
Serial Number
int64 1
6k
| Issue Number
int64 75.6k
112k
| Title
stringlengths 3
357
| Labels
stringlengths 3
241
⌀ | Body
stringlengths 9
74.5k
⌀ | Comments
int64 0
867
|
|---|---|---|---|---|---|
3,501 | 94,541 |
DISABLED test_pickle_nn_RNN_eval_mode_cuda_float64 (__main__.TestModuleCUDA)
|
module: rnn, triaged
|
Platforms: linux
This test was disabled because it is failing on master ([recent examples](http://torch-ci.com/failure/test_pickle_nn_RNN_eval_mode_cuda_float64%2CTestModuleCUDA)).
cc @zou3519
| 1 |
3,502 | 94,511 |
Performance does not meet expectations when training OPT-30 with FSDP, there may be problems with cpu offloading
|
oncall: distributed, module: fsdp
|
### 🐛 Describe the bug
### Code
```python
import os
import argparse
import functools
import torch
from itertools import chain
import torch.nn as nn
import torch.optim as optim
from transformers import (
OPTForCausalLM,
AutoTokenizer,
default_data_collator,
)
from transformers.models.opt.modeling_opt import OPTDecoderLayer, OPTAttention
from datasets import load_dataset
from torch.utils.data import DataLoader
from torch.optim.lr_scheduler import StepLR
import torch.distributed as dist
import torch.multiprocessing as mp
from torch.distributed.fsdp import (
MixedPrecision,
FullyShardedDataParallel as FSDP
)
from torch.distributed.fsdp.fully_sharded_data_parallel import (
CPUOffload,
)
from torch.distributed.fsdp.wrap import (
size_based_auto_wrap_policy,
transformer_auto_wrap_policy,
)
from torch.distributed.algorithms._checkpoint.checkpoint_wrapper import (
checkpoint_wrapper,
)
def getDataset():
raw_datasets = load_dataset("wikitext", "wikitext-2-v1")
tokenizer = AutoTokenizer.from_pretrained("facebook/opt-30b")
column_names = raw_datasets["train"].column_names
text_column_name = "text" if "text" in column_names else column_names[0]
def tokenize_function(examples):
return tokenizer(examples[text_column_name])
tokenized_datasets = raw_datasets.map(
tokenize_function,
batched=True,
num_proc=1,
remove_columns=column_names,
load_from_cache_file=False,
desc="Running tokenizer on dataset",
)
def group_texts(examples):
# Concatenate all texts.
concatenated_examples = {
k: list(chain(*examples[k])) for k in examples.keys()}
total_length = len(concatenated_examples[list(examples.keys())[0]])
# We drop the small remainder, we could add padding if the model supported it instead of this drop, you can
# customize this part to your needs.
if total_length >= 1024:
total_length = (total_length // 1024) * 1024
# Split by chunks of max_len.
result = {
k: [t[i: i + 1024]
for i in range(0, total_length, 1024)]
for k, t in concatenated_examples.items()
}
result["labels"] = result["input_ids"].copy()
return result
lm_datasets = tokenized_datasets.map(
group_texts,
batched=True,
num_proc=1,
load_from_cache_file=False,
desc=f"Grouping texts in chunks of {1024}",
)
return lm_datasets["train"]
def setup(rank, world_size):
os.environ['MASTER_ADDR'] = 'localhost'
os.environ['MASTER_PORT'] = '12355'
# initialize the process group
dist.init_process_group("nccl", rank=rank, world_size=world_size)
def cleanup():
dist.destroy_process_group()
def train(args, model, rank, world_size, train_loader, optimizer, epoch):
model.train()
ddp_loss = torch.zeros(2).to(rank)
for batch_idx, batch in enumerate(train_loader):
input_ids = batch["input_ids"].to(rank)
attention_mask = batch["attention_mask"].to(rank)
labels = batch["labels"].to(rank)
outputs = model(input_ids=input_ids,
attention_mask=attention_mask, labels=labels)
optimizer.zero_grad()
loss = outputs.loss
loss.backward()
optimizer.step()
ddp_loss[0] += loss.item()
ddp_loss[1] += len(input_ids)
if rank == 0:
print(batch_idx, " *"*10)
dist.all_reduce(ddp_loss, op=dist.ReduceOp.SUM)
if rank == 0:
print('Train Epoch: {} \tLoss: {:.6f}'.format(
epoch, ddp_loss[0] / ddp_loss[1]))
def fsdp_main(rank, world_size, args):
setup(rank, world_size)
train_dataset = getDataset()
train_loader = DataLoader(
train_dataset, collate_fn=default_data_collator,
batch_size=1, num_workers=1
)
my_auto_wrap_policy = functools.partial(
size_based_auto_wrap_policy, min_num_params=100000
)
# my_auto_wrap_policy = functools.partial(
# transformer_auto_wrap_policy, transformer_layer_cls={
# OPTDecoderLayer, OPTAttention, nn.LayerNorm, nn.Linear}
# )
torch.cuda.set_device(rank)
init_start_event = torch.cuda.Event(enable_timing=True)
init_end_event = torch.cuda.Event(enable_timing=True)
if rank == 0:
print("*"*10+"loading to cpu"+"*"*10)
model = OPTForCausalLM.from_pretrained("facebook/opt-30b")
model = checkpoint_wrapper(model, offload_to_cpu=True)
model = FSDP(model,
cpu_offload=CPUOffload(CPUOffload(offload_params=True)),
auto_wrap_policy=my_auto_wrap_policy,
mixed_precision=MixedPrecision(param_dtype=torch.float16,
reduce_dtype=torch.float16,
buffer_dtype=torch.float16,
keep_low_precision_grads=True)
)
if rank == 0:
print("*"*10+"print the fsdp model"+"*"*10)
print(model)
print_file = open("./model", 'w')
print(model, file=print_file)
print()
optimizer = optim.Adam(model.parameters(), lr=args.lr)
# optimizer = optim.SGD(model.parameters(), lr=args.lr)
scheduler = StepLR(optimizer, step_size=1, gamma=args.gamma)
init_start_event.record()
for epoch in range(1, args.epochs + 1):
train(args, model, rank, world_size, train_loader,
optimizer, epoch)
scheduler.step()
init_end_event.record()
if rank == 0:
print(
f"CUDA event elapsed time: {init_start_event.elapsed_time(init_end_event) / 1000}sec")
print(f"{model}")
cleanup()
if __name__ == '__main__':
# Training settings
parser = argparse.ArgumentParser(description='PyTorch OPT Example')
parser.add_argument('--batch-size', type=int, default=1, metavar='N',
help='input batch size for training (default: 64)')
parser.add_argument('--epochs', type=int, default=1, metavar='N',
help='number of epochs to train (default: 14)')
parser.add_argument('--lr', type=float, default=1.0, metavar='LR',
help='learning rate (default: 1.0)')
parser.add_argument('--gamma', type=float, default=0.7, metavar='M',
help='Learning rate step gamma (default: 0.7)')
parser.add_argument('--no-cuda', action='store_true', default=False,
help='disables CUDA training')
parser.add_argument('--seed', type=int, default=1, metavar='S',
help='random seed (default: 1)')
args = parser.parse_args()
torch.manual_seed(args.seed)
WORLD_SIZE = torch.cuda.device_count()
mp.spawn(fsdp_main,
args=(WORLD_SIZE, args),
nprocs=WORLD_SIZE,
join=True)
```
### Bug
The GPU memory in the forward stage is normal, but the GPU memory overflows in the backward stage. According to the principle of fsdp, it is judged that the memory usage of the GPU should not overflow at this time.
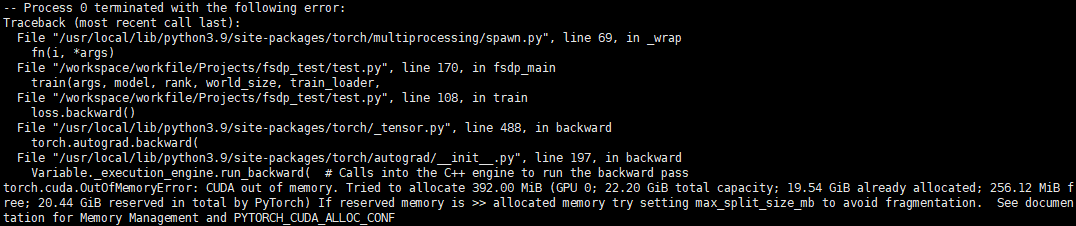
### Versions
host with 4 A10 GPU, 236 CPU cores and 974G memory
torch==1.13.1+cu116
transformers==4.26.0
cc @mrshenli @pritamdamania87 @zhaojuanmao @satgera @rohan-varma @gqchen @aazzolini @osalpekar @jiayisuse @H-Huang @kwen2501 @awgu
| 6 |
3,503 | 94,504 |
[mypy] skipping mypy for a few torch/fx and torch/_subclass files
|
module: lint, triaged
|
### 🐛 Describe the bug
In PR https://github.com/pytorch/pytorch/pull/94173, the below files were failing on mypy. The PR doesn't change these files but probably some import causes mypy to be run on these files and they fail.
Since it is not a regression, the PR now excludes those files from mypy checks. This issue is to track the same.
Files:
```
torch/fx/proxy.py
torch/fx/passes/shape_prop.py
torch/fx/node.py
torch/fx/experimental/symbolic_shapes.py
torch/fx/experimental/proxy_tensor.py
torch/_subclasses/fake_utils.py
torch/_subclasses/fake_tensor.py
```
### Versions
https://github.com/pytorch/pytorch/pull/94173
| 0 |
3,504 | 94,496 |
Dynamo captures only CUDA streams in FX graph
|
triaged, module: dynamo
|
### 🐛 Describe the bug
The current Dynamo captures torch.cuda.stream with https://github.com/pytorch/pytorch/pull/93808. However, for other backends with streams, the capture wouldn't happen. There should be a mechanism for Dynamo to recognize other backend streams.
### Versions
PyTorch version: 2.0.0.dev20230208+cu117
Is debug build: False
CUDA used to build PyTorch: 11.7
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.5 LTS (x86_64)
GCC version: (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0
Clang version: 10.0.0-4ubuntu1
CMake version: version 3.25.2
Libc version: glibc-2.31
Python version: 3.8.10 (default, Nov 14 2022, 12:59:47) [GCC 9.4.0] (64-bit runtime)
Python platform: Linux-5.10.147+-x86_64-with-glibc2.29
Is CUDA available: True
CUDA runtime version: 11.2.152
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration: GPU 0: Tesla T4
Nvidia driver version: 510.47.03
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.1.1
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.1.1
/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.1.1
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_infer.so.8.1.1
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.1.1
/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.1.1
/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.1.1
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
Address sizes: 46 bits physical, 48 bits virtual
CPU(s): 2
On-line CPU(s) list: 0,1
Thread(s) per core: 2
Core(s) per socket: 1
Socket(s): 1
NUMA node(s): 1
Vendor ID: GenuineIntel
CPU family: 6
Model: 85
Model name: Intel(R) Xeon(R) CPU @ 2.00GHz
Stepping: 3
CPU MHz: 2000.168
BogoMIPS: 4000.33
Hypervisor vendor: KVM
Virtualization type: full
L1d cache: 32 KiB
L1i cache: 32 KiB
L2 cache: 1 MiB
L3 cache: 38.5 MiB
NUMA node0 CPU(s): 0,1
Vulnerability Itlb multihit: Not affected
Vulnerability L1tf: Mitigation; PTE Inversion
Vulnerability Mds: Vulnerable; SMT Host state unknown
Vulnerability Meltdown: Vulnerable
Vulnerability Mmio stale data: Vulnerable
Vulnerability Retbleed: Vulnerable
Vulnerability Spec store bypass: Vulnerable
Vulnerability Spectre v1: Vulnerable: __user pointer sanitization and usercopy barriers only; no swapgs barriers
Vulnerability Spectre v2: Vulnerable, IBPB: disabled, STIBP: disabled, PBRSB-eIBRS: Not affected
Vulnerability Srbds: Not affected
Vulnerability Tsx async abort: Vulnerable
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ss ht syscall nx pdpe1gb rdtscp lm constant_tsc rep_good nopl xtopology nonstop_tsc cpuid tsc_known_freq pni pclmulqdq ssse3 fma cx16 pcid sse4_1 sse4_2 x2apic movbe popcnt aes xsave avx f16c rdrand hypervisor lahf_lm abm 3dnowprefetch invpcid_single ssbd ibrs ibpb stibp fsgsbase tsc_adjust bmi1 hle avx2 smep bmi2 erms invpcid rtm mpx avx512f avx512dq rdseed adx smap clflushopt clwb avx512cd avx512bw avx512vl xsaveopt xsavec xgetbv1 xsaves arat md_clear arch_capabilities
Versions of relevant libraries:
[pip3] numpy==1.24.2
[pip3] pytorch-triton==2.0.0+0d7e753227
[pip3] torch==2.0.0.dev20230208+cu117
[pip3] torchaudio==0.13.1+cu116
[pip3] torchsummary==1.5.1
[pip3] torchtext==0.14.1
[pip3] torchvision==0.14.1+cu116
[conda] Could not collect
cc @mlazos @soumith @voznesenskym @yanboliang @penguinwu @anijain2305 @EikanWang @jgong5 @Guobing-Chen @XiaobingSuper @zhuhaozhe @blzheng @Xia-Weiwen @wenzhe-nrv @jiayisunx @desertfire
| 3 |
3,505 | 94,474 |
pybind11 SymNode binding is a footgun py::cast
|
triaged, module: pybind
|
### 🐛 Describe the bug
Say you have a SymNode and you want to convert it into a PyObject. You might try `py::cast` it. But that will give you a `_C.SymNode`; if it was a Python SymNode you wanted it to unwrap directly. Big footgun.
### Versions
master
| 0 |
3,506 | 94,471 |
[Functionalization] `index_reduce_` op tests with functionalization enabled
|
triaged, module: meta tensors, module: functionalization
|
### 🐛 Describe the bug
With functionalization, the existing `index_reduce_` python op test (https://github.com/pytorch/pytorch/blob/master/test/test_torch.py#L3035) fails.
To reproduce (this is one of the sample inputs to the `index_reduce_` test linked above):
```
import torch
import functorch
def test():
dest = torch.tensor([[[ 0.0322, 1.2734, -3.4688, 8.1875, -4.2500],
[-5.6250, 1.3828, 7.7188, 0.3887, 5.5312],
[ 3.2344, 5.0312, -7.4062, 1.2422, -0.1719],
[-6.0312, 6.2188, -1.1641, -0.3203, 0.2637]],
[[-6.9688, -3.5938, 2.6406, 4.3125, 0.1348],
[ 4.5000, -0.5938, -5.5312, -1.8281, 1.1562],
[ 1.5781, -1.7891, 3.8906, 1.2969, 1.9688],
[-6.5000, 2.4375, -4.8125, 3.0312, 1.9453]],
[[ 0.2002, 7.7188, 1.5547, -7.6875, -2.5781],
[-4.1562, 1.8125, 6.5625, 8.2500, 5.4062],
[ 4.2812, 6.5625, -3.3906, 1.7266, 8.8750],
[-6.9375, 7.0625, 3.4844, -7.9375, 8.5625]]], dtype=torch.bfloat16)
idx = torch.tensor([], dtype=torch.int64)
src = torch.empty((3, 4, 0), dtype=torch.bfloat16)
dest.index_reduce_(2, idx, src, 'mean', include_self=False)
```
Output:
```
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/opt/conda/lib/python3.8/site-packages/torch/_functorch/vmap.py", line 39, in fn
return f(*args, **kwargs)
File "/opt/conda/lib/python3.8/site-packages/torch/_functorch/eager_transforms.py", line 1582, in wrapped
func_outputs = func(*func_args, **func_kwargs)
File "<stdin>", line 18, in test
File "/opt/conda/lib/python3.8/site-packages/torch/_decomp/decompositions.py", line 3314, in inplace_op
out = outplace_op(*args, **kwargs)
File "/opt/conda/lib/python3.8/site-packages/torch/_ops.py", line 499, in __call__
return self._op(*args, **kwargs or {})
IndexError: select(): index 0 out of range for tensor of size [3, 4, 0] at dimension 2
```
Full dispatch trace logs: https://gist.github.com/wonjoolee95/d6c2c31df8a3342ddbf56523c0eeab66
Full dispatch trace logs without functionalization: https://gist.github.com/wonjoolee95/8a9c2543b0b017f9df049da57fc84dce
The error itself seems to be clear -- due to some index out-bound-error, as the code tries to access index 0 at dimension 2 of shape [3, 4, 0] as mentioned in the error logs; however, this only happens when functionalization is enabled. The last few bits of the dispatch trace seems suspicious. Without functionalization, the dispatch looks like:
```
[call] op=[aten::index_reduce_], key=[AutogradCPU]
[redispatch] op=[aten::index_reduce_], key=[ADInplaceOrView]
[redispatch] op=[aten::index_reduce_], key=[CPU]
[call] op=[aten::to.dtype], key=[CPU]
[call] op=[aten::index_fill_.int_Scalar], key=[CPU]
[call] op=[aten::as_strided], key=[CPU]
[call] op=[aten::as_strided], key=[CPU]
```
However, with functionalization, it looks like:
```
[call] op=[aten::index_reduce_], key=[FuncTorchDynamicLayerFrontMode]
[callBoxed] op=[aten::index_reduce_], key=[Functionalize]
[call] op=[aten::index_reduce_], key=[Meta]
[callBoxed] op=[aten::index_reduce], key=[Meta]
[call] op=[aten::select.int], key=[Meta]
[call] op=[aten::as_strided], key=[Meta]
[call] op=[aten::select.int], key=[Meta]
```
Just looking at it at a high-level, seems like functionalization now decomposes into `select.int` that might deal with indices differently compared to the previous ops?
Please let me know if you need any more information.
cc @ezyang @eellison @bdhirsh @soumith @alanwaketan
### Versions
Nightly
| 10 |
3,507 | 94,457 |
LSTM on CPU is significantly slower on PyTorch compared to other frameworks
|
module: performance, module: cpu, triaged
|
### 🐛 Describe the bug
Hello everybody.
I’ve been experimenting with different models and different frameworks, and I’ve noticed that, when using CPU, training a LSTM model on the IMDB dataset is 3x to 5x slower on PyTorch (around 739 seconds) compared to the Keras and TensorFlow implementations (around 201 seconds and around 135 seconds, respectively). Moreover, I’ve also noticed that the first epoch takes significantly more time than the rest of the epochs:
```
-PyTorch: Epoch 1 done in 235.0469572544098s
-PyTorch: Epoch 2 done in 125.87335634231567s
-PyTorch: Epoch 3 done in 125.26632475852966s
-PyTorch: Epoch 4 done in 126.59195327758789s
-PyTorch: Epoch 5 done in 126.00697541236877s
```
Which doesn’t occur when using the other frameworks:
Keras:
```
Epoch 1/5
98/98 [==============================] - 41s 408ms/step - loss: 0.5280 - accuracy: 0.7300
Epoch 2/5
98/98 [==============================] - 40s 404ms/step - loss: 0.3441 - accuracy: 0.8566
Epoch 3/5
98/98 [==============================] - 40s 406ms/step - loss: 0.2384 - accuracy: 0.9080
Epoch 4/5
98/98 [==============================] - 40s 406ms/step - loss: 0.1625 - accuracy: 0.9386
Epoch 5/5
98/98 [==============================] - 40s 406ms/step - loss: 0.1176 - accuracy: 0.9580
```
TensorFlow:
```
-TensorFlow: Epoch 1 done in 37.287458419799805s
-TensorFlow: Epoch 2 done in 36.93708920478821s
-TensorFlow: Epoch 3 done in 36.85307550430298s
-TensorFlow: Epoch 4 done in 37.23605704307556s
-TensorFlow: Epoch 5 done in 37.04216718673706s
```
While using GPU, the problem seems to disappear.
PyTorch:
```
-PyTorch: Epoch 1 done in 2.6681089401245117s
-PyTorch: Epoch 2 done in 2.623263120651245s
-PyTorch: Epoch 3 done in 2.6285109519958496s
-PyTorch: Epoch 4 done in 2.6813976764678955s
-PyTorch: Epoch 5 done in 2.6470844745635986s
```
Keras:
```
Epoch 1/5
98/98 [==============================] - 6s 44ms/step - loss: 0.5434 - accuracy: 0.7220
Epoch 2/5
98/98 [==============================] - 4s 44ms/step - loss: 0.4673 - accuracy: 0.7822
Epoch 3/5
98/98 [==============================] - 4s 45ms/step - loss: 0.2500 - accuracy: 0.8998
Epoch 4/5
98/98 [==============================] - 4s 46ms/step - loss: 0.1581 - accuracy: 0.9434
Epoch 5/5
98/98 [==============================] - 4s 46ms/step - loss: 0.0985 - accuracy: 0.9660
```
TensorFlow:
```
-TensorFlow: Epoch 1 done in 4.04967999458313s
-TensorFlow: Epoch 2 done in 2.443302869796753s
-TensorFlow: Epoch 3 done in 2.450983762741089s
-TensorFlow: Epoch 4 done in 2.4626052379608154s
-TensorFlow: Epoch 5 done in 2.4663102626800537s
```
Here’s the information on my PyTorch build:
```
PyTorch built with:
- GCC 7.3
- C++ Version: 201402
- Intel(R) Math Kernel Library Version 2020.0.0 Product Build 20191122 for Intel(R) 64 architecture applications
- Intel(R) MKL-DNN v2.2.3 (Git Hash 7336ca9f055cf1bfa13efb658fe15dc9b41f0740)
- OpenMP 201511 (a.k.a. OpenMP 4.5)
- LAPACK is enabled (usually provided by MKL)
- NNPACK is enabled
- CPU capability usage: AVX2
- CUDA Runtime 10.2
- NVCC architecture flags: -gencode;arch=compute_37,code=sm_37;-gencode;arch=compute_50,code=sm_50;-gencode;arch=compute_60,code=sm_60;-gencode;arch=compute_70,code=sm_70
- CuDNN 7.6.5
- Magma 2.5.2
- Build settings: BLAS_INFO=mkl, BUILD_TYPE=Release, CUDA_VERSION=10.2, CUDNN_VERSION=7.6.5, CXX_COMPILER=/opt/rh/devtoolset-7/root/usr/bin/c++, CXX_FLAGS= -Wno-deprecated -fvisibility-inlines-hidden -DUSE_PTHREADPOOL -fopenmp -DNDEBUG -DUSE_KINETO -DUSE_FBGEMM -DUSE_QNNPACK -DUSE_PYTORCH_QNNPACK -DUSE_XNNPACK -DSYMBOLICATE_MOBILE_DEBUG_HANDLE -DEDGE_PROFILER_USE_KINETO -O2 -fPIC -Wno-narrowing -Wall -Wextra -Werror=return-type -Wno-missing-field-initializers -Wno-type-limits -Wno-array-bounds -Wno-unknown-pragmas -Wno-sign-compare -Wno-unused-parameter -Wno-unused-variable -Wno-unused-function -Wno-unused-result -Wno-unused-local-typedefs -Wno-strict-overflow -Wno-strict-aliasing -Wno-error=deprecated-declarations -Wno-stringop-overflow -Wno-psabi -Wno-error=pedantic -Wno-error=redundant-decls -Wno-error=old-style-cast -fdiagnostics-color=always -faligned-new -Wno-unused-but-set-variable -Wno-maybe-uninitialized -fno-math-errno -fno-trapping-math -Werror=format -Wno-stringop-overflow, LAPACK_INFO=mkl, PERF_WITH_AVX=1, PERF_WITH_AVX2=1, PERF_WITH_AVX512=1, TORCH_VERSION=1.10.0, USE_CUDA=ON, USE_CUDNN=ON, USE_EXCEPTION_PTR=1, USE_GFLAGS=OFF, USE_GLOG=OFF, USE_MKL=ON, USE_MKLDNN=ON, USE_MPI=OFF, USE_NCCL=ON, USE_NNPACK=ON, USE_OPENMP=ON
```
Here’s the model’s code:
```
class PyTorchLSTMMod(torch.nn.Module):
"""This class implements the LSTM model using PyTorch.
Arguments
---------
initializer: function
The weight initialization function from the torch.nn.init module that is used to initialize
the initial weights of the models.
vocabulary_size: int
The number of words that are to be considered among the words that used most frequently.
embedding_size: int
The number of dimensions to which the words will be mapped to.
hidden_size: int
The number of features of the hidden state.
dropout: float
The dropout rate that will be considered during training.
"""
def __init__(self, initializer, vocabulary_size, embedding_size, hidden_size, dropout):
super().__init__()
self.embed = torch.nn.Embedding(num_embeddings=vocabulary_size, embedding_dim=embedding_size)
self.dropout1 = torch.nn.Dropout(dropout)
self.lstm = torch.nn.LSTM(input_size=embedding_size, hidden_size=hidden_size, batch_first=True)
initializer(self.lstm.weight_ih_l0)
torch.nn.init.orthogonal_(self.lstm.weight_hh_l0)
self.dropout2 = torch.nn.Dropout(dropout)
self.fc = torch.nn.Linear(in_features=hidden_size, out_features=1)
def forward(self, inputs, is_training=False):
"""This function implements the forward pass of the model.
Arguments
---------
inputs: Tensor
The set of samples the model is to infer.
is_training: boolean
This indicates whether the forward pass is occuring during training
(i.e., if we should consider dropout).
"""
x = inputs
x = self.embed(x)
if is_training:
x = self.dropout1(x)
o, (h, c) = self.lstm(x)
out = h[-1]
if is_training:
out = self.dropout2(out)
f = self.fc(out)
return f.flatten()#torch.sigmoid(f).flatten()
def train_pytorch(self, optimizer, epoch, train_loader, device, data_type, log_interval):
"""This function implements a single epoch of the training process of the PyTorch model.
Arguments
---------
self: PyTorchLSTMMod
The model that is to be trained.
optimizer: torch.nn.optim
The optimizer to be used during the training process.
epoch: int
The epoch associated with the training process.
train_loader: DataLoader
The DataLoader that is used to load the training data during the training process.
Note that the DataLoader loads the data according to the batch size
defined with it was initialized.
device: string
The string that indicates which device is to be used at runtime (i.e., GPU or CPU).
data_type: string
This string indicates whether mixed precision is to be used or not.
log_interval: int
The interval at which the model logs the process of the training process
in terms of number of batches passed through the model.
"""
self.train()
epoch_start = time.time()
loss_fn = torch.nn.BCEWithLogitsLoss()
if data_type == 'mixed':
scaler = torch.cuda.amp.GradScaler()
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
if data_type == 'mixed':
with torch.cuda.amp.autocast():
output = self(data, is_training=True)
loss = loss_fn(output, target)
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()
else:
output = self(data, is_training=True)
loss = loss_fn(output, target)
loss.backward()
optimizer.step()
if log_interval == -1:
continue
if batch_idx % log_interval == 0:
print('Train set, Epoch {}\tLoss: {:.6f}'.format(
epoch, loss.item()))
print("-PyTorch: Epoch {} done in {}s\n".format(epoch, time.time() - epoch_start))
def test_pytorch(self, test_loader, device, data_type):
"""This function implements the testing process of the PyTorch model and returns the accuracy
obtained on the testing dataset.
Arguments
---------
model: torch.nn.Module
The model that is to be tested.
test_loader: DataLoader
The DataLoader that is used to load the testing data during the testing process.
Note that the DataLoader loads the data according to the batch size
defined with it was initialized.
device: string
The string that indicates which device is to be used at runtime (i.e., GPU or CPU).
data_type: string
This string indicates whether mixed precision is to be used or not.
"""
self.eval()
with torch.no_grad():
#Loss and correct prediction accumulators
test_loss = 0
correct = 0
total = 0
loss_fn = torch.nn.BCEWithLogitsLoss()
for data, target in test_loader:
data, target = data.to(device), target.to(device)
if data_type == 'mixed':
with torch.cuda.amp.autocast():
outputs = self(data).detach()
test_loss += loss_fn(outputs, target).detach()
preds = (outputs >= 0.5).float() == target
correct += preds.sum().item()
total += preds.size(0)
else:
outputs = self(data).detach()
test_loss += loss_fn(outputs, target).detach()
preds = (outputs >= 0.5).float() == target
correct += preds.sum().item()
total += preds.size(0)
#Print log
test_loss /= len(test_loader.dataset)
print('\nTest set, Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
100. * (correct / total)))
return 100. * (correct / total)
```
I'm on a Ubuntu 18.04.4 system equipped with an NVIDIA Quadro RTX 4000 GPU with 8GB of VRAM and an Intel(R) Core(TM) i9-9900K CPU running at 3.60GHz. I've already tried to run this code on separate machines, but the behavior seems to occur only on the system described above. I've also try to play around with number of threads, to no avail.
I have also created a repo for the sake of reproducibility: https://github.com/jd2151171/pytorch_question
Any ideas what could be the cause of this?
Thanks!
### Versions
The version of relevant libraries are:
numpy==1.19.5
torch==1.10.0
torchaudio==0.10.0
torchvision==0.11.1
mkl==2022.2.1
mkl-fft==1.3.0
mkl-random==1.2.1
mkl-service==2.4.0
cc @ngimel @jgong5 @mingfeima @XiaobingSuper @sanchitintel @ashokei @jingxu10
| 4 |
3,508 | 94,454 |
Document and promise reproducibility torch.randn / torch.rand / torch.randint family behavior on CPU devices
|
feature, triaged, module: random
|
### 🚀 The feature, motivation and pitch
In PyTorch's documentation: https://pytorch.org/docs/stable/notes/randomness.html#reproducibility The reproduciblity of RNG is not guaranteed cross different releases / commits / platforms. While it is difficult to guarantee reproducibility with exotic hardware or GPU, it is beneficial, and practically unchanged for CPU on PyTorch end.
This pitch suggests we revisit some of our CPU implementations, and further promise stability / reproducibility for CPU-based RNG. In the context of where I am coming from (generative AI), what comes to known as "the seed" helps many creators to verify images generated by other creators and to build new work upon that. The noise tensor init from that seed is often small in size (4x64x64) thus performance is not a concern.
#### Counterargument
This pitch will force us to fix on using MT19937 family of RNGs as the starting point. While it is robust, there may be future, better, faster RNGs that better suit.
The community already moved on to use GPU-based RNG, which makes this pitch moot. There is no stability / reproducibility whatsoever with GPU RNGs, making this suggestion a fool.
#### Questions
Upon further investigate current PyTorch implementation, there are some questions on whether the current implementation on CPU is optimal. For example, when number of elements smaller than 16, we currently sample from double precision and then cast back to float when fill in `torch.randn([15], dtype=torch.float)`: https://github.com/pytorch/pytorch/blob/master/aten/src/ATen/native/cpu/DistributionTemplates.h#L192 When there are more than 16 elements, we use float throughout.
### Alternatives
There are a few alternatives:
#### Declare a particular RNG mode that is guaranteed reproducibility cross releases / commits / platforms.
This helps us to continue iterate on main RNG implementation while let whoever wants stability to opt-in. It does incur the cost of maintaining another implementation eventually.
#### Don't guarantee any stability / reproducibility.
Continue doing this will not break things. But the stability / reproducibility is practically guaranteed due to very little change in CPU RNG implementation. This may risk a future when we actually break RNG reproducibility (because we can), there are incompatibility concerns when upgrade.
I won't discuss the situation where we guarantee stability / reproducibility cross hardware, as that may not be practical at all.
### Additional context
_No response_
cc @pbelevich
| 0 |
3,509 | 94,451 |
`jacrev` raise "Cannot access storage of TensorWrapper" error when computing the grad of `storage`
|
module: autograd, triaged, actionable, module: functorch
|
### 🐛 Describe the bug
`jacrev` raise "Cannot access storage of TensorWrapper" error when computing the grad of `storage`. By contrast, the `torch.autograd.jacobian` will return the gradient without any error
```py
import torch
from torch.autograd.functional import jacobian
from torch.func import jacrev, jacfwd
torch.manual_seed(420)
a = torch.zeros((3, 3)).bfloat16()
def func(a):
def TEMP_FUNC(a):
"""[WIP] BFloat16 support on CPU
"""
b = a * 2
b.storage()
return b
return TEMP_FUNC(a)
test_inputs = [a]
print(func(a))
# tensor([[0., 0., 0.],
# [0., 0., 0.],
# [0., 0., 0.]], dtype=torch.bfloat16)
print(jacobian(func, a, vectorize=True, strategy="reverse-mode"))
# succeed
print(jacrev(func)(a))
# NotImplementedError: Cannot access storage of TensorWrapper
```
### Versions
```
PyTorch version: 2.0.0.dev20230105
Is debug build: False
CUDA used to build PyTorch: 11.7
ROCM used to build PyTorch: N/A
OS: Ubuntu 22.04.1 LTS (x86_64)
GCC version: (Ubuntu 11.3.0-1ubuntu1~22.04) 11.3.0
Clang version: Could not collect
CMake version: version 3.22.1
Libc version: glibc-2.35
Python version: 3.9.15 (main, Nov 24 2022, 14:31:59) [GCC 11.2.0] (64-bit runtime)
Python platform: Linux-5.15.0-56-generic-x86_64-with-glibc2.35
Is CUDA available: True
CUDA runtime version: 11.7.99
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration:
GPU 0: NVIDIA GeForce RTX 3090
GPU 1: NVIDIA GeForce RTX 3090
GPU 2: NVIDIA GeForce RTX 3090
Nvidia driver version: 515.86.01
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_infer.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.4.1
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.23.5
[pip3] torch==2.0.0.dev20230105
[pip3] torchaudio==2.0.0.dev20230105
[pip3] torchvision==0.15.0.dev20230105
[conda] blas 1.0 mkl
[conda] mkl 2021.4.0 h06a4308_640
[conda] mkl-service 2.4.0 py39h7f8727e_0
[conda] mkl_fft 1.3.1 py39hd3c417c_0
[conda] mkl_random 1.2.2 py39h51133e4_0
[conda] numpy 1.23.5 py39h14f4228_0
[conda] numpy-base 1.23.5 py39h31eccc5_0
[conda] pytorch 2.0.0.dev20230105 py3.9_cuda11.7_cudnn8.5.0_0 pytorch-nightly
[conda] pytorch-cuda 11.7 h67b0de4_2 pytorch-nightly
[conda] pytorch-mutex 1.0 cuda pytorch-nightly
[conda] torchaudio 2.0.0.dev20230105 py39_cu117 pytorch-nightly
[conda] torchtriton 2.0.0+0d7e753227 py39 pytorch-nightly
[conda] torchvision 0.15.0.dev20230105 py39_cu117 pytorch-nightly
```
cc @ezyang @albanD @zou3519 @gqchen @pearu @nikitaved @soulitzer @Lezcano @Varal7 @Chillee @samdow @soumith @kshitij12345 @janeyx99
| 1 |
3,510 | 94,450 |
Pickling OneCycleLR.state_dict() with an unpickleable optimizer will result in an error.
|
module: optimizer, module: pickle, triaged, needs research
|
### 🐛 Describe the bug
OneCycleLR.state_dict() returns a bound method of OneCycleLR. Pickling the state_dict() also pickles the optimizer object attached to the OneCycleLR class instance. This can result in a pickling fail if the attached optimizer itself isn't pickleable.
gist can be found here: https://gist.github.com/MikhailKardash/69c8e98c0e23dc01c99627a43a84981d
### Versions
PyTorch version: 1.9.0+cu102
Is debug build: False
CUDA used to build PyTorch: 10.2
ROCM used to build PyTorch: N/A
OS: Ubuntu 22.04.1 LTS (x86_64)
GCC version: (Ubuntu 11.3.0-1ubuntu1~22.04) 11.3.0
Clang version: Could not collect
CMake version: Could not collect
Libc version: glibc-2.35
Python version: 3.8.15 (default, Nov 24 2022, 15:19:38) [GCC 11.2.0] (64-bit runtime)
Python platform: Linux-5.15.79.1-microsoft-standard-WSL2-x86_64-with-glibc2.17
Is CUDA available: True
CUDA runtime version: Could not collect
CUDA_MODULE_LOADING set to:
GPU models and configuration: GPU 0: NVIDIA T1200 Laptop GPU
Nvidia driver version: 517.13
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Address sizes: 39 bits physical, 48 bits virtual
Byte Order: Little Endian
CPU(s): 16
On-line CPU(s) list: 0-15
Vendor ID: GenuineIntel
Model name: 11th Gen Intel(R) Core(TM) i7-11850H @ 2.50GHz
CPU family: 6
Model: 141
Thread(s) per core: 2
Core(s) per socket: 8
Socket(s): 1
Stepping: 1
BogoMIPS: 4992.00
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ss ht syscall nx pdpe1gb rdtscp lm constant_tsc arch_perfmon rep_good nopl xtopology tsc_reliable nonstop_tsc cpuid pni pclmulqdq ssse3 fma cx16 pdcm pcid sse4_1 sse4_2 movbe popcnt aes xsave avx f16c rdrand hypervisor lahf_lm abm 3dnowprefetch invpcid_single ssbd ibrs ibpb stibp ibrs_enhanced fsgsbase bmi1 avx2 smep bmi2 erms invpcid avx512f avx512dq rdseed adx smap avx512ifma clflushopt clwb avx512cd sha_ni avx512bw avx512vl xsaveopt xsavec xgetbv1 xsaves avx512vbmi umip avx512_vbmi2 gfni vaes vpclmulqdq avx512_vnni avx512_bitalg avx512_vpopcntdq rdpid fsrm avx512_vp2intersect flush_l1d arch_capabilities
Hypervisor vendor: Microsoft
Virtualization type: full
L1d cache: 384 KiB (8 instances)
L1i cache: 256 KiB (8 instances)
L2 cache: 10 MiB (8 instances)
L3 cache: 24 MiB (1 instance)
Vulnerability Itlb multihit: Not affected
Vulnerability L1tf: Not affected
Vulnerability Mds: Not affected
Vulnerability Meltdown: Not affected
Vulnerability Mmio stale data: Not affected
Vulnerability Retbleed: Mitigation; Enhanced IBRS
Vulnerability Spec store bypass: Mitigation; Speculative Store Bypass disabled via prctl and seccomp
Vulnerability Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization
Vulnerability Spectre v2: Mitigation; Enhanced IBRS, IBPB conditional, RSB filling, PBRSB-eIBRS SW sequence
Vulnerability Srbds: Not affected
Vulnerability Tsx async abort: Not affected
Versions of relevant libraries:
[pip3] mypy==0.910
[pip3] mypy-extensions==0.4.3
[pip3] numpy==1.23.5
[pip3] pytorch-lightning==1.5.9
[pip3] torch==1.9.0
[pip3] torchaudio==0.13.1
[pip3] torchmetrics==0.11.0
[pip3] torchvision==0.10.0
[conda] _tflow_select 2.3.0 mkl
[conda] blas 1.0 mkl
[conda] cpuonly 2.0 0 pytorch
[conda] ffmpeg 4.3 hf484d3e_0 pytorch
[conda] mkl 2021.4.0 h06a4308_640
[conda] mkl-service 2.4.0 py38h7f8727e_0
[conda] mkl_fft 1.3.1 py38hd3c417c_0
[conda] mkl_random 1.2.2 py38h51133e4_0
[conda] numpy 1.23.5 py38h14f4228_0
[conda] numpy-base 1.23.5 py38h31eccc5_0
[conda] pytorch-lightning 1.5.9 pypi_0 pypi
[conda] pytorch-mutex 1.0 cpu pytorch
[conda] torch 1.9.0 pypi_0 pypi
[conda] torchaudio 0.13.1 py38_cpu pytorch
[conda] torchmetrics 0.11.0 pypi_0 pypi
[conda] torchvision 0.10.0 pypi_0 pypi
cc @vincentqb @jbschlosser @albanD @janeyx99
| 1 |
3,511 | 94,443 |
A better error msg for `cuda.jiterator` when input is on `cpu`
|
triaged, module: jiterator
|
### 🐛 Describe the bug
A better error msg may be needed for `cuda.jiterator` when input is on `cpu`. Now it will raise an INTERNAL ASSERT FAILED, such as
```py
import torch
torch.manual_seed(420)
x = torch.rand(3)
y = torch.rand(3)
def func(x, y):
fn = torch.cuda.jiterator._create_multi_output_jit_fn(
"""
template <typename T>
T binary_2outputs(T i0, T i1, T& out0, T& out1) {
out0 = i0 + i1;
out1 = i0 - i1;
}
""",
num_outputs=2)
out0, out1 = fn(x, y)
return out0, out1
func(x, y)
# RuntimeError: t == DeviceType::CUDA INTERNAL ASSERT FAILED at
# "/opt/conda/conda-bld/pytorch_1672906354936/work/c10/cuda/impl/CUDAGuardImpl.h":25,
# please report a bug to PyTorch.
```
### Versions
```
PyTorch version: 2.0.0.dev20230105
Is debug build: False
CUDA used to build PyTorch: 11.7
ROCM used to build PyTorch: N/A
OS: Ubuntu 22.04.1 LTS (x86_64)
GCC version: (Ubuntu 11.3.0-1ubuntu1~22.04) 11.3.0
Clang version: Could not collect
CMake version: version 3.22.1
Libc version: glibc-2.35
Python version: 3.9.15 (main, Nov 24 2022, 14:31:59) [GCC 11.2.0] (64-bit runtime)
Python platform: Linux-5.15.0-56-generic-x86_64-with-glibc2.35
Is CUDA available: True
CUDA runtime version: 11.7.99
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration:
GPU 0: NVIDIA GeForce RTX 3090
GPU 1: NVIDIA GeForce RTX 3090
GPU 2: NVIDIA GeForce RTX 3090
Nvidia driver version: 515.86.01
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_infer.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.4.1
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.23.5
[pip3] torch==2.0.0.dev20230105
[pip3] torchaudio==2.0.0.dev20230105
[pip3] torchvision==0.15.0.dev20230105
[conda] blas 1.0 mkl
[conda] mkl 2021.4.0 h06a4308_640
[conda] mkl-service 2.4.0 py39h7f8727e_0
[conda] mkl_fft 1.3.1 py39hd3c417c_0
[conda] mkl_random 1.2.2 py39h51133e4_0
[conda] numpy 1.23.5 py39h14f4228_0
[conda] numpy-base 1.23.5 py39h31eccc5_0
[conda] pytorch 2.0.0.dev20230105 py3.9_cuda11.7_cudnn8.5.0_0 pytorch-nightly
[conda] pytorch-cuda 11.7 h67b0de4_2 pytorch-nightly
[conda] pytorch-mutex 1.0 cuda pytorch-nightly
[conda] torchaudio 2.0.0.dev20230105 py39_cu117 pytorch-nightly
[conda] torchtriton 2.0.0+0d7e753227 py39 pytorch-nightly
[conda] torchvision 0.15.0.dev20230105 py39_cu117 pytorch-nightly
```
cc @mruberry @ngimel
| 1 |
3,512 | 94,441 |
`get_debug_state` a script function causes INTERNAL ASSERT FAILED
|
oncall: jit, triaged
|
### 🐛 Describe the bug
`get_debug_state` a script function causes INTERNAL ASSERT FAILED
```py
import torch
input = torch.randn(1, 2, 3)
def func(input):
trace = torch.jit.trace(lambda x: x * x, [input])
script_fn = torch.jit.script(trace)
script_fn.get_debug_state()
func(input)
# RuntimeError: optimized_plan_ INTERNAL ASSERT FAILED
# at "/opt/conda/conda-bld/pytorch_1672906354936/work/torch/csrc/jit/runtime/profiling_graph_executor_impl.cpp":697,
# please report a bug to PyTorch.
```
### Versions
```
PyTorch version: 2.0.0.dev20230105
Is debug build: False
CUDA used to build PyTorch: 11.7
ROCM used to build PyTorch: N/A
OS: Ubuntu 22.04.1 LTS (x86_64)
GCC version: (Ubuntu 11.3.0-1ubuntu1~22.04) 11.3.0
Clang version: Could not collect
CMake version: version 3.22.1
Libc version: glibc-2.35
Python version: 3.9.15 (main, Nov 24 2022, 14:31:59) [GCC 11.2.0] (64-bit runtime)
Python platform: Linux-5.15.0-56-generic-x86_64-with-glibc2.35
Is CUDA available: True
CUDA runtime version: 11.7.99
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration:
GPU 0: NVIDIA GeForce RTX 3090
GPU 1: NVIDIA GeForce RTX 3090
GPU 2: NVIDIA GeForce RTX 3090
Nvidia driver version: 515.86.01
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_infer.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.4.1
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.23.5
[pip3] torch==2.0.0.dev20230105
[pip3] torchaudio==2.0.0.dev20230105
[pip3] torchvision==0.15.0.dev20230105
[conda] blas 1.0 mkl
[conda] mkl 2021.4.0 h06a4308_640
[conda] mkl-service 2.4.0 py39h7f8727e_0
[conda] mkl_fft 1.3.1 py39hd3c417c_0
[conda] mkl_random 1.2.2 py39h51133e4_0
[conda] numpy 1.23.5 py39h14f4228_0
[conda] numpy-base 1.23.5 py39h31eccc5_0
[conda] pytorch 2.0.0.dev20230105 py3.9_cuda11.7_cudnn8.5.0_0 pytorch-nightly
[conda] pytorch-cuda 11.7 h67b0de4_2 pytorch-nightly
[conda] pytorch-mutex 1.0 cuda pytorch-nightly
[conda] torchaudio 2.0.0.dev20230105 py39_cu117 pytorch-nightly
[conda] torchtriton 2.0.0+0d7e753227 py39 pytorch-nightly
[conda] torchvision 0.15.0.dev20230105 py39_cu117 pytorch-nightly
```
cc @EikanWang @jgong5 @wenzhe-nrv @sanchitintel
| 1 |
3,513 | 94,434 |
Exporting the operator 'aten::_transformer_encoder_layer_fwd' to ONNX opset version 13 is not supported
|
module: onnx, low priority, triaged, onnx-needs-info
|
### 🐛 Describe the bug
I just wanted to export to onnx torch.nn.TransformerEncoder, and got this type of error
raise errors.UnsupportedOperatorError(
torch.onnx.errors.UnsupportedOperatorError: Exporting the operator 'aten::_transformer_encoder_layer_fwd' to ONNX opset version 13 is not supported.)
### Versions
numpy==1.24.1
pytorch-lightning==1.9.0
torch==1.13.1
torchaudio==0.13.1
torchdata==0.5.1
torchmetrics==0.11.1
torchvision==0.14.1
| 8 |
3,514 | 94,429 |
[RFC]FSDP API should make limit_all_gathers and forward_prefetch both default to be True
|
triaged, module: fsdp
|
### 🚀 The feature, motivation and pitch
limit_all_gathers=True can avoid over-prefetch when CPU thread is fast;
forward_prefetch=True can help more prefetch when CPU thread is slow;
so basically we can always explicitly prefetch but with rate limiter;
We probably need to make number of all_gathers be the same for forward_prefetch and limit_all_gathers code paths.
Have both to be True in default should work fine no matter CPU thread is fast or slow, so that users do not tune these by themselves. We can do some experiments to confirm this.
### Alternatives
_No response_
### Additional context
_No response_
cc @mrshenli @rohan-varma @awgu
| 1 |
3,515 | 94,428 |
nn.TransformerEncoderLayer fastpath (BetterTransformer) is much slower with src_key_padding_mask
|
oncall: transformer/mha
|
### 🐛 Describe the bug
TransformerEncoder runs much slower with src_key_padding_mask than without any padding. On v100, it takes ~8.8ms for bert-base batch size 1 seq 128 with mask set while only takes ~4.5ms without mask.
```
import torch
import timeit
def test_transformerencoder_fastpath():
"""
Test TransformerEncoder fastpath output matches slowpath output
"""
torch.manual_seed(1234)
nhead = 12
d_model = 768
dim_feedforward = 4 * d_model
batch_first = True
device = "cuda"
model = torch.nn.TransformerEncoder(
torch.nn.TransformerEncoderLayer(
d_model=d_model,
nhead=nhead,
dim_feedforward=dim_feedforward,
batch_first=batch_first),
num_layers=12,
).to(device).half().eval()
# each input is (input, mask)
input_value = torch.rand(8, 128, d_model)
mask_value = [ [0] * 128] + [[0] * 64 + [1] * 64] * 7
input = torch.tensor(input_value, device=device, dtype=torch.get_default_dtype()).half() # half input
src_key_padding_mask = torch.tensor(mask_value, device=device, dtype=torch.bool) # bool mask
with torch.no_grad():
print(f'''With mask: {timeit.timeit("model(input, src_key_padding_mask=src_key_padding_mask)", globals=locals(), number=1000)}"''')
print(f'''Without mask: {timeit.timeit("model(input)", globals=locals(), number=1000)}''')
test_transformerencoder_fastpath()
```
### Versions
ollecting environment information...
PyTorch version: 1.13.1+cu116
Is debug build: False
CUDA used to build PyTorch: 11.6
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.5 LTS (x86_64)
GCC version: (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0
Clang version: Could not collect
CMake version: version 3.25.0
Libc version: glibc-2.31
Python version: 3.8.10 (default, Nov 14 2022, 12:59:47) [GCC 9.4.0] (64-bit runtime)
Python platform: Linux-5.15.0-1031-azure-x86_64-with-glibc2.29
Is CUDA available: True
CUDA runtime version: 11.6.124
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration: GPU 0: Tesla V100-PCIE-16GB
Nvidia driver version: 510.108.03
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_infer.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.4.1
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
Address sizes: 46 bits physical, 48 bits virtual
CPU(s): 6
On-line CPU(s) list: 0-5
Thread(s) per core: 1
Core(s) per socket: 6
Socket(s): 1
NUMA node(s): 1
Vendor ID: GenuineIntel
CPU family: 6
Model: 79
Model name: Intel(R) Xeon(R) CPU E5-2690 v4 @ 2.60GHz
Stepping: 1
CPU MHz: 2593.993
BogoMIPS: 5187.98
Hypervisor vendor: Microsoft
Virtualization type: full
L1d cache: 192 KiB
L1i cache: 192 KiB
L2 cache: 1.5 MiB
L3 cache: 35 MiB
NUMA node0 CPU(s): 0-5
Vulnerability Itlb multihit: KVM: Mitigation: VMX unsupported
Vulnerability L1tf: Mitigation; PTE Inversion
Vulnerability Mds: Mitigation; Clear CPU buffers; SMT Host state unknown
Vulnerability Meltdown: Mitigation; PTI
Vulnerability Mmio stale data: Vulnerable: Clear CPU buffers attempted, no microcode; SMT Host state unknown
Vulnerability Retbleed: Not affected
Vulnerability Spec store bypass: Vulnerable
Vulnerability Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization
Vulnerability Spectre v2: Mitigation; Retpolines, STIBP disabled, RSB filling, PBRSB-eIBRS Not affected
Vulnerability Srbds: Not affected
Vulnerability Tsx async abort: Mitigation; Clear CPU buffers; SMT Host state unknown
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ss ht syscall nx pdpe1gb rdtscp lm constant_tsc rep_good nopl xtopology cpuid pni pclmulqdq ssse3 fma cx16 pcid sse4_1 sse4_2 movbe popcnt aes xsave avx f16c rdrand hypervisor lahf_lm abm 3dnowprefetch invpcid_single pti fsgsbase bmi1 hle avx2 smep bmi2 erms invpcid rtm rdseed adx smap xsaveopt md_clear
Versions of relevant libraries:
[pip3] numpy==1.24.1
[pip3] torch==1.13.1+cu116
[conda] Could not collect
cc @jbschlosser @bhosmer @cpuhrsch @erichan1
| 2 |
3,516 | 94,414 |
[fake_tensor] torch._subclasses.fake_tensor.DynamicOutputShapeException when calling torch.nonzero using aot_function
|
triaged, oncall: pt2, module: dynamic shapes, module: graph breaks
|
### 🐛 Describe the bug
This issue appears related to https://github.com/pytorch/torchdynamo/issues/1886 but for torch.nonzero instead of torch.repeat_interleave (there are probably others as well).
For some reason using torch._dynamo.optimize works but using aot_function does not. I think this has something to do with needing a graph break but I'm not sure.
It's possible my minimal use case here is too simple; my real use case involves a bunch of computation and then using torch.nonzero to precompute tensor indices that are used later. I'm using aot_function to try and automatically generate code for the forward and backward passes. As a workaround I'm able to split my input into two functions, one that contains everything before the torch.nonzero call and another that takes the resulting indices from the torch.nonzero call as a parameter.
### Error logs
Failed to collect metadata on function, produced code may be suboptimal. Known situations this can occur are inference mode only compilation involving resize_ or prims (!schema.hasAnyAliasInfo() INTERNAL ASSERT FAILED); if your situation looks different please file a bug to PyTorch.
