
Serial Number
int64 1
6k
| Issue Number
int64 75.6k
112k
| Title
stringlengths 3
357
| Labels
stringlengths 3
241
⌀ | Body
stringlengths 9
74.5k
⌀ | Comments
int64 0
867
|
|---|---|---|---|---|---|
4,101 | 89,673 |
MPS bug on `torch.transpose` and `torch.log`
|
triaged, module: mps
|
### 🐛 Describe the bug
The following code uses `torch.transpose` and `torch.log` for computing the loss value.
However, it seems that the application order of the above two functions causes the different results.
```python
#!/usr/bin/env python3
import argparse
import torch
torch.random.manual_seed(31337)
parser = argparse.ArgumentParser()
parser.add_argument("--bug", help="use buggy path", action="store_true")
parser.add_argument("--device", help="specify device", type=str, default="cpu")
args = parser.parse_args()
class Diff:
def __init__(self, model, device, use_bug):
self.model = model
self.device = device
self.use_bug = use_bug
self.lossfn = torch.nn.NLLLoss(reduction="sum")
def forward(self, x0_indices):
x_indices = torch.zeros((1+1, x0_indices.shape[0], self.model.length), dtype=torch.long).to(self.device)
q = torch.zeros((1+1, x0_indices.shape[0], self.model.length, 2)).to(self.device)
x_indices[0,] = x0_indices
q[1,] = 0.5*torch.ones(q[1,].shape)
x_indices[1,] = torch.distributions.Categorical(q[1,]).sample()
return x_indices, q
def loss(self, x0_indices):
x_indices, q = self.forward(x0_indices)
if self.use_bug:
pt = torch.log(torch.transpose(self.model(x_indices[1,], 1), -2, -1))
else:
pt = torch.transpose(torch.log(self.model(x_indices[1,], 1)), -2, -1)
qt = torch.log(torch.transpose(q[1,], -2, -1))
return self.lossfn(pt, x_indices[0,])
class MLP(torch.nn.Module):
def __init__(self, length):
super().__init__()
self.length = length
self.embed_input = torch.nn.Embedding(2, 50, padding_idx=0)
self.readouts = torch.nn.Linear(50, 2)
self.softmax = torch.nn.Softmax(dim=-1)
def forward(self, x_indices, t):
x = self.embed_input(x_indices)
x = x.reshape((x.shape[0], self.length, -1))
return self.softmax(self.readouts(x))
x0_indices = torch.zeros((200, 20))
for i in range(x0_indices.shape[0]):
for j in range(i%5, x0_indices.shape[1], 5):
x0_indices[i, j] = 1
model = MLP(x0_indices.shape[1]).to(args.device)
diff = Diff(model, args.device, args.bug)
optim = torch.optim.Adam(diff.model.parameters())
for epoch in range(10000):
loss = diff.loss(x0_indices)
print(f"[*] epoch={epoch}: loss={loss.item():.3f}")
if loss < 0.0:
print(f"[-] loss is not positive")
break
optim.zero_grad()
loss.backward()
optim.step()
```
Here is my result:
```
% python3 pytorch_mps_bug.py --device cpu
[*] epoch=0: loss=2608.710
...
[*] epoch=9999: loss=2001.556
% python3 pytorch_mps_bug.py --device cpu --bug
[*] epoch=0: loss=2608.710
...
[*] epoch=9999: loss=2001.556
% python3 pytorch_mps_bug.py --device mps
[*] epoch=0: loss=3261.913
...
[*] epoch=9999: loss=0.016
% python3 pytorch_mps_bug.py --device mps --bug
[*] epoch=0: loss=105.605
[*] epoch=1: loss=66.850
[*] epoch=2: loss=28.175
[*] epoch=3: loss=-10.516
[-] loss is not positive
```
At least, I think loss values (`torch.nn.NLLLoss`) should not be negative value, because `torch.nn.Softmax` is applied.
In addition, the loss values after 10,000 epochs on CPU and MPS avoiding buggy path are different.
I wonder why this difference happens.
### Versions
On my Apple M2 MacBook Air:
```
% curl https://raw.githubusercontent.com/pytorch/pytorch/master/torch/utils/collect_env.py > ./collect_env.py
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 17278 100 17278 0 0 479k 0 --:--:-- --:--:-- --:--:-- 581k
% python3 ./collect_env.py
Collecting environment information...
PyTorch version: 1.13.0a0+git6dc8fba
Is debug build: False
CUDA used to build PyTorch: None
ROCM used to build PyTorch: N/A
OS: macOS 13.0.1 (arm64)
GCC version: Could not collect
Clang version: 14.0.0 (clang-1400.0.29.202)
CMake version: version 3.24.3
Libc version: N/A
Python version: 3.10.6 | packaged by conda-forge | (main, Aug 22 2022, 20:38:29) [Clang 13.0.1 ] (64-bit runtime)
Python platform: macOS-13.0.1-arm64-arm-64bit
Is CUDA available: False
CUDA runtime version: No CUDA
CUDA_MODULE_LOADING set to: N/A
GPU models and configuration: No CUDA
Nvidia driver version: No CUDA
cuDNN version: No CUDA
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.23.4
[pip3] torch==1.13.0a0+git7c98e70
[conda] numpy 1.23.4 py310h5d7c261_1 conda-forge
[conda] torch 1.13.0a0+git7c98e70 dev_0 <develop>
```
cc @kulinseth @albanD @malfet @DenisVieriu97 @razarmehr @abhudev
| 2 |
4,102 | 89,657 |
MPS device ComplexFloat
|
triaged, module: fft, module: mps
|
### 🐛 Describe the bug
Hello, I am using torch 1.13 on my mac with M1 chip and I want to calculate the fft2 on a image. My target is to use it in the Focal Frequency Loss described [here](https://arxiv.org/pdf/2012.12821.pdf).
I simply do
import torch
img = img.unsqueeze(0).to("mps:0") # img has now shape (1, 3, 480, 640) preprocessed before using monai transforms
freq = torch.fft.fft2(img, norm="ortho")
and I get this message error:
Output exceeds the [size limit](command:workbench.action.openSettings?[). Open the full output data [in a text editor](command:workbench.action.openLargeOutput?78c97743-d5c9-4858-99cb-94815ed4009d)
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
Cell In [9], line 2
1 img = img.unsqueeze(0).to("mps:0")
----> 2 freq = torch.fft.fft2(img, norm="ortho")
File ~/miniforge3/envs/torch13/lib/python3.10/site-packages/monai/data/meta_tensor.py:249, in
MetaTensor.__torch_function__(cls, func, types, args, kwargs)
247 if kwargs is None:
248 kwargs = {}
--> 249 ret = super().__torch_function__(func, types, args, kwargs)
250 # if `out` has been used as argument, metadata is not copied, nothing to do.
251 # if "out" in kwargs:
252 # return ret
253 # we might have 1 or multiple outputs. Might be MetaTensor, might be something
254 # else (e.g., `__repr__` returns a string).
255 # Convert to list (if necessary), process, and at end remove list if one was added.
256 if (
257 hasattr(torch, "return_types")
258 and hasattr(func, "__name__")
(...)
262 ):
263 # for torch.max(torch.tensor(1.0), dim=0), the return type is named-tuple like
File ~/miniforge3/envs/torch13/lib/python3.10/site-packages/torch/_tensor.py:1278, in Tensor.__torch_function__(cls, func,types, args, kwargs)
1275 return NotImplemented
...
-> 1278 ret = func(*args, **kwargs)
1279 if func in get_default_nowrap_functions():
1280 return ret
TypeError: Trying to convert ComplexFloat to the MPS backend but it does not have support for that dtype.
It works when the image is not sent to MPS:
img = img.unsqueeze(0)
freq = torch.fft.fft2(img, norm="ortho")
mag = torch.sqrt(freq.real.pow(2) + freq.imag.pow(2))
mag.shape
and I get:
(1, 3, 480, 640)
thanks in advance for the help.
### Versions
my installed packages are:
- python 3.10.6
- torch 1.13
- monai 1.0.1
cc @mruberry @peterbell10 @kulinseth @albanD @malfet @DenisVieriu97 @razarmehr @abhudev
| 0 |
4,103 | 93,450 |
torchinductor tests attempt to access internet
|
triaged, bug
|
### 🐛 Describe the bug
Run the tests somewhere without an outbound internet connection, e.g.,
```
$ python test/inductor/test_torchinductor.py -k test_cudnn_rnn
```
```
CondaHTTPError: HTTP 000 CONNECTION FAILED for url <https://conda.anaconda.org/conda-forge/linux-64/curre
nt_repodata.json>
Elapsed: -
An HTTP error occurred when trying to retrieve this URL.
HTTP errors are often intermittent, and a simple retry will get you on your way.
'https://conda.anaconda.org/conda-forge/linux-64'
```
### Error logs
_No response_
### Minified repro
_No response_
| 3 |
4,104 | 89,634 |
[ONNX] torch.onnx.export can not export the grad of conv when the op is in CPU
|
module: onnx, triaged
|
### 🐛 Describe the bug
pytorch onnx exportor can not export the backward of conv2d op when it's in CPU, but it can export it when it's in CUDA device.
```python
import torch
from torch import nn
class MyModule(nn.Module):
def __init__(self) -> None:
super().__init__()
self.conv = nn.Conv2d(4, 64, (3, 3), stride=(1,1), padding=(1,1), dilation=(1,1), groups=1)
def forward(self, x):
x = x.detach().requires_grad_(True)
y = self.conv(x).sum()
g = torch.autograd.grad(y, x)[0]
return y-g
def export_model(device):
model = MyModule().to(device)
def freeze_model(m):
for p in m.parameters():
p.requires_grad_(False)
return m
model = freeze_model(model)
torch.onnx.export(model, torch.ones([1,4,16,16]).to(device), f"conv-{device}.onnx", verbose=True)
print(torch.__version__)
# should work w/o error
export_model('cuda')
# has RuntimeError: Found an unsupported argument type in the JIT tracer. File a bug report.
export_model('cpu')
```
The error log is
```
Exported graph: graph(%onnx::Conv_0 : Float(1, 4, 16, 16, strides=[1024, 256, 16, 1], requires_grad=0, device=cuda:0),
%conv.weight : Float(64, 4, 3, 3, strides=[36, 9, 3, 1], requires_grad=0, device=cuda:0),
%conv.bias : Float(64, strides=[1], requires_grad=0, device=cuda:0)):
%/conv/Conv_output_0 : Float(1, 64, 16, 16, strides=[16384, 256, 16, 1], requires_grad=0, device=cuda:0) = onnx::Conv[dilations=[1, 1], group=1, kernel_shape=[3, 3], pads=[1, 1, 1, 1], strides=[1, 1], onnx_name="/conv/Conv"](%onnx::Conv_0, %conv.weight, %conv.bias), scope: __main__.MyModule::/torch.nn.modules.conv.Conv2d::conv # /home/litao/workspace/dl-frameworks-howto/venv/lib/python3.10/site-packages/torch/nn/modules/conv.py:458:0
%/ReduceSum_output_0 : Float(requires_grad=1, device=cuda:0) = onnx::ReduceSum[keepdims=0, onnx_name="/ReduceSum"](%/conv/Conv_output_0), scope: __main__.MyModule:: # /home/litao/workspace/dl-frameworks-howto/./export_backward.py:9:0
%/Constant_output_0 : Float(1, 4, 16, 16, strides=[1024, 256, 16, 1], requires_grad=0, device=cuda:0) = onnx::Constant[value=<Tensor>, onnx_name="/Constant"](), scope: __main__.MyModule:: # /home/litao/workspace/dl-frameworks-howto/./export_backward.py:10:0
%6 : Float(1, 4, 16, 16, strides=[1024, 256, 16, 1], requires_grad=1, device=cuda:0) = onnx::Sub[onnx_name="/Sub"](%/ReduceSum_output_0, %/Constant_output_0), scope: __main__.MyModule:: # /home/litao/workspace/dl-frameworks-howto/./export_backward.py:10:0
return (%6)
1.13.0+cu117
Traceback (most recent call last):
File "/home/litao/workspace/dl-frameworks-howto/./export_backward.py", line 30, in <module>
export_model('cpu')
File "/home/litao/workspace/dl-frameworks-howto/./export_backward.py", line 23, in export_model
torch.onnx.export(model, torch.ones([1,4,16,16]).to(device), f"conv-{device}.onnx", verbose=True)
File "/home/litao/workspace/dl-frameworks-howto/venv/lib/python3.10/site-packages/torch/onnx/utils.py", line 504, in export
_export(
File "/home/litao/workspace/dl-frameworks-howto/venv/lib/python3.10/site-packages/torch/onnx/utils.py", line 1529, in _export
graph, params_dict, torch_out = _model_to_graph(
File "/home/litao/workspace/dl-frameworks-howto/venv/lib/python3.10/site-packages/torch/onnx/utils.py", line 1111, in _model_to_graph
graph, params, torch_out, module = _create_jit_graph(model, args)
File "/home/litao/workspace/dl-frameworks-howto/venv/lib/python3.10/site-packages/torch/onnx/utils.py", line 987, in _create_jit_graph
graph, torch_out = _trace_and_get_graph_from_model(model, args)
File "/home/litao/workspace/dl-frameworks-howto/venv/lib/python3.10/site-packages/torch/onnx/utils.py", line 891, in _trace_and_get_graph_from_model
trace_graph, torch_out, inputs_states = torch.jit._get_trace_graph(
File "/home/litao/workspace/dl-frameworks-howto/venv/lib/python3.10/site-packages/torch/jit/_trace.py", line 1184, in _get_trace_graph
outs = ONNXTracedModule(f, strict, _force_outplace, return_inputs, _return_inputs_states)(*args, **kwargs)
File "/home/litao/workspace/dl-frameworks-howto/venv/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1190, in _call_impl
return forward_call(*input, **kwargs)
File "/home/litao/workspace/dl-frameworks-howto/venv/lib/python3.10/site-packages/torch/jit/_trace.py", line 127, in forward
graph, out = torch._C._create_graph_by_tracing(
File "/home/litao/workspace/dl-frameworks-howto/venv/lib/python3.10/site-packages/torch/jit/_trace.py", line 118, in wrapper
outs.append(self.inner(*trace_inputs))
File "/home/litao/workspace/dl-frameworks-howto/venv/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1190, in _call_impl
return forward_call(*input, **kwargs)
File "/home/litao/workspace/dl-frameworks-howto/venv/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1178, in _slow_forward
result = self.forward(*input, **kwargs)
File "/home/litao/workspace/dl-frameworks-howto/./export_backward.py", line 11, in forward
g = torch.autograd.grad(y, x)[0]
File "/home/litao/workspace/dl-frameworks-howto/venv/lib/python3.10/site-packages/torch/autograd/__init__.py", line 300, in grad
return Variable._execution_engine.run_backward( # Calls into the C++ engine to run the backward pass
RuntimeError: Found an unsupported argument type in the JIT tracer. File a bug report.
```
### Versions
Collecting environment information...
PyTorch version: 1.13.0+cu117
Is debug build: False
CUDA used to build PyTorch: 11.7
ROCM used to build PyTorch: N/A
OS: Ubuntu 22.04.1 LTS (x86_64)
GCC version: (Ubuntu 11.3.0-1ubuntu1~22.04) 11.3.0
Clang version: 14.0.0-1ubuntu1
CMake version: version 3.22.1
Libc version: glibc-2.35
Python version: 3.10.6 (main, Nov 2 2022, 18:53:38) [GCC 11.3.0] (64-bit runtime)
Python platform: Linux-5.15.0-53-generic-x86_64-with-glibc2.35
Is CUDA available: True
CUDA runtime version: Could not collect
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration:
GPU 0: NVIDIA GeForce GTX 1060 6GB
GPU 1: NVIDIA GeForce RTX 2060 SUPER
Nvidia driver version: 520.61.05
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] mypy==0.991
[pip3] mypy-extensions==0.4.3
[pip3] numpy==1.23.4
[pip3] torch==1.13.0
[conda] Could not collect
| 3 |
4,105 | 89,630 |
[dynamo] RuntimeError: Failed running call_function aten.nll_loss_backward(*(FakeTensor(FakeTensor(...
|
triaged, module: dynamo
|
### 🐛 Describe the bug
I'm seeing the following error when running with dynamo
```
RuntimeError: Failed running call_function aten.nll_loss_backward(*(FakeTensor(FakeTensor(..., device='meta', size=(1,)), cpu), FakeTensor(FakeTensor(..., device='meta', size=(3,)), cpu)), **{'target': FakeTensor(FakeTensor(..., device='meta', size=(3,), dtype=torch.int64), cpu), 'weight': None, 'reduction': 0, 'ignore_index': 10, 'total_weight': FakeTensor(FakeTensor(..., device='meta', size=()), cpu)}):
Index tensor must have the same number of dimensions as self tensor
```
repro:
```python
import torch
import torch._dynamo as dynamo
@dynamo.optimize("eager")
def forward(grad_output, input, target, total_weight):
return torch.ops.aten.nll_loss_backward(grad_output,
input,
target=target,
weight=None,
reduction=0,
ignore_index=10,
total_weight=total_weight)
forward(torch.randn(1), torch.randn(3), torch.tensor([2, 3, 0]),
torch.tensor(3.))
```
Full error log: https://gist.github.com/silvasean/5dd4b1667c9e451d12dac84e8a473173
### Versions
Collecting environment information...
PyTorch version: 1.14.0.dev20221114+cpu
Is debug build: False
CUDA used to build PyTorch: None
ROCM used to build PyTorch: N/A
OS: Debian GNU/Linux rodete (x86_64)
GCC version: (Debian 12.2.0-3) 12.2.0
Clang version: 14.0.6-2
CMake version: version 3.25.0
Libc version: glibc-2.35
Python version: 3.10.8 (main, Nov 3 2022, 15:17:13) [GCC 12.2.0] (64-bit runtime)
Python platform: Linux-5.18.16-1rodete4-amd64-x86_64-with-glibc2.35
Is CUDA available: False
CUDA runtime version: No CUDA
GPU models and configuration: No CUDA
Nvidia driver version: No CUDA
cuDNN version: No CUDA
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.23.4
[pip3] torch==1.14.0.dev20221114+cpu
[pip3] torchvision==0.15.0.dev20221114+cpu
[conda] Could not collect
cc @mlazos @soumith @voznesenskym @yanboliang @penguinwu @anijain2305 @EikanWang @jgong5 @Guobing-Chen @chunyuan-w @XiaobingSuper @zhuhaozhe @blzheng @Xia-Weiwen @wenzhe-nrv @jiayisunx @desertfire
| 0 |
4,106 | 89,629 |
[dynamo] RuntimeError: Failed running call_function aten.convolution_backward(*(FakeTensor(FakeTensor(..
|
triaged, module: dynamo
|
### 🐛 Describe the bug
```
TypeError: new_empty(): argument 'size' (position 1) must be tuple of ints, but found element of type NoneType at pos 0
...
RuntimeError: Failed running call_function aten.convolution_backward(*(FakeTensor(FakeTensor(..., device='meta', size=(2, 2, 8, 8)), cpu), FakeTensor(FakeTensor(..., device='meta', size=(2, 2, 6, 6)), cpu), FakeTensor(FakeTensor(..., device='meta', size=(2, 2, 3, 3)), cpu)), **{'bias_sizes': None, 'stride': [1, 1], 'padding': [2, 2], 'dilation': [1, 1], 'transposed': False, 'output_padding': [0], 'groups': 1, 'output_mask': [True, True, True]}):
new_empty(): argument 'size' (position 1) must be tuple of ints, but found element of type NoneType at pos 0
(scroll up for backtrace)
```
```python
import torch
import torch._dynamo as dynamo
@dynamo.optimize("eager")
def forward(grad_out, input_vec, weight):
return torch.ops.aten.convolution_backward(
grad_out,
input_vec,
weight,
bias_sizes=None,
stride=[1, 1],
padding=[2, 2],
dilation=[1, 1],
transposed=False,
output_padding=[0],
groups=1,
output_mask=[True, True, True])
forward(torch.randn(2, 2, 8, 8), torch.randn(2, 2, 6, 6),
torch.randn(2, 2, 3, 3))
```
Full error log: https://gist.github.com/silvasean/068ec6759d9f29f0b9255e5fc1c62e0a
### Versions
Collecting environment information...
PyTorch version: 1.14.0.dev20221114+cpu
Is debug build: False
CUDA used to build PyTorch: None
ROCM used to build PyTorch: N/A
OS: Debian GNU/Linux rodete (x86_64)
GCC version: (Debian 12.2.0-3) 12.2.0
Clang version: 14.0.6-2
CMake version: version 3.25.0
Libc version: glibc-2.35
Python version: 3.10.8 (main, Nov 3 2022, 15:17:13) [GCC 12.2.0] (64-bit runtime)
Python platform: Linux-5.18.16-1rodete4-amd64-x86_64-with-glibc2.35
Is CUDA available: False
CUDA runtime version: No CUDA
GPU models and configuration: No CUDA
Nvidia driver version: No CUDA
cuDNN version: No CUDA
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.23.4
[pip3] torch==1.14.0.dev20221114+cpu
[pip3] torchvision==0.15.0.dev20221114+cpu
[conda] Could not collect
cc @mlazos @soumith @voznesenskym @yanboliang @penguinwu @anijain2305 @EikanWang @jgong5 @Guobing-Chen @chunyuan-w @XiaobingSuper @zhuhaozhe @blzheng @Xia-Weiwen @wenzhe-nrv @jiayisunx @desertfire
| 0 |
4,107 | 89,627 |
[dynamo] RuntimeError: Failed running call_function aten.lift_fresh_copy(*(FakeTensor(FakeTensor(...
|
triaged, module: dynamo
|
### 🐛 Describe the bug
I'm observing this error from the following minimal repro.
```
RuntimeError: Failed running call_function aten.lift_fresh_copy(*(FakeTensor(FakeTensor(..., device='meta', size=(2, 3)), cpu),), **{}):
maximum recursion depth exceeded while calling a Python object
```
```
import torch
import torch._dynamo as dynamo
@dynamo.optimize("eager")
def forward(x):
return torch.ops.aten.lift_fresh_copy(x)
forward(torch.randn(2, 3))
```
Full error log: https://gist.github.com/silvasean/3ff689aea2a9da64d20899ff159ab52e
### Versions
Collecting environment information...
PyTorch version: 1.14.0.dev20221114+cpu
Is debug build: False
CUDA used to build PyTorch: None
ROCM used to build PyTorch: N/A
OS: Debian GNU/Linux rodete (x86_64)
GCC version: (Debian 12.2.0-3) 12.2.0
Clang version: 14.0.6-2
CMake version: version 3.25.0
Libc version: glibc-2.35
Python version: 3.10.8 (main, Nov 3 2022, 15:17:13) [GCC 12.2.0] (64-bit runtime)
Python platform: Linux-5.18.16-1rodete4-amd64-x86_64-with-glibc2.35
Is CUDA available: False
CUDA runtime version: No CUDA
GPU models and configuration: No CUDA
Nvidia driver version: No CUDA
cuDNN version: No CUDA
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.23.4
[pip3] torch==1.14.0.dev20221114+cpu
[pip3] torchvision==0.15.0.dev20221114+cpu
[conda] Could not collect
cc @mlazos @soumith @voznesenskym @yanboliang @penguinwu @anijain2305 @EikanWang @jgong5 @Guobing-Chen @chunyuan-w @XiaobingSuper @zhuhaozhe @blzheng @Xia-Weiwen @wenzhe-nrv @jiayisunx @desertfire
| 0 |
4,108 | 89,617 |
Can not access to "sbgemm" routine with user-defined OpenBLAS
|
module: build, triaged, module: bfloat16, module: openblas
|
### 🐛 Describe the bug
I want to build a pytorch with OpenBLAS and use sbgemm.
If OpenBLAS is installed in the default path and BLAS is not specified when pytorch build, it will go to FindBLAS.cmake and set BLAS_HAS_SBGEMM.
However, if I specify the OpenBLAS path in the following way, and specify BLAS as OpenBLAS:
```bash
OpenBLAS_HOME=<My OpenBLAS Path> BLAS=OpenBLAS MAX_JOBS=16 python setup.py develop
```
It will go to FindOpenBLAS.cmake but not FindBLAS.cmake, and not set BLAS_HAS_SBGEMM. Finally, the built PyTorch cannot use the GEMM support for BFloat16.
### Versions
Collecting environment information...
PyTorch version: 1.14.0a0
Is debug build: False
CUDA used to build PyTorch: None
ROCM used to build PyTorch: N/A
OS: Ubuntu Jammy Jellyfish (development branch) (aarch64)
GCC version: (Ubuntu 11.3.0-1ubuntu1~22.04) 11.3.0
Clang version: Could not collect
CMake version: version 3.22.1
Libc version: glibc-2.35
Python version: 3.10.6 (main, Nov 2 2022, 18:53:38) [GCC 11.3.0] (64-bit runtime)
Python platform: Linux-5.10.134-12.2.al8.aarch64-aarch64-with-glibc2.35
Is CUDA available: False
CUDA runtime version: No CUDA
CUDA_MODULE_LOADING set to: N/A
GPU models and configuration: No CUDA
Nvidia driver version: No CUDA
cuDNN version: No CUDA
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.23.4
[pip3] torch==1.14.0a0+gitunknown
[pip3] torchvision==0.14.0a0
[conda] Could not collect
cc @malfet @seemethere
| 0 |
4,109 | 89,609 |
NVFuser failing masked.{amax|amin|sum} extremal and correctness tests
|
triaged, module: nvfuser
|
### 🐛 Describe the bug
See https://github.com/pytorch/pytorch/actions/runs/3535610687/jobs/5934088992
### Versions
https://github.com/pytorch/pytorch/pull/87880
cc @kevinstephano @jjsjann123
| 3 |
4,110 | 89,601 |
Building PyTorch with Vulkan backend fails (1.13 and master)
|
triaged, module: vulkan
|
### 🐛 Describe the bug
Trying to build pytorch on linux with vulkan as the backend following these instructions (https://pytorch.org/tutorials/prototype/vulkan_workflow.html) fails. Just for reference, what I ran to try building:
```
export USE_VULKAN=1
export USE_VULKAN_SHADERC_RUNTIME=1
export USE_VULKAN_WRAPPER=0
export USE_CUDA=0
export USE_ROCM=0
python3 setup.py bdist_wheel
```
For 1.13
The first error encountered is already described here: https://github.com/pytorch/pytorch/issues/89105
If the `layernorm.glsl` file is updated to remove the quotation marks referred to in the linked issue, I eventually hit the following error:
```
[5403/6393] Building CXX object caffe2/CMakeFiles/torch_cpu.dir/__/torch/csrc/jit/codegen/onednn/graph_helper.cpp.o
FAILED: caffe2/CMakeFiles/torch_cpu.dir/__/torch/csrc/jit/codegen/onednn/graph_helper.cpp.o
/usr/bin/c++ -DAT_PER_OPERATOR_HEADERS -DBUILD_ONEDNN_GRAPH -DCPUINFO_SUPPORTED_PLATFORM=1 -DFMT_HEADER_ONLY=1 -DFXDIV_USE_INLINE_ASSEMBLY=0 -DHAVE_MALLOC_USABLE_SIZE=1 -DHAVE_MMAP=1 -DHAVE_SHM_OPEN=1 -DHAVE_SHM_UNLINK=1 -DMINIZ_DISABLE_ZIP_READER_CRC32_CHECKS -DNNP_CONVOLUTION_ONLY=0 -DNNP_INFERENCE_ONLY=0 -DONNXIFI_ENABLE_EXT=1 -DONNX_ML=1 -DONNX_NAMESPACE=onnx_torch -DUSE_C10D_GLOO -DUSE_DISTRIBUTED -DUSE_EXTERNAL_MZCRC -DUSE_RPC -DUSE_TENSORPIPE -D_FILE_OFFSET_BITS=64 -Dtorch_cpu_EXPORTS -I/home/me/Dev/scratch/pytorch_vk/pytorch/build/aten/src -I/home/me/Dev/scratch/pytorch_vk/pytorch/aten/src -I/home/me/Dev/scratch/pytorch_vk/pytorch/build -I/home/me/Dev/scratch/pytorch_vk/pytorch -I/home/me/Dev/scratch/pytorch_vk/pytorch/cmake/../third_party/benchmark/include -I/home/me/Dev/scratch/pytorch_vk/pytorch/third_party/onnx -I/home/me/Dev/scratch/pytorch_vk/pytorch/build/third_party/onnx -I/home/me/Dev/scratch/pytorch_vk/pytorch/third_party/foxi -I/home/me/Dev/scratch/pytorch_vk/pytorch/build/third_party/foxi -I/home/me/Dev/scratch/pytorch_vk/pytorch/torch/csrc/api -I/home/me/Dev/scratch/pytorch_vk/pytorch/torch/csrc/api/include -I/home/me/Dev/scratch/pytorch_vk/pytorch/caffe2/aten/src/TH -I/home/me/Dev/scratch/pytorch_vk/pytorch/build/caffe2/aten/src/TH -I/home/me/Dev/scratch/pytorch_vk/pytorch/build/caffe2/aten/src -I/home/me/Dev/scratch/pytorch_vk/pytorch/build/caffe2/../aten/src -I/home/me/Dev/scratch/pytorch_vk/pytorch/torch/csrc -I/home/me/Dev/scratch/pytorch_vk/pytorch/third_party/miniz-2.1.0 -I/home/me/Dev/scratch/pytorch_vk/pytorch/third_party/kineto/libkineto/include -I/home/me/Dev/scratch/pytorch_vk/pytorch/third_party/kineto/libkineto/src -I/home/me/Dev/scratch/pytorch_vk/pytorch/build/vulkan -I/home/me/Dev/scratch/pytorch_vk/pytorch/aten/../third_party/VulkanMemoryAllocator -I/home/me/Dev/scratch/pytorch_vk/pytorch/aten/../third_party/catch/single_include -I/home/me/Dev/scratch/pytorch_vk/pytorch/aten/src/ATen/.. -I/home/me/Dev/scratch/pytorch_vk/pytorch/third_party/FXdiv/include -I/home/me/Dev/scratch/pytorch_vk/pytorch/c10/.. -I/home/me/Dev/scratch/pytorch_vk/pytorch/third_party/pthreadpool/include -I/home/me/Dev/scratch/pytorch_vk/pytorch/third_party/cpuinfo/include -I/home/me/Dev/scratch/pytorch_vk/pytorch/third_party/QNNPACK/include -I/home/me/Dev/scratch/pytorch_vk/pytorch/aten/src/ATen/native/quantized/cpu/qnnpack/include -I/home/me/Dev/scratch/pytorch_vk/pytorch/aten/src/ATen/native/quantized/cpu/qnnpack/src -I/home/me/Dev/scratch/pytorch_vk/pytorch/third_party/cpuinfo/deps/clog/include -I/home/me/Dev/scratch/pytorch_vk/pytorch/third_party/NNPACK/include -I/home/me/Dev/scratch/pytorch_vk/pytorch/third_party/fbgemm/include -I/home/me/Dev/scratch/pytorch_vk/pytorch/third_party/fbgemm -I/home/me/Dev/scratch/pytorch_vk/pytorch/third_party/fbgemm/third_party/asmjit/src -I/home/me/Dev/scratch/pytorch_vk/pytorch/third_party/ittapi/src/ittnotify -I/home/me/Dev/scratch/pytorch_vk/pytorch/third_party/FP16/include -I/home/me/Dev/scratch/pytorch_vk/pytorch/third_party/tensorpipe -I/home/me/Dev/scratch/pytorch_vk/pytorch/build/third_party/tensorpipe -I/home/me/Dev/scratch/pytorch_vk/pytorch/third_party/tensorpipe/third_party/libnop/include -I/home/me/Dev/scratch/pytorch_vk/pytorch/third_party/fmt/include -I/home/me/Dev/scratch/pytorch_vk/pytorch/build/third_party/ideep/mkl-dnn/third_party/oneDNN/include -I/home/me/Dev/scratch/pytorch_vk/pytorch/third_party/ideep/mkl-dnn/third_party/oneDNN/src/../include -I/home/me/Dev/scratch/pytorch_vk/pytorch/third_party/flatbuffers/include -isystem /home/me/Dev/scratch/pytorch_vk/pytorch/build/third_party/gloo -isystem /home/me/Dev/scratch/pytorch_vk/pytorch/cmake/../third_party/gloo -isystem /home/me/Dev/scratch/pytorch_vk/pytorch/cmake/../third_party/googletest/googlemock/include -isystem /home/me/Dev/scratch/pytorch_vk/pytorch/cmake/../third_party/googletest/googletest/include -isystem /home/me/Dev/scratch/pytorch_vk/pytorch/third_party/protobuf/src -isystem /home/me/Dev/scratch/pytorch_vk/pytorch/third_party/gemmlowp -isystem /home/me/Dev/scratch/pytorch_vk/pytorch/third_party/neon2sse -isystem /home/me/Dev/scratch/pytorch_vk/pytorch/third_party/XNNPACK/include -isystem /home/me/Dev/scratch/pytorch_vk/pytorch/third_party/ittapi/include -isystem /home/me/Dev/scratch/pytorch_vk/pytorch/cmake/../third_party/eigen -isystem /home/me/Dev/scratch/pytorch_vk/pytorch/third_party/ideep/mkl-dnn/third_party/oneDNN/include -isystem /home/me/Dev/scratch/pytorch_vk/pytorch/third_party/ideep/include -isystem /home/me/Dev/scratch/pytorch_vk/pytorch/third_party/ideep/mkl-dnn/include -isystem /home/me/Dev/scratch/pytorch_vk/pytorch/build/include -Wno-deprecated -fvisibility-inlines-hidden -DUSE_PTHREADPOOL -fopenmp -DNDEBUG -DUSE_KINETO -DLIBKINETO_NOCUPTI -DUSE_FBGEMM -DUSE_QNNPACK -DUSE_PYTORCH_QNNPACK -DUSE_XNNPACK -DUSE_VULKAN -DUSE_VULKAN_API -DUSE_VULKAN_SHADERC_RUNTIME -DSYMBOLICATE_MOBILE_DEBUG_HANDLE -DEDGE_PROFILER_USE_KINETO -O2 -fPIC -Wno-narrowing -Wall -Wextra -Werror=return-type -Werror=non-virtual-dtor -Wno-missing-field-initializers -Wno-type-limits -Wno-array-bounds -Wno-unknown-pragmas -Wunused-local-typedefs -Wno-unused-parameter -Wno-unused-function -Wno-unused-result -Wno-strict-overflow -Wno-strict-aliasing -Wno-error=deprecated-declarations -Wno-stringop-overflow -Wno-psabi -Wno-error=pedantic -Wno-error=redundant-decls -Wno-error=old-style-cast -fdiagnostics-color=always -faligned-new -Wno-unused-but-set-variable -Wno-maybe-uninitialized -fno-math-errno -fno-trapping-math -Werror=format -Werror=cast-function-type -Wno-stringop-overflow -DHAVE_AVX2_CPU_DEFINITION -O3 -DNDEBUG -DNDEBUG -fPIC -DCAFFE2_USE_GLOO -DTH_HAVE_THREAD -Wall -Wextra -Wno-unused-parameter -Wno-unused-function -Wno-unused-result -Wno-missing-field-initializers -Wno-write-strings -Wno-unknown-pragmas -Wno-type-limits -Wno-array-bounds -Wno-sign-compare -Wno-strict-overflow -Wno-strict-aliasing -Wno-error=deprecated-declarations -Wno-missing-braces -Wno-maybe-uninitialized -fvisibility=hidden -O2 -fopenmp -DCAFFE2_BUILD_MAIN_LIB -pthread -DASMJIT_STATIC -std=gnu++14 -MD -MT caffe2/CMakeFiles/torch_cpu.dir/__/torch/csrc/jit/codegen/onednn/graph_helper.cpp.o -MF caffe2/CMakeFiles/torch_cpu.dir/__/torch/csrc/jit/codegen/onednn/graph_helper.cpp.o.d -o caffe2/CMakeFiles/torch_cpu.dir/__/torch/csrc/jit/codegen/onednn/graph_helper.cpp.o -c /home/me/Dev/scratch/pytorch_vk/pytorch/torch/csrc/jit/codegen/onednn/graph_helper.cpp
/home/me/Dev/scratch/pytorch_vk/pytorch/torch/csrc/jit/codegen/onednn/graph_helper.cpp: In function ‘torch::jit::fuser::onednn::Operator torch::jit::fuser::onednn::createOperator(torch::jit::Node*)’:
/home/me/Dev/scratch/pytorch_vk/pytorch/torch/csrc/jit/codegen/onednn/graph_helper.cpp:168:42: error: ‘HardTanh’ is not a member of ‘torch::jit::fuser::onednn::opkind’ {aka ‘dnnl::graph::op::kind’}
168 | return makeEltwiseOp(node, opkind::HardTanh)
| ^~~~~~~~
/home/me/Dev/scratch/pytorch_vk/pytorch/torch/csrc/jit/codegen/onednn/graph_helper.cpp:173:42: error: ‘HardTanh’ is not a member of ‘torch::jit::fuser::onednn::opkind’ {aka ‘dnnl::graph::op::kind’}
173 | return makeEltwiseOp(node, opkind::HardTanh)
| ^~~~~~~~
[5408/6393] Building CXX object caffe2/CMakeFiles/torch_cpu.dir/__/torch/csrc/jit/codegen/onednn/interface.cpp.o
/home/me/Dev/scratch/pytorch_vk/pytorch/torch/csrc/jit/codegen/onednn/interface.cpp: In function ‘torch::jit::Operation torch::jit::createLlgaKernel(const torch::jit::Node*)’:
/home/me/Dev/scratch/pytorch_vk/pytorch/torch/csrc/jit/codegen/onednn/interface.cpp:97:3: warning: ‘torch::jit::Operation::Operation(F&&) [with F = torch::jit::createLlgaKernel(const torch::jit::Node*)::<lambda(torch::jit::Stack*)>; typename std::enable_if<std::is_constructible<std::function<void(std::vector<c10::IValue>*)>, F&&>::value, int>::type <anonymous> = 0]’ is deprecated: Please use void(Stack&) to register operator instead. [-Wdeprecated-declarations]
97 | };
| ^
In file included from /home/me/Dev/scratch/pytorch_vk/pytorch/aten/src/ATen/core/boxing/KernelFunction.h:5,
from /home/me/Dev/scratch/pytorch_vk/pytorch/aten/src/ATen/core/dispatch/Dispatcher.h:4,
from /home/me/Dev/scratch/pytorch_vk/pytorch/torch/csrc/jit/runtime/operator.h:6,
from /home/me/Dev/scratch/pytorch_vk/pytorch/torch/csrc/jit/ir/ir.h:7,
from /home/me/Dev/scratch/pytorch_vk/pytorch/torch/csrc/jit/codegen/onednn/defer_size_check.h:3,
from /home/me/Dev/scratch/pytorch_vk/pytorch/torch/csrc/jit/codegen/onednn/interface.cpp:2:
/home/me/Dev/scratch/pytorch_vk/pytorch/aten/src/ATen/core/stack.h:25:3: note: declared here
25 | Operation(F&& raw): op_([raw = std::forward<F>(raw)](Stack& stack) {
| ^~~~~~~~~
/home/me/Dev/scratch/pytorch_vk/pytorch/torch/csrc/jit/codegen/onednn/interface.cpp: In function ‘torch::jit::Operation torch::jit::createLlgaGuardKernel(const torch::jit::Node*)’:
/home/me/Dev/scratch/pytorch_vk/pytorch/torch/csrc/jit/codegen/onednn/interface.cpp:162:3: warning: ‘torch::jit::Operation::Operation(F&&) [with F = torch::jit::createLlgaGuardKernel(const torch::jit::Node*)::<lambda(torch::jit::Stack*)>; typename std::enable_if<std::is_constructible<std::function<void(std::vector<c10::IValue>*)>, F&&>::value, int>::type <anonymous> = 0]’ is deprecated: Please use void(Stack&) to register operator instead. [-Wdeprecated-declarations]
162 | };
| ^
In file included from /home/me/Dev/scratch/pytorch_vk/pytorch/aten/src/ATen/core/boxing/KernelFunction.h:5,
from /home/me/Dev/scratch/pytorch_vk/pytorch/aten/src/ATen/core/dispatch/Dispatcher.h:4,
from /home/me/Dev/scratch/pytorch_vk/pytorch/torch/csrc/jit/runtime/operator.h:6,
from /home/me/Dev/scratch/pytorch_vk/pytorch/torch/csrc/jit/ir/ir.h:7,
from /home/me/Dev/scratch/pytorch_vk/pytorch/torch/csrc/jit/codegen/onednn/defer_size_check.h:3,
from /home/me/Dev/scratch/pytorch_vk/pytorch/torch/csrc/jit/codegen/onednn/interface.cpp:2:
/home/me/Dev/scratch/pytorch_vk/pytorch/aten/src/ATen/core/stack.h:25:3: note: declared here
25 | Operation(F&& raw): op_([raw = std::forward<F>(raw)](Stack& stack) {
| ^~~~~~~~~
[5415/6393] Building CXX object caffe2/CMakeFiles/torch_cpu.dir/__/torch/csrc/autograd/generated/VariableType_2.cpp.o
ninja: build stopped: subcommand failed.
```
I also tried the master branch since there seems be a bunch of changes in the vulkan files. I hit the following error when trying to bulid off master:
```
/home/me/Dev/scratch/pytorch_vk/pytorch/aten/src/ATen/native/vulkan/ops/Convolution.cpp: In function ‘at::native::vulkan::api::ShaderSource at::native::vulkan::ops::conv2d::get_shader(at::IntArrayRef, at::IntArrayRef, at::IntArrayRef, at::IntArrayRef, at::native::vulkan::ops::Conv2dMethod, bool, bool)’:
/home/me/Dev/scratch/pytorch_vk/pytorch/aten/src/ATen/native/vulkan/ops/Convolution.cpp:299:28: error: ‘quantized_conv2d’ was not declared in this scope; did you mean ‘quantized_conv2d_glsl’?
299 | shader = VK_SHADER(quantized_conv2d);
| ^~~~~~~~~~~~~~~~
| quantized_conv2d_glsl
/home/me/Dev/scratch/pytorch_vk/pytorch/aten/src/ATen/native/vulkan/ops/Convolution.cpp:299:18: error: ‘VK_SHADER’ was not declared in this scope
299 | shader = VK_SHADER(quantized_conv2d);
| ^~~~~~~~~
/home/me/Dev/scratch/pytorch_vk/pytorch/aten/src/ATen/native/vulkan/ops/Convolution.cpp:302:28: error: ‘quantized_conv2d_dw’ was not declared in this scope; did you mean ‘quantized_conv2d_glsl’?
302 | shader = VK_SHADER(quantized_conv2d_dw);
| ^~~~~~~~~~~~~~~~~~~
| quantized_conv2d_glsl
/home/me/Dev/scratch/pytorch_vk/pytorch/aten/src/ATen/native/vulkan/ops/Convolution.cpp:305:28: error: ‘quantized_conv2d_pw_2x2’ was not declared in this scope; did you mean ‘quantized_conv2d_pw_2x2_glsl’?
305 | shader = VK_SHADER(quantized_conv2d_pw_2x2);
| ^~~~~~~~~~~~~~~~~~~~~~~
| quantized_conv2d_pw_2x2_glsl
/home/me/Dev/scratch/pytorch_vk/pytorch/aten/src/ATen/native/vulkan/ops/Convolution.cpp:313:24: error: ‘conv_transpose2d’ was not declared in this scope; did you mean ‘conv_transpose2d_glsl’?
313 | shader = VK_SHADER(conv_transpose2d);
| ^~~~~~~~~~~~~~~~
| conv_transpose2d_glsl
/home/me/Dev/scratch/pytorch_vk/pytorch/aten/src/ATen/native/vulkan/ops/Convolution.cpp:313:14: error: ‘VK_SHADER’ was not declared in this scope
313 | shader = VK_SHADER(conv_transpose2d);
| ^~~~~~~~~
/home/me/Dev/scratch/pytorch_vk/pytorch/aten/src/ATen/native/vulkan/ops/Convolution.cpp:319:32: error: expected primary-expression before ‘)’ token
319 | shader = VK_SHADER(conv2d);
| ^
/home/me/Dev/scratch/pytorch_vk/pytorch/aten/src/ATen/native/vulkan/ops/Convolution.cpp:319:16: error: ‘VK_SHADER’ was not declared in this scope
319 | shader = VK_SHADER(conv2d);
| ^~~~~~~~~
/home/me/Dev/scratch/pytorch_vk/pytorch/aten/src/ATen/native/vulkan/ops/Convolution.cpp:322:26: error: ‘conv2d_dw’ was not declared in this scope; did you mean ‘qconv2d_vk’?
322 | shader = VK_SHADER(conv2d_dw);
| ^~~~~~~~~
| qconv2d_vk
/home/me/Dev/scratch/pytorch_vk/pytorch/aten/src/ATen/native/vulkan/ops/Convolution.cpp:325:26: error: ‘conv2d_pw_2x2’ was not declared in this scope
325 | shader = VK_SHADER(conv2d_pw_2x2);
| ^~~~~~~~~~~~~
[5369/6406] Building CXX object caffe2/CMakeFiles/torch_cpu.dir/__/aten/src/ATen/native/cpu/BinaryOpsKernel.cpp.DEFAULT.cpp.o
ninja: build stopped: subcommand failed.
```
### Versions
Collecting environment information...
PyTorch version: N/A
Is debug build: N/A
CUDA used to build PyTorch: N/A
ROCM used to build PyTorch: N/A
OS: Ubuntu 22.04.1 LTS (x86_64)
GCC version: (Ubuntu 11.3.0-1ubuntu1~22.04) 11.3.0
Clang version: Could not collect
CMake version: version 3.25.0
Libc version: glibc-2.35
Python version: 3.10.6 (main, Nov 2 2022, 18:53:38) [GCC 11.3.0] (64-bit runtime)
Python platform: Linux-5.15.0-53-generic-x86_64-with-glibc2.35
Is CUDA available: N/A
CUDA runtime version: Could not collect
CUDA_MODULE_LOADING set to: N/A
GPU models and configuration: Could not collect
Nvidia driver version: Could not collect
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: N/A
Versions of relevant libraries:
[pip3] numpy==1.23.5
[conda] Could not collect
| 0 |
4,111 | 89,597 |
Caching a model's weights and state_dict to disk to save RAM
|
module: nn, triaged
|
### 🚀 The feature, motivation and pitch
Hello, is there a way that I could cache a model's weights to the disk to save RAM? Similar to how the `.cpu` could be invoked to move the model's weights from the GPU to the CPU to save VRAM. There was an [issue](https://github.com/pytorch/pytorch/issues/24119) on this from a few years ago on MMAPed tensors from disk but I haven't been able to find anything on achieving something similar with model weights and state dicts. I'm not sure if this is possible in the current PyTorch implementation but any help would be much appreciated.
### Alternatives
`torch.load` but that incurs basically the same time penalty as just loading a model directly from the disk.
### Additional context
_No response_
cc @albanD @mruberry @jbschlosser @walterddr @kshitij12345 @saketh-are
| 3 |
4,112 | 89,574 |
Finish deprecation of autograd decorator over class objects
|
module: autograd, triaged
|
Finish the deprecation cycle from https://github.com/pytorch/pytorch/pull/89522 after 2 versions of PyTorch have passed.
We can simply make it an error.
cc @ezyang @zou3519 @gqchen @pearu @nikitaved @soulitzer @Lezcano @Varal7
| 0 |
4,113 | 93,447 |
[Inductor] [CPU] LSTM is not using oneDNN in tts_angular
|
triaged
|
### Description
Comparing the performance of `tts_angular` between inductor and IPEX backend, inductor is worse than IPEX due to LSTM OP.
In IPEX, LSTM is using oneDNN lstm primitive while in inductor, LSTM falls back to PyTorch (not using oneDNN).
