
Serial Number
int64 1
6k
| Issue Number
int64 75.6k
112k
| Title
stringlengths 3
357
| Labels
stringlengths 3
241
⌀ | Body
stringlengths 9
74.5k
⌀ | Comments
int64 0
867
|
|---|---|---|---|---|---|
3,701 | 92,375 |
operations failed in TorchScript interpreter
|
oncall: jit
|
### 🐛 Describe the bug
when I use torch.jit._get_trace_graph to trace my model on GPU,it happens that
The PyTorch internal failed reason is:
The following operation failed in the TorchScript interpreter.
Traceback of TorchScript (most recent call last):
File "/xxxx/python37/lib/python3.7/site-packages/torchvision/models/detection/roi_heads.py", line 466, in _onnx_paste_masks_in_image_loop
res_append = torch.zeros(0, im_h, im_w)
for i in range(masks.size(0)):
mask_res = _onnx_paste_mask_in_image(masks[i][0], boxes[i], im_h, im_w)
~~~~~~~~~~~~~~~~~~~~~~~~~ <--- HERE
mask_res = mask_res.unsqueeze(0)
res_append = torch.cat((res_append, mask_res))
File "/xxx/site-packages/torchvision/models/detection/roi_heads.py", line 430, in _onnx_paste_mask_in_image
zero = torch.zeros(1, dtype=torch.int64)
w = box[2] - box[0] + one
~~~~~~~~~~~~~~~~~~~~~ <--- HERE
h = box[3] - box[1] + one
w = torch.max(torch.cat((w, one)))
RuntimeError: Expected all tensors to be on the same device, but found at least two devices, cuda:0 and cpu!
### Versions
pytorch 1.12
cc @EikanWang @jgong5 @wenzhe-nrv @sanchitintel
| 0 |
3,702 | 92,350 |
TypeError: no implementation found for 'torch._ops.aten.max.default' on types that implement __torch_dispatch__: [<class 'torch.masked.maskedtensor.core.MaskedTensor'>]
|
triaged, module: masked operators
|
### 🐛 Describe the bug
My problem with MaskedTensor is that the stacktrace is extremely incorrect and vague, I am unable to debug the source of any error. It claims here that the "max" is not supported but there is no max in the code, and it doesn't even reference a relevant line, there is no way the for loop line is erroring as there is no pytorch code there.
```
/usr/local/lib/python3.8/dist-packages/torch/masked/maskedtensor/core.py:299: UserWarning: max is not implemented in __torch_dispatch__ for MaskedTensor.
If you would like this operator to be supported, please file an issue for a feature request at https://github.com/pytorch/maskedtensor/issues with a minimal reproducible code snippet.
In the case that the semantics for the operator are not trivial, it would be appreciated to also include a proposal for the semantics.
warnings.warn(msg)
Traceback (most recent call last):
File "adam_aug_lagrangian.py", line 90, in <module>
for outermost_training_iter in range(num_training_iters):
File "/usr/local/lib/python3.8/dist-packages/torch/masked/maskedtensor/core.py", line 274, in __torch_function__
ret = func(*args, **kwargs)
TypeError: no implementation found for 'torch._ops.aten.max.default' on types that implement __torch_dispatch__: [<class 'torch.masked.maskedtensor.core.MaskedTensor'>]
```
### Versions
```
Collecting environment information...
PyTorch version: 1.13.1+cu117
Is debug build: False
CUDA used to build PyTorch: 11.7
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.5 LTS (x86_64)
GCC version: (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0
Clang version: Could not collect
CMake version: version 3.16.3
Libc version: glibc-2.31
Python version: 3.8.10 (default, Nov 14 2022, 12:59:47) [GCC 9.4.0] (64-bit runtime)
Python platform: Linux-5.4.0-132-generic-x86_64-with-glibc2.29
Is CUDA available: True
CUDA runtime version: Could not collect
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration: GPU 0: NVIDIA RTX A5000
Nvidia driver version: 465.19.01
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.23.1
[pip3] pytorch-minimize==0.0.2
[pip3] torch==1.13.1
[conda] Could not collect
```
| 0 |
3,703 | 93,511 |
support setattr of arbitrary user provided types in tracing
|
triaged, bug, oncall: pt2
|
### 🐛 Describe the bug
Dynamo already support patching nn.Module attribute outside of forward call (e.g. during model initialization): https://github.com/pytorch/pytorch/pull/91018 . But some use cases (e.g. detectrons's RCNN model) need patch nn.Module attribute in forward method ( fb internal link: https://fburl.com/code/vvekrxl6 ). Dynamo does not support this right now.
### Error logs
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/shunting/cpython/build/install/lib/python3.9/importlib/__init__.py", line 169, in reload
_bootstrap._exec(spec, module)
File "<frozen importlib._bootstrap>", line 613, in _exec
File "<frozen importlib._bootstrap_external>", line 790, in exec_module
File "<frozen importlib._bootstrap>", line 228, in _call_with_frames_removed
File "/home/shunting/learn/misc.py", line 20, in <module>
gm, guards = dynamo.export(MyModule(), *inputs, aten_graph=True, tracing_mode="symbolic")
File "/home/shunting/pytorch/torch/_dynamo/eval_frame.py", line 616, in export
result_traced = opt_f(*args, **kwargs)
File "/home/shunting/pytorch/torch/nn/modules/module.py", line 1482, in _call_impl
return forward_call(*args, **kwargs)
File "/home/shunting/pytorch/torch/_dynamo/eval_frame.py", line 82, in forward
return self.dynamo_ctx(self._orig_mod.forward)(*args, **kwargs)
File "/home/shunting/pytorch/torch/_dynamo/eval_frame.py", line 211, in _fn
return fn(*args, **kwargs)
File "/home/shunting/pytorch/torch/_dynamo/eval_frame.py", line 332, in catch_errors
return callback(frame, cache_size, hooks)
File "/home/shunting/pytorch/torch/_dynamo/convert_frame.py", line 103, in _fn
return fn(*args, **kwargs)
File "/home/shunting/pytorch/torch/_dynamo/utils.py", line 90, in time_wrapper
r = func(*args, **kwargs)
File "/home/shunting/pytorch/torch/_dynamo/convert_frame.py", line 339, in _convert_frame_assert
return _compile(
File "/home/shunting/pytorch/torch/_dynamo/convert_frame.py", line 398, in _compile
out_code = transform_code_object(code, transform)
File "/home/shunting/pytorch/torch/_dynamo/bytecode_transformation.py", line 341, in transform_code_object
transformations(instructions, code_options)
File "/home/shunting/pytorch/torch/_dynamo/convert_frame.py", line 385, in transform
tracer.run()
File "/home/shunting/pytorch/torch/_dynamo/symbolic_convert.py", line 1686, in run
super().run()
File "/home/shunting/pytorch/torch/_dynamo/symbolic_convert.py", line 537, in run
and self.step()
File "/home/shunting/pytorch/torch/_dynamo/symbolic_convert.py", line 500, in step
getattr(self, inst.opname)(inst)
File "/home/shunting/pytorch/torch/_dynamo/symbolic_convert.py", line 1048, in STORE_ATTR
BuiltinVariable(setattr)
File "/home/shunting/pytorch/torch/_dynamo/variables/builtin.py", line 375, in call_function
return super().call_function(tx, args, kwargs)
File "/home/shunting/pytorch/torch/_dynamo/variables/base.py", line 230, in call_function
unimplemented(f"call_function {self} {args} {kwargs}")
File "/home/shunting/pytorch/torch/_dynamo/exc.py", line 67, in unimplemented
raise Unsupported(msg)
torch._dynamo.exc.Unsupported: call_function BuiltinVariable(setattr) [UserDefinedClassVariable(), ConstantVariable(str), GetAttrVariable(UserDefinedClassVariable(), run_cos)] {}
from user code:
File "/home/shunting/learn/misc.py", line 10, in forward
MyModule.run = MyModule.run_cos
Set torch._dynamo.config.verbose=True for more information
You can suppress this exception and fall back to eager by setting:
torch._dynamo.config.suppress_errors = True
### Minified repro
```
import torch
from torch import nn
import torch._dynamo as dynamo
class MyModule(nn.Module):
def __init__(self):
super().__init__()
def forward(self, x):
MyModule.run = MyModule.run_cos
return self.run(x)
def run(self, x):
return torch.sin(x)
def run_cos(self, x):
return torch.cos(x)
inputs = [torch.rand(5)]
gm, guards = dynamo.export(MyModule(), *inputs, aten_graph=True, tracing_mode="symbolic")
print(f"Graph is {gm.graph}")
```
cc @ezyang @soumith @msaroufim @wconstab @ngimel @bdhirsh
| 4 |
3,704 | 92,339 |
fft.fftshift, fft.ifftshift, roll not implemented
|
triaged, module: fft, module: mps
|
### 🚀 The feature, motivation and pitch
I am working on Bragg CDI reconstruction and the algorithm uses fftshift and ifftshift. I would like to be able to run the code on MPS device.
### Alternatives
I can implement the functions with roll but it's also not supported for the MPS device.
### Additional context
_No response_
cc @mruberry @peterbell10 @kulinseth @albanD @malfet @DenisVieriu97 @razarmehr @abhudev
| 7 |
3,705 | 92,331 |
backward(inputs= does not need to execute grad_fn of the inputs
|
module: bc-breaking, module: autograd, triaged, actionable, topic: bc breaking
|
Per title, we currently execute grad_fn of the inputs when running `.backward()` with the `inputs=` argument. We should avoid unnecessarily doing this extra compute since it is not actually necessary for the computation of the gradients wrt the inputs.
This is bc-breaking. This is mostly a bug-fix but a case where users may depend on this behavior is if they depend on hooks registered to Node to execute for the backward(inputs= case. Fixing this will require some changes to how we compute `needed` in the engine.
cc @ezyang @gchanan @albanD @zou3519 @gqchen @pearu @nikitaved @Lezcano @Varal7
| 1 |
3,706 | 92,330 |
Simplify module backward hooks to use multi-grad hooks instead
|
module: bc-breaking, module: autograd, module: nn, triaged, needs research, topic: bc breaking
|
Since modules can take in multiple inputs and return multiple outputs, currently we use a dummy custom autograd Function to ensure that there is a single grad_fn Node that we can attach our hook to. A multi-grad hook can be used to solve this issue in a less hacky way.
Note that this would be a bc-breaking change, as the hooks would be register to tensor instead of grad_fn, and the recorded backward graph would be different.
cc @ezyang @gchanan @albanD @zou3519 @gqchen @pearu @nikitaved @Lezcano @Varal7 @mruberry @jbschlosser @walterddr @mikaylagawarecki @saketh-are
| 2 |
3,707 | 92,310 |
[Releng] Windows AMI needs to be pinned for release
|
high priority, oncall: releng, triaged
|
### 🐛 Describe the bug
Windows AMI needs to be pinned for release.
### Versions
nightly, test
cc @ezyang @gchanan @zou3519
| 0 |
3,708 | 92,302 |
Cost & performance estimation for Windows Arm64 compilation
|
module: windows, triaged
|
This issue is about cost & performance estimation of CI/CD pipeline for building Windows Arm64 Pytorch.
Scope: In case current analyses is not sufficient, we want more detail analyses, but not with maximum precision.
cc @peterjc123 @mszhanyi @skyline75489 @nbcsm
| 0 |
3,709 | 92,294 |
jit.fork stalls multiprocessing dataloader
|
oncall: jit, module: dataloader, module: data
|
### 🐛 Describe the bug
Using `torch.jit.fork` with multiprocessing dataloaders stalls the dataloader.
I would expect one of the following:
1. The dataloader would simply work.
2. An error would result from trying to run `jit.fork` outside of the main process.
3. The documentation would warn of incompatability between `jit.fork` and parallel dataloaders.
Option #2 and/or #3 would probably be most realistic, due to the nature of the `multiprocessing` module.
``` python
import torch as th
def foo(x):
return x+1
@th.jit.script
def jit_fork_foo(x):
return th.jit.wait(th.jit.fork(foo, x))
class Dataset(th.utils.data.IterableDataset):
def __iter__(self):
while True:
yield jit_fork_foo(th.tensor([1]))
ds = Dataset()
dl_nomp = th.utils.data.DataLoader(ds, batch_size=2, num_workers=0)
dl_mp = th.utils.data.DataLoader(ds, batch_size=2, num_workers=2)
print("No multiprocessing ", next(iter(dl_nomp))) #returns as expected
print("multiprocessing ", next(iter(dl_mp))) #stalls
```
### Versions
```PyTorch version: 1.14.0a0+410ce96
Is debug build: False
CUDA used to build PyTorch: 11.8
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.5 LTS (x86_64)
GCC version: (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0
Clang version: Could not collect
CMake version: version 3.24.1
Libc version: glibc-2.31
Python version: 3.8.10 (default, Nov 14 2022, 12:59:47) [GCC 9.4.0] (64-bit runtime)
Python platform: Linux-5.4.0-125-generic-x86_64-with-glibc2.29
Is CUDA available: True
CUDA runtime version: 11.8.89
CUDA_MODULE_LOADING set to: LAZY
Nvidia driver version: 470.141.03
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.7.0
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.7.0
/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.7.0
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_infer.so.8.7.0
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.7.0
/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.7.0
/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.7.0
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.24.1
[pip3] pytorch-quantization==2.1.2
[pip3] torch==1.14.0a0+410ce96
[pip3] torch-tensorrt==1.3.0a0
[pip3] torchtext==0.13.0a0+fae8e8c
[pip3] torchvision==0.15.0a0
```
cc @EikanWang @jgong5 @wenzhe-nrv @sanchitintel @SsnL @VitalyFedyunin @ejguan @NivekT
| 1 |
3,710 | 93,510 |
RuntimeError: one of the variables needed for gradient computation has been modified by an inplace operation
|
triaged, bug, oncall: pt2
|
### 🐛 Describe the bug
RuntimeError: one of the variables needed for gradient computation has been modified by an inplace operation: [torch.cuda.HalfTensor [1024]] is at version 24; expected version 23 instead. Hint: enable anomaly detection to find the operation that failed to compute its gradient, with torch.autograd.set_detect_anomaly(True).
### Error logs
[2023-01-17 16:14:06,580] torch._inductor.ir: [WARNING] DeviceCopy
[2023-01-17 16:14:06,584] torch._inductor.ir: [WARNING] DeviceCopy
[2023-01-17 16:14:06,587] torch._inductor.ir: [WARNING] DeviceCopy
[2023-01-17 16:14:06,617] torch._inductor.ir: [WARNING] DeviceCopy
[2023-01-17 16:14:06,638] torch._inductor.ir: [WARNING] DeviceCopy
[2023-01-17 16:14:06,638] torch._inductor.ir: [WARNING] DeviceCopy
[2023-01-17 16:14:06,671] torch._inductor.ir: [WARNING] DeviceCopy
[2023-01-17 16:14:06,679] torch._inductor.ir: [WARNING] DeviceCopy
[2023-01-17 16:14:06,726] torch._inductor.compile_fx: [WARNING] skipping cudagraphs due to multiple devices
[2023-01-17 16:14:06,736] torch._inductor.compile_fx: [WARNING] skipping cudagraphs due to multiple devices
[2023-01-17 16:14:06,743] torch._inductor.compile_fx: [WARNING] skipping cudagraphs due to multiple devices
[2023-01-17 16:14:06,759] torch._inductor.compile_fx: [WARNING] skipping cudagraphs due to multiple devices
[2023-01-17 16:14:06,778] torch._inductor.compile_fx: [WARNING] skipping cudagraphs due to multiple devices
[2023-01-17 16:14:06,787] torch._inductor.compile_fx: [WARNING] skipping cudagraphs due to multiple devices
[2023-01-17 16:14:06,820] torch._inductor.compile_fx: [WARNING] skipping cudagraphs due to multiple devices
[2023-01-17 16:14:06,831] torch._inductor.compile_fx: [WARNING] skipping cudagraphs due to multiple devices
/home/tiger/.local/lib/python3.7/site-packages/torch/cuda/graphs.py:82: UserWarning: The CUDA Graph is empty. This ususally means that the graph was attempted to be captured on wrong device or stream. (Triggered internally at ../aten/src/ATen/cuda/CUDAGraph.cpp:191.)
super(CUDAGraph, self).capture_end()
/home/tiger/.local/lib/python3.7/site-packages/torch/cuda/graphs.py:82: UserWarning: The CUDA Graph is empty. This ususally means that the graph was attempted to be captured on wrong device or stream. (Triggered internally at ../aten/src/ATen/cuda/CUDAGraph.cpp:191.)
super(CUDAGraph, self).capture_end()
/home/tiger/.local/lib/python3.7/site-packages/torch/cuda/graphs.py:82: UserWarning: The CUDA Graph is empty. This ususally means that the graph was attempted to be captured on wrong device or stream. (Triggered internally at ../aten/src/ATen/cuda/CUDAGraph.cpp:191.)
super(CUDAGraph, self).capture_end()
/home/tiger/.local/lib/python3.7/site-packages/torch/cuda/graphs.py:82: UserWarning: The CUDA Graph is empty. This ususally means that the graph was attempted to be captured on wrong device or stream. (Triggered internally at ../aten/src/ATen/cuda/CUDAGraph.cpp:191.)
super(CUDAGraph, self).capture_end()
/home/tiger/.local/lib/python3.7/site-packages/torch/cuda/graphs.py:82: UserWarning: The CUDA Graph is empty. This ususally means that the graph was attempted to be captured on wrong device or stream. (Triggered internally at ../aten/src/ATen/cuda/CUDAGraph.cpp:191.)
super(CUDAGraph, self).capture_end()
/home/tiger/.local/lib/python3.7/site-packages/torch/cuda/graphs.py:82: UserWarning: The CUDA Graph is empty. This ususally means that the graph was attempted to be captured on wrong device or stream. (Triggered internally at ../aten/src/ATen/cuda/CUDAGraph.cpp:191.)
super(CUDAGraph, self).capture_end()
/home/tiger/.local/lib/python3.7/site-packages/torch/cuda/graphs.py:82: UserWarning: The CUDA Graph is empty. This ususally means that the graph was attempted to be captured on wrong device or stream. (Triggered internally at ../aten/src/ATen/cuda/CUDAGraph.cpp:191.)
super(CUDAGraph, self).capture_end()
/home/tiger/.local/lib/python3.7/site-packages/torch/cuda/graphs.py:82: UserWarning: The CUDA Graph is empty. This ususally means that the graph was attempted to be captured on wrong device or stream. (Triggered internally at ../aten/src/ATen/cuda/CUDAGraph.cpp:191.)
super(CUDAGraph, self).capture_end()
Traceback (most recent call last):
File "fsdp_pretrain.py", line 423, in <module>
Traceback (most recent call last):
File "fsdp_pretrain.py", line 423, in <module>
main(args)
File "fsdp_pretrain.py", line 318, in main
main(args)
File "fsdp_pretrain.py", line 318, in main
scaler.scale(loss).backward()
File "/home/tiger/.local/lib/python3.7/site-packages/torch/_tensor.py", line 489, in backward
self, gradient, retain_graph, create_graph, inputs=inputsscaler.scale(loss).backward()
File "/home/tiger/.local/lib/python3.7/site-packages/torch/autograd/__init__.py", line 199, in backward
File "/home/tiger/.local/lib/python3.7/site-packages/torch/_tensor.py", line 489, in backward
allow_unreachable=True, accumulate_grad=True) # Calls into the C++ engine to run the backward pass
File "/home/tiger/.local/lib/python3.7/site-packages/torch/autograd/function.py", line 276, in apply
self, gradient, retain_graph, create_graph, inputs=inputs
File "/home/tiger/.local/lib/python3.7/site-packages/torch/autograd/__init__.py", line 199, in backward
return user_fn(self, *args)
File "/home/tiger/.local/lib/python3.7/site-packages/torch/_functorch/aot_autograd.py", line 1848, in backward
allow_unreachable=True, accumulate_grad=True) # Calls into the C++ engine to run the backward pass
File "/home/tiger/.local/lib/python3.7/site-packages/torch/autograd/function.py", line 276, in apply
return user_fn(self, *args)
File "/home/tiger/.local/lib/python3.7/site-packages/torch/_functorch/aot_autograd.py", line 1848, in backward
list(ctx.symints) + list(ctx.saved_tensors) + list(contiguous_args)
RuntimeError: one of the variables needed for gradient computation has been modified by an inplace operation: [torch.cuda.HalfTensor [1024]] is at version 24; expected version 23 instead. Hint: enable anomaly detection to find the operation that failed to compute its gradient, with torch.autograd.set_detect_anomaly(True).
list(ctx.symints) + list(ctx.saved_tensors) + list(contiguous_args)
RuntimeError: one of the variables needed for gradient computation has been modified by an inplace operation: [torch.cuda.HalfTensor [1024]] is at version 24; expected version 23 instead. Hint: enable anomaly detection to find the operation that failed to compute its gradient, with torch.autograd.set_detect_anomaly(True).
Traceback (most recent call last):
File "fsdp_pretrain.py", line 423, in <module>
Traceback (most recent call last):
File "fsdp_pretrain.py", line 423, in <module>
main(args)
File "fsdp_pretrain.py", line 318, in main
scaler.scale(loss).backward()
File "/home/tiger/.local/lib/python3.7/site-packages/torch/_tensor.py", line 489, in backward
self, gradient, retain_graph, create_graph, inputs=inputs
File "/home/tiger/.local/lib/python3.7/site-packages/torch/autograd/__init__.py", line 199, in backward
allow_unreachable=True, accumulate_grad=True) # Calls into the C++ engine to run the backward pass
File "/home/tiger/.local/lib/python3.7/site-packages/torch/autograd/function.py", line 276, in apply
return user_fn(self, *args)
File "/home/tiger/.local/lib/python3.7/site-packages/torch/_functorch/aot_autograd.py", line 1848, in backward
list(ctx.symints) + list(ctx.saved_tensors) + list(contiguous_args)main(args)
RuntimeError File "fsdp_pretrain.py", line 318, in main
: one of the variables needed for gradient computation has been modified by an inplace operation: [torch.cuda.HalfTensor [1024]] is at version 24; expected version 23 instead. Hint: enable anomaly detection to find the operation that failed to compute its gradient, with torch.autograd.set_detect_anomaly(True).
scaler.scale(loss).backward()
File "/home/tiger/.local/lib/python3.7/site-packages/torch/_tensor.py", line 489, in backward
self, gradient, retain_graph, create_graph, inputs=inputs
File "/home/tiger/.local/lib/python3.7/site-packages/torch/autograd/__init__.py", line 199, in backward
allow_unreachable=True, accumulate_grad=True) # Calls into the C++ engine to run the backward pass
File "/home/tiger/.local/lib/python3.7/site-packages/torch/autograd/function.py", line 276, in apply
return user_fn(self, *args)
File "/home/tiger/.local/lib/python3.7/site-packages/torch/_functorch/aot_autograd.py", line 1848, in backward
list(ctx.symints) + list(ctx.saved_tensors) + list(contiguous_args)
RuntimeError: one of the variables needed for gradient computation has been modified by an inplace operation: [torch.cuda.HalfTensor [1024]] is at version 24; expected version 23 instead. Hint: enable anomaly detection to find the operation that failed to compute its gradient, with torch.autograd.set_detect_anomaly(True).
Traceback (most recent call last):
File "fsdp_pretrain.py", line 423, in <module>
main(args)
File "fsdp_pretrain.py", line 318, in main
scaler.scale(loss).backward()
File "/home/tiger/.local/lib/python3.7/site-packages/torch/_tensor.py", line 489, in backward
self, gradient, retain_graph, create_graph, inputs=inputs
File "/home/tiger/.local/lib/python3.7/site-packages/torch/autograd/__init__.py", line 199, in backward
allow_unreachable=True, accumulate_grad=True) # Calls into the C++ engine to run the backward pass
File "/home/tiger/.local/lib/python3.7/site-packages/torch/autograd/function.py", line 276, in apply
return user_fn(self, *args)
File "/home/tiger/.local/lib/python3.7/site-packages/torch/_functorch/aot_autograd.py", line 1848, in backward
list(ctx.symints) + list(ctx.saved_tensors) + list(contiguous_args)
RuntimeError: one of the variables needed for gradient computation has been modified by an inplace operation: [torch.cuda.HalfTensor [1024]] is at version 24; expected version 23 instead. Hint: enable anomaly detection to find the operation that failed to compute its gradient, with torch.autograd.set_detect_anomaly(True).
Traceback (most recent call last):
File "fsdp_pretrain.py", line 423, in <module>
main(args)
File "fsdp_pretrain.py", line 318, in main
scaler.scale(loss).backward()
File "/home/tiger/.local/lib/python3.7/site-packages/torch/_tensor.py", line 489, in backward
self, gradient, retain_graph, create_graph, inputs=inputs
File "/home/tiger/.local/lib/python3.7/site-packages/torch/autograd/__init__.py", line 199, in backward
allow_unreachable=True, accumulate_grad=True) # Calls into the C++ engine to run the backward pass
File "/home/tiger/.local/lib/python3.7/site-packages/torch/autograd/function.py", line 276, in apply
return user_fn(self, *args)
File "/home/tiger/.local/lib/python3.7/site-packages/torch/_functorch/aot_autograd.py", line 1848, in backward
list(ctx.symints) + list(ctx.saved_tensors) + list(contiguous_args)
RuntimeError: one of the variables needed for gradient computation has been modified by an inplace operation: [torch.cuda.HalfTensor [1024]] is at version 24; expected version 23 instead. Hint: enable anomaly detection to find the operation that failed to compute its gradient, with torch.autograd.set_detect_anomaly(True).
text: Unable to write to output stream.
text: Unable to write to output stream.
text: Unable to write to output stream.
text: Unable to write to output stream.
text: Unable to write to output stream.
text: Unable to write to output stream.
text: Unable to write to output stream.
text: Unable to write to output stream.
text: Unable to write to output stream.
text: Unable to write to output stream.
text: Unable to write to output stream.
text: Unable to write to output stream.
text: Unable to write to output stream.
Traceback (most recent call last):
File "fsdp_pretrain.py", line 423, in <module>
Traceback (most recent call last):
File "fsdp_pretrain.py", line 423, in <module>
text: Unable to write to output stream.
text: Unable to write to output stream.
main(args)
File "fsdp_pretrain.py", line 318, in main
main(args)
File "fsdp_pretrain.py", line 318, in main
scaler.scale(loss).backward()
File "/home/tiger/.local/lib/python3.7/site-packages/torch/_tensor.py", line 489, in backward
self, gradient, retain_graph, create_graph, inputs=inputs
File "/home/tiger/.local/lib/python3.7/site-packages/torch/autograd/__init__.py", line 199, in backward
allow_unreachable=True, accumulate_grad=True) # Calls into the C++ engine to run the backward pass
File "/home/tiger/.local/lib/python3.7/site-packages/torch/autograd/function.py", line 276, in apply
return user_fn(self, *args)
File "/home/tiger/.local/lib/python3.7/site-packages/torch/_functorch/aot_autograd.py", line 1848, in backward
scaler.scale(loss).backward()
File "/home/tiger/.local/lib/python3.7/site-packages/torch/_tensor.py", line 489, in backward
self, gradient, retain_graph, create_graph, inputs=inputs
File "/home/tiger/.local/lib/python3.7/site-packages/torch/autograd/__init__.py", line 199, in backward
allow_unreachable=True, accumulate_grad=True) # Calls into the C++ engine to run the backward pass
File "/home/tiger/.local/lib/python3.7/site-packages/torch/autograd/function.py", line 276, in apply
return user_fn(self, *args)
File "/home/tiger/.local/lib/python3.7/site-packages/torch/_functorch/aot_autograd.py", line 1848, in backward
list(ctx.symints) + list(ctx.saved_tensors) + list(contiguous_args)
RuntimeError: one of the variables needed for gradient computation has been modified by an inplace operation: [torch.cuda.HalfTensor [1024]] is at version 24; expected version 23 instead. Hint: enable anomaly detection to find the operation that failed to compute its gradient, with torch.autograd.set_detect_anomaly(True).
list(ctx.symints) + list(ctx.saved_tensors) + list(contiguous_args)
RuntimeError: one of the variables needed for gradient computation has been modified by an inplace operation: [torch.cuda.HalfTensor [1024]] is at version 24; expected version 23 instead. Hint: enable anomaly detection to find the operation that failed to compute its gradient, with torch.autograd.set_detect_anomaly(True).
cc @ezyang @soumith @msaroufim @wconstab @ngimel @bdhirsh
| 4 |
3,711 | 92,292 |
"Get Started" tells us to use the anaconda installer for PyTorch 3.x - but this should be python 3.x
|
oncall: binaries
|
### 📚 The doc issue
[Anaconda](https://pytorch.org/get-started/locally/#anaconda)
To install Anaconda, you will use the [64-bit graphical installer](https://www.anaconda.com/download/#windows) for PyTorch 3.x.
### Suggest a potential alternative/fix
[Anaconda](https://pytorch.org/get-started/locally/#anaconda)
To install Anaconda, you will use the [64-bit graphical installer](https://www.anaconda.com/download/#windows) for Python 3.x.
Tiny issue (o: hope the feedback helps
cc @ezyang @seemethere @malfet
| 1 |
3,712 | 92,285 |
InstanceNorm operator support for Vulkan devices
|
triaged, module: vulkan
|
### 🚀 The feature, motivation and pitch
At present, only BatchNorm op is supported for Vulkan drivers. The model file throws an error when using InstanceNorm on a Vulkan device ( Adreno )
### Alternatives
I have replaced InstanceNorm with BatchNorm for the time being
### Additional context
_No response_
| 1 |
3,713 | 92,273 |
Always install cpu version automatically
|
oncall: binaries
|
### 🐛 Describe the bug
Hi!
I use following cmd to install pytorch
```
conda install pytorch==1.12.1 torchvision==0.13.1 torchaudio==0.12.1 cudatoolkit=10.2 -c pytorch
```
however I got the result:
```
## Package Plan ##
environment location: D:\anaconda3
added / updated specs:
- cudatoolkit=10.2
- pytorch==1.12.1
- torchaudio==0.12.1
- torchvision==0.13.1
The following packages will be downloaded:
package | build
---------------------------|-----------------
conda-22.9.0 | py38haa95532_0 888 KB defaults
cudatoolkit-10.2.89 | h74a9793_1 317.2 MB defaults
libuv-1.40.0 | he774522_0 255 KB defaults
pytorch-1.12.1 | py3.8_cpu_0 133.8 MB pytorch
pytorch-mutex-1.0 | cpu 3 KB pytorch
torchaudio-0.12.1 | py38_cpu 3.5 MB pytorch
torchvision-0.13.1 | py38_cpu 6.2 MB pytorch
------------------------------------------------------------
Total: 461.9 MB
The following NEW packages will be INSTALLED:
cudatoolkit anaconda/pkgs/main/win-64::cudatoolkit-10.2.89-h74a9793_1
libuv anaconda/pkgs/main/win-64::libuv-1.40.0-he774522_0
pytorch pytorch/win-64::pytorch-1.12.1-py3.8_cpu_0
pytorch-mutex pytorch/noarch::pytorch-mutex-1.0-cpu
torchaudio pytorch/win-64::torchaudio-0.12.1-py38_cpu
torchvision pytorch/win-64::torchvision-0.13.1-py38_cpu
The following packages will be UPDATED:
conda pkgs/main::conda-4.9.2-py38haa95532_0 --> anaconda/pkgs/main::conda-22.9.0-py38haa95532_0
Proceed ([y]/n)?
```
I wonder why conda install cpu version automatically? How to install gpu version?
This is my hardware information:
```
Tue Jan 17 10:04:01 2023
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 516.94 Driver Version: 516.94 CUDA Version: 11.7 |
|-------------------------------+----------------------+----------------------+
| GPU Name TCC/WDDM | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 NVIDIA GeForce ... WDDM | 00000000:65:00.0 On | N/A |
| 0% 43C P8 20W / 370W | 885MiB / 24576MiB | 6% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
```
Could you please give me some advice? Thanks in advance.
### Versions
pytorch==1.12.1 torchvision==0.13.1 torchaudio==0.12.1 cudatoolkit=10.2
cc @ezyang @seemethere @malfet
| 3 |
3,714 | 92,260 |
distributions.Beta returning incorrect results at 0 and 1
|
module: distributions, triaged
|
### 🐛 Describe the bug
The beta distribution has support either on [0, 1] or, for some implementations, on (0, 1). However, the PyTorch version appears to have support on [0, 1] but it returns `-inf` or `nan` on those values.
```
In [31]: beta = torch.distributions.Beta(torch.tensor([1.0]), torch.tensor([1.0]), validate_args=True)
In [32]: beta.support
Out[32]: Interval(lower_bound=0.0, upper_bound=1.0)
In [33]: beta.log_prob(torch.tensor([1.0]))
Out[33]: tensor([nan])
In [34]: beta.log_prob(torch.tensor([0.0]))
Out[34]: tensor([nan])
In [35]: beta = torch.distributions.Beta(torch.tensor([2.0]), torch.tensor([2.0]), validate_args=True)
In [36]: beta.log_prob(torch.tensor([0.0]))
Out[36]: tensor([-inf])
In [37]: beta.log_prob(torch.tensor([1.0]))
Out[37]: tensor([-inf])
```
Note that we did not get a `ValueError` when we passed 0 and 1 even though `validate_args=True` was set, but we did get `-inf` and/or `nan` even though that's not the correct answer. Also, the `support` seems to indicate that 0 and 1 are legal (though I couldn't find documentation of the `Interval` class so I'm not sure if that's supposed to be inclusive or exclusive).
### Versions
PyTorch version: 1.13.0+cu116
Is debug build: False
CUDA used to build PyTorch: 11.6
ROCM used to build PyTorch: N/A
OS: Debian GNU/Linux 11 (bullseye) (x86_64)
GCC version: (Debian 10.2.1-6) 10.2.1 20210110
Clang version: Could not collect
CMake version: version 3.18.4
Libc version: glibc-2.31
Python version: 3.10.6 (main, Oct 11 2022, 01:13:46) [GCC 10.2.1 20210110] (64-bit runtime)
Python platform: Linux-5.10.0-20-cloud-amd64-x86_64-with-glibc2.31
Is CUDA available: True
CUDA runtime version: 11.8.89
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration: GPU 0: NVIDIA A100-SXM4-40GB
Nvidia driver version: 520.61.05
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.24.1
[pip3] torch==1.13.0+cu116
[pip3] torchvision==0.14.0+cu116
[conda] Could not collect
cc @fritzo @neerajprad @alicanb @nikitaved
| 2 |
3,715 | 92,259 |
[discussion] Fused MLPs
|
feature, triaged, oncall: pt2, module: inductor
|
### 🚀 The feature, motivation and pitch
I just stumbled on https://twitter.com/DrJimFan/status/1615018393601716224, there is https://github.com/NVlabs/tiny-cuda-nn which fuses small MLPs for fast training and inference. Can Inductor / Triton generate similar PTX / memory placement?
It seems at least as a good comparison target for benchmark
### Alternatives
_No response_
### Additional context
_No response_
cc @ezyang @soumith @msaroufim @wconstab @ngimel @bdhirsh @mlazos @voznesenskym @yanboliang @penguinwu @anijain2305 @EikanWang @jgong5 @Guobing-Chen @chunyuan-w @XiaobingSuper @zhuhaozhe @blzheng @Xia-Weiwen @wenzhe-nrv @jiayisunx @peterbell10 @desertfire
| 1 |
3,716 | 92,252 |
`model.to("cuda:0")` does not release all CPU memory
|
module: memory usage, triaged
|
### 🐛 Describe the bug
As per title, placing a model on GPU does not seem to release all allocated CPU memory:
```python
import os, psutil
import torch
import gc
from transformers import AutoModelForSpeechSeq2Seq
import torch
process = psutil.Process(os.getpid())
print(f"Before loading model on CPU: {process.memory_info().rss / 1e6:.2f} MB")
model = AutoModelForSpeechSeq2Seq.from_pretrained("openai/whisper-medium")
print(f"After loading model on CPU: {process.memory_info().rss / 1e6:.2f} MB")
model = model.to("cuda:0")
gc.collect()
print(f"After to('cuda:0'): {process.memory_info().rss / 1e6:.2f} MB")
for name, param in model.named_parameters():
assert param.device == torch.device("cuda:0")
```
prints:
```
Before loading model on CPU: 424.26 MB
After loading model on CPU: 3500.97 MB
After to('cuda:0'): 1472.24 MB
```
Is this expected? The model is about 3 GB.
The same can be checked with `free -h`.
### Versions
PyTorch version: 1.13.1+cu117
Is debug build: False
CUDA used to build PyTorch: 11.7
ROCM used to build PyTorch: N/A
OS: Ubuntu 22.04.1 LTS (x86_64)
GCC version: (Ubuntu 11.3.0-1ubuntu1~22.04) 11.3.0
Clang version: 14.0.0-1ubuntu1
CMake version: version 3.25.0
Libc version: glibc-2.35
Python version: 3.9.12 (main, Apr 5 2022, 06:56:58) [GCC 7.5.0] (64-bit runtime)
Python platform: Linux-5.15.0-57-generic-x86_64-with-glibc2.35
Is CUDA available: True
CUDA runtime version: 11.7.99
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration: GPU 0: NVIDIA GeForce RTX 3060 Laptop GPU
Nvidia driver version: 515.86.01
cuDNN version: Probably one of the following:
/usr/local/cuda-11.7/targets/x86_64-linux/lib/libcudnn.so.8.7.0
/usr/local/cuda-11.7/targets/x86_64-linux/lib/libcudnn_adv_infer.so.8.7.0
/usr/local/cuda-11.7/targets/x86_64-linux/lib/libcudnn_adv_train.so.8.7.0
/usr/local/cuda-11.7/targets/x86_64-linux/lib/libcudnn_cnn_infer.so.8.7.0
/usr/local/cuda-11.7/targets/x86_64-linux/lib/libcudnn_cnn_train.so.8.7.0
/usr/local/cuda-11.7/targets/x86_64-linux/lib/libcudnn_ops_infer.so.8.7.0
/usr/local/cuda-11.7/targets/x86_64-linux/lib/libcudnn_ops_train.so.8.7.0
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] mypy-extensions==0.4.3
[pip3] numpy==1.22.4
[pip3] torch==1.13.1
[pip3] torch-model-archiver==0.6.1
[pip3] torch-tb-profiler==0.4.0
[pip3] torch-workflow-archiver==0.2.5
[pip3] torchaudio==0.13.0
[pip3] torchinfo==1.7.0
[pip3] torchserve==0.6.1
[pip3] torchtriton==2.0.0+0d7e753227
[pip3] torchvision==0.14.0
[conda] cudatoolkit 11.3.1 h2bc3f7f_2 anaconda
[conda] numpy 1.22.4 pypi_0 pypi
[conda] torch 1.13.1 pypi_0 pypi
[conda] torch-model-archiver 0.6.1 pypi_0 pypi
[conda] torch-tb-profiler 0.4.0 dev_0 <develop>
[conda] torch-workflow-archiver 0.2.5 pypi_0 pypi
[conda] torchaudio 0.13.0 pypi_0 pypi
[conda] torchinfo 1.7.0 pypi_0 pypi
[conda] torchserve 0.6.1 pypi_0 pypi
[conda] torchtriton 2.0.0+0d7e753227 pypi_0 pypi
[conda] torchvision 0.14.0 pypi_0 pypi
| 0 |
3,717 | 92,251 |
`torch.load(..., map_location="cuda:0")` allocates memory on both CPU and GPU
|
module: serialization, triaged, module: python frontend
|
### 🐛 Describe the bug
As per title, using `torch.load(..., map_location="cuda:0")` allocates memory on CPU while I think it should not.
Reproduce:
```
wget https://huggingface.co/openai/whisper-medium/resolve/main/pytorch_model.bin
```
Then:
```python
import os, psutil
import gc
import torch
process = psutil.Process(os.getpid())
print(f"Before torch.load: {process.memory_info().rss / 1e6:.2f} MB")
res = torch.load("/path/to/pytorch_model.bin", map_location=torch.device("cuda:0"))
gc.collect()
print(f"After torch.load: {process.memory_info().rss / 1e6:.2f} MB")
```
prints:
```
Before torch.load: 290.95 MB
After torch.load: 3355.66 MB
```
and you can check with `nvidia-smi` that memory is reserved as well on GPU.
### Versions
PyTorch version: 1.13.1+cu117
Is debug build: False
CUDA used to build PyTorch: 11.7
ROCM used to build PyTorch: N/A
OS: Ubuntu 22.04.1 LTS (x86_64)
GCC version: (Ubuntu 11.3.0-1ubuntu1~22.04) 11.3.0
Clang version: 14.0.0-1ubuntu1
CMake version: version 3.25.0
Libc version: glibc-2.35
Python version: 3.9.12 (main, Apr 5 2022, 06:56:58) [GCC 7.5.0] (64-bit runtime)
Python platform: Linux-5.15.0-57-generic-x86_64-with-glibc2.35
Is CUDA available: True
CUDA runtime version: 11.7.99
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration: GPU 0: NVIDIA GeForce RTX 3060 Laptop GPU
Nvidia driver version: 515.86.01
cuDNN version: Probably one of the following:
/usr/local/cuda-11.7/targets/x86_64-linux/lib/libcudnn.so.8.7.0
/usr/local/cuda-11.7/targets/x86_64-linux/lib/libcudnn_adv_infer.so.8.7.0
/usr/local/cuda-11.7/targets/x86_64-linux/lib/libcudnn_adv_train.so.8.7.0
/usr/local/cuda-11.7/targets/x86_64-linux/lib/libcudnn_cnn_infer.so.8.7.0
/usr/local/cuda-11.7/targets/x86_64-linux/lib/libcudnn_cnn_train.so.8.7.0
/usr/local/cuda-11.7/targets/x86_64-linux/lib/libcudnn_ops_infer.so.8.7.0
/usr/local/cuda-11.7/targets/x86_64-linux/lib/libcudnn_ops_train.so.8.7.0
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] mypy-extensions==0.4.3
[pip3] numpy==1.22.4
[pip3] torch==1.13.1
[pip3] torch-model-archiver==0.6.1
[pip3] torch-tb-profiler==0.4.0
[pip3] torch-workflow-archiver==0.2.5
[pip3] torchaudio==0.13.0
[pip3] torchinfo==1.7.0
[pip3] torchserve==0.6.1
[pip3] torchtriton==2.0.0+0d7e753227
[pip3] torchvision==0.14.0
[conda] cudatoolkit 11.3.1 h2bc3f7f_2 anaconda
[conda] numpy 1.22.4 pypi_0 pypi
[conda] torch 1.13.1 pypi_0 pypi
[conda] torch-model-archiver 0.6.1 pypi_0 pypi
[conda] torch-tb-profiler 0.4.0 dev_0 <develop>
[conda] torch-workflow-archiver 0.2.5 pypi_0 pypi
[conda] torchaudio 0.13.0 pypi_0 pypi
[conda] torchinfo 1.7.0 pypi_0 pypi
[conda] torchserve 0.6.1 pypi_0 pypi
[conda] torchtriton 2.0.0+0d7e753227 pypi_0 pypi
[conda] torchvision 0.14.0 pypi_0 pypi
cc @mruberry @albanD
| 3 |
3,718 | 92,250 |
torch.cuda.is_available() returns True even if the CUDA hardware can't run pytorch
|
module: cuda, triaged
|
### 🐛 Describe the bug
My desktop has an ancient GPU that cannot be used with PyTorch. Nevertheless `torch.cuda.is_available()` returns True; I get an error later on when I try to run any computation.
I would have hoped to receive False from `torch.cuda.is_available()`.
I'm sorry that this example is rather long; it arose when I tried running the Quickstart tutorial and I don't yet know enough about PyTorch to strip this down to a minimal example.
```python
torch.cuda.is_available()
```
```
True
```
```python
device="cuda"
# Define model
class NeuralNetwork(nn.Module):
def __init__(self):
super().__init__()
self.flatten = nn.Flatten()
self.linear_relu_stack = nn.Sequential(
nn.Linear(28*28, 512),
nn.ReLU(),
nn.Linear(512, 512),
nn.ReLU(),
nn.Linear(512, 10)
)
def forward(self, x):
x = self.flatten(x)
logits = self.linear_relu_stack(x)
return logits
model = NeuralNetwork().to(device)
```
```
/home/peridot/software/miniconda3/envs/ml-torch/lib/python3.10/site-packages/torch/cuda/__init__.py:132: UserWarning:
Found GPU0 Quadro K600 which is of cuda capability 3.0.
PyTorch no longer supports this GPU because it is too old.
The minimum cuda capability supported by this library is 3.7.
warnings.warn(old_gpu_warn % (d, name, major, minor, min_arch // 10, min_arch % 10))
```
If I then go on to do an actual calculation I get a RuntimeError:
```python
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=1e-3)
def train(dataloader, model, loss_fn, optimizer):
size = len(dataloader.dataset)
model.train()
for batch, (X, y) in enumerate(dataloader):
X, y = X.to(device), y.to(device)
# Compute prediction error
pred = model(X)
loss = loss_fn(pred, y)
# Backpropagation
optimizer.zero_grad()
loss.backward()
optimizer.step()
if batch % 100 == 0:
loss, current = loss.item(), batch * len(X)
print(f"loss: {loss:>7f} [{current:>5d}/{size:>5d}]")
# Download training data from open datasets.
training_data = datasets.FashionMNIST(
root="data",
train=True,
download=True,
transform=ToTensor(),
)
train_dataloader = DataLoader(training_data, shuffle=True)
train(train_dataloader, model, loss_fn, optimizer)
```
```
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
Cell In[3], line 54
45 training_data = datasets.FashionMNIST(
46 root="data",
47 train=True,
48 download=True,
49 transform=ToTensor(),
50 )
52 train_dataloader = DataLoader(training_data, shuffle=True)
---> 54 train(train_dataloader, model, loss_fn, optimizer)
Cell In[3], line 32, in train(dataloader, model, loss_fn, optimizer)
29 X, y = X.to(device), y.to(device)
31 # Compute prediction error
---> 32 pred = model(X)
33 loss = loss_fn(pred, y)
35 # Backpropagation
File ~/software/miniconda3/envs/ml-torch/lib/python3.10/site-packages/torch/nn/modules/module.py:1194, in Module._call_impl(self, *input, **kwargs)
1190 # If we don't have any hooks, we want to skip the rest of the logic in
1191 # this function, and just call forward.
1192 if not (self._backward_hooks or self._forward_hooks or self._forward_pre_hooks or _global_backward_hooks
1193 or _global_forward_hooks or _global_forward_pre_hooks):
-> 1194 return forward_call(*input, **kwargs)
1195 # Do not call functions when jit is used
1196 full_backward_hooks, non_full_backward_hooks = [], []
Cell In[3], line 17, in NeuralNetwork.forward(self, x)
15 def forward(self, x):
16 x = self.flatten(x)
---> 17 logits = self.linear_relu_stack(x)
18 return logits
File ~/software/miniconda3/envs/ml-torch/lib/python3.10/site-packages/torch/nn/modules/module.py:1194, in Module._call_impl(self, *input, **kwargs)
1190 # If we don't have any hooks, we want to skip the rest of the logic in
1191 # this function, and just call forward.
1192 if not (self._backward_hooks or self._forward_hooks or self._forward_pre_hooks or _global_backward_hooks
1193 or _global_forward_hooks or _global_forward_pre_hooks):
-> 1194 return forward_call(*input, **kwargs)
1195 # Do not call functions when jit is used
1196 full_backward_hooks, non_full_backward_hooks = [], []
File ~/software/miniconda3/envs/ml-torch/lib/python3.10/site-packages/torch/nn/modules/container.py:204, in Sequential.forward(self, input)
202 def forward(self, input):
203 for module in self:
--> 204 input = module(input)
205 return input
File ~/software/miniconda3/envs/ml-torch/lib/python3.10/site-packages/torch/nn/modules/module.py:1194, in Module._call_impl(self, *input, **kwargs)
1190 # If we don't have any hooks, we want to skip the rest of the logic in
1191 # this function, and just call forward.
1192 if not (self._backward_hooks or self._forward_hooks or self._forward_pre_hooks or _global_backward_hooks
1193 or _global_forward_hooks or _global_forward_pre_hooks):
-> 1194 return forward_call(*input, **kwargs)
1195 # Do not call functions when jit is used
1196 full_backward_hooks, non_full_backward_hooks = [], []
File ~/software/miniconda3/envs/ml-torch/lib/python3.10/site-packages/torch/nn/modules/linear.py:114, in Linear.forward(self, input)
113 def forward(self, input: Tensor) -> Tensor:
--> 114 return F.linear(input, self.weight, self.bias)
RuntimeError: CUDA error: CUBLAS_STATUS_ALLOC_FAILED when calling `cublasCreate(handle)`
```
### Versions
Collecting environment information...
/home/peridot/software/miniconda3/envs/ml-torch/lib/python3.10/site-packages/torch/cuda/__init__.py:132: UserWarning:
Found GPU0 Quadro K600 which is of cuda capability 3.0.
PyTorch no longer supports this GPU because it is too old.
The minimum cuda capability supported by this library is 3.7.
warnings.warn(old_gpu_warn % (d, name, major, minor, min_arch // 10, min_arch % 10))
PyTorch version: 1.13.1
Is debug build: False
CUDA used to build PyTorch: 11.6
ROCM used to build PyTorch: N/A
OS: Ubuntu 22.10 (x86_64)
GCC version: (Ubuntu 12.2.0-3ubuntu1) 12.2.0
Clang version: Could not collect
CMake version: Could not collect
Libc version: glibc-2.36
Python version: 3.10.8 (main, Nov 24 2022, 14:13:03) [GCC 11.2.0] (64-bit runtime)
Python platform: Linux-5.19.0-28-generic-x86_64-with-glibc2.36
Is CUDA available: True
CUDA runtime version: 11.6.124
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration: GPU 0: Quadro K600
Nvidia driver version: 470.161.03
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] mypy==0.991
[pip3] mypy-extensions==0.4.3
[pip3] numpy==1.24.1
[pip3] torch==1.13.1
[pip3] torchaudio==0.13.1
[pip3] torchvision==0.14.1
[conda] blas 1.0 mkl
[conda] ffmpeg 4.3 hf484d3e_0 pytorch
[conda] mkl 2021.4.0 h06a4308_640
[conda] mkl-service 2.4.0 py310h7f8727e_0
[conda] mkl_fft 1.3.1 py310hd6ae3a3_0
[conda] mkl_random 1.2.2 py310h00e6091_0
[conda] numpy 1.23.5 py310hd5efca6_0
[conda] numpy-base 1.23.5 py310h8e6c178_0
[conda] pytorch 1.13.1 py3.10_cuda11.6_cudnn8.3.2_0 pytorch
[conda] pytorch-cuda 11.6 h867d48c_1 pytorch
[conda] pytorch-mutex 1.0 cuda pytorch
[conda] torchaudio 0.13.1 py310_cu116 pytorch
[conda] torchvision 0.14.1 py310_cu116 pytorch
cc @ngimel
| 3 |
3,719 | 92,246 |
test_qnnpack_add fails
|
oncall: mobile, module: xnnpack
|
### 🐛 Describe the bug
The test fails with this:
```
test_qnnpack_add (quantization.core.test_quantized_op.TestQNNPackOps) ... Falsifying example: test_qnnpack_add(
A=(array([1.], dtype=float32), (1.0, 0, torch.qint8)),
zero_point=127,
scale_A=0.057,
scale_B=0.008,
scale_C=0.003,
self=<quantization.core.test_quantized_op.TestQNNPackOps testMethod=test_qnnpack_add>,
)
FAIL
```
The test_qnnpack_add_broadcast fails due to similar reasons.
With a bit of code reading I found this:
- `qA.dequantize()` and `qB.dequantize()` are zero due to the scaling and a zero_point of 127
- Hence the [groundtruth C](https://github.com/pytorch/pytorch/blob/76c88364ed6ffcef41743c8370d6ff1306e0100d/test/quantization/core/test_quantized_op.py#L5914) is also zero which is passed to `_quantize` yielding `qC = [0]`
- But the `qC_qnnp.int_repr = [127]`
More intermediates:
```
qA = tensor([0.], size=(1,), dtype=torch.qint8,
quantization_scheme=torch.per_tensor_affine, scale=0.057, zero_point=127)
qB = tensor([0.], size=(1,), dtype=torch.qint8,
quantization_scheme=torch.per_tensor_affine, scale=0.008, zero_point=127)
qA/qB.dequantize() = tensor([0.])
qC_qnnp = tensor([0.3810], size=(1,), dtype=torch.qint8,
quantization_scheme=torch.per_tensor_affine, scale=0.003, zero_point=0)
qC_qnnp.int_repr() = tensor([127], dtype=torch.int8)
qC_qnnp.dequantize() = tensor([0.3810])
```
### Versions
PyTorch 1.12.1
cc @jerryzh168 @jianyuh @raghuramank100 @jamesr66a @vkuzo @jgong5 @Xia-Weiwen @leslie-fang-intel
| 3 |
3,720 | 92,245 |
CapabilityBasedPartitioner incorrectly sorts the graph, causing optimizer return/output node to be first
|
triaged, module: fx, oncall: pt2
|
### 🐛 Describe the bug
Hello. I prepared code to test custom backends for torch.compile functionality. One of the things my backend is doing is using fx.Interpreter to go through all operations (via fake tensors) and propagate device info. Then I use this information to cluster some of the operations via CapabilityBasedPartitioner. For purpose of this bug I have simplified the code, it is available here:
https://gist.github.com/kbadz-pl/9bff0459fa37f4231125c0163aec4b89
Issue is that when I try to run partitioning and merging over optimizer code, it seems to wrongly treat return/output node because it has no arguments/predecessors. It ends up being first and effectively causing optimizer to not run at all (checked in the run traces).
