = -9
res = torch._remove_batch_dim(
input=input,
level=level,
batch_size=batch_size,
out_dim=out_dim,
)
````
The output:
````
free(): invalid pointer
Aborted (core dumped)
````
But if `out_dim` is changed from -9 to -18, a segment fault is triggered, the code is as following:
````python
import torch
input = torch.rand([3], dtype=torch.float32)
level = 114
batch_size = 26
out_dim = -18
res = torch._remove_batch_dim(
input=input,
level=level,
batch_size=batch_size,
out_dim=out_dim,
)
````
The output is:
````
Segmentation fault (core dumped)
````
### Versions
Collecting environment information...
PyTorch version: 2.0.0.dev20230210+cu118
Is debug build: False
CUDA used to build PyTorch: 11.8
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.5 LTS (x86_64)
GCC version: (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0
Clang version: 11.0.0-2~ubuntu20.04.1
CMake version: version 3.25.0
Libc version: glibc-2.31
Python version: 3.10.6 (main, Oct 24 2022, 16:07:47) [GCC 11.2.0] (64-bit runtime)
Python platform: Linux-5.15.0-57-generic-x86_64-with-glibc2.31
Is CUDA available: True
CUDA runtime version: 11.8.89
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration: GPU 0: Tesla V100-PCIE-16GB
Nvidia driver version: 520.61.05
cuDNN version: Probably one of the following:
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn.so.8.1.1
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_adv_infer.so.8.1.1
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_adv_train.so.8.1.1
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_cnn_infer.so.8.1.1
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_cnn_train.so.8.1.1
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_ops_infer.so.8.1.1
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_ops_train.so.8.1.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn.so.8.2.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn_adv_infer.so.8.2.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn_adv_train.so.8.2.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn_cnn_infer.so.8.2.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn_cnn_train.so.8.2.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn_ops_infer.so.8.2.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn_ops_train.so.8.2.1
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
Address sizes: 46 bits physical, 48 bits virtual
CPU(s): 48
On-line CPU(s) list: 0-47
Thread(s) per core: 2
Core(s) per socket: 12
Socket(s): 2
NUMA node(s): 2
Vendor ID: GenuineIntel
CPU family: 6
Model: 85
Model name: Intel(R) Xeon(R) Silver 4214 CPU @ 2.20GHz
Stepping: 7
CPU MHz: 2200.000
BogoMIPS: 4400.00
Virtualization: VT-x
L1d cache: 768 KiB
L1i cache: 768 KiB
L2 cache: 24 MiB
L3 cache: 33 MiB
NUMA node0 CPU(s): 0-11,24-35
NUMA node1 CPU(s): 12-23,36-47
Vulnerability Itlb multihit: KVM: Mitigation: VMX disabled
Vulnerability L1tf: Not affected
Vulnerability Mds: Not affected
Vulnerability Meltdown: Not affected
Vulnerability Mmio stale data: Mitigation; Clear CPU buffers; SMT vulnerable
Vulnerability Retbleed: Mitigation; Enhanced IBRS
Vulnerability Spec store bypass: Mitigation; Speculative Store Bypass disabled via prctl and seccomp
Vulnerability Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization
Vulnerability Spectre v2: Mitigation; Enhanced IBRS, IBPB conditional, RSB filling, PBRSB-eIBRS SW sequence
Vulnerability Srbds: Not affected
Vulnerability Tsx async abort: Mitigation; TSX disabled
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc art arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc cpuid aperfmperf pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid dca sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm 3dnowprefetch cpuid_fault epb cat_l3 cdp_l3 invpcid_single intel_ppin ssbd mba ibrs ibpb stibp ibrs_enhanced tpr_shadow vnmi flexpriority ept vpid ept_ad fsgsbase tsc_adjust bmi1 avx2 smep bmi2 erms invpcid cqm mpx rdt_a avx512f avx512dq rdseed adx smap clflushopt clwb intel_pt avx512cd avx512bw avx512vl xsaveopt xsavec xgetbv1 xsaves cqm_llc cqm_occup_llc cqm_mbm_total cqm_mbm_local dtherm ida arat pln pts hwp_epp pku ospke avx512_vnni md_clear flush_l1d arch_capabilities
Versions of relevant libraries:
[pip3] numpy==1.23.4
[pip3] pytorch-triton==2.0.0+0d7e753227
[pip3] torch==2.0.0.dev20230210+cu118
[pip3] torchaudio==2.0.0.dev20230209+cu118
[pip3] torchvision==0.15.0.dev20230209+cu118
[conda] numpy 1.23.4 pypi_0 pypi
[conda] pytorch-triton 2.0.0+0d7e753227 pypi_0 pypi
[conda] torch 2.0.0.dev20230210+cu118 pypi_0 pypi
[conda] torchaudio 2.0.0.dev20230209+cu118 pypi_0 pypi
[conda] torchvision 0.15.0.dev20230209+cu118 pypi_0 pypi
cc @zou3519
| 1 |
3,495 | 94,591 |
Issue with `upsample_nearest2d` decomposition
|
triaged, module: decompositions
|
### 🐛 Describe the bug
After the decomposition of `upsample_nearest2d` getting updated here: https://github.com/pytorch/pytorch/commit/8ecda19607a819d0387341b6c2d31d29e05a33ab, it results out in invalid index accesses. For example. consider the following case, where both the PyTorch implementation of the op and decomp are used:
```
import torch
from typing import Callable, cast, Iterable, List, Optional, Tuple, Union
from torch import sym_float, sym_int, Tensor
import torch._prims_common as utils
def _compute_upsample_nearest_indices(input, output_size, scales):
