
Serial Number
int64 1
6k
| Issue Number
int64 75.6k
112k
| Title
stringlengths 3
357
| Labels
stringlengths 3
241
⌀ | Body
stringlengths 9
74.5k
⌀ | Comments
int64 0
867
|
|---|---|---|---|---|---|
3,601 | 93,358 |
Minifier launcher incorrectly runs backwards even when original reproducer didn't run backwards
|
triaged, oncall: pt2
|
### 🐛 Describe the bug
The launch script looks like
```
torch._dynamo.debug_utils.MINIFIER_SPAWNED = True
compiler_fn = BACKENDS["dynamo_accuracy_minifier_backend"]
dynamo_minifier_backend = functools.partial(
compiler_fn,
compiler_name="inductor",
)
opt_mod = torch._dynamo.optimize(dynamo_minifier_backend)(mod)
with torch.cuda.amp.autocast(enabled=False):
opt_mod(*args)
```
This calls
```
@register_backend
def dynamo_accuracy_minifier_backend(gm, example_inputs, compiler_name):
from functorch.compile import minifier
from torch._dynamo.optimizations.backends import BACKENDS
if compiler_name == "inductor":
from torch._inductor.compile_fx import compile_fx
compiler_fn = compile_fx
else:
compiler_fn = BACKENDS[compiler_name]
# Set the eval mode to remove randomness.
gm.eval()
# Check Accuracy
if backend_accuracy_fails(gm, example_inputs, compiler_fn):
```
backend_accuracy_fails is not passed `only_fwd`.
### Versions
master
cc @soumith @msaroufim @wconstab @ngimel @bdhirsh
| 1 |
3,602 | 93,354 |
minifier_launcher.py silently swallows "ran into runtime exception which is likely an unrelated an issue" warnings
|
triaged, oncall: pt2
|
### 🐛 Describe the bug
Sometimes, minifier launcher complains that "Input graph did not fail the tester". But in fact, there was just a problem in the minifier infrastructure code itself. However, minifier runs are done in a subprocess, and the stdout/stderr is piped to a file, so you can't see a message like this:
```
(/home/ezyang/local/b/pytorch-env) [ezyang@devgpu020.ftw1 ~/local/b/pytorch (4162c7e9)]$ python /data/users/ezyang/b/pytorch/torch_compile_debug/run_2023_01_30_14_12_59_772449/minifier/minifier_launcher.py
While minifying the program in accuracy minification mode,ran into a runtime exception which is likely an unrelated issue. Skipping this graph
Traceback (most recent call last):
File "/data/users/ezyang/b/pytorch/torch/_dynamo/debug_utils.py", line 881, in backend_accuracy_fails
compiled_gm = compiler_fn(copy.deepcopy(gm), clone_inputs(example_inputs))
File "/home/ezyang/local/b/pytorch-env/lib/python3.9/copy.py", line 153, in deepcopy
y = copier(memo)
File "/data/users/ezyang/b/pytorch/torch/fx/graph_module.py", line 708, in __deepcopy__
fake_mod.__dict__ = copy.deepcopy(self.__dict__, memo)
File "/home/ezyang/local/b/pytorch-env/lib/python3.9/copy.py", line 146, in deepcopy
y = copier(x, memo)
File "/home/ezyang/local/b/pytorch-env/lib/python3.9/copy.py", line 230, in _deepcopy_dict
y[deepcopy(key, memo)] = deepcopy(value, memo)
File "/home/ezyang/local/b/pytorch-env/lib/python3.9/copy.py", line 172, in deepcopy
y = _reconstruct(x, memo, *rv)
File "/home/ezyang/local/b/pytorch-env/lib/python3.9/copy.py", line 270, in _reconstruct
state = deepcopy(state, memo)
File "/home/ezyang/local/b/pytorch-env/lib/python3.9/copy.py", line 146, in deepcopy
y = copier(x, memo)
File "/home/ezyang/local/b/pytorch-env/lib/python3.9/copy.py", line 230, in _deepcopy_dict
y[deepcopy(key, memo)] = deepcopy(value, memo)
File "/home/ezyang/local/b/pytorch-env/lib/python3.9/copy.py", line 161, in deepcopy
rv = reductor(4)
TypeError: cannot pickle '_thread._local' object
Traceback (most recent call last):
File "/data/users/ezyang/b/pytorch/torch_compile_debug/run_2023_01_30_14_12_59_772449/minifier/minifier_launcher.py", line 517, in <module>
minifier(
File "/data/users/ezyang/b/pytorch/torch/_functorch/fx_minifier.py", line 97, in minifier
raise RuntimeError("Input graph did not fail the tester")
RuntimeError: Input graph did not fail the tester
```
This is bad and makes it seem like there was something wrong with the minified example, when there actually was something wrong with the minifier.
### Versions
master
cc @soumith @msaroufim @wconstab @ngimel @bdhirsh
| 0 |
3,603 | 93,350 |
Tensorboard SummaryWriter with cloud storage does not work on Mac
|
oncall: visualization
|
### 🐛 Describe the bug
I have been trying to use google cloud storage with the Tensorboard logger in pytorch lightning, but it seems to do incomplete writes. I created an example using SummaryWriter that produces the same results.
I have been able to confirm this is working fine on linux.
I am aware that underlying this may not be pytorch issue, but haven't been able to isolate the tensorboard logic, nor have I been able to setup tensorflow on mac to test this. I would appreciate some help with isolating the issue further if the issue is in tensorboard or another library.
Dependencies:
`pip install tensorboard torch gcsfs numpy`
```python
import numpy as np
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter("gs://test-bucket-124/summary_writer_test/")
r = 5
for i in range(100):
writer.add_scalars('run_14h', {'xsinx':i*np.sin(i/r),
'xcosx':i*np.cos(i/r),
'tanx': np.tan(i/r)}, i)
writer.close()
```
Open tensorboard:
`tensorboard --logdir gs://test-bucket-124/summary_writer_test/`
Result:
<img width="391" alt="Screenshot 2023-01-31 at 10 55 48" src="https://user-images.githubusercontent.com/1589858/215727823-85af3574-a01f-411a-8a07-447011aeeb32.png">
Expected:
<img width="378" alt="Screenshot 2023-01-31 at 10 59 04" src="https://user-images.githubusercontent.com/1589858/215728501-e761a0d1-043b-4686-8920-fb11b19e3d0e.png">
### Versions
Collecting environment information...
PyTorch version: 1.13.1
Is debug build: False
CUDA used to build PyTorch: None
ROCM used to build PyTorch: N/A
OS: macOS 13.0.1 (arm64)
GCC version: Could not collect
Clang version: 14.0.0 (clang-1400.0.29.202)
CMake version: Could not collect
Libc version: N/A
Python version: 3.10.9 (main, Dec 15 2022, 17:11:09) [Clang 14.0.0 (clang-1400.0.29.202)] (64-bit runtime)
Python platform: macOS-13.0.1-arm64-arm-64bit
Is CUDA available: False
CUDA runtime version: No CUDA
CUDA_MODULE_LOADING set to: N/A
GPU models and configuration: No CUDA
Nvidia driver version: No CUDA
cuDNN version: No CUDA
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.24.1
[pip3] torch==1.13.1
[conda] efficientnet-pytorch 0.7.1 pypi_0 pypi
[conda] numpy 1.22.4 pypi_0 pypi
[conda] numpy-base 1.21.5 py39hadd41eb_3
[conda] pytorch-lightning 1.9.0 pypi_0 pypi
[conda] pytorch-sphinx-theme 0.0.24 dev_0 <develop>
[conda] segmentation-models-pytorch 0.3.1 pypi_0 pypi
[conda] torch 1.13.0 pypi_0 pypi
[conda] torchaudio 0.13.1 py39_cpu pytorch
[conda] torchdata 0.5.0 pypi_0 pypi
[conda] torchmetrics 0.9.3 pypi_0 pypi
[conda] torchtext 0.14.0 pypi_0 pypi
[conda] torchvision 0.13.1 pypi_0 pypi
[conda] torchx 0.3.0 pypi_0 pypi
| 0 |
3,604 | 93,347 |
when I want to use a new backend, how to deal with the op with 'device' argument?
|
triaged, module: backend
|
### 🐛 Describe the bug
Hi
I saw the generated code in python_torch_functionsEverything.cpp line 4763, there are so many tricks for the op with 'device' argument, such as init CUDA device, `torch::utils::maybe_initialize_cuda(options);`
```
static PyObject * THPVariable_arange(PyObject* self_, PyObject* args, PyObject* kwargs)
{
HANDLE_TH_ERRORS
static PythonArgParser parser({
"arange(Scalar end, *, Tensor out=None, ScalarType? dtype=None, Layout? layout=None, Device? device=None, bool? pin_memory=False, bool? requires_grad=False)",
"arange(Scalar start, Scalar end, *, ScalarType? dtype=None, Layout? layout=None, Device? device=None, bool? pin_memory=False, bool? requires_grad=False)",
"arange(Scalar start, Scalar end, Scalar step=1, *, Tensor out=None, ScalarType? dtype=None, Layout? layout=None, Device? device=None, bool? pin_memory=False, bool? requires_grad=False)",
}, /*traceable=*/true);
ParsedArgs<9> parsed_args;
auto _r = parser.parse(nullptr, args, kwargs, parsed_args);
if(_r.has_torch_function()) {
return handle_torch_function(_r, nullptr, args, kwargs, THPVariableFunctionsModule, "torch");
}
switch (_r.idx) {
case 0: {
if (_r.isNone(1)) {
// aten::arange(Scalar end, *, ScalarType? dtype=None, Layout? layout=None, Device? device=None, bool? pin_memory=None) -> Tensor
const auto options = TensorOptions()
.dtype(_r.scalartypeOptional(2))
.device(_r.deviceWithDefault(4, torch::tensors::get_default_device()))
.layout(_r.layoutOptional(3))
.requires_grad(_r.toBool(6))
.pinned_memory(_r.toBool(5));
torch::utils::maybe_initialize_cuda(options);
```
when I want to use a new backend which also need to init like CUDA, so I want to add some code to make my backend running fine, It is that ok ?
thanks.
### Versions
new backend
python:3.7.5
pytorch: 2.0.0
CUDA: None
| 1 |
3,605 | 93,346 |
Quantized Transformer ONNX Export Fails
|
module: onnx, oncall: quantization, triaged
|
### 🐛 Describe the bug
I am trying to export the torch-native PTQ model using the timm repo. I am working on exporting the deit_tiny_patch_16 model.
The model conversion is however failing with runtime error:
```RuntimeError: ONNX symbolic expected node type prim::TupleConstruct, got `%456 : Tensor = onnx::Concat[axis=1](%quantize_per_tensor_5, %patch_embed_norm) # <eval_with_key>.10:32:0```
I am not aware on how to debug this specific type of issue, tried changing the specific layer to suppress if the error is because of that layer, however, I start getting the error in some other layer.
For reproducing, we just need to export the quantized timm network, timm can be directly cloned, and the torch-native quantization can be used from https://pytorch.org/blog/quantization-in-practice/ .
Basically,
```
import timm
import torch
from torch.quantization import quantize_fx
torch_model = timm.create_model('deit_tiny_patch16_224')
backend = "fbgemm"
qconfig_dict = {"": torch.quantization.get_default_qconfig(backend)}
model_prepared = quantize_fx.prepare_fx(torch_model, qconfig_dict)
# We can skip the calibration for the export purpose
model_quantized = quantize_fx.convert_fx(model_prepared)
torch.onnx.export(model_quantized,
x,
'model.onnx',
export_params=True,
opset_version=13,
do_constant_folding=False,
input_names=['input'],
output_names=['output'],
dynamic_axes={"input":{0:"batch_size"},
"output":{0:"batch_size"}}
)
```
### Versions
Collecting environment information...
PyTorch version: 1.12.1
Is debug build: False
CUDA used to build PyTorch: 11.3
ROCM used to build PyTorch: N/A
OS: Ubuntu 18.04.6 LTS (x86_64)
GCC version: (Ubuntu 7.5.0-3ubuntu1~18.04) 7.5.0
Clang version: Could not collect
CMake version: Could not collect
Libc version: glibc-2.27
Python version: 3.8.13 (default, Oct 21 2022, 23:50:54) [GCC 11.2.0] (64-bit runtime)
Python platform: Linux-5.4.0-136-generic-x86_64-with-glibc2.17
Is CUDA available: True
CUDA runtime version: Could not collect
CUDA_MODULE_LOADING set to:
GPU models and configuration:
GPU 0: NVIDIA Graphics Device
GPU 1: NVIDIA Graphics Device
GPU 2: NVIDIA Graphics Device
Nvidia driver version: 465.19.01
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.23.3
[pip3] torch==1.12.1
[pip3] torchaudio==0.12.1
[pip3] torchvision==0.13.1
[conda] blas 1.0 mkl
[conda] cudatoolkit 11.3.1 h2bc3f7f_2
[conda] ffmpeg 4.3 hf484d3e_0 pytorch
[conda] mkl 2021.4.0 h06a4308_640
[conda] mkl-service 2.4.0 py38h7f8727e_0
[conda] mkl_fft 1.3.1 py38hd3c417c_0
[conda] mkl_random 1.2.2 py38h51133e4_0
[conda] numpy 1.23.3 py38h14f4228_1
[conda] numpy-base 1.23.3 py38h31eccc5_1
[conda] pytorch 1.12.1 py3.8_cuda11.3_cudnn8.3.2_0 pytorch
[conda] pytorch-mutex 1.0 cuda pytorch
[conda] torchaudio 0.12.1 py38_cu113 pytorch
[conda] torchvision 0.13.1 py38_cu113 pytorch
cc @jerryzh168 @jianyuh @raghuramank100 @jamesr66a @vkuzo @jgong5 @Xia-Weiwen @leslie-fang-intel
| 3 |
3,606 | 93,345 |
aten::int_repr not supported in torch.onnx.export
|
module: onnx, triaged
|
### 🚀 The feature, motivation and pitch
```python
import torch.onnx
import torch
class Model(torch.nn.Module):
def forward(self, x):
y = torch.quantize_per_tensor(x, 1., 0, torch.qint8)
return y.int_repr()
model = Model()
model.eval()
args = torch.ones(1, 1, 28, 28)
print(model(args))
torch.onnx.export(model, # model being run
args, # model input (or a tuple for multiple inputs)
"out.onnx", # where to save the model (can be a file or file-like object)
opset_version=16, # the ONNX version to export the model to
input_names = ['input'], # the model's input names
output_names = ['output'])
```
currently says
```
torch.onnx.errors.UnsupportedOperatorError: Exporting the operator 'aten::int_repr' to ONNX opset version 16 is not supported. Please feel free to request support or submit a pull request on PyTorch GitHub: https://github.com/pytorch/pytorch/issues.
```
I'd like to see this supported.
quantize_per_tensor+ int_repr + clamp is a useful way to represent quantization to less than 8 bits.
### Alternatives
_No response_
### Additional context
I have never developed on pytorch. But considering that dequantize(quantize_per_tensor(x)) already emits a cast op in ONNX,
I think the effort to do this would be small. I might be able to do it you could provide pointers about where to implement and where to add tests.
| 0 |
3,607 | 93,319 |
Minifier should not use pickle to save state into minifier launcher
|
triaged, module: fx, module: functorch
|
### 🐛 Describe the bug
So hard to read!
### Versions
master
cc @SherlockNoMad @soumith @EikanWang @jgong5 @wenzhe-nrv @zou3519 @Chillee @samdow @kshitij12345 @janeyx99
| 1 |
3,608 | 93,317 |
Minifier doesn't save/load functorch config
|
triaged, module: fx, module: functorch
|
### 🐛 Describe the bug
self explanatory
### Versions
master
cc @SherlockNoMad @soumith @EikanWang @jgong5 @wenzhe-nrv @zou3519 @Chillee @samdow @kshitij12345 @janeyx99
| 0 |
3,609 | 93,315 |
Convention for printing the "internal representation" of compiled functions from inductor/other backends
|
triaged, module: inductor
|
### 🐛 Describe the bug
It doesn't really make sense to print a function wrapped in torch.compile, but as a framework developer sometimes I am dealing with compiled_fn prior to frame installation and it would be nice to be able to debug print them and see what was compiled with them. Typically you don't get anything useful because it's some trampoline function (like `align_inputs`) before eventually getting to some eval'ed code. But maybe keeping the graph around for printing here would be handy? IDK, food for thought.
BTW, printing compiled_fn (via a series of hacks) is how I diagnosed #93308
### Versions
master
cc @mlazos @soumith @voznesenskym @yanboliang @penguinwu @anijain2305 @EikanWang @jgong5 @Guobing-Chen @chunyuan-w @XiaobingSuper @zhuhaozhe @blzheng @Xia-Weiwen @wenzhe-nrv @jiayisunx @peterbell10 @desertfire
| 0 |
3,610 | 93,311 |
[CI] PyTorch Windows Test AMIs contains CUDA-11.3 installation
|
module: windows, module: ci, triaged
|
### 🐛 Describe the bug
See:
```
runneruser@EC2AMAZ-3VOMLSP C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA>dir
Volume in drive C has no label.
Volume Serial Number is 60AC-DF3B
Directory of C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA
12/20/2022 02:16 AM <DIR> .
12/20/2022 02:16 AM <DIR> ..
12/20/2022 02:07 AM <DIR> v11.3
12/20/2022 02:10 AM <DIR> v11.6
12/20/2022 02:13 AM <DIR> v11.7
12/20/2022 02:16 AM <DIR> v11.8
0 File(s) 0 bytes
6 Dir(s) 225,786,408,960 bytes free
```
### Versions
CI
cc @peterjc123 @mszhanyi @skyline75489 @nbcsm @seemethere @pytorch/pytorch-dev-infra
| 1 |
3,611 | 93,307 |
`torch.compile()` failed on Huggingface Flan-T5 `torch._dynamo.exc.Unsupported: call_function UserDefinedObjectVariable(forward) [] OrderedDict()`
|
high priority, triage review, triaged, oncall: pt2
|
### 🐛 Describe the bug
Attempting to compile Flan-T5 (and other `AutoModelForSeq2SeqLM` models) from Huggingface.
Possibly related to https://github.com/huggingface/transformers/issues/21013, and https://dev-discuss.pytorch.org/t/torchdynamo-update-3-gpu-inference-edition/460/12?u=kastan
Minimal reproduction:
```python
import torch
from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
model_name = "google/flan-t5-base"
model = AutoModelForSeq2SeqLM.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = torch.compile(model)
from torch import _dynamo
_dynamo.config.verbose = True
_dynamo.explain(model)
```
### Error logs
```text
[2023-01-30 14:56:10,297] torch._dynamo.symbolic_convert: [DEBUG] TRACE CALL_FUNCTION_EX 1 [UserDefinedObjectVariable(forward), TupleVariable(), ConstDictVariable()]
[2023-01-30 14:56:10,297] torch._dynamo.symbolic_convert: [DEBUG] break_graph_if_unsupported triggered compile
Traceback (most recent call last):
File "/home/kastanday/utils/mambaforge3/envs/torch2.0/lib/python3.10/site-packages/torch/_dynamo/symbolic_convert.py", line 333, in wrapper
return inner_fn(self, inst)
File "/home/kastanday/utils/mambaforge3/envs/torch2.0/lib/python3.10/site-packages/torch/_dynamo/symbolic_convert.py", line 1027, in CALL_FUNCTION_EX
self.call_function(fn, argsvars.items, kwargsvars.items)
File "/home/kastanday/utils/mambaforge3/envs/torch2.0/lib/python3.10/site-packages/torch/_dynamo/symbolic_convert.py", line 461, in call_function
self.push(fn.call_function(self, args, kwargs))
File "/home/kastanday/utils/mambaforge3/envs/torch2.0/lib/python3.10/site-packages/torch/_dynamo/variables/user_defined.py", line 261, in call_function
return super().call_function(tx, args, kwargs)
File "/home/kastanday/utils/mambaforge3/envs/torch2.0/lib/python3.10/site-packages/torch/_dynamo/variables/base.py", line 230, in call_function
unimplemented(f"call_function {self} {args} {kwargs}")
File "/home/kastanday/utils/mambaforge3/envs/torch2.0/lib/python3.10/site-packages/torch/_dynamo/exc.py", line 71, in unimplemented
raise Unsupported(msg)
torch._dynamo.exc.Unsupported: call_function UserDefinedObjectVariable(forward) [] OrderedDict()
...
[2023-01-30 14:56:10,313] torch._dynamo.symbolic_convert: [DEBUG] TRACE starts_line /home/kastanday/utils/mambaforge3/envs/torch2.0/lib/python3.10/site-packages/transformers/models/t5/modeling_t5.py:1623
[2023-01-30 14:56:10,313] torch._dynamo.symbolic_convert: [DEBUG] TRACE LOAD_CONST ('input_ids', 'attention_mask', 'inputs_embeds', 'head_mask', 'output_attentions', 'output_hidden_states', 'return_dict') [NNModuleVariable(), ConstantVariable(NoneType), ConstantVariable(NoneType), ConstantVariable(NoneType), ConstantVariable(NoneType), ConstantVariable(NoneType), ConstantVariable(NoneType), ConstantVariable(bool)]
[2023-01-30 14:56:10,313] torch._dynamo.symbolic_convert: [DEBUG] TRACE CALL_FUNCTION_KW 7 [NNModuleVariable(), ConstantVariable(NoneType), ConstantVariable(NoneType), ConstantVariable(NoneType), ConstantVariable(NoneType), ConstantVariable(NoneType), ConstantVariable(NoneType), ConstantVariable(bool), ConstantVariable(tuple)]
/home/kastanday/utils/mambaforge3/envs/torch2.0/lib/python3.10/site-packages/dill/_dill.py:1890: PicklingWarning: Pickling a PyCapsule (None) does not pickle any C data structures and could cause segmentation faults or other memory errors when unpickling.
warnings.warn('Pickling a PyCapsule (%s) does not pickle any C data structures and could cause segmentation faults or other memory errors when unpickling.' % (name,), PicklingWarning)
Traceback (most recent call last):
File "/home/kastanday/utils/mambaforge3/envs/torch2.0/lib/python3.10/site-packages/torch/_dynamo/convert_frame.py", line 323, in _compile
out_code = transform_code_object(code, transform)
File "/home/kastanday/utils/mambaforge3/envs/torch2.0/lib/python3.10/site-packages/torch/_dynamo/bytecode_transformation.py", line 339, in transform_code_object
transformations(instructions, code_options)
File "/home/kastanday/utils/mambaforge3/envs/torch2.0/lib/python3.10/site-packages/torch/_dynamo/convert_frame.py", line 310, in transform
tracer.run()
File "/home/kastanday/utils/mambaforge3/envs/torch2.0/lib/python3.10/site-packages/torch/_dynamo/symbolic_convert.py", line 1715, in run
super().run()
File "/home/kastanday/utils/mambaforge3/envs/torch2.0/lib/python3.10/site-packages/torch/_dynamo/symbolic_convert.py", line 564, in run
and self.step()
File "/home/kastanday/utils/mambaforge3/envs/torch2.0/lib/python3.10/site-packages/torch/_dynamo/symbolic_convert.py", line 527, in step
getattr(self, inst.opname)(inst)
File "/home/kastanday/utils/mambaforge3/envs/torch2.0/lib/python3.10/site-packages/torch/_dynamo/symbolic_convert.py", line 333, in wrapper
return inner_fn(self, inst)
File "/home/kastanday/utils/mambaforge3/envs/torch2.0/lib/python3.10/site-packages/torch/_dynamo/symbolic_convert.py", line 1039, in CALL_FUNCTION_KW
self.call_function(fn, args, kwargs)
File "/home/kastanday/utils/mambaforge3/envs/torch2.0/lib/python3.10/site-packages/torch/_dynamo/symbolic_convert.py", line 461, in call_function
self.push(fn.call_function(self, args, kwargs))
File "/home/kastanday/utils/mambaforge3/envs/torch2.0/lib/python3.10/site-packages/torch/_dynamo/variables/nn_module.py", line 228, in call_function
fn = mod.forward.__func__
AttributeError: 'function' object has no attribute '__func__'
from user code:
File "/home/kastanday/utils/mambaforge3/envs/torch2.0/lib/python3.10/site-packages/transformers/models/t5/modeling_t5.py", line 1623, in forward
encoder_outputs = self.encoder(
Finally...
torch._dynamo.exc.InternalTorchDynamoError
```
### Minified repro
Unable to produce due to same error as above `torch._dynamo.exc.InternalTorchDynamoError`.
### Versions
```
PyTorch version: 2.0.0.dev20230130+cu117
Is debug build: False
CUDA used to build PyTorch: 11.7
ROCM used to build PyTorch: N/A
OS: CentOS Linux release 7.9.2009 (Core) (x86_64)
GCC version: (GCC) 4.8.5 20150623 (Red Hat 4.8.5-44)
Clang version: Could not collect
CMake version: version 3.25.0
Libc version: glibc-2.17
Python version: 3.10.8 | packaged by conda-forge | (main, Nov 22 2022, 08:26:04) [GCC 10.4.0] (64-bit runtime)
Python platform: Linux-3.10.0-1160.66.1.el7.x86_64-x86_64-with-glibc2.17
Is CUDA available: True
CUDA runtime version: 11.6.112
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration:
GPU 0: Tesla V100-PCIE-32GB
GPU 1: Tesla V100-PCIE-32GB
GPU 2: Tesla V100-PCIE-32GB
GPU 3: Tesla V100-PCIE-16GB
Nvidia driver version: 510.47.03
cuDNN version: /usr/lib64/libcudnn.so.7.6.5
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] mypy-extensions==0.4.3
[pip3] numpy==1.24.1
[pip3] pytorch-triton==2.0.0+0d7e753227
[pip3] torch==2.0.0.dev20230130+cu117
[pip3] torchvision==0.14.1
[conda] numpy 1.24.1 pypi_0 pypi
[conda] pytorch-triton 2.0.0+0d7e753227 pypi_0 pypi
[conda] torch 2.0.0.dev20230130+cu117 pypi_0 pypi
[conda] torchvision 0.14.1 pypi_0 pypi
```
cc @ezyang @gchanan @zou3519 @kadeng @msaroufim @wconstab @bdhirsh @anijain2305 @soumith @ngimel
| 2 |
3,612 | 93,288 |
Errors when running the fsdp benchmarks for hf_Bert and hf_T5
|
triaged, module: fsdp, bug, oncall: pt2, module: dynamo
|
### 🐛 RuntimeError thrown by Dynamo in FSDP benchmark script.
Hi,
I'm using https://github.com/pytorch/pytorch/blob/master/benchmarks/dynamo/distributed.py to run tests on nightly branch from Jan 28'th (which I've built && installed on my Docker container).
This is my base DLC: `763104351884.dkr.ecr.us-east-1.amazonaws.com/pytorch-training:1.13.1-gpu-py39-cu117-ubuntu20.04-sagemaker` (download it using awscli; https://docs.aws.amazon.com/AmazonECR/latest/userguide/getting-started-cli.html)
PT-1.13 was purged from the container and PT2 nightly from 28th was installed.
In particular for `hf_Bert`, `hf_GPT2` and `hf_T5` (the first two with the FSDP wrapper). I'm observing the errors attached below (trace mentions dynamo, so tagging it in the `torch.compile` cohort),
Run command:
```bash
# pytorch commit: 5d6a4f697cac34d15262aad8afab096170d29ce1
torchrun --nnodes 1 --nproc_per_node 8 --master_addr localhost --master_port 9001 distributed.py --dynamo inductor --torchbench_model hf_T5 --fsdp
```
Note commit in the versions below is different because I have some minor change to the build file to include directories to get the build to succeed on my base DLC.
I've attached the minified graph below, but that doesn't reproduce the issue.
```bash
TORCHDYNAMO_REPRO_AFTER="dynamo" torchrun --nnodes 1 --nproc_per_node 8 --master_addr localhost --master_port 9001 distributed.py --dynamo inductor --torchbench_model hf_T5 --fsdp
```
Any pointers to get this working OR just any example of working FSDP wrapper would be very helpful!
### Error logs
```
Traceback (most recent call last):
File "/opt/conda/lib/python3.9/site-packages/torch/_dynamo/convert_frame.py", line 323, in _compile
out_code = transform_code_object(code, transform)
File "/opt/conda/lib/python3.9/site-packages/torch/_dynamo/bytecode_transformation.py", line 341, in transform_code_object
transformations(instructions, code_options)
File "/opt/conda/lib/python3.9/site-packages/torch/_dynamo/convert_frame.py", line 310, in transform
tracer.run()
File "/opt/conda/lib/python3.9/site-packages/torch/_dynamo/symbolic_convert.py", line 1717, in run
super().run()
File "/opt/conda/lib/python3.9/site-packages/torch/_dynamo/symbolic_convert.py", line 563, in run
and self.step()
File "/opt/conda/lib/python3.9/site-packages/torch/_dynamo/symbolic_convert.py", line 526, in step
getattr(self, inst.opname)(inst)
File "/opt/conda/lib/python3.9/site-packages/torch/_dynamo/symbolic_convert.py", line 332, in wrapper
return inner_fn(self, inst)
File "/opt/conda/lib/python3.9/site-packages/torch/_dynamo/symbolic_convert.py", line 999, in CALL_FUNCTION
self.call_function(fn, args, {})
File "/opt/conda/lib/python3.9/site-packages/torch/_dynamo/symbolic_convert.py", line 460, in call_function
self.push(fn.call_function(self, args, kwargs))
File "/opt/conda/lib/python3.9/site-packages/torch/_dynamo/variables/nn_module.py", line 559, in call_function
return variables.UserFunctionVariable(
File "/opt/conda/lib/python3.9/site-packages/torch/_dynamo/variables/functions.py", line 259, in call_function
return super(UserFunctionVariable, self).call_function(tx, args, kwargs)
File "/opt/conda/lib/python3.9/site-packages/torch/_dynamo/variables/functions.py", line 92, in call_function
return tx.inline_user_function_return(
File "/opt/conda/lib/python3.9/site-packages/torch/_dynamo/symbolic_convert.py", line 496, in inline_user_function_return
result = InliningInstructionTranslator.inline_call(self, fn, args, kwargs)
File "/opt/conda/lib/python3.9/site-packages/torch/_dynamo/symbolic_convert.py", line 1795, in inline_call
return cls.inline_call_(parent, func, args, kwargs)
File "/opt/conda/lib/python3.9/site-packages/torch/_dynamo/symbolic_convert.py", line 1851, in inline_call_
tracer.run()
File "/opt/conda/lib/python3.9/site-packages/torch/_dynamo/symbolic_convert.py", line 563, in run
and self.step()
File "/opt/conda/lib/python3.9/site-packages/torch/_dynamo/symbolic_convert.py", line 526, in step
getattr(self, inst.opname)(inst)
File "/opt/conda/lib/python3.9/site-packages/torch/_dynamo/symbolic_convert.py", line 1064, in LOAD_ATTR
result = BuiltinVariable(getattr).call_function(
File "/opt/conda/lib/python3.9/site-packages/torch/_dynamo/variables/builtin.py", line 322, in call_function
result = handler(tx, *args, **kwargs)
File "/opt/conda/lib/python3.9/site-packages/torch/_dynamo/variables/builtin.py", line 736, in call_getattr
obj.var_getattr(tx, name).clone(source=source).add_options(options)
File "/opt/conda/lib/python3.9/site-packages/torch/_dynamo/variables/user_defined.py", line 342, in var_getattr
return VariableBuilder(tx, source)(subobj).add_options(options)
File "/opt/conda/lib/python3.9/site-packages/torch/_dynamo/variables/builder.py", line 170, in __call__
return self._wrap(value).clone(**self.options())
File "/opt/conda/lib/python3.9/site-packages/torch/_dynamo/variables/builder.py", line 236, in _wrap
return self.wrap_tensor(value)
File "/opt/conda/lib/python3.9/site-packages/torch/_dynamo/variables/builder.py", line 646, in wrap_tensor
tensor_variable = wrap_fx_proxy(
File "/opt/conda/lib/python3.9/site-packages/torch/_dynamo/variables/builder.py", line 761, in wrap_fx_proxy
return wrap_fx_proxy_cls(
File "/opt/conda/lib/python3.9/site-packages/torch/_dynamo/variables/builder.py", line 821, in wrap_fx_proxy_cls
example_value = wrap_to_fake_tensor_and_record(
File "/opt/conda/lib/python3.9/site-packages/torch/_dynamo/variables/builder.py", line 972, in wrap_to_fake_tensor_and_record
fake_e = wrap_fake_exception(
File "/opt/conda/lib/python3.9/site-packages/torch/_dynamo/utils.py", line 783, in wrap_fake_exception
return fn()
File "/opt/conda/lib/python3.9/site-packages/torch/_dynamo/variables/builder.py", line 973, in <lambda>
lambda: tx.fake_mode.from_tensor(
File "/opt/conda/lib/python3.9/site-packages/torch/_subclasses/fake_tensor.py", line 1082, in from_tensor
return self.fake_tensor_converter(
File "/opt/conda/lib/python3.9/site-packages/torch/_subclasses/fake_tensor.py", line 291, in __call__
return self.from_real_tensor(
File "/opt/conda/lib/python3.9/site-packages/torch/_subclasses/fake_tensor.py", line 248, in from_real_tensor
out = self.meta_converter(
File "/opt/conda/lib/python3.9/site-packages/torch/_subclasses/meta_utils.py", line 502, in __call__
r = self.meta_tensor(
File "/opt/conda/lib/python3.9/site-packages/torch/_subclasses/meta_utils.py", line 275, in meta_tensor
base = self.meta_tensor(
File "/opt/conda/lib/python3.9/site-packages/torch/_subclasses/meta_utils.py", line 433, in meta_tensor
r.grad = self.meta_tensor(
RuntimeError: assigned grad has data of a different size
from user code:
File "/opt/conda/lib/python3.9/site-packages/transformers/models/t5/modeling_t5.py", line 542, in <graph break in forward>
attn_output = self.o(attn_output)
File "/opt/conda/lib/python3.9/site-packages/torch/nn/modules/linear.py", line 114, in forward
return F.linear(input, self.weight, self.bias)
Set torch._dynamo.config.verbose=True for more information
```
### Minified repro
```python
# minifier_launcher.py
import os
from math import inf
import torch
from torch import tensor, device
import torch.fx as fx
import functools
import torch._dynamo
from torch._dynamo.debug_utils import run_fwd_maybe_bwd
from torch._dynamo.optimizations.backends import BACKENDS
from torch._dynamo.testing import rand_strided
import torch._dynamo.config
import torch._inductor.config
torch._dynamo.config.load_config(b'\x80\x04\x95\xb9\x07\x00\x00\x00\x00\x00\x00}\x94(\x8c\x08__name__\x94\x8c\x14torch._dynamo.config\x94\x8c\x07__doc__\x94N\x8c\x0b__package__\x94\x8c\rtorch._dynamo\x94\x8c\n__loader__\x94\x8c\x1a_frozen_importlib_external\x94\x8c\x10SourceFileLoader\x94\x93\x94)\x81\x94}\x94(\x8c\x04name\x94h\x02\x8c\x04path\x94\x8c>/opt/conda/lib/python3.9/site-packages/torch/_dynamo/config.py\x94ub\x8c\x08__spec__\x94\x8c\x11_frozen_importlib\x94\x8c\nModuleSpec\x94\x93\x94)\x81\x94}\x94(h\x0ch\x02\x8c\x06loader\x94h\n\x8c\x06origin\x94h\x0e\x8c\x0cloader_state\x94N\x8c\x1asubmodule_search_locations\x94N\x8c\r_set_fileattr\x94\x88\x8c\x07_cached\x94\x8cV/opt/conda/lib/python3.9/site-packages/torch/_dynamo/__pycache__/config.cpython-39.pyc\x94\x8c\r_initializing\x94\x89ub\x8c\x08__file__\x94h\x0e\x8c\n__cached__\x94h\x1b\x8c\x07abspath\x94\x8c\tposixpath\x94h\x1f\x93\x94\x8c\x07dirname\x94h h"\x93\x94\x8c\x0eHAS_REFS_PRIMS\x94\x88\x8c\tlog_level\x94K\x1e\x8c\x0boutput_code\x94\x89\x8c\rlog_file_name\x94N\x8c\x07verbose\x94\x89\x8c\x11output_graph_code\x94\x89\x8c\x12verify_correctness\x94\x89\x8c\x12minimum_call_count\x94K\x01\x8c\x15dead_code_elimination\x94\x88\x8c\x10cache_size_limit\x94K@\x8c\x14specialize_int_float\x94\x88\x8c\x0edynamic_shapes\x94\x89\x8c\x10guard_nn_modules\x94\x89\x8c\x0cnormalize_ir\x94\x89\x8c\x1btraceable_tensor_subclasses\x94\x8f\x94\x8c\x0fsuppress_errors\x94\x89\x8c\x15replay_record_enabled\x94\x89\x8c rewrite_assert_with_torch_assert\x94\x88\x8c\x12print_graph_breaks\x94\x89\x8c\x07disable\x94\x89\x8c*allowed_functions_module_string_ignorelist\x94\x8f\x94(\x8c\rtorch.testing\x94\x8c\x0btorch._refs\x94\x8c\rtorch._decomp\x94\x8c\x13torch.distributions\x94\x8c\x0ctorch._prims\x94\x90\x8c\x16capture_scalar_outputs\x94\x89\x8c\x19enforce_cond_guards_match\x94\x88\x8c\x0coptimize_ddp\x94\x88\x8c\x1araise_on_ctx_manager_usage\x94\x88\x8c\x1craise_on_unsafe_aot_autograd\x94\x89\x8c\rdynamo_import\x94\x8c\rtorch._dynamo\x94\x8c\x0finductor_import\x94\x8c\x0ftorch._inductor\x94\x8c\x18error_on_nested_fx_trace\x94\x88\x8c\tallow_rnn\x94\x89\x8c\x08base_dir\x94\x8c&/opt/conda/lib/python3.9/site-packages\x94\x8c\x0edebug_dir_root\x94\x8cN/fsx/pytorch-nightly/pytorch-2.0/pytorch/benchmarks/dynamo/torch_compile_debug\x94\x8c)DO_NOT_USE_legacy_non_fake_example_inputs\x94\x89\x8c\x15_AccessLimitingConfig\x94}\x94(\x8c\n__module__\x94h\x02\x8c\x0b__setattr__\x94h\x02\x8c!_AccessLimitingConfig.__setattr__\x94\x93\x94h\x03Nu\x8c\x15_allowed_config_names\x94\x8f\x94(\x8c\x0eexternal_utils\x94h6\x8c\x12constant_functions\x94h\x06h&\x8c\x0c__builtins__\x94h%hPh5\x8c!skipfiles_inline_module_allowlist\x94h(h\x0fhBh*h/h.h\x1fhD\x8c\x07logging\x94\x8c\x02os\x94\x8c\x05torch\x94h)h$h0h7hIh4h8h@h2h9h-\x8c\x03sys\x94hGh,h+hKhAhEh1hOh\x01hMh\x1dh\'h\x03h"\x8c\x0brepro_level\x94hJ\x8c\nModuleType\x94hCh\x1eh\x04\x8c\x0brepro_after\x94\x90\x8c\x1cget_config_serialization_fns\x94\x8c\x1atorch._dynamo.config_utils\x94hc\x93\x94u.')
torch._inductor.config.load_config(b'\x80\x04\x95\xd3\x08\x00\x00\x00\x00\x00\x00}\x94(\x8c\x08__name__\x94\x8c\x16torch._inductor.config\x94\x8c\x07__doc__\x94N\x8c\x0b__package__\x94\x8c\x0ftorch._inductor\x94\x8c\n__loader__\x94\x8c\x1a_frozen_importlib_external\x94\x8c\x10SourceFileLoader\x94\x93\x94)\x81\x94}\x94(\x8c\x04name\x94h\x02\x8c\x04path\x94\x8c@/opt/conda/lib/python3.9/site-packages/torch/_inductor/config.py\x94ub\x8c\x08__spec__\x94\x8c\x11_frozen_importlib\x94\x8c\nModuleSpec\x94\x93\x94)\x81\x94}\x94(h\x0ch\x02\x8c\x06loader\x94h\n\x8c\x06origin\x94h\x0e\x8c\x0cloader_state\x94N\x8c\x1asubmodule_search_locations\x94N\x8c\r_set_fileattr\x94\x88\x8c\x07_cached\x94\x8cX/opt/conda/lib/python3.9/site-packages/torch/_inductor/__pycache__/config.cpython-39.pyc\x94\x8c\r_initializing\x94\x89ub\x8c\x08__file__\x94h\x0e\x8c\n__cached__\x94h\x1b\x8c\x05debug\x94\x89\x8c\x10disable_progress\x94\x88\x8c\x10verbose_progress\x94\x89\x8c\x0bcpp_wrapper\x94\x89\x8c\x03dce\x94\x89\x8c\x14static_weight_shapes\x94\x88\x8c\x0csize_asserts\x94\x88\x8c\x10pick_loop_orders\x94\x88\x8c\x0finplace_buffers\x94\x88\x8c\x11benchmark_harness\x94\x88\x8c\x0fepilogue_fusion\x94\x89\x8c\x15epilogue_fusion_first\x94\x89\x8c\x0cmax_autotune\x94\x89\x8c\x17realize_reads_threshold\x94K\x04\x8c\x17realize_bytes_threshold\x94M\xd0\x07\x8c\x1brealize_acc_reads_threshold\x94K\x08\x8c\x0ffallback_random\x94\x89\x8c\x12implicit_fallbacks\x94\x88\x8c\rprefuse_nodes\x94\x88\x8c\x0btune_layout\x94\x89\x8c\x11aggressive_fusion\x94\x89\x8c\x0fmax_fusion_size\x94K@\x8c\x1bunroll_reductions_threshold\x94K\x08\x8c\x0ecomment_origin\x94\x89\x8c\tis_fbcode\x94h\x02h7\x93\x94\x8c\x0fcompile_threads\x94K \x8c\x13kernel_name_max_ops\x94K\n\x8c\x0finductor_import\x94\x8c\x0ftorch._inductor\x94\x8c\rshape_padding\x94\x89\x8c\x0epermute_fusion\x94\x89\x8c\x1aprofiler_mark_wrapper_call\x94\x89\x8c\x03cpp\x94}\x94(\x8c\n__module__\x94h\x02\x8c\x07threads\x94J\xff\xff\xff\xff\x8c\x0fdynamic_threads\x94\x89\x8c\x07simdlen\x94N\x8c\x0emin_chunk_size\x94M\x00\x10\x8c\x03cxx\x94N\x8c\x03g++\x94\x86\x94\x8c\x15enable_kernel_profile\x94\x89h\x03Nu\x8c\x06triton\x94}\x94(hBh\x02\x8c\ncudagraphs\x94\x89\x8c\x10debug_sync_graph\x94\x89\x8c\x11debug_sync_kernel\x94\x89\x8c\x0bconvolution\x94\x8c\x04aten\x94\x8c\x0edense_indexing\x94\x89\x8c\tmax_tiles\x94K\x02\x8c\x12autotune_pointwise\x94\x88\x8c tiling_prevents_pointwise_fusion\x94\x88\x8c tiling_prevents_reduction_fusion\x94\x88\x8c\x14ordered_kernel_names\x94\x89\x8c\x18descriptive_kernel_names\x94\x89h\x03Nu\x8c\x05trace\x94}\x94(hBh\x02\x8c\x07enabled\x94\x89\x8c\tdebug_log\x94\x88\x8c\x08info_log\x94\x89\x8c\x08fx_graph\x94\x88\x8c\rir_pre_fusion\x94\x88\x8c\x0eir_post_fusion\x94\x88\x8c\x0boutput_code\x94\x88\x8c\rgraph_diagram\x94\x89\x8c\x0fcompile_profile\x94\x89\x8c\nupload_tar\x94Nh\x03Nu\x8c\x15InductorConfigContext\x94}\x94(hBh\x02\x8c\x0f__annotations__\x94}\x94(\x8c\rstatic_memory\x94\x8c\x08builtins\x94\x8c\x04bool\x94\x93\x94\x8c\x0ematmul_padding\x94hlh+hl\x8c\x12triton_convolution\x94hj\x8c\x03str\x94\x93\x94\x8c\x17rematerialize_threshold\x94hj\x8c\x03int\x94\x93\x94\x8c\x1brematerialize_acc_threshold\x94hsu\x8c\x05_save\x94h\x02\x8c\x1bInductorConfigContext._save\x94\x93\x94\x8c\x06_apply\x94h\x02\x8c\x1cInductorConfigContext._apply\x94\x93\x94\x8c\x08__init__\x94h\x02\x8c\x1eInductorConfigContext.__init__\x94\x93\x94\x8c\t__enter__\x94h\x02\x8c\x1fInductorConfigContext.__enter__\x94\x93\x94\x8c\x08__exit__\x94h\x02\x8c\x1eInductorConfigContext.__exit__\x94\x93\x94h\x03Nu\x8c\x1cget_config_serialization_fns\x94\x8c\x1atorch._dynamo.config_utils\x94h\x84\x93\x94u.')
# REPLACEABLE COMMENT FOR TESTING PURPOSES
args = [((8, 1024), (1024, 1), torch.int64, 'cuda', False), ((32128, 512), (512, 1), torch.float32, 'cuda', True)]
args = [rand_strided(sh, st, dt, dev).requires_grad_(rg) for (sh, st, dt, dev, rg) in args]
from torch.nn import *
class Repro(torch.nn.Module):
def __init__(self):
super().__init__()
def forward(self, input_ids : torch.Tensor, self_embed_tokens_weight : torch.Tensor):
view = input_ids.view(-1, 1024); input_ids = None
embedding = torch.nn.functional.embedding(view, self_embed_tokens_weight, None, None, 2.0, False, False); view = self_embed_tokens_weight = None
ones = torch.ones(8, 1024)
to = ones.to(device(type='cuda', index=0)); ones = None
return (to, embedding)
mod = Repro()
# Setup debug minifier compiler
torch._dynamo.debug_utils.MINIFIER_SPAWNED = True
compiler_fn = BACKENDS["dynamo_minifier_backend"]
dynamo_minifier_backend = functools.partial(
compiler_fn,
compiler_name="inductor",
)
opt_mod = torch._dynamo.optimize(dynamo_minifier_backend)(mod)
with torch.cuda.amp.autocast(enabled=False):
opt_mod(*args)
```
### Versions
```
Collecting environment information...