Traceback (most recent call last):
File "/torch/_functorch/aot_autograd.py", line 1381, in aot_wrapper_dedupe
fw_metadata, _out = run_functionalized_fw_and_collect_metadata(flat_fn)(
File "/torch/_functorch/aot_autograd.py", line 578, in inner
flat_f_outs = f(*flat_f_args)
File "/torch/_functorch/aot_autograd.py", line 2314, in flat_fn
tree_out = fn(*args, **kwargs)
File "<stdin>", line 2, in f
File "/torch/utils/_stats.py", line 15, in wrapper
return fn(*args, **kwargs)
File "/torch/_subclasses/fake_tensor.py", line 928, in __torch_dispatch__
op_impl_out = op_impl(self, func, *args, **kwargs)
File "/torch/_subclasses/fake_tensor.py", line 379, in dyn_shape
raise DynamicOutputShapeException(func)
torch._subclasses.fake_tensor.DynamicOutputShapeException: aten.nonzero.default
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/torch/_functorch/aot_autograd.py", line 2334, in returned_function
compiled_fn = create_aot_dispatcher_function(
File "/torch/2.0.0-03c7/lib/python3.10/site-packages/torch/_dynamo/utils.py", line 163, in time_wrapper
r = func(*args, **kwargs)
File "/torch/_functorch/aot_autograd.py", line 2184, in create_aot_dispatcher_function
compiled_fn = compiler_fn(flat_fn, fake_flat_args, aot_config)
File "/torch/_functorch/aot_autograd.py", line 1504, in aot_wrapper_dedupe
compiled_fn = compiler_fn(wrapped_flat_fn, deduped_flat_args, aot_config)
File "/torch/2.0.0-03c7/lib/python3.10/site-packages/torch/_functorch/aot_autograd.py", line 1056, in aot_dispatch_base
fw_module = make_fx(flat_fn, aot_config.decompositions)(*tmp_flat_args)
File "/torch/2.0.0-03c7/lib/python3.10/site-packages/torch/fx/experimental/proxy_tensor.py", line 716, in wrapped
t = dispatch_trace(wrap_key(func, args, fx_tracer), tracer=fx_tracer, concrete_args=tuple(phs))
File "/torch/2.0.0-03c7/lib/python3.10/site-packages/torch/_dynamo/eval_frame.py", line 209, in _fn
return fn(*args, **kwargs)
File "/torch/2.0.0-03c7/lib/python3.10/site-packages/torch/fx/experimental/proxy_tensor.py", line 450, in dispatch_trace
graph = tracer.trace(root, concrete_args)
File "/torch/2.0.0-03c7/lib/python3.10/site-packages/torch/_dynamo/eval_frame.py", line 209, in _fn
return fn(*args, **kwargs)
File "/torch/fx/_symbolic_trace.py", line 778, in trace
(self.create_arg(fn(*args)),),
File "/torch/fx/experimental/proxy_tensor.py", line 466, in wrapped
out = f(*tensors)
File "<string>", line 1, in <lambda>
File "/torch/_functorch/aot_autograd.py", line 1502, in wrapped_flat_fn
return flat_fn(*add_dupe_args(args))
File "/torch/_functorch/aot_autograd.py", line 2314, in flat_fn
tree_out = fn(*args, **kwargs)
File "<stdin>", line 2, in f
File "/torch/utils/_stats.py", line 15, in wrapper
return fn(*args, **kwargs)
File "/torch/fx/experimental/proxy_tensor.py", line 494, in __torch_dispatch__
return self.inner_torch_dispatch(func, types, args, kwargs)
File "/torch/2.0.0-03c7/lib/python3.10/site-packages/torch/fx/experimental/proxy_tensor.py", line 519, in inner_torch_dispatch
out = proxy_call(self, func, args, kwargs)
File "/torch/fx/experimental/proxy_tensor.py", line 352, in proxy_call
out = func(*args, **kwargs)
File "/torch/_ops.py", line 284, in __call__
return self._op(*args, **kwargs or {})
File "/torch/utils/_stats.py", line 15, in wrapper
return fn(*args, **kwargs)
File "/torch/_subclasses/fake_tensor.py", line 928, in __torch_dispatch__
op_impl_out = op_impl(self, func, *args, **kwargs)
File "/torch/_subclasses/fake_tensor.py", line 379, in dyn_shape
raise DynamicOutputShapeException(func)
torch._subclasses.fake_tensor.DynamicOutputShapeException: aten.nonzero.default
### Minified repro
import torch
import functorch
from typing import List
import torch._dynamo
from functorch.compile import aot_function, aot_module
def f(x):
return torch.nonzero(x > 0)
x = torch.ones([4,4])
x[0][3] = 0
x[1][2] = 0
opt_fn = torch._dynamo.optimize("eager")(f)
y = opt_fn(x) #Works
def my_compiler(gm: torch.fx.GraphModule, example_inputs: List[torch.Tensor]):
print(gm.code)
return gm.forward
aot_fun = aot_function(f,fw_compiler=my_compiler,bw_compiler=my_compiler)
y1 = aot_fun(x) #Error
### Versions
>>> print(torch.__version__)
2.0.0.dev20230207+cu117
>>> torch.version.git_version
'1530b798ceeff749a7cc5833d9d9627778bd998a'
cc @ezyang @msaroufim @wconstab @bdhirsh @anijain2305 @soumith @ngimel
| 10 |
3,517 | 94,397 |
jacfwd and jacrev are fundamentally broken for complex inputs
|
module: autograd, triaged, module: complex, complex_autograd, module: functorch
|
### 🐛 Describe the bug
Follow up of https://github.com/pytorch/pytorch/issues/90499
Consider a map `f : C -> C`. `f` is called holomorphic if it's complex differentiable. By the Cauchy-Riemann equations), one shows that this is equivalent to it being real differentiable as functions `f : R^2 -> R^2` and their `2 x 2` Jacobian being representable using one complex number. Now, there are functions that are not holomorphic, the simplest of them being `x.conj()`. These are functions whose Jacobian *cannot* be represented using complex numbers. For example the Jacobian of `x.conj()` is given by the matrix `[[1, 0], [0, 1]]`. The Jacobian vector product at a vector `v \in C` is given by `v.conj()`. There is no complex number `z` such that `z*v = v.conj()`.
All this says that `jacfwd` and `jacrev` should *always* return a real Jacobian, as there is no easy test for when a function is holomorphic. More on this a possible APIs moving forward at the end though.
A few examples that are broken ATM.
```python
>>> x = torch.tensor(0.5+1.7j, dtype=torch.complex64)
>>> jacfwd(torch.conj)(x) # should return tensor([[ 1, 0], [ 0, -1]])
tensor(1.-0.j)
>>> jacrev(torch.conj)(x) # should return tensor([[ 1, 0], [ 0, -1]])
tensor(1.-0.j)
>>> jacfwd(torch.abs)(x) # should return tensor([[0.2822, 0.9594]])
tensor(0.2822)
>>> jacrev(torch.abs)(x) # almost! Should return tensor([[0.2822], [0.9594]])
tensor(0.2822+0.9594j)
>>> jacfwd(torch.Tensor.cfloat)(torch.ones(())) # should return tensor([[1, 0]])
tensor(1.+0.j)
>>> jacrev(torch.Tensor.cfloat)(torch.ones(())) # should return tensor([[1], [0]])
tensor(1.)
```
Note that there is no non-constant holomorphic function from `R -> C` or `C -> R` so none of the functions above are holomorphic and PyTorch should never return complex "Jacobians".
There is no easy way to test whether a function is holomorphic, but we do know that a composition of holomorphic functions is holomorphic. As such, a possible API for this would be to have a kwarg `holomorphic: bool = False` that if set to `True` it tries to return a complex Jacobian if possible. This would be implemented by having a list of functions which are holomorphic, and making sure these are the only ones called in the computaiton of `jacfwd` / `jacrev`.
### Versions
master
cc @ezyang @gchanan @zou3519 @albanD @gqchen @pearu @nikitaved @soulitzer @Lezcano @Varal7 @anjali411 @dylanbespalko @mruberry @Chillee @samdow @soumith @kshitij12345 @janeyx99
| 30 |
3,518 | 94,395 |
`func.jacrev()` should be implemented as `func.jacfwd().mT.contiguous()`
|
triaged, module: complex, module: functorch
|
### 🐛 Describe the bug
Forward AD is (should be?) faster to execute theoretically than backward AD, because it does not need to create a graph, save intermediate tensors, etc. Furthermore its formulas are simpler than those for the backward, so they should be faster for that reason as well.
We would also not have issues like https://github.com/pytorch/pytorch/issues/90499.
### Versions
master
cc @ezyang @anjali411 @dylanbespalko @mruberry @Lezcano @nikitaved @zou3519 @Chillee @samdow @soumith @kshitij12345 @janeyx99
| 7 |
3,519 | 94,392 |
[pt20][eager] Lamb optimizer cannot be used in the compiled function
|
triaged, oncall: pt2, module: dynamo
|
### 🐛 Describe the bug
When I using `torch.compile` to compile a method including the `step` process of the `Lamb` optimizer. It would fail at the second iteration.
### Error logs
```python
[2023-02-08 19:17:53,174] torch._dynamo.variables.torch: [WARNING] Profiler will be ignored
Traceback (most recent call last):
File "/nvme/mazerun/.conda/envs/torch2.0/lib/python3.10/site-packages/torch/_dynamo/convert_frame.py", line 324, in _compile
out_code = transform_code_object(code, transform)
File "/nvme/mazerun/.conda/envs/torch2.0/lib/python3.10/site-packages/torch/_dynamo/bytecode_transformation.py", line 361, in transform_code_object
transformations(instructions, code_options)
File "/nvme/mazerun/.conda/envs/torch2.0/lib/python3.10/site-packages/torch/_dynamo/convert_frame.py", line 311, in transform
tracer.run()
File "/nvme/mazerun/.conda/envs/torch2.0/lib/python3.10/site-packages/torch/_dynamo/symbolic_convert.py", line 1683, in run
super().run()
File "/nvme/mazerun/.conda/envs/torch2.0/lib/python3.10/site-packages/torch/_dynamo/symbolic_convert.py", line 569, in run
and self.step()
File "/nvme/mazerun/.conda/envs/torch2.0/lib/python3.10/site-packages/torch/_dynamo/symbolic_convert.py", line 532, in step
getattr(self, inst.opname)(inst)
File "/nvme/mazerun/.conda/envs/torch2.0/lib/python3.10/site-packages/torch/_dynamo/symbolic_convert.py", line 338, in wrapper
return inner_fn(self, inst)
File "/nvme/mazerun/.conda/envs/torch2.0/lib/python3.10/site-packages/torch/_dynamo/symbolic_convert.py", line 144, in impl
self.push(fn_var.call_function(self, self.popn(nargs), {}))
File "/nvme/mazerun/.conda/envs/torch2.0/lib/python3.10/site-packages/torch/_dynamo/variables/builtin.py", line 495, in call_function
result = handler(tx, *args, **kwargs)
File "/nvme/mazerun/.conda/envs/torch2.0/lib/python3.10/site-packages/torch/_dynamo/variables/builtin.py", line 703, in call_getitem
return args[0].call_method(tx, "__getitem__", args[1:], kwargs)
File "/nvme/mazerun/.conda/envs/torch2.0/lib/python3.10/site-packages/torch/_dynamo/variables/dicts.py", line 68, in call_method
return self.getitem_const(args[0])
File "/nvme/mazerun/.conda/envs/torch2.0/lib/python3.10/site-packages/torch/_dynamo/variables/dicts.py", line 53, in getitem_const
return self.items[ConstDictVariable.get_key(arg)].add_options(self, arg)
KeyError: exp_avg_sq
from user code:
File "/nvme/mazerun/.conda/envs/torch2.0/lib/python3.10/site-packages/timm/optim/lamb.py", line 161, in step
exp_avg, exp_avg_sq = state['exp_avg'], state['exp_avg_sq']
Set torch._dynamo.config.verbose=True for more information
You can suppress this exception and fall back to eager by setting:
torch._dynamo.config.suppress_errors = True
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "/nvme/mazerun/repro.py", line 31, in <module>
opt(data, optimizer)
File "/nvme/mazerun/.conda/envs/torch2.0/lib/python3.10/site-packages/torch/_dynamo/eval_frame.py", line 209, in _fn
return fn(*args, **kwargs)
File "/nvme/mazerun/repro.py", line 20, in train_step
loss.backward()
File "/nvme/mazerun/repro.py", line 21, in <graph break in train_step>
optimizer.step()
File "/nvme/mazerun/.conda/envs/torch2.0/lib/python3.10/site-packages/torch/optim/optimizer.py", line 265, in wrapper
out = func(*args, **kwargs)
File "/nvme/mazerun/.conda/envs/torch2.0/lib/python3.10/site-packages/torch/utils/_contextlib.py", line 115, in decorate_context
return func(*args, **kwargs)
File "/nvme/mazerun/.conda/envs/torch2.0/lib/python3.10/site-packages/torch/_dynamo/eval_frame.py", line 330, in catch_errors
return callback(frame, cache_size, hooks)
File "/nvme/mazerun/.conda/envs/torch2.0/lib/python3.10/site-packages/torch/_dynamo/convert_frame.py", line 404, in _convert_frame
result = inner_convert(frame, cache_size, hooks)
File "/nvme/mazerun/.conda/envs/torch2.0/lib/python3.10/site-packages/torch/_dynamo/convert_frame.py", line 104, in _fn
return fn(*args, **kwargs)
File "/nvme/mazerun/.conda/envs/torch2.0/lib/python3.10/site-packages/torch/_dynamo/convert_frame.py", line 262, in _convert_frame_assert
return _compile(
File "/nvme/mazerun/.conda/envs/torch2.0/lib/python3.10/site-packages/torch/_dynamo/utils.py", line 163, in time_wrapper
r = func(*args, **kwargs)
File "/nvme/mazerun/.conda/envs/torch2.0/lib/python3.10/site-packages/torch/_dynamo/convert_frame.py", line 394, in _compile
raise InternalTorchDynamoError() from e
torch._dynamo.exc.InternalTorchDynamoError
```
### Minified repro
```python
from timm.optim import Lamb
import torch
import torch.nn as nn
class Repro(nn.Module):
def __init__(self):
super().__init__()
self.linear1 = nn.Linear(4, 4)
self.linear2 = nn.Linear(4, 4)
def forward(self, x):
x = self.linear1(x)
x = self.linear2(x)
return x
def train_step(self, x, optimizer):
loss = self(x).mean()
loss.backward()
optimizer.step()
if __name__ == "__main__":
model = Repro().cuda()
optimizer = Lamb(model.parameters())
opt = torch.compile(model.train_step, backend='eager')
data = torch.rand(2, 4).cuda()
for i in range(2):
opt(data, optimizer)
```
### Versions
```
timm 0.6.12
torch 2.0.0.dev20230207+cu117
torchvision 0.15.0.dev20230207+cu117
numpy 1.24.2
```
cc @ezyang @soumith @msaroufim @wconstab @ngimel @bdhirsh @voznesenskym @yanboliang @penguinwu @anijain2305 @EikanWang @jgong5 @Guobing-Chen @XiaobingSuper @zhuhaozhe @blzheng @Xia-Weiwen @wenzhe-nrv @jiayisunx @desertfire
| 1 |
3,520 | 94,388 |
Inconsistent results when using torch.Tensor.bernoulli with float instead of Tensor probabilities
|
module: distributions, triaged, module: random, module: determinism
|
### 🐛 Describe the bug
When using `torch.Tensor.bernoulli` with a float value for `p` the results does not match the results when doing bernoulli manually (see case B) or when using a Tensor storing the probabilities.
I created 4 tests:
- B: manual bernoulli
- C: the test that fails, using `p` as float
- D: using a Tensor for probabilities
- E: same, with inplace bernoulli
```python
import torch
A = torch.zeros(15)
p = 0.75
torch.manual_seed(314159)
R = torch.rand_like(A)
B = (R < p).to(torch.float)
print('B:', B)
torch.manual_seed(314159)
C = A.bernoulli(p)
print('C:', C)
torch.manual_seed(314159)
p_ = torch.ones_like(A) * p
D = p_.bernoulli()
print('D:', D)
torch.manual_seed(314159)
E = A.detach().clone().bernoulli_(p_)
print('E:', E)
print()
print('Summary')
print('B == C', (B == C).all())
print('B == D', (B == D).all())
print('B == E', (B == E).all())
```
Output:
```
B: tensor([1., 0., 1., 1., 1., 0., 1., 1., 1., 1., 1., 1., 1., 1., 1.])
C: tensor([1., 0., 0., 1., 1., 0., 1., 1., 1., 1., 1., 1., 1., 1., 1.])
D: tensor([1., 0., 1., 1., 1., 0., 1., 1., 1., 1., 1., 1., 1., 1., 1.])
E: tensor([1., 0., 1., 1., 1., 0., 1., 1., 1., 1., 1., 1., 1., 1., 1.])
Summary
B == C tensor(False)
B == D tensor(True)
B == E tensor(True)
```
As you can see, the 3rd value in case C is different from the other cases. You can also increase the size of A, same result. If you look at `R`, the 3rd value is not even close to 0.75, so it cannot be a numerical problem.
### Versions
Collecting environment information...
PyTorch version: 1.13.1+cu117
Is debug build: False
CUDA used to build PyTorch: 11.7
ROCM used to build PyTorch: N/A
OS: CentOS Linux 7 (Core) (x86_64)
GCC version: (GCC) 10.3.0
Clang version: Could not collect
CMake version: version 3.24.2
Libc version: glibc-2.17
Python version: 3.7.12 (default, Feb 6 2022, 20:29:18) [GCC 10.2.1 20210130 (Red Hat 10.2.1-11)] (64-bit runtime)
Python platform: Linux-3.10.0-1160.76.1.el7.x86_64-x86_64-with-centos-7.9.2009-Core
Is CUDA available: False
CUDA runtime version: 11.4.120
GPU models and configuration: Could not collect
Nvidia driver version: Could not collect
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.21.6
[pip3] pytorch-lightning==1.6.4
[pip3] torch==1.13.1
[pip3] torchmetrics==0.9.1
[pip3] torchvision==0.14.1
[conda] Could not collect
cc @fritzo @neerajprad @alicanb @nikitaved @pbelevich @mruberry @kurtamohler
| 1 |
3,521 | 94,378 |
[dynamo] equivalent conditions get different optimized code
|
triaged, oncall: pt2, module: dynamo
|
### 🐛 Describe the bug
When I run the following example code, I got three fx graphs. One is to get the result of `ta.sum() < 0`, the other two are to get the result of `3 * ta + tb` and `ta + 3 * tb` respectively. When I change the condition to `0 > ta.sum()`, dynamo fails to get a single fx graph and keeps the original bytecode.
```
import torch
import torch._dynamo as torchdynamo
import logging
torchdynamo.config.log_level = logging.INFO
torchdynamo.config.output_code = True
@torchdynamo.optimize("eager")
def toy_example(ta, tb):
if ta.sum() < 0:
return ta + 3 * tb
else:
return 3 * ta + tb
x = torch.randn(4, 4)
y = torch.randn(4, 4)
toy_example(x, y)
```
The output bytecode when the condition is `ta.sum() < 0`.
```
9 0 LOAD_GLOBAL 1 (__compiled_fn_0)
2 LOAD_FAST 0 (ta)
4 CALL_FUNCTION 1
6 UNPACK_SEQUENCE 1
8 POP_JUMP_IF_FALSE 20
10 LOAD_GLOBAL 2 (__resume_at_12_1)
12 LOAD_FAST 0 (ta)
14 LOAD_FAST 1 (tb)
16 CALL_FUNCTION 2
18 RETURN_VALUE
>> 20 LOAD_GLOBAL 3 (__resume_at_24_2)
22 LOAD_FAST 0 (ta)
24 LOAD_FAST 1 (tb)
26 CALL_FUNCTION 2
28 RETURN_VALUE
```
The output bytecode when the condition is `0 > ta.sum()`.
```
11 0 LOAD_CONST 1 (0)
2 LOAD_FAST 0 (ta)
4 LOAD_ATTR 0 (sum)
6 CALL_FUNCTION 0
8 COMPARE_OP 4 (>)
10 POP_JUMP_IF_FALSE 24
12 12 LOAD_FAST 0 (ta)
14 LOAD_CONST 2 (3)
16 LOAD_FAST 1 (tb)
18 BINARY_MULTIPLY
20 BINARY_ADD
22 RETURN_VALUE
14 >> 24 LOAD_CONST 2 (3)
26 LOAD_FAST 0 (ta)
28 BINARY_MULTIPLY
30 LOAD_FAST 1 (tb)
32 BINARY_ADD
34 RETURN_VALUE
```
I wonder whether it is a bug or feature, its behavior just changes though the two conditions are equivalent.
### Versions
Collecting environment information...
PyTorch version: 2.0.0.dev20230207+cu118
Is debug build: False
CUDA used to build PyTorch: 11.8
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.5 LTS (x86_64)
GCC version: (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0
Clang version: Could not collect
CMake version: version 3.25.0
Libc version: glibc-2.31
Python version: 3.9.16 (main, Jan 11 2023, 16:05:54) [GCC 11.2.0] (64-bit runtime)
Python platform: Linux-5.15.0-58-generic-x86_64-with-glibc2.31
Is CUDA available: True
CUDA runtime version: 11.8.89
GPU models and configuration:
GPU 0: NVIDIA A100 80GB PCIe
GPU 1: NVIDIA A100 80GB PCIe
GPU 2: NVIDIA A100 80GB PCIe
GPU 3: NVIDIA A100 80GB PCIe
GPU 4: NVIDIA A100 80GB PCIe
GPU 5: NVIDIA A100 80GB PCIe
GPU 6: NVIDIA A100 80GB PCIe
GPU 7: NVIDIA A100 80GB PCIe
Nvidia driver version: 520.61.05
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.24.1
[pip3] pytorch-triton==2.0.0+0d7e753227
[pip3] torch==2.0.0.dev20230207+cu118
[pip3] torchaudio==2.0.0.dev20230205+cu118
[pip3] torchdynamo==1.14.0.dev0
[pip3] torchtriton==2.0.0+f16138d447
[pip3] torchvision==0.15.0.dev20230205+cu118
[conda] numpy 1.24.1 pypi_0 pypi
[conda] pytorch-triton 2.0.0+0d7e753227 pypi_0 pypi
[conda] torch 2.0.0.dev20230207+cu118 pypi_0 pypi
[conda] torchaudio 2.0.0.dev20230205+cu118 pypi_0 pypi
[conda] torchdynamo 1.14.0.dev0 pypi_0 pypi
[conda] torchtriton 2.0.0+f16138d447 pypi_0 pypi
[conda] torchvision 0.15.0.dev20230205+cu118 pypi_0 pypi
cc @ezyang @soumith @msaroufim @wconstab @ngimel @bdhirsh @voznesenskym @yanboliang @penguinwu @anijain2305 @EikanWang @jgong5 @Guobing-Chen @XiaobingSuper @zhuhaozhe @blzheng @Xia-Weiwen @wenzhe-nrv @jiayisunx @desertfire
| 1 |
3,522 | 94,374 |
[fx] const_fold.split_const_subgraphs leads to UserWarning
|
triaged, module: fx
|
### 🐛 Describe the bug
```python
import functorch
import torch
from torch.fx.experimental import const_fold
from functools import partial
torch.manual_seed(0)
def fn(x, y):
z = x + torch.ones_like(x)
z1 = z.sin().cos().exp().log()
z2 = z1 * y
z3 = x + 2 * y
return z2, z3
x = torch.randn(3, 1)
y = torch.randn(3, 1)
par_fn = partial(fn, x)
graph = functorch.make_fx(par_fn)(y)
mod_folded: const_fold.FoldedGraphModule = const_fold.split_const_subgraphs(graph)
```
Output
```
torch/fx/experimental/const_fold.py:250: UserWarning: Attempted to insert a get_attr Node with no underlying reference in the owning GraphModule! Call GraphModule.add_submodule to add the necessary submodule, GraphModule.add_parameter to add the necessary Parameter, or nn.Module.register_buffer to add the necessary buffer
new_node = root_const_gm.graph.get_attr(in_node.target)
```
### Versions
master
cc @ezyang @SherlockNoMad @soumith @EikanWang @jgong5 @wenzhe-nrv
| 1 |
3,523 | 94,371 |
QAT + torch.autocast does not work with default settings, missing fused fake_quant support for half
|
oncall: quantization, low priority, triaged
|
### 🐛 Describe the bug
QAT + torch.autocast should be composable. It currently doesn't work with default settings of QAT:
```
import torch
import torch.nn as nn
from torch.ao.quantization.quantize_fx import prepare_fx
from troch.ao.quantization import get_default_qat_qconfig_mapping
m = nn.Sequential(nn.Linear(1, 1)).cuda()
data = torch.randn(1, 1).cuda()
# note: setting version to 0, which disables fused fake_quant, works without issues
qconfig_mapping = get_default_qat_qconfig_mapping('fbgemm', version=1)
mp = quantize_fx.prepare_fx(m, qconfig_mapping, (data,))
with torch.autocast('cuda'):
res = mp(data)
res.sum().backward()
```
The script above fails with this:
```
Traceback (most recent call last):
File "/data/users/vasiliy/pytorch/../tmp/test.py", line 23, in <module>
res = mp(data)
File "/data/users/vasiliy/pytorch/torch/fx/graph_module.py", line 660, in call_wrapped
return self._wrapped_call(self, *args, **kwargs)
File "/data/users/vasiliy/pytorch/torch/fx/graph_module.py", line 279, in __call__
raise e
File "/data/users/vasiliy/pytorch/torch/fx/graph_module.py", line 269, in __call__
return super(self.cls, obj).__call__(*args, **kwargs) # type: ignore[misc]
File "/data/users/vasiliy/pytorch/torch/nn/modules/module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "<eval_with_key>.2", line 8, in forward
File "/data/users/vasiliy/pytorch/torch/nn/modules/module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "/data/users/vasiliy/pytorch/torch/ao/quantization/fake_quantize.py", line 342, in forw
ard
return torch.fused_moving_avg_obs_fake_quant(
RuntimeError: expected scalar type Float but found Half
```
Note that using unfused fake_quants works correctly (this can be configured by using `version=0` in `get_default_qat_qconfig_mapping`. It looks like the cuda kernel for the fused fake quant + observer (`FusedObsFakeQuant.cu`) does not support `torch.half` yet.
### Versions
master
cc @jerryzh168 @jianyuh @raghuramank100 @jamesr66a @jgong5 @Xia-Weiwen @leslie-fang-intel
| 0 |
3,524 | 94,336 |
`scatter` fails the gradient computation in reverse mode for `src` when `index` is empty
|
module: autograd, triaged, actionable, module: scatter & gather ops
|
### 🐛 Describe the bug
`scatter` fails the gradient computation in reverse mode for `src` when `index` is empty. As documentation, when `index` is empty, `scatter` will just return the `self` unchanged. That said, the output has no relation with the `src` and should just return 0 as the gradient
```py
import torch
from torch.func import jacrev
torch.manual_seed(420)
src = torch.tensor([[1, 2, 3], [4, 5, 6]], dtype=torch.float)
input_tensor = torch.randn(2, 3)
def func(input_tensor, src):
index = torch.tensor([], dtype=torch.long)
output = torch.scatter(input_tensor, 0, index, src)
return output
print(input_tensor)
# tensor([[-1.6977, 0.6374, 0.0781],
# [-0.4140, 1.5172, 0.0473]])
print(func(input_tensor, src))
# tensor([[-1.6977, 0.6374, 0.0781],
# [-0.4140, 1.5172, 0.0473]])
print(jacrev(func, 1)(input_tensor, src))
# RuntimeError: Function ScatterBackward0 returned an invalid gradient at index 1 - got [0] but expected shape compatible with [2, 3]
```
### Versions
```
PyTorch version: 2.0.0.dev20230105
Is debug build: False
CUDA used to build PyTorch: 11.7
ROCM used to build PyTorch: N/A
OS: Ubuntu 22.04.1 LTS (x86_64)
GCC version: (Ubuntu 11.3.0-1ubuntu1~22.04) 11.3.0
Clang version: Could not collect
CMake version: version 3.22.1
Libc version: glibc-2.35
Python version: 3.9.15 (main, Nov 24 2022, 14:31:59) [GCC 11.2.0] (64-bit runtime)
Python platform: Linux-5.15.0-56-generic-x86_64-with-glibc2.35
Is CUDA available: True
CUDA runtime version: 11.7.99
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration:
GPU 0: NVIDIA GeForce RTX 3090
GPU 1: NVIDIA GeForce RTX 3090
GPU 2: NVIDIA GeForce RTX 3090
Nvidia driver version: 515.86.01
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_infer.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.4.1
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.23.5
[pip3] torch==2.0.0.dev20230105
[pip3] torchaudio==2.0.0.dev20230105
[pip3] torchvision==0.15.0.dev20230105
[conda] blas 1.0 mkl
[conda] mkl 2021.4.0 h06a4308_640
[conda] mkl-service 2.4.0 py39h7f8727e_0
[conda] mkl_fft 1.3.1 py39hd3c417c_0
[conda] mkl_random 1.2.2 py39h51133e4_0
[conda] numpy 1.23.5 py39h14f4228_0
[conda] numpy-base 1.23.5 py39h31eccc5_0
[conda] pytorch 2.0.0.dev20230105 py3.9_cuda11.7_cudnn8.5.0_0 pytorch-nightly
[conda] pytorch-cuda 11.7 h67b0de4_2 pytorch-nightly
[conda] pytorch-mutex 1.0 cuda pytorch-nightly
[conda] torchaudio 2.0.0.dev20230105 py39_cu117 pytorch-nightly
[conda] torchtriton 2.0.0+0d7e753227 py39 pytorch-nightly
[conda] torchvision 0.15.0.dev20230105 py39_cu117 pytorch-nightly
```
cc @ezyang @albanD @zou3519 @gqchen @pearu @nikitaved @soulitzer @Lezcano @Varal7 @mikaylagawarecki
| 2 |
3,525 | 94,333 |
cpu log1p for bfloat16 gives wrong result.
|
module: cpu, triaged, module: bfloat16
|
### 🐛 Describe the bug
cpu log1p for bfloat16 gives inf on big number.
```
>>> import torch
>>> x = torch.tensor(1.821e+38).bfloat16()
>>> x
tensor(1.8210e+38, dtype=torch.bfloat16)
>>> x.log1p()
tensor(inf, dtype=torch.bfloat16)
>>> x = torch.tensor(1.821e+38).bfloat16().cuda()
>>> x.log1p()
tensor(88., device='cuda:0', dtype=torch.bfloat16)
```
### Versions
I'm on upstream master commit:
```
commit 59c1b5025f64f9a8ce87fc96b738fbbbb1191d91 (HEAD -> master, origin/master, origin/HEAD)
Author: Jerry Zhang <jerryzh168@gmail.com>
Date: Mon Feb 6 10:45:04 2023 -0800
[quant][fx][pt2e] Refactor prepare so it's aligned better with the new API plan in pt2e (#94011)
Summary:
There are three things that happens in the current prepare code,
(1). user express their intention of how they want the model to be quantized with QConfigMapping, we translate that to
node.meta["target_dtype_info"]
(2). we validate the setting against BackendConfig
(3). insert observers based on the validated node.meta["target_dtype_info"]
previously (2) and (3) are mixed together, this PR tries to move (2) closer to (1), with one edge case left, this refactor
moves us closer to our target design for quantization in pytorch 2.0 export path
this is a follow up PR for https://github.com/pytorch/pytorch/pull/92641
Test Plan:
python test/test_quantization.py TestQuantizeFx
python test/test_quantization.py TestQuantizeFxOps
python test/test_quantization.py TestQuantizeFxModels
Reviewers:
Subscribers:
Tasks:
Tags:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94011
Approved by: https://github.com/vkuzo
```
```
root@d446ac0a67d7:/opt/pytorch/pytorch# python collect_env.py
Collecting environment information...
PyTorch version: 2.0.0a0+git59c1b50
Is debug build: False
CUDA used to build PyTorch: 12.0
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.5 LTS (x86_64)
GCC version: (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0
Clang version: Could not collect
CMake version: version 3.25.2
Libc version: glibc-2.31
Python version: 3.10.9 (main, Feb 7 2023, 00:37:12) [GCC 9.4.0] (64-bit runtime)
Python platform: Linux-5.4.0-126-generic-x86_64-with-glibc2.31
Is CUDA available: True
CUDA runtime version: 12.0.140
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration: GPU 0: NVIDIA A100 80GB PCIe
Nvidia driver version: 525.85.05
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.7.0
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.7.0
/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.7.0
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_infer.so.8.7.0
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.7.0
/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.7.0
/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.7.0
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
Address sizes: 43 bits physical, 48 bits virtual
CPU(s): 64
On-line CPU(s) list: 0-63
Thread(s) per core: 2
Core(s) per socket: 32
Socket(s): 1
NUMA node(s): 1
Vendor ID: AuthenticAMD
CPU family: 23
Model: 49
Model name: AMD Ryzen Threadripper PRO 3975WX 32-Cores
Stepping: 0
Frequency boost: enabled
CPU MHz: 2062.854
CPU max MHz: 3500.0000
CPU min MHz: 2200.0000
BogoMIPS: 6987.16
Virtualization: AMD-V
L1d cache: 1 MiB
L1i cache: 1 MiB
L2 cache: 16 MiB
L3 cache: 128 MiB
NUMA node0 CPU(s): 0-63
Vulnerability Itlb multihit: Not affected
Vulnerability L1tf: Not affected
Vulnerability Mds: Not affected
Vulnerability Meltdown: Not affected
Vulnerability Mmio stale data: Not affected
Vulnerability Spec store bypass: Vulnerable
Vulnerability Spectre v1: Vulnerable: __user pointer sanitization and usercopy barriers only; no swapgs barriers
Vulnerability Spectre v2: Vulnerable, IBPB: disabled, STIBP: disabled
Vulnerability Srbds: Not affected
Vulnerability Tsx async abort: Not affected
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ht syscall nx mmxext fxsr_opt pdpe1gb rdtscp lm constant_tsc rep_good nopl nonstop_tsc cpuid extd_apicid aperfmperf pni pclmulqdq monitor ssse3 fma cx16 sse4_1 sse4_2 x2apic movbe popcnt aes xsave avx f16c rdrand lahf_lm cmp_legacy svm extapic cr8_legacy abm sse4a misalignsse 3dnowprefetch osvw ibs skinit wdt tce topoext perfctr_core perfctr_nb bpext perfctr_llc mwaitx cpb cat_l3 cdp_l3 hw_pstate sme ssbd mba sev ibpb stibp vmmcall fsgsbase bmi1 avx2 smep bmi2 cqm rdt_a rdseed adx smap clflushopt clwb sha_ni xsaveopt xsavec xgetbv1 xsaves cqm_llc cqm_occup_llc cqm_mbm_total cqm_mbm_local clzero irperf xsaveerptr wbnoinvd arat npt lbrv svm_lock nrip_save tsc_scale vmcb_clean flushbyasid decodeassists pausefilter pfthreshold avic v_vmsave_vmload vgif umip rdpid overflow_recov succor smca
Versions of relevant libraries:
[pip3] numpy==1.23.5
[pip3] torch==2.0.0a0+git59c1b50
[pip3] torchvision==0.15.0a0+85983a5
[conda] Could not collect
```
cc @jgong5 @mingfeima @XiaobingSuper @sanchitintel @ashokei @jingxu10
| 4 |
3,526 | 94,322 |
RFC: Enabling AVX512 dispatch for compute-intensive ATen ops
|
module: performance, module: cpu, triaged, module: intel
|
# 🚀 The feature, motivation and pitch
## Summary
On some more recent x86-64 architectures, AVX512 performs better than AVX2 on compute-bound workloads, and AVX512 instructions do not cause as much throttling as they did on older CPU architectures. Eager mode performance can thus be improved on such machines.
Targeting for PyTorch 2.1, we propose enabling the dispatch of AVX512 ATen kernels if they'd be _expected_ to perform better than their AVX2 counterparts. The default ATen CPU capability would thus be AVX512.
## Approach
### Naïve solution
First, we would extend & enhance the coverage of individual ATen ops in [OpBench](https://github.com/pytorch/pytorch/tree/master/benchmarks/operator_benchmark), which would offer us more insights into ATen kernel performance characteristics by varying certain factors such as vectorization ISA, thread-pool size, memory layout, dtype, etc. OpBench already benchmarks for various input-sizes. #104655 is an example PR towards this endeavor.
[We are trying to enable AVX512 dispatch for kernels that _always_ perform well with AVX512](https://github.com/pytorch/pytorch/pull/104165). This solution is easier to implement, as it entails only enabling AVX512 dispatch for compute-bound ATen ops, and disabling AVX512 dispatch for memory-bound ATen ops. We would not compile AVX512 kernels of memory-bound ATen ops to reduce the binary-size. This approach is quite restrictive & would disable AVX512 dispatch for most ATen ops. This set of kernels is quite small, as we are aiming for high precision & low recall.
### Can we do better?
Rather than disable AVX512 dispatch for all kernels that perform poorly with AVX512 in certain cases, we can enable AVX512 dispatch for the cases in which AVX512 performance would be better. We would have to analyze oodles of data gleaned with OpBench (n factors such as CPU generation, dtype, input size, number of threads, etc) to drive this task.
The second solution requires more fine-grained analysis of ATen ops' characteristics, so we are starting with the first one, and plan to gradually move towards the second one.
### Tasks that will be completed soon (have open PRs)
- [ ] Extend OpBench coverage - #104655
- [ ] Enable AVX512 dispatch of those AVX512 ATen kernels that would always perform better than their AVX2 counterparts. - #104165
### Tasks under investigation
- [ ] A new design PoC for AVX-n kernel dispatch.
- [ ] Adoption of new design.
We welcome your comments & are open to changing our approach after discussion. Thanks!
cc @ngimel @jgong5 @mingfeima @XiaobingSuper @ashokei @jingxu10 @frank-wei @malfet
### Alternatives
_No response_
### Additional context
Currently, the default ATen CPU capability is AVX2 but users can use the environment variable `ATEN_CPU_CAPABILITY=avx512` to use AVX512 ATen kernels
| 0 |
3,527 | 94,311 |
Unimplemented lowering - torch.jit.script
|
oncall: jit
|
### 🐛 Describe the bug
When running a simple module compiled with `torch.jit.script`, I run into an error asking me to report a bug :slightly_smiling_face: Code to reproduce:
```python
import torch
class Dummy(torch.nn.Module):
def __init__(self):
super().__init__()
self.zero = torch.tensor(0)
def forward(self):
return self.zero.round().int()
dummy = Dummy()
traced = torch.jit.script(dummy)
traced()
traced() # the bug only appears on the second time the module is run
```
The error I get:
```
RuntimeError Traceback (most recent call last)
Cell In[10], line 1
----> 1 traced()
File /storage/Users/mikolaj/repos/ml-mri/.venv/lib/python3.8/site-packages/torch/nn/modules/module.py:1194, in Module._call_impl(self, *input, **kwargs)
1190 # If we don't have any hooks, we want to skip the rest of the logic in
1191 # this function, and just call forward.
1192 if not (self._backward_hooks or self._forward_hooks or self._forward_pre_hooks or _global_backward_hooks
1193 or _global_forward_hooks or _global_forward_pre_hooks):
-> 1194 return forward_call(*input, **kwargs)
1195 # Do not call functions when jit is used
1196 full_backward_hooks, non_full_backward_hooks = [], []
RuntimeError: false INTERNAL ASSERT FAILED at "../torch/csrc/jit/tensorexpr/llvm_codegen.cpp":1967, please report a bug to PyTorch. Unimplemented lowering for intrinsic '25' for input of dtype Long in LLVM codegen of the fuser. This error occured in the fuser. You can turn off the fuser with torch.jit.enable_fusion(False).
```
The bug doesn't happen when I actually use `torch.tensor(0)` instead of `self.zero`, and `.round()` and `.int()` are both necessary, but the same thing happens with them in either order.
### Versions
Collecting environment information...
PyTorch version: 1.13.1+cu117
Is debug build: False
CUDA used to build PyTorch: 11.7
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.5 LTS (x86_64)
GCC version: (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0
Clang version: Could not collect
CMake version: version 3.16.3
Libc version: glibc-2.31
Python version: 3.8.10 (default, Nov 14 2022, 12:59:47) [GCC 9.4.0] (64-bit runtime)
Python platform: Linux-5.15.0-58-generic-x86_64-with-glibc2.29
Is CUDA available: True
CUDA runtime version: Could not collect
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration: GPU 0: NVIDIA GeForce GTX 1060 6GB
Nvidia driver version: 510.108.03
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.7.0
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.7.0
/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.7.0
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_infer.so.8.7.0
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.7.0
/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.7.0
/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.7.0
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
Address sizes: 39 bits physical, 48 bits virtual
CPU(s): 12
On-line CPU(s) list: 0-11
Thread(s) per core: 2
Core(s) per socket: 6
Socket(s): 1
NUMA node(s): 1
Vendor ID: GenuineIntel
CPU family: 6
Model: 158
Model name: Intel(R) Core(TM) i7-8700 CPU @ 3.20GHz
Stepping: 10
CPU MHz: 3876.903
CPU max MHz: 4600,0000
CPU min MHz: 800,0000
BogoMIPS: 6399.96
Virtualization: VT-x
L1d cache: 192 KiB
L1i cache: 192 KiB
L2 cache: 1,5 MiB
L3 cache: 12 MiB
NUMA node0 CPU(s): 0-11
Vulnerability Itlb multihit: KVM: Mitigation: VMX disabled
Vulnerability L1tf: Mitigation; PTE Inversion; VMX conditional cache flushes, SMT vulnerable
Vulnerability Mds: Mitigation; Clear CPU buffers; SMT vulnerable
Vulnerability Meltdown: Mitigation; PTI
Vulnerability Mmio stale data: Mitigation; Clear CPU buffers; SMT vulnerable
Vulnerability Retbleed: Mitigation; IBRS
Vulnerability Spec store bypass: Mitigation; Speculative Store Bypass disabled via prctl and seccomp
Vulnerability Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization
Vulnerability Spectre v2: Mitigation; IBRS, IBPB conditional, RSB filling, PBRSB-eIBRS Not affected
Vulnerability Srbds: Mitigation; Microcode
Vulnerability Tsx async abort: Mitigation; TSX disabled
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc art arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc cpuid aperfmperf pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm 3dnowprefetch cpuid_fault epb invpcid_single pti ssbd ibrs ibpb stibp tpr_shadow vnmi flexpriority ept vpid ept_ad fsgsbase tsc_adjust bmi1 avx2 smep bmi2 erms invpcid mpx rdseed adx smap clflushopt intel_pt xsaveopt xsavec xgetbv1 xsaves dtherm ida arat pln pts hwp hwp_notify hwp_act_window hwp_epp md_clear flush_l1d arch_capabilities
Versions of relevant libraries:
[pip3] mypy==0.982
[pip3] mypy-extensions==0.4.3
[pip3] numpy==1.24.1
[pip3] pytorch-lightning==1.8.6
[pip3] torch==1.13.1
[pip3] torch-interpol==0.2.1
[pip3] torchmetrics==0.11.0
[pip3] torchvision==0.14.1
[conda] Could not collect
cc @EikanWang @jgong5 @wenzhe-nrv @sanchitintel
| 2 |
3,528 | 94,304 |
RuntimeError: p.block != nullptr && p.block->ptr != nullptr INTERNAL ASSERT FAILED at "../c10/cuda/CUDACachingAllocator.cpp":1275, please report a bug to PyTorch.
|
triaged, module: assert failure, module: CUDACachingAllocator
|
### 🐛 Describe the bug
self.model = timm.create_model('swin_large_patch4_window12_384', num_classes=4, pretrained=False).to(device)
pre = torch.load(
'model_swin_large_patch4_window12_384.pth', map_location=device)
new_state = OrderedDict()
for k, v in pre.items(): # 去除关键字”model"
name = k[6:]
new_state[name] = v
self.model.load_state_dict(new_state)
self.model.eval()
If the code is written as follows——
self.model = timm.create_model('swin_large_patch4_window12_384', num_classes=10, pretrained=False).to(device)
pre = torch.load(
'model_swin_large_patch4_window12_384.pth', map_location=device)
new_state = OrderedDict()
for k, v in pre.items(): # 去除关键字”model"
name = k[6:]
new_state[name] = v
self.model.load_state_dict(new_state)
for param in self.model.parameters():
param.requires_grad = False
self.model.eval()
this error will not appear!!
### Error logs
outputs = model_D5(img, imfo)
File "/opt/conda/envs/pyt/lib/python3.7/site-packages/torch/nn/modules/module.py", line 1130, in _call_impl
return forward_call(*input, **kwargs)
File "/data/zqf/embryo_prediction_rate/ExtractModel.py", line 25, in forward
File "/opt/conda/envs/pyt/lib/python3.7/site-packages/torch/nn/modules/module.py", line 1130, in _call_impl
return forward_call(*input, **kwargs)
File "/opt/conda/envs/pyt/lib/python3.7/site-packages/timm/models/swin_transformer.py", line 568, in forward
x = self.forward_features(x)
File "/opt/conda/envs/pyt/lib/python3.7/site-packages/timm/models/swin_transformer.py", line 558, in forward_features
x = self.layers(x)
File "/opt/conda/envs/pyt/lib/python3.7/site-packages/torch/nn/modules/module.py", line 1130, in _call_impl
return forward_call(*input, **kwargs)
File "/opt/conda/envs/pyt/lib/python3.7/site-packages/torch/nn/modules/container.py", line 139, in forward
input = module(input)
File "/opt/conda/envs/pyt/lib/python3.7/site-packages/torch/nn/modules/module.py", line 1130, in _call_impl
return forward_call(*input, **kwargs)
File "/opt/conda/envs/pyt/lib/python3.7/site-packages/timm/models/swin_transformer.py", line 420, in forward
x = self.blocks(x)
File "/opt/conda/envs/pyt/lib/python3.7/site-packages/torch/nn/modules/module.py", line 1130, in _call_impl
return forward_call(*input, **kwargs)
File "/opt/conda/envs/pyt/lib/python3.7/site-packages/torch/nn/modules/container.py", line 139, in forward
input = module(input)
File "/opt/conda/envs/pyt/lib/python3.7/site-packages/torch/nn/modules/module.py", line 1130, in _call_impl
return forward_call(*input, **kwargs)
File "/opt/conda/envs/pyt/lib/python3.7/site-packages/timm/models/swin_transformer.py", line 325, in forward
x = x + self.drop_path(self.mlp(self.norm2(x)))
File "/opt/conda/envs/pyt/lib/python3.7/site-packages/torch/nn/modules/module.py", line 1130, in _call_impl
return forward_call(*input, **kwargs)
File "/opt/conda/envs/pyt/lib/python3.7/site-packages/timm/models/layers/mlp.py", line 27, in forward
x = self.fc1(x)
File "/opt/conda/envs/pyt/lib/python3.7/site-packages/torch/nn/modules/module.py", line 1130, in _call_impl
return forward_call(*input, **kwargs)
File "/opt/conda/envs/pyt/lib/python3.7/site-packages/torch/nn/modules/linear.py", line 114, in forward
return F.linear(input, self.weight, self.bias)
RuntimeError: p.block != nullptr && p.block->ptr != nullptr INTERNAL ASSERT FAILED at "../c10/cuda/CUDACachingAllocator.cpp":1275, please report a bug to PyTorch.
### Minified repro
_No response_
### Versions
pytorch 1.12.0+cu113
cc @ezyang @soumith @msaroufim @wconstab @ngimel @bdhirsh
| 1 |
3,529 | 94,294 |
CUBLAS_STATUS_NOT_SUPPORTED when calling cublasDgemv
|
module: cuda, triaged, module: cublas
|
### 🐛 Describe the bug
When running the `distributed/test_data_parallel` or `test_nn` test it fails with
```
ERROR: test_data_parallel (__main__.TestDataParallel)
----------------------------------------------------------------------
Traceback (most recent call last):
File "/dev/shm/s3248973-EasyBuild/PyTorch/1.12.1/foss-2021b-CUDA-11.4.1/pytorch-v1.12.1/test/distributed/test_data_parallel.py", line 353, in test_data_parallel
out = dp.data_parallel(l, i, dev_id)
File "/tmp/easybuild-tmp/eb-HhIeo8/tmpUxRyEj/lib/python3.9/site-packages/torch/nn/parallel/data_parallel.py", line 231, in data_parallel
outputs = parallel_apply(replicas, inputs, module_kwargs, used_device_ids)
File "/tmp/easybuild-tmp/eb-HhIeo8/tmpUxRyEj/lib/python3.9/site-packages/torch/nn/parallel/parallel_apply.py", line 86, in parallel_apply
output.reraise()
File "/tmp/easybuild-tmp/eb-HhIeo8/tmpUxRyEj/lib/python3.9/site-packages/torch/_utils.py", line 461, in reraise
raise exception
RuntimeError: Caught RuntimeError in replica 0 on device 0.
Original Traceback (most recent call last):
File "/tmp/easybuild-tmp/eb-HhIeo8/tmpUxRyEj/lib/python3.9/site-packages/torch/nn/parallel/parallel_apply.py", line 61, in _worker
output = module(*input, **kwargs)
File "/tmp/easybuild-tmp/eb-HhIeo8/tmpUxRyEj/lib/python3.9/site-packages/torch/nn/modules/module.py", line 1130, in _call_impl
return forward_call(*input, **kwargs)
File "/tmp/easybuild-tmp/eb-HhIeo8/tmpUxRyEj/lib/python3.9/site-packages/torch/nn/modules/linear.py", line 114, in forward
return F.linear(input, self.weight, self.bias)
RuntimeError: CUDA error: CUBLAS_STATUS_NOT_SUPPORTED when calling `cublasLtMatmulAlgoGetHeuristic( ltHandle, computeDesc.descriptor(), Adesc.descriptor(), Bdesc.descriptor(), Cdesc.descriptor(), Cdesc.descriptor(), preference.descriptor(), 1, &heuristicResult, &returnedResult)`
```
and
```
ERROR: test_spectral_norm (__main__.TestNN)
----------------------------------------------------------------------
Traceback (most recent call last):
File "/dev/shm/s3248973-EasyBuild/PyTorch/1.12.1/foss-2021b-CUDA-11.4.1/pytorch-v1.12.1/test/test_nn.py", line 4593, in test_spectral_norm
gradcheck(fn, (input.clone().requires_grad_(),), check_batched_grad=False)
File "/tmp/easybuild-tmp/eb-HhIeo8/tmpUxRyEj/lib/python3.9/site-packages/torch/testing/_internal/common_utils.py", line 3019, in gradcheck
return torch.autograd.gradcheck(fn, inputs, **kwargs)
File "/tmp/easybuild-tmp/eb-HhIeo8/tmpUxRyEj/lib/python3.9/site-packages/torch/autograd/gradcheck.py", line 1414, in gradcheck
return _gradcheck_helper(**args)
File "/tmp/easybuild-tmp/eb-HhIeo8/tmpUxRyEj/lib/python3.9/site-packages/torch/autograd/gradcheck.py", line 1423, in _gradcheck_helper
func_out = func(*tupled_inputs)
File "/dev/shm/s3248973-EasyBuild/PyTorch/1.12.1/foss-2021b-CUDA-11.4.1/pytorch-v1.12.1/test/test_nn.py", line 4590, in fn
out1 = wrapped_m(input)
File "/tmp/easybuild-tmp/eb-HhIeo8/tmpUxRyEj/lib/python3.9/site-packages/torch/nn/modules/module.py", line 1130, in _call_impl
return forward_call(*input, **kwargs)
File "/tmp/easybuild-tmp/eb-HhIeo8/tmpUxRyEj/lib/python3.9/site-packages/torch/nn/parallel/data_parallel.py", line 168, in forward
outputs = self.parallel_apply(replicas, inputs, kwargs)
File "/tmp/easybuild-tmp/eb-HhIeo8/tmpUxRyEj/lib/python3.9/site-packages/torch/nn/parallel/data_parallel.py", line 178, in parallel_apply
return parallel_apply(replicas, inputs, kwargs, self.device_ids[:len(replicas)])
File "/tmp/easybuild-tmp/eb-HhIeo8/tmpUxRyEj/lib/python3.9/site-packages/torch/nn/parallel/parallel_apply.py", line 86, in parallel_apply
output.reraise()
File "/tmp/easybuild-tmp/eb-HhIeo8/tmpUxRyEj/lib/python3.9/site-packages/torch/_utils.py", line 461, in reraise
raise exception
RuntimeError: Caught RuntimeError in replica 0 on device 0.
Original Traceback (most recent call last):
File "/tmp/easybuild-tmp/eb-HhIeo8/tmpUxRyEj/lib/python3.9/site-packages/torch/nn/parallel/parallel_apply.py", line 61, in _worker
output = module(*input, **kwargs)
File "/tmp/easybuild-tmp/eb-HhIeo8/tmpUxRyEj/lib/python3.9/site-packages/torch/nn/modules/module.py", line 1137, in _call_impl
result = hook(self, input)
File "/tmp/easybuild-tmp/eb-HhIeo8/tmpUxRyEj/lib/python3.9/site-packages/torch/nn/utils/spectral_norm.py", line 105, in __call__
setattr(module, self.name, self.compute_weight(module, do_power_iteration=module.training))
File "/tmp/easybuild-tmp/eb-HhIeo8/tmpUxRyEj/lib/python3.9/site-packages/torch/nn/utils/spectral_norm.py", line 84, in compute_weight
v = normalize(torch.mv(weight_mat.t(), u), dim=0, eps=self.eps, out=v)
RuntimeError: CUDA error: CUBLAS_STATUS_NOT_SUPPORTED when calling `cublasDgemv(handle, op, m, n, &alpha, a, lda, x, incx, &beta, y, incy)`
```
I found that `test_nn` uses `torch.nn.DataParallel` when multiple GPUs are present so I assume it is the same issue.
That error isn't listed in the NVIDIA docs for `cublasDgemv` so I don't know why it fails.
