
Serial Number
int64 1
6k
| Issue Number
int64 75.6k
112k
| Title
stringlengths 3
357
| Labels
stringlengths 3
241
⌀ | Body
stringlengths 9
74.5k
⌀ | Comments
int64 0
867
|
|---|---|---|---|---|---|
4,001 | 90,507 |
Functionalization on inplace_views should properly reflect autograd metadata
|
triaged, module: functionalization, oncall: pt2
|
There's a bug in AOT Autograd today:
```
from functorch.compile import aot_function, nop
def f(x):
out = x * 2
out.unsqueeze_(0)
return out
# works
f(torch.ones(2, requires_grad=True)).mul_(2)
compiled_f = aot_function(f, fw_compiler=nop)
# Fails
compiled_f(torch.ones(2, requires_grad=True)).mul_(2)
# prints:
RuntimeError: Output 0 of CompiledFunctionBackward is a view and is being modified inplace. This view was created inside a custom Function (or because an input was returned as-is) and the autograd logic to handle view+inplace would override the custom backward associated with the custom Function, leading to incorrect gradients. This behavior is forbidden. You can fix this by cloning the output of the custom Function.
```
The problem is that:
(1) In the eager code, `out` is not a (differentiable) view. `out._is_view() == False`
(2) In the compiled code, functionalization runs and converts the program into:
```
def f_functionalized(x):
out = x * 2
out_updated = x.unsqueeze(0)
# out_updated is a view! out_updated._is_view() == True
return out_updated
```
When we return an output that has `._is_view()` from an `autograd.Function.forward()`, we are not allowed to mutate it.
From talking with @ezyang, a reasonable fix would be inside of functionalization: functionalization should respect the autograd view metadata when handling inplace_view ops. One way to do that is:
(1) For every inplace view op (e.g. `transpose_()`), and a corresponding `_unsafe_transpose()` op , that autograd doesn't know is an aliasing operator
(2) When functionalization sees `x.transpose_()`, it should decide to dispatch into either `.transpose()` or `._unsafe_tranpose()`, depending on whether `x` is currently a differentiable view.
cc @ezyang @soumith @msaroufim @wconstab @ngimel
| 0 |
4,002 | 90,485 |
Tensor indexing and slicing documentation should explicitly state that indexing follows numpy semantics and link to the numpy indexing documentation.
|
module: docs, triaged, module: numpy
|
### 📚 The doc issue
It's my understanding that indexing a tensor with `[]`/`Tensor.__getitem__`/`Tensor.__setitem__` works like numpy, but this is not mentioned in the [Indexing, Slicing, Joining, Mutating Ops](https://pytorch.org/docs/stable/torch.html#indexing-slicing-joining) docs.
Related discussion: https://discuss.pytorch.org/t/selecting-from-a-2d-tensor-with-rows-of-column-indexes/167717
### Suggest a potential alternative/fix
Add to the [tensor indexing](https://pytorch.org/docs/stable/torch.html#indexing-slicing-joining) docs that this works like numpy, and link to the numpy indexing docs. Maybe https://numpy.org/doc/stable/user/basics.indexing.html or https://numpy.org/doc/stable/user/basics.indexing.html#advanced-indexing.
cc @svekars @carljparker @mruberry @rgommers
| 0 |
4,003 | 90,481 |
Internal assert when ctx.saved_tensors fails when saving results of an intermediate view tensor with torch.utils.checkpoint and use_reentrant=False
|
module: checkpoint, module: autograd, triaged, has workaround, actionable
|
### 🐛 Describe the bug
Whenever we try to save a reshaped tensor (even without actually changing the shape) in the context, an error occurs at the point of retrieving it during backward when we use it with `torch.utils.checkpoint` and `use_reentrant=False`:
```python
import torch
from torch.utils.checkpoint import checkpoint
class CustomOp(torch.autograd.Function):
@staticmethod
def forward(ctx, x):
ctx.save_for_backward(x.reshape(x.shape)) # error due to this reshape
return x
@staticmethod
def backward(ctx, grad):
x = ctx.saved_tensors # this fails
return grad
input = torch.tensor(0., requires_grad=True)
op = CustomOp()
checkpoint(lambda x: op.apply(x), input, use_reentrant=False).backward()
```
```
Traceback (most recent call last):
File "reproduce_checkpoint.py", line 20, in <module>
checkpoint(lambda x: op.apply(x), input, use_reentrant=False).backward()
File ".../lib/python3.10/site-packages/torch/_tensor.py", line 487, in backward
torch.autograd.backward(
File ".../lib/python3.10/site-packages/torch/autograd/__init__.py", line 197, in backward
Variable._execution_engine.run_backward( # Calls into the C++ engine to run the backward pass
File ".../lib/python3.10/site-packages/torch/autograd/function.py", line 267, in apply
return user_fn(self, *args)
File "reproduce_checkpoint.py", line 13, in backward
x = ctx.saved_tensors # this fails
RuntimeError: !grad_accumulator_.expired() INTERNAL ASSERT FAILED at "/opt/conda/conda-bld/pytorch_1666643003845/work/torch/csrc/autograd/saved_variable.cpp":216, please report a bug to PyTorch. No grad accumulator for a saved leaf
```
A couple of notes:
- If the reshape operation is removed, it works okay.
- If the result of the reshape is multiplied by a constant, it also works fine.
- If `use_reentrant` is set to `True`, then error also disappears.
### Versions
Collecting environment information...
PyTorch version: 1.13.0
Is debug build: False
CUDA used to build PyTorch: 11.6
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.4 LTS (x86_64)
GCC version: (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0
Clang version: 10.0.0-4ubuntu1
CMake version: version 3.22.4
Libc version: glibc-2.31
Python version: 3.10.8 (main, Nov 24 2022, 14:13:03) [GCC 11.2.0] (64-bit runtime)
Python platform: Linux-5.13.0-1025-aws-x86_64-with-glibc2.31
Is CUDA available: True
CUDA runtime version: 11.6.124
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration:
GPU 0: NVIDIA A100-SXM4-40GB
Nvidia driver version: 510.47.03
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.23.4
[pip3] torch==1.13.0
[pip3] torchaudio==0.13.0
[pip3] torchvision==0.14.0
[conda] blas 1.0 mkl
[conda] ffmpeg 4.3 hf484d3e_0 pytorch
[conda] mkl 2021.4.0 h06a4308_640
[conda] mkl-service 2.4.0 py310h7f8727e_0
[conda] mkl_fft 1.3.1 py310hd6ae3a3_0
[conda] mkl_random 1.2.2 py310h00e6091_0
[conda] numpy 1.23.4 py310hd5efca6_0
[conda] numpy-base 1.23.4 py310h8e6c178_0
[conda] pytorch 1.13.0 py3.10_cuda11.6_cudnn8.3.2_0 pytorch
[conda] pytorch-cuda 11.6 h867d48c_0 pytorch
[conda] pytorch-mutex 1.0 cuda pytorch
[conda] torchaudio 0.13.0 py310_cu116 pytorch
[conda] torchvision 0.14.0 py310_cu116 pytorch
cc @ezyang @albanD @zou3519 @gqchen @pearu @nikitaved @soulitzer @Lezcano @Varal7
| 2 |
4,004 | 90,469 |
Dynamo and cond with free variables creates malformed graph
|
triaged, oncall: pt2, module: dynamo
|
### 🐛 Describe the bug
repro
```
diff --git a/test/dynamo/test_export.py b/test/dynamo/test_export.py
index b0640f6511..8fb8754c51 100644
--- a/test/dynamo/test_export.py
+++ b/test/dynamo/test_export.py
@@ -1443,8 +1443,10 @@ class ExportTests(torch._dynamo.test_case.TestCase):
self.linear = torch.nn.Linear(3, 3)
def forward(self, pred, x):
+ y = x * 2
+
def true_fn(val):
- return self.linear(val) * torch.tensor(2)
+ return self.linear(val) * torch.tensor(2) * y
def false_fn(val):
return self.linear(val) * torch.tensor(-1)
```
the true graph ends up being
```
def forward(self, x):
self_linear = self.self_linear(x); x = None
tensor = torch.tensor(2)
mul = self_linear * tensor; self_linear = tensor = None
mul_1 = mul * mul; mul = mul = None
return mul_1
```
which is so bad
### Versions
master
cc @soumith @msaroufim @wconstab @ngimel @bdhirsh @mlazos @voznesenskym @yanboliang @penguinwu @anijain2305 @EikanWang @jgong5 @Guobing-Chen @chunyuan-w @XiaobingSuper @zhuhaozhe @blzheng @Xia-Weiwen @wenzhe-nrv @jiayisunx @desertfire
| 2 |
4,005 | 90,466 |
Saving a scripted module to a buffer does not work.
|
oncall: jit
|
### 🐛 Describe the bug
A scripted pytorch module can not be saved to a buffer. It will instead save the module to a file with the name of the buffer-object.
According to the [documentation](https://pytorch.org/docs/stable/generated/torch.jit.ScriptModule.html#torch.jit.ScriptModule.save), the following code should have saved the model to the buffer. Instead the model is written to a file with the name of the buffer's __str__ representation. The buffer remains empty.
I expected the buffer to not be empty and that no file would be made on the filesystem.
```import torch
import io
class Model(torch.nn.Module):
def forward(self, x):
return x+1
model = Model().cuda()
traced = torch.jit.script(model, torch.ones(1, 3, 128, 128, device='cuda'))
with io.BytesIO() as buf:
traced.save(buf)
```
### Versions
```
Collecting environment information...
PyTorch version: 1.13.0
Is debug build: False
CUDA used to build PyTorch: 11.6
ROCM used to build PyTorch: N/A
OS: Ubuntu 22.04.1 LTS (x86_64)
GCC version: (Ubuntu 11.3.0-1ubuntu1~22.04) 11.3.0
Clang version: Could not collect
CMake version: Could not collect
Libc version: glibc-2.35
Python version: 3.9.15 (main, Nov 24 2022, 14:31:59) [GCC 11.2.0] (64-bit runtime)
Python platform: Linux-5.15.0-53-generic-x86_64-with-glibc2.35
Is CUDA available: True
CUDA runtime version: 11.6.124
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration: GPU 0: NVIDIA GeForce RTX 3090
Nvidia driver version: 520.61.05
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.23.4
[pip3] torch==1.13.0
[pip3] torchaudio==0.13.0
[pip3] torchvision==0.14.0
[conda] blas 1.0 mkl
[conda] ffmpeg 4.3 hf484d3e_0 pytorch
[conda] mkl 2021.4.0 h06a4308_640
[conda] mkl-service 2.4.0 py39h7f8727e_0
[conda] mkl_fft 1.3.1 py39hd3c417c_0
[conda] mkl_random 1.2.2 py39h51133e4_0
[conda] numpy 1.23.4 py39h14f4228_0
[conda] numpy-base 1.23.4 py39h31eccc5_0
[conda] pytorch 1.13.0 py3.9_cuda11.6_cudnn8.3.2_0 pytorch
[conda] pytorch-cuda 11.6 h867d48c_0 pytorch
[conda] pytorch-mutex 1.0 cuda pytorch
[conda] torchaudio 0.13.0 py39_cu116 pytorch
[conda] torchvision 0.14.0 py39_cu116 pytorch
```
cc @EikanWang @jgong5 @wenzhe-nrv @sanchitintel
| 0 |
4,006 | 90,465 |
[FSDP] Revisit meta device initialization
|
oncall: distributed, triaged, module: fsdp
|
### Context
Today, `FullyShardedDataParallel` (FSDP) supports meta device initialization via two paths, where the precondition is that the `module` passed to FSDP has some parameter on meta device:
1. The user passes `param_int_fn=None` (e.g. by default).
2. The user passes an explicit `param_init_fn`.
https://github.com/pytorch/pytorch/blob/dc40b6d04320baf26b940225a65f40466ebf3664/torch/distributed/fsdp/fully_sharded_data_parallel.py#L249
In case 1, FSDP has its own code to provide a default parameter initialization function. In case 2, FSDP calls the passed-in function.
### Issue
Both the default parameter initialization function and the example explicit `param_init_fn` in the unit tests (`test_fsdp_meta.py`) have a silent correctness issue.
The (undocumented) invariant required of the `param_init_fn` is as follows:
> A `param_init_fn` should only modify the parameters managed by the FSDP instance to which the function is passed.
The contrapositive is that a `param_init_fn` **should not** modify any parameters not managed by the FSDP instance, which we currently violate.
#### 1: Default Meta Device Initialization
https://github.com/pytorch/pytorch/blob/dc40b6d04320baf26b940225a65f40466ebf3664/torch/distributed/fsdp/_init_utils.py#L529-L537
#### 2: `test_fsdp_meta.py` Example `param_init_fn`
https://github.com/pytorch/pytorch/blob/dc40b6d04320baf26b940225a65f40466ebf3664/test/distributed/fsdp/test_fsdp_meta.py#L96-L105
**The problematic line is `module.to_empty()`.**
FSDP supports nested wrapping, in which case initialization runs bottom-up. This means that for a nested case, the child materializes its meta-device parameters, and then the parent materializes its meta-device parameters. When the parent does so, it calls `parent_module.to_empty()`, which affects **all** parameters in `parent_module`, including those in `child_module`.
At this point in the execution, there are two choices, both of which are wrong. Either the specific `nn.Module.reset_parameters()` implementation affects all parameters in its tree (i.e. `.parameters(recurse=True)`), or it affects only immediately-owned parameters (i.e. `.parameters(recurse=False)`).
- [`recurse=False`] Any child FSDP instance's parameters are now left as uninitialized memory (like `torch.empty()`). Moreover, if an FSDP instance is applied to a module with submodules with parameters, then `recurse=False` will not include those submodules' parameters.
- [`recurse=True`] Any child FSDP instance's parameters are re-initialized. This is arguably "less wrong" than the `recurse=False` case, but it is still wrong. Re-initialization can silently advance the random seed, and random in-place initialization depends on parameter shape, which means that re-initializing parameters after flattening/sharding produces different results (thanks @min-xu-ai for flagging this to Fairscale users!).
A correct `param_init_fn` should skip parameters already processed by FSDP. However, we do not have any public API for detecting this, which means that writing a correct `param_init_fn` is impractical today.
Here is an example `param_init_fn` I wrote for `test_fully_shard.py`:
```
def param_init_fn(module: nn.Module):
for submodule in module.modules():
for param_name, param in submodule.named_parameters(recurse=False):
if not _is_fsdp_flattened(param) and param.is_meta:
materialized_param = nn.Parameter(
torch.empty_like(param, device=torch.device("cuda"))
)
nn.init.uniform_(materialized_param)
setattr(submodule, param_name, materialized_param)
```
This is manually implementing the parameter swapping logic from the `module.to()` variants and requires the private `_is_fsdp_flattened()` function, making this unsatisfactory to me.
This issue is meant to track the progress on revisiting this meta device initialization. Ultimately, our goal is just to support a robust and usable deferred initialization API, which does not strictly require us to stay with this meta device initialization (e.g. we could migrate to PyTorch-native `FakeTensor` if that works).
cc @mrshenli @pritamdamania87 @zhaojuanmao @satgera @rohan-varma @gqchen @aazzolini @osalpekar @jiayisuse @H-Huang @kwen2501
| 2 |
4,007 | 90,464 |
PR #89436 looks like it causes or enables a memory leak
|
module: memory usage, triaged, module: mps
|
### 🐛 Describe the bug
Running InvokeAI using a pytorch built from master with PR #89436 applied uses way more memory than without the PR applied and that memory does not get released after image generation has completed, it looks a lot like a memory leak.
initial Run without the PR the Python executable uses between 8 to 12 Gb which ebbs and flows thoughout the process and releases memory down to ~7Gb afterward image generation.
With the PR, there is a similar pattern during the sampling phase, but post sampling, the memory usage start to consistently increase to just under 20Gb and that memory is not released once image generation is complete.
These are the command I used to test (including typo and errors)
First without the pr
``` 1001 cd Torch/test_venv
1002 . bin/activate
1003 ls -lrt
1004 ls -lrt
1005 cd ..
1006 ks
1007 ls
1008 cd pytorch
1009 ls
1010 cd ..
1011 rm -rf pytorch
1012 git clone https://github.com/pytorch/pytorch.git
1013 cd build_pytorch
1014 ls
1015 cd ..
1016 ls
1017 pip uninstall torch torchvision
1018 cd build_pytorch
1019 xs ../pytorch
1020 cd ../pytorch
1021 CMAKE_PREFIX_PATH=/Users/xxx/Torch/build_pytorch USE_DISTRIBUTED=ON USE_GLOO=OFF MACOSX_DEPLOYMENT_TARGET=13.0 CC=clang CXX=clang++ python setup.py install\n
1022 cd ../InvokeAI
1023 export PYTORCH_ENABLE_MPS_FALLBACK=1
1024 python scripts/invoke.py
1025 vi ~/.invokeai
1026 python scripts/invoke.py
1027 pip3 install -U --pre torchvision --extra-index-url https://download.pytorch.org/whl/nightly/cpu
1028 python scripts/invoke.py
1029 open /Users/xxx/SSD/Source/Python/invoke_output/000041.1013875009.png
```
And to test with the PR (same terminal session, so PYTORCH_ENABLE_MPS_FALLBACK was still set)
``` 1030 cd ../pytorch
1031 pip uninstall torch torchvision
1032 pip uninstall torch torchvision
1033 pip uninstall torch torchvision
1034 cd ..
1035 rm -rf pytorch
1036 git clone https://github.com/pytorch/pytorch.git
1037 cd pytorch
1038 git fetch origin pull/89436/head:test_89436
1039 git checkout test_89436
1040 CMAKE_PREFIX_PATH=/Users/xxx/Torch/build_pytorch USE_DISTRIBUTED=ON USE_GLOO=OFF MACOSX_DEPLOYMENT_TARGET=13.0 CC=clang CXX=clang++ python setup.py install\n
1041 pip3 install -U --pre torchvision --extra-index-url https://download.pytorch.org/whl/nightly/cpu
1042 cd ../InvokeAI
1043 python scripts/invoke.py
```
The same prompt and parameters where used for both runs.
Timing show a big improvement in the sampling speed (hope you can keep that it back to 12.1 speeds)
and the massive slow done for the post sampling phase where the memory issues occur.
Without the PR
```>> Ksampler using karras noise schedule (steps < 30)
>> Sampling with k_lms starting at step 0 of 10 (10 new sampling steps)
100%|█████████████████████████████████████| 10/10 [01:51<00:00, 11.11s/it]
Generating: 100%|██████████████████████████| 1/1 [02:00<00:00, 120.42s/it]
>> Usage stats:
>> 1 image(s) generated in 121.02s```
With the PR
```>> Ksampler using karras noise schedule (steps < 30)
>> Sampling with k_lms starting at step 0 of 10 (10 new sampling steps)
100%|█████████████████████████████████████| 10/10 [00:45<00:00, 4.59s/it]
Generating: 100%|██████████████████████████| 1/1 [05:03<00:00, 303.23s/it]
>> Usage stats:
>> 1 image(s) generated in 303.56s```
### Versions
PyTorch version: 1.14.0a0+gitf6fbbdc
Is debug build: False
CUDA used to build PyTorch: None
ROCM used to build PyTorch: N/A
OS: macOS 13.0.1 (arm64)
GCC version: Could not collect
Clang version: 14.0.0 (clang-1400.0.29.202)
CMake version: version 3.25.0
Libc version: N/A
Python version: 3.10.8 (main, Nov 9 2022, 16:53:27) [Clang 12.0.5 (clang-1205.0.22.9)] (64-bit runtime)
Python platform: macOS-13.0.1-arm64-arm-64bit
Is CUDA available: False
CUDA runtime version: No CUDA
CUDA_MODULE_LOADING set to: N/A
GPU models and configuration: No CUDA
Nvidia driver version: No CUDA
cuDNN version: No CUDA
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.23.4
[pip3] pytorch-lightning==1.7.7
[pip3] torch==1.14.0a0+gitf6fbbdc
[pip3] torch-fidelity==0.3.0
[pip3] torchdiffeq==0.2.3
[pip3] torchmetrics==0.10.0
[pip3] torchsde==0.2.5
[pip3] torchvision==0.15.0.dev20221207
[conda] Could not collect
```
cc @kulinseth @albanD @malfet @DenisVieriu97 @razarmehr @abhudev
| 0 |
4,008 | 90,460 |
Assertion failed: scales.is_weights() && "Resize scales must be an initializer!"
|
module: onnx, triaged, onnx-needs-info
|
### 🐛 Describe the bug
(base) [root@localhost road_water_yolov5-7.0]# python export.py --weights weights/yolov5s.pt --device 0 --include onnx engine
export: data=data/coco128.yaml, weights=['weights/yolov5s.pt'], imgsz=[640, 640], batch_size=1, device=0, half=False, inplace=False, keras=False, optimize=False, int8=False, dynamic=False, simplify=False, opset=12, verbose=False, workspace=4, nms=False, agnostic_nms=False, topk_per_class=100, topk_all=100, iou_thres=0.45, conf_thres=0.25, include=['onnx', 'engine']
Unknown option: -C
usage: git [--version] [--help] [-c name=value]
[--exec-path[=<path>]] [--html-path] [--man-path] [--info-path]
[-p|--paginate|--no-pager] [--no-replace-objects] [--bare]
[--git-dir=<path>] [--work-tree=<path>] [--namespace=<name>]
<command> [<args>]
YOLOv5 🚀 2022-12-2 Python-3.9.12 torch-1.12.1 CUDA:0 (NVIDIA GeForce RTX 3080 Ti, 12054MiB)
Fusing layers...
YOLOv5s summary: 213 layers, 7225885 parameters, 0 gradients, 16.4 GFLOPs
PyTorch: starting from weights/yolov5s.pt with output shape (1, 25200, 85) (14.1 MB)
ONNX: starting export with onnx 1.12.0...
ONNX: export success ✅ 2.7s, saved as weights/yolov5s.onnx (28.0 MB)
TensorRT: starting export with TensorRT 8.2.5.1...
[12/08/2022-18:42:33] [TRT] [I] [MemUsageChange] Init CUDA: CPU +466, GPU +0, now: CPU 3433, GPU 1917 (MiB)
[12/08/2022-18:42:34] [TRT] [I] [MemUsageSnapshot] Begin constructing builder kernel library: CPU 3433 MiB, GPU 1917 MiB
[12/08/2022-18:42:34] [TRT] [I] [MemUsageSnapshot] End constructing builder kernel library: CPU 3586 MiB, GPU 1961 MiB
[12/08/2022-18:42:34] [TRT] [I] ----------------------------------------------------------------
[12/08/2022-18:42:34] [TRT] [I] Input filename: weights/yolov5s.onnx
[12/08/2022-18:42:34] [TRT] [I] ONNX IR version: 0.0.7
[12/08/2022-18:42:34] [TRT] [I] Opset version: 12
[12/08/2022-18:42:34] [TRT] [I] Producer name: pytorch
[12/08/2022-18:42:34] [TRT] [I] Producer version: 1.12.1
[12/08/2022-18:42:34] [TRT] [I] Domain:
[12/08/2022-18:42:34] [TRT] [I] Model version: 0
[12/08/2022-18:42:34] [TRT] [I] Doc string:
[12/08/2022-18:42:34] [TRT] [I] ----------------------------------------------------------------
[12/08/2022-18:42:34] [TRT] [W] onnx2trt_utils.cpp:366: Your ONNX model has been generated with INT64 weights, while TensorRT does not natively support INT64. Attempting to cast down to INT32.
[12/08/2022-18:42:34] [TRT] [E] ModelImporter.cpp:773: While parsing node number 141 [Resize -> "onnx::Concat_271"]:
[12/08/2022-18:42:34] [TRT] [E] ModelImporter.cpp:774: --- Begin node ---
[12/08/2022-18:42:34] [TRT] [E] ModelImporter.cpp:775: input: "onnx::Resize_266"
input: "onnx::Resize_270"
input: "onnx::Resize_445"
output: "onnx::Concat_271"
name: "Resize_141"
op_type: "Resize"
attribute {
name: "coordinate_transformation_mode"
s: "asymmetric"
type: STRING
}
attribute {
name: "cubic_coeff_a"
f: -0.75
type: FLOAT
}
attribute {
name: "mode"
s: "nearest"
type: STRING
}
attribute {
name: "nearest_mode"
s: "floor"
type: STRING
}
[12/08/2022-18:42:34] [TRT] [E] ModelImporter.cpp:776: --- End node ---
[12/08/2022-18:42:34] [TRT] [E] ModelImporter.cpp:779: ERROR: builtin_op_importers.cpp:3609 In function importResize:
[8] Assertion failed: scales.is_weights() && "Resize scales must be an initializer!"
TensorRT: export failure ❌ 4.1s: failed to load ONNX file: weights/yolov5s.onnx
ONNX: starting export with onnx 1.12.0...
ONNX: export success ✅ 2.6s, saved as weights/yolov5s.onnx (28.0 MB)
Export complete (11.8s)
Results saved to /root/workplace/road_water_yolov5-7.0/weights
Detect: python detect.py --weights weights/yolov5s.onnx
Validate: python val.py --weights weights/yolov5s.onnx
PyTorch Hub: model = torch.hub.load('ultralytics/yolov5', 'custom', 'weights/yolov5s.onnx')
Visualize: https://netron.app
### Versions
env:
torch 1.12.1
torchaudio 0.12.1
torchvision 0.13.1
NVIDIA-SMI 470.63.01 Driver Version: 470.63.01 CUDA Version: 11.4
cuda:11.4
cudnn: cudann:cudnn-11.4-linux-x64-v8.2.4.15.tgz 8.2.4
tensorrt: 8.2.5.1
(base) [root@localhost road_water_yolov5-7.0]# python export.py --weights weights/yolov5s.pt --device 0 --include onnx engine
export: data=data/coco128.yaml, weights=['weights/yolov5s.pt'], imgsz=[640, 640], batch_size=1, device=0, half=False, inplace=False, keras=False, optimize=False, int8=False, dynamic=False, simplify=False, opset=12, verbose=False, workspace=4, nms=False, agnostic_nms=False, topk_per_class=100, topk_all=100, iou_thres=0.45, conf_thres=0.25, include=['onnx', 'engine']
Unknown option: -C
usage: git [--version] [--help] [-c name=value]
[--exec-path[=<path>]] [--html-path] [--man-path] [--info-path]
[-p|--paginate|--no-pager] [--no-replace-objects] [--bare]
[--git-dir=<path>] [--work-tree=<path>] [--namespace=<name>]
<command> [<args>]
YOLOv5 🚀 2022-12-2 Python-3.9.12 torch-1.12.1 CUDA:0 (NVIDIA GeForce RTX 3080 Ti, 12054MiB)
Fusing layers...
YOLOv5s summary: 213 layers, 7225885 parameters, 0 gradients, 16.4 GFLOPs
PyTorch: starting from weights/yolov5s.pt with output shape (1, 25200, 85) (14.1 MB)
ONNX: starting export with onnx 1.12.0...
ONNX: export success ✅ 2.7s, saved as weights/yolov5s.onnx (28.0 MB)
TensorRT: starting export with TensorRT 8.2.5.1...
[12/08/2022-18:42:33] [TRT] [I] [MemUsageChange] Init CUDA: CPU +466, GPU +0, now: CPU 3433, GPU 1917 (MiB)
[12/08/2022-18:42:34] [TRT] [I] [MemUsageSnapshot] Begin constructing builder kernel library: CPU 3433 MiB, GPU 1917 MiB
[12/08/2022-18:42:34] [TRT] [I] [MemUsageSnapshot] End constructing builder kernel library: CPU 3586 MiB, GPU 1961 MiB
[12/08/2022-18:42:34] [TRT] [I] ----------------------------------------------------------------
[12/08/2022-18:42:34] [TRT] [I] Input filename: weights/yolov5s.onnx
[12/08/2022-18:42:34] [TRT] [I] ONNX IR version: 0.0.7
[12/08/2022-18:42:34] [TRT] [I] Opset version: 12
[12/08/2022-18:42:34] [TRT] [I] Producer name: pytorch
[12/08/2022-18:42:34] [TRT] [I] Producer version: 1.12.1
[12/08/2022-18:42:34] [TRT] [I] Domain:
[12/08/2022-18:42:34] [TRT] [I] Model version: 0
[12/08/2022-18:42:34] [TRT] [I] Doc string:
[12/08/2022-18:42:34] [TRT] [I] ----------------------------------------------------------------
[12/08/2022-18:42:34] [TRT] [W] onnx2trt_utils.cpp:366: Your ONNX model has been generated with INT64 weights, while TensorRT does not natively support INT64. Attempting to cast down to INT32.
[12/08/2022-18:42:34] [TRT] [E] ModelImporter.cpp:773: While parsing node number 141 [Resize -> "onnx::Concat_271"]:
[12/08/2022-18:42:34] [TRT] [E] ModelImporter.cpp:774: --- Begin node ---
[12/08/2022-18:42:34] [TRT] [E] ModelImporter.cpp:775: input: "onnx::Resize_266"
input: "onnx::Resize_270"
input: "onnx::Resize_445"
output: "onnx::Concat_271"
name: "Resize_141"
op_type: "Resize"
attribute {
name: "coordinate_transformation_mode"
s: "asymmetric"
type: STRING
}
attribute {
name: "cubic_coeff_a"
f: -0.75
type: FLOAT
}
attribute {
name: "mode"
s: "nearest"
type: STRING
}
attribute {
name: "nearest_mode"
s: "floor"
type: STRING
}
[12/08/2022-18:42:34] [TRT] [E] ModelImporter.cpp:776: --- End node ---
[12/08/2022-18:42:34] [TRT] [E] ModelImporter.cpp:779: ERROR: builtin_op_importers.cpp:3609 In function importResize:
[8] Assertion failed: scales.is_weights() && "Resize scales must be an initializer!"
TensorRT: export failure ❌ 4.1s: failed to load ONNX file: weights/yolov5s.onnx
ONNX: starting export with onnx 1.12.0...
ONNX: export success ✅ 2.6s, saved as weights/yolov5s.onnx (28.0 MB)
Export complete (11.8s)
Results saved to /root/workplace/road_water_yolov5-7.0/weights
Detect: python detect.py --weights weights/yolov5s.onnx
Validate: python val.py --weights weights/yolov5s.onnx
PyTorch Hub: model = torch.hub.load('ultralytics/yolov5', 'custom', 'weights/yolov5s.onnx')
Visualize: https://netron.app
| 1 |
4,009 | 90,459 |
Strange issue with tensor asyncio and RPC
|
oncall: distributed
|
### 🐛 Describe the bug
Hi Folks,
I have a bizarre issue and can't narrow down a problem. I'll update a case if you can provide more debug commands for this issue.
## platform and system
* Latest torch version, CUDA 11.7, Python 3.10 and 3.11 ( test both)
* Test CPU , CUDA , Linux , MacOs, WSL2 , Docker.
Consider on the same host, communicating over RPC, mainly to address the issue of torch.mp.
i.e., I need one process to detach the tensor from CUDA to the CPU, send
it to the agent and upload it back to GPU.
Thus,
Agent <--- > Observer.
(Observer takes the tensors and sends via async RPC on request from Agent, it async call
and Observer responds as torch.future).
```
Observer:
# agent will issue this call, and foobar_rpc put tensor take a tensor from cuda
# to CPU and send.
foobar_rpc():
tensor.clone().cpu()
```
The agent takes the torch future and puts the asyncio queue.
Now in the asyncio dequeue phase (i.e, asyncio wait on queue), does
```
Agent
async def the_rpc_call()
fu = rpc_async().foobar() # args etc. removed to make it clear
await THE_QUEUE.put(the_fu)
```
```
async def foo_consumer()
# skip code for a loop, not relevant.
the_future = THE_QUEUE.get() # <- asyncio queue
the_future.wait() # wait for torch future
val = future.value() # read value
x, y = val # ( let assume and x and y two named tuple)
i.e.,
x.rewards <-- is tensor
x.observation. <-- is tensor
x.someint <-- native python type
# If I do all good
xsum=torch.sum(x.rewards, dim=0)
print(xsum) # <-- no issue
some_dict , list etc = xsum # <--- error in RPC , or blocking>
left_hand = xsum.clone() # <-- error
left_hand = copy_ same error etc.
# if I try to do anything else, it either
# block or crash, or I see an error in RPC
await some_foo(x, y)
no errors. at all
```
It looks like somewhere in downstream code, it either has a lock, but on read-only, it works; on left-hand assignment, it fails for tensors. But if that is the case, the last call some_foo (x, y) should produce the same behavior. i.e., if I pass x and y to downstream code, I have an issue now.
Does RPC logic in torch, do anything specific with the tensor it receives somewhere deep in a C library with the tensors it receives?
Thank you,
### Versions
Linux
```
Collecting environment information...
PyTorch version: 1.13.0
Is debug build: False
CUDA used to build PyTorch: 11.7
ROCM used to build PyTorch: N/A
OS: Ubuntu 22.10 (x86_64)
GCC version: (conda-forge gcc 10.4.0-19) 10.4.0
Clang version: Could not collect
CMake version: version 3.22.1
Libc version: glibc-2.36
Python version: 3.10.8 (main, Nov 24 2022, 14:13:03) [GCC 11.2.0] (64-bit runtime)
Python platform: Linux-5.19.0-26-generic-x86_64-with-glibc2.36
Is CUDA available: True
CUDA runtime version: 11.7.99
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration: GPU 0: NVIDIA GeForce RTX 3090
Nvidia driver version: 520.61.05
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.23.4
[pip3] torch==1.13.0
[pip3] torchvision==0.14.0
[pip3] torchviz==0.0.2
[conda] blas 1.0 mkl
[conda] ffmpeg 4.3 hf484d3e_0 pytorch
[conda] mkl 2021.4.0 h06a4308_640
[conda] mkl-service 2.4.0 py310h7f8727e_0
[conda] mkl_fft 1.3.1 py310hd6ae3a3_0
[conda] mkl_random 1.2.2 py310h00e6091_0
[conda] numpy 1.23.4 py310hd5efca6_0
[conda] numpy-base 1.23.4 py310h8e6c178_0
[conda] pytorch 1.13.0 py3.10_cuda11.7_cudnn8.5.0_0 pytorch
[conda] pytorch-cuda 11.7 h67b0de4_0 pytorch
[conda] pytorch-mutex 1.0 cuda pytorch
[conda] torchvision 0.14.0 py310_cu117 pytorch
[conda] torchviz 0.0.2 pypi_0 pypi
```
This is on mac 1.12
```
Collecting environment information...
PyTorch version: 1.12.0
Is debug build: False
CUDA used to build PyTorch: None
ROCM used to build PyTorch: N/A
OS: macOS 13.0.1 (x86_64)
GCC version: Could not collect
Clang version: 14.0.0 (clang-1400.0.29.202)
CMake version: version 3.24.3
Libc version: N/A
Python version: 3.8.13 (default, Mar 28 2022, 06:16:26) [Clang 12.0.0 ] (64-bit runtime)
Python platform: macOS-10.16-x86_64-i386-64bit
Is CUDA available: False
CUDA runtime version: No CUDA
CUDA_MODULE_LOADING set to: N/A
GPU models and configuration: No CUDA
Nvidia driver version: No CUDA
cuDNN version: No CUDA
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.22.4
[pip3] torch==1.12.0
[pip3] torchaudio==0.12.0
[pip3] torchvision==0.13.0
[conda] blas 1.0 mkl
[conda] mkl 2021.4.0 hecd8cb5_637
[conda] mkl-service 2.4.0 py38h9ed2024_0
[conda] mkl_fft 1.3.1 py38h4ab4a9b_0
[conda] mkl_random 1.2.2 py38hb2f4e1b_0
[conda] numpy 1.22.4 pypi_0 pypi
[conda] numpy-base 1.22.3 py38h3b1a694_0
[conda] torch 1.12.0 pypi_0 pypi
[conda] torchaudio 0.12.0 pypi_0 pypi
[conda] torchvision 0.13.0 pypi_0 pypi
```
cc @mrshenli @pritamdamania87 @zhaojuanmao @satgera @rohan-varma @gqchen @aazzolini @osalpekar @jiayisuse @H-Huang @kwen2501 @awgu
| 0 |
4,010 | 90,447 |
Different behavior for complex numbers operations with numpy
|
triaged, module: complex, module: numpy, module: NaNs and Infs
|
### 🐛 Describe the bug
I am working with complex numbers and finding a different behavior between numpy and pytorch. When dividing by `0.0+0.0j` numpy produces `-inf+nanj ` and pytorch ` nan+nanj`. Afterward, I calculate the exponential, which in numpy evaluates to `0.0-0.0j` while pytorch propagates the nans. I am not sure what the correct behavior should be, but I think it is interesting to note the difference between the two packages. In my real code I add a small epsilon to the division to avoid the proliferation of nans, so this is not a real problem.
Here is the pytorch code
```python
import torch
x = torch.tensor([0.0+0.0j, 0.0+1.0j, 1.0+0.0j, 1.0+1.0j], requires_grad=True)
print(x)
l = -1.0/x
print(l)
s = torch.exp(l)
print(s)
loss = torch.mean(s)
print(loss)
loss.backward()
print(x.grad)
```
Output
```
tensor([0.+0.j, 0.+1.j, 1.+0.j, 1.+1.j], requires_grad=True)
tensor([ nan+nanj, 0.0000+1.0000j, -1.0000+0.0000j, -0.5000+0.5000j],
grad_fn=<MulBackward0>)
tensor([ nan+nanj, 0.5403+0.8415j, 0.3679+0.0000j, 0.5323+0.2908j],
grad_fn=<ExpBackward0>)
tensor(nan+nanj, grad_fn=<MeanBackward0>)
tensor([ nan+nanj, -0.1351+0.2104j, 0.0920-0.0000j, 0.0363+0.0665j])
```
And in numpy
```python
import numpy as np
x = np.asarray([0.0+0.0j, 0.0+1.0j, 1.0+0.0j, 1.0+1.0j])
print(x)
l = -1.0/x
print(l)
s = np.exp(l)
print(s)
loss = np.mean(s)
print(loss)
```
Output
```
[0.+0.j 0.+1.j 1.+0.j 1.+1.j]
[-inf+nanj 0. +1.j -1. +0.j -0.5+0.5j]
[0. -0.j 0.54030231+0.84147098j 0.36787944+0.j
0.53228073+0.29078629j]
(0.3601156193138132+0.2830643182551471j)
/tmp/ipykernel_6873/682756051.py:3: RuntimeWarning: divide by zero encountered in divide
l = -1.0/x
/tmp/ipykernel_6873/682756051.py:3: RuntimeWarning: invalid value encountered in divide
l = -1.0/x
```
### Versions
```
Collecting environment information...