PyTorch version: 2.0.0a0+git5876d91
Is debug build: False
CUDA used to build PyTorch: 11.7
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.5 LTS (x86_64)
GCC version: (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0
Clang version: Could not collect
CMake version: version 3.24.3
Libc version: glibc-2.31
Python version: 3.9.13 | packaged by conda-forge | (main, May 27 2022, 16:58:50) [GCC 10.3.0] (64-bit runtime)
Python platform: Linux-4.14.296-222.539.amzn2.x86_64-x86_64-with-glibc2.31
Is CUDA available: True
CUDA runtime version: 11.7.99
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration: <redacted>
Nvidia driver version: 470.103.01
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.5.0
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.5.0
/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.5.0
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_infer.so.8.5.0
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.5.0
/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.5.0
/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.5.0
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] bert-pytorch==0.0.1a4
[pip3] clip-anytorch==2.5.0
[pip3] CoCa-pytorch==0.0.7
[pip3] dalle2-pytorch==1.10.5
[pip3] ema-pytorch==0.1.4
[pip3] functorch==1.14.0a0+408bcf1
[pip3] mypy-extensions==0.4.3
[pip3] numpy==1.23.5
[pip3] pytorch-transformers==1.2.0
[pip3] pytorch-warmup==0.1.1
[pip3] rotary-embedding-torch==0.2.1
[pip3] torch==2.0.0a0+git5876d91
[pip3] torch-fidelity==0.3.0
[pip3] torch-struct==0.5
[pip3] torchaudio==2.0.0a0+4699ef2
[pip3] torchdata==0.6.0a0+a1612ee
[pip3] torchmetrics==0.11.0
[pip3] torchrec-nightly==2023.1.29
[pip3] torchtext==0.15.0a0+f653dac
[pip3] torchvision==0.15.0a0+c35e8d5
[pip3] vector-quantize-pytorch==0.10.15
[conda] bert-pytorch 0.0.1a4 dev_0 <develop>
[conda] clip-anytorch 2.5.0 pypi_0 pypi
[conda] coca-pytorch 0.0.7 pypi_0 pypi
[conda] dalle2-pytorch 1.10.5 pypi_0 pypi
[conda] ema-pytorch 0.1.4 pypi_0 pypi
[conda] functorch 1.14.0a0+408bcf1 pypi_0 pypi
[conda] magma-cuda117 2.6.1 1 pytorch
[conda] mkl 2022.2.1 h84fe81f_16997 conda-forge
[conda] mkl-include 2023.0.0 h84fe81f_25396 conda-forge
[conda] numpy 1.23.5 pypi_0 pypi
[conda] pytorch-transformers 1.2.0 pypi_0 pypi
[conda] pytorch-warmup 0.1.1 pypi_0 pypi
[conda] rotary-embedding-torch 0.2.1 pypi_0 pypi
[conda] torch 2.0.0a0+git5876d91 pypi_0 pypi
[conda] torch-fidelity 0.3.0 pypi_0 pypi
[conda] torch-struct 0.5 pypi_0 pypi
[conda] torchaudio 2.0.0a0+4699ef2 pypi_0 pypi
[conda] torchdata 0.6.0a0+a1612ee pypi_0 pypi
[conda] torchmetrics 0.11.0 pypi_0 pypi
[conda] torchrec-nightly 2023.1.29 pypi_0 pypi
[conda] torchtext 0.15.0a0+f653dac pypi_0 pypi
[conda] torchvision 0.15.0a0+c35e8d5 pypi_0 pypi
[conda] vector-quantize-pytorch 0.10.15 pypi_0 pypi
```
cc @zhaojuanmao @mrshenli @rohan-varma @awgu @ezyang @soumith @msaroufim @wconstab @ngimel @bdhirsh @voznesenskym @penguinwu @anijain2305 @EikanWang @jgong5 @Guobing-Chen @XiaobingSuper @zhuhaozhe @blzheng @Xia-Weiwen @wenzhe-nrv @jiayisunx @desertfire
| 11 |
3,613 | 93,281 |
Estimate effort needed to bring PyTorch to Windows Arm64
|
module: windows, triaged
|
Past efforts enabled Windows Arm64 support for libtorch. This effort is now [under testing](https://github.com/pytorch/pytorch/issues/92304).
Next step for this effort is to bring rest of Pytorch to Arm64 and first step is investigate what is missing. That should allow us to evaluate amount of work needed.
### Goals of this ticket
- Review attached list of dependencies (something might be missing).
- Identify why we need each of those dependencies.
- Identify which dependencies are missing Arm64 support.
### Pytorch dependencies
- [ ] CUDA
- [ ] Custom Protobuf
- [ ] Threads
- [ ] protobuf
- [ ] BLAS
- [ ] FFTW
- [ ] pthreadpool
- [ ] Caffe2
- [ ] QNNPACK
- [ ] PYTORCH_QNNPACK
- [ ] NNPACK
- [ ] XNNPACK
- [ ] Vulkan
- [ ] gflags
- [ ] Google-glog
- [ ] Googletest and benchmark
- [ ] FBGEMM
- [ ] LMDB
- [ ] LevelDB
- [ ] Snappy
- [ ] NUMA
- [ ] ZMQ
- [ ] Redis
- [ ] OpenCV
- [ ] FFMPEG
- [ ] EIGEN
- [ ] Python
- [ ] pybind11
- [ ] MPI
- [ ] OpenMP
- [ ] Android
- [ ] Kernel asserts
- [ ] LLVM
- [ ] cuDNN
- [ ] HIP
- [ ] ROCm
- [ ] NCCL
- [ ] UCC
- [ ] CUB
- [ ] Onnx
- [ ] Kineto
### Minimum viable product
For the purpose of the estimation of an initial effort to bring PyTorch to Windows Arm64 we define the MVP as a locally and natively compiled PyTorch binaries with a minimum set of dependencies enabling CPU-only features passing the PyTorch core tests suites (`test_autograd.py`, `test_modules.py`, `test_nn.py`, `test_ops.py`, `test_ops_fwd_gradients.py`, `test_ops_gradients.py`, `test_ops_jit.py`, and `test_torch.py`).
### Gap analysis
Although the PyTorch codebase itself currently compiles on Windows Arm64 using Visual Studion 2022 (Build Tools) fine, the resulting binaries are not 100% functional, in a sense of MVP definition, and most of the issues originate from the dependencies (especially OpenBLAS).
From the external PyTorch dependencies, only the following are needed to fullfill the NVP, i.e., to pass all the core tests:
- [OpenBLAS](https://github.com/xianyi/OpenBLAS) - The most of the test failures listed in the issues bellow originate from this dependency.
- [SciPy ](https://github.com/scipy/scipy) - This Python package is needed for running the tests and it is not a direct dependency of PyTorch itself. Official PIP Windows Arm64 pre-built package is not available and compiling it with `pip install` fails due to missing Fortran compiler (adding it to the Windows Arm64 system is not a straightforward task). There is a 3rd party package available at https://github.com/cgohlke/win_arm64-wheels that works.
- [NumPy](https://github.com/numpy/numpy) - The above 3rd party SciPy Windows Arm64 package does not work with the official NumPy PIP package. The 3rd party NumPy package from the same source needs to be used.
Other dependencies might be selected from the PyTorch codebase (submodules) and do not require any changes except of:
- [cpuinfo](https://github.com/pytorch/cpuinfo) - The upstream main branch contains changes needed for Windows Arm64 already, updating the PyTorch repository to that version will require update of [XNNPACK](https://github.com/google/XNNPACK) and fix of Buck build in the [PyTorch](https://github.com/pytorch/pytorch) repository. Some additional changes for particular CPUs might be reqired.
Currently, to pass all PyTorch core tests, the following issues has to be relolved, they fall into two categories, the issues that either crash or block the entire test run:
- https://github.com/orgs/pytorch/projects/27/views/19?pane=issue&itemId=29013308 - have preliminary fix
- https://github.com/orgs/pytorch/projects/27/views/19?pane=issue&itemId=29020667 - RC unknown, either deadlock or "infinite" loop of some sort due to using uninitialized value in loop condition.
- https://github.com/orgs/pytorch/projects/27/views/19?pane=issue&itemId=29023111 - RC unknown, access violation connected to C++ template expansion.
and "regular" test failures:
- https://github.com/orgs/pytorch/projects/27/views/19?pane=issue&itemId=27702131 - RC unknown
- https://github.com/orgs/pytorch/projects/27/views/19?pane=issue&itemId=27702449 - RC unknown
- https://github.com/orgs/pytorch/projects/27/views/19?pane=issue&itemId=27702773 - RC unknown
- https://github.com/orgs/pytorch/projects/27/views/19?pane=issue&itemId=27703046 - RC unknown
- https://github.com/orgs/pytorch/projects/27/views/19?pane=issue&itemId=27703676 - RC unknown
- https://github.com/orgs/pytorch/projects/27/views/19?pane=issue&itemId=27703801 - RC unknown
- https://github.com/orgs/pytorch/projects/27/views/19?pane=issue&itemId=27705583 - RC unknown
- https://github.com/orgs/pytorch/projects/27/views/19?pane=issue&itemId=27705812 - RC unknown
- https://github.com/orgs/pytorch/projects/27/views/19?pane=issue&itemId=28831055 - RC unknown
- https://github.com/orgs/pytorch/projects/27/views/19?pane=issue&itemId=28838928 - RC unknown
Additionally, the following tasks should be considered as well:
- https://github.com/orgs/pytorch/projects/27/views/19?pane=issue&itemId=29035519 - invalid VCRuntime detection
- https://github.com/orgs/pytorch/projects/27/views/19?pane=issue&itemId=27700678 - investigation task
### Technical Notes
- Currently, some of the tests need to be explicitly excluded from the run as they are either crashing the test run entirely or stucking forever. For the list of those excluded tests refer to this VSCode launch.json file https://github.com/Blackhex/pytorch/commit/d0706220ae3437be1c751149c63807d45abda268.
cc @peterjc123 @mszhanyi @skyline75489 @nbcsm
| 1 |
3,614 | 93,275 |
Bug in torch.linalg.svd
|
triaged, module: mkl
|
### 🐛 Describe the bug
`torch.linalg.svd` produces an error for some sufficiently large inputs. As the error message says this is most likely a bug in the implementation calling the backend library.
**Example (run on CPU):**
```
import torch
A = torch.randn(172032,30000)
U,S,V = torch.linalg.svd(A,full_matrices=False)
```
yields
```
Intel MKL ERROR: Parameter 12 was incorrect on entry to SGESDD.
Traceback (most recent call last):
File "<my_path>/lib/python3.8/site-packages/spyder_kernels/py3compat.py", line 356, in compat_exec
exec(code, globals, locals)
File "<my_home_path>/PythonFiles/pytorch_test.py", line 14, in <module>
U,S,V = torch.linalg.svd(A,full_matrices=False)
RuntimeError: false INTERNAL ASSERT FAILED at "../aten/src/ATen/native/LinearAlgebraUtils.h":289, please report a bug to PyTorch. linalg.svd: Argument 12 has illegal value. Most certainly there is a bug in the implementation calling the backend library.
```
### Versions
PyTorch version: 1.12.0+cu102
Is debug build: False
CUDA used to build PyTorch: 10.2
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.5 LTS (x86_64)
GCC version: (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0
Clang version: Could not collect
CMake version: version 3.16.3
Libc version: glibc-2.31
Python version: 3.8.10 (default, Nov 14 2022, 12:59:47) [GCC 9.4.0] (64-bit runtime)
Python platform: Linux-5.15.0-56-generic-x86_64-with-glibc2.29
Is CUDA available: True
CUDA runtime version: Could not collect
CUDA_MODULE_LOADING set to:
GPU models and configuration: GPU 0: NVIDIA RTX A6000
Nvidia driver version: 515.86.01
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] mpi4torch==0.1.0
[pip3] mypy-extensions==0.4.3
[pip3] numpy==1.23.0
[pip3] numpydoc==1.4.0
[pip3] torch==1.12.0
[pip3] torchvision==0.13.0
[conda] No relevant packages
| 4 |
3,615 | 93,264 |
Bad conversion from torch.split(2d_tensor,splitsize_list) to SplitToSequence OP (onnx export)
|
module: onnx, triaged
|
### 🐛 Describe the bug
```python
torch.split(concat_feat_mat,idx_list)
```
When I use the instruction in model define and try to export it as onnx model, some execution errors are found.
> the onnx converter will construct a SplitToSequence with seq(tensor(int64)) type input, which is not supported.
### Versions
PyTorch version: 1.13.1
Is debug build: False
CUDA used to build PyTorch: None
ROCM used to build PyTorch: N/A
OS: macOS 10.15.7 (x86_64)
GCC version: Could not collect
Clang version: 11.0.3 (clang-1103.0.32.62)
CMake version: version 3.23.2
Libc version: N/A
Python version: 3.10.8 (main, Nov 24 2022, 08:09:04) [Clang 14.0.6 ] (64-bit runtime)
Python platform: macOS-10.15.7-x86_64-i386-64bit
Is CUDA available: False
CUDA runtime version: No CUDA
CUDA_MODULE_LOADING set to: N/A
GPU models and configuration: No CUDA
Nvidia driver version: No CUDA
cuDNN version: No CUDA
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.23.5
[pip3] pytorch-model-summary==0.1.1
[pip3] torch==1.13.1
[pip3] torch-tb-profiler==0.4.1
[pip3] torchaudio==0.13.1
[pip3] torchinfo==1.7.1
[pip3] torchsummary==1.5.1
[pip3] torchvision==0.14.1
[conda] blas 1.0 mkl
[conda] ffmpeg 4.3 h0a44026_0 pytorch
[conda] mkl 2021.4.0 hecd8cb5_637
[conda] mkl-service 2.4.0 py310hca72f7f_0
[conda] mkl_fft 1.3.1 py310hf879493_0
[conda] mkl_random 1.2.2 py310hc081a56_0
[conda] numpy 1.23.5 py310h9638375_0
[conda] numpy-base 1.23.5 py310ha98c3c9_0
[conda] pytorch 1.13.1 py3.10_0 pytorch
[conda] pytorch-model-summary 0.1.1 py_0 conda-forge
[conda] torch-tb-profiler 0.4.1 pypi_0 pypi
[conda] torchaudio 0.13.1 py310_cpu pytorch
[conda] torchinfo 1.7.1 pyhd8ed1ab_0 conda-forge
[conda] torchsummary 1.5.1 pypi_0 pypi
[conda] torchvision 0.14.1 py310_cpu pytorch
| 0 |
3,616 | 93,262 |
`torch.compile` produce wrong result in `interpolate` when `mode=bilinear`
|
triaged, oncall: pt2, module: aotdispatch
|
### 🐛 Describe the bug
The following program prints different results in eager mode and compile mode. The difference exists only if `mode` is set to `bilinear`.
```python
import torch
def fn(input):
return torch.nn.functional.interpolate(input, size=[1, 1], mode="bilinear")
# works fine if `mode` is set to other values such as "nearest" and "bicubic"
x = torch.rand([2, 8, 7, 10])
ret_eager = fn(x)
compiled = torch.compile(fn)
ret_compiled = compiled(x)
for r1, r2 in zip(ret_eager, ret_compiled):
assert torch.allclose(r1, r2), (r1, r2)
print('==== Check OK! ====')
"""
Traceback (most recent call last):
File "repro.py", line 14, in <module>
assert torch.allclose(r1, r2), (r1, r2)
AssertionError: (
tensor([[[0.5000]], [[0.5813]], [[0.5536]], [[0.2098]], [[0.3442]], [[0.7828]], [[0.6382]], [[0.3412]]]),
tensor([[[0.1909]], [[0.8426]], [[0.0925]], [[0.1988]], [[0.0879]], [[0.0518]], [[0.7094]], [[0.6926]]]))
"""
```
### Versions
<details><summary><b>Environment</b> <i>[Click to expand]</i></summary>
```
PyTorch version: 2.0.0.dev20230129+cu117
Is debug build: False
CUDA used to build PyTorch: 11.7
ROCM used to build PyTorch: N/A
OS: Ubuntu 22.04.1 LTS (x86_64)
GCC version: (Ubuntu 11.3.0-1ubuntu1~22.04) 11.3.0
Clang version: 11.1.0-6
CMake version: version 3.22.1
Libc version: glibc-2.35
Python version: 3.10.6 (main, Nov 14 2022, 16:10:14) [GCC 11.3.0] (64-bit runtime)
Python platform: Linux-5.15.0-56-generic-x86_64-with-glibc2.35
Is CUDA available: True
CUDA runtime version: 11.6.124
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration:
GPU 0: NVIDIA GeForce RTX 3090
GPU 1: NVIDIA GeForce RTX 3090
GPU 2: NVIDIA GeForce RTX 3090
Nvidia driver version: 515.86.01
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_infer.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.4.1
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.21.5
[pip3] pytorch-triton==2.0.0+0d7e753227
[pip3] torch==2.0.0.dev20230129+cu117
[pip3] torchaudio==2.0.0.dev20230118+cu117
[pip3] torchvision==0.15.0.dev20230118+cu117
[conda] blas 1.0 mkl
[conda] cudatoolkit 11.3.1 h2bc3f7f_2
[conda] mkl 2021.4.0 h06a4308_640
[conda] mkl-service 2.4.0 py39h7f8727e_0
[conda] mkl_fft 1.3.1 py39hd3c417c_0
[conda] mkl_random 1.2.2 py39h51133e4_0
[conda] numpy 1.21.5 py39he7a7128_1
[conda] numpy-base 1.21.5 py39hf524024_1
[conda] numpydoc 1.2 pyhd3eb1b0_0
[conda] torch 1.14.0a0+gitce2f870 pypi_0 pypi
```
</details>
cc @ezyang @soumith @msaroufim @wconstab @ngimel @bdhirsh @mlazos @voznesenskym @yanboliang @penguinwu @anijain2305 @EikanWang @jgong5 @Guobing-Chen @chunyuan-w @XiaobingSuper @zhuhaozhe @blzheng @Xia-Weiwen @wenzhe-nrv @jiayisunx @peterbell10 @desertfire
| 3 |
3,617 | 93,255 |
MaskRCNN model loaded fail with torch::jit::load(model_path) (C++ API)
|
oncall: jit
|
### 🐛 Describe the bug
Environment:
* Pytorch: 1.11.0 (for training) -> platform: ubuntu 20.04
* torchvision: 0.12.0
* libtorch-cpu: 1.13.1 (for predicting) -> platform: windows 10
Describe:
I'm trying to get a scripted model with torch.jit.script (python) and load it using the C++ API, however I get a Debug Error when executing torch::jit::load


Here is model code:
```
def get_model_instance_segmentation(num_classes, load_pretrain_weights=True):
# get maskrcnn model form torchvision.models
# load an instance segmentation model pre-trained on COCO
model = torchvision.models.detection.maskrcnn_resnet50_fpn(pretrained=load_pretrain_weights)
# get number of input features for the classifier
in_features = model.roi_heads.box_predictor.cls_score.in_features
# replace the pre-trained head with a new one
model.roi_heads.box_predictor = FastRCNNPredictor(in_features, num_classes)
# now get the number of input features for the mask classifier
in_features_mask = model.roi_heads.mask_predictor.conv5_mask.in_channels
hidden_layer = 256
# and replace the mask predictor with a new one
model.roi_heads.mask_predictor = MaskRCNNPredictor(in_features_mask,
hidden_layer,
num_classes)
return model
```
After trained MaskRCNN model, I convert it to torch script with code:
```
def generate_torch_script(pytorch_model, device, img_file, save_path):
# input of the model (from pil image to tensor, do not normalize image)
original_img = Image.open(img_file).convert('RGB') # load image
data_transform = transforms.Compose([transforms.ToTensor()])
img = data_transform(original_img)
img = torch.unsqueeze(img, dim=0).to(device) # expand batch dimension to device
# export the model
pytorch_model.eval()
if device.type == 'cpu':
pytorch_model = pytorch_model.cpu()
traced_script_module = torch.jit.script(pytorch_model, img)
traced_script_module.save(save_path)
```
Additionally, the export script model can work correctly with python api:
```
def main():
# load image
assert os.path.exists(IMG_PATH), f"{IMG_PATH} does not exits."
original_img = Image.open(IMG_PATH).convert('RGB')
# from pil image to tensor, do not normalize image
data_transform = transforms.Compose([transforms.ToTensor()])
img = data_transform(original_img)
# check onnx model
model_script = torch.jit.load(model_save_path)
model_script.eval()
with torch.no_grad():
predictions = model_script([img.to(device)])[1][0]
predict_boxes = predictions["boxes"].to("cpu").numpy()
predict_classes = predictions["labels"].to("cpu").numpy()
predict_scores = predictions["scores"].to("cpu").numpy()
predict_mask = predictions["masks"].to("cpu").numpy()
```
### Versions
Here is the minimal code using the C++ API:
```
#include <torch/script.h> // One-stop header.
#include <iostream>
#include <memory>
std::string model_path = "C:/Users/GilbertPan/Desktop/libtorch_deploy/traced_model.pt";
int main() {
torch::jit::script::Module module;
try {
// Deserialize the ScriptModule from a file using torch::jit::load().
module = torch::jit::load(model_path); // fail
}
catch (const c10::Error& e) {
std::cerr << "error loading the model\n";
return -1;
}
std::cout << "ok\n";
return 0;
}
```
cc @EikanWang @jgong5 @wenzhe-nrv @sanchitintel
| 0 |
3,618 | 93,249 |
`min` reduction on float16 tensor failed on certain shapes
|
triaged, module: inductor
|
### 🐛 Describe the bug
### 🐛 Describe the bug
The following program leads to an error.
```python
import torch
def fn(x):
o = x.min(1).values
return o
x = torch.rand((2, 8, 2), dtype=torch.float16) # AssertionError
# x = torch.rand((2, 7, 2), dtype=torch.float16) # works fine
fn(x)
print('==== CPU Eager mode OK! ====')
compiled = torch.compile(fn)
compiled(x)
print('==== CPU compiled mode OK! ====')
compiled(x.cuda())
print('==== GPU compiled mode OK! ====')
```
<details>
<summary>Error logs</summary>
```python
==== CPU Eager mode OK! ====
[2023-01-29 22:59:43,416] torch._inductor.scheduler: [CRITICAL] Error in codegen for ComputedBuffer(name='buf0', layout=FixedLayout('cpu', torch.float16, size=[2, 2], stride=[2, 1]), data=Reduction(
'cpu',
torch.float16,
tmp0 = load(arg0_1, i1 + 2 * r0 + 16 * i0)
return tmp0
,
ranges=[2, 2],
reduction_ranges=[8],
reduction_type=min,
origins={arg0_1, min_1}
))
Traceback (most recent call last):
File "/home/colin/miniconda3/envs/py10/lib/python3.10/site-packages/torch/_dynamo/output_graph.py", line 692, in call_user_compiler
compiled_fn = compiler_fn(gm, self.fake_example_inputs())
File "/home/colin/miniconda3/envs/py10/lib/python3.10/site-packages/torch/_dynamo/debug_utils.py", line 1047, in debug_wrapper
compiled_gm = compiler_fn(gm, example_inputs, **kwargs)
File "/home/colin/miniconda3/envs/py10/lib/python3.10/site-packages/torch/__init__.py", line 1331, in __call__
return self.compile_fn(model_, inputs_)
File "/home/colin/miniconda3/envs/py10/lib/python3.10/site-packages/torch/_dynamo/optimizations/backends.py", line 24, in inner
return fn(gm, example_inputs, **kwargs)
File "/home/colin/miniconda3/envs/py10/lib/python3.10/site-packages/torch/_dynamo/optimizations/backends.py", line 61, in inductor
return compile_fx(*args, **kwargs)
File "/home/colin/miniconda3/envs/py10/lib/python3.10/site-packages/torch/_inductor/compile_fx.py", line 413, in compile_fx
return aot_autograd(
File "/home/colin/miniconda3/envs/py10/lib/python3.10/site-packages/torch/_dynamo/optimizations/training.py", line 74, in compiler_fn
cg = aot_module_simplified(gm, example_inputs, **kwargs)
File "/home/colin/miniconda3/envs/py10/lib/python3.10/site-packages/torch/_functorch/aot_autograd.py", line 2483, in aot_module_simplified
compiled_fn = create_aot_dispatcher_function(
File "/home/colin/miniconda3/envs/py10/lib/python3.10/site-packages/torch/_dynamo/utils.py", line 160, in time_wrapper
r = func(*args, **kwargs)
File "/home/colin/miniconda3/envs/py10/lib/python3.10/site-packages/torch/_functorch/aot_autograd.py", line 2180, in create_aot_dispatcher_function
compiled_fn = compiler_fn(flat_fn, fake_flat_args, aot_config)
File "/home/colin/miniconda3/envs/py10/lib/python3.10/site-packages/torch/_functorch/aot_autograd.py", line 1411, in aot_wrapper_dedupe
return compiler_fn(flat_fn, leaf_flat_args, aot_config)
File "/home/colin/miniconda3/envs/py10/lib/python3.10/site-packages/torch/_functorch/aot_autograd.py", line 1061, in aot_dispatch_base
compiled_fw = aot_config.fw_compiler(fw_module, flat_args)
File "/home/colin/miniconda3/envs/py10/lib/python3.10/site-packages/torch/_dynamo/utils.py", line 160, in time_wrapper
r = func(*args, **kwargs)
File "/home/colin/miniconda3/envs/py10/lib/python3.10/site-packages/torch/_inductor/compile_fx.py", line 388, in fw_compiler
return inner_compile(
File "/home/colin/miniconda3/envs/py10/lib/python3.10/site-packages/torch/_dynamo/debug_utils.py", line 586, in debug_wrapper
compiled_fn = compiler_fn(gm, example_inputs, **kwargs)
File "/home/colin/miniconda3/envs/py10/lib/python3.10/site-packages/torch/_inductor/debug.py", line 239, in inner
return fn(*args, **kwargs)
File "/home/colin/miniconda3/envs/py10/lib/python3.10/contextlib.py", line 79, in inner
return func(*args, **kwds)
File "/home/colin/miniconda3/envs/py10/lib/python3.10/site-packages/torch/_inductor/compile_fx.py", line 151, in compile_fx_inner
compiled_fn = graph.compile_to_fn()
File "/home/colin/miniconda3/envs/py10/lib/python3.10/site-packages/torch/_inductor/graph.py", line 560, in compile_to_fn
return self.compile_to_module().call
File "/home/colin/miniconda3/envs/py10/lib/python3.10/site-packages/torch/_dynamo/utils.py", line 160, in time_wrapper
r = func(*args, **kwargs)
File "/home/colin/miniconda3/envs/py10/lib/python3.10/site-packages/torch/_inductor/graph.py", line 545, in compile_to_module
code = self.codegen()
File "/home/colin/miniconda3/envs/py10/lib/python3.10/site-packages/torch/_inductor/graph.py", line 496, in codegen
self.scheduler.codegen()
File "/home/colin/miniconda3/envs/py10/lib/python3.10/site-packages/torch/_dynamo/utils.py", line 160, in time_wrapper
r = func(*args, **kwargs)
File "/home/colin/miniconda3/envs/py10/lib/python3.10/site-packages/torch/_inductor/scheduler.py", line 1122, in codegen
self.get_backend(device).codegen_nodes(node.get_nodes())
File "/home/colin/miniconda3/envs/py10/lib/python3.10/site-packages/torch/_inductor/codegen/cpp.py", line 1510, in codegen_nodes
cpp_kernel_proxy.codegen_nodes(nodes)
File "/home/colin/miniconda3/envs/py10/lib/python3.10/site-packages/torch/_inductor/codegen/cpp.py", line 1410, in codegen_nodes
scalar_kernel = codegen_kernel(CppKernel)
File "/home/colin/miniconda3/envs/py10/lib/python3.10/site-packages/torch/_inductor/codegen/cpp.py", line 1382, in codegen_kernel
run(kernel)
File "/home/colin/miniconda3/envs/py10/lib/python3.10/site-packages/torch/_inductor/codegen/cpp.py", line 1399, in run
node.run(vars, reduction_vars)
File "/home/colin/miniconda3/envs/py10/lib/python3.10/site-packages/torch/_inductor/scheduler.py", line 345, in run
self.codegen(index_vars)
File "/home/colin/miniconda3/envs/py10/lib/python3.10/site-packages/torch/_inductor/scheduler.py", line 367, in codegen
self._body(*index_vars)
File "/home/colin/miniconda3/envs/py10/lib/python3.10/site-packages/torch/_inductor/ir.py", line 3911, in __call__
result = self.root_block()
File "/home/colin/miniconda3/envs/py10/lib/python3.10/site-packages/torch/_inductor/ir.py", line 4008, in __call__
return InterpreterShim(graph, submodules).run(V.get_ops_handler())
File "/home/colin/miniconda3/envs/py10/lib/python3.10/site-packages/torch/fx/interpreter.py", line 136, in run
self.env[node] = self.run_node(node)
File "/home/colin/miniconda3/envs/py10/lib/python3.10/site-packages/torch/fx/interpreter.py", line 177, in run_node
return getattr(self, n.op)(n.target, args, kwargs)
File "/home/colin/miniconda3/envs/py10/lib/python3.10/site-packages/torch/fx/interpreter.py", line 271, in call_method
return getattr(self_obj, target)(*args_tail, **kwargs)
File "/home/colin/miniconda3/envs/py10/lib/python3.10/site-packages/torch/_inductor/sizevars.py", line 591, in reduction
return self._inner.reduction(
File "/home/colin/miniconda3/envs/py10/lib/python3.10/site-packages/torch/_inductor/codegen/common.py", line 601, in reduction
return self.reduction(
File "/home/colin/miniconda3/envs/py10/lib/python3.10/site-packages/torch/_inductor/codegen/cpp.py", line 699, in reduction
float16_reduction_prefix(reduction_type)
File "/home/colin/miniconda3/envs/py10/lib/python3.10/site-packages/torch/_inductor/codegen/cpp.py", line 143, in float16_reduction_prefix
assert rtype in (
AssertionError: float16 user-defined reduction only supports 'sum' and 'any' but got min
While executing %reduction : [#users=1] = call_method[target=reduction](args = (%ops, buf0, torch.float16, torch.float16, min, %get_index_1, %load), kwargs = {})
Original traceback:
None
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "/home/colin/code/path/bug.py", line 12, in <module>
compiled(x)
File "/home/colin/miniconda3/envs/py10/lib/python3.10/site-packages/torch/_dynamo/eval_frame.py", line 211, in _fn
return fn(*args, **kwargs)
File "/home/colin/miniconda3/envs/py10/lib/python3.10/site-packages/torch/_dynamo/eval_frame.py", line 332, in catch_errors
return callback(frame, cache_size, hooks)
File "/home/colin/miniconda3/envs/py10/lib/python3.10/site-packages/torch/_dynamo/convert_frame.py", line 403, in _convert_frame
result = inner_convert(frame, cache_size, hooks)
File "/home/colin/miniconda3/envs/py10/lib/python3.10/site-packages/torch/_dynamo/convert_frame.py", line 103, in _fn
return fn(*args, **kwargs)
File "/home/colin/miniconda3/envs/py10/lib/python3.10/site-packages/torch/_dynamo/convert_frame.py", line 261, in _convert_frame_assert
return _compile(
File "/home/colin/miniconda3/envs/py10/lib/python3.10/site-packages/torch/_dynamo/utils.py", line 160, in time_wrapper
r = func(*args, **kwargs)
File "/home/colin/miniconda3/envs/py10/lib/python3.10/site-packages/torch/_dynamo/convert_frame.py", line 323, in _compile
out_code = transform_code_object(code, transform)
File "/home/colin/miniconda3/envs/py10/lib/python3.10/site-packages/torch/_dynamo/bytecode_transformation.py", line 341, in transform_code_object
transformations(instructions, code_options)
File "/home/colin/miniconda3/envs/py10/lib/python3.10/site-packages/torch/_dynamo/convert_frame.py", line 310, in transform
tracer.run()
File "/home/colin/miniconda3/envs/py10/lib/python3.10/site-packages/torch/_dynamo/symbolic_convert.py", line 1727, in run
super().run()
File "/home/colin/miniconda3/envs/py10/lib/python3.10/site-packages/torch/_dynamo/symbolic_convert.py", line 564, in run
and self.step()
File "/home/colin/miniconda3/envs/py10/lib/python3.10/site-packages/torch/_dynamo/symbolic_convert.py", line 527, in step
getattr(self, inst.opname)(inst)
File "/home/colin/miniconda3/envs/py10/lib/python3.10/site-packages/torch/_dynamo/symbolic_convert.py", line 1793, in RETURN_VALUE
self.output.compile_subgraph(self)
File "/home/colin/miniconda3/envs/py10/lib/python3.10/site-packages/torch/_dynamo/output_graph.py", line 539, in compile_subgraph
self.compile_and_call_fx_graph(tx, list(reversed(stack_values)), root)
File "/home/colin/miniconda3/envs/py10/lib/python3.10/site-packages/torch/_dynamo/output_graph.py", line 610, in compile_and_call_fx_graph
compiled_fn = self.call_user_compiler(gm)
File "/home/colin/miniconda3/envs/py10/lib/python3.10/site-packages/torch/_dynamo/utils.py", line 160, in time_wrapper
r = func(*args, **kwargs)
File "/home/colin/miniconda3/envs/py10/lib/python3.10/site-packages/torch/_dynamo/output_graph.py", line 697, in call_user_compiler
raise BackendCompilerFailed(self.compiler_fn, e) from e
torch._dynamo.exc.BackendCompilerFailed: debug_wrapper raised AssertionError: float16 user-defined reduction only supports 'sum' and 'any' but got min
While executing %reduction : [#users=1] = call_method[target=reduction](args = (%ops, buf0, torch.float16, torch.float16, min, %get_index_1, %load), kwargs = {})
Original traceback:
None
Set torch._dynamo.config.verbose=True for more information
You can suppress this exception and fall back to eager by setting:
torch._dynamo.config.suppress_errors = True
```
</details>
### Versions
```python
Collecting environment information...
PyTorch version: 2.0.0.dev20230129+cu117
Is debug build: False
CUDA used to build PyTorch: 11.7
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.5 LTS (x86_64)
GCC version: (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0
Clang version: 10.0.0-4ubuntu1
CMake version: version 3.25.0
Libc version: glibc-2.31
Python version: 3.10.9 (main, Jan 11 2023, 15:21:40) [GCC 11.2.0] (64-bit runtime)
Python platform: Linux-5.15.0-58-generic-x86_64-with-glibc2.31
Is CUDA available: True
CUDA runtime version: Could not collect
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration: GPU 0: NVIDIA GeForce RTX 2080 Ti
Nvidia driver version: 510.85.02
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.7.0
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.7.0
/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.7.0
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_infer.so.8.7.0
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.7.0
/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.7.0
/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.7.0
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] mypy-extensions==0.4.3
[pip3] numpy==1.24.1
[pip3] pytorch-triton==2.0.0+0d7e753227
[pip3] torch==2.0.0.dev20230129+cu117
[pip3] torchaudio==2.0.0.dev20230129+cu117
[pip3] torchvision==0.15.0.dev20230129+cu117
[conda] numpy 1.24.1 pypi_0 pypi
[conda] pytorch-triton 2.0.0+0d7e753227 pypi_0 pypi
[conda] torch 2.0.0.dev20230129+cu117 pypi_0 pypi
[conda] torchaudio 2.0.0.dev20230129+cu117 pypi_0 pypi
[conda] torchvision 0.15.0.dev20230129+cu117 pypi_0 pypi
```
cc @mlazos @soumith @voznesenskym @yanboliang @penguinwu @anijain2305 @EikanWang @jgong5 @Guobing-Chen @chunyuan-w @XiaobingSuper @zhuhaozhe @blzheng @Xia-Weiwen @wenzhe-nrv @jiayisunx @peterbell10 @desertfire
| 0 |
3,619 | 93,240 |
USE_CUDNN=1 doesn't force cmake to fail if cudnn is not found
|
module: build, module: cuda, triaged, enhancement, module: build warnings
|
### 🐛 Describe the bug
self explanatory
### Versions
master
cc @malfet @seemethere @ngimel
| 2 |
3,620 | 93,235 |
Well known way to request user backtrace when inside Dynamo
|
triaged, module: dynamo
|
### 🐛 Describe the bug
A nice debugging tool is to save tracebacks from library code for later. However, if you are symbolically evaluating a Dynamo frame, a user is typically interested in the USER frame, not the framework frame (which is a bunch of impenetrable gobbeldygook.) Need some global function that makes it easy to get what the current user frame (as tracked by Dynamo) is.
### Versions
master
cc @mlazos @soumith @voznesenskym @yanboliang @penguinwu @anijain2305 @EikanWang @jgong5 @Guobing-Chen @chunyuan-w @XiaobingSuper @zhuhaozhe @blzheng @Xia-Weiwen @wenzhe-nrv @jiayisunx @desertfire
| 0 |
3,621 | 93,231 |
Minifier produces minifier script that doesn't fail accuracy on Background_Matting (dynamic shapes, inductor, inference)
|
triaged, module: fx, module: functorch
|
### 🐛 Describe the bug
Original command: `TORCHDYNAMO_REPRO_AFTER="dynamo" TORCHDYNAMO_REPRO_LEVEL=4 python benchmarks/dynamo/torchbench.py --accuracy --ci --inductor --explain --only Background_Matting --dynamic-shapes`
Produced script: https://gist.github.com/aaeef0a8803356d35c5b3fcbc535a506 (after fixing bilinear problems)
```
$ python /data/users/ezyang/b/pytorch/torch_compile_debug/run_2023_01_29_10_36_06_349645/minifier/minifier_launcher.py
/data/users/ezyang/b/pytorch/torch/_inductor/compile_fx.py:89: UserWarning: TensorFloat32 tensor cores for float32 matrix multiplication available but not enabled. Consider setting `torch.set_float32_matmul_precision('high')` for better performance.
warnings.warn(
[2023-01-29 10:37:31,679] torch._dynamo.debug_utils: [ERROR] Input graph does not fail accuracy testing
```
### Versions
master 7e449e8ba701046bde5512aad60403a2b22e98a9
cc @SherlockNoMad @soumith @EikanWang @jgong5 @wenzhe-nrv @zou3519 @Chillee @samdow @kshitij12345 @janeyx99
| 0 |
3,622 | 93,230 |
Minifier does not run on LearningToPaint (dynamic shapes, inductor, inference)
|
triaged, module: inductor
|
### 🐛 Describe the bug
LearningToPaint fails accuracy with inference dynamic shapes inductor. However, the minifier never triggers even when you ask for it:
```
(/home/ezyang/local/b/pytorch-env) [ezyang@devgpu020.ftw1 ~/local/b/pytorch (dbaba22e)]$ TORCHDYNAMO_REPRO_
AFTER="aot" TORCHDYNAMO_REPRO_LEVEL=4 python benchmarks/dynamo/torchbench.py --accuracy --ci --inductor --explain --only LearningToPaint --dynamic-shapes cuda eval LearningToPaint [2023-01-29 10:24:26,025] torch._dynamo.utils: [ERROR] RMSE
(res-fp64): 0.00007, (ref-fp64): 0.00000 and shape=torch.Size([4, 65])
FAIL
Dynamo produced 1 graph(s) covering 72 ops
(/home/ezyang/local/b/pytorch-env) [ezyang@devgpu020.ftw1 ~/local/b/pytorch (dbaba22e)]$ TORCHDYNAMO_REPRO_
AFTER="dynamo" TORCHDYNAMO_REPRO_LEVEL=4 python benchmarks/dynamo/torchbench.py --accuracy --ci --inductor
--explain --only LearningToPaint --dynamic-shapes
cuda eval LearningToPaint [2023-01-29 10:25:25,055] torch._dynamo.utils: [ERROR] RMSE
(res-fp64): 0.00007, (ref-fp64): 0.00000 and shape=torch.Size([4, 65])
FAIL Dynamo produced 1 graph(s) covering 72 ops
```
### Versions
master
cc @mlazos @soumith @voznesenskym @yanboliang @penguinwu @anijain2305 @EikanWang @jgong5 @Guobing-Chen @chunyuan-w @XiaobingSuper @zhuhaozhe @blzheng @Xia-Weiwen @wenzhe-nrv @jiayisunx @peterbell10 @desertfire
| 1 |
3,623 | 93,227 |
squeezenet1_1 fails accuracy with AMP (but not on CI and dashboard); minifier does not work (when not using cuDNN?)
|
triaged, shadow review, module: amp (automated mixed precision)
|
### 🐛 Describe the bug
Passes:
```
$ python benchmarks/dynamo/torchbench.py --accuracy --ci --inductor --explain --float32 --only squeezenet1_1
cuda eval squeezenet1_1 PASS
```
Fails:
```
$ python benchmarks/dynamo/torchbench.py --accuracy --ci --inductor --explain --only squeezenet1_1 cuda eval squeezenet1_1 [2023-01-29 10:08:26,792] torch._dynamo.utils: [ERROR] RMSE
(res-fp64): 0.00684, (ref-fp64): 0.00162 and shape=torch.Size([4, 1000])
```
The generated minifier script does not work. Script: https://gist.github.com/2e8cf91ee94dc60aeb08fad36338bfd1
Fails with https://gist.github.com/ezyang/3112ada879393bbbb8c0e70d740e7fac
```
Traceback (most recent call last):
File "/data/users/ezyang/b/pytorch/torch/_dynamo/utils.py", line 1167, in run_node
return nnmodule(*args, **kwargs)
File "/data/users/ezyang/b/pytorch/torch/nn/modules/module.py", line 1488, in _call_impl
return forward_call(*args, **kwargs)
File "/data/users/ezyang/b/pytorch/torch/nn/modules/conv.py", line 463, in forward
return self._conv_forward(input, self.weight, self.bias)
File "/data/users/ezyang/b/pytorch/torch/nn/modules/conv.py", line 459, in _conv_forward
return F.conv2d(input, weight, bias, self.stride,
RuntimeError: Input type (c10::Half) and bias type (float) should be the same
```
Maybe my problem is I don't have cuDNN on this build (smh)
```
PyTorch built with:
- GCC 8.5
- C++ Version: 201703
- Intel(R) oneAPI Math Kernel Library Version 2022.1-Product Build 20220311 for Intel(R) 64 architecture applications
- Intel(R) MKL-DNN v2.7.3 (Git Hash 6dbeffbae1f23cbbeae17adb7b5b13f1f37c080e)
- OpenMP 201511 (a.k.a. OpenMP 4.5)
- LAPACK is enabled (usually provided by MKL)
- NNPACK is enabled
- CPU capability usage: AVX2
- CUDA Runtime 11.4
- NVCC architecture flags: -gencode;arch=compute_80,code=sm_80
- Magma 2.6.1
- Build settings: BLAS_INFO=mkl, BUILD_TYPE=Release, CUDA_VERSION=11.4, CXX_COMPILER=/usr/bin/c++, CXX_FLAGS= -Wno-deprecated -fvisibility-inlines-hidden -DUSE_PTHREADPOOL -fopenmp -DNDEBUG -DUSE_KINETO -DLIBKINETO_NOROCTRACER -DUSE_FBGEMM -DUSE_QNNPACK -DUSE_PYTORCH_QNNPACK -DUSE_XNNPACK -DSYMBOLICATE_MOBILE_DEBUG_HANDLE -DEDGE_PROFILER_USE_KINETO -O2 -fPIC -Wall -Wextra -Werror=return-type -Werror=non-virtual-dtor -Werror=bool-operation -Wnarrowing -Wno-missing-field-initializers -Wno-type-limits -Wno-array-bounds -Wno-unknown-pragmas -Wunused-local-typedefs -Wno-unused-parameter -Wno-unused-function -Wno-unused-result -Wno-strict-overflow -Wno-strict-aliasing -Wno-error=deprecated-declarations -Wno-stringop-overflow -Wno-psabi -Wno-error=pedantic -Wno-error=redundant-decls -Wno-error=old-style-cast -fdiagnostics-color=always -faligned-new -Wno-unused-but-set-variable -Wno-maybe-uninitialized -fno-math-errno -fno-trapping-math -Werror=format -Werror=cast-function-type -Wno-stringop-overflow, LAPACK_INFO=mkl, PERF_WITH_AVX=1, PERF_WITH_AVX2=1, PERF_WITH_AVX512=1, TORCH_DISABLE_GPU_ASSERTS=ON, TORCH_VERSION=2.0.0, USE_CUDA=ON, USE_CUDNN=OFF, USE_EXCEPTION_PTR=1, USE_GFLAGS=OFF, USE_GLOG=OFF, USE_MKL=ON, USE_MKLDNN=ON, USE_MPI=OFF, USE_NCCL=ON, USE_NNPACK=ON, USE_OPENMP=ON, USE_ROCM=OFF,
```
### Versions
master
cc @mcarilli @ptrblck @leslie-fang-intel @jgong5
| 2 |
3,624 | 93,206 |
Build from Source Issues on MacOS Ventura 13.2
|
module: build, triaged, module: macos
|
### 🐛 Describe the bug
If I build Pytorch from source on MacOS 13.2 using 'MACOSX_DEPLOYMENT_TARGET=11.0 ' I get these linker errors:
```
Undefined symbols for architecture x86_64:
"unsigned short caffe2::TypeMeta::addTypeMetaData<std::__1::unique_ptr<std::__1::atomic<bool>, std::__1::default_delete<std::__1::atomic<bool> > > >()", referenced from:
std::__1::unique_ptr<std::__1::atomic<bool>, std::__1::default_delete<std::__1::atomic<bool> > >* caffe2::Blob::GetMutable<std::__1::unique_ptr<std::__1::atomic<bool>, std::__1::default_delete<std::__1::atomic<bool> > > >() in atomic_ops.cc.o
std::__1::unique_ptr<std::__1::atomic<bool>, std::__1::default_delete<std::__1::atomic<bool> > > const& caffe2::Blob::Get<std::__1::unique_ptr<std::__1::atomic<bool>, std::__1::default_delete<std::__1::atomic<bool> > > >() const in atomic_ops.cc.o
ld: symbol(s) not found for architecture x86_64
clang: error: linker command failed with exit code 1 (use -v to see invocation)
```
If I build Pytorch from source on MacOS 13.2 using 'MACOSX_DEPLOYMENT_TARGET=10.9 ' I get these linker errors:
```
ld: warning: -pie being ignored. It is only used when linking a main executable
ld: unsupported tapi file type '!tapi-tbd' in YAML file '/Applications/Xcode.app/Contents/Developer/Platforms/MacOSX.platform/Developer/SDKs/MacOSX.sdk/usr/lib/libSystem.tbd' for architecture x86_64
clang-14: error: linker command failed with exit code 1 (use -v to see invocation)
error: command '/Users/davidlaxer/anaconda3/envs/AI-Feynman/bin/x86_64-apple-darwin13.4.0-clang' failed with exit code 1
```
I found this thread on the error message ' unsupported tapi file type '!tapi-tbd' in YAML file' on Apple Developer Support:
https://developer.apple.com/forums/thread/699629
The problem may be in this version of clang:
Python version: 3.10.9 (main, Jan 11 2023, 09:18:20) [Clang 14.0.6 ] (64-bit runtime)
Any suggestions?
### Versions
```
% python collect_env.py
Collecting environment information...