### Versions
- PyTorch 1.12.1
- CUDA 11.4.1
- Python 3.9
cc @ngimel @csarofeen @ptrblck @xwang233
| 9 |
3,530 | 94,293 |
torchdynamo.export doesn't work with float multiplication
|
triaged, oncall: pt2, module: dynamo
|
### 🐛 Describe the bug
```python
class A(torch.nn.Module):
def __init__(self, feature=4.0):
super().__init__()
self.feature = feature
def forward(self, x):
return int(x.shape[-1] * self.feature // 3)
torchdynamo.config.dynamic_shapes = True
torchdynamo.config.specialize_int_float = False
gm, _ = torchdynamo.export(A(), torch.ones(6, 1), aten_graph=True, tracing_mode="symbolic")
print(gm.graph)
print(gm(torch.ones(6, 1)))
```
Gives following error:
```
[2023-02-07 01:02:45,906] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo start tracing forward
[2023-02-07 01:02:45,910] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo done tracing forward (RETURN_VALUE)
[2023-02-07 01:02:45,912] torch._dynamo.output_graph: [INFO] Step 2: calling compiler function dynamo_normalization_capturing_compiler
[2023-02-07 01:02:45,912] torch._dynamo.output_graph: [INFO] Step 2: done compiler function dynamo_normalization_capturing_compiler
Traceback (most recent call last):
File "/mnt/xarfuse/uid-25280/92716d6a-seed-nspid4026533181_cgpid14161962-ns-4026533178/torch/fx/graph_module.py", line 269, in __call__
return super(self.cls, obj).__call__(*args, **kwargs) # type: ignore[misc]
File "/mnt/xarfuse/uid-25280/92716d6a-seed-nspid4026533181_cgpid14161962-ns-4026533178/torch/nn/modules/module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "<eval_with_key>.44", line 8, in forward
floordiv = mul.__floordiv__(3); mul = None
AttributeError: 'NotImplementedType' object has no attribute '__floordiv__'
Call using an FX-traced Module, line 8 of the traced Module's generated forward function:
mul = getitem_1.__mul__(4.0); getitem_1 = None
floordiv = mul.__floordiv__(3); mul = None
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ <--- HERE
sym_int = torch.sym_int(floordiv); floordiv = None
return (sym_int,)
'NotImplementedType' object has no attribute '__floordiv__'
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
<ipython-input-16-abb9cc343398> in <module>
10 torchdynamo.config.dynamic_shapes = True
11 torchdynamo.config.specialize_int_float = False
---> 12 gm, _ = torchdynamo.export(A(), torch.ones(6, 1), aten_graph=True, tracing_mode="symbolic")
13 print(gm.graph)
14 print(gm(torch.ones(6, 1)))
/mnt/xarfuse/uid-25280/92716d6a-seed-nspid4026533181_cgpid14161962-ns-4026533178/torch/_dynamo/eval_frame.py in export(f, aten_graph, decomposition_table, tracing_mode, *args, **kwargs)
591 )(f)
592 # TODO(voz): We may have instances of `f` that mutate inputs, we should track sideffects and reject.
--> 593 result_traced = opt_f(*args, **kwargs)
594 remove_from_cache(f)
595
/mnt/xarfuse/uid-25280/92716d6a-seed-nspid4026533181_cgpid14161962-ns-4026533178/torch/nn/modules/module.py in _call_impl(self, *args, **kwargs)
1499 or _global_backward_pre_hooks or _global_backward_hooks
1500 or _global_forward_hooks or _global_forward_pre_hooks):
-> 1501 return forward_call(*args, **kwargs)
1502 # Do not call functions when jit is used
1503 full_backward_hooks, non_full_backward_hooks = [], []
/mnt/xarfuse/uid-25280/92716d6a-seed-nspid4026533181_cgpid14161962-ns-4026533178/torch/_dynamo/eval_frame.py in forward(self, *args, **kwargs)
80
81 def forward(self, *args, **kwargs):
---> 82 return self.dynamo_ctx(self._orig_mod.forward)(*args, **kwargs)
83
84
/mnt/xarfuse/uid-25280/92716d6a-seed-nspid4026533181_cgpid14161962-ns-4026533178/torch/_dynamo/eval_frame.py in _fn(*args, **kwargs)
207 dynamic_ctx.__enter__()
208 try:
--> 209 return fn(*args, **kwargs)
210 finally:
211 set_eval_frame(prior)
<ipython-input-16-abb9cc343398> in forward(self, x)
4 self.feature = feature
5
----> 6 def forward(self, x):
7 return int(x.shape[-1] * self.feature // 3)
8
/mnt/xarfuse/uid-25280/92716d6a-seed-nspid4026533181_cgpid14161962-ns-4026533178/torch/_dynamo/eval_frame.py in _fn(*args, **kwargs)
207 dynamic_ctx.__enter__()
208 try:
--> 209 return fn(*args, **kwargs)
210 finally:
211 set_eval_frame(prior)
/mnt/xarfuse/uid-25280/92716d6a-seed-nspid4026533181_cgpid14161962-ns-4026533178/torch/_dynamo/eval_frame.py in result_capturing_wrapper(*graph_inputs)
575 graph_captured_input = graph_inputs
576 assert graph is not None
--> 577 graph_captured_result = graph(*graph_inputs)
578 return graph_captured_result
579
/mnt/xarfuse/uid-25280/92716d6a-seed-nspid4026533181_cgpid14161962-ns-4026533178/torch/fx/graph_module.py in call_wrapped(self, *args, **kwargs)
658
659 def call_wrapped(self, *args, **kwargs):
--> 660 return self._wrapped_call(self, *args, **kwargs)
661
662 cls.__call__ = call_wrapped
/mnt/xarfuse/uid-25280/92716d6a-seed-nspid4026533181_cgpid14161962-ns-4026533178/torch/fx/graph_module.py in __call__(self, obj, *args, **kwargs)
275 print(_WrappedCall._generate_error_message(topmost_framesummary),
276 file=sys.stderr)
--> 277 raise e.with_traceback(None)
278 else:
279 raise e
AttributeError: 'NotImplementedType' object has no attribute '__floordiv__'
```
I think this happens when we try to extract example_value by running the node which throws an NotImplemented exception which is incorrectly wrapped as python value.
cc: @ezyang @voznesenskym @Chillee
### Versions
master
cc @ezyang @soumith @msaroufim @wconstab @ngimel @bdhirsh @voznesenskym @yanboliang @penguinwu @anijain2305 @EikanWang @jgong5 @Guobing-Chen @XiaobingSuper @zhuhaozhe @blzheng @Xia-Weiwen @wenzhe-nrv @jiayisunx @desertfire
| 1 |
3,531 | 94,292 |
What type of attributes does symbolic function support?
|
triaged
|
### 📚 The doc issue
I read the doc of [symbolic](https://pytorch.org/docs/stable/onnx.html#static-symbolic-method) but no related introduction.
I read the source code and get supported [suffix](https://github.com/pytorch/pytorch/blob/master/torch/onnx/_patch_torch.py#L15), but I still don't know what types each letter represents.
### Suggest a potential alternative/fix
By the way, I want to ask whether symbolic support boolean attributes and integer array attributes?
| 0 |
3,532 | 94,288 |
when group number is 2,and channel is 2, dim H and dim W is 1, N is 10,the result should be 0,but now it is not 0
|
needs reproduction, module: nn, triaged
|
### 🐛 Describe the bug
>>> import torch
>>> I = nn.GroupNorm(27,27)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
NameError: name 'nn' is not defined
>>> I = torch.nn.GroupNorm(27,27)
>>> a = randn(7,27)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
NameError: name 'randn' is not defined
>>> a = torch.randn(7,27)
>>> torch.manual_seed(5)
<torch._C.Generator object at 0x7f4f1834ecd0>
>>> a = torch.randn(7,27)
>>> I(a)
tensor([[ 1.2420e-06, 4.4450e-06, 2.8146e-05, -2.7697e-05, -2.7378e-05,
2.4824e-06, 3.0881e-07, -1.2316e-05, 1.3925e-06, -2.2128e-07,
-6.3924e-07, -2.2589e-06, -1.4301e-05, 7.2754e-06, -5.9164e-06,
-7.5575e-06, 5.4801e-06, -1.0688e-05, -3.2239e-06, -6.6209e-06,
1.5516e-08, 1.4135e-06, 1.4828e-06, -2.2104e-07, -7.4949e-06,
3.0266e-06, 1.6571e-07],
[ 1.3628e-05, 6.1235e-06, 3.9398e-06, 2.9506e-06, -1.7197e-05,
-3.2242e-07, 6.8471e-06, 1.8621e-05, 1.5777e-06, -1.8100e-05,
3.0841e-06, -1.2667e-05, -2.3845e-05, -3.8274e-07, -1.3123e-05,
1.8532e-07, -2.5002e-05, 1.4786e-05, -3.5292e-06, 4.6312e-06,
-1.9182e-05, 1.0847e-05, 1.4511e-06, -3.7718e-06, 1.2998e-05,
1.6685e-06, -9.0398e-07],
[-3.1831e-06, 1.4123e-05, 8.5552e-06, -1.4640e-05, 1.6709e-05,
-6.3199e-07, -1.5356e-06, -7.1696e-06, 2.7216e-06, -4.6709e-07,
-5.7627e-06, -6.7139e-06, -2.5343e-06, 8.6930e-06, 3.7191e-07,
-4.7174e-07, -5.8475e-06, 1.8038e-06, 2.7000e-06, 7.4899e-06,
-1.5217e-06, -1.7065e-06, 1.6060e-05, 1.6792e-06, -2.2474e-05,
7.8671e-07, 1.2854e-05],
[ 6.3056e-07, 2.7398e-06, -7.0782e-06, -3.6881e-07, -2.0484e-06,
-7.2676e-06, -1.3552e-06, -2.5187e-06, -2.5435e-06, -1.1345e-05,
6.4821e-06, 1.4438e-05, -4.5725e-07, -8.0922e-07, -8.1018e-07,
-9.8973e-06, -4.4933e-07, 1.0686e-05, -6.4787e-06, 1.0367e-05,
2.2368e-06, 4.6794e-07, -1.4239e-06, 1.9035e-06, 1.0057e-05,
-3.8203e-06, 1.3498e-05],
[-9.5793e-07, -1.1093e-06, 5.8058e-06, 2.2553e-06, -1.2267e-06,
-3.7207e-06, -5.9217e-06, 6.5989e-06, -1.0802e-07, -1.1834e-05,
1.5252e-05, -3.0359e-06, 1.1093e-06, -1.1412e-05, 8.8085e-06,
3.8818e-06, 2.8706e-06, 1.6555e-06, 2.7609e-05, 2.8201e-08,
2.6906e-06, 1.4979e-05, -5.7026e-07, -5.8951e-07, 6.7806e-06,
4.1802e-06, 4.3913e-07],
[-1.5025e-05, -4.5446e-06, -3.5332e-06, 2.6579e-06, 1.3302e-06,
-6.0469e-06, 2.1574e-06, 4.8372e-06, -1.7929e-05, -9.9434e-06,
2.1165e-07, -5.5064e-06, -1.2874e-05, 1.3432e-05, -4.8724e-06,
-2.4987e-06, -6.0053e-07, 1.6070e-06, -1.7542e-05, -1.2139e-06,
-9.6766e-08, 3.4656e-06, 3.0953e-07, -1.6683e-06, -7.7117e-06,
-8.4427e-07, -1.5087e-05],
[ 6.0170e-06, -1.2650e-06, -1.0803e-05, -2.4405e-06, -4.0247e-06,
1.1792e-05, 1.3692e-05, -1.0577e-05, -3.6142e-06, 1.1554e-06,
-2.4077e-05, 2.3481e-06, 1.5554e-06, -3.3266e-08, 6.3666e-06,
-1.3359e-05, 3.8248e-07, 5.4745e-06, 2.8983e-06, 5.4382e-06,
4.1145e-06, 2.4674e-06, 2.2288e-05, -1.3930e-07, 5.4979e-06,
-6.9288e-06, -3.5444e-06]], grad_fn=<NativeGroupNormBackward>)
### Versions
wget https://raw.githubusercontent.com/pytorch/pytorch/master/torch/utils/collect_env.py
# For security purposes, please check the contents of collect_env.py before running it.
python collect_env.py
cc @albanD @mruberry @jbschlosser @walterddr @saketh-are
| 4 |
3,533 | 94,286 |
bugs when try parallel test code
|
oncall: distributed
|
### 🐛 Describe the bug
I am try the test parallel code from pytorch: https://pytorch.org/tutorials/intermediate/ddp_tutorial.html
but it shows this error on my cluster machine:
2
Running basic DDP example on rank 0.
Running basic DDP example on rank 1.
[W socket.cpp:426] [c10d] The server socket cannot be initialized on [::]:12355 (errno: 97 - Address family not supported by protocol).
[W socket.cpp:601] [c10d] The client socket cannot be initialized to connect to [localhost.localdomain]:12355 (errno: 97 - Address family not supported by protocol).
[W socket.cpp:601] [c10d] The client socket cannot be initialized to connect to [localhost.localdomain]:12355 (errno: 97 - Address family not supported by protocol).
[W socket.cpp:601] [c10d] The client socket cannot be initialized to connect to [localhost.localdomain]:12355 (errno: 97 - Address family not supported by protocol).
[W socket.cpp:601] [c10d] The client socket cannot be initialized to connect to [localhost.localdomain]:12355 (errno: 97 - Address family not supported by protocol).
could you please help me ? Thanks!
### Versions
Collecting environment information...
PyTorch version: 1.13.1+cu117
Is debug build: False
CUDA used to build PyTorch: 11.7
ROCM used to build PyTorch: N/A
OS: CentOS Linux 7 (Core) (x86_64)
GCC version: (GCC) 4.8.5 20150623 (Red Hat 4.8.5-39)
Clang version: Could not collect
CMake version: Could not collect
Libc version: glibc-2.17
Python version: 3.8.15 | packaged by conda-forge | (default, Jan 26 2023, 10:47:49) [GCC 11.3.0] (64-bit runtime)
Python platform: Linux-3.10.0-1160.71.1.el7.x86_64-x86_64-with-glibc2.10
Is CUDA available: True
CUDA runtime version: Could not collect
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration:
GPU 0: NVIDIA A100-PCIE-40GB
GPU 1: NVIDIA A100-PCIE-40GB
GPU 2: NVIDIA A100-PCIE-40GB
GPU 3: NVIDIA A100-PCIE-40GB
Nvidia driver version: 495.44
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 48
On-line CPU(s) list: 0-47
Thread(s) per core: 1
Core(s) per socket: 24
Socket(s): 2
NUMA node(s): 2
Vendor ID: GenuineIntel
CPU family: 6
Model: 106
Model name: Intel(R) Xeon(R) Gold 6342 CPU @ 2.80GHz
Stepping: 6
CPU MHz: 2800.000
BogoMIPS: 5600.00
Virtualization: VT-x
L1d cache: 48K
L1i cache: 32K
L2 cache: 1280K
L3 cache: 36864K
NUMA node0 CPU(s): 0,2,4,6,8,10,12,14,16,18,20,22,24,26,28,30,32,34,36,38,40,42,44,46
NUMA node1 CPU(s): 1,3,5,7,9,11,13,15,17,19,21,23,25,27,29,31,33,35,37,39,41,43,45,47
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb
rdtscp lm constant_tsc art arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc aperfmperf eagerfpu pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3
sdbg fma cx16 xtpr pdcm pcid dca sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm 3dnowprefetch epb cat_l3 invpcid_sing
le intel_pt ssbd mba ibrs ibpb stibp ibrs_enhanced tpr_shadow vnmi flexpriority ept vpid fsgsbase tsc_adjust bmi1 hle avx2 smep bmi2 erms invpcid rtm cqm rdt_a av
x512f avx512dq rdseed adx smap avx512ifma clflushopt clwb avx512cd sha_ni avx512bw avx512vl xsaveopt xsavec xgetbv1 cqm_llc cqm_occup_llc cqm_mbm_total cqm_mbm_lo
cal dtherm ida arat pln pts avx512vbmi umip pku ospke avx512_vbmi2 gfni vaes vpclmulqdq avx512_vnni avx512_bitalg avx512_vpopcntdq md_clear pconfig spec_ctrl inte
l_stibp flush_l1d arch_capabilities
Versions of relevant libraries:
[pip3] discrete-key-value-bottleneck-pytorch==0.0.7
[pip3] enformer-pytorch==0.5.6
[pip3] numpy==1.23.5
[pip3] torch==1.13.1
[pip3] torchaudio==0.7.0a0+a853dff
[pip3] torchmetrics==0.11.0
[pip3] torchvision==0.8.2
[pip3] vector-quantize-pytorch==0.10.15
[conda] blas 1.0 mkl
[conda] cudatoolkit 11.0.3 h88f8997_11 conda-forge
[conda] discrete-key-value-bottleneck-pytorch 0.0.7 pypi_0 pypi
[conda] enformer-pytorch 0.5.6 dev_0 <develop>
[conda] mkl 2021.4.0 h06a4308_640
[conda] mkl-service 2.4.0 py38h95df7f1_0 conda-forge
[conda] mkl_fft 1.3.1 py38h8666266_1 conda-forge
[conda] mkl_random 1.2.2 py38h1abd341_0 conda-forge
[conda] numpy 1.23.5 py38h14f4228_0
[conda] numpy-base 1.23.5 py38h31eccc5_0
[conda] torch 1.13.1 pypi_0 pypi
[conda] torchaudio 0.7.2 py38 pytorch
[conda] torchmetrics 0.11.0 pypi_0 pypi
[conda] torchvision 0.8.2 py38_cu110 pytorch
[conda] vector-quantize-pytorch 0.10.15 pypi_0 pypi
cc @mrshenli @pritamdamania87 @zhaojuanmao @satgera @rohan-varma @gqchen @aazzolini @osalpekar @jiayisuse @H-Huang @kwen2501 @awgu
| 1 |
3,534 | 94,280 |
ONNX export produces hundreds of weight/bias/Matmul/etc. files alongside the `.onnx` file, and the `.onnx` file seems to be incorrect.
|
module: onnx, triaged
|
### 🐛 Describe the bug
When exporting to ONNX, [hundreds of files](https://i.imgur.com/4wg7Unf.png) are produced with names like:
```
Qformer.bert.encoder.layer.8.intermediate_query.dense.bias
onnx__MatMul_6331
visual_encoder.blocks.30.mlp.fc2.weight
```
and the final ONNX file doesn't seem to be correct - I think it's missing an input (it has the `image` input, but not the `text` one). Though that *could* just be a mistake in the export options that I've set, or something.
Here's a notebook that replicates this. Just click "Runtime > Run all", but I think you'll need a high-RAM runtime else it might crash: https://colab.research.google.com/gist/josephrocca/2d367775455b4f0d72b40a274d7b05e0/copy-of-blip2_image_text_matching.ipynb
A commenter on [this thread](https://discuss.pytorch.org/t/why-torch-onnx-export-generate-so-many-files/157151/3?u=josephrocca) suggested that this happens when the model is larger than 2GB, which seems plausible because in this case the model is indeed larger than 2GB.
IIUC, normally if an ONNX file is larger than 2GB (a protobuf limit?), the model will be packaged into a zip file along with the weights as separate files, so maybe that's what is supposed to happen here, except for some reason the zip isn't being created?
### Versions
```
PyTorch version: 1.13.1+cu116
Is debug build: False
CUDA used to build PyTorch: 11.6
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.5 LTS (x86_64)
GCC version: (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0
Clang version: 10.0.0-4ubuntu1
CMake version: version 3.22.6
Libc version: glibc-2.31
Python version: 3.8.10 (default, Nov 14 2022, 12:59:47) [GCC 9.4.0] (64-bit runtime)
Python platform: Linux-5.10.147+-x86_64-with-glibc2.29
Is CUDA available: False
CUDA runtime version: 11.2.152
CUDA_MODULE_LOADING set to: N/A
GPU models and configuration: Could not collect
Nvidia driver version: Could not collect
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.1.1
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.1.1
/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.1.1
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_infer.so.8.1.1
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.1.1
/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.1.1
/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.1.1
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
Address sizes: 46 bits physical, 48 bits virtual
CPU(s): 4
On-line CPU(s) list: 0-3
Thread(s) per core: 2
Core(s) per socket: 2
Socket(s): 1
NUMA node(s): 1
Vendor ID: GenuineIntel
CPU family: 6
Model: 79
Model name: Intel(R) Xeon(R) CPU @ 2.20GHz
Stepping: 0
CPU MHz: 2199.998
BogoMIPS: 4399.99
Hypervisor vendor: KVM
Virtualization type: full
L1d cache: 64 KiB
L1i cache: 64 KiB
L2 cache: 512 KiB
L3 cache: 55 MiB
NUMA node0 CPU(s): 0-3
Vulnerability Itlb multihit: Not affected
Vulnerability L1tf: Mitigation; PTE Inversion
Vulnerability Mds: Vulnerable; SMT Host state unknown
Vulnerability Meltdown: Vulnerable
Vulnerability Mmio stale data: Vulnerable
Vulnerability Retbleed: Vulnerable
Vulnerability Spec store bypass: Vulnerable
Vulnerability Spectre v1: Vulnerable: __user pointer sanitization and usercopy barriers only; no swapgs barriers
Vulnerability Spectre v2: Vulnerable, IBPB: disabled, STIBP: disabled, PBRSB-eIBRS: Not affected
Vulnerability Srbds: Not affected
Vulnerability Tsx async abort: Vulnerable
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ss ht syscall nx pdpe1gb rdtscp lm constant_tsc rep_good nopl xtopology nonstop_tsc cpuid tsc_known_freq pni pclmulqdq ssse3 fma cx16 pcid sse4_1 sse4_2 x2apic movbe popcnt aes xsave avx f16c rdrand hypervisor lahf_lm abm 3dnowprefetch invpcid_single ssbd ibrs ibpb stibp fsgsbase tsc_adjust bmi1 hle avx2 smep bmi2 erms invpcid rtm rdseed adx smap xsaveopt arat md_clear arch_capabilities
Versions of relevant libraries:
[pip3] numpy==1.21.6
[pip3] torch==1.13.1+cu116
[pip3] torchaudio==0.13.1+cu116
[pip3] torchsummary==1.5.1
[pip3] torchtext==0.14.1
[pip3] torchvision==0.14.1+cu116
[conda] Could not collect
```
| 2 |
3,535 | 94,261 |
GroupNorm ONNX export does not reproduce same output
|
module: onnx, triaged
|
### 🐛 Describe the bug
If I export the nn.GroupNorm module, the created ONNX export does not create the same output as the torch module. Minimal reproducable example:
```
import onnxruntime as ort
import torch.nn as nn
import torch
test_input = torch.randn(1, 256, 256, 256)
b = nn.GroupNorm(32, 256)
test_output = b(test_input)
torch.onnx.export(b, test_input, "group_norm.onnx", verbose=False, opset_version=17)
sess = ort.InferenceSession("group_norm.onnx", providers=['CPUExecutionProvider'])
onnx_out = sess.run(None, {sess.get_inputs()[0].name: test_input.detach().numpy()})
torch.testing.assert_close(torch.from_numpy(onnx_out[0]), test_output)
```
### Versions
PyTorch version: 1.13.1+cu117
Is debug build: False
CUDA used to build PyTorch: 11.7
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.5 LTS (x86_64)
GCC version: (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0
Clang version: Could not collect
CMake version: version 3.16.3
Libc version: glibc-2.17
Python version: 3.7.16 (default, Jan 17 2023, 22:20:44) [GCC 11.2.0] (64-bit runtime)
Python platform: Linux-5.15.0-1026-aws-x86_64-with-debian-bullseye-sid
Is CUDA available: True
CUDA runtime version: 11.2.152
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration: GPU 0: NVIDIA A10G
Nvidia driver version: 515.65.01
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
Address sizes: 48 bits physical, 48 bits virtual
CPU(s): 4
On-line CPU(s) list: 0-3
Thread(s) per core: 2
Core(s) per socket: 2
Socket(s): 1
NUMA node(s): 1
Vendor ID: AuthenticAMD
CPU family: 23
Model: 49
Model name: AMD EPYC 7R32
Stepping: 0
CPU MHz: 2799.622
BogoMIPS: 5599.24
Hypervisor vendor: KVM
Virtualization type: full
L1d cache: 64 KiB
L1i cache: 64 KiB
L2 cache: 1 MiB
L3 cache: 8 MiB
NUMA node0 CPU(s): 0-3
Vulnerability Itlb multihit: Not affected
Vulnerability L1tf: Not affected
Vulnerability Mds: Not affected
Vulnerability Meltdown: Not affected
Vulnerability Mmio stale data: Not affected
Vulnerability Retbleed: Mitigation; untrained return thunk; SMT enabled with STIBP protection
Vulnerability Spec store bypass: Mitigation; Speculative Store Bypass disabled via prctl and seccomp
Vulnerability Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization
Vulnerability Spectre v2: Mitigation; Retpolines, IBPB conditional, STIBP always-on, RSB filling, PBRSB-eIBRS Not affected
Vulnerability Srbds: Not affected
Vulnerability Tsx async abort: Not affected
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ht syscall nx mmxext fxsr_opt pdpe1gb rdtscp lm constant_tsc rep_good nopl nonstop_tsc cpuid extd_apicid aperfmperf tsc_known_freq pni pclmulqdq ssse3 fma cx16 sse4_1 sse4_2 movbe popcnt aes xsave avx f16c rdrand hypervisor lahf_lm cmp_legacy cr8_legacy abm sse4a misalignsse 3dnowprefetch topoext ssbd ibrs ibpb stibp vmmcall fsgsbase bmi1 avx2 smep bmi2 rdseed adx smap clflushopt clwb sha_ni xsaveopt xsavec xgetbv1 clzero xsaveerptr rdpru wbnoinvd arat npt nrip_save rdpid
Versions of relevant libraries:
[pip3] numpy==1.21.6
[pip3] torch==1.13.1
[pip3] torchaudio==0.13.1
[pip3] torchvision==0.14.1
[conda] numpy 1.21.6 pypi_0 pypi
[conda] torch 1.13.1 pypi_0 pypi
[conda] torchaudio 0.13.1 pypi_0 pypi
[conda] torchvision 0.14.1 pypi_0 pypi
| 0 |
3,536 | 94,238 |
`PyTorchFileWriter` should drop the GIL while writing files
|
module: serialization, triaged
|
### 🐛 Describe the bug
`torch.save` does all of its actual file IO via the internal `PyTorchFileWriter` class.
However, this class does not drop the GIL while doing file I/O, resulting in long hangs if one thread is executing a `torch.save`. We can see this by repeatedly saving a tensor on a thread while watching for overly-long hangs on another:
https://gist.github.com/nelhage/1567e34c9e385c7e57ce88440a3b1525
Running this, I see output like
```
❯ python torch_save.py
Unexpected latency! Sleep=0.82s
Saved tensor in 0.80s
Unexpected latency! Sleep=0.19s
Saved tensor in 1.00s
Unexpected latency! Sleep=0.15s
Unexpected latency! Sleep=0.17s
Saved tensor in 1.06s
Unexpected latency! Sleep=0.19s
Saved tensor in 1.05s
Unexpected latency! Sleep=0.81s
Saved tensor in 1.03s
```
By comparison, if I save the tensor using `numpy`, we see no such hangs:
```
❯ python torch_save.py numpy
Saved tensor in 0.54s
Saved tensor in 0.63s
Saved tensor in 0.65s
Saved tensor in 0.65s
Saved tensor in 0.74s
Saved tensor in 0.65s
Saved tensor in 0.65s
Saved tensor in 0.72s
…
```
### Versions
```
PyTorch version: 1.13.0+cu117
Is debug build: False
CUDA used to build PyTorch: 11.7
ROCM used to build PyTorch: N/A
OS: Ubuntu 22.04.1 LTS (x86_64)
GCC version: (Ubuntu 11.3.0-1ubuntu1~22.04) 11.3.0
Clang version: 16.0.0-++20220813052912+eaf0aa1f1fbd-1~exp1~20220813173018.344
CMake version: version 3.22.1
Libc version: glibc-2.35
Python version: 3.11.0 (main, Nov 6 2022, 16:51:40) [GCC 11.3.0] (64-bit runtime)
Python platform: Linux-5.15.0-56-generic-x86_64-with-glibc2.35
Is CUDA available: True
CUDA runtime version: Could not collect
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration: GPU 0: NVIDIA GeForce RTX 2080 SUPER
Nvidia driver version: 515.86.01
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.7.0
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.7.0
/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.7.0
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_infer.so.8.7.0
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.7.0
/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.7.0
/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.7.0
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Address sizes: 43 bits physical, 48 bits virtual
Byte Order: Little Endian
CPU(s): 24
On-line CPU(s) list: 0-23
Vendor ID: AuthenticAMD
Model name: AMD Ryzen 9 3900X 12-Core Processor
CPU family: 23
Model: 113
Thread(s) per core: 2
Core(s) per socket: 12
Socket(s): 1
Stepping: 0
Frequency boost: enabled
CPU max MHz: 4672.0698
CPU min MHz: 2200.0000
BogoMIPS: 7585.70
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ht syscall nx mmxext fxsr_opt pdpe1gb rdtscp lm constant_tsc rep_good nopl nonstop_tsc cpuid extd_apicid aperfmperf rapl pni pclmulqdq monitor ssse3 fma cx16 sse4_1 sse4_2 movbe popcnt aes xsave avx f16c rdrand lahf_lm cmp_legacy svm extapic cr8_legacy abm sse4a misalignsse 3dnowprefetch osvw ibs skinit wdt tce topoext perfctr_core perfctr_nb bpext perfctr_llc mwaitx cpb cat_l3 cdp_l3 hw_pstate ssbd mba ibpb stibp vmmcall fsgsbase bmi1 avx2 smep bmi2 cqm rdt_a rdseed adx smap clflushopt clwb sha_ni xsaveopt xsavec xgetbv1 xsaves cqm_llc cqm_occup_llc cqm_mbm_total cqm_mbm_local clzero irperf xsaveerptr rdpru wbnoinvd arat npt lbrv svm_lock nrip_save tsc_scale vmcb_clean flushbyasid decodeassists pausefilter pfthreshold avic v_vmsave_vmload vgif v_spec_ctrl umip rdpid overflow_recov succor smca sme sev sev_es
Virtualization: AMD-V
L1d cache: 384 KiB (12 instances)
L1i cache: 384 KiB (12 instances)
L2 cache: 6 MiB (12 instances)
L3 cache: 64 MiB (4 instances)
NUMA node(s): 1
NUMA node0 CPU(s): 0-23
Vulnerability Itlb multihit: Not affected
Vulnerability L1tf: Not affected
Vulnerability Mds: Not affected
Vulnerability Meltdown: Not affected
Vulnerability Mmio stale data: Not affected
Vulnerability Retbleed: Mitigation; untrained return thunk; SMT enabled with STIBP protection
Vulnerability Spec store bypass: Mitigation; Speculative Store Bypass disabled via prctl and seccomp
Vulnerability Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization
Vulnerability Spectre v2: Mitigation; Retpolines, IBPB conditional, STIBP always-on, RSB filling, PBRSB-eIBRS Not affected
Vulnerability Srbds: Not affected
Vulnerability Tsx async abort: Not affected
Versions of relevant libraries:
[pip3] mypy-extensions==0.4.3
[pip3] numpy==1.23.4
[pip3] torch==1.13.0
[conda] Could not collect
```
cc @mruberry
| 1 |
3,537 | 94,233 |
unsqueeze a single dimension multiple times
|
feature, triaged, module: viewing and reshaping
|
### 🚀 The feature, motivation and pitch
Originally discussed in https://github.com/pytorch/pytorch/issues/30702#issuecomment-570678356. One usecase is that it could be used for (implementation details of) broadcasting right by inserting unitary dimensions `lambda x, y: y.unsqueeze(dim = -1, repeat = x.dim() - y.dim())`
In the wild would be useful e.g. here: https://github.com/pytorch/pytorch/pull/94227#pullrequestreview-1286167590
It already exists in C++: https://github.com/pytorch/pytorch/blob/68f378210666c079326139b6557e8a601fc89ebf/tools/autograd/templates/Functions.cpp#L173
### Alternatives
_No response_
### Additional context
_No response_
| 1 |
3,538 | 94,208 |
`zeros_like` + `fill_` makes the gradient computation in forward mode fail
|
triaged, module: forward ad
|
### 🐛 Describe the bug
`zeros_like` + `fill_` makes the gradient computation in forward mode fail
```py
import torch
from torch.autograd.functional import jacobian
torch.manual_seed(420)
input_data = torch.rand(3, 3)
def func(input_data):
# output_data = input_data.clone() # this works
output_data = torch.zeros_like(input_data) # this fails
output_data.fill_(input_data.mean())
return output_data
jacobian(func, input_data, vectorize=True, strategy="forward-mode")
# RuntimeError: output with shape [1, 3, 3] doesn't match the broadcast shape [9, 3, 3]
```
By contrast, when replacing `torch.zeros_like` with `clone`, this will succeed and return the correct gradient
```py
import torch
from torch.autograd.functional import jacobian
torch.manual_seed(420)
input_data = torch.rand(3, 3)
def func(input_data):
output_data = input_data.clone() # this works
# output_data = torch.zeros_like(input_data) # this fails
output_data.fill_(input_data.mean())
return output_data
print(jacobian(func, input_data, vectorize=True, strategy="forward-mode"))
# succeed
```
### Versions
```
PyTorch version: 2.0.0.dev20230105
Is debug build: False
CUDA used to build PyTorch: 11.7
ROCM used to build PyTorch: N/A
OS: Ubuntu 22.04.1 LTS (x86_64)
GCC version: (Ubuntu 11.3.0-1ubuntu1~22.04) 11.3.0
Clang version: Could not collect
CMake version: version 3.22.1
Libc version: glibc-2.35
Python version: 3.9.15 (main, Nov 24 2022, 14:31:59) [GCC 11.2.0] (64-bit runtime)
Python platform: Linux-5.15.0-56-generic-x86_64-with-glibc2.35
Is CUDA available: True
CUDA runtime version: 11.7.99
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration:
GPU 0: NVIDIA GeForce RTX 3090
GPU 1: NVIDIA GeForce RTX 3090
GPU 2: NVIDIA GeForce RTX 3090
Nvidia driver version: 515.86.01
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_infer.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.4.1
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.23.5
[pip3] torch==2.0.0.dev20230105
[pip3] torchaudio==2.0.0.dev20230105
[pip3] torchvision==0.15.0.dev20230105
[conda] blas 1.0 mkl
[conda] mkl 2021.4.0 h06a4308_640
[conda] mkl-service 2.4.0 py39h7f8727e_0
[conda] mkl_fft 1.3.1 py39hd3c417c_0
[conda] mkl_random 1.2.2 py39h51133e4_0
[conda] numpy 1.23.5 py39h14f4228_0
[conda] numpy-base 1.23.5 py39h31eccc5_0
[conda] pytorch 2.0.0.dev20230105 py3.9_cuda11.7_cudnn8.5.0_0 pytorch-nightly
[conda] pytorch-cuda 11.7 h67b0de4_2 pytorch-nightly
[conda] pytorch-mutex 1.0 cuda pytorch-nightly
[conda] torchaudio 2.0.0.dev20230105 py39_cu117 pytorch-nightly
[conda] torchtriton 2.0.0+0d7e753227 py39 pytorch-nightly
[conda] torchvision 0.15.0.dev20230105 py39_cu117 pytorch-nightly
```
| 0 |
3,539 | 94,186 |
Addition of hybrid CSR tensors produces incorrect and invalid CSR tensor
|
module: sparse, triaged, module: correctness (silent), bug
|
## Issue description
As in the title
## Code example
```python
>>> x=torch.ones((2, 2, 2)).to_sparse(layout=torch.sparse_csr, dense_dim=1)
>>> x
tensor(crow_indices=tensor([0, 2, 4]),
col_indices=tensor([0, 1, 0, 1]),
values=tensor([[1., 1.],
[1., 1.],
[1., 1.],
[1., 1.]]), size=(2, 2, 2), nnz=4,
layout=torch.sparse_csr)
>>> x + x
tensor(crow_indices=tensor([0, 2, 4]),
col_indices=tensor([0, 1, 0, 1]),
values=tensor([2., 2., 2., 2.]), size=(2, 2, 2), nnz=4,
layout=torch.sparse_csr)
```
The expected result is
```python
>>> x + x
tensor(crow_indices=tensor([0, 2, 4]),
col_indices=tensor([0, 1, 0, 1]),
values=tensor([[2., 2.],
[2., 2.],
[2., 2.],
[2., 2.]]), size=(2, 2, 2), nnz=4,
layout=torch.sparse_csr)
```
## System Info
- PyTorch: master
cc @alexsamardzic @nikitaved @cpuhrsch @amjames @bhosmer
| 2 |
3,540 | 94,185 |
Addition of CSC/BSR/BSC tensors raises RuntimeError exceptions
|
module: sparse, triaged
|
## Issue description
As in the title.
## Code example
```python
>>> x=torch.ones((2, 2)).to_sparse_csc()
>>> x + x
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
RuntimeError: col_indices expected sparse row compressed tensor layout but got SparseCsc
>>> x=torch.ones((2, 2)).to_sparse_bsr((1, 1))
>>> x + x
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
RuntimeError: empty_sparse_compressed expected sparse compressed (non-block) tensor layout but got SparseBsr
>>> x=torch.ones((2, 2)).to_sparse_bsc((1, 1))
>>> x + x
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
RuntimeError: empty_sparse_compressed expected sparse compressed (non-block) tensor layout but got SparseBsc
```
The addition of CSR tensors works as expected:
```python
>>> x=torch.ones((2, 2)).to_sparse_csr()
>>> x + x
tensor(crow_indices=tensor([0, 2, 4]),
col_indices=tensor([0, 1, 0, 1]),
values=tensor([2., 2., 2., 2.]), size=(2, 2), nnz=4,
layout=torch.sparse_csr)
```
## System Info
- PyTorch: master
cc @alexsamardzic @nikitaved @cpuhrsch @amjames @bhosmer
| 0 |
3,541 | 94,183 |
Addition of batch CSR tensors produces incorrect and invalid CSR tensor
|
module: sparse, triaged, module: correctness (silent), bug
|
## Issue description
As in the title.
## Code example
```python
>>> x=torch.ones((2, 2, 3)).to_sparse_csr()
>>> x
tensor(crow_indices=tensor([[0, 3, 6],
[0, 3, 6]]),
col_indices=tensor([[0, 1, 2, 0, 1, 2],
[0, 1, 2, 0, 1, 2]]),
values=tensor([[1., 1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1., 1.]]), size=(2, 2, 3), nnz=6,
layout=torch.sparse_csr)
>>> y=x.add(x) # or x + x
>>> y
tensor(crow_indices=tensor([[0, 3, 6],
[0, 3, 6]]),
col_indices=tensor([0, 1, 2, 0, 1, 2]),
values=tensor([2., 2., 2., 2., 2., 2.]), size=(2, 2, 3), nnz=6,
layout=torch.sparse_csr)
>>> torch._validate_sparse_csr_tensor_args(y.crow_indices(), y.col_indices(), y.values(), y.shape)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
RuntimeError: crow_indices and col_indices dimensionalities must be equal but got 2 and 1, respectively
```
The expected result is
```python
>>> y
tensor(crow_indices=tensor([[0, 3, 6],
[0, 3, 6]]),
col_indices=tensor([[0, 1, 2, 0, 1, 2],
[0, 1, 2, 0, 1, 2]]),
values=tensor([[2., 2., 2., 2., 2., 2.],
[2., 2., 2., 2., 2., 2.]]), size=(2, 2, 3), nnz=6,
layout=torch.sparse_csr)
```
In place addition produces garbage as well:
```python
>>> x.add_(x)
tensor(crow_indices=tensor([[0, 3, 6],
[0, 3, 6]]),
col_indices=tensor([0, 1, 2, 0, 1, 2]),
values=tensor([2., 2., 2., 2., 2., 2.]), size=(2, 2, 3), nnz=6,
layout=torch.sparse_csr)
```
## System Info
- PyTorch: master
cc @alexsamardzic @nikitaved @cpuhrsch @amjames @bhosmer
| 2 |
3,542 | 94,174 |
[pt2] The min and max parameters of torch.clamp do not support numpy format
|
triaged, oncall: pt2, module: dynamo
|
### 🐛 Describe the bug
```python
import torch
import numpy as np
def fn(input):
max_ratio = np.abs(np.log(4))
dwh = input.clamp(min=-max_ratio, max=max_ratio)
return dwh
x = torch.rand([1]).cuda()
ret_eager = fn(x)
print('==== Eager mode OK! ====')
compiled = torch.compile(fn, backend='eager')
ret_compiled = compiled(x)
print('==== torchcomp mode OK! ====')
```
```shell
RuntimeError: Expected all tensors to be on the same device, but found at least two devices, cuda:0 and cpu! (when checking argument for argument min in method wrapper_CUDA_clamp_Tensor)
```
### Error logs
_No response_
### Minified repro
_No response_
### Versions
Pytorch version: 2.0.0.dev20230131+cu116
cc @ezyang @soumith @msaroufim @wconstab @ngimel @bdhirsh @voznesenskym @yanboliang @penguinwu @anijain2305 @EikanWang @jgong5 @Guobing-Chen @XiaobingSuper @zhuhaozhe @blzheng @Xia-Weiwen @wenzhe-nrv @jiayisunx @desertfire
| 2 |
3,543 | 94,167 |
Faster `pad_sequence` and `tensor_split` function with CUDA kernel, are they possible?
|
module: rnn, triaged, oncall: pt2, module: dynamic shapes
|
### 🚀 The feature, motivation and pitch
I was using `torch.nn.utils.rnn.pad_sequence()` to pad a list of variable length tensors. However, I find the padding operation is not so fast. Although I found that this operation has already been moved to C++ side for shorter run time. It is still slow compared to other operations with CUDA kernel support.
(I briefly profiled the computation to see this. Data size about 4000 1D tensors after spliting, maximum vector length about 200 float64 numbers. Running time without profiler 0.05s.

Is it possible to get a CUDA kernel support version of these operation? I found a possible implementation [here](https://github.com/frostblue-wukong/Paddle-Lite/commit/126691f01f96aa0dbe34417165cb0cb09b7e557a), but I am not handy in CUDA kernel. Could you add a feature for this?
### Alternatives
I have tried pad_sequence and tensor_split with GPU tensors and CPU tensors, and I found that CPU tensors have a shorter runing time. So I guess that C++ side padding and splitting does not have a CUDA kernel yet?
### Additional context
_No response_
cc @zou3519 @ezyang @soumith @msaroufim @wconstab @ngimel @bdhirsh
| 3 |
3,544 | 94,164 |
Pytorch 2.0: Detection models from torchvision don't work with onnx and tensorrt backends
|
module: onnx, triaged, oncall: pt2
|
### 🐛 Describe the bug
Detection models (ssd, retinanet, RCNN-s) from torchvision don't work with onnx and tensorrt backends.
```
model = maskrcnn_resnet50_fpn_v2()
device = torch.device('cuda')
model.to(device).eval()
model = torch.compile(model, backend='onnxrt')
input_data = torch.randn(3, 224, 224)
with torch.no_grad():
result = model([input_data.to(device)])
```
Error:
```
/home/user/anaconda3/envs/pytorch2test/lib/python3.10/site-packages/torch/jit/_check.py:172: UserWarning: The TorchScript type system doesn't support instance-level annotations on empty non-base types in `__init__`. Instead, either 1) use a type annotation in the class body, or 2) wrap the type in `torch.jit.Attribute`.
warnings.warn("The TorchScript type system doesn't support "
Traceback (most recent call last):
File "/home/user/anaconda3/envs/pytorch2test/lib/python3.10/site-packages/torch/_dynamo/output_graph.py", line 670, in call_user_compiler
compiled_fn = compiler_fn(gm, self.fake_example_inputs())
File "/home/user/anaconda3/envs/pytorch2test/lib/python3.10/site-packages/torch/_dynamo/debug_utils.py", line 1055, in debug_wrapper
compiled_gm = compiler_fn(gm, example_inputs)
File "/home/user/anaconda3/envs/pytorch2test/lib/python3.10/site-packages/torch/_dynamo/backends/common.py", line 101, in wrapper
return fn(model, inputs, **kwargs)
File "/home/user/anaconda3/envs/pytorch2test/lib/python3.10/site-packages/torch/_dynamo/backends/onnxrt.py", line 51, in onnxrt
return onnxrt(gm, example_inputs, filename=tmp.name)
File "/home/user/anaconda3/envs/pytorch2test/lib/python3.10/site-packages/torch/_dynamo/backends/common.py", line 101, in wrapper
return fn(model, inputs, **kwargs)
File "/home/user/anaconda3/envs/pytorch2test/lib/python3.10/site-packages/torch/_dynamo/backends/onnxrt.py", line 66, in onnxrt
torch.jit.script(gm),
File "/home/user/anaconda3/envs/pytorch2test/lib/python3.10/site-packages/torch/jit/_script.py", line 1286, in script
return torch.jit._recursive.create_script_module(
File "/home/user/anaconda3/envs/pytorch2test/lib/python3.10/site-packages/torch/jit/_recursive.py", line 480, in create_script_module
return create_script_module_impl(nn_module, concrete_type, stubs_fn)
File "/home/user/anaconda3/envs/pytorch2test/lib/python3.10/site-packages/torch/jit/_recursive.py", line 546, in create_script_module_impl
create_methods_and_properties_from_stubs(concrete_type, method_stubs, property_stubs)
File "/home/user/anaconda3/envs/pytorch2test/lib/python3.10/site-packages/torch/jit/_recursive.py", line 397, in create_methods_and_properties_from_stubs
concrete_type._create_methods_and_properties(property_defs, property_rcbs, method_defs, method_rcbs, method_defaults)
RuntimeError:
Arguments for call are not valid.
The following variants are available:
aten::device(str a) -> Device:
Argument a not provided.
device(str type) -> Device:
Keyword argument index unknown.
The original call is:
File "<eval_with_key>.1", line 5
def forward(self, image : torch.Tensor):
as_tensor = torch.as_tensor([0.485, 0.456, 0.406], dtype = torch.float32, device = device(type='cuda', index=0))
~~~~~~ <--- HERE
as_tensor_1 = torch.as_tensor([0.229, 0.224, 0.225], dtype = torch.float32, device = device(type='cuda', index=0))
getitem = as_tensor[(slice(None, None, None), None, None)]; as_tensor = None
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "/home/user/PycharmProjects/pytorch2test/main.py", line 55, in <module>
benchmark(model, dtype='fp32', input_shape=(3, 224, 224), nruns=1000)
File "/home/user/PycharmProjects/pytorch2test/main.py", line 25, in benchmark
features = model(input_data)
File "/home/user/anaconda3/envs/pytorch2test/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "/home/user/anaconda3/envs/pytorch2test/lib/python3.10/site-packages/torch/_dynamo/eval_frame.py", line 82, in forward
return self.dynamo_ctx(self._orig_mod.forward)(*args, **kwargs)
File "/home/user/anaconda3/envs/pytorch2test/lib/python3.10/site-packages/torch/_dynamo/eval_frame.py", line 209, in _fn
return fn(*args, **kwargs)
File "/home/user/anaconda3/envs/pytorch2test/lib/python3.10/site-packages/torchvision/models/detection/generalized_rcnn.py", line 83, in forward
images, targets = self.transform(images, targets)
File "/home/user/anaconda3/envs/pytorch2test/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "/home/user/anaconda3/envs/pytorch2test/lib/python3.10/site-packages/torchvision/models/detection/transform.py", line 129, in forward
image = self.normalize(image)
File "/home/user/anaconda3/envs/pytorch2test/lib/python3.10/site-packages/torch/_dynamo/eval_frame.py", line 330, in catch_errors
return callback(frame, cache_size, hooks)
File "/home/user/anaconda3/envs/pytorch2test/lib/python3.10/site-packages/torch/_dynamo/convert_frame.py", line 404, in _convert_frame
result = inner_convert(frame, cache_size, hooks)
File "/home/user/anaconda3/envs/pytorch2test/lib/python3.10/site-packages/torch/_dynamo/convert_frame.py", line 104, in _fn
return fn(*args, **kwargs)
File "/home/user/anaconda3/envs/pytorch2test/lib/python3.10/site-packages/torch/_dynamo/convert_frame.py", line 262, in _convert_frame_assert
return _compile(
File "/home/user/anaconda3/envs/pytorch2test/lib/python3.10/site-packages/torch/_dynamo/utils.py", line 163, in time_wrapper
r = func(*args, **kwargs)
File "/home/user/anaconda3/envs/pytorch2test/lib/python3.10/site-packages/torch/_dynamo/convert_frame.py", line 324, in _compile
out_code = transform_code_object(code, transform)
File "/home/user/anaconda3/envs/pytorch2test/lib/python3.10/site-packages/torch/_dynamo/bytecode_transformation.py", line 361, in transform_code_object
transformations(instructions, code_options)
File "/home/user/anaconda3/envs/pytorch2test/lib/python3.10/site-packages/torch/_dynamo/convert_frame.py", line 311, in transform
tracer.run()
File "/home/user/anaconda3/envs/pytorch2test/lib/python3.10/site-packages/torch/_dynamo/symbolic_convert.py", line 1715, in run
super().run()
File "/home/user/anaconda3/envs/pytorch2test/lib/python3.10/site-packages/torch/_dynamo/symbolic_convert.py", line 564, in run
and self.step()
File "/home/user/anaconda3/envs/pytorch2test/lib/python3.10/site-packages/torch/_dynamo/symbolic_convert.py", line 527, in step
getattr(self, inst.opname)(inst)
File "/home/user/anaconda3/envs/pytorch2test/lib/python3.10/site-packages/torch/_dynamo/symbolic_convert.py", line 1781, in RETURN_VALUE
self.output.compile_subgraph(self)
File "/home/user/anaconda3/envs/pytorch2test/lib/python3.10/site-packages/torch/_dynamo/output_graph.py", line 517, in compile_subgraph
self.compile_and_call_fx_graph(tx, list(reversed(stack_values)), root)
File "/home/user/anaconda3/envs/pytorch2test/lib/python3.10/site-packages/torch/_dynamo/output_graph.py", line 588, in compile_and_call_fx_graph
compiled_fn = self.call_user_compiler(gm)
File "/home/user/anaconda3/envs/pytorch2test/lib/python3.10/site-packages/torch/_dynamo/utils.py", line 163, in time_wrapper
r = func(*args, **kwargs)
File "/home/user/anaconda3/envs/pytorch2test/lib/python3.10/site-packages/torch/_dynamo/output_graph.py", line 675, in call_user_compiler
raise BackendCompilerFailed(self.compiler_fn, e) from e
torch._dynamo.exc.BackendCompilerFailed: onnxrt raised RuntimeError:
Arguments for call are not valid.
The following variants are available:
aten::device(str a) -> Device:
Argument a not provided.
device(str type) -> Device:
Keyword argument index unknown.
The original call is:
File "<eval_with_key>.1", line 5
def forward(self, image : torch.Tensor):
as_tensor = torch.as_tensor([0.485, 0.456, 0.406], dtype = torch.float32, device = device(type='cuda', index=0))
~~~~~~ <--- HERE
as_tensor_1 = torch.as_tensor([0.229, 0.224, 0.225], dtype = torch.float32, device = device(type='cuda', index=0))
getitem = as_tensor[(slice(None, None, None), None, None)]; as_tensor = None
Set torch._dynamo.config.verbose=True for more information
You can suppress this exception and fall back to eager by setting:
torch._dynamo.config.suppress_errors = True
```
### Versions
PyTorch version: 2.0.0.dev20230204+cu117
Is debug build: False
CUDA used to build PyTorch: 11.7
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.3 LTS (x86_64)
GCC version: (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0
Clang version: Could not collect
CMake version: version 3.25.2
Libc version: glibc-2.31
Python version: 3.10.8 (main, Nov 24 2022, 14:13:03) [GCC 11.2.0] (64-bit runtime)
Python platform: Linux-5.15.0-52-generic-x86_64-with-glibc2.31
Is CUDA available: True
CUDA runtime version: Could not collect
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration: GPU 0: NVIDIA GeForce RTX 3090
Nvidia driver version: 510.47.03
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.2.4
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.2.4
/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.2.4
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_infer.so.8.2.4
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.2.4
/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.2.4
/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.2.4
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.24.1
[pip3] pytorch-triton==2.0.0+0d7e753227
[pip3] torch==2.0.0.dev20230204+cu117
[pip3] torch2trt==0.4.0
[pip3] torchtriton==2.0.0+0d7e753227
[pip3] torchvision==0.15.0.dev20230204+cu117
[conda] numpy 1.24.1 pypi_0 pypi
[conda] pytorch-triton 2.0.0+0d7e753227 pypi_0 pypi
[conda] torch 2.0.0.dev20230204+cu117 pypi_0 pypi
[conda] torch2trt 0.4.0 pypi_0 pypi
[conda] torchtriton 2.0.0+0d7e753227 pypi_0 pypi
[conda] torchvision 0.15.0.dev20230204+cu117 pypi_0 pypi
cc @ezyang @soumith @msaroufim @wconstab @ngimel @bdhirsh
| 5 |
3,545 | 94,162 |
DISABLED test_index_select_scalar (__main__.TestNLLLoss)
|
triaged, module: flaky-tests, skipped, module: mps
|
Platforms: mac, macos
This test was disabled because it is failing in CI. See [recent examples](https://hud.pytorch.org/failure/test_index_select_scalar) and the most recent trunk [workflow logs](https://github.com/pytorch/pytorch/runs/11122655837).
Over the past 72 hours, it has flakily failed in 2 workflow(s).