# For each dim in output_size, compute the set of input indices used
# to produce the upsampled output.
indices = []
num_spatial_dims = len(output_size)
for d in range(num_spatial_dims):
# Math matches aten/src/ATen/native/cpu/UpSampleKernel.cpp
# Indices are computed as following:
# scale = isize / osize
# input_index = floor(output_index * scale)
# Same as OpenCV INTER_NEAREST
osize = output_size[d]
output_indices = torch.arange(osize, dtype=input.dtype, device=input.device)
isize = input.shape[-num_spatial_dims + d]
scale = isize / (isize * scales[d]) if scales[d] is not None else isize / osize
input_indices = (output_indices * scale).to(torch.int64)
for _ in range(num_spatial_dims - 1 - d):
input_indices = input_indices.unsqueeze(-1)
indices.append(input_indices)
return tuple(indices)
def upsample_nearest2d(
input: Tensor,
output_size: List[int],
scales_h: Optional[float] = None,
scales_w: Optional[float] = None,
) -> Tensor:
h_indices, w_indices = _compute_upsample_nearest_indices(
input, output_size, (scales_h, scales_w)
)
result = input[:, :, h_indices, w_indices]
# convert output to correct memory format, if necessary
memory_format = utils.suggest_memory_format(input)
# following "heuristic: only use channels_last path when it's faster than the contiguous path"
_, n_channels, _, _ = input.shape
if input.device.type == "cuda" and n_channels < 4:
memory_format = torch.contiguous_format
result = result.contiguous(memory_format=memory_format)
return result
inputVec = torch.rand((2, 3, 2, 2))
out_torch = torch._C._nn.upsample_nearest2d(
inputVec, output_size=[6, 10], scales_h=2.3, scales_w=4.7
)
out_decomp = upsample_nearest2d(
inputVec, output_size=[6, 10], scales_h=2.3, scales_w=4.7
)
print(out_torch == out_decomp)
```
If you run this code the decomp will give the following error:
```
Traceback (most recent call last):
File "/home/vivek/work/misc/vivekkhandelwal1-pytorch/upsample_nearest2d.py", line 58, in <module>
out_decomp = upsample_nearest2d(
File "/home/vivek/work/misc/vivekkhandelwal1-pytorch/upsample_nearest2d.py", line 38, in upsample_nearest2d
result = input[:, :, h_indices, w_indices]
IndexError: index 2 is out of bounds for dimension 0 with size 2
```
If we revert the changes made at this line (https://github.com/pytorch/pytorch/blob/8ecda19607a819d0387341b6c2d31d29e05a33ab/torch/_decomp/decompositions.py#L2059) particularly, then it works fine.