PyTorch version: 2.0.0a0+git2f0b0c5
Is debug build: False
CUDA used to build PyTorch: None
ROCM used to build PyTorch: N/A
OS: macOS 13.2 (x86_64)
GCC version: Could not collect
Clang version: 14.0.0 (clang-1400.0.29.202)
CMake version: version 3.22.1
Libc version: N/A
Python version: 3.10.9 (main, Jan 11 2023, 09:18:20) [Clang 14.0.6 ] (64-bit runtime)
Python platform: macOS-10.16-x86_64-i386-64bit
Is CUDA available: False
CUDA runtime version: No CUDA
CUDA_MODULE_LOADING set to: N/A
GPU models and configuration: No CUDA
Nvidia driver version: No CUDA
cuDNN version: No CUDA
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] audiolm-pytorch==0.0.1
[pip3] mypy-extensions==0.4.3
[pip3] numpy==1.23.5
[pip3] pytorch-transformers==1.1.0
[pip3] torch==2.0.0a0+gitf8b2879
[pip3] torch-struct==0.5
[pip3] torch-summary==1.4.5
[pip3] torch-utils==0.1.2
[pip3] torchaudio==0.13.0.dev20221015
[pip3] torchtraining-nightly==1604016577
[pip3] torchvision==0.15.0a0+8985b59
[pip3] vector-quantize-pytorch==0.9.2
[conda] nomkl 3.0 0
[conda] numpy 1.23.5 py310he50c29a_0
[conda] numpy-base 1.23.5 py310h992e150_0
[conda] pytorch-transformers 1.1.0 pypi_0 pypi
[conda] torch 2.0.0a0+gitf8b2879 pypi_0 pypi
[conda] torch-struct 0.5 pypi_0 pypi
[conda] torch-summary 1.4.5 pypi_0 pypi
[conda] torch-utils 0.1.2 pypi_0 pypi
[conda] torchaudio 0.13.0.dev20221015 pypi_0 pypi
[conda] torchtraining-nightly 1604016577 pypi_0 pypi
[conda] torchvision 0.15.0a0+8985b59 pypi_0 pypi
[conda] vector-quantize-pytorch 0.9.2 pypi_0 pypi
```
[output.txt](https://github.com/pytorch/pytorch/files/10527902/output.txt)
cc @malfet @seemethere @albanD
| 4 |
3,625 | 93,197 |
Add Support for RockChip NPUs (RKNN(2))
|
triaged, module: arm
|
### 🚀 The feature, motivation and pitch
The new generation of RockChip Socs have been released for a long time and rockchip’s Socs, they have a huge share of the arm SBC market and are pretty common in the field of SBC PCs, and they’ve been set up NPUs for some of their mainstream products for example like RK3399Pro and RK3588Family and some more, it means a lot to us and has a huge development potential, and FastDeploy from PaddlePaddle https://github.com/PaddlePaddle/FastDeploy already supported RKNN2 for RK3588Family, we hope to see PyTorch supported as well ! Thanks in advance.
Best Regards
### Alternatives
https://github.com/PaddlePaddle/FastDeploy
The following project have already been supported
Might be referable
### Additional context
_No response_
cc @malfet
| 0 |
3,626 | 93,188 |
Why is AvgPool2D taking longer than Conv2D for the same input?
|
module: performance, module: cpu, triaged
|
### 🐛 Describe the bug
I could be missing something obvious, but when I feed the same input tensor (with shape (20, 1, 28, 28)) to both AvgPool2D and Conv2D, I notice that AvgPool2D takes 56% of the running time and Conv2D takes 39% of the running time. i.e. AvgPool2D is taking 143% of the time that Conv2D is taking for the same input tensor.
Please find the reproduction here: https://colab.research.google.com/drive/1qu7Y9qe6yts7Dp4W4eL8j0Fe-5sgXQvm
Here's the code that can reproduce it (mentioned inline for readability - is the same as in the colab, which also has the output/results).
```
import torch
from torch import nn
from torch.profiler import profile, record_function, ProfilerActivity
with torch.inference_mode():
avgpool2d = nn.AvgPool2d(3, stride=1)
conv2d = nn.Conv2d(in_channels=1, out_channels=1, kernel_size=3, padding=0)
cv2d_input = torch.randn((20, 1, 28, 28))
ap2d_input = torch.randn((20, 1, 28, 28)) # conv2d(cv2d_input)
print("Shape of Conv2d Input: {}".format(cv2d_input.shape))
print("Shape of AvgPool2D Input: {}".format(ap2d_input.shape))
with profile(activities=[ProfilerActivity.CPU], profile_memory=True, record_shapes=True) as prof:
for _ in range(1000):
avgpool2d(ap2d_input)
conv2d(cv2d_input)
print(prof.key_averages().table(sort_by="cpu_time_total", row_limit=20))
```
Output:
```
Shape of Conv2d Input: torch.Size([20, 1, 28, 28])
Shape of AvgPool2D Input: torch.Size([20, 1, 28, 28])
---------------------------- ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------
Name Self CPU % Self CPU CPU total % CPU total CPU time avg CPU Mem Self CPU Mem # of Calls
---------------------------- ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------
aten::avg_pool2d 56.80% 540.816ms 56.80% 540.816ms 540.816us 51.57 Mb 51.57 Mb 1000
aten::conv2d 1.11% 10.533ms 42.40% 403.724ms 403.724us 51.57 Mb 211.25 Kb 1000
aten::convolution 1.03% 9.773ms 41.54% 395.539ms 395.539us 51.57 Mb 1.03 Mb 1000
aten::_convolution 1.09% 10.391ms 41.00% 390.432ms 390.432us 51.57 Mb 211.25 Kb 1000
aten::mkldnn_convolution 39.20% 373.237ms 39.98% 380.677ms 380.677us 51.57 Mb 5.93 Mb 1000
aten::empty 0.60% 5.713ms 0.60% 5.713ms 2.857us 51.42 Mb 51.42 Mb 2000
aten::as_strided_ 0.18% 1.727ms 0.18% 1.727ms 1.727us -5.78 Mb -5.78 Mb 1000
[memory] 0.00% 0.000us 0.00% 0.000us 0.000us -103.15 Mb -103.15 Mb 2000
---------------------------- ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------
Self CPU time total: 952.190ms
```
### Versions
1.13.1+cu116
cc @ngimel @jgong5 @mingfeima @XiaobingSuper @sanchitintel @ashokei @jingxu10
| 9 |
3,627 | 93,173 |
[RFC] PT2-Friendly Traceable, Functional Collective Communication APIs
|
oncall: distributed, triaged, oncall: pt2, module: ProxyTensor
|
### 🚀 Traceable Collectives!
Collective APIs (e.g. all_reduce, all_gather, ...) are used in distributed PyTorch programs, but do not compose cleanly with compilers.
Specifically, torchDynamo and the AotAutograd pipeline for decompositions and functionalization do not work with the existing c10d collective APIs
* there are not functional variants of these collectives
* ProcessGroup and Work objects interfere with graph tracing and pollute the IR with non-tensor objects
XLA also currently has to implement some workarounds, to marry the XLA collective ops via lazy tensor tracing with the existing PyTorch / C10D side. They have to use a custom ProcessGroup implementation and swizzle PTD PG creation functions.
**Goals**
1) provide collectives that are **traceable** with the PT2 stack and XLA stack
2) provide **functional** collectives, which are easier for IR transformations to reason about
3) support **eager and compiled** flows with the same API
4) use **plain data types** in the traced API
5) allow tracing/compilation **without requiring process group init**
6) **support different frontends** (DTensors, ProcessGroups, etc)
7) support **autograd** for collective ops
8) clean up c10d python bindings and dispatcher registrations
**Non-goals**
1) Introduce multiple stream semantics in inductor
<img width="1530" alt="image" src="https://user-images.githubusercontent.com/4984825/216402330-b78e08ff-7d51-407b-aaee-f06aca9b60ec.png">
### New traceable collectives python API
```
def collective(input:Tensor, *, group: GROUP_TYPE) -> AsyncTensor
```
`GROUP_TYPE` is a Union over List<rank>, DeviceMesh, ProcessGroup, etc. It allows flexible usage by different frontends.
`AsyncTensor` is a Tensor subclass that calls `wait()` automatically when the tensor is used by another op.
### New Dispatcher Collectives
```
aten::collective(Tensor, *, str tag, int[] ranks, int stride) -> Tensor`
```
These are the ops that actually get traced into a graph and can be manipulated by compiler passes.
The collective ops are functional, but compilers may be able to convert them to inplace. They are asynchronous.
These ops support meta device (for traceability), and support backwards via derivatives.yaml.
The semantics of these ops are that they return a real tensor, but you aren't allowed to access its data or storage.
```
c10d.wait(Tensor) -> Tensor
```
`wait()` must be called on the output of any collective before its underlying data or storage is accessed.
* It is valid to peek at the size() or stride() (or probably other metadata) of a tensor returned from a collective, but not its data.
* wait() is the only way to make an output from collectives safe to use by other non collective ops
* we are considering whether wait(collective(collective)) can be implemented safely, but by default we assume it is not
The semantics of wait are that you must only access the storage of the tensor returned from wait. You can't think of wait as mutating its input tensor and making it safe to use.
### Alternatives
The following style of API has also been considered. Its main disadvantage is in requiring a user to first initialize a processgroup, but it is also opaque and not easily interchangeable with lists of ranks or DTensors. It doesn't allow us to easily represent MPMD collectives.
```
pg = init_process_group()
pg_id = dist.register_process_group(pg)
collective(tensor, pg_id)
```
### Detailed Proposal
See [Traceable Collectives Design](https://docs.google.com/document/d/1Jqa68gvuVeFWZJFOiukmb58jAaUEET1GVMkd1GOMRT4/edit)
cc @mrshenli @pritamdamania87 @zhaojuanmao @satgera @rohan-varma @gqchen @aazzolini @osalpekar @jiayisuse @H-Huang @kwen2501 @awgu @ezyang @soumith @msaroufim @ngimel @bdhirsh
| 23 |
3,628 | 93,518 |
TorchDynamo Performance Dashboard (float32)
|
triaged, oncall: pt2
|
cc @soumith @msaroufim @wconstab @ngimel @bdhirsh
| 64 |
3,629 | 93,161 |
Segmentation fault between Numpy and Pytorch using torch.bmm
|
oncall: binaries, module: crash, triaged
|
### 🐛 Describe the bug
When running the following script (taken from the torch.bmm documentation) in terminal:
```python
# test.py
import numpy as np
import torch
mat1 = torch.randn(10, 3, 4)
mat2 = torch.randn(10, 4, 5)
res = torch.bmm(mat1, mat2)
print(res.size())
```
The terminal returns
```
> python test.py
zsh: segmentation fault python3 test.py
```
However, importing `torch` **before** `numpy` works as expected, and the terminal returns
```
> python test.py
torch.Size([10, 3, 5])
```
I am running on Python 3.9.16, Pytorch 1.13.1, and Numpy 1.21.2.
### Versions
PyTorch version: 1.13.1
Is debug build: False
CUDA used to build PyTorch: None
ROCM used to build PyTorch: N/A
OS: macOS 13.0.1 (x86_64)
GCC version: Could not collect
Clang version: 14.0.0 (clang-1400.0.29.202)
CMake version: Could not collect
Libc version: N/A
Python version: 3.9.16 (main, Jan 11 2023, 10:02:19) [Clang 14.0.6 ] (64-bit runtime)
Python platform: macOS-10.16-x86_64-i386-64bit
Is CUDA available: False
CUDA runtime version: No CUDA
CUDA_MODULE_LOADING set to: N/A
GPU models and configuration: No CUDA
Nvidia driver version: No CUDA
cuDNN version: No CUDA
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] functorch==1.13.1
[pip3] mypy-extensions==0.4.3
[pip3] numpy==1.21.2
[pip3] pytorch-lightning==1.9.0
[pip3] torch==1.13.1
[pip3] torchaudio==0.10.1
[pip3] torchcde==0.2.5
[pip3] torchdiffeq==0.2.3
[pip3] torchdyn==1.0.3
[pip3] torchmetrics==0.11.0
[pip3] torchode==0.1.3
[pip3] torchsde==0.2.5
[pip3] torchtyping==0.1.4
[pip3] torchvision==0.11.2
[conda] blas 1.0 mkl
[conda] functorch 1.13.1 pypi_0 pypi
[conda] mkl 2021.4.0 hecd8cb5_637
[conda] mkl-service 2.4.0 py39h9ed2024_0
[conda] mkl_fft 1.3.1 py39h4ab4a9b_0
[conda] mkl_random 1.2.2 py39hb2f4e1b_0
[conda] numpy 1.21.2 py39h4b4dc7a_0
[conda] numpy-base 1.21.2 py39he0bd621_0
[conda] pytorch-lightning 1.9.0 pypi_0 pypi
[conda] torch 1.13.1 pypi_0 pypi
[conda] torchaudio 0.10.1 py39_cpu pytorch
[conda] torchcde 0.2.5 pypi_0 pypi
[conda] torchdiffeq 0.2.3 pypi_0 pypi
[conda] torchdyn 1.0.3 dev_0 <develop>
[conda] torchmetrics 0.11.0 pypi_0 pypi
[conda] torchode 0.1.3 pypi_0 pypi
[conda] torchsde 0.2.5 pypi_0 pypi
[conda] torchtyping 0.1.4 pypi_0 pypi
[conda] torchvision 0.11.2 py39_cpu pytorch
cc @ezyang @seemethere @malfet
| 5 |
3,630 | 93,154 |
Support for VeLO optimizer.
|
module: optimizer, triaged, needs research
|
### 🚀 The feature, motivation and pitch
VeLO: Training Versatile Learned Optimizers by Scaling Up
https://arxiv.org/abs/2211.09760
the velo optimizer sames very good, is there any plan to support it?
### Alternatives
_No response_
### Additional context
_No response_
cc @vincentqb @jbschlosser @albanD @janeyx99
| 2 |
3,631 | 93,152 |
Dynamo doesn't support dict(list_argument)
|
triaged, oncall: pt2, module: dynamo
|
### 🐛 Describe the bug
```
import torch._dynamo
def f(x):
y = dict([('a', x)])
return y['a']
print(torch._dynamo.export(f, torch.randn(3)))
```
gives
```
File "/data/users/ezyang/b/pytorch/torch/_dynamo/symbolic_convert.py", line 526, in step
getattr(self, inst.opname)(inst)
File "/data/users/ezyang/b/pytorch/torch/_dynamo/symbolic_convert.py", line 332, in wrapper
return inner_fn(self, inst)
File "/data/users/ezyang/b/pytorch/torch/_dynamo/symbolic_convert.py", line 999, in CALL_FUNCTION
self.call_function(fn, args, {})
File "/data/users/ezyang/b/pytorch/torch/_dynamo/symbolic_convert.py", line 460, in call_function
self.push(fn.call_function(self, args, kwargs))
File "/data/users/ezyang/b/pytorch/torch/_dynamo/variables/builtin.py", line 341, in call_function
return super().call_function(tx, args, kwargs)
File "/data/users/ezyang/b/pytorch/torch/_dynamo/variables/base.py", line 230, in call_function
unimplemented(f"call_function {self} {args} {kwargs}")
File "/data/users/ezyang/b/pytorch/torch/_dynamo/exc.py", line 71, in unimplemented
raise Unsupported(msg)
torch._dynamo.exc.Unsupported: call_function BuiltinVariable(dict) [ListVariable()] {}
from user code:
File "/data/users/ezyang/b/pytorch/a.py", line 5, in f
y = dict([('a', x)])
Set torch._dynamo.config.verbose=True for more information
```
This is extracted from torchvision maskrcnn, but actually it doesn't use dict, it uses OrderedDict (but see https://github.com/pytorch/pytorch/issues/93151 ). But dict ought to work too.
### Versions
master
cc @soumith @msaroufim @wconstab @ngimel @bdhirsh @mlazos @voznesenskym @yanboliang @penguinwu @anijain2305 @EikanWang @jgong5 @Guobing-Chen @chunyuan-w @XiaobingSuper @zhuhaozhe @blzheng @Xia-Weiwen @wenzhe-nrv @jiayisunx @desertfire
| 1 |
3,632 | 93,151 |
Dynamo doesn't support OrderedDict
|
triaged, oncall: pt2, module: dynamo
|
### 🐛 Describe the bug
```
import torch._dynamo
from collections import OrderedDict
def f(x):
y = OrderedDict()
y['a'] = x
return y['a']
print(torch._dynamo.export(f, torch.randn(3)))
```
gives
```
out_code = transform_code_object(code, transform)
File "/data/users/ezyang/b/pytorch/torch/_dynamo/bytecode_transformation.py", line 341, in transform_code_object
transformations(instructions, code_options)
File "/data/users/ezyang/b/pytorch/torch/_dynamo/convert_frame.py", line 310, in transform
tracer.run()
File "/data/users/ezyang/b/pytorch/torch/_dynamo/symbolic_convert.py", line 1717, in run
super().run()
File "/data/users/ezyang/b/pytorch/torch/_dynamo/symbolic_convert.py", line 563, in run
and self.step()
File "/data/users/ezyang/b/pytorch/torch/_dynamo/symbolic_convert.py", line 526, in step
getattr(self, inst.opname)(inst)
File "/data/users/ezyang/b/pytorch/torch/_dynamo/symbolic_convert.py", line 332, in wrapper
return inner_fn(self, inst)
File "/data/users/ezyang/b/pytorch/torch/_dynamo/symbolic_convert.py", line 999, in CALL_FUNCTION
self.call_function(fn, args, {})
File "/data/users/ezyang/b/pytorch/torch/_dynamo/symbolic_convert.py", line 460, in call_function
self.push(fn.call_function(self, args, kwargs))
File "/data/users/ezyang/b/pytorch/torch/_dynamo/variables/misc.py", line 723, in call_function
unimplemented("call_function in skip_files " + path)
File "/data/users/ezyang/b/pytorch/torch/_dynamo/exc.py", line 71, in unimplemented
raise Unsupported(msg)
torch._dynamo.exc.Unsupported: call_function in skip_files /home/ezyang/local/b/pytorch-env/lib/python3.9/collections/__init__.py
from user code:
File "/data/users/ezyang/b/pytorch/a.py", line 5, in f
y = OrderedDict()
```
This code was extracted from torchvision maskrcnn.
### Versions
master
cc @soumith @msaroufim @wconstab @ngimel @bdhirsh @mlazos @voznesenskym @yanboliang @penguinwu @anijain2305 @EikanWang @jgong5 @Guobing-Chen @chunyuan-w @XiaobingSuper @zhuhaozhe @blzheng @Xia-Weiwen @wenzhe-nrv @jiayisunx @desertfire
| 2 |
3,633 | 93,134 |
Failed to Open libnvrtc-builtins.so.11.7
|
oncall: jit, module: cuda
|
### 🐛 Describe the bug
When running a model with a custom layer jitted with torchscript, the following error is thrown when attempting to use it via Rust bindings (e.g. tch):
```
panicked at 'called `Result::unwrap()` on an `Err` value: Torch("The following operation failed in the TorchScript interpreter.
Traceback of TorchScript (most recent call last):
RuntimeError: false INTERNAL ASSERT FAILED at \"../torch/csrc/jit/codegen/cuda/executor_utils.cpp
--A BUNCH OF C++ TRASH--
CUDA NVRTC compile error: nvrtc: error: failed to open libnvrtc-builtins.so.11.7. Make sure that libnvrtc-builtins.so.11.7 is installed correctly.")'
```
I've installed libtorch via the Pytorch download and it actually has the shared library `libnvrtc-builtins.so.11.7` but it's named `libnvrtc-builtins-7237cb5d.so.11.7` or some other thing. Anyways, the simple workaround is to literally rename the shared library to `libnvrtc-builtins.so.11.7`, but I suppose this isn't desirable since there's a reason it's named this.
The example model is huge but I was able to narrow it down to the layer that triggers this. I don't know if the layer, itself, triggers this, but if you bolt it onto a bigger model, it seems to trigger the tomfoolery described above:
```
from torch import Module
import math
import torch
class NormalOutputLayer(Module):
"""
An output layer that takes in an 2N inputs which represent the means and standard deviations of n normal
distributions, and outputs N elements that are sampled from those distributions.
:param samples: Number of samples to draw.
:param reduce: Reduction method. Can be "mean," "mean_std,", "median," "49th", "49th_std", "sum," or None.
Default is None.
"""
def __init__(self, samples: int = 1, reduce: str = None):
super(NormalOutputLayer, self).__init__()
if samples <= 0:
raise ValueError(f"Samples must be an integer greater than 0")
if (
reduce is not None
and reduce != "mean"
and reduce != "sum"
and reduce != "mean_std"
and reduce != "median"
and reduce != "49th"
and reduce != "49th_std"
):
raise ValueError(f"Unknown reduction method: {reduce}")
self.samples = samples
self.reduce = reduce
def forward(self, mu: torch.Tensor, sigma: torch.Tensor):
"""
Dynamically generates normal distributions and samples from them. This layer will take the elements along the
last axis and use the first half of the values as the mu values and the last half as the sigma values.
:param mu: Tensor that contains the means.
:param sigma: Tensor that contains the standard deviations.
:return: N samples from a normal distribution that have been reduced appropriately.
"""
if mu.size() != sigma.size():
raise ValueError(
f"mu tensor and sigma tensor are not equal: {mu.size()} vs {sigma.size()}"
)
# Squeeze batched input that has only one element.
if len(mu.size()) == 2 and mu.size()[0] == 1:
manually_batch_output = True
mu = torch.squeeze(mu)
sigma = torch.squeeze(sigma)
else:
manually_batch_output = False
normal_dist = Normal(loc=mu, scale=sigma)
# Re-parametrization trick (ref: https://stackoverflow.com/q/60533150/16070598)
samples = normal_dist.rsample(sample_shape=[self.samples])
if self.reduce == "mean":
result = torch.mean(samples, dim=0)
return torch.unsqueeze(result, dim=0) if manually_batch_output else result
elif self.reduce == "sum":
result = torch.sum(samples, dim=0)
return torch.unsqueeze(result, dim=0) if manually_batch_output else result
elif self.reduce == "mean_std":
std, mean = torch.std_mean(samples, dim=0)
result = torch.transpose(torch.stack((mean, std)), 0, 1)
return torch.unsqueeze(result, dim=0) if manually_batch_output else result
elif self.reduce == "median":
result = torch.quantile(samples, 0.5, dim=0)
return torch.unsqueeze(result, dim=0) if manually_batch_output else result
elif self.reduce == "49th":
result = torch.quantile(samples, 0.49, dim=0)
return torch.unsqueeze(result, dim=0) if manually_batch_output else result
elif self.reduce == "49th_std":
quantile = torch.quantile(samples, 0.49, dim=0)
std = torch.std(samples, dim=0)
result = torch.transpose(torch.stack((quantile, std)), 0, 1)
return torch.unsqueeze(result, dim=0) if manually_batch_output else result
elif self.reduce is None:
return torch.unsqueeze(samples, dim=0) if manually_batch_output else samples
else:
raise ValueError(f"Unknown reduce method: {self.reduce}")
```
The `Normal` class is as follows:
```
import math
import torch
class Normal:
"""
Creates a normal (also called Gaussian) distribution parameterized by
:attr:`loc` and :attr:`scale`. This is a copy of PyTorch's
torch.distributions.Normal class that is compatiable with PyTorch's
JIT script operation.
Example::
>>> # xdoctest: +IGNORE_WANT("non-deterinistic")
>>> m = Normal(torch.tensor([0.0]), torch.tensor([1.0]))
>>> m.sample() # normally distributed with loc=0 and scale=1
tensor([ 0.1046])
Args:
loc (float or Tensor): mean of the distribution (often referred to as mu)
scale (float or Tensor): standard deviation of the distribution
(often referred to as sigma)
"""
@property
def mean(self):
return self.loc
@property
def stddev(self):
return self.scale
@property
def variance(self):
return self.stddev.pow(2)
def __init__(self, loc: torch.Tensor, scale: torch.Tensor):
resized_ = torch.broadcast_tensors(loc, scale)
self.loc = resized_[0]
self.scale = resized_[1]
self._batch_shape = list(self.loc.size())
def _extended_shape(self, sample_shape: list[int]) -> list[int]:
return sample_shape + self._batch_shape
def sample(self, sample_shape: list[int]) -> torch.Tensor:
shape = self._extended_shape(sample_shape)
return torch.normal(self.loc.expand(shape), self.scale.expand(shape))
def rsample(self, sample_shape: list[int]) -> torch.Tensor:
shape: list[int] = self._extended_shape(sample_shape)
eps = torch.normal(
torch.zeros(shape, device=self.loc.device),
torch.ones(shape, device=self.scale.device),
)
return self.loc + eps * self.scale
def log_prob(self, value: torch.Tensor) -> torch.Tensor:
var = self.scale**2
log_scale = self.scale.log()
return (
-((value - self.loc) ** 2) / (2 * var)
- log_scale
- math.log(math.sqrt(2 * math.pi))
)
def entropy(self) -> torch.Tensor:
return 0.5 + 0.5 * math.log(2 * math.pi) + torch.log(self.scale)
```
### Versions
```
Collecting environment information...
PyTorch version: 1.13.0
Is debug build: False
CUDA used to build PyTorch: 11.6
ROCM used to build PyTorch: N/A
OS: Pop!_OS 22.04 LTS (x86_64)
GCC version: (Ubuntu 11.3.0-1ubuntu1~22.04) 11.3.0
Clang version: Could not collect
CMake version: version 3.22.1
Libc version: glibc-2.35
Python version: 3.10.6 (main, Oct 24 2022, 16:07:47) [GCC 11.2.0] (64-bit runtime)
Python platform: Linux-6.0.12-76060006-generic-x86_64-with-glibc2.35
Is CUDA available: True
CUDA runtime version: 11.6.124
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration: GPU 0: NVIDIA GeForce RTX 2080 Super with Max-Q Design
Nvidia driver version: 515.65.01
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] mypy-extensions==0.4.3
[pip3] numpy==1.23.3
[pip3] torch==1.13.0
[pip3] torchaudio==0.13.0
[pip3] torchvision==0.14.0
[conda] blas 1.0 mkl
[conda] ffmpeg 4.3 hf484d3e_0 pytorch
[conda] mkl 2021.4.0 h06a4308_640
[conda] mkl-service 2.4.0 py310h7f8727e_0
[conda] mkl_fft 1.3.1 py310hd6ae3a3_0
[conda] mkl_random 1.2.2 py310h00e6091_0
[conda] numpy 1.23.3 py310hd5efca6_1
[conda] numpy-base 1.23.3 py310h8e6c178_1
[conda] pytorch 1.13.0 py3.10_cuda11.6_cudnn8.3.2_0 pytorch
[conda] pytorch-cuda 11.6 h867d48c_0 pytorch
[conda] pytorch-mutex 1.0 cuda pytorch
[conda] torchaudio 0.13.0 py310_cu116 pytorch
[conda] torchvision 0.14.0 py310_cu116 pytorch
```
cc @EikanWang @jgong5 @wenzhe-nrv @sanchitintel @ngimel
| 2 |
3,634 | 93,121 |
[RFC] Flop counters in PyTorch
|
feature, triaged, module: python frontend
|
### 🚀 The feature, motivation and pitch
Lots of people have built flop counters/asked for FLOP counters (or other performance counters) in PyTorch. There's a litany of requests, but some common ones include: 1. coverage (i.e. no restrictions on how the model is written, capturing backwards, etc.), 2. module-level grouping, 3. customization (i.e. being able to modify flop formulas), and 4. Capturing metrics other than FLOPs (like memory bandwidth).
There's another factor that's relevant with `PyTorch 2.0`, which is whether it works in eager-mode or under `torch.compile`. Some of these features are a lot of easier to do in eager mode (coverage/module-level grouping), and others are a lot easier to do in compiled mode (capturing memory bandwidth or non-matmul FLOPs).
I propose we add 2 different flop counters to PyTorch, one that's eager based and one that's graph based.
The eager one (implemented similarly to [this](https://dev-discuss.pytorch.org/t/the-ideal-pytorch-flop-counter-with-torch-dispatch/505/5)).
- Works with all operations in eager mode (forwards, backwards, checkpointing, functorch, w.e.)
- Only counts GMACs (no memory accesses, no non-matmul FLOPs)
- Provides module-level breakdowns
- Provides a context manager API where it counts all flops executed within the context manager.
- Provides an API where you can override formulas for each (aten) op.
Compiled flop counter:
- Works with ... most operations in eager mode (the stuff that torch.compile can compile at least).
- Can count FLOPs (for some formula for it...) and memory accesses.
- Does not provide module-level breakdowns.
- Probably also a context manager API.
- No easy API for overriding formulas for each op (I guess we can provide a way to say, map cos to however many flops you want, but that's less clear).
cc: @Jokeren @rwightman, @ppwwyyxx. @ezyang
### Alternatives
N/A
### Additional context
_No response_
cc @albanD
| 8 |
3,635 | 93,081 |
[Releng] [Conda] Optimize PyTorch packaging
|
oncall: releng, triaged
|
### 🐛 Describe the bug
We should publish `libtorch` package on Anaconda (that contains Python independent bulky library `libtorch_cpu/libtorch_cuda` and others) and make `pytorch` depend on it
### Versions
1.13
| 0 |
3,636 | 93,061 |
DISABLED test_inplace_grad_index_put_cuda_float64 (__main__.TestBwdGradientsCUDA)
|
module: cuda, triaged, module: flaky-tests, skipped, module: unknown, oncall: pt2
|
Platforms: inductor
This test was disabled because it is failing in CI. See [recent examples](https://hud.pytorch.org/flakytest?name=test_inplace_grad_index_put_cuda_float64&suite=TestBwdGradientsCUDA) and the most recent trunk [workflow logs](https://github.com/pytorch/pytorch/runs/10898454314).
Over the past 3 hours, it has been determined flaky in 3 workflow(s) with 3 failures and 3 successes.
**Debugging instructions (after clicking on the recent samples link):**
DO NOT ASSUME THINGS ARE OKAY IF THE CI IS GREEN. We now shield flaky tests from developers so CI will thus be green but it will be harder to parse the logs.
To find relevant log snippets:
1. Click on the workflow logs linked above
2. Click on the Test step of the job so that it is expanded. Otherwise, the grepping will not work.
3. Grep for `test_inplace_grad_index_put_cuda_float64`
4. There should be several instances run (as flaky tests are rerun in CI) from which you can study the logs.
cc @ptrblck @ezyang @msaroufim @wconstab @bdhirsh @anijain2305 @ngimel
| 25 |
3,637 | 93,045 |
DISABLED test_forward_mode_AD_linalg_det_singular_cuda_complex128 (__main__.TestFwdGradientsCUDA)
|
module: autograd, module: rocm, triaged, module: flaky-tests, skipped
|
Platforms: rocm
This test was disabled because it is failing on master ([recent examples](http://torch-ci.com/failure/FAILED%20test_ops_fwd_gradients.py%3A%3ATestFwdGradientsCUDA%3A%3Atest_forward_mode_AD_linalg_det_singular_cuda_complex128%20-%20torch.autograd.gradcheck.GradcheckError%3A%20While%20considering%20the%20imaginary%20part%20of%20complex%20inputs%20only%2C%20Jacobian%20computed%20with%20forward%20mode%20mismatch%20for%20output%200%20with%20respect%20to%20input%200%2C)).
cc @ezyang @albanD @zou3519 @gqchen @pearu @nikitaved @soulitzer @Lezcano @Varal7 @jeffdaily @sunway513 @jithunnair-amd @pruthvistony @ROCmSupport
| 8 |
3,638 | 93,044 |
DISABLED test_fn_grad_linalg_det_singular_cuda_complex128 (__main__.TestBwdGradientsCUDA)
|
module: autograd, module: rocm, triaged, module: flaky-tests, skipped
|
Platforms: rocm
This test was disabled because it is failing on master ([recent examples](http://torch-ci.com/failure/FAILED%20test_ops_gradients.py%3A%3ATestBwdGradientsCUDA%3A%3Atest_fn_grad_linalg_det_singular_cuda_complex128%20-%20torch.autograd.gradcheck.GradcheckError%3A%20While%20considering%20the%20imaginary%20part%20of%20complex%20outputs%20only%2C%20Jacobian%20mismatch%20for%20output%200%20with%20respect%20to%20input%200%2C)).
```
2023-02-11T01:56:39.7602066Z ____ TestBwdGradientsCUDA.test_fn_grad_linalg_det_singular_cuda_complex128 _____
2023-02-11T01:56:39.7602422Z Traceback (most recent call last):
2023-02-11T01:56:39.7602787Z File "/var/lib/jenkins/pytorch/test/test_ops_gradients.py", line 26, in test_fn_grad
2023-02-11T01:56:39.7603184Z self._grad_test_helper(device, dtype, op, op.get_op())
2023-02-11T01:56:39.7603774Z File "/opt/conda/envs/py_3.8/lib/python3.8/site-packages/torch/testing/_internal/common_utils.py", line 4266, in _grad_test_helper
2023-02-11T01:56:39.7604415Z return self._check_helper(device, dtype, op, variant, 'gradcheck', check_forward_ad=check_forward_ad,
2023-02-11T01:56:39.7605075Z File "/opt/conda/envs/py_3.8/lib/python3.8/site-packages/torch/testing/_internal/common_utils.py", line 4235, in _check_helper
2023-02-11T01:56:39.7605514Z self.assertTrue(gradcheck(fn, gradcheck_args,
2023-02-11T01:56:39.7606082Z File "/opt/conda/envs/py_3.8/lib/python3.8/site-packages/torch/testing/_internal/common_utils.py", line 3790, in gradcheck
2023-02-11T01:56:39.7606529Z return torch.autograd.gradcheck(fn, inputs, **kwargs)
2023-02-11T01:56:39.7607096Z File "/opt/conda/envs/py_3.8/lib/python3.8/site-packages/torch/autograd/gradcheck.py", line 1470, in gradcheck
2023-02-11T01:56:39.7607468Z return _gradcheck_helper(**args)
2023-02-11T01:56:39.7608020Z File "/opt/conda/envs/py_3.8/lib/python3.8/site-packages/torch/autograd/gradcheck.py", line 1484, in _gradcheck_helper
2023-02-11T01:56:39.7608503Z _gradcheck_real_imag(gradcheck_fn, func, func_out, tupled_inputs, outputs, eps,
2023-02-11T01:56:39.7609132Z File "/opt/conda/envs/py_3.8/lib/python3.8/site-packages/torch/autograd/gradcheck.py", line 1104, in _gradcheck_real_imag
2023-02-11T01:56:39.7609590Z gradcheck_fn(imag_fn, imag_func_out, tupled_inputs, imag_outputs, eps,
2023-02-11T01:56:39.7610268Z File "/opt/conda/envs/py_3.8/lib/python3.8/site-packages/torch/autograd/gradcheck.py", line 1363, in _fast_gradcheck
2023-02-11T01:56:39.7610751Z _check_analytical_numerical_equal(analytical_vJu, numerical_vJu, complex_indices,
2023-02-11T01:56:39.7611411Z File "/opt/conda/envs/py_3.8/lib/python3.8/site-packages/torch/autograd/gradcheck.py", line 1335, in _check_analytical_numerical_equal
2023-02-11T01:56:39.7611948Z raise GradcheckError(_get_notallclose_msg(a, n, j, i, complex_indices, test_imag, is_forward_ad) + jacobians_str)
2023-02-11T01:56:39.7612577Z torch.autograd.gradcheck.GradcheckError: While considering the imaginary part of complex outputs only, Jacobian mismatch for output 0 with respect to input 0,
2023-02-11T01:56:39.7613233Z numerical:tensor(-0.0969+0.7254j, device='cuda:0', dtype=torch.complex128)
2023-02-11T01:56:39.7613704Z analytical:tensor(0.+0.j, device='cuda:0', dtype=torch.complex128)
2023-02-11T01:56:39.7613922Z
2023-02-11T01:56:39.7614193Z The above quantities relating the numerical and analytical jacobians are computed
2023-02-11T01:56:39.7614644Z in fast mode. See: https://github.com/pytorch/pytorch/issues/53876 for more background
2023-02-11T01:56:39.7615095Z about fast mode. Below, we recompute numerical and analytical jacobians in slow mode:
2023-02-11T01:56:39.7615334Z
2023-02-11T01:56:39.7615410Z Numerical:
2023-02-11T01:56:39.7615691Z tensor([[-0.7813+0.5384j],
2023-02-11T01:56:39.7615976Z [ 0.3935-1.0799j],
2023-02-11T01:56:39.7616235Z [-0.5603-0.2725j],
2023-02-11T01:56:39.7616509Z [-0.0583-0.5772j],
2023-02-11T01:56:39.7616730Z [ 0.4626+0.5289j],
2023-02-11T01:56:39.7616982Z [ 0.3111-0.2199j],
2023-02-11T01:56:39.7617250Z [ 1.1665-0.1440j],
2023-02-11T01:56:39.7617517Z [-1.0504+0.9609j],
2023-02-11T01:56:39.7617888Z [ 0.4595+0.6201j]], device='cuda:0', dtype=torch.complex128)
2023-02-11T01:56:39.7618174Z Analytical:
2023-02-11T01:56:39.7618395Z tensor([[0.+0.j],
2023-02-11T01:56:39.7618602Z [0.+0.j],
2023-02-11T01:56:39.7618815Z [0.+0.j],
2023-02-11T01:56:39.7619026Z [0.+0.j],
2023-02-11T01:56:39.7619221Z [0.+0.j],
2023-02-11T01:56:39.7619424Z [0.+0.j],
2023-02-11T01:56:39.7619627Z [0.+0.j],
2023-02-11T01:56:39.7619816Z [0.+0.j],
2023-02-11T01:56:39.7620170Z [0.+0.j]], device='cuda:0', dtype=torch.complex128)
2023-02-11T01:56:39.7620363Z
2023-02-11T01:56:39.7620614Z The max per-element difference (slow mode) is: 1.4236150551283344.
```
cc @ezyang @albanD @zou3519 @gqchen @pearu @nikitaved @soulitzer @Lezcano @Varal7 @jeffdaily @sunway513 @jithunnair-amd @pruthvistony @ROCmSupport
| 7 |
3,639 | 93,017 |
numpy v1.24 does not work with `writer.add_histogram`
|
triaged, module: tensorboard
|
### 🐛 Describe the bug
https://github.com/pytorch/pytorch/blob/664058fa83f1d8eede5d66418abff6e20bd76ca8/torch/utils/tensorboard/summary.py#L380
There is a problem when running this using the latest numpy v1.24.
This is an example of the type of error I get:
```
>>> import numpy as np
>>> a = np.random.randint(0, 100, 10)
>>> np.greater(a, 0, dtype=np.int64)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: No loop matching the specified signature and casting was found for ufunc greater
```
When using any version of numpy 1.23 or earlier, this error does not come up.
### Versions
```
Collecting environment information...
PyTorch version: 1.12.1
Is debug build: False
CUDA used to build PyTorch: 11.3
ROCM used to build PyTorch: N/A
OS: Ubuntu 18.04.1 LTS (x86_64)
GCC version: (Ubuntu 8.4.0-1ubuntu1~18.04) 8.4.0
Clang version: 6.0.0-1ubuntu2 (tags/RELEASE_600/final)
CMake version: version 3.25.2
Libc version: glibc-2.27
Python version: 3.8.15 | packaged by conda-forge | (default, Nov 22 2022, 08:49:35) [GCC 10.4.0] (64-bit runtime)
Python platform: Linux-4.15.0-136-generic-x86_64-with-glibc2.10
Is CUDA available: True
CUDA runtime version: 11.1.74
CUDA_MODULE_LOADING set to:
GPU models and configuration:
GPU 0: GeForce GTX 1080 Ti
GPU 1: GeForce GTX 1080 Ti
GPU 2: TITAN V
GPU 3: TITAN V
GPU 4: TITAN V
GPU 5: Tesla V100-PCIE-16GB
GPU 6: Quadro GP100
GPU 7: Quadro GP100
Nvidia driver version: 455.23.05
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.24.1
[pip3] torch==1.12.1
[pip3] torchaudio==0.12.1
[pip3] torchvision==0.13.1
[conda] blas 2.116 mkl conda-forge
[conda] blas-devel 3.9.0 16_linux64_mkl conda-forge
[conda] cudatoolkit 11.3.1 h9edb442_11 conda-forge
[conda] ffmpeg 4.3 hf484d3e_0 pytorch
[conda] libblas 3.9.0 16_linux64_mkl conda-forge
[conda] libcblas 3.9.0 16_linux64_mkl conda-forge
[conda] liblapack 3.9.0 16_linux64_mkl conda-forge
[conda] liblapacke 3.9.0 16_linux64_mkl conda-forge
[conda] mkl 2022.1.0 h84fe81f_915 conda-forge
[conda] mkl-devel 2022.1.0 ha770c72_916 conda-forge
[conda] mkl-include 2022.1.0 h84fe81f_915 conda-forge
[conda] numpy 1.24.1 py38hab0fcb9_0 conda-forge
[conda] pytorch 1.12.1 py3.8_cuda11.3_cudnn8.3.2_0 pytorch
[conda] pytorch-mutex 1.0 cuda pytorch
[conda] torchaudio 0.12.1 py38_cu113 pytorch
[conda] torchvision 0.13.1 py38_cu113 pytorch
```
| 0 |
3,640 | 93,009 |
ptxas segfault with PT2
|
triaged, oncall: pt2, module: inductor
|
### 🐛 Describe the bug
Sometimes ptxas segfaults when you trigger it via Triton/Inductor/PT2. Apparently the new Triton MLIR rewrite is supposed to fix it.
It looks something like this
```
(/home/ezyang/local/a/pytorch-env) [ezyang@devgpu020.ftw1 ~/local/a/pytorch (20bf77f9)]$ python benchmark
s/dynamo/torchbench.py --ci --amp --inductor --accuracy --training --only dlrm
cuda train dlrm sh: line 1: 3723415 Segmentation fault (core dumped) p
txas -v --gpu-name=sm_80 /tmp/file1TgA5S -o /tmp/file1TgA5S.o 2> /tmp/filebVYSuU
ERROR:common:Internal Triton PTX codegen error:
concurrent.futures.process._RemoteTraceback:
"""
```
### Versions
master
cc @soumith @msaroufim @wconstab @ngimel @bdhirsh @mlazos @voznesenskym @yanboliang @penguinwu @anijain2305 @EikanWang @jgong5 @Guobing-Chen @chunyuan-w @XiaobingSuper @zhuhaozhe @blzheng @Xia-Weiwen @wenzhe-nrv @jiayisunx @peterbell10 @desertfire
| 2 |
3,641 | 93,002 |
Replace pattern fails on incompatible function arguments
|
oncall: fx
|
### 🐛 Describe the bug
replace_pattern fails on incompatible function arguments in Replacement. Expectation is Tensor and it receives a Proxy.
```
import torch
from torch.fx import symbolic_trace, replace_pattern
class LN(torch.nn.Module):
def __init__(self, h):
super().__init__()
self.model = torch.nn.LayerNorm(h)
def forward(self, input):
out = self.model(input)
return out
class Pattern(torch.nn.Module):
def __init__(self, h):
super().__init__()
self.model = torch.nn.LayerNorm(h)
def forward(self, input):
out = self.model(input)
return out
class Replacement(torch.nn.Module):
def __init__(self, h):
super().__init__()
from apex.contrib.layer_norm.layer_norm import FastLayerNorm
self.model = FastLayerNorm(h)
def forward(self, input):
out = self.model(input)
return out
def test_ln():
shape = (4,512,2048)
in_t = torch.rand(shape, device='cuda', dtype=torch.float16)
net = LN(2048).cuda().half()
traced_module = symbolic_trace(net)
replace_pattern(traced_module, Pattern(2048), Replacement(2048))
outputs = traced_module(in_t)
test_ln()
```
This is the error produced
```
Traceback (most recent call last):
File "/scratch/mojitos/debug_scripts/temp.py", line 41, in <module>
test_ln()
File "/scratch/mojitos/debug_scripts/temp.py", line 37, in test_ln
replace_pattern(traced_module, Pattern(2048), Replacement(2048))
File "/opt/pytorch/pytorch/torch/fx/subgraph_rewriter.py", line 196, in replace_pattern
match_and_replacements = _replace_pattern(gm, pattern, replacement)
File "/opt/pytorch/pytorch/torch/fx/subgraph_rewriter.py", line 244, in _replace_pattern
replacement_graph = symbolic_trace(replacement).graph
File "/opt/pytorch/pytorch/torch/fx/_symbolic_trace.py", line 1070, in symbolic_trace
graph = tracer.trace(root, concrete_args)
File "/opt/pytorch/pytorch/torch/fx/_symbolic_trace.py", line 739, in trace
(self.create_arg(fn(*args)),),
File "/scratch/mojitos/debug_scripts/temp.py", line 29, in forward
out = self.model(input)
File "/opt/pytorch/pytorch/torch/fx/_symbolic_trace.py", line 717, in module_call_wrapper
return self.call_module(mod, forward, args, kwargs)
File "/opt/pytorch/pytorch/torch/fx/_symbolic_trace.py", line 434, in call_module
return forward(*args, **kwargs)
File "/opt/pytorch/pytorch/torch/fx/_symbolic_trace.py", line 710, in forward
return _orig_module_call(mod, *args, **kwargs)
File "/opt/pytorch/pytorch/torch/nn/modules/module.py", line 1488, in _call_impl
return forward_call(*args, **kwargs)
File "/usr/local/lib/python3.10/site-packages/apex/contrib/layer_norm/layer_norm.py", line 53, in forward
return _fast_layer_norm(x, self.weight, self.bias, self.epsilon)
File "/usr/local/lib/python3.10/site-packages/apex/contrib/layer_norm/layer_norm.py", line 37, in _fast_layer_norm
return FastLayerNormFN.apply(*args)
File "/opt/pytorch/pytorch/torch/autograd/function.py", line 453, in apply
return super().apply(*args, **kwargs)
File "/usr/local/lib/python3.10/site-packages/apex/contrib/layer_norm/layer_norm.py", line 16, in forward
ymat, mu, rsigma = fast_layer_norm.ln_fwd(xmat, gamma, beta, epsilon)
TypeError: ln_fwd(): incompatible function arguments. The following argument types are supported:
1. (arg0: torch.Tensor, arg1: torch.Tensor, arg2: torch.Tensor, arg3: float) -> List[torch.Tensor]
Invoked with: Proxy(view), Proxy(contiguous_1), Proxy(contiguous_2), 1e-05
```
### Versions
```
Collecting environment information...
PyTorch version: 2.0.0a0+git5e0d345
Is debug build: False
CUDA used to build PyTorch: 12.0
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.5 LTS (x86_64)
GCC version: (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0
Clang version: Could not collect
CMake version: version 3.25.0
Libc version: glibc-2.31
Python version: 3.10.9 (main, Jan 17 2023, 00:37:25) [GCC 9.4.0] (64-bit runtime)
Python platform: Linux-4.15.0-142-generic-x86_64-with-glibc2.31
Is CUDA available: True
CUDA runtime version: 12.0.140
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration: GPU 0: NVIDIA A100 80GB PCIe
Nvidia driver version: 525.60.13
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.7.0
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.7.0
/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.7.0
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_infer.so.8.7.0
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.7.0
/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.7.0
/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.7.0
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.23.5
[pip3] torch==2.0.0a0+git5e0d345
[pip3] torchvision==0.15.0a0+035d99f
[conda] Could not collect
```
cc @ezyang @SherlockNoMad @EikanWang @jgong5 @wenzhe-nrv
| 0 |
3,642 | 92,998 |
[BE] Improve FSDP <> AC Unit Tests
|
oncall: distributed, triaged, module: fsdp
|
Composing PyTorch Fully Sharded Data Parallel (FSDP) and activation checkpointing (AC) is tested in [`test_fsdp_checkpoint.py`](https://github.com/pytorch/pytorch/blob/master/test/distributed/fsdp/test_fsdp_checkpoint.py). While we have used FSDP and AC together in several real workloads, our unit tests warrant a revamp. This issue tracks some questions and work items.