### Profiling
<html>
<body>
<!--StartFragment-->
tts_angular | IPEX (LSTM uses oneDNN) | inductor (LSTM uses stock PyTorch)
-- | -- | --
occurrences | 3 | 3
LSTM time | 52.031ms | 104.763ms
Total time | 59.767ms | 109.785ms
LSTM time / Total time | 87.06% | 95.43%
<!--EndFragment-->
</body>
</html>
| 3 |
4,114 | 93,446 |
[Inductor] [CPU] Vectorization not supporting python pass-in scalar double in speech_transformer
|
triaged
|
### Description
Comparing performances of `speech_transformer` with backends inductor and IPEX, inductor is 0.68 IPEX. The main reason is that vectorization does not support python pass-in scalar double.
### Profiling and Code snippet

```
kernel_cpp_8 = async_compile.cpp('''
#include "/tmp/tmp8ofgbidl/rp/crpdeql3xwpfmcyakwtqpzihz525if6mt25mozau77xvmnh7vqyu.h"
extern "C" void kernel(float* __restrict__ in_out_ptr0,
const bool* __restrict__ in_ptr0,
const double* __restrict__ in_ptr2,
const float* __restrict__ in_ptr3,
float* __restrict__ out_ptr0,
float* __restrict__ out_ptr2,
float* __restrict__ out_ptr4)
{
auto in_ptr1 = in_out_ptr0;
auto out_ptr1 = in_out_ptr0;
auto out_ptr3 = in_out_ptr0;
#pragma omp parallel num_threads(28)
{
#pragma omp for
for(long i0=0; i0<80; i0+=1)
{
#pragma GCC ivdep
for(long i1=0; i1<204; i1+=1)
{
{
{
float tmp7 = -std::numeric_limits<float>::infinity();
for(long i2=0; i2<204; i2+=1)
{
{
auto tmp0 = in_ptr0[i2 + (204*(i0 % 10))];
auto tmp2 = in_ptr1[i2 + (204*i1) + (41616*i0)];
auto tmp3 = in_ptr2[0];
auto tmp1 = -std::numeric_limits<float>::infinity();
auto tmp4 = static_cast<float>(tmp3);
auto tmp5 = tmp2 / tmp4;
auto tmp6 = tmp0 ? tmp1 : tmp5;
tmp7 = std::max(tmp7, tmp6);
}
}
out_ptr0[i1 + (204*i0)] = tmp7;
}
}
}
}
#pragma omp for
for(long i0=0; i0<80; i0+=1)
{
#pragma GCC ivdep
for(long i1=0; i1<204; i1+=1)
{
#pragma GCC ivdep
for(long i2=0; i2<204; i2+=1)
{
{
{
auto tmp0 = in_ptr0[i2 + (204*(i0 % 10))];
auto tmp2 = in_ptr1[i2 + (204*i1) + (41616*i0)];
auto tmp3 = in_ptr2[0];
auto tmp7 = out_ptr0[i1 + (204*i0)];
auto tmp1 = -std::numeric_limits<float>::infinity();
auto tmp4 = static_cast<float>(tmp3);
auto tmp5 = tmp2 / tmp4;
auto tmp6 = tmp0 ? tmp1 : tmp5;
auto tmp8 = tmp6 - tmp7;
auto tmp9 = std::exp(tmp8);
out_ptr1[i2 + (204*i1) + (41616*i0)] = tmp9;
}
}
}
}
}
#pragma omp for
for(long i0=0; i0<16320; i0+=1)
{
{
#pragma omp declare reduction(+:at::vec::Vectorized<float>:omp_out += omp_in) initializer(omp_priv={{0}})
float tmp1 = 0;
auto tmp1_vec = at::vec::Vectorized<float>(tmp1);
for(long i1=0; i1<12; i1+=1)
{
auto tmp0 = at::vec::Vectorized<float>::loadu(out_ptr1 + (16*i1) + (204*i0));
tmp1_vec += tmp0;
}
tmp1 = at::vec::vec_reduce_all<float>([](at::vec::Vectorized<float>& x, at::vec::Vectorized<float>&y) {return x + y;}, tmp1_vec);
#pragma omp simd simdlen(8) reduction(+:tmp1)
for(long i1=192; i1<204; i1+=1)
{
auto tmp0 = out_ptr1[i1 + (204*i0)];
tmp1 += tmp0;
}
out_ptr2[i0] = tmp1;
}
}
#pragma omp for
for(long i0=0; i0<16320; i0+=1)
{
for(long i1=0; i1<12; i1+=1)
{
auto tmp0 = at::vec::Vectorized<float>::loadu(out_ptr1 + (16*i1) + (204*i0));
auto tmp1 = at::vec::Vectorized<float>(out_ptr2[i0]);
auto tmp2 = tmp0 / tmp1;
tmp2.store(out_ptr3 + (16*i1) + (204*i0));
}
#pragma omp simd simdlen(8)
for(long i1=192; i1<204; i1+=1)
{
auto tmp0 = out_ptr1[i1 + (204*i0)];
auto tmp1 = out_ptr2[i0];
auto tmp2 = tmp0 / tmp1;
out_ptr3[i1 + (204*i0)] = tmp2;
}
}
#pragma omp for collapse(2)
for(long i0=0; i0<8; i0+=1)
{
for(long i1=0; i1<2040; i1+=1)
{
for(long i2=0; i2<4; i2+=1)
{
auto tmp0 = at::vec::Vectorized<float>::loadu(in_ptr3 + (16*i2) + (64*i0) + (512*i1));
tmp0.store(out_ptr4 + (16*i2) + (64*i1) + (130560*i0));
}
#pragma omp simd simdlen(8)
for(long i2=64; i2<64; i2+=1)
{
auto tmp0 = in_ptr3[i2 + (64*i0) + (512*i1)];
out_ptr4[i2 + (64*i1) + (130560*i0)] = tmp0;
}
}
}
}
}
''')
```
According to the profiling analysis, bottlenecks are `kernel_cpp_8, kernel_cpp_14, kernel_cpp_20, kernel_cpp_2, kernel_cpp_32 and kernel_cpp_26`, which are the implementations for the same Python code snippet:
```
attn = attn / self.temperature
attn = attn.masked_fill(mask, -np.inf)
code: attn = self.softmax(attn)
```
As `self.temperature` in Python, a.k.a. `__restrict__ in_ptr2` in C++, is a double scalar, vectorization is not applied.
### Minified repro
`python benchmarks/dynamo/torchbench.py --performance --float32 -dcpu -n50 --inductor --no-skip --dashboard -k "speech_transformer" --cold_start_latency --channels-last`
cc @EikanWang @jgong5
| 0 |
4,115 | 93,445 |
[accuracy] [aot_eager] mobilenet_v2_quantized_qat fails accuracy
|
triaged, bug, oncall: pt2, module: dynamic shapes, module: aotdispatch
|
### 🐛 Describe the bug
I am expecting `aot_eager` to be really close to pytorch native for any model. But, `mobilenet_v2_quantized_qat` fails accuracy. Minifier is not helping here (I am going to dive deeper into this). So, a couple of questions
1) Is something special about this model that can affect the accuracy?
2) Long time ago - I relaxed the accuracy check for another similar model `resnet50_quantized_qat`, and used cosine similarity. But, I think its too relaxed. If I tighten the check back, this model fails accuracy as well.
`python benchmarks/dynamo/torchbench.py --training --accuracy --device cuda --backend=aot_eager --float32 --only=mobilenet_v2_quantized_qat`
### Error logs
_No response_
### Minified repro
_No response_
cc @ezyang @soumith @msaroufim @wconstab @ngimel @bdhirsh
| 9 |
4,116 | 93,444 |
[Inductor] [CPU] Maxpooling is not vectorized in shufflenet_v2_x1_0
|
triaged
|
### Description
Comparing performances of `shufflenet_v2_x1_0` with backends inductor and IPEX, inductor is 0.74 IPEX. One main reason is the long time consuming of Maxpooling because Maxpooling is not vectorized due to masked load sematic, the other one is reported in https://github.com/pytorch/torchdynamo/issues/1915.
### Profiling and Code snippet
`kernel_cpp_0` is for `torch.ops.aten.max_pool2d_with_indices` implementation.
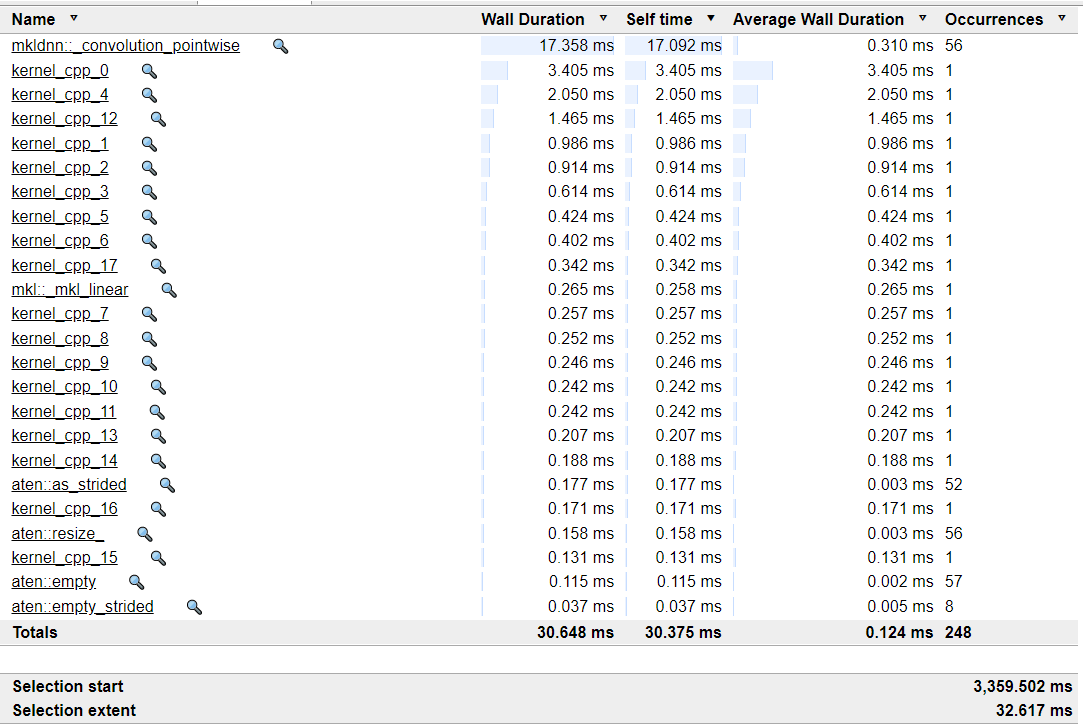
```
kernel_cpp_0 = async_compile.cpp('''
#include "/home/neo/workspace/workspace01_dynamotest/pytorch/torch/_inductor/codegen/cpp_prefix.h"
extern "C" void kernel(const float* __restrict__ in_ptr0,
float* __restrict__ out_ptr0,
float* __restrict__ out_ptr1,
float* __restrict__ out_ptr2)
{
RECORD_FUNCTION(__FUNCTION__, c10::ArrayRef<c10::IValue>({}));
#pragma omp parallel num_threads(28)
{
#pragma omp for
for(long i0=0; i0<64; i0+=1)
{
#pragma GCC ivdep
for(long i1=0; i1<56; i1+=1)
{
#pragma GCC ivdep
for(long i2=0; i2<56; i2+=1)
{
#pragma GCC ivdep
for(long i3=0; i3<24; i3+=1)
{
{
{
auto tmp0 = static_cast<long>((-1) + (2*i1));
auto tmp1 = static_cast<long>(0);
auto tmp2 = tmp0 >= tmp1;
auto tmp3 = static_cast<long>(112);
auto tmp4 = tmp0 < tmp3;
auto tmp5 = tmp2 & tmp4;
auto tmp6 = static_cast<long>((-1) + (2*i2));
auto tmp7 = tmp6 >= tmp1;
auto tmp8 = tmp6 < tmp3;
auto tmp9 = tmp7 & tmp8;
auto tmp10 = tmp5 & tmp9;
float tmp11 = -std::numeric_limits<float>::infinity();
if(tmp10)
{
auto tmp12 = in_ptr0[(-2712) + i3 + (48*i2) + (5376*i1) + (301056*i0)];
tmp11 = tmp12;
}
auto tmp13 = static_cast<long>((-113) + (2*i2) + (224*i1));
auto tmp14 = static_cast<long>(2*i2);
auto tmp15 = tmp14 >= tmp1;
auto tmp16 = tmp14 < tmp3;
auto tmp17 = tmp15 & tmp16;
auto tmp18 = tmp5 & tmp17;
float tmp19 = -std::numeric_limits<float>::infinity();
if(tmp18)
{
auto tmp20 = in_ptr0[(-2688) + i3 + (48*i2) + (5376*i1) + (301056*i0)];
tmp19 = tmp20;
}
auto tmp21 = static_cast<long>((-112) + (2*i2) + (224*i1));
auto tmp22 = tmp19 > tmp11;
auto tmp23 = tmp22 ? tmp21 : tmp13;
auto tmp24 = std::max(tmp19, tmp11);
auto tmp25 = static_cast<long>(1 + (2*i2));
auto tmp26 = tmp25 >= tmp1;
auto tmp27 = tmp25 < tmp3;
auto tmp28 = tmp26 & tmp27;
auto tmp29 = tmp5 & tmp28;
float tmp30 = -std::numeric_limits<float>::infinity();
if(tmp29)
{
auto tmp31 = in_ptr0[(-2664) + i3 + (48*i2) + (5376*i1) + (301056*i0)];
tmp30 = tmp31;
}
auto tmp32 = static_cast<long>((-111) + (2*i2) + (224*i1));
auto tmp33 = tmp30 > tmp24;
auto tmp34 = tmp33 ? tmp32 : tmp23;
auto tmp35 = std::max(tmp30, tmp24);
auto tmp36 = static_cast<long>(2*i1);
auto tmp37 = tmp36 >= tmp1;
auto tmp38 = tmp36 < tmp3;
auto tmp39 = tmp37 & tmp38;
auto tmp40 = tmp39 & tmp9;
float tmp41 = -std::numeric_limits<float>::infinity();
if(tmp40)
{
auto tmp42 = in_ptr0[(-24) + i3 + (48*i2) + (5376*i1) + (301056*i0)];
tmp41 = tmp42;
}
auto tmp43 = static_cast<long>((-1) + (2*i2) + (224*i1));
auto tmp44 = tmp41 > tmp35;
auto tmp45 = tmp44 ? tmp43 : tmp34;
auto tmp46 = std::max(tmp41, tmp35);
auto tmp47 = tmp39 & tmp17;
float tmp48 = -std::numeric_limits<float>::infinity();
if(tmp47)
{
auto tmp49 = in_ptr0[i3 + (48*i2) + (5376*i1) + (301056*i0)];
tmp48 = tmp49;
}
auto tmp50 = static_cast<long>((2*i2) + (224*i1));
auto tmp51 = tmp48 > tmp46;
auto tmp52 = tmp51 ? tmp50 : tmp45;
auto tmp53 = std::max(tmp48, tmp46);
auto tmp54 = tmp39 & tmp28;
float tmp55 = -std::numeric_limits<float>::infinity();
if(tmp54)
{
auto tmp56 = in_ptr0[24 + i3 + (48*i2) + (5376*i1) + (301056*i0)];
tmp55 = tmp56;
}
auto tmp57 = static_cast<long>(1 + (2*i2) + (224*i1));
auto tmp58 = tmp55 > tmp53;
auto tmp59 = tmp58 ? tmp57 : tmp52;
auto tmp60 = std::max(tmp55, tmp53);
auto tmp61 = static_cast<long>(1 + (2*i1));
auto tmp62 = tmp61 >= tmp1;
auto tmp63 = tmp61 < tmp3;
auto tmp64 = tmp62 & tmp63;
auto tmp65 = tmp64 & tmp9;
float tmp66 = -std::numeric_limits<float>::infinity();
if(tmp65)
{
auto tmp67 = in_ptr0[2664 + i3 + (48*i2) + (5376*i1) + (301056*i0)];
tmp66 = tmp67;
}
auto tmp68 = static_cast<long>(111 + (2*i2) + (224*i1));
auto tmp69 = tmp66 > tmp60;
auto tmp70 = tmp69 ? tmp68 : tmp59;
auto tmp71 = std::max(tmp66, tmp60);
auto tmp72 = tmp64 & tmp17;
float tmp73 = -std::numeric_limits<float>::infinity();
if(tmp72)
{
auto tmp74 = in_ptr0[2688 + i3 + (48*i2) + (5376*i1) + (301056*i0)];
tmp73 = tmp74;
}
auto tmp75 = static_cast<long>(112 + (2*i2) + (224*i1));
auto tmp76 = tmp73 > tmp71;
auto tmp77 = tmp76 ? tmp75 : tmp70;
auto tmp78 = std::max(tmp73, tmp71);
auto tmp79 = tmp64 & tmp28;
float tmp80 = -std::numeric_limits<float>::infinity();
if(tmp79)
{
auto tmp81 = in_ptr0[2712 + i3 + (48*i2) + (5376*i1) + (301056*i0)];
tmp80 = tmp81;
}
auto tmp82 = static_cast<long>(113 + (2*i2) + (224*i1));
auto tmp83 = tmp80 > tmp78;
auto tmp84 = tmp83 ? tmp82 : tmp77;
auto tmp85 = std::max(tmp80, tmp78);
out_ptr0[i3 + (24*i2) + (1344*i1) + (75264*i0)] = tmp85;
}
}
}
}
}
}
#pragma omp for
for(long i0=0; i0<64; i0+=1)
{
#pragma GCC ivdep
for(long i1=0; i1<24; i1+=1)
{
#pragma GCC ivdep
for(long i2=0; i2<3136; i2+=1)
{
{
{
auto tmp0 = out_ptr0[i1 + (24*i2) + (75264*i0)];
out_ptr1[i1 + (24*i2) + (75264*i0)] = tmp0;
out_ptr2[i1 + (24*i2) + (75264*i0)] = tmp0;
}
}
}
}
}
}
}
''')
```
### Minified repro
`python benchmarks/dynamo/torchbench.py --performance --float32 -dcpu -n50 --inductor --no-skip --dashboard -k "shufflenet_v2_x1_0" --cold_start_latency --channels-last`
cc @EikanWang @jgong5
| 0 |
4,117 | 93,443 |
Partitioner generates useless constant SymInt edges between forward-backwards
|
triaged, bug, oncall: pt2
|
### 🐛 Describe the bug
Suppose you have a size saved for backwards; at time of tracing that node, it was symbolic. However, later, we discovered it was in fact constant (because, e.g., we added it to a parameter). The FX graph still passes the symbolic shape around, but we happen to know it's constant. Fine. Then, we run the partitioner. The partitioner can't tell that a SymInt is constant, and will generate an edge from forwards to backwards to transfer the constant int, which is totally unnecessary.
Symbolic shapes branch is currently hacking around this with https://github.com/pytorch/pytorch/pull/84246/commits/1a5ff545370639f17d40f5f6157eefd9fc74d93b which forces constant nodes to get const propagated before we partition.
cc @soumith @msaroufim @wconstab @ngimel @bdhirsh
### Error logs
_No response_
### Minified repro
_No response_
| 4 |
4,118 | 93,442 |
AOTAutograd generates useless tangent inputs for SymInt outputs
|
triaged, bug, oncall: pt2
|
### 🐛 Describe the bug
If you AOTAutograd a graph that returns an int, the joint forward-backward will take an int tangent for this argument. This is useless. It is also wrong: the int tangent will be specified to be a specific symbolic int, but in fact you will always get None instead from the autograd engine.
This is annoying to fix because we must determine what the tangents to pass in are outside of the joint forwards backwards, but the calculation what actually needs tangents is inside joint forward backwards. Need to hoist it out.
cc @soumith @msaroufim @wconstab @ngimel @bdhirsh @bhdirsh
### Error logs
_No response_
### Minified repro
_No response_
| 0 |
4,119 | 89,546 |
Unable to launch CUDA Graph with DDP model
|
oncall: distributed
|
### 🐛 Describe the bug
Hello! I am unable to get a CUDA Graph to replay when using a DDP model. I am unsure if this is because I am not doing the required steps to make both play nice with each other, or if this is a legitimate bug. I appreciate any help nonetheless! Here is a toy case which replicates my issue:
```python
import os.path
import torch.multiprocessing as mp
import torch.distributed
import torch.nn as nn
import socket
from contextlib import closing
def train(rank: str,
port: str,
world_size: int,
model: nn.Module):
# Init for DDP
MASTER_ADDR = '127.0.0.1'
os.environ['MASTER_ADDR'] = MASTER_ADDR
os.environ['MASTER_PORT'] = port
torch.distributed.init_process_group('nccl', rank=rank, world_size=world_size)
device = f'cuda:{rank}'
model = model.to(device)
static_input = torch.rand((1, 1, 300, 300, 20), device=device, dtype=torch.float)
s = torch.cuda.Stream()
with torch.cuda.stream(s):
model = torch.nn.parallel.DistributedDataParallel(model)
for _ in range(20):
x = model(static_input)
torch.cuda.current_stream().wait_stream(s)
optimizer = torch.optim.AdamW(model.parameters(), lr=0.01)
# Captures the graph
# To allow capture, automatically sets a side stream as the current stream in the context
g = torch.cuda.CUDAGraph()
optimizer.zero_grad()
with torch.cuda.graph(g):
x = model(static_input)
x.sum().backward() # silly loss function...
optimizer.step()
# Fills the graph's input memory with new data to compute on
static_input.copy_(torch.rand((1, 1, 300, 300, 20), device=device, dtype=torch.float))
for _ in range(100):
g.replay()
print('we got through the stream...')
# cleanup
torch.distributed.destroy_process_group(rank)
if __name__ == '__main__':
os.environ["NCCL_ASYNC_ERROR_HANDLING"] = "0"
os.environ["CUDA_LAUNCH_BLOCKING"] = "1"
def find_free_port():
""" https://stackoverflow.com/questions/1365265/on-localhost-how-do-i-pick-a-free-port-number """
with closing(socket.socket(socket.AF_INET, socket.SOCK_STREAM)) as s:
s.bind(('', 0))
s.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
return str(s.getsockname()[1])
port = find_free_port()
print(f'{torch.cuda.nccl.version() =}')
print(f'{torch.__version__ =}')
print(f'{torch.version.cuda=}')
world_size = 2
model = nn.Sequential(nn.Conv3d(1, 1, kernel_size=(3, 3, 3), padding=(1, 1, 1)),
nn.ReLU())
mp.spawn(train, args=(port, world_size, model), nprocs=world_size, join=True)
```
This gives the error stack trace:
```
torch.cuda.nccl.version() =(2, 14, 3)
torch.__version__ ='1.14.0.dev20221027'
torch.version.cuda='11.7'
Traceback (most recent call last):
File "/home/chris/Desktop/CudaGraphDDP/main.py", line 83, in <module>
mp.spawn(train, args=(port, world_size, model), nprocs=world_size, join=True)
File "/home/chris/anaconda3/envs/deeplearning/lib/python3.9/site-packages/torch/multiprocessing/spawn.py", line 240, in spawn
return start_processes(fn, args, nprocs, join, daemon, start_method='spawn')
File "/home/chris/anaconda3/envs/deeplearning/lib/python3.9/site-packages/torch/multiprocessing/spawn.py", line 198, in start_processes
while not context.join():
File "/home/chris/anaconda3/envs/deeplearning/lib/python3.9/site-packages/torch/multiprocessing/spawn.py", line 160, in join
raise ProcessRaisedException(msg, error_index, failed_process.pid)
torch.multiprocessing.spawn.ProcessRaisedException:
-- Process 1 terminated with the following error:
Traceback (most recent call last):
File "/home/chris/Desktop/CudaGraphDDP/main.py", line 44, in train
x = model(static_input)
File "/home/chris/anaconda3/envs/deeplearning/lib/python3.9/site-packages/torch/nn/modules/module.py", line 1423, in _call_impl
return forward_call(*input, **kwargs)
File "/home/chris/anaconda3/envs/deeplearning/lib/python3.9/site-packages/torch/nn/parallel/distributed.py", line 1096, in forward
output = self._run_ddp_forward(*inputs, **kwargs)
File "/home/chris/anaconda3/envs/deeplearning/lib/python3.9/site-packages/torch/nn/parallel/distributed.py", line 1052, in _run_ddp_forward
return module_to_run(*inputs, **kwargs)
File "/home/chris/anaconda3/envs/deeplearning/lib/python3.9/site-packages/torch/nn/modules/module.py", line 1423, in _call_impl
return forward_call(*input, **kwargs)
File "/home/chris/anaconda3/envs/deeplearning/lib/python3.9/site-packages/torch/nn/modules/container.py", line 204, in forward
input = module(input)
File "/home/chris/anaconda3/envs/deeplearning/lib/python3.9/site-packages/torch/nn/modules/module.py", line 1423, in _call_impl
return forward_call(*input, **kwargs)
File "/home/chris/anaconda3/envs/deeplearning/lib/python3.9/site-packages/torch/nn/modules/conv.py", line 613, in forward
return self._conv_forward(input, self.weight, self.bias)
File "/home/chris/anaconda3/envs/deeplearning/lib/python3.9/site-packages/torch/nn/modules/conv.py", line 608, in _conv_forward
return F.conv3d(
RuntimeError: CUDA error: operation not permitted when stream is capturing
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/home/chris/anaconda3/envs/deeplearning/lib/python3.9/site-packages/torch/multiprocessing/spawn.py", line 69, in _wrap
fn(i, *args)
File "/home/chris/Desktop/CudaGraphDDP/main.py", line 46, in train
optimizer.step()
File "/home/chris/anaconda3/envs/deeplearning/lib/python3.9/site-packages/torch/cuda/graphs.py", line 159, in __exit__
self.cuda_graph.capture_end()
File "/home/chris/anaconda3/envs/deeplearning/lib/python3.9/site-packages/torch/cuda/graphs.py", line 81, in capture_end
super(CUDAGraph, self).capture_end()
RuntimeError: CUDA error: operation failed due to a previous error during capture
```
### Versions
Collecting environment information...
PyTorch version: 1.14.0.dev20221027
Is debug build: False
CUDA used to build PyTorch: 11.7
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.5 LTS (x86_64)
GCC version: (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0
Clang version: 10.0.0-4ubuntu1
CMake version: version 3.22.5
Libc version: glibc-2.31
Python version: 3.9.12 (main, Jun 1 2022, 11:38:51) [GCC 7.5.0] (64-bit runtime)
Python platform: Linux-5.14.0-1054-oem-x86_64-with-glibc2.31
Is CUDA available: True
CUDA runtime version: 11.7.99
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration:
GPU 0: NVIDIA RTX A6000
GPU 1: NVIDIA RTX A6000
Nvidia driver version: 515.65.01
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] adabelief-pytorch==0.2.1
[pip3] numpy==1.22.3
[pip3] torch==1.14.0.dev20221027+cu117
[pip3] torchaudio==0.14.0.dev20221027
[pip3] torchvision==0.15.0.dev20221027
[conda] adabelief-pytorch 0.2.1 pypi_0 pypi
[conda] blas 1.0 mkl
[conda] cudatoolkit 11.3.1 h2bc3f7f_2
[conda] mkl 2021.4.0 h06a4308_640
[conda] mkl-service 2.4.0 py39h7f8727e_0
[conda] mkl_fft 1.3.1 py39hd3c417c_0
[conda] mkl_random 1.2.2 py39h51133e4_0
[conda] numpy 1.22.3 py39he7a7128_0
[conda] numpy-base 1.22.3 py39hf524024_0
[conda] pytorch 1.14.0.dev20221027 py3.9_cuda11.7_cudnn8.5.0_0 pytorch-nightly
[conda] pytorch-cuda 11.7 h67b0de4_0 pytorch-nightly
[conda] pytorch-mutex 1.0 cuda pytorch
[conda] torch 1.14.0.dev20221027+cu117 pypi_0 pypi
[conda] torchaudio 0.14.0.dev20221027 py39_cu117 pytorch-nightly
[conda] torchvision 0.13.0 pypi_0 pypi
cc @mrshenli @pritamdamania87 @zhaojuanmao @satgera @rohan-varma @gqchen @aazzolini @osalpekar @jiayisuse @H-Huang @kwen2501 @awgu
| 4 |
4,120 | 89,492 |
Feature Request: deterministic CUDA cumsum
|
feature, module: cuda, triaged, module: determinism
|
### 🚀 The feature, motivation and pitch
There is no deterministic implementation for `cumsum_cuda_kernel`. It would be nice to have this!
### Alternatives
_No response_
### Additional context
This can currently still be used by setting the `warn_only` flag to `True`.
Warning:
`cumsum_cuda_kernel does not have a deterministic implementation, but you set 'torch.use_deterministic_algorithms(True, warn_only=True)'. You can file an issue at https://github.com/pytorch/pytorch/issues to help us prioritize adding deterministic support for this operation. (Triggered internally at ../aten/src/ATen/Context.cpp:82.)`
cc @ngimel @mruberry @kurtamohler
| 10 |
4,121 | 89,491 |
build: cmake: functorch.so not installed at expected location
|
module: build, triaged
|
### 🐛 Describe the bug
When building with cmake, the functorch library gets installed to `${DESTDIR}/${PROJECT_SOURCE_DIR}/functorch/`, which is unexpected:
```sh
$ cmake .. -DCMAKE_INSTALL_PREFIX=/usr ...
...
$ make install DESTDIR=$PWD/install
...
$ ls install
home usr
$ find install/home
install/home/$USER/path/to/pytorch.git/functorch/functorch.so
```
The functorch library is moved by setup.py later, but nevertheless I'd expect that unless the quirk is documented, the cmake stage installed files in standard locations.
### Versions
pytorch cf9476554fce9a9c909eebd7439f4b3f4d208f6c
cc @malfet @seemethere
| 2 |
4,122 | 89,490 |
build: cmake: ability to disable -Werror* (-Werror considered harmful)
|
module: build, triaged
|
### 🐛 Describe the bug
Tried to compile pytorch with gcc 12 and it failed instead of warning due to `-Werror`.
Now while I'm convinced that leaving `-Werror` in the build files elsewhere than in the developer / CI environment is insanity, and I'm not alone (https://flameeyes.blog/2009/02/25/future-proof-your-code-dont-use-werror/ ; https://embeddedartistry.com/blog/2017/05/22/werror-is-not-your-friend/ ; https://news.ycombinator.com/item?id=28745949 ...), I'm simply requesting the ability of controlling it (eg. https://github.com/dotnet/runtime/issues/7122 ; https://github.com/RobotLocomotion/drake/issues/2428 ...) so source distribution is future-proof.
### Versions
PyTorch version: 1.13.0+cu117
cc @malfet @seemethere
| 3 |
4,123 | 89,489 |
build: cmake: need to uniformize installation of libraries in CMAKE_INSTALL_LIBDIR (not lib)
|
module: build, module: cpp, triaged, needs research
|
### 🐛 Describe the bug
Installed pytorch from source, with cmake.
In particular I noticed that some libraries are installed in a hard-coded `$DESTDIR/$CMAKE_INSTALL_PREFIX/lib`, which is not expected on x86_64 (should be `.../lib64` from `CMAKE_INSTALL_LIBDIR`).
Looking at the cmake files:
```sh
git grep CMAKE_INSTALL_LIBDIR
git grep "DESTINATION lib"
```
and found issues.
So I propose to do this:
```sh
git grep " lib)" | perl -pe 's/(.*):(.*)$\s*/\1/g' | grep CMakeLists.txt | uniq | while read file; do sed -i -e 's@ lib)@ ${CMAKE_INSTALL_LIBDIR})@' "$file"; done
```
then reviewing with `git gui` or something else, to get rid of false positives (eg. test executables shouldn't go there, and it's OK for the deployed platform-agnostic `.py` files to be in `.../lib`).
### Versions
PyTorch version: 1.13.0+cu117
cc @malfet @seemethere @jbschlosser
| 4 |
4,124 | 89,484 |
kind_.is_prim() INTERNAL ASSERT FAILED at "../torch/csrc/jit/ir/ir.cpp":1098
|
oncall: jit, module: cpp
|
### 🐛 Describe the bug
## I am inferencing using for loop to inference multiple images. However, I got errors when second index is looping.
- what(): kind_.is_prim() INTERNAL ASSERT FAILED at "../torch/csrc/jit/ir/ir.cpp":1098, please report a bug to PyTorch. Only prim ops are allowed to not have a registered operator but aten::mul doesn't have one either. We don't know if this op has side effects.
- Exception raised from hasSideEffects at ../torch/csrc/jit/ir/ir.cpp:1098 (most recent call first):
frame #0: c10::Error::Error(c10::SourceLocation, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >) + 0x69 (0x7f50519f3b29 in /workspace/ffmpeg/ffmpeg_sources/libtorch-1.8.0/lib/libc10.so)
frame #1: torch::jit::Node::hasSideEffects() const + 0x319 (0x7f4fe085f429 in /workspace/ffmpeg/ffmpeg_sources/libtorch-1.8.0/lib/libtorch_cpu.so)
frame #2: <unknown function> + 0x35f6b18 (0x7f4fe08d8b18 in /workspace/ffmpeg/ffmpeg_sources/libtorch-1.8.0/lib/libtorch_cpu.so)
frame #3: <unknown function> + 0x35f8761 (0x7f4fe08da761 in /workspace/ffmpeg/ffmpeg_sources/libtorch-1.8.0/lib/libtorch_cpu.so)
frame #4: <unknown function> + 0x35f97a5 (0x7f4fe08db7a5 in /workspace/ffmpeg/ffmpeg_sources/libtorch-1.8.0/lib/libtorch_cpu.so)
frame #5: torch::jit::EliminateDeadCode(torch::jit::Block*, std::function<void (std::unordered_set<torch::jit::Value const*, std::hash<torch::jit::Value const*>, std::equal_to<torch::jit::Value const*>, std::allocator<torch::jit::Value const*> > const&)>, torch::jit::DCESideEffectPolicy) + 0x213 (0x7f4fe08d2553 in /workspace/ffmpeg/ffmpeg_sources/libtorch-1.8.0/lib/libtorch_cpu.so)
frame #6: torch::jit::differentiate(std::shared_ptr<torch::jit::Graph>&) + 0xa53 (0x7f4fe0a2af73 in /workspace/ffmpeg/ffmpeg_sources/libtorch-1.8.0/lib/libtorch_cpu.so)
frame #7: <unknown function> + 0x377e667 (0x7f4fe0a60667 in /workspace/ffmpeg/ffmpeg_sources/libtorch-1.8.0/lib/libtorch_cpu.so)
frame #8: <unknown function> + 0x377f5e9 (0x7f4fe0a615e9 in /workspace/ffmpeg/ffmpeg_sources/libtorch-1.8.0/lib/libtorch_cpu.so)
frame #9: <unknown function> + 0x378014e (0x7f4fe0a6214e in /workspace/ffmpeg/ffmpeg_sources/libtorch-1.8.0/lib/libtorch_cpu.so)
frame #10: <unknown function> + 0x3752a24 (0x7f4fe0a34a24 in /workspace/ffmpeg/ffmpeg_sources/libtorch-1.8.0/lib/libtorch_cpu.so)
frame #11: torch::jit::GraphFunction::operator()(std::vector<c10::IValue, std::allocator<c10::IValue> >, std::unordered_map<std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >, c10::IValue, std::hash<std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > >, std::equal_to<std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > >, std::allocator<std::pair<std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const, c10::IValue> > > const&) + 0x3a (0x7f4fe074f51a in /workspace/ffmpeg/ffmpeg_sources/libtorch-1.8.0/lib/libtorch_cpu.so)
frame #12: torch::jit::Method::operator()(std::vector<c10::IValue, std::allocator<c10::IValue> >, std::unordered_map<std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >, c10::IValue, std::hash<std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > >, std::equal_to<std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > >, std::allocator<std::pair<std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const, c10::IValue> > > const&) + 0x16a (0x7f4fe075e9ca in /workspace/ffmpeg/ffmpeg_sources/libtorch-1.8.0/lib/libtorch_cpu.so)
frame #13: torch::jit::Module::forward(std::vector<c10::IValue, std::allocator<c10::IValue> >) + 0x103 (0x563e74dfe037 in ./libtorch-build)
frame #14: FaceGAN::process(cv::Mat) + 0x554 (0x563e74e137f6 in ./libtorch-build)
frame #15: FaceEnhancement::process(cv::Mat) + 0x63c (0x563e74e1ac80 in ./libtorch-build)
frame #16: main + 0x44c (0x563e74defac5 in ./libtorch-build)
frame #17: __libc_start_main + 0xf3 (0x7f4f60a3d0b3 in /usr/lib/x86_64-linux-gnu/libc.so.6)
frame #18: _start + 0x2e (0x563e74def5be in ./libtorch-build)
```cpp
at::Tensor FaceGAN::process(cv::Mat _img) {
cv::resize(_img, _img, cv::Size(insize, insize));
at::Tensor input =
torch::from_blob(_img.data, {_img.rows, _img.cols, 3}, torch::kByte);
input = input.permute({2, 0, 1}).div(255.0);
input = (input - 0.5) / 0.5;
input = input.unsqueeze(0);
input = input.to(torch::kFloat32).to(torch::Device(torch::kCUDA, device));
std::vector<torch::jit::IValue> inputs;
inputs.push_back(input);
at::Tensor output = module.forward(inputs).toTensor();
output = output * 0.5 + 0.5;
output = output.squeeze().detach();
output = output.permute({1, 2, 0});
output = output.mul(255.0);
output = output.clamp(0, 255).to(torch::kU8).to(torch::kCPU);
output = output.contiguous();
return output;
}
void main(){
at::Tensor facebs, landms;
std::tie(facebs, landms) = facedetector.process(_img);
for (int i = 0; i < facebs.sizes()[0]; i++) {
if (facebs[i][4].item().toFloat() < threshold) continue;
at::Tensor facial5points = landms[i].reshape({2, 5});
cv::Mat tfm_inv;
cv::Mat of;
std::tie(of, tfm_inv) =
this->warp_and_crop_face(_img, facial5points, reference_5pts, img_size);
at::Tensor tensor_ef = facegan.process(of);
cv::Mat resultImg(tensor_ef.size(0), tensor_ef.size(1), CV_8UC3);
std::memcpy((void*)resultImg.data, tensor_ef.data_ptr(),
sizeof(torch::kU8) * tensor_ef.numel());
cvtColor(resultImg, resultImg, cv::COLOR_RGB2BGR);
std::string save_path = "temp" + std::to_string(i) + ".png";
cv::imwrite(save_path, resultImg);
}
```
### Versions
PyTorch version: 1.8.2+cu111
Is debug build: False
CUDA used to build PyTorch: 11.1
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.3 LTS (x86_64)
GCC version: (Ubuntu 9.3.0-17ubuntu1~20.04) 9.3.0
Clang version: Could not collect
CMake version: version 3.14.4
Libc version: glibc-2.31
Python version: 3.8.10 (default, Sep 28 2021, 16:10:42) [GCC 9.3.0] (64-bit runtime)
Python platform: Linux-4.18.0-348.20.1.el8_5.x86_64-x86_64-with-glibc2.29
Is CUDA available: True
CUDA runtime version: 11.5.50
CUDA_MODULE_LOADING set to:
GPU models and configuration:
GPU 0: NVIDIA A100-SXM4-40GB
GPU 1: NVIDIA A100-SXM4-40GB
GPU 2: NVIDIA A100-SXM4-40GB
GPU 3: NVIDIA A100-SXM4-40GB
GPU 4: NVIDIA A100-SXM4-40GB
GPU 5: NVIDIA A100-SXM4-40GB
GPU 6: NVIDIA A100-SXM4-40GB
GPU 7: NVIDIA A100-SXM4-40GB
Nvidia driver version: 470.103.01
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.3.1
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.3.1
/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.3.1
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_infer.so.8.3.1
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.3.1
/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.3.1
/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.3.1
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.21.4
[pip3] torch==1.8.2+cu111
[pip3] torchaudio==0.8.2
[pip3] torchvision==0.9.2+cu111
[conda] Could not collect
cc @EikanWang @jgong5 @wenzhe-nrv @sanchitintel @jbschlosser
| 0 |
4,125 | 89,483 |
Unexpected behavior from torchscript (mixing trace with script)
|
oncall: jit
|
### 🐛 Describe the bug
Hi,
I have encountered some unexpected behavior with mixing torch.jit.script and torch.jit.trace. Here’s a example to reproduce.
```python
import torch
import numpy as np
@torch.jit.script
def select_rows(
nums: int,
data: torch.Tensor,
size: int
):
valid_choice = torch.multinomial(torch.ones(nums).float(), size)
return data[valid_choice]
def do_selection(x):
return select_rows(x.shape[0], x, x.shape[0])
t_4 = torch.tensor(np.array([1, 2, 3, 4]))
t_7 = torch.tensor(np.array([1, 2, 3, 4, 5, 6, 7]))
traced_selection = torch.jit.trace(do_selection, t_4)
print(traced_selection(t_4))
>>> tensor([3, 1, 2, 4]) # A random arrangement of the input data.
print(traced_selection(t_7))
>>> tensor([1, 3, 2, 4])
# Another random arrangement, but of the TRACED EXAMPLE!
# Expected a random arrangement of the current input of size 7!
```
In my actual example, def do_selection() is extremely complicated, and cannot be scripted using torch.jit.script . What are my options here? Is this the expected behavior?
Thanks.
### Versions
PyTorch version: 1.10.0
Is debug build: False
CUDA used to build PyTorch: None
ROCM used to build PyTorch: N/A
OS: macOS 12.4 (x86_64)
GCC version: Could not collect
Clang version: 13.0.0 (clang-1300.0.27.3)
CMake version: Could not collect
Libc version: N/A
Python version: 3.9.13 (main, Aug 25 2022, 18:29:29) [Clang 12.0.0 ] (64-bit runtime)
Python platform: macOS-10.16-x86_64-i386-64bit
Is CUDA available: False
CUDA runtime version: No CUDA
CUDA_MODULE_LOADING set to: N/A
GPU models and configuration: No CUDA
Nvidia driver version: No CUDA
cuDNN version: No CUDA
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.19.5
[pip3] pytorch-lightning==1.1.4
[pip3] torch==1.10.0
[pip3] torchaudio==0.10.0
[pip3] torchmetrics==0.10.0rc0
[pip3] torchvision==0.11.0
[conda] numpy 1.19.5 pypi_0 pypi
[conda] pytorch-lightning 1.1.4 pypi_0 pypi
[conda] torch 1.10.0 pypi_0 pypi
[conda] torchaudio 0.10.0 pypi_0 pypi
[conda] torchmetrics 0.10.0rc0 pypi_0 pypi
[conda] torchvision 0.11.0 pypi_0 pypi
cc @EikanWang @jgong5 @wenzhe-nrv @sanchitintel
| 1 |
4,126 | 89,482 |
torch.split: argument 'split_sizes' (position 1) must be tuple of ints, not list
|
triaged, module: sorting and selection
|
### 🐛 Describe the bug
torch.split(tensor, split_sizes, dim=0) : split_sizes data type is int or list(int)
import torch
tensor = torch.rand([5, 5], dtype=torch.float64)
split_sizes = [True, 3, False, True]
out = torch.split(tensor, split_sizes)
print(out)
result : TypeError: split_with_sizes(): argument 'split_sizes' (position 1) must be tuple of ints, not list
The value of input split_sizes is [True, 3, False, True], which is a list type. Although the value in the list is not necessarily legal, the exception thrown by the following code does not meet the actual requirements. The exception information says split_sizes must be tuple of ints, not list, does not match the official document description.
### Versions
pytorch: 1.12.1
Python version: 3.8
CUDA/cuDNN version: cuDNN 11.3
GPU models and configuration: RTX3060
Operating System:Windows
| 2 |
4,127 | 89,459 |
Higher order derivatives of sinc explode
|
triaged, module: derivatives, actionable
|
### 🐛 Describe the bug
First order derivatives of `torch.sinc(x)` are fine at `x=0`: they were previously reported as exploding in https://github.com/pytorch/pytorch/issues/56760 and https://github.com/pytorch/pytorch/issues/53989 and were fixed in https://github.com/pytorch/pytorch/pull/56763.
However, higher order derivatives or `torch.sinc(x)` at `x=0` still explode:
```python
zero = torch.zeros(1, requires_grad = True)
dx = torch.autograd.grad(torch.sinc(zero), zero, create_graph=True)[0]
torch.autograd.grad(dx, zero)[0]
tensor([nan])
```
By reading off the Taylor series of `sinc(x) = sin(x)/x = 1- x^2/3! + x^4/5! ...`, we get that the second derivative should have of limit of `-1/3`.
### Versions
PyTorch version: 1.12.1
Is debug build: False
CUDA used to build PyTorch: None
ROCM used to build PyTorch: N/A
OS: macOS 12.5.1 (x86_64)
GCC version: Could not collect
Clang version: 12.0.5 (clang-1205.0.22.11)
CMake version: version 3.22.1
Libc version: N/A
Python version: 3.10.4 (main, Mar 31 2022, 03:38:35) [Clang 12.0.0 ] (64-bit runtime)
Python platform: macOS-10.16-x86_64-i386-64bit
Is CUDA available: False
CUDA runtime version: No CUDA
CUDA_MODULE_LOADING set to: N/A
GPU models and configuration: No CUDA
Nvidia driver version: No CUDA
cuDNN version: No CUDA
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.23.1
[pip3] torch==1.12.1
[conda] Could not collect
cc @ezyang @albanD @zou3519 @gqchen @pearu @nikitaved @soulitzer @Lezcano @Varal7
| 1 |
4,128 | 93,438 |
Partitioner that doesn't require functionalized graph
|
triaged, bug, oncall: pt2
|
### 🐛 Describe the bug
We should have a partitioner that doesn't require functionalized graph; this would allow us to easily ablate functionalization when debugging issues caused by functionalization.
### Error logs
_No response_
### Minified repro
_No response_
cc @soumith @msaroufim @wconstab @ngimel @bdhirsh
| 0 |
4,129 | 93,437 |
Accuracy minifier can find spurious accuracy failures involving uninitialized memory
|
triaged, bug, oncall: pt2
|
### 🐛 Describe the bug
Suppose you have a graph like
```
y = x.new_empty(10)
y.fill_(0)
```
Suppose you are accuracy minifying. Removing the fill_ will cause an accuracy failure, because the uninitialized memory will trigger a difference. Oops.
Here is a quick and dirty way to remove non-determinism from uninitialized CUDA memory
```
diff --git a/c10/cuda/CUDACachingAllocator.cpp b/c10/cuda/CUDACachingAllocator.cpp
index 9876259522..f54e66138b 100644
--- a/c10/cuda/CUDACachingAllocator.cpp
+++ b/c10/cuda/CUDACachingAllocator.cpp
@@ -2140,6 +2140,7 @@ class NativeCachingAllocator : public CUDAAllocator {
if (C10_UNLIKELY(interp)) {
(*interp)->trace_gpu_memory_allocation(reinterpret_cast<uintptr_t>(r));
}
+ cudaMemset(r, 0, size);
return {r, r, &uncached_delete, Device(DeviceType::CUDA, device)};
}
if (size != 0) {
@@ -2147,6 +2148,7 @@ class NativeCachingAllocator : public CUDAAllocator {
const_cast<NativeCachingAllocator*>(this)->malloc(
&r, device, size, cuda::getCurrentCUDAStream(device));
}
+ cudaMemset(r, 0, size);
return {r, r, &local_raw_delete, Device(DeviceType::CUDA, device)};
}
DeleterFnPtr raw_deleter() const override {
```
Need some sort of proper fix.
### Error logs
_No response_
### Minified repro
_No response_
cc @soumith @msaroufim @wconstab @ngimel @bdhirsh
| 0 |
4,130 | 93,436 |
Accuracy minifier should also work even if an exception is raised
|
triaged, bug, oncall: pt2
|
### 🐛 Describe the bug
If you use accuracy minifier on a model that errors when optimized, the accuracy minifier does nothing. But accuracy minification should be a superset of both testing for accuracy failures AND raised exceptions.