PyTorch version: 1.13.0
Is debug build: False
CUDA used to build PyTorch: 11.7
ROCM used to build PyTorch: N/A
OS: CentOS Linux 7 (Core) (x86_64)
GCC version: (GCC) 4.8.5 20150623 (Red Hat 4.8.5-44)
Clang version: Could not collect
CMake version: version 2.8.12.2
Libc version: glibc-2.17
Python version: 3.10.8 (main, Nov 4 2022, 13:48:29) [GCC 11.2.0] (64-bit runtime)
Python platform: Linux-3.10.0-1160.76.1.el7.x86_64-x86_64-with-glibc2.17
Is CUDA available: True
CUDA runtime version: 10.1.243
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration:
GPU 0: Quadro RTX 8000
GPU 1: Quadro RTX 8000
GPU 2: Quadro RTX 8000
GPU 3: Quadro RTX 8000
GPU 4: Quadro RTX 8000
GPU 5: Quadro RTX 8000
GPU 6: Quadro RTX 8000
Nvidia driver version: 510.39.01
cuDNN version: /usr/lib64/libcudnn.so.7.6.5
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.23.4
[pip3] torch==1.13.0
[pip3] torchaudio==0.13.0
[pip3] torchvision==0.14.0
[conda] blas 1.0 mkl
[conda] ffmpeg 4.3 hf484d3e_0 pytorch
[conda] mkl 2021.4.0 h06a4308_640
[conda] mkl-service 2.4.0 py310h7f8727e_0
[conda] mkl_fft 1.3.1 py310hd6ae3a3_0
[conda] mkl_random 1.2.2 py310h00e6091_0
[conda] numpy 1.23.4 py310hd5efca6_0
[conda] numpy-base 1.23.4 py310h8e6c178_0
[conda] pytorch 1.13.0 py3.10_cuda11.7_cudnn8.5.0_0 pytorch
[conda] pytorch-cuda 11.7 h67b0de4_0 pytorch
[conda] pytorch-mutex 1.0 cuda pytorch
[conda] torchaudio 0.13.0 py310_cu117 pytorch
[conda] torchvision 0.14.0 py310_cu117 pytorch
```
cc @ezyang @anjali411 @dylanbespalko @mruberry @Lezcano @nikitaved @rgommers
| 0 |
4,011 | 90,440 |
RuntimeError: Placeholder storage has not been allocated on MPS device!
|
triaged, module: mps
|
### 🐛 Describe the bug
I get an error every time I attempt to use MPS to train a model on my M1 Mac. The error occurs at first training step (so first call of `model(x)`). MRE:
```
import torch
from torch import nn
from torch.utils.data import DataLoader, Dataset
import pandas as pd
import numpy as np
device = torch.device('mps')
class MyLSTM(nn.Module):
def __init__(self, hidden_size, num_layers, output_size, input_dim):
super().__init__()
self.hidden_size = hidden_size
self.num_layers = num_layers
self.input_dim = input_dim
self.lstm = nn.LSTM(input_size=input_dim, hidden_size=hidden_size, num_layers=num_layers, batch_first=True)
self.fc = nn.Linear(hidden_size, output_size)
def forward(self, x):
h0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size)
c0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size)
out, _ = self.lstm(x, (h0, c0))
out = self.fc(out[:, -1, :])
return out
def train_step(model, criterion, optimizer, x, y):
model.train()
optimizer.zero_grad()
y_pred = model(x)
loss = criterion(y_pred, y)
loss.backward()
optimizer.step()
return loss.item()
def train_model(model, criterion, optimizer, train_loader, val_loader, epochs=100):
train_losses = []
for epoch in range(epochs):
print("Epoch", epoch)
train_loss = 0
for x, y in train_loader:
train_loss += train_step(model, criterion, optimizer, x, y)
train_loss /= len(train_loader)
train_losses.append(train_loss)
print("Train loss:", train_loss)
return train_losses
class MyDataset(Dataset):
def __init__(self, df, window_size):
self.df = df
self.window_size = window_size
self.data = []
self.labels = []
for i in range(len(df) - window_size):
x = torch.tensor(df.iloc[i:i+window_size].values, dtype=torch.float, device=device)
y = torch.tensor(df.iloc[i+window_size].values, dtype=torch.float, device=device)
self.data.append(x)
self.labels.append(y)
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
return self.data[idx], self.labels[idx]
class MyDataLoader(DataLoader):
def __init__(self, dataset, window_size, batch_size, shuffle=True):
self.dataset = dataset
super().__init__(self.dataset, batch_size=batch_size, shuffle=shuffle)
df = pd.DataFrame(np.random.randint(0,100,size=(100, 1)))
model = MyLSTM(1, 1, 1, 1)
model.to(device)
train_data = MyDataset(df, 5)
train_loader = MyDataLoader(train_data, 5, 16)
criterion = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.01)
train_losses = train_model(model, criterion, optimizer, train_loader, None, epochs=10)
```
I receive the following traceback:
```
Traceback (most recent call last):
File "min_mps.py", line 83, in <module>
train_losses = train_model(model, criterion, optimizer, train_loader, None, epochs=10)
File "min_mps.py", line 44, in train_model
train_loss += train_step(model, criterion, optimizer, x, y)
File "min_mps.py", line 32, in train_step
y_pred = model(x)
File "~/miniconda3/envs/jaxenv/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1480, in _call_impl
return forward_call(*args, **kwargs)
File "min_mps.py", line 24, in forward
out, _ = self.lstm(x, (h0, c0))
File "~/miniconda3/envs/jaxenv/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1480, in _call_impl
return forward_call(*args, **kwargs)
File "~/miniconda3/envs/jaxenv/lib/python3.10/site-packages/torch/nn/modules/rnn.py", line 776, in forward
result = _VF.lstm(input, hx, self._flat_weights, self.bias, self.num_layers,
RuntimeError: Placeholder storage has not been allocated on MPS device!
```
### Versions
```
Python version: 3.10.8 (main, Nov 24 2022, 08:08:27) [Clang 14.0.6 ] (64-bit runtime)
Python platform: macOS-13.0-arm64-arm-64bit
Is CUDA available: False
CUDA runtime version: No CUDA
CUDA_MODULE_LOADING set to: N/A
GPU models and configuration: No CUDA
Nvidia driver version: No CUDA
cuDNN version: No CUDA
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.22.4
[pip3] torch==1.14.0.dev20221207
[pip3] torchaudio==0.14.0.dev20221207
[pip3] torchvision==0.15.0.dev20221207
[conda] numpy 1.22.4 pypi_0 pypi
[conda] torch 1.14.0.dev20221207 pypi_0 pypi
[conda] torchaudio 0.14.0.dev20221207 pypi_0 pypi
[conda] torchvision 0.15.0.dev20221207 pypi_0 pypi
```
Also note if relevant I'm running Mac OS 13.0. I also have tried this on the 1.13 stable release, same issue.
cc @kulinseth @albanD @malfet @DenisVieriu97 @razarmehr @abhudev
| 4 |
4,012 | 90,439 |
Torch 1.13 Onnx Scope name not correct!
|
module: onnx, triaged
|
### 🐛 Describe the bug
In torch 1.13.0, Onnx Scope name was introduced which replaces the old Onnx node format (`Conv_0`, `Relu_1`, ...) into a new format that captures the pytorch submodule name. But the actual onnx node name may not always correspond to a submodule and instead needs some further post-processing.
Example:
```python
import io
import onnx
import torch
from torchvision.models import resnet18
buffer = io.BytesIO()
torch.onnx.export(resnet18(), torch.randn(1, 3, 224, 224), buffer)
buffer.seek(0, 0)
onnx_model = onnx.load(buffer)
for node in onnx_model.graph.node:
print(node.name)
```
Output:
```
...
/conv1/Conv
/relu/Relu
/maxpool/MaxPool
/layer1/layer1.0/conv1/Conv
/layer1/layer1.0/relu/Relu
/layer1/layer1.0/conv2/Conv
...
/layer4/layer4.1/relu_1/Relu
/avgpool/GlobalAveragePool
/Flatten
/fc/Gemm
```
As we can see here for `ResNet18`, there is no submodule Conv named `layer1.layer1.0.conv1` in the model but rather `layer1.0.conv1`. So, its onnx node name should be `/layer1/0/conv1/Conv`.
Sidenote: Ideally it would have been more helpful to have the submodule name as the onnx node name i.e. `layer1.0.conv1` instead of `/layer1/layer1.0/conv1/Conv`.
### Versions
```
Collecting environment information...
PyTorch version: 1.13.0
Is debug build: False
CUDA used to build PyTorch: None
ROCM used to build PyTorch: N/A
OS: macOS 13.0.1 (arm64)
GCC version: Could not collect
Clang version: 14.0.0 (clang-1400.0.29.202)
CMake version: version 3.22.1
Libc version: N/A
Python version: 3.8.13 | packaged by conda-forge | (default, Mar 25 2022, 06:04:14) [Clang 12.0.1 ] (64-bit runtime)
Python platform: macOS-13.0.1-arm64-arm-64bit
Is CUDA available: False
CUDA runtime version: No CUDA
CUDA_MODULE_LOADING set to: N/A
GPU models and configuration: No CUDA
Nvidia driver version: No CUDA
cuDNN version: No CUDA
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] mypy==0.971
[pip3] mypy-extensions==0.4.3
[pip3] numpy==1.23.1
[pip3] pytorch-sphinx-theme==0.0.19
[pip3] torch==1.13.0
[pip3] torchaudio==0.13.0.dev20221003
[pip3] torchpack==0.3.1
[pip3] torchprofile==0.0.4
[pip3] torchvision==0.14.0
[conda] cpuonly 2.0 0 pytorch-nightly
[conda] numpy 1.23.1 py38h42add53_0
[conda] numpy-base 1.23.1 py38hadd41eb_0
[conda] pytorch-mutex 1.0 cpu pytorch-nightly
[conda] pytorch-sphinx-theme 0.0.19 pypi_0 pypi
[conda] torch 1.13.0 pypi_0 pypi
[conda] torchaudio 0.13.0.dev20221003 py38_cpu pytorch-nightly
[conda] torchpack 0.3.1 pypi_0 pypi
[conda] torchprofile 0.0.4 pypi_0 pypi
[conda] torchvision 0.14.0 pypi_0 pypi
```
| 7 |
4,013 | 90,424 |
A few functions in fbgemm_utils.cpp are defined in global namespace
|
module: cpp, oncall: quantization, triaged
|
### 🐛 Describe the bug
This file defines a few functions in the global namespace, e.g. these:
https://github.com/pytorch/pytorch/blob/e0f681aa85e4466a4096fcb8c3465ed662820760/aten/src/ATen/native/quantized/cpu/fbgemm_utils.cpp#L29-L30
And more in the same file.
That looks wrong.
### Versions
latest on github
cc @jbschlosser @jerryzh168 @jianyuh @raghuramank100 @jamesr66a @vkuzo @jgong5 @Xia-Weiwen @leslie-fang-intel
| 4 |
4,014 | 90,412 |
Importing numpy makes Tensor min max crash
|
triaged, module: numpy
|
### 🐛 Describe the bug
`torch.Tensor.max()` and `torch.Tensor.min()` work fine when when getting the overall extremum, but as soon as I specify the axis, e.g. `torch.Tensor.max(dim=-1)`, the script crashes quietly. Importantly, there is NO error thrown. Weirdly the script works about 20% of the time and doesnt 80% of the time. Rebooting the OS doesn't work.
```python
import itertools
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.autograd import Variable
import functorch as FT
import functools
# create data
torch.manual_seed(0)
TAU = 0.01
P = torch.softmax(torch.randn(10,3), dim=-1)
Y = torch.distributions.Categorical(P).sample().unsqueeze(dim=-1)
def func(f: torch.Tensor, y: torch.Tensor, tau: float) -> torch.Tensor:
f_true = f[torch.arange(f.shape[0]), y]
print(f.max())
f_pred = f.max(dim=-1)
print("NOT CRASHED :D")
c_out = func(P, Y, TAU)
print(c_out)
```
This runs well and prints `tensor(0.7848)` then crashes. The same behaviour can be observed for `torch.max` and `torch.min`.
As soon as I remove the import of `numpy` this works fine. Importing numpy after `torch` also works.
This suggests, that having numpy readily available breaks `torch.min` and `torch.max` when applied over certain dimensions.
### Versions
PyTorch version: 1.13.0
Is debug build: False
CUDA used to build PyTorch: None
ROCM used to build PyTorch: N/A
OS: macOS 13.0 (x86_64)
GCC version: Could not collect
Clang version: 14.0.0 (clang-1400.0.29.202)
CMake version: Could not collect
Libc version: N/A
Python version: 3.10.4 (main, Mar 31 2022, 03:38:35) [Clang 12.0.0 ] (64-bit runtime)
Python platform: macOS-10.16-x86_64-i386-64bit
Is CUDA available: False
CUDA runtime version: No CUDA
CUDA_MODULE_LOADING set to: N/A
GPU models and configuration: No CUDA
Nvidia driver version: No CUDA
cuDNN version: No CUDA
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] mypy-extensions==0.4.3
[pip3] numpy==1.23.1
[pip3] pytorch-lightning==1.7.2
[pip3] torch==1.13.0
[pip3] torchaudio==0.13.0
[pip3] torchinfo==1.7.0
[pip3] torchmetrics==0.9.3
[pip3] torchvision==0.14.0
[conda] blas 1.0 mkl
[conda] mkl 2021.4.0 hecd8cb5_637
[conda] mkl-service 2.4.0 py310hca72f7f_0
[conda] mkl_fft 1.3.1 py310hf879493_0
[conda] mkl_random 1.2.2 py310hc081a56_0
[conda] numpy 1.23.1 py310hdcd3fac_0
[conda] numpy-base 1.23.1 py310hfd2de13_0
[conda] pytorch-lightning 1.7.2 pypi_0 pypi
[conda] torch 1.13.0 pypi_0 pypi
[conda] torchaudio 0.13.0 pypi_0 pypi
[conda] torchinfo 1.7.0 pypi_0 pypi
[conda] torchmetrics 0.9.3 pypi_0 pypi
[conda] torchvision 0.14.0 pypi_0 pypi
cc @mruberry @rgommers
| 10 |
4,015 | 90,398 |
IValue(c10::List<IValue>) constructor is confusing and undocumented
|
module: internals, triaged
|
### 📚 The doc issue
Constructing `IValue` from `std::vector<IValue>` is not possible at the moment, or otherwise esoteric and undocumented.
For collections of tensors, one can simply create a vector<Tensor> and pass them in to an overloaded IValue constructor. For instance, assuming `data` is a C-style Tensor array whose length is described by `num_datums`, one can write:
```
std::vector<torch::Tensor> inputs;
for (int i = 0; i < num_datums; i++) inputs.push_back(*data[i]);
*output = new torch::IValue(inputs);
```
My expectation is that the same would be true for vector<IValue>, i.e., assuming data is now a C-style IValue array, I would expect to be able to write:
```
std::vector<torch::IValue> inputs;
for (int i = 0; i < num_datums; i++) inputs.push_back(*data[i]);
*output = new torch::IValue(inputs);
```
However, this results in a compilation error:
```
static_assert(!std::is_same<T, IValue>::value, "This constructor is not valid for List<IValue>. Please use c10::impl::GenericList(elementType) instead.");
```
It is likewise impossible to replace vector with any form of `c10::List` or `c10::GenericList` for the exact same reason. A basic stack allocation of either of those structures, such as
```
c10::impl::GenericList inputs;
```
yields the exact same compilation error.
What is the expected way to create an IValue with a list of other IValue instances?
### Suggest a potential alternative/fix
_No response_
cc @ezyang @bhosmer @smessmer @ljk53 @bdhirsh
| 5 |
4,016 | 90,395 |
Cannot add target-level dependencies to non-existent target "gloo_cuda".
|
module: build, triaged
|
### 🐛 Describe the bug
Building pytorch from source (master branch, commmit 508916128d3f5fa213b44f3a1ebc317e34b0bca5), receiving following output for
```console
$ USE_SYSTEM_LIBS=1 MAX_JOBS=2 TORCH_CUDA_ARCH_LIST=3.5 python setup.py install
...
Found gloo: /usr/lib64/libgloo.so
CMake Error at cmake/Dependencies.cmake:1500 (add_dependencies):
Cannot add target-level dependencies to non-existent target "gloo_cuda".
The add_dependencies works for top-level logical targets created by the
add_executable, add_library, or add_custom_target commands. If you want to
add file-level dependencies see the DEPENDS option of the add_custom_target
and add_custom_command commands.
Call Stack (most recent call first):
CMakeLists.txt:715 (include)
...
```
<details><summary>Full output</summary>
```console
CMake Warning (dev) at /usr/share/cmake/Modules/CMakeDependentOption.cmake:89 (message):
Policy CMP0127 is not set: cmake_dependent_option() supports full Condition
Syntax. Run "cmake --help-policy CMP0127" for policy details. Use the
cmake_policy command to set the policy and suppress this warning.
Call Stack (most recent call first):
CMakeLists.txt:245 (cmake_dependent_option)
This warning is for project developers. Use -Wno-dev to suppress it.
CMake Warning (dev) at /usr/share/cmake/Modules/CMakeDependentOption.cmake:89 (message):
Policy CMP0127 is not set: cmake_dependent_option() supports full Condition
Syntax. Run "cmake --help-policy CMP0127" for policy details. Use the
cmake_policy command to set the policy and suppress this warning.
Call Stack (most recent call first):
CMakeLists.txt:276 (cmake_dependent_option)
This warning is for project developers. Use -Wno-dev to suppress it.
-- std::exception_ptr is supported.
-- Current compiler supports avx512f extension. Will build fbgemm.
-- Caffe2: CUDA detected: 11.8
-- Caffe2: CUDA nvcc is: /opt/cuda/bin/nvcc
-- Caffe2: CUDA toolkit directory: /opt/cuda
-- Caffe2: Header version is: 11.8
-- Found cuDNN: v8.6.0 (include: /opt/cuda/include, library: /opt/cuda/lib64/libcudnn.so)
-- /opt/cuda/lib64/libnvrtc.so shorthash is 672ee683
CMake Warning at cmake/public/utils.cmake:385 (message):
In the future we will require one to explicitly pass TORCH_CUDA_ARCH_LIST
to cmake instead of implicitly setting it as an env variable. This will
become a FATAL_ERROR in future version of pytorch.
Call Stack (most recent call first):
cmake/public/cuda.cmake:437 (torch_cuda_get_nvcc_gencode_flag)
cmake/Dependencies.cmake:43 (include)
CMakeLists.txt:715 (include)
-- Added CUDA NVCC flags for: -gencode;arch=compute_35,code=sm_35
-- Caffe2: Found protobuf with new-style protobuf targets.
-- Caffe2 protobuf include directory: /usr/include
-- Trying to find preferred BLAS backend of choice: MKL
-- MKL_THREADING = OMP
CMake Warning (dev) at /usr/share/cmake/Modules/FindPackageHandleStandardArgs.cmake:438 (message):
The package name passed to `find_package_handle_standard_args` (OpenMP_C)
does not match the name of the calling package (OpenMP). This can lead to
problems in calling code that expects `find_package` result variables
(e.g., `_FOUND`) to follow a certain pattern.
Call Stack (most recent call first):
cmake/Modules/FindOpenMP.cmake:576 (find_package_handle_standard_args)
cmake/Modules/FindMKL.cmake:233 (FIND_PACKAGE)
cmake/Modules/FindMKL.cmake:328 (CHECK_ALL_LIBRARIES)
cmake/Dependencies.cmake:210 (find_package)
CMakeLists.txt:715 (include)
This warning is for project developers. Use -Wno-dev to suppress it.
CMake Warning (dev) at /usr/share/cmake/Modules/FindPackageHandleStandardArgs.cmake:438 (message):
The package name passed to `find_package_handle_standard_args` (OpenMP_CXX)
does not match the name of the calling package (OpenMP). This can lead to
problems in calling code that expects `find_package` result variables
(e.g., `_FOUND`) to follow a certain pattern.
Call Stack (most recent call first):
cmake/Modules/FindOpenMP.cmake:576 (find_package_handle_standard_args)
cmake/Modules/FindMKL.cmake:233 (FIND_PACKAGE)
cmake/Modules/FindMKL.cmake:328 (CHECK_ALL_LIBRARIES)
cmake/Dependencies.cmake:210 (find_package)
CMakeLists.txt:715 (include)
This warning is for project developers. Use -Wno-dev to suppress it.
CMake Warning at cmake/Modules/FindMKL.cmake:411 (MESSAGE):
MKL libraries files are found, but MKL header files are not. You can get
them by `conda install mkl-include` if using conda (if it is missing, run
`conda upgrade -n root conda` first), and `pip install mkl-devel` if using
pip. If build fails with header files available in the system, please make
sure that CMake will search the directory containing them, e.g., by setting
CMAKE_INCLUDE_PATH.
Call Stack (most recent call first):
cmake/Dependencies.cmake:210 (find_package)
CMakeLists.txt:715 (include)
-- MKL_THREADING = OMP
CMake Warning (dev) at /usr/share/cmake/Modules/FindPackageHandleStandardArgs.cmake:438 (message):
The package name passed to `find_package_handle_standard_args` (OpenMP_C)
does not match the name of the calling package (OpenMP). This can lead to
problems in calling code that expects `find_package` result variables
(e.g., `_FOUND`) to follow a certain pattern.
Call Stack (most recent call first):
cmake/Modules/FindOpenMP.cmake:576 (find_package_handle_standard_args)
cmake/Modules/FindMKL.cmake:233 (FIND_PACKAGE)
cmake/Modules/FindMKL.cmake:328 (CHECK_ALL_LIBRARIES)
cmake/public/mkl.cmake:1 (find_package)
cmake/Dependencies.cmake:212 (include)
CMakeLists.txt:715 (include)
This warning is for project developers. Use -Wno-dev to suppress it.
CMake Warning (dev) at /usr/share/cmake/Modules/FindPackageHandleStandardArgs.cmake:438 (message):
The package name passed to `find_package_handle_standard_args` (OpenMP_CXX)
does not match the name of the calling package (OpenMP). This can lead to
problems in calling code that expects `find_package` result variables
(e.g., `_FOUND`) to follow a certain pattern.
Call Stack (most recent call first):
cmake/Modules/FindOpenMP.cmake:576 (find_package_handle_standard_args)
cmake/Modules/FindMKL.cmake:233 (FIND_PACKAGE)
cmake/Modules/FindMKL.cmake:328 (CHECK_ALL_LIBRARIES)
cmake/public/mkl.cmake:1 (find_package)
cmake/Dependencies.cmake:212 (include)
CMakeLists.txt:715 (include)
This warning is for project developers. Use -Wno-dev to suppress it.
CMake Warning at cmake/Modules/FindMKL.cmake:411 (MESSAGE):
MKL libraries files are found, but MKL header files are not. You can get
them by `conda install mkl-include` if using conda (if it is missing, run
`conda upgrade -n root conda` first), and `pip install mkl-devel` if using
pip. If build fails with header files available in the system, please make
sure that CMake will search the directory containing them, e.g., by setting
CMAKE_INCLUDE_PATH.
Call Stack (most recent call first):
cmake/public/mkl.cmake:1 (find_package)
cmake/Dependencies.cmake:212 (include)
CMakeLists.txt:715 (include)
CMake Warning at cmake/Dependencies.cmake:225 (message):
MKL could not be found. Defaulting to Eigen
Call Stack (most recent call first):
CMakeLists.txt:715 (include)
CMake Warning at cmake/Dependencies.cmake:263 (message):
Preferred BLAS (MKL) cannot be found, now searching for a general BLAS
library
Call Stack (most recent call first):
CMakeLists.txt:715 (include)
-- MKL_THREADING = OMP
-- Checking for [mkl_intel_lp64 - mkl_gnu_thread - mkl_core - gomp - pthread - m - dl]
-- Library mkl_intel_lp64: /usr/lib64/libmkl_intel_lp64.so
-- Library mkl_gnu_thread: /usr/lib64/libmkl_gnu_thread.so
-- Library mkl_core: /usr/lib64/libmkl_core.so
CMake Warning (dev) at /usr/share/cmake/Modules/FindPackageHandleStandardArgs.cmake:438 (message):
The package name passed to `find_package_handle_standard_args` (OpenMP_C)
does not match the name of the calling package (OpenMP). This can lead to
problems in calling code that expects `find_package` result variables
(e.g., `_FOUND`) to follow a certain pattern.
Call Stack (most recent call first):
cmake/Modules/FindOpenMP.cmake:576 (find_package_handle_standard_args)
cmake/Modules/FindMKL.cmake:233 (FIND_PACKAGE)
cmake/Modules/FindMKL.cmake:328 (CHECK_ALL_LIBRARIES)
cmake/Modules/FindBLAS.cmake:99 (FIND_PACKAGE)
cmake/Dependencies.cmake:264 (find_package)
CMakeLists.txt:715 (include)
This warning is for project developers. Use -Wno-dev to suppress it.
CMake Warning (dev) at /usr/share/cmake/Modules/FindPackageHandleStandardArgs.cmake:438 (message):
The package name passed to `find_package_handle_standard_args` (OpenMP_CXX)
does not match the name of the calling package (OpenMP). This can lead to
problems in calling code that expects `find_package` result variables
(e.g., `_FOUND`) to follow a certain pattern.
Call Stack (most recent call first):
cmake/Modules/FindOpenMP.cmake:576 (find_package_handle_standard_args)
cmake/Modules/FindMKL.cmake:233 (FIND_PACKAGE)
cmake/Modules/FindMKL.cmake:328 (CHECK_ALL_LIBRARIES)
cmake/Modules/FindBLAS.cmake:99 (FIND_PACKAGE)
cmake/Dependencies.cmake:264 (find_package)
CMakeLists.txt:715 (include)
This warning is for project developers. Use -Wno-dev to suppress it.
-- Library gomp: -fopenmp
-- Library pthread: /usr/lib64/libpthread.a
-- Library m: /usr/lib64/libm.so
-- Library dl: /usr/lib64/libdl.a
CMake Warning at cmake/Modules/FindMKL.cmake:411 (MESSAGE):
MKL libraries files are found, but MKL header files are not. You can get
them by `conda install mkl-include` if using conda (if it is missing, run
`conda upgrade -n root conda` first), and `pip install mkl-devel` if using
pip. If build fails with header files available in the system, please make
sure that CMake will search the directory containing them, e.g., by setting
CMAKE_INCLUDE_PATH.
Call Stack (most recent call first):
cmake/Modules/FindBLAS.cmake:99 (FIND_PACKAGE)
cmake/Dependencies.cmake:264 (find_package)
CMakeLists.txt:715 (include)
-- MKL library not found
-- Checking for [blis]
-- Library blis: BLAS_blis_LIBRARY-NOTFOUND
-- Checking for [Accelerate]
-- Library Accelerate: BLAS_Accelerate_LIBRARY-NOTFOUND
-- Checking for [vecLib]
-- Library vecLib: BLAS_vecLib_LIBRARY-NOTFOUND
-- Checking for [flexiblas]
-- Library flexiblas: BLAS_flexiblas_LIBRARY-NOTFOUND
-- Checking for [openblas]
-- Library openblas: BLAS_openblas_LIBRARY-NOTFOUND
-- Checking for [openblas - pthread - m]
-- Library openblas: BLAS_openblas_LIBRARY-NOTFOUND
-- Checking for [openblas - pthread - m - gomp]
-- Library openblas: BLAS_openblas_LIBRARY-NOTFOUND
-- Checking for [goto2 - gfortran]
-- Library goto2: BLAS_goto2_LIBRARY-NOTFOUND
-- Checking for [goto2 - gfortran - pthread]
-- Library goto2: BLAS_goto2_LIBRARY-NOTFOUND
-- Checking for [acml - gfortran]
-- Library acml: BLAS_acml_LIBRARY-NOTFOUND
-- Checking for [blis]
-- Library blis: BLAS_blis_LIBRARY-NOTFOUND
-- Could NOT find Atlas (missing: Atlas_CLAPACK_INCLUDE_DIR Atlas_BLAS_LIBRARY)
-- Checking for [ptf77blas - atlas - gfortran]
-- Library ptf77blas: BLAS_ptf77blas_LIBRARY-NOTFOUND
-- Checking for []
-- Cannot find a library with BLAS API. Not using BLAS.
-- Using pocketfft in directory: /tmp/pytorch/third_party/pocketfft/
-- Found pthreadpool: /usr/lib64/libpthreadpool.so
Found cpuinfo: /usr/lib64/libcpuinfo.so
-- Brace yourself, we are building NNPACK
-- NNPACK backend is x86-64
-- Found XNNPACK: /usr/lib64/libXNNPACK.so
-- Found benchmark: /usr/lib64/libbenchmark.so
CMake Warning (dev) at /usr/share/cmake/Modules/FindPackageHandleStandardArgs.cmake:438 (message):
The package name passed to `find_package_handle_standard_args` (OpenMP_C)
does not match the name of the calling package (OpenMP). This can lead to
problems in calling code that expects `find_package` result variables
(e.g., `_FOUND`) to follow a certain pattern.
Call Stack (most recent call first):
cmake/Modules/FindOpenMP.cmake:576 (find_package_handle_standard_args)
third_party/fbgemm/CMakeLists.txt:85 (find_package)
This warning is for project developers. Use -Wno-dev to suppress it.
-- Found OpenMP_C: -fopenmp
CMake Warning (dev) at /usr/share/cmake/Modules/FindPackageHandleStandardArgs.cmake:438 (message):
The package name passed to `find_package_handle_standard_args` (OpenMP_CXX)
does not match the name of the calling package (OpenMP). This can lead to
problems in calling code that expects `find_package` result variables
(e.g., `_FOUND`) to follow a certain pattern.
Call Stack (most recent call first):
cmake/Modules/FindOpenMP.cmake:576 (find_package_handle_standard_args)
third_party/fbgemm/CMakeLists.txt:85 (find_package)
This warning is for project developers. Use -Wno-dev to suppress it.
-- Found OpenMP_CXX: -fopenmp
CMake Warning at third_party/fbgemm/CMakeLists.txt:87 (message):
OpenMP found! OpenMP_C_INCLUDE_DIRS =
CMake Warning at third_party/fbgemm/CMakeLists.txt:186 (message):
==========
CMake Warning at third_party/fbgemm/CMakeLists.txt:187 (message):
CMAKE_BUILD_TYPE = Release
CMake Warning at third_party/fbgemm/CMakeLists.txt:188 (message):
CMAKE_CXX_FLAGS_DEBUG is -g
CMake Warning at third_party/fbgemm/CMakeLists.txt:189 (message):
CMAKE_CXX_FLAGS_RELEASE is -O3 -DNDEBUG
CMake Warning at third_party/fbgemm/CMakeLists.txt:190 (message):
==========
** AsmJit Summary **
ASMJIT_DIR=/tmp/pytorch/third_party/fbgemm/third_party/asmjit
ASMJIT_TEST=FALSE
ASMJIT_TARGET_TYPE=STATIC
ASMJIT_DEPS=pthread;rt
ASMJIT_LIBS=asmjit;pthread;rt
ASMJIT_CFLAGS=-DASMJIT_STATIC
ASMJIT_PRIVATE_CFLAGS=-Wall;-Wextra;-Wconversion;-fno-math-errno;-fno-threadsafe-statics;-fno-semantic-interposition;-DASMJIT_STATIC
ASMJIT_PRIVATE_CFLAGS_DBG=
ASMJIT_PRIVATE_CFLAGS_REL=-O2;-fmerge-all-constants;-fno-enforce-eh-specs
-- Found system Eigen at /usr/include/eigen3
-- Found PythonInterp: /tmp/venv/bin/python (found suitable version "3.10.8", minimum required is "3.0")
-- Found pybind11: /usr/include (found version "2.10.0")
-- pybind11 include dirs: /usr/include;/usr/include/python3.10
-- Adding OpenMP CXX_FLAGS: -fopenmp
-- Will link against OpenMP libraries: /usr/lib/gcc/x86_64-pc-linux-gnu/11.3.0/libgomp.so;/usr/lib64/libpthread.a
CMake Warning at cmake/public/utils.cmake:385 (message):
In the future we will require one to explicitly pass TORCH_CUDA_ARCH_LIST
to cmake instead of implicitly setting it as an env variable. This will
become a FATAL_ERROR in future version of pytorch.
Call Stack (most recent call first):
cmake/External/nccl.cmake:13 (torch_cuda_get_nvcc_gencode_flag)
cmake/Dependencies.cmake:1395 (include)
CMakeLists.txt:715 (include)
CMake Warning at cmake/External/nccl.cmake:69 (message):
Enabling NCCL library slimming
Call Stack (most recent call first):
cmake/Dependencies.cmake:1395 (include)
CMakeLists.txt:715 (include)
-- Converting CMAKE_CUDA_FLAGS to CUDA_NVCC_FLAGS:
CUDA_NVCC_FLAGS = -Xfatbin;-compress-all;-DONNX_NAMESPACE=onnx;-gencode;arch=compute_35,code=sm_35;-Xcudafe;--diag_suppress=cc_clobber_ignored,--diag_suppress=integer_sign_change,--diag_suppress=useless_using_declaration,--diag_suppress=set_but_not_used,--diag_suppress=field_without_dll_interface,--diag_suppress=base_class_has_different_dll_interface,--diag_suppress=dll_interface_conflict_none_assumed,--diag_suppress=dll_interface_conflict_dllexport_assumed,--diag_suppress=implicit_return_from_non_void_function,--diag_suppress=unsigned_compare_with_zero,--diag_suppress=declared_but_not_referenced,--diag_suppress=bad_friend_decl;--expt-relaxed-constexpr;--expt-extended-lambda
CUDA_NVCC_FLAGS_DEBUG = -g;-g;-lineinfo;--source-in-ptx
CUDA_NVCC_FLAGS_RELEASE = -O3;-DNDEBUG
CUDA_NVCC_FLAGS_RELWITHDEBINFO = -O2;-g;-DNDEBUG;-g;-lineinfo;--source-in-ptx
CUDA_NVCC_FLAGS_MINSIZEREL = -O1;-DNDEBUG
-- summary of build options:
Install prefix: /tmp/pytorch/torch
Target system: Linux
Compiler:
C compiler: /usr/bin/cc
CFLAGS: -fopenmp
Found gloo: /usr/lib64/libgloo.so
CMake Error at cmake/Dependencies.cmake:1500 (add_dependencies):
Cannot add target-level dependencies to non-existent target "gloo_cuda".
The add_dependencies works for top-level logical targets created by the
add_executable, add_library, or add_custom_target commands. If you want to
add file-level dependencies see the DEPENDS option of the add_custom_target
and add_custom_command commands.
Call Stack (most recent call first):
CMakeLists.txt:715 (include)
--
-- ******** Summary ********
-- CMake version : 3.24.3
-- CMake command : /usr/bin/cmake
-- System : Linux
-- C++ compiler : /usr/bin/c++
-- C++ compiler version : 11.3.0
-- CXX flags : -fvisibility-inlines-hidden -DUSE_PTHREADPOOL -fopenmp -Wnon-virtual-dtor
-- Build type : Release
-- Compile definitions : ONNX_ML=1;ONNXIFI_ENABLE_EXT=1
-- CMAKE_PREFIX_PATH : /tmp/venv/lib/python3.10/site-packages;/opt/cuda
-- CMAKE_INSTALL_PREFIX : /tmp/pytorch/torch
-- CMAKE_MODULE_PATH : /tmp/pytorch/cmake/Modules;/tmp/pytorch/cmake/public/../Modules_CUDA_fix
--
-- ONNX version : 1.4.1
-- ONNX NAMESPACE : onnx
-- ONNX_BUILD_TESTS :
-- ONNX_BUILD_BENCHMARKS :
-- ONNX_USE_LITE_PROTO :
-- ONNXIFI_DUMMY_BACKEND :
--
-- Protobuf compiler : /usr/bin/protoc
-- Protobuf includes : /usr/include
-- Protobuf libraries : /usr/lib64/libprotobuf.so
-- BUILD_ONNX_PYTHON :
-- Found onnx: /usr/lib64/libonnx.so /usr/lib64/libonnx_proto.so
-- Found CUDA with FP16 support, compiling with torch.cuda.HalfTensor
-- Adding -DNDEBUG to compile flags
-- MAGMA not found. Compiling without MAGMA support
-- Could not find hardware support for NEON on this machine.
-- No OMAP3 processor on this machine.
-- No OMAP4 processor on this machine.
-- MKL_THREADING = OMP
-- Checking for [mkl_intel_lp64 - mkl_gnu_thread - mkl_core - gomp - pthread - m - dl]
-- Library mkl_intel_lp64: /usr/lib64/libmkl_intel_lp64.so
-- Library mkl_gnu_thread: /usr/lib64/libmkl_gnu_thread.so
-- Library mkl_core: /usr/lib64/libmkl_core.so
CMake Warning (dev) at /usr/share/cmake/Modules/FindPackageHandleStandardArgs.cmake:438 (message):
The package name passed to `find_package_handle_standard_args` (OpenMP_C)
does not match the name of the calling package (OpenMP). This can lead to
problems in calling code that expects `find_package` result variables
(e.g., `_FOUND`) to follow a certain pattern.
Call Stack (most recent call first):
cmake/Modules/FindOpenMP.cmake:576 (find_package_handle_standard_args)
cmake/Modules/FindMKL.cmake:233 (FIND_PACKAGE)
cmake/Modules/FindMKL.cmake:328 (CHECK_ALL_LIBRARIES)
cmake/Modules/FindBLAS.cmake:99 (FIND_PACKAGE)
cmake/Modules/FindLAPACK.cmake:22 (FIND_PACKAGE)
cmake/Dependencies.cmake:1770 (find_package)
CMakeLists.txt:715 (include)
This warning is for project developers. Use -Wno-dev to suppress it.
CMake Warning (dev) at /usr/share/cmake/Modules/FindPackageHandleStandardArgs.cmake:438 (message):
The package name passed to `find_package_handle_standard_args` (OpenMP_CXX)
does not match the name of the calling package (OpenMP). This can lead to
problems in calling code that expects `find_package` result variables
(e.g., `_FOUND`) to follow a certain pattern.
Call Stack (most recent call first):
cmake/Modules/FindOpenMP.cmake:576 (find_package_handle_standard_args)
cmake/Modules/FindMKL.cmake:233 (FIND_PACKAGE)
cmake/Modules/FindMKL.cmake:328 (CHECK_ALL_LIBRARIES)
cmake/Modules/FindBLAS.cmake:99 (FIND_PACKAGE)
cmake/Modules/FindLAPACK.cmake:22 (FIND_PACKAGE)
cmake/Dependencies.cmake:1770 (find_package)
CMakeLists.txt:715 (include)
This warning is for project developers. Use -Wno-dev to suppress it.
-- Library gomp: -fopenmp
-- Library pthread: /usr/lib64/libpthread.a
-- Library m: /usr/lib64/libm.so
-- Library dl: /usr/lib64/libdl.a
CMake Warning at cmake/Modules/FindMKL.cmake:411 (MESSAGE):
MKL libraries files are found, but MKL header files are not. You can get
them by `conda install mkl-include` if using conda (if it is missing, run
`conda upgrade -n root conda` first), and `pip install mkl-devel` if using
pip. If build fails with header files available in the system, please make
sure that CMake will search the directory containing them, e.g., by setting
CMAKE_INCLUDE_PATH.
Call Stack (most recent call first):
cmake/Modules/FindBLAS.cmake:99 (FIND_PACKAGE)
cmake/Modules/FindLAPACK.cmake:22 (FIND_PACKAGE)
cmake/Dependencies.cmake:1770 (find_package)
CMakeLists.txt:715 (include)
-- MKL library not found
-- Checking for [blis]
-- Library blis: BLAS_blis_LIBRARY-NOTFOUND
-- Checking for [Accelerate]
-- Library Accelerate: BLAS_Accelerate_LIBRARY-NOTFOUND
-- Checking for [vecLib]
-- Library vecLib: BLAS_vecLib_LIBRARY-NOTFOUND
-- Checking for [flexiblas]
-- Library flexiblas: BLAS_flexiblas_LIBRARY-NOTFOUND
-- Checking for [openblas]
-- Library openblas: BLAS_openblas_LIBRARY-NOTFOUND
-- Checking for [openblas - pthread - m]
-- Library openblas: BLAS_openblas_LIBRARY-NOTFOUND
-- Checking for [openblas - pthread - m - gomp]
-- Library openblas: BLAS_openblas_LIBRARY-NOTFOUND
-- Checking for [goto2 - gfortran]
-- Library goto2: BLAS_goto2_LIBRARY-NOTFOUND
-- Checking for [goto2 - gfortran - pthread]
-- Library goto2: BLAS_goto2_LIBRARY-NOTFOUND
-- Checking for [acml - gfortran]
-- Library acml: BLAS_acml_LIBRARY-NOTFOUND
-- Checking for [blis]
-- Library blis: BLAS_blis_LIBRARY-NOTFOUND
-- Could NOT find Atlas (missing: Atlas_CLAPACK_INCLUDE_DIR Atlas_BLAS_LIBRARY)
-- Checking for [ptf77blas - atlas - gfortran]
-- Library ptf77blas: BLAS_ptf77blas_LIBRARY-NOTFOUND
-- Checking for []
-- Cannot find a library with BLAS API. Not using BLAS.
-- LAPACK requires BLAS
-- Cannot find a library with LAPACK API. Not using LAPACK.
disabling ROCM because NOT USE_ROCM is set
-- MIOpen not found. Compiling without MIOpen support
-- Will build oneDNN Graph
-- MKL_THREADING = OMP
-- Checking for [mkl_intel_lp64 - mkl_gnu_thread - mkl_core - gomp - pthread - m - dl]
-- Library mkl_intel_lp64: /usr/lib64/libmkl_intel_lp64.so
-- Library mkl_gnu_thread: /usr/lib64/libmkl_gnu_thread.so
-- Library mkl_core: /usr/lib64/libmkl_core.so
CMake Warning (dev) at /usr/share/cmake/Modules/FindPackageHandleStandardArgs.cmake:438 (message):
The package name passed to `find_package_handle_standard_args` (OpenMP_C)
does not match the name of the calling package (OpenMP). This can lead to
problems in calling code that expects `find_package` result variables
(e.g., `_FOUND`) to follow a certain pattern.
Call Stack (most recent call first):
cmake/Modules/FindOpenMP.cmake:576 (find_package_handle_standard_args)
cmake/Modules/FindMKL.cmake:233 (FIND_PACKAGE)
cmake/Modules/FindMKL.cmake:328 (CHECK_ALL_LIBRARIES)
cmake/Modules/FindBLAS.cmake:99 (FIND_PACKAGE)
cmake/Modules/FindMKLDNN.cmake:27 (FIND_PACKAGE)
cmake/public/mkldnn.cmake:7 (find_package)
cmake/Dependencies.cmake:1814 (include)
CMakeLists.txt:715 (include)
This warning is for project developers. Use -Wno-dev to suppress it.