SGD graph before partitioning:

SGD graph after partitioning and merging:
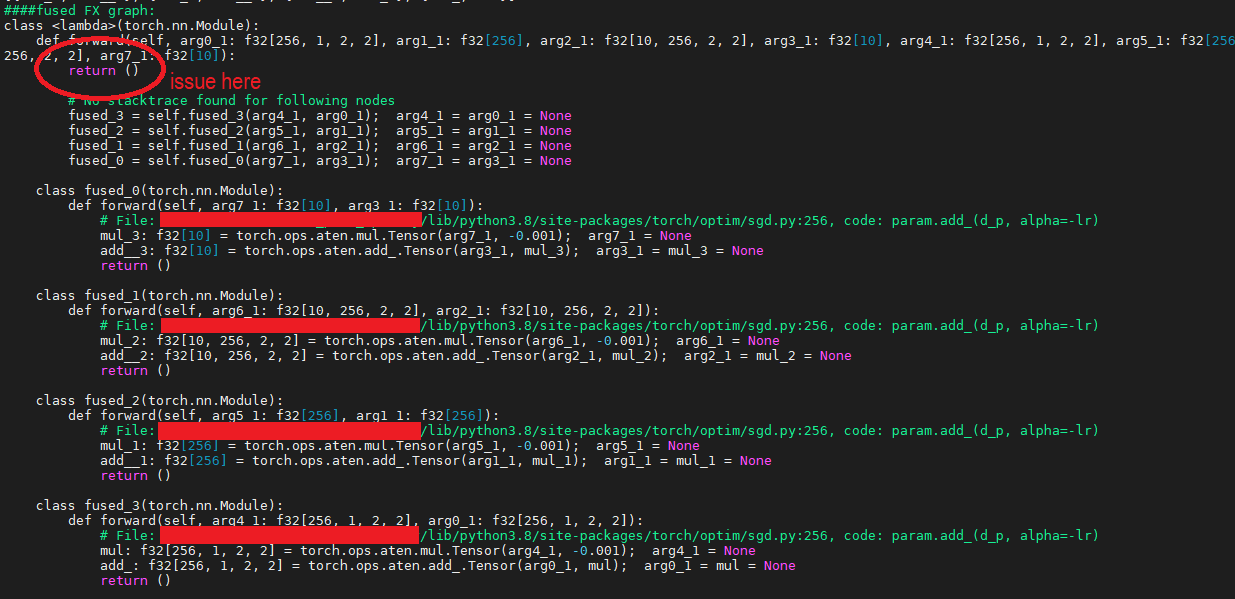
### Versions
PyTorch version: 2.0.0.dev20230116+cpu
Is debug build: False
CUDA used to build PyTorch: None
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.3 LTS (x86_64)
GCC version: (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0
Clang version: Could not collect
CMake version: version 3.16.3
Libc version: glibc-2.31
Python version: 3.8.10 (default, Nov 14 2022, 12:59:47) [GCC 9.4.0] (64-bit runtime)
Python platform: Linux-5.4.0-126-generic-x86_64-with-glibc2.29
Is CUDA available: False
CUDA runtime version: No CUDA
CUDA_MODULE_LOADING set to: N/A
GPU models and configuration: No CUDA
Nvidia driver version: No CUDA
cuDNN version: No CUDA
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.24.1
[pip3] torch==2.0.0.dev20230116+cpu
[pip3] torchaudio==2.0.0.dev20230115+cpu
[pip3] torchvision==0.15.0.dev20230115+cpu
[conda] Could not collect
cc @ezyang @SherlockNoMad @soumith @EikanWang @jgong5 @wenzhe-nrv @msaroufim @wconstab @ngimel @bdhirsh
| 6 |
3,721 | 92,244 |
Infinite recursion when tracing through lift_fresh_copy OP in Adam optimizer
|
module: optimizer, triaged, oncall: pt2, module: fakeTensor
|
### 🐛 Describe the bug
Hello. I prepared code to test custom backends for torch.compile functionality. One of the things my backend is doing is using fx.Interpreter to go through all operations (via fake tensors) and propagate device info. Then I use this information to cluster some of the operations via CapabilityBasedPartitioner. For purpose of this bug I have simplified the code, it is available here: https://gist.github.com/kbadz-pl/53d6cf36ac467039a0fa3170e7d5157b
Issue is that when fx.Interpreter tries to run_node over **lift_fresh_copy** operation, it goes into infinite recursion and crashes.

I did not see such issue with other OPs. Issue does not occur for example for SGD (it does not contain such OP) or by disabling fake tensors. You can test it by changing to SGD in line 106 or disabling fake tensors in line 15 of my file.
### Versions
PyTorch version: 2.0.0.dev20230116+cpu
Is debug build: False
CUDA used to build PyTorch: None
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.3 LTS (x86_64)
GCC version: (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0
Clang version: Could not collect
CMake version: version 3.16.3
Libc version: glibc-2.31
Python version: 3.8.10 (default, Nov 14 2022, 12:59:47) [GCC 9.4.0] (64-bit runtime)
Python platform: Linux-5.4.0-126-generic-x86_64-with-glibc2.29
Is CUDA available: False
CUDA runtime version: No CUDA
CUDA_MODULE_LOADING set to: N/A
GPU models and configuration: No CUDA
Nvidia driver version: No CUDA
cuDNN version: No CUDA
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.24.1
[pip3] torch==2.0.0.dev20230116+cpu
[pip3] torchaudio==2.0.0.dev20230115+cpu
[pip3] torchvision==0.15.0.dev20230115+cpu
[conda] Could not collect
cc @vincentqb @jbschlosser @albanD @janeyx99 @ezyang @soumith @msaroufim @wconstab @ngimel @bdhirsh
| 6 |
3,722 | 92,230 |
Add torch::jit::ScriptModule to the C++ API
|
oncall: jit
|
### 🚀 The feature, motivation and pitch
I'd like to implement a model in C++ with some submodules defined in C++ being subclasses of `torch::nn::Module` and a submodule being a `torch::jit::Module`. This is a common use case when your design your own model based around some well known backbone for which a torchscripted version is available.
I'm not sure about the best way to do this, but I believe that I must build my own wrapper subclassing `torch::nn::Module` around the JIT module. Such wrapper would register the parameters of the JIT module, and build recursively wrappers around its submodules. The wrapper would also need to overide `train()`, `eval()`, `to()` ... and delegate them to the JIT module. A bit ugly but it should work.
The thing is, I'm not really developing in C++, but in Java (or whatever language using a binding to the C++ API). In that case, writing a C++ subclass of `torch::nn::Module` that wraps the `torch::jit::Module` is not an available option.
So is it possible, either to make `torch::jit::Module` inherit from `torch:nn::Module` (I guess not) or provide a ready to be used C++ `torch::jit::ScriptModule` wrapper class, just like the Python counterpart ?
### Alternatives
_No response_
### Additional context
_No response_
cc @EikanWang @jgong5 @wenzhe-nrv @sanchitintel
| 0 |
3,723 | 92,226 |
Hijacked package names from nightly repository
|
oncall: binaries, security
|
### 🐛 Describe the bug
In response to this
https://pytorch.org/blog/compromised-nightly-dependency/
I checked if there are other package names in the pytorch nightly package index. I found two package names that I could register on pypi (torchaudio-nightly, pytorch-csprng).
I reported this to facebook's bugbounty program (as your security policy says), however it seems facebook no longer is responsible here (see also #91570). Facebook's security team came to the conclusion that the issue is not severe.
Nevertheless I now have registered these package names on pypi and I am wondering what to do with them. I would prefer to transmit ownership of the account to the pytorch team so you can decide what to do with them and if you want to keep them registered to block the names.
### Versions
irrelevant/nightly
cc @ezyang @seemethere @malfet
| 3 |
3,724 | 92,223 |
Improve make_fx tracing speed
|
module: performance, triaged, module: ProxyTensor
|
### 🚀 The feature, motivation and pitch
We observed that tracing a model using make_fx is sometimes much slower than actually running a model, and the observation has been consistent across different model sizes. For our big model sometimes we see a 30s+ tracing time.
While we understand tracing is usually only done once throughout the training process, the slow tracing speed has a direct impact on startup time, which leads to a very unpleasant debug-test experience.
```
import torch
from functorch import make_fx
import time
def main():
model = ...
input = ...
start = time.perf_counter()
model(input)
end = time.perf_counter()
print(f"time to execute {end - start}")
start = time.perf_counter()
traced = make_fx(model)(input)
end = time.perf_counter()
print(f"time to trace {end - start}")
```
```
time to execute 0.04433171300000005
time to trace 0.47819954299999967
```
### Alternatives
_No response_
### Additional context
_No response_
cc @ngimel @ezyang @SherlockNoMad @soumith @EikanWang @jgong5 @wenzhe-nrv
| 0 |
3,725 | 92,217 |
false INTERNAL ASSERT FAILED at "../c10/cuda/CUDAGraphsC10Utils.h":73, please report a bug to PyTorch. Unknown CUDA graph CaptureStatus32680
|
triaged, module: cuda graphs
|
### 🐛 Describe the bug
hello i used this code in colab:
seed = 72
torch.manual_seed(seed) # Insert any integer
torch.cuda.manual_seed(seed) # Insert any integer
i got a Error says:
RuntimeError: false INTERNAL ASSERT FAILED at "../c10/cuda/CUDAGraphsC10Utils.h":73, please report a bug to PyTorch. Unknown CUDA graph CaptureStatus32680
### Versions
wget https://raw.githubusercontent.com/pytorch/pytorch/master/torch/utils/collect_env.py
# For security purposes, please check the contents of collect_env.py before running it.
python collect_env.py
cc @mcarilli @ezyang
| 0 |
3,726 | 92,206 |
RuntimeError: derivative for aten::mps_linear_backward is not implemented
|
module: autograd, triaged, actionable, module: mps
|
### 🐛 Describe the bug
when I calculate the second derivative of the model, using my MacBook Air with M1, the bug is shown as below
<img width="1017" alt="image" src="https://user-images.githubusercontent.com/87766834/212471926-f4df0537-ac7e-42dc-b80e-a9d063314a14.png">
Another question: what amazes me most is that when I using the other computer with Windows PyTorch on cuda, the codes can run successfully...
I just want to know how to solve the problem on my MacBook shown in the picture above.
### Versions
15 u_pred = model(f_tmp)
16 du_df=torch.autograd.grad(outputs =u_pred, inputs = f_tmp,
17 grad_outputs = torch.ones_like(u_pred).to(device),
18 create_graph = True,
19 allow_unused=True
20 )[0]
---> 21 ddu_ddf=torch.autograd.grad(outputs =du_df, inputs = f_tmp,
22 grad_outputs = torch.ones_like(du_df).to(device),
23 create_graph = True,
24 allow_unused=True
25 )[0]
cc @ezyang @albanD @zou3519 @gqchen @pearu @nikitaved @soulitzer @Lezcano @Varal7 @kulinseth @malfet @DenisVieriu97 @razarmehr @abhudev
| 9 |
3,727 | 93,509 |
Triton Autotuning Cache-Clearing Adds 256MB Memory Overhead
|
triaged, bug, oncall: pt2
|
### 🐛 Describe the bug
In inductor autotuning, we invoke triton's do_bench which internally allocates a [256mb tensor](https://github.com/openai/triton/blob/259f4c5f7d4ecb8c64c519fe669318a15d6f75f2/python/triton/testing.py#L162) that is used to clear the cache.
From a practical standpoint, 256 MB is insignificant on a 40GB machine, however for a 12GB RTX 3080 this is a 2% overhead. Additionally, it's a non-linear factor, which throws off memory usage stats for small batch sizes. It has a big effect on the torchbench performance dashboard because low batch sizes are being used. E.g. `resnet18` is at .69 compression with autotuning, and ~1 without.
We could pass a handle to other allocated memory that is not being used in the autotuned kernel to avoid the additional allocation.
### Error logs
_No response_
### Minified repro
_No response_
cc @ezyang @soumith @msaroufim @wconstab @ngimel @bdhirsh
| 0 |
3,728 | 92,175 |
test_fx_passes generate bad test names
|
module: tests, oncall: fx
|
I am not sure how they get generated but some tests are named things like `test_partitioner_fn_<function TestPartitionFunctions_forward13 at 0x7f35079131a0>_expected_partition_[['add_2', 'add_1', 'add']]_bookend_non_compute_pass_False`.
I am amazed that this doesn't break anything very loudly. But this is definitely not going to work well with all the infra around detecting flaky tests and disabling broken things (the memory address there...).
These tests should be updated to have sane names!
cc @mruberry @ezyang @SherlockNoMad @EikanWang @jgong5 @wenzhe-nrv
| 0 |
3,729 | 92,173 |
"multi device" tests get skipped in standard CI
|
module: ci, module: tests, triaged
|
## Concern
The general concern is that people think they're adding tests to CI but these tests are getting skipped, which is bamboozling. Specifically, I wonder how many tests there are across our codebase that require multiple GPUs but are NOT on the multigpu shard, meaning they are always skipped (our runners only have 1 GPU).
This stemmed from my noticing the `@deviceCountAtLeast(2)` decorator while reviewing a PR, and then a brief search revealed that there are 18 instances of this decorator throughout our codebase. There may other ways people guard/skip tests based on # devices (such as with if statements/with TEST_MULTIGPU).
To add another layer to this onion, even if people knew about the multigpu shard and how to add a test to it, the multigpu config runs on a periodic cadence, so people may not realize that these tests they added never even ran on the CI of their PR.
## Potential Next Steps
1. Document in deviceCountAtLeast that these do NOT run in most CI, and that tests with this decorator should be added to https://github.com/pytorch/pytorch/blob/master/.jenkins/pytorch/multigpu-test.sh
2. Run existing unrun tests like `test_clip_grad_norm_multi_device` on the multigpu config
3. I understand that the multigpu shard was historically hardware-constrained. @pytorch/pytorch-dev-infra Is there a near future where multigpu can run on trunk instead of periodic?
cc @seemethere @malfet @pytorch/pytorch-dev-infra @mruberry
| 12 |
3,730 | 92,171 |
PyTorch 1.13.1 hangs with `torch.distributed.init_process_group`
|
oncall: distributed
|
### 🐛 Describe the bug
Hi there,
We're upgrading from `PyTorch` `1.12.1` to `1.13.1`, and find that it hangs with `torch.distributed.init_process_group` with `1.13.1` while not `1.12.1`, with the following source code when I turn on `CUDA_LAUNCH_BLOCKING=1`:
```
def ddp_init(self, core):
import torch.distributed as dist
# ...
init_method = f"tcp://{ip}:{main_port}"
dist.init_process_group(
self.cfg.ddp_dist_backend,
rank=core.rank(),
world_size=core.size(),
init_method=init_method,
)
dist.barrier()
```
where `self.cfg.ddp_dist_backend = nccl`.
- We look at https://discuss.pytorch.org/t/torch-distributed-init-process-group-hangs-with-4-gpus-with-backend-nccl-but-not-gloo/149061/1, and `IOMMU` should be `disabled` as:
```
ubuntu@compute-dy-worker-80:~$ sudo lspci -vvv | grep ACSCtl
ubuntu@compute-dy-worker-80:~$
```
### Versions
```
root@compute-dy-worker-80:/# python collect_env.py
Collecting environment information...
PyTorch version: 1.13.1+cu117
Is debug build: False
CUDA used to build PyTorch: 11.7
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.5 LTS (x86_64)
GCC version: (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0
Clang version: Could not collect
CMake version: version 3.24.3
Libc version: glibc-2.31
Python version: 3.9.13 | packaged by conda-forge | (main, May 27 2022, 16:58:50) [GCC 10.3.0] (64-bit runtime)
Python platform: Linux-5.4.0-1080-aws-x86_64-with-glibc2.31
Is CUDA available: True
CUDA runtime version: 11.7.99
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration:
GPU 0: NVIDIA A100-SXM4-40GB
GPU 1: NVIDIA A100-SXM4-40GB
GPU 2: NVIDIA A100-SXM4-40GB
GPU 3: NVIDIA A100-SXM4-40GB
GPU 4: NVIDIA A100-SXM4-40GB
GPU 5: NVIDIA A100-SXM4-40GB
GPU 6: NVIDIA A100-SXM4-40GB
GPU 7: NVIDIA A100-SXM4-40GB
Nvidia driver version: 510.47.03
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.5.0
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.5.0
/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.5.0
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_infer.so.8.5.0
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.5.0
/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.5.0
/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.5.0
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.23.5
[pip3] sagemaker-pytorch-training==2.7.0
[pip3] torch==1.13.1+cu117
[pip3] torchaudio==0.13.1+cu117
[pip3] torchdata==0.5.1
[pip3] torchnet==0.0.4
[pip3] torchvision==0.14.1+cu117
[conda] Could not collect
root@compute-dy-worker-80:/#
```
```
root@compute-dy-worker-80:/# pip show conda
Name: conda
Version: 22.11.1
Summary: OS-agnostic, system-level binary package manager.
Home-page: https://github.com/conda/conda
Author: Anaconda, Inc.
Author-email: conda@continuum.io
License: BSD-3-Clause
Location: /opt/conda/lib/python3.9/site-packages
Requires: pluggy, pycosat, requests, ruamel.yaml, tqdm
Required-by: mamba
root@compute-dy-worker-80:/#
```
Thank you.
cc @mrshenli @pritamdamania87 @zhaojuanmao @satgera @rohan-varma @gqchen @aazzolini @osalpekar @jiayisuse @H-Huang @kwen2501 @awgu
| 1 |
3,731 | 92,151 |
Exception in distributed context doesn't propagate to child processes launched with multiprocessing
|
oncall: distributed
|
### 🐛 Describe the bug
I'm using `torch.distributed` to launch multi GPU trainings and `torch.multiprocessing` in data preparation but I have an issue if an exception is raised in a child process.
Here is an example:
- I use 2 devices (launching my script using `torchrun --nproc_per_node=2 myscript.py`)
- on each device, the main process (called main:0 and main:1) starts a child process (called child:0 and child:1)
- if child raises an exception, I catch this exception to raise it in main aswell
- then, main:0 is killed thanks to SIGTERM
- but, child:0 isn't killed and thus it becomes a zombie process that keeps using resources and blocks the end of the whole process
Here a snippet that you can run using `torchrun --nproc_per_node=2 tmp.py` on a machine with at least 2 GPUs to reproduce this issue:
```python
# tmp.py
import time
import torch
from torch import multiprocessing
def main():
torch.distributed.init_process_group("nccl")
device = torch.device(torch.distributed.get_rank())
torch.cuda.set_device(device)
ctx = multiprocessing.get_context("spawn")
exc_queue = ctx.Queue(1)
torch.Tensor([1]).to(device) # useful to display active processes in nvidia-smi
process = ctx.Process(target=subprocess, args=(device, exc_queue), daemon=True)
process.start()
print(f"main:{device.index} started")
process.join()
print(f"child:{device.index} has joined")
if not exc_queue.empty():
exc = exc_queue.get()
raise RuntimeError("subprocess failed") from exc
print(f"main:{device.index} finished")
def subprocess(device: torch.device, exc_queue: multiprocessing.Queue):
try:
torch.Tensor([1]).to(device) # useful to display active processes in nvidia-smi
print(f"child:{device.index} started")
if device.index:
# emulating an exception that occurs only on a single device
time.sleep(3)
raise RuntimeError()
while True:
# emulating the "normal" behavior of the subprocess such as reading data
print(f"child:{device.index} in loop")
time.sleep(4)
except Exception as exc:
exc_queue.put(exc)
raise exc
if __name__ == "__main__":
main()
```
Here is the traceback I got:
```pyhon
$ torchrun --nproc_per_node=2 tmp.py
WARNING:torch.distributed.run:
*****************************************
Setting OMP_NUM_THREADS environment variable for each process to be 1 in default, to avoid your system being overloaded, please further tune the variable for optimal performance in your application as needed.
*****************************************
main:0 started
main:1 started
child:0 started
child:0 in loop
child:1 started
Process SpawnProcess-1:
Traceback (most recent call last):
File "/opt/rh/rh-python38/root/usr/lib64/python3.8/multiprocessing/process.py", line 315, in _bootstrap
self.run()
File "/opt/rh/rh-python38/root/usr/lib64/python3.8/multiprocessing/process.py", line 108, in run
self._target(*self._args, **self._kwargs)
File "./tmp.py", line 40, in subprocess
raise exc
File "./tmp.py", line 33, in subprocess
raise RuntimeError()
RuntimeError
child:1 has joined
RuntimeError
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "tmp.py", line 44, in <module>
main()
File "tmp.py", line 22, in main
raise RuntimeError("subprocess failed") from exc
RuntimeError: subprocess failed
child:0 in loop
WARNING:torch.distributed.elastic.multiprocessing.api:Sending process 178624 closing signal SIGTERM
ERROR:torch.distributed.elastic.multiprocessing.api:failed (exitcode: 1) local_rank: 1 (pid: 178625) of binary: ./venv/bin/python
Traceback (most recent call last):
File "./venv/bin/torchrun", line 8, in <module>
sys.exit(main())
File "./venv/lib64/python3.8/site-packages/torch/distributed/elastic/multiprocessing/errors/__init__.py", line 345, in wrapper
return f(*args, **kwargs)
File "./venv/lib64/python3.8/site-packages/torch/distributed/run.py", line 761, in main
run(args)
File "./venv/lib64/python3.8/site-packages/torch/distributed/run.py", line 752, in run
elastic_launch(
File "./venv/lib64/python3.8/site-packages/torch/distributed/launcher/api.py", line 131, in __call__
return launch_agent(self._config, self._entrypoint, list(args))
File "./venv/lib64/python3.8/site-packages/torch/distributed/launcher/api.py", line 245, in launch_agent
raise ChildFailedError(
torch.distributed.elastic.multiprocessing.errors.ChildFailedError:
============================================================
tmp.py FAILED
------------------------------------------------------------
Failures:
<NO_OTHER_FAILURES>
------------------------------------------------------------
Root Cause (first observed failure):
[0]:
time : 2023-01-13_07:23:42
host : bv4sxk2.pnp.melodis.com
rank : 1 (local_rank: 1)
exitcode : 1 (pid: 178625)
error_file: <N/A>
traceback : To enable traceback see: https://pytorch.org/docs/stable/elastic/errors.html
============================================================
$ child:0 in loop
child:0 in loop
child:0 in loop
... # the loop keeps running endlessly
```
When looking at nvidia-smi after all processes have been killed except child:0 I see child:0 process still occupying memory.
Is there a way to make sure all children processes are killed when one of the main processes is killed in a distributed context ?
Thanks
### Versions
```
Collecting environment information...
PyTorch version: 1.12.1+cu116
Is debug build: False
CUDA used to build PyTorch: 11.6
ROCM used to build PyTorch: N/A
OS: CentOS Linux 7 (Core) (x86_64)
GCC version: (GCC) 9.3.1 20200408 (Red Hat 9.3.1-2)
Clang version: 14.0.6 ( 14.0.6-4sh.el7)
CMake version: version 3.24.3
Libc version: glibc-2.17
Python version: 3.8.13 (default, Aug 16 2022, 12:16:29) [GCC 9.3.1 20200408 (Red Hat 9.3.1-2)] (64-bit runtime)
Python platform: Linux-3.10.0-693.2.2.el7.x86_64-x86_64-with-glibc2.2.5
Is CUDA available: True
CUDA runtime version: Could not collect
CUDA_MODULE_LOADING set to:
GPU models and configuration:
GPU 0: NVIDIA Tesla P100-PCIE-16GB
GPU 1: NVIDIA Tesla P100-PCIE-16GB
Nvidia driver version: 465.19.01
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] mypy==0.991
[pip3] mypy-extensions==0.4.3
[pip3] numpy==1.23.4
[pip3] torch==1.12.1+cu116
[pip3] torch-summary==1.4.5
[pip3] torch-tb-profiler==0.4.0
[pip3] torchaudio==0.12.1+cu116
[conda] Could not collect
```
cc @mrshenli @pritamdamania87 @zhaojuanmao @satgera @rohan-varma @gqchen @aazzolini @osalpekar @jiayisuse @H-Huang @kwen2501 @awgu
| 2 |
3,732 | 92,148 |
Occassional OverflowError with mps running yolov7
|
triaged, module: mps
|
### 🐛 Describe the bug
clone the project from https://github.com/WongKinYiu/yolov7 and instal packages in `requirments.txt`
and modify function ```select_device``` in ./utils/pytorch_utils.py like below
```python
def select_device(device='', batch_size=None):
# device = 'cpu' or '0' or '0,1,2,3'
s = f'YOLOR 🚀 {git_describe() or date_modified()} torch {torch.__version__} ' # string
cpu = device.lower() == 'cpu'
if cpu:
os.environ['CUDA_VISIBLE_DEVICES'] = '-1' # force torch.cuda.is_available() = False
elif device: # non-cpu device requested
os.environ['CUDA_VISIBLE_DEVICES'] = device # set environment variable
assert torch.cuda.is_available(), f'CUDA unavailable, invalid device {device} requested' # check availability
cuda = not cpu and torch.cuda.is_available()
mps = not cpu and torch.backends.mps.is_available()
if cuda:
n = torch.cuda.device_count()
if n > 1 and batch_size: # check that batch_size is compatible with device_count
assert batch_size % n == 0, f'batch-size {batch_size} not multiple of GPU count {n}'
space = ' ' * len(s)
for i, d in enumerate(device.split(',') if device else range(n)):
p = torch.cuda.get_device_properties(i)
s += f"{'' if i == 0 else space}CUDA:{d} ({p.name}, {p.total_memory / 1024 ** 2}MB)\n" # bytes to MB
elif mps:
s += 'MPS\n'
else:
s += 'CPU\n'
logger.info(s.encode().decode('ascii', 'ignore') if platform.system() == 'Windows' else s) # emoji-safe
return torch.device('cuda:0' if cuda else 'mps' if mps else 'cpu')
```
this literally select mps when it is available.
then run with command
```export PYTORCH_ENABLE_MPS_FALLBACK=1; python detect.py --weights yolov7-e6e.pt --source path/to/source.png```
The error
```
Traceback (most recent call last):
File "/Users/Frank/PycharmProjects/yolov7/detect.py", line 197, in <module>
detect()
File "/Users/Frank/PycharmProjects/yolov7/detect.py", line 130, in detect
plot_one_box(xyxy, im0, label=label, color=colors[int(cls)], line_thickness=1)
File "/Users/Frank/PycharmProjects/yolov7/utils/plots.py", line 61, in plot_one_box
c1, c2 = (int(x[0]), int(x[1])), (int(x[2]), int(x[3]))
OverflowError: cannot convert float infinity to integer
Namespace(weights=['yolov7-e6e.pt'], source='/Users/Frank/Notebooks/jupyter/skiing_img/images/0.png', img_size=640, conf_thres=0.25, iou_thres=0.45, device='', view_img=False, save_txt=False, save_conf=False, nosave=False, classes=None, agnostic_nms=False, augment=False, update=False, project='runs/detect', name='exp', exist_ok=False, no_trace=False)
```
occurs 4 times out of 11 runs.
### Versions
```PyTorch version: 1.13.1
Is debug build: False
CUDA used to build PyTorch: None
ROCM used to build PyTorch: N/A
OS: macOS 13.1 (arm64)
GCC version: Could not collect
Clang version: 14.0.0 (clang-1400.0.29.202)
CMake version: version 3.23.0
Libc version: N/A
Python version: 3.9.15 (main, Nov 24 2022, 08:28:41) [Clang 14.0.6 ] (64-bit runtime)
Python platform: macOS-13.1-arm64-arm-64bit
Is CUDA available: False
CUDA runtime version: No CUDA
CUDA_MODULE_LOADING set to: N/A
GPU models and configuration: No CUDA
Nvidia driver version: No CUDA
cuDNN version: No CUDA
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.23.5
[pip3] torch==1.13.1
[pip3] torchvision==0.14.1
[conda] numpy 1.23.5 pypi_0 pypi
[conda] torch 1.13.1 pypi_0 pypi
[conda] torchvision 0.14.1 pypi_0 pypi
```
gcc version given by `gcc --version`is
```
Apple clang version 14.0.0 (clang-1400.0.29.202)
Target: arm64-apple-darwin22.2.0
Thread model: posix
```
cc @kulinseth @albanD @malfet @DenisVieriu97 @razarmehr @abhudev
| 0 |
3,733 | 92,135 |
[PT2.0 Feature Proposal] TorchInductor CPU FP32 Inference Optimization
|
triaged, oncall: pt2
|
### 🚀 The feature, motivation and pitch
As part of the PyTorch 2.0 compilation stack, TorchInductor CPU backend optimization brings notable performance improvements via graph compilation over the PyTorch eager mode. The performance improvements on various backends are tracked on the dashboard: https://github.com/pytorch/pytorch/issues/93531
There was also an earlier poster about the work: https://dev-discuss.pytorch.org/t/torchinductor-update-4-cpu-backend-started-to-show-promising-performance-boost/874
### Alternatives
_No response_
### Additional context
- Fusion and Memory Layout Optimization for Conv and GEMM
- https://github.com/pytorch/pytorch/pull/90890
- https://github.com/pytorch/pytorch/pull/90264
- https://github.com/pytorch/pytorch/pull/90265
- https://github.com/pytorch/pytorch/pull/90266
- https://github.com/pytorch/pytorch/pull/90267
- https://github.com/pytorch/pytorch/pull/87050
- https://github.com/pytorch/pytorch/pull/87063
- https://github.com/pytorch/pytorch/pull/87064
- https://github.com/pytorch/pytorch/pull/87065
- https://github.com/pytorch/pytorch/pull/87066
- https://github.com/pytorch/pytorch/pull/87435
- https://github.com/pytorch/pytorch/pull/88048
- https://github.com/pytorch/pytorch/pull/88403
- https://github.com/pytorch/pytorch/pull/88412
- https://github.com/pytorch/pytorch/pull/88414
- https://github.com/pytorch/pytorch/pull/88794
- https://github.com/pytorch/pytorch/pull/88864
- https://github.com/pytorch/pytorch/pull/88988
- https://github.com/pytorch/pytorch/pull/89109
- https://github.com/pytorch/pytorch/pull/89209
- https://github.com/pytorch/pytorch/pull/90259
- https://github.com/pytorch/pytorch/pull/89746
- https://github.com/pytorch/pytorch/pull/89278
- https://github.com/pytorch/pytorch/pull/89265
- https://github.com/pytorch/pytorch/pull/91433
- https://github.com/pytorch/pytorch/pull/91953
- https://github.com/pytorch/pytorch/pull/91954
- https://github.com/pytorch/pytorch/pull/91955
- https://github.com/pytorch/pytorch/pull/91956
- Inductor Lowering Enhancement
- https://github.com/pytorch/pytorch/pull/89904
- https://github.com/pytorch/pytorch/pull/89838
- https://github.com/pytorch/pytorch/pull/91233
- https://github.com/pytorch/pytorch/pull/91605
- https://github.com/pytorch/pytorch/pull/90814
- Runtime Optimization
- https://github.com/pytorch/pytorch/pull/87037
- https://github.com/pytorch/pytorch/pull/89377
- Vectorization Optimization
- https://github.com/pytorch/pytorch/pull/90283
- https://github.com/pytorch/pytorch/pull/91074
- https://github.com/pytorch/pytorch/pull/91076
- https://github.com/pytorch/pytorch/pull/90750
- https://github.com/pytorch/pytorch/pull/87068
- https://github.com/pytorch/pytorch/pull/87356
- https://github.com/pytorch/pytorch/pull/88160
- https://github.com/pytorch/pytorch/pull/88482
- https://github.com/pytorch/pytorch/pull/88736
- https://github.com/pytorch/pytorch/pull/88298
- https://github.com/pytorch/pytorch/pull/90270
- https://github.com/pytorch/pytorch/pull/89837
- https://github.com/pytorch/pytorch/pull/91613
- https://github.com/pytorch/pytorch/pull/91755
- https://github.com/pytorch/pytorch/pull/91532
- CPP Wrapper
- https://github.com/pytorch/pytorch/pull/89744
- https://github.com/pytorch/pytorch/pull/88167
- https://github.com/pytorch/pytorch/pull/88560
- https://github.com/pytorch/pytorch/pull/88561
- https://github.com/pytorch/pytorch/pull/88666
- https://github.com/pytorch/pytorch/pull/88667
- https://github.com/pytorch/pytorch/pull/90754
- Profiling and Debuggability
- https://github.com/pytorch/pytorch/pull/89674
- https://github.com/pytorch/pytorch/pull/89367
- https://github.com/pytorch/pytorch/pull/90008
- Benchmarking Enhancement
- https://github.com/pytorch/pytorch/pull/88477
- https://github.com/pytorch/pytorch/pull/90641
- https://github.com/pytorch/pytorch/pull/91870
- https://github.com/pytorch/pytorch/pull/90150
cc @ezyang @soumith @msaroufim @wconstab @ngimel @bdhirsh @jansel @desertfire @Chillee @penguinwu @jgong5 @fzhao3
| 0 |
3,734 | 92,134 |
[Bug][Dataloader] unable to mmap 2048 bytes from file <filename not specified>: Cannot allocate memory (12)
|
module: multiprocessing, module: dataloader, triaged
|
### 🐛 Describe the bug
Hi,
Here is the results i observed when i was running my workload with PyTorch 1.13 on Ubuntu 20.04 to train RN50 with imageNet:
When i run 25 epochs, the error is thrown as below:
```
Epoch: [25][3096/5005] Time 0.551 ( 0.548) Data 0.000 ( 0.001) Loss 1.9055e+00 (2.1268e+00) Acc@1 57.81 ( 51.79) Acc@5 79.69 ( 76.05)
Epoch: [25][3097/5005] Time 0.547 ( 0.548) Data 0.000 ( 0.001) Loss 1.9593e+00 (2.1268e+00) Acc@1 55.08 ( 51.80) Acc@5 81.25 ( 76.06)
Exception in thread Thread-52:
Traceback (most recent call last):
File "/home/gta/miniconda3/envs/zejun/lib/python3.9/threading.py", line 973, in _bootstrap_inner
self.run()
File "/home/gta/miniconda3/envs/zejun/lib/python3.9/threading.py", line 910, in run
self._target(*self._args, **self._kwargs)
File "/home/gta/miniconda3/envs/zejun/lib/python3.9/site-packages/torch/utils/data/_utils/pin_memory.py", line 52, in _pin_memory_loop
do_one_step()
File "/home/gta/miniconda3/envs/zejun/lib/python3.9/site-packages/torch/utils/data/_utils/pin_memory.py", line 29, in do_one_step
r = in_queue.get(timeout=MP_STATUS_CHECK_INTERVAL)
File "/home/gta/miniconda3/envs/zejun/lib/python3.9/multiprocessing/queues.py", line 122, in get
return _ForkingPickler.loads(res)
File "/home/gta/miniconda3/envs/zejun/lib/python3.9/site-packages/torch/multiprocessing/reductions.py", line 294, in rebuild_storage_fd
storage = cls._new_shared_fd(fd, size)
RuntimeError: falseINTERNAL ASSERT FAILED at "/home/gta/zejun/pytorch/aten/src/ATen/MapAllocator.cpp":323, please report a bug to PyTorch. unable to mmap 2048 bytes from file <filename not specified>: Cannot allocate memory (12)
```
This Runtime Error is thrown from torch dataloader. I found the community has had this issue: https://discuss.pytorch.org/t/pytorch-cannot-allocate-memory/134754.
I set the dataloader workers to be 0 and the error is missing, but the training time increases too much when using the single process to fetch and decode the dataset. I also check the host memory usage and no oom happen. The fd limitation of one process is also not exceeded. Thus we wonder if the issue can be fixed, otherwise it may block the model training with PyTorch.
### Versions
PyTorch 1.13
Python 3.9
Torchvision 1.14
Running BS: 256
Model: ResNet50
Dataset: ImageNet
Ubuntu 20.04
Host Mem 128G
CPU: Intel Xeon Gold 6342
cc @SsnL @VitalyFedyunin @ejguan @NivekT
| 20 |
3,735 | 92,132 |
Torchrun seems to have problem with virtual environment
|
oncall: distributed, triaged, oncall: r2p
|
## Issue description
Use torchrun (inside a virtual environment) to launch a Python script. The script can not import modules installed in that virtual environment. Changing to use torch.distributed.launch to launch works well but that method has been depreciated.
## Code example
* Create a venv, activate the venv
* Install a module, say "pip install datasets"
* Write a python script (test.py) to load datasets
```
# This is test.py
import datasets
```
* Do the following
```
torchrun \
--nnodes=1 \
--nproc_per_node=8 \
--max_restarts=0 \
--rdzv_id=123456 \
--rdzv_backend=c10d \
--rdzv_endpoint=localhost \
test.py
```
You will get "ModuleNotFoundError: No module named 'datasets'"
* Changing from 'torchrun' to 'python3 -m torch.distributed.launch', then it all works.
```
python3 -m torch.distributed.launch \
--standalone \
--nnodes=1 \
--nproc_per_node=8 \
test.py
```
## System Info
Python 3.10.6
PyTorch 1.12.0
Linux (CentOS 7)
cc @mrshenli @pritamdamania87 @zhaojuanmao @satgera @rohan-varma @gqchen @aazzolini @osalpekar @jiayisuse @H-Huang @kwen2501 @awgu
| 9 |
3,736 | 92,131 |
DISABLED test_cuda_variable_sharing (__main__.TestMultiprocessing)
|
triaged, module: flaky-tests, skipped, module: unknown
|
Platforms: rocm
This test was disabled because it is failing in CI. See [recent examples](https://hud.pytorch.org/flakytest?name=test_cuda_variable_sharing&suite=TestMultiprocessing) and the most recent trunk [workflow logs](https://github.com/pytorch/pytorch/runs/10617465804).
Over the past 3 hours, it has been determined flaky in 2 workflow(s) with 2 failures and 2 successes.
**Debugging instructions (after clicking on the recent samples link):**
DO NOT BE ALARMED IF THE CI IS GREEN. We now shield flaky tests from developers so CI will thus be green but it will be harder to parse the logs.
To find relevant log snippets:
1. Click on the workflow logs linked above
2. Click on the Test step of the job so that it is expanded. Otherwise, the grepping will not work.
3. Grep for `test_cuda_variable_sharing`
4. There should be several instances run (as flaky tests are rerun in CI) from which you can study the logs.
| 1 |
3,737 | 92,130 |
Unable to export timm models with torch._dynamo
|
triaged, module: dynamo
|
### 🐛 Describe the bug
I'm trying to export timm models using torch._dynamo to make use of the graph, but it is failing for most of the networks.
import torch; import timm
import torch._dynamo as dynamo
model_list = ['efficientnet_el',' efficientnet_es', 'efficientnet_em', 'efficientnet_el', 'efficientnet_b0', 'efficientnet_b2', 'efficientnet_b4', 'efficientnet_lite0', 'efficientnet_lite1', 'efficientnet_lite2', 'efficientnet_lite3', 'efficientnet_lite4', 'efficientnetv2_s', 'efficientnetv2_m', 'efficientnetv2_l', 'mobilenetv2_035', 'resnet18', 'resnet34', 'resnet50', 'wide_resnet50_2', 'swinv2_tiny_window8_256', 'swinv2_small_window8_256', 'swinv2_base_window8_256', 'swinv2_large_window12_192_22k', 'dla46x_c', 'dla46_c', 'dla60x_c', 'mobilenetv3_small_050', 'lcnet_050', 'mobilenetv2_050', 'mnasnet_small', 'tf_mobilenetv3_small_075', 'mobilenetv3_small_075', 'tinynet_e', 'tinynet_d', 'lcnet_075', 'tinynet_c', 'mobilenetv3_small_100', 'regnetx_002', 'semnasnet_075', 'lcnet_100', 'xcit_nano_12_p8_384_dist', 'xcit_nano_12_p8_224_dist', 'xcit_nano_12_p16_384_dist', 'xcit_nano_12_p8_224', 'xcit_nano_12_p16_224_dist', 'xcit_nano_12_p16_224', 'regnety_002', 'mobilenetv2_100', 'tinynet_b', 'semnasnet_100', 'mixnet_s', 'regnety_004', 'mnasnet_100', 'spnasnet_100', 'mobilenetv2_110d', 'pit_ti_224', 'mixnet_m', 'pit_ti_distilled_224', 'regnetx_004', 'hardcorenas_b', 'ghostnet_100', 'hardcorenas_a', 'efficientnet_es_pruned', 'resnet10t', 'mobilenetv3_large_100_miil', 'mobilenetv3_rw', 'mobilenetv3_large_100', 'hardcorenas_c', 'fbnetc_100', 'convit_tiny', 'vit_tiny_patch16_224', 'deit_tiny_patch16_224', 'vit_tiny_patch16_384', 'mobilenetv2_120d', 'deit_tiny_distilled_patch16_224', 'regnety_006', 'mobilenetv2_140', 'tinynet_a', 'regnetx_006', 'regnety_008', 'ese_vovnet19b_dw', 'xcit_tiny_12_p8_384_dist', 'xcit_tiny_12_p8_224_dist', 'xcit_tiny_12_p8_224', 'xcit_tiny_12_p16_384_dist', 'xcit_tiny_12_p16_224_dist', 'xcit_tiny_12_p16_224', 'mixnet_l', 'hardcorenas_d', 'densenet121', 'tv_densenet121', 'hardcorenas_e', 'gernet_s', 'hardcorenas_f']
for name in model_list:
try:
model = timm.create_model(name)
inp = torch.rand((1, 3, 224, 224))
model(inp)
except:
print("Failed with Input")
continue
try:
model_graph = torch._dynamo.export(model, torch.randn(1,3,224,224))
print("Passed")
except:
print("Failed")
### Versions
Collecting environment information...
PyTorch version: 2.0.0.dev20230112
Is debug build: False
CUDA used to build PyTorch: 11.7
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.5 LTS (x86_64)
GCC version: (Ubuntu 11.1.0-1ubuntu1~20.04) 11.1.0
Clang version: 10.0.0-4ubuntu1
CMake version: version 3.25.0
Libc version: glibc-2.31
Python version: 3.10.8 (main, Nov 24 2022, 14:13:03) [GCC 11.2.0] (64-bit runtime)
Python platform: Linux-5.15.0-56-generic-x86_64-with-glibc2.31
Is CUDA available: True
CUDA runtime version: 11.7.99
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration:
GPU 0: NVIDIA GeForce GT 1030
GPU 1: NVIDIA RTX A6000
GPU 2: NVIDIA RTX A6000
Nvidia driver version: 515.86.01
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.6.0
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.6.0
/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.6.0
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_infer.so.8.6.0
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.6.0
/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.6.0
/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.6.0
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.23.5
[pip3] torch==2.0.0.dev20230112
[pip3] torchaudio==2.0.0.dev20230112
[pip3] torchvision==0.15.0.dev20230112
[conda] blas 1.0 mkl
[conda] mkl 2021.4.0 h06a4308_640
[conda] mkl-service 2.4.0 py310h7f8727e_0
[conda] mkl_fft 1.3.1 py310hd6ae3a3_0
[conda] mkl_random 1.2.2 py310h00e6091_0
[conda] numpy 1.23.5 py310hd5efca6_0
[conda] numpy-base 1.23.5 py310h8e6c178_0
[conda] pytorch 2.0.0.dev20230112 py3.10_cuda11.7_cudnn8.5.0_0 pytorch-nightly
[conda] pytorch-cuda 11.7 h67b0de4_2 pytorch-nightly
[conda] pytorch-mutex 1.0 cuda pytorch-nightly
[conda] torchaudio 2.0.0.dev20230112 py310_cu117 pytorch-nightly
[conda] torchtriton 2.0.0+0d7e753227 py310 pytorch-nightly
[conda] torchvision 0.15.0.dev20230112 py310_cu117 pytorch-nightly
cc @mlazos @soumith @voznesenskym @yanboliang @penguinwu @anijain2305 @EikanWang @jgong5 @Guobing-Chen @chunyuan-w @XiaobingSuper @zhuhaozhe @blzheng @Xia-Weiwen @wenzhe-nrv @jiayisunx @desertfire
| 0 |
3,738 | 92,128 |
Forward arguments are not updated in DDP
|
oncall: distributed, triaged
|
### 🐛 Describe the bug
I am using the example from [Initialize DDP with torch.distributed.run/torchrun](https://pytorch.org/tutorials/intermediate/ddp_tutorial.html#initialize-ddp-with-torch-distributed-run-torchrun). I add a dict state_info as an additional input to the forward function, which will track the state of each forward call. However, the dict is not updated in DDP. The codes are:
```
import torch
import torch.distributed as dist
import torch.nn as nn
import torch.optim as optim
from torch.nn.parallel import DistributedDataParallel as DDP
class ToyModel(nn.Module):
def __init__(self):
super(ToyModel, self).__init__()
self.net1 = nn.Linear(10, 10)
self.relu = nn.ReLU()
self.net2 = nn.Linear(10, 5)
def forward(self, x, state_info):
state_info['tmp'] = 10 # additional input that tracks the state
return self.net2(self.relu(self.net1(x)))
def demo_basic():
dist.init_process_group("nccl")
rank = dist.get_rank()
print(f"Start running basic DDP example on rank {rank}.")
# create model and move it to GPU with id rank
device_id = rank % torch.cuda.device_count()
model = ToyModel().to(device_id)
ddp_model = DDP(model, device_ids=[device_id])
loss_fn = nn.MSELoss()
optimizer = optim.SGD(ddp_model.parameters(), lr=0.001)
optimizer.zero_grad()
state_info = {'tmp': 0}
print(state_info) ####### print function 1
outputs = ddp_model(torch.randn(20, 10), state_info)
labels = torch.randn(20, 5).to(device_id)
loss_fn(outputs, labels).backward()
optimizer.step()
print(state_info) ####### print function 2, the dict is not updated here
if __name__ == "__main__":
demo_basic()
```
For the second print function, state_info is not changed, i.e. not changed to 10. When DDP is not used, state_info is changed. It is said that this is not a feature of DDP. Reference: [Forward arguments are not updated in DDP](https://discuss.pytorch.org/t/forward-arguments-are-not-updated-in-ddp/169748/2?u=yzxhd).
### Versions
Collecting environment information...
PyTorch version: 1.9.1
Is debug build: False
CUDA used to build PyTorch: 10.2
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.5 LTS (x86_64)
GCC version: (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0
Clang version: Could not collect
CMake version: version 3.21.3
Libc version: glibc-2.31
Python version: 3.8.11 (default, Aug 3 2021, 15:09:35) [GCC 7.5.0] (64-bit runtime)
Python platform: Linux-5.4.0-136-generic-x86_64-with-glibc2.17
Is CUDA available: True
CUDA runtime version: 10.2.89
CUDA_MODULE_LOADING set to:
GPU models and configuration:
GPU 0: NVIDIA GeForce RTX 2080 Ti
GPU 1: NVIDIA GeForce GTX 1080 Ti
Nvidia driver version: 470.161.03
cuDNN version: Probably one of the following:
/usr/local/cuda-10.2/targets/x86_64-linux/lib/libcudnn.so.8.2.2
/usr/local/cuda-10.2/targets/x86_64-linux/lib/libcudnn_adv_infer.so.8.2.2
/usr/local/cuda-10.2/targets/x86_64-linux/lib/libcudnn_adv_train.so.8.2.2
/usr/local/cuda-10.2/targets/x86_64-linux/lib/libcudnn_cnn_infer.so.8.2.2
/usr/local/cuda-10.2/targets/x86_64-linux/lib/libcudnn_cnn_train.so.8.2.2
/usr/local/cuda-10.2/targets/x86_64-linux/lib/libcudnn_ops_infer.so.8.2.2
/usr/local/cuda-10.2/targets/x86_64-linux/lib/libcudnn_ops_train.so.8.2.2
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] neural-renderer-pytorch==1.1.3
[pip3] numpy==1.23.5
[pip3] pytorch3d==0.6.0
[pip3] torch==1.9.1
[pip3] torch-cluster==1.5.9
[pip3] torch-geometric==2.0.2
[pip3] torch-scatter==2.0.8
[pip3] torch-sparse==0.6.12
[pip3] torchaudio==0.9.0a0+a85b239
[pip3] torchvision==0.10.1
[conda] blas 1.0 mkl
[conda] cudatoolkit 10.2.89 hfd86e86_1
[conda] ffmpeg 4.3 hf484d3e_0 pytorch
[conda] libblas 3.9.0 11_linux64_mkl conda-forge
[conda] libcblas 3.9.0 11_linux64_mkl conda-forge
[conda] liblapack 3.9.0 11_linux64_mkl conda-forge
[conda] mkl 2021.3.0 h06a4308_520
[conda] mkl-service 2.4.0 py38h7f8727e_0
[conda] mkl_fft 1.3.0 py38h42c9631_2
[conda] mkl_random 1.2.2 py38h51133e4_0
[conda] neural-renderer-pytorch 1.1.3 pypi_0 pypi
[conda] numpy 1.23.5 pypi_0 pypi
[conda] pytorch 1.9.1 py3.8_cuda10.2_cudnn7.6.5_0 pytorch
[conda] pytorch3d 0.6.0 pypi_0 pypi
[conda] torch-cluster 1.5.9 pypi_0 pypi
[conda] torch-geometric 2.0.2 pypi_0 pypi
[conda] torch-scatter 2.0.8 pypi_0 pypi
[conda] torch-sparse 0.6.12 pypi_0 pypi
[conda] torchaudio 0.9.1 py38 pytorch
[conda] torchvision 0.10.1 py38_cu102 pytorch
cc @mrshenli @pritamdamania87 @zhaojuanmao @satgera @rohan-varma @gqchen @aazzolini @osalpekar @jiayisuse @H-Huang @kwen2501 @awgu
| 0 |
3,739 | 92,086 |
Error while building pytorch mobile binaries from source
|
triaged, oncall: mobile
|
### 🐛 Describe the bug
I am trying to build pytorch mobile binaries with PyTorch 1.13.1 based on the instructions here. https://pytorch.org/mobile/android/#building-pytorch-android-from-source
I am building this on M1 Mac (OS 12.6.1) using android studio Dolphin 2021.3.1.
CMake and other versions mentioned below.