### Error logs
_No response_
### Minified repro
_No response_
cc @soumith @msaroufim @wconstab @ngimel @bdhirsh
| 1 |
4,131 | 89,438 |
Allow `low` and `high` to be tensors in `torch.randint`
|
feature, triaged, module: random
|
### 🚀 The feature, motivation and pitch
In `torch.randint`, allow `low` and `high` to be tensors (currently, only int are allowed), like in `numpy.random.randint`.
```python
from torch import randint, tensor
randint(3) # ERROR
randint(3, 7) # ERROR
randint(3, 7, (3,)) # OK
randint(tensor([0, 1]), tensor([5, 4])) # ERROR
```
```python
from numpy.random import randint
from numpy import array
randint(3) # OK
randint(3, 7) # OK
randint(3, 7, (3,)) # OK
randint(array([0, 1]), array([5, 4])) # OK
```
### Alternatives
Keep using the following syntax
```python
from torch import concatenate, tensor, randint
lows, highs = tensor([0, 1]), tensor([5, 4])
concatenate([randint(low, high, (1,)) for low, high in zip(lows, highs)])
```
### Additional context
It would require to make the parameter `size` optional.
cc @pbelevich
| 4 |
4,132 | 89,431 |
The problem caused by the parameter dim of torch.norm
|
module: error checking, triaged, module: edge cases
|
### 🐛 Describe the bug
pytorch1.12.1
code 1 : The test code dim=False, but the thrown exception describes dim as a list.
import torch
input = torch.rand([5, 5, 5], dtype=torch.float64)
out = torch.norm(input, p='fro', dim=False, keepdim=False, out=None, dtype=None)
print(out)
result: TypeError: frobenius_norm(): argument 'dim' (position 2) must be tuple of ints, not list
code 2 : The test code dim=False, the exception thrown is correct.
import torch
input = torch.rand([5, 5, 5], dtype=torch.float64)
out = torch.norm(input, p='fro', dim="False", keepdim=False, out=None, dtype=None)
print(out)
result: TypeError: frobenius_norm(): argument 'dim' (position 2) must be tuple of ints, not str
pytorch1.8.0
code 1 : In the pytorch1.8 version, dim is still set to False, and the program can run successfully, because the program automatically treats False as a value of 0..
import torch
input = torch.rand([5, 5, 5], dtype=torch.float64)
out = torch.norm(input, p='fro', dim=False, keepdim=False, out=None, dtype=None)
print(out)
result: tensor([[1.3522, 1.1940, 0.7555, 1.3410, 1.3593],
[1.0926, 1.0986, 1.3429, 1.0170, 1.1915],
[1.1807, 1.4252, 1.5389, 1.2257, 1.5626],
[1.5249, 0.9933, 1.2927, 1.7106, 1.6482],
[1.1870, 1.0370, 1.6912, 1.0616, 1.0801]], dtype=torch.float64)
Question 1: Why is False treated as a list in the first test code?
Question 2: Why can’t False be treated as a value of 0 on a higher version, because when compiled according to the bottom layer of python, False will be set to 0, so why does the program fail?
### Versions
pytorch: 1.12.1
pytorch: 1.8.0
Python version: 3.8
CUDA/cuDNN version: cuDNN 11.3
GPU models and configuration: RTX3060
Operating System:Windows
| 2 |
4,133 | 89,421 |
fx.wrap is ignored with make_fx proxy tensor tracer
|
triaged, module: fx
|
### 🐛 Describe the bug
`torch.fx.wrap` is used to create a "leaf function" that will be preserved as a `call_function` node in the FX trace instead of being
traced through. However, it works only with `torch.fx.symbolic_trace`.
```py
import torch
from torch.fx.experimental.proxy_tensor import make_fx
M = N = K = 32
a = torch.randn(M, K, device="cuda", dtype=torch.float16)
b = torch.randn(N, K, device="cuda", dtype=torch.float16)
bias = torch.randn(N, device="cuda", dtype=torch.float16)
@torch.fx.wrap # doesn't work with make_fx!
def my_gelu(x):
return torch.nn.functional.gelu(x)
def func(a, b, bias):
linear = torch.nn.functional.linear(a, b, bias=bias)
y = my_gelu(linear)
return y
gm = make_fx(func)(a, b, bias)
gm.graph.print_tabular()
# opcode name target args kwargs
# ------------- ------ ------------------ ---------------- --------
# placeholder a_1 a_1 () {}
# placeholder b_1 b_1 () {}
# placeholder bias_1 bias_1 () {}
# call_function t aten.t.default (b_1,) {}
# call_function addmm aten.addmm.default (bias_1, a_1, t) {}
# call_function gelu aten.gelu.default (addmm,) {} # Should be "my_gelu" function here!
# output output output (gelu,) {}
```
The current alternative to make `make_fx` not trace through custom functions is to create a custom `torch.library.Library` with `CompositeExplicitAutograd` dispatch key. This alternative is much more complicated than using `fx.wrap`.
### Versions
master branch.
cc @ezyang @SherlockNoMad @soumith @EikanWang @jgong5 @wenzhe-nrv
| 1 |
4,134 | 89,420 |
Edge case: torch.baddbmm supports double x int8 x int8 inputs on CPU but not CUDA
|
triaged, module: type promotion, module: linear algebra, module: edge cases
|
### 🐛 Describe the bug
Test on the CPU:
import torch
input = torch.rand([], dtype=torch.float64)
batch1 = torch.randint(-2, 128, [10, 3, 4], dtype=torch.int8)
batch2 = torch.randint(-8, 128, [10, 4, 5], dtype=torch.int8)
out = torch.baddbmm(input, batch1, batch2)
print(out)
result:RuntimeError: expected scalar type Char but found Double
Test on the GPU:
import torch
input = torch.rand([], dtype=torch.float64).cuda()
batch1 = torch.randint(-2, 128, [10, 3, 4], dtype=torch.int8).cuda()
batch2 = torch.randint(-8, 128, [10, 4, 5], dtype=torch.int8).cuda()
out = torch.baddbmm(input, batch1, batch2)
print(out)
result: RuntimeError: expected scalar type Double but found Char
torch.baddbmm behaves differently in different pytorch versions. First, in pytorch1.8, the exceptions thrown by the CPU and GPU are completely opposite;
### Versions
pytorch: 1.8
Python version: 3.8
CUDA/cuDNN version: cuDNN 11.3
GPU models and configuration: RTX3060
Operating System:Windows
cc @nairbv @mruberry @jianyuh @nikitaved @pearu @walterddr @IvanYashchuk @xwang233 @Lezcano
| 3 |
4,135 | 89,419 |
torch.equal can still run successfully when the parameter types are different.
|
triaged, module: numpy, module: type promotion
|
### 🐛 Describe the bug
Test on the CPU:
import torch
input = torch.rand([5, 5], dtype=torch.float64)
other = torch.rand([5, 5], dtype=torch.complex64)
out = torch.equal(input, other)
print(out)
result: RuntimeError: Expected object of scalar type double but got scalar type struct c10::complex<float> for argument 'other'
Test on the GPU:
import torch
input = torch.rand([5, 5], dtype=torch.float64).cuda()
other = torch.rand([5, 5], dtype=torch.complex64).cuda()
out = torch.equal(input, other)
print(out)
result: False
Although the two parameters input and other of torch.equal are both of Tensor type, but input is of double type and other is of complex type, but when running on the GPU, it gets False. According to understanding, an exception should be thrown.
### Versions
pytorch: 1.8
Python version: 3.8
CUDA/cuDNN version: cuDNN 11.3
GPU models and configuration: RTX3060
Operating System:Windows
cc @mruberry @rgommers @nairbv
| 1 |
4,136 | 89,418 |
torch.floor_divide: The dividend of torch.floor_divide is set to 0, but it can still run on the GPU.
|
module: error checking, triaged
|
### 🐛 Describe the bug
Test on the GPU:
import torch
input = torch.randint(2, 8, [1, 8], dtype=torch.int64)
other = 0
out = torch.floor_divide(input, other)
print(out)
result: RuntimeError: ZeroDivisionError
Test on the GPU:
import torch
input = torch.randint(2, 8, [1, 8], dtype=torch.int64).cuda()
other = 0
out = torch.floor_divide(input, other)
print(out)
result: RuntimeError: tensor([[4294967295, 4294967295, 4294967295, 4294967295, 4294967295, 4294967295, 4294967295, 4294967295]], device='cuda:0')
The dividend of torch.floor_divide is set to 0, but it can still run on the GPU.
### Versions
pytorch: 1.8
Python version: 3.8
CUDA/cuDNN version: cuDNN 11.3
GPU models and configuration: RTX3060
Operating System:Windows
| 1 |
4,137 | 89,417 |
OSError: libcublas.so.11: cannot open shared object file: No such file or directory
|
oncall: binaries
|
### 🐛 Describe the bug
import torch
### Versions
python 3.10.6
torch==1.13.0
linux x86_64
posix
cc @ezyang @seemethere @malfet
| 10 |
4,138 | 89,416 |
When the torch.masked_select operator passes in the same parameters, it behaves differently on CPU and GPU.
|
triaged, module: masked operators
|
### 🐛 Describe the bug
Test on the CPU:
import torch
input = torch.rand([], dtype=torch.float64)
out = torch.logcumsumexp(input, dim=1)
print(out)
result: IndexError: Dimension out of range (expected to be in range of [-1, 0], but got 1)
Test on the CPU:
import torch
input = torch.rand([], dtype=torch.float64).cuda()
out = torch.logcumsumexp(input, dim=1)
print(out)
result: IndexError: tensor(0.4230, device='cuda:0', dtype=torch.float64)
When the torch.masked_select operator passes in the same parameters, it behaves differently on CPU and GPU.
### Versions
pytorch: 1.12.1
Python version: 3.8
CUDA/cuDNN version: cuDNN 11.3
GPU models and configuration: RTX3060
Operating System:Windows
| 1 |
4,139 | 89,408 |
torch.nn.MultiLabelMarginLoss has different performance on CPU and GPU.
|
module: loss, triaged
|
### 🐛 Describe the bug
Test on the CPU:
import torch
loss = torch.nn.MultiLabelMarginLoss()
x = torch.randn((1, 4))
y = torch.randint(4, 16, [1, 4])
out = loss(x, y)
print(out)
result: RuntimeError: argument #2 'target' is out of range
Test on the GPU:
import torch
loss = torch.nn.MultiLabelMarginLoss().cuda()
x = torch.randn((1, 4)).cuda()
y = torch.randint(4, 16, [1, 4]).cuda()
out = loss(x, y)
print(out)
result: tensor(5.7001, device='cuda:0')
torch.nn.MultiLabelMarginLoss has different performance on CPU and GPU.
### Versions
pytorch: 1.12.1
Python version: 3.8
CUDA/cuDNN version: cuDNN 11.3
GPU models and configuration: RTX3060
Operating System:Windows
| 3 |
4,140 | 89,407 |
[MPS] Using unsqueeze in inference mode returns anomalous result
|
triaged, inference mode, module: mps
|
### 🐛 Describe the bug
Using unsqueeze in inference mode returns anomalous result.
..It may looks no problem, but it will negatively affect later processing.
```python
@torch.inference_mode() # required
def cake():
mps = torch.device("mps")
a = torch.arange(5, device = mps)
test_idx = 1 # 1..*
assert torch.equal(
a[test_idx].unsqueeze(0),
a[test_idx].cpu().unsqueeze(0).to(mps)
)
cake()
```
```
Traceback (most recent call last):
File "/test.py", line 17, in <module>
cake()
File "/opt/homebrew/Caskroom/miniconda/base/envs/test/lib/python3.10/site-packages/torch/autograd/grad_mode.py", line 27, in decorate_context
return func(*args, **kwargs)
File "/test.py", line 13, in cake
assert torch.equal(
AssertionError
```
### Versions
```
PyTorch version: 1.14.0.dev20221119
Is debug build: False
CUDA used to build PyTorch: None
ROCM used to build PyTorch: N/A
OS: macOS 12.6 (arm64)
GCC version: Could not collect
Clang version: 14.0.0 (clang-1400.0.29.102)
CMake version: version 3.24.2
Libc version: N/A
Python version: 3.10.6 (main, Oct 7 2022, 15:17:36) [Clang 12.0.0 ] (64-bit runtime)
Python platform: macOS-12.6-arm64-arm-64bit
Is CUDA available: False
CUDA runtime version: No CUDA
CUDA_MODULE_LOADING set to: N/A
GPU models and configuration: No CUDA
Nvidia driver version: No CUDA
cuDNN version: No CUDA
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.23.4
[pip3] torch==1.14.0.dev20221119
[pip3] torchvision==0.15.0.dev20221119
[conda] numpy 1.23.4 pypi_0 pypi
[conda] torch 1.14.0.dev20221119 pypi_0 pypi
[conda] torchvision 0.15.0.dev20221119 pypi_0 pypi
```
cc @kulinseth @albanD @malfet @DenisVieriu97 @razarmehr @abhudev
| 0 |
4,141 | 89,406 |
stacks file from profiler is empty
|
oncall: profiler
|
### 🐛 Describe the bug
When running the following code, the resulting .stacks files are empty.
Also, the tensorboard chart shows 50/50 split between CPU & "other" but no time spent in the GPU.
I suspect this is not a bug, but me mis-using the API. Yet, I'm not sure how.
```python
import torch
class Mlp(torch.nn.Module):
def __init__(self):
super().__init__()
self.fc1 = torch.nn.Linear(100, 100)
self.act = torch.nn.ReLU()
self.fc2 = torch.nn.Linear(100, 100)
def forward(self, x):
return self.fc2(self.act(self.fc1(x)))
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.mlp1 = Mlp()
self.mlp2 = Mlp()
def forward(self, x):
return self.mlp2(self.mlp1(x))
from torch.utils.data import DataLoader
import torchdata.datapipes.iter as dp
from torch.profiler import profile, ProfilerActivity
def make_mock_dataloader():
pipe = dp.IterableWrapper([torch.rand(100) for _ in range(1000)])
return DataLoader(pipe, batch_size=32, num_workers=2, drop_last=True)
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
net = Net().to(device=device)
target_traces = 2
traces_saved = 0
def trace_handler(prof: "torch.profiler.profile"):
global traces_saved
from os.path import join
print("SAVING TRACE")
tb_dir = join("./output2", "traces", str(traces_saved))
handler = torch.profiler.tensorboard_trace_handler(
tb_dir, worker_name=f"rank0"
)
handler(prof)
prof.export_stacks(path=join(tb_dir, f"rank0.cuda.stacks"), metric="self_cuda_time_total")
prof.export_stacks(path=join(tb_dir, f"rank0.cpu.stacks"), metric="self_cpu_time_total")
# print(prof.events())
traces_saved += 1
if traces_saved == target_traces:
prof.stop()
prof = profile(
activities=[ProfilerActivity.CPU, ProfilerActivity.CUDA],
# profile_memory=True,
with_stack=True,
# with_modules=True,
# record_shapes=True,
schedule=torch.profiler.schedule(
skip_first=5, wait=1, warmup=5, active=5, repeat=target_traces
),
on_trace_ready=trace_handler,
)
prof.start()
for idx, batch in enumerate(make_mock_dataloader()):
print(f"idx: {idx}")
batch = batch.to(device=device)
out = net(batch)
out.sum().backward()
net.zero_grad()
prof.step()
```
### Versions
Collecting environment information...
PyTorch version: 1.14.0.dev20221027+cu116
Is debug build: False
CUDA used to build PyTorch: 11.6
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.5 LTS (x86_64)
GCC version: (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0
Clang version: Could not collect
CMake version: Could not collect
Libc version: glibc-2.31
Python version: 3.8.15 (default, Nov 4 2022, 20:59:55) [GCC 11.2.0] (64-bit runtime)
Python platform: Linux-5.15.0-50-generic-x86_64-with-glibc2.17
Is CUDA available: True
CUDA runtime version: Could not collect
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration:
GPU 0: NVIDIA GeForce GTX 1080 Ti
GPU 1: NVIDIA GeForce GTX 1080 Ti
Nvidia driver version: 515.65.01
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.4.0
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.4.0
/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.4.0
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_infer.so.8.4.0
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.4.0
/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.4.0
/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.4.0
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] mypy-boto3-cloudformation==1.25.4
[pip3] mypy-boto3-dynamodb==1.25.0
[pip3] mypy-boto3-ec2==1.25.5
[pip3] mypy-boto3-lambda==1.25.0
[pip3] mypy-boto3-rds==1.25.1
[pip3] mypy-boto3-s3==1.25.0
[pip3] mypy-boto3-sqs==1.25.0
[pip3] mypy-extensions==0.4.3
[pip3] numpy==1.23.4
[pip3] torch==1.14.0.dev20221027+cu116
[pip3] torch-tb-profiler==0.4.0
[pip3] torchdata==0.6.0.dev20221027
[pip3] torchsnapshot-nightly==2022.10.29
[pip3] torchvision==0.15.0a0+edb3a80
[conda] numpy 1.23.4 pypi_0 pypi
[conda] torch 1.14.0.dev20221027+cu116 pypi_0 pypi
[conda] torch-tb-profiler 0.4.0 pypi_0 pypi
[conda] torchdata 0.6.0.dev20221027 pypi_0 pypi
[conda] torchsnapshot-nightly 2022.10.29 pypi_0 pypi
[conda] torchvision 0.15.0a0+edb3a80 pypi_0 pypi
cc @robieta @chaekit @aaronenyeshi @ngimel @nbcsm @guotuofeng @guyang3532 @gaoteng-git @tiffzhaofb
| 4 |
4,142 | 89,395 |
DISABLED test_coalesce_reference_cycle_cpu_float64 (__main__.TestSparseCPU)
|
module: sparse, triaged, module: flaky-tests, skipped, module: dynamo
|
Platforms: dynamo
This test was disabled because it is failing in CI. See [recent examples](https://hud.pytorch.org/flakytest?name=test_coalesce_reference_cycle_cpu_float64&suite=TestSparseCPU) and the most recent trunk [workflow logs](https://github.com/pytorch/pytorch/runs/9604615961).
Over the past 3 hours, it has been determined flaky in 3 workflow(s) with 3 failures and 3 successes.
**Debugging instructions (after clicking on the recent samples link):**
DO NOT BE ALARMED IF THE CI IS GREEN. We now shield flaky tests from developers so CI will thus be green but it will be harder to parse the logs.
To find relevant log snippets:
1. Click on the workflow logs linked above
2. Click on the Test step of the job so that it is expanded. Otherwise, the grepping will not work.
3. Grep for `test_coalesce_reference_cycle_cpu_float64`
4. There should be several instances run (as flaky tests are rerun in CI) from which you can study the logs.
```
2022-11-20T01:57:36.5512960Z test_coalesce_reference_cycle_cpu_float64 (__main__.TestSparseCPU) ... [2022-11-20 01:57:12,155] torch._dynamo.convert_frame: [ERROR] WON'T CONVERT test_coalesce_reference_cycle test_sparse.py line 272
2022-11-20T01:57:36.5513300Z due to:
2022-11-20T01:57:36.5513473Z Traceback (most recent call last):
2022-11-20T01:57:36.5513866Z File "/opt/conda/lib/python3.7/site-packages/torch/_dynamo/variables/builder.py", line 820, in wrap_fx_proxy_cls
2022-11-20T01:57:36.5514214Z + f"{typestr(example_value)} {proxy.node.op} {proxy.node.target}"
2022-11-20T01:57:36.5514633Z AssertionError: torch.* op returned non-Tensor _WeakTensorRef call_function <class 'torch._C._WeakTensorRef'>
2022-11-20T01:57:36.5514849Z
2022-11-20T01:57:36.5514920Z from user code:
2022-11-20T01:57:36.5515153Z File "test_sparse.py", line 278, in test_coalesce_reference_cycle
2022-11-20T01:57:36.5515399Z t_ref = torch._C._WeakTensorRef(t)
2022-11-20T01:57:36.5515527Z
2022-11-20T01:57:36.5515642Z Set torch._dynamo.config.verbose=True for more information
2022-11-20T01:57:36.5515799Z
2022-11-20T01:57:36.5515803Z
2022-11-20T01:57:36.5516068Z [2022-11-20 01:57:12,164] torch._dynamo.convert_frame: [ERROR] WON'T CONVERT test_sparse_sum test_sparse.py line 284
2022-11-20T01:57:36.5516328Z due to:
2022-11-20T01:57:36.5516511Z Traceback (most recent call last):
2022-11-20T01:57:36.5516853Z File "/opt/conda/lib/python3.7/site-packages/torch/_dynamo/utils.py", line 1093, in run_node
2022-11-20T01:57:36.5517126Z return node.target(*args, **kwargs)
2022-11-20T01:57:36.5517668Z RuntimeError: The tensor has a non-zero number of elements, but its data is not allocated yet. Caffe2 uses a lazy allocation, so you will need to call mutable_data() or raw_mutable_data() to actually allocate memory.
2022-11-20T01:57:36.5517964Z
2022-11-20T01:57:36.5518089Z The above exception was the direct cause of the following exception:
2022-11-20T01:57:36.5518255Z
2022-11-20T01:57:36.5518347Z Traceback (most recent call last):
2022-11-20T01:57:36.5518698Z File "/opt/conda/lib/python3.7/site-packages/torch/_dynamo/utils.py", line 1104, in run_node
2022-11-20T01:57:36.5518942Z ) from e
2022-11-20T01:57:36.5519550Z RuntimeError: Failed running call_function <built-in method sparse_coo_tensor of type object at 0x7fa2bdc44d08>(*(FakeTensor(FakeTensor(..., device='meta', size=(2, 1), dtype=torch.int64), cpu), FakeTensor(FakeTensor(..., device='meta', size=(1, 1, 4), dtype=torch.float64), cpu)), **{}):
2022-11-20T01:57:36.5520294Z The tensor has a non-zero number of elements, but its data is not allocated yet. Caffe2 uses a lazy allocation, so you will need to call mutable_data() or raw_mutable_data() to actually allocate memory.
2022-11-20T01:57:36.5520690Z (scroll up for backtrace)
2022-11-20T01:57:36.5520809Z
2022-11-20T01:57:36.5520978Z The above exception was the direct cause of the following exception:
2022-11-20T01:57:36.5521145Z
2022-11-20T01:57:36.5521224Z Traceback (most recent call last):
2022-11-20T01:57:36.5521589Z File "/opt/conda/lib/python3.7/site-packages/torch/_dynamo/utils.py", line 1072, in get_fake_value
2022-11-20T01:57:36.5521873Z raise TorchRuntimeError() from e
2022-11-20T01:57:36.5522112Z torch._dynamo.exc.TorchRuntimeError:
2022-11-20T01:57:36.5522244Z
2022-11-20T01:57:36.5522315Z from user code:
2022-11-20T01:57:36.5522530Z File "test_sparse.py", line 288, in test_sparse_sum
2022-11-20T01:57:36.5522765Z S = torch.sparse_coo_tensor(i, v)
2022-11-20T01:57:36.5522879Z
2022-11-20T01:57:36.5523008Z Set torch._dynamo.config.verbose=True for more information
2022-11-20T01:57:36.5523164Z
2022-11-20T01:57:36.5523168Z
2022-11-20T01:57:36.5523236Z FAIL (0.015s)
```
cc @nikitaved @pearu @cpuhrsch @amjames @bhosmer @mlazos @soumith @voznesenskym @yanboliang @penguinwu @anijain2305 @EikanWang @jgong5 @Guobing-Chen @chunyuan-w @XiaobingSuper @zhuhaozhe @blzheng @Xia-Weiwen @wenzhe-nrv @jiayisunx @desertfire
| 8 |
4,143 | 89,394 |
torch.nn.TransformerEncoderLayer missing exception description information.
|
module: nn, module: error checking, triaged, oncall: transformer/mha
|
### 🐛 Describe the bug
import torch
encoder_layer = torch.nn.TransformerEncoderLayer(d_model=52, nhead=1)
src = torch.rand(10, 32, 512)
out = encoder_layer(src)
When running this code, an AssertionError is thrown directly without giving effective information about the exception. The real error is that d_model is not equal to the third value in src. It is recommended to use the pytorch1.8.0 version. When this happens, throw Display the corresponding exception information.
### Versions
pytorch: 1.8.0
Python version: 3.8
CUDA/cuDNN version: cuDNN 11.1
GPU models and configuration: RTX3060
Operating System:Windows
cc @albanD @mruberry @jbschlosser @walterddr @kshitij12345 @saketh-are @bhosmer @cpuhrsch @erichan1
| 2 |
4,144 | 89,393 |
Edge case: CPU bool abs is not supported
|
triaged, module: numpy, module: edge cases
|
### 🐛 Describe the bug
Test on the CPU:
import torch
m = torch.nn.Softsign()
input = torch.randint(0, 2, [2], dtype=torch.bool)
print(m(input))
result:RuntimeError: "abs_cpu" not implemented for 'Bool'
Test on the GPU:
import torch
m = torch.nn.Softsign().cuda()
input = torch.randint(0, 2, [2], dtype=torch.bool).cuda()
print(m(input))
result: tensor([0.5000, 0.0000], device='cuda:0')
When torch.nn.Softsign runs on the CPU, it will throw an exception of "abs_cpu" not implemented for 'Bool', but on the GPU, it can run normally.
The same situation exists for torch.nn.functional.softsign.
### Versions
pytorch: 1.8
Python version: 3.8
CUDA/cuDNN version: cuDNN 11.3
GPU models and configuration: RTX3060
Operating System:Windows
cc @mruberry @rgommers @albanD @jbschlosser @walterddr @kshitij12345 @saketh-are
| 4 |
4,145 | 89,386 |
How can i patch the torch.jit in the second solution? Could not figure out entrypoint ?
|
oncall: jit
|
Here are the workarounds I found to make things work.
### Solution 1: patch torchvision 0.2.2 (dirty and painful)
Pyinstaller works well with torchvision 0.2.2, thus if you do not use too many functionnalities of more recent version of torchvision, you can "patch" old torchvision 0.2.2 by adding the needed new tools. Note that this may need you first use compiled file of torchvision >= 3.0 (_C.so).
### Solution 2: Keep recent torchvision & patch torch.jit in your entry point
I found some monkey patch on stackoverflow and dev blogs that simply overwrite 2 methods of torch.jit.
Simply add this path at the beginning of your entry point:
```
def script_method(fn, _rcb=None):
return fn
def script(obj, optimize=True, _frames_up=0, _rcb=None):
return obj
import torch.jit
torch.jit.script_method = script_method
torch.jit.script = script
```
I still think there should be a more direct way to do that with pyinstaller, but this works for me.
I hope it will help others too.
_Originally posted by @Sstrap in https://github.com/pytorch/vision/issues/1899#issuecomment-598200938_
cc @EikanWang @jgong5 @wenzhe-nrv @sanchitintel
| 0 |
4,146 | 89,381 |
torch.nn.ReplicationPad1d:The description of the exception information thrown is not accurate
|
module: error checking, triaged, module: padding
|
### 🐛 Describe the bug
code1:
import torch
m = torch.nn.ReplicationPad1d("max")
input = torch.arange(8, dtype=torch.float).reshape(1, 2, 4)
print(m(input))
result: TypeError: pad(): argument 'pad' (position 2) must be tuple of ints, not tuple
For the padding in torch.nn.ReplicationPad1d(padding), the input of the test code is of type str, but the exception information thrown is of type tuple.
The same problem exists with torch.nn.ReplicationPad2d.
### Versions
pytorch: 1.12.1
Python version: 3.8
CUDA/cuDNN version: cuDNN 11.3
GPU models and configuration: RTX3060
Operating System:Windows
| 2 |
4,147 | 89,374 |
jit.trace dost not support nested dict outputs
|
oncall: jit
|
### 🐛 Describe the bug
We have a complicated model which return value is a tuple of nested dict:
```python
def forward(self, inputs)
# .....
decoder_outputs = {'feature_a': inputs['feature_a'], 'feature_b': inputs['feature_b']}
predictions = {
'feature_a': {'targets': inputs['feature_a'], 'probs': inputs['feature_a']},
'feature_b': {'targets': inputs['feature_b'], 'probs': inputs['feature_b']}
}
return predictions, decoder_outputs
```
We want to trace the model, save it as jit model type, but we got the following error:
```
of traced region cannot be understood by the tracer, only outputs matchingdict[Union[str, Tensor], Union[Tensor, Tuple[Tensor, ...]]] can be a dictionary output of a traced function
```
Fully reproducible scripts:
1) test on simple dict return
```python
import torch
inputs = {
'feature_a': torch.Tensor([[101, 7770, 1107, 4638, 5381, 2605, 4511, 1351, 102, 0]]),
'feature_b': torch.Tensor([[101, 7770, 1107, 4638, 5381, 2605, 4511, 1351, 102, 0]])
}
def fn_simple_dict(inputs):
decoder_outputs = {'feature_a': inputs['feature_a'], 'feature_b': inputs['feature_b']}
predictions = {
'feature_a': inputs['feature_a'],
'feature_b': inputs['feature_b']
}
return predictions, decoder_outputs
torch.jit.trace(fn_simple_dict, inputs, strict=False)
```
All is OK. `<torch.jit.ScriptFunction at 0x112096e50>`
2) test on nested dict return
```python
import torch
inputs = {
'feature_a': torch.Tensor([[101, 7770, 1107, 4638, 5381, 2605, 4511, 1351, 102, 0]]),
'feature_b': torch.Tensor([[101, 7770, 1107, 4638, 5381, 2605, 4511, 1351, 102, 0]])
}
def fn_nested_dict(inputs):
decoder_outputs = {'feature_a': inputs['feature_a'], 'feature_b': inputs['feature_b']}
predictions = {
'feature_a': {'targets': inputs['feature_a'], 'probs': inputs['feature_a']},
'feature_b': {'targets': inputs['feature_b'], 'probs': inputs['feature_b']}
}
return predictions, decoder_outputs
torch.jit.trace(fn_nested_dict, inputs, strict=False)
```
We got an error:
```
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
Input In [6], in <cell line: 17>()
11 predictions = {
12 'feature_a': {'targets': inputs['feature_a'], 'probs': inputs['feature_a']},
13 'feature_b': {'targets': inputs['feature_b'], 'probs': inputs['feature_b']}
14 }
15 return predictions, decoder_outputs
---> 17 torch.jit.trace(fn_nested_dict, inputs, strict=False)
File ~/works/tools/py38/.venv/lib/python3.8/site-packages/torch/jit/_trace.py:778, in trace(func, example_inputs, optimize, check_trace, check_inputs, check_tolerance, strict, _force_outplace, _module_class, _compilation_unit)
772 raise AttributeError(
773 "trace doesn't support compiling individual module's functions.\n"
774 "Please use trace_module"
775 )
777 name = _qualified_name(func)
--> 778 traced = torch._C._create_function_from_trace(
779 name, func, example_inputs, var_lookup_fn, strict, _force_outplace
780 )
782 # Check the trace against new traces created from user-specified inputs
783 if check_trace:
RuntimeError: output 1 ({feature_a: {targets: 101 7770 1107 4638 5381 2605 4511 1351 102 0
[ CPUFloatType{1,10} ], probs: 101 7770 1107 4638 5381 2605 4511 1351 102 0
[ CPUFloatType{1,10} ]}, feature_b: {targets: 101 7770 1107 4638 5381 2605 4511 1351 102 0
[ CPUFloatType{1,10} ], probs: 101 7770 1107 4638 5381 2605 4511 1351 102 0
[ CPUFloatType{1,10} ]}}) of traced region cannot be understood by the tracer, only outputs matchingdict[Union[str, Tensor], Union[Tensor, Tuple[Tensor, ...]]] can be a dictionary output of a traced function
```
Is there any workaround for this error? Thank you a lot
### Versions
```
Collecting environment information...
PyTorch version: 1.8.0
Is debug build: False
CUDA used to build PyTorch: None
ROCM used to build PyTorch: N/A
OS: macOS 12.3 (x86_64)
GCC version: Could not collect
Clang version: 13.0.0 (clang-1300.0.27.3)
CMake version: Could not collect
Python version: 3.8 (64-bit runtime)
Is CUDA available: False
CUDA runtime version: No CUDA
GPU models and configuration: No CUDA
Nvidia driver version: No CUDA
cuDNN version: No CUDA
HIP runtime version: N/A
MIOpen runtime version: N/A
Versions of relevant libraries:
[pip] Could not collect
[conda] Could not collect
```
cc @EikanWang @jgong5 @wenzhe-nrv @sanchitintel @VitalyFedyunin @mingfeima @XiaobingSuper @ashokei @jingxu10
| 1 |
4,148 | 89,372 |
prod_cpu not implemented for 'BFloat16'
|
module: cpu, triaged, module: bfloat16
|
### 🐛 Describe the bug
Test on the CPU:
import torch
m = torch.nn.Hardshrink()
input = torch.rand([2], dtype=torch.bfloat16)
print(m(input))
result: RuntimeError: "hardshrink_cpu" not implemented for 'BFloat16'
Test on the GPU:
import torch
m = torch.nn.Hardshrink()
input = torch.rand([2], dtype=torch.bfloat16).cuda()
print(m(input))
result: tensor([0.9102, 0.0000], device='cuda:0', dtype=torch.bfloat16)
In the pytorch 1.8 version, hardshrink_cpu does not support BFloat16 and Half, but cuda does. Then in the latest version, hardshrink_cpu already supports BFloat16, but it still does not support Half.
torch.nn.Softshrink has the same problem.
### Versions
pytorch: 1.8
Python version: 3.8
CUDA/cuDNN version: cuDNN 11.3
GPU models and configuration: RTX3060
Operating System:Windows
cc @VitalyFedyunin @jgong5 @mingfeima @XiaobingSuper @sanchitintel @ashokei @jingxu10
| 9 |
4,149 | 89,370 |
torch.nn.functional.normalize: whether true is equal to 1
|
triaged, module: norms and normalization
|
### 🐛 Describe the bug
pytorch 1.8:
import torch
input = torch.rand([2, 3], dtype=torch.float32)
print(torch.nn.functional.normalize(input, p=2.0, dim=True))
result : tensor([[0.7107, 0.6418, 0.2883], [0.0826, 0.2365, 0.9681]])
pytorch 1.12:
import torch
input = torch.rand([2, 3], dtype=torch.float32)
print(torch.nn.functional.normalize(input, p=2.0, dim=True))
result : TypeError: norm() received an invalid combination of arguments - got (Tensor, float, list, keepdim=bool), but expected one of: ... ....
pytorch 1.12:
import torch
input = torch.rand([2, 3], dtype=torch.float32)
print(torch.nn.functional.normalize(input, p=2.0, dim=1))
result : tensor([[0.1417, 0.4098, 0.9011], [0.3879, 0.4451, 0.8071]])
pytorch 1.12:
print(True == 1)
result : True
In both pytorch1.8 and pytorch1.12, the same code yields different results. Both pytorch versions work successfully when dim is changed from True to 1, but from a python perspective, the default value of True is 1. True==1 results in True, so I think the advanced version of torch.nn.functional.normalizeis handling True improperly.
### Versions
pytorch: 1.12
Python version: 3.8
CUDA/cuDNN version: cuDNN 11.3
GPU models and configuration: RTX3060
Operating System:Windows
pytorch: 1.8.0
Python version: 3.8
CUDA/cuDNN version: cuDNN 11.1
GPU models and configuration: RTX3060
Operating System:Windows
| 1 |
4,150 | 89,369 |
RuntimeError: CUDA error: device-side assert triggered
|
module: loss, triaged
|
### 🐛 Describe the bug
import torch
input = torch.rand([210, 6], dtype=torch.float32).cuda()
target = torch.randint(0, 8, [210], dtype=torch.uint8).cuda()
try:
print(torch.nn.functional.nll_loss(input, target))
except Exception as e:
print(str(e))
result : RuntimeError: CUDA error: device-side assert triggered.CUDA kernel errors might be asynchronously reported at some other API call,so the stacktrace below might be incorrect.For debugging consider passing CUDA_LAUNCH_BLOCKING=1.
When running on cuda, the test code problem should be Target 7 is out of bounds. The exception thrown is out of bounds. Expected object of scalar type Long but got scalar type Byte for argument #2 'target' in call to _thnn_nll_loss_forward. Expected object of scalar type long but got scalar type byte for argument #2 'target' in call to _thnn_nLL_loss_forward.
torch.nn.NLLLoss also has the same problem.
### Versions
pytorch: 1.12.1
Python version: 3.8
CUDA/cuDNN version: cuDNN 11.3
GPU models and configuration: RTX3060
Operating System:Windows
| 2 |
4,151 | 89,362 |
torch.nn.functional.embedding_bag throws an exception when it runs on a CPU, but it runs successfully on a GPU.
|
module: nn, module: cuda, module: error checking, triaged, actionable, module: embedding
|
### 🐛 Describe the bug
Test on the CPU:
import torch
input = torch.randint(-5, 1, [1, 2], dtype=torch.int64)
weight = torch.rand([2, 3], dtype=torch.float32)
print(torch.nn.functional.embedding_bag(input, weight))
result: RuntimeError: Index 0 is out of bounds: -1, range 0 to 2
Test on the GPU:
import torch
input = torch.randint(-5, 1, [1, 2], dtype=torch.int64).cuda()
weight = torch.rand([2, 3], dtype=torch.float32).cuda()
print(torch.nn.functional.embedding_bag(input, weight))
result: tensor([[0., 0., 0.]], device='cuda:0')
embedding_bag execution on a CPU throws an exception, but it runs successfully on a GPU.
### Versions
pytorch: 1.12.1
Python version: 3.8
CUDA/cuDNN version: cuDNN 11.3
GPU models and configuration: RTX3060
Operating System:Windows
cc @albanD @mruberry @jbschlosser @walterddr @kshitij12345 @saketh-are @ngimel
| 2 |
4,152 | 89,361 |
Documentation: torch.nn.functional.embedding docs could more clearly state the requirement that weight be a 2D tensor
|
module: docs, module: nn, triaged, module: embedding, topic: docs
|
### 🐛 Describe the bug
import torch
input = torch.tensor([[1, 2, 4, 5], [4, 3, 2, 9]])
embedding_matrix = torch.rand(10)
print(torch.nn.functional.embedding(input, embedding_matrix))
pytorch 1.9.0:
result: tensor([[0.3005, 0.3053, 0.9081, 0.4288], [0.9081, 0.8599, 0.3053, 0.1734]])
pytorch 1.12.1:
result: RuntimeError: 'weight' must be 2-D
The descriptions in the pytorch1.8 and pytorch1.12 official documentation are the same, but 1.8 will run successfully with the same parameters, while 1.12 will throw an exception.
### Versions
pytorch: 1.9.0
Python version: 3.8
CUDA/cuDNN version: cuDNN 11.1
GPU models and configuration: RTX3060
Operating System:Windows
pytorch: 1.12.1
Python version: 3.8
CUDA/cuDNN version: cuDNN 11.3
GPU models and configuration: RTX3060
Operating System:Windows
cc @svekars @carljparker @albanD @mruberry @jbschlosser @walterddr @kshitij12345 @saketh-are
| 2 |
4,153 | 89,357 |
Quantizable LSTM has different behavior than LSTM in bidirectional setting
|
oncall: quantization, module: rnn, triaged
|
## Issue description
The quantizable LSTM has a different behavior than the regular LSTM module in the bidirectional setting with multiple layers. In particular, the input parameters of the 2nd to n-th layer of the quantizable LSTM do not take the backward cells into account.
## Code example
The relevant code lines are
**Quantizable LSTM:**
https://github.com/pytorch/pytorch/blob/c2ce79f06eb4a8cec2f9cfbdf3a1a4021a0a4cfa/torch/ao/nn/quantizable/modules/rnn.py#L320-L324
**Regular LSTM:**
https://github.com/pytorch/pytorch/blob/c2ce79f06eb4a8cec2f9cfbdf3a1a4021a0a4cfa/torch/nn/modules/rnn.py#L92-L94
The proposed solution would be to use this code in the quantized LSTM model
```
for layer in range(1, num_layers):
layers.append(_LSTMLayer(self.hidden_size * num_directions,
self.hidden_size,
self.bias, batch_first=False,
bidirectional=self.bidirectional,
**factory_kwargs))
```
## System Info
PyTorch version: 1.11.0
Is debug build: False
CUDA used to build PyTorch: 11.3
ROCM used to build PyTorch: N/A
OS: Red Hat Enterprise Linux release 8.6 (Ootpa) (x86_64)
GCC version: (GCC) 8.5.0 20210514 (Red Hat 8.5.0-10)
Clang version: 13.0.1 (Red Hat 13.0.1-2.module+el8.6.0+15487+86bd2a95)
CMake version: version 3.20.2
Libc version: glibc-2.28
Python version: 3.9.12 | packaged by conda-forge | (main, Mar 24 2022, 23:25:59) [GCC 10.3.0] (64-bit runtime)
Python platform: Linux-4.18.0-372.26.1.el8_6.x86_64-x86_64-with-glibc2.28
Is CUDA available: True
CUDA runtime version: Could not collect
CUDA_MODULE_LOADING set to:
GPU models and configuration: GPU 0: Tesla V100-SXM2-32GB
Nvidia driver version: 520.61.05
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.19.5
[pip3] torch==1.11.0
[pip3] torchaudio==0.11.0
[pip3] torchvision==0.12.0
[conda] blas 1.0 mkl
[conda] cudatoolkit 11.3.1 h2bc3f7f_2
[conda] ffmpeg 4.3 hf484d3e_0 pytorch
[conda] mkl 2021.4.0 h8d4b97c_729 conda-forge
[conda] mkl-service 2.4.0 py39h7e14d7c_0 conda-forge
[conda] mkl_fft 1.3.1 py39h0c7bc48_1 conda-forge
[conda] mkl_random 1.2.2 py39hde0f152_0 conda-forge
[conda] numpy 1.19.5 pypi_0 pypi
[conda] pytorch 1.11.0 py3.9_cuda11.3_cudnn8.2.0_0 pytorch
[conda] pytorch-mutex 1.0 cuda pytorch
[conda] torchaudio 0.11.0 py39_cu113 pytorch
[conda] torchvision 0.12.0 py39_cu113 pytorch
cc @jerryzh168 @jianyuh @raghuramank100 @jamesr66a @vkuzo @jgong5 @Xia-Weiwen @leslie-fang-intel @zou3519
| 2 |
4,154 | 89,354 |
Per-sample input xfail / test generation
|
triaged, module: testing
|
### 🐛 Describe the bug
In https://github.com/pytorch/pytorch/pull/89332 I added a new sample input, and as a result, I had to disable cat testing on MPS entirely, because only *that* sample input was computed incorrectly on MPS. It would be nice if I could have only xfail'ed that sample input.
In general, running all sample inputs in a single test is problematic, as you cannot easily tell if there is only one sample input that is problematic / which sample input is problematic. Creating a separate test per sample input feels like it would be better.
### Versions
master
| 0 |
4,155 | 89,344 |
AdaptiveAvgPool1d failed in the lower version
|
module: nn, triaged, module: pooling
|
### 🐛 Describe the bug
pytorch 1.8 :
import torch
m = torch.nn.AdaptiveAvgPool1d(5)
input = [torch.randn(1, 64),]
print(m(*input))
result: RuntimeError: Expected 3-dimensional tensor, but got 2-dimensional tensor for argument #1 'self' (while checking arguments for adaptive_avg_pool1d)
pytorch 1.12 :
import torch
m = torch.nn.AdaptiveAvgPool1d(5)
input = [torch.randn(1, 64),]
print(m(*input))
result: tensor([[-0.2048, 0.0213, 0.1549, 0.5774, -0.3389]])
It is not clear why an exception is raised in pytorch 1.8, but not in other versions.
### Versions
pytorch: 1.8.0
Python version: 3.8
CUDA/cuDNN version: cuDNN 11.1
GPU models and configuration: RTX3060
Operating System:Windows
pytorch: 1.12
Python version: 3.9
CUDA/cuDNN version: cuDNN 11.6
GPU models and configuration: RTX3060
Operating System:Windows
cc @albanD @mruberry @jbschlosser @walterddr @kshitij12345 @saketh-are
| 2 |
4,156 | 89,343 |
AdaptiveAvgPool1d throws different exceptions when using the gpu
|
module: nn, module: cuda, module: error checking, triaged, actionable, module: pooling
|
### 🐛 Describe the bug
Test on the CPU:
import torch
m = torch.nn.AdaptiveAvgPool1d(-2)
input = torch.rand([1, 64, 8], dtype=torch.float32)
m(input)
result: RuntimeError: Trying to create tensor with negative dimension -2: [1, 64, 1, -2]
Test on the GPU:
import torch
m = torch.nn.AdaptiveAvgPool1d(-2).cuda()
input = torch.rand([1, 64, 8], dtype=torch.float32).cuda()
m(input)
result:RuntimeError: setStorage: sizes [1, 64, -2], strides [64, 1, 1], storage offset 0, and itemsize 4 requiring a storage size of 244 are out of bounds for storage of size 0
As we can see, torch.nn.AdaptiveAvgPool1d running the same code on the CPU and GPU throws different exceptions.
### Versions
pytorch: 1.8.0
Python version: 3.8
CUDA/cuDNN version: cuDNN 11.1
GPU models and configuration: RTX3060
Operating System:Windows
cc @albanD @mruberry @jbschlosser @walterddr @kshitij12345 @saketh-are @ngimel
| 2 |
4,157 | 89,342 |
torch.mm: Exceptions thrown on the CPU and GPU are inconsistent
|
module: cuda, module: error checking, triaged
|
### 🐛 Describe the bug
Example 1:
Test on the CPU:
import torch
input = torch.rand([5, 3], dtype=torch.float32)
mat2 = torch.rand([64, 1], dtype=torch.float32)
resCPU = torch.mm(input, mat2)
result: RuntimeError: mat1 and mat2 shapes cannot be multiplied (5x3 and 64x1)
Test on the GPU:
import torch
input = torch.rand([5, 3], dtype=torch.float32).cuda()
mat2 = torch.rand([64, 1], dtype=torch.float32).cuda()
resCPU = torch.mm(input, mat2)
result: RuntimeError: mat1 dim 1 must match mat2 dim 0
Example 2:
Test on the CPU:
import torch
input = torch.rand([2], dtype=torch.float32)
mat2 = torch.rand([64, 1], dtype=torch.float32)
resCPU = torch.mm(input, mat2)
result: RuntimeError: self must be a matrix
Test on the GPU:
import torch
input = torch.rand([2], dtype=torch.float32).cuda()
mat2 = torch.rand([64, 1], dtype=torch.float32).cuda()
resCPU = torch.mm(input, mat2)
result: RuntimeError: tensors must be 2-D
As we can see, torch.mm running the same code on the CPU and GPU throws different exceptions.
torch.matmul and torch.bmm also have the same situation.
### Versions
pytorch: 1.8.0
Python version: 3.8
CUDA/cuDNN version: cuDNN 11.1
GPU models and configuration: RTX3060
Operating System:Windows
cc @ngimel
| 2 |
4,158 | 89,336 |
Conv2d error on M1 mac, RuntimeError: NNPACK SpatialConvolution_updateOutput failed
|
module: convolution, triaged, module: macos, module: arm
|
### 🐛 Describe the bug
I encounter a runtime error when using Conv2d with padding in the forward pass on my M1 Mac. The error is RuntimeError: NNPACK SpatialConvolution_updateOutput failed
### How to reproduce the error
On a Macbook, install anaconda `osx-arm64` version, create a conda environment with python `3.10`, and install the latest version of Pytorch (1.13.0)
```
conda create -n test python=3.10
conda activate test
conda install pytorch torchvision torchaudio -c pytorch
```
Then in this environment, some minimal code to reproduce this error is
```python
import torch
import torch.nn as nn
model = nn.Conv2d(3, 16, kernel_size=3, padding=3)
input = torch.rand(16, 3, 60, 60)
model(input)
```
The error message is this:
```
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/opt/anaconda3/envs/test/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1190, in _call_impl
return forward_call(*input, **kwargs)
File "/opt/anaconda3/envs/test/lib/python3.10/site-packages/torch/nn/modules/conv.py", line 463, in forward
return self._conv_forward(input, self.weight, self.bias)
File "/opt/anaconda3/envs/test/lib/python3.10/site-packages/torch/nn/modules/conv.py", line 459, in _conv_forward
return F.conv2d(input, weight, bias, self.stride,
RuntimeError: NNPACK SpatialConvolution_updateOutput failed
```
### More details from my testing results
I tested this code and found this error only happens on my Macbook pro with an M1 processor; this error does not happen on Ubuntu or Windows machines.