CMake Warning (dev) at /usr/share/cmake/Modules/FindPackageHandleStandardArgs.cmake:438 (message):
The package name passed to `find_package_handle_standard_args` (OpenMP_CXX)
does not match the name of the calling package (OpenMP). This can lead to
problems in calling code that expects `find_package` result variables
(e.g., `_FOUND`) to follow a certain pattern.
Call Stack (most recent call first):
cmake/Modules/FindOpenMP.cmake:576 (find_package_handle_standard_args)
cmake/Modules/FindMKL.cmake:233 (FIND_PACKAGE)
cmake/Modules/FindMKL.cmake:328 (CHECK_ALL_LIBRARIES)
cmake/Modules/FindBLAS.cmake:99 (FIND_PACKAGE)
cmake/Modules/FindMKLDNN.cmake:27 (FIND_PACKAGE)
cmake/public/mkldnn.cmake:7 (find_package)
cmake/Dependencies.cmake:1814 (include)
CMakeLists.txt:715 (include)
This warning is for project developers. Use -Wno-dev to suppress it.
-- Library gomp: -fopenmp
-- Library pthread: /usr/lib64/libpthread.a
-- Library m: /usr/lib64/libm.so
-- Library dl: /usr/lib64/libdl.a
CMake Warning at cmake/Modules/FindMKL.cmake:411 (MESSAGE):
MKL libraries files are found, but MKL header files are not. You can get
them by `conda install mkl-include` if using conda (if it is missing, run
`conda upgrade -n root conda` first), and `pip install mkl-devel` if using
pip. If build fails with header files available in the system, please make
sure that CMake will search the directory containing them, e.g., by setting
CMAKE_INCLUDE_PATH.
Call Stack (most recent call first):
cmake/Modules/FindBLAS.cmake:99 (FIND_PACKAGE)
cmake/Modules/FindMKLDNN.cmake:27 (FIND_PACKAGE)
cmake/public/mkldnn.cmake:7 (find_package)
cmake/Dependencies.cmake:1814 (include)
CMakeLists.txt:715 (include)
-- MKL library not found
-- Checking for [blis]
-- Library blis: BLAS_blis_LIBRARY-NOTFOUND
-- Checking for [Accelerate]
-- Library Accelerate: BLAS_Accelerate_LIBRARY-NOTFOUND
-- Checking for [vecLib]
-- Library vecLib: BLAS_vecLib_LIBRARY-NOTFOUND
-- Checking for [flexiblas]
-- Library flexiblas: BLAS_flexiblas_LIBRARY-NOTFOUND
-- Checking for [openblas]
-- Library openblas: BLAS_openblas_LIBRARY-NOTFOUND
-- Checking for [openblas - pthread - m]
-- Library openblas: BLAS_openblas_LIBRARY-NOTFOUND
-- Checking for [openblas - pthread - m - gomp]
-- Library openblas: BLAS_openblas_LIBRARY-NOTFOUND
-- Checking for [goto2 - gfortran]
-- Library goto2: BLAS_goto2_LIBRARY-NOTFOUND
-- Checking for [goto2 - gfortran - pthread]
-- Library goto2: BLAS_goto2_LIBRARY-NOTFOUND
-- Checking for [acml - gfortran]
-- Library acml: BLAS_acml_LIBRARY-NOTFOUND
-- Checking for [blis]
-- Library blis: BLAS_blis_LIBRARY-NOTFOUND
-- Could NOT find Atlas (missing: Atlas_CLAPACK_INCLUDE_DIR Atlas_BLAS_LIBRARY)
-- Checking for [ptf77blas - atlas - gfortran]
-- Library ptf77blas: BLAS_ptf77blas_LIBRARY-NOTFOUND
-- Checking for []
-- Cannot find a library with BLAS API. Not using BLAS.
-- MKLDNN_CPU_RUNTIME = OMP
-- cmake version: 3.24.3
CMake Deprecation Warning at third_party/ideep/mkl-dnn/CMakeLists.txt:36 (cmake_policy):
The OLD behavior for policy CMP0025 will be removed from a future version
of CMake.
The cmake-policies(7) manual explains that the OLD behaviors of all
policies are deprecated and that a policy should be set to OLD only under
specific short-term circumstances. Projects should be ported to the NEW
behavior and not rely on setting a policy to OLD.
-- DNNL_TARGET_ARCH: X64
-- DNNL_LIBRARY_NAME: dnnl
CMake Warning (dev) at /usr/share/cmake/Modules/FindPackageHandleStandardArgs.cmake:438 (message):
The package name passed to `find_package_handle_standard_args` (OpenMP_C)
does not match the name of the calling package (OpenMP). This can lead to
problems in calling code that expects `find_package` result variables
(e.g., `_FOUND`) to follow a certain pattern.
Call Stack (most recent call first):
cmake/Modules/FindOpenMP.cmake:576 (find_package_handle_standard_args)
third_party/ideep/mkl-dnn/third_party/oneDNN/cmake/OpenMP.cmake:69 (find_package)
third_party/ideep/mkl-dnn/third_party/oneDNN/CMakeLists.txt:117 (include)
This warning is for project developers. Use -Wno-dev to suppress it.
-- Found OpenMP_C: -fopenmp
CMake Warning (dev) at /usr/share/cmake/Modules/FindPackageHandleStandardArgs.cmake:438 (message):
The package name passed to `find_package_handle_standard_args` (OpenMP_CXX)
does not match the name of the calling package (OpenMP). This can lead to
problems in calling code that expects `find_package` result variables
(e.g., `_FOUND`) to follow a certain pattern.
Call Stack (most recent call first):
cmake/Modules/FindOpenMP.cmake:576 (find_package_handle_standard_args)
third_party/ideep/mkl-dnn/third_party/oneDNN/cmake/OpenMP.cmake:69 (find_package)
third_party/ideep/mkl-dnn/third_party/oneDNN/CMakeLists.txt:117 (include)
This warning is for project developers. Use -Wno-dev to suppress it.
-- Found OpenMP_CXX: -fopenmp
-- Could NOT find Doxyrest (missing: DOXYREST_EXECUTABLE)
-- Found PythonInterp: /tmp/venv/bin/python (found suitable version "3.10.8", minimum required is "2.7")
-- Enabled workload: TRAINING
-- Enabled primitives: ALL
-- Enabled primitive CPU ISA: ALL
-- Enabled primitive GPU ISA: ALL
-- Primitive cache is enabled
CMake Warning (dev) at /usr/share/cmake/Modules/FindPackageHandleStandardArgs.cmake:438 (message):
The package name passed to `find_package_handle_standard_args` (OpenMP_C)
does not match the name of the calling package (OpenMP). This can lead to
problems in calling code that expects `find_package` result variables
(e.g., `_FOUND`) to follow a certain pattern.
Call Stack (most recent call first):
cmake/Modules/FindOpenMP.cmake:576 (find_package_handle_standard_args)
third_party/ideep/mkl-dnn/cmake/OpenMP.cmake:62 (find_package)
third_party/ideep/mkl-dnn/CMakeLists.txt:179 (include)
This warning is for project developers. Use -Wno-dev to suppress it.
CMake Warning (dev) at /usr/share/cmake/Modules/FindPackageHandleStandardArgs.cmake:438 (message):
The package name passed to `find_package_handle_standard_args` (OpenMP_CXX)
does not match the name of the calling package (OpenMP). This can lead to
problems in calling code that expects `find_package` result variables
(e.g., `_FOUND`) to follow a certain pattern.
Call Stack (most recent call first):
cmake/Modules/FindOpenMP.cmake:576 (find_package_handle_standard_args)
third_party/ideep/mkl-dnn/cmake/OpenMP.cmake:62 (find_package)
third_party/ideep/mkl-dnn/CMakeLists.txt:179 (include)
This warning is for project developers. Use -Wno-dev to suppress it.
-- DNNL_GRAPH_BUILD_FOR_CI is set to be OFF
-- Compiling oneDNN Graph with CPU runtime OMP support
-- Graph compiler backend is disabled.
-- Set version definitions to /tmp/pytorch/third_party/ideep/mkl-dnn/src/utils/verbose.cpp
-- Compiled partition cache is enabled
-- Found MKL-DNN: TRUE
-- Version: 7.0.3
-- Build type: Release
-- CXX_STANDARD: 14
-- Required features: cxx_variadic_templates
-- Using Kineto with CUPTI support
-- Configuring Kineto dependency:
-- KINETO_SOURCE_DIR = /tmp/pytorch/third_party/kineto/libkineto
-- KINETO_BUILD_TESTS = OFF
-- KINETO_LIBRARY_TYPE = static
-- CUDA_SOURCE_DIR = /opt/cuda
-- CUDA_INCLUDE_DIRS = /opt/cuda/include
-- CUPTI_INCLUDE_DIR = /opt/cuda/extras/CUPTI/include
-- CUDA_cupti_LIBRARY = /opt/cuda/extras/CUPTI/lib64/libcupti.so
-- Found CUPTI
-- Found PythonInterp: /tmp/venv/bin/python (found version "3.10.8")
INFO ROCM_SOURCE_DIR =
-- Kineto: FMT_SOURCE_DIR = /tmp/pytorch/third_party/fmt
-- Kineto: FMT_INCLUDE_DIR = /tmp/pytorch/third_party/fmt/include
INFO CUPTI_INCLUDE_DIR = /opt/cuda/extras/CUPTI/include
INFO ROCTRACER_INCLUDE_DIR = /include/roctracer
-- Configured Kineto
CMake Warning (dev) at /usr/share/cmake/Modules/CMakeDependentOption.cmake:89 (message):
Policy CMP0127 is not set: cmake_dependent_option() supports full Condition
Syntax. Run "cmake --help-policy CMP0127" for policy details. Use the
cmake_policy command to set the policy and suppress this warning.
Call Stack (most recent call first):
CMakeLists.txt:718 (cmake_dependent_option)
This warning is for project developers. Use -Wno-dev to suppress it.
-- GCC 11.3.0: Adding gcc and gcc_s libs to link line
-- don't use NUMA
-- headers outputs:
-- sources outputs:
-- declarations_yaml outputs:
-- Using ATen parallel backend: OMP
Found sleef: /usr/lib64/libsleef.so
AT_INSTALL_INCLUDE_DIR include/ATen/core
core header install: /tmp/pytorch/build/aten/src/ATen/core/TensorBody.h
core header install: /tmp/pytorch/build/aten/src/ATen/core/aten_interned_strings.h
core header install: /tmp/pytorch/build/aten/src/ATen/core/enum_tag.h
-- /usr/bin/c++ /tmp/pytorch/torch/abi-check.cpp -o /tmp/pytorch/build/abi-check
-- Determined _GLIBCXX_USE_CXX11_ABI=1
CMake Warning (dev) at torch/CMakeLists.txt:386:
Syntax Warning in cmake code at column 107
Argument not separated from preceding token by whitespace.
This warning is for project developers. Use -Wno-dev to suppress it.
CMake Warning (dev) at torch/CMakeLists.txt:386:
Syntax Warning in cmake code at column 115
Argument not separated from preceding token by whitespace.
This warning is for project developers. Use -Wno-dev to suppress it.
CMake Warning at cmake/public/utils.cmake:385 (message):
In the future we will require one to explicitly pass TORCH_CUDA_ARCH_LIST
to cmake instead of implicitly setting it as an env variable. This will
become a FATAL_ERROR in future version of pytorch.
Call Stack (most recent call first):
torch/CMakeLists.txt:338 (torch_cuda_get_nvcc_gencode_flag)
CMake Warning (dev) at /usr/share/cmake/Modules/FindPackageHandleStandardArgs.cmake:438 (message):
The package name passed to `find_package_handle_standard_args` (OpenMP_C)
does not match the name of the calling package (OpenMP). This can lead to
problems in calling code that expects `find_package` result variables
(e.g., `_FOUND`) to follow a certain pattern.
Call Stack (most recent call first):
cmake/Modules/FindOpenMP.cmake:576 (find_package_handle_standard_args)
caffe2/CMakeLists.txt:1224 (find_package)
This warning is for project developers. Use -Wno-dev to suppress it.
CMake Warning (dev) at /usr/share/cmake/Modules/FindPackageHandleStandardArgs.cmake:438 (message):
The package name passed to `find_package_handle_standard_args` (OpenMP_CXX)
does not match the name of the calling package (OpenMP). This can lead to
problems in calling code that expects `find_package` result variables
(e.g., `_FOUND`) to follow a certain pattern.
Call Stack (most recent call first):
cmake/Modules/FindOpenMP.cmake:576 (find_package_handle_standard_args)
caffe2/CMakeLists.txt:1224 (find_package)
This warning is for project developers. Use -Wno-dev to suppress it.
-- pytorch is compiling with OpenMP.
OpenMP CXX_FLAGS: -fopenmp.
OpenMP libraries: /usr/lib/gcc/x86_64-pc-linux-gnu/11.3.0/libgomp.so;/usr/lib64/libpthread.a.
-- Caffe2 is compiling with OpenMP.
OpenMP CXX_FLAGS: -fopenmp.
OpenMP libraries: /usr/lib/gcc/x86_64-pc-linux-gnu/11.3.0/libgomp.so;/usr/lib64/libpthread.a.
-- Using lib/python3.10/site-packages as python relative installation path
CMake Warning at CMakeLists.txt:1087 (message):
Generated cmake files are only fully tested if one builds with system glog,
gflags, and protobuf. Other settings may generate files that are not well
tested.
--
-- ******** Summary ********
-- General:
-- CMake version : 3.24.3
-- CMake command : /usr/bin/cmake
-- System : Linux
-- C++ compiler : /usr/bin/c++
-- C++ compiler id : GNU
-- C++ compiler version : 11.3.0
-- Using ccache if found : ON
-- Found ccache : /usr/bin/ccache
-- CXX flags : -fvisibility-inlines-hidden -DUSE_PTHREADPOOL -fopenmp -DNDEBUG -DUSE_KINETO -DUSE_FBGEMM -DUSE_QNNPACK -DUSE_PYTORCH_QNNPACK -DUSE_XNNPACK -DSYMBOLICATE_MOBILE_DEBUG_HANDLE -DEDGE_PROFILER_USE_KINETO -O2 -fPIC -Wall -Wextra -Werror=return-type -Werror=non-virtual-dtor -Werror=range-loop-construct -Wnarrowing -Wno-missing-field-initializers -Wno-type-limits -Wno-array-bounds -Wno-unknown-pragmas -Wunused-local-typedefs -Wno-unused-parameter -Wno-unused-function -Wno-unused-result -Wno-strict-overflow -Wno-strict-aliasing -Wno-error=deprecated-declarations -Wno-stringop-overflow -Wno-psabi -Wno-error=pedantic -Wno-error=redundant-decls -Wno-error=old-style-cast -fdiagnostics-color=always -faligned-new -Wno-unused-but-set-variable -Wno-maybe-uninitialized -fno-math-errno -fno-trapping-math -Werror=format -Werror=cast-function-type -Wno-stringop-overflow
-- Build type : Release
-- Compile definitions : ONNX_ML=1;ONNXIFI_ENABLE_EXT=1;ONNX_NAMESPACE=onnx;HAVE_MMAP=1;_FILE_OFFSET_BITS=64;HAVE_SHM_OPEN=1;HAVE_SHM_UNLINK=1;HAVE_MALLOC_USABLE_SIZE=1;USE_EXTERNAL_MZCRC;MINIZ_DISABLE_ZIP_READER_CRC32_CHECKS;USE_FLASH_ATTENTION
-- CMAKE_PREFIX_PATH : /tmp/venv/lib/python3.10/site-packages;/opt/cuda
-- CMAKE_INSTALL_PREFIX : /tmp/pytorch/torch
-- USE_GOLD_LINKER : OFF
--
-- TORCH_VERSION : 1.14.0
-- CAFFE2_VERSION : 1.14.0
-- BUILD_CAFFE2 : OFF
-- BUILD_CAFFE2_OPS : OFF
-- BUILD_STATIC_RUNTIME_BENCHMARK: OFF
-- BUILD_TENSOREXPR_BENCHMARK: OFF
-- BUILD_NVFUSER_BENCHMARK: OFF
-- BUILD_BINARY : OFF
-- BUILD_CUSTOM_PROTOBUF : OFF
-- Link local protobuf : ON
-- BUILD_DOCS : OFF
-- BUILD_PYTHON : True
-- Python version : 3.10.8
-- Python executable : /tmp/venv/bin/python
-- Pythonlibs version : 3.10.8
-- Python library : /usr/lib64/libpython3.10.so.1.0
-- Python includes : /usr/include/python3.10
-- Python site-packages: lib/python3.10/site-packages
-- BUILD_SHARED_LIBS : ON
-- CAFFE2_USE_MSVC_STATIC_RUNTIME : OFF
-- BUILD_TEST : True
-- BUILD_JNI : OFF
-- BUILD_MOBILE_AUTOGRAD : OFF
-- BUILD_LITE_INTERPRETER: OFF
-- INTERN_BUILD_MOBILE :
-- TRACING_BASED : OFF
-- USE_BLAS : 0
-- USE_LAPACK : 0
-- USE_ASAN : OFF
-- USE_TSAN : OFF
-- USE_CPP_CODE_COVERAGE : OFF
-- USE_CUDA : ON
-- Split CUDA :
-- CUDA static link : OFF
-- USE_CUDNN : ON
-- USE_EXPERIMENTAL_CUDNN_V8_API: ON
-- CUDA version : 11.8
-- USE_FLASH_ATTENTION : ON
-- cuDNN version : 8.6.0
-- CUDA root directory : /opt/cuda
-- CUDA library : /opt/cuda/lib64/stubs/libcuda.so
-- cudart library : /opt/cuda/lib64/libcudart.so
-- cublas library : /opt/cuda/lib64/libcublas.so
-- cufft library : /opt/cuda/lib64/libcufft.so
-- curand library : /opt/cuda/lib64/libcurand.so
-- cuDNN library : /opt/cuda/lib64/libcudnn.so
-- nvrtc : /opt/cuda/lib64/libnvrtc.so
-- CUDA include path : /opt/cuda/include
-- NVCC executable : /opt/cuda/bin/nvcc
-- CUDA compiler : /opt/cuda/bin/nvcc
-- CUDA flags : -Xfatbin -compress-all -DONNX_NAMESPACE=onnx -gencode arch=compute_35,code=sm_35 -Xcudafe --diag_suppress=cc_clobber_ignored,--diag_suppress=integer_sign_change,--diag_suppress=useless_using_declaration,--diag_suppress=set_but_not_used,--diag_suppress=field_without_dll_interface,--diag_suppress=base_class_has_different_dll_interface,--diag_suppress=dll_interface_conflict_none_assumed,--diag_suppress=dll_interface_conflict_dllexport_assumed,--diag_suppress=implicit_return_from_non_void_function,--diag_suppress=unsigned_compare_with_zero,--diag_suppress=declared_but_not_referenced,--diag_suppress=bad_friend_decl --expt-relaxed-constexpr --expt-extended-lambda -Wno-deprecated-gpu-targets --expt-extended-lambda -DCUB_WRAPPED_NAMESPACE=at_cuda_detail -DCUDA_HAS_FP16=1 -D__CUDA_NO_HALF_OPERATORS__ -D__CUDA_NO_HALF_CONVERSIONS__ -D__CUDA_NO_HALF2_OPERATORS__ -D__CUDA_NO_BFLOAT16_CONVERSIONS__
-- CUDA host compiler :
-- CUDA --device-c : OFF
-- USE_TENSORRT : OFF
-- USE_ROCM : OFF
-- USE_EIGEN_FOR_BLAS : ON
-- USE_FBGEMM : ON
-- USE_FAKELOWP : OFF
-- USE_KINETO : ON
-- USE_FFMPEG : OFF
-- USE_GFLAGS : OFF
-- USE_GLOG : OFF
-- USE_LEVELDB : OFF
-- USE_LITE_PROTO : OFF
-- USE_LMDB : OFF
-- USE_METAL : OFF
-- USE_PYTORCH_METAL : OFF
-- USE_PYTORCH_METAL_EXPORT : OFF
-- USE_MPS : OFF
-- USE_FFTW : OFF
-- USE_MKL : OFF
-- USE_MKLDNN : ON
-- USE_MKLDNN_ACL : OFF
-- USE_MKLDNN_CBLAS : OFF
-- USE_UCC : OFF
-- USE_ITT : ON
-- USE_NCCL : ON
-- USE_SYSTEM_NCCL : OFF
-- USE_NCCL_WITH_UCC : OFF
-- USE_NNPACK : ON
-- USE_NUMPY : ON
-- USE_OBSERVERS : ON
-- USE_OPENCL : OFF
-- USE_OPENCV : OFF
-- USE_OPENMP : ON
-- USE_TBB : OFF
-- USE_VULKAN : OFF
-- USE_PROF : OFF
-- USE_QNNPACK : ON
-- USE_PYTORCH_QNNPACK : ON
-- USE_XNNPACK : ON
-- USE_REDIS : OFF
-- USE_ROCKSDB : OFF
-- USE_ZMQ : OFF
-- USE_DISTRIBUTED : ON
-- USE_MPI : OFF
-- USE_GLOO : ON
-- USE_GLOO_WITH_OPENSSL : OFF
-- USE_TENSORPIPE : ON
-- Public Dependencies : caffe2::Threads
-- Private Dependencies : pthreadpool;cpuinfo;qnnpack;pytorch_qnnpack;nnpack;XNNPACK;fbgemm;ittnotify;fp16;tensorpipe;gloo;onnx_proto;onnx;foxi_loader;rt;fmt::fmt-header-only;kineto;gcc_s;gcc;dl
-- USE_COREML_DELEGATE : OFF
-- BUILD_LAZY_TS_BACKEND : ON
-- TORCH_DISABLE_GPU_ASSERTS : ON
-- Configuring incomplete, errors occurred!
See also "/tmp/pytorch/build/CMakeFiles/CMakeOutput.log".
See also "/tmp/pytorch/build/CMakeFiles/CMakeError.log".
Building wheel torch-1.14.0a0+git5089161
-- Building version 1.14.0a0+git5089161
cmake -GNinja -DBUILD_PYTHON=True -DBUILD_TEST=True -DCMAKE_BUILD_TYPE=Release -DCMAKE_INSTALL_PREFIX=/tmp/pytorch/torch -DCMAKE_PREFIX_PATH=/tmp/venv/lib/python3.10/site-packages -DJAVA_HOME=/home/ruslan/.gentoo/java-config-2/current-user-vm -DNUMPY_INCLUDE_DIR=/tmp/venv/lib/python3.10/site-packages/numpy/core/include -DPYTHON_EXECUTABLE=/tmp/venv/bin/python -DPYTHON_INCLUDE_DIR=/usr/include/python3.10 -DPYTHON_LIBRARY=/usr/lib64/libpython3.10.so.1.0 -DTORCH_BUILD_VERSION=1.14.0a0+git5089161 -DUSE_NUMPY=True -DUSE_SYSTEM_LIBS=1 /tmp/pytorch
```
</details>
### Versions
```console
$ python collect_env.py
Collecting environment information...
PyTorch version: N/A
Is debug build: N/A
CUDA used to build PyTorch: N/A
ROCM used to build PyTorch: N/A
OS: Gentoo Linux (x86_64)
GCC version: (Gentoo 11.3.0 p7) 11.3.0
Clang version: 15.0.3
CMake version: version 3.24.3
Libc version: glibc-2.36
Python version: 3.10.8 (main, Nov 20 2022, 21:32:29) [GCC 11.3.0] (64-bit runtime)
Python platform: Linux-5.15.77-x86_64-gt-730-sl-x86_64-AMD_Athlon-tm-_II_X2_240_Processor-with-glibc2.36
Is CUDA available: N/A
CUDA runtime version: 11.8.89
CUDA_MODULE_LOADING set to: N/A
GPU models and configuration: GPU 0: NVIDIA GeForce GT 730
Nvidia driver version: 470.141.03
cuDNN version: Probably one of the following:
/opt/cuda/targets/x86_64-linux/lib/libcudnn.so.8.6.0
/opt/cuda/targets/x86_64-linux/lib/libcudnn_adv_infer.so.8.6.0
/opt/cuda/targets/x86_64-linux/lib/libcudnn_adv_train.so.8.6.0
/opt/cuda/targets/x86_64-linux/lib/libcudnn_cnn_infer.so.8.6.0
/opt/cuda/targets/x86_64-linux/lib/libcudnn_cnn_train.so.8.6.0
/opt/cuda/targets/x86_64-linux/lib/libcudnn_ops_infer.so.8.6.0
/opt/cuda/targets/x86_64-linux/lib/libcudnn_ops_train.so.8.6.0
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: N/A
Versions of relevant libraries:
[pip3] numpy==1.23.5
[pip3] torchaudio==0.12.1+cu113
[pip3] torchvision==0.13.1+cu113
[conda] Could not collect
```
cc @malfet @seemethere
| 2 |
4,017 | 90,394 |
FX graph mode quant: backendconfig configuration missing for torch.nn.GRU
|
oncall: quantization, triaged
|
### 🐛 Describe the bug
`torch.nn.GRU` should be in https://pytorch.org/docs/1.13/quantization-backend-configuration.html, for dynamic quantization but it is not. We should add it. Note: other recurrent layers are already there.
This was reported in https://discuss.pytorch.org/t/quantization-not-decreasing-model-size-static-and-qat/87319/11
### Versions
master
cc @jerryzh168 @jianyuh @raghuramank100 @jamesr66a @jgong5 @Xia-Weiwen @leslie-fang-intel
| 2 |
4,018 | 90,374 |
torch.utils.tensorboard import fails if a new protobuf > 3.20 is installed (bug in tensorboard/tensorflow but better guard against it)
|
oncall: visualization
|
### 🐛 Describe the bug
With a new version of protobuf 4.21.8, `import torch.utils.tensorboard` unconditionally imports `tensorboard.compat` / `tensorboard.compat.event_pb2`, etc which were generated with an old `protoc` (and friends which isn't happy given). Pytorch version 1.10 is quite antique, but probably the tensorboard writer code hasn't changed in a while.
This also affects pytorch lightning and all other dependent packages, such as nemo.
Sorry for an image stack trace - a friend stumbled on this bug, not myself.
I'd prefer that `import torch.utils.tensorboard` succeeded, but only creating `SummaryWriter` instance would fail in case of dependency issues (with protobuf / tensorboard etc). Also, it might be good if it just worked with newer protobuf, maybe a non-compat tensorboard functionality could be used or explicitly some good protobuf version could be checked.
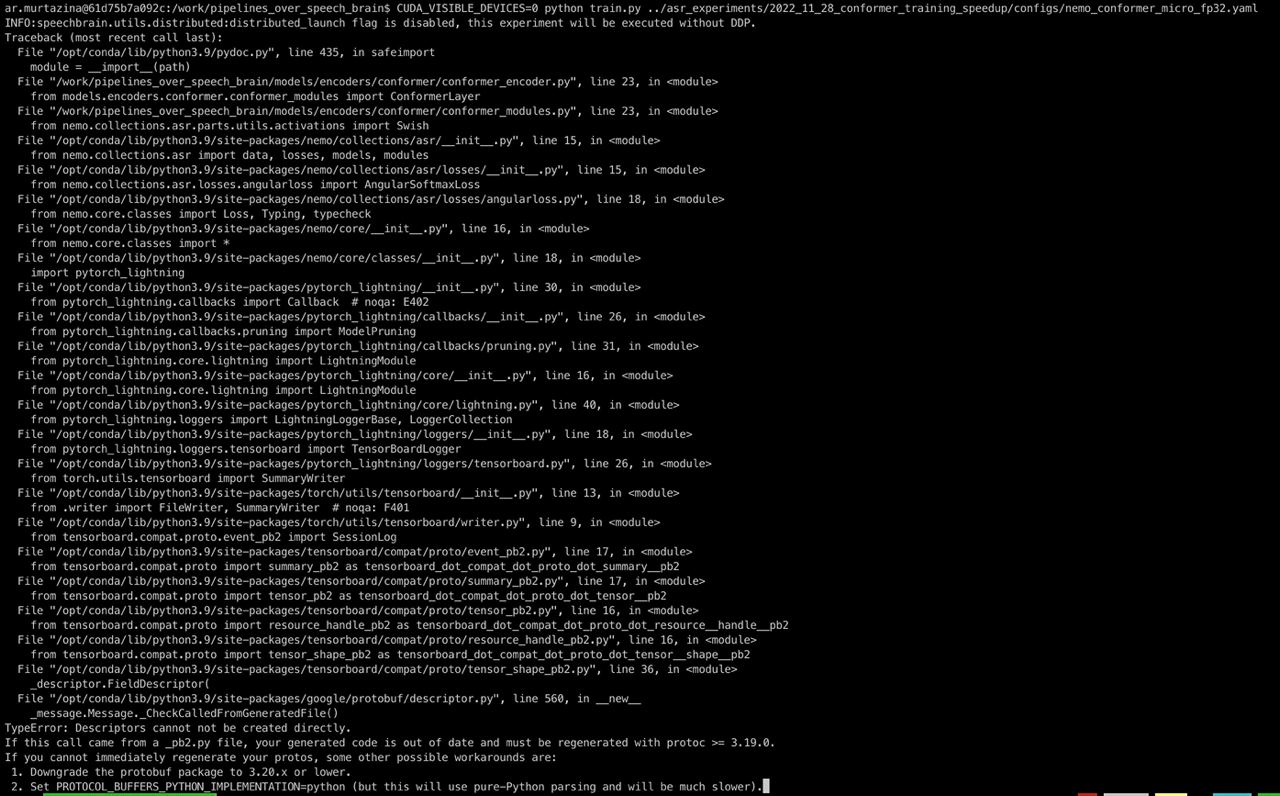
### Versions
pytorch-lightning 1.6.3
torch 1.10.1
protobuf 4.21.8
tensorboard 2.8.0
| 2 |
4,019 | 90,373 |
"Reached a code path in Module.get_extra_state() that should never be called."
|
needs reproduction, oncall: jit, triaged
|
### 🐛 Describe the bug
I got the run time error mentioned in the title when calling `get_extra_state` on a `RecursiveScriptModule` created from an `nn.Dropout` module.
I was just playing around so don't know if it even makes sense, but since the error specifically told me to report it I thought I should.
If nothing else, this error should probably be changed.
Image of entire error stack:
### Versions
Collecting environment information...
PyTorch version: 1.13.0
Is debug build: False
CUDA used to build PyTorch: 11.7
ROCM used to build PyTorch: N/A
OS: Microsoft Windows 10 Pro
GCC version: (tdm64-1) 9.2.0
Clang version: Could not collect
CMake version: Could not collect
Libc version: N/A
Python version: 3.10.6 | packaged by conda-forge | (main, Oct 24 2022, 16:02:16) [MSC v.1916 64 bit (AMD64)] (64-bit runtime)
Python platform: Windows-10-10.0.19044-SP0
Is CUDA available: True
CUDA runtime version: 11.7.99
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration: GPU 0: NVIDIA GeForce RTX 2060
Nvidia driver version: 516.94
cuDNN version: C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.7\bin\cudnn_ops_train64_8.dll
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.23.3
[pip3] torch==1.13.0
[pip3] torchaudio==0.13.0
[pip3] torchvision==0.14.0
[conda] blas 1.0 mkl
[conda] mkl 2021.4.0 haa95532_640
[conda] mkl-service 2.4.0 py310h2bbff1b_0
[conda] mkl_fft 1.3.1 py310ha0764ea_0
[conda] mkl_random 1.2.2 py310h4ed8f06_0
[conda] numpy 1.23.3 py310h60c9a35_0
[conda] numpy-base 1.23.3 py310h04254f7_0
[conda] pytorch 1.13.0 py3.10_cuda11.7_cudnn8_0 pytorch
[conda] pytorch-cuda 11.7 h67b0de4_0 pytorch
[conda] pytorch-mutex 1.0 cuda pytorch
[conda] torchaudio 0.13.0 pypi_0 pypi
[conda] torchvision 0.14.0 pypi_0 pypi
cc @EikanWang @jgong5 @wenzhe-nrv @sanchitintel @mruberry @jbschlosser @walterddr @kshitij12345 @saketh-are
| 1 |
4,020 | 90,369 |
[JIT] Wrong type inference leads to misleading error message
|
oncall: jit
|
### 🐛 Describe the bug
```python
import torch
def fn(x: torch.Tensor):
mul = torch.mul(x, 1) # This is a integer tensor not a bool tensor
return torch.sub(mul, mul)
o = fn(True) # Pass eager mode.
print("Output dtype:", o.dtype, "which is not bool")
# jit trace
traced = torch.jit.trace(fn, (torch.ones((), dtype=torch.bool),))
```
It throws a runtime error:
```
torch.jit._trace.TracingCheckError: Tracing failed sanity checks!
encountered an exception while running the trace with test inputs.
Exception:
The following operation failed in the TorchScript interpreter.
Traceback of TorchScript (most recent call last):
/dev/nnsmith-ganler/test.py(6): fn
/miniconda3/lib/python3.9/site-packages/torch/jit/_trace.py(856): trace
/dev/nnsmith-ganler/test.py(12): <module>
RuntimeError: Subtraction, the `-` operator, with two bool tensors is not supported. Use the `^` or `logical_xor()` operator instead.
```
saying that `torch.sub` is applied boolean tensors which are not supported. However, the `mul` tensor is not boolean but integer. So this is a false postive due to a wrong type inference.
Note: this bug is detected by a fuzzer learnt from existing PyTorch CI tests.
### Versions
<details><summary><b>Env </b> <i>[click to expand]</i></summary>
<div>
```python
"""
Collecting environment information...
PyTorch version: 1.14.0.dev20221202+cu117
Is debug build: False
CUDA used to build PyTorch: 11.7
ROCM used to build PyTorch: N/A
OS: Ubuntu 22.04.1 LTS (x86_64)
GCC version: (Ubuntu 11.3.0-1ubuntu1~22.04) 11.3.0
Clang version: Could not collect
CMake version: version 3.25.0
Libc version: glibc-2.35
Python version: 3.9.12 (main, Apr 5 2022, 06:56:58) [GCC 7.5.0] (64-bit runtime)
Python platform: Linux-5.15.0-56-generic-x86_64-with-glibc2.35
Is CUDA available: True
CUDA runtime version: 11.6.124
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration:
GPU 0: NVIDIA GeForce RTX 3090
GPU 1: NVIDIA GeForce RTX 3090
GPU 2: NVIDIA GeForce RTX 3090
Nvidia driver version: 515.86.01
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_infer.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.4.1
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] mypy-extensions==0.4.3
[pip3] numpy==1.23.3
[pip3] onnx2torch==1.5.3
[pip3] torch==1.14.0.dev20221202+cu117
[pip3] torchaudio==0.14.0.dev20221203+cu117
[pip3] torchtriton==2.0.0+0d7e753227
[pip3] torchvision==0.15.0.dev20221203+cpu
[conda] numpy 1.23.3 pypi_0 pypi
[conda] onnx2torch 1.5.3 pypi_0 pypi
[conda] torch 1.14.0.dev20221202+cu117 pypi_0 pypi
[conda] torchaudio 0.14.0.dev20221203+cu117 pypi_0 pypi
[conda] torchtriton 2.0.0+0d7e753227 pypi_0 pypi
[conda] torchvision 0.15.0.dev20221203+cpu pypi_0 pypi
"""
```
</div>
</details>
cc @EikanWang @jgong5 @wenzhe-nrv @sanchitintel
| 0 |
4,021 | 93,470 |
Get the error: AttributeError: Can't pickle local object 'convert_frame.<locals>._convert_frame'
|
triaged, bug, oncall: pt2, module: dynamo
|
### 🐛 Describe the bug
When adding the line:
`model = torch.compile(model)` after loading the model, this error occurs. When removing the line, the script functions as intended.
### Error logs
File "/opt/anaconda3/envs/ml1/lib/python3.8/multiprocessing/process.py", line 121, in start
self._popen = self._Popen(self)
File "/opt/anaconda3/envs/ml1/lib/python3.8/multiprocessing/context.py", line 224, in _Popen
return _default_context.get_context().Process._Popen(process_obj)
File "/opt/anaconda3/envs/ml1/lib/python3.8/multiprocessing/context.py", line 284, in _Popen
return Popen(process_obj)
File "/opt/anaconda3/envs/ml1/lib/python3.8/multiprocessing/popen_spawn_posix.py", line 32, in __init__
super().__init__(process_obj)
File "/opt/anaconda3/envs/ml1/lib/python3.8/multiprocessing/popen_fork.py", line 19, in __init__
self._launch(process_obj)
File "/opt/anaconda3/envs/ml1/lib/python3.8/multiprocessing/popen_spawn_posix.py", line 47, in _launch
reduction.dump(process_obj, fp)
File "/opt/anaconda3/envs/ml1/lib/python3.8/multiprocessing/reduction.py", line 60, in dump
ForkingPickler(file, protocol).dump(obj)
AttributeError: Can't pickle local object 'convert_frame.<locals>._convert_frame'
### Minified repro
_No response_
cc @ezyang @msaroufim @wconstab @bdhirsh @anijain2305 @voznesenskym @penguinwu @EikanWang @jgong5 @Guobing-Chen @XiaobingSuper @zhuhaozhe @blzheng @Xia-Weiwen @wenzhe-nrv @jiayisunx @ipiszy @soumith @ngimel
| 12 |
4,022 | 90,367 |
[JIT] INTERNAL ASSERT FAILED `torch.add` with boolean primitive constant
|
oncall: jit
|
### 🐛 Describe the bug
```python
import torch
def fn(x): # Error ~ bool primitive
return torch.add(x, 1)
traced = torch.jit.trace(fn, (torch.zeros((), dtype=torch.int),))
def fn(x): # Error ~ bool primitive
return torch.add(x, False)
# eager: OK
torch.add(torch.zeros((), dtype=torch.bool), True)
# jit trace
traced = torch.jit.trace(fn, (torch.zeros((), dtype=torch.bool),))
```
Similar to https://github.com/pytorch/pytorch/issues/90366 but for `torch.add`.
### Versions
<details><summary><b>Env </b> <i>[click to expand]</i></summary>
<div>
```python
"""
Collecting environment information...