**Existing Unit Tests**
- [ ] What is the difference between `test_basic_checkpoint_end_to_end()` and `test_checkpoint_fsdp_wrapping()`? Is one a superset of the other?
- It looks like `test_basic_checkpoint_end_to_end` does not use any nested application of FSDP or AC, while `test_checkpoint_fsdp_wrapping()` does. In that case, can we consolidate to just one with nested application (which represents real use cases)?
- [ ] `test_basic_checkpoint_end_to_end()` and `test_checkpoint_fsdp_wrapping()` test checkpointing the root module (i.e. entire model). Should we include that in our unit tests?
- Checkpointing the root module implies re-running the entire forward pass in the backward pass and is not realistic.
- FSDP <> AC does not preserve inductive tree structure. Even if `Checkpoint(FSDP(module))` works for a root module `module`, that does not imply that using that having `Checkpoint(FSDP(module))` as a submodule in a larger module tree will continue to work.
- [ ] `test_basic_checkpoint_end_to_end()` and `test_checkpoint_fsdp_wrapping()` do not test the non-reentrant checkpointing implementation. However, adding tests for it leads to some errors:
- In `test_basic_checkpoint_end_to_end()`, `checkpointed_fsdp` fails for non-reentrant.
- In `test_checkpoint_fsdp_wrapping()`, `ckpt_sequential_wrapped_fsdp` fails for non-reentrant. This one might be fixable by modifying FSDP's `pre_forward` and `post_forward` to skip if the handle training state is `BACKWARD_PRE`.
**Adding Unit Tests**
https://github.com/pytorch/pytorch/pull/92935 is a draft PR adding unit tests for several more ways to compose FSDP with AC. We may choose to land or not depending on feedback.
After resolving these items, we should consider doing the same for `fully_shard` <> `_composable.checkpoint`.
cc @mrshenli @pritamdamania87 @zhaojuanmao @satgera @rohan-varma @gqchen @aazzolini @osalpekar @jiayisuse @H-Huang @kwen2501
| 0 |
3,643 | 92,990 |
Feature request: access to variable
|
oncall: transformer/mha
|
### 🚀 The feature, motivation and pitch
In `torch.nn.functional.multi_head_attention_forward`, there is a variable, `use_separate_proj_weight` that can not be controled by the users of Transformers. I would have liked to use NON-shared weights.
In `torch.nn.modules.transformers.TransformerEncoderLayer.self_attn`, during the forward, use_separate_proj_weight is set to False only in the case where the dimensions for Q, K, V are not the same. This is verified during initialisation of self_attn. But user can't control this if dimensions are the same.
(same with the decoder)
Could you add an option to control if weights are shared? Thank you very much!
### Alternatives
_No response_
### Additional context
_No response_
cc @jbschlosser @bhosmer @cpuhrsch @erichan1
| 0 |
3,644 | 92,987 |
Test Failure: TestUpgraders.test_aten_div_scalar_at_3 on a big-endian machine (issue in torch.jit.load())
|
oncall: jit
|
### 🐛 Describe the bug
When I execute the following test case on a big-endian machine, I got the test failure due to the runtime error. We expect that this test should also pass on a big-endian machine.
```python
$ python test/test_jit.py TestUpgraders.test_aten_div_scalar_at_3
CUDA not available, skipping tests
monkeytype is not installed. Skipping tests for Profile-Directed Typing
E
======================================================================
ERROR: test_aten_div_scalar_at_3 (jit.test_upgraders.TestUpgraders)
----------------------------------------------------------------------
Traceback (most recent call last):
File "/home/ishizaki/PyTorch/master/test/jit/test_upgraders.py", line 246, in test_aten_div_scalar_at_3
loaded_model = torch.jit.load(model_path)
File "/home/ishizaki/PyTorch/master/torch/jit/_serialization.py", line 162, in load
cpp_module = torch._C.import_ir_module(cu, str(f), map_location, _extra_files)
RuntimeError: Unexpected end of pickler archive.
```
The minimum program to reproduce this issue is here. So, `torch.jit.load()` does not seem to work correctly on a big-endian platform.
```python
import torch
loaded_model = torch.jit.load("test/jit/fixtures/test_versioned_div_scalar_float_v3.pt")
```
I believe that `torch.jit.load()` reads the multiple-byte data without swapping on a big-endian machine while pickle serialization store data as mostly little-endian (as shown in #92910).
### Versions
```
PyTorch version: 2.0.0a0+git215f4fc
Is debug build: True
CUDA used to build PyTorch: None
ROCM used to build PyTorch: N/A
OS: Ubuntu 22.04.1 LTS (s390x)
GCC version: (Ubuntu 11.3.0-1ubuntu1~22.04) 11.3.0
Clang version: Could not collect
CMake version: version 3.22.1
Libc version: glibc-2.35
Python version: 3.10.6 (main, Nov 14 2022, 16:10:14) [GCC 11.3.0] (64-bit runtime)
Python platform: Linux-5.4.0-125-generic-s390x-with-glibc2.35
Is CUDA available: False
CUDA runtime version: No CUDA
CUDA_MODULE_LOADING set to: N/A
GPU models and configuration: No CUDA
Nvidia driver version: No CUDA
cuDNN version: No CUDA
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: False
Versions of relevant libraries:
[pip3] numpy==1.24.1
[pip3] torch==2.0.0a0+git17c570c
[conda] Could not collect
```
cc @EikanWang @jgong5 @wenzhe-nrv @sanchitintel
| 0 |
3,645 | 92,977 |
ONNX export of batch_norm for unknown channel size issue.
|
module: onnx, triaged
|
### 🐛 Describe the bug
Trying to convert https://github.com/GXYM/TextBPN-Plus-Plus into ONNX format.
I take initial model from https://github.com/GXYM/TextBPN-Plus-Plus/blob/main/network/textnet.py
```
torch.onnx.export(model,
dummy_input,
"TextBPM_dyn.onnx",
export_params=True,
opset_version=16,
do_constant_folding=True,
input_names = ['modelInput'],
output_names = ['modelOutput'],
dynamic_axes={'modelInput' : [0, 2, 3],
'modelOutput' : {0 : 'batch_size'}})
```
However, I face the following issue:
```
SymbolicValueError: Unsupported: ONNX export of batch_norm for unknown channel size. [Caused by the value 'input.195 defined in (%input.195 : Float(*, *, *, strides=[720, 20, 1], requires_grad=1, device=cuda:0) = onnx::ScatterND(%903, %925, %940), scope: network.textnet_onnx.TextNet::/network.textnet_onnx.Evolution::BPN # /home/experiments/a.rogachev/TextBPN-Plus-Plus/network/layers/gcn_utils.py:102:0
)' (type 'Tensor') in the TorchScript graph. The containing node has kind 'onnx::ScatterND'.]
(node defined in /home/experiments/a.rogachev/TextBPN-Plus-Plus/network/layers/gcn_utils.py(102): get_node_feature
/home/experiments/a.rogachev/TextBPN-Plus-Plus/network/textnet_onnx.py(142): evolve_poly
/home/experiments/a.rogachev/TextBPN-Plus-Plus/network/textnet_onnx.py(159): forward
/opt/conda/lib/python3.10/site-packages/torch/nn/modules/module.py(1176): _slow_forward
/opt/conda/lib/python3.10/site-packages/torch/nn/modules/module.py(1192): _call_impl
/home/experiments/a.rogachev/TextBPN-Plus-Plus/network/textnet_onnx.py(203): forward
/opt/conda/lib/python3.10/site-packages/torch/nn/modules/module.py(1176): _slow_forward
/opt/conda/lib/python3.10/site-packages/torch/nn/modules/module.py(1192): _call_impl
/opt/conda/lib/python3.10/site-packages/torch/jit/_trace.py(111): wrapper
/opt/conda/lib/python3.10/site-packages/torch/jit/_trace.py(104): forward
/opt/conda/lib/python3.10/site-packages/torch/nn/modules/module.py(1192): _call_impl
/opt/conda/lib/python3.10/site-packages/torch/jit/_trace.py(1183): _get_trace_graph
/opt/conda/lib/python3.10/site-packages/torch/onnx/utils.py(890): _trace_and_get_graph_from_model
/opt/conda/lib/python3.10/site-packages/torch/onnx/utils.py(967): _create_jit_graph
/opt/conda/lib/python3.10/site-packages/torch/onnx/utils.py(1108): _model_to_graph
/opt/conda/lib/python3.10/site-packages/torch/onnx/utils.py(1501): _export
/opt/conda/lib/python3.10/site-packages/torch/onnx/utils.py(512): export
/tmp/ipykernel_134/739478525.py(8): <module>
/opt/conda/lib/python3.10/site-packages/IPython/core/interactiveshell.py(3430): run_code
/opt/conda/lib/python3.10/site-packages/IPython/core/interactiveshell.py(3341): run_ast_nodes
/opt/conda/lib/python3.10/site-packages/IPython/core/interactiveshell.py(3168): run_cell_async
/opt/conda/lib/python3.10/site-packages/IPython/core/async_helpers.py(129): _pseudo_sync_runner
/opt/conda/lib/python3.10/site-packages/IPython/core/interactiveshell.py(2970): _run_cell
/opt/conda/lib/python3.10/site-packages/IPython/core/interactiveshell.py(2941): run_cell
/opt/conda/lib/python3.10/site-packages/ipykernel/zmqshell.py(540): run_cell
/opt/conda/lib/python3.10/site-packages/ipykernel/ipkernel.py(386): do_execute
/opt/conda/lib/python3.10/site-packages/ipykernel/kernelbase.py(702): execute_request
/opt/conda/lib/python3.10/site-packages/ipykernel/kernelbase.py(385): dispatch_shell
/opt/conda/lib/python3.10/site-packages/ipykernel/kernelbase.py(498): process_one
/opt/conda/lib/python3.10/site-packages/ipykernel/kernelbase.py(512): dispatch_queue
/opt/conda/lib/python3.10/asyncio/events.py(80): _run
/opt/conda/lib/python3.10/asyncio/base_events.py(1863): _run_once
/opt/conda/lib/python3.10/asyncio/base_events.py(597): run_forever
/opt/conda/lib/python3.10/site-packages/tornado/platform/asyncio.py(212): start
/opt/conda/lib/python3.10/site-packages/ipykernel/kernelapp.py(714): start
/opt/conda/lib/python3.10/site-packages/traitlets/config/application.py(990): launch_instance
/opt/conda/lib/python3.10/site-packages/ipykernel_launcher.py(12): <module>
/opt/conda/lib/python3.10/runpy.py(75): _run_code
/opt/conda/lib/python3.10/runpy.py(191): _run_module_as_main
)
Inputs:
#0: 903 defined in (%903 : Float(*, *, *, strides=[720, 20, 1], requires_grad=0, device=cuda:0) = onnx::Cast[to=1](%901), scope: network.textnet_onnx.TextNet::/network.textnet_onnx.Evolution::BPN # /home/experiments/a.rogachev/TextBPN-Plus-Plus/network/layers/gcn_utils.py:99:0
) (type 'Tensor')
#1: 925 defined in (%925 : Long(*, 3, device=cpu) = onnx::Transpose[perm=[1, 0]](%924), scope: network.textnet_onnx.TextNet::/network.textnet_onnx.Evolution::BPN # /home/experiments/a.rogachev/TextBPN-Plus-Plus/network/layers/gcn_utils.py:102:0
) (type 'Tensor')
#2: 940 defined in (%940 : Float(*, device=cpu) = onnx::Slice(%927, %934, %936, %939), scope: network.textnet_onnx.TextNet::/network.textnet_onnx.Evolution::BPN # /home/experiments/a.rogachev/TextBPN-Plus-Plus/network/layers/gcn_utils.py:102:0
) (type 'Tensor')
Outputs:
#0: input.195 defined in (%input.195 : Float(*, *, *, strides=[720, 20, 1], requires_grad=1, device=cuda:0) = onnx::ScatterND(%903, %925, %940), scope: network.textnet_onnx.TextNet::/network.textnet_onnx.Evolution::BPN # /home/experiments/a.rogachev/TextBPN-Plus-Plus/network/layers/gcn_utils.py:102:0
) (type 'Tensor')
```
Looks like the problem happens with the [BPN](https://github.com/GXYM/TextBPN-Plus-Plus/blob/5b535bd43bf2bb188793f4fb545a23fe075ecdcb/network/textnet.py#L209) part.
### Versions
OS: Ubuntu 18.04.6 LTS (x86_64)
GCC version: (Ubuntu 7.5.0-3ubuntu1~18.04) 7.5.0
Clang version: Could not collect
CMake version: version 3.22.1
Libc version: glibc-2.27
Python version: 3.10.8 (main, Nov 4 2022, 13:48:29) [GCC 11.2.0] (64-bit runtime)
Python platform: Linux-3.10.0-1160.76.1.el7.x86_64-x86_64-with-glibc2.27
Is CUDA available: True
CUDA runtime version: 11.6.124
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration:
GPU 0: Tesla T4
GPU 1: Tesla T4
GPU 2: Tesla T4
GPU 3: Tesla T4
Nvidia driver version: 470.63.01
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.4.0
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.4.0
/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.4.0
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_infer.so.8.4.0
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.4.0
/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.4.0
/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.4.0
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.24.1
[pip3] torch==1.13.1
[pip3] torchelastic==0.2.2
[pip3] torchtext==0.14.1
[pip3] torchvision==0.14.1
[conda] blas 1.0 mkl
[conda] ffmpeg 4.3 hf484d3e_0 pytorch
[conda] mkl 2021.4.0 h06a4308_640
[conda] mkl-service 2.4.0 py310h7f8727e_0
[conda] mkl_fft 1.3.1 py310hd6ae3a3_0
[conda] mkl_random 1.2.2 py310h00e6091_0
[conda] numpy 1.22.3 py310hfa59a62_0
[conda] numpy-base 1.22.3 py310h9585f30_0
[conda] pytorch 1.13.1 py3.10_cuda11.6_cudnn8.3.2_0 pytorch
[conda] pytorch-cuda 11.6 h867d48c_1 pytorch
[conda] pytorch-mutex 1.0 cuda pytorch
[conda] torchelastic 0.2.2 pypi_0 pypi
[conda] torchtext 0.14.1 py310 pytorch
[conda] torchvision 0.14.1 py310_cu116 pytorch
| 2 |
3,646 | 92,967 |
Tracking issue for segfaults and floating point exceptions on 1.12.0
|
triaged
|
### 🐛 Describe the bug
- [ ] [Segfault when running torch.remainder](https://drive.google.com/drive/folders/1jA5Cpn99rPn9lYThZWkBH42nqVPzqhXe?usp=share_link)
- [ ] [Segfault when running torch.cuda.comm.broadcast_coalesced](https://drive.google.com/drive/folders/1-ETSBXl4xu-ab8Pwsx3RUHvUbFf9frPR?usp=share_link)
- [ ] [Segfault when running torch.add](https://drive.google.com/drive/folders/1mZmGRNQWwgjHqIOU0l4IGs8IyflxOaoS?usp=share_link)
- [ ] [Segfault when running torch.bitwise_and](https://drive.google.com/drive/folders/1plZksdun90wJs_lwAvwaQZQQikwT21_H?usp=share_link)
- [ ] [Segfault when running torch.bitwise_xor](https://drive.google.com/drive/folders/1V0-5G28M7OnEWFYVWXxoNc-Ok-WsxBSc?usp=share_link)
- [ ] [Segfault when running torch.div2](https://drive.google.com/drive/folders/1PqE5zu1Lbd20eXjhDHZqDO0Lw0P4ExBw?usp=share_link)
- [ ] [Segfault when running torch.div](https://drive.google.com/drive/folders/1KKmq44ft9QOzKbElUHR0C3H03rD9j0P0?usp=share_link)
- [ ] [Segfault when running torch.floor_divide](https://drive.google.com/drive/folders/1Zsr7sJCdmHRJZqOT1cd4JzJbkPowDn27?usp=share_link)
- [ ] [Segfault when running torch.fmod](https://drive.google.com/drive/folders/1w2K3k11RxMHhq-0urnZaEi-1v7rtd7Dj?usp=share_link)
- [ ] [Segfault when running torch.gt](https://drive.google.com/drive/folders/1CzAqXDfS11U4jMP2bw6BmIveeIO3410G?usp=share_link)
- [ ] [Segfault when running torch.inverse](https://drive.google.com/drive/folders/1lkbMUD7dsbDuQr3XRZrASljLoXM6RNPJ?usp=share_link)
- [ ] [Segfault when running torch.le](https://drive.google.com/drive/folders/1evE2hJP-AEs7XInukfO0nCGjqTaO-zqM?usp=share_link)
- [ ] [Segfault when running torch.ge](https://drive.google.com/drive/folders/17RtDKt36NHEho0HTJZjeAEbkT-upO4Ci?usp=share_link)
- [ ] [Segfault when running torch.lt](https://drive.google.com/drive/folders/1yIIdp2AhNK4Ijy7Z5x1eLBmvYm2_2laB?usp=share_link)
- [ ] [Segfault when running torch.lu_unpack](https://drive.google.com/drive/folders/1wT6zNZG5-9T7El5aCVgHfhQ05PaWRf-A?usp=share_link)
- [ ] [Segfault when running torch.max22 ](https://drive.google.com/drive/folders/1VYKv2Ud0tUp6_KlhKV8zY_NXurbK37Pc?usp=share_link)
- [ ] [Floating point exception when running torch.nn.functional.conv_transpose2d](https://drive.google.com/drive/folders/1zml0DkTYieoSZ4nkCIXxsO7HYoXO_c15?usp=share_link)
- [ ] [Floating point exception when running torch.nn.functional.conv_transpose1d](https://drive.google.com/drive/folders/13chOzyrFbQMcYMsA2zv-0m30WGjtJGre?usp=share_link)
- [ ] [Segfault when running torch.cuda.comm.broadcast_coalesced](https://drive.google.com/drive/folders/1EFsgNhsnUNqxTHQCop_wfOz1SEDDJW5b?usp=share_link)
- [ ] [Floating point exception when running torch.nn.functional.conv2d](https://drive.google.com/drive/folders/1o2yrAlcqz_nkZcdqTs6COyJ8rZDHvwuk?usp=share_link)
- [ ] [Segfault when running torch.mul](https://drive.google.com/drive/folders/1Rh1xigvDufJ9Ff_462lMIv3H-fH6176C?usp=share_link)
### Versions
```
PyTorch version: 1.12.0
Is debug build: False
CUDA used to build PyTorch: 10.2
ROCM used to build PyTorch: N/A
OS: Ubuntu 22.04.1 LTS (x86_64)
GCC version: (Ubuntu 11.3.0-1ubuntu1~22.04) 11.3.0
Clang version: Could not collect
CMake version: Could not collect
Libc version: glibc-2.35
Python version: 3.9.15 (main, Nov 24 2022, 14:31:59) [GCC 11.2.0] (64-bit runtime)
Python platform: Linux-5.15.0-58-generic-x86_64-with-glibc2.35
Is CUDA available: True
CUDA runtime version: Could not collect
CUDA_MODULE_LOADING set to:
GPU models and configuration: GPU 0: NVIDIA GeForce GTX 1660 Ti
Nvidia driver version: 525.78.01
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.23.5
[pip3] torch==1.12.0
[pip3] torchaudio==0.12.0
[pip3] torchvision==0.13.0
[conda] blas 1.0 mkl
[conda] cudatoolkit 10.2.89 hfd86e86_1
[conda] ffmpeg 4.3 hf484d3e_0 pytorch
[conda] mkl 2021.4.0 h06a4308_640
[conda] mkl-service 2.4.0 py39h7f8727e_0
[conda] mkl_fft 1.3.1 py39hd3c417c_0
[conda] mkl_random 1.2.2 py39h51133e4_0
[conda] numpy 1.23.5 py39h14f4228_0
[conda] numpy-base 1.23.5 py39h31eccc5_0
[conda] pytorch 1.12.0 py3.9_cuda10.2_cudnn7.6.5_0 pytorch
[conda] pytorch-mutex 1.0 cuda pytorch
[conda] torchaudio 0.12.0 py39_cu102 pytorch
[conda] torchvision 0.13.0 py39_cu102 pytorch
```
| 3 |
3,647 | 92,942 |
test_jit_fuser_te SIGIOT's frequently during dynamo testing
|
triaged, module: testing, oncall: pt2, module: dynamo
|
### 🐛 Describe the bug
See this for example https://hud.pytorch.org/hud/pytorch/pytorch/master/1?per_page=50&name_filter=test%20(dynamo%2C%201
Backtrace often looks as follows (see https://github.com/pytorch/pytorch/actions/runs/4000620927/jobs/6866135571 )
```
#0 __GI_raise (sig=sig@entry=6) at ../sysdeps/unix/sysv/linux/raise.c:51
#1 0x00007f7fbfb857f1 in __GI_abort () at abort.c:79
#2 0x00007f7fbfbce837 in __libc_message (action=action@entry=do_abort,
fmt=fmt@entry=0x7f7fbfcfba7b "%s\n") at ../sysdeps/posix/libc_fatal.c:181
#3 0x00007f7fbfbd58ba in malloc_printerr (
str=str@entry=0x7f7fbfcf9cfc "malloc(): memory corruption")
at malloc.c:5342
#4 0x00007f7fbfbd9a04 in _int_malloc (
av=av@entry=0x7f7fbff30c40 <main_arena>, bytes=bytes@entry=128)
at malloc.c:3748
#5 0x00007f7fbfbda55b in _int_memalign (av=0x7f7fbff30c40 <main_arena>,
alignment=64, bytes=<optimized out>) at malloc.c:4[68](https://github.com/pytorch/pytorch/actions/runs/4000620927/jobs/6866135571#step:15:69)3
#6 0x00007f7fbfbdffda in _mid_memalign (address=<optimized out>, bytes=1,
alignment=<optimized out>) at malloc.c:3324
#7 __posix_memalign (memptr=0x7ffcba020590, alignment=<optimized out>,
size=1) at malloc.c:5361
#8 0x00007f7fa66222a2 in c10::alloc_cpu(unsigned long) ()
from /opt/conda/envs/py_3.7/lib/python3.7/site-packages/torch/lib/libc10.so
#9 0x00007f7fa6600fd3 in c10::DefaultCPUAllocator::allocate(unsigned long) const ()
from /opt/conda/envs/py_3.7/lib/python3.7/site-packages/torch/lib/libc10.so
#10 0x00007f7fa7728f09 in c10::StorageImpl::StorageImpl(c10::StorageImpl::use_byte_size_t, c10::SymInt, c10::Allocator*, bool) ()
from /opt/conda/envs/py_3.7/lib/python3.7/site-packages/torch/lib/libtorch_cpu.so
#11 0x00007f7fa7728dad in c10::intrusive_ptr<c10::StorageImpl, c10::detail::intrusive_target_default_null_type<c10::StorageImpl> > c10::intrusive_ptr<c10::StorageImpl, c10::detail::intrusive_target_default_null_type<c10::StorageImpl> >::make<c10::StorageImpl::use_byte_size_t, unsigned long&, c10::Allocator*&, bool>(c10::StorageImpl::use_byte_size_t&&, unsigned long&, c10::Allocator*&, bool&&) ()
from /opt/conda/envs/py_3.7/lib/python3.7/site-packages/torch/lib/libtorch_cpu.so
#12 0x00007f7fa772[70](https://github.com/pytorch/pytorch/actions/runs/4000620927/jobs/6866135571#step:15:71)[72](https://github.com/pytorch/pytorch/actions/runs/4000620927/jobs/6866135571#step:15:73) in at::TensorBase at::detail::_empty_strided_generic<c10::ArrayRef<long> >(c10::ArrayRef<long>, c10::ArrayRef<long>, c10::Allocator*, c10::DispatchKeySet, c10::ScalarType) ()
from /opt/conda/envs/py_3.7/lib/python3.7/site-packages/torch/lib/libtorch_cpu.so
#13 0x00007f7fa77263b4 in at::detail::empty_strided_cpu(c10::ArrayRef<long>, c10::ArrayRef<long>, c10::optional<c10::ScalarType>, c10::optional<c10::Layout>, c10::optional<c10::Device>, c10::optional<bool>) ()
from /opt/conda/envs/py_3.7/lib/python3.7/site-packages/torch/lib/libtorch_cpu.so
#14 0x00007f7fa7f[73](https://github.com/pytorch/pytorch/actions/runs/4000620927/jobs/6866135571#step:15:74)a09 in at::native::empty_strided_cpu(c10::ArrayRef<long>, c10::ArrayRef<long>, c10::optional<c10::ScalarType>, c10::optional<c10::Layout>, c10::optional<c10::Device>, c10::optional<bool>) ()
from /opt/conda/envs/py_3.7/lib/python3.7/site-packages/torch/lib/libtorch_cpu.so
#15 0x00007f7fa8bdcea2 in at::(anonymous namespace)::(anonymous namespace)::wrapper_CPU__empty_strided(c10::ArrayRef<c10::SymInt>, c10::ArrayRef<c10::SymInt>, c10::optional<c10::ScalarType>, c10::optional<c10::Layout>, c10::optional<c10::Device>, c10::optional<bool>) ()
from /opt/conda/envs/py_3.7/lib/python3.7/site-packages/torch/lib/libtorch_cpu.so
#16 0x00007f7fa8c8d468 in c10::impl::wrap_kernel_functor_unboxed_<c10::impl::detail::WrapFunctionIntoFunctor_<c10::CompileTimeFunctionPointer<at::Tensor (c10::ArrayRef<c10::SymInt>, c10::ArrayRef<c10::SymInt>, c10::optional<c10::ScalarType>, c10::optional<c10::Layout>, c10::optional<c10::Device>, c10::optional<bool>), &at::(anonymous namespace)::(anonymous namespace)::wrapper_CPU__empty_strided>, at::Tensor, c10::guts::typelist::typelist<c10::ArrayRef<c10::SymInt>, c10::ArrayRef<c10::SymInt>, c10::optional<c10::ScalarType>, c10::optional<c10::Layout>, c10::optional<c10::Device>, c10::optional<bool> > >, at::Tensor (c10::ArrayRef<c10::SymInt>, c10::ArrayRef<c10::SymInt>, c10::optional<c10::ScalarType>, c10::optional<c10::Layout>, c10::optional<c10::Device>, c10::optional<bool>)>::call(c10::OperatorKernel*, c10::DispatchKeySet, c10::ArrayRef<c10::SymInt>, c10::ArrayRef<c10::SymInt>, c10::optional<c10::ScalarType>, c10::optional<c10::Layout>, c10::optional<c10::Device>, c10::optional<bool>) ()
from /opt/conda/envs/py_3.7/lib/python3.7/site-packages/torch/lib/libtorch_cpu.so
#17 0x00007f7fa88d02c7 in at::Tensor c10::Dispatcher::redispatch<at::Tensor, c10::ArrayRef<c10::SymInt>, c10::ArrayRef<c10::SymInt>, c10::optional<c10::ScalarType>, c10::optional<c10::Layout>, c10::optional<c10::Device>, c10::optional<bool> >(c10::TypedOperatorHandle<at::Tensor (c10::ArrayRef<c10::SymInt>, c10::ArrayRef<c10::SymInt>, c10::optional<c10::ScalarType>, c10::optional<c10::Layout>, c10::optional<c10::Device>, c10::optional<bool>)> const&, c10::DispatchKeySet, c10::ArrayRef<c10::SymInt>, c10::ArrayRef<c10::SymInt>, c10::optional<c10::ScalarType>, c10::optional<c10::Layout>, c10::optional<c10::Device>, c10::optional<bool>) const ()
from /opt/conda/envs/py_3.7/lib/python3.7/site-packages/torch/lib/libtorch_cpu.so
#18 0x00007f7fa87f3733 in at::_ops::empty_strided::redispatch(c10::DispatchKeySet, c10::ArrayRef<c10::SymInt>, c10::ArrayRef<c10::SymInt>, c10::optional<c10::ScalarType>, c10::optional<c10::Layout>, c10::optional<c10::Device>, c10::optional<bool>) ()
from /opt/conda/envs/py_3.7/lib/python3.7/site-packages/torch/lib/libtorch_cpu.so
#19 0x00007f7fa8bb678c in c10::impl::wrap_kernel_functor_unboxed_<c10::impl::detail::WrapFunctionIntoFunctor_<c10::CompileTimeFunctionPointer<at::Tensor (c10::ArrayRef<c10::SymInt>, c10::ArrayRef<c10::SymInt>, c10::optional<c10::ScalarType>, c10::optional<c10::Layout>, c10::optional<c10::Device>, c10::optional<bool>), &at::(anonymous namespace)::empty_strided>, at::Tensor, c10::guts::typelist::typelist<c10::ArrayRef<c10::SymInt>, c10::ArrayRef<c10::SymInt>, c10::optional<c10::ScalarType>, c10::optional<c10::Layout>, c10::optional<c10::Device>, c10::optional<bool> > >, at::Tensor (c10::ArrayRef<c10::SymInt>, c10::ArrayRef<c10::SymInt>, c10::optional<c10::ScalarType>, c10::optional<c10::Layout>, c10::optional<c10::Device>, c10::optional<bool>)>::call(c10::OperatorKernel*, c10::DispatchKeySet, c10::ArrayRef<c10::SymInt>, c10::ArrayRef<c10::SymInt>, c10::optional<c10::ScalarType>, c10::optional<c10::Layout>, c10::optional<c10::Device>, c10::optional<bool>) ()
from /opt/conda/envs/py_3.7/lib/python3.7/site-packages/torch/lib/libtorch_cpu.so
#20 0x00007f7fa87f322b in at::_ops::empty_strided::call(c10::ArrayRef<c10::SymInt>, c10::ArrayRef<c10::SymInt>, c10::optional<c10::ScalarType>, c10::optional<c10::Layout>, c10::optional<c10::Device>, c10::optional<bool>) ()
from /opt/conda/envs/py_3.7/lib/python3.7/site-packages/torch/lib/libtorch_cpu.so
#21 0x00007f7fa[77](https://github.com/pytorch/pytorch/actions/runs/4000620927/jobs/6866135571#step:15:78)beb00 in at::empty_strided(c10::ArrayRef<long>, c10::ArrayRef<long>, c10::TensorOptions) ()
from /opt/conda/envs/py_3.7/lib/python3.7/site-packages/torch/lib/libtorch_cpu.so
#22 0x00007f7fa7f429c0 in at::native::_to_copy(at::Tensor const&, c10::optional<c10::ScalarType>, c10::optional<c10::Layout>, c10::optional<c10::Device>, c10::optional<bool>, bool, c10::optional<c10::MemoryFormat>) ()
from /opt/conda/envs/py_3.7/lib/python3.7/site-packages/torch/lib/libtorch_cpu.so
#23 0x00007f7fa8ea45c0 in c10::impl::wrap_kernel_functor_unboxed_<c10::impl::detail::WrapFunctionIntoFunctor_<c10::CompileTimeFunctionPointer<at::Tensor (at::Tensor const&, c10::optional<c10::ScalarType>, c10::optional<c10::Layout>, c10::optional<c10::Device>, c10::optional<bool>, bool, c10::optional<c10::MemoryFormat>), &at::(anonymous namespace)::(anonymous namespace)::wrapper_CompositeExplicitAutograd___to_copy>, at::Tensor, c10::guts::typelist::typelist<at::Tensor const&, c10::optional<c10::ScalarType>, c10::optional<c10::Layout>, c10::optional<c10::Device>, c10::optional<bool>, bool, c10::optional<c10::MemoryFormat> > >, at::Tensor (at::Tensor const&, c10::optional<c10::ScalarType>, c10::optional<c10::Layout>, c10::optional<c10::Device>, c10::optional<bool>, bool, c10::optional<c10::MemoryFormat>)>::call(c10::OperatorKernel*, c10::DispatchKeySet, at::Tensor const&, c10::optional<c10::ScalarType>, c10::optional<c10::Layout>, c10::optional<c10::Device>, c10::optional<bool>, bool, c10::optional<c10::MemoryFormat>) ()
from /opt/conda/envs/py_3.7/lib/python3.7/site-packages/torch/lib/libtorch_cpu.so
#24 0x00007f7fa84b6e[80](https://github.com/pytorch/pytorch/actions/runs/4000620927/jobs/6866135571#step:15:81) in at::_ops::_to_copy::redispatch(c10::DispatchKeySet, at::Tensor const&, c10::optional<c10::ScalarType>, c10::optional<c10::Layout>, c10::optional<c10::Device>, c10::optional<bool>, bool, c10::optional<c10::MemoryFormat>) ()
from /opt/conda/envs/py_3.7/lib/python3.7/site-packages/torch/lib/libtorch_cpu.so
#25 0x00007f7fa8bc70d3 in c10::impl::wrap_kernel_functor_unboxed_<c10::impl::detail::WrapFunctionIntoFunctor_<c10::CompileTimeFunctionPointer<at::Tensor (at::Tensor const&, c10::optional<c10::ScalarType>, c10::optional<c10::Layout>, c10::optional<c10::Device>, c10::optional<bool>, bool, c10::optional<c10::MemoryFormat>), &at::(anonymous namespace)::_to_copy>, at::Tensor, c10::guts::typelist::typelist<at::Tensor const&, c10::optional<c10::ScalarType>, c10::optional<c10::Layout>, c10::optional<c10::Device>, c10::optional<bool>, bool, c10::optional<c10::MemoryFormat> > >, at::Tensor (at::Tensor const&, c10::optional<c10::ScalarType>, c10::optional<c10::Layout>, c10::optional<c10::Device>, c10::optional<bool>, bool, c10::optional<c10::MemoryFormat>)>::call(c10::OperatorKernel*, c10::DispatchKeySet, at::Tensor const&, c10::optional<c10::ScalarType>, c10::optional<c10::Layout>, c10::optional<c10::Device>, c10::optional<bool>, bool, c10::optional<c10::MemoryFormat>) ()
from /opt/conda/envs/py_3.7/lib/python3.7/site-packages/torch/lib/libtorch_cpu.so
```
### Versions
CI
cc @ezyang @soumith @msaroufim @wconstab @ngimel @bdhirsh @mlazos @voznesenskym @yanboliang @penguinwu @anijain2305 @EikanWang @jgong5 @Guobing-Chen @chunyuan-w @XiaobingSuper @zhuhaozhe @blzheng @Xia-Weiwen @wenzhe-nrv @jiayisunx @desertfire
| 4 |
3,648 | 92,927 |
Inplace fused (leaky)relu+(leaky)dropout for memory savings (I think, can be made fully allocation-less if never fully allocating random mask in FlashAttention style and recover the mask from the output)
|
feature, triaged, oncall: pt2, module: aotdispatch
|
### 🚀 The feature, motivation and pitch
It's possible that such an inplace fusion is already possible with dynamo, but if not, it's quite good to have for saving memory. Also maybe worth introducing some torch.nn.fused namespace which would have torch.nn.fused.ReLU_Dropout, torch.nn.fused.Conv2d_BatchNorm2d_LeakyReLU_Dropout or some other similar modules that in the ultimate case might be defined as `torch.compile(nn.Sequential(nn.ReLU(inplace=True), nn.Dropout(inplace=True)))`, but in the meanwhile can be hand-optimized for these very frequent cases and some documentation can exist which can present some guarantees and tests that these work and are expected to consume this much memory.
My earlier issue in torchvision:
https://github.com/pytorch/vision/issues/4851
### Alternatives
_No response_
### Additional context
_No response_
cc @albanD @mruberry @jbschlosser @walterddr @saketh-are @ezyang @soumith @msaroufim @wconstab @ngimel @bdhirsh
| 21 |
3,649 | 92,920 |
Add Stride Argument For Constructors
|
triaged, enhancement, module: tensor creation
|
### 🚀 The feature, motivation and pitch
randn, full, ones, and zeros dont have a stride argument. The lack of the stride argument makes it difficult to write functional decompositions. For instance, `randn_like` I would like to decompose functionally, but because there is no way to pass along the stride of the input, I need to write it as the following:
```
@register_decomposition(aten.randn_like)
def randn_like(
a,
*,
dtype: Optional[torch.dtype] = None,
device: Optional[torch.device] = None,
layout: Optional[torch.layout] = None,
pin_memory: bool = False,
memory_format: torch.memory_format = None,
):
result = torch.empty_like(a, dtype=dtype, device=device, layout=layout, pin_memory=pin_memory, memory_format=memory_format)
result.random_(0, 1)
return result
```
### Alternatives
_No response_
### Additional context
_No response_
cc @gchanan @mruberry
| 0 |
3,650 | 92,916 |
[Functionalization] Some ops need additional meta tensor support after functionalization
|
triaged, module: xla, module: meta tensors, module: functionalization
|
### 🐛 Describe the bug
**Summary**
With functionalization enabled, PyTorch/XLA saw new test failures due to ops requiring additional meta tensor support. The ops that we saw these errors are:
- `aten::_amp_foreach_non_finite_check_and_unscale_`
- `aten::nan_to_num.out`
The entire error logs for for one of these ops are:
> ```C++ exception with description "Could not run 'aten::_amp_foreach_non_finite_check_and_unscale_' with arguments from the 'Meta' backend. This could be because the operator doesn't exist for this backend, or was omitted during the selective/custom build process (if using custom build). If you are a Facebook employee using PyTorch on mobile, please visit https://fburl.com/ptmfixes for possible resolutions. 'aten::_amp_foreach_non_finite_check_and_unscale_' is only available for these backends: [XLA, BackendSelect, Python, FuncTorchDynamicLayerBackMode, Functionalize, Named, Conjugate, Negative, ZeroTensor, ADInplaceOrView, AutogradOther, AutogradCPU, AutogradCUDA, AutogradHIP, AutogradXLA, AutogradMPS, AutogradIPU, AutogradXPU, AutogradHPU, AutogradVE, AutogradLazy, AutogradMeta, AutogradMTIA, AutogradPrivateUse1, AutogradPrivateUse2, AutogradPrivateUse3, AutogradNestedTensor, Tracer, AutocastCPU, AutocastCUDA, FuncTorchBatched, FuncTorchVmapMode, Batched, VmapMode, FuncTorchGradWrapper, PythonTLSSnapshot, FuncTorchDynamicLayerFrontMode, PythonDispatcher].```
**Steps to reproduce**
For `aten::_amp_foreach_non_finite_check_and_unscale_`:
```
import torch
import functorch
def test():
self_tensor = torch.tensor([1, 2, 3, 4])
found_inf = torch.tensor(0)
inv_scale = torch.tensor(0.2)
print(torch._amp_foreach_non_finite_check_and_unscale_([self_tensor], found_inf, inv_scale))
functorch.functionalize(test)()
```
Output:
```
/opt/conda/lib/python3.8/site-packages/torch/_functorch/deprecated.py:93: UserWarning: We've integrated functorch into PyTorch. As the final step of the integration, functorch.functionalize is deprecated as of PyTorch 2.0 and will be deleted in a future version of PyTorch >= 2.3. Please use torch.func.functionalize instead; see the PyTorch 2.0 release notes and/or the torch.func migration guide for more details https://pytorch.org/docs/master/func.migrating.html
warn_deprecated('functionalize')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/opt/conda/lib/python3.8/site-packages/torch/_functorch/vmap.py", line 39, in fn
return f(*args, **kwargs)
File "/opt/conda/lib/python3.8/site-packages/torch/_functorch/eager_transforms.py", line 1582, in wrapped
func_outputs = func(*func_args, **func_kwargs)
File "<stdin>", line 5, in test
NotImplementedError: Could not run 'aten::_amp_foreach_non_finite_check_and_unscale_' with arguments from the 'Meta' backend. This could be because the operator doesn't exist for this backend, or was omitted during the selective/custom build process (if using custom build). If you are a Facebook employee using PyTorch on mobile, please visit https://fburl.com/ptmfixes for possible resolutions. 'aten::_amp_foreach_non_finite_check_and_unscale_' is only available for these backends: [XLA, BackendSelect, Python, FuncTorchDynamicLayerBackMode, Functionalize, Named, Conjugate, Negative, ZeroTensor, ADInplaceOrView, AutogradOther, AutogradCPU, AutogradCUDA, AutogradHIP, AutogradXLA, AutogradMPS, AutogradIPU, AutogradXPU, AutogradHPU, AutogradVE, AutogradLazy, AutogradMeta, AutogradMTIA, AutogradPrivateUse1, AutogradPrivateUse2, AutogradPrivateUse3, AutogradNestedTensor, Tracer, AutocastCPU, AutocastCUDA, FuncTorchBatched, FuncTorchVmapMode, Batched, VmapMode, FuncTorchGradWrapper, PythonTLSSnapshot, FuncTorchDynamicLayerFrontMode, PythonDispatcher].
```
### Versions
Nightly
cc @bdhirsh @ezyang @eellison @soumith
| 4 |
3,651 | 92,912 |
functorch.functionalize doesn't error out with logcumsumexp.out
|
triaged, module: xla, module: meta tensors, module: functionalization
|
### 🐛 Describe the bug
logcumsumexp.out will error out if the given output buffer's dtype is different from the input, but somehow that property is violated after functionalization, here is the PoC:
```
import torch
import functorch
def poc6():
device = 'cpu'
axis = -1
# Check input and inplace_output type mismatch
b = torch.randn(5, 2, device=device, dtype=torch.float64)
inplace_out = torch.zeros(5, 2, device=device, dtype=torch.float32)
try:
torch.logcumsumexp(b, axis, out=inplace_out)
except Exception as e:
print(e)
print("CPU")
poc6()
print()
print("CPU Functionalize")
functorch.functionalize(poc6)()
```
Output:
```
ptxla@t1v-n-307ffe96-w-0:/workspaces/work/pytorch/xla$ python poc6.py
CPU
expected scalar_type Double but found Float
CPU Functionalize
```
### Versions
Nightly.
CC @bdhirsh @wonjoolee95 @JackCaoG
cc @bdhirsh @ezyang @eellison @soumith
| 2 |
3,652 | 93,517 |
Triton MLIR benchmarks
|
triaged, oncall: pt2
|
float32/amp dynamo benchmark runs on triton master
cc @ezyang @soumith @msaroufim @wconstab @ngimel @bdhirsh
| 17 |
3,653 | 92,910 |
torch.jit.save() generates different contents in a file among different endian machines
|
oncall: jit, module: POWER
|
### 🐛 Describe the bug
When I execute the following program on little (x86_64) and big (s390x) endian machines, I realized that the contents of `scriptmodule.pt` are different (e.g. at first two bytes in the below results, `4b50` v.s. `504b`). IMHO, the contents are stored as machine-native endian.
Then, `torch.jit.load()` reads data by assuming the contents are stored as machine-native endian. As a result, the file `scriptmodule.pt` cannot be portable among different endian machines. For example, reading the file, which is stored on a little-endian machine, on a big-endian machime causes an exception. We expect that this file should be portable among machines.
I cannot find the specification of the serialization format (e.g. endianness in the serialization format) at [the API](https://pytorch.org/docs/stable/generated/torch.jit.save.html). ~~Is there any specification document for this serialization format?~~ I found [the document](https://github.com/pytorch/pytorch/blob/master/torch/csrc/jit/docs/serialization.md). However, I cannot see the description about endianness. Is there any further specification documents regarding endianness?
```python
import torch
class MyModule(torch.nn.Module):
def forward(self, x):
return x + 511
m = torch.jit.script(MyModule())
torch.jit.save(m, 'scriptmodule.pt')
```
The part of the result of `od -x scriptmodule.pt` on little endian machine (full result is [here](https://gist.github.com/kiszk/6c1bfe25b8c78fb4e2cf125ab997c3e4))
```
0000000 4b50 0403 0000 0808 0000 0000 0000 0000
0000020 0000 0000 0000 0000 0000 0015 000d 6373
0000040 6972 7470 6f6d 7564 656c 642f 7461 2e61
0000060 6b70 466c 0942 5a00 5a5a 5a5a 5a5a 5a5a
0000100 0280 5f63 745f 726f 6863 5f5f 4d0a 4d79
0000120 646f 6c75 0a65 0071 8129 287d 0858 0000
0000140 7400 6172 6e69 6e69 7167 8801 1658 0000
0000160 5f00 7369 665f 6c75 5f6c 6162 6b63 6177
0000200 6472 685f 6f6f 716b 4e02 6275 0371 502e
0000220 074b b608 67c1 4ff2 0000 4f00 0000 5000
0000240 034b 1404 0800 0808 0000 0000 0000 0000
0000260 0000 0000 0000 0000 1e00 2500 7300 7263
0000300 7069 6d74 646f 6c75 2f65 6f63 6564 5f2f
0000320 745f 726f 6863 5f5f 702e 4679 2142 5a00
0000340 5a5a 5a5a 5a5a 5a5a 5a5a 5a5a 5a5a 5a5a
*
```
The part of the result of `od -x scriptmodule.pt` on big endian machine (full result is [here](https://gist.github.com/kiszk/6c1bfe25b8c78fb4e2cf125ab997c3e4))
```
0000000 504b 0304 0000 0808 0000 0000 0000 0000
0000020 0000 0000 0000 0000 0000 1500 0d00 7363
0000040 7269 7074 6d6f 6475 6c65 2f64 6174 612e
0000060 706b 6c46 4209 005a 5a5a 5a5a 5a5a 5a5a
0000100 8002 635f 5f74 6f72 6368 5f5f 0a4d 794d
0000120 6f64 756c 650a 7100 2981 7d28 5800 0000
0000140 0874 7261 696e 696e 6771 0188 5800 0000
0000160 165f 6973 5f66 756c 6c5f 6261 636b 7761
0000200 7264 5f68 6f6f 6b71 024e 7562 7103 2e50
0000220 4b07 08f3 4c76 c34f 0000 004f 0000 0050
0000240 4b03 0414 0008 0808 0000 0000 0000 0000
0000260 0000 0000 0000 0000 001e 0025 0073 6372
0000300 6970 746d 6f64 756c 652f 636f 6465 2f5f
0000320 5f74 6f72 6368 5f5f 2e70 7946 4221 005a
0000340 5a5a 5a5a 5a5a 5a5a 5a5a 5a5a 5a5a 5a5a
*
```
### Versions
```
PyTorch version: 2.0.0a0+git215f4fc
Is debug build: True
CUDA used to build PyTorch: None
ROCM used to build PyTorch: N/A
OS: Ubuntu 22.04.1 LTS (s390x)
GCC version: (Ubuntu 11.3.0-1ubuntu1~22.04) 11.3.0
Clang version: Could not collect
CMake version: version 3.22.1
Libc version: glibc-2.35
Python version: 3.10.6 (main, Nov 14 2022, 16:10:14) [GCC 11.3.0] (64-bit runtime)
Python platform: Linux-5.4.0-125-generic-s390x-with-glibc2.35
Is CUDA available: False
CUDA runtime version: No CUDA
CUDA_MODULE_LOADING set to: N/A
GPU models and configuration: No CUDA
Nvidia driver version: No CUDA
cuDNN version: No CUDA
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: False
Versions of relevant libraries:
[pip3] numpy==1.24.1
[pip3] torch==2.0.0a0+git17c570c
[conda] Could not collect
```
cc @EikanWang @jgong5 @wenzhe-nrv @sanchitintel
| 5 |
3,654 | 92,909 |
[RFC] XLA Lazy Backend Support In DistributedTensor API
|
triaged, module: xla
|
### 🚀 The feature, motivation and pitch
# TL;DR
The proposed DistributedTensor provides a new abstraction to express tensor distributions with both sharding and replication parallelism strategies in eager mode and non-lazy backends, like `cuda`. We propose to integrate XLAShardedTensor and mark_sharding API integration for `xla` lazy-backend support in the DistributedTensor API. Our goal is to allow PyTorch users to shard a big tensor across `xla` devices with just a few lines of code:
```python
import torch
from torch.distributed import DeviceMesh, Shard, distribute_tensor
mesh = DeviceMesh("xla", list(range(world_size)))
big_tensor = torch.randn(100000, 88)
my_dtensor = distribute_tensor(big_tensor, mesh, [Shard(0)])
```
This example is from the DistributedTensor [[RFC](https://github.com/pytorch/pytorch/issues/88838)], with a main difference being the device type `xla`.