### Versions
PyTorch version: 2.0.0a0+gitf58ba55
Is debug build: False
CUDA used to build PyTorch: 11.6
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.5 LTS (x86_64)
GCC version: (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0
Clang version: 10.0.0-4ubuntu1
CMake version: version 3.25.0
Libc version: glibc-2.31
Python version: 3.10.9 (main, Dec 7 2022, 01:12:00) [GCC 9.4.0] (64-bit runtime)
Python platform: Linux-5.15.0-56-generic-x86_64-with-glibc2.31
Is CUDA available: True
CUDA runtime version: 11.6.55
GPU models and configuration: GPU 0: NVIDIA GeForce RTX 3090
Nvidia driver version: 470.161.03
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_infer.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.4.1
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] mypy-extensions==0.4.3
[pip3] numpy==1.24.1
[pip3] torch==2.0.0a0+gitf58ba55
[conda] Could not collect
cc @SherlockNoMad @ngimel
| 3 |
3,496 | 94,590 |
A Segment Fault can be triggered in torch.affine_grid_generator
|
triaged, module: edge cases
|
### 🐛 Describe the bug
The following code can triger a **Segment Fault** in `torch.affine_grid_generator` in both nightly version and 1.13.0:
````python
import torch
theta = torch.rand([4, 0, 3508594129291644243, 1, 12, 9], dtype=torch.float32)
size = [21, 6, 34, 108]
align_corners = True
res = torch.affine_grid_generator(
theta=theta,
size=size,
align_corners=align_corners,
)
````
The output:
````
Segmentation fault (core dumped)
````
### Versions
Collecting environment information...
PyTorch version: 2.0.0.dev20230210+cu118
Is debug build: False
CUDA used to build PyTorch: 11.8
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.5 LTS (x86_64)
GCC version: (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0
Clang version: 11.0.0-2~ubuntu20.04.1
CMake version: version 3.25.0
Libc version: glibc-2.31
Python version: 3.10.6 (main, Oct 24 2022, 16:07:47) [GCC 11.2.0] (64-bit runtime)
Python platform: Linux-5.15.0-57-generic-x86_64-with-glibc2.31
Is CUDA available: True
CUDA runtime version: 11.8.89
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration: GPU 0: Tesla V100-PCIE-16GB
Nvidia driver version: 520.61.05
cuDNN version: Probably one of the following:
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn.so.8.1.1
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_adv_infer.so.8.1.1
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_adv_train.so.8.1.1
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_cnn_infer.so.8.1.1
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_cnn_train.so.8.1.1
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_ops_infer.so.8.1.1
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_ops_train.so.8.1.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn.so.8.2.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn_adv_infer.so.8.2.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn_adv_train.so.8.2.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn_cnn_infer.so.8.2.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn_cnn_train.so.8.2.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn_ops_infer.so.8.2.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn_ops_train.so.8.2.1
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
Address sizes: 46 bits physical, 48 bits virtual
CPU(s): 48
On-line CPU(s) list: 0-47
Thread(s) per core: 2
Core(s) per socket: 12
Socket(s): 2
NUMA node(s): 2
Vendor ID: GenuineIntel
CPU family: 6
Model: 85
Model name: Intel(R) Xeon(R) Silver 4214 CPU @ 2.20GHz
Stepping: 7
CPU MHz: 2200.000
BogoMIPS: 4400.00
Virtualization: VT-x
L1d cache: 768 KiB
L1i cache: 768 KiB
L2 cache: 24 MiB
L3 cache: 33 MiB
NUMA node0 CPU(s): 0-11,24-35
NUMA node1 CPU(s): 12-23,36-47
Vulnerability Itlb multihit: KVM: Mitigation: VMX disabled
Vulnerability L1tf: Not affected
Vulnerability Mds: Not affected
Vulnerability Meltdown: Not affected
Vulnerability Mmio stale data: Mitigation; Clear CPU buffers; SMT vulnerable
Vulnerability Retbleed: Mitigation; Enhanced IBRS
Vulnerability Spec store bypass: Mitigation; Speculative Store Bypass disabled via prctl and seccomp
Vulnerability Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization
Vulnerability Spectre v2: Mitigation; Enhanced IBRS, IBPB conditional, RSB filling, PBRSB-eIBRS SW sequence
Vulnerability Srbds: Not affected
Vulnerability Tsx async abort: Mitigation; TSX disabled
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc art arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc cpuid aperfmperf pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid dca sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm 3dnowprefetch cpuid_fault epb cat_l3 cdp_l3 invpcid_single intel_ppin ssbd mba ibrs ibpb stibp ibrs_enhanced tpr_shadow vnmi flexpriority ept vpid ept_ad fsgsbase tsc_adjust bmi1 avx2 smep bmi2 erms invpcid cqm mpx rdt_a avx512f avx512dq rdseed adx smap clflushopt clwb intel_pt avx512cd avx512bw avx512vl xsaveopt xsavec xgetbv1 xsaves cqm_llc cqm_occup_llc cqm_mbm_total cqm_mbm_local dtherm ida arat pln pts hwp_epp pku ospke avx512_vnni md_clear flush_l1d arch_capabilities
Versions of relevant libraries:
[pip3] numpy==1.23.4
[pip3] pytorch-triton==2.0.0+0d7e753227
[pip3] torch==2.0.0.dev20230210+cu118
[pip3] torchaudio==2.0.0.dev20230209+cu118
[pip3] torchvision==0.15.0.dev20230209+cu118
[conda] numpy 1.23.4 pypi_0 pypi
[conda] pytorch-triton 2.0.0+0d7e753227 pypi_0 pypi
[conda] torch 2.0.0.dev20230210+cu118 pypi_0 pypi
[conda] torchaudio 2.0.0.dev20230209+cu118 pypi_0 pypi
[conda] torchvision 0.15.0.dev20230209+cu118 pypi_0 pypi
| 0 |
3,497 | 94,586 |
`permute` for named tensors
|
triaged, module: named tensor
|
### 🚀 The feature, motivation and pitch
I called `tensor.permute(...)` and got:
> RuntimeError: aten::permute is not yet supported with named tensors. Please drop names via `tensor = tensor.rename(None)`, call the op with an unnamed tensor, and set names on the result of the operation.