Also, this error only happens when I am using recent PyTorch versions`1.13.0`, `1.12.1`, or `1.12.0`. This error does not appear if I am using PyTorch version `1.11.0`.
Meanwhile, this error only happens when I have `padding=3` in the `nn.Conv2d` construction function. If I delete the `padding` argument, this code will run just fine.
### Versions
```
Collecting environment information...
PyTorch version: 1.13.0
Is debug build: False
CUDA used to build PyTorch: None
ROCM used to build PyTorch: N/A
OS: macOS 13.0.1 (arm64)
GCC version: Could not collect
Clang version: 14.0.0 (clang-1400.0.29.202)
CMake version: Could not collect
Libc version: N/A
Python version: 3.10.8 (main, Nov 4 2022, 08:45:25) [Clang 12.0.0 ] (64-bit runtime)
Python platform: macOS-13.0.1-arm64-arm-64bit
Is CUDA available: False
CUDA runtime version: No CUDA
CUDA_MODULE_LOADING set to: N/A
GPU models and configuration: No CUDA
Nvidia driver version: No CUDA
cuDNN version: No CUDA
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.23.4
[pip3] torch==1.13.0
[pip3] torchaudio==0.13.0
[pip3] torchvision==0.14.0
[conda] numpy 1.23.4 py310hb93e574_0
[conda] numpy-base 1.23.4 py310haf87e8b_0
[conda] pytorch 1.13.0 py3.10_0 pytorch
[conda] torchaudio 0.13.0 py310_cpu pytorch
[conda] torchvision 0.14.0 py310_cpu pytorch
```
cc @kulinseth @albanD @malfet @DenisVieriu97 @razarmehr @abhudev
| 3 |
4,159 | 93,435 |
Segmentation Fault in Triton PTX codegen with cuDNN V8 API and `eca_halonext26ts`
|
triaged, bug, oncall: pt2
|
### 🐛 Describe the bug
When running `--inductor` with cuDNN V8 API `TORCH_CUDNN_V8_API_ENABLED=1` a segfault appears during Triton compilation.
Repro command: ` CUDA_LAUNCH_BLOCKING=1 TORCH_CUDNN_V8_API_ENABLED=1 python -u timm_models.py --amp --training --performance --dashboard --device cuda --inductor --only eca_halonext26ts`
I've observed that running without `TORCH_CUDNN_V8_API_ENABLED=1` first may cause the above to succeed---in order to reproduce `/tmp/torchinductor_root` should be cleared.
CC @eellison @ngimel
### Error logs
```
cuda train eca_halonext26ts ERROR:common:Failed for dynamo Internal Triton PTX codegen error:
Segmentation fault (core dumped)
concurrent.futures.process._RemoteTraceback:
"""
Traceback (most recent call last):
File "/usr/lib/python3.8/concurrent/futures/process.py", line 239, in _process_worker
r = call_item.fn(*call_item.args, **call_item.kwargs)
File "/workspace/pytorch/torch/_inductor/codecache.py", line 334, in _worker_compile
kernel.precompile(warm_cache_only_with_cc=cc)
File "/workspace/pytorch/torch/_inductor/triton_ops/autotune.py", line 58, in precompile
self.launchers = [
File "/workspace/pytorch/torch/_inductor/triton_ops/autotune.py", line 59, in <listcomp>
self._precompile_config(c, warm_cache_only_with_cc)
File "/workspace/pytorch/torch/_inductor/triton_ops/autotune.py", line 73, in _precompile_config
triton.compile( File "/usr/local/lib/python3.8/dist-packages/triton/compiler.py", line 1256, in compile
asm, shared, kernel_name = _compile(fn, signature, device, constants, configs[0], num_warps, num_stages,
File "/usr/local/lib/python3.8/dist-packages/triton/compiler.py", line 901, in _compile
name, asm, shared_mem = _triton.code_gen.compile_ttir(backend, module, device, num_warps, num_stages, extern_libs, cc)
RuntimeError: Internal Triton PTX codegen error:
Segmentation fault (core dumped)
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "/workspace/pytorch/benchmarks/dynamo/common.py", line 1195, in warmup
fn(model, example_inputs)
File "/workspace/pytorch/torch/_dynamo/eval_frame.py", line 174, in _fn
return fn(*args, **kwargs)
File "timm_models.py", line 305, in forward_and_backward_pass
cloned_inputs = clone_inputs(inputs)
File "timm_models.py", line 307, in <graph break in forward_and_backward_pass>
with self.autocast():
File "timm_models.py", line 312, in <graph break in forward_and_backward_pass>
self.grad_scaler.scale(loss).backward()
File "/workspace/pytorch/torch/_tensor.py", line 473, in backward
torch.autograd.backward(
File "/workspace/pytorch/torch/autograd/__init__.py", line 197, in backward
Variable._execution_engine.run_backward( # Calls into the C++ engine to run the backward pass
File "/workspace/pytorch/torch/autograd/function.py", line 270, in apply
return user_fn(self, *args)
File "/workspace/pytorch/functorch/_src/aot_autograd.py", line 558, in backward
CompiledFunction.compiled_bw = aot_config.bw_compiler(
File "/workspace/pytorch/torch/_dynamo/optimizations/backends.py", line 555, in _wrapped_bw_compiler
return disable(disable(bw_compiler)(*args, **kwargs))
File "/workspace/pytorch/torch/_dynamo/eval_frame.py", line 174, in _fn
return fn(*args, **kwargs)
File "/workspace/pytorch/torch/_dynamo/utils.py", line 90, in time_wrapper
r = func(*args, **kwargs)
File "/workspace/pytorch/torch/_inductor/compile_fx.py", line 362, in bw_compiler
return compile_fx_inner(
File "/workspace/pytorch/torch/_dynamo/debug_utils.py", line 473, in debug_wrapper
compiled_fn = compiler_fn(gm, example_inputs, **kwargs)
File "/workspace/pytorch/torch/_inductor/debug.py", line 177, in inner
return fn(*args, **kwargs)
File "/usr/lib/python3.8/contextlib.py", line 75, in inner
return func(*args, **kwds)
File "/workspace/pytorch/torch/_inductor/compile_fx.py", line 122, in compile_fx_inner
compiled_fn = graph.compile_to_fn()
File "/workspace/pytorch/torch/_inductor/graph.py", line 377, in compile_to_fn
return self.compile_to_module().call
File "/workspace/pytorch/torch/_dynamo/utils.py", line 90, in time_wrapper
r = func(*args, **kwargs)
File "/workspace/pytorch/torch/_inductor/graph.py", line 367, in compile_to_module
mod = PyCodeCache.load(code)
File "/workspace/pytorch/torch/_inductor/codecache.py", line 305, in load
exec(code, mod.__dict__, mod.__dict__)
File "/tmp/torchinductor_root/ca/cca3ltcppnb4nxvkkms7vwcjj2wc33znaqbyafcj4bdu3lammdmu.py", line 6836, in <module>
async_compile.wait(globals())
File "/workspace/pytorch/torch/_inductor/codecache.py", line 475, in wait
scope[key] = result.result()
File "/workspace/pytorch/torch/_inductor/codecache.py", line 352, in result
self.future.result()
File "/usr/lib/python3.8/concurrent/futures/_base.py", line 437, in result
return self.__get_result()
File "/usr/lib/python3.8/concurrent/futures/_base.py", line 389, in __get_result
raise self._exception
RuntimeError: Internal Triton PTX codegen error:
Segmentation fault (core dumped)
```
### Minified repro
The minifier command `TORCHDYNAMO_REPRO_AFTER="dynamo" CUDA_LAUNCH_BLOCKING=1 TORCH_CUDNN_V8_API_ENABLED=1 python -u timm_models.py --amp --training --performance --dashboard --device cuda --inductor --only eca_halonext26ts` created an intermediate `repro.py` script as below (the full run was taking multiple hours without stopping so I stopped it before it finished completely). Note that `/tmp/torchinductor_root/` should also be cleared to repro.
```
from math import inf
import torch
from torch import tensor, device
import torch.fx as fx
import torch._dynamo
from torch._dynamo.testing import rand_strided
from torch._dynamo.debug_utils import run_fwd_maybe_bwd
from torch._dynamo.debug_utils import same_two_models
# REPLACEABLE COMMENT FOR TESTING PURPOSES
args = [((), (), torch.int64, 'cuda', False), ((512,), (1,), torch.float32, 'cuda', False), ((512,), (1,), torch.float32, 'cuda', False), ((512,), (1,), torch.float32, 'cuda', True), ((512,), (1,), torch.float32, 'cuda', True), ((), (), torch.int64, 'cuda', False), ((128,), (1,), torch.float32, 'cuda', False), ((128,), (1,), torch.float32, 'cuda', False), ((128,), (1,), torch.float32, 'cuda', True), ((128,), (1,), torch.float32, 'cuda', True), ((), (), torch.int64, 'cuda', False), ((128,), (1,), torch.float32, 'cuda', False), ((128,), (1,), torch.float32, 'cuda', False), ((128,), (1,), torch.float32, 'cuda', True), ((128,), (1,), torch.float32, 'cuda', True), ((), (), torch.int64, 'cuda', False), ((512,), (1,), torch.float32, 'cuda', False), ((512,), (1,), torch.float32, 'cuda', False), ((512,), (1,), torch.float32, 'cuda', True), ((512,), (1,), torch.float32, 'cuda', True), ((), (), torch.int64, 'cuda', False), ((256,), (1,), torch.float32, 'cuda', False), ((256,), (1,), torch.float32, 'cuda', False), ((256,), (1,), torch.float32, 'cuda', True), ((256,), (1,), torch.float32, 'cuda', True), ((), (), torch.int64, 'cuda', False), ((256,), (1,), torch.float32, 'cuda', False), ((256,), (1,), torch.float32, 'cuda', False), ((256,), (1,), torch.float32, 'cuda', True), ((256,), (1,), torch.float32, 'cuda', True), ((), (), torch.int64, 'cuda', False), ((1024,), (1,), torch.float32, 'cuda', False), ((1024,), (1,), torch.float32, 'cuda', False), ((1024,), (1,), torch.float32, 'cuda', True), ((1024,), (1,), torch.float32, 'cuda', True), ((), (), torch.int64, 'cuda', False), ((1024,), (1,), torch.float32, 'cuda', False), ((1024,), (1,), torch.float32, 'cuda', False), ((1024,), (1,), torch.float32, 'cuda', True), ((1024,), (1,), torch.float32, 'cuda', True), ((), (), torch.int64, 'cuda', False), ((256,), (1,), torch.float32, 'cuda', False), ((256,), (1,), torch.float32, 'cuda', False), ((256,), (1,), torch.float32, 'cuda', True), ((256,), (1,), torch.float32, 'cuda', True), ((), (), torch.int64, 'cuda', False), ((256,), (1,), torch.float32, 'cuda', False), ((256,), (1,), torch.float32, 'cuda', False), ((256,), (1,), torch.float32, 'cuda', True), ((256,), (1,), torch.float32, 'cuda', True), ((), (), torch.int64, 'cuda', False), ((1024,), (1,), torch.float32, 'cuda', False), ((1024,), (1,), torch.float32, 'cuda', False), ((1024,), (1,), torch.float32, 'cuda', True), ((1024,), (1,), torch.float32, 'cuda', True), ((), (), torch.int64, 'cuda', False), ((512,), (1,), torch.float32, 'cuda', False), ((512,), (1,), torch.float32, 'cuda', False), ((512,), (1,), torch.float32, 'cuda', True), ((512,), (1,), torch.float32, 'cuda', True), ((), (), torch.int64, 'cuda', False), ((512,), (1,), torch.float32, 'cuda', False), ((512,), (1,), torch.float32, 'cuda', False), ((512,), (1,), torch.float32, 'cuda', True), ((512,), (1,), torch.float32, 'cuda', True), ((), (), torch.int64, 'cuda', False), ((2048,), (1,), torch.float32, 'cuda', False), ((2048,), (1,), torch.float32, 'cuda', False), ((2048,), (1,), torch.float32, 'cuda', True), ((2048,), (1,), torch.float32, 'cuda', True), ((), (), torch.int64, 'cuda', False), ((2048,), (1,), torch.float32, 'cuda', False), ((2048,), (1,), torch.float32, 'cuda', False), ((2048,), (1,), torch.float32, 'cuda', True), ((2048,), (1,), torch.float32, 'cuda', True), ((), (), torch.int64, 'cuda', False), ((512,), (1,), torch.float32, 'cuda', False), ((512,), (1,), torch.float32, 'cuda', False), ((512,), (1,), torch.float32, 'cuda', True), ((512,), (1,), torch.float32, 'cuda', True), ((), (), torch.int64, 'cuda', False), ((512,), (1,), torch.float32, 'cuda', False), ((512,), (1,), torch.float32, 'cuda', False), ((512,), (1,), torch.float32, 'cuda', True), ((512,), (1,), torch.float32, 'cuda', True), ((), (), torch.int64, 'cuda', False), ((2048,), (1,), torch.float32, 'cuda', False), ((2048,), (1,), torch.float32, 'cuda', False), ((2048,), (1,), torch.float32, 'cuda', True), ((2048,), (1,), torch.float32, 'cuda', True), ((), (), torch.int64, 'cuda', False), ((), (), torch.int64, 'cuda', False), ((), (), torch.int64, 'cuda', False), ((), (), torch.int64, 'cuda', False), ((), (), torch.int64, 'cuda', False), ((), (), torch.int64, 'cuda', False), ((), (), torch.int64, 'cuda', False), ((), (), torch.int64, 'cuda', False), ((), (), torch.int64, 'cuda', False), ((), (), torch.int64, 'cuda', False), ((128, 256, 64, 64), (1048576, 4096, 64, 1), torch.float16, 'cuda', True), ((), (), torch.int64, 'cuda', False), ((), (), torch.int64, 'cuda', False), ((), (), torch.int64, 'cuda', False), ((128, 512, 32, 32), (524288, 1024, 32, 1), torch.float16, 'cuda', True)]
args = [rand_strided(sh, st, dt, dev).requires_grad_(rg) for (sh, st, dt, dev, rg) in args]
from torch.nn import *
class Repro(torch.nn.Module):
def __init__(self):
super().__init__()
self.self_self_stages_1_0_drop_path = Identity()
self.self_self_stages_1_0_shortcut_conv = Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False).cuda()
self.self_self_stages_1_0_shortcut_bn_drop = Identity()
self.self_self_stages_1_0_shortcut_bn_act = Identity()
self.self_self_stages_1_0_act = SiLU(inplace=True)
self.self_self_stages_1_1_conv1_1x1_conv = Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False).cuda()
self.self_self_stages_1_1_conv1_1x1_bn_drop = Identity()
self.self_self_stages_1_1_conv1_1x1_bn_act = SiLU(inplace=True)
self.self_self_stages_1_1_conv2_kxk_conv = Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=8, bias=False).cuda()
self.self_self_stages_1_1_conv2_kxk_bn_drop = Identity()
self.self_self_stages_1_1_conv2_kxk_bn_act = SiLU(inplace=True)
self.self_self_stages_1_1_conv2b_kxk = Identity()
self.self_self_stages_1_1_attn_conv = Conv1d(1, 1, kernel_size=(5,), stride=(1,), padding=(2,), bias=False).cuda()
self.self_self_stages_1_1_conv3_1x1_conv = Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False).cuda()
self.self_self_stages_1_1_conv3_1x1_bn_drop = Identity()
self.self_self_stages_1_1_conv3_1x1_bn_act = Identity()
self.self_self_stages_1_1_attn_last = Identity()
self.self_self_stages_1_1_drop_path = Identity()
self.self_self_stages_1_1_shortcut = Identity()
self.self_self_stages_1_1_act = SiLU(inplace=True)
self.self_self_stages_2_0_conv1_1x1_conv = Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False).cuda()
self.self_self_stages_2_0_conv1_1x1_bn_drop = Identity()
self.self_self_stages_2_0_conv1_1x1_bn_act = SiLU(inplace=True)
self.self_self_stages_2_0_conv2_kxk_conv = Conv2d(256, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), groups=16, bias=False).cuda()
self.self_self_stages_2_0_conv2_kxk_bn_drop = Identity()
self.self_self_stages_2_0_conv2_kxk_bn_act = SiLU(inplace=True)
self.self_self_stages_2_0_conv2b_kxk = Identity()
self.self_self_stages_2_0_attn_conv = Conv1d(1, 1, kernel_size=(5,), stride=(1,), padding=(2,), bias=False).cuda()
self.self_self_stages_2_0_conv3_1x1_conv = Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False).cuda()
self.self_self_stages_2_0_conv3_1x1_bn_drop = Identity()
self.self_self_stages_2_0_conv3_1x1_bn_act = Identity()
self.self_self_stages_2_0_attn_last = Identity()
self.self_self_stages_2_0_drop_path = Identity()
self.self_self_stages_2_0_shortcut_conv = Conv2d(512, 1024, kernel_size=(1, 1), stride=(2, 2), bias=False).cuda()
self.self_self_stages_2_0_shortcut_bn_drop = Identity()
self.self_self_stages_2_0_shortcut_bn_act = Identity()
self.self_self_stages_2_0_act = SiLU(inplace=True)
self.self_self_stages_2_1_conv1_1x1_conv = Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False).cuda()
self.self_self_stages_2_1_conv1_1x1_bn_drop = Identity()
self.self_self_stages_2_1_conv1_1x1_bn_act = SiLU(inplace=True)
self.self_self_stages_2_1_conv2_kxk = Identity()
self.self_self_stages_2_1_self_attn_q = Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False).cuda()
self.self_self_stages_2_1_self_attn_kv = Conv2d(256, 384, kernel_size=(1, 1), stride=(1, 1), bias=False).cuda()
self.self_self_stages_2_1_self_attn_pool = Identity()
self.self_self_stages_2_1_post_attn_drop = Identity()
self.self_self_stages_2_1_post_attn_act = SiLU(inplace=True)
self.self_self_stages_2_1_conv3_1x1_conv = Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False).cuda()
self.self_self_stages_2_1_conv3_1x1_bn_drop = Identity()
self.self_self_stages_2_1_conv3_1x1_bn_act = Identity()
self.self_self_stages_2_1_drop_path = Identity()
self.self_self_stages_2_1_shortcut = Identity()
self.self_self_stages_2_1_act = SiLU(inplace=True)
self.self_self_stages_3_0_conv1_1x1_conv = Conv2d(1024, 512, kernel_size=(1, 1), stride=(1, 1), bias=False).cuda()
self.self_self_stages_3_0_conv1_1x1_bn_drop = Identity()
self.self_self_stages_3_0_conv1_1x1_bn_act = SiLU(inplace=True)
self.self_self_stages_3_0_conv2_kxk = Identity()
self.self_self_stages_3_0_self_attn_q = Conv2d(512, 128, kernel_size=(1, 1), stride=(2, 2), bias=False).cuda()
self.self_self_stages_3_0_self_attn_kv = Conv2d(512, 640, kernel_size=(1, 1), stride=(1, 1), bias=False).cuda()
self.self_self_stages_3_0_self_attn_pool = Identity()
self.self_self_stages_3_0_post_attn_drop = Identity()
self.self_self_stages_3_0_post_attn_act = SiLU(inplace=True)
self.self_self_stages_3_0_conv3_1x1_conv = Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False).cuda()
self.self_self_stages_3_0_conv3_1x1_bn_drop = Identity()
self.self_self_stages_3_0_conv3_1x1_bn_act = Identity()
self.self_self_stages_3_0_drop_path = Identity()
self.self_self_stages_3_0_shortcut_conv = Conv2d(1024, 2048, kernel_size=(1, 1), stride=(2, 2), bias=False).cuda()
self.self_self_stages_3_0_shortcut_bn_drop = Identity()
self.self_self_stages_3_0_shortcut_bn_act = Identity()
self.self_self_stages_3_0_act = SiLU(inplace=True)
self.self_self_stages_3_1_conv1_1x1_conv = Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False).cuda()
self.self_self_stages_3_1_conv1_1x1_bn_drop = Identity()
self.self_self_stages_3_1_conv1_1x1_bn_act = SiLU(inplace=True)
self.self_self_stages_3_1_conv2_kxk = Identity()
self.self_self_stages_3_1_self_attn_q = Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False).cuda()
self.self_self_stages_3_1_self_attn_kv = Conv2d(512, 640, kernel_size=(1, 1), stride=(1, 1), bias=False).cuda()
self.self_self_stages_3_1_self_attn_pool = Identity()
self.self_self_stages_3_1_post_attn_drop = Identity()
self.self_self_stages_3_1_post_attn_act = SiLU(inplace=True)
self.self_self_stages_3_1_conv3_1x1_conv = Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False).cuda()
self.self_self_stages_3_1_conv3_1x1_bn_drop = Identity()
self.self_self_stages_3_1_conv3_1x1_bn_act = Identity()
self.self_self_stages_3_1_drop_path = Identity()
self.self_self_stages_3_1_shortcut = Identity()
self.self_self_stages_3_1_act = SiLU(inplace=True)
self.self_self_final_conv = Identity()
self.self_self_head_global_pool_pool = AdaptiveAvgPool2d(output_size=1)
self.self_self_head_global_pool_flatten = Flatten(start_dim=1, end_dim=-1)
self.self_self_head_fc = Linear(in_features=2048, out_features=1000, bias=True).cuda()
self.self_self_head_flatten = Identity()
self.register_buffer('self_self_stages_2_1_self_attn_pos_embed_width_rel', torch.randn([23, 16], dtype=torch.float32).cuda())
self.register_buffer('self_self_stages_2_1_self_attn_pos_embed_height_rel', torch.randn([23, 16], dtype=torch.float32).cuda())
self.register_buffer('self_self_stages_3_0_self_attn_pos_embed_width_rel', torch.randn([23, 16], dtype=torch.float32).cuda())
self.register_buffer('self_self_stages_3_0_self_attn_pos_embed_height_rel', torch.randn([23, 16], dtype=torch.float32).cuda())
self.register_buffer('self_self_stages_3_1_self_attn_pos_embed_width_rel', torch.randn([23, 16], dtype=torch.float32).cuda())
self.register_buffer('self_self_stages_3_1_self_attn_pos_embed_height_rel', torch.randn([23, 16], dtype=torch.float32).cuda())
def forward(self, self_stages_1_0_shortcut_bn_num_batches_tracked_0 : torch.Tensor, self_stages_1_0_shortcut_bn_running_mean : torch.Tensor, self_stages_1_0_shortcut_bn_running_var : torch.Tensor, self_stages_1_0_shortcut_bn_weight : torch.Tensor, self_stages_1_0_shortcut_bn_bias : torch.Tensor, self_stages_1_1_conv1_1x1_bn_num_batches_tracked_0 : torch.Tensor, self_stages_1_1_conv1_1x1_bn_running_mean : torch.Tensor, self_stages_1_1_conv1_1x1_bn_running_var : torch.Tensor, self_stages_1_1_conv1_1x1_bn_weight : torch.Tensor, self_stages_1_1_conv1_1x1_bn_bias : torch.Tensor, self_stages_1_1_conv2_kxk_bn_num_batches_tracked_0 : torch.Tensor, self_stages_1_1_conv2_kxk_bn_running_mean : torch.Tensor, self_stages_1_1_conv2_kxk_bn_running_var : torch.Tensor, self_stages_1_1_conv2_kxk_bn_weight : torch.Tensor, self_stages_1_1_conv2_kxk_bn_bias : torch.Tensor, self_stages_1_1_conv3_1x1_bn_num_batches_tracked_0 : torch.Tensor, self_stages_1_1_conv3_1x1_bn_running_mean : torch.Tensor, self_stages_1_1_conv3_1x1_bn_running_var : torch.Tensor, self_stages_1_1_conv3_1x1_bn_weight : torch.Tensor, self_stages_1_1_conv3_1x1_bn_bias : torch.Tensor, self_stages_2_0_conv1_1x1_bn_num_batches_tracked_0 : torch.Tensor, self_stages_2_0_conv1_1x1_bn_running_mean : torch.Tensor, self_stages_2_0_conv1_1x1_bn_running_var : torch.Tensor, self_stages_2_0_conv1_1x1_bn_weight : torch.Tensor, self_stages_2_0_conv1_1x1_bn_bias : torch.Tensor, self_stages_2_0_conv2_kxk_bn_num_batches_tracked_0 : torch.Tensor, self_stages_2_0_conv2_kxk_bn_running_mean : torch.Tensor, self_stages_2_0_conv2_kxk_bn_running_var : torch.Tensor, self_stages_2_0_conv2_kxk_bn_weight : torch.Tensor, self_stages_2_0_conv2_kxk_bn_bias : torch.Tensor, self_stages_2_0_conv3_1x1_bn_num_batches_tracked_0 : torch.Tensor, self_stages_2_0_conv3_1x1_bn_running_mean : torch.Tensor, self_stages_2_0_conv3_1x1_bn_running_var : torch.Tensor, self_stages_2_0_conv3_1x1_bn_weight : torch.Tensor, self_stages_2_0_conv3_1x1_bn_bias : torch.Tensor, self_stages_2_0_shortcut_bn_num_batches_tracked_0 : torch.Tensor, self_stages_2_0_shortcut_bn_running_mean : torch.Tensor, self_stages_2_0_shortcut_bn_running_var : torch.Tensor, self_stages_2_0_shortcut_bn_weight : torch.Tensor, self_stages_2_0_shortcut_bn_bias : torch.Tensor, self_stages_2_1_conv1_1x1_bn_num_batches_tracked_0 : torch.Tensor, self_stages_2_1_conv1_1x1_bn_running_mean : torch.Tensor, self_stages_2_1_conv1_1x1_bn_running_var : torch.Tensor, self_stages_2_1_conv1_1x1_bn_weight : torch.Tensor, self_stages_2_1_conv1_1x1_bn_bias : torch.Tensor, self_stages_2_1_post_attn_num_batches_tracked_0 : torch.Tensor, self_stages_2_1_post_attn_running_mean : torch.Tensor, self_stages_2_1_post_attn_running_var : torch.Tensor, self_stages_2_1_post_attn_weight : torch.Tensor, self_stages_2_1_post_attn_bias : torch.Tensor, self_stages_2_1_conv3_1x1_bn_num_batches_tracked_0 : torch.Tensor, self_stages_2_1_conv3_1x1_bn_running_mean : torch.Tensor, self_stages_2_1_conv3_1x1_bn_running_var : torch.Tensor, self_stages_2_1_conv3_1x1_bn_weight : torch.Tensor, self_stages_2_1_conv3_1x1_bn_bias : torch.Tensor, self_stages_3_0_conv1_1x1_bn_num_batches_tracked_0 : torch.Tensor, self_stages_3_0_conv1_1x1_bn_running_mean : torch.Tensor, self_stages_3_0_conv1_1x1_bn_running_var : torch.Tensor, self_stages_3_0_conv1_1x1_bn_weight : torch.Tensor, self_stages_3_0_conv1_1x1_bn_bias : torch.Tensor, self_stages_3_0_post_attn_num_batches_tracked_0 : torch.Tensor, self_stages_3_0_post_attn_running_mean : torch.Tensor, self_stages_3_0_post_attn_running_var : torch.Tensor, self_stages_3_0_post_attn_weight : torch.Tensor, self_stages_3_0_post_attn_bias : torch.Tensor, self_stages_3_0_conv3_1x1_bn_num_batches_tracked_0 : torch.Tensor, self_stages_3_0_conv3_1x1_bn_running_mean : torch.Tensor, self_stages_3_0_conv3_1x1_bn_running_var : torch.Tensor, self_stages_3_0_conv3_1x1_bn_weight : torch.Tensor, self_stages_3_0_conv3_1x1_bn_bias : torch.Tensor, self_stages_3_0_shortcut_bn_num_batches_tracked_0 : torch.Tensor, self_stages_3_0_shortcut_bn_running_mean : torch.Tensor, self_stages_3_0_shortcut_bn_running_var : torch.Tensor, self_stages_3_0_shortcut_bn_weight : torch.Tensor, self_stages_3_0_shortcut_bn_bias : torch.Tensor, self_stages_3_1_conv1_1x1_bn_num_batches_tracked_0 : torch.Tensor, self_stages_3_1_conv1_1x1_bn_running_mean : torch.Tensor, self_stages_3_1_conv1_1x1_bn_running_var : torch.Tensor, self_stages_3_1_conv1_1x1_bn_weight : torch.Tensor, self_stages_3_1_conv1_1x1_bn_bias : torch.Tensor, self_stages_3_1_post_attn_num_batches_tracked_0 : torch.Tensor, self_stages_3_1_post_attn_running_mean : torch.Tensor, self_stages_3_1_post_attn_running_var : torch.Tensor, self_stages_3_1_post_attn_weight : torch.Tensor, self_stages_3_1_post_attn_bias : torch.Tensor, self_stages_3_1_conv3_1x1_bn_num_batches_tracked_0 : torch.Tensor, self_stages_3_1_conv3_1x1_bn_running_mean : torch.Tensor, self_stages_3_1_conv3_1x1_bn_running_var : torch.Tensor, self_stages_3_1_conv3_1x1_bn_weight : torch.Tensor, self_stages_3_1_conv3_1x1_bn_bias : torch.Tensor, add, add_1, add_2, add_3, add_4, add_5, add_6, add_8, add_9, add_10, self_self_stages_0_1_act, add_12, add_13, add_14, self_self_stages_1_0_attn_last):
self_self_stages_1_0_drop_path = self.self_self_stages_1_0_drop_path(self_self_stages_1_0_attn_last); self_self_stages_1_0_attn_last = None
self_self_stages_1_0_shortcut_conv = self.self_self_stages_1_0_shortcut_conv(self_self_stages_0_1_act); self_self_stages_0_1_act = None
add_15 = self_stages_1_0_shortcut_bn_num_batches_tracked_0 + 1; self_stages_1_0_shortcut_bn_num_batches_tracked_0 = None
batch_norm_13 = torch.nn.functional.batch_norm(self_self_stages_1_0_shortcut_conv, self_stages_1_0_shortcut_bn_running_mean, self_stages_1_0_shortcut_bn_running_var, self_stages_1_0_shortcut_bn_weight, self_stages_1_0_shortcut_bn_bias, True, 0.1, 1e-05); self_self_stages_1_0_shortcut_conv = self_stages_1_0_shortcut_bn_running_mean = self_stages_1_0_shortcut_bn_running_var = self_stages_1_0_shortcut_bn_weight = self_stages_1_0_shortcut_bn_bias = None
self_self_stages_1_0_shortcut_bn_drop = self.self_self_stages_1_0_shortcut_bn_drop(batch_norm_13); batch_norm_13 = None
self_self_stages_1_0_shortcut_bn_act = self.self_self_stages_1_0_shortcut_bn_act(self_self_stages_1_0_shortcut_bn_drop); self_self_stages_1_0_shortcut_bn_drop = None
add_16 = self_self_stages_1_0_drop_path + self_self_stages_1_0_shortcut_bn_act; self_self_stages_1_0_drop_path = self_self_stages_1_0_shortcut_bn_act = None
self_self_stages_1_0_act = self.self_self_stages_1_0_act(add_16); add_16 = None
self_self_stages_1_1_conv1_1x1_conv = self.self_self_stages_1_1_conv1_1x1_conv(self_self_stages_1_0_act)
add_17 = self_stages_1_1_conv1_1x1_bn_num_batches_tracked_0 + 1; self_stages_1_1_conv1_1x1_bn_num_batches_tracked_0 = None
batch_norm_14 = torch.nn.functional.batch_norm(self_self_stages_1_1_conv1_1x1_conv, self_stages_1_1_conv1_1x1_bn_running_mean, self_stages_1_1_conv1_1x1_bn_running_var, self_stages_1_1_conv1_1x1_bn_weight, self_stages_1_1_conv1_1x1_bn_bias, True, 0.1, 1e-05); self_self_stages_1_1_conv1_1x1_conv = self_stages_1_1_conv1_1x1_bn_running_mean = self_stages_1_1_conv1_1x1_bn_running_var = self_stages_1_1_conv1_1x1_bn_weight = self_stages_1_1_conv1_1x1_bn_bias = None
self_self_stages_1_1_conv1_1x1_bn_drop = self.self_self_stages_1_1_conv1_1x1_bn_drop(batch_norm_14); batch_norm_14 = None
self_self_stages_1_1_conv1_1x1_bn_act = self.self_self_stages_1_1_conv1_1x1_bn_act(self_self_stages_1_1_conv1_1x1_bn_drop); self_self_stages_1_1_conv1_1x1_bn_drop = None
self_self_stages_1_1_conv2_kxk_conv = self.self_self_stages_1_1_conv2_kxk_conv(self_self_stages_1_1_conv1_1x1_bn_act); self_self_stages_1_1_conv1_1x1_bn_act = None
add_18 = self_stages_1_1_conv2_kxk_bn_num_batches_tracked_0 + 1; self_stages_1_1_conv2_kxk_bn_num_batches_tracked_0 = None
batch_norm_15 = torch.nn.functional.batch_norm(self_self_stages_1_1_conv2_kxk_conv, self_stages_1_1_conv2_kxk_bn_running_mean, self_stages_1_1_conv2_kxk_bn_running_var, self_stages_1_1_conv2_kxk_bn_weight, self_stages_1_1_conv2_kxk_bn_bias, True, 0.1, 1e-05); self_self_stages_1_1_conv2_kxk_conv = self_stages_1_1_conv2_kxk_bn_running_mean = self_stages_1_1_conv2_kxk_bn_running_var = self_stages_1_1_conv2_kxk_bn_weight = self_stages_1_1_conv2_kxk_bn_bias = None
self_self_stages_1_1_conv2_kxk_bn_drop = self.self_self_stages_1_1_conv2_kxk_bn_drop(batch_norm_15); batch_norm_15 = None
self_self_stages_1_1_conv2_kxk_bn_act = self.self_self_stages_1_1_conv2_kxk_bn_act(self_self_stages_1_1_conv2_kxk_bn_drop); self_self_stages_1_1_conv2_kxk_bn_drop = None
self_self_stages_1_1_conv2b_kxk = self.self_self_stages_1_1_conv2b_kxk(self_self_stages_1_1_conv2_kxk_bn_act); self_self_stages_1_1_conv2_kxk_bn_act = None
mean_3 = self_self_stages_1_1_conv2b_kxk.mean((2, 3))
view_6 = mean_3.view(128, 1, -1); mean_3 = None
self_self_stages_1_1_attn_conv = self.self_self_stages_1_1_attn_conv(view_6); view_6 = None
sigmoid_3 = self_self_stages_1_1_attn_conv.sigmoid(); self_self_stages_1_1_attn_conv = None
view_7 = sigmoid_3.view(128, -1, 1, 1); sigmoid_3 = None
expand_as_3 = view_7.expand_as(self_self_stages_1_1_conv2b_kxk); view_7 = None
mul_3 = self_self_stages_1_1_conv2b_kxk * expand_as_3; self_self_stages_1_1_conv2b_kxk = expand_as_3 = None
self_self_stages_1_1_conv3_1x1_conv = self.self_self_stages_1_1_conv3_1x1_conv(mul_3); mul_3 = None
add_19 = self_stages_1_1_conv3_1x1_bn_num_batches_tracked_0 + 1; self_stages_1_1_conv3_1x1_bn_num_batches_tracked_0 = None
batch_norm_16 = torch.nn.functional.batch_norm(self_self_stages_1_1_conv3_1x1_conv, self_stages_1_1_conv3_1x1_bn_running_mean, self_stages_1_1_conv3_1x1_bn_running_var, self_stages_1_1_conv3_1x1_bn_weight, self_stages_1_1_conv3_1x1_bn_bias, True, 0.1, 1e-05); self_self_stages_1_1_conv3_1x1_conv = self_stages_1_1_conv3_1x1_bn_running_mean = self_stages_1_1_conv3_1x1_bn_running_var = self_stages_1_1_conv3_1x1_bn_weight = self_stages_1_1_conv3_1x1_bn_bias = None
self_self_stages_1_1_conv3_1x1_bn_drop = self.self_self_stages_1_1_conv3_1x1_bn_drop(batch_norm_16); batch_norm_16 = None
self_self_stages_1_1_conv3_1x1_bn_act = self.self_self_stages_1_1_conv3_1x1_bn_act(self_self_stages_1_1_conv3_1x1_bn_drop); self_self_stages_1_1_conv3_1x1_bn_drop = None
self_self_stages_1_1_attn_last = self.self_self_stages_1_1_attn_last(self_self_stages_1_1_conv3_1x1_bn_act); self_self_stages_1_1_conv3_1x1_bn_act = None
self_self_stages_1_1_drop_path = self.self_self_stages_1_1_drop_path(self_self_stages_1_1_attn_last); self_self_stages_1_1_attn_last = None
self_self_stages_1_1_shortcut = self.self_self_stages_1_1_shortcut(self_self_stages_1_0_act); self_self_stages_1_0_act = None
add_20 = self_self_stages_1_1_drop_path + self_self_stages_1_1_shortcut; self_self_stages_1_1_drop_path = self_self_stages_1_1_shortcut = None
self_self_stages_1_1_act = self.self_self_stages_1_1_act(add_20); add_20 = None
self_self_stages_2_0_conv1_1x1_conv = self.self_self_stages_2_0_conv1_1x1_conv(self_self_stages_1_1_act)
add_21 = self_stages_2_0_conv1_1x1_bn_num_batches_tracked_0 + 1; self_stages_2_0_conv1_1x1_bn_num_batches_tracked_0 = None
batch_norm_17 = torch.nn.functional.batch_norm(self_self_stages_2_0_conv1_1x1_conv, self_stages_2_0_conv1_1x1_bn_running_mean, self_stages_2_0_conv1_1x1_bn_running_var, self_stages_2_0_conv1_1x1_bn_weight, self_stages_2_0_conv1_1x1_bn_bias, True, 0.1, 1e-05); self_self_stages_2_0_conv1_1x1_conv = self_stages_2_0_conv1_1x1_bn_running_mean = self_stages_2_0_conv1_1x1_bn_running_var = self_stages_2_0_conv1_1x1_bn_weight = self_stages_2_0_conv1_1x1_bn_bias = None
self_self_stages_2_0_conv1_1x1_bn_drop = self.self_self_stages_2_0_conv1_1x1_bn_drop(batch_norm_17); batch_norm_17 = None
self_self_stages_2_0_conv1_1x1_bn_act = self.self_self_stages_2_0_conv1_1x1_bn_act(self_self_stages_2_0_conv1_1x1_bn_drop); self_self_stages_2_0_conv1_1x1_bn_drop = None
self_self_stages_2_0_conv2_kxk_conv = self.self_self_stages_2_0_conv2_kxk_conv(self_self_stages_2_0_conv1_1x1_bn_act); self_self_stages_2_0_conv1_1x1_bn_act = None
add_22 = self_stages_2_0_conv2_kxk_bn_num_batches_tracked_0 + 1; self_stages_2_0_conv2_kxk_bn_num_batches_tracked_0 = None
batch_norm_18 = torch.nn.functional.batch_norm(self_self_stages_2_0_conv2_kxk_conv, self_stages_2_0_conv2_kxk_bn_running_mean, self_stages_2_0_conv2_kxk_bn_running_var, self_stages_2_0_conv2_kxk_bn_weight, self_stages_2_0_conv2_kxk_bn_bias, True, 0.1, 1e-05); self_self_stages_2_0_conv2_kxk_conv = self_stages_2_0_conv2_kxk_bn_running_mean = self_stages_2_0_conv2_kxk_bn_running_var = self_stages_2_0_conv2_kxk_bn_weight = self_stages_2_0_conv2_kxk_bn_bias = None
self_self_stages_2_0_conv2_kxk_bn_drop = self.self_self_stages_2_0_conv2_kxk_bn_drop(batch_norm_18); batch_norm_18 = None
self_self_stages_2_0_conv2_kxk_bn_act = self.self_self_stages_2_0_conv2_kxk_bn_act(self_self_stages_2_0_conv2_kxk_bn_drop); self_self_stages_2_0_conv2_kxk_bn_drop = None
self_self_stages_2_0_conv2b_kxk = self.self_self_stages_2_0_conv2b_kxk(self_self_stages_2_0_conv2_kxk_bn_act); self_self_stages_2_0_conv2_kxk_bn_act = None
mean_4 = self_self_stages_2_0_conv2b_kxk.mean((2, 3))
view_8 = mean_4.view(128, 1, -1); mean_4 = None
self_self_stages_2_0_attn_conv = self.self_self_stages_2_0_attn_conv(view_8); view_8 = None
sigmoid_4 = self_self_stages_2_0_attn_conv.sigmoid(); self_self_stages_2_0_attn_conv = None
view_9 = sigmoid_4.view(128, -1, 1, 1); sigmoid_4 = None
expand_as_4 = view_9.expand_as(self_self_stages_2_0_conv2b_kxk); view_9 = None
mul_4 = self_self_stages_2_0_conv2b_kxk * expand_as_4; self_self_stages_2_0_conv2b_kxk = expand_as_4 = None
self_self_stages_2_0_conv3_1x1_conv = self.self_self_stages_2_0_conv3_1x1_conv(mul_4); mul_4 = None
add_23 = self_stages_2_0_conv3_1x1_bn_num_batches_tracked_0 + 1; self_stages_2_0_conv3_1x1_bn_num_batches_tracked_0 = None
batch_norm_19 = torch.nn.functional.batch_norm(self_self_stages_2_0_conv3_1x1_conv, self_stages_2_0_conv3_1x1_bn_running_mean, self_stages_2_0_conv3_1x1_bn_running_var, self_stages_2_0_conv3_1x1_bn_weight, self_stages_2_0_conv3_1x1_bn_bias, True, 0.1, 1e-05); self_self_stages_2_0_conv3_1x1_conv = self_stages_2_0_conv3_1x1_bn_running_mean = self_stages_2_0_conv3_1x1_bn_running_var = self_stages_2_0_conv3_1x1_bn_weight = self_stages_2_0_conv3_1x1_bn_bias = None
self_self_stages_2_0_conv3_1x1_bn_drop = self.self_self_stages_2_0_conv3_1x1_bn_drop(batch_norm_19); batch_norm_19 = None
self_self_stages_2_0_conv3_1x1_bn_act = self.self_self_stages_2_0_conv3_1x1_bn_act(self_self_stages_2_0_conv3_1x1_bn_drop); self_self_stages_2_0_conv3_1x1_bn_drop = None
self_self_stages_2_0_attn_last = self.self_self_stages_2_0_attn_last(self_self_stages_2_0_conv3_1x1_bn_act); self_self_stages_2_0_conv3_1x1_bn_act = None
self_self_stages_2_0_drop_path = self.self_self_stages_2_0_drop_path(self_self_stages_2_0_attn_last); self_self_stages_2_0_attn_last = None
self_self_stages_2_0_shortcut_conv = self.self_self_stages_2_0_shortcut_conv(self_self_stages_1_1_act); self_self_stages_1_1_act = None
add_24 = self_stages_2_0_shortcut_bn_num_batches_tracked_0 + 1; self_stages_2_0_shortcut_bn_num_batches_tracked_0 = None
batch_norm_20 = torch.nn.functional.batch_norm(self_self_stages_2_0_shortcut_conv, self_stages_2_0_shortcut_bn_running_mean, self_stages_2_0_shortcut_bn_running_var, self_stages_2_0_shortcut_bn_weight, self_stages_2_0_shortcut_bn_bias, True, 0.1, 1e-05); self_self_stages_2_0_shortcut_conv = self_stages_2_0_shortcut_bn_running_mean = self_stages_2_0_shortcut_bn_running_var = self_stages_2_0_shortcut_bn_weight = self_stages_2_0_shortcut_bn_bias = None
self_self_stages_2_0_shortcut_bn_drop = self.self_self_stages_2_0_shortcut_bn_drop(batch_norm_20); batch_norm_20 = None
self_self_stages_2_0_shortcut_bn_act = self.self_self_stages_2_0_shortcut_bn_act(self_self_stages_2_0_shortcut_bn_drop); self_self_stages_2_0_shortcut_bn_drop = None
add_25 = self_self_stages_2_0_drop_path + self_self_stages_2_0_shortcut_bn_act; self_self_stages_2_0_drop_path = self_self_stages_2_0_shortcut_bn_act = None
self_self_stages_2_0_act = self.self_self_stages_2_0_act(add_25); add_25 = None
self_self_stages_2_1_conv1_1x1_conv = self.self_self_stages_2_1_conv1_1x1_conv(self_self_stages_2_0_act)
add_26 = self_stages_2_1_conv1_1x1_bn_num_batches_tracked_0 + 1; self_stages_2_1_conv1_1x1_bn_num_batches_tracked_0 = None
batch_norm_21 = torch.nn.functional.batch_norm(self_self_stages_2_1_conv1_1x1_conv, self_stages_2_1_conv1_1x1_bn_running_mean, self_stages_2_1_conv1_1x1_bn_running_var, self_stages_2_1_conv1_1x1_bn_weight, self_stages_2_1_conv1_1x1_bn_bias, True, 0.1, 1e-05); self_self_stages_2_1_conv1_1x1_conv = self_stages_2_1_conv1_1x1_bn_running_mean = self_stages_2_1_conv1_1x1_bn_running_var = self_stages_2_1_conv1_1x1_bn_weight = self_stages_2_1_conv1_1x1_bn_bias = None
self_self_stages_2_1_conv1_1x1_bn_drop = self.self_self_stages_2_1_conv1_1x1_bn_drop(batch_norm_21); batch_norm_21 = None
self_self_stages_2_1_conv1_1x1_bn_act = self.self_self_stages_2_1_conv1_1x1_bn_act(self_self_stages_2_1_conv1_1x1_bn_drop); self_self_stages_2_1_conv1_1x1_bn_drop = None