# Motivation
The proposed DistributedTensor APIs (distribute_tensor, distribute_module) allow the user to express various types of tensor distributions with just a few lines of code. While simple and generic enough to express many common parallelism paradigms, its current support for backend devices does not entail lazy backends, like `xla`. PyTorch/XLA offers a set of lower-level XLAShardedTensor APIs that exposes sharding annotations for the tensors residing on the `xla` devices. Both DistributedTensor and XLAShardedTensor support sharding and replication parallelism strategies, defined by a logical device mesh and a sharding placement spec. Here, we propose to integrate the low-level XLAShardedTensor APIs into the high-level DistributedTensor APIs, so that a user can use the same set of DistributedTensor APIs to express tensor distributions with both sharding and replication parallelism strategies.
# Pitch
We integrate `xla` backend specific XLAShardedTensor APIs into the high-level DistributedTensor APIs (distribute_tensor, distribute_module) so the user can use the same DistributedTensor APIs to express tensor distributions (sharding or replication) on CPU, GPU and `xla` backend devices, like TPU. Some restrictions apply to the tensor distributions on `xla` backend: partial tensor distribution is only available in DistributedTensor native backends, as the strategy is “forbidden from constructor” and only used for the intermediary results (tensors); XLAShardedTensor APIs may propagates sharding and currently assume a fixed device assignments to the logical mesh; the output tensor(s) is replicated unless sharded explicitly by the user.
The call to the high-level DistributedTensor API can easily be translated into the low-level XLAShardedTensor API based on the following conversions:
- [DeviceMesh](https://github.com/pytorch/pytorch/blob/f20b3f2e5734b23a9e0a898196ddf77aa90323b8/torch/distributed/_tensor/device_mesh.py#L52) <> [Mesh](https://github.com/pytorch/xla/blob/6e6bb07e696c51a555a7d33433508ba236703a35/torch_xla/experimental/xla_sharding.py#L12) to denote the logical device topology.
- List[[Placement](https://github.com/pytorch/pytorch/blob/f20b3f2e5734b23a9e0a898196ddf77aa90323b8/torch/distributed/_tensor/placement_types.py#L13)] <> Tuple[int, None] to specify the sharding strategy (tiled or replicated).
- [DistributedTensor](https://github.com/pytorch/pytorch/issues/88838) <> [XLAShardedTensor](https://github.com/pytorch/xla/issues/3871) to return or to shard across different backends.
## Conversions
### DeviceMesh <> Mesh
DistributedTensor API (e.g., distribute_tensor(...)) works with a device mesh, declared by a DeviceMesh instance. It is a subclass of torch.device, and describes the sharded tensor or module placements. For instance, the following mesh defines a 1-by-4 logical device mesh:
```python
# DistributedTensor API
dt_mesh = DeviceMesh("xla", [0, 1, 2, 3])
```
The first argument is the device type, “xla”, and the mesh is described by the list of logical device IDs (global rank), [0, 1, 2, 3], which implies a single host (per row) with 4 devices. If the mesh is defined with “xla”, then the DistributedTensor API can call the XLAShardedTensor API with the same mesh topology with a shape (1, 4):
```python
from torch_xla.distributed.xla_sharding import Mesh
# XLAShardedTensor API
mesh_shape = (1, 4)
device_ids = [0, 1, 2, 3] # re-arranged per mesh_shape
axes_name = (‘x’, ‘y’) # optional
xla_mesh = Mesh(device_ids, mesh_shape, axes_name)
```
The conversion from DistributedTensor DeviceMesh to XLAShardedTensor Mesh is straightforward:
```python
dt_mesh = DeviceMesh("xla", [0, 1, 2, 3])
dt_mesh.mesh.shape
>> (1, 4)
def convert_to_xla_mesh(mesh: DeviceMeshBase):
assert torch.numel(dt_mesh.mesh) == len(xm.xrt_world_size())
return Mesh(dt_mesh.mesh.flatten(), dt_mesh.shape)
xla_mesh = convert_to_xla_mesh(dt_mesh)
xla_mesh.mesh_shape
>> (1, 4)
```
We can also define DeviceMeshBase for some common properties and interface between DeviceMesh and Mesh:
```python
class MeshBase(abc.ABC):
device_type: str
mesh: torch.Tensor
def __init__(self, device_type, mesh):
self.device_type = device_type
self.mesh = mesh
@property
def shape(self):
return self.mesh.shape
@property
def ndim(self):
return self.mesh.ndim
# torch.distributed._tensor.device_mesh
class DeviceMesh(MeshBase):
def __init__(self, device_type: str, mesh: MeshExprT, dim_groups: Optional[List[ProcessGroup]] = None, ) -> None:
mesh = (mesh.detach() if isinstance(mesh, torch.Tesnor) else torch.tensor(mesh, dtype=torch.int))
super().__init__(device_type, mesh)
...
# torh_xla.experimental.xla_sharding
class Mesh(MeshBase):
def __init__(self, device_ids: Union[np.ndarray, List], mesh_shape: Tuple[int, ...], axis_names: Tuple[str, ...] = None):
if not isinstance(device_ids, np.ndarray):
device_ids = np.array(device_ids)
mesh = torch.tensor(device_ids.reshape(mesh_shape))
super().__init__("xla", mesh)
...
```
### List[Placement] <> Tuple[int, None]
One can convert the DistributedTensor placement specs into the XLAShardedTensor partitioning specs by mapping the “per mesh dimension sharding” (DistributedTensor) to the “per tensor dimension sharding” (XLAShardedTensor). For an illustration, consider an input tensor of shape (4, 8, 8) and its sharding across a (2, 4) device mesh. Namely, the first tensor dimension will be sharded 4-way across the second dimension of the device mesh, and the rest will be replicated.
In DistributedTensor, this is expressed with a placement spec, [Replicate(), Shard(0)] where each of the spec elements describes how the corresponding mesh dimension will be used, replicated or sharded. Finally, Shard(0) means that the first dimension of the input tensor (index 0) will be sharded, in this case over the second dimension of the mesh.
```python
import torch
from torch.distributed.tensor import distribute_tensor, DeviceMesh, Shard, Replicate
m1 = torch.randn(4, 8, 8)
# Mesh partitioning, each device holds 1/4-th of the input with
# replicated overlaps. The first input tensioner dimension is split 4-way.
dt_mesh = DeviceMesh("cuda", torch.arange(8).reshape(2, 4))
m1_sharded = distribute_tensor(m1, dt_mesh, [Replicate(), Shard(0)])
```
In XLAShardedTensor, the same sharding strategy is denoted by a partition spec, (1, None, None). Each spec element describes how the corresponding input tensor dimension will be mapped to the device mesh. For example, partition_spec[0] = 1 indicates that the first dimension of the input tensor will be mapped to the second dimension (index 1) of the device mesh, thus split 4-way. None means replication, and the rest of the input dimensions will be replicated.
```python
import torch
import torch_xla.distributed.xla_sharding as xs
from torch_xla.distributed.xla_sharding import Mesh
m1 = torch.randn(4, 8, 8).to(xm.xla_device())
xla_mesh = Mesh(torch.arange(8), (2,4))
# Mesh partitioning, each device holds 1/4-th of the input with
# replicated overlaps. The first input tensioner dimension is split 4-way.
partition_spec = (1, None, None)
m1_sharded = xs.mark_sharding(m1, mesh, partition_spec)
```
Note that the XLAShardedTensor uses a different sharding spec representation, where a sharding strategy is declared “per tensor dimension”. We can transform DT placement specs (Shard or Replicate) into partition specs,
```python
m1 = torch.randn(4, 8, 8)
def convert_to_xla_partition_spec(tensor: torch.Tensor, placement_spec: List[Placement]):
# per tensor dimension sharding
sharding_spec = tuple([None] * len(tensor.shape))
for mesh_idx, spec in enumerate(placement_spec):
if instance(spec, Shard):
# mesh_idx to tensor_idx (spec.dim)
sharding_spec[spec.dim] = mesh_idx
# Replicate defaults to None
sharding_spec = convert_to_xla_partition_spec(m1, [Replicate(), Shard(0)])
print(sharding_spec)
>> (1, None, None)
```
### DistributedTensor <> XLAShardedTensor
Tensor distributions on the `xla` backend triggers the XLA compiler to partition and propagates the sharding, the final result is the same as if the computation were not sharded, and the result is replicated across the devices. This is the side-effects of the `xla` backend tensor distribution. One can avoid such side-effects and just apply torch ops to the sharded tensors, by taking the returned XLAShardedTensor and converting it to DistributedTensor. This conversion requires that the DistributedTensor resides on the CPU.
```python
# distribute_tensor with xla backend returns XLAShardedTensor
t = torch.randn(4, 8)
mesh_shape = torch.arange(8).reshape(2, 4)
xla_mesh = DeviceMesh("xla", mesh_shape)
xt = distribute_tensor(t, xla_mesh, [Replicate(), Shard(0)])
# XLAShardedTensor is collected on the host for the conversion
cpu_mesh = DeviceMesh(“cpu”, [0, 1])
dt = DistributedTensor.from_local(xt.global_tensor.to("cpu"), cpu_mesh, [Replicate(), Shard(0)])
# DistributedTensor can be converted to XLAShardedTensor
xt = xs.mark_sharding(dt.global_tensor, tuple(mesh_shape), (1, None))
```
## DistributedTensor API with `xla` device
### distribute_tensor
Calling distribute_tensor with an `xla` device_mesh will trigger a mark_sharding API call with the transformed input arguments:
```python
def distribute_tensor(tensor: torch.Tensor, device_mesh: DeviceMesh=None, placements: List[Placement]=None) -> torch.Tensor:
# distribute the tensor according to device_mesh and placements, tensor could be a "meta" tensor.
...
# Annotates sharding and returns an XLAShardedTensor
if device_mesh.device_type == 'xla':
# import torch_xla.experimental.xla_sharding as xs
xla_mesh = convert_to_xla_mesh(device_mesh)
partition_spec = convert_to_xla_partition_spec(tensor, placements)
xla_tensor = xs.mark_sharding(tensor, xla_mesh, parittion_spec)
return xla_tensor
```
The distribute_tensor API returns a torch.Tensor that can be either DistributedTensor or XLAShardedTensor.
### distributed_module
This API is currently mainly used for manual sharding specification, not like GSPMD automatic style sharding propagation, i.e. it allows the user to specify sharding, and treat the rest of the module parameters as replicated. Currently we are in the process of deciding if we want to use this API or a new API to do GSPMD style sharding propagation. We can revisit this with XLA GSPMD integration later if we settled in the API.
### Alternatives
We want to make the DistributedTensor API to be device agnostic and also support the `xla` lazy backend. PyTorch/XLA provides a set of lower-level APIs which can be integrated into DT to support the distributed tensor execution on the lazy backend, with some limitations. The goal is to promote more consistent user experiences across different backends, and use the same abstraction as possible. An alternative is to integrate into other distributed tensor abstractions and their APIs, which we may consider after integrating with DT first, if need to.
cc @bdhirsh @wanchaol @JackCaoG @steventk-g @fduwjj @alanwaketan @miladm
| 1 |
3,655 | 92,907 |
Unable to find an engine to execute when using pip to install but not with conda
|
oncall: binaries, module: cudnn, module: convolution, triaged
|
When I tried to run resnet34 model test with the nightly version that is installed with pip in cuda 11.6 with A100 gpu.
~~UPDATE: As mentioned in Notes below, it seems that the problem caused by `torchtriton` package. I can resolve the problem by manually install `torchtriton` via conda: `conda install torchtriton -c pytorch-nightly`~~
## Here is the command to reproduce the error:
```
pip3 install --pre torch torchvision --extra-index-url https://download.pytorch.org/whl/nightly/cu116
pip install pytest
git clone git@github.com:pytorch/vision.git
cd vision/test
pytest test_models.py -k test_classification_model -k resnet34
```
## And I got the following error:
```
Traceback (most recent call last):
File "/fsx/users/yosuamichael/repos/temp/vision/test/test_models.py", line 688, in test_classification_model
out = model(x)
File "/fsx/users/yosuamichael/conda/envs/tv_test/lib/python3.8/site-packages/torch/nn/modules/module.py", line 1488, in _call_impl
return forward_call(*args, **kwargs)
File "/fsx/users/yosuamichael/conda/envs/tv_test/lib/python3.8/site-packages/torchvision/models/resnet.py", line 285, in forward
return self._forward_impl(x)
File "/fsx/users/yosuamichael/conda/envs/tv_test/lib/python3.8/site-packages/torchvision/models/resnet.py", line 268, in _forward_impl
x = self.conv1(x)
File "/fsx/users/yosuamichael/conda/envs/tv_test/lib/python3.8/site-packages/torch/nn/modules/module.py", line 1488, in _call_impl
return forward_call(*args, **kwargs)
File "/fsx/users/yosuamichael/conda/envs/tv_test/lib/python3.8/site-packages/torch/nn/modules/conv.py", line 463, in forward
return self._conv_forward(input, self.weight, self.bias)
File "/fsx/users/yosuamichael/conda/envs/tv_test/lib/python3.8/site-packages/torch/nn/modules/conv.py", line 459, in _conv_forward
return F.conv2d(input, weight, bias, self.stride,
RuntimeError: GET was unable to find an engine to execute this computation
```
Which quite an unexpected error. When I tried to install using conda, i.e. change the installation line to:
```
conda install pytorch torchvision pytorch-cuda=11.6 -c pytorch-nightly -c nvidia
```
then it actually works as expected, I get assertion error (which is expected) like:
```
Mismatched elements: 10 / 50 (20.0%)
Greatest absolute difference: 0.01226806640625 at index (0, 39) (up to 0.001 allowed)
Greatest relative difference: 0.003982544439953874 at index (0, 49) (up to 0.001 allowed)
```
Hence, I think there is something wrong with the pip installation.
## Environment
Here is the result of `collect_env.py` when I use pip installation:
```
Collecting environment information...
PyTorch version: 2.0.0.dev20230124+cu116
Is debug build: False
CUDA used to build PyTorch: 11.6
ROCM used to build PyTorch: N/A
OS: Ubuntu 18.04.6 LTS (x86_64)
GCC version: (Ubuntu 9.4.0-1ubuntu1~18.04) 9.4.0
Clang version: 6.0.0-1ubuntu2 (tags/RELEASE_600/final)
CMake version: version 3.25.0
Libc version: glibc-2.27
Python version: 3.8.16 (default, Jan 17 2023, 23:13:24) [GCC 11.2.0] (64-bit runtime)
Python platform: Linux-5.4.0-1069-aws-x86_64-with-glibc2.17
Is CUDA available: True
CUDA runtime version: 11.6.112
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration: GPU 0: NVIDIA A100-SXM4-40GB
Nvidia driver version: 510.47.03
cuDNN version: Probably one of the following:
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn.so.8.0.5
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_adv_infer.so.8.0.5
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_adv_train.so.8.0.5
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_cnn_infer.so.8.0.5
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_cnn_train.so.8.0.5
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_ops_infer.so.8.0.5
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_ops_train.so.8.0.5
/usr/local/cuda-11.1/targets/x86_64-linux/lib/libcudnn.so.8.0.5
/usr/local/cuda-11.1/targets/x86_64-linux/lib/libcudnn_adv_infer.so.8.0.5
/usr/local/cuda-11.1/targets/x86_64-linux/lib/libcudnn_adv_train.so.8.0.5
/usr/local/cuda-11.1/targets/x86_64-linux/lib/libcudnn_cnn_infer.so.8.0.5
/usr/local/cuda-11.1/targets/x86_64-linux/lib/libcudnn_cnn_train.so.8.0.5
/usr/local/cuda-11.1/targets/x86_64-linux/lib/libcudnn_ops_infer.so.8.0.5
/usr/local/cuda-11.1/targets/x86_64-linux/lib/libcudnn_ops_train.so.8.0.5
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn.so.8.1.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn_adv_infer.so.8.1.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn_adv_train.so.8.1.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn_cnn_infer.so.8.1.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn_cnn_train.so.8.1.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn_ops_infer.so.8.1.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn_ops_train.so.8.1.1
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.24.1
[pip3] pytorch-triton==2.0.0+0d7e753227
[pip3] torch==2.0.0.dev20230124+cu116
[pip3] torchvision==0.15.0.dev20230124+cu116
[conda] numpy 1.24.1 pypi_0 pypi
[conda] pytorch-triton 2.0.0+0d7e753227 pypi_0 pypi
[conda] torch 2.0.0.dev20230124+cu116 pypi_0 pypi
[conda] torchvision 0.15.0.dev20230124+cu116 pypi_0 pypi
```
And here is the result of collect_env.py when I install using conda:
```
Collecting environment information...
PyTorch version: 2.0.0.dev20230124
Is debug build: False
CUDA used to build PyTorch: 11.6
ROCM used to build PyTorch: N/A
OS: Ubuntu 18.04.6 LTS (x86_64)
GCC version: (Ubuntu 9.4.0-1ubuntu1~18.04) 9.4.0
Clang version: 6.0.0-1ubuntu2 (tags/RELEASE_600/final)
CMake version: version 3.25.0
Libc version: glibc-2.27
Python version: 3.8.16 (default, Jan 17 2023, 23:13:24) [GCC 11.2.0] (64-bit runtime)
Python platform: Linux-5.4.0-1069-aws-x86_64-with-glibc2.17
Is CUDA available: True
CUDA runtime version: 11.6.112
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration: GPU 0: NVIDIA A100-SXM4-40GB
Nvidia driver version: 510.47.03
cuDNN version: Probably one of the following:
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn.so.8.0.5
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_adv_infer.so.8.0.5
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_adv_train.so.8.0.5
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_cnn_infer.so.8.0.5
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_cnn_train.so.8.0.5
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_ops_infer.so.8.0.5
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_ops_train.so.8.0.5
/usr/local/cuda-11.1/targets/x86_64-linux/lib/libcudnn.so.8.0.5
/usr/local/cuda-11.1/targets/x86_64-linux/lib/libcudnn_adv_infer.so.8.0.5
/usr/local/cuda-11.1/targets/x86_64-linux/lib/libcudnn_adv_train.so.8.0.5
/usr/local/cuda-11.1/targets/x86_64-linux/lib/libcudnn_cnn_infer.so.8.0.5
/usr/local/cuda-11.1/targets/x86_64-linux/lib/libcudnn_cnn_train.so.8.0.5
/usr/local/cuda-11.1/targets/x86_64-linux/lib/libcudnn_ops_infer.so.8.0.5
/usr/local/cuda-11.1/targets/x86_64-linux/lib/libcudnn_ops_train.so.8.0.5
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn.so.8.1.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn_adv_infer.so.8.1.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn_adv_train.so.8.1.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn_cnn_infer.so.8.1.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn_cnn_train.so.8.1.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn_ops_infer.so.8.1.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn_ops_train.so.8.1.1
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.23.5
[pip3] pytorch-triton==2.0.0+0d7e753227
[pip3] torch==2.0.0.dev20230124+cu116
[pip3] torchvision==0.15.0.dev20230124
[conda] blas 1.0 mkl
[conda] mkl 2021.4.0 h06a4308_640
[conda] mkl-service 2.4.0 py38h7f8727e_0
[conda] mkl_fft 1.3.1 py38hd3c417c_0
[conda] mkl_random 1.2.2 py38h51133e4_0
[conda] numpy 1.23.5 py38h14f4228_0
[conda] numpy-base 1.23.5 py38h31eccc5_0
[conda] pytorch 2.0.0.dev20230124 py3.8_cuda11.6_cudnn8.3.2_0 pytorch-nightly
[conda] pytorch-cuda 11.6 h867d48c_2 pytorch-nightly
[conda] pytorch-mutex 1.0 cuda pytorch-nightly
[conda] pytorch-triton 2.0.0+0d7e753227 pypi_0 pypi
[conda] torch 2.0.0.dev20230124+cu116 pypi_0 pypi
[conda] torchtriton 2.0.0+0d7e753227 py38 pytorch-nightly
[conda] torchvision 0.15.0.dev20230124 py38_cu116 pytorch-nightly
```
## Notes
- I have also tried to install from `.whl` files archived in s3, and I found that the problem starts to occur since the nightly version `2022-12-15`. The version `2022-12-14` dont get the error `RuntimeError: GET was unable to find an engine to execute this computation`.
- After further investigation, seems like the problem is on the pytorch core package since I got the same exact behaviour when we install torchvision via source, will move the issue to pytorch/pytorch for this.
~~- The error is resolved when I manually install `torchtriton` using conda. So the following command will work as expected:~~ --> This only seems to fix because it actually replace the pytorch core
cc @ezyang @seemethere @malfet @csarofeen @ptrblck @xwang233
| 4 |
3,656 | 92,888 |
[LibTorch] pickle_save output cannot be reloaded using pickle_load in Windows
|
oncall: jit
|
### 🐛 Describe the bug
For the following code, it works in Mac but crashed in Windows for the last step
```
#include <torch/script.h>
torch::jit::IValue tensor(torch::randn({1, 64}));
std::vector<char> input = torch::jit::pickle_save(tensor);
tensor = torch::jit::pickle_load(input);
```
Error messages:
`Microsoft C++ exception: c10::Error at memory location 0x0000000C8155E460`
### Versions
LibTorch version is latest stable 1.13.1.
cc @EikanWang @jgong5 @wenzhe-nrv @sanchitintel
| 0 |
3,657 | 92,884 |
[RFC] Make more operations inplace (GELU, BatchNorm, LayerNorm)
|
module: nn, triaged, enhancement, actionable
|
### 🚀 The feature, motivation and pitch
# Make more operations inplace (GELU, BatchNorm, LayerNorm)
## **Summary**
Hi PyTorch team,
We would like to enable users to make the following operations inplace: LayerNorm, BatchNorm and GELU.
## **Motivation**
In-place operations can lower the amount of memory used by operators in specific cases with minimal overhead
compared to other methods of reducing the memory footprint of models such as activation checkpointing, this
can then lead to increased performance in the form of throughput gains through batch size improvements. In-place
GELU and In-place LayerNorm combined for example, leads to an activation memory footprint savings of over
10% for Huggingface BERT at a sequence length of 512.
These benefits and prior art are described in the papers listed in the prior arts. Currently, in the
github repositories associated with these papers these In-place versions of these operators are implemented as
PyTorch modules that must be imported.
The value add of this feature would be allowing users to take advantage of these operators directly from PyTorch.
This would have no impact to other users of the library.
## **Proposed Implementation**
Our proposed implementation is to add an inplace flag to existing modules, which can then be set to True to enable
the in-place version, such as with dropout for example.
`torch.nn.Dropout1d(p=0.5, inplace=False)`
The existing LayerNorm module, for example, would change from
`torch.nn.LayerNorm(normalized_shape, eps=1e-05, elementwise_affine=True, device=None, dtype=None)`
to
`torch.nn.LayerNorm(normalized_shape, eps=1e-05, elementwise_affine=True, inplace=False, device=None, dtype=None)`.
Internally, this can then be handled as other inplace operators with a custom implementation in ATen, and adding
the appropriate flags in the Autograd engine. Suggestions on how to do this would be welcome.
## **Metrics**
The main metric to evaluate whether this change is successful is to evaluate the memory usage of a model with
and without this change.
## **Drawbacks**
There are little to no drawbacks considering that the implementation cost is low, it does not introduce any breaking changes,
and this is not a torch wide change that would affect all users.
However, we note the In-place GELU is lossy, and this needs to be communicated/handled correctly.
## **Alternatives**
An alternative design would be to add these In-place versions as separate operators. For example, add an
`InPlaceLayerNorm` layer as its own separate module.
## **Prior Art**
These ideas are introduced in the following papers:
[In-Place Activated BatchNorm for Memory-Optimized Training of DNNs (CVPR '18)](https://openaccess.thecvf.com/content_cvpr_2018/papers/Bulo_In-Place_Activated_BatchNorm_CVPR_2018_paper.pdf)
Github repository: https://github.com/mapillary/inplace_abn
[Tempo: Accelerating Transformer-Based Model Training through Memory Footprint Reduction (NeurIPS '22)](https://openreview.net/forum?id=xqyEG7EhTZ)
Github repository: https://github.com/UofT-EcoSystem/Tempo
Example usage of Tempo:
```
from tempo.inplace_gelu import InplaceGelu
from tempo.inplace_layernorm import InplaceLayerNorm
from tempo.combined import Combined
# Original LayerNorm in Transformer model
# self.LayerNorm = nn.LayerNorm(config.hidden_size, eps=1e-12)
# Replace it with Tempo's InplaceLayerNorm
self.LayerNorm = InplaceLayerNorm(config.hidden_size, eps=1e-12)
```
## **Unresolved questions**
* How to deal with the lossy nature of GELU
* Exact implementation details
### Alternatives
See above
cc @albanD @mruberry @jbschlosser @walterddr @saketh-are
| 12 |
3,658 | 92,866 |
JIT Function Fails when run a second time
|
oncall: jit
|
### 🐛 Describe the bug
JITed function fails after being run a second time on the same exact inputs with error:
RuntimeError: tensor_type->scalarType().has_value() INTERNAL ASSERT FAILED. Missing Scalar Type information.
JIT Function Code:
```
import torch
from typing import List
@torch.jit.script
def sh_basis(degs: List[int], dirs, kappa=None):
# evaluate a list of degrees
if kappa is not None:
kappa = kappa.reshape(-1)
x, y, z = dirs.T[0], dirs.T[1], dirs.T[2]
xx, yy, zz = x * x, y * y, z * z
x4, y4, z4 = x**4, y**4, z**4
x6, y6, z6 = x**6, y**6, z**6
x8, y8, z8 = x**8, y**8, z**8
x10, y10, z10 = x**10, y**10, z**10
x12, y12, z12 = x**12, y**12, z**12
x14, y14, z14 = x**14, y**14, z**14
x16, y16, z16 = x**16, y**16, z**16
values = []
for deg in degs:
scale = Al(deg, kappa) if kappa is not None else 1
if deg == 0:
values.append(scale*0.28209479177387814 * torch.ones_like(x))
if deg == 1:
values.extend([
# scale*-0.690988*y,
# scale*0.488603*z,
# scale*-0.345494*x
-scale*0.488603*x,
scale*0.488603*z,
-scale*0.488603*y
])
if deg == 2:
values.extend([
scale*1.092548*y*x,
-scale*1.092548*y*z,
scale*0.315392*(3*zz - 1),
-scale*1.092548*x*y,
scale*0.546274*(xx-yy),
# scale*1.5451*x*y,
# scale*-1.5451*y*z,
# scale*(0.946176*zz - 0.315392),
# scale*-0.772548*x*z,
# scale*(0.386274*xx - 0.386274*yy)
])
if deg == 4:
values.extend([
2.50334*x*y*(xx - yy),
-1.77013*y*z*(-3*xx + yy),
0.946175*x*y*(7*zz - 1),
0.669047*y*z*(7*zz - 3),
3.70251*z4 - 3.17358*zz + 0.317358,
0.669047*x*z*(7*zz - 3),
(0.473087*xx - 0.473087*yy)*(7*zz - 1),
1.77013*x*z*(xx - 3*yy),
0.625836*x4 - 3.755016*xx*yy + 0.625836*y4,
])
if deg == 8:
values.extend([
5.83141*x*y*(x6 - 7*x4*yy + 7*xx*y4 - y6),
-2.91571*y*z*(-7*x6 + 35*x4*yy - 21*xx*y4 + y6),
1.06467*x*y*(15*zz - 1)*(3*x4 - 10*xx*yy + 3*y4),
3.44991*y*z*(5*zz - 1)*(5*x4 - 10*xx*yy + y4),
1.91367*x*y*(xx - yy)*(65*z4 - 26*zz + 1),
-1.23527*y*z*(-3*xx + yy)*(39*z4 - 26*zz + 3),
0.912305*x*y*(143*z6 - 143*z4 + 33*zz - 1),
0.109041*y*z*(715*z6 - 1001*z4 + 385*zz - 35),
58.47336495*z8 - 109.15028124*z6 + 62.9713161*z4 - 11.4493302*zz + 0.31803695,
0.109041*x*z*(715*z6 - 1001*z4 + 385*zz - 35),
(0.456152*xx - 0.456152*yy)*(143*z6 - 143*z4 + 33*zz - 1),
1.23527*x*z*(xx - 3*yy)*(39*z4 - 26*zz + 3),
(0.478417*x4 - 2.870502*xx*yy + 0.478417*y4)*(65*z4 - 26*zz + 1),
3.44991*x*z*(5*zz - 1)*(x4 - 10*xx*yy + 5*y4),
(15*zz - 1)*(0.532333*x6 - 7.984995*x4*yy + 7.984995*xx*y4 - 0.532333*y6),
2.91571*x*z*(x6 - 21*x4*yy + 35*xx*y4 - 7*y6),
0.728927*x8 - 20.409956*x6*yy + 51.02489*x4*y4 - 20.409956*xx*y6 + 0.728927*y8,
])
if deg == 16:
values.extend([
13.7174*x*y*(x14 - 35*x12*yy + 273*x10*y4 - 715*x8*y6 + 715*x6*y8 - 273*x4*y10 + 35*xx*y12 - y14),
-4.84985*y*z*(-15*x14 + 455*x12*yy - 3003*x10*y4 + 6435*x8*y6 - 5005*x6*y8 + 1365*x4*y10 - 105*xx*y12 + y14),
1.23186*x*y*(31*zz - 1)*(7*x12 - 182*x10*yy + 1001*x8*y4 - 1716*x6*y6 + 1001*x4*y8 - 182*xx*y10 + 7*y12),
1.94775*y*z*(31*zz - 3)*(13*x12 - 286*x10*yy + 1287*x8*y4 - 1716*x6*y6 + 715*x4*y8 - 78*xx*y10 + y12),
0.723375*x*y*(899*z4 - 174*zz + 3)*(3*x10 - 55*x8*yy + 198*x6*y4 - 198*x4*y6 + 55*xx*y8 - 3*y10),
-0.427954*y*z*(899*z4 - 290*zz + 15)*(-11*x10 + 165*x8*yy - 462*x6*y4 + 330*x4*y6 - 55*xx*y8 + y10),
0.20174*x*y*(8091*z6 - 3915*z4 + 405*zz - 5)*(5*x8 - 60*x6*yy + 126*x4*y4 - 60*xx*y6 + 5*y8),
0.194401*y*z*(8091*z6 - 5481*z4 + 945*zz - 35)*(9*x8 - 84*x6*yy + 126*x4*y4 - 36*xx*y6 + y8),
0.54985*x*y*(x6 - 7*x4*yy + 7*xx*y4 - y6)*(40455*z8 - 36540*z6 + 9450*z4 - 700*zz + 7),
-0.336713*y*z*(-7*x6 + 35*x4*yy - 21*xx*y4 + y6)*(13485*z8 - 15660*z6 + 5670*z4 - 700*zz + 21),
0.0444044*x*y*(3*x4 - 10*xx*yy + 3*y4)*(310155*z10 - 450225*z8 + 217350*z6 - 40250*z4 + 2415*zz - 21),
0.0313986*y*z*(5*x4 - 10*xx*yy + y4)*(310155*z10 - 550275*z8 + 341550*z6 - 88550*z4 + 8855*zz - 231),
0.166146*x*y*(xx - yy)*(310155*z12 - 660330*z10 + 512325*z8 - 177100*z6 + 26565*z4 - 1386*zz + 11),
-0.0515197*y*z*(-3*xx + yy)*(310155*z12 - 780390*z10 + 740025*z8 - 328900*z6 + 69069*z4 - 6006*zz + 143),
0.00631775*x*y*(5892950.0*z14 - 17298600.0*z12 + 19684700.0*z10 - 10935900.0*z8 + 3062060.0*z6 - 399399*z4 + 19019*zz - 143),
0.00115346*y*z*(17678800.0*z14 - 59879900.0*z12 + 80528200.0*z10 - 54679600.0*z8 + 19684700.0*z6 - 3594590.0*z4 + 285285*zz - 6435),
14862.935214*z16 - 57533.910858*z14 + 90269.063271*z12 - 73552.588389*z10 + 33098.5905939*z8 - 8058.7928655*z6 + 959.37986754*z4 - 43.280250156*zz + 0.3182371335,
0.00115346*x*z*(17678800.0*z14 - 59879900.0*z12 + 80528200.0*z10 - 54679600.0*z8 + 19684700.0*z6 - 3594590.0*z4 + 285285*zz - 6435),
(0.00315887*xx - 0.00315887*yy)*(5892950.0*z14 - 17298600.0*z12 + 19684700.0*z10 - 10935900.0*z8 + 3062060.0*z6 - 399399*z4 + 19019*zz - 143),
0.0515197*x*z*(xx - 3*yy)*(310155*z12 - 780390*z10 + 740025*z8 - 328900*z6 + 69069*z4 - 6006*zz + 143),
(0.0415365*x4 - 0.249219*xx*yy + 0.0415365*y4)*(310155*z12 - 660330*z10 + 512325*z8 - 177100*z6 + 26565*z4 - 1386*zz + 11),
0.0313986*x*z*(x4 - 10*xx*yy + 5*y4)*(310155*z10 - 550275*z8 + 341550*z6 - 88550*z4 + 8855*zz - 231),
(0.0222022*x6 - 0.333033*x4*yy + 0.333033*xx*y4 - 0.0222022*y6)*(310155*z10 - 450225*z8 + 217350*z6 - 40250*z4 + 2415*zz - 21),
0.336713*x*z*(x6 - 21*x4*yy + 35*xx*y4 - 7*y6)*(13485*z8 - 15660*z6 + 5670*z4 - 700*zz + 21),
(0.0687312*x8 - 1.9244736*x6*yy + 4.811184*x4*y4 - 1.9244736*xx*y6 + 0.0687312*y8)*(40455*z8 - 36540*z6 + 9450*z4 - 700*zz + 7),
0.194401*x*z*(8091*z6 - 5481*z4 + 945*zz - 35)*(x8 - 36*x6*yy + 126*x4*y4 - 84*xx*y6 + 9*y8),
(8091*z6 - 3915*z4 + 405*zz - 5)*(0.10087*x10 - 4.53915*x8*yy + 21.1827*x6*y4 - 21.1827*x4*y6 + 4.53915*xx*y8 - 0.10087*y10),
0.427954*x*z*(899*z4 - 290*zz + 15)*(x10 - 55*x8*yy + 330*x6*y4 - 462*x4*y6 + 165*xx*y8 - 11*y10),
(899*z4 - 174*zz + 3)*(0.180844*x12 - 11.935704*x10*yy + 89.51778*x8*y4 - 167.099856*x6*y6 + 89.51778*x4*y8 - 11.935704*xx*y10 + 0.180844*y12),
1.94775*x*z*(31*zz - 3)*(x12 - 78*x10*yy + 715*x8*y4 - 1716*x6*y6 + 1287*x4*y8 - 286*xx*y10 + 13*y12),
(31*zz - 1)*(0.615932*x14 - 56.049812*x12*yy + 616.547932*x10*y4 - 1849.643796*x8*y6 + 1849.643796*x6*y8 - 616.547932*x4*y10 + 56.049812*xx*y12 - 0.615932*y14),
4.84985*x*z*(x14 - 105*x12*yy + 1365*x10*y4 - 5005*x8*y6 + 6435*x6*y8 - 3003*x4*y10 + 455*xx*y12 - 15*y14),
0.857341*x16 - 102.88092*x14*yy + 1560.36062*x12*y4 - 6865.586728*x10*y6 + 11033.97867*x8*y8 - 6865.586728*x6*y10 + 1560.36062*x4*y12 - 102.88092*xx*y14 + 0.857341*y16,
])
return torch.stack(values, dim=-1)
```
How to reproduce the error:
```
Python 3.10.5 | packaged by conda-forge | (main, Jun 14 2022, 07:06:46) [GCC 10.3.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import torch
>>> from modules.sh import sh_basis
>>> device = torch.device('cuda')
>>> vecs = torch.rand((10000, 3), device=device)
>>> kappa = torch.rand((10000, 1), device=device)
>>> sh_basis([0, 1, 2, 4], vecs, kappa)
tensor([[ 2.8209e-01, -7.4768e-02, 1.0519e-01, ..., -1.8813e-03,
-8.9227e-01, -4.4803e-01],
[ 2.8209e-01, -4.2040e-05, 1.3623e-04, ..., -2.3001e-01,
-2.3584e-01, 1.1216e-01],
[ 2.8209e-01, -8.7236e-03, 1.7843e-02, ..., -2.0500e-02,
-6.4801e-02, -1.3913e-02],
...,
[ 2.8209e-01, -2.6438e-02, 9.2806e-02, ..., 1.4510e-01,
1.8478e-02, 7.0536e-04],
[ 2.8209e-01, -7.5585e-12, 7.9083e-12, ..., 5.1023e-01,
-8.5628e-01, -7.5704e-01],
[ 2.8209e-01, -2.9055e-02, 1.1445e-01, ..., 3.6547e-02,
-1.2329e-03, -1.0240e-03]], device='cuda:0')
>>> sh_basis([0, 1, 2, 4], vecs, kappa)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
RuntimeError: tensor_type->scalarType().has_value() INTERNAL ASSERT FAILED at "/opt/conda/conda-bld/pytorch_1659484803030/work/torch/csrc/jit/codegen/cuda/type_promotion.cpp":111, please report a bug to PyTorch. Missing Scalar Type information
```
### Versions
PyTorch version: 1.12.1
Is debug build: False
CUDA used to build PyTorch: 11.6
ROCM used to build PyTorch: N/A
OS: Manjaro Linux (x86_64)
GCC version: (GCC) 12.2.0
Clang version: 14.0.6
CMake version: version 3.24.0
Libc version: glibc-2.36
Python version: 3.10.5 | packaged by conda-forge | (main, Jun 14 2022, 07:06:46) [GCC 10.3.0] (64-bit runtime)
Python platform: Linux-5.15.85-1-MANJARO-x86_64-with-glibc2.36
Is CUDA available: True
CUDA runtime version: 11.8.89
CUDA_MODULE_LOADING set to:
GPU models and configuration: GPU 0: NVIDIA GeForce RTX 3090
Nvidia driver version: 525.60.11
cuDNN version: Probably one of the following:
/usr/lib/libcudnn.so.8.6.0
/usr/lib/libcudnn_adv_infer.so.8.6.0
/usr/lib/libcudnn_adv_train.so.8.6.0
/usr/lib/libcudnn_cnn_infer.so.8.6.0
/usr/lib/libcudnn_cnn_train.so.8.6.0
/usr/lib/libcudnn_ops_infer.so.8.6.0
/usr/lib/libcudnn_ops_train.so.8.6.0
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.23.1
[pip3] pytorch-lightning==1.7.7
[pip3] torch==1.12.1
[pip3] torch-ema==0.3
[pip3] torch-scatter==2.0.9
[pip3] torchaudio==0.12.1
[pip3] torchmetrics==0.10.2
[pip3] torchvision==0.13.1
[conda] blas 1.0 mkl
[conda] cudatoolkit 11.6.0 hecad31d_10 conda-forge
[conda] ffmpeg 4.3 hf484d3e_0 pytorch
[conda] libblas 3.9.0 12_linux64_mkl conda-forge
[conda] libcblas 3.9.0 12_linux64_mkl conda-forge
[conda] liblapack 3.9.0 12_linux64_mkl conda-forge
[conda] mkl 2021.4.0 h06a4308_640
[conda] mkl-service 2.4.0 py310h7f8727e_0
[conda] mkl_fft 1.3.1 py310hd6ae3a3_0
[conda] mkl_random 1.2.2 py310h00e6091_0
[conda] numpy 1.22.4 pypi_0 pypi
[conda] numpy-base 1.23.1 py310hcba007f_0
[conda] pytorch 1.12.1 py3.10_cuda11.6_cudnn8.3.2_0 pytorch
[conda] pytorch-lightning 1.7.7 pypi_0 pypi
[conda] pytorch-mutex 1.0 cuda pytorch
[conda] pytorch-scatter 2.0.9 py310_torch_1.12.0_cu116 pyg
[conda] torch-ema 0.3 pypi_0 pypi
[conda] torchaudio 0.12.1 py310_cu116 pytorch
[conda] torchmetrics 0.10.2 pypi_0 pypi
[conda] torchvision 0.13.1 py310_cu116 pytorch
cc @EikanWang @jgong5 @wenzhe-nrv @sanchitintel
| 2 |
3,659 | 92,855 |
Profiler documentation doesn't mention some exports are mutually exclusive
|
oncall: profiler
|
### 📚 The doc issue
The [profiler documentation](https://pytorch.org/docs/stable/profiler.html) and the tutorials on it don't mention that the tensorboard and chrome trace exports are mutually exclusive. I had setup an initial run to dump out all the supported formats of profiling information as I was unsure which tool would prove most useful, and when exporting a chrome trace after using the tensorboard output hook I get a stack trace like:
```
File "/path/to/venv/lib/python3.8/site-packages/torch/profiler/profiler.py", line 136, in export_chrome_trace
return self.profiler.export_chrome_trace(path)
File "/path/to/venv/lib/python3.8/site-packages/torch/autograd/profiler.py", line 278, in export_chrome_trace
self.kineto_results.save(path) # type: ignore[union-attr]
RuntimeError: Trace is already saved.
```
This is presumably related to [this line](https://github.com/pytorch/pytorch/blob/master/torch/csrc/profiler/kineto_shim.h#L112) which notes "Kineto's save is destructive" but as far as I can tell this fact isn't documented anywhere, and it probably should be.
### Suggest a potential alternative/fix
Add a note to the profiler docs page saying which export methods are mutually exclusive, and update the tutorials to note that.
cc @robieta @chaekit @aaronenyeshi @ngimel @nbcsm @guotuofeng @guyang3532 @gaoteng-git @tiffzhaofb
| 1 |
3,660 | 92,838 |
Enable OnDemand for Open Source CI
|
triaged
|
### 🚀 The feature, motivation and pitch
### A Common Scenario
You submit PR to PyTorch and and a test fails on a CI machine that is significantly different from your local coding environment.
Instead of using `with-ssh` you can quickly fire up a github codespaces or other OnDemand instance that has your code checked out and you are free to debug without the time limit.
### Alternatives
An alternative solution is to tag the failing pull request with the label `with-ssh`. This will allow a user to ssh into the CI machine and gives the user 2 hours (I think more time can be requested) to try and debug the error. This is far better than nothing but for non vim users and general UX it can be hard to complete the required debug work.
### Additional context
Besides debugging purposes this could also be very helpful for first time contributors. Having a ready made environment that has been streamlined for PyTorch development.
| 7 |
3,661 | 92,835 |
Double free when running torch.linalg.ldl_solve
|
triaged, module: edge cases
|
### 🐛 Describe the bug
```
import torch
import numpy as np
arg_1_tensor = torch.rand([5, 5], dtype=torch.float32)
arg_1 = arg_1_tensor.clone()
arg_2_tensor = torch.randint(-2048,8,[5], dtype=torch.int32)
arg_2 = arg_2_tensor.clone()
arg_3_tensor = torch.rand([5, 1], dtype=torch.float32)
arg_3 = arg_3_tensor.clone()
arg_4 = False
try:
res = torch.linalg.ldl_solve(arg_1,arg_2,arg_3,hermitian=arg_4,)
except Exception as e:
print("Error:"+str(e))
```
Log message:
```
double free or corruption (out)
Aborted
```
### Versions
```
PyTorch version: 1.13.1
Is debug build: False
CUDA used to build PyTorch: 11.6
ROCM used to build PyTorch: N/A
OS: Ubuntu 22.04.1 LTS (x86_64)
GCC version: (Ubuntu 11.3.0-1ubuntu1~22.04) 11.3.0
Clang version: Could not collect
CMake version: Could not collect
Libc version: glibc-2.35
Python version: 3.9.15 (main, Nov 24 2022, 14:31:59) [GCC 11.2.0] (64-bit runtime)
Python platform: Linux-5.15.0-58-generic-x86_64-with-glibc2.35
Is CUDA available: True
CUDA runtime version: 11.6.124
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration: GPU 0: NVIDIA GeForce GTX 1660 Ti
Nvidia driver version: 525.78.01
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.23.5
[pip3] torch==1.13.1
[pip3] torchaudio==0.13.1
[pip3] torchvision==0.14.1
[conda] blas 1.0 mkl
[conda] ffmpeg 4.3 hf484d3e_0 pytorch
[conda] mkl 2021.4.0 h06a4308_640
[conda] mkl-service 2.4.0 py39h7f8727e_0
[conda] mkl_fft 1.3.1 py39hd3c417c_0
[conda] mkl_random 1.2.2 py39h51133e4_0
[conda] numpy 1.23.5 py39h14f4228_0
[conda] numpy-base 1.23.5 py39h31eccc5_0
[conda] pytorch 1.13.1 py3.9_cuda11.6_cudnn8.3.2_0 pytorch
[conda] pytorch-cuda 11.6 h867d48c_1 pytorch
[conda] pytorch-mutex 1.0 cuda pytorch
[conda] torchaudio 0.13.1 py39_cu116 pytorch
[conda] torchvision 0.14.1 py39_cu116 pytorch
```
| 1 |
3,662 | 92,828 |
segfault when running torch.igamma
|
triaged
|
### 🐛 Describe the bug
```
import torch
import numpy as np
arg_1_tensor = torch.randint(0,2,[], dtype=torch.bool)
arg_1 = arg_1_tensor.clone()
arg_2_tensor = torch.rand([3], dtype=torch.float32)
arg_2 = arg_2_tensor.clone()
arg_3_tensor = torch.neg(torch.rand([3, 3, 3], dtype=torch.float16))
arg_3 = arg_3_tensor.clone()
try:
res = torch.igamma(arg_1,arg_2,out=arg_3,)
except Exception as e:
print("Error:"+str(e))
```
### Versions
```
PyTorch version: 1.12.0
Is debug build: False
CUDA used to build PyTorch: 10.2
ROCM used to build PyTorch: N/A
OS: Ubuntu 22.04.1 LTS (x86_64)
GCC version: (Ubuntu 11.3.0-1ubuntu1~22.04) 11.3.0
Clang version: Could not collect
CMake version: Could not collect
Libc version: glibc-2.35
Python version: 3.9.15 (main, Nov 24 2022, 14:31:59) [GCC 11.2.0] (64-bit runtime)
Python platform: Linux-5.15.0-58-generic-x86_64-with-glibc2.35
Is CUDA available: True
CUDA runtime version: Could not collect
CUDA_MODULE_LOADING set to:
GPU models and configuration: GPU 0: NVIDIA GeForce GTX 1660 Ti
Nvidia driver version: 525.78.01
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.23.5
[pip3] torch==1.12.0
[pip3] torchaudio==0.12.0
[pip3] torchvision==0.13.0
[conda] blas 1.0 mkl
[conda] cudatoolkit 10.2.89 hfd86e86_1
[conda] ffmpeg 4.3 hf484d3e_0 pytorch
[conda] mkl 2021.4.0 h06a4308_640
[conda] mkl-service 2.4.0 py39h7f8727e_0
[conda] mkl_fft 1.3.1 py39hd3c417c_0
[conda] mkl_random 1.2.2 py39h51133e4_0
[conda] numpy 1.23.5 py39h14f4228_0
[conda] numpy-base 1.23.5 py39h31eccc5_0
[conda] pytorch 1.12.0 py3.9_cuda10.2_cudnn7.6.5_0 pytorch
[conda] pytorch-mutex 1.0 cuda pytorch
[conda] torchaudio 0.12.0 py39_cu102 pytorch
[conda] torchvision 0.13.0 py39_cu102 pytorch
```
| 1 |
3,663 | 92,820 |
Ability to manually set the gradient in FSDP while inside `summon_full_params` and make it persistent
|
needs reproduction, oncall: distributed, triaged, module: fsdp
|
### 🚀 The feature, motivation and pitch
Hello, I'm working on training large models with Differential Privacy and I'm using PyTorch FSDP to avoid out of memory issues.