PyTorch version: 1.14.0.dev20221202+cu117
Is debug build: False
CUDA used to build PyTorch: 11.7
ROCM used to build PyTorch: N/A
OS: Ubuntu 22.04.1 LTS (x86_64)
GCC version: (Ubuntu 11.3.0-1ubuntu1~22.04) 11.3.0
Clang version: Could not collect
CMake version: version 3.25.0
Libc version: glibc-2.35
Python version: 3.9.12 (main, Apr 5 2022, 06:56:58) [GCC 7.5.0] (64-bit runtime)
Python platform: Linux-5.15.0-56-generic-x86_64-with-glibc2.35
Is CUDA available: True
CUDA runtime version: 11.6.124
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration:
GPU 0: NVIDIA GeForce RTX 3090
GPU 1: NVIDIA GeForce RTX 3090
GPU 2: NVIDIA GeForce RTX 3090
Nvidia driver version: 515.86.01
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_infer.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.4.1
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] mypy-extensions==0.4.3
[pip3] numpy==1.23.3
[pip3] onnx2torch==1.5.3
[pip3] torch==1.14.0.dev20221202+cu117
[pip3] torchaudio==0.14.0.dev20221203+cu117
[pip3] torchtriton==2.0.0+0d7e753227
[pip3] torchvision==0.15.0.dev20221203+cpu
[conda] numpy 1.23.3 pypi_0 pypi
[conda] onnx2torch 1.5.3 pypi_0 pypi
[conda] torch 1.14.0.dev20221202+cu117 pypi_0 pypi
[conda] torchaudio 0.14.0.dev20221203+cu117 pypi_0 pypi
[conda] torchtriton 2.0.0+0d7e753227 pypi_0 pypi
[conda] torchvision 0.15.0.dev20221203+cpu pypi_0 pypi
"""
```
</div>
</details>
cc @EikanWang @jgong5 @wenzhe-nrv @sanchitintel
| 0 |
4,023 | 90,366 |
[JIT] INTERNAL ASSERT FAILED `torch.mul` with boolean primitive constant
|
oncall: jit
|
### 🐛 Describe the bug
```python
import torch
def fn(x): # OK ~ int,float,etc. primitive
return torch.mul(x, 1)
traced = torch.jit.trace(fn, (torch.zeros((), dtype=torch.int),))
def fn(x): # Error ~ bool primitive
return torch.mul(x, True)
# eager: OK
torch.mul(torch.zeros((), dtype=torch.bool), True)
# jit trace
traced = torch.jit.trace(fn, (torch.zeros((), dtype=torch.bool),))
```
<details><summary><b>Log</b> <i>[click to expand]</i></summary>
<div>
```
"""
Traceback (most recent call last):
File "/home/jiawei/miniconda3/lib/python3.9/site-packages/torch/jit/_trace.py", line 460, in run_mod_and_filter_tensor_outputs
outs = wrap_retval(mod(*_clone_inputs(inputs)))
RuntimeError: 0 INTERNAL ASSERT FAILED at "../torch/csrc/jit/ir/alias_analysis.cpp":608, please report a bug to PyTorch. We don't have an op for aten::mul but it isn't a special case. Argument types: Tensor, bool,
Candidates:
aten::mul.Tensor(Tensor self, Tensor other) -> Tensor
aten::mul.Scalar(Tensor self, Scalar other) -> Tensor
aten::mul.out(Tensor self, Tensor other, *, Tensor(a!) out) -> Tensor(a!)
aten::mul.Scalar_out(Tensor self, Scalar other, *, Tensor(a!) out) -> Tensor(a!)
aten::mul.left_t(t[] l, int n) -> t[]
aten::mul.right_(int n, t[] l) -> t[]
aten::mul.int(int a, int b) -> int
aten::mul.complex(complex a, complex b) -> complex
aten::mul.float(float a, float b) -> float
aten::mul.int_complex(int a, complex b) -> complex
aten::mul.complex_int(complex a, int b) -> complex
aten::mul.float_complex(float a, complex b) -> complex
aten::mul.complex_float(complex a, float b) -> complex
aten::mul.int_float(int a, float b) -> float
aten::mul.float_int(float a, int b) -> float
aten::mul(Scalar a, Scalar b) -> Scalar
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "/test.py", line 18, in <module>
traced = torch.jit.trace(fn, (torch.zeros((), dtype=torch.bool),))
File "/home/jiawei/miniconda3/lib/python3.9/site-packages/torch/jit/_trace.py", line 881, in trace
_check_trace(
File "/home/jiawei/miniconda3/lib/python3.9/site-packages/torch/autograd/grad_mode.py", line 34, in decorate_context
return func(*args, **kwargs)
File "/home/jiawei/miniconda3/lib/python3.9/site-packages/torch/jit/_trace.py", line 551, in _check_trace
traced_outs = run_mod_and_filter_tensor_outputs(traced_func, inputs, "trace")
File "/home/jiawei/miniconda3/lib/python3.9/site-packages/torch/jit/_trace.py", line 466, in run_mod_and_filter_tensor_outputs
raise TracingCheckError(
torch.jit._trace.TracingCheckError: Tracing failed sanity checks!
encountered an exception while running the trace with test inputs.
Exception:
0 INTERNAL ASSERT FAILED at "../torch/csrc/jit/ir/alias_analysis.cpp":608, please report a bug to PyTorch. We don't have an op for aten::mul but it isn't a special case. Argument types: Tensor, bool,
Candidates:
aten::mul.Tensor(Tensor self, Tensor other) -> Tensor
aten::mul.Scalar(Tensor self, Scalar other) -> Tensor
aten::mul.out(Tensor self, Tensor other, *, Tensor(a!) out) -> Tensor(a!)
aten::mul.Scalar_out(Tensor self, Scalar other, *, Tensor(a!) out) -> Tensor(a!)
aten::mul.left_t(t[] l, int n) -> t[]
aten::mul.right_(int n, t[] l) -> t[]
aten::mul.int(int a, int b) -> int
aten::mul.complex(complex a, complex b) -> complex
aten::mul.float(float a, float b) -> float
aten::mul.int_complex(int a, complex b) -> complex
aten::mul.complex_int(complex a, int b) -> complex
aten::mul.float_complex(float a, complex b) -> complex
aten::mul.complex_float(complex a, float b) -> complex
aten::mul.int_float(int a, float b) -> float
aten::mul.float_int(float a, int b) -> float
aten::mul(Scalar a, Scalar b) -> Scalar
"""
```
</div>
</details>
`torch.mul(x, ${CONSTANT})` works when `CONSTANT` is `int/float/...` but failed at `bool`. The torch eager mode also supports using boolean as constant operand of `torch.mul`. We should fix this case to ensure the code compatibility from eager to jit.
### Versions
<details><summary><b>Env </b> <i>[click to expand]</i></summary>
<div>
```python
"""
Collecting environment information...
PyTorch version: 1.14.0.dev20221202+cu117
Is debug build: False
CUDA used to build PyTorch: 11.7
ROCM used to build PyTorch: N/A
OS: Ubuntu 22.04.1 LTS (x86_64)
GCC version: (Ubuntu 11.3.0-1ubuntu1~22.04) 11.3.0
Clang version: Could not collect
CMake version: version 3.25.0
Libc version: glibc-2.35
Python version: 3.9.12 (main, Apr 5 2022, 06:56:58) [GCC 7.5.0] (64-bit runtime)
Python platform: Linux-5.15.0-56-generic-x86_64-with-glibc2.35
Is CUDA available: True
CUDA runtime version: 11.6.124
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration:
GPU 0: NVIDIA GeForce RTX 3090
GPU 1: NVIDIA GeForce RTX 3090
GPU 2: NVIDIA GeForce RTX 3090
Nvidia driver version: 515.86.01
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_infer.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.4.1
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] mypy-extensions==0.4.3
[pip3] numpy==1.23.3
[pip3] onnx2torch==1.5.3
[pip3] torch==1.14.0.dev20221202+cu117
[pip3] torchaudio==0.14.0.dev20221203+cu117
[pip3] torchtriton==2.0.0+0d7e753227
[pip3] torchvision==0.15.0.dev20221203+cpu
[conda] numpy 1.23.3 pypi_0 pypi
[conda] onnx2torch 1.5.3 pypi_0 pypi
[conda] torch 1.14.0.dev20221202+cu117 pypi_0 pypi
[conda] torchaudio 0.14.0.dev20221203+cu117 pypi_0 pypi
[conda] torchtriton 2.0.0+0d7e753227 pypi_0 pypi
[conda] torchvision 0.15.0.dev20221203+cpu pypi_0 pypi
"""
```
</div>
</details>
cc @EikanWang @jgong5 @wenzhe-nrv @sanchitintel
| 0 |
4,024 | 90,365 |
[JIT] INTERNAL ASSERT FAILED when dispatching for `torch.Tensor.view`
|
oncall: jit
|
### 🐛 Describe the bug
```python
import torch
def fn(x):
return torch.Tensor.view(x, torch.int32)
traced = torch.jit.trace(fn, (torch.zeros((1,), dtype=torch.int32),))
"""
Traceback (most recent call last):
File "test.py", line 9, in <module>
traced = torch.jit.trace(fn, (torch.zeros((1,), dtype=torch.int32),))
File "/miniconda3/lib/python3.9/site-packages/torch/jit/_trace.py", line 856, in trace
traced = torch._C._create_function_from_trace(
RuntimeError: 0 INTERNAL ASSERT FAILED at "../torch/csrc/jit/ir/alias_analysis.cpp":608, please report a bug to PyTorch. We don't have an op for aten::view but it isn't a special case. Argument types: Tensor, int,
Candidates:
aten::view(Tensor(a) self, SymInt[] size) -> Tensor(a)
aten::view.dtype(Tensor(a) self, ScalarType dtype) -> Tensor(a)
"""
```
`Tensor.view(dtype=...)` is listed to be supported by PyTorch JIT (see [here](https://pytorch.org/docs/stable/jit_builtin_functions.html#supported-tensor-methods)) and in dispatching it shows the candidate `aten::view.dtype`. However, it is not found so it seems to be a dispatching bug?
Note: this bug is found by a fuzzer.
### Versions
```python
"""
Collecting environment information...
PyTorch version: 1.14.0.dev20221202+cu117
Is debug build: False
CUDA used to build PyTorch: 11.7
ROCM used to build PyTorch: N/A
OS: Ubuntu 22.04.1 LTS (x86_64)
GCC version: (Ubuntu 11.3.0-1ubuntu1~22.04) 11.3.0
Clang version: Could not collect
CMake version: version 3.25.0
Libc version: glibc-2.35
Python version: 3.9.12 (main, Apr 5 2022, 06:56:58) [GCC 7.5.0] (64-bit runtime)
Python platform: Linux-5.15.0-56-generic-x86_64-with-glibc2.35
Is CUDA available: True
CUDA runtime version: 11.6.124
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration:
GPU 0: NVIDIA GeForce RTX 3090
GPU 1: NVIDIA GeForce RTX 3090
GPU 2: NVIDIA GeForce RTX 3090
Nvidia driver version: 515.86.01
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_infer.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.4.1
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] mypy-extensions==0.4.3
[pip3] numpy==1.23.3
[pip3] onnx2torch==1.5.3
[pip3] torch==1.14.0.dev20221202+cu117
[pip3] torchaudio==0.14.0.dev20221203+cu117
[pip3] torchtriton==2.0.0+0d7e753227
[pip3] torchvision==0.15.0.dev20221203+cpu
[conda] numpy 1.23.3 pypi_0 pypi
[conda] onnx2torch 1.5.3 pypi_0 pypi
[conda] torch 1.14.0.dev20221202+cu117 pypi_0 pypi
[conda] torchaudio 0.14.0.dev20221203+cu117 pypi_0 pypi
[conda] torchtriton 2.0.0+0d7e753227 pypi_0 pypi
[conda] torchvision 0.15.0.dev20221203+cpu pypi_0 pypi
"""
```
cc @EikanWang @jgong5 @wenzhe-nrv @sanchitintel
| 1 |
4,025 | 90,347 |
[ONNX] test_mask_rcnn in test_models_onnxruntime.py failed with ONNX version==1.13.0
|
module: onnx, triaged, onnx-triaged
|
### 🐛 Describe the bug
In https://github.com/pytorch/pytorch/pull/90337, the test failed when ONNX version bumped to 1.13.0.
### Versions
Nightly PyTorch
| 0 |
4,026 | 90,320 |
[RFC] Allow FSDP mixed precision for only certain type of submodules
|
oncall: distributed, module: fsdp
|
### 🚀 The feature, motivation and pitch
Mixed Precision frequently runs into unsupported operator for the lower precision issue, or just worse / degraded accuracy if some operators / modules are run in lower precision.
For FSDP native mixed precision, if users are aware of these operators and the modules that they belong to, it could be useful to simply exclude these modules from mixed precision and still get the performance enhancements by having rest of the module in mixed precision.
One useful API might be to ignore some modules for mixed precision, or the reverse direction, specify explicitly which modules to be mixed precision.
For the latter, we could add a `modules_for_mixed_precision` arg to `MixedPrecision` configuration, if this is non-None, it specifies the types of modules we should apply mixed precision on.
### Alternatives
_No response_
### Additional context
_No response_
cc @mrshenli @pritamdamania87 @zhaojuanmao @satgera @gqchen @aazzolini @osalpekar @jiayisuse @H-Huang @kwen2501 @awgu
| 0 |
4,027 | 90,318 |
[Tracking Issue] Mixed precision does not work with ignored modules
|
oncall: distributed, module: fsdp
|
### 🐛 Describe the bug
This is just a tracking issue, the root cause and repro is given in https://github.com/pytorch/pytorch/pull/89971
### Versions
main
cc @mrshenli @pritamdamania87 @zhaojuanmao @satgera @gqchen @aazzolini @osalpekar @jiayisuse @H-Huang @kwen2501 @awgu
| 0 |
4,028 | 90,305 |
Inconsistent Hash of IValue between aten/src/ATen/core/ivalue.cpp and aten/src/ATen/core/Dict_inl.h
|
oncall: jit
|
### 🐛 Describe the bug
Recently, I'm using libtorch 1.13.0 using C++ in VS 2022. I want to create a torch::Dict, which maps tuple<string, string, string> to tuple<string, string, string>. After I create the tuple key, I use torch::IValue::hash(key) and this works. However, when I want to insert (key, value) into dict, the program raises error in DictKeyHash::operator()(const IValue& ivalue) (the function is in aten/src/ATen/core/Dict_inl.h). It says can't hash IValues.
The reason is that DictKeyHash::operator() only supports to hash int, string, double, complex double, bool, tensor and device. However, the funciton torch::IValue::hash in aten/src/ATen/core/ivalue.cpp supports None, Bool, Double, Tensor, Storage, Int, SymInt, SymFloat, String, Tuple, and Device. **There is a conflict between two hash function. The first one cannot hash None, Storage, SymInt, SymFloat, Tuple, and the second one cannot hash complex double.**
Is it a bug? Can these hash functions be consistent? Thanks!
Here's my code.
`#include <iostream>
#include <torch/torch.h>
int main() {
torch::TupleTypePtr pt = torch::TupleType::create({torch::StringType::get(), torch::StringType::get(), torch::StringType::get()});
std::cout << pt->str() << "\n";
c10::Dict<torch::IValue, torch::IValue> dict(pt, pt);
torch::IValue key(std::make_tuple("one", "one", "one"));
std::cout << torch::IValue::hash(key) << "\n";
dict.insert(key, key); // <- will fail in DictKeyHash::operator()
return 0;
}
`
### Versions
Windows 10, Visual Studio 2022, C++, libtorch 1.13.0 with cuda
cc @EikanWang @jgong5 @wenzhe-nrv @sanchitintel @jbschlosser
| 1 |
4,029 | 90,301 |
Unknown buildin op: aten::pad
|
oncall: jit
|
### 🐛 Describe the bug
I'm loading a torchscript EffiecientNet model from Monai into c++ via:
` auto m = torch::jit::load(datapath + "enet-b0_.pt");
`
Here is the text from the error that gets thrown:
Unknown builtin op: aten::pad. Here are some suggestions: aten::svd aten::cat aten::prod aten::put aten::ord aten::grad aten::pop aten::gcd aten::var aten::std aten::add aten::max aten::... ...}
The libtorch code is running under Windows 10, built with VS2019, version 1.10.2+cu113.
I checked the current version of op_registry.cpp, but don't see aten::pad listed, so I'm guessing getting a new build won't help.
### Versions
Collecting environment information...
PyTorch version: 1.13.0
Is debug build: False
CUDA used to build PyTorch: 11.6
ROCM used to build PyTorch: N/A
OS: Microsoft Windows Server 2019 Standard
GCC version: Could not collect
Clang version: Could not collect
CMake version: Could not collect
Libc version: N/A
Python version: 3.8.8 (default, Apr 13 2021, 15:08:03) [MSC v.1916 64 bit (AMD64)] (64-bit runtime)
Python platform: Windows-10-10.0.17763-SP0
Is CUDA available: True
CUDA runtime version: 11.6.124
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration:
GPU 0: Tesla V100S-PCIE-32GB
GPU 1: Tesla V100S-PCIE-32GB
GPU 2: Tesla V100S-PCIE-32GB
GPU 3: Tesla V100S-PCIE-32GB
Nvidia driver version: 516.94
cuDNN version: C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.6\bin\cudnn_ops_train64_8.dll
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] mypy-extensions==0.4.3
[pip3] numpy==1.20.1
[pip3] numpydoc==1.1.0
[pip3] torch==1.13.0
[pip3] torchaudio==0.13.0
[pip3] torchinfo==1.7.1
[pip3] torchvision==0.14.0
[conda] blas 1.0 mkl
[conda] mkl 2021.2.0 haa95532_296
[conda] mkl-service 2.3.0 py38h2bbff1b_1
[conda] mkl_fft 1.3.0 py38h277e83a_2
[conda] mkl_random 1.2.1 py38hf11a4ad_2
[conda] numpy 1.20.1 py38h34a8a5c_0
[conda] numpy-base 1.20.1 py38haf7ebc8_0
[conda] numpydoc 1.1.0 pyhd3eb1b0_1
[conda] pytorch 1.13.0 py3.8_cuda11.6_cudnn8_0 pytorch
[conda] pytorch-cuda 11.6 h867d48c_0 pytorch
[conda] pytorch-mutex 1.0 cuda pytorch
[conda] torchaudio 0.13.0 pypi_0 pypi
[conda] torchinfo 1.7.1 pyhd8ed1ab_0 conda-forge
[conda] torchvision 0.14.0 pypi_0 pypi
cc @EikanWang @jgong5 @wenzhe-nrv @sanchitintel
| 0 |
4,030 | 93,468 |
torch._dynamo.exc.Unsupported: dynamic shapes: arange
|
triaged, bug, oncall: pt2
|
### 🐛 Describe the bug
While giving a try with pytorch2 on OpenNMT-py
using these two lines:
```
rawmodel = build_model(model_opt, opt, vocabs, checkpoint)
model = torch.compile(rawmodel, fullgraph=True, backend='nvprims_aten')
```
### Error logs
getting this:
```
from user code:
File "/home/vincent/nlp/OpenNMT-py/onmt/encoders/transformer.py", line 126, in forward
mask = ~sequence_mask(src_len).unsqueeze(1)
File "/home/vincent/nlp/OpenNMT-py/onmt/utils/misc.py", line 58, in sequence_mask
return (torch.arange(0, max_len, device=lengths.device)
Set torch._dynamo.config.verbose=True for more information
You can suppress this exception and fall back to eager by setting:
torch._dynamo.config.suppress_errors = True
```
### Minified repro
_No response_
cc @ezyang @soumith @msaroufim @wconstab @ngimel @bdhirsh
| 58 |
4,031 | 90,289 |
quantization qconfig: can we set per-channel quant as default for qnnpack?
|
oncall: quantization, triaged
|
### 🐛 Describe the bug
The current default qconfig for qnnpack is per-tensor quantization. Can we update the default qnnpack qconfig to per-channel quantization? I heard that per-channel has been supported for awhile in the qnnpack kernels - is that still true? Is there anything blocking us from upgrading the default?
Motivation: PTQ accuracy on MobileNetV3 + ImageNet 1k is:
* 0.75282 fp32 baseline
* 0.40968 with qnnpack default (per-tensor quant)
* 0.6747 with qnnpack default but per-channel quant enabled
### Versions
master
cc @jerryzh168 @jianyuh @raghuramank100 @jamesr66a @jgong5 @Xia-Weiwen @leslie-fang-intel
| 3 |
4,032 | 90,288 |
quantization observers: can we relax the default epsilon value?
|
oncall: quantization, low priority, triaged
|
### 🐛 Describe the bug
In `https://github.com/pytorch/pytorch/blob/master/torch/ao/quantization/observer.py#L208`, the epsilon value used to determine the uniform quantization scale is defined as
```
eps=torch.finfo(torch.float32).eps
```
This resolves to 1.19e-7 for float32, and the value from `finfo` is chosen so that he smallest representable number such that 1.0 + eps != 1.0. This definition is generic might not apply well to choosing the quantization scale, I would expect the smallest uniform quantization scale value to be determined by restrictions of the underlying backend. For example, for XNNPACK the recommended epsilon value is 2e-12.
On the pretrained weights of MobileNetV3 on ImageNet-1K from torchvision, the weights of the `features.4.block.2.fc1` and `features.4.block.2.fc2` layers are too small in magnitude for PTQ to work correctly with the current default scale value, leading to poor quantization accuracy of these layers in PTQ.
We should consider epsilon in a smarter way. I would expect the overall impact to be low as this is an edge case, but it will be a free accuracy win for PTQ for that edge case.
### Versions
master
cc @jerryzh168 @jianyuh @raghuramank100 @jamesr66a @jgong5 @Xia-Weiwen @leslie-fang-intel
| 4 |
4,033 | 90,284 |
Public API definition is not compatible with `torch.testing`
|
triaged, module: testing, module: python frontend
|
`torch.testing` uses the following layout
```
torch/testing
├── _comparison.py
├── _creation.py
├── __init__.py
├── _internal
│ ├── ...
```
`__init__.py` has the following contents:
https://github.com/pytorch/pytorch/blob/be5108d5f925e9b4ed2a5380dc41e33345a6ec6b/torch/testing/__init__.py#L1-L3
Meaning, we have two private namespaces, namely `_comparison` and `_creation`, in which everything is implemented and only very few functions that should be public are imported into the `torch.testing` namespace.
This standard Python packaging, but it violates the [Public API definition and documentation](https://github.com/pytorch/pytorch/wiki/Public-API-definition-and-documentation)
For example
```pycon
>>> fn = torch.testing.assert_close
>>> fn.__module__
'torch.testing._comparison'
>>> fn.__name__
'assert_close'
```
> Other objects, in particular functions and classes, are public if
- > they have a `__module__` attribute,
:heavy_check_mark:
- > it starts with `torch.`,
:heavy_check_mark:
- > corresponds to a public submodule and
:heavy_multiplication_x:
- > the object's name itself does not start with “_”.
:heavy_check_mark:
`assert_close` is _exposed_ in an public submodule, but it is _implemented_ in a private one.
Unfortunately, without extra hacks, it is impossible to infer the exposure point by just looking at the object. Up until now, all functions that `__init__.py` exposes are part of the allow list
https://github.com/pytorch/pytorch/blob/c6942dbbfbf836450898aa9a0c08aefe437d0765/test/allowlist_for_publicAPI.json#L1026
and thus will be ignored by
https://github.com/pytorch/pytorch/blob/c6942dbbfbf836450898aa9a0c08aefe437d0765/test/test_public_bindings.py#L280
However, #90005 tries to add another function to `torch.testing` with the same setup as before. This now trips CI:
```
# torch.testing.assert_not_close:
- Is public: it is an attribute that does not start with `_` on a module that does not have `__all__` defined
- Does NOT look public: because its `__module__` attribute (`torch.testing._comparison`) is not within the torch library or does not start with the submodule where it is defined (`torch.testing`)
- You can do either of these two things to fix this problem:
- To make it NOT public: either define a `__all__` for `torch.testing` or add a `_` at the beginning of the name
- To make it look public: make sure the `__module__` is properly set and points to a submodule of `torch.testing`
```
Adding a redundant `__all__` to `torch/testing/__init__.py` also doesn't help:
```
# torch.testing.assert_not_close:
- Is public: it is inside the module's (`torch.testing`) `__all__`
- Does NOT look public: because its `__module__` attribute (`torch.testing._comparison`) is not within the torch library or does not start with the submodule where it is defined (`torch.testing`)
- You can do either of these two things to fix this problem:
- To make it NOT public: remove it from the modules's (`torch.testing`) `__all__`
- To make it look public: make sure the `__module__` is properly set and points to a submodule of `torch.testing`
```
Since the first suggestion is not helpful here, we can follow the second one, but it is hacky. For example, we can place the following snippet at the end of`__init__.py`:
```py
def fix_module_attr():
for name, obj in globals().items():
if not name.startswith("_"):
obj.__module__ = __package__
fix_module_attr()
del fix_module_attr
```
Another, and my preferred, solution would be to reword the policy and in turn fix the test to allow simple scenarios as above. I'm also ok to just add all `torch.testing` functions to the allow list, since there are only a few and I don't expect a sudden influx in the future. However
https://github.com/pytorch/pytorch/blob/c6942dbbfbf836450898aa9a0c08aefe437d0765/test/test_public_bindings.py#L292-L295
cc @albanD
| 11 |
4,034 | 90,277 |
cannot backward()
|
needs reproduction, triaged, module: mps
|
### 🐛 Describe the bug
loc("total derivative last state"("(mpsFileLoc): /AppleInternal/Library/BuildRoots/810eba08-405a-11ed-86e9-6af958a02716/Library/Caches/com.apple.xbs/Sources/MetalPerformanceShadersGraph/mpsgraph/MetalPerformanceShadersGraph/Core/Files/MPSGraphUtilities.mm":228:0)): error: input types 'tensor<1x61x64xf32>' and 'tensor<1x32x64xf32>' are not broadcast compatible
LLVM ERROR: Failed to infer result type(s).
when I try to train model on maps which contains nn.LSTM block. when backward(). it crashed.
however, cpu is ok
### Versions
pytorch 1.13
cc @kulinseth @albanD @malfet @DenisVieriu97 @razarmehr @abhudev
| 1 |
4,035 | 90,276 |
make_fx loses node.stack_trace / turn on AOTAutograd by default for all backends
|
high priority, triaged, oncall: pt2
|
### 🐛 Describe the bug
It appears that make_fx loses the node.stack_trace on the relevant nodes. This makes it difficult to integrate into a production compiler since it makes debugging of the resulting model much more difficult. It would be nice if make_fx preserved the node.stack_trace.
```
import torch
import torch._dynamo as dynamo
import functorch
from typing import List
def my_backend(gm: torch.fx.GraphModule,
example_inputs: List[torch.Tensor]):
gm.print_readable()
make_fx_gm = functorch.make_fx(gm)(*example_inputs)
make_fx_gm.print_readable()
return make_fx_gm
@dynamo.optimize(my_backend)
def f(x):
return x * x
f(torch.rand(3))
```
Output:
```
# The graph captured by TorchDynamo
class GraphModule(torch.nn.Module):
def forward(self, x : torch.Tensor):
# File: /tmp/repro2.py:16, code: return x * x
mul = x * x; x = None
return (mul,)
# The result of make_fx
class <lambda>(torch.nn.Module):
def forward(self, arg0_1: f32[3]):
# No stacktrace found for following nodes <------------ missing node.stack_trace
mul: f32[3] = torch.ops.aten.mul.Tensor(arg0_1, arg0_1); arg0_1 = None
return (mul,)
```
### Versions
Collecting environment information...
PyTorch version: 1.14.0.dev20221201+cpu
Is debug build: False
CUDA used to build PyTorch: None
ROCM used to build PyTorch: N/A
OS: Debian GNU/Linux rodete (x86_64)
GCC version: (Debian 12.2.0-3) 12.2.0
Clang version: 14.0.6-2
CMake version: version 3.25.0
Libc version: glibc-2.35
Python version: 3.10.8 (main, Nov 3 2022, 15:17:13) [GCC 12.2.0] (64-bit runtime)
Python platform: Linux-5.19.11-1rodete1-amd64-x86_64-with-glibc2.35
Is CUDA available: False
CUDA runtime version: No CUDA
GPU models and configuration: No CUDA
Nvidia driver version: No CUDA
cuDNN version: No CUDA
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.24.0rc1
[pip3] torch==1.14.0.dev20221201+cpu
[pip3] torchvision==0.15.0.dev20221201+cpu
[conda] Could not collect
cc @ezyang @gchanan @zou3519 @soumith @msaroufim @wconstab @ngimel @bdhirsh
| 4 |
4,036 | 90,263 |
Is it possible to add a parameter in torch.onnx.export to skip the prim::PythonOp subgraph process when exporting the autograd function?
|
module: onnx, triaged
|
### 🚀 The feature, motivation and pitch
Torch 1.13 adds a new feature: Inlined prim::PythonOp for Autograd Function Export (https://github.com/pytorch/pytorch/pull/74765). When tracing, all operations in the autograd function will be recorded as a subgraph of autograd function node. However, this subgraph seems to be useless if a custom symbolic function is implemented in autograd function defination or registered by register_custom_symbolic_op, in which cases the autograd function will be exported as one single node.
In my cases, some operations in my custom autograd functions may also be incompatible with this subgraph process or the following passes. Is it possible that a parameter is added in torch.onnx.export interface to control this subgraph trace or just skip subgraph tracing when a symbolic function is registered by register_custom_op_symbolic or implemented in the autograd function defination?
### Alternatives
_No response_
### Additional context
_No response_
| 3 |
4,037 | 90,261 |
Why torch.mode return different value between CPU and GPU
|
module: cuda, triaged
|
### 🐛 Describe the bug
For this case,
```
tensor_input = torch.Tensor([[[[-0.6572, -0.0377, 0.2676, -0.2568, -1.6279, -0.3259, -0.1349,
-0.6699, 1.0273, 0.0203, -0.7080, 0.9360, 0.8535, 0.0132,
1.2920, -0.4414, -0.5073, -0.5352, 0.2313, 0.1196, -0.7681,
-0.9087, -0.4175, -0.0583, -1.1299, 1.5000, 0.0756, 0.4622,
-0.5273, 1.7432, -0.8896, 1.7295, -0.7310, -0.7080, -0.0253,
0.7202, 2.2656, 1.2324, 1.0000, 0.8584, -3.2207, 0.0425,
-1.3242, -0.0217, 0.2297, -0.3833, -0.0539, 1.2920, -0.6719,
0.3425, 1.4785, 0.6108, 0.5913, -1.3027, -1.0791]]]])
value_gpu, index_gpu = torch.mode(tensor_input.cuda(), -1, False)
value_cpu, index_cpu = torch.mode(tensor_input.cpu(), -1, False)
print("value_gpu is: ", value_gpu)
print("value_cpu is: ", value_cpu)
```
the running result is:
```
value_gpu is: tensor([[[1.2920]]], device='cuda:0')
value_cpu is: tensor([[[-0.7080]]])
```
For the input tensor, 1.2920 and -0.7080, both values above appear twice, why CPU return -0.7080, while GPU return 1.2920 ?
If all point values appear only once, CPU and GPU will return the minimum, why partial point value appear twice, CPU still return the minimum, while GPU will not return the minimum?
I wonder if this phenomenon is reasonable?
### Versions
pytorch v1.10.2 with CUDA10.2
cc @ngimel
| 4 |
4,038 | 90,256 |
LibTorch static build from source missing libshm.so
|
module: build, triaged
|
### 🐛 Describe the bug
Hi everyone,
I am trying to build LibTorch from source. I am following directions given in this link:
https://github.com/pytorch/pytorch/blob/orig/release/1.13/docs/libtorch.rst
I git cloned version 1.13.0 and then ran the following:
mkdir pytorch-build
cd pytorch-build
cmake -DBUILD_SHARED_LIBS:BOOL=OFF -DCMAKE_BUILD_TYPE:STRING=Release -DUSE_CUDA:BOOL=OFF -DPYTHON_EXECUTABLE:PATH=`which python3` -DUSE_CUDNN:BOOL=OFF -DCMAKE_INSTALL_PREFIX:PATH=../pytorch-install ../pytorch
cmake --build . --target install
I am getting the following output during build configuration:
[build_config.txt](https://github.com/pytorch/pytorch/files/10160473/build_config.txt)
And then an error during build process itself:
...
[ 97%] Building CXX object caffe2/CMakeFiles/torch_cpu.dir/__/aten/src/ATen/native/cpu/Activation.cpp.AVX2.cpp.o
[ 97%] Linking CXX static library ../lib/libtorch_cpu.a
[ 97%] Built target torch_cpu
[ 97%] Building CXX object caffe2/CMakeFiles/torch.dir/__/empty.cpp.o
[ 97%] Linking CXX static library ../lib/libtorch.a
[ 97%] Built target torch
[ 97%] Built target python_copy_files
[ 97%] Building C object sleef/src/libm/CMakeFiles/mkrename_gnuabi.dir/mkrename_gnuabi.c.o
[ 97%] Linking C executable ../../bin/mkrename_gnuabi
[ 97%] Built target mkrename_gnuabi
[ 97%] Building C object sleef/src/libm/CMakeFiles/mkmasked_gnuabi.dir/mkmasked_gnuabi.c.o
[ 97%] Linking C executable ../../bin/mkmasked_gnuabi
[ 97%] Built target mkmasked_gnuabi
[ 97%] Building C object sleef/src/common/CMakeFiles/arraymap.dir/arraymap.c.o
[ 97%] Built target arraymap
[ 97%] Building C object sleef/src/common/CMakeFiles/addSuffix.dir/addSuffix.c.o
[ 97%] Linking C executable ../../bin/addSuffix
[ 97%] Built target addSuffix
[ 97%] Building CXX object caffe2/torch/lib/libshm/CMakeFiles/shm.dir/core.cpp.o
[ 97%] Linking CXX shared library ../../../../lib/libshm.so
/usr/bin/ld: cannot find $<TARGET_FILE:dnnl_graph>: No such file or directory
collect2: error: ld returned 1 exit status
gmake[2]: *** [caffe2/torch/lib/libshm/CMakeFiles/shm.dir/build.make:124: lib/libshm.so] Error 1
gmake[1]: *** [CMakeFiles/Makefile2:5384: caffe2/torch/lib/libshm/CMakeFiles/shm.dir/all] Error 2
gmake: *** [Makefile:146: all] Error 2
For the full output of cmake build command, please see:
[build.txt](https://github.com/pytorch/pytorch/files/10162179/build.txt)
I am not sure what I am doing wrong. I also find it interesting that up to that point, all libraries linked were static and this is the first shared library that is being linked.
Thank you in advance,
Pavel.
### Versions
Collecting environment information...
PyTorch version: N/A
Is debug build: N/A
CUDA used to build PyTorch: N/A
ROCM used to build PyTorch: N/A
OS: Ubuntu 22.04.1 LTS (x86_64)
GCC version: (Ubuntu 11.3.0-1ubuntu1~22.04) 11.3.0
Clang version: Could not collect
CMake version: version 3.22.1
Libc version: glibc-2.35
Python version: 3.10.6 (main, Nov 2 2022, 18:53:38) [GCC 11.3.0] (64-bit runtime)
Python platform: Linux-5.15.0-56-generic-x86_64-with-glibc2.35
Is CUDA available: N/A
CUDA runtime version: Could not collect
CUDA_MODULE_LOADING set to: N/A
GPU models and configuration: GPU 0: NVIDIA GeForce RTX 2070 SUPER
Nvidia driver version: 515.86.01
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: N/A
Versions of relevant libraries:
[pip3] mypy==0.991
[pip3] mypy-extensions==0.4.3
[pip3] numpy==1.23.1
[pip3] types-mypy-extensions==0.4
[conda] Could not collect
cc @malfet @seemethere
| 0 |
4,039 | 90,245 |
[Distributed] `Invalid scalar type` when `dist.scatter()` boolean tensor
|
oncall: distributed
|
### 🐛 Describe the bug
I am trying to scatter boolean tensor but failed with error: `Invalid scalar type` while it works well with dtype=uint8.
**torch version: 1.13.0+cu117**
```
def worker(rank, world_size):
...
dtype = th.uint8
dtype = th.bool
scatter_list = [ th.tensor([True, True, True, True], dtype=dtype) for _ in range(4) ]
gather_list = [ th.tensor([False, False, False, False], dtype=dtype) for _ in range(4) ]
for i in range(world_size):
dist.scatter(gather_list[i], scatter_list if i == rank else [], src=i)
```
```
File "/home/ubuntu/.local/lib/python3.6/site-packages/torch/distributed/distributed_c10d.py", line 2290, in scatter
work.wait()
RuntimeError: Invalid scalar type
```
This error also happens in other distributed call like `dist.all_reduce()`.
```
import os
import torch
from torch import distributed as dist
import torch.multiprocessing as mp
def worker(rank, world_size):
os.environ['MASTER_ADDR'] = 'localhost'
os.environ['MASTER_PORT'] = '12355'
device = 'cpu' #'cuda'
dist.init_process_group('gloo' if device == 'cpu' else 'nccl', rank=rank, world_size=world_size)
dtype = torch.bool
#dtype = torch.uint8
tensor = torch.tensor([0,1], dtype=dtype)
dist.all_reduce(tensor)
if __name__ == '__main__':
mp.spawn(worker, args=(2,), nprocs=2, join=True)
```
### Versions
Collecting environment information...
PyTorch version: 1.13.0+cu117
Is debug build: False
CUDA used to build PyTorch: 11.7
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.5 LTS (x86_64)
GCC version: (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0
Clang version: Could not collect
CMake version: version 3.16.3
Libc version: glibc-2.31
Python version: 3.8.10 (default, Jun 22 2022, 20:18:18) [GCC 9.4.0] (64-bit runtime)
Python platform: Linux-5.15.0-1022-aws-x86_64-with-glibc2.29
Is CUDA available: True
CUDA runtime version: 11.7.99
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration: GPU 0: Tesla T4
Nvidia driver version: 515.65.01
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.24.0rc1
[pip3] torch==1.13.0
[pip3] torchaudio==0.13.0
[pip3] torchvision==0.14.0
[conda] No relevant packages
cc @mrshenli @pritamdamania87 @zhaojuanmao @satgera @rohan-varma @gqchen @aazzolini @osalpekar @jiayisuse @H-Huang @kwen2501 @awgu
| 5 |
4,040 | 93,466 |
Strategy for optimizing away transient dynamic shapes / device syncs
|
triaged, bug, oncall: pt2
|
### 🐛 Describe the bug
Context: https://github.com/pytorch/xla/issues/4248
The key subtlety here is that although in principle we can perform these optimizations, we need to make sure not to "give up" too early by graph breaking immediately when the sync/dynamically sized output occurs. This may mean some metadata associated with tensors has to be computed more lazily (since to compute it eagerly would require a sync.) Also related to unbacked symints.
cc @soumith @msaroufim @wconstab @ngimel @bdhirsh @voznesenskym
### Error logs
_No response_
### Minified repro
_No response_
| 1 |
4,041 | 93,465 |
Graph breaks with HuggingFace Stable Diffusion
|
triaged, bug
|
### 🐛 Describe the bug
Using this as a tracking issue for graph breaks in HuggingFace Stable Diffusion. I'm going over the outputs from `explain` api, and trying to understand the different graph breaks and how to avoid them.
- [ ] Number of graphs do not match with number of graph break reasons. (Example script shows 105 graphs vs 75 reasons)
- [ ] call_function UserDefinedObjectVariable: source is a user defined class wrapping torch.Tensor as attribute. Can this be supported in dynamo?
```python
@dataclass
class Transformer2DModelOutput(BaseOutput):
sample: torch.FloatTensor
...
def some_func(...):
...
return Transformer2DModelOutput(sample=output)
```
- [ ] data dependent operator: aten._local_scalar_dense.default: What's the recommended step to work around this issue? Can symbolic number help supporting this inside dynamo?
```
File "/home/bowbao/diffusers/src/diffusers/schedulers/scheduling_pndm.py:337", line 337, in step_plms
prev_sample = self._get_prev_sample(sample, timestep, prev_timestep, model_output)
File "/home/bowbao/diffusers/src/diffusers/schedulers/scheduling_pndm.py:371", line 371, in _get_prev_sample
alpha_prod_t = self.alphas_cumprod[timestep]
```
- [ ] Tensor.numpy: computation in numpy.