I am getting the following error when I run `sh ./scripts/build_pytorch_android.sh`
FYI, I am noticing the same error when building iOS binaries too
```
Run Build Command(s):/usr/bin/make -f Makefile cmTC_09f60/fast && /Library/Developer/CommandLineTools/usr/bin/make -f CMakeFiles/cmTC_09f60.dir/build.make CMakeFiles/cmTC_09f60.dir/build
Building CXX object CMakeFiles/cmTC_09f60.dir/src.cxx.o
/Users/agunapal/Library/Android/sdk/ndk/25.1.8937393/toolchains/llvm/prebuilt/darwin-x86_64/bin/clang++ --target=armv7-none-linux-androideabi21 --sysroot=/Users/agunapal/Library/Android/sdk/ndk/25.1.8937393/toolchains/llvm/prebuilt/darwin-x86_64/sysroot -DCAFFE2_NEED_TO_TURN_OFF_DEPRECATION_WARNING -g -DANDROID -fdata-sections -ffunction-sections -funwind-tables -fstack-protector-strong -no-canonical-prefixes -D_FORTIFY_SOURCE=2 -march=armv7-a -mthumb -Wformat -Werror=format-security -frtti -fexceptions -ffunction-sections -fdata-sections -std=c++14 -fPIE -std=gnu++14 -MD -MT CMakeFiles/cmTC_09f60.dir/src.cxx.o -MF CMakeFiles/cmTC_09f60.dir/src.cxx.o.d -o CMakeFiles/cmTC_09f60.dir/src.cxx.o -c /Users/agunapal/Documents/pytorch/pytorch/build_android_armeabi-v7a/CMakeFiles/CMakeScratch/TryCompile-wdnPM8/src.cxx
/Users/agunapal/Documents/pytorch/pytorch/build_android_armeabi-v7a/CMakeFiles/CMakeScratch/TryCompile-wdnPM8/src.cxx:1:10: fatal error: 'glog/stl_logging.h' file not found
#include <glog/stl_logging.h>
^~~~~~~~~~~~~~~~~~~~
1 error generated.
make[1]: *** [CMakeFiles/cmTC_09f60.dir/src.cxx.o] Error 1
make: *** [cmTC_09f60/fast] Error 2
```
I am also noticing another error
```
In file included from /Users/agunapal/Documents/pytorch/pytorch/build_android_armeabi-v7a/CMakeFiles/CMakeScratch/TryCompile-T8DW2n/src.cxx:4:
/Users/agunapal/Library/Android/sdk/ndk/25.1.8937393/toolchains/llvm/prebuilt/darwin-x86_64/lib64/clang/14.0.6/include/immintrin.h:14:2: error: "This header is only meant to be used on x86 and x64 architecture"
#error "This header is only meant to be used on x86 and x64 architecture"
^
```
[CMakeError.log](https://github.com/pytorch/pytorch/files/10404419/CMakeError.log)
CMake summary:
```
-- General:
-- CMake version : 3.25.1
-- CMake command : /opt/homebrew/Cellar/cmake/3.25.1/bin/cmake
-- System : Android
-- C++ compiler : /Users/agunapal/Library/Android/sdk/ndk/25.1.8937393/toolchains/llvm/prebuilt/darwin-x86_64/bin/clang++
-- C++ compiler id : Clang
-- C++ compiler version : 14.0.6
-- Using ccache if found : ON
-- Found ccache : CCACHE_PROGRAM-NOTFOUND
-- CXX flags : -g -DANDROID -fdata-sections -ffunction-sections -funwind-tables -fstack-protector-strong -no-canonical-prefixes -D_FORTIFY_SOURCE=2 -march=armv7-a -mthumb -Wformat -Werror=format-security -frtti -fexceptions -ffunction-sections -fdata-sections -Wno-deprecated -fvisibility-inlines-hidden -DUSE_PTHREADPOOL -DUSE_VULKAN_WRAPPER -DUSE_PYTORCH_QNNPACK -DUSE_XNNPACK -DUSE_VULKAN -DUSE_VULKAN_API -DBUILD_LITE_INTERPRETER -DSYMBOLICATE_MOBILE_DEBUG_HANDLE -O2 -fPIC -Wno-narrowing -Wall -Wextra -Werror=return-type -Werror=non-virtual-dtor -Wno-missing-field-initializers -Wno-type-limits -Wno-array-bounds -Wno-unknown-pragmas -Wunused-local-typedefs -Wno-unused-parameter -Wno-unused-function -Wno-unused-result -Wno-strict-overflow -Wno-strict-aliasing -Wno-error=deprecated-declarations -Wvla-extension -Wno-range-loop-analysis -Wno-pass-failed -Wno-error=pedantic -Wno-error=redundant-decls -Wno-error=old-style-cast -Wconstant-conversion -Wno-invalid-partial-specialization -Wno-typedef-redefinition -Wno-unused-private-field -Wno-inconsistent-missing-override -Wno-c++14-extensions -Wno-constexpr-not-const -Wno-missing-braces -Wunused-lambda-capture -Wunused-local-typedef -Qunused-arguments -fcolor-diagnostics -fdiagnostics-color=always -Wno-unused-but-set-variable -fno-math-errno -fno-trapping-math -Werror=format -Werror=cast-function-type -g0
-- Build type : Release
-- Compile definitions :
-- CMAKE_PREFIX_PATH : /Users/agunapal/opt/anaconda3/envs/torchmobile/lib/python3.8/site-packages;/Users/agunapal/Library/Android/sdk/ndk/25.1.8937393/toolchains/llvm/prebuilt/darwin-x86_64
-- CMAKE_INSTALL_PREFIX : /Users/agunapal/Documents/pytorch/pytorch/build_android_armeabi-v7a/install
-- USE_GOLD_LINKER : OFF
--
-- TORCH_VERSION : 1.13.0
-- CAFFE2_VERSION : 1.13.0
-- BUILD_CAFFE2 : OFF
-- BUILD_CAFFE2_OPS : OFF
-- BUILD_STATIC_RUNTIME_BENCHMARK: OFF
-- BUILD_TENSOREXPR_BENCHMARK: OFF
-- BUILD_NVFUSER_BENCHMARK: OFF
-- BUILD_BINARY : OFF
-- BUILD_CUSTOM_PROTOBUF : OFF
-- Protobuf compiler :
-- Protobuf includes :
-- Protobuf libraries :
-- BUILD_DOCS : OFF
-- BUILD_PYTHON : OFF
-- BUILD_SHARED_LIBS : OFF
-- CAFFE2_USE_MSVC_STATIC_RUNTIME : ON
-- BUILD_TEST : OFF
-- BUILD_JNI : OFF
-- BUILD_MOBILE_AUTOGRAD : OFF
-- BUILD_LITE_INTERPRETER: ON
-- INTERN_BUILD_MOBILE : ON
-- TRACING_BASED : OFF
-- USE_BLAS : 1
-- BLAS :
-- BLAS_HAS_SBGEMM :
-- USE_LAPACK : 0
-- USE_ASAN : OFF
-- USE_CPP_CODE_COVERAGE : OFF
-- USE_CUDA : OFF
-- USE_ROCM : OFF
-- USE_EIGEN_FOR_BLAS : ON
-- USE_FBGEMM : OFF
-- USE_FAKELOWP : OFF
-- USE_KINETO : OFF
-- USE_FFMPEG : OFF
-- USE_GFLAGS : OFF
-- USE_GLOG : OFF
-- USE_LEVELDB : OFF
-- USE_LITE_PROTO : OFF
-- USE_LMDB : OFF
-- USE_METAL : OFF
-- USE_PYTORCH_METAL : OFF
-- USE_PYTORCH_METAL_EXPORT : OFF
-- USE_MPS : OFF
-- USE_FFTW : OFF
-- USE_MKL :
-- USE_MKLDNN : OFF
-- USE_UCC : OFF
-- USE_ITT : OFF
-- USE_NCCL : OFF
-- USE_NNPACK : ON
-- USE_NUMPY : ON
-- USE_OBSERVERS : OFF
-- USE_OPENCL : OFF
-- USE_OPENCV : OFF
-- USE_OPENMP : OFF
-- USE_TBB : OFF
-- USE_VULKAN : ON
-- USE_VULKAN_FP16_INFERENCE : OFF
-- USE_VULKAN_RELAXED_PRECISION : OFF
-- USE_VULKAN_SHADERC_RUNTIME : OFF
-- USE_PROF : OFF
-- USE_QNNPACK : OFF
-- USE_PYTORCH_QNNPACK : ON
-- USE_XNNPACK : ON
-- USE_REDIS : OFF
-- USE_ROCKSDB : OFF
-- USE_ZMQ : OFF
-- USE_DISTRIBUTED : OFF
-- Public Dependencies : caffe2::Threads
-- Private Dependencies : eigen_blas;pthreadpool;cpuinfo;pytorch_qnnpack;XNNPACK;VulkanWrapper;fp16;log;fmt::fmt-header-only;dl
-- USE_COREML_DELEGATE : OFF
-- BUILD_LAZY_TS_BACKEND : OFF
```
### Versions
```
Collecting environment information...
PyTorch version: N/A
Is debug build: N/A
CUDA used to build PyTorch: N/A
ROCM used to build PyTorch: N/A
OS: macOS 12.6.1 (x86_64)
GCC version: Could not collect
Clang version: 14.0.0 (clang-1400.0.29.202)
CMake version: version 3.25.1
Libc version: N/A
Python version: 3.8.15 (default, Nov 24 2022, 09:04:07) [Clang 14.0.6 ] (64-bit runtime)
Python platform: macOS-10.16-x86_64-i386-64bit
Is CUDA available: N/A
CUDA runtime version: Could not collect
CUDA_MODULE_LOADING set to: N/A
GPU models and configuration: Could not collect
Nvidia driver version: Could not collect
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: N/A
Versions of relevant libraries:
[pip3] numpy==1.24.1
[conda] numpy 1.24.1 pypi_0 pypi
```
| 4 |
3,740 | 92,078 |
DISABLED test_cdist_large_batch (__main__.TestMPS)
|
triaged, module: flaky-tests, skipped, module: mps
|
Platforms: mac, macos
This test was disabled because it is failing in CI. See [recent examples](https://hud.pytorch.org/failure/test_cdist_large_batch) and the most recent trunk [workflow logs](https://github.com/pytorch/pytorch/runs/10604384288).
Over the past 72 hours, it has flakily failed in 2 workflow(s).
**Debugging instructions (after clicking on the recent samples link):**
To find relevant log snippets:
1. Click on the workflow logs linked above
2. Grep for `test_cdist_large_batch`
cc @kulinseth @albanD @malfet @DenisVieriu97 @razarmehr @abhudev
| 1 |
3,741 | 92,073 |
compilig MultiHeadAttention
|
oncall: jit
|
### 🐛 Describe the bug
If `vdim` or `kdim` is different from `embed_model` the `nn.MultiheadAttention` module throws error when calling `torch.jit.scritp` on it.
```python
import torch
m = torch.nn.MultiheadAttention(10, 10, vdim=5)
torch.jit.script(m)
```
### Versions
Collecting environment information...
PyTorch version: 1.13.0+cu117
Is debug build: False
CUDA used to build PyTorch: 11.7
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.5 LTS (x86_64)
GCC version: (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0
Clang version: Could not collect
CMake version: version 3.16.3
Libc version: glibc-2.31
Python version: 3.8.5 (default, Sep 4 2020, 07:30:14) [GCC 7.3.0] (64-bit runtime)
Python platform: Linux-5.15.0-56-generic-x86_64-with-glibc2.10
Is CUDA available: True
CUDA runtime version: 10.1.243
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration: GPU 0: Quadro RTX 6000
Nvidia driver version: 510.47.03
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] mypy-extensions==0.4.3
[pip3] numpy==1.19.2
[pip3] numpydoc==1.1.0
[pip3] open-clip-torch==2.8.2
[pip3] torch==1.13.0
[pip3] torchaudio==0.9.0a0+33b2469
[pip3] torchvision==0.10.0
[conda] blas 1.0 mkl
[conda] cudatoolkit 10.2.89 hfd86e86_1
[conda] mkl 2020.2 256
[conda] mkl-service 2.3.0 py38he904b0f_0
[conda] mkl_fft 1.2.0 py38h23d657b_0
[conda] mkl_random 1.1.1 py38h0573a6f_0
[conda] numpy 1.19.2 py38h54aff64_0
[conda] numpy-base 1.19.2 py38hfa32c7d_0
[conda] numpydoc 1.1.0 pyhd3eb1b0_1
[conda] open-clip-torch 2.8.2 dev_0 <develop>
[conda] torch 1.13.0 pypi_0 pypi
[conda] torchaudio 0.9.0 py38 pytorch
[conda] torchvision 0.10.0 py38_cu102 pytorch
cc @EikanWang @jgong5 @wenzhe-nrv @sanchitintel
| 1 |
3,742 | 92,072 |
Implement forward AD with grid_sampler_2d
|
triaged, module: forward ad
|
### 🚀 The feature, motivation and pitch
I have a use case where I need to calculate the singular vectors of the jacobian of a function which generates and images and sends it through the vgg network used in stylegan2-ada for the [PPL implementation](https://github.com/NVlabs/stylegan2-ada-pytorch/blob/main/metrics/perceptual_path_length.py)
I use `torch.autograd.functional.jacobian`and would like to use `vectorize=True`, `strategy='forward-mode` but run into the following
```
RuntimeError: Trying to use forward AD with grid_sampler_2d that does not support it because it has not been implemented yet.
Please file an issue to PyTorch at https://github.com/pytorch/pytorch/issues/new?template=feature-request.yml so that we can prioritize its implementation.
Note that forward AD support for some operators require PyTorch to be built with TorchScript and for JIT to be enabled. If the environment var PYTORCH_JIT=0 is set or if the library is not built with TorchScript, some operators may no longer be used with forward AD.
```
| 0 |
3,743 | 92,041 |
jit testing fails on 3.11 debug build
|
oncall: jit
|
test_jit fails very loundly on 3.11 debug build:
It prints thousands of
```
gc:0: ResourceWarning: Object of type torch._C.ScriptFunction is not untracked before destruction
```
And then crash with
```
Modules/gcmodule.c:442: update_refs: Assertion "gc_get_refs(gc) != 0" failed
Enable tracemalloc to get the memory block allocation traceback
object address : 0x7f7f48661800
object refcount : 0
object type : 0x6a5a2c0
object type name: torch._C.ScriptFunction
object repr : <refcnt 0 at 0x7f7f48661800>
Fatal Python error: _PyObject_AssertFailed: _PyObject_AssertFailed
Python runtime state: initialized
```
cc @EikanWang @jgong5 @wenzhe-nrv @sanchitintel
| 0 |
3,744 | 92,029 |
Update docs URLs in torch/_functorch/autograd_function.py to stable before 2.0
|
triaged
|
To be filled in
| 0 |
3,745 | 92,011 |
[Releng] Add repo dispatch via webhook to trigger domain builds after the core
|
oncall: releng, triaged
|
### 🐛 Describe the bug
Add repo dispatch via webhook to trigger domain builds after the core
### Versions
nightly
| 2 |
3,746 | 92,007 |
Add plots of LRSchedulers to doc to make it easier to read
|
module: docs, triaged, actionable, module: LrScheduler
|
We can do something similar to what we have for activation functions https://pytorch.org/docs/stable/generated/torch.nn.ReLU.html?highlight=relu#torch.nn.ReLU
A simple script similar to the one shared in https://github.com/pytorch/pytorch/issues/91765 can be used a the basis for generating these plots.
cc @svekars @carljparker
| 0 |
3,747 | 91,996 |
autograd.functional.jacobian : Imaginary part is lost for functions with real input and complex output.
|
module: autograd, triaged, has workaround
|
### 🐛 Describe the bug
As per title, similar to #90499
```python
import torch
import functorch
m = torch.tensor([[0.30901699437494745, 0.9510565162951535], [-0.9510565162951535, 0.30901699437494745]], dtype=torch.double)
def fn(m):
return m * 0.5j
jacfwd_o = functorch.jacfwd(fn)(m)
jacobian_o = torch.autograd.functional.jacobian(fn, m)
print(jacfwd_o)
print(jacobian_o)
```
Output:
```
tensor([[[[0.+0.5000j, 0.+0.0000j],
[0.+0.0000j, 0.+0.0000j]],
[[0.+0.0000j, 0.+0.5000j],
[0.+0.0000j, 0.+0.0000j]]],
[[[0.+0.0000j, 0.+0.0000j],
[0.+0.5000j, 0.+0.0000j]],
[[0.+0.0000j, 0.+0.0000j],
[0.+0.0000j, 0.+0.5000j]]]], dtype=torch.complex128)
tensor([[[[0., 0.],
[0., 0.]],
[[0., 0.],
[0., 0.]]],
[[[0., 0.],
[0., 0.]],
[[0., 0.],
[0., 0.]]]], dtype=torch.float64)
```
### Versions
master
cc @ezyang @albanD @zou3519 @gqchen @pearu @nikitaved @soulitzer @Lezcano @Varal7
| 1 |
3,748 | 91,990 |
export does not support boolean tensor indexing
|
triaged, module: dynamic shapes, module: dynamo
|
```
import torch._dynamo
torch._dynamo.config.dynamic_shapes=True
def foo(images, handedness):
right_hand_mask = handedness == 1
images[right_hand_mask] = images[right_hand_mask].flip(-1)
torch._dynamo.export(foo, torch.randint(0, 256, (512, 1, 1, 96, 96)), torch.randint(0, 1, (512, 1, 1)))
```
raises:
```
dynamic shape operator: aten.index.Tensor
```
My ideal behavior would be that we are capable of returning a tensor with "new" shapes that are unbacked symints, similar to what we want from nonzero.
Internal command to reproduce the issue: P595150412
cc @mlazos @soumith @voznesenskym @yanboliang @penguinwu @anijain2305 @EikanWang @jgong5 @Guobing-Chen @chunyuan-w @XiaobingSuper @zhuhaozhe @blzheng @Xia-Weiwen @wenzhe-nrv @jiayisunx @desertfire
| 4 |
3,749 | 91,989 |
Torch's affinity setting lead to openvino using only one core.
|
triaged, module: intel, intel priority
|
### 🐛 Describe the bug
Torch's affinity setting lead to openvino using only one core.
I export a pytorch resnet50 model to OpenVINO IR Model with following steps.
1. export resnet50 to onnx model
```
from torchvision.models import resnet50
from openvino.runtime import Core
import torch
from pathlib import Path
model = resnet50()
model.eval()
dummy_input = torch.randn((1, 3, 224, 224),
generator=None,
device="cpu",
dtype=torch.float32)
onnx_path = Path("resnet50.onnx")
if not onnx_path.exists():
torch.onnx.export(
model,
dummy_input,
onnx_path,
opset_version=11,
do_constant_folding=False,
)
```
2. Convert onnx model to openvino IR model:
```
mo --input_model "resnet50.onnx" --input_shape "[1,3, 224, 224]" --mean_values="[123.675, 116.28 , 103.53]" --scale_values="[58.395, 57.12 , 57.375]" --data_type FP32 --output_dir model
```
3. Export Intel KMP affinity env:
```
export LD_PRELOAD=conda_env_home/lib/libiomp5.so # like /usr/local/envs/test/lib/libiomp5.so
export KMP_AFFINITY=granularity=fine,compact,1,0
```
4. At last, run openvino inference:
```
from openvino.runtime import Core
from pathlib import Path
import numpy as np
dummy_input = np.random.randn(1, 3, 224, 224)
config = {
"CPU_THREADS_NUM": "48"
}
ie = Core()
classification_model_xml = "model/resnet50.xml"
model = ie.read_model(model=classification_model_xml)
import torch # if import torch here, openvino will use only one core.
compiled_model = ie.compile_model(model, "CPU", config)
# import torch # if import torch here, openvino will use 48 cores.
input_layer = compiled_model.input(0)
output_layer = compiled_model.output(0)
ir = compiled_model.create_infer_request()
import time
s = time.time()
for i in range(200):
ir.infer(inputs={input_layer.any_name: dummy_input})
print("time cost: " + str(time.time() - s))
```
BTW: gomp affinity `export OMP_PROC_BIND=CLOSE` has the same hehaviour.
### Versions
torch: 1.13.1
python: 3.7.10
cpu: Intel(R) Xeon(R) Gold 6252 CPU @ 2.10GHz
Set up env with
```
conda create -n test -y python==3.7.10 setuptools==58.0.4
conda activate test
conda install intel-openmp
pip3 install torch torchvision
pip3 install openvino openvino-dev
```
cc @frank-wei @jgong5 @mingfeima @XiaobingSuper @sanchitintel @ashokei @jingxu10
| 10 |
3,750 | 91,986 |
An error happend when I convert pytorch model to onnx
|
module: onnx, triaged
|
### 🐛 Describe the bug
Recently I have been experimenting with virtual try-on(VTON). Due to the performance requirements of the competition, I intend to convert the VTON pytorch model to onnx model, on one hand to reduce the model size and on the other hand to improve the running speed on CPU.
But there were some problems when I converted the model. The pytorch model's name is' gen.pth'(for generating the image after trying on clothes) and it takes two inputs, a tensor with shape [1, 9, 1024, 768] and a tensor with shape [1, 7, 1024, 768].
**Here is the code:**
```
dummy_input0 = torch.randn(1, 9, 1024, 768)
dummy_input1 = torch.randn(1, 7, 1024, 768)
with warnings.catch_warnings():
warnings.filterwarnings("ignore")
if not onnx_path.exists():
torch.onnx.export(
generator,
(dummy_input0,
dummy_input1),
onnx_path,
)
print(f"ONNX model exported to {onnx_path}.")
else:
print(f"ONNX model {onnx_path} already exists.")
```
**Here is the error message:**
```
> ---------------------------------------------------------------------------
> RuntimeError Traceback (most recent call last)
> Cell In[9], line 8
> 6 warnings.filterwarnings("ignore")
> 7 if not onnx_path.exists():
> ----> 8 torch.onnx.export(
> 9 generator,
> 10 (dummy_input0,
> 11 dummy_input1),
> 12 onnx_path,
> 13 )
> 14 print(f"ONNX model exported to {onnx_path}.")
> 15 else:
>
> File E:\Anaconda3\envs\openvino_env\lib\site-packages\torch\onnx\__init__.py:350, in export(model, args, f, export_params, verbose, training, input_names, output_names, operator_export_type, opset_version, do_constant_folding, dynamic_axes, keep_initializers_as_inputs, custom_opsets, export_modules_as_functions)
> 74 r"""
> 75 Exports a model into ONNX format. If ``model`` is not a
> 76 :class:`torch.jit.ScriptModule` nor a :class:`torch.jit.ScriptFunction`, this runs
> (...)
> 345 model to the file ``f`` even if this is raised.
> 346 """
> 348 from torch.onnx import utils
> --> 350 return utils.export(
> 351 model,
> 352 args,
> 353 f,
> 354 export_params,
> 355 verbose,
> 356 training,
> 357 input_names,
> 358 output_names,
> 359 operator_export_type,
> 360 opset_version,
> 361 do_constant_folding,
> 362 dynamic_axes,
> 363 keep_initializers_as_inputs,
> 364 custom_opsets,
> 365 export_modules_as_functions,
> 366 )
>
> File E:\Anaconda3\envs\openvino_env\lib\site-packages\torch\onnx\utils.py:163, in export(model, args, f, export_params, verbose, training, input_names, output_names, operator_export_type, opset_version, do_constant_folding, dynamic_axes, keep_initializers_as_inputs, custom_opsets, export_modules_as_functions)
> 145 def export(
> 146 model,
> 147 args,
> (...)
> 160 export_modules_as_functions=False,
> 161 ):
> --> 163 _export(
> 164 model,
> 165 args,
> 166 f,
> 167 export_params,
> 168 verbose,
> 169 training,
> 170 input_names,
> 171 output_names,
> 172 operator_export_type=operator_export_type,
> 173 opset_version=opset_version,
> 174 do_constant_folding=do_constant_folding,
> 175 dynamic_axes=dynamic_axes,
> 176 keep_initializers_as_inputs=keep_initializers_as_inputs,
> 177 custom_opsets=custom_opsets,
> 178 export_modules_as_functions=export_modules_as_functions,
> 179 )
>
> File E:\Anaconda3\envs\openvino_env\lib\site-packages\torch\onnx\utils.py:1074, in _export(model, args, f, export_params, verbose, training, input_names, output_names, operator_export_type, export_type, opset_version, do_constant_folding, dynamic_axes, keep_initializers_as_inputs, fixed_batch_size, custom_opsets, add_node_names, onnx_shape_inference, export_modules_as_functions)
> 1071 dynamic_axes = {}
> 1072 _validate_dynamic_axes(dynamic_axes, model, input_names, output_names)
> -> 1074 graph, params_dict, torch_out = _model_to_graph(
> 1075 model,
> 1076 args,
> 1077 verbose,
> 1078 input_names,
> 1079 output_names,
> 1080 operator_export_type,
> 1081 val_do_constant_folding,
> 1082 fixed_batch_size=fixed_batch_size,
> 1083 training=training,
> 1084 dynamic_axes=dynamic_axes,
> 1085 )
> 1087 # TODO: Don't allocate a in-memory string for the protobuf
> 1088 defer_weight_export = (
> 1089 export_type is not torch.onnx.ExportTypes.PROTOBUF_FILE
> 1090 )
>
> File E:\Anaconda3\envs\openvino_env\lib\site-packages\torch\onnx\utils.py:731, in _model_to_graph(model, args, verbose, input_names, output_names, operator_export_type, do_constant_folding, _disable_torch_constant_prop, fixed_batch_size, training, dynamic_axes)
> 728 params_dict = _get_named_param_dict(graph, params)
> 730 try:
> --> 731 graph = _optimize_graph(
> 732 graph,
> 733 operator_export_type,
> 734 _disable_torch_constant_prop=_disable_torch_constant_prop,
> 735 fixed_batch_size=fixed_batch_size,
> 736 params_dict=params_dict,
> 737 dynamic_axes=dynamic_axes,
> 738 input_names=input_names,
> 739 module=module,
> 740 )
> 741 except Exception as e:
> 742 torch.onnx.log("Torch IR graph at exception: ", graph)
>
> File E:\Anaconda3\envs\openvino_env\lib\site-packages\torch\onnx\utils.py:308, in _optimize_graph(graph, operator_export_type, _disable_torch_constant_prop, fixed_batch_size, params_dict, dynamic_axes, input_names, module)
> 306 _C._jit_pass_onnx_set_dynamic_input_shape(graph, dynamic_axes, input_names)
> 307 _C._jit_pass_onnx_lint(graph)
> --> 308 graph = _C._jit_pass_onnx(graph, operator_export_type)
> 309 _C._jit_pass_onnx_lint(graph)
> 310 _C._jit_pass_lint(graph)
>
> File E:\Anaconda3\envs\openvino_env\lib\site-packages\torch\onnx\__init__.py:416, in _run_symbolic_function(*args, **kwargs)
> 413 def _run_symbolic_function(*args, **kwargs):
> 414 from torch.onnx import utils
> --> 416 return utils._run_symbolic_function(*args, **kwargs)
>
> File E:\Anaconda3\envs\openvino_env\lib\site-packages\torch\onnx\utils.py:1406, in _run_symbolic_function(g, block, n, inputs, env, operator_export_type)
> 1404 if op_name == "PythonOp":
> 1405 inputs = (n, *inputs)
> -> 1406 return symbolic_fn(g, *inputs, **attrs)
> 1407 elif ns == "onnx":
> 1408 # Clone node to trigger ONNX shape inference
> 1409 attrs = {k + "_" + n.kindOf(k)[0]: n[k] for k in n.attributeNames()} # type: ignore[attr-defined]
>
> File E:\Anaconda3\envs\openvino_env\lib\site-packages\torch\onnx\symbolic_helper.py:234, in parse_args.<locals>.decorator.<locals>.wrapper(g, *args, **kwargs)
> 229 if len(kwargs) == 1:
> 230 assert "_outputs" in kwargs, (
> 231 f"Symbolic function {fn.__name__}'s '**kwargs' can only contain '_outputs' key at '**kwargs'. "
> 232 f"{FILE_BUG_MSG}"
> 233 )
> --> 234 return fn(g, *args, **kwargs)
>
> File E:\Anaconda3\envs\openvino_env\lib\site-packages\torch\onnx\symbolic_opset9.py:1963, in instance_norm(g, input, weight, bias, running_mean, running_var, use_input_stats, momentum, eps, cudnn_enabled)
> 1961 if weight is None or symbolic_helper._is_none(weight):
> 1962 if channel_size is None:
> -> 1963 raise RuntimeError(
> 1964 "Unsupported: ONNX export of instance_norm for unknown " "channel size."
> 1965 )
> 1966 weight_value = torch.tensor([1.0] * channel_size).type(
> 1967 "torch." + input.type().scalarType() + "Tensor"
> 1968 )
> 1969 weight = g.op("Constant", value_t=weight_value)
>
> RuntimeError: Unsupported: ONNX export of instance_norm for unknown channel size.
```
### Versions
```
E:\Anaconda3\envs\openvino_env\python.exe E:\fuchuang\openvino\openvino_notebooks-main\notebooks\102-viton-putorch-to-openvino\collet_env.py
Collecting environment information...
PyTorch version: 1.12.1
Is debug build: False
CUDA used to build PyTorch: Could not collect
ROCM used to build PyTorch: N/A
OS: Microsoft Windows 11 家庭中文版
GCC version: Could not collect
Clang version: Could not collect
CMake version: Could not collect
Libc version: N/A
Python version: 3.9.15 (main, Nov 24 2022, 14:39:17) [MSC v.1916 64 bit (AMD64)] (64-bit runtime)
Python platform: Windows-10-10.0.22000-SP0
Is CUDA available: False
CUDA runtime version: Could not collect
CUDA_MODULE_LOADING set to: N/A
GPU models and configuration: GPU 0: NVIDIA GeForce RTX 3060 Laptop GPU
Nvidia driver version: 512.78
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.23.5
[pip3] torch==1.13.0
[pip3] torchvision==0.14.0
[conda] blas 1.0 mkl
[conda] mkl 2021.4.0 haa95532_640
[conda] mkl-service 2.4.0 py39h2bbff1b_0
[conda] mkl_fft 1.3.1 py39h277e83a_0
[conda] mkl_random 1.2.2 py39hf11a4ad_0
[conda] numpy 1.23.4 pypi_0 pypi
[conda] numpy-base 1.23.5 py39h4da318b_0
[conda] pytorch 1.12.1 cpu_py39h5e1f01c_0
[conda] torch 1.13.0 pypi_0 pypi
[conda] torchvision 0.14.0 pypi_0 pypi
Process finished with exit code 0
```
| 3 |
3,751 | 91,982 |
sympy failure on model when dynamic_shapes=True
|
triaged, module: dynamic shapes, module: dynamo
|
Error looks like:
```
Traceback (most recent call last):
File "torch/_dynamo/utils.py", line 1078, in run_node
return node.target(*args, **kwargs)
RuntimeError: TypeError: cannot determine truth value of Relational
At:
sympy/core/relational.py(297): __nonzero__
torch/fx/experimental/symbolic_shapes.py(943): _maybe_guard_eq
torch/fx/experimental/symbolic_shapes.py(989): evaluate_expr
torch/fx/experimental/symbolic_shapes.py(209): bool_
```
This is happening on an internal model. Full stack trace: P595091810.
Repro: patch D42443834 and run the command in the comment: https://fburl.com/diff/f5nphw9a
cc @mlazos @soumith @voznesenskym @yanboliang @penguinwu @anijain2305 @EikanWang @jgong5 @Guobing-Chen @chunyuan-w @XiaobingSuper @zhuhaozhe @blzheng @Xia-Weiwen @wenzhe-nrv @jiayisunx @desertfire
| 1 |
3,752 | 91,970 |
Unknown CUDA graph CaptureStatus21852
|
needs reproduction, triaged
|
### 🐛 Describe the bug
Hi there,
We're getting unknown CUDA graph errors with PyTorch 1.13.1. Though it is flaky, it shows up twice, and might be worthwhile looking into & getting fixed.
Here is the stack trace:
```
[1,17]<stdout>:[2023-01-06 19 (tel:2023010619):46:19.112: C smdistributed/modelparallel/torch/worker.py:110] [17] Hit an exception for 9008/0 on thread 1: false INTERNAL ASSERT FAILED at "../c10/cuda/CUDAGraphsC10Utils.h":73, please report a bug to PyTorch. Unknown CUDA graph CaptureStatus21852
[1,17]<stdout>:[2023-01-06 19 (tel:2023010619):46:19.114: C smdistributed/modelparallel/torch/worker.py:115] [17] File "/opt/conda/lib/python3.9/site-packages/smdistributed/modelparallel/torch/worker.py", line 515, in thread_compute
[1,17]<stdout>: self.thread_execute_backward(req)
[1,17]<stdout>: File "/opt/conda/lib/python3.9/site-packages/smdistributed/modelparallel/torch/worker.py", line 486, in thread_execute_backward
[1,17]<stdout>: self._bwd_aggregated_execute(req, mod, parent_mod)
[1,17]<stdout>: File "/opt/conda/lib/python3.9/site-packages/smdistributed/modelparallel/torch/worker.py", line 415, in _bwd_aggregated_execute
[1,17]<stdout>: torch.autograd.backward(all_outputs, all_grads, retain_graph=retain)
[1,17]<stdout>: File "/opt/conda/lib/python3.9/site-packages/torch/autograd/*init*.py", line 197, in backward
[1,17]<stdout>: Variable._execution_engine.run_backward( # Calls into the C++ engine to run the backward pass
[1,17]<stdout>: File "/opt/conda/lib/python3.9/site-packages/torch/autograd/function.py", line 267, in apply
[1,17]<stdout>: return user_fn(self, *args)
[1,17]<stdout>: File "/opt/conda/lib/python3.9/site-packages/smdistributed/modelparallel/torch/patches/checkpoint.py", line 228, in backward
[1,17]<stdout>: outputs = ctx.run_function(*_args, *kwargs)*
*[1,17]<stdout>: File "/opt/conda/lib/python3.9/contextlib.py", line 137, in __exit_*
*[1,17]<stdout>: self.gen.throw(typ, value, traceback)*
*[1,17]<stdout>: File "/opt/conda/lib/python3.9/site-packages/torch/random.py", line 129, in fork_rng*
*[1,17]<stdout>: torch.cuda.set_rng_state(gpu_rng_state, device)*
*[1,17]<stdout>: File "/opt/conda/lib/python3.9/site-packages/torch/cuda/random.py", line 64, in set_rng_state*
*[1,17]<stdout>: lazy_call(cb)*
*[1,17]<stdout>: File "/opt/conda/lib/python3.9/site-packages/torch/cuda/__init_.py", line 165, in _lazy_call*
*[1,17]<stdout>: callable()*
*[1,17]<stdout>: File "/opt/conda/lib/python3.9/site-packages/torch/cuda/random.py", line 62, in cb*
*[1,17]<stdout>: default_generator.set_state(new_state_copy)*
*[1,17]<stdout>:*
*[1,17]<stdout>:[**2023-01-06 19* (tel:2023010619)*:46:19.114: C smdistributed/modelparallel/torch/worker.py:116] [17] Parent exec stack ['main', 'main/module', 'main/module/module', 'main/module/module/transformer', 'main/module/module/transformer/seq_layers', 'main/module/module/transformer/seq_layers/30', 'main/module/module/transformer/seq_layers/30/attention']*
*[1,17]<stdout>:[**2023-01-06 19* (tel:2023010619)*:46:19.114: C smdistributed/modelparallel/torch/worker.py:117] [17] Req <ModExecReq::BWD::mb:0, module:main, sender_module: main, requester:0, executor:0, position: -1>*
*[1,17]<stderr>:[compute-st-worker-26:00059]* * Process received signal
*[1,17]<stderr>:[compute-st-worker-26:00059] Signal: Segmentation fault (11)*
*[1,17]<stderr>:[compute-st-worker-26:00059] Signal code: Address not mapped (1)*
*[1,17]<stderr>:[compute-st-worker-26:00059] Failing at address: (nil)*
*[1,17]<stderr>:[compute-st-worker-26:00059] [ 0] /usr/lib/x86_64-linux-gnu/libpthread.so.0(+0x14420)[0x7f79b11b8420]*
*[1,17]<stderr>:[compute-st-worker-26:00059] [ 1] /opt/conda/lib/python3.9/site-packages/torch/lib/libc10_cuda.so(+0x2735d)[0x7f78c176b35d]*
*[1,17]<stderr>:[compute-st-worker-26:00059] [ 2] /opt/conda/lib/python3.9/site-packages/torch/lib/libc10_cuda.so(+0x43183)[0x7f78c1787183]*
*[1,17]<stderr>:[compute-st-worker-26:00059] [ 3] [1,17]<stderr>:/opt/conda/lib/python3.9/site-packages/torch/lib/libc10_cuda.so(+0x44c38)[0x7f78c1788c38]*
*[1,17]<stderr>:[compute-st-worker-26:00059] [ 4] /opt/conda/lib/python3.9/site-packages/torch/lib/libc10_cuda.so(+0x44e92)[0x7f78c1788e92]*
*[1,17]<stderr>:[compute-st-worker-26:00059] [ 5] [1,17]<stderr>:/opt/conda/lib/python3.9/site-packages/torch/lib/libtorch_cpu.so(_ZN2at6detail13empty_genericEN3c108ArrayRefIlEEPNS1_9AllocatorENS1_14DispatchKeySetENS1_10ScalarTypeENS1_8optionalINS1_12MemoryFormatEEE+0xabf)[0x7f78c317e2bf]*
*[1,17]<stderr>:[compute-st-worker-26:00059] [ 6] [1,17]<stderr>:/opt/conda/lib/python3.9/site-packages/torch/lib/libtorch_cuda_cpp.so(_ZN2at6detail10empty_cudaEN3c108ArrayRefIlEENS1_10ScalarTypeENS1_8optionalINS1_6DeviceEEENS5_INS1_12MemoryFormatEEE+0x111)[0x7f78dca67ac1]*
*[1,17]<stderr>:[compute-st-worker-26:00059] [ 7] [1,17]<stderr>:/opt/conda/lib/python3.9/site-packages/torch/lib/libtorch_cuda_cpp.so(_ZN2at6detail10empty_cudaEN3c108ArrayRefIlEENS1_8optionalINS1_10ScalarTypeEEENS4_INS1_6LayoutEEENS4_INS1_6DeviceEEENS4_IbEENS4_INS1_12MemoryFormatEEE+0x31)[0x7f78dca67d91]*
*[1,17]<stderr>:[compute-st-worker-26:00059] [ 8] [1,17]<stderr>:/opt/conda/lib/python3.9/site-packages/torch/lib/libtorch_cuda_cpp.so(_ZN2at6detail10empty_cudaEN3c108ArrayRefIlEERKNS1_13TensorOptionsE+0x10f)[0x7f78dca67eff]*
*[1,17]<stderr>:[compute-st-worker-26:00059] [ 9] [1,17]<stderr>:/opt/conda/lib/python3.9/site-packages/torch/lib/libtorch_cuda_cu.so(+0x2d1622b)[0x7f789949022b]*
*[1,17]<stderr>:[compute-st-worker-26:00059] [10] [1,17]<stderr>:/opt/conda/lib/python3.9/site-packages/torch/lib/libtorch_cuda_cu.so(+0x2dda806)[0x7f7899554806]*
*[1,17]<stderr>:[compute-st-worker-26:00059] [11] [1,17]<stderr>:/opt/conda/lib/python3.9/site-packages/torch/lib/libtorch_cpu.so(_ZN2at4meta14structured_cat4metaERKN3c108IListRefINS_6TensorEEEl+0xc09)[0x7f78c383a339]*
*[1,17]<stderr>:[compute-st-worker-26:00059] [12] [1,17]<stderr>:/opt/conda/lib/python3.9/site-packages/torch/lib/libtorch_cuda_cu.so(+0x2d23c27)[0x7f789949dc27]*
*[1,17]<stderr>:[compute-st-worker-26:00059] [13] [1,17]<stderr>:/opt/conda/lib/python3.9/site-packages/torch/lib/libtorch_cuda_cu.so(+0x2d23cd0)[0x7f789949dcd0]*
*[1,17]<stderr>:[compute-st-worker-26:00059] [14] [1,17]<stderr>:/opt/conda/lib/python3.9/site-packages/torch/lib/libtorch_cpu.so(_ZN2at4_ops3cat10redispatchEN3c1014DispatchKeySetERKNS2_8IListRefINS_6TensorEEEl+0x78)[0x7f78c3c561f8]*
*[1,17]<stderr>:[compute-st-worker-26:00059] [15] [1,17]<stderr>:/opt/conda/lib/python3.9/site-packages/torch/lib/libtorch_cpu.so(+0x3dc37a1)[0x7f78c56057a1]*
*[1,17]<stderr>:[compute-st-worker-26:00059] [16] [1,17]<stderr>:/opt/conda/lib/python3.9/site-packages/torch/lib/libtorch_cpu.so(+0x3dc43d3)[0x7f78c56063d3]*
*[1,17]<stderr>:[compute-st-worker-26:00059] [17] [1,17]<stderr>:/opt/conda/lib/python3.9/site-packages/torch/lib/libtorch_cpu.so(_ZN2at4_ops3cat4callERKN3c108IListRefINS_6TensorEEEl+0x1a9)[0x7f78c3c99929]*
*[1,17]<stderr>:[compute-st-worker-26:00059] [18] [1,17]<stderr>:/opt/conda/lib/python3.9/site-packages/torch/lib/libtorch_python.so(+0x5c83d3)[0x7f78ec50a3d3]*
*[1,17]<stderr>:[compute-st-worker-26:00059] [19] [1,17]<stderr>:/opt/conda/bin/python(+0x14e26c)[0x555c0737c26c]*
*[1,17]<stderr>:[compute-st-worker-26:00059] [20] [1,17]<stderr>:/opt/conda/bin/python(PyObject_Call+0x157)[0x555c0737a487]*
*[1,17]<stderr>:[compute-st-worker-26:00059] [21] [1,17]<stderr>:/opt/conda/bin/python(_PyEval_EvalFrameDefault+0x5f20)[0x555c0735f860]*
*[1,17]<stderr>:[compute-st-worker-26:00059] [22] /opt/conda/bin/python(+0x12a967)[0x555c07358967]*
*[1,17]<stderr>:[compute-st-worker-26:00059] [23] [1,17]<stderr>:/opt/conda/bin/python(_PyFunction_Vectorcall+0xb9)[0x555c0736ad39]*
*[1,17]<stderr>:[compute-st-worker-26:00059] [24] [1,17]<stderr>:/opt/conda/bin/python(_PyEval_EvalFrameDefault+0x3c3)[0x555c07359d03]*
*[1,17]<stderr>:[compute-st-worker-26:00059] [25] /opt/conda/bin/python(+0x12a967)[0x555c07358967]*
*[1,17]<stderr>:[compute-st-worker-26:00059] [26] /opt/conda/bin/python(_PyFunction_Vectorcall+0xb9)[0x555c0736ad39]*
*[1,17]<stderr>:[compute-st-worker-26:00059] [27] [1,17]<stderr>:/opt/conda/bin/python(PyObject_Call+0xb4)[0x555c0737a3e4]*
*[1,17]<stderr>:[compute-st-worker-26:00059] [28] [1,17]<stderr>:/opt/conda/bin/python(_PyEval_EvalFrameDefault+0x39fa)[0x555c0735d33a]*
*[1,17]<stderr>:[compute-st-worker-26:00059] [29] /opt/conda/bin/python(+0x12a967)[0x555c07358967]*
*[1,17]<stderr>:[compute-st-worker-26:00059] * End of error message *
Primary job terminated normally, but 1 process returned
a non-zero exit code. Per user-direction, the job has been aborted.
mpirun.real noticed that process rank 17 with PID 59 on node compute-st-worker-26 exited on signal 11 (Segmentation fault).
```
Thank you.
### Versions
```
# python collect_env.py
Collecting environment information...
PyTorch version: 1.13.1+cu117
Is debug build: False
CUDA used to build PyTorch: 11.7
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.5 LTS (x86_64)
GCC version: (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0
Clang version: Could not collect
CMake version: version 3.24.3
Libc version: glibc-2.31
Python version: 3.9.13 | packaged by conda-forge | (main, May 27 2022, 16:58:50) [GCC 10.3.0] (64-bit runtime)
Python platform: Linux-5.4.0-1080-aws-x86_64-with-glibc2.31
Is CUDA available: True
CUDA runtime version: 11.7.99
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration:
GPU 0: NVIDIA A100-SXM4-40GB
GPU 1: NVIDIA A100-SXM4-40GB
GPU 2: NVIDIA A100-SXM4-40GB
GPU 3: NVIDIA A100-SXM4-40GB
GPU 4: NVIDIA A100-SXM4-40GB
GPU 5: NVIDIA A100-SXM4-40GB
GPU 6: NVIDIA A100-SXM4-40GB
GPU 7: NVIDIA A100-SXM4-40GB
Nvidia driver version: 510.47.03
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.5.0
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.5.0
/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.5.0
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_infer.so.8.5.0
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.5.0
/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.5.0
/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.5.0
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.23.5
[pip3] sagemaker-pytorch-training==2.7.0
[pip3] torch==1.13.1+cu117
[pip3] torchaudio==0.13.1+cu117
[pip3] torchdata==0.5.1
[pip3] torchnet==0.0.4
[pip3] torchvision==0.14.1+cu117
[conda] Could not collect
```
```
# pip show conda
Name: conda
Version: 22.11.1
Summary: OS-agnostic, system-level binary package manager.
Home-page: https://github.com/conda/conda
Author: Anaconda, Inc.
Author-email: conda@continuum.io
License: BSD-3-Clause
Location: /opt/conda/lib/python3.9/site-packages
Requires: pluggy, pycosat, requests, ruamel.yaml, tqdm
Required-by: mamba
```
| 1 |
3,753 | 93,502 |
Torchdynamo with onnxrt backend generating fake tensor errors
|
triaged, bug, oncall: pt2
|
### 🐛 Describe the bug
Hi,
I'm trying to use torchdynamo with onnxrt (both onnxrt_cuda and onnxrt_cpu backends) following the resnet example described in https://pytorch.org/tutorials/intermediate/dynamo_tutorial.html but I'm hitting an error
"torch._dynamo.exc.BackendCompilerFailed: onnxrt_cuda raised Exception: Please convert all Tensors to FakeTensors first or instantiate FakeTensorMode with 'allow_non_fake_inputs'. Found in aten.convolution.default(*(FakeTensor(FakeTensor(..., device='meta', size=(16, 3, 128, 128)), cuda:0), Parameter containing:
tensor([[[[...]]]], device='cuda:0', requires_grad=True),"
I've tried many examples from torchbench and all are hitting same error. It does not happen with other backends e.g. aot_cudagraphs etc. I've also force set the FakeTensorMode in fake_tensor.py but that hit another error down the line. Am I missing something obvious here?
Torch version: 2.0.0a0+gitdf46ba4
onnxrt version: 1.13.1
I was thinking something obvious is missing here before I dig into this in detail.
### Error logs
"torch._dynamo.exc.BackendCompilerFailed: onnxrt_cuda raised Exception: Please convert all Tensors to FakeTensors first or instantiate FakeTensorMode with 'allow_non_fake_inputs'. Found in aten.convolution.default(*(FakeTensor(FakeTensor(..., device='meta', size=(16, 3, 128, 128)), cuda:0), Parameter containing:
tensor([[[[...]]]], device='cuda:0', requires_grad=True),"
### Minified repro
import torch
import torch._dynamo as dynamo
# Returns the result of running `fn()` and the time it took for `fn()` to run,
# in seconds. We use CUDA events and synchronization for the most accurate
# measurements.
def timed(fn):
start = torch.cuda.Event(enable_timing=True)
end = torch.cuda.Event(enable_timing=True)
start.record()
result = fn()
end.record()
torch.cuda.synchronize()
return result, start.elapsed_time(end) / 1000
# Generates random input and targets data for the model, where `b` is
# batch size.
def generate_data(b):
return (
torch.randn(b, 3, 128, 128).to(torch.float32).cuda(),
torch.randint(1000, (b,)).cuda(),
)
from torchvision.models import resnet18
def init_model():
return resnet18().to(torch.float32).cuda()
def eval(mod, inp):
return mod(inp)
torch._dynamo.config.verbose=True
model = init_model()
eval_opt = dynamo.optimize("onnxrt_cuda")(eval)
inp = generate_data(16)[0]
print("eager:", timed(lambda: eval(model, inp))[1])
print("dynamo:", timed(lambda: eval_opt(model, inp))[1])
cc @ezyang @soumith @msaroufim @wconstab @ngimel @bdhirsh
| 3 |
3,754 | 91,968 |
Pytorch is using system-installed mkl-dnn.
|
module: build, triaged
|
### 🐛 Describe the bug
As you can see from the build log of candidate look up, pytorch build is using system-installed MKLDNN, causing build failure recently when their latest release has moved to 3.0
```
root@0fa9f135c79b:/tmp/scratch/pytorch/build# cmake --build . -- -j1
[1/2] ccache /usr/bin/g++-10 -DGFLAGS_IS_A_DLL=0 -DGOOGLE_GLOG_DLL_DECL="" -DGOOGLE_GLOG_DLL_DECL_FOR_UNITTESTS="" -DHAVE_MALLOC_USABLE_SIZE=1 -DHAVE_MMAP=1 -DHAVE_SHM_OPEN=1 -DHAVE_SHM_UNLINK=1 -DIDEEP_USE_MKL -DMINIZ_DISABLE_ZIP_READER_CRC32_CHECKS -DONNXIFI_ENABLE_EXT=1 -DONNX_ML=1 -DONNX_NAMESPACE=onnx_torch -DPROTOBUF_USE_DLLS -DUSE_C10D_GLOO -DUSE_C10D_MPI -DUSE_C10D_NCCL -DUSE_DISTRIBUTED -DUSE_EXTERNAL_MZCRC -DUSE_FLASH_ATTENTION -DUSE_RPC -DUSE_TENSORPIPE -D_FILE_OFFSET_BITS=64 -Dcaffe2_pybind11_state_gpu_EXPORTS -I/tmp/scratch/pytorch/build/aten/src -I/tmp/scratch/pytorch/aten/src -I/tmp/scratch/pytorch/build -I/tmp/scratch/pytorch -I/tmp/scratch/pytorch/cmake/../third_party/benchmark/include -I/tmp/scratch/pytorch/cmake/../third_party/cudnn_frontend/include -I/tmp/scratch/pytorch/build/caffe2/contrib/aten -I/tmp/scratch/pytorch/third_party/onnx -I/tmp/scratch/pytorch/build/third_party/onnx -I/tmp/scratch/pytorch/third_party/foxi -I/tmp/scratch/pytorch/build/third_party/foxi -I/tmp/scratch/pytorch/build/caffe2/aten/src -I/tmp/scratch/pytorch/aten/../third_party/catch/single_include -I/tmp/scratch/pytorch/aten/src/ATen/.. -I/tmp/scratch/pytorch/third_party/miniz-2.1.0 -I/tmp/scratch/pytorch/caffe2/core/nomnigraph/include -I/tmp/scratch/pytorch/torch/csrc/api -I/tmp/scratch/pytorch/torch/csrc/api/include -I/tmp/scratch/pytorch/c10/.. -I/tmp/scratch/pytorch/c10/cuda/../.. -isystem /tmp/scratch/pytorch/build/third_party/gloo -isystem /tmp/scratch/pytorch/cmake/../third_party/gloo -isystem /tmp/scratch/pytorch/cmake/../third_party/googletest/googlemock/include -isystem /tmp/scratch/pytorch/cmake/../third_party/googletest/googletest/include -isystem /opt/intel/oneapi/mkl/latest/include -isystem /tmp/scratch/pytorch/third_party/gemmlowp -isystem /tm
p/scratch/pytorch/third_party/neon2sse -isystem /tmp/scratch/pytorch/third_party/XNNPACK/include -isystem /usr/local/include/opencv4 -isystem /tmp/scratch/pytorch/third_party/ittapi/include -isystem /usr/local/include/eigen3 -isystem /usr/lib/x86_64-linux-gnu/openmpi/include -isystem /usr/lib/x86_64-linux-gnu/openmpi/include/openmpi -isystem /usr/local/cuda/include -isystem /tmp/scratch/pytorch/third_party/ideep/include -isystem /tmp/scratch/pytorch/third_party/ideep/mkl-dnn/include -isystem /usr/local/lib/python3.9/dist-packages/numpy/core/include -isystem /usr/include/python3.9 -isystem /tmp/scratch/pytorch/cmake/../third_party/pybind11/include -fdebug-prefix-map='/tmp/scratch'='/usr/local/src' -g1 -fvisibility-inlines-hidden -DUSE_PTHREADPOOL -fopenmp -DNDEBUG -DUSE_KINETO -DLIBKINETO_NOROCTRACER -DUSE_FBGEMM -DUSE_QNNPACK -DUSE_PYTORCH_QNNPACK -DUSE_XNNPACK -DSYMBOLICATE_MOBILE_DEBUG_HANDLE -DEDGE_PROFILER_USE_KINETO -O2 -fPIC -Wall -Wextra -Werror=return-type -Werror=non-virtual-dtor -Wnarrowing -Wno-missing-field-initializers -Wno-type-limits -Wno-array-bounds -Wno-unknown-pragmas -Wunused-local-typedefs -Wno-unused-parameter -Wno-unused-function -Wno-unused-result -Wno-strict-overflow -Wno-strict-aliasing -Wno-error=deprecated-declarations -Wno-stringop-overflow -Wno-psabi -Wno-error=pedantic -Wno-error=redundant-decls -Wno-error=old-style-cast -fdiagnostics-color=always -faligned-new -Wno-unused-but-set-variable -Wno-maybe-uninitialized -fno-math-errno -fno-trapping-math -Werror=format -Werror=cast-function-type -Wno-stringop-overflow -DHAVE_AVX512_CPU_DEFINITION -DHAVE_AVX2_CPU_DEFINITION -O3 -DNDEBUG -DNDEBUG -fPIC -march=native -fvisibility=hidden -DCAFFE2_USE_GLOO -DTH_HAVE_THREAD -DUSE_NUMPY -pthread -std=gnu++17 -MD -MT caffe2/CMakeFile
s/caffe2_pybind11_state_gpu.dir/python/pybind_state_ideep.cc.o -MF caffe2/CMakeFiles/caffe2_pybind11_state_gpu.dir/python/pybind_state_ideep.cc.o.d -o caffe2/CMakeFiles/caffe2_pybind11_state_gpu.dir/python/pybind_state_ideep.cc.o -c /tmp/scratch/pytorch/caffe2/python/pybind_state_ideep.cc
FAILED: caffe2/CMakeFiles/caffe2_pybind11_state_gpu.dir/python/pybind_state_ideep.cc.o
ccache /usr/bin/g++-10 -DGFLAGS_IS_A_DLL=0 -DGOOGLE_GLOG_DLL_DECL="" -DGOOGLE_GLOG_DLL_DECL_FOR_UNITTESTS="" -DHAVE_MALLOC_USABLE_SIZE=1 -DHAVE_MMAP=1 -DHAVE_SHM_OPEN=1 -DHAVE_SHM_UNLINK=1 -DIDEEP_USE_MKL -DMINIZ_DISABLE_ZIP_READER_CRC32_CHECKS -DONNXIFI_ENABLE_EXT=1 -DONNX_ML=1 -DONNX_NAMESPACE=onnx_torch -DPROTOBUF_USE_DLLS -DUSE_C10D_GLOO -DUSE_C10D_MPI -DUSE_C10D_NCCL -DUSE_DISTRIBUTED -DUSE_EXTERNAL_MZCRC -DUSE_FLASH_ATTENTION -DUSE_RPC -DUSE_TENSORPIPE -D_FILE_OFFSET_BITS=64 -Dcaffe2_pybind11_state_gpu_EXPORTS -I/tmp/scratch/pytorch/build/aten/src -I/tmp/scratch/pytorch/aten/src -I/tmp/scratch/pytorch/build -I/tmp/scratch/pytorch -I/tmp/scratch/pytorch/cmake/../third_party/benchmark/include -I/tmp/scratch/pytorch/cmake/../third_party/cudnn_frontend/include -I/tmp/scratch/pytorch/build/caffe2/contrib/aten -I/tmp/scratch/pytorch/third_party/onnx -I/tmp/scratch/pytorch/build/third_party/onnx -I/tmp/scratch/pytorch/third_party/foxi -I/tmp/scratch/pytorch/build/third_party/foxi -I/tmp/scratch/pytorch/build/caffe2/aten/src -I/tmp/scratch/pytorch/aten/../third_party/catch/single_include -I/tmp/scratch/pytorch/aten/src/ATen/.. -I/tmp/scratch/pytorch/third_party/miniz-2.1.0 -I/tmp/scratch/pytorch/caffe2/core/nomnigraph/include -I/tmp/scratch/pytorch/torch/csrc/api -I/tmp/scratch/pytorch/torch/csrc/api/include -I/tmp/scratch/pytorch/c10/.. -I/tmp/scratch/pytorch/c10/cuda/../.. -isystem /tmp/scratch/pytorch/build/third_party/gloo -isystem /tmp/scratch/pytorch/cmake/../third_party/gloo -isystem /tmp/scratch/pytorch/cmake/../third_party/googletest/googlemock/include -isystem /tmp/scratch/pytorch/cmake/../third_party/googletest/googletest/include -isystem /opt/intel/oneapi/mkl/latest/include -isystem /tmp/scratch/pytorch/third_party/gemmlowp -isystem /tmp/scra
tch/pytorch/third_party/neon2sse -isystem /tmp/scratch/pytorch/third_party/XNNPACK/include -isystem /usr/local/include/opencv4 -isystem /tmp/scratch/pytorch/third_party/ittapi/include -isystem /usr/local/include/eigen3 -isystem /usr/lib/x86_64-linux-gnu/openmpi/include -isystem /usr/lib/x86_64-linux-gnu/openmpi/include/openmpi -isystem /usr/local/cuda/include -isystem /tmp/scratch/pytorch/third_party/ideep/include -isystem /tmp/scratch/pytorch/third_party/ideep/mkl-dnn/include -isystem /usr/local/lib/python3.9/dist-packages/numpy/core/include -isystem /usr/include/python3.9 -isystem /tmp/scratch/pytorch/cmake/../third_party/pybind11/include -fdebug-prefix-map='/tmp/scratch'='/usr/local/src' -g1 -fvisibility-inlines-hidden -DUSE_PTHREADPOOL -fopenmp -DNDEBUG -DUSE_KINETO -DLIBKINETO_NOROCTRACER -DUSE_FBGEMM -DUSE_QNNPACK -DUSE_PYTORCH_QNNPACK -DUSE_XNNPACK -DSYMBOLICATE_MOBILE_DEBUG_HANDLE -DEDGE_PROFILER_USE_KINETO -O2 -fPIC -Wall -Wextra -Werror=return-type -Werror=non-virtual-dtor -Wnarrowing -Wno-missing-field-initializers -Wno-type-limits -Wno-array-bounds -Wno-unknown-pragmas -Wunused-local-typedefs -Wno-unused-parameter -Wno-unused-function -Wno-unused-result -Wno-strict-overflow -Wno-strict-aliasing -Wno-error=deprecated-declarations -Wno-stringop-overflow -Wno-psabi -Wno-error=pedantic -Wno-error=redundant-decls -Wno-error=old-style-cast -fdiagnostics-color=always -faligned-new -Wno-unused-but-set-variable -Wno-maybe-uninitialized -fno-math-errno -fno-trapping-math -Werror=format -Werror=cast-function-type -Wno-stringop-overflow -DHAVE_AVX512_CPU_DEFINITION -DHAVE_AVX2_CPU_DEFINITION -O3 -DNDEBUG -DNDEBUG -fPIC -march=native -fvisibility=hidden -DCAFFE2_USE_GLOO -DTH_HAVE_THREAD -DUSE_NUMPY -pthread -std=gnu++17 -MD -MT caffe2/CMakeFiles/caff
e2_pybind11_state_gpu.dir/python/pybind_state_ideep.cc.o -MF caffe2/CMakeFiles/caffe2_pybind11_state_gpu.dir/python/pybind_state_ideep.cc.o.d -o caffe2/CMakeFiles/caffe2_pybind11_state_gpu.dir/python/pybind_state_ideep.cc.o -c /tmp/scratch/pytorch/caffe2/python/pybind_state_ideep.cc
In file included from /tmp/scratch/pytorch/third_party/ideep/include/ideep/tensor.hpp:4,
from /tmp/scratch/pytorch/third_party/ideep/include/ideep.hpp:40,
from /tmp/scratch/pytorch/caffe2/ideep/ideep_utils.h:6,
from /tmp/scratch/pytorch/caffe2/python/pybind_state_ideep.cc:12:
/tmp/scratch/pytorch/third_party/ideep/include/ideep/attributes.hpp: In constructor ‘ideep::attr_t::attr_t(int, const scale_t&)’:
/tmp/scratch/pytorch/third_party/ideep/include/ideep/attributes.hpp:20:5: error: ‘set_output_scales’ was not declared in this scope; did you mean ‘get_output_scales’?