What I'm doing right now is having each gpu compute a sample gradient, clip it to a max norm and then summing it to a local variable. I would then like to reduce the local gradients across gpus by summing them together and then set this value to model's parameters `grad` attribute so that I can then call `optimizer.step()`.
My code basically looks like this:
with FSDP.summon_full_params(model, with_grads=True):
for i, param in enumerate(model.parameters()):
if param.requires_grad:
all_params_grad = [torch.zeros_like(param.grad).to(rank) for _ in range(world_size)]
dist.all_gather(all_params_grad, params_grad[i].cuda())
# sum the gradients across the gpus
sum = torch.stack(all_params_grad).sum(0)
param.grad = sum.type(param.grad.type()).to(param.grad.device)
param.grad = privacy_engine.add_noise(param.grad) / batch_size
where `params_grad[i]` contains the local sum of the clipped sample gradients. The problem is that right after exiting the context, if I try to access the parameters grad values they will all be None and so taking a step won't update the model.
Is there a way to workaround this? Any help would really be appreciated!
### Alternatives
_No response_
### Additional context
_No response_
cc @mrshenli @pritamdamania87 @zhaojuanmao @satgera @rohan-varma @gqchen @aazzolini @osalpekar @jiayisuse @H-Huang @kwen2501 @awgu
| 3 |
3,664 | 92,818 |
Segfault when running torch.atan2
|
triaged, module: complex
|
### 🐛 Describe the bug
Probably due to empty tensor:
```
import torch
import numpy as np
arg_1_tensor = torch.rand([], dtype=torch.float16)
arg_1 = arg_1_tensor.clone()
arg_2_tensor = torch.rand([3], dtype=torch.complex64)
arg_2 = arg_2_tensor.clone()
arg_3_tensor = torch.rand([3, 3, 3], dtype=torch.complex128)
arg_3 = arg_3_tensor.clone()
try:
res = torch.atan2(arg_1,arg_2,out=arg_3,)
except Exception as e:
print("Error:"+str(e))
```
Please note that this is a machine generated test cases (using fuzz testing).
### Versions
```
PyTorch version: 1.13.1
Is debug build: False
CUDA used to build PyTorch: 10.2
ROCM used to build PyTorch: N/A
OS: Ubuntu 22.04.1 LTS (x86_64)
GCC version: (Ubuntu 11.3.0-1ubuntu1~22.04) 11.3.0
Clang version: Could not collect
CMake version: Could not collect
Libc version: glibc-2.35
Python version: 3.9.15 (main, Nov 24 2022, 14:31:59) [GCC 11.2.0] (64-bit runtime)
Python platform: Linux-5.15.0-58-generic-x86_64-with-glibc2.35
Is CUDA available: True
CUDA runtime version: Could not collect
CUDA_MODULE_LOADING set to:
GPU models and configuration: GPU 0: NVIDIA GeForce GTX 1660 Ti
Nvidia driver version: 525.78.01
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.23.5
[pip3] torch==1.12.0
[pip3] torchaudio==0.12.0
[pip3] torchvision==0.13.0
[conda] blas 1.0 mkl
[conda] cudatoolkit 10.2.89 hfd86e86_1
[conda] ffmpeg 4.3 hf484d3e_0 pytorch
[conda] mkl 2021.4.0 h06a4308_640
[conda] mkl-service 2.4.0 py39h7f8727e_0
[conda] mkl_fft 1.3.1 py39hd3c417c_0
[conda] mkl_random 1.2.2 py39h51133e4_0
[conda] numpy 1.23.5 py39h14f4228_0
[conda] numpy-base 1.23.5 py39h31eccc5_0
[conda] pytorch 1.12.0 py3.9_cuda10.2_cudnn7.6.5_0 pytorch
[conda] pytorch-mutex 1.0 cuda pytorch
[conda] torchaudio 0.12.0 py39_cu102 pytorch
[conda] torchvision 0.13.0 py39_cu102 pytorch
```
cc @ezyang @anjali411 @dylanbespalko @mruberry @Lezcano @nikitaved
| 2 |
3,665 | 92,812 |
torch.fx fails to trace through "+" op between torch.Size and torch.fx.proxy.Proxy
|
oncall: fx
|
### 🐛 Describe the bug
torch.fx.proxy.Proxy + torch.Size - works
tuple(torch.Size) + torch.fx.proxy.Proxy - works
torch.Size + torch.fx.proxy.Proxy doesn't work
```python
import torch
import torch.nn as nn
class Model(nn.Module):
def __init__(self):
super().__init__()
self.linear = nn.Linear(3, 3)
def forward(self, x):
input_shape = x.shape
hidden_states = self.linear(x)
y1 = (hidden_states.size(-1), ) + input_shape
y2 = tuple(input_shape) + (hidden_states.size(-1), )
y3 = input_shape + (hidden_states.size(-1), )
torch.fx.symbolic_trace(Model(), concrete_args={'x': torch.randint(100, (2, 3))})
```
```
TypeError Traceback (most recent call last)
[<ipython-input-5-386c563846a8>](https://localhost:8080/#) in <module>
15
16
---> 17 torch.fx.symbolic_trace(Model(), concrete_args={'x': torch.randint(100, (2, 3))})
2 frames
[/usr/local/lib/python3.8/dist-packages/torch/fx/_symbolic_trace.py](https://localhost:8080/#) in symbolic_trace(root, concrete_args)
1068 """
1069 tracer = Tracer()
-> 1070 graph = tracer.trace(root, concrete_args)
1071 name = (
1072 root.__class__.__name__ if isinstance(root, torch.nn.Module) else root.__name__
[/usr/local/lib/python3.8/dist-packages/torch/fx/_symbolic_trace.py](https://localhost:8080/#) in trace(self, root, concrete_args)
737 "output",
738 "output",
--> 739 (self.create_arg(fn(*args)),),
740 {},
741 type_expr=fn.__annotations__.get("return", None),
[<ipython-input-5-386c563846a8>](https://localhost:8080/#) in forward(self, x)
12 y1 = (hidden_states.size(-1), ) + input_shape
13 y2 = tuple(input_shape) + (hidden_states.size(-1), )
---> 14 y3 = input_shape + (hidden_states.size(-1), )
15
16
TypeError: torch.Size() takes an iterable of 'int' (item 2 is 'Proxy')
```
### Versions
```
Collecting environment information...
PyTorch version: 1.13.1+cu116
Is debug build: False
CUDA used to build PyTorch: 11.6
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.5 LTS (x86_64)
GCC version: (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0
Clang version: 10.0.0-4ubuntu1
CMake version: version 3.22.6
Libc version: glibc-2.31
Python version: 3.8.10 (default, Nov 14 2022, 12:59:47) [GCC 9.4.0] (64-bit runtime)
Python platform: Linux-5.10.147+-x86_64-with-glibc2.29
Is CUDA available: False
CUDA runtime version: 11.2.152
CUDA_MODULE_LOADING set to: N/A
GPU models and configuration: Could not collect
Nvidia driver version: Could not collect
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.1.1
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.1.1
/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.1.1
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_infer.so.8.1.1
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.1.1
/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.1.1
/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.1.1
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.21.6
[pip3] torch==1.13.1+cu116
[pip3] torchaudio==0.13.1+cu116
[pip3] torchsummary==1.5.1
[pip3] torchtext==0.14.1
[pip3] torchvision==0.14.1+cu116
[conda] Could not collect
```
cc @ezyang @SherlockNoMad @EikanWang @jgong5 @wenzhe-nrv
| 5 |
3,666 | 92,811 |
[complex] Jacobian of a non-holomorphic complex valued function
|
triaged, complex_autograd
|
### 🐛 Describe the bug
```python
import torch
def fn(x):
return x.conj()
x = torch.randn(1, dtype=torch.cdouble)
jac = torch.autograd.functional.jacobian(fn, x)
print(jac) # tensor([[1.-0.j]], dtype=torch.complex128)
```
`conj` is not a holomorphic function and the Jacobian can't be represented with just a complex number.
cc: @lezcano
### Versions
master
| 1 |
3,667 | 92,804 |
Dynamo graph break due to context manager do not resume inside/outside the context manager
|
feature, module: cuda, triaged, oncall: pt2, module: dynamo
|
### 🐛 Describe the bug
Dynamo doesn't seem to support user defined cuda streams and doesn't create graphs for ops in the user stream context.
Example code:
```from torch._dynamo import optimize
import torch._dynamo as dynamo
import torch
dynamo.config.log_level = dynamo.config.logging.DEBUG
torch._dynamo.reset()
def my_compiler(gm: torch.fx.GraphModule, example_inputs: List[torch.Tensor]):
print(gm.code)
print(gm.graph)
gm.graph.print_tabular()
return gm.forward
s = torch.cuda.Stream()
@dynamo.optimize(my_compiler)
def fn(t) -> torch.Tensor:
tmp1 = torch.mul(t, 5)
tmp2 = torch.add(tmp1, 2)
with torch.cuda.stream(s):
r = torch.relu(tmp2)
return r
i = torch.Tensor([-2, 3]).to('cuda')
r = fn(i)
print(f"r = {r}")
```
Even though the output is correct, Dynamo seems to break the graph when the user stream context is seen -
```[2023-01-23 04:54:12,808] torch._dynamo.symbolic_convert: [DEBUG] break_graph_if_unsupported triggered compile
Traceback (most recent call last):
File "/usr/local/lib/python3.8/dist-packages/torch/_dynamo/utils.py", line 420, in proxy_args_kwargs
proxy_args = tuple(arg.as_proxy() for arg in args)
File "/usr/local/lib/python3.8/dist-packages/torch/_dynamo/utils.py", line 420, in <genexpr>
proxy_args = tuple(arg.as_proxy() for arg in args)
File "/usr/local/lib/python3.8/dist-packages/torch/_dynamo/variables/base.py", line 206, in as_proxy
raise NotImplementedError(str(self))
NotImplementedError: UserDefinedObjectVariable(Stream)
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/usr/local/lib/python3.8/dist-packages/torch/_dynamo/symbolic_convert.py", line 307, in wrapper
return inner_fn(self, inst)
File "/usr/local/lib/python3.8/dist-packages/torch/_dynamo/symbolic_convert.py", line 974, in CALL_FUNCTION
self.call_function(fn, args, {})
File "/usr/local/lib/python3.8/dist-packages/torch/_dynamo/symbolic_convert.py", line 435, in call_function
self.push(fn.call_function(self, args, kwargs))
File "/usr/local/lib/python3.8/dist-packages/torch/_dynamo/variables/torch.py", line 476, in call_function
*proxy_args_kwargs(args, kwargs),
File "/usr/local/lib/python3.8/dist-packages/torch/_dynamo/utils.py", line 427, in proxy_args_kwargs
raise unimplemented(
File "/usr/local/lib/python3.8/dist-packages/torch/_dynamo/exc.py", line 71, in unimplemented
raise Unsupported(msg)
torch._dynamo.exc.Unsupported: call_function args: UserDefinedObjectVariable(Stream)
[2023-01-23 04:54:12,810] torch._dynamo.output_graph: [DEBUG] restore_graphstate: removed 0 nodes
[2023-01-23 04:54:12,811] torch._dynamo.output_graph: [DEBUG] COMPILING GRAPH due to GraphCompileReason(reason='call_function args: UserDefinedObjectVariable(Stream) ', user_stack=[<FrameSummary file <ipython-input-12-f1436f0fcd91>, line 20 in fn>])
```
It seems there is no graph captured for the ops in the user stream context, as there is a no graph with relu (op in the user stream context in the example code) seen below -
```
def forward(self, t : torch.Tensor):
mul = torch.mul(t, 5); t = None
add = torch.add(mul, 2); mul = None
return (add,)
graph():
%t : torch.Tensor [#users=1] = placeholder[target=t]
%mul : [#users=1] = call_function[target=torch.mul](args = (%t, 5), kwargs = {})
%add : [#users=1] = call_function[target=torch.add](args = (%mul, 2), kwargs = {})
return (add,)
opcode name target args kwargs
------------- ------ ------------------------------------------------------ --------- --------
placeholder t t () {}
call_function mul <built-in method mul of type object at 0x7f2e333dbe40> (t, 5) {}
call_function add <built-in method add of type object at 0x7f2e333dbe40> (mul, 2) {}
output output output ((add,),) {}
```
Is there a way to capture the user stream ops in a graph via dynamo?
### Versions
PyTorch version: 2.0.0.dev20230122+cu117
Is debug build: False
CUDA used to build PyTorch: 11.7
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.5 LTS (x86_64)
GCC version: (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0
Clang version: 10.0.0-4ubuntu1
CMake version: version 3.25.0
Libc version: glibc-2.31
Python version: 3.8.10 (default, Nov 14 2022, 12:59:47) [GCC 9.4.0] (64-bit runtime)
Python platform: Linux-5.10.147+-x86_64-with-glibc2.29
Is CUDA available: True
CUDA runtime version: 11.2.152
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration: GPU 0: Tesla T4
Nvidia driver version: 460.32.03
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.1.1
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.1.1
/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.1.1
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_infer.so.8.1.1
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.1.1
/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.1.1
/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.1.1
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.24.1
[pip3] pytorch-triton==2.0.0+0d7e753227
[pip3] torch==2.0.0.dev20230122+cu117
[pip3] torchaudio==0.13.1+cu116
[pip3] torchsummary==1.5.1
[pip3] torchtext==0.14.1
[pip3] torchvision==0.14.1+cu116
[conda] Could not collect
cc @ezyang @gchanan @zou3519 @soumith @msaroufim @wconstab @ngimel @bdhirsh @mlazos @voznesenskym @yanboliang @penguinwu @anijain2305 @EikanWang @jgong5 @Guobing-Chen @chunyuan-w @XiaobingSuper @zhuhaozhe @blzheng @Xia-Weiwen @wenzhe-nrv @jiayisunx @desertfire
| 23 |
3,668 | 92,801 |
[BE] move _apply_to_tensors from FSDP to torch.distributed.utils, use in _recursive_to
|
oncall: distributed, triaged, better-engineering, module: ddp
|
### 🚀 The feature, motivation and pitch
_recursive_to function has some specific logic for iterating through container types, _apply_to_tensors in FSDP does this a bit more generally. We should move this to torch.distributed.utils and have _recursive_to use this function.
### Alternatives
_No response_
### Additional context
_No response_
cc @mrshenli @pritamdamania87 @zhaojuanmao @satgera @gqchen @aazzolini @osalpekar @jiayisuse @H-Huang @kwen2501 @awgu
| 1 |
3,669 | 92,794 |
Segmentation fault when running torch.ge
|
needs reproduction, triaged
|
### 🐛 Describe the bug
Due to dimension mismatch:
```
import torch
import numpy as np
arg_1_tensor = torch.rand([3], dtype=torch.float32)
arg_1 = arg_1_tensor.clone()
arg_2_tensor = torch.randint(0,8,[], dtype=torch.uint8)
arg_2 = arg_2_tensor.clone()
arg_3_tensor = torch.neg(torch.rand([3, 3, 3], dtype=torch.complex64))
arg_3 = arg_3_tensor.clone()
try:
res = torch.ge(arg_1,arg_2,out=arg_3,)
except Exception as e:
print("Error:"+str(e))
```
### Versions
```
PyTorch version: 1.12.0
Is debug build: False
CUDA used to build PyTorch: 10.2
ROCM used to build PyTorch: N/A
OS: Ubuntu 22.04.1 LTS (x86_64)
GCC version: (Ubuntu 11.3.0-1ubuntu1~22.04) 11.3.0
Clang version: Could not collect
CMake version: Could not collect
Libc version: glibc-2.35
Python version: 3.9.15 (main, Nov 24 2022, 14:31:59) [GCC 11.2.0] (64-bit runtime)
Python platform: Linux-5.15.0-58-generic-x86_64-with-glibc2.35
Is CUDA available: True
CUDA runtime version: Could not collect
CUDA_MODULE_LOADING set to:
GPU models and configuration: GPU 0: NVIDIA GeForce GTX 1660 Ti
Nvidia driver version: 525.78.01
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.23.5
[pip3] torch==1.12.0
[pip3] torchaudio==0.12.0
[pip3] torchvision==0.13.0
[conda] blas 1.0 mkl
[conda] cudatoolkit 10.2.89 hfd86e86_1
[conda] ffmpeg 4.3 hf484d3e_0 pytorch
[conda] mkl 2021.4.0 h06a4308_640
[conda] mkl-service 2.4.0 py39h7f8727e_0
[conda] mkl_fft 1.3.1 py39hd3c417c_0
[conda] mkl_random 1.2.2 py39h51133e4_0
[conda] numpy 1.23.5 py39h14f4228_0
[conda] numpy-base 1.23.5 py39h31eccc5_0
[conda] pytorch 1.12.0 py3.9_cuda10.2_cudnn7.6.5_0 pytorch
[conda] pytorch-mutex 1.0 cuda pytorch
[conda] torchaudio 0.12.0 py39_cu102 pytorch
[conda] torchvision 0.13.0 py39_cu102 pytorch
```
| 3 |
3,670 | 92,783 |
Process get killed when running torch.combinations
|
needs reproduction, module: performance, triaged, module: edge cases
|
### 🐛 Describe the bug
Process get killed even when feeding tensor with lower dimensions:
```
import torch
import numpy as np
arg_1_tensor = torch.randint(-512,16384,[4], dtype=torch.int16)
arg_1 = arg_1_tensor.clone()
arg_2 = 17
arg_3 = False
try:
res = torch.combinations(arg_1,r=arg_2,with_replacement=arg_3,)
except Exception as e:
print("Error:"+str(e))
```
### Versions
```
PyTorch version: 1.13.1
Is debug build: False
CUDA used to build PyTorch: 11.6
ROCM used to build PyTorch: N/A
OS: Ubuntu 22.04.1 LTS (x86_64)
GCC version: (Ubuntu 11.3.0-1ubuntu1~22.04) 11.3.0
Clang version: Could not collect
CMake version: Could not collect
Libc version: glibc-2.35
Python version: 3.9.15 (main, Nov 24 2022, 14:31:59) [GCC 11.2.0] (64-bit runtime)
Python platform: Linux-5.15.0-58-generic-x86_64-with-glibc2.35
Is CUDA available: True
CUDA runtime version: 11.6.124
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration: GPU 0: NVIDIA GeForce GTX 1660 Ti
Nvidia driver version: 525.78.01
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.23.5
[pip3] torch==1.13.1
[pip3] torchaudio==0.13.1
[pip3] torchvision==0.14.1
[conda] blas 1.0 mkl
[conda] ffmpeg 4.3 hf484d3e_0 pytorch
[conda] mkl 2021.4.0 h06a4308_640
[conda] mkl-service 2.4.0 py39h7f8727e_0
[conda] mkl_fft 1.3.1 py39hd3c417c_0
[conda] mkl_random 1.2.2 py39h51133e4_0
[conda] numpy 1.23.5 py39h14f4228_0
[conda] numpy-base 1.23.5 py39h31eccc5_0
[conda] pytorch 1.13.1 py3.9_cuda11.6_cudnn8.3.2_0 pytorch
[conda] pytorch-cuda 11.6 h867d48c_1 pytorch
[conda] pytorch-mutex 1.0 cuda pytorch
[conda] torchaudio 0.13.1 py39_cu116 pytorch
[conda] torchvision 0.14.1 py39_cu116 pytorch
```
cc @ngimel
| 1 |
3,671 | 92,781 |
Floating point exception when running torch.nn.AdaptiveMaxPool3d
|
triaged
|
### 🐛 Describe the bug
Probably due to zero argument:
```
results = dict()
import torch
arg_1 = 0
arg_2 = True
arg_class = torch.nn.AdaptiveMaxPool3d(arg_1,return_indices=arg_2,)
arg_3_0_tensor = torch.rand([2, 2, 4, 4, 4], dtype=torch.float32)
arg_3_0 = arg_3_0_tensor.clone()
arg_3 = [arg_3_0,]
try:
results["res_cpu"] = arg_class(*arg_3)
except Exception as e:
print("Error:"+str(e))
arg_class = arg_class.cuda()
arg_3_0 = arg_3_0_tensor.clone().cuda()
arg_3 = [arg_3_0,]
try:
results["res_gpu"] = arg_class(*arg_3)
except Exception as e:
print("Error:"+str(e))
print(results)
```
### Versions
```
PyTorch version: 1.13.1
Is debug build: False
CUDA used to build PyTorch: 11.6
ROCM used to build PyTorch: N/A
OS: Ubuntu 22.04.1 LTS (x86_64)
GCC version: (Ubuntu 11.3.0-1ubuntu1~22.04) 11.3.0
Clang version: Could not collect
CMake version: Could not collect
Libc version: glibc-2.35
Python version: 3.9.15 (main, Nov 24 2022, 14:31:59) [GCC 11.2.0] (64-bit runtime)
Python platform: Linux-5.15.0-58-generic-x86_64-with-glibc2.35
Is CUDA available: True
CUDA runtime version: 11.6.124
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration: GPU 0: NVIDIA GeForce GTX 1660 Ti
Nvidia driver version: 525.78.01
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.23.5
[pip3] torch==1.13.1
[pip3] torchaudio==0.13.1
[pip3] torchvision==0.14.1
[conda] blas 1.0 mkl
[conda] ffmpeg 4.3 hf484d3e_0 pytorch
[conda] mkl 2021.4.0 h06a4308_640
[conda] mkl-service 2.4.0 py39h7f8727e_0
[conda] mkl_fft 1.3.1 py39hd3c417c_0
[conda] mkl_random 1.2.2 py39h51133e4_0
[conda] numpy 1.23.5 py39h14f4228_0
[conda] numpy-base 1.23.5 py39h31eccc5_0
[conda] pytorch 1.13.1 py3.9_cuda11.6_cudnn8.3.2_0 pytorch
[conda] pytorch-cuda 11.6 h867d48c_1 pytorch
[conda] pytorch-mutex 1.0 cuda pytorch
[conda] torchaudio 0.13.1 py39_cu116 pytorch
[conda] torchvision 0.14.1 py39_cu116 pytorch
```
| 3 |
3,672 | 92,778 |
Process get killed when running torch.normal
|
triaged, module: numpy
|
### 🐛 Describe the bug
Process get killed when feeding negative large or even small tensors:
```
import torch
import numpy as np
arg_1_tensor = torch.neg(torch.rand([60000], dtype=torch.float16))
arg_1 = arg_1_tensor.clone()
arg_2_tensor = torch.rand([60000, 1], dtype=torch.float64)
arg_2 = arg_2_tensor.clone()
try:
res = torch.normal(arg_1,arg_2,)
except Exception as e:
print("Error:"+str(e))
```
### Versions
```
PyTorch version: 1.13.1
Is debug build: False
CUDA used to build PyTorch: 11.6
ROCM used to build PyTorch: N/A
OS: Ubuntu 22.04.1 LTS (x86_64)
GCC version: (Ubuntu 11.3.0-1ubuntu1~22.04) 11.3.0
Clang version: Could not collect
CMake version: Could not collect
Libc version: glibc-2.35
Python version: 3.9.15 (main, Nov 24 2022, 14:31:59) [GCC 11.2.0] (64-bit runtime)
Python platform: Linux-5.15.0-58-generic-x86_64-with-glibc2.35
Is CUDA available: True
CUDA runtime version: 11.6.124
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration: GPU 0: NVIDIA GeForce GTX 1660 Ti
Nvidia driver version: 525.78.01
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.23.5
[pip3] torch==1.13.1
[pip3] torchaudio==0.13.1
[pip3] torchvision==0.14.1
[conda] blas 1.0 mkl
[conda] ffmpeg 4.3 hf484d3e_0 pytorch
[conda] mkl 2021.4.0 h06a4308_640
[conda] mkl-service 2.4.0 py39h7f8727e_0
[conda] mkl_fft 1.3.1 py39hd3c417c_0
[conda] mkl_random 1.2.2 py39h51133e4_0
[conda] numpy 1.23.5 py39h14f4228_0
[conda] numpy-base 1.23.5 py39h31eccc5_0
[conda] pytorch 1.13.1 py3.9_cuda11.6_cudnn8.3.2_0 pytorch
[conda] pytorch-cuda 11.6 h867d48c_1 pytorch
[conda] pytorch-mutex 1.0 cuda pytorch
[conda] torchaudio 0.13.1 py39_cu116 pytorch
[conda] torchvision 0.14.1 py39_cu116 pytorch
```
cc @mruberry @rgommers
| 1 |
3,673 | 92,776 |
segfault when running torch.lu_unpack
|
module: crash, triaged, module: linear algebra, module: edge cases
|
### 🐛 Describe the bug
Probably due to negative tensor.
```
import torch
import numpy as np
arg_1_tensor = torch.rand([1, 0, 5, 5], dtype=torch.float64)
arg_1 = arg_1_tensor.clone()
arg_2_tensor = torch.randint(-512,256,[1, 0], dtype=torch.int32)
arg_2 = arg_2_tensor.clone()
arg_3 = True
try:
res = torch.lu_unpack(arg_1,arg_2,unpack_pivots=arg_3,)
except Exception as e:
print("Error:"+str(e))
```
### Versions
```
PyTorch version: 1.13.1
Is debug build: False
CUDA used to build PyTorch: 11.6
ROCM used to build PyTorch: N/A
OS: Ubuntu 22.04.1 LTS (x86_64)
GCC version: (Ubuntu 11.3.0-1ubuntu1~22.04) 11.3.0
Clang version: Could not collect
CMake version: Could not collect
Libc version: glibc-2.35
Python version: 3.9.15 (main, Nov 24 2022, 14:31:59) [GCC 11.2.0] (64-bit runtime)
Python platform: Linux-5.15.0-58-generic-x86_64-with-glibc2.35
Is CUDA available: True
CUDA runtime version: 11.6.124
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration: GPU 0: NVIDIA GeForce GTX 1660 Ti
Nvidia driver version: 525.78.01
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.23.5
[pip3] torch==1.13.1
[pip3] torchaudio==0.13.1
[pip3] torchvision==0.14.1
[conda] blas 1.0 mkl
[conda] ffmpeg 4.3 hf484d3e_0 pytorch
[conda] mkl 2021.4.0 h06a4308_640
[conda] mkl-service 2.4.0 py39h7f8727e_0
[conda] mkl_fft 1.3.1 py39hd3c417c_0
[conda] mkl_random 1.2.2 py39h51133e4_0
[conda] numpy 1.23.5 py39h14f4228_0
[conda] numpy-base 1.23.5 py39h31eccc5_0
[conda] pytorch 1.13.1 py3.9_cuda11.6_cudnn8.3.2_0 pytorch
[conda] pytorch-cuda 11.6 h867d48c_1 pytorch
[conda] pytorch-mutex 1.0 cuda pytorch
[conda] torchaudio 0.13.1 py39_cu116 pytorch
[conda] torchvision 0.14.1 py39_cu116 pytorch
```
cc @jianyuh @nikitaved @pearu @mruberry @walterddr @IvanYashchuk @xwang233 @Lezcano
| 1 |
3,674 | 92,758 |
no attribute torch._dynamo unless you explicitly import torch._dynamo
|
triaged, module: dynamo
|
### 🐛 Describe the bug
Installed PT 2.0 with CUDA 11.6
```
pip3 install numpy --pre torch torchvision torchaudio --force-reinstall --index-url https://download.pytorch.org/whl/nightly/cu116
```
Trying to optimize a workload. Not seeing improvement, so I want to use torch._dynamo explainer and verbose logging. Can't actually use torch._dynamo unless I import it. Saw the same issue here https://github.com/pytorch/pytorch/issues/90167#issuecomment-1340253038. Not sure if this is a duplicate of a bug @netw0rkf10w may have filed.
```
Python 3.9.5 (default, Jun 4 2021, 12:28:51)
[GCC 7.5.0] :: Anaconda, Inc. on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import torch
>>> torch.__version__
'2.0.0.dev20230121+cu116'
>>> torch._dynamo
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: module 'torch' has no attribute '_dynamo'
>>> import torch._dynamo
>>> torch._dynamo
<module 'torch._dynamo' from '/data/home/erichan1/.virtualenvs/pt_two/lib/python3.9/site-packages/torch/_dynamo/__init__.py'>
```
### Versions
Collecting environment information...
PyTorch version: 2.0.0.dev20230121+cu116
Is debug build: False
CUDA used to build PyTorch: 11.6
ROCM used to build PyTorch: N/A
OS: Ubuntu 18.04.6 LTS (x86_64)
GCC version: (Ubuntu 9.4.0-1ubuntu1~18.04) 9.4.0
Clang version: 6.0.0-1ubuntu2 (tags/RELEASE_600/final)
CMake version: version 3.25.0
Libc version: glibc-2.27
Python version: 3.9.5 (default, Jun 4 2021, 12:28:51) [GCC 7.5.0] (64-bit runtime)
Python platform: Linux-5.4.0-1069-aws-x86_64-with-glibc2.27
Is CUDA available: True
CUDA runtime version: 11.6.112
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration: GPU 0: NVIDIA A100-SXM4-40GB
Nvidia driver version: 510.47.03
cuDNN version: Probably one of the following:
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn.so.8.0.5
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_adv_infer.so.8.0.5
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_adv_train.so.8.0.5
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_cnn_infer.so.8.0.5
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_cnn_train.so.8.0.5
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_ops_infer.so.8.0.5
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_ops_train.so.8.0.5
/usr/local/cuda-11.1/targets/x86_64-linux/lib/libcudnn.so.8.0.5
/usr/local/cuda-11.1/targets/x86_64-linux/lib/libcudnn_adv_infer.so.8.0.5
/usr/local/cuda-11.1/targets/x86_64-linux/lib/libcudnn_adv_train.so.8.0.5
/usr/local/cuda-11.1/targets/x86_64-linux/lib/libcudnn_cnn_infer.so.8.0.5
/usr/local/cuda-11.1/targets/x86_64-linux/lib/libcudnn_cnn_train.so.8.0.5
/usr/local/cuda-11.1/targets/x86_64-linux/lib/libcudnn_ops_infer.so.8.0.5
/usr/local/cuda-11.1/targets/x86_64-linux/lib/libcudnn_ops_train.so.8.0.5
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn.so.8.1.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn_adv_infer.so.8.1.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn_adv_train.so.8.1.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn_cnn_infer.so.8.1.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn_cnn_train.so.8.1.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn_ops_infer.so.8.1.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn_ops_train.so.8.1.1
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.24.1
[pip3] pytorch-triton==2.0.0+0d7e753227
[pip3] torch==2.0.0.dev20230121+cu116
[pip3] torchaudio==2.0.0.dev20230121+cu116
[pip3] torchvision==0.15.0.dev20230121+cu116
[conda] numpy 1.21.6 pypi_0 pypi
[conda] torch 1.12.1 pypi_0 pypi
[conda] torch-tb-profiler 0.3.1 pypi_0 pypi
[conda] torchmetrics 0.9.3 pypi_0 pypi
[conda] torchrec 0.2.0 pypi_0 pypi
[conda] torchvision 0.13.1 pypi_0 pypi
[conda] torchx-nightly 2022.7.25 pypi_0 pypi
cc @mlazos @soumith @voznesenskym @yanboliang @penguinwu @anijain2305 @EikanWang @jgong5 @Guobing-Chen @chunyuan-w @XiaobingSuper @zhuhaozhe @blzheng @Xia-Weiwen @wenzhe-nrv @jiayisunx @desertfire
| 0 |
3,675 | 92,752 |
'MPS' issue: torch.multinomial() returning [-9223372036854775808]
|
triaged, module: mps
|
### 🐛 Describe the bug
torch.multinomial(probs, num_samples=1) returning is returning: [-9223372036854775808]
Here's an example:
```
% ipython
Python 3.10.9 (main, Jan 11 2023, 09:18:20) [Clang 14.0.6 ]
Type 'copyright', 'credits' or 'license' for more information
IPython 8.7.0 -- An enhanced Interactive Python. Type '?' for help.
In [1]: import numpy as np
In [2]: import torch
In [3]: probs = torch.tensor(np.loadtxt("probs0.txt"), dtype=torch.float32, device
...: ='mps')
In [4]: torch.multinomial(probs, num_samples=1)
Out[4]:
tensor([[-9223372036854775808],
[-9223372036854775808],
[-9223372036854775808],
[-9223372036854775808],
[-9223372036854775808],
[-9223372036854775808],
[-9223372036854775808],
[-9223372036854775808],
[-9223372036854775808],
[-9223372036854775808]], device='mps:0')
In [5]: probs = torch.tensor(np.loadtxt("probs0.txt"), dtype=torch.float32, device
...: ='cpu')
In [6]: torch.multinomial(probs, num_samples=1)
Out[6]:
tensor([[13],
[ 1],
[13],
[ 0],
[13],
[81],
[13],
[81],
[13],
[ 0]])
```
[probs0.txt](https://github.com/pytorch/pytorch/files/10472535/probs0.txt)
### Versions
```
% python collect_env.py
Collecting environment information...
PyTorch version: 2.0.0a0+gitf4b804e
Is debug build: False
CUDA used to build PyTorch: None
ROCM used to build PyTorch: N/A
OS: macOS 13.1 (x86_64)
GCC version: Could not collect
Clang version: 14.0.0 (clang-1400.0.29.202)
CMake version: version 3.22.1
Libc version: N/A
Python version: 3.10.9 (main, Jan 11 2023, 09:18:20) [Clang 14.0.6 ] (64-bit runtime)
Python platform: macOS-10.16-x86_64-i386-64bit
Is CUDA available: False
CUDA runtime version: No CUDA
CUDA_MODULE_LOADING set to: N/A
GPU models and configuration: No CUDA
Nvidia driver version: No CUDA
cuDNN version: No CUDA
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] audiolm-pytorch==0.0.1
[pip3] mypy-extensions==0.4.3
[pip3] numpy==1.23.5
[pip3] pytorch-transformers==1.1.0
[pip3] torch==2.0.0a0+gitf8b2879
[pip3] torch-struct==0.5
[pip3] torch-summary==1.4.5
[pip3] torch-utils==0.1.2
[pip3] torchaudio==0.13.0.dev20221015
[pip3] torchtraining-nightly==1604016577
[pip3] torchvision==0.15.0a0+8985b59
[pip3] vector-quantize-pytorch==0.9.2
[conda] nomkl 3.0 0
[conda] numpy 1.23.5 py310he50c29a_0
[conda] numpy-base 1.23.5 py310h992e150_0
[conda] pytorch-transformers 1.1.0 pypi_0 pypi
[conda] torch 2.0.0a0+git7ef7c57 pypi_0 pypi
[conda] torch-struct 0.5 pypi_0 pypi
[conda] torch-summary 1.4.5 pypi_0 pypi
[conda] torch-utils 0.1.2 pypi_0 pypi
[conda] torchaudio 0.13.0.dev20221015 pypi_0 pypi
[conda] torchtraining-nightly 1604016577 pypi_0 pypi
[conda] torchvision 0.15.0a0+8985b59 pypi_0 pypi
[conda] vector-quantize-pytorch 0.9.2 pypi_0 pypi
```
cc @kulinseth @albanD @malfet @DenisVieriu97 @razarmehr @abhudev
| 9 |
3,676 | 92,742 |
[JIT] Consecutive use of `addmm` Leads to Exception
|
oncall: jit
|
### 🐛 Describe the bug
The following program behave inconsistently between eager mode and JIT, which arises from consecutive use of `addmm`. If `torch.jit.optimize_for_inference` is removed, the program works fine.
To reproduce:
```python
import torch
class Model(torch.nn.Module):
def __init__(self):
super().__init__()
self.v1 = torch.nn.Parameter(torch.rand([64, 32]))
self.v2 = torch.nn.Parameter(torch.rand([64, 32]))
self.v3 = torch.nn.Parameter(torch.rand([32, 32]))
def forward(self, i1, i2):
r1 = torch.addmm(self.v2, self.v1, i1)
r2 = torch.addmm(r1, i2, self.v3)
return r2
i1 = torch.rand([32, 32])
i2 = torch.rand([64, 32])
fn = Model()
fn.eval()
fn(i1, i2)
print("Eager model ... OK!")
exported = torch.jit.trace(fn, (i1, i2))
exported = torch.jit.optimize_for_inference(exported) # works w/o this line
exported(i1, i2)
print("JIT ... OK!")
"""
Eager model ... OK!
Traceback (most recent call last):
File "model.py", line 27, in <module>
exported(i1, i2)
File "python3.10/site-packages/torch/nn/modules/module.py", line 1488, in _call_impl
return forward_call(*args, **kwargs)
RuntimeError:
The size of tensor a (64) must match the size of tensor b (32) at non-singleton dimension 0
The above operation failed shape propagation in this context:
File "<string>", line 3
def addmm(self: Tensor, mat1: Tensor, mat2: Tensor, beta: number = 1.0, alpha: number = 1.0):
return self + mat1.mm(mat2)
~~~~~~~~~~~~~~~~~~~ <--- HERE
def batch_norm(input : Tensor, running_mean : Optional[Tensor], running_var : Optional[Tensor], training : bool, momentum : float, eps : float) -> Tensor:
"""
```
### Versions
<details><summary><b>Environment</b> <i>[Click to expand]</i></summary>
```
PyTorch version: 2.0.0.dev20230119+cu117
Is debug build: False
CUDA used to build PyTorch: 11.7
ROCM used to build PyTorch: N/A
OS: Ubuntu 22.04.1 LTS (x86_64)
GCC version: (Ubuntu 11.3.0-1ubuntu1~22.04) 11.3.0
Clang version: 11.1.0-6
CMake version: version 3.22.1
Libc version: glibc-2.35
Python version: 3.10.6 (main, Nov 14 2022, 16:10:14) [GCC 11.3.0] (64-bit runtime)
Python platform: Linux-5.15.0-56-generic-x86_64-with-glibc2.35
Is CUDA available: True
CUDA runtime version: 11.6.124
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration:
GPU 0: NVIDIA GeForce RTX 3090
GPU 1: NVIDIA GeForce RTX 3090
GPU 2: NVIDIA GeForce RTX 3090
Nvidia driver version: 515.86.01
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_infer.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.4.1
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.21.5
[pip3] pytorch-triton==2.0.0+0d7e753227
[pip3] torch==2.0.0.dev20230119+cu117
[pip3] torchaudio==2.0.0.dev20230118+cu117
[pip3] torchvision==0.15.0.dev20230118+cu117
[conda] blas 1.0 mkl
[conda] cudatoolkit 11.3.1 h2bc3f7f_2
[conda] mkl 2021.4.0 h06a4308_640
[conda] mkl-service 2.4.0 py39h7f8727e_0
[conda] mkl_fft 1.3.1 py39hd3c417c_0
[conda] mkl_random 1.2.2 py39h51133e4_0
[conda] numpy 1.21.5 py39he7a7128_1
[conda] numpy-base 1.21.5 py39hf524024_1
[conda] numpydoc 1.2 pyhd3eb1b0_0
[conda] torch 1.14.0a0+gitce2f870 pypi_0 pypi
```
</details>
cc @EikanWang @jgong5 @wenzhe-nrv @sanchitintel
| 2 |
3,677 | 92,740 |
[JIT] Applying `conv2d` over Constants Leads to Exception
|
oncall: jit
|
### 🐛 Describe the bug
The following program throws an exception in JIT. This seems to be a fault in evaluating a constant expression. i.e., applying `conv2d` over a constant.
```python
import torch
class Model(torch.nn.Module):
def __init__(self):
super().__init__()
self.conv = torch.nn.Conv2d(1, 288, kernel_size=(1, 1))
self.v0 = torch.nn.Parameter(torch.rand([1, 1, 14, 14]))
def forward(self):
v1 = self.conv(self.v0)
v2 = torch.nn.functional.relu(v1, inplace=True) # works w/o this line
return v2
fn = Model().eval()
fn()
print("Eager mode ... OK!")
exported = torch.jit.trace(fn, ())
exported = torch.jit.optimize_for_inference(exported)
exported()
print("JIT mode ... OK!")
"""
Eager mode ... OK!
Traceback (most recent call last):
File "model.py", line 22, in <module>
exported()
File "python3.10/site-packages/torch/nn/modules/module.py", line 1488, in _call_impl
return forward_call(*args, **kwargs)
RuntimeError: The following operation failed in the TorchScript interpreter.
Traceback of TorchScript (most recent call last):
%transposed:bool, %output_padding:int[], %groups:int, %benchmark:bool,
%deterministic:bool, %cudnn_enabled:bool, %allow_tf32:bool):
%r = aten::conv2d(%a, %w, %b, %stride, %padding, %dilation, %groups)
~~~~ <--- HERE
return (%r)
RuntimeError: Input type (torch.FloatTensor) and weight type (Mkldnntorch.FloatTensor) should be the same
"""
```
### Versions
<details><summary> <b> Environment </b> <i> [Click to expand] </i></summary>
```
PyTorch version: 2.0.0.dev20230119+cu117
Is debug build: False
CUDA used to build PyTorch: 11.7
ROCM used to build PyTorch: N/A
OS: Ubuntu 22.04.1 LTS (x86_64)
GCC version: (Ubuntu 11.3.0-1ubuntu1~22.04) 11.3.0
Clang version: 11.1.0-6
CMake version: version 3.22.1
Libc version: glibc-2.35
Python version: 3.10.6 (main, Nov 14 2022, 16:10:14) [GCC 11.3.0] (64-bit runtime)
Python platform: Linux-5.15.0-56-generic-x86_64-with-glibc2.35
Is CUDA available: True
CUDA runtime version: 11.6.124
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration:
GPU 0: NVIDIA GeForce RTX 3090
GPU 1: NVIDIA GeForce RTX 3090
GPU 2: NVIDIA GeForce RTX 3090
Nvidia driver version: 515.86.01
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_infer.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.4.1
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.21.5
[pip3] pytorch-triton==2.0.0+0d7e753227
[pip3] torch==2.0.0.dev20230119+cu117
[pip3] torchaudio==2.0.0.dev20230118+cu117
[pip3] torchvision==0.15.0.dev20230118+cu117
[conda] blas 1.0 mkl
[conda] cudatoolkit 11.3.1 h2bc3f7f_2
[conda] mkl 2021.4.0 h06a4308_640
[conda] mkl-service 2.4.0 py39h7f8727e_0
[conda] mkl_fft 1.3.1 py39hd3c417c_0
[conda] mkl_random 1.2.2 py39h51133e4_0
[conda] numpy 1.21.5 py39he7a7128_1
[conda] numpy-base 1.21.5 py39hf524024_1
[conda] numpydoc 1.2 pyhd3eb1b0_0
[conda] torch 1.14.0a0+gitce2f870 pypi_0 pypi
```
</details>
cc @EikanWang @jgong5 @wenzhe-nrv @sanchitintel @mingfeima @XiaobingSuper @ashokei @jingxu10
| 4 |
3,678 | 93,515 |
Dynamo can not trace 'int(a_scalar_tensor.item())'
|
triaged, bug, oncall: pt2
|
### 🐛 Describe the bug
RCNN model in detectron2 need this support: ( https://www.internalfb.com/code/fbsource/[ca89130b9eae0efd5bb1cbbff1006cc1556d0b4f]/fbcode/vision/fair/detectron2/detectron2/export/c10.py?lines=483-489 )
### Error logs
Traceback (most recent call last):
File "/home/shunting/learn/dynamo/temp.py", line 12, in <module>
gm, guards = export(f, inp, aten_graph=True, tracing_mode="symbolic")
File "/home/shunting/pytorch/torch/_dynamo/eval_frame.py", line 605, in export
result_traced = opt_f(*args, **kwargs)
File "/home/shunting/pytorch/torch/_dynamo/eval_frame.py", line 211, in _fn
return fn(*args, **kwargs)
File "/home/shunting/pytorch/torch/_dynamo/eval_frame.py", line 332, in catch_errors
return callback(frame, cache_size, hooks)
File "/home/shunting/pytorch/torch/_dynamo/convert_frame.py", line 103, in _fn
return fn(*args, **kwargs)
File "/home/shunting/pytorch/torch/_dynamo/convert_frame.py", line 261, in _convert_frame_assert
return _compile(
File "/home/shunting/pytorch/torch/_dynamo/utils.py", line 154, in time_wrapper
r = func(*args, **kwargs)
File "/home/shunting/pytorch/torch/_dynamo/convert_frame.py", line 324, in _compile
out_code = transform_code_object(code, transform)
File "/home/shunting/pytorch/torch/_dynamo/bytecode_transformation.py", line 341, in transform_code_object
transformations(instructions, code_options)
File "/home/shunting/pytorch/torch/_dynamo/convert_frame.py", line 311, in transform
tracer.run()
File "/home/shunting/pytorch/torch/_dynamo/symbolic_convert.py", line 1693, in run
super().run()
File "/home/shunting/pytorch/torch/_dynamo/symbolic_convert.py", line 539, in run
and self.step()
File "/home/shunting/pytorch/torch/_dynamo/symbolic_convert.py", line 502, in step
getattr(self, inst.opname)(inst)
File "/home/shunting/pytorch/torch/_dynamo/symbolic_convert.py", line 307, in wrapper
return inner_fn(self, inst)
File "/home/shunting/pytorch/torch/_dynamo/symbolic_convert.py", line 975, in CALL_FUNCTION
self.call_function(fn, args, {})
File "/home/shunting/pytorch/torch/_dynamo/symbolic_convert.py", line 435, in call_function
self.push(fn.call_function(self, args, kwargs))
File "/home/shunting/pytorch/torch/_dynamo/variables/builtin.py", line 346, in call_function
return super().call_function(tx, args, kwargs)
File "/home/shunting/pytorch/torch/_dynamo/variables/base.py", line 230, in call_function
unimplemented(f"call_function {self} {args} {kwargs}")
File "/home/shunting/pytorch/torch/_dynamo/exc.py", line 71, in unimplemented
raise Unsupported(msg)
torch._dynamo.exc.Unsupported: call_function BuiltinVariable(int) [TensorVariable()] {}
### Minified repro
```
from torch._dynamo import export
from torch._dynamo import config
import torch
from torch import nn
config.capture_scalar_outputs = True
inp = torch.rand(3)
def f(inp):
return torch.full(int(inp[0].item()), 5)
gm, guards = export(f, inp, aten_graph=True, tracing_mode="symbolic")
print(f"Export return graph:\n{gm.graph}")
```
cc @ezyang @soumith @msaroufim @wconstab @ngimel @bdhirsh
| 0 |
3,679 | 92,736 |
[FSDP] Add `foreach` support to `FSDP.clip_grad_norm_()`
|
oncall: distributed, triaged, module: fsdp
|
See https://github.com/pytorch/pytorch/pull/91846 for `torch.nn.utils.clip_grad_norm_()` changes. Since `FSDP.clip_grad_norm_()` has to re-implement the logic to include gradient unsharding, we have to manually upstream improvements like this.
cc @mrshenli @pritamdamania87 @zhaojuanmao @satgera @rohan-varma @gqchen @aazzolini @osalpekar @jiayisuse @H-Huang @kwen2501
| 0 |
3,680 | 93,514 |
iter(TensorVariable) fail
|
triaged, bug, oncall: pt2
|
### 🐛 Describe the bug
Dynamo does not support iterating thru a tensor variable so far. Dynamo fail to trace even if the first dimension of the TensorVariable is static. In this case, the fix is simple since we can unroll the loop and generated items by calling `getitem`. But the problem becomes more complex if the first dimension of the tensor variable is dynamic.