**Debugging instructions (after clicking on the recent samples link):**
To find relevant log snippets:
1. Click on the workflow logs linked above
2. Grep for `test_index_select_scalar`
Test file path: `test_mps.py`
cc @kulinseth @albanD @malfet @DenisVieriu97 @razarmehr @abhudev
```
2023-02-05T21:48:19.5597380Z FAIL [0.002s]: test_index_select_scalar (__main__.TestNLLLoss)
2023-02-05T21:48:19.5597530Z ----------------------------------------------------------------------
2023-02-05T21:48:19.5597590Z Traceback (most recent call last):
2023-02-05T21:48:19.5597760Z File "/Users/ec2-user/runner/_work/pytorch/pytorch/test/test_mps.py", line 5128, in test_index_select_scalar
2023-02-05T21:48:19.5597800Z helper(22, 0, [])
2023-02-05T21:48:19.5597950Z File "/Users/ec2-user/runner/_work/pytorch/pytorch/test/test_mps.py", line 5125, in helper
2023-02-05T21:48:19.5598020Z self.assertEqual(idx_result, idx_result_cpu)
2023-02-05T21:48:19.5598240Z File "/Users/ec2-user/runner/_work/_temp/conda_environment_4098394330/lib/python3.9/site-packages/torch/testing/_internal/common_utils.py", line 2926, in assertEqual
2023-02-05T21:48:19.5598290Z assert_equal(
2023-02-05T21:48:19.5598490Z File "/Users/ec2-user/runner/_work/_temp/conda_environment_4098394330/lib/python3.9/site-packages/torch/testing/_comparison.py", line 1244, in assert_equal
2023-02-05T21:48:19.5598550Z raise error_metas[0].to_error(msg)
2023-02-05T21:48:19.5598610Z AssertionError: Scalars are not close!
2023-02-05T21:48:19.5598620Z
2023-02-05T21:48:19.5598710Z Absolute difference: 0.5 (up to 1e-05 allowed)
2023-02-05T21:48:19.5598810Z Relative difference: 1.0 (up to 1.3e-06 allowed)
```
| 7 |
3,546 | 94,161 |
JIT: Dropout fails codegen on the third forward passes
|
triaged, module: nvfuser
|
### 🐛 Describe the bug
Dropout in combination with an activation function causes an issue, but only under the following conditions:
1. on CUDA (CPU works)
2. the code is jitted
3. model is in evaluation mode (works in training mode)
4. during the third forward pass
```py
import torch
class MLP(torch.nn.Module):
def __init__(self):
super().__init__()
self.dropout = torch.nn.Dropout(0.5)
self.activation = torch.nn.ReLU()
self.layers = torch.nn.ModuleList([torch.nn.Linear(1, 1) for _ in range(2)])
def forward(self, x):
for layer in self.layers:
# x = self.dropout(layer(x)) # works
# x = self.activation(layer(x)) # works
# x = self.activation(self.activation(layer(x))) # works
x = self.activation(self.dropout(layer(x))) # fails
# x = self.dropout(self.dropout(layer(x))) # also fails
return x
model = torch.jit.script(MLP()).cuda()
data = torch.rand(100, 1, device="cuda")
model.eval()
for i in range(10):
print(i)
model(data)
```
``` sh
$ python test.py
0
1
2
~/.cache/pypoetry/virtualenvs/maps-Z5Tpx6_g-py3.11/lib/python3.11/site-packages/torch/nn/modules/module.py:1194: UserWarning: FALLBACK path has been taken inside: runCudaFusionGroup. This is an indication that codegen Failed for some reason.
To debug try disable codegen fallback path via setting the env variable `export PYTORCH_NVFUSER_DISABLE=fallback`
(Triggered internally at ../torch/csrc/jit/codegen/cuda/manager.cpp:331.)
return forward_call(*input, **kwargs)
3
4
5
6
7
8
9
$ PYTORCH_NVFUSER_DISABLE=fallback python test.py
0
1
2
Traceback (most recent call last):
File "/projects/maps/workspace/twoertwein/test.py", line 28, in <module>
model(data)
File "/usr0/home/twoertwe/.cache/pypoetry/virtualenvs/maps-Z5Tpx6_g-py3.11/lib/python3.11/site-packages/torch/nn/modules/module.py", line 1194, in _call_impl
return forward_call(*input, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
RuntimeError: The following operation failed in the TorchScript interpreter.
Traceback of TorchScript (most recent call last):
RuntimeError: The following operation failed in the TorchScript interpreter.
Traceback of TorchScript (most recent call last):
RuntimeError: thread_predicates_.find(tv_inp) != thread_predicates_.end() INTERNAL ASSERT FAILED at "../torch/csrc/jit/codegen/cuda/lower_thread_predicate.cpp":221, please report a bug to PyTorch. Thread predicate map was not initialized, couldn't find T1_l[ 0 ]
### Versions
Collecting environment information...
PyTorch version: 1.13.1+cu116
Is debug build: False
CUDA used to build PyTorch: 11.6
ROCM used to build PyTorch: N/A
OS: Debian GNU/Linux 11 (bullseye) (x86_64)
GCC version: (Debian 10.2.1-6) 10.2.1 20210110
Clang version: Could not collect
CMake version: version 3.18.4
Libc version: glibc-2.31
Python version: 3.11.1 (main, Jan 23 2023, 21:04:06) [GCC 10.2.1 20210110] (64-bit runtime)
Python platform: Linux-5.13.0-51-generic-x86_64-with-glibc2.31
Is CUDA available: True
CUDA runtime version: Could not collect
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration: GPU 0: NVIDIA GeForce RTX 2080 Ti
Nvidia driver version: 470.129.06
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
Address sizes: 46 bits physical, 48 bits virtual
CPU(s): 32
On-line CPU(s) list: 0-31
Thread(s) per core: 2
Core(s) per socket: 8
Socket(s): 2
NUMA node(s): 2
Vendor ID: GenuineIntel
CPU family: 6
Model: 63
Model name: Intel(R) Xeon(R) CPU E5-2640 v3 @ 2.60GHz
Stepping: 2
CPU MHz: 2476.493
CPU max MHz: 3400.0000
CPU min MHz: 1200.0000
BogoMIPS: 5200.33
Virtualization: VT-x
L1d cache: 512 KiB
L1i cache: 512 KiB
L2 cache: 4 MiB
L3 cache: 40 MiB
NUMA node0 CPU(s): 0,2,4,6,8,10,12,14,16,18,20,22,24,26,28,30
NUMA node1 CPU(s): 1,3,5,7,9,11,13,15,17,19,21,23,25,27,29,31
Vulnerability Itlb multihit: KVM: Mitigation: VMX disabled
Vulnerability L1tf: Mitigation; PTE Inversion; VMX conditional cache flushes, SMT vulnerable
Vulnerability Mds: Mitigation; Clear CPU buffers; SMT vulnerable
Vulnerability Meltdown: Mitigation; PTI
Vulnerability Mmio stale data: Mitigation; Clear CPU buffers; SMT vulnerable
Vulnerability Spec store bypass: Mitigation; Speculative Store Bypass disabled via prctl and seccomp
Vulnerability Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization
Vulnerability Spectre v2: Mitigation; Retpolines, IBPB conditional, IBRS_FW, STIBP conditional, RSB filling
Vulnerability Srbds: Not affected
Vulnerability Tsx async abort: Not affected
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc cpuid aperfmperf pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid dca sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm cpuid_fault epb invpcid_single pti ssbd ibrs ibpb stibp tpr_shadow vnmi flexpriority ept vpid ept_ad fsgsbase tsc_adjust bmi1 avx2 smep bmi2 erms invpcid cqm xsaveopt cqm_llc cqm_occup_llc dtherm ida arat pln pts md_clear flush_l1d
Versions of relevant libraries:
[pip3] mypy-extensions==1.0.0
[pip3] numpy==1.24.1
[pip3] torch==1.13.1+cu116
[conda] Could not collect
cc @kevinstephano @jjsjann123
| 0 |
3,547 | 94,160 |
Subclassed Tensors Decrease Training GPU Throughput by ~40%
|
high priority, triaged, module: __torch_function__, tensor subclass, oncall: pt2
|
### 🐛 Describe the bug
Reopening #79321 per @lezcano's [comment](https://github.com/pytorch/pytorch/issues/79321#issuecomment-1383178277) as the ~40% reduction in training performance is still repeatable in PyTorch 1.13 and PyTorch 2.0.
I created a [minimal reproduction script](https://github.com/warner-benjamin/subclassed_tensors) with no external dependencies outside of a standard PyTorch install. I benchmarked PyTorch 1.13 with Cuda 11.7 and PyTorch 2.0 (Feb 5) with Cuda 11.8 on my local GPU, using a ResNet50, 224px image size, batch size of 96, and mixed precision.
In all cases, using subclassed tensors results in up to ~40% worse performance, undoing both the expected channels last and `torch.compile` speedup.
I am a contributor to [fastai](https://docs.fast.ai) which uses subclassed tensors for multiple features, including preserving metadata, built in display methods, and dispatching based on the subclassed tensor type. I created a workaround where fastai casts any subclassed tensor back to `torch.Tensor` before passing a batch to the model.
If this performance bug can't be fixed or a subclassed tensor should always be cast back to a `torch.Tensor` before use, I think the [subclassing tensor documentation](https://pytorch.org/docs/stable/notes/extending.html#subclassing-torch-tensor) needs to be updated to warn about performance degradation, as right now it reads as if subclassed tensors should behave the same as normal tensors.
## PyTorch 1.13: Samples/Second
| Subclass | Channels Last | Mean | Std Dev |
|----------|---------------|-----------------------|--------------------------|
| False | False | 865.11 | 46.73 |
| False | True | 1033.73 | 57.12 |
| True | False | 683.34 | 36.24 |
| True | True | 627.90 | 32.99 |
## PyTorch 2.0: Samples/Second
| Subclass | Channels Last | Compile | Mean | Std Dev |
|----------|---------------|---------|-----------------------|--------------------------|
| False | False | False | 850.30 | 48.07 |
| False | True | False | 1050.69 | 59.87 |
| False | True | True | 1074.00 | 63.65 |
| True | False | False | 684.66 | 36.84 |
| True | True | False | 640.14 | 34.48 |
| True | True | True | 637.26 | 34.90 |
### Versions
PyTorch version: 2.0.0.dev20230205
Is debug build: False
CUDA used to build PyTorch: 11.8
GCC version: (Ubuntu 11.3.0-1ubuntu1~22.04) 11.3.0
Clang version: Could not collect
CMake version: Could not collect
Libc version: glibc-2.35
Python version: 3.9.16 | packaged by conda-forge | (main, Feb 1 2023, 21:39:03) [GCC 11.3.0] (64-bit runtime)
Python platform: Linux-6.0.12-76060006-generic-x86_64-with-glibc2.35
Is CUDA available: True
CUDA runtime version: 11.8.89
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration: GPU 0: NVIDIA GeForce RTX 3080 Ti
Nvidia driver version: 525.78.01
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[conda] blas 2.16 mkl conda-forge
[conda] libblas 3.8.0 16_mkl conda-forge
[conda] libcblas 3.8.0 16_mkl conda-forge
[conda] liblapack 3.8.0 16_mkl conda-forge
[conda] liblapacke 3.8.0 16_mkl conda-forge
[conda] mkl 2020.2 256
[conda] numpy 1.22.4 py39hc58783e_0 conda-forge
[conda] pytorch 2.0.0.dev20230205 py3.9_cuda11.8_cudnn8.7.0_0 pytorch-nightly
[conda] pytorch-cuda 11.8 h8dd9ede_2 pytorch-nightly
[conda] pytorch-mutex 1.0 cuda pytorch-nightly
[conda] torchaudio 2.0.0.dev20230205 py39_cu118 pytorch-nightly
[conda] torchtriton 2.0.0+0d7e753227 py39 pytorch-nightly
[conda] torchvision 0.15.0.dev20230205 py39_cu118 pytorch-nightly
cc @ezyang @gchanan @zou3519 @hameerabbasi @rgommers @peterbell10 @msaroufim @albanD @soumith @wconstab @ngimel @bdhirsh
| 2 |
3,548 | 94,132 |
Asking for a LAZYMODULEMIXIN warning
|
module: nn, module: molly-guard, triaged, module: lazy
|
Hi, I spent several days trying to understand why a gcn model (from pytorch geometric) produced different results on different runs, despite the manual seed setting.
The answer was due to the way lazy modules in PyTorch initialize parameters differently than other modules in a same ML model. (as described here: https://pytorch.org/docs/stable/generated/torch.nn.modules.lazy.LazyModuleMixin.html ). To mitigate this unpleasant situation, could you add a warning about reproducibility of experiments when using a lazy module? Thank you in advance
cc @albanD @mruberry @jbschlosser @walterddr @saketh-are
| 1 |
3,549 | 94,131 |
faster WeightedRandomSampler implementation based on alias method
|
module: dataloader, triaged
|
### 🚀 The feature, motivation and pitch
Since the weights are discrete and often fixed, I think the `WeightedRandomSampler` with replacement could be based on [alias method](https://en.wikipedia.org/wiki/Alias_method). In this implementation, the random values can be drawn from the distribution in O(1) time. The weight list has the same size as the dataset. When it comes to large datasets, the new method can be better.
Here is my solution, I implemented a `WeightedRandomSampler2` with scipy:
```python
from torch.utils.data import WeightedRandomSampler
from scipy.stats.sampling import DiscreteAliasUrn
class WeightedRandomSampler2(WeightedRandomSampler):
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
urng = np.random.default_rng()
self.rng = DiscreteAliasUrn(self.weights, random_state=urng)
def __iter__(self):
if self.replacement:
yield from iter(self.rng.rvs(self.num_samples))
else:
return super().__iter__()
```
### Alternatives
https://www.keithschwarz.com/darts-dice-coins/
https://github.com/Tecnarca/Vose-Alias-Method
https://gist.github.com/orlp/e9b31d3397a7dd3e34d6bc862ce3b88d
### Additional context
```python
import numpy as np
w = np.random.random(10_000_000)
w /= w.sum()
```
```python
%%time
s1 = WeightedRandomSampler(w, 3)
```
>Wall time: 0 ns
```python
%%time
list(s1)
```
>Wall time: 63.1 ms
[729931, 4124692, 4903810]
```python
%%time
s2 = WeightedRandomSampler2(w, 3)
```
>Wall time: 235 ms
```python
%%time
list(s2)
```
>Wall time: 0 ns
[3887197, 7289214, 2292607]
We can see that although the initialization of `WeightedRandomSampler2` is slower, its random number generation is much faster. Typically, the initialization runs only once, while the generation runs tens of thousands of times.
Furthermore, if given a larger weight list, say `w = np.random.random(100_000_000)`, the `WeightedRandomSampler` will raise a `RuntimeError: number of categories cannot exceed 2^24`, but the number generation of the `WeightedRandomSampler2` still tasks `Wall time: 0 ns`.
Therefore, I propose to implement the sampler using alias method.
cc @SsnL @VitalyFedyunin @ejguan @NivekT
| 8 |
3,550 | 94,125 |
A Floating Point Exception can be trigerred in torch._C._nn.slow_conv3d
|
module: crash, triaged, module: edge cases
|
### 🐛 Describe the bug
A **Floating Point Exception** can be trigerred in `torch._C._nn.slow_conv3d` with the following code:
````python
import torch
input = torch.rand([9, 5, 13, 0], dtype=torch.float32)
weight = torch.rand([7, 0, 11], dtype=torch.float32)
kernel_size = [1, 2, 3]
bias = torch.rand([10, 10, 2, 6], dtype=torch.float32)
stride = 1
torch._C._nn.slow_conv3d(
input=input,
weight=weight,
kernel_size=kernel_size,
bias=bias,
stride=1,
)
````
Output:
````
Floating point exception (core dumped)
````
### Versions
Collecting environment information...
PyTorch version: 1.13.1+cu117
Is debug build: False
CUDA used to build PyTorch: 11.7
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.5 LTS (x86_64)
GCC version: (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0
Clang version: 11.0.0-2~ubuntu20.04.1
CMake version: version 3.16.3
Libc version: glibc-2.31
Python version: 3.10.6 (main, Oct 24 2022, 16:07:47) [GCC 11.2.0] (64-bit runtime)
Python platform: Linux-5.15.0-57-generic-x86_64-with-glibc2.31
Is CUDA available: True
CUDA runtime version: 11.8.89
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration: GPU 0: Tesla V100-PCIE-16GB
Nvidia driver version: 520.61.05
cuDNN version: Probably one of the following:
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn.so.8.1.1
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_adv_infer.so.8.1.1
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_adv_train.so.8.1.1
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_cnn_infer.so.8.1.1
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_cnn_train.so.8.1.1
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_ops_infer.so.8.1.1
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_ops_train.so.8.1.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn.so.8.2.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn_adv_infer.so.8.2.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn_adv_train.so.8.2.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn_cnn_infer.so.8.2.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn_cnn_train.so.8.2.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn_ops_infer.so.8.2.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn_ops_train.so.8.2.1
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
Address sizes: 46 bits physical, 48 bits virtual
CPU(s): 48
On-line CPU(s) list: 0-47
Thread(s) per core: 2
Core(s) per socket: 12
Socket(s): 2
NUMA node(s): 2
Vendor ID: GenuineIntel
CPU family: 6
Model: 85
Model name: Intel(R) Xeon(R) Silver 4214 CPU @ 2.20GHz
Stepping: 7
CPU MHz: 2200.000
BogoMIPS: 4400.00
Virtualization: VT-x
L1d cache: 768 KiB
L1i cache: 768 KiB
L2 cache: 24 MiB
L3 cache: 33 MiB
NUMA node0 CPU(s): 0-11,24-35
NUMA node1 CPU(s): 12-23,36-47
Vulnerability Itlb multihit: KVM: Mitigation: VMX disabled
Vulnerability L1tf: Not affected
Vulnerability Mds: Not affected
Vulnerability Meltdown: Not affected
Vulnerability Mmio stale data: Mitigation; Clear CPU buffers; SMT vulnerable
Vulnerability Retbleed: Mitigation; Enhanced IBRS
Vulnerability Spec store bypass: Mitigation; Speculative Store Bypass disabled via prctl and seccomp
Vulnerability Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization
Vulnerability Spectre v2: Mitigation; Enhanced IBRS, IBPB conditional, RSB filling, PBRSB-eIBRS SW sequence
Vulnerability Srbds: Not affected
Vulnerability Tsx async abort: Mitigation; TSX disabled
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc art arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc cpuid aperfmperf pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid dca sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm 3dnowprefetch cpuid_fault epb cat_l3 cdp_l3 invpcid_single intel_ppin ssbd mba ibrs ibpb stibp ibrs_enhanced tpr_shadow vnmi flexpriority ept vpid ept_ad fsgsbase tsc_adjust bmi1 avx2 smep bmi2 erms invpcid cqm mpx rdt_a avx512f avx512dq rdseed adx smap clflushopt clwb intel_pt avx512cd avx512bw avx512vl xsaveopt xsavec xgetbv1 xsaves cqm_llc cqm_occup_llc cqm_mbm_total cqm_mbm_local dtherm ida arat pln pts hwp_epp pku ospke avx512_vnni md_clear flush_l1d arch_capabilities
Versions of relevant libraries:
[pip3] numpy==1.23.4
[pip3] torch==1.13.1
[conda] numpy 1.23.4 pypi_0 pypi
[conda] torch 1.13.1 pypi_0 pypi
| 2 |
3,551 | 94,115 |
`cat` fails the gradient computation in forward mode with empty tensors when used with legacy vmap
|
triaged, module: edge cases, module: forward ad
|
### 🐛 Describe the bug
`cat` fails the gradient computation in forward mode but succeeds in reverse mode
```py
import torch
from torch.autograd.functional import jacobian
torch.manual_seed(420)
x = torch.randn(4, 3, 32, 32)
empty = torch.Tensor([])
def func(x, empty):
res1 = torch.cat([x, empty], dim=1)
return res1
jacobian(func, (x, empty), vectorize=True, strategy="reverse-mode")
# succeed
jacobian(func, (x, empty), vectorize=True, strategy="forward-mode")
# RuntimeError: Tensors must have same number of dimensions: got 5 and 2
```
### Versions
```
PyTorch version: 2.0.0.dev20230105
Is debug build: False
CUDA used to build PyTorch: 11.7
ROCM used to build PyTorch: N/A
OS: Ubuntu 22.04.1 LTS (x86_64)
GCC version: (Ubuntu 11.3.0-1ubuntu1~22.04) 11.3.0
Clang version: Could not collect
CMake version: version 3.22.1
Libc version: glibc-2.35
Python version: 3.9.15 (main, Nov 24 2022, 14:31:59) [GCC 11.2.0] (64-bit runtime)
Python platform: Linux-5.15.0-56-generic-x86_64-with-glibc2.35
Is CUDA available: True
CUDA runtime version: 11.7.99
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration:
GPU 0: NVIDIA GeForce RTX 3090
GPU 1: NVIDIA GeForce RTX 3090
GPU 2: NVIDIA GeForce RTX 3090
Nvidia driver version: 515.86.01
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_infer.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.4.1
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.23.5
[pip3] torch==2.0.0.dev20230105
[pip3] torchaudio==2.0.0.dev20230105
[pip3] torchvision==0.15.0.dev20230105
[conda] blas 1.0 mkl
[conda] mkl 2021.4.0 h06a4308_640
[conda] mkl-service 2.4.0 py39h7f8727e_0
[conda] mkl_fft 1.3.1 py39hd3c417c_0
[conda] mkl_random 1.2.2 py39h51133e4_0
[conda] numpy 1.23.5 py39h14f4228_0
[conda] numpy-base 1.23.5 py39h31eccc5_0
[conda] pytorch 2.0.0.dev20230105 py3.9_cuda11.7_cudnn8.5.0_0 pytorch-nightly
[conda] pytorch-cuda 11.7 h67b0de4_2 pytorch-nightly
[conda] pytorch-mutex 1.0 cuda pytorch-nightly
[conda] torchaudio 2.0.0.dev20230105 py39_cu117 pytorch-nightly
[conda] torchtriton 2.0.0+0d7e753227 py39 pytorch-nightly
[conda] torchvision 0.15.0.dev20230105 py39_cu117 pytorch-nightly
```
| 1 |
3,552 | 94,112 |
dynamo crashes on optimizer initialization
|
module: optimizer, triaged, oncall: pt2
|
### 🐛 Describe the bug
Below gives a `NotImplementedError: ListIteratorVariable() has no type` error
However @mlazos suggested a simple workaround to move `opt = torch.optim.Adam(m.parameters(), lr=0.01)` out of the `train()` function and that fixed it
```python
import torch
import torch._inductor.config as config
config.trace.enabled = True
torch._dynamo.config.verbose=True
class HelloModule(torch.nn.Module):
def __init__(self):
super().__init__()
self.linear = torch.nn.Linear(1, 1).cuda()
def forward(self, x):
x = self.linear(x)
x_2 = torch.relu(x)
y = torch.relu(x_2)
return x_2 + y
m = HelloModule()
@torch.compile
def f():
opt = torch.optim.Adam(m.parameters(), lr=0.01)
for i in range(5):
opt.zero_grad()
out = m(torch.ones(1).to(device='cuda:0'))
loss = out.sum()
loss.backward()
opt.step()
f()
```
### Error logs
```
(nightly) ubuntu@ip-172-31-39-186:~/test$ python hello.py
/opt/conda/envs/nightly/lib/python3.10/site-packages/torch/_inductor/compile_fx.py:89: UserWarning: TensorFloat32 tensor cores for float32 matrix multiplication available but not enabled. Consider setting `torch.set_float32_matmul_precision('high')` for better performance.
warnings.warn(
[2023-02-04 01:34:10,325] torch._inductor.debug: [WARNING] model__0_inference_0 debug trace: /home/ubuntu/test/torch_compile_debug/run_2023_02_04_01_34_10_324777/aot_torchinductor/model__0_inference_0.0
Traceback (most recent call last):
File "/opt/conda/envs/nightly/lib/python3.10/site-packages/torch/_dynamo/convert_frame.py", line 324, in _compile
out_code = transform_code_object(code, transform)
File "/opt/conda/envs/nightly/lib/python3.10/site-packages/torch/_dynamo/bytecode_transformation.py", line 339, in transform_code_object
transformations(instructions, code_options)
File "/opt/conda/envs/nightly/lib/python3.10/site-packages/torch/_dynamo/convert_frame.py", line 311, in transform
tracer.run()
File "/opt/conda/envs/nightly/lib/python3.10/site-packages/torch/_dynamo/symbolic_convert.py", line 1715, in run
super().run()
File "/opt/conda/envs/nightly/lib/python3.10/site-packages/torch/_dynamo/symbolic_convert.py", line 564, in run
and self.step()
File "/opt/conda/envs/nightly/lib/python3.10/site-packages/torch/_dynamo/symbolic_convert.py", line 527, in step
getattr(self, inst.opname)(inst)
File "/opt/conda/envs/nightly/lib/python3.10/site-packages/torch/_dynamo/symbolic_convert.py", line 333, in wrapper
return inner_fn(self, inst)
File "/opt/conda/envs/nightly/lib/python3.10/site-packages/torch/_dynamo/symbolic_convert.py", line 990, in CALL_FUNCTION
self.call_function(fn, args, {})
File "/opt/conda/envs/nightly/lib/python3.10/site-packages/torch/_dynamo/symbolic_convert.py", line 461, in call_function
self.push(fn.call_function(self, args, kwargs))
File "/opt/conda/envs/nightly/lib/python3.10/site-packages/torch/_dynamo/variables/builtin.py", line 322, in call_function
result = handler(tx, *args, **kwargs)
File "/opt/conda/envs/nightly/lib/python3.10/site-packages/torch/_dynamo/variables/builtin.py", line 571, in call_isinstance
arg_type = arg.python_type()
File "/opt/conda/envs/nightly/lib/python3.10/site-packages/torch/_dynamo/variables/base.py", line 146, in python_type
raise NotImplementedError(f"{self} has no type")
NotImplementedError: ListIteratorVariable() has no type
from user code:
File "/opt/conda/envs/nightly/lib/python3.10/site-packages/torch/optim/optimizer.py", line 162, in <graph break in __init__>
if isinstance(params, torch.Tensor):
You can suppress this exception and fall back to eager by setting:
torch._dynamo.config.suppress_errors = True
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "/home/ubuntu/test/hello.py", line 64, in <module>
f()
File "/opt/conda/envs/nightly/lib/python3.10/site-packages/torch/_dynamo/eval_frame.py", line 209, in _fn
return fn(*args, **kwargs)
File "/home/ubuntu/test/hello.py", line 54, in f
opt = torch.optim.Adam(m.parameters(), lr=0.01)
File "/opt/conda/envs/nightly/lib/python3.10/site-packages/torch/optim/adam.py", line 33, in __init__
super(Adam, self).__init__(params, defaults)
File "/opt/conda/envs/nightly/lib/python3.10/site-packages/torch/optim/optimizer.py", line 157, in __init__
self._optimizer_step_pre_hooks: Dict[int, Callable] = OrderedDict()
File "/opt/conda/envs/nightly/lib/python3.10/site-packages/torch/optim/optimizer.py", line 158, in <graph break in __init__>
self._optimizer_step_post_hooks: Dict[int, Callable] = OrderedDict()
File "/opt/conda/envs/nightly/lib/python3.10/site-packages/torch/optim/optimizer.py", line 160, in <graph break in __init__>
self._patch_step_function()
File "/opt/conda/envs/nightly/lib/python3.10/site-packages/torch/_dynamo/eval_frame.py", line 330, in catch_errors
return callback(frame, cache_size, hooks)
File "/opt/conda/envs/nightly/lib/python3.10/site-packages/torch/_dynamo/convert_frame.py", line 404, in _convert_frame
result = inner_convert(frame, cache_size, hooks)
File "/opt/conda/envs/nightly/lib/python3.10/site-packages/torch/_dynamo/convert_frame.py", line 104, in _fn
return fn(*args, **kwargs)
File "/opt/conda/envs/nightly/lib/python3.10/site-packages/torch/_dynamo/convert_frame.py", line 262, in _convert_frame_assert
return _compile(
File "/opt/conda/envs/nightly/lib/python3.10/site-packages/torch/_dynamo/utils.py", line 163, in time_wrapper
r = func(*args, **kwargs)
File "/opt/conda/envs/nightly/lib/python3.10/site-packages/torch/_dynamo/convert_frame.py", line 394, in _compile
raise InternalTorchDynamoError() from e
torch._dynamo.exc.InternalTorchDynamoError
```
### Minified repro
n
### Versions
n
cc @vincentqb @jbschlosser @albanD @janeyx99 @ezyang @soumith @wconstab @ngimel @bdhirsh
| 1 |
3,553 | 94,111 |
`svd` triggers INTERNAL ASSERT FAILED when computing jacobian in forward mode
|
module: autograd, triaged, module: complex, has workaround, module: linear algebra, module: forward ad
|
### 🐛 Describe the bug
`svd` triggers INTERNAL ASSERT FAILED when computing jacobian in forward mode
```py
import torch
from torch.autograd.functional import jacobian
torch.manual_seed(420)
a = torch.randn(10, 10, dtype=torch.cfloat, requires_grad=True)
def func(a):
r = torch.svd(a)
return r
jacobian(func, (a, ), vectorize=True, strategy="forward-mode")
# RuntimeError: !this_view_meta->has_fw_view() INTERNAL ASSERT FAILED
# at "/opt/conda/conda-bld/pytorch_1672906354936/work/torch/csrc/autograd/autograd_meta.cpp":256,
# please report a bug to PyTorch.
# Expected the output of forward differentiable view operations to have the tangent have the same layout as primal
```
### Versions
```
PyTorch version: 2.0.0.dev20230105
Is debug build: False
CUDA used to build PyTorch: 11.7
ROCM used to build PyTorch: N/A
OS: Ubuntu 22.04.1 LTS (x86_64)
GCC version: (Ubuntu 11.3.0-1ubuntu1~22.04) 11.3.0
Clang version: Could not collect
CMake version: version 3.22.1
Libc version: glibc-2.35
Python version: 3.9.15 (main, Nov 24 2022, 14:31:59) [GCC 11.2.0] (64-bit runtime)
Python platform: Linux-5.15.0-56-generic-x86_64-with-glibc2.35
Is CUDA available: True
CUDA runtime version: 11.7.99
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration:
GPU 0: NVIDIA GeForce RTX 3090
GPU 1: NVIDIA GeForce RTX 3090
GPU 2: NVIDIA GeForce RTX 3090
Nvidia driver version: 515.86.01
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_infer.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.4.1
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.23.5
[pip3] torch==2.0.0.dev20230105
[pip3] torchaudio==2.0.0.dev20230105
[pip3] torchvision==0.15.0.dev20230105
[conda] blas 1.0 mkl
[conda] mkl 2021.4.0 h06a4308_640
[conda] mkl-service 2.4.0 py39h7f8727e_0
[conda] mkl_fft 1.3.1 py39hd3c417c_0
[conda] mkl_random 1.2.2 py39h51133e4_0
[conda] numpy 1.23.5 py39h14f4228_0
[conda] numpy-base 1.23.5 py39h31eccc5_0
[conda] pytorch 2.0.0.dev20230105 py3.9_cuda11.7_cudnn8.5.0_0 pytorch-nightly
[conda] pytorch-cuda 11.7 h67b0de4_2 pytorch-nightly
[conda] pytorch-mutex 1.0 cuda pytorch-nightly
[conda] torchaudio 2.0.0.dev20230105 py39_cu117 pytorch-nightly
[conda] torchtriton 2.0.0+0d7e753227 py39 pytorch-nightly
[conda] torchvision 0.15.0.dev20230105 py39_cu117 pytorch-nightly
```
cc @ezyang @albanD @zou3519 @gqchen @pearu @nikitaved @soulitzer @Lezcano @Varal7 @anjali411 @dylanbespalko @mruberry @jianyuh @walterddr @IvanYashchuk @xwang233
| 3 |
3,554 | 94,086 |
`MSELoss` fails to compute the gradients when inputs have different dtype
|
module: autograd, module: nn, triaged, actionable
|
### 🐛 Describe the bug
`MSELoss` fails to compute the gradients when inputs have different dtype
```py
import torch
from torch.autograd.functional import jacobian
x = torch.randn(1, dtype=torch.float32)
y = torch.randn(1, dtype=torch.float64)
def func(x, y):
loss_32 = torch.nn.MSELoss()(x, y)
return loss_32
print(func(x, y))
# tensor(0.1797, dtype=torch.float64)
print(jacobian(func, (x, y), vectorize=True, strategy="reverse-mode"))
# RuntimeError: Found dtype Double but expected Float
print(jacobian(func, (x, y), vectorize=True, strategy="forward-mode"))
# RuntimeError: Found dtype Float but expected Double
```
By contrast, if the operation is multiplication, it is successful to compute the gradients
```py
import torch
from torch.autograd.functional import jacobian
x = torch.randn(1, dtype=torch.float32)
y = torch.randn(1, dtype=torch.float64)
def func(x, y):
# loss_32 = torch.nn.MSELoss()(x, y)
loss_32 = x * y
return loss_32
print(func(x, y))
# tensor([1.1445], dtype=torch.float64)
print(jacobian(func, (x, y), vectorize=True, strategy="reverse-mode"))
# (tensor([[1.2829]]), tensor([[0.8921]], dtype=torch.float64))
print(jacobian(func, (x, y), vectorize=True, strategy="forward-mode"))
# [tensor([[1.2829]], dtype=torch.float64), tensor([[0.8921]], dtype=torch.float64)]
```
Thus, I think it should be that this case in `MSELoss` is neglected by mistake
### Versions
```
PyTorch version: 2.0.0.dev20230105
Is debug build: False
CUDA used to build PyTorch: 11.7
ROCM used to build PyTorch: N/A
OS: Ubuntu 22.04.1 LTS (x86_64)
GCC version: (Ubuntu 11.3.0-1ubuntu1~22.04) 11.3.0
Clang version: Could not collect
CMake version: version 3.22.1
Libc version: glibc-2.35
Python version: 3.9.15 (main, Nov 24 2022, 14:31:59) [GCC 11.2.0] (64-bit runtime)
Python platform: Linux-5.15.0-56-generic-x86_64-with-glibc2.35
Is CUDA available: True
CUDA runtime version: 11.7.99
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration:
GPU 0: NVIDIA GeForce RTX 3090
GPU 1: NVIDIA GeForce RTX 3090
GPU 2: NVIDIA GeForce RTX 3090
Nvidia driver version: 515.86.01
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_infer.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.4.1
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.23.5
[pip3] torch==2.0.0.dev20230105
[pip3] torchaudio==2.0.0.dev20230105
[pip3] torchvision==0.15.0.dev20230105
[conda] blas 1.0 mkl
[conda] mkl 2021.4.0 h06a4308_640
[conda] mkl-service 2.4.0 py39h7f8727e_0
[conda] mkl_fft 1.3.1 py39hd3c417c_0
[conda] mkl_random 1.2.2 py39h51133e4_0
[conda] numpy 1.23.5 py39h14f4228_0
[conda] numpy-base 1.23.5 py39h31eccc5_0
[conda] pytorch 2.0.0.dev20230105 py3.9_cuda11.7_cudnn8.5.0_0 pytorch-nightly
[conda] pytorch-cuda 11.7 h67b0de4_2 pytorch-nightly
[conda] pytorch-mutex 1.0 cuda pytorch-nightly
[conda] torchaudio 2.0.0.dev20230105 py39_cu117 pytorch-nightly
[conda] torchtriton 2.0.0+0d7e753227 py39 pytorch-nightly
[conda] torchvision 0.15.0.dev20230105 py39_cu117 pytorch-nightly
```
cc @ezyang @albanD @zou3519 @gqchen @pearu @nikitaved @soulitzer @Lezcano @Varal7 @mruberry @jbschlosser @walterddr @saketh-are
| 1 |
3,555 | 94,085 |
`unfold` fails in forward mode when unfolding a scalar tensor
|
triaged, module: forward ad
|
### 🐛 Describe the bug
`unfold` fails in forward mode when unfolding a scalar tensor but succeeds in reverse mode.
```py
import torch
from torch.autograd.functional import jacobian
inp = torch.rand([], dtype=torch.float64)
def func(inp):
res = inp.unfold(0,1,1)
return res
print(func(inp))
# tensor([0.4578], dtype=torch.float64)
print(jacobian(func, (inp,), vectorize=True, strategy="reverse-mode"))
# (tensor([1.], dtype=torch.float64),)
print(jacobian(func, (inp,), vectorize=True, strategy="forward-mode"))
# Fail
# IndexError: Dimension out of range (expected to be in range of [-1, 0], but got 1)
```
Actually, I am not sure whether the direct call should raise an error since the 0-dim would be *undefined* for scalar tensor. But at least the behavior should be consistent for all cases.
### Versions
```
PyTorch version: 2.0.0.dev20230105
Is debug build: False
CUDA used to build PyTorch: 11.7
ROCM used to build PyTorch: N/A
OS: Ubuntu 22.04.1 LTS (x86_64)
GCC version: (Ubuntu 11.3.0-1ubuntu1~22.04) 11.3.0
Clang version: Could not collect
CMake version: version 3.22.1
Libc version: glibc-2.35
Python version: 3.9.15 (main, Nov 24 2022, 14:31:59) [GCC 11.2.0] (64-bit runtime)
Python platform: Linux-5.15.0-56-generic-x86_64-with-glibc2.35
Is CUDA available: True
CUDA runtime version: 11.7.99
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration:
GPU 0: NVIDIA GeForce RTX 3090
GPU 1: NVIDIA GeForce RTX 3090
GPU 2: NVIDIA GeForce RTX 3090
Nvidia driver version: 515.86.01
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_infer.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.4.1
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.23.5
[pip3] torch==2.0.0.dev20230105
[pip3] torchaudio==2.0.0.dev20230105
[pip3] torchvision==0.15.0.dev20230105
[conda] blas 1.0 mkl
[conda] mkl 2021.4.0 h06a4308_640
[conda] mkl-service 2.4.0 py39h7f8727e_0
[conda] mkl_fft 1.3.1 py39hd3c417c_0
[conda] mkl_random 1.2.2 py39h51133e4_0
[conda] numpy 1.23.5 py39h14f4228_0
[conda] numpy-base 1.23.5 py39h31eccc5_0
[conda] pytorch 2.0.0.dev20230105 py3.9_cuda11.7_cudnn8.5.0_0 pytorch-nightly
[conda] pytorch-cuda 11.7 h67b0de4_2 pytorch-nightly
[conda] pytorch-mutex 1.0 cuda pytorch-nightly
[conda] torchaudio 2.0.0.dev20230105 py39_cu117 pytorch-nightly
[conda] torchtriton 2.0.0+0d7e753227 py39 pytorch-nightly
[conda] torchvision 0.15.0.dev20230105 py39_cu117 pytorch-nightly
```
| 0 |
3,556 | 94,083 |
Tracker for `scatter_reduce` additional reduction options requests
|
triaged, module: scatter & gather ops
|
Feel free to add further requests to this issue
- [ ] logsumexp #31394
- [ ] indices of max and min #80439 #83980
- [ ] [composite reductions in pytorch_scatter ](https://github.com/rusty1s/pytorch_scatter/tree/master/torch_scatter/composite) (softmax, std, logsumexp)
| 0 |
3,557 | 94,061 |
[dynamo] enable export path to preserve a meaningful parameter name in the exported graph module
|
triaged, enhancement, oncall: pt2
|
### 🚀 The feature, motivation and pitch
```python
import torch
import torch.nn as nn
import torch._dynamo as torchdynamo
class MyMod(torch.nn.Module):
def __init__(self):
super().__init__()
self.register_buffer("running_mean", torch.zeros(3,))
self.register_buffer("running_var", torch.zeros(3,))
self.weight = nn.Parameter(torch.zeros(3), requires_grad=True)
self.li = nn.Linear(3, 3)
def forward(self, input):
return (torch.batch_norm(input, self.li(self.weight), None, self.running_mean, self.running_var, False, 0.1, 1e-5, False)[0].cos(),)
m = MyMod()
m.eval()
input = torch.randn(2, 3, 1, 2)
print("before export", m)
em, _ = torchdynamo.export(m, input, aten_graph=True, tracing_mode="symbolic")
print("after export", em)
```
The above code produces the following output:
```
before export MyMod(
(li): Linear(in_features=3, out_features=3, bias=True)
)
after export GraphModule()
def forward(self, orig_arg_0):
arg0, = fx_pytree.tree_flatten_spec(([orig_arg_0], {}), self._in_spec)
_param_constant0 = self._param_constant0
t_default = torch.ops.aten.t.default(_param_constant0); _param_constant0 = None
_param_constant1 = self._param_constant1
unsqueeze_default = torch.ops.aten.unsqueeze.default(_param_constant1, 0); _param_constant1 = None
mm_default = torch.ops.aten.mm.default(unsqueeze_default, t_default); unsqueeze_default = t_default = None
squeeze_dim = torch.ops.aten.squeeze.dim(mm_default, 0); mm_default = None
_param_constant2 = self._param_constant2
add_tensor = torch.ops.aten.add.Tensor(squeeze_dim, _param_constant2); squeeze_dim = _param_constant2 = None
empty_memory_format = torch.ops.aten.empty.memory_format([0], dtype = torch.uint8, layout = torch.strided, device = device(type='cpu'))
_tensor_constant0 = self._tensor_constant0
_tensor_constant1 = self._tensor_constant1
_native_batch_norm_legit_default = torch.ops.aten._native_batch_norm_legit.default(arg0, add_tensor, None, _tensor_constant0, _tensor_constant1, False, 0.1, 1e-05); arg0 = add_tensor = _tensor_constant0 = _tensor_constant1 = None
getitem = _native_batch_norm_legit_default[0]
getitem_1 = _native_batch_norm_legit_default[1]
getitem_2 = _native_batch_norm_legit_default[2]; _native_batch_norm_legit_default = None
select_int = torch.ops.aten.select.int(getitem, 0, 0); getitem = None
cos_default = torch.ops.aten.cos.default(select_int); select_int = None
return pytree.tree_unflatten([cos_default], self._out_spec)
# To see more debug info, please use `graph_module.print_readable()`
```
We can see that when aten_graph=True, the information about module hierarchy and the parameter name is lost in the exported graph module: they are replaced by anonymous names such _param_constant or _tensor_constant.
### Alternatives
_No response_
### Additional context
_No response_
cc @ezyang @soumith @msaroufim @wconstab @ngimel @bdhirsh
| 0 |
3,558 | 94,021 |
Set AVX2 is minimum supported instruction set for Linux X86
|
triaged, enhancement, module: intel
|
### 🐛 Describe the bug
Some of the ops already throwing this cryptic `Your CPU does not support FBGEMM`, which simply means CPU does not support AVX2 instruction set. Which makes me wonder, should we make it a uniform rule for the entire PyTorch codebase on x86?
https://github.com/pytorch/pytorch/blob/f84f89b1c3f2bc74512e7a7b05ae6185164a9b3e/aten/src/ATen/native/cpu/utils.h#L104
### Versions
CI
cc @frank-wei @jgong5 @mingfeima @XiaobingSuper @sanchitintel @ashokei @jingxu10
| 2 |
3,559 | 94,017 |
Type promotion for accumulate operation differs between eager and CPP dynamo
|
module: cpu, triaged, bug, oncall: pt2
|
### 🐛 Describe the bug
Discovered while looking at `CpuTests.test_tmp_not_defined_issue2`, where result of reduction op for a float tensor is stored in float scalar, which results in slight accuracy discrepancy between eager and dynamo, see:
```
% python test_torchinductor.py -v -k test_tmp_not_defined_issue2_cpu
test_tmp_not_defined_issue2_cpu (__main__.CpuTests) ... /Users/nshulga/git/pytorch/pytorch/test/inductor/test_torchinductor.py:278: UserWarning: TypedStorage is deprecated. It will be removed in the future and UntypedStorage will be the only storage class. This should only matter to you if you are using storages directly. To access UntypedStorage directly, use tensor.untyped_storage() instead of tensor.storage()
buffer = torch.as_strided(x, (x.storage().size(),), (1,), 0).clone()
[2023-02-02 16:22:56,261] torch._inductor.compile_fx: [INFO] Step 3: torchinductor compiling FORWARDS graph 0
from ctypes import c_void_p, c_long
import torch
import random
from torch import empty_strided, as_strided, device
from torch._inductor.codecache import AsyncCompile
from torch._inductor.select_algorithm import extern_kernels
aten = torch.ops.aten
assert_size_stride = torch._C._dynamo.guards.assert_size_stride
async_compile = AsyncCompile()
kernel_cpp_0 = async_compile.cpp('''
#include "/var/folders/gp/67vtnf450p79stdw457xqkvr0000gn/T/torchinductor_nshulga/77/c7773nj5pwikpmm2pwa62rcudlf7p3if7eyqb5k4sjsvewwje4le.h"
extern "C" void kernel(const float* __restrict__ in_ptr0,
const float* __restrict__ in_ptr1,
const float* __restrict__ in_ptr2,
float* __restrict__ out_ptr0)
{
{
{
float tmp5 = 0;
#pragma omp parallel num_threads(8)
{
#pragma omp for reduction(+:tmp5)
for(long i0=0; i0<140800; i0+=1)
{
auto tmp0 = in_ptr0[i0];
auto tmp1 = in_ptr1[0];
auto tmp3 = in_ptr2[i0];
auto tmp2 = tmp0 / tmp1;
auto tmp4 = tmp2 * tmp3;
tmp5 += tmp4;
}
}
out_ptr0[0] = tmp5;
}
}
}
''')
async_compile.wait(globals())
del async_compile
def call(args):
primals_1, primals_2, primals_3 = args
args.clear()
buf0 = empty_strided((), (), device='cpu', dtype=torch.float32)
kernel_cpp_0(c_void_p(primals_3.data_ptr()), c_void_p(primals_2.data_ptr()), c_void_p(primals_1.data_ptr()), c_void_p(buf0.data_ptr()))
return (buf0, primals_1, primals_2, primals_3, )
if __name__ == "__main__":
from torch._dynamo.testing import rand_strided
from torch._inductor.utils import print_performance
primals_1 = rand_strided((1, 88, 40, 40), (140800, 1600, 40, 1), device='cpu', dtype=torch.float32)
primals_2 = rand_strided((), (), device='cpu', dtype=torch.float32)
primals_3 = rand_strided((1, 88, 40, 40), (140800, 1600, 40, 1), device='cpu', dtype=torch.float32)
print_performance(lambda: call([primals_1, primals_2, primals_3]))
[2023-02-02 16:22:56,298] torch._inductor.compile_fx: [INFO] Step 3: torchinductor done compiling FORWARDS graph 0
FAIL
======================================================================
FAIL: test_tmp_not_defined_issue2_cpu (__main__.CpuTests)
----------------------------------------------------------------------
Traceback (most recent call last):
File "/Users/nshulga/git/pytorch/pytorch/test/inductor/test_torchinductor.py", line 5394, in <lambda>
other_cls, f"{name}_{suffix}", lambda self, value=value: value(self)
File "/Users/nshulga/git/pytorch/pytorch/test/inductor/test_torchinductor.py", line 5091, in test_tmp_not_defined_issue2
self.common(forward, args)
File "/Users/nshulga/miniforge3/lib/python3.9/unittest/mock.py", line 1336, in patched
return func(*newargs, **newkeywargs)
File "/Users/nshulga/git/pytorch/pytorch/test/inductor/test_torchinductor.py", line 389, in check_model
self.assertEqual(
File "/Users/nshulga/git/pytorch/pytorch/torch/testing/_internal/common_utils.py", line 2926, in assertEqual
assert_equal(
File "/Users/nshulga/git/pytorch/pytorch/torch/testing/_comparison.py", line 1244, in assert_equal
raise error_metas[0].to_error(msg)
AssertionError: Scalars are not close!
Absolute difference: 0.359375 (up to 1e-05 allowed)
Relative difference: 1.7807008110627664e-06 (up to 1.3e-06 allowed)
The failure occurred for item [1]
----------------------------------------------------------------------
Ran 1 test in 0.481s
FAILED (failures=1)
```
generated for
https://github.com/pytorch/pytorch/blob/7db4d813c3e30cdc6c9937e0c2ff68f4a84edf49/test/inductor/test_torchinductor.py#L5126-L5130
### Error logs
_No response_
### Minified repro
_No response_
### Versions
CI
cc @jgong5 @mingfeima @XiaobingSuper @sanchitintel @ashokei @jingxu10 @ezyang @soumith @msaroufim @wconstab @ngimel @bdhirsh
| 2 |
3,560 | 94,010 |
Type promotion mismatch between eager and inductor pow
|
triaged, oncall: pt2, module: cpu inductor
|
### 🐛 Describe the bug
`CpuTests.test_pow2` is failing because of the mismatch between scalar type promotion for eager and inductor, see
https://github.com/pytorch/pytorch/blob/37a28255cb9c2a78fd2a27ed7921e8c9672a57ab/aten/src/ATen/native/cpu/PowKernel.cpp#L112-L115
vs
```c++
extern "C" void kernel(const float* __restrict__ in_ptr0,
float* __restrict__ out_ptr0,
float* __restrict__ out_ptr1)
{
#pragma omp parallel num_threads(12)
{
{
#pragma omp for
for(long i0=0; i0<256; i0+=1)
{
auto tmp1 = in_ptr0[i0];
auto tmp0 = static_cast<float>(1000);
auto tmp2 = std::pow(tmp0, tmp1);
auto tmp3 = std::pow(tmp1, tmp0);
out_ptr0[i0] = tmp2;
out_ptr1[i0] = tmp3;
}
}
}
}
```
generated for
https://github.com/pytorch/pytorch/blob/7db4d813c3e30cdc6c9937e0c2ff68f4a84edf49/test/inductor/test_torchinductor.py#L2991-L2992
Moving type to `torch.float64` make test pass
### Error logs
_No response_
### Minified repro
_No response_
### Versions
CI
cc @ezyang @soumith @msaroufim @wconstab @ngimel @bdhirsh
| 2 |
3,561 | 94,003 |
test_nccl_warn_not_in_group_debug_detail is flaky
|
oncall: distributed, triaged, module: flaky-tests
|
### 🐛 Describe the bug
Error: https://github.com/pytorch/pytorch/actions/runs/4066116189/jobs/7002264428
cc @mrshenli @pritamdamania87 @zhaojuanmao @satgera @gqchen @aazzolini @osalpekar @jiayisuse @H-Huang @kwen2501 @awgu
### Versions
main
| 0 |
3,562 | 93,982 |
`linalg.lstsq` fails the gradient computation in forward mode
|
triaged, module: forward ad
|
### 🐛 Describe the bug
`linalg.lstsq` fails the gradient computation in forward mode but succeed in the reverse mode
```py
import torch
from torch.autograd.functional import jacobian
A = torch.randn(2, 3, 3)
b = torch.randn(2, 3)
def func(A, b):
x = torch.linalg.lstsq(A, b, )
return x
print(jacobian(func, (A, b), vectorize=True, strategy="reverse-mode"))
# succeed
print(jacobian(func, (A, b), vectorize=True, strategy="forward-mode"))
# fail
# RuntimeError: mat1 and mat2 shapes cannot be multiplied (6x3 and 2x3)
```
### Versions
```
PyTorch version: 2.0.0.dev20230105
Is debug build: False
CUDA used to build PyTorch: 11.7
ROCM used to build PyTorch: N/A
OS: Ubuntu 22.04.1 LTS (x86_64)
GCC version: (Ubuntu 11.3.0-1ubuntu1~22.04) 11.3.0
Clang version: Could not collect
CMake version: version 3.22.1
Libc version: glibc-2.35
Python version: 3.9.15 (main, Nov 24 2022, 14:31:59) [GCC 11.2.0] (64-bit runtime)
Python platform: Linux-5.15.0-56-generic-x86_64-with-glibc2.35
Is CUDA available: True
CUDA runtime version: 11.7.99
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration:
GPU 0: NVIDIA GeForce RTX 3090
GPU 1: NVIDIA GeForce RTX 3090
GPU 2: NVIDIA GeForce RTX 3090
Nvidia driver version: 515.86.01
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_infer.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.4.1
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.23.5
[pip3] torch==2.0.0.dev20230105
[pip3] torchaudio==2.0.0.dev20230105
[pip3] torchvision==0.15.0.dev20230105
[conda] blas 1.0 mkl
[conda] mkl 2021.4.0 h06a4308_640
[conda] mkl-service 2.4.0 py39h7f8727e_0
[conda] mkl_fft 1.3.1 py39hd3c417c_0
[conda] mkl_random 1.2.2 py39h51133e4_0
[conda] numpy 1.23.5 py39h14f4228_0
[conda] numpy-base 1.23.5 py39h31eccc5_0
[conda] pytorch 2.0.0.dev20230105 py3.9_cuda11.7_cudnn8.5.0_0 pytorch-nightly
[conda] pytorch-cuda 11.7 h67b0de4_2 pytorch-nightly
[conda] pytorch-mutex 1.0 cuda pytorch-nightly
[conda] torchaudio 2.0.0.dev20230105 py39_cu117 pytorch-nightly
[conda] torchtriton 2.0.0+0d7e753227 py39 pytorch-nightly
[conda] torchvision 0.15.0.dev20230105 py39_cu117 pytorch-nightly
```
| 1 |
3,563 | 93,955 |
Enable Link Time Optimization in PyTorch 2.0 Release Binaries - Smaller, Faster, Better Binaries
|
oncall: binaries, module: performance, module: build, oncall: releng, triaged, topic: performance
|
### 🚀 The feature, motivation and pitch
The PyTorch binaries are huge. See #34058. So huge in fact, we've needed to refactor our codebase just so they fit in pip and conda. And that we plan on setting up binary size alerts: https://github.com/pytorch/pytorch/issues/93991. And that we want to split up our conda for faster installs: https://github.com/pytorch/pytorch/issues/93081 .