20 | set_output_scales(mask, scales);
| ^~~~~~~~~~~~~~~~~
| get_output_scales
/tmp/scratch/pytorch/third_party/ideep/include/ideep/attributes.hpp: In member function ‘std::pair<std::vector<float>, int> ideep::attr_t::get_output_scales() const’:
/tmp/scratch/pytorch/third_party/ideep/include/ideep/attributes.hpp:41:9: error: ‘dnnl_primitive_attr_get_output_scales’ was not declared in this scope; did you mean ‘dnnl_primitive_attr_get_post_ops’?
41 | dnnl_primitive_attr_get_output_scales(
| ^~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
| dnnl_primitive_attr_get_post_ops
/tmp/scratch/pytorch/third_party/ideep/include/ideep/attributes.hpp: In member function ‘void ideep::attr_t::get_zero_points(int, int&, std::vector<int>&) const’:
/tmp/scratch/pytorch/third_party/ideep/include/ideep/attributes.hpp:56:29: error: ‘get_zero_points’ is not a member of ‘dnnl::primitive_attr’
56 | dnnl::primitive_attr::get_zero_points(arg, mask, zero_points);
| ^~~~~~~~~~~~~~~
/tmp/scratch/pytorch/third_party/ideep/include/ideep/attributes.hpp: In static member function ‘static ideep::attr_t ideep::attr_t::fuse_swish_sum(float, float, float, float)’:
/tmp/scratch/pytorch/third_party/ideep/include/ideep/attributes.hpp:75:85: error: no matching function for call to ‘dnnl::post_ops::append_eltwise(float&, dnnl::algorithm, float&, float&)’
75 | po.append_eltwise(swish_scale, algorithm::eltwise_swish, swish_alpha, swish_beta);
| ^
In file included from /usr/local/include/dnnl.hpp:20,
from /tmp/scratch/pytorch/third_party/ideep/include/ideep/abstract_types.hpp:5,
from /tmp/scratch/pytorch/third_party/ideep/include/ideep.hpp:39,
from /tmp/scratch/pytorch/caffe2/ideep/ideep_utils.h:6,
from /tmp/scratch/pytorch/caffe2/python/pybind_state_ideep.cc:12:
/usr/local/include/oneapi/dnnl/dnnl.hpp:2992:10: note: candidate: ‘void dnnl::post_ops::append_eltwise(dnnl::algorithm, float, float)’
2992 | void append_eltwise(algorithm aalgorithm, float alpha, float beta) {
| ^~~~~~~~~~~~~~
/usr/local/include/oneapi/dnnl/dnnl.hpp:2992:10: note: candidate expects 3 arguments, 4 provided
In file included from /tmp/scratch/pytorch/third_party/ideep/include/ideep/tensor.hpp:4,
from /tmp/scratch/pytorch/third_party/ideep/include/ideep.hpp:40,
from /tmp/scratch/pytorch/caffe2/ideep/ideep_utils.h:6,
from /tmp/scratch/pytorch/caffe2/python/pybind_state_ideep.cc:12:
/tmp/scratch/pytorch/third_party/ideep/include/ideep/attributes.hpp: In static member function ‘static ideep::attr_t ideep::attr_t::fuse_relu(float, float, float)’:
/tmp/scratch/pytorch/third_party/ideep/include/ideep/attributes.hpp:87:66: error: no matching function for call to ‘dnnl::post_ops::append_eltwise(float&, dnnl::algorithm, float&, float&)’
87 | po.append_eltwise(scale, algorithm::eltwise_relu, alpha, beta);
| ^
In file included from /usr/local/include/dnnl.hpp:20,
from /tmp/scratch/pytorch/third_party/ideep/include/ideep/abstract_types.hpp:5,
from /tmp/scratch/pytorch/third_party/ideep/include/ideep.hpp:39,
from /tmp/scratch/pytorch/caffe2/ideep/ideep_utils.h:6,
from /tmp/scratch/pytorch/caffe2/python/pybind_state_ideep.cc:12:
/usr/local/include/oneapi/dnnl/dnnl.hpp:2992:10: note: candidate: ‘void dnnl::post_ops::append_eltwise(dnnl::algorithm, float, float)’
2992 | void append_eltwise(algorithm aalgorithm, float alpha, float beta) {
| ^~~~~~~~~~~~~~
/usr/local/include/oneapi/dnnl/dnnl.hpp:2992:10: note: candidate expects 3 arguments, 4 provided
In file included from /tmp/scratch/pytorch/third_party/ideep/include/ideep/tensor.hpp:4,
from /tmp/scratch/pytorch/third_party/ideep/include/ideep.hpp:40,
from /tmp/scratch/pytorch/caffe2/ideep/ideep_utils.h:6,
from /tmp/scratch/pytorch/caffe2/python/pybind_state_ideep.cc:12:
/tmp/scratch/pytorch/third_party/ideep/include/ideep/attributes.hpp: In static member function ‘static ideep::attr_t ideep::attr_t::fuse_gelu(float, float, float, ideep::algorithm)’:
/tmp/scratch/pytorch/third_party/ideep/include/ideep/attributes.hpp:99:52: error: no matching function for call to ‘dnnl::post_ops::append_eltwise(float&, ideep::algorithm&, float&, float&)’
99 | po.append_eltwise(scale, gelu_type, alpha, beta);
| ^
In file included from /usr/local/include/dnnl.hpp:20,
from /tmp/scratch/pytorch/third_party/ideep/include/ideep/abstract_types.hpp:5,
from /tmp/scratch/pytorch/third_party/ideep/include/ideep.hpp:39,
from /tmp/scratch/pytorch/caffe2/ideep/ideep_utils.h:6,
from /tmp/scratch/pytorch/caffe2/python/pybind_state_ideep.cc:12:
/usr/local/include/oneapi/dnnl/dnnl.hpp:2992:10: note: candidate: ‘void dnnl::post_ops::append_eltwise(dnnl::algorithm, float, float)’
2992 | void append_eltwise(algorithm aalgorithm, float alpha, float beta) {
| ^~~~~~~~~~~~~~
/usr/local/include/oneapi/dnnl/dnnl.hpp:2992:10: note: candidate expects 3 arguments, 4 provided
In file included from /tmp/scratch/pytorch/third_party/ideep/include/ideep/tensor.hpp:4,
from /tmp/scratch/pytorch/third_party/ideep/include/ideep.hpp:40,
from /tmp/scratch/pytorch/caffe2/ideep/ideep_utils.h:6,
from /tmp/scratch/pytorch/caffe2/python/pybind_state_ideep.cc:12:
/tmp/scratch/pytorch/third_party/ideep/include/ideep/attributes.hpp: In static member function ‘static ideep::attr_t ideep::attr_t::fuse_elu(float, float, float)’:
/tmp/scratch/pytorch/third_party/ideep/include/ideep/attributes.hpp:110:65: error: no matching function for call to ‘dnnl::post_ops::append_eltwise(float&, dnnl::algorithm, float&, float&)’
110 | po.append_eltwise(scale, algorithm::eltwise_elu, alpha, beta);
| ^
In file included from /usr/local/include/dnnl.hpp:20,
from /tmp/scratch/pytorch/third_party/ideep/include/ideep/abstract_types.hpp:5,
from /tmp/scratch/pytorch/third_party/ideep/include/ideep.hpp:39,
from /tmp/scratch/pytorch/caffe2/ideep/ideep_utils.h:6,
from /tmp/scratch/pytorch/caffe2/python/pybind_state_ideep.cc:12:
/usr/local/include/oneapi/dnnl/dnnl.hpp:2992:10: note: candidate: ‘void dnnl::post_ops::append_eltwise(dnnl::algorithm, float, float)’
2992 | void append_eltwise(algorithm aalgorithm, float alpha, float beta) {
| ^~~~~~~~~~~~~~
/usr/local/include/oneapi/dnnl/dnnl.hpp:2992:10: note: candidate expects 3 arguments, 4 provided
In file included from /tmp/scratch/pytorch/third_party/ideep/include/ideep/tensor.hpp:4,
from /tmp/scratch/pytorch/third_party/ideep/include/ideep.hpp:40,
from /tmp/scratch/pytorch/caffe2/ideep/ideep_utils.h:6,
from /tmp/scratch/pytorch/caffe2/python/pybind_state_ideep.cc:12:
/tmp/scratch/pytorch/third_party/ideep/include/ideep/attributes.hpp: In static member function ‘static ideep::attr_t ideep::attr_t::fuse_sigmoid(float, float, float)’:
/tmp/scratch/pytorch/third_party/ideep/include/ideep/attributes.hpp:121:70: error: no matching function for call to ‘dnnl::post_ops::append_eltwise(float&, dnnl::algorithm, float&, float&)’
121 | po.append_eltwise(scale, algorithm::eltwise_logistic, alpha, beta);
| ^
In file included from /usr/local/include/dnnl.hpp:20,
from /tmp/scratch/pytorch/third_party/ideep/include/ideep/abstract_types.hpp:5,
from /tmp/scratch/pytorch/third_party/ideep/include/ideep.hpp:39,
from /tmp/scratch/pytorch/caffe2/ideep/ideep_utils.h:6,
from /tmp/scratch/pytorch/caffe2/python/pybind_state_ideep.cc:12:
/usr/local/include/oneapi/dnnl/dnnl.hpp:2992:10: note: candidate: ‘void dnnl::post_ops::append_eltwise(dnnl::algorithm, float, float)’
2992 | void append_eltwise(algorithm aalgorithm, float alpha, float beta) {
| ^~~~~~~~~~~~~~
/usr/local/include/oneapi/dnnl/dnnl.hpp:2992:10: note: candidate expects 3 arguments, 4 provided
In file included from /tmp/scratch/pytorch/third_party/ideep/include/ideep/tensor.hpp:4,
from /tmp/scratch/pytorch/third_party/ideep/include/ideep.hpp:40,
from /tmp/scratch/pytorch/caffe2/ideep/ideep_utils.h:6,
from /tmp/scratch/pytorch/caffe2/python/pybind_state_ideep.cc:12:
/tmp/scratch/pytorch/third_party/ideep/include/ideep/attributes.hpp: In static member function ‘static ideep::attr_t ideep::attr_t::fuse_swish(float, float, float)’:
/tmp/scratch/pytorch/third_party/ideep/include/ideep/attributes.hpp:132:67: error: no matching function for call to ‘dnnl::post_ops::append_eltwise(float&, dnnl::algorithm, float&, float&)’
132 | po.append_eltwise(scale, algorithm::eltwise_swish, alpha, beta);
| ^
In file included from /usr/local/include/dnnl.hpp:20,
from /tmp/scratch/pytorch/third_party/ideep/include/ideep/abstract_types.hpp:5,
from /tmp/scratch/pytorch/third_party/ideep/include/ideep.hpp:39,
from /tmp/scratch/pytorch/caffe2/ideep/ideep_utils.h:6,
from /tmp/scratch/pytorch/caffe2/python/pybind_state_ideep.cc:12:
/usr/local/include/oneapi/dnnl/dnnl.hpp:2992:10: note: candidate: ‘void dnnl::post_ops::append_eltwise(dnnl::algorithm, float, float)’
2992 | void append_eltwise(algorithm aalgorithm, float alpha, float beta) {
| ^~~~~~~~~~~~~~
/usr/local/include/oneapi/dnnl/dnnl.hpp:2992:10: note: candidate expects 3 arguments, 4 provided
In file included from /tmp/scratch/pytorch/third_party/ideep/include/ideep/tensor.hpp:4,
from /tmp/scratch/pytorch/third_party/ideep/include/ideep.hpp:40,
from /tmp/scratch/pytorch/caffe2/ideep/ideep_utils.h:6,
from /tmp/scratch/pytorch/caffe2/python/pybind_state_ideep.cc:12:
/tmp/scratch/pytorch/third_party/ideep/include/ideep/attributes.hpp: In static member function ‘static ideep::attr_t ideep::attr_t::fuse_tanh(float, float, float)’:
/tmp/scratch/pytorch/third_party/ideep/include/ideep/attributes.hpp:143:66: error: no matching function for call to ‘dnnl::post_ops::append_eltwise(float&, dnnl::algorithm, float&, float&)’
143 | po.append_eltwise(scale, algorithm::eltwise_tanh, alpha, beta);
| ^
In file included from /usr/local/include/dnnl.hpp:20,
from /tmp/scratch/pytorch/third_party/ideep/include/ideep/abstract_types.hpp:5,
from /tmp/scratch/pytorch/third_party/ideep/include/ideep.hpp:39,
from /tmp/scratch/pytorch/caffe2/ideep/ideep_utils.h:6,
from /tmp/scratch/pytorch/caffe2/python/pybind_state_ideep.cc:12:
/usr/local/include/oneapi/dnnl/dnnl.hpp:2992:10: note: candidate: ‘void dnnl::post_ops::append_eltwise(dnnl::algorithm, float, float)’
2992 | void append_eltwise(algorithm aalgorithm, float alpha, float beta) {
| ^~~~~~~~~~~~~~
/usr/local/include/oneapi/dnnl/dnnl.hpp:2992:10: note: candidate expects 3 arguments, 4 provided
In file included from /tmp/scratch/pytorch/third_party/ideep/include/ideep/tensor.hpp:4,
from /tmp/scratch/pytorch/third_party/ideep/include/ideep.hpp:40,
from /tmp/scratch/pytorch/caffe2/ideep/ideep_utils.h:6,
from /tmp/scratch/pytorch/caffe2/python/pybind_state_ideep.cc:12:
/tmp/scratch/pytorch/third_party/ideep/include/ideep/attributes.hpp: In static member function ‘static ideep::attr_t ideep::attr_t::fuse_mish(float, float, float)’:
/tmp/scratch/pytorch/third_party/ideep/include/ideep/attributes.hpp:154:66: error: no matching function for call to ‘dnnl::post_ops::append_eltwise(float&, dnnl::algorithm, float&, float&)’
154 | po.append_eltwise(scale, algorithm::eltwise_mish, alpha, beta);
| ^
In file included from /usr/local/include/dnnl.hpp:20,
from /tmp/scratch/pytorch/third_party/ideep/include/ideep/abstract_types.hpp:5,
from /tmp/scratch/pytorch/third_party/ideep/include/ideep.hpp:39,
from /tmp/scratch/pytorch/caffe2/ideep/ideep_utils.h:6,
from /tmp/scratch/pytorch/caffe2/python/pybind_state_ideep.cc:12:
/usr/local/include/oneapi/dnnl/dnnl.hpp:2992:10: note: candidate: ‘void dnnl::post_ops::append_eltwise(dnnl::algorithm, float, float)’
2992 | void append_eltwise(algorithm aalgorithm, float alpha, float beta) {
| ^~~~~~~~~~~~~~
/usr/local/include/oneapi/dnnl/dnnl.hpp:2992:10: note: candidate expects 3 arguments, 4 provided
In file included from /tmp/scratch/pytorch/third_party/ideep/include/ideep/tensor.hpp:4,
from /tmp/scratch/pytorch/third_party/ideep/include/ideep.hpp:40,
from /tmp/scratch/pytorch/caffe2/ideep/ideep_utils.h:6,
from /tmp/scratch/pytorch/caffe2/python/pybind_state_ideep.cc:12:
/tmp/scratch/pytorch/third_party/ideep/include/ideep/attributes.hpp: In static member function ‘static ideep::attr_t ideep::attr_t::residual(float, float, float, float)’:
/tmp/scratch/pytorch/third_party/ideep/include/ideep/attributes.hpp:167:71: error: no matching function for call to ‘dnnl::post_ops::append_eltwise(float&, dnnl::algorithm, float&, float&)’
167 | po.append_eltwise(relu_scale, algorithm::eltwise_relu, alpha, beta);
| ^
In file included from /usr/local/include/dnnl.hpp:20,
from /tmp/scratch/pytorch/third_party/ideep/include/ideep/abstract_types.hpp:5,
from /tmp/scratch/pytorch/third_party/ideep/include/ideep.hpp:39,
from /tmp/scratch/pytorch/caffe2/ideep/ideep_utils.h:6,
from /tmp/scratch/pytorch/caffe2/python/pybind_state_ideep.cc:12:
/usr/local/include/oneapi/dnnl/dnnl.hpp:2992:10: note: candidate: ‘void dnnl::post_ops::append_eltwise(dnnl::algorithm, float, float)’
2992 | void append_eltwise(algorithm aalgorithm, float alpha, float beta) {
| ^~~~~~~~~~~~~~
/usr/local/include/oneapi/dnnl/dnnl.hpp:2992:10: note: candidate expects 3 arguments, 4 provided
In file included from /tmp/scratch/pytorch/third_party/ideep/include/ideep/tensor.hpp:4,
from /tmp/scratch/pytorch/third_party/ideep/include/ideep.hpp:40,
from /tmp/scratch/pytorch/caffe2/ideep/ideep_utils.h:6,
from /tmp/scratch/pytorch/caffe2/python/pybind_state_ideep.cc:12:
/tmp/scratch/pytorch/third_party/ideep/include/ideep/attributes.hpp: In static member function ‘static ideep::attr_t ideep::attr_t::residual_with_sum_zero_point(float, int32_t, float, float, float)’:
/tmp/scratch/pytorch/third_party/ideep/include/ideep/attributes.hpp:181:71: error: no matching function for call to ‘dnnl::post_ops::append_eltwise(float&, dnnl::algorithm, float&, float&)’
181 | po.append_eltwise(relu_scale, algorithm::eltwise_relu, alpha, beta);
| ^
In file included from /usr/local/include/dnnl.hpp:20,
from /tmp/scratch/pytorch/third_party/ideep/include/ideep/abstract_types.hpp:5,
from /tmp/scratch/pytorch/third_party/ideep/include/ideep.hpp:39,
from /tmp/scratch/pytorch/caffe2/ideep/ideep_utils.h:6,
from /tmp/scratch/pytorch/caffe2/python/pybind_state_ideep.cc:12:
/usr/local/include/oneapi/dnnl/dnnl.hpp:2992:10: note: candidate: ‘void dnnl::post_ops::append_eltwise(dnnl::algorithm, float, float)’
2992 | void append_eltwise(algorithm aalgorithm, float alpha, float beta) {
| ^~~~~~~~~~~~~~
/usr/local/include/oneapi/dnnl/dnnl.hpp:2992:10: note: candidate expects 3 arguments, 4 provided
In file included from /tmp/scratch/pytorch/third_party/ideep/include/ideep/tensor.hpp:4,
from /tmp/scratch/pytorch/third_party/ideep/include/ideep.hpp:40,
from /tmp/scratch/pytorch/caffe2/ideep/ideep_utils.h:6,
from /tmp/scratch/pytorch/caffe2/python/pybind_state_ideep.cc:12:
/tmp/scratch/pytorch/third_party/ideep/include/ideep/attributes.hpp: In static member function ‘static ideep::attr_t ideep::attr_t::fuse_clamp(float, float)’:
/tmp/scratch/pytorch/third_party/ideep/include/ideep/attributes.hpp:189:77: error: no matching function for call to ‘dnnl::post_ops::append_eltwise(double, dnnl::algorithm, float&, float&)’
189 | po.append_eltwise(1.0, algorithm::eltwise_clip, lower_bound, upper_bound);
| ^
In file included from /usr/local/include/dnnl.hpp:20,
from /tmp/scratch/pytorch/third_party/ideep/include/ideep/abstract_types.hpp:5,
from /tmp/scratch/pytorch/third_party/ideep/include/ideep.hpp:39,
from /tmp/scratch/pytorch/caffe2/ideep/ideep_utils.h:6,
from /tmp/scratch/pytorch/caffe2/python/pybind_state_ideep.cc:12:
/usr/local/include/oneapi/dnnl/dnnl.hpp:2992:10: note: candidate: ‘void dnnl::post_ops::append_eltwise(dnnl::algorithm, float, float)’
2992 | void append_eltwise(algorithm aalgorithm, float alpha, float beta) {
| ^~~~~~~~~~~~~~
/usr/local/include/oneapi/dnnl/dnnl.hpp:2992:10: note: candidate expects 3 arguments, 4 provided
In file included from /tmp/scratch/pytorch/third_party/ideep/include/ideep/tensor.hpp:4,
from /tmp/scratch/pytorch/third_party/ideep/include/ideep.hpp:40,
from /tmp/scratch/pytorch/caffe2/ideep/ideep_utils.h:6,
from /tmp/scratch/pytorch/caffe2/python/pybind_state_ideep.cc:12:
/tmp/scratch/pytorch/third_party/ideep/include/ideep/attributes.hpp: In static member function ‘static ideep::attr_t ideep::attr_t::fuse_hardswish(float, float, float)’:
/tmp/scratch/pytorch/third_party/ideep/include/ideep/attributes.hpp:200:71: error: no matching function for call to ‘dnnl::post_ops::append_eltwise(float&, dnnl::algorithm, float&, float&)’
200 | po.append_eltwise(scale, algorithm::eltwise_hardswish, alpha, beta);
| ^
In file included from /usr/local/include/dnnl.hpp:20,
from /tmp/scratch/pytorch/third_party/ideep/include/ideep/abstract_types.hpp:5,
from /tmp/scratch/pytorch/third_party/ideep/include/ideep.hpp:39,
from /tmp/scratch/pytorch/caffe2/ideep/ideep_utils.h:6,
from /tmp/scratch/pytorch/caffe2/python/pybind_state_ideep.cc:12:
/usr/local/include/oneapi/dnnl/dnnl.hpp:2992:10: note: candidate: ‘void dnnl::post_ops::append_eltwise(dnnl::algorithm, float, float)’
2992 | void append_eltwise(algorithm aalgorithm, float alpha, float beta) {
| ^~~~~~~~~~~~~~
/usr/local/include/oneapi/dnnl/dnnl.hpp:2992:10: note: candidate expects 3 arguments, 4 provided
In file included from /tmp/scratch/pytorch/third_party/ideep/include/ideep/tensor.hpp:4,
from /tmp/scratch/pytorch/third_party/ideep/include/ideep.hpp:40,
from /tmp/scratch/pytorch/caffe2/ideep/ideep_utils.h:6,
from /tmp/scratch/pytorch/caffe2/python/pybind_state_ideep.cc:12:
/tmp/scratch/pytorch/third_party/ideep/include/ideep/attributes.hpp: In static member function ‘static ideep::attr_t ideep::attr_t::fuse_abs(float, float, float)’:
/tmp/scratch/pytorch/third_party/ideep/include/ideep/attributes.hpp:211:65: error: no matching function for call to ‘dnnl::post_ops::append_eltwise(float&, dnnl::algorithm, float&, float&)’
211 | po.append_eltwise(scale, algorithm::eltwise_abs, alpha, beta);
| ^
In file included from /usr/local/include/dnnl.hpp:20,
from /tmp/scratch/pytorch/third_party/ideep/include/ideep/abstract_types.hpp:5,
from /tmp/scratch/pytorch/third_party/ideep/include/ideep.hpp:39,
from /tmp/scratch/pytorch/caffe2/ideep/ideep_utils.h:6,
from /tmp/scratch/pytorch/caffe2/python/pybind_state_ideep.cc:12:
/usr/local/include/oneapi/dnnl/dnnl.hpp:2992:10: note: candidate: ‘void dnnl::post_ops::append_eltwise(dnnl::algorithm, float, float)’
2992 | void append_eltwise(algorithm aalgorithm, float alpha, float beta) {
| ^~~~~~~~~~~~~~
/usr/local/include/oneapi/dnnl/dnnl.hpp:2992:10: note: candidate expects 3 arguments, 4 provided
In file included from /tmp/scratch/pytorch/third_party/ideep/include/ideep/tensor.hpp:4,
from /tmp/scratch/pytorch/third_party/ideep/include/ideep.hpp:40,
from /tmp/scratch/pytorch/caffe2/ideep/ideep_utils.h:6,
from /tmp/scratch/pytorch/caffe2/python/pybind_state_ideep.cc:12:
/tmp/scratch/pytorch/third_party/ideep/include/ideep/attributes.hpp: In static member function ‘static ideep::attr_t ideep::attr_t::fuse_exp(float, float, float)’:
/tmp/scratch/pytorch/third_party/ideep/include/ideep/attributes.hpp:222:65: error: no matching function for call to ‘dnnl::post_ops::append_eltwise(float&, dnnl::algorithm, float&, float&)’
222 | po.append_eltwise(scale, algorithm::eltwise_exp, alpha, beta);
| ^
In file included from /usr/local/include/dnnl.hpp:20,
from /tmp/scratch/pytorch/third_party/ideep/include/ideep/abstract_types.hpp:5,
from /tmp/scratch/pytorch/third_party/ideep/include/ideep.hpp:39,
from /tmp/scratch/pytorch/caffe2/ideep/ideep_utils.h:6,
from /tmp/scratch/pytorch/caffe2/python/pybind_state_ideep.cc:12:
/usr/local/include/oneapi/dnnl/dnnl.hpp:2992:10: note: candidate: ‘void dnnl::post_ops::append_eltwise(dnnl::algorithm, float, float)’
2992 | void append_eltwise(algorithm aalgorithm, float alpha, float beta) {
| ^~~~~~~~~~~~~~
/usr/local/include/oneapi/dnnl/dnnl.hpp:2992:10: note: candidate expects 3 arguments, 4 provided
In file included from /tmp/scratch/pytorch/third_party/ideep/include/ideep/tensor.hpp:4,
from /tmp/scratch/pytorch/third_party/ideep/include/ideep.hpp:40,
from /tmp/scratch/pytorch/caffe2/ideep/ideep_utils.h:6,
from /tmp/scratch/pytorch/caffe2/python/pybind_state_ideep.cc:12:
/tmp/scratch/pytorch/third_party/ideep/include/ideep/attributes.hpp: In static member function ‘static ideep::attr_t ideep::attr_t::fuse_square(float, float, float)’:
/tmp/scratch/pytorch/third_party/ideep/include/ideep/attributes.hpp:233:68: error: no matching function for call to ‘dnnl::post_ops::append_eltwise(float&, dnnl::algorithm, float&, float&)’
233 | po.append_eltwise(scale, algorithm::eltwise_square, alpha, beta);
| ^
In file included from /usr/local/include/dnnl.hpp:20,
from /tmp/scratch/pytorch/third_party/ideep/include/ideep/abstract_types.hpp:5,
from /tmp/scratch/pytorch/third_party/ideep/include/ideep.hpp:39,
from /tmp/scratch/pytorch/caffe2/ideep/ideep_utils.h:6,
from /tmp/scratch/pytorch/caffe2/python/pybind_state_ideep.cc:12:
/usr/local/include/oneapi/dnnl/dnnl.hpp:2992:10: note: candidate: ‘void dnnl::post_ops::append_eltwise(dnnl::algorithm, float, float)’
2992 | void append_eltwise(algorithm aalgorithm, float alpha, float beta) {
| ^~~~~~~~~~~~~~
/usr/local/include/oneapi/dnnl/dnnl.hpp:2992:10: note: candidate expects 3 arguments, 4 provided
In file included from /tmp/scratch/pytorch/third_party/ideep/include/ideep/tensor.hpp:4,
from /tmp/scratch/pytorch/third_party/ideep/include/ideep.hpp:40,
from /tmp/scratch/pytorch/caffe2/ideep/ideep_utils.h:6,
from /tmp/scratch/pytorch/caffe2/python/pybind_state_ideep.cc:12:
/tmp/scratch/pytorch/third_party/ideep/include/ideep/attributes.hpp: In static member function ‘static ideep::attr_t ideep::attr_t::fuse_log(float, float, float)’:
/tmp/scratch/pytorch/third_party/ideep/include/ideep/attributes.hpp:244:65: error: no matching function for call to ‘dnnl::post_ops::append_eltwise(float&, dnnl::algorithm, float&, float&)’
244 | po.append_eltwise(scale, algorithm::eltwise_log, alpha, beta);
| ^
In file included from /usr/local/include/dnnl.hpp:20,
from /tmp/scratch/pytorch/third_party/ideep/include/ideep/abstract_types.hpp:5,
from /tmp/scratch/pytorch/third_party/ideep/include/ideep.hpp:39,
from /tmp/scratch/pytorch/caffe2/ideep/ideep_utils.h:6,
from /tmp/scratch/pytorch/caffe2/python/pybind_state_ideep.cc:12:
/usr/local/include/oneapi/dnnl/dnnl.hpp:2992:10: note: candidate: ‘void dnnl::post_ops::append_eltwise(dnnl::algorithm, float, float)’
2992 | void append_eltwise(algorithm aalgorithm, float alpha, float beta) {
| ^~~~~~~~~~~~~~
/usr/local/include/oneapi/dnnl/dnnl.hpp:2992:10: note: candidate expects 3 arguments, 4 provided
In file included from /tmp/scratch/pytorch/third_party/ideep/include/ideep/tensor.hpp:4,
from /tmp/scratch/pytorch/third_party/ideep/include/ideep.hpp:40,
from /tmp/scratch/pytorch/caffe2/ideep/ideep_utils.h:6,
from /tmp/scratch/pytorch/caffe2/python/pybind_state_ideep.cc:12:
/tmp/scratch/pytorch/third_party/ideep/include/ideep/attributes.hpp: In static member function ‘static ideep::attr_t ideep::attr_t::fuse_round(float, float, float)’:
/tmp/scratch/pytorch/third_party/ideep/include/ideep/attributes.hpp:255:67: error: no matching function for call to ‘dnnl::post_ops::append_eltwise(float&, dnnl::algorithm, float&, float&)’
255 | po.append_eltwise(scale, algorithm::eltwise_round, alpha, beta);
| ^
In file included from /usr/local/include/dnnl.hpp:20,
from /tmp/scratch/pytorch/third_party/ideep/include/ideep/abstract_types.hpp:5,
from /tmp/scratch/pytorch/third_party/ideep/include/ideep.hpp:39,
from /tmp/scratch/pytorch/caffe2/ideep/ideep_utils.h:6,
from /tmp/scratch/pytorch/caffe2/python/pybind_state_ideep.cc:12:
/usr/local/include/oneapi/dnnl/dnnl.hpp:2992:10: note: candidate: ‘void dnnl::post_ops::append_eltwise(dnnl::algorithm, float, float)’
2992 | void append_eltwise(algorithm aalgorithm, float alpha, float beta) {
| ^~~~~~~~~~~~~~
/usr/local/include/oneapi/dnnl/dnnl.hpp:2992:10: note: candidate expects 3 arguments, 4 provided
In file included from /tmp/scratch/pytorch/third_party/ideep/include/ideep/tensor.hpp:4,
from /tmp/scratch/pytorch/third_party/ideep/include/ideep.hpp:40,
from /tmp/scratch/pytorch/caffe2/ideep/ideep_utils.h:6,
from /tmp/scratch/pytorch/caffe2/python/pybind_state_ideep.cc:12:
/tmp/scratch/pytorch/third_party/ideep/include/ideep/attributes.hpp: In static member function ‘static ideep::attr_t ideep::attr_t::fuse_sqrt(float, float, float)’:
/tmp/scratch/pytorch/third_party/ideep/include/ideep/attributes.hpp:266:66: error: no matching function for call to ‘dnnl::post_ops::append_eltwise(float&, dnnl::algorithm, float&, float&)’
266 | po.append_eltwise(scale, algorithm::eltwise_sqrt, alpha, beta);
| ^
In file included from /usr/local/include/dnnl.hpp:20,
from /tmp/scratch/pytorch/third_party/ideep/include/ideep/abstract_types.hpp:5,
from /tmp/scratch/pytorch/third_party/ideep/include/ideep.hpp:39,
from /tmp/scratch/pytorch/caffe2/ideep/ideep_utils.h:6,
from /tmp/scratch/pytorch/caffe2/python/pybind_state_ideep.cc:12:
/usr/local/include/oneapi/dnnl/dnnl.hpp:2992:10: note: candidate: ‘void dnnl::post_ops::append_eltwise(dnnl::algorithm, float, float)’
2992 | void append_eltwise(algorithm aalgorithm, float alpha, float beta) {
| ^~~~~~~~~~~~~~
/usr/local/include/oneapi/dnnl/dnnl.hpp:2992:10: note: candidate expects 3 arguments, 4 provided
In file included from /tmp/scratch/pytorch/third_party/ideep/include/ideep/tensor.hpp:4,
from /tmp/scratch/pytorch/third_party/ideep/include/ideep.hpp:40,
from /tmp/scratch/pytorch/caffe2/ideep/ideep_utils.h:6,
from /tmp/scratch/pytorch/caffe2/python/pybind_state_ideep.cc:12:
/tmp/scratch/pytorch/third_party/ideep/include/ideep/attributes.hpp: In static member function ‘static ideep::attr_t ideep::attr_t::fuse_pow(float, float, float)’:
/tmp/scratch/pytorch/third_party/ideep/include/ideep/attributes.hpp:277:65: error: no matching function for call to ‘dnnl::post_ops::append_eltwise(float&, dnnl::algorithm, float&, float&)’
277 | po.append_eltwise(scale, algorithm::eltwise_pow, alpha, beta);
| ^
In file included from /usr/local/include/dnnl.hpp:20,
from /tmp/scratch/pytorch/third_party/ideep/include/ideep/abstract_types.hpp:5,
from /tmp/scratch/pytorch/third_party/ideep/include/ideep.hpp:39,
from /tmp/scratch/pytorch/caffe2/ideep/ideep_utils.h:6,
from /tmp/scratch/pytorch/caffe2/python/pybind_state_ideep.cc:12:
/usr/local/include/oneapi/dnnl/dnnl.hpp:2992:10: note: candidate: ‘void dnnl::post_ops::append_eltwise(dnnl::algorithm, float, float)’
2992 | void append_eltwise(algorithm aalgorithm, float alpha, float beta) {
| ^~~~~~~~~~~~~~
/usr/local/include/oneapi/dnnl/dnnl.hpp:2992:10: note: candidate expects 3 arguments, 4 provided
In file included from /tmp/scratch/pytorch/third_party/ideep/include/ideep/tensor.hpp:4,
from /tmp/scratch/pytorch/third_party/ideep/include/ideep.hpp:40,
from /tmp/scratch/pytorch/caffe2/ideep/ideep_utils.h:6,
from /tmp/scratch/pytorch/caffe2/python/pybind_state_ideep.cc:12:
/tmp/scratch/pytorch/third_party/ideep/include/ideep/attributes.hpp: In member function ‘std::tuple<dnnl::primitive::kind, float, float, float, dnnl::algorithm, int> ideep::attr_t::get_params(int) const’:
/tmp/scratch/pytorch/third_party/ideep/include/ideep/attributes.hpp:338:61: error: no matching function for call to ‘dnnl::post_ops::get_params_eltwise(int&, float&, ideep::algorithm&, float&, float&)’
338 | po.get_params_eltwise(index, scale, alg, alpha, beta);
| ^
In file included from /usr/local/include/dnnl.hpp:20,
from /tmp/scratch/pytorch/third_party/ideep/include/ideep/abstract_types.hpp:5,
from /tmp/scratch/pytorch/third_party/ideep/include/ideep.hpp:39,
from /tmp/scratch/pytorch/caffe2/ideep/ideep_utils.h:6,
from /tmp/scratch/pytorch/caffe2/python/pybind_state_ideep.cc:12:
/usr/local/include/oneapi/dnnl/dnnl.hpp:3004:10: note: candidate: ‘void dnnl::post_ops::get_params_eltwise(int, dnnl::algorithm&, float&, float&) const’
3004 | void get_params_eltwise(
| ^~~~~~~~~~~~~~~~~~
/usr/local/include/oneapi/dnnl/dnnl.hpp:3004:10: note: candidate expects 4 arguments, 5 provided
In file included from /tmp/scratch/pytorch/third_party/ideep/include/ideep.hpp:40,
from /tmp/scratch/pytorch/caffe2/ideep/ideep_utils.h:6,
from /tmp/scratch/pytorch/caffe2/python/pybind_state_ideep.cc:12:
/tmp/scratch/pytorch/third_party/ideep/include/ideep/tensor.hpp: At global scope:
/tmp/scratch/pytorch/third_party/ideep/include/ideep/tensor.hpp:14:27: error: ‘dnnl_blocking_desc_t’ does not name a type
14 | using blocking_desc_t = dnnl_blocking_desc_t;
| ^~~~~~~~~~~~~~~~~~~~
/tmp/scratch/pytorch/third_party/ideep/include/ideep/tensor.hpp:438:11: error: ‘blocking_desc_t’ does not name a type
438 | const blocking_desc_t& blocking_desc() const {
| ^~~~~~~~~~~~~~~
/tmp/scratch/pytorch/third_party/ideep/include/ideep/tensor.hpp: In copy constructor ‘ideep::tensor::desc::desc(const ideep::tensor::desc&)’:
/tmp/scratch/pytorch/third_party/ideep/include/ideep/tensor.hpp:27:50: error: ‘const struct ideep::tensor::desc’ has no member named ‘data’; did you mean ‘std::shared_ptr<dnnl_memory_desc> dnnl::handle<dnnl_memory_desc*>::data_’? (not accessible from this context)
27 | desc(const desc& adesc) : memory::desc(adesc.data) {
| ^~~~
In file included from /usr/local/include/oneapi/dnnl/dnnl.hpp:35,
from /usr/local/include/dnnl.hpp:20,
from /tmp/scratch/pytorch/third_party/ideep/include/ideep/abstract_types.hpp:5,
from /tmp/scratch/pytorch/third_party/ideep/include/ideep.hpp:39,
from /tmp/scratch/pytorch/caffe2/ideep/ideep_utils.h:6,
from /tmp/scratch/pytorch/caffe2/python/pybind_state_ideep.cc:12:
/usr/local/include/oneapi/dnnl/dnnl_common.hpp:130:60: note: declared private here
130 | std::shared_ptr<typename std::remove_pointer<T>::type> data_ {0};
| ^~~~~
In file included from /tmp/scratch/pytorch/third_party/ideep/include/ideep.hpp:40,
from /tmp/scratch/pytorch/caffe2/ideep/ideep_utils.h:6,
from /tmp/scratch/pytorch/caffe2/python/pybind_state_ideep.cc:12:
/tmp/scratch/pytorch/third_party/ideep/include/ideep/tensor.hpp: In constructor ‘ideep::tensor::desc::desc(const dnnl::memory::desc&, dnnl::memory::dim)’:
/tmp/scratch/pytorch/third_party/ideep/include/ideep/tensor.hpp:32:74: error: ‘const struct dnnl::memory::desc’ has no member named ‘data’; did you mean ‘std::shared_ptr<dnnl_memory_desc> dnnl::handle<dnnl_memory_desc*>::data_’? (not accessible from this context)
32 | desc(const memory::desc& adesc, dim groups = 1) : memory::desc(adesc.data) {
| ^~~~
In file included from /usr/local/include/oneapi/dnnl/dnnl.hpp:35,
from /usr/local/include/dnnl.hpp:20,
from /tmp/scratch/pytorch/third_party/ideep/include/ideep/abstract_types.hpp:5,
from /tmp/scratch/pytorch/third_party/ideep/include/ideep.hpp:39,
from /tmp/scratch/pytorch/caffe2/ideep/ideep_utils.h:6,
from /tmp/scratch/pytorch/caffe2/python/pybind_state_ideep.cc:12:
/usr/local/include/oneapi/dnnl/dnnl_common.hpp:130:60: note: declared private here
130 | std::shared_ptr<typename std::remove_pointer<T>::type> data_ {0};
| ^~~~~
In file included from /tmp/scratch/pytorch/third_party/ideep/include/ideep.hpp:40,
from /tmp/scratch/pytorch/caffe2/ideep/ideep_utils.h:6,
from /tmp/scratch/pytorch/caffe2/python/pybind_state_ideep.cc:12:
/tmp/scratch/pytorch/third_party/ideep/include/ideep/tensor.hpp: In member function ‘void ideep::tensor::desc::to_bytes(ideep::utils::bytestring&) const’:
/tmp/scratch/pytorch/third_party/ideep/include/ideep/tensor.hpp:65:27: error: ‘data’ was not declared in this scope
65 | for (int i = 0; i < data.ndims; i++) {
| ^~~~
/tmp/scratch/pytorch/third_party/ideep/include/ideep/tensor.hpp:65:27: note: suggested alternatives:
In file included from /usr/include/c++/10/array:41,
from /usr/include/c++/10/tuple:39,
from /usr/include/c++/10/bits/hashtable_policy.h:34,
from /usr/include/c++/10/bits/hashtable.h:35,
from /usr/include/c++/10/unordered_map:46,
from /tmp/scratch/pytorch/caffe2/python/pybind_state.h:3,
from /tmp/scratch/pytorch/caffe2/python/pybind_state_ideep.cc:7:
/usr/include/c++/10/bits/range_access.h:319:5: note: ‘std::data’
319 | data(initializer_list<_Tp> __il) noexcept
| ^~~~
In file included from /tmp/scratch/pytorch/build/aten/src/ATen/MethodOperators.h:122,
from /tmp/scratch/pytorch/build/aten/src/ATen/core/TensorBody.h:40,
from /tmp/scratch/pytorch/caffe2/core/operator.h:36,
from /tmp/scratch/pytorch/caffe2/python/pybind_state.h:10,
from /tmp/scratch/pytorch/caffe2/python/pybind_state_ideep.cc:7:
/tmp/scratch/pytorch/build/aten/src/ATen/ops/data_ops.h:17:18: note: ‘at::_ops::data’
17 | struct TORCH_API data {
| ^~~~
In file included from /tmp/scratch/pytorch/third_party/ideep/include/ideep.hpp:40,
from /tmp/scratch/pytorch/caffe2/ideep/ideep_utils.h:6,
from /tmp/scratch/pytorch/caffe2/python/pybind_state_ideep.cc:12:
/tmp/scratch/pytorch/third_party/ideep/include/ideep/tensor.hpp:72:21: error: ‘blocking_desc’ was not declared in this scope; did you mean ‘is_blocking_desc’?
72 | auto& blk = blocking_desc();
| ^~~~~~~~~~~~~
| is_blocking_desc
/tmp/scratch/pytorch/third_party/ideep/include/ideep/tensor.hpp:74:29: error: ‘data’ was not declared in this scope
74 | for (int i = 0; i < data.ndims; i++) {
| ^~~~
/tmp/scratch/pytorch/third_party/ideep/include/ideep/tensor.hpp:74:29: note: suggested alternatives:
In file included from /usr/include/c++/10/array:41,
from /usr/include/c++/10/tuple:39,
from /usr/include/c++/10/bits/hashtable_policy.h:34,
from /usr/include/c++/10/bits/hashtable.h:35,
from /usr/include/c++/10/unordered_map:46,
from /tmp/scratch/pytorch/caffe2/python/pybind_state.h:3,
from /tmp/scratch/pytorch/caffe2/python/pybind_state_ideep.cc:7:
/usr/include/c++/10/bits/range_access.h:319:5: note: ‘std::data’
319 | data(initializer_list<_Tp> __il) noexcept
| ^~~~
In file included from /tmp/scratch/pytorch/build/aten/src/ATen/MethodOperators.h:122,
from /tmp/scratch/pytorch/build/aten/src/ATen/core/TensorBody.h:40,
from /tmp/scratch/pytorch/caffe2/core/operator.h:36,
from /tmp/scratch/pytorch/caffe2/python/pybind_state.h:10,
from /tmp/scratch/pytorch/caffe2/python/pybind_state_ideep.cc:7:
/tmp/scratch/pytorch/build/aten/src/ATen/ops/data_ops.h:17:18: note: ‘at::_ops::data’
17 | struct TORCH_API data {
| ^~~~
In file included from /tmp/scratch/pytorch/third_party/ideep/include/ideep.hpp:40,
from /tmp/scratch/pytorch/caffe2/ideep/ideep_utils.h:6,
from /tmp/scratch/pytorch/caffe2/python/pybind_state_ideep.cc:12:
/tmp/scratch/pytorch/third_party/ideep/include/ideep/tensor.hpp: In member function ‘int ideep::tensor::desc::get_ndims() const’:
/tmp/scratch/pytorch/third_party/ideep/include/ideep/tensor.hpp:86:29: error: ‘data’ was not declared in this scope
86 | return is_grouped() ? data.ndims - 1 : data.ndims;
| ^~~~
/tmp/scratch/pytorch/third_party/ideep/include/ideep/tensor.hpp:86:29: note: suggested alternatives:
In file included from /usr/include/c++/10/array:41,
from /usr/include/c++/10/tuple:39,
from /usr/include/c++/10/bits/hashtable_policy.h:34,
from /usr/include/c++/10/bits/hashtable.h:35,
from /usr/include/c++/10/unordered_map:46,
from /tmp/scratch/pytorch/caffe2/python/pybind_state.h:3,
from /tmp/scratch/pytorch/caffe2/python/pybind_state_ideep.cc:7:
/usr/include/c++/10/bits/range_access.h:319:5: note: ‘std::data’
319 | data(initializer_list<_Tp> __il) noexcept
| ^~~~
In file included from /tmp/scratch/pytorch/build/aten/src/ATen/MethodOperators.h:122,
from /tmp/scratch/pytorch/build/aten/src/ATen/core/TensorBody.h:40,
from /tmp/scratch/pytorch/caffe2/core/operator.h:36,
from /tmp/scratch/pytorch/caffe2/python/pybind_state.h:10,
from /tmp/scratch/pytorch/caffe2/python/pybind_state_ideep.cc:7:
/tmp/scratch/pytorch/build/aten/src/ATen/ops/data_ops.h:17:18: note: ‘at::_ops::data’
17 | struct TORCH_API data {
| ^~~~
In file included from /tmp/scratch/pytorch/third_party/ideep/include/ideep.hpp:40,
from /tmp/scratch/pytorch/caffe2/ideep/ideep_utils.h:6,
from /tmp/scratch/pytorch/caffe2/python/pybind_state_ideep.cc:12:
/tmp/scratch/pytorch/third_party/ideep/include/ideep/tensor.hpp: In member function ‘ideep::tensor::dim_t ideep::tensor::desc::get_dim(int) const’:
/tmp/scratch/pytorch/third_party/ideep/include/ideep/tensor.hpp:92:35: error: ‘data’ was not declared in this scope
92 | if (index < 0 || index >= data.ndims)
| ^~~~
/tmp/scratch/pytorch/third_party/ideep/include/ideep/tensor.hpp:92:35: note: suggested alternatives:
In file included from /usr/include/c++/10/array:41,
from /usr/include/c++/10/tuple:39,
from /usr/include/c++/10/bits/hashtable_policy.h:34,
from /usr/include/c++/10/bits/hashtable.h:35,
from /usr/include/c++/10/unordered_map:46,
from /tmp/scratch/pytorch/caffe2/python/pybind_state.h:3,
from /tmp/scratch/pytorch/caffe2/python/pybind_state_ideep.cc:7:
/usr/include/c++/10/bits/range_access.h:319:5: note: ‘std::data’
319 | data(initializer_list<_Tp> __il) noexcept
| ^~~~
In file included from /tmp/scratch/pytorch/build/aten/src/ATen/MethodOperators.h:122,
from /tmp/scratch/pytorch/build/aten/src/ATen/core/TensorBody.h:40,
from /tmp/scratch/pytorch/caffe2/core/operator.h:36,
from /tmp/scratch/pytorch/caffe2/python/pybind_state.h:10,
from /tmp/scratch/pytorch/caffe2/python/pybind_state_ideep.cc:7:
/tmp/scratch/pytorch/build/aten/src/ATen/ops/data_ops.h:17:18: note: ‘at::_ops::data’
17 | struct TORCH_API data {
| ^~~~
In file included from /tmp/scratch/pytorch/third_party/ideep/include/ideep.hpp:40,
from /tmp/scratch/pytorch/caffe2/ideep/ideep_utils.h:6,
from /tmp/scratch/pytorch/caffe2/python/pybind_state_ideep.cc:12:
/tmp/scratch/pytorch/third_party/ideep/include/ideep/tensor.hpp:94:16: error: ‘data’ was not declared in this scope
94 | return data.dims[index];
```
### Versions
Current master, on Debian 11/Ubuntu 22.04 with distro-stock python.
cc @malfet @seemethere
| 10 |
3,755 | 92,075 |
Hessian produces wrong results, but works if I add a perturbation
|
triaged
|
I have the following function I would like the Hessian of:
```python
def rbf(x1, x2, l):
diff = x1/l - x2/l
dist = torch.linalg.norm(diff)
return torch.exp(-dist * dist)
```
Taking the Hessian with `functorch.jacfwd` and `functorch.grad` seems to get me an incorrect result on a naive example. According to my derivation by hand, this should return `2.0 / l**2 * torch.eye(16)`. If I add a small number to one of the terms, the Hessian function returns the correct result:
```python
jacfwdgrad_rbf = jacfwd(grad(rbf, argnums=0), argnums=1) # doing d^2f/dx1dx2
a = torch.randn(16)
l = 1.0
print(torch.allclose(jacfwdgrad_rbf(a, a, l), 2/l/l * torch.eye(16))) # prints False
print(torch.allclose(jacfwdgrad_rbf(a, a+1e-8, l), 2/l/l * torch.eye(16))) # prints True
```
Is there some bug that means the former check doesn't work, or is there something I'm missing?
| 4 |
3,756 | 91,965 |
Proxy/cache server option/hooks for downloading model checkpoints and dataset archive files in cloud environment
|
triaged, module: hub
|
### 🚀 The feature, motivation and pitch
Often in cloud environments, we may want to cache the pretrained model checkpoints (e.g. certain torchvision resnet50) and dataset archives (e.g. COCO tar files) on a custom endpoint (e.g. S3 bucket with http access) for faster downloads and avoiding overloading public servers, especially given problems with over-downloading in all DDP replicas: https://github.com/pytorch/pytorch/issues/68320
It would be nice to have some mechanisms / hooks in torch domain libraries for rewriting the URLs. (maybe in torch.hub?)
It would also be nice to generalize content-addressability of checkpoints (at least as an option). Currently some checkpoints have hashes in their file names in torchvision, but maybe it's not made obligatory.
An advanced hook could by itself avoid race-conditioned downloads and could by itself download to S3 bucket (via boto3) and then return the fixed path
### Alternatives
_No response_
### Additional context
_No response_
cc @nairbv @NicolasHug @vmoens @jdsgomes
| 1 |
3,757 | 91,958 |
CUDA error `CUBLAS_STATUS_NOT_INITIALIZED`
|
module: cuda, triaged, module: cublas
|
### 🐛 Describe the bug
I am using PyTorch through another library ([TabNet](https://github.com/dreamquark-ai/tabnet)).