self_self_stages_2_1_conv2_kxk = self.self_self_stages_2_1_conv2_kxk(self_self_stages_2_1_conv1_1x1_bn_act); self_self_stages_2_1_conv1_1x1_bn_act = None
self_self_stages_2_1_self_attn_q = self.self_self_stages_2_1_self_attn_q(self_self_stages_2_1_conv2_kxk)
reshape = self_self_stages_2_1_self_attn_q.reshape(-1, 16, 2, 8, 2, 8); self_self_stages_2_1_self_attn_q = None
permute = reshape.permute(0, 1, 3, 5, 2, 4); reshape = None
reshape_1 = permute.reshape(1024, 16, -1, 4); permute = None
transpose = reshape_1.transpose(1, 3); reshape_1 = None
self_self_stages_2_1_self_attn_kv = self.self_self_stages_2_1_self_attn_kv(self_self_stages_2_1_conv2_kxk); self_self_stages_2_1_conv2_kxk = None
pad = torch.nn.functional.pad(self_self_stages_2_1_self_attn_kv, [2, 2, 2, 2]); self_self_stages_2_1_self_attn_kv = None
unfold = pad.unfold(2, 12, 8); pad = None
unfold_1 = unfold.unfold(3, 12, 8); unfold = None
reshape_2 = unfold_1.reshape(1024, 48, 4, -1); unfold_1 = None
permute_1 = reshape_2.permute(0, 2, 3, 1); reshape_2 = None
split = torch.functional.split(permute_1, [16, 32], dim = -1); permute_1 = None
getitem = split[0]
getitem_1 = split[1]; split = None
transpose_1 = getitem.transpose(-1, -2); getitem = None
matmul = transpose @ transpose_1; transpose_1 = None
mul_5 = matmul * 0.25; matmul = None
reshape_3 = transpose.reshape(-1, 8, 8, 16); transpose = None
self_self_stages_2_1_self_attn_pos_embed_width_rel = self.self_self_stages_2_1_self_attn_pos_embed_width_rel
transpose_2 = self_self_stages_2_1_self_attn_pos_embed_width_rel.transpose(-1, -2); self_self_stages_2_1_self_attn_pos_embed_width_rel = None
matmul_1 = reshape_3 @ transpose_2; transpose_2 = None
reshape_4 = matmul_1.reshape(-1, 8, 23); matmul_1 = None
pad_1 = torch.nn.functional.pad(reshape_4, [0, 1]); reshape_4 = None
flatten = pad_1.flatten(1); pad_1 = None
pad_2 = torch.nn.functional.pad(flatten, [0, 15]); flatten = None
reshape_5 = pad_2.reshape(-1, 9, 23); pad_2 = None
getitem_2 = reshape_5[(slice(None, None, None), slice(None, 8, None), slice(11, None, None))]; reshape_5 = None
reshape_6 = getitem_2.reshape(4096, 8, 1, 8, 12); getitem_2 = None
expand = reshape_6.expand(-1, -1, 12, -1, -1); reshape_6 = None
permute_2 = expand.permute((0, 1, 3, 2, 4)); expand = None
transpose_3 = reshape_3.transpose(1, 2); reshape_3 = None
self_self_stages_2_1_self_attn_pos_embed_height_rel = self.self_self_stages_2_1_self_attn_pos_embed_height_rel
transpose_4 = self_self_stages_2_1_self_attn_pos_embed_height_rel.transpose(-1, -2); self_self_stages_2_1_self_attn_pos_embed_height_rel = None
matmul_2 = transpose_3 @ transpose_4; transpose_3 = transpose_4 = None
reshape_7 = matmul_2.reshape(-1, 8, 23); matmul_2 = None
pad_3 = torch.nn.functional.pad(reshape_7, [0, 1]); reshape_7 = None
flatten_1 = pad_3.flatten(1); pad_3 = None
pad_4 = torch.nn.functional.pad(flatten_1, [0, 15]); flatten_1 = None
reshape_8 = pad_4.reshape(-1, 9, 23); pad_4 = None
getitem_3 = reshape_8[(slice(None, None, None), slice(None, 8, None), slice(11, None, None))]; reshape_8 = None
reshape_9 = getitem_3.reshape(4096, 8, 1, 8, 12); getitem_3 = None
expand_1 = reshape_9.expand(-1, -1, 12, -1, -1); reshape_9 = None
permute_3 = expand_1.permute((0, 3, 1, 4, 2)); expand_1 = None
add_27 = permute_3 + permute_2; permute_3 = permute_2 = None
reshape_10 = add_27.reshape(1024, 4, 64, -1); add_27 = None
add_28 = mul_5 + reshape_10; mul_5 = reshape_10 = None
softmax = add_28.softmax(dim = -1); add_28 = None
matmul_3 = softmax @ getitem_1; softmax = getitem_1 = None
transpose_5 = matmul_3.transpose(1, 3); matmul_3 = None
reshape_11 = transpose_5.reshape(-1, 8, 8, 2, 2); transpose_5 = None
permute_4 = reshape_11.permute(0, 3, 1, 4, 2); reshape_11 = None
contiguous = permute_4.contiguous(); permute_4 = None
view_10 = contiguous.view(128, 256, 16, 16); contiguous = None
self_self_stages_2_1_self_attn_pool = self.self_self_stages_2_1_self_attn_pool(view_10); view_10 = None
add_29 = self_stages_2_1_post_attn_num_batches_tracked_0 + 1; self_stages_2_1_post_attn_num_batches_tracked_0 = None
batch_norm_22 = torch.nn.functional.batch_norm(self_self_stages_2_1_self_attn_pool, self_stages_2_1_post_attn_running_mean, self_stages_2_1_post_attn_running_var, self_stages_2_1_post_attn_weight, self_stages_2_1_post_attn_bias, True, 0.1, 1e-05); self_self_stages_2_1_self_attn_pool = self_stages_2_1_post_attn_running_mean = self_stages_2_1_post_attn_running_var = self_stages_2_1_post_attn_weight = self_stages_2_1_post_attn_bias = None
self_self_stages_2_1_post_attn_drop = self.self_self_stages_2_1_post_attn_drop(batch_norm_22); batch_norm_22 = None
self_self_stages_2_1_post_attn_act = self.self_self_stages_2_1_post_attn_act(self_self_stages_2_1_post_attn_drop); self_self_stages_2_1_post_attn_drop = None
self_self_stages_2_1_conv3_1x1_conv = self.self_self_stages_2_1_conv3_1x1_conv(self_self_stages_2_1_post_attn_act); self_self_stages_2_1_post_attn_act = None
add_30 = self_stages_2_1_conv3_1x1_bn_num_batches_tracked_0 + 1; self_stages_2_1_conv3_1x1_bn_num_batches_tracked_0 = None
batch_norm_23 = torch.nn.functional.batch_norm(self_self_stages_2_1_conv3_1x1_conv, self_stages_2_1_conv3_1x1_bn_running_mean, self_stages_2_1_conv3_1x1_bn_running_var, self_stages_2_1_conv3_1x1_bn_weight, self_stages_2_1_conv3_1x1_bn_bias, True, 0.1, 1e-05); self_self_stages_2_1_conv3_1x1_conv = self_stages_2_1_conv3_1x1_bn_running_mean = self_stages_2_1_conv3_1x1_bn_running_var = self_stages_2_1_conv3_1x1_bn_weight = self_stages_2_1_conv3_1x1_bn_bias = None
self_self_stages_2_1_conv3_1x1_bn_drop = self.self_self_stages_2_1_conv3_1x1_bn_drop(batch_norm_23); batch_norm_23 = None
self_self_stages_2_1_conv3_1x1_bn_act = self.self_self_stages_2_1_conv3_1x1_bn_act(self_self_stages_2_1_conv3_1x1_bn_drop); self_self_stages_2_1_conv3_1x1_bn_drop = None
self_self_stages_2_1_drop_path = self.self_self_stages_2_1_drop_path(self_self_stages_2_1_conv3_1x1_bn_act); self_self_stages_2_1_conv3_1x1_bn_act = None
self_self_stages_2_1_shortcut = self.self_self_stages_2_1_shortcut(self_self_stages_2_0_act); self_self_stages_2_0_act = None
add_31 = self_self_stages_2_1_drop_path + self_self_stages_2_1_shortcut; self_self_stages_2_1_drop_path = self_self_stages_2_1_shortcut = None
self_self_stages_2_1_act = self.self_self_stages_2_1_act(add_31); add_31 = None
self_self_stages_3_0_conv1_1x1_conv = self.self_self_stages_3_0_conv1_1x1_conv(self_self_stages_2_1_act)
add_32 = self_stages_3_0_conv1_1x1_bn_num_batches_tracked_0 + 1; self_stages_3_0_conv1_1x1_bn_num_batches_tracked_0 = None
batch_norm_24 = torch.nn.functional.batch_norm(self_self_stages_3_0_conv1_1x1_conv, self_stages_3_0_conv1_1x1_bn_running_mean, self_stages_3_0_conv1_1x1_bn_running_var, self_stages_3_0_conv1_1x1_bn_weight, self_stages_3_0_conv1_1x1_bn_bias, True, 0.1, 1e-05); self_self_stages_3_0_conv1_1x1_conv = self_stages_3_0_conv1_1x1_bn_running_mean = self_stages_3_0_conv1_1x1_bn_running_var = self_stages_3_0_conv1_1x1_bn_weight = self_stages_3_0_conv1_1x1_bn_bias = None
self_self_stages_3_0_conv1_1x1_bn_drop = self.self_self_stages_3_0_conv1_1x1_bn_drop(batch_norm_24); batch_norm_24 = None
self_self_stages_3_0_conv1_1x1_bn_act = self.self_self_stages_3_0_conv1_1x1_bn_act(self_self_stages_3_0_conv1_1x1_bn_drop); self_self_stages_3_0_conv1_1x1_bn_drop = None
self_self_stages_3_0_conv2_kxk = self.self_self_stages_3_0_conv2_kxk(self_self_stages_3_0_conv1_1x1_bn_act); self_self_stages_3_0_conv1_1x1_bn_act = None
self_self_stages_3_0_self_attn_q = self.self_self_stages_3_0_self_attn_q(self_self_stages_3_0_conv2_kxk)
reshape_12 = self_self_stages_3_0_self_attn_q.reshape(-1, 16, 2, 4, 2, 4); self_self_stages_3_0_self_attn_q = None
permute_5 = reshape_12.permute(0, 1, 3, 5, 2, 4); reshape_12 = None
reshape_13 = permute_5.reshape(1024, 16, -1, 4); permute_5 = None
transpose_6 = reshape_13.transpose(1, 3); reshape_13 = None
self_self_stages_3_0_self_attn_kv = self.self_self_stages_3_0_self_attn_kv(self_self_stages_3_0_conv2_kxk); self_self_stages_3_0_conv2_kxk = None
pad_5 = torch.nn.functional.pad(self_self_stages_3_0_self_attn_kv, [2, 2, 2, 2]); self_self_stages_3_0_self_attn_kv = None
unfold_2 = pad_5.unfold(2, 12, 8); pad_5 = None
unfold_3 = unfold_2.unfold(3, 12, 8); unfold_2 = None
reshape_14 = unfold_3.reshape(1024, 80, 4, -1); unfold_3 = None
permute_6 = reshape_14.permute(0, 2, 3, 1); reshape_14 = None
split_1 = torch.functional.split(permute_6, [16, 64], dim = -1); permute_6 = None
getitem_4 = split_1[0]
getitem_5 = split_1[1]; split_1 = None
transpose_7 = getitem_4.transpose(-1, -2); getitem_4 = None
matmul_4 = transpose_6 @ transpose_7; transpose_7 = None
mul_6 = matmul_4 * 0.25; matmul_4 = None
reshape_15 = transpose_6.reshape(-1, 4, 4, 16); transpose_6 = None
self_self_stages_3_0_self_attn_pos_embed_width_rel = self.self_self_stages_3_0_self_attn_pos_embed_width_rel
transpose_8 = self_self_stages_3_0_self_attn_pos_embed_width_rel.transpose(-1, -2); self_self_stages_3_0_self_attn_pos_embed_width_rel = None
matmul_5 = reshape_15 @ transpose_8; transpose_8 = None
reshape_16 = matmul_5.reshape(-1, 4, 23); matmul_5 = None
pad_6 = torch.nn.functional.pad(reshape_16, [0, 1]); reshape_16 = None
flatten_2 = pad_6.flatten(1); pad_6 = None
pad_7 = torch.nn.functional.pad(flatten_2, [0, 19]); flatten_2 = None
reshape_17 = pad_7.reshape(-1, 5, 23); pad_7 = None
getitem_6 = reshape_17[(slice(None, None, None), slice(None, 4, None), slice(11, None, None))]; reshape_17 = None
reshape_18 = getitem_6.reshape(4096, 4, 1, 4, 12); getitem_6 = None
expand_2 = reshape_18.expand(-1, -1, 12, -1, -1); reshape_18 = None
permute_7 = expand_2.permute((0, 1, 3, 2, 4)); expand_2 = None
transpose_9 = reshape_15.transpose(1, 2); reshape_15 = None
self_self_stages_3_0_self_attn_pos_embed_height_rel = self.self_self_stages_3_0_self_attn_pos_embed_height_rel
transpose_10 = self_self_stages_3_0_self_attn_pos_embed_height_rel.transpose(-1, -2); self_self_stages_3_0_self_attn_pos_embed_height_rel = None
matmul_6 = transpose_9 @ transpose_10; transpose_9 = transpose_10 = None
reshape_19 = matmul_6.reshape(-1, 4, 23); matmul_6 = None
pad_8 = torch.nn.functional.pad(reshape_19, [0, 1]); reshape_19 = None
flatten_3 = pad_8.flatten(1); pad_8 = None
pad_9 = torch.nn.functional.pad(flatten_3, [0, 19]); flatten_3 = None
reshape_20 = pad_9.reshape(-1, 5, 23); pad_9 = None
getitem_7 = reshape_20[(slice(None, None, None), slice(None, 4, None), slice(11, None, None))]; reshape_20 = None
reshape_21 = getitem_7.reshape(4096, 4, 1, 4, 12); getitem_7 = None
expand_3 = reshape_21.expand(-1, -1, 12, -1, -1); reshape_21 = None
permute_8 = expand_3.permute((0, 3, 1, 4, 2)); expand_3 = None
add_33 = permute_8 + permute_7; permute_8 = permute_7 = None
reshape_22 = add_33.reshape(1024, 4, 16, -1); add_33 = None
add_34 = mul_6 + reshape_22; mul_6 = reshape_22 = None
softmax_1 = add_34.softmax(dim = -1); add_34 = None
matmul_7 = softmax_1 @ getitem_5; softmax_1 = getitem_5 = None
transpose_11 = matmul_7.transpose(1, 3); matmul_7 = None
reshape_23 = transpose_11.reshape(-1, 4, 4, 2, 2); transpose_11 = None
permute_9 = reshape_23.permute(0, 3, 1, 4, 2); reshape_23 = None
contiguous_1 = permute_9.contiguous(); permute_9 = None
view_11 = contiguous_1.view(128, 512, 8, 8); contiguous_1 = None
self_self_stages_3_0_self_attn_pool = self.self_self_stages_3_0_self_attn_pool(view_11); view_11 = None
add_35 = self_stages_3_0_post_attn_num_batches_tracked_0 + 1; self_stages_3_0_post_attn_num_batches_tracked_0 = None
batch_norm_25 = torch.nn.functional.batch_norm(self_self_stages_3_0_self_attn_pool, self_stages_3_0_post_attn_running_mean, self_stages_3_0_post_attn_running_var, self_stages_3_0_post_attn_weight, self_stages_3_0_post_attn_bias, True, 0.1, 1e-05); self_self_stages_3_0_self_attn_pool = self_stages_3_0_post_attn_running_mean = self_stages_3_0_post_attn_running_var = self_stages_3_0_post_attn_weight = self_stages_3_0_post_attn_bias = None
self_self_stages_3_0_post_attn_drop = self.self_self_stages_3_0_post_attn_drop(batch_norm_25); batch_norm_25 = None
self_self_stages_3_0_post_attn_act = self.self_self_stages_3_0_post_attn_act(self_self_stages_3_0_post_attn_drop); self_self_stages_3_0_post_attn_drop = None
self_self_stages_3_0_conv3_1x1_conv = self.self_self_stages_3_0_conv3_1x1_conv(self_self_stages_3_0_post_attn_act); self_self_stages_3_0_post_attn_act = None
add_36 = self_stages_3_0_conv3_1x1_bn_num_batches_tracked_0 + 1; self_stages_3_0_conv3_1x1_bn_num_batches_tracked_0 = None
batch_norm_26 = torch.nn.functional.batch_norm(self_self_stages_3_0_conv3_1x1_conv, self_stages_3_0_conv3_1x1_bn_running_mean, self_stages_3_0_conv3_1x1_bn_running_var, self_stages_3_0_conv3_1x1_bn_weight, self_stages_3_0_conv3_1x1_bn_bias, True, 0.1, 1e-05); self_self_stages_3_0_conv3_1x1_conv = self_stages_3_0_conv3_1x1_bn_running_mean = self_stages_3_0_conv3_1x1_bn_running_var = self_stages_3_0_conv3_1x1_bn_weight = self_stages_3_0_conv3_1x1_bn_bias = None
self_self_stages_3_0_conv3_1x1_bn_drop = self.self_self_stages_3_0_conv3_1x1_bn_drop(batch_norm_26); batch_norm_26 = None
self_self_stages_3_0_conv3_1x1_bn_act = self.self_self_stages_3_0_conv3_1x1_bn_act(self_self_stages_3_0_conv3_1x1_bn_drop); self_self_stages_3_0_conv3_1x1_bn_drop = None
self_self_stages_3_0_drop_path = self.self_self_stages_3_0_drop_path(self_self_stages_3_0_conv3_1x1_bn_act); self_self_stages_3_0_conv3_1x1_bn_act = None
self_self_stages_3_0_shortcut_conv = self.self_self_stages_3_0_shortcut_conv(self_self_stages_2_1_act); self_self_stages_2_1_act = None
add_37 = self_stages_3_0_shortcut_bn_num_batches_tracked_0 + 1; self_stages_3_0_shortcut_bn_num_batches_tracked_0 = None
batch_norm_27 = torch.nn.functional.batch_norm(self_self_stages_3_0_shortcut_conv, self_stages_3_0_shortcut_bn_running_mean, self_stages_3_0_shortcut_bn_running_var, self_stages_3_0_shortcut_bn_weight, self_stages_3_0_shortcut_bn_bias, True, 0.1, 1e-05); self_self_stages_3_0_shortcut_conv = self_stages_3_0_shortcut_bn_running_mean = self_stages_3_0_shortcut_bn_running_var = self_stages_3_0_shortcut_bn_weight = self_stages_3_0_shortcut_bn_bias = None
self_self_stages_3_0_shortcut_bn_drop = self.self_self_stages_3_0_shortcut_bn_drop(batch_norm_27); batch_norm_27 = None
self_self_stages_3_0_shortcut_bn_act = self.self_self_stages_3_0_shortcut_bn_act(self_self_stages_3_0_shortcut_bn_drop); self_self_stages_3_0_shortcut_bn_drop = None
add_38 = self_self_stages_3_0_drop_path + self_self_stages_3_0_shortcut_bn_act; self_self_stages_3_0_drop_path = self_self_stages_3_0_shortcut_bn_act = None
self_self_stages_3_0_act = self.self_self_stages_3_0_act(add_38); add_38 = None
self_self_stages_3_1_conv1_1x1_conv = self.self_self_stages_3_1_conv1_1x1_conv(self_self_stages_3_0_act)
add_39 = self_stages_3_1_conv1_1x1_bn_num_batches_tracked_0 + 1; self_stages_3_1_conv1_1x1_bn_num_batches_tracked_0 = None
batch_norm_28 = torch.nn.functional.batch_norm(self_self_stages_3_1_conv1_1x1_conv, self_stages_3_1_conv1_1x1_bn_running_mean, self_stages_3_1_conv1_1x1_bn_running_var, self_stages_3_1_conv1_1x1_bn_weight, self_stages_3_1_conv1_1x1_bn_bias, True, 0.1, 1e-05); self_self_stages_3_1_conv1_1x1_conv = self_stages_3_1_conv1_1x1_bn_running_mean = self_stages_3_1_conv1_1x1_bn_running_var = self_stages_3_1_conv1_1x1_bn_weight = self_stages_3_1_conv1_1x1_bn_bias = None
self_self_stages_3_1_conv1_1x1_bn_drop = self.self_self_stages_3_1_conv1_1x1_bn_drop(batch_norm_28); batch_norm_28 = None
self_self_stages_3_1_conv1_1x1_bn_act = self.self_self_stages_3_1_conv1_1x1_bn_act(self_self_stages_3_1_conv1_1x1_bn_drop); self_self_stages_3_1_conv1_1x1_bn_drop = None
self_self_stages_3_1_conv2_kxk = self.self_self_stages_3_1_conv2_kxk(self_self_stages_3_1_conv1_1x1_bn_act); self_self_stages_3_1_conv1_1x1_bn_act = None
self_self_stages_3_1_self_attn_q = self.self_self_stages_3_1_self_attn_q(self_self_stages_3_1_conv2_kxk)
reshape_24 = self_self_stages_3_1_self_attn_q.reshape(-1, 16, 1, 8, 1, 8); self_self_stages_3_1_self_attn_q = None
permute_10 = reshape_24.permute(0, 1, 3, 5, 2, 4); reshape_24 = None
reshape_25 = permute_10.reshape(1024, 16, -1, 1); permute_10 = None
transpose_12 = reshape_25.transpose(1, 3); reshape_25 = None
self_self_stages_3_1_self_attn_kv = self.self_self_stages_3_1_self_attn_kv(self_self_stages_3_1_conv2_kxk); self_self_stages_3_1_conv2_kxk = None
pad_10 = torch.nn.functional.pad(self_self_stages_3_1_self_attn_kv, [2, 2, 2, 2]); self_self_stages_3_1_self_attn_kv = None
unfold_4 = pad_10.unfold(2, 12, 8); pad_10 = None
unfold_5 = unfold_4.unfold(3, 12, 8); unfold_4 = None
reshape_26 = unfold_5.reshape(1024, 80, 1, -1); unfold_5 = None
permute_11 = reshape_26.permute(0, 2, 3, 1); reshape_26 = None
split_2 = torch.functional.split(permute_11, [16, 64], dim = -1); permute_11 = None
getitem_8 = split_2[0]
getitem_9 = split_2[1]; split_2 = None
transpose_13 = getitem_8.transpose(-1, -2); getitem_8 = None
matmul_8 = transpose_12 @ transpose_13; transpose_13 = None
mul_7 = matmul_8 * 0.25; matmul_8 = None
reshape_27 = transpose_12.reshape(-1, 8, 8, 16); transpose_12 = None
self_self_stages_3_1_self_attn_pos_embed_width_rel = self.self_self_stages_3_1_self_attn_pos_embed_width_rel
transpose_14 = self_self_stages_3_1_self_attn_pos_embed_width_rel.transpose(-1, -2); self_self_stages_3_1_self_attn_pos_embed_width_rel = None
matmul_9 = reshape_27 @ transpose_14; transpose_14 = None
reshape_28 = matmul_9.reshape(-1, 8, 23); matmul_9 = None
pad_11 = torch.nn.functional.pad(reshape_28, [0, 1]); reshape_28 = None
flatten_4 = pad_11.flatten(1); pad_11 = None
pad_12 = torch.nn.functional.pad(flatten_4, [0, 15]); flatten_4 = None
reshape_29 = pad_12.reshape(-1, 9, 23); pad_12 = None
getitem_10 = reshape_29[(slice(None, None, None), slice(None, 8, None), slice(11, None, None))]; reshape_29 = None
reshape_30 = getitem_10.reshape(1024, 8, 1, 8, 12); getitem_10 = None
expand_4 = reshape_30.expand(-1, -1, 12, -1, -1); reshape_30 = None
permute_12 = expand_4.permute((0, 1, 3, 2, 4)); expand_4 = None
transpose_15 = reshape_27.transpose(1, 2); reshape_27 = None
self_self_stages_3_1_self_attn_pos_embed_height_rel = self.self_self_stages_3_1_self_attn_pos_embed_height_rel
transpose_16 = self_self_stages_3_1_self_attn_pos_embed_height_rel.transpose(-1, -2); self_self_stages_3_1_self_attn_pos_embed_height_rel = None
matmul_10 = transpose_15 @ transpose_16; transpose_15 = transpose_16 = None
reshape_31 = matmul_10.reshape(-1, 8, 23); matmul_10 = None
pad_13 = torch.nn.functional.pad(reshape_31, [0, 1]); reshape_31 = None
flatten_5 = pad_13.flatten(1); pad_13 = None
pad_14 = torch.nn.functional.pad(flatten_5, [0, 15]); flatten_5 = None
reshape_32 = pad_14.reshape(-1, 9, 23); pad_14 = None
getitem_11 = reshape_32[(slice(None, None, None), slice(None, 8, None), slice(11, None, None))]; reshape_32 = None
reshape_33 = getitem_11.reshape(1024, 8, 1, 8, 12); getitem_11 = None
expand_5 = reshape_33.expand(-1, -1, 12, -1, -1); reshape_33 = None
permute_13 = expand_5.permute((0, 3, 1, 4, 2)); expand_5 = None
add_40 = permute_13 + permute_12; permute_13 = permute_12 = None
reshape_34 = add_40.reshape(1024, 1, 64, -1); add_40 = None
add_41 = mul_7 + reshape_34; mul_7 = reshape_34 = None
softmax_2 = add_41.softmax(dim = -1); add_41 = None
matmul_11 = softmax_2 @ getitem_9; softmax_2 = getitem_9 = None
transpose_17 = matmul_11.transpose(1, 3); matmul_11 = None
reshape_35 = transpose_17.reshape(-1, 8, 8, 1, 1); transpose_17 = None
permute_14 = reshape_35.permute(0, 3, 1, 4, 2); reshape_35 = None
contiguous_2 = permute_14.contiguous(); permute_14 = None
view_12 = contiguous_2.view(128, 512, 8, 8); contiguous_2 = None
self_self_stages_3_1_self_attn_pool = self.self_self_stages_3_1_self_attn_pool(view_12); view_12 = None
add_42 = self_stages_3_1_post_attn_num_batches_tracked_0 + 1; self_stages_3_1_post_attn_num_batches_tracked_0 = None
batch_norm_29 = torch.nn.functional.batch_norm(self_self_stages_3_1_self_attn_pool, self_stages_3_1_post_attn_running_mean, self_stages_3_1_post_attn_running_var, self_stages_3_1_post_attn_weight, self_stages_3_1_post_attn_bias, True, 0.1, 1e-05); self_self_stages_3_1_self_attn_pool = self_stages_3_1_post_attn_running_mean = self_stages_3_1_post_attn_running_var = self_stages_3_1_post_attn_weight = self_stages_3_1_post_attn_bias = None
self_self_stages_3_1_post_attn_drop = self.self_self_stages_3_1_post_attn_drop(batch_norm_29); batch_norm_29 = None
self_self_stages_3_1_post_attn_act = self.self_self_stages_3_1_post_attn_act(self_self_stages_3_1_post_attn_drop); self_self_stages_3_1_post_attn_drop = None
self_self_stages_3_1_conv3_1x1_conv = self.self_self_stages_3_1_conv3_1x1_conv(self_self_stages_3_1_post_attn_act); self_self_stages_3_1_post_attn_act = None
add_43 = self_stages_3_1_conv3_1x1_bn_num_batches_tracked_0 + 1; self_stages_3_1_conv3_1x1_bn_num_batches_tracked_0 = None
batch_norm_30 = torch.nn.functional.batch_norm(self_self_stages_3_1_conv3_1x1_conv, self_stages_3_1_conv3_1x1_bn_running_mean, self_stages_3_1_conv3_1x1_bn_running_var, self_stages_3_1_conv3_1x1_bn_weight, self_stages_3_1_conv3_1x1_bn_bias, True, 0.1, 1e-05); self_self_stages_3_1_conv3_1x1_conv = self_stages_3_1_conv3_1x1_bn_running_mean = self_stages_3_1_conv3_1x1_bn_running_var = self_stages_3_1_conv3_1x1_bn_weight = self_stages_3_1_conv3_1x1_bn_bias = None
self_self_stages_3_1_conv3_1x1_bn_drop = self.self_self_stages_3_1_conv3_1x1_bn_drop(batch_norm_30); batch_norm_30 = None
self_self_stages_3_1_conv3_1x1_bn_act = self.self_self_stages_3_1_conv3_1x1_bn_act(self_self_stages_3_1_conv3_1x1_bn_drop); self_self_stages_3_1_conv3_1x1_bn_drop = None
self_self_stages_3_1_drop_path = self.self_self_stages_3_1_drop_path(self_self_stages_3_1_conv3_1x1_bn_act); self_self_stages_3_1_conv3_1x1_bn_act = None
self_self_stages_3_1_shortcut = self.self_self_stages_3_1_shortcut(self_self_stages_3_0_act); self_self_stages_3_0_act = None
add_44 = self_self_stages_3_1_drop_path + self_self_stages_3_1_shortcut; self_self_stages_3_1_drop_path = self_self_stages_3_1_shortcut = None
self_self_stages_3_1_act = self.self_self_stages_3_1_act(add_44); add_44 = None
self_self_final_conv = self.self_self_final_conv(self_self_stages_3_1_act); self_self_stages_3_1_act = None
self_self_head_global_pool_pool = self.self_self_head_global_pool_pool(self_self_final_conv); self_self_final_conv = None
self_self_head_global_pool_flatten = self.self_self_head_global_pool_flatten(self_self_head_global_pool_pool); self_self_head_global_pool_pool = None
self_self_head_fc = self.self_self_head_fc(self_self_head_global_pool_flatten); self_self_head_global_pool_flatten = None
self_self_head_flatten = self.self_self_head_flatten(self_self_head_fc); self_self_head_fc = None
return (self_self_head_flatten, add, add_1, add_2, add_3, add_4, add_5, add_6, add_8, add_9, add_10, add_12, add_13, add_14, add_15, add_17, add_18, add_19, add_21, add_22, add_23, add_24, add_26, add_29, add_30, add_32, add_35, add_36, add_37, add_39, add_42, add_43)
mod = Repro()
opt_mod = torch._dynamo.optimize("inductor")(mod)
with torch.cuda.amp.autocast(enabled=True):
ref = run_fwd_maybe_bwd(mod, args)
res = run_fwd_maybe_bwd(opt_mod, args)
```
cc @ezyang @soumith @msaroufim @wconstab @ngimel @bdhirsh
| 0 |
4,160 | 93,434 |
[inductor][Seg fault] Inductor segfaulting with few AMP models
|
triaged, bug, oncall: pt2
|
### 🐛 Describe the bug
The following repro segfaults. Note that **it is flaky**, so might need to run multiple times.
### Error logs
~~~
Traceback (most recent call last):
File "/scratch/anijain/work/pytorch/fail_triton.py", line 17, in <module>
triton_fused_scatter_add_new_zeros_408_scatter_add_1_new_zeros_409_unsqueeze_1189_expand_15 = async_compile.triton('''
File "/scratch/anijain/work/pytorch/torch/_inductor/codecache.py", line 463, in triton
return _load_kernel(source_code)
File "/scratch/anijain/work/pytorch/torch/_inductor/codecache.py", line 339, in _load_kernel
kernel.precompile()
File "/scratch/anijain/work/pytorch/torch/_inductor/triton_ops/autotune.py", line 58, in precompile
self.launchers = [
File "/scratch/anijain/work/pytorch/torch/_inductor/triton_ops/autotune.py", line 59, in <listcomp>
self._precompile_config(c, warm_cache_only_with_cc)
File "/scratch/anijain/work/pytorch/torch/_inductor/triton_ops/autotune.py", line 84, in _precompile_config
binary = triton.compile(
File "/scratch/anijain/work/triton/python/triton/compiler.py", line 1256, in compile
asm, shared, kernel_name = _compile(fn, signature, device, constants, configs[0], num_warps, num_stages,
File "/scratch/anijain/work/triton/python/triton/compiler.py", line 901, in _compile
name, asm, shared_mem = _triton.code_gen.compile_ttir(backend, module, device, num_warps, num_stages, extern_libs, cc)
RuntimeError: Internal Triton PTX codegen error:
Segmentation fault (core dumped)
~~~
### Minified repro
~~~
from ctypes import c_void_p, c_long
import torch
import random
from torch import empty_strided, as_strided, device
from torch._inductor.codecache import AsyncCompile
aten = torch.ops.aten
assert_size_stride = torch._C._dynamo.guards.assert_size_stride
async_compile = AsyncCompile()
import triton
import triton.language as tl
from torch._inductor.triton_ops.autotune import grid
from torch._C import _cuda_getCurrentRawStream as get_cuda_stream
triton_fused_scatter_add_new_zeros_408_scatter_add_1_new_zeros_409_unsqueeze_1189_expand_15 = async_compile.triton('''
import triton
import triton.language as tl
from torch._inductor.ir import ReductionHint
from torch._inductor.ir import TileHint
from torch._inductor.triton_ops.autotune import pointwise
from torch._inductor.utils import instance_descriptor
@pointwise(size_hints=[1048576], filename=__file__, meta={'signature': {0: '*i64', 1: '*fp16', 2: '*fp16', 3: 'i32'}, 'device': 0, 'constants': {}, 'configs': [instance_descriptor(divisible_by_16=(0, 1, 2, 3), equal_to_1=())]})
@triton.jit
def kernel(in_ptr0, in_ptr1, out_ptr0, xnumel, XBLOCK : tl.constexpr):
xnumel = 900000
xoffset = tl.program_id(0) * XBLOCK
xindex = xoffset + tl.reshape(tl.arange(0, XBLOCK), [XBLOCK])
xmask = xindex < xnumel
x3 = (xindex // 90)
x4 = xindex
x0 = xindex % 90
x2 = (xindex // 450000)
tmp0 = tl.load(in_ptr0 + (x3), xmask)
tmp1 = tl.load(in_ptr1 + (x4), xmask).to(tl.float32)
tl.atomic_add(out_ptr0 + (x0 + (90*tmp0) + (6905250*x2) + tl.zeros([XBLOCK], tl.int32)), tmp1, xmask)
''')
async_compile.wait(globals())
del async_compile
~~~
cc @ezyang @soumith @msaroufim @wconstab @ngimel @bdhirsh
| 4 |
4,161 | 93,432 |
Should torchdynamo specialize on nn.Module
|
triaged, oncall: pt2
|
This is an open design question with several discussion threads, and unclear motivations and perf/risk tradeoffs. I'm opening the issue in part to organize the discussion, and see if we can align on a direction.
There are 2 behaviors that are interesting and somewhat orthogonal.
1. dynamo **specializes** on nn.module instances, meaning it places a (ref?) to the module in its traced graphmodule's `.parameters` field, and guards only on the id() of the nn.module matching at runtime. It also monkeypatches the module's __setattr__ so that it can detect (most) changes to the module at runtime, and invalidate the specialization, causing a recompile
2. **`call_module`** nodes are inserted in the graph for nn.Modules, rather than tracing into the module and recording torch function calls.
(1) is a potential issue in that we cannot detect modifications to C++ part of nn.Module that don't go through python API, e.g. some sketchy stuff FSDP does). But it is also an important perf optimization because it reduces the number of guards in the system, and provides a way for backend compilers to keep a list of .parameters() tensors separate from input tensors, and apply specializing optimizations just to the parameters.
(2) could be an issue if code inside nn.modules isn't well behaved- tracing deeper would be safer, at the cost of more exposure to having graph-breaks. It has been proposed to change just (2) to unify dynamo's IR trace level, even if (1) is left as it is.
For now i'm not proposing to rush to a change or a decision, but i'd like to sharpen the above description, including the set of constraints and problems and goals based on your feedback.
cc @ezyang @soumith @msaroufim @ngimel @bdhirsh
| 2 |
4,162 | 89,320 |
`masked_fill` with `FloatTensor` mask will never mask but fails silently.
|
triaged, module: correctness (silent), module: masked operators
|
### 🐛 Describe the bug
Passing `bool` or `int` tensors as a mask input to `masked_fill` returns the excepted result, but a `float` tensor will not mask and returns input tensor silently.
```
import torch
x = torch.rand(4, 4)
m = torch.rand(4, 4) > 0.5
print(m, '\n')
print(x.masked_fill(m , 0.), '\n')
print(x.masked_fill(m.int() , 0.), '\n')
print(x.masked_fill(m.float() , 0.), '\n')
```
Output:
```
tensor([[False, False, True, True],
[ True, False, False, False],
[ True, True, False, False],
[ True, True, False, False]])
tensor([[0.8455, 0.7714, 0.0000, 0.0000],
[0.0000, 0.1767, 0.9352, 0.1114],
[0.0000, 0.0000, 0.7616, 0.2102],
[0.0000, 0.0000, 0.4796, 0.1690]])
tensor([[0.8455, 0.7714, 0.0000, 0.0000],
[0.0000, 0.1767, 0.9352, 0.1114],
[0.0000, 0.0000, 0.7616, 0.2102],
[0.0000, 0.0000, 0.4796, 0.1690]])
tensor([[0.8455, 0.7714, 0.7397, 0.3867],
[0.8923, 0.1767, 0.9352, 0.1114],
[0.9112, 0.1297, 0.7616, 0.2102],
[0.9136, 0.0941, 0.4796, 0.1690]])
```
I feel this behaviour is inconsistent with python's behaviour: `bool(0.0) == False` and `bool(1.0) == True` and should return the same as the other two examples. In any case, it should at least fail when a `FloatTensor` is passed as a mask.
### Versions
```
$ python collect_env.py
Collecting environment information...
PyTorch version: 1.13.0
Is debug build: False
CUDA used to build PyTorch: 11.8
ROCM used to build PyTorch: N/A
OS: Arch Linux (x86_64)
GCC version: (GCC) 12.2.0
Clang version: 14.0.6
CMake version: version 3.24.3
Libc version: glibc-2.36
Python version: 3.10.8 (main, Nov 1 2022, 14:18:21) [GCC 12.2.0] (64-bit runtime)
Python platform: Linux-6.0.8-arch1-1-x86_64-with-glibc2.36
Is CUDA available: True
CUDA runtime version: 11.8.89
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration: GPU 0: NVIDIA GeForce GTX 1080 Ti
Nvidia driver version: 520.56.06
cuDNN version: Probably one of the following:
/usr/lib/libcudnn.so.8.6.0
/usr/lib/libcudnn_adv_infer.so.8.6.0
/usr/lib/libcudnn_adv_train.so.8.6.0
/usr/lib/libcudnn_cnn_infer.so.8.6.0
/usr/lib/libcudnn_cnn_train.so.8.6.0
/usr/lib/libcudnn_ops_infer.so.8.6.0
/usr/lib/libcudnn_ops_train.so.8.6.0
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] mypy==0.982
[pip3] mypy-extensions==0.4.3
[pip3] numpy==1.23.4
[pip3] rotary-embedding-torch==0.1.5
[pip3] torch==1.13.0
[pip3] torchtext==0.10.0a0+0d670e0
[conda] nomkl 3.0 0
```
I also reproduced this on a Ubuntu 20 internal node, but don't have access to the env right now.
| 0 |
4,163 | 89,303 |
code sharing for fundamental ops in quantization
|
oncall: quantization, triaged
|
### 🐛 Describe the bug
As @vkuzo mentioned in https://github.com/pytorch/pytorch/pull/89269#discussion_r1026672280 we should share the code for ops that's critical for numerics in quantization, such as quantize_per_tensor, quantize_per_channel, fake quantize, and dequantize ops, this will help us to have identical numerics across different flows (QAT, PTQ) and different APIs (convert_to_reference_fx, _convert_to_reference_decomposed_fx)
### Versions
master
cc @jianyuh @raghuramank100 @jamesr66a @vkuzo @jgong5 @Xia-Weiwen @leslie-fang-intel
| 0 |
4,164 | 89,301 |
Meta implementation for copy_ is wrong
|
triaged, module: meta tensors
|
### 🐛 Describe the bug
Currently, the meta impl for copy_ just returns self without performing any checks. This is wrong and we should fix this.
CPU tensor: (correctly fails)
```
>>> x=torch.randn([5, 1]).expand(5, 5)
>>> x.stride()
(1, 0)
>>> sqrt=x.sqrt()
>>> sqrt.stride()
(5, 1)
>>> x.copy_(sqrt)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
RuntimeError: unsupported operation: more than one element of the written-to tensor refers to a single memory location. Please clone() the tensor before performing the operation.
```
Meta (incorrectly passes):
```
>>> x=torch.randn([5, 1], device='meta').expand(5, 5)
>>> sqrt=x.sqrt()
>>> x.copy_(sqrt)
tensor(..., device='meta', size=(5, 5))
```
### Versions
master
cc @ezyang @eellison @bdhirsh @soumith
| 0 |
4,165 | 93,431 |
[dynamic shapes] detectron2 dynamic shapes fails
|
triaged, oncall: pt2
|
- Install dynamo
- Install D2 (full instruction is [here](https://docs.google.com/document/d/1iOXyMHAkfWw0eKOV-E0yzvMNLIUB0sBRacvEfDNJC88/edit?usp=sharing))
```bash
pip3 install opencv-python
pip3 install scipy
pip3 install shapely
sudo apt install ninja-build # make compilation faster
git clone git@github.com:facebookresearch/detectron2.git
cd detectron2
TORCH_CUDA_ARCH_LIST="Pascal;Volta" pip3 install -e .
Add dynamo model optimization after this line https://github.com/facebookresearch/detectron2/blob/main/tools/lazyconfig_train_net.py#L73
cd projects/ViTDet
```
```bash
python lazy_train_net.py --config-file configs/sanity_check.py --num-gpus 2 dataloader.train.total_batch_size=2
```
It will throw error here https://github.com/facebookresearch/detectron2/blob/main/detectron2/structures/image_list.py#L122
cc @ezyang @msaroufim @wconstab @ngimel @bdhirsh
| 5 |
4,166 | 89,293 |
fbgemm_avx512 build failure
|
module: build, triaged
|
### 🐛 Describe the bug
I'm building git master with the [same Arch recipe](https://raw.githubusercontent.com/archlinux/svntogit-community/packages/python-pytorch/trunk/PKGBUILD).
My CPU is Ryzen 2 and does NOT support AVX-512. fbgemm is programmed wrongly and demands `fbgemm_avx512` even when the main project has disabled it:
```
-- Found OpenMP: TRUE
CMake Warning at third_party/fbgemm/CMakeLists.txt:74 (message):
OpenMP found! OpenMP_C_INCLUDE_DIRS =
File "<string>", line 1
exec(open('defs.bzl').read());print(';'.join(get_fbgemm_avx2_srcs(msvc=)))
^
SyntaxError: invalid syntax
File "<string>", line 1
exec(open('defs.bzl').read());print(';'.join(get_fbgemm_inline_avx2_srcs(msvc=)))
^
SyntaxError: invalid syntax
File "<string>", line 1
exec(open('defs.bzl').read());print(';'.join(get_fbgemm_avx512_srcs(msvc=)))
^
SyntaxError: invalid syntax
File "<string>", line 1
exec(open('defs.bzl').read());print(';'.join(get_fbgemm_inline_avx512_srcs(msvc=)))
^
SyntaxError: invalid syntax
CMake Error at third_party/fbgemm/CMakeLists.txt:135 (target_compile_options):
Cannot specify compile options for target "fbgemm_avx512" which is not
built by this project.
CMake Warning at third_party/fbgemm/CMakeLists.txt:170 (message):
==========
CMake Warning at third_party/fbgemm/CMakeLists.txt:171 (message):
CMAKE_BUILD_TYPE = Release
CMake Warning at third_party/fbgemm/CMakeLists.txt:172 (message):
CMAKE_CXX_FLAGS_DEBUG is -g
CMake Warning at third_party/fbgemm/CMakeLists.txt:173 (message):
CMAKE_CXX_FLAGS_RELEASE is -O3 -DNDEBUG
CMake Warning at third_party/fbgemm/CMakeLists.txt:174 (message):
==========
** AsmJit Summary **
ASMJIT_DIR=./src/pytorch/third_party/fbgemm/third_party/asmjit
ASMJIT_TEST=FALSE
ASMJIT_TARGET_TYPE=STATIC
ASMJIT_DEPS=pthread;rt
ASMJIT_LIBS=asmjit;pthread;rt
ASMJIT_CFLAGS=-DASMJIT_STATIC
ASMJIT_PRIVATE_CFLAGS=-Wall;-Wextra;-Wconversion;-fno-math-errno;-fno-threadsafe-statics;-fno-semantic-interposition;-DASMJIT_STATIC
ASMJIT_PRIVATE_CFLAGS_DBG=
ASMJIT_PRIVATE_CFLAGS_REL=-O2;-fmerge-all-constants;-fno-enforce-eh-specs
CMake Error at third_party/fbgemm/CMakeLists.txt:235 (target_include_directories):
Cannot specify include directories for target "fbgemm_avx512" which is not
built by this project.
CMake Error at third_party/fbgemm/CMakeLists.txt:262 (target_compile_definitions):
Cannot specify compile definitions for target "fbgemm_avx512" which is not
built by this project.
CMake Error at cmake/Dependencies.cmake:826 (set_property):
set_property could not find TARGET fbgemm_avx512. Perhaps it has not yet
been created.