I really would have expected that named tensors would work for such a fundamental low-level function, esp since named tensors have been around for many years now. Are they actually used? (#60832)
### Alternatives
_No response_
### Additional context
_No response_
cc @zou3519
| 1 |
3,498 | 94,575 |
[Dynamo] Key Mismatch When Loading Checkpoints Trained with Dynamo
|
high priority, module: serialization, triaged, oncall: pt2, module: dynamo
|
### 🐛 Describe the bug
We find that the state key of a model trained with TorchDynamo and TorchInductor changed. More specifically, the original model has a state key like `model.param` while a model trained with TorchDynamo has a state key like `model._orig_mod.param`. This can be an issue when someone else is trying to load the checkpoint, and it is even worse if the one loading the checkpoint doesn't perform strict state key check.
One might argue that it's the user's responsibility to save the checkpoint with `model._orig_mod` instead of `model`. But as the name with leading underscore `_orig_mod` suggested, I think the user shouldn't care about which model he is trying to save. Instead, I'd suggest removing the key `_orig_mod` inside PyTorch when loading the checkpoint.
Here's a minaml example to reproduce the issue:
```python
#!/usr/bin/env python
import torch
from torch._dynamo import optimize
torch.manual_seed(0)
class Model(torch.nn.Module):
def __init__(self, channels):
super(Model, self).__init__()
self.layers = torch.nn.Sequential(
torch.nn.Conv2d(channels, channels, 1),
torch.nn.ReLU(),
torch.nn.Conv2d(channels, channels, 1),
torch.nn.ReLU(),
)
def forward(self, x):
return self.layers(x)
n, c, h, w = 8, 640, 16, 16
x = torch.randn((n, c, h, w))
model = Model(c)
jit_model = optimize("inductor")(model)
jit_model(x)
torch.save(jit_model.state_dict(), "model.pt")
# Someone else is trying to load the checkpoint
model = Model(c)
model.load_state_dict(torch.load("model.pt"))
```
The error message I got:
```console
$ python bug.py
Traceback (most recent call last):
File "bug-5.py", line 31, in <module>
model.load_state_dict(torch.load("model.pt"))
File "/usr/local/lib/python3.8/dist-packages/torch/nn/modules/module.py", line 2001, in load_state_dict
raise RuntimeError('Error(s) in loading state_dict for {}:\n\t{}'.format(
RuntimeError: Error(s) in loading state_dict for Model:
Missing key(s) in state_dict: "layers.0.weight", "layers.0.bias", "layers.2.weight", "layers.2.bias".
Unexpected key(s) in state_dict: "_orig_mod.layers.0.weight", "_orig_mod.layers.0.bias", "_orig_mod.layers.2.weight", "_orig_mod.layers.2.bias".