### Error logs
```log
Dynamo produced 105 graphs with 104 graph break and 1367 ops
Break reasons:
1. call_function UserDefinedObjectVariable(CLIPTokenizer) [ListVariable()] {'padding': ConstantVariable(str), 'max_length': ConstantVariable(int), 'truncation': ConstantVariable(bool), 'return_tensors': ConstantVariable(str)}
File "/home/bowbao/diffusers/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion.py:285", line 285, in <graph break in _encode_prompt>
return_tensors="pt",
2. call_function UserDefinedClassVariable() [] {'sample': TensorVariable()}
File "/home/bowbao/diffusers/src/diffusers/models/attention.py:221", line 221, in forward
return Transformer2DModelOutput(sample=output)
3. data dependent operator: aten._local_scalar_dense.default
File "/home/bowbao/diffusers/src/diffusers/schedulers/scheduling_pndm.py:337", line 337, in step_plms
prev_sample = self._get_prev_sample(sample, timestep, prev_timestep, model_output)
File "/home/bowbao/diffusers/src/diffusers/schedulers/scheduling_pndm.py:371", line 371, in _get_prev_sample
alpha_prod_t = self.alphas_cumprod[timestep]
4. data dependent operator: aten._local_scalar_dense.default
File "/home/bowbao/diffusers/src/diffusers/schedulers/scheduling_pndm.py:372", line 372, in <graph break in _get_prev_sample>
alpha_prod_t_prev = self.alphas_cumprod[prev_timestep] if prev_timestep >= 0 else self.final_alpha_cumprod
5. call_function UserDefinedClassVariable() [] {'sample': TensorVariable()}
File "/home/bowbao/diffusers/src/diffusers/models/vae.py:586", line 586, in decode
return DecoderOutput(sample=dec)
6. Tensor.numpy
File "/home/bowbao/diffusers/src/diffusers/pipelines/stable_diffusion/safety_checker.py:56", line 56, in forward
special_cos_dist = cosine_distance(image_embeds, self.special_care_embeds).cpu().float().numpy()
7. Tensor.numpy
File "/home/bowbao/diffusers/src/diffusers/pipelines/stable_diffusion/safety_checker.py:57", line 57, in <graph break in forward>
cos_dist = cosine_distance(image_embeds, self.concept_embeds).cpu().float().numpy()
TorchDynamo compilation metrics:
Function Runtimes (s)
--------------------------------------------------- ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
convert_frame_assert.<locals>._convert_frame_assert 0.1300, 0.0086, 0.0030, 0.0030, 0.0000, 0.0042, 0.0001, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.3416, 0.3279, 0.3279, 0.0081, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0001, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0001, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0001, 0.0000, 0.0000, 0.0000, 0.0000, 0.0115, 0.0000, 0.0120, 1.0618, 0.0001, 0.0001, 0.0000, 0.0000, 1.0440, 0.0074, 0.0036, 0.0057, 0.0000, 0.0029, 0.0016, 0.9361, 0.0241, 0.5783, 0.5774, 0.0163, 0.0016, 0.1725, 0.0350, 0.1384, 0.0017, 0.0000, 0.0000, 0.0000, 0.0026, 0.0029, 0.0000, 0.0352, 0.1380, 0.0060, 0.1713, 0.1389, 0.0014, 0.0021, 0.0023, 0.0351, 0.1375, 0.0060, 0.0377, 0.1374, 0.0014, 0.0021, 0.0023, 0.0347, 0.1368, 0.0060, 0.0704, 0.1692, 0.0024, 0.0012, 0.0007, 0.0349, 0.0031, 0.0023, 0.1366, 0.0014, 0.0021, 0.0023, 0.0350, 0.1263, 0.1744, 0.0375, 0.1372, 0.0384, 0.1364, 0.0381, 0.1366, 0.0082, 0.0375, 0.1365, 0.0375, 0.1366, 0.0374, 0.1367, 0.0082, 0.0375, 0.1374, 0.0374, 0.1375, 0.0375, 0.1362, 0.0016, 0.0000, 0.0021, 0.0023, 0.0123, 0.0158, 0.0062, 0.0074, 0.0065, 0.0153, 0.0034, 0.0017, 0.0000, 0.0022, 0.0022, 0.0187, 0.0165, 0.0034, 0.0178, 0.0155, 0.0034, 0.0209, 0.0189, 0.0036, 0.0227, 0.0213, 0.0035, 0.0238, 0.0217, 0.0036, 0.0237, 0.0216, 0.0034, 0.0240, 0.0216, 0.0035, 0.0235, 0.0219, 0.0034, 0.0236, 0.0217, 0.0036, 0.0235, 0.0216, 0.0035, 0.0237, 0.0216, 0.0035, 0.0233, 0.0216, 0.0036, 0.0240, 0.0216, 0.0034, 0.0233, 0.0217, 0.0035, 0.0236, 0.0217, 0.0034, 0.0235, 0.0215, 0.0035, 0.0239, 0.0218, 0.0036, 0.0235, 0.0222, 0.0035, 0.0236, 0.0216, 0.0037, 0.0236, 0.0217, 0.0034, 0.0238, 0.0215, 0.0035, 0.0235, 0.0216, 0.0036, 0.0240, 0.0216, 0.0034, 0.0234, 0.0216, 0.0035, 0.0245, 0.0218, 0.0035, 0.0235, 0.0216, 0.0037, 0.0240, 0.0216, 0.0035, 0.0236, 0.0215, 0.0036, 0.0238, 0.0218, 0.0035, 0.0241, 0.0216, 0.0035, 0.0237, 0.0215, 0.0037, 0.0237, 0.0217, 0.0035, 0.0236, 0.0216, 0.0036, 0.0243, 0.0221, 0.0036, 0.0236, 0.0215, 0.0037, 0.0238, 0.0220, 0.0037, 0.0237, 0.0215, 0.0037, 0.0234, 0.0219, 0.0035, 0.0237, 0.0216, 0.0035, 0.0235, 0.0219, 0.0035, 0.0236, 0.0216, 0.0035, 0.0237, 0.0216, 0.0035, 0.0237, 0.0215, 0.0035, 0.0236, 0.0216, 0.0035, 0.0238, 0.0216, 0.0035, 0.0236, 0.0215, 0.0035, 0.0238, 0.0218, 0.0035, 0.0234, 0.0215, 0.0036, 0.0237, 0.0221, 0.0035, 0.0235, 0.0216, 0.0150, 0.0035, 0.4317, 0.5953, 0.0018, 0.0000, 0.0022, 0.0024, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0001, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 2.0281, 0.0753, 0.0055, 0.0000, 0.0000, 0.0000
graphs: 105
reasons: 75
```
### Minified repro
```python
import torch
from diffusers import StableDiffusionPipeline
from torch import _dynamo as torchdynamo
pipe = StableDiffusionPipeline.from_pretrained(
"runwayml/stable-diffusion-v1-5",
torch_dtype=torch.float16,
revision="fp16",
)
pipe = pipe.to("cuda")
prompt = "a photo of an astronaut riding a horse on mars"
def fn(x):
return pipe(x)
(
explanation,
out_guards,
graphs,
ops_per_graph,
break_reasons,
explanation_verbose,
) = torchdynamo.explain(fn, prompt)
print(explanation_verbose) # Dynamo produced 105 graphs with 104 graph break and 1367 ops
print(f"graphs: {len(graphs)}") # 105
print(f"reasons: {len(break_reasons)}") # 75
```
| 4 |
4,042 | 90,194 |
Unexpected behaviour of 1.13.0
|
triaged, module: advanced indexing
|
### 🐛 Describe the bug
Hello, an unexpected behaviour appeared in PyTorch 1.13.0. I do not see it in Release Notes. Or is it a feature? Why can't I do it this way?
The following code works well in 1.12.1 but fails in 1.13.0:
```python
import torch
mask = torch.full((3,), True, dtype=bool, device='cuda')
array = torch.tensor([1, 2, 3], dtype=torch.float32, device='cpu')
array = array[mask]
print(array)
```
1.13.0 gives the following error:
```bash
RuntimeError: indices should be either on cpu or on the same device as the indexed tensor (cpu)
```
### Versions
pytorch=1.13.0
| 3 |
4,043 | 90,181 |
Graph is renamed in torch.jit
|
oncall: jit
|
### 🐛 Describe the bug
The graph of a model is renamed when is converted into torchscript.
I have prepared a toy model for this.
```
import torch
import torchvision
import tensorrt
import torch_tensorrt
class ToyModel(torch.nn.Module):
def __init__(self):
super().__init__()
self.gaus = torchvision.transforms.GaussianBlur([33, 33], [4., 4.])
self.conv = torch.nn.Conv2d(3, 64, (3,3))
self.relu = torch.nn.ReLU()
def forward(self, x):
x = self.relu(self.conv(x))
x = self.gaus(x)
return x
model1 = ToyModel().eval().to('cuda')
model2 = ToyModel().eval().to('cuda')
traced1 = torch.jit.trace(model1, torch.randn(1,3,224,224).to('cuda'))
traced2 = torch.jit.trace(model2, torch.randn(1,3,224,224).to('cuda'))
print(traced1.graph)
print(traced2.graph)
```
The names in the graphs change as I show below
Here the first graph
```
graph(%self.1 : __torch__.ToyModel,
%x.1 : Float(1, 3, 224, 224, strides=[150528, 50176, 224, 1], requires_grad=0, device=cuda:0)):
%gaus : __torch__.torchvision.transforms.transforms.GaussianBlur = prim::GetAttr[name="gaus"](%self.1)
%relu : __torch__.torch.nn.modules.activation.ReLU = prim::GetAttr[name="relu"](%self.1)
%conv : __torch__.torch.nn.modules.conv.Conv2d = prim::GetAttr[name="conv"](%self.1)
%190 : Tensor = prim::CallMethod[name="forward"](%conv, %x.1)
%191 : Tensor = prim::CallMethod[name="forward"](%relu, %190)
%192 : Tensor = prim::CallMethod[name="forward"](%gaus, %191)
return (%192)
```
Here the second graph
```
graph(%self.1 : __torch__.___torch_mangle_7.ToyModel,
%x.1 : Float(1, 3, 224, 224, strides=[150528, 50176, 224, 1], requires_grad=0, device=cuda:0)):
%gaus : __torch__.torchvision.transforms.transforms.___torch_mangle_4.GaussianBlur = prim::GetAttr[name="gaus"](%self.1)
%relu : __torch__.torch.nn.modules.activation.___torch_mangle_6.ReLU = prim::GetAttr[name="relu"](%self.1)
%conv : __torch__.torch.nn.modules.conv.___torch_mangle_5.Conv2d = prim::GetAttr[name="conv"](%self.1)
%190 : Tensor = prim::CallMethod[name="forward"](%conv, %x.1)
%191 : Tensor = prim::CallMethod[name="forward"](%relu, %190)
%192 : Tensor = prim::CallMethod[name="forward"](%gaus, %191)
return (%192)
```
Why happens this rename? This is relationed with other error https://github.com/pytorch/TensorRT/issues/1526
### Versions
PyTorch version: 1.11.0+cu113
Is debug build: False
CUDA used to build PyTorch: 11.3
ROCM used to build PyTorch: N/A
OS: Ubuntu 22.04.1 LTS (x86_64)
GCC version: (Ubuntu 11.3.0-1ubuntu1~22.04) 11.3.0
Clang version: Could not collect
CMake version: Could not collect
Libc version: glibc-2.35
Python version: 3.10.6 (main, Nov 2 2022, 18:53:38) [GCC 11.3.0] (64-bit runtime)
Python platform: Linux-5.15.0-56-generic-x86_64-with-glibc2.35
Is CUDA available: True
CUDA runtime version: Could not collect
CUDA_MODULE_LOADING set to:
GPU models and configuration: GPU 0: NVIDIA GeForce RTX 3090
Nvidia driver version: 525.60.11
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.23.5
[pip3] torch==1.11.0+cu113
[pip3] torch-tensorrt==1.1.0
[pip3] torchvision==0.12.0+cu113
[conda] No relevant packages
cc @EikanWang @jgong5 @wenzhe-nrv @sanchitintel
| 0 |
4,044 | 93,464 |
wav2vec2 model: error trying to do inference
|
triaged, bug
|
### 🐛 Describe the bug
I tried to do torch.compile() on the second most downloaded model of facebook on huggingface: https://huggingface.co/facebook/wav2vec2-large-960h-lv60-self
I took the example of usage they provide and just added the torch.compile() step.
I also tried with an another custom audio sample earlier, and strangely, it ran, but very slowly compared to the original model...
But it had the same prediction result
### Error logs
Here is the warnings and the traceback:
```
Some weights of Wav2Vec2ForCTC were not initialized from the model checkpoint at facebook/wav2vec2-large-960h-lv60-self and are newly initialized: ['wav2vec2.masked_spec_embed']
You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
No CUDA runtime is found, using CUDA_HOME='/usr/local/cuda'
Found cached dataset librispeech_asr_dummy (/home/noetits/.cache/huggingface/datasets/patrickvonplaten___librispeech_asr_dummy/clean/2.1.0/f2c70a4d03ab4410954901bde48c54b85ca1b7f9bf7d616e7e2a72b5ee6ddbfc)
It is strongly recommended to pass the ``sampling_rate`` argument to this function. Failing to do so can result in silent errors that might be hard to debug.
/home/noetits/miniconda3/envs/.../lib/python3.10/site-packages/torch/storage.py:315: UserWarning: TypedStorage is deprecated. It will be removed in the future and UntypedStorage will be the only storage class. This should only matter to you if you are using storages directly.
warnings.warn(message, UserWarning)
/home/noetits/miniconda3/envs/.../lib/python3.10/site-packages/torch/storage.py:315: UserWarning: TypedStorage is deprecated. It will be removed in the future and UntypedStorage will be the only storage class. This should only matter to you if you are using storages directly.
warnings.warn(message, UserWarning)
---------------------------------------------------------------------------
AssertionError Traceback (most recent call last)
Cell In [1], line 17
14 input_values = processor(ds[0]["audio"]["array"], return_tensors="pt", padding="longest").input_values
16 # retrieve logits
---> 17 logits = model(input_values).logits
19 # take argmax and decode
20 predicted_ids = torch.argmax(logits, dim=-1)
File ~/miniconda3/envs/.../lib/python3.10/site-packages/torch/nn/modules/module.py:1480, in Module._call_impl(self, *args, **kwargs)
1475 # If we don't have any hooks, we want to skip the rest of the logic in
1476 # this function, and just call forward.
1477 if not (self._backward_hooks or self._backward_pre_hooks or self._forward_hooks or self._forward_pre_hooks
1478 or _global_backward_pre_hooks or _global_backward_hooks
1479 or _global_forward_hooks or _global_forward_pre_hooks):
-> 1480 return forward_call(*args, **kwargs)
1481 # Do not call functions when jit is used
1482 full_backward_hooks, non_full_backward_hooks = [], []
File ~/miniconda3/envs/.../lib/python3.10/site-packages/torch/_dynamo/eval_frame.py:80, in OptimizedModule.forward(self, *args, **kwargs)
79 def forward(self, *args, **kwargs):
---> 80 return self.dynamo_ctx(self._orig_mod.forward)(*args, **kwargs)
File ~/miniconda3/envs/.../lib/python3.10/site-packages/torch/_dynamo/eval_frame.py:209, in _TorchDynamoContext.__call__.<locals>._fn(*args, **kwargs)
207 dynamic_ctx.__enter__()
208 try:
--> 209 return fn(*args, **kwargs)
210 finally:
211 set_eval_frame(prior)
File ~/miniconda3/envs/.../lib/python3.10/site-packages/transformers/models/wav2vec2/modeling_wav2vec2.py:1742, in Wav2Vec2ForCTC.forward(self, input_values, attention_mask, output_attentions, output_hidden_states, return_dict, labels)
1732 r"""
1733 labels (`torch.LongTensor` of shape `(batch_size, target_length)`, *optional*):
1734 Labels for connectionist temporal classification. Note that `target_length` has to be smaller or equal to
(...)
1737 config.vocab_size - 1]`.
1738 """
1740 return_dict = return_dict if return_dict is not None else self.config.use_return_dict
-> 1742 outputs = self.wav2vec2(
1743 input_values,
1744 attention_mask=attention_mask,
1745 output_attentions=output_attentions,
1746 output_hidden_states=output_hidden_states,
1747 return_dict=return_dict,
1748 )
1750 hidden_states = outputs[0]
1751 hidden_states = self.dropout(hidden_states)
File ~/miniconda3/envs/.../lib/python3.10/site-packages/torch/nn/modules/module.py:1480, in Module._call_impl(self, *args, **kwargs)
1475 # If we don't have any hooks, we want to skip the rest of the logic in
1476 # this function, and just call forward.
1477 if not (self._backward_hooks or self._backward_pre_hooks or self._forward_hooks or self._forward_pre_hooks
1478 or _global_backward_pre_hooks or _global_backward_hooks
1479 or _global_forward_hooks or _global_forward_pre_hooks):
-> 1480 return forward_call(*args, **kwargs)
1481 # Do not call functions when jit is used
1482 full_backward_hooks, non_full_backward_hooks = [], []
File ~/miniconda3/envs/.../lib/python3.10/site-packages/transformers/models/wav2vec2/modeling_wav2vec2.py:1308, in Wav2Vec2Model.forward(self, input_values, attention_mask, mask_time_indices, output_attentions, output_hidden_states, return_dict)
1304 hidden_states[mask_feature_indices] = 0
1306 return hidden_states
-> 1308 @add_start_docstrings_to_model_forward(WAV_2_VEC_2_INPUTS_DOCSTRING)
1309 @add_code_sample_docstrings(
1310 processor_class=_PROCESSOR_FOR_DOC,
1311 checkpoint=_CHECKPOINT_FOR_DOC,
1312 output_type=Wav2Vec2BaseModelOutput,
1313 config_class=_CONFIG_FOR_DOC,
1314 modality="audio",
1315 expected_output=_EXPECTED_OUTPUT_SHAPE,
1316 )
1317 def forward(
1318 self,
1319 input_values,
1320 attention_mask=None,
1321 mask_time_indices=None,
1322 output_attentions=None,
1323 output_hidden_states=None,
1324 return_dict=None,
1325 ):
1326 output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
1327 output_hidden_states = (
1328 output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
1329 )
File ~/miniconda3/envs/.../lib/python3.10/site-packages/torch/_dynamo/eval_frame.py:209, in _TorchDynamoContext.__call__.<locals>._fn(*args, **kwargs)
207 dynamic_ctx.__enter__()
208 try:
--> 209 return fn(*args, **kwargs)
210 finally:
211 set_eval_frame(prior)
File ~/miniconda3/envs/.../lib/python3.10/site-packages/functorch/_src/aot_autograd.py:2107, in aot_module_simplified.<locals>.forward(*runtime_args)
2105 full_args.extend(params_flat)
2106 full_args.extend(runtime_args)
-> 2107 return compiled_fn(full_args)
File ~/miniconda3/envs/.../lib/python3.10/site-packages/functorch/_src/aot_autograd.py:811, in make_boxed_func.<locals>.g(args)
810 def g(args):
--> 811 return f(*args)
File ~/miniconda3/envs/.../lib/python3.10/site-packages/functorch/_src/aot_autograd.py:1687, in aot_dispatch_autograd.<locals>.debug_compiled_function(*args)
1681 elif not can_require_grad:
1682 assert not a.requires_grad, format_guard_bug_msg(
1683 aot_config,
1684 f"{describe_input(i, aot_config)} would not require grad"
1685 )
-> 1687 return compiled_function(*args)
File ~/miniconda3/envs/.../lib/python3.10/site-packages/functorch/_src/aot_autograd.py:1551, in aot_dispatch_autograd.<locals>.compiled_function(*args)
1548 else:
1549 args_with_synthetic_bases = args
-> 1551 all_outs = CompiledFunction.apply(*args_with_synthetic_bases)
1552 if CompiledFunction.num_aliasing_metadata_outs > 0:
1553 outs = all_outs[:-CompiledFunction.num_aliasing_metadata_outs]
File ~/miniconda3/envs/.../lib/python3.10/site-packages/functorch/_src/aot_autograd.py:1455, in aot_dispatch_autograd.<locals>.CompiledFunction.forward(ctx, *deduped_flat_tensor_args)
1447 @staticmethod
1448 def forward(ctx, *deduped_flat_tensor_args):
1449
(...)
1453 # - Note that in the synthetic bases case, mutated_inputs will correspond to an updated version
1454 # of the original view, and not the synthetic base
-> 1455 fw_outs = call_func_with_args(
1456 CompiledFunction.compiled_fw, deduped_flat_tensor_args, disable_amp=disable_amp
1457 )
1459 num_non_aliased_outs = CompiledFunction.num_non_aliased_outs
1460 num_aliasing_metadata_outs = CompiledFunction.num_aliasing_metadata_outs
File ~/miniconda3/envs/.../lib/python3.10/site-packages/functorch/_src/aot_autograd.py:836, in call_func_with_args(f, args, steal_args, disable_amp)
834 try:
835 if hasattr(f, "_boxed_call"):
--> 836 out = normalize_as_list(f(args))
837 else:
838 # TODO: Please remove soon
839 # https://github.com/pytorch/pytorch/pull/83137#issuecomment-1211320670
840 warnings.warn(
841 "Your compiler for AOTAutograd is returning a a function that doesn't take boxed arguments. "
842 "Please wrap it with functorch.compile.make_boxed_func or handle the boxed arguments yourself. "
843 "See https://github.com/pytorch/pytorch/pull/83137#issuecomment-1211320670 for rationale."
844 )
File /tmp/torchinductor_noetits/dh/cdhukqo6kp2i5wvu22fwo63insaj3b7qi4fq4a6rr52eycvrif32.py:1270, in call(args)
1268 del primals_33
1269 buf1 = aten.convolution(buf0, primals_1, primals_2, (5,), (0,), (1,), False, (0,), 1)
-> 1270 assert_size_stride(buf1, (1, 512, 14879), (7618048, 14879, 1))
1271 del primals_2
1272 buf2 = empty_strided((1, 14879, 1), (14879, 1, 14879), device='cpu', dtype=torch.float32)
AssertionError: expected size 512==512, stride 1==14879 at dim=1
```
### Minified repro
I didn't try the minifier, but with the huggingface example, if you add just the `torch.compile()`, I assume you can reproduce the problem
Versions:
Working on a WSL UBUNTU 22.04 LTS
torch 1.14.0.dev20221204+cpu
torchaudio 0.14.0.dev20221204+cpu
torchvision 0.15.0.dev20221204+cpu
```
from transformers import Wav2Vec2Processor, Wav2Vec2ForCTC
from datasets import load_dataset
import torch
# load model and processor
processor = Wav2Vec2Processor.from_pretrained("facebook/wav2vec2-large-960h-lv60-self")
model = Wav2Vec2ForCTC.from_pretrained("facebook/wav2vec2-large-960h-lv60-self")
model=torch.compile(model)
# load dummy dataset and read soundfiles
ds = load_dataset("patrickvonplaten/librispeech_asr_dummy", "clean", split="validation")
# tokenize
input_values = processor(ds[0]["audio"]["array"], return_tensors="pt", padding="longest").input_values
# retrieve logits
logits = model(input_values).logits
# take argmax and decode
predicted_ids = torch.argmax(logits, dim=-1)
transcription = processor.batch_decode(predicted_ids)
```
| 4 |
4,045 | 90,171 |
Option to let DistributedDataParallel know in advance unused parameters at each forward pass
|
oncall: distributed, enhancement
|
### 🚀 The feature, motivation and pitch
**Motivation:** In models with stochastic depth and the like, at each forward pass some layers (or parts of them) are skipped and thus one needs to set `find_unused_parameters=True`, which makes training much slower in general. Yet, one can implement these models in such a way that the unused parameters at each step are known **in advance** (e.g., the layer sampling is done before the model forward pass and not on-the-fly). It would then be great if we could feed this information to the DDP model so that it doesn't need to find the unused parameters.
The usage could be something like the following:
```python
model = DistributedDataParallel(model, find_unused_parameters=False)
for x in dataloader:
# random_layer_sampling should return the same layers across GPUs
layers_to_skip = random_layer_sampling(model)
p = get_parameters(layers_to_skip)
output = model(x, unused_parameters=p)
...
```
### Alternatives
Currently there is no option other than setting `find_unused_parameters=True`.
### Additional context
_No response_
cc @mrshenli @pritamdamania87 @zhaojuanmao @satgera @rohan-varma @gqchen @aazzolini @osalpekar @jiayisuse @H-Huang @kwen2501 @awgu
| 5 |
4,046 | 90,169 |
Unable to export CFlow model to ONNX
|
module: onnx, triaged
|
### 🐛 Describe the bug
I am trying to export the [Cflow-ad](https://github.com/gudovskiy/cflow-ad) model to onnx format.
This model has an Encoder-Decoder architecture.
The Encoder is a feature extractor network (like Resnet18, MoblinetV3 etc..) that takes an image as an input, while the decoder **loops** over the intermediate feature vectors of the encoder and does some specific "positional encoding" on the layers.
In the source code, the **decoder** is a list of decoders.
In addition, there is no "Cflow model" class in the source code, therefore I wrote a simple Cflow module class to help export the model, as follows:
```
class CFlow(torch.nn.Module):
def __init__(self, c):
super(CFlow, self).__init__()
L = c.pool_layers
self.encoder, self.pool_layers, self.pool_dims = load_encoder_arch(c, L)
self.encoder = self.encoder.to(c.device).eval()
self.decoders = [load_decoder_arch(c, pool_dim) for pool_dim in self.pool_dims]
self.decoders = [decoder.to(c.device) for decoder in self.decoders]
params = list(self.decoders[0].parameters())
for l in range(1, L):
params += list(self.decoders[l].parameters())
# optimizer
self.optimizer = torch.optim.Adam(params, lr=c.lr)
self.N=256
def forward(self, x):
P = c.condition_vec
#print(self.decoders)
self.decoders = [decoder.eval() for decoder in self.decoders]
height = list()
width = list()
i=0
test_dist = [list() for layer in self.pool_layers]
test_loss = 0.0
test_count = 0
start = time.time()
_ = self.encoder(x)
with torch.no_grad():
for l, layer in enumerate(self.pool_layers):
e = activation[layer] # BxCxHxW
#
B, C, H, W = e.size()
S = H * W
E = B * S
#
if i == 0: # get stats
height.append(H)
width.append(W)
#
p = positionalencoding2d(P, H, W).to(c.device).unsqueeze(0).repeat(B, 1, 1, 1)
c_r = p.reshape(B, P, S).transpose(1, 2).reshape(E, P) # BHWxP
e_r = e.reshape(B, C, S).transpose(1, 2).reshape(E, C) # BHWxC
decoder = self.decoders[l]
FIB = E // self.N + int(E % self.N > 0) # number of fiber batches
for f in range(FIB):
if f < (FIB - 1):
idx = torch.arange(f * self.N, (f + 1) * self.N)
else:
idx = torch.arange(f * self.N, E)
#
c_p = c_r[idx] # NxP
e_p = e_r[idx] # NxC
# m_p = m_r[idx] > 0.5 # Nx1
#
if 'cflow' in c.dec_arch:
z, log_jac_det = decoder(e_p, [c_p, ])
else:
z, log_jac_det = decoder(e_p)
#
decoder_log_prob = get_logp(C, z, log_jac_det)
log_prob = decoder_log_prob / C # likelihood per dim
loss = -log_theta(log_prob)
test_loss += t2np(loss.sum())
test_count += len(loss)
test_dist[l] = test_dist[l] + log_prob.detach().cpu().tolist()
return height, width, test_dist
```
The argument 'c' is a config variable used to obtain useful parameters.
After the class is defined, I set all the needed parameters as in [main](https://github.com/gudovskiy/cflow-ad/blob/master/main.py).
Then, I added the following code to start the export:
```
model = CFlow(c)
print("Created !!!")
PATH = 'weights/mvtec_mobilenet_v3_large_freia-cflow_pl3_cb8_inp256_run0_Model_2022-11-08-10:50:39.pt'
model=load_weights(model,PATH)
model.eval()
batch_size = 1
x = torch.randn(batch_size, 3, 256, 256).to(c.device)
out=model(x)
```
The load_weights method is as follows:
```
def load_weights(model, filename):
path = os.path.join(filename)
state = torch.load(path)
model.encoder.load_state_dict(state['encoder_state_dict'], strict=False)
decoders = [decoder.load_state_dict(state, strict=False) for decoder, state in
zip(model.decoders, state['decoder_state_dict'])]
print('Loading weights from {}'.format(filename))
return model
```
Finally:
```
torch.onnx.export(
model,
x,
custom-d.onnx",
export_params=True,
verbose=True,
opset_version=11,
input_names=["input"],
output_names=["output"],
)
```
The code runs successfully, however no model is exported and thousands of lines are printed on the screen, like:
```
9.5554e-02 -2.4600e-02 7.8328e-02 1.0419e-02
4.5502e-02 1.4899e-03 -7.2213e-02 -3.1233e-02
1.0151e-01 -2.4369e-02 5.9177e-03 6.9262e-02
7.9299e-02 -3.7462e-02 7.7214e-03 -4.8352e-02
3.6798e-02 6.1700e-02 6.9149e-02 3.8857e-02
1.8279e-02 2.8520e-02 1.0628e-03 -7.4530e-03
[ torch.cuda.FloatTensor{296,148} ]
```
**What am I doing wrong? How can I export the model correctly?**
Check the full code [here](https://gist.github.com/Tekno-H/e114d6d843b3582f82c4a2a3cea1d46e)
I have been stuck on this problem for a while and can figure out how to solve it, any help is appreciated.
Thanks in advance.
### Versions
```
PyTorch version: 1.12.1+cu102
Is debug build: False
CUDA used to build PyTorch: 10.2
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.5 LTS (x86_64)
GCC version: (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0
Clang version: Could not collect
CMake version: version 3.16.3
Libc version: glibc-2.31
Python version: 3.8.13 (default, Mar 28 2022, 11:38:47) [GCC 7.5.0] (64-bit runtime)
Python platform: Linux-5.15.0-56-generic-x86_64-with-glibc2.17
Is CUDA available: True
CUDA runtime version: 11.5.119
CUDA_MODULE_LOADING set to:
GPU models and configuration: GPU 0: NVIDIA GeForce GTX 1050 Ti
Nvidia driver version: 495.29.05
cuDNN version: Probably one of the following:
/usr/local/cuda-11.5/targets/x86_64-linux/lib/libcudnn.so.8
/usr/local/cuda-11.5/targets/x86_64-linux/lib/libcudnn_adv_infer.so.8
/usr/local/cuda-11.5/targets/x86_64-linux/lib/libcudnn_adv_train.so.8
/usr/local/cuda-11.5/targets/x86_64-linux/lib/libcudnn_cnn_infer.so.8
/usr/local/cuda-11.5/targets/x86_64-linux/lib/libcudnn_cnn_train.so.8
/usr/local/cuda-11.5/targets/x86_64-linux/lib/libcudnn_ops_infer.so.8
/usr/local/cuda-11.5/targets/x86_64-linux/lib/libcudnn_ops_train.so.8
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] mypy-extensions==0.4.3
[pip3] numpy==1.23.3
[pip3] torch==1.12.1
[pip3] torchvision==0.13.1
[conda] numpy 1.23.3 pypi_0 pypi
[conda] torch 1.12.1 pypi_0 pypi
[conda] torchvision 0.13.1 pypi_0 pypi
```
| 23 |
4,047 | 90,166 |
[dynamo] CommandLine Error: Option 'amdgpu-assume-external-call-stack-size' registered more than once
|
triaged, oncall: pt2
|
### 🐛 Describe the bug
I want to try out the new PyTorch 2.0 and see whether it can speed up my code.
I have upgraded PyTorch through the get start section and the code can run smoothly after the upgrade. However, after adding `torch.compile`, the code raises an error:
```
/home/xingyuan/miniconda3/envs/vpt-pt2.0/lib/python3.9/site-packages/torch/storage.py:315: UserWarning: TypedStorage is deprecated. It will be removed in the future and UntypedStorage will be the only storage class. This should only matter to you if you are using storages directly.
warnings.warn(message, UserWarning)
/home/xingyuan/miniconda3/envs/vpt-pt2.0/lib/python3.9/site-packages/torch/storage.py:315: UserWarning: TypedStorage is deprecated. It will be removed in the future and UntypedStorage will be the only storage class. This should only matter to you if you are using storages directly.
warnings.warn(message, UserWarning)
[2022-12-05 10:43:27,836] torch._inductor.graph: [WARNING] Creating implicit fallback for:
target: aten._thnn_fused_gru_cell.default
args[0]: TensorBox(StorageBox(
MatrixMultiply(
name=buf3,
layout=FlexibleLayout('cuda', torch.float32, size=[50, 1536], stride=[1536, 1]),
inputs=[ConcatKernel(name='buf2', layout=FixedLayout('cuda', torch.float32, size=[50, 134], stride=[134, 1]), inputs=[ComputedBuffer(name='buf0', layout=AliasedLayout('cuda', torch.float32, size=[50, 128], stride=[134, 1]), data=Pointwise(
'cuda',
torch.float32,
load(primals_30, i1 + 128 * i0),
ranges=[50, 128],
origins={cat}
)), ComputedBuffer(name='buf1', layout=AliasedLayout('cuda', torch.float32, size=[50, 6], stride=[134, 1]), data=Pointwise(
'cuda',
torch.float32,
load(primals_31, i1 + 6 * i0),
ranges=[50, 6],
origins={cat}
))]), ReinterpretView(
StorageBox(
InputBuffer(name='primals_1', layout=FixedLayout('cuda', torch.float32, size=[1536, 134], stride=[134, 1]))
),
FixedLayout('cuda', torch.float32, size=[134, 1536], stride=[1, 134]),
no origins?
)],
constant_args=(),
kwargs={},
output_view=None,
origins={primals_1, permute, mm, cat}
)
))
args[1]: TensorBox(StorageBox(
MatrixMultiply(
name=buf4,
layout=FlexibleLayout('cuda', torch.float32, size=[50, 1536], stride=[1536, 1]),
inputs=[InputBuffer(name='primals_29', layout=FixedLayout('cuda', torch.float32, size=[50, 512], stride=[512, 1])), ReinterpretView(
StorageBox(
InputBuffer(name='primals_2', layout=FixedLayout('cuda', torch.float32, size=[1536, 512], stride=[512, 1]))
),
FixedLayout('cuda', torch.float32, size=[512, 1536], stride=[1, 512]),
no origins?
)],
constant_args=(),
kwargs={},
output_view=None,
origins={primals_29, primals_2, permute_1, mm_1}
)
))
args[2]: TensorBox(StorageBox(
InputBuffer(name='primals_29', layout=FixedLayout('cuda', torch.float32, size=[50, 512], stride=[512, 1]))
))
args[3]: TensorBox(StorageBox(
InputBuffer(name='primals_3', layout=FixedLayout('cuda', torch.float32, size=[1536], stride=[1]))
))
args[4]: TensorBox(StorageBox(
InputBuffer(name='primals_4', layout=FixedLayout('cuda', torch.float32, size=[1536], stride=[1]))
))
[2022-12-05 10:43:27,850] torch._inductor.ir: [WARNING] Using FallbackKernel: torch.ops.aten._thnn_fused_gru_cell.default
[2022-12-05 10:43:27,878] torch._inductor.graph: [WARNING] Creating implicit fallback for:
target: aten.normal_functional.default
args[0]: TensorBox(StorageBox(
Pointwise(
'cuda',
torch.float32,
constant(0, torch.float32),
ranges=[50, 128],
origins={empty}
)
))
[2022-12-05 10:43:27,882] torch._inductor.ir: [WARNING] Using FallbackKernel: torch.ops.aten.normal_functional.default
: CommandLine Error: Option 'amdgpu-assume-external-call-stack-size' registered more than once!
LLVM ERROR: inconsistency in registered CommandLine options
Aborted (core dumped)
```
I tried the debugging options [here](https://pytorch.org/docs/master/dynamo/faq.html#why-is-my-code-crashing), i.e. `dynamo.optimize("eager")` and `torch._dynamo.config.verbose=True`. But the error is still the same and no further details log is shown.
### Versions
Collecting environment information...
PyTorch version: 1.14.0.dev20221204+cu117
Is debug build: False
CUDA used to build PyTorch: 11.7
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.3 LTS (x86_64)
GCC version: (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0
Clang version: Could not collect
CMake version: version 3.25.0
Libc version: glibc-2.31
Python version: 3.9.15 (main, Nov 24 2022, 14:31:59) [GCC 11.2.0] (64-bit runtime)
Python platform: Linux-5.10.0-1057-oem-x86_64-with-glibc2.31
Is CUDA available: True
CUDA runtime version: 11.7.99
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration: GPU 0: NVIDIA GeForce GTX 1080 Ti
Nvidia driver version: 520.56.06
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.23.1
[pip3] torch==1.14.0.dev20221204+cu117
[pip3] torchtriton==2.0.0+0d7e753227
[conda] cudatoolkit 11.7.0 hd8887f6_10 nvidia
[conda] numpy 1.23.1 pypi_0 pypi
[conda] pytorch-cuda 11.7 h67b0de4_0 pytorch
[conda] torch 1.14.0.dev20221204+cu117 pypi_0 pypi
[conda] torchtriton 2.0.0+0d7e753227 pypi_0 pypi
cc @ezyang @gchanan @zou3519 @soumith @msaroufim @wconstab @ngimel @bdhirsh
| 2 |
4,048 | 90,147 |
[Feature Proposal] Extend torch hub to better support cloud serving and edge deployment
|
feature, triaged, module: hub
|
### 🚀 The feature, motivation and pitch
**TL;DR**: Extend torch hub to better support cloud serving and edge deployment by:
1. Extend the `hubconf.py` as an entrypoint for serving and deployment, like [HuggingFace Inferece Handler](https://huggingface.co/philschmid/layoutlm-funsd/blob/main/handler.py)
2. (Optional) Allow third-party infra providers to integrate model deployment and performance reporting to the hub website.
### Background
I was a PhD researcher a while ago and am now an AI practitioner in the industry. From my personal experience and observation, the pytorch hub provides incremental value to researchers, because:
1. Researchers usually rely on conferences and their own networks to find the latest models.
2. Researchers are familiar with cloning a repo, peeking into the source and doing modifications. The simple `torch.hub.load` interface is not very much helpful to them.
However, industry community usually don't have the advantages mentioned above, therefore the hub can be a valuable information source to them. But when they choose a model, they not only want an interface to run some sample data, deployment easiness and model performance are also important factors to consider.
That's why huggingface transformers, yolo-series, and mmdetection are very popular.
But not all researchers like to submit their models to those repos due to the extensive customizations needed, therefore, a lightweight hubconf.py could just reduce the gap between research and production need.
### Proposed changes
`hubconf.py`: provides a reference format to share models, and acts as an interface for deployment, benchmarking and serving.
A very rough example is shown below, just for discussion purpose.
```
__model__ = ["MyModel"]
def MyModel:
def __init__(self, pretrained=False, **kwargs):
self.model = build_model(pretrained=pretrained)
def forward(self, x: Union[Tuple[Any, ...], torch.Tensor]) -> Union[Tuple[Any, ...], torch.Tensor]:
# Core tensor-in, tensor-out model function
return self.model(x)
def get_input(self):
# get sample data
return preprocess(cv2.imread('assets/img1.png'))
def inference(self, data: Dict[str, Any]) -> Dict[str, Any]:
# optional, for model serving only
output = self.model(preprocess(data['input']))
return {"predictions": postprocess(output)}
```
Hub website: "Discover and publish models to a pre-trained model repository designed for research exploration." -> "For research exploration and production use". And in the future, allow third-party providers to plug in model statistics based on `hubconf.py`
**Disclaimer**
Our company is currently working on an MLOps platform to facilitate the production of PyTorch models. We see a clear benefit that a shared protocol could further reduce the friction between research and industry communities. We would like to hear feedback from PyTorch team and we are also open to take the initial effort to extend the hubconf and adopt open-source repos to fit this extended format.
### Alternatives
_No response_
### Additional context
_No response_
cc @nairbv @NicolasHug @vmoens @jdsgomes
| 1 |
4,049 | 90,138 |
p.block != nullptr && p.block->ptr != nullptr INTERNAL ASSERT FAILED
|
needs reproduction, triaged
|
### 🐛 Describe the bug
Traceback (most recent call last):
File "main.py", line 141, in <module>
output = model(train_img)
File "/opt/conda/lib/python3.7/site-packages/torch/nn/modules/module.py", line 889, in _call_impl
result = self.forward(*input, **kwargs)
File "/opt/conda/lib/python3.7/site-packages/timm/models/efficientnet.py", line 557, in forward
x = self.forward_features(x)
File "/opt/conda/lib/python3.7/site-packages/timm/models/efficientnet.py", line 545, in forward_features
x = self.blocks(x)
File "/opt/conda/lib/python3.7/site-packages/torch/nn/modules/module.py", line 889, in _call_impl
result = self.forward(*input, **kwargs)
File "/opt/conda/lib/python3.7/site-packages/torch/nn/modules/container.py", line 119, in forward
input = module(input)
File "/opt/conda/lib/python3.7/site-packages/torch/nn/modules/module.py", line 889, in _call_impl
result = self.forward(*input, **kwargs)
File "/opt/conda/lib/python3.7/site-packages/torch/nn/modules/container.py", line 119, in forward
input = module(input)
File "/opt/conda/lib/python3.7/site-packages/torch/nn/modules/module.py", line 889, in _call_impl
result = self.forward(*input, **kwargs)
File "/opt/conda/lib/python3.7/site-packages/timm/models/efficientnet_blocks.py", line 185, in forward
x = self.se(x)
File "/opt/conda/lib/python3.7/site-packages/torch/nn/modules/module.py", line 889, in _call_impl
result = self.forward(*input, **kwargs)
File "/opt/conda/lib/python3.7/site-packages/timm/models/efficientnet_blocks.py", line 56, in forward
return x * self.gate(x_se)
RuntimeError: p.block != nullptr && p.block->ptr != nullptr INTERNAL ASSERT FAILED at "/pytorch/c10/cuda/CUDACachingAllocator.cpp":689, please report a bug to PyTorch.