We should do everything we can to do to keep them small without sacrificing performance. One now commonly supported compiler feature we can use to both make the binaries smaller and potentially faster is Link Time Optimization. Upgrading to C++17 means that we Pytorch can only be built by newer compilers that have full LTO support anyway.
I tested it for the CPU only the libraries for PyTorch and found a nearly 10-20MB reduction in the size of the binaries. This is likely to be even more pronounced on CUDA.
Why now?
* PyTorch 2.0 is overhauling a large part of the build structure of the library anyway
* Upgrading to C++17 and dropping a lot of legacy code should make this easier, and ensure that only newer compilers are supported that have fewer LTO bugs.
* Now that the minimum support CUDA version is 11.2, we now can try to enable `-dlto` option for CUDA since it's supported which promises faster CUDA compilation and smaller CUDA binaries through supported device linking.
Benefits:
* Smaller binaries
* Potentially better performance
* Better warnings / diagnostics thanks to more info available at link time.
* Potentially faster build times for CUDA kernels.
Steps:
* Ideally, this should be as simple as turning the `CMAKE_INTERPROCEDURAL_OPTIMIZATION` config option on for release builds. I'll need to contact releng about how to best do this. However, gcc only supports FAT/classical LTO compilation, which means that the linking stage can take a lot longer so we may need to adjust timeouts on the workers that build them. https://cmake.org/cmake/help/latest/variable/CMAKE_INTERPROCEDURAL_OPTIMIZATION.html
* Clang supports ThinLTO and LTO (defaulting to ThinLTO). ThinLTO adds minimal build overhead, but is not supported by gcc. However, it is also more likely to crash / segfault during the build process due to added complexity. If we this working, we could even enable it by default in Release builds. We can also force clang to use gcc's slower form of lto too.
* [Optional]: Enabling `-dlto` flag on nvcc would probably be the trickiest part, ~as that option does not have a CMake flag to enable it yet, and it does come with some limitations (not supporting ffast-math when doing dlto etc..~.). (Apparently it does, but only on the newest CMake: https://gitlab.kitware.com/cmake/cmake/-/merge_requests/7389). However, this also promises the biggest potential size saving gains. If even 10% can be saved from the full cuda build, that's can result in nearly 100mb smaller binaries: https://developer.nvidia.com/blog/improving-gpu-app-performance-with-cuda-11-2-device-lto/ see this blogpost for more info in that regards. It could even be dramatically more if it can deduplicate assembly code across microarchs at link time. Edit: apparently the LTO would only matter in CUDA_SEPERABLE_BUILD mode, which allows faster CUDA compilation.
POC:
I tested on a libtorch build with gcc-9 and no IntelMKL and was able to shrink the binaries from 199MB -> 184MB resulting in a 7-8% reduction in binary size. I did not do any benchmarking, but this could result in a performance increase as well, for just a little compilation time increase. I also did not try enabling LTO on any of the third party libraries so the savings would likely be more if we pursued this fully. The only issue I encountered were some linking errors when trying to force enabling it on protobuff, but after looking at some issues, it may be fixed as easily as pass `-no-as-needed` to gcc or just using a newer gcc.
### Alternatives
Let the binaries remain huge.
### Additional context
Happy to help facilitate this, but I could definitely use some help from the releng/infra teams especially for testing this on all possible configs. The MVP would be just getting this working on GCC, but Clang, MSVC, and the CUDA compilers all support this as well. Help wanted on this project for sure.
cc @ezyang @seemethere @malfet @ngimel @soumith @albanD
| 3 |
3,564 | 93,947 |
[RFC] Support Huge Model Init Without mallocs for Compile/Distributed Use Cases
|
oncall: distributed, triaged
|
### 🚀 The feature, motivation and pitch
<todo -- lets gather existing thoughts here and develop the RFC>
### Alternatives
_No response_
### Additional context
_No response_
cc @mrshenli @pritamdamania87 @zhaojuanmao @satgera @rohan-varma @gqchen @aazzolini @osalpekar @jiayisuse @H-Huang @kwen2501 @awgu
| 4 |
3,565 | 93,944 |
error: no member named 'residual_with_sum_zero_point' in 'ideep::attr_t
|
module: build, triaged, module: macos
|
### 🐛 Describe the bug
Compilation error building Pytorch from source on MacOS 13.2:
```
/Users/davidlaxer/pytorch/aten/src/ATen/native/quantized/cpu/qconv.cpp:1307:43: error: no member named 'residual_with_sum_zero_point' in 'ideep::attr_t'
op_attr = kReluFused ? ideep::attr_t::residual_with_sum_zero_point() : ideep::attr_t::fuse_sum();
```
Here's the command:
```
% export CMAKE_PREFIX_PATH=${CONDA_PREFIX:-"$(dirname $(which conda))/../"}
python setup.py develop
Building wheel torch-2.0.0a0+git769eca6
-- Building version 2.0.0a0+git769eca6
cmake --build . --target install --config Release
[67/359] Building CXX object caffe2/CM.../ATen/native/quantized/cpu/qconv.cpp.o
FAILED: caffe2/CMakeFiles/torch_cpu.dir/__/aten/src/ATen/native/quantized/cpu/qconv.cpp.o
/Applications/Xcode.app/Contents/Developer/Toolchains/XcodeDefault.xctoolchain/usr/bin/clang++ -DAT_PER_OPERATOR_HEADERS -DCPUINFO_SUPPORTED_PLATFORM=1 -DFMT_HEADER_ONLY=1 -DFXDIV_USE_INLINE_ASSEMBLY=0 -DHAVE_MMAP=1 -DHAVE_SHM_OPEN=1 -DHAVE_SHM_UNLINK=1 -DMINIZ_DISABLE_ZIP_READER_CRC32_CHECKS -DNNP_CONVOLUTION_ONLY=0 -DNNP_INFERENCE_ONLY=0 -DONNXIFI_ENABLE_EXT=1 -DONNX_ML=1 -DONNX_NAMESPACE=onnx_torch -DUSE_C10D_GLOO -DUSE_DISTRIBUTED -DUSE_EXTERNAL_MZCRC -DUSE_RPC -DUSE_TENSORPIPE -D_FILE_OFFSET_BITS=64 -Dtorch_cpu_EXPORTS -I/Users/davidlaxer/pytorch/build/aten/src -I/Users/davidlaxer/pytorch/aten/src -I/Users/davidlaxer/pytorch/build -I/Users/davidlaxer/pytorch -I/Users/davidlaxer/pytorch/cmake/../third_party/benchmark/include -I/Users/davidlaxer/pytorch/third_party/onnx -I/Users/davidlaxer/pytorch/build/third_party/onnx -I/Users/davidlaxer/pytorch/third_party/foxi -I/Users/davidlaxer/pytorch/build/third_party/foxi -I/Users/davidlaxer/pytorch/torch/csrc/api -I/Users/davidlaxer/pytorch/torch/csrc/api/include -I/Users/davidlaxer/pytorch/caffe2/aten/src/TH -I/Users/davidlaxer/pytorch/build/caffe2/aten/src/TH -I/Users/davidlaxer/pytorch/build/caffe2/aten/src -I/Users/davidlaxer/pytorch/build/caffe2/../aten/src -I/Users/davidlaxer/pytorch/torch/csrc -I/Users/davidlaxer/pytorch/third_party/miniz-2.1.0 -I/Users/davidlaxer/pytorch/third_party/kineto/libkineto/include -I/Users/davidlaxer/pytorch/third_party/kineto/libkineto/src -I/Users/davidlaxer/pytorch/aten/../third_party/catch/single_include -I/Users/davidlaxer/pytorch/aten/src/ATen/.. -I/Users/davidlaxer/pytorch/third_party/FXdiv/include -I/Users/davidlaxer/pytorch/c10/.. -I/Users/davidlaxer/pytorch/third_party/pthreadpool/include -I/Users/davidlaxer/pytorch/third_party/cpuinfo/include -I/Users/davidlaxer/pytorch/third_party/QNNPACK/include -I/Users/davidlaxer/pytorch/aten/src/ATen/native/quantized/cpu/qnnpack/include -I/Users/davidlaxer/pytorch/aten/src/ATen/native/quantized/cpu/qnnpack/src -I/Users/davidlaxer/pytorch/third_party/cpuinfo/deps/clog/include -I/Users/davidlaxer/pytorch/third_party/NNPACK/include -I/Users/davidlaxer/pytorch/third_party/fbgemm/include -I/Users/davidlaxer/pytorch/third_party/fbgemm -I/Users/davidlaxer/pytorch/third_party/fbgemm/third_party/asmjit/src -I/Users/davidlaxer/pytorch/third_party/ittapi/src/ittnotify -I/Users/davidlaxer/pytorch/third_party/FP16/include -I/Users/davidlaxer/pytorch/third_party/tensorpipe -I/Users/davidlaxer/pytorch/build/third_party/tensorpipe -I/Users/davidlaxer/pytorch/third_party/tensorpipe/third_party/libnop/include -I/Users/davidlaxer/pytorch/third_party/fmt/include -I/Users/davidlaxer/pytorch/build/third_party/ideep/mkl-dnn/third_party/oneDNN/include -I/Users/davidlaxer/pytorch/third_party/ideep/mkl-dnn/third_party/oneDNN/src/../include -I/Users/davidlaxer/pytorch/third_party/flatbuffers/include -isystem /Users/davidlaxer/pytorch/build/third_party/gloo -isystem /Users/davidlaxer/pytorch/cmake/../third_party/gloo -isystem /Users/davidlaxer/pytorch/cmake/../third_party/googletest/googlemock/include -isystem /Users/davidlaxer/pytorch/cmake/../third_party/googletest/googletest/include -isystem /Users/davidlaxer/pytorch/third_party/gemmlowp -isystem /Users/davidlaxer/pytorch/third_party/neon2sse -isystem /Users/davidlaxer/pytorch/third_party/XNNPACK/include -isystem /Users/davidlaxer/pytorch/third_party/ittapi/include -isystem /Users/davidlaxer/pytorch/cmake/../third_party/eigen -isystem /usr/local/include -isystem /Users/davidlaxer/pytorch/third_party/ideep/include -isystem /Users/davidlaxer/pytorch/build/include -march=core2 -mtune=haswell -mssse3 -ftree-vectorize -fPIC -fPIE -fstack-protector-strong -O2 -pipe -isystem /Users/davidlaxer/anaconda3/envs/AI-Feynman/include -Wno-deprecated -fvisibility-inlines-hidden -DUSE_PTHREADPOOL -Xpreprocessor -fopenmp -DNDEBUG -DUSE_KINETO -DLIBKINETO_NOCUPTI -DLIBKINETO_NOROCTRACER -DUSE_FBGEMM -DUSE_QNNPACK -DUSE_PYTORCH_QNNPACK -DUSE_XNNPACK -DSYMBOLICATE_MOBILE_DEBUG_HANDLE -O2 -fPIC -Wall -Wextra -Werror=return-type -Werror=non-virtual-dtor -Werror=braced-scalar-init -Werror=range-loop-construct -Werror=bool-operation -Winconsistent-missing-override -Wnarrowing -Wno-missing-field-initializers -Wno-type-limits -Wno-array-bounds -Wno-unknown-pragmas -Wunused-local-typedefs -Wno-unused-parameter -Wno-unused-function -Wno-unused-result -Wno-strict-overflow -Wno-strict-aliasing -Wno-error=deprecated-declarations -Wvla-extension -Wno-range-loop-analysis -Wno-pass-failed -Wsuggest-override -Wno-error=pedantic -Wno-error=redundant-decls -Wno-error=old-style-cast -Wconstant-conversion -Wno-invalid-partial-specialization -Wno-typedef-redefinition -Wno-unused-private-field -Wno-inconsistent-missing-override -Wno-constexpr-not-const -Wno-missing-braces -Wunused-lambda-capture -Wunused-local-typedef -Qunused-arguments -fcolor-diagnostics -fdiagnostics-color=always -fno-math-errno -fno-trapping-math -Werror=format -Werror=cast-function-type -DUSE_MPS -fno-objc-arc -Wno-unguarded-availability-new -Wno-unused-private-field -Wno-missing-braces -Wno-constexpr-not-const -DHAVE_AVX512_CPU_DEFINITION -DHAVE_AVX2_CPU_DEFINITION -O3 -DNDEBUG -DNDEBUG -isysroot /Applications/Xcode.app/Contents/Developer/Platforms/MacOSX.platform/Developer/SDKs/MacOSX.sdk -fPIC -DCAFFE2_USE_GLOO -DTH_HAVE_THREAD -Wall -Wextra -Wno-unused-parameter -Wno-unused-function -Wno-unused-result -Wno-missing-field-initializers -Wno-write-strings -Wno-unknown-pragmas -Wno-type-limits -Wno-array-bounds -Wno-sign-compare -Wno-strict-overflow -Wno-strict-aliasing -Wno-error=deprecated-declarations -Wno-missing-braces -Wno-range-loop-analysis -fvisibility=hidden -O2 -Xpreprocessor -fopenmp -DCAFFE2_BUILD_MAIN_LIB -DASMJIT_STATIC -std=gnu++17 -MD -MT caffe2/CMakeFiles/torch_cpu.dir/__/aten/src/ATen/native/quantized/cpu/qconv.cpp.o -MF caffe2/CMakeFiles/torch_cpu.dir/__/aten/src/ATen/native/quantized/cpu/qconv.cpp.o.d -o caffe2/CMakeFiles/torch_cpu.dir/__/aten/src/ATen/native/quantized/cpu/qconv.cpp.o -c /Users/davidlaxer/pytorch/aten/src/ATen/native/quantized/cpu/qconv.cpp
/Users/davidlaxer/pytorch/aten/src/ATen/native/quantized/cpu/qconv.cpp:1307:43: error: no member named 'residual_with_sum_zero_point' in 'ideep::attr_t'
op_attr = kReluFused ? ideep::attr_t::residual_with_sum_zero_point() : ideep::attr_t::fuse_sum();
~~~~~~~~~~~~~~~^
1 error generated.
[84/359] Building CXX object caffe2/CM...nctorch/BatchRulesDecompositions.cpp.o
ninja: build stopped: subcommand failed.
```
### Versions
```
% python collect_env.py
Collecting environment information...
PyTorch version: N/A
Is debug build: N/A
CUDA used to build PyTorch: N/A
ROCM used to build PyTorch: N/A
OS: macOS 13.2 (x86_64)
GCC version: Could not collect
Clang version: 14.0.0 (clang-1400.0.29.202)
CMake version: version 3.22.1
Libc version: N/A
Python version: 3.10.9 (main, Jan 11 2023, 09:18:20) [Clang 14.0.6 ] (64-bit runtime)
Python platform: macOS-10.16-x86_64-i386-64bit
Is CUDA available: N/A
CUDA runtime version: Could not collect
CUDA_MODULE_LOADING set to: N/A
GPU models and configuration: Could not collect
Nvidia driver version: Could not collect
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: N/A
Versions of relevant libraries:
[pip3] audiolm-pytorch==0.0.1
[pip3] mypy-extensions==0.4.3
[pip3] numpy==1.23.5
[pip3] pytorch-transformers==1.1.0
[pip3] torch==2.0.0a0+gitf8b2879
[pip3] torch-struct==0.5
[pip3] torch-summary==1.4.5
[pip3] torch-utils==0.1.2
[pip3] torchaudio==0.13.0.dev20221015
[pip3] torchtraining-nightly==1604016577
[pip3] torchvision==0.15.0a0+8985b59
[pip3] vector-quantize-pytorch==0.9.2
[conda] nomkl 3.0 0
[conda] numpy 1.23.5 py310he50c29a_0
[conda] numpy-base 1.23.5 py310h992e150_0
[conda] pytorch-transformers 1.1.0 pypi_0 pypi
[conda] torch 2.0.0a0+gitf8b2879 pypi_0 pypi
[conda] torch-struct 0.5 pypi_0 pypi
[conda] torch-summary 1.4.5 pypi_0 pypi
[conda] torch-utils 0.1.2 pypi_0 pypi
[conda] torchaudio 0.13.0.dev20221015 pypi_0 pypi
[conda] torchtraining-nightly 1604016577 pypi_0 pypi
[conda] torchvision 0.15.0a0+8985b59 pypi_0 pypi
[conda] vector-quantize-pytorch 0.9.2 pypi_0 pypi
```
cc @malfet @seemethere @albanD
| 0 |
3,566 | 93,943 |
`torch.jit.trace` memory usage increase although forward is constant, and gets much slower than forward with model depth increase
|
oncall: jit
|
### 🐛 Describe the bug
Using `traced_model = torch.jit.trace(model, example_inputs)`, memory usage is increasing over the model depth although with `result = model(example_inputs)` the memory usage is constant.
The model in question has a loop construct where a submodule is called iteratively.
Note that for both running `forward` and `torch.jit.trace`, the decorator `torch.inference_mode()` is used.
The submodule inside the loop is a unet, and it is already a `ScriptModule` when calling `torch.jit.trace` on the whole model. Not tracing it in advance does not change the results.
I notice that `torch.jit.trace` alternates using all the physical CPU cores, and using only one CPU core. Not sure why.
The results are:
<details>
<summary>Slowdown of `torch.jit.trace`</summary>

</details>
<details>
<summary>Memory usage of `torch.jit.trace`, with the inner unet pretraced</summary>
* n_loop = 30: max allocation `5270 MB`, `max_mem/n_loop = 175.66`
* n_loop = 40: max allocation `6592 MB`, `max_mem/n_loop = 164.8`
* n_loop = 50: max allocation `8084 MB`, `max_mem/n_loop = 161.68`
* n_loop = 60: max allocation `9532 MB`, `max_mem/n_loop = 158.86`
* n_loop = 120: max allocation `18181 MB`, `max_mem/n_loop = 151.50`
</details>
The loop looks like this: https://github.com/fxmarty/optimum/blob/9ef352b0f1775fe5e0048490722ea931aa6f4fd5/research/stable_diffusion_end_to_end_onnx/scriptable_pipeline_stable_diffusion.py#L298-L318
The script to run the forward is: https://github.com/fxmarty/optimum/blob/9ef352b0f1775fe5e0048490722ea931aa6f4fd5/research/stable_diffusion_end_to_end_onnx/run_custom_pytorch_pipeline.py
The script to run `torch.jit.trace` is: https://github.com/fxmarty/optimum/blob/9ef352b0f1775fe5e0048490722ea931aa6f4fd5/research/stable_diffusion_end_to_end_onnx/create_scriptmodule_by_tracing.py
### Versions
PyTorch version: 1.13.1+cu117
Is debug build: False
CUDA used to build PyTorch: 11.7
ROCM used to build PyTorch: N/A
OS: Ubuntu 22.04.1 LTS (x86_64)
GCC version: (Ubuntu 11.3.0-1ubuntu1~22.04) 11.3.0
Clang version: 14.0.0-1ubuntu1
CMake version: version 3.25.0
Libc version: glibc-2.35
Python version: 3.9.12 (main, Apr 5 2022, 06:56:58) [GCC 7.5.0] (64-bit runtime)
Python platform: Linux-5.15.0-58-generic-x86_64-with-glibc2.35
Is CUDA available: True
CUDA runtime version: 11.7.99
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration: GPU 0: NVIDIA GeForce RTX 3060 Laptop GPU
Nvidia driver version: 515.86.01
cuDNN version: Probably one of the following:
/usr/local/cuda-11.7/targets/x86_64-linux/lib/libcudnn.so.8.7.0
/usr/local/cuda-11.7/targets/x86_64-linux/lib/libcudnn_adv_infer.so.8.7.0
/usr/local/cuda-11.7/targets/x86_64-linux/lib/libcudnn_adv_train.so.8.7.0
/usr/local/cuda-11.7/targets/x86_64-linux/lib/libcudnn_cnn_infer.so.8.7.0
/usr/local/cuda-11.7/targets/x86_64-linux/lib/libcudnn_cnn_train.so.8.7.0
/usr/local/cuda-11.7/targets/x86_64-linux/lib/libcudnn_ops_infer.so.8.7.0
/usr/local/cuda-11.7/targets/x86_64-linux/lib/libcudnn_ops_train.so.8.7.0
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] mypy-extensions==0.4.3
[pip3] numpy==1.22.4
[pip3] torch==1.13.1
[pip3] torch-model-archiver==0.6.1
[pip3] torch-workflow-archiver==0.2.5
[pip3] torchinfo==1.7.0
[pip3] torchserve==0.6.1
[pip3] torchtriton==2.0.0+0d7e753227
[pip3] torchvision==0.14.1
[conda] cudatoolkit 11.3.1 h2bc3f7f_2 anaconda
[conda] numpy 1.22.4 pypi_0 pypi
[conda] torch 1.13.1 pypi_0 pypi
[conda] torch-model-archiver 0.6.1 pypi_0 pypi
[conda] torch-workflow-archiver 0.2.5 pypi_0 pypi
[conda] torchinfo 1.7.0 pypi_0 pypi
[conda] torchserve 0.6.1 pypi_0 pypi
[conda] torchtriton 2.0.0+0d7e753227 pypi_0 pypi
[conda] torchvision 0.14.1 pypi_0 pypi
cc @EikanWang @jgong5 @wenzhe-nrv @sanchitintel
| 7 |
3,567 | 93,938 |
[FSDP] `summon_full_params(writeback=True, rank0_only=True)`
|
oncall: distributed, triaged, module: fsdp
|
`writeback=True` and `rank0_only=True` currently raises an error. We should be able to implement this setting by having rank 0 broadcast the unsharded `FlatParameter` to all ranks before writing back.
cc @mrshenli @pritamdamania87 @zhaojuanmao @satgera @rohan-varma @gqchen @aazzolini @osalpekar @jiayisuse @H-Huang @kwen2501
| 0 |
3,568 | 93,937 |
onnx_torch.ModelProto exceeded maximum protobuf size of 2GB
|
module: onnx, triaged
|
### 🐛 Describe the bug
When I export onnx for large model, I get this error:
```bash
[libprotobuf ERROR /opt/pytorch/pytorch/third_party/protobuf/src/google/protobuf/message_lite.cc:457] onnx_tor
ch.ModelProto exceeded maximum protobuf size of 2GB: 4649393993
```
My code is:
```python
import onnx
import torch
from diffusers import UNet2DConditionModel
unet = UNet2DConditionModel.from_pretrained("CompVis/stable-diffusion-v1-4",
torch_dtype=torch.float16,
revision="fp16",
subfolder="unet",
use_auth_token=YOUR_TOKEN)
unet.cuda()
with torch.inference_mode(), torch.autocast("cuda"):
inputs = torch.randn(2,4,64,64, dtype=torch.half, device='cuda'), torch.randn(1, dtype=torch.half, device='cuda'), torch.randn(2, 77, 768, dtype=torch.half, device='cuda')
# Export the model
torch.onnx.export(unet, # model being run
inputs, # model input (or a tuple for multiple inputs)
"unet_v1_4_fp16_pytorch.onnx", # where to save the model (can be a file or file-like object)
export_params=True, # store the trained parameter weights inside the model file
opset_version=12, # the ONNX version to export the model to
do_constant_folding=True, # whether to execute constant folding for optimization
input_names = ['input_0', 'input_1', 'input_2'],
output_names = ['output_0'])
```
### Versions
docker run --gpus all -it --rm nvcr.io/nvidia/pytorch:22.12-py3
| 3 |
3,569 | 93,935 |
[pt20][aot_eager] Exceed Python recursion limit with huge model or frequent recompilation
|
triaged, ezyang's list, oncall: pt2, module: dynamic shapes, module: dynamo
|
### 🐛 Describe the bug
`aot_eager` backend wraps `bw_compiler` constantly on each graph break & recompilation, making the function call exceeds Python recursion limit for huge model or frequent recompilations. Repro example below
```python
import torch
import torch.nn as nn
import torch._dynamo as dynamo
from torch._dynamo import disallow_in_graph
import random
# manually simulate graph breaks
def graph_break():
pass
disallow_in_graph(graph_break)
class Repro(nn.Module):
def __init__(self):
super().__init__()
self.linear1 = nn.Linear(4, 4)
self.linear2 = nn.Linear(4, 4)
self.linear3 = nn.Linear(4, 4)
def forward(self, x):
x = self.linear1(x)
graph_break()
x = self.linear2(x)
graph_break()
x = self.linear3(x)
return x
if __name__ == '__main__':
model = Repro().cuda()
opt = torch.compile(model, backend='aot_eager')
# variable batch_size to simulate recompilations
for batch_size in range(3):
data = torch.randn(batch_size, 4).cuda()
out = opt(data)
loss = out.sum()
loss.backward()
```
Add the following lines to [torch/_dynamo/optimizations/training.py](https://github.com/pytorch/pytorch/blob/a2fded30012e26d8c469d2b668a226315794a559/torch/_dynamo/optimizations/training.py#L54-L56) and then run the above script, the results as follow
```python
def _wrapped_bw_compiler(*args, **kwargs):
global _count
_count += 1
print(f'{_count}: {bw_compiler}')
return eval_frame.disable(eval_frame.disable(bw_compiler)(*args, **kwargs))
```

Is this intended or a bug? What else can I do apart from reducing `torch._dynamo.config.cache_size_limit` and increasing `sys.setrecursionlimit()` to prevent this issue?
### Versions
```text
PyTorch version: 2.0.0.dev20230201+cu116
Is debug build: False
CUDA used to build PyTorch: 11.6
ROCM used to build PyTorch: N/A
OS: CentOS Linux 7 (Core) (x86_64)
GCC version: (GCC) 8.5.0
Clang version: Could not collect
CMake version: version 3.25.0
Libc version: glibc-2.17
Python version: 3.8.15 (default, Nov 24 2022, 15:19:38) [GCC 11.2.0] (64-bit runtime)
Python platform: Linux-3.10.0-957.el7.x86_64-x86_64-with-glibc2.17
Is CUDA available: True
CUDA runtime version: 11.6.124
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration:
GPU 0: NVIDIA A100-SXM4-80GB
GPU 1: NVIDIA A100-SXM4-80GB
GPU 2: NVIDIA A100-SXM4-80GB
GPU 3: NVIDIA A100-SXM4-80GB
GPU 4: NVIDIA A100-SXM4-80GB
GPU 5: NVIDIA A100-SXM4-80GB
GPU 6: NVIDIA A100-SXM4-80GB
GPU 7: NVIDIA A100-SXM4-80GB
Nvidia driver version: 515.65.01
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.24.1
[pip3] pytorch-triton==2.0.0+0d7e753227
[pip3] torch==2.0.0.dev20230201+cu116
[pip3] torchaudio==2.0.0.dev20230112+cu116
[pip3] torchvision==0.15.0.dev20230131+cu116
[conda] numpy 1.24.1 pypi_0 pypi
[conda] pytorch-triton 2.0.0+0d7e753227 pypi_0 pypi
[conda] torch 2.0.0.dev20230201+cu116 pypi_0 pypi
[conda] torchaudio 2.0.0.dev20230112+cu116 pypi_0 pypi
[conda] torchvision 0.15.0.dev20230131+cu116 pypi_0 pypi
```
cc @ezyang @soumith @msaroufim @wconstab @ngimel @bdhirsh @mlazos @voznesenskym @yanboliang @penguinwu @anijain2305 @EikanWang @jgong5 @Guobing-Chen @XiaobingSuper @zhuhaozhe @blzheng @Xia-Weiwen @wenzhe-nrv @jiayisunx @desertfire
| 4 |
3,570 | 93,927 |
Cannot export models which access int/float stored as module attributes (they get unspecialized into inputs, which makes export choke)
|
triaged, oncall: pt2, module: dynamo, module: export
|
### 🐛 Describe the bug
```python
import torch
import torch._dynamo as torchdynamo
class Foo(torch.nn.Module):
def __init__(
self,
input_dim,
):
super().__init__()
self.torch_module = torch.nn.LayerNorm(
input_dim, eps=1e-5, elementwise_affine=True
)
def forward(self, input):
output = torch.nn.functional.layer_norm(
input,
self.torch_module.normalized_shape,
self.torch_module.weight,
self.torch_module.bias,
self.torch_module.eps,
).type_as(input)
return output
mod = Foo(128)
inp = torch.randn(3, 128)
gm, _ = torchdynamo.export(mod, inp, aten_graph=True, tracing_mode="symbolic")
print(gm.graph)
```
Above snippet fails with following error:
```
RuntimeError Traceback (most recent call last)
/mnt/xarfuse/uid-245563/fcd20915-seed-nspid4026531836_cgpid15299599-ns-4026531840/torch/_dynamo/utils.py in run_node(output_graph, node, args, kwargs, nnmodule)
1185 if op == "call_function":
-> 1186 return node.target(*args, **kwargs)
1187 elif op == "call_method":
/mnt/xarfuse/uid-245563/fcd20915-seed-nspid4026531836_cgpid15299599-ns-4026531840/torch/nn/functional.py in layer_norm(input, normalized_shape, weight, bias, eps)
2514 )
-> 2515 return torch.layer_norm(input, normalized_shape, weight, bias, eps, torch.backends.cudnn.enabled)
2516
RuntimeError: tried to get Double out of SymFloat
The above exception was the direct cause of the following exception:
RuntimeError Traceback (most recent call last)
/mnt/xarfuse/uid-245563/fcd20915-seed-nspid4026531836_cgpid15299599-ns-4026531840/torch/_dynamo/utils.py in get_fake_value(node, tx)
1143 with tx.fake_mode, enable_python_dispatcher():
-> 1144 return wrap_fake_exception(
1145 lambda: run_node(tx.output, node, args, kwargs, nnmodule)
/mnt/xarfuse/uid-245563/fcd20915-seed-nspid4026531836_cgpid15299599-ns-4026531840/torch/_dynamo/utils.py in wrap_fake_exception(fn)
805 try:
--> 806 return fn()
807 except UnsupportedFakeTensorException as e:
/mnt/xarfuse/uid-245563/fcd20915-seed-nspid4026531836_cgpid15299599-ns-4026531840/torch/_dynamo/utils.py in <lambda>()
1144 return wrap_fake_exception(
-> 1145 lambda: run_node(tx.output, node, args, kwargs, nnmodule)
1146 )
/mnt/xarfuse/uid-245563/fcd20915-seed-nspid4026531836_cgpid15299599-ns-4026531840/torch/_dynamo/utils.py in run_node(output_graph, node, args, kwargs, nnmodule)
1197 except Exception as e:
-> 1198 raise RuntimeError(
1199 f"Failed running {op} {node.target}(*{args}, **{kwargs}):\n{e}\n(scroll up for backtrace)"
RuntimeError: Failed running call_function <function layer_norm at 0x7fb50495c5e0>(*(FakeTensor(FakeTensor(..., device='meta', size=(s0, s1)), cpu), (128,), FakeTensor(Parameter(FakeTensor(..., device='meta', size=(128,), requires_grad=True)), cpu), FakeTensor(Parameter(FakeTensor(..., device='meta', size=(128,), requires_grad=True)), cpu), FakeTensor(FakeTensor(..., device='meta', size=()), cpu)), **{}):
tried to get Double out of SymFloat
(scroll up for backtrace)
The above exception was the direct cause of the following exception:
TorchRuntimeError Traceback (most recent call last)
<ipython-input-33-58348d11309a> in <module>
24 mod = Foo(128)
25 inp = torch.randn(3, 128)
---> 26 gm, _ = torchdynamo.export(mod, inp, aten_graph=True, tracing_mode="symbolic")
27 print(gm.graph)
/mnt/xarfuse/uid-245563/fcd20915-seed-nspid4026531836_cgpid15299599-ns-4026531840/torch/_dynamo/eval_frame.py in export(f, aten_graph, decomposition_table, tracing_mode, *args, **kwargs)
602 )(f)
603 # TODO(voz): We may have instances of `f` that mutate inputs, we should track sideffects and reject.
--> 604 result_traced = opt_f(*args, **kwargs)
605 remove_from_cache(f)
606
/mnt/xarfuse/uid-245563/fcd20915-seed-nspid4026531836_cgpid15299599-ns-4026531840/torch/nn/modules/module.py in _call_impl(self, *args, **kwargs)
1486 or _global_backward_pre_hooks or _global_backward_hooks
1487 or _global_forward_hooks or _global_forward_pre_hooks):
-> 1488 return forward_call(*args, **kwargs)
1489 # Do not call functions when jit is used
1490 full_backward_hooks, non_full_backward_hooks = [], []
/mnt/xarfuse/uid-245563/fcd20915-seed-nspid4026531836_cgpid15299599-ns-4026531840/torch/_dynamo/eval_frame.py in forward(self, *args, **kwargs)
80
81 def forward(self, *args, **kwargs):
---> 82 return self.dynamo_ctx(self._orig_mod.forward)(*args, **kwargs)
83
84
/mnt/xarfuse/uid-245563/fcd20915-seed-nspid4026531836_cgpid15299599-ns-4026531840/torch/_dynamo/eval_frame.py in _fn(*args, **kwargs)
209 dynamic_ctx.__enter__()
210 try:
--> 211 return fn(*args, **kwargs)
212 finally:
213 set_eval_frame(prior)
/mnt/xarfuse/uid-245563/fcd20915-seed-nspid4026531836_cgpid15299599-ns-4026531840/torch/_dynamo/eval_frame.py in catch_errors(frame, cache_size)
330
331 with compile_lock:
--> 332 return callback(frame, cache_size, hooks)
333
334 catch_errors._torchdynamo_orig_callable = callback # type: ignore[attr-defined]
/mnt/xarfuse/uid-245563/fcd20915-seed-nspid4026531836_cgpid15299599-ns-4026531840/torch/_dynamo/convert_frame.py in _fn(*args, **kwargs)
101 torch.fx.graph_module._forward_from_src = fx_forward_from_src_skip_result
102 try:
--> 103 return fn(*args, **kwargs)
104 finally:
105 torch._C._set_grad_enabled(prior_grad_mode)
/mnt/xarfuse/uid-245563/fcd20915-seed-nspid4026531836_cgpid15299599-ns-4026531840/torch/_dynamo/convert_frame.py in _convert_frame_assert(frame, cache_size, hooks)
259 initial_grad_state = torch.is_grad_enabled()
260
--> 261 return _compile(
262 frame.f_code,
263 frame.f_globals,
/mnt/xarfuse/uid-245563/fcd20915-seed-nspid4026531836_cgpid15299599-ns-4026531840/torch/_dynamo/utils.py in time_wrapper(*args, **kwargs)
160 compilation_metrics[key] = []
161 t0 = time.time()
--> 162 r = func(*args, **kwargs)
163 time_spent = time.time() - t0
164 # print(f"Dynamo timer: key={key}, latency={latency:.2f} sec")
/mnt/xarfuse/uid-245563/fcd20915-seed-nspid4026531836_cgpid15299599-ns-4026531840/torch/_dynamo/convert_frame.py in _compile(code, globals, locals, builtins, compiler_fn, one_graph, export, hooks, frame)
321 for attempt in itertools.count():
322 try:
--> 323 out_code = transform_code_object(code, transform)
324 orig_code_map[out_code] = code
325 break
/mnt/xarfuse/uid-245563/fcd20915-seed-nspid4026531836_cgpid15299599-ns-4026531840/torch/_dynamo/bytecode_transformation.py in transform_code_object(code, transformations, safe)
337 propagate_line_nums(instructions)
338
--> 339 transformations(instructions, code_options)
340
341 fix_vars(instructions, code_options)
/mnt/xarfuse/uid-245563/fcd20915-seed-nspid4026531836_cgpid15299599-ns-4026531840/torch/_dynamo/convert_frame.py in transform(instructions, code_options)
308 mutated_closure_cell_contents,
309 )
--> 310 tracer.run()
311 output = tracer.output
312 assert output is not None
/mnt/xarfuse/uid-245563/fcd20915-seed-nspid4026531836_cgpid15299599-ns-4026531840/torch/_dynamo/symbolic_convert.py in run(self)
1713 def run(self):
1714 _step_logger()(logging.INFO, f"torchdynamo start tracing {self.f_code.co_name}")
-> 1715 super().run()
1716
1717 def match_nested_cell(self, name, cell):
/mnt/xarfuse/uid-245563/fcd20915-seed-nspid4026531836_cgpid15299599-ns-4026531840/torch/_dynamo/symbolic_convert.py in run(self)
562 self.instruction_pointer is not None
563 and not self.output.should_exit
--> 564 and self.step()
565 ):
566 pass
/mnt/xarfuse/uid-245563/fcd20915-seed-nspid4026531836_cgpid15299599-ns-4026531840/torch/_dynamo/symbolic_convert.py in step(self)
525 if not hasattr(self, inst.opname):
526 unimplemented(f"missing: {inst.opname}")
--> 527 getattr(self, inst.opname)(inst)
528
529 return inst.opname != "RETURN_VALUE"
/mnt/xarfuse/uid-245563/fcd20915-seed-nspid4026531836_cgpid15299599-ns-4026531840/torch/_dynamo/symbolic_convert.py in wrapper(self, inst)
331 reason = None
332 try:
--> 333 return inner_fn(self, inst)
334 except Unsupported as excp:
335 if self.has_backedge() and self.should_compile_partial_graph():
/mnt/xarfuse/uid-245563/fcd20915-seed-nspid4026531836_cgpid15299599-ns-4026531840/torch/_dynamo/symbolic_convert.py in CALL_FUNCTION(self, inst)
988 args = self.popn(inst.argval)
989 fn = self.pop()
--> 990 self.call_function(fn, args, {})
991
992 @break_graph_if_unsupported(push=1)
/mnt/xarfuse/uid-245563/fcd20915-seed-nspid4026531836_cgpid15299599-ns-4026531840/torch/_dynamo/symbolic_convert.py in call_function(self, fn, args, kwargs)
459 for x in itertools.chain(args, kwargs.values())
460 )
--> 461 self.push(fn.call_function(self, args, kwargs))
462
463 def update_locals_and_stack(self, oldvar: VariableTracker, newvar: VariableTracker):
/mnt/xarfuse/uid-245563/fcd20915-seed-nspid4026531836_cgpid15299599-ns-4026531840/torch/_dynamo/variables/torch.py in call_function(self, tx, args, kwargs)
469 fn_ = sym_sqrt
470
--> 471 tensor_variable = wrap_fx_proxy(
472 tx=tx,
473 proxy=tx.output.create_proxy(
/mnt/xarfuse/uid-245563/fcd20915-seed-nspid4026531836_cgpid15299599-ns-4026531840/torch/_dynamo/variables/builder.py in wrap_fx_proxy(tx, proxy, example_value, **options)
754
755 def wrap_fx_proxy(tx, proxy, example_value=None, **options):
--> 756 return wrap_fx_proxy_cls(
757 target_cls=TensorVariable,
758 tx=tx,
/mnt/xarfuse/uid-245563/fcd20915-seed-nspid4026531836_cgpid15299599-ns-4026531840/torch/_dynamo/variables/builder.py in wrap_fx_proxy_cls(target_cls, tx, proxy, example_value, ignore_subclass, **options)
789 with preserve_rng_state():
790 if example_value is None:
--> 791 example_value = get_fake_value(proxy.node, tx)
792
793 # Handle recursive calls here
/mnt/xarfuse/uid-245563/fcd20915-seed-nspid4026531836_cgpid15299599-ns-4026531840/torch/_dynamo/utils.py in get_fake_value(node, tx)
1163 ):
1164 unimplemented("guard on data-dependent symbolic int/float")
-> 1165 raise TorchRuntimeError() from e
1166
1167
TorchRuntimeError:
from user code:
File "<ipython-input-33-58348d11309a>", line 15, in forward
output = torch.nn.functional.layer_norm(
Set torch._dynamo.config.verbose=True for more information
You can suppress this exception and fall back to eager by setting:
torch._dynamo.config.suppress_errors = True
```
### Versions
master
cc @ezyang @soumith @msaroufim @wconstab @ngimel @bdhirsh @mlazos @voznesenskym @yanboliang @penguinwu @anijain2305 @EikanWang @jgong5 @Guobing-Chen @XiaobingSuper @zhuhaozhe @blzheng @Xia-Weiwen @wenzhe-nrv @jiayisunx @desertfire
| 5 |
3,571 | 93,923 |
Dynamo uses CONSTANT_MATCH guards for string inputs
|
triaged, oncall: pt2, module: dynamo
|
### 🐛 Describe the bug
There are cases when we define pytorch modules that take strings or list[str] as inputs. For example, torchtext.vocab which does vocab lookup for string tokens, and modules that use torchtext.vocab underlying.
With jit script this works fine and string inputs are treated as variable input, but with dynamo they are somehow treated as constants, leading to recompilation every time the values change.
I'm not sure if this is expected behavior. If yes, this can be quite more restrictive than torchscript, especially for model export
### Error logs

The compiled graph should not have `[1, 0]` as constants
### Minified repro
_No response_
### Versions
PyTorch version: 2.0.0.dev20230201+cpu
Is debug build: False
CUDA used to build PyTorch: None
ROCM used to build PyTorch: N/A
OS: Ubuntu 22.04.1 LTS (x86_64)
GCC version: (Ubuntu 11.2.0-19ubuntu1) 11.2.0
Clang version: Could not collect
CMake version: Could not collect
Libc version: glibc-2.35
Python version: 3.10.5 | packaged by conda-forge | (main, Jun 14 2022, 07:04:59) [GCC 10.3.0] (64-bit runtime)
Python platform: Linux-5.10.130-118.517.amzn2.x86_64-x86_64-with-glibc2.35
Is CUDA available: False
CUDA runtime version: No CUDA
CUDA_MODULE_LOADING set to: N/A
GPU models and configuration: No CUDA
Nvidia driver version: No CUDA
cuDNN version: No CUDA
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.22.4
[pip3] pytorch-lightning==1.5.10
[pip3] torch==2.0.0.dev20230201+cpu
[pip3] torch-tb-profiler==0.4.0
[pip3] torchdata==0.6.0.dev20230201
[pip3] torchmetrics==0.9.3
[pip3] torchtext==0.15.0.dev20230201+cpu
[conda] nomkl 1.0 h5ca1d4c_0 conda-forge
[conda] numpy 1.22.4 py310h4ef5377_0 conda-forge
[conda] pytorch-lightning 1.5.10 pypi_0 pypi
[conda] torch 2.0.0.dev20230201+cpu pypi_0 pypi
[conda] torch-tb-profiler 0.4.0 pypi_0 pypi
[conda] torchdata 0.6.0.dev20230201 pypi_0 pypi
[conda] torchmetrics 0.9.3 pypi_0 pypi
[conda] torchtext 0.15.0.dev20230201+cpu pypi_0 pypi
cc @ezyang @soumith @msaroufim @wconstab @ngimel @bdhirsh @mlazos @voznesenskym @yanboliang @penguinwu @anijain2305 @EikanWang @jgong5 @Guobing-Chen @XiaobingSuper @zhuhaozhe @blzheng @Xia-Weiwen @wenzhe-nrv @jiayisunx @desertfire
| 14 |
3,572 | 93,913 |
[BUG] jit.trace not working for torchvision ViT models
|
oncall: jit
|
### 🐛 Describe the bug
torch.jit.trace is not working for torchvision vision transformer models, i.e. vit_b_16, vit_b_32, and vit_l_16, vit_l_32. It made a TracingCheckError.
### Versions
pytorch 1.13.0
torchvision v0.14
cc @EikanWang @jgong5 @wenzhe-nrv @sanchitintel
| 1 |
3,573 | 93,906 |
[dynamo]: Unsupported: call_method ListVariable() copy [] {}
|
triaged, oncall: pt2, module: dynamo
|
### 🐛 Describe the bug
Using nightlies (and triton from `HEAD`, though unlikely that matters here), I am unable to use `torch.compile(model, fullgraph=True, dynamic=False)` with SWinv2 provided by `torchvision` due to this line: https://github.com/pytorch/vision/blob/b094075cbc8834d63a9fa8ae08bcad3d72a43321/torchvision/models/swin_transformer.py#L156
```python
shift_size = shift_size.copy()
```
It makes a local copy of a list of integers passed by reference to avoid mutations in the method affecting the original.
Excerpt from traceback:
```python
...
File "/usr/local/lib/python3.10/site-packages/torch/_dynamo/exc.py", line 71, in unimplemented
raise Unsupported(msg)
torch._dynamo.exc.Unsupported: call_method ListVariable() copy [] {}
from user code:
File "/usr/local/lib/python3.10/site-packages/torchvision-0.15.0a0-py3.10-linux-x86_64.egg/torchvision/models/swin_transformer.py", line 381, in forward
return shifted_window_attention(
File "/usr/local/lib/python3.10/site-packages/torchvision-0.15.0a0-py3.10-linux-x86_64.egg/torchvision/models/swin_transformer.py", line 156, in shifted_window_attention
shift_size = shift_size.copy()
```
This could be fixed by rewriting the `.copy` as a list comprehension (`shift_size = [n for n in shift_size]`), which I have done locally to ensure that fixes the issue. (And so this would belong in Torchvision's issue tracker.)
However, the `copy` method is commonplace and more concise than a list comprehension which does effectively the same thing.
What would the level of effort be to add support for `copy` to Dynamo, even if only for primitive types? (I'm not sure what would be involved in supporting `copy` with arbitrary objects.)