```
### Versions
```text
Collecting environment information... [34/17196]
PyTorch version: 1.14.0a0+44dac51
Is debug build: False
CUDA used to build PyTorch: 12.0
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.5 LTS (x86_64)
GCC version: (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0
Clang version: Could not collect
CMake version: version 3.24.1
Libc version: glibc-2.31
Python version: 3.8.10 (default, Nov 14 2022, 12:59:47) [GCC 9.4.0] (64-bit runtime)
Python platform: Linux-5.4.0-99-generic-x86_64-with-glibc2.29
Is CUDA available: True
CUDA runtime version: 12.0.140
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration: GPU 0: NVIDIA A100-SXM4-80GB
Nvidia driver version: 515.65.01
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.7.0
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.7.0
/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.7.0
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_infer.so.8.7.0
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.7.0
/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.7.0
/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.7.0
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
Address sizes: 43 bits physical, 48 bits virtual
CPU(s): 128
On-line CPU(s) list: 0-127
Thread(s) per core: 1
Core(s) per socket: 64
Socket(s): 2
NUMA node(s): 8
Vendor ID: AuthenticAMD
CPU family: 23
Model: 49
Model name: AMD EPYC 7742 64-Core Processor
Stepping: 0
Frequency boost: enabled
CPU MHz: 3087.518
CPU max MHz: 2250.0000
CPU min MHz: 1500.0000
BogoMIPS: 4491.73
Virtualization: AMD-V
L1d cache: 4 MiB
L1i cache: 4 MiB
L2 cache: 64 MiB
L3 cache: 512 MiB
NUMA node0 CPU(s): 0-15
NUMA node1 CPU(s): 16-31
NUMA node2 CPU(s): 32-47
NUMA node3 CPU(s): 48-63
NUMA node4 CPU(s): 64-79
NUMA node5 CPU(s): 80-95
NUMA node6 CPU(s): 96-111
NUMA node7 CPU(s): 112-127
Vulnerability Itlb multihit: Not affected
Vulnerability L1tf: Not affected
Vulnerability Mds: Not affected
Vulnerability Meltdown: Not affected
Vulnerability Spec store bypass: Mitigation; Speculative Store Bypass disabled via prctl
Vulnerability Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization
Vulnerability Spectre v2: Vulnerable, IBPB: disabled, STIBP: disabled
Vulnerability Srbds: Not affected
Vulnerability Tsx async abort: Not affected
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ht syscall nx mmxext fxsr_opt pdpe1gb rdtscp lm constant_tsc rep_good nopl nonst
op_tsc cpuid extd_apicid aperfmperf pni pclmulqdq monitor ssse3 fma cx16 sse4_1 sse4_2 movbe popcnt aes xsave avx f16c rdrand lahf_lm cmp_legacy svm extapic cr8_legacy abm sse4a misalignsse 3dnowprefetch osvw ib
s skinit wdt tce topoext perfctr_core perfctr_nb bpext perfctr_llc mwaitx cpb cat_l3 cdp_l3 hw_pstate sme ssbd mba sev ibrs ibpb stibp vmmcall fsgsbase bmi1 avx2 smep bmi2 cqm rdt_a rdseed adx smap clflushopt cl
wb sha_ni xsaveopt xsavec xgetbv1 xsaves cqm_llc cqm_occup_llc cqm_mbm_total cqm_mbm_local clzero irperf xsaveerptr wbnoinvd arat npt lbrv svm_lock nrip_save tsc_scale vmcb_clean flushbyasid decodeassists pausef
ilter pfthreshold avic v_vmsave_vmload vgif umip rdpid overflow_recov succor smca
Versions of relevant libraries:
[pip3] numpy==1.22.2
[pip3] pytorch-quantization==2.1.2
[pip3] torch==1.14.0a0+44dac51
[pip3] torch-tensorrt==1.4.0.dev0
[pip3] torchtext==0.13.0a0+fae8e8c
[pip3] torchvision==0.15.0a0
[conda] Could not collect
```
cc @ezyang @gchanan @zou3519 @mruberry @soumith @msaroufim @wconstab @ngimel @bdhirsh @voznesenskym @penguinwu @anijain2305 @EikanWang @jgong5 @Guobing-Chen @XiaobingSuper @zhuhaozhe @blzheng @Xia-Weiwen @wenzhe-nrv @jiayisunx @desertfire @mlazos @yanboliang
| 3 |
3,499 | 94,544 |
Abort Caused by Virtual Function
|
module: build, triaged, module: regression
|
### 🐛 Describe the bug
`Abort` happens when PyTorch releasing its resources (i.e., when Python terminates) in
```cpp
struct TORCH_API OperatorKernel : public c10::intrusive_ptr_target {
- // Abort triggered.
- ~OperatorKernel() override = default;
+ // Old thing works well.