### Versions
pytorch1.8+cu11
| 1 |
4,050 | 90,126 |
torch._dynamo.exc.BackendCompilerFailed: compile_fx raised TypeError: tqdm.__init__() got an unexpected keyword argument 'desc'
|
triaged, module: hub
|
### 🐛 Describe the bug
Clean python 3.10.5 virtualenv:
```sh
pip3 install numpy --pre torch[dynamo] --force-reinstall --extra-index-url https://download.pytorch.org/whl/nightly/cu117
```
Then code:
```
import torch
import torch._dynamo as dynamo
@dynamo.optimize("inductor")
def opt_foo2(x, y):
a = torch.sin(x)
b = torch.cos(x)
return a + b
print(opt_foo2(torch.randn(10, 10), torch.randn(10, 10)))
```
Results in:
```
Traceback (most recent call last):
File "/home/kevin/.pyenv/versions/plugin/lib/python3.10/site-packages/torch/_dynamo/output_graph.py", line 546, in call_user_compiler
compiled_fn = compiler_fn(gm, self.example_inputs())
File "/home/kevin/.pyenv/versions/plugin/lib/python3.10/site-packages/torch/_dynamo/debug_utils.py", line 911, in debug_wrapper
compiled_gm = compiler_fn(gm, example_inputs, **kwargs)
File "/home/kevin/.pyenv/versions/plugin/lib/python3.10/site-packages/torch/_inductor/compile_fx.py", line 398, in compile_fx
return aot_autograd(
File "/home/kevin/.pyenv/versions/plugin/lib/python3.10/site-packages/torch/_dynamo/optimizations/training.py", line 80, in compiler_fn
cg = aot_module_simplified(gm, example_inputs, **kwargs)
File "/home/kevin/.pyenv/versions/plugin/lib/python3.10/site-packages/functorch/_src/aot_autograd.py", line 2093, in aot_module_simplified
compiled_fn = create_aot_dispatcher_function(
File "/home/kevin/.pyenv/versions/plugin/lib/python3.10/site-packages/torch/_dynamo/utils.py", line 90, in time_wrapper
r = func(*args, **kwargs)
File "/home/kevin/.pyenv/versions/plugin/lib/python3.10/site-packages/functorch/_src/aot_autograd.py", line 1792, in create_aot_dispatcher_function
compiled_fn = compiler_fn(flat_fn, fake_flat_tensor_args, aot_config)
File "/home/kevin/.pyenv/versions/plugin/lib/python3.10/site-packages/functorch/_src/aot_autograd.py", line 1163, in aot_wrapper_dedupe
fw_metadata, _out, _num_aliasing_metadata_outs = run_functionalized_fw_and_collect_metadata(
File "/home/kevin/.pyenv/versions/plugin/lib/python3.10/site-packages/functorch/_src/aot_autograd.py", line 272, in inner
outs = f(*f_args)
File "/home/kevin/.pyenv/versions/plugin/lib/python3.10/site-packages/functorch/_src/aot_autograd.py", line 2065, in functional_call
out = Interpreter(mod).run(*args[params_len:], **kwargs)
File "/home/kevin/.pyenv/versions/plugin/lib/python3.10/site-packages/torch/fx/interpreter.py", line 123, in run
for node in tqdm(self.module.graph.nodes,
TypeError: tqdm.__init__() got an unexpected keyword argument 'desc'
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "/home/kevin/fedtorch/plugin/example.py", line 9, in <module>
print(opt_foo2(torch.randn(10, 10), torch.randn(10, 10)))
File "/home/kevin/.pyenv/versions/plugin/lib/python3.10/site-packages/torch/_dynamo/eval_frame.py", line 209, in _fn
return fn(*args, **kwargs)
File "/home/kevin/.pyenv/versions/plugin/lib/python3.10/site-packages/torch/_dynamo/eval_frame.py", line 329, in catch_errors
return callback(frame, cache_size)
File "/home/kevin/.pyenv/versions/plugin/lib/python3.10/site-packages/torch/_dynamo/convert_frame.py", line 468, in _convert_frame
result = inner_convert(frame, cache_size)
File "/home/kevin/.pyenv/versions/plugin/lib/python3.10/site-packages/torch/_dynamo/convert_frame.py", line 102, in _fn
return fn(*args, **kwargs)
File "/home/kevin/.pyenv/versions/plugin/lib/python3.10/site-packages/torch/_dynamo/utils.py", line 90, in time_wrapper
r = func(*args, **kwargs)
File "/home/kevin/.pyenv/versions/plugin/lib/python3.10/site-packages/torch/_dynamo/convert_frame.py", line 339, in _convert_frame_assert
return _compile(
File "/home/kevin/.pyenv/versions/plugin/lib/python3.10/site-packages/torch/_dynamo/convert_frame.py", line 395, in _compile
out_code = transform_code_object(code, transform)
File "/home/kevin/.pyenv/versions/plugin/lib/python3.10/site-packages/torch/_dynamo/bytecode_transformation.py", line 341, in transform_code_object
transformations(instructions, code_options)
File "/home/kevin/.pyenv/versions/plugin/lib/python3.10/site-packages/torch/_dynamo/convert_frame.py", line 382, in transform
tracer.run()
File "/home/kevin/.pyenv/versions/plugin/lib/python3.10/site-packages/torch/_dynamo/symbolic_convert.py", line 1625, in run
super().run()
File "/home/kevin/.pyenv/versions/plugin/lib/python3.10/site-packages/torch/_dynamo/symbolic_convert.py", line 484, in run
and self.step()
File "/home/kevin/.pyenv/versions/plugin/lib/python3.10/site-packages/torch/_dynamo/symbolic_convert.py", line 454, in step
getattr(self, inst.opname)(inst)
File "/home/kevin/.pyenv/versions/plugin/lib/python3.10/site-packages/torch/_dynamo/symbolic_convert.py", line 1687, in RETURN_VALUE
self.output.compile_subgraph(self)
File "/home/kevin/.pyenv/versions/plugin/lib/python3.10/site-packages/torch/_dynamo/output_graph.py", line 440, in compile_subgraph
self.compile_and_call_fx_graph(tx, list(reversed(stack_values)), root)
File "/home/kevin/.pyenv/versions/plugin/lib/python3.10/site-packages/torch/_dynamo/output_graph.py", line 511, in compile_and_call_fx_graph
compiled_fn = self.call_user_compiler(gm)
File "/home/kevin/.pyenv/versions/plugin/lib/python3.10/site-packages/torch/_dynamo/output_graph.py", line 551, in call_user_compiler
raise BackendCompilerFailed(self.compiler_fn, e) from e
torch._dynamo.exc.BackendCompilerFailed: compile_fx raised TypeError: tqdm.__init__() got an unexpected keyword argument 'desc'
Set torch._dynamo.config.verbose=True for more information
You can suppress this exception and fall back to eager by setting:
torch._dynamo.config.suppress_errors = True
```
### Versions
PyTorch version: 1.14.0.dev20221202+cu117
Is debug build: False
CUDA used to build PyTorch: 11.7
ROCM used to build PyTorch: N/A
OS: Ubuntu 22.04.1 LTS (x86_64)
GCC version: (Ubuntu 11.3.0-1ubuntu1~22.04) 11.3.0
Clang version: 14.0.0-1ubuntu1
CMake version: version 3.25.0
Libc version: glibc-2.35
Python version: 3.10.5 (main, Sep 21 2022, 20:11:40) [GCC 11.2.0] (64-bit runtime)
Python platform: Linux-5.15.74.2-microsoft-standard-WSL2-x86_64-with-glibc2.35
Is CUDA available: True
CUDA runtime version: Could not collect
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration: GPU 0: NVIDIA GeForce RTX 2070 SUPER
Nvidia driver version: 526.98
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.24.0rc1
[pip3] torch==1.14.0.dev20221202+cu117
[pip3] torchaudio==0.14.0.dev20221203+cu117
[pip3] torchtriton==2.0.0+0d7e753227
[pip3] torchvision==0.15.0.dev20221203+cpu
cc @nairbv @NicolasHug @vmoens @jdsgomes @mlazos @soumith @voznesenskym @yanboliang @penguinwu @anijain2305 @EikanWang @jgong5 @Guobing-Chen @chunyuan-w @XiaobingSuper @zhuhaozhe @blzheng @Xia-Weiwen @wenzhe-nrv @jiayisunx @desertfire
| 1 |
4,051 | 90,115 |
Couldn't install pytorch 2.0
|
needs reproduction, oncall: binaries, triaged
|
### 🐛 Describe the bug
Using the command in V100 cuda 11.7 with py3.8:
```bash
pip3 install numpy --pre torch[dynamo] torchvision torchaudio --force-reinstall --extra-index-url https://download.pytorch.org/whl/nightly/cu117
```
but got following information while installing torchaudio and torchvision:
```bash
Collecting torchaudio
Downloading https://download.pytorch.org/whl/nightly/cu117/torchaudio-0.14.0.dev20221202%2Bcu117-cp38-cp38-linux_x86_64.whl (4.2 MB)
|████████████████████████████████| 4.2 MB 270 kB/s
Downloading https://download.pytorch.org/whl/nightly/cu117/torchaudio-0.14.0.dev20221201%2Bcu117-cp38-cp38-linux_x86_64.whl (4.2 MB)
|████████████████████████████████| 4.2 MB 668 kB/s
Downloading https://download.pytorch.org/whl/nightly/cu117/torchaudio-0.14.0.dev20221130%2Bcu117-cp38-cp38-linux_x86_64.whl (4.2 MB)
|████████████████████████████████| 4.2 MB 665 kB/s
Downloading https://download.pytorch.org/whl/nightly/cu117/torchaudio-0.14.0.dev20221129%2Bcu117-cp38-cp38-linux_x86_64.whl (4.2 MB)
|████████████████████████████████| 4.2 MB 906 kB/s
Downloading https://download.pytorch.org/whl/nightly/cu117/torchaudio-0.14.0.dev20221128%2Bcu117-cp38-cp38-linux_x86_64.whl (4.2 MB)
|████████████████████████████████| 4.2 MB 694 kB/s
Downloading https://download.pytorch.org/whl/nightly/cu117/torchaudio-0.14.0.dev20221127%2Bcu117-cp38-cp38-linux_x86_64.whl (4.2 MB)
|████████████████████████████████| 4.2 MB 694 kB/s
Downloading https://download.pytorch.org/whl/nightly/cu117/torchaudio-0.14.0.dev20221126%2Bcu117-cp38-cp38-linux_x86_64.whl (4.2 MB)
|████████████████████████████████| 4.2 MB 674 kB/s
Downloading https://download.pytorch.org/whl/nightly/cu117/torchaudio-0.14.0.dev20221125%2Bcu117-cp38-cp38-linux_x86_64.whl (4.2 MB)
|████████████████████████████████| 4.2 MB 685 kB/s
Downloading https://download.pytorch.org/whl/nightly/cu117/torchaudio-0.14.0.dev20221124%2Bcu117-cp38-cp38-linux_x86_64.whl (4.2 MB)
|████████████████████████████████| 4.2 MB 693 kB/s
Downloading https://download.pytorch.org/whl/nightly/cu117/torchaudio-0.14.0.dev20221123%2Bcu117-cp38-cp38-linux_x86_64.whl (4.2 MB)
|████████████████████████████████| 4.2 MB 689 kB/s
..........
NFO: pip is looking at multiple versions of torchvision to determine which version is compatible with other requirements. This could take a while.
Collecting torchvision
.........
INFO: pip is looking at multiple versions of torchtriton to determine which version is compatible with other requirements. This could take a while.
INFO: pip is looking at multiple versions of torch[dynamo] to determine which version is compatible with other requirements. This could take a while.
```
### Versions
torch.1.14
cc @ezyang @seemethere @malfet
| 7 |
4,052 | 90,114 |
documentation need to be as per python version
|
module: docs, triaged
|
### 📚 The doc issue
something like this,
python 3.9
```
def init_weights(m):
if isinstance(m, nn.Linear):
nn.init.normal_(m.weight)
nn.init.normal_(m.bias)
model = nn.Sequential(nn.Linear(2, 2))
model.apply(init_weights)
```
python 3.10
```
def init_weights(m):
match m:
case nn.Linear():
nn.init.normal_(m.weight)
nn.init.normal_(m.bias)
model = nn.Sequential(nn.Linear(2, 2))
model.apply(init_weights)
```
motivation -
docs of FastAPI https://fastapi.tiangolo.com/tutorial/body/,
pydantic https://pydantic-docs.helpmanual.io/usage/dataclasses/
follow a similar strategy
### Suggest a potential alternative/fix
no
cc @svekars @carljparker
| 0 |
4,053 | 90,113 |
AOTAutograd input dedup needs a strategy for fake tensor args
|
triaged, module: fakeTensor, module: aotdispatch
|
### 🐛 Describe the bug
To be filled out, realized this as I was falling asleep.
### Versions
No
| 0 |
4,054 | 90,111 |
no matches found: torch[dynamo]
|
module: docs, triaged, actionable, oncall: pt2
|
### 🐛 Describe the bug
Following [PyTorch 2.0 Official Guide](https://pytorch.org/blog/Accelerating-Hugging-Face-and-TIMM-models/), I am trying to install it using
```bash
pip3 install numpy --pre torch[dynamo] --force-reinstall --extra-index-url https://download.pytorch.org/whl/nightly/cu117
```
Resulting in the following error
```
zsh: no matches found: torch[dynamo]
```
Thanks
### Versions
```
OS: Ubuntu 22.10 (x86_64)
GCC version: (Ubuntu 12.2.0-3ubuntu1) 12.2.0
Clang version: Could not collect
CMake version: version 3.25.0
Libc version: glibc-2.36
Python version: 3.9.13 (main, Aug 25 2022, 23:26:10) [GCC 11.2.0] (64-bit runtime)
Python platform: Linux-5.19.0-26-generic-x86_64-with-glibc2.36
Is CUDA available: True
CUDA runtime version: Could not collect
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration: GPU 0: NVIDIA GeForce RTX 3090
Nvidia driver version: 515.76
cuDNN version: Probably one of the following:
/usr/local/cuda-11.7/targets/x86_64-linux/lib/libcudnn.so.8
/usr/local/cuda-11.7/targets/x86_64-linux/lib/libcudnn_adv_infer.so.8
/usr/local/cuda-11.7/targets/x86_64-linux/lib/libcudnn_adv_train.so.8
/usr/local/cuda-11.7/targets/x86_64-linux/lib/libcudnn_cnn_infer.so.8
/usr/local/cuda-11.7/targets/x86_64-linux/lib/libcudnn_cnn_train.so.8
/usr/local/cuda-11.7/targets/x86_64-linux/lib/libcudnn_ops_infer.so.8
/usr/local/cuda-11.7/targets/x86_64-linux/lib/libcudnn_ops_train.so.8
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] mypy-extensions==0.4.3
[pip3] numpy==1.24.0rc1
[pip3] torch==1.14.0.dev20221202+cu117
[pip3] torchaudio==0.12.1+cu116
[pip3] torchtriton==2.0.0+0d7e753227
[pip3] torchvision==0.13.1+cu116
[conda] numpy 1.24.0rc1 pypi_0 pypi
[conda] torch 1.14.0.dev20221202+cu117 pypi_0 pypi
[conda] torchaudio 0.12.1+cu116 pypi_0 pypi
[conda] torchtriton 2.0.0+0d7e753227 pypi_0 pypi
[conda] torchvision 0.13.1+cu116 pypi_0 pypi
````
cc @svekars @carljparker @ezyang @soumith
| 6 |
4,055 | 90,107 |
Tensor.uniform_ fails to compile when using torch._dynamo
|
triaged, module: initialization, module: dynamo
|
### 🐛 Describe the bug
Compiler expects `torch.uniform_` method to need a dtype & device arguments.
```python
import torch
def gen_uniform(shape):
r = torch.empty(shape, dtype=torch.float32)
return r.uniform_(0, 1)
class Model1(torch.nn.Module):
def forward(self):
return gen_uniform([10, 20])
model1 = torch.compile(Model1())
print(model1())
```
```
Exception has occurred: BackendCompilerFailed (note: full exception trace is shown but execution is paused at: _run_module_as_main)
_compile_fn raised TypeError: uniform() missing 2 required keyword-only arguments: 'dtype' and 'device'
While executing %uniform_ : [#users=1] = call_method[target=uniform_](args = (%empty, 0, 1), kwargs = {})
Original traceback:
Module stack: {}
File "test.py", line 5, in gen_uniform
return r.uniform_(0, 1)
| File "test.py", line 9, in forward
return gen_uniform([10, 20])
```
### Versions
```
Collecting environment information...
PyTorch version: 1.14.0 - commit acd68f90970e325caf155cbcfbd30b8a3f3f0b38
Is debug build: False
CUDA used to build PyTorch: 11.8
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.5 LTS (x86_64)
GCC version: (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0
Clang version: Could not collect
CMake version: version 3.25.0
Libc version: glibc-2.31
Python version: 3.8.10 (default, Jun 22 2022, 20:18:18) [GCC 9.4.0] (64-bit runtime)
Python platform: Linux-5.13.0-1023-aws-x86_64-with-glibc2.29
Is CUDA available: True
CUDA runtime version: 11.8
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration:
GPU 0: NVIDIA A100-SXM4-40GB
GPU 1: NVIDIA A100-SXM4-40GB
GPU 2: NVIDIA A100-SXM4-40GB
GPU 3: NVIDIA A100-SXM4-40GB
GPU 4: NVIDIA A100-SXM4-40GB
GPU 5: NVIDIA A100-SXM4-40GB
GPU 6: NVIDIA A100-SXM4-40GB
GPU 7: NVIDIA A100-SXM4-40GB
Nvidia driver version: 520.61.05
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.6.0
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.6.0
/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.6.0
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_infer.so.8.6.0
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.6.0
/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.6.0
/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.6.0
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] mypy-extensions==0.4.3
[pip3] numpy==1.17.4
[pip3] pytorch-lightning==1.8.3.post1
[pip3] rotary-embedding-torch==0.1.5
[pip3] torch==1.14.0
[pip3] torchdata==0.5.0
[pip3] torchmetrics==0.11.0
[pip3] torchvision==0.15.0a0+01c11a0
[conda] Could not collect
```
cc @mlazos @soumith @voznesenskym @yanboliang @penguinwu @anijain2305 @EikanWang @jgong5 @Guobing-Chen @chunyuan-w @XiaobingSuper @zhuhaozhe @blzheng @Xia-Weiwen @wenzhe-nrv @jiayisunx @desertfire
| 2 |
4,056 | 90,057 |
[GradScaler] Inconsistent scale values across different GPUs caused by uneven inputs for AMP DDP training
|
triaged, module: amp (automated mixed precision)
|
### 🐛 Describe the bug
Hello, I want to add [Automatic Mixed Precision (AMP)](https://pytorch.org/docs/master/amp.html?highlight=gradscaler#) training into my DDP training codes.
In my case, different GPUs could have uneven inputs during the training process. Thus I use model.join() to handle this problem and it works.
However, to realize the AMP training, I use the [torch.cuda.amp.GradScaler](https://pytorch.org/docs/master/amp.html#torch.cuda.amp.GradScaler) class. Due to the uneven inputs problem, we get inconsistent scale values after several epochs, which gradually causes a large loss difference and training error.
For example,
1. Due to data imbalance, rank 0 could run more batches/iterations using model.join().
2. Since growth_interval is same (default: 2000) for rank 0 and 1, after several training epochs, rank 0 and 1 could run different numbers of batchs/iterations, which leads to different growth timestamp of scale. As shown below, at Epoch 17 Iter 2071, they got different scale values.


I think this could be a bug of torch.cuda.amp.GradScaler while using uneven inputs for DDP training.
**There should be some synchronization mechanism to keep the consistency of the scale value (or the growth_tracker) across different GPUs in the case of uneven inputs.**
Thanks a lot if you can help answer my question!
### Versions
pytorch 1.12.1
2 * A100
cc @mcarilli @ptrblck @leslie-fang-intel @jgong5
| 1 |
4,057 | 90,065 |
forward-mode AD formula for torch.add (and possibly others) accidentally upcasts float32 to float64
|
module: performance, module: autograd, triaged, actionable, ZeroTensor, module: forward ad, module: functorch
|
```python
import torch
import functorch
print(functorch.__version__)
# '1.13.0+cu117'
dtype = torch.float32
device = torch.device('cpu')
def foo(x):
# unpack
q, p = x
# add float, ok with adding int
q, p = q + 1.0, p + 1.0
return torch.stack([q, p])
x = torch.tensor([0.0, 0.0], dtype=dtype, device=device)
print(functorch.jacfwd(foo)(x))
print()
# tensor([[1., 0.],
# [0., 1.]], dtype=torch.float64)
print(functorch.jacrev(foo)(x))
print()
# tensor([[1., 0.],
# [0., 1.]])
```
cc @VitalyFedyunin @ngimel @ezyang @albanD @zou3519 @gqchen @pearu @nikitaved @soulitzer @Lezcano @Varal7 @Chillee @samdow @soumith
| 9 |
4,058 | 90,052 |
DDP overlapped optimizer: set grads to None enhancements
|
oncall: distributed, module: data parallel, module: ddp
|
### 🚀 The feature, motivation and pitch
https://github.com/pytorch/pytorch/pull/89194 is adding DDP overlapped optimizer with very basic support for setting grads to None, i.e. it will set all DDP managed parameters grads to None. As enhancements, we should:
1. Only set grads to None for the parameters with in backwards optimizers which might not necessarily be all DDP parameters
2. set grads to None as we run the optimizer step, to save memory. Currently peak memory is not reduced because we only set the grads to None at the end of backwards.
There is currently no use case for (1) and DDP reducer current implementation blocks doing (2) effectively, so both of these require follow up discussion.
### Alternatives
_No response_
### Additional context
_No response_
cc @mrshenli @pritamdamania87 @zhaojuanmao @satgera @gqchen @aazzolini @osalpekar @jiayisuse @H-Huang @kwen2501 @awgu
| 0 |
4,059 | 90,019 |
[feature request] Need dtype torch.complex64 support on MPS Device
|
feature, triaged, module: mps
|
If you have a question or would like help and support, please ask at our
[forums](https://discuss.pytorch.org/).
If you are submitting a feature request, please preface the title with [feature request].
If you are submitting a bug report, please fill in the following details.
## Issue description
I need to simulate a script that is using math functions that are complex ( complex64 or cfloat type matrix).
## Code example
myMatrix = torch.tensor(4000, 4000, dtype=torch.cfloat, device='mps')
## System Info
Python version: 3.9.6 (default, Sep 26 2022, 11:37:49) [Clang 14.0.0 (clang-1400.0.29.202)] (64-bit runtime)
Python platform: macOS-13.0.1-arm64-arm-64bit
Is CUDA available: N/A
CUDA runtime version: Could not collect
CUDA_MODULE_LOADING set to: N/A
GPU models and configuration: Could not collect
Nvidia driver version: Could not collect
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: N/A
- PyTorch or Caffe2: PyTorch
- How you installed PyTorch (conda, pip, source): conda
- Build command you used (if compiling from source): pip3 install torch torchvision torchaudio
- OS: Ventura 13.0.1
- PyTorch version: 1.13.0
Is MPS (Metal Performance Shader) built? True
Is MPS available? True
- Python version: Python 3.9.6
- CUDA/cuDNN version: N/A
- GPU models and configuration: Apple GPU 10 Core (MacBook Air M2)
- GCC version (if compiling from source): Apple clang version 14.0.0 (clang-1400.0.29.202)
- CMake version: GNU Make 3.81
- Versions of any other relevant libraries:
cc @kulinseth @albanD @malfet @DenisVieriu97 @razarmehr @abhudev
| 4 |
4,060 | 93,463 |
Traceable tensor subclasses cannot actually be used with AOTAutograd
|
triaged, bug
|
### 🐛 Describe the bug
This patch fails:
```
diff --git a/test/dynamo/test_modules.py b/test/dynamo/test_modules.py
index 6dde69efff..4821b27e05 100644
--- a/test/dynamo/test_modules.py
+++ b/test/dynamo/test_modules.py
@@ -725,10 +725,12 @@ class NNModuleTests(torch._dynamo.test_case.TestCase):
x = torch.randn(1).as_subclass(TensorProxy)
cnt = torch._dynamo.testing.CompileCounter()
out1 = foo(x)
- opt_foo = torch._dynamo.optimize(cnt, nopython=True)(foo)
+ assert isinstance(out1, TensorProxy)
+ opt_foo = torch._dynamo.optimize("aot_eager", nopython=True)(foo)
out2 = opt_foo(x)
+ assert isinstance(out2, TensorProxy)
- self.assertEqual(cnt.op_count, 4)
+ # self.assertEqual(cnt.op_count, 4)
self.assertTrue(torch._dynamo.testing.same(out1, out2))
finally:
```
c.f.
```
File "/data/users/ezyang/a/pytorch/torch/_dynamo/convert_frame.py", line 339, in _convert_frame_assert
return _compile(
File "/data/users/ezyang/a/pytorch/torch/_dynamo/convert_frame.py", line 395, in _compile
out_code = transform_code_object(code, transform)
File "/data/users/ezyang/a/pytorch/torch/_dynamo/bytecode_transformation.py", line 341, in transform_code_object
transformations(instructions, code_options)
File "/data/users/ezyang/a/pytorch/torch/_dynamo/convert_frame.py", line 382, in transform
tracer.run()
File "/data/users/ezyang/a/pytorch/torch/_dynamo/symbolic_convert.py", line 1615, in run
super().run()
File "/data/users/ezyang/a/pytorch/torch/_dynamo/symbolic_convert.py", line 484, in run
and self.step()
File "/data/users/ezyang/a/pytorch/torch/_dynamo/symbolic_convert.py", line 454, in step
getattr(self, inst.opname)(inst)
File "/data/users/ezyang/a/pytorch/torch/_dynamo/symbolic_convert.py", line 1677, in RETURN_VALUE
self.output.compile_subgraph(self)
File "/data/users/ezyang/a/pytorch/torch/_dynamo/output_graph.py", line 464, in compile_subgraph
self.compile_and_call_fx_graph(tx, pass2.graph_output_vars(), root)
File "/data/users/ezyang/a/pytorch/torch/_dynamo/output_graph.py", line 511, in compile_and_call_fx_graph
compiled_fn = self.call_user_compiler(gm)
File "/data/users/ezyang/a/pytorch/torch/_dynamo/output_graph.py", line 551, in call_user_compiler
raise BackendCompilerFailed(self.compiler_fn, e) from e
torch._dynamo.exc.BackendCompilerFailed: compiler_fn raised UnsupportedFakeTensorException: meta converter nyi
Set torch._dynamo.config.verbose=True for more information
```
The root cause of the problem is that torch function should be eliminated from inputs to the compiler, but we just directly pass in the tensor subclass as is. But even if we eliminated it as input from the compiler, we also have to eliminate it from the runtime input to the compiled function, AND we need to reconstruct the subclasses from the output.
Eager accidentally works because the tests are too trivial, and the inner traced function is identical to the outer function calls, so we end up just doing the conventional torch function path.
### Error logs
_No response_
### Minified repro
_No response_
| 0 |
4,061 | 93,462 |
TensorWithTFOverrideVariable unwraps too early
|
triaged, bug
|
### 🐛 Describe the bug
TensorWithTFOverrideVariable.call_method unwraps immediately before inlining `__torch_function__`. But the logical unwrapping doesn't truly happen until you make a super() call inside torch function (or you DisableTorchFunction). This means recursive calls to torch function are not handled correctly right now.
### Error logs
_No response_
### Minified repro
_No response_
| 1 |
4,062 | 90,000 |
Can not use x=torch.tensor(b), to create a Tensor out of a List[List[Tensor]] (A List of Lists of Tensors)
|
oncall: jit, triaged
|
### 🐛 Describe the bug
Can not use x=torch.tensor(b), to create a Tensor out of a List[List[Tensor]] (A List of Lists of Tensors) in Torchscript
Minimal Sample:
``` python
@torch.jit.script_if_tracing
def get_boxes(batch_bboxes):
s = torch.jit.annotate(List[List[Tensor]], [])
s.append([torch.tensor(3.14)]
s.append([torch.tensor(42.23)]
bb = torch.tensor(s)
```
``` bash
RuntimeError: The following operation failed in the TorchScript interpreter.
Traceback of TorchScript (most recent call last):
bb = torch.tensor(b)
~~~~~~~~~~~~ <--- HERE
RuntimeError: Input must be of ints, floats, or bools, got Tensor
```
### Versions
OS: macOS 12.2.1 (x86_64)
GCC version: Could not collect
Clang version: 13.1.6 (clang-1316.0.21.2)
CMake version: version 3.21.3
Libc version: N/A
Python version: 3.8.10 (v3.8.10:3d8993a744, May 3 2021, 08:55:58) [Clang 6.0 (clang-600.0.57)] (64-bit runtime)
Python platform: macOS-10.16-x86_64-i386-64bit
Is CUDA available: False
CUDA runtime version: No CUDA
CUDA_MODULE_LOADING set to: N/A
GPU models and configuration: No CUDA
Nvidia driver version: No CUDA
cuDNN version: No CUDA
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.23.5
[pip3] torch==1.13.0
[pip3] torchvision==0.14.0
[conda] Could not collect
cc @EikanWang @jgong5 @wenzhe-nrv @sanchitintel
| 4 |
4,063 | 93,461 |
Support getattr/setattr user properties on Tensor
|
triaged, bug
|
### 🐛 Describe the bug
Tensor subclasses typically make use of storing properties on Tensor. This is not supported at all by TensorVariable and will cause graph breaks, making most applications of tensor subclasses not actually work.
### Error logs
_No response_
### Minified repro
_No response_
| 1 |
4,064 | 89,987 |
Error in Adam.step(): If capturable=True, params and state_steps must be CUDA tensors.
|
module: optimizer, triaged, actionable
|
When the Adam optimizer is initialized by explicitly specifying the `capturable` flag for each parameter group, if the `capturable` flag of some group is different from default/global setting (e.g. the argument `capturable` of Adam's initializer), the error occurs in `Adam.step()`.
Here is a simple test script:
```python
import torch
x = torch.nn.Parameter(torch.empty(1, device="cuda"))
params_groups = [{
"params": [x],
"capturable": True
}]
optimizer = torch.optim.Adam(params_groups)
y = x ** 2
optimizer.zero_grad()
y.backward()
optimizer.step()
```
which outputs:
```shell
Traceback (most recent call last):
File ".../test_adam.py", line 12, in <module>
optimizer.step()
File ".../lib/python3.10/site-packages/torch/optim/optimizer.py", line 140, in wrapper
out = func(*args, **kwargs)
File ".../lib/python3.10/site-packages/torch/optim/optimizer.py", line 23, in _use_grad
ret = func(self, *args, **kwargs)
File ".../lib/python3.10/site-packages/torch/optim/adam.py", line 234, in step
adam(params_with_grad,
File ".../lib/python3.10/site-packages/torch/optim/adam.py", line 300, in adam
func(params,
File ".../lib/python3.10/site-packages/torch/optim/adam.py", line 348, in _single_tensor_adam
assert param.is_cuda and step_t.is_cuda, "If capturable=True, params and state_steps must be CUDA tensors."
AssertionError: If capturable=True, params and state_steps must be CUDA tensors.
```
PyTorch version: 1.13.0
-----------------------------------------
I traced the script of Adam and found that the device of state_steps for each parameter is determined by default `capturable` and `fused` settings:
https://github.com/pytorch/pytorch/blob/0e7918b9317d0a481c3747264b3584c37dc4a28f/torch/optim/adam.py#L212-L216
In `_single_tensor_adam()`, it will check the device of state_steps against the `capturable` setting of the corresponding parameter group:
https://github.com/pytorch/pytorch/blob/0e7918b9317d0a481c3747264b3584c37dc4a28f/torch/optim/adam.py#L347-L348
which is called by `step()` as:
https://github.com/pytorch/pytorch/blob/0e7918b9317d0a481c3747264b3584c37dc4a28f/torch/optim/adam.py#L234-L252
It seems that the inconsistency causes the error.
A simple solution is changing the L212-L216 of adam.py to determine the device by group's `capturable` and `fused` settings, but I'm not sure it's logically correct and will not cause other side effects:
```python
state['step'] = (
torch.zeros((1,), dtype=torch.float, device=p.device)
if group['capturable'] or group['fused']
else torch.tensor(0.)
)
```
cc @vincentqb @jbschlosser @albanD @janeyx99
| 1 |
4,065 | 93,458 |
minified code can not produce fp64_ref result
|
triaged
|
Minified code:
```
import torch._inductor.overrides
import torch
from torch import tensor, device
import torch.fx as fx
from torch._dynamo.testing import rand_strided
from math import inf
from torch.fx.experimental.proxy_tensor import make_fx
# torch version: 1.14.0a0+fb
# torch cuda version: 11.4.0
# CUDA Info:
# nvcc not found
# GPU Hardware Info:
# NVIDIA A100-PG509-200 : 8
from torch.nn import *
class Repro(torch.nn.Module):
def __init__(self):
super().__init__()
def forward(self, arg147_1, arg149_1, arg151_1, arg153_1, add_37, permute_62, permute_63, permute_64, permute_65):
convert_element_type_11 = torch.ops.prims.convert_element_type.default(add_37, torch.float32); add_37 = None
addmm_60 = torch.ops.aten.addmm.default(arg147_1, convert_element_type_11, permute_62); arg147_1 = permute_62 = None
addmm_61 = torch.ops.aten.addmm.default(arg149_1, addmm_60, permute_63); arg149_1 = addmm_60 = permute_63 = None
mul_54 = torch.ops.aten.mul.Tensor(convert_element_type_11, addmm_61); addmm_61 = None
add_38 = torch.ops.aten.add.Tensor(mul_54, convert_element_type_11); mul_54 = convert_element_type_11 = None
addmm_62 = torch.ops.aten.addmm.default(arg151_1, add_38, permute_64); arg151_1 = add_38 = permute_64 = None
addmm_63 = torch.ops.aten.addmm.default(arg153_1, addmm_62, permute_65); arg153_1 = addmm_62 = permute_65 = None
return (addmm_63,)
args = [((256,), (1,), torch.float32, 'cuda'), ((7616,), (1,), torch.float32, 'cuda'), ((256,), (1,), torch.float32, 'cuda'), ((7616,), (1,), torch.float32, 'cuda'), ((8, 7616), (7616, 1), torch.float32, 'cuda'), ((7616, 256), (1, 7616), torch.float32, 'cuda'), ((256, 7616), (1, 256), torch.float32, 'cuda'), ((7616, 256), (1, 7616), torch.float32, 'cuda'), ((256, 7616), (1, 256), torch.float32, 'cuda')]
args = [rand_strided(sh, st, dt, dev) for (sh, st, dt, dev) in args]
mod = make_fx(Repro().to(device="cuda"))(*args)
from torch._inductor.compile_fx import compile_fx_inner
from torch._dynamo.debug_utils import same_two_models
compiled = compile_fx_inner(mod, args)
assert same_two_models(mod, compiled, args, only_fwd=True), "Accuracy failed"
```
Warning:
```
[WARNING] Could not generate fp64 outputs
```
The problem is likely coming from `torch.ops.prims.convert_element_type.default(add_37, torch.float32)` and it is not a bug, but not being able to compare with `fp64_ref` sometimes can lead minifier to a wrong direction when minifying accuracy errors.
| 1 |
4,066 | 89,959 |
Calling item() on symbolic shape fake tensor should give more clear error message
|
triaged, module: inductor
|
### 🐛 Describe the bug
Right now it says `RuntimeError: Cannot call numel() on tensor with symbolic sizes/strides` which is bad
### Versions
master
cc @mlazos @soumith @voznesenskym @yanboliang @penguinwu @anijain2305 @EikanWang @jgong5 @Guobing-Chen @chunyuan-w @XiaobingSuper @zhuhaozhe @blzheng @Xia-Weiwen @wenzhe-nrv @jiayisunx @peterbell10 @desertfire
| 1 |
4,067 | 89,954 |
Random sampling from a tensor constructed on MPS device, results in elements returning as torch.zeros(tensor[i].shape)
|
triaged, module: mps
|
### 🐛 Describe the bug
**Constructing a tensor on the MPS device and sampling random indices with the following code results in the random replacement of tensor[i] with the equivalent of torch.zeros(tensor.shape):**
```
import numpy as np
import torch
def sample(inputs: torch.tensor, num_samples: int):
samples = np.random.choice(inputs.shape[0], num_samples)
inputs = inputs[samples]
return inputs
# np_inputs is of type np.ndarray with shape (-1, 2, 384)
inputs = torch.tensor(np_inputs, dtype=torch.float, device=torch.device('mps')).view(-1, 1, 2, 384)
inputs = sample(inputs, num_samples)
```
Other observations:
- the distribution of zeroed elements seems to biased towards higher indices. For example with the above code, with tensor shape (N, C, H, W) and N=1,643,000 with num_samples=630,000, inputs[-1 ] has always been returned as the equivalent of torch.zeros(inputs[i].shape)
- behavior is the same with np_inputs dtype=np.float64 and np.float32
- behavior also occurs when using torch.from_numpy if the devices is set to MPS
- behavior occurs even if the tensor is moved back to cpu() for sampling if it was constructed on the MPS device.
**Constructing the tensor on cpu, with the following code produced the expected behavior:**
```
import numpy as np
import torch
def sample(inputs: torch.tensor, num_samples: int):
samples = np.random.choice(inputs.shape[0], num_samples)
inputs = inputs[samples].to(torch.device('mps')
return inputs
# np_inputs is of type np.ndarray with shape (-1, 2, 384)
inputs = torch.tensor(np_inputs, dtype=torch.float).view(-1, 1, 2, 384)
inputs = sample(inputs, num_samples)
```
Constructing and sampling the tensor on cpu, and then moving the tensor to MPS results in the expected behavior, the tensor values are not zeroed and the returned tensor is composed of elements from the array of random indices.
### Versions
Hardware: Apple 16" M1Max 64GB 4TB
OS: Monterey 12.4 (21F79)
Python: 3.9.4
[conda] numpy 1.23.2 py39h3668e8b_0 conda-forge
[conda] pytorch 1.13.0.dev20220922 py3.9_0 pytorch-nightly
[conda] pytorch-lightning 1.5.8 pyhd8ed1ab_0 conda-forge
[conda] pytorch3d 0.0.1 pypi_0 pypi
[conda] torchaudio 0.13.0.dev20220922 py39_cpu pytorch-nightly
[conda] torchfile 0.1.0 py_0 conda-forge
[conda] torchgeometry 0.1.2 pypi_0 pypi
[conda] torchmetrics 0.10.3 pyhd8ed1ab_0 conda-forge
[conda] torchvision 0.14.0.dev20220923 py39_cpu pytorch-nightly
cc @kulinseth @albanD @malfet @DenisVieriu97 @razarmehr @abhudev
| 0 |
4,068 | 89,942 |
Random K compression hook in PyTorch DDP
|
feature, triaged, module: ddp
|
### 🚀 The feature, motivation and pitch
Currently Pytorch DDP supports a few default compression hooks, namely fp16, bf16, and PowerSGD. However, there are a myraid of other compression types that exist in literature with various degrees of success. Often in literature these methods are rewritten by each research team leading to a lot of duplicate work, increased difficulty of reproducibility, and also increasing the barrier for others to experiment with the same techniques.
A common and simple compression method is Random-K, which all reduces only some percent (to be determined by the user) of tensor elements. We have implemented Random-K as a DDP hook and would like to contribute it back to PyTorch so there can be a standard, reusable Random-K compression method available to all. Our implementation is based upon the implementation in [GRACE](https://github.com/sands-lab/grace).
[EDIT]: We are also interested in adding other compression hooks, such as Top-K and [Deep Gradient Compression](https://github.com/synxlin/deep-gradient-compression) to the DDP library if the maintainers are interested.
Let me know what you think!
Best,
Harrison
### Alternatives
_No response_
### Additional context
_No response_
| 1 |
4,069 | 89,908 |
Export to ONNX with export_modules_as_functions works wrong
|
module: onnx, triaged
|
### 🐛 Describe the bug
Export to onnx with `export_modules_as_functions` provides wrong types in some cases. Here is short example which result that first `some_op` has type `SomeOp.1` but second `SomeOp`.