When I run the fit of a model, this library calls [this](https://github.com/pytorch/pytorch/blob/1892c75a45f599bd7ea652b10c379325abca8648/torch/nn/modules/linear.py#L114) function which causes the following error:
```
RuntimeError: CUDA error: CUBLAS_STATUS_NOT_INITIALIZED when calling `cublasCreate(handle)`
// my calls stack (omitted)
File "/app/.venv/lib/python3.10/site-packages/pytorch_tabnet/abstract_model.py", line 241, in fit
self._train_epoch(train_dataloader)
File "/app/.venv/lib/python3.10/site-packages/pytorch_tabnet/abstract_model.py", line 457, in _train_epoch
batch_logs = self._train_batch(X, y)
File "/app/.venv/lib/python3.10/site-packages/pytorch_tabnet/abstract_model.py", line 495, in _train_batch
output, M_loss = self.network(X)
File "torch/nn/modules/module.py", line 1194, in _call_impl
return forward_call(*input, **kwargs)
File "/app/.venv/lib/python3.10/site-packages/pytorch_tabnet/tab_network.py", line 586, in forward
return self.tabnet(x)
File "torch/nn/modules/module.py", line 1194, in _call_impl
return forward_call(*input, **kwargs)
File "/app/.venv/lib/python3.10/site-packages/pytorch_tabnet/tab_network.py", line 471, in forward
steps_output, M_loss = self.encoder(x)
File "torch/nn/modules/module.py", line 1194, in _call_impl
return forward_call(*input, **kwargs)
File "/app/.venv/lib/python3.10/site-packages/pytorch_tabnet/tab_network.py", line 156, in forward
att = self.initial_splitter(x)[:, self.n_d :]
File "torch/nn/modules/module.py", line 1194, in _call_impl
return forward_call(*input, **kwargs)
File "/app/.venv/lib/python3.10/site-packages/pytorch_tabnet/tab_network.py", line 706, in forward
x = self.shared(x)
File "torch/nn/modules/module.py", line 1194, in _call_impl
return forward_call(*input, **kwargs)
File "/app/.venv/lib/python3.10/site-packages/pytorch_tabnet/tab_network.py", line 743, in forward
x = self.glu_layers[0](x)
File "torch/nn/modules/module.py", line 1194, in _call_impl
return forward_call(*input, **kwargs)
File "/app/.venv/lib/python3.10/site-packages/pytorch_tabnet/tab_network.py", line 772, in forward
x = self.fc(x)
File "torch/nn/modules/module.py", line 1194, in _call_impl
return forward_call(*input, **kwargs)
File "torch/nn/modules/linear.py", line 114, in forward
return F.linear(input, self.weight, self.bias)
```
Can you help me solve the problem? Unfortunately I cannot provide a script to reproduce the problem, but if there is any other information that can help I can provide it
### Versions
```
PyTorch version: 1.13.1+cu117
Is debug build: False
CUDA used to build PyTorch: 11.7
ROCM used to build PyTorch: N/A
OS: Ubuntu 22.04.1 LTS (x86_64)
GCC version: Could not collect
Clang version: Could not collect
CMake version: Could not collect
Libc version: glibc-2.35
Python version: 3.10.6 (main, Nov 14 2022, 16:10:14) [GCC 11.3.0] (64-bit runtime)
Python platform: Linux-5.10.133+-x86_64-with-glibc2.35
Is CUDA available: True
CUDA runtime version: Could not collect
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration:
GPU 0: Tesla T4
GPU 1: Tesla T4
Nvidia driver version: 470.141.03
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.6.0
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.6.0
/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.6.0
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_infer.so.8.6.0
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.6.0
/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.6.0
/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.6.0
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.24.1
[pip3] pytorch-tabnet==4.0
[pip3] torch==1.13.1
[conda] Could not collect
```
cc @ngimel @csarofeen @ptrblck @xwang233
| 1 |
3,758 | 91,951 |
[PT2.0 Feature Proposal] GNN inference and training optimization on CPU
|
feature, triaged, oncall: pt2
|
### 🚀 The feature, motivation and pitch
This ticket is per request from Ibrahim Siddiqui as part of PT2.0 feature proposal process. The feature proposal has also been submitted @ https://docs.google.com/spreadsheets/d/1TzGkWuUMF1yTe88adz1dt2mzbIsZLd3PBasy588VWgk/edit#gid=790902532
Graph Neural Networks (GNNs) is a powerful tool to analyze graph structure data. This proposed feature is targeted at improving GNN inference and training performance on CPU. PyG is a very popular library built upon PyTorch for GNN. Performance of PyG strongly depends on PyTorch. Currently on CPU, GNN models of PyG run extremely slow due to the lack of GNN-related sparse matrix multiplication ops (i.e., spmm_reduce) and the lack of several critical kernel level optimizations (scatter/gather, etc.) tuned for GNN compute.
We submitted PRs to optimize the more critical hot spots, and demonstrated a 2-5x performance speedup on PyG benchmarks/examples, OGB benchmarks for single node inference and training.
To be specific, the following kernels are optimized from torch side (for inference and training stage, targeting at torch 2.0):
- scatter_add and scatter_reduce: this is the hotspot in Message Passing when the edge index is stored in COO, which takes 49% of runtime in SAGE + Reddit.
- spmm_reduce: this is the hotspot in Message Passing when the edge index is stored in CSR, which takes 97% of runtime in GCN + ogbn-products.
- Gather: backward of scatter_add. Current implementation from ATen is not efficient when the index is an expanded tensor.
- sampled_addmm: this one can be used for feature aggregation when the edge index is in CSR, the current CPU impl is a reference design which converts the sparse tensor back to dense for computation.
The following will be nice to have:
- segment_reduce: used when the edge index is logically CSR but physically stored in individual dense tensors. The current impl in torch is a reference (single thread and non-vectorized).
- Multi-Aggregation mode: for scatter_reduce or spmm_reduce, the graph might want to initiate multiple ‘reduce’ types spontaneously. Allowing multi-aggregation mode would greatly save time for such scenarios since the src feature matrix (which is usually very large and accessed in an in-direct order) could be only read once.
### Alternatives
_No response_
### Additional context
**Here are the PRs that are required for this feature:**
* #82703
* #83727
* #87586
**There PRs are nice to have for PT2.0.**
* #90978
* #91500
cc @ezyang @soumith @msaroufim @wconstab @ngimel @bdhirsh
| 1 |
3,759 | 91,950 |
RuntimeError: philox_cuda_state for an unexpected CUDA generator used during capture
|
triaged, module: random, module: cuda graphs
|
### 🐛 Describe the bug
I have created a custom GraphCudaCapture Module but it raised the error below. I wonder why the generator needs to be defined and fixed.
```python
@dataclass
class CudaGraphRecord:
graph = None
args = None
kwargs = None
output = None
cuda_graph_created: bool = False
enable_cuda_graph: bool = True
class CudaGraphBatchRecord(dict):
def __init__(self, enable_cuda_graph):
super().__init__()
self.enable_cuda_graph = enable_cuda_graph
def __getitem__(self, key):
if key not in self:
self[key] = CudaGraphRecord(enable_cuda_graph=self.enable_cuda_graph)
for item, value in self.items():
if item == key:
return value
raise Exception()
class CudaGraphInferenceModule(torch.nn.Module):
# Inspired from https://github.com/microsoft/DeepSpeed/blob/master/deepspeed/model_implementations/diffusers/vae.py
inference_methods = ["forward"]
def __init__(self, module, enable_cuda_graph = True):
super().__init__()
self.module = module
self.module.requires_grad_(requires_grad=False)
self.module.to(memory_format=torch.channels_last)
self.cuda_graph_records = {}
for method_name in self.inference_methods:
fn = getattr(self, f"_{method_name}")
assert fn
self.cuda_graph_records[method_name] = CudaGraphBatchRecord(enable_cuda_graph=enable_cuda_graph)
setattr(self, method_name, partial(self._apply_fn, fn=fn, graph_record=self.cuda_graph_records[method_name]))
def __getattr__(self, key):
if hasattr(self._modules["module"], key) and key not in self.__dict__:
return getattr(self._modules["module"], key)
if key == "module":
return self._modules["module"]
return object.__getattribute__(self, key)
def _graph_replay(self, graph_record, *args, **kwargs):
for i in range(len(args)):
if torch.is_tensor(args[i]):
graph_record.args[i].copy_(args[i])
for k in kwargs:
if torch.is_tensor(kwargs[k]):
graph_record.kwargs[k].copy_(kwargs[k])
graph_record.graph.replay()
return graph_record.output
def extract_batch_size(self, *args, **kwargs) -> int:
raise NotImplementedError
def _apply_fn(self, *args, fn=None, graph_record=None, **kwargs):
batch_size = self.extract_batch_size(*args, **kwargs)
if graph_record[batch_size].enable_cuda_graph:
if graph_record[batch_size].cuda_graph_created:
outputs = self._graph_replay(graph_record[batch_size], *args, **kwargs)
else:
self._create_cuda_graph(fn, graph_record[batch_size], *args, **kwargs)
outputs = self._graph_replay(graph_record[batch_size], *args, **kwargs)
return outputs
else:
return self._forward(*args, **kwargs)
def _create_cuda_graph(self, fn, graph_record, *args, **kwargs):
# Warmup to create the workspace and cublas handle
cuda_stream = torch.cuda.Stream()
cuda_stream.wait_stream(torch.cuda.current_stream())
with torch.cuda.stream(cuda_stream):
for _ in range(3):
fn(*args, **kwargs)
torch.cuda.current_stream().wait_stream(cuda_stream)
# Capture inputs to the graph
graph_record.graph = torch.cuda.CUDAGraph()
graph_record.args = args
graph_record.kwargs = kwargs
with torch.cuda.graph(graph_record.graph):
# Store output
graph_record.output = fn(*graph_record.args, **graph_record.kwargs)
graph_record.cuda_graph_created = True
```
```python
INFO: File "/home/zeus/.local/lib/python3.8/site-packages/uvicorn/protocols/http/httptools_impl.py", line 419, in run_asgi
result = await app( # type: ignore[func-returns-value]
INFO: File "/home/zeus/.local/lib/python3.8/site-packages/uvicorn/middleware/proxy_headers.py", line 78, in __call__
return await self.app(scope, receive, send)
INFO: File "/home/zeus/.local/lib/python3.8/site-packages/fastapi/applications.py", line 270, in __call__
await super().__call__(scope, receive, send)
INFO: File "/home/zeus/.local/lib/python3.8/site-packages/starlette/applications.py", line 124, in __call__
await self.middleware_stack(scope, receive, send)
INFO: File "/home/zeus/.local/lib/python3.8/site-packages/starlette/middleware/errors.py", line 184, in __call__
raise exc
INFO: File "/home/zeus/.local/lib/python3.8/site-packages/starlette/middleware/errors.py", line 162, in __call__
await self.app(scope, receive, _send)
INFO: File "/home/zeus/.local/lib/python3.8/site-packages/starlette/middleware/exceptions.py", line 79, in __call__
raise exc
INFO: File "/home/zeus/.local/lib/python3.8/site-packages/starlette/middleware/exceptions.py", line 68, in __call__
await self.app(scope, receive, sender)
INFO: File "/home/zeus/.local/lib/python3.8/site-packages/fastapi/middleware/asyncexitstack.py", line 21, in __call__
raise e
INFO: File "/home/zeus/.local/lib/python3.8/site-packages/fastapi/middleware/asyncexitstack.py", line 18, in __call__
await self.app(scope, receive, send)
INFO: File "/home/zeus/.local/lib/python3.8/site-packages/starlette/routing.py", line 706, in __call__
await route.handle(scope, receive, send)
INFO: File "/home/zeus/.local/lib/python3.8/site-packages/starlette/routing.py", line 276, in handle
await self.app(scope, receive, send)
INFO: File "/home/zeus/.local/lib/python3.8/site-packages/starlette/routing.py", line 66, in app
response = await func(request)
INFO: File "/home/zeus/.local/lib/python3.8/site-packages/fastapi/routing.py", line 235, in app
raw_response = await run_endpoint_function(
INFO: File "/home/zeus/.local/lib/python3.8/site-packages/fastapi/routing.py", line 163, in run_endpoint_function
return await run_in_threadpool(dependant.call, **values)
INFO: File "/home/zeus/.local/lib/python3.8/site-packages/starlette/concurrency.py", line 41, in run_in_threadpool
return await anyio.to_thread.run_sync(func, *args)
INFO: File "/home/zeus/.local/lib/python3.8/site-packages/anyio/to_thread.py", line 31, in run_sync
return await get_asynclib().run_sync_in_worker_thread(
INFO: File "/home/zeus/.local/lib/python3.8/site-packages/anyio/_backends/_asyncio.py", line 937, in run_sync_in_worker_thread
return await future
INFO: File "/home/zeus/.local/lib/python3.8/site-packages/anyio/_backends/_asyncio.py", line 867, in run
result = context.run(func, *args)
INFO: File "/home/zeus/.local/lib/python3.8/site-packages/lightning/app/components/serve/python_server.py", line 253, in predict_fn
return self.predict(request)
INFO: File "app.py", line 34, in predict
images = self._model.predict_step(prompts=texts, batch_idx=0)
INFO: File "/content/venv/lib/python3.8/site-packages/ldm/lightning.py", line 92, in predict_step
samples_ddim, _ = self.sampler.sample(
INFO: File "/home/zeus/.local/lib/python3.8/site-packages/torch/autograd/grad_mode.py", line 27, in decorate_context
return func(*args, **kwargs)
INFO: File "/content/venv/lib/python3.8/site-packages/ldm/models/diffusion/dpm_solver/sampler.py", line 85, in sample
x = dpm_solver.sample(img, steps=S, skip_type="time_uniform", method="multistep", order=2, lower_order_final=True)
INFO: File "/content/venv/lib/python3.8/site-packages/ldm/models/diffusion/dpm_solver/dpm_solver.py", line 1057, in sample
model_prev_list.append(self.model_fn(x, vec_t))
INFO: File "/content/venv/lib/python3.8/site-packages/ldm/models/diffusion/dpm_solver/dpm_solver.py", line 372, in model_fn
return self.data_prediction_fn(x, t)
INFO: File "/content/venv/lib/python3.8/site-packages/ldm/models/diffusion/dpm_solver/dpm_solver.py", line 356, in data_prediction_fn
noise = self.noise_prediction_fn(x, t)
INFO: File "/content/venv/lib/python3.8/site-packages/ldm/models/diffusion/dpm_solver/dpm_solver.py", line 350, in noise_prediction_fn
return self.model(x, t)
INFO: File "/content/venv/lib/python3.8/site-packages/ldm/models/diffusion/dpm_solver/dpm_solver.py", line 311, in model_fn
noise_uncond, noise = noise_pred_fn(x_in, t_in, cond=c_in).chunk(2)
INFO: File "/content/venv/lib/python3.8/site-packages/ldm/models/diffusion/dpm_solver/dpm_solver.py", line 264, in noise_pred_fn
output = model(x, t_input, cond, **model_kwargs)
INFO: File "/content/venv/lib/python3.8/site-packages/ldm/models/diffusion/dpm_solver/sampler.py", line 75, in <lambda>
lambda x, t, c: self.model.apply_model(x, t, c),
INFO: File "/content/venv/lib/python3.8/site-packages/ldm/models/diffusion/ddpm.py", line 858, in apply_model
x_recon = self.model(x_noisy, t, **cond)
INFO: File "/home/zeus/.local/lib/python3.8/site-packages/torch/nn/modules/module.py", line 1194, in _call_impl
return forward_call(*input, **kwargs)
INFO: File "/content/venv/lib/python3.8/site-packages/ldm/deepspeed_replace.py", line 83, in _apply_fn
outputs = self._graph_replay(graph_record[batch_size], *args, **kwargs)
INFO: File "/content/venv/lib/python3.8/site-packages/ldm/deepspeed_replace.py", line 73, in _graph_replay
graph_record.graph.replay()
INFO: File "/home/zeus/.local/lib/python3.8/site-packages/torch/cuda/graphs.py", line 87, in replay
super(CUDAGraph, self).replay()
INFO: RuntimeError: philox_cuda_state for an unexpected CUDA generator used during capture. In regions captured by CUDA graphs, you may only use the default CUDA RNG generator on the device that's current when capture begins. If you need a non-default (user-supplied) generator, or a generator on another device, please file an issue.
ERROR: Exception in ASGI application
```
### Versions
```bash
Collecting environment information...
PyTorch version: 1.13.1+cu116
Is debug build: False
CUDA used to build PyTorch: 11.6
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.5 LTS (x86_64)
GCC version: (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0
Clang version: Could not collect
CMake version: version 3.25.0
Libc version: glibc-2.31
Python version: 3.8.10 (default, Nov 14 2022, 12:59:47) [GCC 9.4.0] (64-bit runtime)
Python platform: Linux-5.4.0-135-generic-x86_64-with-glibc2.29
Is CUDA available: True
CUDA runtime version: 11.6.124
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration:
GPU 0: NVIDIA GeForce RTX 3090
GPU 1: NVIDIA GeForce RTX 3090
GPU 2: NVIDIA GeForce RTX 3090
GPU 3: NVIDIA GeForce RTX 3090
GPU 4: NVIDIA GeForce RTX 3090
GPU 5: NVIDIA GeForce RTX 3090
GPU 6: NVIDIA GeForce RTX 3090
Nvidia driver version: 520.61.05
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.24.0
[pip3] open-clip-torch==2.7.0
[pip3] pytorch-lightning==1.8.6
[pip3] torch==1.13.1+cu116
[pip3] torchmetrics==0.11.0
[pip3] torchvision==0.14.1+cu116
[conda] Could not collect
```
cc @pbelevich @mcarilli @ezyang
| 3 |
3,760 | 93,501 |
_pack_padded_sequence fails in dynamo due to requiring a non-fake 2nd argument
|
triaged, bug, oncall: pt2, mlperf
|
### 🐛 Describe the bug
`_pack_padded_sequence()` op takes a 2nd argument as a tensor of integers. The current implementation fails in dynamo when trying to `get_fake_value()`, because the 2nd argument is converted to a fake tensor.
Repro:
```python
import torch
import torch._dynamo
def fn(x, seq_lens):
return torch.nn.utils.rnn.pack_padded_sequence(x, seq_lens.tolist(), batch_first=True)
args = [torch.rand((4, 4, 4)), torch.ones([4], dtype=torch.int64)]
fn(*args)
fn_opt = torch._dynamo.optimize("eager")(fn)
fn_opt(*args)
```
Stacktrace:
```python
$ python repro_pack.py
Traceback (most recent call last):
File "/scratch/dberard/dynamo38/pytorch/torch/_dynamo/utils.py", line 1078, in run_node
return node.target(*args, **kwargs)
File "/scratch/dberard/dynamo38/pytorch/torch/nn/utils/rnn.py", line 263, in pack_padded_sequence
_VF._pack_padded_sequence(input, lengths, batch_first)
File "/scratch/dberard/dynamo38/pytorch/torch/_subclasses/fake_tensor.py", line 916, in __torch_dispatch__
r = func(*args, **kwargs)
File "/scratch/dberard/dynamo38/pytorch/torch/_ops.py", line 284, in __call__
return self._op(*args, **kwargs or {})
RuntimeError: 'lengths' argument should be a 1D CPU int64 tensor, but got 1D meta Long tensor
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "/scratch/dberard/dynamo38/pytorch/torch/_dynamo/utils.py", line 1037, in get_fake_value
return wrap_fake_exception(
File "/scratch/dberard/dynamo38/pytorch/torch/_dynamo/utils.py", line 714, in wrap_fake_exception
return fn()
File "/scratch/dberard/dynamo38/pytorch/torch/_dynamo/utils.py", line 1038, in <lambda>
lambda: run_node(tx.output, node, args, kwargs, nnmodule)
File "/scratch/dberard/dynamo38/pytorch/torch/_dynamo/utils.py", line 1090, in run_node
raise RuntimeError(
RuntimeError: Failed running call_function <function pack_padded_sequence at 0x7f86cc82c0d0>(*(FakeTensor(FakeTensor(..., device='meta', size=(4, 4, 4)), cpu), [1, 1, 1, 1]), **{'batch_
first': True}):
'lengths' argument should be a 1D CPU int64 tensor, but got 1D meta Long tensor
(scroll up for backtrace)
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "repro_pack.py", line 11, in <module>
fn_opt(*args)
File "/scratch/dberard/dynamo38/pytorch/torch/_dynamo/eval_frame.py", line 212, in _fn
return fn(*args, **kwargs)
File "repro_pack.py", line 5, in fn
return torch.nn.utils.rnn.pack_padded_sequence(x, seq_lens.tolist(), batch_first=True)
File "/scratch/dberard/dynamo38/pytorch/torch/_dynamo/eval_frame.py", line 333, in catch_errors
return callback(frame, cache_size, hooks)
File "/scratch/dberard/dynamo38/pytorch/torch/_dynamo/convert_frame.py", line 480, in _convert_frame
result = inner_convert(frame, cache_size, hooks)
File "/scratch/dberard/dynamo38/pytorch/torch/_dynamo/convert_frame.py", line 103, in _fn
return fn(*args, **kwargs)
File "/scratch/dberard/dynamo38/pytorch/torch/_dynamo/utils.py", line 94, in time_wrapper
r = func(*args, **kwargs)
File "/scratch/dberard/dynamo38/pytorch/torch/_dynamo/convert_frame.py", line 339, in _convert_frame_assert
return _compile(
File "/scratch/dberard/dynamo38/pytorch/torch/_dynamo/convert_frame.py", line 400, in _compile
out_code = transform_code_object(code, transform)
File "/scratch/dberard/dynamo38/pytorch/torch/_dynamo/bytecode_transformation.py", line 341, in transform_code_object
transformations(instructions, code_options)
File "/scratch/dberard/dynamo38/pytorch/torch/_dynamo/convert_frame.py", line 387, in transform
tracer.run()
File "/scratch/dberard/dynamo38/pytorch/torch/_dynamo/symbolic_convert.py", line 1684, in run
super().run()
File "/scratch/dberard/dynamo38/pytorch/torch/_dynamo/symbolic_convert.py", line 538, in run
and self.step()
File "/scratch/dberard/dynamo38/pytorch/torch/_dynamo/symbolic_convert.py", line 501, in step
getattr(self, inst.opname)(inst)
File "/scratch/dberard/dynamo38/pytorch/torch/_dynamo/symbolic_convert.py", line 307, in wrapper
return inner_fn(self, inst)
File "/scratch/dberard/dynamo38/pytorch/torch/_dynamo/symbolic_convert.py", line 1015, in CALL_FUNCTION_KW
self.call_function(fn, args, kwargs)
File "/scratch/dberard/dynamo38/pytorch/torch/_dynamo/symbolic_convert.py", line 435, in call_function
self.push(fn.call_function(self, args, kwargs))
File "/scratch/dberard/dynamo38/pytorch/torch/_dynamo/variables/torch.py", line 470, in call_function
tensor_variable = wrap_fx_proxy(
File "/scratch/dberard/dynamo38/pytorch/torch/_dynamo/variables/builder.py", line 731, in wrap_fx_proxy
return wrap_fx_proxy_cls(
File "/scratch/dberard/dynamo38/pytorch/torch/_dynamo/variables/builder.py", line 766, in wrap_fx_proxy_cls
example_value = get_fake_value(proxy.node, tx)
File "/scratch/dberard/dynamo38/pytorch/torch/_dynamo/utils.py", line 1057, in get_fake_value
raise TorchRuntimeError() from e
torch._dynamo.exc.TorchRuntimeError:
from user code:
File "repro_pack.py", line 5, in <graph break in fn>
return torch.nn.utils.rnn.pack_padded_sequence(x, seq_lens.tolist(), batch_first=True)
Set torch._dynamo.config.verbose=True for more information
You can suppress this exception and fall back to eager by setting:
torch._dynamo.config.suppress_errors = True
```
Failure occurs here: https://github.com/pytorch/pytorch/blob/32e9b29ce92604908bbe6f73796aa17e82b4462f/aten/src/ATen/native/PackedSequence.cpp#L25
### Error logs
_No response_
### Minified repro
_No response_
cc @ezyang @msaroufim @wconstab @bdhirsh @anijain2305 @soumith @ngimel
| 7 |
3,761 | 91,943 |
elastic job failed when scale down
|
oncall: distributed, triaged, oncall: r2p
|
### 🐛 Describe the bug
i run one job with three worker in k8s cluster,just like this command:
```shell
torchrun --nnodes=1:3 --nproc_per_node=1 --rdzv_id=1 --rdzv_backend=c10d --max_restarts=100 --rdzv_endpoint=172.22.154.120:60001 /wdk/elasticjob/pytorch/main.py --arch resnet50 --epochs 100 --batch-size 128 /wdk/imagenet/
```
when i delete a worker,the job should keep running .but in my test,the job is terminated,the worker0 job is like this
the worker 1 log is like this:
any suggestions? thanks
### Versions
1.13
cc @mrshenli @pritamdamania87 @zhaojuanmao @satgera @rohan-varma @gqchen @aazzolini @osalpekar @jiayisuse @H-Huang @kwen2501 @awgu
| 2 |
3,762 | 91,940 |
torchrun elastic always “address already in use” error
|
oncall: distributed, triaged, oncall: r2p
|
### 🐛 Describe the bug
i run the model in k8s pod, there is no other process in the pod. but this problem occurs frequently. the torch version is 1.13. i submit the job use this command:
```shell
torchrun --nnodes=1:3 --nproc_per_node=1 --rdzv_id=1 --rdzv_backend=c10d --max_restarts=100 --rdzv_endpoint=172.22.154.120:60001 /wdk/elasticjob/pytorch/main.py --arch resnet50 --epochs 100 --batch-size 128 /wdk/imagenet/
```
the error is like this

after check the pytorch code, the code will bind to get a port,then release this port as the master port. maybe this is the reason.
``` python
def get_socket_with_port() -> socket.socket:
"""
Returns a free port on localhost that is "reserved" by binding a temporary
socket on it. Close the socket before passing the port to the entity
that requires it. Usage example
::
sock = _get_socket_with_port()
with closing(sock):
port = sock.getsockname()[1]
sock.close()
# there is still a race-condition that some other process
# may grab this port before func() runs
func(port)
"""
addrs = socket.getaddrinfo(
host="localhost", port=None, family=socket.AF_UNSPEC, type=socket.SOCK_STREAM
)
for addr in addrs:
family, type, proto, _, _ = addr
s = socket.socket(family, type, proto)
try:
s.bind(("localhost", 0))
s.listen(0)
return s
except OSError as e:
s.close()
log.info("Socket creation attempt failed.", exc_info=e)
raise RuntimeError("Failed to create a socket")
````
Any method to slove this problem ?thanks.
### Versions
1.13
cc @mrshenli @pritamdamania87 @zhaojuanmao @satgera @rohan-varma @gqchen @aazzolini @osalpekar @jiayisuse @H-Huang @kwen2501 @awgu
| 5 |
3,763 | 91,936 |
Fails to build on ppc64le with clang
|
module: cpu, triaged, module: vectorization
|
### 🐛 Describe the bug
FreeBSD 13.1-RELEASE / powerpc64le with LLVM 13 (same error with LLVM 14 and 15):
```
/usr/bin/c++ -DAT_PER_OPERATOR_HEADERS -DCPUINFO_SUPPORTED_PLATFORM=0 -DFMT_HEADER_ONLY=1 -DHAVE_MALLOC_USABLE_SIZE=1 -DHAVE_MMAP=1 -DHAVE_SHM_OPEN=1 -DHAVE_SHM_UNLINK=1 -DMINIZ_DISABLE_ZIP_READER_CRC32_CHECKS -DONNXIFI_ENABLE_EXT=1 -DONNX_ML=1 -DONNX_NAMESPACE=onnx -DUSE_EXTERNAL_MZCRC -D_FILE_OFFSET_BITS=64 -Dtorch_cpu_EXPORTS -I/wrkdirs/usr/ports/misc/pytorch/work/.build/aten/src -I/wrkdirs/usr/ports/misc/pytorch/work/pytorch-v1.13.1/aten/src -I/wrkdirs/usr/ports/misc/pytorch/work/.build -I/wrkdirs/usr/ports/misc/pytorch/work/pytorch-v1.13.1 -I/wrkdirs/usr/ports/misc/pytorch/work/pytorch-v1.13.1/third_party/foxi -I/wrkdirs/usr/ports/misc/pytorch/work/.build/third_party/foxi -I/wrkdirs/usr/ports/misc/pytorch/work/pytorch-v1.13.1/torch/csrc/api -I/wrkdirs/usr/ports/misc/pytorch/work/pytorch-v1.13.1/torch/csrc/api/include -I/wrkdirs/usr/ports/misc/pytorch/work/pytorch-v1.13.1/caffe2/aten/src/TH -I/wrkdirs/usr/ports/misc/pytorch/work/.build/caffe2/aten/src/TH -I/wrkdirs/usr/ports/misc/pytorch/work/.build/caffe2/aten/src -I/wrkdirs/usr/ports/misc/pytorch/work/.build/caffe2/../aten/src -I/wrkdirs/usr/ports/misc/pytorch/work/pytorch-v1.13.1/torch/csrc -I/wrkdirs/usr/ports/misc/pytorch/work/pytorch-v1.13.1/third_party/miniz-2.1.0 -I/wrkdirs/usr/ports/misc/pytorch/work/pytorch-v1.13.1/third_party/kineto/libkineto/include -I/wrkdirs/usr/ports/misc/pytorch/work/pytorch-v1.13.1/third_party/kineto/libkineto/src -I/wrkdirs/usr/ports/misc/pytorch/work/pytorch-v1.13.1/aten/../third_party/catch/single_include -I/wrkdirs/usr/ports/misc/pytorch/work/pytorch-v1.13.1/aten/src/ATen/.. -I/wrkdirs/usr/ports/misc/pytorch/work/pytorch-v1.13.1/c10/.. -I/wrkdirs/usr/ports/misc/pytorch/work/pytorch-v1.13.1/third_party/cpuinfo/include -I/wrkdirs/usr/ports/misc/pytorch/work/pytorch-v1.13.1/third_party/FP16/include -I/wrkdirs/usr/ports/misc/pytorch/work/pytorch-v1.13.1/third_party/fmt/include -I/wrkdirs/usr/ports/misc/pytorch/work/pytorch-v1.13.1/third_party/flatbuffers/include -isystem /wrkdirs/usr/ports/misc/pytorch/work/pytorch-v1.13.1/cmake/../third_party/eigen -isystem /wrkdirs/usr/ports/misc/pytorch/work/pytorch-v1.13.1/caffe2 -O2 -pipe -fstack-protector-strong -isystem /usr/local/include -fno-strict-aliasing -isystem /usr/local/include -Wno-deprecated -fvisibility-inlines-hidden -fopenmp=libomp -DNDEBUG -DUSE_KINETO -DLIBKINETO_NOCUPTI -DSYMBOLICATE_MOBILE_DEBUG_HANDLE -DEDGE_PROFILER_USE_KINETO -O2 -fPIC -Wno-narrowing -Wall -Wextra -Werror=return-type -Werror=non-virtual-dtor -Wno-missing-field-initializers -Wno-type-limits -Wno-array-bounds -Wno-unknown-pragmas -Wunused-local-typedefs -Wno-unused-parameter -Wno-unused-function -Wno-unused-result -Wno-strict-overflow -Wno-strict-aliasing -Wno-error=deprecated-declarations -Wvla-extension -Wno-range-loop-analysis -Wno-pass-failed -Wno-error=pedantic -Wno-error=redundant-decls -Wno-error=old-style-cast -Wconstant-conversion -Wno-invalid-partial-specialization -Wno-typedef-redefinition -Wno-unused-private-field -Wno-inconsistent-missing-override -Wno-c++14-extensions -Wno-constexpr-not-const -Wno-missing-braces -Wunused-lambda-capture -Wunused-local-typedef -Qunused-arguments -fcolor-diagnostics -fdiagnostics-color=always -Wno-unused-but-set-variable -fno-math-errno -fno-trapping-math -Werror=format -Werror=cast-function-type -O2 -pipe -fstack-protector-strong -isystem /usr/local/include -fno-strict-aliasing -isystem /usr/local/include -DNDEBUG -DNDEBUG -fPIC -DTH_HAVE_THREAD -Wall -Wextra -Wno-unused-parameter -Wno-unused-function -Wno-unused-result -Wno-missing-field-initializers -Wno-write-strings -Wno-unknown-pragmas -Wno-type-limits -Wno-array-bounds -Wno-sign-compare -Wno-strict-overflow -Wno-strict-aliasing -Wno-error=deprecated-declarations -Wno-missing-braces -Wno-range-loop-analysis -fvisibility=hidden -O2 -fopenmp=libomp -DCAFFE2_BUILD_MAIN_LIB -pthread -std=gnu++14 -MD -MT caffe2/CMakeFiles/torch_cpu.dir/__/aten/src/ATen/native/Col2Im.cpp.o -MF caffe2/CMakeFiles/torch_cpu.dir/__/aten/src/ATen/native/Col2Im.cpp.o.d -o caffe2/CMakeFiles/torch_cpu.dir/__/aten/src/ATen/native/Col2Im.cpp.o -c /wrkdirs/usr/ports/misc/pytorch/work/pytorch-v1.13.1/aten/src/ATen/native/Col2Im.cpp
In file included from /wrkdirs/usr/ports/misc/pytorch/work/pytorch-v1.13.1/aten/src/ATen/native/Col2Im.cpp:6:
In file included from /wrkdirs/usr/ports/misc/pytorch/work/pytorch-v1.13.1/aten/src/ATen/native/im2col.h:7:
In file included from /wrkdirs/usr/ports/misc/pytorch/work/pytorch-v1.13.1/aten/src/ATen/native/cpu/utils.h:3:
In file included from /wrkdirs/usr/ports/misc/pytorch/work/pytorch-v1.13.1/aten/src/ATen/cpu/vec/vec.h:6:
In file included from /wrkdirs/usr/ports/misc/pytorch/work/pytorch-v1.13.1/aten/src/ATen/cpu/vec/vec256/vec256.h:19:
In file included from /wrkdirs/usr/ports/misc/pytorch/work/pytorch-v1.13.1/aten/src/ATen/cpu/vec/vec256/vsx/vec256_common_vsx.h:5:
/wrkdirs/usr/ports/misc/pytorch/work/pytorch-v1.13.1/aten/src/ATen/cpu/vec/vec256/vsx/vsx_helpers.h:57:10: error: excess elements in scalar initializer
vint16 vint0 = {0, 0, 0, 0 ,0, 0, 0, 0};
^ ~~~~~~~~~~~~~~~~~~~~~~
/wrkdirs/usr/ports/misc/pytorch/work/pytorch-v1.13.1/aten/src/ATen/cpu/vec/vec256/vsx/vsx_helpers.h:58:10: error: no matching function for call to 'vec_vsubuhm'
return vec_vsubuhm(vint0, vec_in);
^~~~~~~~~~~
/usr/lib/clang/13.0.0/include/altivec.h:11949:45: note: candidate function not viable: no known conversion from 'vint16' (aka 'short') to '__vector short' (vector of 8 'short' values) for 1st argument
static __inline__ vector short __ATTRS_o_ai vec_vsubuhm(vector short __a,
^
/usr/lib/clang/13.0.0/include/altivec.h:11954:45: note: candidate function not viable: no known conversion from 'vint16' (aka 'short') to '__vector __bool unsigned short' (vector of 8 'unsigned short' values) for 1st argument
static __inline__ vector short __ATTRS_o_ai vec_vsubuhm(vector bool short __a,
^
/usr/lib/clang/13.0.0/include/altivec.h:11959:45: note: candidate function not viable: no known conversion from 'vint16' (aka 'short') to '__vector short' (vector of 8 'short' values) for 1st argument
static __inline__ vector short __ATTRS_o_ai vec_vsubuhm(vector short __a,
^
/usr/lib/clang/13.0.0/include/altivec.h:11965:1: note: candidate function not viable: no known conversion from 'vint16' (aka 'short') to '__vector unsigned short' (vector of 8 'unsigned short' values) for 1st argument
vec_vsubuhm(vector unsigned short __a, vector unsigned short __b) {
^
/usr/lib/clang/13.0.0/include/altivec.h:11970:1: note: candidate function not viable: no known conversion from 'vint16' (aka 'short') to '__vector __bool unsigned short' (vector of 8 'unsigned short' values) for 1st argument
vec_vsubuhm(vector bool short __a, vector unsigned short __b) {
^
/usr/lib/clang/13.0.0/include/altivec.h:11975:1: note: candidate function not viable: no known conversion from 'vint16' (aka 'short') to '__vector unsigned short' (vector of 8 'unsigned short' values) for 1st argument
vec_vsubuhm(vector unsigned short __a, vector bool short __b) {
^
In file included from /wrkdirs/usr/ports/misc/pytorch/work/pytorch-v1.13.1/aten/src/ATen/native/Col2Im.cpp:6:
In file included from /wrkdirs/usr/ports/misc/pytorch/work/pytorch-v1.13.1/aten/src/ATen/native/im2col.h:7:
In file included from /wrkdirs/usr/ports/misc/pytorch/work/pytorch-v1.13.1/aten/src/ATen/native/cpu/utils.h:3:
In file included from /wrkdirs/usr/ports/misc/pytorch/work/pytorch-v1.13.1/aten/src/ATen/cpu/vec/vec.h:6:
In file included from /wrkdirs/usr/ports/misc/pytorch/work/pytorch-v1.13.1/aten/src/ATen/cpu/vec/vec256/vec256.h:19:
In file included from /wrkdirs/usr/ports/misc/pytorch/work/pytorch-v1.13.1/aten/src/ATen/cpu/vec/vec256/vsx/vec256_common_vsx.h:5:
/wrkdirs/usr/ports/misc/pytorch/work/pytorch-v1.13.1/aten/src/ATen/cpu/vec/vec256/vsx/vsx_helpers.h:62:10: error: excess elements in scalar initializer
vint32 vint0 = {0, 0, 0, 0};
^ ~~~~~~~~~~
/wrkdirs/usr/ports/misc/pytorch/work/pytorch-v1.13.1/aten/src/ATen/cpu/vec/vec256/vsx/vsx_helpers.h:63:10: error: no matching function for call to 'vec_vsubuwm'
return vec_vsubuwm(vint0, vec_in);
^~~~~~~~~~~
/usr/lib/clang/13.0.0/include/altivec.h:11983:43: note: candidate function not viable: no known conversion from 'vint32' (aka 'int') to '__vector int' (vector of 4 'int' values) for 1st argument
static __inline__ vector int __ATTRS_o_ai vec_vsubuwm(vector int __a,
^
/usr/lib/clang/13.0.0/include/altivec.h:11988:43: note: candidate function not viable: no known conversion from 'vint32' (aka 'int') to '__vector __bool unsigned int' (vector of 4 'unsigned int' values) for 1st argument
static __inline__ vector int __ATTRS_o_ai vec_vsubuwm(vector bool int __a,
^
/usr/lib/clang/13.0.0/include/altivec.h:11993:43: note: candidate function not viable: no known conversion from 'vint32' (aka 'int') to '__vector int' (vector of 4 'int' values) for 1st argument
static __inline__ vector int __ATTRS_o_ai vec_vsubuwm(vector int __a,
^
/usr/lib/clang/13.0.0/include/altivec.h:11999:1: note: candidate function not viable: no known conversion from 'vint32' (aka 'int') to '__vector unsigned int' (vector of 4 'unsigned int' values) for 1st argument
vec_vsubuwm(vector unsigned int __a, vector unsigned int __b) {
^
/usr/lib/clang/13.0.0/include/altivec.h:12004:1: note: candidate function not viable: no known conversion from 'vint32' (aka 'int') to '__vector __bool unsigned int' (vector of 4 'unsigned int' values) for 1st argument
vec_vsubuwm(vector bool int __a, vector unsigned int __b) {
^
/usr/lib/clang/13.0.0/include/altivec.h:12009:1: note: candidate function not viable: no known conversion from 'vint32' (aka 'int') to '__vector unsigned int' (vector of 4 'unsigned int' values) for 1st argument
vec_vsubuwm(vector unsigned int __a, vector bool int __b) {
^
In file included from /wrkdirs/usr/ports/misc/pytorch/work/pytorch-v1.13.1/aten/src/ATen/native/Col2Im.cpp:6:
In file included from /wrkdirs/usr/ports/misc/pytorch/work/pytorch-v1.13.1/aten/src/ATen/native/im2col.h:7:
In file included from /wrkdirs/usr/ports/misc/pytorch/work/pytorch-v1.13.1/aten/src/ATen/native/cpu/utils.h:3:
In file included from /wrkdirs/usr/ports/misc/pytorch/work/pytorch-v1.13.1/aten/src/ATen/cpu/vec/vec.h:6:
In file included from /wrkdirs/usr/ports/misc/pytorch/work/pytorch-v1.13.1/aten/src/ATen/cpu/vec/vec256/vec256.h:19:
In file included from /wrkdirs/usr/ports/misc/pytorch/work/pytorch-v1.13.1/aten/src/ATen/cpu/vec/vec256/vsx/vec256_common_vsx.h:5:
/wrkdirs/usr/ports/misc/pytorch/work/pytorch-v1.13.1/aten/src/ATen/cpu/vec/vec256/vsx/vsx_helpers.h:67:10: error: excess elements in scalar initializer
vint64 vint0 = {0, 0};
^ ~~~~
/wrkdirs/usr/ports/misc/pytorch/work/pytorch-v1.13.1/aten/src/ATen/cpu/vec/vec256/vsx/vsx_helpers.h:68:10: error: use of undeclared identifier 'vec_vsubudm'
return vec_vsubudm(vint0, vec_in);
^
/wrkdirs/usr/ports/misc/pytorch/work/pytorch-v1.13.1/aten/src/ATen/cpu/vec/vec256/vsx/vsx_helpers.h:144:57: error: no matching function for call to 'vec_min'
C10_VSX_VEC_NAN_PROPAG(vec_min_nan2, vfloat32, vbool32, vec_min)
^~~~~~~
/wrkdirs/usr/ports/misc/pytorch/work/pytorch-v1.13.1/aten/src/ATen/cpu/vec/vec256/vsx/vsx_helpers.h:137:16: note: expanded from macro 'C10_VSX_VEC_NAN_PROPAG'
type tmp = func(a, b); \
^~~~
/usr/lib/clang/13.0.0/include/altivec.h:5690:1: note: candidate function not viable: no known conversion from 'const vfloat32' (aka 'const float') to '__vector signed char' (vector of 16 'signed char' values) for 1st argument
vec_min(vector signed char __a, vector signed char __b) {
^
/usr/lib/clang/13.0.0/include/altivec.h:5695:1: note: candidate function not viable: no known conversion from 'const vfloat32' (aka 'const float') to '__vector __bool unsigned char' (vector of 16 'unsigned char' values) for 1st argument
vec_min(vector bool char __a, vector signed char __b) {
^
/usr/lib/clang/13.0.0/include/altivec.h:5700:1: note: candidate function not viable: no known conversion from 'const vfloat32' (aka 'const float') to '__vector signed char' (vector of 16 'signed char' values) for 1st argument
vec_min(vector signed char __a, vector bool char __b) {
^
/usr/lib/clang/13.0.0/include/altivec.h:5705:1: note: candidate function not viable: no known conversion from 'const vfloat32' (aka 'const float') to '__vector unsigned char' (vector of 16 'unsigned char' values) for 1st argument
vec_min(vector unsigned char __a, vector unsigned char __b) {
^
/usr/lib/clang/13.0.0/include/altivec.h:5710:1: note: candidate function not viable: no known conversion from 'const vfloat32' (aka 'const float') to '__vector __bool unsigned char' (vector of 16 'unsigned char' values) for 1st argument
vec_min(vector bool char __a, vector unsigned char __b) {
^
/usr/lib/clang/13.0.0/include/altivec.h:5715:1: note: candidate function not viable: no known conversion from 'const vfloat32' (aka 'const float') to '__vector unsigned char' (vector of 16 'unsigned char' values) for 1st argument
vec_min(vector unsigned char __a, vector bool char __b) {
^
/usr/lib/clang/13.0.0/include/altivec.h:5719:45: note: candidate function not viable: no known conversion from 'const vfloat32' (aka 'const float') to '__vector short' (vector of 8 'short' values) for 1st argument
static __inline__ vector short __ATTRS_o_ai vec_min(vector short __a,
^
/usr/lib/clang/13.0.0/include/altivec.h:5724:45: note: candidate function not viable: no known conversion from 'const vfloat32' (aka 'const float') to '__vector __bool unsigned short' (vector of 8 'unsigned short' values) for 1st argument
static __inline__ vector short __ATTRS_o_ai vec_min(vector bool short __a,
^
/usr/lib/clang/13.0.0/include/altivec.h:5729:45: note: candidate function not viable: no known conversion from 'const vfloat32' (aka 'const float') to '__vector short' (vector of 8 'short' values) for 1st argument
static __inline__ vector short __ATTRS_o_ai vec_min(vector short __a,
^
/usr/lib/clang/13.0.0/include/altivec.h:5735:1: note: candidate function not viable: no known conversion from 'const vfloat32' (aka 'const float') to '__vector unsigned short' (vector of 8 'unsigned short' values) for 1st argument
vec_min(vector unsigned short __a, vector unsigned short __b) {
^
/usr/lib/clang/13.0.0/include/altivec.h:5740:1: note: candidate function not viable: no known conversion from 'const vfloat32' (aka 'const float') to '__vector __bool unsigned short' (vector of 8 'unsigned short' values) for 1st argument
vec_min(vector bool short __a, vector unsigned short __b) {
^
/usr/lib/clang/13.0.0/include/altivec.h:5745:1: note: candidate function not viable: no known conversion from 'const vfloat32' (aka 'const float') to '__vector unsigned short' (vector of 8 'unsigned short' values) for 1st argument
vec_min(vector unsigned short __a, vector bool short __b) {
^
/usr/lib/clang/13.0.0/include/altivec.h:5749:43: note: candidate function not viable: no known conversion from 'const vfloat32' (aka 'const float') to '__vector int' (vector of 4 'int' values) for 1st argument
static __inline__ vector int __ATTRS_o_ai vec_min(vector int __a,
^
/usr/lib/clang/13.0.0/include/altivec.h:5754:43: note: candidate function not viable: no known conversion from 'const vfloat32' (aka 'const float') to '__vector __bool unsigned int' (vector of 4 'unsigned int' values) for 1st argument
static __inline__ vector int __ATTRS_o_ai vec_min(vector bool int __a,
^
/usr/lib/clang/13.0.0/include/altivec.h:5759:43: note: candidate function not viable: no known conversion from 'const vfloat32' (aka 'const float') to '__vector int' (vector of 4 'int' values) for 1st argument
static __inline__ vector int __ATTRS_o_ai vec_min(vector int __a,
^
/usr/lib/clang/13.0.0/include/altivec.h:5765:1: note: candidate function not viable: no known conversion from 'const vfloat32' (aka 'const float') to '__vector unsigned int' (vector of 4 'unsigned int' values) for 1st argument
vec_min(vector unsigned int __a, vector unsigned int __b) {
^
/usr/lib/clang/13.0.0/include/altivec.h:5770:1: note: candidate function not viable: no known conversion from 'const vfloat32' (aka 'const float') to '__vector __bool unsigned int' (vector of 4 'unsigned int' values) for 1st argument
vec_min(vector bool int __a, vector unsigned int __b) {
^
/usr/lib/clang/13.0.0/include/altivec.h:5775:1: note: candidate function not viable: no known conversion from 'const vfloat32' (aka 'const float') to '__vector unsigned int' (vector of 4 'unsigned int' values) for 1st argument
vec_min(vector unsigned int __a, vector bool int __b) {
^
/usr/lib/clang/13.0.0/include/altivec.h:5781:1: note: candidate function not viable: no known conversion from 'const vfloat32' (aka 'const float') to '__vector long long' (vector of 2 'long long' values) for 1st argument
vec_min(vector signed long long __a, vector signed long long __b) {
^
/usr/lib/clang/13.0.0/include/altivec.h:5786:1: note: candidate function not viable: no known conversion from 'const vfloat32' (aka 'const float') to '__vector __bool unsigned long long' (vector of 2 'unsigned long long' values) for 1st argument
vec_min(vector bool long long __a, vector signed long long __b) {
^
/usr/lib/clang/13.0.0/include/altivec.h:5791:1: note: candidate function not viable: no known conversion from 'const vfloat32' (aka 'const float') to '__vector long long' (vector of 2 'long long' values) for 1st argument
vec_min(vector signed long long __a, vector bool long long __b) {
^
/usr/lib/clang/13.0.0/include/altivec.h:5796:1: note: candidate function not viable: no known conversion from 'const vfloat32' (aka 'const float') to '__vector unsigned long long' (vector of 2 'unsigned long long' values) for 1st argument
vec_min(vector unsigned long long __a, vector unsigned long long __b) {
^
/usr/lib/clang/13.0.0/include/altivec.h:5801:1: note: candidate function not viable: no known conversion from 'const vfloat32' (aka 'const float') to '__vector __bool unsigned long long' (vector of 2 'unsigned long long' values) for 1st argument
vec_min(vector bool long long __a, vector unsigned long long __b) {
^
/usr/lib/clang/13.0.0/include/altivec.h:5806:1: note: candidate function not viable: no known conversion from 'const vfloat32' (aka 'const float') to '__vector unsigned long long' (vector of 2 'unsigned long long' values) for 1st argument
vec_min(vector unsigned long long __a, vector bool long long __b) {
^
/usr/lib/clang/13.0.0/include/altivec.h:5811:45: note: candidate function not viable: no known conversion from 'const vfloat32' (aka 'const float') to '__vector float' (vector of 4 'float' values) for 1st argument
static __inline__ vector float __ATTRS_o_ai vec_min(vector float __a,
^
/usr/lib/clang/13.0.0/include/altivec.h:5821:46: note: candidate function not viable: no known conversion from 'const vfloat32' (aka 'const float') to '__vector double' (vector of 2 'double' values) for 1st argument
static __inline__ vector double __ATTRS_o_ai vec_min(vector double __a,
^
In file included from /wrkdirs/usr/ports/misc/pytorch/work/pytorch-v1.13.1/aten/src/ATen/native/Col2Im.cpp:6:
In file included from /wrkdirs/usr/ports/misc/pytorch/work/pytorch-v1.13.1/aten/src/ATen/native/im2col.h:7:
In file included from /wrkdirs/usr/ports/misc/pytorch/work/pytorch-v1.13.1/aten/src/ATen/native/cpu/utils.h:3:
In file included from /wrkdirs/usr/ports/misc/pytorch/work/pytorch-v1.13.1/aten/src/ATen/cpu/vec/vec.h:6:
In file included from /wrkdirs/usr/ports/misc/pytorch/work/pytorch-v1.13.1/aten/src/ATen/cpu/vec/vec256/vec256.h:19:
In file included from /wrkdirs/usr/ports/misc/pytorch/work/pytorch-v1.13.1/aten/src/ATen/cpu/vec/vec256/vsx/vec256_common_vsx.h:5:
/wrkdirs/usr/ports/misc/pytorch/work/pytorch-v1.13.1/aten/src/ATen/cpu/vec/vec256/vsx/vsx_helpers.h:144:1: error: no matching function for call to 'vec_cmpne'
C10_VSX_VEC_NAN_PROPAG(vec_min_nan2, vfloat32, vbool32, vec_min)
^~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
/wrkdirs/usr/ports/misc/pytorch/work/pytorch-v1.13.1/aten/src/ATen/cpu/vec/vec256/vsx/vsx_helpers.h:138:19: note: expanded from macro 'C10_VSX_VEC_NAN_PROPAG'
btype nan_a = vec_cmpne(a, a); \
^~~~~~~~~
/usr/lib/clang/13.0.0/include/altivec.h:2002:1: note: candidate function not viable: no known conversion from 'const vfloat32' (aka 'const float') to '__vector __bool unsigned char' (vector of 16 'unsigned char' values) for 1st argument
vec_cmpne(vector bool char __a, vector bool char __b) {
^
/usr/lib/clang/13.0.0/include/altivec.h:2007:1: note: candidate function not viable: no known conversion from 'const vfloat32' (aka 'const float') to '__vector signed char' (vector of 16 'signed char' values) for 1st argument
vec_cmpne(vector signed char __a, vector signed char __b) {
^
/usr/lib/clang/13.0.0/include/altivec.h:2012:1: note: candidate function not viable: no known conversion from 'const vfloat32' (aka 'const float') to '__vector unsigned char' (vector of 16 'unsigned char' values) for 1st argument
vec_cmpne(vector unsigned char __a, vector unsigned char __b) {
^
/usr/lib/clang/13.0.0/include/altivec.h:2017:1: note: candidate function not viable: no known conversion from 'const vfloat32' (aka 'const float') to '__vector __bool unsigned short' (vector of 8 'unsigned short' values) for 1st argument
vec_cmpne(vector bool short __a, vector bool short __b) {
^
/usr/lib/clang/13.0.0/include/altivec.h:2022:1: note: candidate function not viable: no known conversion from 'const vfloat32' (aka 'const float') to '__vector short' (vector of 8 'short' values) for 1st argument
vec_cmpne(vector signed short __a, vector signed short __b) {
^
/usr/lib/clang/13.0.0/include/altivec.h:2027:1: note: candidate function not viable: no known conversion from 'const vfloat32' (aka 'const float') to '__vector unsigned short' (vector of 8 'unsigned short' values) for 1st argument
vec_cmpne(vector unsigned short __a, vector unsigned short __b) {
^
/usr/lib/clang/13.0.0/include/altivec.h:2032:1: note: candidate function not viable: no known conversion from 'const vfloat32' (aka 'const float') to '__vector __bool unsigned int' (vector of 4 'unsigned int' values) for 1st argument
vec_cmpne(vector bool int __a, vector bool int __b) {
^
/usr/lib/clang/13.0.0/include/altivec.h:2037:1: note: candidate function not viable: no known conversion from 'const vfloat32' (aka 'const float') to '__vector int' (vector of 4 'int' values) for 1st argument
vec_cmpne(vector signed int __a, vector signed int __b) {
^