### Error logs
<details>
```python
Traceback (most recent call last):
File "/bsrt/bsrt/main.py", line 144, in <module>
trainer.fit( # type: ignore
File "/usr/local/lib/python3.10/site-packages/pytorch_lightning/trainer/trainer.py", line 608, in fit
call._call_and_handle_interrupt(
File "/usr/local/lib/python3.10/site-packages/pytorch_lightning/trainer/call.py", line 38, in _call_and_handle_interrupt
return trainer_fn(*args, **kwargs)
File "/usr/local/lib/python3.10/site-packages/pytorch_lightning/trainer/trainer.py", line 650, in _fit_impl
self._run(model, ckpt_path=self.ckpt_path)
File "/usr/local/lib/python3.10/site-packages/pytorch_lightning/trainer/trainer.py", line 1103, in _run
results = self._run_stage()
File "/usr/local/lib/python3.10/site-packages/pytorch_lightning/trainer/trainer.py", line 1182, in _run_stage
self._run_train()
File "/usr/local/lib/python3.10/site-packages/pytorch_lightning/trainer/trainer.py", line 1205, in _run_train
self.fit_loop.run()
File "/usr/local/lib/python3.10/site-packages/pytorch_lightning/loops/loop.py", line 199, in run
self.advance(*args, **kwargs)
File "/usr/local/lib/python3.10/site-packages/pytorch_lightning/loops/fit_loop.py", line 267, in advance
self._outputs = self.epoch_loop.run(self._data_fetcher)
File "/usr/local/lib/python3.10/site-packages/pytorch_lightning/loops/loop.py", line 199, in run
self.advance(*args, **kwargs)
File "/usr/local/lib/python3.10/site-packages/pytorch_lightning/loops/epoch/training_epoch_loop.py", line 213, in advance
batch_output = self.batch_loop.run(kwargs)
File "/usr/local/lib/python3.10/site-packages/pytorch_lightning/loops/loop.py", line 199, in run
self.advance(*args, **kwargs)
File "/usr/local/lib/python3.10/site-packages/pytorch_lightning/loops/batch/training_batch_loop.py", line 88, in advance
outputs = self.optimizer_loop.run(optimizers, kwargs)
File "/usr/local/lib/python3.10/site-packages/pytorch_lightning/loops/loop.py", line 199, in run
self.advance(*args, **kwargs)
File "/usr/local/lib/python3.10/site-packages/pytorch_lightning/loops/optimization/optimizer_loop.py", line 202, in advance
result = self._run_optimization(kwargs, self._optimizers[self.optim_progress.optimizer_position])
File "/usr/local/lib/python3.10/site-packages/pytorch_lightning/loops/optimization/optimizer_loop.py", line 241, in _run_optimization
closure()
File "/usr/local/lib/python3.10/site-packages/pytorch_lightning/loops/optimization/optimizer_loop.py", line 149, in __call__
self._result = self.closure(*args, **kwargs)
File "/usr/local/lib/python3.10/site-packages/pytorch_lightning/loops/optimization/optimizer_loop.py", line 135, in closure
step_output = self._step_fn()
File "/usr/local/lib/python3.10/site-packages/pytorch_lightning/loops/optimization/optimizer_loop.py", line 419, in _training_step
training_step_output = self.trainer._call_strategy_hook("training_step", *kwargs.values())
File "/usr/local/lib/python3.10/site-packages/pytorch_lightning/trainer/trainer.py", line 1485, in _call_strategy_hook
output = fn(*args, **kwargs)
File "/usr/local/lib/python3.10/site-packages/pytorch_lightning/strategies/strategy.py", line 378, in training_step
return self.model.training_step(*args, **kwargs)
File "/bsrt/bsrt/lightning_bsrt.py", line 206, in training_step
srs: Tensor = self(bursts)
File "/usr/local/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "/bsrt/bsrt/lightning_bsrt.py", line 198, in forward
ret: Tensor = self.model(bursts)
File "/usr/local/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "/usr/local/lib/python3.10/site-packages/torch/_dynamo/eval_frame.py", line 82, in forward
return self.dynamo_ctx(self._orig_mod.forward)(*args, **kwargs)
File "/usr/local/lib/python3.10/site-packages/torch/_dynamo/eval_frame.py", line 209, in _fn
return fn(*args, **kwargs)
File "/usr/local/lib/python3.10/site-packages/torch/_dynamo/eval_frame.py", line 330, in catch_errors
return callback(frame, cache_size, hooks)
File "/usr/local/lib/python3.10/site-packages/torch/_dynamo/convert_frame.py", line 103, in _fn
return fn(*args, **kwargs)
File "/usr/local/lib/python3.10/site-packages/torch/_dynamo/convert_frame.py", line 261, in _convert_frame_assert
return _compile(
File "/usr/local/lib/python3.10/site-packages/torch/_dynamo/utils.py", line 162, in time_wrapper
r = func(*args, **kwargs)
File "/usr/local/lib/python3.10/site-packages/torch/_dynamo/convert_frame.py", line 323, in _compile
out_code = transform_code_object(code, transform)
File "/usr/local/lib/python3.10/site-packages/torch/_dynamo/bytecode_transformation.py", line 339, in transform_code_object
transformations(instructions, code_options)
File "/usr/local/lib/python3.10/site-packages/torch/_dynamo/convert_frame.py", line 310, in transform
tracer.run()
File "/usr/local/lib/python3.10/site-packages/torch/_dynamo/symbolic_convert.py", line 1715, in run
super().run()
File "/usr/local/lib/python3.10/site-packages/torch/_dynamo/symbolic_convert.py", line 564, in run
and self.step()
File "/usr/local/lib/python3.10/site-packages/torch/_dynamo/symbolic_convert.py", line 527, in step
getattr(self, inst.opname)(inst)
File "/usr/local/lib/python3.10/site-packages/torch/_dynamo/symbolic_convert.py", line 333, in wrapper
return inner_fn(self, inst)
File "/usr/local/lib/python3.10/site-packages/torch/_dynamo/symbolic_convert.py", line 990, in CALL_FUNCTION
self.call_function(fn, args, {})
File "/usr/local/lib/python3.10/site-packages/torch/_dynamo/symbolic_convert.py", line 461, in call_function
self.push(fn.call_function(self, args, kwargs))
File "/usr/local/lib/python3.10/site-packages/torch/_dynamo/variables/functions.py", line 289, in call_function
return super().call_function(tx, args, kwargs)
File "/usr/local/lib/python3.10/site-packages/torch/_dynamo/variables/functions.py", line 259, in call_function
return super(UserFunctionVariable, self).call_function(tx, args, kwargs)
File "/usr/local/lib/python3.10/site-packages/torch/_dynamo/variables/functions.py", line 92, in call_function
return tx.inline_user_function_return(
File "/usr/local/lib/python3.10/site-packages/torch/_dynamo/symbolic_convert.py", line 497, in inline_user_function_return
result = InliningInstructionTranslator.inline_call(self, fn, args, kwargs)
File "/usr/local/lib/python3.10/site-packages/torch/_dynamo/symbolic_convert.py", line 1793, in inline_call
return cls.inline_call_(parent, func, args, kwargs)
File "/usr/local/lib/python3.10/site-packages/torch/_dynamo/symbolic_convert.py", line 1849, in inline_call_
tracer.run()
File "/usr/local/lib/python3.10/site-packages/torch/_dynamo/symbolic_convert.py", line 564, in run
and self.step()
File "/usr/local/lib/python3.10/site-packages/torch/_dynamo/symbolic_convert.py", line 527, in step
getattr(self, inst.opname)(inst)
File "/usr/local/lib/python3.10/site-packages/torch/_dynamo/symbolic_convert.py", line 333, in wrapper
return inner_fn(self, inst)
File "/usr/local/lib/python3.10/site-packages/torch/_dynamo/symbolic_convert.py", line 990, in CALL_FUNCTION
self.call_function(fn, args, {})
File "/usr/local/lib/python3.10/site-packages/torch/_dynamo/symbolic_convert.py", line 461, in call_function
self.push(fn.call_function(self, args, kwargs))
File "/usr/local/lib/python3.10/site-packages/torch/_dynamo/variables/nn_module.py", line 244, in call_function
return tx.inline_user_function_return(
File "/usr/local/lib/python3.10/site-packages/torch/_dynamo/symbolic_convert.py", line 497, in inline_user_function_return
result = InliningInstructionTranslator.inline_call(self, fn, args, kwargs)
File "/usr/local/lib/python3.10/site-packages/torch/_dynamo/symbolic_convert.py", line 1793, in inline_call
return cls.inline_call_(parent, func, args, kwargs)
File "/usr/local/lib/python3.10/site-packages/torch/_dynamo/symbolic_convert.py", line 1849, in inline_call_
tracer.run()
File "/usr/local/lib/python3.10/site-packages/torch/_dynamo/symbolic_convert.py", line 564, in run
and self.step()
File "/usr/local/lib/python3.10/site-packages/torch/_dynamo/symbolic_convert.py", line 527, in step
getattr(self, inst.opname)(inst)
File "/usr/local/lib/python3.10/site-packages/torch/_dynamo/symbolic_convert.py", line 333, in wrapper
return inner_fn(self, inst)
File "/usr/local/lib/python3.10/site-packages/torch/_dynamo/symbolic_convert.py", line 990, in CALL_FUNCTION
self.call_function(fn, args, {})
File "/usr/local/lib/python3.10/site-packages/torch/_dynamo/symbolic_convert.py", line 461, in call_function
self.push(fn.call_function(self, args, kwargs))
File "/usr/local/lib/python3.10/site-packages/torch/_dynamo/variables/nn_module.py", line 184, in call_function
tx.call_function(
File "/usr/local/lib/python3.10/site-packages/torch/_dynamo/symbolic_convert.py", line 461, in call_function
self.push(fn.call_function(self, args, kwargs))
File "/usr/local/lib/python3.10/site-packages/torch/_dynamo/variables/nn_module.py", line 244, in call_function
return tx.inline_user_function_return(
File "/usr/local/lib/python3.10/site-packages/torch/_dynamo/symbolic_convert.py", line 497, in inline_user_function_return
result = InliningInstructionTranslator.inline_call(self, fn, args, kwargs)
File "/usr/local/lib/python3.10/site-packages/torch/_dynamo/symbolic_convert.py", line 1793, in inline_call
return cls.inline_call_(parent, func, args, kwargs)
File "/usr/local/lib/python3.10/site-packages/torch/_dynamo/symbolic_convert.py", line 1849, in inline_call_
tracer.run()
File "/usr/local/lib/python3.10/site-packages/torch/_dynamo/symbolic_convert.py", line 564, in run
and self.step()
File "/usr/local/lib/python3.10/site-packages/torch/_dynamo/symbolic_convert.py", line 527, in step
getattr(self, inst.opname)(inst)
File "/usr/local/lib/python3.10/site-packages/torch/_dynamo/symbolic_convert.py", line 333, in wrapper
return inner_fn(self, inst)
File "/usr/local/lib/python3.10/site-packages/torch/_dynamo/symbolic_convert.py", line 990, in CALL_FUNCTION
self.call_function(fn, args, {})
File "/usr/local/lib/python3.10/site-packages/torch/_dynamo/symbolic_convert.py", line 461, in call_function
self.push(fn.call_function(self, args, kwargs))
File "/usr/local/lib/python3.10/site-packages/torch/_dynamo/variables/nn_module.py", line 244, in call_function
return tx.inline_user_function_return(
File "/usr/local/lib/python3.10/site-packages/torch/_dynamo/symbolic_convert.py", line 497, in inline_user_function_return
result = InliningInstructionTranslator.inline_call(self, fn, args, kwargs)
File "/usr/local/lib/python3.10/site-packages/torch/_dynamo/symbolic_convert.py", line 1793, in inline_call
return cls.inline_call_(parent, func, args, kwargs)
File "/usr/local/lib/python3.10/site-packages/torch/_dynamo/symbolic_convert.py", line 1849, in inline_call_
tracer.run()
File "/usr/local/lib/python3.10/site-packages/torch/_dynamo/symbolic_convert.py", line 564, in run
and self.step()
File "/usr/local/lib/python3.10/site-packages/torch/_dynamo/symbolic_convert.py", line 527, in step
getattr(self, inst.opname)(inst)
File "/usr/local/lib/python3.10/site-packages/torch/_dynamo/symbolic_convert.py", line 333, in wrapper
return inner_fn(self, inst)
File "/usr/local/lib/python3.10/site-packages/torch/_dynamo/symbolic_convert.py", line 1039, in CALL_FUNCTION_KW
self.call_function(fn, args, kwargs)
File "/usr/local/lib/python3.10/site-packages/torch/_dynamo/symbolic_convert.py", line 461, in call_function
self.push(fn.call_function(self, args, kwargs))
File "/usr/local/lib/python3.10/site-packages/torch/_dynamo/variables/functions.py", line 259, in call_function
return super(UserFunctionVariable, self).call_function(tx, args, kwargs)
File "/usr/local/lib/python3.10/site-packages/torch/_dynamo/variables/functions.py", line 92, in call_function
return tx.inline_user_function_return(
File "/usr/local/lib/python3.10/site-packages/torch/_dynamo/symbolic_convert.py", line 497, in inline_user_function_return
result = InliningInstructionTranslator.inline_call(self, fn, args, kwargs)
File "/usr/local/lib/python3.10/site-packages/torch/_dynamo/symbolic_convert.py", line 1793, in inline_call
return cls.inline_call_(parent, func, args, kwargs)
File "/usr/local/lib/python3.10/site-packages/torch/_dynamo/symbolic_convert.py", line 1849, in inline_call_
tracer.run()
File "/usr/local/lib/python3.10/site-packages/torch/_dynamo/symbolic_convert.py", line 564, in run
and self.step()
File "/usr/local/lib/python3.10/site-packages/torch/_dynamo/symbolic_convert.py", line 527, in step
getattr(self, inst.opname)(inst)
File "/usr/local/lib/python3.10/site-packages/torch/_dynamo/symbolic_convert.py", line 333, in wrapper
return inner_fn(self, inst)
File "/usr/local/lib/python3.10/site-packages/torch/_dynamo/symbolic_convert.py", line 990, in CALL_FUNCTION
self.call_function(fn, args, {})
File "/usr/local/lib/python3.10/site-packages/torch/_dynamo/symbolic_convert.py", line 461, in call_function
self.push(fn.call_function(self, args, kwargs))
File "/usr/local/lib/python3.10/site-packages/torch/_dynamo/variables/misc.py", line 674, in call_function
return self.obj.call_method(tx, self.name, args, kwargs).add_options(self)
File "/usr/local/lib/python3.10/site-packages/torch/_dynamo/variables/lists.py", line 239, in call_method
return super().call_method(tx, name, args, kwargs)
File "/usr/local/lib/python3.10/site-packages/torch/_dynamo/variables/lists.py", line 101, in call_method
return super(BaseListVariable, self).call_method(tx, name, args, kwargs)
File "/usr/local/lib/python3.10/site-packages/torch/_dynamo/variables/base.py", line 253, in call_method
raise unimplemented(f"call_method {self} {name} {args} {kwargs}")
File "/usr/local/lib/python3.10/site-packages/torch/_dynamo/exc.py", line 71, in unimplemented
raise Unsupported(msg)
torch._dynamo.exc.Unsupported: call_method ListVariable() copy [] {}
from user code:
File "/usr/local/lib/python3.10/site-packages/torchvision-0.15.0a0-py3.10-linux-x86_64.egg/torchvision/models/swin_transformer.py", line 381, in forward
return shifted_window_attention(
File "/usr/local/lib/python3.10/site-packages/torchvision-0.15.0a0-py3.10-linux-x86_64.egg/torchvision/models/swin_transformer.py", line 156, in shifted_window_attention
shift_size = shift_size.copy()
Set torch._dynamo.config.verbose=True for more information
You can suppress this exception and fall back to eager by setting:
torch._dynamo.config.suppress_errors = True
```
</details>
### Minified repro
_No response_
### Versions
```text
PyTorch version: 2.0.0a0+git569f2e3
Is debug build: False
CUDA used to build PyTorch: 11.8
ROCM used to build PyTorch: N/A
OS: Ubuntu 22.04.1 LTS (x86_64)
GCC version: (Ubuntu 11.3.0-1ubuntu1~22.04) 11.3.0
Clang version: 16.0.0 (++20230130103025+16a5dd495d02-1~exp1~20230130223133.7)
CMake version: version 3.25.2
Libc version: glibc-2.35
Python version: 3.10.9+ (main, Feb 1 2023, 12:46:32) [Clang 16.0.0 (++20230130103025+16a5dd495d02-1~exp1~20230130223133.7)] (64-bit runtime)
Python platform: Linux-6.1.8-200.fc37.x86_64-x86_64-with-glibc2.35
Is CUDA available: True
CUDA runtime version: 11.8.89
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration: GPU 0: NVIDIA GeForce RTX 4090
Nvidia driver version: 525.85.12
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.7.0
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.7.0
/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.7.0
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_infer.so.8.7.0
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.7.0
/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.7.0
/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.7.0
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.21.4
[pip3] pytorch-lightning==1.9.0
[pip3] torch==2.0.0a0+git569f2e3
[pip3] torch-fidelity==0.3.0
[pip3] torchmetrics==0.11.1
[pip3] torchvision==0.15.0a0
[conda] Could not collect
```
cc @ezyang @soumith @msaroufim @wconstab @ngimel @bdhirsh @mlazos @voznesenskym @yanboliang @penguinwu @anijain2305 @EikanWang @jgong5 @Guobing-Chen @XiaobingSuper @zhuhaozhe @blzheng @Xia-Weiwen @wenzhe-nrv @jiayisunx @desertfire
| 3 |
3,574 | 93,905 |
[Dynamo] Don't graph break on einops
|
high priority, triaged, enhancement, oncall: pt2, module: dynamic shapes, module: dynamo
|
### 🚀 The feature, motivation and pitch
Einops is a very popular library in PyTorch code, so we should aim to not graph break on it. For example, see https://github.com/lucidrains/vit-pytorch/blob/main/vit_pytorch/cait.py#L95
It currently causes dynamo to graph break.
```
import torch
from einops import rearrange
from torch._dynamo import allow_in_graph
# allow_in_graph(rearrange)
@torch.compile(fullgraph=True)
def f(x):
x = x.cos()
return rearrange(x, 'b n -> (b n)').sin()
f(torch.randn(20, 20, device='cuda'))
```
If you uncomment the `allow_in_graph` though, it works.
`cast(Tensor, tensor)` causes the break (for pytorch tensors it's a no-op).
### Alternatives
_No response_
### Additional context
_No response_
cc @ezyang @gchanan @zou3519 @msaroufim @wconstab @bdhirsh @anijain2305 @voznesenskym @penguinwu @EikanWang @jgong5 @Guobing-Chen @XiaobingSuper @zhuhaozhe @blzheng @Xia-Weiwen @wenzhe-nrv @jiayisunx @ipiszy @chenyang78 @soumith @ngimel @desertfire @mlazos @yanboliang
| 7 |
3,575 | 93,900 |
Why does the torch model have no memory leaks under gpu, but there is a memory leak under cpu, torch version 1.10.1
|
needs reproduction, triaged
|
### 🐛 Describe the bug
Why does the torch model have no memory leaks under gpu, but there is a memory leak under cpu, torch version 1.10.1
### Versions
Why does the torch model have no memory leaks under gpu, but there is a memory leak under cpu, torch version 1.10.1
| 3 |
3,576 | 93,890 |
[Dynamo] torch.autocast context manager doesn't support graph break
|
triaged, oncall: pt2, module: dynamo
|
### 🐛 Describe the bug
I wrote a unittest that is being skipped to track this failure:
https://github.com/pytorch/pytorch/pull/92917/files#diff-0daa64329e2d8648fc119f7809dc810c744508d345ea023116614ccc17e57dbeR2708
When raising the unimplemented here: https://github.com/pytorch/pytorch/pull/92917/files#diff-7bd43c6b174845f3450be42c8460ed021d1b39a98510cbea5d4e7e3a0b9d8d4fR494
the following error message is produced:
``` bash
Traceback (most recent call last):
File "/scratch/drisspg/work/pytorch/torch/_dynamo/convert_frame.py", line 323, in _compile
out_code = transform_code_object(code, transform)
File "/scratch/drisspg/work/pytorch/torch/_dynamo/bytecode_transformation.py", line 339, in transform_code_object
transformations(instructions, code_options)
File "/scratch/drisspg/work/pytorch/torch/_dynamo/convert_frame.py", line 310, in transform
tracer.run()
File "/scratch/drisspg/work/pytorch/torch/_dynamo/symbolic_convert.py", line 1715, in run
super().run()
File "/scratch/drisspg/work/pytorch/torch/_dynamo/symbolic_convert.py", line 564, in run
and self.step()
File "/scratch/drisspg/work/pytorch/torch/_dynamo/symbolic_convert.py", line 527, in step
getattr(self, inst.opname)(inst)
File "/scratch/drisspg/work/pytorch/torch/_dynamo/symbolic_convert.py", line 363, in wrapper
self.output.compile_subgraph(self, reason=reason)
File "/scratch/drisspg/work/pytorch/torch/_dynamo/output_graph.py", line 480, in compile_subgraph
tx.prune_dead_locals()
File "/scratch/drisspg/work/pytorch/torch/_dynamo/symbolic_convert.py", line 446, in prune_dead_locals
self.output.side_effects.prune_dead_object_new(self)
File "/scratch/drisspg/work/pytorch/torch/_dynamo/side_effects.py", line 268, in prune_dead_object_new
VariableTracker.apply(visit, (tx.stack, tx.symbolic_locals))
File "/scratch/drisspg/work/pytorch/torch/_dynamo/variables/base.py", line 106, in apply
result = tuple(cls.apply(fn, v, cache, skip_fn) for v in value)
File "/scratch/drisspg/work/pytorch/torch/_dynamo/variables/base.py", line 106, in <genexpr>
result = tuple(cls.apply(fn, v, cache, skip_fn) for v in value)
File "/scratch/drisspg/work/pytorch/torch/_dynamo/variables/base.py", line 104, in apply
result = [cls.apply(fn, v, cache, skip_fn) for v in value]
File "/scratch/drisspg/work/pytorch/torch/_dynamo/variables/base.py", line 104, in <listcomp>
result = [cls.apply(fn, v, cache, skip_fn) for v in value]
File "/scratch/drisspg/work/pytorch/torch/_dynamo/variables/base.py", line 96, in apply
updated_dict[key] = cls.apply(
File "/scratch/drisspg/work/pytorch/torch/_dynamo/variables/base.py", line 99, in apply
result = fn(value.clone(**updated_dict))
File "/scratch/drisspg/work/pytorch/torch/_dynamo/variables/base.py", line 65, in clone
return self.__class__(**args)
File "/scratch/drisspg/work/pytorch/torch/_dynamo/variables/base.py", line 27, in __call__
obj = type.__call__(cls, *args, **kwargs)
File "/scratch/drisspg/work/pytorch/torch/_dynamo/variables/misc.py", line 388, in __init__
super(AutocastModeVariable, self).__init__(
File "/scratch/drisspg/work/pytorch/torch/_dynamo/variables/misc.py", line 170, in __init__
super(ContextWrappingVariable, self).__init__(**kwargs)
TypeError: __init__() got an unexpected keyword argument 'mode'
```
### Versions
https://github.com/pytorch/pytorch/pull/92917
This will be merged to master though.
cc @ezyang @gchanan @zou3519 @soumith @msaroufim @wconstab @ngimel @bdhirsh @mlazos @voznesenskym @yanboliang @penguinwu @anijain2305 @EikanWang @jgong5 @Guobing-Chen @XiaobingSuper @zhuhaozhe @blzheng @Xia-Weiwen @wenzhe-nrv @jiayisunx @desertfire
| 8 |
3,577 | 93,884 |
Importing tensorflow (2.12) before torch (2.0) hangs at import torch
|
oncall: binaries, triaged
|
### 🐛 Describe the bug
I am trying to set up a bleeding edge machine (2x4090, TF 2.12-dev, torch 2.0-dev) and stumbled on something strange.
If I run this code
```
import tensorflow as tf
print('TF-version:',tf.__version__)
import torch
print('Torch-version:',torch.__version__)
```
It hangs on "import torch". And I have to ctrl-D out of it
It then prints
```
terminate called after throwing an instance of 'std::runtime_error'
what(): random_device could not be read
```
While if I change the order of tensorflow and torch
```
import torch
print('Torch-version:',torch.__version__)
import tensorflow as tf
print('TF-version:',tf.__version__)
```
it works!
printing
```
Torch-version: 2.0.0.dev20230131+cu118
2023-02-01 21:59:13.899074: E tensorflow/tsl/lib/monitoring/collection_registry.cc:81] Cannot register 2 metrics with the same name: /tensorflow/core/bfc_allocator_delay
TF-version: 2.12.0-dev20230127
```
### Versions
Collecting environment information...
PyTorch version: 2.0.0.dev20230131+cu118
Is debug build: False
CUDA used to build PyTorch: 11.8
ROCM used to build PyTorch: N/A
OS: Ubuntu 22.04.1 LTS (x86_64)
GCC version: (Ubuntu 11.3.0-1ubuntu1~22.04) 11.3.0
Clang version: 14.0.0-1ubuntu1
CMake version: version 3.25.0
Libc version: glibc-2.35
Python version: 3.10.6 (main, Nov 14 2022, 16:10:14) [GCC 11.3.0] (64-bit runtime)
Python platform: Linux-5.15.0-58-generic-x86_64-with-glibc2.35
Is CUDA available: True
CUDA runtime version: 12.0.140
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration:
GPU 0: NVIDIA GeForce RTX 4090
GPU 1: NVIDIA GeForce RTX 4090
Nvidia driver version: 525.85.12
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.7.0
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.7.0
/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.7.0
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_infer.so.8.7.0
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.7.0
/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.7.0
/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.7.0
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.24.1
[pip3] pytorch-triton==2.0.0+0d7e753227
[pip3] torch==2.0.0.dev20230131+cu118
[pip3] torchaudio==2.0.0.dev20230131+cu118
[pip3] torchvision==0.15.0.dev20230131+cu118
[conda] Could not collect
TF-version: 2.12.0-dev20230127
cc @ezyang @seemethere @malfet
| 3 |
3,578 | 93,880 |
`PYTORCH_DEBUG_MODE`, better invalid index embedding lookup error message on cuda
|
high priority, triaged, needs design, module: python frontend
|
### 🚀 The feature, motivation and pitch
You can read the detailed presentation of the problem and the ensuing discussion here:
https://pytorch.slack.com/archives/C3PDTEV8E/p1675216222317729
The outcome of discussion with @ngimel and @Chillee is this:
1. introduce a new `PYTORCH_DEBUG_MODE` env var which allows for slow validations which we don't want in the normal mode. This mode is to be activated by users when things go wrong and additional hinting is needed from pytorch. Item (2) will be the first user of this mode, but then I hope more similar user-friendly validations will be added in the future. e.g. hinting at bad sizes of matrices which don't align with `% 16`, and then wave and tile quantization as another example. the other candidates would be any op that will now be able to pre-validate its inputs on the python side and thus give a better error than the async cuda error.
2. rewrite `nn.Embedding.__call__` to validate on the python side if `PYTORCH_DEBUG_MODE=1` that the index inputs aren't larger than the target matrix size and provide a user-friendly assert before the call is dispatched to cuda - since once it's gone to cuda the error message is a big disaster and very often doesn't tell where the problem is - see the slack thread for examples of such horrors.
3. bonus: while at it make the `IndexError: index out of range in self` on cpu more user friendly to align with other pytorch ops where actual sizes/dimensions are reported as part of the assert message, for example:
```
e = torch.nn.Embedding(10,10)
x = torch.tensor([[10]])
e(x)
---
before: IndexError: index out of range in self
after: IndexError: index 10 is out of max range 9
```
The actual check can be something as simple as:
```
if torch.where(x.flatten() >= e.weight.shape[0])[0].shape[0] > 0:
raise ValueError(f"the inputs contain indices that are higher than {e.weight.shape[0]-1} which is the highest index of the embedding")
```
I'm not sure if we want to dump all the bad indices, perhaps just the highest one? But I trust you'd find a much more generic way to do that. I'm surely not thinking about the edge cases and only made it work with the simple example above.
p.s. in [this Issue thread](https://github.com/huggingface/transformers/issues/21378) that prompted this feature request you can see how badly it sometimes gets and the error messages are completely wrong and aren't pointing to the source of the problem
cc @ezyang @gchanan @zou3519 @albanD
| 11 |
3,579 | 93,864 |
Inductor miscompilation with dynamic shapes from Background_Matting
|
triaged, oncall: pt2, module: dynamic shapes, module: inductor
|
### 🐛 Describe the bug
Repro script: https://gist.github.com/100ea386eaad5041ed18303e277e39e2
Minifier did not work, due to https://github.com/pytorch/pytorch/issues/93857
I confirmed that this script fails accuracy with dynamic shapes, and doesn't fail without
Full model repro command is `TORCHDYNAMO_REPRO_FORWARD_ONLY=1 TORCHDYNAMO_REPRO_AFTER=dynamo TORCHDYNAMO_REPRO_LEVEL=4 python benchmarks/dynamo/torchbench.py --accuracy --backend inductor --explain --only Background_Matting --float32 --dynamic-shapes --disable-cudagraphs` but to actually get the minifier to produce anything at all you need https://github.com/pytorch/pytorch/pull/93856 https://github.com/pytorch/pytorch/pull/93853 https://github.com/pytorch/pytorch/pull/93850 https://github.com/pytorch/pytorch/pull/93403
cc @soumith @msaroufim @wconstab @ngimel @bdhirsh @mlazos @voznesenskym @yanboliang @penguinwu @anijain2305 @EikanWang @jgong5 @Guobing-Chen @XiaobingSuper @zhuhaozhe @blzheng @Xia-Weiwen @wenzhe-nrv @jiayisunx @peterbell10 @desertfire @Chillee
### Versions
master
| 0 |
3,580 | 93,860 |
Minifier related: perhaps same_two_models should reseed between the regular and optimized runs?
|
triaged, oncall: pt2, module: minifier
|
### 🐛 Describe the bug
same_two_models doesn't reseed before running the two models. Maybe it should?
One countervailing factor here is that, we don't generally preserve RNG algorithm on compilation. So they won't match anyway, even if we reseed.
Maybe same_two_models should run the source model twice to see if there is RNG involved? But we also need to be careful about input mutations.
### Versions
master
cc @soumith @msaroufim @wconstab @ngimel @bdhirsh
| 0 |
3,581 | 93,859 |
Bitwise-perfect method for (de)serializing tensors in base64
|
feature, module: serialization, triaged
|
### 🚀 The feature, motivation and pitch
- Convenient for pasting directly into repro code/comment on GitHub without attaching other files (also considering severe file extension limitations of GitHub file attachment)
- Currently (at least, some time ago), some properties of Tensors (such as coalesced-ness) might be lost after existing torch.save+torch.load roundtrip, so need a bitwise perfect C++ Tensor object reconstruction with its layout/sparse structures/bitfields/storage/strides for reproducing/demonstrating problems with these, so a concise text-based format (typically for small tensors) would be useful!
Original context and proposal in https://github.com/pytorch/pytorch/issues/73479#issuecomment-1056903431
Related on general use of utility for base64 torch.save/torch.load (?) format for repro purposes: https://github.com/pytorch/pytorch/issues/93366#issuecomment-1411988364
cc @mruberry @pearu
### Alternatives
_No response_
### Additional context
_No response_
| 0 |
3,582 | 93,857 |
Minifier has trouble correctly setting up requires_grad'ness of inputs for forward only
|
triaged, oncall: pt2, module: minifier
|
### 🐛 Describe the bug
Try running the minifier launcher at https://gist.github.com/2a361f0f7613fe6e609c14cb18717454 with https://github.com/pytorch/pytorch/pull/93853 https://github.com/pytorch/pytorch/pull/93403 https://github.com/pytorch/pytorch/pull/93856
A lot of minification attempts fail with
```
Traceback (most recent call last):
File "/data/users/ezyang/b/pytorch/torch/_dynamo/debug_utils.py", line 672, in same_two_models
res = run_fwd_maybe_bwd(opt_gm, example_inputs, only_fwd)
File "/data/users/ezyang/b/pytorch/torch/_dynamo/debug_utils.py", line 632, in run_fwd_maybe_bwd
out = gm(args)
File "/data/users/ezyang/b/pytorch/torch/_functorch/aot_autograd.py", line 996, in g
return f(*args)
File "/data/users/ezyang/b/pytorch/torch/_dynamo/eval_frame.py", line 211, in _fn
return fn(*args, **kwargs)
File "/data/users/ezyang/b/pytorch/torch/_functorch/aot_autograd.py", line 2497, in forward
return compiled_fn(full_args)
File "/data/users/ezyang/b/pytorch/torch/_functorch/aot_autograd.py", line 996, in g
return f(*args)
File "/data/users/ezyang/b/pytorch/torch/_functorch/aot_autograd.py", line 2061, in debug_compiled_function
assert not a.requires_grad, format_guard_bug_msg(
AssertionError: At compilation time, graph 12 was compiled under the assumption that input 3 would not require grad, but at runtime this was not the case. This indicates a guard bug in AOTAutograd or Dynamo, please file a bug to PyTorch.
```
```
File "/data/users/ezyang/b/pytorch/torch/_dynamo/convert_frame.py", line 310, in transform
tracer.run()
File "/data/users/ezyang/b/pytorch/torch/_dynamo/symbolic_convert.py", line 1715, in run
super().run()
File "/data/users/ezyang/b/pytorch/torch/_dynamo/symbolic_convert.py", line 564, in run
and self.step()
File "/data/users/ezyang/b/pytorch/torch/_dynamo/symbolic_convert.py", line 527, in step
getattr(self, inst.opname)(inst)
File "/data/users/ezyang/b/pytorch/torch/_dynamo/symbolic_convert.py", line 1781, in RETURN_VALUE
self.output.compile_subgraph(self)
File "/data/users/ezyang/b/pytorch/torch/_dynamo/output_graph.py", line 563, in compile_subgraph
self.compile_and_call_fx_graph(tx, pass2.graph_output_vars(), root)
File "/data/users/ezyang/b/pytorch/torch/_dynamo/output_graph.py", line 610, in compile_and_call_fx_graph
compiled_fn = self.call_user_compiler(gm)
File "/data/users/ezyang/b/pytorch/torch/_dynamo/utils.py", line 162, in time_wrapper
r = func(*args, **kwargs)
File "/data/users/ezyang/b/pytorch/torch/_dynamo/output_graph.py", line 697, in call_user_compiler
raise BackendCompilerFailed(self.compiler_fn, e) from e
torch._dynamo.exc.BackendCompilerFailed: debug_wrapper raised RuntimeError: a leaf Variable that requires grad is being used in an in-place operation.
```
The minifier should be more clever about how it sets up inputs.
### Versions
master
cc @soumith @msaroufim @wconstab @ngimel @bdhirsh
| 0 |
3,583 | 93,855 |
Enable CUPTI
|
module: windows, triaged
|
Pytorch for Windows does not support CUPTI (Cuda Profiling Tools Interface) at this moment.
This is needed for Kineto (Pytorch Profiling library).
There was a try to enable it in [this PR](https://github.com/pytorch/pytorch/pull/65608), but after merge CI/CD started to fail so PR was reverted.
Expectations
- Enable CUPTI for Pytorch on Windows
cc @peterjc123 @mszhanyi @skyline75489 @nbcsm
| 0 |
3,584 | 93,854 |
torchdim can not be compiled for Python-3.11 on Windows
|
module: windows, triaged, module: functorch
|
### 🐛 Describe the bug
As it uses _PyOpcode_Deopt and _PyOpcode_Caches that are not guaranteed to be a public symbols
So attempts to compile fails as follows:
```
dim.cpp.obj : error LNK2019: unresolved external symbol _PyOpcode_Caches referenced in function "struct _object * __cdecl _dims<&struct py::object __cdecl create_dim(struct py::object,struct py::handle)>(struct _object *,struct _object * const *,__int64,struct _object *)" (??$_dims@$1?create_dim@@YA?AUobject@py@@U23@Uhandle@3@@Z@@YAPEAU_object@@PEAU0@PEBQEAU0@_J0@Z)
```
### Versions
CI
cc @peterjc123 @mszhanyi @skyline75489 @nbcsm @zou3519 @Chillee @samdow @soumith @kshitij12345 @janeyx99
| 2 |
3,585 | 93,852 |
save_config/load_config for torch._dynamo.config and friends hardcodes file paths
|
triaged, oncall: pt2, module: dynamo
|
### 🐛 Describe the bug
bad!!!
### Versions
master
cc @soumith @msaroufim @wconstab @ngimel @bdhirsh @voznesenskym @yanboliang @penguinwu @anijain2305 @EikanWang @jgong5 @Guobing-Chen @XiaobingSuper @zhuhaozhe @blzheng @Xia-Weiwen @wenzhe-nrv @jiayisunx @desertfire
| 2 |
3,586 | 93,847 |
Failures in cuda11.7-py3.10-gcc7-sm86-periodic-dynamo-benchmarks
|
triaged, oncall: pt2
|
When Migrating our CI from CUDA 11.6 to CUDA 11.7. Here: https://github.com/pytorch/pytorch/pull/93406
I see multiple failures in cuda11.7-py3.10-gcc7-sm86-periodic-dynamo-benchmarks workflow.
Github Workflow failure: https://github.com/pytorch/pytorch/actions/runs/4060149836/jobs/6989215115
aot_eager_all [internal link](https://www.internalfb.com/intern/paste/P610917589/):
```
Error: al maml [2023-02-01 03:15:46,456] torch._dynamo.utils: [ERROR] Accuracy failed: allclose not within tol=0.0001
Error: ain tinynet_a [2023-02-01 04:32:59,763] torch._dynamo.utils: [ERROR] RMSE (res-fp64): 0.00769, (ref-fp64): 0.00072 and shape=torch.Size([32])
Error: 2-01 04:32:59,763] torch._dynamo.utils: [ERROR] Accuracy failed for key name bn1.weight.grad
FAIL
Error: ain gernet_l [2023-02-01 04:20:23,425] torch._dynamo.utils: [ERROR] RMSE (res-fp64): 0.02019, (ref-fp64): 0.00534 and shape=torch.Size([640])
Error: 2-01 04:20:23,425] torch._dynamo.utils: [ERROR] Accuracy failed for key name stages.3.0.shortcut.bn.running_var
FAIL
Error: ain gluon_xception65 [2023-02-01 04:21:35,059] torch._dynamo.utils: [ERROR] RMSE (res-fp64): 0.00408, (ref-fp64): 0.00054 and shape=torch.Size([728])
Error: 2-01 04:21:35,060] torch._dynamo.utils: [ERROR] Accuracy failed for key name mid.block17.rep.bn1.weight.grad
FAIL
```
dynamic_aot_eager_torchbench [internal link](https://www.internalfb.com/intern/paste/P610917994):
```
Error: al maml [2023-02-01 03:15:46,456] torch._dynamo.utils: [ERROR] Accuracy failed: allclose not within tol=0.0001
```
dynamic_aot_eager_timm 1 [internal link](https://www.internalfb.com/intern/paste/P610918613)
```
Error: ain gernet_l [2023-02-01 03:27:46,292] torch._dynamo.utils: [ERROR] RMSE (res-fp64): 0.02019, (ref-fp64): 0.00534 and shape=torch.Size([640])
Error: 2-01 03:27:46,292] torch._dynamo.utils: [ERROR] Accuracy failed for key name stages.3.0.shortcut.bn.running_var
FAIL
Error: ain gluon_xception65 [2023-02-01 03:30:28,459] torch._dynamo.utils: [ERROR] RMSE (res-fp64): 0.00408, (ref-fp64): 0.00054 and shape=torch.Size([728])
Error: 2-01 03:30:28,459] torch._dynamo.utils: [ERROR] Accuracy failed for key name mid.block17.rep.bn1.weight.grad
FAIL
```
dynamic_aot_eager_timm 2 [internal link](https://www.internalfb.com/intern/paste/P610919025):
```
Error: ain tinynet_a [2023-02-01 03:47:04,591] torch._dynamo.utils: [ERROR] RMSE (res-fp64): 0.00769, (ref-fp64): 0.00072 and shape=torch.Size([32])
Error: 2-01 03:47:04,591] torch._dynamo.utils: [ERROR] Accuracy failed for key name bn1.weight.grad
FAIL
```
cc @ezyang @soumith @msaroufim @wconstab @ngimel @bdhirsh @malfet @ptrblck
### Versions
CI 31.01.2023
| 5 |
3,587 | 93,846 |
large number of temporary files generated when using dataloader with num_workers>0
|
high priority, module: dataloader, triaged, module: openmp
|
### 🐛 Describe the bug
Hi.
I recently noticed an issue when I use the dataloader ('torch.utils.data.DataLoader') with passing 'num_workers>0'. When this parallel process is activated, it generated a large number of temporary files starting with '__KMP_REGISTERED_LIB*' under a shard folder '/dev/shm' under my Linux system. And they are not automatically deleted, which surprised me. The number generated is proportional to the number of workers used. I think this should probably be fixed by something like temporary files should be deleted at the end of script. Thank you
### Versions
PyTorch version: 1.10.1+cu111 Is debug build: False CUDA used to build PyTorch: 11.1 ROCM used to build PyTorch: N/A OS: Ubuntu 20.04.5 LTS (x86_64) GCC version: (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0 Clang version: Could not collect CMake version: version 3.16.3 Libc version: glibc-2.10 Python version: 3.7.9 (default, Aug 31 2020, 12:42:55) [GCC 7.3.0] (64-bit runtime) Python platform: Linux-5.4.0-137-generic-x86_64-with-debian-bullseye-sid Is CUDA available: True CUDA runtime version: 11.0.221 CUDA_MODULE_LOADING set to: GPU models and configuration: GPU 0: A100-SXM4-40GB GPU 1: A100-SXM4-40GB GPU 2: A100-SXM4-40GB GPU 3: A100-SXM4-40GB GPU 4: A100-SXM4-40GB GPU 5: A100-SXM4-40GB GPU 6: A100-SXM4-40GB GPU 7: A100-SXM4-40GB Nvidia driver version: 450.216.04 cuDNN version: Probably one of the following: /usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn.so.8.1.1 /usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_adv_infer.so.8.1.1 /usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_adv_train.so.8.1.1 /usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_cnn_infer.so.8.1.1 /usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_cnn_train.so.8.1.1 /usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_ops_infer.so.8.1.1 /usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_ops_train.so.8.1.1 /usr/local/cuda-11.3/targets/x86_64-linux/lib/libcudnn.so.8.2.1 /usr/local/cuda-11.3/targets/x86_64-linux/lib/libcudnn_adv_infer.so.8.2.1 /usr/local/cuda-11.3/targets/x86_64-linux/lib/libcudnn_adv_train.so.8.2.1 /usr/local/cuda-11.3/targets/x86_64-linux/lib/libcudnn_cnn_infer.so.8.2.1 /usr/local/cuda-11.3/targets/x86_64-linux/lib/libcudnn_cnn_train.so.8.2.1 /usr/local/cuda-11.3/targets/x86_64-linux/lib/libcudnn_ops_infer.so.8.2.1 /usr/local/cuda-11.3/targets/x86_64-linux/lib/libcudnn_ops_train.so.8.2.1 HIP runtime version: N/A MIOpen runtime version: N/A Is XNNPACK available: True Versions of relevant libraries: [pip3] block.bootstrap.pytorch==0.1.6 [pip3] bootstrap.pytorch==0.0.13 [pip3] numpy==1.21.2 [pip3] torch==1.10.1+cu111 [pip3] torchaudio==0.10.1+rocm4.1 [pip3] torchsummary==1.5.1 [pip3] torchvision==0.11.2+cu111 [conda] blas 1.0 mkl [conda] block-bootstrap-pytorch 0.1.6 pypi_0 pypi [conda] bootstrap-pytorch 0.0.13 pypi_0 pypi [conda] cudatoolkit 11.1.74 h6bb024c_0 nvidia [conda] ffmpeg 4.3 hf484d3e_0 pytorch [conda] mkl 2021.3.0 h06a4308_520 [conda] mkl-service 2.4.0 py37h7f8727e_0 [conda] mkl_fft 1.3.1 py37hd3c417c_0 [conda] mkl_random 1.2.2 py37h51133e4_0 [conda] numpy 1.20.0 pypi_0 pypi [conda] numpy-base 1.21.2 py37h79a1101_0 [conda] pytorch-mutex 1.0 cuda pytorch [conda] torch 1.10.1+cu111 pypi_0 pypi [conda] torchaudio 0.10.1+rocm4.1 pypi_0 pypi [conda] torchsummary 1.5.1 pypi_0 pypi [conda] torchvision 0.11.2+cu111 pypi_0 pypi
cc @ezyang @gchanan @zou3519 @SsnL @VitalyFedyunin @ejguan @NivekT
| 2 |
3,588 | 93,843 |
EmbeddingBag to support mini-batches with offsets
|
triaged, enhancement, module: nestedtensor
|
### 🚀 The feature, motivation and pitch
Currently, the `forward` method of `EmbeddingBag`, when offsets are passed, supports only 1D inputs. Hence, training / inference on mini-batches of data isn't supported with offsets.
Offsets are very useful when training on tabular datasets with "multi-valued" cells, such as movie genres, since we may want to sum / average the embeddings associated with several genres to a single vector. There can also be weighted multi-valued cells, for example, when the multiple values are generated by an auxiliary model, and the weights represent the confidence of the model in its prediction. For example, consider automatic extraction of movie genres from their title and description.
### Alternatives
Two possible alternatives:
1. Using a regular `torch.nn.Embedding` class, extract the embedding vectors, multiply by weights manually, and aggregate them. In this case we lose the efficiency of the EmbeddingBag class, which doesn't have to actually create the full embedding tensor. This idea is relevant only if the number of features in each mini-batch item is the same.
2. Use an EmbeddingBag in our model, decompose the mini-batch to its constituent items, and compute the output of the model for each item using a for-loop.
### Additional context
_No response_
cc @cpuhrsch @jbschlosser @bhosmer @drisspg @mikaylagawarecki
| 2 |
3,589 | 93,838 |
ONNX Export Fails: Model input type is Dict[str, Tensor]
|
module: onnx, triaged
|
### 🐛 Describe the bug
I tried to export a pytorch model to onnx and the model input type is Dict[str, Tensor], but it fails with _**Couldn't lower all tuples**_ errror.
sorry I can't upload model as it's our internal one.
The same input, the model can output normally as below:
```python
import torch
from typing import Dict, List, Tuple
device = torch.device("cuda")
model = torch.load("model.pt")
input_dict: Dict[str, torch.Tensor] ={'input1': torch.tensor([1],dtype=torch.float64,device=device),
'input2': torch.tensor([1],dtype=torch.float64,device=device),
'input3': torch.tensor([1],dtype=torch.float64,device=device)
}
model(input_dict)
```
And I will get output as below:
```python
Output(prediction=tensor([[19.3254]], device='cuda:0', grad_fn=<ReluBackward0>))
```
But when I use the same input for onnx export:
```python
torch.onnx.export(user_model, (input_dict, {}), "onnx_model.onnx", verbose = True, input_names = ["input1","input2","input3"], output_names = ["output_spec"])
```
```python
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/usr/local/lib/python3.8/dist-packages/torch/onnx/utils.py", line 504, in export
_export(
File "/usr/local/lib/python3.8/dist-packages/torch/onnx/utils.py", line 1529, in _export
graph, params_dict, torch_out = _model_to_graph(
File "/usr/local/lib/python3.8/dist-packages/torch/onnx/utils.py", line 1115, in _model_to_graph
graph = _optimize_graph(
File "/usr/local/lib/python3.8/dist-packages/torch/onnx/utils.py", line 582, in _optimize_graph
_C._jit_pass_lower_all_tuples(graph)
RuntimeError: Couldn't lower all tuples.
```
### Versions
PyTorch version: 1.13.1+cu117
CUDA used to build PyTorch: 11.7
OS: Ubuntu 20.04.5 LTS (x86_64)
GCC version: (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0
CMake version: version 3.24.3
Libc version: glibc-2.31
Python version: 3.8.10
CUDA runtime version: 11.8.89
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration:
GPU 0: Tesla V100-SXM2-32GB
Nvidia driver version: 450.51.06
Versions of relevant libraries:
[pip3] mypy-extensions==0.4.3
[pip3] numpy==1.22.4
[pip3] torch==1.13.1
[pip3] torchsummary==1.5.1
| 0 |
3,590 | 93,830 |
[pt2] MMDet meets Exception: Please convert all Tensors to FakeTensors first or instantiate FakeTensorMode error with aot_eager backend
|
high priority, needs reproduction, triaged, oncall: pt2, module: fakeTensor
|
### 🐛 Describe the bug
Training RetinaNet models with aot_eager backend got ` Exception: Please convert all Tensors to FakeTensors first or instantiate FakeTensorMode with 'allow_non_fake_inputs'`
Note: It is not the error at the beginning of the training, but the error after training for 13 iter.
### Error logs
```shell
Traceback (most recent call last):
File "pt20/lib/python3.8/site-packages/torch/_dynamo/output_graph.py", line 692, in call_user_compiler
compiled_fn = compiler_fn(gm, self.fake_example_inputs())
File "pt20/lib/python3.8/site-packages/torch/_dynamo/debug_utils.py", line 1024, in debug_wrapper
run_fwd_maybe_bwd(compiled_gm, example_inputs)
File "pt20/lib/python3.8/site-packages/torch/_dynamo/debug_utils.py", line 624, in run_fwd_maybe_bwd
out = gm(args)
File "pt20/lib/python3.8/site-packages/torch/_functorch/aot_autograd.py", line 996, in g
return f(*args)
File "pt20/lib/python3.8/site-packages/torch/_dynamo/eval_frame.py", line 211, in _fn
return fn(*args, **kwargs)
File "pt20/lib/python3.8/site-packages/torch/_functorch/aot_autograd.py", line 2497, in forward
return compiled_fn(full_args)
File "pt20/lib/python3.8/site-packages/torch/_functorch/aot_autograd.py", line 996, in g
return f(*args)
File "pt20/lib/python3.8/site-packages/torch/_functorch/aot_autograd.py", line 2066, in debug_compiled_function
return compiled_function(*args)
File "pt20/lib/python3.8/site-packages/torch/_functorch/aot_autograd.py", line 1930, in compiled_function
all_outs = CompiledFunction.apply(*args_with_synthetic_bases)
File "pt20/lib/python3.8/site-packages/torch/autograd/function.py", line 508, in apply
return super().apply(*args, **kwargs)
File "pt20/lib/python3.8/site-packages/torch/_functorch/aot_autograd.py", line 1714, in forward
fw_outs = call_func_with_args(
File "/pt20/lib/python3.8/site-packages/torch/_functorch/aot_autograd.py", line 1021, in call_func_with_args
out = normalize_as_list(f(args))
File "/pt20/lib/python3.8/site-packages/torch/_functorch/aot_autograd.py", line 996, in g
return f(*args)
File "/mnt/petrelfs/huanghaian/miniconda3/envs/pt20/lib/python3.8/site-packages/torch/fx/graph_module.py", line 660, in call_wrapped
return self._wrapped_call(self, *args, **kwargs)
File "pt20/lib/python3.8/site-packages/torch/fx/graph_module.py", line 279, in __call__
raise e
File "/pt20/lib/python3.8/site-packages/torch/fx/graph_module.py", line 269, in __call__
return super(self.cls, obj).__call__(*args, **kwargs) # type: ignore[misc]
File "pt20/lib/python3.8/site-packages/torch/nn/modules/module.py", line 1488, in _call_impl
return forward_call(*args, **kwargs)
File "<eval_with_key>.33", line 111, in forward
File "pt20/lib/python3.8/site-packages/torch/_ops.py", line 284, in __call__
return self._op(*args, **kwargs or {})
File "pt20/lib/python3.8/site-packages/torch/utils/_stats.py", line 15, in wrapper
return fn(*args, **kwargs)
File "pt20/lib/python3.8/site-packages/torch/_subclasses/fake_tensor.py", line 656, in __torch_dispatch__
return func(*args, **kwargs)
File "pt20/lib/python3.8/site-packages/torch/_ops.py", line 284, in __call__
return self._op(*args, **kwargs or {})
File "pt20/lib/python3.8/site-packages/torch/_subclasses/fake_tensor.py", line 835, in __torch_dispatch__
args, kwargs = self.validate_and_convert_non_fake_tensors(
File "pt20/lib/python3.8/site-packages/torch/_subclasses/fake_tensor.py", line 983, in validate_and_convert_non_fake_tensors
return tree_map_only(
File "/lib/python3.8/site-packages/torch/utils/_pytree.py", line 266, in tree_map_only
return tree_map(map_only(ty)(fn), pytree)
File "pt20/lib/python3.8/site-packages/torch/utils/_pytree.py", line 196, in tree_map
return tree_unflatten([fn(i) for i in flat_args], spec)
File "pt20/lib/python3.8/site-packages/torch/utils/_pytree.py", line 196, in <listcomp>
return tree_unflatten([fn(i) for i in flat_args], spec)
File "pt20/lib/python3.8/site-packages/torch/utils/_pytree.py", line 247, in inner
return f(x)
File pt20/lib/python3.8/site-packages/torch/_subclasses/fake_tensor.py", line 975, in validate
raise Exception(
Exception: Please convert all Tensors to FakeTensors first or instantiate FakeTensorMode with 'allow_non_fake_inputs'. Found in aten.convolution.default(*(FakeTensor(FakeTensor(..., device='meta', size=(2, 3, 640, 640)), cuda:0), Parameter containing:
tensor([[[[ 1.3335e-02, 1.4664e-02, -1.5351e-02, ..., -4.0896e-02,
-4.3034e-02, -7.0755e-02],
[ 4.1205e-03, 5.8477e-03, 1.4948e-02, ..., 2.2060e-03,
-2.0912e-02, -3.8517e-02],
[ 2.2331e-02, 2.3595e-02, 1.6120e-02, ..., 1.0281e-01,
```
### Minified repro
### 1 Install dependencied of OpenMMLab
```shell
ninja
git+https://github.com/open-mmlab/mmengine@experimental/compile
git+https://github.com/open-mmlab/mmcv@2.x
git clone git@github.com:open-mmlab/mmdetection.git
cd mmdet
git checkout dev-3.x
pip install -r requirements.txt
pip install -e .
```
### 2 Modify the `configs/_base_/default_runtime.py`
```python
compile = dict(
target='train_step', # (train_step, forward, model)
verbose=True,
backend='aot_eager',
dynamic=False,
)
```
### 3 Launch training
`python tools/train.py configs/retinanet/retinanet_r50_fpn_1x_coco.py`
### Versions
Pytorch version: 2.0.0.dev20230131+cu116
cc @ezyang @gchanan @zou3519 @msaroufim @wconstab @bdhirsh @anijain2305 @soumith @ngimel
| 8 |
3,591 | 93,826 |
torch.jit.script does not work with DataParallel
|
oncall: jit
|
If you have a question or would like help and support, please ask at our
[forums](https://discuss.pytorch.org/).
If you are submitting a feature request, please preface the title with [feature request].
If you are submitting a bug report, please fill in the following details.
## Issue description
I was trying to generate a ScriptModule for 3DMPPE to deploy those models on torchserve. However, when I tried to run `torch.jit.script(DataParallel(PoseNet()))`, I got the following error:
```
Traceback (most recent call last):
File "/Users/yeonwoosung/Desktop/musculoskeletal-checker/ai_engine/rootnet_trace.py", line 55, in <module>
script_module = torch.jit.script(rootnet_pose_model)
File "/Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages/torch/jit/_script.py", line 1286, in script
return torch.jit._recursive.create_script_module(
File "/Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages/torch/jit/_recursive.py", line 476, in create_script_module
return create_script_module_impl(nn_module, concrete_type, stubs_fn)
File "/Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages/torch/jit/_recursive.py", line 488, in create_script_module_impl
method_stubs = stubs_fn(nn_module)
File "/Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages/torch/jit/_recursive.py", line 757, in infer_methods_to_compile
stubs.append(make_stub_from_method(nn_module, method))
File "/Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages/torch/jit/_recursive.py", line 69, in make_stub_from_method
return make_stub(func, method_name)
File "/Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages/torch/jit/_recursive.py", line 54, in make_stub
ast = get_jit_def(func, name, self_name="RecursiveScriptModule")
File "/Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages/torch/jit/frontend.py", line 293, in get_jit_def
return build_def(parsed_def.ctx, fn_def, type_line, def_name, self_name=self_name, pdt_arg_types=pdt_arg_types)
File "/Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages/torch/jit/frontend.py", line 331, in build_def
param_list = build_param_list(ctx, py_def.args, self_name, pdt_arg_types)
File "/Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages/torch/jit/frontend.py", line 355, in build_param_list
raise NotSupportedError(ctx_range, _vararg_kwarg_err)
torch.jit.frontend.NotSupportedError: Compiled functions can't take variable number of arguments or use keyword-only arguments with defaults:
File "/Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages/torch/nn/parallel/data_parallel.py", line 150
def forward(self, *inputs, **kwargs):
~~~~~~~ <--- HERE
with torch.autograd.profiler.record_function("DataParallel.forward"):
```
So, it seems like the `torch.jit.script` does not like variable-length arguments such as *args and **kwargs..
What I want to ask is:
1) Do you have any plan to support DataParallel for torchsciprt?
2) Is there any other way that I could convert DataParallel model to TorchScript model?
## System Info
```
Collecting environment information...
PyTorch version: 1.13.1+cu117
Is debug build: False
CUDA used to build PyTorch: 11.7
ROCM used to build PyTorch: N/A
OS: Ubuntu 22.04.1 LTS (x86_64)
GCC version: (Ubuntu 11.3.0-1ubuntu1~22.04) 11.3.0
Clang version: Could not collect
CMake version: Could not collect
Libc version: glibc-2.35
Python version: 3.10.6 (main, Nov 14 2022, 16:10:14) [GCC 11.3.0] (64-bit runtime)
Python platform: Linux-5.15.0-58-generic-x86_64-with-glibc2.35
Is CUDA available: True
CUDA runtime version: 12.0
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration: GPU 0: NVIDIA GeForce RTX 3070 Ti Laptop GPU
Nvidia driver version: 525.78.01
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.24.1
[pip3] torch==1.13.1
[pip3] torchvision==0.14.1
[conda] Could not collect
```
- PyTorch or Caffe2: PyTorch
- How you installed PyTorch (conda, pip, source): pip
- Build command you used (if compiling from source):
- OS: Ubuntu
- PyTorch version: 1.13.1
- Python version: 3.10.6
- CUDA/cuDNN version: 12.0
- GPU models and configuration: Nvidia GeForce 3070Ti
cc @EikanWang @jgong5 @wenzhe-nrv @sanchitintel
| 0 |
3,592 | 93,819 |
`log_softmax` + `pad` triggers assertion fail in compile mode
|
triaged, oncall: pt2, module: inductor, ciflow/inductor
|
### 🐛 Describe the bug
The following program works fine in eager mode but raises assertion fail in compile mode. It's worth noting that `torch.float64` tensor is necessary for triggering this issue.