```python
class SomeOp(torch.nn.Module):
def __init__(self):
super(SomeOp, self).__init__()
def forward(self, x: torch.Tensor, y: torch.Tensor) -> torch.Tensor:
height, width = x.shape[2:]
res = torch.cat([y[:, 0:1, :, :] / width, y[:, 1:2, :, :] / height], 1)
return res
class TestNet(torch.nn.Module):
def __init__(self):
super().__init__()
self.conv = torch.nn.Conv2d(2, 2, 1)
self.some_op = SomeOp()
def forward(self, x, y):
return self.some_op(self.some_op(x, y), y)
net = TestNet()
x = torch.rand((1, 2, 16, 16))
y = torch.rand((1, 2, 16, 16))
onnx_path = os.path.join(this_dir, 'test.onnx')
torch.onnx.export(net, (x, y), onnx_path,
verbose=True, opset_version=16,
export_modules_as_functions={SomeOp})
```
Result graph:
```
Exported graph: graph(%onnx::Slice_1 : Float(1, 2, 16, 16, strides=[512, 256, 16, 1], requires_grad=0, device=cpu)):
= onnx::LocalFunctionDef[graph=<Graph>, name="SomeOp.1", domain="__main__", attributes=annotate(List[str], [])]()
= onnx::LocalFunctionDef[graph=<Graph>, name="SomeOp", domain="__main__", attributes=annotate(List[str], [])]()
%/some_op/SomeOp.1_output_0 : Float(1, 1, 16, 16, strides=[512, 256, 16, 1], requires_grad=0, device=cpu), %/some_op/SomeOp.1_output_1 : Float(1, 1, 16, 16, strides=[512, 256, 16, 1], requires_grad=0, device=cpu) = __main__::SomeOp.1[onnx_name="/some_op/SomeOp.1"](%onnx::Slice_1), scope: __main__.TestNet::/__main__.SomeOp::some_op
%19 : Float(1, 2, 16, 16, strides=[512, 256, 16, 1], requires_grad=0, device=cpu) = __main__::SomeOp[onnx_name="/some_op_1/SomeOp"](%/some_op/SomeOp.1_output_0, %/some_op/SomeOp.1_output_1), scope: __main__.TestNet::/__main__.SomeOp::some_op
return (%19)
```
<img width="230" alt="image" src="https://user-images.githubusercontent.com/2921717/204782411-3cd94964-0fca-4362-ba05-91d748188b0c.png">
### Versions
PyTorch version: 1.13.0
Is debug build: False
CUDA used to build PyTorch: None
ROCM used to build PyTorch: N/A
OS: macOS 12.4 (x86_64)
GCC version: Could not collect
Clang version: 13.1.6 (clang-1316.0.21.2.5)
CMake version: version 3.24.2
Libc version: N/A
Python version: 3.10.6 | packaged by conda-forge | (main, Aug 22 2022, 20:43:44) [Clang 13.0.1 ] (64-bit runtime)
Python platform: macOS-12.4-x86_64-i386-64bit
Is CUDA available: False
CUDA runtime version: No CUDA
CUDA_MODULE_LOADING set to: N/A
GPU models and configuration: No CUDA
Nvidia driver version: No CUDA
cuDNN version: No CUDA
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.23.5
[pip3] torch==1.13.0
[conda] libblas 3.9.0 16_osx64_mkl conda-forge
[conda] libcblas 3.9.0 16_osx64_mkl conda-forge
[conda] liblapack 3.9.0 16_osx64_mkl conda-forge
[conda] liblapacke 3.9.0 16_osx64_mkl conda-forge
[conda] mkl 2022.1.0 hf3af037_209
[conda] numpy 1.23.5 pypi_0 pypi
[conda] torch 1.13.0 pypi_0 pypi
| 1 |
4,070 | 89,907 |
nn.CrossEntropy/nn.NLLLoss : Request for option to specify invalid ignore_index for perf. optimization
|
module: loss, triaged
|
### 🚀 The feature, motivation and pitch
nn.CrossEentropy and nn.NLLLoss functions have the argument "ignore_index" to specify the target index to be ignored during loss calculation
Eg: Pls ref:
https://pytorch.org/docs/stable/generated/torch.nn.CrossEntropyLoss.html
The default value is -100 and as per the definition at the above link, any value (even outside the usual class range) can be specified as ignore_index value.
And there is no option to specify that ingore_index value is not valid.( i.e, All elements of target are to be considered for loss calculation)
In fact some models seem to intentionally set targets to be ignored as -100 since default ignore_index is -100.
(https://github.com/huggingface/transformers/blob/main/src/transformers/models/layoutxlm/tokenization_layoutxlm.py)
Looking for whether the target tensor contains any element with ignore_index value can have computational overhead especially with large target tensors.
But there is no target to be ignored in the case of many models.
So the current API results in unnecessary overhead in many cases.
Can PyTorch provide an option to indicate the backends whether the inore_index argument is invalid
(so that sifting though the target tensor for ignore_index can be avoided)
Say, with an API update with a "specific" ingore_index value or an additional argument?
This can improve the training times if going forward backends and training scripts can adopt this change.
When the default value was set as -100, was it intended to be used as as an invalid_ignore index?
Can models use -100 as invalid ignore_index? If yes, may be just a document update is enough from Pytorch side.
And hopefully existing models can make corresponding change when upgrading for a Pytorch version with this specification.
### Alternatives
_No response_
### Additional context
_No response_
| 5 |
4,071 | 93,457 |
[Dynamo] Examples that recompile beyond cache size limit
|
triaged
|
Collecting small repros that demonstrate cache size limit violation.
**Case 1** - From `vision_maskrcnn`
**Solution** - Could be solved by Unspec work
~~~
import torch
import torch._dynamo as dynamo
import logging
dynamo.config.cache_size_limit = 2
dynamo.config.log_level = logging.DEBUG
dynamo.config.print_graph_breaks = True
def fn(box):
w = int(box[2] + box[0])
h = int(box[3] - box[1])
return w + h
torch.manual_seed(0)
args = [torch.randint(0, 10000, size=(4,), dtype=torch.int64) for _ in range(10)]
opt_fn = dynamo.optimize("eager")(fn)
res = [opt_fn(arg) for arg in args]
print(res)
~~~
**Case 2** - From `tactotron2`
There is a temporary fix - https://github.com/pytorch/pytorch/pull/88857 that skips the frame entirely, but it might be suboptimal
~~~
def inner(x):
return torch.sin(x)
def fn(x):
for _ in range(100):
inner(x)
torch._dynamo.graph_break()
return x
~~~
**Case 3** - Just trying on my own
**Solution** - Could be solved by Unspec work, however 1 to 5 are common numbers. If I change the n from 1 to 5, to 200 to 205, unspec would work.
~~~
import torch
import torch._dynamo as dynamo
import logging
dynamo.config.cache_size_limit = 2
dynamo.config.log_level = logging.DEBUG
dynamo.config.print_graph_breaks = True
def fn(x, n):
return x + n
x = torch.randn(4)
opt_fn = dynamo.optimize("eager")(fn)
for n in range(5):
opt_fn(x, n)
~~~
| 0 |
4,072 | 93,456 |
Way to run accuracy minifier on only one particular subgraph
|
triaged, bug
|
### 🐛 Describe the bug
Accuracy minifier may get stuck on an early subgraph. In this case, it may be helpful to ask the minifier to not run on those subgraphs, and only run on the one that you suspect is problematic (or you can do some sort of ablation and find all the subgraphs that are failing accuracy, so you can then discard the ones that are just because the accuracy minifier doesn't work.)
### Error logs
_No response_
### Minified repro
_No response_
| 0 |
4,073 | 89,884 |
[RFC] PyTorch Tensor Parallel(TP) User API for Distributed Training
|
triaged, module: dtensor
|
### 🚀 The feature, motivation and pitch
# 🚀 Feature
Provide a detailed API design for high-level PyTorch Tensor Parallelism API design. This is an evolvement of PyTorch Sharding introduced in https://github.com/pytorch/pytorch/issues/72138 and is directly built on top of DTensor proposed in https://github.com/pytorch/pytorch/issues/88838. We want users to only focus on how their modules to be distributed and hide all other details. (Caveat, for now, we only support linear/transformer based models).
# Motivation
To scale the large model training, especially transformer based model training, multiple parallelism paradigms are proposed and considered. Among them, model parallelism like Megatron-LM is getting popular together with 3D parallelism. We have already proposed a standardized sharding api in the past (https://github.com/pytorch/pytorch/issues/72138). Now to enable more generic data distributions more than sharding across hosts, we have proposed a new design of Distributed Tensor (DTensor) in https://github.com/pytorch/pytorch/issues/88838 and we want to not only provide similar functionality of model parallelism as Megatron on top of DTensor, but also provide better usability so that users don't need to change their model to use tensor parallelism directly.
# Pitch
We are proposing APIs which cover three different use cases during module annotation. These APIs not only include the TP-only case, it also covers 2D parallel and 3D parallel down the road.
- One base Parallel Style Class and three children in-house parallel style. This is extendible so that users can create their own parallel styles if the in-house ones do not meet their requirements.
```python
class ParallelStyle(ABC):
"""
The parallel style user wants the module or submodule to be parallelized.
We can add more in future, but this seems sufficient for immediate needs.
Users can extend this class to build their own parallel style with customized input/output preparations.
"""
_prepare_input: Callable[[Union[Tensor, DTensor], Optional[DeviceMesh], Optional[Int]], DTensor]
_prepare_output: Callable[[DTensor, Optional[DeviceMesh], Optional[Int]], Union[Tensor, DTensor]]
class RowwiseParallel(ParallelStyle):
"""
Partitioning the row of a module.
We assume the input to be a sharded DTensor and output to be a replicated DTensor.
"""
def __init__(self):
super().__init__(MakeInputShard, MakeOutputReplicated)
Class ColwiseParallel(ParallelStyle):
"""
Partitioning the column of a tensor or module.
We assume the input to be a Replicated DTensor and output to be a Replicated DTensor.
"""
def __init__(self):
super().__init__(MakeInputReplicated, MakeOutputReplicated)
class PairwiseParallel(ParallelStyle):
"""
We concatenate colwise and rowwise styles as a fixed pair like what Megatron-LM(https://arxiv.org/abs/1909.08053) is doing.
We assume both input and output to a Replicated DTensor.
We now only support Multihead Attention, MLP and transformer for this style.
We also need to assume the input is a nn.Multihead Attention, nn.Transformer or even-number layers of nn.Linear for now. """
def __init__(self):
super().__init__(MakeInputReplicated(), MakeOutputReplicated())
```
- One API for module level parallel and the user needs to specify what parallel style they want to apply to the whole module or users can specify parallel style per the module path. For PairwiseParallelStyle, we only support it for MHA, MLP and transformer models for now.
```python
def parallelize_module(
module: nn.Module,
device_mesh: DeviceMesh,
parallelize_plan: Union[ParallelStyle, Dict[str, ParallelStyle]],
tp_mesh_dim: int=0,
) -> None:
'''
This function converts all module parameters to distributed tensor parameters according to the `parallelize_plan` specified.
Users can always use FSDP or DDP as a fallback if the model does not fall into the type we support here.
Args:
module (nn.Module): user module to be partitioned.
parallel_plan (ParallelPlan): the parallel plan which the user wants.
device_mesh (DeviceMesh): the device mesh to place the module.
tp_mesh_dim (int): the dimension of TP in the device mesh.
'''
# Code example is shown as following
import torch
import torch.distributed.tensor_parallel as tp
from torch.distributed.fsdp import FullyShardedDataParallel as FSDP
from torch.distributed import DeviceMesh
# initialize a new device mesh for TP for the given tp world size
device_mesh = DeviceMesh("cuda", torch.arange(world_size))
# colwise parallel of a Linear module
layer_one = torch.nn.Linear(8,16)
tp.parallelize_module(layer_one, tp.ColwiseParallel(), device_mesh)
# rowwise parallel of a Linear module
layer_two = torch.nn.Linear(16,8)
tp.parallelize_module(layer_two, tp.RowwiseParallel(), device_mesh)
# Megatron-LM style pairwise parallel for a transformer model
# Users do not need to specify col/row wise parallel for each module or parameter.
transformer_model = torch.nn.Transformer(nhead=16, num_encoder_layers=12)
pairwise_style = tp.PairwiseParallelStyle()
tp.parallelize_module(transformer_model, pairwise_style, device_mesh)
# Customized module
class DemoModel(torch.nn.Module):
def __init__(self):
super(SimpleModel, self).__init__()
self.attn = AttentionModule(...) # Defined by user.
self.layer_norm = LayerNorm(...)
self.mlp = CustomizedMLP(...) # Defined by user.
def forward(self, x):
return self.mlp(self.layer_norm(self.attn(x)))
customized_model = DemoModel(...)
tp.parallelize_module(customized_model, {“attn”: pairwise_style, “mlp”: pairwise_style}, device_mesh)
```
- For 2D parallel, the code is similar. To recap how we do 2D parallelism with FSDP. We will first parallelize modules within 8 GPUs on each host and then wrap the module with FSDP. Basically TP first shards the weight of a module and then FSDP shards the local tensor of TP-sharded weights. And another common practice of 2D parallel is to perform it on each layer of a transformer encoder or decoder rather than directly applying it to the whole model directly.
```python
# Below is another example showing 2D parallel with FSDP.
# initialize a new device mesh for 2D parallel for the given world size
device_mesh_2D = DeviceMesh("cuda", torch.arange(world_size).reshape(dp_size, tp_size))
# Pairwise parallelize a transformer model
transformer_model = torch.nn.Transformer(nhead=16, num_encoder_layers=12)
parallelize_module(transformer_model, tp_style, device_mesh_2D, tp_mesh_dim=1)
# Wrap the transformer with FSDP
dp_pg = device_mesh_2D.get_dim_groups()[0]
transformer_model = FSDP(transformer_model, pg=dp_pg)
```
### Low-level API for TP:
We also want to build some low-level APIs to provide more flexibility and usability for users as we continue to build more high-level TP features.
```python
def _parallelize_mlp(
module: nn.Module,
device_mesh: DeviceMesh,
parallel_style: ParallelStyle=PairwiseParallelStyle(),
tp_mesh_dim: int=0,
) -> None:
'''
This function assumes the input module is a sequence of nn.Linear and we parallelize the module based on the given parallel style.
Args:
module (nn.Module): user module to be partitioned.
device_mesh (DeviceMesh): the device mesh to place the module.
parallel_style (ParallelStyle): Parallel style with input/output preparation.
tp_mesh_dim (int): the dimension of TP in the device mesh.
'''
def _parallelize_multihead_attn(
module: nn.Module,
device_mesh: DeviceMesh,
parallel_style: ParallelStyle=PairwiseParallelStyle(),
tp_mesh_dim: int=0,
) -> None:
'''
This function assumes the input module is a class of nn.MultiheadAttention or a customized multihead attention. We will replace it with our own version of the multihead attention module.
We directly assume the input module will be a nn.MultiheadAttention or module which has a similar structure.
Args:
module (nn.Module): user module to be partitioned.
device_mesh (DeviceMesh): the device mesh to place the module.
parallel_style (ParallelStyle): Parallel style with input/output preparation.
tp_mesh_dim (int): the dimension of TP in the device mesh.
'''
def _parallelize_linear(
module: nn.Module,
device_mesh: DeviceMesh,
parallel_style: ParallelStyle=ColwiseParallel(),
tp_mesh_dim: int=0,
) -> None:
'''
This function assumes the input module is a class of nn.Linear.
We directly assume the input module will be a nn.Linear.
Args:
module (nn.Module): user module to be partitioned.
device_mesh (DeviceMesh): the device mesh to place the module.
parallel_style (ParallelStyle): Parallel style with input/output preparation.
tp_mesh_dim (int): the dimension of TP in the device mesh.
'''
| 4 |
4,074 | 93,455 |
Performance regression on interpolation in Kornia
|
triaged, bug
|
### 🐛 Describe the bug
When compiling the rescale function of kornia.geometry.transform.rescale (which conv2d + interpolation) with dynamo/inductor we see a performance regression of up to 4x in CUDA and smaller but constant regression on CPU.
These are timing results for eager vs dynamo:
```
[---------------------------------------- Rescale ----------------------------------------]
| eager_cpu | eager_cuda | dynamo_cpu | dynamo_cuda | opencv
1 threads: --------------------------------------------------------------------------------
[1, 32, 0.5] | 23.8 | 14.2 | 45.3 | 53.0 | 18.5
[1, 32, 1.5] | 65.1 | 14.2 | 86.4 | 52.6 | 18.7
[1, 64, 0.5] | 48.9 | 13.9 | 71.4 | 52.8 | 39.5
[1, 64, 1.5] | 210.2 | 14.3 | 239.6 | 53.3 | 39.6
[1, 128, 0.5] | 147.7 | 14.0 | 182.4 | 53.0 | 120.3
[1, 128, 1.5] | 808.8 | 14.2 | 867.7 | 53.2 | 120.2
[1, 256, 0.5] | 557.6 | 13.9 | 612.4 | 53.5 | 442.3
[1, 256, 1.5] | 3214.4 | 14.2 | 3269.5 | 54.2 | 440.6
[1, 512, 0.5] | 2155.5 | 14.3 | 2210.9 | 53.0 | 1736.9
[1, 512, 1.5] | 12733.5 | 18.1 | 12769.2 | 61.7 | 1736.2
[2, 32, 0.5] | 32.3 | 14.3 | 55.0 | 53.4 | 36.1
[2, 32, 1.5] | 114.5 | 14.2 | 136.9 | 53.7 | 35.9
[2, 64, 0.5] | 81.3 | 14.0 | 111.0 | 53.6 | 77.8
[2, 64, 1.5] | 409.1 | 14.2 | 455.3 | 53.3 | 77.8
[2, 128, 0.5] | 287.9 | 14.2 | 332.5 | 53.1 | 238.7
[2, 128, 1.5] | 1597.3 | 14.3 | 1652.7 | 53.2 | 238.9
[2, 256, 0.5] | 1085.8 | 14.0 | 1134.3 | 53.1 | 881.6
[2, 256, 1.5] | 6348.1 | 14.1 | 6415.3 | 55.8 | 881.0
[2, 512, 0.5] | 4236.6 | 14.1 | 4303.3 | 53.2 | 3464.7
[2, 512, 1.5] | 25832.0 | 26.2 | 26018.7 | 70.9 | 3469.2
[5, 32, 0.5] | 57.4 | 14.2 | 81.3 | 53.4 | 88.1
[5, 32, 1.5] | 261.4 | 14.1 | 290.9 | 55.8 | 88.3
[5, 64, 0.5] | 183.2 | 13.9 | 220.0 | 56.3 | 192.6
[5, 64, 1.5] | 1009.4 | 14.3 | 1058.6 | 55.7 | 192.8
[5, 128, 0.5] | 688.6 | 14.3 | 734.5 | 56.1 | 594.0
[5, 128, 1.5] | 3953.8 | 13.9 | 4003.5 | 55.9 | 595.4
[5, 256, 0.5] | 2658.2 | 14.2 | 2720.4 | 55.5 | 2210.5
[5, 256, 1.5] | 15882.5 | 17.8 | 20457.2 | 61.2 | 2206.8
[5, 512, 0.5] | 10680.2 | 14.0 | 10915.5 | 66.2 | 8679.6
[5, 512, 1.5] | 111027.6 | 87.6 | 111251.9 | 138.8 | 8665.6
[9, 32, 0.5] | 91.0 | 14.1 | 118.0 | 57.2 | 158.5
[9, 32, 1.5] | 463.1 | 15.2 | 505.1 | 61.3 | 158.7
[9, 64, 0.5] | 323.9 | 15.0 | 368.8 | 66.7 | 344.5
[9, 64, 1.5] | 1799.3 | 15.2 | 1857.8 | 65.9 | 345.1
[9, 128, 0.5] | 1222.4 | 15.4 | 1282.7 | 66.1 | 1072.3
[9, 128, 1.5] | 7070.1 | 15.3 | 7134.2 | 65.8 | 1073.4
[9, 256, 0.5] | 4778.1 | 15.5 | 4862.1 | 65.5 | 3974.5
[9, 128, 1.5] | 7070.1 | 15.3 | 7134.2 | 65.8 | 1073.4
[9, 256, 0.5] | 4778.1 | 15.5 | 4862.1 | 65.5 | 3974.5
[9, 256, 1.5] | 29078.0 | 30.2 | 32856.6 | 79.8 | 3972.6
[9, 512, 0.5] | 19593.3 | 33.4 | 19761.1 | 117.8 | 15543.2
[9, 512, 1.5] | 202600.8 | 147.0 | 202055.1 | 227.9 | 15562.6
4 threads: --------------------------------------------------------------------------------
[1, 32, 0.5] | 23.7 | 14.3 | 31.3 | 34.7 | 18.7
[1, 32, 1.5] | 65.0 | 14.4 | 72.6 | 34.1 | 18.8
[1, 64, 0.5] | 48.9 | 14.1 | 57.1 | 34.3 | 39.6
[1, 64, 1.5] | 156.6 | 14.2 | 164.9 | 34.7 | 40.0
[1, 128, 0.5] | 166.4 | 14.0 | 182.7 | 34.2 | 120.3
[1, 128, 1.5] | 634.1 | 14.2 | 651.7 | 34.0 | 120.3
[1, 256, 0.5] | 318.9 | 14.0 | 337.9 | 34.1 | 441.1
[1, 256, 1.5] | 2394.8 | 14.3 | 2397.3 | 34.2 | 442.4
[1, 512, 0.5] | 1121.7 | 14.3 | 1146.3 | 34.2 | 1738.7
[1, 512, 1.5] | 9302.0 | 18.1 | 9266.6 | 34.3 | 1737.7
[2, 32, 0.5] | 32.3 | 14.3 | 39.9 | 34.4 | 35.9
[2, 32, 1.5] | 137.7 | 14.2 | 146.8 | 34.3 | 36.0
[2, 64, 0.5] | 81.4 | 14.0 | 91.0 | 34.3 | 78.0
[2, 64, 1.5] | 335.8 | 14.1 | 345.3 | 34.0 | 77.9
[2, 128, 0.5] | 316.6 | 14.2 | 346.8 | 34.0 | 238.9
[2, 128, 1.5] | 1219.4 | 14.4 | 1240.1 | 34.1 | 238.9
[2, 256, 0.5] | 590.4 | 14.0 | 611.9 | 34.3 | 880.0
[2, 256, 1.5] | 4657.5 | 14.1 | 4697.3 | 34.0 | 881.5
[2, 512, 0.5] | 2165.1 | 14.1 | 2186.8 | 34.1 | 3466.0
[2, 512, 1.5] | 18391.2 | 26.1 | 18398.1 | 41.8 | 3476.7
[5, 32, 0.5] | 57.6 | 14.4 | 65.4 | 33.8 | 88.2
[5, 32, 1.5] | 326.9 | 14.2 | 339.6 | 34.1 | 88.2
[5, 64, 0.5] | 223.6 | 14.2 | 240.0 | 34.3 | 192.8
[5, 64, 1.5] | 789.4 | 14.2 | 810.0 | 34.0 | 192.7
[5, 128, 0.5] | 760.8 | 14.2 | 784.4 | 33.8 | 595.3
[5, 128, 1.5] | 2983.4 | 14.2 | 2994.6 | 34.3 | 605.7
[5, 256, 0.5] | 1405.6 | 14.3 | 1424.7 | 33.7 | 2210.3
[5, 256, 1.5] | 11539.5 | 17.8 | 11553.5 | 34.2 | 2205.0
[5, 512, 0.5] | 5361.9 | 14.0 | 5373.1 | 41.2 | 8668.3
[5, 512, 1.5] | 61519.4 | 87.3 | 61506.9 | 113.1 | 8679.6
[9, 32, 0.5] | 91.1 | 14.2 | 98.5 | 34.3 | 158.1
[9, 32, 1.5] | 538.4 | 15.2 | 553.1 | 34.5 | 157.9
[9, 64, 0.5] | 365.3 | 15.0 | 387.8 | 37.7 | 345.4
[9, 64, 1.5] | 1388.3 | 15.2 | 1416.0 | 37.6 | 345.8
[9, 128, 0.5] | 1284.0 | 15.4 | 1306.2 | 37.4 | 1073.4
[9, 128, 1.5] | 5332.5 | 15.3 | 5407.2 | 37.5 | 1072.3
[9, 256, 0.5] | 2490.2 | 15.5 | 2503.7 | 37.7 | 3969.1
[9, 256, 1.5] | 20731.2 | 29.9 | 20729.8 | 48.7 | 3976.7
[9, 512, 0.5] | 9657.5 | 33.4 | 9725.7 | 87.8 | 15561.7
[9, 512, 1.5] | 113171.0 | 147.0 | 113178.5 | 197.6 | 15578.7
Times are in microseconds (us).
```
To reproduce:
```
pip install kornia opencv-python
git clone https://github.com/kornia/kornia-benchmark
cd kornia-benchmark/dynamo
python test_rescale.py
```
### Error logs
_No response_
### Minified repro
_No response_
| 1 |
4,075 | 89,868 |
No pytorch_jni.dll file in libtorch 1.13.0 lib folder
|
oncall: java
|
### 🐛 Describe the bug
# Run details
I am trying to load and run inference on a pytorch model in java using the code below:
```java
import org.pytorch.IValue;
import org.pytorch.Module;
import org.pytorch.Tensor;
import java.util.Arrays;
public class App
{
public static void main( String[] args )
{
Module mod = Module.load("demo-model.pt1");
Tensor data = Tensor.fromBlob(new int[] {1, 2, 3, 4, 5, 6}, new long[] {2, 3} );
IValue result = mod.forward(IValue.from(data), IValue.from(3.0));
Tensor output = result.toTensor();
System.out.println("shape: " + Arrays.toString(output.shape()));
System.out.println("data: " + Arrays.toString(output.getDataAsFloatArray()));
System.exit(0);
}
}
```
To run I am:
* Adding downloaded and extracted `libtorch 1.13.0` to system path:
```set PATH=%PATH%;\libtorch1.13.0\lib;```
* Compiling and running with required jars: `pytorch_java_only 1.12.2`, `nativeloader 0.10.4`, `fbjni-java-only 0.3.0`:
```
javac -cp ".;\pytorch_java_only\1.12.2\pytorch_java_only-1.12.2.jar;\nativeloader\0.10.4\nativeloader-0.10.4.jar;\fbjni-java-only\0.3.0\fbjni-java-only-0.3.0.jar;" App.java
```
```
java -cp ".;\pytorch_java_only\1.12.2\pytorch_java_only-1.12.2.jar;\nativeloader\0.10.4\nativeloader-0.10.4.jar;\fbjni-java-only\0.3.0\fbjni-java-only-0.3.0.jar;" App
```
# Error
The error I am getting pertains to the `pytorch_jni.dll` file not being present in newer versions of libtorch. Libtorch>1.10.0

# Reason for error and possible fixes
* The error seems to happen in newer visions of libtorch. i.e: Libtorch>1.10.0
* The above error **DOES NOT** happen with `libtorch 1.10.0` as the `pytorch_jni.dll` is present in the lib folder:

* The error **DOES** happen with `libtorch 1.13.0` as the `pytorch_jni.dll` is **NOT** present in the lib folder. Instead there is `libtorch_jni.so`:

* There seems to be a `libtorch_jni.so` file in libtorch 1.13.0 but no `pytorch_jni.dll`.
* Could this issue be fixed with updating `pytorch_java_only 1.12.2` to look for and read `libtorch_jni.so` in libtorch vesions > 1.10.0 instead of `pytorch_jni.dll`.
* Please make fixes to use pytorch_java_only with newer versions of libtorch. This would be much appreciated. Thanks.
https://github.com/pytorch/java-demo/issues/25
https://github.com/pytorch/java-demo/issues/6
### Versions
* libtorch 1.13.0 (https://download.pytorch.org/libtorch/cpu/libtorch-win-shared-with-deps-1.13.0%2Bcpu.zip)
* pytorch_java_only 1.12.2 (https://mvnrepository.com/artifact/org.pytorch/pytorch_java_only/1.12.2)
* nativeloader 0.10.4 (https://mvnrepository.com/artifact/com.facebook.soloader/nativeloader/0.10.4)
* fbjni-java-only 0.3.0 (https://mvnrepository.com/artifact/com.facebook.fbjni/fbjni-java-only/0.3.0)
| 1 |
4,076 | 89,835 |
torch1.13 quantized model export onnx error
|
module: onnx, triaged
|
### 🐛 Describe the bug
model_quantized = model_quantized.cpu()
torch.onnx.export(
model_quantized,
inp,
file_onnx,
export_params = True,
opset_version=13,
verbose = True,
)
Traceback (most recent call last):
File "test2.py", line 18, in <module>
torch.onnx.export(
File "/opt/conda/envs/torch13/lib/python3.8/site-packages/torch/onnx/utils.py", line 504, in export
_export(
File "/opt/conda/envs/torch13/lib/python3.8/site-packages/torch/onnx/utils.py", line 1568, in _export
) = graph._export_onnx( # type: ignore[attr-defined]
RuntimeError: !node->kind().is_aten() && !node->kind().is_prim() && !node->kind().is_attr() INTERNAL ASSERT FAILED at "../torch/csrc/jit/serialization/export.cpp":891, please report a bug to PyTorch.
### Versions
PyTorch version: 1.13.0+cu117
Is debug build: False
CUDA used to build PyTorch: 11.7
ROCM used to build PyTorch: N/A
OS: Ubuntu 18.04.5 LTS (x86_64)
GCC version: (Ubuntu 7.5.0-3ubuntu1~18.04) 7.5.0
Clang version: Could not collect
CMake version: Could not collect
Libc version: glibc-2.31
Python version: 3.8.8 (default, Feb 24 2021, 21:46:12) [GCC 7.3.0] (64-bit runtime)
Python platform: Linux-5.15.0-53-generic-x86_64-with-glibc2.10
Is CUDA available: True
CUDA runtime version: 11.1.105
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration:
GPU 0: NVIDIA GeForce RTX 3090
GPU 1: NVIDIA GeForce RTX 3090
GPU 2: NVIDIA GeForce RTX 3090
GPU 3: NVIDIA GeForce RTX 3090
Nvidia driver version: 470.141.03
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.0.5
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.0.5
/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.0.5
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_infer.so.8.0.5
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.0.5
/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.0.5
/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.0.5
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.23.3
[pip3] torch==1.13.0
[pip3] torch-pruning==0.2.8
[pip3] torch-summary==1.4.5
[pip3] torchelastic==0.2.2
[pip3] torchreid==1.4.0
[pip3] torchstat==0.0.6
[pip3] torchsummaryX==1.3.0
[pip3] torchtext==0.9.0
[pip3] torchvision==0.14.0
[conda] autotorch 0.0.1 pypi_0 pypi
[conda] blas 1.0 mkl
[conda] cudatoolkit 11.1.74 h6bb024c_0 nvidia
[conda] ffmpeg 4.3 hf484d3e_0 pytorch
[conda] mkl 2020.2 256
[conda] mkl-service 2.3.0 py38he904b0f_0
[conda] mkl_fft 1.3.0 py38h54f3939_0
[conda] mkl_random 1.1.1 py38h0573a6f_0
[conda] numpy 1.23.3 pypi_0 pypi
[conda] numpy-base 1.19.2 py38hfa32c7d_0
[conda] torch 1.13.0 pypi_0 pypi
[conda] torch-pruning 0.2.8 pypi_0 pypi
[conda] torch-summary 1.4.5 pypi_0 pypi
[conda] torchelastic 0.2.2 pypi_0 pypi
[conda] torchreid 1.4.0 pypi_0 pypi
[conda] torchstat 0.0.6 pypi_0 pypi
[conda] torchsummaryx 1.3.0 pypi_0 pypi
[conda] torchtext 0.9.0 py38 pytorch
[conda] torchvision 0.14.0 pypi_0 pypi
| 3 |
4,077 | 89,834 |
Wrong output type hint for `F.one_hot`
|
module: typing, triaged
|
### 🐛 Describe the bug
Type hint for `torch.nn.functional.one_hot` seems not to work properly.
```python
# one_hot_type.py
import torch
import torch.nn.functional as F
x = torch.tensor([0, 1, 2]).long()
reveal_type(F.one_hot(x))
```
```shell
$ mypy one_hot_type.py
one_hot_type.py:5: note: Revealed type is "Any"
Success: no issues found in 1 source file
```
Expected Tensor, got Any.
### Versions
PyTorch version: 1.14.0.dev20221117
Is debug build: False
CUDA used to build PyTorch: None
ROCM used to build PyTorch: N/A
OS: macOS 13.0.1 (x86_64)
GCC version: Could not collect
Clang version: 15.0.3
CMake version: version 3.24.2
Libc version: N/A
Python version: 3.9.13 (main, May 24 2022, 21:28:31) [Clang 13.1.6 (clang-1316.0.21.2)] (64-bit runtime)
Python platform: macOS-13.0.1-x86_64-i386-64bit
Is CUDA available: False
CUDA runtime version: No CUDA
CUDA_MODULE_LOADING set to: N/A
GPU models and configuration: No CUDA
Nvidia driver version: No CUDA
cuDNN version: No CUDA
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] mypy==0.982
[pip3] mypy-extensions==0.4.3
[pip3] numpy==1.23.3
[pip3] torch==1.14.0.dev20221117
[pip3] torch-tb-profiler==0.4.0
[pip3] torchaudio==0.14.0.dev20221117
[pip3] torchvision==0.15.0.dev20221117
[conda] Could not collect
cc @ezyang @malfet @rgommers @xuzhao9 @gramster
| 1 |
4,078 | 89,829 |
update transformer init function
|
oncall: transformer/mha
|
### 🚀 The feature, motivation and pitch
Once a transformer instance is created, like below:
`
model_pytorch = nn.Transformer(nhead=16, num_encoder_layers=2, num_decoder_layers=2)
`
I cannot access it's num_encoder_layers by **model_pytorch.num_encoder_layers**, TransformerEncoder, TransformerDecoder, TransformerEncoderLayer, TransformerDecoderLayer alike.
This is extremely suffering when doing quantization, like below:
`
Transformer.from_torch(model_pytorch)
`
say I have a self-defined Transformer class, it's really hard to create my instance from original pytorch instance, because I cannot access init value elegantly.
### Alternatives
_No response_
### Additional context
_No response_
cc @jbschlosser @bhosmer @cpuhrsch @erichan1
| 0 |
4,079 | 89,820 |
The current example for `torch.mode` is IMHO confusing and has room for improvement.
|
module: docs, triaged
|
### 📚 The issue
I believe that example for any torch operator should be in such a way that it is obvious what to see what the operator does. This is more important for an operator that is as simple as `torch.mode`. The current example does not show the tensor and it is constructed in such a way that all the modes occur together. So, the indices returned are all the same and leads to confusion (e.g. [a post on StackOverflow](https://stackoverflow.com/questions/74608692/how-yo-get-the-torch-mode-s-output-indeces-can-details/74608850#74608850)).
### Potential alternative
Instead I suggest something like this:
```python
>>> b = torch.randint(4, (5, 7))
>>> b
tensor([[0, 0, 0, 2, 0, 0, 2],
[0, 3, 0, 0, 2, 0, 1],
[2, 2, 2, 0, 0, 0, 3],
[2, 2, 3, 0, 1, 1, 0],
[1, 1, 0, 0, 2, 0, 2]])
>>> torch.mode(b, 0)
torch.return_types.mode(
values=tensor([0, 2, 0, 0, 0, 0, 2]),
indices=tensor([1, 3, 4, 4, 2, 4, 4]))
```
Users can see the tensor, it is clear what the modes are and where they occur.
cc @svekars @carljparker
| 0 |
4,080 | 89,817 |
Basic math operations produce a "floating point exception"
|
needs reproduction, module: crash, module: cpu, triaged
|
### 🐛 Describe the bug
When I try to run the following simple piece of code:
```python
import numpy as np
import torch
np.random.seed(42)
x = torch.from_numpy(np.random.rand(100)).float()
print(x)
exp_x = torch.exp(x)
print(exp_x)
```
I get a `floating point exception` that kills my Python interpreter:
```
(venv) [tgebhard@g108] ~ % python test.py
tensor([0.3745, 0.9507, 0.7320, 0.5987, 0.1560, 0.1560, 0.0581, 0.8662, 0.6011,
0.7081, 0.0206, 0.9699, 0.8324, 0.2123, 0.1818, 0.1834, 0.3042, 0.5248,
0.4319, 0.2912, 0.6119, 0.1395, 0.2921, 0.3664, 0.4561, 0.7852, 0.1997,
0.5142, 0.5924, 0.0465, 0.6075, 0.1705, 0.0651, 0.9489, 0.9656, 0.8084,
0.3046, 0.0977, 0.6842, 0.4402, 0.1220, 0.4952, 0.0344, 0.9093, 0.2588,
0.6625, 0.3117, 0.5201, 0.5467, 0.1849, 0.9696, 0.7751, 0.9395, 0.8948,
0.5979, 0.9219, 0.0885, 0.1960, 0.0452, 0.3253, 0.3887, 0.2713, 0.8287,
0.3568, 0.2809, 0.5427, 0.1409, 0.8022, 0.0746, 0.9869, 0.7722, 0.1987,
0.0055, 0.8155, 0.7069, 0.7290, 0.7713, 0.0740, 0.3585, 0.1159, 0.8631,
0.6233, 0.3309, 0.0636, 0.3110, 0.3252, 0.7296, 0.6376, 0.8872, 0.4722,
0.1196, 0.7132, 0.7608, 0.5613, 0.7710, 0.4938, 0.5227, 0.4275, 0.0254,
0.1079])
zsh: floating point exception python test.py
(venv) [tgebhard@g108] ~ %
```
The problem also occurs for other mathematical operations such as `torch.log()` or `torch.cos()`. It seems like it only happens if the size of the input tensor is at least 100, though.
**Moreover, the issue only occurs on _some_ machines, under some specific circumstances:** My local machine will run the code above without any problem, but one of the machines at work reproducibly gives the error above, but _only_ if I request at least 14 CPU cores (it's a batch queue system based on HTCondor). It might, therefore, be the case that only this particular machine has a problem. Any pointers for debugging this are greatly appreciated! 🙂
### Versions
Information about the Python environment:
```
PyTorch version: 1.13.0+cu117
Is debug build: False
CUDA used to build PyTorch: 11.7
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.2 LTS (x86_64)
GCC version: (Ubuntu 9.3.0-17ubuntu1~20.04) 9.3.0
Clang version: Could not collect
CMake version: version 3.16.3
Libc version: glibc-2.31
Python version: 3.8.10 (default, Jun 2 2021, 10:49:15) [GCC 9.4.0] (64-bit runtime)
Python platform: Linux-5.4.0-80-generic-x86_64-with-glibc2.29
Is CUDA available: False
CUDA runtime version: Could not collect
CUDA_MODULE_LOADING set to: N/A
GPU models and configuration: No devices found.
Nvidia driver version: Could not collect
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.23.5
[pip3] pytorch-lightning==1.8.3.post0
[pip3] torch==1.13.0
[pip3] torchmetrics==0.10.3
[conda] Could not collect
```
Information about the machine where the problem occurs (output of `lscpu`):
```
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
Address sizes: 43 bits physical, 48 bits virtual
CPU(s): 256
On-line CPU(s) list: 0,1,9-16,26-31
Off-line CPU(s) list: 2-8,17-25,32-255
Thread(s) per core: 0
Core(s) per socket: 64
Socket(s): 2
NUMA node(s): 2
Vendor ID: AuthenticAMD
CPU family: 23
Model: 49
Model name: AMD EPYC 7662 64-Core Processor
Stepping: 0
Frequency boost: enabled
CPU MHz: 1499.941
CPU max MHz: 2000.0000
CPU min MHz: 1500.0000
BogoMIPS: 3999.98
Virtualization: AMD-V
L1d cache: 2 MiB
L1i cache: 2 MiB
L2 cache: 32 MiB
L3 cache: 256 MiB
NUMA node0 CPU(s): 0-63,128-191
NUMA node1 CPU(s): 64-127,192-255
Vulnerability Itlb multihit: Not affected
Vulnerability L1tf: Not affected
Vulnerability Mds: Not affected
Vulnerability Meltdown: Not affected
Vulnerability Spec store bypass: Mitigation; Speculative Store Bypass disabled via prctl and seccomp
Vulnerability Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization
Vulnerability Spectre v2: Mitigation; Full AMD retpoline, IBPB conditional, IBRS_FW, STIBP conditional, RSB filling
Vulnerability Srbds: Not affected
Vulnerability Tsx async abort: Not affected
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ht syscall nx mmxext fxsr_opt pdpe1gb rdtscp lm constant_tsc rep_good nopl nonstop_tsc cpui
d extd_apicid aperfmperf pni pclmulqdq monitor ssse3 fma cx16 sse4_1 sse4_2 x2apic movbe popcnt aes xsave avx f16c rdrand lahf_lm cmp_legacy svm extapic cr8_legacy abm sse4a misalignsse 3dn
owprefetch osvw ibs skinit wdt tce topoext perfctr_core perfctr_nb bpext perfctr_llc mwaitx cpb cat_l3 cdp_l3 hw_pstate sme ssbd mba sev ibrs ibpb stibp vmmcall fsgsbase bmi1 avx2 smep bmi2
cqm rdt_a rdseed adx smap clflushopt clwb sha_ni xsaveopt xsavec xgetbv1 xsaves cqm_llc cqm_occup_llc cqm_mbm_total cqm_mbm_local clzero irperf xsaveerptr wbnoinvd arat npt lbrv svm_lock n
rip_save tsc_scale vmcb_clean flushbyasid decodeassists pausefilter pfthreshold avic v_vmsave_vmload vgif umip rdpid overflow_recov succor smca
```
cc @VitalyFedyunin @jgong5 @mingfeima @XiaobingSuper @sanchitintel @ashokei @jingxu10
| 26 |
4,081 | 89,784 |
InvokeAI using MPS is broken by torch nightlies since torch-1.14.0.dev20221104 inclusive
|
triaged, module: correctness (silent), module: mps
|
### 🐛 Describe the bug
I'm sorry this is going to be very generic, but I've been occasionally testing InvokeAI, a Stable Diffusion front end with the pytorch nightlies to see if the speed lost since 13.0 has returned.