/usr/lib/clang/13.0.0/include/altivec.h:2042:1: note: candidate function not viable: no known conversion from 'const vfloat32' (aka 'const float') to '__vector unsigned int' (vector of 4 'unsigned int' values) for 1st argument
vec_cmpne(vector unsigned int __a, vector unsigned int __b) {
^
/usr/lib/clang/13.0.0/include/altivec.h:2047:1: note: candidate function not viable: no known conversion from 'const vfloat32' (aka 'const float') to '__vector float' (vector of 4 'float' values) for 1st argument
vec_cmpne(vector float __a, vector float __b) {
^
/usr/lib/clang/13.0.0/include/altivec.h:2054:1: note: candidate function not viable: no known conversion from 'const vfloat32' (aka 'const float') to '__vector __bool unsigned long long' (vector of 2 'unsigned long long' values) for 1st argument
vec_cmpne(vector bool long long __a, vector bool long long __b) {
^
/usr/lib/clang/13.0.0/include/altivec.h:2060:1: note: candidate function not viable: no known conversion from 'const vfloat32' (aka 'const float') to '__vector long long' (vector of 2 'long long' values) for 1st argument
vec_cmpne(vector signed long long __a, vector signed long long __b) {
^
/usr/lib/clang/13.0.0/include/altivec.h:2066:1: note: candidate function not viable: no known conversion from 'const vfloat32' (aka 'const float') to '__vector unsigned long long' (vector of 2 'unsigned long long' values) for 1st argument
vec_cmpne(vector unsigned long long __a, vector unsigned long long __b) {
^
/usr/lib/clang/13.0.0/include/altivec.h:2092:1: note: candidate function not viable: no known conversion from 'const vfloat32' (aka 'const float') to '__vector double' (vector of 2 'double' values) for 1st argument
vec_cmpne(vector double __a, vector double __b) {
^
In file included from /wrkdirs/usr/ports/misc/pytorch/work/pytorch-v1.13.1/aten/src/ATen/native/Col2Im.cpp:6:
In file included from /wrkdirs/usr/ports/misc/pytorch/work/pytorch-v1.13.1/aten/src/ATen/native/im2col.h:7:
In file included from /wrkdirs/usr/ports/misc/pytorch/work/pytorch-v1.13.1/aten/src/ATen/native/cpu/utils.h:3:
In file included from /wrkdirs/usr/ports/misc/pytorch/work/pytorch-v1.13.1/aten/src/ATen/cpu/vec/vec.h:6:
In file included from /wrkdirs/usr/ports/misc/pytorch/work/pytorch-v1.13.1/aten/src/ATen/cpu/vec/vec256/vec256.h:19:
In file included from /wrkdirs/usr/ports/misc/pytorch/work/pytorch-v1.13.1/aten/src/ATen/cpu/vec/vec256/vsx/vec256_common_vsx.h:5:
/wrkdirs/usr/ports/misc/pytorch/work/pytorch-v1.13.1/aten/src/ATen/cpu/vec/vec256/vsx/vsx_helpers.h:144:1: error: no matching function for call to 'vec_cmpne'
C10_VSX_VEC_NAN_PROPAG(vec_min_nan2, vfloat32, vbool32, vec_min)
^~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
/wrkdirs/usr/ports/misc/pytorch/work/pytorch-v1.13.1/aten/src/ATen/cpu/vec/vec256/vsx/vsx_helpers.h:139:19: note: expanded from macro 'C10_VSX_VEC_NAN_PROPAG'
btype nan_b = vec_cmpne(b, b); \
^~~~~~~~~
/usr/lib/clang/13.0.0/include/altivec.h:2002:1: note: candidate function not viable: no known conversion from 'const vfloat32' (aka 'const float') to '__vector __bool unsigned char' (vector of 16 'unsigned char' values) for 1st argument
vec_cmpne(vector bool char __a, vector bool char __b) {
^
/usr/lib/clang/13.0.0/include/altivec.h:2007:1: note: candidate function not viable: no known conversion from 'const vfloat32' (aka 'const float') to '__vector signed char' (vector of 16 'signed char' values) for 1st argument
vec_cmpne(vector signed char __a, vector signed char __b) {
^
/usr/lib/clang/13.0.0/include/altivec.h:2012:1: note: candidate function not viable: no known conversion from 'const vfloat32' (aka 'const float') to '__vector unsigned char' (vector of 16 'unsigned char' values) for 1st argument
vec_cmpne(vector unsigned char __a, vector unsigned char __b) {
^
/usr/lib/clang/13.0.0/include/altivec.h:2017:1: note: candidate function not viable: no known conversion from 'const vfloat32' (aka 'const float') to '__vector __bool unsigned short' (vector of 8 'unsigned short' values) for 1st argument
vec_cmpne(vector bool short __a, vector bool short __b) {
^
/usr/lib/clang/13.0.0/include/altivec.h:2022:1: note: candidate function not viable: no known conversion from 'const vfloat32' (aka 'const float') to '__vector short' (vector of 8 'short' values) for 1st argument
vec_cmpne(vector signed short __a, vector signed short __b) {
^
/usr/lib/clang/13.0.0/include/altivec.h:2027:1: note: candidate function not viable: no known conversion from 'const vfloat32' (aka 'const float') to '__vector unsigned short' (vector of 8 'unsigned short' values) for 1st argument
vec_cmpne(vector unsigned short __a, vector unsigned short __b) {
^
/usr/lib/clang/13.0.0/include/altivec.h:2032:1: note: candidate function not viable: no known conversion from 'const vfloat32' (aka 'const float') to '__vector __bool unsigned int' (vector of 4 'unsigned int' values) for 1st argument
vec_cmpne(vector bool int __a, vector bool int __b) {
^
/usr/lib/clang/13.0.0/include/altivec.h:2037:1: note: candidate function not viable: no known conversion from 'const vfloat32' (aka 'const float') to '__vector int' (vector of 4 'int' values) for 1st argument
vec_cmpne(vector signed int __a, vector signed int __b) {
^
/usr/lib/clang/13.0.0/include/altivec.h:2042:1: note: candidate function not viable: no known conversion from 'const vfloat32' (aka 'const float') to '__vector unsigned int' (vector of 4 'unsigned int' values) for 1st argument
vec_cmpne(vector unsigned int __a, vector unsigned int __b) {
^
/usr/lib/clang/13.0.0/include/altivec.h:2047:1: note: candidate function not viable: no known conversion from 'const vfloat32' (aka 'const float') to '__vector float' (vector of 4 'float' values) for 1st argument
vec_cmpne(vector float __a, vector float __b) {
^
/usr/lib/clang/13.0.0/include/altivec.h:2054:1: note: candidate function not viable: no known conversion from 'const vfloat32' (aka 'const float') to '__vector __bool unsigned long long' (vector of 2 'unsigned long long' values) for 1st argument
vec_cmpne(vector bool long long __a, vector bool long long __b) {
^
/usr/lib/clang/13.0.0/include/altivec.h:2060:1: note: candidate function not viable: no known conversion from 'const vfloat32' (aka 'const float') to '__vector long long' (vector of 2 'long long' values) for 1st argument
vec_cmpne(vector signed long long __a, vector signed long long __b) {
^
/usr/lib/clang/13.0.0/include/altivec.h:2066:1: note: candidate function not viable: no known conversion from 'const vfloat32' (aka 'const float') to '__vector unsigned long long' (vector of 2 'unsigned long long' values) for 1st argument
vec_cmpne(vector unsigned long long __a, vector unsigned long long __b) {
^
/usr/lib/clang/13.0.0/include/altivec.h:2092:1: note: candidate function not viable: no known conversion from 'const vfloat32' (aka 'const float') to '__vector double' (vector of 2 'double' values) for 1st argument
vec_cmpne(vector double __a, vector double __b) {
^
In file included from /wrkdirs/usr/ports/misc/pytorch/work/pytorch-v1.13.1/aten/src/ATen/native/Col2Im.cpp:6:
In file included from /wrkdirs/usr/ports/misc/pytorch/work/pytorch-v1.13.1/aten/src/ATen/native/im2col.h:7:
In file included from /wrkdirs/usr/ports/misc/pytorch/work/pytorch-v1.13.1/aten/src/ATen/native/cpu/utils.h:3:
In file included from /wrkdirs/usr/ports/misc/pytorch/work/pytorch-v1.13.1/aten/src/ATen/cpu/vec/vec.h:6:
In file included from /wrkdirs/usr/ports/misc/pytorch/work/pytorch-v1.13.1/aten/src/ATen/cpu/vec/vec256/vec256.h:19:
In file included from /wrkdirs/usr/ports/misc/pytorch/work/pytorch-v1.13.1/aten/src/ATen/cpu/vec/vec256/vsx/vec256_common_vsx.h:5:
/wrkdirs/usr/ports/misc/pytorch/work/pytorch-v1.13.1/aten/src/ATen/cpu/vec/vec256/vsx/vsx_helpers.h:144:1: error: no matching function for call to 'vec_sel'
C10_VSX_VEC_NAN_PROPAG(vec_min_nan2, vfloat32, vbool32, vec_min)
^~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
/wrkdirs/usr/ports/misc/pytorch/work/pytorch-v1.13.1/aten/src/ATen/cpu/vec/vec256/vsx/vsx_helpers.h:140:11: note: expanded from macro 'C10_VSX_VEC_NAN_PROPAG'
tmp = vec_sel(tmp, a, nan_a); \
^~~~~~~
/usr/lib/clang/13.0.0/include/altivec.h:8505:51: note: candidate function not viable: no known conversion from 'vfloat32' (aka 'float') to '__vector signed char' (vector of 16 'signed char' values) for 1st argument
static __inline__ vector signed char __ATTRS_o_ai vec_sel(
^
/usr/lib/clang/13.0.0/include/altivec.h:8511:1: note: candidate function not viable: no known conversion from 'vfloat32' (aka 'float') to '__vector signed char' (vector of 16 'signed char' values) for 1st argument
vec_sel(vector signed char __a, vector signed char __b, vector bool char __c) {
^
/usr/lib/clang/13.0.0/include/altivec.h:8516:1: note: candidate function not viable: no known conversion from 'vfloat32' (aka 'float') to '__vector unsigned char' (vector of 16 'unsigned char' values) for 1st argument
vec_sel(vector unsigned char __a, vector unsigned char __b,
^
/usr/lib/clang/13.0.0/include/altivec.h:8521:53: note: candidate function not viable: no known conversion from 'vfloat32' (aka 'float') to '__vector unsigned char' (vector of 16 'unsigned char' values) for 1st argument
static __inline__ vector unsigned char __ATTRS_o_ai vec_sel(
^
/usr/lib/clang/13.0.0/include/altivec.h:8527:1: note: candidate function not viable: no known conversion from 'vfloat32' (aka 'float') to '__vector __bool unsigned char' (vector of 16 'unsigned char' values) for 1st argument
vec_sel(vector bool char __a, vector bool char __b, vector unsigned char __c) {
^
/usr/lib/clang/13.0.0/include/altivec.h:8531:49: note: candidate function not viable: no known conversion from 'vfloat32' (aka 'float') to '__vector __bool unsigned char' (vector of 16 'unsigned char' values) for 1st argument
static __inline__ vector bool char __ATTRS_o_ai vec_sel(vector bool char __a,
^
/usr/lib/clang/13.0.0/include/altivec.h:8537:45: note: candidate function not viable: no known conversion from 'vfloat32' (aka 'float') to '__vector short' (vector of 8 'short' values) for 1st argument
static __inline__ vector short __ATTRS_o_ai vec_sel(vector short __a,
^
/usr/lib/clang/13.0.0/include/altivec.h:8543:45: note: candidate function not viable: no known conversion from 'vfloat32' (aka 'float') to '__vector short' (vector of 8 'short' values) for 1st argument
static __inline__ vector short __ATTRS_o_ai vec_sel(vector short __a,
^
/usr/lib/clang/13.0.0/include/altivec.h:8550:1: note: candidate function not viable: no known conversion from 'vfloat32' (aka 'float') to '__vector unsigned short' (vector of 8 'unsigned short' values) for 1st argument
vec_sel(vector unsigned short __a, vector unsigned short __b,
^
/usr/lib/clang/13.0.0/include/altivec.h:8556:1: note: candidate function not viable: no known conversion from 'vfloat32' (aka 'float') to '__vector unsigned short' (vector of 8 'unsigned short' values) for 1st argument
vec_sel(vector unsigned short __a, vector unsigned short __b,
^
/usr/lib/clang/13.0.0/include/altivec.h:8562:50: note: candidate function not viable: no known conversion from 'vfloat32' (aka 'float') to '__vector __bool unsigned short' (vector of 8 'unsigned short' values) for 1st argument
static __inline__ vector bool short __ATTRS_o_ai vec_sel(
^
/usr/lib/clang/13.0.0/include/altivec.h:8568:1: note: candidate function not viable: no known conversion from 'vfloat32' (aka 'float') to '__vector __bool unsigned short' (vector of 8 'unsigned short' values) for 1st argument
vec_sel(vector bool short __a, vector bool short __b, vector bool short __c) {
^
/usr/lib/clang/13.0.0/include/altivec.h:8572:43: note: candidate function not viable: no known conversion from 'vfloat32' (aka 'float') to '__vector int' (vector of 4 'int' values) for 1st argument
static __inline__ vector int __ATTRS_o_ai vec_sel(vector int __a,
^
/usr/lib/clang/13.0.0/include/altivec.h:8578:43: note: candidate function not viable: no known conversion from 'vfloat32' (aka 'float') to '__vector int' (vector of 4 'int' values) for 1st argument
static __inline__ vector int __ATTRS_o_ai vec_sel(vector int __a,
^
/usr/lib/clang/13.0.0/include/altivec.h:8584:52: note: candidate function not viable: no known conversion from 'vfloat32' (aka 'float') to '__vector unsigned int' (vector of 4 'unsigned int' values) for 1st argument
static __inline__ vector unsigned int __ATTRS_o_ai vec_sel(
^
/usr/lib/clang/13.0.0/include/altivec.h:8590:1: note: candidate function not viable: no known conversion from 'vfloat32' (aka 'float') to '__vector unsigned int' (vector of 4 'unsigned int' values) for 1st argument
vec_sel(vector unsigned int __a, vector unsigned int __b, vector bool int __c) {
^
/usr/lib/clang/13.0.0/include/altivec.h:8595:1: note: candidate function not viable: no known conversion from 'vfloat32' (aka 'float') to '__vector __bool unsigned int' (vector of 4 'unsigned int' values) for 1st argument
vec_sel(vector bool int __a, vector bool int __b, vector unsigned int __c) {
^
/usr/lib/clang/13.0.0/include/altivec.h:8599:48: note: candidate function not viable: no known conversion from 'vfloat32' (aka 'float') to '__vector __bool unsigned int' (vector of 4 'unsigned int' values) for 1st argument
static __inline__ vector bool int __ATTRS_o_ai vec_sel(vector bool int __a,
^
/usr/lib/clang/13.0.0/include/altivec.h:8605:45: note: candidate function not viable: no known conversion from 'vfloat32' (aka 'float') to '__vector float' (vector of 4 'float' values) for 1st argument
static __inline__ vector float __ATTRS_o_ai vec_sel(vector float __a,
^
/usr/lib/clang/13.0.0/include/altivec.h:8613:45: note: candidate function not viable: no known conversion from 'vfloat32' (aka 'float') to '__vector float' (vector of 4 'float' values) for 1st argument
static __inline__ vector float __ATTRS_o_ai vec_sel(vector float __a,
^
/usr/lib/clang/13.0.0/include/altivec.h:8623:1: note: candidate function not viable: no known conversion from 'vfloat32' (aka 'float') to '__vector double' (vector of 2 'double' values) for 1st argument
vec_sel(vector double __a, vector double __b, vector bool long long __c) {
^
/usr/lib/clang/13.0.0/include/altivec.h:8630:1: note: candidate function not viable: no known conversion from 'vfloat32' (aka 'float') to '__vector double' (vector of 2 'double' values) for 1st argument
vec_sel(vector double __a, vector double __b, vector unsigned long long __c) {
^
/usr/lib/clang/13.0.0/include/altivec.h:8637:1: note: candidate function not viable: no known conversion from 'vfloat32' (aka 'float') to '__vector __bool unsigned long long' (vector of 2 'unsigned long long' values) for 1st argument
vec_sel(vector bool long long __a, vector bool long long __b,
^
/usr/lib/clang/13.0.0/include/altivec.h:8643:1: note: candidate function not viable: no known conversion from 'vfloat32' (aka 'float') to '__vector __bool unsigned long long' (vector of 2 'unsigned long long' values) for 1st argument
vec_sel(vector bool long long __a, vector bool long long __b,
^
/usr/lib/clang/13.0.0/include/altivec.h:8650:1: note: candidate function not viable: no known conversion from 'vfloat32' (aka 'float') to '__vector long long' (vector of 2 'long long' values) for 1st argument
vec_sel(vector signed long long __a, vector signed long long __b,
^
/usr/lib/clang/13.0.0/include/altivec.h:8657:1: note: candidate function not viable: no known conversion from 'vfloat32' (aka 'float') to '__vector long long' (vector of 2 'long long' values) for 1st argument
vec_sel(vector signed long long __a, vector signed long long __b,
^
/usr/lib/clang/13.0.0/include/altivec.h:8664:1: note: candidate function not viable: no known conversion from 'vfloat32' (aka 'float') to '__vector unsigned long long' (vector of 2 'unsigned long long' values) for 1st argument
vec_sel(vector unsigned long long __a, vector unsigned long long __b,
^
/usr/lib/clang/13.0.0/include/altivec.h:8671:1: note: candidate function not viable: no known conversion from 'vfloat32' (aka 'float') to '__vector unsigned long long' (vector of 2 'unsigned long long' values) for 1st argument
vec_sel(vector unsigned long long __a, vector unsigned long long __b,
^
In file included from /wrkdirs/usr/ports/misc/pytorch/work/pytorch-v1.13.1/aten/src/ATen/native/Col2Im.cpp:6:
In file included from /wrkdirs/usr/ports/misc/pytorch/work/pytorch-v1.13.1/aten/src/ATen/native/im2col.h:7:
In file included from /wrkdirs/usr/ports/misc/pytorch/work/pytorch-v1.13.1/aten/src/ATen/native/cpu/utils.h:3:
In file included from /wrkdirs/usr/ports/misc/pytorch/work/pytorch-v1.13.1/aten/src/ATen/cpu/vec/vec.h:6:
In file included from /wrkdirs/usr/ports/misc/pytorch/work/pytorch-v1.13.1/aten/src/ATen/cpu/vec/vec256/vec256.h:19:
In file included from /wrkdirs/usr/ports/misc/pytorch/work/pytorch-v1.13.1/aten/src/ATen/cpu/vec/vec256/vsx/vec256_common_vsx.h:5:
/wrkdirs/usr/ports/misc/pytorch/work/pytorch-v1.13.1/aten/src/ATen/cpu/vec/vec256/vsx/vsx_helpers.h:144:1: error: no matching function for call to 'vec_sel'
C10_VSX_VEC_NAN_PROPAG(vec_min_nan2, vfloat32, vbool32, vec_min)
^~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
/wrkdirs/usr/ports/misc/pytorch/work/pytorch-v1.13.1/aten/src/ATen/cpu/vec/vec256/vsx/vsx_helpers.h:141:12: note: expanded from macro 'C10_VSX_VEC_NAN_PROPAG'
return vec_sel(tmp, b, nan_b); \
^~~~~~~
/usr/lib/clang/13.0.0/include/altivec.h:8505:51: note: candidate function not viable: no known conversion from 'vfloat32' (aka 'float') to '__vector signed char' (vector of 16 'signed char' values) for 1st argument
static __inline__ vector signed char __ATTRS_o_ai vec_sel(
^
/usr/lib/clang/13.0.0/include/altivec.h:8511:1: note: candidate function not viable: no known conversion from 'vfloat32' (aka 'float') to '__vector signed char' (vector of 16 'signed char' values) for 1st argument
vec_sel(vector signed char __a, vector signed char __b, vector bool char __c) {
^
/usr/lib/clang/13.0.0/include/altivec.h:8516:1: note: candidate function not viable: no known conversion from 'vfloat32' (aka 'float') to '__vector unsigned char' (vector of 16 'unsigned char' values) for 1st argument
vec_sel(vector unsigned char __a, vector unsigned char __b,
^
/usr/lib/clang/13.0.0/include/altivec.h:8521:53: note: candidate function not viable: no known conversion from 'vfloat32' (aka 'float') to '__vector unsigned char' (vector of 16 'unsigned char' values) for 1st argument
static __inline__ vector unsigned char __ATTRS_o_ai vec_sel(
^
/usr/lib/clang/13.0.0/include/altivec.h:8527:1: note: candidate function not viable: no known conversion from 'vfloat32' (aka 'float') to '__vector __bool unsigned char' (vector of 16 'unsigned char' values) for 1st argument
vec_sel(vector bool char __a, vector bool char __b, vector unsigned char __c) {
^
/usr/lib/clang/13.0.0/include/altivec.h:8531:49: note: candidate function not viable: no known conversion from 'vfloat32' (aka 'float') to '__vector __bool unsigned char' (vector of 16 'unsigned char' values) for 1st argument
static __inline__ vector bool char __ATTRS_o_ai vec_sel(vector bool char __a,
^
/usr/lib/clang/13.0.0/include/altivec.h:8537:45: note: candidate function not viable: no known conversion from 'vfloat32' (aka 'float') to '__vector short' (vector of 8 'short' values) for 1st argument
static __inline__ vector short __ATTRS_o_ai vec_sel(vector short __a,
^
/usr/lib/clang/13.0.0/include/altivec.h:8543:45: note: candidate function not viable: no known conversion from 'vfloat32' (aka 'float') to '__vector short' (vector of 8 'short' values) for 1st argument
static __inline__ vector short __ATTRS_o_ai vec_sel(vector short __a,
^
/usr/lib/clang/13.0.0/include/altivec.h:8550:1: note: candidate function not viable: no known conversion from 'vfloat32' (aka 'float') to '__vector unsigned short' (vector of 8 'unsigned short' values) for 1st argument
vec_sel(vector unsigned short __a, vector unsigned short __b,
^
/usr/lib/clang/13.0.0/include/altivec.h:8556:1: note: candidate function not viable: no known conversion from 'vfloat32' (aka 'float') to '__vector unsigned short' (vector of 8 'unsigned short' values) for 1st argument
vec_sel(vector unsigned short __a, vector unsigned short __b,
^
/usr/lib/clang/13.0.0/include/altivec.h:8562:50: note: candidate function not viable: no known conversion from 'vfloat32' (aka 'float') to '__vector __bool unsigned short' (vector of 8 'unsigned short' values) for 1st argument
static __inline__ vector bool short __ATTRS_o_ai vec_sel(
^
/usr/lib/clang/13.0.0/include/altivec.h:8568:1: note: candidate function not viable: no known conversion from 'vfloat32' (aka 'float') to '__vector __bool unsigned short' (vector of 8 'unsigned short' values) for 1st argument
vec_sel(vector bool short __a, vector bool short __b, vector bool short __c) {
^
/usr/lib/clang/13.0.0/include/altivec.h:8572:43: note: candidate function not viable: no known conversion from 'vfloat32' (aka 'float') to '__vector int' (vector of 4 'int' values) for 1st argument
static __inline__ vector int __ATTRS_o_ai vec_sel(vector int __a,
^
/usr/lib/clang/13.0.0/include/altivec.h:8578:43: note: candidate function not viable: no known conversion from 'vfloat32' (aka 'float') to '__vector int' (vector of 4 'int' values) for 1st argument
static __inline__ vector int __ATTRS_o_ai vec_sel(vector int __a,
^
/usr/lib/clang/13.0.0/include/altivec.h:8584:52: note: candidate function not viable: no known conversion from 'vfloat32' (aka 'float') to '__vector unsigned int' (vector of 4 'unsigned int' values) for 1st argument
static __inline__ vector unsigned int __ATTRS_o_ai vec_sel(
^
/usr/lib/clang/13.0.0/include/altivec.h:8590:1: note: candidate function not viable: no known conversion from 'vfloat32' (aka 'float') to '__vector unsigned int' (vector of 4 'unsigned int' values) for 1st argument
vec_sel(vector unsigned int __a, vector unsigned int __b, vector bool int __c) {
^
/usr/lib/clang/13.0.0/include/altivec.h:8595:1: note: candidate function not viable: no known conversion from 'vfloat32' (aka 'float') to '__vector __bool unsigned int' (vector of 4 'unsigned int' values) for 1st argument
vec_sel(vector bool int __a, vector bool int __b, vector unsigned int __c) {
^
/usr/lib/clang/13.0.0/include/altivec.h:8599:48: note: candidate function not viable: no known conversion from 'vfloat32' (aka 'float') to '__vector __bool unsigned int' (vector of 4 'unsigned int' values) for 1st argument
static __inline__ vector bool int __ATTRS_o_ai vec_sel(vector bool int __a,
^
/usr/lib/clang/13.0.0/include/altivec.h:8605:45: note: candidate function not viable: no known conversion from 'vfloat32' (aka 'float') to '__vector float' (vector of 4 'float' values) for 1st argument
static __inline__ vector float __ATTRS_o_ai vec_sel(vector float __a,
^
/usr/lib/clang/13.0.0/include/altivec.h:8613:45: note: candidate function not viable: no known conversion from 'vfloat32' (aka 'float') to '__vector float' (vector of 4 'float' values) for 1st argument
static __inline__ vector float __ATTRS_o_ai vec_sel(vector float __a,
^
/usr/lib/clang/13.0.0/include/altivec.h:8623:1: note: candidate function not viable: no known conversion from 'vfloat32' (aka 'float') to '__vector double' (vector of 2 'double' values) for 1st argument
vec_sel(vector double __a, vector double __b, vector bool long long __c) {
^
/usr/lib/clang/13.0.0/include/altivec.h:8630:1: note: candidate function not viable: no known conversion from 'vfloat32' (aka 'float') to '__vector double' (vector of 2 'double' values) for 1st argument
vec_sel(vector double __a, vector double __b, vector unsigned long long __c) {
^
/usr/lib/clang/13.0.0/include/altivec.h:8637:1: note: candidate function not viable: no known conversion from 'vfloat32' (aka 'float') to '__vector __bool unsigned long long' (vector of 2 'unsigned long long' values) for 1st argument
vec_sel(vector bool long long __a, vector bool long long __b,
^
/usr/lib/clang/13.0.0/include/altivec.h:8643:1: note: candidate function not viable: no known conversion from 'vfloat32' (aka 'float') to '__vector __bool unsigned long long' (vector of 2 'unsigned long long' values) for 1st argument
vec_sel(vector bool long long __a, vector bool long long __b,
^
/usr/lib/clang/13.0.0/include/altivec.h:8650:1: note: candidate function not viable: no known conversion from 'vfloat32' (aka 'float') to '__vector long long' (vector of 2 'long long' values) for 1st argument
vec_sel(vector signed long long __a, vector signed long long __b,
^
/usr/lib/clang/13.0.0/include/altivec.h:8657:1: note: candidate function not viable: no known conversion from 'vfloat32' (aka 'float') to '__vector long long' (vector of 2 'long long' values) for 1st argument
vec_sel(vector signed long long __a, vector signed long long __b,
^
/usr/lib/clang/13.0.0/include/altivec.h:8664:1: note: candidate function not viable: no known conversion from 'vfloat32' (aka 'float') to '__vector unsigned long long' (vector of 2 'unsigned long long' values) for 1st argument
vec_sel(vector unsigned long long __a, vector unsigned long long __b,
^
/usr/lib/clang/13.0.0/include/altivec.h:8671:1: note: candidate function not viable: no known conversion from 'vfloat32' (aka 'float') to '__vector unsigned long long' (vector of 2 'unsigned long long' values) for 1st argument
vec_sel(vector unsigned long long __a, vector unsigned long long __b,
^
In file included from /wrkdirs/usr/ports/misc/pytorch/work/pytorch-v1.13.1/aten/src/ATen/native/Col2Im.cpp:6:
In file included from /wrkdirs/usr/ports/misc/pytorch/work/pytorch-v1.13.1/aten/src/ATen/native/im2col.h:7:
In file included from /wrkdirs/usr/ports/misc/pytorch/work/pytorch-v1.13.1/aten/src/ATen/native/cpu/utils.h:3:
In file included from /wrkdirs/usr/ports/misc/pytorch/work/pytorch-v1.13.1/aten/src/ATen/cpu/vec/vec.h:6:
In file included from /wrkdirs/usr/ports/misc/pytorch/work/pytorch-v1.13.1/aten/src/ATen/cpu/vec/vec256/vec256.h:19:
In file included from /wrkdirs/usr/ports/misc/pytorch/work/pytorch-v1.13.1/aten/src/ATen/cpu/vec/vec256/vsx/vec256_common_vsx.h:5:
/wrkdirs/usr/ports/misc/pytorch/work/pytorch-v1.13.1/aten/src/ATen/cpu/vec/vec256/vsx/vsx_helpers.h:145:57: error: no matching function for call to 'vec_max'
C10_VSX_VEC_NAN_PROPAG(vec_max_nan2, vfloat32, vbool32, vec_max)
^~~~~~~
/wrkdirs/usr/ports/misc/pytorch/work/pytorch-v1.13.1/aten/src/ATen/cpu/vec/vec256/vsx/vsx_helpers.h:137:16: note: expanded from macro 'C10_VSX_VEC_NAN_PROPAG'
type tmp = func(a, b); \
^~~~
/usr/lib/clang/13.0.0/include/altivec.h:4786:1: note: candidate function not viable: no known conversion from 'const vfloat32' (aka 'const float') to '__vector signed char' (vector of 16 'signed char' values) for 1st argument
vec_max(vector signed char __a, vector signed char __b) {
^
/usr/lib/clang/13.0.0/include/altivec.h:4791:1: note: candidate function not viable: no known conversion from 'const vfloat32' (aka 'const float') to '__vector __bool unsigned char' (vector of 16 'unsigned char' values) for 1st argument
vec_max(vector bool char __a, vector signed char __b) {
^
/usr/lib/clang/13.0.0/include/altivec.h:4796:1: note: candidate function not viable: no known conversion from 'const vfloat32' (aka 'const float') to '__vector signed char' (vector of 16 'signed char' values) for 1st argument
vec_max(vector signed char __a, vector bool char __b) {
^
/usr/lib/clang/13.0.0/include/altivec.h:4801:1: note: candidate function not viable: no known conversion from 'const vfloat32' (aka 'const float') to '__vector unsigned char' (vector of 16 'unsigned char' values) for 1st argument
vec_max(vector unsigned char __a, vector unsigned char __b) {
^
/usr/lib/clang/13.0.0/include/altivec.h:4806:1: note: candidate function not viable: no known conversion from 'const vfloat32' (aka 'const float') to '__vector __bool unsigned char' (vector of 16 'unsigned char' values) for 1st argument
vec_max(vector bool char __a, vector unsigned char __b) {
^
/usr/lib/clang/13.0.0/include/altivec.h:4811:1: note: candidate function not viable: no known conversion from 'const vfloat32' (aka 'const float') to '__vector unsigned char' (vector of 16 'unsigned char' values) for 1st argument
vec_max(vector unsigned char __a, vector bool char __b) {
^
/usr/lib/clang/13.0.0/include/altivec.h:4815:45: note: candidate function not viable: no known conversion from 'const vfloat32' (aka 'const float') to '__vector short' (vector of 8 'short' values) for 1st argument
static __inline__ vector short __ATTRS_o_ai vec_max(vector short __a,
^
/usr/lib/clang/13.0.0/include/altivec.h:4820:45: note: candidate function not viable: no known conversion from 'const vfloat32' (aka 'const float') to '__vector __bool unsigned short' (vector of 8 'unsigned short' values) for 1st argument
static __inline__ vector short __ATTRS_o_ai vec_max(vector bool short __a,
^
/usr/lib/clang/13.0.0/include/altivec.h:4825:45: note: candidate function not viable: no known conversion from 'const vfloat32' (aka 'const float') to '__vector short' (vector of 8 'short' values) for 1st argument
static __inline__ vector short __ATTRS_o_ai vec_max(vector short __a,
^
/usr/lib/clang/13.0.0/include/altivec.h:4831:1: note: candidate function not viable: no known conversion from 'const vfloat32' (aka 'const float') to '__vector unsigned short' (vector of 8 'unsigned short' values) for 1st argument
vec_max(vector unsigned short __a, vector unsigned short __b) {
^
/usr/lib/clang/13.0.0/include/altivec.h:4836:1: note: candidate function not viable: no known conversion from 'const vfloat32' (aka 'const float') to '__vector __bool unsigned short' (vector of 8 'unsigned short' values) for 1st argument
vec_max(vector bool short __a, vector unsigned short __b) {
^
/usr/lib/clang/13.0.0/include/altivec.h:4841:1: note: candidate function not viable: no known conversion from 'const vfloat32' (aka 'const float') to '__vector unsigned short' (vector of 8 'unsigned short' values) for 1st argument
vec_max(vector unsigned short __a, vector bool short __b) {
^
/usr/lib/clang/13.0.0/include/altivec.h:4845:43: note: candidate function not viable: no known conversion from 'const vfloat32' (aka 'const float') to '__vector int' (vector of 4 'int' values) for 1st argument
static __inline__ vector int __ATTRS_o_ai vec_max(vector int __a,
^
/usr/lib/clang/13.0.0/include/altivec.h:4850:43: note: candidate function not viable: no known conversion from 'const vfloat32' (aka 'const float') to '__vector __bool unsigned int' (vector of 4 'unsigned int' values) for 1st argument
static __inline__ vector int __ATTRS_o_ai vec_max(vector bool int __a,
^
/usr/lib/clang/13.0.0/include/altivec.h:4855:43: note: candidate function not viable: no known conversion from 'const vfloat32' (aka 'const float') to '__vector int' (vector of 4 'int' values) for 1st argument
static __inline__ vector int __ATTRS_o_ai vec_max(vector int __a,
^
/usr/lib/clang/13.0.0/include/altivec.h:4861:1: note: candidate function not viable: no known conversion from 'const vfloat32' (aka 'const float') to '__vector unsigned int' (vector of 4 'unsigned int' values) for 1st argument
vec_max(vector unsigned int __a, vector unsigned int __b) {
^
/usr/lib/clang/13.0.0/include/altivec.h:4866:1: note: candidate function not viable: no known conversion from 'const vfloat32' (aka 'const float') to '__vector __bool unsigned int' (vector of 4 'unsigned int' values) for 1st argument
vec_max(vector bool int __a, vector unsigned int __b) {
^
/usr/lib/clang/13.0.0/include/altivec.h:4871:1: note: candidate function not viable: no known conversion from 'const vfloat32' (aka 'const float') to '__vector unsigned int' (vector of 4 'unsigned int' values) for 1st argument
vec_max(vector unsigned int __a, vector bool int __b) {
^
/usr/lib/clang/13.0.0/include/altivec.h:4877:1: note: candidate function not viable: no known conversion from 'const vfloat32' (aka 'const float') to '__vector long long' (vector of 2 'long long' values) for 1st argument
vec_max(vector signed long long __a, vector signed long long __b) {
^
/usr/lib/clang/13.0.0/include/altivec.h:4882:1: note: candidate function not viable: no known conversion from 'const vfloat32' (aka 'const float') to '__vector __bool unsigned long long' (vector of 2 'unsigned long long' values) for 1st argument
vec_max(vector bool long long __a, vector signed long long __b) {
^
/usr/lib/clang/13.0.0/include/altivec.h:4887:1: note: candidate function not viable: no known conversion from 'const vfloat32' (aka 'const float') to '__vector long long' (vector of 2 'long long' values) for 1st argument
vec_max(vector signed long long __a, vector bool long long __b) {
^
/usr/lib/clang/13.0.0/include/altivec.h:4892:1: note: candidate function not viable: no known conversion from 'const vfloat32' (aka 'const float') to '__vector unsigned long long' (vector of 2 'unsigned long long' values) for 1st argument
vec_max(vector unsigned long long __a, vector unsigned long long __b) {
^
/usr/lib/clang/13.0.0/include/altivec.h:4897:1: note: candidate function not viable: no known conversion from 'const vfloat32' (aka 'const float') to '__vector __bool unsigned long long' (vector of 2 'unsigned long long' values) for 1st argument
vec_max(vector bool long long __a, vector unsigned long long __b) {
^
/usr/lib/clang/13.0.0/include/altivec.h:4902:1: note: candidate function not viable: no known conversion from 'const vfloat32' (aka 'const float') to '__vector unsigned long long' (vector of 2 'unsigned long long' values) for 1st argument
vec_max(vector unsigned long long __a, vector bool long long __b) {
^
/usr/lib/clang/13.0.0/include/altivec.h:4907:45: note: candidate function not viable: no known conversion from 'const vfloat32' (aka 'const float') to '__vector float' (vector of 4 'float' values) for 1st argument
static __inline__ vector float __ATTRS_o_ai vec_max(vector float __a,
^
/usr/lib/clang/13.0.0/include/altivec.h:4917:46: note: candidate function not viable: no known conversion from 'const vfloat32' (aka 'const float') to '__vector double' (vector of 2 'double' values) for 1st argument
static __inline__ vector double __ATTRS_o_ai vec_max(vector double __a,
^
In file included from /wrkdirs/usr/ports/misc/pytorch/work/pytorch-v1.13.1/aten/src/ATen/native/Col2Im.cpp:6:
In file included from /wrkdirs/usr/ports/misc/pytorch/work/pytorch-v1.13.1/aten/src/ATen/native/im2col.h:7:
In file included from /wrkdirs/usr/ports/misc/pytorch/work/pytorch-v1.13.1/aten/src/ATen/native/cpu/utils.h:3:
In file included from /wrkdirs/usr/ports/misc/pytorch/work/pytorch-v1.13.1/aten/src/ATen/cpu/vec/vec.h:6:
In file included from /wrkdirs/usr/ports/misc/pytorch/work/pytorch-v1.13.1/aten/src/ATen/cpu/vec/vec256/vec256.h:19:
In file included from /wrkdirs/usr/ports/misc/pytorch/work/pytorch-v1.13.1/aten/src/ATen/cpu/vec/vec256/vsx/vec256_common_vsx.h:5:
/wrkdirs/usr/ports/misc/pytorch/work/pytorch-v1.13.1/aten/src/ATen/cpu/vec/vec256/vsx/vsx_helpers.h:145:1: error: no matching function for call to 'vec_cmpne'
C10_VSX_VEC_NAN_PROPAG(vec_max_nan2, vfloat32, vbool32, vec_max)
^~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
/wrkdirs/usr/ports/misc/pytorch/work/pytorch-v1.13.1/aten/src/ATen/cpu/vec/vec256/vsx/vsx_helpers.h:138:19: note: expanded from macro 'C10_VSX_VEC_NAN_PROPAG'
btype nan_a = vec_cmpne(a, a); \
^~~~~~~~~
/usr/lib/clang/13.0.0/include/altivec.h:2002:1: note: candidate function not viable: no known conversion from 'const vfloat32' (aka 'const float') to '__vector __bool unsigned char' (vector of 16 'unsigned char' values) for 1st argument
vec_cmpne(vector bool char __a, vector bool char __b) {
^
/usr/lib/clang/13.0.0/include/altivec.h:2007:1: note: candidate function not viable: no known conversion from 'const vfloat32' (aka 'const float') to '__vector signed char' (vector of 16 'signed char' values) for 1st argument
vec_cmpne(vector signed char __a, vector signed char __b) {
^
/usr/lib/clang/13.0.0/include/altivec.h:2012:1: note: candidate function not viable: no known conversion from 'const vfloat32' (aka 'const float') to '__vector unsigned char' (vector of 16 'unsigned char' values) for 1st argument
vec_cmpne(vector unsigned char __a, vector unsigned char __b) {
^
/usr/lib/clang/13.0.0/include/altivec.h:2017:1: note: candidate function not viable: no known conversion from 'const vfloat32' (aka 'const float') to '__vector __bool unsigned short' (vector of 8 'unsigned short' values) for 1st argument
vec_cmpne(vector bool short __a, vector bool short __b) {
^
/usr/lib/clang/13.0.0/include/altivec.h:2022:1: note: candidate function not viable: no known conversion from 'const vfloat32' (aka 'const float') to '__vector short' (vector of 8 'short' values) for 1st argument
vec_cmpne(vector signed short __a, vector signed short __b) {
^
/usr/lib/clang/13.0.0/include/altivec.h:2027:1: note: candidate function not viable: no known conversion from 'const vfloat32' (aka 'const float') to '__vector unsigned short' (vector of 8 'unsigned short' values) for 1st argument
vec_cmpne(vector unsigned short __a, vector unsigned short __b) {
^
/usr/lib/clang/13.0.0/include/altivec.h:2032:1: note: candidate function not viable: no known conversion from 'const vfloat32' (aka 'const float') to '__vector __bool unsigned int' (vector of 4 'unsigned int' values) for 1st argument
vec_cmpne(vector bool int __a, vector bool int __b) {
^
/usr/lib/clang/13.0.0/include/altivec.h:2037:1: note: candidate function not viable: no known conversion from 'const vfloat32' (aka 'const float') to '__vector int' (vector of 4 'int' values) for 1st argument
vec_cmpne(vector signed int __a, vector signed int __b) {
^
/usr/lib/clang/13.0.0/include/altivec.h:2042:1: note: candidate function not viable: no known conversion from 'const vfloat32' (aka 'const float') to '__vector unsigned int' (vector of 4 'unsigned int' values) for 1st argument
vec_cmpne(vector unsigned int __a, vector unsigned int __b) {
^
/usr/lib/clang/13.0.0/include/altivec.h:2047:1: note: candidate function not viable: no known conversion from 'const vfloat32' (aka 'const float') to '__vector float' (vector of 4 'float' values) for 1st argument
vec_cmpne(vector float __a, vector float __b) {
^
/usr/lib/clang/13.0.0/include/altivec.h:2054:1: note: candidate function not viable: no known conversion from 'const vfloat32' (aka 'const float') to '__vector __bool unsigned long long' (vector of 2 'unsigned long long' values) for 1st argument
vec_cmpne(vector bool long long __a, vector bool long long __b) {
^
/usr/lib/clang/13.0.0/include/altivec.h:2060:1: note: candidate function not viable: no known conversion from 'const vfloat32' (aka 'const float') to '__vector long long' (vector of 2 'long long' values) for 1st argument
vec_cmpne(vector signed long long __a, vector signed long long __b) {
^
/usr/lib/clang/13.0.0/include/altivec.h:2066:1: note: candidate function not viable: no known conversion from 'const vfloat32' (aka 'const float') to '__vector unsigned long long' (vector of 2 'unsigned long long' values) for 1st argument
vec_cmpne(vector unsigned long long __a, vector unsigned long long __b) {
^
/usr/lib/clang/13.0.0/include/altivec.h:2092:1: note: candidate function not viable: no known conversion from 'const vfloat32' (aka 'const float') to '__vector double' (vector of 2 'double' values) for 1st argument
vec_cmpne(vector double __a, vector double __b) {
^
```
### Versions
1.13.1
cc @jgong5 @mingfeima @XiaobingSuper @sanchitintel @ashokei @jingxu10
| 2 |
3,764 | 91,908 |
from torch import * does not import dtypes
|
triaged, actionable, module: python frontend
|
### 🐛 Describe the bug
There are several names on the `torch` module that are not included in `__all__`:
```py
>>> d = {}
>>> exec('from torch import *', d)
>>> import torch
>>> sorted([i for i in set(dir(torch)) - set(d) if not i.startswith('_')])
['Any', 'BFloat16Storage', 'BFloat16Tensor', 'Callable', 'ComplexDoubleStorage', 'ComplexFloatStorage', 'HalfStorage', 'HalfTensor', 'LoggerBase', 'PRIVATE_OPS', 'QInt32Storage', 'QInt8Storage', 'QUInt2x4Storage', 'QUInt4x2Storage', 'QUInt8Storage', 'Set', 'Storage', 'StorageBase', 'TYPE_CHECKING', 'USE_GLOBAL_DEPS', 'USE_RTLD_GLOBAL_WITH_LIBTORCH', 'Union', 'amp', 'ao', 'attr', 'autocast', 'autograd', 'backends', 'bfloat16', 'bool', 'broadcast_shapes', 'builtins', 'candidate', 'cdouble', 'cfloat', 'chalf', 'channels_last', 'channels_last_3d', 'classes', 'classproperty', 'compiled_with_cxx11_abi', 'complex128', 'complex32', 'complex64', 'contiguous_format', 'cpu', 'ctypes', 'cuda', 'distributed', 'distributions', 'double', 'eig', 'fft', 'float', 'float16', 'float32', 'float64', 'from_dlpack', 'functional', 'futures', 'fx', 'get_file_path', 'half', 'hub', 'inspect', 'int', 'int16', 'int32', 'int64', 'int8', 'jit', 'legacy_contiguous_format', 'library', 'linalg', 'long', 'lstsq', 'lu', 'masked', 'matrix_rank', 'multiprocessing', 'name', 'nested', 'nn', 'obj', 'onnx', 'ops', 'optim', 'os', 'overrides', 'package', 'pca_lowrank', 'per_channel_affine', 'per_channel_affine_float_qparams', 'per_channel_symmetric', 'per_tensor_affine', 'per_tensor_symmetric', 'platform', 'prepare_multiprocessing_environment', 'preserve_format', 'profiler', 'qint32', 'qint8', 'quantization', 'quantized_gru', 'quantized_lstm', 'quasirandom', 'quint2x4', 'quint4x2', 'quint8', 'random', 'return_types', 'serialization', 'set_default_dtype', 'set_grad_enabled', 'short', 'solve', 'sparse', 'sparse_bsc', 'sparse_bsr', 'sparse_coo', 'sparse_csc', 'sparse_csr', 'special', 'storage', 'strided', 'svd_lowrank', 'sys', 'testing', 'textwrap', 'to_dlpack', 'torch', 'torch_version', 'types', 'uint8', 'unique', 'utils', 'version']
```
Most of these are just submodules and types so are probably intentionally not included, but it seems to me that the dtype names (`int8`, `int16`, `float32`, etc.) should be included.
### Versions
Collecting environment information...
PyTorch version: 1.13.0
Is debug build: False
CUDA used to build PyTorch: None
ROCM used to build PyTorch: N/A
OS: macOS 12.6.2 (x86_64)
GCC version: Could not collect
Clang version: 11.1.0
CMake version: version 3.25.1
Libc version: N/A
Python version: 3.9.15 | packaged by conda-forge | (main, Nov 22 2022, 08:55:37) [Clang 14.0.6 ] (64-bit runtime)
Python platform: macOS-12.6.2-x86_64-i386-64bit
Is CUDA available: False
CUDA runtime version: No CUDA
CUDA_MODULE_LOADING set to: N/A
GPU models and configuration: No CUDA
Nvidia driver version: No CUDA
cuDNN version: No CUDA
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] mypy==0.991
[pip3] mypy-extensions==0.4.3
[pip3] numpy==1.23.5
[pip3] numpydoc==1.5.0
[pip3] torch==1.13.0
[conda] cpuonly 1.0 0 pytorch-nightly
[conda] mkl 2022.2.1 h44ed08c_16952 conda-forge
[conda] numpy 1.23.5 py39hdfa1d0c_0 conda-forge
[conda] numpydoc 1.5.0 pyhd8ed1ab_0 conda-forge
[conda] pytorch 1.13.0 cpu_py39h0a103a1_0 conda-forge
[conda] torch 1.11.0a0+git5347dab dev_0 <develop>
cc @albanD
| 1 |
3,765 | 91,903 |
Profiling with stack enabled results in error when Python's cProfile is also running
|
oncall: profiler
|
### 🐛 Describe the bug
I am trying to use cProfile and torch's profiler at the same time, and this worked fine for me before I updated Pytorch from 1.11 to 1.13 (with conda). Here's an example:
```python
import torch
import cProfile
# set up profilers
c_prof = cProfile.Profile()
schedule = torch.profiler.schedule(
wait=1, warmup=1, active=1, repeat=1
)
torch_prof = torch.profiler.profile(
schedule=schedule,
with_stack=True # results in error
)
# enable python profiler first
c_prof.enable()
# enable torch profiler second
torch_prof.start()
# profile some code
for i in range(3):
t = torch.rand(4, 4)
torch_prof.step() # error on last step
print(f'step {i+1} complete')
# disable profilers
torch_prof.stop()
c_prof.disable()
```
out:
```
step 1 complete
step 2 complete
STAGE:2023-01-09 13:06:00 24668:24668 ActivityProfilerController.cpp:294] Completed Stage: Warm Up
Output exceeds the size limit. Open the full output data in a text editor
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
Cell In[1], line 21
19 for i in range(3):
20 t = torch.rand(4, 4)
---> 21 torch_prof.step()
22 print(f'step {i+1} complete')
24 torch_prof.stop()
File ~/anaconda3/envs/py39/lib/python3.9/site-packages/torch/profiler/profiler.py:500, in profile.step(self)
497 self.step_num += 1
498 self.current_action = self.schedule(self.step_num)
--> 500 self._transit_action(prev_action, self.current_action)
502 prof.kineto_step()
503 if self.record_steps:
File ~/anaconda3/envs/py39/lib/python3.9/site-packages/torch/profiler/profiler.py:515, in profile._transit_action(self, prev_action, current_action)
513 if action_list:
514 for action in action_list:
--> 515 action()
File ~/anaconda3/envs/py39/lib/python3.9/site-packages/torch/profiler/profiler.py:119, in _KinetoProfile.stop_trace(self)
117 def stop_trace(self):
118 assert self.profiler is not None
--> 119 self.profiler.__exit__(None, None, None)
...
232 use_cuda=self.use_cuda,
233 profile_memory=self.profile_memory,
234 with_flops=self.with_flops)
RuntimeError: stack.size() INTERNAL ASSERT FAILED at "/opt/conda/conda-bld/pytorch_1670525539683/work/torch/csrc/autograd/profiler_python.cpp":884, please report a bug to PyTorch. Python replay stack is empty.
```
### Versions
PyTorch version: 1.13.1
Is debug build: False
CUDA used to build PyTorch: 11.7
ROCM used to build PyTorch: N/A
OS: CentOS Linux 7 (Core) (x86_64)
GCC version: (GCC) 4.8.5 20150623 (Red Hat 4.8.5-44)
Clang version: Could not collect
CMake version: Could not collect
Libc version: glibc-2.17
Python version: 3.9.12 (main, Jun 1 2022, 11:38:51) [GCC 7.5.0] (64-bit runtime)
Python platform: Linux-3.10.0-1160.80.1.el7.x86_64-x86_64-with-glibc2.17
Is CUDA available: True
CUDA runtime version: 11.7.99
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration:
GPU 0: NVIDIA A100 80GB PCIe
GPU 1: NVIDIA A100 80GB PCIe
Nvidia driver version: 520.61.05
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.23.5
[pip3] torch==1.13.1
[pip3] torch-cluster==1.6.0
[pip3] torch-geometric==2.2.0
[pip3] torch-scatter==2.1.0
[pip3] torch-sparse==0.6.16
[pip3] torch-tb-profiler==0.4.0
[pip3] torchaudio==0.13.1
[pip3] torchvision==0.14.1
[conda] blas 1.0 mkl
[conda] cudatoolkit 11.3.1 h2bc3f7f_2
[conda] ffmpeg 4.3 hf484d3e_0 pytorch
[conda] mkl 2021.4.0 h06a4308_640
[conda] mkl-service 2.4.0 py39h7f8727e_0
[conda] mkl_fft 1.3.1 py39hd3c417c_0
[conda] mkl_random 1.2.2 py39h51133e4_0
[conda] numpy 1.23.5 py39h14f4228_0
[conda] numpy-base 1.23.5 py39h31eccc5_0
[conda] pyg 2.2.0 py39_torch_1.13.0_cu117 pyg
[conda] pytorch 1.13.1 py3.9_cuda11.7_cudnn8.5.0_0 pytorch
[conda] pytorch-cluster 1.6.0 py39_torch_1.13.0_cu117 pyg
[conda] pytorch-cuda 11.7 h67b0de4_1 pytorch
[conda] pytorch-mutex 1.0 cuda pytorch
[conda] pytorch-scatter 2.1.0 py39_torch_1.13.0_cu117 pyg
[conda] pytorch-sparse 0.6.16 py39_torch_1.13.0_cu117 pyg
[conda] torch-tb-profiler 0.4.0 pypi_0 pypi
[conda] torchaudio 0.13.1 py39_cu117 pytorch
[conda] torchvision 0.14.1 py39_cu117 pytorch
cc @robieta @chaekit @aaronenyeshi @ngimel @nbcsm @guotuofeng @guyang3532 @gaoteng-git @tiffzhaofb
| 0 |
3,766 | 91,902 |
ONNXRuntime outputs numerically incorrect results for mixed precision models.
|
module: onnx, triaged
|
### 🐛 Describe the bug
https://github.com/microsoft/onnxruntime/issues/14189
Transferring onnx pytorch exporter related issues.
### Versions
See attached original issue link. Thanks.
| 0 |
3,767 | 91,898 |
Lazily start worker threads in the autograd engine
|
module: autograd, triaged, better-engineering, actionable
|
As per title.