We have discussions between shunting314 , @ezyang , @voznesenskym , @suo , @Chillee . Here are some thoughts for possible solutions
- rewrite user code by using torch.map explicitly
- let user pass in the information indicating if a dimension is dynamic or not
- assume the dimension to be static, specialize on that when compiling the fx graph and add a guard to the guard set
So the underlying problem is how we handle loop with potentially variable number of iterations.
User code that fail to be traced: https://www.internalfb.com/code/fbsource/[ca89130b9eae0efd5bb1cbbff1006cc1556d0b4f]/fbcode/vision/fair/detectron2/detectron2/export/c10.py?lines=483-489
### Error logs
_No response_
### Minified repro
_No response_
cc @ezyang @soumith @msaroufim @wconstab @ngimel @bdhirsh
| 0 |
3,681 | 92,701 |
set_default_device/torch.device has performance impact for non-factory functions
|
module: performance, triaged, module: __torch_function__
|
### 🐛 Describe the bug
Because it is implemented as a TorchFunctionMode, we interpose ALL functions even if we actually do nothing on those functions. We have ideas for how to optimize this but have delayed doing so until someone actually has a problem. This is a placeholder issue to track people having this problem.
### Versions
master
cc @hameerabbasi @rgommers @peterbell10 @soumith @msaroufim @wconstab @ngimel @bdhirsh
| 2 |
3,682 | 92,694 |
API to check for errors in c10d.ProcessGroupNCCL
|
oncall: distributed
|
### 🚀 The feature, motivation and pitch
ProcessGroupNCCL has two options to detect and deal with errors:
1. `NCCL_BLOCKING_WAIT` which is blocking and causes host to device synchronization resulting in perf degradation but raises an appropriate exception in-line in your training code.
2. `NCCL_ASYNC_ERROR_HANDLING` which polls in the background and kills the process if errors are detected.
In certain cases neither of these options are ideal and users would like to inspect ProcessGroup errors themselves and appropriately recover from them if possible.
As a result, the proposal here is to expose an API like `ProcessGroup.hasErrorOrTimedOut` based on which users can take custom actions if an error is indeed discovered. Happy to contribute a PR for this.
### Alternatives
Considered `NCCL_BLOCKING_WAIT` and `NCCL_ASYNC_ERROR_HANDLING` as mentioned above
### Additional context
_No response_
cc @mrshenli @zhaojuanmao @satgera @rohan-varma @gqchen @aazzolini @osalpekar @jiayisuse @H-Huang @kwen2501 @awgu
| 3 |
3,683 | 92,691 |
DDP+inductor+profiler crashes on toy model
|
high priority, module: crash, triaged, oncall: profiler, bug, oncall: pt2, module: inductor
|
### 🐛 Describe the bug
Running through a set of commands I planned to demo for Q/A, I encountered this. I can work around using aot_eager.
Broken (inductor):
`python benchmarks/dynamo/distributed.py --toy_model --ddp --dynamo_no_optimize_ddp --dynamo inductor --profile`
note: crash happens with or without ddp graph-split optimizer. Repro above disables it to simplify.
Works (aot_eager):
`python benchmarks/dynamo/distributed.py --toy_model --ddp --dynamo_no_optimize_ddp --dynamo aot_eager --profile`
Stack Trace
```
STAGE:2023-01-20 17:46:46 9079:9079 ActivityProfilerController.cpp:300] Completed Stage: Warm Up
Traceback (most recent call last):
File "benchmarks/dynamo/distributed.py", line 168, in <module>
t_total = fn(f"{model_name}_{world_size}")
File "benchmarks/dynamo/distributed.py", line 109, in run_model
profile_model(args, model, inputs, rank)
File "benchmarks/dynamo/distributed.py", line 41, in profile_model
loss.backward()
File "/scratch/whc/work/pytorch/torch/profiler/profiler.py", line 508, in __exit__
self.stop()
File "/scratch/whc/work/pytorch/torch/profiler/profiler.py", line 520, in stop
self._transit_action(self.current_action, None)
File "/scratch/whc/work/pytorch/torch/profiler/profiler.py", line 548, in _transit_action
action()
File "/scratch/whc/work/pytorch/torch/profiler/profiler.py", line 139, in stop_trace
self.profiler.__exit__(None, None, None)
File "/scratch/whc/work/pytorch/torch/autograd/profiler.py", line 230, in __exit__
torch.cuda.synchronize()
File "/scratch/whc/work/pytorch/torch/cuda/__init__.py", line 597, in synchronize
return torch._C._cuda_synchronize()
RuntimeError: CUDA error: an illegal memory access was encountered
CUDA kernel errors might be asynchronously reported at some other API call, so the stacktrace below might be incor
rect.
For debugging consider passing CUDA_LAUNCH_BLOCKING=1.
Compile with `TORCH_USE_CUDA_DSA` to enable device-side assertions.
[W CUDAGuardImpl.h:124] Warning: CUDA warning: an illegal memory access was encountered (function destroyEvent)
terminate called after throwing an instance of 'c10::Error'
what(): CUDA error: an illegal memory access was encountered
CUDA kernel errors might be asynchronously reported at some other API call, so the stacktrace below might be incorrect.
For debugging consider passing CUDA_LAUNCH_BLOCKING=1.
Compile with `TORCH_USE_CUDA_DSA` to enable device-side assertions.
Exception raised from c10_cuda_check_implementation at /scratch/whc/work/pytorch/c10/cuda/CUDAException.cpp:41 (most recent call first):
frame #0: c10::Error::Error(c10::SourceLocation, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >) + 0x7d (0x7f5d7062744d in /scratch/whc/work/pytorch/torch/lib/libc10.so)
frame #1: c10::detail::torchCheckFail(char const*, char const*, unsigned int, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&) + 0xde (0x7f5d70625ade in /scratch/whc/work/pytorch/torch/lib/libc10.so)
frame #2: c10::cuda::c10_cuda_check_implementation(int, char const*, char const*, int, bool) + 0x1a0 (0x7f5d708aae50 in /scratch/whc/work/pytorch/torch/lib/libc10_cuda.so)
frame #3: <unknown function> + 0x10811 (0x7f5d7087a811 in /scratch/whc/work/pytorch/torch/lib/libc10_cuda.so)
frame #4: <unknown function> + 0x14b76 (0x7f5d7087eb76 in /scratch/whc/work/pytorch/torch/lib/libc10_cuda.so)
frame #5: <unknown function> + 0x7ab64f (0x7f5d8727864f in /scratch/whc/work/pytorch/torch/lib/libtorch_python.so)
frame #6: c10::TensorImpl::~TensorImpl() + 0xe9 (0x7f5d70608d79 in /scratch/whc/work/pytorch/torch/lib/libc10.so)
frame #7: c10::TensorImpl::~TensorImpl() + 0x9 (0x7f5d70608e09 in /scratch/whc/work/pytorch/torch/lib/libc10.so)
frame #8: c10d::Reducer::~Reducer() + 0x528 (0x7f5d75fef808 in /scratch/whc/work/pytorch/torch/lib/libtorch_cpu.so)
frame #9: <unknown function> + 0xd57ea5 (0x7f5d87824ea5 in /scratch/whc/work/pytorch/torch/lib/libtorch_python.so)
frame #10: <unknown function> + 0xd57d5f (0x7f5d87824d5f in /scratch/whc/work/pytorch/torch/lib/libtorch_python.so)
frame #11: <unknown function> + 0x25d9bb (0x7f5d86d2a9bb in /scratch/whc/work/pytorch/torch/lib/libtorch_python.so)
frame #12: <unknown function> + 0x25d6ac (0x7f5d86d2a6ac in /scratch/whc/work/pytorch/torch/lib/libtorch_python.so)
frame #13: python() [0x4c294a]
frame #14: python() [0x4f2307]
frame #15: python() [0x4e9a47]
frame #16: python() [0x4c294a]
frame #17: python() [0x4f2307]
frame #18: python() [0x4d1b68]
frame #19: python() [0x4e5058]
frame #20: python() [0x4e506b]
frame #21: python() [0x4b5827]
<omitting python frames>
frame #27: __libc_start_main + 0xe7 (0x7f5db99b1c87 in /lib/x86_64-linux-gnu/libc.so.6)
frame #28: python() [0x56196e]
Aborted (core dumped)
```
### Versions
clean build of my whole env, with pytorch@2891cecd8db3086353794c5ffbbf9e8ba854fca1
Collecting environment information...
PyTorch version: 2.0.0a0+git663bf4b
Is debug build: False
CUDA used to build PyTorch: 11.6
ROCM used to build PyTorch: N/A
OS: Ubuntu 18.04.6 LTS (x86_64)
GCC version: (Ubuntu 9.4.0-1ubuntu1~18.04) 9.4.0
Clang version: 10.0.0-4ubuntu1~18.04.2
CMake version: version 3.25.0
Libc version: glibc-2.27
Python version: 3.8.16 (default, Jan 17 2023, 23:13:24) [GCC 11.2.0] (64-bit runtime)
Python platform: Linux-5.4.0-1069-aws-x86_64-with-glibc2.17
Is CUDA available: True
CUDA runtime version: 11.6.112
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration:
GPU 0: NVIDIA A100-SXM4-40GB
GPU 1: NVIDIA A100-SXM4-40GB
Nvidia driver version: 510.47.03
cuDNN version: Probably one of the following:
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn.so.8.0.5
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_adv_infer.so.8.0.5
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_adv_train.so.8.0.5
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_cnn_infer.so.8.0.5
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_cnn_train.so.8.0.5
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_ops_infer.so.8.0.5
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_ops_train.so.8.0.5
/usr/local/cuda-11.1/targets/x86_64-linux/lib/libcudnn.so.8.0.5
/usr/local/cuda-11.1/targets/x86_64-linux/lib/libcudnn_adv_infer.so.8.0.5
/usr/local/cuda-11.1/targets/x86_64-linux/lib/libcudnn_adv_train.so.8.0.5
/usr/local/cuda-11.1/targets/x86_64-linux/lib/libcudnn_cnn_infer.so.8.0.5
/usr/local/cuda-11.1/targets/x86_64-linux/lib/libcudnn_cnn_train.so.8.0.5
/usr/local/cuda-11.1/targets/x86_64-linux/lib/libcudnn_ops_infer.so.8.0.5
/usr/local/cuda-11.1/targets/x86_64-linux/lib/libcudnn_ops_train.so.8.0.5
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn.so.8.1.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn_adv_infer.so.8.1.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn_adv_train.so.8.1.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn_cnn_infer.so.8.1.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn_cnn_train.so.8.1.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn_ops_infer.so.8.1.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn_ops_train.so.8.1.1
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] mypy==0.960
[pip3] mypy-extensions==0.4.3
[pip3] numpy==1.23.1
[pip3] torch==2.0.0a0+git2891cec
[pip3] torchdata==0.5.1
[pip3] torchtext==0.15.0a0+569d48d
[pip3] torchvision==0.15.0a0+c06d52b
[conda] magma-cuda116 2.6.1 1 pytorch
[conda] mkl 2022.1.0 hc2b9512_224
[conda] mkl-include 2022.1.0 h06a4308_224
[conda] numpy 1.23.1 pypi_0 pypi
[conda] torch 2.0.0a0+git2891cec dev_0 <develop>
[conda] torchdata 0.5.1 pypi_0 pypi
[conda] torchtext 0.15.0a0+569d48d dev_0 <develop>
[conda] torchvision 0.15.0a0+c06d52b dev_0 <develop>
cc @ezyang @gchanan @zou3519 @robieta @chaekit @aaronenyeshi @ngimel @nbcsm @guotuofeng @guyang3532 @gaoteng-git @tiffzhaofb @soumith @msaroufim @bdhirsh @mlazos @voznesenskym @yanboliang @penguinwu @anijain2305 @EikanWang @jgong5 @Guobing-Chen @chunyuan-w @XiaobingSuper @zhuhaozhe @blzheng @Xia-Weiwen @wenzhe-nrv @jiayisunx @peterbell10 @desertfire
| 8 |
3,684 | 92,683 |
Torchscript troubles with complex values. RuntimeError: isInt() INTERNAL ASSERT FAILED
|
oncall: jit, triaged, module: complex
|
### 🐛 Describe the bug
Torchscript errors out when creating imaginary coefficients. This simple example runs fine in pytorch without torchscript. I'd expect to get the same result with torch and torchscript.
```
import torch
class SimpleEx(torch.nn.Module):
def __init__(self):
super(SimpleEx, self).__init__()
self.k = 1.23
def forward(self):
a = torch.randn(3)
b = torch.randn(11,11)
return 1j*self.k/2*(1-a[1])/a[0]*b
if __name__ == '__main__':
se = torch.jit.script(SimpleEx())
se_out = se()
print(se_out)
```
The following error is produced when running as a module
Traceback (most recent call last):
File "/usr/lib/python3.8/runpy.py", line 194, in _run_module_as_main
return _run_code(code, main_globals, None,
File "/usr/lib/python3.8/runpy.py", line 87, in _run_code
exec(code, run_globals)
File "/home/user/SimpleEx.py", line 17, in <module>
se_out = se()
File "/home/user/my_venv/lib/python3.8/site-packages/torch/nn/modules/module.py", line 1194, in _call_impl
return forward_call(*input, **kwargs)
RuntimeError: The following operation failed in the TorchScript interpreter.
Traceback of TorchScript (most recent call last):
File "/home/user/SimpleEx.py", line 12, in forward
a = torch.randn(3)
b = torch.randn(11,11)
return 1j*self.k/2*(1-a[1])/a[0]*b
~~~~~~~~~~~ <--- HERE
RuntimeError: isInt() INTERNAL ASSERT FAILED at "../aten/src/ATen/core/ivalue.h":602, please report a bug to PyTorch.
### Versions
Collecting environment information...
PyTorch version: 1.13.1+cpu
Is debug build: False
CUDA used to build PyTorch: Could not collect
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.5 LTS (x86_64)
GCC version: (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0
Clang version: Could not collect
CMake version: version 3.16.3
Libc version: glibc-2.31
Python version: 3.8.10 (default, Nov 14 2022, 12:59:47) [GCC 9.4.0] (64-bit runtime)
Python platform: Linux-5.4.0-136-generic-x86_64-with-glibc2.29
Is CUDA available: False
CUDA runtime version: Could not collect
CUDA_MODULE_LOADING set to: N/A
GPU models and configuration: GPU 0: Quadro P1000
Nvidia driver version: 495.29.05
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.23.4
[pip3] torch==1.13.1+cpu
[pip3] torchvision==0.14.1+cpu
[conda] Could not collect
cc @EikanWang @jgong5 @wenzhe-nrv @sanchitintel @ezyang @anjali411 @dylanbespalko @mruberry @Lezcano @nikitaved
| 3 |
3,685 | 92,674 |
[JIT] `Linear` + `BatchNorm2d` Trigger Inconsistency between Eager Mode and JIT
|
oncall: jit
|
### 🐛 Describe the bug
The following program succeeded in eager mode, but threw a runtime error in `optimize_for_inference`. The inconsistency appears only if the two operators `Linear` and `BatchNorm2d` are used together. If we use a single operator, the program works fine.
```python
import torch
class Model(torch.nn.Module):
def __init__(self):
super().__init__()
self.Linear = torch.nn.Linear(1, 3)
self.BatchNorm = torch.nn.BatchNorm2d(2)
def forward(self, input):
v1 = self.Linear(input)
v2 = self.BatchNorm(v1)
return v2
x = torch.rand([12, 2, 7, 1])
fn = Model()
fn(x)
print("Eager mode ... OK!")
exported = torch.jit.trace(fn, x)
exported = torch.jit.optimize_for_inference(exported) # works w/o this line
print("JIT ... OK!")
"""
Eager mode ... OK!
Traceback (most recent call last):
File "model.py", line 21, in <module>
exported = torch.jit.optimize_for_inference(exported)
File "python3.10/site-packages/torch/jit/_freeze.py", line 215, in optimize_for_inference
mod = freeze(mod.eval(), preserved_attrs=other_methods)
File "python3.10/site-packages/torch/jit/_freeze.py", line 117, in freeze
run_frozen_optimizations(out, optimize_numerics, preserved_methods)
File "python3.10/site-packages/torch/jit/_freeze.py", line 166, in run_frozen_optimizations
torch._C._jit_pass_optimize_frozen_graph(mod.graph, optimize_numerics)
RuntimeError: The size of tensor a (3) must match the size of tensor b (2) at non-singleton dimension 0
"""
```
### Versions
<details><summary> <b> Environment </b> <i> [Click to expand] </i></summary>
```
PyTorch version: 2.0.0.dev20230119+cu117
Is debug build: False
CUDA used to build PyTorch: 11.7
ROCM used to build PyTorch: N/A
OS: Ubuntu 22.04.1 LTS (x86_64)
GCC version: (Ubuntu 11.3.0-1ubuntu1~22.04) 11.3.0
Clang version: 11.1.0-6
CMake version: version 3.22.1
Libc version: glibc-2.35
Python version: 3.10.6 (main, Nov 14 2022, 16:10:14) [GCC 11.3.0] (64-bit runtime)
Python platform: Linux-5.15.0-56-generic-x86_64-with-glibc2.35
Is CUDA available: True
CUDA runtime version: 11.6.124
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration:
GPU 0: NVIDIA GeForce RTX 3090
GPU 1: NVIDIA GeForce RTX 3090
GPU 2: NVIDIA GeForce RTX 3090
Nvidia driver version: 515.86.01
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_infer.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.4.1
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.21.5
[pip3] pytorch-triton==2.0.0+0d7e753227
[pip3] torch==2.0.0.dev20230119+cu117
[pip3] torchaudio==2.0.0.dev20230118+cu117
[pip3] torchvision==0.15.0.dev20230118+cu117
[conda] blas 1.0 mkl
[conda] cudatoolkit 11.3.1 h2bc3f7f_2
[conda] mkl 2021.4.0 h06a4308_640
[conda] mkl-service 2.4.0 py39h7f8727e_0
[conda] mkl_fft 1.3.1 py39hd3c417c_0
[conda] mkl_random 1.2.2 py39h51133e4_0
[conda] numpy 1.21.5 py39he7a7128_1
[conda] numpy-base 1.21.5 py39hf524024_1
[conda] numpydoc 1.2 pyhd3eb1b0_0
[conda] torch 1.14.0a0+gitce2f870 pypi_0 pypi
```
</details>
cc @EikanWang @jgong5 @wenzhe-nrv @sanchitintel
| 1 |
3,686 | 92,670 |
14k github models TorchDynamo + TorchInductor bugs umbrella task
|
triaged, oncall: pt2, module: inductor, module: dynamo
|
We are welcome contributions, please check [14k github models test and debug env setup](https://github.com/pytorch/pytorch/issues/93667#issue-1565238954) for how to reproduce these issues.
### TorchDynamo ([pass rate tracker](https://github.com/pytorch/pytorch/issues/93667))
* [x] pytest ./generated/test_BlinkDL_RWKV_LM.py -k test_005 [Subclasses torch.jit.ScriptModule - unusual usage, not a priority]
* [x] pytest ./generated/test_INVOKERer_DeepRFT.py -k test_010 https://github.com/pytorch/pytorch/pull/91840 (@davidberard98)
* [x] pytest ./generated/test_assassint2017_abdominal_multi_organ_segmentation.py -k test_000 https://github.com/pytorch/pytorch/pull/93043 (@davidberard98)
* [x] pytest ./generated/test_facebookresearch_ClassyVision.py -k test_008
* [x] pytest ./generated/test_facebookresearch_denoiser.py -k test_005 [fails eager]
* [x] pytest ./generated/test_facebookresearch_pytext.py -k test_001 (shape_as_tensor handling)
* [x] pytest ./generated/test_fangwei123456_spikingjelly.py -k test_016 @davidberard98 https://github.com/pytorch/pytorch/pull/94658
* [ ] pytest ./generated/test_github_pengge_PyTorch_progressive_growing_of_gans.py -k test_002 [numpy.ndarray] (https://github.com/pytorch/pytorch/issues/93684 ?)
* [x] pytest ./generated/test_guanfuchen_semseg.py -k test_034 [segfault in triton]
* [x] pytest ./generated/test_ludwig_ai_ludwig.py -k test_018 (@yanboliang)
* [x] pytest ./generated/test_nianticlabs_simplerecon.py -k test_001 [segfault in triton]
* [ ] pytest ./generated/test_pytorch_translate.py -k test_006 (InternalTorchDynamoError: 'int' object has no attribute 'view')
* [x] pytest ./generated/test_easezyc_deep_transfer_learning.py -k test_004 (cc @davidberard98, this is regression caused by #91840) https://github.com/pytorch/pytorch/pull/94332
* [x] pytest ./generated/test_ELEKTRONN_elektronn3.py -k test_018 (#92922) @yanboliang
* [x] pytest ./generated/test_HaSai666_rec_pangu.py -k test_017 (#92926) @yanboliang
* [x] pytest ./generated/test_Shmuma_ptan.py -k test_002 (#93177) @yanboliang
* [x] pytest ./generated/test_awslabs_sockeye.py -k test_009 (#94145) @yanboliang
* [x] pytest ./generated/test_lorenmt_mtan.py -k test_005 (invalid combination of arguments) (#97508) @lantiankaikai
* [x] pytest ./generated/test_ustcml_RecStudio.py -k test_036 (invalid combination of arguments) (#97508) @lantiankaikai
* [x] pytest ./generated/test_PeterouZh_CIPS_3D.py -k test_003 (#97810) @lantiankaikai
* [x] pytest ./generated/test_IDEA_CCNL_Fengshenbang_LM.py -k test_008 (https://github.com/pytorch/pytorch/pull/101141) @yanboliang
* [ ] pytest ./generated/test_VainF_pytorch_msssim.py -k test_000 @lyoka
* [ ] pytest ./generated/test_sony_sqvae.py -k test_007 (Tensor-likes are not close!) @chaekit
### TorchInductor ([pass rate tracker](https://github.com/pytorch/pytorch/issues/93667))
* [x] pytest ./generated/test_baal_org_baal.py -k test_011 https://github.com/pytorch/pytorch/pull/96634 @ngimel
* [x] pytest ./generated/test_ZhaoJ9014_face_evoLVe.py -k test_000 (@yanboliang)
* [x] pytest ./generated/test_ACheun9_Pytorch_implementation_of_Mobile_Former.py -k test_002 [addmm(inp, mat1, mat2) with scalar inp] @davidberard98
* [x] pytest ./generated/test_BloodAxe_pytorch_toolbelt.py -k test_070 (https://github.com/pytorch/pytorch/pull/101051) @yanboliang
* [x] pytest ./generated/test_adriansahlman_stylegan2_pytorch.py -k test_000 (#98448) @chaekit
* [ ] pytest ./generated/test_HomebrewNLP_revlib.py -k test_004 (KeyError: 'val')
* [x] pytest ./generated/test_ProGamerGov_neural_dream.py -k test_000 (LoweringException: AssertionError: target: aten.avg_pool2d.default) @yanboliang (https://github.com/pytorch/pytorch/pull/96727)
* [x] pytest ./generated/test_NKI_AI_direct.py -k test_009 (Unhandled FakeTensor Device Propagation for aten.copy.default, found two different devices cpu, cuda:0) (https://github.com/pytorch/pytorch/pull/102677) @davidberard98
* [ ] pytest ./generated/test_XuyangBai_PointDSC.py -k test_004 (RuntimeError: as_strided_scatter: sizes [4], strides [85], storage offset 256 and itemsize 4 requiring a storage size of 2048 are out of bounds for storage of size 1024) (#98483) @lantiankaikai
* [ ] pytest ./generated/test_agrimgupta92_sgan.py -k test_000 (RuntimeError: Input and hidden tensors are not at the same device, found input tensor at cuda:0 and hidden tensor at cpu)
* [x] pytest ./generated/test_hkchengrex_XMem.py -k test_013 (LoweringException: AssertionError: target: aten.index_put.default) @yanboliang (https://github.com/pytorch/pytorch/pull/97105)
* [ ] pytest ./generated/test_laddie132_Match_LSTM.py -k test_009 (RuntimeError: masked_fill only supports boolean masks, but got dtype Byte)
* [x] pytest ./generated/test_nlp_uoregon_trankit.py -k test_021 (LoweringException: AssertionError: target: aten.cat.default) (#98517) @yanboliang
* [x] pytest ./generated/test_open_mmlab_mmclassification.py -k test_006 (LoweringException: RuntimeError: Tensor must have a last dimension with stride 1. target: aten.view_as_complex.default)
* [ ] pytest ./generated/test_HKUST_KnowComp_MnemonicReader.py -k test_003 (NotImplementedError: could not find kernel for aten._cudnn_rnn_flatten_weight.default at dispatch key DispatchKey.Meta)
* [x] pytest ./generated/test_DKuan_MADDPG_torch.py -k test_002 (RuntimeError: backwards not supported on prim)
* [x] https://github.com/pytorch/pytorch/pull/99671 (@yanboliang)
* [ ] pytest ./generated/test_adapter_hub_adapter_transformers.py -k test_115 (https://github.com/pytorch/pytorch/pull/100115) @bdhirsh (fixed once the PR is in)
* [x] pytest ./generated/test_yizhou_wang_RODNet.py -k test_000 (https://github.com/pytorch/pytorch/pull/102664) @williamwen42
* [x] pytest ./generated/test_shinianzhihou_ChangeDetection.py -k test_027 (AssertionError: Unexpected fake buffer _tensor_constant0 Enable TORCH_FAKE_TENSOR_DEBUG=1 to get creation stack traces on fake tensors.) (repro reported to https://github.com/pytorch/pytorch/issues/102989) @williamwen42
* [x] pytest ./generated/test_clovaai_lffont.py -k test_008 (triton codegen error) (https://github.com/pytorch/pytorch/issues/103481, fixed by https://github.com/pytorch/pytorch/pull/103527) @williamwen42
* [ ] pytest ./generated/test_adriansahlman_stylegan2_pytorch.py -k test_000 (TypeError: unsupported operand type(s) for *: 'NoneType' and 'Tensor')
* [x] pytest ./generated/test_alibaba_EasyCV.py -k test_054 (Please check that Nodes in the graph are topologically ordered) (https://github.com/pytorch/pytorch/pull/103794) @yanboliang
* [ ] pytest ./generated/test_adriansahlman_stylegan2_pytorch.py -k test_000
cc @ezyang @soumith @msaroufim @wconstab @ngimel @bdhirsh @mlazos @voznesenskym @penguinwu @anijain2305 @EikanWang @jgong5 @Guobing-Chen @chunyuan-w @XiaobingSuper @zhuhaozhe @blzheng @Xia-Weiwen @wenzhe-nrv @jiayisunx @peterbell10 @desertfire
| 0 |
3,687 | 92,654 |
Traced model output differs on C++ and Python
|
oncall: jit
|
### 🐛 Describe the bug
Hey guys. Currently, I'm facing a problem related to the output of a model in C++ and Python.
The model receives a set of PointCloud voxels and outputs a feature map to decode the 3D bounding box. I'll provide the model to reproduce the issue.
I'm converting the PyTorch model to JIT as follows:
```
pillars = np.load("pillars.npy")
coors_batch = np.load("coors_batch.npy")
npoints_per_pillar = np.load("npoints_per_pillar.npy")
example_input = (
pillars, coors_batch, npoints_per_pillar
)
traced_model = torch.jit.trace(model_torch, example_input)
# traced_script_module = torch.jit.script(model, example_input)
torch.jit.save(traced_model, "point_pillar.pt")
# print("[INFO] Model converted.")
model_traced = torch.jit.load("point_pillar.pt")
out1_trace, out2_trace, out3_trace = model_traced(pillars, coors_batch, npoints_per_pillar)
print('[INFO] Class Pred Shape = {}'.format(out1_trace.shape))
print('[INFO] Class Pred max = {}'.format(out1_trace.max()))
print('[INFO] Box Pred Shape = {}'.format(out2_trace.shape))
print('[INFO] Box Pred max = {}'.format(out2_trace.max()))
print('[INFO] Direction Pred Shape = {}'.format(out3_trace.shape))
print('[INFO] Direction Pred max = {}'.format(out3_trace.max()))
print("[INFO] Out1 = {}".format(torch.abs(out1_trace - out1_torch).max()))
print("[INFO] Out2 = {}".format(torch.abs(out2_trace - out2_torch).max()))
print("[INFO] Out3 = {}".format(torch.abs(out3_trace - out3_torch).max()))
```
The above code outputs 0.0 for all the last lines, i.e. no difference at all.
```
[INFO] Class Pred Shape = torch.Size([1, 18, 248, 216])
[INFO] Class Pred max = 2.3731374740600586
[INFO] Box Pred Shape = torch.Size([1, 42, 248, 216])
[INFO] Box Pred max = 1.7485209703445435
[INFO] Direction Pred Shape = torch.Size([1, 12, 248, 216])
[INFO] Direction Pred max = 7.032490253448486
[INFO] Out1 = 0.0
[INFO] Out2 = 0.0
[INFO] Out3 = 0.0
```
However, when I load the same traced model in C++ with Libtorch, I receive a different output. Here's a sample:
```
#include <torch/script.h> // One-stop header.
#include <iostream>
#include <memory>
#include "inference/PointPillars.h"
#include <chrono>
#include <fstream>
#include <c10/cuda/CUDACachingAllocator.h>
#include <Eigen/Dense>
#include <cassert>
int main(int argc, const char* argv[]) {
std::string modelPath = "./point_pillar.pt";
torch::NoGradGuard no_grad_guard;
bool CUDA = true;
model = torch::jit::load(modelPath);
detector->preprocess(xyzi, inputs);
for (auto input : inputs) {
std::cout << "Inputs = " << input.toTensor().sizes() << std::endl;
std::cout << "Inputs max = " << input.toTensor().max() << std::endl;
}
// Allocating placeholders
torch::Tensor clsPred;
torch::Tensor boxPred;
torch::Tensor dirPred;
detector->detect(inputs, clsPred, boxPred, dirPred);
std::cout << "[INFO] Class Pred shape = " << clsPred.sizes() << std::endl;
std::cout << "[INFO] Class Pred max = " << clsPred.max() << std::endl;
std::cout << "[INFO] Box Pred shape = " << boxPred.sizes() << std::endl;
std::cout << "[INFO] Box Pred max = " << boxPred.max() << std::endl;
std::cout << "[INFO] Direction Pred shape = " << dirPred.sizes() << std::endl;
std::cout << "[INFO] Direction Pred max = " << dirPred.max() << std::endl;
std::cout << "[INFO] Done inference." << std::endl;
return 0;
}
```
That outputs the following tensors:
```
INFO] Class Pred shape = [1, 18, 248, 216]
[INFO] Class Pred max = -4.45092
[ CUDAFloatType{} ]
[INFO] Box Pred shape = [1, 42, 248, 216]
[INFO] Box Pred max = 1.36825
[ CUDAFloatType{} ]
[INFO] Direction Pred shape = [1, 12, 248, 216]
[INFO] Direction Pred max = 7.03276
[ CUDAFloatType{} ]
```
At the end, the last tensor, `Direction`, seems to be close, but the others aren't.
- Versions:
- The Python PyTorch version that I'm using is `'1.9.0+cu111'`.
- The Libtorch Version is `libtorch-cxx11-abi-shared-with-deps-1.13.0+cu117`.
### Versions
Collecting environment information...
PyTorch version: 1.9.0+cu111
Is debug build: False
CUDA used to build PyTorch: 11.1
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.5 LTS (x86_64)
GCC version: (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0
Clang version: Could not collect
CMake version: version 3.23.1
Libc version: glibc-2.31
Python version: 3.8.10 (default, Jun 22 2022, 20:18:18) [GCC 9.4.0] (64-bit runtime)
Python platform: Linux-5.15.0-58-generic-x86_64-with-glibc2.29
Is CUDA available: True
CUDA runtime version: 11.8.89
CUDA_MODULE_LOADING set to:
GPU models and configuration: GPU 0: NVIDIA GeForce RTX 3060 Laptop GPU
Nvidia driver version: 520.61.05
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.7.0
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.7.0
/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.7.0
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_infer.so.8.7.0
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.7.0
/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.7.0
/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.7.0
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.24.1
[pip3] torch==1.9.0+cu111
[pip3] torch2trt==0.4.0
[pip3] torchaudio==0.9.0
[pip3] torchvision==0.10.0+cu111
[conda] Could not collect
cc @EikanWang @jgong5 @wenzhe-nrv @sanchitintel
| 1 |
3,688 | 92,600 |
Update quantization to make source files complient with /Zc:lambda
|
triage review, module: windows, oncall: quantization, triaged
|
# Summary
While working on this PR: [#91909](https://github.com/pytorch/pytorch/pull/91909) which uses a c++ 17 optional flag to enable the updated lambda preprocessor https://learn.microsoft.com/en-us/cpp/build/reference/zc-lambda?view=msvc-170, I was unable to get windows builds to pass applying this globally. The failing tests:
```
C:\actions-runner\_work\pytorch\pytorch\aten\src\ATen\native\quantized\cuda\AffineQuantizer.cu(45): error C2326: 'scalar_t at::native::_GLOBAL__N__809cb215_18_AffineQuantizer_cu_95ed4547_5828::quantize_tensor_per_tensor_affine_cuda::<lambda_1>::()::<lambda_1>::()::<lambda_1>::operator ()(float,scalar_t) const': function cannot access 'qmin'
C:\actions-runner\_work\pytorch\pytorch\aten\src\ATen\native\quantized\cuda\AffineQuantizer.cu(45): error C2326: 'scalar_t at::native::_GLOBAL__N__809cb215_18_AffineQuantizer_cu_95ed4547_5828::quantize_tensor_per_tensor_affine_cuda::<lambda_1>::()::<lambda_1>::()::<lambda_1>::operator ()(float,scalar_t) const': function cannot access 'qmax'
C:\actions-runner\_work\pytorch\pytorch\aten\src\ATen\native\quantized\cuda\AffineQuantizer.cu(45): error C2326: 'scalar_t at::native::_GLOBAL__N__809cb215_18_AffineQuantizer_cu_95ed4547_5828::quantize_tensor_per_tensor_affine_cuda::<lambda_1>::()::<lambda_2>::()::<lambda_1>::operator ()(float,scalar_t) const': function cannot access 'qmin'
```
In c++ 20 the updated lambda expression will become the default. So in order to smooth the transition we should update the lambda expression in this file to be conforming.
cc @peterjc123 @mszhanyi @skyline75489 @nbcsm @vladimir-aubrecht @iremyux @Blackhex @cristianPanaite @jerryzh168 @jianyuh @raghuramank100 @jamesr66a @vkuzo @jgong5 @Xia-Weiwen @leslie-fang-intel
| 0 |
3,689 | 92,594 |
INTERNAL ASSERT FAILED when mixed dtypes for `addcmul_`
|
triaged, module: assert failure, module: type promotion
|
### 🐛 Describe the bug
`gradcheck` triggers INTERNAL ASSERT FAILED when input with `float64`
For example,
```py
import torch
dtype = torch.float64
x = torch.randn(1,1,1, dtype=dtype)
y = torch.randn(1,1,1, dtype=dtype)
def func(x, y):
return torch.ones(1,1,1).addcmul_(x, y)
torch.autograd.gradcheck(func, (x.clone().requires_grad_(), y.clone().requires_grad_()))
```
```
RuntimeError: !needs_dynamic_casting<func_t>::check(iter) INTERNAL ASSERT FAILED at "/opt/conda/conda-bld/pytorch_1672906354936/work/aten/src/ATen/native/cpu/Loops.h":347, please report a bug to PyTorch.
```
If the dtype is `float32`
```py
dtype = torch.float32
x = torch.randn(1,1,1, dtype=dtype)
y = torch.randn(1,1,1, dtype=dtype)
def func(x, y):
return torch.ones(1,1,1).addcmul_(x, y)
torch.autograd.gradcheck(func, (x.clone().requires_grad_(), y.clone().requires_grad_()))
```
```
GradcheckError: Jacobian mismatch for output 0 with respect to input 0,
numerical:tensor([[-0.1788]])
analytical:tensor([[-0.1625]])
```
### Versions
```
PyTorch version: 2.0.0.dev20230105
Is debug build: False
CUDA used to build PyTorch: 11.7
ROCM used to build PyTorch: N/A
OS: Ubuntu 22.04.1 LTS (x86_64)
GCC version: (Ubuntu 11.3.0-1ubuntu1~22.04) 11.3.0
Clang version: Could not collect
CMake version: version 3.22.1
Libc version: glibc-2.35
Python version: 3.9.15 (main, Nov 24 2022, 14:31:59) [GCC 11.2.0] (64-bit runtime)
Python platform: Linux-5.15.0-56-generic-x86_64-with-glibc2.35
Is CUDA available: True
CUDA runtime version: 11.7.99
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration:
GPU 0: NVIDIA GeForce RTX 3090
GPU 1: NVIDIA GeForce RTX 3090
GPU 2: NVIDIA GeForce RTX 3090
Nvidia driver version: 515.86.01
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_infer.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.4.1
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.23.5
[pip3] torch==2.0.0.dev20230105
[pip3] torchaudio==2.0.0.dev20230105
[pip3] torchvision==0.15.0.dev20230105
[conda] blas 1.0 mkl
[conda] mkl 2021.4.0 h06a4308_640
[conda] mkl-service 2.4.0 py39h7f8727e_0
[conda] mkl_fft 1.3.1 py39hd3c417c_0
[conda] mkl_random 1.2.2 py39h51133e4_0
[conda] numpy 1.23.5 py39h14f4228_0
[conda] numpy-base 1.23.5 py39h31eccc5_0
[conda] pytorch 2.0.0.dev20230105 py3.9_cuda11.7_cudnn8.5.0_0 pytorch-nightly
[conda] pytorch-cuda 11.7 h67b0de4_2 pytorch-nightly
[conda] pytorch-mutex 1.0 cuda pytorch-nightly
[conda] torchaudio 2.0.0.dev20230105 py39_cu117 pytorch-nightly
[conda] torchtriton 2.0.0+0d7e753227 py39 pytorch-nightly
[conda] torchvision 0.15.0.dev20230105 py39_cu117 pytorch-nightly
```
cc @nairbv @mruberry
| 1 |
3,690 | 92,582 |
Some tests in test_torchinductor.py fail locally
|
triaged, oncall: pt2, module: inductor
|
### 🐛 Describe the bug
```
FAILED test/inductor/test_torchinductor.py::CudaTests::test_convolution1_cuda - AssertionError: Tensor-likes are not close!
FAILED test/inductor/test_torchinductor.py::CudaTests::test_linear_packed_cuda - AssertionError: Tensor-likes are not close!
FAILED test/inductor/test_torchinductor.py::CudaReproTests::test_input_channels_last - AssertionError: False is not true
```
Full logs:
<details>
```
============================= test session starts ==============================
platform linux -- Python 3.9.16, pytest-7.2.1, pluggy-1.0.0 -- /home/ezyang/local/b/pytorch-env/bin/python
cachedir: .pytest_cache
benchmark: 4.0.0 (defaults: timer=time.perf_counter disable_gc=False min_rounds=5 min_time=0.000005 max_time=1.0 calibration_precision=10 warmup=False warmup_iterations=100000)
hypothesis profile 'default' -> database=DirectoryBasedExampleDatabase('/data/users/ezyang/b/pytorch/.hypothesis/examples')
rootdir: /data/users/ezyang/b/pytorch, configfile: pytest.ini
plugins: benchmark-4.0.0, hydra-core-1.1.2, hypothesis-6.62.1, csv-3.0.0
collecting ... collected 751 items / 748 deselected / 3 selected
test/inductor/test_torchinductor.py::CudaTests::test_convolution1_cuda FAILED [ 33%]
test/inductor/test_torchinductor.py::CudaTests::test_linear_packed_cuda FAILED [ 66%]
test/inductor/test_torchinductor.py::CudaReproTests::test_input_channels_last FAILED [100%]
=================================== FAILURES ===================================
_______________________ CudaTests.test_convolution1_cuda _______________________
Traceback (most recent call last):
File "/data/users/ezyang/b/pytorch/test/inductor/test_torchinductor.py", line 2133, in test_convolution1
self.common(
File "/home/ezyang/local/b/pytorch-env/lib/python3.9/unittest/mock.py", line 1336, in patched
return func(*newargs, **newkeywargs)
File "/data/users/ezyang/b/pytorch/test/inductor/test_torchinductor.py", line 475, in check_model_cuda
check_model(
File "/home/ezyang/local/b/pytorch-env/lib/python3.9/unittest/mock.py", line 1336, in patched
return func(*newargs, **newkeywargs)
File "/data/users/ezyang/b/pytorch/test/inductor/test_torchinductor.py", line 363, in check_model
self.assertEqual(
File "/data/users/ezyang/b/pytorch/torch/testing/_internal/common_utils.py", line 2934, in assertEqual
assert_equal(
File "/data/users/ezyang/b/pytorch/torch/testing/_comparison.py", line 1244, in assert_equal
raise error_metas[0].to_error(msg)
AssertionError: Tensor-likes are not close!