Call Stack (most recent call first):
CMakeLists.txt:719 (include)
```
### Versions
```
PyTorch version: N/A
Is debug build: N/A
CUDA used to build PyTorch: N/A
ROCM used to build PyTorch: N/A
OS: Arch Linux (x86_64)
GCC version: (GCC) 12.2.0
Clang version: 14.0.6
CMake version: version 3.25.0
Libc version: glibc-2.36
Python version: 3.10.8 (main, Nov 1 2022, 14:18:21) [GCC 12.2.0] (64-bit runtime)
Python platform: Linux-6.1.0-1-rc5-mainline-x86_64-with-glibc2.36
Is CUDA available: N/A
CUDA runtime version: Could not collect
CUDA_MODULE_LOADING set to: N/A
GPU models and configuration: Could not collect
Nvidia driver version: Could not collect
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: N/A
Versions of relevant libraries:
[pip3] mypy==0.982
[pip3] mypy-extensions==0.4.3
[pip3] mypy-protobuf==2.9
[pip3] numpy==1.23.4
[pip3] numpy-quaternion==2022.4.2
[pip3] numpydoc==1.5.0
[pip3] oldest-supported-numpy==2022.5.28
[pip3] pytorch-lightning==1.7.7
[pip3] torchaudio==0.12.1+58da317
[pip3] torchfile==0.1.0
[pip3] torchmetrics==0.10.0
[pip3] torchvision==0.14.0a0
[conda] Could not collect
```
cc @malfet @seemethere
| 0 |
4,167 | 93,430 |
[Inductor] [CPU] Crash failure in torchbench model mobilenet_v2_quantized_qat & resnet50_quantized_qat
|
triaged, bug, oncall: pt2
|
### 🐛 Describe the bug
This failure found in the latest [ TorchInductor CPU Performance Dashboard](https://github.com/pytorch/pytorch/issues/93531) refresh test with below error log
SW info:
SW |Nightly commit |Master/Main commit
--|--|--
Pytorch |[0662e90](https://github.com/pytorch/pytorch/commit/0662e90840324708ada3bca6ec316cce8250dc49) |[e2f0648](https://github.com/pytorch/pytorch/commit/e2f0648750f2d0d0ac648728ce4c514db178cfa1)
Torchbench |/ |[022dfe3](https://github.com/pytorch/benchmark/commit/022dfe3d89db9278119bf1cd179997076b5ec5b5)
torchaudio |[4b10b6a](https://github.com/pytorch/audio/commit/4b10b6adece473ad70e221bb3f9442d11906111f) |[74f9a89](https://github.com/pytorch/audio/commit/74f9a894fcd4e7d635919803b364e47577a2b6e8)
torchtext |[71e4561](https://github.com/pytorch/text/commit/71e456119d39cf72a511ce6acb10b737e02102d3) |[c047efe](https://github.com/pytorch/text/commit/c047efeba813ac943cb8046a49e858a8b529d577)
torchvision |[797e1ac](https://github.com/pytorch/vision/commit/797e1acf043621c5b53319032a269cbe1190b018) |[ffd5a56](https://github.com/pytorch/vision/commit/ffd5a567eb90abf6b5555063da434d3c130d540f)
detail info reference the [Dashboard](https://github.com/pytorch/pytorch/issues/93531)
### Error logs
```
ERROR:common:Failed for dynamo
from user code:
File "benchmarks/dynamo/torchbench.py", line 361, in forward_pass
return mod(*inputs)
File "<eval_with_key>.8", line 7, in forward
quantize_per_tensor = torch.quantize_per_tensor(x, features_0_0_input_scale_0, features_0_0_input_zero_point_0, torch.quint8); x = features_0_0_input_scale_0 = features_0_0_input_zero_point_0 = None
Set torch._dynamo.config.verbose=True for more information
You can suppress this exception and fall back to eager by setting:
torch._dynamo.config.suppress_errors = True
Traceback (most recent call last):
File "/workspace/pytorch/torch/_subclasses/fake_tensor.py", line 887, in __torch_dispatch__
r = func(*args, **kwargs)
File "/workspace/pytorch/torch/_ops.py", line 285, in __call__
return self._op(*args, **kwargs or {})
File "/workspace/pytorch/torch/_ops.py", line 367, in _get_dispatch
final_key = resolve_key(self, key)
File "/workspace/pytorch/torch/_ops.py", line 107, in resolve_key
raise NotImplementedError(f"could not find kernel for {op} at dispatch key {k}")
NotImplementedError: could not find kernel for aten.quantize_per_tensor.tensor_qparams at dispatch key DispatchKey.Meta
```
<details>
<summary>see more</summary>
```
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/workspace/pytorch/torch/_dynamo/utils.py", line 1076, in run_node
return node.target(*args, **kwargs)
File "/workspace/pytorch/torch/_subclasses/fake_tensor.py", line 892, in __torch_dispatch__
return run_fallback_kernel(self, func, args, kwargs, not_implemented_error)
File "/workspace/pytorch/torch/_subclasses/fake_tensor.py", line 1068, in run_fallback_kernel
return tree_map(map_out, r)
File "/workspace/pytorch/torch/utils/_pytree.py", line 195, in tree_map
return tree_unflatten([fn(i) for i in flat_args], spec)
File "/workspace/pytorch/torch/utils/_pytree.py", line 195, in <listcomp>
return tree_unflatten([fn(i) for i in flat_args], spec)
File "/workspace/pytorch/torch/_subclasses/fake_tensor.py", line 1064, in map_out
return fake_mode.fake_tensor_converter(fake_mode, e)
File "/workspace/pytorch/torch/_subclasses/fake_tensor.py", line 262, in __call__
return self.from_real_tensor(fake_mode, t, make_constant, shape_env=shape_env)
File "/workspace/pytorch/torch/_subclasses/fake_tensor.py", line 214, in from_real_tensor
raise UnsupportedFakeTensorException("quantized nyi in meta tensors")
torch._subclasses.fake_tensor.UnsupportedFakeTensorException: quantized nyi in meta tensors
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "/workspace/pytorch/torch/_dynamo/utils.py", line 1042, in get_fake_value
return wrap_fake_exception(
File "/workspace/pytorch/torch/_dynamo/utils.py", line 721, in wrap_fake_exception
return fn()
File "/workspace/pytorch/torch/_dynamo/utils.py", line 1043, in <lambda>
lambda: run_node(tx.output, node, args, kwargs, nnmodule)
File "/workspace/pytorch/torch/_dynamo/utils.py", line 1085, in run_node
raise RuntimeError(
RuntimeError: Failed running call_function <built-in method quantize_per_tensor of type object at 0x7fab96d3fd20>(*(FakeTensor(FakeTensor(..., device='meta', size=(96, 3, 224, 224)), cpu), FakeTensor(FakeTensor(..., device='meta', size=()), cpu), FakeTensor(FakeTensor(..., device='meta', size=(), dtype=torch.int64), cpu), torch.quint8), **{}):
quantized nyi in meta tensors
(scroll up for backtrace)
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "/workspace/pytorch/benchmarks/dynamo/common.py", line 1204, in warmup
fn(model, example_inputs)
File "/workspace/pytorch/torch/_dynamo/eval_frame.py", line 169, in _fn
return fn(*args, **kwargs)
File "/workspace/pytorch/torch/_dynamo/eval_frame.py", line 247, in catch_errors
return callback(frame, cache_size)
File "/workspace/pytorch/torch/_dynamo/convert_frame.py", line 476, in _convert_frame
result = inner_convert(frame, cache_size)
File "/workspace/pytorch/torch/_dynamo/convert_frame.py", line 118, in _fn
return fn(*args, **kwargs)
File "/workspace/pytorch/torch/_dynamo/utils.py", line 89, in time_wrapper
r = func(*args, **kwargs)
File "/workspace/pytorch/torch/_dynamo/convert_frame.py", line 349, in _convert_frame_assert
return _compile(
File "/workspace/pytorch/torch/_dynamo/convert_frame.py", line 404, in _compile
out_code = transform_code_object(code, transform)
File "/workspace/pytorch/torch/_dynamo/bytecode_transformation.py", line 341, in transform_code_object
transformations(instructions, code_options)
File "/workspace/pytorch/torch/_dynamo/convert_frame.py", line 392, in transform
tracer.run()
File "/workspace/pytorch/torch/_dynamo/symbolic_convert.py", line 1612, in run
super().run()
File "/workspace/pytorch/torch/_dynamo/symbolic_convert.py", line 478, in run
and self.step()
File "/workspace/pytorch/torch/_dynamo/symbolic_convert.py", line 448, in step
getattr(self, inst.opname)(inst)
File "/workspace/pytorch/torch/_dynamo/symbolic_convert.py", line 282, in wrapper
return inner_fn(self, inst)
File "/workspace/pytorch/torch/_dynamo/symbolic_convert.py", line 942, in CALL_FUNCTION_EX
self.call_function(fn, argsvars.items, kwargsvars.items)
File "/workspace/pytorch/torch/_dynamo/symbolic_convert.py", line 390, in call_function
self.push(fn.call_function(self, args, kwargs))
File "/workspace/pytorch/torch/_dynamo/variables/nn_module.py", line 222, in call_function
return tx.inline_user_function_return(
File "/workspace/pytorch/torch/_dynamo/symbolic_convert.py", line 419, in inline_user_function_return
result = InliningInstructionTranslator.inline_call(self, fn, args, kwargs)
File "/workspace/pytorch/torch/_dynamo/symbolic_convert.py", line 1684, in inline_call
return cls.inline_call_(parent, func, args, kwargs)
File "/workspace/pytorch/torch/_dynamo/symbolic_convert.py", line 1738, in inline_call_
tracer.run()
File "/workspace/pytorch/torch/_dynamo/symbolic_convert.py", line 478, in run
and self.step()
File "/workspace/pytorch/torch/_dynamo/symbolic_convert.py", line 448, in step
getattr(self, inst.opname)(inst)
File "/workspace/pytorch/torch/_dynamo/symbolic_convert.py", line 282, in wrapper
return inner_fn(self, inst)
File "/workspace/pytorch/torch/_dynamo/symbolic_convert.py", line 905, in CALL_FUNCTION
self.call_function(fn, args, {})
File "/workspace/pytorch/torch/_dynamo/symbolic_convert.py", line 390, in call_function
self.push(fn.call_function(self, args, kwargs))
File "/workspace/pytorch/torch/_dynamo/variables/torch.py", line 406, in call_function
tensor_variable = wrap_fx_proxy(
File "/workspace/pytorch/torch/_dynamo/variables/builder.py", line 636, in wrap_fx_proxy
return wrap_fx_proxy_cls(
File "/workspace/pytorch/torch/_dynamo/variables/builder.py", line 676, in wrap_fx_proxy_cls
example_value = get_fake_value(proxy.node, tx)
File "/workspace/pytorch/torch/_dynamo/utils.py", line 1055, in get_fake_value
raise TorchRuntimeError() from e
torch._dynamo.exc.TorchRuntimeError:
from user code:
File "benchmarks/dynamo/torchbench.py", line 361, in forward_pass
return mod(*inputs)
File "<eval_with_key>.8", line 7, in forward
quantize_per_tensor = torch.quantize_per_tensor(x, features_0_0_input_scale_0, features_0_0_input_zero_point_0, torch.quint8); x = features_0_0_input_scale_0 = features_0_0_input_zero_point_0 = None
Set torch._dynamo.config.verbose=True for more information
You can suppress this exception and fall back to eager by setting:
torch._dynamo.config.suppress_errors = True
```
</details>
### Minified repro
`python benchmarks/dynamo/torchbench.py --performance --float32 -dcpu -n50 --inductor --no-skip --dashboard --only=mobilenet_v2_quantized_qat `
cc @ezyang @soumith @msaroufim @wconstab @ngimel @bdhirsh
| 10 |
4,168 | 89,283 |
torch.randn and torch.normal sometimes produce NaN on mps device
|
triaged, module: random, module: mps
|
### 🐛 Describe the bug
Using the function torch.randn (and torch.normal) on the mps device sometimes produces unexpected NaN in the generated tensor.
```python
import torch
for i in range(10000):
jitter = torch.randn((32, 1000), device="mps")
if torch.any(torch.isnan(jitter)):
print(f"NaN generated at iter: {i}")
break
```
```bash
>>> NaN generated at iter: 246
```
### Versions
```bash
>>> python collect_env.py
Collecting environment information...
PyTorch version: 1.13.0
Is debug build: False
CUDA used to build PyTorch: None
ROCM used to build PyTorch: N/A
OS: macOS 12.6 (arm64)
GCC version: Could not collect
Clang version: 14.0.0 (clang-1400.0.29.102)
CMake version: Could not collect
Libc version: N/A
Python version: 3.10.7 (main, Nov 9 2022, 12:38:27) [Clang 14.0.0 (clang-1400.0.29.102)] (64-bit runtime)
Python platform: macOS-12.6-arm64-arm-64bit
Is CUDA available: False
CUDA runtime version: No CUDA
CUDA_MODULE_LOADING set to: N/A
GPU models and configuration: No CUDA
Nvidia driver version: No CUDA
cuDNN version: No CUDA
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] mypy-extensions==0.4.3
[pip3] numpy==1.23.4
[pip3] torch==1.13.0
[pip3] torchmetrics==0.10.2
[conda] Could not collect
```
cc @pbelevich @kulinseth @albanD @malfet @DenisVieriu97 @razarmehr @abhudev
| 2 |
4,169 | 89,277 |
NotImplementedError: The operator 'aten::upsample_nearest1d.out' is not current implemented for the MPS device
|
triaged, module: mps
|
## Issue description
It seems nn.Upsample(scale_factor=self.upsample_kernels[k]) has not implemented for M1
Provide a short description.
I have created an encoder and decoder model in the decoding part for upsampling I have used nn.Upsample(). It is working in CUDA environment but not working in M1
## Code example
filters=[128*2, 64*2, 32*2, 16*2]
upsample_kernels=[1, 2, 2, 2]
in_channels=512
out_channels=3
upsamples = nn.ModuleList([nn.Sequential(
nn.Upsample(scale_factor=upsample_kernels[k]),
ConvBNReLU(
in_channels=in_channels if k == 0 else filters[k - 1],
out_channels=filters[k],
kernel_size=kernel_size,
activation='relu',
)
) for k in range(4)])
class ConvBNReLU(nn.Module):
def __init__(self, in_channels=5, out_channels=5, kernel_size=3, dilation=1, activation="relu"):
super().__init__()
self.in_channels = in_channels
self.out_channels = out_channels
self.kernel_size = kernel_size
self.dilation = dilation
self.activation = activation
self.padding = (self.kernel_size + (self.kernel_size - 1) * (self.dilation - 1) - 1) // 2
self.layers = nn.Sequential(
nn.ConstantPad1d(padding=(self.padding, self.padding), value=0),
nn.Conv1d(
in_channels=self.in_channels,
out_channels=self.out_channels,
kernel_size=self.kernel_size,
dilation=self.dilation,
bias=True,
),
nn.ReLU(),
nn.BatchNorm1d(self.out_channels),
)
nn.init.xavier_uniform_(self.layers[1].weight)
nn.init.zeros_(self.layers[1].bias)
def forward(self, x):
return self.layers(x)
Please try to provide a minimal example to repro the bug.
Error messages and stack traces are also helpful.
NotImplementedError Traceback (most recent call last)
Input In [21], in <cell line: 1>()
----> 1 model, loss_tracking = doormodeltraining.Train_The_Model(model, trainLoader, valLoader, criterion, DEVICE, opt, scheduler, wandb, epoches=epoches, min=min_, max=max_, )
File ~/Documents/pytorchGPUM1/doorstuff/doormodeltraining.py:72, in Train_The_Model(model, trainLoader, valLoader, criterion, DEVICE, opt, scheduler, wandb, epoches, min, max, is_dim)
70 x= x.to(DEVICE)
71 Y = Y.to(DEVICE)
---> 72 pred = model(x)
73 #print(pred.shape)
74 #loss = criterion(pred, Y)
75 opt.zero_grad()
File ~/opt/anaconda3/envs/m1torch/lib/python3.9/site-packages/torch/nn/modules/module.py:1130, in Module._call_impl(self, *input, **kwargs)
1126 # If we don't have any hooks, we want to skip the rest of the logic in
1127 # this function, and just call forward.
1128 if not (self._backward_hooks or self._forward_hooks or self._forward_pre_hooks or _global_backward_hooks
1129 or _global_forward_hooks or _global_forward_pre_hooks):
-> 1130 return forward_call(*input, **kwargs)
1131 # Do not call functions when jit is used
1132 full_backward_hooks, non_full_backward_hooks = [], []
File ~/Documents/pytorchGPUM1/doorstuff/models.py:462, in custUtime.forward(self, x)
460 # print(x1.shape)
461 x=torch.cat((x,x1), 1)
--> 462 x = self.decoder(x, shortcuts, shortcuts2 )
463 x = self.conv1(x)
464 x= self.conv2(x)
File ~/opt/anaconda3/envs/m1torch/lib/python3.9/site-packages/torch/nn/modules/module.py:1130, in Module._call_impl(self, *input, **kwargs)
1126 # If we don't have any hooks, we want to skip the rest of the logic in
1127 # this function, and just call forward.
1128 if not (self._backward_hooks or self._forward_hooks or self._forward_pre_hooks or _global_backward_hooks
1129 or _global_forward_hooks or _global_forward_pre_hooks):
-> 1130 return forward_call(*input, **kwargs)
1131 # Do not call functions when jit is used
1132 full_backward_hooks, non_full_backward_hooks = [], []
File ~/Documents/pytorchGPUM1/doorstuff/models.py:298, in Decoder.forward(self, z, shortcuts, shortcuts2)
294 i=0
296 for upsample, block, shortcut1, shortcut2 in zip(self.upsamples, self.blocks, shortcuts[::-1], shortcuts[::-1]):
297 # print("z before upsample ", z.shape)
--> 298 z = upsample(z)
299 # print("z after upsample " , z.shape)
300 # print("shortcut shape ", shortcut1.shape)
301 # print("shortcut2 shape ", shortcut2.shape)
302 z = torch.cat([shortcut1, shortcut2, z], dim=1)
File ~/opt/anaconda3/envs/m1torch/lib/python3.9/site-packages/torch/nn/modules/module.py:1130, in Module._call_impl(self, *input, **kwargs)
1126 # If we don't have any hooks, we want to skip the rest of the logic in
1127 # this function, and just call forward.
1128 if not (self._backward_hooks or self._forward_hooks or self._forward_pre_hooks or _global_backward_hooks
1129 or _global_forward_hooks or _global_forward_pre_hooks):
-> 1130 return forward_call(*input, **kwargs)
1131 # Do not call functions when jit is used
1132 full_backward_hooks, non_full_backward_hooks = [], []
File ~/opt/anaconda3/envs/m1torch/lib/python3.9/site-packages/torch/nn/modules/container.py:139, in Sequential.forward(self, input)
137 def forward(self, input):
138 for module in self:
--> 139 input = module(input)
140 return input
File ~/opt/anaconda3/envs/m1torch/lib/python3.9/site-packages/torch/nn/modules/module.py:1130, in Module._call_impl(self, *input, **kwargs)
1126 # If we don't have any hooks, we want to skip the rest of the logic in
1127 # this function, and just call forward.
1128 if not (self._backward_hooks or self._forward_hooks or self._forward_pre_hooks or _global_backward_hooks
1129 or _global_forward_hooks or _global_forward_pre_hooks):
-> 1130 return forward_call(*input, **kwargs)
1131 # Do not call functions when jit is used
1132 full_backward_hooks, non_full_backward_hooks = [], []
File ~/opt/anaconda3/envs/m1torch/lib/python3.9/site-packages/torch/nn/modules/upsampling.py:153, in Upsample.forward(self, input)
152 def forward(self, input: Tensor) -> Tensor:
--> 153 return F.interpolate(input, self.size, self.scale_factor, self.mode, self.align_corners,
154 recompute_scale_factor=self.recompute_scale_factor)
File ~/opt/anaconda3/envs/m1torch/lib/python3.9/site-packages/torch/nn/functional.py:3908, in interpolate(input, size, scale_factor, mode, align_corners, recompute_scale_factor, antialias)
3905 raise ValueError("Anti-alias option is only supported for bilinear and bicubic modes")
3907 if input.dim() == 3 and mode == "nearest":
-> 3908 return torch._C._nn.upsample_nearest1d(input, output_size, scale_factors)
3909 if input.dim() == 4 and mode == "nearest":
3910 return torch._C._nn.upsample_nearest2d(input, output_size, scale_factors)
NotImplementedError: The operator 'aten::upsample_nearest1d.out' is not current implemented for the MPS device. If you want this op to be added in priority during the prototype phase of this feature, please comment on https://github.com/pytorch/pytorch/issues/77764. As a temporary fix, you can set the environment variable `PYTORCH_ENABLE_MPS_FALLBACK=1` to use the CPU as a fallback for this op. WARNING: this will be slower than running natively on MPS.
## System Info
Please copy and paste the output from our
[environment collection script](https://raw.githubusercontent.com/pytorch/pytorch/master/torch/utils/collect_env.py)
(or fill out the checklist below manually).
You can get the script and run it with:
```
wget https://raw.githubusercontent.com/pytorch/pytorch/master/torch/utils/collect_env.py
# For security purposes, please check the contents of collect_env.py before running it.
python collect_env.py
```
- PyTorch or Caffe2:
- How you installed PyTorch (conda, pip, source):
- Build command you used (if compiling from source):
- OS:
- PyTorch version:
- Python version:
- CUDA/cuDNN version:
- GPU models and configuration:
- GCC version (if compiling from source):
- CMake version:
- Versions of any other relevant libraries:
cc @kulinseth @albanD @malfet @DenisVieriu97 @razarmehr @abhudev
| 0 |
4,170 | 89,275 |
torch.addcdiv: input, tensor1, and tensor2 parameters should be of the same type
|
module: docs, triaged, module: assert failure
|
### 📚 The doc issue
In the latest article, for torch.addcdiv(input, tensor1, tensor2, *, value=1, out=None) operator, the input, tensor1, tensor2 types are not required to be consistent, but simply referred to as tensors. But in a real test, something goes wrong.
For example:
import torch
input = torch.rand([1], dtype=torch.float64)
tensor1 = torch.rand([5, 5, 1], dtype=torch.float64)
tensor2 = torch.rand([1, 5], dtype=torch.float32)
value = 1
print(torch.addcdiv(input, tensor1, tensor2, value=value))
result: RuntimeError: !(has_different_input_dtypes && !config.promote_inputs_to_common_dtype_ && (has_undefined_outputs || config.enforce_safe_casting_to_output_ || config.cast_common_dtype_to_outputs_))INTERNAL ASSERT FAILED at "..\\aten\\src\\ATen\\TensorIterator.cpp":331, please report a bug to PyTorch.
### Suggest a potential alternative/fix
Add input, tensor1, and tensor2 parameters of the same type.
cc @svekars @carljparker
| 2 |
4,171 | 93,428 |
[aot_eager] [hf_Longformer] Cannot view a tensor with shape
|
triaged, bug, oncall: pt2, module: aotdispatch
|
### 🐛 Describe the bug
_No response_
### Error logs
~~~
Traceback (most recent call last):
File "/scratch/anijain/work/pytorch/repro.py", line 52, in <module>
res = run_fwd_maybe_bwd(opt_mod, args)
File "/scratch/anijain/work/pytorch/torch/_dynamo/debug_utils.py", line 505, in run_fwd_maybe_bwd
out = gm(args)
File "/scratch/anijain/work/pytorch/functorch/_src/aot_autograd.py", line 321, in g
return f(*args)
File "/scratch/anijain/work/pytorch/torch/nn/modules/module.py", line 1427, in _call_impl
return forward_call(*input, **kwargs)
File "/scratch/anijain/work/pytorch/torch/_dynamo/eval_frame.py", line 66, in forward
return self.dynamo_ctx(self._orig_mod.forward)(*args, **kwargs)
File "/scratch/anijain/work/pytorch/torch/_dynamo/eval_frame.py", line 174, in _fn
return fn(*args, **kwargs)
File "/scratch/anijain/work/pytorch/repro.py", line 25, in forward
def forward(self, transpose, as_strided, transpose_8):
File "/scratch/anijain/work/pytorch/torch/_dynamo/eval_frame.py", line 174, in _fn
return fn(*args, **kwargs)
File "/scratch/anijain/work/pytorch/functorch/_src/aot_autograd.py", line 951, in forward
return compiled_f(
File "/scratch/anijain/work/pytorch/functorch/_src/aot_autograd.py", line 937, in new_func
compiled_fn = create_aot_dispatcher_function(
File "/scratch/anijain/work/torchdynamo/torchdynamo/utils.py", line 86, in time_wrapper
r = func(*args, **kwargs)
File "/scratch/anijain/work/pytorch/functorch/_src/aot_autograd.py", line 657, in create_aot_dispatcher_function
aot_dispatch_autograd(flat_fn, fake_flat_tensor_args, aot_config)
File "/scratch/anijain/work/pytorch/functorch/_src/aot_autograd.py", line 486, in aot_dispatch_autograd
fx_g = make_fx(
File "/scratch/anijain/work/pytorch/torch/fx/experimental/proxy_tensor.py", line 657, in wrapped
t = dispatch_trace(wrap_key(func, args, fx_tracer), tracer=fx_tracer, concrete_args=tuple(phs))
File "/scratch/anijain/work/pytorch/torch/_dynamo/eval_frame.py", line 174, in _fn
return fn(*args, **kwargs)
File "/scratch/anijain/work/pytorch/torch/fx/experimental/proxy_tensor.py", line 417, in dispatch_trace
graph = tracer.trace(root, concrete_args)
File "/scratch/anijain/work/pytorch/torch/_dynamo/eval_frame.py", line 174, in _fn
return fn(*args, **kwargs)
File "/scratch/anijain/work/pytorch/torch/fx/_symbolic_trace.py", line 739, in trace
(self.create_arg(fn(*args)),),
File "/scratch/anijain/work/pytorch/torch/fx/_symbolic_trace.py", line 614, in flatten_fn
tree_out = root_fn(*tree_args)
File "/scratch/anijain/work/pytorch/torch/fx/experimental/proxy_tensor.py", line 431, in wrapped
out = f(*tensors)
File "/scratch/anijain/work/pytorch/functorch/_src/aot_autograd.py", line 189, in inner
outs = f(*f_args, **f_kwargs)
File "/scratch/anijain/work/pytorch/functorch/_src/aot_autograd.py", line 257, in joint_forward_backward
backward_out = torch.autograd.grad(
File "/scratch/anijain/work/pytorch/torch/autograd/__init__.py", line 300, in grad
return Variable._execution_engine.run_backward( # Calls into the C++ engine to run the backward pass
File "/scratch/anijain/work/pytorch/torch/fx/experimental/proxy_tensor.py", line 457, in __torch_dispatch__
return self.inner_torch_dispatch(func, types, args, kwargs)
File "/scratch/anijain/work/pytorch/torch/fx/experimental/proxy_tensor.py", line 482, in inner_torch_dispatch
out = proxy_call(self, func, args, kwargs)
File "/scratch/anijain/work/pytorch/torch/fx/experimental/proxy_tensor.py", line 321, in proxy_call
out = func(*args, **kwargs)
File "/scratch/anijain/work/pytorch/torch/_ops.py", line 285, in __call__
return self._op(*args, **kwargs or {})
File "/scratch/anijain/work/pytorch/torch/_subclasses/fake_tensor.py", line 887, in __torch_dispatch__
r = func(*args, **kwargs)
File "/scratch/anijain/work/pytorch/torch/_ops.py", line 285, in __call__
return self._op(*args, **kwargs or {})
File "/scratch/anijain/work/pytorch/torch/_refs/__init__.py", line 3851, in view
return _reshape_view_helper(a, *shape, allow_copy=False)
File "/scratch/anijain/work/pytorch/torch/_refs/__init__.py", line 3137, in _reshape_view_helper
raise ValueError(msg)
ValueError: Cannot view a tensor with shape torch.Size([4, 12, 1024, 513]) and strides (6303744, 513, 6156, 1) as a tensor with shape (48, 4, 256, 513)!
~~~
### Minified repro
~~~
from math import inf
import torch
from torch import tensor, device
import torch.fx as fx
import torch._dynamo
from torch._dynamo.testing import rand_strided
from torch._dynamo.debug_utils import run_fwd_maybe_bwd
from torch._dynamo.debug_utils import same_two_models
# REPLACEABLE COMMENT FOR TESTING PURPOSES
args = [((1024, 4, 768), (768, 786432, 1), torch.float32, 'cuda', True), ((48, 3, 512, 64), (64, 786432, 3072, 1), torch.float16, 'cuda', True), ((4, 1024, 1, 513), (525312, 513, 525312, 1), torch.float16, 'cuda', False)]
args = [rand_strided(sh, st, dt, dev).requires_grad_(rg) for (sh, st, dt, dev, rg) in args]
from torch.nn import *
class Repro(torch.nn.Module):
def __init__(self):
super().__init__()
self.self_self_layer_0_attention_self_key = Linear(in_features=768, out_features=768, bias=True).cuda()
def forward(self, transpose, as_strided, transpose_8):
self_self_layer_0_attention_self_key = self.self_self_layer_0_attention_self_key(transpose); transpose = None
view_1 = self_self_layer_0_attention_self_key.view(1024, 4, 12, 64); self_self_layer_0_attention_self_key = None
transpose_2 = view_1.transpose(0, 1); view_1 = None
transpose_4 = transpose_2.transpose(1, 2); transpose_2 = None
reshape_1 = transpose_4.reshape(48, 1024, 64); transpose_4 = None
view_3 = reshape_1.view(48, 2, 512, 64); reshape_1 = None
as_strided_1 = view_3.as_strided(size = [48, 3, 512, 64], stride = [64, 786432, 3072, 1]); view_3 = None
einsum = torch.functional.einsum('bcxd,bcyd->bcxy', (as_strided, as_strided_1)); as_strided = as_strided_1 = None
pad = torch.nn.functional.pad(einsum, (0, 0, 0, 1)); einsum = None
view_4 = pad.view(48, 3, 512, 513); pad = None
new_empty = view_4.new_empty((48, 4, 256, 513))
getitem_3 = view_4[(slice(None, None, None), 0, slice(None, 255, None), slice(-255, None, None))]; view_4 = None
new_empty[(slice(None, None, None), 0, slice(1, 256, None), slice(1, 256, None))] = getitem_3; setitem_3 = new_empty; getitem_3 = None
view_5 = new_empty.view(4, 12, 1024, 513); new_empty = None
transpose_5 = view_5.transpose(2, 1); view_5 = None
transpose_5 += transpose_8; iadd = transpose_5; transpose_5 = transpose_8 = None
return (iadd,)
mod = Repro()
opt_mod = torch._dynamo.optimize("aot_eager")(mod)
with torch.cuda.amp.autocast(enabled=True):
ref = run_fwd_maybe_bwd(mod, args)
res = run_fwd_maybe_bwd(opt_mod, args)
~~~
cc @ezyang @soumith @msaroufim @wconstab @ngimel @bdhirsh
| 17 |
4,172 | 89,255 |
torch.lobpcg should support black-box linear operators like SciPy
|
feature, triaged, module: linear algebra
|
### 🚀 The feature, motivation and pitch
Currently, the `torch.lobpcg` matrix-free eigensolver only supports fully materialized dense or sparse tensors as input. This makes it impossible to, for example, pass in a Hessian-vector product callable from `functorch` when you know that the Hessian of the function you're using will be positive definite. This is in contrast to [the SciPy implementation](https://docs.scipy.org/doc/scipy/reference/generated/scipy.sparse.linalg.lobpcg.html), which allows the user to provide a black-box `LinearOperator` callable as input. Since the algorithm itself is matrix-free and only relies on matrix-vector products to compute its solution, there's no _algorithmic_ reason why support for black-box callables couldn't be added relatively easily AFAICT.
### Alternatives
_No response_
### Additional context
_No response_
cc @jianyuh @nikitaved @pearu @mruberry @walterddr @IvanYashchuk @xwang233 @Lezcano
| 3 |
4,173 | 89,254 |
`torch.nn.ReplicationPad2D` Report "invalid configuration argument" Error under Compute Sanitizer
|
module: nn, module: error checking, triaged, module: padding
|
### 🐛 Describe the bug
A test of `torch.nn.Replication2D` reports "invalid configuration argument" error when it's run under compute sanitizer. Without sanitizers it terminates normally on GPU.
Test:
```python
import torch
def test():
arg_class = torch.nn.ReplicationPad2d([0,0,30,1024,-1,0])
arg_tensor = torch.rand([1, 1, 3, 3], dtype=torch.float32).clone().cuda()
arg = [arg_tensor,]
res = arg_class(*arg)
test()
```
Error log:
```
========= COMPUTE-SANITIZER
========= Program hit cudaErrorInvalidConfiguration (error 9) due to "invalid configuration argument" on CUDA API call to cudaLaunchKernel.
=========
========= Program hit cudaErrorInvalidConfiguration (error 9) due to "invalid configuration argument" on CUDA API call to cudaGetLastError.
=========
========= ERROR SUMMARY: 2 errors
```
### Versions
```
PyTorch version: 1.14.0a0+gitbdc9911
Is debug build: False
CUDA used to build PyTorch: 11.6
ROCM used to build PyTorch: N/A
OS: Ubuntu 22.04.1 LTS (x86_64)
GCC version: (Ubuntu 11.3.0-1ubuntu1~22.04) 11.3.0
Clang version: 11.1.0-6
CMake version: version 3.22.1
Libc version: glibc-2.35
Python version: 3.10.6 (main, Nov 2 2022, 18:53:38) [GCC 11.3.0] (64-bit runtime)
Python platform: Linux-5.15.0-52-generic-x86_64-with-glibc2.35
Is CUDA available: True
CUDA runtime version: 11.6.124
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration:
GPU 0: NVIDIA GeForce RTX 3090
GPU 1: NVIDIA GeForce RTX 3090
GPU 2: NVIDIA GeForce RTX 3090
Nvidia driver version: 515.65.01
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_infer.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.4.1
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.21.5
[pip3] torch==1.14.0a0+gitbdc9911
[pip3] torchvision==0.13.1
[conda] blas 1.0 mkl
[conda] cudatoolkit 11.3.1 h2bc3f7f_2
[conda] mkl 2021.4.0 h06a4308_640
[conda] mkl-service 2.4.0 py39h7f8727e_0
[conda] mkl_fft 1.3.1 py39hd3c417c_0
[conda] mkl_random 1.2.2 py39h51133e4_0
[conda] numpy 1.21.5 py39he7a7128_1
[conda] numpy-base 1.21.5 py39hf524024_1
[conda] numpydoc 1.2 pyhd3eb1b0_0
[conda] torch 1.14.0a0+gitce2f870 pypi_0 pypi
```
cc @albanD @mruberry @jbschlosser @walterddr @kshitij12345 @saketh-are
| 1 |
4,174 | 89,245 |
sm_80 support
|
module: cuda, triaged
|
### 🐛 Describe the bug
Why isn't sm_80 support shipped by default?
*GPU* with CUDA capability sm_80 is not compatible with the current PyTorch installation.
The current PyTorch install supports CUDA capabilities sm_37 sm_50 sm_60 sm_70.
### Versions
latest
cc @ngimel
| 6 |
4,175 | 89,241 |
Can't use JIT modules traced with AMP autocast, with Triton Server (or any C++ environment) - freeze() issue ?
|
oncall: jit
|
### 🐛 Describe the bug
We have recently found out at NVIDIA that Triton's libtorch backend can't run TorchScript modules exported via torch.jit.trace() with amp.autocast.
There is still outstanding issue about lack of true autocast support in C++ here: https://github.com/pytorch/pytorch/issues/44710.
For our purposes(inference), we would actually prefer a different solution:
I think after jit.freeze() and jit.optimize_for_inference, there should be no more _autocast_to_xxx nodes in the graph - they should be resolved according to current settings and frozen - like onnx.export does. Now we still see those after jit.freeze() and jit.optimize_for_inference:
context = torch.index(_4, _9)
max_len = (torch.size(context))[-1]
ids = torch.arange(0, max_len, dtype=None, layout=None, device=ops.prim.device(lens_sorted))
mask = torch.lt(ids, torch.unsqueeze(lens_sorted, 1))
_10 = torch.to(mask, ops.prim.dtype(context))
mask0 = torch.unsqueeze(_10, 1)
_11 = torch._autocast_to_full_precision(context, True, False)
_12 = torch._autocast_to_full_precision(mask0, True, False)
input = torch.mul(_11, _12)
_13 = __torch__.torch.autograd.grad_mode.no_grad.__new__(__torch__.torch.autograd.grad_mode.no_grad)
_13.prev = False
with _13:
_14 = torch._autocast_to_reduced_precision(mask0, True, False, 5, 15)
update_mask = torch.conv1d(_14, CONSTANTS.c2, None, [1], [2])
update_mask_filled = torch.masked_fill(update_mask, torch.eq(update_mask, 0), 5)
_15 = torch._autocast_to_full_precision(update_mask_filled, True, False)
_16 = torch._autocast_to_full_precision(torch.reciprocal(_15), True, False)
mask_ratio = torch.mul(_16, 5)
update_mask0 = torch.clamp(update_mask, 0, 1)
_17 = torch._autocast_to_full_precision(mask_ratio, True, False)
_18 = torch._autocast_to_full_precision(update_mask0, True, False)
mask_ratio0 = torch.mul(_17, _18)
_19 = torch._autocast_to_reduced_precision(input, True, False, 5, 15)
_20 = torch.conv1d(_19, CONSTANTS.c3, CONSTANTS.c4, [1], [2])
_21 = torch._autocast_to_full_precision(_20, True, False)
### Versions
PyTorch version: 1.13.0a0+d0d6b1f
Is debug build: False
CUDA used to build PyTorch: 11.8
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.5 LTS (x86_64)
GCC version: (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0
Clang version: Could not collect
CMake version: version 3.22.2
Libc version: glibc-2.31
Python version: 3.8.13 | packaged by conda-forge | (default, Mar 25 2022, 06:04:10) [GCC 10.3.0] (64-bit runtime)
Python platform: Linux-5.15.0-46-generic-x86_64-with-glibc2.10
Is CUDA available: True
CUDA runtime version: 11.8.89
GPU models and configuration: GPU 0: NVIDIA RTX A5000
Nvidia driver version: 515.65.01
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.6.0
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.6.0
/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.6.0
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_infer.so.8.6.0
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.6.0
/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.6.0
/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.6.0
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] functorch==0.3.0a0
[pip3] k2==1.21.dev20221109+cuda11.8.torch1.13.0a0
[pip3] numpy==1.22.2
[pip3] pytorch-lightning==1.7.7
[pip3] pytorch-quantization==2.1.2
[pip3] torch==1.13.0a0+d0d6b1f
[pip3] torch-tensorrt==1.3.0a0
[pip3] torchaudio==0.13.0
[pip3] torchmetrics==0.10.2
[pip3] torchvision==0.14.0a0
[conda] functorch 0.3.0a0 pypi_0 pypi
[conda] k2 1.21.dev20221109+cuda11.8.torch1.13.0a0 pypi_0 pypi
[conda] mkl 2020.4 h726a3e6_304 conda-forge
[conda] mkl-include 2020.4 h726a3e6_304 conda-forge
[conda] numpy 1.22.2 py38h6ae9a64_0 conda-forge
[conda] pytorch-lightning 1.7.7 pypi_0 pypi
[conda] pytorch-quantization 2.1.2 pypi_0 pypi
[conda] torch 1.13.0a0+d0d6b1f pypi_0 pypi
[conda] torch-tensorrt 1.3.0a0 pypi_0 pypi
[conda] torchaudio 0.13.0 pypi_0 pypi
[conda] torchmetrics 0.10.2 pypi_0 pypi
[conda] torchvision 0.14.0a0 pypi_0 pypi
cc @EikanWang @jgong5 @wenzhe-nrv @sanchitintel
| 6 |
4,176 | 89,219 |
Dynamo + NNC: incorrect results with in-place ops on inputs
|
triaged, NNC, module: dynamo
|
### 🐛 Describe the bug
```python
import torch
import torch._dynamo
def fn(x, y):
x += y
return x
fn2 = torch._dynamo.optimize("nnc")(fn)
print(fn(torch.ones(1), torch.ones(1)))
print(fn2(torch.ones(1), torch.ones(1)))
```
prints:
```
tensor([2.])
tensor([6.])
```
Clearly the FX -> NNC conversion (through tracing?) is not sound wrt to in-place ops.
### Versions
1.14.0.dev20221117+cpu
cc @EikanWang @jgong5 @mlazos @soumith @voznesenskym @yanboliang @penguinwu @anijain2305 @Guobing-Chen @chunyuan-w @XiaobingSuper @zhuhaozhe @blzheng @Xia-Weiwen @wenzhe-nrv @jiayisunx @desertfire
| 0 |
4,177 | 89,218 |
`torch.nn.LayerNorm` Abort with "invalid device ordinal" Error
|
module: nn, module: error checking, triaged, module: norms and normalization
|
### 🐛 Describe the bug
A test case of `torch.nn.LayerNorm` aborted with error message "CUDA error: invalid device ordinal" even if there's no device assignment in the code.
Test:
```python
import torch
def test():
arg_class = torch.nn.LayerNorm(720,1e-05,[18,1024],24,)
arg_tensor = torch.rand([64, 128, 720], dtype=torch.float32).clone().cuda()
arg = [arg_tensor,]
res = arg_class(*arg)
test()
```
Error log:
```
Traceback (most recent call last):
File "/home/yuyao/trial/test.py", line 9, in <module>
test()
File "/home/yuyao/trial/test.py", line 4, in test
arg_class = torch.nn.LayerNorm(720,1e-05,[18,1024],24,)
File "/home/yuyao/.local/lib/python3.10/site-packages/torch/nn/modules/normalization.py", line 176, in __init__
self.weight = Parameter(torch.empty(self.normalized_shape, **factory_kwargs))
RuntimeError: CUDA error: invalid device ordinal
CUDA kernel errors might be asynchronously reported at some other API call,so the stacktrace below might be incorrect.
For debugging consider passing CUDA_LAUNCH_BLOCKING=1.
```
### Versions
```
PyTorch version: 1.14.0a0+gitbdc9911
Is debug build: False
CUDA used to build PyTorch: 11.6
ROCM used to build PyTorch: N/A
OS: Ubuntu 22.04.1 LTS (x86_64)
GCC version: (Ubuntu 11.3.0-1ubuntu1~22.04) 11.3.0
Clang version: 11.1.0-6
CMake version: version 3.22.1
Libc version: glibc-2.35
Python version: 3.10.6 (main, Nov 2 2022, 18:53:38) [GCC 11.3.0] (64-bit runtime)
Python platform: Linux-5.15.0-52-generic-x86_64-with-glibc2.35
Is CUDA available: True
CUDA runtime version: 11.6.124
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration:
GPU 0: NVIDIA GeForce RTX 3090
GPU 1: NVIDIA GeForce RTX 3090
GPU 2: NVIDIA GeForce RTX 3090
Nvidia driver version: 515.65.01
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_infer.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.4.1
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.21.5
[pip3] torch==1.14.0a0+gitbdc9911
[pip3] torchvision==0.13.1
[conda] blas 1.0 mkl
[conda] cudatoolkit 11.3.1 h2bc3f7f_2
[conda] mkl 2021.4.0 h06a4308_640
[conda] mkl-service 2.4.0 py39h7f8727e_0
[conda] mkl_fft 1.3.1 py39hd3c417c_0
[conda] mkl_random 1.2.2 py39h51133e4_0
[conda] numpy 1.21.5 py39he7a7128_1
[conda] numpy-base 1.21.5 py39hf524024_1
[conda] numpydoc 1.2 pyhd3eb1b0_0
[conda] torch 1.14.0a0+gitce2f870 pypi_0 pypi
```
cc @albanD @mruberry @jbschlosser @walterddr @kshitij12345 @saketh-are
| 1 |
4,178 | 89,212 |
[BF16] Visit all the type cast from integer to BF16 type for potential accuracy loss
|
module: cpu, triaged, intel
|
## Issue description
BF16 cannot accurately represent all integer values outside the range of [-255,255]. When there is a cast from an integer value from BF16 data type, there would be potential accuracy loss. Typically, such a type cast is used in pixel index calculation in ops such as upsample, pooling etc. FP32 is preferred in these cases. See https://github.com/pytorch/pytorch/issues/88939 for a related functionality issue.
## Code example
`area_pixel_compute_scale` (https://github.com/jgong5/pytorch/blob/fc60a1865eafc985217eccc0251f82014041e6a7/aten/src/ATen/native/UpSample.h#L263) is one of the examples and used in a lot of places. There are also direct usage of `static_cast<scalar_t>` from integer to bf16, such as https://github.com/jgong5/pytorch/blob/fc60a1865eafc985217eccc0251f82014041e6a7/aten/src/ATen/native/FractionalMaxPool2d.cpp#L139
cc @VitalyFedyunin @mingfeima @XiaobingSuper @sanchitintel @ashokei @jingxu10
| 4 |
4,179 | 89,208 |
`torch.nn.CTCLoss` Trigger out-of-bound Read under Compute Sanitizer
|
module: nn, module: loss, module: cuda, triaged, module: sanitizers
|
### 🐛 Describe the bug
A test case for `torch.nn.CTCLoss` triggers out-of-bound read error under compute sanitizer. Without sanitizers, the test terminates normally.
A similar issue is #88047, but the test shown in that issue won't trigger an error when it's run in GPU, so I open a new issue here.
Test:
```python
import torch
def test():
ctc_loss = torch.nn.CTCLoss()
arg_1_0 = torch.rand([50, 16, 20], dtype=torch.float32).clone().cuda()
arg_1_1 = torch.randint(-8,0,[16, 30], dtype=torch.int64).clone().cuda()
arg_1_2 = torch.randint(-128,0,[16], dtype=torch.int64).clone().cuda()
arg_1_3 = torch.randint(-16384,0,[16], dtype=torch.int64).clone().cuda()
arg_1 = [arg_1_0,arg_1_1,arg_1_2,arg_1_3,]
res = ctc_loss(*arg_1)
test()
```
Error log:
```
========= COMPUTE-SANITIZER
========= Invalid __global__ read of size 4 bytes
========= at 0x2400 in _ZN2at6native43_GLOBAL__N__ab835dce_10_LossCTC_cu_88d8892b29ctc_loss_log_alpha_gpu_kernelIflEEvPT_PKS3_PKllPKT0_S8_lS4_llllllS8_lll
========= by thread (0,2,0) in block (0,0,0)
========= Address 0x7fb73cdf9960 is out of bounds
========= and is 26,272 bytes before the nearest allocation at 0x7fb73ce00000 of size 2,097,152 bytes
=========
========= Invalid __global__ read of size 4 bytes
========= at 0x2400 in _ZN2at6native43_GLOBAL__N__ab835dce_10_LossCTC_cu_88d8892b29ctc_loss_log_alpha_gpu_kernelIflEEvPT_PKS3_PKllPKT0_S8_lS4_llllllS8_lll
========= by thread (0,3,0) in block (0,0,0)
========= Address 0x7fb73cdfa1c4 is out of bounds
========= and is 24,124 bytes before the nearest allocation at 0x7fb73ce00000 of size 2,097,152 bytes
=========
========= Invalid __global__ read of size 4 bytes
========= at 0x2400 in _ZN2at6native43_GLOBAL__N__ab835dce_10_LossCTC_cu_88d8892b29ctc_loss_log_alpha_gpu_kernelIflEEvPT_PKS3_PKllPKT0_S8_lS4_llllllS8_lll
========= by thread (0,5,0) in block (0,0,0)
========= Address 0x7fb73cdf5f30 is out of bounds
========= and is 41,168 bytes before the nearest allocation at 0x7fb73ce00000 of size 2,097,152 bytes
=========
========= Invalid __global__ read of size 4 bytes
========= at 0x2400 in _ZN2at6native43_GLOBAL__N__ab835dce_10_LossCTC_cu_88d8892b29ctc_loss_log_alpha_gpu_kernelIflEEvPT_PKS3_PKllPKT0_S8_lS4_llllllS8_lll
========= by thread (0,6,0) in block (0,0,0)
========= Address 0x7fb73cdfbd64 is out of bounds
========= and is 17,052 bytes before the nearest allocation at 0x7fb73ce00000 of size 2,097,152 bytes
=========
========= Invalid __global__ read of size 4 bytes
========= at 0x2400 in _ZN2at6native43_GLOBAL__N__ab835dce_10_LossCTC_cu_88d8892b29ctc_loss_log_alpha_gpu_kernelIflEEvPT_PKS3_PKllPKT0_S8_lS4_llllllS8_lll
========= by thread (0,8,0) in block (0,0,0)
========= Address 0x7fb73cdfb120 is out of bounds
========= and is 20,192 bytes before the nearest allocation at 0x7fb73ce00000 of size 2,097,152 bytes
=========
========= Invalid __global__ read of size 4 bytes
========= at 0x2400 in _ZN2at6native43_GLOBAL__N__ab835dce_10_LossCTC_cu_88d8892b29ctc_loss_log_alpha_gpu_kernelIflEEvPT_PKS3_PKllPKT0_S8_lS4_llllllS8_lll
========= by thread (0,14,0) in block (0,0,0)
========= Address 0x7fb73cdf6fb8 is out of bounds
========= and is 36,936 bytes before the nearest allocation at 0x7fb73ce00000 of size 2,097,152 bytes
=========
========= Program hit cudaErrorLaunchFailure (error 719) due to "unspecified launch failure" on CUDA API call to cudaStreamSynchronize.
=========
========= Program hit cudaErrorLaunchFailure (error 719) due to "unspecified launch failure" on CUDA API call to cudaGetLastError.
=========
Traceback (most recent call last):
File "/home/yuyao/trial/test.py", line 12, in <module>
test()
File "/home/yuyao/trial/test.py", line 10, in test
res = ctc_loss(*arg_1)
File "/home/yuyao/.local/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1427, in _call_impl
return forward_call(*input, **kwargs)
File "/home/yuyao/.local/lib/python3.10/site-packages/torch/nn/modules/loss.py", line 1756, in forward
return F.ctc_loss(log_probs, targets, input_lengths, target_lengths, self.blank, self.reduction,
File "/home/yuyao/.local/lib/python3.10/site-packages/torch/nn/functional.py", line 2630, in ctc_loss
return torch.ctc_loss(
RuntimeError: CUDA error: unspecified launch failure
CUDA kernel errors might be asynchronously reported at some other API call,so the stacktrace below might be incorrect.
For debugging consider passing CUDA_LAUNCH_BLOCKING=1.
========= Target application returned an error
========= ERROR SUMMARY: 8 errors
```
### Versions
```
PyTorch version: 1.14.0a0+gitbdc9911
Is debug build: False
CUDA used to build PyTorch: 11.6
ROCM used to build PyTorch: N/A
OS: Ubuntu 22.04.1 LTS (x86_64)
GCC version: (Ubuntu 11.3.0-1ubuntu1~22.04) 11.3.0
Clang version: 11.1.0-6
CMake version: version 3.22.1
Libc version: glibc-2.35
Python version: 3.10.6 (main, Nov 2 2022, 18:53:38) [GCC 11.3.0] (64-bit runtime)
Python platform: Linux-5.15.0-52-generic-x86_64-with-glibc2.35
Is CUDA available: True
CUDA runtime version: 11.6.124
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration:
GPU 0: NVIDIA GeForce RTX 3090
GPU 1: NVIDIA GeForce RTX 3090
GPU 2: NVIDIA GeForce RTX 3090
Nvidia driver version: 515.65.01
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_infer.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.4.1
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.21.5
[pip3] torch==1.14.0a0+gitbdc9911
[pip3] torchvision==0.13.1
[conda] blas 1.0 mkl
[conda] cudatoolkit 11.3.1 h2bc3f7f_2
[conda] mkl 2021.4.0 h06a4308_640
[conda] mkl-service 2.4.0 py39h7f8727e_0
[conda] mkl_fft 1.3.1 py39hd3c417c_0
[conda] mkl_random 1.2.2 py39h51133e4_0
[conda] numpy 1.21.5 py39he7a7128_1
[conda] numpy-base 1.21.5 py39hf524024_1
[conda] numpydoc 1.2 pyhd3eb1b0_0
[conda] torch 1.14.0a0+gitce2f870 pypi_0 pypi
```
cc @albanD @mruberry @jbschlosser @walterddr @kshitij12345 @saketh-are @ngimel
| 0 |
4,180 | 89,204 |
Libtorch's CPU inference is much slower on Windows than on Linux
|
module: performance, module: windows, triaged
|
## Issue description
I found that PyTorch / LibTorch version 1.10 with certain topologies (classifiers with Fully-Connected/Dense-Layers) is during CPU inference significantly slower on Windows 10 than on Linux.