This can be done by doing the thread startup in the `Engine::ready_queue` method when the corresponding queue is used for the first time.
cc @ezyang @zou3519 @gqchen @pearu @nikitaved @soulitzer @Lezcano @Varal7
| 0 |
3,768 | 91,889 |
ToTensor deadlock in subprocess
|
module: multiprocessing, triaged
|
🐛 Describe the bug
I load a checkpoint in main process, then I start a subprocess to call ToTensor and the subprocess hang forever.
the following codes will reproduce my problem:
```python
import numpy as np
from PIL import Image
from multiprocessing import Process
import torchvision
from torchvision.transforms import ToTensor
a = np.ones((224, 224, 3), dtype=np.uint8)
a = Image.fromarray(a, mode='RGB')
model = torchvision.models.resnet50(True)
p = Process(target=ToTensor(), args=(a,))
p.start()
p.join()
print('end')
```
### Versions
torch version: 1.12.0
torchvision version: 0.13.0
cc @VitalyFedyunin @ejguan
| 4 |
3,769 | 91,888 |
No setting to allow collecting the first trace early.
|
oncall: profiler
|
The default schedule behavior is to 'wait' immediately following the skip_first steps. As a consequence, if we want to wait 5k steps between traces, the earliest possible trace we can collect is after 5k steps. We'd like to be able to record a trace early in training, like at step 100, and then subsequently once every 5k steps.
cc @robieta @chaekit @aaronenyeshi @ngimel @nbcsm @guotuofeng @guyang3532 @gaoteng-git @tiffzhaofb
| 1 |
3,770 | 91,887 |
Only the first logged trace in a given log dir is visible in tensorboard.
|
triaged, module: tensorboard
|
As per title.
Is this an expected limitation?
| 1 |
3,771 | 91,879 |
ddp vs fsdp
|
oncall: distributed, module: fsdp
|
### 🐛 Describe the bug
I used fsdp+ShardedGradScaler to train my model. Compared with apex. amp+ddp, the precision of my model has decreased.
The ddp is like
```
model, optimizer = amp.initialize(model, optimizer,
num_losses=len(task2scaler),
enabled=opts.optimizer["fp16"], opt_level='O2')
model = DDP(model, device_ids=[get_local_rank()], output_device=get_local_rank(), find_unused_parameters=False)
with amp.scale_loss(loss, optimizer, delay_unscale=delay_unscale,
loss_id=task2scaler[name]) as scaled_loss:
scaled_loss.backward()
```
and the fsdp is like
```
model = FSDP(model,
auto_wrap_policy=t5_auto_wrap_policy,
mixed_precision=MixedPrecision(
param_dtype=torch.bfloat16,
# Gradient communication precision.
reduce_dtype=torch.bfloat16,
# Buffer precision.
buffer_dtype=torch.bfloat16,
),
device_id=torch.cuda.current_device(),
sharding_strategy=ShardingStrategy.SHARD_GRAD_OP, # ZERO2
backward_prefetch=BackwardPrefetch.BACKWARD_PRE)
```
What is possible reason?
### Versions
。
cc @mrshenli @pritamdamania87 @zhaojuanmao @satgera @rohan-varma @gqchen @aazzolini @osalpekar @jiayisuse @H-Huang @kwen2501 @awgu
| 9 |
3,772 | 91,863 |
torch.Categorical samples indexes with 0 probability when given logits as argument
|
module: distributions, triaged
|
### 🐛 Describe the bug
`torch.distributions.Categorical` samples indexes with 0 probability when given logits as argument.
## To reproduce
```python
import torch
from torch.distributions import Categorical
logits = torch.ones((1_000_000, 500))
logits[:, 1:] = -1e5
probs = Categorical(logits=logits)
sample = probs.sample()
torch.sum(sample > 0)
```
### Expected behaviour
The sum should be 0, because probs.sample() should only extract the index 0, because the other logits are $-10^5$ while the logit for the index 0 is 1
### Versions
[pip3] mypy-extensions==0.4.3
[pip3] numpy==1.21.5
[pip3] numpydoc==1.4.0
[pip3] torch==2.0.0.dev20230105
[pip3] torchaudio==2.0.0.dev20230105
[pip3] torchvision==0.15.0.dev20230105
[conda] blas 1.0 mkl
[conda] cpuonly 2.0 0 pytorch-nightly
[conda] mkl 2021.4.0 haa95532_640
[conda] mkl-service 2.4.0 py39h2bbff1b_0
[conda] mkl_fft 1.3.1 py39h277e83a_0
[conda] mkl_random 1.2.2 py39hf11a4ad_0
[conda] numpy 1.21.5 py39h7a0a035_3
[conda] numpy-base 1.21.5 py39hca35cd5_3
[conda] numpydoc 1.4.0 py39haa95532_0
[conda] pytorch 2.0.0.dev20230105 py3.9_cpu_0 pytorch-nightly
[conda] pytorch-mutex 1.0 cpu pytorch
[conda] torchaudio 2.0.0.dev20230105 py39_cpu pytorch-nightly
[conda] torchvision 0.15.0.dev20230105 py39_cpu pytorch-nightly
cc @fritzo @neerajprad @alicanb @nikitaved
| 0 |
3,773 | 91,856 |
torchrun --help is too slow
|
oncall: distributed, triaged, oncall: r2p, topic: improvements, topic: performance
|
### 🚀 The feature, motivation and pitch
```
❯ hyperfine -Nw3 -r10 'torchrun --help'
Benchmark 1: torchrun --help
Time (mean ± σ): 943.2 ms ± 7.1 ms [User: 855.5 ms, System: 84.6 ms]
Range (min … max): 933.9 ms … 959.5 ms 10 runs
```
`torchrun --help` need to wait 1 second -- I advise to move the parse_args part to `torch/distributed/run/__main__.py`, And don't import any slow code in `__main__.py`, then if not `--help` after parse_args, import true main function and pass parsed args to it. It should fasten `torchrun --help`.
### Alternatives
_No response_
### Additional context
_No response_
cc @mrshenli @pritamdamania87 @zhaojuanmao @satgera @rohan-varma @gqchen @aazzolini @osalpekar @jiayisuse @H-Huang @kwen2501 @awgu
| 1 |
3,774 | 91,855 |
torchrun default value of command line options
|
oncall: distributed, triaged, oncall: r2p
|
### 🚀 The feature, motivation and pitch
1. Now `torchrun`'s `--nproc_per_node`'s default value is `1`. Why not use `auto`? `auto` decides the value automatically, which seems to be better than fixed integer.
> --nproc_per_node NPROC_PER_NODE
> Number of workers per node; supported values: [auto,
> cpu, gpu, int].
2. Now `torchrun`'s `--start_method`'s default value is `spawn`. I can understant its reasom: windows only support spawn while unix support spawn, fork, forkserver. So use `spawn` as default value can make it work by default in more OSs. However, according to <https://docs.python.org/3/library/multiprocessing.html#contexts-and-start-methods>
> spawn
> ... Starting a process using this method is rather slow compared to using fork or forkserver.
So why not provide a value named `auto`, when the OS is unix, it chooses `fork/forkserver` which is faster, when the OS is windows, it chooses `spawn`? It seems to be better than fixed method, maybe it can be the default value of `--start_method`?
TIA for discussion!
### Alternatives
_No response_
### Additional context
_No response_
cc @mrshenli @pritamdamania87 @zhaojuanmao @satgera @rohan-varma @gqchen @aazzolini @osalpekar @jiayisuse @H-Huang @kwen2501 @awgu
| 2 |
3,775 | 91,942 |
jacrev over huber function
|
needs reproduction, triaged, module: functorch
|
I get the following error when trying to jacrev through this:
```
def huber(input_, delta=1.0):
out = torch.zeros_like(input_)
out[input_ < delta] = .5 * input_[input_ < delta] **2
out[input_ >= delta] = delta*(torch.abs(input_[input_ >= delta]) - .5*delta)
return out
```
Here's the error:
```
File "/home/drake/drake-stacking/src/comparisons/newton_raphson_equality.py", line 85, in <module>
from copy import deepcopy
File "/home/drake/drake-stacking/src/utils/trajopt_class.py", line 299, in get_newton_with_equality_step
res = jacrev(jacrev(self.lagrangian_from_flat, argnums=0), argnums=(0, 1))(self.param_model.get_primal_var_param_flat(),
File "/usr/local/lib/python3.9/dist-packages/functorch/_src/eager_transforms.py", line 459, in wrapper_fn
vjp_out = _vjp_with_argnums(func, *args, argnums=argnums, has_aux=has_aux)
File "/usr/local/lib/python3.9/dist-packages/functorch/_src/vmap.py", line 35, in fn
return f(*args, **kwargs)
File "/usr/local/lib/python3.9/dist-packages/functorch/_src/eager_transforms.py", line 289, in _vjp_with_argnums
primals_out = func(*primals)
File "/usr/local/lib/python3.9/dist-packages/functorch/_src/eager_transforms.py", line 474, in wrapper_fn
results = vmap(vjp_fn)(basis)
File "/usr/local/lib/python3.9/dist-packages/functorch/_src/vmap.py", line 362, in wrapped
return _flat_vmap(
File "/usr/local/lib/python3.9/dist-packages/functorch/_src/vmap.py", line 35, in fn
return f(*args, **kwargs)
File "/usr/local/lib/python3.9/dist-packages/functorch/_src/vmap.py", line 489, in _flat_vmap
batched_outputs = func(*batched_inputs, **kwargs)
File "/usr/local/lib/python3.9/dist-packages/functorch/_src/eager_transforms.py", line 323, in wrapper
result = _autograd_grad(flat_primals_out, flat_diff_primals, flat_cotangents,
File "/usr/local/lib/python3.9/dist-packages/functorch/_src/eager_transforms.py", line 113, in _autograd_grad
grad_inputs = torch.autograd.grad(diff_outputs, inputs, grad_outputs,
File "/usr/local/lib/python3.9/dist-packages/torch/autograd/__init__.py", line 300, in grad
return Variable._execution_engine.run_backward( # Calls into the C++ engine to run the backward pass
RuntimeError: values.dim() >= num_leading_nones + max_index_dim INTERNAL ASSERT FAILED at "../aten/src/ATen/functorch/BatchRulesScatterOps.cpp":571, please report a bug to PyTorch.
```
cc @zou3519 @Chillee @samdow @soumith @kshitij12345 @janeyx99
| 2 |
3,776 | 91,842 |
Adding a page for subfolder/subfile overview/descriptions in the developer wiki
|
module: docs, triaged
|
### 🚀 The feature, motivation and pitch
Hi!
As noted here (https://dev-discuss.pytorch.org/t/what-should-we-do-about-developer-documentation/491/10), the developer documentation could be improved upon by adding a few more things.
I want to add a page in the developer wikis which discuss the overview/intentions of each subfolder/subfiles in the main repo (a brief example of what I mean here : https://dear-opera-8cc.notion.site/Pytorch-c16c4b333e9648139e8448aa0171744f )
### Alternatives
_No response_
### Additional context
_No response_
cc @svekars @carljparker
| 4 |
3,777 | 91,841 |
torch.onnx.export is throwing RuntimeError: prim::TupleUnpack not matched to tuple construct
|
module: onnx, triaged
|
### 🐛 Describe the bug
I want to export my SSD model to onnx format, so I modified my model with a new helper function below to dump the onnx.
```
def save_onnx_model(model,device):
dummy_input = torch.rand(32,3,800,800, dtype = torch.float16, requires_grad=False, device = device)
input_names = ['modelInput']
output_names = ['Out0', 'Out1', 'Out2', 'Out3', 'Out4', 'Out5', 'Out6']
with torch.cuda.amp.autocast(enabled=True):
torch.onnx.export(model, # model being run
(dummy_input,), # model input (or a tuple for multiple inputs)
"ImageClassifier.onnx", # where to save the model
export_params=True, # store the trained parameter weights inside the model file
opset_version=11, # the ONNX version to export the model to
verbose=True,
do_constant_folding=True, # whether to execute constant folding for optimization
input_names = input_names, # the model's input names
output_names = output_names, # the model's output names
dynamic_axes={'modelInput' : {0 : 'batch_size'}, # variable length axes
'Out0' : {0 : 'batch_size'},
'Out1' : {0 : 'batch_size'},
'Out2' : {0 : 'batch_size'},
'Out3' : {0 : 'batch_size'},
'Out4' : {0 : 'batch_size'},
'Out5' : {0 : 'batch_size'},
'Out6' : {0 : 'batch_size'},
})
print(" ")
print('Model has been converted to ONNX')
```
However, i am getting error messages from pytorch jit.
This is the Verbose information
%6182 : Half(32, 120087, 4, strides=[480348, 4, 1], requires_grad=1, device=cuda:0) = aten::cat(%6180, %6181) # /workspace/ssd/model/retinanet.py:466:0
%6183 : (Half(32, 256, 100, 100, strides=[2560000, 1, 25600, 256], requires_grad=1, device=cuda:0), Half(32, 256, 50, 50, strides=[640000, 1, 12800, 256], requires_grad=1, device=cuda:0), Half(32, 256, 25, 25, strides=[160000, 1, 6400, 256], requires_grad=1, device=cuda:0), Half(32, 256, 13, 13, strides=[43264, 1, 3328, 256], requires_grad=1, device=cuda:0), Half(32, 256, 7, 7, strides=[12544, 1, 1792, 256], requires_grad=1, device=cuda:0), Half(32, 120087, 264, strides=[31702968, 264, 1], requires_grad=1, device=cuda:0), Half(32, 120087, 4, strides=[480348, 4, 1], requires_grad=1, device=cuda:0)) = prim::TupleConstruct(%5144, %5352, %5560, %5768, %5976, %5059, %6182)
return (%6183)
```
Traceback (most recent call last):
File "train.py", line 651, in <module>
main(args)
File "train.py", line 562, in main
metric_logger, accuracy = train_one_epoch(model=model,
File "/workspace/ssd/engine.py", line 237, in train_one_epoch
save_onnx_model(model,device)
File "/workspace/ssd/engine.py", line 169, in save_onnx_model
torch.onnx.export(model, # model being run
File "/opt/conda/lib/python3.8/site-packages/torch/onnx/utils.py", line 479, in export
_export(
File "/opt/conda/lib/python3.8/site-packages/torch/onnx/utils.py", line 1419, in _export
graph, params_dict, torch_out = _model_to_graph(
File "/opt/conda/lib/python3.8/site-packages/torch/onnx/utils.py", line 1063, in _model_to_graph
graph = _optimize_graph(
File "/opt/conda/lib/python3.8/site-packages/torch/onnx/utils.py", line 551, in _optimize_graph
_C._jit_pass_lower_all_tuples(graph)
**RuntimeError: prim::TupleUnpack not matched to tuple construct**
```
Not sure if people have seen similar errors before. What is causing the TupleUnpack not matched to tuple construct Runtime error here?
### Versions
torch version: 1.13
| 0 |
3,778 | 91,839 |
Missing python 3.11 on anaconda for torch 1.13.1
|
oncall: binaries
|
### 🐛 Describe the bug
There is a torch 1.13.1 package with Python 3.11:
https://download.pytorch.org/whl/cpu/torch-1.13.1%2Bcpu-cp311-cp311-linux_x86_64.whl
However, there are no packages for Python 3.11 at
https://anaconda.org/pytorch/pytorch/files
### Versions
torch 1.13.1
cc @ezyang @seemethere @malfet
| 6 |
3,779 | 91,827 |
[inductor] `triton.runtime.jit` does not provide `get_cuda_stream`
|
triaged, oncall: pt2, module: inductor
|
### 🐛 Describe the bug
Installing and using newer versions of Triton (either from master or from the `triton-mlir` branches) with Python 3.10 fails with an `ImportError` due to https://github.com/pytorch/pytorch/blob/94262efc7d381ace82aa74ed2f5f5ec76f8fca95/torch/_inductor/triton_ops/autotune.py#L27
`triton.runtime.jit` doesn't seem to make that symbol available. Instead, they use an `import as` to get a function of that same name from `torch` (this line is consistent across `master`, `legacy-backend`, and the new `triton-mlir` branch): https://github.com/openai/triton/blob/899bb0a0e7592612300913179d1a7d5baf5d4db5/python/triton/runtime/jit.py#L19
Inductor's codeine wrapper does as well: https://github.com/pytorch/pytorch/blob/94262efc7d381ace82aa74ed2f5f5ec76f8fca95/torch/_inductor/codegen/wrapper.py#L289
Should `autotune.py` be changed to match?
### Versions
```text
Collecting environment information...
PyTorch version: 2.0.0a0+git77c2a8a
Is debug build: False
CUDA used to build PyTorch: 11.8
ROCM used to build PyTorch: N/A
OS: Ubuntu 22.04.1 LTS (x86_64)
GCC version: (Ubuntu 11.3.0-1ubuntu1~22.04) 11.3.0
Clang version: 16.0.0 (++20230106042333+ea0cd51a4958-1~exp1~20230106042433.666)
CMake version: version 3.25.0
Libc version: glibc-2.35
Python version: 3.10.9+ (8af15cf:8af15cf, Jan 6 2023, 18:00:43) [Clang 16.0.0 (++20230106042333+ea0cd51a4958-1~exp1~20230106042433.666)] (64-bit runtime)
Python platform: Linux-6.0.15-300.fc37.x86_64-x86_64-with-glibc2.35
Is CUDA available: True
CUDA runtime version: 11.8.89
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration: GPU 0: NVIDIA GeForce RTX 4090
Nvidia driver version: 525.60.13
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.7.0
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.7.0
/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.7.0
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_infer.so.8.7.0
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.7.0
/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.7.0
/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.7.0
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.24.0
[pip3] torch==2.0.0a0+git77c2a8a
[pip3] torchvision==0.15.0a0+32d254b
[conda] Could not collect
```
cc @ezyang @soumith @msaroufim @wconstab @ngimel @bdhirsh @mlazos @voznesenskym @yanboliang @penguinwu @anijain2305 @EikanWang @jgong5 @Guobing-Chen @chunyuan-w @XiaobingSuper @zhuhaozhe @blzheng @Xia-Weiwen @wenzhe-nrv @jiayisunx @peterbell10 @desertfire
| 5 |
3,780 | 91,810 |
[Bug/functorch] Cannot use `tensor.detach().numpy()` for `GradTrackingTensor`: Cannot access data pointer of Tensor that doesn't have storage
|
triaged, module: functorch
|
### 🐛 Describe the bug
I'm trying to convert some intermediate tensors to numpy arrays. This is a common use case for Reinforcement Learning (RL) tasks.
I put the sampling process in my objective function. The PyTorch module takes `observation` tensor and produces `action`, then the `action` is converted to a numpy array and sent to the RL environment.
The pipeline is:
```python
def fpolicy(params, observation):
# forward model
logits = fmodel(params, observation)
dist = torch.distributions.Categorical(logits=logits)
action = dist.sample()
logprob = dist.log_prob(action)
return action, logprob
def sample(params):
batch = []
observation = env.reset()
for i in range(horizon):
action, action_logprob = fpolicy(params, observation)
action_numpy = action.detach().cpu().numpy() # <== has side effect here: `.numpy()` access the data storage
next_observation, reward, *_ = env.step(action_numpy)
batch.append((observation, action_logprob, reward, next_observation))
observations, action_logprobs, rewards, next_observations = tuple(zip*(batch))
observations = torch.from_numpy(np.stack(observations))
action_logprobs = torch.stack(action_logprobs)
rewards = torch.from_numpy(np.stack(rewards))
next_observations = torch.from_numpy(np.stack(next_observations))
return observations, action_logprobs, rewards, next_observations
def objective(params):
observations, action_logprobs, rewards, next_observations = sample(params)
return (rewards * action_logprobs).mean()
grad_fn = functorch.grad(objective)
grads = grad_fn(params)
```
While interacting with the environment, only the value of the tensor is used, the computation graph has been detached.
In `functorch.grad` / `functorch.vjp`, the input `params` tensors are wrapped as `GradTrackingTensor`, the all intermediate tensors will also be `GradTrackingTensor` (e.g., the `action` tensor). They can be `.detach()` but cannot convert to numpy arrays `.numpy()`.
A minimal script to reproduce this:
```python
import functorch
import torch
def mean(x):
mu = x.mean()
mu.detach() # OK
mu.detach().cpu() # OK
mu.detach().cpu().numpy() # FAIL
return mu
grad_fn = functorch.grad(mean)
grads = grad_fn(torch.randn(8))
```
```python
╭───────────────────────────────────────────── Traceback (most recent call last) ─────────────────────────────────────────────╮
│ /home/PanXuehai/test.py:12 in <module> │
│ │
│ 9 │ return mu │
│ 10 │
│ 11 grad_fn = functorch.grad(mean) │
│ ❱ 12 grads = grad_fn(torch.randn(8)) │
│ 13 │
│ │
│ /home/PanXuehai/Miniconda3/envs/torchopt/lib/python3.9/site-packages/functorch/_src/eager_transforms.py:1241 in wrapper │
│ │
│ 1238 │ """ │
│ 1239 │ @wraps(func) │
│ 1240 │ def wrapper(*args, **kwargs): │
│ ❱ 1241 │ │ results = grad_and_value(func, argnums, has_aux=has_aux)(*args, **kwargs) │
│ 1242 │ │ if has_aux: │
│ 1243 │ │ │ grad, (_, aux) = results │
│ 1244 │ │ │ return grad, aux │
│ │
│ /home/PanXuehai/Miniconda3/envs/torchopt/lib/python3.9/site-packages/functorch/_src/vmap.py:35 in fn │
│ │
│ 32 │ @functools.wraps(f) │
│ 33 │ def fn(*args, **kwargs): │
│ 34 │ │ with torch.autograd.graph.disable_saved_tensors_hooks(message): │
│ ❱ 35 │ │ │ return f(*args, **kwargs) │
│ 36 │ return fn │
│ 37 │
│ 38 │
│ │
│ /home/PanXuehai/Miniconda3/envs/torchopt/lib/python3.9/site-packages/functorch/_src/eager_transforms.py:1111 in wrapper │
│ │
│ 1108 │ │ │ │ diff_args = _slice_argnums(args, argnums, as_tuple=False) │
│ 1109 │ │ │ │ tree_map_(partial(_create_differentiable, level=level), diff_args) │
│ 1110 │ │ │ │ │
│ ❱ 1111 │ │ │ │ output = func(*args, **kwargs) │
│ 1112 │ │ │ │ if has_aux: │
│ 1113 │ │ │ │ │ if not (isinstance(output, tuple) and len(output) == 2): │
│ 1114 │ │ │ │ │ │ raise RuntimeError( │
│ │
│ /home/PanXuehai/test.py:8 in mean │
│ │
│ 5 │ mu = x.mean() │
│ 6 │ mu.detach() # OK │
│ 7 │ mu.detach().cpu() # OK │
│ ❱ 8 │ mu.detach().cpu().numpy() # FAIL │
│ 9 │ return mu │
│ 10 │
│ 11 grad_fn = functorch.grad(mean) │
╰─────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────╯
RuntimeError: Cannot access data pointer of Tensor that doesn't have storage
```
### Versions
```text
Collecting environment information...
PyTorch version: 1.13.1
Is debug build: False
CUDA used to build PyTorch: 11.7
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.5 LTS (x86_64)
GCC version: (conda-forge gcc 10.4.0-19) 10.4.0
Clang version: 10.0.1
CMake version: version 3.22.1
Libc version: glibc-2.31
Python version: 3.9.15 (main, Nov 24 2022, 14:31:59) [GCC 11.2.0] (64-bit runtime)
Python platform: Linux-5.15.79.1-microsoft-standard-WSL2-x86_64-with-glibc2.31
Is CUDA available: True
CUDA runtime version: 11.7.99
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration: GPU 0: NVIDIA GeForce RTX 3090
Nvidia driver version: 527.56
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] mypy==0.991
[pip3] mypy-extensions==0.4.3
[pip3] numpy==1.23.5
[pip3] torch==1.13.1
[pip3] torchopt==0.6.1.dev7+g6cb2b4f
[pip3] torchvision==0.14.1
[pip3] torchviz==0.0.2
[conda] blas 1.0 mkl
[conda] cudatoolkit 11.3.1 h2bc3f7f_2
[conda] mkl 2021.4.0 h06a4308_640
[conda] mkl-service 2.4.0 py39h7f8727e_0
[conda] mkl_fft 1.3.1 py39hd3c417c_0
[conda] mkl_random 1.2.2 py39h51133e4_0
[conda] numpy 1.23.5 py39h14f4228_0
[conda] numpy-base 1.23.5 py39h31eccc5_0
[conda] pytorch 1.13.1 py3.9_cuda11.7_cudnn8.5.0_0
[conda] pytorch-cuda 11.7 h67b0de4_1
[conda] pytorch-mutex 1.0 cuda
[conda] torchopt 0.6.1.dev7+g6cb2b4f pypi_0
[conda] torchvision 0.14.1 py39_cu117
[conda] torchviz 0.0.2 pypi_0
```
cc @zou3519 @Chillee @samdow @soumith
| 10 |
3,781 | 91,809 |
Better API for `torch.cov` (and `Tensor.cov`)
|
feature, triaged, module: python frontend
|
### 🚀 The feature, motivation and pitch
Currently, the `cov` computes the mean internally and there is no way to reduce the computation if the mean is pre-computed/known or required alongside the covariance.
Potential new API (in Python):
```py
x = torch.rand(4,4)
m = x.mean()
c = x.cov(mean=m)
```
```py
x = torch.rand(4,4)
c, m = x.cov_and_mean()
```
### Alternatives
_No response_
### Additional context
[Doc](https://pytorch.org/docs/master/generated/torch.cov.html#torch.cov)
cc @albanD
| 0 |
3,782 | 91,799 |
Codegen for in_out_ptr seems suboptimal
|
triaged, oncall: pt2, module: inductor
|
### 🐛 Describe the bug
When compiling the forward of hfBert, the following kernel is generated under the name of
```
triton_fused_add_97_convert_element_type_134_getitem_49_rsqrt_24_var_mean_24_view_228_40
```
```python
@triton.jit
def triton_(in_out_ptr0, in_out_ptr1, in_out_ptr2, seed0, in_ptr1, in_ptr2, in_ptr3, out_ptr1, xnumel, rnumel, XBLOCK : tl.constexpr, RBLOCK : tl.constexpr):
xnumel = 8192
rnumel = 768
xoffset = tl.program_id(0) * XBLOCK
xindex = xoffset + tl.reshape(tl.arange(0, XBLOCK), [XBLOCK, 1])
xmask = xindex < xnumel
rbase = tl.reshape(tl.arange(0, RBLOCK), [1, RBLOCK])
tmp0 = tl.load(seed0 + (0 + tl.zeros([XBLOCK, RBLOCK], tl.int32)), None)
x0 = xindex
for roffset in range(0, rnumel, RBLOCK):
rindex = roffset + rbase
rmask = rindex < rnumel
r1 = rindex
tmp6 = tl.load(in_out_ptr0 + (r1 + (768*x0)), rmask & xmask, eviction_policy='evict_last').to(tl.float32)
tmp10 = tl.load(in_ptr1 + (r1 + (768*x0)), rmask & xmask, eviction_policy='evict_last').to(tl.float32)
tmp1 = 754974720 + r1 + (768*x0)
tmp2 = tl.rand(tmp0, tmp1)
tmp3 = 0.1
tmp4 = tmp2 > tmp3
tmp5 = tmp4.to(tl.float32)
tmp7 = tmp5 * tmp6
tmp8 = 1.1111111111111112
tmp9 = tmp7 * tmp8
tmp11 = tmp9 + tmp10
tl.store(in_out_ptr0 + (r1 + (768*x0) + tl.zeros([XBLOCK, RBLOCK], tl.int32)), tmp11, rmask & xmask)
_tmp14 = tl.zeros([XBLOCK, RBLOCK], tl.float32) + 0
for roffset in range(0, rnumel, RBLOCK):
rindex = roffset + rbase
rmask = rindex < rnumel
r1 = rindex
tmp12 = tl.load(in_out_ptr0 + (r1 + (768*x0)), rmask & xmask, eviction_policy='evict_last').to(tl.float32)
tmp13 = tmp12.to(tl.float32)
_tmp14 = tl.where(xmask & rmask, _tmp14 + tmp13, _tmp14)
...
```
Those two for loops could be fused into one saving the load of `in_out_ptr0` (we would still need to store it as it's used later on though.
### Versions
master
cc @ezyang @soumith @msaroufim @wconstab @ngimel @bdhirsh @mlazos @voznesenskym @yanboliang @penguinwu @anijain2305 @EikanWang @jgong5 @Guobing-Chen @chunyuan-w @XiaobingSuper @zhuhaozhe @blzheng @Xia-Weiwen @wenzhe-nrv @jiayisunx @peterbell10 @desertfire
| 4 |
3,783 | 91,760 |
Inconsistent rank among torch.distributed primitives
|
oncall: distributed, triaged
|
### 🐛 Describe the bug
Currently, the distributed communication primitives under `torch.distributed` enforce some checks on each worker's rank and their corresponding arguments passed. There exist many `my_rank=get_rank()` in [distributed_c10d.py].(https://github.com/pytorch/pytorch/blob/ad782ff7df950dfda64e271dd4ee3c6128971103/torch/distributed/distributed_c10d.py)
The following is an example.
https://github.com/pytorch/pytorch/blob/8c172fa98a52e95675e9425ac4b23f190f53f9ed/torch/distributed/distributed_c10d.py#L2315-L2321
It seems strange that there are many widely-used primitives forces using `global_rank` even when `group` is specified. For example, the `dist.gather`.
https://github.com/pytorch/pytorch/blob/8c172fa98a52e95675e9425ac4b23f190f53f9ed/torch/distributed/distributed_c10d.py#L2674-L2676
The `get_rank()` above without an argument `group` passed will return the `global_rank` of the caller worker, which is different from the above.
I am wondering if it is a bug or if there is any documentation on using `global_rank` only in these primitives.
### Versions
current master ad782ff7df950dfda64e271dd4ee3c6128971103
cc @mrshenli @pritamdamania87 @zhaojuanmao @satgera @rohan-varma @gqchen @aazzolini @osalpekar @jiayisuse @H-Huang @kwen2501 @awgu
| 3 |
3,784 | 91,759 |
Error while building pytorch from source on windows - Ninja Build Stopped, Subcommand Failed
|
triaged
|
### 🐛 Describe the bug
I am attempting to build pytorch from source on Windows without CUDA by creating a fork, cloning my forked repository to my computer, and then running the following commands in the anaconda prompt
```cd pytorch
conda activate
python setup.py develop
```
I have Visual Studio 2019 installed. This process is returning the following error
```
...
[3699/5990] Building CXX object third_party\googletest\goo...ck\CMakeFiles\gmock.dir\__\googletest\src\gtest-all.cc.obj
cl : Command line warning D9025 : overriding '/w' with '/W4'
[3700/5990] Building CXX object third_party\googletest\googletest\CMakeFiles\gtest.dir\src\gtest-all.cc.obj
cl : Command line warning D9025 : overriding '/w' with '/W4'
ninja: build stopped: subcommand failed.
```
I do not fully understand the meaning of the error ```ninja: build stopped, subcommand failed``` and would appreciate if someone could provide some guidance on what might be causing this.
Other errors in the command line output (which is a lot of lines long so I haven't attached it all) are things like
```
...\third_party\benchmark\src\benchmark.cc(192) error C3536: '<end>$L0': cannot be used before it is initialized
...\third_party\benchmark\src\benchmark.cc(192): error C3536: 'name': cannot be used before it is initialized
...\third_party\benchmark\src\benchmark.cc(192): error C2679: binary '[': no operator found which takes a right-hand operand of type 'int' (or there is no acceptable conversion)
...\third_party\benchmark\src\benchmark.cc(306): error C2923: 'std::map': 'PerFamilyRunReports' is not a valid template type argument for parameter '_Ty'
```
These errors make me believe it might be connected to the C++ compiler?
Previously, I **have** been able to build Pytorch from source successfully and do not know what I might have changed.
Thanks!
### Versions
```
Collecting environment information...
PyTorch version: N/A
Is debug build: N/A
CUDA used to build PyTorch: N/A
ROCM used to build PyTorch: N/A
OS: Microsoft Windows 11 Home
GCC version: (i686-win32-dwarf-rev0, Built by MinGW-W64 project) 8.1.0
Clang version: Could not collect
CMake version: version 3.22.1
Libc version: N/A
Python version: 3.8.15 (default, Nov 24 2022, 14:38:14) [MSC v.1916 64 bit (AMD64)] (64-bit runtime)
Python platform: Windows-10-10.0.22000-SP0
Is CUDA available: N/A
CUDA runtime version: Could not collect
CUDA_MODULE_LOADING set to: N/A
GPU models and configuration: Could not collect
Nvidia driver version: Could not collect
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: N/A
Versions of relevant libraries:
[pip3] mypy==0.812
[pip3] mypy-extensions==0.4.3
[pip3] numpy==1.23.4
[pip3] numpydoc==1.5.0
[conda] blas 1.0 mkl
[conda] cpuonly 2.0 0 pytorch
[conda] mkl 2021.4.0 haa95532_640
[conda] mkl-include 2022.1.0 haa95532_193
[conda] mkl-service 2.4.0 py38h2bbff1b_0
[conda] mkl_fft 1.3.1 py38h277e83a_0
[conda] mkl_random 1.2.2 py38hf11a4ad_0
[conda] numpy 1.23.4 py38h3b20f71_0
[conda] numpy-base 1.23.4 py38h4da318b_0
[conda] numpydoc 1.5.0 py38haa95532_0
[conda] pytorch-mutex 1.0 cpu pytorch
```
| 1 |
3,785 | 91,754 |
CUDA error: initialization error
|
module: cuda, triaged, module: regression, module: nvfuser
|
### 🐛 Describe the bug
Consider the following code.
```python
from multiprocessing import Process
import os
import torch
print(torch.__version__)
@torch.jit.script
def distance_classification():
return "distance_classification"
class X(torch.nn.Module):
x = distance_classification()
def train_on_node():
print(f"XXXXXYYYYZZZZ 3 pid={os.getpid()}")
torch._C._cuda_init()
print(f"XXXXXYYYYZZZZ 4 pid={os.getpid()}")
return 123
p = Process(target=train_on_node, args=())
p.start()
p.join()
```
On PyTorch 1.11 it executed without a problem:
```
1.11.0+cu102
XXXXXYYYYZZZZ 3 pid=3739
XXXXXYYYYZZZZ 4 pid=3739
```
On PyTorch 1.12.0 it throws this error
```
1.12.0+cu102
XXXXXYYYYZZZZ 3 pid=2660
Process Process-1:
Traceback (most recent call last):
File "/usr/lib/python3.8/multiprocessing/process.py", line 315, in _bootstrap
self.run()
File "/usr/lib/python3.8/multiprocessing/process.py", line 108, in run
self._target(*self._args, **self._kwargs)
File "<ipython-input-1-7de82f15ef1a>", line 17, in train_on_node
torch._C._cuda_init()
RuntimeError: !in_bad_fork INTERNAL ASSERT FAILED at "../torch/csrc/cuda/Module.cpp":587, please report a bug to PyTorch.
```
On PyTorch 1.13.0 it throws this error
```
1.13.0+cu117
XXXXXYYYYZZZZ 3 pid=4944
Process Process-1:
Traceback (most recent call last):
File "/usr/lib/python3.8/multiprocessing/process.py", line 315, in _bootstrap
self.run()
File "/usr/lib/python3.8/multiprocessing/process.py", line 108, in run
self._target(*self._args, **self._kwargs)
File "<ipython-input-1-7de82f15ef1a>", line 17, in train_on_node
torch._C._cuda_init()
RuntimeError: CUDA error: initialization error
CUDA kernel errors might be asynchronously reported at some other API call,so the stacktrace below might be incorrect.
For debugging consider passing CUDA_LAUNCH_BLOCKING=1.
```
I'd like to understand if is this a regression or intended behavior. If it's intended behavior, what would be a recommendation to fix it in our user code?
### Versions
1.13.0
1.12.0
cc @ngimel @kevinstephano @jjsjann123
| 4 |
3,786 | 91,753 |
SymIntType gets translated to int when going through pybind
|
triaged, oncall: pt2, module: dynamic shapes
|
```
import torch
print(torch.ops.aten.sym_size.int._schema)
print(torch.ops.aten.sym_size.int._schema.returns[0].type)
```
produces:
```
aten::sym_size.int(Tensor self, int dim) -> SymInt
int
```
I would expect the second line to be `torch.SymInt`. Somewhere something is going funky, although it seems the binding for `SymInt` has been properly done here: https://github.com/pytorch/pytorch/blob/master/torch/csrc/jit/python/python_ir.cpp#L996
cc @ezyang @soumith @msaroufim @wconstab @ngimel @bdhirsh
| 8 |
3,787 | 91,751 |
[bazel] replace //c10:headers dependency by //c10 dependency
|
triaged, module: bazel
|
### 🐛 Describe the bug
Follow-up from https://github.com/pytorch/pytorch/pull/91422
As @dagitses pointed out, there is no real reason to make the `//c10:headers` public, if they are available on the `//c10`.
Currently they are not as demonstrated by the following bazel queries
```
sergei.vorobev@cs-7xn77uoy-gpu-homedir-848671:~/workspaces/c2/src/github.robot.car/cruise/cruise$ bazel query 'somepath(@pytorch//c10, @pytorch//c10:headers)'
WARNING: build volume is nearly full (104.165 GB remain). Free up space to avoid running out of disk!
INFO: Invocation ID: ddea5aba-8c65-11ed-b684-42010ad8716a
INFO: Empty results
Loading: 18 packages loaded
sergei.vorobev@cs-7xn77uoy-gpu-homedir-848671:~/workspaces/c2/src/github.robot.car/cruise/cruise$ bazel query 'somepath(@pytorch//c10:headers, @pytorch//c10)'
WARNING: build volume is nearly full (104.165 GB remain). Free up space to avoid running out of disk!
INFO: Invocation ID: e3970a9e-8c65-11ed-b684-42010ad8716a
INFO: Empty results
Loading: 0 packages loaded
```
This issue it to track the unification of this bazel build aspect: to expose the headers on the lib target.
### Versions
master
| 0 |
3,788 | 91,738 |
tracing torchvision detection model results in an error
|
oncall: jit, module: vision
|
### 🐛 Describe the bug
The detection API isn't compatible with torch.jit.trace because the forward for detection models results in a list of dictionaries.
```python
torch.jit.trace(func=torchvision.models.detection.fasterrcnn_resnet50_fpn_v2().eval(), example_inputs=torch.rand(1, 3, 512, 512))
```
```
/usr/local/lib/python3.8/dist-packages/torch/nn/functional.py:3908: UserWarning: To copy construct from a tensor, it is recommended to use sourceTensor.clone().detach() or sourceTensor.clone().detach().requires_grad_(True), rather than torch.tensor(sourceTensor).
(torch.floor((input.size(i + 2).float() * torch.tensor(scale_factors[i], dtype=torch.float32)).float()))
/usr/local/lib/python3.8/dist-packages/torchvision/ops/boxes.py:157: UserWarning: To copy construct from a tensor, it is recommended to use sourceTensor.clone().detach() or sourceTensor.clone().detach().requires_grad_(True), rather than torch.tensor(sourceTensor).
boxes_x = torch.min(boxes_x, torch.tensor(width, dtype=boxes.dtype, device=boxes.device))
/usr/local/lib/python3.8/dist-packages/torchvision/ops/boxes.py:159: UserWarning: To copy construct from a tensor, it is recommended to use sourceTensor.clone().detach() or sourceTensor.clone().detach().requires_grad_(True), rather than torch.tensor(sourceTensor).
boxes_y = torch.min(boxes_y, torch.tensor(height, dtype=boxes.dtype, device=boxes.device))
/usr/local/lib/python3.8/dist-packages/torch/__init__.py:827: TracerWarning: Converting a tensor to a Python boolean might cause the trace to be incorrect. We can't record the data flow of Python values, so this value will be treated as a constant in the future. This means that the trace might not generalize to other inputs!
assert condition, message
/usr/local/lib/python3.8/dist-packages/torchvision/models/detection/transform.py:298: UserWarning: To copy construct from a tensor, it is recommended to use sourceTensor.clone().detach() or sourceTensor.clone().detach().requires_grad_(True), rather than torch.tensor(sourceTensor).
torch.tensor(s, dtype=torch.float32, device=boxes.device)
/usr/local/lib/python3.8/dist-packages/torchvision/models/detection/transform.py:299: UserWarning: To copy construct from a tensor, it is recommended to use sourceTensor.clone().detach() or sourceTensor.clone().detach().requires_grad_(True), rather than torch.tensor(sourceTensor).
/ torch.tensor(s_orig, dtype=torch.float32, device=boxes.device)
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
[<ipython-input-54-9a5e30e34328>](https://localhost:8080/#) in <module>
----> 1 torch.jit.trace(func=torchvision.models.detection.fasterrcnn_resnet50_fpn_v2().eval(), example_inputs=torch.rand(1, 3, 512, 512))
1 frames
[/usr/local/lib/python3.8/dist-packages/torch/jit/_trace.py](https://localhost:8080/#) in trace_module(mod, inputs, optimize, check_trace, check_inputs, check_tolerance, strict, _force_outplace, _module_class, _compilation_unit)
974 example_inputs = make_tuple(example_inputs)
975
--> 976 module._c._create_method_from_trace(
977 method_name,
978 func,
RuntimeError: Only tensors, lists, tuples of tensors, or dictionary of tensors can be output from traced functions
```
### Versions
Collecting environment information...
PyTorch version: 1.13.0+cu116
Is debug build: False
CUDA used to build PyTorch: 11.6
ROCM used to build PyTorch: N/A
OS: Ubuntu 18.04.6 LTS (x86_64)
GCC version: (Ubuntu 7.5.0-3ubuntu1~18.04) 7.5.0
Clang version: 6.0.0-1ubuntu2 (tags/RELEASE_600/final)
CMake version: version 3.22.6
Libc version: glibc-2.27
Python version: 3.8.16 (default, Dec 7 2022, 01:12:13) [GCC 7.5.0] (64-bit runtime)
Python platform: Linux-5.10.133+-x86_64-with-glibc2.27
Is CUDA available: True
CUDA runtime version: 11.2.152
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration: GPU 0: Tesla T4
Nvidia driver version: 460.32.03
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.1.1
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.1.1
/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.1.1
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_infer.so.8.1.1
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.1.1
/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.1.1
/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.1.1
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.21.6
[pip3] torch==1.13.0+cu116
[pip3] torchaudio==0.13.0+cu116
[pip3] torchsummary==1.5.1
[pip3] torchtext==0.14.0
[pip3] torchvision==0.14.0+cu116
[conda] Could not collect
cc @EikanWang @jgong5 @wenzhe-nrv @sanchitintel @datumbox @vfdev-5 @pmeier
| 0 |
3,789 | 91,737 |
[MPS] Improve the performance of torch.linear()
|
triaged, enhancement, module: backend, module: mps
|
The MPS's linear operation uses the temporary workaround #91114 to improve the performance.
However, that workaround is limited to specific tensor sizes. With the upcoming Ventura updates, a more generic fix will be available that would optimize MatMul ops for a wider range of tensor sizes.
I'm creating this issue to track the progress of MatMul optimizations, and also as a reminder to remove the workaround in torch.linear() once the generic solution becomes available.
cc @kulinseth @albanD @malfet @DenisVieriu97 @abhudev
| 0 |
3,790 | 91,719 |
Errors using torch.compile() on wav2vec2 model
|
triaged, ezyang's list, oncall: pt2, module: dynamic shapes, module: inductor, module: dynamo
|
### 🐛 Describe the bug
I've been experimenting with enabling torch.compile() for the wav2vec2 model in torchaudio, and ran into a few issues with it. My code can be found [here](https://github.com/pytorch/audio/pull/2941). Here's a summary of the issues I found, with reproduction instructions for each:
### 1) Errors with `inference_mode()`
To reproduce this, change the `no_grad()` to `inference_mode()` in `examples/asr/librispeech_ctc_decoder/inference.py`, and run it:
```
python examples/asr/librispeech_ctc_decoder/inference.py --librispeech_path /PATH/TO/LIBRISPEECH --batch_size 2 --compile
```
It produces the error "RuntimeError: Inference tensors do not track version counter.", but continues to run. Full stack trace is [here](https://gist.githubusercontent.com/kalakris/5764ba0d412c8e2d250f9c14ada3d4f9/raw/3b7ee3151fab49dc300dcdc631f88c65a6bbed0f/inference_mode.txt).
### 2) Errors with `dynamic=True`
Ideally, we'd want to run wav2vec2 with dynamic tensor sizes per call. But I wasn't able to do that. To reproduce, uncomment line 47 of `examples/asr/librispeech_ctc_decoder/inference.py`, comment out line 48, and run it:
```
python examples/asr/librispeech_ctc_decoder/inference.py --librispeech_path /PATH/TO/LIBRISPEECH --batch_size 2 --compile
```
Stack trace is [here](https://gist.githubusercontent.com/kalakris/5764ba0d412c8e2d250f9c14ada3d4f9/raw/3b7ee3151fab49dc300dcdc631f88c65a6bbed0f/dynamic_equals_true.txt).
### 3) Errors when passing the `lengths` parameter to the model
When batching inputs to this model, we need to pass in the lengths of each sample as well. Unfortunately this performs some operations which seems to break with `torch.compile()`. To reproduce, uncomment line 93 of `examples/asr/librispeech_ctc_decoder/inference.py`, comment out line 94, and run it:
```
python examples/asr/librispeech_ctc_decoder/inference.py --librispeech_path /PATH/TO/LIBRISPEECH --batch_size 2 --compile
```
Stack trace is [here](https://gist.githubusercontent.com/kalakris/5764ba0d412c8e2d250f9c14ada3d4f9/raw/3b7ee3151fab49dc300dcdc631f88c65a6bbed0f/with_lengths_parameter.txt).
### Versions
PyTorch version: 2.0.0.dev20221216
Is debug build: False
CUDA used to build PyTorch: 11.6
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.4 LTS (x86_64)
GCC version: (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0
Clang version: Could not collect
CMake version: version 3.16.3
Libc version: glibc-2.31
Python version: 3.10.8 (main, Nov 24 2022, 14:13:03) [GCC 11.2.0] (64-bit runtime)
Python platform: Linux-5.4.0-124-generic-x86_64-with-glibc2.31
Is CUDA available: True
CUDA runtime version: 11.6.112
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration: GPU 0: Tesla V100-SXM2-32GB
Nvidia driver version: 470.141.03
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.23.4
[pip3] torch==2.0.0.dev20221216
[pip3] torchaudio==0.14.0.dev20221216
[pip3] torchvision==0.15.0.dev20221216
[conda] blas 1.0 mkl
[conda] mkl 2021.4.0 h06a4308_640
[conda] mkl-service 2.4.0 py310h7f8727e_0
[conda] mkl_fft 1.3.1 py310hd6ae3a3_0
[conda] mkl_random 1.2.2 py310h00e6091_0
[conda] numpy 1.23.4 py310hd5efca6_0
[conda] numpy-base 1.23.4 py310h8e6c178_0
[conda] pytorch 2.0.0.dev20221216 py3.10_cuda11.6_cudnn8.3.2_0 pytorch-nightly
[conda] pytorch-cuda 11.6 h867d48c_2 pytorch-nightly
[conda] pytorch-mutex 1.0 cuda pytorch-nightly
[conda] torchaudio 0.14.0.dev20221216 py310_cu116 pytorch-nightly
[conda] torchtriton 2.0.0+0d7e753227 py310 pytorch-nightly
[conda] torchvision 0.15.0.dev20221216 py310_cu116 pytorch-nightly
cc @ezyang @soumith @msaroufim @wconstab @ngimel @bdhirsh @mlazos @voznesenskym @yanboliang @penguinwu @anijain2305 @EikanWang @jgong5 @Guobing-Chen @chunyuan-w @XiaobingSuper @zhuhaozhe @blzheng @Xia-Weiwen @wenzhe-nrv @jiayisunx @peterbell10 @desertfire @mthrok
| 16 |
3,791 | 91,716 |
linspace (and arange) behaves differently on GPU and CPU
|
triaged
|
### 🐛 Describe the bug
There seems to be numerical inconsistencies when `torch.linspace` is run on GPU vs on CPU, especially when the step size isn't an integer. This difference becomes more obvious when other operations are performed downstream, such as sine and cosine.
The following example can also be reproduced on Google Colab's GPU runtime.
```python
import numpy as np
import torch
from matplotlib import pyplot as plt
n = 200
start, end = -100, 100
device = "cuda"
a = torch.linspace(start, end, steps=n).to(device="cuda")
b = torch.linspace(start, end, steps=n, device="cuda")
print(torch.allclose(a, b)) # this is True, as expected
print(torch.allclose(a.sin(), b.sin())) # this is False, the error becomes non-negligible
# plot error against array index
plt.scatter(np.arange(n), (a - b).cpu().numpy())
plt.show()
```
The same issue also exists for `torch.arange`:
```python
import numpy as np
import torch
from matplotlib import pyplot as plt
start, end = -100, 100
step_size = np.random.rand() * 10
device = "cuda"
c = torch.arange(start, end, step=step_size).to(device="cuda")
d = torch.arange(start, end, step=step_size, device="cuda")
print(torch.allclose(c, d)) # this is mostly True, as expected
print(torch.allclose(c.sin(), d.sin())) # this is False, the error becomes non-negligible
# plot error against array index
plt.scatter(np.arange(len(c)), (c - d).cpu().numpy())
plt.show()
```
### Versions
Collecting environment information...
PyTorch version: 1.13.0+cu116
Is debug build: False
CUDA used to build PyTorch: 11.6
ROCM used to build PyTorch: N/A
OS: Ubuntu 18.04.6 LTS (x86_64)
GCC version: (Ubuntu 7.5.0-3ubuntu1~18.04) 7.5.0
Clang version: 6.0.0-1ubuntu2 (tags/RELEASE_600/final)
CMake version: version 3.22.6
Libc version: glibc-2.27
Python version: 3.8.16 (default, Dec 7 2022, 01:12:13) [GCC 7.5.0] (64-bit runtime)
Python platform: Linux-5.10.133+-x86_64-with-glibc2.27
Is CUDA available: True
CUDA runtime version: 11.2.152
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration: GPU 0: Tesla T4
Nvidia driver version: 460.32.03
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.1.1
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.1.1
/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.1.1
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_infer.so.8.1.1
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.1.1
/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.1.1
/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.1.1
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.21.6
[pip3] torch==1.13.0+cu116
[pip3] torchaudio==0.13.0+cu116
[pip3] torchsummary==1.5.1
[pip3] torchtext==0.14.0
[pip3] torchvision==0.14.0+cu116
[conda] Could not collect
| 3 |
3,792 | 91,713 |
Dynamo minifier fails with false internal assert on torch-nightly
|
triaged, oncall: pt2
|
### 🐛 Describe the bug
This issue came up when I tried to debug #91710, so the setup is the same.
I'm running a modified Stable Diffusion code with `@torch.compile` [applied on one of the functions](https://github.com/sgrigory/stablediffusion2/blob/115130e4a9c8562225f24e6929575906752c79f9/ldm/models/diffusion/plms.py#L187). The compilation breaks with `TypeError: object of type 'tuple_iterator' has no len()` (separate issue #91710).
After adding a minifier with `TORCHDYNAMO_REPRO_AFTER="dynamo"` I'm getting `RuntimeError: false INTERNAL ASSERT FAILED at "../c10/cuda/CUDAGraphsC10Utils.h":73, please report a bug to PyTorch. Unknown CUDA graph CaptureStatus1256814507.`
Note:
- The error doesn't go away after setting `torch._inductor.config.triton.cudagraphs = False`
- The full code is [here](https://github.com/sgrigory/stablediffusion2/tree/115130e4a9c8562225f24e6929575906752c79f9)
@msaroufim
<details>
<summary>Show full error log</summary>
```
$ TORCHDYNAMO_REPRO_AFTER="dynamo" with-proxy python stable-diffusion/scripts/txt2img.py --prompt "A photo" --seed 187 --plms --config stable-diffusion/configs/stable-diffusion/v2-inference_native_mha.yaml --ckpt /tmp/model_native_mha.ckpt --n_iter 1 --n_samples 1
------------------------------------------------------
Global seed set to 187
Loading model from /tmp/model_native_mha.ckpt
Global Step: 875000
No module 'xformers'. Proceeding without it.
LatentDiffusion: Running in eps-prediction mode
DiffusionWrapper has 865.99 M params.
making attention of type 'vanilla' with 512 in_channels
Working with z of shape (1, 4, 32, 32) = 4096 dimensions.
making attention of type 'vanilla' with 512 in_channels
Creating invisible watermark encoder (see https://github.com/ShieldMnt/invisible-watermark)...
Sampling: 0%| | 0/1 [00:00<?, ?it/sData shape for PLMS sampling is (1, 4, 64, 64) | 0/1 [00:00<?, ?it/s]
Running PLMS Sampling with 50 timesteps
[2023-01-04 01:54:32,224] torch._dynamo.debug_utils: [WARNING] Compiled Fx GraphModule failed. Creating script to minify the error.