+ virtual ~OperatorKernel() = default;
};
```
After reverting `f172feae0d6e6e510d2133ed10dd76dbcaf0f0fe` (#93069), it works again. My build command is `DEBUG=1 VERBOSE=1 USE_KINETO=0 TORCH_CUDA_ARCH_LIST="7.0;7.2" PATH=/cuda-11.8/lib64:/cuda-11.8/include:/cuda-11.8/bin:$PATH CUDACXX=/cuda-11.8/bin/nvcc ONNX_NAMESPACE=onnx1 BUILD_SHARED_LIBS=1 BUILD_CAFFE2=0 BUILD_CAFFE2_OPS=0 USE_GLOO=1 USE_NCCL=0 USE_NUMPY=1 USE_OBSERVERS=1 USE_OPENMP=1 USE_DISTRIBUTED=1 USE_MPI=1 BUILD_PYTHON=1 USE_MKLDNN=0 USE_CUDA=1 BUILD_TEST=1 USE_FBGEMM=1 USE_NNPACK=1 USE_QNNPACK=0 USE_XNNPACK=1 python3 setup.py develop 2>&1 | tee build.log`.
### Versions
Latest master branch.
cc @malfet @seemethere
| 3 |
3,500 | 94,542 |
torch.lgamma CUDA driver error
|
needs reproduction, triaged, module: special
|
### 🐛 Describe the bug
I have Pytorch 1.13.1 with cuda 11.7 and NVIDIA drivers 515.65.01 on a Titan V GPU. The following code
```
import torch
x = torch.tensor(5, device="cuda")
torch.lgamma(x)
```
produces the error: `RuntimeError: CUDA driver error: invalid argument`. The same code works fine if the tensor is on the CPU instead of cuda. How do I fix this?
### Versions
Collecting environment information...
PyTorch version: 1.13.1+cu117
Is debug build: False
CUDA used to build PyTorch: 11.7
ROCM used to build PyTorch: N/A
OS: Ubuntu 18.04.6 LTS (x86_64)
GCC version: (Ubuntu 7.5.0-3ubuntu1~18.04) 7.5.0
Clang version: 6.0.0-1ubuntu2 (tags/RELEASE_600/final)
CMake version: version 3.10.2
Libc version: glibc-2.27
Python version: 3.10.4 (main, Mar 31 2022, 08:41:55) [GCC 7.5.0] (64-bit runtime)
Python platform: Linux-4.15.0-204-generic-x86_64-with-glibc2.27
Is CUDA available: True
CUDA runtime version: 8.0.61
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration: GPU 0: NVIDIA TITAN V
Nvidia driver version: 515.65.01
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.5.1.10
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.0.5
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.0.5
/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.0.5
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_infer.so.8.0.5
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.0.5
/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.0.5
/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.0.5
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 40
On-line CPU(s) list: 0-39
Thread(s) per core: 2
Core(s) per socket: 10
Socket(s): 2
NUMA node(s): 2
Vendor ID: GenuineIntel
CPU family: 6
Model: 85
Model name: Intel(R) Xeon(R) Gold 5215 CPU @ 2.50GHz
Stepping: 7
CPU MHz: 1316.888
CPU max MHz: 2501.0000
CPU min MHz: 1000.0000
BogoMIPS: 5000.00
Virtualization: VT-x
L1d cache: 32K
L1i cache: 32K
L2 cache: 1024K
L3 cache: 14080K
NUMA node0 CPU(s): 0-9,20-29
NUMA node1 CPU(s): 10-19,30-39
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc art arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc cpuid ape
rfmperf pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid dca sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm 3dnowprefetch cpuid_fault epb cat_l3 cdp_l3 invpcid_single intel
_ppin ssbd mba ibrs ibpb stibp ibrs_enhanced tpr_shadow vnmi flexpriority ept vpid fsgsbase tsc_adjust bmi1 avx2 smep bmi2 erms invpcid cqm mpx rdt_a avx512f avx512dq rdseed adx smap clflushopt clwb intel_pt avx512cd avx512bw avx512vl xsaveopt xsavec xge
tbv1 xsaves cqm_llc cqm_occup_llc cqm_mbm_total cqm_mbm_local dtherm ida arat pln pts pku ospke avx512_vnni md_clear flush_l1d arch_capabilities
Versions of relevant libraries:
[pip3] numpy==1.24.2
[pip3] torch==1.13.1
[pip3] torchtext==0.14.1
[conda] numpy 1.24.2 pypi_0 pypi
[conda] torch 1.13.1 pypi_0 pypi
[conda] torchtext 0.14.1 pypi_0 pypi
cc @mruberry @kshitij12345
| 2 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.