```python
import torch
def fn(v1_0):
v4_0 = torch.nn.functional.log_softmax(v1_0, 2, _stacklevel=17, dtype=None)
v2_0 = torch.nn.functional.pad(v4_0, [0, 0, 1, 0], mode='constant', value=None)
return [v2_0]
x = torch.rand([1, 2, 1, 5], dtype=torch.float64)
ret_eager = fn(x)
print('==== Eager mode OK! ====')
compiled = torch.compile(fn)
print('==== torchcomp compilation OK! ====')
ret_compiled = compiled(x)
print('==== torchcomp mode OK! ====')
```
### Error logs
<details><summary>Original error logs</summary>
```
==== Eager mode OK! ====
==== torchcomp compilation OK! ====
python3.8/site-packages/torch/_inductor/compile_fx.py:90: UserWarning: TensorFloat32 tensor cores for float32 matrix multiplication available but not enabled. Consider setting `torch.set_float32_matmul_precision('high')` for better performance.
warnings.warn(
Traceback (most recent call last):
File "python3.8/site-packages/torch/_dynamo/output_graph.py", line 692, in call_user_compiler
compiled_fn = compiler_fn(gm, self.fake_example_inputs())
File "python3.8/site-packages/torch/_dynamo/debug_utils.py", line 1047, in debug_wrapper
compiled_gm = compiler_fn(gm, example_inputs, **kwargs)
File "python3.8/site-packages/torch/__init__.py", line 1324, in __call__
return self.compile_fn(model_, inputs_)
File "python3.8/site-packages/torch/_dynamo/optimizations/backends.py", line 24, in inner
return fn(gm, example_inputs, **kwargs)
File "python3.8/site-packages/torch/_dynamo/optimizations/backends.py", line 61, in inductor
return compile_fx(*args, **kwargs)
File "python3.8/site-packages/torch/_inductor/compile_fx.py", line 413, in compile_fx
return aot_autograd(
File "python3.8/site-packages/torch/_dynamo/optimizations/training.py", line 74, in compiler_fn
cg = aot_module_simplified(gm, example_inputs, **kwargs)
File "python3.8/site-packages/torch/_functorch/aot_autograd.py", line 2483, in aot_module_simplified
compiled_fn = create_aot_dispatcher_function(
File "python3.8/site-packages/torch/_dynamo/utils.py", line 161, in time_wrapper
r = func(*args, **kwargs)
File "python3.8/site-packages/torch/_functorch/aot_autograd.py", line 2180, in create_aot_dispatcher_function
compiled_fn = compiler_fn(flat_fn, fake_flat_args, aot_config)
File "python3.8/site-packages/torch/_functorch/aot_autograd.py", line 1411, in aot_wrapper_dedupe
return compiler_fn(flat_fn, leaf_flat_args, aot_config)
File "python3.8/site-packages/torch/_functorch/aot_autograd.py", line 1061, in aot_dispatch_base
compiled_fw = aot_config.fw_compiler(fw_module, flat_args)
File "python3.8/site-packages/torch/_dynamo/utils.py", line 161, in time_wrapper
r = func(*args, **kwargs)
File "python3.8/site-packages/torch/_inductor/compile_fx.py", line 388, in fw_compiler
return inner_compile(
File "python3.8/site-packages/torch/_dynamo/debug_utils.py", line 586, in debug_wrapper
compiled_fn = compiler_fn(gm, example_inputs, **kwargs)
File "python3.8/site-packages/torch/_inductor/debug.py", line 239, in inner
return fn(*args, **kwargs)
File "/opt/miniconda3/lib/python3.8/contextlib.py", line 75, in inner
return func(*args, **kwds)
File "python3.8/site-packages/torch/_inductor/compile_fx.py", line 151, in compile_fx_inner
compiled_fn = graph.compile_to_fn()
File "python3.8/site-packages/torch/_inductor/graph.py", line 567, in compile_to_fn
return self.compile_to_module().call
File "python3.8/site-packages/torch/_dynamo/utils.py", line 161, in time_wrapper
r = func(*args, **kwargs)
File "python3.8/site-packages/torch/_inductor/graph.py", line 552, in compile_to_module
code = self.codegen()
File "python3.8/site-packages/torch/_inductor/graph.py", line 501, in codegen
self.scheduler = Scheduler(self.buffers)
File "python3.8/site-packages/torch/_dynamo/utils.py", line 161, in time_wrapper
r = func(*args, **kwargs)
File "python3.8/site-packages/torch/_inductor/scheduler.py", line 567, in __init__
self.nodes.append(SchedulerNode(self, node, group_fn))
File "python3.8/site-packages/torch/_inductor/scheduler.py", line 234, in __init__
super().__init__(scheduler, node)
File "python3.8/site-packages/torch/_inductor/scheduler.py", line 58, in __init__
self.set_read_writes(node.get_read_writes())
File "python3.8/site-packages/torch/_inductor/utils.py", line 206, in wrapper
setattr(self, key, fn(self))
File "python3.8/site-packages/torch/_inductor/ir.py", line 2034, in get_read_writes
return extract_read_writes(
File "python3.8/site-packages/torch/_inductor/dependencies.py", line 273, in extract_read_writes
fn(*args)
File "python3.8/site-packages/torch/_inductor/ir.py", line 373, in store_output
return ops.store(output_name, indexer(vars), self.inner_fn(vars))
File "python3.8/site-packages/torch/_inductor/lowering.py", line 2461, in offset_fn
return mask(new_index)
File "python3.8/site-packages/torch/_inductor/lowering.py", line 2454, in mask
return ops.masked(mask, lambda: x_loader(index), fill_value)
File "python3.8/site-packages/torch/_inductor/virtualized.py", line 104, in inner
line = getattr(self.parent_handler, name)(*args, **kwargs)
File "python3.8/site-packages/torch/_inductor/virtualized.py", line 75, in masked
return f"masked({mask}, {body()}, {other})"
File "python3.8/site-packages/torch/_inductor/lowering.py", line 2454, in <lambda>
return ops.masked(mask, lambda: x_loader(index), fill_value)
File "python3.8/site-packages/torch/_inductor/lowering.py", line 344, in inner_fn
return fn(*[load(index) for load in loaders])
File "python3.8/site-packages/torch/_inductor/lowering.py", line 344, in <listcomp>
return fn(*[load(index) for load in loaders])
File "python3.8/site-packages/torch/_inductor/lowering.py", line 344, in inner_fn
return fn(*[load(index) for load in loaders])
File "python3.8/site-packages/torch/_inductor/lowering.py", line 344, in <listcomp>
return fn(*[load(index) for load in loaders])
File "python3.8/site-packages/torch/_inductor/ir.py", line 791, in fn
return inner_fn(index, reduction_index)
File "python3.8/site-packages/torch/_inductor/lowering.py", line 3241, in loader
assert all(index[i] == 0 for i in reduced_idx)
AssertionError
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "repro.py", line 16, in <module>
ret_compiled = compiled(x)
File "python3.8/site-packages/torch/_dynamo/eval_frame.py", line 211, in _fn
return fn(*args, **kwargs)
File "python3.8/site-packages/torch/_dynamo/eval_frame.py", line 332, in catch_errors
return callback(frame, cache_size, hooks)
File "python3.8/site-packages/torch/_dynamo/convert_frame.py", line 403, in _convert_frame
result = inner_convert(frame, cache_size, hooks)
File "python3.8/site-packages/torch/_dynamo/convert_frame.py", line 103, in _fn
return fn(*args, **kwargs)
File "python3.8/site-packages/torch/_dynamo/convert_frame.py", line 261, in _convert_frame_assert
return _compile(
File "python3.8/site-packages/torch/_dynamo/utils.py", line 161, in time_wrapper
r = func(*args, **kwargs)
File "python3.8/site-packages/torch/_dynamo/convert_frame.py", line 323, in _compile
out_code = transform_code_object(code, transform)
File "python3.8/site-packages/torch/_dynamo/bytecode_transformation.py", line 339, in transform_code_object
transformations(instructions, code_options)
File "python3.8/site-packages/torch/_dynamo/convert_frame.py", line 310, in transform
tracer.run()
File "python3.8/site-packages/torch/_dynamo/symbolic_convert.py", line 1715, in run
super().run()
File "python3.8/site-packages/torch/_dynamo/symbolic_convert.py", line 564, in run
and self.step()
File "python3.8/site-packages/torch/_dynamo/symbolic_convert.py", line 527, in step
getattr(self, inst.opname)(inst)
File "python3.8/site-packages/torch/_dynamo/symbolic_convert.py", line 1781, in RETURN_VALUE
self.output.compile_subgraph(self)
File "python3.8/site-packages/torch/_dynamo/output_graph.py", line 563, in compile_subgraph
self.compile_and_call_fx_graph(tx, pass2.graph_output_vars(), root)
File "python3.8/site-packages/torch/_dynamo/output_graph.py", line 610, in compile_and_call_fx_graph
compiled_fn = self.call_user_compiler(gm)
File "python3.8/site-packages/torch/_dynamo/utils.py", line 161, in time_wrapper
r = func(*args, **kwargs)
File "python3.8/site-packages/torch/_dynamo/output_graph.py", line 697, in call_user_compiler
raise BackendCompilerFailed(self.compiler_fn, e) from e
torch._dynamo.exc.BackendCompilerFailed: debug_wrapper raised AssertionError:
Set torch._dynamo.config.verbose=True for more information
You can suppress this exception and fall back to eager by setting:
torch._dynamo.config.suppress_errors = True
```
</details>
<details><summary>Minified repro error logs</summary>
```
python3.8/site-packages/torch/_inductor/compile_fx.py:90: UserWarning: TensorFloat32 tensor cores for float32 matrix multiplication available but not enabled. Consider setting `torch.set_float32_matmul_precision('high')` for better performance.
warnings.warn(
Traceback (most recent call last):
File "repro.py", line 51, in <module>
compiled = compile_fx_inner(mod, args)
File "python3.8/site-packages/torch/_dynamo/debug_utils.py", line 586, in debug_wrapper
compiled_fn = compiler_fn(gm, example_inputs, **kwargs)
File "python3.8/site-packages/torch/_inductor/debug.py", line 239, in inner
return fn(*args, **kwargs)
File "/opt/miniconda3/lib/python3.8/contextlib.py", line 75, in inner
return func(*args, **kwds)
File "python3.8/site-packages/torch/_inductor/compile_fx.py", line 151, in compile_fx_inner
compiled_fn = graph.compile_to_fn()
File "python3.8/site-packages/torch/_inductor/graph.py", line 567, in compile_to_fn
return self.compile_to_module().call
File "python3.8/site-packages/torch/_dynamo/utils.py", line 161, in time_wrapper
r = func(*args, **kwargs)
File "python3.8/site-packages/torch/_inductor/graph.py", line 552, in compile_to_module
code = self.codegen()
File "python3.8/site-packages/torch/_inductor/graph.py", line 501, in codegen
self.scheduler = Scheduler(self.buffers)
File "python3.8/site-packages/torch/_dynamo/utils.py", line 161, in time_wrapper
r = func(*args, **kwargs)
File "python3.8/site-packages/torch/_inductor/scheduler.py", line 567, in __init__
self.nodes.append(SchedulerNode(self, node, group_fn))
File "python3.8/site-packages/torch/_inductor/scheduler.py", line 234, in __init__
super().__init__(scheduler, node)
File "python3.8/site-packages/torch/_inductor/scheduler.py", line 58, in __init__
self.set_read_writes(node.get_read_writes())
File "python3.8/site-packages/torch/_inductor/utils.py", line 206, in wrapper
setattr(self, key, fn(self))
File "python3.8/site-packages/torch/_inductor/ir.py", line 2034, in get_read_writes
return extract_read_writes(
File "python3.8/site-packages/torch/_inductor/dependencies.py", line 273, in extract_read_writes
fn(*args)
File "python3.8/site-packages/torch/_inductor/ir.py", line 373, in store_output
return ops.store(output_name, indexer(vars), self.inner_fn(vars))
File "python3.8/site-packages/torch/_inductor/lowering.py", line 2461, in offset_fn
return mask(new_index)
File "python3.8/site-packages/torch/_inductor/lowering.py", line 2454, in mask
return ops.masked(mask, lambda: x_loader(index), fill_value)
File "python3.8/site-packages/torch/_inductor/virtualized.py", line 104, in inner
line = getattr(self.parent_handler, name)(*args, **kwargs)
File "python3.8/site-packages/torch/_inductor/virtualized.py", line 75, in masked
return f"masked({mask}, {body()}, {other})"
File "python3.8/site-packages/torch/_inductor/lowering.py", line 2454, in <lambda>
return ops.masked(mask, lambda: x_loader(index), fill_value)
File "python3.8/site-packages/torch/_inductor/lowering.py", line 344, in inner_fn
return fn(*[load(index) for load in loaders])
File "python3.8/site-packages/torch/_inductor/lowering.py", line 344, in <listcomp>
return fn(*[load(index) for load in loaders])
File "python3.8/site-packages/torch/_inductor/lowering.py", line 344, in inner_fn
return fn(*[load(index) for load in loaders])
File "python3.8/site-packages/torch/_inductor/lowering.py", line 344, in <listcomp>
return fn(*[load(index) for load in loaders])
File "python3.8/site-packages/torch/_inductor/ir.py", line 791, in fn
return inner_fn(index, reduction_index)
File "python3.8/site-packages/torch/_inductor/lowering.py", line 3241, in loader
assert all(index[i] == 0 for i in reduced_idx)
AssertionError
```
</details>
### Minified repro
```python
import torch._inductor.overrides
import torch
from torch import tensor, device
import torch.fx as fx
from torch._dynamo.testing import rand_strided
from math import inf
from torch.fx.experimental.proxy_tensor import make_fx
import torch._dynamo.config
import torch._inductor.config
torch._dynamo.config.load_config(b'\x80\x04\x95\xad\x07\x00\x00\x00\x00\x00\x00}\x94(\x8c\x08__name__\x94\x8c\x14torch._dynamo.config\x94\x8c\x07__doc__\x94N\x8c\x0b__package__\x94\x8c\rtorch._dynamo\x94\x8c\n__loader__\x94\x8c\x1a_frozen_importlib_external\x94\x8c\x10SourceFileLoader\x94\x93\x94)\x81\x94}\x94(\x8c\x04name\x94h\x02\x8c\x04path\x94\x8cF/home/yuyao/.local/lib/python3.8/site-packages/torch/_dynamo/config.py\x94ub\x8c\x08__spec__\x94\x8c\x11_frozen_importlib\x94\x8c\nModuleSpec\x94\x93\x94)\x81\x94}\x94(h\x0ch\x02\x8c\x06loader\x94h\n\x8c\x06origin\x94h\x0e\x8c\x0cloader_state\x94N\x8c\x1asubmodule_search_locations\x94N\x8c\r_set_fileattr\x94\x88\x8c\x07_cached\x94\x8c^/home/yuyao/.local/lib/python3.8/site-packages/torch/_dynamo/__pycache__/config.cpython-38.pyc\x94\x8c\r_initializing\x94\x89ub\x8c\x08__file__\x94h\x0e\x8c\n__cached__\x94h\x1b\x8c\x07abspath\x94\x8c\tposixpath\x94h\x1f\x93\x94\x8c\x07dirname\x94h h"\x93\x94\x8c\tlog_level\x94K\x1e\x8c\x0boutput_code\x94\x89\x8c\rlog_file_name\x94N\x8c\x07verbose\x94\x89\x8c\x11output_graph_code\x94\x89\x8c\x12verify_correctness\x94\x89\x8c\x12minimum_call_count\x94K\x01\x8c\x15dead_code_elimination\x94\x88\x8c\x10cache_size_limit\x94K@\x8c\x14specialize_int_float\x94\x88\x8c\x0edynamic_shapes\x94\x89\x8c\x10guard_nn_modules\x94\x89\x8c\x0cnormalize_ir\x94\x89\x8c\x1btraceable_tensor_subclasses\x94\x8f\x94\x8c\x0fsuppress_errors\x94\x89\x8c\x15replay_record_enabled\x94\x89\x8c rewrite_assert_with_torch_assert\x94\x88\x8c\x12print_graph_breaks\x94\x89\x8c\x07disable\x94\x89\x8c*allowed_functions_module_string_ignorelist\x94\x8f\x94(\x8c\x13torch.distributions\x94\x8c\x0ctorch._prims\x94\x8c\rtorch._decomp\x94\x8c\x0btorch._refs\x94\x8c\rtorch.testing\x94\x90\x8c\x16capture_scalar_outputs\x94\x89\x8c\x19enforce_cond_guards_match\x94\x88\x8c\x0coptimize_ddp\x94\x88\x8c\x1araise_on_ctx_manager_usage\x94\x88\x8c\x1craise_on_unsafe_aot_autograd\x94\x89\x8c\rdynamo_import\x94\x8c\rtorch._dynamo\x94\x8c\x0finductor_import\x94\x8c\x0ftorch._inductor\x94\x8c\x18error_on_nested_fx_trace\x94\x88\x8c\tallow_rnn\x94\x89\x8c\x08base_dir\x94\x8c./home/yuyao/.local/lib/python3.8/site-packages\x94\x8c\x0edebug_dir_root\x94\x8c)/home/yuyao/bug_repro/torch_compile_debug\x94\x8c)DO_NOT_USE_legacy_non_fake_example_inputs\x94\x89\x8c\x15_AccessLimitingConfig\x94}\x94(\x8c\n__module__\x94h\x02\x8c\x0b__setattr__\x94\x8c\x14torch._dynamo.config\x94\x8c!_AccessLimitingConfig.__setattr__\x94\x93\x94h\x03Nu\x8c\x15_allowed_config_names\x94\x8f\x94(h\x1dh7\x8c\nModuleType\x94hB\x8c\x02os\x94h5h@h\x04h/h*hOh$\x8c\x07logging\x94hDh3h1\x8c\x12constant_functions\x94h.\x8c\x0brepro_level\x94h0\x8c\x03sys\x94\x8c\x05torch\x94h\x1fh\x01hNhChIhHhAh(h%hJh\x03h\x0fh&h)h-\x8c!skipfiles_inline_module_allowlist\x94h8h\x1e\x8c\x0brepro_after\x94\x8c\x0c__builtins__\x94hLh4h,hF\x8c\x0eexternal_utils\x94h"h\x06h6h\'h+h?\x90\x8c\x1cget_config_serialization_fns\x94\x8c\x1atorch._dynamo.config_utils\x94hc\x93\x94u.')
torch._inductor.config.load_config(b'\x80\x04\x95\x07\t\x00\x00\x00\x00\x00\x00}\x94(\x8c\x08__name__\x94\x8c\x16torch._inductor.config\x94\x8c\x07__doc__\x94N\x8c\x0b__package__\x94\x8c\x0ftorch._inductor\x94\x8c\n__loader__\x94\x8c\x1a_frozen_importlib_external\x94\x8c\x10SourceFileLoader\x94\x93\x94)\x81\x94}\x94(\x8c\x04name\x94h\x02\x8c\x04path\x94\x8cH/home/yuyao/.local/lib/python3.8/site-packages/torch/_inductor/config.py\x94ub\x8c\x08__spec__\x94\x8c\x11_frozen_importlib\x94\x8c\nModuleSpec\x94\x93\x94)\x81\x94}\x94(h\x0ch\x02\x8c\x06loader\x94h\n\x8c\x06origin\x94h\x0e\x8c\x0cloader_state\x94N\x8c\x1asubmodule_search_locations\x94N\x8c\r_set_fileattr\x94\x88\x8c\x07_cached\x94\x8c`/home/yuyao/.local/lib/python3.8/site-packages/torch/_inductor/__pycache__/config.cpython-38.pyc\x94\x8c\r_initializing\x94\x89ub\x8c\x08__file__\x94h\x0e\x8c\n__cached__\x94h\x1b\x8c\x05debug\x94\x89\x8c\x10disable_progress\x94\x88\x8c\x10verbose_progress\x94\x89\x8c\x0bcpp_wrapper\x94\x89\x8c\x03dce\x94\x89\x8c\x14static_weight_shapes\x94\x88\x8c\x0csize_asserts\x94\x88\x8c\x10pick_loop_orders\x94\x88\x8c\x0finplace_buffers\x94\x88\x8c\x11benchmark_harness\x94\x88\x8c\x0fepilogue_fusion\x94\x89\x8c\x15epilogue_fusion_first\x94\x89\x8c\x0cmax_autotune\x94\x89\x8c\x17realize_reads_threshold\x94K\x04\x8c\x17realize_bytes_threshold\x94M\xd0\x07\x8c\x1brealize_acc_reads_threshold\x94K\x08\x8c\x0ffallback_random\x94\x89\x8c\x12implicit_fallbacks\x94\x88\x8c\rprefuse_nodes\x94\x88\x8c\x0btune_layout\x94\x89\x8c\x11aggressive_fusion\x94\x89\x8c\x0fmax_fusion_size\x94K@\x8c\x1bunroll_reductions_threshold\x94K\x08\x8c\x0ecomment_origin\x94\x89\x8c\tis_fbcode\x94\x8c\x16torch._inductor.config\x94h7\x93\x94\x8c\x0fcompile_threads\x94K \x8c\x13kernel_name_max_ops\x94K\n\x8c\x0finductor_import\x94\x8c\x0ftorch._inductor\x94\x8c\rshape_padding\x94\x89\x8c\x0epermute_fusion\x94\x89\x8c\x1aprofiler_mark_wrapper_call\x94\x89\x8c\x03cpp\x94}\x94(\x8c\n__module__\x94h\x02\x8c\x07threads\x94J\xff\xff\xff\xff\x8c\x0fdynamic_threads\x94\x89\x8c\x07simdlen\x94N\x8c\x0emin_chunk_size\x94M\x00\x10\x8c\x03cxx\x94N\x8c\x03g++\x94\x86\x94\x8c\x15enable_kernel_profile\x94\x89h\x03Nu\x8c\x06triton\x94}\x94(hCh\x02\x8c\ncudagraphs\x94\x88\x8c\x10debug_sync_graph\x94\x89\x8c\x11debug_sync_kernel\x94\x89\x8c\x0bconvolution\x94\x8c\x04aten\x94\x8c\x0edense_indexing\x94\x89\x8c\tmax_tiles\x94K\x02\x8c\x12autotune_pointwise\x94\x88\x8c tiling_prevents_pointwise_fusion\x94\x88\x8c tiling_prevents_reduction_fusion\x94\x88\x8c\x14ordered_kernel_names\x94\x89\x8c\x18descriptive_kernel_names\x94\x89h\x03Nu\x8c\x05trace\x94}\x94(hCh\x02\x8c\x07enabled\x94\x89\x8c\tdebug_log\x94\x88\x8c\x08info_log\x94\x89\x8c\x08fx_graph\x94\x88\x8c\rir_pre_fusion\x94\x88\x8c\x0eir_post_fusion\x94\x88\x8c\x0boutput_code\x94\x88\x8c\rgraph_diagram\x94\x89\x8c\x0fcompile_profile\x94\x89\x8c\nupload_tar\x94Nh\x03Nu\x8c\x15InductorConfigContext\x94}\x94(hCh\x02\x8c\x0f__annotations__\x94}\x94(\x8c\rstatic_memory\x94\x8c\x08builtins\x94\x8c\x04bool\x94\x93\x94\x8c\x0ematmul_padding\x94hm\x8c\x0cmax_autotune\x94hm\x8c\x12triton_convolution\x94hk\x8c\x03str\x94\x93\x94\x8c\x17rematerialize_threshold\x94hk\x8c\x03int\x94\x93\x94\x8c\x1brematerialize_acc_threshold\x94huu\x8c\x05_save\x94h8\x8c\x1bInductorConfigContext._save\x94\x93\x94\x8c\x06_apply\x94h8\x8c\x1cInductorConfigContext._apply\x94\x93\x94\x8c\x08__init__\x94h8\x8c\x1eInductorConfigContext.__init__\x94\x93\x94\x8c\t__enter__\x94h8\x8c\x1fInductorConfigContext.__enter__\x94\x93\x94\x8c\x08__exit__\x94h8\x8c\x1eInductorConfigContext.__exit__\x94\x93\x94h\x03Nu\x8c\x1cget_config_serialization_fns\x94\x8c\x1atorch._dynamo.config_utils\x94h\x86\x93\x94u.')
# REPLACEABLE COMMENT FOR TESTING PURPOSES
# torch version: 2.0.0.dev20230131+cu117
# torch cuda version: 11.7
# torch git version: b2690c3ceae36fa6681a0c7cedcc8db7f5d9814a
# CUDA Info:
# nvcc not found
# GPU Hardware Info:
# NVIDIA RTX A6000 : 4
from torch.nn import *
class Repro(torch.nn.Module):
def __init__(self):
super().__init__()
def forward(self, sub, exp):
sum_1 = torch.ops.aten.sum.dim_IntList(exp, [2], True); exp = None
log = torch.ops.aten.log.default(sum_1); sum_1 = None
sub_1 = torch.ops.aten.sub.Tensor(sub, log); sub = log = None
constant_pad_nd = torch.ops.aten.constant_pad_nd.default(sub_1, [0, 0, 1, 0], 0.0); sub_1 = None
return (constant_pad_nd,)
args = [((1, 2, 1, 5), (10, 5, 5, 1), torch.float64, 'cpu'), ((1, 2, 1, 5), (10, 5, 5, 1), torch.float64, 'cpu')]
args = [rand_strided(sh, st, dt, dev) for (sh, st, dt, dev) in args]
mod = make_fx(Repro())(*args)
from torch._inductor.compile_fx import compile_fx_inner
from torch._dynamo.debug_utils import same_two_models
compiled = compile_fx_inner(mod, args)
ref = compiled(args)
```
### Versions
<details><summary><b>Environment</b> <i>[Click to expand]</i></summary>
```
PyTorch version: 2.0.0.dev20230131+cu117
Is debug build: False
CUDA used to build PyTorch: 11.7
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.5 LTS (x86_64)
GCC version: (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0
Clang version: 10.0.0-4ubuntu1
CMake version: version 3.16.3
Libc version: glibc-2.31
Python version: 3.8.13 (default, Mar 28 2022, 11:38:47) [GCC 7.5.0] (64-bit runtime)
Python platform: Linux-5.4.0-137-generic-x86_64-with-glibc2.17
Is CUDA available: True
CUDA runtime version: Could not collect
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration:
GPU 0: NVIDIA RTX A6000
GPU 1: NVIDIA RTX A6000
GPU 2: NVIDIA RTX A6000
GPU 3: NVIDIA RTX A6000
Nvidia driver version: 510.68.02
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.2.2
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.2.2
/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.2.2
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_infer.so.8.2.2
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.2.2
/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.2.2
/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.2.2
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.23.5
[pip3] pytorch-triton==2.0.0+0d7e753227
[pip3] torch==2.0.0.dev20230131+cu117
[pip3] torchaudio==2.0.0.dev20230126+cu117
[pip3] torchvision==0.15.0.dev20230126+cu117
[conda] No relevant packages
```
</details>
cc @ezyang @soumith @msaroufim @wconstab @ngimel @bdhirsh @mlazos @voznesenskym @yanboliang @penguinwu @anijain2305 @EikanWang @jgong5 @Guobing-Chen @XiaobingSuper @zhuhaozhe @blzheng @Xia-Weiwen @wenzhe-nrv @jiayisunx @peterbell10 @desertfire
| 2 |
3,593 | 93,394 |
MaskRCNN with `torch.compile` fails with `CUDA error: an illegal memory`
|
high priority, triaged, ezyang's list, oncall: pt2
|
### 🐛 Describe the bug
Hi,
I'm working with Jan 28 nightly build of PyTorch (nightly branch)
https://github.com/pytorch/pytorch/commit/5d6a4f697cac34d15262aad8afab096170d29ce1
I'm doing DDP training for MaskRCNN using the DeepLearningExamples
https://github.com/HerringForks/DeepLearningExamples/tree/master/PyTorch/Segmentation/MaskRCNN/pytorch
I'm using the wiki text dataset: https://huggingface.co/datasets/wikitext
I'm working on an EC2 setup with `p4d.24xlarge` instance.
Find instance specification here: https://aws.amazon.com/ec2/instance-types/p4/
The model was adapted with a single line code change in the trainer.
https://github.com/HerringForks/DeepLearningExamples/blob/master/PyTorch/Segmentation/MaskRCNN/pytorch/tools/train_net.py#L99
```bash
model = torch.compile(model)
```
Here is the run command
```bash
python /DeepLearningExamples/PyTorch/Segmentation/MaskRCNN/pytorch/tools/train_net.py \
--config-file /DeepLearningExamples/PyTorch/Segmentation/MaskRCNN/pytorch/configs/e2e_mask_rcnn_R_50_FPN_1x_32GPU_4bs.yaml \
--skip-test \
--max_steps 100 \
--fp16 \
--skip_checkpoint \
--data-dir wiki-text
```
I've attached the minified scripts but they do not reproduce the error.
### Error logs
```
2023-01-31 20:25:44,228 maskrcnn_benchmark.trainer INFO: Start training
max_iter: 100
/opt/conda/lib/python3.9/site-packages/torch/_inductor/compile_fx.py:90: UserWarning: TensorFloat32 tensor cores for float32 matrix multiplication available but not enabled. Consider setting `torch.set_float32_matmul_precision('high')` for better performance.
warnings.warn(
Traceback (most recent call last):
File "/opt/conda/lib/python3.9/site-packages/torch/_functorch/aot_autograd.py", line 100, in preserve_rng_state
yield
File "/opt/conda/lib/python3.9/site-packages/torch/_functorch/aot_autograd.py", line 2172, in create_aot_dispatcher_function
compiled_fn = compiler_fn(flat_fn, fake_flat_args, aot_config)
File "/opt/conda/lib/python3.9/site-packages/torch/_functorch/aot_autograd.py", line 1411, in aot_wrapper_dedupe
return compiler_fn(flat_fn, leaf_flat_args, aot_config)
File "/opt/conda/lib/python3.9/site-packages/torch/_functorch/aot_autograd.py", line 1061, in aot_dispatch_base
compiled_fw = aot_config.fw_compiler(fw_module, flat_args)
File "/opt/conda/lib/python3.9/site-packages/torch/_dynamo/utils.py", line 160, in time_wrapper
r = func(*args, **kwargs)
File "/opt/conda/lib/python3.9/site-packages/torch/_inductor/compile_fx.py", line 388, in fw_compiler
return inner_compile(
File "/opt/conda/lib/python3.9/site-packages/torch/_dynamo/debug_utils.py", line 586, in debug_wrapper
compiled_fn = compiler_fn(gm, example_inputs, **kwargs)
File "/opt/conda/lib/python3.9/site-packages/torch/_inductor/debug.py", line 239, in inner
return fn(*args, **kwargs)
File "/opt/conda/lib/python3.9/contextlib.py", line 79, in inner
return func(*args, **kwds)
File "/opt/conda/lib/python3.9/site-packages/torch/_inductor/compile_fx.py", line 151, in compile_fx_inner
compiled_fn = graph.compile_to_fn()
File "/opt/conda/lib/python3.9/site-packages/torch/_inductor/graph.py", line 560, in compile_to_fn
return self.compile_to_module().call
File "/opt/conda/lib/python3.9/site-packages/torch/_dynamo/utils.py", line 160, in time_wrapper
r = func(*args, **kwargs)
File "/opt/conda/lib/python3.9/site-packages/torch/_inductor/graph.py", line 549, in compile_to_module
mod = PyCodeCache.load(code)
File "/opt/conda/lib/python3.9/site-packages/torch/_inductor/codecache.py", line 504, in load
exec(code, mod.__dict__, mod.__dict__)
File "/tmp/torchinductor_ec2-user/2h/c2h6rhx27sjn25y6qfejavuwmfbj7hlo66wdk32skv4vsgyhg6xm.py", line 79, in <module>
async_compile.wait(globals())
File "/opt/conda/lib/python3.9/site-packages/torch/_inductor/codecache.py", line 691, in wait
scope[key] = result.result()
File "/opt/conda/lib/python3.9/site-packages/torch/_inductor/codecache.py", line 550, in result
kernel = self.kernel = _load_kernel(self.source_code)
File "/opt/conda/lib/python3.9/site-packages/torch/_inductor/codecache.py", line 530, in _load_kernel
kernel.precompile()
File "/opt/conda/lib/python3.9/site-packages/torch/_inductor/triton_ops/autotune.py", line 67, in precompile
self.launchers = [
File "/opt/conda/lib/python3.9/site-packages/torch/_inductor/triton_ops/autotune.py", line 68, in <listcomp>
self._precompile_config(c, warm_cache_only_with_cc)
File "/opt/conda/lib/python3.9/site-packages/torch/_inductor/triton_ops/autotune.py", line 92, in _precompile_config
torch.cuda.synchronize(torch.cuda.current_device())
File "/opt/conda/lib/python3.9/site-packages/torch/cuda/__init__.py", line 597, in synchronize
return torch._C._cuda_synchronize()
RuntimeError: CUDA error: an illegal memory access was encountered
CUDA kernel errors might be asynchronously reported at some other API call, so the stacktrace below might be incorrect.
For debugging consider passing CUDA_LAUNCH_BLOCKING=1.
Compile with `TORCH_USE_CUDA_DSA` to enable device-side assertions.
```
### Minified repro
TORCHDYNAMO_REPRO_AFTER="dynamo"
```python
import os
from math import inf
import torch
from torch import tensor, device
import torch.fx as fx
import functools
import torch._dynamo
from torch._dynamo.debug_utils import run_fwd_maybe_bwd
from torch._dynamo.optimizations.backends import BACKENDS
from torch._dynamo.testing import rand_strided
import torch._dynamo.config
import torch._inductor.config
torch._dynamo.config.load_config(b'\x80\x04\x95\xa1\x07\x00\x00\x00\x00\x00\x00}\x94(\x8c\x08__name__\x94\x8c\x14torch._dynamo.config\x94\x8c\x07__doc__\x94N\x8c\x0b__package__\x94\x8c\rtorch._dynamo\x94\x8c\n__loader__\x94\x8c\x1a_frozen_importlib_external\x94\x8c\x10SourceFileLoader\x94\x93\x94)\x81\x94}\x94(\x8c\x04name\x94h\x02\x8c\x04path\x94\x8c>/opt/conda/lib/python3.9/site-packages/torch/_dynamo/config.py\x94ub\x8c\x08__spec__\x94\x8c\x11_frozen_importlib\x94\x8c\nModuleSpec\x94\x93\x94)\x81\x94}\x94(h\x0ch\x02\x8c\x06loader\x94h\n\x8c\x06origin\x94h\x0e\x8c\x0cloader_state\x94N\x8c\x1asubmodule_search_locations\x94N\x8c\r_set_fileattr\x94\x88\x8c\x07_cached\x94\x8cV/opt/conda/lib/python3.9/site-packages/torch/_dynamo/__pycache__/config.cpython-39.pyc\x94\x8c\r_initializing\x94\x89ub\x8c\x08__file__\x94h\x0e\x8c\n__cached__\x94h\x1b\x8c\x07abspath\x94\x8c\tposixpath\x94h\x1f\x93\x94\x8c\x07dirname\x94h h"\x93\x94\x8c\x0eHAS_REFS_PRIMS\x94\x88\x8c\tlog_level\x94K\x1e\x8c\x0boutput_code\x94\x89\x8c\rlog_file_name\x94N\x8c\x07verbose\x94\x89\x8c\x11output_graph_code\x94\x89\x8c\x12verify_correctness\x94\x89\x8c\x12minimum_call_count\x94K\x01\x8c\x15dead_code_elimination\x94\x88\x8c\x10cache_size_limit\x94K@\x8c\x14specialize_int_float\x94\x88\x8c\x0edynamic_shapes\x94\x89\x8c\x10guard_nn_modules\x94\x89\x8c\x0cnormalize_ir\x94\x89\x8c\x1btraceable_tensor_subclasses\x94\x8f\x94\x8c\x0fsuppress_errors\x94\x89\x8c\x15replay_record_enabled\x94\x89\x8c rewrite_assert_with_torch_assert\x94\x88\x8c\x12print_graph_breaks\x94\x89\x8c\x07disable\x94\x89\x8c*allowed_functions_module_string_ignorelist\x94\x8f\x94(\x8c\rtorch.testing\x94\x8c\x0btorch._refs\x94\x8c\x0ctorch._prims\x94\x8c\x13torch.distributions\x94\x8c\rtorch._decomp\x94\x90\x8c\x16capture_scalar_outputs\x94\x89\x8c\x19enforce_cond_guards_match\x94\x88\x8c\x0coptimize_ddp\x94\x88\x8c\x1araise_on_ctx_manager_usage\x94\x88\x8c\x1craise_on_unsafe_aot_autograd\x94\x89\x8c\rdynamo_import\x94\x8c\rtorch._dynamo\x94\x8c\x0finductor_import\x94\x8c\x0ftorch._inductor\x94\x8c\x18error_on_nested_fx_trace\x94\x88\x8c\tallow_rnn\x94\x89\x8c\x08base_dir\x94\x8c&/opt/conda/lib/python3.9/site-packages\x94\x8c\x0edebug_dir_root\x94\x8c6/fsx/karan/pt2_benchmarks/maskrcnn/torch_compile_debug\x94\x8c)DO_NOT_USE_legacy_non_fake_example_inputs\x94\x89\x8c\x15_AccessLimitingConfig\x94}\x94(\x8c\n__module__\x94h\x02\x8c\x0b__setattr__\x94h\x02\x8c!_AccessLimitingConfig.__setattr__\x94\x93\x94h\x03Nu\x8c\x15_allowed_config_names\x94\x8f\x94(h,hIh-h\x1ehKh6h\x0fh(h)h5h/h%\x8c\x0brepro_after\x94h\x03\x8c\x12constant_functions\x94hGhOh0\x8c\x02os\x94hCh*h\x06h7h1hA\x8c!skipfiles_inline_module_allowlist\x94hB\x8c\x05torch\x94\x8c\x0c__builtins__\x94h.\x8c\x07logging\x94hDh9h"h\x04h\x1fh+hJ\x8c\nModuleType\x94h@h\x01h\'hEh4\x8c\x0eexternal_utils\x94hMh8h\x1dhPh&h2\x8c\x0brepro_level\x94\x8c\x03sys\x94h$\x90\x8c\x1cget_config_serialization_fns\x94\x8c\x1atorch._dynamo.config_utils\x94hc\x93\x94u.')
torch._inductor.config.load_config(b'\x80\x04\x95\xd3\x08\x00\x00\x00\x00\x00\x00}\x94(\x8c\x08__name__\x94\x8c\x16torch._inductor.config\x94\x8c\x07__doc__\x94N\x8c\x0b__package__\x94\x8c\x0ftorch._inductor\x94\x8c\n__loader__\x94\x8c\x1a_frozen_importlib_external\x94\x8c\x10SourceFileLoader\x94\x93\x94)\x81\x94}\x94(\x8c\x04name\x94h\x02\x8c\x04path\x94\x8c@/opt/conda/lib/python3.9/site-packages/torch/_inductor/config.py\x94ub\x8c\x08__spec__\x94\x8c\x11_frozen_importlib\x94\x8c\nModuleSpec\x94\x93\x94)\x81\x94}\x94(h\x0ch\x02\x8c\x06loader\x94h\n\x8c\x06origin\x94h\x0e\x8c\x0cloader_state\x94N\x8c\x1asubmodule_search_locations\x94N\x8c\r_set_fileattr\x94\x88\x8c\x07_cached\x94\x8cX/opt/conda/lib/python3.9/site-packages/torch/_inductor/__pycache__/config.cpython-39.pyc\x94\x8c\r_initializing\x94\x89ub\x8c\x08__file__\x94h\x0e\x8c\n__cached__\x94h\x1b\x8c\x05debug\x94\x89\x8c\x10disable_progress\x94\x88\x8c\x10verbose_progress\x94\x89\x8c\x0bcpp_wrapper\x94\x89\x8c\x03dce\x94\x89\x8c\x14static_weight_shapes\x94\x88\x8c\x0csize_asserts\x94\x88\x8c\x10pick_loop_orders\x94\x88\x8c\x0finplace_buffers\x94\x88\x8c\x11benchmark_harness\x94\x88\x8c\x0fepilogue_fusion\x94\x89\x8c\x15epilogue_fusion_first\x94\x89\x8c\x0cmax_autotune\x94\x89\x8c\x17realize_reads_threshold\x94K\x04\x8c\x17realize_bytes_threshold\x94M\xd0\x07\x8c\x1brealize_acc_reads_threshold\x94K\x08\x8c\x0ffallback_random\x94\x89\x8c\x12implicit_fallbacks\x94\x88\x8c\rprefuse_nodes\x94\x88\x8c\x0btune_layout\x94\x89\x8c\x11aggressive_fusion\x94\x89\x8c\x0fmax_fusion_size\x94K@\x8c\x1bunroll_reductions_threshold\x94K\x08\x8c\x0ecomment_origin\x94\x89\x8c\tis_fbcode\x94h\x02h7\x93\x94\x8c\x0fcompile_threads\x94K \x8c\x13kernel_name_max_ops\x94K\n\x8c\x0finductor_import\x94\x8c\x0ftorch._inductor\x94\x8c\rshape_padding\x94\x89\x8c\x0epermute_fusion\x94\x89\x8c\x1aprofiler_mark_wrapper_call\x94\x89\x8c\x03cpp\x94}\x94(\x8c\n__module__\x94h\x02\x8c\x07threads\x94J\xff\xff\xff\xff\x8c\x0fdynamic_threads\x94\x89\x8c\x07simdlen\x94N\x8c\x0emin_chunk_size\x94M\x00\x10\x8c\x03cxx\x94N\x8c\x03g++\x94\x86\x94\x8c\x15enable_kernel_profile\x94\x89h\x03Nu\x8c\x06triton\x94}\x94(hBh\x02\x8c\ncudagraphs\x94\x88\x8c\x10debug_sync_graph\x94\x89\x8c\x11debug_sync_kernel\x94\x89\x8c\x0bconvolution\x94\x8c\x04aten\x94\x8c\x0edense_indexing\x94\x89\x8c\tmax_tiles\x94K\x02\x8c\x12autotune_pointwise\x94\x88\x8c tiling_prevents_pointwise_fusion\x94\x88\x8c tiling_prevents_reduction_fusion\x94\x88\x8c\x14ordered_kernel_names\x94\x89\x8c\x18descriptive_kernel_names\x94\x89h\x03Nu\x8c\x05trace\x94}\x94(hBh\x02\x8c\x07enabled\x94\x89\x8c\tdebug_log\x94\x88\x8c\x08info_log\x94\x89\x8c\x08fx_graph\x94\x88\x8c\rir_pre_fusion\x94\x88\x8c\x0eir_post_fusion\x94\x88\x8c\x0boutput_code\x94\x88\x8c\rgraph_diagram\x94\x89\x8c\x0fcompile_profile\x94\x89\x8c\nupload_tar\x94Nh\x03Nu\x8c\x15InductorConfigContext\x94}\x94(hBh\x02\x8c\x0f__annotations__\x94}\x94(\x8c\rstatic_memory\x94\x8c\x08builtins\x94\x8c\x04bool\x94\x93\x94\x8c\x0ematmul_padding\x94hlh+hl\x8c\x12triton_convolution\x94hj\x8c\x03str\x94\x93\x94\x8c\x17rematerialize_threshold\x94hj\x8c\x03int\x94\x93\x94\x8c\x1brematerialize_acc_threshold\x94hsu\x8c\x05_save\x94h\x02\x8c\x1bInductorConfigContext._save\x94\x93\x94\x8c\x06_apply\x94h\x02\x8c\x1cInductorConfigContext._apply\x94\x93\x94\x8c\x08__init__\x94h\x02\x8c\x1eInductorConfigContext.__init__\x94\x93\x94\x8c\t__enter__\x94h\x02\x8c\x1fInductorConfigContext.__enter__\x94\x93\x94\x8c\x08__exit__\x94h\x02\x8c\x1eInductorConfigContext.__exit__\x94\x93\x94h\x03Nu\x8c\x1cget_config_serialization_fns\x94\x8c\x1atorch._dynamo.config_utils\x94h\x84\x93\x94u.')
# REPLACEABLE COMMENT FOR TESTING PURPOSES
args = [((128, 64, 200, 336), (4300800, 67200, 336, 1), torch.float16, 'cuda', False), ((64,), (1,), torch.float32, 'cuda', False), ((64,), (1,), torch.float32, 'cuda', False), ((64,), (1,), torch.float32, 'cuda', False), ((64,), (1,), torch.float32, 'cuda', False)]
args = [rand_strided(sh, st, dt, dev).requires_grad_(rg) for (sh, st, dt, dev, rg) in args]
from torch.nn import *
class Repro(torch.nn.Module):
def __init__(self):
super().__init__()
def forward(self, _stack0 : torch.Tensor, self_bn1_weight : torch.Tensor, self_bn1_bias : torch.Tensor, self_bn1_running_mean : torch.Tensor, self_bn1_running_var : torch.Tensor):
half = self_bn1_weight.half(); self_bn1_weight = None
half_1 = self_bn1_bias.half(); self_bn1_bias = None
half_2 = self_bn1_running_mean.half(); self_bn1_running_mean = None
half_3 = self_bn1_running_var.half(); self_bn1_running_var = None
rsqrt = half_3.rsqrt()
mul = half * rsqrt; rsqrt = None
mul_1 = half_2 * mul
sub = half_1 - mul_1; mul_1 = None
reshape = mul.reshape(1, -1, 1, 1); mul = None
reshape_1 = sub.reshape(1, -1, 1, 1); sub = None
mul_2 = _stack0 * reshape; _stack0 = reshape = None
add = mul_2 + reshape_1; mul_2 = reshape_1 = None
relu_ = torch.relu_(add); add = None
return (relu_, half, half_1, half_2, half_3)
mod = Repro()
# Setup debug minifier compiler
torch._dynamo.debug_utils.MINIFIER_SPAWNED = True
compiler_fn = BACKENDS["dynamo_minifier_backend"]
dynamo_minifier_backend = functools.partial(
compiler_fn,
compiler_name="inductor",
)
opt_mod = torch._dynamo.optimize(dynamo_minifier_backend)(mod)
with torch.cuda.amp.autocast(enabled=True):
opt_mod(*args)
```
TORCHDYNAMO_REPRO_AFTER="aot"
```python
isolate_fails_code_str = None
import torch
from torch import tensor, device
import torch.fx as fx
from torch._dynamo.testing import rand_strided
from math import inf
from torch.fx.experimental.proxy_tensor import make_fx
import torch._dynamo.config
import torch._inductor.config
torch._dynamo.config.load_config(b'\x80\x04\x95\xa1\x07\x00\x00\x00\x00\x00\x00}\x94(\x8c\x08__name__\x94\x8c\x14torch._dynamo.config\x94\x8c\x07__doc__\x94N\x8c\x0b__package__\x94\x8c\rtorch._dynamo\x94\x8c\n__loader__\x94\x8c\x1a_frozen_importlib_external\x94\x8c\x10SourceFileLoader\x94\x93\x94)\x81\x94}\x94(\x8c\x04name\x94h\x02\x8c\x04path\x94\x8c>/opt/conda/lib/python3.9/site-packages/torch/_dynamo/config.py\x94ub\x8c\x08__spec__\x94\x8c\x11_frozen_importlib\x94\x8c\nModuleSpec\x94\x93\x94)\x81\x94}\x94(h\x0ch\x02\x8c\x06loader\x94h\n\x8c\x06origin\x94h\x0e\x8c\x0cloader_state\x94N\x8c\x1asubmodule_search_locations\x94N\x8c\r_set_fileattr\x94\x88\x8c\x07_cached\x94\x8cV/opt/conda/lib/python3.9/site-packages/torch/_dynamo/__pycache__/config.cpython-39.pyc\x94\x8c\r_initializing\x94\x89ub\x8c\x08__file__\x94h\x0e\x8c\n__cached__\x94h\x1b\x8c\x07abspath\x94\x8c\tposixpath\x94h\x1f\x93\x94\x8c\x07dirname\x94h h"\x93\x94\x8c\x0eHAS_REFS_PRIMS\x94\x88\x8c\tlog_level\x94K\x1e\x8c\x0boutput_code\x94\x89\x8c\rlog_file_name\x94N\x8c\x07verbose\x94\x89\x8c\x11output_graph_code\x94\x89\x8c\x12verify_correctness\x94\x89\x8c\x12minimum_call_count\x94K\x01\x8c\x15dead_code_elimination\x94\x88\x8c\x10cache_size_limit\x94K@\x8c\x14specialize_int_float\x94\x88\x8c\x0edynamic_shapes\x94\x89\x8c\x10guard_nn_modules\x94\x89\x8c\x0cnormalize_ir\x94\x89\x8c\x1btraceable_tensor_subclasses\x94\x8f\x94\x8c\x0fsuppress_errors\x94\x89\x8c\x15replay_record_enabled\x94\x89\x8c rewrite_assert_with_torch_assert\x94\x88\x8c\x12print_graph_breaks\x94\x89\x8c\x07disable\x94\x89\x8c*allowed_functions_module_string_ignorelist\x94\x8f\x94(\x8c\rtorch.testing\x94\x8c\x0ctorch._prims\x94\x8c\x0btorch._refs\x94\x8c\x13torch.distributions\x94\x8c\rtorch._decomp\x94\x90\x8c\x16capture_scalar_outputs\x94\x89\x8c\x19enforce_cond_guards_match\x94\x88\x8c\x0coptimize_ddp\x94\x88\x8c\x1araise_on_ctx_manager_usage\x94\x88\x8c\x1craise_on_unsafe_aot_autograd\x94\x89\x8c\rdynamo_import\x94\x8c\rtorch._dynamo\x94\x8c\x0finductor_import\x94\x8c\x0ftorch._inductor\x94\x8c\x18error_on_nested_fx_trace\x94\x88\x8c\tallow_rnn\x94\x89\x8c\x08base_dir\x94\x8c&/opt/conda/lib/python3.9/site-packages\x94\x8c\x0edebug_dir_root\x94\x8c6/fsx/karan/pt2_benchmarks/maskrcnn/torch_compile_debug\x94\x8c)DO_NOT_USE_legacy_non_fake_example_inputs\x94\x89\x8c\x15_AccessLimitingConfig\x94}\x94(\x8c\n__module__\x94h\x02\x8c\x0b__setattr__\x94h\x02\x8c!_AccessLimitingConfig.__setattr__\x94\x93\x94h\x03Nu\x8c\x15_allowed_config_names\x94\x8f\x94(h%hIhGh9h\x01\x8c\x07logging\x94\x8c\x05torch\x94h.\x8c\x0brepro_after\x94\x8c\x0brepro_level\x94hChDh*hBh2\x8c!skipfiles_inline_module_allowlist\x94h&h6\x8c\x12constant_functions\x94h$\x8c\nModuleType\x94h\x06h"hK\x8c\x03sys\x94h0hJh(\x8c\x02os\x94h\x03h)hEhP\x8c\x0eexternal_utils\x94h8h@hOh5hMh+h7hAh\x0fh\'\x8c\x0c__builtins__\x94h-h,h/h\x1dh\x1eh\x1fh1h4h\x04\x90\x8c\x1cget_config_serialization_fns\x94\x8c\x1atorch._dynamo.config_utils\x94hc\x93\x94u.')
torch._inductor.config.load_config(b'\x80\x04\x95\xd3\x08\x00\x00\x00\x00\x00\x00}\x94(\x8c\x08__name__\x94\x8c\x16torch._inductor.config\x94\x8c\x07__doc__\x94N\x8c\x0b__package__\x94\x8c\x0ftorch._inductor\x94\x8c\n__loader__\x94\x8c\x1a_frozen_importlib_external\x94\x8c\x10SourceFileLoader\x94\x93\x94)\x81\x94}\x94(\x8c\x04name\x94h\x02\x8c\x04path\x94\x8c@/opt/conda/lib/python3.9/site-packages/torch/_inductor/config.py\x94ub\x8c\x08__spec__\x94\x8c\x11_frozen_importlib\x94\x8c\nModuleSpec\x94\x93\x94)\x81\x94}\x94(h\x0ch\x02\x8c\x06loader\x94h\n\x8c\x06origin\x94h\x0e\x8c\x0cloader_state\x94N\x8c\x1asubmodule_search_locations\x94N\x8c\r_set_fileattr\x94\x88\x8c\x07_cached\x94\x8cX/opt/conda/lib/python3.9/site-packages/torch/_inductor/__pycache__/config.cpython-39.pyc\x94\x8c\r_initializing\x94\x89ub\x8c\x08__file__\x94h\x0e\x8c\n__cached__\x94h\x1b\x8c\x05debug\x94\x89\x8c\x10disable_progress\x94\x88\x8c\x10verbose_progress\x94\x89\x8c\x0bcpp_wrapper\x94\x89\x8c\x03dce\x94\x89\x8c\x14static_weight_shapes\x94\x88\x8c\x0csize_asserts\x94\x88\x8c\x10pick_loop_orders\x94\x88\x8c\x0finplace_buffers\x94\x88\x8c\x11benchmark_harness\x94\x88\x8c\x0fepilogue_fusion\x94\x89\x8c\x15epilogue_fusion_first\x94\x89\x8c\x0cmax_autotune\x94\x89\x8c\x17realize_reads_threshold\x94K\x04\x8c\x17realize_bytes_threshold\x94M\xd0\x07\x8c\x1brealize_acc_reads_threshold\x94K\x08\x8c\x0ffallback_random\x94\x89\x8c\x12implicit_fallbacks\x94\x88\x8c\rprefuse_nodes\x94\x88\x8c\x0btune_layout\x94\x89\x8c\x11aggressive_fusion\x94\x89\x8c\x0fmax_fusion_size\x94K@\x8c\x1bunroll_reductions_threshold\x94K\x08\x8c\x0ecomment_origin\x94\x89\x8c\tis_fbcode\x94h\x02h7\x93\x94\x8c\x0fcompile_threads\x94K \x8c\x13kernel_name_max_ops\x94K\n\x8c\x0finductor_import\x94\x8c\x0ftorch._inductor\x94\x8c\rshape_padding\x94\x89\x8c\x0epermute_fusion\x94\x89\x8c\x1aprofiler_mark_wrapper_call\x94\x89\x8c\x03cpp\x94}\x94(\x8c\n__module__\x94h\x02\x8c\x07threads\x94J\xff\xff\xff\xff\x8c\x0fdynamic_threads\x94\x89\x8c\x07simdlen\x94N\x8c\x0emin_chunk_size\x94M\x00\x10\x8c\x03cxx\x94N\x8c\x03g++\x94\x86\x94\x8c\x15enable_kernel_profile\x94\x89h\x03Nu\x8c\x06triton\x94}\x94(hBh\x02\x8c\ncudagraphs\x94\x88\x8c\x10debug_sync_graph\x94\x89\x8c\x11debug_sync_kernel\x94\x89\x8c\x0bconvolution\x94\x8c\x04aten\x94\x8c\x0edense_indexing\x94\x89\x8c\tmax_tiles\x94K\x02\x8c\x12autotune_pointwise\x94\x88\x8c tiling_prevents_pointwise_fusion\x94\x88\x8c tiling_prevents_reduction_fusion\x94\x88\x8c\x14ordered_kernel_names\x94\x89\x8c\x18descriptive_kernel_names\x94\x89h\x03Nu\x8c\x05trace\x94}\x94(hBh\x02\x8c\x07enabled\x94\x89\x8c\tdebug_log\x94\x88\x8c\x08info_log\x94\x89\x8c\x08fx_graph\x94\x88\x8c\rir_pre_fusion\x94\x88\x8c\x0eir_post_fusion\x94\x88\x8c\x0boutput_code\x94\x88\x8c\rgraph_diagram\x94\x89\x8c\x0fcompile_profile\x94\x89\x8c\nupload_tar\x94Nh\x03Nu\x8c\x15InductorConfigContext\x94}\x94(hBh\x02\x8c\x0f__annotations__\x94}\x94(\x8c\rstatic_memory\x94\x8c\x08builtins\x94\x8c\x04bool\x94\x93\x94\x8c\x0ematmul_padding\x94hlh+hl\x8c\x12triton_convolution\x94hj\x8c\x03str\x94\x93\x94\x8c\x17rematerialize_threshold\x94hj\x8c\x03int\x94\x93\x94\x8c\x1brematerialize_acc_threshold\x94hsu\x8c\x05_save\x94h\x02\x8c\x1bInductorConfigContext._save\x94\x93\x94\x8c\x06_apply\x94h\x02\x8c\x1cInductorConfigContext._apply\x94\x93\x94\x8c\x08__init__\x94h\x02\x8c\x1eInductorConfigContext.__init__\x94\x93\x94\x8c\t__enter__\x94h\x02\x8c\x1fInductorConfigContext.__enter__\x94\x93\x94\x8c\x08__exit__\x94h\x02\x8c\x1eInductorConfigContext.__exit__\x94\x93\x94h\x03Nu\x8c\x1cget_config_serialization_fns\x94\x8c\x1atorch._dynamo.config_utils\x94h\x84\x93\x94u.')