Today is the first time I've tested in a while and it was broken, generating colour noise not an image,
so I've been going back through the nightlies to see where the breakage is.
torch-1.14.0.dev20221102 works,
torch-1.14.0.dev20221103 works if https://github.com/pytorch/pytorch/pull/87974 is reverted
torch-1.14.0.dev20221104 is broken if https://github.com/pytorch/pytorch/pull/87974 is reverted
torch-1.14.0.dev20221105 is broken
That in theory narrows it down to https://github.com/pytorch/pytorch/pull/82809 and https://github.com/pytorch/pytorch/pull/88319 if its a MPS only issue
### Versions
PyTorch version: 1.14.0.dev20221103
Is debug build: False
CUDA used to build PyTorch: None
ROCM used to build PyTorch: N/A
OS: macOS 13.0.1 (arm64)
GCC version: Could not collect
Clang version: 14.0.0 (clang-1400.0.29.202)
CMake version: version 3.25.0
Libc version: N/A
Python version: 3.10.8 (main, Nov 9 2022, 16:53:27) [Clang 12.0.5 (clang-1205.0.22.9)] (64-bit runtime)
Python platform: macOS-13.0.1-arm64-arm-64bit
Is CUDA available: False
CUDA runtime version: No CUDA
CUDA_MODULE_LOADING set to: N/A
GPU models and configuration: No CUDA
Nvidia driver version: No CUDA
cuDNN version: No CUDA
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.23.4
[pip3] pytorch-lightning==1.7.7
[pip3] torch==1.14.0.dev20221103
[pip3] torch-fidelity==0.3.0
[pip3] torchdiffeq==0.2.3
[pip3] torchmetrics==0.10.0
[pip3] torchsde==0.2.5
[pip3] torchvision==0.15.0.dev20221128
[conda] Could not collect
cc @kulinseth @albanD @malfet @DenisVieriu97 @razarmehr @abhudev
| 4 |
4,082 | 89,764 |
addcmul on CUDA does not have the correct FMA behavior
|
module: numerical-stability, module: cuda, triaged
|
### 🐛 Describe the bug
To reproduce the result:
``` python
import torch
x = torch.randn(1000)
y = torch.randn(1000)
result = x*y
diff = torch.addcmul(-result, x, y)
print("diff_cpu:", diff.abs().max().item())
x = x.cuda()
y = y.cuda()
result = x*y
diff = torch.addcmul(-result, x, y)
print("diff_cuda:", diff.abs().max().item())
# obtaining reference using double precision
xDouble = x.double()
yDouble = y.double()
diffDouble = xDouble*yDouble - result
print("diff_double:", diffDouble.abs().max().item())
```
Outputs:
```
diff_cpu: 2.250976649520453e-07
diff_cuda: 0.0
diff_double: 2.250976649520453e-07
```
### Versions
Pytorch installed via PIP
Outputs from collect_env.py:
Collecting environment information...
PyTorch version: 1.13.0+cu117
Is debug build: False
CUDA used to build PyTorch: 11.7
ROCM used to build PyTorch: N/A
OS: Ubuntu 22.04.1 LTS (x86_64)
GCC version: (Ubuntu 11.3.0-1ubuntu1~22.04) 11.3.0
Clang version: Could not collect
CMake version: version 3.22.1
Libc version: glibc-2.35
Python version: 3.10.6 (main, Nov 2 2022, 18:53:38) [GCC 11.3.0] (64-bit runtime)
Python platform: Linux-5.15.0-53-generic-x86_64-with-glibc2.35
Is CUDA available: True
CUDA runtime version: 11.8.89
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration:
GPU 0: NVIDIA GeForce RTX 3090
GPU 1: NVIDIA GeForce RTX 3090
Nvidia driver version: 520.61.05
cuDNN version: Probably one of the following:
/usr/local/cuda-9.1/targets/x86_64-linux/lib/libcudnn.so.6
/usr/local/cuda-9.1/targets/x86_64-linux/lib/libcudnn.so.7
/usr/local/lib/libcudnn.so.6
/usr/local/lib/libcudnn.so.7
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] memory-efficient-attention-pytorch==0.0.27
[pip3] numpy==1.23.4
[pip3] torch==1.13.0
[pip3] torch-tb-profiler==0.4.0
[pip3] torchaudio==0.13.0
[pip3] torchvision==0.14.0
[conda] Could not collect
cc @ngimel
| 1 |
4,083 | 89,763 |
DISABLED test_hf_bert_ddp_inductor (__main__.TestFakeDistributedSingleProc)
|
triaged, skipped, module: inductor
|
Platforms: linux
This test was disabled because it is failing on master ([recent examples](http://torch-ci.com/failure/test_hf_bert_ddp_inductor)).
This is a test on inductor that started failing over Thanksgiving break
cc @mlazos @soumith @voznesenskym @yanboliang @penguinwu @anijain2305 @EikanWang @jgong5 @Guobing-Chen @chunyuan-w @XiaobingSuper @zhuhaozhe @blzheng @Xia-Weiwen @wenzhe-nrv @jiayisunx @peterbell10 @desertfire
| 1 |
4,084 | 93,454 |
MMDet 3.x cannot run successfully in inductor mode
|
triaged, bug
|
### 🐛 Describe the bug
Hi guys, I'm going to verify dynamo on mmdet 3.x branch, but I'm getting some errors
Environmental information
``` bash
sys.platform: linux
Python: 3.8.15 (default, Nov 4 2022, 20:59:55) [GCC 11.2.0]
CUDA available: True
numpy_random_seed: 2147483648
NVCC: Cuda compilation tools, release 11.7, V11.7.99
GCC: gcc (GCC) 9.3.1 20200408 (Red Hat 9.3.1-2)
PyTorch: 1.14.0.dev20221123
PyTorch compiling details: PyTorch built with:
- GCC 9.3
- C++ Version: 201402
- Intel(R) oneAPI Math Kernel Library Version 2021.4-Product Build 20210904 for Intel(R) 64 architecture applications
- Intel(R) MKL-DNN v2.7.0 (Git Hash 650085b2f3643aad05c629425983491d63b5c289)
- OpenMP 201511 (a.k.a. OpenMP 4.5)
- LAPACK is enabled (usually provided by MKL)
- NNPACK is enabled
- CPU capability usage: AVX2
- CUDA Runtime 11.7
- NVCC architecture flags: -gencode;arch=compute_37,code=sm_37;-gencode;arch=compute_50,code=sm_50;-gencode;arch=compute_60,code=sm_60;-gencode;arch=compute_61,code=sm_61;-gencode;arch=compute_70,code=sm_70;-gencode;arch=compute_75,code=sm_75;-gencode;arch=compute_80,code=sm_80;-gencode;arch=compute_86,code=sm_86;-gencode;arch=compute_37,code=compute_37
- CuDNN 8.5
- Magma 2.6.1
- Build settings: BLAS_INFO=mkl, BUILD_TYPE=Release, CUDA_VERSION=11.7, CUDNN_VERSION=8.5.0, CXX_COMPILER=/opt/rh/devtoolset-9/root/usr/bin/c++, CXX_FLAGS= -fabi-version=11 -Wno-deprecated -fvisibility-inlines-hidden -DUSE_PTHREADPOOL -fopenmp -DNDEBUG -DUSE_KINETO -DUSE_FBGEMM -DUSE_QNNPACK -DUSE_PYTORCH_QNNPACK -DUSE_XNNPACK -DSYMBOLICATE_MOBILE_DEBUG_HANDLE -O2 -fPIC -Wall -Wextra -Werror=return-type -Werror=non-virtual-dtor -Wnarrowing -Wno-missing-field-initializers -Wno-type-limits -Wno-array-bounds -Wno-unknown-pragmas -Wunused-local-typedefs -Wno-unused-parameter -Wno-unused-function -Wno-unused-result -Wno-strict-overflow -Wno-strict-aliasing -Wno-error=deprecated-declarations -Wno-stringop-overflow -Wno-psabi -Wno-error=pedantic -Wno-error=redundant-decls -Wno-error=old-style-cast -fdiagnostics-color=always -faligned-new -Wno-unused-but-set-variable -Wno-maybe-uninitialized -fno-math-errno -fno-trapping-math -Werror=format -Werror=cast-function-type -Wno-stringop-overflow, LAPACK_INFO=mkl, PERF_WITH_AVX=1, PERF_WITH_AVX2=1, PERF_WITH_AVX512=1, TORCH_DISABLE_GPU_ASSERTS=ON, TORCH_VERSION=1.14.0, USE_CUDA=ON, USE_CUDNN=ON, USE_EXCEPTION_PTR=1, USE_GFLAGS=OFF, USE_GLOG=OFF, USE_MKL=ON, USE_MKLDNN=ON, USE_MPI=OFF, USE_NCCL=ON, USE_NNPACK=ON, USE_OPENMP=ON, USE_ROCM=OFF,
TorchVision: 0.15.0.dev20221123
OpenCV: 4.6.0
MMEngine: 0.3.1
MMDetection: 3.0.0rc3+3f6dc71
```
The installation command is as follows:
```bash
git clone https://github.com/open-mmlab/mmdetection.git
git clone https://github.com/open-mmlab/mmcv.git
git clone https://github.com/C1rN09/mmengine.git
cd mmengine
git checkout dynamo_1
pip install -e .
cd ../mmcv
git checkout 2.x
MMCV_WITH_OPS=1 pip install -e .
cd ../mmdetection
git checkout dev-3.x
pip install -e .
python tools/train.py configs/retinanet/retinanet_r50_fpn_1x_coco.py
```
## 1 eager mode
I use eager mode to verify that it works successfully at first.

I modified the following code:` torch.Tensor -> torch.tensor.` I got the following error after modifying the code

I modified the following code: `range -> tuple(range)`. I got the following error after modifying the code

Remove all `dtype` parameters and use `float()` instead
- https://github.com/open-mmlab/mmdetection/blob/dev-3.x/mmdet/models/task_modules/prior_generators/anchor_generator.py#L222,
- https://github.com/open-mmlab/mmdetection/blob/dev-3.x/mmdet/models/dense_heads/base_dense_head.py#L262
At this point, it works successfully, but it is very slow and some warning
## 2 aot_eager mode
It can run but very slowly.
## 3 inductor mode
I get the error as below
By the way, I train with `MMYOLO`, which can run successfully in inductor mode with a simple modification. But it is very slow and will OOM.
### Error logs
_No response_
### Minified repro
_No response_
| 2 |
4,085 | 89,757 |
third-order gradient of torch.pow with tensor args and certain input returns NaN
|
module: autograd, triaged, module: NaNs and Infs
|
Hi, `torch.pow` with two tensor arguments results in wrong higher order derivatives.
```python
# functorch.__version__
# '1.13.0+cu117'
import torch
import functorch
jacobian = functorch.jacrev
x = torch.tensor([0.0, 0.0], dtype=torch.float64)
y = torch.tensor([0.0, 0.0], dtype=torch.float64)
def foo(x, y):
x1, x2 = x
y1, y2 = y
return torch.stack([x1*x2*y1*y2])
def bar1(x, y):
power = torch.tensor([1, 1, 1, 1], dtype=torch.int64)
state = torch.cat([x, y])
state = torch.pow(state, power)
return torch.stack([state.prod(-1)])
def bar2(x, y):
power = [1, 1, 1, 1]
# power = torch.tensor([1, 1, 1, 1], dtype=torch.int64) # -- will also break
state = torch.cat([x, y])
state = torch.stack([s**p for s, p in zip(state, power)])
return torch.stack([state.prod(-1)])
print(foo(x, y).numpy())
print(bar1(x, y).numpy())
print(bar2(x, y).numpy())
# d^2(d^2(f)/d(y^2))/d(x^2)
print(jacobian(jacobian(lambda x: jacobian(jacobian(lambda y: foo(x, y)))(y)))(x).flatten().numpy())
print(jacobian(jacobian(lambda x: jacobian(jacobian(lambda y: bar1(x, y)))(y)))(x).flatten().numpy())
print(jacobian(jacobian(lambda x: jacobian(jacobian(lambda y: bar2(x, y)))(y)))(x).flatten().numpy())
# jacobian = functorch.jacrev
# [0.]
# [0.]
# [0.]
# [0. 0. 0. 0. 0. 1. 1. 0. 0. 1. 1. 0. 0. 0. 0. 0.]
# [nan nan nan nan nan nan nan nan nan nan nan nan nan nan nan nan]
# [0. 0. 0. 0. 0. 1. 1. 0. 0. 1. 1. 0. 0. 0. 0. 0.]
# jacobian = functorch.jacfwd
# [0.]
# [0.]
# [0.]
# [0. 0. 0. 0. 0. 1. 1. 0. 0. 1. 1. 0. 0. 0. 0. 0.]
# [0. 0. 0. 0. 0. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
# [0. 0. 0. 0. 0. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
```
cc @ezyang @gchanan @zou3519 @albanD @gqchen @pearu @nikitaved @soulitzer @Lezcano @Varal7 @Chillee @samdow @soumith
| 11 |
4,086 | 89,738 |
[MPS] Add support for aten::repeat_interleave.self_Tensor for MPS backend
|
triaged, module: mps
|
### 🚀 The feature, motivation and pitch
detectron2/modeling/poolers.py:66: UserWarning: The operator 'aten::repeat_interleave.self_Tensor' is not currently supported on the MPS backend and will fall back to run on the CPU. This may have performance implications. (Triggered internally at /Users/runner/work/_temp/anaconda/conda-bld/pytorch_1666646703877/work/aten/src/ATen/mps/MPSFallback.mm:11.)
indices = torch.repeat_interleave(
### Alternatives
_No response_
### Additional context
_No response_
cc @kulinseth @albanD @malfet @DenisVieriu97 @razarmehr @abhudev
| 1 |
4,087 | 89,730 |
torch.addbmm throws different exception differences on CPU and GPU.
|
module: cuda, module: error checking, triaged
|
### 🐛 Describe the bug
torch.addbmm runs under the pytorch1.8 version. The exceptions thrown by the test code on the CPU and GPU are very different.
Test on the CPU:
import torch
input = torch.rand([5], dtype=torch.float64)
batch1 = torch.randint(-128, 1024, [10, 3, 4], dtype=torch.int64)
batch2 = torch.randint(-64, 2, [10, 4, 5], dtype=torch.int8)
out = torch.addbmm(input, batch1, batch2)
result: RuntimeError: expected scalar type Double but found Long
Test on the GPU:
import torch
input = torch.rand([5], dtype=torch.float64).cuda()
batch1 = torch.randint(-128, 1024, [10, 3, 4], dtype=torch.int64).cuda()
batch2 = torch.randint(-64, 2, [10, 4, 5], dtype=torch.int8).cuda()
out = torch.addbmm(input, batch1, batch2)
result: RuntimeError: expected scalar type Double but found Char
torch.baddbmm has the same problem.
### Versions
pytorch: 1.8
Python version: 3.8
CUDA/cuDNN version: cuDNN 11.3
GPU models and configuration: RTX3060
Operating System:Windows
cc @ngimel
| 6 |
4,088 | 89,724 |
Sample Weighted BatchNorm1d
|
feature, module: nn, triaged, needs research, module: norms and normalization
|
### 🚀 The feature, motivation and pitch
I recently worked on a project involving graph neural networks where batch normalization with weighted samples (nodes) helped improve prediction performance. This was especially useful in my use case where graphs could vary quite significantly in size and weights reduce influence of larger graphs (those having more nodes) within the batch. Weights can also be used to compress graphs, improving performance. I don't believe there is a way currently to pass sample weights to the batch norm layer, so I wrote my own. This version of course, doesn't have the performance of the original BatchNorm1d layer. I was wondering whether it would be worthwhile for me to implement this directly.
### Alternatives
The only feasible alternative I could come up with was repeating samples such that the behavior was replicated through the current BatchNorm1d i.e. if a sample contained [0, 1] with respective weights [1/3, 2/3] the sample could be expanded to [0, 1, 1]. Though, this is obviously inefficient.
### Additional context
There is a weighted form of Welford's algorithm: [https://en.wikipedia.org/wiki/Algorithms_for_calculating_variance#Weighted_incremental_algorithm](url), so performance can likely be retained (though this will of course be tested).
cc @albanD @mruberry @jbschlosser @walterddr @kshitij12345 @saketh-are
| 0 |
4,089 | 89,718 |
`torch.Tensor.flatten` Trigger Segmentation Fault when trying to provide and output named dim
|
module: crash, triaged, module: named tensor
|
## 🐛 Describe the bug
A test for `torch.Tensor.flatten` triggers segmentation fault when named dim is provided.
### Test
```python
import torch
def test():
tensor = torch.rand([2, 3, 5, 7, 11], dtype=torch.float32)
_ = torch.Tensor.flatten(tensor, 2, 9, 'features')
test()
```
### Error log
`segmentation fault`
## Versions
```
PyTorch version: 1.14.0a0+gitbdc9911
Is debug build: False
CUDA used to build PyTorch: 11.6
ROCM used to build PyTorch: N/A
OS: Ubuntu 22.04.1 LTS (x86_64)
GCC version: (Ubuntu 11.3.0-1ubuntu1~22.04) 11.3.0
Clang version: 11.1.0-6
CMake version: version 3.22.1
Libc version: glibc-2.35
Python version: 3.10.6 (main, Nov 2 2022, 18:53:38) [GCC 11.3.0] (64-bit runtime)
Python platform: Linux-5.15.0-52-generic-x86_64-with-glibc2.35
Is CUDA available: True
CUDA runtime version: 11.6.124
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration:
GPU 0: NVIDIA GeForce RTX 3090
GPU 1: NVIDIA GeForce RTX 3090
GPU 2: NVIDIA GeForce RTX 3090
Nvidia driver version: 515.65.01
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_infer.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.4.1
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.21.5
[pip3] torch==1.14.0a0+gitbdc9911
[pip3] torchvision==0.13.1
[conda] blas 1.0 mkl
[conda] cudatoolkit 11.3.1 h2bc3f7f_2
[conda] mkl 2021.4.0 h06a4308_640
[conda] mkl-service 2.4.0 py39h7f8727e_0
[conda] mkl_fft 1.3.1 py39hd3c417c_0
[conda] mkl_random 1.2.2 py39h51133e4_0
[conda] numpy 1.21.5 py39he7a7128_1
[conda] numpy-base 1.21.5 py39hf524024_1
[conda] numpydoc 1.2 pyhd3eb1b0_0
[conda] torch 1.14.0a0+gitce2f870 pypi_0 pypi
```
cc @ezyang @gchanan @zou3519
| 2 |
4,090 | 89,716 |
DDP hangs on forward pass of transformer
|
oncall: distributed
|
### 🐛 Describe the bug
I'm facing an issue where DDP is hanging sometimes. A relevant code snippet is below. The setup is fairly simple: I have an encoder, and I want to do a forward pass on one GPU but not the other. Based on which GPU I let it do the forward pass on, I see varying results as to what processes complete.
I'm running the file as follows:
```
export CUDA_VISIBLE_DEVICES=5,6
python -m torch.distributed.launch --nproc_per_node=2 ddp.py
```
Here is the file ddp.py:
```python
import torch
import argparse
from transformers import RobertaModel
from torch.nn.parallel import DistributedDataParallel as DDP
def main():
parser = argparse.ArgumentParser()
parser.add_argument("--local_rank", type=int, default=-1,
help="For distributed training: local_rank")
args = parser.parse_args()
torch.cuda.set_device(args.local_rank)
device = torch.device("cuda", args.local_rank)
torch.distributed.init_process_group(backend='nccl')
args.device = device
encoder = RobertaModel.from_pretrained("microsoft/codebert-base")
encoder.to(device)
encoder = DDP(encoder, device_ids=[args.local_rank], output_device=args.local_rank, find_unused_parameters=False)
source_ids = torch.zeros([8, 256]).long().to(device)
source_mask = torch.ones([8, 256]).long().to(device)
# devices = [-1, 1] # 0 started, 1 started, 1 done, unexpected
devices = [-1, 0] # 0 started, 1 started, unexpected
# devices = [-1, 0, 1] # 0 started, 0 started, 0 done, 0 done, expected
if args.local_rank not in devices:
print("process 1 started")
output = encoder(source_ids, attention_mask=source_mask)
torch.distributed.barrier()
print("process 1 done")
if args.local_rank in devices:
print("process 0 started")
torch.distributed.barrier()
print("process 0 done")
if __name__ == "__main__":
main()
```
### Versions
Collecting environment information...
PyTorch version: 1.12.1+cu102
Is debug build: False
CUDA used to build PyTorch: 10.2
ROCM used to build PyTorch: N/A
OS: Ubuntu 16.04.7 LTS (x86_64)
GCC version: (Ubuntu 5.5.0-12ubuntu1~16.04) 5.5.0 20171010
Clang version: Could not collect
CMake version: version 3.24.2
Libc version: glibc-2.23
Python version: 3.8.15 (default, Nov 24 2022, 15:19:38) [GCC 11.2.0] (64-bit runtime)
Python platform: Linux-4.4.0-210-generic-x86_64-with-glibc2.17
Is CUDA available: True
CUDA runtime version: Could not collect
CUDA_MODULE_LOADING set to:
GPU models and configuration:
GPU 0: GeForce GTX 1080 Ti
GPU 1: GeForce GTX 1080 Ti
GPU 2: GeForce GTX 1080 Ti
GPU 3: GeForce GTX 1080 Ti
GPU 4: GeForce GTX 1080 Ti
GPU 5: GeForce GTX 1080 Ti
GPU 6: GeForce GTX 1080 Ti
GPU 7: GeForce GTX 1080 Ti
Nvidia driver version: 460.27.04
cuDNN version: /usr/lib/x86_64-linux-gnu/libcudnn.so.6.0.21
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.22.4
[pip3] torch==1.12.1
[pip3] torchaudio==0.12.1
[pip3] torchvision==0.13.1
[pip3] torchviz==0.0.2
[conda] mkl 2022.2.1 pypi_0 pypi
[conda] mkl-fft 1.3.1 pypi_0 pypi
[conda] mkl-random 1.2.2 pypi_0 pypi
[conda] mkl-service 2.4.0 pypi_0 pypi
[conda] numpy 1.22.4 pypi_0 pypi
[conda] torch 1.12.1 pypi_0 pypi
[conda] torchaudio 0.12.1 pypi_0 pypi
[conda] torchvision 0.13.1 pypi_0 pypi
[conda] torchviz 0.0.2 pypi_0 pypi
cc @mrshenli @pritamdamania87 @zhaojuanmao @satgera @rohan-varma @gqchen @aazzolini @osalpekar @jiayisuse @H-Huang @kwen2501 @awgu
| 3 |
4,091 | 89,714 |
Segfault on torch.nn.functional.one_hot with large tensor on Python 3.9
|
needs reproduction, module: crash, triaged
|
### 🐛 Describe the bug
Running `torch.nn.functional.one_hot(...)` on a large tensor (like 10,000 elements) segfaults:
```
import torch
t = torch.randint(0, 6, size=(10000, 1))
torch.nn.functional.one_hot(t)
```
Results in a segfault (no stack trace)
```
Process finished with exit code 139 (interrupted by signal 11: SIGSEGV)
```
### Versions
Collecting environment information...
PyTorch version: 1.13.0
Is debug build: False
CUDA used to build PyTorch: Could not collect
ROCM used to build PyTorch: N/A
OS: macOS 10.15.7 (x86_64)
GCC version: Could not collect
Clang version: 12.0.0 (clang-1200.0.32.29)
CMake version: Could not collect
Libc version: N/A
Python version: 3.9.13 (main, Aug 25 2022, 18:29:29) [Clang 12.0.0 ] (64-bit runtime)
Python platform: macOS-10.15.7-x86_64-i386-64bit
Is CUDA available: False
CUDA runtime version: Could not collect
CUDA_MODULE_LOADING set to: N/A
GPU models and configuration: Could not collect
Nvidia driver version: 1.1.0
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.23.3
[pip3] torch==1.13.0
[pip3] torchaudio==0.13.0
[pip3] torchvision==0.14.0
[conda] blas 1.0 mkl
[conda] mkl 2021.4.0 hecd8cb5_637
[conda] mkl-service 2.4.0 py39h9ed2024_0
[conda] mkl_fft 1.3.1 py39h4ab4a9b_0
[conda] mkl_random 1.2.2 py39hb2f4e1b_0
[conda] numpy 1.23.3 pypi_0 pypi
[conda] numpy-base 1.23.1 py39h3b1a694_0
[conda] torch 1.13.0 pypi_0 pypi
[conda] torchaudio 0.13.0 pypi_0 pypi
[conda] torchvision 0.14.0 pypi_0 pypi
cc @ezyang @gchanan @zou3519
| 5 |
4,092 | 89,708 |
M1 mps issue
|
triaged, module: mps
|
### 🐛 Describe the bug
I've been tracing an issue that arose while using yolov5 object detector/classifier on the recently supported 'mps' device. The issue first manifested itself as objects being detected in the wrong locations (sometimes). Some of the time it performs the detection correctly, which leads me to believe this isn't a major issue.
Tracing the issue: https://github.com/ultralytics/yolov5/issues/10178
It looks like this is a torch issue and not a yolo issue.
I would really appreciate some help tracing the root of the problem further, or even some hints on where to look next.
### Versions
```
PyTorch version: 1.14.0.dev20221116
Is debug build: False
CUDA used to build PyTorch: None
ROCM used to build PyTorch: N/A
OS: macOS 12.3 (arm64)
GCC version: Could not collect
Clang version: 13.1.6 (clang-1316.0.21.2.5)
CMake version: Could not collect
Libc version: N/A
Python version: 3.10.6 | packaged by conda-forge | (main, Aug 22 2022, 20:38:29) [Clang 13.0.1 ] (64-bit runtime)
Python platform: macOS-12.3-arm64-arm-64bit
Is CUDA available: False
CUDA runtime version: No CUDA
CUDA_MODULE_LOADING set to: N/A
GPU models and configuration: No CUDA
Nvidia driver version: No CUDA
cuDNN version: No CUDA
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.23.4
[pip3] torch==1.14.0.dev20221116
[pip3] torchaudio==0.14.0.dev20221116
[pip3] torchvision==0.15.0.dev20221116
[conda] numpy 1.23.4 pypi_0 pypi
[conda] torch 1.14.0.dev20221116 pypi_0 pypi
[conda] torchaudio 0.14.0.dev20221116 pypi_0 pypi
[conda] torchvision 0.15.0.dev20221116 pypi_0 pypi
```
cc @kulinseth @albanD @malfet @DenisVieriu97 @razarmehr @abhudev
| 0 |
4,093 | 89,699 |
amd windows
|
module: windows, module: rocm, triaged
|
### 🚀 The feature, motivation and pitch
add it for amd windows too
### Alternatives
_No response_
### Additional context
_No response_
cc @peterjc123 @mszhanyi @skyline75489 @nbcsm @jeffdaily @sunway513 @jithunnair-amd @pruthvistony @ROCmSupport
| 0 |
4,094 | 93,453 |
TensorWithTFOverrideVariable don't store fake tensor (they store real tensor)
|
triaged, oncall: pt2, module: dynamo
|
### 🐛 Describe the bug
The proximal cause for the problem is this line in utils.py:
```
def wrap_to_fake_tensor(e, fake_mode):
if type(e) in (torch.Tensor, torch.nn.Parameter):
return wrap_fake_exception(
lambda: make_fake_tensor(
e, fake_mode, static_shapes=config.dynamic_shapes is False
)
)
else:
return e
```
When we attempt to wrap the tensor to become fake, we bypass this process if it's not exactly a Tensor or Parameter. This means the real tensor gets stored on `example_value`.
This causes problems for dynamic shape guards as failing to fakeify the tensor here means subsequent call to `super().__torch_function__` looks at the returned tensor and says "well golly I've never seen this tensor before, I guess it must be an input" and generates guards that are impossible to actually fulfill.
cc @msaroufim @wconstab @bdhirsh @anijain2305 @voznesenskym @penguinwu @EikanWang @jgong5 @Guobing-Chen @XiaobingSuper @zhuhaozhe @blzheng @Xia-Weiwen @wenzhe-nrv @jiayisunx @chenyang78 @aakhundov @vkuzo
### Error logs
_No response_
### Minified repro
_No response_
| 0 |
4,095 | 89,688 |
Enable NCCL for PyTorch on Windows
|
oncall: distributed, module: windows, triaged
|
PyTorch has several backends for [distributed computing](https://pytorch.org/docs/stable/distributed.html). One of them is NVidia NCCL where main benefit is distributed computing for most Devices on GPU.
Unfortunately NVidia NCCL is not supported on Windows, but it is supported for other platforms.
Goal of this ticket is map importance of this feature, find out blockers and if needed start up work stream on this feature.
**Open questions**
- Investigate impact of missing NCCL support (Who needs it? Is it important for Windows to support it?)
- If NCCL support is important for Windows, are there any blockers? What needs to be done to support it?
cc @mrshenli @pritamdamania87 @zhaojuanmao @satgera @rohan-varma @gqchen @aazzolini @osalpekar @jiayisuse @H-Huang @kwen2501 @awgu @peterjc123 @mszhanyi @skyline75489 @nbcsm
| 3 |
4,096 | 93,452 |
Dynamo is over-guarding on Tensor locals
|
triaged, bug
|
### 🐛 Describe the bug
two for one example:
```
import torch
import torch._dynamo
def g(x, y, z):
return x * 2 + 1
@torch._dynamo.optimize("eager")
def f(x, y, z):
print("woof")
z = x * 2
z = x + 1
print("warf")
return g(z, y, z)
f(torch.randn(2), torch.randn(3), 4)
```
The graph between woof and warf generates a TENSOR_MATCH guard on y. The function call to g generates a TENSOR_MATCH guard on y. In both cases, this guard is completely unnecessary.
The extra guards here are especially pernicious because if you have a long function body with some graph breaks, the intermediate fragments will guard on ALL of the inputs, even if the broken up subgraphs only deal with a subset of variables.
### Error logs
_No response_
### Minified repro
_No response_
| 2 |
4,097 | 89,686 |
MultiProcess tests fail when run on nodes with 1 GPU
|
oncall: distributed, triaged
|
### 🐛 Describe the bug
We are building PyTorch on HPC nodes, some of the (build) nodes only have 1 GPU.
Running the test then fails, e.g. with
```
Running distributed/fsdp/test_distributed_checkpoint ... [2022-11-24 11:32:28.143789]
Executing ['/rds/projects/2017/branfosj-rse/easybuild/EL8-ice/software/Python/3.9.5-GCCcore-10.3.0/bin/python', 'distributed/fsdp/test_distributed_checkpoint.py', '-v'] ... [2022-11-24 11:32:28.143928]
test_distributed_checkpoint_state_dict_type_StateDictType_LOCAL_STATE_DICT (__main__.TestDistributedCheckpoint) ... INFO:torch.testing._internal.common_distributed:Started process 0 with pid 733462
INFO:torch.testing._internal.common_distributed:Started process 1 with pid 733463
dist init r=0, world=2
INFO:torch.distributed.distributed_c10d:Added key: store_based_barrier_key:1 to store for rank: 0
dist init r=1, world=2
INFO:torch.distributed.distributed_c10d:Added key: store_based_barrier_key:1 to store for rank: 1
INFO:torch.distributed.distributed_c10d:Rank 1: Completed store-based barrier for key:store_based_barrier_key:1 with 2 nodes.
INFO:torch.distributed.distributed_c10d:Rank 0: Completed store-based barrier for key:store_based_barrier_key:1 with 2 nodes.
Process process 0:
Traceback (most recent call last):
File "/rds/projects/2017/branfosj-rse/easybuild/EL8-ice/software/Python/3.9.5-GCCcore-10.3.0/lib/python3.9/multiprocessing/process.py", line 315, in _bootstrap
self.run()
File "/rds/projects/2017/branfosj-rse/easybuild/EL8-ice/software/Python/3.9.5-GCCcore-10.3.0/lib/python3.9/multiprocessing/process.py", line 108, in run
self._target(*self._args, **self._kwargs)
File "/dev/shm/branfosj/tmp-up-EL8/eb-usbph1a0/tmp_jxl19_q/lib/python3.9/site-packages/torch/testing/_internal/common_fsdp.py", line 427, in _run
dist.barrier()
File "/dev/shm/branfosj/tmp-up-EL8/eb-usbph1a0/tmp_jxl19_q/lib/python3.9/site-packages/torch/distributed/distributed_c10d.py", line 2784, in barrier
work = default_pg.barrier(opts=opts)
RuntimeError: NCCL error in: ../torch/csrc/distributed/c10d/ProcessGroupNCCL.cpp:1191, invalid usage, NCCL version 2.10.3
ncclInvalidUsage: This usually reflects invalid usage of NCCL library (such as too many async ops, too many collectives at once, mixing streams in a group, etc).
Process process 1:
Traceback (most recent call last):
File "/rds/projects/2017/branfosj-rse/easybuild/EL8-ice/software/Python/3.9.5-GCCcore-10.3.0/lib/python3.9/multiprocessing/process.py", line 315, in _bootstrap
self.run()
File "/rds/projects/2017/branfosj-rse/easybuild/EL8-ice/software/Python/3.9.5-GCCcore-10.3.0/lib/python3.9/multiprocessing/process.py", line 108, in run
self._target(*self._args, **self._kwargs)
File "/dev/shm/branfosj/tmp-up-EL8/eb-usbph1a0/tmp_jxl19_q/lib/python3.9/site-packages/torch/testing/_internal/common_fsdp.py", line 427, in _run
dist.barrier()
File "/dev/shm/branfosj/tmp-up-EL8/eb-usbph1a0/tmp_jxl19_q/lib/python3.9/site-packages/torch/distributed/distributed_c10d.py", line 2784, in barrier
work = default_pg.barrier(opts=opts)
RuntimeError: NCCL error in: ../torch/csrc/distributed/c10d/ProcessGroupNCCL.cpp:1191, invalid usage, NCCL version 2.10.3
ncclInvalidUsage: This usually reflects invalid usage of NCCL library (such as too many async ops, too many collectives at once, mixing streams in a group, etc).
FAIL
```
With a bit of debugging I found the cause is the [implementation of `skip_if_lt_x_gpu`](https://github.com/pytorch/pytorch/blob/master/torch/testing/_internal/common_distributed.py#L161):
It is implemented to call `sys.exit` when the test function is called and there are not enough GPUs. However for the distributed tests this is wrong:
Before calling the test function the test class `setup` function is called which calls `spawn_processes`: https://github.com/pytorch/pytorch/blob/master/torch/testing/_internal/common_fsdp.py#L699
The ProcessGroup entry function `_bootstrap` will then make the processes run into a barrier which seems to be implemented using NCCL leading to the bug when there are not enough GPUs available, i.e. world_size is larger than the number of the GPUs.
The solution is to not try and implement a custom skip-decorator but rather use the one from `unittest`. E.g.:
```
def skip_if_lt_x_gpu(x):
return unittest.skipIf(not torch.cuda.is_available() or torch.cuda.device_count() < x)
```
### Versions
PyTorch 1.12.1 and master
cc @mrshenli @pritamdamania87 @zhaojuanmao @satgera @rohan-varma @gqchen @aazzolini @osalpekar @jiayisuse @H-Huang @kwen2501 @awgu
| 0 |
4,098 | 93,451 |
PTX codegen race?
|
triaged, bug, oncall: pt2
|
### 🐛 Describe the bug
See CI log at https://github.com/pytorch/pytorch/actions/runs/3545111323/jobs/5953152353
### Error logs
_No response_
### Minified repro
_No response_
cc @soumith @msaroufim @wconstab @ngimel @bdhirsh
| 0 |
4,099 | 89,684 |
`positive_semidefinite` constraint fails on CUDA 11.7
|
module: distributions, triaged, module: linear algebra
|
### 🐛 Describe the bug
Using PyTorch 1.12.1 with CUDA 11.7 I'm seeing a test failure in `test_constraints`.
The issue can be reproduced by:
```
$ python -c 'import torch; print(torch.distributions.constraints.positive_semidefinite.check(torch.cuda.DoubleTensor([[1., 2], [2., 4]])))'
tensor(False, device='cuda:0')
```
The CPU version works:
```
$ python -c 'import torch; print(torch.distributions.constraints.positive_semidefinite.check(torch.DoubleTensor([[1., 2], [2., 4]])))'
tensor(True)
```
I further traced this down to the use of CUSolver for `syevd`:
```
$ python -c 'import torch; print(torch.linalg.eigvalsh(torch.cuda.DoubleTensor([[1., 2], [2., 4]])))'
tensor([-4.1211e-34, 5.0000e+00], device='cuda:0', dtype=torch.float64)
```
The correct result (on CPU and WolframAlpha) is `tensor([0., 5.], dtype=torch.float64)`
In a[ related issue](https://github.com/pytorch/pytorch/issues/41688#issuecomment-661633369) @vishwakftw wrote
> I believe this is not an actual issue.
but as for such checks this seems to be an example where it is an issue, so I'd request to review this.
### Versions
PyTorch 1.12.1
CUDA 11.7
cc @fritzo @neerajprad @alicanb @nikitaved @jianyuh @pearu @mruberry @walterddr @IvanYashchuk @xwang233 @Lezcano
| 4 |
4,100 | 89,675 |
[ONNX] torch.onnx.export snapshots the grads as constants in onnx when op is in cuda device
|
module: onnx, triaged
|
### 🐛 Describe the bug
When exporting a module whose forward function includes some `torch.autograd.grad` call, torch.onnx.export saves the results tensor of `torch.autograd.grad` call as constants, instead of saves the nodes which computes the grad to onnx.
This seems to be a bug.
```python
import torch
from torch import nn
class MyModule(nn.Module):
def __init__(self) -> None:
super().__init__()
self.conv = nn.Linear(16, 15)
def forward(self, x):
x = x.detach().requires_grad_(True)
y = self.conv(x).sum()
g = torch.autograd.grad(y, x)[0]
return y-g
def export_model(device):
model = MyModule().to(device)
def freeze_model(m):
for p in m.parameters():
p.requires_grad_(False)
return m
model = freeze_model(model)
torch.onnx.export(model, torch.ones([1,4,16,16]).to(device), f"linear-{device}.onnx", verbose=True)
export_model('cpu')
export_model('cuda')
```
Exported onnx model of cpu looks like this

We can see that the backward function of linear is recorded as a GEMM in onnx, which is expected.
Export onnx model of cuda looks like this
This onnx model is different with the cpu version, it snapshots the grads as a constants tensors, and attached it to the input B of the "Sub" node.
### Versions
Collecting environment information...
PyTorch version: 1.13.0
Is debug build: False
CUDA used to build PyTorch: 11.7
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.5 LTS (x86_64)
GCC version: (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0
Clang version: 10.0.0-4ubuntu1
CMake version: version 3.22.5
Libc version: glibc-2.31
Python version: 3.10.8 (main, Nov 4 2022, 13:48:29) [GCC 11.2.0] (64-bit runtime)
Python platform: Linux-5.4.0-131-generic-x86_64-with-glibc2.31
Is CUDA available: True
CUDA runtime version: 11.7.99
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration:
GPU 0: NVIDIA Graphics Device
GPU 1: Tesla T4
GPU 2: NVIDIA T4 32GB
GPU 3: Tesla V100S-PCIE-32GB
GPU 4: Quadro RTX 8000
GPU 5: Tesla P4
Nvidia driver version: 520.40
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.23.4
[pip3] torch==1.13.0
[pip3] torchaudio==0.13.0
[pip3] torchvision==0.14.0
[conda] blas 1.0 mkl
[conda] ffmpeg 4.3 hf484d3e_0 pytorch
[conda] mkl 2021.4.0 h06a4308_640
[conda] mkl-service 2.4.0 py310h7f8727e_0
[conda] mkl_fft 1.3.1 py310hd6ae3a3_0
[conda] mkl_random 1.2.2 py310h00e6091_0
[conda] numpy 1.23.4 py310hd5efca6_0
[conda] numpy-base 1.23.4 py310h8e6c178_0
[conda] pytorch 1.13.0 py3.10_cuda11.7_cudnn8.5.0_0 pytorch
[conda] pytorch-cuda 11.7 h67b0de4_0 pytorch
[conda] pytorch-mutex 1.0 cuda pytorch
[conda] torchaudio 0.13.0 py310_cu117 pytorch
[conda] torchvision 0.14.0 py310_cu117 pytorch
| 3 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.