The model used in the following problem description is created and trained within a Pytorch environment (Python 3.9) and exported using `Torch JIT Script`. After the trained model has been exported, it is called in a C++ (libtorch).
The average runtimes over a hundred dummy images times are listed below. Multithreading was disabled to perform the measurement.
**Windows**
```
218ms
```
**Linux**
```
40ms
```
The CPUs are not identical but the gap in runtime can't be explained by the CPUs. In general, the CPU on the Windows machine should perform better on single core tasks.
In both cases, PyTorch is linked against Intel's MKL (oneAPI 2021.3.0). MKLDNN is enabled on both platforms. The compiler on Windows is MSVC 14.29.30133 and on Linux the compiler is gcc (SUSE Linux) 7.5.0. By default, the MKL is linked statically on Windows and dynamically on Linux.
The following instructions were used for the build of PyTorch:
[Build Description](https://github.com/pytorch/pytorch#from-source)
## Code example
To reproduce the results, the following Code snippets are required.
**Note:** The input dimensions in the following examples are 256, 256, 1 (HWC).
**Python Script for the model:**
```
import torch.nn as nn
import torch
import torch.nn.functional as F
class Model(nn.Module):
def __init__(self, num_classes):
super().__init__()
self.conv1 = nn.Conv2d(in_channels=1, out_channels=12, kernel_size=5, stride=1, padding=1)
self.bn1 = nn.BatchNorm2d(12)
self.conv2 = nn.Conv2d(in_channels=12, out_channels=12, kernel_size=5, stride=1, padding=1)
self.bn2 = nn.BatchNorm2d(12)
self.pool = nn.MaxPool2d(2,2)
self.conv4 = nn.Conv2d(in_channels=12, out_channels=24, kernel_size=5, stride=1, padding=1)
self.bn4 = nn.BatchNorm2d(24)
self.conv5 = nn.Conv2d(in_channels=24, out_channels=24, kernel_size=5, stride=1, padding=1)
self.bn5 = nn.BatchNorm2d(24)
self.fc1 = nn.Linear(24*122*122, num_classes)
def forward(self, input):
output = F.relu(self.bn1(self.conv1(input)))
output = F.relu(self.bn2(self.conv2(output)))
output = self.pool(output)
output = F.relu(self.bn4(self.conv4(output)))
output = F.relu(self.bn5(self.conv5(output)))
#print(output.shape)
output = output.view(-1, 24*122*122)
output = self.fc1(output)
return output
```
**Python code to export the model:**
```
traced_script_module = torch.jit.trace(model, images)
traced_script_module.save(params["model_path"] + f'CP_epoch{epoch + 1}.pt')
```
**C++ Program to measure the runtime**
```
void test()
{
at::set_num_threads(1);
at::init_num_threads();
torch::jit::script::Module module = torch::jit::load("classifier.pt", c10::DeviceType::CPU);
module.eval();
cv::Mat m = cv::Mat::ones(256, 256, CV_8UC1);
torch::Tensor tensor_image = torch::from_blob(m.data, { m.rows, m.cols, m.channels() }, at::kByte);
tensor_image = tensor_image.permute({ 2,0,1 });
tensor_image = tensor_image.toType(torch::kFloat32);
tensor_image.to(c10::DeviceType::CPU);
torch::Tensor output;
auto start = std::chrono::high_resolution_clock::now();
int runs = 100;
for (size_t i = 0; i < runs; i++)
{
output = module.forward({ tensor_image }).toTensor().detach();
}
auto duration = std::chrono::duration_cast<std::chrono::milliseconds>(std::chrono::high_resolution_clock::now() - start).count();
std::cout << duration / (float) runs << std::endl;
}
```
## System Info
PyTorch version: 1.10.0
Is debug build: False
CUDA used to build PyTorch: 11.3
ROCM used to build PyTorch: N/A
OS: openSUSE Leap 15.3 (x86_64)
GCC version: (SUSE Linux) 7.5.0
Clang version: 12.0.1
CMake version: version 3.17.5
Libc version: glibc-2.31
Python version: 3.9.7 (default, Sep 16 2021, 13:09:58) [GCC 7.5.0] (64-bit runtime)
Python platform: Linux-5.3.18-150300.59.68-default-x86_64-with-glibc2.31
Is CUDA available: True
CUDA runtime version: Could not collect
CUDA_MODULE_LOADING set to:
GPU models and configuration: GPU 0: NVIDIA RTX A4000
Nvidia driver version: 515.43.04
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] mypy-extensions==0.4.3
[pip3] numpy==1.20.3
[pip3] numpydoc==1.1.0
[pip3] torch==1.10.0
[pip3] torchaudio==0.10.0
[pip3] torchsummary==1.5.1
[pip3] torchvision==0.11.0
[conda] blas 1.0 mkl
[conda] cudatoolkit 11.3.1 h2bc3f7f_2
[conda] ffmpeg 4.3 hf484d3e_0 pytorch
[conda] mkl 2021.4.0 h06a4308_640
[conda] mkl-service 2.4.0 py39h7f8727e_0
[conda] mkl_fft 1.3.1 py39hd3c417c_0
[conda] mkl_random 1.2.2 py39h51133e4_0
[conda] numpy 1.20.3 py39hf144106_0
[conda] numpy-base 1.20.3 py39h74d4b33_0
[conda] numpydoc 1.1.0 pyhd3eb1b0_1
[conda] pytorch 1.10.0 py3.9_cuda11.3_cudnn8.2.0_0 pytorch
[conda] pytorch-mutex 1.0 cuda pytorch
[conda] torchaudio 0.10.0 py39_cu113 pytorch
[conda] torchsummary 1.5.1 pypi_0 pypi
[conda] torchvision 0.11.0 py39_cu113 pytorch
cc @VitalyFedyunin @ngimel @peterjc123 @mszhanyi @skyline75489 @nbcsm
| 4 |
4,181 | 93,426 |
[Inductor] [CPU] accuracy failure in torchbench model detectron2_fcos_r_50_fpn
|
triaged, bug, oncall: pt2, module: cpu inductor
|
### 🐛 Describe the bug
This failure was found in latest **TorchInductor CPU Performance Dashboard** refresh test in https://github.com/pytorch/pytorch/issues/93531
SW information
SW | Nightly commit | Master/Main commit
----|--------|-----
Pytorch |[637228b](https://github.com/blzheng/pytorch/commit/637228bcc4d2566fb617bbf1c4abeff69b3bdae7) |[46796fe](https://github.com/blzheng/pytorch/commit/46796fe5e9b74602d45927304773fdcda1c3215a)
Torchbench| / |[022dfe3](https://github.com/pytorch/benchmark/commit/022dfe3d89db9278119bf1cd179997076b5ec5b5)
torchaudio |[4b10b6a](https://github.com/pytorch/audio/commit/4b10b6adece473ad70e221bb3f9442d11906111f) |[74f9a89](https://github.com/pytorch/audio/commit/74f9a894fcd4e7d635919803b364e47577a2b6e8)
torchtext |[71e4561](https://github.com/pytorch/text/commit/71e456119d39cf72a511ce6acb10b737e02102d3) |[c047efe](https://github.com/pytorch/text/commit/c047efeba813ac943cb8046a49e858a8b529d577)
torchvision |[797e1ac](https://github.com/pytorch/vision/commit/797e1acf043621c5b53319032a269cbe1190b018) |[ffd5a56](https://github.com/pytorch/vision/commit/ffd5a567eb90abf6b5555063da434d3c130d540f)
detail info reference the [Dashboard](https://github.com/pytorch/pytorch/issues/93531)
### Error logs
`RuntimeError: Storage size calculation overflowed with sizes=[2, 3, 140639896720224, 140639896720384]`
### Minified repro
`python benchmarks/dynamo/torchbench.py --accuracy --float32 -dcpu -n50 --inductor --no-skip --dashboard --only=detectron2_fcos_r_50_fpn --batch_size 2 `
cc @ezyang @soumith @msaroufim @wconstab @ngimel @bdhirsh
| 1 |
4,182 | 89,197 |
Collective operations do not work with `torch.BoolTensor`s on `gloo` and raise `Invalid scalar type`
|
oncall: distributed
|
### 🐛 Describe the bug
Hi, collective operations do not work with `torch.BoolTensor`s on backend `gloo`. Actually `GENERATE_ALL_TYPES` macro in `torch/csrc/distributed/c10d/ProcessGroupGloo.cpp` seems to raise `RuntimeError: Invalid scalar type`.
To reproduce:
```python
import torch.distributed as dist
tensor = torch.empty((5,),dtype=torch.bool)
if dist.get_rank() == 0:
gather_list = [torch.empty((5,),dtype=torch.bool) for _ in range(dist.get_world_size())]
else:
gather_list = None
dist.gather(tensor, gather_list)
```
This is also the case for `all_gather`, `reduce`, `all_reduce` and `broadcast`. Changing `dtype=torch.bool` to `dtype=torch.uint8` resolves the error, while `torch.bool == torch.uint8` evaluates to `True`.
### Versions
PyTorch version: 1.13.0.dev20220927+cpu
Is debug build: False
CUDA used to build PyTorch: Could not collect
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.4 LTS (x86_64)
GCC version: (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0
Clang version: Could not collect
CMake version: version 3.16.3
Libc version: glibc-2.31
Python version: 3.8.10 (default, Jun 22 2022, 20:18:18) [GCC 9.4.0] (64-bit runtime)
Python platform: Linux-5.4.0-126-generic-x86_64-with-glibc2.29
Is CUDA available: False
CUDA runtime version: Could not collect
CUDA_MODULE_LOADING set to: N/A
GPU models and configuration: GPU 0: GeForce 820M
Nvidia driver version: 340.108
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] mypy==0.991
[pip3] mypy-extensions==0.4.3
[pip3] numpy==1.21.5
[pip3] pytorch-fid==0.1.1
[pip3] pytorch-ignite==0.4.10
[pip3] pytorch-sphinx-theme==0.0.24
[pip3] torch==1.13.0.dev20220927+cpu
[pip3] torch-model-archiver==0.6.0
[pip3] torch-tb-profiler==0.4.0
[pip3] torch-workflow-archiver==0.2.4
[pip3] torchaudio==0.13.0.dev20220923+cpu
[pip3] torchfile==0.1.0
[pip3] torchserve==0.6.0
[pip3] torchvision==0.14.0.dev20220926+cpu
[conda] Could not collect
cc @mrshenli @pritamdamania87 @zhaojuanmao @satgera @rohan-varma @gqchen @aazzolini @osalpekar @jiayisuse @H-Huang @kwen2501 @awgu
| 0 |
4,183 | 93,425 |
[aot-autograd] [hf_BigBird] Output 0 of CompiledFunctionBackward is a view and is being modified inplace
|
triaged, ezyang's list, bug, module: aotdispatch
|
### 🐛 Describe the bug
Following repro fails.
cc @ezyang @bdhirsh @Chillee
### Error logs
~~~
Traceback (most recent call last):
File "/scratch/anijain/work/pytorch/failures/bigbird.py", line 23, in <module>
opt_fn(a, b).sum().backward()
File "/scratch/anijain/work/pytorch/torch/_dynamo/eval_frame.py", line 174, in _fn
return fn(*args, **kwargs)
File "/scratch/anijain/work/pytorch/failures/bigbird.py", line 15, in fn
c.unsqueeze_(2)
RuntimeError: Output 0 of CompiledFunctionBackward is a view and is being modified inplace. This view was created inside a custom Function (or because an input was returned as-is) and the autograd logic to handle view+inplace would override the custom backward associated with the custom Function, leading to incorrect gradients. This behavior is forbidden. You can fix this by cloning the output of the custom Function.
~~~
### Minified repro
~~~
import torch
import torch._dynamo
def torch_bmm_nd(inp_1, inp_2, ndim=4):
"""Fast nd matrix multiplication"""
# faster replacement of torch.einsum ("bhqk,bhkd->bhqd")
return torch.bmm(inp_1.reshape((-1,) + inp_1.shape[-2:]), inp_2.reshape((-1,) + inp_2.shape[-2:])).view(
inp_1.shape[: ndim - 2] + (inp_1.shape[ndim - 2], inp_2.shape[ndim - 1])
)
@torch._dynamo.skip
def fn(x, y):
c = torch_bmm_nd(x, y)
c.unsqueeze_(2)
return c
a = torch.randn(torch.Size([2, 12, 64, 1024]), requires_grad=True)
b = torch.randn(torch.Size([2, 12, 1024, 64]), requires_grad=True)
ref = fn(a, b).sum().backward()
opt_fn = torch._dynamo.optimize("aot_eager")(fn)
opt_fn(a, b).sum().backward()
~~~
| 7 |
4,184 | 89,185 |
[feature request] Add ability to preserve traced shape during torch.jit.save and torch.jit.load
|
oncall: jit
|
## Issue description
I would like to be able to access the shape information of a traced model after loading the traced version of a model. It is my understanding that this isn't always desirable so to preserve current workflows, I propose adding an optional parameter that defaults to false in torch.jit.load that will allow this information to be restored. I also understand that this can add more data to the saved model so I think that there should be a parameter that allows this information to be saved, but that it default to True so that this feature will work when loading models by default as in most models the extra space should be negligible.
## Code example
I would like to support the below example
```
import os
import torch
from torchvision.models import resnet50, ResNet50_Weights
model=resnet50(weights=ResNet50_Weights.IMAGENET1K_V1)
traced = torch.jit.trace(model, torch.rand(1, 3, 224, 224))
traced.forward(torch.rand(1,3,224,224))
input_sizes = [ x.type().sizes() for x in traced.graph.inputs() ]
torch.jit.save(traced, "/tmp/resnet50pt")
loaded = torch.jit.load("/tmp/resnet50pt", _retrace=True)
loaded_input_sizess = [ x.type().sizes() for x in loaded.graph.inputs() ]
assert loaded_inputs == inputs
```
## System Info
This shouldn't be relevant in this case.
## Extra Notes
I'm already working on implementing this, just wanted to confirm that this seemed reasonable
cc @EikanWang @jgong5 @wenzhe-nrv @sanchitintel
| 2 |
4,185 | 93,424 |
Complex Not Supported in Torchinductor
|
triaged, bug, oncall: pt2
|
### 🐛 Describe the bug
A linear layer with complex valued weights (e.g. nn.Linear(inp_size, out_size, dtype=torch.complex64)) produces the following NotImplementedError with `dynamo.optimize()(model)`
### Error logs
```
Traceback (most recent call last):
File "*/lib/python3.10/site-packages/torch/_dynamo/eval_frame.py", line 169, in _fn
return fn(*args, **kwargs)
File "*/lib/python3.10/site-packages/functorch/_src/aot_autograd.py", line 951, in forward
return compiled_f(
File "*/lib/python3.10/site-packages/functorch/_src/aot_autograd.py", line 937, in new_func
compiled_fn = create_aot_dispatcher_function(
File "*/lib/python3.10/site-packages/functorch/_src/aot_autograd.py", line 657, in create_aot_dispatcher_function
aot_dispatch_autograd(flat_fn, fake_flat_tensor_args, aot_config)
File "*/lib/python3.10/site-packages/functorch/_src/aot_autograd.py", line 501, in aot_dispatch_autograd
fw_module, bw_module = aot_config.partition_fn(fx_g, joint_inputs)
File "*/lib/python3.10/site-packages/functorch/_src/partitioners.py", line 420, in min_cut_rematerialization_partition
weight = get_node_weight(node)
File "*/lib/python3.10/site-packages/functorch/_src/partitioners.py", line 382, in get_node_weight
mem_sz = _size_of(node)
File "*/lib/python3.10/site-packages/functorch/_src/partitioners.py", line 225, in _size_of
return _tensor_nbytes(to_size_hint(val.numel()), val.dtype)
File "*/lib/python3.10/site-packages/functorch/_src/partitioners.py", line 206, in _tensor_nbytes
raise NotImplementedError("Don't know the size of dtype ", dtype)
NotImplementedError: ("Don't know the size of dtype ", torch.complex64)
```
### Minified repro
_No response_
cc @ezyang @soumith @msaroufim @wconstab @ngimel @bdhirsh
| 10 |
4,186 | 89,160 |
Got many TestDTensorOpsCUDA.test_dtensor_op_db_X test failures
|
module: cuda, triaged
|
### 🐛 Describe the bug
Saw many TestDTensorOpsCUDA.test_dtensor_op_db_X test failures
A list of failures saw today
- TestDTensorOpsCUDA.test_dtensor_op_db_full_like_cuda_float32 (6.956 s)
- TestDTensorOpsCUDA.test_dtensor_op_db_ones_like_cuda_float32 (7.18 s)
- TestDTensorOpsCUDA.test_dtensor_op_db_logical_not_cuda_float32 (6.967 s)
- TestDTensorOpsCUDA.test_dtensor_op_db_eq_cuda_float32 (7.259 s)
- TestDTensorOpsCUDA.test_dtensor_op_db_isfinite_cuda_float32 (7.059 s)
- TestDTensorOpsCUDA.test_dtensor_op_db_isnan_cuda_float32 (7.463 s)
- TestDTensorOpsCUDA.test_dtensor_op_db_jiterator_binary_return_by_ref_cuda_float32 (8.164 s)
- TestDTensorOpsCUDA.test_dtensor_op_db_jiterator_binary_cuda_float32 (7.968 s)
- TestDTensorOpsCUDA.test_dtensor_op_db_jiterator_4inputs_with_extra_args_cuda_float32 (8.061 s)
- TestDTensorOpsCUDA.test_dtensor_op_db_bmm_cuda_float32 (7.18 s)
- TestDTensorOpsCUDA.test_dtensor_op_db_jiterator_2inputs_2outputs_cuda_float32 (7.971 s)
- TestDTensorOpsCUDA.test_dtensor_op_db_jiterator_unary_cuda_float32 (8.265 s)
Sample failure stacktraces:
```python
TestDTensorOpsCUDA.test_dtensor_op_db_full_like_cuda_float32 (6.956 s)
Traceback (most recent call last):
File "/opt/pytorch/pytorch/torch/testing/_internal/common_distributed.py", line 527, in wrapper
self._join_processes(fn)
File "/opt/pytorch/pytorch/torch/testing/_internal/common_distributed.py", line 753, in _join_processes
self._check_return_codes(elapsed_time)
File "/opt/pytorch/pytorch/torch/testing/_internal/common_distributed.py", line 798, in _check_return_codes
raise RuntimeError(error)
RuntimeError: Process 3 exited with error code 10 and exception:
Traceback (most recent call last):
File "/opt/pytorch/pytorch/test/distributed/_tensor/test_dtensor_ops.py", line 617, in run_dtensor_crossref
dtensor_rs = tree_map(to_replicate, dtensor_rs)
File "/opt/pytorch/pytorch/torch/utils/_pytree.py", line 195, in tree_map
return tree_unflatten([fn(i) for i in flat_args], spec)
File "/opt/pytorch/pytorch/torch/utils/_pytree.py", line 195, in <listcomp>
return tree_unflatten([fn(i) for i in flat_args], spec)
File "/opt/pytorch/pytorch/test/distributed/_tensor/test_dtensor_ops.py", line 581, in to_replicate
e.redistribute(test_case.mesh, test_case.mesh.ndim * [Replicate()])
File "/opt/pytorch/pytorch/torch/distributed/_tensor/api.py", line 374, in redistribute
return Redistribute.apply(self, device_mesh, placements)
File "/opt/pytorch/pytorch/torch/distributed/_tensor/redistribute.py", line 205, in forward
return redistribute_dtensor(input, device_mesh, placements)
File "/opt/pytorch/pytorch/torch/distributed/_tensor/redistribute.py", line 177, in redistribute_dtensor
new_local_tensor = _redistribute_with_local_tensor(
File "/opt/pytorch/pytorch/torch/distributed/_tensor/redistribute.py", line 109, in _redistribute_with_local_tensor
new_local_tensor = current_placement._to_replicate_tensor(
File "/opt/pytorch/pytorch/torch/distributed/_tensor/placement_types.py", line 206, in _to_replicate_tensor
mesh.all_gather(gathered_list, CommTensor(local_tensor.contiguous()), mesh_dim=mesh_dim) # type: ignore[arg-type]
File "/opt/pytorch/pytorch/torch/distributed/_tensor/device_mesh.py", line 366, in all_gather
return all_gather(
File "/opt/pytorch/pytorch/torch/distributed/distributed_c10d.py", line 1346, in wrapper
return func(*args, **kwargs)
File "/opt/pytorch/pytorch/torch/distributed/distributed_c10d.py", line 2343, in all_gather
work = group.allgather([tensor_list], [tensor])
RuntimeError: Tensors must be CUDA and dense
Exception raised from check_gpu_tensors_different_devices at /opt/pytorch/pytorch/torch/csrc/distributed/c10d/ProcessGroupNCCL.cpp:1343 (most recent call first):
frame #0: c10::Error::Error(c10::SourceLocation, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >) + 0x6c (0x7f78a468d43c in /opt/pytorch/pytorch/torch/lib/libc10.so)
frame #1: c10::detail::torchCheckFail(char const*, char const*, unsigned int, char const*) + 0xf5 (0x7f78a4657f4d in /opt/pytorch/pytorch/torch/lib/libc10.so)
frame #2: <unknown function> + 0xf7e25d (0x7f78a56b825d in /opt/pytorch/pytorch/torch/lib/libtorch_cuda.so)
frame #3: c10d::ProcessGroupNCCL::allgather(std::vector<std::vector<at::Tensor, std::allocator<at::Tensor> >, std::allocator<std::vector<at::Tensor, std::allocator<at::Tensor> > > >&, std::vector<at::Tensor, std::allocator<at::Tensor> >&, c10d::AllgatherOptions const&) + 0x4a (0x7f78a56cd34a in /opt/pytorch/pytorch/torch/lib/libtorch_cuda.so)
frame #4: <unknown function> + 0x4fc9919 (0x7f78cde85919 in /opt/pytorch/pytorch/torch/lib/libtorch_cpu.so)
frame #5: <unknown function> + 0x4fd0362 (0x7f78cde8c362 in /opt/pytorch/pytorch/torch/lib/libtorch_cpu.so)
frame #6: c10d::ops::allgather(c10::intrusive_ptr<c10d::ProcessGroup, c10::detail::intrusive_target_default_null_type<c10d::ProcessGroup> > const&, std::vector<std::vector<at::Tensor, std::allocator<at::Tensor> >, std::allocator<std::vector<at::Tensor, std::allocator<at::Tensor> > > > const&, std::vector<at::Tensor, std::allocator<at::Tensor> > const&, c10d::AllgatherOptions const&) + 0x157 (0x7f78cde89727 in /opt/pytorch/pytorch/torch/lib/libtorch_cpu.so)
frame #7: <unknown function> + 0xc0ae81 (0x7f78d52c2e81 in /opt/pytorch/pytorch/torch/lib/libtorch_python.so)
frame #8: <unknown function> + 0x3e9b7d (0x7f78d4aa1b7d in /opt/pytorch/pytorch/torch/lib/libtorch_python.so)
frame #9: <unknown function> + 0x13c00e (0x5591d359a00e in /opt/conda/bin/python)
frame #10: _PyObject_MakeTpCall + 0x3bf (0x5591d358f13f in /opt/conda/bin/python)
frame #11: <unknown function> + 0x166ca0 (0x5591d35c4ca0 in /opt/conda/bin/python)
frame #12: _PyEval_EvalFrameDefault + 0x4f83 (0x5591d3639923 in /opt/conda/bin/python)
frame #13: _PyEval_EvalCodeWithName + 0x260 (0x5591d362a600 in /opt/conda/bin/python)
frame #14: _PyFunction_Vectorcall + 0x594 (0x5591d362bbc4 in /opt/conda/bin/python)
frame #15: PyObject_Call + 0x319 (0x5591d35954a9 in /opt/conda/bin/python)
frame #16: _PyEval_EvalFrameDefault + 0x1f07 (0x5591d36368a7 in /opt/conda/bin/python)
frame #17: _PyEval_EvalCodeWithName + 0x888 (0x5591d362ac28 in /opt/conda/bin/python)
frame #18: _PyFunction_Vectorcall + 0x594 (0x5591d362bbc4 in /opt/conda/bin/python)
frame #19: _PyEval_EvalFrameDefault + 0x1510 (0x5591d3635eb0 in /opt/conda/bin/python)
frame #20: _PyEval_EvalCodeWithName + 0x260 (0x5591d362a600 in /opt/conda/bin/python)
frame #21: _PyFunction_Vectorcall + 0x594 (0x5591d362bbc4 in /opt/conda/bin/python)
frame #22: <unknown function> + 0x166b2e (0x5591d35c4b2e in /opt/conda/bin/python)
frame #23: _PyEval_EvalFrameDefault + 0x1510 (0x5591d3635eb0 in /opt/conda/bin/python)
frame #24: _PyEval_EvalCodeWithName + 0xd5f (0x5591d362b0ff in /opt/conda/bin/python)
frame #25: _PyFunction_Vectorcall + 0x594 (0x5591d362bbc4 in /opt/conda/bin/python)
frame #26: _PyEval_EvalFrameDefault + 0x4c0 (0x5591d3634e60 in /opt/conda/bin/python)
frame #27: _PyFunction_Vectorcall + 0x1b7 (0x5591d362b7e7 in /opt/conda/bin/python)
frame #28: _PyEval_EvalFrameDefault + 0x71b (0x5591d36350bb in /opt/conda/bin/python)
frame #29: _PyFunction_Vectorcall + 0x1b7 (0x5591d362b7e7 in /opt/conda/bin/python)
frame #30: _PyEval_EvalFrameDefault + 0x71b (0x5591d36350bb in /opt/conda/bin/python)
frame #31: _PyFunction_Vectorcall + 0x1b7 (0x5591d362b7e7 in /opt/conda/bin/python)
frame #32: PyObject_Call + 0x7d (0x5591d359520d in /opt/conda/bin/python)
frame #33: THPFunction_apply(_object*, _object*) + 0x56f (0x7f78d4e1a9af in /opt/pytorch/pytorch/torch/lib/libtorch_python.so)
frame #34: <unknown function> + 0x13c09d (0x5591d359a09d in /opt/conda/bin/python)
frame #35: _PyObject_MakeTpCall + 0x3bf (0x5591d358f13f in /opt/conda/bin/python)
frame #36: _PyEval_EvalFrameDefault + 0x5434 (0x5591d3639dd4 in /opt/conda/bin/python)
frame #37: _PyEval_EvalCodeWithName + 0x260 (0x5591d362a600 in /opt/conda/bin/python)
frame #38: _PyFunction_Vectorcall + 0x534 (0x5591d362bb64 in /opt/conda/bin/python)
frame #39: _PyEval_EvalFrameDefault + 0x4c0 (0x5591d3634e60 in /opt/conda/bin/python)
frame #40: _PyEval_EvalCodeWithName + 0x888 (0x5591d362ac28 in /opt/conda/bin/python)
frame #41: _PyFunction_Vectorcall + 0x594 (0x5591d362bbc4 in /opt/conda/bin/python)
frame #42: _PyEval_EvalFrameDefault + 0x71b (0x5591d36350bb in /opt/conda/bin/python)
frame #43: _PyEval_EvalCodeWithName + 0x888 (0x5591d362ac28 in /opt/conda/bin/python)
frame #44: _PyFunction_Vectorcall + 0x594 (0x5591d362bbc4 in /opt/conda/bin/python)
frame #45: _PyEval_EvalFrameDefault + 0x71b (0x5591d36350bb in /opt/conda/bin/python)
frame #46: _PyEval_EvalCodeWithName + 0xd5f (0x5591d362b0ff in /opt/conda/bin/python)
frame #47: _PyFunction_Vectorcall + 0x594 (0x5591d362bbc4 in /opt/conda/bin/python)
frame #48: _PyEval_EvalFrameDefault + 0x71b (0x5591d36350bb in /opt/conda/bin/python)
frame #49: _PyEval_EvalCodeWithName + 0xd5f (0x5591d362b0ff in /opt/conda/bin/python)
frame #50: _PyFunction_Vectorcall + 0x594 (0x5591d362bbc4 in /opt/conda/bin/python)
frame #51: _PyEval_EvalFrameDefault + 0x71b (0x5591d36350bb in /opt/conda/bin/python)
frame #52: _PyEval_EvalCodeWithName + 0xd5f (0x5591d362b0ff in /opt/conda/bin/python)
frame #53: _PyFunction_Vectorcall + 0x594 (0x5591d362bbc4 in /opt/conda/bin/python)
frame #54: _PyEval_EvalFrameDefault + 0x71b (0x5591d36350bb in /opt/conda/bin/python)
frame #55: _PyEval_EvalCodeWithName + 0x260 (0x5591d362a600 in /opt/conda/bin/python)
frame #56: _PyFunction_Vectorcall + 0x534 (0x5591d362bb64 in /opt/conda/bin/python)
frame #57: _PyEval_EvalFrameDefault + 0x71b (0x5591d36350bb in /opt/conda/bin/python)
frame #58: _PyEval_EvalCodeWithName + 0xd5f (0x5591d362b0ff in /opt/conda/bin/python)
frame #59: _PyFunction_Vectorcall + 0x594 (0x5591d362bbc4 in /opt/conda/bin/python)
frame #60: PyObject_Call + 0x319 (0x5591d35954a9 in /opt/conda/bin/python)
frame #61: _PyEval_EvalFrameDefault + 0x1f07 (0x5591d36368a7 in /opt/conda/bin/python)
frame #62: _PyEval_EvalCodeWithName + 0x888 (0x5591d362ac28 in /opt/conda/bin/python)
frame #63: _PyFunction_Vectorcall + 0x594 (0x5591d362bbc4 in /opt/conda/bin/python)
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "/opt/pytorch/pytorch/torch/testing/_internal/common_distributed.py", line 651, in run_test
getattr(self, test_name)()
File "/opt/pytorch/pytorch/torch/testing/_internal/common_distributed.py", line 529, in wrapper
fn()
File "/opt/pytorch/pytorch/torch/testing/_internal/common_utils.py", line 2048, in wrapper
method(*args, **kwargs)
File "/opt/pytorch/pytorch/torch/testing/_internal/common_device_type.py", line 391, in instantiated_test
raise rte
File "/opt/pytorch/pytorch/torch/testing/_internal/common_device_type.py", line 378, in instantiated_test
result = test(self, **param_kwargs)
File "/opt/pytorch/pytorch/torch/testing/_internal/common_device_type.py", line 828, in test_wrapper
return test(*args, **kwargs)
File "/opt/pytorch/pytorch/torch/testing/_internal/common_utils.py", line 1313, in wrapper
fn(*args, **kwargs)
File "/opt/pytorch/pytorch/test/distributed/_tensor/test_dtensor_ops.py", line 694, in test_dtensor_op_db
check_dtensor_func(self, test, op)
File "/opt/pytorch/pytorch/test/distributed/_tensor/test_dtensor_ops.py", line 647, in check_dtensor_func
test_func()
File "/opt/pytorch/pytorch/test/distributed/_tensor/test_dtensor_ops.py", line 687, in test
run_dtensor_crossref(self, op.op, args, kwargs)
File "/opt/pytorch/pytorch/test/distributed/_tensor/test_dtensor_ops.py", line 638, in run_dtensor_crossref
raise RuntimeError(
RuntimeError: failed to run: torch.full_like, with (*[tensor([-7.5478, -8.4496, 7.9123, 6.4738], device='cuda:3',
requires_grad=True), -8.067646980285645], **{'device': 'cpu'})
```
Also, this test introduces CUDA illegal memory access
```
python test/distributed/_tensor/test_dtensor_ops.py -v -k test_dtensor_op_db_jiterator_2inputs_2outputs_cuda_float32
```
stacktraces (4,000 lines):
https://gist.github.com/xwang233/9feb59c637418aa4ce84d917960afbde
### Versions
https://github.com/pytorch/pytorch/commit/f20b3f2e5734b23a9e0a898196ddf77aa90323b8
V100x8
cuda 11.8
Related: #88838
cc @ngimel @wanchaol
| 7 |
4,187 | 89,158 |
Support disallowing calls to certain instance methods in TorchDynamo
|
triaged, module: dynamo
|
### 🚀 The feature, motivation and pitch
Currently TorchDynamo supports disallowing functions in captured graphs through `torch._dynamo.disallow_in_graph`. However, there is no way to disallow instance methods, for example, `Tensor.copy_`.
It would be a useful feature to exclude method calls as well, so that the model can be optimized by the backend even if the backend lacks support for some ops used in the model. Currently I have to patch the internal class of TorchDynamo, like
```py
import functools
import torch
import torch._dynamo
torch._dynamo.disallow_in_graph([torch.sub, torch.Tensor.__setitem__, torch.Tensor.copy_])
def backend(gm, example_inputs):
print(gm.graph)
return gm.forward
@torch._dynamo.optimize(backend)
def fn(x, y):
x = torch.add(x, 1)
x[0:2] = torch.zeros(2)
x = torch.add(x, 2)
x = torch.sub(x, 0)
x = torch.add(x, 3)
x.copy_(y)
x = torch.add(x, 4)
return x
fn(torch.ones(8), torch.zeros(8))
def _patch():
cls = torch._dynamo.variables.tensor.TensorVariable
old_method = cls.call_method
@functools.wraps(old_method)
def call_method(self, tx, name, args, kwargs):
if name == "__setitem__" or name == "copy_":
raise torch._dynamo.exc.Unsupported("Tensor __setitem__ not supported")
return old_method(self, tx, name, args, kwargs)
cls.call_method = call_method
_patch()
print("TensorVariable call_method patched")
torch._dynamo.reset()
fn(torch.ones(8), torch.zeros(8))
```
cc @mlazos @soumith @voznesenskym @yanboliang @penguinwu @anijain2305 @EikanWang @jgong5 @Guobing-Chen @chunyuan-w @XiaobingSuper @zhuhaozhe @blzheng @Xia-Weiwen @wenzhe-nrv @jiayisunx @desertfire @junrushao
### Alternatives
_No response_
### Additional context
_No response_
| 0 |
4,188 | 89,136 |
[FSDP] Adam Gives Different Results Where Only Difference Is Flattening
|
oncall: distributed, module: fsdp
|
Consider the following unit test (that relies on some imports from `common_fsdp.py`):
```
def test(self):
local_model = TransformerWithSharedParams.init(
self.process_group,
FSDPInitMode.NO_FSDP,
CUDAInitMode.CUDA_BEFORE,
deterministic=True,
)
fsdp_model = FSDP(
copy.deepcopy(local_model),
sharding_strategy=ShardingStrategy.NO_SHARD,
)
ddp_model = DDP(local_model, device_ids=[self.rank])
ddp_optim = torch.optim.Adam(ddp_model.parameters(), lr=1e-2)
fsdp_optim = torch.optim.Adam(fsdp_model.parameters(), lr=1e-2)
max_norm = 1
norm_type = 1
device = torch.device("cuda")
for i in range(10):
ddp_optim.zero_grad(set_to_none=True)
fsdp_optim.zero_grad(set_to_none=True)
inp = ddp_model.module.get_input(device)
for model in (ddp_model, fsdp_model):
out = model(*inp)
loss = nn.functional.cross_entropy(
out.view(-1, out.size(-1)), inp[1].view(-1), reduction="sum"
)
loss.backward()
ddp_total_norm = torch.nn.utils.clip_grad_norm_(
ddp_model.parameters(),
max_norm=max_norm,
norm_type=norm_type,
)
fsdp_total_norm = torch.nn.utils.clip_grad_norm_(
fsdp_model.parameters(),
max_norm=max_norm,
norm_type=norm_type,
)
self.assertEqual(ddp_total_norm, fsdp_total_norm)
ddp_flat_grad = torch.cat(tuple(p.grad.flatten() for p in ddp_model.parameters()))
fsdp_flat_grad = torch.cat(tuple(p.grad.flatten() for p in fsdp_model.parameters()))
self.assertEqual(ddp_flat_grad, fsdp_flat_grad)
ddp_flat_param = torch.cat(tuple(p.flatten() for p in ddp_model.parameters()))
fsdp_flat_param = torch.cat(tuple(p.flatten() for p in fsdp_model.parameters()))
self.assertEqual(ddp_flat_param, fsdp_flat_param)
ddp_optim.step()
fsdp_optim.step()
ddp_flat_param = torch.cat(tuple(p.flatten() for p in ddp_model.parameters()))
fsdp_flat_param = torch.cat(tuple(p.flatten() for p in fsdp_model.parameters()))
self.assertEqual(ddp_flat_param, fsdp_flat_param)
```
On the `i == 3` iteration, the assertion `self.assertEqual(ddp_flat_param, fsdp_flat_param)` *after* the optimizer steps fails.
```
Mismatched elements: 2 / 8427 (0.0%)
Greatest absolute difference: 1.0077477327286033e-05 at index (6610,) (up to 1e-05 allowed)
Greatest relative difference: 8.842818419533154 at index (6610,) (up to 1.3e-06 allowed)
```
The unit test initializes a model (`TransformerWithSharedParams`) and constructs `DDP` and `FSDP` (`NO_SHARD`) instances, which should be semantically equivalent. The _only_ relevant difference should be that FSDP has flattened all parameters into one `FlatParameter`.
We run a training loop that includes `torch.nn.utils.clip_grad_norm_(max_norm=1, norm_type=1)` and uses Adam optimizer. We have 3 checks: (1) gradient elements match after backward and clipping, (2) parameter elements match immediately before optimizer step, and (3) parameter elements match immediately after optimizer step.
Since (1) and (2) pass but (3) does not (on the `i == 3` iteration), this suggests that the optimizer step is not producing the same results. As discussed above, the only difference is that the `fsdp_model` parameters are "bucketed" into a `FlatParameter` (1D containing all the same elements), while the `ddp_model` parameters preserve the original shapes.
A couple of notes:
- [!!] The mismatch does not happen if we pass `use_orig_params=True` to the FSDP constructor. This is a key observation. For `use_orig_params=True`, the optimizer operates on the parameters with their original shapes, just like DDP. This suggests that operating on the flattened parameter is indeed the cause for the difference.
- The mismatch does not happen when using `SGD` instead of `Adam`.
- The mismatch does not happen if we remove the `torch.nn.utils.clip_grad_norm_()`. However, since we have check (1), this should rule out that `clip_grad_norm_()` is producing mismatching results. Rather, we may be relying on `clip_grad_norm_()` to have the gradients be at a sufficiently small magnitude.
- The mismatch also does happen when using `loss = out.sum()` instead of the `cross_entropy` computation.
It requires some nontrivial effort to simplify this repro to be equivalent but not rely on DDP, FSDP, or the FSDP utils from `common_fsdp.py`. I will hold off on that for now.
cc @mrshenli @pritamdamania87 @zhaojuanmao @satgera @rohan-varma @gqchen @aazzolini @osalpekar @jiayisuse @H-Huang @kwen2501
| 1 |
4,189 | 89,133 |
[FSDP] Investigate Unit Testing when Gradient Computation Differs on CPU/GPU
|
oncall: distributed, triaged, module: fsdp
|
Consider the following unit test (relying on some imports from `common_fsdp.py`):
```
def test_cpu_gpu_parity(self):
cpu_model = TransformerWithSharedParams.init(
self.process_group,
FSDPInitMode.NO_FSDP,
CUDAInitMode.CUDA_NEVER,
deterministic=True,
)
gpu_model = copy.deepcopy(cpu_model).cuda()
cpu_inp = cpu_model.get_input(torch.device("cpu"))
gpu_inp = gpu_model.get_input(torch.device("cuda"))
for t1, t2 in zip(cpu_inp, gpu_inp):
assert torch.equal(t1, t2.cpu()) # same input except device
for p1, p2 in zip(cpu_model.parameters(), gpu_model.parameters()):
assert torch.equal(p1, p2.cpu()) # same parameters except device
cpu_out = cpu_model(*cpu_inp)
cpu_out.sum().backward()
gpu_out = gpu_model(*gpu_inp)
gpu_out.sum().backward()
for p1, p2 in zip(cpu_model.parameters(), gpu_model.parameters()):
assert torch.equal(p1, p2.cpu())
assert torch.equal(p1.grad, p2.grad.cpu()), f"{torch.linalg.vector_norm(p1.grad - p2.grad.cpu())}"
```
This fails on the last line:
```
assert torch.equal(p1.grad, p2.grad.cpu()), f"{torch.linalg.vector_norm(p1.grad - p2.grad.cpu())}"
AssertionError: 2.398389005975332e-05
```
This slight difference in the computed gradients makes downstream testing infeasible (e.g. testing `clip_grad_norm_()`). This is relevant when testing DDP and FSDP parity when only FSDP is offloading parameters to CPU (since DDP does not support that natively).
We need to find a workaround for this for the unit testing coverage.
cc @mrshenli @pritamdamania87 @zhaojuanmao @satgera @rohan-varma @gqchen @aazzolini @osalpekar @jiayisuse @H-Huang @kwen2501
| 0 |
4,190 | 93,423 |
[`NotImplementedError: AutogradFunctionVariable() is not a constant`] using xFormers
|
triaged, bug, oncall: pt2
|
### 🐛 Describe the bug
The failure seems to happen with this line:
https://github.com/facebookresearch/xformers/blob/fd21b404c41303fc8a6e506244ae7fb539110e6e/xformers/ops/memory_efficient_attention.py#L371-L374
### Error logs
```
torch version 1.14.0.dev20221115+cu117
Running forward
Traceback (most recent call last):
File "/scratch/XXXX/xformers-py10-pytorchN-cu117/lib/python3.10/site-packages/torch/_dynamo/convert_frame.py", line 404, in _compile
out_code = transform_code_object(code, transform)
File "/scratch/XXXX/xformers-py10-pytorchN-cu117/lib/python3.10/site-packages/torch/_dynamo/bytecode_transformation.py", line 341, in transform_code_object
transformations(instructions, code_options)
File "/scratch/XXXX/xformers-py10-pytorchN-cu117/lib/python3.10/site-packages/torch/_dynamo/convert_frame.py", line 392, in transform
tracer.run()
File "/scratch/XXXX/xformers-py10-pytorchN-cu117/lib/python3.10/site-packages/torch/_dynamo/symbolic_convert.py", line 1518, in run
super().run()
File "/scratch/XXXX/xformers-py10-pytorchN-cu117/lib/python3.10/site-packages/torch/_dynamo/symbolic_convert.py", line 384, in run
and self.step()
File "/scratch/XXXX/xformers-py10-pytorchN-cu117/lib/python3.10/site-packages/torch/_dynamo/symbolic_convert.py", line 354, in step
getattr(self, inst.opname)(inst)
File "/scratch/XXXX/xformers-py10-pytorchN-cu117/lib/python3.10/site-packages/torch/_dynamo/symbolic_convert.py", line 188, in wrapper
return inner_fn(self, inst)
File "/scratch/XXXX/xformers-py10-pytorchN-cu117/lib/python3.10/site-packages/torch/_dynamo/symbolic_convert.py", line 811, in CALL_FUNCTION
self.call_function(fn, args, {})
File "/scratch/XXXX/xformers-py10-pytorchN-cu117/lib/python3.10/site-packages/torch/_dynamo/symbolic_convert.py", line 296, in call_function
self.push(fn.call_function(self, args, kwargs))
File "/scratch/XXXX/xformers-py10-pytorchN-cu117/lib/python3.10/site-packages/torch/_dynamo/variables/misc.py", line 572, in call_function
return self.obj.call_method(tx, self.name, args, kwargs).add_options(self)
File "/scratch/XXXX/xformers-py10-pytorchN-cu117/lib/python3.10/site-packages/torch/_dynamo/variables/misc.py", line 65, in call_method
inner_fn = self.const_getattr(self, name)
File "/scratch/XXXX/xformers-py10-pytorchN-cu117/lib/python3.10/site-packages/torch/_dynamo/variables/misc.py", line 40, in const_getattr
search_type = self.typevar.as_python_constant()
File "/scratch/XXXX/xformers-py10-pytorchN-cu117/lib/python3.10/site-packages/torch/_dynamo/variables/base.py", line 137, in as_python_constant
raise NotImplementedError(f"{self} is not a constant")
NotImplementedError: AutogradFunctionVariable() is not a constant
from user code:
File "/scratch/XXXX/xformers/xformers/ops/memory_efficient_attention.py", line 373, in supports
if not super(MemoryEfficientAttentionCutlassOp, cls).supports(d):
You can suppress this exception and fall back to eager by setting:
torch._dynamo.config.suppress_errors = True
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "/scratch/XXXX/xformers/timm_try.py", line 24, in <module>
model(inp, inp, inp)
File "/scratch/XXXX/xformers-py10-pytorchN-cu117/lib/python3.10/site-packages/torch/_dynamo/eval_frame.py", line 137, in __call__
return self.forward(*args, **kwargs)
File "/scratch/XXXX/xformers-py10-pytorchN-cu117/lib/python3.10/site-packages/torch/_dynamo/eval_frame.py", line 134, in forward
return optimized_forward(*args, **kwargs)
File "/scratch/XXXX/xformers-py10-pytorchN-cu117/lib/python3.10/site-packages/torch/_dynamo/eval_frame.py", line 169, in _fn
return fn(*args, **kwargs)
File "/scratch/XXXX/xformers/timm_try.py", line 16, in forward
return xops.memory_efficient_attention(q, k, v)
File "/scratch/XXXX/xformers/xformers/ops/memory_efficient_attention.py", line 923, in memory_efficient_attention
).op
File "/scratch/XXXX/xformers/xformers/ops/memory_efficient_attention.py", line 790, in op
if op.supports(self):
File "/scratch/XXXX/xformers-py10-pytorchN-cu117/lib/python3.10/site-packages/torch/_dynamo/eval_frame.py", line 247, in catch_errors
return callback(frame, cache_size)
File "/scratch/XXXX/xformers-py10-pytorchN-cu117/lib/python3.10/site-packages/torch/_dynamo/convert_frame.py", line 476, in _convert_frame
result = inner_convert(frame, cache_size)
File "/scratch/XXXX/xformers-py10-pytorchN-cu117/lib/python3.10/site-packages/torch/_dynamo/convert_frame.py", line 118, in _fn
return fn(*args, **kwargs)
File "/scratch/XXXX/xformers-py10-pytorchN-cu117/lib/python3.10/site-packages/torch/_dynamo/utils.py", line 89, in time_wrapper
r = func(*args, **kwargs)
File "/scratch/XXXX/xformers-py10-pytorchN-cu117/lib/python3.10/site-packages/torch/_dynamo/convert_frame.py", line 349, in _convert_frame_assert
return _compile(
File "/scratch/XXXX/xformers-py10-pytorchN-cu117/lib/python3.10/site-packages/torch/_dynamo/convert_frame.py", line 466, in _compile
raise InternalTorchDynamoError() from e
torch._dynamo.exc.InternalTorchDynamoError
```
### Repro
```
"""
conda install python=3.10 cudatoolkit=11.7 -c nvidia
python -m pip install numpy ninja --pre torch[dynamo] torchvision --force-reinstall --extra-index-url https://download.pytorch.org/whl/nightly/cu117
pip install -v -U git+https://github.com/facebookresearch/xformers.git@main#egg=xformers
# (this can take dozens of minutes)
"""
import torch
import torch._dynamo as dynamo
import xformers.ops as xops
torch._dynamo.config.verbose=True
device = "cuda"
dtype = torch.half
class xFormersMHA(torch.nn.Module):
def forward(self, q, k, v):
return xops.memory_efficient_attention(q, k, v)
model = xFormersMHA().to(device).to(dtype)
inp = torch.zeros([2, 10, 16, 128]).to(device).to(dtype)
print("torch version", torch.__version__)
model = dynamo.optimize()(model)
print("Running forward")
model(inp, inp, inp)
```
cc @ezyang @soumith @msaroufim @wconstab @ngimel @bdhirsh @fmassa
| 0 |
4,191 | 89,127 |
torch.normal(...) on MPS sometimes produces NaN's
|
triaged, module: mps
|
### 🐛 Describe the bug
PyTorch: 1.14.0.dev20221020.
Calling torch.normal(...) on MPS (Apple M1 Pro chip) sometimes produces nan's. I have found the issue exists with a variety of means and std's. Problem does not seem to occur when generating the tensor on the CPU then moving to MPS.