# REPLACEABLE COMMENT FOR TESTING PURPOSES
# torch version: 2.0.0a0+git5876d91
# torch cuda version: 11.7
# torch git version: 5876d91752ee335f3dc018616f3513f514527386
# CUDA Info:
# nvcc: NVIDIA (R) Cuda compiler driver
# Copyright (c) 2005-2022 NVIDIA Corporation
# Built on Wed_Jun__8_16:49:14_PDT_2022
# Cuda compilation tools, release 11.7, V11.7.99
# Build cuda_11.7.r11.7/compiler.31442593_0
# GPU Hardware Info:
# NVIDIA A100-SXM4-40GB : 8
from torch.nn import *
class Repro(torch.nn.Module):
def __init__(self):
super().__init__()
def forward(self, arg0_1, arg1_1, arg2_1, arg3_1, arg4_1):
convert_element_type = torch.ops.prims.convert_element_type.default(arg1_1, torch.float16); arg1_1 = None
convert_element_type_1 = torch.ops.prims.convert_element_type.default(arg2_1, torch.float16); arg2_1 = None
convert_element_type_2 = torch.ops.prims.convert_element_type.default(arg3_1, torch.float16); arg3_1 = None
convert_element_type_3 = torch.ops.prims.convert_element_type.default(arg4_1, torch.float16); arg4_1 = None
convert_element_type_4 = torch.ops.prims.convert_element_type.default(convert_element_type_3, torch.float32)
rsqrt = torch.ops.aten.rsqrt.default(convert_element_type_4); convert_element_type_4 = None
mul = torch.ops.aten.mul.Tensor(convert_element_type, rsqrt); rsqrt = None
mul_1 = torch.ops.aten.mul.Tensor(convert_element_type_2, mul)
sub = torch.ops.aten.sub.Tensor(convert_element_type_1, mul_1); mul_1 = None
view = torch.ops.aten.view.default(mul, [1, 64, 1, 1]); mul = None
view_1 = torch.ops.aten.view.default(sub, [1, 64, 1, 1]); sub = None
mul_2 = torch.ops.aten.mul.Tensor(arg0_1, view); arg0_1 = view = None
add = torch.ops.aten.add.Tensor(mul_2, view_1); mul_2 = view_1 = None
relu_ = torch.ops.aten.relu_.default(add); add = None
return (relu_, convert_element_type, convert_element_type_1, convert_element_type_2, convert_element_type_3)
args = [((128, 64, 200, 336), (4300800, 67200, 336, 1), torch.float16, 'cuda'), ((64,), (1,), torch.float32, 'cuda'), ((64,), (1,), torch.float32, 'cuda'), ((64,), (1,), torch.float32, 'cuda'), ((64,), (1,), torch.float32, 'cuda')]
args = [rand_strided(sh, st, dt, dev) for (sh, st, dt, dev) in args]
mod = make_fx(Repro())(*args)
from functools import partial
from torch._dynamo.debug_utils import (
isolate_fails,
dump_compiler_graph_state,
)
from functorch.compile import minifier
env_variables = {"CUDA_VISIBLE_DEVICES": "1"}
minifier(
mod,
args,
module_fails=partial(isolate_fails, env=env_variables, compiler_name="inductor", patch_code=isolate_fails_code_str),
dump_state=partial(dump_compiler_graph_state, compiler_name="inductor"),
)
```
### Versions
```bash
Collecting environment information...
PyTorch version: 2.0.0a0+git5876d91
Is debug build: False
CUDA used to build PyTorch: 11.7
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.5 LTS (x86_64)
GCC version: (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0
Clang version: Could not collect
CMake version: version 3.24.3
Libc version: glibc-2.31
Python version: 3.9.13 | packaged by conda-forge | (main, May 27 2022, 16:58:50) [GCC 10.3.0] (64-bit runtime)
Python platform: Linux-4.14.296-222.539.amzn2.x86_64-x86_64-with-glibc2.31
Is CUDA available: True
CUDA runtime version: 11.7.99
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration: NVIDIA A100-SXM4-40GB
Nvidia driver version: 470.103.01
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.5.0
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.5.0
/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.5.0
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_infer.so.8.5.0
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.5.0
/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.5.0
/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.5.0
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] bert-pytorch==0.0.1a4
[pip3] clip-anytorch==2.5.0
[pip3] CoCa-pytorch==0.0.7
[pip3] dalle2-pytorch==1.10.5
[pip3] ema-pytorch==0.1.4
[pip3] functorch==1.14.0a0+408bcf1
[pip3] mypy-extensions==0.4.3
[pip3] numpy==1.23.5
[pip3] pytorch-transformers==1.2.0
[pip3] pytorch-warmup==0.1.1
[pip3] rotary-embedding-torch==0.2.1
[pip3] torch==2.0.0a0+git5876d91
[pip3] torch-fidelity==0.3.0
[pip3] torch-struct==0.5
[pip3] torchaudio==2.0.0a0+4699ef2
[pip3] torchdata==0.6.0a0+a1612ee
[pip3] torchmetrics==0.11.0
[pip3] torchrec-nightly==2023.1.29
[pip3] torchtext==0.15.0a0+f653dac
[pip3] torchvision==0.15.0a0+c35e8d5
[pip3] vector-quantize-pytorch==0.10.15
[conda] bert-pytorch 0.0.1a4 dev_0 <develop>
[conda] clip-anytorch 2.5.0 pypi_0 pypi
[conda] coca-pytorch 0.0.7 pypi_0 pypi
[conda] dalle2-pytorch 1.10.5 pypi_0 pypi
[conda] ema-pytorch 0.1.4 pypi_0 pypi
[conda] functorch 1.14.0a0+408bcf1 pypi_0 pypi
[conda] magma-cuda117 2.6.1 1 pytorch
[conda] mkl 2022.2.1 h84fe81f_16997 conda-forge
[conda] mkl-include 2023.0.0 h84fe81f_25396 conda-forge
[conda] numpy 1.23.5 pypi_0 pypi
[conda] pytorch-transformers 1.2.0 pypi_0 pypi
[conda] pytorch-warmup 0.1.1 pypi_0 pypi
[conda] rotary-embedding-torch 0.2.1 pypi_0 pypi
[conda] torch 2.0.0a0+git5876d91 pypi_0 pypi
[conda] torch-fidelity 0.3.0 pypi_0 pypi
[conda] torch-struct 0.5 pypi_0 pypi
[conda] torchaudio 2.0.0a0+4699ef2 pypi_0 pypi
[conda] torchdata 0.6.0a0+a1612ee pypi_0 pypi
[conda] torchmetrics 0.11.0 pypi_0 pypi
[conda] torchrec-nightly 2023.1.29 pypi_0 pypi
[conda] torchtext 0.15.0a0+f653dac pypi_0 pypi
[conda] torchvision 0.15.0a0+c35e8d5 pypi_0 pypi
[conda] vector-quantize-pytorch 0.10.15 pypi_0 pypi
```
cc @ezyang @gchanan @zou3519 @soumith @msaroufim @wconstab @ngimel @bdhirsh
| 3 |
3,594 | 93,386 |
[pt2] cannot compile function having `gt`, `expand` and `add_`
|
triaged, module: functionalization, oncall: pt2
|
### 🐛 Describe the bug
It seems that all of the three operators are needed to trigger this issue.
```python
import torch
def fn(v0):
# v0: ()
v1 = torch.gt(v0, v0) # v1: ()
v2 = v1.expand(1, 1) # v2: (1, 1)
v3 = v2.add_(v2, alpha=1) # torch.Tensor.add_-8 # v3: (1, 1)
return v3
x = torch.tensor([True])
fn(x)
print('==== Eager mode OK! ====')
compiled = torch.compile(fn)
compiled(x)
print('==== torch.compile mode OK! ====')
```
### Error logs
<details>
<summary>click to expand</summary>
```python
==== Eager mode OK! ====
Traceback (most recent call last):
File "/home/colin/miniconda3/envs/py10/lib/python3.10/site-packages/torch/_dynamo/output_graph.py", line 692, in call_user_compiler
compiled_fn = compiler_fn(gm, self.fake_example_inputs())
File "/home/colin/miniconda3/envs/py10/lib/python3.10/site-packages/torch/_dynamo/debug_utils.py", line 1047, in debug_wrapper
compiled_gm = compiler_fn(gm, example_inputs, **kwargs)
File "/home/colin/miniconda3/envs/py10/lib/python3.10/site-packages/torch/__init__.py", line 1324, in __call__
return self.compile_fn(model_, inputs_)
File "/home/colin/miniconda3/envs/py10/lib/python3.10/site-packages/torch/_dynamo/optimizations/backends.py", line 24, in inner
return fn(gm, example_inputs, **kwargs)
File "/home/colin/miniconda3/envs/py10/lib/python3.10/site-packages/torch/_dynamo/optimizations/backends.py", line 61, in inductor
return compile_fx(*args, **kwargs)
File "/home/colin/miniconda3/envs/py10/lib/python3.10/site-packages/torch/_inductor/compile_fx.py", line 413, in compile_fx
return aot_autograd(
File "/home/colin/miniconda3/envs/py10/lib/python3.10/site-packages/torch/_dynamo/optimizations/training.py", line 74, in compiler_fn
cg = aot_module_simplified(gm, example_inputs, **kwargs)
File "/home/colin/miniconda3/envs/py10/lib/python3.10/site-packages/torch/_functorch/aot_autograd.py", line 2483, in aot_module_simplified
compiled_fn = create_aot_dispatcher_function(
File "/home/colin/miniconda3/envs/py10/lib/python3.10/site-packages/torch/_dynamo/utils.py", line 161, in time_wrapper
r = func(*args, **kwargs)
File "/home/colin/miniconda3/envs/py10/lib/python3.10/site-packages/torch/_functorch/aot_autograd.py", line 2180, in create_aot_dispatcher_function
compiled_fn = compiler_fn(flat_fn, fake_flat_args, aot_config)
File "/home/colin/miniconda3/envs/py10/lib/python3.10/site-packages/torch/_functorch/aot_autograd.py", line 1411, in aot_wrapper_dedupe
return compiler_fn(flat_fn, leaf_flat_args, aot_config)
File "/home/colin/miniconda3/envs/py10/lib/python3.10/site-packages/torch/_functorch/aot_autograd.py", line 1061, in aot_dispatch_base
compiled_fw = aot_config.fw_compiler(fw_module, flat_args)
File "/home/colin/miniconda3/envs/py10/lib/python3.10/site-packages/torch/_dynamo/utils.py", line 161, in time_wrapper
r = func(*args, **kwargs)
File "/home/colin/miniconda3/envs/py10/lib/python3.10/site-packages/torch/_inductor/compile_fx.py", line 388, in fw_compiler
return inner_compile(
File "/home/colin/miniconda3/envs/py10/lib/python3.10/site-packages/torch/_dynamo/debug_utils.py", line 586, in debug_wrapper
compiled_fn = compiler_fn(gm, example_inputs, **kwargs)
File "/home/colin/miniconda3/envs/py10/lib/python3.10/site-packages/torch/_inductor/debug.py", line 239, in inner
return fn(*args, **kwargs)
File "/home/colin/miniconda3/envs/py10/lib/python3.10/contextlib.py", line 79, in inner
return func(*args, **kwds)
File "/home/colin/miniconda3/envs/py10/lib/python3.10/site-packages/torch/_inductor/compile_fx.py", line 151, in compile_fx_inner
compiled_fn = graph.compile_to_fn()
File "/home/colin/miniconda3/envs/py10/lib/python3.10/site-packages/torch/_inductor/graph.py", line 567, in compile_to_fn
return self.compile_to_module().call
File "/home/colin/miniconda3/envs/py10/lib/python3.10/site-packages/torch/_dynamo/utils.py", line 161, in time_wrapper
r = func(*args, **kwargs)
File "/home/colin/miniconda3/envs/py10/lib/python3.10/site-packages/torch/_inductor/graph.py", line 552, in compile_to_module
code = self.codegen()
File "/home/colin/miniconda3/envs/py10/lib/python3.10/site-packages/torch/_inductor/graph.py", line 501, in codegen
self.scheduler = Scheduler(self.buffers)
File "/home/colin/miniconda3/envs/py10/lib/python3.10/site-packages/torch/_dynamo/utils.py", line 161, in time_wrapper
r = func(*args, **kwargs)
File "/home/colin/miniconda3/envs/py10/lib/python3.10/site-packages/torch/_inductor/scheduler.py", line 567, in __init__
self.nodes.append(SchedulerNode(self, node, group_fn))
File "/home/colin/miniconda3/envs/py10/lib/python3.10/site-packages/torch/_inductor/scheduler.py", line 234, in __init__
super().__init__(scheduler, node)
File "/home/colin/miniconda3/envs/py10/lib/python3.10/site-packages/torch/_inductor/scheduler.py", line 58, in __init__
self.set_read_writes(node.get_read_writes())
File "/home/colin/miniconda3/envs/py10/lib/python3.10/site-packages/torch/_inductor/utils.py", line 206, in wrapper
setattr(self, key, fn(self))
File "/home/colin/miniconda3/envs/py10/lib/python3.10/site-packages/torch/_inductor/ir.py", line 2035, in get_read_writes
self.get_store_function(),
File "/home/colin/miniconda3/envs/py10/lib/python3.10/site-packages/torch/_inductor/ir.py", line 2040, in get_store_function
indexer = self.layout.as_fixed().make_indexer()
File "/home/colin/miniconda3/envs/py10/lib/python3.10/site-packages/torch/_inductor/ir.py", line 1883, in make_indexer
return self.target.make_indexer()
AttributeError: 'ExpandView' object has no attribute 'make_indexer'
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "/home/colin/code/path/bug.py", line 16, in <module>
compiled(x)
File "/home/colin/miniconda3/envs/py10/lib/python3.10/site-packages/torch/_dynamo/eval_frame.py", line 211, in _fn
return fn(*args, **kwargs)
File "/home/colin/miniconda3/envs/py10/lib/python3.10/site-packages/torch/_dynamo/eval_frame.py", line 332, in catch_errors
return callback(frame, cache_size, hooks)
File "/home/colin/miniconda3/envs/py10/lib/python3.10/site-packages/torch/_dynamo/convert_frame.py", line 403, in _convert_frame
result = inner_convert(frame, cache_size, hooks)
File "/home/colin/miniconda3/envs/py10/lib/python3.10/site-packages/torch/_dynamo/convert_frame.py", line 103, in _fn
return fn(*args, **kwargs)
File "/home/colin/miniconda3/envs/py10/lib/python3.10/site-packages/torch/_dynamo/convert_frame.py", line 261, in _convert_frame_assert
return _compile(
File "/home/colin/miniconda3/envs/py10/lib/python3.10/site-packages/torch/_dynamo/utils.py", line 161, in time_wrapper
r = func(*args, **kwargs)
File "/home/colin/miniconda3/envs/py10/lib/python3.10/site-packages/torch/_dynamo/convert_frame.py", line 323, in _compile
out_code = transform_code_object(code, transform)
File "/home/colin/miniconda3/envs/py10/lib/python3.10/site-packages/torch/_dynamo/bytecode_transformation.py", line 339, in transform_code_object
transformations(instructions, code_options)
File "/home/colin/miniconda3/envs/py10/lib/python3.10/site-packages/torch/_dynamo/convert_frame.py", line 310, in transform
tracer.run()
File "/home/colin/miniconda3/envs/py10/lib/python3.10/site-packages/torch/_dynamo/symbolic_convert.py", line 1715, in run
super().run()
File "/home/colin/miniconda3/envs/py10/lib/python3.10/site-packages/torch/_dynamo/symbolic_convert.py", line 564, in run
and self.step()
File "/home/colin/miniconda3/envs/py10/lib/python3.10/site-packages/torch/_dynamo/symbolic_convert.py", line 527, in step
getattr(self, inst.opname)(inst)
File "/home/colin/miniconda3/envs/py10/lib/python3.10/site-packages/torch/_dynamo/symbolic_convert.py", line 1781, in RETURN_VALUE
self.output.compile_subgraph(self)
File "/home/colin/miniconda3/envs/py10/lib/python3.10/site-packages/torch/_dynamo/output_graph.py", line 539, in compile_subgraph
self.compile_and_call_fx_graph(tx, list(reversed(stack_values)), root)
File "/home/colin/miniconda3/envs/py10/lib/python3.10/site-packages/torch/_dynamo/output_graph.py", line 610, in compile_and_call_fx_graph
compiled_fn = self.call_user_compiler(gm)
File "/home/colin/miniconda3/envs/py10/lib/python3.10/site-packages/torch/_dynamo/utils.py", line 161, in time_wrapper
r = func(*args, **kwargs)
File "/home/colin/miniconda3/envs/py10/lib/python3.10/site-packages/torch/_dynamo/output_graph.py", line 697, in call_user_compiler
raise BackendCompilerFailed(self.compiler_fn, e) from e
torch._dynamo.exc.BackendCompilerFailed: debug_wrapper raised AttributeError: 'ExpandView' object has no attribute 'make_indexer'
Set torch._dynamo.config.verbose=True for more information
You can suppress this exception and fall back to eager by setting:
torch._dynamo.config.suppress_errors = True
```
</details>
### Minified repro
The generated minifier cannot run successfully:
```python
isolate_fails_code_str = None
import torch
from torch import tensor, device
import torch.fx as fx
from torch._dynamo.testing import rand_strided
from math import inf
from torch.fx.experimental.proxy_tensor import make_fx
import torch._dynamo.config
import torch._inductor.config
torch._dynamo.config.load_config(b'\x80\x04\x95\x00\x08\x00\x00\x00\x00\x00\x00}\x94(\x8c\x08__name__\x94\x8c\x14torch._dynamo.config\x94\x8c\x07__doc__\x94N\x8c\x0b__package__\x94\x8c\rtorch._dynamo\x94\x8c\n__loader__\x94\x8c\x1a_frozen_importlib_external\x94\x8c\x10SourceFileLoader\x94\x93\x94)\x81\x94}\x94(\x8c\x04name\x94h\x02\x8c\x04path\x94\x8cU/home/colin/miniconda3/envs/py10/lib/python3.10/site-packages/torch/_dynamo/config.py\x94ub\x8c\x08__spec__\x94\x8c\x11_frozen_importlib\x94\x8c\nModuleSpec\x94\x93\x94)\x81\x94}\x94(h\x0ch\x02\x8c\x06loader\x94h\n\x8c\x06origin\x94h\x0e\x8c\x0cloader_state\x94N\x8c\x1asubmodule_search_locations\x94N\x8c\r_set_fileattr\x94\x88\x8c\x07_cached\x94\x8cn/home/colin/miniconda3/envs/py10/lib/python3.10/site-packages/torch/_dynamo/__pycache__/config.cpython-310.pyc\x94\x8c\r_initializing\x94\x89ub\x8c\x08__file__\x94h\x0e\x8c\n__cached__\x94h\x1b\x8c\x07abspath\x94\x8c\tposixpath\x94h\x1f\x93\x94\x8c\x07dirname\x94h h"\x93\x94\x8c\tlog_level\x94K\x1e\x8c\x0boutput_code\x94\x89\x8c\rlog_file_name\x94N\x8c\x07verbose\x94\x89\x8c\x11output_graph_code\x94\x89\x8c\x12verify_correctness\x94\x89\x8c\x12minimum_call_count\x94K\x01\x8c\x15dead_code_elimination\x94\x88\x8c\x10cache_size_limit\x94K@\x8c\x14specialize_int_float\x94\x88\x8c\x0edynamic_shapes\x94\x89\x8c\x10guard_nn_modules\x94\x89\x8c\x0cnormalize_ir\x94\x89\x8c\x1btraceable_tensor_subclasses\x94\x8f\x94\x8c\x0fsuppress_errors\x94\x89\x8c\x15replay_record_enabled\x94\x89\x8c rewrite_assert_with_torch_assert\x94\x88\x8c\x12print_graph_breaks\x94\x89\x8c\x07disable\x94\x89\x8c*allowed_functions_module_string_ignorelist\x94\x8f\x94(\x8c\x0ctorch._prims\x94\x8c\rtorch._decomp\x94\x8c\x0btorch._refs\x94\x8c\rtorch.testing\x94\x8c\x13torch.distributions\x94\x90\x8c\x16capture_scalar_outputs\x94\x89\x8c\x19enforce_cond_guards_match\x94\x88\x8c\x0coptimize_ddp\x94\x88\x8c\x1araise_on_ctx_manager_usage\x94\x88\x8c\x1craise_on_unsafe_aot_autograd\x94\x89\x8c\rdynamo_import\x94\x8c\rtorch._dynamo\x94\x8c\x0finductor_import\x94\x8c\x0ftorch._inductor\x94\x8c\x18error_on_nested_fx_trace\x94\x88\x8c\tallow_rnn\x94\x89\x8c\x08base_dir\x94\x8c=/home/colin/miniconda3/envs/py10/lib/python3.10/site-packages\x94\x8c\x0edebug_dir_root\x94\x8cc/home/colin/code/nnsmith-autoinf/pt2_0131_n3_cpu_opt_2/bug-exec-48-1-2863572895/torch_compile_debug\x94\x8c)DO_NOT_USE_legacy_non_fake_example_inputs\x94\x89\x8c\x15_AccessLimitingConfig\x94}\x94(\x8c\n__module__\x94h\x02\x8c\x0b__setattr__\x94h\x02\x8c!_AccessLimitingConfig.__setattr__\x94\x93\x94h\x03Nu\x8c\x15_allowed_config_names\x94\x8f\x94(hFhDh5\x8c\x03sys\x94h8h+h,h4h\x06h-h)h\x1eh"h\x1f\x8c\nModuleType\x94h\'h@hI\x8c!skipfiles_inline_module_allowlist\x94hNhBh0h3h\x1dhJh%h(hH\x8c\x0brepro_level\x94h\x04h6\x8c\x07logging\x94\x8c\x05torch\x94h.h?h\x01h&h\x03h$h/hC\x8c\x0brepro_after\x94hL\x8c\x02os\x94h1hA\x8c\x0c__builtins__\x94h7\x8c\x12constant_functions\x94h*hOh\x0f\x8c\x0eexternal_utils\x94\x90\x8c\x1cget_config_serialization_fns\x94\x8c\x1atorch._dynamo.config_utils\x94hb\x93\x94u.')
torch._inductor.config.load_config(b'\x80\x04\x95\x02\t\x00\x00\x00\x00\x00\x00}\x94(\x8c\x08__name__\x94\x8c\x16torch._inductor.config\x94\x8c\x07__doc__\x94N\x8c\x0b__package__\x94\x8c\x0ftorch._inductor\x94\x8c\n__loader__\x94\x8c\x1a_frozen_importlib_external\x94\x8c\x10SourceFileLoader\x94\x93\x94)\x81\x94}\x94(\x8c\x04name\x94h\x02\x8c\x04path\x94\x8cW/home/colin/miniconda3/envs/py10/lib/python3.10/site-packages/torch/_inductor/config.py\x94ub\x8c\x08__spec__\x94\x8c\x11_frozen_importlib\x94\x8c\nModuleSpec\x94\x93\x94)\x81\x94}\x94(h\x0ch\x02\x8c\x06loader\x94h\n\x8c\x06origin\x94h\x0e\x8c\x0cloader_state\x94N\x8c\x1asubmodule_search_locations\x94N\x8c\r_set_fileattr\x94\x88\x8c\x07_cached\x94\x8cp/home/colin/miniconda3/envs/py10/lib/python3.10/site-packages/torch/_inductor/__pycache__/config.cpython-310.pyc\x94\x8c\r_initializing\x94\x89ub\x8c\x08__file__\x94h\x0e\x8c\n__cached__\x94h\x1b\x8c\x05debug\x94\x89\x8c\x10disable_progress\x94\x88\x8c\x10verbose_progress\x94\x89\x8c\x0bcpp_wrapper\x94\x89\x8c\x03dce\x94\x89\x8c\x14static_weight_shapes\x94\x88\x8c\x0csize_asserts\x94\x88\x8c\x10pick_loop_orders\x94\x88\x8c\x0finplace_buffers\x94\x88\x8c\x11benchmark_harness\x94\x88\x8c\x0fepilogue_fusion\x94\x89\x8c\x15epilogue_fusion_first\x94\x89\x8c\x0cmax_autotune\x94\x89\x8c\x17realize_reads_threshold\x94K\x04\x8c\x17realize_bytes_threshold\x94M\xd0\x07\x8c\x1brealize_acc_reads_threshold\x94K\x08\x8c\x0ffallback_random\x94\x89\x8c\x12implicit_fallbacks\x94\x88\x8c\rprefuse_nodes\x94\x88\x8c\x0btune_layout\x94\x89\x8c\x11aggressive_fusion\x94\x89\x8c\x0fmax_fusion_size\x94K@\x8c\x1bunroll_reductions_threshold\x94K\x08\x8c\x0ecomment_origin\x94\x89\x8c\tis_fbcode\x94h\x02h7\x93\x94\x8c\x0fcompile_threads\x94K\x10\x8c\x13kernel_name_max_ops\x94K\n\x8c\x0finductor_import\x94\x8c\x0ftorch._inductor\x94\x8c\rshape_padding\x94\x89\x8c\x0epermute_fusion\x94\x89\x8c\x1aprofiler_mark_wrapper_call\x94\x89\x8c\x03cpp\x94}\x94(\x8c\n__module__\x94h\x02\x8c\x07threads\x94J\xff\xff\xff\xff\x8c\x0fdynamic_threads\x94\x89\x8c\x07simdlen\x94N\x8c\x0emin_chunk_size\x94M\x00\x10\x8c\x03cxx\x94N\x8c\x03g++\x94\x86\x94\x8c\x15enable_kernel_profile\x94\x89h\x03Nu\x8c\x06triton\x94}\x94(hBh\x02\x8c\ncudagraphs\x94\x88\x8c\x10debug_sync_graph\x94\x89\x8c\x11debug_sync_kernel\x94\x89\x8c\x0bconvolution\x94\x8c\x04aten\x94\x8c\x0edense_indexing\x94\x89\x8c\tmax_tiles\x94K\x02\x8c\x12autotune_pointwise\x94\x88\x8c tiling_prevents_pointwise_fusion\x94\x88\x8c tiling_prevents_reduction_fusion\x94\x88\x8c\x14ordered_kernel_names\x94\x89\x8c\x18descriptive_kernel_names\x94\x89h\x03Nu\x8c\x05trace\x94}\x94(hBh\x02\x8c\x07enabled\x94\x89\x8c\tdebug_log\x94\x88\x8c\x08info_log\x94\x89\x8c\x08fx_graph\x94\x88\x8c\rir_pre_fusion\x94\x88\x8c\x0eir_post_fusion\x94\x88\x8c\x0boutput_code\x94\x88\x8c\rgraph_diagram\x94\x89\x8c\x0fcompile_profile\x94\x89\x8c\nupload_tar\x94Nh\x03Nu\x8c\x15InductorConfigContext\x94}\x94(hBh\x02\x8c\x0f__annotations__\x94}\x94(\x8c\rstatic_memory\x94\x8c\x08builtins\x94\x8c\x04bool\x94\x93\x94\x8c\x0ematmul_padding\x94hlh+hl\x8c\x12triton_convolution\x94hj\x8c\x03str\x94\x93\x94\x8c\x17rematerialize_threshold\x94hj\x8c\x03int\x94\x93\x94\x8c\x1brematerialize_acc_threshold\x94hsu\x8c\x05_save\x94h\x02\x8c\x1bInductorConfigContext._save\x94\x93\x94\x8c\x06_apply\x94h\x02\x8c\x1cInductorConfigContext._apply\x94\x93\x94\x8c\x08__init__\x94h\x02\x8c\x1eInductorConfigContext.__init__\x94\x93\x94\x8c\t__enter__\x94h\x02\x8c\x1fInductorConfigContext.__enter__\x94\x93\x94\x8c\x08__exit__\x94h\x02\x8c\x1eInductorConfigContext.__exit__\x94\x93\x94h\x03Nu\x8c\x1cget_config_serialization_fns\x94\x8c\x1atorch._dynamo.config_utils\x94h\x84\x93\x94u.')
# REPLACEABLE COMMENT FOR TESTING PURPOSES
# torch version: 2.0.0.dev20230131+cu117
# torch cuda version: 11.7
# torch git version: b2690c3ceae36fa6681a0c7cedcc8db7f5d9814a
# CUDA Info:
# nvcc not found
# GPU Hardware Info:
# NVIDIA GeForce RTX 2080 Ti : 1
from torch.nn import *
class Repro(torch.nn.Module):
def __init__(self):
super().__init__()
def forward(self, arg0_1):
gt = torch.ops.aten.gt.Tensor(arg0_1, arg0_1); arg0_1 = None
expand = torch.ops.aten.expand.default(gt, [1, 1]); gt = None
mul = torch.ops.aten.mul.Tensor(expand, 1)
add_ = torch.ops.aten.add_.Tensor(expand, mul); expand = mul = None
return (add_,)
args = [((1,), (1,), torch.bool, 'cpu')]
args = [rand_strided(sh, st, dt, dev) for (sh, st, dt, dev) in args]
mod = make_fx(Repro())(*args)
from functools import partial
from torch._dynamo.debug_utils import (
isolate_fails,
dump_compiler_graph_state,
)
from functorch.compile import minifier
env_variables = {"CUDA_VISIBLE_DEVICES": "0"}
minifier(
mod,
args,
module_fails=partial(isolate_fails, env=env_variables, compiler_name="inductor", patch_code=isolate_fails_code_str),
dump_state=partial(dump_compiler_graph_state, compiler_name="inductor"),
)
```
<details>
<summary>output of the minifier</summary>
```python
Traceback (most recent call last):
File "/home/colin/code/path/torch_compile_debug/run_2023_01_31_13_10_14_408106/minifier/minifier_launcher.py", line 48, in <module>
mod = make_fx(Repro())(*args)
File "/home/colin/miniconda3/envs/py10/lib/python3.10/site-packages/torch/fx/experimental/proxy_tensor.py", line 702, in wrapped
t = dispatch_trace(wrap_key(func, args, fx_tracer), tracer=fx_tracer, concrete_args=tuple(phs))
File "/home/colin/miniconda3/envs/py10/lib/python3.10/site-packages/torch/fx/experimental/proxy_tensor.py", line 440, in dispatch_trace
graph = tracer.trace(root, concrete_args)
File "/home/colin/miniconda3/envs/py10/lib/python3.10/site-packages/torch/fx/_symbolic_trace.py", line 778, in trace
(self.create_arg(fn(*args)),),
File "/home/colin/miniconda3/envs/py10/lib/python3.10/site-packages/torch/fx/experimental/proxy_tensor.py", line 456, in wrapped
out = f(*tensors)
File "<string>", line 1, in <lambda>
File "/home/colin/miniconda3/envs/py10/lib/python3.10/site-packages/torch/fx/_symbolic_trace.py", line 756, in module_call_wrapper
return self.call_module(mod, forward, args, kwargs)
File "/home/colin/miniconda3/envs/py10/lib/python3.10/site-packages/torch/fx/experimental/proxy_tensor.py", line 406, in call_module
return forward(*args, **kwargs)
File "/home/colin/miniconda3/envs/py10/lib/python3.10/site-packages/torch/fx/_symbolic_trace.py", line 749, in forward
return _orig_module_call(mod, *args, **kwargs)
File "/home/colin/miniconda3/envs/py10/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1488, in _call_impl
return forward_call(*args, **kwargs)
File "/home/colin/code/path/torch_compile_debug/run_2023_01_31_13_10_14_408106/minifier/minifier_launcher.py", line 43, in forward
add_ = torch.ops.aten.add_.Tensor(expand, mul); expand = mul = None
File "/home/colin/miniconda3/envs/py10/lib/python3.10/site-packages/torch/_ops.py", line 284, in __call__
return self._op(*args, **kwargs or {})
File "/home/colin/miniconda3/envs/py10/lib/python3.10/site-packages/torch/utils/_stats.py", line 15, in wrapper
return fn(*args, **kwargs)
File "/home/colin/miniconda3/envs/py10/lib/python3.10/site-packages/torch/fx/experimental/proxy_tensor.py", line 484, in __torch_dispatch__
return self.inner_torch_dispatch(func, types, args, kwargs)
File "/home/colin/miniconda3/envs/py10/lib/python3.10/site-packages/torch/fx/experimental/proxy_tensor.py", line 509, in inner_torch_dispatch
out = proxy_call(self, func, args, kwargs)
File "/home/colin/miniconda3/envs/py10/lib/python3.10/site-packages/torch/fx/experimental/proxy_tensor.py", line 342, in proxy_call
out = func(*args, **kwargs)
File "/home/colin/miniconda3/envs/py10/lib/python3.10/site-packages/torch/_ops.py", line 284, in __call__
return self._op(*args, **kwargs or {})
RuntimeError: result type Long can't be cast to the desired output type Bool
```
</details>
### Versions
```python
Collecting environment information...
PyTorch version: 2.0.0.dev20230131+cu117
Is debug build: False
CUDA used to build PyTorch: 11.7
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.5 LTS (x86_64)
GCC version: (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0
Clang version: 10.0.0-4ubuntu1
CMake version: version 3.25.0
Libc version: glibc-2.31
Python version: 3.10.9 (main, Jan 11 2023, 15:21:40) [GCC 11.2.0] (64-bit runtime)
Python platform: Linux-5.15.0-58-generic-x86_64-with-glibc2.31
Is CUDA available: True
CUDA runtime version: Could not collect
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration: GPU 0: NVIDIA GeForce RTX 2080 Ti
Nvidia driver version: 510.85.02
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.7.0
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.7.0
/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.7.0
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_infer.so.8.7.0
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.7.0
/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.7.0
/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.7.0
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] mypy-extensions==0.4.3
[pip3] numpy==1.24.1
[pip3] pytorch-triton==2.0.0+0d7e753227
[pip3] torch==2.0.0.dev20230131+cu117
[pip3] torchaudio==2.0.0.dev20230131+cu117
[pip3] torchvision==0.15.0.dev20230131+cu117
[conda] numpy 1.24.1 pypi_0 pypi
[conda] pytorch-triton 2.0.0+0d7e753227 pypi_0 pypi
[conda] torch 2.0.0.dev20230131+cu117 pypi_0 pypi
[conda] torchaudio 2.0.0.dev20230131+cu117 pypi_0 pypi
[conda] torchvision 0.15.0.dev20230131+cu117 pypi_0 pypi
```
cc @ezyang @soumith @msaroufim @wconstab @ngimel @bdhirsh
| 3 |
3,595 | 93,378 |
(DDP) RoBERTa_large training with `torch.compile` results in OOM and other issues
|
triaged, oncall: pt2
|
### 🐛 Describe the bug
Hi,
I'm working with Jan 28 nightly build of PyTorch (nightly branch)
https://github.com/pytorch/pytorch/commit/5d6a4f697cac34d15262aad8afab096170d29ce1
RoBERTa architecture here: https://arxiv.org/pdf/1907.11692.pdf
The model definition && training scripts come from Fairseq
1. Trainer: https://github.com/facebookresearch/fairseq/blob/main/fairseq/trainer.py
2. Model def (RoBERTa Large): https://github.com/facebookresearch/fairseq/blob/main/fairseq/models/roberta/model.py#L34
The script was adapted by wrapping the `wrapped_model` in `trainer.py`
```
self._wrapped_model = torch.compile(self._wrapped_model)
```
I'm using the wiki text dataset: https://huggingface.co/datasets/wikitext
I'm working on an EC2 setup with `p4d.24xlarge` instance.
Find instance specification here: https://aws.amazon.com/ec2/instance-types/p4/
These are the hyperparameter settings:
```bash
fairseq-train wikitext --adam-eps 1e-06 --arch roberta_large --attention-dropout 0.1 --clip-norm 0.0 --criterion masked_lm --distributed-backend nccl --distributed-no-spawn --dropout 0.1 --encoder-embed-dim 2048 --encoder-ffn-embed-dim 8192 --encoder-layers 24 --log-format simple --log-interval 10 --lr 0.0001 --lr-scheduler polynomial_decay --max-sentences 8 --max-update 500 --optimizer adam --sample-break-mode complete --skip-invalid-size-inputs-valid-test --task masked_lm --tokens-per-sample 512 --total-num-update 100 --update-freq 1 --weight-decay 0.01 --no-save --memory-efficient-fp16 --skip-invalid-size-inputs-valid-test --no-last-checkpoints
```
Note that to replicate this setup, you will have to rebuild Apex against the latest version of PT, I couldn't do this in the PyTorch nightly images because of CUDA missing dependencies on that container. Perhaps the PyTorch nightly devel container will have these dependencies (will validate later today).
Once that is done, you will have to rebuild Fairseq.
Fairseq uses quite a few torchscript annotation and conditional code branching such as `if torch.jit.tracing: do_f`, and I've observed that dynamo symbolic converter throws this warning
```
[2023-01-28 17:07:39,262] torch._dynamo.symbolic_convert: [DEBUG] FAILED INLINING <code object forward_scriptable at 0x7fe3ac862f50, file "/fairseq/fairseq/models/transformer/transformer_encoder.py", line 173>
```
https://github.com/facebookresearch/fairseq/blob/main/fairseq/models/transformer/transformer_encoder.py#L173
> What is the guidance on using torchscript in conjunction to torch.compile? Is it recommended to not do that?
However, this won't cause compilation to stop but down the road inductor will throw an error
```
File "/opt/conda/lib/python3.9/site-packages/torch/_inductor/triton_ops/autotune.py", line 187, in run
result = launcher(
File "<string>", line 6, in launcher
ValueError: Pointer argument (at 0) cannot be accessed from Triton (cpu tensor?)
```
training works fine runs fine without torch.compile wrap.
So, I'm not certain if this is an issue specifically with my setup but I can confirm that I can run a few of the dynamo benchmarks successfully. I'll try to get fairseq working on the nightly container
--
Anyways after removing the jit branches in code, the training continues but runs into OOM issues. The /fsx/pytorch-nightly/pytorch-2.0/pytorch/aten/src/ATen/cuda/CUDAGraph.cpp fails to allocate memory.
More questions.
These warnings:
/opt/conda/lib/python3.9/site-packages/torch/nn/functional.py:4872: UserWarning: This function is deprecated please rebuild your models with the public version of sdpa.
warnings.warn("This function is deprecated please rebuild your models with the public version of sdpa.")
[2023-01-31 16:46:36,214] torch._inductor.lowering: [WARNING] using triton random, expect difference from eager
-> What is actionable for these? Specifically, for spda, what is the recommendation? Any particular library that should be used. What is the private (as opposed to public) version of SPDA?
Moreover, I've attached the minified scripts, but they don't reproduce the issue. Do they really help you as a domain specialist if the problem is not reproducible?
I've not tried running this without the DDP wrapper, but eventually I need to train this model/its variants on a large cluster, so even if the non DDP version works, thats not helpful.
Moreover, all the artifacts pasted here are collected with `mpirun -np 1 <command>`, so use DDP with 1 rank. This is not relevant, but giving you the full picture.
### Error logs
```
/opt/conda/lib/python3.9/site-packages/torch/cuda/graphs.py:82: UserWarning: The CUDA Graph is empty. This ususally means that the graph was attempted to be captured on wrong device or stream. (Triggered internally at /fsx/pytorch-nightly/pytorch-2.0/pytorch/aten/src/ATen/cuda/CUDAGraph.cpp:191.)
super(CUDAGraph, self).capture_end()
2023-01-31 16:46:57 | WARNING | fairseq.trainer | |===========================================================================|
| PyTorch CUDA memory summary, device ID 0 |
|---------------------------------------------------------------------------|
| CUDA OOMs: 1 | cudaMalloc retries: 1 |
|===========================================================================|
| Metric | Cur Usage | Peak Usage | Tot Alloc | Tot Freed |
|---------------------------------------------------------------------------|
| Allocated memory | 32019 MiB | 32019 MiB | 66253 MiB | 34234 MiB |
| from large pool | 32007 MiB | 32007 MiB | 65929 MiB | 33922 MiB |
| from small pool | 12 MiB | 12 MiB | 323 MiB | 311 MiB |
|---------------------------------------------------------------------------|
| Active memory | 32019 MiB | 32019 MiB | 66253 MiB | 34234 MiB |
| from large pool | 32007 MiB | 32007 MiB | 65929 MiB | 33922 MiB |
| from small pool | 12 MiB | 12 MiB | 323 MiB | 311 MiB |
|---------------------------------------------------------------------------|
| GPU reserved memory | 39034 MiB | 39034 MiB | 57400 MiB | 18366 MiB |
| from large pool | 38856 MiB | 38856 MiB | 57160 MiB | 18304 MiB |
| from small pool | 178 MiB | 178 MiB | 240 MiB | 62 MiB |
|---------------------------------------------------------------------------|
| Non-releasable memory | 4116 MiB | 4129 MiB | 15251 MiB | 11135 MiB |
| from large pool | 3950 MiB | 3962 MiB | 14611 MiB | 10660 MiB |
| from small pool | 165 MiB | 167 MiB | 640 MiB | 474 MiB |
|---------------------------------------------------------------------------|
| Allocations | 2847 | 2847 | 4943 | 2096 |
| from large pool | 1275 | 1275 | 2281 | 1006 |
| from small pool | 1572 | 1572 | 2662 | 1090 |
|---------------------------------------------------------------------------|
| Active allocs | 2847 | 2847 | 4943 | 2096 |
| from large pool | 1275 | 1275 | 2281 | 1006 |
| from small pool | 1572 | 1572 | 2662 | 1090 |
|---------------------------------------------------------------------------|
| GPU reserved segments | 1211 | 1211 | 1705 | 494 |
| from large pool | 1122 | 1122 | 1585 | 463 |
| from small pool | 89 | 89 | 120 | 31 |
|---------------------------------------------------------------------------|
| Non-releasable allocs | 549 | 549 | 1403 | 854 |
| from large pool | 410 | 410 | 851 | 441 |
| from small pool | 139 | 139 | 552 | 413 |
|---------------------------------------------------------------------------|
| Oversize allocations | 0 | 0 | 0 | 0 |
|---------------------------------------------------------------------------|
| Oversize GPU segments | 0 | 0 | 0 | 0 |
|===========================================================================|
2023-01-31 16:46:57 | ERROR | fairseq.trainer | OOM during optimization, irrecoverable
Traceback (most recent call last):
File "/opt/conda/bin/fairseq-train", line 8, in <module>
sys.exit(cli_main())
File "/fsx/roberta/fairseq/fairseq_cli/train.py", line 574, in cli_main
distributed_utils.call_main(cfg, main)
File "/fsx/roberta/fairseq/fairseq/distributed/utils.py", line 393, in call_main
distributed_main(cfg.distributed_training.device_id, main, cfg, kwargs)
File "/fsx/roberta/fairseq/fairseq/distributed/utils.py", line 366, in distributed_main
main(cfg, **kwargs)
File "/fsx/roberta/fairseq/fairseq_cli/train.py", line 205, in main
valid_losses, should_stop = train(cfg, trainer, task, epoch_itr)
File "/opt/conda/lib/python3.9/contextlib.py", line 79, in inner
return func(*args, **kwds)
File "/fsx/roberta/fairseq/fairseq_cli/train.py", line 331, in train
log_output = trainer.train_step(samples)
File "/opt/conda/lib/python3.9/contextlib.py", line 79, in inner
return func(*args, **kwds)
File "/fsx/roberta/fairseq/fairseq/trainer.py", line 1034, in train_step
raise e
File "/fsx/roberta/fairseq/fairseq/trainer.py", line 979, in train_step
self.task.optimizer_step(
File "/fsx/roberta/fairseq/fairseq/tasks/fairseq_task.py", line 545, in optimizer_step
optimizer.step()
File "/fsx/roberta/fairseq/fairseq/optim/fp16_optimizer.py", line 450, in step
self.wrapped_optimizer.step(closure, groups=groups)
File "/fsx/roberta/fairseq/fairseq/optim/fairseq_optimizer.py", line 135, in step
self.optimizer.step(closure)
File "/opt/conda/lib/python3.9/site-packages/torch/optim/optimizer.py", line 253, in wrapper
out = func(*args, **kwargs)
File "/fsx/roberta/fairseq/fairseq/optim/fused_adam.py", line 329, in step
state["exp_avg_sq"] = torch.zeros_like(
torch.cuda.OutOfMemoryError: CUDA out of memory. Tried to allocate 64.00 MiB (GPU 0; 39.59 GiB total capacity; 31.27 GiB already allocated; 66.19 MiB free; 38.12 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
```
### Minified repro
Details too long to add in this comment. Repro details after dynamo/AOT are here: https://gist.github.com/0x6b64/966c2900fc7609d8bb9eaec22f8d6cc0
### Versions
```bash
Collecting environment information...
PyTorch version: 2.0.0a0+git5876d91
Is debug build: False
CUDA used to build PyTorch: 11.7
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.5 LTS (x86_64)
GCC version: (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0
Clang version: Could not collect
CMake version: version 3.24.3
Libc version: glibc-2.31
Python version: 3.9.13 | packaged by conda-forge | (main, May 27 2022, 16:58:50) [GCC 10.3.0] (64-bit runtime)
Python platform: Linux-4.14.296-222.539.amzn2.x86_64-x86_64-with-glibc2.31
Is CUDA available: True
CUDA runtime version: 11.7.99
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration: NVIDIA A100-SXM4-40GB
Nvidia driver version: 470.103.01
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.5.0
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.5.0
/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.5.0
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_infer.so.8.5.0
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.5.0
/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.5.0
/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.5.0
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] bert-pytorch==0.0.1a4
[pip3] clip-anytorch==2.5.0
[pip3] CoCa-pytorch==0.0.7
[pip3] dalle2-pytorch==1.10.5
[pip3] ema-pytorch==0.1.4
[pip3] functorch==1.14.0a0+408bcf1
[pip3] mypy-extensions==0.4.3
[pip3] numpy==1.23.5
[pip3] pytorch-transformers==1.2.0
[pip3] pytorch-warmup==0.1.1
[pip3] rotary-embedding-torch==0.2.1
[pip3] torch==2.0.0a0+git5876d91
[pip3] torch-fidelity==0.3.0
[pip3] torch-struct==0.5
[pip3] torchaudio==2.0.0a0+4699ef2
[pip3] torchdata==0.6.0a0+a1612ee
[pip3] torchmetrics==0.11.0
[pip3] torchrec-nightly==2023.1.29
[pip3] torchtext==0.15.0a0+f653dac
[pip3] torchvision==0.15.0a0+c35e8d5
[pip3] vector-quantize-pytorch==0.10.15
[conda] bert-pytorch 0.0.1a4 dev_0 <develop>
[conda] clip-anytorch 2.5.0 pypi_0 pypi
[conda] coca-pytorch 0.0.7 pypi_0 pypi
[conda] dalle2-pytorch 1.10.5 pypi_0 pypi
[conda] ema-pytorch 0.1.4 pypi_0 pypi
[conda] functorch 1.14.0a0+408bcf1 pypi_0 pypi
[conda] magma-cuda117 2.6.1 1 pytorch
[conda] mkl 2022.2.1 h84fe81f_16997 conda-forge
[conda] mkl-include 2023.0.0 h84fe81f_25396 conda-forge
[conda] numpy 1.23.5 pypi_0 pypi
[conda] pytorch-transformers 1.2.0 pypi_0 pypi
[conda] pytorch-warmup 0.1.1 pypi_0 pypi
[conda] rotary-embedding-torch 0.2.1 pypi_0 pypi
[conda] torch 2.0.0a0+git5876d91 pypi_0 pypi
[conda] torch-fidelity 0.3.0 pypi_0 pypi
[conda] torch-struct 0.5 pypi_0 pypi
[conda] torchaudio 2.0.0a0+4699ef2 pypi_0 pypi
[conda] torchdata 0.6.0a0+a1612ee pypi_0 pypi
[conda] torchmetrics 0.11.0 pypi_0 pypi
[conda] torchrec-nightly 2023.1.29 pypi_0 pypi
[conda] torchtext 0.15.0a0+f653dac pypi_0 pypi
[conda] torchvision 0.15.0a0+c35e8d5 pypi_0 pypi
[conda] vector-quantize-pytorch 0.10.15 pypi_0 pypi
```
cc @ezyang @soumith @msaroufim @wconstab @ngimel @bdhirsh
| 7 |
3,596 | 93,367 |
Aot accuracy minifier with dynamic shapes doesn't work
|
triaged, oncall: pt2
|
### 🐛 Describe the bug
The typical symptom of this problem is that you have an accuracy problem, you successfully get the minifier to dump a minifier launcher (this in and of itself is nontrivial, see other issues I've filed), but then the minifier launcher claims there's nothing wrong with your program. Closer inspection (see also https://github.com/pytorch/pytorch/issues/93364 ) reveals that the minifier launcher is compiling your program differently than the actual, live execution. What's going on?
In fact, the algorithm the aot accuracy minifier and real execution take are quite different. So there actually isn't any reason to expect them to give the same result.
The aot minifier strategy looks like this:
1. Dump the GraphModule of post AOTAutograd operations (torch.ops.aten) into the test file
2. At minifier launch time, retrace it with `make_fx(gm)` (sic; notice that we don't pass `tracing_mode` here; more on this shortly)
3. Pass it directly `compile_fx_inner` from inductor
This is... problematic. Here are the reasons I know about, though there may be more.
* Most obviously, `make_fx` is being called without any tracing mode. So you will in fact get a static shape trace here. Oops.
* But let's say you fix that. Well, `make_fx` has a different algorithm for symbolicating the input fake tensors than Dynamo does. In particular, Dynamo creates a ShapeEnv, does some stuff which Dynamo might only know about, and then we reuse that when we run AOTAutograd. `make_fx` knows about none of this. In particular, you will lose guards that are not evident from the ATen graph trace.
The "correct" way to fix this is to try to more faithfully recreate the dynamic shapes environment as seen from real time execution.
### Versions
master
cc @soumith @msaroufim @wconstab @ngimel @bdhirsh
| 0 |
3,597 | 93,366 |
Option for minifier to dump the actual tensor inputs/parameters to be used
|
triaged, oncall: pt2
|
### 🐛 Describe the bug
Often randn is fine, but sometimes it is not. Would be nice to be easily run the minifier launcher against the original inputs to see if the input data actually mattered.
### Versions
master
cc @soumith @msaroufim @wconstab @ngimel @bdhirsh
| 3 |
3,598 | 93,364 |
Minifier should also dump compilation artifacts from the real execution for ease of sanity checking
|
triaged, oncall: pt2
|
### 🐛 Describe the bug
I just diagnosed a few minifier bugs which root caused down to "minifier didn't accurately replicate state from the original run and so the minifier ran compiled code that wasn't the same compiled code as the original run." It would be really good if it were easier to sanity check minifier results in this case.
One of the easiest things that can be done is to dump the inductor debug output from the real run (which contains the IR for all the Triton programs we compiled), and then make it easy to diff this against the debug output from the minifier launcher run. Hand inspection can make it clear if the code is not compiling the same way. Similarly, dumping the FX graph being fed into Dynamo can also be instructive.
### Versions
master
cc @soumith @msaroufim @wconstab @ngimel @bdhirsh
| 0 |
3,599 | 93,362 |
Make torch.testing functions overrideable with torch_function?
|
triaged, module: __torch_function__, module: testing
|
This is confusing for users.
cc @hameerabbasi @rgommers @peterbell10 @ezyang
| 2 |
3,600 | 93,361 |
Inductor miscompilation with dynamic shapes from LearningToPaint
|
triaged, oncall: pt2
|
### 🐛 Describe the bug
To run the repro script, you must patch in https://github.com/pytorch/pytorch/pull/93308 because of dynamic shape related problems in minifier infrastructure
The repro script is https://gist.github.com/0054b61f8e9cc5135e6e6d6f5d2caf0d
When run, it fails with
```
[2023-01-31 06:20:26,667] torch._dynamo.utils: [ERROR] Accuracy failed: allclose not within tol=0.001
Traceback (most recent call last):
File "/data/users/ezyang/b/pytorch/repro.py", line 75, in <module>
raise AccuracyError("Dynamo failed")
__main__.AccuracyError: Dynamo failed
```
By turning off dynamic shapes by modifying `USE_DYNAMIC_SHAPES`, you can see that inductor compiles without accuracy error. So it should be a dynamic shapes related miscompilation.
The minifier wasn't able to simplify this repro any further, unfortunately. The aot minifier does not work as it has fundamental problems with dynamic shapes.
This miscompilation is minified from LearningToPaint. Repro command is `TORCHDYNAMO_REPRO_AFTER=dynamo TORCHDYNAMO_REPRO_LEVEL=4 python benchmarks/dynamo/torchbench.py --accuracy --backend inductor --explain --only LearningToPaint --float32 --dynamic-shapes --disable-cudagraphs` but you need at least the patches I quoted above and possibly more to actually get the minifier to work. My full branch state at time of successful minification was https://github.com/ezyang/pytorch/tree/LearningToPaint-successful-minify
**UPDATE.** Updated repro to avoid running backwards
### Versions
master
cc @soumith @msaroufim @wconstab @ngimel @bdhirsh
| 0 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.