Mismatched elements: 32 / 2352 (1.4%)
Greatest absolute difference: 0.00048828125 at index (0, 0, 8, 7) (up to 6e-05 allowed)
Greatest relative difference: 0.054365733113673806 at index (0, 1, 4, 1) (up to 0.001 allowed)
The failure occurred for item [0]
----------------------------- Captured stdout call -----------------------------
from ctypes import c_void_p, c_long
import torch
import random
from torch import empty_strided, as_strided, device
from torch._inductor.codecache import AsyncCompile
from torch._inductor.select_algorithm import extern_kernels
aten = torch.ops.aten
assert_size_stride = torch._C._dynamo.guards.assert_size_stride
async_compile = AsyncCompile()
import triton
import triton.language as tl
from torch._inductor.triton_ops.autotune import grid
from torch._C import _cuda_getCurrentRawStream as get_cuda_stream
triton_fused_le_relu_0 = async_compile.triton('''
import triton
import triton.language as tl
from torch._inductor.ir import ReductionHint
from torch._inductor.ir import TileHint
from torch._inductor.triton_ops.autotune import pointwise
from torch._inductor.utils import instance_descriptor
@pointwise(size_hints=[4096], filename=__file__, meta={'signature': {0: '*fp32', 1: '*fp32', 2: '*i1', 3: 'i32'}, 'device': 0, 'constants': {}, 'mutated_arg_names': ['in_out_ptr0'], 'configs': [instance_descriptor(divisible_by_16=(0, 1, 2, 3), equal_to_1=())]})
@triton.jit
def triton_(in_out_ptr0, in_ptr0, out_ptr0, xnumel, XBLOCK : tl.constexpr):
xnumel = 2352
xoffset = tl.program_id(0) * XBLOCK
xindex = xoffset + tl.arange(0, XBLOCK)[:]
xmask = xindex < xnumel
x3 = xindex
x1 = (xindex // 196) % 6
tmp0 = tl.load(in_out_ptr0 + (x3), xmask)
tmp1 = tl.load(in_ptr0 + (x1), xmask)
tmp2 = tmp0 + tmp1
tmp3 = tl.where(0 != 0, 0, tl.where(0 > tmp2, 0, tmp2))
tmp4 = 0.0
tmp5 = tmp3 <= tmp4
tl.store(in_out_ptr0 + (x3 + tl.zeros([XBLOCK], tl.int32)), tmp3, xmask)
tl.store(out_ptr0 + (x3 + tl.zeros([XBLOCK], tl.int32)), tmp5, xmask)
''')
async_compile.wait(globals())
del async_compile
def call(args):
primals_1, primals_2, primals_3 = args
args.clear()
with torch.cuda._DeviceGuard(0):
torch.cuda.set_device(0) # no-op to ensure context
buf0 = aten.convolution(primals_3, primals_1, None, (1, 1), (0, 0), (1, 1), False, (0, 0), 1)
assert_size_stride(buf0, (2, 6, 14, 14), (1176, 196, 14, 1))
buf1 = as_strided(buf0, (2, 6, 14, 14), (1176, 196, 14, 1)); del buf0 # reuse
buf2 = empty_strided((2, 6, 14, 14), (1176, 196, 14, 1), device='cuda', dtype=torch.bool)
stream0 = get_cuda_stream(0)
triton_fused_le_relu_0.run(buf1, primals_2, buf2, 2352, grid=grid(2352), stream=stream0)
del primals_2
return (buf1, primals_1, primals_3, buf2, )
if __name__ == "__main__":
from torch._dynamo.testing import rand_strided
from torch._inductor.utils import print_performance
primals_1 = rand_strided((6, 5, 3, 3), (45, 9, 3, 1), device='cuda:0', dtype=torch.float32)
primals_2 = rand_strided((6, ), (1, ), device='cuda:0', dtype=torch.float32)
primals_3 = rand_strided((2, 5, 16, 16), (1280, 256, 16, 1), device='cuda:0', dtype=torch.float32)
print_performance(lambda: call([primals_1, primals_2, primals_3]))
from ctypes import c_void_p, c_long
import torch
import random
from torch import empty_strided, as_strided, device
from torch._inductor.codecache import AsyncCompile
from torch._inductor.select_algorithm import extern_kernels
aten = torch.ops.aten
assert_size_stride = torch._C._dynamo.guards.assert_size_stride
async_compile = AsyncCompile()
import triton
import triton.language as tl
from torch._inductor.triton_ops.autotune import grid
from torch._C import _cuda_getCurrentRawStream as get_cuda_stream
triton_fused_le_relu_0 = async_compile.triton('''
import triton
import triton.language as tl
from torch._inductor.ir import ReductionHint
from torch._inductor.ir import TileHint
from torch._inductor.triton_ops.autotune import pointwise
from torch._inductor.utils import instance_descriptor
@pointwise(size_hints=[4096], filename=__file__, meta={'signature': {0: '*fp16', 1: '*fp16', 2: '*i1', 3: 'i32'}, 'device': 0, 'constants': {}, 'mutated_arg_names': ['in_out_ptr0'], 'configs': [instance_descriptor(divisible_by_16=(0, 1, 2, 3), equal_to_1=())]})
@triton.jit
def triton_(in_out_ptr0, in_ptr0, out_ptr0, xnumel, XBLOCK : tl.constexpr):
xnumel = 2352
xoffset = tl.program_id(0) * XBLOCK
xindex = xoffset + tl.arange(0, XBLOCK)[:]
xmask = xindex < xnumel
x3 = xindex
x1 = (xindex // 196) % 6
tmp0 = tl.load(in_out_ptr0 + (x3), xmask).to(tl.float32)
tmp1 = tl.load(in_ptr0 + (x1), xmask).to(tl.float32)
tmp2 = tmp0 + tmp1
tmp3 = tl.where(0 != 0, 0, tl.where(0 > tmp2, 0, tmp2))
tmp4 = 0.0
tmp5 = tmp3 <= tmp4
tl.store(in_out_ptr0 + (x3 + tl.zeros([XBLOCK], tl.int32)), tmp3, xmask)
tl.store(out_ptr0 + (x3 + tl.zeros([XBLOCK], tl.int32)), tmp5, xmask)
''')
async_compile.wait(globals())
del async_compile
def call(args):
primals_1, primals_2, primals_3 = args
args.clear()
with torch.cuda._DeviceGuard(0):
torch.cuda.set_device(0) # no-op to ensure context
buf0 = aten.convolution(primals_3, primals_1, None, (1, 1), (0, 0), (1, 1), False, (0, 0), 1)
assert_size_stride(buf0, (2, 6, 14, 14), (1176, 196, 14, 1))
buf1 = as_strided(buf0, (2, 6, 14, 14), (1176, 196, 14, 1)); del buf0 # reuse
buf2 = empty_strided((2, 6, 14, 14), (1176, 196, 14, 1), device='cuda', dtype=torch.bool)
stream0 = get_cuda_stream(0)
triton_fused_le_relu_0.run(buf1, primals_2, buf2, 2352, grid=grid(2352), stream=stream0)
del primals_2
return (buf1, primals_1, primals_3, buf2, )
if __name__ == "__main__":
from torch._dynamo.testing import rand_strided
from torch._inductor.utils import print_performance
primals_1 = rand_strided((6, 5, 3, 3), (45, 9, 3, 1), device='cuda:0', dtype=torch.float16)
primals_2 = rand_strided((6, ), (1, ), device='cuda:0', dtype=torch.float16)
primals_3 = rand_strided((2, 5, 16, 16), (1280, 256, 16, 1), device='cuda:0', dtype=torch.float16)
print_performance(lambda: call([primals_1, primals_2, primals_3]))
----------------------------- Captured stderr call -----------------------------
/data/users/ezyang/b/pytorch/torch/backends/cudnn/__init__.py:93: UserWarning: PyTorch was compiled without cuDNN/MIOpen support. To use cuDNN/MIOpen, rebuild PyTorch making sure the library is visible to the build system.
warnings.warn(
/data/users/ezyang/b/pytorch/test/inductor/test_torchinductor.py:265: UserWarning: TypedStorage is deprecated. It will be removed in the future and UntypedStorage will be the only storage class. This should only matter to you if you are using storages directly. To access UntypedStorage directly, use tensor.untyped_storage() instead of tensor.storage()
buffer = torch.as_strided(x, (x.storage().size(),), (1,), 0).clone()
/data/users/ezyang/b/pytorch/test/inductor/test_torchinductor.py:265: UserWarning: TypedStorage is deprecated. It will be removed in the future and UntypedStorage will be the only storage class. This should only matter to you if you are using storages directly. To access UntypedStorage directly, use tensor.untyped_storage() instead of tensor.storage()
buffer = torch.as_strided(x, (x.storage().size(),), (1,), 0).clone()
------------------------------ Captured log call -------------------------------
INFO torch._inductor.compile_fx:logging.py:121 Step 3: torchinductor compiling FORWARDS graph 0
INFO torch._inductor.compile_fx:logging.py:121 Step 3: torchinductor done compiling FORWARDS graph 0
INFO torch._inductor.compile_fx:logging.py:121 Step 3: torchinductor compiling FORWARDS graph 1
INFO torch._inductor.compile_fx:logging.py:121 Step 3: torchinductor done compiling FORWARDS graph 1
______________________ CudaTests.test_linear_packed_cuda _______________________
Traceback (most recent call last):
File "/data/users/ezyang/b/pytorch/test/inductor/test_torchinductor.py", line 1872, in test_linear_packed
self.common(
File "/home/ezyang/local/b/pytorch-env/lib/python3.9/unittest/mock.py", line 1336, in patched
return func(*newargs, **newkeywargs)
File "/data/users/ezyang/b/pytorch/test/inductor/test_torchinductor.py", line 475, in check_model_cuda
check_model(
File "/home/ezyang/local/b/pytorch-env/lib/python3.9/unittest/mock.py", line 1336, in patched
return func(*newargs, **newkeywargs)
File "/data/users/ezyang/b/pytorch/test/inductor/test_torchinductor.py", line 363, in check_model
self.assertEqual(
File "/data/users/ezyang/b/pytorch/torch/testing/_internal/common_utils.py", line 2934, in assertEqual
assert_equal(
File "/data/users/ezyang/b/pytorch/torch/testing/_comparison.py", line 1244, in assert_equal
raise error_metas[0].to_error(msg)
AssertionError: Tensor-likes are not close!
Mismatched elements: 13 / 180 (7.2%)
Greatest absolute difference: 0.000244140625 at index (0, 0, 15) (up to 1e-05 allowed)
Greatest relative difference: 0.06147772137619854 at index (0, 0, 29) (up to 0.001 allowed)
----------------------------- Captured stdout call -----------------------------
from ctypes import c_void_p, c_long
import torch
import random
from torch import empty_strided, as_strided, device
from torch._inductor.codecache import AsyncCompile
from torch._inductor.select_algorithm import extern_kernels
aten = torch.ops.aten
assert_size_stride = torch._C._dynamo.guards.assert_size_stride
async_compile = AsyncCompile()
import triton
import triton.language as tl
from torch._inductor.triton_ops.autotune import grid
from torch._C import _cuda_getCurrentRawStream as get_cuda_stream
async_compile.wait(globals())
del async_compile
def call(args):
arg0_1, arg1_1, arg2_1 = args
args.clear()
with torch.cuda._DeviceGuard(0):
torch.cuda.set_device(0) # no-op to ensure context
buf0 = empty_strided((6, 30), (30, 1), device='cuda', dtype=torch.float32)
extern_kernels.addmm(arg1_1, as_strided(arg2_1, (6, 10), (10, 1)), as_strided(arg0_1, (10, 30), (1, 10)), alpha=1, beta=1, out=buf0)
del arg0_1
del arg1_1
del arg2_1
return (as_strided(buf0, (2, 3, 30), (90, 30, 1)), )
if __name__ == "__main__":
from torch._dynamo.testing import rand_strided
from torch._inductor.utils import print_performance
arg0_1 = rand_strided((30, 10), (10, 1), device='cuda:0', dtype=torch.float32)
arg1_1 = rand_strided((30, ), (1, ), device='cuda:0', dtype=torch.float32)
arg2_1 = rand_strided((2, 3, 10), (30, 10, 1), device='cuda:0', dtype=torch.float32)
print_performance(lambda: call([arg0_1, arg1_1, arg2_1]))
from ctypes import c_void_p, c_long
import torch
import random
from torch import empty_strided, as_strided, device
from torch._inductor.codecache import AsyncCompile
from torch._inductor.select_algorithm import extern_kernels
aten = torch.ops.aten
assert_size_stride = torch._C._dynamo.guards.assert_size_stride
async_compile = AsyncCompile()
import triton
import triton.language as tl
from torch._inductor.triton_ops.autotune import grid
from torch._C import _cuda_getCurrentRawStream as get_cuda_stream
async_compile.wait(globals())
del async_compile
def call(args):
arg0_1, arg1_1, arg2_1 = args
args.clear()
with torch.cuda._DeviceGuard(0):
torch.cuda.set_device(0) # no-op to ensure context
buf0 = empty_strided((6, 30), (30, 1), device='cuda', dtype=torch.float16)
extern_kernels.addmm(arg1_1, as_strided(arg2_1, (6, 10), (10, 1)), as_strided(arg0_1, (10, 30), (1, 10)), alpha=1, beta=1, out=buf0)
del arg0_1
del arg1_1
del arg2_1
return (as_strided(buf0, (2, 3, 30), (90, 30, 1)), )
if __name__ == "__main__":
from torch._dynamo.testing import rand_strided
from torch._inductor.utils import print_performance
arg0_1 = rand_strided((30, 10), (10, 1), device='cuda:0', dtype=torch.float16)
arg1_1 = rand_strided((30, ), (1, ), device='cuda:0', dtype=torch.float16)
arg2_1 = rand_strided((2, 3, 10), (30, 10, 1), device='cuda:0', dtype=torch.float16)
print_performance(lambda: call([arg0_1, arg1_1, arg2_1]))
----------------------------- Captured stderr call -----------------------------
/data/users/ezyang/b/pytorch/test/inductor/test_torchinductor.py:265: UserWarning: TypedStorage is deprecated. It will be removed in the future and UntypedStorage will be the only storage class. This should only matter to you if you are using storages directly. To access UntypedStorage directly, use tensor.untyped_storage() instead of tensor.storage()
buffer = torch.as_strided(x, (x.storage().size(),), (1,), 0).clone()
/data/users/ezyang/b/pytorch/test/inductor/test_torchinductor.py:265: UserWarning: TypedStorage is deprecated. It will be removed in the future and UntypedStorage will be the only storage class. This should only matter to you if you are using storages directly. To access UntypedStorage directly, use tensor.untyped_storage() instead of tensor.storage()
buffer = torch.as_strided(x, (x.storage().size(),), (1,), 0).clone()
------------------------------ Captured log call -------------------------------
INFO torch._inductor.compile_fx:logging.py:121 Step 3: torchinductor compiling FORWARDS graph 2
INFO torch._inductor.compile_fx:logging.py:121 Step 3: torchinductor done compiling FORWARDS graph 2
INFO torch._inductor.compile_fx:logging.py:121 Step 3: torchinductor compiling FORWARDS graph 3
INFO torch._inductor.compile_fx:logging.py:121 Step 3: torchinductor done compiling FORWARDS graph 3
___________________ CudaReproTests.test_input_channels_last ____________________
Traceback (most recent call last):
File "/data/users/ezyang/b/pytorch/test/inductor/test_torchinductor.py", line 5881, in test_input_channels_last
self.assertTrue(
File "/home/ezyang/local/b/pytorch-env/lib/python3.9/unittest/case.py", line 688, in assertTrue
raise self.failureException(msg)
AssertionError: False is not true
----------------------------- Captured stdout call -----------------------------
from ctypes import c_void_p, c_long
import torch
import random
from torch import empty_strided, as_strided, device
from torch._inductor.codecache import AsyncCompile
from torch._inductor.select_algorithm import extern_kernels
aten = torch.ops.aten
assert_size_stride = torch._C._dynamo.guards.assert_size_stride
async_compile = AsyncCompile()
import triton
import triton.language as tl
from torch._inductor.triton_ops.autotune import grid
from torch._C import _cuda_getCurrentRawStream as get_cuda_stream
triton_fused_convolution_0 = async_compile.triton('''
import triton
import triton.language as tl
from torch._inductor.ir import ReductionHint
from torch._inductor.ir import TileHint
from torch._inductor.triton_ops.autotune import pointwise
from torch._inductor.utils import instance_descriptor
@pointwise(size_hints=[8, 256], tile_hint=TileHint.SQUARE,filename=__file__, meta={'signature': {0: '*fp32', 1: '*fp32', 2: 'i32', 3: 'i32'}, 'device': 0, 'constants': {}, 'mutated_arg_names': [], 'configs': [instance_descriptor(divisible_by_16=(0, 1, 3), equal_to_1=())]})
@triton.jit
def triton_(in_ptr0, out_ptr0, xnumel, ynumel, XBLOCK : tl.constexpr, YBLOCK : tl.constexpr):
xnumel = 6
ynumel = 256
xoffset = tl.program_id(0) * XBLOCK
xindex = xoffset + tl.arange(0, XBLOCK)[:, None]
xmask = xindex < xnumel
yoffset = tl.program_id(1) * YBLOCK
yindex = yoffset + tl.arange(0, YBLOCK)[None, :]
ymask = yindex < ynumel
x0 = xindex % 3
x1 = (xindex // 3)
y2 = yindex
x3 = xindex
tmp0 = tl.load(in_ptr0 + (x0 + (3*y2) + (768*x1)), xmask & ymask)
tl.store(out_ptr0 + (y2 + (256*x3) + tl.zeros([XBLOCK, YBLOCK], tl.int32)), tmp0, xmask & ymask)
''')
triton_fused_convolution_1 = async_compile.triton('''
import triton
import triton.language as tl
from torch._inductor.ir import ReductionHint
from torch._inductor.ir import TileHint
from torch._inductor.triton_ops.autotune import pointwise
from torch._inductor.utils import instance_descriptor
@pointwise(size_hints=[2048], filename=__file__, meta={'signature': {0: '*fp32', 1: '*fp32', 2: 'i32'}, 'device': 0, 'constants': {}, 'mutated_arg_names': ['in_out_ptr0'], 'configs': [instance_descriptor(divisible_by_16=(0, 1, 2), equal_to_1=())]})
@triton.jit
def triton_(in_out_ptr0, in_ptr0, xnumel, XBLOCK : tl.constexpr):
xnumel = 1536
xoffset = tl.program_id(0) * XBLOCK
xindex = xoffset + tl.arange(0, XBLOCK)[:]
xmask = xindex < xnumel
x3 = xindex
x1 = (xindex // 256) % 3
tmp0 = tl.load(in_out_ptr0 + (x3), xmask)
tmp1 = tl.load(in_ptr0 + (x1), xmask)
tmp2 = tmp0 + tmp1
tl.store(in_out_ptr0 + (x3 + tl.zeros([XBLOCK], tl.int32)), tmp2, xmask)
''')
async_compile.wait(globals())
del async_compile
def call(args):
primals_1, primals_2, primals_3 = args
args.clear()
with torch.cuda._DeviceGuard(0):
torch.cuda.set_device(0) # no-op to ensure context
buf0 = empty_strided((2, 3, 16, 16), (768, 256, 16, 1), device='cuda', dtype=torch.float32)
stream0 = get_cuda_stream(0)
triton_fused_convolution_0.run(primals_3, buf0, 6, 256, grid=grid(6, 256), stream=stream0)
buf1 = aten.convolution(buf0, primals_1, None, (1, 1), (0, 0), (1, 1), False, (0, 0), 1)
assert_size_stride(buf1, (2, 3, 16, 16), (768, 256, 16, 1))
del buf0
buf2 = as_strided(buf1, (2, 3, 16, 16), (768, 256, 16, 1)); del buf1 # reuse
triton_fused_convolution_1.run(buf2, primals_2, 1536, grid=grid(1536), stream=stream0)
del primals_2
return (buf2, primals_1, primals_3, )
if __name__ == "__main__":
from torch._dynamo.testing import rand_strided
from torch._inductor.utils import print_performance
primals_1 = rand_strided((3, 3, 1, 1), (3, 1, 1, 1), device='cuda:0', dtype=torch.float32)
primals_2 = rand_strided((3, ), (1, ), device='cuda:0', dtype=torch.float32)
primals_3 = rand_strided((2, 3, 16, 16), (768, 1, 48, 3), device='cuda:0', dtype=torch.float32)
print_performance(lambda: call([primals_1, primals_2, primals_3]))
from ctypes import c_void_p, c_long
import torch
import random
from torch import empty_strided, as_strided, device
from torch._inductor.codecache import AsyncCompile
from torch._inductor.select_algorithm import extern_kernels
aten = torch.ops.aten
assert_size_stride = torch._C._dynamo.guards.assert_size_stride
async_compile = AsyncCompile()
import triton
import triton.language as tl
from torch._inductor.triton_ops.autotune import grid
from torch._C import _cuda_getCurrentRawStream as get_cuda_stream
triton_fused_convolution_0 = async_compile.triton('''
import triton
import triton.language as tl
from torch._inductor.ir import ReductionHint
from torch._inductor.ir import TileHint
from torch._inductor.triton_ops.autotune import pointwise
from torch._inductor.utils import instance_descriptor
@pointwise(size_hints=[8, 256], tile_hint=TileHint.SQUARE,filename=__file__, meta={'signature': {0: '*fp32', 1: '*fp32', 2: 'i32', 3: 'i32'}, 'device': 0, 'constants': {}, 'mutated_arg_names': [], 'configs': [instance_descriptor(divisible_by_16=(0, 1, 3), equal_to_1=())]})
@triton.jit
def triton_(in_ptr0, out_ptr0, xnumel, ynumel, XBLOCK : tl.constexpr, YBLOCK : tl.constexpr):
xnumel = 6
ynumel = 256
xoffset = tl.program_id(0) * XBLOCK
xindex = xoffset + tl.arange(0, XBLOCK)[:, None]
xmask = xindex < xnumel
yoffset = tl.program_id(1) * YBLOCK
yindex = yoffset + tl.arange(0, YBLOCK)[None, :]
ymask = yindex < ynumel
x0 = xindex % 3
x1 = (xindex // 3)
y2 = yindex
x3 = xindex
tmp0 = tl.load(in_ptr0 + (x0 + (3*y2) + (768*x1)), xmask & ymask)
tl.store(out_ptr0 + (y2 + (256*x3) + tl.zeros([XBLOCK, YBLOCK], tl.int32)), tmp0, xmask & ymask)
''')
triton_fused_convolution_1 = async_compile.triton('''
import triton
import triton.language as tl
from torch._inductor.ir import ReductionHint
from torch._inductor.ir import TileHint
from torch._inductor.triton_ops.autotune import pointwise
from torch._inductor.utils import instance_descriptor
@pointwise(size_hints=[2048], filename=__file__, meta={'signature': {0: '*fp32', 1: '*fp32', 2: 'i32'}, 'device': 0, 'constants': {}, 'mutated_arg_names': ['in_out_ptr0'], 'configs': [instance_descriptor(divisible_by_16=(0, 1, 2), equal_to_1=())]})
@triton.jit
def triton_(in_out_ptr0, in_ptr0, xnumel, XBLOCK : tl.constexpr):
xnumel = 1536
xoffset = tl.program_id(0) * XBLOCK
xindex = xoffset + tl.arange(0, XBLOCK)[:]
xmask = xindex < xnumel
x3 = xindex
x1 = (xindex // 256) % 3
tmp0 = tl.load(in_out_ptr0 + (x3), xmask)
tmp1 = tl.load(in_ptr0 + (x1), xmask)
tmp2 = tmp0 + tmp1
tl.store(in_out_ptr0 + (x3 + tl.zeros([XBLOCK], tl.int32)), tmp2, xmask)
''')
async_compile.wait(globals())
del async_compile
def call(args):
primals_1, primals_2, primals_3 = args
args.clear()
with torch.cuda._DeviceGuard(0):
torch.cuda.set_device(0) # no-op to ensure context
buf0 = empty_strided((2, 3, 16, 16), (768, 256, 16, 1), device='cuda', dtype=torch.float32)
stream0 = get_cuda_stream(0)
triton_fused_convolution_0.run(primals_3, buf0, 6, 256, grid=grid(6, 256), stream=stream0)
buf1 = aten.convolution(buf0, primals_1, None, (1, 1), (0, 0), (1, 1), False, (0, 0), 1)
assert_size_stride(buf1, (2, 3, 16, 16), (768, 256, 16, 1))
del buf0
buf2 = as_strided(buf1, (2, 3, 16, 16), (768, 256, 16, 1)); del buf1 # reuse
triton_fused_convolution_1.run(buf2, primals_2, 1536, grid=grid(1536), stream=stream0)
del primals_2
return (buf2, primals_1, primals_3, )
if __name__ == "__main__":
from torch._dynamo.testing import rand_strided
from torch._inductor.utils import print_performance
primals_1 = rand_strided((3, 3, 1, 1), (3, 1, 1, 1), device='cuda:0', dtype=torch.float32)
primals_2 = rand_strided((3, ), (1, ), device='cuda:0', dtype=torch.float32)
primals_3 = rand_strided((2, 3, 16, 16), (768, 1, 48, 3), device='cuda:0', dtype=torch.float32)
print_performance(lambda: call([primals_1, primals_2, primals_3]))
----------------------------- Captured stderr call -----------------------------
/data/users/ezyang/b/pytorch/test/inductor/test_torchinductor.py:265: UserWarning: TypedStorage is deprecated. It will be removed in the future and UntypedStorage will be the only storage class. This should only matter to you if you are using storages directly. To access UntypedStorage directly, use tensor.untyped_storage() instead of tensor.storage()
buffer = torch.as_strided(x, (x.storage().size(),), (1,), 0).clone()
------------------------------ Captured log call -------------------------------
INFO torch._inductor.compile_fx:logging.py:121 Step 3: torchinductor compiling FORWARDS graph 4
INFO torch._inductor.compile_fx:logging.py:121 Step 3: torchinductor done compiling FORWARDS graph 4
INFO torch._inductor.compile_fx:logging.py:121 Step 3: torchinductor compiling FORWARDS graph 5
INFO torch._inductor.compile_fx:logging.py:121 Step 3: torchinductor done compiling FORWARDS graph 5
=========================== short test summary info ============================
FAILED test/inductor/test_torchinductor.py::CudaTests::test_convolution1_cuda
FAILED test/inductor/test_torchinductor.py::CudaTests::test_linear_packed_cuda
FAILED test/inductor/test_torchinductor.py::CudaReproTests::test_input_channels_last
====================== 3 failed, 748 deselected in 12.28s ======================
```
</details>
This is on a fairly normal source build of PyTorch on a Meta A100 devgpu. NVIDIA PG509-210, driver and runtime is CUDA 11.4
Also, this test incorrectly fails when built without cudnn (but the "fix" for this is to build with cudnn lol)
```
FAILED test/inductor/test_torchinductor.py::CudaTests::test_cudnn_rnn_cuda - RuntimeError: _cudnn_rnn: ATen not compiled with cuDNN support
```
### Versions
master
cc @soumith @msaroufim @wconstab @ngimel @bdhirsh @mlazos @voznesenskym @yanboliang @penguinwu @anijain2305 @EikanWang @jgong5 @Guobing-Chen @chunyuan-w @XiaobingSuper @zhuhaozhe @blzheng @Xia-Weiwen @wenzhe-nrv @jiayisunx @peterbell10 @desertfire
| 2 |
3,691 | 92,580 |
Improve Fake Tensor Error When Data Ptr is Accessed
|
triaged, module: fakeTensor
|
### 🐛 Describe the bug
The error is not very informative as is:
```
The tensor has a non-zero number of elements, but its data is not allocated yet. Caffe2 uses a lazy allocation, so you will need to call mutable_data() or raw_mutable_data() to actually allocate memory.?
```
### Versions
...
| 0 |
3,692 | 92,563 |
[JIT] INTERNAL ASSERT FAILED when `Conv2d` and `clamp` used together
|
oncall: jit
|
### 🐛 Describe the bug
The following model works for eager mode but triggers an INTERNAL ASSERT FAILED error in `torch.jit.optimize_for_inference()`.
```python
import torch
class Model(torch.nn.Module):
def __init__(self):
super().__init__()
self.m = torch.nn.Conv2d(1, 4, kernel_size=(1, 1))
def forward(self, input):
v = self.m(input)
return torch.clamp(v, min=0, max=1) # works w/o this line
"""
The error is triggered by combined use of "Conv2d" and "clamp",
without any of which it works fine.
"""
x = torch.ones(1, 1, 1, 1)
fn = Model().eval()
fn(x)
print("Eager mode works")
exported = torch.jit.trace(fn, (x,))
exported = torch.jit.optimize_for_inference(exported)
exported(x)
print("JIT works")
"""
Eager mode works
Traceback (most recent call last):
File "model.py", line 20, in <module>
exported = torch.jit.optimize_for_inference(exported)
File "python3.10/site-packages/torch/jit/_freeze.py", line 217, in optimize_for_inference
torch._C._jit_pass_optimize_for_inference(mod._c, other_methods)
RuntimeError: isDouble() INTERNAL ASSERT FAILED at "pytorch/aten/src/ATen/core/ivalue.h":524, please report a bug to PyTorch.
"""
```
The error is triggered by combined use of `Conv2d` and `clamp`, without any of which it works fine.
### Versions
<details><summary><b>Environment </b> <i>[click to expand]</i></summary>
```
PyTorch version: 1.14.0a0+gitbdc9911
Is debug build: False
CUDA used to build PyTorch: 11.6
ROCM used to build PyTorch: N/A
OS: Ubuntu 22.04.1 LTS (x86_64)
GCC version: (Ubuntu 11.3.0-1ubuntu1~22.04) 11.3.0
Clang version: 11.1.0-6
CMake version: version 3.22.1
Libc version: glibc-2.35
Python version: 3.10.6 (main, Nov 14 2022, 16:10:14) [GCC 11.3.0] (64-bit runtime)
Python platform: Linux-5.15.0-56-generic-x86_64-with-glibc2.35
Is CUDA available: True
CUDA runtime version: 11.6.124
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration:
GPU 0: NVIDIA GeForce RTX 3090
GPU 1: NVIDIA GeForce RTX 3090
GPU 2: NVIDIA GeForce RTX 3090
Nvidia driver version: 515.86.01
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_infer.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.4.1
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.21.5
[pip3] torch==1.14.0a0+gitbdc9911
[conda] blas 1.0 mkl
[conda] cudatoolkit 11.3.1 h2bc3f7f_2
[conda] mkl 2021.4.0 h06a4308_640
[conda] mkl-service 2.4.0 py39h7f8727e_0
[conda] mkl_fft 1.3.1 py39hd3c417c_0
[conda] mkl_random 1.2.2 py39h51133e4_0
[conda] numpy 1.21.5 py39he7a7128_1
[conda] numpy-base 1.21.5 py39hf524024_1
[conda] numpydoc 1.2 pyhd3eb1b0_0
[conda] torch 1.14.0a0+gitce2f870 pypi_0 pypi
```
</details>
cc @EikanWang @jgong5 @wenzhe-nrv @sanchitintel
| 0 |
3,693 | 92,561 |
Spurious side effect diff when cond branches call different functions in outer scope
|
triaged, oncall: pt2, module: dynamo
|
### 🐛 Describe the bug
Consider the following code where we're calling `cond` with branches `shallow` and `deep`, such that `deep` references functions in outer scope that `shallow` doesn't.
```python
class Module(torch.nn.Module):
def forward(self, pred, x):
return self.indirection(pred, x)
def indirection(self, pred, x):
def true_fn(y):
return y + 2
def false_fn(y):
return y - 2
def shallow(x):
return x * 2
def deep(x):
return cond(
x[0][0] > 0,
true_fn,
false_fn,
[x],
)
return cond(pred, shallow, deep, [x])
```
Trying to export this code leads to an exception:
```
<snip>
File "<snip>/torch/_dynamo/variables/torch.py", line 831, in call_function
unimplemented(true_cmp.diff(false_cmp))
File "<snip>/torch/_dynamo/exc.py", line 67, in unimplemented
raise Unsupported(msg)
torch._dynamo.exc.Unsupported: id_to_variable keys: odict_keys([140465014772608, 140465014771968, 140465014772496]) != odict_keys([])
```
### Versions
PyTorch version: 1.14.0a0+gited9cd47
Is debug build: False
CUDA used to build PyTorch: None
ROCM used to build PyTorch: N/A
OS: macOS 13.1 (x86_64)
GCC version: Could not collect
Clang version: 13.0.0 (clang-1300.0.29.30)
CMake version: version 3.22.1
Libc version: N/A
Python version: 3.9.13 (main, Aug 25 2022, 18:29:29) [Clang 12.0.0 ] (64-bit runtime)
Python platform: macOS-10.16-x86_64-i386-64bit
Is CUDA available: False
CUDA runtime version: No CUDA
CUDA_MODULE_LOADING set to: N/A
GPU models and configuration: No CUDA
Nvidia driver version: No CUDA
cuDNN version: No CUDA
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] mypy-extensions==0.4.3
[pip3] numpy==1.21.5
[pip3] numpydoc==1.4.0
[pip3] torch==1.14.0a0+gited9cd47
[conda] blas 1.0 mkl
[conda] mkl 2021.4.0 hecd8cb5_637
[conda] mkl-include 2022.1.0 hecd8cb5_209
[conda] mkl-service 2.4.0 py39h9ed2024_0
[conda] mkl_fft 1.3.1 py39h4ab4a9b_0
[conda] mkl_random 1.2.2 py39hb2f4e1b_0
[conda] numpy 1.21.5 py39h2e5f0a9_3
[conda] numpy-base 1.21.5 py39h3b1a694_3
[conda] numpydoc 1.4.0 py39hecd8cb5_0
[conda] torch 1.14.0a0+gited9cd47 dev_0 <develop>
cc @ezyang @soumith @msaroufim @wconstab @ngimel @bdhirsh @mlazos @voznesenskym @yanboliang @penguinwu @anijain2305 @EikanWang @jgong5 @Guobing-Chen @chunyuan-w @XiaobingSuper @zhuhaozhe @blzheng @Xia-Weiwen @wenzhe-nrv @jiayisunx @desertfire
| 0 |
3,694 | 92,558 |
[JIT][TracingCheckError] inplace ops incompatible with `contiguous(.., channels_last)`
|
oncall: jit
|
### 🐛 Describe the bug
The following `fn` (inplace `transpose` + `contiguous(..., channels_last)`) which works for eager mode but cannot be compiled by `torch.jit.trace`, which seems to be a bug in alias analysis? It also seems to be similar to https://github.com/pytorch/pytorch/issues/23993
```python
import torch
def fn(x):
# v1: [3, 1, 7, 7] alias of x
v1 = torch.Tensor.transpose_(x, 0, 1)
# v2: [3, 1, 7, 7] alias of x
v2 = torch.Tensor.contiguous(x, memory_format=torch.channels_last)
return v1, v2
# There are a few ways for making it "work":
# 1. Remove `memory_format=torch.channels_last` from `torch.Tensor.contiguous`
# 2. Add any non-inplace of before `transpose_` such as `x = torch.relu(x)`
# 3. Add any non-inplace operator after `torch.Tensor.contiguous` such as `torch.cos`
# 4: Use any shape-preserving inplace op to replace `transpose_` such as `torch..relu_`
# 5. Only return v1 or v2 not both.
# 6. Let the input channel dimension to be 1 instead of something greater than 1.
# 7. Use `check_trace=False` in `torch.jit.trace`
# eager
res = fn(torch.rand([1, 2, 4, 4]))
print("Eager mode... Success!")
# compile
torch.jit.trace(fn, torch.rand([1, 2, 4, 4]))
"""
Eager mode... Success!
Traceback (most recent call last):
File "test.py", line 25, in <module>
torch.jit.trace(fn, torch.rand([1, 2, 4, 4]))
...
File "/miniconda3/lib/python3.9/site-packages/torch/jit/_trace.py", line 561, in _check_trace
raise TracingCheckError(*diag_info)
torch.jit._trace.TracingCheckError: Tracing failed sanity checks!
ERROR: Graphs differed across invocations!
Graph diff:
graph(%x.1 : Tensor):
%1 : int = prim::Constant[value=0]() # test.py:6:0
%2 : int = prim::Constant[value=1]() # test.py:6:0
%x : Tensor = aten::transpose_(%x.1, %1, %2) # test.py:6:0
%4 : int = prim::Constant[value=2]() # test.py:8:0
%5 : Tensor = aten::contiguous(%x, %4) # test.py:8:0
- %6 : (Tensor, Tensor) = prim::TupleConstruct(%5, %5)
? ^
+ %6 : (Tensor, Tensor) = prim::TupleConstruct(%x, %5)
? ^
return (%6)
First diverging operator:
Node diff:
- %6 : (Tensor, Tensor) = prim::TupleConstruct(%5, %5)
? ^
+ %6 : (Tensor, Tensor) = prim::TupleConstruct(%x, %5)
?
"""
```
There are a few ways to make it "work", which hopefully can help debugging:
1. Remove `memory_format=torch.channels_last` from `torch.Tensor.contiguous`
2. Add any non-inplace of before `transpose_` such as `x = torch.relu(x)`
3. Add any non-inplace operator after `torch.Tensor.contiguous` such as `torch.cos`
4. Use any shape-preserving inplace op to replace `transpose_` such as `torch.relu_`
5. Only return v1 or v2 not both.
6. Let the input channel dimension be 1 instead of something greater than 1.
7. Use `check_trace=False` in `torch.jit.trace`
### Versions
<details><summary><b>Environment </b> <i>[click to expand]</i></summary>
<div>
```python
"""
Collecting environment information...
PyTorch version: 1.14.0.dev20221202+cu117
Is debug build: False
CUDA used to build PyTorch: 11.7
ROCM used to build PyTorch: N/A
OS: Ubuntu 22.04.1 LTS (x86_64)
GCC version: (Ubuntu 11.3.0-1ubuntu1~22.04) 11.3.0
Clang version: Could not collect
CMake version: version 3.25.0
Libc version: glibc-2.35
Python version: 3.9.12 (main, Apr 5 2022, 06:56:58) [GCC 7.5.0] (64-bit runtime)
Python platform: Linux-5.15.0-56-generic-x86_64-with-glibc2.35
Is CUDA available: True
CUDA runtime version: 11.6.124
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration:
GPU 0: NVIDIA GeForce RTX 3090
GPU 1: NVIDIA GeForce RTX 3090
GPU 2: NVIDIA GeForce RTX 3090
Nvidia driver version: 515.86.01
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_infer.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.4.1
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] mypy-extensions==0.4.3
[pip3] numpy==1.23.3
[pip3] onnx2torch==1.5.3
[pip3] torch==1.14.0.dev20221202+cu117
[pip3] torchaudio==0.14.0.dev20221203+cu117
[pip3] torchtriton==2.0.0+0d7e753227
[pip3] torchvision==0.15.0.dev20221203+cpu
[conda] numpy 1.23.3 pypi_0 pypi
[conda] onnx2torch 1.5.3 pypi_0 pypi
[conda] torch 1.14.0.dev20221202+cu117 pypi_0 pypi
[conda] torchaudio 0.14.0.dev20221203+cu117 pypi_0 pypi
[conda] torchtriton 2.0.0+0d7e753227 pypi_0 pypi
[conda] torchvision 0.15.0.dev20221203+cpu pypi_0 pypi
"""
```
</div>
</details>
cc @EikanWang @jgong5 @wenzhe-nrv @sanchitintel
| 1 |
3,695 | 92,554 |
Major bug in Transformers' masks
|
high priority, triage review, oncall: transformer/mha, module: correctness (silent)
|
### 🐛 Describe the bug
In torch.nn.functional, line 5174 in current code:

`attn_mask = attn_mask.masked_fill(key_padding_mask, float("-inf"))`
Fills `-inf` value wherever `key_padding_mask` is True. However, `key_padding_masks` actually contains -inf values instead of True values. So the padding mask is actually ignored. Replacing by:
`attn_mask = attn_mask.masked_fill(key_padding_mask < 0, float("-inf")`
Gives the correct expected mask.
### Versions
Current github code. (master branch, Jan 18, 2023)
cc @ezyang @gchanan @zou3519 @albanD @mruberry @jbschlosser @walterddr @saketh-are @bhosmer @cpuhrsch @erichan1
| 11 |
3,696 | 92,548 |
[JIT] Inconsistency in tensor shape between eager mode and JIT
|
oncall: jit
|
### 🐛 Describe the bug
When the inplace operator `unsqueeze_` is used after `expand`, the program behavior in JIT differs from that in eager mode. Here's a minimal reproduction:
```python
import torch
def fn(input):
v = torch.Tensor.expand(input, [2, 2, 3])
torch.Tensor.unsqueeze_(input, dim=-1) # works with non-inplace version "unsqueeze"
return v
x = torch.rand([2, 1, 3])
fn(x)
print("Eager mode ... OK!")
traced_fn = torch.jit.trace(fn, x)
print("JIT ... OK!")
"""
Eager mode ... OK!
Traceback (most recent call last):
File "model.py", line 11, in <module>
traced_fn = torch.jit.trace(fn, x)
File "python3.10/site-packages/torch/jit/_trace.py", line 856, in trace
traced = torch._C._create_function_from_trace(
File "model.py", line 4, in fn
v = torch.Tensor.expand(input, [2, 2, 3])
RuntimeError: expand(torch.FloatTensor{[2, 1, 3, 1]}, size=[2, 2, 3]): the number of sizes
provided (3) must be greater or equal to the number of dimensions in the tensor (4)
"""
```
Although `torch.Tensor.unsqueeze_` is an in-place operator, it appears after `torch.Tensor.expand` and it shouldn't have impact on the shape of `input`. In jit it seems that there's something wrong with the execution order.
### Versions
<details><summary> <b>Environment</b> <i> [click to expand] </i> </summary>
```
PyTorch version: 1.14.0a0+gitbdc9911
Is debug build: False
CUDA used to build PyTorch: 11.6
ROCM used to build PyTorch: N/A
OS: Ubuntu 22.04.1 LTS (x86_64)
GCC version: (Ubuntu 11.3.0-1ubuntu1~22.04) 11.3.0
Clang version: 11.1.0-6
CMake version: version 3.22.1
Libc version: glibc-2.35
Python version: 3.10.6 (main, Nov 14 2022, 16:10:14) [GCC 11.3.0] (64-bit runtime)
Python platform: Linux-5.15.0-56-generic-x86_64-with-glibc2.35
Is CUDA available: True
CUDA runtime version: 11.6.124
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration:
GPU 0: NVIDIA GeForce RTX 3090
GPU 1: NVIDIA GeForce RTX 3090
GPU 2: NVIDIA GeForce RTX 3090
Nvidia driver version: 515.86.01
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_infer.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.4.1
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.21.5
[pip3] torch==1.14.0a0+gitbdc9911
[conda] blas 1.0 mkl
[conda] cudatoolkit 11.3.1 h2bc3f7f_2
[conda] mkl 2021.4.0 h06a4308_640
[conda] mkl-service 2.4.0 py39h7f8727e_0
[conda] mkl_fft 1.3.1 py39hd3c417c_0
[conda] mkl_random 1.2.2 py39h51133e4_0
[conda] numpy 1.21.5 py39he7a7128_1
[conda] numpy-base 1.21.5 py39hf524024_1
[conda] numpydoc 1.2 pyhd3eb1b0_0
[conda] torch 1.14.0a0+gitce2f870 pypi_0 pypi
```
</details>
cc @EikanWang @jgong5 @wenzhe-nrv @sanchitintel
| 0 |
3,697 | 92,542 |
Pytorch AMP performance issue.
|
triaged, module: memory format, module: amp (automated mixed precision)
|
### 🐛 Describe the bug
I found that different models have large speed differences between AMP and FP32 training configurations with NHWC and NCHW data types. pytorch seems to only optimize matmul and conv2d, while batchnorm support for nhwc is poor. The batchnorm layer of nhwc is very slow, and the speed recovers after freezing the bn layers. In addition, the transpose of nchw also consumes 10% of the latency. I collected performance data.
Demo codes:
`
```
import torch
import torch.nn as nn
import time
import torch.backends.cudnn as cudnn
from torchvision.models import resnet101
cudnn.benchmark=True/False
class SimpleLayer(nn.Module):
def __init__(self):
super(SimpleLayer, self).__init__()
self.conv1=nn.Sequential(nn.Conv2d(192,192,3,1,1),nn.ReLU(),nn.Conv2d(192,192,3,1,1),nn.ReLU(),nn.Conv2d(192,192,3,1,1),nn.ReLU(),nn.Conv2d(192,192,3,1,1),nn.ReLU())
def forward(self,x):
return self.conv1(x)
Model=SimpleLayer/resnet101().to("cuda:0", memory_format=torch.channels_last)
Model.eval()
Data=torch.randn(8,3,224,224).to("cuda:0", memory_format=torch.channels_last)
while True:
stimes=time.time()
with torch.amp.autocast(device_type='cuda'):
for _ in range(10):
_=Model(Data)
torch.cuda.synchronize()
times=time.time()-stimes
print(10/times)
```
`
Speed SimpleLayer
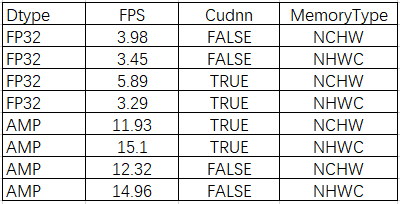
VGG19
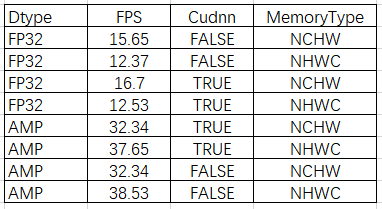
Resnet101
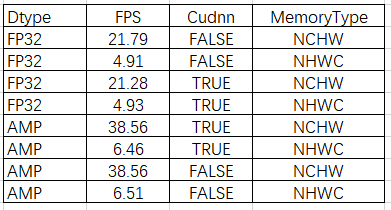
EfficientNet-B6

SwinBase
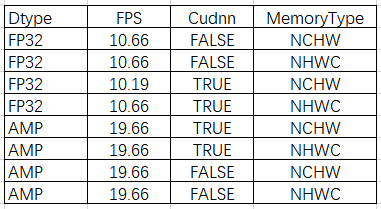
resnet101-cudnn-amp-nchw

resnet101-cudnn-amp-nhwc

### Versions
Pytorch 1.11 Cudnn 11.6
cc @jamesr66a @mcarilli @ptrblck @leslie-fang-intel @jgong5
| 0 |
3,698 | 92,535 |
multiprocessing not work on WSL2
|
module: multiprocessing, triaged, module: wsl
|
### 🐛 Describe the bug
Hi there,
**🐛 Describe the bug**
Torch multiprocessing seems not work on WSL2 + Ubuntu20.04.
```
import torch
from torch.multiprocessing import set_start_method, Pipe, Process
def func(data):
print("in func")
# data = conn.recv()
print(data) # .item()
if __name__ == "__main__":
set_start_method('spawn', force=True)
device = torch.device("cuda") # "cuda:0"
data = torch.tensor([1, 2, 3]).to(device)
proc = Process(target=func, args=(data,))
proc.start()
proc.join()
```
When trying to run this code, it is stuck. (Even `collect_env.py` stuck)
**Versions**:
```
Cuda 11.7
WSL2: ubuntu20.04
Pytorch: 1.13.1+cu117
```
I actually tried other pytorch versions still the same issue.
Thanks.
### Versions
Hi there,
**🐛 Describe the bug**
Torch multiprocessing seems not work on WSL2 + Ubuntu20.04.
```
import torch
from torch.multiprocessing import set_start_method, Pipe, Process
def func(data):
print("in func")
# data = conn.recv()
print(data) # .item()
if __name__ == "__main__":
set_start_method('spawn', force=True)
device = torch.device("cuda") # "cuda:0"
data = torch.tensor([1, 2, 3]).to(device)
proc = Process(target=func, args=(data,))
proc.start()
proc.join()
```
When trying to run this code, it is stuck. (Even `collect_env.py` stuck)
**Versions**:
```
Cuda 11.7
WSL2: ubuntu20.04
Pytorch: 1.13.1+cu117
```
I actually tried other pytorch versions still the same issue.
Thanks.
cc @VitalyFedyunin @ejguan
| 3 |
3,699 | 92,528 |
INTERNAL ASSERT FAILED: Expected OwnerRRef with id GloballyUniqueId(created_on=0, local_id=0) to be created.
|
oncall: distributed
|
### 🐛 Describe the bug
When data gets too big, an error is thrown and crashes.
[E request_callback_no_python.cpp:559] Received error while processing request type 261: false INTERNAL ASSERT FAILED at "../torch/csrc/distributed/rpc/rref_context.cpp":393, please report a bug to PyTorch. Expected OwnerRRef with id GloballyUniqueId(created_on=0, local_id=0) to be created.
It only happens when data stored on ram gets too big
### Versions
torch==1.13.0
cc @mrshenli @pritamdamania87 @zhaojuanmao @satgera @rohan-varma @gqchen @aazzolini @osalpekar @jiayisuse @H-Huang @kwen2501 @awgu
| 1 |
3,700 | 92,398 |
[Inductor] support complex dtypes
|
triaged, module: complex, module: random, module: inductor
|
### 🚀 The feature, motivation and pitch
I see Inductor cpp codgegen `DTYPE_TO_CPP`, `DTYPE_TO_ATEN` do not support complex dtypes.
https://github.com/pytorch/pytorch/blob/9b173b87b2587ee085aaef65e1a0fdebd90d5229/torch/_inductor/codegen/cpp.py#L31-L55
For example, with `randn` (complex dtype support is missing for other ops as well (e.g., `rand`, `sqrt`, etc))
```python
import torch
def foo(x):
return torch.randn(x.size(), dtype=x.dtype)
opt_foo = torch.compile(foo)
print("eager: ", foo(torch.empty(1, dtype=torch.complex64)))
print("inductor: ", opt_foo(torch.empty(1, dtype=torch.complex64)))
```
raises the following error from codegen
```
return f"static_cast<{DTYPE_TO_CPP[dtype]}>(randn_cpu({seed}, {offset}));"
KeyError: 'torch.complex64\n\nWhile executing %randn : [#users=1] = call_method[target=randn](args = (%ops, %bitwise_xor, %constant_1, torch.complex64), kwargs = {})\nOriginal traceback:\nNone'
```
I wonder if there's any context to why complex dtypes are currently generally not supported in Inductor.
For `randn`, we can extend `Philox4_32` `randn` to support complex dtypes.
```
Z ~ Complex Normal(0, 1)
Z = 1/sqrt(2) * [X + Xj], X ~ Normal(0, 1)
```
### Alternatives
_No response_
### Additional context
_No response_
cc @ezyang @anjali411 @dylanbespalko @mruberry @Lezcano @nikitaved @pbelevich @mlazos @soumith @voznesenskym @yanboliang @penguinwu @anijain2305 @EikanWang @jgong5 @Guobing-Chen @chunyuan-w @XiaobingSuper @zhuhaozhe @blzheng @Xia-Weiwen @wenzhe-nrv @jiayisunx @peterbell10 @desertfire
| 10 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.