Minimal example:
```
import torch
mps = torch.device('mps')
cpu = torch.device('cpu')
for i in range(100):
print(torch.any(torch.isnan(torch.normal(0, 1, size=(1000, 1000), device=mps))))
# occasionally prints True
for i in range(100):
print(torch.any(torch.isnan(torch.normal(0, 1, size=(1000, 1000), device=cpu).to(mps))))
# doesn't print True
```
### Versions
Collecting environment information...
PyTorch version: 1.14.0.dev20221020
Is debug build: False
CUDA used to build PyTorch: None
ROCM used to build PyTorch: N/A
OS: macOS 12.6 (arm64)
GCC version: Could not collect
Clang version: 14.0.0 (clang-1400.0.29.102)
CMake version: Could not collect
Libc version: N/A
Python version: 3.10.6 (main, Sep 9 2022, 11:31:09) [Clang 13.1.6 (clang-1316.0.21.2.5)] (64-bit runtime)
Python platform: macOS-12.6-arm64-arm-64bit
Is CUDA available: False
CUDA runtime version: No CUDA
CUDA_MODULE_LOADING set to: N/A
GPU models and configuration: No CUDA
Nvidia driver version: No CUDA
cuDNN version: No CUDA
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] mypy==0.910
[pip3] mypy-extensions==0.4.3
[pip3] numpy==1.23.2
[pip3] torch==1.14.0.dev20221020
[pip3] torchaudio==0.13.0.dev20220911
[pip3] torchinfo==1.7.0
[pip3] torchsummary==1.5.1
[pip3] torchvision==0.14.0.dev20220911
[conda] Could not collect
cc @kulinseth @albanD @malfet @DenisVieriu97 @razarmehr @abhudev
| 0 |
4,192 | 89,125 |
binary_cross_entropy/bce_with_logits (+ other loss functions) for nested_tensor
|
module: loss, triaged, module: nestedtensor
|
### 🚀 The feature, motivation and pitch
For multi-task learning, it could be useful to have loss functions support nested_tensors. Some of the reductions might not be so useful for some loss functions as currently implemented since they seem to assume regularly sized inputs, but at least something could be implemented when reduce="none".
```
import torch
from torch.nn.functional import binary_cross_entropy
nt = torch.nested.nested_tensor([[1.0, 0.4, 0.2], [0.1]])
print(binary_cross_entropy(nt, nt, reduce="none"))
```
Current output
```
/home/frankier/edu/doc/bert_ordinal/nightlytorchplay/losstest.py:5: UserWarning: The PyTorch API of nested tensors is in prototype stage and will change in the near future. (Triggered internally at ../aten/src/ATen/NestedTensorImpl.cpp:177.)
nt = torch.nested.nested_tensor([[1.0, 0.4, 0.2], [0.1]])
Traceback (most recent call last):
File "/home/frankier/edu/doc/bert_ordinal/nightlytorchplay/losstest.py", line 7, in <module>
print(binary_cross_entropy(nt, nt, reduction="none"))
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/frankier/edu/doc/bert_ordinal/nightlytorchplay/venv/lib/python3.11/site-packages/torch/nn/functional.py", line 3087, in binary_cross_entropy
if target.size() != input.size():
^^^^^^^^^^^^^
RuntimeError: Internal error: NestedTensorImpl doesn't support sizes. Please file an issue on https://github.com/pytorch/nestedtensor
```
### Alternatives
If this were possible https://github.com/pytorch/pytorch/issues/89124 it might provide a good/easy workaround.
### Additional context
_No response_
cc @cpuhrsch @jbschlosser @bhosmer @drisspg @mikaylagawarecki
| 2 |
4,193 | 89,124 |
Zero-copy way to make flat tensor into a nested_tensor given a shape
|
triaged, module: nestedtensor
|
### 🚀 The feature, motivation and pitch
If it were possible to create a nested_tensor from a flat tensor with the correct layout, we could always work around elementwise functions which are not (yet) supported by nested_tensor e.g.
```
a_shape = [t.size() for t in a.unbind()]
tensor.nested.nested_tensor_from_values_as(elementwise_function(a.values()), a)
# OR
tensor.nested.nested_tensor_from_values(elementwise_function(a.values()), a_shape)
```
### Alternatives
Copying or trying to work with the flat tensor directly.
### Additional context
I am currently trying to use unsupported loss functions in their unreduced form
cc @cpuhrsch @jbschlosser @bhosmer @drisspg @mikaylagawarecki
| 1 |
4,194 | 89,116 |
Implement generic batch normalization layer.
|
oncall: distributed, feature, module: nn, triaged, needs research
|
### 🚀 The feature, motivation and pitch
Currently, the SyncBatchNorm module in PyTorch only has a `convert_sync_batchnorm` method to convert other Batch Normalization layers to SyncBatchNorm. However, it does not implement any method to revert the layers to their original classes.
However, implementing this would require either saving the original class type inside the SyncBatchNorm or implementing 1d, 2d, and 3d implementations of SyncBatchNorm. It would be preferable to implement instead a generic BatchNorm layer that can handle arbitrary dimensions.
Therefore, I would like to propose a generic `BatchNorm` layer that can handle arbitrary dimensions and can convert any related BatchNorm layer to itself, similar to `convert_sync_batchnorm`. This would allow removing the SyncBatchNorm layer for non-distributed inference and can convert any previous models to the new BatchNorm layer. Since the current functional `batch_norm` function is dimension neutral, the implementation will not be complicated.
### Alternatives
Possibly save the original dimensions in the SyncBatchNorm layer. However, this would not work if the original model is unknown.
### Additional context
SyncBatchNorm causes issues on single-process CPU inference and is challenging to convert to ONNX, etc. Having a generic BatchNorm would be the minimally invasive approach. Other issues have also proposed this solution before.
Also, I am willing to contribute.
https://github.com/pytorch/pytorch/issues/41081
https://github.com/pytorch/pytorch/issues/82464
cc @mrshenli @pritamdamania87 @zhaojuanmao @satgera @rohan-varma @gqchen @aazzolini @osalpekar @jiayisuse @H-Huang @kwen2501 @awgu @albanD @mruberry @jbschlosser @walterddr @kshitij12345 @saketh-are
| 10 |
4,195 | 89,114 |
jit.script() fails to resolve/cast Optional[Tensor] fields of sub-modules or base classes of the object being scripted
|
oncall: jit
|
### 🐛 Describe the bug
Here: in scripted module, I can't use 'bias' of neither inherited nor contained Conv1d class, because script() fails to cast Optional[Tensor] to Tensor, even under 'is not None' condition.
Curiously enough, if I add an unrelated data member (slide_winsize: float below) - if fixes type resolution for base class. Unfortunately, I was not able to find a workaround to force it to properly handle self.c1d.bias below.
```
import torch
from torch import Tensor
from torch.nn import Conv1d
class PartialConv1d(Conv1d):
# Uncomment this to make script() work
# slide_winsize: float
def __init__(self, *args, **kwargs):
super(PartialConv1d, self).__init__(*args, **kwargs)
self.c1d = Conv1d(*args, **kwargs)
def forward(self, input, mask):
input = torch.mul(input, mask)
raw_out = self.c1d(input)
# Can that somehow be made to work ?
# Or direct reference to Conv1d.forward(self, ...) as static method ?
# super(PartialConv1d, self).forward(input)
raw_out = self._conv_forward(input, self.weight, self.bias)
if self.bias is not None:
nch = self.out_channels # This always works
# Those two work with slide_winsize above uncommented, otherwise error out:
# 'Optional[Tensor]' object has no attribute or method 'view'.
my_view = self.bias.view(1,1,self.out_channels)
# Variable 'my_bias' is annotated with type Tensor but is being assigned to a value of type Optional[Tensor]
my_bias:Tensor = self.bias
# This fails even with slide_winsize uncommented
# my_bias2:Tensor = self.c1d.bias
bias_view = my_bias.view(1, self.out_channels, 1)
output = torch.mul(raw_out - bias_view, 0.5) + bias_view
return output
args = {'kernel_size': 1, 'stride': 1, 'padding': 0, 'dilation': 1, 'bias': True}
c1 = PartialConv1d(1024, 80, **args)
w = c1.weight
s = w.shape
rand_in = torch.ones(1, s[1], s[2], dtype=w.dtype, device=w.device)
lens = torch.ones(1, 1, s[2], dtype=w.dtype, device=w.device)
c1.forward(rand_in, lens)
c2 = torch.jit.script(c1)
```
### Versions
PyTorch version: 1.13.0a0+d0d6b1f
Is debug build: False
CUDA used to build PyTorch: 11.8
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.5 LTS (x86_64)
GCC version: (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0
Clang version: Could not collect
CMake version: version 3.22.2
Libc version: glibc-2.31
Python version: 3.8.13 | packaged by conda-forge | (default, Mar 25 2022, 06:04:10) [GCC 10.3.0] (64-bit runtime)
Python platform: Linux-5.15.0-46-generic-x86_64-with-glibc2.10
Is CUDA available: True
CUDA runtime version: 11.8.89
GPU models and configuration: GPU 0: NVIDIA RTX A5000
Nvidia driver version: 515.65.01
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.6.0
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.6.0
/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.6.0
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_infer.so.8.6.0
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.6.0
/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.6.0
/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.6.0
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] functorch==0.3.0a0
[pip3] k2==1.21.dev20221109+cuda11.8.torch1.13.0a0
[pip3] numpy==1.22.2
[pip3] pytorch-lightning==1.7.7
[pip3] pytorch-quantization==2.1.2
[pip3] torch==1.13.0a0+d0d6b1f
[pip3] torch-tensorrt==1.3.0a0
[pip3] torchaudio==0.13.0
[pip3] torchmetrics==0.10.2
[pip3] torchvision==0.14.0a0
[conda] functorch 0.3.0a0 pypi_0 pypi
[conda] k2 1.21.dev20221109+cuda11.8.torch1.13.0a0 pypi_0 pypi
[conda] mkl 2020.4 h726a3e6_304 conda-forge
[conda] mkl-include 2020.4 h726a3e6_304 conda-forge
[conda] numpy 1.22.2 py38h6ae9a64_0 conda-forge
[conda] pytorch-lightning 1.7.7 pypi_0 pypi
[conda] pytorch-quantization 2.1.2 pypi_0 pypi
[conda] torch 1.13.0a0+d0d6b1f pypi_0 pypi
[conda] torch-tensorrt 1.3.0a0 pypi_0 pypi
[conda] torchaudio 0.13.0 pypi_0 pypi
[conda] torchmetrics 0.10.2 pypi_0 pypi
[conda] torchvision 0.14.0a0 pypi_0 pypi
r
cc @EikanWang @jgong5 @wenzhe-nrv @sanchitintel
| 0 |
4,196 | 89,105 |
Bad string in GLSL shader
|
triaged, module: vulkan, topic: build
|
### 🐛 Describe the bug
Hi,
I'm trying to compile the Vulkan inference backend using the instructions here: https://pytorch.org/tutorials/prototype/vulkan_workflow.html. I've checked out tag `v.1.13.0`, and I'm on Ubuntu 20.04.
I ran
```
USE_VULKAN=1 USE_VULKAN_SHADERC_RUNTIME=1 USE_VULKAN_WRAPPER=0 python setup.py install
```
The build stops on:
```
/home/user/pytorch/build/vulkan/ATen/native/vulkan/glsl.cpp:1166:1: error: unable to find string literal operator ‘operator""fully’ with ‘const char [1326]’, ‘long unsigned int’ arguments
1166 | " // and compute partial sums of texels that are "fully filled"\n"
```
This problem seems to originate on this [line](https://github.com/pytorch/pytorch/blob/60ffeb986648420810098cba6ac0ad1cee06bd95/aten/src/ATen/native/vulkan/glsl/layernorm.glsl#L38), with the quotes that aren't escaped when the shaders are gathered into `glsl.cpp`. `layernorm.glsl` is unchanged in master so this should still apply (unless the tool that puts `glsl.cpp` together corrects it).
### Versions
Results of collect env
```
PyTorch version: N/A
Is debug build: N/A
CUDA used to build PyTorch: N/A
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.5 LTS (x86_64)
GCC version: (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0
Clang version: Could not collect
CMake version: version 3.16.3
Libc version: glibc-2.31
Python version: 3.8.10 (default, Jun 22 2022, 20:18:18) [GCC 9.4.0] (64-bit runtime)
Python platform: Linux-5.15.0-52-generic-x86_64-with-glibc2.29
Is CUDA available: N/A
CUDA runtime version: Could not collect
CUDA_MODULE_LOADING set to: N/A
GPU models and configuration: Could not collect
Nvidia driver version: Could not collect
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: N/A
Versions of relevant libraries:
[pip3] numpy==1.23.4
[conda] Could not collect
```
| 1 |
4,197 | 96,337 |
pytreeify decorators
|
feature, triaged, module: pytree, module: functorch
|
Hello Functorch!
I am working on rewriting the PennyLane pytorch interface (quantum software) and I think your project can be really useful!
Currently I am trying to bypass the limitation of `autograd.Function` that only supports returning Tensor or a tuple of Tensor as return type. I have read that you want to be able to support `autograd.Function` https://github.com/pytorch/functorch/issues/1031 in Functorch. Do you think it will be possible to define functions (`autograd.Function`) that return arbitrarily nested tuple structure? Like in Jax I would like to define `custom_vjp` (vjp needs to match Pytree structure of the function parameters) or `custom_jvp` (jvp needs to match Pytree structure of the function return).
To summarize: when you add support for custom gradient (with autograd.Function) can you also remove the structure limitation of the function return type `autograd.Function`? Or alternatively if you don't add this support but build your own custom_vjp, custom_jvp can try to avoid any limitation for the return type of functions?
Example with `autograd.function`:
```
import functorch
class ExecuteTapesNew(torch.autograd.Function):
@staticmethod
def forward(ctx, param_0, param_1, param_2, param_3):
#Support Pytree structure
return tuple([tuple([param_0, param_1]), tuple([param_2, param_3])])
@staticmethod
def backward(ctx, *dys):
jac = compute_jac(params)
vjp = dys * jacobian
# VJP match the structure of the parameters
return tuple(vjp)
def execute(param_0, param_1, param_2, param_3):
return ExecuteTapesNew.apply(param_0, param_1, param_2, param_3)
jac = functorch.jacrev(execute, argnums=(0,1,2,3))(param_0, param_1, param_2, param_3)
```
Example Jax like:
```
@jax.custom_vjp
def f(param_0, param_1, param_2, param_3):
return tuple([tuple([param_0, param_1]), tuple([param_2, param_3])])
def f_fwd(param_0, param_1, param_2, param_3):
return f(param_0, param_1, param_2, param_3), ()
def f_bwd(res, g):
return (param_0*g, param_1*g, param_2*g, param_3*g)
f.defvjp(f_fwd, f_bwd)
```
cc @zou3519 @soumith @Chillee @samdow @kshitij12345 @janeyx99
| 7 |
4,198 | 89,080 |
Unable to backprop through dense weighted sum of sparse_coo_tensors
|
module: sparse, triaged
|
### 🐛 Describe the bug
I can't find a way to perform a weighted sum of `sparse_coo_tensors` using a dense tensor parameter without running into an `aten::sum.dim_IntList` NotImplementedError. This seems like a common use-case, so I was wondering if there's a workaround, or correct way to accomplish this operation.
```python
import torch
sp_mtx1 = torch.eye(10, dtype=float).to_sparse_coo().cuda()
sp_mtx2 = torch.eye(10, dtype=float).to_sparse_coo().cuda()
sp_mtx_comb = torch.stack([sp_mtx1, sp_mtx2], 0) # (2, 10, 10)
weight = torch.rand([2], dtype=float, requires_grad=True).cuda()
weighted = sp_mtx_comb*weight.view(-1,1,1) # (2, 10, 10)
weighted_sum = torch.sparse.sum(weighted, 0) # (10, 10)
loss = torch.sparse.sum(weighted_sum)
loss.backward()
```
This example produces the following traceback:
```
def test_reproduce_cuda_config_err():
sp_mtx0 = torch.eye(10, dtype=float).to_sparse_coo().cuda()
sp_mtx1 = torch.eye(10, dtype=float).to_sparse_coo().cuda()
sp_mtx = torch.stack([sp_mtx0, sp_mtx1], 0)
weight = torch.tensor([1.0, 2.0], dtype=float, requires_grad=True).cuda()
res = sp_mtx*weight.view(-1,1,1)
print(res)
weighted_sum = torch.sparse.sum(res, 0)
print(weighted_sum)
loss = torch.sparse.sum(weighted_sum)
> loss.backward()
test_reproduce.py:17:
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
../../.conda/envs/torch113/lib/python3.10/site-packages/torch/_tensor.py:487: in backward
torch.autograd.backward(
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
tensors = (tensor(30., device='cuda:0', dtype=torch.float64, grad_fn=<SumBackward0>),), grad_tensors = None, retain_graph = False, create_graph = False, grad_variables = None
inputs = ()
def backward(
tensors: _TensorOrTensors,
grad_tensors: Optional[_TensorOrTensors] = None,
retain_graph: Optional[bool] = None,
create_graph: bool = False,
grad_variables: Optional[_TensorOrTensors] = None,
inputs: Optional[_TensorOrTensors] = None,
) -> None:
r"""Computes the sum of gradients of given tensors with respect to graph
leaves.
The graph is differentiated using the chain rule. If any of ``tensors``
are non-scalar (i.e. their data has more than one element) and require
gradient, then the Jacobian-vector product would be computed, in this
case the function additionally requires specifying ``grad_tensors``.
It should be a sequence of matching length, that contains the "vector"
in the Jacobian-vector product, usually the gradient of the differentiated
function w.r.t. corresponding tensors (``None`` is an acceptable value for
all tensors that don't need gradient tensors).
This function accumulates gradients in the leaves - you might need to zero
``.grad`` attributes or set them to ``None`` before calling it.
See :ref:`Default gradient layouts<default-grad-layouts>`
for details on the memory layout of accumulated gradients.
.. note::
Using this method with ``create_graph=True`` will create a reference cycle
between the parameter and its gradient which can cause a memory leak.
We recommend using ``autograd.grad`` when creating the graph to avoid this.
If you have to use this function, make sure to reset the ``.grad`` fields of your
parameters to ``None`` after use to break the cycle and avoid the leak.
.. note::
If you run any forward ops, create ``grad_tensors``, and/or call ``backward``
in a user-specified CUDA stream context, see
:ref:`Stream semantics of backward passes<bwd-cuda-stream-semantics>`.
.. note::
When ``inputs`` are provided and a given input is not a leaf,
the current implementation will call its grad_fn (even though it is not strictly needed to get this gradients).
It is an implementation detail on which the user should not rely.
See https://github.com/pytorch/pytorch/pull/60521#issuecomment-867061780 for more details.
Args:
tensors (Sequence[Tensor] or Tensor): Tensors of which the derivative will be
computed.
grad_tensors (Sequence[Tensor or None] or Tensor, optional): The "vector" in
the Jacobian-vector product, usually gradients w.r.t. each element of
corresponding tensors. None values can be specified for scalar Tensors or
ones that don't require grad. If a None value would be acceptable for all
grad_tensors, then this argument is optional.
retain_graph (bool, optional): If ``False``, the graph used to compute the grad
will be freed. Note that in nearly all cases setting this option to ``True``
is not needed and often can be worked around in a much more efficient
way. Defaults to the value of ``create_graph``.
create_graph (bool, optional): If ``True``, graph of the derivative will
be constructed, allowing to compute higher order derivative products.
Defaults to ``False``.
inputs (Sequence[Tensor] or Tensor, optional): Inputs w.r.t. which the gradient
be will accumulated into ``.grad``. All other Tensors will be ignored. If
not provided, the gradient is accumulated into all the leaf Tensors that
were used to compute the attr::tensors.
"""
if torch._C._are_functorch_transforms_active():
raise RuntimeError(
"backward() called inside a functorch transform. This is not "
"supported, please use functorch.grad or functorch.vjp instead "
"or call backward() outside of functorch transforms.")
if grad_variables is not None:
warnings.warn("'grad_variables' is deprecated. Use 'grad_tensors' instead.")
if grad_tensors is None:
grad_tensors = grad_variables
else:
raise RuntimeError("'grad_tensors' and 'grad_variables' (deprecated) "
"arguments both passed to backward(). Please only "
"use 'grad_tensors'.")
if inputs is not None and len(inputs) == 0:
raise RuntimeError("'inputs' argument to backward() cannot be empty.")
tensors = (tensors,) if isinstance(tensors, torch.Tensor) else tuple(tensors)
inputs = (inputs,) if isinstance(inputs, torch.Tensor) else \
tuple(inputs) if inputs is not None else tuple()
grad_tensors_ = _tensor_or_tensors_to_tuple(grad_tensors, len(tensors))
grad_tensors_ = _make_grads(tensors, grad_tensors_, is_grads_batched=False)
if retain_graph is None:
retain_graph = create_graph
# The reason we repeat same the comment below is that
# some Python versions print out the first line of a multi-line function
# calls in the traceback and some print out the last line
> Variable._execution_engine.run_backward( # Calls into the C++ engine to run the backward pass
tensors, grad_tensors_, retain_graph, create_graph, inputs,
allow_unreachable=True, accumulate_grad=True) # Calls into the C++ engine to run the backward pass
E NotImplementedError: Could not run 'aten::sum.dim_IntList' with arguments from the 'SparseCUDA' backend. This could be because the operator doesn't exist for this backend, or was omitted during the selective/custom build process (if using custom build). If you are a Facebook employee using PyTorch on mobile, please visit https://fburl.com/ptmfixes for possible resolutions. 'aten::sum.dim_IntList' is only available for these backends: [CPU, CUDA, HIP, MPS, IPU, XPU, HPU, VE, Meta, PrivateUse1, PrivateUse2, PrivateUse3, FPGA, ORT, Vulkan, Metal, QuantizedCPU, QuantizedCUDA, QuantizedHIP, QuantizedMPS, QuantizedIPU, QuantizedXPU, QuantizedHPU, QuantizedVE, QuantizedMeta, QuantizedPrivateUse1, QuantizedPrivateUse2, QuantizedPrivateUse3, CustomRNGKeyId, MkldnnCPU, SparseCsrCPU, SparseCsrCUDA, NestedTensorCPU, BackendSelect, Python, FuncTorchDynamicLayerBackMode, Functionalize, Named, Conjugate, Negative, ZeroTensor, ADInplaceOrView, AutogradOther, AutogradCPU, AutogradCUDA, AutogradHIP, AutogradXLA, AutogradMPS, AutogradIPU, AutogradXPU, AutogradHPU, AutogradVE, AutogradLazy, AutogradMeta, AutogradPrivateUse1, AutogradPrivateUse2, AutogradPrivateUse3, AutogradNestedTensor, Tracer, AutocastCPU, AutocastCUDA, FuncTorchBatched, FuncTorchVmapMode, Batched, VmapMode, FuncTorchGradWrapper, PythonTLSSnapshot, FuncTorchDynamicLayerFrontMode, PythonDispatcher].
E
E Undefined: registered at /opt/conda/conda-bld/pytorch_1666643003845/work/build/aten/src/ATen/RegisterCompositeExplicitAutogradNonFunctional.cpp:21389 [default backend kernel]
E CPU: registered at /opt/conda/conda-bld/pytorch_1666643003845/work/build/aten/src/ATen/RegisterCPU.cpp:30798 [kernel]
E CUDA: registered at /opt/conda/conda-bld/pytorch_1666643003845/work/build/aten/src/ATen/RegisterCUDA.cpp:43635 [kernel]
E HIP: registered at /opt/conda/conda-bld/pytorch_1666643003845/work/build/aten/src/ATen/RegisterCompositeExplicitAutogradNonFunctional.cpp:21389 [default backend kernel]
E MPS: registered at /opt/conda/conda-bld/pytorch_1666643003845/work/build/aten/src/ATen/RegisterCompositeExplicitAutogradNonFunctional.cpp:21389 [default backend kernel]
E IPU: registered at /opt/conda/conda-bld/pytorch_1666643003845/work/build/aten/src/ATen/RegisterCompositeExplicitAutogradNonFunctional.cpp:21389 [default backend kernel]
E XPU: registered at /opt/conda/conda-bld/pytorch_1666643003845/work/build/aten/src/ATen/RegisterCompositeExplicitAutogradNonFunctional.cpp:21389 [default backend kernel]
E HPU: registered at /opt/conda/conda-bld/pytorch_1666643003845/work/build/aten/src/ATen/RegisterCompositeExplicitAutogradNonFunctional.cpp:21389 [default backend kernel]
E VE: registered at /opt/conda/conda-bld/pytorch_1666643003845/work/build/aten/src/ATen/RegisterCompositeExplicitAutogradNonFunctional.cpp:21389 [default backend kernel]
E Meta: registered at /opt/conda/conda-bld/pytorch_1666643003845/work/build/aten/src/ATen/RegisterMeta.cpp:26815 [kernel]
E PrivateUse1: registered at /opt/conda/conda-bld/pytorch_1666643003845/work/build/aten/src/ATen/RegisterCompositeExplicitAutogradNonFunctional.cpp:21389 [default backend kernel]
E PrivateUse2: registered at /opt/conda/conda-bld/pytorch_1666643003845/work/build/aten/src/ATen/RegisterCompositeExplicitAutogradNonFunctional.cpp:21389 [default backend kernel]
E PrivateUse3: registered at /opt/conda/conda-bld/pytorch_1666643003845/work/build/aten/src/ATen/RegisterCompositeExplicitAutogradNonFunctional.cpp:21389 [default backend kernel]
E FPGA: registered at /opt/conda/conda-bld/pytorch_1666643003845/work/build/aten/src/ATen/RegisterCompositeExplicitAutogradNonFunctional.cpp:21389 [default backend kernel]
E ORT: registered at /opt/conda/conda-bld/pytorch_1666643003845/work/build/aten/src/ATen/RegisterCompositeExplicitAutogradNonFunctional.cpp:21389 [default backend kernel]
E Vulkan: registered at /opt/conda/conda-bld/pytorch_1666643003845/work/build/aten/src/ATen/RegisterCompositeExplicitAutogradNonFunctional.cpp:21389 [default backend kernel]
E Metal: registered at /opt/conda/conda-bld/pytorch_1666643003845/work/build/aten/src/ATen/RegisterCompositeExplicitAutogradNonFunctional.cpp:21389 [default backend kernel]
E QuantizedCPU: registered at /opt/conda/conda-bld/pytorch_1666643003845/work/build/aten/src/ATen/RegisterCompositeExplicitAutogradNonFunctional.cpp:21389 [default backend kernel]
E QuantizedCUDA: registered at /opt/conda/conda-bld/pytorch_1666643003845/work/build/aten/src/ATen/RegisterCompositeExplicitAutogradNonFunctional.cpp:21389 [default backend kernel]
E QuantizedHIP: registered at /opt/conda/conda-bld/pytorch_1666643003845/work/build/aten/src/ATen/RegisterCompositeExplicitAutogradNonFunctional.cpp:21389 [default backend kernel]
E QuantizedMPS: registered at /opt/conda/conda-bld/pytorch_1666643003845/work/build/aten/src/ATen/RegisterCompositeExplicitAutogradNonFunctional.cpp:21389 [default backend kernel]
E QuantizedIPU: registered at /opt/conda/conda-bld/pytorch_1666643003845/work/build/aten/src/ATen/RegisterCompositeExplicitAutogradNonFunctional.cpp:21389 [default backend kernel]
E QuantizedXPU: registered at /opt/conda/conda-bld/pytorch_1666643003845/work/build/aten/src/ATen/RegisterCompositeExplicitAutogradNonFunctional.cpp:21389 [default backend kernel]
E QuantizedHPU: registered at /opt/conda/conda-bld/pytorch_1666643003845/work/build/aten/src/ATen/RegisterCompositeExplicitAutogradNonFunctional.cpp:21389 [default backend kernel]
E QuantizedVE: registered at /opt/conda/conda-bld/pytorch_1666643003845/work/build/aten/src/ATen/RegisterCompositeExplicitAutogradNonFunctional.cpp:21389 [default backend kernel]
E QuantizedMeta: registered at /opt/conda/conda-bld/pytorch_1666643003845/work/build/aten/src/ATen/RegisterCompositeExplicitAutogradNonFunctional.cpp:21389 [default backend kernel]
E QuantizedPrivateUse1: registered at /opt/conda/conda-bld/pytorch_1666643003845/work/build/aten/src/ATen/RegisterCompositeExplicitAutogradNonFunctional.cpp:21389 [default backend kernel]
E QuantizedPrivateUse2: registered at /opt/conda/conda-bld/pytorch_1666643003845/work/build/aten/src/ATen/RegisterCompositeExplicitAutogradNonFunctional.cpp:21389 [default backend kernel]
E QuantizedPrivateUse3: registered at /opt/conda/conda-bld/pytorch_1666643003845/work/build/aten/src/ATen/RegisterCompositeExplicitAutogradNonFunctional.cpp:21389 [default backend kernel]
E CustomRNGKeyId: registered at /opt/conda/conda-bld/pytorch_1666643003845/work/build/aten/src/ATen/RegisterCompositeExplicitAutogradNonFunctional.cpp:21389 [default backend kernel]
E MkldnnCPU: registered at /opt/conda/conda-bld/pytorch_1666643003845/work/build/aten/src/ATen/RegisterCompositeExplicitAutogradNonFunctional.cpp:21389 [default backend kernel]
E SparseCsrCPU: registered at /opt/conda/conda-bld/pytorch_1666643003845/work/build/aten/src/ATen/RegisterCompositeExplicitAutogradNonFunctional.cpp:21389 [default backend kernel]
E SparseCsrCUDA: registered at /opt/conda/conda-bld/pytorch_1666643003845/work/build/aten/src/ATen/RegisterCompositeExplicitAutogradNonFunctional.cpp:21389 [default backend kernel]
E NestedTensorCPU: registered at /opt/conda/conda-bld/pytorch_1666643003845/work/build/aten/src/ATen/RegisterNestedTensorCPU.cpp:457 [kernel]
E BackendSelect: fallthrough registered at /opt/conda/conda-bld/pytorch_1666643003845/work/aten/src/ATen/core/BackendSelectFallbackKernel.cpp:3 [backend fallback]
E Python: registered at /opt/conda/conda-bld/pytorch_1666643003845/work/aten/src/ATen/core/PythonFallbackKernel.cpp:140 [backend fallback]
E FuncTorchDynamicLayerBackMode: registered at /opt/conda/conda-bld/pytorch_1666643003845/work/aten/src/ATen/functorch/DynamicLayer.cpp:488 [backend fallback]
E Functionalize: registered at /opt/conda/conda-bld/pytorch_1666643003845/work/aten/src/ATen/FunctionalizeFallbackKernel.cpp:291 [backend fallback]
E Named: fallthrough registered at /opt/conda/conda-bld/pytorch_1666643003845/work/aten/src/ATen/core/NamedRegistrations.cpp:11 [kernel]
E Conjugate: registered at /opt/conda/conda-bld/pytorch_1666643003845/work/aten/src/ATen/ConjugateFallback.cpp:18 [backend fallback]
E Negative: registered at /opt/conda/conda-bld/pytorch_1666643003845/work/aten/src/ATen/native/NegateFallback.cpp:18 [backend fallback]
E ZeroTensor: registered at /opt/conda/conda-bld/pytorch_1666643003845/work/aten/src/ATen/ZeroTensorFallback.cpp:86 [backend fallback]
E ADInplaceOrView: fallthrough registered at /opt/conda/conda-bld/pytorch_1666643003845/work/aten/src/ATen/core/VariableFallbackKernel.cpp:64 [backend fallback]
E AutogradOther: registered at /opt/conda/conda-bld/pytorch_1666643003845/work/torch/csrc/autograd/generated/VariableType_2.cpp:16899 [autograd kernel]
E AutogradCPU: registered at /opt/conda/conda-bld/pytorch_1666643003845/work/torch/csrc/autograd/generated/VariableType_2.cpp:16899 [autograd kernel]
E AutogradCUDA: registered at /opt/conda/conda-bld/pytorch_1666643003845/work/torch/csrc/autograd/generated/VariableType_2.cpp:16899 [autograd kernel]
E AutogradHIP: registered at /opt/conda/conda-bld/pytorch_1666643003845/work/torch/csrc/autograd/generated/VariableType_2.cpp:16899 [autograd kernel]
E AutogradXLA: registered at /opt/conda/conda-bld/pytorch_1666643003845/work/torch/csrc/autograd/generated/VariableType_2.cpp:16899 [autograd kernel]
E AutogradMPS: registered at /opt/conda/conda-bld/pytorch_1666643003845/work/torch/csrc/autograd/generated/VariableType_2.cpp:16899 [autograd kernel]
E AutogradIPU: registered at /opt/conda/conda-bld/pytorch_1666643003845/work/torch/csrc/autograd/generated/VariableType_2.cpp:16899 [autograd kernel]
E AutogradXPU: registered at /opt/conda/conda-bld/pytorch_1666643003845/work/torch/csrc/autograd/generated/VariableType_2.cpp:16899 [autograd kernel]
E AutogradHPU: registered at /opt/conda/conda-bld/pytorch_1666643003845/work/torch/csrc/autograd/generated/VariableType_2.cpp:16899 [autograd kernel]
E AutogradVE: registered at /opt/conda/conda-bld/pytorch_1666643003845/work/torch/csrc/autograd/generated/VariableType_2.cpp:16899 [autograd kernel]
E AutogradLazy: registered at /opt/conda/conda-bld/pytorch_1666643003845/work/torch/csrc/autograd/generated/VariableType_2.cpp:16899 [autograd kernel]
E AutogradMeta: registered at /opt/conda/conda-bld/pytorch_1666643003845/work/torch/csrc/autograd/generated/VariableType_2.cpp:16899 [autograd kernel]
E AutogradPrivateUse1: registered at /opt/conda/conda-bld/pytorch_1666643003845/work/torch/csrc/autograd/generated/VariableType_2.cpp:16899 [autograd kernel]
E AutogradPrivateUse2: registered at /opt/conda/conda-bld/pytorch_1666643003845/work/torch/csrc/autograd/generated/VariableType_2.cpp:16899 [autograd kernel]
E AutogradPrivateUse3: registered at /opt/conda/conda-bld/pytorch_1666643003845/work/torch/csrc/autograd/generated/VariableType_2.cpp:16899 [autograd kernel]
E AutogradNestedTensor: registered at /opt/conda/conda-bld/pytorch_1666643003845/work/torch/csrc/autograd/generated/VariableType_2.cpp:17970 [kernel]
E Tracer: registered at /opt/conda/conda-bld/pytorch_1666643003845/work/torch/csrc/autograd/generated/TraceType_2.cpp:16890 [kernel]
E AutocastCPU: fallthrough registered at /opt/conda/conda-bld/pytorch_1666643003845/work/aten/src/ATen/autocast_mode.cpp:482 [backend fallback]
E AutocastCUDA: registered at /opt/conda/conda-bld/pytorch_1666643003845/work/aten/src/ATen/autocast_mode.cpp:328 [kernel]
E FuncTorchBatched: registered at /opt/conda/conda-bld/pytorch_1666643003845/work/aten/src/ATen/functorch/BatchRulesReduceOps.cpp:371 [kernel]
E FuncTorchVmapMode: fallthrough registered at /opt/conda/conda-bld/pytorch_1666643003845/work/aten/src/ATen/functorch/VmapModeRegistrations.cpp:28 [backend fallback]
E Batched: registered at /opt/conda/conda-bld/pytorch_1666643003845/work/aten/src/ATen/BatchingRegistrations.cpp:1068 [kernel]
E VmapMode: fallthrough registered at /opt/conda/conda-bld/pytorch_1666643003845/work/aten/src/ATen/VmapModeRegistrations.cpp:33 [backend fallback]
E FuncTorchGradWrapper: registered at /opt/conda/conda-bld/pytorch_1666643003845/work/aten/src/ATen/functorch/TensorWrapper.cpp:189 [backend fallback]
E PythonTLSSnapshot: registered at /opt/conda/conda-bld/pytorch_1666643003845/work/aten/src/ATen/core/PythonFallbackKernel.cpp:148 [backend fallback]
E FuncTorchDynamicLayerFrontMode: registered at /opt/conda/conda-bld/pytorch_1666643003845/work/aten/src/ATen/functorch/DynamicLayer.cpp:484 [backend fallback]
E PythonDispatcher: registered at /opt/conda/conda-bld/pytorch_1666643003845/work/aten/src/ATen/core/PythonFallbackKernel.cpp:144 [backend fallback]
../../.conda/envs/torch113/lib/python3.10/site-packages/torch/autograd/__init__.py:197: NotImplementedError
```
### Versions
PyTorch version: 1.13.0
Is debug build: False
CUDA used to build PyTorch: 11.6
ROCM used to build PyTorch: N/A
OS: NAME="Red Hat Enterprise Linux Server" (x86_64)
GCC version: (GCC) 4.8.5 20150623 (Red Hat 4.8.5-44)
Clang version: Could not collect
CMake version: Could not collect
Libc version: glibc-2.17
Python version: 3.10.8 (main, Nov 4 2022, 13:48:29) [GCC 11.2.0] (64-bit runtime)
Python platform: Linux-3.10.0-1160.59.1.el7.x86_64-x86_64-with-glibc2.17
Is CUDA available: True
CUDA runtime version: 11.6.124
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration: GPU 0: NVIDIA TITAN RTX
Nvidia driver version: 510.47.03
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.23.3
[pip3] torch==1.13.0
[pip3] torchaudio==0.13.0
[pip3] torchvision==0.14.0
[conda] blas 1.0 mkl
[conda] ffmpeg 4.3 hf484d3e_0 pytorch
[conda] mkl 2021.4.0 h06a4308_640
[conda] mkl-fft 1.3.1 pypi_0 pypi
[conda] mkl-random 1.2.2 pypi_0 pypi
[conda] mkl-service 2.4.0 pypi_0 pypi
[conda] mkl_fft 1.3.1 py310hd6ae3a3_0
[conda] mkl_random 1.2.2 py310h00e6091_0
[conda] numpy 1.23.3 pypi_0 pypi
[conda] numpy-base 1.23.3 py310h8e6c178_1
[conda] pytorch 1.13.0 py3.10_cuda11.6_cudnn8.3.2_0 pytorch
[conda] pytorch-cuda 11.6 h867d48c_0 pytorch
[conda] pytorch-mutex 1.0 cuda pytorch
[conda] torch 1.13.0 pypi_0 pypi
[conda] torchaudio 0.13.0 pypi_0 pypi
[conda] torchvision 0.14.0 pypi_0 pypi
cc @nikitaved @pearu @cpuhrsch @amjames @bhosmer
| 0 |
4,199 | 89,076 |
Transformers model tracing not working
|
oncall: jit
|
### 🐛 Describe the bug
When using torch.neuron.trace to compile a transformer model, an error appears : torch.jit.trace failed with following error: 0INTERNAL ASSERT FAILED at "../torch/csrc/jit/ir/alias_analysis.cpp":607, please report a bug to PyTorch. We don't have an op for aten::constant_pad_nd but it isn't a special case.
- Code to reproduce
```
import torch
from torch import nn
import torch_neuron
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained(
pretrained_model_name_or_path='shtoshni/longformer_coreference_joint', use_fast=True
)
model = AutoModel.from_pretrained(
pretrained_model_name_or_path='shtoshni/longformer_coreference_joint',
output_hidden_states=False,
add_pooling_layer=False,
return_dict = False,
)
model.eval()
#model wrapper
class Mymodel(nn.Module):
def __init__(self):
super(Mymodel,self).__init__()
self.pretrained = AutoModel.from_pretrained(
pretrained_model_name_or_path='shtoshni/longformer_coreference_joint',
output_hidden_states=False,
add_pooling_layer=False,
#return_dict = False,
)
#self.pretrained.eval()
def forward(self,*x):
self.pretrained.eval()
x = list(x)
y = self.pretrained(*x)
return y[0]
sequence_0 = "The company HuggingFace is based in New York City"
sequence_1 = "HuggingFace's headquarters are situated in Manhattan"
max_length=128
paraphrase = tokenizer.encode_plus(sequence_0, sequence_1, max_length=max_length, padding='max_length', truncation=True, return_tensors="pt")
example_inputs_paraphrase = paraphrase['input_ids'], paraphrase['attention_mask']
mymodel = Mymodel()
mymodel.eval()
model_neuron = torch.neuron.trace(mymodel, example_inputs_paraphrase)
```
- Error message
```
RuntimeError Traceback (most recent call last)
~/anaconda3/lib/python3.7/site-packages/torch_neuron/decorators.py in torch_trace_error_handler()
1526 try:
-> 1527 yield
1528 except RuntimeError as e:
~/anaconda3/lib/python3.7/site-packages/torch_neuron/convert.py in to_graph(func_or_mod, example_inputs, return_trace, **kwargs)
218 with track_script() as script_tracker, torch_trace_error_handler():
--> 219 jit_trace = torch.jit.trace(func_or_mod, example_inputs, **kwargs)
220 original_name = getattr(jit_trace, 'original_name',
~/anaconda3/lib/python3.7/site-packages/torch/jit/_trace.py in trace(func, example_inputs, optimize, check_trace, check_inputs, check_tolerance, strict, _force_outplace, _module_class, _compilation_unit)
749 _force_outplace,
--> 750 _module_class,
751 )
~/anaconda3/lib/python3.7/site-packages/torch/jit/_trace.py in trace_module(mod, inputs, optimize, check_trace, check_inputs, check_tolerance, strict, _force_outplace, _module_class, _compilation_unit)
964 _force_outplace,
--> 965 argument_names,
966 )
RuntimeError: 0INTERNAL ASSERT FAILED at "../torch/csrc/jit/ir/alias_analysis.cpp":607, please report a bug to PyTorch. We don't have an op for aten::constant_pad_nd but it isn't a special case. Argument types: Tensor, int[], bool,
Candidates:
...
torch.jit.trace failed with following error: 0INTERNAL ASSERT FAILED at "../torch/csrc/jit/ir/alias_analysis.cpp":607, please report a bug to PyTorch. We don't have an op for aten::constant_pad_nd but it isn't a special case. Argument types: Tensor, int[], bool,
Candidates:
aten::constant_pad_nd(Tensor self, int[] pad, Scalar value=0) -> (Tensor)
```
### Versions
PyTorch version: 1.11.0+cu102
Is debug build: False
CUDA used to build PyTorch: 10.2
ROCM used to build PyTorch: N/A
OS: Ubuntu 18.04.6 LTS (x86_64)
GCC version: (Ubuntu 7.5.0-3ubuntu1~18.04) 7.5.0
Clang version: Could not collect
CMake version: version 3.21.3
Libc version: glibc-2.10
Python version: 3.7.10 | packaged by conda-forge | (default, Feb 19 2021, 16:07:37) [GCC 9.3.0] (64-bit runtime)
Python platform: Linux-5.4.0-1088-aws-x86_64-with-debian-buster-sid
Is CUDA available: True
CUDA runtime version: 10.0.130
CUDA_MODULE_LOADING set to:
GPU models and configuration: GPU 0: Tesla T4
Nvidia driver version: 450.142.00
cuDNN version: Probably one of the following:
/usr/local/cuda-10.1/targets/x86_64-linux/lib/libcudnn.so.7.6.5
/usr/local/cuda-10.2/targets/x86_64-linux/lib/libcudnn.so.7.6.5
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn.so.8.0.5
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_adv_infer.so.8.0.5
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_adv_train.so.8.0.5
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_cnn_infer.so.8.0.5
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_cnn_train.so.8.0.5
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_ops_infer.so.8.0.5
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_ops_train.so.8.0.5
/usr/local/cuda-11.1/targets/x86_64-linux/lib/libcudnn.so.8.0.5
/usr/local/cuda-11.1/targets/x86_64-linux/lib/libcudnn_adv_infer.so.8.0.5
/usr/local/cuda-11.1/targets/x86_64-linux/lib/libcudnn_adv_train.so.8.0.5
/usr/local/cuda-11.1/targets/x86_64-linux/lib/libcudnn_cnn_infer.so.8.0.5
/usr/local/cuda-11.1/targets/x86_64-linux/lib/libcudnn_cnn_train.so.8.0.5
/usr/local/cuda-11.1/targets/x86_64-linux/lib/libcudnn_ops_infer.so.8.0.5
/usr/local/cuda-11.1/targets/x86_64-linux/lib/libcudnn_ops_train.so.8.0.5
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] mypy-extensions==0.4.3
[pip3] numpy==1.19.2
[pip3] numpydoc==1.1.0
[pip3] torch==1.11.0
[pip3] torch-model-archiver==0.6.0
[pip3] torch-neuron==1.11.0.2.3.0.0
[pip3] torchserve==0.6.0
[conda] blas 1.0 mkl
[conda] mkl 2020.2 256
[conda] mkl-service 2.3.0 py37he8ac12f_0
[conda] mkl_fft 1.2.1 py37h54f3939_0
[conda] mkl_random 1.1.1 py37h0573a6f_0
[conda] numpy 1.19.2 py37h54aff64_0
[conda] numpy-base 1.19.2 py37hfa32c7d_0
[conda] numpydoc 1.1.0 pyhd3eb1b0_1
[conda] torch 1.11.0 pypi_0 pypi
[conda] torch-model-archiver 0.6.0 pypi_0 pypi
[conda] torch-neuron 1.11.0.2.3.0.0 pypi_0 pypi
[conda] torchserve 0.6.0 pypi_0 pypi
cc @EikanWang @jgong5 @wenzhe-nrv @sanchitintel
| 2 |
4,200 | 89,068 |
view_copy out= does not reshape zero element tensors
|
triaged, module: viewing and reshaping, module: functionalization
|
### 🐛 Describe the bug
from [how-does-out-work-in-pytorch](https://github.com/pytorch/pytorch/wiki/Developer-FAQ#how-does-out-work-in-pytorch)
> if an out tensor has no elements it will be resized to the shape, stride, and memory format of the output of the computation.
however I get the following error when trying this:
```
In [4]: torch.view_copy(x, [3], out=torch.tensor([]))
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
Input In [4], in <cell line: 1>()
----> 1 torch.view_copy(x, [3], out=torch.tensor([]))
RuntimeError: The size of tensor a (0) must match the size of tensor b (3) at non-singleton dimension 0
```
### Versions
Collecting environment information...
PyTorch version: 1.14.0a0+gitcef13eb
Is debug build: False
CUDA used to build PyTorch: 11.7
ROCM used to build PyTorch: N/A
OS: Ubuntu 18.04.6 LTS (x86_64)
GCC version: (Ubuntu 7.5.0-3ubuntu1~18.04) 7.5.0
Clang version: Could not collect
CMake version: version 3.24.1
Libc version: glibc-2.27
Python version: 3.8.13 | packaged by conda-forge | (default, Mar 25 2022, 06:04:10) [GCC 10.3.0] (64-bit runtime)
Python platform: Linux-4.15.0-147-generic-x86_64-with-glibc2.10
Is CUDA available: True
CUDA runtime version: Could not collect
GPU models and configuration:
GPU 0: Quadro RTX 8000
GPU 1: Quadro RTX 8000
Nvidia driver version: 515.65.01
cuDNN version: Probably one of the following:
/usr/local/cuda-10.1/targets/x86_64-linux/lib/libcudnn.so.7
/usr/local/cuda-10.2.89/targets/x86_64-linux/lib/libcudnn.so.7
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] functorch==0.3.0a0+9166625
[pip3] mypy==0.812
[pip3] mypy-extensions==0.4.3
[pip3] numpy==1.23.2
[pip3] torch==1.14.0a0+git6dbde84
[conda] functorch 0.3.0a0+9166625 dev_0 <develop>
[conda] magma-cuda117 2.6.1 1 pytorch
[conda] mkl 2022.1.0 h84fe81f_915 conda-forge
[conda] mkl-include 2022.1.0 h84fe81f_915 conda-forge
[conda] numpy 1.23.2 py38h3a7f9d9_0 conda-forge
[conda] torch 1.14.0a0+git6dbde84 dev_0 <develop>
cc @bdhirsh @ezyang @soumith
| 2 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.