[2023-01-04 01:54:32,227] torch._dynamo.debug_utils: [WARNING] Writing minified repro to /data/sandcastle/boxes/fbsource/torch_compile_debug/run_2023_01_04_01_54_32_226774/minifier/minifier_launcher.py
PLMS Sampler: 0%| | 0/50 [00:01<?, ?it/s]
data: 0%| | 0/1 [00:02<?, ?it/s]
Sampling: 0%| | 0/1 [00:02<?, ?it/s]
Traceback (most recent call last):
File "/home/grigorysizov/anaconda3/envs/ldm/lib/python3.8/site-packages/torch/_functorch/aot_autograd.py", line 77, in preserve_rng_state
yield
File "/home/grigorysizov/anaconda3/envs/ldm/lib/python3.8/site-packages/torch/_functorch/aot_autograd.py", line 2052, in create_aot_dispatcher_function
compiled_fn = compiler_fn(flat_fn, fake_flat_tensor_args, aot_config)
File "/home/grigorysizov/anaconda3/envs/ldm/lib/python3.8/site-packages/torch/_functorch/aot_autograd.py", line 1307, in aot_wrapper_dedupe
return compiler_fn(flat_fn, leaf_flat_args, aot_config)
File "/home/grigorysizov/anaconda3/envs/ldm/lib/python3.8/site-packages/torch/_functorch/aot_autograd.py", line 957, in aot_dispatch_base
compiled_fw = aot_config.fw_compiler(fw_module, flat_args)
File "/home/grigorysizov/anaconda3/envs/ldm/lib/python3.8/site-packages/torch/_dynamo/utils.py", line 88, in time_wrapper
r = func(*args, **kwargs)
File "/home/grigorysizov/anaconda3/envs/ldm/lib/python3.8/site-packages/torch/_inductor/compile_fx.py", line 373, in fw_compiler
return inner_compile(
File "/home/grigorysizov/anaconda3/envs/ldm/lib/python3.8/site-packages/torch/_dynamo/debug_utils.py", line 588, in debug_wrapper
compiled_fn = compiler_fn(gm, example_inputs, **kwargs)
File "/home/grigorysizov/anaconda3/envs/ldm/lib/python3.8/site-packages/torch/_inductor/debug.py", line 223, in inner
return fn(*args, **kwargs)
File "/home/grigorysizov/anaconda3/envs/ldm/lib/python3.8/contextlib.py", line 75, in inner
return func(*args, **kwds)
File "/home/grigorysizov/anaconda3/envs/ldm/lib/python3.8/site-packages/torch/_inductor/compile_fx.py", line 140, in compile_fx_inner
compiled_fn = graph.compile_to_fn()
File "/home/grigorysizov/anaconda3/envs/ldm/lib/python3.8/site-packages/torch/_inductor/graph.py", line 538, in compile_to_fn
return self.compile_to_module().call
File "/home/grigorysizov/anaconda3/envs/ldm/lib/python3.8/site-packages/torch/_dynamo/utils.py", line 88, in time_wrapper
r = func(*args, **kwargs)
File "/home/grigorysizov/anaconda3/envs/ldm/lib/python3.8/site-packages/torch/_inductor/graph.py", line 527, in compile_to_module
mod = PyCodeCache.load(code)
File "/home/grigorysizov/anaconda3/envs/ldm/lib/python3.8/site-packages/torch/_inductor/codecache.py", line 468, in load
exec(code, mod.dict, mod.dict)
File "/tmp/torchinductor_grigorysizov/hx/chxvn6a46wyylpjtjd4dhohms25zpkk4b4nakhhnykqyqkn6qcbk.py", line 131, in <module>
async_compile.wait(globals())
File "/home/grigorysizov/anaconda3/envs/ldm/lib/python3.8/site-packages/torch/_inductor/codecache.py", line 663, in wait
scope[key] = result.result()
File "/home/grigorysizov/anaconda3/envs/ldm/lib/python3.8/site-packages/torch/_inductor/codecache.py", line 522, in result
kernel = self.kernel = _load_kernel(self.source_code)
File "/home/grigorysizov/anaconda3/envs/ldm/lib/python3.8/site-packages/torch/_inductor/codecache.py", line 502, in _load_kernel
kernel.precompile()
File "/home/grigorysizov/anaconda3/envs/ldm/lib/python3.8/site-packages/torch/_inductor/triton_ops/autotune.py", line 59, in precompile
self.launchers = [
File "/home/grigorysizov/anaconda3/envs/ldm/lib/python3.8/site-packages/torch/_inductor/triton_ops/autotune.py", line 60, in <listcomp>
self._precompile_config(c, warm_cache_only_with_cc)
File "/home/grigorysizov/anaconda3/envs/ldm/lib/python3.8/site-packages/torch/_inductor/triton_ops/autotune.py", line 84, in _precompile_config
torch.cuda.synchronize(torch.cuda.current_device())
File "/home/grigorysizov/anaconda3/envs/ldm/lib/python3.8/site-packages/torch/cuda/init.py", line 577, in synchronize
return torch._C._cuda_synchronize()
RuntimeError: CUDA error: an illegal memory access was encountered
CUDA kernel errors might be asynchronously reported at some other API call,so the stacktrace below might be incorrect.
For debugging consider passing CUDA_LAUNCH_BLOCKING=1.
Compile with TORCH_USE_CUDA_DSA to enable device-side assertions.
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/home/grigorysizov/anaconda3/envs/ldm/lib/python3.8/site-packages/torch/_dynamo/output_graph.py", line 680, in call_user_compiler
compiled_fn = compiler_fn(gm, self.fake_example_inputs())
File "/home/grigorysizov/anaconda3/envs/ldm/lib/python3.8/site-packages/torch/_dynamo/debug_utils.py", line 1006, in debug_wrapper
compiled_gm = compiler_fn(
File "/home/grigorysizov/anaconda3/envs/ldm/lib/python3.8/site-packages/torch/init.py", line 1190, in call
return self.compile_fn(model_, inputs_)
File "/home/grigorysizov/anaconda3/envs/ldm/lib/python3.8/site-packages/torch/_inductor/compile_fx.py", line 398, in compile_fx
return aot_autograd(
File "/home/grigorysizov/anaconda3/envs/ldm/lib/python3.8/site-packages/torch/_dynamo/optimizations/training.py", line 78, in compiler_fn
cg = aot_module_simplified(gm, example_inputs, **kwargs)
File "/home/grigorysizov/anaconda3/envs/ldm/lib/python3.8/site-packages/torch/_functorch/aot_autograd.py", line 2355, in aot_module_simplified
compiled_fn = create_aot_dispatcher_function(
File "/home/grigorysizov/anaconda3/envs/ldm/lib/python3.8/site-packages/torch/_dynamo/utils.py", line 88, in time_wrapper
r = func(*args, **kwargs)
File "/home/grigorysizov/anaconda3/envs/ldm/lib/python3.8/site-packages/torch/_functorch/aot_autograd.py", line 2057, in create_aot_dispatcher_function
return compiled_fn
File "/home/grigorysizov/anaconda3/envs/ldm/lib/python3.8/contextlib.py", line 131, in exit
self.gen.throw(type, value, traceback)
File "/home/grigorysizov/anaconda3/envs/ldm/lib/python3.8/site-packages/torch/_functorch/aot_autograd.py", line 81, in preserve_rng_state
torch.cuda.set_rng_state(cuda_rng_state)
File "/home/grigorysizov/anaconda3/envs/ldm/lib/python3.8/site-packages/torch/cuda/random.py", line 64, in set_rng_state
_lazy_call(cb)
File "/home/grigorysizov/anaconda3/envs/ldm/lib/python3.8/site-packages/torch/cuda/init.py", line 176, in _lazy_call
callable()
File "/home/grigorysizov/anaconda3/envs/ldm/lib/python3.8/site-packages/torch/cuda/random.py", line 62, in cb
default_generator.set_state(new_state_copy)
RuntimeError: false INTERNAL ASSERT FAILED at "../c10/cuda/CUDAGraphsC10Utils.h":73, please report a bug to PyTorch. Unknown CUDA graph CaptureStatus1588869035
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "stable-diffusion/scripts/txt2img.py", line 325, in <module>
main(opt)
File "stable-diffusion/scripts/txt2img.py", line 275, in main
samples, _ = sampler.sample(S=opt.steps,
File "/home/grigorysizov/anaconda3/envs/ldm/lib/python3.8/site-packages/torch/autograd/grad_mode.py", line 34, in decorate_context
return func(*args, **kwargs)
File "/data/sandcastle/boxes/fbsource/stable-diffusion/ldm/models/diffusion/plms.py", line 99, in sample
samples, intermediates = self.plms_sampling(conditioning, size,
File "/home/grigorysizov/anaconda3/envs/ldm/lib/python3.8/site-packages/torch/autograd/grad_mode.py", line 34, in decorate_context
return func(*args, **kwargs)
File "/data/sandcastle/boxes/fbsource/stable-diffusion/ldm/models/diffusion/plms.py", line 167, in plms_sampling
outs = self.p_sample_plms(img, cond, ts, index=index, use_original_steps=ddim_use_original_steps,
File "/home/grigorysizov/anaconda3/envs/ldm/lib/python3.8/site-packages/torch/_dynamo/eval_frame.py", line 212, in _fn
return fn(*args, **kwargs)
File "/home/grigorysizov/anaconda3/envs/ldm/lib/python3.8/site-packages/torch/autograd/grad_mode.py", line 34, in decorate_context
return func(*args, **kwargs)
File "/data/sandcastle/boxes/fbsource/stable-diffusion/ldm/models/diffusion/plms.py", line 232, in p_sample_plms
e_t = get_model_output(x, t)
File "/data/sandcastle/boxes/fbsource/stable-diffusion/ldm/models/diffusion/plms.py", line 202, in get_model_output
e_t_uncond, e_t = self.model.apply_model(x_in, t_in, c_in).chunk(2)
File "/data/sandcastle/boxes/fbsource/stable-diffusion/ldm/models/diffusion/ddpm.py", line 858, in apply_model
x_recon = self.model(x_noisy, t, **cond)
File "/home/grigorysizov/anaconda3/envs/ldm/lib/python3.8/site-packages/torch/nn/modules/module.py", line 1482, in _call_impl
return forward_call(*args, **kwargs)
File "/data/sandcastle/boxes/fbsource/stable-diffusion/ldm/models/diffusion/ddpm.py", line 1329, in forward
out = self.diffusion_model(x, t, context=cc)
File "/home/grigorysizov/anaconda3/envs/ldm/lib/python3.8/site-packages/torch/nn/modules/module.py", line 1482, in _call_impl
return forward_call(*args, **kwargs)
File "/data/sandcastle/boxes/fbsource/stable-diffusion/ldm/modules/diffusionmodules/openaimodel.py", line 770, in forward
emb = self.time_embed(t_emb)
File "/home/grigorysizov/anaconda3/envs/ldm/lib/python3.8/site-packages/torch/nn/modules/module.py", line 1482, in _call_impl
return forward_call(*args, **kwargs)
File "/home/grigorysizov/anaconda3/envs/ldm/lib/python3.8/site-packages/torch/_dynamo/eval_frame.py", line 333, in catch_errors
return callback(frame, cache_size, hooks)
File "/home/grigorysizov/anaconda3/envs/ldm/lib/python3.8/site-packages/torch/_dynamo/convert_frame.py", line 480, in _convert_frame
result = inner_convert(frame, cache_size, hooks)
File "/home/grigorysizov/anaconda3/envs/ldm/lib/python3.8/site-packages/torch/_dynamo/convert_frame.py", line 103, in _fn
return fn(*args, **kwargs)
File "/home/grigorysizov/anaconda3/envs/ldm/lib/python3.8/site-packages/torch/_dynamo/utils.py", line 88, in time_wrapper
r = func(*args, **kwargs)
File "/home/grigorysizov/anaconda3/envs/ldm/lib/python3.8/site-packages/torch/_dynamo/convert_frame.py", line 339, in _convert_frame_assert
return _compile(
File "/home/grigorysizov/anaconda3/envs/ldm/lib/python3.8/site-packages/torch/_dynamo/convert_frame.py", line 400, in _compile
out_code = transform_code_object(code, transform)
File "/home/grigorysizov/anaconda3/envs/ldm/lib/python3.8/site-packages/torch/_dynamo/bytecode_transformation.py", line 341, in transform_code_object
transformations(instructions, code_options)
File "/home/grigorysizov/anaconda3/envs/ldm/lib/python3.8/site-packages/torch/_dynamo/convert_frame.py", line 387, in transform
tracer.run()
File "/home/grigorysizov/anaconda3/envs/ldm/lib/python3.8/site-packages/torch/_dynamo/symbolic_convert.py", line 1684, in run
super().run()
File "/home/grigorysizov/anaconda3/envs/ldm/lib/python3.8/site-packages/torch/_dynamo/symbolic_convert.py", line 538, in run
and self.step()
File "/home/grigorysizov/anaconda3/envs/ldm/lib/python3.8/site-packages/torch/_dynamo/symbolic_convert.py", line 501, in step
getattr(self, inst.opname)(inst)
File "/home/grigorysizov/anaconda3/envs/ldm/lib/python3.8/site-packages/torch/_dynamo/symbolic_convert.py", line 1750, in RETURN_VALUE
self.output.compile_subgraph(self)
File "/home/grigorysizov/anaconda3/envs/ldm/lib/python3.8/site-packages/torch/_dynamo/output_graph.py", line 533, in compile_subgraph
self.compile_and_call_fx_graph(tx, list(reversed(stack_values)), root)
File "/home/grigorysizov/anaconda3/envs/ldm/lib/python3.8/site-packages/torch/_dynamo/output_graph.py", line 604, in compile_and_call_fx_graph
compiled_fn = self.call_user_compiler(gm)
File "/home/grigorysizov/anaconda3/envs/ldm/lib/python3.8/site-packages/torch/_dynamo/output_graph.py", line 685, in call_user_compiler
raise BackendCompilerFailed(self.compiler_fn, e) from e
torch._dynamo.exc.BackendCompilerFailed: debug_wrapper raised RuntimeError: false INTERNAL ASSERT FAILED at "../c10/cuda/CUDAGraphsC10Utils.h":73, please report a bug to PyTorch. Unknown CUDA graph CaptureStatus1588869035
Set torch._dynamo.config.verbose=True for more information
Minifier script written to /data/sandcastle/boxes/fbsource/torch_compile_debug/run_2023_01_04_01_54_32_226774/minifier/minifier_launcher.py. Run this script to find the smallest traced graph which reproduces this error.
You can suppress this exception and fall back to eager by setting:
torch._dynamo.config.suppress_errors = True
```
</details>
### Versions
```
PyTorch version: 2.0.0.dev20230102+cu117
Is debug build: False
CUDA used to build PyTorch: 11.7
ROCM used to build PyTorch: N/A
OS: CentOS Stream 8 (x86_64)
GCC version: (GCC) 8.5.0 20210514 (Red Hat 8.5.0-17)
Clang version: Could not collect
CMake version: version 3.25.0
Libc version: glibc-2.28
Python version: 3.8.5 (default, Sep 4 2020, 07:30:14) [GCC 7.3.0] (64-bit runtime)
Python platform: Linux-5.12.0-0_fbk9_clang_7032_gb6cf154957d9-x86_64-with-glibc2.10
Is CUDA available: True
CUDA runtime version: Could not collect
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration:
GPU 0: Tesla V100-SXM2-16GB
GPU 1: Tesla V100-SXM2-16GB
GPU 2: Tesla V100-SXM2-16GB
GPU 3: Tesla V100-SXM2-16GB
GPU 4: Tesla V100-SXM2-16GB
GPU 5: Tesla V100-SXM2-16GB
GPU 6: Tesla V100-SXM2-16GB
GPU 7: Tesla V100-SXM2-16GB
Nvidia driver version: 470.57.02
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.23.1
[pip3] open-clip-torch==2.0.2
[pip3] pytorch-lightning==1.4.2
[pip3] pytorch-triton==2.0.0+0d7e753227
[pip3] torch==2.0.0.dev20230102+cu117
[pip3] torchmetrics==0.6.0
[pip3] torchvision==0.15.0.dev20230102+cu117
[conda] blas 1.0 mkl
[conda] cudatoolkit 11.4.1 h8ab8bb3_9 nvidia
[conda] mkl 2021.4.0 h06a4308_640
[conda] mkl-service 2.4.0 py38h7f8727e_0
[conda] mkl_fft 1.3.1 py38hd3c417c_0
[conda] mkl_random 1.2.2 py38h51133e4_0
[conda] numpy 1.23.1 py38h6c91a56_0
[conda] numpy-base 1.23.1 py38ha15fc14_0
[conda] open-clip-torch 2.0.2 pypi_0 pypi
[conda] pytorch-lightning 1.4.2 pypi_0 pypi
[conda] pytorch-triton 2.0.0+0d7e753227 pypi_0 pypi
[conda] torch 2.0.0.dev20230102+cu117 pypi_0 pypi
[conda] torchmetrics 0.6.0 pypi_0 pypi
[conda] torchvision 0.15.0.dev20230102+cu117 pypi_0 pypi
```
cc @ezyang @soumith @msaroufim @wconstab @ngimel @bdhirsh
| 0 |
3,793 | 91,710 |
`@torch.compile` fails with `InternalTorchDynamoError` on torch-nightly
|
triaged, oncall: pt2
|
### 🐛 Describe the bug
I'm running a modified Stable Diffusion code with `@torch.compile` [applied on one of the functions](https://github.com/sgrigory/stablediffusion2/blob/115130e4a9c8562225f24e6929575906752c79f9/ldm/models/diffusion/plms.py#L187). The compilation breaks with `TypeError: object of type 'tuple_iterator' has no len()` (full logs below)
The error goes away if [here](https://github.com/sgrigory/stablediffusion2/blob/115130e4a9c8562225f24e6929575906752c79f9/ldm/modules/diffusionmodules/util.py#L113-L114) I replace
```
args = tuple(inputs) + tuple(params)
return CheckpointFunction.apply(func, len(inputs), *args)
```
with
```
return CheckpointFunction.apply(func, len(inputs), *inputs, *params)
```
so this is probably something about how tuples are treated.
Note:
- The checkpointing function in question memorizes results of the forward pass for the backward pass, no saving on disk
- The error doesn't go away after setting `torch._inductor.config.triton.cudagraphs = False`
- The full code is [here](https://github.com/sgrigory/stablediffusion2/tree/115130e4a9c8562225f24e6929575906752c79f9)
<details>
<summary>Show full error log</summary>
```
$ TORCHDYNAMO_REPRO_AFTER="dynamo" with-proxy python stable-diffusion/scripts/txt2img.py --prompt "A photo" --seed 187 --plms --config stable-diffusion/configs/stable-diffusion/v2-inference_native_mha.yaml --ckpt /tmp/model_native_mha.ckpt --n_iter 1 --n_samples 1
---------------------------------------------------------
Global seed set to 187
Loading model from /tmp/model_native_mha.ckpt
Global Step: 875000
No module 'xformers'. Proceeding without it.
LatentDiffusion: Running in eps-prediction mode
DiffusionWrapper has 865.99 M params.
making attention of type 'vanilla' with 512 in_channels
Working with z of shape (1, 4, 32, 32) = 4096 dimensions.
making attention of type 'vanilla' with 512 in_channels
Creating invisible watermark encoder (see https://github.com/ShieldMnt/invisible-watermark)...
Sampling: 0%| | 0/1 [00:00<?, ?it/sData shape for PLMS sampling is (1, 4, 64, 64) | 0/1 [00:00<?, ?it/s]
Running PLMS Sampling with 50 timesteps
PLMS Sampler: 0%| | 0/50 [00:03<?, ?it/s]
data: 0%| | 0/1 [00:03<?, ?it/s]
Sampling: 0%| | 0/1 [00:03<?, ?it/s]
Traceback (most recent call last):
File "/home/grigorysizov/anaconda3/envs/ldm/lib/python3.8/site-packages/torch/_dynamo/convert_frame.py", line 440, in _compile
check_fn = CheckFunctionManager(
File "/home/grigorysizov/anaconda3/envs/ldm/lib/python3.8/site-packages/torch/_dynamo/guards.py", line 518, in init
guard.create(local_builder, global_builder)
File "/home/grigorysizov/anaconda3/envs/ldm/lib/python3.8/site-packages/torch/_guards.py", line 163, in create
return self.create_fn(self.source.select(local_builder, global_builder), self)
File "/home/grigorysizov/anaconda3/envs/ldm/lib/python3.8/site-packages/torch/_dynamo/guards.py", line 298, in LIST_LENGTH
code.append(f"len({ref}) == {len(value)}")
TypeError: object of type 'tuple_iterator' has no len()
Set torch._dynamo.config.verbose=True for more information
You can suppress this exception and fall back to eager by setting:
torch._dynamo.config.suppress_errors = True
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "stable-diffusion/scripts/txt2img.py", line 325, in <module>
main(opt)
File "stable-diffusion/scripts/txt2img.py", line 275, in main
samples, _ = sampler.sample(S=opt.steps,
File "/home/grigorysizov/anaconda3/envs/ldm/lib/python3.8/site-packages/torch/autograd/grad_mode.py", line 34, in decorate_context
return func(*args, **kwargs)
File "/data/sandcastle/boxes/fbsource/stable-diffusion/ldm/models/diffusion/plms.py", line 99, in sample
samples, intermediates = self.plms_sampling(conditioning, size,
File "/home/grigorysizov/anaconda3/envs/ldm/lib/python3.8/site-packages/torch/autograd/grad_mode.py", line 34, in decorate_context
return func(*args, **kwargs)
File "/data/sandcastle/boxes/fbsource/stable-diffusion/ldm/models/diffusion/plms.py", line 167, in plms_sampling
outs = self.p_sample_plms(img, cond, ts, index=index, use_original_steps=ddim_use_original_steps,
File "/home/grigorysizov/anaconda3/envs/ldm/lib/python3.8/site-packages/torch/_dynamo/eval_frame.py", line 212, in _fn
return fn(*args, **kwargs)
File "/home/grigorysizov/anaconda3/envs/ldm/lib/python3.8/site-packages/torch/autograd/grad_mode.py", line 34, in decorate_context
return func(*args, **kwargs)
File "/data/sandcastle/boxes/fbsource/stable-diffusion/ldm/models/diffusion/plms.py", line 232, in p_sample_plms
e_t = get_model_output(x, t)
File "/data/sandcastle/boxes/fbsource/stable-diffusion/ldm/models/diffusion/plms.py", line 202, in get_model_output
e_t_uncond, e_t = self.model.apply_model(x_in, t_in, c_in).chunk(2)
File "/data/sandcastle/boxes/fbsource/stable-diffusion/ldm/models/diffusion/ddpm.py", line 858, in apply_model
x_recon = self.model(x_noisy, t, **cond)
File "/home/grigorysizov/anaconda3/envs/ldm/lib/python3.8/site-packages/torch/nn/modules/module.py", line 1482, in _call_impl
return forward_call(*args, **kwargs)
File "/data/sandcastle/boxes/fbsource/stable-diffusion/ldm/models/diffusion/ddpm.py", line 1329, in forward
out = self.diffusion_model(x, t, context=cc)
File "/home/grigorysizov/anaconda3/envs/ldm/lib/python3.8/site-packages/torch/nn/modules/module.py", line 1482, in _call_impl
return forward_call(*args, **kwargs)
File "/data/sandcastle/boxes/fbsource/stable-diffusion/ldm/modules/diffusionmodules/openaimodel.py", line 778, in forward
h = module(h, emb, context)
File "/home/grigorysizov/anaconda3/envs/ldm/lib/python3.8/site-packages/torch/nn/modules/module.py", line 1482, in _call_impl
return forward_call(*args, **kwargs)
File "/data/sandcastle/boxes/fbsource/stable-diffusion/ldm/modules/diffusionmodules/openaimodel.py", line 82, in forward
x = layer(x, emb)
File "/home/grigorysizov/anaconda3/envs/ldm/lib/python3.8/site-packages/torch/nn/modules/module.py", line 1482, in _call_impl
return forward_call(*args, **kwargs)
File "/data/sandcastle/boxes/fbsource/stable-diffusion/ldm/modules/diffusionmodules/openaimodel.py", line 249, in forward
return checkpoint(
File "/home/grigorysizov/anaconda3/envs/ldm/lib/python3.8/site-packages/torch/_dynamo/eval_frame.py", line 333, in catch_errors
return callback(frame, cache_size, hooks)
File "/home/grigorysizov/anaconda3/envs/ldm/lib/python3.8/site-packages/torch/_dynamo/convert_frame.py", line 480, in _convert_frame
result = inner_convert(frame, cache_size, hooks)
File "/home/grigorysizov/anaconda3/envs/ldm/lib/python3.8/site-packages/torch/_dynamo/convert_frame.py", line 103, in _fn
return fn(*args, **kwargs)
File "/home/grigorysizov/anaconda3/envs/ldm/lib/python3.8/site-packages/torch/_dynamo/utils.py", line 88, in time_wrapper
r = func(*args, **kwargs)
File "/home/grigorysizov/anaconda3/envs/ldm/lib/python3.8/site-packages/torch/_dynamo/convert_frame.py", line 339, in _convert_frame_assert
return _compile(
File "/home/grigorysizov/anaconda3/envs/ldm/lib/python3.8/site-packages/torch/_dynamo/convert_frame.py", line 470, in _compile
raise InternalTorchDynamoError() from e
torch._dynamo.exc.InternalTorchDynamoError
```
</details>
@msaroufim
### Versions
```
PyTorch version: 2.0.0.dev20230102+cu117
Is debug build: False
CUDA used to build PyTorch: 11.7
ROCM used to build PyTorch: N/A
OS: CentOS Stream 8 (x86_64)
GCC version: (GCC) 8.5.0 20210514 (Red Hat 8.5.0-17)
Clang version: Could not collect
CMake version: version 3.25.0
Libc version: glibc-2.28
Python version: 3.8.5 (default, Sep 4 2020, 07:30:14) [GCC 7.3.0] (64-bit runtime)
Python platform: Linux-5.12.0-0_fbk9_clang_7032_gb6cf154957d9-x86_64-with-glibc2.10
Is CUDA available: True
CUDA runtime version: Could not collect
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration:
GPU 0: Tesla V100-SXM2-16GB
GPU 1: Tesla V100-SXM2-16GB
GPU 2: Tesla V100-SXM2-16GB
GPU 3: Tesla V100-SXM2-16GB
GPU 4: Tesla V100-SXM2-16GB
GPU 5: Tesla V100-SXM2-16GB
GPU 6: Tesla V100-SXM2-16GB
GPU 7: Tesla V100-SXM2-16GB
Nvidia driver version: 470.57.02
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.23.1
[pip3] open-clip-torch==2.0.2
[pip3] pytorch-lightning==1.4.2
[pip3] pytorch-triton==2.0.0+0d7e753227
[pip3] torch==2.0.0.dev20230102+cu117
[pip3] torchmetrics==0.6.0
[pip3] torchvision==0.15.0.dev20230102+cu117
[conda] blas 1.0 mkl
[conda] cudatoolkit 11.4.1 h8ab8bb3_9 nvidia
[conda] mkl 2021.4.0 h06a4308_640
[conda] mkl-service 2.4.0 py38h7f8727e_0
[conda] mkl_fft 1.3.1 py38hd3c417c_0
[conda] mkl_random 1.2.2 py38h51133e4_0
[conda] numpy 1.23.1 py38h6c91a56_0
[conda] numpy-base 1.23.1 py38ha15fc14_0
[conda] open-clip-torch 2.0.2 pypi_0 pypi
[conda] pytorch-lightning 1.4.2 pypi_0 pypi
[conda] pytorch-triton 2.0.0+0d7e753227 pypi_0 pypi
[conda] torch 2.0.0.dev20230102+cu117 pypi_0 pypi
[conda] torchmetrics 0.6.0 pypi_0 pypi
[conda] torchvision 0.15.0.dev20230102+cu117 pypi_0 pypi
```
cc @ezyang @soumith @msaroufim @wconstab @ngimel @bdhirsh
| 1 |
3,794 | 91,700 |
Add vmap support for torch.linalg.vander
|
good first issue, triaged, module: functorch
|
## Tasks
Add vmap support for the following PyTorch operations. That is, each one needs a batching rule.
- [ ] torch.linalg.vander
## Expected behavior
Currently, when one does vmap over them, they raise a warning suggesting the batching rule is not implemented:
```py
import torch
from functorch import vmap
x = torch.randn(4, 3, 2)
z = vmap(torch.linalg.vander)(x)
# UserWarning: There is a performance drop because we have not yet implemented the batching rule
```
We expect to not see a warning
## Read this!
See this note for more context https://github.com/pytorch/pytorch/blob/master/functorch/writing_batching_rules.md
If you're new to developing PyTorch and/or function transforms, we would recommend reading through https://github.com/pytorch/pytorch/wiki/Core-Frontend-Onboarding#unit-8-function-transforms-optional
Should likely be similar to the `view_as_complex` operator here
https://github.com/pytorch/pytorch/blob/master/aten/src/ATen/functorch/BatchRulesUnaryOps.cpp#L64-L72
using the macro here
https://github.com/pytorch/pytorch/blob/master/aten/src/ATen/functorch/BatchRulesUnaryOps.cpp#L94
Please reach out on this issue if there's any questions!
## Testing
`pytest test/functorch/test_vmap.py -v -k "op_has_batch_rule and vander"` should pass (currently, it is an expected failure).
cc @zou3519 @Chillee @soumith
| 4 |
3,795 | 91,699 |
Segmentation fault after trying to create a tensor with float values
|
needs reproduction, module: rocm, triaged
|
I'm running PyTorch with ROCm inside a docker container on Ubuntu 20.04, and PyTorch gives me a segmentation fault whenever i try to create a tensor with float values in it using my GPU (e.g. ```torch.tensor([0.]).to('cuda')```). It's weird because it works perfectly fine with int tensors (e.g. ```torch.tensor([0]).to('cuda')```). Also there is no such problem if i use my CPU (e.g. ```torch.tensor([0.]).to('cpu')```).
Example code to reproduce the error is present below:
```python
import torch
print(torch.tensor([0.]).to('cuda'))
```
The error message is as follows:
```
Segmentation fault (core dumped)
```
I've tried debugging with gdb in an attempt to pinpoint the source of the issue:
```
(gdb) r -c "import torch; print(torch.cuda.is_available()); print(torch.tensor([0.]).to('cuda'))"
Starting program: /opt/conda/bin/python -c "import torch; print(torch.cuda.is_available()); print(torch.tensor([0.]).to('cuda'))"
[Thread debugging using libthread_db enabled]
Using host libthread_db library "/lib/x86_64-linux-gnu/libthread_db.so.1".
[Detaching after fork from child process 4469]
[New Thread 0x7ffe55e3b700 (LWP 4470)]
[New Thread 0x7ffe5363a700 (LWP 4471)]
[New Thread 0x7ffe50e39700 (LWP 4472)]
[New Thread 0x7ffe4e638700 (LWP 4473)]
[New Thread 0x7ffe4be37700 (LWP 4474)]
[New Thread 0x7ffe49636700 (LWP 4475)]
[New Thread 0x7ffe46e35700 (LWP 4476)]
[New Thread 0x7ffe44634700 (LWP 4477)]
[New Thread 0x7ffe41e33700 (LWP 4478)]
[New Thread 0x7ffe3f632700 (LWP 4479)]
[New Thread 0x7ffe3ee31700 (LWP 4480)]
[New Thread 0x7ffe3720b700 (LWP 4481)]
[New Thread 0x7ffe36a0a700 (LWP 4482)]
[Thread 0x7ffe36a0a700 (LWP 4482) exited]
True
Thread 1 "python" received signal SIGSEGV, Segmentation fault.
0x00007fffbd2274c5 in ?? () from /opt/rocm/lib/libamdhip64.so.5
```
### Versions
```
PyTorch version: 1.13.0a0+git941769a
Is debug build: False
CUDA used to build PyTorch: N/A
ROCM used to build PyTorch: 5.4.22801-aaa1e3d8
OS: Ubuntu 20.04.5 LTS (x86_64)
GCC version: (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0
Clang version: 15.0.0 (https://github.com/RadeonOpenCompute/llvm-project roc-5.4.0 22465 d6f0fe8b22e3d8ce0f2cbd657ea14b16043018a5)
CMake version: version 3.22.1
Libc version: glibc-2.31
Python version: 3.8.13 (default, Mar 28 2022, 11:38:47) [GCC 7.5.0] (64-bit runtime)
Python platform: Linux-5.15.0-56-generic-x86_64-with-glibc2.17
Is CUDA available: True
CUDA runtime version: Could not collect
CUDA_MODULE_LOADING set to:
GPU models and configuration: Radeon RX 580 Series
Nvidia driver version: Could not collect
cuDNN version: Could not collect
HIP runtime version: 5.4.22801
MIOpen runtime version: 2.19.0
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] mypy==0.960
[pip3] mypy-extensions==0.4.3
[pip3] numpy==1.22.4
[pip3] torch==1.13.0a0+git941769a
[pip3] torchvision==0.14.0a0+bd70a78
[conda] mkl 2022.0.1 h06a4308_117
[conda] mkl-include 2022.0.1 h06a4308_117
[conda] numpy 1.22.4 pypi_0 pypi
[conda] torch 1.13.0a0+git941769a pypi_0 pypi
[conda] torchvision 0.14.0a0+bd70a78 pypi_0 pypi
```
cc @ezyang @gchanan @zou3519 @jeffdaily @sunway513 @jithunnair-amd @pruthvistony @ROCmSupport
| 5 |
3,796 | 91,697 |
Build from source fails: undefined reference to caffe2::DeviceQuery
|
module: build, triaged
|
### 🐛 Describe the bug
Trying to build the latest version of libtorch to use it in a c++ project.
```
cmake -D BUILD_SHARED_LIBS=ON -D CMAKE_BUILD_TYPE=Release -D USE_CUDA=ON -D USE_CUDNN=ON -D BUILD_PYTHON=OFF -D BUILD_TEST=OFF -D CMAKE_INSTALL_PREFIX=../pytorch-install -D USE_SYSTEM_NCCL=OFF -D BUILD_BINARY=ON -D USE_PRECOMPILED_HEADERS=ON -D USE_SYSTEM_EIGEN_INSTALL=ON ..
cmake --build . --target install
```
I got this error:
```
[ 76%] Building CXX object caffe2/CMakeFiles/torch_cuda.dir/__/torch/csrc/jit/passes/frozen_conv_add_relu_fusion_cuda.cpp.o
[ 76%] Building CXX object caffe2/CMakeFiles/torch_cuda.dir/__/torch/csrc/jit/tensorexpr/cuda_codegen.cpp.o
[ 76%] Building CXX object caffe2/CMakeFiles/torch_cuda.dir/__/torch/csrc/jit/runtime/register_cuda_ops.cpp.o
[ 76%] Building CUDA object caffe2/CMakeFiles/torch_cuda.dir/__/aten/src/ATen/native/cuda/Unique.cu.o
[ 76%] Linking CXX shared library ../lib/libtorch_cuda.so
[ 76%] Built target torch_cuda
[ 76%] Building CXX object caffe2/CMakeFiles/torch.dir/__/empty.cpp.o
[ 76%] Linking CXX shared library ../lib/libtorch.so
[ 76%] Built target torch
[ 76%] Built target torch_global_deps
[ 76%] Linking C executable ../../bin/mkrename_gnuabi
[ 76%] Built target mkrename_gnuabi
[ 76%] Linking C executable ../../bin/mkmasked_gnuabi
[ 76%] Built target mkmasked_gnuabi
[ 76%] Built target arraymap
[ 76%] Linking C executable ../../bin/addSuffix
[ 76%] Built target addSuffix
[ 76%] Building CXX object binaries/CMakeFiles/parallel_info.dir/parallel_info.cc.o
[ 76%] Linking CXX executable ../bin/parallel_info
[ 76%] Built target parallel_info
[ 76%] Building CXX object binaries/CMakeFiles/record_function_benchmark.dir/record_function_benchmark.cc.o
[ 76%] Linking CXX executable ../bin/record_function_benchmark
[ 76%] Built target record_function_benchmark
[ 76%] Building CXX object binaries/CMakeFiles/speed_benchmark_torch.dir/speed_benchmark_torch.cc.o
....pytorch/binaries/speed_benchmark_torch.cc: In function ‘int main(int, char**)’:
..../pytorch/binaries/speed_benchmark_torch.cc:270:33: warning: comparison of integer expressions of different signedness: ‘int’ and ‘c10::List<c10::IValue>::size_type’ {aka ‘long unsigned int’} [-Wsign-compare]
270 | if (FLAGS_use_bundled_input >= all_inputs.size()) {
| ~~~~~~~~~~~~~~~~~~~~~~~~^~~~~~~~~~~~~~~~~~~~
..../pytorch/binaries/speed_benchmark_torch.cc: In instantiation of ‘c10::IValue {anonymous}::vkRunner<T>::run(T&, const std::vector<c10::IValue>&) [with T = torch::jit::Module]’:
..../pytorch/binaries/speed_benchmark_torch.cc:180:23: required from here
..../pytorch/binaries/speed_benchmark_torch.cc:200:27: warning: comparison of integer expressions of different signedness: ‘int’ and ‘c10::List<at::Tensor>::size_type’ {aka ‘long unsigned int’} [-Wsign-compare]
200 | for (int i=0; i < input_as_list.size(); ++i) {
| ~~^~~~~~~~~~~~~~~~~~~~~~
[ 76%] Linking CXX executable ../bin/speed_benchmark_torch
[ 76%] Built target speed_benchmark_torch
[ 76%] Building CXX object binaries/CMakeFiles/compare_models_torch.dir/compare_models_torch.cc.o
[ 76%] Linking CXX executable ../bin/compare_models_torch
[ 76%] Built target compare_models_torch
[ 76%] Building CXX object binaries/CMakeFiles/inspect_gpu.dir/inspect_gpu.cc.o
[ 76%] Linking CXX executable ../bin/inspect_gpu
/usr/bin/ld: CMakeFiles/inspect_gpu.dir/inspect_gpu.cc.o: in function `main':
inspect_gpu.cc:(.text.startup+0x4c): undefined reference to `caffe2::GlobalInit(int*, char***)'
/usr/bin/ld: inspect_gpu.cc:(.text.startup+0x1a3): undefined reference to `caffe2::DeviceQuery(int)'
/usr/bin/ld: inspect_gpu.cc:(.text.startup+0x1c5): undefined reference to `caffe2::GetCudaPeerAccessPattern(std::vector<std::vector<bool, std::allocator<bool> >, std::allocator<std::vector<bool, std::allocator<bool> > > >*)'
collect2: error: ld returned 1 exit status
make[2]: *** [binaries/CMakeFiles/inspect_gpu.dir/build.make:107: bin/inspect_gpu] Error 1
make[1]: *** [CMakeFiles/Makefile2:6382: binaries/CMakeFiles/inspect_gpu.dir/all] Error 2
make: *** [Makefile:146: all] Error 2
```
### Versions
```
PyTorch version: 1.12.0+cu116
Is debug build: False
CUDA used to build PyTorch: 11.6
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.1 LTS (fossa-b X00) (x86_64)
GCC version: (Ubuntu 10.3.0-1ubuntu1~20.04) 10.3.0
Clang version: 10.0.0-4ubuntu1
CMake version: version 3.25.1
Libc version: glibc-2.31
Python version: 3.8.10 (default, Jun 22 2022, 20:18:18) [GCC 9.4.0] (64-bit runtime)
Python platform: Linux-5.14.0-1054-oem-x86_64-with-glibc2.29
Is CUDA available: True
CUDA runtime version: 11.8.89
CUDA_MODULE_LOADING set to:
GPU models and configuration: GPU 0: NVIDIA GeForce RTX 3080 Laptop GPU
Nvidia driver version: 520.61.05
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.6.0
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.6.0
/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.6.0
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_infer.so.8.6.0
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.6.0
/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.6.0
/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.6.0
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] mypy-extensions==0.4.3
[pip3] numpy==1.23.1
[pip3] numpy-ringbuffer==0.2.2
[pip3] pytorch-lightning==1.6.3
[pip3] pytorchcv==0.0.67
[pip3] torch==1.12.0+cu116
[pip3] torchaudio==0.12.0+cu116
[pip3] torchmetrics==0.8.2
[pip3] torchvision==0.13.0+cu116
[conda] Could not collect
```
Please ignore the pip ones and conda as they're not relevant.
cc @ezyang @seemethere @malfet
| 8 |
3,797 | 91,692 |
[discussion] Analyzing a list of tensors stored as intermediate values / saved_for_backward in autograd graph
|
module: autograd, good first issue, triaged, actionable
|
### 🚀 The feature, motivation and pitch
It's useful for understanding memory usage and if memory can be saved by refatoring to fusion + inplace
The parent issue would be https://github.com/pytorch/pytorch/issues/1529, here's the scope is only on stored intermediate values in autograd graph.
But overall, being able to get a list of all tensors and storages currently allocated (including from C++) is very useful for simple form of memory profiling (even ignoring possible memory overlaps / views etc)
E.g. it would be interesting to compare theses lists for vanilla fp32 TransformerEncoder, autocast+bf16 TransformerEncoder, autocast+fp16 TransformerEncoder, BetterTransformer / efficient_attention / flash_attention variants of TransformerEncoder. This utility should also clearly demonstrate the effect of activation checkpointing / CPU offloading techniques; Reversible Transformers / Reversible ConvNets and would be very useful for pedagogical use and debugging
Some previous discussion: https://discuss.pytorch.org/t/memory-size-of-all-tensors-referenced-by-autograd-graph/169227/4
### Alternatives
_No response_
### Additional context
_No response_
cc @ezyang @albanD @zou3519 @gqchen @pearu @nikitaved @soulitzer @Lezcano @Varal7
| 9 |
3,798 | 91,688 |
quantization fuse in convert_fx leave a wrong dequantize node when fuse multiple-input node
|
oncall: quantization, triaged
|
### 🐛 Describe the bug
I need to fuse a residual node to a single layer:
```Python
y = some_quantized_tensor
x = some_quantized_tensor
x = bn(conv(x))
x = x + y
x = relu(x)
```
to
```Python
x = conv_with_add_relu(x, y)
```
When I use following test code:
```Python
from collections import OrderedDict
import contextlib
import operator
import torch
import torch.nn.functional as F
import torch.nn as nn
from torch.ao.quantization.fx.match_utils import (
MatchAllNode,
)
from torch.ao.quantization.quantize_fx import (
fuse_fx,
)
from torch.ao.quantization.backend_config import (
get_qnnpack_backend_config,
BackendConfig,
BackendPatternConfig,
DTypeConfig,
ObservationType,
get_fbgemm_backend_config
)
from torch.ao.quantization import get_default_qconfig_mapping
import torch.ao.quantization.quantize_fx as qfx
class M(torch.nn.Module):
def __init__(self):
super().__init__()
self.conv = torch.nn.Conv2d(3, 3, 3)
self.bn = torch.nn.BatchNorm2d(3)
self.relu = torch.nn.ReLU()
self.maxpool = torch.nn.MaxPool2d(3)
self.iden = nn.Identity()
def forward(self, x):
y = x
y = self.iden(x)
x = self.conv(x)
x = self.bn(x)
x = torch.add(x, y)
x = self.relu(x)
return x
m = M().eval()
def fuse_conv_bn_relu(is_qat, relu, add_pattern):
_, bn_pattern, _ = add_pattern
bn, conv = bn_pattern
return conv
def conv_bn_res_relu_root_node_getter(pattern):
relu, add_pattern = pattern
_, bn_pattern, _ = add_pattern
bn, conv = bn_pattern
return conv
def conv_bn_res_relu_extra_inputs_getter(pattern):
""" get inputs pattern for extra inputs, inputs for root node
are assumed to be copied over from root node to the fused node
"""
relu, add_pattern = pattern
_, bn_pattern, extra_input = add_pattern
bn, conv = bn_pattern
return [extra_input]
fbgemm_weighted_op_int8_dtype_config = DTypeConfig(
input_dtype=torch.quint8,
output_dtype=torch.quint8,
weight_dtype=torch.qint8,
bias_dtype=torch.float,
)
# for pytorch <= 1.13
# conv_bn_res_relu_config = BackendPatternConfig((nn.ReLU, (operator.add, (nn.BatchNorm2d, nn.Conv2d), MatchAllNode))) \
# .set_fuser_method(fuse_conv_bn_relu) \
# ._set_root_node_getter(conv_bn_res_relu_root_node_getter) \
# ._set_extra_inputs_getter(conv_bn_res_relu_extra_inputs_getter)
# for pytorch master
conv_bn_res_relu_config = BackendPatternConfig() \
._set_pattern_complex_format((nn.ReLU, (torch.add, (nn.BatchNorm2d, nn.Conv2d), MatchAllNode))) \
.set_fuser_method(fuse_conv_bn_relu) \
._set_root_node_getter(conv_bn_res_relu_root_node_getter) \
._set_extra_inputs_getter(conv_bn_res_relu_extra_inputs_getter) \
.set_dtype_configs(fbgemm_weighted_op_int8_dtype_config)
backend_config = get_fbgemm_backend_config().set_backend_pattern_config(conv_bn_res_relu_config)
# m = fuse_fx(m, backend_config=backend_config)
qmapping = get_default_qconfig_mapping()
prepared_model = qfx.prepare_fx(m, qmapping, (), backend_config=backend_config)
converted_model = qfx.convert_fx(prepared_model, qconfig_mapping=qmapping, backend_config=backend_config)
converted_model.print_readable()
```
I found that the second input of conv_add in converted node is a dequantized tensor, which cause error in my project:
```Python
class GraphModule(torch.nn.Module):
def forward(self, x):
# No stacktrace found for following nodes
iden_input_scale_0 = self.iden_input_scale_0
iden_input_zero_point_0 = self.iden_input_zero_point_0
quantize_per_tensor = torch.quantize_per_tensor(x, iden_input_scale_0, iden_input_zero_point_0, torch.quint8); x = iden_input_scale_0 = iden_input_zero_point_0 = None
# File: /home/yy/anaconda3/envs/cpudev/lib/python3.8/site-packages/torch/ao/quantization/fx/tracer.py:103, code: return super().call_module(m, forward, args, kwargs)
iden = self.iden(quantize_per_tensor)
# No stacktrace found for following nodes
dequantize_1 = iden.dequantize(); iden = None
# File: /home/yy/anaconda3/envs/cpudev/lib/python3.8/site-packages/torch/ao/quantization/fx/tracer.py:103, code: return super().call_module(m, forward, args, kwargs)
conv = self.conv(quantize_per_tensor, dequantize_1); quantize_per_tensor = dequantize_1 = None
# No stacktrace found for following nodes
dequantize_2 = conv.dequantize(); conv = None
return dequantize_2
```
The ```dequantize_1``` in graphmodule code should be a quantized tensor.
### Versions
Collecting environment information...
PyTorch version: 2.0.0.dev20221231
Is debug build: False
CUDA used to build PyTorch: Could not collect
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.5 LTS (x86_64)
GCC version: (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0
Clang version: 11.0.0 (https://github.com/llvm/llvm-project.git 0160ad802e899c2922bc9b29564080c22eb0908c)
CMake version: Could not collect
Libc version: glibc-2.31
Python version: 3.8.15 (default, Nov 24 2022, 15:19:38) [GCC 11.2.0] (64-bit runtime)
Python platform: Linux-5.15.0-56-generic-x86_64-with-glibc2.17
Is CUDA available: False
CUDA runtime version: 11.7.99
CUDA_MODULE_LOADING set to: N/A
GPU models and configuration: GPU 0: NVIDIA GeForce RTX 3080 Laptop GPU
Nvidia driver version: 525.60.11
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.23.5
[pip3] torch==2.0.0.dev20221231
[pip3] torchaudio==2.0.0.dev20221231
[pip3] torchvision==0.15.0.dev20221231
[conda] blas 1.0 mkl
[conda] cpuonly 2.0 0 pytorch-nightly
[conda] mkl 2021.4.0 h06a4308_640
[conda] mkl-service 2.4.0 py38h7f8727e_0
[conda] mkl_fft 1.3.1 py38hd3c417c_0
[conda] mkl_random 1.2.2 py38h51133e4_0
[conda] numpy 1.23.5 py38h14f4228_0
[conda] numpy-base 1.23.5 py38h31eccc5_0
[conda] pytorch 2.0.0.dev20221231 py3.8_cpu_0 pytorch-nightly
[conda] pytorch-mutex 1.0 cpu pytorch-nightly
[conda] torchaudio 2.0.0.dev20221231 py38_cpu pytorch-nightly
[conda] torchvision 0.15.0.dev20221231 py38_cpu pytorch-nightly
cc @jerryzh168 @jianyuh @raghuramank100 @jamesr66a @vkuzo @jgong5 @Xia-Weiwen @leslie-fang-intel
| 7 |
3,799 | 91,686 |
Sparse tensor not supported (Minkowski Engine)
|
oncall: jit
|
### SparseTensor' object is not iterable
- I have a pytorch model trained on Minkowski Engine library and i want to deploy this model on torchserve.I am facing issues while converting '.pth' model to the serialized '.pt' model.
- python enviornment -
1. python 3.7, pytorch 1.8, Minkowski Engine (0.4.3) [https://github.com/NVIDIA/MinkowskiEngine]
2. python 3.8, pythorch 1.10, Minkowski Engine 0.5.4
Tried on both these enviornments, got same following issue.
- preprocessing used in input file :
`preprocessed_data = ME.SparseTensor(features, coordinates)`
- I used torch.jit functions to convert the model into serialized form, but i am getting errors due to sparse tensor class of minkowski engine dependency in model.
### Error logs
I used various methods for converting '.pth' model to '.pt' serialized model.
1. torch.jit.trace, got following error :
`Traceback (most recent call last):
File "model_pt_converter.py", line 65, in <module>
traced_script_module = torch.jit.trace(model, preprocessed_data)
File "/home/vinayak/miniconda3/envs/serve/lib/python3.7/site-packages/torch/jit/_trace.py", line 750, in trace
_module_class,
File "/home/vinayak/miniconda3/envs/serve/lib/python3.7/site-packages/torch/jit/_trace.py", line 941, in trace_module
example_inputs = make_tuple(example_inputs)
File "/home/vinayak/miniconda3/envs/serve/lib/python3.7/site-packages/torch/jit/_trace.py", line 542, in make_tuple
return tuple(example_inputs)
TypeError: 'SparseTensor' object is not iterable`
2. using torch.jit.script,
`torch.jit.frontend.UnsupportedNodeError: global variables aren't supported:`
`SparseTensor.__init__' is being compiled since it was called from '__torch__.SparseTensor.SparseTensor`
`__torch__.SparseTensor.SparseTensor' is being compiled since it was called from 'MinkowskiConvolution.forward`
3. I also tried to serve the .pth model directly, the model is not getting loaded throwing following issues -
` Load model failed: s2b-model, error: Worker died`
`error: unrecognized arguments: --sock-type unix --sock-name /tmp/.ts.sock.9002`
`java.lang.InterruptedException: null`I have a pytorch model trained on Minkowski Engine library and i want to deploy this model on torchserve.I am facing issues while converting '.pth' model to the serialized '.pt' model.
python enviornment -
1. python 3.7, pytorch 1.8, Minkowski Engine (0.4.3) [https://github.com/NVIDIA/MinkowskiEngine]
2. python 3.8, pythorch 1.10, Minkowski Engine 0.5.4
Tried on both these enviornments, got same following issue.
preprocessing used in input file :
`preprocessed_data = ME.SparseTensor(features, coordinates)`
- I used various methods for converting '.pth' model to '.pt' serialized model.
1. torch.jit.trace, got following error :
`Traceback (most recent call last):
File "model_pt_converter.py", line 65, in <module>
traced_script_module = torch.jit.trace(model, preprocessed_data)
File "/home/vinayak/miniconda3/envs/serve/lib/python3.7/site-packages/torch/jit/_trace.py", line 750, in trace
_module_class,
File "/home/vinayak/miniconda3/envs/serve/lib/python3.7/site-packages/torch/jit/_trace.py", line 941, in trace_module
example_inputs = make_tuple(example_inputs)
File "/home/vinayak/miniconda3/envs/serve/lib/python3.7/site-packages/torch/jit/_trace.py", line 542, in make_tuple
return tuple(example_inputs)
TypeError: 'SparseTensor' object is not iterable`
2. using torch.jit.script,
`torch.jit.frontend.UnsupportedNodeError: global variables aren't supported:`
`SparseTensor.__init__' is being compiled since it was called from '__torch__.SparseTensor.SparseTensor`
`__torch__.SparseTensor.SparseTensor' is being compiled since it was called from 'MinkowskiConvolution.forward`
3. I also tried to serve the .pth model directly, the model is not getting loaded throwing following issues -
` Load model failed: s2b-model, error: Worker died`
`error: unrecognized arguments: --sock-type unix --sock-name /tmp/.ts.sock.9002`
`java.lang.InterruptedException: null`
### Installation instructions
- Installed torchserve using pip and pytorch using conda.
- Didn't used docker image.
### Versions
-------------------------------------------------------------------------------------------
Environment headers
------------------------------------------------------------------------------------------
Torchserve branch:
torchserve==0.7.0
torch-model-archiver==0.7.0
Python version: 3.7 (64-bit runtime)
Python executable: /home/vinayak/miniconda3/envs/serve/bin/python
Versions of relevant python libraries:
future==0.18.2
numpy==1.21.5
nvgpu==0.9.0
psutil==5.9.4
requests==2.28.1
torch==1.8.2
torch-model-archiver==0.7.0
torch-workflow-archiver==0.2.6
torchaudio==0.8.2
torchserve==0.7.0
torchvision==0.13.1a0
wheel==0.37.1
torch==1.8.2
**Warning: torchtext not present ..
torchvision==0.13.1a0
torchaudio==0.8.2
Java Version:
OS: Pop!_OS 20.04 LTS
GCC version: (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0
Clang version: N/A
CMake version: N/A
cc @EikanWang @jgong5 @wenzhe-nrv @sanchitintel
| 0 |
3,800 | 91,678 |
Wrong in building torch from source
|
triaged
|
### 🐛 Describe the bug
When I build torch-v1.12.1 from source, there is something wrong "caffe2/CMakeFiles/torch_cuda.dir/__/torch/csrc/distributed/c10d/quantization/quantization_gpu.cu.o No such file or directory"
and the compile failed..
### Versions
Version: 1.12.1
CUDA 10.2 (nvidia-smi)
CUDA: 10.2.89 (nvcc)
CUDNN: 7.6.5
GCC/G++:7.5.0
| 4 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.